
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Создание простой 2D игры на Android
Доброго дня всем!
Когда я писал эту «игру» у меня возникала масса вопросов по поводу зацикливания спрайтов так что бы они появлялись через определенное время, так же были проблемы с обнаружением столкновений двух спрайтов и более, все эти вопросы я сегодня хочу осветить в этом посте так как в интернете я не нашел нормального ответа на мои вопросы и пришлось делать самому. Пост ни на что не претендует, я новичок в разработке игр под android и пишу я для новичков в данной отрасли. Кому стало интересно прошу под кат.
#### Постановка задачи:
Игра должна представлять из себя поле (сцену) на котором располагается ниндзя и призраки. Нинзя должен защищать свою базу от этих призраков стреляя по ним.
Пример такой игры можно посмотреть в [android market'e](https://market.android.com/details?id=com.droidhen.defender&hl=ru). Хотя я сильно замахнулся, у нас будет только похожая идея.
Вот как будет выглядеть игра:

#### Начало разработки
Создаем проект. Запускаем Eclipse — File — Android Project — Defens — Main.java.
Открываем наш файл Main.java и изменяем весь код на код который ниже:
Main.java
```
public class Main extends Activity {
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
// если хотим, чтобы приложение постоянно имело портретную ориентацию
setRequestedOrientation(ActivityInfo.SCREEN_ORIENTATION_LANDSCAPE);
// если хотим, чтобы приложение было полноэкранным
getWindow().addFlags(WindowManager.LayoutParams.FLAG_FULLSCREEN);
// и без заголовка
requestWindowFeature(Window.FEATURE_NO_TITLE);
setContentView(new GameView(this));
}
}
```
Код ниже говорит нашей главной функции что запускать нужно не \*.xml файл темы, а класс который у нас является самой сценой.
```
setContentView(new GameView(this));
```
Дальше Вам нужно создать класс GameView.java который будет служить для нас главным классом на котором будет производится прорисовка всех объектов. Так же в этом классе будет находится и наш поток в котором будет обрабатываться прорисовка объектов в потоке для уменьшения нагрузки игры на процессор. Вот как будет выглядеть класс когда на сцене у нас ничего не происходит:
GameView.java
```
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.Random;
import towe.def.GameView.GameThread;
import android.content.Context;
import android.graphics.Bitmap;
import android.graphics.BitmapFactory;
import android.graphics.Canvas;
import android.graphics.Color;
import android.view.MotionEvent;
import android.view.SurfaceHolder;
import android.view.SurfaceView;
public class GameView extends SurfaceView
{
/**Объект класса GameLoopThread*/
private GameThread mThread;
public int shotX;
public int shotY;
/**Переменная запускающая поток рисования*/
private boolean running = false;
//-------------Start of GameThread--------------------------------------------------\\
public class GameThread extends Thread
{
/**Объект класса*/
private GameView view;
/**Конструктор класса*/
public GameThread(GameView view)
{
this.view = view;
}
/**Задание состояния потока*/
public void setRunning(boolean run)
{
running = run;
}
/** Действия, выполняемые в потоке */
public void run()
{
while (running)
{
Canvas canvas = null;
try
{
// подготовка Canvas-а
canvas = view.getHolder().lockCanvas();
synchronized (view.getHolder())
{
// собственно рисование
onDraw(canvas);
}
}
catch (Exception e) { }
finally
{
if (canvas != null)
{
view.getHolder().unlockCanvasAndPost(canvas);
}
}
}
}
}
//-------------End of GameThread--------------------------------------------------\\
public GameView(Context context)
{
super(context);
mThread = new GameThread(this);
/*Рисуем все наши объекты и все все все*/
getHolder().addCallback(new SurfaceHolder.Callback()
{
/*** Уничтожение области рисования */
public void surfaceDestroyed(SurfaceHolder holder)
{
boolean retry = true;
mThread.setRunning(false);
while (retry)
{
try
{
// ожидание завершение потока
mThread.join();
retry = false;
}
catch (InterruptedException e) { }
}
}
/** Создание области рисования */
public void surfaceCreated(SurfaceHolder holder)
{
mThread.setRunning(true);
mThread.start();
}
/** Изменение области рисования */
public void surfaceChanged(SurfaceHolder holder, int format, int width, int height)
{
}
});
}
/**Функция рисующая все спрайты и фон*/
protected void onDraw(Canvas canvas) {
canvas.drawColor(Color.WHITE);
}
}
```
Из комментариев надеюсь понятно какая функция что делает. Этот класс является базовым по этому в нем мы будем производиться все действия (функции) которые будут происходить в игре, но для начало нам нужно сделать еще несколько классов Переходи к следующему пункту — создание спрайтов.
#### Создание спрайтов
Спрайты это маленькие картинки в 2D-играх, которые передвигаются. Это могут быть человечки, боеприпасы или даже облака. В этой игре мы будем иметь три различных типа спрайта: Нинзя , призрак , и снаряд .
Сейчас мы будем использовать не анимированные спрайты но в будущем я вставлю спрайты в проэкт, если тянет научиться делать спрайты прошу во [второй урок по созданию игры](http://dajver.blogspot.com/2012/01/android-2.html) под android.
Теперь загрузите эти картинки в папку res/drawable для того, чтобы Eclipse мог увидеть эти картинки и вставить в Ваш проект.
Следующий рисунок должен визуально помочь понять как будет располагаться игрок на экране.

Скучная картинка… Давайте лучше создадим этого самого игрока.
Нам нужно разместить спрайт на экране, как это сделать? Создаем класс Player.java и записываем в него следующее:
Player.java
```
import android.graphics.Bitmap;
import android.graphics.Canvas;
public class Player
{
/**Объект главного класса*/
GameView gameView;
//спрайт
Bitmap bmp;
//х и у координаты рисунка
int x;
int y;
//конструктор
public Player(GameView gameView, Bitmap bmp)
{
this.gameView = gameView;
this.bmp = bmp; //возвращаем рисунок
this.x = 0; //отступ по х нет
this.y = gameView.getHeight() / 2; //делаем по центру
}
//рисуем наш спрайт
public void onDraw(Canvas c)
{
c.drawBitmap(bmp, x, y, null);
}
}
```
Все очень просто и понятно, наш игрок будет стоять на месте и ничего не делать, кроме как стрелять по врагу но стрельба будет реализована в классе пуля (снаряд), который будем делать дальше.
Создаем еще один файл классов и назовем его Bullet.java, этот класс будет определять координаты полета, скорость полета и другие параметры пули. И так, создали файл, и пишем в него следующее:
Bullet.java
```
import android.graphics.Bitmap;
import android.graphics.Canvas;
import android.graphics.Rect;
public class Bullet
{
/**Картинка*/
private Bitmap bmp;
/**Позиция*/
public int x;
public int y;
/**Скорость по Х=15*/
private int mSpeed=25;
public double angle;
/**Ширина*/
public int width;
/**Ввыоста*/
public int height;
public GameView gameView;
/**Конструктор*/
public Bullet(GameView gameView, Bitmap bmp) {
this.gameView=gameView;
this.bmp=bmp;
this.x = 0; //позиция по Х
this.y = 120; //позиция по У
this.width = 27; //ширина снаряда
this.height = 40; //высота снаряда
//угол полета пули в зависипости от координаты косания к экрану
angle = Math.atan((double)(y - gameView.shotY) / (x - gameView.shotX));
}
/**Перемещение объекта, его направление*/
private void update() {
x += mSpeed * Math.cos(angle); //движение по Х со скоростью mSpeed и углу заданном координатой angle
y += mSpeed * Math.sin(angle); // движение по У -//-
}
/**Рисуем наши спрайты*/
public void onDraw(Canvas canvas) {
update(); //говорим что эту функцию нам нужно вызывать для работы класса
canvas.drawBitmap(bmp, x, y, null);
}
}
```
Из комментариев должно быть понятно что пуля выполняет только одно действие — она должна лететь по направлению указанному игроком.
#### Рисуем спрайты на сцене
Для того что бы нарисовать эти два класса которые мы создали, нам нужно отредактировать код в классе GameView.java, добавить несколько методов которые будут возвращать нам наши рисунки. Полностью весь код я писать не буду, буду приводить только код нужных мне методов.
Для начала нам нужно создать объекты классов Bullet и Player для того что бы отобразить их на экране, для этого создадим список пуль, что бы они у нас никогда не заканчивались, и обычный объект класса игрока.
*Шапка GameView*
```
private List ball = new ArrayList();
private Player player;
Bitmap players;
```
Дальше нам нужно присвоить картинки нашим классам, находим конструктор GameView и вставляем в самый конец две строчки:
*GameView.java — Конструктор GameView*
```
players= BitmapFactory.decodeResource(getResources(), R.drawable.player2);
player= new Player(this, guns);
```
И в методе onDraw(Canvas c); делаем видимыми эти спрайты. Проходим по всей коллекции наших элементов сгенерировавшихся в списке.
GameView,java
```
/**Функция рисующая все спрайты и фон*/
protected void onDraw(Canvas canvas) {
canvas.drawColor(Color.WHITE);
Iterator j = ball.iterator();
while(j.hasNext()) {
Bullet b = j.next();
if(b.x >= 1000 || b.x <= 1000) {
b.onDraw(canvas);
} else {
j.remove();
}
}
canvas.drawBitmap(guns, 5, 120, null);
}
```
А для того что бы пули начали вылетать при нажатии на экран, нужно создать метод createSprites(); который будет возвращать наш спрайт.
GameView.java
```
public Bullet createSprite(int resouce) {
Bitmap bmp = BitmapFactory.decodeResource(getResources(), resouce);
return new Bullet(this, bmp);
}
```
Ну и в конце концов создаем еще один метод — onTouch(); который собственно будет отлавливать все касания по экрану и устремлять пулю в ту точку где было нажатия на экран.
GameView.java
```
public boolean onTouchEvent(MotionEvent e)
{
shotX = (int) e.getX();
shotY = (int) e.getY();
if(e.getAction() == MotionEvent.ACTION_DOWN)
ball.add(createSprite(R.drawable.bullet));
return true;
}
```
Если хотите сделать что бы нажатие обрабатывалось не единоразово, т.е. 1 нажатие — 1 пуля, а 1 нажатие — и пока не отпустишь оно будет стрелять, нужно удалить *if(e.getAction() == MotionEvent.ACTION\_DOWN) { }*
и оставить только *ball.add(createSprite(R.drawable.bullet));*.
Все, запускаем нашу игру и пробуем стрелять. Должно выйти вот такое:
#### Враги
Для того что бы нам не было скучно играться, нужно создать врагов. Для этого нам придется создать еще один класс который будет называться Enemy.java и который будет уметь отображать и направлять нашего врага на нашу базу. Класс довольно простой по этому смотрим код ниже:
Enemy.java
```
import java.util.Random;
import android.graphics.Bitmap;
import android.graphics.Canvas;
import android.graphics.Rect;
public class Enemy
{
/**Х и У коорданаты*/
public int x;
public int y;
/**Скорость*/
public int speed;
/**Выосота и ширина спрайта*/
public int width;
public int height;
public GameView gameView;
public Bitmap bmp;
/**Конструктор класса*/
public Enemy(GameView gameView, Bitmap bmp){
this.gameView = gameView;
this.bmp = bmp;
Random rnd = new Random();
this.x = 900;
this.y = rnd.nextInt(300);
this.speed = rnd.nextInt(10);
this.width = 9;
this.height = 8;
}
public void update(){
x -= speed;
}
public void onDraw(Canvas c){
update();
c.drawBitmap(bmp, x, y, null);
}
}
```
И так что происходит в этом классе? Рассказываю: мы объявили жизненно важные переменные для нашего врага, высота ширина и координаты. Для размещения их на сцене я использовал класс Random() для того что бы когда они будут появляться на сцене, появлялись на все в одной точке, а в разных точках и на разных координатах. Скорость так же является у нас рандомной что бы каждый враг шел с разной скоростью, скорость у нас начинается с 0 и заканчивается 10, 10 — максимальная скорость которой может достигнуть враг. Двигаться они будут с права налево, для того что бы они не были сразу видны на сцене я закинул их на 900 пикселей за видимость экрана. Так что пока они дойдут можно уже будет подготовиться по полной к атаке.
Дальше нам нужно отобразить врага на сцене, для этого в классе GameView.java делаем следующее:
Создаем список врагов для того что бы они никогда не заканчивались и создаем битмап который будет содержать спрайт:
*Шапка GameView*
```
private List enemy = new ArrayList();
Bitmap enemies;
```
Далее создаем новый поток для задания скорости появления врагов на экране:
*Шапка GameView*
```
private Thread thred = new Thread(this);
```
И имплементируем класс Runuble, вот как должна выглядеть инициализация класса GameView:
```
public class GameView extends SurfaceView implements Runnable
```
Теперь у Вас еклипс требует создать метод run(), создайте его, он будет иметь следующий вид:
*В самом низу класса GameView*
```
public void run() {
while(true) {
Random rnd = new Random();
try {
Thread.sleep(rnd.nextInt(2000));
enemy.add(new Enemy(this, enemies));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
```
Здесь мы создаем поток который будет создавать спрайт от 0 до 2000 милисекунд или каждые 0, 1 или 2 секунды.
Теперь в конструкторе в самом конце пишем инициализируем наш спрайт с классом для отображения на сцене:
*Конструктор GameView*
```
enemies = BitmapFactory.decodeResource(getResources(), R.drawable.target);
enemy.add(new Enemy(this, enemies));
```
Ну и конечно же нам нужно объявить эти методы в onDraw(); Вот значит и пишем в нем следующее:
*Метод onDraw() в GameView*
```
Iterator i = enemy.iterator();
while(i.hasNext()) {
Enemy e = i.next();
if(e.x >= 1000 || e.x <= 1000) {
e.onDraw(canvas);
} else {
i.remove();
}
}
```
Снова проходим по коллекции врагов с помощью итератора и проверяем — если враг зашел за предел в 1000 пикселей — удаляем его, так как если мы не будем удалять у нас пямять закакается и телефон зависнет, а нам такие проблемы не нужны. Все игра готова для запуска.
Запускаем нашу игру и что мы увидим? А вот что:
Но что я вижу? О нет!!! Пули никак не убивают наших призраков что же делать? А я Вам скажу что делать, нам нужно создать метод который будет образовывать вокруг каждого спрайта — прямоугольник и будет сравнивать их на коллизии. Следующая тема будет об этом.
#### Обнаружение столкновений
И так, у нас есть спрайт, у нас есть сцена, у нас все это даже движется красиво, но какая польза от всего этого когда у нас на сцене ничего не происходит кроме хождения туда сюда этих спрайтов?
С этой функцией я навозился по полной, даже как-то так выходило что психовал и уходил гулять по улице)) Самый трудный метод, хотя выглядеть совершенно безобидно…
Ладно, давайте уже создадим этот метод и не будем много разглагольствовать… Где то в конце класса GameView создаем метод testCollision() и пишем следующий код:
*В самом низу класса GameView.java*
```
/*Проверка на столкновения*/
private void testCollision() {
Iterator b = ball.iterator();
while(b.hasNext()) {
Bullet balls = b.next();
Iterator i = enemy.iterator();
while(i.hasNext()) {
Enemy enemies = i.next();
if ((Math.abs(balls.x - enemies.x) <= (balls.width + enemies.width) / 2f)
&& (Math.abs(balls.y - enemies.y) <= (balls.height + enemies.height) / 2f)) {
i.remove();
b.remove();
}
}
}
}
```
И так, что у нас происходит в этом методе? Мы создаем один итератор и запускаем цикл для просмотра всей коллекции спрайтов, и говорим что каждый следующий спрайт пули будет первым.
Дальше создаем еще один итератор с другим списком спрайтов и снова переопределяем и говорим что каждый следующий спрайт врага будет первым. И создаем оператор ветвления — if() который собственно и проверяет на столкновения наши спрайты. В нем я использовал математическую функцию модуль (abs) которая возвращает мне абсолютное целое от двух прямоугольников.
Внутри ифа происходит сравнения двух прямоугольников Модуль от (Пуля по координате Х минус координата врага по координате Х меньше либо равен ширина пули плюс ширина врага / 2 (делим на два для нахождения центра прямоугольника)) и (Модуль от (Пуля по координате У минус координата врага по координате У меньше либо равен ширина пули плюс ширина врага / 2 (делим на два для нахождения центра прямоугольника)));
И в конце всего, если пуля таки достала до врага — мы удаляем его со сцены с концами.
Ну и для того что бы эта функция стала работать записываем её в метод run() который находится в классе GameThread, ниже нашего метода рисования onDraw().
Вот что у нас получается после запуска приложения: | https://habr.com/ru/post/136802/ | null | ru | null |
# Kubernetes 1.10: обзор основных новшеств
В конце марта состоялся релиз [Kubernetes 1.10](https://kubernetes.io/blog/2018/03/27/kubernetes-1.10-stabilizing-storage-security-networking/). Поддерживая нашу традицию рассказывать подробности о наиболее значимых изменениях в очередном релизе Kubernetes, публикуем этот обзор, подготовленный на основе [CHANGELOG-1.10](https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG-1.10.md), а также многочисленных issues, pull requests и design proposals. Итак, что же нового приносит K8s 1.10?

Хранилища
---------
[**Mount propagation**](https://github.com/jsafrane/community/blob/7a2b2f7d88b50ee7e83dcca79dc96fac96988084/contributors/design-proposals/propagation.md) — возможность контейнеров подключать тома как `rslave`, чтобы примонтированные каталоги хоста были видны внутри контейнера (значение `HostToContainer`), или как `rshared`, чтобы примонтированные каталоги контейнера были видны на хосте (значение `Bidirectional`). Статус — бета-версия ([документация](https://kubernetes.io/docs/concepts/storage/volumes/#mount-propagation) на сайте). Не поддерживается в Windows.
Добавлена возможность создания **локальных постоянных хранилищ** ([Local Persistent Storage](https://github.com/vishh/community/blob/ba62a3f6cb9a301e95c4b64b9052455bdac9a3fe/contributors/design-proposals/local-storage-overview.md#persistent-local-storage)), т.е. `PersistentVolumes` (PVs) теперь могут быть не только сетевыми томами, но и основываться на локально подключённых дисках. Нововведение преследует две цели: а) улучшить производительность (у локальных SSD скорость лучше, чем у сетевых дисков), б) обеспечить возможность использования более дешёвых хранилищ на железных (bare metal) инсталляциях Kubernetes. Эти работы введутся вместе с созданием Ephemeral Local Storage, [ограничения/лимиты](https://github.com/kubernetes/features/issues/361) в котором (впервые представленные в [K8s 1.8](https://habrahabr.ru/company/flant/blog/338230/)) также получили улучшения в очередном релизе — объявлены бета-версией и по умолчанию теперь включены.
Стало доступным (в бета-версии) «**планирование томов с учётом топологии**» *([Topology Aware Volume Scheduling](https://github.com/kubernetes/features/issues/490))*, идея которого сводится к тому, что стандартный планировщик Kubernetes знает (и учитывает) ограничения топологии томов, а в процессе привязки `PersistentVolumeClaims` (PVCs) к PVs учитываются решения планировщика. Реализовано это таким образом, что под теперь может запрашивать PVs, которые должны быть совместимы с другими его ограничениями: требованиями к ресурсам, политиками affinity/anti-affinity. При этом планирование подов, не использующих PVs с ограничениями, должно происходить с прежней производительностью. Подробности — в [design-proposals](https://github.com/msau42/community/blob/6e486a390fc73ff1deb2441abf2c5838e568d438/contributors/design-proposals/storage/volume-topology-scheduling.md).
Среди прочих улучшений в поддержке томов / файловых систем:
* улучшения в Ceph RBD с [возможностью](https://github.com/kubernetes/kubernetes/pull/58916) использования клиента rbd-nbd (на основе популярной библиотеки librbd) в pkg/volume/rbd;
* [поддержка](https://github.com/kubernetes/kubernetes/pull/55866) монтирования Ceph FS через FUSE;
* в плагине для AWS EBS [добавлена](https://github.com/kubernetes/kubernetes/pull/58625) поддержка блочных томов и `volumeMode`, а также поддержка блочных томов [появилась](https://github.com/kubernetes/kubernetes/pull/58710) в плагине GCE PD;
* [возможность](https://github.com/kubernetes/kubernetes/pull/58794) изменения размера тома даже в тех случаях, когда он примонтирован.
Наконец, [были добавлены](https://github.com/kubernetes/features/issues/496) (и объявлены стабильными) **дополнительные метрики**, говорящие о внутреннем состоянии подсистемы хранения в Kubernetes и предназначенные для отладки, а также получения расширенного представления о состоянии кластера. Например, теперь для каждого тома (по `volume_plugin`) можно узнать общее время на операции mount/umount и attach/detach, общее время privision'а и удаления, а также количество томов в `ActualStateofWorld` и `DesiredStateOfWorld`, bound/unbound PVCs и PVs, количество используемых подами PVCs и др. Подробнее — см. [документацию](https://github.com/gnufied/community/blob/1a6217c00d01f4f24efb36bfc942df9592542e46/contributors/design-proposals/storage/additional-volume-metrics.md).
Kubelet, узлы и управление ими
------------------------------
*Kubelet* получил возможность настройки через **версионируемый конфигурационный файл** (вместо традиционного способа с флагами в командной строке), имеющий структуру `KubeletConfiguration`. Чтобы *Kubelet* подхватил конфиг, необходимо запускать его с флагом `--config` (подробности см. в [документации](https://kubernetes.io/docs/tasks/administer-cluster/kubelet-config-file/)). Такой подход называется рекомендуемым, поскольку упрощает разворачивание узлов и управление конфигурациями. Это стало возможным благодаря появлению группы API под названием `kubelet.config.k8s.io`, которая для релиза Kubernetes 1.10 имеет статус бета-версии. Пример конфигурационного файла для *Kubelet*:
```
kind: KubeletConfiguration
apiVersion: kubelet.config.k8s.io/v1beta1
evictionHard:
memory.available: "200Mi"
```
С помощью новой опции в спецификации пода, `shareProcessNamespace` в `PodSpec`, контейнеры теперь могут использовать **общее для пода пространство имён для процессов** *(PID namespace)*. Ранее этой возможности не было из-за отсутствия [необходимой поддержки](https://github.com/moby/moby/pull/22481) в Docker, что привело к появлению дополнительного API, который с тех пор используется некоторыми образами контейнеров… Теперь всё [унифицировали](https://github.com/kubernetes/community/blob/master/contributors/design-proposals/node/pod-pid-namespace.md), сохранив обратную совместимость. Результат реализации — поддержка трёх режимов разделения пространств имён PID в Container Runtime Interface (CRI): для каждого контейнера (т.е. свой namespace у каждого контейнера), для пода (общий namespace для контейнеров пода), для узла. Статус готовности — альфа.
Другое значимое изменение в CRI — появление поддержки **Windows Container Configuration**. До сих пор в CRI можно было конфигурировать только Linux-контейнеры, однако в спецификации исполняемой среды OCI (Open Container Initiative, [Runtime Specification](https://github.com/opencontainers/runtime-spec)) описаны и особенности других платформ — в частности, [Windows](https://github.com/opencontainers/runtime-spec/blob/master/config-windows.md). Теперь в CRI [поддерживаются](https://github.com/JiangtianLi/community/blob/6d08a8213318d63d8ab49fe326afdb6b49037e33/contributors/design-proposals/node/cri-windows.md) ограничения по ресурсам памяти и процессора для Windows-контейнеров (альфа-версия).
Кроме того, статуса бета-версии достигли три разработки Resource Management Working Group:
1. [CPU Manager](https://kubernetes.io/docs/tasks/administer-cluster/cpu-management-policies/) (назначение подам конкретных ядер процессора — подробнее о нём писали в [статье про K8s 1.8](https://habrahabr.ru/company/flant/blog/338230/));
2. [Huge Pages](https://kubernetes.io/docs/tasks/manage-hugepages/scheduling-hugepages/) (возможность использования подами 2Mi и 1Gi Huge Pages, что актуально для приложений, потребляющих большие объёмы памяти);
3. [Device Plugin](https://kubernetes.io/docs/concepts/cluster-administration/device-plugins/) (фреймворк для вендоров, позволяющий объявлять в *kubelet* ресурсы: например, от GPU, NIC, FPGA, InfiniBand и т.п. — без необходимости модифицировать основной код Kubernetes).
**Количество процессов, запущенных в поде**, теперь [можно ограничивать](https://github.com/kubernetes/kubernetes/pull/57973) с помощью параметра `--pod-max-pids` для консольной команды *kubelet*. Реализация имеет статус альфа-версии и требует включения фичи `SupportPodPidsLimit`.
Благодаря тому, что в containerd 1.1 появилась родная поддержка CRI v1alpha2, в Kubernetes 1.10 с containerd 1.1 можно работать напрямую, без необходимости в «посреднике» cri-containerd *(подробнее мы о нём писали в конце [этой статьи](https://habrahabr.ru/company/flant/blog/340010/))*. В CRI-O тоже обновили версию CRI до v1alpha2, а в сам CRI (Container Runtime Interface) добавили поддержку указания GID контейнера в `LinuxSandboxSecurityContext` и в `LinuxContainerSecurityContext` (в дополнение к UID) — поддержка реализована для *dockershim* и имеет статус альфа-версии.
Сеть
----
Опция с использованием CoreDNS вместо *kube-dns* достигла статуса бета-версии. В частности, это [принесло](https://github.com/kubernetes/website/pull/7638/files#diff-e1afcdac8d5e8458274b3c481c5ebcdaR33) возможность **миграции на CoreDNS** при апгрейде с помощью *kubeadm* кластера, использующего *kube-dns*: в этом случае *kubeadm* сгенерирует конфигурацию CoreDNS (т.е. `Corefile`) на основе `ConfigMap` из *kube-dns*.
Традиционно `/etc/resolv.conf` на поде управляется *kubelet*, а данные этого конфига генерируются на основе `pod.dnsPolicy`. В Kubernetes 1.10 (в статусе бета-версии) [представлена](https://github.com/kubernetes/features/issues/504) поддержка **конфигурации `resolv.conf` для пода**. Для этого в `PodSpec` добавлено поле `dnsParams`, которое позволяет переписывать имеющиеся настройки DNS. Подробнее — в [design-proposals](https://github.com/bowei/community/blob/eb79043a77170cc4e340d47f2835de5fb75d0d31/contributors/design-proposals/network/pod-resolv-conf.md). Иллюстрация использования `dnsPolicy: Custom` с `dnsParams`:
```
# Pod spec
apiVersion: v1
kind: Pod
metadata: {"namespace": "ns1", "name": "example"}
spec:
...
dnsPolicy: Custom
dnsParams:
nameservers: ["1.2.3.4"]
search:
- ns1.svc.cluster.local
- my.dns.search.suffix
options:
- name: ndots
value: 2
- name: edns0
```
В *kube-proxy* [добавлена](https://github.com/kubernetes/features/issues/539) опция, позволяющая определять **диапазон IP-адресов для `NodePort`**, т.е. инициировать фильтрацию допустимых значений с помощью `--nodeport-addresses` (со значением по умолчанию `0.0.0.0/0`, т.е. пропускать всё, чему соответствует нынешнее поведение `NodePort`). Предусмотрена [реализация](https://github.com/m1093782566/community/blob/beb68d448e09c307a3ac24146b7165e3fa2bcf02/contributors/design-proposals/network/nodeport-ip-range.md#kube-proxy-implementation-suport) в *kube-proxy* для iptables, Linux userspace, IPVS, Window userspace, winkernel. Статус — альфа-версия.
Аутентификация
--------------
Добавлены новые методы аутентификации (альфа-версия):
1. **внешние клиентские провайдеры**: отвечая на давние запросы пользователей K8s на exec-based plugins, в *kubectl* (client-go) [реализовали](https://github.com/kubernetes/features/issues/541) поддержку [исполняемых плагинов](https://github.com/ericchiang/community/blob/2bfa7e1e624a5c87cbd1d07566e617563e2280fd/contributors/design-proposals/auth/kubectl-exec-plugins.md), которые могут получать аутентификационные данные исполнением произвольной команды и чтением её вывода (плагин GCP тоже может быть настроен на вызов команд, отличных от *gcloud*). Один из вариантов применения — облачные провайдеры смогут создавать собственные системы аутентификации (вместо использования стандартных механизмов Kubernetes);
2. **TokenRequest API** для [получения](https://github.com/mikedanese/community/blob/5f9d2c45bd7dc45367eaae5dafb206609fd14c88/contributors/design-proposals/auth/bound-service-account-tokens.md) токенов JWT (JSON Web Tokens), привязанных к клиентам *(audience)* и времени.
Кроме того, стабильный статус [получила](https://github.com/kubernetes/features/issues/279) возможность ограничения доступа узлов к определённым API (с помощью режима авторизации `Node` и admission-плагина `NodeRestriction`) с целью выдавать им разрешение только на ограниченное число объектов и связанных с ними секретов.
CLI
---
Достигнут прогресс в **переработке вывода**, показываемого командами `kubectl get` и `kubectl describe`. Глобальная задача [инициативы](https://github.com/kubernetes/features/issues/515), получившей в Kubernetes 1.10 статус бета-версии, заключается в том, что получение столбцов для табличного отображения данных должно происходить на стороне сервера (а не клиента), — это делается с целью улучшить пользовательский интерфейс при работе с расширениями. Начавшаяся ранее (в K8s 1.8) работа на серверной стороне доведена до уровня беты, а также [были проведены](https://github.com/kubernetes/kubernetes/issues/58536) основные изменения на стороне клиента.
В *kubectl port-forward* добавлена [возможность](https://github.com/kubernetes/kubernetes/pull/59705) использования имени ресурса для выбора подходящего пода (и флаг `--pod-running-timeout` для ожидания, пока хотя бы один под будет запущен), а также [поддержка](https://github.com/kubernetes/kubernetes/pull/59809) указания сервиса для проброса порта (например: `kubectl port-forward svc/myservice 8443:443`).
Новые сокращённые имена для команд *kubectl*: `cj` вместо `CronJobs`, `crds` — `CustomResourceDefinition`. Например, стала доступна команда `kubectl get crds`.
Другие изменения
----------------
* [API Aggregation](https://github.com/kubernetes/features/issues/263), т.е. агрегация пользовательских apiservers с основным API в Kubernetes, получил стабильный статус и официально готов к использованию в production.
* *Kubelet* и *kube-proxy* теперь [могут запускаться](https://github.com/kubernetes/kubernetes/pull/60144) как родные службы в Windows. Добавлена поддержка Windows Service Control Manager (SCM) и экспериментальная [поддержка изоляции](https://github.com/kubernetes/kubernetes/pull/58751) с Hyper-V для подов с единственным контейнером.
* Функция *Persistent Volume Claim Protection* (`PVCProtection`), «защищающая» от возможного удаления PVCs, которые активно используются подами, переименована в `Storage Protection` и [доведена](https://github.com/kubernetes/kubernetes/pull/59052) до бета-версии.
* Альфа-версия [поддержки Azure](https://github.com/kubernetes/features/issues/514) в *cluster-autoscaler*.
Совместимость
-------------
* Поддерживаемая версия **etcd** — 3.1.12. При этом etcd2 в качестве бэкенда объявлена устаревшей, её поддержка будет удалена в релизе Kubernetes 1.13.
* Проверенные версии **Docker** — от 1.11.2 до 1.13.1 и 17.03.x (не изменились с релиза K8s 1.9).
* Версия **Go** — 1.9.3 (вместо 1.9.2), минимально поддерживаемая — 1.9.1.
* Версия **CNI** — 0.6.0.
P.S.
----
Читайте также в нашем блоге:
* «[Kubernetes 1.9: обзор основных новшеств](https://habrahabr.ru/company/flant/blog/344220/)»;
* «[Четыре релиза 1.0 от CNCF и главные анонсы про Kubernetes с KubeCon 2017](https://habrahabr.ru/company/flant/blog/344098/)»;
* «[Kubernetes 1.8: обзор основных новшеств](https://habrahabr.ru/company/flant/blog/338230/)»;
* «[Docker 17.06 и Kubernetes 1.7: ключевые новшества](https://habrahabr.ru/company/flant/blog/332160/)»;
* «[Инфраструктура с Kubernetes как доступная услуга](https://habrahabr.ru/company/flant/blog/341760/)». | https://habr.com/ru/post/353114/ | null | ru | null |
# Атаки на JSON Web Tokens

#### Содержание:
* Что такое JWT?
+ Заголовок
+ Полезная нагрузка
+ Подпись
+ Что такое SECRET\_KEY?
* Атаки на JWT:
+ Базовые атаки:
1. Нет алгоритма
2. Изменяем алгоритм с RS256 на HS256
3. Без проверки подписи
4. Взлом секретного ключа
5. Использование произвольных файлов для проверки
+ Продвинутые атаки:
1. SQL-инъекция
2. Параметр поддельного заголовка
3. Внедрение заголовка ответа HTTP
4. Прочие уязвимости
### Что такое JSON Web Token?
Веб-токен JSON обычно используется для авторизации в клиент-серверных приложениях. JWT состоит из трех элементов:
* Заголовок
* Полезная нагрузка
* Подпись
#### Заголовок
Это объект JSON, который представляет собой метаданные токена. Чаще всего состоит из двух полей:
* Тип токена
* Алгоритм хэширования
[Официальный сайт](https://jwt.io/introduction/) предлагает два алгоритма хэширования:
* «HS256»
* «RS256»
Но на самом деле любой алгоритм с приватным ключом может быть использован.
#### Полезная нагрузка
Это также объект JSON, который используется для хранения такой информации о пользователе, как:
* идентификатор
* имя пользователя
* роль
* время генерации токена и т.д.
#### Подпись
Это наиболее важная часть, поскольку она определяет целостность токена путем подписания заголовка и полезной нагрузки в кодировке Base64-URL, разделенных точкой (.) с секретным ключом. Например, чтобы сгенерировать токен с помощью алгоритма HS256, псевдокод будет таким:
```
// Use Base64-URL algorithm for encoding and concatenate with a dotdata = (base64urlEncode(header) + '.' + base64urlEncode(payload))// Use HS256 algorithm with "SECRET_KEY" string as a secretsignature = HMACSHA256(data , SECRET_KEY)// Complete token
JWT = data + "." + base64UrlEncode(signature)
```

#### Что такое SECRET\_KEY?
Как правило, JWT может быть сгенерирован с помощью двух механизмов шифрования, таких как:
* Симметричное
* Ассиметричное
**Симметричное шифрование:**
Этот механизм требует единственного ключа для создания и проверки JWT.
Например, пользователь "Vasya" сгенерировал JWT с «h1dd1n\_m1ss1g3» в качестве секретного ключа. Любой человек, знающий этот ключ, может с его помощью изменить токен. JWT при этом останется действительным.
*Самый распространенный алгоритм для этого типа — HS256.*
**Асимметричное шифрование:**
Этот механизм требует открытого ключа для проверки и закрытого ключа для подписи.
Например, если "Vasya" использовал это шифрование, то он единственный, кто может создать новый токен, используя закрытый ключ, тогда как "Petya" может только проверить токен с помощью открытого ключа, но не может его изменить.
*Наиболее распространенный алгоритм для этого типа — RS256.*

### Атаки на JWT
Чтобы подделать токен, необходимо иметь правильные ключи (например, секретный ключ для HS256, открытый и закрытый ключи для RS256), но если конфигурация JWT не реализована правильно, то есть много способов обойти элементы управления, которые позволяют изменить токен и получить несанкционированный доступ.
### Базовые атаки
Для выполнения всех этих атак нам понадобиться [JWT\_Tool](https://github.com/ticarpi/jwt_tool/)
#### 1. Нет алгоритма
Если приложению не удается проверить значение заголовка «alg», то мы можем изменить его значение на «none», и таким образом оно исключает необходимость действительной подписи для проверки. Например:
```
// Modified Header of JWT after changing the "alg" parameter{
"alg": "none",
"typ": "JWT"
}
```
**Команда:**
```
python3 jwt_tool.py -X a
```

Здесь jwt\_tool создал различные полезные нагрузки для использования этой уязвимости и обхода всех ограничений, пропустив раздел «Подпись».
#### 2. Изменяем алгоритм с RS256 на HS256
Как было сказано выше, алгоритму RS256 нужен закрытый ключ для подделки данных и соответствующий открытый ключ для проверки подлинности подписи. Но если мы сможем изменить алгоритм подписи с RS256 на HS256, мы заставим приложение использовать только один ключ для выполнения обеих задач, что является нормальным поведением алгоритма HMAC.
Таким образом рабочий процесс будет преобразован из асимметричного в симметричное шифрование. Теперь мы можем подписывать новые токены тем же открытым ключом.
**Команда:**
```
python3 jwt_tool.py -S hs256 -k public.pem
```
В данном случае мы сначала загружаем открытый ключ (public.pem) из приложения, а затем подписываем токен с помощью алгоритма HS256, используя этот ключ. Таким образом, мы можем создавать новые токены и вставлять полезную нагрузку в любое существующее утверждение.
#### 3. Без проверки подписи
Иногда при фаззинге данных в разделе заголовка и полезной нагрузки приложение не возвращает ошибку. Это значит, что подпись не проверяется после того, как она была подписана сервером авторизации. Таким образом, мы можем вставить любую полезную нагрузку в заявку, а токен всегда будет действительным.
**Команда:**
```
python3 jwt_tool.py -I -pc name -pv admin
```
Здесь часть подписи не проверяется, а значит можно смягчить утверждение «имени» в разделе полезной нагрузки, сделав себя «администратором».
#### 4. Взлом секретного ключа
Мы можем получить доступ к файлу SECRET\_KEY с помощью уязвимостей, таких как
* LFI
* XXE
* SSRF
Если это невозможно, то все равно можно провести другие атаки, чтобы проверить, использует ли токен какую-либо слабую секретную строку для шифрования.
*Для этой цели можно использовать расширение BurpSuite под названием JWT Heartbreaker.*
Такое раскрытие поставит под угрозу весь механизм безопасности, поскольку теперь мы можем генерировать произвольные токены с секретным ключом.
Но чтобы убедиться, что полученная нами строка является действительным ключом SECRET\_KEY или нет? Мы можем использовать функцию Crack в jwt\_tool.
**Команда:**
```
python3 jwt_tool.py -C -d secrets.txt
// Use -p flag for a string
```
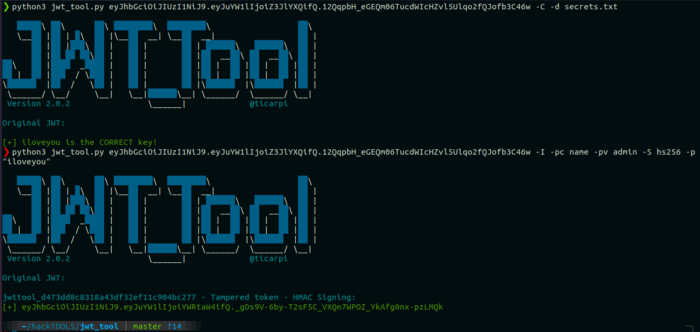
#### 5. Использование произвольных файлов для проверки
Key ID (kid) – это необязательный заголовок, имеющий строковый тип, который используется для обозначения конкретного ключа, присутствующего в файловой системе или базе данных, а затем использования его содержимого для проверки подписи. Этот параметр полезен, если приложение имеет несколько ключей для подписи токенов, но может быть опасным, если он является инъекционным, поскольку в этом случае злоумышленник может указать на конкретный файл, содержимое которого предсказуемо.
Например, «/dev/null» называется нулевым файлом устройства и всегда ничего не возвращает, поэтому он отлично работает в системах на основе Unix.
**Команда:**
```
python3 jwt_tool.py -I -hc kid -hv "../../dev/null" -S hs256 -p ""
```
В качестве альтернативы можно использовать любой файл, присутствующий в корневом веб-каталоге, например, CSS или JS. Также можно использовать его содержимое для проверки подписи.
**Другое решение проблемы:**
```
python3 jwt_tool.py -I -hc kid -hv "путь / к / файлу" -S hs256 -p "Содержимое файла"
```
### Продвинутые атаки:
#### 1. SQL-инъекция
Эта уязвимость может возникнуть, если любой параметр, который извлекает какое-либо значение из базы данных, не очищается должным образом. Благодаря чему можно решать CTF задачи.
Например, если приложение использует алгоритм RS256, но открытый ключ виден в заявлении «pk» в разделе Payload, тогда можно преобразовать алгоритм подписи в HS256 и создавать новые токены.
**Команда для подсчета количества столбцов:**
```
python3 jwt_tool.py -I -pc name -pv "imparable' ORDER BY 1--" -S hs256 -k public.pem// Increment the value by 1 until an error will occur
```
#### 2. Параметр поддельного заголовка
JSON Web Key Set (JWKS) — это набор открытых ключей, которые используются для проверки токена. Вот пример:

Этот файл хранится на доверенном сервере, приложение может указывать на этот файл через параметры заголовка:
* «jku»
* «x5u»
Но мы можем управлять URL-адресом с помощью таких уловок, как:
* открытый редирект
* добавление символа @ после имени хоста и т. д.
Затем мы можем перенаправить Приложение на наш вредоносный сервер вместо доверенного сервера и генерировать новые токены, так как мы контролируем как открытые, так и закрытые ключи.
**JSON Set URL (jku):**
Этот параметр указывает на набор открытых ключей в формате JSON (атрибуты **n** и **e** в **JWKS**), а «jwt\_tool» автоматически создает файл JWKS с именем «jwttool\_custom\_jwks.json» для этой атаки при первом запуске инструмента после установки.
**Команда:**
```
python3 jwt_tool.py -X s -ju "https://attacker.com/jwttool\_custom\_jwks.json"
```
**X.509 URL (x5u):**
Этот параметр указывает на сертификат открытого ключа X.509 или цепочку сертификатов (атрибут **x5c** в **JWKS**). Вы можете сгенерировать этот сертификат с соответствующим закрытым ключом следующим образом:
```
openssl req -newkey rsa:2048 -nodes -keyout private.pem -x509 -days 365 -out attacker.crt -subj "/C=AU/L=Brisbane/O=CompanyName/CN=pentester"
```
Здесь с использованием OpenSSL сертификат был создан в «attacker.crt», который теперь может быть встроен в файл JWKS с атрибутом «x5c», а его эксплуатация может осуществляться следующим образом:
```
python3 jwt_tool.py -S rs256 -pr private.pem -I -hc x5u -hv "https://attacker.com/custom\_x5u.json"
```
**Встроенные открытые ключи:**
Если сервер встраивает открытые ключи непосредственно в токен с помощью параметров «jwk» (JSON Web Key) или «x5c» (цепочка сертификатов X.509), попробуйте заменить их своими собственными открытыми ключами и подписать токен соответствующим закрытым ключом.
#### 3. Внедрение заголовка ответа HTTP
Предположим, что если приложение ограничивает любой управляемый URL-адрес в параметрах «jku» или «x5c», тогда мы можем использовать уязвимость внедрения заголовка ответа, чтобы добавить встроенный JWKS в ответ HTTP и заставить приложение использовать это для проверки подписи.
#### 4. Прочие уязвимости
Веб-токены JSON – это еще одна форма пользовательского ввода, все параметры в которой должны быть очищены должным образом, иначе это может привести к уязвимостям, таким как:
* LFI
* RCE и другим.
Но это не означает, что приложение по-прежнему безопасно, ведь, если злоумышленник не может подделать JWT, он попытается украсть их с помощью неправильной конфигурации:
* XSS
* CSRF
* CORS и т. д.
Удачных пентестов!
[](https://alexhost.com/ru/dedicated-servers/) | https://habr.com/ru/post/536364/ | null | ru | null |
# На что соглашается человек, когда разрешает все куки
Люди не читают инструкций. Вы почти наверняка не читали лицензионное соглашение Windows, не читали лицензионное соглашение iTunes, не читали условия Linux GPL или любого другого программного обеспечения.
Это нормально. Такова наша природа.
То же самое происходит в интернете. В последнее время благодаря GDPR и другим законам часто приходится видеть всплывающие сообщения, где вас спрашивают разрешения на использование cookies.

Большинство нажимает «Согласиться» — и продолжает жить как ни в чём ни бывало. Никто ведь не читает политику конфиденциальности, верно?
Разработчик Конрад Акунга (Conrad Akunga) [решил разобраться, какие конкретно условия предусмотрены соглашением об использовании](http://www.conradakunga.com/blog/what-do-you-actually-agree-to-when-you-accept-all-cookies/). Для примера он взял новостной сайт Reuters. Это абсолютно произвольный пример, у большинства других сайтов тоже есть свои правила.
Вот эти правила:
> 
Обратите внимание на полосу прокрутки. Дальше идёт продолжение.
****Ещё шесть экранов с текстом**





**
Если вкратце, документ информирует пользователя о нескольких вещах:
* Что веб-сайт собирает и обрабатывает данные
* Что для этого он работает с различными партнёрами
* Что сайт хранит некоторые данные на вашем устройстве с помощью файлов cookie
* Что некоторые файлы cookie строго необходимы (определяется сайтом). Их нельзя отключить.
* Некоторые персональные данные могут быть проданы партнёрам для предоставления соответствующего контента
* Вы можете персонализировать рекламу, но не удалить её
Вероятно, все эти запутанные меню компания разработала, чтобы создать некую видимость прозрачности, открытости к диалогу. Но вы всё равно не можете отключить «основные» cookie, поскольку они нужны для работы сайта.
Вы также не можете полностью отключить рекламу. Таким образом, ваш единственный выбор — либо смотреть рекламу, выбранную случайным образом, либо рекламу, которая, по мнению провайдера, может иметь к вам какое-то отношение.
И ещё один пункт о партнёрах, которым продаются ваши персональные данные. Список партнёров общий для всех сайтов, которые сотрудничают с IAB.
Кто же эти «партнёры»?
Если нажать на соответствующую кнопку, то появится следующее окно:
> 
Обратите внимание, насколько маленький ползунок на полосе прокрутки. Наверное, там их сотни. Под названием каждой компании — ссылка на политику конфиденциальности.
> 
Это не одна и та же ссылка, а разные! Каждая из них ведёт на уникальную политику конфиденциальности каждого партнёра. Сколько человек на самом деле пойдёт по этим ссылкам вручную, чтобы прочитать условия? Это просто нереально.
Конрад Акунга воспользовался инструментами разработчика Chrome, чтобы извлечь реальный список партнёров со ссылками на условия конфиденциальности каждого из них.

Скопированный список он вставил в VSCode — и получил огромный файл на 3835 строк, который после форматирования (`Alt + Shift + F`) разбился в чудовище на 54 399 строк.

Конрад написал программку, которая с помощью регулярных выражений извлекает нужные фрагменты данных — названия компаний с URL — и генерирует результат в формате Markdown по шаблону.
```
Log.Logger = new LoggerConfiguration()
.WriteTo.Console()
.CreateLogger();
// Define the regex to extact vendor and url
var reg = new Regex("\"vendor-title\">(?.\*?)<.\*?vendor-privacy-notice\".\*?href=\"(?.\*?)\"",
RegexOptions.Compiled);
// Load the vendors into a string, and replace all newlines with spaces to mitigate
// formatting issues from irregular use of the newline
var vendors = File.ReadAllText("vendors.html").Replace(Environment.NewLine, " ");
// Match against the vendors html file
var matches = reg.Matches(vendors);
Log.Information("There were {num} matches", matches.Count);
// extract the vendor number, name and their url, ordering by the name first.
var vendorInfo = matches.OrderBy(match => match.Groups["company"].Value)
.Select((match, index) =>
new
{
Index = index + 1,
Name = match.Groups["company"].Value,
URL = match.Groups["url"].Value
});
// Create a string builder to progressively build the markdown
var sb = new StringBuilder();
// Append headers
sb.AppendLine($"Listing As At 30 December 2020 08:10 GMT");
sb.AppendLine();
sb.AppendLine("|-|Vendor| URL |");
sb.AppendLine("|---|---|---|");
// Append the vendor details
foreach (var vendor in vendorInfo)
sb.AppendLine($"|{vendor.Index}|{vendor.Name}|[{vendor.URL}]({vendor.URL})|");
// Delete existing markdown file, if present
if (File.Exists("vendors.md"))
File.Delete("vendors.md");
//Write markdown to file
File.WriteAllText("vendors.md", sb.ToString());
```
В результате получился список всех партнёров, и у каждой — свой уникальный документ c условиями конфиденциальности. Вот этот список: [vendors.md](https://raw.githubusercontent.com/conradakunga/BlogCode/master/30%20Dec%202021%20-%20GDPR%20Data%20Vendors/vendors.md).
В нём **647 компаний**.
Очевидно, что *никто* не сможет ознакомиться со всеми этими условиями прежде, чем нажать кнопку «Согласиться», делает вывод автор.
Помните, что эти рекламные провайдеры предоставляют одни и те же услуги разным сайтам. Они однозначно идентифицируют браузер и устройство, поэтому могут анализировать и отслеживать ваши действия на разных сайтах для создания максимально точного профиля. На каждого якобы анонимного пользователя собираются [большие объёмы данных](https://privacyinternational.org/long-read/2433/i-asked-online-tracking-company-all-my-data-and-heres-what-i-found).
Код для парсинга из этой статьи [опубликован на Github](https://github.com/conradakunga/BlogCode/tree/master/30%20Dec%202021%20-%20GDPR%20Data%20Vendors). | https://habr.com/ru/post/544036/ | null | ru | null |
# Python как предельный случай C++. Часть 2/2
Продолжение. Начало в «[Python как предельный случай C++. Часть 1/2](https://habr.com/ru/post/464385/)».
Переменные и типы данных
========================
Теперь, когда мы окончательно разобрались с математикой, давайте определимся, что в нашем языке должны означать переменные.
В С++ у программиста есть выбор: использовать автоматические переменные, размещаемые в стеке, или держать значения в памяти данных программы, помещая в стек только указатели на эти значения. Что, если мы выберем для Python только одну из этих опций?
Разумеется, мы не можем всегда использовать только значения переменных, так как большие структуры данных не поместятся в стек, либо их постоянное перемещение по стеку создаст проблемы с производительностью. Поэтому мы будем использовать в Python только указатели. Это концептуально упростит язык.
Таким образом, выражение
```
a = 3
```
будет означать то, что мы создали в памяти данных программы (так называемой «куче») объект «3» и сделали имя “a” ссылкой на него. А выражение
```
b = a
```
в таком случае будет означать, что мы заставили переменную “b” ссылаться на тот же объект в памяти, на который ссылается “a”, иначе говоря − скопировали указатель.
Если всё является указателем, то сколько списочных типов нам нужно реализовать в нашем языке? Разумеется, только один − список указателей! Вы можете использовать его для хранения целых, строк, других списков, чего угодно − ведь всё это указатели.
Сколько типов хэш-таблиц нам нужно реализовать? (В Python этот тип принято называть «словарём» − `dict`.) Один! Пусть он связывает указатели на ключи с указателями на значения.
Таким образом, нам не нужно реализовывать в нашем языка огромную часть спецификации C++ − шаблоны, поскольку все операции мы производим над объектами, а объекты всегда доступны по указателю. Конечно же, программы, написанные на Python, не обязаны ограничиваться работой с указателями: существуют библиотеки вроде NumPy, при помощи которых учёные работают с массивами данных в памяти, как они бы делали это в Fortran. Но основа языка − выражения вроде “a = 3” − всегда работают с указателями.
Концепция «всё является указателем» также упрощает до предела композицию типов. Хотите список словарей? Просто создайте список и поместите туда словари! Не нужно спрашивать у Python разрешения, не нужно объявлять дополнительные типы, всё работает «из коробки».
А что, если мы хотим использовать составные объекты в качестве ключей? Ключ в словаре должен иметь неизменяемое значение, иначе как искать значения по нему? Списки могут изменяться, поэтому их нельзя использовать в данном качестве. Для подобных ситуаций в Python есть тип данных, который, аналогично списку, является последовательностью объектов, но, в отличие от списка, последовательность эта не изменяется. Этот тип называется кортеж или `tuple` (произносится как «тьюпл» или «тапл»).
Кортежи в Python решают давнюю проблему скриптовых языков. Если вас не впечатляет эта возможность, то вы, наверное, никогда не пытались использовать для серьёзной работы с данными скриптовые языки, в которых в качестве ключа в хэш-таблицах можно использовать только строки или только примитивные типы.
Другая возможность, которую дают нам кортежи − возврат из функции нескольких значений без необходимости объявлять для этого дополнительные типы данных, как это приходится делать в C и C++. Более того, чтобы было проще пользоваться данной возможностью, оператор присваивания был наделён возможностью автоматически распаковывать кортежи в отдельные переменные.
```
def get_address():
...
return host, port
host, port = get_address()
```
У распаковки есть несколько полезных побочных эффектов, например, обмен переменных значениями можно записать так:
```
x, y = y, x
```
Всё является указателем, значит, функции и типы данных могут использоваться как данные. Если вы знакомы с книгой «Паттерны проектирования» за авторством «Банды четырёх», вы должны помнить, какие сложные и запутанные способы она предлагает для того, чтобы параметризовать выбор типа объекта, создаваемого вашей программой во время выполнения. Действительно, во многих языках программирования это сложно сделать! В Python все эти сложности улетучиваются, поскольку мы знаем, что функция может вернуть тип данных, что и функции, и типы данных − это просто ссылки, а ссылки можно хранить, например, в словарях. Это упрощает задачу до предела.
Дэвид Вилер говорил: «Все проблемы в программировании решаются путём создания дополнительного уровня косвенности». Использование ссылок в Python − это тот уровень косвенности, который традиционно применяется для решения множества проблем во многих языках, в том числе и в C++. Но если там он используется явно, и это приводит к усложнению программ, то в Python он используется неявно, единоообразно в отношении данных всех типов, и дружественно к пользователю.
Но если всё является ссылками, то на что ссылаются эти ссылки? В языках вроде C++ есть множество типов. Давайте оставим в Python только один тип данных − объект! Специалисты в области теории типов неодобрительно качают головами, но я считаю, что один исходный тип данных, от которого производятся все остальные типы в языке − это хорошая идея, обеспечивающая единообразность языка и простоту его использования.
Что касается конкретного содержимого памяти, то различные реализации Python (PyPy, Jython или MicroPython) могут управлять памятью по-разному. Но, чтобы лучше понять, как именно реализуется простота и единообразность Python, сформировать правильную ментальную модель, лучше обратиться к эталонной реализации Python на языке C, называемой CPython, которую мы можем загрузить на сайте [python.org](https://python.org/).
```
struct {
struct _typeobject *ob_type;
/* followed by object’s data */
}
```
То, что мы увидим в исходном коде CPython − это структура, которая состоит из указателя на информацию о типе данной переменной и полезной нагрузки, которая определяет конкретное значение переменной.
Как же устроена информация о типе? Снова углубимся в исходный код CPython.
```
struct _typeobject {
/* ... */
getattrfunc tp_getattr;
setattrfunc tp_setattr;
/* ... */
newfunc tp_new;
freefunc tp_free;
/* ... */
binaryfunc nb_add;
binaryfunc nb_subtract;
/* ... */
richcmpfunc tp_richcompare;
/* ... */
}
```
Мы видим указатели на функции, которые обеспечивают выполнение всех операций, которые возможны для данного типа: сложение, вычитание, сравнение, доступ к атрибутам, индексирование, слайсинг и т. д. Эти операции знают, как работать с полезной нагрузкой, которая расположена в памяти ниже указателя на информацию о типе, будь то целое число, строка или объект типа, созданного пользователем.
Это радикальным образом отличается от C и C++, в которых информация о типе ассоциируется с именами, а не со значениями переменных. В Python все имена ассоциированы со ссылками. Значение по ссылке, в свою очередь, имеет тип. В этом и заключается суть динамических языков.
Чтобы реализовать все возможности языка, нам достаточно определить две операции над ссылками. Одна из них наиболее очевидна − это копирование. Когда мы присваиваем значение переменнной, слоту в словаре или атрибуту объекта, мы копируем ссылки. Это простая, быстрая и совершенно безопасная операция: копирование ссылок не изменяет содержимое объекта.
Вторая операция − это вызов функции или метода. Как мы показали выше, программа на Python может взаимодействовать с памятью только посредством методов, реализованных во встроенных объектах. Поэтому она не может вызвать ошибку, связанную с обращением к памяти.
У вас может возникнуть вопрос: если все переменные содержат ссылки, то как я могу защитить от изменений значение пременной, передав её функции как параметр?
```
n = 3
some_function(n)
# Q: I just passed a pointer!
# Could some_function() have changed “3”?
```
Ответ заключается в том, что простые типы в Python являются неизменяемыми: в них попросту не реализован тот метод, который отвечает за изменение их значения. Неизменяемые (иммутабельные) `int`, `float`, `tuple` или `str` обеспечивают в языках типа «всё является указателем» тот же семантический эффект, который в C обеспечивают автоматические переменные.
Унифицированные типы и методы максимально упрощают применение обобщённого программирования, или дженериков. Функции `min()`, `max()`, `sum()` и им подобные являются встроенными, нет нужды их импортировать. И они работают с любыми типами данных, в которых реализованы операции сравнения для `min()` и `max()`, сложения для `sum()` и т. д.
Создание объектов
=================
Мы выяснили в общих чертах, как должны вести себя объекты. Теперь определим, как мы будем их создавать. Это − вопрос синтаксиса языка. C++ поддерживает как минимум три способа создания объекта:
1. Автоматический, объявлением переменной данного класса:
```
my_class c(arg);
```
2. С помощью оператора `new`:
```
my_class *c = new my_class(arg);
```
3. Фабричный, при помощи вызова произвольной функции, возвращающей указатель:
```
my_class *c = my_factory(arg);
```
Как вы уже, наверное, догадались, изучив способ мышления создателей Python на вышеприведённых примерах, теперь мы должны выбрать один из них.
Из той же книги «Банды четырёх» мы узнали, что фабрика − это самый гибкий и универсальный способ создания объектов. Поэтому в Python реализован только этот способ.
Помимо универсальности, этот способ хорош тем, что для его обеспечения не нужно перегружать язык лишним синтаксисом: вызов функции уже реализован в нашем языке, а фабрика − это не что иное, как функция.
Другое правило создания объектов в Python таково: любой тип данных является собственной фабрикой. Конечно, вы можете написать сколько угодно дополнительных, кастомных фабрик (которые будут являться обычными функциями или методами, конечно же), но общее правило останется в силе:
```
# Let’s make type objects
# their own type’s factories!
c = MyClass()
i = int('7')
f = float(length)
s = str(bytes)
```
Все типы являются вызываемыми объектами, и все они возвращают значения своего типа, определяемые аргументами, переданными при вызове.
Таким образом, с использованием только базового синтаксиса языка, могут быть инкапсулированы любые манипуляции при создании объектов, вроде паттернов «Арена» или «Приспособленец», поскольку ещё одна замечательная идея, позаимствованная из C++, заключается в том, что тип сам определяет, как происходит порождение его объектов, как оператор `new` работает для него.
Как насчёт NULL?
================
Обработка пустого указателя добавляет программе сложности, так что мы объявим NULL вне закона. Синтакс Python не даёт возможности создать нулевой указатель. Две элементарные операции над указателями, о которых мы говорили ранее, определены таким образом, что любая переменная указывает на какой-то объект.
Как следствие этого, пользователь не может средствами языка Python создать ошибку, связанную с обращением к памяти, типа ошибки сегментации или выхода за границы буфера. Иными словами, программы на Python не подвержены двум самым опасным типам уязвимостей, которые угрожают безопасности Интернета в течение последних 20 лет.
Вы можете спросить: «Если структура операций над объектами неизменна, как мы видели ранее, то как же пользователи будут создавать собственные классы, с методами и атрибутами, не перечисленными в этой структуре?»
Магия заключена в том, что для пользовательских классов Python имеет очень простую «заготовку» с небольшим числом реализованных методов. Вот самые важные из них:
```
struct _typeobject {
getattrfunc tr_getattr;
setattrfunc tr_setattr;
/* ... */
newfunc tp_new;
/* ... */
}
```
`tp_new()` создаёт для пользовательского класса хэш-таблицу, такую же, как для типа `dict`. `tp_getattr()` извлекает что-то из этой хэш-таблицы, а `tp_setattr()`, наоборот, что-то туда кладёт. Таким образом, способность произвольных классов хранить любые методы и атрибуты обеспечивается не на уровне структур языка C, а уровнем выше − хэш-таблицей. (Разумеется, за исключением некоторых случаев, связанных с оптимизацией производительности.)
Модификаторы доступа
====================
Что же нам делать со всеми теми правилами и концепциями, которые в C++ построены вокруг ключевых слов `private` и `protected`? Python, будучи скриптовым языком, не нуждается в них. У нас уже есть «защищённые» части языка − это данные встроенных типов. Ни при каких условиях Python не позволит программе, например, манипулировать битами числа с плавающей запятой! Этого уровня инкапсуляции вполне достаточно, чтобы поддержать целостность самого языка. Мы, создатели Python, считаем, что целостность языка − это единственный хороший предлог для сокрытия информации. Все остальные структуры и данные пользовательской программы считаются публичными.
Вы можете написать символ подчёркивания (`_`) в начале имени атрибута класса, чтобы предупредить коллегу: на этот атрибут не стоит полагаться. Но в остальном Python выучил уроки начала 90-х: тогда многие верили в то, что основной причиной того, что мы пишем раздутые, нечитаемые и забагованные программы, является недостаток приватных переменных. Думаю, следующие 20 лет убедили всех в индустрии программирования: приватные переменные − это не единственное, и далеко не самое эффективное средство от раздутых и забагованных программ. Поэтому создатели Python решили даже не беспокоиться по поводу приватных переменных, и, как видите, не прогадали.
Управление памятью
==================
Что же происходит с нашими объектами, числами и строками на более низком уровне? Как именно они размещаются в памяти, как CPython обеспечивает совместный доступ к ним, когда и при каких условиях они уничтожаются?
И в этом случае мы выбрали наиболее общий, предсказуемый и производительный способ работы с памятью: со стороны C-программы все наши объекты − это [разделяемые указатели](https://en.cppreference.com/w/cpp/memory/shared_ptr).
С учётом этого знания те структуры данных, которые мы рассмотрели ранее, в части «Переменные и типы данных», должны быть дополнены следующим образом:
```
struct {
Py_ssize_t ob_refcnt;
struct {
struct _typeobject *ob_type;
/* followed by object’s data */
}
}
```
Итак, каждый объект в Python (мы имеем в виду реализацию CPython, разумеется) имеет свой счётчик ссылок. Как только он становится равным нулю, объект может быть удалён.
Механизм подсчёта ссылок не опирается на дополнительные вычисления или фоновые процессы − объект может быть уничтожен мгновенно. Кроме того, он обеспечивает высокую локальность данных: зачастую память снова начинает использоваться сразу после освобождения. Только что уничтоженный объект, скорее всего, недавно использовался, а значит, находился в кэше процессора. Поэтому и только что созданный объект останется в кэше. Эти два фактора − простота и локальность − делают подсчёт ссылок очень производительным способом сборки мусора.
(Из-за того, что объекты в реальных программах нередко ссылаются друг на друга, счётчик ссылок в определённых случаях не может опуститься до нуля, даже когда объекты больше не используются в программе. Поэтому в CPython есть и второй механизм сбора мусора − фоновый, основанный на поколениях объектов. − *прим. перев.*)
Ошибки разработчиков Python
===========================
Мы старались разработать язык, который будет достаточно прост для новичков, но и достаточно привлекателен для профессионалов. При этом нам не удалось избежать ошибок в понимании и использовании инструментов, которые мы сами и создали.
Python 2 из-за инерции мышления, связанной со скриптовыми языками, пытался преобразовывать строковые типы, как делал бы это язык с нестрогой типизацией. Если вы попытаетесь объединить байтовую строку со строкой в Unicode, интерпретатор неявно преобразует байтовую строку в Unicode при помощи той кодовой таблицы, которая имеется в данной системе, и представит результат в Unicode:
```
>>> 'byte string ' + u'unicode string'
u'byte string unicode string'
```
В результате некоторые веб-сайты отлично работали, пока их пользователи использовали английский язык, но выдавали загадочные ошибки при использовании символов других алфавитов.
Эта ошибка проектирования языка была исправлена в Python 3:
```
>>> b'byte string ' + u'unicode string'
TypeError: can't concat bytes to str
```
Похожая ошибка в Python 2 была связана с «наивной» сортировкой списков, состоящих из несравнимых элементов:
```
>>> sorted(['b', 1, 'a', 2])
[1, 2, 'a', 'b']
```
Python 3 в этом случае даёт пользователю понять, что тот пытается сделать что-то не слишком осмысленное:
```
>>> sorted(['b', 1, 'a', 2])
TypeError: unorderable types: int() < str()
```
Злоупотребления
===============
Пользователи и сейчас иногда злоупотребляют динамической природой языка Python, а тогда, в 90-х, когда лучшие практики ещё не были широко известны, это происходило особенно часто:
```
class Address(object):
def __init__(self, host, port):
self.host = host
self.port = port
```
«Но это же неоптимально!» − говорили некоторые, − «Что, если порт не отличается от дефолтного значения? Мы всё равно тратим на его хранение целый атрибут класса!» И в результате получалось что-то вроде
```
class Address(object):
def __init__(self, host, port=None):
self.host = host
if port is not None: # so terrible
self.port = port
```
Так в программе появляются объекты одного типа, с которыми, тем не менее, нельзя работать единообразно, так как одни из них имеют некий атрибут, а другие − нет! И мы не можем прикоснуться к этому атрибуту, не проверив заранее его наличие:
```
# code was forced to use introspection
# (terrible!)
if hasattr(addr, 'port'):
print(addr.port)
```
В настоящее время обилие `hasattr()`, `isinstance()` и прочей интроспекции является верным признаком плохого кода, а лучшей практикой считается делать атрибуты всегда присутствующими в объекте. Это обеспечивает более простой синтаксис при обращении к нему:
```
# today’s best practice:
# every atribute always present
if addr.port is not None:
print(addr.port)
```
Так, ранние эксперименты с динамически добавляемыми и удаляемыми атрибутами завершились, и теперь мы рассматриваем классы в Python примерно так же, как и в C++.
Другой дурной привычкой раннего Python было использование функций, в которых аргумент может иметь совершенно разные типы. Например, вы можете подумать, что для пользователя может быть слишком сложно создавать каждый раз список с именами колонок, и сто́ит разрешить ему передавать их также в виде одной строки, где имена отдельных колонок разделены, скажем, запятой:
```
class Dataframe(object):
def __init__(self, columns):
if isinstance(columns, str):
columns = columns.split(',')
self.columns = columns
```
Но такой подход может породить свои проблемы. Например, что, если пользователь случайно передаст нам строку, которая не предназначена для того, чтобы быть использована как список имён колонок? Или если имя колонки должно содержать запятую?
Также такой код сложнее поддерживать, отлаживать, и особенно тестировать: в тестах может быть предусмотрена проверка только одного из двух поддерживаемых нами типов, но покрытие всё равно составит 100%, и мы не протестируем другой тип.
В итоге мы пришли к тому, что Python даёт пользователю возможность передавать функции аргументы какого угодно типа, но большинство из них в большинстве ситуаций будут использовать функцию так же, как они делали бы это в C: передавать ей аргумент одного типа.
Необходимость использования `eval()` в программе считается явным архитектурным просчётом. Скорее всего, вы просто не сообразили, как сделать то же самое нормальным способом. Но в некоторых случаях − например, если вы пишете программу типа Jupyter notebook или онлайн-песочницу для запуска и тестирования пользовательского кода − использование `eval()` вполне оправдано, и в этом типе задач Python проявляет себя великолепно! Действительно, реализовать нечто подобное на C++ было бы намного сложнее.
Как мы уже показали выше, интроспекция (`getattr()`, `hasattr()`, `isinstance()`) не всегда является хорошим средством для выполнения типичных пользовательских задач. Но эти возможности, тем не менее, встроены в язык, и они просто сверкают в ситуациях, когда наш код должен описывать сам себя: логгирование, тестирование, статическая проверка, отладка!
Эра консолидации
================
В заключение мне хочется отметить следующее: мы живём в такое время, когда лучшие практики разработки на различных языках проявляют тенденцию к консолидации. 20 лет назад я не смог бы даже упомянуть разделяемые указатели в контексте того, что объединяет C++ и Python. А сегодня сообщества, сформировавшиеся вокруг разных языков программирования, свободно обмениваются лучшими практиками. И это изменение произошло в течение девяностых и нулевых.
Чтобы получить количественные измерения в подтверждение моей гипотезы, я мониторил использование `shared_ptr` в TensorFlow примерно с 2016 по 2018 год.
TensorFlow − это большой и во многом образцовый C++-проект, но большинство программистов знают его лишь в качестве Python-библиотеки (а C++ − в качестве сборочной системы TensorFlow, наверное).
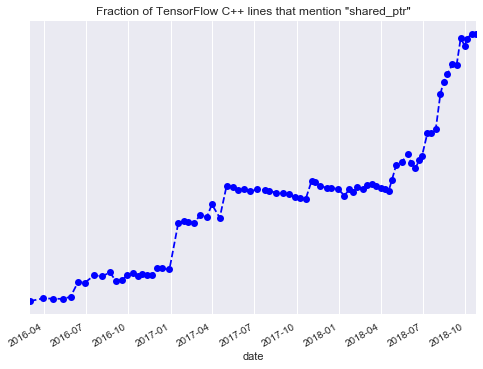
На диаграмме по вертикали изображено соотношение строк кода TensorFlow, использующих `shared_ptr`, к общему числу строк кода. В лучших традициях Кремниевой долины, этот график направлен строго вверх.
Так куда же направляется современный C++? В начале мы говорили о предельных случаях. Что происходит на графике, который мы видим? Если время стремится к бесконечности, то всё становится разделёнными указателями, и C++ становится Python! | https://habr.com/ru/post/464405/ | null | ru | null |
# Upgrade Viola Jones
В [моём предыдущем топике](http://habrahabr.ru/blogs/algorithm/133826/) я старался показать, как метод Viola Jones работает, с помощью каких технологий и внутренних алгоритмов. В данном посте, дабы не прерывать цепочку, будет также много теории, будет показано *за счет чего* можно улучшить и до того прекрасный метод. Если здесь описать еще и *программную реализацию*, то будет огромное полотно, которое читать будет очень неудобно, и смотреться это никак не будет — решено разбить объем информации на два отдельных поста. Ниже — теория, мало картинок, но много полезного.
### Возникающие проблемы на этапах распознавания эмоций
Человек даже не замечает, как он просто справляется с задачами обнаружения лиц и эмоций при помощи своего зрения. Когда глаз смотрит на окружающие лица людей, предметы, природу, подсознательно не чувствуется, какой объем работы проделывает мозг, чтобы обработать весь поток визуальной информации. Человеку не составит труда найти знакомого человека на фотографии, или отличить ехидную гримассу от улыбки.
Человек пытается *воссоздать и построить* компьютерную систему обнаружения лиц и эмоций — ему это отчасти удается, но каждый раз приходится сталкиваться с большими проблемами при распознавании. Компьютеры в наше время беспрепятственно могут хранить огромные объемы информации, картинки, видео- и аудио файлы. Но отыскать вычислительным системам с такой же легкостью, к примеру, нужную фотографию с определенной эмоцией нужного человека из собственной личной фотогалереи — сложная задача. Решению такой задачи мешают некоторые **факторы**:
* Разный размер искомых объектов, а также масштаб изображений;
* Определяемый объект может находиться где угодно на изображении;
* Совершенно другой объект может быть похож на искомый;
* Предмет, который мы воспринимаем как что-то отдельное, на изображении никак не выделен, и находится на фоне других предметов, сливается с ними;
* Старые и необработанные фотографии — на них всегда присутствуют «отвлекающие» систему царапины, помехи, искажения, а на сканируемых фото нередко появляются разного рода [муары](http://ru.wikipedia.org/wiki/%D0%9C%D1%83%D0%B0%D1%80_%D0%BC%D0%BD%D0%BE%D0%B3%D0%BE%D0%BA%D1%80%D0%B0%D1%81%D0%BE%D1%87%D0%BD%D0%BE%D0%B9_%D0%BF%D0%B5%D1%87%D0%B0%D1%82%D0%B8);
* Не стоит забывать, что во многих алгоритмах распознавания (также и в Виола-Джонс) работа идет с 2D-пространстве непосредственно. Поэтому поворот искомого объекта и изменение угла обзора относительно заданных координатных осей проекции влияют на его проекцию в 2D. Один и тот же объект может давать совершенно разную картинку, в зависимости от поворота или расстояния до него. Искомое лицо может быть повернуто в плоскости изображения. Даже относительно небольшое изменение ориентации лица относительно камеры влечет за собой серьезное изменение изображения лица и о распознании мимики данного лица уже и речи быть не может;
* Качество изображения или кадра: засветы и неправильный [баланс белого](http://ru.wikipedia.org/wiki/%D0%91%D0%B0%D0%BB%D0%B0%D0%BD%D1%81_%D0%B1%D0%B5%D0%BB%D0%BE%D0%B3%D0%BE_%D1%86%D0%B2%D0%B5%D1%82%D0%B0), цветокоррекция и другие параметры безусловно влияют на распознавание объекта;
* Расовая принадлежность людей: цвет кожи, расположение и размеры отдельных распознаваемых признаков;
* Сильное изменение выражения лица. Например, чересчур показное действо может сильно оказать влияние на правильное распознавание определенной эмоции;
* Индивидуальные особенности лица человека, такие как усы, борода, очки, морщины, существенно осложняют автоматическое распознавание;
* Часть лица вообще может быть невидима или обрезана;
* Лица может не быть совсем на фотографии, но машина, как ей кажется, правильно определяет другие объекты за лицо и черты лица и детектирует именно их.
Список можно продолжать еще долго. Но внимание заострено на самых важных моментах, поэтому перечислять все мешающие параметры нет смысла.
### Критерии выбора метода в задаче распознавания эмоций
Сравнение качества распознавания разнообразных методов осложнено многими причинами. Одна из них, и самая весомая – это то, что в большинстве случаев опираться можно только на данные испытаний, предоставляемые самими авторами, так как проведение крупномасштабного исследования по реализации большинства известных методов и сравнения их между собой на едином наборе изображений не представляется возможным:
* необходима универсальная коллекция тестовых данных;
* должны присутствовать одинаковые наборы данных;
* необходимы вычислительная мощность — ресурсы уровня одной лаборатории для этого малы;
* высокая трудоемкость исследования данных алгоритмов;
* на основе информации, предоставляемой авторами методов, также сложно провести корректное сравнение, поскольку проверка методов часто производится на разных наборах изображений, с разной формулировкой условий успешного и неуспешного обнаружения. К тому же проверка для многих методов первой категории производилась на значительно меньших наборах изображений.
*Основные моменты*, влияющие на выбор метода решения задачи, и *условия критериев* выявлены следующие (в процессе разработки интересуют те, которые выделены курсивом, наиболее оптимальные):
• ограничения на лица:
— ограниченный, предопределенный набор людей;
— ограничения на возможную расу людей либо на характерные отличия на лице (к примеру, растительность на лице, очки);
— *отсутствие ограничений*.
• положение лица на изображении:
— фронтальное;
— наклон под известным углом;
— *любой наклон*.
• тип изображения:
— цветное;
— черно-белое;
- *любое*.
• масштаб лица:
— полностью в «основном кадре»;
— локализовано в определенном месте с определенными размерами;
— *неважно*.
• разрешение и качество изображения:
— плохое/плохое;
— плохое/хорошее;
— только хорошее;
- *любое*.
• шумы, помехи, муары:
— слабые;
— сильные;
— *неважно*.
• количество лиц на изображении:
— известно;
— примерно известно;
— *неизвестно*.
• освещение:
— известно;
— приблизительно известно;
— *любое*.
• фон:
— фиксированный;
— контрастный однотонный;
— слабоконтрастный зашумленный;
— неизвестный;
— *без разницы*.
• важность исследования:
— *важнее идентифицировать все лица и черты*;
— минимизировать ошибки ложных обнаружений путем минимизации обнаружений на изображении.
### Предлагаемые улучшения
Метод Виолы-Джонса иногда выдает поразительные ошибки, о чем упоминали некоторые Хабраюзеры. Поэтому, самым логичным решением в данной ситуации было модифицировать алгоритм Виолы-Джонса и улучшить его характеристики распознавания, если это вообще возможно.
Предлагаемый ниже метод *предполагает возможное избавление* от:
* больших ограничений в виде недостаточной освещенности, существующих помех на изображении и неразличимого объекта на фоне с помощью предварительной обработки изображения;
* проблемы угла наклона лица путем тренировки новых каскадов, специально обученных на нахождение наклоненной головы;
* неточностей обнаружения эмоций на лице человека путем перечисленных выше пунктов, путем введения новых примитивов Хаара, расширяющих стандартный набор, реализуемый в алгоритме Виолы-Джонса и путем обучения большого количества каскадов, специально заточенных под то или иное состояние черты лица определенной эмоции.
С учетом заявленного выше, данный метод работы должен снизить время определения эмоции.
Схема нового метода представлена на рисунке ниже:

#### Дополнительные примитивы Хаара
Итак, для повышения возможностей алгоритма и качества нахождения наклоненных черт лица я предлагаю такой вариант новых типов признаков, как на рисунке.Такие признаки были выбраны не случайно, а в связи с силуэтами искомых черт лица. С помощью данных признаков программа будет искать намного быстрее нос, брови и рот, но при этом на другие черты лица будет тратить чуть больше времени, чем в стандартном алгоритме, но дополнительные признаки стоит внедрить: в-целом, выигрываются миллисекунды распознавания и незначительно, но увеличивается точность.
#### Предварительная обработка изображения
[Описанные алгоритмы](http://habrahabr.ru/blogs/algorithm/133826/), которые использует метод Виолы — Джонса имеют достаточно широкое применение. Сам же метод может удачно взаимодействовать с другими алгоритмами и может быть адаптирован под определенные нужды и требования. Также, он работает не только со статичными изображениями, можно беспрепятственно обрабатывать данные в реальном времени. Однако даже он не обеспечивает идеальное распознавание эмоций. Попробуем еще выше поднять процент распознавания с помощью Виолы-Джонса. Для этого, с целью увеличения производительности принято решение выполнять *предварительную обработку изображения*.
Для создания быстрого и надежного способа определения вероятных областей лица человека с целью ускорения обработки на дальнейших этапах обнаружения, предлагается *алгоритм определения и выделения граничных контуров*. *Идея* данного подхода заключается в том, что можно *подчеркнуть те области*, в которых *с наибольшей вероятностью* можно будет найти *лицо и его черты*. Тем самым достигается не только ускорение работы алгоритма, но и уменьшается вероятность ложных обнаружений лиц. Данные этапы будут проиллюстрированы на исходной картинке:

##### Изображение в градациях серого
Для начала нужно перевести изображение в [градации серого](http://ru.wikipedia.org/wiki/%D0%A1%D0%B5%D1%80%D0%B0%D1%8F_%D1%88%D0%BA%D0%B0%D0%BB%D0%B0). Для этого удобно представить изображение в цветовой модели [YUV](http://ru.wikipedia.org/wiki/YUV). Для этого выполняется конверсия:
`* Y = 0.299 \* R + 0.587 \* G + 0.114 \* B;
* U = -0.14713 \* R - 0.28886 \* G + 0.436 \* B; (1.1)
* V = 0.615 \* R - 0.51499 \* G - 0.10001 \* B;`, где R, G и B – *это интенсивности заданных цветов*, если совсем точно, то это матрицы, описывающие компоненты модели (R,G,B). Y в формуле – это *яркостная составляющая*, а U и V — *цветоразностные составляющие*, так называемые сигналы цветности (эти три параметра тоже представлены матрицами, описывающими компоненты модели (Y,U,V)). Присутствующие в формуле коэффициенты перевода постоянны и определяются особенностями человеческого восприятия. Для полутонового изображения важно только значение первой составляющей.

##### Пространственная фильтрация
Переведенное полутоновое изображение сглаживается и осуществляется *пространственное дифференцирование* — вычисляется градиент функции интенсивности в каждой точке изображения. Предполагается, что области соответствуют реальным объектам, или их частям, а границы областей соответствуют границам реальных объектов. Используется обнаружение разрывов яркости с помощью *скользящей маски (sliding window)*. В разных учебниках и статьях ее по разному называют, обычно именуют фильтром или ядром, которое представляет собой квадратную матрицу, соответствующую сопоставленным Y исходного изображения. Схема пространственной фильтрации изображена ниже:

##### Оператор Собеля
В применяемом методе, использующем специальные ядра, известные как «[операторы Собеля](http://ru.wikipedia.org/wiki/%D0%9E%D0%BF%D0%B5%D1%80%D0%B0%D1%82%D0%BE%D1%80_%D0%A1%D0%BE%D0%B1%D0%B5%D0%BB%D1%8F)», действующие в области изображения размером 3\*3 используется весовой коэффициент 2 для средних элементов. Коэффициенты ядра выбраны так, чтобы при его применении одновременно выполнялось сглаживание в одном направлении и вычисление пространственной производной – в другом. Маски, используемые оператором Собеля, отображены ниже:

По ним получаем составляющие градиента Gx и Gy:
`Gx = (z7 + 2z8 + z9) – (z1 + 2z2 + z3) (1.2)
и
Gy = (z3 + 2z6 + z9) – (z1 + 2z4 + z7) (1.3)`
Для вычисления величины градиента эти составляющие необходимо использовать совместно:
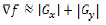 (1.4)
или 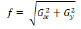 (1.5)
Результат показывает, насколько «резко» или «плавно» меняется яркость изображения в каждой точке, а значит, вероятность нахождения точки на грани, а также ориентацию границы. Результатом работы оператора Собеля в точке области постоянной яркости будет нулевой вектор, а в точке, лежащей на границе областей различной яркости — вектор, пересекающий границу в направлении увеличения яркости. Также, результат работы — перевод фотографии в граничные контуры (это можно видеть на преобразованной картинке):

##### Пороговая классификация
Далее, то же полутоновое изображение подвергается *пороговой классификации (thresholding)*, или выбору порога по яркости. Смысл такого порога заключается в том, чтобы отделить искомый светлый объект (foreground) и темный фон (background), где объект — это совокупность тех пикселей, яркость которых превышает порог (I > T), а фон — совокупность остальных пикселей, яркость которых ниже порога (I < T). Примерный алгоритм работы с *глобальным порогом* в автоматическом режиме выглядит так:
1. Выбирается начальная оценка порога Т – это может быть средний уровень яркости изображения (полусумма минимальной и максимальной яркости, min+max/2) или любой другой критерий порога;
2. Производится некая сегментация изображения с помощью порога Т — в результате образуются две группы пикселей: G1, состоящая из пикселей с яркостью больше T, и G2, состоящая из пикселей с яркостью меньше или равной T;
3. Вычисляются средние значения μ1 и μ2 яркостей пикселей по областям G1 и G2;
4. Вычисляется новое значение порога T = 0.5 \* (μ1 + μ2);
5. Повторяются шаги со второго по четвертый до тех пор, пока разница значений порога Т предыдущего и T вычисленного в последней итерации не окажется меньше наперед заданного параметра ε.

##### Бинаризация методом Отсу
Оператор Собеля не может этого сделать, так как дает очень много шумов и помех, поэтому полутоновое изображение необходимо *бинаризировать*. Существуют десятки методов выбора порога, но выбран именно метод, придуманный японским ученым [Нобуюки Отсу (Otsu's Method)](http://en.wikipedia.org/wiki/Otsu's_method) в 1979 году [1], т.к. он быстр и эффективен. Значения яркостей пикселей изображения можно рассматривать как случайные величины, а их гистограмму – как оценку плотности распределения вероятностей. Если плотности распределения вероятностей известны, то можно определить оптимальный (в смысле минимума ошибки) порог для сегментации изображения на два класса c0 и c1 (объекты и фон). **Гистограмма** — это набор бинов (или столбцов), каждый из которых характеризует количество попаданий в него элементов выборки. В случае полутонового изображения — это пиксели различной яркости, которые могут принимать целые значения от 0 до 255. Благодаря гистограмме человеку видны *два четко разделяющихся класса*. Суть метода Отсу заключается в том, чтобы выставить порог между классами таким образом, чтобы каждый из них был *как можно более «плотным»*. Если выражаться математическим языком, то это сводится к минимизации внутриклассовой дисперсии, которая определяется как взвешенная сумма дисперсий двух классов (т.е. это сумма отклонений от математических ожиданий данных классов):
`σw2 = w1 * σ12 + w2 * σ22,` (1.6)
где σw – внутриклассовая дисперсия, σ1 и σ2 – дисперсии, а w1 и w2 — вероятности первого и второго классов соответственно. В алгоритме Отсу минимизация внутриклассовой дисперсии **эквивалентна** максимизации межклассовой дисперсии, которая равна:
`σb2 = w1 * w2 (μ1 – μ2)2 ,` (1.7)
где σb – межклассовая дисперсия, w1 и w2 — вероятности первого и второго классов соответственно, а μ1 и μ2 — средние арифметические значения для каждого из классов. *Совокупная дисперсия* выражается формулой
`σT2 = σw2 + σb2.` (1.8)
*Общая схема быстрого алгоритма* такова:
1. Вычисляем гистограмму (один проход через массив пикселей). Дальше нужна только гистограмма; проходов по всему изображению больше не требуется.
2. Начиная с порога t = 1, проходим через всю гистограмму, на каждом шаге пересчитывая дисперсию σb(t). Если на каком-то из шагов дисперсия оказалась больше максимума, то дисперсия обновляется и T = t.
3. Искомый порог равен T.
В более точной реализации есть параметры, которые позволяют убыстрить алгоритм, к примеру, проход через гистограмму делается не от 1 до 254, а от min до (max -1) яркости. «Классическая» бинаризация показана на фотографии ниже:

*Достоинствами* метода Отсу являются:
* Простота реализации;
* Хорошо адаптируем к разным изображениям, выбирая наиболее оптимальный порог;
* Временнáя сложность алгоритма O(N) операций, где N выражается количеством пикселей в изображении.
*Недостатки* метода:
* Такая пороговая бинаризация очень зависит от равномерной распределенности яркости на изображении. Решение – это использование нескольких локальных порогов вместо одного глобального.
##### Детектор границ Канни
Итак, исходя из предыдущих шагов обработки изображения, получены края изображения и разбиение порогом в соответствии со значениями яркости. Теперь, чтобы закрепить результат, необходимо применить *[детектор границ Канни](http://habrahabr.ru/blogs/image_processing/114589/) (Canny)* для нахождения и окончательного связывания краёв объектов на изображении в контуры. Джон Канни в своих исследованиях [2] добился построения фильтра, оптимального по критериям выделения, локализации и минимизации нескольких откликов одного края.
С помощью алгоритма Канни решаются такие задачи:
1. Подавление «ложных» максимумов. Только некоторые из максимумов отмечаются как границы;
2. Последующая двойная пороговая фильтрация. Потенциальные границы определяются порогами. Разбиение на тонкие края (edge thinning);
3. Подавление всех неоднозначных краёв, не принадлежащих каким-либо границам областей. Связывание краёв в контуры (edge linking).
В работе Канни применяется такое понятие как *подавление «ложных» максимумов (non-maximum suppression)*, которое означает, что пикселями границ назначаются такие точки, где достигается *локальный максимум градиента в направлении найденного вектора градиента*. С помощью оператора Собеля получается угол направления вектора границы (следует из формулы 1.4):
`β(x,y) = arctg(Gx/Gy),` (1.9)
где β(x,y) — угол между направлением вектора ∇f в точке (x,y) и осью y, а Gy и Gx — составляющие градиента. Значение направления вектора должно быть кратно 45°. Угол направления вектора границы округляется до одного из четырех углов, представляющих вертикаль, горизонталь и две диагонали (к примеру, 0, 45, 90 и 135 градусов). Затем условиями проверяется, достигает ли величина градиента локального максимума в соответствующем направлении вектора. Ниже разобран пример *для маски 3\*3*:
* если угол направления градиента равен нулю, точка будет считаться границей, если её интенсивность больше чем у точки выше и ниже рассматриваемой точки;
* если угол направления градиента равен 90 градусам, точка будет считаться границей, если её интенсивность больше чем у точки слева и справа рассматриваемой точки;
* если угол направления градиента равен 135 градусам, точка будет считаться границей, если её интенсивность больше чем у точек находящихся в верхнем левом и нижнем правом углу от рассматриваемой точки;
* если угол направления градиента равен 45 градусам, точка будет считаться границей, если её интенсивность больше чем у точек находящихся в верхнем правом и нижнем левом углу от рассматриваемой точки.
После подавления локальных неопределенностей, края становятся более точными и тонкими. Таким образом, получается двоичное изображение, содержащее границы (так называемые *«тонкие края»*). Их можно видеть на преобразованном изображении:

Выделение границ Канни использует *два порога фильтрации*:
* если значение пикселя выше верхней границы – он принимает максимальное значение и граница считается достоверной, пиксель выделен;
* если ниже – пиксель подавляется;
* точки со значением, попадающим в диапазон между порогами, принимают фиксированное среднее значение;
* затем найденные пиксели со средним фиксированным добавляются к группе, если они соприкасаются с группой по одному из четырех направлений.
##### Причесывание изображения
После детектора Канни изображение подвергается [морфологической операции](http://gliffer.ru/articles/algoritmi--matematicheskaya-morfologiya/) дилатации – расширения, утолщения найденных границ за счет того, что по ним пробегается структурообразующее множество.
И, наконец, последним действием является вычитание полученного бинаризованного изображения из оригинала. Примерно должно получиться вот такое изображение на выходе из подготовки хитрого котэ и заплаканного обалдевшего ребенка к распознаванию их эмоций:

### Выводы
Данный подход универсален, расширяем и если обучено достаточное количество каскадов классификаторов, то метод нахождения работает очень быстро и практически безошибочно.
Подытожим:
Есть в наличии подробно рассмотренный механизм работы алгоритма Виолы-Джонса (Viola-Jones) и описаны в данном посте предложенные мной подходы к повышению эффективности решения задачи обнаружения эмоций человека. Естественно, это не единственный вариант модификации метода. Можете попробовать свои. С помощью таких апгрейдов возможно теоретическое улучшение метода.
Теперь должна быть показана состоятельность данного алгоритма и его применимость на практике. О его реализации я расскажу в своем следующем посте и покажу с помощью иллюстраций. Спасибо за внимание! Надеюсь, что Вам было интересно!
### Список литературы
1. Otsu, N., «A Threshold Selection Method from Gray-Level Histograms,» IEEE Transactions on Systems, Man, and Cybernetics, Vol. 9, № 1,1979., pp. 62- 66
2. John Canny, « A Computational Approach to Edge Detection», IEEE Transactions on pattern analysis and machine intelligence, Vol.8, № 6, 1986., pp.679 -698
3. [Алгоритмы выделения контуров изображений](http://habrahabr.ru/blogs/image_processing/114452/) | https://habr.com/ru/post/133909/ | null | ru | null |
# Зачем, когда и как использовать multithreading и multiprocessing в Python
***Салют, хабровчане. Прямо сейчас в OTUS открыт набор на курс [«Machine Learning»](https://otus.pw/V1RB/), в связи с этим мы перевели для вас одну очень интересную «сказочку». Поехали.***

---
Давным-давно, в далекой-далекой галактике…
Жил в маленькой деревушке посреди пустыни мудрый и могущественный волшебник. И звали его Дамблдальф. Он был не просто мудр и могущественен, но и помогал людям, которые приезжали из далеких земель, чтобы просить помощи у волшебника. Наша история началась, когда один путник принес волшебнику магический свиток. Путник не знал, что было в свитке, он лишь знал, что если кто-то и сможет раскрыть все тайны свитка, то это именно Дамблдальф.
### Глава 1: Однопоточность, однопроцессность
Если вы еще не догадались, я проводил аналогию с процессором и его функциями. Наш волшебник – это процессор, а свиток – это список ссылок, которые ведут к силе Python и знанию, чтобы овладеть ею.
Первой мыслью волшебника, который без особого труда расшифровал список, было послать своего верного друга (Гарригорна? Знаю, знаю, что звучит ужасно) в каждое из мест, которые были описаны в свитке, чтобы найти и принести то, что он сможет там отыскать.
```
In [1]:
import urllib.request
from concurrent.futures import ThreadPoolExecutor
In [2]:
urls = [
'http://www.python.org',
'https://docs.python.org/3/',
'https://docs.python.org/3/whatsnew/3.7.html',
'https://docs.python.org/3/tutorial/index.html',
'https://docs.python.org/3/library/index.html',
'https://docs.python.org/3/reference/index.html',
'https://docs.python.org/3/using/index.html',
'https://docs.python.org/3/howto/index.html',
'https://docs.python.org/3/installing/index.html',
'https://docs.python.org/3/distributing/index.html',
'https://docs.python.org/3/extending/index.html',
'https://docs.python.org/3/c-api/index.html',
'https://docs.python.org/3/faq/index.html'
]
In [3]:
%%time
results = []
for url in urls:
with urllib.request.urlopen(url) as src:
results.append(src)
CPU times: user 135 ms, sys: 283 µs, total: 135 ms
Wall time: 12.3 s
In [ ]:
```
Как видите, мы просто перебираем URL-адреса один за другим с помощью цикла for и читаем ответ. Благодаря *%%time* и магии *IPython*, мы можем увидеть, что с моим печальным интернетом это заняло около 12 секунд.
### Глава 2: Multithreading
Неспроста волшебник славился своей мудростью, он быстро смог придумать куда более эффективный способ. Вместо того, чтобы посылать одного человека в каждое место по порядку, почему бы не собрать отряд надежных соратников и не отправить их в разные концы света одновременно! Волшебник сможет разом объединить все знания, которые они принесут!
Все верно, вместо просмотра списка в цикле последовательно, мы можем использовать *multithreading* (многопоточность) для доступа к нескольким URL-адресам одновременно.
```
In [1]:
import urllib.request
from concurrent.futures import ThreadPoolExecutor
In [2]:
urls = [
'http://www.python.org',
'https://docs.python.org/3/',
'https://docs.python.org/3/whatsnew/3.7.html',
'https://docs.python.org/3/tutorial/index.html',
'https://docs.python.org/3/library/index.html',
'https://docs.python.org/3/reference/index.html',
'https://docs.python.org/3/using/index.html',
'https://docs.python.org/3/howto/index.html',
'https://docs.python.org/3/installing/index.html',
'https://docs.python.org/3/distributing/index.html',
'https://docs.python.org/3/extending/index.html',
'https://docs.python.org/3/c-api/index.html',
'https://docs.python.org/3/faq/index.html'
]
In [4]:
%%time
with ThreadPoolExecutor(4) as executor:
results = executor.map(urllib.request.urlopen, urls)
CPU times: user 122 ms, sys: 8.27 ms, total: 130 ms
Wall time: 3.83 s
In [5]:
%%time
with ThreadPoolExecutor(8) as executor:
results = executor.map(urllib.request.urlopen, urls)
CPU times: user 122 ms, sys: 14.7 ms, total: 137 ms
Wall time: 1.79 s
In [6]:
%%time
with ThreadPoolExecutor(16) as executor:
results = executor.map(urllib.request.urlopen, urls)
CPU times: user 143 ms, sys: 3.88 ms, total: 147 ms
Wall time: 1.32 s
In [ ]:
```
Гораздо лучше! Почти как… магия. Использование нескольких потоков может значительно ускорить выполнение многих задач, связанных с вводом-выводом. В моем случае большая часть времени, затраченного на чтение URL-адресов, связана с задержками сети. Программы, привязанные к вводу-выводу, проводят большую часть времени жизни в ожидании, как вы уже догадались, ввода или вывода (подобно тому, как волшебник ждет, пока его друзья съездят в места из свитка и вернутся обратно). Это может быть ввод-вывод из сети, базы данных, файла или от пользователя. Такой ввод-вывод как правило занимает много времени, поскольку источнику может потребоваться выполнить предварительную обработку перед передачей данных на ввод-вывод. Например, процессор, будет считать гораздо быстрее, чем сетевое соединение будет передавать данные (по скорости примерно, как Флэш против вашей бабушки).
***Примечание**: `multithreading` может быть очень полезна в таких задачах, как очистка веб-страниц.*
### Глава 3: Multiprocessing
Шли годы, слава о добром волшебнике росла, а вместе с ней росла и зависть одного нелицеприятного темного волшебника (Саруморта? Или может Воландемана?). Вооруженной немеряной хитростью и движимый завистью, темный волшебник наложил на Дамблдальфа страшное проклятие. Когда проклятие настигло его, Дамблдальф понял, что у него есть всего несколько мгновений, чтобы отразить его. В отчаянии он рылся в своих книгах заклинаний и быстро нашел одно контрзаклятие, которое должно было сработать. Единственная проблема заключалась в том, что волшебнику нужно было вычислить сумму всех простых чисел меньше 1 000 000. Странное, конечно, заклятье, но что имеем.
Волшебник знал, что вычисление значения будет тривиальным, если у него будет достаточно времени, но такой роскоши у него не было. Несмотря на то, что он великий волшебник, все же и он ограничен своей человечностью и может проверять на простоту всего одно число за раз. Если бы он решил просто просуммировать простые числа друг за другом, времени ушло бы слишком много. Когда до того, чтобы применить контрзаклятье остались считанные секунды, он вдруг вспомнил заклятье *multiprocessing*, которое узнал из магического свитка много лет назад. Это заклинание позволит ему копировать себя, чтобы распределить числа между своими копиями и проверять несколько одновременно. И в итоге все, что ему нужно будет сделать – это просто сложить числа, которые он и его копии обнаружат.
```
In [1]:
from multiprocessing import Pool
In [2]:
def if_prime(x):
if x <= 1:
return 0
elif x <= 3:
return x
elif x % 2 == 0 or x % 3 == 0:
return 0
i = 5
while i**2 <= x:
if x % i == 0 or x % (i + 2) == 0:
return 0
i += 6
return x
In [17]:
%%time
answer = 0
for i in range(1000000):
answer += if_prime(i)
CPU times: user 3.48 s, sys: 0 ns, total: 3.48 s
Wall time: 3.48 s
In [18]:
%%time
if __name__ == '__main__':
with Pool(2) as p:
answer = sum(p.map(if_prime, list(range(1000000))))
CPU times: user 114 ms, sys: 4.07 ms, total: 118 ms
Wall time: 1.91 s
In [19]:
%%time
if __name__ == '__main__':
with Pool(4) as p:
answer = sum(p.map(if_prime, list(range(1000000))))
CPU times: user 99.5 ms, sys: 30.5 ms, total: 130 ms
Wall time: 1.12 s
In [20]:
%%timeit
if __name__ == '__main__':
with Pool(8) as p:
answer = sum(p.map(if_prime, list(range(1000000))))
729 ms ± 3.02 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
In [21]:
%%timeit
if __name__ == '__main__':
with Pool(16) as p:
answer = sum(p.map(if_prime, list(range(1000000))))
512 ms ± 39.8 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
In [22]:
%%timeit
if __name__ == '__main__':
with Pool(32) as p:
answer = sum(p.map(if_prime, list(range(1000000))))
518 ms ± 13.3 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
In [23]:
%%timeit
if __name__ == '__main__':
with Pool(64) as p:
answer = sum(p.map(if_prime, list(range(1000000))))
621 ms ± 10.5 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
In [ ]:
```
У современных процессоров больше одного ядра, поэтому мы можем ускорить выполнение задач, используя модуль многопроцессной обработки *multiprocessing*. Задачи, завязанные на процессоре – это программы, которые большую часть времени своей работы выполняют вычисления на процессоре (тривиальные математические вычисления, обработку изображений и т.д.). Если вычисления могут выполняться независимо друг от друга, мы имеем возможность разделить их между доступными ядрами процессора, тем самым получив значительный прирост в скорости обработки.
Все, что вам нужно сделать, это:
1. Определить применяемую функцию
2. Подготовить список элементов, к которым будет применена функция;
3. Породить процессы с помощью `multiprocessing.Pool`. Число, которое будет передано в `Pool()`, будет равно числу порожденных процессов. Встраивание оператора `with` гарантирует, что все процессы будут убиты после завершения их работы.
4. Объедините выходные данные из процесса Pool с помощью функции `map`. Входными данными для map будет функция, применяемая к каждому элементу, и сам список элементов.
***Примечание**: Функцию можно определить так, чтобы выполнять любую задачу, которая может быть выполнена параллельно. Например, функция может содержать код для записи результата вычисления в файл.*
Итак, зачем нам разделять `multiprocessing` и `multithreading`? Если вы когда-либо пытались повысить производительность выполнения задачи на процессоре с помощью multithreading, в итоге эффект получался ровно обратный. Это просто ужасно! Давайте разберёмся, как так вышло.
Подобно тому, как волшебник ограничен своей человеческой природой и может вычислять всего одно число в единицу времени, Python поставляется с такой вещью, которая называется **Global Interpreter Lock (GIL)**. Python с радостью позволит вам породить столько потоков, сколько вы захотите, но **GIL** гарантирует, что только один из этих потоков будет выполняться в любой момент времени.
Для задачи, связанной с вводом-выводом, такая ситуация совершенно нормальна. Один поток отправляет запрос на один URL-адрес и ждет ответа, только потом этот поток может быть заменен другим, который отправит другой запрос на другой URL-адрес. Поскольку поток не должен ничего делать, пока он не получит ответа, нет никакой разницы, что в данный момент времени выполняется всего один поток.
Для задач, выполняемых на процессоре, наличие нескольких потоков почти также бесполезно, как соски на доспехах. Поскольку в единицу времени может выполняться только один поток, даже если вы порождаете несколько, каждому из которых будет выделено число для проверки на простоту, процессор все равно будет работать только с одном потоком. По сути, эти числа все равно будут проверяться одно за другим. А издержки работы с несколькими потоками будут способствовать снижению производительности, которые вы как раз можете наблюдать при использовании `multithreading` в задачах, выполняемых на процессоре.
Чтобы обойти это «ограничение», мы используем модуль `multiprocessing`. Вместо использования потоков, multiprocessing использует, как бы вам это сказать… несколько процессов. Каждый процесс получает свой личный интерпретатор и пространство в памяти, поэтому GIL не будет вас ограничивать. По сути, каждый процесс будет использовать свое ядро процессора и работать со своим уникальным числом, и выполняться это будет одновременно с работой других процессов. Как мило с их стороны!
Вы можете заметить, что нагрузка на центральный процессор будет выше, когда вы будете использовать `multiprocessing` по сравнению с обычным циклом for или даже `multithreading`. Так происходит, потому что ваша программа использует не одно ядро, а несколько. И это хорошо!
Помните, что `multiprocessing` имеет свои издержки на управление несколькими процессами, которые обычно серьезнее, чем издержки multithreading. (Multiprocessing порождает отдельные интерпретаторы и назначает каждому процессу свою область памяти, так что да!) То есть, как правило, лучше использовать облегченную версию multithreading, когда вы хотите выкрутиться таким способом (вспомните про задачи, связанные с вводом-выводом). А вот когда вычисление на процессоре становится бутылочным горлышком, приходит время модуля `multiprocessing`. Но помните, что с большой силой приходит большая ответственность.
Если вы породите больше процессов, чем ваш процессор может обработать в единицу времени, то заметите, что производительность начнет падать. Так происходит, потому что операционная система должна делать больше работы, тасуя процессы между ядрами процессора, потому что процессов больше. В реальности все может быть еще сложнее, чем я рассказал сегодня, но основную идею я донес. Например, в моей системе производительность упадет, когда количество процессов будет равно 16. Все потому, что в моем процессоре всего 16 логических ядер.
### Глава 4: Заключение
* В задачах, связанных с вводом-выводом, `multithreading` может повысить производительность.
* В задачах, связанных с вводом-выводом, `multiprocessing` также может повысить производительность, но издержки, как правило, оказываются выше, чем при использовании `multithreading`.
* Существование Python GIL дает нам понять, что в любой момент времени в программе может выполняться всего один поток.
* В задачах, связанных с процессором, использование `multithreading` может понизить производительность.
* В задачах, связанных с процессором, использование `multiprocessing` может повысить производительность.
* Волшебники потрясающие!
На этом мы сегодня закончим знакомство с `multithreading` и `multiprocessing` в Python. А теперь идите и побеждайте!
---
[«Моделирование COVID-19 с помощью анализа графов и парсинга открытых данных». Бесплатный урок.](https://otus.pw/V1RB/) | https://habr.com/ru/post/501056/ | null | ru | null |
# HKDF: как получать новые ключи и при чем тут хэш-функции
Для современных алгоритмов шифрования одним из факторов, влияющих на криптостойкость, является длина ключа. Согласно [стандарту NIST](https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-57pt1r4.pdf), криптографическая стойкость алгоритмов должна быть не менее 112 бит. Для симметричных алгоритмов это означает, что минимальная длина ключа [должна составлять](https://ru.wikipedia.org/wiki/%D0%A3%D1%80%D0%BE%D0%B2%D0%B5%D0%BD%D1%8C_%D0%BA%D1%80%D0%B8%D0%BF%D1%82%D0%BE%D1%81%D1%82%D0%BE%D0%B9%D0%BA%D0%BE%D1%81%D1%82%D0%B8#%D0%A1%D1%80%D0%B0%D0%B2%D0%BD%D0%B8%D1%82%D0%B5%D0%BB%D1%8C%D0%BD%D1%8B%D0%B9_%D1%81%D0%BF%D0%B8%D1%81%D0%BE%D0%BA_%D1%83%D1%80%D0%BE%D0%B2%D0%BD%D0%B5%D0%B9_%D0%BA%D1%80%D0%B8%D0%BF%D1%82%D0%BE%D1%81%D1%82%D0%BE%D0%B9%D0%BA%D0%BE%D1%81%D1%82%D0%B8_%D0%B0%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC%D0%BE%D0%B2) 224 бит, для асимметричных, основанных на теории чисел (например, на решении задачи факторизации для алгоритма [RSA](https://ru.wikipedia.org/wiki/RSA)), минимальная надёжная длина - 2048 бит [1]. Не спасает от использования ключей большого размера и криптография на эллиптических кривых.
Но что поделать, если существующие ключи не обладают достаточной длиной для их безопасного использования в выбранных нами алгоритмах? Или же нам нужно получить больше ключей, чем у нас есть? Тут на помощь приходит **KDF** (Key Derivation Function) - это функция, которая формирует один или несколько криптографически стойких секретных ключей на основе заданного секретного значения (в литературе именуемого главным, а иногда мастер ключом) с помощью псевдослучайной функции. И что особенно важно, она позволяет задавать длину ключа, создаваемого в результате своей работы, а его стойкость будет такой же, как и у случайного ключа той же длины [2], [3].
Именно о KDF и пойдет речь далее. Мы рассмотрим общий принцип работы, одну из версий этой функции - **HKDF**, а также разберем, как она может быть реализована на Python'е.
Часть 1. Общий принцип работы KDF
---------------------------------
Замечательная статья с введением в тему: [ссылка](https://habr.com/ru/post/259199/)
В целом, работу KDF можно представить как процесс из двух шагов, именуемый "извлечь-затем-растянуть" (по-английски - extract-and-expand):
1. сначала из главного ключа "извлекается" псевдослучайный ключ фиксированной длины. Его цель - "сконцентрировать" энтропию входного ключа в короткий, но криптографически стойкий ключ. Необходимость этого шага будет обоснована чуть ниже;
2. затем значение, сгенерированное на первом шаге, "растягивается" в ключ заданной длины или в несколько ключей. Во втором случае задается их суммарная длина.
![Рис 1. Алгоритм работы KDF [4]](https://habrastorage.org/r/w1560/getpro/habr/upload_files/1c8/bcc/d4e/1c8bccd4ef00c38fffa625fe7c0734a2.png "Рис 1. Алгоритм работы KDF [4]")Рис 1. Алгоритм работы KDF [4]Рассмотрим каждый из шагов работы функции более детально.
**Randomness Extraction:**Первую часть нашего алгоритма - шаг извлечения ключа из входных данных - можно представить как функцию двух аргументов:
где:
* *SKM (Source Keying Material)* - секретное (в некоторой литературе обозначаемое как главное) значение, на основе которого формируется сначала псевдослучайный ключ PRK, а затем - ключ заданной длины или несколько ключей. Это и есть тот ключ, который "растягивает" KDF;
* *XTR (randomness eXTRactor)* - [экстрактор случайности](https://ru.wikipedia.org/wiki/%D0%AD%D0%BA%D1%81%D1%82%D1%80%D0%B0%D0%BA%D1%82%D0%BE%D1%80_%D1%81%D0%BB%D1%83%D1%87%D0%B0%D0%B9%D0%BD%D0%BE%D1%81%D1%82%D0%B8). Его можно представить как функцию, принимающую на вход исходный ключ SKM и генерирующую на его основе выходной ключ PRK. Важное свойство этой функции заключается в том, что созданный с ее помощью ключ выглядит независимым от источника и является равномерно распределённым (в статистическом и вычислительном смысле);
* *PRK (PseudoRandom Key)* - псевдослучайный ключ. Это значение является выходным для первого шага алгоритма;
* *XTSalt (eXTractor Salt)* - криптографическая [соль](https://ru.wikipedia.org/wiki/%D0%A1%D0%BE%D0%BB%D1%8C_(%D0%BA%D1%80%D0%B8%D0%BF%D1%82%D0%BE%D0%B3%D1%80%D0%B0%D1%84%D0%B8%D1%8F)), т.е. случайное (не обязательно секретное) значение, используемое для усложнения определения прообраза функции, создающей псевдослучайный ключ. Оно может быть константой или не использоваться вовсе.
Пока это выглядит как довольно абстрактное определение с горой аббревиатур, приправленных солью. Но это лишь общий вид - в конкретных реализациях KDF места обозначений занимают реальные данные и криптографические функции. Например, HKDF, о которой пойдет речь во второй части статьи, в качестве экстрактора использует хэш-функции.
**Key Expansion:**На втором шаге из полученного ранее псевдослучайного ключа (*PRK*) создается ключ заданной длины *L*, или же набор ключей той же суммарной длины. Также представим этот процесс в виде функции:
где:
* *PRF\* (PseudoRandom Function with variable length)* - псевдослучайная функция, способная выдавать значения переменной длины. Для достижения этого свойства зачастую используют обычную псевдослучайную функцию с расширением выходных данных с помощью различных режимов работы, таких как [counter и feedback mode](https://nvlpubs.nist.gov/nistpubs/Legacy/SP/nistspecialpublication800-108.pdf);
* *CTXInfo (context information)* - строка контекстной информации (так же, как и соль, может быть просто заданной заранее константой, в том числе нулем). Содержит в себе сведения, например, о приложении, в котором используется функция;
* *PRK* - выходное значение первого шага;
* *DKM (Derived Keying Material)* - выходной ключ длины *L*.
Можно заметить, что с достижением первоначальной цели получения ключа заданной заранее длины второй шаг алгоритма справляется в одиночку. Так для чего вообще нужен первый? Не является ли это пустой тратой вычислительных ресурсов?
Оказывается, в этом переходе между шагами кроется наибольшая сложность в разработке функций формирования ключа. Если главный ключ не является случайным или псевдослучайным, KDF не может "растянуть" его так, чтобы получившийся ключ был криптографически стойким. Этим обосновывается необходимость первого шага, на котором из "неидеальных" входных данных формируется псевдослучайный ключ, который служит основой для последующей генерации выходного ключа.
Конечно же, если главный ключ - уже (псевдо-)случайное значение, его можно использовать в качестве входных данных второго шага, пропустив первый. Например, *premaster secret* в протоколе [*TLS*](https://ru.wikipedia.org/wiki/TLS#%D0%9F%D1%80%D0%BE%D1%86%D0%B5%D0%B4%D1%83%D1%80%D0%B0_%D0%BF%D0%BE%D0%B4%D1%82%D0%B2%D0%B5%D1%80%D0%B6%D0%B4%D0%B5%D0%BD%D0%B8%D1%8F_%D1%81%D0%B2%D1%8F%D0%B7%D0%B8_%D0%B2_TLS_%D0%B2_%D0%B4%D0%B5%D1%82%D0%B0%D0%BB%D1%8F%D1%85) является псевдослучайной строкой, за исключением первых двух байт ([IETF](https://tools.ietf.org/html/rfc5869#section-3.3)). Но даже в таком случае шаг извлечения может быть необходимым, если, например, размер главного ключа больше, чем того требует псевдослучайная функция *PRF\** (этот параметр зависит от реализации *PRF\** в конкретном алгоритме).
Часть 2. HKDF
-------------
**HKDF** (HMAC Key Derivation Function) является одной из реализаций механизма KDF. В алгоритме KDF в качестве псевдослучайной функции (обозначенной выше как PRF\*), а также экстрактора псевдослучайной ключа, используется механизм [HMAC](https://ru.wikipedia.org/wiki/HMAC).
**Алгоритм HKDF**Представим схему HMAC в виде функции от двух аргументов, где первый из них - это всегда ключ, а второй - данные, которые будут хэшироваться вместе с ключом. Также обозначим как *HashLen* размер выходных данных (в октетах), используемый в данном алгоритме. Символом || обозначается конкатенация ("склеивание") строк. То есть под записью HMAC(key, a || b) подразумевается, что хэш-функция с заданным ключом key действует на конкатенацию a и b.
Зная это, алгоритм HKDF можно записать в виде:
где *XTS*, *SKM* и *CTXInfo* обозначают то же, что и в общем принципе работы KDF, а значения *K(i), i = 1,...,t* определяются согласно правилу:
1. **PRK = HMAC-Hash(XTS, SKM)** - первый шаг алгоритма, на котором из исходных данных ключа (*SKM*) генерируется псевдослучайный ключ (*PRK*). При этом длина *PRK* определяется функцией, используемой в конкретной схеме HMAC (HMAC-Hash) и составляет *HashLen* октетов. Обратите внимание, что ключом для этой хэш-функции является соль, а "сообщением" - наш исходный ключ. В случае, когда энтропия *SKM* достаточно велика, *PRK* будет не отличим от случайного.
2. **K(1) = HMAC-Hash(PRK, CTXinfo || 0)**,
**K(i+1) = HMAC-Hash(PRK, K(i) || CTXinfo || i)**, 1 ≤ i < t,
где *t = L/HashLen* - количество "блоков", необходимых для получения конечного ключа длины L. Число *i* в формуле для второго и последующих шагов представляется в шестнадцатеричном виде. В случае, когда требуемая длина ключа не кратна *HashLen*, выходным значением алгоритма являются *L* первых октетов *K*. При этом существует ограничение на *L: L ≤ 255 \* HashLen*.
![Рис 2. Схема работы HKDF [4]](https://habrastorage.org/r/w1560/getpro/habr/upload_files/205/a2a/ff1/205a2aff1c895a67d1937409307ad397.png "Рис 2. Схема работы HKDF [4]")Рис 2. Схема работы HKDF [4]Как было отмечено в описании общего алгоритма KDF, соль - опциональное поле; при отсутствии предоставленного значения, на вход подается строка нулей длины *HashLen*. Но ее использование существенно увеличивает безопасность всей схемы, уменьшает зависимость выходного ключа от главного, и гарантирует независимость результатов работы хэш-функций, ведь значение *XTSalt* является ее ключом на шаге создания *PRK*.
@nusr\_et via InstagramЕще одним необязательным аргументом является контекстная информация. Однако для некоторых приложений она является необходимым условием работы. Дело в том, что контекст позволяет связать получившийся в результате работы алгоритма "длинный" ключ с информацией, специфичной для приложений и пользователей. Такой информацией может служить, например, номера протоколов, идентификаторы алгоритмов и т.д. Это становится особенно важным, когда разные приложения используют HKDF с одним и тем же входным главным ключом, потому что в этом случае контекст позволяет генерировать различные выходные данные. Единственным и крайне важным условием для контекстной информации является ее независимость от входного ключа *SKM*.
Часть 3. Реализация HKDF
------------------------
Схема HKDF реализована во многих языках программирования: [Java](https://github.com/patrickfav/hkdf), [JavaScript](https://www.npmjs.com/package/futoin-hkdf), [PHP](https://www.php.net/manual/en/function.hash-hkdf.php), [Python](https://github.com/casebeer/python-hkdf). Рассмотрим, например, [реализацию](https://en.wikipedia.org/wiki/HKDF#Example:_Python_implementation) на питоне, чтобы разобраться в принципе ее работы не только на уровне описания алгоритма, но и работающей функции:
```
import hashlib
import hmac
from math import ceil
hash_len = 32
def hmac_sha256(key, data):
return hmac.new(key, data, hashlib.sha256).digest()
def hkdf(length: int, ikm, salt: bytes = b"", CTXinfo: bytes = b"") -> bytes:
# соль - опциональное поле, поэтому, если не задано пользователем,
# используем строку нулей длины hash_len:
if len(salt) == 0:
salt = bytes([0] * hash_len)
# Первый шаг: из предоставленного ключа генерируем псевдослучайный ключ
# с помощью хэш-функции:
prk = hmac_sha256(salt, ikm)
k_i = b"0" # на первом шаге в хэш-функцию подается 0
dkm = b"" # Derived Keying Material
t = ceil(length / hash_len)
# Второй шаг: с помощью хэш-функции вычисляем K(i), конкатенация которых
# и является результатом работы функции. Заметим, что на каждом шаге
# для вычисления K(i) используется предыдущее значение K(i-1):
for i in range(t):
k_i = hmac_sha256(prk, k_i + CTXinfo + bytes([1 + i]))
dkm += k_i
# Если длина не кратна hash_len, то возвращаются первые length октетов:
return dkm[:length]
```
Убедимся в работоспособности примера:
```
>>> output = hkdf(100, b"input_key", b"add_some_salt")
>>>
>>> print(''.join('{:02x}'.format(byte) for byte in output))
2bcd8350cc31b6945b23b2a47add4d5ec4b1bd9fad0387590bf4e9f4d34ea456e63267c765e7cd5451df1f6f18f41eaba20de594fd8c6a008120276438d18fc4122ec152fff03204c966261b60408a569b6b0e3527ae4a34570c62b2d060fd15f3176a36
>>>
>>> print(len(out))
100
```
Как можно увидеть, наша функция `hkdf` сгенерировала ключ output на основе входного ключа "input\_key" и соли "add\_some\_salt". Обратите внимание, что на вход подаются не строки, а последовательности байтов, они лишь представлены в виде строк для наглядности. Конвертируется одно в другое [вот так](https://stackoverflow.com/a/606199). Длина выходного ключа составила 100 байт, именно столько, сколько мы потребовали первым аргументом!
**Источники мудрости:**
* Описание IETF: <https://tools.ietf.org/html/rfc5869>
* Более расширенное описание и замечания по использованию: <https://eprint.iacr.org/2010/264>
* Видео-лекция об общих принципах работы KDF: <https://www.coursera.org/lecture/crypto/key-derivation-A1ETP>
* [1] <https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-131Ar2.pdf>, стр 9.
* [2] <https://nvlpubs.nist.gov/nistpubs/Legacy/SP/nistspecialpublication800-108.pdf>, стр 16-19;
* [3] <https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-57pt1r5.pdf>, стр 108-109;
* [4] Общие рекомендации на тему использования KDF: <https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-56Cr2.pdf>, стр 17, 22 | https://habr.com/ru/post/531324/ | null | ru | null |
# Руководство по Node.js, часть 10: стандартные модули, потоки, базы данных, NODE_ENV
Этот материал завершает серию переводов руководства по Node.js. Сегодня мы поговорим о модулях os, events и http, обсудим работу с потоками и базами данных, затронем вопрос использования Node.js при разработке приложений и в продакшне.
[](https://habr.com/company/ruvds/blog/425667/)
**[Советуем почитать] Другие части цикла**Часть 1: [Общие сведения и начало работы](https://habr.com/company/ruvds/blog/422893/)
Часть 2: [JavaScript, V8, некоторые приёмы разработки](https://habr.com/company/ruvds/blog/423153/)
Часть 3: [Хостинг, REPL, работа с консолью, модули](https://habr.com/company/ruvds/blog/423701/)
Часть 4: [npm, файлы package.json и package-lock.json](https://habr.com/company/ruvds/blog/423703/)
Часть 5: [npm и npx](https://habr.com/company/ruvds/blog/423705/)
Часть 6: [цикл событий, стек вызовов, таймеры](https://habr.com/company/ruvds/blog/424553/)
Часть 7: [асинхронное программирование](https://habr.com/company/ruvds/blog/424555/)
Часть 8: [протоколы HTTP и WebSocket](https://habr.com/company/ruvds/blog/424557/)
Часть 9: [работа с файловой системой](https://habr.com/company/ruvds/blog/424969/)
Часть 10: [стандартные модули, потоки, базы данных, NODE\_ENV](https://habr.com/company/ruvds/blog/425667/)
[Полная PDF-версия руководства по Node.js](https://habr.com/company/ruvds/blog/428576/)
Модуль Node.js os
-----------------
Модуль `os` даёт доступ ко многим функциям, которые можно использовать для получения информации об операционной системе и об аппаратном обеспечении компьютера, на котором работает Node.js. Это стандартный модуль, устанавливать его не надо, для работы с ним из кода его достаточно подключить:
```
const os = require('os')
```
Здесь имеются несколько полезных свойств, которые, в частности, могут пригодиться при работе с файлами.
Так, свойство `os.EOL` позволяет узнать используемый в системе разделитель строк (признак конца строки). В Linux и macOS это `\n`, в Windows — `\r\n`.
Надо отметить, что упоминая тут «Linux и macOS», мы говорим о POSIX-совместимых платформах. Ради краткости изложения менее популярные платформы мы тут не упоминаем.
Свойство `os.constants.signals` даёт сведения о константах, используемых для обработки сигналов процессов наподобие `SIGHUP`, `SIGKILL`, и так далее. [Здесь](https://nodejs.org/api/os.html#os_signal_constants) можно найти подробности о них.
Свойство `os.constants.errno` содержит константы, используемые для сообщений об ошибках — наподобие `EADDRINUSE`, `EOVERFLOW`.
Теперь рассмотрим основные методы модуля `os`.
### ▍os.arch()
Этот метод возвращает строку, идентифицирующую архитектуру системы, например — `arm`, `x64`, `arm64`.
### ▍os.cpus()
Возвращает информацию о процессорах, доступных в системе. Например, эти сведения могут выглядеть так:
```
[ { model: 'Intel(R) Core(TM)2 Duo CPU P8600 @ 2.40GHz',
speed: 2400,
times:
{ user: 281685380,
nice: 0,
sys: 187986530,
idle: 685833750,
irq: 0 } },
{ model: 'Intel(R) Core(TM)2 Duo CPU P8600 @ 2.40GHz',
speed: 2400,
times:
{ user: 282348700,
nice: 0,
sys: 161800480,
idle: 703509470,
irq: 0 } } ]
```
### ▍os.endianness()
Возвращает `BE` или `LE` в зависимости от того, какой [порядок байтов](https://ru.wikipedia.org/wiki/%D0%9F%D0%BE%D1%80%D1%8F%D0%B4%D0%BE%D0%BA_%D0%B1%D0%B0%D0%B9%D1%82%D0%BE%D0%B2) (Big Engian или Little Endian) был использован для компиляции бинарного файла Node.js.
### ▍os.freemem()
Возвращает количество свободной системной памяти в байтах.
### ▍os.homedir()
Возвращает путь к домашней директории текущего пользователя. Например — `'/Users/flavio'`.
### ▍os.hostname()
Возвращает имя хоста.
### ▍os.loadavg()
Возвращает, в виде массива, данные о средних значениях нагрузки, вычисленные операционной системой. Эта информация имеет смысл только в Linux и macOS. Выглядеть она может так:
```
[ 3.68798828125, 4.00244140625, 11.1181640625 ]
```
### ▍os.networkInterfaces()
Возвращает сведения о сетевых интерфейсах, доступных в системе. Например:
```
{ lo0:
[ { address: '127.0.0.1',
netmask: '255.0.0.0',
family: 'IPv4',
mac: 'fe:82:00:00:00:00',
internal: true },
{ address: '::1',
netmask: 'ffff:ffff:ffff:ffff:ffff:ffff:ffff:ffff',
family: 'IPv6',
mac: 'fe:82:00:00:00:00',
scopeid: 0,
internal: true },
{ address: 'fe80::1',
netmask: 'ffff:ffff:ffff:ffff::',
family: 'IPv6',
mac: 'fe:82:00:00:00:00',
scopeid: 1,
internal: true } ],
en1:
[ { address: 'fe82::9b:8282:d7e6:496e',
netmask: 'ffff:ffff:ffff:ffff::',
family: 'IPv6',
mac: '06:00:00:02:0e:00',
scopeid: 5,
internal: false },
{ address: '192.168.1.38',
netmask: '255.255.255.0',
family: 'IPv4',
mac: '06:00:00:02:0e:00',
internal: false } ],
utun0:
[ { address: 'fe80::2513:72bc:f405:61d0',
netmask: 'ffff:ffff:ffff:ffff::',
family: 'IPv6',
mac: 'fe:80:00:20:00:00',
scopeid: 8,
internal: false } ] }
```
### ▍os.platform()
Возвращает сведения о платформе, для которой был скомпилирован Node.js. Вот некоторые из возможных возвращаемых значений:
* darwin
* freebsd
* linux
* openbsd
* win32
### ▍os.release()
Возвращает строку, идентифицирующую номер релиза операционной системы.
### ▍os.tmpdir()
Возвращает путь к заданной в системе директории для хранения временных файлов.
### ▍os.totalmem()
Возвращает общее количество системной памяти в байтах.
### ▍os.type()
Возвращает сведения, позволяющие идентифицировать операционную систему. Например:
* `Linux` — Linux.
* `Darwin` — macOS.
* `Windows_NT` — Windows.
### ▍os.uptime()
Возвращает время работы системы в секундах с последней перезагрузки.
Модуль Node.js events
---------------------
Модуль `events` предоставляет нам класс `EventEmitter`, который предназначен для работы с событиями на платформе Node.js. Мы уже немного говорили об этом модуле в [седьмой](https://habr.com/company/ruvds/blog/424555/) части этой серии материалов. [Вот](https://nodejs.org/api/events.html) документация к нему. Здесь рассмотрим API этого модуля. Напомним, что для использования его в коде нужно, как это обычно бывает со стандартными модулями, его подключить. После этого надо создать новый объект `EventEmitter`. Выглядит это так:
```
const EventEmitter = require('events')
const door = new EventEmitter()
```
Объект класса `EventEmitter` пользуется стандартными механизмами, в частности — следующими событиями:
* `newListener` — это событие вызывается при добавлении обработчика событий.
* `removeListener` — вызывается при удалении обработчика.
Рассмотрим наиболее полезные методы объектов класса `EventEmitter` (подобный объект в названиях методов обозначен как `emitter`).
### ▍emitter.addListener()
Псевдоним для метода `emitter.on()`.
### ▍emitter.emit()
Генерирует событие. Синхронно вызывает все обработчики события в том порядке, в котором они были зарегистрированы.
### ▍emitter.eventNames()
Возвращает массив, который содержит зарегистрированные события.
### ▍emitter.getMaxListeners()
Возвращает максимальное число обработчиков, которые можно добавить к объекту класса `EventEmitter`. По умолчанию это 10. При необходимости этот параметр можно увеличить или уменьшить с использованием метода `setMaxListeners()`.
### ▍emitter.listenerCount()
Возвращает количество обработчиков события, имя которого передаётся данному методу в качестве параметра:
```
door.listenerCount('open')
```
### ▍emitter.listeners()
Возвращает массив обработчиков события для соответствующего события, имя которого передано этому методу:
```
door.listeners('open')
```
### ▍emitter.off()
Псевдоним для метода `emitter.removeListener()`, появившийся в Node 10.
### ▍emitter.on()
Регистрируеn коллбэк, который вызывается при генерировании события. Вот как им пользоваться:
```
door.on('open', () => {
console.log('Door was opened')
})
```
### ▍emitter.once()
Регистрирует коллбэк, который вызывается только один раз — при первом возникновении события, для обработки которого зарегистрирован этот коллбэк. Например:
```
const EventEmitter = require('events')
const ee = new EventEmitter()
ee.once('my-event', () => {
//вызвать этот коллбэк один раз при первом возникновении события
})
```
### ▍emitter.prependListener()
При регистрации обработчика с использованием методов `on()` или `addListener()` этот обработчик добавляется в конец очереди обработчиков и вызывается для обработки соответствующего события последним. При использовании метода `prependListener()` обработчик добавляется в начало очереди, что приводит к тому, что он будет вызываться для обработки события первым.
### ▍emitter.prependOnceListener()
Этот метод похож на предыдущий. А именно, когда обработчик, предназначенный для однократного вызова, регистрируется с помощью метода `once()`, он оказывается последним в очереди обработчиков и последним вызывается. Метод `prependOnceListener()` позволяет добавить такой обработчик в начало очереди.
### ▍emitter.removeAllListeners()
Данный метод удаляет все обработчики для заданного события, зарегистрированные в соответствующем объекте. Пользуются им так:
```
door.removeAllListeners('open')
```
### ▍emitter.removeListener()
Удаляет заданный обработчик, который нужно передать данному методу. Для того чтобы сохранить обработчик для последующего удаления соответствующий коллбэк можно назначить переменной. Выглядит это так:
```
const doSomething = () => {}
door.on('open', doSomething)
door.removeListener('open', doSomething)
```
### ▍emitter.setMaxListeners()
Этот метод позволяет задать максимальное количество обработчиков, которые можно добавить к отдельному событию в экземпляре класса `EventEmitter`. По умолчанию, как уже было сказано, можно добавить до 10 обработчиков для конкретного события. Это значение можно изменить. Пользуются данным методом так:
```
door.setMaxListeners(50)
```
Модуль Node.js http
-------------------
В [восьмой](https://habr.com/company/ruvds/blog/424557/) части этой серии материалов мы уже говорили о стандартном модуле Node.js `http`. Он даёт в распоряжение разработчика механизмы, предназначенные для создания HTTP-серверов. Он является основным модулем, применяемым для решения задач обмена данными по сети в Node.js. Подключить его в коде можно так:
```
const http = require('http')
```
В его состав входят свойства, методы и классы. Поговорим о них.
### ▍Свойства
#### http.METHODS
В этом свойстве перечисляются все поддерживаемые методы HTTP:
```
> require('http').METHODS
[ 'ACL',
'BIND',
'CHECKOUT',
'CONNECT',
'COPY',
'DELETE',
'GET',
'HEAD',
'LINK',
'LOCK',
'M-SEARCH',
'MERGE',
'MKACTIVITY',
'MKCALENDAR',
'MKCOL',
'MOVE',
'NOTIFY',
'OPTIONS',
'PATCH',
'POST',
'PROPFIND',
'PROPPATCH',
'PURGE',
'PUT',
'REBIND',
'REPORT',
'SEARCH',
'SUBSCRIBE',
'TRACE',
'UNBIND',
'UNLINK',
'UNLOCK',
'UNSUBSCRIBE' ]
```
#### http.STATUS\_CODES
Здесь содержатся коды состояния HTTP и их описания:
```
> require('http').STATUS_CODES
{ '100': 'Continue',
'101': 'Switching Protocols',
'102': 'Processing',
'200': 'OK',
'201': 'Created',
'202': 'Accepted',
'203': 'Non-Authoritative Information',
'204': 'No Content',
'205': 'Reset Content',
'206': 'Partial Content',
'207': 'Multi-Status',
'208': 'Already Reported',
'226': 'IM Used',
'300': 'Multiple Choices',
'301': 'Moved Permanently',
'302': 'Found',
'303': 'See Other',
'304': 'Not Modified',
'305': 'Use Proxy',
'307': 'Temporary Redirect',
'308': 'Permanent Redirect',
'400': 'Bad Request',
'401': 'Unauthorized',
'402': 'Payment Required',
'403': 'Forbidden',
'404': 'Not Found',
'405': 'Method Not Allowed',
'406': 'Not Acceptable',
'407': 'Proxy Authentication Required',
'408': 'Request Timeout',
'409': 'Conflict',
'410': 'Gone',
'411': 'Length Required',
'412': 'Precondition Failed',
'413': 'Payload Too Large',
'414': 'URI Too Long',
'415': 'Unsupported Media Type',
'416': 'Range Not Satisfiable',
'417': 'Expectation Failed',
'418': 'I\'m a teapot',
'421': 'Misdirected Request',
'422': 'Unprocessable Entity',
'423': 'Locked',
'424': 'Failed Dependency',
'425': 'Unordered Collection',
'426': 'Upgrade Required',
'428': 'Precondition Required',
'429': 'Too Many Requests',
'431': 'Request Header Fields Too Large',
'451': 'Unavailable For Legal Reasons',
'500': 'Internal Server Error',
'501': 'Not Implemented',
'502': 'Bad Gateway',
'503': 'Service Unavailable',
'504': 'Gateway Timeout',
'505': 'HTTP Version Not Supported',
'506': 'Variant Also Negotiates',
'507': 'Insufficient Storage',
'508': 'Loop Detected',
'509': 'Bandwidth Limit Exceeded',
'510': 'Not Extended',
'511': 'Network Authentication Required' }
```
#### http.globalAgent
Данное свойство указывает на глобальный экземпляр класса `http.Agent`. Он используется для управления соединениями. Его можно считать ключевым компонентом HTTP-подсистемы Node.js. Подробнее о классе `http.Agent` мы поговорим ниже.
### ▍Методы
#### http.createServer()
Возвращает новый экземпляр класса `http.Server`. Вот как пользоваться этим методом для создания HTTP-сервера:
```
const server = http.createServer((req, res) => {
//в этом коллбэке будут обрабатываться запросы
})
```
#### http.request()
Позволяет выполнить HTTP-запрос к серверу, создавая экземпляр класса `http.ClientRequest`.
#### http.get()
Этот метод похож на `http.request()`, но он автоматически устанавливает метод HTTP в значение `GET` и автоматически же вызывает команду вида `req.end()`.
### ▍Классы
Модуль HTTP предоставляет 5 классов — `Agent`, `ClientRequest`, `Server`, `ServerResponse` и `IncomingMessage`. Рассмотрим их.
#### http.Agent
Глобальный экземпляр класса `http.Agent`, создаваемый Node.js, используется для управления соединениями. Он применяется в качестве значения по умолчанию всеми HTTP-запросами и обеспечивает постановку запросов в очередь и повторное использование сокетов. Кроме того, он поддерживает пул сокетов, что позволяет обеспечить высокую производительность сетевой подсистемы Node.js. При необходимости можно создать собственный объект `http.Agent`.
#### http.ClientRequest
Объект класса `http.ClientRequest`, представляющий собой выполняющийся запрос, создаётся при вызове методов `http.request()` или `http.get()`. При получении ответа на запрос вызывается событие `response`, в котором передаётся ответ — экземпляр `http.IncomingMessage`. Данные, полученные после выполнения запроса, можно обработать двумя способами:
* Можно вызвать метод `response.read()`.
* В обработчике события `response` можно настроить прослушиватель для события `data`, что позволяет работать с потоковыми данными.
#### http.Server
Экземпляры этого класса используются для создания серверов с применением команды `http.createServer()`. После того, как у нас имеется объект сервера, мы можем воспользоваться его методами:
* Метод `listen()` используется для запуска сервера и организации ожидания и обработки входящих запросов.
* Метод `close()` останавливает сервер.
#### http.ServerResponse
Этот объект создаётся классом `http.Server` и передаётся в качестве второго параметра событию `request` при его возникновении. Обычно подобным объектам в коде назначают имя `res`:
```
const server = http.createServer((req, res) => {
//res - это объект http.ServerResponse
})
```
В таких обработчиках, после того, как ответ сервера будет готов к отправке клиенту, вызывают метод `end()`, завершающий формирование ответа. Этот метод необходимо вызывать после завершения формирования каждого ответа.
Вот методы, которые используются для работы с HTTP-заголовками:
* `getHeaderNames()` — возвращает список имён установленных заголовков.
* `getHeaders()` — возвращает копию установленных HTTP-заголовков.
* `setHeader('headername', value)` — устанавливает значение для заданного заголовка.
* `getHeader('headername')` — возвращает установленный заголовок.
* `removeHeader('headername')` — удаляет установленный заголовок.
* `hasHeader('headername')` — возвращает `true` если в ответе уже есть заголовок, имя которого передано этому методу.
* `headersSent()` — возвращает `true` если заголовки уже отправлены клиенту.
После обработки заголовков их можно отправить клиенту, вызвав метод `response.writeHead()`, который, в качестве первого параметра, принимает код состояния. В качестве второго и третьего параметров ему можно передать сообщение, соответствующее коду состояния, и заголовки.
Для отправки данных клиенту в теле ответа используют метод `write()`. Он отправляет буферизованные данные в поток HTTP-ответа.
Если до этого заголовки ещё не были установлены командой `response.writeHead()`, сначала будут отправлены заголовки с кодом состояния и сообщением, которые заданы в запросе. Задавать их значения можно, устанавливая значения для свойств `statusCode` и `statusMessage`:
```
response.statusCode = 500
response.statusMessage = 'Internal Server Error'
```
#### http.IncomingMessage
Объект класса `http.IncomingMessage` создаётся в ходе работы следующих механизмов:
* `http.Server` — при обработке события `request`.
* `http.ClientRequest` — при обработке события `response`.
Его можно использовать для работы с данными ответа. А именно:
* Для того чтобы узнать код состояния ответа и соответствующее сообщение используются свойства `statusCode` и `statusMessage`.
* Заголовки ответа можно посмотреть, обратившись к свойству `headers` или `rawHearders` (для получения списка необработанных заголовков).
* Метод запроса можно узнать, воспользовавшись свойством `method`.
* Узнать используемую версию HTTP можно с помощью свойства `httpVersion`.
* Для получения URL предназначено свойство `url`.
* Свойство `socket` позволяет получить объект `net.Socket`, связанный с соединением.
Данные ответа представлены в виде потока так как объект `http.IncomingMessage` реализует интерфейс `Readable Stream`.
Работа с потоками в Node.js
---------------------------
Потоки — это одна из фундаментальных концепций, используемых в Node.js-приложениях. Потоки — это инструменты, которые позволяют выполнять чтение и запись файлов, организовывать сетевое взаимодействие систем, и, в целом — эффективно реализовывать операции обмена данными.
Концепция потоков не уникальна для Node.js. Они появились в ОС семейства Unix десятки лет назад. В частности, программы могут взаимодействовать друг с другом, передавая потоки данных с использованием конвейеров (с применением символа конвейера — `|`).
Если представить себе, скажем, чтение файла без использования потоков, то, в ходе выполнения соответствующей команды, содержимое файла будет целиком считано в память, после чего с этим содержимым можно будет работать.
Благодаря использованию механизма потоков файлы можно считывать и обрабатывать по частям, что избавляет от необходимости хранить в памяти большие объёмы данных.
Модуль Node.js [stream](https://nodejs.org/api/stream.html) представляет собой основу, на которой построены все API, поддерживающие работу с потоками.
### ▍О сильных сторонах использования потоков
Потоки, в сравнении с другими способами обработки данных, отличаются следующими преимуществами:
* Эффективное использование памяти. Работа с потоком не предполагает хранения в памяти больших объёмов данных, загружаемых туда заранее, до того, как появится возможность их обработать.
* Экономия времени. Данные, получаемые из потока, можно начать обрабатывать гораздо быстрее, чем в случае, когда для того, чтобы приступить к их обработке, приходится ждать их полной загрузки.
### ▍Пример работы с потоками
Традиционный пример работы с потоками демонстрирует чтение файла с диска.
Сначала рассмотрим код, в котором потоки не используются. Стандартный модуль Node.js `fs` позволяет прочитать файл, после чего его можно передать по протоколу HTTP в ответ на запрос, полученный HTTP-сервером:
```
const http = require('http')
const fs = require('fs')
const server = http.createServer(function (req, res) {
fs.readFile(__dirname + '/data.txt', (err, data) => {
res.end(data)
})
})
server.listen(3000)
```
Метод `readFile()`, использованный здесь, позволяет прочесть файл целиком. Когда чтение будет завершено, он вызывает соответствующий коллбэк.
Метод `res.end(data)`, вызываемый в коллбэке, отправляет содержимое файла клиенту.
Если размер файла велик, то эта операция займёт немало времени. Вот тот же пример переписанный с использованием потоков:
```
const http = require('http')
const fs = require('fs')
const server = http.createServer((req, res) => {
const stream = fs.createReadStream(__dirname + '/data.txt')
stream.pipe(res)
})
server.listen(3000)
```
Вместо того, чтобы ждать того момента, когда файл будет полностью прочитан, мы начинаем передавать его данные клиенту сразу после того, как первая порция этих данных будет готова к отправке.
### ▍Метод pipe()
В предыдущем примере мы использовали конструкцию вида `stream.pipe(res)`, в которой вызывается метод файлового потока `pipe()`. Этот метод берёт данные из их источника и отправляет их в место назначения.
Его вызывают для потока, представляющего собой источник данных. В данном случае это — файловый поток, который отправляют в HTTP-ответ.
Возвращаемым значением метода `pipe()` является целевой поток. Это очень удобно, так как позволяет объединять в цепочки несколько вызовов метода `pipe()`:
```
src.pipe(dest1).pipe(dest2)
```
Это равносильно такой конструкции:
```
src.pipe(dest1)
dest1.pipe(dest2)
```
### ▍API Node.js, в которых используются потоки
Потоки — полезный механизм, в результате многие модули ядра Node.js предоставляют стандартные возможности по работе с потоками. Перечислим некоторые из них:
* `process.stdin` — возвращает поток, подключённый к `stdin`.
* `process.stdout` — возвращает поток, подключённый к `stdout`.
* `process.stderr` — возвращает поток, подключённый к `stderr`.
* `fs.createReadStream()` — создаёт читаемый поток для работы с файлом.
* `fs.createWriteStream()`— создаёт записываемый поток для работы с файлом.
* `net.connect()` — инициирует соединение, основанное на потоке.
* `http.request()` — возвращает экземпляр класса `http.ClientRequest`, предоставляющий доступ к записываемому потоку.
* `zlib.createGzip()` — сжимает данные с использованием алгоритма `gzip` и отправляет их в поток.
* `zlib.createGunzip()` — выполняет декомпрессию `gzip`-потока.
* `zlib.createDeflate()` — сжимает данные с использованием алгоритма `deflate` и отправляет их в поток.
* `zlib.createInflate()` — выполняет декомпрессию `deflate`-потока.
### ▍Разные типы потоков
Существует четыре типа потоков:
* Поток для чтения (`Readable`) — это поток, из которого можно читать данные. Записывать данные в такой поток нельзя. Когда в такой поток поступают данные, они буферизуются до того момента пока потребитель данных не приступит к их чтению.
* Поток для записи (`Writable`) — это поток, в который можно отправлять данные. Читать из него данные нельзя.
* Дуплексный поток (`Duplex`) — в такой поток можно и отправлять данные и читать их из него. По существу это — комбинация потока для чтения и потока для записи.
* Трансформирующий поток (`Transform`) — такие потоки похожи на дуплексные потоки, разница заключается в том, что то, что поступает на вход этих потоков, преобразует то, что из них можно прочитать.
### ▍Создание потока для чтения
Поток для чтения можно создать и инициализировать, воспользовавшись возможностями модуля `stream`:
```
const Stream = require('stream')
const readableStream = new Stream.Readable()
```
Теперь в поток можно поместить данные, которые позже сможет прочесть потребитель этих данных:
```
readableStream.push('hi!')
readableStream.push('ho!')
```
### ▍Создание потока для записи
Для того чтобы создать записываемый поток нужно расширить базовый объект `Writable` и реализовать его метод `_write()`. Для этого сначала создадим соответствующий поток:
```
const Stream = require('stream')
const writableStream = new Stream.Writable()
```
Затем реализуем его метод `_write()`:
```
writableStream._write = (chunk, encoding, next) => {
console.log(chunk.toString())
next()
}
```
Теперь к такому потоку можно подключить поток, предназначенный для чтения:
```
process.stdin.pipe(writableStream)
```
### ▍Получение данных из потока для чтения
Для того чтобы получить данные из потока, предназначенного для чтения, воспользуемся потоком для записи:
```
const Stream = require('stream')
const readableStream = new Stream.Readable()
const writableStream = new Stream.Writable()
writableStream._write = (chunk, encoding, next) => {
console.log(chunk.toString())
next()
}
readableStream.pipe(writableStream)
readableStream.push('hi!')
readableStream.push('ho!')
readableStream.push(null)
```
Команда `readableStream.push(null)` сообщает об окончании вывода данных.
Работать с потоками для чтения можно и напрямую, обрабатывая событие `readable`:
```
readableStream.on('readable', () => {
console.log(readableStream.read())
})
```
### ▍Отправка данных в поток для записи
Для отправки данных в поток для записи используется метод `write()`:
```
writableStream.write('hey!\n')
```
### ▍Сообщение потоку для записи о том, что запись данных завершена
Для того чтобы сообщить потоку для записи о том, что запись данных в него завершена, можно воспользоваться его методом `end()`:
```
writableStream.end()
```
Этот метод принимает несколько необязательных параметров. В частности, ему можно передать последнюю порцию данных, которые надо записать в поток.
Основы работы с MySQL в Node.js
-------------------------------
MySQL является одной из самых популярных СУБД в мире. В экосистеме Node.js имеется несколько пакетов, которые позволяют взаимодействовать с MySQL-базами, то есть — сохранять в них данные, получать данные из баз и выполнять другие операции.
Мы будем использовать пакет [mysqljs/mysql](https://github.com/mysqljs/mysql). Этот проект, который существует уже очень давно, собрал более 12000 звёзд на GitHub. Для того чтобы воспроизвести следующие примеры, вам понадобится MySQL-сервер.
### ▍Установка пакета
Для установки этого пакета воспользуйтесь такой командой:
```
npm install mysql
```
### ▍Инициализация подключения к базе данных
Сначала подключим пакет в программе:
```
const mysql = require('mysql')
```
После этого создадим соединение:
```
const options = {
user: 'the_mysql_user_name',
password: 'the_mysql_user_password',
database: 'the_mysql_database_name'
}
const connection = mysql.createConnection(options)
```
Теперь попытаемся подключиться к базе данных:
```
connection.connect(err => {
if (err) {
console.error('An error occurred while connecting to the DB')
throw err
}
}
```
### ▍Параметры соединения
В вышеприведённом примере объект `options` содержал три параметра соединения:
```
const options = {
user: 'the_mysql_user_name',
password: 'the_mysql_user_password',
database: 'the_mysql_database_name'
}
```
На самом деле этих параметров существует гораздо больше. В том числе — следующие:
* `host` — имя хоста, на котором расположен MySQL-сервер, по умолчанию — `localhost`.
* `port` — номер порта сервера, по умолчанию — `3306`.
* `socketPath` — используется для указания сокета Unix вместо хоста и порта.
* `debug` — позволяет работать в режиме отладки, по умолчанию эта возможность отключена.
* `trace` — позволяет выводить сведения о трассировке стека при возникновении ошибок, по умолчанию эта возможность включена.
* `ssl` — используется для настройки SSL-подключения к серверу.
### ▍Выполнение запроса SELECT
Теперь всё готово к выполнению SQL-запросов к базе данных. Для выполнения запросов используется метод соединения `query`, который принимает запрос и коллбэк. Если операция завершится успешно — коллбэк будет вызван с передачей ему данных, полученных из базы. В случае ошибки в коллбэк попадёт соответствующий объект ошибки. Вот как это выглядит при выполнении запроса на выборку данных:
```
connection.query('SELECT * FROM todos', (error, todos, fields) => {
if (error) {
console.error('An error occurred while executing the query')
throw error
}
console.log(todos)
})
```
При формировании запроса можно использовать значения, которые будут автоматически встроены в строку запроса:
```
const id = 223
connection.query('SELECT * FROM todos WHERE id = ?', [id], (error, todos, fields) => {
if (error) {
console.error('An error occurred while executing the query')
throw error
}
console.log(todos)
})
```
Для передачи в запрос нескольких значений можно, в качестве второго параметра, использовать массив:
```
const id = 223
const author = 'Flavio'
connection.query('SELECT * FROM todos WHERE id = ? AND author = ?', [id, author], (error, todos, fields) => {
if (error) {
console.error('An error occurred while executing the query')
throw error
}
console.log(todos)
})
```
### ▍Выполнение запроса INSERT
Запросы `INSERT` используются для записи данных в базу. Например, запишем в базу данных объект:
```
const todo = {
thing: 'Buy the milk'
author: 'Flavio'
}
connection.query('INSERT INTO todos SET ?', todo, (error, results, fields) => {
if (error) {
console.error('An error occurred while executing the query')
throw error
}
})
```
Если у таблицы, в которую добавляются данные, есть первичный ключ со свойством `auto_increment`, его значение будет возвращено в виде `results.insertId`:
```
const todo = {
thing: 'Buy the milk'
author: 'Flavio'
}
connection.query('INSERT INTO todos SET ?', todo, (error, results, fields) => {
if (error) {
console.error('An error occurred while executing the query')
throw error
}}
const id = results.resultId
console.log(id)
)
```
### ▍Закрытие соединения с базой данных
После того как работа с базой данных завершена и пришло время закрыть соединение — воспользуйтесь его методом `end()`:
```
connection.end()
```
Это приведёт к правильному завершению работы с базой данных.
О разнице между средой разработки и продакшн-средой
---------------------------------------------------
Создавая приложения в среде Node.js можно использовать различные конфигурации для окружения разработки и продакшн-окружения.
По умолчанию платформа Node.js работает в окружении разработки. Для того чтобы указать ей на то, что код выполняется в продакшн-среде, можно настроить переменную окружения `NODE_ENV`:
```
NODE_ENV=production
```
Обычно это делается в командной строке. В Linux, например, это выглядит так:
```
export NODE_ENV=production
```
Лучше, однако, поместить подобную команду в конфигурационный файл наподобие `.bash_profile` (при использовании Bash), так как в противном случае такие настройки не сохраняются после перезагрузки системы.
Настроить значение переменной окружения можно, воспользовавшись следующей конструкцией при запуске приложения:
```
NODE_ENV=production node app.js
```
Эта переменная окружения широко используется во внешних библиотеках для Node.js. Установка `NODE_ENV` в значение `production` обычно означает следующее:
* До минимума сокращается логирование.
* Используется больше уровней кэширования для оптимизации производительности.
Например, [Pug](https://pugjs.org/api/express.html) — библиотека для работы с шаблонами, используемая Express, готовится к работе в режиме отладки в том случае, если переменная `NODE_ENV` не установлена в значение `production`. Представления Express, в режиме разработки, генерируются при обработке каждого запроса. В продакшн-режиме они кэшируются. Есть и множество других подобных примеров.
Express предоставляет конфигурационные хуки для каждого окружения. То, какой именно будет вызван, зависит от значения `NODE_ENV`:
```
app.configure('development', () => {
//...
})
app.configure('production', () => {
//...
})
app.configure('production', 'staging', () => {
//...
})
```
Например, с их помощью можно использовать различные обработчики событий для разных режимов:
```
app.configure('development', () => {
app.use(express.errorHandler({ dumpExceptions: true, showStack: true }));
})
app.configure('production', () => {
app.use(express.errorHandler())
})
```
### ▍Итоги
Надеемся, освоив это руководство, вы узнали о платформе Node.js достаточно много для того, чтобы приступить к работе с ней. Полагаем, теперь вы, даже если начали читать первую статью этого цикла, совершенно не разбираясь в Node.js, сможете начать писать что-то своё, с интересном читать чужой код и с толком пользоваться [документацией](https://nodejs.org/api/documentation.html) к Node.js.
**Уважаемые читатели!** Если вы прочли эту серию публикаций, не имея знаний о разработке для Node.js, просим рассказать о том, как вы оцениваете свой уровень теперь.
[](https://ruvds.com/ru-rub/#order) | https://habr.com/ru/post/425667/ | null | ru | null |
# Упрощаем лог действий пользователя

В предыдущих статьях мы сделали большое и доброе дело — научились автоматически собирать предысторию падения программы и отправлять её с крэш-репортом. Для [WinForms](https://habrahabr.ru/company/devexpress/blog/342530/), [WPF](https://habrahabr.ru/company/devexpress/blog/343358/), [ASP, Javascript](https://habrahabr.ru/company/devexpress/blog/343816/). Теперь научимся показывать все эти горы информации в удобоваримом виде.
Казалось бы, чего ещё не хватает, сиди и читай лог внимательно, там всё достаточно подробно написано. Даже слишком подробно, пожалуй. Прямо отладочный лог какой-то. Тоже штука несомненно полезная, но мы-то хотели чуть другого. Мы хотели знать, что пользователь делал перед тем, как программа завалилась. Шаги для воспроизведения. Как человек будет в письме разработчику описывать свои действия человеческим языком? Наверное, что-то типа:
`Я запустил программу
Нажал кнопку «Edit Something»
Открылось диалоговое окно «Edit»
Далее я ткнул мышкой в поле «Name»
Ввёл своё имя
Нажал Enter
И тут-то у меня всё упало`
А у нас что? По сути, вроде то же самое, но изобилует массой «излишних» подробностей: мышку нажал, мышку отпустил, кнопку нажал, символ ввёл, кнопку отпустил и тому подобное.
Попробуем на серверной стороне преобразовать логи к более удобному виду, непосредственно перед показом на страничке. Реализуем несколько «упрощалок», которые будем одну за другой натравливать на исходный лог, и посмотрим, что получится.
Начнём с мышки.
Вот так выглядит в логе двойной клик левой кнопкой мыши для платформы WinForms:

С виду несложно — ищем в логе последовательность событий down/up/doubleClick/up и заменяем её на одну запись о doubleClick. При этом надо убедиться, что в найденной последовательности у всех событий одна и та же кнопка мыши (левая в нашем примере), и что все события происходят над одним и тем же окном. Также, во избежание недоразумений, лучше проверить, что координаты всех четырёх событий не выходят за пределы квадрата размером [SystemInformation.DragSize](https://msdn.microsoft.com/en-us/library/system.windows.forms.systeminformation.dragsize(v=vs.110).aspx). Делать это мы будем на сервере, а DragSize по-хорошему надо бы использовать с клиентской машины. В реальности же, даже если и удастся поймать ситуацию, в которой они различаются, то это мало на что повлияет. Поэтому осознанно пренебрегаем этим и используем фиксированные значения.
Координаты мышки придётся присылать с клиента:
```
void AppendMouseCoords(ref Message m, Dictionary data) {
data["x"] = GetMouseX(m.LParam).ToString();
data["y"] = GetMouseY(m.LParam).ToString();
}
int GetMouseX(IntPtr param) {
int value = param.ToInt32();
return value & 0xFFFF;
}
int GetMouseY(IntPtr param) {
int value = param.ToInt32();
return (value >> 16) & 0xFFFF;
}
```
Следующая «упрощалка» будет заниматься одиночными кликами:
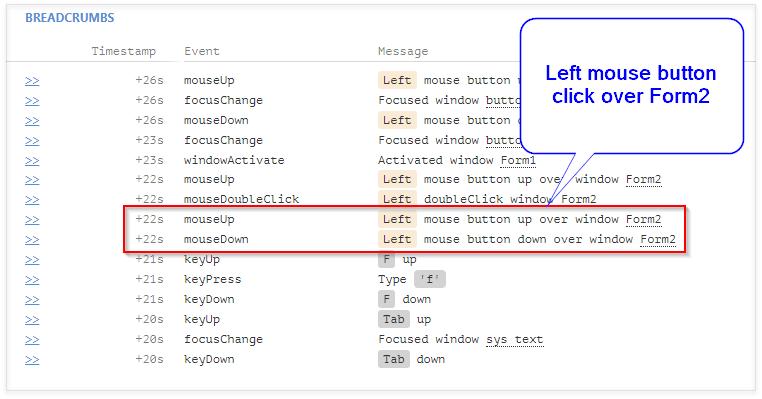
Всё то же самое, что и для двойного клика, только проще и короче. Единственное, о чём надо не забыть, так это о том, что сначала надо запроцессить все двойные клики, а уже в том, что получилось, искать одинарные.
Перейдём к клавиатурному вводу.
Одиночное нажатие алфавитно-цифровой клавиши:
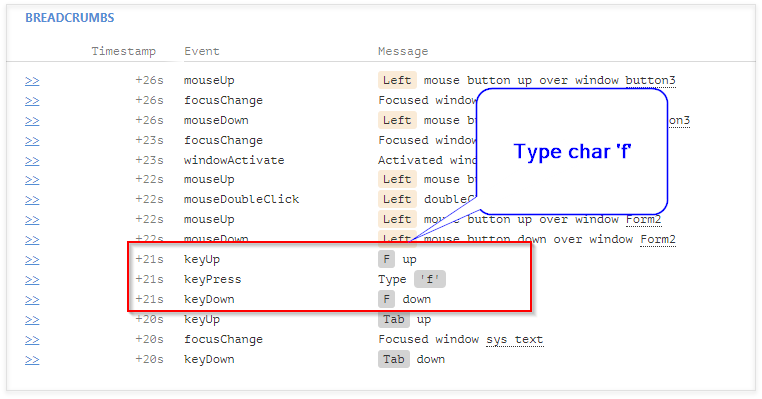
На первый взгляд, всё то же, что и с мышкой, какие тут могут быть проблемы? У нас тут записано 3 события: [WM\_KEYDOWN](https://msdn.microsoft.com/en-us/library/windows/desktop/ms646280(v=vs.85).aspx), [WM\_CHAR](https://msdn.microsoft.com/en-us/library/windows/desktop/ms646276(v=vs.85).aspx) и [WM\_KEYUP](https://msdn.microsoft.com/en-us/library/windows/desktop/ms646281(v=vs.85).aspx). Что у них есть общего, чтобы понять, что все 3 записи относятся к одному событию — нажатию кнопки F? А общего у них только сканкод в битах с 16 по 23, поскольку WM\_KEYDOWN и WM\_KEYUP содержат в себе [Virtual Key Code](https://msdn.microsoft.com/en-us/library/windows/desktop/dd375731(v=vs.85).aspx), который не зависит от текущего языка ввода. А вот WM\_CHAR содержит уже юникодный символ, который соответствует нажатой клавише (или комбинации клавиш, или вообще последовательности IME ввода). Сканкод надо также прислать с клиента, при этом не забыть спрятать его при вводе паролей:
```
void ProcessKeyMessage(ref Message m, bool isUp) {
// etc
data["scanCode"] = maskKey ? "0" : GetScanCode(m.LParam).ToString();
// etc
}
int GetScanCode(IntPtr param) {
int value = param.ToInt32();
return (value >> 16) & 0xFF;
}
```
Ну вот, ~~выключаем газ, снимаем чайник с плиты, выливаем воду и сводим задачу к уже решённой,~~ теперь можно, как и для мышки, свернуть тройки событий в одно. «Ага, такой большой, а всё ещё в сказки веришь!» — сказала реальность:
Оказывается, при быстром наборе keyUp может неслабо так отставать от соответствующих keyDown и keyPress. Поэтому искать просто 3 последовательных записи определённого вида не выйдет. Придётся от найденной начальной точки (keyDown) искать соответствующие keyPress и затем keyUp. До конца списка искать? Так это сразу квадратичная сложность получается, здравствуйте, тормоза! Да и события keyPress может не быть вообще, если была нажата не алфавитно-цифровая клавиша. Поэтому будем искать не далее фиксированного количества записей от начальной, число выберем исходя из здравого смысла и исправим при необходимости. Пусть будет 15, по 2-3 записи на одну клавишу, это будет означать 5-8 одновременно нажатых и неотпущенных клавиш. Для нормального «гражданского» ввода более чем достаточно.
Итак, отдельные нажатия клавиш свернули до ввода отдельных символов (type char). Теперь можно попробовать объединить неразрывные последовательности type char в одну большую type text. Хотя насчёт неразрывности я, пожалуй, погорячился — до, внутри и после последовательности type char вполне себе допустимы нажатия и отпускания клавиш Shift, что также необходимо учесть при сворачивании цепочки событий.
С алфавитно-цифровым вводом всё, теперь можно свернуть и оставшиеся пары keyDown/keyUp, больших сюрпризов там уже не предвидится.
Что там у нас ещё осталось? Фокус.
Смена фокуса мышкой:

Ищем и заменяем тройку записей на одну, контролируем соответствие координат мыши.
Смена фокуса с клавиатуры:

Очень похоже на мышку, но важно не наколоться на том, что keyDown приходит в окно, которое теряет фокус, а keyUp — в окно, которое его получает.
Теперь попробуем собрать это всё вместе и посмотрим.
Было:
Стало:

Почувствуйте разницу, как говорится. Информация та же самая, зато оформлена гораздо компактнее и читается более естественно.
В первом приближении с WinForms закончили. Переходим к WPF.
До определённой степени WPF похож на WinForms, и можно использовать почти все вышеописанные правила. Но, как помним из курса школьной математики, чтобы задачу решить типовым способом, для начала к этому способу ее надо привести. Давайте взглянем, что мы имеем на входе:

Видно, что мы имеем по несколько логов на каждое действие, и обычный mouse down эвент превращается в 4 записи, так как шлётся нам от каждого наследника Control по визуальному дереву от окна до самой кнопки. При достаточно комплексном UI без подобного пути может быть затруднительно понять, куда именно произошёл клик. Однако подобные пути изрядно захламляют вид лога, что отбивает всякую охоту его читать.
В результате дискуссий мы пришли к выводу, что оптимальным решением будет сократить этот список логов до одного, последнего и, опционально, позволить показать все. Почему последнего? Потому что сообщение о клике в кнопку более полезно, чем о клике в окно.
Но как понять, что перед тобой блок из логов, относящихся к одному действию? А элементарно, все эвенты от одного действия получают один и тот же объект EventArgs. Поэтому мы просто присваиваем каждому объекту аргументов некий уникальный идентификатор и записываем его в логи.
```
class PreviousArgs {
public EventArgs EventArgs { get; set; }
public string Id { get; set; }
}
PreviousArgs previousArgs = null;
short currentId = 0;
Dictionary CollectCommonProperties(FrameworkElement source,
EventArgs e) {
Dictionary properties = new Dictionary();
properties["Name"] = source.Name;
properties["ClassName"] = source.GetType().ToString();
if(previousArgs == null) {
previousArgs = new PreviousArgs() {
EventArgs = e,
Id = (currentId++).ToString("X")
};
} else {
if(e == null || !Object.ReferenceEquals(previousArgs.EventArgs, e)) {
previousArgs = new PreviousArgs() {
EventArgs = e,
Id = (currentId++).ToString("X")
};
}
}
properties["#e"] = previousArgs.Id;
}
```
После этого на сервере мы отбрасываем все логи, относящиеся к одному эвенту, кроме последнего. Получаем:
Хорошо, размер лога сильно сократили, и теперь уже почти похоже на WinForms, а значит можно пробовать применить правила, описанные выше.
Чтобы заработали правила сворачивания кликов мышки, нам не хватает сбора координат. Координаты относительно рутового элемента мы получим при помощи метода [MouseEventArgs.GetPosition](https://msdn.microsoft.com/en-us/library/ms591423(v=vs.110).aspx), а координаты относительно окна — при помощи [Visual.PointToScreen](https://msdn.microsoft.com/en-us/library/system.windows.media.visual.pointtoscreen(v=vs.110).aspx):
```
void CollectMousePosition(IDictionary properties,
FrameworkElement source,
MouseButtonEventArgs e) {
IInputElement inputElement = GetRootInputElement(source);
if(inputElement != null) {
Point relativePosition = e.GetPosition(inputElement);
properties["x"] = relativePosition.X.ToString();
properties["y"] = relativePosition.Y.ToString();
if(inputElement is Visual) {
Point screenPosition =
(inputElement as Visual).PointToScreen(relativePosition);
properties["sx"] = screenPosition.X.ToString();
properties["sy"] = screenPosition.Y.ToString();
}
}
}
IInputElement GetRootInputElement(FrameworkElement source) {
return GetRootInputElementCore(source, null);
}
IInputElement GetRootInputElementCore(FrameworkElement source,
IInputElement lastInputElement) {
if(source is IInputElement)
lastInputElement = source as IInputElement;
if(source != null) {
return GetRootInputElementCore(source.Parent as FrameworkElement,
lastInputElement);
}
return lastInputElement;
}
```
Теперь у нас вполне успешно сворачиваются клик и двойной клик.
Теперь взглянем на перемещение фокуса. В отличие от WinForms в WPF мы используем два эвента: GotFocus и LostFocus, соответственно, и записей лога у нас две. Ну да и ничего страшного, просто поправим логику, чтобы при сворачивании искался либо FocusChanged, либо пара из Got и Lost focus эвентов.
В принципе, с WPF на этом и закончили. К сожалению, свернуть ввод текста мы не можем, так как TextInput эвент полностью оторван от клавиатуры, и никаких аналогов scan code там нет. В результате нам удалось добиться вот такого внешнего вида:

Все удобно, понятно и гораздо нагляднее, чем в самом начале.
На этом серия статей про breadcrumbs заканчивается. Как разработчики мы будем благодарны, если вы поделитесь своим мнением об этой фиче. Или идеями, как ещё можно упростить лог бредкрамбсов, чтобы Logify заговорил полностью человеческим языком.
И, конечно же, это не последняя статья от нашей команды. Не стесняйтесь спрашивать нас о том, что вам интересно, и мы обязательно ответим на все ваши вопросы. А самые интересные из них вполне могут стать основой для новой статьи. | https://habr.com/ru/post/344980/ | null | ru | null |
# Создание AngularJS приложения c использованием Firebase
В этой статье я хочу рассказать о связке AngularJS и [Firebase](http://www.firebase.com) в качестве хранилища данных.
Про AngularJS на Хабре написано много, а вот про Firebase совсем чуть-чуть. По этому я решил заполнить этот пробел. Что же такое Firebase?
Firebase — это мощный сервис, предоставляющий API для хранения и синхронизации данных в реальном времени, сервер, на котором эти данные хранятся. Также из коробки мы имеем аутентификацию пользователей и поддержку различных платформ и фреймворков. Более подробную информацию можно получить на [официальном сайте](http://www.firebase.com).
Также Firebase предоставляет замечательную библиотеку для AngularJS — [AngularFire](https://www.firebase.com/docs/web/libraries/angular/api.html).
Используя AngularJS и его прекрасный двусторонний дата биндинг вместе с Firebase, мы можем получить трехстороннюю синхронизацию данных. Однако, обо всем по порядку.
#### Getting started
Первым делом мы должны создать бесплатный аккаунт. Это можно сделать, пройдя по ссылке: [www.firebase.com/signup](https://www.firebase.com/signup/). После регистрации вы получите уникальный URL, который, в дальнейшем, будет использоваться для хранения и синхронизации данных.
Следующий шаг — добавление скриптов в ваш проект. Для использования AngularFire необходимо подключить следующие файлы:
```
```
Также Firebase и AngularFire доступны для установки с помощью bower:
```
bower install firebase angularfire
```
После подключения необходимых скриптов мы можем добавить Firebase в наш AngularJS проект в качестве зависимостей.
Прежде всего, нужно добавить зависимость в модуль:
```
var app = angular.module("sampleApp", ["firebase"]);
```
После чего мы можем использовать его в контроллерах, директивах и сервисах:
```
app.controller("SampleCtrl", ["$scope", "$firebase",
function($scope, $firebase) {
var ref = new Firebase("https://.firebaseio.com/");
// create an AngularFire reference to the data
var sync = $firebase(ref);
// download the data into a local object
$scope.data = sync.$asObject();
}
]);
```
#### Трехстороннее связывание
AngularJS известен своим двухсторонним связыванием дынных между моделью JavaScript и DOM. Используя Farebase в связке с AngularJS мы можем организовать, так называемое «трехстороннее связывание», которое позволит нам синхронизировать изменения в модели JavaScript, DOM и Firebase в реальном времени.
Для этого мы можем использовать метод $asObject(), чтобы создать синхронизируемый объект и привязать его к переменной из нашего $scope, с помощью метода $bindTo(). Вот пример кода:
```
var app = angular.module("sampleApp", ["firebase"]);
app.controller("SampleCtrl", function($scope, $firebase) {
var ref = new Firebase("https://.firebaseio.com/data");
var sync = $firebase(ref);
// download the data into a local object
var syncObject = sync.$asObject();
// synchronize the object with a three-way data binding
// click on `index.html` above to see it used in the DOM!
syncObject.$bindTo($scope, "data");
});
```
#### Работа с коллекциями
Трехстороннее связывание данных прекрасно работает с простыми объектами вида ключ/значение, но довольно часто возникают задачи, когда необходимо работать с коллекциями (массивами). Для этого мы можем использовать метод $asArray().
Мы можем получить коллекцию с сервера вызвав метод $asArray, которая будет доступна только для чтения и добавить его в наш $scope:
```
var app = angular.module("sampleApp", ["firebase"]);
app.controller("SampleCtrl", function($scope, $firebase) {
var ref = new Firebase("https://.firebaseio.com/messages");
var sync = $firebase(ref);
// create a synchronized array for use in our HTML code
$scope.messages = sync.$asArray();
});
```
Учитывая тот фактор, что массив одновременно синхронизирован с сервером и клиентом, его модификация может повредить целостность данных (повредить данные путем управления не теми записями), поэтому его нельзя модифицировать, используя методы push() и splice().
Для этого AngularFire предоставляет набор методов для работы с массивами ($add, $save, $remove). Вот пример синхронизации массива данных:
```
var app = angular.module("sampleApp", ["firebase"]);
app.controller("SampleCtrl", function($scope, $firebase) {
var ref = new Firebase("https://.firebaseio.com/messages");
var sync = $firebase(ref);
$scope.messages = sync.$asArray();
$scope.addMessage = function(text) {
$scope.messages.$add({text: text});
}
});
```
#### Добавление аутентификации
Firebase предоставляет службу аутентификации, которая предлагает решение управления пользовательскими данными и аутентификацию полностью на стороне клиента. Из коробки Firebase поддерживает анонимную аутентификацию, с помощью e-mail и пароля, а также аутентификацию с использованием популярных OAuth провайдеров (Facebook, Github, Google, Twitter).
Библиотека AngularFire предоставляет нам сервис — $firebaseAuth, который является оберткой для методов аутентификации, поставляемых библиотекой Firebase. Данный сервис может быть добавлен в ваши сервисы, контроллеры и директивы в качестве зависимости. Вот пример аутентификации с помощью Facebook:
```
app.controller("SampleCtrl", ["$scope", "$firebaseAuth",
function($scope, $firebaseAuth) {
var ref = new Firebase("https://.firebaseio.com/");
var auth = $firebaseAuth(ref);
auth.$authWithOAuthPopup("facebook").then(function(authData) {
console.log("Logged in as:", authData.uid);
}).catch(function(error) {
console.error("Authentication failed: ", error);
});
}
]);
```
Более подробно об аутентификации можно прочитать на [официальном сайте](https://www.firebase.com/docs/web/guide/user-auth.html).
#### Что дальше?
В данный момент я работаю над одним проектом, который использует Firebase как хранилище данных. В следующей статье я хочу рассказать о том, как применил данный сервис на живом проекте и что из этого вышло. | https://habr.com/ru/post/244209/ | null | ru | null |
# Wi-Fi сети: проникновение и защита. 1) Матчасть

Синоптики предсказывают, что к 2016 году ~~наступит второй ледниковый период~~ трафик в беспроводных сетях [на 10% превзойдёт трафик в проводном Ethernet](http://www.cisco.com/c/en/us/solutions/collateral/service-provider/ip-ngn-ip-next-generation-network/white_paper_c11-481360.html#wp9001447). При этом от года в год частных точек доступа становится [примерно на 20% больше](http://www.statista.com/statistics/218601/global-number-of-private-hotspots-since-2009/).
При таком тренде не может ~~не~~ радовать то, что [80% владельцев сетей не меняют пароли доступа по умолчанию](http://graphs.net/wifi-stats.html). В их число входят и сети компаний.
Этим циклом статей я хочу собрать воедино описания существующих технологии защит, их проблемы и способы обхода, таким образом, что в конце читатель сам сможет сказать, как сделать свою сеть непробиваемой, ~~и даже наглядно продемонстрировать проблемы на примере незадачливого соседа~~ (do not try this at home, kids). Практическая сторона взлома будет освещена с помощью **[Kali Linux](http://kali.org)** (бывший Backtrack 5) в следующих частях.
Статья по мере написания выросла с 5 страниц до 40, поэтому я решил разбить её на части. Этот цикл — не просто инструкция, как нужно и не нужно делать, а подробное объяснение причин для этого. Ну, а кто хочет инструкций — они такие:
> Используйте WPA2-PSK-CCMP с паролем от 12 символов `a-z` (2000+ лет перебора на ATI-кластере). Измените имя сети по умолчанию на нечто уникальное (защита от rainbow-таблиц). Отключите WPS (достаточно перебрать 10000 комбинаций PIN). Не полагайтесь на MAC-фильтрацию и скрытие SSID.
>
>
**Оглавление:**
**1)** Матчасть
**2)** [Kali. Скрытие SSID. MAC-фильтрация. WPS](http://habrahabr.ru/post/225483/)
**3)** [WPA. OpenCL/CUDA. Статистика подбора](http://habrahabr.ru/post/226431/)
Но сначала — матчасть.
#### Передайте мне сахар
Представьте, что вы — устройство, которое принимает инструкции. К вам может подключиться каждый желающий и отдать любую команду. Всё хорошо, но на каком-то этапе потребовалось фильтровать личностей, которые могут вами управлять. Вот здесь и начинается самое интересное.
Как понять, кто может отдать команду, а кто нет? Первое, что приходит в голову — по паролю. Пусть каждый клиент перед тем, как передать новую команду, передаст некий пароль. Таким образом, вы будете выполнять только команды, которые сопровождались корректным паролем. ~~Остальные — фтопку.~~
Именно так работает базовая авторизация HTTP (Auth Basic):
```
AuthType Basic
AuthName "My super secret zone!"
AuthUserFile /home/.htpasswd
Require valid-user
```
После успешной авторизации браузер просто-напросто будет передавать определённый заголовок при каждом запросе в закрытую зону:
```
Authorization: Basic YWRtaW46cGFzcw==
```
То есть исходное:
```
echo -n 'admin:pass' | base64
# YWRtaW46cGFzcw==
```
У данного подхода есть один большой недостаток — так как пароль (или логин-пароль, что по сути просто две части того же пароля) передаётся по каналу «как есть» — кто угодно может встрять между вами и клиентом и получить ваш пароль на блюдечке. А затем использовать его и распоряжаться вами, как угодно!
Для предотвращения подобного безобразия можно прибегнуть к хитрости: использовать какой-либо двухсторонний алгоритм шифрования, где закрытым ключом будет как раз наш пароль, и явно его никогда не передавать. Однако проблемы это не решит — достаточно один раз узнать пароль и можно будет расшифровать любые данные, переданные в прошлом и будущем, плюс шифровать собственные и успешно маскироваться под клиента. А учитывая то, что пароль предназначен для человека, а люди склонны использовать далеко не весь набор из 256 байт в каждом символе, да и символов этих обычно около 6-8… в общем, комсомол не одобрит.
Что делать? А поступим так, как поступают настоящие конспираторы: при первом контакте придумаем длинную случайную строку (достаточно длинную, чтобы её нельзя было подобрать, пока светит это солнце), запомним её и все дальнейшие передаваемые данные будем шифровать с использованием этого «псевдонима» для настоящего пароля. А ещё периодически менять эту строку — ~~тогда джедаи вообще не пройдут~~.
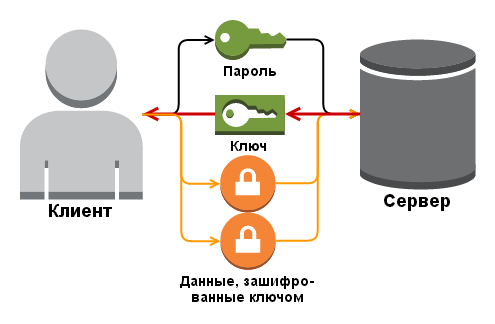
Первые две передачи (зелёные иконки на рисунке выше) — это фаза с «пожатием рук» (handshake), когда сначала мы говорим серверу о нашей легитимности, показывая правильный пароль, на что сервер нам отвечает случайной строкой, которую мы затем используем для шифрования и передачи любых данных.
Итак, для подбора ключа хакеру нужно будет либо найти уязвимость в алгоритме его генерации (как в случае с [Dual\_EC\_DRBG](https://en.wikipedia.org/wiki/Dual_EC_DRBG)), либо арендовать сотню-другую параллельных вселенных и несколько тысяч ATI-ферм для решения этой задачи при своей жизни. Всё это благодаря тому, что случайный ключ может быть любой длины и содержать любые коды из доступных 256, потому что пользователю-человеку никогда не придётся с ним работать.
Именно такая схема с временным ключом (сеансовый ключ, session key или ticket) в разных вариациях и используется сегодня во многих системах — в том числе SSL/TLS и стандартах защиты беспроводных сетей, о которых будет идти речь.
#### План атаки
Внимательные читатели, конечно, заметили, что как бы мы не хитрили — от передачи пароля и временного ключа в открытой или хэшированной форме нам никуда не деться. Как результат — достаточно хакеру перехватить передачу на этой фазе, и он сможет читать все последующие данные, а также участвовать в процессе, вставляя свои пять копеек. И отличить его невозможно, так как вся информация, которой бы мог руководствоваться сервер для выдачи временного ключа или проверки доступа базируется именно на том, что было в начале передачи — handshake. Поэтому хакер знает всё то же, что и сервер, и клиент, и может водить обоих за нос, пока не истечёт срок действия временного ключа.
Наша задача при взломе любой передачи так или иначе сводится к перехвату рукопожатия, из которого можно будет либо вытащить временный ключ, либо исходный пароль, либо и то, и другое. В целом, это довольно долгое занятие и требует определённой удачи.
Но это в идеальном мире…
#### Механизмы защиты Wi-Fi
Технологии создаются людьми и почти во всех из них есть ошибки, иногда достаточно критические, чтобы обойти любую самую хорошую в теории защиту. Ниже мы пробежимся по списку существующих механизмов защиты передачи данных по радиоканалу (то есть не затрагивая SSL, VPN и другие более высокоуровневые способы).
##### OPEN

**OPEN** — это отсутствие всякой защиты. Точка доступа и клиент никак не маскируют передачу данных. Почти любой беспроводной адаптер в любом ноутбуке с Linux может быть установлен в режим прослушки, когда вместо отбрасывания пакетов, предназначенных не ему, он будет их фиксировать и передавать в ОС, где их можно спокойно просматривать. ~~Кто у нас там полез в Твиттер?~~
Именно по такому принципу работают проводные сети — в них нет встроенной защиты и «врезавшись» в неё или просто подключившись к хабу/свичу сетевой адаптер будет получать пакеты всех находящихся в этом сегменте сети устройств в открытом виде. Однако с беспроводной сетью «врезаться» можно из любого места — 10-20-50 метров и больше, причём расстояние зависит не только от мощности вашего передатчика, но и от длины антенны хакера. Поэтому открытая передача данных по беспроводной сети гораздо более опасна.
В этом цикле статей такой тип сети не рассматривается, так как взламывать тут нечего. Если вам нужно пользоваться открытой сетью в кафе или аэропорту — используйте VPN (избегая PPTP) и SSL (`https://`, но при этом поставьте [HTTPS Everywhere](https://www.eff.org/https-everywhere), или параноидально следите, чтобы из адресной строки «внезапно» не исчез замок, если кто включит `sslstrip` — что, впрочем, переданных паролей уже не спасёт), и даже всё вместе. Тогда ваших котиков никто не увидит.
##### WEP

**WEP** — первый стандарт защиты Wi-Fi. Расшифровывается как *Wired Equivalent Privacy* («эквивалент защиты проводных сетей»), но на деле он даёт намного меньше защиты, чем эти самые проводные сети, так как имеет множество огрехов и взламывается множеством разных способов, что из-за расстояния, покрываемого передатчиком, делает данные более уязвимыми. Его нужно избегать почти так же, как и открытых сетей — безопасность он обеспечивает только на короткое время, спустя которое любую передачу можно полностью раскрыть вне зависимости от сложности пароля. Ситуация усугубляется тем, что пароли в WEP — это либо 40, либо 104 бита, что есть крайне короткая комбинация и подобрать её можно за секунды (это без учёта ошибок в самом шифровании).
WEP был придуман в конце 90-х, что его оправдывает, а вот тех, кто им до сих пор пользуется — нет. Я до сих пор на 10-20 WPA-сетей стабильно нахожу хотя бы одну WEP-сеть.
На практике существовало несколько алгоритмов шифровки передаваемых данных — Neesus, MD5, Apple — но все они так или иначе небезопасны. Особенно примечателен первый, эффективная длина которого — 21 бит (~5 символов).
Основная проблема WEP — в фундаментальной ошибке проектирования. Как было проиллюстрировано в начале — шифрование потока делается с помощью временного ключа. WEP фактически передаёт несколько байт этого самого ключа вместе с каждым пакетом данных. Таким образом, вне зависимости от сложности ключа раскрыть любую передачу можно просто имея достаточное число перехваченных пакетов (несколько десятков тысяч, что довольно мало для активно использующейся сети).
К слову, в 2004 IEEE объявили WEP устаревшим из-за того, что стандарт «не выполнил поставленные перед собой цели [обеспечения безопасности беспроводных сетей]».
~~Про атаки на WEP будет сказано в третьей части.~~ Скорее всего в этом цикле про WEP не будет, так как статьи и так получились очень большие, а распространённость WEP стабильно снижается. Кому надо — легко может найти руководства на других ресурсах.
##### WPA и WPA2

**WPA** — второе поколение, пришедшее на смену WEP. Расшифровывается как *Wi-Fi Protected Access*. Качественно иной уровень защиты благодаря принятию во внимание ошибок WEP. Длина пароля — произвольная, от 8 до 63 байт, что сильно затрудняет его подбор (сравните с 3, 6 и 15 байтами в WEP).
Стандарт поддерживает различные алгоритмы шифрования передаваемых данных после рукопожатия: TKIP и CCMP. Первый — нечто вроде мостика между WEP и WPA, который был придуман на то время, пока IEEE были заняты созданием полноценного алгоритма CCMP. TKIP так же, как и WEP, страдает от некоторых типов атак, и в целом не безопасен. Сейчас используется редко (хотя почему вообще ещё применяется — мне не понятно) и в целом использование WPA с TKIP [почти то же, что и использование простого WEP](http://www.findmysoft.com/news/Wi-Fi-NOT-Protected-Access-Prove-Hacking-Experts/).
Одна из занятных особенностей TKIP — в возможности так называемой Michael-атаки. Для быстрого залатывания некоторых особо критичных дыр в WEP в TKIP было введено правило, что точка доступа обязана блокировать все коммуникации через себя (то есть «засыпать») на 60 секунд, если обнаруживается атака на подбор ключа (описана во второй части). Michael-атака — простая передача «испорченных» пакетов для полного отключения всей сети. Причём в отличии от обычного DDoS тут достаточно всего двух (*двух*) пакетов для гарантированного выведения сети из строя на одну минуту.

WPA отличается от WEP и тем, что шифрует данные каждого клиента по отдельности. После рукопожатия генерируется временный ключ — PTK — который используется для кодирования передачи этого клиента, но никакого другого. Поэтому даже если вы проникли в сеть, то прочитать пакеты других клиентов вы сможете только, когда перехватите их рукопожатия — каждого по отдельности. Демонстрация этого с помощью Wireshark будет в третьей части.
Кроме разных алгоритмов шифрования, WPA(2) поддерживают два разных режима начальной аутентификации (проверки пароля для доступа клиента к сети) — PSK и Enterprise. **PSK** (иногда его называют *WPA Personal*) — вход по единому паролю, который вводит клиент при подключении. Это просто и удобно, но в случае больших компаний может быть проблемой — допустим, у вас ушёл сотрудник и чтобы он не мог больше получить доступ к сети приходится ~~применять способ из «Людей в чёрном»~~ менять пароль для всей сети и уведомлять об этом других сотрудников. **Enterprise** снимает эту проблему благодаря наличию множества ключей, хранящихся на отдельном сервере — RADIUS. Кроме того, Enterprise стандартизирует сам процесс аутентификации в протоколе EAP (Extensible Authentication Protocol), что позволяет написать собственный ~~велосипед~~ алгоритм. Короче, одни плюшки для больших дядей.
В этом цикле будет подробно разобрана атака на WPA(2)-PSK, так как Enterprise — это совсем другая история, так как используется только в больших компаниях.
##### WPS/QSS

**WPS**, он же ~~Qikk aSS~~ **QSS** — интересная технология, которая позволяет нам вообще не думать о пароле, а просто ~~добавить воды~~ нажать на кнопку и тут же подключиться к сети. По сути это «легальный» метод обхода защиты по паролю вообще, но удивительно то, что он получил широкое распространение при очень серьёзном просчёте в самой системе допуска — это спустя годы после печального опыта с WEP.
WPS позволяет клиенту подключиться к точке доступа по 8-символьному коду, состоящему из цифр (PIN). Однако из-за ошибки в стандарте нужно угадать лишь 4 из них. Таким образом, достаточно всего-навсего 10000 попыток подбора и *вне зависимости от сложности пароля для доступа к беспроводной сети* вы автоматически получаете этот доступ, а с ним в придачу — и этот самый пароль как он есть.
Учитывая, что это взаимодействие происходит до любых проверок безопасности, в секунду можно отправлять по 10-50 запросов на вход через WPS, и через 3-15 часов (иногда больше, иногда меньше) вы получите ключи ~~от рая~~.
Когда данная уязвимость была раскрыта производители стали внедрять ограничение на число попыток входа (rate limit), после превышения которого точка доступа автоматически на какое-то время отключает WPS — однако до сих пор таких устройств не больше половины от уже выпущенных без этой защиты. Даже больше — временное отключение кардинально ничего не меняет, так как при одной попытке входа в минуту нам понадобится всего `10000/60/24 = 6,94` дней. А PIN обычно отыскивается раньше, чем проходится весь цикл.
Хочу ещё раз обратить ваше внимание, что при включенном WPS ваш пароль будет неминуемо раскрыт вне зависимости от своей сложности. Поэтому если вам вообще нужен WPS — включайте его только когда производится подключение к сети, а в остальное время держите этот бекдор выключенным.
Атака на WPS будет рассмотрена во второй части.
p.s: так как тема очень обширная, в материал могли закрасться ошибки и неточности. Вместо криков «автор ничего не понимает» лучше использовать комментарии и [ЛС](http://habrahabr.ru/conversations/). Это будет только приветствоваться.
**Оглавление:**
**1)** Матчасть
**2)** [Kali. Скрытие SSID. MAC-фильтрация. WPS](http://habrahabr.ru/post/225483/)
**3)** [WPA. OpenCL/CUDA. Статистика подбора](http://habrahabr.ru/post/226431/) | https://habr.com/ru/post/224955/ | null | ru | null |
# Полная синхронизация общих папок, контактов, календарей между распределенными серверами Kerio Connect
Добрый день, Хабр!
### Задача
В моей организации используют почтовый сервер на платформе Kerio Connect, в разных городах установлены почтовые сервера обслуживающие своих пользователей. Распределенной структуры изначально не было, так как домены отличаются на третьем уровне с указанием города площадки. Все работало и всех устраивало. В один прекрасный день — руководство поставила задачу, общий календарь дел между всеми площадками!
### Предыстория
Изначально идея была — поднять Распределенный почтовый домен Kerio и он сам все сделает. Сказано, сделано распределенный домен был создан, но не тут-то было, сервер готов был синхронизировать календари, папки, контакты — между доменами находящимися на одном сервере, но вовсе не собирался синхронизировать данные между несколькими серверами.
Такого подвоха я, конечно, не ожидал и долго не мог поверить в отсутствие необходимого мне функционала. Позже нашел документальное подтверждение этому факту. Чем был очень сильно озадачен и разочарован.
Задача плавно перетекла в проблему.
**Какие были варианты**
* Создать двух клиентов на разных серверах, которые каким-то сторонним ПО обменивали необходимые данные. Нужно было найти это самое сторонние ПО, которое бы реализовывало данный функционал – не люблю такие грабли, но казалось что это единственно быстрое решение.
* Написать свой собственный скрипт синхронизации данных между серверами. Дело в том, что Kerio хранит каждый объект как отдельный файл, соответственно требовалась разработать скрипт работы с файлами, но в виду достаточного кол-ва источников задача казалось несколько сложной, тем более что нужно было выполнять множественные проверки корректности данных, вдруг кто-то создаст задачу в одинаковый промежуток времени и тд и тп.
Забегая вперед скажу, что Kerio хоть и хранит объект как отдельный файл, он не настолько глуп, чтобы при каждом обращении к объекту спрашивать — как дела у файловой системы.
Потратив на размышления большое количество времени, изрисовав кучу бумажек с планами “по захвату вражеской территории”, в 6 часу ура я принял два верных решения:
* Первое решение – делать свое и ничего стороннего не искать.
* Второе решение — идти спать.
Уже утром я проснулся с одной единственно и верной мыслью, которая сократилась до нескольких букв – DFS
### Решение
**Само решение выглядело следующим образом**
* привести все сервера, которые будут участвовать в синхронизации к OS Windows. (Часть была на Linux. требовалась миграция почтовых данных на другую OS)
* Определится со структурой каталогов, которые будут участвовать в синхронизации — они должны быть идентичные.
* Определить все почтовые сервера под один домен с единым DFS пространством.
* Создать выше упомянутый распределенный домен Kerio, так как в моем случае требуется синхронизация данных, не только между серверами но и между доменами, вторым может заниматься сервер Kerio самостоятельно. (в отличие от первого)
* Натравить синхронизируемые каталоги на пространство DFS.
* Придумать какой-нибудь костыль (ведь без костыля нельзя)
### Реализация
Пример на двух почтовых серверах (может быть больше)
#### 1. Kerio Distributed domain

*Master не участвует в синхронизации, но это не обязательное условие.*
Расписывать, как поднять распределенный домен Kerio не буду, ничего сложного в этом нет, можно изучить официальный [манул](https://manuals.gfi.com/en/kerio/connect/content/server-configuration/domains/distributed-domains-in-kerio-connect-1178.html)
В конечном итоге в консоли администрирования вы должны увидеть следующую картинку:


Далее меня интересовали общие папки, на сервере Master можно указать следующие варианты:


**Особая для каждого домена** — сервер не будет синхронизировать общедоступные папки между доменами
**Общие для всех доменов** — все сервера откажутся от существующих общих папок в каждом домене и создадут новые единые папки для всех доменов на каждом из почтовом сервере.
Внимание! Данная опция хоть и меняет политику настройки на всех серверах, синхронизацию производит отдельно от каждого из серверов (то есть — без единого общего пространства)
У администратора — останется возможность, распределять доступы между пользователями.
в моем случае — все свои и мне нужна полная синхронизация (В вашем случае решение может быть другим) на каждом сервере нужно создать одинаковые наборы доменов которые необходимо синхронизировать.
#### 2. Каталоги данных Kerio
Теперь необходимо создать одинаковые общие каталоги, которые необходимо синхронизировать на каждом из серверов. Папки, Календари, Контакты.
Совет – создавайте каталоги на английском языке, в том случаи, если вы создадите их на латинице, директория будет иметь название в какой-то непонятной кодировке, это как минимум неудобно.
Теперь необходимо найти физические пути почтовых папок на каждом сервере.
Общие для всех доменов `~DataMail\mail\#public\Синхронизируемый каталог\#msgs`
Особая для каждого домена `~DataMail\mail\**Domain**\#public\Синхронизируемый каталог\#msgs`
Обратите внимании, что мы будем синхронизировать не весь каталог, а только контейнер с данными **#msgs** — тут хранятся сами объекты, все остальные данные для каждого из серверов должны быть свои.
#### 3. DFS
Подробно как настраивать DFS, также расписывать не буду, информации по данному вопросу достаточно.
DFS — это служба роли в Windows Server, которая предоставляет возможность объединения общих папок, находящихся на разных серверах
[Ссылка на документ MS DFS](https://docs.microsoft.com/ru-ru/windows-server/storage/dfs-namespaces/dfs-overview)
Перед настройкой DFS – необходимо остановить все почтовые сервера которые будут участвовать в синхронизации данных.
По окончанию настройки вы должны получить следующую картинку для каждой из синхронизируемых папок

публиковать реплицируемые папки нам естественно не нужно.

После того как произойдет реплицирование (а реплецировать там особо нечего — папки пусты) почтовые сервера можно запустить.
Далее можно наполнить данными один из почтовых серверов и проверить что данные реплицируются корректно.
#### 4. Костыль
**Описание размышления**
Как вы можете убедиться после того как данные начали синхронизироваться (DFS), в том случаи если вы что либо создали на первом сервере — на втором сервере что-то как-то ничего не появляется, либо появляется но как-то не всегда.
Отчаивается не стоит оно конечно рано или поздно там появится, но лучше рано, чем поздно. Потому как поздно это через 6 – 12 часов.
Все дело в том, что как только вы что-то создали на первом сервере, на втором и последующих файл конечно сразу же появится благодаря системе DFS, однако в том случае если данный почтовый каталог уже был кем-то прочитан ранее и его запросят повторно, сервер не будет перечитывать папку #msgs а выплюнет данные из своего собственного индекса, который может уже давно не соответствовать нашей действительности.
У Kerio есть механизм перечитывания индекса, но он может сработать часов этак через шесть, при этом за эти 6 часов актуальность задачи в календаре может быть несколько утеряна.
Для того чтобы проверить работу синхронизации прям сейчас, можно удалить файл в соответствующем синхронизируемом каталоге index.fld, после повторного обращения к папке на почтовом сервере и при отсутствии данного файла Kerio перечитает каталог и данные появятся. Казалась бы, вот оно решение, удаляй файл при изменении данных, но это работает не каждый раз, а только первый раз, далее Kerio почему-то теряет всякий интерес к index.fld
Так и еще начинает выплевывать непонятные для пользователя сообщения — про какой-то индекс и что он там уже что-то делает.
Есть еще вариант, что-то создать — в момент создания нового объекта сервер вдруг сообразит, что имя файла, которое он хотел присвоить уже занято, но тут снежный ком и это тупиковый вариант.
Как же быть?
Если еще раз обратить внимание на уже знакомую нам картинку.

Но в другой плоскости, можно заметить очень интересную и нужную нам сейчас кнопку — **Переиндексировать папки**
И действительно. Если нажать на данную кнопку на почтовом сервере, который не знает о том что у него уже что-то изменилось в синхронизируемом #msgs, мы получим стабильный, быстрый результат. Все скрытое станет явным.
В журнале можно посмотреть, сколько занимает времени данный процесс, в моем случаи с несколькими тысячами (15 тыс) записей около 3-4 минут.
Остались только придумать, как собственно нажать на данную кнопку, тогда когда нам это нужно.
Оказывается у **Kerio** есть свой **API**
[Описание](https://manuals.gfi.com/en/kerio/connect/content/api/getting-started-with-the-kerio-product-apis-1997.html)
[Документация](https://manuals.gfi.com/en/kerio/api/index.htm)
Функция, которая выполняет нашу задачу, выглядит так –
`session = callMethod("Domains.checkPublicFoldersIntegrity",{}, token)`
Из всего выше изложенного нам нужно написать скрипт, который мониторил бы состояние интересующих папок и в том случаи, если что-то изменилось, выполнял для нас нужную нам функцию.
Хочу сказать, что я написал несколько разных версий скриптов выполняющих разные проверки, остановился на том, который все выводы строит исходя из количества файлов.
#### Реализация скрипта
**Пример скрипта CMD и описание**
***Re-index.bat***
```
@echo off
set dir=%~dp0
%dir:~0,2%
CD "%~dp0\"
md "%CD%\LOG\"
md "%CD%\Setup\"
ECHO -Start- >> "%CD%\LOG\%Computername%.log"
ECHO Start -> %Computername% %Date% %Time% >> "%CD%\LOG\%Computername%.log"
SetLocal EnableDelayedExpansion
for /f "UseBackQ Delims=" %%A IN ("%CD%\Setup\%Computername%.List") do (
set /a c+=1
set "m!c!=%%A"
)
set d=%c%
Echo Folder = %c%
ECHO Folder = %c% >> "%CD%\LOG\%Computername%.log"
ECHO.
ECHO. >> "%CD%\LOG\%Computername%.log"
:start
cls
if %c% LSS 1 exit
set /a id=1
set R=0
:Find
REM PF-Start
if "%id%" gtr "%c%" if %R% == 1 Goto Reindex
if "%id%" gtr "%c%" timeout 60 && Goto start
For /F "tokens=1-3" %%a IN ('Dir "!m%id%!\#msgs\" /-C/S/A:-D') Do Set 2DirSize!id!=!DS!& Set DS=%%c
if "2DirSize!id!" == "" set 1DirSize!id!=!2DirSize%id%!
echo %id%
ECHO !m%id%!
echo Count [ !1DirSize%id%! -- !2DirSize%id%! ]
if "!1DirSize%id%!" == "!2DirSize%id%!" ECHO Synk
REM DEL index.fld
if "!1DirSize%id%!" NEQ "!2DirSize%id%!" del /f /q !m%id%!\index.fld && del /f /q !m%id%!\indexlog.fld && del /f /q !m%id%!\search.fld && set R=1 && ECHO RE-index Count && ECHO RE-index Count %Date% %Time% - Delete !m%id%! >> "%CD%\LOG\%Computername%.log"
set 1DirSize!id!=!2DirSize%id%!
ECHO.
ECHO.
set /a id+=1
goto Find
:Reindex
ECHO. >> "%CD%\LOG\%Computername%.log"
ECHO --- RE-INDEX - Start - %Date% %Time% --- >> "%CD%\LOG\%Computername%.log"
ECHO. >> ----------------------------------- >> "%CD%\LOG\%Computername%.log"
call PublicFolders.py
timeout 60
goto start
exit
```
Копия скрипта запускается на каждом почтовом сервере (можно в качестве службы, Адм права не требуются)
Скрипт читает файл `\Setup\%Computername%.List`
Где %Computername% — имя текущего сервера (Директория может содержать сразу списки всех серверов.)
Файл %Computername%.List – содержит полные пути синхронизируемых директорий, каждый путь записан в новой строке, пустых строк содержать не должен.
После первого запуска скрипт выполняет процедуру индексации, в не зависимости необходима она или нет, также скрипт создает индекс количества файлов в каждой из синхронизируемой директории.
Задача скрипта сводится к подсчету всех файлов в указанной директории.
По окончанию подсчета каждой директории, если хотя бы в одной директории текущее значение файлов, не совпадает с предыдущем, скрипт удаляет файлы из корневой директории синхронизируемого почтового каталога: `index.fld, indexlog.fld, search.fld` и запускает процесс индексации — общих почтовых папок.
В директорию LOG сваливается информация о выполнении задач.
**Процесс индексации**
Процесс индексации сводится к выполнению функции API Kerio
Session = callMethod("Domains.checkPublicFoldersIntegrity",{}, token)
Пример выполнения приведен на – python
***PublicFolders.py***
```
import json
import urllib.request
import http.cookiejar
""" Cookie storage is necessary for session handling """
jar = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(jar))
urllib.request.install_opener(opener)
""" Hostname or ip address of your Kerio Control instance with protocol, port and credentials """
server = "http://127.0.0.1:4040"
username = "user"
password = "password"
def callMethod(method, params, token = None):
"""
Remotely calls given method with given params.
:param: method string with fully qualified method name
:param: params dict with parameters of remotely called method
:param: token CSRF token is always required except login method. Use method "Session.login" to obtain this token.
"""
data = {"method": method ,"id":1, "jsonrpc":"2.0", "params": params}
req = urllib.request.Request(url = server + '/admin/api/jsonrpc/')
req.add_header('Content-Type', 'application/json')
if (token is not None):
req.add_header('X-Token', token)
httpResponse = urllib.request.urlopen(req, json.dumps(data).encode())
if (httpResponse.status == 200):
body = httpResponse.read().decode()
return json.loads(body)
session = callMethod("Session.login", {"userName":username, "password":password, "application":{"vendor":"Kerio", "name":"Control Api-Local", "version":"Python"}})
token = session["result"]["token"]
print (session)
session = callMethod("Domains.checkPublicFoldersIntegrity",{"domainId": "test2.local"}, token)
print (session)
callMethod("Session.logout",{}, token)
```
<http://127.0.0.1:4040> можно оставить как есть, однако если вам требуется HTTPS — python должен доверять сертификату Kerio.
Также в файле необходимо указать учетную запись с правами на выполнения данной функции (Адм – общих почтовых папок) почтового сервера.
Надеюсь, моя статья будет полезна администраторам Kerio Connect. | https://habr.com/ru/post/509832/ | null | ru | null |
# Три подсказки для Wordle
Для того, чтобы "сломать" эту популярную в начале 22-го игру не нужно городить огород, достаточно [подглядеть ответ в консоли разработчика](https://betterprogramming.pub/how-to-beat-wordle-every-day-an-easy-cheat-3c1dc51bc4fc).
Я люблю игры, но платонически, как произведения исксства, то есть я люблю как они сделаны, но не очень люблю играть. Однако такие игры как wordle способны меня захватить.
На хабре да и в интернете в общем есть много ботов, уоторые угадывают слово с трех попыток, но мне захотелось сделать чуть иначе: добавить возможность взвать подсказку. В целом метод их добычи очень похож на алгоритмы работы "[решалок](https://habr.com/ru/post/647391/)", но здесь я опишу своими словами от первого лица как, почему, и куда это вставлять.
Начнем с того, что это мой первый пост на хабре, я не являюсь программистом или математиком. Я работаю режиссером монтажа (если меня тут не забанят, я буду писать об этом) и являюсь энтузиастом програмирования, это помогает мне в работе и в отдыхе, люблю головоломки. Так что не чувствуйте себя стесненными дать какой-то совет, указать на ошибки или откровенную тупость. Так же не надейтесь на какой-то уровень знания компьютер сайенс выше 11-го класса районной школы.
Чтобы запускать скрипт, я буду использовать расширение для Chrome "[User JavaScript and CSS](https://chrome.google.com/webstore/detail/user-javascript-and-css/nbhcbdghjpllgmfilhnhkllmkecfmpld)", суперполезная штука для решения рутинных проблем.
### 1. Шаг первый
Для начала нам нужно извлечь список слов и поколдовать с буквами. Для этого нам нужен список слов. Прямо из консоли, в отличие от правильного ответа, его, увы, не получить. Поэтому будем использовать fetch:
```
let regex = /(?<=La=\[).+(?=\]\,Ta)/gm,
alphabet = {},
wordsList = [],
weights = {};
// Каждый день у игры новый хэш, его легко достать из объекта window,
// затем в тексте файла нужно найти переменную со списком слов
// и превратить ее из текста в массив
fetch(`main.${window.wordle.hash}.js`)
.then(response => response.text())
.then(data => wordsList = JSON.parse(`[${regex.exec(data)}]`))
.then(_ => getWeights ());
function getWeights () {
// Мы просто проходимся по каждой букве каждого слова
// и добавляем к счетчику в объекте alphabet
wordsList.forEach(w => {
w.split("").forEach(
l => {alphabet[l] = alphabet[l] ? alphabet[l]+1 : 1
})
});
// Было бы неплохо его (объект alphabet) отсортировать
var sortable = [];
for (var letter in alphabet) {
sortable.push([letter, alphabet[letter]]);
}
sortable.sort(function(a, b) {
return a[1] - b[1];
});
// Заполняем "таблицу мер и весов"
sortable.forEach((l, i) => {
weights[l[0]] = i
});
}
```
### 2. Первая подсказка
Нужные данные мы получили, можем двигаться непосредственно к созданию подсказок!
Для выбора стартового слова народ обычно смотрит на частотность появления букв на той или иной позиции слов из списка. Таким образом лучшим словом может оказаться то, в котором одна и та же буква может повторяться (но скорее всего не окажется). Я же решил, что для первой подсказки лучше всего использовать как можно больше букв (ну то есть пять, максимум, край), поэтому я хочу найти слово в котором встречаются самые частые буквы не повторяясь. Скорее всего это будут слова SLATE, LATER или LASER, тут все зависит от списка слов, который, как я понимаю иногда меняется. Даже если не так, то это хорошее упражнение:
```
// Нам понадобятся само приложение, к которому можно обратиться
// через querySelector и переменные для подсказок
let app = document.querySelector("game-app"),
let firstBest = ["", 0],
secondBest = ["", 0],
thirdBest = ["", 0];
function getFirstGuess () {
// Теперь считаем суммарный вес каждого слова
wordsList.forEach(w => {
weight = 0;
// Причем для этого мы убираем повторяющиеся буквы,
// чтобы например слова с двумя «l» не были слишком тяжелыми -
// они нам не интересны
[...new Set(w.split(""))].forEach(l => {
weight += weights[l];
});
if (weight > firstBest[1]) {
firstBest = [w, weight]
}
});
// Выводим подсказку на табло
print(firstBest[0])
}
```
Пробуем. 3/5 букв присутствуют в ответе. Неплохо!У меня пока что всегда стартовое слово получается LATER. Не очень весело, но это лучший вариант за неимением других данных.
### 3. Спорный момент
Как поступить? Какую стратегию применить для второй подсказки?
С одной стороны нужно отталкиваться от результата первой: сколько букв угадали, какие на своих местах? Если мало - надо проверить еще часто встречающиеся буквы, чтобы они не пересекались с буквами из первой подсказки. Принцип тот же:
```
function getSecondGuess () {
// Это я объясню позже
secondBest = ["", 0];
// Здесь нам понадобятся результаты предыдущей попытки
let evaulations = app.letterEvaluations;
// Снова считаем вес
wordsList.forEach(w => {
weight = 0;
[...new Set(w.split(""))].forEach(l => {
weight += weights[l];
});
// Но теперь с условием:
// в самом "тяжелом" слове не должно быть букв
// из первой подсказки и тех, которые как игра нам сказала,
// отсутствуют в правильном решении
unique = !firstBest[0]
.split("").some(el => {return w.includes(el)})
&& [...new Set(w.split(""))].every(el =>
evaulations[el] != "absent"
);
if (weight > secondBest[1] && unique) {
secondBest = [w, weight]
}
});
print(secondBest[0])
}
```
Если же в первой попытке много букв попали в точку, это подсказка скорее всего не будет очень информативной, возможно это просто будут пять букв мимо.
Не густо. Однако теперь у меня есть целых семь букв, которых в правильном ответе точно не встретишь, что сокращает алфавит до 19-и символов. А ввести я могу еще 20!Но я ведь не ставлю задачу угадать слово во чтобы то ни стало в два шага!? Нет. Задача — добавить подсказки, а отсутствие подходящих букв это тоже подсказка. Пока двинемся дальше.
### 4. Очень много условий
В качестве третье подсказки, чтобы она была полезна, нам нужно:
1. Буквы, которые встали на свои места в предыдущих попытках, использовать в соответствующих позициях
2. Все буквы, которые присутствуют в слове, но стоят на неправильном месте должны оказаться на других позициях
3. Буквы, которых нет в слове, разумеется в третьей подсказке быть не должно
Звучит как план. Возможно третья попытка даже будет правильным ответом. Проверим?
```
function getThirdGuess () {
// К этому вернемся позже
thirdBest = ["", 0];
evaulations = app.letterEvaluations;
// Ищем буквы, присутствующие в ответе, на своих и на чужих местах
let correct = [undefined, undefined, undefined, undefined, undefined],
wrongPlace = {};
app.boardState.forEach((w, i) => {
if (app.evaluations[i] != null) {
app.evaluations[i].forEach(
(e,j) => {
if (e == "correct") {
correct[j] = w[j]
} else if (e == "present") {
if (wrongPlace[w[j]]) {
wrongPlace[w[j]].push(j)
} else {
wrongPlace[w[j]] = [j]
}
}
})
}
}) // Ужас, но что поделать
// Тут я соберу все присутствующие и правильные буквы
// Начинается путаница с названиями переменных, прошу простить
let present = Object.entries(evaulations)
.filter(e =>
e[1] == "present" || e[1] == "correct"
).map(e => e[0]);
// Снова считаем массы
wordsList.forEach(w => {
weight = 0;
let letters = [...new Set(w.split(""))];
letters.forEach(l => {
weight += weights[l];
});
// Мама, не выгоняй меня из дома, я проверяю:
// 1. В слове нет отсутствующих в ответе букв
// 2. Каждая присутствующая буква есть в слове
// 3. Каждая правильная буква на правильной позиции
// 4. Все угаданные на не правильном месте буквы стоят
// в других местах
let passing = letters
.every(el => evaulations[el] != "absent")
&& present.every(el => w.includes(el))
&& w.split("")
.every((el, i) => correct[i] == el || correct[i] == undefined)
&& w.split("")
.every((el, i) => ![...wrongPlace[el]||[]].includes(i));
if (weight >= thirdBest[1] && passing) {
thirdBest = [w, weight]
}
});
print(thirdBest[0])
}
```
Ладно, у меня такая риторика, будто мне стыдно за этот код. Но нет! Ну разве что может чуть-чуть.
Мда. А разговоров-то было...Как-то не похоже на правильный ответ. Но ведь наша цель — подсказка! Это она и есть. В багажнике у этой подсказки было 26 вариантов, она выбрала тот, где буквы встречаются чаще всего, и дала: пожалуйста, третья буква точно A, четвертая и пятая возможно какая-то из букв R и E. А может первая и вторая просто поменяны местами? Тогда это слово может быть ERASE. Но буквы S в правильном ответе нет. Окей, слова FRAER в списке нет, но зато есть куча слов, заканчивающихся на ARE: FLARE например. Буква L тоже не подходит, но давайте я попробую, чтобы ускорить процесс:
Я начинаю догадываться...Нет сомнений, мы имеем дело со словом FRAME. Есть еще FLAME и FLAKE, но там и там вторая буква L.
Три подсказки и два самостоятельных хода. Задача решена
### 5. Столько всего интересного
Столько всего интересного я пропущу, если не захочу копнуть глубже, куда-то в сторону науки о данных. Ничего в этом не понимаю, но очень хочется.
Я заметил, что вторая подсказка выглядит как-то глупо, но так ли это? Чтобы проверить, я добавил возможность вызывать подсказки по нескольку раз. Для этого я просто очищаю предложенное лучшее слово и снова запускаю алгоритм.
```
someBest = ["", 0];
```
Жмем на подсказки, пока не получим правильный ответ.Давайте попробуем после третьей подсказки вызвать ее еще раз. Получим GRAPE. Классное слово, почему я сам о нем не подумал? Вариантов остается тоже немного, и вызвав третью подсказку третий раз, мы получаем правильный ответ. Ура!
А что если вызвать вторую подсказку два раза? Снова ничего примечательного: ну окей, ну одна буковка. Но прикол в том, что мы использовали уже 15 букв, столько же симфолов осталось в алфавите, четыре из которых есть в слове. Больше вторая подсказка нам ничего не даст, просто нет слов, отвечающих критериям. В этом случае у алгоритма третьей подсказки тоже остается очень мало вариантов для выбора.
А если мы опустим вторую подсказку и сразу обратимся к третьей? Ведь ее алгоритм возможно более эффективен, в случае, когда мы знаем так много букв? Увы, это не так. Третий алгоритм не сокращает алфавит так сильно, он перебирает всего по две буквы, когда второй делает пять за раз.
Выводы мне, лично сделать сложно, поэтому я обращусь к сообществу. Если вы можете посоветовать ресурсы, где можно весело, играючи и на практике поизучать алгоритмы подбора, не стесняйте себя в комментариях, буду крайне благодарен.
### 6. О красоте
Давайте добавим подсказочки в интерфейс.
```
// Сперва нужно создать функцию print,
// чтобы выводить рехультат подсказок на табло
function print(w, enter=false) {
// Делается это с помощью KeyboardEvent'ов:
// именно так работает экранная клавиатура в игре
w.split("").forEach(l =>
window.dispatchEvent(
new KeyboardEvent('keydown', {'key': l})
));
if (enter) {
window.dispatchEvent(
new KeyboardEvent('keydown', {'key': 'Enter'})
);
}
}
// Еще одна помогайка, название говорит само за себя
function applyStyle(el, style){
Object.entries(style).forEach(p => {
el.style[p[0]] = p[1];
})
}
// Создадим контейнер для кнопок,
// а так же найдем куда его поместить (для этого придется
// залезть в сумеречную зону)
let suggestions = document.createElement("div"),
header = document.querySelector("game-app").shadowRoot
.querySelector("game-theme-manager > div > header");
// Накинем стиль на контейнер и кнопки
// Я делаю это здесь, а не в поле CSS потому что он находится
// в Shadow Root и CSS до него не доберется
applyStyle(suggestions, {
display: "grid",
gridTemplateColumns: "repeat(3, 1fr)",
gridGap: "5px",
justifyItems: "center",
padding: "10px",
margin: "auto",
boxSizing: "border-box",
maxWidth: "350px",
width: "100%",
fontSize: "1.5rem",
lineHeight: "2rem",
fontWeight: "bold",
verticalAlign: "middle",
color: "var(--tile-text-color)",
});
let buttonStyle = {
textAlign: "center",
width: "100%",
background: "#a52a2a"
};
// Чтобы не повторяться соорудил вот это
let buttons = [
["First", getFirstGuess],
["Second", getSecondGuess],
["Third", getThirdGuess]
].forEach(b => {
let el = document.createElement("div");
applyStyle(el, buttonStyle);
el.innerText = b[0];
el.onclick = b[1];
suggestions.appendChild(el);
});
// Добавили кнопки в интерфейс
header.after(suggestions);
```
Теперь у нас есть кнопки. Красные. Большие.На этом, пожалуй все. Получилось объемнее, чем я ожидал, пока писал уложил в голове всю проделанную работу. Кстати о работке: на написание скрипта я потратил около двух-трех часов, столько же на написание статьи. То есть не очень уж трудозатратно это все. Если этот текст поддолкнул вас в каким-нибудь действиям, например поизучать предмет, я буду очень рад увидеть ваши заметки в комментариях или ответном тексте.
[Скрипт целиком пожно посмотреть тут](https://gist.github.com/cyrillsemenov/ffc4e13e219c1fe76eceecf92107ede0)
**UPD:**
Игра окончательно переехала на сайт nytimes, и вмсете с этим кое-что изменилось в скрипте (имена переменных и путь для вставки кнопок). Поскольку никакой существенной концептуальной разницы это не вносит, я не буду менять текст статьи, но обновлю gist.
 | https://habr.com/ru/post/651251/ | null | ru | null |
# Упрощение проверки кода и улучшение согласованности с помощью пользовательских правил eslint
Если вы рассматриваете запросы на исправление или создаете программное обеспечение в команде, пользовательские правила eslint могут сэкономить вам много времени. Вот как это делается.
### Слаженность команды > личные предпочтения
Спагетти-код. Каждый из нас хотя бы раз в своей карьере слышал это слово. Код, который настолько запутан, что из него невозможно извлечь какой-то смысл. Даже если выясняется, что это мы его написали.
Сложность программирования — не единственная проблема, с которой сталкиваются команды разработчиков. Поймите, разработка — ремесло, и это очень личное. Со временем у каждого из нас вырабатываются свои личные предпочтения, как мы называем переменные, делаем отступы в коде или где ставим скобки. И как только вы начинаете работать с кем-то еще, эти предпочтения могут стать причиной множества проблем и заставить вас потерять много драгоценного времени.
Если каждый разработчик в команде будет фиксировать код, написанный в соответствии со своими предпочтениями, то в итоге вы получите беспорядок, который трудно поддерживать. Пересмотр кода и исправление чего-либо в коде, написанном кем-то другим, отнимает все больше и больше времени. Документирование приложения превращается в кошмар. И так вся кодовая база превращается в кошмар, к которому никто не хочет прикасаться.
Некоторые команды придумывают руководства по кодированию, что является отличным первым шагом к обеспечению согласованности. Однако если это документ, который необходимо выполнять вручную, он быстро окажется на полке, покрытый паутиной. Рекомендации по кодированию — это замечательно, но вы должны иметь возможность применять их автоматически. Давайте будем реалистами, никто не будет просматривать всю вашу кодовую базу после рефакторинга, чтобы убедиться, что все соответствует. Особенно, если у вас сжатые сроки.
Если вы создаете приложения на JavaScript/TypeScript, [eslint](https://eslint.org/) — отличный способ обеспечить соблюдение стилей кодирования. По мере набора текста вы получаете мгновенные уведомления о том, что не так и как это исправить. Существует множество предустановленных правил, которые можно использовать в качестве отправной точки. Тем не менее, вы действительно выиграете, если внедрите в eslint специальные рекомендации вашей команды.
### Согласованность кода на практике: CLI для Microsoft 365
Я являюсь одним из мейнтейнеров [CLI для Microsoft 365](https://aka.ms/cli-m365) — инструмента командной строки с открытым исходным кодом, который помогает управлять проектами Microsoft 365 и SharePoint Framework на любой платформе. Он встроен в TypeScript и работает на Node.js.
Мы работаем над CLI для Microsoft 365 уже 3,5 года. С помощью еженедельных бета-релизов было отгружено достаточно много кода. Почти 6 500 файлов. При этом у нас накопился некоторый технический долг, который постепенно устраняется с каждым крупным релизом. Все для того, чтобы обеспечить стабильную работу для наших пользователей.
CLI для Microsoft 365 — это проект с открытым исходным кодом, и у нас есть несколько замечательных участников. Все они из разных организаций, команд и имеют разные предпочтения в кодировании. Но наша задача — следить за тем, чтобы все изменения, которые они вносят, были синхронизированы с нашей кодовой базой. С течением времени некоторые из участников приходят и уходят. Мы — мейнтейнеры — остаемся в проекте и поддерживаем его. Часто нам или другим необходимо вернуться к чужому коду и что-то изменить. А поскольку это проект с открытым исходным кодом, над которым многие работают в свободное время, нужно сделать это быстро.
Изначально мы начали с [контрольного списка](https://github.com/pnp/cli-microsoft365/wiki/PR-checklist) для проверки PR. И до сих пор им пользуемся. Он содержит наиболее важные вещи, которые нужно проверять для каждого PR. Но он не охватывает всего. И если PR — это огромный рефакторинг, то считается, что все вроде бы хорошо, если он создан и тесты пройдены. Реалии жизни. Чтобы исправить это, мы решили использовать eslint.
Решение использовать eslint мы приняли по двум основным причинам. Хотелось повысить согласованность кода с помощью форматирования и именования, а также автоматизировать проверку кода по нашему контрольному PR списку. Для решения первой задачи мы использовали стандартные правила, поставляемые с eslint, настроенные под наши нужды. Для второй мы создали собственные правила. Вот как это сделать.
### Создание пользовательского правила для eslint
eslint — это линтер, который использует [правила](https://eslint.org/docs/rules/) для проверки определенных аспектов вашего кода. Он идеально подходит для обеспечения обратной связи в реальном времени для кода, который вы пишете, и проверки его соответствия вашим рекомендациям по кодированию. Вы также можете включить его в CI/CD-канал, чтобы убедиться, что все PR соответствуют вашим рекомендациям.
[Основы пользовательских правил](https://eslint.org/docs/developer-guide/working-with-rules) описаны на сайте eslint. Вот некоторые вещи, которые я узнал, создавая их для CLI Microsoft 365.
### Проверьте имя класса команд CLI для Microsoft 365
Чтобы проверить, можно ли использовать eslint в CLI для Microsoft 365, мы провели одну из первых проверок, которые выполняются в процессе ревью PR: убедитесь, что имя класса команды соответствует соглашению об именовании `ServiceCommandNameCommand`, например, `AadAppAddCommand`. Файлы команд в CLI для Microsoft 365 организованы в папки, и мы определяем правильное имя класса для каждой команды на основе расположения ее файлов.
### Настройка плагина eslint с пользовательскими правилами
eslint поддерживает пользовательские правила с помощью плагинов. Плагин eslint - это пакет npm. И это первая проблема, которую нам нужно было решить. Мы не видели смысла в поддержке отдельного пакета npm с набором правил, специфичных для CLI Microsoft 365, который никто больше не будет использовать. К счастью, оказалось, что вполне удобно создать его в подпапке и из нее в корневом проекте установить npm-пакет.
Поскольку со временем мы, вероятно, будем добавлять больше правил, то решили организовать их так, чтобы каждое было расположено в отдельном файле.
Следуя требованиям eslint, каждое правило затем экспортируется в переменную rules в файле **index.js**.
```
module.exports.rules = {
'correct-command-class-name': require('./rules/correct-command-class-name'),
'correct-command-name': require('./rules/correct-command-name')
};
```
**index.js** указывается как основная точка входа пакета плагина в **package.json**:
```
{
"name": "eslint-plugin-cli-microsoft365",
"version": "1.0.0",
"main": "lib/index.js"
}
```
Последнее, что осталось сделать для подключения правила к eslint, это добавить его в коллекцию rules в .eslintrc.js корневого проекта:
```
module.exports = {
// [...] trimmed for brevity
"plugins": [
"@typescript-eslint",
"cli-microsoft365"
]
"rules": {
"cli-microsoft365/correct-command-class-name": "error"
// [...] trimmed for brevity
}
// [...] trimmed for brevity
}
```
Это была самая сложная часть - настроить все и увидеть, как пользовательское правило применяется в процессе линтинга. Как только это было сделано, я перешел к созданию самого правила.
### Определение селектора правила
При создании правил eslint вам нужно указать им, какой узел в файле кода они должны исследовать. Это можно сделать, указав [селектор](https://eslint.org/docs/developer-guide/selectors).
Для правила, которое проверяет имя класса команды, я использовал `ClassDeclaration`. Для другого правила, которое проверяет имя const, содержащего фактическое имя команды, понадобился более сложный селектор: `MethodDefinition[key.name = "name"] MemberExpression > Identifier[name != "commands"]`. Использование селекторов не является тривиальным и требует понимания того, как код переводится в абстрактные синтаксические деревья. [AST Explorer](https://astexplorer.net/) - это отличный ресурс, позволяющий увидеть, как ваш код переводится в AST с помощью eslint.
Выбор правильного селектора важен, поскольку он позволит вам минимизировать объем кода, необходимого для исследования узла. Также необходимо помнить, что селектор будет применен ко всему файлу. Если eslint найдет несколько совпадений, он будет выполнять правило для каждого совпадения.
### Сделайте ваше правило поддающимся исправлению
При создании пользовательских правил eslint следует сделать их автоматически исправляемыми. Когда мы ввели правило именования классов команд в CLI, то обнаружили, что десятки команд используют несогласованные имена. Вместо того чтобы исправлять их вручную одну за другой, мы воспользовались eslint, который исправил эти имена за нас!
Чтобы сообщить eslint о том, что ваше правило можно исправить, в метаданных правила установите свойство `fixable` в code.
```
module.exports = {
meta: {
type: 'problem',
docs: {
description: 'Incorrect command class name',
suggestion: true
},
fixable: 'code'
// [...] trimmed for brevity
}
// [...] trimmed for brevity
}
```
Затем в коде правила, когда вы обнаружили, что оно нарушено, сообщите о фактическом узле, который следует исправить. Это может быть непросто!
При проверке имени класса команды я использовал селектор `ClassDeclaration`, который дает мне доступ к узлу объявления класса с такой информацией, как имя класса, родительский класс, является ли класс абстрактным и так далее. Но если бы я сообщил об этом узле просто как о месте, которое нужно исправить, eslint заменил бы весь блок класса только правильным именем класса! Поэтому вместо этого при сообщении об узле сбоя мне нужно указать node.id, который является узлом, содержащим имя класса.
```
if (actualClassName !== expectedClassName) {
context.report({
node: node.id,
messageId: 'invalidName',
data: {
actualClassName,
expectedClassName
},
fix: fixer => fixer.replaceText(node.id, expectedClassName)
});
}
```
### Резюме
Если вы работаете над проектом вместе с другими разработчиками, сохранение согласованности кодовой базы поможет вам работать быстрее. Чем больше ваша организация и многочисленнее команда разработчиков, тем важнее обеспечить согласованность кода. Если вы создаете приложения на JavaScript или TypeScript, стандартный набор правил eslint — отличное начало. Добавление пользовательских правил, соответствующих рекомендациям вашей команды, действительно поможет вам автоматизировать проверку кода, сэкономить время и обеспечить согласованность кода.
---
> Материал подготовлен в рамках курса [«JavaScript Developer. Basic»](https://otus.pw/39kN/). Всех желающих приглашаем на открытый практический урок **«Тесты и TDD в работе javascript разработчика».** Мы разберем на примере, как писать тесты и следовать подходу TDD. [**>> РЕГИСТРАЦИЯ**](https://otus.pw/Ap5L/)
>
> | https://habr.com/ru/post/576534/ | null | ru | null |
# Rosserial & STM32
Робототехническая операционная система ROS является довольно мощной платформой для создания робототехнических систем, которая включает все необходимое для разработки своих проектов от простейших программных компонентов, называемых “узлами”, и протокола обмена данными до среды симулирования реальной робототехнической платформы Gazebo. В основном ROS используется в связке с такими микроконтроллерами на платформе Arduino. Интернет переполнен всевозможными туториалами о связке ROS и Arduino.
В данный момент не существует информации об использовании робототехнической операционной системы ROS в связке с микроконтроллером STM32. Интернет переполнен только вопросами.

#### Начнем работу
Для работы с STM32 нам понадобится STM32CubeMX и SystemworkbenchforSTM32. Информации об их установке в сети предостаточно, не будем на этом останавливаться.
**Для конфигурации контроллера зайдем в STM32CubeMX**
Создадим новый проект.

Выберем микроконтроллер, у меня STM32f103c8t6.

В периферии указываем, что у на подключен внешний кварцевый резонатор, у нас их 2
Настраиваем выводы, через которые можно включать отладку контроллера, (забегая вперед, если проект будет на С++, отладка может не работать)
Настроим 13 вывод порта С, к нему подключен встроенный светодиод.
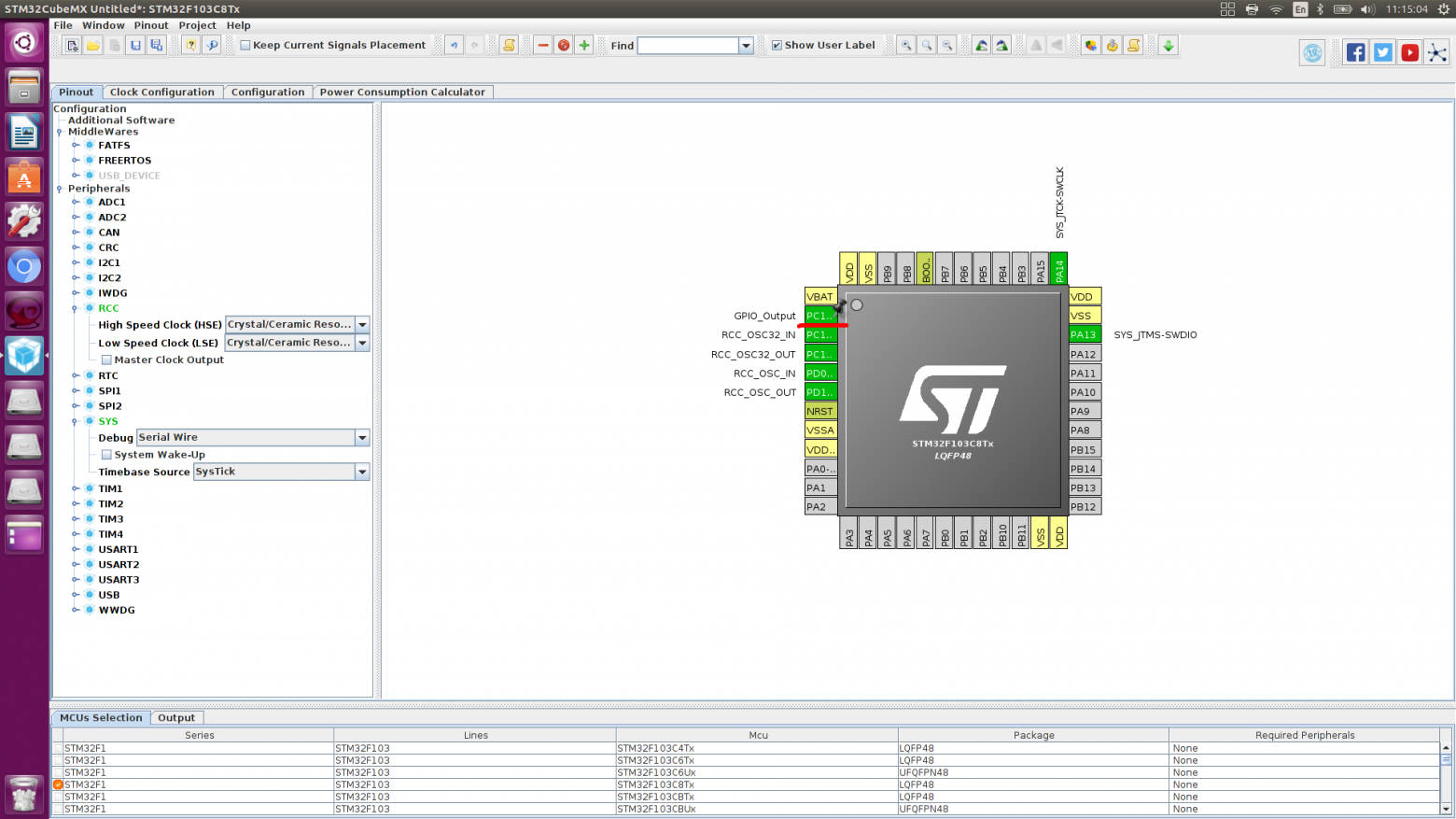
Настроим выводы UART.
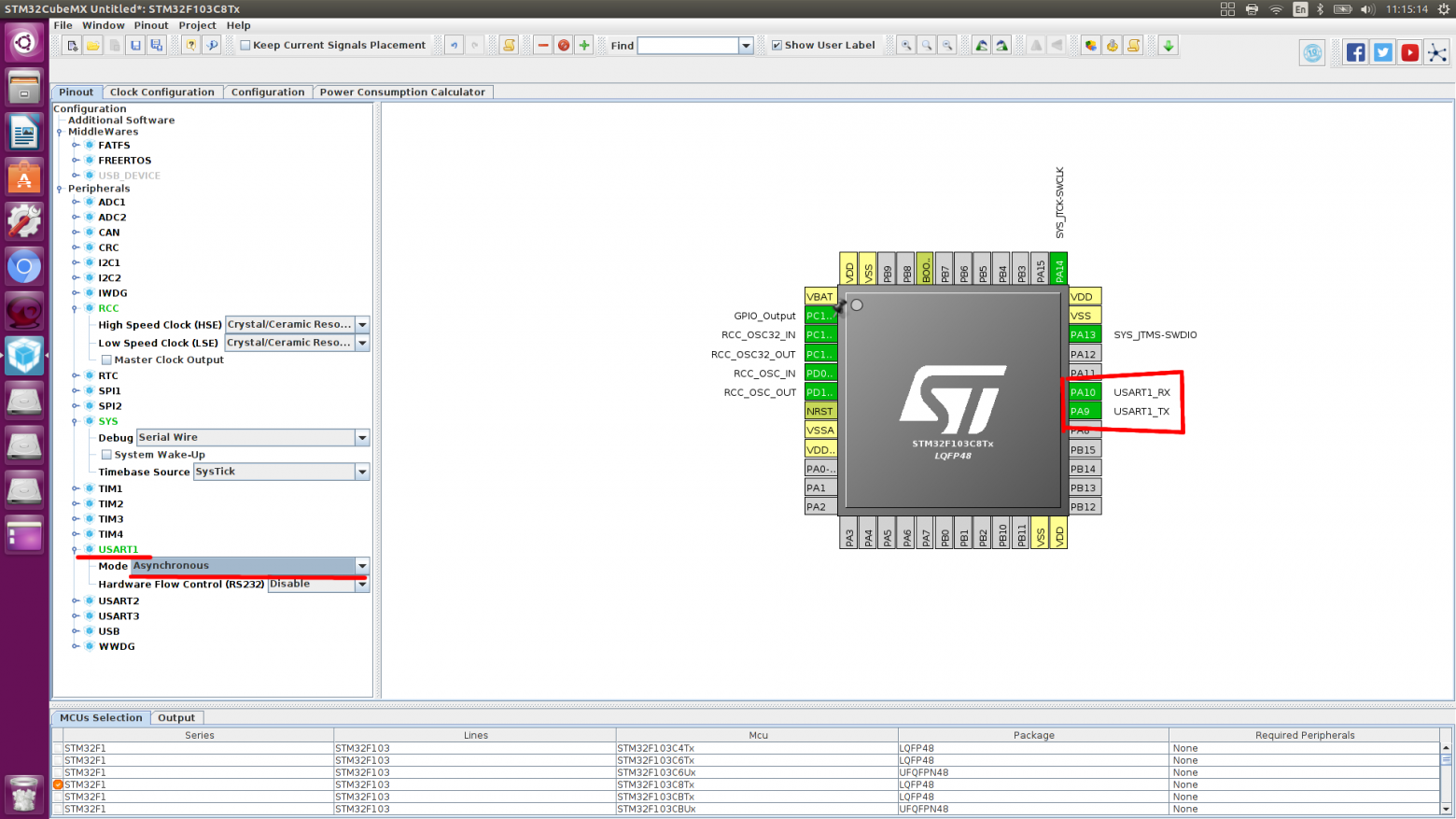
Перейдем в Сlock\_configuration и выполним настройки как на картинке.

#### Перейдем к более детальной настройке периферии
**UART**
Настройка скорости обмена данных.
Настройка DMA.

Настройка прерывания, нужно указать глобальное прерывание по UART

#### Настройка GPIO

#### Настройка сборки проекта
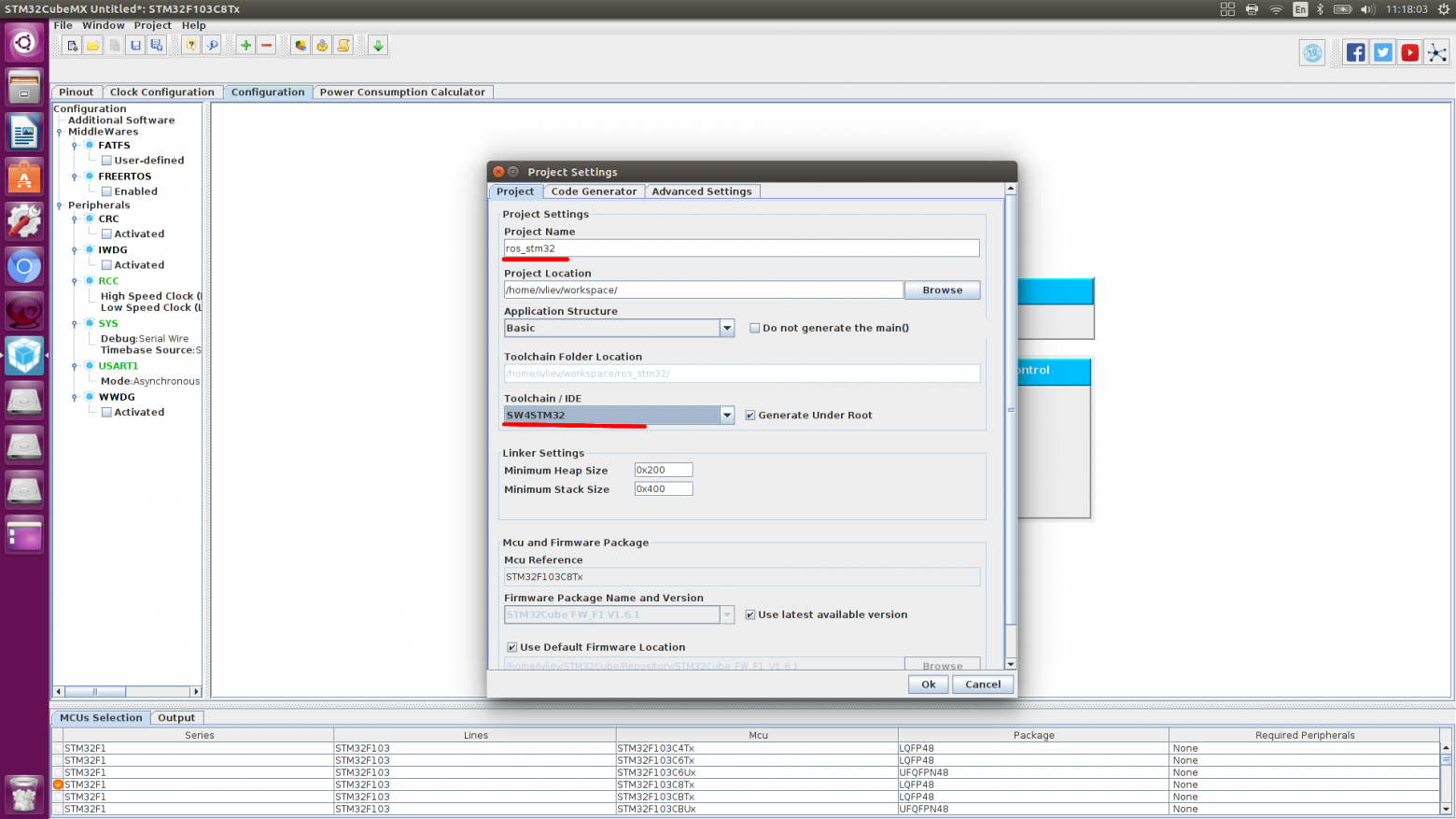
Ждем пока соберется
Открываем проект,

#### Создание проекта под System Workbench For STM32
Открыв данный проект в SW4STM32, дописав некоторое управление периферией, собрав его, и прошив контроллер, я не получил никакого результата.
Поэтому создаем новый проект по следующей инструкции, и переносим конфигурацию полученную STM32CubeMX.
#### Создание проекта под System Workbench For STM32
1) Нажмите File > New > C Project
2) C Project
1) Введите название проекта
2) Выберите тип проекта: Executable > Ac6 STM32 MCU Project
3) Выберите Toolchains: Ac6 STM32 MCU GCC
4) Нажмите «Далее»

3) Выбираем микроконтроллер
1) Нажмите «Create a new custom board»
1) Сохранить Определение новой платы
2) Введите имя новой платы: STM32F103
3) Выберите чип платы: STM32F1
4) Выберите МСU: STM32F103RCTx
5) Нажмите «ОК».
2) Выберите плату, которое вы только что создали!
1) Выбрать серию: STM32F1
2) Выберите плату: STM32F103
3) Нажмите «Далее»

4) Подключаем библиотеки HAL
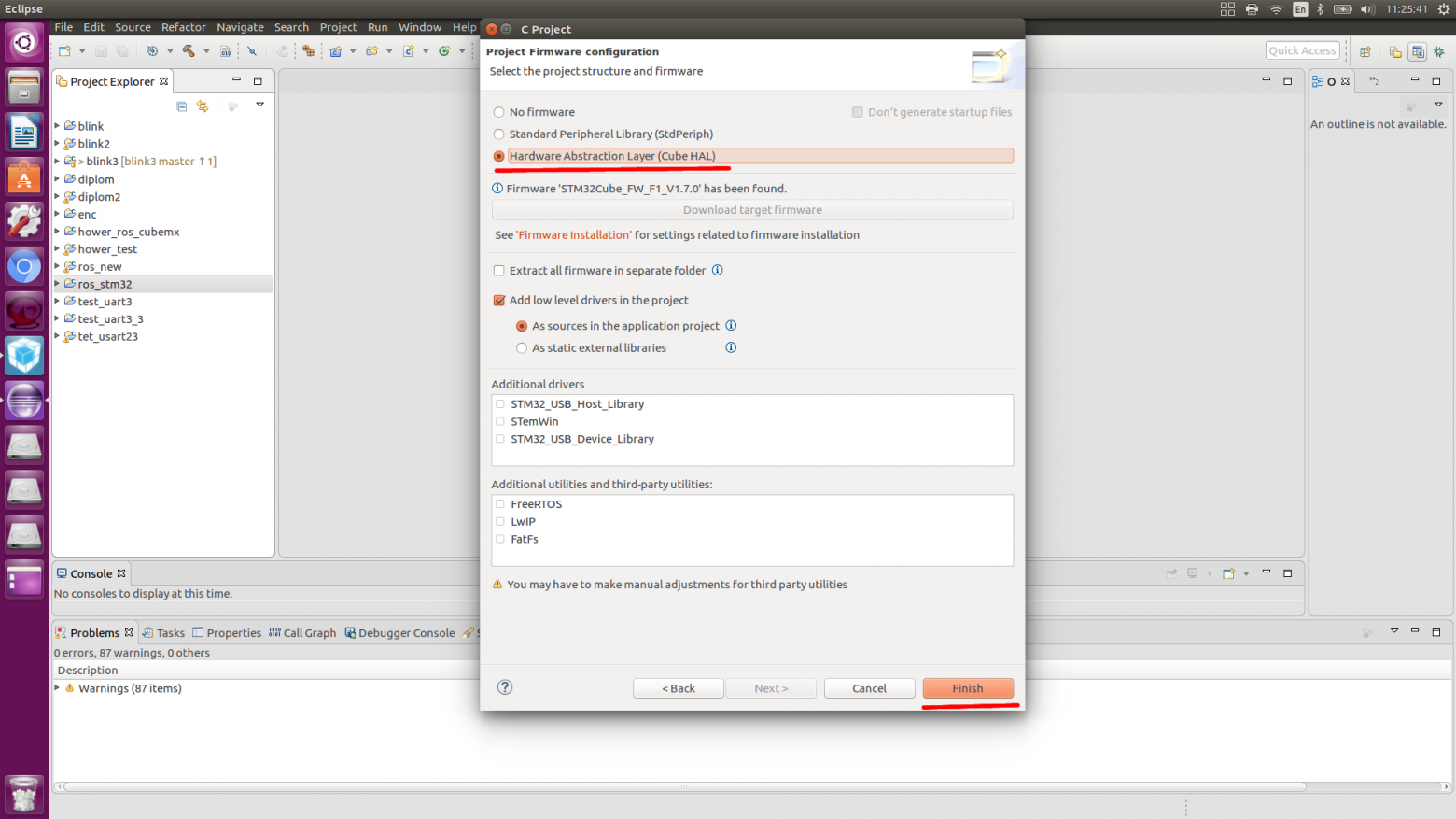
5) Нажмите «Finish»
#### Добавление файлов
Копируем содержимое файлов src и inc, созданных кубом в наши файлы, также копируем STM32F103C8Tx\_FLASH.ld
Для проверки работоспособности самой STM32 и кода в цикл while прописываем следующие строки
```
HAL_GPIO_TogglePin(GPIOC, GPIO_PIN_13);
HAL_Delay(100);
```
Тут мы просто моргаем светодиодом.
При сборке могут возникнуть проблемы в файле stm32f1xx\_hal\_msp.c
Ошибку связанную с функцией void HAL\_MspInit(void) исправляем следующим образом.
Открываем папку с библиотекой HAL\_Driver, идем /src открываем файл stm32f1xx\_hal\_msp\_template.c и закомментируем эту же функцию:
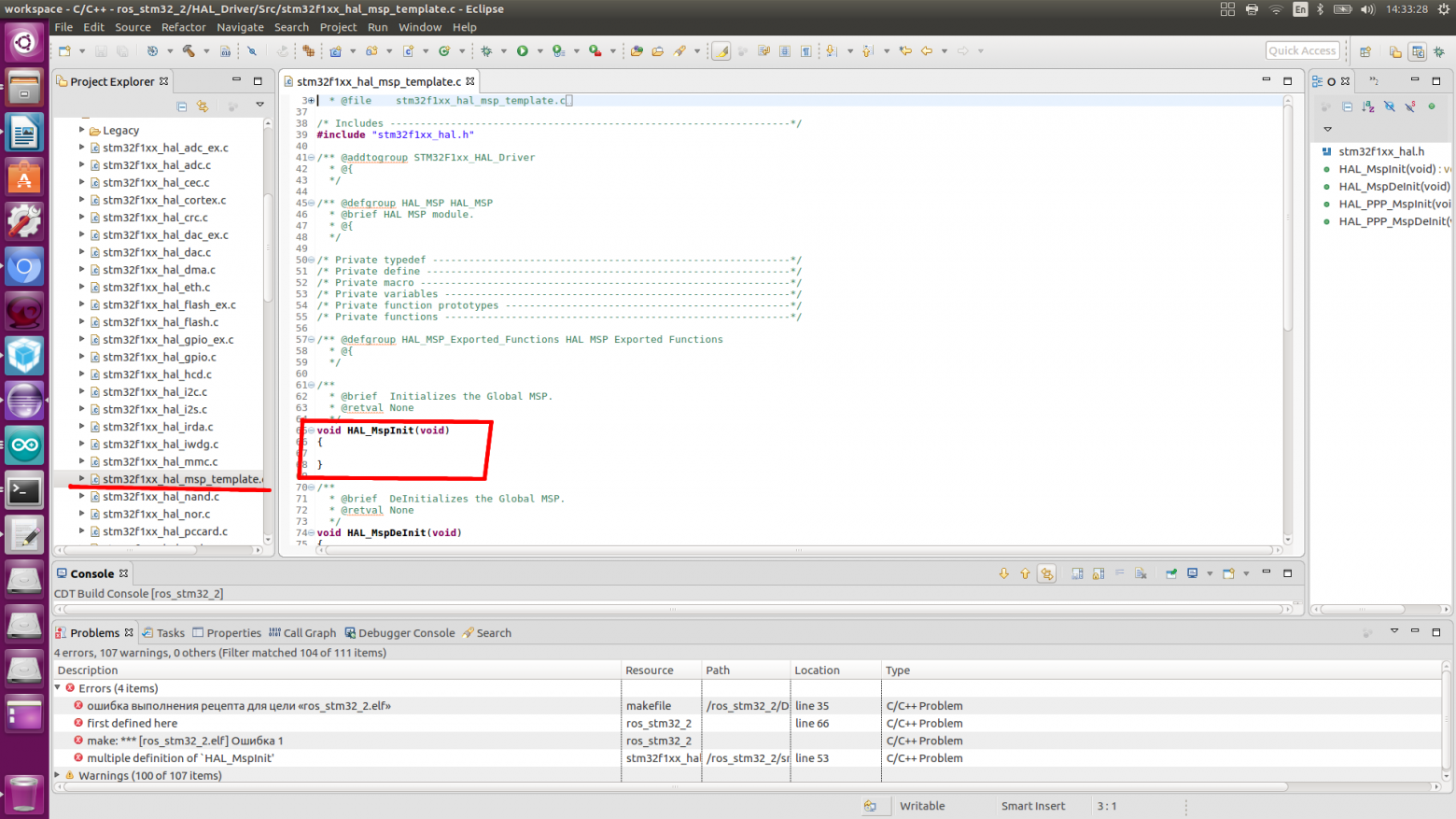
Собираем заново (должно собраться без ошибок)
Забыл упомянуть для прошивки контроллера понадобится утилита st-flash.
```
$ sudo apt-get install cmake
$ sudo apt-get install libusb-1.0.0
$ git clone github.com/texane/stlink.git
$ cd stlink
$ make release
$ cd build/Release; sudo make install
$ sudo ldconfig
```
Использование ST link
Проверка обнаружения ST link:
```
$ st-info —probe
```
В ответ мы должны увидеть что-то вроде:
```
Found 1 stlink programmers
serial: 563f7206513f52504832153f
openocd: "\x56\x3f\x72\x06\x51\x3f\x52\x50\x48\x32\x15\x3f"
flash: 262144 (pagesize: 2048)
sram: 65536
chipid: 0x0414
descr: F1 High-density device
```
Для прошивки контроллера переходим в папку нашего проекта и и прошиваем контроллер через следующий команду:
```
cd workspace/ros_stm32_2/
st-flash write Debug/ros_stm32_2.bin 0x8000000
```
Проверили. Все работает. Двигаемся дальше.
Так как библиотеки ROS написаны на C++, переводим наш проект в проект С++, и изменяем формат файлов main.c, stm32f1xx\_hal\_msp.c, stm32f1xx\_it.c в .cpp
Клонируем мой репозиторий с библиотеками рос и нужными файлами для работы rosserial на STM32.
```
git clone https://gitlab.com/ivliev123/ros_lib
```
Вставляем склонированную папку в проект
Перейдем в настройки проект (Properties), первым делом подключаем библиотеку, переходим…
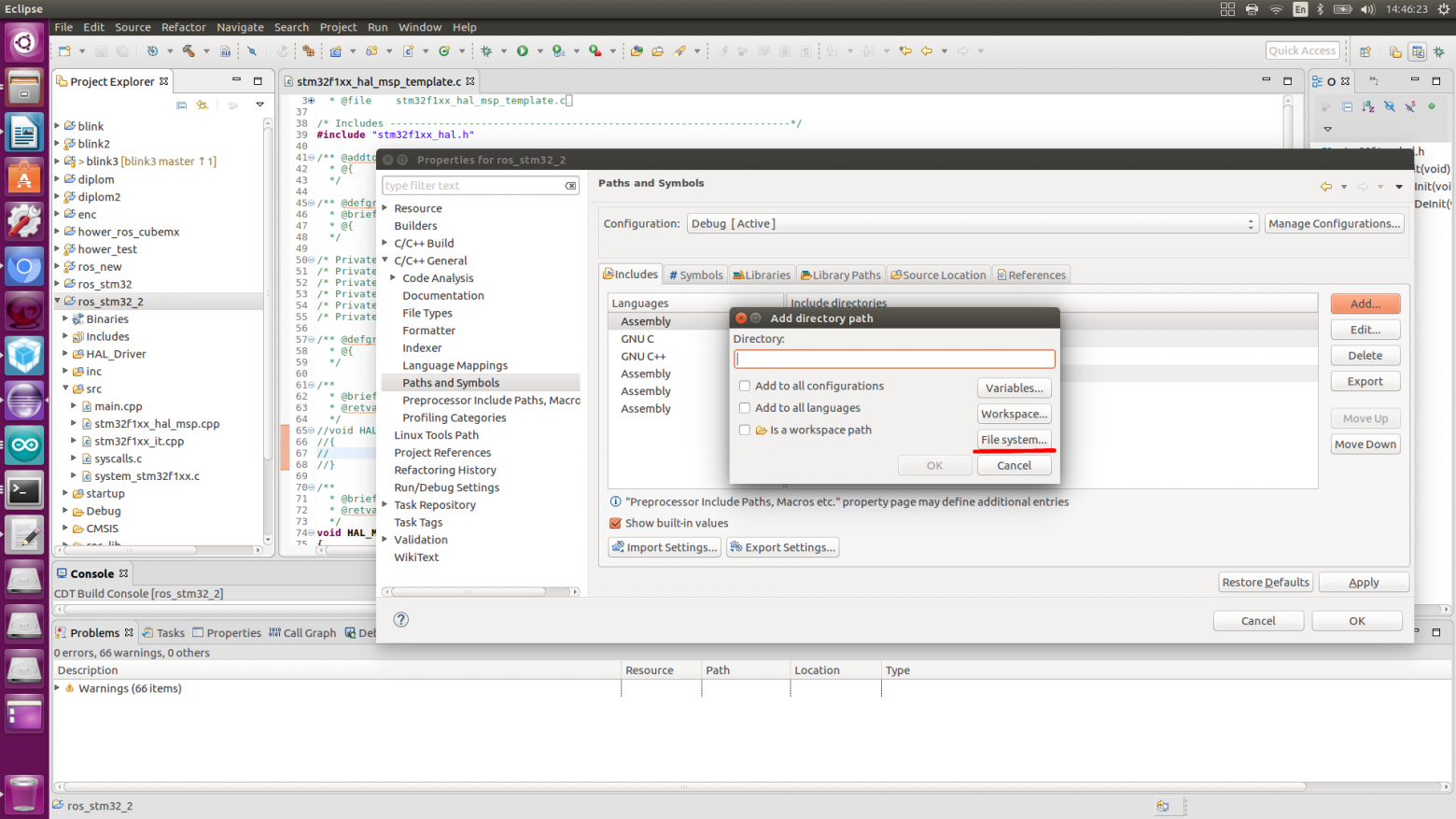
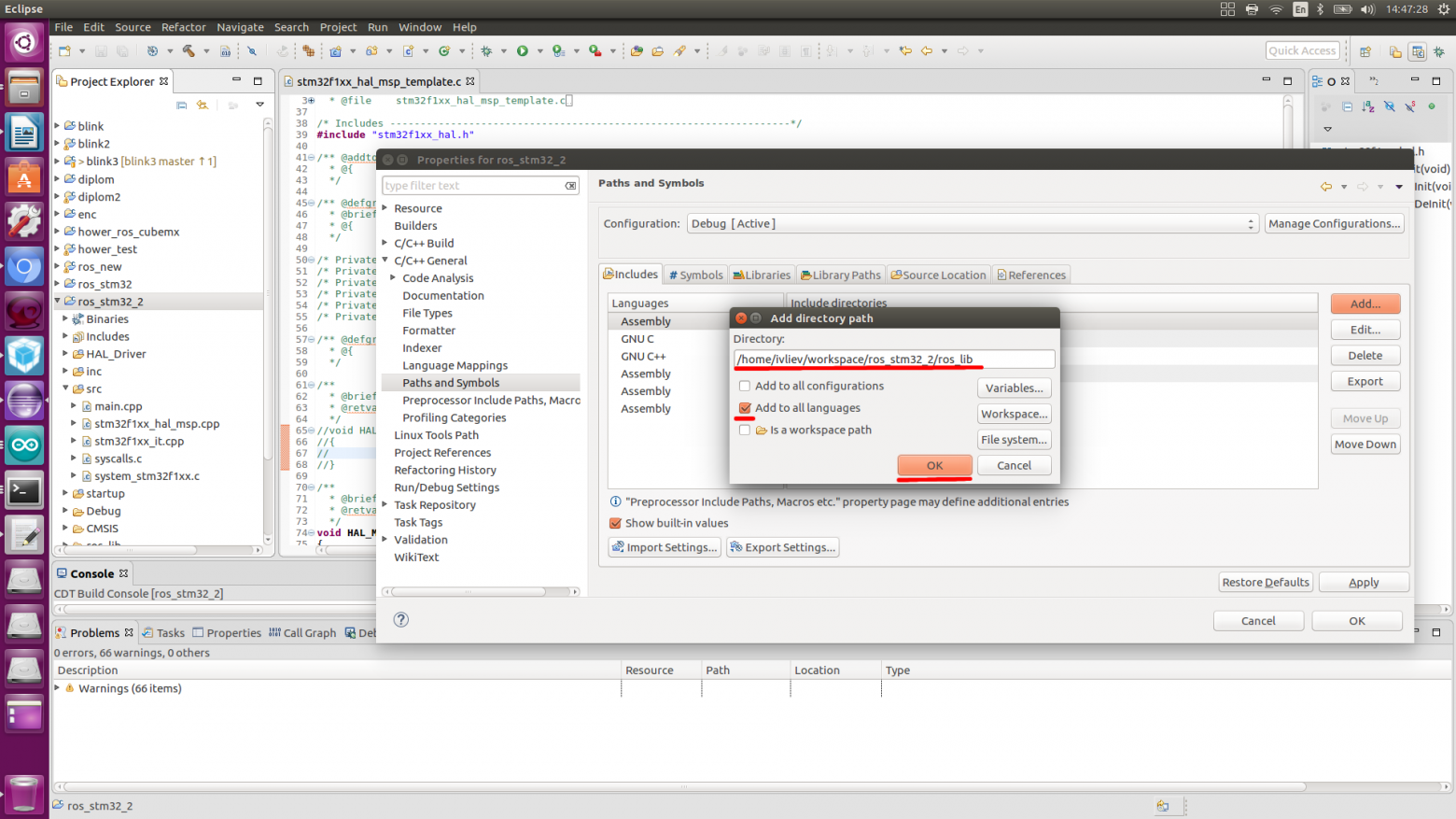
Изменяем компоновщик

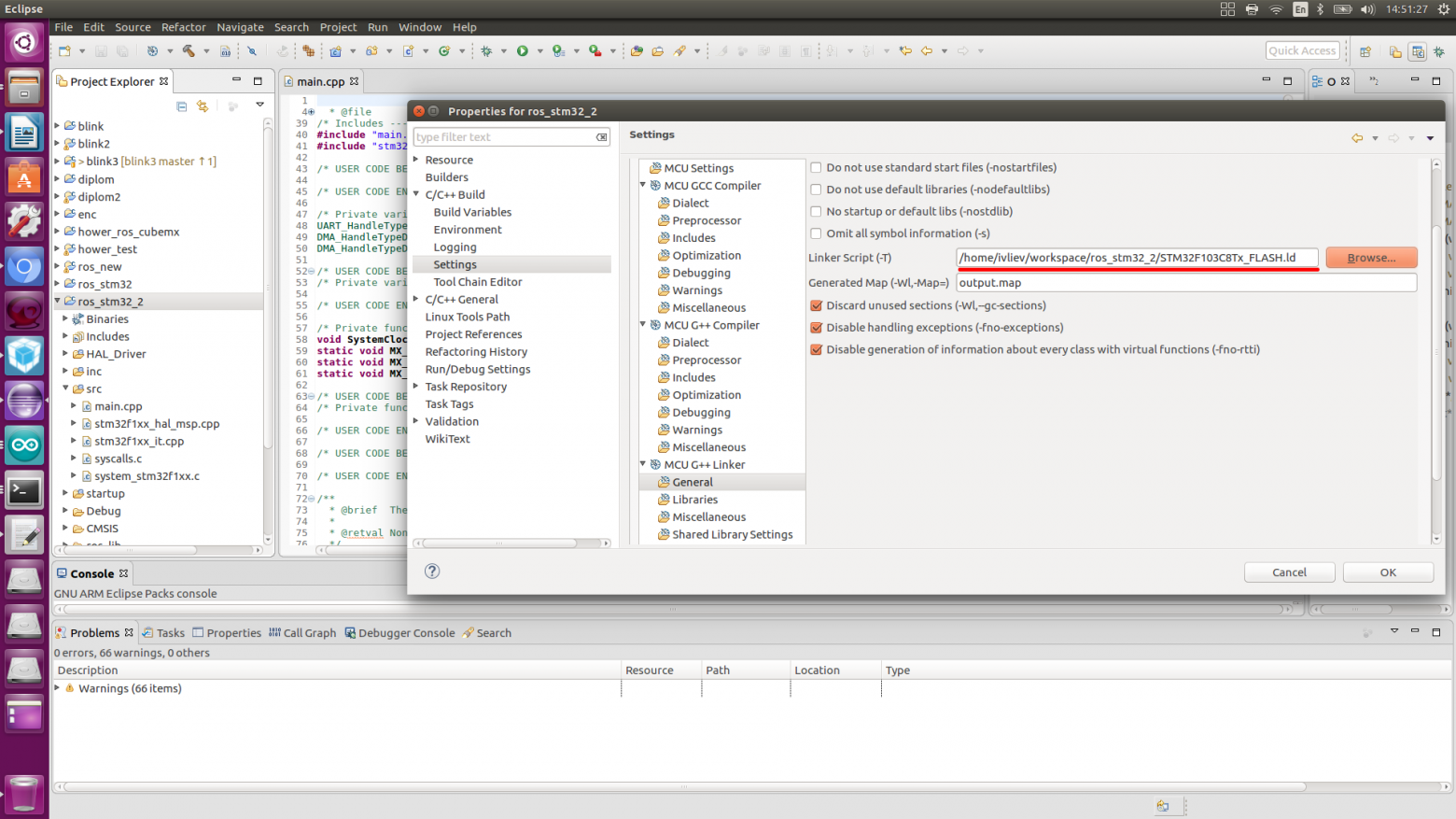
Выполняем оптимизацию


Ну теперь внесем некие изменения в main.cpp, так как он почти пустой, первое что делаем подключаем библиотеку ROS, и библиотеки для взаимодействия с топиками ROS, а точней с типами данных этих топиков.
```
#include
#include
#include
```
Создадим узел, топик публикующий данный и принимающий
```
void led_cb( const std_msgs::UInt16& cmd_msg){
HAL_GPIO_TogglePin(GPIOC, GPIO_PIN_13);
}
ros::NodeHandle nh;
std_msgs::String str_msg;
ros::Publisher chatter("chatter", &str_msg);
ros::Subscriber sub("led", led\_cb);
```
Инициализируем узел и топики в main.
```
nh.initNode();
nh.advertise(chatter);
nh.subscribe(sub);
```
Также добавим переменные для работы со временем и то что будем публиковать.
```
const char * hello = "Hello World!!";
int chatter_interval = 1000.0 / 2;
int chatter_last = HAL_GetTick();
```
В цикле while у нас будет следующее. Будем публиковать нашу фразу через определенное время.
```
if (nh.connected())
{
if(HAL_GetTick() - chatter_last > chatter_interval)
{
str_msg.data = hello;
chatter.publish(&str_msg);
chatter_last = HAL_GetTick();
}
}
nh.spinOnce();
```
Собираем проект.
Могут появится следующие ошибки:

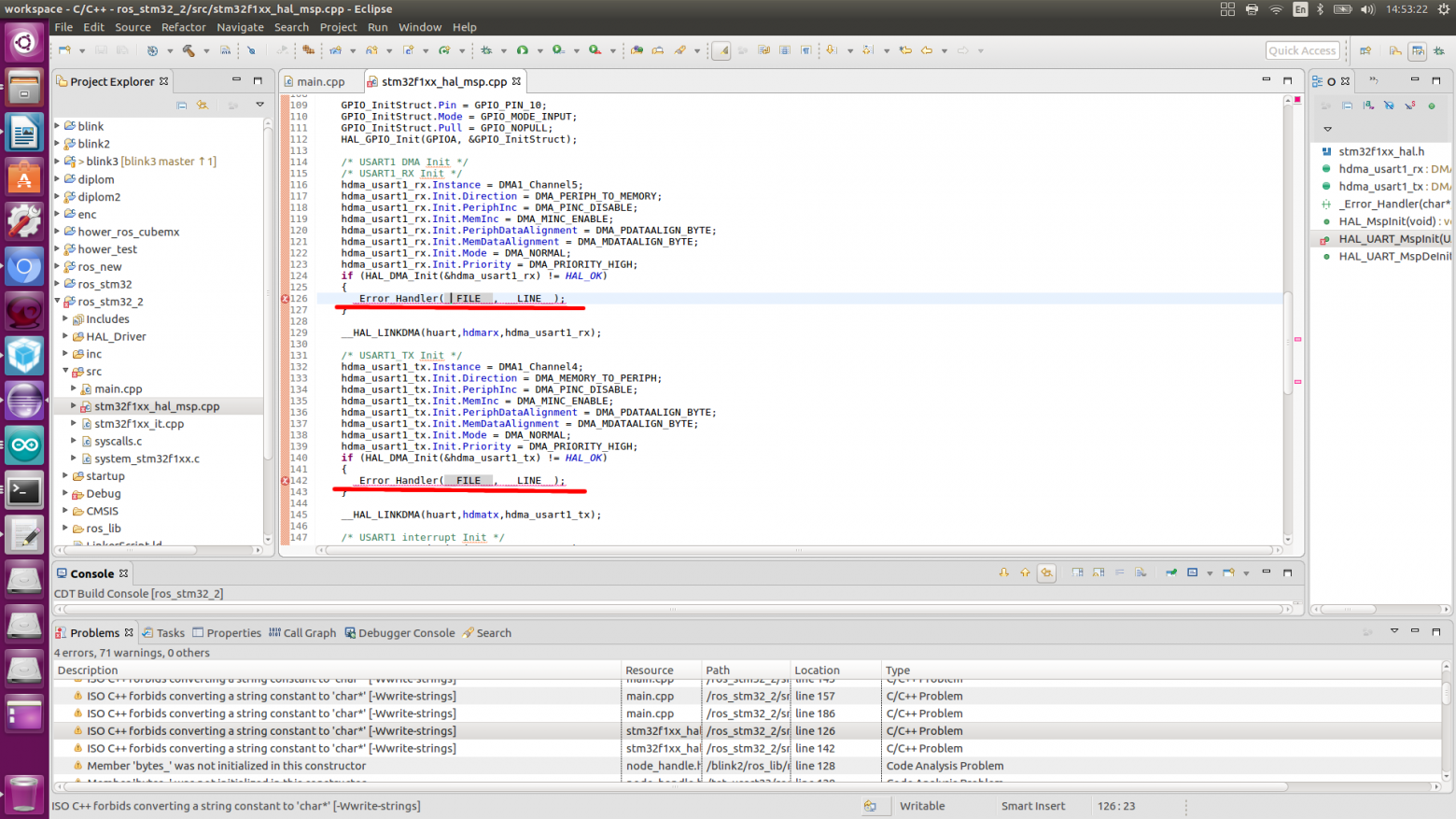

Собираем заново и прошиваем.
Теперь непосредственно само взаимодействие с ROS.
В одном терминале запускаем ROS.
```
roscore
```
В следующем запускаем узел.
```
rosrun rosserial_python serial_node.py /dev/ttyUSB0
```
Получаем следующее
```
[INFO] [1551788593.109252]: ROS Serial Python Node
[INFO] [1551788593.124198]: Connecting to /dev/ttyUSB0 at 57600 baud
[INFO] [1551788595.233498]: Requesting topics...
[INFO] [1551788595.258554]: Note: publish buffer size is 2048 bytes
[INFO] [1551788595.259532]: Setup publisher on chatter [std_msgs/String]
[INFO] [1551788595.275572]: Note: subscribe buffer size is 2048 bytes
[INFO] [1551788595.276682]: Setup subscriber on led [std_msgs/UInt16]
```
Далее в новом окне терминала, смотрим, топики
```
rostopic list
```
Получаем следующие топики:
```
/chatter
/diagnostics
/led
/rosout
/rosout_agg
```
В топик chatter контроллер публикует фразу.
Можем его послушать через команду
```
rostopic echo /chatter
```

Теперь отправим данные в топик led.
```
rostopic pub /led std_msgs/UInt16 "data: 0"
```
И у нас должно изменится состояние светодиода. | https://habr.com/ru/post/443022/ | null | ru | null |
# Magento 2. Добавление картинок в динамический массив
Приветствую вас, хабравчане! Немного набравшись смелости решил написать свою первую статью, точнее поделиться небольшим опытом, в интересной, как мне показалось теме, а именно как в динамический массив в конфиге, добавить загрузчик файлов.
Итак начнем.
Для начала создадим модуль, и базовую структуру модуля
Mr/ImageDynamicConfig/registration.php
```
php
\Magento\Framework\Component\ComponentRegistrar::register(
\Magento\Framework\Component\ComponentRegistrar::MODULE,
'Mr_ImageDynamicConfig',
__DIR__
);</code
```
Mr/ImageDynamicConfig/etc/module.xml
```
xml version="1.0"?
```
Далее начнем описывать все необходимые элементы, шаг за шагом:
И первым на очереди, создадим сам конфиг:
Mr/ImageDynamicConfig/etc/adminhtml/system.xml
```
xml version="1.0"?
Mr
separator-top
Image Array Swatch
mr
Mr\_ImageDynamicConfig::config
Image
Mr\ImageDynamicConfig\Block\Adminhtml\System\Config\ImageFields
Mr\ImageDynamicConfig\Model\Config\Backend\Serialized\ArraySerialized
var/uploads/swatch/image\_serializer
```
Для динамического массива строка Mr\ImageDynamicConfig\Block\Adminhtml\System\Config\ImageFields совсем не нова, и класс ImageFields рендерит все основные колонки и показывает как они должны выглядеть
Mr/ImageDynamicConfig/Block/Adminhtml/System/Config/ImageFields.php
```
php
declare(strict_types=1);
namespace Mr\ImageDynamicConfig\Block\Adminhtml\System\Config;
use Magento\Config\Block\System\Config\Form\Field\FieldArray\AbstractFieldArray;
class ImageFields extends AbstractFieldArray
{
const IMAGE_FIELD = 'image';
const NAME_FIELD = 'name';
private $imageRenderer;
protected function _prepareToRender()
{
$this-addColumn(
self::IMAGE_FIELD,
[
'label' => __('Image'),
'renderer' => $this->getImageRenderer()
]
);
$this->addColumn(
self::NAME_FIELD,
[
'label' => __('Name'),
]
);
$this->_addAfter = false;
$this->_addButtonLabel = __('Add');
}
private function getImageRenderer()
{
if (!$this->imageRenderer) {
$this->imageRenderer = $this->getLayout()->createBlock(
\Mr\ImageDynamicConfig\Block\Adminhtml\Form\Field\ImageColumn::class,
'',
['data' => ['is_render_to_js_template' => true]]
);
}
return $this->imageRenderer;
}
}
```
тут в методе \_prepareToRender объявляем колонки, которые будут в динамическом массиве, и если в колонке есть поле отличное от текстового инпута, описываем для этого поля рендерер (метод getImageRenderer). На строке 38 рендерим блок \Mr\ImageDynamicConfig\Block\Adminhtml\Form\Field\ImageColumn, который и будет отдавать нам вместо инпута html - код с выбором файлов и отображением файла
Mr/ImageDynamicConfig/Block/Adminhtml/Form/Field/ImageColumn.php
```
php
declare(strict_types=1);
namespace Mr\ImageDynamicConfig\Block\Adminhtml\Form\Field;
use Mr\ImageDynamicConfig\Block\Adminhtml\ImageButton;
class ImageColumn extends \Magento\Framework\View\Element\AbstractBlock
{
public function setInputName(string $value)
{
return $this-setName($value);
}
public function setInputId(string $value)
{
return $this->setId($value);
}
protected function _toHtml(): string
{
$imageButton = $this->getLayout()
->createBlock(ImageButton::class)
->setData('id', $this->getId())
->setData('name', $this->getName());
return $imageButton->toHtml();
}
}
```
В перегруженном методе \_toHtml рендерим блок Mr\ImageDynamicConfig\Block\Adminhtml\ImageButton, который будет отдавать нам темплейт с html - кодом
Mr/ImageDynamicConfig/Block/Adminhtml//ImageButton.php
```
php
declare(strict_types=1);
namespace Mr\ImageDynamicConfig\Block\Adminhtml;
class ImageButton extends \Magento\Backend\Block\Template
{
protected $_template = 'Mr_ImageDynamicConfig::config/array_serialize/swatch_image.phtml';
private $assetRepository;
public function __construct(
\Magento\Backend\Block\Template\Context $context,
\Magento\Framework\View\Asset\Repository $assetRepository,
array $data = []
) {
$this-assetRepository = $assetRepository;
parent::__construct($context, $data);
}
public function getAssertRepository(): \Magento\Framework\View\Asset\Repository
{
return $this->assetRepository;
}
}
```
Публичный метод getAssertRepository нам нужен, чтобы вывести полный url на css файл в темплейте.
Mr/ImageDynamicConfig/view/adminhtml/templates/config/array\_serialize/swatch\_image.phtml
```
php
/*** @var \Mr\ImageDynamicConfig\Block\Adminhtml\ImageButton $block */
$css = $block-getAssertRepository()->createAsset("Mr_ImageDynamicConfig::css/image_button.css");
?>
![]()
= \_\_("File") ?
require(["jquery"], function (jq) {
jq(function () {
const id = "<?=$block->getId()?>"
const imageId = "swatch\_image\_image\_<?=$block->getId()?>"
const data = jq("#" + id).val();
if (data) {
jq("#" + imageId).attr("src", data)
jq("#" + imageId).attr("value", data)
}
});
});
```
В этом темплейте отображается инпут для загрузки, и вывода загруженной картинки. С одной стороны очень странное решение сделать скрытый инпут:
а после из него вставлять в img тег значение:
```
jq(function () {
const id = "=$block-getId()?>"
const imageId = "swatch_image_image_=$block-getId()?>"
const data = jq("#" + id).val();
if (data) {
jq("#" + imageId).attr("src", data)
jq("#" + imageId).attr("value", data)
}
});
```
Но, когда Magento рендерит форму в конфиге, чтобы вставить туда значение, она пытается найти input с id и записать в value это значение. По-этому я сделал скрытый инпут и через jquery прокинул в source img путь на картинку
Таким образом, мы разобрали frontend\_model и как вывести image input в динамический массив.
Теперь рассмотрим этап - загрузки картинок.
Для этого используется backend\_model, и в обычных случаях, когда нужно просто добавить динамический массив в конфиг, то прокидываем в backend\_model Magento\Config\Model\Config\Backend\Serialized\ArraySerialized и на этом все наши проблемы решены, но ArraySerialized не работает с загрузкой и сохранением картинок, и по этому на его основе делаем свой array serializer
Mr/ImageDynamicConfig/Model/Config/Backend/Serialized/ArraySerialized
```
php
declare(strict_types=1);
namespace Mr\ImageDynamicConfig\Model\Config\Backend\Serialized;
use Magento\Framework\Serialize\Serializer\Json;
use Mr\ImageDynamicConfig\Block\Adminhtml\System\Config\ImageFields;
class ArraySerialized extends \Magento\Config\Model\Config\Backend\Serialized\ArraySerialized
{
private $imageUploaderFactory;
private $imageConfig;
public function __construct(
\Magento\Framework\Model\Context $context,
\Magento\Framework\Registry $registry,
\Magento\Framework\App\Config\ScopeConfigInterface $config,
\Magento\Framework\App\Cache\TypeListInterface $cacheTypeList,
\Mr\ImageDynamicConfig\Model\Config\ImageConfig $imageConfig,
\Mr\ImageDynamicConfig\Model\ImageUploaderFactory $imageUploaderFactory,
\Magento\Framework\Model\ResourceModel\AbstractResource $resource = null,
\Magento\Framework\Data\Collection\AbstractDb $resourceCollection = null,
array $data = [],
Json $serializer = null
) {
$this-imageUploaderFactory = $imageUploaderFactory;
$this->imageConfig = $imageConfig;
parent::__construct(
$context,
$registry,
$config,
$cacheTypeList,
$resource,
$resourceCollection,
$data,
$serializer
);
}
public function beforeSave(): ArraySerialized
{
$value = $this->getValue();
$value = $this->mapRows($value);
$this->setValue($value);
return parent::beforeSave();
}
private function mapRows(array $rows): array
{
$iconUploader = $this->imageUploaderFactory->create([
'path' => $this->getPath(),
'uploadDir' => $this->getUploadDir(),
]);
$uploadedFiles = $iconUploader->upload();
$swatches = $this->imageConfig->getSwatches();
foreach ($rows as $id => $data) {
if (isset($uploadedFiles[$id])) {
$rows[$id][ImageFields::IMAGE_FIELD] = $uploadedFiles[$id];
continue;
}
if (!isset($swatches[$id])) {
unset($swatches[$id]);
} else {
$rows[$id] = $this->matchRow($data, $swatches[$id]);
}
}
return $rows;
}
private function matchRow(array $row, array $configTabIcon): array
{
foreach ($row as $fieldName => $value) {
if (is_array($value) && $fieldName == ImageFields::IMAGE_FIELD) {
$row[ImageFields::IMAGE_FIELD] = $configTabIcon[ImageFields::IMAGE_FIELD];
}
}
return $row;
}
private function getUploadDir(): string
{
$fieldConfig = $this->getFieldConfig();
if (!array_key_exists('upload_dir', $fieldConfig)) {
throw new \Magento\Framework\Exception\LocalizedException(
__('The base directory to upload file is not specified.')
);
}
if (is_array($fieldConfig['upload_dir'])) {
$uploadDir = $fieldConfig['upload_dir']['value'];
if (array_key_exists('scope_info', $fieldConfig['upload_dir'])
&& $fieldConfig['upload_dir']['scope_info']
) {
$uploadDir = $this->_appendScopeInfo($uploadDir);
}
if (array_key_exists('config', $fieldConfig['upload_dir'])) {
$uploadDir = $this->getUploadDirPath($uploadDir);
}
} else {
$uploadDir = (string)$fieldConfig['upload_dir'];
}
return $uploadDir;
}
}
```
Тут немного заострим внимание на методе mapRows, на строках 50-54 загружаем картинку, на строках 56-66 модифицируем данные из конфига, добавляем/заменяем картинку в массив конфига и остальные поля тоже добавляем/обновляем
класс ImageUploader:
Mr/ImageDynamicConfig/Model/ImageUploader.php
```
php
declare(strict_types=1);
namespace Mr\ImageDynamicConfig\Model;
use Magento\MediaStorage\Model\File\Uploader;
class ImageUploader
{
private $arrayFileModifier;
private $uploaderFactory;
private $uploadDir;
private $allowExtensions;
public function __construct(
\Mr\ImageDynamicConfig\Model\ArrayFileModifier $arrayFileModifier,
\Magento\MediaStorage\Model\File\UploaderFactory $uploaderFactory,
string $uploadDir,
array $allowExtensions
) {
$this-arrayFileModifier = $arrayFileModifier;
$this->uploaderFactory = $uploaderFactory;
$this->uploadDir = $uploadDir;
$this->allowExtensions = $allowExtensions;
}
public function upload(): array
{
$result = [];
$files = $this->arrayFileModifier->modify();
if (!$files) {
return $result;
}
foreach ($files as $id => $file) {
try {
$uploader = $this->uploaderFactory->create(['fileId' => $id]);
$uploader->setAllowedExtensions($this->allowExtensions);
$uploader->setAllowRenameFiles(true);
$uploader->addValidateCallback('size', $this, 'validateMaxSize');
$newFileName = $this->getNewFileName($uploader);
$uploader->save($this->uploadDir, $newFileName);
$result[$id] = $this->getFullFilPath($newFileName);
} catch (\Exception $e) {
throw new \Magento\Framework\Exception\LocalizedException(__('%1', $e->getMessage()));
}
}
return $result;
}
private function getNewFileName(Uploader $uploader): string
{
return sprintf(
'%s.%s',
uniqid(),
$uploader->getFileExtension()
);
}
private function getFullFilPath(string $filename): string
{
return sprintf(
'/%s/%s',
$this->uploadDir,
$filename
);
}
}
```
В этом классе есть строчка $files = $this->arrayFileModifier->modify(); Этот modifier нам нужен чтобы привести массив, который к нам пришел, из формы такого вида:
в понятный для аплоудера:
чтобы передать id $uploader = $this->uploaderFactory->create(['fileId' => $id]);
и аплоудер знал с чем ему работать.
И последний пазлик - класс для работы с конфигом
Mr/ImageDynamicConfig/Model/Config/ImageConfig
```
php
declare(strict_types=1);
namespace Mr\ImageDynamicConfig\Model\Config;
use Magento\Framework\App\Config\ScopeConfigInterface;
use Magento\Framework\Serialize\SerializerInterface;
class ImageConfig
{
const XML_PATH_IMAGE_SERIALIZER = 'swatch/image_serializer/';
private $scopeConfig;
private $serializer;
public function __construct(
SerializerInterface $serializer,
ScopeConfigInterface $scopeConfig
) {
$this-scopeConfig = $scopeConfig;
$this->serializer = $serializer;
}
public function getSwatches(): array
{
$data = $this->scopeConfig->getValue(self::XML_PATH_IMAGE_SERIALIZER . 'image');
if (!$data) {
return [];
}
return $this->serializer->unserialize($data);
}
}
```
И сам результат:
Эпилог
[Репозиторий модуля на гитхабе](https://github.com/mavlikhanov/image_dymanic_config/tree/main)
Надеюсь данная статья покажется кому-нибудь интересной и/или полезной. Если есть замечания/предложения/вопросы добро пожаловать в комментарии.
Благодарю за внимание. | https://habr.com/ru/post/658167/ | null | ru | null |
# Safari — просмотр исходного кода страницы в TextMate
Большинство пользователей Safari, по тем или иным причинам просматривающие исходный код страниц (View Source), ощущают некоторые неудобства из-за отсутствия подсветки синтаксиса. Существует несколько способов справиться с этой проблемой. Я остановлюсь, на мой взгляд, на самом интересном. Лично мне удобнее всего всего просматривать код в том же редакторе, в котором я работаю повседневно — TextMate.
**Задача:** при нажатии определенного Shortcut-а отобразить исходный код страницы в TextMate
1. Запускаем Automator.
2. В качестве шаблона (Template for Your Workflow) выбираем Service
3. Из списка доступных действий (Actions) выбираем Run AppleScript и перетаскиваем его в рабочую область.
4. В качестве входящего параметра выбираем no input — это позволит нам запускать сервис не совершая дополнительных действий, например не выделяя фрагмент текста.
5. Выбираем приложение из которго этот сервис будет доступен. Можно не выбирать ничего и тогда сервис будет вызываться, например в Firefox. Меня интересовал непосредственно Safari, поэтому в выпадающем списке выбрал именно его.

6. Листинг исходного кода нашего AppleScript:
`tell application "Safari" to set theSource to source of document 1
-- saving it to a file seems to be needed to get TextMate to do color coding
set fp to open for access "Macintosh HD:tmp:TextMate temp file.txt" with write permission
write theSource to fp
close access fp
-- open the temp file in TextMate
tell application "TextMate"
activate
open "Macintosh HD:tmp:TextMate temp file.txt"
end tell`
7. Сохраняем сервис (File->Save As) и присваиваем ему любое имя, например View Source in TextMate.
8. Дело осталось за малым — назначить комбинацию клавиш для нашего сервиса. Заходим в System Preferences -> Keyboard -> Keyboard Shortcuts
9. В левой панели выбираем Services
10. В правой панели выбираем наш сервис, который должен находиться в разделе General
11. Двойной клик справа от названия сервиса позволит назначить комбинацию клавиш. Можно использовать что-то вроде Cmd+U, тогда Shortcut будет таким же, как в Firefox

Можно попробовать использовать вместо TextMate любой другой редактор, кому какой нравится. Для этого надо будет отредактировать код AppleScript.
На этом пожалуй все. Надеюсь пригодиться. | https://habr.com/ru/post/90327/ | null | ru | null |
# Cистематическая уязвимость сайтов, созданных на CMS 1С-Битрикс
Написать о систематических уязвимостях сайтов, созданных на коммерческих CMS, подтолкнул [пост](https://habrahabr.ru/company/bitrix/blog/305704/), в котором были описаны риски взлома «защищенных» CMS.
В этой статье основное внимание уделяется компрометации ресурсов по причине «человеческого фактора», а тема эксплуатации уязвимостей сайтов и веб-атак была обойдена предположением существования «неуязвимых» CMS. Предположение о существовании «неуязвимых» CMS, возможно, имеет право на существование, как пример, безопасность готового интернет-магазина «из коробки» на CMS 1C-Битрикс очень высока, и найти более-менее серьезные уязвимости кода «коробочной версии» вряд ли удастся.
Другое дело безопасность конечного продукта, созданного на такой CMS, и самое главное, систематика проявления уязвимостей высокого уровня угроз у этих сайтов. Исходя из нашей практики по обеспечению безопасности сайтов (компания InSafety), а также статистики, которую мы собираем по уязвимостям платформ (CMS), не менее чем у пятидесяти процентов сайтов, созданных на платформе 1С-Битрикс c личными кабинетами пользователей, существует возможность эксплуатации хранимых XSS-атак.
> **Платформа:** CMS 1C-Битрикс 15.0 и выше
>
> **Угроза безопасности:** хранимая XSS-атака
>
> **Систематика:** не менее 50% сайтов с личными кабинетами пользователей
Уязвимость кода, позволяющая эксплуатацию XSS атаки, заключается в недостаточной фильтрации данных полей формы регистрационной информации личного кабинета пользователя ресурса, которые передаются в БД.
**Пример**
Разработчик сохраняет данные, например, имя пользователя из $\_REQUEST, через API Битрикса, то они не фильтруются полностью, и тэги сохраняются. Например, передаем строку в поле формы «имя» ЛК пользователя сайта:
```
test">[](#)
```

Данные передаются через обычный input в $\_POST['name'] и далее в $USER->Update, например, так:
```
$USER->Update($USER->GetID(),array(
'NAME' => $_POST['name'],
));
```
HTML-код не будет санирован и будет запомнен в имени пользователя «как есть». Скриншот админки сайта:

Результат:

**Этот пример наглядно демонстрирует наличие угрозы безопасности**
В предложенной демонстрации существовании угрозы, было показано внедрение HTML кода, а не JS, что предполагает типовая XSS-атака. Это обусловлено тем, что у большинстве сайтов, разработанных на CMS 1C-Битрикс, попытку внедрения JS-кода заблокирует фильтр проактивной защиты.
Внедрение большинства синтаксических тегов HTML кода, проактивной защитой CMS 1C-Битрикс не фильтруется. Такая демонстрация обнаружения уязвимости кода абсолютно безопасна и наглядна. В случае, когда фильтр проактивной защиты 1С-Битрикс по какой-то причине отключен, вышеописанная уязвимость кода позволяет эксплуатировать хранимые XSS-атаки в «классической» реализации.
Уровень угрозы безопасности для сайта от внедрения любого (будь то JS или HTML) несанкционированного кода, как и его вывода без должной фильтрации, крайне высок.
По понятным причинам, в этой статье не предлагаются варианты реальной эксплуатации атаки, как с включенным, так и с отключенным фильтром проактивной защиты.
### Защита от XSS-атаки
Защитить свой сайт от возможности эксплуатации XSS атаки достаточно просто. Для этого следует фильтровать входные и выходные данные путем экранирования символов и преобразования спецсимволов в HTML-сущности. В php это можно сделать с помощью функций htmlspecialchars(), htmlentities(), strip\_tags().
**Пример:**
```
$name = strip_tags($_POST['name']);
$name = htmlentities($_POST['name'], ENT_QUOTES, "UTF-8");
$name = htmlspecialchars($_POST['name'], ENT_QUOTES);
```
Кроме этого следует явно указывать кодировку страниц сайта:
```
Header("Content-Type: text/html; charset=utf-8");
```
Способов защиты от XSS атак множество, к примеру, существуют варианты запрета на передачу кавычек и скобок (фильтрация данных по черному списку) на уровне конфигурации веб-сервера.
Пример для NGINX: (запись в конфигурационный файл)
```
location / {
if ($args ~* '^.*(<|>|").*'){
return 403;
}
if ($args ~* '^.*(%3C|%3E|%22).*'){
return 403;
}
}
```
Для веб-сервера Apache это будет запись в файл .htaccess:
```
RewriteEngine on
RewriteCond %{HTTP_USER_AGENT} (<|>|"|%3C|%3E|%22) [NC,OR]
RewriteRule ^{правило}
```
Фильтрация данных по черному списку применима далеко не для всех сайтов. Применять такой способ защиты от атак, следует с большой осторожностью, так как можно заблокировать легальные запросы.
### Заключение
Вышеозначенная угроза безопасности на веб-приложения, является наиболее популярной и известной атакой. Про XSS атаки и защиту от них, написано тысячи статей и публикаций.
В практике нашей компании уязвимость к XSS атакам личных кабинетов пользователей была обнаружена осенью 2015 года. Весною 2016 года наша статистика уязвимых сайтов на CMS 1С-Битрикс явно указывала на наличие возможности эксплуатации атаки у более 50% процентов исследуемых сайтов. В апреле 2016 года, понимая, что уязвимость кода в этом разделе носит системный характер, мы передали всю информацию по угрозе безопасности в компанию Битрикс. Сотрудники компании Битрикс приняли информацию, сообщив в обратной связи, что приняли меры, исправив документацию к системе. **Несмотря на принятые меры, вышеописанная угроза безопасности для сайтов на 1С-Битрикс остаётся крайне актуальной на сегодняшний день.**
Надеюсь, что эта информация будет полезной для разработчиков и владельцев сайтов, созданных на платформе 1C-Битрикс.
*Нужно понимать, что эксперименты с безопасностью чужих сайтов, не говоря о эксплуатации атаки в криминальных целях, может повлечь уголовную ответственность. Вся информация по угрозе безопасности сайтов, в этом посте, предоставлена с целью повышения общего уровня ИБ конечных продуктов на платформе 1C-Битрикс.* | https://habr.com/ru/post/307734/ | null | ru | null |
# ESET: анализ новых компонентов Zebrocy
Кибегруппа Sednit действует минимум с 2004 и регулярно фигурирует в новостях. Считается, что Sednit (более известные как Fancy Bear) стоят за взломом Национального комитета Демократической партии США перед выборами 2016 года, Всемирного антидопингового агентства (WADA), телевизионной сети TV5Monde и другими атаками. В арсенале группы набор вредоносных инструментов, некоторые из которых мы задокументировали [в прошлом отчете](https://www.welivesecurity.com/wp-content/uploads/2016/10/eset-sednit-full.pdf).
Недавно мы выпустили отчет о [LoJax](https://habr.com/ru/company/eset/blog/425251/) – UEFI-рутките, который также имеет отношение к Sednit и использовался в атаках на Балканах, в Центральной и Восточной Европе.
В августе 2018 года операторы Sednit развернули два новых компонента Zebrocy, и с этого момента мы наблюдаем всплеск использования этого инструмента. Zebrocy – набор из загрузчиков, дропперов и бэкдоров. Загрузчики и дропперы предназначены для разведки, в то время как бэкдоры обеспечивают персистентность и шпионские возможности. У этих новых компонентов необычный способ эксфильтрации собранных данных через связанные с почтовыми службами протоколы SMTP и POP3.

Жертвы новых инструментов напоминают пострадавших, упомянутых в нашем предыдущем посте про [Zebrocy](https://habr.com/post/359022/), а также у [Лаборатории Касперского](https://securelist.com/masha-and-these-bears/84311/). Цели атак находятся в Центральной Азии, Центральной и Восточной Европе, это преимущественно посольства, министерства иностранных дел и дипломаты.
### Обзор

*Рисунок 1. Схема старых и новых компонентов Zebrocy*
На протяжении двух лет кибергруппа Sednit в качестве вектора заражения Zebrocy использовала фишинговые письма (варианты 1 и 2 в таблице выше). После компрометации атакующие применяли различные загрузчики первого этапа для сбора информации о жертве и, в случае заинтересованности, через несколько часов или дней разворачивали один из бэкдоров второго уровня.
Классическая схема кампании Zebrocy – получение жертвой архива во вложении к письму. Архив содержит два файла, один из которых – безобидный документ, а второй – исполняемый файл. Атакующие пытаются обмануть жертву, называя второй файл типичным для документа или изображения именем и используя «двойное расширение».
В новой кампании (вариант 3 в таблице) применяется более запутанная схема – ее разберем ниже.
### Delphi-дроппер
Первый бинарный файл – Delphi-дроппер, что довольно необычно для кампании Zebrocy. В большинстве случаев это, скорее, загрузчик, устанавливаемый в системе жертвы на первом этапе атаки.
С помощью нескольких методов дроппер усложняет реверс-инжиниринг. В исследованных образцах он использует ключевое слово *liver* для обозначения начала и конца ключевых элементов, как показано ниже.
```
$ yara -s tag_yara.yar SCANPASS_QXWEGRFGCVT_323803488900X_jpeg.exe
find_tag SCANPASS_QXWEGRFGCVT_323803488900X_jpeg.exe
0x4c260:$tag: l\x00i\x00v\x00e\x00r\x00
0x6f000:$tag: liver
0x6f020:$tag: liver
0x13ab0c:$tag: liver
```
Правило YARA выше ищет строку *liver*. Первая строка *liver* используется в коде, но ничего не разделяет, в то время как остальные разделяют дескриптор ключа, изображение (ниже приведен его hexdump) и зашифрованный компонент в дроппере.
```
$ hexdump -Cn 48 -s 0x6f000 SCANPASS_QXWEGRFGCVT_323803488900X_jpeg.exe
0006f000 6c 69 76 65 72 4f 70 65 6e 41 69 72 33 39 30 34 |liverOpenAir3904|
0006f010 35 5f 42 61 79 72 65 6e 5f 4d 75 6e 63 68 65 6e |5_Bayren_Munchen|
0006f020 6c 69 76 65 72 ff d8 ff e0 00 10 4a 46 49 46 00 |liver……JFIF.|
```
Сначала данные сохраняются в картинку с именем файла *C:\Users\public\Pictures\scanPassport.jpg*, если такой файл еще не существует.
Интересно, что файл дроппера называется *SCANPASS\_QXWEGRFGCVT\_323803488900X\_jpeg.exe*, что также подсказывает о фишинговой схеме, связанной с паспортами и информацией о путешествиях. Это может означать, что оператор мог знать цель фишингового сообщения. Дроппер открывает изображение и, если файл уже существует, прекращает исполнение. В ином случае он его открывает и получает дескриптор ключа *OpenAir39045\_Bayren\_Munchen*. Изображение отсутствует, хотя формат и верный – см. рисунок ниже.
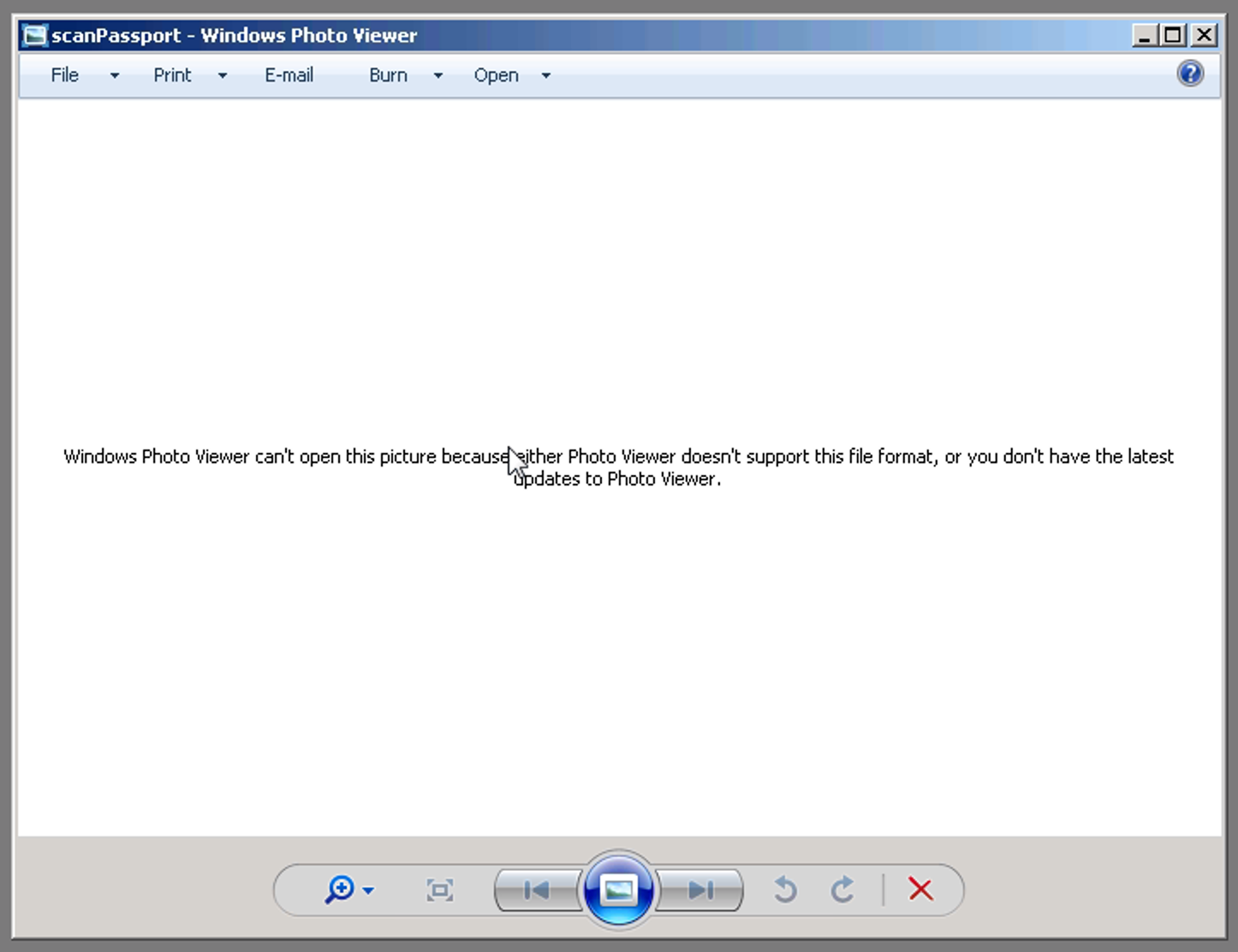
*Рисунок 2. ScanPassport.jpg*
Строка дескриптора ключа содержит *Bayren\_Munchen* – скорее всего, это отсылка к футбольной команде FC Bayern Munich. В любом случае, важно не содержимое дескриптора, а его длина, с помощью которой можно получить ключ XOR для расшифровки компонента.
Чтобы получить ключ XOR, дроппер ищет последнее ключевое слово *liver* и делает от него отступ на длину дескриптора. Длина ключа XOR – 27 (0x1b) байт (идентично длине дескриптора ключа).
С помощью ключа XOR и простого цикла дроппер расшифровывает последнюю часть – зашифрованный компонент, находящийся сразу после последнего тэга до конца файла. Обратите внимание, что MZ заголовок исполняемого компонента начинается сразу после ключевого слова *liver*, а ключ XOR получается из части заголовка PE, обычно являющимся последовательностью 0x00 байтов, восстанавливаемых после расшифровки компонента, как показано на рисунке ниже.

*Рисунок 3. Зашифрованный компонент (слева) по сравнению с расшифрованным компонентом (справа)*
Компонент сбрасывается в *C:\Users\Public\Documents\AcrobatReader.txt* и преобразует файл в *C:\Users\Public\Documents\AcrobatReader.exe*.
Возможно, это попытка обойти защиту ПК, выдающую предупреждение, когда бинарный файл сбрасывает на диск файл с расширением .exe.
В очередной раз оператор пытается обмануть жертву, и, если она обратит внимание на директорию, то увидит картину как на следующем рисунке:

*Рисунок 4. Компонент выглядит как файл PDF*
По умолчанию Windows скрывает расширение, и этим пользуется злоумышленник, сбрасывающий исполняемый файл в папку «Документы» и маскирующий его под PDF.
Наконец, дроппер выполняет размещенный компонент и завершает работу.
### Почтовый загрузчик MSIL
Доставляемый компонент предыдущего дроппера – запакованный с помощью UPX загрузчик MSIL. Для лучшего понимания логика процесса описана ниже, затем приведен исходный код и рассматривается схема управления.
Главный метод вызывает *Run* для запуска приложения, которое затем создает форму *Form1*.
```
{
Application.EnableVisualStyles();
Application.SetCompatibleTextRenderingDefault(false);
Application.Run((Form) new Form1());
}
```
*Form1* назначает множество переменных, включая новый [Timer](https://docs.microsoft.com/en-us/dotnet/api/system.timers.timer) для семи из них.
```
this.start = new Timer(this.components);
this.inf = new Timer(this.components);
this.txt = new Timer(this.components);
this.subject = new Timer(this.components);
this.run = new Timer(this.components);
this.load = new Timer(this.components);
this.screen = new Timer(this.components);
```
У объекта Timer есть три важных поля:
* Enabled: указывает на включенное состояние таймера
* Interval: время между событиями в миллисекундах
* Tick: коллбэк выполняется по истечении интервала таймера и в случае включенного таймера
Поля обозначены следующим образом:
```
this.start.Enabled = true;
this.start.Interval = 120000;
this.start.Tick += new EventHandler(this.start_Tick);
this.inf.Interval = 10000;
this.inf.Tick += new EventHandler(this.inf_Tick);
this.txt.Interval = 120000;
this.txt.Tick += new EventHandler(this.txt_Tick);
this.subject.Interval = 120000;
this.subject.Tick += new EventHandler(this.subject_Tick);
this.run.Interval = 60000;
this.run.Tick += new EventHandler(this.run_Tick);
this.load.Interval = 120000;
this.load.Tick += new EventHandler(this.load_Tick);
this.screen.Interval = 8000;
this.screen.Tick += new EventHandler(this.screen_Tick);
```
Для каждого объекта выставляется интервал *Interval* от 8 секунд до 2 минут. Коллбэк добавляется в обработчик события. Обратите внимание, что только *start* выставляет значение «истина» для *Enabled*, что означает, что спустя 2 минуты (12 000 миллисекунд = 120 секунд) *start\_Tick* будет вызван обработчиком события.
```
private void start_Tick(object sender, EventArgs e)
{
try
{
this.start.Enabled = false;
Lenor lenor = new Lenor();
this.dir = !Directory.Exists(this.label15.Text.ToString()) ? this.label16.Text.ToString() + "\" : this.label15.Text.ToString() + "\";
this.att = this.dir + "audev.txt";
this._id = lenor.id(this.dir);
this.inf.Enabled = true;
}
```
Далее каждый метод демонстрирует идентичное поведение – меняет значение *Enabled* на *false* в начале. Метод выполняется, а затем меняет значение *Enabled* следующего объекта на *true*, что активирует следующий таймер. Переменная *Enabled* используется оператором для создания нечто вроде машины состояний – если функция не срабатывает, механизм повторяет ее выполнение, пока не получит положительный результат. Время между исполнениями двух функций может использоваться как попытка обойти антивирусную защиту через добавление задержки.
Теперь, после описания структуры каждого метода, перейдем к алгоритму управления. Ниже приведен обзор шагов в виде обмена электронными письмами между ящиками.

*Рисунок 5. Обмен электронными письмами*
Малварь проверяет существование определенного пути, используемого для сброса каждого из файлов в процессе исполнения. По возможности используется *C:\Users\Public\Videos\*, в ином случае – *C:\Documents and Settings\All Users\Documents\* в качестве директории по умолчанию. Обратите внимание, что второй путь специфичен для Windows XP, в то время как первый – для Vista и выше.
16-байтовый *id* генерируется посредством конкатенации серийного номера тома C: и имени пользователя; он хранится в файле *audev.txt*.
Загрузчик собирает следующую информацию:
— текущий путь приложения
— версия операционной системы
— системная директория
— пользовательский домен
— имя машины
— имя пользователя
— текущий часовой пояс
— текущая дата
— список логических дисков и информация о каждом из них (модель, серийный номер, и т.д.)
— листинг директории *C:\Program Files\* и *C:\Program Files (x86)\*
— список процессов
Эти данные хранятся в файле *C:\Users\Public\Videos\si.ini* и отправляются письмом во вложении через SMTPS с помощью дефолтного порта 465. Тело письма содержит строку *SI* (что, возможно, означает System Information), получатель письма – *[email protected]*. Для всего обмена информацией тема писем обозначена как *id*.
Оператор решил завести несколько запасных адресов и отправляет то же письмо двум другим получателям, скорее всего, на случай, если основной адрес не работает. После отправки письма загрузчик удаляет файл *si.ini*.
В процессе первого запуска малвари создается файл *set.txt* с текстом *{System\_Parametrs = 10}* внутри и запись в ключе реестра Windows.

*Рисунок 6. Персистентность в реестре*
Один скриншот делается под именем *scx.bin* с компьютера жертвы и отправляется вложением по электронной почте с текстом *SC* (что может означать Screenshot) в теле письма.
После отправки малварь связывается с почтовым ящиком *[email protected]* по протоколу POP3 через SSL (порт 995) и ищет сообщения с темой, которая соответствует *id*. Если такое сообщение существует и тело не пусто, малварь расшифровывает его и отправляет сообщение с *okey* в теле на *[email protected]*. Содержимое ранее полученного сообщения очищается и парсится следующим образом:
```
string[] strArray = this._adr.Replace("B&", "").Replace("Db", "").Split('%');
string str1 = strArray[0];
string str2 = strArray[1];
```
Получаются две строки: первая – это пароль, а вторая – имя пользователя для адреса почты.
Новые учетные данные используются для подключения к полученному почтовому ящику, поиска в нем сообщения с темой, совпадающей с *id* малвари, и приложения со строкой *audev* в имени файла. Если оба условия выполняются, малварь сохраняет приложение и удаляет сообщение с сервера.
Журнал сообщений отправляется на *[email protected]*, а сообщения, полученные через POP3, приходят от адресата с недавно полученными пользовательскими данными.
Схема атакующих усложняет расследование. Во-первых, если у вас есть загрузчик с письмами, вы не можете подключиться к почтовому ящику, содержащему следующий этап.
Во-вторых, если вы получаете учетные данные для почты, вы все равно не можете достать следующую полезную нагрузку, потому что она удаляется после получения.
Когда загрузчик успешно записывает вложение на диск, он отправляет в почте сообщение с *okey2* в теле и вложение *l.txt*, содержащее *090*. Этот же файл перезаписывается нулями, и малварь пробует получить другое сообщение. Если это срабатывает, отправляется файл *l.txt* с *okey3* в теле. Содержимое вложения – директория и имя файла. Малварь перемещает файл *audev* по этому адресу. Наконец, малварь отправляет письмо с *okey4* в теле и *l.txt* во вложении. Это запускает исполняемый файл — *audev.exe* и проверяет в списке процессов наличие строки *audev*.
```
Process.Start(this.rn);
foreach (Process process in Process.GetProcesses())
{
if (process.ProcessName.Contains("audev"))
}
```
Если обнаруживается такое имя, будет отправлено последнее письмо, содержащее в теле *okey5* и *l.txt* во вложении. Наконец, удаляется *l.txt* и *set.txt*, удаляется созданный ключ реестра Windows, и работа программы завершается.
### Почтовый загрузчик на Delphi
Основная роль загрузчика – оценить важность скомпрометированной системы и, если она представляется интересной, загрузить и выполнить последний загрузчик Zebrocy.
Бинарный файл написан на Delphi и упакован с помощью UPX. Полное определение объекта *TForm1* можно найти в разделе с его ресурсами, в нем приведены некоторые используемые параметры конфигурации. Следующие разделы описывают инициализацию, возможности и сетевой протокол загрузчика.
### Инициализация
Сначала производится расшифровка набора строк, являющихся адресами электронной почты и паролями. Оператор применяет алгоритм шифрования [AES ECB](https://en.wikipedia.org/wiki/Block_cipher_mode_of_operation%23Electronic_Codebook_(ECB)). Каждая строка расшифровывается по шестнадцатеричному разряду, где первые четыре байта соответствуют финальному размеру расшифровываемой строки (расшифрованные строки в конце могут содержать некоторые отступы). В объекте *TForm1* содержится два AES ключа: первый используется для шифрования данных, а второй – для их расшифровки.
Адреса почты и пароли используются оператором для отправления команд для малвари, а также для получения информации, собранной с компьютера жертвы. Применяются протоколы связи SMTP и POP3 – оба через SSL. Для использования OpenSSL малварь скидывает и применяет две динамические библиотеки OpenSSL: *libeay32.dll (98c348cab0f835d6cf17c3a31cd5811f86c0388b)* и *ssleay32.dll(6d981d71895581dfb103170486b8614f7f203bdc)*.

*Рисунок 7. Свойства OpenSSL DLL*
Обратите внимание, что все файлы сбрасываются в рабочую директорию малвари *C:\Users\Public\*.
Персистентность обеспечивается во время первого исполнения малвари посредством известной [техники](http://www.hexacorn.com/blog/2014/11/14/beyond-good-ol-run-key-part-18/) скриптов сценария входа. Создается файл со скриптом *registration.bat* и пишется несколько строк из объекта *TForm1*. Финальный скрипт выглядит следующим образом:
```
reg add HKCU\Environment /v "UserInitMprLogonScript" /t REG_EXPAND_SZ /d "C:\Users\Public\Videos\audev.exe" /f
del C:\Users\Public\Videos\registr.bat
exit
```
В последнюю (но не по важности) очередь малварь создает *id*, таким же образом, как и в ранее описанных бинарных файлах Zebrocy. Она получает имя пользователя с помощью *GetUserNameW* Windows API и добавляет в начало серийный номер диска C:\.
### Возможности
Учитывая, что для процесса сбора информации о жертве есть несколько условий и порядок действий, ниже приведено описание различных его возможностей. Конфигурация сканирования хранится в объекте *TForm1*, где сгруппированы семь различных возможностей для сбора информации с компьютера жертвы.
Начиная с простого сканирования, первая информация, которую может получить малварь, связана с файлами со следующими расширениями: *.docx, .xlsx, .pdf, .pptx, .rar, .zip, .jpg, .bmp, .tiff*. Для каждого из файлов, обнаруженных на диске, малварь получает полный путь и последнюю дату изменения. Эта информация шифруется с помощью ключа AES, о котором мы говорили ранее, и сохраняется в файл *0.txt*. Другое сканирование нацелено на расширения *.dat, .json, .db* и, как и в предыдущем случае, получает полный путь и последнюю дату изменения файла. Затем шифрует их и хранит в файле *57.txt*.
Листинг запущенных процессов – еще одна возможность малвари, позволяющая хранить информацию в файле *08.txt*. Это выглядит следующим образом:
```
======Listing_of_processes=======
[System Process]
System
smss.exe
csrss.exe
wininit.exe
csrss.exe
winlogon.exe
services.exe
lsass.exe
[…]
```
В файле *i.txt* собирается общая информация о компьютере жертвы, а также некоторые данные о малвари (номер версии и путь, по которому она выполняется). См. в примере ниже:
```
v7.00
C:\Users\Public\Videos\audev.txt
============================================
Log_Drivers:
C: fixed; size= 102297 Mb, free=83927 Mb S/N: [redacted]
==================================================
OSV: Windows 7
WinType: 32
WinDir: C:\Windows
Lang: English (United States)
TZ: UTC1:0 Romance Standard Time
HostN: [redacted]-PC
User: [redacted]
===============S_LIST=====================
C:\Program Files\Common Files
C:\Program Files\desktop.ini
C:\Program Files\DVD Maker
C:\Program Files\Internet Explorer
C:\Program Files\Microsoft.NET
C:\Program Files\MSBuild
C:\Program Files\Reference Assemblies
C:\Program Files\Uninstall Information
C:\Program Files\Windows Defender
[…]
```
Малварь может делать скриншоты, которые сохраняются в формате *2\[YYYY-mm-dd HH-MM-SS]-Image\_001.jpg*, и генерирует другой файл *2\sa.bin*, заполненный списком путей к файлам всех снятых скриншотов. Последняя возможность – перечисление сетевых компонентов и данных о системе, результат записывается в *4.txt*.
### Сетевой протокол
Почтовый загрузчик Delphi – сравнительно новое дополнение инструментария Zebrocy, в нем предусмотрен новый способ эксфильтрации данных и получения команд от оператора. Эксфильтрация довольно проста, но производит много шума в сети, так как ранее собранные зашифрованные файлы отправляются через SMTPS, каждая версия файла – трижды.

Тема письма – *id* жертвы, и файл отправляется в виде приложения с ключевым словом, соответствующим содержимому файла. Обратите внимание, что для каждого файла есть отправляемая зашифрованная версия.

Скриншоты и файлы по обоим сканированиям тоже отправляются, но с другими ключевыми словами.

*Рисунок 8. Пример письма с передаваемыми данными*
В то время как при эксфильтрации данных используется протокол SMTP, бинарный файл связывается с адресом почты *[email protected]* через POP3 и парсит письма. Тело письма содержит различные ключевые слова, интерпретируемые малварью в качестве команд.

После выполнения лог дебаггера и результат команд (если есть) отправляются назад оператору. Например, после команды на сканирование оператор получает файл, содержащий список файлов с совпадающими расширениями вместе с каждым таким файлом.
В то время как у этого загрузчика есть функции бэкдора, он сбрасывает в систему загрузчик на Delphi, уже связанный с данной группой, которые мы описывали в предыдущей [статье](https://www.welivesecurity.com/2018/04/24/sednit-update-analysis-zebrocy/) о Zebrocy.
### Заключение
В прошлом мы уже видели пересечения Zebrocy и традиционных для Sednit вредоносных программ. Мы ловили Zebrocy на сбросе в систему XAgent – флагманского бэкдора Sednit, поэтому с высокой долей уверенности приписываем авторство Zebrocy этой кибергруппе.
Тем не менее, анализ бинарных файлов выявил ошибки на уровне языка, а также разработку, указывающую на иной уровень квалификации авторов. Оба загрузчика применяют почтовые протоколы для эксфильтрации данных и идентичные механизмы для сбора одной и той же информации. Однако они создают много шума в сети и системе, создавая множество файлов и пересылая их. В процессе анализа почтового загрузчика на Delphi нам показалось, что некоторые функции пропали, но строки все еще оставались в бинарном файле. Этот набор инструментов используется группой Sednit, но мы полагаем, что он разрабатывается другой командой – менее опытной, в сравнении с создателями традиционных компонентов Sednit.
Компоненты Zebrocy – дополнение в инструментарии Sednit, и недавние события могут объяснить повышенное активное использование бинарных файлов Zebrocy вместо традиционной малвари.
### Индикаторы компрометации
**Имена файлов, SHA-1 и детектирование продуктами ESET**
1. SCANPASS\_QXWEGRFGCVT\_323803488900X\_jpeg.exe — 7768fd2812ceff05db8f969a7bed1de5615bfc5a — **Win32/Sednit.ORQ**
2. C:\Users\public\Pictures\scanPassport.jpg — da70c54a8b9fd236793bb2ab3f8a50e6cd37e2df
3. C:\Users\Public\Documents\AcrobatReader.{exe,txt} — a225d457c3396e647ffc710cd1edd4c74dc57152 — **MSIL/Sednit.D**
4. C:\Users\Public\Videos\audev.txt — a659a765536d2099ecbde988d6763028ff92752e — **Win32/Sednit.CH**
5. %TMP%\Indy0037C632.tmp — 20954fe36388ae8b1174424c8e4996ea2689f747 — **Win32/TrojanDownloader.Sednit.CMR**
6. %TMP%\Indy01863A21.tmp — e0d8829d2e76e9bb02e3b375981181ae02462c43 — **Win32/TrojanDownloader.Sednit.CMQ**
**Email**
*[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]* | https://habr.com/ru/post/437236/ | null | ru | null |
# Smarty vs. Twig: производительность
[Smarty](http://www.smarty.net/) — один из самых старых шаблонизаторов для PHP. Если вы программируете на PHP — скорее всего, вам приходилось работать с ним. В 2010 году вышла третья версия этого шаблонизатора. Smarty 3 был написан с чистого листа, с активным использованием PHP5. Вместе с этим Smarty получил обновлённый синтаксис и современные возможности, включая [наследование](http://www.smarty.net/docs/en/advanced.features.template.inheritance.tpl), [песочницу](http://www.smarty.net/docs/en/advanced.features.tpl#advanced.features.security) и др.
[Twig](http://twig.sensiolabs.org/) — молодой шаблонизатор от разработчиков Symfony. Авторы [позиционируют](http://habrahabr.ru/blogs/php/76021/) его как быстрый и функциональный шаблонизатор. По возможностям он во многом похож на Smarty 3. Twig отличает несколько другой синтаксис, а так же заявленная высокая производительность. Проверим?
### Тестирование
При тестировании мы намеренно будем использовать достаточно сложные шаблоны, чтобы время обработки было ощутимым. Собственно это время мы и будем оценивать, для чего мы подготовим соответствующие скрипты.
Код для Smarty получился очень простым:
```
$data = json_decode(file_get_contents('data.json'), true);
require('smarty/Smarty.class.php');
$smarty = new Smarty();
$smarty->compile_check = false;
$start = microtime(true);
$smarty->assign($data);
$smarty->fetch('demo.tpl');
echo microtime(true)-$start;
```
Для Twig несколько сложнее:
```
$data = json_decode(file_get_contents('data.json'), true);
require('twig/Autoloader.php');
Twig_Autoloader::register();
$loader = new Twig_Loader_Filesystem('templates');
$twig = new Twig_Environment($loader, array(
'cache' => 'templates_c',
'autoescape' => false,
'auto_reload' => false,
));
$start = microtime(true);
$template = $twig->loadTemplate('demo.tpl');
$template->render($data);
echo microtime(true)-$start;
```
Оба шаблонизатора настроены похожим образом: выключено автоматическое экранирование, отключена автоматическая перекомпиляция шаблонов при изменениях.
#### Получение значений переменных
Получение значений переменных — наиболее активно используемая операция. В сложных шаблонах она может использоваться по нескольку сотен раз. Поначалу может показаться, что скорость выполнения этой операции не должна зависеть от шаблонизатора, однако это не так. Для хранения шаблонных переменных должна использоваться какая-то структура. Чем она проще — тем быстрее работает получение значений переменных. Для оценки производительности этой операции сгенерируем шаблон, в котором будет просто выводиться значение 10000 переменных и ничего более.
Smarty:
```
{$var0} {$var1} {$var2} {$var3} {$var4} ...
```
Twig:
```
{{ var0 }} {{ var1 }} {{ var2 }} {{ var3 }} {{ var4 }} ...
```
Результат:
| | Компиляция | Выполнение |
| --- | --- | --- |
| Smarty 3.1.1 | 16.320 сек. | 0.058 сек. |
| Twig 1.2.0 | 9.757 сек. | 0.083 сек. |
В таблице приведены средние значения из нескольких последовательных тестов. Как видно, десять тысяч синтаксических конструкций очень долго компилировалось обоими участниками теста. Smarty в этом плане сильно отстал от Twig. Однако, компиляция выполняется всего один раз, а в дальнейшем работает уже скомпилированная версия шаблона, поэтому время работы последнего намного важнее. И здесь уже Smarty уверенно на ≈30% быстрее оппонента.
#### Обход массивов и вывод значений полей
Ни один более-менее серьёзный шаблон не обходится без foreach. Для теста напишем шаблон, который выводит по 10 полей из 1000 элементов массива.
Smarty:
```
{foreach $array as $item}
{$item.id} {$item.title} {$item.var1} {$item.var2} {$item.var3} {$item.var4} {$item.var5} {$item.var6} {$item.var5} {$item.var6}
{/foreach}
```
Twig:
```
{% for item in array %}
{{ item.id }} {{ item.title }} {{ item.var1 }} {{ item.var2 }} {{ item.var3 }} {{ item.var4 }} {{ item.var5 }} {{ item.var6 }} {{ item.var5 }} {{ item.var6 }}
{% endfor %}
```
Результат:
| | Компиляция | Выполнение |
| --- | --- | --- |
| Smarty 3.1.1 | 0.065 сек. | 0.009 сек. |
| Twig 1.2.0 | 0.131 сек. | 0.082 сек. |
Здесь происходит нечто невероятное: скомпилированный шаблон Smarty выполняется почти в 10 раз быстрее, чем вариант Twig! Более того, даже компиляция+выполнение в Smarty работает быстрее выполнения готового скомпилированного шаблона в Twig. Из этого можно сделать вывод, что компилятор шаблонов Smarty инициализируется быстрее Twig, но судя по предыдущему тесту работает медленнее, что на маленьких шаблонах практически незаметно.
#### Наследование
Наследование шаблонов — это очень удобный механизм. Только из-за этого можно полюбить тестируемые шаблонизаторы :) Давайте узнаем, какие накладные расходы появляются при использовании наследования в Smarty и Twig. Для этого создадим один родительский шаблон с 500 блоками, и ещё 500 маленьких шаблонов, каждый из которых будет наследоваться друг от друга, заполняя статическими данными один из 500 блоков родительского шаблона. Шаблонизатору отдадим на растерзание последнего в цепочке.
Результат:
| | Компиляция | Выполнение |
| --- | --- | --- |
| Smarty 3.1.1 | 1.329 сек. | 0.002 сек. |
| Twig 1.2.0 | 2.641 сек. | 0.121 сек. |
Smarty отработал в 60 раз быстрее. Если взглянуть на скомпилированный код, то легко понять, что это не предел. Smarty объединил всю цепочку из наследуемых шаблонов в один большой файл, будто изначально и не было никакого наследования. То есть в результате при использовании наследования вообще нет потерь производительности! Twig же старательно создал для каждого шаблона по красивому классу и файлу, и при каждой генерации страницы загружает всё это добро.
### Итого
Вывод напрашивается сам собой: Smarty быстрее Twig. Компиляция больших шаблонов занимает больше времени, но в результате мы получаем лучшую производительность.
Для тестирования использовался ноутбук. Pentium Dual-Core T4200 (2 GHz), 3GB RAM — ничего сверхъестественного. Использованная версия PHP — 5.3. На случай, если у вас появится желание самостоятельно оценить производительность Smarty и Twig на вашем оборудовании, вы можете скачать исходные коды всех тестов [одним архивом](http://veg.slutsk.net/habr/smarty_vs_twig.7z). | https://habr.com/ru/post/128083/ | null | ru | null |
# Cocos2d-x: Используем собственный C++ класс в Lua
Всем доброго времени суток.
Так уж сложилось, что про использование cocos2d-x Lua в природе существует довольно мало информационных материалов, даже с учётом англоязычных источников. Поэтому во многом приходится разбираться самому, копаясь в чужом коде и читая (часто не особо содержательную) документацию.
В этой статье я хочу хотя бы частично исправить эту несправедливость и рассказать о расширении стандартного функционала доступного в cocos2d-x Lua с помощью нативных классов.
С этой задачей я столкнулся, можно сказать, лицом к лицу после осознания собственных скудных знаний Lua. Тогда же и созрело решение часть игровой логики написать на старом добром C++.
Итак, кому интересен данный процесс прошу под кат.
В качестве отправной точки примем то, что у вас установлена и настроена CocosCode IDE. Если нет, то об этом есть неплохая статья на русском вот [здесь](http://habrahabr.ru/post/232013/).
#### 1. Создаём наш С++ класс
Начнём с создания класса, который мы будем подключать к Lua.
**MyClass.hpp**
```
#ifndef MyClass_hpp
#define MyClass_hpp
#include "cocos2d.h"
#include
using std::string;
namespace cocos2d {
class MyClass : public cocos2d::Ref
{
public:
MyClass();
~MyClass();
bool init();
string myFunction();
CREATE\_FUNC(MyClass);
};
} //namespace cocos2d
#endif
```
Здесь следует обратить внимание на то, что наш класс должен быть наследником от Ref, что вызвано особенностями управления памятью в cocos2d-x.
**MyClass.cpp**
```
#include "MyClass.hpp"
using namespace cocos2d;
MyClass::MyClass() {}
MyClass::~MyClass() {}
bool MyClass::init()
{
return true;
}
string MyClass::myMethod()
{
return "Hello, Habrahabr!";
}
```
Файлы с нашим классом мы помещаем в директорию «myclass», которую создаём в /framework/cocos2d-x/cocos/ (внутри проекта). Если у вас нет папки framework, то в CocosCode нужно выполнить следующее:
Клацнуть правой кнопкой мыши на проект -> Cocos Tools -> Add Native Code Support
#### 2. Создаём Lua обёртку для нашего класса
Для этого в папке /frameworks/cocos2d-x/tools/tolua создадим следующий файл:
**cocos2dx\_myclass.ini**[cocos2dx\_myclass]
# the prefix to be added to the generated functions. You might or might not use this in your own
# templates
prefix = cocos2dx\_myclass
# create a target namespace (in javascript, this would create some code like the equiv. to `ns = ns || {}`)
# all classes will be embedded in that namespace
target\_namespace =
android\_headers = -I%(androidndkdir)s/platforms/android-14/arch-arm/usr/include -I%(androidndkdir)s/sources/cxx-stl/gnu-libstdc++/4.7/libs/armeabi-v7a/include -I%(androidndkdir)s/sources/cxx-stl/gnu-libstdc++/4.7/include -I%(androidndkdir)s/sources/cxx-stl/gnu-libstdc++/4.8/libs/armeabi-v7a/include -I%(androidndkdir)s/sources/cxx-stl/gnu-libstdc++/4.8/include
android\_flags = -D\_SIZE\_T\_DEFINED\_
clang\_headers = -I%(clangllvmdir)s/lib/clang/3.3/include
clang\_flags = -nostdinc -x c++ -std=c++11
cocos\_headers = -I%(cocosdir)s/cocos -I%(cocosdir)s/myclass -I%(cocosdir)s/cocos/base -I%(cocosdir)s/cocos/platform/android
cocos\_flags = -DANDROID
cxxgenerator\_headers =
# extra arguments for clang
extra\_arguments = %(android\_headers)s %(clang\_headers)s %(cxxgenerator\_headers)s %(cocos\_headers)s %(android\_flags)s %(clang\_flags)s %(cocos\_flags)s %(extra\_flags)s
# what headers to parse
headers = %(cocosdir)s/cocos/myclass/MyClass.hpp
# what classes to produce code for. You can use regular expressions here. When testing the regular
# expression, it will be enclosed in "^$", like this: "^Menu\*$".
classes = MyClass.\*
# what should we skip? in the format ClassName::[function function]
# ClassName is a regular expression, but will be used like this: "^ClassName$" functions are also
# regular expressions, they will not be surrounded by "^$". If you want to skip a whole class, just
# add a single "\*" as functions. See bellow for several examples. A special class name is "\*", which
# will apply to all class names. This is a convenience wildcard to be able to skip similar named
# functions from all classes.
skip =
rename\_functions =
rename\_classes =
# for all class names, should we remove something when registering in the target VM?
remove\_prefix =
# classes for which there will be no «parent» lookup
classes\_have\_no\_parents =
# base classes which will be skipped when their sub-classes found them.
base\_classes\_to\_skip =
# classes that create no constructor
# Set is special and we will use a hand-written constructor
abstract\_classes =
# Determining whether to use script object(js object) to control the lifecycle of native(cpp) object or the other way around. Supported values are 'yes' or 'no'.
script\_control\_cpp = no
Вдаваться в подробности содержимого этого файла я не буду, об этом можно прочесть [здесь](http://www.cocos2d-x.org/wiki/How_to_use_bindings-generator).
Теперь нам нужно добавить только что созданный ini файл в сценарий генерации Lua обёрток. Для этого откроем genbindings.py и добавим перед закрывающей фигурной скобкой следующую строку:
```
cmd_args = {'cocos2dx.ini' : ('cocos2d-x', 'lua_cocos2dx_auto'), \
'cocos2dx_extension.ini' : ('cocos2dx_extension', 'lua_cocos2dx_extension_auto'), \
'cocos2dx_ui.ini' : ('cocos2dx_ui', 'lua_cocos2dx_ui_auto'), \
'cocos2dx_studio.ini' : ('cocos2dx_studio', 'lua_cocos2dx_studio_auto'), \
'cocos2dx_spine.ini' : ('cocos2dx_spine', 'lua_cocos2dx_spine_auto'), \
'cocos2dx_physics.ini' : ('cocos2dx_physics', 'lua_cocos2dx_physics_auto'), \
'cocos2dx_experimental_video.ini' : ('cocos2dx_experimental_video', 'lua_cocos2dx_experimental_video_auto'), \
'cocos2dx_experimental.ini' : ('cocos2dx_experimental', 'lua_cocos2dx_experimental_auto'), \
'cocos2dx_controller.ini' : ('cocos2dx_controller', 'lua_cocos2dx_controller_auto'), \
'cocos2dx_myclass.ini' : ('cocos2dx_myclass', 'lua_cocos2dx_myclass_auto') \
}
```
Запускаем genbindings.py. В случае успешного проведения всех описанных выше манипуляций, у нас должны появиться следующие файлы (в директории /frameworks/cocos2d-x/cocos/scripting/lua-binding):
* lua\_cocos2dx\_myclass\_auto.hpp
* lua\_cocos2dx\_myclass\_auto.cpp
* ./api/MyClass.lua
Теперь у нас есть всё необходимое для подключения нашего класса к Lua. Этот процесс состоит из двух однотипных процедур: одна для iOS, другая для Android.
#### 3.1. Подключение файлов к iOS
Открываем проект приложения. Первым делом, добавим С++ исходники к cocos2d\_libs:
Теперь добавляем сгенерированные файлы к cocos2d\_lua\_bindings:
Не забудем также задать путь к заголовочным файлам в cocos2d\_lua\_bindings -> Build Settings -> User Header Search Paths
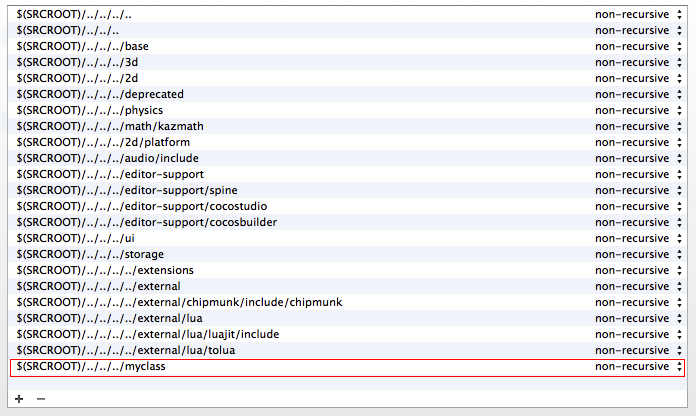
Пользуясь удобным случаем, зарегистрируем наш класс в AppDelegate.cpp:
```
...
#include "ConfigParser.h"
// Это наш сгенерированный заголовочный файл
#include "lua_cocos2dx_myclass_auto.hpp"
using namespace CocosDenshion;
bool AppDelegate::applicationDidFinishLaunching()
{
...
// set FPS. the default value is 1.0/60 if you don't call this
director->setAnimationInterval(1.0 / 60);
auto engine = LuaEngine::getInstance();
ScriptEngineManager::getInstance()->setScriptEngine(engine);
LuaStack* stack = engine->getLuaStack();
stack->setXXTEAKeyAndSign("2dxLua", strlen("2dxLua"), "XXTEA", strlen("XXTEA"));
// А тут мы регистрируем наш класс
register_all_cocos2dx_myclass(stack->getLuaState());
#if (COCOS2D_DEBUG>0)
if (startRuntime())
return true;
#endif
engine->executeScriptFile(ConfigParser::getInstance()->getEntryFile().c_str());
return true;
}
...
```
На этом наши приключения с iOS заканчиваются.
#### 3.2. Подключение файлов к Android
Здесь по сути всё аналогично предыдущему разделу. Нужно подключить исходники класса к cocos2d-x проекту и сгенерированные файлы к cocos2dx\_lua проекту. Разница только в том, что дело придется иметь с текстовыми файлами Android.mk.
Добавляем файлы нашего класса в проект кокоса. Для этого вносим несколько дополнений в файл /frameworks/cocos2d-x/cocos/Android.mk
Здесь (указываем \*.cpp файлы):
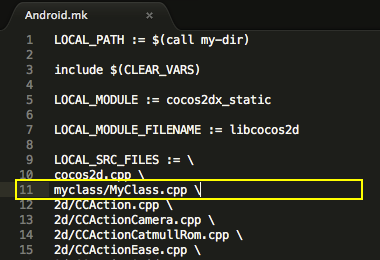
И вот здесь (указываем путь к заголовочным файлам):
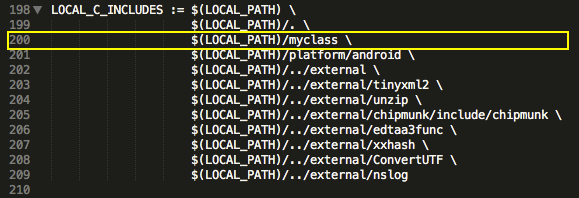
Теперь осталось подключить сгенерированные файлы к cocos2d\_lua. Для этого нужно отредактировать файл /frameworks/cocos2d-x/cocos/scripting/lua-bindings/Android.mk
Тут (указываем \*.cpp файл):
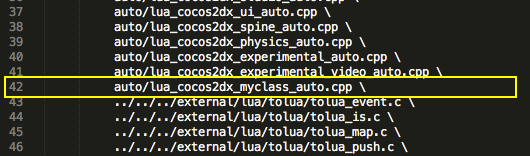
И ещё вот тут (указываем путь к заголовочному файлу):
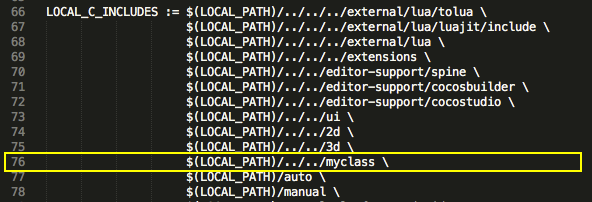
#### 4. Обновляем среду выполнения
В принципе, всё уже будет работать, если запускать проект в XCode или Eclipse. Чтобы всё работало и в CocosCode IDE, нужно пересобрать среду выполнения. Для этого щёлкаем правой кнопкой мыши на проект -> Cocos Tools -> Build Custom Runtimes. Вот и всё.
#### 5. Запускаем, радуемся
Не вижу особого смысла показывать результаты в виде скриншотов одной единственной строки в консоле. Тем не менее, вывод будет таким:
```
[Lua Debug]: Hello, Habrahabr!
```
Аналогичным образом с помощью binding-generator-a можно добавлять свои классы и в cocos2d-js. Следует однако предупредить, что на нормальный запуск самого генератора мне пришлось потратить добрые пару часов. Возился с несоответствием разных необходимых библиотек. Если всё делать как написано, то проблем быть не должно (указания по настройке генератора можно найти вот [здесь](https://github.com/cocos2d/bindings-generator)).
#### P.S.
На мой взгляд, «подвязка» движка к скриптовым языкам в некоторых случаях может здорово упростить жизнь. Не знаю, упростила ли она жизнь мне в конечном итоге, но интересный опыт я приобрел. | https://habr.com/ru/post/241694/ | null | ru | null |
# Как организовать код в Python-проекте, чтобы потом не пожалеть
> *Каждая минута, потраченная на организацию своей деятельности, экономит вам целый час.***Бенджамин Франклин**
>
>
Python отличается от таких языков программирования, как C# или Java, заставляющих программиста давать классам имена, соответствующие именам файлов, в которых находится код этих классов.
Python — это самый гибкий язык программирования из тех, с которыми мне приходилось сталкиваться. А когда имеешь дело с чем-то «слишком гибким» — возрастает вероятность принятия неправильных решений.
* Хотите держать все классы проекта в единственном файле `main.py`? Да, это возможно.
* Надо читать переменную окружения? Берите и читайте там, где это нужно.
* Требуется модифицировать поведение функции? Почему бы не прибегнуть к декоратору!?
Применение многих идей, которые легко реализовать, может привести к негативным последствиям, к появлению кода, который очень тяжело поддерживать.
Но, если вы точно знаете о том, что делаете, последствия гибкости Python не обязательно окажутся плохими.
Здесь я собираюсь представить вашему вниманию рекомендации по организации Python-кода, которые сослужили мне хорошую службу, когда я работал в разных компаниях и взаимодействовал со многими людьми.
### Структура Python-проекта
Сначала обратим внимание на структуру директорий проекта, на именование файлов и организацию модулей.
Рекомендую держать все файлы модулей в директории `src`, а тесты — в поддиректории `tests` этой директории:
```
├── src
│ ├── /\*
│ │ ├── \_\_init\_\_.py
│ │ └── many\_files.py
│ │
│ └── tests/\*
│ └── many\_tests.py
│
├── .gitignore
├── pyproject.toml
└── README.md
```
Здесь — это главный модуль проекта. Если вы не знаете точно — какой именно модуль у вас главный — подумайте о том, что пользователи проекта будут устанавливать командой `pip install`, и о том, как, по вашему мнению, должна выглядеть команда `import` для вашего модуля.
Часто имя главного модуля совпадает с именем всего проекта. Но это — не некое жёсткое правило.
#### Аргументы в пользу директории src
Я видел множество проектов, устроенных по-другому.
Например, в проекте может отсутствовать директория `src`, а все модули будут просто лежать в его корневой директории:
```
non_recommended_project
├── /\*
│ ├── \_\_init\_\_.py
│ └── many\_files.py
│
├── .gitignore
│
├── tests/\*
│ └── many\_tests.py
│
├── pyproject.toml
│
├── /\*
│ ├── \_\_init\_\_.py
│ └── many\_files.py
│
└── README.md
```
Уныло смотрится проект, в структуре которого нет никакого порядка из-за того, что его папки и файлы просто расположены по алфавиту, в соответствии с правилами сортировки объектов в IDE.
Главная причина, по которой рекомендуется пользоваться папкой `src`, заключается в том, чтобы активный код проекта был бы собран в одной директории, а настройки, параметры CI/CD, метаданные проекта находились бы за пределами этой директории.
Единственный минус такого подхода заключается в том, что, без дополнительных усилий, не получится воспользоваться в своём коде командой вида `import module_a`. Для этого потребуется кое-что сделать. Ниже мы поговорим о том, как решить эту проблему.
### Именование файлов
#### Правило №1: тут нет файлов
Во-первых — в Python нет таких сущностей, как «файлы», и я заметил, что это — главный источник путаницы для новичков.
Если вы находитесь в директории, содержащей файл `__init__.py`, то это — директория, включающая в себя модули, а не файлы.
Рассматривайте каждый модуль, как пространство имён.
Я говорю о «пространстве имён», так как нельзя сказать с уверенностью — имеется ли в модуле множество функций и классов, или только константы. В нём может присутствовать практически всё что угодно, или лишь несколько сущностей пары видов.
#### Правило №2: если нужно — держите сущности в одном месте
Совершенно нормально, когда в одном модуле имеется несколько классов. Так и стоит организовывать код (но, конечно, только если классы связаны с модулем).
Выделяйте классы в отдельные модули только в том случае, если модуль становится слишком большим, или если его разные части направлены на решение различных задач.
Часто встречается мнение, что это — пример неудачного приёма работы. Те, кто так считают, находятся под влиянием опыта, полученного после использования других языков программирования, которые принуждают к другим решениям (например — это Java и C#).
#### Правило №3: давайте модулям имена, представляющие собой существительные во множественном числе
Давая модулям имена, следуйте общему правилу, в соответствии с которым эти имена должны представлять собой существительные во множественном числе. При этом они должны отражать особенности предметной области проекта.
Правда, у этого правила есть и исключение. Модули могут называться `core`, `main.py` или похожим образом, что указывает на то, что они представляют собой некую единичную сущность. Подбирая имена модулей, руководствуйтесь здравым смыслом, а если сомневаетесь — придерживайтесь вышеприведённого правила.
#### Реальный пример именования модулей
Вот мой проект — [Google Maps Crawler](https://github.com/guilatrova/GMaps-Crawler), созданный в качестве примера.
Этот проект направлен на сбор данных из Google Maps с использованием Selenium и на их представление в виде, удобном для дальнейшей обработки ([тут](https://guicommits.com/selenium-example-with-python-gmaps/), если интересно, можно об этом почитать).
Вот текущее состояние дерева проекта (тут выделены исключения из правила №3):
```
gmaps_crawler
├── src
│ └── gmaps_crawler
│ ├── __init__.py
│ ├── config.py (форма единственного числа)
│ ├── drivers.py
│ ├── entities.py
│ ├── exceptions.py
│ ├── facades.py
│ ├── main.py (форма единственного числа)
│ └── storages.py
│
├── .gitignore
├── pyproject.toml
└── README.md
```
Весьма естественным кажется такой импорт классов и функций:
```
from gmaps_crawler.storages import get_storage
from gmaps_crawler.entities import Place
from gmaps_crawler.exceptions import CantEmitPlace
```
Можно понять, что в `exceptions` может иметься как один, так и множество классов исключений.
Именование модулей существительными множественного числа отличается следующими приятными особенностями:
* Модули не слишком «малы» (в том смысле, что предполагается, что один модуль может включать в себя несколько классов).
* Их, если нужно, в любой момент можно разбить на более мелкие модули.
* «Множественные» имена дают программисту сильное ощущение того, что он знает о том, что может быть внутри соответствующих модулей.
### Именование классов, функций и переменных
Некоторые программисты считают, что давать сущностям имена — это непросто. Но если заранее определиться с правилами именования, эта задача становится уже не такой сложной.
#### Имена функций и методов должны быть глаголами
Функции и методы представляют собой действия, или нечто, выполняющее действия.
Функция или метод — это не просто нечто «существующее». Это — нечто «действующее».
Действия чётко определяются глаголами.
Вот — несколько удачных примеров из реального проекта, над которым я раньше работал:
```
def get_orders():
...
def acknowledge_event():
...
def get_delivery_information():
...
def publish():
...
```
А вот — несколько неудачных примеров:
```
def email_send():
...
def api_call():
...
def specific_stuff():
...
```
Тут не очень ясно — возвращают ли функции объект, позволяющий выполнить обращение к API, или они сами выполняют какие-то действия, например — отправку письма.
Я могу представить себе такой сценарий использования функции с неудачным именем:
```
email_send.title = "title"
email_send.dispatch()
```
У рассмотренного правила есть и некоторые исключения:
* Создание функции `main()`, которую вызовут в главной точке входа приложения — это хороший повод нарушить это правило.
* Использование `@property` для того, чтобы обращаться с методом класса как с атрибутом, тоже допустимо.
#### Имена переменных и констант должны быть существительными
Имена переменных и констант всегда должны быть существительными и никогда — глаголами (это позволяет чётко отделить их от функций).
Вот примеры удачных имён:
```
plane = Plane()
customer_id = 5
KEY_COMPARISON = "abc"
```
Вот — неудачные имена:
```
fly = Plane()
get_customer_id = 5
COMPARE_KEY = "abc"
```
А если переменная или константа представляют собой список или коллекцию — им подойдёт имя, представленное существительным во множественном числе:
```
planes: list[Plane] = [Plane()] # Даже если содержит всего один элемент
customer_ids: set[int] = {5, 12, 22}
KEY_MAP: dict[str, str] = {"123": "abc"} # Имена словарей остаются существительными в единственном числе
```
#### Имена классов должны говорить сами за себя, но использование суффиксов — это нормально
Отдавайте предпочтение именам классов, понятным без дополнительных пояснений. При этом можно использовать и суффиксы, вроде `Service`, `Strategy`, `Middleware`, но — только в крайнем случае, когда они необходимы для чёткого описания цели существования класса.
Всегда давайте классам имена в единственном, а не во множественном числе. Имена во множественном числе напоминают имена коллекций элементов (например — если я вижу имя `orders`, то я полагаю, что это — список или итерируемый объект). Поэтому, выбирая имя класса, напоминайте себе, что после создания экземпляра класса в нашем распоряжении оказывается единственный объект.
#### Классы представляют собой некие сущности
Классы, представляющие нечто из бизнес-среды, должны называться в соответствии с названиями связанных с ними сущностей (и имена должны быть существительными!). Например — `Order`, `Sale`, `Store`, `Restaurant` и так далее.
#### Пример использования суффиксов
Представим, что надо создать класс, ответственный за отправку электронных писем. Если назвать его просто `Email`, цель его существования будет неясна.
Кто-то может решить, что он может олицетворять некую сущность:
```
email = Email() # Предполагаемый пример использования
email.title = "Title"
email.body = create_body()
email.send_to = "guilatrova.dev"
send_email(email)
```
Такой класс следует назвать `EmailSender` или `EmailService`.
### Соглашения по именованию сущностей
Следуйте этим соглашениям по именованию сущностей:
| | | |
| --- | --- | --- |
| **Тип** | **Общедоступный** | **Внутренний** |
| Пакеты (директории) | `lower_with_under` | — |
| Модули (файлы) | `lower_with_under.py` | — |
| Классы | `CapWords` | — |
| Функции и методы | `lower_with_under()` | `_lower_with_under()` |
| Константы | `ALL_CAPS_UNDER` | `_ALL_CAPS_UNDER` |
#### Отступление о «приватных» методах
Если имя метода выглядит как `__method(self)` (любой метод, имя которого начинается с двух символов подчёркивания), то Python не позволит внешним классам/методам вызывать этот метод обычным образом. Некоторые, узнавая об этом, считают, что это нормально.
Тем, кто, вроде меня, пришёл в Python из C#, может показаться странным то, что (пользуясь вышеприведённым руководством) метод класса нельзя защитить.
Но у Гвидо ван Россума есть достойная причина считать, что на это есть веские основания: «Мы все тут взрослые, ответственные люди».
Это значит, что если вы знаете, что не должны вызывать метод, тогда вы и не будете этого делать — если только не абсолютно уверены в своих действиях.
В конце концов, если вы и правда решите вызвать некий приватный метод, то вы для этого сделаете что-то неординарное (в C# это называется Reflection).
Поэтому давайте своим приватным методам/функциям имена, начинающиеся с одного символа подчёркивания, указывающего на то, что они предназначены лишь для внутреннего использования, и смиритесь с этим.
### Когда создавать функцию, а когда — класс?
Мне несколько раз задавали вопрос, вынесенный в заголовок этого раздела.
Если вы следуете рекомендациям, приведённым выше, то ваши модули будут понятными, а понятные модули — это эффективный способ организации функций:
```
from gmaps_crawler import storages
storages.get_storage() # Похоже на класс, но экземпляр не создаётся, а имя - это существительное во множественном числе
storages.save_to_storage() # Так может называться функция, хранящаяся в модуле
```
Иногда в модуле можно разглядеть некое подмножество чем-то связанных функций. В таких случаях подобные функции имеет смысл выделить в класс.
#### Пример группировки подмножества функций
Предположим, имеется уже встречавшийся нам модуль `storages` с 4 функциями:
```
def format_for_debug(some_data):
...
def save_debug(some_data):
"""Выводит данные на экран"""
formatted_data = format_for_debug(some_data)
print(formatted_data)
def create_s3(bucket):
"""Создаёт бакет s3, если он не существует"""
...
def save_s3(some_data):
s3 = create_s3("bucket_name")
...
```
S3 — это облачное хранилище Amazon (AWS), подходящее для хранения любых данных. Это — нечто вроде Google Drive для программ.
Проанализировав этот код, мы можем сказать следующее:
* Разработчик может сохранять данные в режиме отладки (`save_debug`) (они просто выводятся на экран), или в S3 (`save_s3`) (они попадают в облако).
* Функция `save_debug` использует функцию `format_for_debug`.
* Функция `save_s3` использует функцию `create_s3`.
Тут я вижу две группы функций, но не нахожу причины хранить их код в разных модулях, так как они, вроде бы, невелики. Поэтому меня устроит их оформление в виде классов:
```
class DebugStorage:
def format_for_debug(self, some_data):
...
def save_debug(self, some_data):
"""Выводит данные на экран"""
formatted_data = self.format_for_debug(some_data)
print(formatted_data)
class S3Storage:
def create_s3(self, bucket):
"""Создаёт бакет s3, если он не существует"""
...
def save_s3(self, some_data):
s3 = self.create_s3("bucket_name")
...
```
Вот эмпирическое правило, помогающее решить вопрос о функциях и классах:
* Всегда начинайте с функций.
* Переходите к классам в том случае, если у вас возникает ощущение, что вы можете сгруппировать различные подмножества функций.
### Создание модулей и точки входа в приложение
У каждого приложения есть точка входа.
То есть — имеется единственный модуль (другими словами — файл), который запускает приложение. Это может быть как отдельный скрипт, так и большой модуль.
Когда бы вы ни создавали точку входа в приложение — обязательно добавьте в код проверку на то, что этот код выполняется, а не импортируется:
```
def execute_main():
...
if __name__ == "__main__": # Добавьте это условие
execute_main()
```
Сделав это, вы обеспечите то, что импорт этого кода не приведёт к его случайному выполнению. Выполняться он будет только в том случае, если будет запущен явным образом.
#### Файл \_\_main\_\_.py
Вы, возможно, заметили, что некоторые Python-пакеты можно вызывать, пользуясь ключом `-m`:
```
python -m pytest
python -m tryceratops
python -m faust
python -m flake8
python -m black
```
Система относится к таким пакетам почти как к обычным утилитам командной строки, так как запускать их ещё можно так:
```
pytest
tryceratops
faust
flake8
black
```
Для того чтобы оснастить ваш проект такой возможностью — нужно добавить файл `__main.py__` в главный модуль:
```
├── src
│ ├── example\_module Главный модуль
│ │ ├── \_\_init\_\_.py
│ │ ├── \_\_main\_\_.py Добавьте сюда этот файл
│ │ └── many\_files.py
│ │
│ └── tests/\*
│ └── many\_tests.py
│
├── .gitignore
├── pyproject.toml
└── README.md
```
И не забудьте, что и тут, в файле `__main__.py`, понадобится проверка `__name__ == "__main__"`.
Когда вы установите свой модуль — вы сможете запускать его командой вида `python -m example_module`.
О, а приходите к нам работать? 🤗 💰Мы в [**wunderfund.io**](http://wunderfund.io/) занимаемся [высокочастотной алготорговлей](https://en.wikipedia.org/wiki/High-frequency_trading) с 2014 года. Высокочастотная торговля — это непрерывное соревнование лучших программистов и математиков всего мира. Присоединившись к нам, вы станете частью этой увлекательной схватки.
Мы предлагаем интересные и сложные задачи по анализу данных и low latency разработке для увлеченных исследователей и программистов. Гибкий график и никакой бюрократии, решения быстро принимаются и воплощаются в жизнь.
Сейчас мы ищем плюсовиков, питонистов, дата-инженеров и мл-рисерчеров.
[Присоединяйтесь к нашей команде.](http://wunderfund.io/#join_us) | https://habr.com/ru/post/678634/ | null | ru | null |
# xonsh — python как замена shell
Удивительно, на на хабре до сих пор нет поста о такой, весьма интересной, замене шеллу как [xonsh](https://xon.sh/) ([github](https://github.com/xonsh/xonsh)), с моей точки зрения синтаксис всяких shell'ов ужасен и не вижу никаких оснований сохранять его в 21 веке, а Python, в свою очередь, обладает прекрасным синтаксисом и массой других преимуществ, поэтому, на мой взгляд, он и должен быть языком автоматизации по умолчанию, [чего и пытаеся достичь](https://xon.sh/faq.html#why-xonsh) xonsh.
Какое-то время использую xonsh, поэтому думаю, что могу рассказать о нём достаточно для того, чтобы начать пользоваться.
Оговорки:
* xonsh это только про Python 3, но [это норма](https://habr.com/company/otus/blog/425233/).
* xonsh ещё не релизнулся (версия 0.8.3 на момент написания), видимо по мнению разработчиков ещё не все желаемые фичи реализованы, но по моим ощущениям всё работает (если разобраться с отличиями, о чём ниже).
Основная особенность xonsh в том, что он ["магически"](https://xon.sh/tutorial.html#python-mode-vs-subprocess-mode) угадывает что вы ввели — команду питона или шелла, и это работает вполне хорошо.
Вставлять питонные код в команды шелла можно с помощью [собаки](https://xon.sh/tutorial.html#python-evaluation-with).
Не буду подробно останавливаться, на том, какие есть возможности в xonsh, это понятно и наглядно описано в [документации](https://xon.sh/tutorial.html) и всяких [статьях](https://opensource.com/article/18/9/xonsh-bash-alternative), с моей точки зрения достаточно уже того, что вы можете получить нормальный синтаксис циклов в шелле:
```
worldmind@x ~ $ for i in range(3):
............... echo $SHELL
```
Поэтому я постараюсь сосредоточиться на том, что не описано или описано плохо.
Установка
---------
Я буду описывать установку (для Debian/Ubuntu) не требующую права суперпользователя, хотя я только недавно перешёл на такую схему, раньше я ставил в системные папки, прописывал его в `/etc/shells` и менял шелл командой `chsh`, но на первый взгляд всё работает также и при новом способе и он мне кажется более правильным, не хочется засорять систему пакетами не из репозиториев, но тут каждый решает для себя сам.
Ставим pip если ещё не:
```
sudo apt-get install python3-pip
```
Ставим xonsh (без sudo), я привожу команду которая устанавливает все опциональные зависимости, чтобы получить все плюшки задуманные авторами, если кто-то хочет минимальную установку, то можно удалить квадратные скобки с содержимым:
```
pip3 install --user xonsh[ptk,pygments,proctitle,linux]
```
Скорее всего у вас уже, где-нибудь в `.profile` в PATH добавляются пути к локальной папке с бинарниками `$HOME/.local/bin`, но они добавляются только при их наличии, поэтому нужно перезапустить терминал, чтобы этот код отработал и бинарник xonsh можно было запустить и посмотреть.
Обновление стандартно:
```
pip3 install --user xonsh --upgrade
```
### venv
Ставим venv если хотим пользоваться соответствующим функционалом (см. далее про vox):
```
sudo apt-get install python3-venv
```
Всякие venv заточены под конкретные шеллы, поэтому xonsh предлагает свою обёртку называемую [vox](https://xon.sh/python_virtual_environments.html), но для комфортного использования стоит устанавливать расширение [avox](https://github.com/astronouth7303/xontrib-avox):
```
pip3 install --user xontrib-avox
```
### Установка pyenv
Если есть необходимость в виртуальных окружениях с произвольной версией питона, то нужно склонировать pyenv предварительно [установив зависимости для сборки питона](https://github.com/pyenv/pyenv/wiki):
```
git clone https://github.com/pyenv/pyenv.git ~/.pyenv
```
Далее в примере конфига можно узреть установку пары переменных окружения для использования pyenv.
### Запуск
Теперь у нас всё установлено и осталось сделать xonsh шеллом, для того, чтобы не менять ничего вне юзерской папки я использую следующий код (по мотивам [SO](https://unix.stackexchange.com/questions/136423/making-zsh-default-shell-without-root-access)) для баша (если у вас другой шелл, то вы знаете что делать, но не используйте .profile т.к. xonsh его тоже читает) добавленный в `.bashrc`:
```
# set default shell without editing /etc/shells
if [ "${XONSH_VERSION:-unset}" = "unset" ] ; then
export SHELL=$HOME/.local/bin/xonsh
exec $HOME/.local/bin/xonsh -l
fi
```
Перезапускаем шелл и, если всё прошло удачно, вы уже в xonsh т.е. по сути в питон консоли и можете например производить вычисления прямо в командной строке, например узнать сколько будет `2+2`.
Настройка
---------
Прежде чем начать пользоваться, стоит создать конфигурационный файл `.xonshrc`:
```
aliases['g'] = 'git'
import os
local_bin = '{}/.local/bin'.format($HOME)
if os.path.isdir(local_bin):
$PATH.append(local_bin)
$PYENV_ROOT = '%s/.pyenv' % $HOME
$PATH.insert(0, '%s/bin' % $PYENV_ROOT)
xontrib load vox
$PROJECT_DIRS = ["~/projects"]
xontrib load avox
```
Перезапускам шелл для применения новых настроек.
Стоит обратить внимание на человеческую модель данных — [алиасы](https://xon.sh/tutorial.html#aliases) это словарь, пути это список, вроде очевидно, но почему-то не всегда оно так.
Также, мы в конфиге импортировали модуль `os` это значит что он уже будет доступен в нашем шелле, таким образом можно наимпортить нужных модулей и получить своё, удобное окружение.
Начало приведённого файла больше для демонстрации возможностей, а вот последние три строки позволяют удобно использовать виртуальные окружения, пример использования которых далее.
Использование виртуальных окружений
-----------------------------------
Создаём папку проекта (avox ожидает что все проекты лежат в `$PROJECT_DIRS`):
```
mkdir -p projects/test
```
Создаём виртуальное окружение для этого проекта:
```
vox new test
```
Благодаря настроенному дополнению `avox` нам достаточно перейти в папку проекта чтобы активировать виртуальное окружение, никаких странных `source ./bin/activate` выполнять не нужно:
```
worldmind@x ~ $ cd projects/test/
(test) worldmind@x ~/projects/test $ pip install see
...
(test) worldmind@x ~/projects/test $ python -c 'import see'
```
По выходу из папки виртуальное окружение деактивируется:
```
(test) worldmind@x ~/projects/test $ cd
worldmind@x ~ $ python3 -c 'import see' err>out | fgrep 'NotFound'
ModuleNotFoundError: No module named 'see'
```
Заодно можно увидеть более человеческую работу с [перенаправлением потоков ввода-вывода](https://xon.sh/tutorial.html#input-output-redirection), кто никогда не забывал как это делать во всяких башах пусть первым кинет в меня коментом.
~~Для полноты картины хотело бы, чтобы в этих виртуальных окружениях можно было бы использовать произвольную версию питона, например установленную через pyenv, но пока [не срослось](https://github.com/xonsh/xonsh/issues/692), а самому подкостылить руки не дошли.~~
UPD: Не так давно xonsh [научили](https://github.com/xonsh/xonsh/issues/692#issuecomment-452309797) использовать произвольную версию питона в виртуальных окружениях.
Устанавливаем желаемую версию питона (список доступных `pyenv install --list`):
```
pyenv install 3.7.2
```
Создаём виртуальное окружение с ней:
```
mkdir projects/projectwith3.7
vox new -p $PYENV_ROOT/versions/3.7.2/bin/python projectwith3.7
```
Проверяем:
```
(projectwith3.7) worldmind@x ~/projects/projectwith3.7 $ python --version
Python 3.7.2
```
Грабли
------
Единственное на что я накнулся это [отличия в эскейпинге](https://xon.sh/tutorial_subproc_strings.html#no-escape):
```
find . -name data.txt -exec echo {} \;
```
не будет работать, ибо эскейпинг обратным слэшем не работает в xonsh и фигурные скобки имеют специальное значение, нужно использовать кавычки, например так:
```
find . -name .xonshrc -exec echo '{}' ';'
```
некоторые отличия от bash есть в виде таблицы в [документации](https://xon.sh/bash_to_xsh.html).
Вывод
-----
Мне кажется, что xonsh это хорошой претендент на нормальный шелл будущего для всех, а особенно он должен понравиться питонистам. Начните пользоваться (установка без sudo упрощает откат назад, можно просто удалить папку), чтобы понять всё ли там есть лично для вас, может это то, что вы искали, но боялись установить.
Дополнения в комментариях
-------------------------
1. [Установка переменных окружения для папок](https://habr.com/ru/post/429892/#comment_20820286).
2. [Хуки на активацию виртуального окружения](https://habr.com/ru/post/429892/#comment_20875628) | https://habr.com/ru/post/429892/ | null | ru | null |
# Настройка Xdebug3 для Laravel-приложения в Docker
Начнём пожалуй, со структуры, в которой всё будет:
```
docker/
├── docker-compose.yml
├── .env
├── .env.example
├── .gitignore
└── services
├── database
│ ├── dump
│ └── .gitignore
├── nginx
│ └── site.conf
└── php
├── Dockerfile
└── php.ini
```
А теперь обо всём по порядку:
Файл `.gitingore` содержит только одну строчку `/.env`
Файл `.env.example` в начале проекта такой же, как и `.env`
В файле `docker-compose.yml` содержится информация про все наши сервисы:
```
version: "3.7"
services:
php:
build:
args:
uname: ${PHP_UNAME}
uid: ${PHP_UID}
gid: ${PHP_GID}
context: ./services/php
container_name: ${PROJECT_NAME}_php
image: ${PROJECT_NAME}_php
restart: unless-stopped
working_dir: /var/www/
volumes:
- ./services/php/php.ini:/usr/local/etc/php/php.ini
- ../:/var/www
environment:
COMPOSER_MEMORY_LIMIT: 2G
XDEBUG_CONFIG: client_host=${XDEBUG_REMOTE_HOST} client_port=${XDEBUG_STORM_PORT} remote_enable=1
PHP_IDE_CONFIG: serverName=${XDEBUG_STORM_SERVER_NAME}
networks:
- main_network
depends_on:
- db
db:
image: mysql:5.6
restart: unless-stopped
container_name: ${PROJECT_NAME}_db
command: --default-authentication-plugin=mysql_native_password
environment:
MYSQL_DATABASE: ${DB_DATABASE}
MYSQL_ROOT_PASSWORD: ${DB_ROOT_PASSWORD}
MYSQL_PASSWORD: ${DB_PASSWORD}
MYSQL_USER: ${DB_USERNAME}
ports:
- ${DB_LOCAL_PORT}:3306
volumes:
- ./services/database/dump:/var/lib/mysql
networks:
- main_network
nginx:
image: nginx:1.17-alpine
restart: unless-stopped
container_name: ${PROJECT_NAME}_nginx
ports:
- ${NGINX_LOCAL_PORT}:80
volumes:
- ../:/var/www
- ./services/nginx:/etc/nginx/conf.d
networks:
- main_network
depends_on:
- php
networks:
main_network:
driver: bridge
name: ${PROJECT_NAME}_main_network
ipam:
driver: default
config:
- subnet: ${SUBNET_IP}/${SUBNET_MASK}
```
Из важного здесь стоит отметить `./services/php/php.ini:/usr/local/etc/php/php.ini` - наш локальный файл `php.ini` (там некоторые конфиги дебаггера) будет намаплен на тот что внутри контейнера. `XDEBUG_CONFIG` - будет задана переменная окружения внутри контейнера `php`, которую потом будет испльзовать xdebug вместо значений по-умолчанию. Здесь мы задаем `client_host` - хост, к которому xdebug будет пытаться подключиться при инициации отладочного соединения. Этот адрес должен быть адресом машины, на которой ваш PhpStorm прослушивает входящие отладочные соединения. Получается так, что наша локальная машина находится в одной подсети с запущеными контейнерами, а её адресс будет первым в этой подсети. Таким образом, мы всегда можем знать каким будет адресс нашей машины, и позже зададим это значение в переменную `XDEBUG_REMOTE_HOST` . В `CLIENT_PORT` нужно будет задать порт, установленный на прослушивание в IDE (9003). `XDEBUG_STORM_SERVER_NAME` - имя сервера, который мы создадим в IDE позже. Этот параметр нужен, чтобы сообщить PhpStorm, как сопоставлять пути при подключении с докера (ведь у вас же открыты локальные файлы в редакторе, а код работает на удалённых; хотя при испльзовании volumes это не совсем так).
Вот, как выглядит файл окружения `.env` :
```
PROJECT_NAME=my_project
DB_DATABASE=my_project_db
DB_USERNAME=my_project
DB_PASSWORD=p@$$w0rd
DB_ROOT_PASSWORD=toor
PHP_UNAME=dev
PHP_UID=1000
PHP_GID=1000
DB_LOCAL_PORT=3377
NGINX_LOCAL_PORT=8077
XDEBUG_STORM_SERVER_NAME=Docker
XDEBUG_REMOTE_HOST=192.168.227.1
XDEBUG_STORM_PORT=9003
SUBNET_IP=192.168.227.0
SUBNET_MASK=28
```
На счёт подсети для проекта, то здесь мы задали `192.168.227.0` с маской 28, то-есть для всех устройств остаётся `32 - 28 = 4 бита`, что равносильно `2 ** 4 - 1 = 15 контейнеров`. Не 16 потому что в подсеть входит также наша локальная машина, которая, кстати, будет иметь адресс `192.168.227.1`. Именно это значение мы задали в переменную `XDEBUG_REMOTE_HOST`.
Настройки веб-сервера `site.conf`:
```
server {
listen 80;
server_name 127.0.0.1 localhost;
client_max_body_size 5m;
error_log /var/log/nginx/error.log;
access_log /var/log/nginx/access.log;
root /var/www/public;
index index.php;
location / {
try_files $uri $uri/ /index.php?$query_string;
gzip_static on;
}
location ~ \.php$ {
try_files $uri =404;
fastcgi_split_path_info ^(.+\.php)(/.+)$;
fastcgi_pass php:9000;
fastcgi_index index.php;
include fastcgi_params;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
fastcgi_param PATH_INFO $fastcgi_path_info;
}
}
```
В нашем Dockerfile (тот что для php) нужно не забыть установить и включить xdebug. Для этого добавляем 2 строчки:
```
RUN pecl install xdebug
RUN docker-php-ext-enable xdebug
```
Стоит отметить, что будет испльзована последняя (то-есть 3) версия (есть различия в конфигурации по сравнению с 2).
Полный `Dockerfile`:
```
FROM php:7.4-fpm
# Arguments defined in docker-compose.yml
ARG uname
ARG gid
ARG uid
# Install system dependencies
RUN apt-get update \
&& apt-get install -y \
git \
curl \
dpkg-dev \
libpng-dev \
libjpeg-dev \
libonig-dev \
libxml2-dev \
libpq-dev \
libzip-dev \
zip \
unzip \
cron
RUN pecl install xdebug
RUN docker-php-ext-enable xdebug
RUN docker-php-ext-configure gd \
--enable-gd \
--with-jpeg
ADD ./php.ini /usr/local/etc/php/php.ini
# Clear cache
RUN apt-get clean && rm -rf /var/lib/apt/lists/*
# Install PHP extensions
RUN docker-php-ext-install pdo pdo_mysql pdo_pgsql pgsql mbstring exif pcntl bcmath gd sockets zip
# Get latest Composer
COPY --from=composer:latest /usr/bin/composer /usr/bin/composer
# Create system user to run Composer and Artisan Commands
RUN groupadd --gid $gid $uname
RUN useradd -G www-data,root -s /bin/bash --uid $uid --gid $gid $uname
RUN mkdir -p /home/$uname/.composer && \
chown -R $uname:$uname /home/$uname
# Set working directory
WORKDIR /var/www
USER $uname
# Expose port 9000 and start php-fpm server
EXPOSE 9000
CMD ["php-fpm"]
```
Также, зададим некоторые параметры исплнения в `php.ini` :
```
max_execution_time=1000
max_input_time=1000
xdebug.mode=debug
xdebug.log="/var/www/xdebug.log"
xdebug.remote_enable=1
```
Запустим наше приложение:
```
docker-compose up -d
```
И дальше пойдём в PhpStorm для настройки:
Создадим сервер с названием Docker и cделаем маппинг локального корня проекта (`/var/www/quizzy.loc`) на путь, по которому он лежит в докере (`/var/www`):
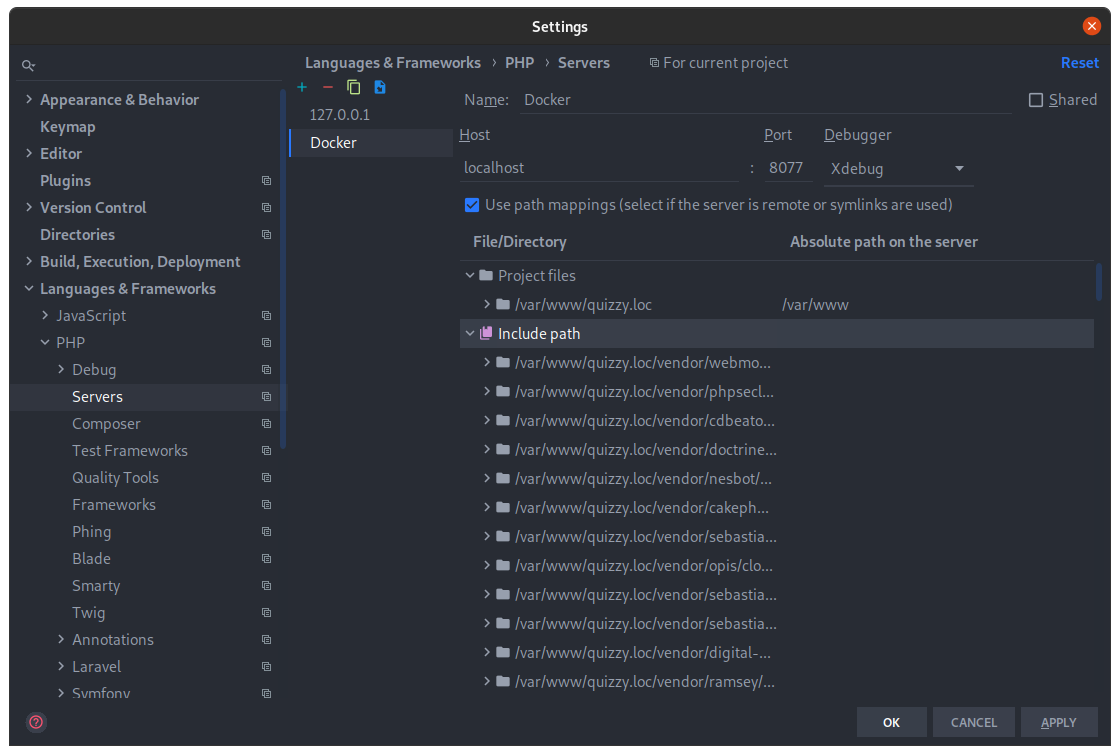Дальше, нам нужно будет настроить использование интерпретатора php из докера:
Настраиваем php interpreterВыбираем сервис, в котором находится php и указываем путь к интерпретатору")Задаём параметры запуска (через exec)Теперь можем перейти в подпункт "Debug" и настроить порт на котором запускать:
Настраиваем дебаггерПроверим, работает ли Xdebug:
Теперь можем поставить брейкпоинт в нашем коде и начать прослушивание входящих подключений:
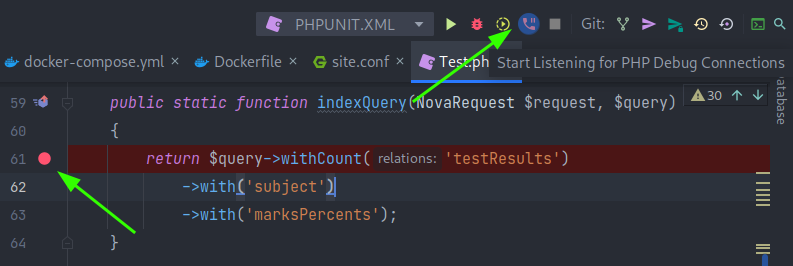Переходим в наш любимый браузер Firefox, устанавливаем и включаем [плагин](https://addons.mozilla.org/en-GB/firefox/addon/xdebug-helper-for-firefox/) на нужной странице:
Перезагружаем страницу, и в PhpStrom должен поймать подключение:
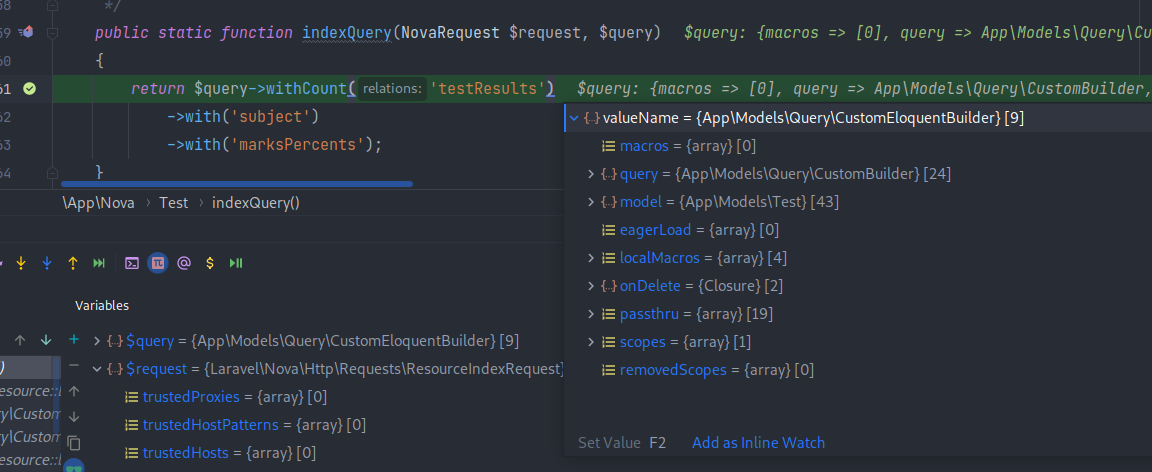 | https://habr.com/ru/post/540072/ | null | ru | null |
# Упрощение анализа дампов памяти windows или Очередной твик контекстного меню
Многие пользователи операционных систем windows рано или поздно сталкиваются с необходимостью выяснить почему же любимая операционка «падает в бсод».
О том что это, как искать причину и как её (в зависимости от ситуации) устранять в интернете написано уже немало, но что делать, если нужно выяснить причину максимально быстро и делать это приходится регулярно как, например, работникам сервисов или завсегдатаям компьютерных форумов?
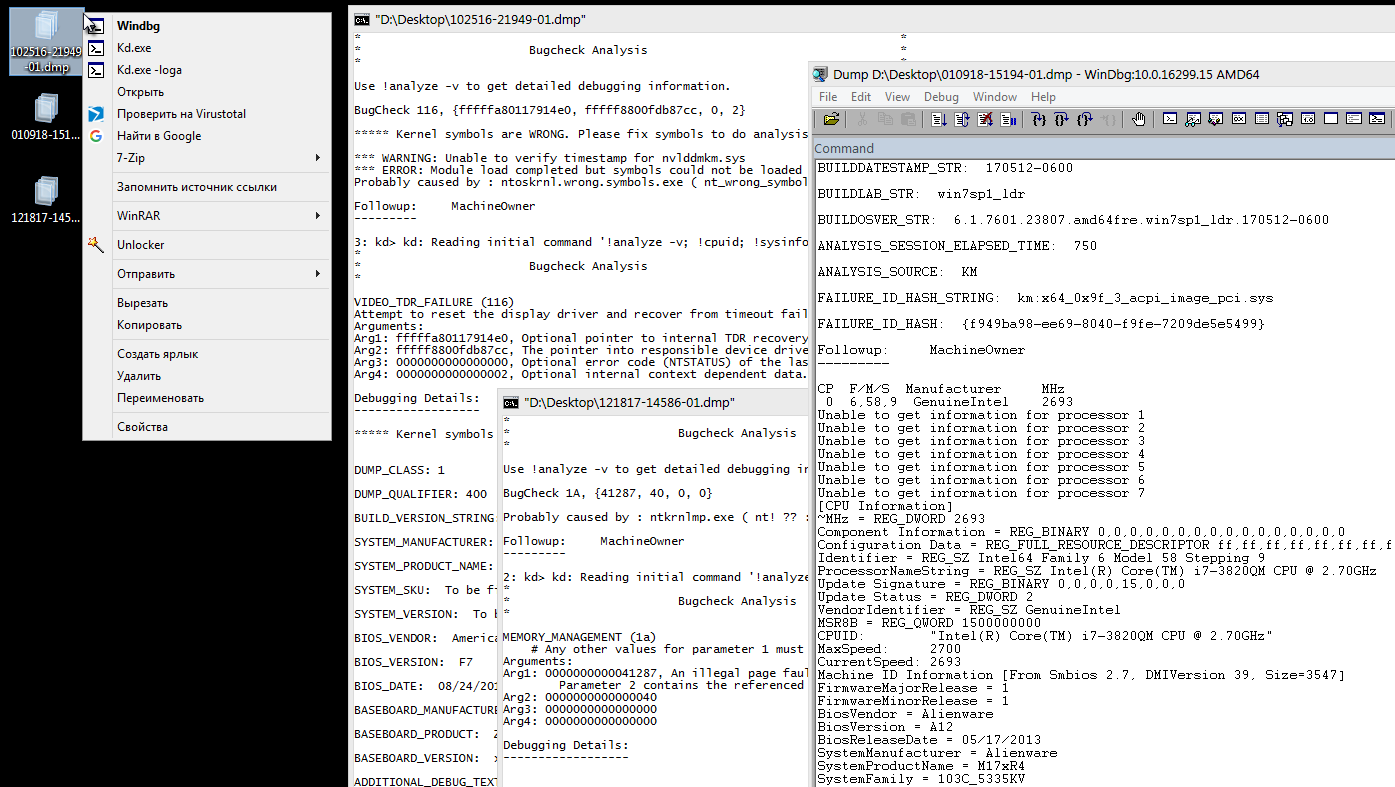
Упростить задачу могут пресловутые твики контекстного меню, благо делаются они довольно просто.
**Подготовка**Для начала понадобится установить пакет с дебаггером windbg.exe, консольным вариантом kd.exe и прочим необходимым содержимым.
Это пакеты **X64 Debuggers And Tools-x64\_en-us.msi** или **X86 Debuggers And Tools-x86\_en-us.msi** на выбор в зависимости от разрядности используемой ОС и/или личных предпочтений.
Отдельных ссылок на сайте microsoft вы не найдете, но данные пакеты находятся в составе [Windows Driver Kit](https://developer.microsoft.com/ru-ru/windows/hardware/windows-driver-kit), его можно скачать без установки выбрав соответствующий режим работы инсталятора, пакеты по завершении скачивания будут лежать в папке **\Windows Kits\10\WDK\Installers**.
Если кому-то нужно, то я загрузил их отдельно на Я.Диск:
[X64 Debuggers And Tools-x64\_en-us.msi](https://yadi.sk/d/KAPj3vDL3RKGCn)
[X86 Debuggers And Tools-x86\_en-us.msi](https://yadi.sk/d/1770KWk03RKGCp)
Я решил не устанавливать дебаггер, а просто распаковать msi:
```
msiexec /a "D:\Desktop\X64 Debuggers And Tools-x64_en-us.msi" /qb targetdir="D:\Desktop\Temp"
```
Такого «портабельного» варианта более чем достаточно. После, для собственного удобства, переместил нужное содержимое из нескольких вложенных папок в **C:\Portable\Debug**, чтобы получилось:
`C:\Portable\Debug\windbg.exe
C:\Portable\Debug\kd.exe`
+ все остальное. От этого пути и будем отталкиваться в дальнейшем (плюс я внес его в %PATH% опять же, для удобства).
На этом подготовительные мероприятия можно считать завершенными и переходить к описанию процесса создания твика.
Так как в моей задаче предполагается, что дампов бывает много и часто, то нужно максимально ускорить процесс, при этом сделать его достаточно информативным для беглого анализа.
#### Разбираемся с ключами и командами дебаггера
В качестве основы для будущего твика возьмем вот такой батник, на который достаточно перетянуть нужный дамп.
Для лучшего восприятия информации, в моём понимании, я инвертировал цвета консоли и задал размер окна консоли побольше.
```
@echo off
title text %1
mode con: cols=170
color F0
title "%1"
kd.exe -nosqm -sup -z "%1" ^
-y srv*"C:\Symbols"*http://msdl.microsoft.com/download/symbols -i srv*"C:\Symbols"*http://msdl.microsoft.com/download/symbols -c ^
"!analyze -v; !cpuid; !sysinfo cpuinfo; !sysinfo cpuspeed; !sysinfo machineid; q""
pause
exit /b
```
Тут можно увидеть параметры передаваемые kd.exe, такие как **-y**, **-i** и, собственно, **-z**, которые видели все, кто знает о широко известном в узких кругах [kdfe.cmd](https://encrypted.google.com/search?&q=kdfe.cmd).
```
-i !ImagePath! specifies the location of the executables that generated the
fault (see _NT_EXECUTABLE_IMAGE_PATH)
-y !SymbolsPath! specifies the symbol search path (see _NT_SYMBOL_PATH)
-z !CrashDmpFile! specifies the name of a crash dump file to debug
```
Если брать по аналогии с распространенными инструкциями то тут есть небольшие отличия: в качестве аргументов дополнительно переданы **-nosqm** и **-sup**.
```
-nosqm disables SQM data collection/upload.
-sup enables full public symbol searches
```
В качестве команд:
```
!cpuid
!sysinfo cpuinfo
!sysinfo cpuspeed
!sysinfo machineid
```
Расписывать их не буду, так-как выйдет слишком много копипасты. Кому интересно смогут найти подробнейшую справку **debugger.chm** в любом из двух \*.msi о которых говорилось выше или на docs.microsoft.com [-cpuid](https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/-cpuid) [-sysinfo](https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/-sysinfo). Если вкратце — базовая информация о железе пострадавшего.
Вывод скрипта с использованием kd.exe получится практически аналогичен тому, который получился бы при работе непосредственно через windbg, но результат достигается гораздо быстрее так как ничего не нужно открывать, настраивать папки, открывать дамп через меню и вводить команды в дебаггер.
#### Фильтрация мусорного вывода из консоли
Для первого примера возьмем дамп памяти рандомного юзера. Возникает небольшая проблема с мусором в выводе:
**Скриншот куска вывода консоли**
Такое встречается, например, в дампах юзеров использующих активатор odin, что мы и видим в данном примере.
Полный вывод довольно массивный, потому ссылкой на [pastebin](https://pastebin.com/C308y85b).
Требуется «отфильтровать» ненужные строки оставив только полезную информацию.
Я использовал [findstr](https://technet.microsoft.com/ru-ru/library/bb490907.aspx), получилось вот такое некрасивое но работающее решение:
```
findstr /r /v /c:"^\*\*\* .* \*\*\*" /c:"^\*\*\*\*\*\*\*\*\*\*\*\*\*\*.*"
```
Тут findstr использует две регулярки: одна ищет строки начинающиеся с трех звездочек, одного пробела и заканчивающиеся на пробел и три звездочки. Вторая ищет строки начинающиеся с 14-ти звездочек. Ничего более вразумительного средствами findstr я сделать не смог.
(Использовать символы окончания строк в регулярках findstr на выхлопе kd.exe не рекомендую, могут быть проблемы с видом окончания строк выводимого kd.exe. Вместо \r\n можно получить \n, который findstr не считает окончанием строки.Такие себе грабли.)
Весь код предварительного батника с «фильтром» получился такой:
```
@echo off
title text %1
mode con: cols=170
color F0
title "%1"
kd.exe -nosqm -sup -z "%1" ^
-y srv*"C:\Symbols"*http://msdl.microsoft.com/download/symbols -i srv*"C:\Symbols"*http://msdl.microsoft.com/download/symbols ^
-c "!analyze -v; !cpuid; !sysinfo cpuinfo; !sysinfo cpuspeed; !sysinfo machineid; q" | findstr /r /v /c:"^\*\*\* .* \*\*\*" /c:"^\*\*\*\*\*\*\*\*\*\*\*\*\*\*.*"
pause
exit /b
```
Полный вывод отфильтрованного варианта также на [pastebin](https://pastebin.com/g2yy10gj).
Результат аналогичный, но без «мусора». 290 строк текста против 894-х. Уже лучше, но еще не всё.
#### Быстрое создание лога работы дебаггера
Следующий шаг это добавление создания лога, который можно было бы запостить или отправить куда-нибудь.
Для этого нужно передать kd.exe аргумент -loga <«П:\уть к\логу.log»>
Код принимает следующий вид:
```
@echo off
title text %1
mode con: cols=170
color F0
title "%1"
set "D=%1"
set L=%D:.dmp=.LOG%
kd.exe -nosqm -sup -loga "%L%" -z "%D%" ^
-y srv*"C:\Symbols"*http://msdl.microsoft.com/download/symbols -i srv*"C:\Symbols"*http://msdl.microsoft.com/download/symbols ^
-c "!analyze -v; !cpuid; !sysinfo cpuinfo; !sysinfo cpuspeed; !sysinfo machineid; q" | findstr /r /v /c:"^\*\*\* .* \*\*\*" /c:"^\*\*\*\*\*\*\*\*\*\*\*\*\*\*.*"
pause
exit /b
```
Для файла **102516-21949-01.dmp** будет сформирован лог **102516-21949-01.LOG** в той же папке, что и сам дамп.
В данном случае вывод «мусора» в лог не фильтруется, фильтруется только вывод в консоль, но в моем случае это не принципиально, хотя можно исправить и это очистив лог уже после создания:
```
@echo off
title text %1
mode con: cols=170
color F0
title "%1"
set "D=%1"
set L=%D:.dmp=.LOG%
kd.exe -nosqm -sup -loga "%L%" -z "%D%" ^
-y srv*"C:\Symbols"*http://msdl.microsoft.com/download/symbols -i srv*"C:\Symbols"*http://msdl.microsoft.com/download/symbols ^
-c "!analyze -v; !cpuid; !sysinfo cpuinfo; !sysinfo cpuspeed; !sysinfo machineid; q" | findstr /r /v /c:"^\*\*\* .* \*\*\*" /c:"^\*\*\*\*\*\*\*\*\*\*\*\*\*\*.*"
set CL=%L:.LOG=_CLEAN.LOG%
type "%L%" | findstr /r /v /c:"^\*\*\* .* \*\*\*" /c:"^\*\*\*\*\*\*\*\*\*\*\*\*\*\*.*" >> "%CL%"
del /f /q "%L%"
pause
exit /b
```
### Открытие дампа в windbg
Теперь последний по порядку, но не по значимости шаг: нужна возможность передать дамп непосредственно в windbg.exe и сразу же передать ему команды, которые с большой долей вероятности понадобится вводить. Все делается по аналогии с kd.exe, аргументы и команды принимаемые windbg.exe практически идентичны kd.exe
```
@echo off
windbg.exe -z "%1" -sup -y ^
"srv*C:\Symbols*http://msdl.microsoft.com/download/symbols" -i "srv*C:\Symbols*http://msdl.microsoft.com/download/symbols" -c "!analyze -v; !cpuid; !sysinfo cpuinfo; !sysinfo cpuspeed; !sysinfo machineid"
exit /b
```
В результате дамп откроется сразу в дебаггере и в нем автоматически выполнятся команды перечисленные в ключе **-c**.
Вывод аналогичный самому первому варианту с той разницей, что дамп открыт сразу в windbg, есть возможность вводить команды для дальнейшего анализа из-за отсутствия в передаваемом списке команд команды **q**.
(К слову если в предыдущих вариантах скрипта с kd.exe убрать команду **q** передаваемую в списке команд через аргумент **-c**, то возможность продолжить работу с дампом появится и там, в том числе с записью лога прямо в процессе.)
### Создание твика
Теперь всё это нужно видоизменить, чтобы можно было прикрутить к контекстному меню \*.dmp файлов. Собственно, ради чего это и затевалось.
Получились вот такие «однострочники»:
**Для варианта с фильтрацией вывода консоли**
```
cmd /d /k mode con: cols=170 & color F0 & title "%1" & kd.exe -nosqm -sup -z "%1" -y srv*"C:\Symbols"*http://msdl.microsoft.com/download/symbols -i srv*"C:\Symbols"*http://msdl.microsoft.com/download/symbols -c "!analyze -v; !cpuid; !sysinfo cpuinfo; !sysinfo cpuspeed; !sysinfo machineid; q" | findstr /r /v /c:"^\*\*\* .* \*\*\*" /c:"^\*\*\*\*\*\*\*\*\*\*\*\*\*\*.*"
```
**Для варианта с фильтрацией вывода консоли и с созданием логфайла**
(пришлось использовать [отложенное расширение переменных](http://www.cyberforum.ru/cmd-bat/thread940954.html))
```
cmd /d /v /k mode con: cols=170 & color F0 & title "%1" & set "D=%1"& set L=!D:.dmp=.LOG! & kd.exe -nosqm -sup -loga "!L!" -z "!D!" -y srv*"C:\Symbols"*http://msdl.microsoft.com/download/symbols -i srv*"C:\Symbols"*http://msdl.microsoft.com/download/symbols -c "!analyze -v; !cpuid; !sysinfo cpuinfo; !sysinfo cpuspeed; !sysinfo machineid; q" | findstr /r /v /c:"^\*\*\* .* \*\*\*" /c:"^\*\*\*\*\*\*\*\*\*\*\*\*\*\*.*"
```
**Для открытия дампа непосредственно в windbg.exe**
```
"C:\Portable\Debug\windbg.exe" -z "%1" -sup -y "srv*C:\Symbols*http://msdl.microsoft.com/download/symbols" -i "srv*C:\Symbols*http://msdl.microsoft.com/download/symbols" -c "!analyze -v; !cpuid; !sysinfo cpuinfo; !sysinfo cpuspeed; !sysinfo machineid"
```
В реестре создал следующую структуру разделов:
Был [создан отдельный тип файла](http://whatis.ru/reg/reg_n11.shtml) **dmp\_geek** в разделы реестра которого и вносились изменения. Файлы с расширением \*.dmp были назначены файлами типа **dmp\_geek**.
В каждом разделе command в строковый параметр по умолчанию были внесены соответствующие однострочники + красивости в виде иконок и удобных имен отображаемых имен пунктов в контекстном меню.

Получился твик добавляющий возможность массового открытия выделенных в папке дампов как в консоли так и в дебаггере с фильтрацией «мусора» и создания логов для каждого дампа по необходимости. Экономит довольно много времени.
После «причёсывания» реестра экспортировал всё в итоговый REG файл готовый для применения.
**Содержимое REG файла**
```
Windows Registry Editor Version 5.00
[HKEY_CLASSES_ROOT\.dmp]
@="dmp_geek"
[HKEY_CLASSES_ROOT\dmp_geek]
@="dmp_geek"
"FriendlyTypeName"="Дамп памяти"
[HKEY_CLASSES_ROOT\dmp_geek\DefaultIcon]
@="imageres.dll,142"
[HKEY_CLASSES_ROOT\dmp_geek\shell]
[HKEY_CLASSES_ROOT\dmp_geek\shell\kd.exe]
"MUIVerb"="Kd.exe"
"Icon"="C:\\Portable\\Debug\\windbg.exe,6"
[HKEY_CLASSES_ROOT\dmp_geek\shell\kd.exe\command]
@="cmd /d /k mode con: cols=170 & color F0 & title \"%1\" & \"C:\\Portable\\Debug\\kd.exe\" -nosqm -sup -z \"%1\" -y srv*\"C:\\Symbols\"*http://msdl.microsoft.com/download/symbols -i srv*\"C:\\Symbols\"*http://msdl.microsoft.com/download/symbols -c \"!analyze -v; !cpuid; !sysinfo cpuinfo; !sysinfo cpuspeed; !sysinfo machineid; q\" | findstr /r /v /c:\"^\\*\\*\\* .* \\*\\*\\*\" /c:\"^\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*.*\""
[HKEY_CLASSES_ROOT\dmp_geek\shell\kd.exe_-loga]
"MUIVerb"="Kd.exe -loga"
"Icon"="C:\\Portable\\Debug\\windbg.exe,6"
[HKEY_CLASSES_ROOT\dmp_geek\shell\kd.exe_-loga\command]
@="cmd /d /v /k mode con: cols=170 & color F0 & title \"%1\" & set \"D=%1\"& set L=!D:.dmp=.LOG! & \"C:\\Portable\\Debug\\kd.exe\" -nosqm -sup -loga \"!L!\" -z \"!D!\" -y srv*\"C:\\Symbols\"*http://msdl.microsoft.com/download/symbols -i srv*\"C:\\Symbols\"*http://msdl.microsoft.com/download/symbols -c \"!analyze -v; !cpuid; !sysinfo cpuinfo; !sysinfo cpuspeed; !sysinfo machineid; q\" | findstr /r /v /c:\"^\\*\\*\\* .* \\*\\*\\*\" /c:\"^\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*\\*.*\""
[HKEY_CLASSES_ROOT\dmp_geek\shell\Open]
"MUIVerb"="Windbg"
"Icon"="C:\\Portable\\Debug\\windbg.exe,6"
[HKEY_CLASSES_ROOT\dmp_geek\shell\Open\command]
@="\"C:\\Portable\\Debug\\windbg.exe\" -z \"%1\" -sup -y \"srv*C:\\Symbols*http://msdl.microsoft.com/download/symbols\" -i \"srv*C:\\Symbols*http://msdl.microsoft.com/download/symbols\" -c \"!analyze -v; !cpuid; !sysinfo cpuinfo; !sysinfo cpuspeed; !sysinfo machineid\""
```
→ Скачать с Я.Диска [GEEK\_DMP.reg](https://yadi.sk/d/lNQTU8Sd3RKQtN)
На этом всё. Теперь можно быстро, хоть и поверхностно, проанализировать сразу пачку дампов.
**Использованные материалы, источники, полезные ссылки по теме:**[Debugging Tools for Windows](https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/)
[Компьютерный практикум](http://ab57.ru/cmdlist/findstr.html)
[Реестр windows](http://whatis.ru/reg/reg_n11.shtml)
[Администрирование Windows — Форум программистов и сисадминов](http://www.cyberforum.ru/windows-admin/)
[WinDbg cheat sheet for crash dump analysis](http://www.dumpanalysis.org/CDAPoster.html) | https://habr.com/ru/post/409397/ | null | ru | null |
# Форсаж под нагрузкой на Symfony + HHVM + MongoDB + CouchDB + Varnish

Сегодня хотим рассказать о том, как строили систему, к которой сейчас обращается более 1 млн. уникальных посетителей в день (без учёта запросов к API), о тонкостях архитектуры, а также о тех граблях и подводных камнях, с которыми пришлось столкнуться. Поехали...
### Исходные данные
Система работает на Symfony 2.3 и крутится на дроплетах [DigitalOcean](https://m.do.co/c/d094555af590), работают бодро, никаких замечаний.
### Symfony
У Symfony есть замечательное событие [kernel.terminate](http://symfony.com/doc/current/components/http_kernel/introduction.html#the-kernel-terminate-event). Здесь в фоне после того, как клиент получил ответ от сервера, выполняется вся тяжёлая работа (запись в файлы, сохранение данных в кэш, запись в БД).
Как известно, каждый подгруженный бандл Symfony так или иначе увеличивает потребление памяти. Поэтому для каждого компонента системы подгружаем только необходимый набор бандлов (например, на фронтенде не нужны бандлы админки, а в API не нужны бандлы админки и фронтенда и т.д.). Перечень подгружаемых бандлов в примере сокращён для простоты, в реальности их, конечно, больше:
**Класс /app/BaseAppKernel.php**
```
php
use Symfony\Component\HttpKernel\Kernel;
use Symfony\Component\Config\Loader\LoaderInterface;
class BaseAppKernel extends Kernel
{
protected $bundle_list = array();
public function registerBundles()
{
// Минимально необходимый набор бандлов
$this-bundle_list = array(
new Symfony\Bundle\FrameworkBundle\FrameworkBundle(),
new Symfony\Bundle\SecurityBundle\SecurityBundle(),
new Symfony\Bundle\TwigBundle\TwigBundle(),
new Symfony\Bundle\MonologBundle\MonologBundle(),
new Symfony\Bundle\AsseticBundle\AsseticBundle(),
new Doctrine\Bundle\DoctrineBundle\DoctrineBundle(),
new Sensio\Bundle\FrameworkExtraBundle\SensioFrameworkExtraBundle(),
new Doctrine\Bundle\MongoDBBundle\DoctrineMongoDBBundle()
);
// Здесь когда нужно, подгружаем все бандлы системы
if ($this->needLoadAllBundles()) {
// Admin
$this->addBundle(new Sonata\BlockBundle\SonataBlockBundle());
$this->addBundle(new Sonata\CacheBundle\SonataCacheBundle());
$this->addBundle(new Sonata\jQueryBundle\SonatajQueryBundle());
$this->addBundle(new Sonata\AdminBundle\SonataAdminBundle());
$this->addBundle(new Knp\Bundle\MenuBundle\KnpMenuBundle());
$this->addBundle(new Sonata\DoctrineMongoDBAdminBundle\SonataDoctrineMongoDBAdminBundle());
// Frontend
$this->addBundle(new Likebtn\FrontendBundle\LikebtnFrontendBundle());
// API
$this->addBundle(new Likebtn\ApiBundle\LikebtnApiBundle());
}
return $this->bundle_list;
}
/**
* Проверка, нужно ли подгружать все бандлы.
* Если скрипт запущен в dev- или text-окружении или выполняется очистка кэша prod-окружения,
* подгружаем все бандлы системы
*/
public function needLoadAllBundles()
{
if (in_array($this->getEnvironment(), array('dev', 'test')) ||
$_SERVER['SCRIPT_NAME'] == 'app/console' ||
strstr($_SERVER['SCRIPT_NAME'], 'phpunit')
) {
return true;
} else {
return false;
}
}
/**
* Добавление бандла к списку подгружаемых
*/
public function addBundle($bundle)
{
if (in_array($bundle, $this->bundle_list)) {
return false;
}
$this->bundle_list[] = $bundle;
}
public function registerContainerConfiguration(LoaderInterface $loader)
{
$loader->load(__DIR__.'/config/config_'.$this->getEnvironment().'.yml');
}
}
```
**Класс /app/AppKernel.api.php**
```
php
require_once __DIR__.'/BaseAppKernel.php';
class AppKernel extends BaseAppKernel
{
public function registerBundles()
{
parent::registerBundles();
$this-addBundle(new Likebtn\ApiBundle\LikebtnApiBundle());
return $this->bundle_list;
}
}
```
**Фрагмент /web/app.php**
```
// Все компоненты системы располагаются на своих поддоменах
// Если какой-то компонент располагается в поддиректории,
// просто нужно проверять путь в $_SERVER['REQUEST_URI']
if (strstr($_SERVER['HTTP_HOST'], 'admin.')) {
// Админка
require_once __DIR__.'/../app/AppKernel.admin.php';
} elseif (strstr($_SERVER['HTTP_HOST'], 'api.')) {
// API
require_once __DIR__.'/../app/AppKernel.api.php';
} else {
// Фронтенд
require_once __DIR__.'/../app/AppKernel.php';
}
$kernel = new AppKernel('prod', false);
```
Хитрость в том, что подгружать все бандлы нужно только в dev-окружении и в момент, когда выполняется очистка кэша на prod-окружении.
### MongoDB
В качестве основной БД используется MongoDB на [Compose.io](https://compose.io/). Базу размещаем в том же датацентре, что и основные сервера — благо, Compose [позволяет размещать](https://www.compose.io/digitalocean/) БД в DigitalOcean.
В определённый момент были сложности с медленными запросами, из-за которых общее быстродействие системы начинало снижаться. Решён вопрос был с помощью грамотно составленных индексов. Практически все руководства о создании индексов для MongoDB утверждают, что, если в запросе используются операции выбора диапазона ($in, $gt или $lt), то для такого запроса индекс не будет использоваться ни при каких обстоятельствах, например:
```
{"_id":{"$gt":ObjectId('52d89f120000000000000000')},"ip":"140.101.78.244"}
```
Так вот, это не совсем так. Вот универсальный алгоритм создания индексов, который позволяет использовать индексы и для запросов с выбором диапазонов значений (почему алгоритм именно такой, можно почитать [здесь](http://blog.mongolab.com/2012/06/cardinal-ins/)):
1. Сначала в индекс включаются поля, по которым выбираются конкретные значения.
2. Затем поля, по которым идёт сортировка.
3. И наконец, поля, которые участвуют в выборе диапазона.
И вуаля:

### CouchDB
Данные статистического характера решено было хранить в CouchDB и отдавать напрямую клиентам с помощью JavaScript без авторизации, лишний раз не дёргая сервера. Ранее с данной БД не работали, подкупила фраза «CouchDB предназначен именно для веба».
Когда уже всё было настроено и пришло время нагрузочного тестирования, выяснилось, что с нашим потоком запросов на запись, CouchDB просто захлёбывалась. Практически все руководства по CouchDB прямо не рекомендуют использовать её для часто обновляемых данных, но мы, конечно же, не поверили и понадеялись на авось. Оперативно было сделано аккумулирование данных в Memcached и переброска их в CouchDB через небольшие промежутки времени.
Также у CouchDB есть функция сохранения ревизий документов, которую штатными средствами отключить невозможно. Об этом узнали, когда метаться уже было поздно. Процедура [уплотнения](https://wiki.apache.org/couchdb/Compaction), которая запускается при наступлении определённых условий, старые ревизии удаляет, но тем не менее, память ревизии кушают.

Futon — веб-админка CouchDB, доступна по адресу /\_utils/ всем, в том числе анонимным пользователям. Единственный способ запретить всем желающим смотреть базу, который смогли найти — просто удалить следующие записи конфигурации CouchDB в секции [httpd\_db\_handlers] (админ при этом тоже теряет возможность просматривать списки документов):
```
_all_docs ={couch_mrview_http, handle_all_docs_req}
_changes ={couch_httpd_db, handle_changes_req}
```
В общем, расслабиться CouchDB не давала.
### HHVM
Бэкенды, подготавливающие основной контент, крутятся на [HHVM](http://hhvm.com/), который в нашем случае работает в разы бодрее и стабильнее используемой ранее связки PHP-FPM + APC. Благо Symfony 2.3 [на 100% совместима](http://symfony.com/blog/symfony-2-3-achieves-100-hhvm-compatibility) с HHVM. [Устанавливается](https://docs.hhvm.com/hhvm/installation/linux#debian-8-jessie) HHVM на Debian 8 без каких-либо сложностей.
Чтобы HHVM мог взаимодействовать с базой MongoDB, используется расширение [Mongofill for HHVM](https://github.com/mongofill/mongofill-hhvm), реализованное наполовину на C++, наполовину на PHP. Из-за [небольшого](https://github.com/mongofill/mongofill-hhvm/issues/45) [бага](https://github.com/mongofill/mongofill-hhvm/pull/47), в случае ошибок при выполнении запросов к БД вываливается:
> Fatal error: Class undefined: MongoCursorException
Тем не менее, это не мешает расширению успешно работать в продакшене.
### Varnish
Для кэширования и непосредственно отдачи контента используется монстр Varnish. Здесь были проблемы с тем, что по какой-то причине varnishd периодически убивал детей. Выглядело это примерно так:
```
varnishd[23437]: Child (23438) not responding to CLI, killing it.
varnishd[23437]: Child (23438) died signal=3
varnishd[23437]: Child cleanup complete
varnishd[23437]: child (3786) Started
varnishd[23437]: Child (3786) said Child starts
```
Это приводило к очистке кэша и резкому росту нагрузки на систему в целом. Причин такого поведения, как выяснилось, превеликое множество, как и советов и рецептов по лечению. Сначала грешили на параметр `-p cli_timeout=30s` в /etc/default/varnish, но дело оказалось не в нём. В общем, после довольно длительных экспериментов и перебора параметров, было установлено, что происходило это в те моменты, когда Varnish начинал активно удалять из кэша элементы, чтобы поместить новые. Опытным путём для нашей системы был подобран параметр **beresp.ttl** в default.vcl, отвечающий за время хранения элемента в кэше, и ситуация нормализовалась:
```
sub vcl_fetch {
/* Set how long Varnish will keep it*/
set beresp.ttl = 7d;
}
```
Параметр beresp.ttl нужно было установить таким, чтобы старые элементы удалялись (expired objects) из кэша раньше, чем новым элементам начинало не хватать места (nuked objects) в кэше:
Процент кэш-попаданий при этом держится стабильно в районе **91%**:
Чтобы изменения в настройках вступили в силу, Varnish нужно перезагрузить. Перезагрузка приводит к очистке кэша со всеми вытекающими. Вот хитрость, которая позволяет подгрузить новые параметры конфигурации без перезагрузки Varnish и потери кэша:
```
varnishadm -T 0.0.0.0:6087 -S /etc/varnish/secret
vcl.load config01 /etc/varnish/default.vcl
vcl.use config01
quit
```
*config01 — название новой конфигурации, можно задавать произвольно, например: newconfig, reload и т.д.*
### CloudFlare
CloudFlare прикрывает всё это дело и кэширует статику, а заодно и предоставляет SSL-сертификаты.
У некоторых клиентов были проблемы с доступом к нашему API — они получали запрос на ввод капчи «Challenge Passage». Как выяснилось, CloudFlare использует [Project Honey Pot](https://www.projecthoneypot.org) и другие подобные сервисы, чтобы отслеживать сервера — потенциальные рассыльщики спама, им-то и выдавалось предупреждение. Техподдержка CloudFlare долгое время не могла предложить вразумительного решения. В итоге, помогло простое переключение Security Level на Essentially Off в панели CloudFlare:

### Заключение
На этом пока всё. Нагрузка на проекте росла стремительно, времени на анализ и поиск решений было минимум, поэтому имеем то, что имеем. Будем благодарны, если кто-то предложит более элегантные пути решения вышеописанных задач. | https://habr.com/ru/post/275661/ | null | ru | null |
# Валидация за гранью фола
Обычно, про валидацию в рельсах говорят только хорошее. Сегодня мы поговорим о некоторых ситуациях где система дает сбой.
#### Ситуация раз
При регистрации пользователя мы как обычно хотим сделать подтверждение пароля. Нет проблем, добавляем :confirmation => true. Через какое-то время у сайта появляется мобильное приложение, в котором тоже реализована регистрация, но подтверждения пароля там уже нет. Как поступить в этом случае?
решение под катом
Самый популярный ответ: в контроллере руками проставляем password\_confirmation. Постойте. Какое отношение подтверждение пароля имеет к модели пользователя? Что вообще такое подтверждение пароля? А подтверждение емейла (да, некоторые делают и так)?
#### Ситуация два
Та же регистрация. Емейл как обычно обязательный. Product Owner добавляет задачу интеграции с соц. сетями. Посмотрев документацию по авторизации через твиттер, понимаем что емейл нам не видать. Кто-то, конечно, после авторизации попросит ввести емейл, но в нашем случае руководство против. Нужно авторизовывать без емейла и точка, но при этом форма регистрации должна требовать емейл в любом случае. А что делать в таком случае?
Ответы которые я слышал:
1. скипаем валидацию в регистрации.
2. ставим фейковый емейл — [email protected].
3. путем хаков вырезаем сообщение об ошибки из errors и делаем вид что все хорошо 0\_o.
4. В зависимости от приходящих параметров внутри модели срабатывает кастомная валидация.
Является ли email обязательным для модели юзера при таких требованиях? Ответ: Нет, наше приложение должно корректно работать и при его отсутствии.
А как же тогда форма регистрации?
#### Истина где-то рядом
Если внимательно присмотреться к первой и второй ситуации, становится понятно, что форма это нечто большее чем html кусок (в api кстати нет html, но там тоже есть “форма”). Так вот именно форма в конкретных ситуациях и должна валидировать подтверждение пароля, наличие емейла т.к. это поведение не модели, а конкретной формы в конкретном представлении. Самое забавное, что такой проблемы нет во многих других фреймворках. Модель формы есть в [django](https://docs.djangoproject.com/en/1.4/topics/forms/modelforms/), [zend framework](http://framework.zend.com/manual/ru/zend.form.html), [symfony](http://symfony.com/doc/current/book/forms.html), [yii](http://www.yiiframework.com/wiki/97/extending-cactiveform-for-some-form-display-fixes-and-language-tweaks/). И даже есть [попытки](https://github.com/tizoc/bureaucrat) сделать подобное в rails. Так же можно попробовать реализовать эту функциональность через ActiveModel.
Что лично меня огорчает во всей этой истории, так это то что сами разработчики rails, показывают совершенно не тот путь для решения этих задач. Они добавляют валидаторы наподобие :confirmation => true, фактически нарушая базовый принцип mvc: модель не зависит от представления.
Мы для своих проектов нашли решение и пока он нас в целом устраивает, а заодно решает и еще одну [известную проблему](http://habrahabr.ru/post/139399/). Он заключается в том, что для конкретных форм мы создаем наследников наших моделей и работаем фактически через них. Конечно же это самый натуральный хак, но в попытке написать отдельные формы, я столкнулся со сложностями при реализации nested форм и отложил это дело до лучших времен.
1. Делаем в apps папочку types.
2. Добавляем туда base\_type.rb
```
module BaseType
extend ActiveSupport::Concern
module ClassMethods
def model_name
superclass.model_name
end
end
end
```
3. Создаем нужный type. Пример:
```
class UserEditType < User
include BaseType
attr_accessible :first_name, :second_name
validates :first_name, :presence => true
validates :second_name, :presence => true
end
```
Так с помощью простого наследования мы решили задачу кастомной валидации в зависимости от текущего представления и требований к нему. Правда придется еще поправить завязки некоторых гемов на имя класса, а не model\_name (carrierwave, например, пути строит на основе class), но пока это разрешалось достаточно легко.
Почему он называется Type, а не Form? В api формы как таковой нет, но требования те же. А название Type взято из symfony framework.
Из последнего примера видно, что решается и другая проблема, связанная с attr\_accessible. Вы конечно можете возразить, что для этого можно пользоваться опцией :as, но в реальности она нарушает инкапсуляцию, добавляя в модель информацию о вышележащем слое. | https://habr.com/ru/post/140684/ | null | ru | null |
# Одностраничная IDE в браузере [AngularJS/Ace]

Про редактор Ace, думаю знают все, а сегодня у нас возникла срочная необходимость прикрутить редактор кода с подсветкой синтаксиса к проекту на AngularJS, наткнулся на этот пост — действительно быстро привязал к проекту. Подумал будет полезно многим новичкам — решил перевести, благо короткий. Для удобства расшарил пример в jsfiddle.
*Примечание — громкое название (включающее IDE) взято из оригинала статьи — автор был под впечатлением, фактически — это краткое и удобное руководство по подключению Ace в AngularJS*
Перевод:
Иногда ты сталкиваешься с технологией которая заставит остановиться и задуматься о том как далеко продвинулась веб разработка в последние несколько лет. Для меня одной из таких технологий стал проект Ace. Если Вы незнакомы с ним, Асе, это «высокопроизводительный редактор кода для веба». Он позволяет Вам создавать сайты позволяющие пользователю писать код непосредсвено в их браузере. [LearnAngular](http://www.learn-angular.org/) широко использует Ace.
В этом посте мы рассмотрим как интегрировать редактор Ace в приложение AngularJS с помощью модуля от AngularUI.
#### Шаг 1 — Получаем компоненты
Первое, что мы должны сделать, это получить три необходимые для задачи библиотеки:
* AngularJS — [angularjs.org](https://angularjs.org/), [Google Hosted Libraries](https://developers.google.com/speed/libraries/devguide#angularjs), [cdnjs](http://cdnjs.com/libraries/angular.js),
```
bower install angular
```
* Ace — [ace.c9.io](http://ace.c9.io/), [cdnjs](http://cdnjs.com/libraries/ace),
```
bower install ace
```
* ui-ace — [GitHub](https://github.com/angular-ui/ui-ace),
```
bower install angular-ui-ace\#bower
```
После сделайте ссылки на эти библиотеки в Вашем приложении следующем порядке:
1. AngularJS
2. Ace
3. ui-ace
*(прим. пер. bower использовать необязательно, достаточно указать ссылки на скрипты. Но если Вы захотите использовать все модули Ace скачайте весь каталог [src-noconflict](https://github.com/ajaxorg/ace-builds/) из репозитория)* со сборками
#### Шаг 2 — напишите HTML
```
```
Верите или нет, это весь HTML который необходимый Вам для интеграции Ace в Ваш сайт. Давайте быстро просмотрим, что мы сделали.
Класс **editor** просто объявляется, для того чтобы мы могли сконфигурировать размер редактора используя чуток CSS, как — мы вскоре увидим.
Дериктива **ui-ace** преобразует наш div в редактор Ace. Здесь мы передаем ему параметры, чтобы задать язык программирования и тему. Ace поддерживает [тонну языков](https://github.com/ajaxorg/ace/tree/master/lib/ace/mode) и имеет [довольно много тем](https://github.com/ajaxorg/ace/tree/master/lib/ace/theme). Лучше потратить немного времени на их изучение для получения полноценного представления о том на сколько действительно проект Ace полнофункционален.
В заключении мы добавляем вездесущую дериктиву **ng-model** так что все, что пользователь набирает в редакторе кода связано с нашей областью Angular **$scope**.
Очевидно, что мы можем также это использовать для того чтобы редактор по умолчанию отображал какой нибудь текст.
#### Шаг 3 — Вставьте директиву «ui-ace» в ваш модуль контроллера
```
angular.module("app", ['ui.ace'])
.controller("controller", ["$scope", function($scope) {
$scope.code = "alert('hello world');";
}]);
```
#### Шаг 4 — Прикосновение к CSS
CSS, который мы собираемся применить к редактору необходим, для задания ему размера и положение на нашей странице. Как уже упоминалось ранее, фактический вид редактора определяется темой.
```
.editor {
height: 200px;
}
```
*(прим. пер. без этого маленького участка кода редактор вообще не отобразиться — нет высоты по умолчанию)*
#### Шаг 5 — Попробуйте его.
Вот и все, что нужно делать! Просто несколько строк кода и мы интегрировали чрезвычайно богатый редактор кода в веб-страницу, и можно продолжать и делать все, что мы хотели бы с кодом который пишут наши пользователи. Моё мнение — очень круто!
*От себя. Добавил ещё ссылку на один редактор (который тоже сами используем) оформленный как директива для AngularJS. Не смотря на кажущуюся простоту задачи не все встраиваемые в AngularJS редакторы ведут себя предсказуемо. Например [TinyMice](http://www.tinymce.com/) в наших проектах исправно работал в режиме разработки и ч/з раз запускался у конечных пользователей, т.е. всё загрузилось, а редактор нет. Конкретно в данном случае пришли к выводу что это из-за его размера и оасинхронной загрузки.*
Итоговый вид страницы с инициирующими настройками и демонстрацией содержимого (видно что Ace ничего лишнего не добавляет):
```
.ace\_editor { height: 200px; }
### Содержимое
{{code}}
---
angular.module("app", ['ui.ace'])
.controller("controller", ["$scope", function($scope) {
var langTools = ace.require("ace/ext/language\_tools");
$scope.code = "alert('hello world');";
$scope.load = function(\_editor) {
\_editor.setOptions({
enableBasicAutocompletion:true,
enableSnippets:true,
enableLiveAutocompletion: false
});
};
}]);
```
Далее при работе — все настройки и работа с библиотеками Ace происходит через **\_editor**
#### Ссылки
* Этот код в [jsfiddle](http://jsfiddle.net/login4all/2aMk2/1/)
* [Проект ui-ace](https://github.com/angular-ui/ui-ace)
* [Ace editor](http://ace.c9.io/)
* [textAngular](https://github.com/fraywing/textAngular) | https://habr.com/ru/post/230749/ | null | ru | null |
# «Здравствуй елка — Новый Год!» или программируем NanoCAD с помощью Visual Basic .NET
Намедни просматривая документацию к **NanoCAD API** идущую в комплекте с SDK неожиданно обратил внимания на то, что описание членов классов для .NET API и MultiCAD.NET API дано, как на C# так и на **Visual Basic**. И я подумал: «А ведь это здорово, что есть описание и для VB!»
И хотя если честно я совсем не знаю VB, да и код на старом добром BASIC последний раз видел лет 100 назад, но ведь это же один из языков на котором начинают учить людей азам программирования, поэтому я решил внести свой небольшой вклад в популяризацию программы.
Надо сказать, что на «Хабре» уже есть хорошая статья по [применению VB для NanoCAD](https://habrahabr.ru/post/238867), там рассматривается связка NanoCAD с Excel и то как она в итоге может облегчить строительное проектирование.
Мы же с Вами решим другую, более простую и праздничную задачу, **начертим ёлочку** и поздравим пользователя с новым годом. Несмотря на то, что статья посвящена VB, код на **C#** тоже будет.
А поскольку «Новый год» – праздник затратный то ориентироваться мы будем на **бесплатную для коммерческого использования** версию NanoCAD 5.1 (но по идее без проблем должно работать и под NC 8.X).
Также не обойдем стороной и пользователей **Linux** поскольку код на C# с помощью Mono и Wine можно будет на нём скомпилировать и запустить.
Если честно я сам только недавно начал осваивать API NanoCAD и поэтому моя последняя в этом году предпраздничная статья по сложности кода чем-то напоминает теплый ламповый графический исполнитель **[«Кенгуренок (ROO)»](https://ikt-det.jimdo.com/%D0%B0%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC%D0%B8%D0%BA%D0%B0/%D0%B8%D1%81%D0%BF%D0%BE%D0%BB%D0%BD%D0%B8%D1%82%D0%B5%D0%BB%D0%B8/%D0%B3%D1%80%D0%B0%D1%84%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B9-%D0%B8%D1%81%D0%BF%D0%BE%D0%BB%D0%BD%D0%B8%D1%82%D0%B5%D0%BB%D1%8C-%D0%BA%D0%B5%D0%BD%D0%B3%D1%83%D1%80%D0%B5%D0%BD%D0%BE%D0%BA/)**, но если вас это не останавливает, то милости прошу под кат…

*P.S. Это первая буква слова «Habrahabr» — на большее меня не хватило =)*
Поскольку, мое новое хобби, уже превращается в небольшой цикл статей, на всякий случай приведу под спойлером ссылки на все предыдущие статьи:
**Другие статьи цикла*** [«Лицо без шрама» или первые шаги в Multicad.NET API 7 (для Nanocad 8.1)](https://habrahabr.ru/post/342186/)
* [«Как баран на новые ворота» или пользовательские «псевдо-3D» объекты в NanoCAD с помощью MultiCAD.NET API](https://habrahabr.ru/post/342680/)
* [«Я слежу за тобой» или как из CADa сделать SCADA (MultiCAD.NET API)](https://habrahabr.ru/post/343772/)
* [«Истина в вине» или пробуем программировать NanoCAD под Linux (MultiCAD.NET API)](https://habrahabr.ru/post/344884/)
Для начала как обычно напомню, что **я не программист** и поэтому не все мои мысли в данной статье могут быть на 100% корректными, а также что **с разработчиками NanoCAD я никак не связан**, просто по идейным соображениям популяризую отечественную САПР.
Под конец года не хочется плодить гору текста, поэтому статья будет короткой, вот, что мы разберем.
Содержание:
[Часть I: введение](#I)
[Часть II: пишем код на C#](#II)
[Часть III: пишем код на VB](#III)
[Часть IV: с Наступающим!](#IV)
Часть II: пишем код на C#
--------------------------
Как создать новый проект в Visual Studio 2015 для NC 8.5 я уже [рассказывал раньше](https://habrahabr.ru/post/342680/#II).
В этот раз давайте ради любопытства создадим проект в более легковесной IDE Xamarin Studio ([MonoDevelop](http://www.monodevelop.com/download/)).
Весь процесс спрячу под спойлер.
**Как создать проект C# для NanoCAD 5.1 в IDE Xamarin Studio**Для начала создадим новый проект и выберем библиотеку классов C#

Дадим ему какое-нибудь название
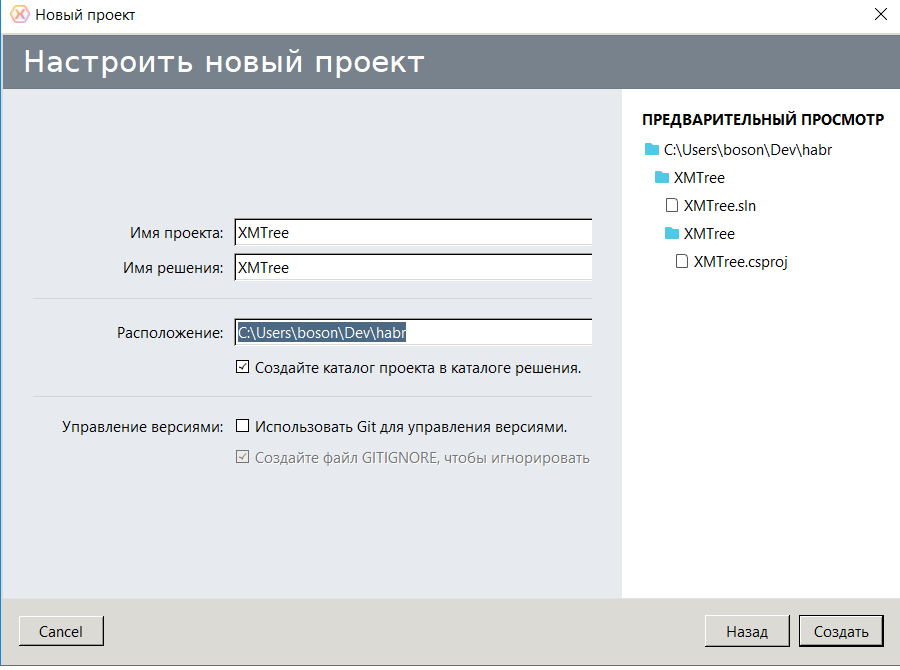
Затем настроим проект нажав по нему ПКМ и выбрав кнопку «параметры»
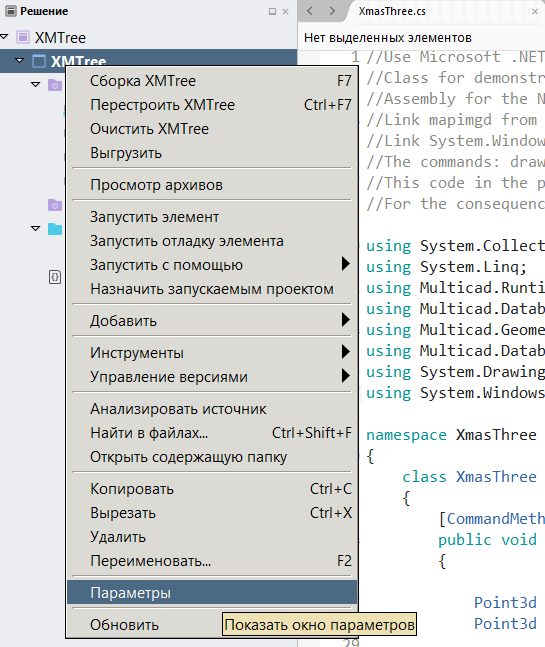
Выберем версию .Net 3.5

Затем для удобства отладки настроим запуск Нанокада по нажатию клавиши «F5»
(при каждом внесении изменений в код, Нанокад надо будет перезапускать полностью)

Затем загрузим ссылки на библиотеки нам нужны те что отображены справа на картинке
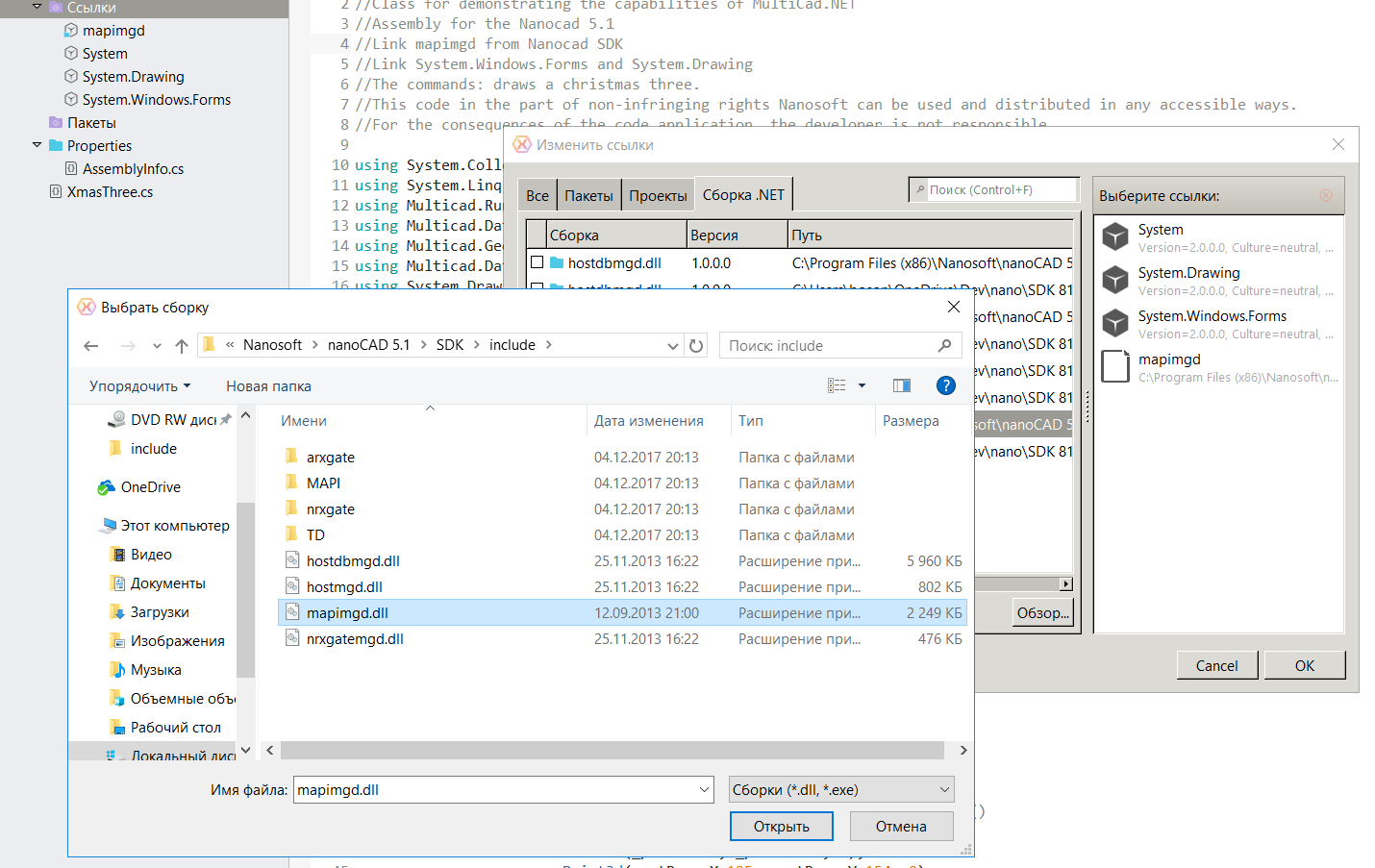
У библиотеки mapimgd не забудьте убрать галочку с пункта «копировать локально»
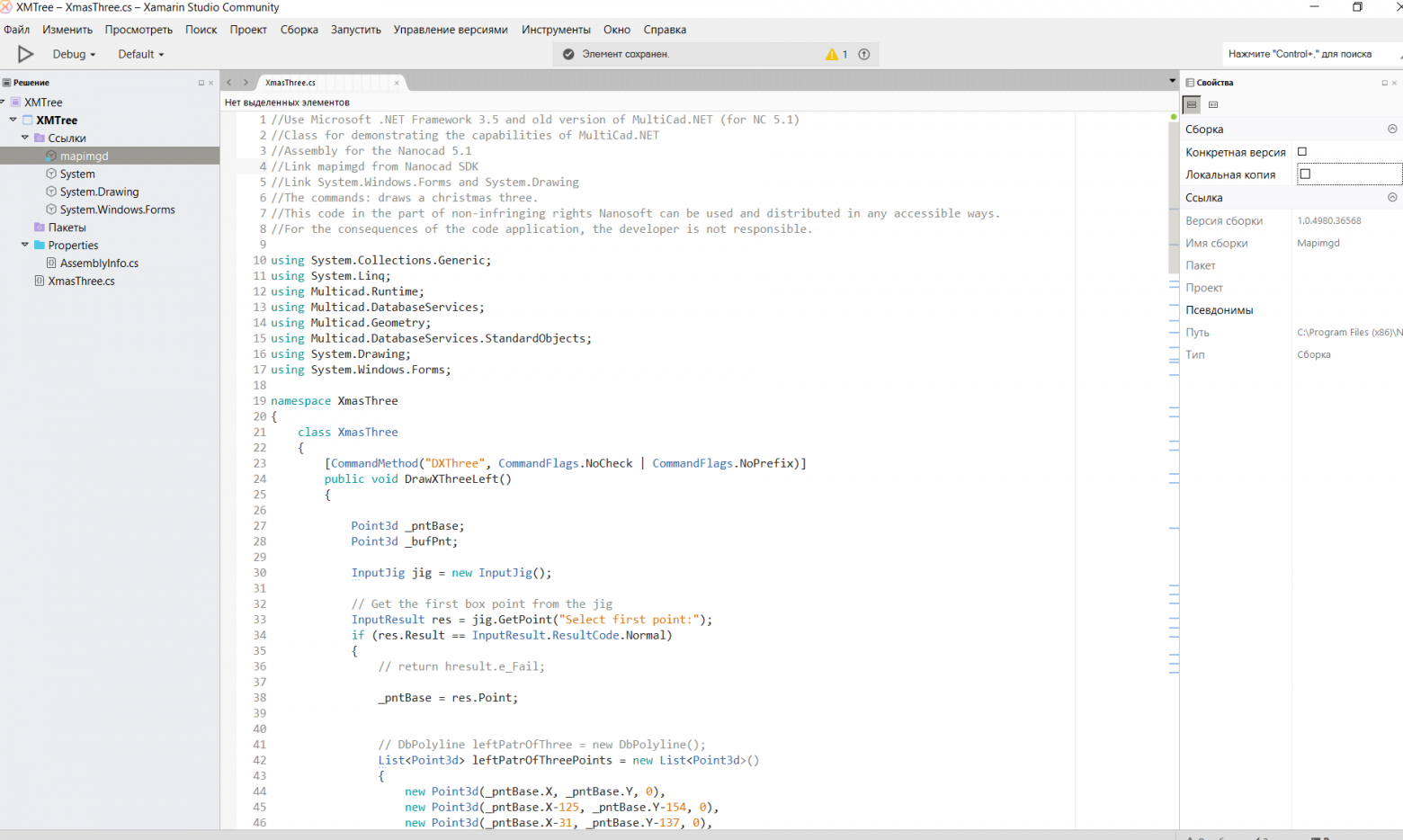
Ну собственно осталось написать код нажать F5 и посмотреть что всё запускается

Чтобы загрузить вашу библиотеку введите команду Netload в консоль NanoCAD и выберете вашу dll (как правило лежит в папке проекта, например, C:\Users\b\Dev\habr\XMTree\XMTree\bin\Debug)
Для того чтобы каждый раз это не делать
Перейдем по адресу C:\ProgramData\Nanosoft\nanoCAD 5.1\DataRW (у вас может отличаться) и найдем или создадим файл load.config следующего содержания
```
```
После чего библиотеки будут подгружаться автоматически при запуске программы.
Аналогичные манипуляции можно провести и под Linux, там для запуска NanoCAD 5.1 нам понадобится Wine, а для программирования MonoDevelop. Подробнее я описывал [в прошлой статье](https://habrahabr.ru/post/344884/#II).
К сожалению, там у меня были некоторые проблемы с Wine и цвета NanoCAD местами битые, поэтому наша ёлочка под Linux будет выглядеть так:
**Ёлочка под Linux**
Код на C# подробно разбирать по кускам не будем, мы практически не делаем ничего нового.
Если кратко, то мы создаем команду, которая рисует полилинии и штрихует их.
Код под спойлером и на [GitHub](https://github.com/bosonbeard/Funny-models-and-scripts/tree/master/2.ForNanoCAD/2.Some_simple_scripts/3.XmasThree) (там же и версия для VB).
**Полный код для NC 5.1 на C#**
```
//Use Microsoft .NET Framework 3.5 and old version of MultiCad.NET (for NC 5.1)
//Class for demonstrating the capabilities of MultiCad.NET
//Assembly for the Nanocad 5.1
//Link mapimgd from Nanocad SDK
//Link System.Windows.Forms and System.Drawing
//The commands: draws a christmas three.
//This code in the part of non-infringing rights Nanosoft can be used and distributed in any accessible ways.
//For the consequences of the code application, the developer is not responsible.
//The code was not tested with NANOCAD 8.X.
// However, it should work, if you update SDK libraries and include NC 8.X dll
using System.Collections.Generic;
using System.Linq;
using Multicad.Runtime;
using Multicad.DatabaseServices;
using Multicad.Geometry;
using Multicad.DatabaseServices.StandardObjects;
using System.Drawing;
using System.Windows.Forms;
namespace XmasThree
{
class XmasThree
{
[CommandMethod("DXThree", CommandFlags.NoCheck | CommandFlags.NoPrefix)]
public void DrawXThree()
{
Point3d _pntBase;
Point3d _bufPnt;
//prompts for installation point entry
InputJig jig = new InputJig();
// Get the first box point from the jig
InputResult res = jig.GetPoint("Select first point:");
//It works only if input was successful
if (res.Result == InputResult.ResultCode.Normal)
{
// The base point is taken from the entry point (click with mouse)
_pntBase = res.Point;
//Draw the outline of the left half of the Christmas tree
//Create base points for the polyline
List leftPatrOfThreePoints = new List()
{
new Point3d(\_pntBase.X, \_pntBase.Y, 0),
new Point3d(\_pntBase.X-125, \_pntBase.Y-154, 0),
new Point3d(\_pntBase.X-31, \_pntBase.Y-137, 0),
new Point3d(\_pntBase.X-181, \_pntBase.Y-287, 0),
new Point3d(\_pntBase.X-31, \_pntBase.Y-253, 0),
new Point3d(\_pntBase.X-242, \_pntBase.Y-400, 0),
new Point3d(\_pntBase.X-37, \_pntBase.Y-400, 0),
new Point3d(\_pntBase.X-37, \_pntBase.Y-454, 0),
new Point3d(\_pntBase.X, \_pntBase.Y-454, 0)
};
//Create a polyline (geometry)
Polyline3d leftPatrOfThree = new Polyline3d(leftPatrOfThreePoints);
//Create a polyline object and place it on the drawing
DbPolyline XThreeLeft = new DbPolyline();
XThreeLeft.Polyline = new Polyline3d(leftPatrOfThree);
XThreeLeft.Polyline.SetClosed(false);
XThreeLeft.DbEntity.Color = Color.Green;
XThreeLeft.DbEntity.AddToCurrentDocument();
//The right part of the tree is obtained by mirroring the left
DbPolyline XThreeRight = new DbPolyline();
XThreeRight.DbEntity.Color = Color.Green;
XThreeRight.Polyline = (Polyline3d)XThreeLeft.Polyline.Mirror(new Plane3d(\_pntBase, new Vector3d(10, 0, 0)));
XThreeRight.DbEntity.AddToCurrentDocument();
//From the right and left sides we make a single contour for hatching
DbPolyline XThreeR = new DbPolyline();
XThreeR.DbEntity.Color = Color.Green;
//XThreeR.Polyline = XThreeRight.Polyline.Clone() as Polyline3d; for NC 8.5
XThreeR.Polyline = XThreeRight.Polyline.GetCopy() as Polyline3d; //FOR NC 5.1
XThreeR.DbEntity.AddToCurrentDocument();
List hatchPoints = new List();
hatchPoints.AddRange(leftPatrOfThreePoints);
hatchPoints.AddRange(XThreeR.Polyline.Points.Reverse().ToList());
Polyline3d hatchContur = new Polyline3d(hatchPoints);
//We will create on the basis of a contour a hatch (geometry) with continuous filling
Hatch hatch = new Hatch(hatchContur, 0, 10, true);
hatch.PattType = PatternType.PreDefined;
hatch.PatternName = "SOLID";
//Based on the geometry of the hatch, we create the document object, set its color properties - green
DbGeometry dbhatch = new DbGeometry();
dbhatch.Geometry = new EntityGeometry(hatch);
dbhatch.DbEntity.Color = Color.Green;
dbhatch.DbEntity.AddToCurrentDocument();
// if you want you can try to draw balls with circles use
// DrawThreeBalls(\_pntBase);
//Similarly, make a Christmas tree toy (octagon)
//red
\_bufPnt = \_pntBase.Subtract(new Vector3d(30, 95, 0));
DbPolyline dbOctoRed = DrawThreeOctogonPl(\_bufPnt);//implicit
dbOctoRed.DbEntity.AddToCurrentDocument();
Hatch hatchCirkRed = new Hatch(dbOctoRed.Polyline, 0, 1, false);
hatchCirkRed.PattType = PatternType.PreDefined;
hatchCirkRed.PatternName = "SOLID";
DbGeometry dbhatchCirkRed = new DbGeometry();
dbhatchCirkRed.Geometry = new EntityGeometry(hatchCirkRed);
dbhatchCirkRed.DbEntity.Color = Color.Red;
dbhatchCirkRed.DbEntity.AddToCurrentDocument();
//green
\_bufPnt = \_pntBase.Subtract(new Vector3d(-40, 200, 0));
DbPolyline dbOctoGreen = DrawThreeOctogonPl(\_bufPnt);//implicit
dbOctoGreen.DbEntity.AddToCurrentDocument();
Hatch hatchCirkGreen = new Hatch(dbOctoGreen.Polyline, 0, 1, false);
hatchCirkGreen.PattType = PatternType.PreDefined;
hatchCirkGreen.PatternName = "SOLID";
DbGeometry dbhatchCirkGreen = new DbGeometry();
dbhatchCirkGreen.Geometry = new EntityGeometry(hatchCirkGreen);
dbhatchCirkGreen.DbEntity.Color = Color.LightSeaGreen;
dbhatchCirkGreen.DbEntity.AddToCurrentDocument();
//blue
\_bufPnt = \_pntBase.Subtract(new Vector3d(-12, 350, 0));
DbPolyline dbOctoBlue = DrawThreeOctogonPl(\_bufPnt);//implicit
dbOctoBlue.DbEntity.AddToCurrentDocument();
Hatch hatchCirkBlue = new Hatch(dbOctoBlue.Polyline, 0, 1, false);
hatchCirkBlue.PattType = PatternType.PreDefined;
hatchCirkBlue.PatternName = "SOLID";
DbGeometry dbhatchCirkBlue = new DbGeometry();
dbhatchCirkBlue.Geometry = new EntityGeometry(hatchCirkBlue);
dbhatchCirkBlue.DbEntity.Color = Color.Blue;
dbhatchCirkBlue.DbEntity.AddToCurrentDocument();
//display the text with congratulations
MessageBox.Show("I Wish You A Merry Christmas And Happy New Year!");
}
}
public Polyline3d DrawThreeOctogonPl(Point3d \_pntB)
{
//Create points for an octagon
List octoPoints = new List()
{
new Point3d(\_pntB.X, \_pntB.Y, 0),
new Point3d(\_pntB.X-15, \_pntB.Y, 0),
new Point3d(\_pntB.X-25, \_pntB.Y-11.3, 0),
new Point3d(\_pntB.X-25, \_pntB.Y-26.3, 0),
new Point3d(\_pntB.X-15, \_pntB.Y-37.6, 0),
new Point3d(\_pntB.X, \_pntB.Y-37.6, 0),
new Point3d(\_pntB.X+9.7, \_pntB.Y-26.3, 0),
new Point3d(\_pntB.X+9.7, \_pntB.Y-11.3, 0),
new Point3d(\_pntB.X, \_pntB.Y, 0)
};
return new Polyline3d(octoPoints);
}
//Draws three balls instead of an octagon, can not earn in NanoCAD 8.X
public void DrawThreeBalls(Point3d \_pntB)
{
CircArc3d circarcRed = new CircArc3d(\_pntB.Subtract(new Vector3d(30, 100, 0)), Vector3d.ZAxis, 15);
DbCircArc dbCircarcRed = circarcRed;//implicit
dbCircarcRed.DbEntity.AddToCurrentDocument();
Hatch hatchCirkRed = new Hatch(circarcRed, 0, 1, false);
hatchCirkRed.PattType = PatternType.PreDefined;
hatchCirkRed.PatternName = "SOLID";
DbGeometry dbhatchCirkRed = new DbGeometry();
dbhatchCirkRed.Geometry = new EntityGeometry(hatchCirkRed);
dbhatchCirkRed.DbEntity.Color = Color.Red;
dbhatchCirkRed.DbEntity.AddToCurrentDocument();
CircArc3d circarcGreen = new CircArc3d(\_pntB.Subtract(new Vector3d(-40, 200, 0)), Vector3d.ZAxis, 15);
DbCircArc dbCircarcGreen = circarcGreen;//implicit
dbCircarcGreen.DbEntity.AddToCurrentDocument();
Hatch hatchCirkGreen = new Hatch(circarcGreen, 0, 1, false);
hatchCirkGreen.PattType = PatternType.PreDefined;
hatchCirkGreen.PatternName = "SOLID";
DbGeometry dbhatchCirkGreen = new DbGeometry();
dbhatchCirkGreen.Geometry = new EntityGeometry(hatchCirkGreen);
dbhatchCirkGreen.DbEntity.Color = Color.LightSeaGreen;
dbhatchCirkGreen.DbEntity.AddToCurrentDocument();
CircArc3d circarcBlue = new CircArc3d(\_pntB.Subtract(new Vector3d(-12, 350, 0)), Vector3d.ZAxis, 15);
DbCircArc dbCircarcBlue = circarcBlue;//implicit
dbCircarcBlue.DbEntity.AddToCurrentDocument();
Hatch hatchCirkBlue = new Hatch(circarcBlue, 0, 1, false);
hatchCirkBlue.PattType = PatternType.PreDefined;
hatchCirkBlue.PatternName = "SOLID";
DbGeometry dbhatchCirkBlue = new DbGeometry();
dbhatchCirkBlue.Geometry = new EntityGeometry(hatchCirkBlue);
dbhatchCirkBlue.DbEntity.Color = Color.Blue;
dbhatchCirkBlue.DbEntity.AddToCurrentDocument();
}
}
}
```
По идее данный код должен заработать и в NC 8.X только надо будет выбрать .NET Framework 4.0 включить в проект mapibasetypes.dll и mapimgd.dll из папки include соответствующей разрядности (x64 или x86) и заменить одну строку (где соответствующий комментарий, а также закомментировать или удалить метод DrawThreeBalls
Получится вот так:
**Полный код для NC 8.X на C#**
```
//Use Microsoft .NET Framework 4 and old version of MultiCad.NET (for NC 8.X)
//Class for demonstrating the capabilities of MultiCad.NET
//Assembly for the Nanocad 8.X
//Link mapimgd and mapibasetypes from Nanocad SDK
//Link System.Windows.Forms and System.Drawing
//The commands: draws a christmas three.
//This code in the part of non-infringing rights Nanosoft can be used and distributed in any accessible ways.
//For the consequences of the code application, the developer is not responsible.
using System.Collections.Generic;
using System.Linq;
using Multicad.Runtime;
using Multicad.DatabaseServices;
using Multicad.Geometry;
using Multicad.DatabaseServices.StandardObjects;
using System.Drawing;
using System.Windows.Forms;
namespace XmasThree
{
class XmasThree
{
[CommandMethod("DXThree", CommandFlags.NoCheck | CommandFlags.NoPrefix)]
public void DrawXThree()
{
Point3d _pntBase;
Point3d _bufPnt;
//prompts for installation point entry
InputJig jig = new InputJig();
// Get the first box point from the jig
InputResult res = jig.GetPoint("Select first point:");
//It works only if input was successful
if (res.Result == InputResult.ResultCode.Normal)
{
// The base point is taken from the entry point (click with mouse)
_pntBase = res.Point;
//Draw the outline of the left half of the Christmas tree
//Create base points for the polyline
List leftPatrOfThreePoints = new List()
{
new Point3d(\_pntBase.X, \_pntBase.Y, 0),
new Point3d(\_pntBase.X-125, \_pntBase.Y-154, 0),
new Point3d(\_pntBase.X-31, \_pntBase.Y-137, 0),
new Point3d(\_pntBase.X-181, \_pntBase.Y-287, 0),
new Point3d(\_pntBase.X-31, \_pntBase.Y-253, 0),
new Point3d(\_pntBase.X-242, \_pntBase.Y-400, 0),
new Point3d(\_pntBase.X-37, \_pntBase.Y-400, 0),
new Point3d(\_pntBase.X-37, \_pntBase.Y-454, 0),
new Point3d(\_pntBase.X, \_pntBase.Y-454, 0)
};
//Create a polyline (geometry)
Polyline3d leftPatrOfThree = new Polyline3d(leftPatrOfThreePoints);
//Create a polyline object and place it on the drawing
DbPolyline XThreeLeft = new DbPolyline();
XThreeLeft.Polyline = new Polyline3d(leftPatrOfThree);
XThreeLeft.Polyline.SetClosed(false);
XThreeLeft.DbEntity.Color = Color.Green;
XThreeLeft.DbEntity.AddToCurrentDocument();
//The right part of the tree is obtained by mirroring the left
DbPolyline XThreeRight = new DbPolyline();
XThreeRight.DbEntity.Color = Color.Green;
XThreeRight.Polyline = (Polyline3d)XThreeLeft.Polyline.Mirror(new Plane3d(\_pntBase, new Vector3d(10, 0, 0)));
XThreeRight.DbEntity.AddToCurrentDocument();
//From the right and left sides we make a single contour for hatching
DbPolyline XThreeR = new DbPolyline();
XThreeR.DbEntity.Color = Color.Green;
XThreeR.Polyline = XThreeRight.Polyline.Clone() as Polyline3d; // for NC 8.5
//XThreeR.Polyline = XThreeRight.Polyline.GetCopy() as Polyline3d; //FOR NC 5.1
XThreeR.DbEntity.AddToCurrentDocument();
List hatchPoints = new List();
hatchPoints.AddRange(leftPatrOfThreePoints);
hatchPoints.AddRange(XThreeR.Polyline.Points.Reverse().ToList());
Polyline3d hatchContur = new Polyline3d(hatchPoints);
//We will create on the basis of a contour a hatch (geometry) with continuous filling
Hatch hatch = new Hatch(hatchContur, 0, 10, true);
hatch.PattType = PatternType.PreDefined;
hatch.PatternName = "SOLID";
//Based on the geometry of the hatch, we create the document object, set its color properties - green
DbGeometry dbhatch = new DbGeometry();
dbhatch.Geometry = new EntityGeometry(hatch);
dbhatch.DbEntity.Color = Color.Green;
dbhatch.DbEntity.AddToCurrentDocument();
// if you want you can try to draw balls with circles use
// DrawThreeBalls(\_pntBase);
//Similarly, make a Christmas tree toy (octagon)
//red
\_bufPnt = \_pntBase.Subtract(new Vector3d(30, 95, 0));
DbPolyline dbOctoRed = DrawThreeOctogonPl(\_bufPnt);//implicit
dbOctoRed.DbEntity.AddToCurrentDocument();
Hatch hatchCirkRed = new Hatch(dbOctoRed.Polyline, 0, 1, false);
hatchCirkRed.PattType = PatternType.PreDefined;
hatchCirkRed.PatternName = "SOLID";
DbGeometry dbhatchCirkRed = new DbGeometry();
dbhatchCirkRed.Geometry = new EntityGeometry(hatchCirkRed);
dbhatchCirkRed.DbEntity.Color = Color.Red;
dbhatchCirkRed.DbEntity.AddToCurrentDocument();
//green
\_bufPnt = \_pntBase.Subtract(new Vector3d(-40, 200, 0));
DbPolyline dbOctoGreen = DrawThreeOctogonPl(\_bufPnt);//implicit
dbOctoGreen.DbEntity.AddToCurrentDocument();
Hatch hatchCirkGreen = new Hatch(dbOctoGreen.Polyline, 0, 1, false);
hatchCirkGreen.PattType = PatternType.PreDefined;
hatchCirkGreen.PatternName = "SOLID";
DbGeometry dbhatchCirkGreen = new DbGeometry();
dbhatchCirkGreen.Geometry = new EntityGeometry(hatchCirkGreen);
dbhatchCirkGreen.DbEntity.Color = Color.LightSeaGreen;
dbhatchCirkGreen.DbEntity.AddToCurrentDocument();
//blue
\_bufPnt = \_pntBase.Subtract(new Vector3d(-12, 350, 0));
DbPolyline dbOctoBlue = DrawThreeOctogonPl(\_bufPnt);//implicit
dbOctoBlue.DbEntity.AddToCurrentDocument();
Hatch hatchCirkBlue = new Hatch(dbOctoBlue.Polyline, 0, 1, false);
hatchCirkBlue.PattType = PatternType.PreDefined;
hatchCirkBlue.PatternName = "SOLID";
DbGeometry dbhatchCirkBlue = new DbGeometry();
dbhatchCirkBlue.Geometry = new EntityGeometry(hatchCirkBlue);
dbhatchCirkBlue.DbEntity.Color = Color.Blue;
dbhatchCirkBlue.DbEntity.AddToCurrentDocument();
//display the text with congratulations
MessageBox.Show("I Wish You A Merry Christmas And Happy New Year!");
}
}
public Polyline3d DrawThreeOctogonPl(Point3d \_pntB)
{
//Create points for an octagon
List octoPoints = new List()
{
new Point3d(\_pntB.X, \_pntB.Y, 0),
new Point3d(\_pntB.X-15, \_pntB.Y, 0),
new Point3d(\_pntB.X-25, \_pntB.Y-11.3, 0),
new Point3d(\_pntB.X-25, \_pntB.Y-26.3, 0),
new Point3d(\_pntB.X-15, \_pntB.Y-37.6, 0),
new Point3d(\_pntB.X, \_pntB.Y-37.6, 0),
new Point3d(\_pntB.X+9.7, \_pntB.Y-26.3, 0),
new Point3d(\_pntB.X+9.7, \_pntB.Y-11.3, 0),
new Point3d(\_pntB.X, \_pntB.Y, 0)
};
return new Polyline3d(octoPoints);
}
}
}
```
Часть III: пишем код на VB
---------------------------
Несмотря на то, что процесс создания проекта в Visual Studio 2015 для VB.NET практически полностью идентичен созданию проекта для C# учитывая, то что статью могут читать люди, не имеющие необходимых навыков, все же разберем этот момент подробней.
Для начала создадим новый проект, выберем библиотеку классов VB.NET и выберем .NET Framework 3.5 (для NC 8.X версию 4.0)
Затем нажмем ПКМ на кнопке «ссылки» справа и добавим ссылки на библиотеки, которые вы установили вместе с SDK для любой из версий NanoCAD.
Для этого проекта нам хватит только mapimgd (для NC 8.5 понадобится еще и mapibasetypes).
Также надо будет загрузить стандартные System.Windows.Forms и System.Drawing
Не забудьте удалить галочку со свойства «копировать локально»

Затем настроим проект нажав по нему ПКМ и выбрав кнопку «свойства»
И для удобства отладки настроим запуск Нанокада по нажатию клавиши «F5»

(при каждом внесении изменений в код, Нанокад надо будет перезапускать полностью)
Чтобы загрузить вашу библиотеку введите команду Netload в консоль NanoCAD и выберете скомпилированную dll (как правило лежит в папке проекта, например, C:\Users\b\Dev\habr\XMTree\XMTree\bin\Debug)
Для того чтобы каждый раз это не делать перейдем по адресу C:\ProgramData\Nanosoft\nanoCAD 5.1\DataRW (у вас может отличаться) и найдем или создадим файл load.config следующего содержания:
```
```
После чего библиотеки будут подгружаться автоматически при запуске программы.
Как я уже говорил, VB.NET я не знаю совсем, но как оказалось если немного знать C# и дать проделать всю черновую работу конвертеру кода из C# в VB (например, [этому](http://kbyte.ru/ru/Services/Converter.aspx)), то для нашей задачи каких-то особых знаний в итоге не потребуется, останется лишь немного подправить.
Полный код команды я размещу под спойлером, а потом разберем его по частям.
**Полный код для NC 5.1 на VB.NET**
```
Imports System.Collections.Generic
Imports Multicad.Runtime
Imports Multicad.DatabaseServices
Imports Multicad.Geometry
Imports Multicad.DatabaseServices.StandardObjects
Imports System.Drawing
Imports System.Windows.Forms
Namespace XmasThree
Class XmasThree
Public Sub DrawXThree()
Dim \_pntBase As Point3d
Dim \_bufPnt As Point3d
Dim jig As New InputJig()
'prompts for installation point entry
Dim res As InputResult = jig.GetPoint("Select first point:")
If res.Result = InputResult.ResultCode.Normal Then
'The base point is taken from the entry point (click with mouse)
\_pntBase = res.Point
'Draw the outline of the left half of the Christmas tree
'Create base points for the polyline
Dim leftPatrOfThreePoints As New List(Of Point3d)() From {
New Point3d(\_pntBase.X, \_pntBase.Y, 0),
New Point3d(\_pntBase.X - 125, \_pntBase.Y - 154, 0),
New Point3d(\_pntBase.X - 31, \_pntBase.Y - 137, 0),
New Point3d(\_pntBase.X - 181, \_pntBase.Y - 287, 0),
New Point3d(\_pntBase.X - 31, \_pntBase.Y - 253, 0),
New Point3d(\_pntBase.X - 242, \_pntBase.Y - 400, 0),
New Point3d(\_pntBase.X - 37, \_pntBase.Y - 400, 0),
New Point3d(\_pntBase.X - 37, \_pntBase.Y - 454, 0),
New Point3d(\_pntBase.X, \_pntBase.Y - 454, 0)
}
'Create a polyline (geometry)
Dim leftPatrOfThree As New Polyline3d(leftPatrOfThreePoints)
'Create a polyline object and place it on the drawing
Dim XThreeLeft As New DbPolyline()
XThreeLeft.Polyline = New Polyline3d(leftPatrOfThree)
XThreeLeft.Polyline.SetClosed(False)
XThreeLeft.DbEntity.Color = Color.Green
XThreeLeft.DbEntity.AddToCurrentDocument()
Dim XThreeRight As New DbPolyline()
XThreeRight.DbEntity.Color = Color.Green
XThreeRight.Polyline = DirectCast(XThreeLeft.Polyline.Mirror(New Plane3d(\_pntBase, New Vector3d(10, 0, 0))), Polyline3d)
XThreeRight.DbEntity.AddToCurrentDocument()
'From the right and left sides we make a single contour for hatching
Dim XThreeR As New DbPolyline()
XThreeR.DbEntity.Color = Color.Green
XThreeR.Polyline = TryCast(XThreeRight.Polyline.GetCopy(), Polyline3d)
XThreeR.DbEntity.AddToCurrentDocument()
Dim hatchPoints As New List(Of Point3d)()
hatchPoints.AddRange(leftPatrOfThreePoints)
hatchPoints.AddRange(XThreeR.Polyline.Points.Reverse().ToList())
Dim hatchContur As New Polyline3d(hatchPoints)
'We will create on the basis of a contour a hatch (geometry) with continuous filling
Dim hatch As New Hatch(hatchContur, 0, 10, True)
hatch.PattType = PatternType.PreDefined
hatch.PatternName = "SOLID"
'Based on the geometry of the hatch, we create the document object, set its color properties - green
Dim dbhatch As New DbGeometry()
dbhatch.Geometry = New EntityGeometry(hatch)
dbhatch.DbEntity.Color = Color.Green
dbhatch.DbEntity.AddToCurrentDocument()
'Similarly, make a Christmas tree toy (octagon)
'red
\_bufPnt = \_pntBase.Subtract(New Vector3d(30, 95, 0))
Dim dbOctoRed As DbPolyline = DrawThreeOctogonPl(\_bufPnt)
dbOctoRed.DbEntity.AddToCurrentDocument()
Dim hatchCirkRed As New Hatch(dbOctoRed.Polyline, 0, 1, False)
hatchCirkRed.PattType = PatternType.PreDefined
hatchCirkRed.PatternName = "SOLID"
Dim dbhatchCirkRed As New DbGeometry()
dbhatchCirkRed.Geometry = New EntityGeometry(hatchCirkRed)
dbhatchCirkRed.DbEntity.Color = Color.Red
dbhatchCirkRed.DbEntity.AddToCurrentDocument()
'green
\_bufPnt = \_pntBase.Subtract(New Vector3d(-40, 200, 0))
Dim dbOctoGreen As DbPolyline = DrawThreeOctogonPl(\_bufPnt)
dbOctoGreen.DbEntity.AddToCurrentDocument()
Dim hatchCirkGreen As New Hatch(dbOctoGreen.Polyline, 0, 1, False)
hatchCirkGreen.PattType = PatternType.PreDefined
hatchCirkGreen.PatternName = "SOLID"
Dim dbhatchCirkGreen As New DbGeometry()
dbhatchCirkGreen.Geometry = New EntityGeometry(hatchCirkGreen)
dbhatchCirkGreen.DbEntity.Color = Color.LightSeaGreen
dbhatchCirkGreen.DbEntity.AddToCurrentDocument()
'blue
\_bufPnt = \_pntBase.Subtract(New Vector3d(-12, 350, 0))
Dim dbOctoBlue As DbPolyline = DrawThreeOctogonPl(\_bufPnt)
dbOctoBlue.DbEntity.AddToCurrentDocument()
Dim hatchCirkBlue As New Hatch(dbOctoBlue.Polyline, 0, 1, False)
hatchCirkBlue.PattType = PatternType.PreDefined
hatchCirkBlue.PatternName = "SOLID"
Dim dbhatchCirkBlue As New DbGeometry()
dbhatchCirkBlue.Geometry = New EntityGeometry(hatchCirkBlue)
dbhatchCirkBlue.DbEntity.Color = Color.Blue
dbhatchCirkBlue.DbEntity.AddToCurrentDocument()
MessageBox.Show("I Wish You A Merry Christmas And Happy New Year!!!")
End If
End Sub
Public Function DrawThreeOctogonPl(\_pntB As Point3d) As Polyline3d
'Create points for an octagon
Dim octoPoints As New List(Of Point3d)() From {
New Point3d(\_pntB.X, \_pntB.Y, 0),
New Point3d(\_pntB.X - 15, \_pntB.Y, 0),
New Point3d(\_pntB.X - 25, \_pntB.Y - 11.3, 0),
New Point3d(\_pntB.X - 25, \_pntB.Y - 26.3, 0),
New Point3d(\_pntB.X - 15, \_pntB.Y - 37.6, 0),
New Point3d(\_pntB.X, \_pntB.Y - 37.6, 0),
New Point3d(\_pntB.X + 9.7, \_pntB.Y - 26.3, 0),
New Point3d(\_pntB.X + 9.7, \_pntB.Y - 11.3, 0),
New Point3d(\_pntB.X, \_pntB.Y, 0)
}
Return New Polyline3d(octoPoints)
End Function
End Class
End Namespace
```
Несмотря на то, что код простой давайте на всякий случай разберем подробно и по частям, ведь для VB мы этого еще раньше не делали.
```
Imports System.Collections.Generic
Imports Multicad.Runtime
Imports Multicad.DatabaseServices
Imports Multicad.Geometry
Imports Multicad.DatabaseServices.StandardObjects
Imports System.Drawing
Imports System.Windows.Forms
```
Импорт пространств имен библиотеки MultiCAD.NET API чтобы чертить, а также библиотек Windows чтобы вывести окошко и назначить цвета штриховке.
```
Namespace XmasThree
Class XmasThree
```
Определяем пространство имен и имя класса
```
Public Sub DrawXThreeLeft()
```
Создаём команду, которая будет потом вводиться в командную строку Нанокад и собственно чертить нашу ёлку.
— имя команды, как мы будем её вызвать из Нанокад, можете задать любое, но лучше по короче, в назначении остальных флагов я не уверен.
*Public Sub DrawXThreeLeft()* — имя функции (метода) для команды это уже внутренняя логика невидимая для пользователя САПР.
```
Dim _pntBase As Point3d
Dim _bufPnt As Point3d
```
Создаем поля класса (переменные), для того чтобы хранить координаты точки вставки и координаты буферной точки вставки для ёлочных украшений.
```
Dim jig As New InputJig()
Dim res As InputResult = jig.GetPoint("Select first point:")
```
Создаем новый объект для ввода в консоль и передаем пользователю приглашение кликнуть мышкой по экрану для определения точки вставки.
```
If res.Result = InputResult.ResultCode.Normal Then
_pntBase = res.Point
```
Если ввод проведен успешно, то дальше рисуется ёлка, если нет, то не делается ничего.
```
Dim leftPatrOfThreePoints As New List(Of Point3d)() From {
New Point3d(_pntBase.X, _pntBase.Y, 0),
New Point3d(_pntBase.X - 125, _pntBase.Y - 154, 0),
New Point3d(_pntBase.X - 31, _pntBase.Y - 137, 0),
New Point3d(_pntBase.X - 181, _pntBase.Y - 287, 0),
New Point3d(_pntBase.X - 31, _pntBase.Y - 253, 0),
New Point3d(_pntBase.X - 242, _pntBase.Y - 400, 0),
New Point3d(_pntBase.X - 37, _pntBase.Y - 400, 0),
New Point3d(_pntBase.X - 37, _pntBase.Y - 454, 0),
New Point3d(_pntBase.X, _pntBase.Y - 454, 0)
}
```
Создаем список с точками, которые определят вершины полилинии (левой половины ёлки)
```
'Create a polyline (geometry)
Dim leftPatrOfThree As New Polyline3d(leftPatrOfThreePoints)
'Create a polyline object and place it on the drawing
Dim XThreeLeft As New DbPolyline()
XThreeLeft.Polyline = New Polyline3d(leftPatrOfThree)
XThreeLeft.Polyline.SetClosed(False)
XThreeLeft.DbEntity.Color = Color.Green
XThreeLeft.DbEntity.AddToCurrentDocument()
```
Вначале создаем геометрию (не видимую на экране) для левой половины ёлки, а потом создаем объект документа, который в итоге командой *XThreeLeft.DbEntity.AddToCurrentDocument()* разместим в пространстве модели чертежа.
```
Dim XThreeRight As New DbPolyline()
XThreeRight.DbEntity.Color = Color.Green
XThreeRight.Polyline = DirectCast(XThreeLeft.Polyline.Mirror(New Plane3d(_pntBase, New Vector3d(10, 0, 0))), Polyline3d)
XThreeRight.DbEntity.AddToCurrentDocument()
```
Для того, чтобы сделать правую половину ёлки, просто отзеркалим левую (аналог команды mirror в самом NanoCAD). Для этого вызовем у полилинии с левой половиной ёлки метод Mirror и не забудем привести тип к Polyline3d, командой DirectCast.
```
Dim XThreeRight As New DbPolyline()
XThreeRight.DbEntity.Color = Color.Green
XThreeRight.Polyline = DirectCast(XThreeLeft.Polyline.Mirror(New Plane3d(_pntBase, New Vector3d(10, 0, 0))), Polyline3d)
XThreeRight.DbEntity.AddToCurrentDocument()
```
Как ни странно напрямую в справке по MultiCAD.NET API в SDK для NC 5.1 я не нашел отсылок на штриховку (hatch), правда они есть в документации к обычному .NET API, но тем не менее штриховка похоже реализована и в MultiCAD.NET API поэтому приведенный ниже код по крайней мере у меня работает нормально.
```
Dim XThreeR As New DbPolyline()
XThreeR.DbEntity.Color = Color.Green
XThreeR.Polyline = TryCast(XThreeRight.Polyline.GetCopy(), Polyline3d)
XThreeR.DbEntity.AddToCurrentDocument()
Dim hatchPoints As New List(Of Point3d)()
hatchPoints.AddRange(leftPatrOfThreePoints)
hatchPoints.AddRange(XThreeR.Polyline.Points.Reverse().ToList())
Dim hatchContur As New Polyline3d(hatchPoints)
```
Для начала объединим точки левой и правой половины елки, причем чтобы линия замкнулась в правильном порядке массив вершин для правой половины надо так «перевернуть» чтобы вершины шли в обратном порядке.
Затем уже привычным способом по списку точек создаем геометрию поли линии.
*Тут код немного избыточный, вы можете самостоятельно переписать его аккуратней*
```
'We will create on the basis of a contour a hatch (geometry) with continuous filling
Dim hatch As New Hatch(hatchContur, 0, 10, True)
hatch.PattType = PatternType.PreDefined
hatch.PatternName = "SOLID"
```
Создаем геометрию для штриховки, воспользовавшись нашим контуром полной ели. В качестве типа штриховки выбираем сплошную заливку (названия штриховок можно подсмотреть в самом Нанокад выбрав команду «штриховка»).
```
Dim dbhatch As New DbGeometry()
dbhatch.Geometry = New EntityGeometry(hatch)
dbhatch.DbEntity.Color = Color.Green
dbhatch.DbEntity.AddToCurrentDocument()
```
Теперь создадим объект чертежа, который и разместим в пространстве модели, предварительно задав ему зеленый цвет.
Развесим наши ёлочные игрушки. Изначально предполагалось заштриховать шарики, но совет по штриховке круга с форума разработчиков у меня работает только для C# версии кода и только в NC 5.1, поэтому мы будем штриховать 8-ми угольники.
```
'Similarly, make a Christmas tree toy (octagon)
'red
_bufPnt = _pntBase.Subtract(New Vector3d(30, 95, 0))
Dim dbOctoRed As DbPolyline = DrawThreeOctogonPl(_bufPnt)
dbOctoRed.DbEntity.AddToCurrentDocument()
Dim hatchCirkRed As New Hatch(dbOctoRed.Polyline, 0, 1, False)
hatchCirkRed.PattType = PatternType.PreDefined
hatchCirkRed.PatternName = "SOLID"
Dim dbhatchCirkRed As New DbGeometry()
dbhatchCirkRed.Geometry = New EntityGeometry(hatchCirkRed)
dbhatchCirkRed.DbEntity.Color = Color.Red
dbhatchCirkRed.DbEntity.AddToCurrentDocument()
```
Весь процесс идентичен тому, что мы делали ранее, единственное отличие, чтобы немного уменьшить объем кода мы создание полилинии для октагона вынесли в отдельный метод *DrawThreeOctogonPl*
Таких «шариков будет» три (красный, зеленый, синий), думаю отдельно разбирать их нет смысла.
Последнее, что осталось это вывести окошко с поздравлением.
```
MessageBox.Show("I Wish You a Merry Christmas and Happy New Year!!!")
End If
End Sub
```
В результате получим следующую картинку.
Для NC 5.1

Для NC 8.1

Часть IV: с Наступающим!
-------------------------
Ну что же может быть кто-то скажет, что мы сейчас сделали бесполезную и никому не нужную «чушь»…

И что это опять очередная статья для новичков, которой не место на Хабре.
Но, помню что в школе когда нас всех пытались научить программированию, начинали именно с простейших задач по рисованию, чего-либо с помощью Кенгуру, а потом уже давали азы Basic *(хотя мне в то время уже больше нравился старый добрый Pascal)*. Да и что греха таить до сих пор вариации на тему Basic являются одним из доступных способов научить людей программированию, взять хотя бы тот же [SmallBasic](https://habrahabr.ru/hub/smallbasic/)
Поэтому учитывая, то что NC 5.1 абсолютно бесплатен для любых целей, а для новых версий NanoCAD можно получить лицензию [для образовательных учреждений](http://www.nanocad.ru/information/news/312530/), то думаю старшая школа и учебные заведения среднего профессионального образования вполне могли бы обратить свой взор на Нанокад и на простых примерах объяснить детям как программировать САПР.
*Хотя справедливости ради надо отметить, что NC это не единственная САПР которую легко использовать в учебных заведениях и у которой есть открытые API, безусловно можно обратится к тому же [«Компасу»](https://habrahabr.ru/company/ascon/blog/328088/)*
В любом случае **желаю всем, счастья и успехов** в наступающем 2018 году!
И надеюсь, что разработчики таки подарят нам в 2018 нормальное обновление для бесплатной версии NanoCAD, с новыми API и под новый NET Framework.
**P.S.** Важно! Чтобы не городить отдельную статью на всякий случай предупрежу людей которые так же как и я ковыряются в API к Nanocad 8.X.
Лично у меня после установки самого последнего обновления Windows 10 в 64 битной версии NanoCAD стали сбоить полилинии (некорректно задается высота). И все написанные ранее команды на C# идут «коту под хвост».
В 32х битной версии всё работает нормально, решение проблемы пока не нашел, так что будьте осторожны перед обновлением Windows 10 если вам это критично. | https://habr.com/ru/post/345834/ | null | ru | null |
# «Font-weight: bolder» для шрифтов со множеством начертаний
Если вы используете шрифт со множеством начертаний, то вам, вероятно, захочется, чтобы теги `strong` и `b` не увеличивали жирность шрифта до фиксированного значения `font-weight:700`, как это происходит по-умолчанию, а использовали промежуточные значения, рассчитанные исходя из жирности шрифта родительского элемента.
Ведь не очень красиво, когда в ультратонком шрифте появляются жирные кляксы тегов `strong`.
Возьмём для примера Open Sans.

Open Sans имеет пять начертаний: Light 300, Normal 400, Semi-Bold 600, Bold 700 и Extra-Bold 800.
Цифры соответствуют значению `font-weight`.
Пусть основной текст имеет начертание Light 300, заголовки и цитаты — Normal 400, а промо-блок — Semi-Bold 600:
```
body {
font-family: 'Open Sans', sans-serif;
font-weight: 300;
}
h1, h2, h3, h4, h5, h6,
blockquote {
font-weight: 400;
}
.promo {
font-weight: 600;
}
```
Тег `strong` может встечаться и в основном тексте, и в цитатах, и промо-блоке. Надо это учесть.
По-умолчанию:
```
strong, b {
font-weight: bold; /* bold = 700 */
}
```
А нам хочется, чтобы у `strong` и `b` для основного текста было Normal 400, для цитат и заголовков — Bold 700, а для промо блока — Extra-Bold 800. Это сохранит контраст между жирным и нежирным текстом примерно равным во всех случаях.
Уверен, многие пробовали использовать `strong {font-weight: bolder;}`, но это не принесло ожидаемого результата — текст стал ещё жирнее, чем ожидалось.
А всё потому, что согласно [спецификации](http://www.w3.org/TR/CSS2/fonts.html#font-boldness), значение `bolder` (`lighter`) увеличивает (уменьшает) *унаследованное* значение `font-weight` до следующего возможного для данного шрифта значения, согласно следующей таблице.
| наследуемое значение | bolder | lighter |
| --- | --- | --- |
| 100 | 400 | 100 |
| 200 | 400 | 100 |
| 300 | 400 | 100 |
| 400 | 700 | 100 |
| 500 | 700 | 100 |
| 600 | 900 | 400 |
| 700 | 900 | 400 |
| 800 | 900 | 700 |
| 900 | 900 | 700 |
Но в браузерной CSS прописано `strong, b {font-weight: bold;}`, т.е. *унаследуется* значение «700», а потом оно ещё и увеличивается до «900». Поэтому кажется, что `bolder` работает неправильно.
Исправить это можно так:
```
/* сбрасываем стандартное «bold»,
шрифт становится таким же как его родительский элемент */
strong, b {
font-weight: inherit;
}
/* теперь bolder будет вычисляться исходя из веса шрифта родительского элемента */
strong, b {
font-weight: bolder;
}
```
Именно так, как два отдельных правила. Первое обнуляет значение `font-weight` из браузерной таблицы стилей, второе задаёт жирность уже в относительных, а не абсолютных единицах.
Теперь нам не придётся заботиться о вложенности элементов — каскад всё сделает автоматически. Мы можем вкладывать теги `strong` друг в друга.
[](http://cssdeck.com/labs/x20utix0)
*Вложенные теги «strong». Толщина шрифта определяется исходя из значения родительского элемента.
[Демка](http://cssdeck.com/labs/x20utix0)*
Ограничения
-----------
Используя относительные значения `font-weight` мы получаем только по три градации жирности шрифта для `bolder` и `lighter` соответственно. Спецификация не гарантирует, что браузеры правильно сопоставят названия начертаний и числовые значения. Не гарантирует, что для шрифта найдётся более жирное или более тонкое начертание. У некоторых шрифтов всего два начертания, у некоторых может быть восемь.
Единственной гарантией при использовании `bolder` / `lighter` является то, что шрифт при значении «`bolder`» не будет тоньше, чем более легкие начертания этого шрифта, а при значении «`lighter`» будет не толще, чем более жирные начертания этого шрифта.
Чтобы более тонко настроить вес шрифта, надо использовать абсолютные значения.
Баги
----
Если у вас шрифт установлен в системе, но не подключен через `@font-face`, то Google Chrome определяет только Normal и Bold начертания шрифта. Чтобы локальный шрифт заработал, нужно дополнительно указать его `font-family`.
```
.fw300 {
font-family: "Open Sans Light", "Open Sans";
font-weight: 300;
}
.fw600 {
font-family: "Open Sans SemiBold", "Open Sans";
font-weight: 600;
}
``` | https://habr.com/ru/post/211612/ | null | ru | null |
# Евросоюз хочет, чтобы платформы вроде GitHub внедрили автоматические фильтры для защиты копирайта
*«Извините, но ваш `git push` нарушает чей-то копирайт, поэтому заблокирован сервером в соответствие с директивой Евросоюза».*
`$ git push
...
remote: Resolving deltas: 100% (2/2), completed with 2 local objects.
remote: error: GH013: Your push could infringe someone's copyright.
remote: We're sorry for interrupting your work, but automated copyright
remote: filters are mandated by the EU's Article 13.
To github.com/vollmera/atom.git
! [remote rejected] patch-1 -> patch-1 (push declined due to article 13 filters)`
Примерно такое сообщение вы увидите в консоли, если будет принята новая [Директива Европарламента о копирайте](http://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX:52016PC0593) с автоматическими фильтрами загружаемого контента. Документ продвигается с подачи правообладателей. Представители GitHub [предупреждают](https://blog.github.com/2018-03-14-eu-proposal-upload-filters-code/), что принятие такого нормативного акта [угрожает свободному ПО](https://savecodeshare.eu/).
Статья 13 новой директивы называется «Использование защищённого контента поставщиками услуг информационного общества, хранящими и предоставляющими доступ к большому количеству произведений и других материалов, загруженных пользователями». Такая формулировка распространяется на любые платформы UGC-контента, в том числе на хостинги с исходным кодом вроде GitHub.
В соответствии с текстом, сервис-провайдеры «должны в сотрудничестве с правообладателями принимать меры по обеспечению функционирования договоров, заключенных с правообладателями на использование их произведений или иного предмета, или по недопущению наличия на их услугах произведений или иного предмета, выявленного правообладателями».
Директива поощряет использование таких мер как «эффективные технологии распознавания контента». При этом GitHub и прочие хостеры обязаны отчитываться перед правообладателями, какие меры они приняли по недопущению нарушений копирайта.
Содействовать сотрудничеству сервис-провайдеров с правообладателями обязаны государства-члены Евросоюза «посредством диалога с заинтересованными сторонами для определения наилучшей практики, такой как надлежащие и соразмерные технологии распознавания контента, принимая во внимание, среди прочего, характер услуг, наличие технологий и их эффективность в свете технологических достижений».

Очевидно, что авторы директивы в первую очередь думали о платформах хостинга видео и музыки. Ограничение их работы исходит из предположения, что правообладатели недополучают прибыль, если защищённые авторским правом работы публикуются на таких платформах бесплатно. Но по сути формулировка статьи 13 распространяется также на платформы для хостинга кода, [о чём предупреждает GitHub](https://blog.github.com/2018-03-14-eu-proposal-upload-filters-code/).
GitHub категорически возражает против внедрения фильтров на загрузку контента. Компания называет эти фильтры [«машинами цензуры»](https://re-publica.com/en/session/stop-censorship-machines-how-can-we-prevent-mandatory-upload-filters-eu) и выражает три главных опасения в связи с их внедрением:
* **Приватность**. Фильтры на загрузку контента — это форма надзора, по сути, [«обязательство по общему мониторингу»](https://www.eff.org/deeplinks/2012/02/eu-court-justice-social-networks), запрещённое законами Евросоюза.
* **Свобода слова**. Требование мониторинга контента противоречит [защите посредников от ответственности](http://eur-lex.europa.eu/LexUriServ/LexUriServ.do?uri=CELEX:32000L0031:en:HTML), закреплённой законами Евросоюза, и поощряет удаление контента.
* **Неэффективность**. Инструменты для автоматического фильтрования контента [известны некачественной работой](https://static1.squarespace.com/static/571681753c44d835a440c8b5/t/58d058712994ca536bbfa47a/1490049138881/FilteringPaperWebsite.pdf): они вызывают много ложных срабатываний и подходят не для всех видов контента. К тому же, внедрение подобных инструментов слишком обременительно, особенно для компаний малого и среднего бизнеса, которые не могут позволить себе сами инструменты или последующие судебные разбирательства.
GitHub считает, что в случае с публикацией исходного кода вышеперечисленные недостатки тоже проявляются, а ложных срабатываний здесь будет особенно много: «Требования от платформ хостинга сканировать и автоматически удалять контент может кардинально повлиять на разработчиков программного обеспечения, когда их зависимости удаляются из-за ложных срабатываний».
Обсуждение статьи 13 новой директивы продолжается в Европарламенте. Депутат от Пиратской партии Юлия Реда [пишет](https://juliareda.eu/2018/02/voss-upload-filters/), что директива «зажигает зелёный свет для запуска машин цензуры». Автор этого предложения — немецкий депутат Аксель Восс (Axel Voss).

*Аксель Восс*
Точнее, он не автор, а «человек, назначенный для протаскивания реформы через параламент», как выражается Реда. Она говорит, что Аксель Восс при публикации проекта проигнорировал обсуждение этой инициативы, которое продолжалось полтора года, проигнорировал работу нескольких комитетов Европарламента, [выступивших против машин цензуры](https://juliareda.eu/2017/11/civil-liberties-censorship-machines/), и даже не прислушался к опубликованному [компромиссному предложению](https://www.spd.de/fileadmin/Dokumente/Koalitionsvertrag/Koalitionsvertrag_2018.pdf) от коалиции немецких партий, где автоматически фильтры на загрузку контента отвергаются как «непропорциональная» мера.
Для принятия директивы Аксель Восс должен заручиться большинством голосов в Комитете по правовым вопросам (JURI) Еврокомиссии. Голосование состоится в конце марта или апреле.
С сайта [ChangeCopyright.org](https://changecopyright.org/en-US/) от организации Mozilla можно бесплатно позвонить в Комитет по правовыми вопросам Еврокомиссии (то есть заказать звонок) и устно высказать свою точку зрения по поводу статьи 13 директивы о копирайте. Текст устного высказывания прилагается.
Юрия Реда призывает распространять мемы через инструменты вроде [SaveTheMeme.net](http://savethememe.net/) и бороться другими доступными способами. | https://habr.com/ru/post/411113/ | null | ru | null |
# Ускорение обработки изображений в Android
[](http://habrahabr.ru/company/intel/blog/263843/) Центральные процессоры и графические ядра современных устройств, работающих под управлением Android, способны на многое. Например, их вычислительную мощность можно направить на обработку изображений.
Для того чтобы это сделать, стоит обратить внимание на технологии OpenCL и RenderScript.
В этом материале рассмотрен пример Android-приложения, в котором показаны методики высокопроизводительной обработки изображений с использованием языков программирования [OpenCL](https://www.khronos.org/opencl/) и [RenderScript](http://developer.android.com/guide/topics/renderscript/compute.html). Эти технологии разработаны с прицелом на возможности графического аппаратного обеспечения, рассчитанного на параллельную обработку данных (шейдерных блоков). Они позволяют ускорить работу со значительными объёмами данных и решение задач, предусматривающих большое число повторов команд. Хотя, для ускорения обработки графики в Android-приложениях, вы можете воспользоваться другими технологиями, в этом материале рассматриваются примеры построения инфраструктуры приложения и реализации графических алгоритмов на OpenCL и RenderScript. Здесь так же рассмотрен класс-обёртка для OpenCL API, который позволяет упростить создание и исполнение приложений, работающих с графикой и использующих OpenCL. Использование исходного кода этого класса в ваших проектах не требует лицензирования.
При подготовке этого материала предполагалось, что его читатели знакомы с технологиями OpenCL и RenderScript, владеют приёмами программирования для платформы Android. Поэтому основное внимание мы уделим рассмотрению механизмов ускорения обработки или программного создания изображений.
Для того чтобы увидеть примеры в деле, вам понадобится Android-устройство, настроенное так, чтобы оно могло исполнять OpenCL-код. Ниже мы поговорим и о том, как организовать рабочую среду для OpenCL-разработки, используя Intel INDE и Android Studio.
Обратите внимание на то, что цель этой статьи – показ особенностей кода OpenCL и RenderScript, о других технологиях мы здесь не говорим. Кроме того, запланирован материал, посвящённый анализу производительности приложений, использующих код на OpenCL и RenderScript, исполняющийся на видеочипах (GPU).
1.1 Интерфейс приложения
------------------------
На экране рассматриваемого приложения присутствует три переключателя, с помощью которых можно выбирать между подсистемами работы с изображениями, использующими RenderScript, OpenCL или машинный код Android. Меню позволяет переключаться между исполнением OpenCL-кода на CPU(центральном процессоре) или на GPU (графическом ядре). Кроме того, из меню можно выбрать графический эффект. Выбор целевого устройства доступен только для OpenCL-кода. Платформа Intel x86 поддерживает выполнение OpenCL и на CPU, и на GPU.
Ниже можно видеть главный экран приложения, на котором отображается эффект плазмы, который генерируется средствами OpenCL.
*Главное окно программы, выбор целевого устройства для исполнения OpenCL-кода*
В правом верхнем углу окна выводятся показатели производительности. Они отображаются для всех трёх поддерживаемых программой способов работы с графикой.
Показатели производительности включают в себя количество кадров в секунду (FPS), время рендеринга кадра (frame render) и время, необходимое для обсчёта эффекта (effect compute elapsed time).
*Показатели производительности*
Обратите внимание на то, что это – лишь один из примеров производительности. Показатели зависят от устройства, на которой запускается код.
1.2. Используемые API и SDK
---------------------------
В дополнение к ADT (Android Development Tool, средствам разработки Android, которые включают Android SDK), при разработке примера использовались SDK RenderScript и Intel SDK для OpenCL, рассчитанные на работу в среде Android.
Intel OpenCL SDK основан на спецификации OpenCL и придерживается её положений. Эта спецификация представляет собой открытый, бесплатный для использования стандарт кросс-платформенной разработки. Подробности – на сайте [Khronos](https://www.khronos.org/opencl/).
RenderScript появился в ADT 2.2. (API Level 8). Это – платформа для выполнения высокопроизводительных вычислений в среде Android. RenderScript, в основном, рассчитан на выполнение задач, допускающих параллельное выполнение вычислений, однако, пользу из него можно извлечь и на вычислениях, которые выполняются последовательно. [Здесь](http://developer.android.com/guide/topics/renderscript/compute.html) вы можете узнать подробности о RenderScript.
Свежая версия ADT, доступная из открытого репозитория Google, включает в себя пакеты, которые нужно импортировать для использования RenderScript, JNI (Java Native Interface, Интерфейс Java с машинным кодом) и набора API времени выполнения.
Дополнительные сведения о разработке с использованием RenderScript можно найти [здесь](http://developer.android.com/guide/topics/renderscript/reference.html), материалы по OpenCL – [здесь](https://software.intel.com/en-us/intel-opencl).
1.3 Код вспомогательной инфраструктуры приложения
-------------------------------------------------
Инфраструктура рассматриваемого приложения состоит из главной Activity и вспомогательных функций. Здесь мы рассмотрим эти функции и код, служащий для настройки пользовательского интерфейса, выбора графического эффекта, а для OpenCL – и для выбора вычислительного устройства, которое следует использовать.
Здесь рассмотрены две основные вспомогательные функции.
Первая, *backgroundThread()*, запускает отдельный поток выполнения, из которого периодически вызывается функция, выполняющая пошаговое применение графического эффекта. Эта функция взята из приложения, которое рассматривается в материале [Начало работы с RenderScript](https://software.intel.com/en-us/articles/renderscript-basic-sample-for-android-os), подробности об этом примере можно найти [здесь](https://software.intel.com/sites/default/files/managed/36/bc/AndroidBasicRenderScript_0.pdf).
Вторая функция, *processStep()*, вызывается из *backgroundThread().* Она*,* в свою очередь, вызывает команды для обработки изображений. Функция полагается на состояние переключателей для определения того, какую именно реализацию алгоритмов следует использовать. В функции *processStep()*, в зависимости от состояния настроек, вызываются методы для обработки изображений с использованием OpenCL, RenderScript или обычного машинного кода, написанного на C/C++. Так как этот код выполняется в фоновом потоке, пользовательский интерфейс не блокируется, поэтому переключаться между реализациями графических алгоритмов можно в любое время. Когда пользователь выбирает эффект, приложение тут же на него переключается.
```
// Метод processStep() выполняется в отдельном (фоновом) потоке.
private void processStep() {
try {
switch (this.type.getCheckedRadioButtonId()) {
case R.id.type_renderN:
oclFlag = 0; // OpenCL выключен
stepRenderNative();
break;
case R.id.type_renderOCL:
oclFlag = 1; // OpenCL включен
stepRenderOpenCL();
break;
case R.id.type_renderRS:
oclFlag = 0; // OpenCL выключен
stepRenderScript();
break;
default:
return;
}
} catch (RuntimeException ex) {
// Обработка исключения и логирование ошибки
Log.wtf("Android Image Processing", "render failed", ex);
}
}
```
1.4 Определение функций, реализованных в машинном коде, в Java
--------------------------------------------------------------
Рассматриваемое приложение реализует класс *NativeLib*, в котором определены функции, используемые для вызова с помощью JNI команд уровня машинного кода, реализующих графические эффекты. В приложении показано три эффекта: эффект плазмы (plasma), тонирование изображения в сепию (sepia) и обесцвечивание (monochrome). Соответственно, в классе определены функции *renderPlasma(…)*, *renderSepia(…)* и *renderMonoChrome(…)*. Эти Java-функции играют роль JNI-точек входа, посредством которых вызывается либо функционал, реализованный в машинном коде, либо – OpenCL-версия графических алгоритмов.
Соответствующая JNI-функция, при запуске выбранного графического эффекта, либо исполняет код, написанный на C/C++, либо настраивает и исполняет программу на OpenCL. Описываемый класс использует пакеты *android.graphics.Bitmap* и *android.content.res.AssetManager*. Объекты *BitMap* используются для отправки графических данных в подсистему их обработки и для получения результатов. Приложение пользуется объектом класса *AssetManager* для того, чтобы получить доступ к OpenCL-файлам (sepia.cl, например). В этих файлах описаны OpenCL-ядра (kernels), представляющие собой функции, реализующие графические алгоритмы.
Ниже показан код класса *NativeLib*. Его можно легко расширить для добавления дополнительных графических эффектов, на это указывает комментарий //TODO.
```
package com.example.imageprocessingoffload;
import android.content.res.AssetManager;
import android.graphics.Bitmap;
public class NativeLib
{
// Реализовано в libimageeffects.so
public static native void renderPlasma(Bitmap bitmapIn, int renderocl, long time_ms, String eName, int devtype, AssetManager mgr);
public static native void renderMonoChrome(Bitmap bitmapIn, Bitmap bitmapOut, int renderocl, long time_ms, String eName, int simXtouch, int simYtouch, int radHi, int radLo, int devtype, AssetManager mgr);
public static native void renderSepia(Bitmap bitmapIn, Bitmap bitmapOut, int renderocl, long time_ms, String eName, int simXtouch, int simYtouch, int radHi, int radLo, int devtype, AssetManager mgr);
//TODO public static native render(…);
//Загрузка библиотеки
static {
System.loadLibrary("imageeffectsoffloading");
}
}
```
Обратите внимание на то, что Android-объекты *AssetManager* и *BitMap* передаются машинному коду в качестве входных и выходных параметров. Объект *AssetManager* используется машинным кодом для доступа к CL-файлам, в которых описаны OpenCL-ядра. Объект *BitMap* содержит пиксельные данные, которые обрабатываются в машинном коде. Тот же тип данных используется и для возврата результата обработки.
Параметр пользовательского интерфейса *deviceType* применяется для того, чтобы указать целевое устройство, на котором будет исполняться OpenCL-код – CPU или GPU. Для достижения такой гибкости ОС Android должна быть соответствующим образом настроена. Современные процессоры Intel Atom и Intel Core могут исполнять OpenCL-инструкции и самостоятельно, и используя встроенные в систему графические чипы.
Параметр *eName* задаёт то, какое именно OpenCL-ядро следует скомпилировать и запустить. В приложении каждому графическому эффекту соответствует собственная JNI-функция, в результате передача имени ядра может показаться ненужной. Однако, в одном CL-файле (то же касается и JNI-функции) можно закодировать несколько схожих графических алгоритмов. В подобной ситуации параметр *eName* мог бы быть использован для указания того, какую конкретную CL-программу (или ядро) нужно компилировать и загружать.
Параметр *renderocl* играет роль флага, указывающего на то, нужно ли исполнять код OpenCL или машинный код, написанный на C/C++. Его значение интерпретируется как истинное, если пользователь активировал переключатель OpenCL, в противном случае флаг остаётся не установленным.
Параметр *time\_ms* используется для передачи отметки времени (в миллисекундах), которая применяется для вычисления показателей производительности. Эффект плазмы, кроме того, ориентируется на это значение при пошаговом обсчёте изображения.
Другие аргументы отражают особенности реализации графических эффектов, в частности, радиальное расширение обработанной области. Например, параметры *simXtouch*, *simYTouch*, *radLo* и *radHi*, совместно со значениями ширины и высоты, используются в эффектах тонирования изображения в сепию и обесцвечивания. С их использованием происходит расчёт и показ того, как обработка изображения начинается в некоей точке, после чего область радиально расширяется до тех пор, пока не заполнит всё изображение.
1.5 Определения и ресурсы, необходимые для запуска машинного кода (C или OpenCL)
--------------------------------------------------------------------------------
Здесь мы рассмотрим определения машинных JNI-функций, реализующих эффекты, показанные в примере. Как уже было упомянуто, каждому эффекту соответствует одна функция. Так сделано для того, чтобы не усложнять повествование и более чётко выделить функциональные элементы, применяемые при ускорении обработки изображений с использованием OpenCL.
Здесь есть ссылки на код, написанный на C, сюда же включены фрагменты этого кода. Сделано это в расчёте на сравнение производительности рассматриваемых технологий в будущих версиях примера.
Одной JNI-функции соответствует одна машинная Java-функция. Поэтому очень важно, чтобы JNI-функции были правильно объявлены и определены. В [Java SDK](http://www.oracle.com/technetwork/java/javase/downloads/index.html) есть средство [javah](http://docs.oracle.com/javase/7/docs/technotes/tools/windows/javah.html), которое помогает генерировать правильные и точные объявления JNI-функций. Это средство рекомендовано использовать для того, чтобы не попадать в сложные ситуации, когда код компилируется правильно, но выдаёт ошибки времени выполнения.
Ниже показаны JNI-функции, соответствующие функциям более низкого уровня для ускоренной обработки изображений. Сигнатуры функций сгенерированы с помощью инструмента javah.
```
// Объявление сигнатуры новой JNI-функции, являющейся точкой входа в
// соответствующую функцию более низкого уровня
#ifndef _Included_com_example_imageprocessingoffload_NativeLib
#define _Included_com_example_imageprocessingoffload_NativeLib
#ifdef __cplusplus
extern "C" {
#endif
/*
* Class: com_example_imageprocessingoffload_NativeLib
* Method: renderPlasma
* Signature: (Landroid/graphics/Bitmap;IJLjava/lang/String;)Ljava/lang/String;
*/
JNIEXPORT void JNICALL Java_com_example_imageprocessingoffload_NativeLib_renderPlasma
(JNIEnv *, jclass, jobject, jint, jlong, jstring, jint, jobject);
/*
* Class: com_example_imageprocessingoffload_NativeLib
* Method: renderMonoChrome
* Signature: (Landroid/graphics/Bitmap;Landroid/graphics/Bitmap;IJLjava/lang/String;)Ljava/lang/String;
*/
JNIEXPORT void JNICALL Java_com_example_imageprocessingoffload_NativeLib_renderMonoChrome
(JNIEnv *, jclass, jobject, jobject, jint, jlong, jstring, jint, jint, jint, jint, jint, jobject);
/*
* Class: com_example_imageprocessingoffload_NativeLib
* Method: renderSepia
* Signature: (Landroid/graphics/Bitmap;Landroid/graphics/Bitmap;IJLjava/lang/String;)Ljava/lang/String;
*/
JNIEXPORT void JNICALL Java_com_example_imageprocessingoffload_NativeLib_renderSepia
(JNIEnv *, jclass, jobject, jobject, jint, jlong, jstring, jint, jint, jint, jint, jint, jobject);
}
#endif
```
Средство *javah* умеет генерировать правильные сигнатуры JNI-функций. Однако, класс или классы, которые определяют машинные функции Java, должны быть уже скомпилированы в Android-проекте. Если нужно сгенерировать заголовочный файл, команду javah можно использовать так:
*{javahLocation} -o {outputFile} -classpath {classpath} {importName}*
В нашем примере сигнатуры функций были созданы следующей командой:
*javah -o junk.h -classpath bin\classes com.example.imageprocessingoffloading.NativeLib*
Сигнатуры JNI-функций из файла *junk.h* затем были добавлены в файл *imageeffects.cpp*, который реализует подготовку и запуск OpenCL или C-кода. Далее, мы выделяем ресурсы, необходимые при запуске OpenCL-кода или машинного кода для эффектов плазмы, обесцвечивания, тонирования в сепию.
1.5.1 Эффект плазмы
-------------------
Функция *Java\_com\_example\_imageprocessingoffload\_NativeLib\_renderPlasma(…)* является входной точкой для исполнения OpenCL-кода или машинного кода, которые реализуют эффект плазмы. Функции *startPlasmaOpenCL(…)*, *runPlasmaOpenCL(…)*, и *runPlasmaNative(…)* являются внешними по отношению к коду из файла *imageeffects.cpp*, они объявлены в отдельном файле *plasmaEffect.cpp*. Исходный код *plasmaEffect.cpp* можно найти [здесь](https://software.intel.com/sites/default/files/managed/46/b1/sourcecode.zip).
Функция *renderPlasma(…)*, являющаяся точкой входа, использует OpenCL-обёртку для запроса у Android поддержки OpenCL. Она вызывает функцию класса-обёртки *::initOpenCL(…)* для инициализации OpenCL-окружения. В качестве типа устройства, при создании OpenCL-контекста, передаётся CPU или GPU. Менеджер ресурсов Android использует параметр *ceName* для идентификации, загрузки и компиляции CL-файла с необходимым ядром.
Если удаётся успешно настроить окружение OpenCL, следующим шагом функции *renderPlasma(…)* является вызов функции *startPlasmaOpenCL()*, которая выделяет OpenCL-ресурсы и начинает исполнение ядра, реализующего эффект плазмы. Обратите внимание на то, что *gOCL* – это глобальная переменная, которая хранит экземпляр класса-обёртки OpenCL. Эта переменная видима для всех JNI-функций, являющихся точками входа. Благодаря такому подходу, OpenCL-окружение можно инициализировать при обращении к любому из поддерживаемых графических эффектов.
При демонстрации эффекта плазмы не используются готовые изображения. Всё, что отображается на экране, сгенерировано программным путём. Параметр *bitmapIn* – это объект класса BitMap, который хранит графические данные, сгенерированные в ходе работы алгоритма. Параметр *pixels*, передаваемый в функцию *startPlasma(…)*, отображается на растровую текстуру и используется машинным кодом или кодом ядра OpenCL для чтения и записи пиксельных данных, которые выводятся на экране. Еще раз отметим, что объект *assetManager* используется для доступа к CL-файлу, который содержит OpenCL-ядро, реализующее эффект плазмы.
```
JNIEXPORT void Java_com_example_imageprocessingoffload_NativeLib_renderPlasma(JNIEnv * env, jclass, jobject bitmapIn, jint renderocl, jlong time_ms, jstring ename, jint devtype, jobject assetManager) {
… // опущено для упрощения примера
// блокируется память для BitMapIn и устанавливается указатель “pixels”, который передаётся OpenCL-функции или функции на машинном коде.
ret = AndroidBitmap_lockPixels(env, bitmapIn, &pixels);
… // опущено для упрощения примера
If OCL not initialized
AAssetManager *amgr = AAssetManager_fromJava(env, assetManager);
gOCL.initOpenCL(clDeviceType, ceName, amgr);
startPlasmaOpenCL((cl_ushort *) pixels, infoIn.height, infoIn.width, (float) time_ms, ceName, cpinit);
else
runPlasmaOpenCL(infoIn.width, infoIn.height, (float) time_ms, (cl_ushort *) pixels);
… // опущено для упрощения примера
}
```
Внешняя функция *startPlasmaOpenCL(…)* создаёт и заполняет буферы *Palette* и *Angles*, которые содержат данные, необходимые для создания эффекта плазмы. Для запуска ядра OpenCL, ответственного за этот эффект, функция полагается на очередь команд OpenCL, контекст и ядро, которые определены в виде данных-членов в классе-обёртке.
Функция *runPlasmaOpenCL(…)* непрерывно вызывает OpenCL-ядро, генерирующее изображение плазмы. Отдельная функция используется один раз, когда ядро OpenCL запускается, последующие вызовы ядра нуждаются лишь в новом значении временной метки во входных данных. Из-за того, что для последующих вызовов ядра нужно передавать лишь аргумент в виде временной метки, возникает необходимость в дополнительной функции.
```
extern int startPlasmaOpenCL(cl_ushort* pixels, cl_int height, cl_int width, cl_float ts, const char* eName, int inittbl);
extern int runPlasmaOpenCL(int width, int height, cl_float ts, cl_ushort *pixels);
extern void runPlasmaNative( AndroidBitmapInfo* info, void* pixels, double t, int inittbl );
```
Функция *runPlasmaNative(…)* содержит реализацию алгоритма создания эффекта плазмы на C. Аргумент *inittbl* используется как логический, его значение указывает на то, нужно ли генерировать наборы данных *Palette* и *Angles*, которые необходимы для работы алгоритма. Код OpenCL-ядра, реализующий эффект плазмы, можно найти в файле *plasmaEffect.cpp*.
```
#define FBITS 16
#define FONE (1 << FBITS)
#define FFRAC(x) ((x) & ((1 << FBITS)-1))
#define FIXED_FROM_FLOAT(x) ((int)((x)*FONE))
/* Цветовая палитра, используемая для рендеринга плазмы */
#define PBITS 8
#define ABITS 9
#define PSIZE (1 << PBITS)
#define ANGLE_2PI (1 << ABITS)
#define ANGLE_MSK (ANGLE_2PI - 1)
#define YT1_INCR FIXED_FROM_FLOAT(1/100.0f)
#define YT2_INCR FIXED_FROM_FLOAT(1/163.0f)
#define XT1_INCR FIXED_FROM_FLOAT(1/173.0f)
#define XT2_INCR FIXED_FROM_FLOAT(1/242.0f)
#define ANGLE_FROM_FIXED(x) ((x) >> (FBITS - ABITS)) & ANGLE_MSK
ushort pfrom_fixed(int x, __global ushort *palette)
{
if (x < 0) x = -x;
if (x >= FONE) x = FONE-1;
int idx = FFRAC(x) >> (FBITS - PBITS);
return palette[idx & (PSIZE-1)];
}
__kernel
void plasma(__global ushort *pixels, int height, int width, float t, __global ushort *palette, __global int *angleLut)
{
int yt1 = FIXED_FROM_FLOAT(t/1230.0f);
int yt2 = yt1;
int xt10 = FIXED_FROM_FLOAT(t/3000.0f);
int xt20 = xt10;
int x = get_global_id(0);
int y = get_global_id(1);
int tid = x+y*width;
yt1 += y*YT1_INCR;
yt2 += y*YT2_INCR;
int base = angleLut[ANGLE_FROM_FIXED(yt1)] + angleLut[ANGLE_FROM_FIXED(yt2)];
int xt1 = xt10;
int xt2 = xt20;
xt1 += x*XT1_INCR;
xt2 += x*XT2_INCR;
int ii = base + angleLut[ANGLE_FROM_FIXED(xt1)] + angleLut[ANGLE_FROM_FIXED(xt2)];
pixels[tid] = pfrom_fixed(ii/4, palette);
}
```
1.5.2 Обесцвечивание изображений
--------------------------------
Функция *Java\_com\_example\_imageprocessingoffload\_NativeLib\_renderMonochrome(…)* является точкой входа для вызова функций обесцвечивания изображения, реализованных в машинном коде или средствами OpenCL. Функции *executeMonochromeOpenCL(…)* и *executeMonochromeNative(…)* являются внешними по отношению к коду из *imageeffects.cpp*, они объявлены в отдельном файле. Как и в случае с эффектом плазмы, функция, играющая роль точки входа, использует OpenCL-обёртку для выполнения запросов, касающихся поддержки OpenCL, к подсистеме управления устройствами Android. Она же вызывает функцию *::initOpenCL(…)*, выполняющую инициализацию OpenCL-окружения.
В следующей паре строк кода показано, что функции *executeMonochromeOpenCL(…)* и *executeMonochromeNative(…)* объявлены с ключевым словом *extern*. Это делает их видимыми для NDK-компилятора. Это необходимо, так как данные функции объявлены в отдельном файле.
```
extern int executeMonochromeOpenCL(cl_uchar4 *srcImage, cl_uchar4 *dstImage, int radiHi, int radiLo, int xt, int yt, int nWidth, int nHeight);
extern int executeMonochromeNative(cl_uchar4 *srcImage, cl_uchar4 *dstImage, int radiHi, int radiLo, int xt, int yt, int nWidth, int nHeight);
```
В отличие от эффекта плазмы, здесь используются входные и выходные изображения. И *bitmapIn*, и *bitmapOut* представляют собой растровые изображения в формате ARGB\_888. Оба они отображаются на CL-буферы векторов типа *cl\_uchar4*. Обратите внимание на то, что здесь производится приведение типов *pixelsIn* и *pixelsOut*, это необходимо для того, чтобы OpenCL смог отобразить BitMap-объекты на буферы векторов *cl\_uchar4*.
```
JNIEXPORT void JNICALL Java_com_example_imageprocessingoffload_NativeLib_renderMonochrome(JNIEnv * env, jclass obj, jobject bitmapIn, jobject bitmapOut, jint renderocl, jlong time_ms, jstring ename, jint xto, jint yto, jint radHi, jint radLo, jint devtype, jobject assetManager) {
… // опущено для упрощения примера
// блокируется память для BitMapIn и устанавливается указатель “pixelsIn”, который передаётся OpenCL-функции или функции на машинном коде.
ret = AndroidBitmap_lockPixels(env, bitmapIn, &pixelsIn);
// блокируется память для BitMapOut и устанавливается указатель “pixelsOut”, который передаётся OpenCL-функции или функции на машинном коде
ret = AndroidBitmap_lockPixels(env, bitmapOut, &pixelsOut);
… // опущено для упрощения примера
If OpenCL
If OCL not initialized
AAssetManager *amgr = AAssetManager_fromJava(env, assetManager);
gOCL.initOpenCL(clDeviceType, ceName, amgr);
else
executeMonochromeOpenCL((cl_uchar4*) pixelsIn,(cl_uchar4*) pixelsOut, radiHi, radiLo, xt, yt, infoIn.width, infoIn.height);
// окончание блока, выполняемого, если OCL инициализирован
else
executeMonochromeNative((cl_uchar4*) pixelsIn,(cl_uchar4*) pixelsOut, radiHi, radiLo, xt, yt, infoIn.width, infoIn.height);
// Окончание блока OpenCL
… // опущено для упрощения примера
}
```
Когда вызывается функция *executeMonochromeOpenCL(…)*, *pixelsIn* и *pixelsOut* преобразуются к типу *cl\_uchar4*-буферов и передаются. Эта функция использует API OpenCL для создания буферов и других нужных для работы ресурсов. Она задаёт аргументы ядра и ставит в очередь необходимые для исполнения OpenCL-ядра команды. Входной буфер изображения формируется как буфер только для чтения (read\_only), для доступа к нему используется указатель *pixelsIn*. Код ядра использует этот указатель для того, чтобы получить входные пиксельные данные изображения. Эти данные, в свою очередь, обрабатываются ядром, входное изображение обесцвечивается. Выходной буфер – это буфер, предназначенный и для чтения, и для записи (read\_write), он хранит результаты обработки изображения, на него указывает *pixelsOut*. Дополнительные сведения об OpenCL можно найти в [Руководстве Intel по программированию и оптимизации](https://software.intel.com/en-us/iocl_opg).
В функции *executeMonochromeNative(…)* алгоритм обесцвечивания изображений реализован на C. Это очень простой алгоритм, использующий вложенные циклы – внешний (y) и внутренний (x), в которых обрабатываются пиксельные данные, а результат сохраняется в переменной *dstImage*, на которую указывает *pixelsOut*. Переменная *srcImage*, на которую указывает *pixelsIn*, используется для получения входных пиксельных данных в формуле алгоритма, где цветное изображение и преобразуется в монохромное.
Вот код ядра OpenCL, реализующий эффект обесцвечивания:
```
constant uchar4 cWhite = {1.0f, 1.0f, 1.0f, 1.0f};
constant float3 channelWeights = {0.299f, 0.587f, 0.114f};
constant float saturationValue = 0.0f;
__kernel void mono (__global uchar4 *in, __global uchar4 *out, int4 intArgs, int width) {
int x = get_global_id(0);
int y = get_global_id(1);
int xToApply = intArgs.x;
int yToApply = intArgs.y;
int radiusHi = intArgs.z;
int radiusLo = intArgs.w;
int tid = x + y * width;
uchar4 c4 = in[tid];
float4 f4 = convert_float4 (c4);
int xRel = x - xToApply;
int yRel = y - yToApply;
int polar = xRel*xRel + yRel*yRel;
if (polar > radiusHi || polar < radiusLo) {
if (polar < radiusLo) {
float4 outPixel = dot (f4.xyz, channelWeights);
outPixel = mix ( outPixel, f4, saturationValue);
outPixel.w = f4.w;
out[tid] = convert_uchar4_sat_rte (outPixel);
}
else {
out[tid] = convert_uchar4_sat_rte (f4);
}
}
else {
out[tid] = convert_uchar4_sat_rte (cWhite);
}
}
```
1.5.3 Тонирование в сепию
-------------------------
Код для тонирования изображения в сепию очень похож на реализацию алгоритма обесцвечивания. Главная разница заключается в том, как обрабатывается цветовая информация пикселей. Здесь используются другие формулы и константы. Ниже показано объявление функций для вызова реализаций алгоритма, реализованных средствами OpenCL и на C. Как видите, функции, за исключением имён, выглядят так же, как функции вызова реализаций алгоритма обесцвечивания.
```
extern int executeSepiaOpenCL(cl_uchar4 *srcImage, cl_uchar4 *dstImage, it int radiHi, int radiLo, int xt, int yt, int nWidth, int nHeight);
extern int executeSepiaNative(cl_uchar4 *srcImage, cl_uchar4 *dstImage, int radiHi, int radiLo, int xt, int yt, int nWidth, int nHeight);
JNIEXPORT jstring JNICALL Java_com_example_imageprocessingoffload_NativeLib_renderSepia(JNIEnv * env, jclass obj, jobject bitmapIn, jobject bitmapOut, jint renderocl, jlong time_ms, jstring ename, jint xto, jint yto, jint radHi, jint radLo, jint devtype, jobject assetManager) { … }
```
Код в *Java\_com\_example\_imageprocessingoffload\_NativeLib\_renderSepia(…)* тоже очень похож на тот, что мы видели для алгоритма обесцвечивания, поэтому он здесь не показан.
Когда вызывается функция *executeSepiaOpenCL(…)*, она преобразует переданные ей значения к нужному типу и передаёт *pixelsIn* и *pixelsOut* в формате *cl\_uchar4*-буферов. Она использует API OpenCL для создания буферов и других необходимых ресурсов. Она же задаёт аргументы для OpenCL-ядра, ставит в очередь команды для исполнения. Входной буфер изображения формируется как буфер только для чтения (read\_only), для доступа к нему используется указатель *pixelsIn*. Код ядра использует указатель для того, чтобы получить пиксельные данные изображения. Эти данные, в свою очередь, обрабатываются ядром, входное изображение окрашивается в сепию. Выходной буфер – это буфер, предназначенный и для чтения, и для записи (read\_write), он хранит результаты обработки изображения, на него указывает *pixelsOut*.
В функции *executeSepiaNative(…)* находится реализация алгоритма тонирования в сепию на C. Это простой алгоритм, состоящий из пары вложенных циклов – внешнего (y), и внутреннего (x). В цикле производится обработка данных, результаты сохраняются в переменной *dstImage*, на которую указывает *pixelsOut*. Переменная *srcImage*, на которую указывает *pixelsIn*, используется для получения входных пиксельных данных в формуле алгоритма, где цветное изображение и окрашивается в сепию.
Ниже показан код OpenCL-ядра для тонирования изображения в сепию.
```
constant uchar4 cWhite = {1, 1, 1, 1};
constant float3 sepiaRed = {0.393f, 0.769f, 0.189f};
constant float3 sepiaGreen = {0.349f, 0.686f, 0.168f};
constant float3 sepiaBlue = {0.272f, 0.534f, 0.131f};
__kernel void sepia(__global uchar4 *in, __global uchar4 *out, int4 intArgs, int2 wh)
{
int x = get_global_id(0);
int y = get_global_id(1);
int width = wh.x;
int height = wh.y;
if(width <= x || height <= y) return;
int xTouchApply = intArgs.x;
int yTouchApply = intArgs.y;
int radiusHi = intArgs.z;
int radiusLo = intArgs.w;
int tid = x + y * width;
uchar4 c4 = in[tid];
float4 f4 = convert_float4(c4);
int xRel = x - xTouchApply;
int yRel = y - yTouchApply;
int polar = xRel*xRel + yRel*yRel;
uchar4 pixOut;
if(polar > radiusHi || polar < radiusLo)
{
if(polar < radiusLo)
{
float4 outPixel;
float tmpR = dot(f4.xyz, sepiaRed);
float tmpG = dot(f4.xyz, sepiaGreen);
float tmpB = dot(f4.xyz, sepiaBlue);
outPixel = (float4)(tmpR, tmpG, tmpB, f4.w);
pixOut = convert_uchar4_sat_rte(outPixel);
}
else
{
pixOut= c4;
}
}
else
{
pixOut = cWhite;
}
out[tid] = pixOut;
}
```
1.6 Программный код и ресурсы, необходимые для RenderScript
-----------------------------------------------------------
Что нужно для того, чтобы заработала RenderScript-реализация графических алгоритмов? Нельзя сказать, что это – непреложное правило или даже рекомендация, но в нашем примере, для простоты, использованы обычные глобальные ресурсы и переменные. Android-разработчики могут использовать различные методы для работы с ресурсами, основываясь на сложности приложения.
В файле *MainActivity.java* объявлены и определены следующие обычно используемые ресурсы.
```
private RenderScript rsContext;
```
Переменная *rsContext* хранит контекст RenderScript, она обычно используется всеми RS-скриптами. Контекст задаётся как часть платформы RenderScript. [Здесь](http://developer.android.com/guide/topics/renderscript/compute.html) можно узнать подробности о внутренних механизмах RenderScript.
```
private ScriptC_plasma plasmaScript;
private ScriptC_mono monoScript;
private ScriptC_sepia sepiaScript;
```
Переменные *plasmaScript*, *monoScript*, и *sepiaScript* – это экземпляры класса-обёртки, который предоставляет доступ к RS-ядрам. Eclipse IDE и Android Studio автоматически генерируют соответствующие Java-классы на основе rs-файлов. То есть, на основе файла *plasma.rs* создаётся класс *ScriptC\_plasma*, на основе *mono.rs* – класс *ScriptC\_mono*. Файл *sepia.rs* служит основой для класса *ScriptC\_sepia*. Эти RenderScript-обёртки создаются автоматически, их можно найти в папке *gen*. Например, обёртку для файла *sepia.rs* можно найти в файле *ScriptC\_sepia.java*. Для того чтобы система могла автоматически сгенерировать Java-код, в rs-файле должно присутствовать полное, синтаксически верное определение RenderScript-ядра, готовое для компиляции. В приложении-примере классы-обёртки импортированы в код MainActivity.java.
```
private Allocation allocationIn;
private Allocation allocationOut;
private Allocation allocationPalette;
private Allocation allocationAngles;
```
Объекты класса *Allocation* предназначены для организации обмена данными с RenderScript-ядрами. Например, *allocationIn* и *allocationOut* хранят графические данные входных и выходных изображений. На вход скрипта подаётся то, на что ссылается *allocationIn*, а в *allocationOut*, после обработки в RS-ядре или ядрах, записывается то, что получилось.
Перед запуском RenderScript-ядра, ответственного за вывод эффекта плазмы, в коде главной Activity осуществляется подготовка входных данных. В частности, для создания этого эффекта необходимы данные, хранящиеся в *allocationPalette* и *allocationAngle*.
Код, необходимый для запуска RS-ядра, связывает воедино подготовленные ресурсы и автоматически сгенерированные RS-обёртки. Он определён во вспомогательной функции *initRS(…)*.
```
protected void initRS() { … };
```
Эта функция инициализирует контекст RenderScript, используя статический метод *create* класса *RenderScript*. Как уже было сказано, контекст нужен для работы RenderScript, ссылка на него хранится в глобальной переменной. Контекст RenderScript требуется для создания экземпляров RS-объектов. Ниже показан код, с помощью которого контекст RenderScript создаётся в области видимости *MainActivity* нашего приложения. Поэтому при вызове метода *RenderScript.create(…)* передаётся «*this*».
```
rsContext = RenderScript.create(this);
```
После того, как создан RS-контекст, начинается работа с конкретными RenderScript-объектами, которые используются для вызовов соответствующих им ядер. В коде, приведенном ниже, показана та часть функции *initRS()*, которая отвечает за создание экземпляров RenderScript-объектов в зависимости от настроек, которые выполнил пользователь.
```
if (effectName.equals("plasma")) {
plasmaScript = new ScriptC_plasma(rsContext);
} else if (effectName.equals("mono")) {
monoScript = new ScriptC_mono(rsContext);
} else if (effectName.equals("sepia")) {
sepiaScript = new ScriptC_sepia(rsContext);
} // сюда можно добавить код для реализации дополнительных эффектов
```
Функция *stepRenderScript(…)* играет вспомогательную роль, она вызывается для запуска RenderScript-ядра выбранного эффекта. Она использует RenderScript-объекты для установки необходимых параметров и запускает выполнение RS-ядер. Ниже показана часть кода функции *stepRenderScript(…)*, ответственная за настройку и запуск эффектов плазмы и обесцвечивания изображения.
```
private void stepRenderScript(…) {
… // опущено для упрощения примера
if(effectName.equals("plasma")) {
plasmaScript.bind_gPalette(allocationPalette);
plasmaScript.bind_gAngles(allocationAngles);
plasmaScript.set_gx(inX - stepCount);
plasmaScript.set_gy(inY - stepCount);
plasmaScript.set_ts(System.currentTimeMillis() - mStartTime);
plasmaScript.set_gScript(plasmaScript);
plasmaScript.invoke_filter(plasmaScript, allocationIn, allocationOut);
}
else if(effectName.equals("mono")) {
// Вычисление параметров для радиального применения эффекта, которые зависят от количества уже выполненных шагов
int radius = (stepApply == -1 ? -1 : 10*(stepCount - stepApply));
int radiusHi = (radius + 2)*(radius + 2);
int radiusLo = (radius - 2)*(radius - 2);
// Установка параметров скрипта.
monoScript.set_radiusHi(radiusHi);
monoScript.set_radiusLo(radiusLo);
monoScript.set_xInput(xToApply);
monoScript.set_yInput(yToApply);
// Запуск скрипта.
monoScript.forEach_root(allocationIn, allocationOut);
if(stepCount > FX_COUNT)
{
stepCount = 0;
stepApply = -1;
}
}
else if(effectName.equals("sepia")) {
… // код, аналогичный таковому для эффекта обесцвечивания
}
… // опущено для упрощения примера
};
```
В RenderScript-ядре, ответственном за эффект плазмы, определены глобальные переменные *gPalette*, *gAngles*, *gx*, *gy* и *gScript*. Платформа RS генерирует функции, которые позволяют передавать необходимые данные ядру. Все переменные объявлены в файле *plasma.rs*. На основе переменных, определенных как *rs\_allocation*, генерируются функции вида *bind\_*. В случае с эффектом плазмы, функции вида *bind\_* создаются для осуществления привязки данных, хранящихся в *allocationPalette* и *allocationAngles* к RenderScript-контексту. Для скалярных аргументов, таких, как *gx*, *gy*, *ts* и *gScript,* создаются методы вида *set\_*, которые позволяют отправлять данные для записи в соответствующие переменные. Скалярные параметры, в нашем случае, применяются для передачи в RenderScript-ядро таких данных, как x, y и отметка времени, нужная для эффекта плазмы. Функция *invoke\_filter(…)* автоматически создаётся на основе определения RenderScript. Объявление пользовательских функций, таких, как *filter()*, в скрипте, генерирующем эффект плазмы, это способ создания настраиваемого и подходящего для повторного использования кода ядра RenderScript.
В случае с эффектом обесцвечивания, параметр *radius* используется для вычисления аргументов *radiusHi* и *radiusLo*. Эти аргументы, вместе с *xInput* и *yInput*, используются для обсчёта и вывода на экран результатов применения эффекта в виде радиально расширяющейся области. Обратите внимание на то, что при работе со скриптом, обесцвечивающим изображение, вместо вызова пользовательской функции, *forEach\_root()* вызывается напрямую. Метод *forEach\_root(…)* –, это стандартный метод, создаваемый платформой RenderScript. Обратите внимание на то, что *radiusHi*, *radiusLo*, *xInput* и *yInput* объявлены в коде ядра как глобальные переменные. Методы вида *set\_* создаются автоматически для передачи данных в ядро.
Взгляните на исходный код эффектов на RenderScript для того, чтобы лучше разобраться в этом примере.
Код ядра RenderScript для реализации эффекта плазмы:
```
#pragma version(1)
#pragma rs java_package_name(com.example.imageprocessingoffload)
rs_allocation *gPalette;
rs_allocation *gAngles;
rs_script gScript;
float ts;
int gx;
int gy;
static int32_t intFromFloat(float xfl) {
return (int32_t)((xfl)*(1 << 16));
}
const float YT1_INCR = (1/100.0f);
const float YT2_INCR = (1/163.0f);
const float XT1_INCR = (1/173.0f);
const float XT2_INCR = (1/242.0f);
static uint16_t pfrom_fixed(int32_t dx) {
unsigned short *palette = (unsigned short *)gPalette;
uint16_t ret;
if (dx < 0) dx = -dx;
if (dx >= (1 << 16)) dx = (1 << 16)-1;
int idx = ((dx & ((1 << 16)-1)) >> 8);
ret = palette[idx & ((1<<8)-1)];
return ret;
}
uint16_t __attribute__((kernel)) root(uint16_t in, uint32_t x, uint32_t y) {
unsigned int *angles = (unsigned int *)gAngles;
uint32_t out = in;
int yt1 = intFromFloat(ts/1230.0f);
int yt2 = yt1;
int xt10 = intFromFloat(ts/3000.0f);
int xt20 = xt10;
int y1 = y*intFromFloat(YT1_INCR);
int y2 = y*intFromFloat(YT2_INCR);
yt1 = yt1 + y1;
yt2 = yt2 + y2;
int a1 = (yt1 >> 7) & ((1<<9)-1);
int a2 = (yt2 >> 7) & ((1<<9)-1);
int base = angles[a1] + angles[a2];
int xt1 = xt10;
int xt2 = xt20;
xt1 += x*intFromFloat(XT1_INCR);
xt2 += x*intFromFloat(XT2_INCR);
a1 = (xt1 >> (16-9)) & ((1<<9)-1);
a2 = (xt2 >> (16-9)) & ((1<<9)-1);
int ii = base + angles[a1] + angles[a2];
out = pfrom_fixed(ii/4);
return out;
}
void filter(rs_script gScript, rs_allocation alloc_in, rs_allocation alloc_out) {
//rsDebug("Inputs TS, X, Y:", ts, gx, gy);
rsForEach(gScript, alloc_in, alloc_out);
}
```
Код ядра RenderScript для обесцвечивания изображения:
```
#pragma version(1)
#pragma rs java_package_name(com.example.imageprocessingoffload)
int radiusHi;
int radiusLo;
int xToApply;
int yToApply;
const float4 gWhite = {1.f, 1.f, 1.f, 1.f};
const float3 channelWeights = {0.299f, 0.587f, 0.114f};
float saturationValue = 0.0f;
uchar4 __attribute__((kernel)) root(const uchar4 in, uint32_t x, uint32_t y)
{
float4 f4 = rsUnpackColor8888(in);
int xRel = x - xToApply;
int yRel = y - yToApply;
int polar = xRel*xRel + yRel*yRel;
uchar4 out;
if(polar > radiusHi || polar < radiusLo) {
if(polar < radiusLo) {
float3 outPixel = dot(f4.rgb, channelWeights);
outPixel = mix( outPixel, f4.rgb, saturationValue);
out = rsPackColorTo8888(outPixel);
}
else {
out = rsPackColorTo8888(f4);
}
}
else {
out = rsPackColorTo8888(gWhite);
}
return out;
}
```
Код RenderScript-ядра для применения к изображению эффекта сепии.
```
#pragma version(1)
#pragma rs java_package_name(com.example.imageprocessingoffload)
#pragma rs_fp_relaxed
int radiusHi;
int radiusLo;
int xTouchApply;
int yTouchApply;
rs_script gScript;
const float4 gWhite = {1.f, 1.f, 1.f, 1.f};
const static float3 sepiaRed = {0.393f, 0.769f, 0.189f};
const static float3 sepiaGreen = {0.349f, 0.686, 0.168f};
const static float3 sepiaBlue = {0.272f, 0.534f, 0.131f};
uchar4 __attribute__((kernel)) sepia(uchar4 in, uint32_t x, uint32_t y)
{
uchar4 result;
float4 f4 = rsUnpackColor8888(in);
int xRel = x - xTouchApply;
int yRel = y - yTouchApply;
int polar = xRel*xRel + yRel*yRel;
if(polar > radiusHi || polar < radiusLo)
{
if(polar < radiusLo)
{
float3 out;
float tmpR = dot(f4.rgb, sepiaRed);
float tmpG = dot(f4.rgb, sepiaGreen);
float tmpB = dot(f4.rgb, sepiaBlue);
out.r = tmpR;
out.g = tmpG;
out.b = tmpB;
result = rsPackColorTo8888(out);
}
else
{
result = rsPackColorTo8888(f4);
}
}
else
{
result = rsPackColorTo8888(gWhite);
}
return result;
}
```
1.7 Настройка рабочей среды и устройств
---------------------------------------
Для того чтобы приступить к программированию под OpenCL, вам понадобится настроить рабочую среду и устройство для запуска кода.
Для настройки рабочей среды можно воспользоваться пакетом [Intel INDE](https://software.intel.com/en-us/intel-inde). В ходе его инсталляции можно выбрать IDE, с которой вы планируете работать. В нашем случае это – Android Studio. Когда установка будет завершена, вы получите, во-первых, IDE, готовую к работе (а так же – Android SDK и NDK, образы эмуляторов), во-вторых – набор OpenCL-библиотек и средства настройки устройств для исполнения OpenCL-приложений. Это может быть Android-эмулятор, планшет или смартфон. Нужно учитывать, что для успешной настройки аппаратного устройства нужны Root-права.
Рассмотрим последовательность шагов, необходимую для запуска примера, описанного в документе [Руководство по работе OpenCL на платформе Android](https://software.intel.com/en-us/android/articles/opencl-basic-sample-for-android-os). Код в руководстве подготовлен с использованием Eclipse IDE, мы же хотим, чтобы с ним можно было работать в Android Studio.
После импорта в Android Studio исходный проект нуждается в доработке. Набор файлов проекта, который подходит для импорта в Android Studio, можно скачать [здесь](http://rghost.ru/7xmSSVQxR). Если конфигурация вашей системы отличается от той, на которой работал этот пример, обратите внимание на пути к папкам Android SDK, NDK и к папке, где содержатся инструменты Intel для работы с OpenCL.
В частности, в файле Android.mk должен присутствовать актуальный путь к корневой директории, в которой находятся OpenCL-инструменты. В нашем случае соответствующая строка выглядит так:
```
INTELOCLSDKROOT="C:\Intel\INDE\code_builder_5.1.0.25"
```
В файле local.properties должны содержаться актуальные пути к Android SDK и NDK.
```
sdk.dir=C\:\\Intel\\INDE\\IDEintegration\\android-sdk-windows
ndk.dir=C\:\\Intel\\INDE\\IDEintegration\\android-ndk-r10d
```
После проверки путей можно приступить к настройке Android-эмулятора. Мы пользовались виртуальным устройством Intel Nexus 7 x86. Его нужно запустить из окна Android Virtual Device Manager.
После того, как эмулятор запущен, нам необходимо выяснить его имя, которое требуется для настройки поддержки OpenCL. Узнать его можно, нажав на кнопку Run в Android Studio и дождавшись появления окна выбора устройства. Нас интересует то, что находится в графе Serial Number. В нашем случае это строка *emulator-5554*.
Теперь откроем командную строку Windows и выполним следующую команду:
```
C:\Intel\INDE\code_builder_5.1.0.25\android-preinstall>opencl_android_install –d emulator-5554
```
Она запускает процесс установки OpenCL-библиотек на устройство, имя которого указано в команде. После того, как система сообщит об успешной установке, можно вернуться к окну выбора устройства Android Studio и, выбрав эмулятор, нажать на кнопку OK. Приложение запустится.

*Тестирование OpenCL-приложения при помощи эмулятора*
Если эмулятор был закрыт, процесс установки OpenCL-библиотек нужно будет повторить.
Та среда разработки, которую мы установили и настроили для работы с OpenCL, подходит и для RenderScript-разработки. Импортируем в Android Studio Eclipse-проект из [Руководства по работе с RenderScript на Android](https://software.intel.com/en-us/articles/renderscript-basic-sample-for-android-os). Он аналогичен тому, который был рассмотрен выше, но реализован средствами RenderScript. Для его запуска дополнительные настройки не требуются.
[Здесь](https://software.intel.com/en-us/intel-opencl) можно найти дополнительные материалы по OpenCL-разработке. Подробности о настройке среды разработки и устройств для работы с OpenCL вы можете найти [здесь](https://software.intel.com/en-us/node/539390).
2. Класс-обёртка OpenCL
-----------------------
Класс-обёртка предоставляет функциональность OpenCL API для компиляции и исполнения OpenCL-ядер. Кроме того, он предоставляет функции-обёртки для API, предназначенные для инициализации среды времени выполнения OpenCL. Основная задача класса состоит в помощи при инициализации и настройке среды времени выполнения. Ниже приведено описание методов класса и комментарии по их использованию. Исходный код класса можно загрузить [здесь](https://software.intel.com/sites/default/files/managed/46/b1/sourcecode.zip).
```
class openclWrapper {
private:
cl_device_id* mDeviceIds; // Хранит идентификаторы OpenCL-устройств (CPU, GPU, и так далее)
cl_kernel mKernel; // Идентификатор ядра
cl_command_queue mCmdQue; // Очередь команд для CL-устройства
cl_context mContext; // Контекст OpenCL
cl_program mProgram; // Идентификатор OpenCL-программы
public:
openclWrapper() {
mDeviceIds = NULL;
mKernel = NULL;
mCmdQue = NULL;
mContext = NULL;
mProgram = NULL;
};
~openclWrapper() { };
cl_context getContext() { return mContext; };
cl_kernel getKernel() { return mKernel; };
cl_command_queue getCmdQue() { return mCmdQue; };
int createContext(cl_device_type deviceType);
bool LoadInlineSource(char* &sourceCode, const char* eName);
bool LoadFileSource(char* &sourceCode, const char* eName, AAssetManager *mgr);
int buildProgram(const char* eName, AAssetManager *mgr);
int createCmdQueue();
int createKernel(const char *kname);
// перегруженная функция
int initOpenCL(cl_device_type clDeviceType, const char* eName, AAssetManager *mgr=NULL);
};
```
Функция *::createContext(cl device)* играет вспомогательную роль. Она, используя выбранное устройство (CPU или GPU), проверяет, поддерживает ли это устройство OpenCL и получает его идентификатор у системы. Получив идентификатор, она создаёт контекст исполнения OpenCL. Функция вызывается в ходе процесса инициализации OpenCL. Она, при успешном завершении, возвращает SUCCESS и устанавливает идентификатор контекста (*mContext*). В противном случае, если система не вернула идентификатор устройства, либо не удалось создать контекст OpenCL, функция возвращает FAIL.
Функция *::createCmdQue()* работает с устройствами, связанными с OpenCL-контекстом. Она использует закрытый член данных *mContext* для создания очереди команд. При успешном завершении функция возвращает SUCCESS и устанавливает идентификатор очереди команд (*mCmdQue*). В противном случае, если не удаётся создать очередь команд для идентификатора устройства, ранее возвращённого функцией *createContext(…)*, возвращается FAIL.
Функция *::buildProgram(effectName, AssetManager)* перегружена. Она принимает название алгоритма обработки изображения (*effectName*) и указатель на менеджер ресурсов Android JNI. Менеджер ресурсов использует название алгоритма для обнаружения и считывания OpenCL-файла, который содержит исходный код соответствующего ядра. Класс-обёртка так же использует название эффекта для поиска и загрузки встроенного (inline) OpenCL-кода. При перегрузке функции в её объявлении ссылка на менеджер ресурсов установлена в NULL по умолчанию. Важное следствие этого заключается в том, что её можно вызвать либо только с параметром *effectName*, либо и с ним, и с рабочим указателем на менеджер ресурсов. После вызова принимается решение о том, нужно ли компилировать OpenCL-код, определенный с использованием механизма встраивания, либо загружать код из отдельного файла. Такой подход позволяет программисту либо строить и разворачивать программу с использованием встроенного кода, в виде строк, либо – в виде отдельных OpenCL-файлов. Указатель на менеджер ресурсов используется либо для вызова функции, которая загружает OpenCL-программу из строки, либо – функции, которая задействует API менеджера ресурсов для чтения исходного кода из OpenCL-файла в буфер.
* Функция *buildProgram(…)* вызывает команду OpenCL API *clCreateProgramWithSource(…)* для создания программы из исходного кода. Это API возвращает сообщения об ошибках в том случае, если в OpenCL-коде есть синтаксические неточности. Программу при таком состоянии дел создать невозможно. Контекст OpenCL и буфер с исходным кодом передаются в виде аргументов. Если компиляция завершилась успешно, *clCreateProgramWithSource(…)* возвращает идентификатор программы.
* Команда *clBuildProgram(…)* принимает идентификатор программы, полученный из *clCreateProgramWithSource(…)* или из *clCreateProgramWithBinary(…)*. Эту команду вызывают для того, чтобы скомпилировать и скомпоновать исполняемый файл программы, который затем планируется запускать на OpenCL-устройстве. Если на данном этапе что-то пойдёт не так, можно воспользоваться *clGetProgramBuildInfo(…)* для сохранения данных по ошибкам компиляции. Соответствующий пример можно найти в исходном коде класса-обёртки.
Функция *::createKernel(…)* принимает имя эффекта и использует объект программы для создания ядра. В случае успешного создания ядра она возвращает SUCCESS. Идентификатор ядра сохраняется в переменной *mKernel*, которая затем используется для задания аргументов ядра, которое реализует соответствующий графический алгоритм, и для его исполнения.
Методы *::getContext()*, *::getCmdQue()* и *::getKernel()* возвращают, соответственно, идентификаторы контекста, очереди команд и ядра. Они используются функциями JNI для постановки в очередь команд, необходимых для исполнения OpenCL-ядер.
Итоги
-----
В этом материале освещены некоторые приёмы OpenCL-программирования, которые можно использовать для ускорения обработки графики в Android-приложениях. OpenCL похожа на RenderScript. Это жизнеспособная и мощная технология, способная взять на себя обработку графической информации, которая требует большой вычислительной мощности. С распространением поддержки OpenCL в большем количестве устройств, полезно знать о её возможностях по работе с графикой, по использованию для этих целей не только ресурсов центрального процессора, но и графического ядра. Надеемся, эти знания помогут вам в создании быстрых и качественных приложений. | https://habr.com/ru/post/263843/ | null | ru | null |
# История одной интеграции, или как мы перестали беспокоиться и полюбили InterSystems Ensemble
[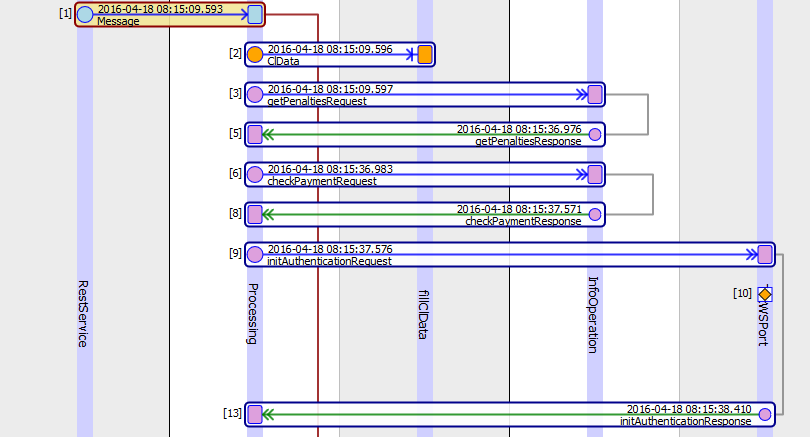](https://habrahabr.ru/company/intersystems/blog/275271/)
▍**Предыстория:** у нашей небольшой, но очень амбициозной компании «Black Mushroom Studio» появилась идея создания e-commerce проекта и реализации мобильного приложения для оплаты некоторых товаров/услуг через платежного агрегатора.
▍**Что было на входе:** каркас приложения на Android, которому, само собой, удобно общаться по HTTP и JSON, и платежная система, предоставившая свое API — web-сервисы с SOAP-содержимым.
▍**Задача:** подружить одно с другим.
На выбор технологии повлияли следующие моменты: скорость разработки и возможность быстрой реакции на изменения. Проект должен был выстрелить. Пока конкуренты производят оценку сроков, мы хотели уже запустить продукт. Пока конкуренты ищут разработчиков, мы уже должны были получать прибыль. При этом ограничительном факторе, все же необходим был серьезный подход, так как вопрос связан с деньгами инвесторов, а это требует повышенного внимания.
Можно долго говорить о достоинствах и недостатках конкретных технологий конкретных вендоров и преимуществах open source, но везде есть свои минусы и плюсы. Проанализировав несколько продуктов (материал для отдельной статьи), мы пришли к выводу, что для решения наших задач, [InterSystems Ensemble](http://www.intersystems.com/ru/our-products/ensemble/ensemble-overview/) подходит больше других.
Практика разработки на Caché ObjectScript была только у одного нашего разработчика, опыта работы именно с Ensemble не было ни у кого. Но довольно сложную логику работы нашего продукта мы реализовали на Ensemble в течении пары недель.
Что нам помогло:
**1.** Ensemble – комплексный продукт, сочетающий в себе СУБД, сервер приложений, интеграционною шину предприятия (ESB), BPM систему и технологию разработки аналитических приложений(BI). Нет необходимости изучать несколько различных решений и связывать их между собой.
**2.** Объектная модель хранения. Если мы хотим сохранить объект в базе данных, мы просто сохраняем его в базе данных.
**3.** Очень простой способ интеграции с внешними/внутренними системами по различным протоколам за счет расширяемой библиотеки адаптеров.
Решение на верхнем уровне
-------------------------
По HTTP-клиент отправляет запрос c JSON-содержимым на порт сервера. Этот порт слушается «черным ящиком» Ensemble. Клиент получает ответ после окончания обработки синхронно.
Что внутри
----------
В Ensemble мы реализовали продукцию (Production — интеграционное решение в Ensemble), состоящую из 3х частей: бизнес-службы, бизнес-процессы, бизнес-операции (далее по тексту эти термины будут идти без приставки бизнес-, для облегчения чтения).
Служба в Ensemble – это компонент, позволяющий принимать запросы по различным протоколам, процесс – это логика работы приложения, операция – это компонент, который позволяет слать исходящие запросы во внешние системы.
Все взаимодействие внутри Ensemble производится на основе очередей «сообщений». Сообщение — объект класса, унаследованного от [Ens.Message](http://docs.intersystems.com/ens20151/csp/docbook/DocBook.UI.Page.cls?KEY=EGDV_messages), позволяет использовать и передавать данные от одной части продукции к другой.
Служба в нашем случае использует HTTP-адаптер, унаследованный от EnsLib.HTTP.InboundAdapter, она получает запрос, отправленный клиентом, преобразует его в «сообщение», и отправляет в процесс. В ответ от бизнес-процесса служба получает «сообщение» с результатами обработки, преобразует его в ответ для клиента.
У нас это выглядит так:
```
Method OnProcessInput(pInput As %Library.AbstractStream, Output pOutput As %Stream.Object) As %Status
{
Set jsonstr = pInput.Read()
// Преобразуем в сообщение
Set st = ##class(%ZEN.Auxiliary.jsonProvider).%ConvertJSONToObject(jsonstr,"invoices.Msg.Message",.tApplication)
Throw:$$$ISERR(st) ##class(%Exception.StatusException).CreateFromStatus(st)
// Некоторая логика дозаполнения сообщения,
// характерная для наших запросов
// Запустим бизнес-процесс
Set outApp=##class(invoices.Msg.Resp).%New()
Set st =..SendRequestSync("Processing",tApplication,.outApp)
Quit:$$$ISERR(st) st
// Преобразуем содержимое ответа в json
Set json=""
Do ##class(invoices.Utils).ObjectToJSON(outApp,,,"aeloqu",.json)
// Запишем json в ответное сообщение
Set pOutput=##class(%GlobalBinaryStream).%New()
Do pOutput.SetAttribute("Content-Type","application/json")
Do pOutput.Write(json)
Quit st
}
```
Бизнес-процесс представляет собой реализацию бизнес-логики нашего приложения. Он содержит последовательность действий, которые необходимо выполнить для того, чтобы вернуть ответ клиенту. Например: сохранить/обновить данные клиента, добавить новую отслеживаемую услугу, запросить статус услуги/оплатить услугу. Без интеграционной платформы нам пришлось бы писать довольно много кода
Что имеем в Ensemble: собираем бизнес-процесс в визуальном редакторе из отдельных элементов. Бизнес процессы описываются на языке Business Process Language (BPL). Элементами могут быть простые (и не очень) присваивания, преобразования данных, вызов определенного кода, синхронный и асинхронный вызов других процессов и операций (об этом чуть ниже).
Преобразование данных в свою очередь крайне удобная штука, позволяет производить маппинг данных, опять же без написания кода:
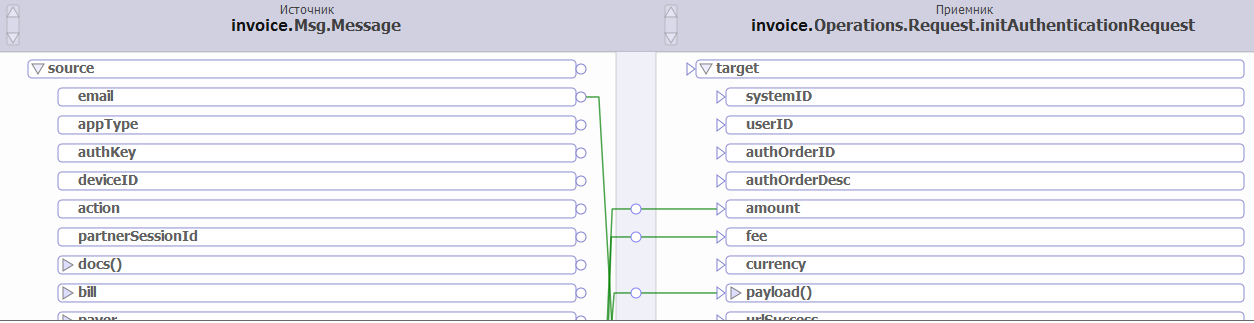
В итоге для себя на каком-то этапе вместо кучи кода получили вот что:
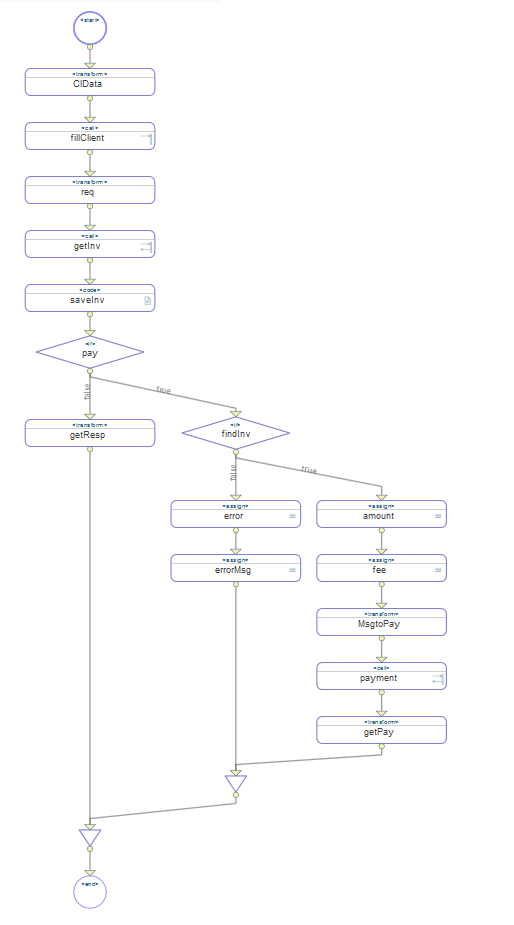
Теперь про операции. Эта сущность позволяет нам реализовать запрос по какому-нибудь протоколу к какой-нибудь внешней системе.
Как это сделали мы: встроенным в студию расширением импортируем из Caché Studio WSDL, предоставленную платежной системой:
Указываем расположение WSDL:
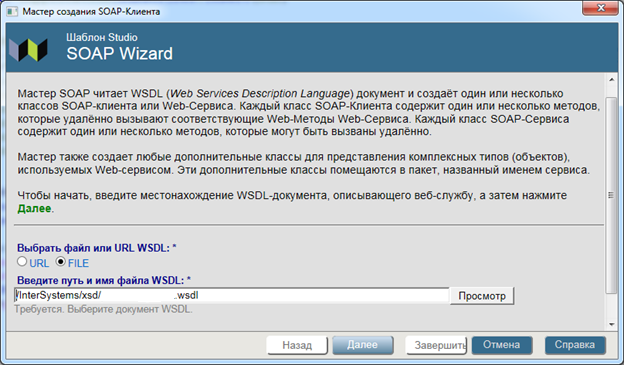
Проставляем при импорте галку «Создать операцию»:
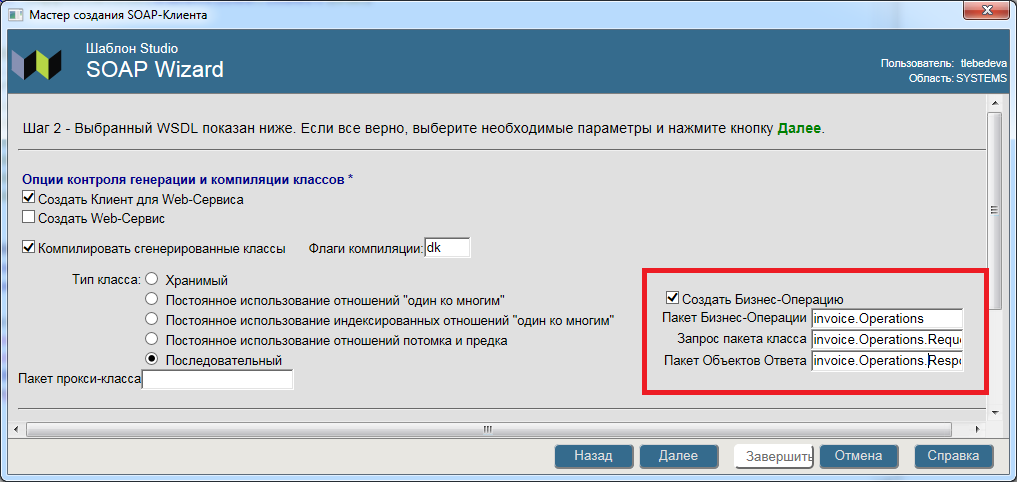
В итоге, получаем готовый код для запросов-ответов к нашей платежной системе. Настраиваем в портале операцию: указываем класс созданной операции:
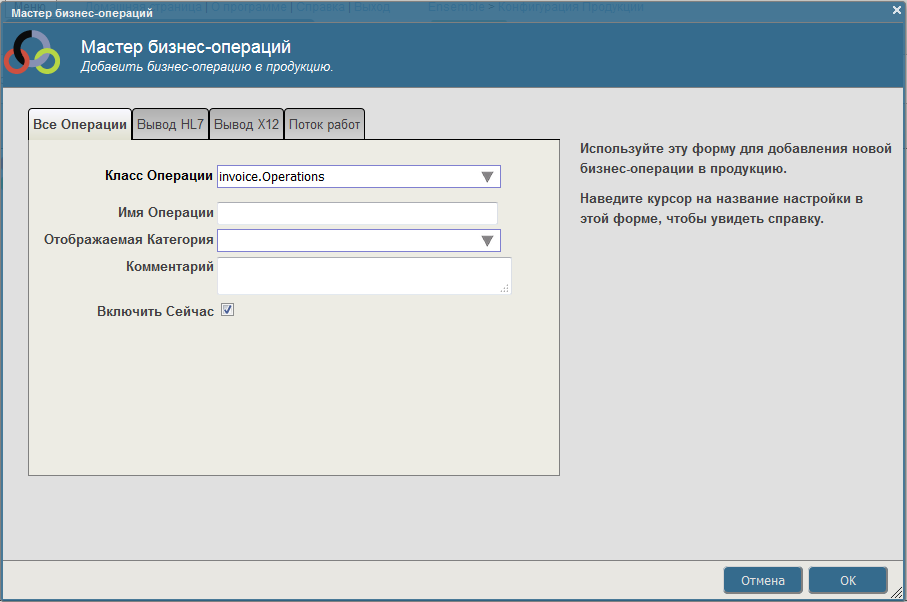
Крепим SSL конфигурацию (её надо предварительно создать через «Портал управления системой» — Администрирование системы — Безопасность — SSL/TLS Конфигурации):
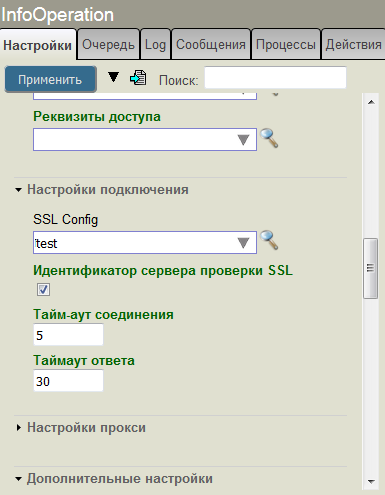
Готово, осталось только вызвать операцию из бизнес-процесса. В нашем случае таких операций получилось две: для информационной составляющей и для платежной составляющей. В итоге для обращения к платежной системе не пришлось написать ни строки кода.
Всё, интеграция готова.
Есть еще отдельный процесс, реализующий PUSH-уведомления встроенными средствами Ensemble, отдельный процесс по получению по SFTP реестров от платежной системы для генерации чеков, собственно само предоставление чеков в формате PDF, но это темы для отдельных статей.
В итоге на реализацию затрачена пара недель (с учетом «вникания» в новую технологию).
Естественно, продукт компании InterSystems не идеален (таких и нет). При реализации походили по граблям, тем более что [документация на Ensemble](http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=SETEnsIntroduction) не самая полная. Но в нашем случае технология прижилась, и прижилась хорошо. Отдельный плюс самой компании за поддержку молодых и амбициозных разработчиков и постоянную готовность проконсультировать. В дальнейшем планируем развитие новых проектов на этой технологии.
На основе данной технологии мы уже запустили [приложение](https://play.google.com/store/apps/details?id=com.blackmushroom.shtrafi), также готовятся к выходу версии приложения для iOS и Web. | https://habr.com/ru/post/275271/ | null | ru | null |
# Получение котировок акций при помощи Python
Привет, Хабр! Представляю вашему вниманию перевод статьи [«Historical Stock Price Data in Python»](https://towardsdatascience.com/historical-stock-price-data-in-python-a0b6dc826836) автора Ishan Shah.
*Статья о том, как получить ежедневные исторические данные по акциям, используя yfinance, и минутные данные, используя alpha vantage.*

Как вы знаете, акции относятся к очень волатильному инструменту и очень важно тщательно анализировать поведение цены, прежде чем принимать какие-либо торговые решения. Ну а сначала надо получить данные и python может помочь в этом.
Биржевые данные могут быть загружены при помощи различных пакетов. В этой статье будут рассмотрены yahoo finance и alpha vantage.
#### Yahoo Finance
Сначала испытаем yfianance пакет. Его можно установить при помощи команды pip install yfinance. Приведенный ниже код показывает, как получить данные для AAPL с 2016 по 2019 год и построить скорректированную цену закрытия (скорректированная цена закрытия на дивиденды и сплиты) на графике.
```
# Import the yfinance. If you get module not found error the run !pip install yfianance from your Jupyter notebook
import yfinance as yf
# Get the data for the stock AAPL
data = yf.download('AAPL','2016-01-01','2019-08-01')
# Import the plotting library
import matplotlib.pyplot as plt
%matplotlib inline
# Plot the close price of the AAPL
data['Adj Close'].plot()
plt.show()
```
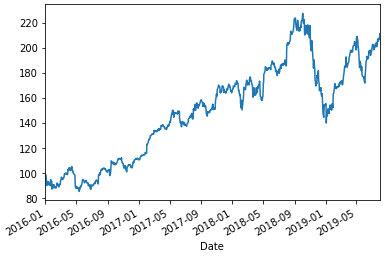
Ну а если необходимо получить по нескольким акциям, то необходимо внести небольшое дополнение в код. Для хранения значений используется DataFrame. При помощи пакета matplotlib и полученных данных можно построить график дневной доходности.
```
# Define the ticker list
import pandas as pd
tickers_list = ['AAPL', 'WMT', 'IBM', 'MU', 'BA', 'AXP']
# Import pandas
data = pd.DataFrame(columns=tickers_list)
# Fetch the data
for ticker in tickers_list:
data[ticker] = yf.download(ticker,'2016-01-01','2019-08-01')['Adj Close']
# Print first 5 rows of the data
data.head()
```
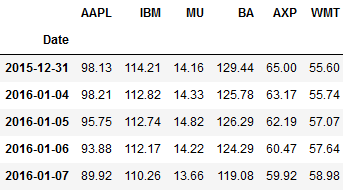
```
# Plot all the close prices
((data.pct_change()+1).cumprod()).plot(figsize=(10, 7))
# Show the legend
plt.legend()
# Define the label for the title of the figure
plt.title("Adjusted Close Price", fontsize=16)
# Define the labels for x-axis and y-axis
plt.ylabel('Price', fontsize=14)
plt.xlabel('Year', fontsize=14)
# Plot the grid lines
plt.grid(which="major", color='k', linestyle='-.', linewidth=0.5)
plt.show()
```
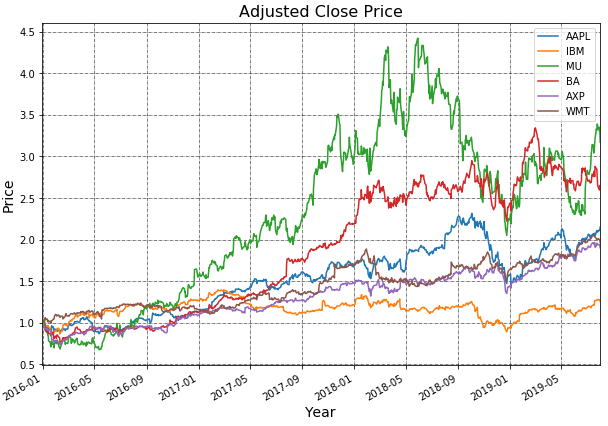
Для значений по российским акциям есть небольшая тонкость. К названию акцию добавляется точка и заглавными буквами ME. Спасибо знатоки на смартлабе подсказали.

#### Получение минутных данных при помощи Alpha vantage
К сожалению, бесплатная версия Yahoo Finance не позволяет получить данные с периодичностью меньше, чем дневная. Для этого можно использовать пакет Alpha vantage, которые позволяет получить такие интервалы, как 1 мин, 5 мин, 15 мин, 30 мин, 60 мин.
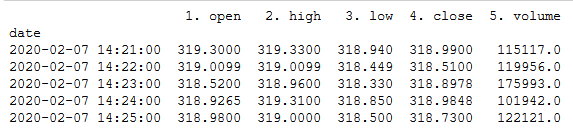
В дальнейшем эти данные можно проанализировать, создать торговую стратегию и оценить эффективность при помощи пакета pyfolio. В нем можно оценить коэффициент Шарпа, коэффициент Сортино, максимальную просадку и многие другие необходимые показатели.
Надеюсь, что мой перевод оригинальной [статьи](https://towardsdatascience.com/historical-stock-price-data-in-python-a0b6dc826836) будет для Вас полезен. Код был проверен и все работает. Но пока для меня остался вопрос в возможности использования Alpha vantage для российского рынка. | https://habr.com/ru/post/487644/ | null | ru | null |
# Отличная статья о сборке продуктов промышленного уровня
Добрейшего.
В октябре в Москве проходила очередная конференция «Разработка ПО». Поехать не смог (да и узнал слишком поздно), однако почитать темы и тезисы докладов, послушать отзывы — такая возможность имелась. Я хоть и в берлоге на берегу моря живу, но инторнеты у нас тоже имеются, да.
Решил узнать, что нынче говорят про SCM в кругах разработчиков — это моё профессиональное хобби. Выяснилось, что почти ничего. Однако был на этом празднике жизни один доклад, который таки оправдывает существование конференции :) Более того, он сильно перекликается с одной из моих старых заметок.
[Issues and Challenges with Industrial-Strength Product Composition](http://cee-secr.org/lang/ru-ru/regular-talks/issues-and-challenges-with-industrial-strength-product-composition/) (Проблемы и спорные вопросы сборки продуктов промышленного уровня). Докладчики — потомки суровых викингов, Лар Бендикс (адъюнкт-профессор из Lund University) и Андреас Горансон (сотрудник Sony-Ericsson).
Что же так порадовало?
Перевод краткого обзора от авторов:
`Одним из инструментов создания продуктовых линеек, а также продуктов, выпускаемых в различных конфигурациях, является компонентно-ориентированный подход. Данный подход, во-первых, допускает немалую степень гибкости процесса создания новых продуктов, а во-вторых, способен снизить временные и финансовые издержки. Однако у подобной гибкости, достигаемой путем сборки продуктов из набора базовых компонентов, существует и обратная сторона. Прежде всего, чрезвычайно сложным оказывается сам процесс построения крупной системы из множества мелких частей – в том числе из-за того, что каждый отдельный компонент может существовать в различных вариациях и исправлениях. Кроме того, в процесс разработки новых компонентов нередко вовлечен целый ряд различных заинтересованных лиц, каждое из которых работает в соответствии со своими потребностями и на своем уровне детализации. Анализируя ситуацию в промышленности, мы определили набор проблем и задач, требующих разрешения для эффективной сборки продукта. Фактологическим и информационным хранилищем может служить разделяемая база компонентов, а база правил (rule base) позволит пользователям принимать решения по конфигурации на более высоком уровне, оперируя понятиями завершенности и связности.`
Нашлись и тезисы, а по сути [полноценная статья](http://www.cs.lth.se/home/Lars_Bendix/Publications/BGSG10b/Moscow-camera-ready.pdf) — там много несложного английского.
В одной старой публикации я упоминал про [компоненты, их версии и продуктовые линейки](http://scm-notes.blogspot.com/2009/09/software-configuration-management_06.html). Поскольку я материал писал на основе опыта работы интегратором в Мотороле, то и проблематика была взята оттуда — из инженерии продуктов промышленного уровня.
А докладчики опирались на богатый работы ещё одного гиганта телекома — Sony-Ericsson и других похожих компаний. Для производителей сотовых телефонов очень важно уметь комбинировать различные фичи своих продуктов в зависимости от оператора, ценового сегмента, форм-фактора, страны продажи и многих других вещей. Отсюда давняя проблема — как обеспечить с наименьшими затратами наилучшую возможность адаптировать продукты под эти условия.
Код всех сложных систем так или иначе разбит на модули, т.е. **компоненты**. А значит, на уровне продукта логичнее оперировать компонентами и их вариациями — **версиями** и **ответвлениями**. В этом направлении работу и повели — разработали модель, учитывающую компоненты и **правила**, по которым компоненты компонуются. Вводится понятие **базы компонентов**, из которой с помощью конфигуратора получается всё разнообразие продуктов, нужных конечному потребителю. Разработанную модель они и описывают. Причем работа идет на стыке SCM, проектирования и управления проектами.
К сожалению, не указано, на какой стадии готовности и практического применения находится эта модель. Зная, что ей занимается человек из коммерческой компании, можно предположить, что работа ведется и в практическом ключе.
Отличная статья, прочитал с удовольствием.
Если есть что кому добавить — велкам. | https://habr.com/ru/post/108059/ | null | ru | null |
# Выразительный Kotlin. Extensions
Никто не любит повторяемый код. Тем не менее, существуют конструкции, которые прижились и укореннились в программировании довольно давно, не смотря на эту самую повторяемость.
Есть такая часто используемая конструкция биндинга данных в android:
```
fun bindCell1(view: View, data: Data) {
view.cell1_text.setText(data.titleId)
view.cell1_icon.setImageResource(data.icon)
}
```
Очевидный метод, у которого есть одна очень досаждающая мне неряшливость — каждый раз необходимо указывать ссылки view. и data. Каждая строка содержит 10 символов, которые очевидны.
И у Kotlin есть способ обойти данную неряшливость — экстеншны (Extensions). Более подробно о них можно почитать [здесь](https://kotlinlang.org/docs/reference/extensions.html).
**Краткая аннотация к статье**В этой статье я не собираюсь кому-то прививать определенный стиль программирования. Я просто хочу показать языковые возможности Kotlin на примере часто встречающейся задачи. Вы можете решать эту задачу как вам угодно, даже не используя Kotlin. Пожалуйста, воздержитесь в комментариях от холиваров — это чисто техническая статья.
Реализуем метод как расширение для класса данных.
Преобразуем нашу конструкцию в
```
fun Data.bindCell1(view: View) {
view.cell1_icon.setImageResource(icon)
view.cell2_text.setText(titleId)
}
```
Как так получается? метод bindSome теперь не сам по себе, а является расширением для класса data. Получается, что это метод ведет себя, как метод самого класса Data. Существует одно ограничение — protected и private сущности в расширениях не видны — что логично, так как в действительности экстеншн не прописан в самом классе. Однако, комбинируя internal и public свойства, можно получать достаточно безопасные комбинации. Соответственно и обращаться теперь можно напрямую к свойствам самого Data-экземпляра.
Теперь попробуем избавиться от префикса *view.*. для этого создадим неизменяемое свойство
```
val Data.bindMethod_cell_2: View.() -> Unit
get() = {
cell2_icon.setImageResource(icon)
cell2_text.setText(titleId)
}
```
#### Как же так?
Теперь свойство bindMethod является расширением для класса MediaData, и при этом же по типу данных — ресширение для View!
#### И что же дальше?
А дальше мы можем вызывать эту конструкцию как обычный метод, при этом передавая View в качестве аргумента!
```
data.bindMethod(view)
```
А если пойдем еще дальше, то сможем передавать View.()->Unit в качестве аргумента.
#### Что нам это дает?
Например, мы можем не типизировать объект RecyclerView от слова вообще, передавая в него только ID лайаута и полученную функцию биндинга. В самом начале, функция bindSome( view:View, data:Data) была строго типизирована, теперь же мы вообще не никак от этого типа данных не зависим. — тип данных (View.()->Unit) привязан только ко View.
#### А пересечение пространств имен?
Бывает, когда имена свойств внутри View и Data совпадают. Чисто технически все это просто обходится (в имени лайаутов можно добавить префикс), но можно и пойти по простому пути:
```
val Data.bindMethod_cell_1: View.() -> Unit
get() = {
this.cell1_icon.setImageResource(this@bindMethod_cell_1.icon)
this.cell1_text.setText(this@bindMethod_cell_1.titleId)
}
```
Разве что конструкция вышла длиннее.
#### А как же аргументы?
Если у bindMethod присутствуют аргументы, при вызове этого метода в качестве первого аргумента передастся объект View, после — остальные аргументы, как мы обычно и вызываем.
```
val Data.bindMethod: (View.(Int, String)->Unit) get() = { intValue, str ->
view.numText.text = str.replace("%s", intValue.toString())
}
//--------------------------------------
data.bindMethod.invoke(view, 0, "str%s")
```
Данный метод позволит позволит нам собрать все методы биндинга в одном месте, и делать, например вот так:
**Пример разделения на отдельные документы**
```
class Data( val name:String, val icon:String)
//-----------------------------------
// DataExtensions.kt
fun Data.carAdapter() = PairUnit>(
R.layout.layout\_car\_cell, {
carcell\_title.text = name
carcell\_icon.setImage(icon)
})
fun Data.motoAdapter() = PairUnit>(
R.layout.layout\_moto\_cell, {
moto\_icon.setImage(icon)
})
```
Обратите внимание, carAdapter и motoAdapter не лежат внутри класса Data. они могут находиться вообще где угодно — хочешь, в экстеншны выноси, хочешь, вместе с классом оставляй. Вызывать их можно откуда угодно, экстеншны импортируются, как классы.
Материалы, используемые в статье, я скомпилировал в [небольшой проект](https://github.com/d-aleksandrov/kotlin_extensions_example) | https://habr.com/ru/post/346900/ | null | ru | null |
# Установка Kubernetes на домашнем сервере с помощью K3s

Но зачем
--------
Знаю, о чем вы думаете — Kubernetes? На домашнем сервере? Кто может быть *настолько* сумасшедшим? Что ж, раньше я согласился бы, однако недавно кое-что изменило мое мнение.
Я начал работать в небольшом стартапе, в котором нет DevOps разработчиков со знанием Kubernetes (в дальнейшем K8s), и даже будучи старым ненавистником K8s из-за его громоздкости, был вынужден признать, что мне не хватает его программного подхода к деплойментам и доступу к подам. Также должен признать, что азарт от укрощения настолько навороченного зверя давно будоражит меня. И вообще, K8s захватывает мир — так что лишние знания не навредят.
Я все еще не *большой фанат* K8s, однако с Docker [всё плохо](https://chrisshort.net/docker-inc-is-dead/), и его проект Swarm давно мертв; [Nomad](https://www.nomadproject.io/) ненамного лучше (или не на 100% бесплатен, так как некоторые функции находятся за «корпоративной» стеной платного доступа), а [Mesos](https://mesos.apache.org/) не набрал критической массы. Все это, к сожалению, делает K8s последней оставшейся технологией оркестрации контейнеров производственного уровня. Не воспринимайте это как похвалу — мы знаем, что в IT успех иногда не равняется качеству (см. Window в 1995 году). И, как я уже сказал, он слишком громоздкий, но недавние улучшения инструментария значительно упростили работу с ним.
Причина, по которой я буду использовать его для своего личного сервера, в основном сводится к воспроизводимости. В моей текущей системе запущено около 35 контейнеров для множества сервисов, таких как wiki, сервер потоковой передачи музыки Airsonic, MinIO хранилище, совместимое с S3 API, и много чего еще, плюс сервера Samba и NFS, к которым обращается Kodi на моем Shield TV и четыре рабочих ПК/ноутбука дома.
Уже почти 5 лет я довольствовался запуском всего этого на [OpenMediaVault](https://www.openmediavault.org/), однако темпы его развития замедлились, и, будучи основанным на Debian, он страдает от проблемы «релизов». Каждый раз, когда выходит новый выпуск Debian, что-то неизбежно ломается на некоторое время. Я жил с этим с Debian 8 или 9, но недавний 11-й выпуск изрядно все поломал, поэтому настало время перемен. Я также подозреваю, что замедление развития OpenMediaVault связано с увеличившейся популярностью K8s среди «типичных» владельцев NAS, если судить по количество [«easy» шаблонов K8s](https://github.com/topics/k8s-at-home) на посвященных ему [Discord-серверах](https://discord.com/invite/k8s-at-home) и Github. Доверие к шаблонам, использующим что попало для решения задачи, — не мой стиль, и если я доверяю чему-то управление своим домашним сервером, то должен непременно понимать что к чему.
Еще мне не нужно убивать уйму времени на обслуживание — обновления автоматизированы, и я редко что-то настраиваю после изначальной установки. На данный момент идет 161-й день аптайма! Однако воспроизведение моей системы было бы по большей части ручной работенкой. Переустановить OpenMediaVault, добавить плагин ZFS, импортировать мой 4-дисковый пул ZFS, настроить Samba и NFS, переустановить [Portainer](https://www.portainer.io/), заново импортировать все мои `docker-compose` файлы… это уже перебор. K8s же управляет *состоянием* кластера, поэтому (теоретически) можно просто переустановить мой сервер, добавить поддержку ZFS, импортировать пул, запустить скрипт, который воссоздает все деплойменты, и вуаля! В теории.
Минуточку. Если вы совершенно новичок — что вообще такое Kubernetes?
Краткий обзор Kubernetes
------------------------
[Kubernetes](https://kubernetes.io/) (по-гречески «кормчий») — это продукт для оркестрации контейнеров, изначально созданный в Google. Однако они не часто используют его внутри компании, что подтверждает теорию о том, что это тщательно продуманный Троянский конь, гарантирующий, что ни одна конкурирующая компания никогда не бросит им вызов в будущем, потому что конкуренты будут тратить все свое время на управление этой штукой (это, как известно, сложно).
В двух словах, вы устанавливаете его на сервере или, что более вероятно, на кластере, а затем развертываете на нем различные типы рабочих нагрузок. Он заботится о создании контейнеров, их масштабировании, создании пространства имен, управлении сетевыми правами доступа, и тому подобное. В основном вы взаимодействуете с ним путем написания YAML файлов и их *применения* к кластеру, обычно при помощи инструмента командной строки под названием `kubectl`, который проверяет и преобразует YAML в полезную нагрузку JSON, которая затем отправляется в REST API эндпоинт кластера.
В K8s есть много концепций, однако я остановлюсь на основных:
* **Под (Pod)**, основная рабочая единица, которая грубо говоря представляет собой один контейнер или набор контейнеров. Поды гарантированно присутствуют на одном и том же узле кластера. K8s назначает подам IP-адреса, поэтому вам не нужно управлять ими. Контейнеры внутри пода доступны друг для друга, но не контейнеры, запущенные на других подах. Вам не следует напрямую управлять подами, это работа Сервисов.
* **Сервисы (Services)** являются точками входа в наборы подов и упрощают управление ими как единым целым. Они не управляют подами напрямую (вместо этого используют ReplicaSets), но в большинстве случаев вам даже не нужно знать, что это такое. Сервисы идентифицируют поды, которыми они управляют, с помощью *меток*.
* **Метки (Labels)**. К каждому объекту в K8s можно прикрепить метаданные. Метки — это одна из их форм, аннотации — другая. Большинство действий в K8s можно ограничить с помощью селектора, указывающего на определенные метки.
* **Тома (Volumes)**, как и в Docker, соединяют контейнеры с хранилищем. На работе у вас будет S3 или что-то подобное с аналогичными гарантиями, но для домашнего сервера мы будем использовать тип тома hostPath, который непосредственно сопоставляется с папками на сервере. В большинстве случаев K8s немного усложняет это — для фактического доступа вам необходимо объявить Persistent Volume (PV) и PersistentVolumeClaim (PVC). Вы можете ограничиться hostPath в конфигурации развертывания, однако PVS и PVCS дадут вам больше контроля над использованием тома.
* Конфигурации **развертывания (deployments)** являются своего рода главными рабочими единицами. Они объявляют, какой Docker-образ использовать, какие сервисы являются частью развертывания, какие тома монтировать и какие порты экспортировать, и заботятся о дополнительных вопросах безопасности.
* **ConfigMaps** — это место, где хранятся данные конфигурации в форме ключ-значение. Среду для развертывания можно взять из ConfigMap — полностью или с определенными ключами.
* **Ingress**. Без этого ваши поды заработают, но будут отрезаны от внешнего мира. В этой статье используются nginx ingresses.
* **Jobs** и **CronJobs** — это разовые или периодические рабочие нагрузки, которые можно выполнять.
Существует еще несколько концепций, которые необходимо освоить, сторонние инструменты могут расширить кластер K8s с помощью пользовательских объектов под названием [CRD](https://kubernetes.io/docs/tasks/extend-kubernetes/custom-resources/custom-resource-definitions/). [Официальная документация](https://kubernetes.io/docs/concepts/) — хорошее место, где можно узнать больше. На данный момент все это поможет нам пройти долгий путь к эффективному рабочему примеру.
Давайте сделаем это!
--------------------
### Шаг 1 — установка Linux
Для начала я рекомендую использовать VirtualBox (он бесплатный) и установить базовую виртуальную машину Debian 11 без рабочего стола, просто с запущенным OpenSSH. Должно работать и с другими дистрибутивами, но большая часть тестирования проходила на Debian. В будущем я планирую перейти на Arch, чтобы избежать «проблемы с релизами», но хорошего понемножку. После освоения настройки виртуальной машины, переход на физический сервер не должен представлять проблемы.
Чтобы предотвратить повторную установку с нуля в случае ошибки (у меня их было много пока не разобрался), можно клонировать виртуальную машину. Таким образом, вы просто удаляете виртуальную машину-клон, снова клонируете главную и повторяете попытку. Также можно использовать снэпшоты главной виртуальной машине, но, по-моему, клонирование более интуитивно.

*Клонирование виртуальной машины*
Убедитесь, что сетевой адаптер вашей клонированной виртуальной машины установлен на `Bridged` и имеет тот же MAC-адрес, что и основная виртуальная машина, чтобы все время получать один и тот же IP-адрес. Это также упростит проброс портов на вашем домашнем маршрутизаторе.

*Установка MAC-адреса для сетевого адаптера виртуальной машины*
Убедитесь, что следующие порты на вашем домашнем маршрутизаторе проброшены на IP-адрес виртуальной машины:
* 80/TCP http
* 443/TCP https
Если вы не находитесь в той же локальной сети, что и виртуальная машина, или используйте удаленный сервер (DigitalOcean, Amazon и т.д.), то также пробросьте следующие порты:
* 22/TCP ssh
* 6443/TCP K8s API
* 10250/UDP kubelet
Прежде чем продолжить, убедитесь, что добавили свой SSH-ключ на сервер и получаете приглашение командной строки c root правами без запроса пароля, когда подключаетесь к нему по SSH. Если добавить:
```
Host k3s
User root
Hostname
```
в ваш файл `.ssh/config`, то при команде `ssh k3s` вы должны получить вышеупомянутое приглашение с правами root.
Также следует установить `kubectl`. Я рекомендую [плагин asdf.](https://github.com/asdf-community/asdf-kubectl)
### Шаг 2 — установка k3s
Полноценный Kubernetes является слишком комплексным и требует больших ресурсов, поэтому мы будем использовать облегченную альтернативу под названием [K3s](https://k3s.io/), гибкое single-binary решение, на 100 % совместимое с обычными K8s.
Чтобы установить K3s и взаимодействовать с нашим сервером, я буду использовать `Makefile` (старая школа — мой стиль). Вверху несколько переменных, которые вам нужно указать:
```
# set your host IP and name
HOST_IP=192.168.1.60
HOST=k3s
# do not change the next line
KUBECTL=kubectl --kubeconfig ~/.kube/k3s-vm-config
```
С IP все понятно, `HOST`— это метка сервера в файле `.ssh/config`, как указано выше. Использовать её проще, чем `user@HOST_IP`, но не стесняйтесь изменять файл Makefile по своему усмотрению. Назначение переменной `KUBECTL` прояснится, как только мы установим K3s. Добавьте в Makefile следующую цель:
```
k3s_install:
ssh ${HOST} 'export INSTALL_K3S_EXEC=" --no-deploy servicelb --no-deploy traefik"; \
curl -sfL https://get.k3s.io | sh -'
scp ${HOST}:/etc/rancher/k3s/k3s.yaml .
sed -r 's/(\b[0-9]{1,3}\.){3}[0-9]{1,3}\b'/"${HOST_IP}"/ k3s.yaml > ~/.kube/k3s-vm-config && rm k3s.yaml
```
ОК, здесь нужно кое-что прояснить. В первой строке происходит подключение к серверу по Ssh и установка K3s с пропуском нескольких компонентов.
* servicelb нам не нужна балансировка нагрузки на одном сервере
* traefik мы будем использовать nginx для ingresses, поэтому нет необходимости устанавливать этот ingress-контроллер
Во второй строке происходит копирование с сервера файла `k3s.yaml`, который создается после установки и включает сертификат для связи с его API. Третья строка заменяет в локальной копии IP-адрес `127.0.0.1` в конфигурации сервера IP-адресом сервера и копирует файл в директорию `.kube` вашей директории $HOME (убедитесь, что она существует). Именно здесь `kubectl` найдет его, так как мы явно установили переменную `KUBECTL` в Makefile для этого файла.
Ожидаемый вывод:
```
ssh k3s 'export INSTALL_K3S_EXEC=" --no-deploy servicelb --no-deploy traefik"; \
curl -sfL https://get.k3s.io | sh -'
[INFO] Finding release for channel stable
[INFO] Using v1.21.7+k3s1 as release
[INFO] Downloading hash https://github.com/k3s-io/k3s/releases/download/v1.21.7+k3s1/sha256sum-amd64.txt
[INFO] Downloading binary https://github.com/k3s-io/k3s/releases/download/v1.21.7+k3s1/k3s
[INFO] Verifying binary download
[INFO] Installing k3s to /usr/local/bin/k3s
[INFO] Skipping installation of SELinux RPM
[INFO] Creating /usr/local/bin/kubectl symlink to k3s
[INFO] Creating /usr/local/bin/crictl symlink to k3s
[INFO] Creating /usr/local/bin/ctr symlink to k3s
[INFO] Creating killall script /usr/local/bin/k3s-killall.sh
[INFO] Creating uninstall script /usr/local/bin/k3s-uninstall.sh
[INFO] env: Creating environment file /etc/systemd/system/k3s.service.env
[INFO] systemd: Creating service file /etc/systemd/system/k3s.service
[INFO] systemd: Enabling k3s unit
Created symlink /etc/systemd/system/multi-user.target.wants/k3s.service → /etc/systemd/system/k3s.service.
[INFO] systemd: Starting k3s
scp k3s:/etc/rancher/k3s/k3s.yaml .
k3s.yaml 100% 2957 13.1MB/s 00:00
sed -r 's/(\b[0-9]{1,3}\.){3}[0-9]{1,3}\b'/"YOUR HOST IP HERE"/ k3s.yaml > ~/.kube/k3s-vm-config && rm k3s.yaml
```
Я предполагаю, что в вашем дистрибутиве, как и в большинстве других, `sed` установлен. Чтобы проверить, что все работает, простая команда `kubectl --kubeconfig ~/.kube/k3s-vm-config get nodes` должна вывести:
```
NAME STATUS ROLES AGE VERSION
k3s-vm Ready control-plane,master 2m4s v1.21.7+k3s1
```
Наш кластер K8s теперь готов к приему рабочих нагрузок!
### Шаг 2.5 Клиенты (опционально)
Если вы хотите иметь приятный пользовательский интерфейс для взаимодействия с
K8s, есть два варианта:
* [k9s](https://k9scli.io/) (CLI) Мне очень нравится, с ним легко работать, идеально подходит для удаленных систем.

*k9s*
* [Lens](http://lens) (GUI) Недавно перешел на него, здесь мне нравятся интегрированные метрики

*Lens*
Эти программы должны найти наши настройки кластера в `~/.kube`.
### Шаг 3 — nginx ingress, Let’s Encrypt и хранилище
Следующая цель в нашем Makefile устанавливает nginx ingress-контроллер и менеджер сертификатов Let’s Encrypt, чтобы наши деплойменты могли иметь валидные сертификаты TLS (бесплатно!). Также там есть класс хранилища по умолчанию, чтобы наши нагрузки без установленного класса использовали дефолтный.
```
base:
${KUBECTL} apply -f k8s/ingress-nginx-v1.0.4.yml
${KUBECTL} wait --namespace ingress-nginx \
--for=condition=ready pod \
--selector=app.kubernetes.io/component=controller \
--timeout=60s
${KUBECTL} apply -f k8s/cert-manager-v1.0.4.yaml
@echo
@echo "waiting for cert-manager pods to be ready... "
${KUBECTL} wait --namespace=cert-manager --for=condition=ready pod --all --timeout=60s
${KUBECTL} apply -f k8s/lets-encrypt-staging.yml
${KUBECTL} apply -f k8s/lets-encrypt-prod.yml
```
Найти используемые мной файлы можно [тут](https://gist.github.com/sardaukar/6a950ea9abcfe651e68876dbc6001fb0). Nginx ingress YAML получен [отсюда](https://github.com/jetstack/cert-manager/releases/download/v1.0.4/cert-manager.yaml), но с одной модификацией на строке 323:
```
dnsPolicy: ClusterFirstWithHostNet
hostNetwork: true
```
таким образом мы можем правильно использовать DNS для нашего случая с одним сервером. Более подробная информация [здесь](https://kubernetes.io/docs/concepts/services-networking/dns-pod-service/).
Файл `cert-manager` слишком большой, чтобы его можно было полностью просмотреть, не стесняйтесь обращаться к [документации](https://cert-manager.io/docs/) по нему. Для выдачи сертификатов Let's Encrypt нам понадобиться определенный объект `ClusterIssuer`. Мы будем использовать два, один для staging API и один для production. Используйте staging issuer для экспериментов, так как в этом случае нет ограничений на скорость выдачи сертификатов, однако имейте в виду, что сертификаты будут недействительными. Обязательно замените адрес электронной почты в обоих issuers на свой собственный.
```
# k8s/lets-encrypt-staging.yml
apiVersion: cert-manager.io/v1
kind: ClusterIssuer
metadata:
name: letsencrypt-staging
namespace: cert-manager
spec:
acme:
server: https://acme-staging-v02.api.letsencrypt.org/directory
email: [email protected]
privateKeySecretRef:
name: letsencrypt-staging
solvers:
- http01:
ingress:
class: nginx
```
```
# k8s/lets-encrypt-prod.yml
apiVersion: cert-manager.io/v1
kind: ClusterIssuer
metadata:
name: letsencrypt-prod
namespace: cert-manager
spec:
acme:
server: https://acme-v02.api.letsencrypt.org/directory
email: [email protected]
privateKeySecretRef:
name: letsencrypt-prod
solvers:
- http01:
ingress:
class: nginx
```
Если бы мы выполнили все инструкции `kubectl apply` одну за другой, процесс, вероятно, завершился бы неудачей, так как нам нужно переходить к cert-менеджеру уже с готовым ingress-контроллером. С этой целью в `kubectl` есть удобная подкоманда `wait`, которая может принимать условия и метки (помните их?) и останавливает процесс до тех пор, пока не будут готовы необходимые компоненты. Рассмотрим подробнее отрывок из примера выше:
```
${KUBECTL} wait --namespace ingress-nginx \
--for=condition=ready pod \
--selector=app.kubernetes.io/component=controller \
--timeout=60s
```
Здесь происходит ожидание в течение 60 секунд, пока все поды, соответствующие селектору `app.kubernetes.io/component=controller`, не станут иметь состояние `ready`. Если истечет время ожидания, Makefile остановится. Однако не беспокойтесь, если в какой-то из целей возникнет ошибка, так как все они являются идемпотентными. В этом случае можно запустить `make base` несколько раз, и если в кластере уже есть определения, они просто останутся неизменными. Попробуйте!
### Шаг 4 — Portrainer
Мне все еще очень нравится, когда [Portainer](https://www.portainer.io/) управляет моим сервером, и, по удачному стечению обстоятельств, он поддерживает как K8s, так и Docker. Давайте постепенно перейдем к соответствующим частям файла YAML:
```
---
apiVersion: v1
kind: Namespace
metadata:
name: portainer
```
Достаточно просто, Portainer определяет собственное пространство имен.
```
---
apiVersion: v1
kind: PersistentVolume
metadata:
labels:
type: local
name: portainer-pv
spec:
storageClassName: local-storage
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/zpool/volumes/portainer/claim"
---
# Source: portainer/templates/pvc.yaml
kind: "PersistentVolumeClaim"
apiVersion: "v1"
metadata:
name: portainer
namespace: portainer
annotations:
volume.alpha.kubernetes.io/storage-class: "generic"
labels:
io.portainer.kubernetes.application.stack: portainer
app.kubernetes.io/name: portainer
app.kubernetes.io/instance: portainer
app.kubernetes.io/version: "ce-latest-ee-2.10.0"
spec:
accessModes:
- "ReadWriteOnce"
resources:
requests:
storage: "1Gi"
```
Этот том (и связанный с ним claim), где Portainer хранит свою конфигурацию. Обратите внимание, что в объявление `PersistentVolume` можно включить `nodeAffinity`, чтобы соответствовать имени хоста сервера (или виртуальной машины). Я пока не нашел способа сделать это лучше.
```
---
# Source: portainer/templates/service.yaml
apiVersion: v1
kind: Service
metadata:
name: portainer
namespace: portainer
labels:
io.portainer.kubernetes.application.stack: portainer
app.kubernetes.io/name: portainer
app.kubernetes.io/instance: portainer
app.kubernetes.io/version: "ce-latest-ee-2.10.0"
spec:
type: NodePort
ports:
- port: 9000
targetPort: 9000
protocol: TCP
name: http
nodePort: 30777
- port: 9443
targetPort: 9443
protocol: TCP
name: https
nodePort: 30779
- port: 30776
targetPort: 30776
protocol: TCP
name: edge
nodePort: 30776
selector:
app.kubernetes.io/name: portainer
app.kubernetes.io/instance: portainer
```
Здесь мы видим определение сервиса. Обратите внимание, как указаны порты (наш ingress будет использовать только один из них). Теперь перейдем к конфигурации развертывания.
```
---
# Source: portainer/templates/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: portainer
namespace: portainer
labels:
io.portainer.kubernetes.application.stack: portainer
app.kubernetes.io/name: portainer
app.kubernetes.io/instance: portainer
app.kubernetes.io/version: "ce-latest-ee-2.10.0"
spec:
replicas: 1
strategy:
type: "Recreate"
selector:
matchLabels:
app.kubernetes.io/name: portainer
app.kubernetes.io/instance: portainer
template:
metadata:
labels:
app.kubernetes.io/name: portainer
app.kubernetes.io/instance: portainer
spec:
nodeSelector:
{}
serviceAccountName: portainer-sa-clusteradmin
volumes:
- name: portainer-pv
persistentVolumeClaim:
claimName: portainer
containers:
- name: portainer
image: "portainer/portainer-ce:latest"
imagePullPolicy: Always
args:
- '--tunnel-port=30776'
volumeMounts:
- name: portainer-pv
mountPath: /data
ports:
- name: http
containerPort: 9000
protocol: TCP
- name: https
containerPort: 9443
protocol: TCP
- name: tcp-edge
containerPort: 8000
protocol: TCP
livenessProbe:
httpGet:
path: /
port: 9443
scheme: HTTPS
readinessProbe:
httpGet:
path: /
port: 9443
scheme: HTTPS
resources:
{}
```
Большую часть этого файла занимают метки метаданных, это то, что связывает все вместе. Мы видим монтирование тома, используемый Doker-образ, порты, а также определения проб readiness и liveness. Они используются в K8s для определения того, готовы ли поды, а также работают и реагируют ли они соответственно.
```
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: portainer-ingress
namespace: portainer
annotations:
kubernetes.io/ingress.class: nginx
cert-manager.io/cluster-issuer: letsencrypt-staging
spec:
rules:
- host: portainer.domain.tld
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: portainer
port:
name: http
tls:
- hosts:
- portainer.domain.tld
secretName: portainer-staging-secret-tls
```
Наконец, ingress, который сопоставляет фактическое доменное имя с этим сервисом. Убедитесь, что у вас есть домен, указывающий на IP-адрес вашего сервера, так как распознаватель вызовов Let's Encrypt зависит от его доступности извне. В нашем случае потребуются записи, указывающие на ваш IP-адрес для `domain.tld` и `*.domain.tld`.
Обратите внимание, как мы получаем сертификат — нам нужно добавить в ingress аннотацию `cert-manager.io/cluster-issuer : letsencrypt-staging` (или `prod`) и ключ `tls` с именем хоста и именем секрета, в котором будет храниться ключ TLS. Если сертификат вам не нужен, просто удалите аннотацию и ключ `tls`.
**Kustomize**
Здесь следует отметить одну вещь: я использую [Kustomize](https://kustomize.io/) для управления файлами YAML при развертывании. Это связано с тем, что другой инструмент, [Kompose](https://kustomize.io/), выводит множество различных YAML файлов при преобразовании docker-compose файлов в файлы K8s. Kustomize упрощает их одновременное применение.
Итак, вот файлы, необходимые для развертывания Portainer:
```
# stacks/portainer/kustomization.yaml
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
resources:
- portainer.yaml
```
```
# stacks/portainer/portainer.yaml
---
apiVersion: v1
kind: Namespace
metadata:
name: portainer
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: portainer-sa-clusteradmin
namespace: portainer
labels:
app.kubernetes.io/name: portainer
app.kubernetes.io/instance: portainer
app.kubernetes.io/version: "ce-latest-ee-2.10.0"
---
apiVersion: v1
kind: PersistentVolume
metadata:
labels:
type: local
name: portainer-pv
spec:
storageClassName: local-storage
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/zpool/volumes/portainer/claim"
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- k3s-vm
---
# Source: portainer/templates/pvc.yaml
kind: "PersistentVolumeClaim"
apiVersion: "v1"
metadata:
name: portainer
namespace: portainer
annotations:
volume.alpha.kubernetes.io/storage-class: "generic"
labels:
io.portainer.kubernetes.application.stack: portainer
app.kubernetes.io/name: portainer
app.kubernetes.io/instance: portainer
app.kubernetes.io/version: "ce-latest-ee-2.10.0"
spec:
accessModes:
- "ReadWriteOnce"
resources:
requests:
storage: "1Gi"
---
# Source: portainer/templates/rbac.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: portainer
labels:
app.kubernetes.io/name: portainer
app.kubernetes.io/instance: portainer
app.kubernetes.io/version: "ce-latest-ee-2.10.0"
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
namespace: portainer
name: portainer-sa-clusteradmin
---
# Source: portainer/templates/service.yaml
apiVersion: v1
kind: Service
metadata:
name: portainer
namespace: portainer
labels:
io.portainer.kubernetes.application.stack: portainer
app.kubernetes.io/name: portainer
app.kubernetes.io/instance: portainer
app.kubernetes.io/version: "ce-latest-ee-2.10.0"
spec:
type: NodePort
ports:
- port: 9000
targetPort: 9000
protocol: TCP
name: http
nodePort: 30777
- port: 9443
targetPort: 9443
protocol: TCP
name: https
nodePort: 30779
- port: 30776
targetPort: 30776
protocol: TCP
name: edge
nodePort: 30776
selector:
app.kubernetes.io/name: portainer
app.kubernetes.io/instance: portainer
---
# Source: portainer/templates/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: portainer
namespace: portainer
labels:
io.portainer.kubernetes.application.stack: portainer
app.kubernetes.io/name: portainer
app.kubernetes.io/instance: portainer
app.kubernetes.io/version: "ce-latest-ee-2.10.0"
spec:
replicas: 1
strategy:
type: "Recreate"
selector:
matchLabels:
app.kubernetes.io/name: portainer
app.kubernetes.io/instance: portainer
template:
metadata:
labels:
app.kubernetes.io/name: portainer
app.kubernetes.io/instance: portainer
spec:
nodeSelector:
{}
serviceAccountName: portainer-sa-clusteradmin
volumes:
- name: portainer-pv
persistentVolumeClaim:
claimName: portainer
containers:
- name: portainer
image: "portainer/portainer-ce:latest"
imagePullPolicy: Always
args:
- '--tunnel-port=30776'
volumeMounts:
- name: portainer-pv
mountPath: /data
ports:
- name: http
containerPort: 9000
protocol: TCP
- name: https
containerPort: 9443
protocol: TCP
- name: tcp-edge
containerPort: 8000
protocol: TCP
livenessProbe:
httpGet:
path: /
port: 9443
scheme: HTTPS
readinessProbe:
httpGet:
path: /
port: 9443
scheme: HTTPS
resources:
{}
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: portainer-ingress
namespace: portainer
annotations:
kubernetes.io/ingress.class: nginx
cert-manager.io/cluster-issuer: letsencrypt-staging
spec:
rules:
- host: portainer.domain.tld
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: portainer
port:
name: http
tls:
- hosts:
- portainer.domain.tld
secretName: portainer-staging-secret-tls
```
Цель в Makefike:
```
portainer:
${KUBECTL} apply -k stacks/portainer
```
Ожидаемый вывод:
```
> make portainer
kubectl --kubeconfig ~/.kube/k3s-vm-config apply -k stacks/portainer
namespace/portainer created
serviceaccount/portainer-sa-clusteradmin created
clusterrolebinding.rbac.authorization.k8s.io/portainer created
service/portainer created
persistentvolume/portainer-pv created
persistentvolumeclaim/portainer created
deployment.apps/portainer created
ingress.networking.k8s.io/portainer-ingress created
```
Так как она идемпотентна, то при повторном запуске вы должны увидеть следующие:
```
> make portainer
kubectl --kubeconfig ~/.kube/k3s-vm-config apply -k stacks/portainer
namespace/portainer unchanged
serviceaccount/portainer-sa-clusteradmin unchanged
clusterrolebinding.rbac.authorization.k8s.io/portainer unchanged
service/portainer unchanged
persistentvolume/portainer-pv unchanged
persistentvolumeclaim/portainer unchanged
deployment.apps/portainer configured
ingress.networking.k8s.io/portainer-ingress unchanged
```
### Шаг 5 — Samba share
Запустить сервер Samba в кластере очень просто. Вот наши файлы YAML:
```
# stacks/samba/kustomization.yaml
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
secretGenerator:
- name: smbcredentials
envs:
- auth.env
resources:
- deployment.yaml
- service.yaml
```
Здесь у нас kustomization со множеством файлов. Когда мы применяем `apply -k` к директории, в которой находится этот файл, все они объединятся в один.
Сервис достаточно простой:
```
# stacks/samba/service.yaml
apiVersion: v1
kind: Service
metadata:
name: smb-server
spec:
ports:
- port: 445
protocol: TCP
name: smb
selector:
app: smb-server
```
Конфигурация развертывания тоже:
```
# stacks/samba/deployment.yaml
kind: Deployment
apiVersion: apps/v1
metadata:
name: smb-server
spec:
replicas: 1
selector:
matchLabels:
app: smb-server
strategy:
type: Recreate
template:
metadata:
name: smb-server
labels:
app: smb-server
spec:
volumes:
- name: smb-volume
hostPath:
path: /zpool/shares/smb
type: DirectoryOrCreate
containers:
- name: smb-server
image: dperson/samba
args: [
"-u",
"$(USERNAME1);$(PASSWORD1)",
"-u",
"$(USERNAME2);$(PASSWORD2)",
"-s",
# name;path;browsable;read-only;guest-allowed;users;admins;writelist;comment
"share;/smbshare/;yes;no;no;all;$(USERNAME1);;mainshare",
"-p"
]
env:
- name: PERMISSIONS
value: "0777"
- name: USERNAME1
valueFrom:
secretKeyRef:
name: smbcredentials
key: username1
- name: PASSWORD1
valueFrom:
secretKeyRef:
name: smbcredentials
key: password1
- name: USERNAME2
valueFrom:
secretKeyRef:
name: smbcredentials
key: username2
- name: PASSWORD2
valueFrom:
secretKeyRef:
name: smbcredentials
key: password2
volumeMounts:
- mountPath: /smbshare
name: smb-volume
ports:
- containerPort: 445
hostPort: 445
```
Обратите внимания, что здесь вместо PV и PVC мы используем `hostPath`. Устанавливаем его `type` как `DirectoryOrCreate,` чтобы каталог был создан в случае его отсутствия.
Мы используем docker-образ [dperson/samba](https://github.com/dperson/samba), который позволяет настраивать пользователей и общие ресурсы на лету. Здесь я указываю один общий ресурс с двумя пользователями (с `USERNAME1` в качестве администратора общего ресурса). Пользователи и пароли берутся из простого файла env:
```
# stacks/samba/auth.env
username1=alice
password1=foo
username2=bob
password2=bar
```
Цель в Makefile:
```
samba:
${KUBECTL} apply -k stacks/samba
```
Ожидаемый результат:
```
> make samba
kubectl --kubeconfig ~/.kube/k3s-vm-config apply -k stacks/samba
secret/smbcredentials-59k7fh7dhm created
service/smb-server created
deployment.apps/smb-server created
```
### Шаг 6 — BookStack
В качестве примера использования Kompose для преобразования `docker-compose.yaml` в файлы K8s воспользуемся отличным wiki-приложением [BookStack](https://github.com/BookStackApp/BookStack).
Это мой оригинальный `docker-compose` файл для BookStack:
```
version: '2'
services:
mysql:
image: mysql:5.7.33
environment:
- MYSQL_ROOT_PASSWORD=secret
- MYSQL_DATABASE=bookstack
- MYSQL_USER=bookstack
- MYSQL_PASSWORD=secret
volumes:
- mysql-data:/var/lib/mysql
ports:
- 3306:3306
bookstack:
image: solidnerd/bookstack:21.05.2
depends_on:
- mysql
environment:
- DB_HOST=mysql:3306
- DB_DATABASE=bookstack
- DB_USERNAME=bookstack
- DB_PASSWORD=secret
volumes:
- uploads:/var/www/bookstack/public/uploads
- storage-uploads:/var/www/bookstack/storage/uploads
ports:
- "8080:8080"
volumes:
mysql-data:
uploads:
storage-uploads:
```
Использовать Kompose просто:
```
> kompose convert -f bookstack-original-compose.yaml
WARN Unsupported root level volumes key - ignoring
WARN Unsupported depends_on key - ignoring
INFO Kubernetes file "bookstack-service.yaml" created
INFO Kubernetes file "mysql-service.yaml" created
INFO Kubernetes file "bookstack-deployment.yaml" created
INFO Kubernetes file "uploads-persistentvolumeclaim.yaml" created
INFO Kubernetes file "storage-uploads-persistentvolumeclaim.yaml" created
INFO Kubernetes file "mysql-deployment.yaml" created
INFO Kubernetes file "mysql-data-persistentvolumeclaim.yaml" created
```
Облом, нам сразу же говорят, что наши тома и использование `depends_on` не поддерживаются. Но их достаточно легко исправить. В интересах краткости и не делая эту статью длиннее, я просто опубликую окончательный результат с некоторыми примечаниями.
```
# stacks/bookstack/kustomization.yaml
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
resources:
- bookstack-build.yaml
```
```
# stacks/bookstack/bookstack-build.yaml
apiVersion: v1
kind: Service
metadata:
labels:
io.kompose.service: bookstack
name: bookstack
spec:
ports:
- name: bookstack-port
port: 10000
targetPort: 8080
- name: bookstack-db-port
port: 10001
targetPort: 3306
selector:
io.kompose.service: bookstack
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: bookstack-storage-uploads-pv
spec:
capacity:
storage: 5Gi
hostPath:
path: >-
/zpool/volumes/bookstack/storage-uploads
type: DirectoryOrCreate
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: local-path
volumeMode: Filesystem
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
labels:
io.kompose.service: bookstack-storage-uploads-pvc
name: bookstack-storage-uploads-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
storageClassName: local-path
volumeName: bookstack-storage-uploads-pv
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: bookstack-uploads-pv
spec:
capacity:
storage: 5Gi
hostPath:
path: >-
/zpool/volumes/bookstack/uploads
type: DirectoryOrCreate
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: local-path
volumeMode: Filesystem
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
labels:
io.kompose.service: bookstack-uploads-pvc
name: bookstack-uploads-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
storageClassName: local-path
volumeName: bookstack-uploads-pv
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: bookstack-mysql-data-pv
spec:
capacity:
storage: 5Gi
hostPath:
path: >-
/zpool/volumes/bookstack/mysql-data
type: DirectoryOrCreate
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: local-path
volumeMode: Filesystem
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
labels:
io.kompose.service: bookstack-mysql-data-pvc
name: bookstack-mysql-data-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
storageClassName: local-path
volumeName: bookstack-mysql-data-pv
---
apiVersion: v1
kind: ConfigMap
metadata:
name: bookstack-config
namespace: default
data:
DB_DATABASE: bookstack
DB_HOST: bookstack:10001
DB_PASSWORD: secret
DB_USERNAME: bookstack
APP_URL: https://bookstack.domain.tld
MAIL_DRIVER: smtp
MAIL_ENCRYPTION: SSL
MAIL_FROM: [email protected]
MAIL_HOST: smtp.domain.tld
MAIL_PASSWORD: vewyvewysecretpassword
MAIL_PORT: "465"
MAIL_USERNAME: [email protected]
---
apiVersion: v1
kind: ConfigMap
metadata:
name: bookstack-mysql-config
namespace: default
data:
MYSQL_DATABASE: bookstack
MYSQL_PASSWORD: secret
MYSQL_ROOT_PASSWORD: secret
MYSQL_USER: bookstack
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
io.kompose.service: bookstack
name: bookstack
spec:
replicas: 1
selector:
matchLabels:
io.kompose.service: bookstack
strategy:
type: Recreate
template:
metadata:
labels:
io.kompose.service: bookstack
spec:
containers:
- name: bookstack
image: reddexx/bookstack:21112
securityContext:
allowPrivilegeEscalation: false
envFrom:
- configMapRef:
name: bookstack-config
ports:
- containerPort: 8080
volumeMounts:
- name: bookstack-uploads-pv
mountPath: /var/www/bookstack/public/uploads
- name: bookstack-storage-uploads-pv
mountPath: /var/www/bookstack/storage/uploads
- name: mysql
image: mysql:5.7.33
envFrom:
- configMapRef:
name: bookstack-mysql-config
ports:
- containerPort: 3306
volumeMounts:
- mountPath: /var/lib/mysql
name: bookstack-mysql-data-pv
volumes:
- name: bookstack-uploads-pv
persistentVolumeClaim:
claimName: bookstack-uploads-pvc
- name: bookstack-storage-uploads-pv
persistentVolumeClaim:
claimName: bookstack-storage-uploads-pvc
- name: bookstack-mysql-data-pv
persistentVolumeClaim:
claimName: bookstack-mysql-data-pvc
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: bookstack-ingress
annotations:
kubernetes.io/ingress.class: nginx
cert-manager.io/cluster-issuer: letsencrypt-staging
spec:
rules:
- host: bookstack.domain.tld
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: bookstack
port:
name: bookstack-port
tls:
- hosts:
- bookstack.domain.tld
secretName: bookstack-staging-secret-tls
```
Kompose преобразует оба контейнера внутри файла `docker-compose` в сервисы, однако я превратил их в один сервис.
Обратите внимание, как config map содержит всю конфигурацию приложения, а затем вводится в конфигурацию развертывание с помощью:
```
envFrom:
- configMapRef:
name: bookstack-config
```
Сегмент `chown` в Makefile связан с особенностью установки docker-образа BookStack. У большинства образов этой проблемы нет, однако PHP-образы ею славятся. Без надлежащих прав для директории на сервере загрузка в wiki не будет работать. Но в нашем Makefile это учитывается:
```
bookstack:
${KUBECTL} apply -k stacks/bookstack
@echo
@echo "waiting for deployments to be ready... "
@${KUBECTL} wait --namespace=default --for=condition=available deployments/bookstack --timeout=60s
@echo
ssh ${HOST} chmod 777 /zpool/volumes/bookstack/storage-uploads/
ssh ${HOST} chmod 777 /zpool/volumes/bookstack/uploads/
```
Здесь мы применяем kustomization и затем ждем, пока оба деплоймента будут готовы, что случится, когда их смонтированные тома будут либо привязаны, либо созданы на сервере. Затем мы подключаемся к серверу по SSH, чтобы изменить владельца томов на правильные идентификаторы пользователей и групп. Не идеально, но работает. Образ MySQL при развертывании в этом не нуждается.
Также внимание, как легко преобразовать директиву `depends_on` из файла `docker-compose`, поскольку поды схожим образом имеют доступ друг к другу по имени.
### Шаг 8 — Все готово!
Полный код [доступен здесь](https://github.com/sardaukar/k8s-at-home-with-k3s). Приведем весь Makefile для завершения картины:
```
# set your host IP and name
HOST_IP=192.168.1.60
HOST=k3s
#### don't change anything below this line!
KUBECTL=kubectl --kubeconfig ~/.kube/k3s-vm-config
.PHONY: k3s_install base bookstack portainer samba
k3s_install:
ssh ${HOST} 'export INSTALL_K3S_EXEC=" --no-deploy servicelb --no-deploy traefik"; \
curl -sfL https://get.k3s.io | sh -'
scp ${HOST}:/etc/rancher/k3s/k3s.yaml .
sed -r 's/(\b[0-9]{1,3}\.){3}[0-9]{1,3}\b'/"${HOST_IP}"/ k3s.yaml > ~/.kube/k3s-vm-config && rm k3s.yaml
base:
${KUBECTL} apply -f k8s/ingress-nginx-v1.0.4.yml
${KUBECTL} wait --namespace ingress-nginx \
--for=condition=ready pod \
--selector=app.kubernetes.io/component=controller \
--timeout=60s
${KUBECTL} apply -f k8s/cert-manager-v1.0.4.yaml
@echo
@echo "waiting for cert-manager pods to be ready... "
${KUBECTL} wait --namespace=cert-manager --for=condition=ready pod --all --timeout=60s
${KUBECTL} apply -f k8s/lets-encrypt-staging.yml
${KUBECTL} apply -f k8s/lets-encrypt-prod.yml
bookstack:
${KUBECTL} apply -k stacks/bookstack
@echo
@echo "waiting for deployments to be ready... "
@${KUBECTL} wait --namespace=default --for=condition=available deployments/bookstack --timeout=60s
@echo
ssh ${HOST} chmod 777 /zpool/volumes/bookstack/storage-uploads/
ssh ${HOST} chmod 777 /zpool/volumes/bookstack/uploads/
portainer:
${KUBECTL} apply -k stacks/portainer
samba:
${KUBECTL} apply -k stacks/samba
```
Заключение
----------
Итак, зачем все это было нужно? Мне потребовалось несколько дней, чтобы все заработало, и я несколько раз бился головой об монитор, однако процесс дал лучшее понимание того, как Kubernetes работает под капотом, как его отлаживать, и теперь с этим Makefile мне требуется всего 4 минуты, чтобы воссоздать конфигурацию NAS для 3 приложений. У меня есть еще дюжина старых `docker-compose` приложений, которые нужно преобразовать, но с каждым разом это все проще.
[](https://cloud.timeweb.com/?utm_source=habr&utm_medium=banner&utm_campaign=cloud&utm_content=direct&utm_term=low) | https://habr.com/ru/post/594533/ | null | ru | null |
# Crime, Race and Lethal Force in the USA — Part 2

In the [previous part](https://habr.com/ru/post/519154/) of this article, I talked about the research background, goals, assumptions, source data, and used tools. Today, without further ado, let's say together…
Chocks Away!
------------
We start by importing the required packages and defining the root folder where the source data sit:
```
import pandas as pd, numpy as np
# root folder path (change for your own!)
ROOT_FOLDER = r'c:\_PROG_\Projects\us_crimes'
```
Lethal Force Fatalities
-----------------------
First let's look into the use of lethal force data. Load the CSV into a new DataFrame:
```
# FENC source CSV
FENC_FILE = ROOT_FOLDER + '\\fatal_enc_db.csv'
# read to DataFrame
df_fenc = pd.read_csv(FENC_FILE, sep=';', header=0, usecols=["Date (Year)", "Subject's race with imputations", "Cause of death", "Intentional Use of Force (Developing)", "Location of death (state)"])
```
You will note that not all the fields are loaded, but only those we'll need in the research: year, victim race (with imputations), cause of death (not used now but may come in useful later on), intentional use of force flag, and the state where the death took place.
It's worth understanding what «subject's race with imputations» means. The fact is, the official / media sources that FENC uses to glean data don't always report the victim's race, resulting in data gaps. To compensate these gaps, the FENC community involves third-party experts who estimate the race by the other available data (with some degree of error). You can read more on this on the [FENC website](https://fatalencounters.org/) or see notes in the original [Excel spreadsheet](https://docs.google.com/spreadsheets/d/1dKmaV_JiWcG8XBoRgP8b4e9Eopkpgt7FL7nyspvzAsE/edit#gid=0) (sheet 2).
We'll then give the columns handier titles and drop the rows with missing data:
```
df_fenc.columns = ['Race', 'State', 'Cause', 'UOF', 'Year']
df_fenc.dropna(inplace=True)
```
Now we hava to unify the race categories with those used in the crime and population datasets we are going to match with, since these datasets use somewhat different racial classifications. The FENC database, for one, singles out the Hispanic/Latino ethnicity, as well as Asian/Pacific Islanders and Middle Easterns. But in this research, we're focusing on Blacks and Whites only. So we must make some aggregation / renaming:
```
df_fenc = df_fenc.replace({'Race': {'European-American/White': 'White',
'African-American/Black': 'Black',
'Hispanic/Latino': 'White', 'Native American/Alaskan': 'American Indian',
'Asian/Pacific Islander': 'Asian', 'Middle Eastern': 'Asian',
'NA': 'Unknown', 'Race unspecified': 'Unknown'}}, value=None)
```
We are leaving only White (now including Hispanic/Latino) and Black victims:
```
df_fenc = df_fenc.loc[df_fenc['Race'].isin(['White', 'Black'])]
```
What's the purpose of the UOF (Use Of Force) field? For this research, we want to analyze only those cases when the police (or other law enforcement agencies) *intentionally* used lethal force. We leave out cases when the death was the result of suicide (for example, when sieged by the police) or pursuit and crash in a vehicle. This constraint follows from two criteria:
1) the circumstances of deaths not directly resulting from use of force don't normally allow of a transparent cause-and-effect link between the acts of the law enforcement officers and the ensuing death (one example could be when a man dies from a heart attack when held at gun-point by a police officer; another common example is when a suspect being arrested shoots him/herself in the head);
2) it is only intentional use of force that counts in official statistics; thus, for instance, the future FBI database I mentioned in the previous part of the article will collect only such cases.
So to leave only intentional use of force cases:
```
df_fenc = df_fenc.loc[df_fenc['UOF'].isin(['Deadly force', 'Intentional use of force'])]
```
For convenience we'll add the full state names. I made a separate [CSV file](https://yadi.sk/d/Fb5NOSiLiVXwDA) for that purpose, which we're now merging with our data:
```
df_state_names = pd.read_csv(ROOT_FOLDER + '\\us_states.csv', sep=';', header=0)
df_fenc = df_fenc.merge(df_state_names, how='inner', left_on='State', right_on='state_abbr')
```
Type `df_fenc.head()` to peek at the resulting dataset:
| | Race | State | Cause | UOF | Year | state\_name | state\_abbr |
| --- | --- | --- | --- | --- | --- | --- | --- |
| 0 | Black | GA | Gunshot | Deadly force | 2000 | Georgia | GA |
| 1 | Black | GA | Gunshot | Deadly force | 2000 | Georgia | GA |
| 2 | Black | GA | Gunshot | Deadly force | 2000 | Georgia | GA |
| 3 | Black | GA | Gunshot | Deadly force | 2000 | Georgia | GA |
| 4 | Black | GA | Gunshot | Deadly force | 2000 | Georgia | GA |
Since we're not going to investigate the individual cases, let's aggregate the data by years and victim races:
```
# group by year and race
ds_fenc_agg = df_fenc.groupby(['Year', 'Race']).count()['Cause']
df_fenc_agg = ds_fenc_agg.unstack(level=1)
# cast numericals to UINT16 to save memory
df_fenc_agg = df_fenc_agg.astype('uint16')
```
The resulting table is indexed by years (2000 — 2020) and contains two columns: 'White' (number of white victims) and 'Black' (number of black victims). Let's take a look at the corresponding plot:
```
plt = df_fenc_agg.plot(xticks=df_fenc_agg.index, color=['olive', 'g'])
plt.set_xticklabels(df_fenc_agg.index, rotation='vertical')
plt.set_xlabel('')
plt.set_ylabel('Number of police victims')
plt
```
[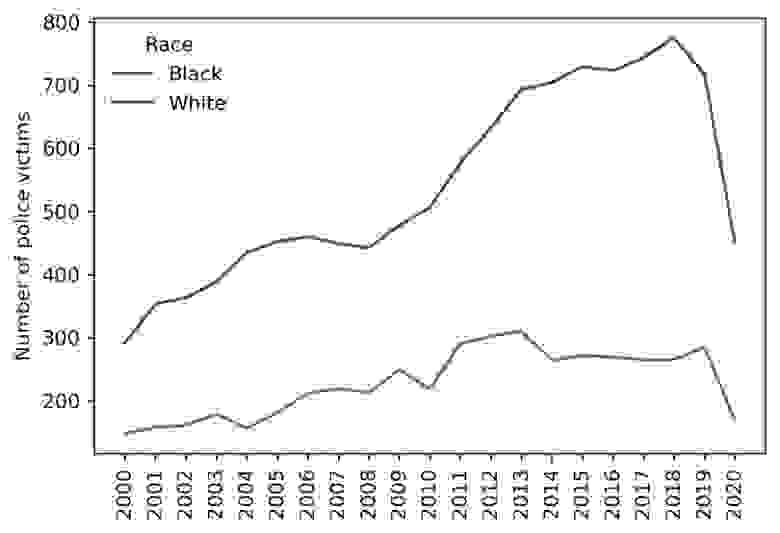](https://habrastorage.org/webt/ck/uv/7o/ckuv7orp_udcp6ieq19v614ca00.jpeg)
**Intermediate conclusion:**
> White police victims outnumber black victims in absolute figures.
>
>
The average difference factor between the two is about 2.4. It's not a far guess that this is due to the difference between the population of the two races in the US. Well, let's look at per capita values then.
Load the population data:
```
# population CSV file (1991 - 2018 data points)
POP_FILE = ROOT_FOLDER + '\\us_pop_1991-2018.csv'
df_pop = pd.read_csv(POP_FILE, index_col=0, dtype='int64')
```
Then merge the data with our dataset:
```
# take only Black and White population for 2000 - 2018
df_pop = df_pop.loc[2000:2018, ['White_pop', 'Black_pop']]
# join dataframes and drop rows with missing values
df_fenc_agg = df_fenc_agg.join(df_pop)
df_fenc_agg.dropna(inplace=True)
# cast population numbers to integer type
df_fenc_agg = df_fenc_agg.astype({'White_pop': 'uint32', 'Black_pop': 'uint32'})
```
OK. Finally, create two new columns with per capita (per million) values dividing the abosulte victim counts by the respective race population and multiplying by one million:
```
df_fenc_agg['White_promln'] = df_fenc_agg['White'] * 1e6 / df_fenc_agg['White_pop']
df_fenc_agg['Black_promln'] = df_fenc_agg['Black'] * 1e6 / df_fenc_agg['Black_pop']
```
Let's see what we get:
| | Black | White | White\_pop | Black\_pop | White\_promln | Black\_promln |
| --- | --- | --- | --- | --- | --- | --- |
| Year | | | | | | |
| 2000 | 148 | 291 | 218756353 | 35410436 | 1.330247 | 4.179559 |
| 2001 | 158 | 353 | 219843871 | 35758783 | 1.605685 | 4.418495 |
| 2002 | 161 | 363 | 220931389 | 36107130 | 1.643044 | 4.458953 |
| 2003 | 179 | 388 | 222018906 | 36455476 | 1.747599 | 4.910099 |
| 2004 | 157 | 435 | 223106424 | 36803823 | 1.949742 | 4.265861 |
| 2005 | 181 | 452 | 224193942 | 37152170 | 2.016112 | 4.871855 |
| 2006 | 212 | 460 | 225281460 | 37500517 | 2.041890 | 5.653255 |
| 2007 | 219 | 449 | 226368978 | 37848864 | 1.983487 | 5.786171 |
| 2008 | 213 | 442 | 227456495 | 38197211 | 1.943229 | 5.576323 |
| 2009 | 249 | 478 | 228544013 | 38545558 | 2.091501 | 6.459888 |
| 2010 | 219 | 506 | 229397472 | 38874625 | 2.205778 | 5.633495 |
| 2011 | 290 | 577 | 230838975 | 39189528 | 2.499578 | 7.399936 |
| 2012 | 302 | 632 | 231992377 | 39623138 | 2.724227 | 7.621809 |
| 2013 | 310 | 693 | 232969901 | 39919371 | 2.974633 | 7.765653 |
| 2014 | 264 | 704 | 233963128 | 40379066 | 3.009021 | 6.538041 |
| 2015 | 272 | 729 | 234940100 | 40695277 | 3.102919 | 6.683822 |
| 2016 | 269 | 723 | 234644039 | 40893369 | 3.081263 | 6.578084 |
| 2017 | 265 | 743 | 235507457 | 41393491 | 3.154889 | 6.401973 |
| 2018 | 265 | 775 | 236173020 | 41617764 | 3.281493 | 6.367473 |
The two rightmost columns now contain per million victim counts for both races. Time to visualize that:
```
plt = df_fenc_agg.loc[:, ['White_promln', 'Black_promln']].plot(xticks=df_fenc_agg.index, color=['g', 'olive'])
plt.set_xticklabels(df_fenc_agg.index, rotation='vertical')
plt.set_xlabel('')
plt.set_ylabel('Number of police victims\nper 1 mln. within race')
plt
```
[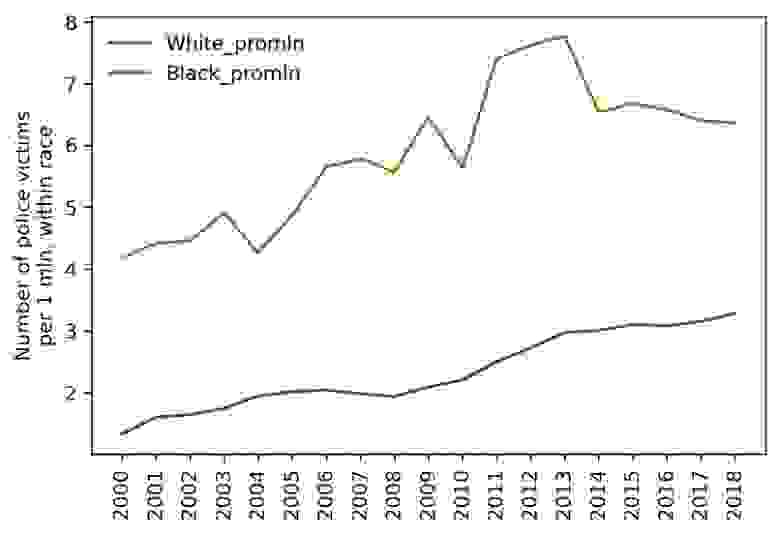](https://habrastorage.org/webt/uq/ku/vd/uqkuvdrtqjwwntliqrl3uc014ca.jpeg)
We'll also display the basic stats for this data by running:
```
df_fenc_agg.loc[:, ['White_promln', 'Black_promln']].describe()
```
| | White\_promln | Black\_promln |
| --- | --- | --- |
| count | 19.000000 | 19.000000 |
| **mean** | **2.336123** | **5.872145** |
| **std** | **0.615133** | **1.133677** |
| min | 1.330247 | 4.179559 |
| 25% | 1.946485 | 4.890977 |
| 50% | 2.091501 | 5.786171 |
| 75% | 2.991827 | 6.558062 |
| max | 3.281493 | 7.765653 |
**Intermediate conclusions:**
> 1. Lethal force results on average in 5.9 per one million Black deaths and 2.3 per one million White deaths (Black victim count is 2.6 greater in unit values).
> 2. Data deviation (scatter) for Blacks is 1.8 higher than for Whites — you can see that the green curve representing White victims is considerably smoother.
> 3. Black victims peaked in 2013 at 7.7 per million; White victims peaked in 2018 at 3.3 per million.
> 4. White victims grow continuously from year to year (by 0.1 — 0.2 per million on average), while Black victims rolled back to their 2009 level after a climax in 2011 — 2013.
>
>
>
>
Thus, we can answer our **first question**:
— ***Can one say the police kill Blacks more frequently than Whites?***
— **Yes, it is a correct inference. Blacks are 2.6 times more likely to meet death by the hands of law enforcement agencies than Whites.**
Bearing in mind this inference, let's go ahead and look at the crime data to see if (and how) they are related to lethal force fatalities and races.
Crime Data
----------
Let's load our crime CSV:
```
CRIMES_FILE = ROOT_FOLDER + '\\culprits_victims.csv'
df_crimes = pd.read_csv(CRIMES_FILE, sep=';', header=0,
index_col=0, usecols=['Year', 'Offense', 'Offender/Victim', 'White',
'White pro capita', 'Black', 'Black pro capita'])
```
Again, as before, we're using only the relevant fields: year, offense type, offender / victim classifier and offense counts for each race (absolute — 'White', 'Black' and per capita — 'White pro capita', 'Black pro capita').
Let's look what we have here (with `df_crimes.head()`):
| | Offense | Offender/Victim | Black | White | Black pro capita | White pro capita |
| --- | --- | --- | --- | --- | --- | --- |
| Year | | | | | | |
| 1991 | All Offenses | Offender | 490 | 598 | 1.518188e-05 | 2.861673e-06 |
| 1991 | All Offenses | Offender | 4 | 4 | 1.239337e-07 | 1.914160e-08 |
| 1991 | All Offenses | Offender | 508 | 122 | 1.573958e-05 | 5.838195e-07 |
| 1991 | All Offenses | Offender | 155 | 176 | 4.802432e-06 | 8.422314e-07 |
| 1991 | All Offenses | Offender | 13 | 19 | 4.027846e-07 | 9.092270e-08 |
We won't need data on offense victims so far, so get rid of them:
```
# leave only offenders
df_crimes1 = df_crimes.loc[df_crimes['Offender/Victim'] == 'Offender']
# leave only 2000 - 2018 data years and remove redundant columns
df_crimes1 = df_crimes1.loc[2000:2018, ['Offense', 'White', 'White pro capita', 'Black', 'Black pro capita']]
```
Here's the resulting dataset (1295 rows \* 5 columns):
| | Offense | White | White pro capita | Black | Black pro capita |
| --- | --- | --- | --- | --- | --- |
| Year | | | | | |
| 2000 | All Offenses | 679 | 0.000003 | 651 | 0.000018 |
| 2000 | All Offenses | 11458 | 0.000052 | 30199 | 0.000853 |
| 2000 | All Offenses | 4439 | 0.000020 | 3188 | 0.000090 |
| 2000 | All Offenses | 10481 | 0.000048 | 5153 | 0.000146 |
| 2000 | All Offenses | 746 | 0.000003 | 63 | 0.000002 |
| ... | ... | ... | ... | ... | ... |
| 2018 | Larceny Theft Offenses | 1961 | 0.000008 | 1669 | 0.000040 |
| 2018 | Larceny Theft Offenses | 48616 | 0.000206 | 30048 | 0.000722 |
| 2018 | Drugs Narcotic Offenses | 555974 | 0.002354 | 223398 | 0.005368 |
| 2018 | Drugs Narcotic Offenses | 305052 | 0.001292 | 63785 | 0.001533 |
| 2018 | Weapon Law Violation | 70034 | 0.000297 | 58353 | 0.001402 |
Now we need to convert the per capita (per 1 person) values to per million values (in keeping with the unit data we use throughout the research). Just multiply the per capita columns by one million:
```
df_crimes1['White_promln'] = df_crimes1['White pro capita'] * 1e6
df_crimes1['Black_promln'] = df_crimes1['Black pro capita'] * 1e6
```
To see the whole picture — how crimes committed by Whites and Blacks are distributed across the offense types, let's aggregate the absolute crime counts by years:
```
df_crimes_agg = df_crimes1.groupby(['Offense']).sum().loc[:, ['White', 'Black']]
```
| | White | Black |
| --- | --- | --- |
| Offense | | |
| All Offenses | 44594795 | 22323144 |
| Assault Offenses | 12475830 | 7462272 |
| Drugs Narcotic Offenses | 9624596 | 3453140 |
| Larceny Theft Offenses | 9563917 | 4202235 |
| Murder And Nonnegligent Manslaughter | 28913 | 39617 |
| Sex Offenses | 833088 | 319366 |
| Weapon Law Violation | 829485 | 678861 |
Or in a graph:
```
plt = df_crimes_agg.plot.barh(color=['g', 'olive'])
plt.set_ylabel('')
plt.set_xlabel('Number of offenses (sum for 2000-2018)')
```
[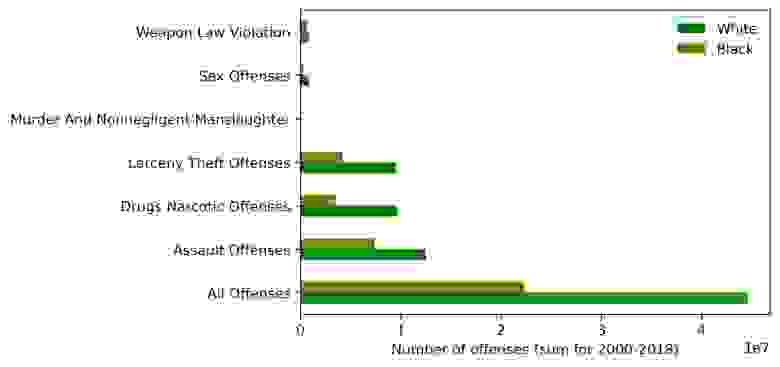](https://habrastorage.org/webt/a3/lw/wz/a3lwwz2zux5w9azxhbyguwsm7we.jpeg)
We can observe here that:
* drug offenses, assaults and 'All Offenses' dominate over the other offense types (murder, weapon law violations and sex offenses)
* in absolute figures, Whites commit more crimes than Blacks (exactly twice as much for the 'All Offenses' category)
Again we realize that no robust conclusions can be made about 'race criminality' without population data. So we're looking at per capita (per million) values:
```
df_crimes_agg1 = df_crimes1.groupby(['Offense']).sum().loc[:, ['White_promln', 'Black_promln']]
```
| | White\_promln | Black\_promln |
| --- | --- | --- |
| Offense | | |
| All Offenses | 194522.307758 | 574905.952459 |
| Assault Offenses | 54513.398833 | 192454.602875 |
| Drugs Narcotic Offenses | 41845.758869 | 88575.523095 |
| Larceny Theft Offenses | 41697.303725 | 108189.184125 |
| Murder And Nonnegligent Manslaughter | 125.943007 | 1016.403706 |
| Sex Offenses | 3633.777035 | 8225.144985 |
| Weapon Law Violation | 3612.671402 | 17389.163849 |
Or as a graph:
```
plt = df_crimes_agg1.plot.barh(color=['g', 'olive'])
plt.set_ylabel('')
plt.set_xlabel('Number of offenses (sum for 2000-2018) per 1 mln. within race')
```
[](https://habrastorage.org/webt/w1/xo/js/w1xojs5kjf-urlypjndmcobis5c.jpeg)
We've got quite a different picture this time. Blacks commit more crimes for each analyzed category than Whites, approaching a triple difference for 'All Offenses'.
We will now leave only the 'All Offenses' category as the most representative of the 7 and sum up the rows by years (since the source data may feature several entries per year, matching the number of reporting agencies).
```
# leave only 'All Offenses' category
df_crimes1 = df_crimes1.loc[df_crimes1['Offense'] == 'All Offenses']
# could also have left assault and murder (try as experiment!)
#df_crimes1 = df_crimes1.loc[df_crimes1['Offense'].str.contains('Assault|Murder')]
# drop absolute columns and aggregate data by years
df_crimes1 = df_crimes1.groupby(level=0).sum().loc[:, ['White_promln', 'Black_promln']]
```
The resulting dataset:
| | White\_promln | Black\_promln |
| --- | --- | --- |
| Year | | |
| 2000 | 6115.058976 | 17697.409882 |
| 2001 | 6829.701429 | 20431.707645 |
| 2002 | 7282.333249 | 20972.838329 |
| 2003 | 7857.691182 | 22218.966500 |
| 2004 | 8826.576863 | 26308.815799 |
| 2005 | 9713.826255 | 30616.569637 |
| 2006 | 10252.894313 | 33189.382429 |
| 2007 | 10566.527362 | 34100.495064 |
| 2008 | 10580.520024 | 34052.276749 |
| 2009 | 10889.263592 | 33954.651792 |
| 2010 | 10977.017218 | 33884.236826 |
| 2011 | 11035.346176 | 32946.454471 |
| 2012 | 11562.836825 | 33150.706035 |
| 2013 | 11211.113491 | 32207.571607 |
| 2014 | 11227.354594 | 31517.346141 |
| 2015 | 11564.786088 | 31764.865490 |
| 2016 | 12193.026562 | 33186.064958 |
| 2017 | 12656.261666 | 34900.390499 |
| 2018 | 13180.171893 | 37805.202605 |
Let's see how it looks on a plot:
```
plt = df_crimes1.plot(xticks=df_crimes1.index, color=['g', 'olive'])
plt.set_xticklabels(df_fenc_agg.index, rotation='vertical')
plt.set_xlabel('')
plt.set_ylabel('Number of offenses\nper 1 mln. within race')
```
[](https://habrastorage.org/webt/c8/6n/xu/c86nxuwdqvodtjkpugnnknvkjpa.jpeg)
**Intermediate conclusions**:
> 1. Whites commit twice as many offenses as Blacks in absolute numbers, but three times as fewer in per capita numbers (per 1 million population within that race).
> 2. Criminality among Whites grows more or less steadily over the entire period of investigation (doubled over 19 years). Criminality among Blacks also grows, but by leaps and starts, showing steep growth from 2001 to 2006, then abating slightly over 2007 — 2016 and plummeting again after 2017. Over the entire period, however, the growth factor is also 2, like with Whites.
> 3. But for the period of decrease in 2007 — 2016, criminality among Blacks grows at a higher rate than that among Whites.
>
>
>
>
We can therefore answer our **second question**:
— ***Which race is statistically more prone to crime?***
— **Crimes committed by Blacks are three times more frequent than crimes committed by Whites.**
Criminality and Lethal Force Fatalities
---------------------------------------
We've now come to the most important part. Let's see if we can answer the third question: *Can one say the police kills in proportion to the number of crimes?*
The question boils down to looking at the correlation between our two datasets — use of force data (from the FENC database) and crime data (from the FBI database).
We start by routinely merging the two datasets into one:
```
# glue together the FENC and CRIMES dataframes
df_uof_crimes = df_fenc_agg.join(df_crimes1, lsuffix='_uof', rsuffix='_cr')
# we won't need the first 2 columns (absolute FENC values), so get rid of them
df_uof_crimes = df_uof_crimes.loc[:, 'White_pop':'Black_promln_cr']
```
The resulting combined data:
| | White\_pop | Black\_pop | White\_promln\_uof | Black\_promln\_uof | White\_promln\_cr | Black\_promln\_cr |
| --- | --- | --- | --- | --- | --- | --- |
| Year | | | | | | |
| 2000 | 218756353 | 35410436 | 1.330247 | 4.179559 | 6115.058976 | 17697.409882 |
| 2001 | 219843871 | 35758783 | 1.605685 | 4.418495 | 6829.701429 | 20431.707645 |
| 2002 | 220931389 | 36107130 | 1.643044 | 4.458953 | 7282.333249 | 20972.838329 |
| 2003 | 222018906 | 36455476 | 1.747599 | 4.910099 | 7857.691182 | 22218.966500 |
| 2004 | 223106424 | 36803823 | 1.949742 | 4.265861 | 8826.576863 | 26308.815799 |
| 2005 | 224193942 | 37152170 | 2.016112 | 4.871855 | 9713.826255 | 30616.569637 |
| 2006 | 225281460 | 37500517 | 2.041890 | 5.653255 | 10252.894313 | 33189.382429 |
| 2007 | 226368978 | 37848864 | 1.983487 | 5.786171 | 10566.527362 | 34100.495064 |
| 2008 | 227456495 | 38197211 | 1.943229 | 5.576323 | 10580.520024 | 34052.276749 |
| 2009 | 228544013 | 38545558 | 2.091501 | 6.459888 | 10889.263592 | 33954.651792 |
| 2010 | 229397472 | 38874625 | 2.205778 | 5.633495 | 10977.017218 | 33884.236826 |
| 2011 | 230838975 | 39189528 | 2.499578 | 7.399936 | 11035.346176 | 32946.454471 |
| 2012 | 231992377 | 39623138 | 2.724227 | 7.621809 | 11562.836825 | 33150.706035 |
| 2013 | 232969901 | 39919371 | 2.974633 | 7.765653 | 11211.113491 | 32207.571607 |
| 2014 | 233963128 | 40379066 | 3.009021 | 6.538041 | 11227.354594 | 31517.346141 |
| 2015 | 234940100 | 40695277 | 3.102919 | 6.683822 | 11564.786088 | 31764.865490 |
| 2016 | 234644039 | 40893369 | 3.081263 | 6.578084 | 12193.026562 | 33186.064958 |
| 2017 | 235507457 | 41393491 | 3.154889 | 6.401973 | 12656.261666 | 34900.390499 |
| 2018 | 236173020 | 41617764 | 3.281493 | 6.367473 | 13180.171893 | 37805.202605 |
Let me refresh you memory on the individual columns here:
1. **White\_pop** — White population
2. **Black\_pop** — Black population
3. **White\_promln\_uof** — White lethal force victims per 1 million Whites
4. **Black\_promln\_uof** — Black lethal force victims per 1 million Blacks
5. **White\_promln\_cr** — Number of crimes committed by Whites per 1 million Whites
6. **Black\_promln\_cr** — Number of crimes committed by Blacks per 1 million Blacks
We next want to see how the police victim and crime curves compare on one plot. For Whites:
```
plt = df_uof_crimes['White_promln_cr'].plot(xticks=df_uof_crimes.index, legend=True)
plt.set_ylabel('Number of White offenses per 1 mln. within race')
plt2 = df_uof_crimes['White_promln_uof'].plot(xticks=df_uof_crimes.index, legend=True, secondary_y=True, style='g')
plt2.set_ylabel('Number of White UOF victims per 1 mln. within race', rotation=90)
plt2.set_xlabel('')
plt.set_xlabel('')
plt.set_xticklabels(df_uof_crimes.index, rotation='vertical')
```
[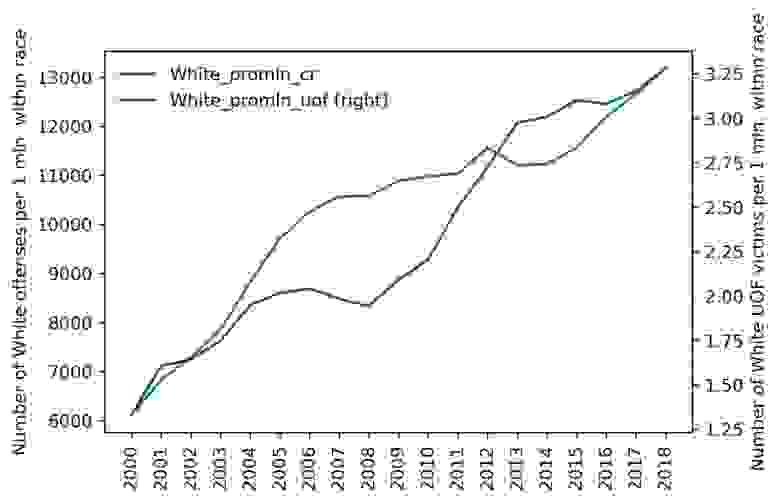](https://habrastorage.org/webt/cg/qy/bi/cgqybi1swb60nc9l20nyws-7au0.jpeg)
The same on a scatter plot:
```
plt = df_uof_crimes.plot.scatter(x='White_promln_cr', y='White_promln_uof')
plt.set_xlabel('Number of White offenses per 1 mln. within race')
plt.set_ylabel('Number of White UOF victims per 1 mln. within race')
```
[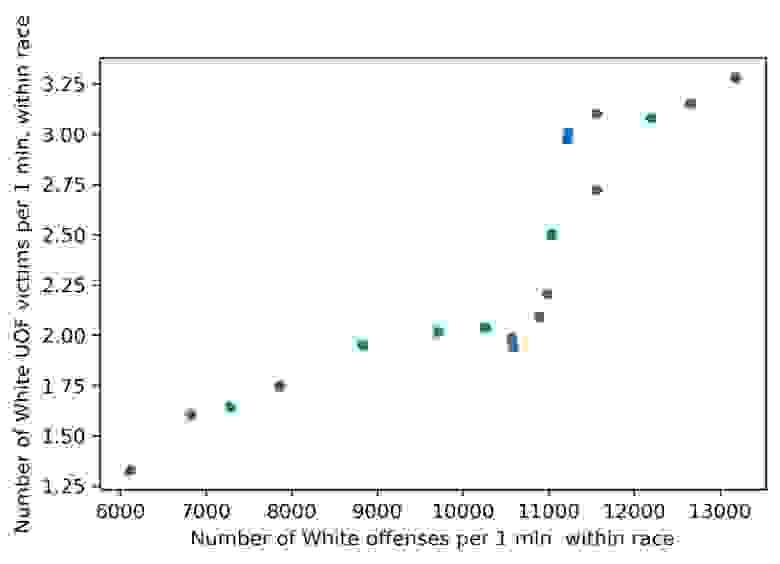](https://habrastorage.org/webt/mo/me/oi/momeoiwaxj_fqy4mzostuzvnons.jpeg)
A quick look at the graphs shows that some correlation is present. OK, now for Blacks:
```
plt = df_uof_crimes['Black_promln_cr'].plot(xticks=df_uof_crimes.index, legend=True)
plt.set_ylabel('Number of Black offenses per 1 mln. within race')
plt2 = df_uof_crimes['Black_promln_uof'].plot(xticks=df_uof_crimes.index, legend=True, secondary_y=True, style='g')
plt2.set_ylabel('Number of Black UOF victims per 1 mln. within race', rotation=90)
plt2.set_xlabel('')
plt.set_xlabel('')
plt.set_xticklabels(df_uof_crimes.index, rotation='vertical')
```
[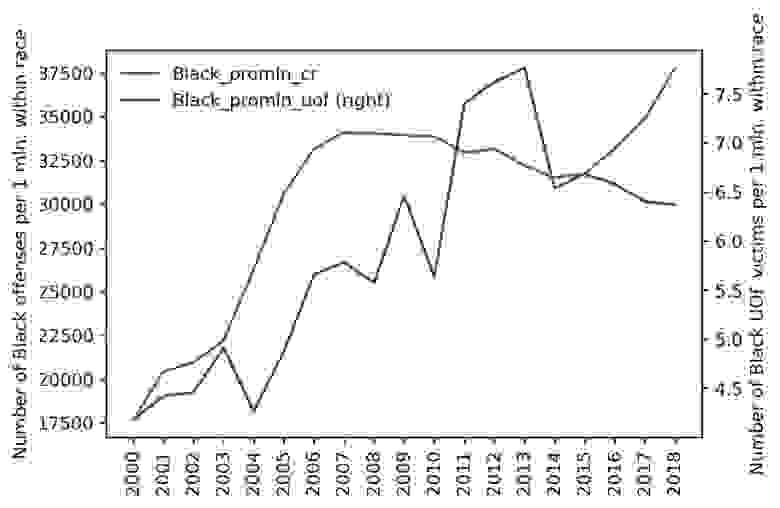](https://habrastorage.org/webt/8n/lo/pw/8nlopwra5t46nofeennonmaht1e.jpeg)
And on a scatter plot:
```
plt = df_uof_crimes.plot.scatter(x='Black_promln_cr', y='Black_promln_uof')
plt.set_xlabel('Number of Black offenses per 1 mln. within race')
plt.set_ylabel('Number of Black UOF victims per 1 mln. within race')
```
[](https://habrastorage.org/webt/p1/ux/wd/p1uxwdjmgslydeoxtsy5htak9zm.jpeg)
Things are much worse here: the two trends duck and bob a lot, though the principle correlation is still visible, the proportion is positive, if non-linear.
We will make use of statistical methods to quantify these correlations, making correlation matrices estimated with the [Pearson correlation coefficient](https://en.wikipedia.org/wiki/Pearson_correlation_coefficient):
```
df_corr = df_uof_crimes.loc[:, ['White_promln_cr', 'White_promln_uof',
'Black_promln_cr', 'Black_promln_uof']].corr(method='pearson')
df_corr.style.background_gradient(cmap='PuBu')
```
We get this table:
| | White\_promln\_cr | White\_promln\_uof | Black\_promln\_cr | Black\_promln\_uof |
| --- | --- | --- | --- | --- |
| White\_promln\_cr | 1.000000 | 0.885470 | 0.949909 | 0.802529 |
| White\_promln\_uof | **0.885470** | 1.000000 | 0.710052 | 0.795486 |
| Black\_promln\_cr | 0.949909 | 0.710052 | 1.000000 | **0.722170** |
| Black\_promln\_uof | 0.802529 | 0.795486 | 0.722170 | 1.000000 |
The correlation coefficients for both races are in bold: it is **0.885** for Whites and **0.722** for Blacks. Thus a positive correlation between lethal force victims and criminality is observed for both races, but it is more prominent for Whites (probably significant) and nears non-significant for Blacks. The latter result is, of course, due to the higher data heterogeneity (scatter) for Black crimes and police victims.
As a final step, let's try to estimate the probability of Black and White offenders to get shot by the police. We have no direct ways to do that, since we don't have information on the criminality of the lethal force victims (who of them was found to be an offender and who was judicially clear). So we can only take the easy path and divide the per capita victim counts by the per capita crime counts for each race and multiply by 100 to show percentage values.
```
# let's look at the aggregate data (with individual year observations collapsed)
df_uof_crimes_agg = df_uof_crimes.loc[:, ['White_promln_cr', 'White_promln_uof',
'Black_promln_cr', 'Black_promln_uof']].agg(['mean', 'sum', 'min', 'max'])
# now calculate the percentage of fatal encounters from the total crime count in each race
df_uof_crimes_agg['White_uof_cr'] = df_uof_crimes_agg['White_promln_uof'] * 100. /
df_uof_crimes_agg['White_promln_cr']
df_uof_crimes_agg['Black_uof_cr'] = df_uof_crimes_agg['Black_promln_uof'] * 100. /
df_uof_crimes_agg['Black_promln_cr']
```
We get this table:
| | White\_promln\_cr | White\_promln\_uof | Black\_promln\_cr | Black\_promln\_uof | White\_uof\_cr | Black\_uof\_cr |
| --- | --- | --- | --- | --- | --- | --- |
| mean | 10238.016198 | 2.336123 | 30258.208024 | 5.872145 | **0.022818** | **0.019407** |
| sum | 194522.307758 | 44.386338 | 574905.952459 | 111.570747 | 0.022818 | 0.019407 |
| min | 6115.058976 | 1.330247 | 17697.409882 | 4.179559 | 0.021754 | 0.023617 |
| max | 13180.171893 | 3.281493 | 37805.202605 | 7.765653 | 0.024897 | 0.020541 |
Let's show the means (in bold above) as a bar chart:
```
plt = df_uof_crimes_agg.loc['mean', ['White_uof_cr', 'Black_uof_cr']].plot.bar(color=['g', 'olive'])
plt.set_ylabel('Ratio of UOF victims to offense count')
plt.set_xticklabels(['White', 'Black'], rotation=0)
```
[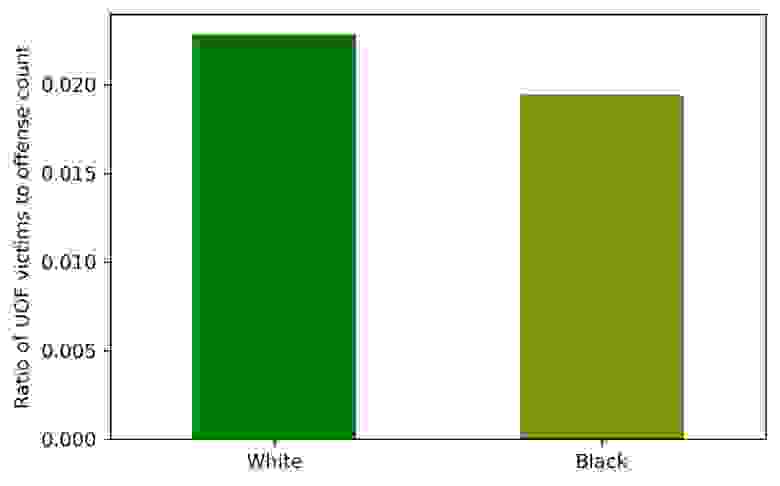](https://habrastorage.org/webt/hd/5-/zv/hd5-zv09i0hrarnffxhubplhmtm.jpeg)
Looking at this chart, you can see that the probability of a White offender to be shot dead by the police is somewhat higher than that of a Black offender. This estimate is certainly quite tentative, but it can give at least some idea.
**Intermediate conclusions**:
> 1. Fatal encounters with law enforcement *are connected* with criminality (number of offenses committed). The correlation though differs between the two races: for Whites, it is almost perfect, for Blacks — far from perfect.
> 2. Looking at the combined police victim / crime charts, it becomes obvious that lethal force victims grow 'in reply to' criminality growth, generally with a few years' lag (this is more conspicuous in the Black data). This phenomenon chimes in with the reasonable notion that the authorities 'react' on criminality (more crimes > more impunity > more closeups with law enforcement > more lethal outcomes).
> 3. White offenders tend to meet death from the police more frequently than Black offenders, although the difference is almost negligible.
>
>
>
>
Finally, the answer to our **third question**:
— ***Can one say the police kills in proportion to the number of crimes?***
— **Yes, this proportion can be observed, though different between the two races: for Whites, it is almost perfect, for Blacks — far from perfect.**
**In the [next (and final) part of the narrative](https://habr.com/ru/post/519640/), we will look into the geographical distribution of the analyzed data across the states.** | https://habr.com/ru/post/519484/ | null | en | null |
# Модуль Bluetooth HC-04 на чипе BC417143B компании CSR
Компания **CSR** (Cambridge Silicon Radio) выпускает специальные чипы для устройств **BlueTooth**. Чипы судя по всему довольно недорогие, потому что господа китайцы предлагают миниатюрные (размером несколько больше симкарты) платки Bluetooth **HC-04** на основе чипа **BC417143B** (семейство **BlueCore4**, см. [1]), которые в России можно купить всего лишь за 6.6 доллара (через dealextreme.com, см. [2] и [3]).

По умолчанию в память FLASH платки HC-04 записано ПО, которое позволяет связать по радио Bluetooth любой наладонник (или телефон, ноутбук и т. п.) со встраиваемой системой на основе микроконтроллера (робот, плата Arduino, любое устройство на микроконтроллере, имеющее TTL-порт UART RS-232). С помощью пакета **CSR CASIRA BLUELAB SDK** (в котором есть рабочие примеры программ Bluetooth) можно самому перепрограммировать модуль HC-04 и создавать свои собственные устройства Bluetooth. Программатор и полноценный аппаратный отладчик для модуля можно легко сделать самому, подключается к компьютеру он через порт LPT (см. [4]). В предлагаемой статье краткое описание инструментария разработки для чипов семейства BlueCore компании CSR, которое можно использовать для быстрого начала написания своих программ для модуля HC-04.
Подробно описывать технические характеристики модуля HC-04 не буду, так как все можно узнать по ссылкам с сайта dealextreme [2]. Напишу только о самом интересном. На борту у модуля стоит чип памяти на 1 мегабайт. Там записано управляющее firmware и все настройки (подробнее далее). На внешние 34 контакта модуля выведены:
— аппаратный **UART**, сигналы TXD, RXD, CTS и RTS.
— последовательный порт **PCM** (для цифрового ввода/вывода звука).
— два аналоговых входа/выхода **AIO**.
— ножка сброса **RESET** (её можно никуда не подключать).
— вход напряжения питания +3.3 вольта, ток потребления максимум 35 мА.
— интерфейс **USB**.
— интерфейс **SPI**, через который прошивается firmware и происходит отладка.
— 12 цифровых порта ввода/вывода **PIO**.
После подачи питания на модуль (3.3 вольта, максимум 35 мА) его можно обнаружить как беспроводное Bluetooth-устройство с профилем последовательного COM-порта. Т. е. на вашем наладоннике (телефоне, ноутбуке и проч.) появится последовательный порт, через который можно напрямую обмениваться данными через TTL-сигналы TX и RX стандартного порта **RS-232**. Firmware HC-04 позволяет AT-командами менять скорость передачи данных в широких пределах (от **1200** до **1382400** бод), причем изменения настройки скорости энергонезависимы, и сохраняются между выключениями питания. Таким образом, благодаря своим малым размерам и низкой цене (в России можно купить за $6.6) модуль HC-04 уже интересен как удобное готовое устройство для беспроводной связи.
Однако, как выяснилось, для модуля HC-04 можно самому писать программы, и записывать их в память чипа. Обзору этих возможностей посвящена основная часть статьи.
#### Инструментарий для разработки
Программатор придется делать самому, так как в России его купить невозможно, никто не продает. Радостно, что схема совсем простая, нет проблем собрать самому. Программатор представляет собой простейший интерфейс **LPT SPI**.

Через этот нехитрый программатор можно слить всю память FLASH модуля HC-04 в двоичные файлы (с помощью утилиты **BlueFlash**), посмотреть и отредактировать настройки модуля и программы (с помощью утилиты **PSTool**). Писать программы firmware и отлаживать (с помощью того же LPT SPI) можно в среде разработки **xIDE**. Имеются многочисленные примеры исходного кода различных устройств Bluetooth, необходимая документация на английском языке. Все эти возможности открываются на операционной системе Windows, если установить CSR CASIRA BLUELAB SDK (инсталляционный пакет занимает примерно 55 мегабайт, после установки занимает 310 мегабайт).
Примеры позволяют создавать устройства Bluetooth роли A (что-то типа мастера Bluetooth, которые сами находят устройства Bluetooth и подключаются к ним. Устройство роли A найти поиском беспроводных устройств невозможно) и роли B (slave устройства Bluetooth, которые можно найти поиском беспроводных устройств). С помощью примеров из CSR CASIRA BLUELAB SDK можно организовать обмен данными между двумя модулями HC-04, в этом случае одно должно реализовать роль A, а другое роль B (штатное firmware, которое записано в HC-04 на заводе, этого делать не позволяет, в нем реализована только роль B).
#### Хранилище настроек, Persistent Store
В память модуля HC-04 вместе с firmware записано множество различных параметров (такие, как адрес Bluetooth, имя устройства, выходная мощность передатчика и проч.), так называемых ключей. Это не просто особенность именно модуля HC-04, так принято в архитектуре BlueCore при программировании приложений. Все ключи могут быть просмотрены утилитой PSTool, при необходимости изменены (если Вы, конечно, понимаете, что делаете) и сохранены в файл **\*.psr**, имеющий удобный текстовый формат. Дамп ключей делается довольно долго (у меня процесс занимал около 2 минут), при этом работа firmware не останавливается. Все ключи, хранящиеся в чипе, разделены по уровням хранения. Уровни привязаны к месту хранения настроек (FLASH, RAM, ROM), а также по времени создания (Implementation, Factory). Ключи каких уровней отображать, выбирают в меню Store (All (TIFR), Implementation Only (I), ROM Only ®, RAM Only (T), Factory Only (F), Not RAM (IFR)). Если один и тот же ключ одновременно определен на разных уровнях и с разными значениями, и выбрано показывать все уровни (All (TIFR)), то будет показано значение ключа, сохраненного на самом верхнем уровне. Значения ключей по умолчанию сохранены в ROM, самый низкий уровень. Ключи времени выполнения сохраняются на самом высоком уровне, Transient (RAM). Несколько уровней сразу обозначаются аббревиатурами из первых букв уровней, например IFR, TIFR. Подробнее об уровнях Persistent Store написано в документе ***blab-ug-008Pb\_PSTool\_User\_Guide.pdf***.
#### Библиотеки BlueCore и SDK компании CSR
В проектах примеров xIDE все тонкости скрыты далеко от глаз пользователя в библиотеках. Библиотеки делятся на 3 класса:
* Foundation Libraries
* Support Libraries
* Profile Libraries
**Foundation Libraries** — основной функционал, низкоуровневая работа с аппаратурой. Поставляется только в бинарном виде, без исходного кода. Заголовочный файл для использования функций Foundation библиотеки — csr.h.
**Support Libraries** — обеспечивают поддержку соединений (RFCOMM, L2CAP и SCO). Заголовочные файлы, и файлы исходного кода находятся в папке ***C:\BlueLab\src\lib***.
**Profile Libraries** — относятся к профилям BlueTooth. Профили – это что-то типа предназначения устройства Bluetooth (например, последовательный порт, аудиоустройство, источник и приемник файлов, интерфейс USB и т. д.). Заголовочные файлы, и файлы исходного кода находятся в папке C:\BlueLab\src\lib.
В чипе BlueCore имеется много разных интерфейсов, источников и приемников данных (Kalimba, PCM, SCO, RFCOMM, L2CAP, UART, Host, USB, HID, Region, File, Audio Notes), которые с помощью библиотек могут достаточно просто соединяться друг стругом и обмениваться данными через потоки (streams). Некоторые источники и приемники данных (Kalimba) относятся к ядрам BlueCore, имеющим на борту DSP. Чип BC417143B, установленный на платке HC-04, относится к семейству BlueCore4 и DSP у него нет. Подробности см. в документе ***CS-110275-UGP1\_Implementing\_Streams\_in\_BlueLab.pdf***.
Для того, чтобы начать использовать библиотеку, нужно подключить директивой #include нужный .h файл и добавить в настройки проекта имя нужной библиотеки Project Properties -> Configuration Properties -> Build System -> Libraries — в поле ввода через запятую указаны имена нужных библиотек (без расширения файла). Библитеки можно пересобрать (процесс довольно долгий!) путем запуска ярлычков BlueLab 41 -> Rebuild -> VM libraries и DSP libraries.
#### Краткое описание xIDE и простейшего приложения
Проекты устройств BlueTooth, которые может найти хост через поиск, имеют суффикс \_b (например spp\_dev\_b). Проекты, которые сами работают как хост, т. е. могут подключить к себе другие устройства BlueTooth, имеют суффикс \_a (например spp\_dev\_a). Устройства с суффиксом \_a нельзя найти хостом через поиск BlueTooth устройств.
Чтобы запустить проект через xIDE, нужно зайти в папку проекта (все проекты демонстрационных примеров находятся в папке ***C:\BlueLab41\apps\examples***) и двойным щелчком запустить файл **\*.xiw** (здесь хранятся настройки Workspace, настройки проекта хранятся в файле **\*.xip**). Автоматически запустится среда разработки xIDE, в которой можно просматривать исходный код проекта и запустить код на компиляцию и отладку. При запуске отладки через LPT SPI автоматически считывается тип чипа, и проект компилируется под него. После компиляции программа автоматически заливается во внешнюю FLASH-память, подключенную к процессору CSR (напомню, что для модулей BlueTooth HC-04 это процессор BC417143B-IQN-E4 (BlueCore4-External device)), и программа запускается на выполнение. После останова отладки, если выключить и снова включить питание, то чип окажется перезаписанным новой скомпилированной программой, которая запустится и начнет работу. Грузится обычный проект а память чипа около минуты (а что Вы хотели от порта LPT?).
Можно самому с нуля написать для HC-04 простейшее приложение, мигающее светодиодом. Для этого нужно запустить xIDE, выбрать Project -> New..., указать тип проекта Bluelab –> Blank VM Project, ввести любое имя проекта (например MyFirstBluelab), выбрать папку для месторасположения проекта (все сделано по аналогии, как в Visual Studio) и нажать OK. Затем нужно создать файл модуля main.c, и ввести туда текст:
``> #include
> #include
>
> #define LED\_1 (1<<1)
>
> typedef struct
> {
> TaskData task;
> uint16 change;
> } ToggleTask;
>
> static void MyHandler (Task t, MessageId id, Message payload)
> {
> uint16 change = ((ToggleTask \*) t)-> change;
> PioSet(change, PioGet() ^ change);
> MessageSendLater (t, 0, 0, 500);
> }
>
> static ToggleTask toggle = { { MyHandler }, LED\_1 };
>
> int main (void)
> {
> PioSetDir (LED\_1, ~0);
> MessageSend(&toggle.task, 0, 0);
> MessageLoop();
> return 0;
> }`Коротко описание листинга (подробности см. в файле ***CS-110344-UGP2\_WritingBlueCoreApplication.pdf***):` | https://habr.com/ru/post/125214/ | null | ru | null |
# Как не надо делать проверку валидности email
Представьте на минутку, что вы — недавно принятый на работу программист, которому предстоит работать с популярной системой управления обучением (LMS) Hot4Learning. Ваш предшественник когда-то поработал над добавлением к системе возможности отправки email — для того, чтобы любой пользователь в школе мог отправить другому пользователю электронное письмо с помощью веб-интерфейса. Но, увы, судьба оказалась к нему неблагосклонна — его сбил автобус, и он так никогда и не завершил свой magnum opus, свою лебединую песню. Ваша задача — довести его дело до конца, добавив функцию валидации введенного email — чтобы можно было быть уверенным, что письма отправляются только в том случае, когда в качестве адресата вводится правильный адрес, привязанный к школе.
Приведем конкретный пример: допустим, Боб — студент в Университете Макгилла, и он должен иметь возможность отправить письмо на любой валидный адрес `@mail.mcgill.ca` или `@mcgill.ca`. Если адрес его подружки Джейн выглядит как `[email protected]`, то тогда Боб имеет полное право отправлять на него письма. В другом случае — скажем, если ее адрес `[email protected]` — он, понятное дело, права на это не имеет, как и на отсылку писем на адрес `[email protected]`.
Итак, ваша задача — реализовать эту возможность; при этом предполагается, что у вас есть список валидных адресов почты для конкретного учебного заведения.
Скорее всего, вы сейчас подумали «Да бросьте, ерунда какая-то, а не задача. Сначала, я создаю строку, в которой делаю конкатенацию всех адресов школы в список с разделителем '|\*\*\*\*|', затем я передаю ее клиенту, присваивая строку переменной внутри тэга ``. Затем, в JavaScript, я создаю массив и присваиваю его переменной, любовно обозванной temp`. Каждый раз, когда пользователь вводит email, я перевожу его в нижний регистр и сохраняю в переменную с заманчивым названием `curForwardUserName`... а еще я создам переменную `validUserName`, которую я сделаю равной строке `'0'`, потому что зачем мне использовать `boolean`, если я могу использовать строку? Затем, я в цикле пройду по всему содержимому `temp`; для каждого адреса почты в `temp` я переведу его в нижний регистр, затем проверю, совпадает ли он с `curForwardUserName` - и если это так, то я задам `validUserName` равной строке `'1'` и вызову `break`. Наконец, если `validUserName` равняется строке `'1'`, то я могу спокойно считать, что `curForwardUserName` - валидный адрес; в противном случае, он нам не подходит"
"Что за бред?" - подумали вы наверняка. Я надеюсь, что вам вряд ли пришло в голову написанное выше. Скорее, в вашей голове появилась следующая мысль: "ОК, очевидно, что валидацию я буду делать на стороне сервера. Я могу хранить валидные адреса почты в структуре данных, которая позволяет проводить сравнения со сложностью в O(1), и затем проверять, содержится ли в ней введенный email". И это нормально - ведь это правильный способ решения задачи.
##### Вот как решит эту задачу ваш мозг
В Python правильный способ решения этой задачи будет выглядеть следующим образом:
```
if input_email in valid_emails_set:
send_email(input_email, another_param, etc)
```
##### А вот как решит эту задачу ваш мозг под наркотиками
Но если злодейка-судьба закинула вас работать с великим и ужасным Hot4Learning, то вы, вполне возможно, всей душой ненавидите свою работу, и вам каждый день приходится от души "упарываться" наркотиками, чтобы вы могли хотя бы до нее дойти. Зато ваш наркомозг способен выдать такое:
*Внимание: NSFWUYWOH (Not Safe For Work Unless You Work On Hot4Learning - Небезопасно Для Работы Только Если Вы Не Разработчик Hot4Learning)*
```
// [какой-то еще код]
var userNamesStr = '[email protected]|\*\*\*\*|[email protected]
|\*\*\*\*|(представим, что здесь лежит еще 70,000 emailов)|\*\*\*\*|[email protected]';
var temp = new Array();
temp = userNamesStr.split('|\*\*\*\*|');
var validUserName = '0';
// [вырезано цензурой]
for( i =0; i< temp.length; i++){
if( curForwardUserName == temp[i].toLowerCase() ) {
validUserName = '1';
break;
}
// [и еще немного бесценной мудрости]
```
Кстати, вышеприведенный код отправляет все 70,000+ адресов Университета Макгилла на клиент при каждой загрузке страницы. Исходный код страницы весит около 2.5MB, считай что чистого текста. Ну, а поскольку тот человек, что занимается код-ревью, и сам сидит на мете - ваш код легким движением руки попадает в продакшн.
##### Голая правда
В прошлом году, IT-отдел Университета МакГилла заменил старую LMS (Blackboard) на новую систему (которая на самом деле называется *не совсем* Hot4Learning, но давайте не будем мелочиться - ведь все остальное в лучших традициях Попова не тронуто). Поскольку старая система рассыпалась на глазах из-за уязвимостей и страдала от кучи других проблем, новую систему ждали с огромной надеждой на светлое будущее. Надежда умерла с той же скоростью, с какой у вышеозначенного наркомана когда-то безвозвратно умерли клетки головного мозга.
Клик на вкладку "email" встречал меня 10 секундами белого экрана и ожиданием того момента, когда браузер наконец загрузит страницу. Возник логичный вопрос - "Какого оно вообще столько грузится? Не может же оно пытаться загрузить все валидные адреса, хехех... Стоп. Блин..."
Словами трудно описать тот ужас, что охватил меня при просмотре исходников страницы. Страшнее в моей жизни был только сон про то, что мне удалось проспать экзамен по криптографии.
Увы, "вживую" вам на этот код полюбоваться уже не удастся - был отправлен баг-репорт как об уязвимости утечки данных, и поставщик ПО за две недели все исправил. Код, приведенный выше - один в один тот, что использовался в приложении - разве что, были опущены не имеющие отношения к его работе места. Все соображения по поводу того, на чем сидит программист-автор, принимаются на мой твиттер `@dellsystem`.
ПРЕДУПРЕЖДЕНИЕ: Злоупотребление наркотиками плохо влияет на ваш исходный код.` | https://habr.com/ru/post/192494/ | null | ru | null |
# Новый софт для шифрования бэкапов

Сквозное шифрование постепенно становится стандартом на файлохостингах и облачных сервисах. Даже если вы храните резервные копии в сейфе, шифрование не будет лишним. А если отправлять файлы на удалённый сервер, тем более.
Хотя остаётся вопрос о мерах государственного контроля, но в данный момент использование стойкой криптографии — законное и надёжное средство для защиты информации.
Существует ряд программ, которые специализируются именно на шифровании бэкапов. Они дополняют стандартный инструментарий для синхронизации файлов и резервного копирования, включающий в себя `rcp`, `scp`, [rsync](https://linux.die.net/man/1/rsync), [casync](https://github.com/systemd/casync), [restic](https://github.com/restic/restic), [bupstash](https://github.com/andrewchambers/bupstash) и другие инструменты. Весь этот софт можно использовать в разных сочетаниях для достижения приемлемого результата. Некоторые программы более универсальны и выполняют несколько функций одновременно, а другие специализируются в чём-то одном.
Новые инструменты появляются постоянно, такие как [kopia](https://github.com/kopia/kopia). Но резервное копирование — специфическая область. Тут главное — надёжность. Поэтому от старых проверенных инструментов отказываются редко. Новым обычно доверяют только спустя некоторое время после их появления, да и то, если за всё предыдущее время не возникло серьёзных проблем. К сожалению, далеко не все программы проходят такую проверку, но BorgBackup прошёл.
BorgBackup: проверено временем
------------------------------
Утилита для резервного копирования [BorgBackup](https://www.borgbackup.org/) — это дедупликатор со сжатием и шифрованием, то есть инструмент 3-в-1. По некоторой функциональности может заменить [restic](https://github.com/restic/restic), [kopia](https://github.com/kopia/kopia), [attic](https://github.com/jborg/attic) и другие программы этой области. BorgBackup считается относительно стабильным вариантом для постоянного использования (например, у restic [известны проблемы](https://github.com/restic/restic/issues/2659) при работе по протоколу CIFS/SMB, а у BorgBackup таких нет).
Основные функции:
* Сжатие бэкапов LZ4, zlib, LZMA, zstd (начиная с версии 1.1.4), экономия места на накопителях
* Безопасное шифрование с аутентификацией
* Возможность монтирования резервных копий с помощью FUSE
* Простая установка на различных платформах: Linux, macOS, BSD и др.
* Открытый код, свободная лицензия, большое сообщество пользователей
Пример использования:
```
$ borg create --stats --progress --compression lz4 /media/backup/borgdemo::bac
kup1 Wallpaper
Enter passphrase for key /media/backup/borgdemo:
------------------------------------------------------------------------------
Archive name: backup1
Archive fingerprint: 9758c7db339a066360bffad17b2ffac4fb368c6722c0be3a47a7a9b63
1f06407
Time (start): Fri, 2023-01-08 21:54:06
Time (end): Fri, 2023-01-08 21:54:17
Duration: 11.40 seconds
Number of files: 1050
Utilization of maximum supported archive size: 0%
------------------------------------------------------------------------------
Original size Compressed size Deduplicated size
This archive: 618.96 MB 617.47 MB 561.67 MB
All archives: 618.96 MB 617.47 MB 561.67 MB
Unique chunks Total chunks
Chunk index: 999 1093
------------------------------------------------------------------------------
```
Добавление одиночных файлов происходит практически мгновенно благодаря дедупликации:
```
$ borg create --stats --progress --compression lz4 /media/backup/borgdemo::bac
kup2 Wallpaper
Enter passphrase for key /media/backup/borgdemo:
------------------------------------------------------------------------------
Archive name: backup2
Archive fingerprint: 5aaf03d1c710cf774f9c9ff1c6317b621c14e519c6bac459f6d64b31e
3bbd200
Time (start): Fri, 2023-01-08 21:54:56
Time (end): Fri, 2023-01-08 21:54:56
Duration: 0.33 seconds
Number of files: 1051
Utilization of maximum supported archive size: 0%
------------------------------------------------------------------------------
Original size Compressed size Deduplicated size
This archive: 618.96 MB 617.47 MB 106.70 kB
All archives: 1.24 GB 1.23 GB 561.77 MB
Unique chunks Total chunks
Chunk index: 1002 2187
------------------------------------------------------------------------------
```
Другие демонстрационные примеры см. [здесь](https://www.borgbackup.org/demo.html).
Bupstash: для одноплатников
---------------------------
Есть мнение, что на маломощных машинах и одноплатниках типа Raspberry Pi вместо BorgBackup более эффективно работает [bupstash](https://github.com/andrewchambers/bupstash), хотя это относительно новая разработка и сам автор не рекомендует её запускать в продакшне.
Dublicati и Kopia: простой интерфейс
------------------------------------
Ещё одна утилита для резервного копирования с шифрованием — [Duplicati](https://www.duplicati.com/). Отличается максимально простым GUI для массового пользователя, есть версия под Windows.

По [некоторым отзывам](https://news.ycombinator.com/item?id=33450632), программа слишком нестабильна, чтобы рекомендовать её для постоянного резервного копирования важной информации. Но другие используют её годами без всяческих нареканий, а простой интерфейс доступен для пользователей любого уровня.
В качестве альтернативы для резервного копирования под Windows относительно недавно появилась программа [Kopia](https://kopia.io/) (также работает на Linux и macOS). Она поддерживает дедупликацию, сжатие и шифрование бэкапов, копирование по маске, шаблоны и проч. Зашифрованные и сжатые бэкапы можно отправлять на один из облачных хостингов или любой удалённый сервер по WebDAV и SFTP.
Шифрование облачных сервисов
----------------------------
Шифрование бэкапов становится стандартом в индустрии. Сервис Amazon S3 недавно тоже начал [автоматическое шифрование всех новых объектов](https://aws.amazon.com/blogs/aws/amazon-s3-encrypts-new-objects-by-default/), добавляемых в хранилище, шифром AES-256 по умолчанию. Схема под названием SSE-S3 выглядит следующим образом:
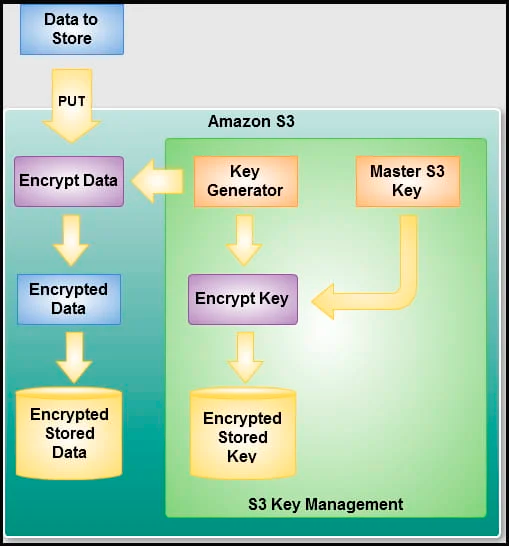
Как несложно видеть, шифрование происходит на стороне сервера, а не у клиента, поэтому такая реализация не попадает под определение полноценного сквозного шифрования (E2E). Однако реализована и альтернативная схема SSE-C, по которой ключи шифрования передаются пользователю.
Никаких дополнительных действий от администраторов не требуется, а производительность операций I/O не пострадает. Схема распространяется только на свежезаписанные данные. Amazon поясняет, что шифрование на сервере внедрили [более десяти лет назад](https://aws.amazon.com/blogs/aws/new-amazon-s3-server-side-encryption/), просто теперь оно станет стандартом по умолчанию. Дополнительно опубликована [инструкция](https://aws.amazon.com/blogs/security/how-to-retroactively-encrypt-existing-objects-in-amazon-s3-using-s3-inventory-amazon-athena-and-s3-batch-operations/) для ретроактивного шифрования старых файлов, сохранённых ранее.
В ноябре 2022 года аналогичные меры [анонсировал](https://blog.dropbox.com/topics/company/dropbox-to-acquire-boxcryptor-assets-bring-end-to-end-encryption-to-business-users) Dropbox. Для реализации этой задачи были приобретены активы компании [Boxcryptor](https://www.boxcryptor.com/en/), которая специализируется именно на сквозном шифровании облачных сервисов.
Раньше считалось, что обязательное шифрование облачных данных — некая экзотическая опция для корпоративных заказчиков и полуподпольных хостингов типа [Mega.nz](https://mega.nz/) от Кима Доткома. Но в последние годы прояснились две вещи:
1. Массовые утечки данных с облачных сервисов не прекращаются.
2. Не только корпоративные, но и частные пользователи болезненно реагируют на утечки своих данных, включая домашние фотографии, видео и др.
По этой причине E2E постепенно внедряется и на массовых сервисах, таких как Dropbox, Amazon S3 и Apple iCloud. Открытым остаётся только вопрос, нужно ли оставлять «бэкдор» для компетентных органов или защита должна быть тотальной.
---
[](https://www.globalsign.com/ru-ru/managed-pki) | https://habr.com/ru/post/714944/ | null | ru | null |
# OFF: Игры подсознания…
Давно уже не заходил на Хабр.
Дел море…
Не то, что писать, читать некогда.
А сегодня вдруг что-то екнуло — дай, думаю, зайду.
Зашел, по привычке глянул дату последнего захода и краем глаза зацепился за строку
`**Зарегистрирован:** 24 августа 2007 в 12:46`
Посмотрел на часы и улыбнулся.
Мы с Хабром ровно 2 года, как дружим — и мысль эта поесетила меня ровно `24 августа 2009 в 12:46`.
Вот такие игры подсознания млин… :) | https://habr.com/ru/post/67830/ | null | ru | null |
# Программирование и передача данных в «Ардуино» по «воздуху» с помощью ESP8266. Часть Третья. Здравствуй, «ANDROID»
Предлагаю вам, уважаемые читатели GeekTimes, очередную статью из цикла по использованию микросхемы ESP8266 в качестве беспроводного моста для AVR микроконтроллеров, на примере аппаратной платформы Arduino Uno (Nano). В этот раз ~~для полета на Луну~~ управления платформой мы задействуем вместо компьютера устройство на базе «ANDROID». Ну, например, смартфон.

Подробности под катом:
Для нашей работы мы воспользуемся инструментарием, который был описан в предыдущей статье — беспроводным программатором BABUINO и модулем передачи кода и данных МPDE (module for programm and data exchange) прошиваемым в ESP8266.
Как выяснилось из откликов пользователей, сам программатор, в общем, пришелся ко двору и некоторые личности даже им успешно пользуются. Ну, в принципе, вещь действительно удобная; запустил приложение под виндой, выбрал hex файл из нужной папки и всё — через несколько секунд программка в нужном устройстве безо всяких проводов. Другое дело, что я зря с излишней горячностью нападал на пользователей софта ARDUINO, пишущих на Wiring C и пользующихся ARDUINO IDE с её скетчами и библиотеками. Безусловно, каждый делает как ему удобно — на ардуинском ли Wiring C или на С из AVR studio. Но в итоге, некоторые пользователи почему-то сразу решили, что программатор никак не совместим с ARDUINO софтом.
На самом деле, проблем с совместимостью, конечно же, никаких нет. Абсолютно также компилируете ваш скетч, где вам удобно до состояния hex файла и совершенно также просто отправляете его через беспроводной программатор на ваш Arduino UNO или NANO.
Обмен данными под софтом ARDUINO тоже никаких проблем не доставляет. Пишете волшебные строчки:
**Serial.begin(9600);**
а дальше что-то типа:
**receiveByte= Serial.read();** // чтение байта из буфера
или:
**Serial.write(receiveByte);** // запись байта
И можете обмениваться байтовыми потоками по WI-FI совершенно спокойно. Ибо AVR микроконтроллер шлёт в ESP8266 и получает байты оттуда по последовательному порту UART, настроить работу с которым в Arduino может, как мы видим, любой гуманитарий.
Теперь же вернёмся к предмету настоящей статьи. Чтобы управлять роботележкой посредством смартфона, безусловно, необходимо написать для этого смартфона соответствующее приложение.
Я, как человек, месяц назад представлявший этот процесс крайне туманно, сейчас могу со всей ответственностью заявить, что дело в сущности это не сложное. Если конечно, у вас есть хоть какие-то начальные знания в области Java.
Ибо при написании Android приложений исходный код пишется на Java, а затем компилируется в стандартный байт-код Java с использованием традиционного инструментария Java. Затем с кодом происходят другие интересные вещи, но эти подробности нам здесь не нужны.
Вроде как, существуют еще возможности для написания приложений на С для отъявленных хардкорщиков ведущих счёт на наносекунды, а также где-то есть какой-то пакет для трансляции вашего кода с Питона, но здесь я ничего подсказать не могу, поскольку уже давно сделал правильный выбор.
Итак, Java и программный пакет Android Studio — интегрированная среда разработки (IDE) для работы с платформой Android основанная на программном обеспечении IntelliJ IDEA от компании JetBrains, официальное средство разработки Android приложений.
Если вы уже работаете с ПО от IntelliJ IDEA, то будете приятно удивлены знакомым интерфейсом.
С основами построения приложений я знакомился по книжке Б.Филлипса и К.Стюарта — «ANDROID» программирование для профессионалов". Как я понял, профессионалами авторы считают читателей, хотя бы немного знакомых с Java SE. Чего-то архи-сложного в этой книге я не нашел, а для наших целей вполне хватит и первого десятка глав книги, благо, что в ней все примеры кода приводятся при работе именно с вышеупомянутой Android Studio.
Отладку приложений можно проводить, как на программном эмуляторе, так и прямо на смартфоне, переключив его в «режим разработчика».
В предыдущей статье было описано управление тележкой через оконное приложение на Windows. То есть весь код для создания HTTP и UDP соединений, а также логика управления у нас уже по идее присутствует. Поэтому взяв на вооружение слоган компании Oracle «Написано в одном месте, работает везде» мы просто перекинем эти классы в новую программу уже для Android приложения. А вот GUI — графический интерфейс пользователя, по понятным причинам придется оставить там, где он был. Но с другой стороны, на Android всё делается очень похоже и довольно быстро, поэтому в накладе мы не останемся.
**ТЫКАЕМ ПАЛЬЦЕМ В ЭКРАН**

Итак создаем новый проект «FourWheelRobotControl» в Android Studio.
Это простое приложение и оно будет состоять из активности (activity)
**Класс MainActivity.java**
```
import android.content.Context;
import android.hardware.Sensor;
import android.support.v7.app.AppCompatActivity;
import android.os.Bundle;
import android.view.MotionEvent;
import android.view.View;
import android.widget.ImageButton;
import android.widget.TextView;
import android.widget.Toast;
public class MainActivity extends AppCompatActivity
{
private ImageButton mButtonUP;
private ImageButton mButtonDOWN;
private ImageButton mButtonLEFT;
private ImageButton mButtonRIGHT;
public static byte direction = 100;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
new HTTP_client(40000);
new Udp_client();
mButtonUP = (ImageButton) findViewById(R.id.imageButtonUP);
mButtonUP.setOnTouchListener(new View.OnTouchListener() {
@Override
public boolean onTouch(View v, MotionEvent event) {
if (event.getAction() == MotionEvent.ACTION_DOWN) {
direction = 3;
}
}
if (event.getAction() == MotionEvent.ACTION_UP) {
direction = 100;
}
return false;
}
});
mButtonDOWN = (ImageButton) findViewById(R.id.imageButtonDown);
mButtonDOWN.setOnTouchListener(new View.OnTouchListener() {
@Override
public boolean onTouch(View v, MotionEvent event) {
if (event.getAction() == MotionEvent.ACTION_DOWN) {
direction = 4;
Toast.makeText(MainActivity.this, "вниз " + direction,
Toast.LENGTH_SHORT).show();
}
if (event.getAction() == MotionEvent.ACTION_UP) {
direction = 100;
}
return false;
}
});
mButtonLEFT = (ImageButton) findViewById(R.id.imageButtonLeft);
mButtonLEFT.setOnTouchListener(new View.OnTouchListener() {
@Override
public boolean onTouch(View v, MotionEvent event) {
if (event.getAction() == MotionEvent.ACTION_DOWN) {
direction = 1;
Toast.makeText(MainActivity.this, "влево " + direction,
Toast.LENGTH_SHORT).show();
}
if (event.getAction() == MotionEvent.ACTION_UP) {
direction = 100;
}
return false;
}
});
mButtonRIGHT = (ImageButton) findViewById(R.id.imageButtonRight);
mButtonRIGHT.setOnTouchListener(new View.OnTouchListener() {
@Override
public boolean onTouch(View v, MotionEvent event) {
if (event.getAction() == MotionEvent.ACTION_DOWN) {
direction = 2;
Toast.makeText(MainActivity.this, "вправо " + direction,
Toast.LENGTH_SHORT).show();
}
if (event.getAction() == MotionEvent.ACTION_UP) {
direction = 100;
}
return false;
}
});
}
```
и макета:
**layout**
```
/spoiler/
activity_main.xml
xml version="1.0" encoding="utf-8"?
```
Его писать ручками не надо, он генерится автоматически после ваших творений в редакторе.
Теперь просто перенесём два класса из программы приведенной в предыдущей статье:
**HTTP\_client.java**
```
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.io.PrintWriter;
import java.net.InetAddress;
import java.net.Socket;
public class HTTP_client extends Thread{
int port;
String s;
public static String host_address="192.168.1.138";// адрес вашего устройства
public String Greetings_from_S;
HTTP_client(int port) {
this.port = port;
start();
}
public void run() {
try (Socket socket = new Socket(host_address,port)){
PrintWriter pw = new PrintWriter(new OutputStreamWriter(socket.getOutputStream()), true);
BufferedReader br = new BufferedReader(new InputStreamReader(socket.getInputStream()));
pw.println("stop data\r");//на всякий случай, вдруг вышли некорректно
pw.println("data\r");// Greetings with SERVER
Greetings_from_S = br.readLine();
if (Greetings_from_S.equals("ready")) {
new Udp_client();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
```
**Udp\_clent.java**
```
import java.net.DatagramPacket;
import java.net.DatagramSocket;
import java.net.InetAddress;
public class Udp_client extends Thread
{
int i =0;
byte [] data = {0};
int udp_port=50000;
InetAddress addr;
DatagramSocket ds;
public Udp_client()
{
try
{
ds = new DatagramSocket();
addr = InetAddress.getByName(HTTP_client.host_address);
}
catch (Exception e)
{
}
start();
}
public void run() {
while (true)
{
byte temp = MainActivity.direction;
String s = "" + MainActivity.direction;
data = s.getBytes();
if(temp!=100 ) {
DatagramPacket pack = new DatagramPacket(data, data.length, addr, udp_port);
try {
ds.send(pack);
i=0;
Thread.sleep(200);
} catch (Exception e) {
}
}
else
{
if(i==0) {
s = "" + 0;
data = s.getBytes();
DatagramPacket pack = new DatagramPacket(data, data.length, addr, udp_port);
try {
ds.send(pack);
Thread.sleep(200);
} catch (Exception e) {
}
}
i=1;// перестаем отправлять нулевые пакеты
}
}
}
}
```
Суть программы осталось той же. MainActivity сначала запускает HTTP и UDP клиенты, а затем ловит нажатия и отжатия экранных кнопок, отправляя код нажатия direction на формирование UDP пакета. А оттуда уже всё — «вперёд»,«назад»,«влево», «вправо» и при отжатии «стоп» уезжают по WI-FI на телегу.
Кроме всего этого, мы должны немного подредактировать файл так называемого манифеста, который опять же, в основном генерится сам.
> Манифест (manifest) представляет собой файл XML с метаданными, описывающими ваше приложение для ОС Android. Файл манифеста всегда называется AndroidManifest.xml и располагается в каталоге app/manifest вашего проекта.
Правда там нам работы совсем немного.
запрещаем повороты экрана:
```
android:screenOrientation="portrait"
```
разрешаем работу в интернет:
```
```
И вот он весь полностью.
**AndroidManifest.xml**
```
xml version="1.0" encoding="utf-8"?
```
При запуске мы должны увидеть что-то вроде:

Вот в сущности и всё. Теперь тележкой можно управлять с мобильника. Приложение крайне простое, ибо демонстрационное, без каких-либо «свистелок и перделок», типа поиска телеги в домашней сети, коннекта, дисконнекта и прочих полезных фич, облегчающих жизнь, но затрудняющих понимание кода.
С другой стороны, управление при помощи экранных кнопок это то же самое,
> «как пить просто водку, даже из горлышка — в этом нет ничего, кроме томления духа и суеты».
И Веня Ерофеев в этом был прав, безусловно.
Гораздо интереснее, к примеру, рулить телегой при помощи штатных акселерометров того же смартфона.
Причём реализуется сия фича тоже крайне просто, через, так называемые интенты. Правда, создавать свои интенты сложнее, чем пользоваться готовыми. К счастью, пользоваться готовыми никто не запрещает.
**АКСЕЛЕРОМЕТР В МАССЫ**

Поэтому наш код в MainActivity (и только в нём) изменится минимально.
Добавим переменные для акселерометра:
```
private SensorManager mSensorManager;
private Sensor mOrientation;
private float xy_angle;
private float xz_angle;
```
Получим сам датчик от системы и зарегистрируем его как слушатель.
```
mSensorManager = (SensorManager) getSystemService(Context.SENSOR_SERVICE); // Получаем менеджер сенсоров
mOrientation = mSensorManager.getDefaultSensor(Sensor.TYPE_ACCELEROMETER); // Получаем датчик положения
mSensorManager.registerListener(this, mOrientation, SensorManager.SENSOR_DELAY_NORMAL);
```
Имплементируем сам интерфейс слушателя:
```
public class MainActivity implements SensorEventListener
```
И пропишем четыре обязательных метода из которых воспользуемся только последним. Методом, отрабатывающим при изменении показаний акселерометра. Вообще-то, я хотел акселерометр сам опрашивать, как обычную периферию с периодом около 100 мс, так как было подозрение (из-за названия onChanged), что метод отрабатывает слишком часто. Но там всё private и фиг за интерфейсы проберёшься.
```
@Override
public void onAccuracyChanged(Sensor sensor, int accuracy) { //Изменение точности показаний датчика
}
@Override
protected void onResume() {
super.onResume();
}
@Override
protected void onPause() {
super.onPause();
}
@Override
public void onSensorChanged(SensorEvent event) {} //Изменение показаний датчиков
```
**В итоге MainActivity.java примет следующий вид**
```
import android.hardware.SensorEvent;
import android.hardware.SensorEventListener;
import android.hardware.SensorManager;
import android.content.Context;
import android.hardware.Sensor;
import android.support.v7.app.AppCompatActivity;
import android.os.Bundle;
import android.widget.ImageButton;
import android.widget.TextView;
public class MainActivity extends AppCompatActivity implements SensorEventListener
{
private ImageButton mButtonUP;
private ImageButton mButtonDOWN;
private ImageButton mButtonLEFT;
private ImageButton mButtonRIGHT;
public static byte direction = 100;
private SensorManager mSensorManager;
private Sensor mOrientation;
private float xy_angle;
private float xz_angle;
private int x;
private int y;
private TextView xyView;
private TextView xzView;
private TextView zyView;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
new HTTP_client(40000);
new Udp_client();
mSensorManager = (SensorManager) getSystemService(Context.SENSOR_SERVICE); // Получаем менеджер сенсоров
mOrientation = mSensorManager.getDefaultSensor(Sensor.TYPE_ACCELEROMETER); // Получаем датчик положения
mSensorManager.registerListener(this, mOrientation, SensorManager.SENSOR_DELAY_NORMAL);
xyView = (TextView) findViewById(R.id.textViewX); //
xzView = (TextView) findViewById(R.id.textViewY); // Наши текстовые поля для вывода показаний
zyView = (TextView) findViewById(R.id.textViewZ);// сюда пихнем "direction"
mButtonUP = (ImageButton) findViewById(R.id.imageButtonUP);
mButtonDOWN = (ImageButton) findViewById(R.id.imageButtonDown);
mButtonLEFT = (ImageButton) findViewById(R.id.imageButtonLeft);
mButtonRIGHT = (ImageButton) findViewById(R.id.imageButtonRight);
// кнопки не используются
}
@Override
public void onAccuracyChanged(Sensor sensor, int accuracy) { //Изменение точности показаний датчика
}
@Override
protected void onResume() {
super.onResume();
}
@Override
protected void onPause() {
super.onPause();
}
@Override
public void onSensorChanged(SensorEvent event) { //Изменение показаний датчиков
xy_angle = event.values[0]*10; //Плоскость XY
xz_angle = event.values[1]*10; //Плоскость XZ
x=-(int) xy_angle*1;
y=-(int) xz_angle*1;
xyView.setText(" x = "+ String.valueOf(x));
xzView.setText(" y = "+String.valueOf(y));
zyView.setText(" direction "+String.valueOf(direction));
if(y>-40&&y<-20){
direction=100;// скорость вперед ноль, никуда не едем, смотрим есть ли повороты
if (x>10){//скорость вправо от 10 до 30 диапазон 20 единиц
direction=(byte)(x+30);
if (direction>60){direction=60;}
}
if(x<-10){
direction=(byte)(-x+50);
if (direction>80){direction=80;}
}
}
else {
if (y > -20) {// едем вперед, диапазон -20: 20 итого 40 единиц
direction = (byte) (y / 2 + 10);
if (direction > 20) {
direction = 20;
}
;
}
if (y < -40) {// едем назад, диапазон -40: -80 итого 40 единиц
direction = (byte) (-y - 20);
if (direction > 40) {
direction = 40;
}
;
}
}
}
}
// итого если direction 100 стоп
// 1-20 вперед , угол от -20
// 21-40 назад , угол от -40
// 41-60 направо, угод 10
// 61-80 налево, угол от -10
```
Программа выводит показания датчиков по двум осям на экран смартфона. Вместо третьей оси, которая не используется, выводится переменная направления «direction». И эти же данные бегут в виде байтового потока на тележку. Правда, из-за того, что поток чисто байтовый, определить, где команда «вперед» или «стоп» было бы затруднительно. Поэтому я поступил просто: каждому направлению и углу наклона соответствует свой диапазон чисел. Грубо говоря 1-20 это «вперёд» с соответствующей скоростью, 21-40 это «назад» и так далее. Конечно, можно было бы передавать по UDP чисто данные, а сами управляющие команды задавать через TCP протокол и это было бы безусловно правильнее. Но для это надо редактировать программу на самой ESP8266, чего мне пока не хочется.
Итак, телега катается по квартире, чутко реагируя на наклоны моего GalaxyS7, но и это как говаривал небезызвестный Веня ещё не то.
> «Теперь же я предлагаю вам последнее и наилучшее. «Венец трудов, превыше всех наград», как сказал поэт. Короче, я предлагаю вам коктейль «Сучий потрох», напиток, затмевающий все. Это уже не напиток — это музыка сфер. „
В наш век Сири и Алексы, чего-то там вертеть руками? Пусть слушается голосового управления!
**А ТЕПЕРЬ СЛУШАЙ МЕНЯ!**

Цитирую:
> На самом деле работать с распознаванием и синтезом речи в Android очень просто. Все сложные вычисления скрыты от нас в довольно элегантную библиотеку с простым API. Вы сможете осилить этот урок, даже если имеете весьма поверхностные знания о программировании для Android.
На самом деле же, у меня всё получилось довольно коряво, но скорее всего потому, что я использовал самый простой вариант, а как следует в данном API не копался. Делается всё тоже через интенты, при помощи которых мы обращаемся к голосовому движку Гугл, а именно к его функции распознавания речи. Поэтому потребуется рабочий Интернет.
Опять меняется лишь MainActivity.java, хотя я еще немного изменил и сам макет (четыре кнопки теперь там вовсе ни к чему, хватит и одной).
В MainActivity.java добавилось следующее:
Тот самый интент:
```
Intent intent = new Intent(RecognizerIntent.ACTION_RECOGNIZE_SPEECH);
intent.putExtra(RecognizerIntent.EXTRA_LANGUAGE_MODEL, RecognizerIntent.LANGUAGE_MODEL_FREE_FORM);
intent.putExtra(RecognizerIntent.EXTRA_PROMPT, "Ну, скажи, куда ехать-то??? ");
startActivityForResult(intent, Print_Words);
```
И то, что он возвращает:
```
@Override
protected void onActivityResult(int requestCode, int resultCode, Intent data) {
//Проверяем успешность получения обратного ответа:
if (requestCode==Print_Words && resultCode==RESULT_OK) {
//Как результат получаем строковый массив слов, похожих на произнесенное:
ArrayListresult=data.getStringArrayListExtra(RecognizerIntent.EXTRA\_RESULTS);
//и отображаем их в элементе TextView:
stroka\_otveta = result.toString();
}
```
А возвращает он массив похожих слов, причем в довольно “мусорной форме», со всякими скобочками и запятыми. И вам лишь остается выбрать слово похожее на то, которое вы сказали. Ну и соответственно, если попалось слово «вперёд», то едем вперёд, если «направо» то направо и так далее. Конечно, надо учитывать, где через «Ё», где запятая лишняя прицепится (скобочки-то я отрезал, а вот на запятые сил уже не хватило).
**В итого сам текст MainActivity.java стал таким**
```
import android.support.v7.app.AppCompatActivity;
import android.os.Bundle;
import android.view.MotionEvent;
import android.view.View;
import android.widget.ImageButton;
import android.widget.TextView;
import java.util.ArrayList;
import android.content.Intent;
import android.speech.RecognizerIntent;
public class MainActivity extends AppCompatActivity {
private ImageButton mButtonUP;
public static byte direction = 100;
public String stroka_otveta;
private static final int Print_Words = 100;
private TextView EnteredText1;
private TextView EnteredText2;
public static TextView EnteredText3;
private boolean slovo_raspoznano =false;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
new Udp_client();
new HTTP_client(40000);
EnteredText1 = (TextView) findViewById(R.id.textViewX); //
EnteredText2 = (TextView) findViewById(R.id.textViewY); //
EnteredText3 = (TextView) findViewById(R.id.textViewZ); //
mButtonUP = (ImageButton) findViewById(R.id.imageButtonUP);
mButtonUP.setOnTouchListener(new View.OnTouchListener() {
@Override
public boolean onTouch(View v, MotionEvent event) {
if (event.getAction() == MotionEvent.ACTION_DOWN){
if(HTTP_client.ok){ //Вызываем RecognizerIntent для голосового ввода и преобразования голоса в текст:
EnteredText3.setText(" http клиент подсоединен");
Intent intent = new Intent(RecognizerIntent.ACTION_RECOGNIZE_SPEECH);
intent.putExtra(RecognizerIntent.EXTRA_LANGUAGE_MODEL, RecognizerIntent.LANGUAGE_MODEL_FREE_FORM);
intent.putExtra(RecognizerIntent.EXTRA_PROMPT, "Ну, скажи, куда ехать-то??? ");
startActivityForResult(intent, Print_Words);
}
else {
EnteredText3.setText(" нетути никого");
}
}
if (event.getAction() == MotionEvent.ACTION_UP ){
}
return false;
}
});
}
@Override
protected void onActivityResult(int requestCode, int resultCode, Intent data) {
//Проверяем успешность получения обратного ответа:
if (requestCode==Print_Words && resultCode==RESULT_OK) {
//Как результат получаем строковый массив слов, похожих на произнесенное:
ArrayListresult=data.getStringArrayListExtra(RecognizerIntent.EXTRA\_RESULTS);
//и отображаем их в элементе TextView:
stroka\_otveta = result.toString();
}
StringBuffer sb = new StringBuffer(stroka\_otveta);
sb.deleteCharAt(stroka\_otveta.length()-1);
sb.deleteCharAt(0);
stroka\_otveta=sb.toString();
String[] words = stroka\_otveta.split("\\s"); // Разбиение строки на слова с помощью разграничителя (пробел)
// Вывод на экран
for(int i = 0; i< words.length;i++) {
if(words[i].equals("налево,")||words[i].equals("налево")) {
direction = 1;
slovo\_raspoznano=true;
stroka\_otveta=words[i];
}
if(words[i].equals("направо,")||words[i].equals("направо")){
direction=2;
slovo\_raspoznano=true;
stroka\_otveta=words[i];
}
if(words[i].equals("назад,")|| words[i].equals("назад")){
direction=4;
slovo\_raspoznano=true;
stroka\_otveta=words[i];
}
if(words[i].equals("вперед,")|| words[i].equals("вперёд,")|| words[i].equals("вперед") || words[i].equals("вперёд")){
direction=3;
slovo\_raspoznano=true;
stroka\_otveta=words[i];
}
if(words[i].equals("стоп,")|| words[i].equals("стой,")|| words[i].equals("стоп") || words[i].equals("стой")){
direction=100;
slovo\_raspoznano=true;
stroka\_otveta=words[i];
}
}
if(!slovo\_raspoznano){
direction=100;
stroka\_otveta="говори внятно, а то них... непонятно";
}
EnteredText1.setText(" "+direction+" " +stroka\_otveta);
slovo\_raspoznano=false;
super.onActivityResult(requestCode, resultCode, data);
}
}
```
Ну и до кучи макет c одной кнопкой
**activity\_main.xml.**
```
xml version="1.0" encoding="utf-8"?
```
Самое удивительное, что действительно ездиет и слушается голоса (как правило). Но, конечно, интерфейс тормозной; пока скажете, пока распознается и вернётся; короче скорость движения выбирайте заранее небольшую или помещение наоборот поширше.
На этом на сегодня всё, буду рад, если понравилось.
 | https://habr.com/ru/post/409107/ | null | ru | null |
# Blazor WebAssembly 3.2.0 Preview 1 release now available
Today we released a new preview update for Blazor WebAssembly with a bunch of great new features and improvements.
Here’s what’s new in this release:
* Version updated to 3.2
* Simplified startup
* Download size improvements
* Support for .NET SignalR client
Get started
-----------
To get started with Blazor WebAssembly 3.2.0 Preview 1 [install the .NET Core 3.1 SDK](https://dotnet.microsoft.com/download/dotnet-core/3.1) and then run the following command:
```
dotnet new -i Microsoft.AspNetCore.Blazor.Templates::3.2.0-preview1.20073.1
```
That’s it! You can find additional docs and samples on [https://blazor.net](https://blazor.net/).
Upgrade an existing project
---------------------------
To upgrade an existing Blazor WebAssembly app from 3.1.0 Preview 4 to 3.2.0 Preview 1:
* Update all Microsoft.AspNetCore.Blazor.\* package references to 3.2.0-preview1.20073.1.
* In *Program.cs* in the Blazor WebAssembly client project replace `BlazorWebAssemblyHost.CreateDefaultBuilder()` with `WebAssemblyHostBuilder.CreateDefault()`.
* Move the root component registrations in the Blazor WebAssembly client project from `Startup.Configure` to *Program.cs* by calling `builder.RootComponents.Add(string selector)`.
* Move the configured services in the Blazor WebAssembly client project from `Startup.ConfigureServices` to *Program.cs* by adding services to the `builder.Services` collection.
* Remove *Startup.cs* from the Blazor WebAssembly client project.
* If you’re hosting Blazor WebAssembly with ASP.NET Core, in your *Server* project replace the call to `app.UseClientSideBlazorFiles(...)` with `app.UseClientSideBlazorFiles(...)`.
Version updated to 3.2
----------------------
In this release we updated the versions of the Blazor WebAssembly packages to 3.2 to distinguish them from the recent .NET Core 3.1 Long Term Support (LTS) release. There is no corresponding .NET Core 3.2 release – the new 3.2 version applies only to Blazor WebAssembly. Blazor WebAssembly is currently based on .NET Core 3.1, but it doesn’t inherit the .NET Core 3.1 LTS status. Instead, the initial release of Blazor WebAssembly scheduled for May of this year will be a *Current* release, which «are supported for three months after a subsequent Current or LTS release» as described in the [.NET Core support policy](https://dotnet.microsoft.com/platform/support/policy/dotnet-core). The next planned release for Blazor WebAssembly after the 3.2 release in May will be with [.NET 5](https://devblogs.microsoft.com/dotnet/introducing-net-5/). This means that once .NET 5 ships you’ll need to update your Blazor WebAssembly apps to .NET 5 to stay in support.
Simplified startup
------------------
We’ve simplified the startup and hosting APIs for Blazor WebAssembly in this release. Originally the startup and hosting APIs for Blazor WebAssembly were designed to mirror the patterns used by ASP.NET Core, but not all of the concepts were relevant. The updated APIs also enable some new scenarios.
Here’s what the new startup code in *Program.cs* looks like:
```
public class Program
{
public static async Task Main(string[] args)
{
var builder = WebAssemblyHostBuilder.CreateDefault(args);
builder.RootComponents.Add("app");
await builder.Build().RunAsync();
}
}
```
Blazor WebAssembly apps now support async `Main` methods for the app entry point.
To a create a default host builder, call `WebAssemblyHostBuilder.CreateDefault()`. Root components and services are configured using the builder; a separate `Startup` class is no longer needed. The following example adds a `WeatherService` so it’s available through dependency injection (DI):
```
public class Program
{
public static async Task Main(string[] args)
{
var builder = WebAssemblyHostBuilder.CreateDefault(args);
builder.Services.AddSingleton();
builder.RootComponents.Add("app");
await builder.Build().RunAsync();
}
}
```
Once the host is built, you can access services from the root DI scope before any components have been rendered. This can be useful if you need to run some initialization logic before anything is rendered:
```
public class Program
{
public static async Task Main(string[] args)
{
var builder = WebAssemblyHostBuilder.CreateDefault(args);
builder.Services.AddSingleton();
builder.RootComponents.Add("app");
var host = builder.Build();
var weatherService = host.Services.GetRequiredService();
await weatherService.InitializeWeatherAsync();
await host.RunAsync();
}
}
```
The host also now provides a central configuration instance for the app. The configuration isn’t populated with any data by default, but you can populate it as required in your app.
```
public class Program
{
public static async Task Main(string[] args)
{
var builder = WebAssemblyHostBuilder.CreateDefault(args);
builder.Services.AddSingleton();
builder.RootComponents.Add("app");
var host = builder.Build();
var weatherService = host.Services.GetRequiredService();
await weatherService.InitializeWeatherAsync(host.Configuration["WeatherServiceUrl"]);
await host.RunAsync();
}
}
```
Download size improvements
--------------------------
Blazor WebAssembly apps run the .NET IL linker on every build to trim unused code from the app. In previous releases only the core framework libraries were trimmed. Starting with this release the Blazor framework assemblies are trimmed as well resulting in a modest size reduction of about 100 KB transferred. As before, if you ever need to turn off linking, add the `false` property to your project file.
Support for the .NET SignalR client
-----------------------------------
You can now use SignalR from your Blazor WebAssembly apps using the .NET SignalR client.
To give SignalR a try from your Blazor WebAssembly app:
1. Create an ASP.NET Core hosted Blazor WebAssembly app.
```
dotnet new blazorwasm -ho -o BlazorSignalRApp
```
2. Add the ASP.NET Core SignalR Client package to the *Client* project.
```
cd BlazorSignalRApp
dotnet add Client package Microsoft.AspNetCore.SignalR.Client
```
3. In the *Server* project, add the following *Hub/ChatHub.cs* class.
```
using System.Threading.Tasks;
using Microsoft.AspNetCore.SignalR;
namespace BlazorSignalRApp.Server.Hubs
{
public class ChatHub : Hub
{
public async Task SendMessage(string user, string message)
{
await Clients.All.SendAsync("ReceiveMessage", user, message);
}
}
}
```
4. In the *Server* project, add the SignalR services in the `Startup.ConfigureServices` method.
```
services.AddSignalR();
```
5. Also add an endpoint for the `ChatHub` in `Startup.Configure`.
```
.UseEndpoints(endpoints =>
{
endpoints.MapDefaultControllerRoute();
endpoints.MapHub("/chatHub");
endpoints.MapFallbackToClientSideBlazor("index.html");
});
```
6. Update *Pages/Index.razor* in the *Client* project with the following markup.
```
@using Microsoft.AspNetCore.SignalR.Client
@page "/"
@inject NavigationManager NavigationManager
User:
Message:
Send Message
---
@foreach (var message in messages)
{
* @message
}
@code {
HubConnection hubConnection;
List messages = new List();
string userInput;
string messageInput;
protected override async Task OnInitializedAsync()
{
hubConnection = new HubConnectionBuilder()
.WithUrl(NavigationManager.ToAbsoluteUri("/chatHub"))
.Build();
hubConnection.On("ReceiveMessage", (user, message) =>
{
var encodedMsg = user + " says " + message;
messages.Add(encodedMsg);
StateHasChanged();
});
await hubConnection.StartAsync();
}
Task Send() => hubConnection.SendAsync("SendMessage", userInput, messageInput);
public bool IsConnected => hubConnection.State == HubConnectionState.Connected;
}
```
7. Build and run the *Server* project
```
cd Server
dotnet run
```
8. Open the app in two separate browser tabs to chat in real time over SignalR.
Known issues
------------
Below is the list of known issues with this release that will get addressed in a future update.
* Running a new ASP.NET Core hosted Blazor WebAssembly app from the command-line results in the warning:
```
CSC : warning CS8034: Unable to load Analyzer assembly C:\Users\user\.nuget\packages\microsoft.aspnetcore.components.analyzers\3.1.0\analyzers\dotnet\cs\Microsoft.AspNetCore.Components.Analyzers.dll : Assembly with same name is already loaded.
```
+ Workaround: This warning can be ignored or suppressed using the `true` MSBuild property.
Feedback
--------
We hope you enjoy the new features in this preview release of Blazor WebAssembly! Please let us know what you think by filing issues on [GitHub](https://github.com/dotnet/aspnetcore/issues).
Thanks for trying out Blazor! | https://habr.com/ru/post/486444/ | null | en | null |
# OSU! Relax (основы)
Привет, Хабр! Представляю вашему вниманию перевод статьи [Adventures in osu! game hacking](https://aixxe.net/2016/10/osu-game-hacking).
Не так давно я начал играть в OSU! и она мне понравилась. Со временем захотелось немного поковыряться во внутренностях этой игры.
Основной анализ beatmap
-----------------------
Итак, как мы будем разбирать beatmap? Мы можем разобрать все, начиная от названия песни, заканчивая настройками сложности. (Мы будем держать вещи простыми и анализируем только моменты времени, объекты попадания и некоторые значения, относящиеся к слайдеру.)
В стандартном режиме игры мы имеем дело с тремя типами объектов: кругом попадание, ползунком и счетчиком. В документации для формата файла .osu указано, что все объекты имеют такие составляющие: X, Y, время, тип. Все они будут включены в нашу структуру.
Я не хочу останавливаться на этом разделе слишком долго, так как это просто чтение каждой строки, ее разделение и сохранение результатов.
Получение игрового времени
--------------------------
Существует несколько различных способов сделать это, но самый простой — с помощью Cheat Engine. Если вы параноик, как я, вы можете сделать эту часть в автономном режиме, в конце концов, было много известных случаев автоматических запретов, связанных с использованием Cheat Engine. По крайней мере, убедитесь, что вы вышли из своего OSU!, прежде чем продолжить.
Начните с открытия Cheat Engine. Если OSU! пока не запущена, запустите её сейчас. Нажмите на значок в верхнем левом углу, чтобы открыть список процессов, отсюда выберите OSU!.exe и нажмите „Attach debugger to process”. Вернитесь к OSU!.. Теперь убедитесь, что никакая музыка не играет. Вы можете сделать это в главном меню, щелкнув на значок остановки в правом верхнем углу.
Теперь вернитесь к Cheat Engine, введите 0 в поле «Значение» и выполните первое сканирование. Как только оно будет закончено, вы увидите больше миллиона результатов. Мы сократим это до нескольких. Вернитесь к OSU! и снова начните воспроизведение музыки. Теперь вернитесь к Cheat Engine, установите для типа сканирования значение «Увеличенное значение» и нажмите «Следующее сканирование». Это значительно уменьшит количество результатов. Продолжайте нажимать кнопку «Следующее сканирование», пока не останется с несколько результатов.
Мы почти получили его. Все, что осталось сейчас, — это динамически получать это значение. Вот почему мы использовали отладчик Cheat Engine раньше. Щелкните правой кнопкой мыши на каждый адрес и выберите <> в раскрывающемся меню. Некоторые из них нам не подходят, но вы должны найти тот, который при разборке выглядит аналогичным.
```
13654FA8 - DB 5D E8 - fistp dword ptr [ebp-18]
13654FAB - 8B 45 E8 - mov eax, [ebp-18]
13654FAE - A3 BC5D7705 - mov [05775DBC], eax
13654FB3 - 8B 35 94382104 - mov esi, [04213894]
13654FB9 - 85 F6 - тест esi, esi
```
Я загрузил базовый внешний сигнатурный сканер, который мы будем использовать позже в нашей реализации.
```
DB 5D E8 8B 45 E8 A3
— Regular or 'IDA-style' signature.
\ XDB \ X5D \ X Е8 \ x8B \ x45 \ X Е8 \ XA3
— Code-style signature.
ххххххх
- — Code-style mask.
```
Обратите внимание, что указанная выше подпись относится только к каналу Stable (Latest) release. Подписи, вероятно, будут отличаться по каналам Stable (Fallback), Beta и Cutting Edge (Experimental), но процесс его поиска будет таким же, как и выше.
Реализация
----------
Теперь нам нужно найти идентификатор процесса OSU! и обработать его. Существует много разных способов сделать это, но вероятно проще всего использовать CreateToolhelp32Snapshot, а также Process32Next для перебора списка процессов.
```
inline const DWORD get_process_id() {
DWORD process_id = NULL;
HANDLE process_list = CreateToolhelp32Snapshot(TH32CS_SNAPPROCESS, NULL);
PROCESSENTRY32 entry = {0};
entry.dwSize = sizeof PROCESSENTRY32;
if (Process32First(process_list, &entry)) {
while (Process32Next(process_list, &entry)) {
if (_wcsicmp(entry.szExeFile, L«osu!.exe») == 0) {
process_id = entry.th32ProcessID;
}
}
}
>
CloseHandle(process_list);
return process_id;
};
game_process_id = get_process_id();
if (!game_process_id) {
return EXIT_FAILURE;
}
```
Теперь у нас есть идентификатор процесса, мы можем открыть дескриптор процесса.
Поскольку нам нужно только считать его память, мы будем использовать PROCESS\_VM\_READ, как желаемый флаг доступа.
```
game_process = OpenProcess (PROCESS_VM_READ, false, game_process_id);
if (! game_process) {
return false;
}
```
Это была большая часть скучного материала. Теперь нам нужны только адрес времени игры и способ отправки ключевых входов, прежде чем мы сможем продолжить. Для первого из них понадобиться подписи, которые мы сделали ранее.
```
> inline const DWORD find_time_address() {
// scan process memory for array of bytes.
DWORD time_ptr = FindPattern(game_process, PBYTE(TIME_SIGNATURE)) + 7;
DWORD time_address = NULL;
if (!ReadProcessMemory(game_process, LPCVOID(time_ptr), &time_address, sizeof DWORD, nullptr)) {
return false;
}
return time_address;
};
inline const int32_t get_elapsed_time() {
// read and return the elapsed time in the current beatmap.
int32_t current_time = NULL;
if (!ReadProcessMemory(game_process, LPCVOID(time_address), ¤t_time, sizeof int32_t, nullptr)) {
return false;
}
return current_time;
};
```
Для последней из этих вспомогательных функций нам понадобится что-то, что будет нажимать клавишу, когда мы ее вызываем. Опять же, есть несколько способов реализовать это, но я нашел keybd\_event, но SendInput будет самым легким. Поскольку keybd\_event устарел, мы будем использовать SendInput,
```
inline void set_key_pressed(char key, bool pressed) {
INPUT key_press = {0};
key_press.type = INPUT_KEYBOARD;
key_press.ki.wVk = VkKeyScanEx(key, GetKeyboardLayout(NULL)) & 0xFF;
key_press.ki.awScan = 0;
key_press.ki.dwExtraInfo = 0;
key_press.ki.dwFlags = (pressed? 0: KEYEVENTF_KEYUP);
SendInput(1, &key_press, sizeof INPUT);
}
```
Все, что осталось, это перебрать удаленные объекты и отправить входы по мере продвижения. Изначально мы находимся в начале beatmap. Теперь мы можем прочитать время, чтобы узнать, где мы находимся на самом деле.
```
size_t current_object = 0;
int32_t time = get_elapsed_time();
for (size_t i = 0; i < active_beatmap.hitobjects.size(); i++) {
if (active_beatmap.hitobjects.at(i).start_time > time) {
current_object = i;
break;
}
}
```
Обязательно добавьте проверку для карт с AudioLeadIn time.
```
while (current_object == 0 && get_elapsed_time() < active_beatmap.hitobjects.begin()->start_time) {
std::this_thread::sleep_for(std::chrono::milliseconds(1));
}
```
Вот где начинается настоящая забава. Возможно, вы ожидали, что эта часть будет сложной, но логика здесь на самом деле довольно прямолинейна. Мы ждем 'start time' текущего объекта, удерживаем ключ, ждем 'end time’, а затем освобождаем его. После того, как мы выпустили ключ, мы переходим к следующему объекту и продолжаем, пока не достигнем конца beatmap.
```
hitobject& object = active_beatmap.hitobjects.at(current_object);
while (current_object < active_beatmap.hitobjects.size()) {
static bool key_down = false;
time = get_elapsed_time();
// hold key
if (time >= (object.start_time — 5) && !key_down) {
set_key_pressed('z', true);
key_down = true;
continue;
}
// release key
if (time > object.end_time && key_down) {
set_key_pressed('z', false);
key_down = false;
current_object++;
object = active_beatmap.hitobjects.at(current_object);
}
std::this_thread::sleep_for(std::chrono::milliseconds(1));
}
```
Обратите внимание, что я вычитал пять миллисекунд со времени начала, это своего рода волшебное число, и ваш пробег может отличаться от него. Он не мог нажать на все кнопки и слайдеры идеально без этого. Я также добавляю две миллисекунды к концу окончания круга в классе beatmap. Поскольку круги не нужно удерживать, мы хотим как можно скорее отпустить их. Если мы отпустим их слишком быстро, нажатие может быть проигнорировано, поэтому нужны дополнительные 2 мс.
Ну, теперь мы готовы скомпилировать и протестировать OSU!Relax! | https://habr.com/ru/post/344552/ | null | ru | null |
# Как у меня было первый раз с Kiwi
##### What's new?
В этой статье хочу рассказать о применении технологии BDD при разработке приложений под iOS.
Было интересно попробывать на практике одну из методологий: TDD или BDD. Выбор пал на BDD. Почему именно он? Очень интересно о нем рассказали на DevCamp'e в харьковском офисе Ciklum. Почему именно Kiwi? О нем также шла речь на этом пресловутом DevCamp'e. Поэтому хотелось все попробывать самому на практике. Так что, кому интересны примеры с BDD, немного сложнее, чем тестирование переворота строки или калькулятора, прошу под кат.
#### Постановка задачи
Какую задачу чаще всего решает разработчик бизнес-приложений под iOS? На мой взгляд, это получение данных с сервера и их отображение юзеру. Для примера было написано приложение, которое решало задачу получения вопросов по тагу «iphone» с сайта «StackOverflow» с последующим их отображением в таблице. Не буду углубляться в тонкости архитектуры и реализации, а лучше подробнее остановлюсь на интересных, по моему мнению, вещах.
#### Как протестировать запрос?
Наверное, у всех были ситуации, когда работая параллельно с web-командой, вы не могли достучаться до сервера. Причины этого могли быть разные, то ли url поменяли, то ли сервис сломался. В общем, не суть важно. А важно то, что было бы хорошо при запуске юнит тестов проверить, а отзывается ли наш сервер?! За общение с сервером отвечает класс «StackOverflowRequest». Нам надо, чтобы при успешном получении данных с сервера вызывался метод «receivedJSON:», а при неудачном — «fetchFailedWithError:». В качестве тестируемых данных выберем валидный и невалидный url.
```
it(@"should recieve receivedJSON", ^
{
NSString *questionsUrlString = @"http://api.stackoverflow.com/1.1/search?tagged=iphone&pagesize=20";
IFStackOverflowRequest *request = [[IFStackOverflowRequest alloc] initWithDelegate:controller urlString:questionsUrlString];
[[request fetchQestions] start];
[[[controller shouldEventuallyBeforeTimingOutAfter(3)] receive] receivedJSON:any()];
});
it(@"should recieve fetchFailedWithError", ^
{
NSString *fakeUrl = @"asda";
IFStackOverflowRequest *request = [[IFStackOverflowRequest alloc] initWithDelegate:controller urlString:fakeUrl];
[[request fetchQestions] start];
[[[controller shouldEventuallyBeforeTimingOutAfter(1)] receive] fetchFailedWithError:any()];
});
```
К сожалению, в данном тесте нарушается одно из условий тестирования: тесты должны проходить быстро. А так как мы ждем ответа от сервера, то это нехорошо. Поэтому я заключил эти 2 теста в блок «ifdef».
##### Как протестировать ожидание данных с сервера?
Как известно, если идет какая-то загрузка/обработка данных, то мы должны это показать пользователю, чтобы не было ощущения, что приложение зависло. Чаще всего это встречается при загрузке картинки с сервера. В моем случае я просто показываю спинер. Алгоритм, по которому я определяю загрузилась ли картинки, реализован с помощью KVO.
```
it(@"spiner should be visible during avatar loading", ^
{
IFQuestionCell *cell = (IFQuestionCell *)[tableDelegate tableView:[UITableView new] cellForRowAtIndexPath:[NSIndexPath indexPathForRow:0 inSection:0]];
UIImageView *askerAvatar = (UIImageView *)[cell objectForPropertyName:@"askerAvatar"];
[askerAvatar.image shouldBeNil];
UIActivityIndicatorView *spiner = (UIActivityIndicatorView *)[cell objectForPropertyName:@"spiner"];
[spiner shouldNotBeNil];
[[theValue(spiner.hidden) should] equal:theValue(NO)];
[[theValue(spiner.isAnimating) should] equal:theValue(YES)];
});
it(@"spiner should be hidden when avatar is loaded", ^
{
IFQuestionCell *cell = (IFQuestionCell *)[tableDelegate tableView:[UITableView new] cellForRowAtIndexPath:[NSIndexPath indexPathForRow:0 inSection:0]];
UIImageView *askerAvatar = (UIImageView *)[cell objectForPropertyName:@"askerAvatar"];
askerAvatar.image = [UIImage new];
UIActivityIndicatorView *spiner = (UIActivityIndicatorView *)[cell objectForPropertyName:@"spiner"];
[spiner shouldNotBeNil];
[[theValue(spiner.hidden) should] equal:theValue(YES)];
});
```
##### Как протестировать правильность заполнения таблицы данными?
Для этих целей я обычно использую объект, который поддерживает протоколы «UITableViewDataSource, UITableViewDelegate». Пожалуй, приводить в статье пример тестирования правильности сортировки и уникальности объектов в таблице я не буду, в виду их банальной реализации. Это можно будет посмотреть в примере. Покажу как протестировать подгрузку новых вопросов. Как известно, сервер не может отдавать нам любое количество данных, которое мы у него запросим. Вместо этого, мы получаем данные порциями. В моем случае — это 20 вопросов за раз. То есть я могу отобразить 20 вопросов, а после того, как юзер доскролил до последнего вопроса, я должен буду сделать запрос на сервер для получения следующей порции вопросов. Чтобы пользователь видел, что пошел запрос на сервер за следующей порцией вопросов, я вместо ячейки с вопросами отображаю ячейку со спинерами.
```
it(@"spiner cell should be last cell, if last cell is not visible on table", ^
{
IFQuestion *q1 = [IFQuestion new];
IFQuestion *q2 = [IFQuestion new];
IFQuestion *q3 = [IFQuestion new];
IFQuestion *q4 = [IFQuestion new];
IFQuestion *q5 = [IFQuestion new];
IFQuestion *q6 = [IFQuestion new];
IFQuestion *q7 = [IFQuestion new];
IFQuestion *q8 = [IFQuestion new];
q1.questionID = 1;
q2.questionID = 2;
q3.questionID = 3;
q4.questionID = 4;
q5.questionID = 5;
q6.questionID = 6;
q7.questionID = 7;
q8.questionID = 8;
[tableDelegate addQuestions:@[q1, q2, q3, q4, q5, q6, q7, q8]];
IFSpinerCell *cell = (IFSpinerCell *)[tableDelegate tableView:tableView cellForRowAtIndexPath:[NSIndexPath indexPathForRow:9 inSection:0]];
NSString *cellClassName = NSStringFromClass ([cell class]);
[[cellClassName should] equal:NSStringFromClass ([IFSpinerCell class])];
for(NSInteger i = 0; i < 9; i++)
{
cell = (IFSpinerCell *)[tableDelegate tableView:tableView cellForRowAtIndexPath:[NSIndexPath indexPathForRow:i inSection:0]];
cellClassName = NSStringFromClass ([cell class]);
[[cellClassName should] equal:NSStringFromClass ([IFQuestionCell class])];
}
});
```
#### P.S.
Полный пример можно найти, пройдя по [этой](https://github.com/IgorFedorchuk/use-bdd) ссылке. Надеюсь, что статья оказалась полезной. Буду рад ответить на ваши вопросы, а также услышать комментарии и предложения. Спасибо. | https://habr.com/ru/post/165725/ | null | ru | null |
# Как работает оптимизирующий компилятор

Оптимизирующие компиляторы — основа современного ПО: они позволяют программистам писать код на понятном для них языке, затем преобразуя его в код, который сможет эффективно исполняться оборудованием. Задача оптимизирующих компиляторов заключается в том, чтобы понять, что делает написанная вами входная программа, и создать выходную программу, которая делает всё то же самое, только быстрее.
В этой статье мы рассмотрим некоторые из основных методик приведения (inference techniques) в оптимизирующих компиляторах: как спроектировать программу, с которой компилятору будет легко работать; какие приведения можно сделать в вашей программе и как использовать их для её уменьшения и ускорения.
Оптимизаторы программ могут выполняться где угодно: как этап большого процесса компилирования ([Scala Optimizer](https://www.lightbend.com/blog/scala-inliner-optimizer)); как отдельная программа, запускаемая после компилятора и перед исполнением ([Proguard](https://www.guardsquare.com/en/products/proguard)); или как часть runtime-среды, которая оптимизирует программу в ходе её исполнения ([JVM JIT-компилятор](https://aboullaite.me/understanding-jit-compiler-just-in-time-compiler/)). Ограничения в работе оптимизаторов варьируются в зависимости от ситуации, но задача у них одна: взять входную программу и преобразовать в выходную, которая делает то же самое, но быстрее.
Сначала мы рассмотрим несколько примеров оптимизаций программы-черновика, чтобы вы понимали, что обычно делают оптимизаторы и как всё это сделать вручную. Затем рассмотрим несколько способов представления программ, и наконец разберём алгоритмы и методики, с помощью которых можно проанализировать программы, а затем сделать их меньше и быстрее.
Программа-черновик
------------------
Все примеры будут приведены на Java. Этот язык очень распространён и компилируется в относительно простой ассемблер — [Java Bytecode](https://en.wikipedia.org/wiki/Java_bytecode). Так мы создадим хорошую основу, благодаря которой сможем исследовать методики оптимизации компилирования на реальных, исполняемых примерах. Все описанные ниже методики применимы почти во всех остальных языках программирования.
Для начала рассмотрим программу-черновик. Она содержит различную логику, регистрирует стандартный результат внутри процесса и возвращает вычисленный результат. Сама по себе программа не имеет смысла, но будет использоваться в качестве иллюстрации того, что можно оптимизировать, сохранив существующее поведение:
```
static int main(int n){
int count = 0, total = 0, multiplied = 0;
Logger logger = new PrintLogger();
while(count < n){
count += 1;
multiplied *= count;
if (multiplied < 100) logger.log(count);
total += ackermann(2, 2);
total += ackermann(multiplied, n);
int d1 = ackermann(n, 1);
total += d1 * multiplied;
int d2 = ackermann(n, count);
if (count % 2 == 0) total += d2;
}
return total;
}
// https://en.wikipedia.org/wiki/Ackermann_function
static int ackermann(int m, int n){
if (m == 0) return n + 1;
else if (n == 0) return ackermann(m - 1, 1);
else return ackermann(m - 1, ackermann(m, n - 1));
}
interface Logger{
public Logger log(Object a);
}
static class PrintLogger implements Logger{
public PrintLogger log(Object a){ System.out.println(a); return this; }
}
static class ErrLogger implements Logger{
public ErrLogger log(Object a){ System.err.println(a); return this; }
}
```
Пока что будем считать, что эта программа — всё, что у нас есть, никакие другие части кода её не вызывают. Она просто вводит данные в `main`, выполняет и возвращает результат. Теперь давайте оптимизировать эту программу.
Примеры оптимизаций
-------------------
#### Приведение типов и инлайнинг
Вы могли заметить, что у переменной `logger` неточный тип: несмотря на метку `Logger`, на основании кода можно сделать вывод, что это специфический подкласс — `PrintLogger`:
```
- Logger logger = new PrintLogger();
+ PrintLogger logger = new PrintLogger();
```
Теперь мы знаем, что `logger` — это `PrintLogger`, и знаем, что вызов `logger.log` может иметь единственную реализацию. Можно инлайнить:
```
- if (multiplied < 100) logger.logcount();
+ if (multiplied < 100) System.out.println(count);
```
Это позволит уменьшить программу за счёт удаления ненужного класса `ErrLogger`, который не используется, а также за счёт удаления разных методов `public Logger` `log`, поскольку мы инлайнили его в единственное место вызова.
Свёртывание констант
--------------------
В ходе исполнения программы `count` и `total` изменяются, а `multiplied` — нет: она начинается с `0` и каждый раз умножается через `multiplied = multiplied * count`, оставаясь равной `0`. Значит, можно заменить её во всей программе на `0`:
```
static int main(int n){
- int count = 0, total = 0, multiplied = 0;
+ int count = 0, total = 0;
PrintLogger logger = new PrintLogger();
while(count < n){
count += 1;
- multiplied *= count;
- if (multiplied < 100) System.out.println(count);
+ if (0 < 100) logger.log(count);
total += ackermann(2, 2);
- total += ackermann(multiplied, n);
+ total += ackermann(0, n);
int d1 = ackermann(n, 1);
- total += d1 * multiplied;
int d2 = ackermann(n, count);
if (count % 2 == 0) total += d2;
}
return total;
}
```
В результате мы видим, что `d1 * multiplied` всегда равно `0`, а значит `total += d1 * multiplied` ничего не делает и может быть удалено:
```
- total += d1 * multiplied
```
#### Удаление мёртвого кода
После свёртывания `multiplied` и осознания, что `total += d1 * multiplied` ничего не делает, можно убрать определение `int d1`:
```
- int d1 = ackermann(n, 1);
```
Это больше не часть программы, и поскольку `ackermann` является чистой функцией, удаление не повлияет на результат выполнения программы.
Аналогично, после инлайнинга `logger.log` сама `logger` больше не используется и может быть удалена:
```
- PrintLogger logger = new PrintLogger();
```
#### Удаление ветви
Теперь первый условный переход в нашем цикле зависит от `0 < 100`. Поскольку это всегда верно, можно просто удалить условие:
```
- if (0 < 100) System.out.println(count);
+ System.out.println(count);
```
Любой условный переход, который всегда верен, можно инлайнить в тело условия, а для переходов, которые всегда неверны, можно удалить условие вместе с его телом.
#### Частичное вычисление
Теперь проанализируем три оставшихся обращения к `ackermann`:
```
total += ackermann(2, 2);
total += ackermann(0, n);
int d2 = ackermann(n, count);
```
* В первом два постоянных аргумента. Функция чистая, и при предварительном вычислении `ackermann(2, 2)` должно быть равно `7.`
* Во втором обращении есть один постоянный аргумент `0` и один неизвестный `n`. Можно передать его в определение `ackermann`, и окажется, что когда `m` равно `0`, функция всегда возвращает `n + 1.`
* В третьем обращении оба аргумента неизвестны: `n` и `count`. Пока что оставим их на месте.
Учитывая, что обращение к `ackermann` определяется так:
```
static int ackermann(int m, int n){
if (m == 0) return n + 1;
else if (n == 0) return ackermann(m - 1, 1);
else return ackermann(m - 1, ackermann(m, n - 1));
}
```
Можно упростить его до:
```
- total += ackermann(2, 2);
+ total += 7
- total += ackermann(0, n);
+ total += n + 1
int d2 = ackermann(n, count);
```
#### Поздняя диспетчеризация
Определение `d2` используется только в условном переходе `if (count % 2 == 0)`. Поскольку вычисление `ackermann` является чистым, можно перенести этот вызов в условный переход, чтобы он не обрабатывался до тех пор, пока не будет использован:
```
- int d2 = ackermann(n, count);
- if (count % 2 == 0) total += d2;
+ if (count % 2 == 0) {
+ int d2 = ackermann(n, count);
+ total += d2;
+ }
```
Это позволит избежать половины обращений к `ackermann(n, count)`, ускорив выполнение программы.
Для сравнения, функция `System.out.println` не является чистой, а значит её нельзя переносить внутрь или за пределы условных переходов без изменения семантики программы.
Оптимизированный результат
--------------------------
Собрав все оптимизации, получим такой исходный код:
```
static int main(int n){
int count = 0, total = 0;
while(count < n){
count += 1;
System.out.println(count);
total += 7;
total += n + 1;
if (count % 2 == 0) {
total += d2;
int d2 = ackermann(n, count);
}
}
return total;
}
static int ackermann(int m, int n){
if (m == 0) return n + 1;
else if (n == 0) return ackermann(m - 1, 1);
else return ackermann(m - 1, ackermann(m, n - 1));
}
```
Хотя мы оптимизировали вручную, всё это можно сделать автоматически. Ниже приведён декомпилированный результат оптимизатора прототипа, который я написал для JVM-программ:
```
static int main(int var0) {
new Demo.PrintLogger();
int var1 = 0;
int var3;
for(int var2 = 0; var2 < var0; var2 = var3) {
System.out.println(var3 = 1 + var2);
int var10000 = var3 % 2;
int var7 = var1 + 7 + var0 + 1;
var1 = var10000 == 0 ? var7 + ackermann(var0, var3) : var7;
}
return var1;
}
static int ackermann__I__TI1__I(int var0) {
if (var0 == 0) return 2;
else return ackermann(var0 - 1, var0 == 0 ? 1 : ackermann__I__TI1__I(var0 - 1););
}
static int ackermann(int var0, int var1) {
if (var0 == 0) return var1 + 1;
else return var1 == 0 ? ackermann__I__TI1__I(var0 - 1) : ackermann(var0 - 1, ackermann(var0, var1 - 1));
}
static class PrintLogger implements Demo.Logger {}
interface Logger {}
```
Декомпилированный код чуть отличается от вручную оптимизированной версии. Кое-что компилятор не смог оптимизировать (например, неиспользуемый вызов `new PrintLogger`), а что-то сделано немного иначе (например, разделены `ackermann` и `ackermann__I__TI1__I`). Но в остальном автоматический оптимизатор сделал всё то же самое, что и я, используя заложенную в него логику.
Возникает вопрос: как?
Промежуточные представления
---------------------------
Если вы попробуете создать собственный оптимизатор, то первый же возникший вопрос будет, пожалуй, самым важным: что такое «программа»?
Несомненно, вы привыкли писать и изменять программы в виде исходного кода. Вы точно исполняли их в виде скомпилированных бинарников, возможно, даже отлаживали бинарники. Вы могли сталкиваться с программами в виде [синтаксического дерева](https://ru.wikipedia.org/wiki/%D0%90%D0%B1%D1%81%D1%82%D1%80%D0%B0%D0%BA%D1%82%D0%BD%D0%BE%D0%B5_%D1%81%D0%B8%D0%BD%D1%82%D0%B0%D0%BA%D1%81%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%BE%D0%B5_%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE), [трёхадресного кода](https://en.wikipedia.org/wiki/Three-address_code), [A-Normal](https://en.wikipedia.org/wiki/A-normal_form), [передачи продолжения (Continuation Passing Style](https://en.wikipedia.org/wiki/Continuation-passing_style)) или [Single Static Assignment](https://ru.wikipedia.org/wiki/SSA).
Существует целый зоопарк разных представлений программ. Здесь мы обсудим самые важные способы представления «программы» внутри оптимизатора.
Исходный код
------------
```
static int ackermann(int m, int n){
if (m == 0) return n + 1;
else if (n == 0) return ackermann(m - 1, 1);
else return ackermann(m - 1, ackermann(m, n - 1));
}
```
Некомпилированный исходный код тоже является представлением вашей программы. Он относительно компактен, удобен для чтения человеком, но у него два недостатка:
* Исходный код содержит все подробности наименований и форматирования, которые важны для программиста, но бесполезны для компьютера.
* Ошибочных программ в виде исходного кода гораздо больше, чем корректных, и при оптимизации нужно удостовериться, что ваша программа из корректного входного исходного кода преобразуется в корректный выходный исходный код.
Эти факторы затрудняют оптимизатору работу с программой в виде исходного кода. Да, вы *можете* преобразовывать такую программу, например, с помощью [регулярных выражений](https://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D0%B3%D1%83%D0%BB%D1%8F%D1%80%D0%BD%D1%8B%D0%B5_%D0%B2%D1%8B%D1%80%D0%B0%D0%B6%D0%B5%D0%BD%D0%B8%D1%8F) выявляя и заменяя паттерны. Однако первый из двух факторов затрудняет надёжное выявление паттернов обилием посторонних подробностей. А второй фактор сильно повышает вероятность запутаться и получить некорректную результирующую программу.
Эти ограничения приемлемы для преобразователей программ, которые исполняются под надзором человека, например, когда можно использовать [Codemod](https://github.com/facebook/codemod) для рефакторинга и преобразования кодовой базы. Однако использовать исходный код в качестве первичной модели автоматизированного оптимизатора нельзя.
Абстрактные синтаксические деревья
----------------------------------
```
static int ackermann(int m, int n){
if (m == 0) return n + 1;
else if (n == 0) return ackermann(m - 1, 1);
else return ackermann(m - 1, ackermann(m, n - 1));
}
IfElse(
cond = BinOp(Ident("m"), "=", Literal(0)),
then = Return(BinOp(Ident("n"), "+", Literal(1)),
else = IfElse(
cond = BinOp(Ident("n"), "=", Literal(0)),
then = Return(Call("ackermann", BinOp(Ident("m"), "-", Literal(1)), Literal(1)),
else = Return(
Call(
"ackermann",
BinOp(Ident("m"), "-", Literal(1)),
Call("ackermann", Ident("m"), BinOp(Ident("n"), "-", Literal(1)))
)
)
)
)
```
Абстрактные синтаксические деревья (AST) — другой распространённый промежуточный формат. Они расположены на следующей ступени лестницы абстракции по сравнению с исходным кодом. Обычно AST отбрасывают всё форматирование исходного кода, отступы и комментарии, но сохраняют имена локальных переменных, которые отбрасываются в более абстрактных представлениях.
Как и исходный код, AST страдают от возможности кодирования ненужной информации, которая не влияет на фактическую семантику программы. Например, следующие два фрагмента кода семантически идентичны; они различаются только именами локальных переменных, но всё ещё имеют разные AST:
```
static int ackermannA(int m, int n){
int p = n;
int q = m;
if (q == 0) return p + 1;
else if (p == 0) return ackermannA(q - 1, 1);
else return ackermannA(q - 1, ackermannA(q, p - 1));
}
Block(
Assign("p", Ident("n")),
Assign("q", Ident("m")),
IfElse(
cond = BinOp(Ident("q"), "==", Literal(0)),
then = Return(BinOp(Ident("p"), "+", Literal(1)),
else = IfElse(
cond = BinOp(Ident("p"), "==", Literal(0)),
then = Return(Call("ackermann", BinOp(Ident("q"), "-", Literal(1)), Literal(1)),
else = Return(
Call(
"ackermann",
BinOp(Ident("q"), "-", Literal(1)),
Call("ackermann", Ident("q"), BinOp(Ident("p"), "-", Literal(1)))
)
)
)
)
)
static int ackermannB(int m, int n){
int r = n;
int s = m;
if (s == 0) return r + 1;
else if (r == 0) return ackermannB(s - 1, 1);
else return ackermannB(s - 1, ackermannB(s, r - 1));
}
Block(
Assign("r", Ident("n")),
Assign("s", Ident("m")),
IfElse(
cond = BinOp(Ident("s"), "==", Literal(0)),
then = Return(BinOp(Ident("r"), "+", Literal(1)),
else = IfElse(
cond = BinOp(Ident("r"), "==", Literal(0)),
then = Return(Call("ackermann", BinOp(Ident("s"), "-", Literal(1)), Literal(1)),
else = Return(
Call(
"ackermann",
BinOp(Ident("s"), "-", Literal(1)),
Call("ackermann", Ident("s"), BinOp(Ident("r"), "-", Literal(1)))
)
)
)
)
)
```
Ключевой момент в том, что хотя AST имеют структуру деревьев, они содержат узлы, которые семантически ведут себя не как деревья: значения `Ident("r")` и `Ident("s")` определяются не содержимым их поддеревьев, а вышерасположенными узлами `Assign("r", ...)` и `Assign("s", ...)`. По сути, между `Ident`’ами и `Assign`’ами есть дополнительные семантические связи, которые столь же важны, как и ребра в древовидной структуре AST:
Эти связи формируют обобщённую графовую структуру, включающую циклы при наличии рекурсивных определений функций.
Байткод
-------
Поскольку в качестве основного языка мы выбрали Java, скомпилированные программы сохраняются в виде Java—байткода в файлах .class.
Вспомним нашу функцию `ackermann`:
```
static int ackermann(int m, int n){
if (m == 0) return n + 1;
else if (n == 0) return ackermann(m - 1, 1);
else return ackermann(m - 1, ackermann(m, n - 1));
}
```
Она компилируется в такой байткод:
```
0: iload_0
1: ifne 8
4: iload_1
5: iconst_1
6: iadd
7: ireturn
8: iload_1
9: ifne 20
12: iload_0
13: iconst_1
14: isub
15: iconst_1
16: invokestatic ackermann:(II)I
19: ireturn
20: iload_0
21: iconst_1
22: isub
23: iload_0
24: iload_1
25: iconst_1
26: isub
27: invokestatic ackermann:(II)I
30: invokestatic ackermann:(II)I
33: ireturn
```
Виртуальная машина Java (JVM), которая выполняет Java—байткод, представляет собой машину с комбинацией стека и регистров: есть стек операндов (STACK), в котором происходит оперирование значениями, и массив локальных переменных (LOCALS), в котором эти значения могут храниться. Функция начинается с N параметров в первых N слотах локальных переменных. По мере исполнения функция перемещает данные в стек, оперирует ими, кладёт обратно в переменные, вызывая `return` для возврата значения вызывающему из стека операндов.
Если аннотировать приведённый выше байткод для представления значений, которые перемещаются между стеком и таблицей локальных переменных, то это будет выглядеть так:
```
BYTECODE LOCALS STACK
|a0|a1| |
0: iload_0 |a0|a1| |a0|
1: ifne 8 |a0|a1| |
4: iload_1 |a0|a1| |a1|
5: iconst_1 |a0|a1| |a1| 1|
6: iadd |a0|a1| |v1|
7: ireturn |a0|a1| |
8: iload_1 |a0|a1| |a1|
9: ifne 20 |a0|a1| |
12: iload_0 |a0|a1| |a0|
13: iconst_1 |a0|a1| |a0| 1|
14: isub |a0|a1| |v2|
15: iconst_1 |a0|a1| |v2| 1|
16: invokestatic ackermann:(II)I |a0|a1| |v3|
19: ireturn |a0|a1| |
20: iload_0 |a0|a1| |a0|
21: iconst_1 |a0|a1| |a0| 1|
22: isub |a0|a1| |v4|
23: iload_0 |a0|a1| |v4|a0|
24: iload_1 |a0|a1| |v4|a0|a1|
25: iconst_1 |a0|a1| |v4|a0|a1| 1|
26: isub |a0|a1| |v4|a0|v5|
27: invokestatic ackermann:(II)I |a0|a1| |v4|v6|
30: invokestatic ackermann:(II)I |a0|a1| |v7|
33: ireturn |a0|a1| |
```
Здесь я с помощью `a0` и `a1` представил аргументы функции, которые в самом начале функции хранятся в таблице LOCALS. `1` представляет константы, загруженные через `iconst_1`, а с `v1` до `v7` — вычисленные промежуточные значения. Здесь три инструкции `ireturn`, возвращающие `v1`, `v3` и `v7`. Эта функция не определяет другие локальные переменные, поэтому массив LOCALS хранит только входные аргументы.
Выше мы видели два варианта нашей функции — `ackermannA` и `ackermannB`. Так они выглядят в байткоде:
```
BYTECODE LOCALS STACK
|a0|a1| |
0: iload_1 |a0|a1| |a1|
1: istore_2 |a0|a1|a1| |
2: iload_0 |a0|a1|a1| |a0|
3: istore_3 |a0|a1|a1|a0| |
4: iload_3 |a0|a1|a1|a0| |a0|
5: ifne 12 |a0|a1|a1|a0| |
8: iload_2 |a0|a1|a1|a0| |a1|
9: iconst_1 |a0|a1|a1|a0| |a1| 1|
10: iadd |a0|a1|a1|a0| |v1|
11: ireturn |a0|a1|a1|a0| |
12: iload_2 |a0|a1|a1|a0| |a1|
13: ifne 24 |a0|a1|a1|a0| |
16: iload_3 |a0|a1|a1|a0| |a0|
17: iconst_1 |a0|a1|a1|a0| |a0| 1|
18: isub |a0|a1|a1|a0| |v2|
19: iconst_1 |a0|a1|a1|a0| |v2| 1|
20: invokestatic ackermannA:(II)I |a0|a1|a1|a0| |v3|
23: ireturn |a0|a1|a1|a0| |
24: iload_3 |a0|a1|a1|a0| |a0|
25: iconst_1 |a0|a1|a1|a0| |a0| 1|
26: isub |a0|a1|a1|a0| |v4|
27: iload_3 |a0|a1|a1|a0| |v4|a0|
28: iload_2 |a0|a1|a1|a0| |v4|a0|a1|
29: iconst_1 |a0|a1|a1|a0| |v4|a0|a1| 1|
30: isub |a0|a1|a1|a0| |v4|a0|v5|
31: invokestatic ackermannA:(II)I |a0|a1|a1|a0| |v4|v6|
34: invokestatic ackermannA:(II)I |a0|a1|a1|a0| |v7|
37: ireturn |a0|a1|a1|a0| |
```
Поскольку исходный код берёт два аргумента и кладёт их в локальные переменные, то у байткода есть соответствующие инструкции загрузить значения аргументов из LOCAL-индексов 0 и 1 и сохранить их под индексами 2 и 3. Однако байткод не интересуют имена ваших локальных переменных: он работает с ними исключительно как с индексами в массиве LOCALS. Поэтому у `ackermannA` и `ackermannB` будут идентичные байткоды. Это логично, ведь они семантически эквивалентны!
Однако `ackermannA` и `ackermannB` компилируются не в тот же байткод, что и исходная `ackermann`: хотя байткод абстрагируется от имён локальных переменных, он всё же не полностью абстрагируется от загрузок и сохранений в/из этих переменных. Нам всё ещё важно, как значения перемещаются по LOCALS и STACK, хотя они и не влияют на фактическое поведение программы.
Помимо отсутствия абстрагирования от загрузок/сохранений, у байткода есть другой недостаток: как и большинство линейных ассемблеров, он очень сильно оптимизирован с точки зрения компактности, и может быть очень трудно модифицировать его, когда речь заходит об оптимизациях.
Чтобы было понятнее, давайте рассмотрим байткод исходной функции `ackermann`:
```
BYTECODE LOCALS STACK
|a0|a1| |
0: iload_0 |a0|a1| |a0|
1: ifne 8 |a0|a1| |
4: iload_1 |a0|a1| |a1|
5: iconst_1 |a0|a1| |a1| 1|
6: iadd |a0|a1| |v1|
7: ireturn |a0|a1| |
8: iload_1 |a0|a1| |a1|
9: ifne 20 |a0|a1| |
12: iload_0 |a0|a1| |a0|
13: iconst_1 |a0|a1| |a0| 1|
14: isub |a0|a1| |v2|
15: iconst_1 |a0|a1| |v2| 1|
16: invokestatic ackermann:(II)I |a0|a1| |v3|
19: ireturn |a0|a1| |
20: iload_0 |a0|a1| |a0|
21: iconst_1 |a0|a1| |a0| 1|
22: isub |a0|a1| |v4|
23: iload_0 |a0|a1| |v4|a0|
24: iload_1 |a0|a1| |v4|a0|a1|
25: iconst_1 |a0|a1| |v4|a0|a1| 1|
26: isub |a0|a1| |v4|a0|v5|
27: invokestatic ackermann:(II)I |a0|a1| |v4|v6|
30: invokestatic ackermann:(II)I |a0|a1| |v7|
33: ireturn |a0|a1| |
```
Сделаем черновое изменение: пусть вызов функции `30: invokestatic ackermann:(II)I` не использует свой первый аргумент. И тогда этот вызов можно заменить эквивалентным вызовом `30: invokestatic ackermann2:(I)I`, который берёт лишь один аргумент. Это распространённая оптимизация, которая позволяет с помощью «удаления мёртвого кода» выкинуть любой код, использующийся для вычисления первого аргумента `30: invokestatic ackermann:(II)I`.
Чтобы это сделать, нам нужно не только заменить инструкцию `30`, но также нужно просмотреть список инструкций и понять, где вычисляется первый аргумент (`v4` в `STACK`), и тоже его удалить. Вернёмся от инструкции `30` к `22`, а от `22` к `21` и `20`. Финальный вариант:
```
BYTECODE LOCALS STACK
|a0|a1| |
0: iload_0 |a0|a1| |a0|
1: ifne 8 |a0|a1| |
4: iload_1 |a0|a1| |a1|
5: iconst_1 |a0|a1| |a1| 1|
6: iadd |a0|a1| |v1|
7: ireturn |a0|a1| |
8: iload_1 |a0|a1| |a1|
9: ifne 20 |a0|a1| |
12: iload_0 |a0|a1| |a0|
13: iconst_1 |a0|a1| |a0| 1|
14: isub |a0|a1| |v2|
15: iconst_1 |a0|a1| |v2| 1|
16: invokestatic ackermann:(II)I |a0|a1| |v3|
19: ireturn |a0|a1| |
- 20: iload_0 |a0|a1| |
- 21: iconst_1 |a0|a1| |
- 22: isub |a0|a1| |
23: iload_0 |a0|a1| |a0|
24: iload_1 |a0|a1| |a0|a1|
25: iconst_1 |a0|a1| |a0|a1| 1|
26: isub |a0|a1| |a0|v5|
27: invokestatic ackermann:(II)I |a0|a1| |v6|
- 30: invokestatic ackermann:(II)I |a0|a1| |v7|
+ 30: invokestatic ackermann2:(I)I |a0|a1| |v7|
33: ireturn |a0|a1| |
```
Мы ещё можем сделать такое несложное изменение в простой функции `ackermann`. Но в больших функциях, используемых в реальных проектах, будет гораздо труднее делать многочисленные, взаимосвязанные изменения. В целом, любое маленькое семантическое изменение вашей программы может потребовать многочисленных изменений по всему байткоду.
Вы могли заметить, что описанное выше изменение мы вносили, анализируя значения в LOCALS и STACK: смотрели, как `v4` передаётся в инструкцию `30` из инструкции `22`, а `22` берёт данные в `a0` и `1`, которые поступают из инструкций `21` и `20`. Эти значения передаются между LOCALS и STACK по принципу графа: от инструкции, вычисляющей значение, в место его дальнейшего использования.
Как и пары `Ident`/`Assign` в наших AST, значения, которые передаются между LOCALS и STACK, формируют граф между точками вычислений значений и точками их использования. Так почему бы нам не начать работать напрямую с графом?
Графы потоков данных
--------------------
Графы потоков данных — это следующий уровень абстракции после байткода. Если расширить наше синтаксическое дерево связями `Ident`/`Assign`, или если мы отследим, как байткод перемещает значения между LOCALS и STACK, то сможем построить граф. Для функции `ackermann` он выглядит так:

В отличие от AST или стеко-регистрового байткода Java, графы потоков данных не используют концепцию «локальная переменная»: вместо этого граф содержит прямые связи между каждым значением и местом его использования. При анализе байткода часто приходится абстрактно интерпретировать LOCALS и STACK, чтобы понять, как движутся значения; анализ AST подразумевает отслеживание дерева и работу с символьной таблицей, содержащей связи `Assign`/`Ident`; а анализ графов потоков данных часто представляет собой прямое отслеживание переходов — чистая идея «перемещения значения», без шелухи представления программы.
Также графами легче манипулировать, чем линейным байткодом: замена узла с вызовом `ackermann` на вызов `ackermann2` и отброс одного из аргументов — это всего лишь изменение узла графа (помечен зелёным) и удаление одной из входных связей вместе с транзитными связями узлами (помечены красным):
Как видите, небольшое изменение в программе (замена `ackermann(int n, int m)` на `ackermann2(int m)`) превращается в относительно локализованное изменение в графе потоков данных.
В целом, работать с графами гораздо легче, чем с линейным байткодом или AST: их просто анализировать и менять.
В этом описании графов нет многих подробностей: кроме фактического физического представления графа существует много других способов моделирования состояния и управления потоком, работа с которыми сложнее и выходит за рамки статьи. Также я опустил ряд подробностей о преобразовании графов, например, о добавлении и удалении связей, прямых и обратных переходах, переходах горизонтальных и вертикальных (по ширине и глубине), и т. д. Если вы изучали алгоритмы, то всё это вам должно быть знакомо.
Наконец, мы опустили алгоритмы преобразования из линейного байткода в граф, а затем из графа обратно в байткод. Это сама по себе интересная задача, но оставляем её вам для самостоятельной проработки.
Анализ
------
После того, как мы получили представление программы, нужно её проанализировать: выяснить какие-то факты, которые позволят вам преобразовать программу без изменения её поведения. Многие рассмотренные выше оптимизации основаны именно на анализе программы:
* Свёртывание констант: результатом работы выражения является известное постоянное значение? Вычисление выражения является чистым?
* Приведение типов и инлайнинг: тип вызова метода является типом с единственной реализацией вызываемого метода?
* Удаление ветвей: является булево условное выражение постоянным?
* Удаление мёртвого кода: является результат компиляции «живым»? То есть он как-то влияет на результат работы программы? Вычисление чистое?
* Поздняя диспетчеризация: вычисление чистое, то есть его можно перенести на другое время?
Чем больше фактов мы знаем о программе, и чем они специфичнее, тем агрессивнее мы можем преобразовать программу, чтобы оптимизировать её без изменения семантики. В этой статье мы обсудим приведение типов, константы, жизнеспособность и доступность, а анализ чистоты будет вашим самостоятельным заданием.
Типы, константы, чистота, жизнеспособность — это некоторые из самых распространённых фактов, которые оптимизатор захочет узнать о вашей программе. Анализ в оптимизаторе выполняется очень похоже на приведение типов при фронтендной проверке типов компилятором.
Структура приведений (Inference Lattice)
----------------------------------------
Для начала давайте решим, как должны работать приводимые типы и константы. По сути, «тип» отражает какое-то наше знание о значении:
* Оно является `Integer`? `String`? `Array[Float]`? `PrintLogger`?
* Это `CharSequence`? То есть значение может быть `String`, а может быть и чем-то вроде `StringBuilder`?
* Или это `Any`, то есть мы не знаем, что это за значение?
Потенциальные типы значения в вашей программе могут быть представлены в виде такой структуры:
Приведение постоянного значения очень похоже на приведение типов: в некотором смысле, постоянное строковое значение `"hello"` является подтипом `String`, так же как `String` является подтипом `CharSequence`. Поскольку у нас есть только одна строка `"hello"`, её можно назвать одиночным типом (Singleton Type) — синглтоном. Расширим нашу структуру синглтонами:
Чем выше мы поднимаемся по структуре типа, присвоенного значению, тем меньше мы о нём знаем. Чем ниже спускаемся, тем больше узнаём. Если мы знаем, что значение относится к одному из двух типов, например, `String` или `StringBuilder`, тогда можем консервативно предположить, что оно относится к ближайшему вышестоящему типу: `CharSequence`. Если мы знаем, что значение равно `0`, или `1`, или `2`, то можно сделать вывод, что это `Integer`.
Можно создать ещё более гранулированную структуру, например, разделив чётные и нечётные числа:

Чем гранулированней структура, тем точнее ваш анализ, но при этом на него уйдёт больше времени. Вам решать, насколько подробно вы будете анализировать.
Приведение count
----------------
Посмотрим на упрощённую версию программы `main`:
```
static int main(int n){
int count = 0, multiplied = 0;
while(count < n){
if (multiplied < 100) logger.log(count);
count += 1;
multiplied *= count;
}
return ...;
}
```
Мы убрали разные обращения к `ackermann`, оставив использование только `count`, `multiplied` и `logger`. Так выглядит граф потоков данных:
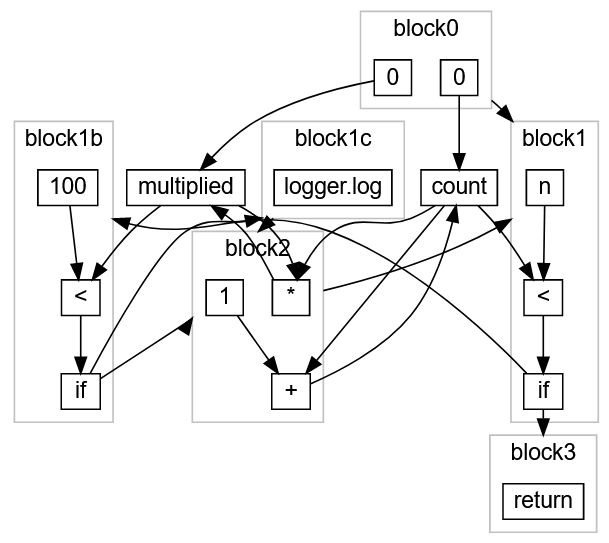
Мы видим, что `count` инициализирован равным `0` в `block0`. Затем поток управления сместился в `block1`, где мы проверяем, выполняется ли условие `count < n`: если да, то идём в `block3` и `return`, иначе идём в `block2`, который инкрементирует `count` на `1` и сохраняет результат в `count`, возвращая управление в `block1` для повтора проверки. Этот цикл работает до тех пор, пока `<` не возвратит `false`, тогда мы идём в `block3` и завершаем программу.
Как это проанализировать?
* Начинаем с `block0`. Нам известно, что `count = 0.`
* Идём в `block1`, мы не знаем, чему равно `n` (это вводимый параметр, он может быть любым числом `Integer`), а значит мы не знаем, куда пойдёт `if`. Придётся рассмотреть `block2` и `block3.`
* Игнорируем `block3`, поскольку это тривиально, и идём в `block1b`, который либо переносит напрямую в `block2`, либо не напрямую, сначала зажурналировав данные в `block1c`. Мы видим, что `block2` берёт `count`, увеличивает его на 1 и кладёт значение обратно в `count.`
* Мы знаем, что `count` может быть равен `0` или `1`: смотрим на созданную выше структуру и приводим `count` к `Integer.`
* Следующий круг: идём через `block1` и приводим `n` и `count` к `Integer`.
* Снова идём в `block2`, теперь `count` изменён на `Integer + 1 -> Integer`. Мы уже знаем, что `count` является `Integer`, поэтому можем завершить анализ.
Приведение multiplied
---------------------
Рассмотрим поблочно другой граф потоков данных, относящийся к `multiplied`:
* Начинаем в `block0`. Мы знаем, что `multiplied` присвоено значение `0.`
* Переходим в `block1`, в котором есть условный переход, который мы не смогли раньше удалить. Переходим в `block2` и `block3` (здесь всё просто).
* В `block2` обнаруживаем, что мы умножили `block2` (равный `0`) на `count` (который ранее определили как `Integer`). Поскольку `0 * Integer -> 0`, можно оставить `multiplied` приведённым к `0.`
* Снова проходим через `block1` и `block2`. `multiplied` всё ещё приведён к `0`, поэтому можно прекратить анализ.
Поскольку `multiplied` приведён к `0`, мы знаем, что:
* `multiplied < 100` можно привести к `true.`
* `if (multiplied < 100) logger.log(count);` можно упростить до `logger.log(count)`.
* Можно убрать все вычисления, которые завершаются в `multiplied`, потому что мы уже знаем, что конечный результат всегда равен `0`.
Эти изменения помечены красным:
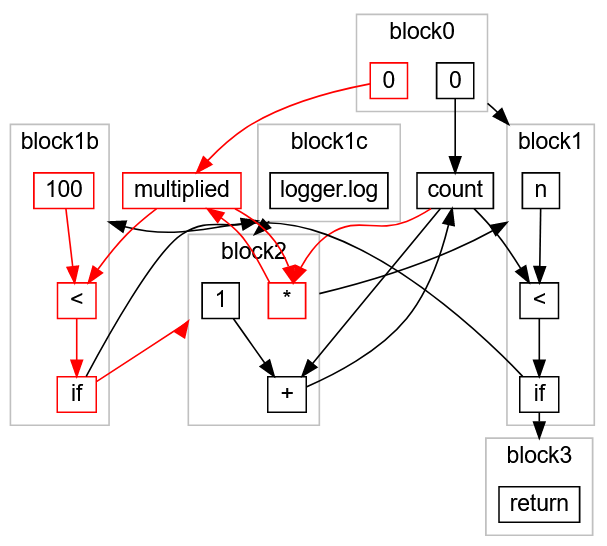
Получается такой граф потоков данных:
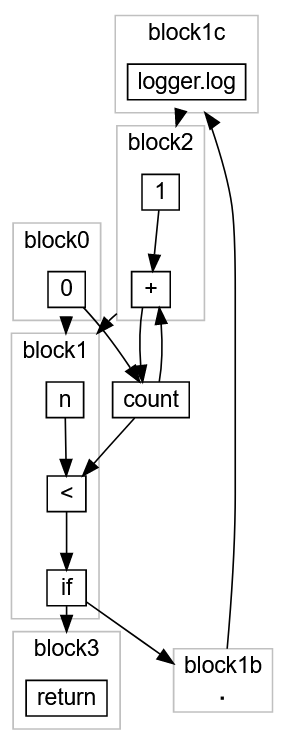
Сериализуем его в байткод и получаем программу:
```
static int main(int n){
int count = 0;
while(count < n){
logger.log(count);
count += 1;
}
return ...;
}
```
Смоделировав программу в виде подходящей структуры данных, нам хватает простых переходов по графу, чтобы упростить запутанный, неэффективный код, превратив его в маленький эффективный цикл.
Приведение `multiplied -> 0` может применяться и в других оптимизациях, например, при частичном вычислении. В целом, приведения позволяют делать новые приведения, а одни оптимизации открывают дорогу новым. Основная трудность в проектировании оптимизатора программ заключается в том, чтобы он эффективно использовал этот каскад возможностей по приведению и оптимизациям.
В этом разделе я показал, как работает приведение в графе потоков данных. Мы рассмотрели:
* Как можно определить структуру приведений для представления наших знаний о каждом значении в программе.
* Как выглядит граф потоков данных для синтетических программ.
* Как идти по графу потоков данных для выполнения приведений каждого значения в программе.
* Как можно использовать эти приведения для выполнения оптимизаций: удаления ветвей или частичных вычислений по мере возможности.
В данном случае мы смогли проанализировать сначала `count`, а затем `multiplied`. Это стало возможным потому, что `multiplied` зависит от `count`, но `count` не зависит от `multiplied`. При взаимной зависимости пришлось бы анализировать переменные вместе, в ходе одного прохода по графу.
Обратите внимание, что приведение — процесс итеративный: вы раз за разом проходите по циклу, пока ваши приведения не перестанут изменяться. В целом, графы потоков данных без циклов (или рекурсий) всегда можно проанализировать за один проход. А программы с циклами или рекурсиями потребуют нескольких итераций анализа.
Сейчас нам хватило только два прохода по циклу `while`, но может случиться так, что анализ потребует `O(глубина структуры приведений)` итераций. Поэтому более подробная структура (например, с разделением на чётные и нечётные числа) может улучшить точность анализа, но и увеличит его длительность, поэтому придётся искать компромиссы.
Такой же подход можно использовать для приведения свойств произвольных рекурсивных функций, как мы сейчас увидим.
Межпроцедурное приведение функций
---------------------------------
Выше мы приводили значения внутри единственного тела функции, ради простоты игнорируя вызовы других функций или методов. Но большинство программ содержат много функций, вызывающих друг друга, так что при работе с реальными программами вам придётся приводить свойства не только одного выражения в функции, но и самих функций, а также приводить их взаимодействие друг с другом в графе вызовов.
Простые нерекурсивные функции
-----------------------------
В большинстве случаев обрабатывать другие функции несложно. Посмотрите на эту программу:
```
static int main(int n){
return called(n, 0);
}
static int called(int x, int y){
return x * y;
}
```
Граф потоков данных для этих двух функций выглядит так:
Приведём возвращаемое значение `main`:
* Приводим `main(n)`
+ Приводим `called(n, 0)`
- Приводим `x * y` к `x = n` и `y = 0`
- `n * 0` равно `0`
+ `called(n, 0)` равно `0`
* `main(n)` равно `0`
Когда в ходе приведения вы достигаете вызова функции, то сначала приведите вызываемого, прежде чем продолжить приведение вызывающего. Этот стек приведений может быть любой глубины и отражать стек вызовов при исполнении программы.
Мы знаем, что `called(n, 0)` равно `0`, и можем это использовать для упрощения графа потоков данных:

Сериализуем его в код:
```
static int main(int n){
return 0;
}
```
Теперь наши функции не рекурсивны: если A вызывает B, вызывает C, вызывает D, затем D возвращает своё приведение к C, B, D и A. Однако если функция A вызывает B и B вызывает A, или даже A рекурсивно вызывает A, то всё это разваливается, поскольку вызовы ничего не возвращают!
Рекурсивная факториальная функция
---------------------------------
Рассмотрим простую рекурсивную функцию, написанную на псевдо Java:
```
public static Any factorial(int n) {
if (n == 1) {
return 1;
} else {
return n * factorial(n - 1);
}
}
```
Она берёт `n` и делает его `int`, но возвращаемый тип помечен как `Any`: объявление не соответствует возвращаемым данным. Мы видим, что `factorial` возвращает `int` (или `Integer` в нашей структуре). Но если перед возвращением полностью анализировать тело `factorial`, то мы проанализируем рекурсивный вызов `factorial` до завершения нашего анализа самой `factorial`, то есть столкнёмся с бесконечной рекурсией! Как нашему движку приведения определить это от нашего имени?
Приведение с Bottom
-------------------
Добавим в нашу структуру приведений специальное значение `Bottom`:

Оно означает «мы ещё не знаем, что это, но вернёмся сюда позднее и заполним». Применим `Bottom` в графе потоков данных для `factorial`:
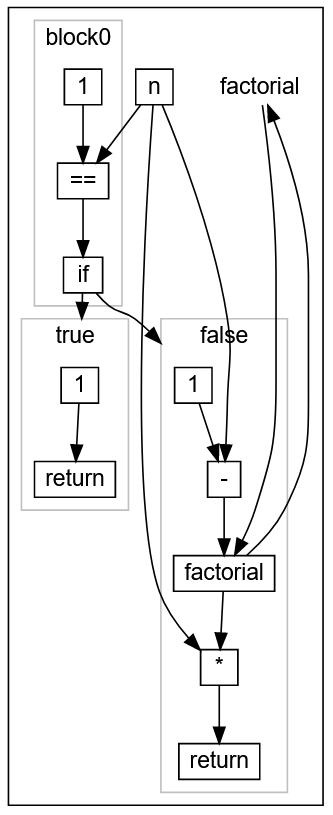
* Начинаем с `block0`. `n` является неизвестным `Integer`, `1` является `1`, тогда результат `n == 1` тоже неизвестен, поэтому придётся анализировать обе ветки `true` и `false`.
* С `true` всё понятно: `return` возвращает `1`.
* В ветке `false` результат `n - 1` благодаря `n` является неизвестным `Integer`.
* `factorial` — это рекурсивный вызов, поэтому пока что сделаем его `Bottom`.
* `*` из `n: Integer` и `factorial`: `Bottom` тоже пока `Bottom`.
* `return` возвращает `Bottom`.
* Вся функция `factorial` возвращает `1` или `Bottom`, а в нашей структуре ближайшим верхнеуровневым приведением для них является `1`.
* Вставим `1` в качестве приведения рекурсивного вызова `factorial`, который ранее мы пометили как `Bottom`.
* `Integer * 1` теперь `Integer`.
* `return` теперь возвращает `Integer`.
* `factorial` теперь возвращает `Integer` или `1`, а ближайшим верхнеуровневым приведением для них будет `Integer`.
* *Снова* приведём рекурсивный вызов `factorial`, на этот раз в виде `Integer`. Выражение `*` берёт `n: Integer` и `factorial: Integer`, которые остались неизменными `Integer`, и теперь приведения можно завершить.
Мы смогли привести возвращаемый `factorial` результат к `Integer`, несмотря на то, что это рекурсивная функция без объявления возвращаемого типа.
Хотя все эти примеры надуманы, они иллюстрируют способ приведения при наличии вызовов функций. С рекурсивными функциями вы можете делать для вызовов заглушки из `Bottom`, когда впервые с ними сталкиваетесь, а по завершении первого аналитического прохода замените заглушки первым приведением и передайте это изменение вверх по графу потока данных.
В данном случае выражение `*` проанализировано трижды:
1. `(n: Integer) * (factorial: Bottom)`
2. `(n: Integer) * (factorial: 1)`
3. `(n: Integer) * (factorial: Integer)`
Как и в случае с приведением константы `multiplied` из цикла, для завершения приведений может потребоваться выполнить до `O(глубина структуры приведений)` проходов. Этот подход обобщает другие стили рекурсивных функций и позволяет приводить другие свойства, например, чистоту.
Приведение жизнеспособности и доступности
-----------------------------------------
Анализ жизнеспособности и доступности — это пара оптимизаций, которые относятся к категории «удаление мёртвого кода». При этом анализе мы ищем код, значения из которого влияют на финальный результат («живой код»), и код, который может быть достигнут потоком управления программы («доступный код»). Весь остальной код можно удалить.
Давайте рассмотрим другую упрощённую версию исходной функции `main`:
```
static int main(int n){
int count = 0, total = 0, multiplied = 0;
while(count < n){
if (multiplied > 100) count += 1;
count += 1;
multiplied *= 2;
total += 1;
}
return count;
}
```
В отличие от предыдущих версий, здесь мы поменяли условный переход в `if (multiplied > 100)` и заменили `multiplied *= count` на `multiplied *= 2`. Так мы упростили графы программы без потери обобщённости.
Обратные проходы для оценки жизнеспособности кода
-------------------------------------------------
Есть две проблемы, которые нужно обнаружить в приведённой выше программе:
* `multiplied > 100` никогда не бывает `true`, поэтому `count += 1` никогда не будет выполнено («недоступно»).
* `total` хранит некоторые вычисленные значения, но одно из них не используется («нежизнеспособно»).
В идеале, программа должна выглядеть так:
```
static int main(int n){
int count = 0;
while(count < n){
count += 1;
}
return count;
}
```
Теперь давайте посмотрим, как анализатор перепишет её автоматически.
Сначала взгляните на граф потоков данных:
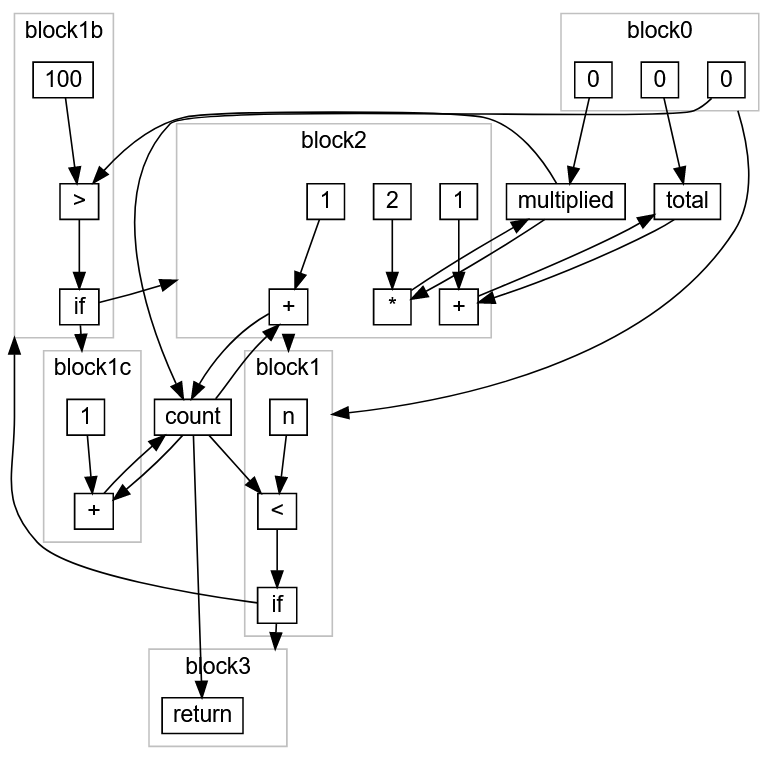
Он гораздо запутаннее графов, которые мы уже видели, но всё ещё читабелен: начинаем в `block0`, идём в `block1`, если одно условие истинно, то идём в `block1b`, если истинно другое условие, то идём в `block1c`, и так далее, пока не завершаем в узле `return` в `block3`.
Убираем мёртвый и недоступный код
---------------------------------
Можем применить такое же приведение типов и констант, как и для поиска `multiplied -> 0`, и модифицировать граф:
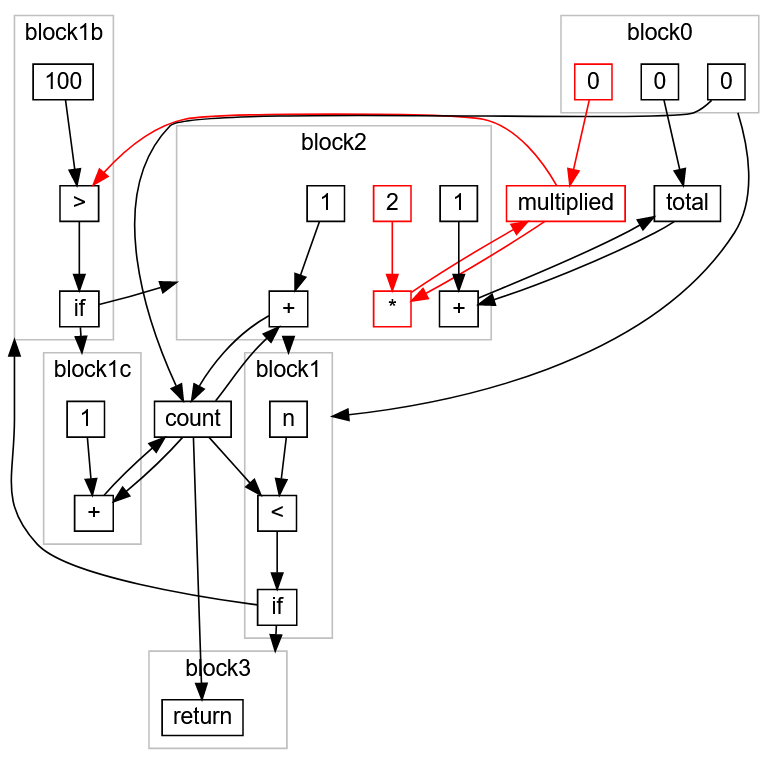
Вот что получилось:
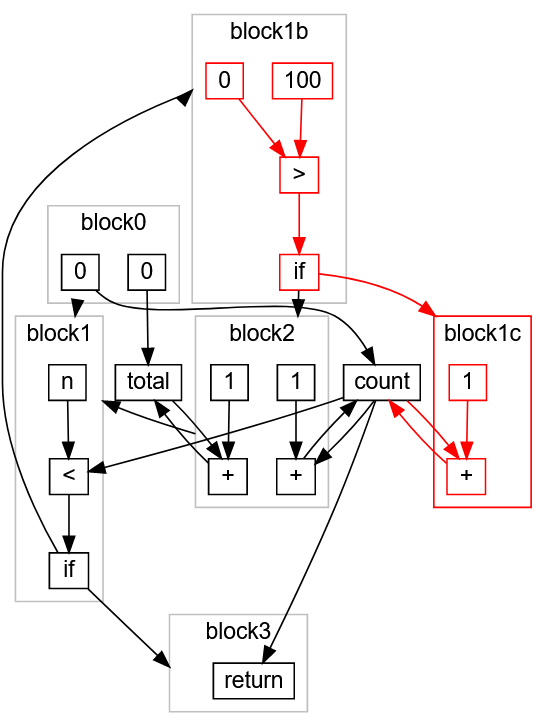
Мы видим, что условный переход в `block1b` (`0 > 100`) никогда не бывает `true`. Значит ветка `false` из условия `block1c` *недоступна* и может быть удалена (как и условие `if`):
Наконец, мы видим «тупиковые узлы» `total` и `>`, которые что-то вычисляют, но не используются ни в одном нисходящем условном переходе, возвращении результатов или вычислении. Это можно понять, пройдя по графу вверх от узла `return`, собирая все *живые* узлы и удаляя остальные: `>`, `100`, `0` в `block1b`, `total`, `0`, и `+ 1`, передаваемый в `total` из `block0` и `block2`. Вот что получилось:
Сериализуем в байткод и получаем «идеальную» программу:
```
static int main(int n){
int count = 0;
while(count < n){
count += 1;
}
return count;
}
```
Заключение
----------
В этой статье мы рассмотрели приведение программы внутри оптимизирующего компилятора:
* Рассмотрели ручные оптимизации программы-черновика.
* Поняли, что эти оптимизации можно делать автоматически с помощью оптимизатора.
* Рассмотрели разные способы, с помощью которых оптимизирующий компилятор может моделировать вашу программу в памяти в виде промежуточного представления. В дальнейшем применяли в статье представление в виде графа потоков данных.
* Рассмотрели методики приведения: «внутрипроцедурные» в рамках одной функции и «межпроцедурные» между несколькими функциями, возможно, рекурсивными.
* Рассмотрели анализ на жизнеспособность и доступность: поиск частей программы, не влияющих на результат её выполнения.
* Рассмотрели применение приведения и анализа для упрощения промежуточного представления, которое можно сериализовать в более простые и компактные программы.
Мы увидели, что можно превратить ручной процесс оптимизации программы в автоматизированный, применяя к простым структурам данных простые алгоритмы.
Это лишь небольшое введение в работу оптимизирующих компиляторов, которые делают наш код быстрее. В статью многое не вошло. Если хотите узнать больше, можете начать с этого:
* [Engineering a Compiler by Keith D Cooper & Linda Torczon](https://www.amazon.com/Engineering-Compiler-Keith-Cooper/dp/012088478X)
* [Combining Analyses, Combining Optimizations by Cliff Noel Click Jr.](https://www.researchgate.net/profile/Cliff_Click/publication/2394127_Combining_Analyses_Combining_Optimizations/links/0a85e537233956f6dd000000.pdf)
* [Advanced Compiler Design and Implementation by Steven Muchnick](https://www.amazon.com/Advanced-Compiler-Design-Implementation-Muchnick/dp/1558603204) | https://habr.com/ru/post/477062/ | null | ru | null |
# Сюрприз fsync() PostgreSQL
 Разработчики СУБД в силу необходимости, озабочены тем, чтобы данные безопасно попадали в постоянное хранилище. Поэтому, когда сообщество PostgreSQL обнаружило, что то, как ядро обрабатывает ошибки ввода-вывода, может привести к потере данных без каких-либо ошибок, сообщаемых в пользовательское пространство, возникло немало недовольства. Проблема, которая усугубляется тем, что PostgreSQL выполняет буферизованный ввод-вывод, оказывается, не является уникальной для Linux, и ее будет нелегко решить даже там.
Крейг Рингер впервые [сообщил о проблеме](https://lwn.net/Articles/752093/) в список рассылки pgsql-hackers в конце марта. Короче говоря, PostgreSQL предполагает, что успешный вызов `fsync()` указывает на то, что все данные, записанные с момента последнего успешного вызова, безопасно перешли в постоянное хранилище. При сбое буферизованной записи ввода-вывода из-за аппаратной ошибки файловые системы реагируют по-разному, но такое поведение обычно включает удаление данных на соответствующих страницах и пометку их как чистых. Поэтому чтение блоков, которые были только что записаны, скорее всего, вернет что-то другое, но не записанные данные.
Что насчет отчетов об ошибках? Год назад на саммите Linux Filesystem, Storage и Memory-Management Summit (LSFMM) включал в себя [сессию](https://lwn.net/Articles/718734/) по сообщениям об ошибках, в которой это все было названо «беспорядком»; ошибки легко могут быть потеряны, так что ни одно приложение никогда их не увидит. [Некоторые патчи](https://lwn.net/Articles/724307/), включенные 4.13, в ходе цикла разработки несколько улучшили ситуацию (и в 4.16 произошли некоторые изменения для её дальнейшего улучшения), однако существуют способы потери уведомлений об ошибках, как будет описано ниже. Если это происходит на сервере PostgreSQL, это может привести к автоматическому повреждению базы данных.
Разработчики PostgreSQL были недовольны. Том Лейн [описал](https://lwn.net/Articles/752096/) это "**повреждением мозга ядра**", в то время как Роберт Хаас [назвал](https://lwn.net/Articles/752097/) "**100% глупостью**". В начале обсуждения разработчики PostgreSQL достаточно четко понимали, как, по их мнению, должно работать ядро: страницы, которые не могут быть записаны, должны храниться в памяти в «грязном» состоянии (для последующих попыток), и соответствующий файловый дескриптор должен быть переведен в состояние постоянной ошибки, чтобы сервер PostgreSQL не мог пропустить наличие проблемы.
#### В каком месте что-то пошло не так
Однако еще до того, как в дискуссию вступило сообщество ядра, стало ясно, что ситуация не настолько проста, как может показаться. Томас Мунро [сообщил](https://lwn.net/Articles/752098/), что Linux не уникален в подобном поведении; OpenBSD и NetBSD также могут не сообщать об ошибках записи в пространство пользователя. И, как выяснилось, то, как PostgreSQL обрабатывает буферизованные операции ввода-вывода, значительно усложняет картину.
Этот механизм [был подробно описан](https://lwn.net/Articles/752101/) Хаасом. Сервер PostgreSQL работает как набор процессов, многие из которых могут выполнять операции ввода-вывода в файлы базы данных. Задание вызова `fsync()`, однако, обрабатывается в одном процессе checkpointer («checkpointer» process), который касается поддержания дискового хранилища в согласованном состоянии, для восстановления после сбоев. Сheckpointer обычно не поддерживает все соответствующие файлы открытыми, поэтому ему часто приходится открывать файл перед вызовом `fsync()`. Именно здесь возникает проблема: даже в ядрах 4.13 и более поздних версиях checkpointer не увидит никаких ошибок, произошедших до открытия файла. Если что-то нехорошее случится до вызова `open()` checkpointer-a, то следующий вызов `fsync()` вернет успех. Существует несколько способов возникновения ошибки ввода-вывода вне вызова `fsync()`; например ядро может столкнуться с одной из них при выполнении фоновой обратной записи. Кто-то, вызывающий `sync()`, может также столкнуться с ошибкой ввода-вывода и «поглотить» полученное состояние ошибки.
Хаас описал такое поведение как неспособное соответствовать ожиданиям PostgreSQL:
> Все, что у вас (или у кого-то) есть — в основном это недоказанное предположение о том,
>
> какие файловые дескрипторы могут иметь отношение к конкретной ошибке, но так получилось, что PostgreSQL никогда не соответствовал ему. Вы можете продолжать говорить, что проблема в наших догадках, но мне кажется не правильно предполагать, что мы — единственная программа, которая их когда-либо делала.
В итоге Джошуа Дрейк [перенес беседу](https://lwn.net/Articles/752103/) в список разработки для ext4, включив часть сообщества разработчиков ядра. Дэйв Чиннер быстро [охарактеризовал](https://lwn.net/Articles/752104/) это поведение как "**рецепт катастрофы, особенно в кросс-платформенном коде, где каждая платформа ОС ведет себя по-разному и почти никогда не соответствует ожидаемому**". Вместо этого Тед Цо [объяснил](https://lwn.net/Articles/752105/), почему затронутые страницы помечаются как чистые после возникновения ошибки ввода-вывода; короче говоря, самой распространенной причиной ошибок ввода-вывода является извлечение пользователем USB-накопителя не вовремя. Если какой-то процесс копировал на этот диск много данных, результатом будет накопление грязных страниц в памяти, возможно, до такой степени, что системе не хватит памяти для других задач. Таким образом, эти страницы не могут быть сохранены и будут очищены, если пользователь хочет, чтобы система оставалась пригодной для использования после такого события.
И Чиннер, и Цо, вместе с другими, заявили, что для PostgreSQL правильное решение — перейти на прямой ввод-вывод (DIO). Использование DIO дает больший уровень контроля над обратной записью (writeback) и вводом-выводом в целом; это включает в себя доступ к информации о том, какие именно операции ввода-вывода могли быть неудачными. Андрес Фройнд, как и ряд других разработчиков PostgreSQL, [признал](https://lwn.net/Articles/752107/), что DIO является лучшим долгосрочным решением. Но он также отметил, что не стоит ждать, что разработчики сейчас по уши окунуться в реализацию этой задачи. Между тем, он [сказал](https://lwn.net/Articles/752108/), что существуют другие программы (он упомянул dpkg), которые также подвержены этому поведению.
#### На пути к краткосрочному решению
В ходе обсуждения значительное [внимание](https://lwn.net/Articles/752110/) было уделено идее, что сбой записи должен приводить к тому, что затронутые страницы будут храниться в памяти в их грязном состоянии. Но разработчики PostgreSQL быстро отошли от этой идеи и не требовали этого. То, что им действительно нужно, в итоге — надежный способ узнать, что-то пошло не так. Учитывая это, обычные механизмы PostgreSQL для обработки ошибок могут справиться с этим; однако в его отсутствие мало что можно сделать.
В какой-то момент обсуждения Цо [упомянул](https://lwn.net/Articles/752112/), что у Google есть собственный механизм обработки ошибок ввода-вывода. Ядро было проинструктировано сообщать об ошибках ввода-вывода через сокет netlink; выделенный процесс получает эти уведомления и отвечает соответственно. Все же этот механизм никогда не делал этого на входе. Фрейнд [указал](https://lwn.net/Articles/752113/), что этот механизм будет «идеальным» для PostgreSQL, поэтому он может появиться в открытом доступе в ближайшее время.
Между тем Джефф Лейтон [задумался](https://lwn.net/Articles/752114/) над другой идеей: установить флаг в суперблоке файловой системы при возникновении ошибки ввода-вывода. Вызов `syncfs()` затем очистит этот флаг и вернет ошибку, если он был установлен. PostgreSQL checkpointer может периодически вызывать `syncfs()` для опроса ошибок в файловой системе, содержащей базу данных. Фройнд [согласился](https://lwn.net/Articles/752114/), что это может быть жизнеспособным решением проблемы.
Конечно, любой такой механизм появится только в новых ядрах; тем временем установки PostgreSQL, как правило, работают на старых ядрах, поддерживаемых корпоративными дистрибутивами. В этих ядрах, по всей видимости, отсутствуют даже те улучшения, которые были включены в 4.13. Для таких систем мало что можно сделать, чтобы помочь PostgreSQL обнаруживать ошибки ввода-вывода. Может хватить запуска демона, который сканирует системный журнал и ищет там сообщения об ошибках ввода-вывода. Не самое элегантное решение, и оно осложняется тем, что разные драйверы блоков и файловые системы, как правило, сообщают об ошибках по-разному, но это может быть наилучшим доступным вариантом.
Следующим шагом, вероятно, станет обсуждение на мероприятии LSFMM 2018 года, которое состоится 23 апреля. Если повезет, появится какое-то решение, которое будет работать для заинтересованных сторон. Однако одна вещь, которая не изменится — это простой факт, что обработку ошибок трудно сделать правильно. | https://habr.com/ru/post/472684/ | null | ru | null |
# Настройка CI/CD скриптов миграции БД с нуля с использованием GitLab и Liquibase
Пролог
------
Добрый день, уважаемые читатели. Совсем недавно мне пришлось осваивать новую для себя область CI/CD, настраивая с нуля доставку скриптов миграции базы данных в одном из проектов. При этом было тяжело преодолеть самый первый этап "глаза боятся", когда задача вроде бы ясна, а с чего начать, не знаешь. Однако вопрос оказался на поверку значительно проще, чем казалось изначально, давая при этом неоспоримые преимущества ценой нескольких часов работы и не требуя никаких дополнительных средств, кроме обозначенных в заголовке.
Полученным опытом я решил поделиться в данной статье, чтобы помочь тем, кто хочет автоматизировать свои рабочие процессы, но не знает, с чего начать.
Оглавление
----------
* [**Введение**](#begin)
* [**Основы**](#basis)
* [**Liquibase**](#liquibase)
* [**Настройка сервера деплоя**](#deploy)
* [**Настройка GitLab Runner**](#runner)
* [**Настройка CI/CD**](#cicd)
* [**Заключение**](#end)
Введение
--------
#### Об авторе
Меня зовут Копытов Дмитрий, я являюсь главным разработчиком и архитектором проектов. Специализируюсь на C#/.NET, Vue.js и Postgres.
К теме CI/CD пришел после получения "в наследство" проекта с уже существующим CI/CD, который пришлось перерабатывать.
#### О статье
В первую очередь статья предназначена для разработчиков, которые хотят внедрить в свои проекты CI/CD, но не знают, с чего начать, а также для тех, кому в наследство достались проекты с уже внедренным CI/CD, суть работы которого им не понятна.
Целью статьи является подробное описание технических аспектов настройки связки GitLab + Liquibase на конкретном примере, а также основы теории, чтобы у читателя отложилась не только сама инструкция, но и понимание процесса. Многие моменты и возможности [GitLab CI/CD](https://docs.gitlab.com/ee/ci/README.html) & [Liquibase](https://www.liquibase.org/) будут сознательно опущены во избежание перегрузки информацией.
Уже после написания большей части статьи, осознал насколько она оказалась большая, но разбить ее на несколько частей не вижу возможности без потери целостности. Приготовьтесь, будет многобукофф.
Перед самой публикацией во время выбора хабов обнаружил схожую [статью](https://habr.com/ru/company/otus/blog/557008/) по автоматизации деплоя Liquibase. Это досадная случайность без злого умысла, не более.
#### Кулинарный рецепт
Для приготовления блюда нужны следующие ингредиенты:
* GitLab Community Edition – хранилище Git
* GitLab Runner – рабочая лошадка CI/CD
* Liquibase, на момент написания статьи версия 4.3.4
* Драйвер Liquibase для целевой БД
* Выделенный сервер с установленными Liquibase и GitLab Runner и доступом к целевой БД для наката скриптов и к GitLab для получения исходников. Необязательно.
* 3 чашки чая или кофе. Обязательно.
---
Основы
------
### Используемые технологии
Все технологии, используемые в статье, являются открытыми, вы можете использовать их совершенно бесплатно без необходимости закупки Premium-фич.
Примеры из статьи (скрипты и конфиги) опубликованы на гитхабе: <https://github.com/Doomer3D/Gliquibase>.
#### GitLab CI/CD
CI/CD у всех на слуху, поэтому не буду вдаваться в детали, отмечу только, что в контексте статьи будет рассмотрен процесс автоматического (при мерже/коммите) или ручного (по команде) наката скриптов миграции базы данных на целевую среду, будь то дев или прод. В качестве конвейера будут использоваться GitLab pipelines, а непосредственным исполнителем будет GitLab Runner, поэтому если вы не используете GitLab в качестве хранилища, статья вам будет по большому счета бесполезна.
Все примеры будут рассмотрены в контексте используемого в нашей компании GitLab Community Edition 13.x.
#### Liquibase
[Liquibase](https://www.liquibase.org/) («ликви») – платформа c открытым кодом, которая позволяет управлять миграциями вашей базы. Если кратко, то Liquibase позволяет описывать скрипты наката и отката базы в виде файлов чейнжсетов (changeset). Сами скрипты при этом могут быть как обычными SQL-командами, так и БД-независимыми описаниями изменений, которые будут преобразованы в скрипт конкретно для вашей базы. Список поддерживаемых БД можно найти здесь: <https://www.liquibase.org/get-started/databases>.
Liquibase написан на Java, поэтому может быть запущен на любой машине с JVM.
В статье будет рассмотрен Oracle 19 в качестве целевой базы, потому что именно для него настраивал деплой на рабочем проекте. Но, как писал выше, тип базы не имеет принципиального значения.
### Схема работы
В данном разделе я сначала хотел нарисовать схему, но быстро понял, что давно не рисовал диаграммы процессов, поэтому постараюсь объяснить на пальцах.
Когда разработчик делает коммит или мерж реквест, запускается конвейер CI/CD, называемый пайплайном (pipeline), который включает в себя этапы (stage), состоящие из джобов (job).
В нашем примере будет один этап – деплой (deploy), т.е. применение скриптов наката. При этом будет столько джобов, сколько стендов мы имеем. Предположим, что у нас всего два стенда – дев и прод. Соответственно, будет два джоба – деплой на дев (deploy-dev) и деплой на прод (deploy-prod), которые будут отличаться целевой БД. Кроме того, деплой на прод мы хотим запускать только вручную, по команде, а не в момент мержа или коммита.
Джобы обрабатываются раннером (GitLab Runner) – специальной программой, которая скачивает себе исходники проекта и выполняет скрипты на сервере деплоя, при этом раннеру передаются различные параметры в виде переменных окружения. Это может быть пользовательская информация, хранимая в настройках проекта, такая как адрес и логин/пароль сервера БД, а также информация о самом процессе CI/CD, например, название ветки, автор, текст коммита и т.п.
**Важно!** Раннер сам обращается к GitLab по http, а не наоборот, поэтому машина с раннером должна иметь доступ к GitLab, в то время как разработчик и сервер GitLab могут ничего не знать о машине, где находится раннер.
Если оба стенда – дев и прод, доступны с одной машины, достаточно будет одного раннера, однако обычно прод находится в другой сети, тогда в ней должен быть отдельный раннер с доступом к БД прода.
В нашем случае раннер будет вызывать Liquibase через командную строку. В параметрах к Liquibase будет передана информация о целевой базе и используемом драйвере, а сами скрипты наката Liquibase сформирует из описаний миграций из файлов вашего проекта.
В случае успеха, если скрипты отработали без ошибок, пайплайн считается успешным, а мерж реквест вливается в ветку. Картина будет примерно такой:
В противном случае пайплайн будет в состоянии failed:
Мы сможем провалиться в джоб и посмотреть логи, чтобы найти ошибку или перезапустить пайплайн, если проблема была в сетевом доступе. В моей практике была ситуация, что поднятый VPN на машине деплоя в какой-то момент стал блокировать доступ к GitLab по доменному имени, при этом пайплайн оказывался в состоянии pending, т.е. ожидал, что раннер подхватит джоб, но этого не происходило. Правка hosts и перезапуск пайплайна разрешили проблему.
Итак, подытожим, как выглядит схема работы:
1. Разработчик делает мерж реквест или коммит в ветку.
2. Запускается пайплайн, который исполняет ассоциированный с этой веткой джоб.
3. Джоб инициирует раннер, находящийся на удаленной машине.
4. Раннер скачивает исходники и выполняет скрипт, вызывающий Liquibase.
5. Liquibase генерирует и исполняет скрипты наката/отката.
6. ...
7. Profit!
А теперь обо всем по порядку.
---
Liquibase
---------
Этот раздел посвящен Liquibase. Здесь не будет полного изложения документации, потому что эта тема для отдельной статьи или даже для цикла статей, но я постараюсь осветить основы Liquibase.
Ссылка на официальную документацию по Liquibase: <https://docs.liquibase.com/concepts/basic/home.html>
Предполагается, что если вы, уважаемый читатель, вышли на эту статью, то имеете хотя бы начальное знакомство с Liquibase, именуемом в народе «ликви», но если нет, я все же изложу вкратце, что это такое и с чем его едят.
Liquibase – это платформа управления и наката миграций БД. В основе лежит понятие чейнжсета (changeset) – атомарного изменения базы. Чейнжсетом, например, может быть создание таблицы в базе, добавление колонки/триггера, или наполнение таблицы данными. Чейнжсеты объединяются в чейнжлоги (changelog), которые выстраиваются в цепочку, которая применяется на целевой БД последовательно, таким образом обновляя базу до актуального состояния.
### changelog
Начнем рассмотрение Liquibase с понятия чейнжлога. Чейнжлог – это отдельный файл, содержащий в себе чейнжсеты или ссылки на другие чейнжлоги. Порядок включения чейнжлогов/чейнжсетов определяет порядок их наката. Как и чейнжсеты, чейнжлоги могут быть описаны в одном из четырех форматов: [**SQL**](https://docs.liquibase.com/concepts/basic/sql-format.html), [**XML**](https://docs.liquibase.com/concepts/basic/xml-format.html), [**JSON**](https://docs.liquibase.com/concepts/basic/json-format.html) и [**YAML**](https://docs.liquibase.com/concepts/basic/yaml-format.html). В статье будут рассмотрены форматы SQL и XML как наиболее популярные и удобочитаемые.
Один из чейнжлогов является корневым, т.е. именно от него идет раскручивание всей цепочки. Назовем его мастером и дадим имя master.xml. Этот чейнжлог несет в себе функцию аккумуляции ссылок на другие чейнжлоги. Изначально у нас в проекте был один такой аккумулятор, в который последовательно дописывались ссылки на другие файлы, которые складировались в той же папке. Это приводило к двум проблемам:
* Папка со временем разрослась до гигантских размеров, и ориентироваться в ней стало невозможно.
* Когда с файлом стали работать два разработчика, изменение файла неизбежно приводило к конфликтам, которые приходилось решать.
Во избежание этих проблем рекомендую придерживаться другого подхода, связанного с разбиением задач по релизам/версиям/датам или каким-либо критериям, чтобы отдельные папки с изменениями были небольшими по размеру. В качестве примера приведу структуру тестового проекта для этой статьи.
Структура проектаФайлы Liquibase хранятся в папке db/changelog, в корне лежит мастер-файл master.xml
В отдельных папках, соответствующих релизам 156 и 157, складируются чейнжлоги. В общем случае один таск = один чейнжлог. Также отдельно выделена папка common для служебных целей, там лежит скрипт пре-миграции, который выполняется при каждом накате скриптов. Аналогичным образом можно было бы добавить скрипт пост-миграции, если это нужно.
Разберем файл master.xml:
```
xml version="1.0" encoding="UTF-8"?
```
XML-файл выглядит несколько перегруженным неймспейсами, пусть это вас сильно не волнует. Это стандартная обертка для любого XML-файла Liquibase.
Раздел [**preConditions**](https://docs.liquibase.com/concepts/advanced/preconditions.html) определяет различные параметры запуска, конкретно здесь мы указываем, что используем oracle, но также можно указать имя пользователя, от которого будет происходить запуск скриптов. Более плотно preConditions используются в чейнжсетах.
Далее идет включение скриптов в нужной последовательности. Для этого существуют команды [**include**](https://docs.liquibase.com/concepts/advanced/include.html) (включение отдельного файла) и [**includeAll**](https://docs.liquibase.com/concepts/advanced/includeall.html) (включение папки).
Использование includeAll позволяет избежать проблем с конфликтами при правке файла-аккумулятора внутри релиза, но тогда нужно выработать стратегию именования файлов, т.к. их включение будет происходить в алфавитном порядке. В примере выше я использую дату + номер таска, но этого будет недостаточно в реальном проекте, если изменения по таску с меньшим номером нужно применить после таска с большим номером, и при этом они будут в один день.
Как альтернативу includeAll вы можете внутри папки релиза создать свой мастер-файл (аккумулятор скриптов релиза), в который включать ссылки на отдельные скрипты, что в целом менее удобно.
### changeset
Чейнжсеты описываются внутри файлов чейнжлогов в виде отдельных блоков. Рассмотрим на примере файла 2021-05-01 TASK-001 CREATE TEST TABLE.xml:
```
xml version="1.0" encoding="UTF-8"?
```
В файле описан чейнжсет, который создает таблицу TEST с тремя колонками. При этом описание происходит в виртуальных сущностях, которые транслируются в скрипты для конкретной БД.
Элемент [**preConditions**](https://docs.liquibase.com/concepts/advanced/preconditions.html) указывает, что чейнжсет нужно применять только в случае, если таблица не существует в базе.
Элемент [**rollback**](https://docs.liquibase.com/workflows/liquibase-community/using-rollback.html) указывает, как нужно откатывать скрипт, если такой механизм планируется использовать. Откаты в нашей стране, конечно, популярны, но выходят за рамки данной статьи.
Рассмотрим основные атрибуты чейнжсетов.
| | |
| --- | --- |
| **Атрибут** | **Описание** |
| id | Идентификатор, **обязательный атрибут**, использование см. ниже. |
| author | Автор, **обязательный атрибут**, использование см. ниже. |
| dbms | Фильтр баз данных, для которых применяется чейнжсет. |
| contexts | Контексты, для которых применяется чейнжсет. Например, мы можем указать, что чейнжсет применяется только на проде или везде, кроме прода.Подробнее по [ссылке](https://docs.liquibase.com/concepts/advanced/contexts.html). |
| runAlways | Булево. Указывает, что чейнжсет применяется при каждом запуске. Полезно для скриптов установки контекста окружения, см. ниже. |
| runOnChange | Булево. Указывает, что чейнжсет применяется при изменении содержимого. Полезно для скриптов создания recreatable-объектов, таких как процедуры, вьюхи, триггеры и т.п. |
Подробную документацию по чейнжсетам можно почитать по [ссылке](https://docs.liquibase.com/concepts/basic/changeset.html).
#### DATABASECHANGELOG
Чейнжсеты, которые были применены к базе, сохраняются в специальную таблицу [**DATABASECHANGELOG**](https://docs.liquibase.com/concepts/basic/databasechangelog-table.html), в паре с которой идет таблица [**DATABASECHANGELOGLOCK**](https://docs.liquibase.com/concepts/basic/databasechangeloglock-table.html), обеспечивающая параллельную работу нескольких экземпляров Liquibase.
В таблице нет физических ключей, но у самих чейнжсетов есть уникальный ключ – это комбинация идентификатора, автора и имени файла. Политика именования чейнжсетов у всех может быть своя, у нас исторически сложился формат <дата>-<номер><ФИ автора>, например 20210501-01KD. Отмечу, что это мой первый проект с использованием Liquibase, поэтому не буду давать советов, как лучше именовать чейнжсеты.
Также у каждого чейнжсета вычисляется MD5-сумма на основе его тела, поэтому нельзя просто так менять файл чейнжсета, если он уже был применен к базе. Это может иметь значение при разработке, особенно при освоении Liquibase. Поначалу вы будете часто ошибаться с тем, как правильно составить чейнжсет, в итоге в базе окажется сохраненный чейнжсет с MD-5 суммой и неверно выполненный скрипт. В этом случае нужно будет вручную откатить его изменения, а также удалить соответствующие записи из DATABASECHANGELOG.
#### runAlways
База данных предоставляет инструменты для настройки контекста окружения, что может быть полезно, например, в сценарии аудита таблиц, когда записи, измененные скриптами, выполненных через Liquibase, нужно как-то помечать. Мы это решаем через установку переменной сессии USER\_ID.
Для этой цели в описании мастер-чейнжлога включается скрипт пре-миграции, который занимается настройкой окружения. Приведу его текст:
```
xml version="1.0" encoding="UTF-8"?
-- устанавливаем в контекст сессии пользователя liquibase
CALL DBMS\_SESSION.SET\_CONTEXT('CLIENTCONTEXT','USER\_ID', 13);
```
Здесь в качестве тела используется SQL-скрипт, который записывает в переменную сессии USER\_ID значение 13 – наш внутренний идентификатор пользователя Liquibase. Этот скрипт будет влиять на все последующие скрипты, поэтому помечен флагом runAlways и включен перед скриптами релизов.
#### SQL-чейнжсет
Чейнжсеты можно оформлять и в формате SQL, что особенно полезно при написании сложных запросов. Рассмотрим файл 2021-05-01 TASK-002 TEST.sql, который выполняется сразу после создания таблицы TEST:
```
--liquibase formatted sql
--changeset Doomer:20210501-02
--preconditions onFail:MARK_RAN
--precondition-sql-check expectedResult:1 SELECT COUNT(*) FROM ALL_TABLES WHERE TABLE_NAME = 'TEST' AND OWNER = 'STROY';
--precondition-sql-check expectedResult:0 SELECT COUNT(*) FROM TEST WHERE ID = 1;
insert into TEST (ID, CODE, NAME)
values (1, 'TEST', 'Какое-то значение');
--rollback not required
--changeset Doomer:20210501-03
--preconditions onFail:MARK_RAN
--precondition-sql-check expectedResult:1 SELECT COUNT(*) FROM ALL_TABLES WHERE TABLE_NAME = 'TEST' AND OWNER = 'STROY';
--precondition-sql-check expectedResult:1 SELECT COUNT(*) FROM TEST WHERE ID = 1;
update TEST
set NAME = 'CONTEXT USER_ID=' || nvl(SYS_CONTEXT('CLIENTCONTEXT', 'USER_ID'), 'NULL')
where ID = 1;
--rollback not required
```
Это файл с двумя чейнжсетами в составе.
Первый добавляет новую запись в таблицу TEST, проверяя существование таблицы и отсутствие элемента с ID = 1. Если одно из условий не выполнится, чейнжсет не будет применен, но будет помечен в DATABASECHANGELOG как выполненный (MARK\_RAN). Подробнее можно почитать в документации по [**preConditions**](https://docs.liquibase.com/concepts/advanced/preconditions.html).
Второй чейнжсет обновляет созданную запись значением из переменной сессии USER\_ID.
После наката скриптов мы предсказуемо увидим следующую картину в таблице TEST:
К сожалению, формат статьи и ее и без того обширная тема не позволяет описать чейнжсеты Liquibase более подробно, но тут можно только сказать классическое RTFM.
### Командная строка Liquibase
Liquibase является консольным приложением, поэтому нужно понимать, как его вызывать. Вообще, это тема больше относится к области GitLab Runner'а, но чтобы не смешивать обе темы, рассмотрим вызов Liquibase в этом разделе.
Документация по командам Liquibase: <https://docs.liquibase.com/commands/community/home.html>
Нас в первую очередь интересуют команды:
* [**update**](https://docs.liquibase.com/commands/community/update.html) – применение изменений
* [**updateSQL**](https://docs.liquibase.com/commands/community/updatesql.html) – получение SQL-скриптов для анализа, полезно для обучения
Обе команды имеют схожий набор параметров, поэтому рассмотрим основные из них на нашем тестовом примере:
| | | |
| --- | --- | --- |
| **Параметр** | **Описание** | **Пример значения** |
| changeLogFile | Путь к мастер-файлу чейнжлога, **обязательный параметр** | master.xml |
| url | Адрес БД, **обязательный параметр** | jdbc:oracle:thin:1.2.3.4:1521:orastb |
| username | Логин пользователя БД, **обязательный параметр** | vasya |
| password | Пароль пользователя БД, **обязательный параметр** | pupkin |
| defaultSchemaName | Имя схемы по умолчанию | DATA |
| contexts | Контекст БД для фильтров чейнжсетов по контексту | dev / prod |
| driver | Тип драйвера БД | oracle.jdbc.OracleDriver |
| classpath | Путь до драйвера | /usr/share/liquibase/4.3.4/drivers/ojdbc10.jar |
| outputFile | Путь до файла, куда выводить результат для команды updateSQL. Если не указано, вывод будет в консоль. | |
Для обучения можно создать батник, который будет запускать Liquibase c вашим скриптом до его добавления в гите. Разумеется, надо помнить о необходимости отката изменений (см. выше). Рядом помещаете папку с Liquibase и драйвером, об установке которых рассказывается в следующем разделе, а также файл скрипта.
Пример батника для Windows:
```
call "C:\Temp\liqui\liquibase-4.3.1\liquibase.bat" ^
--defaultSchemaName=STROY ^
--driver=oracle.jdbc.OracleDriver ^
--classpath="C:\Temp\liqui\ojdbc5.jar" ^
--url=jdbc:oracle:thin:@1.2.3.4:1521:dev ^
--username=xxx ^
--password=yyy ^
--changeLogFile=.\master.xml ^
--contexts="dev"
--logLevel=info ^
updateSQL
```
---
Настройка сервера деплоя
------------------------
Выделенный сервер для деплоя, вообще говоря, не обязателен. Это может быть самая простая машина, которая имеет доступ к целевой базе данных, чтобы подключиться и накатить скрипты, и к серверу GitLab, откуда будут взяты исходники проекта. В целях безопасности эту машину можно изолировать от прочих ресурсов.
В нашей компании используются виртуальные машины на основе Centos 7, поэтому все примеры команд буду приводить именно для него. Также я исхожу из предположения, что вы знакомы с основами работы в консоли Linux.
#### Установка Java
Liquibase рекомендует использовать Java 11+, давайте установим его. Я использую OpenJRE 11:
```
sudo yum install java-11-openjdk
java --version
```
#### Установка Liquibase
Официальная документация: <https://www.liquibase.org/get-started/quickstart>
Liquibase не требует установки, потому что является программой на Java. Заходим на сайт и скачиваем [архив с программой](https://www.liquibase.org/download). Архив распаковываем в папку по вашему усмотрению, но для себя я решил использовать путь /usr/share/liquibase/, например /usr/share/liquibase/4.3.4
Там же, в папке с установленным Liquibase, создаем папку drivers и копируем в нее нужный драйвер для вашей БД. В моем случае это был ojdbc10.jar
Проверяем, что Liquibase работает:
```
cd /usr/share/liquibase/4.3.4
liquibase --version
```
#### Установка Git
Git является зависимостью GitLab Runner и ставится автоматически, но нужно отметить одну неприятную особенность, характерную для Centos 7 и, возможно, для других версий пингвинообразных. Если вы просто установите GitLab Runner на голую ось, он потянет за собой git в виде зависимости, который в стандартном репозитории имеет версию 1.8. Эта версия откровенно баганая, что в связке с GitLab приводит к тому, что в какой-то момент, причем не сразу, CI/CD перестает работать с выдачей совершенно непонятной ошибки.
Чтобы избежать неприятных сюрпризов, необходимо установить более свежую версию git до установки GitLab Runner:
```
# проверяем текущую версию гита
git --version
# удаляем гит, если он версии 1.8
sudo yum remove git*
# устанавливаем последнюю версию гита на момент написания статьи (2.30)
sudo yum -y install https://packages.endpoint.com/rhel/7/os/x86_64/endpoint-repo-1.7-1.x86_64.rpm
sudo yum install git
```
#### Установка GitLab Runner
Официальная документация: <https://docs.gitlab.com/runner/install/linux-manually.html>
```
# добавляем репу
curl -L "https://packages.gitlab.com/install/repositories/runner/gitlab-runner/script.rpm.sh" | sudo bash
# устанавливаем
export GITLAB_RUNNER_DISABLE_SKEL=true; sudo -E yum install gitlab-runner
```
---
Настройка GitLab Runner
-----------------------
В этом разделе будет рассказано о том, как создать и настроить свой экземпляр GitLab Runner, который будет вызывать Liquibase.
Ссылка на официальную документацию по GitLab Runner: <https://docs.gitlab.com/runner/configuration/>
Для начала, нужно узнать, куда был установлен раннер, и дать ему права на исполнение:
```
# определяем место установки
which gitlab-runner # /usr/bin/gitlab-runner
# выдаем права на исполнение
sudo chmod +x /usr/bin/gitlab-runner
```
Далее, нужно создать пользователя для сервиса раннера и установить демона. Вполне возможно, что эти шаги уже были выполнены при установке.
```
# создаем пользователя
sudo useradd --comment 'GitLab Runner' --create-home gitlab-runner --shell /bin/bash
# запускаем демона
sudo gitlab-runner install --user=gitlab-runner --working-directory=/home/gitlab-runner
```
Управлять сервисом раннера можно по аналогии с systemctl:
```
# статус сервиса
sudo gitlab-runner status
# запуск сервиса
sudo gitlab-runner start
# останов сервиса
sudo gitlab-runner stop
# получения списка зарегистрированных раннеров
sudo gitlab-runner list
```
После завершения настройки сервиса GitLab Runner нужно создать экземпляр раннера для запуска Liquibase. Для этого воспользуемся командой `register`, но перед этим нам нужно получить токен для нашего проекта в GitLab.
Переходим в интерфейсе GitLab в раздел `Settings ⇨ CI/CD ⇨ Runners`. Здесь мы видим список доступных нам раннеров, которые либо привязаны к группе проектов, либо к конкретному проекту. У меня этот список выглядит примерно так (немного законспирировал имена):
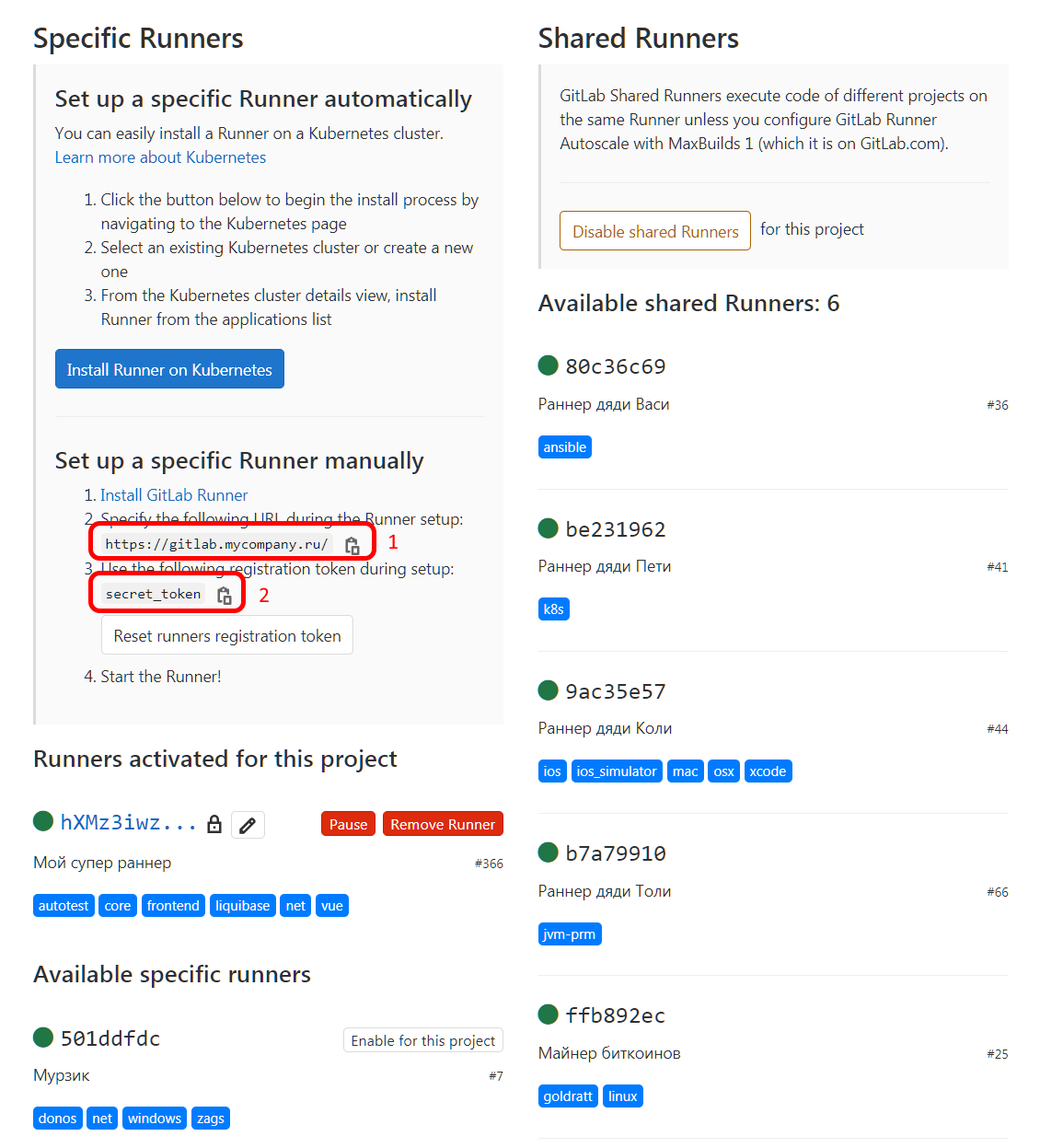Нас интересуют два пункта:
1. Адрес вашего GitLab. Раннер будет обращаться к нему для получения исходников и команд на запуск джобов.
2. Токен для регистрации раннера. По нему раннер будет связан с нашим проектом или группой, если происходит настройка раннера для группы в целом.
Также у каждого раннера вы можете видеть теги, выделенные синим цветом. Это своего рода метки, по которым определяется, будет ли использовать раннер для конкретного джоба, об этом подробнее будет рассказано ниже. Пока достаточно знать, что раннер будет запущен, если его теги содержат теги джоба.
#### Регистрация раннера
Для создания раннера нужно выполнить команду `sudo gitlab-runner register`
Вас попросят ввести следующие параметры:
1. `Enter the GitLab instance URL`
Вводим адрес вашего GitLab
2. `Enter the registration token`
Вводим токен
3. `Enter a description for the runner`
Вводим имя раннера, например, my-awesome-runner
4. `Enter tags for the runner`
Вводим теги раннера через запятую. Пример: liquibase,dev
Выбор можно позже изменить через интерфейс GitLab CI/CD
5. `Enter an executor`
Выбираем механизм исполнения раннера. Подробнее по [ссылке](https://docs.gitlab.com/runner/executors/README.html).
Вводим shell
[**shell**](https://docs.gitlab.com/runner/executors/README.html#shell-executor) – это простейший механизм исполнения команд оболочки целевой ОС. Мы будем использовать скрипты на bash.
После регистрации раннера можно проверить его наличие через команду `sudo gitlab-runner list` или через интерфейс GitLab CI/CD:
my-awesome-runnerНастройка CI/CD
---------------
Информация о том, что делать в процессе CI/CD хранится в файлах проекта. Главным является файл [**.gitlab-ci.yml**](https://docs.gitlab.com/ee/ci/quick_start/#create-a-gitlab-ciyml-file) в корне. Остальные файлы, в нашем случае скрипты на bash, размещаются на усмотрение разработчика, например, в папке `/ci`.
Все тонкости конфигурации тянут на отдельную статью, да и опыта в данной области у меня маловато, но то, что использовано в тестовом проекте, будет разложено по полочкам.
Для начала отмечу, что есть встроенный линтер для файла `.gitlab-ci.yml`, доступный по относительному пути `ci/lint` в проекте, например: https://gitlab.example.com/gitlab-org/my-project/-/ci/lint. Рекомендую воспользоваться им перед пушем конфига. Также предполагается, что вы знакомы с форматом [**YAML**](https://ru.wikipedia.org/wiki/YAML).
Полный листинг конфига в тестовом проекте:
```
variables:
LIQUIBASE_VERSION: "4.3.4"
stages:
- deploy
deploy-dev:
stage: deploy
tags:
- liquibase
- dev
script:
- 'bash ./ci/deploy-db.sh $DEV_DB $DEV_DB_USER $DEV_DB_PASS'
environment:
name: dev
only:
- dev
deploy-prod:
stage: deploy
tags:
- liquibase
- prod
script:
- 'bash ./ci/deploy-db.sh $DEV_DB $DEV_DB_USER $DEV_DB_PASS'
environment:
name: prod
when: manual
only:
- prod
```
#### Переменные
Документация: <https://docs.gitlab.com/ee/ci/variables/README.html>
```
variables:
LIQUIBASE_VERSION: "4.3.4"
```
В этом блоке описаны переменные окружения, которые в дальнейшем можно использовать в скриптах. Переменная LIQUIBASE\_VERSION указывает на версию Liquibase, которая будет применяться для наката скриптов миграции. Если мы захотим сменить версию, просто установим новую версию Liquibase и поменяем значение этой переменной.
На самом деле, лучше описать эту переменную в настройках проекта, о чем мы поговорим далее, но это просто пример того, как можно использовать переменные в конфиге.
Переменные проекта можно настроить в разделе `Settings ⇨ CI/CD ⇨ Variables`.
Пример того, как выглядят переменные в интерфейсе:
CI/CD VariablesПомимо переменных, описанных в непосредственно и конфиге и в настройках проекта, существует целый ряд [**предопределенных переменных**](https://docs.gitlab.com/ee/ci/variables/predefined_variables.html), относящихся к процессу CI/CD, таких как имя коммита, ветки или имя пользователя, совершившего коммит. Они могут быть полезны для настройки обратной связи, например, для автоматических уведомлений по результатам деплоя.
#### Этапы (stages)
```
stages:
- deploy
```
В этом блоке перечисляются этапы деплоя, о которых рассказано в разделе описания [**схемы работы**](#scheme).
#### Джобы (jobs)
Рассмотрим на примере джоба деплоя на дев:
```
deploy-dev:
stage: deploy
tags:
- liquibase
- dev
script:
- 'bash ./ci/deploy-db.sh $DEV_DB $DEV_DB_USER $DEV_DB_PASS'
environment:
name: dev
only:
- dev
```
Строка `stage: deploy` указывает на этап, к которому относится данный джоб.
Теги перечислены массивом, т.е. это **liquibase** и **dev**. Наш ранее созданный раннер отреагирует на эти теги и запустит скрипты в разделе `script`. Важно отметить, что в джобе прода указан тег **prod**, поэтому раннер для него должен быть отдельный, исходя из соображений, что он, вероятно, находится в другой сети. А вообще, один и тот же раннер может обслуживать несколько проектов, если это требуется.
Блок environment указывает на [**окружение**](https://docs.gitlab.com/ee/ci/environments/), которое можно настроить в отдельном разделе по пути `Operations ⇨ Environments`. Это своего рода дашборд ваших стендов (дев, предпрод, прод и т.п.), где можно увидеть их статус и выполнить, например, ручной деплой. Также можно настроить переменные, привязанные к окружению, но это премиум-фича, которую мне попробовать не удалось.
Пример страницы окружений:
EnvironmentsБлок `only` указывает, для каких веток нужно применять данный джоб. Его братом является блок `except`, который указывает для каких веток джоб применять не нужно. Помимо веток можно настроить более сложные условия: <https://docs.gitlab.com/ee/ci/jobs/job_control.html>.
Для прода мы также указали `when: manual`. Это означает, что запуск деплоя для прода будет в ручном режиме при нажатии на кнопку в пайплайне, а не в момент коммита. Это позволит нам ~~собрать чемодан до того, как что-то пойдет не так~~ выполнить деплой в запланированное время.
Мерж в прод, ручной запуск#### Скрипт наката
В блоке `script` мы указываем список скриптов, которые будут выполнены раннером. Так как у нас shell-исполнитель на линуксе, будем использовать bash. Все переменные автоматически передаются в скрипт в виде переменных окружения, но т.к. реквизиты базы отличаются для разных стендов, передаем их непосредственно при вызове скрипта.
Разберем непосредственно скрипт вызова Liquibase:
```
#!/bin/bash
echo "Environment: $CI_ENVIRONMENT_NAME"
cd db/changelog
/usr/share/liquibase/$LIQUIBASE_VERSION/liquibase \
--classpath=/usr/share/liquibase/$LIQUIBASE_VERSION/drivers/ojdbc10.jar \
--driver=oracle.jdbc.OracleDriver \
--changeLogFile=master.xml \
--contexts="$CI_ENVIRONMENT_NAME" \
--defaultSchemaName=STROY \
--url=jdbc:oracle:thin:@$1 \
--username=$2 \
--password=$3 \
--logLevel=info \
update
```
Подробно параметры вызова Liquibase описаны в соответствующем [разделе](#liquibase).
Переменные DEV\_DB, DEV\_DB\_USER, DEV\_DB\_PASS приходят в скрипт в виде $1, $2 и $3 соответственно. Помимо них мы используем указанное в джобе имя окружения, которое приходит в предопределенной переменной $CI\_ENVIRONMENT\_NAME, что можно использовать, чтобы какие-то скрипты накатывались только на определенном стенде, а не на всех.
Если все настроено правильно, то после коммита конфига и скриптов в гит, заработает деплой.
Успешный лог пайплайна для Liquibase выглядит примерно так:
#### Отклонение мержей с ошибками
Если процесс деплоя пойдет с ошибками, можно не допустить соответствующий мерж. Особенно это полезно, если в CI/CD встроены тесты как отдельный этап. В нашем примере тестов нет, но Liquibase тоже может сломаться, если, например, указаны неверные пути до файлов.
Для запрета ошибочных мержей нужно установить галочку в разделе `General ⇨ Merge requests`.
**Важно!** Галочку нужно устанавливать после настройки CI/CD, иначе перестанут проходить любые мержи.

---
Заключение
----------
Статья оказалась большой, но это не должно вас пугать. На самом деле мне удалось с нуля и без каких-либо предварительных знаний разобраться и настроить проект с деплоем примерно за 5 часов времени в пятницу вечером. Очень надеюсь, что данная статья поможет вам освоить деплой быстрее, а кого-то направит на путь CI/CD.
Если какие-то моменты остались за кадром, и есть желание узнать о них подробнее, пишите в комментариях. Буду иметь в виду, но обещать ничего не стану, т.к. эта статья, например, отняла у меня более 20 часов времени в течение трех недель, что в два-три раза больше среднего времени на написание статьи.
Как обычно, если понравилась статья, посмотрите другие:
* Интересная статья, обязательная к прочтению: [Умный парсер числа, записанного прописью](https://habr.com/ru/post/453642/)
* [Автоматическое обновление скриптов после деплоя](https://habr.com/ru/post/527026/)
* [Классовая сериализация на JavaScript с поддержкой циклических ссылок](https://habr.com/ru/post/413113/) | https://habr.com/ru/post/557706/ | null | ru | null |
# Как использовать шаблон Circuit Breaker в приложении Spring Boot
В этом посте я покажу, как мы можем использовать шаблон Circuit Breaker в приложении Spring Boot. Когда я говорю «шаблон Circuit Breaker» имеется в виду архитектурный шаблон автоматического выключателя. Netflix опубликовал библиотеку Hysterix для работы с автоматическими выключателями. В рамках этого поста я покажу, как мы можем использовать шаблон автоматического выключателя, используя библиотеку **resilence4j**в приложении Spring Boot.
Изображение с сайта Pixabay - Автор Jürgen Diermaier
### Что такое автоматический выключатель?
Концепция автоматического выключателя пришла из электротехники. В большинстве электрических сетей автоматические выключатели представляют собой выключатели, которые защищают сеть от повреждений, вызванных перегрузкой по току или коротким замыканием.
Точно так же в программном обеспечении автоматический выключатель останавливает вызов удаленного сервиса, если мы знаем, что вызов этого сервиса либо завершится сбоем, либо истечет время ожидания. Преимущество этого подхода заключается в экономии ресурсов и упреждающем поиске и устранении неисправностей удаленных вызовов процедур.
Автоматический выключатель принимает решение об остановке вызова на основе предыдущей истории вызовов. Но есть альтернативные способы обработки вызовов. Обычно автоматический выключатель отслеживает предыдущие вызовы. Предположим, что 4 из 5 вызовов завершились неудачно или истекло время, тогда следующий вызов завершится ошибкой. Это помогает более активно обрабатывать ошибки при вызове сервиса, а сервис вызывающего абонента может обрабатывать ответ по-другому, предоставляя пользователям приложения что-то лучше, чем просто страницу с ошибкой.
Другой случай срабатывания автоматического выключателя — это, когда вызовы удаленного сервиса не работают в течение определенного времени. Автоматический выключатель сработает и не допустит следующего вызова, пока удаленное обслуживание не исправит ошибку.
### Библиотека Resilience4J
У нас есть код, в котором мы вызываем удаленный сервис. Модуль автоматического выключателя из `resilience4j`библиотеки будет иметь лямбда-выражение для вызова удаленный сервис `supplier`для получения значений из вызова удаленного сервиса. Я покажу это на примере. Автоматический выключатель декорирует этот вызов удаленного обслуживания таким образом, чтобы он мог отслеживать ответы и состояния переключателя.
#### Различные конфигурации библиотеки Resilience4j
Чтобы понять концепцию автоматического выключателя, мы рассмотрим различные конфигурации, предлагаемые этой библиотекой.
* `slidingWindowType()`— эта конфигурация называется скользящее окно. В основном именно она помогает принять решение о том, как будет работать автоматический выключатель. Есть два типа скользящих окон: `COUNT_BASED`и `TIME_BASED`. Скользящее окно автоматического выключателя `COUNT_BASED`будет учитывать количество вызовов удаленного сервиса, в то время как `TIME_BASED`скользящее окно автоматического выключателя будет учитывать вызовы удаленного сервиса в течение определенного периода времени.
* `failureRateThreshold()`— настраивает порог частоты отказов в процентах. Если x процентов вызовов не работают, выключатель отключается.
* `slidingWindowSize()`— эта настройка помогает определить количество вызовов, которые следует учитывать при включении автоматического выключателя.
* `slowCallRateThreshold()`— настраивает порог низкой скорости вызова в процентах. Если x процентов вызовов являются медленными, автоматический выключатель отключается.
* `slowCallDurationThreshold`— настраивает порог продолжительности времени, при котором вызовы считаются медленными.
* `minimumNumberOfCalls()`— минимальное необходимое количество вызовов, перед которым автоматический выключатель может рассчитать частоту ошибок.
* `ignoreException()`— этот параметр позволяет вам настроить исключение, которое автоматический выключатель может игнорировать и не будет учитываться при успешном или неудачном вызове удаленного сервиса.
* `waitDurationInOpenState()`— Продолжительность, в течение которой автоматический выключатель должен оставаться в разомкнутом состоянии перед переходом в полуоткрытое состояние. Значение по умолчанию - 60 секунд.
### COUNT-BASED автоматический выключатель
При использовании `resilience4j`библиотеки всегда можно использовать конфигурации по умолчанию, которые предлагает автоматический выключатель. Конфигурации по умолчанию основаны на типе COUNT-BASED скользящего окна.
Так как же нам создать автоматический выключатель для скользящего окна типа COUNT-BASED?
```
CircuitBreakerConfig circuitBreakerConfig = CircuitBreakerConfig.custom()
.slidingWindowType(CircuitBreakerConfig.SlidingWindowType.COUNT_BASED)
.slidingWindowSize(10)
.slowCallRateThreshold(65.0f)
.slowCallDurationThreshold(Duration.ofSeconds(3))
.build();
CircuitBreakerRegistry circuitBreakerRegistry =
CircuitBreakerRegistry.of(circuitBreakerConfig);
CircuitBreaker cb = circuitBreakerRegistry.circuitBreaker("BooksSearchServiceBasedOnCount");
```
В приведенном выше примере мы создаем конфигурацию автоматического выключателя, которая включает тип скользящего окна `COUNT_BASED`. Этот автоматический выключатель записывает результат 10 вызовов для переключения автоматического выключателя в `closed`состояние. Если 65% вызовов являются медленными, а продолжительность медленных вызовов превышает 3 секунды, автоматический выключатель отключается.
`CircuitBreakerRegistry` — фабрика по созданию выключателя.
### Time-Based автоматический выключатель
Теперь об `Time-Based`автоматическом выключателе.
```
CircuitBreakerConfig circuitBreakerConfig = CircuitBreakerConfig.custom()
.slidingWindowType(CircuitBreakerConfig.SlidingWindowType.TIME_BASED)
.minimumNumberOfCalls(3)
.slidingWindowSize(10)
.failureRateThreshold(70.0f)
.build();
CircuitBreakerRegistry circuitBreakerRegistry =
CircuitBreakerRegistry.of(circuitBreakerConfig);
CircuitBreaker cb = circuitBreakerRegistry.circuitBreaker("BookSearchServiceBasedOnTime");
```
В приведенном выше примере мы создаем конфигурацию автоматического выключателя, которая включает в себя скользящее окно типа `TIME_BASED`. Автоматический выключатель фиксирует отказ вызовов после минимум 3 вызовов. Если 70 процентов вызовов терпят неудачу, срабатывает автоматический выключатель.
### Пример автоматического выключателя в приложении Spring Boot
Мы рассмотрели необходимые понятия об автоматическом выключателе. Теперь я покажу, что мы можем использовать автоматический выключатель в приложении Spring Boot.
С одной стороны, у нас есть REST приложение, `BooksApplication`которое хранит основные сведения о библиотечных книгах. С другой стороны, у нас есть приложение, `Circuitbreakerdemo`которое вызывает приложение REST с помощью `RestTemplate`. Декорируем наш REST-вызов с помощью автоматического выключателя.
`BooksApplication`хранит информацию о книгах в таблице базы данных MySQL `librarybooks`. В REST контроллере этого приложения есть `GET`и `POST`методы.
```
package com.betterjavacode.books.controllers;
import com.betterjavacode.books.daos.BookDao;
import com.betterjavacode.books.models.Book;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
import java.util.ArrayList;
import java.util.List;
import java.util.Optional;
@CrossOrigin("https://localhost:8443")
@RestController
@RequestMapping("/v1/library")
public class BookController
{
@Autowired
BookDao bookDao;
@GetMapping("/books")
public ResponseEntity getAllBooks(@RequestParam(required = false) String bookTitle)
{
try
{
List listOfBooks = new ArrayList<>();
if(bookTitle == null || bookTitle.isEmpty())
{
bookDao.findAll().forEach(listOfBooks::add);
}
else
{
bookDao.findByTitleContaining(bookTitle).forEach(listOfBooks::add);
}
if(listOfBooks.isEmpty())
{
return new ResponseEntity<>(HttpStatus.NO\_CONTENT);
}
return new ResponseEntity<>(listOfBooks, HttpStatus.OK);
}
catch (Exception e)
{
return new ResponseEntity<>(null, HttpStatus.INTERNAL\_SERVER\_ERROR);
}
}
@GetMapping("/books/{id}")
public ResponseEntity getBookById(@PathVariable("id") long id)
{
try
{
Optional bookOptional = bookDao.findById(id);
return new ResponseEntity<>(bookOptional.get(), HttpStatus.OK);
}
catch (Exception e)
{
return new ResponseEntity<>(null, HttpStatus.INTERNAL\_SERVER\_ERROR);
}
}
@PostMapping("/books")
public ResponseEntity addABookToLibrary(@RequestBody Book book)
{
try
{
Book createdBook = bookDao.save(new Book(book.getTitle(), book.getAuthor(),
book.getIsbn()));
return new ResponseEntity<>(createdBook, HttpStatus.CREATED);
}
catch (Exception e)
{
return new ResponseEntity<>(null, HttpStatus.INTERNAL\_SERVER\_ERROR);
}
}
@PutMapping("/books/{id}")
public ResponseEntity updateABook(@PathVariable("id") long id, @RequestBody Book book)
{
Optional bookOptional = bookDao.findById(id);
if(bookOptional.isPresent())
{
Book updatedBook = bookOptional.get();
updatedBook.setTitle(book.getTitle());
updatedBook.setAuthor(book.getAuthor());
updatedBook.setIsbn(book.getIsbn());
return new ResponseEntity<>(bookDao.save(updatedBook), HttpStatus.OK);
}
else
{
return new ResponseEntity<>(HttpStatus.NOT\_FOUND);
}
}
@DeleteMapping("/books/{id}")
public ResponseEntity deleteABook(@PathVariable("id") long id)
{
try
{
bookDao.deleteById(id);
return new ResponseEntity<>(HttpStatus.NO\_CONTENT);
}
catch (Exception e)
{
return new ResponseEntity<>(HttpStatus.INTERNAL\_SERVER\_ERROR);
}
}
}
```
С другой стороны, в нашем приложении `Circuitbreakerdemo`есть контроллер с шаблоном thymeleaf, поэтому пользователь может получить доступ к приложению в браузере.
В демонстрационных целях я определил CircuitBreaker в отдельном компоненте, который я буду использовать в своем service классе.
```
@Bean
public CircuitBreaker countCircuitBreaker()
{
CircuitBreakerConfig circuitBreakerConfig = CircuitBreakerConfig.custom()
.slidingWindowType(CircuitBreakerConfig.SlidingWindowType.COUNT_BASED)
.slidingWindowSize(10)
.slowCallRateThreshold(65.0f)
.slowCallDurationThreshold(Duration.ofSeconds(3))
.build();
CircuitBreakerRegistry circuitBreakerRegistry =
CircuitBreakerRegistry.of(circuitBreakerConfig);
CircuitBreaker cb = circuitBreakerRegistry.circuitBreaker("BooksSearchServiceBasedOnCount");
return cb;
}
@Bean
public CircuitBreaker timeCircuitBreaker()
{
CircuitBreakerConfig circuitBreakerConfig = CircuitBreakerConfig.custom()
.slidingWindowType(CircuitBreakerConfig.SlidingWindowType.TIME_BASED)
.minimumNumberOfCalls(3)
.slidingWindowSize(10)
.failureRateThreshold(70.0f)
.build();
CircuitBreakerRegistry circuitBreakerRegistry =
CircuitBreakerRegistry.of(circuitBreakerConfig);
CircuitBreaker cb = circuitBreakerRegistry.circuitBreaker("BookSearchServiceBasedOnTime");
return cb;
}
```
Я определил два компонента: один для автоматического выключателя на основе счетчика, а другой - для автоматического выключателя на основе времени.
`BookStoreService`будет содержать вызывающее приложение BooksApplication и отображать доступные книги. Этот сервис будет выглядеть так:
```
@Controller
public class BookStoreService
{
private static final Logger LOGGER = LoggerFactory.getLogger(BookStoreService.class);
@Autowired
public BookManager bookManager;
@Autowired
private CircuitBreaker countCircuitBreaker;
@RequestMapping(value = "/home", method= RequestMethod.GET)
public String home(HttpServletRequest request, Model model)
{
return "home";
}
@RequestMapping(value = "/books", method=RequestMethod.GET)
public String books(HttpServletRequest request, Model model)
{
Supplier booksSupplier =
countCircuitBreaker.decorateSupplier(() -> bookManager.getAllBooksFromLibrary());
LOGGER.info("Going to start calling the REST service with Circuit Breaker");
List books = null;
for(int i = 0; i < 15; i++)
{
try
{
LOGGER.info("Retrieving books from returned supplier");
books = booksSupplier.get();
}
catch(Exception e)
{
LOGGER.error("Could not retrieve books from supplier", e);
}
}
model.addAttribute("books", books);
return "books";
}
}
```
Поэтому, когда пользователь кликает на ссылку на главной странице, мы получаем книги из нашей REST-сервиса BooksApplication.
Я автоматически подключил бин для `countCircuitBreaker`. В демонстрационных целях я буду вызывать REST сервис 15 раз подряд, чтобы получить все книги. Таким образом, я смогу имитировать прерывание на стороне моей REST-сервиса.
Наш автоматический выключатель декорирует сервис `supplier`, который выполняет REST-вызов удаленного сервиса и сохраняет результат нашего удаленного вызова.
В этой демонстрации мы вызываем наш REST-сервис последовательно, но вызовы удаленного сервиса также могут происходить параллельно. Автоматический выключатель по-прежнему будет отслеживать результаты независимо от последовательных или параллельных вызовов.
### Демо
Давайте теперь посмотрим на живой демонстрации, как автоматический выключатель будет работать. Мой REST-сервис работает на порту 8443, а мое `Circuitbreakerdemo`приложение - на порту 8743.
Сначала я запускаю оба приложения и открываю домашнюю страницу `Circuitbreakerdemo`приложения. На главной странице есть ссылка для просмотра всех книг из магазина.
Теперь, чтобы смоделировать некоторые ошибки, я добавил следующий код в свой вызов RestTemplate, который в основном спит в течение 3 секунд, прежде чем вернуть результат вызова REST.
```
public List getAllBooksFromLibrary ()
{
HttpHeaders httpHeaders = new HttpHeaders();
httpHeaders.setContentType(MediaType.APPLICATION_JSON);
ResponseEntity responseEntity;
long startTime = System.currentTimeMillis();
LOGGER.info("Start time = {}", startTime);
try
{
responseEntity= restTemplate.exchange(buildUrl(),
HttpMethod.GET, null, new ParameterizedTypeReference()
{});
if(responseEntity != null && responseEntity.hasBody())
{
Thread.sleep(3000);
LOGGER.info("Total time to retrieve results = {}",
System.currentTimeMillis() - startTime);
return responseEntity.getBody();
}
}
catch (URISyntaxException | InterruptedException e)
{
LOGGER.error("URI has a wrong syntax", e);
}
LOGGER.info("No result found, returning an empty list");
return new ArrayList<>();
}
```
Короче говоря, мой контур автоматического выключателя будет вызывать удаленный сервис достаточное количество раз, чтобы преодолеть порог в 65 процентов медленных вызовов продолжительностью более 3 секунд. Как только я нажму на ссылку `here`, я получу результат, но мой автоматический выключатель будет разомкнут и не будет разрешать дальнейшие вызовы, пока он будет в состоянии `half-open`либо `closed`.
Вы можете заметить, что мы начали получать исключение, `CallNotPermittedException,`когда автоматический выключатель был в состоянии `OPEN`. Кроме того, выключатель был отключен при выполнении 10 вызовов. Это потому, что размер нашего скользящего окна равен 10.
Другой способ - смоделировать ошибку, отключив REST сервис или сервис базы данных. Таким образом, вызовы REST могут занять больше времени, чем требуется.
Теперь давайте переключим `COUNT_BASED`автоматический выключатель на `TIME_BASED`автоматический выключатель. В `TIME_BASED`автоматическом выключателе мы отключим наш REST-сервис через секунду, а затем щелкнем `here`ссылку с домашней страницы. Если 70 процентов вызовов за последние 10 секунд не работают, наш автоматический выключатель сработает.
Поскольку REST-сервис закрыт, мы увидим следующие ошибки в `Circuitbreakdemo`приложении
Мы увидим несколько ошибок до того, как автоматический выключатель будет в `OPEN`состоянии.
Еще одна конфигурация, которую мы всегда можем добавить, как долго мы хотим держать выключатель в разомкнутом состоянии. Для демонстрации я добавил, что автоматический выключатель будет в разомкнутом состоянии в течение 10 секунд.
### Как обращаться с OPEN выключателями?
Возникает вопрос, как обращаться с OPEN выключателями? К счастью, `resilience4j`предлагает резервную конфигурацию с утилитой `Decorators`. В большинстве случаев вы всегда можете настроить ее так, чтобы получить результат предыдущих успешных результатов, чтобы пользователи могли работать с приложением.
### Вывод
В этом посте я рассказал, как использовать автоматический выключатель в приложении Spring Boot. Код для этой демонстрации доступен [**здесь**](https://github.com/yogsma/circuitbreakerdemo).
В этой демонстрации я не рассмотрел, как отслеживать события выключателя, поскольку библиотека `resilience4j`позволяет сохранять эти события с метриками, которые можно отслеживать с помощью системы мониторинга.
### Рекомендации для прочтения
1. Библиотека [**Resilience4J**](https://resilience4j.readme.io/docs/circuitbreaker)
2. Автоматический выключатель с Resilience4j - [**Circuit Breaker**](https://reflectoring.io/circuitbreaker-with-resilience4j/) | https://habr.com/ru/post/544074/ | null | ru | null |
# Простой в использовании контейнер состояния для React приложения под названием Xstore
Уважаемые коллеги, представляю вашему вниманию и на ваше осуждение контейнер для управления состоянием React приложения **xstore**. Он определенно является таким маленьким детским велосипедом рядом с большим и сверкающим мотоциклом Redux. Все мы программисты JavaScript являемся такой большой и не сбавляющей обороты фабрикой по производству велосипедов.
Для более менее просто начинающих или начинающих свое знакомство с React JavaScript программистов Redux может показаться несколько сложной штукой, которая иногда непонятно как работает и к которой сложно "законнектиться", хочется чего-то попроще, чего-то похожего на данный маленький велосипед.
Давайте рассмотрим его поближе.
Установка
---------
```
npm install --save xstore
```
Использование
-------------
Для начала нам нужно добавить в хранилище "обработчики".
(Пример обработчика представлен в блоке ниже)
*index.js*
```
import React from 'react'
import ReactDOM from 'react-dom'
import Store from 'xstore'
import App from './components/App'
import user from './store_handlers/user'
import dictionary from './store_handlers/dictionary'
// Имя обработчика не должно содержать символ "_".
// В данном случае мы имеем два обработчика: user и dictionary.
Store.addHandlers({
user,
dictionary
});
ReactDOM.render(
,
document.getElementById('root')
);
```
Далее идет пример обработчика "user".
В нем содержится редьюсер "init", который нужен, чтобы определить начальное состояние хранилища "user".
*./store\_handlers/user.js*
```
import axios from 'axios'
const DEFAULT_STATE = {
name: 'user',
status: 'alive'
}
/**
===============
Reducers
===============
*/
// Будет автоматически вызван для инициализации начального состояния.
// Если данный редьюсер не существует, начальное состояние будет пустым объектом.
// Вызывайте этот редьюсер, чтобы сбросить состояние до начального.
// Для вызова используйте this.props.dispatch('USER_INIT').
const init = () => {
return DEFAULT_STATE;
}
// this.props.dispatch('USER_CHANGED', {name: 'NewName'})
const changed = (state, data) => {
return {
...state,
...data
}
}
/**
===============
Actions
===============
*/
// this.props.doAction('USER_CHANGE', {data})
const change = ({dispatch}, data) => {
// {dispatch, doAction, getState, state}
dispatch('USER_CHANGED', data);
}
// this.props.doAction('USER_LOAD', {id: userId})
const load = ({dispatch}, data) => {
// {dispatch, doAction, getState, state}
axios.get('/api/load.php', data)
.then(({data}) => {
dispatch('USER_CHANGED', data);
});
}
// Этот объект конечно же должен быть обязательно такого вида
export default {
actions: {
load,
change
// remove, save, add_item, remove_this_extra_item, .....
},
reducers: {
init,
changed
// removed, saved, item_added, this_extra_item_removed, .....
}
}
```
Далее пример того, как подключить компонент к хранилищу.
*./components/ComponentToConnect/index.js*
```
import React from 'react'
import Store from 'xstore'
class ComponentToConnect extends React.Component {
render() {
// Свойства user и dictionary будут получены из хранилища.
let {user, dictionary} = this.props;
return (
....
)
}
loadUser(userId) {
// Вызов экшена в компоненте.
this.props.doAction('USER_LOAD', {id: userId});
}
setUser(userData) {
// Вызов редьюсера в компоненте.
// Но лучше так не делать и вызывать только экшены.
this.props.dispatch('USER_CHANGED', userData);
}
}
// Непосредственно подключение к хранилищу.
const params = {
has: 'user, dictionary'
}
export default Store.connect(ComponentToConnect, params);
```
Возможные опции "params" для подключения:
```
{
// Названия хранилищ, к которым будет подключен компонент:
has: 'user, dictionary',
// или по-другому:
has: ['user', 'dictionary'],
// Если необходимы только некоторые поля из хранилища:
has: 'user:name|status, dictionary:userStatuses',
// или
has: ['user:name|status', 'dictionary:userStatuses'],
// Компонент будет ждать содержимое данных хранилищ, и только тогда отрисуется.
shouldHave: 'user,dictionary',
// или
shouldHave: ['user', 'dictionary'],
// Чтобы извлечь данные из нескольких хранилищ на верхний уровень, установите в true.
// В результате компонент получит пропсы "name", "status", "userStatuses" вместо "user" и "dictionary"
flat: true,
// Нужен, чтобы добавить префикс к извлеченным данным, работает только если flat = true.
// В результате компонент получит пропсы "user_name", "user_status", "dictionary_userStatuses"
withPrefix: true,
// Вы можете добавить обработчики непосредственно здесь.
// Если в этом списке содержатся все необходимые, параметр "has" можно не передавать.
handlers: {
user,
dictionary
}
}
```
Список публичных методов хранилища:
```
import Store from 'xstore'
// Возвращает клонированный объект содержащий в себе данные всех хранилищ:
let state = Store.getState();
// Возвращает клонированный объект содержащий в себе данные хранилища "user":
let userState = Store.getState('user');
// Возвращает поле "name" из хранилища "user":
let userName = Store.getState('user.name');
// Возвращает поле с индексом 0 из поля "items" из хранилища "user":
let someItem = Store.getState('user.items.0');
// Добавление обработчиков:
Store.addHandlers({
user: userHandler,
dictionary: dictionaryHandler
})
// Вызов экшена "load" хранилища "user":
// Название экшена будет приведено в нижний регистр, так что не зависит от регистра.
Store.doAction('USER_LOAD', {id: userId});
// Вызов редьюсера "loaded" хранилища "user":
Store.dispatch('USER_LOADED', data);
// Подписка компонента на изменения хранилища:
Store.connect(Component, params);
```
### А теперь о том как это работает:
Метод "connect" создает новый HOC класс XStoreConnect, который скрывает в себе всю логику по взаимодействию компонента и хранилища. Данный класс подписывается на изменения хранилища и, когда там происходят какие-то изменения, им вызывается метод setState защищенный от вызова извне (например через this.refs.xStoreConnect.setState(...)), после чего данный компонент перерисовывается, тем самым обновляя пропсы в обёрнутом компоненте.
Прямое изменение состояния компонента-обёртки this.refs.xStoreConnect.state = something тоже ни к чему не приведет, данный класс умеет находить внедренные данные и удалять их.
**Код компонента-обёртки**
```
// .... Здесь еще много функционала хранилища
const LOCAL_OBJECT_CHECKER = {};
const connect = (ComponentToConnect, connectProps) => {
let ready = false;
let {
has,
handlers,
shouldHave: shouldHaveString,
flat,
withPrefix
} = connectProps;
if (!has && handlers instanceof Object) {
has = Object.keys(handlers);
}
let shouldHave = [];
if (typeof shouldHaveString == 'string') {
shouldHaveString = shouldHaveString.split(',');
for (let item of shouldHaveString) {
if (item) {
shouldHave.push(item.trim());
}
}
}
let doUnsubscribe,
doCleanState,
stateItemsQuantity;
return class XStoreConnect extends React.Component {
constructor() {
super();
const updater = (state) => {
stateItemsQuantity = Object.keys(state).length;
if (ready) {
this.setState(state, LOCAL_OBJECT_CHECKER);
} else {
this.state = state;
}
}
doUnsubscribe = () => {
unsubscribe(updater);
}
doCleanState = () => {
cleanStateFromInjectedItems(updater, this.state);
}
subscribe(updater, {has, handlers, flat, withPrefix});
}
setState(state, localObjectChecker) {
if (state instanceof Object && localObjectChecker === LOCAL_OBJECT_CHECKER) {
super.setState(state);
}
}
componentWillMount() {
ready = true;
}
componentWillUnmount() {
ready = false;
doUnsubscribe();
}
render() {
let {props, state} = this;
let newStateKeysQuantity = Object.keys(state).length;
if (stateItemsQuantity != newStateKeysQuantity) {
doCleanState();
}
for (let item of shouldHave) {
if (state[item] === undefined) {
return null;
}
}
let componentProps = {
...props,
...state,
doAction,
dispatch
};
return
}
}
}
```
Генерация файлов обработчиков из командной строки:
--------------------------------------------------
```
npm install -g xstore
xstore create-handler filename
```
Также можно прописать в "scripts" в "package.json":
```
{
scripts: {
"create-handler": "node node_modules/xstore/bin/exec.js"
}
}
npm run create-handler filename
```
Эта команда создаст файл filename.js (если такого не существует) с шаблонным кодом обработчика.
Вот и всё, совсем просто не так ли? А теперь можете пинать. Буду рад советам и разумной критике, уважаемые коллеги. | https://habr.com/ru/post/341768/ | null | ru | null |
# Developer Blog #1 – Android 2D Game
> *Дата начала разработки: 10 августа 2021 года.*
>
>
Содержание
----------
* [Среда разработки](#%D0%A1%D1%80%D0%B5%D0%B4%D0%B0%20%D1%80%D0%B0%D0%B7%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%BA%D0%B8)
* [Интерфейс](#%D0%98%D0%BD%D1%82%D0%B5%D1%80%D1%84%D0%B5%D0%B9%D1%81)
* [Настройки – звуки, музыка, локализация](#%D0%9D%D0%B0%D1%81%D1%82%D1%80%D0%BE%D0%B9%D0%BA%D0%B8%20%E2%80%93%20%D0%B7%D0%B2%D1%83%D0%BA%D0%B8,%20%D0%BC%D1%83%D0%B7%D1%8B%D0%BA%D0%B0,%20%D0%BB%D0%BE%D0%BA%D0%B0%D0%BB%D0%B8%D0%B7%D0%B0%D1%86%D0%B8%D1%8F)
* [Графика](#%D0%93%D1%80%D0%B0%D1%84%D0%B8%D0%BA%D0%B0)
* [Управление](#%D0%A3%D0%BF%D1%80%D0%B0%D0%B2%D0%BB%D0%B5%D0%BD%D0%B8%D0%B5)
* [Объекты и инвентарь](#%D0%9E%D0%B1%D1%8A%D0%B5%D0%BA%D1%82%D1%8B%20%D0%B8%20%D0%B8%D0%BD%D0%B2%D0%B5%D0%BD%D1%82%D0%B0%D1%80%D1%8C)
* [Итоги](#%D0%98%D1%82%D0%BE%D0%B3%D0%B8)
---
Среда разработки
----------------
В качестве среды разработки был выбран бесплатный кроссплатформенный движок [Solar2D v2021.3649](https://solar2d.com) (бывший Corona SDK) от компании Corona Labs Inc. При разработке приложений используется язык [Lua v5.4.3](https://www.lua.org) – по идеологии и реализации язык ближе всего к JavaScript.
Официальные логотипыSolar2D обладает полноценным симулятором и простейшей консолью отладки. Также присутствует очень удобная функция Live Build – тестирование приложения одновременно на нескольких устройствах и разных платформах в режиме реального времени. Для работы данной функции необходимо, чтобы компьютер и устройство были подключены к одной локальной сети.
> *«Просто как по волшебству.»*
>
>
Как среда разработки, так и язык программирования обладают официальной документацией. Практически вся актуальная документация на английском языке:
* [Solar2D](https://docs.coronalabs.com)
* [Lua 5.4](https://www.lua.org/manual/5.4)
Но встречается и русскоязычная информация:
* [Lua 5.3](http://lua.org.ru/contents_ru.html)
* [Язык Lua и Corona SDK (1/3 часть)](https://habr.com/ru/post/344304), [Язык Lua и Corona SDK (2/3 часть)](https://habr.com/ru/post/344312) и [Язык Lua и Corona SDK (3/3 часть)](https://habr.com/ru/post/344562)
Есть и русскоязычные видео:
* [Счётчик калорий](https://youtube.com/playlist?list=PL0lO_mIqDDFXp107z01qN09pff0PVuQG6)
* [Flappy Bird](https://youtu.be/8-KAySYuhCw)
* [Работа с аудио, физикой, анимацией](https://youtube.com/playlist?list=PLAbPZuYPFlMiPf1JviLLdMVNBcT9r4RV5)
* [Pass The](https://youtube.com/playlist?list=PLUQVebD5zCbP2EPBLpq-QDU44hxhJ_tlF)
* [Игра про дрон #1](https://youtu.be/XnJmOyr8HZ4) и [Игра про дрон #2](https://youtu.be/SOJ5nYMEFhA)
Немного примеров проектов:
* <https://docs.coronalabs.com/guide/programming/index.html>
* <https://www.solar2dplayground.com>
---
Интерфейс
---------
В файле *config.lua* задаются параметры конфигурации. Среди таких параметров задаётся и метод масштабирования. Был выбран метод *«adaptive»*, который выбирает ширину и высоту динамического содержимого в зависимости от устройства.
```
application = {
content = {
scale = "adaptive",
}
}
```
В связи с особенностями данного метода для заданий размеров и положений объектов необходимо использовать свойства *display.contentWidth* и *display.contentHeight*, а также расчёты с этими свойствами. Для этого в файле *main.lua*, который является основным файлом любой программы, написанной на Solar2D, были заданы глобальные переменные:
```
_W = display.contentWidth
_H = display.contentHeight
_CenterX = display.contentCenterX
_CenterY = display.contentCenterY
```
На основе вышеизложенного реализовано главное меню.
Главное менюЭффект нажатия кнопки главного менюПоложение кнопок по вертикали задаётся универсальной формулой:
```
buttonHeight*lengthTable(buttons) + ((_H - buttonHeight*5)/6)*(lengthTable(buttons) - 1)
```
Первое слагаемое задаёт положение кнопки, а второе слагаемое отвечает за отступ между кнопками, начиная со второй кнопки.
Также разработаны окна паузы и подтверждения выхода из игры. Дизайн данных окон не является конечным.
Окно паузыОкно подтверждения выхода из игрыПараметры сборки приложения указываются в файле *build.settings*. Так как игра будет в горизонтальном положении, то укажем начальную ориентацию, а также допустимые варианты ориентации экрана:
```
settings = {
orientation = {
default = "landscapeRight",
supported = {"landscapeRight", "landscapeLeft"}
}
}
```
В этом же файле можно задать и заставку при открытии приложения. Дизайн заставки не является конечным.
```
settings = {
splashScreen = {
enable = true,
image = "Images/launchScreen.png"
}
}
```
ЗаставкаРеализована пробная иконка приложения как для API уровня <26 (Android 7.0 и ниже), так и для API уровня ≥26 (Android 8.0 и выше). Для этого по пути *AndroidResources/res/* созданы и правильно названы соответствующие файлы иконок для разных плотностей экранов Android.
---
Настройки – звуки, музыка, локализация
--------------------------------------
Ещё одним разделом в файле *build.settings* является раздел настроек сборки для устройств Android.
```
settings = {
android = {
isGame = true,
minSdkVersion = "15",
versionCode = "1"
}
}
```
Здесь для Google Play классифицируется приложение, как игра. Указывается минимальная версия SDK. Минимальный уровень API в Solar2D – 15 (Android 4.0.3). Также внутренний номер версии. Этот номер используется для определения более новой версии приложения – более высокие числа указывают на более новую версию приложения. Данная строка будет обычным инкрементом при выпуске новых версий.
В экране настроек реализовано изменение громкости звуков и фоновой музыки, а также локализация всего текста игры. Язык текста меняется в режиме реального времени, и никаких перезапусков не требуется.
Окно настроек
> *Положение текста над ручками слайдеров будет исправлено.*
>
>
На данный момент игра планируется на 4-х языках:
* Русский
* English
* Deutsch
* Українська
Реализованы звуки шагов персонажа, нажатий на различные кнопки. Реализована фоновая музыка. Звуки и музыка не являются конечным.
Экран настроек также можно вызвать из окна паузы во время игры. Дизайн окна настроек не является конечным.
Сохранение всех настроек производится с помощью метода системной функции:
```
system.setPreferences("app", table)
```
---
Графика
-------
Реализована анимация движения главного героя.
Анимация движения главного герояНачата разработка карты для первой главы сюжета.
Начальный этап разработки карты
---
Управление
----------
Реализован джойстик для управления главным героем.
Джойстик управления главным героемДля созданий джойстика был создан отдельный модуль *joystick.lua* вида:
```
local class = {}
function class.createJoystick()
-- function body
end
return class
```
Из основного файла джойстик создаётся следующим образом:
```
local moduleJoystick = require("Module.joystick")
function scene:create(event)
local joystick = moduleJoystick.createJoystick()
end
scene:addEventListener("create", scene)
return scene
```
Смена анимации движения главного героя происходит при пересечений центром джойстика линий ± 45° с проверкой на текущее значение последовательности кадров для предотвращения бесконечной смены анимации. Схематично это выглядит так:
Схема смены анимации движения главного герояКак при касании по экрану внутри джойстика, так и при уходе движения касания за джойстик центр джойстика всегда движется только по окружности фона джойстика. Серые круги означают возможные касания, чёрные круги – желаемое положение центра джойстика.
Схема возможных касаний и желаемых положений центра джойстикаДля этого была решена геометрическая задача. Имеем центр джойстика (x1,y1) и точку касания по экрану, которая вышла за джойстик (x2,y2). Необходимо найти точку на окружности (x3,y3).
Геометрическая задача для желаемого положения центра джойстикаВ итоге получим формулы, которые необходимо указать для положения центра джойстика при касании по джойстику.
Математические формулы положения центра джойстика:

```
local alfa = math.atan(deltaY/deltaX)
centerJoystick.x = math.cos(alfa)*radiusBgJoystic*sign(deltaX) + centerJoystickPositionX
centerJoystick.y = math.sin(alfa)*radiusBgJoystic*sign(deltaX) + centerJoystickPositionY
```
В переменной *deltaX* записывается величина отклонения по оси X точки касания по экрану от центра фона джойстика. Аналогично, и *deltaY*. Соответственно, *sign(deltaX)* информирует о движении влево или вправо от центра фона джойстика.
> *Сейчас начать движение можно только проведя по фону джойстика, но в планах добавить возможность начать движение и по клику на фон джойстика.*
>
>
В основном движение главного героя имитируется перемещением карты, а сам главный герой остаётся в центре экрана. В случае, когда карта достигает своей границы, то уже начинает перемещаться главный герой, пока не встретит границы карты, которые будут и границей экрана.
> *В планах разработать карту таким образом, добавив по краям карты некий фон, чтобы персонаж навсегда оставался в центре экрана.*
>
>
Реализована коллизия карты и главного героя, которая предотвращает движение главного героя в местах, где движение по логике невозможно – стены, обрывы, горы, здания, предметы интерьера. Для наглядности и тестирования видимость коллизии включена.
Коллизия карты и главного герояРеализовано сохранение позиций карты, игрока, объектов. При повторном открытии игровой сцены всё будет, как и перед выходом.
---
Объекты и инвентарь
-------------------
Добавлены объекты основной валюты: болты и монеты. Дизайн объектов не является конечным. Был создан файл JSON записями вида:
```
{
"type": {
"name": "",
"icon": "path",
"description": ""
},
}
```
Solar2D поддерживает JSON5, в котором добавлена возможность добавлять комментарии, а так же возможность не удалять запятую при копировании у последнего элемента.
Болт и монетаРеализован инвентарь. Дизайн окна инвентаря не является конечным. А также создан JSON файл инвентаря вида:
```
{
"item**": {
"type": "",
"count": 0
},
}
```
ИнвентарьДругая выбранная ячейка в инвентаре
> *Обязательно будет добавлена локализация объектов получаемых из JSON файла всех объектов.*
>
>
Реализован спавн монеты, сохранение позиций при выходе со сцены и новое положение при подборе монеты. Подобранная монета, естественно, увеличивает количество монет в инвентаре. Все собранные монеты сохраняются в инвентаре при повторном входе на сцену.
> *В планах отключать анимацию монеты при выходе её за пределы экрана.*
>
>
Монета на сцене
> *Важным моментом, который уже решён аналитически, является проверка на несовпадение коллизии карты и позиции при спавне монетки. После программной реализации решение данной задачи, а также других методов решения такой задачи будет рассказано в следующем Developer Blog, который планируется выйти через месяц.*
>
>
---
Итоги
-----
Данный Developer Blog показывает объём работы, выполненный за первый месяц работы над игрой, включая знакомство со средой разработки и языком программирования. На текущий момент больших сложностей со средой разработки и языком программирования пока не возникало.
Все желающие могут протестировать всё реализованное, скачав документ ниже.
[APK: Скачать](https://vk.com/doc-191304509_612073965)
Как только игра приобретёт более-менее играбельный вид, то будет набрана команда постоянных тестеров, а пока о всех найденных ошибках можно будет написать в комментариях под постом с этой статьёй, в соответствующем [обсуждении](https://vk.com/topic-191304509_40415366) нашей группы ВКонтакте или на нашу почту:
> [email protected]
>
>
Об идеях и предложениях пока рано говорить, но в будущем мы обязательно постараемся выслушать мнение аудитории. А пока будут исправляться моменты, которые были указаны в данном Developer Blog, а также будет начато программирование первой главы сюжета. | https://habr.com/ru/post/579990/ | null | ru | null |
# «Умные» формы eXpressApp Framework (XAF). Часть 1
Прочитав обзор [«Что нужно от форм?»](http://habrahabr.ru/blogs/erp_systems/139328/), мне захотелось рассказать, как в нашем фреймворке для быстрого создания LOB приложений [eXpressApp Framework](http://habrahabr.ru/company/devexpress/blog/140325/) устроены «универсальные, динамически изменяемые формы».

В первой части моего рассказа я продемонстрирую реализацию элементов динамики на примере популярных задач фильтрации значения, управления видимостью и доступностью, а также контроля данных полей на форме вот такого вот необычного бизнес объекта:
```
[DomainComponent]
public interface ICustomer : IOrganization, IAccount { }
```
#### В начале было Слово… точнее бизнес объект!
Из коробки фреймворк предоставляет несколько основных видов форм или «Views», предназначение которых во многом понятно из названия:
• List View – служит для представления списка бизнес объектов;
• Detail View – служит для представления детальной информации об объекте;
• Dashboard View – служит для показа нескольких различных представлений, т.е. является контейнером, который в общем случае ничего не знает о бизнес объектах.
И причем здесь бизнес объект? Дело в том, что eXpressApp Framework умеет автоматически генерировать эти формы на базе определений бизнес объектов/сущностей. Технически, фреймворк сначала создает метаданные, представляющие скелет будущего приложения, а потом во время его исполнения использует эти метаданные для построения конечного пользовательского интерфейса, включая системы навигации и команд, CRUD представления объектов, а также многое другое, что сейчас принято называть модным словечком «UI Scaffolding».
Думаю достаточно теории, давайте продемонстрируем вышесказанное на конкретном примере. Сначала создадим бизнес сущность ICustomer (для простоты вместо классов я буду использовать интерфейсы или *Domain Components*, как мы их называем):
```
[DomainComponent]
public interface ICustomer : IOrganization, IAccount { }
```
, которая будет у нас состоять из нескольких компонент:
```
[DomainComponent]
public interface IAccount {
string Email { get; set; }
string Password { get; set; }
}
[DomainComponent]
public interface IPerson {
string LastName { get; set; }
string FirstName { get; set; }
DateTime Birthday { get; set; }
}
[DomainComponent]
public interface IOrganization {
string Name { get; set; }
IList Staff { get; }
IPerson Manager { get; set; }
}
```
Чтобы оценить, насколько фреймворк облегчает жизнь разработчика, приведу результат, полученный после первого запуска приложения, которое содержит только бизнес сущности из примера выше:

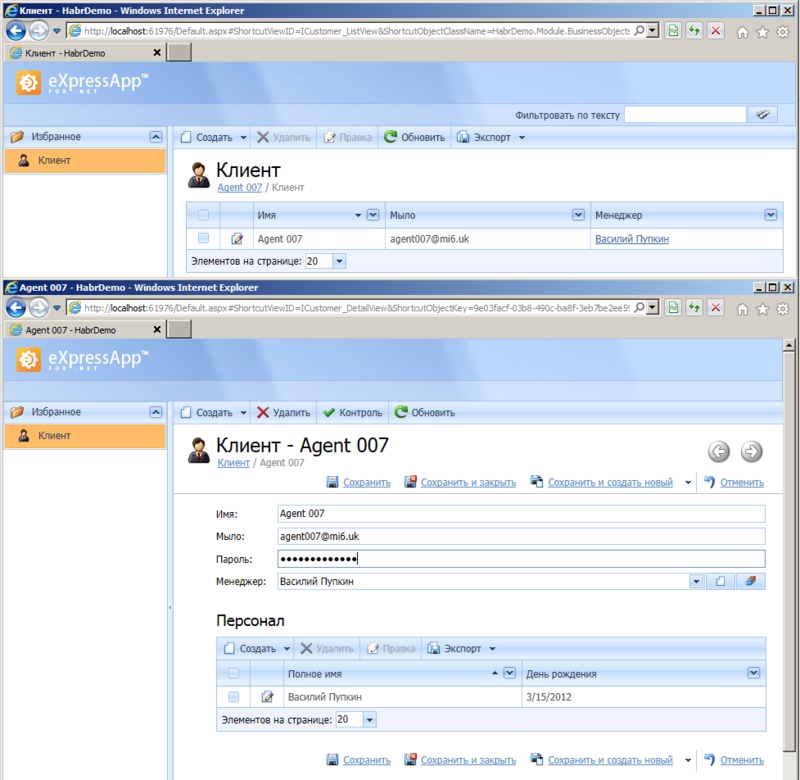
Хочу отдельно отметить, что во многом благодаря наличию слоя метаданных, наш фреймворк умеет автоматически строить пользовательский интерфейс для нескольких платформ, используя одну и ту же базу кода (в общем случае это бизнес сущности, контроллеры и команды, редакторы полей и представлений).
Так, в нашем случае имея одну лишь бизнес сущность ICustomer, я за несколько минут получил многофункциональные Windows и Web приложения.
#### Запускаем сердце «умной» формы
Если честно, то мне очень понравился термин ПУЗы (Поле-Условие-Значение), который активно использовался автором [предыдущей статьи](http://habrahabr.ru/blogs/erp_systems/139328/) для определения элементов динамики или правил поведения формы. Одним из популярных подходов к объявлению ПУЗов является декларативный подход, подразумевающий украшение атрибутами бизнес объекта и его членов (наверняка хорошо знакомый вам по [Data Annotations](http://msdn.microsoft.com/en-us/library/dd901590(v=vs.95).aspx)). В этой главе я расскажу, как в нашем фреймворке, используя декларативный подход, реализовать несколько популярных бизнес-правил.
##### Фильтрация значений полей в зависимости от бизнес правила
Одним из способов фильтрации значений полей является использование встроенных атрибутов: *DataSourceProperty* и *DataSourceCriteria* ([узнать о них больше из документации](http://documentation.devexpress.com/#Xaf/CustomDocument2993)). Например, нам нужно, чтобы свойство Manager нашего IOrganization показывало только записи из коллекции Staff, а не все записи типа IPerson. Сделать это очень просто:
```
[DataSourceProperty("Staff")]
IPerson Manager { get; set; }
```
Как вы могли догадаться, главным параметром этого атрибута является имя свойства, содержащего список объектов нужного типа. Атрибут достаточно умен, чтобы понимать вложенные свойства. Так, например, если бы у нас было свойство Department с коллекцией Staff, мы могли бы написать вот так:
```
[DataSourceProperty("Department.Staff")]
```
Если мы хотим дополнительно уточнить фильтр, добавим DataSourceCriteriaAttribute c необходимым критерием:
```
[DataSourceProperty("Staff"),DataSourceCriteria("StartsWith(FirstName, '123')")]
IPerson Manager { get; set; }
```
В итоге мы получим вот такой вот ожидаемый результат:

Не забываем, что всё это будет также прекрасно работать и в Вебе. Если нужно, вы также можете управлять этими фильтрами через метаданные приложения. Конечно же, можно реализовать и более сложные условия, в которых критерий задается не специальным [объектно-ориентированным языком критериев](http://documentation.devexpress.com/#XPO/CustomDocument4928), а программным кодом (например, в простейшем случае мы можем объявить приватное свойство, которое будет возвращать какой угодно список отфильтрованных объектов для DataSourcePropertyAttribute). Больше примеров по реализации этого сценария в нашем фреймворке можно [найти в документации](http://documentation.devexpress.com/#Xaf/CustomDocument2681).
##### Контроль значений полей в зависимости от бизнес-правила
Давайте сделаем наше поле Manager обязательным, если коллекция Staff не пуста. Для этого воспользуемся встроенным атрибутом *RuleRequiredField* и выставим необходимое условие в его параметр TargetCriteria:
```
[RuleRequiredField(TargetCriteria = "Staff.Count > 0")]
IPerson Manager { get; set; }
```
Всё это довольно просто, но что если нам нужно реализовать что-то посложнее обязательного поля? На это у фреймворка тоже есть ответ, так как «из коробки» он предосталяет [пару десятков популярных правил](http://documentation.devexpress.com/#Xaf/DevExpressPersistentValidation) контроля данных, пригодных почти на все случаи жизни.
Проверим это! Например, мы хотим убедиться, что поле Email нашего IAccount будет уникальным и валидным адресом электронной почты. Для этого достаточно добавить еще парочку готовых атрибутов:
```
[RuleRequiredField, RuleUniqueValue]
[RuleRegularExpression(@"^[_a-z0-9-]+(\.[_a-z0-9-]+)*@[a-z0-9-]+(\.[a-z0-9-]+)*(\.[a-z]{2,4})$")]
string Email { get; set; }
```
Визуализация ошибок выполнена средствами встроенного модуля Validation, который используется в новом решении eXpressApp Framework по умолчанию:

Стоит ли напоминать, что также присутствует легкая возможность создать более сложные правила контроля данных в коде, или же настроить существующие правила/объявить новые в метаданных приложения:

Узнать больше о возможностях контроля данных форм можно [из документации](http://documentation.devexpress.com/#Xaf/CustomDocument3009).
##### Изменения внешнего вида, видимости и доступности полей, а также других элементов управления в зависимости от бизнесс-правила
Эта функциональность предоставляется встроенным модулем [Conditional Appearance](http://documentation.devexpress.com/#Xaf/CustomDocument3286), который легко добавить в наш проект простым перетаскиванием из Visual Studio Toolbox, находясь в дизайнере модуля (показан на рисунке ниже) или дизайнере всего XAF приложения:

В результате, в проект будет добавлена ссылка на сборку модуля. После этого вы получите возможность использовать встроенный *AppearanceAttribute* для настройки стиля, доступности, видимости редакторов и заголовков полей, а также других элементов управления, типа команд меню «Сохранить», «Обновить» и пр.
Итак, начнем:
1. ###### Изменение стиля
```
[Appearance("MarkUnsafePasswordInRed", "Len(Password) < 6", FontColor = "Red")]
string Password { get; set; }
```
Это правило подстветит поле Password красным, если в нем будет меньше шести символов:

В реальном приложении, я думаю, такой подсветкой мало кого испугаешь, и наверное лучше опять же применить правило контроля данных вот с такой вот регуляркой: "^(?=.\*[a-zA-Z])(?=.\*\d).{6,}$".
Вы также можете менять цвет фона и настройки шрифта с помощью одноименных параметров атрибута.
Отдельно хотел отвлечься ~~«потрындеть»~~ на подсветку полей, так как по опыту она часто оказывается полезной не только для индикации состояния объекта (нормально/так себе/плохо), но и для подсказки правильной последовательности шагов на форме (“workflow”).
Так, например, в нашей внутренней системе отслеживания ошибок (кстати, написанной на XAF еще году в 2006) у меня настроено следующее правило, которое подсвечивает зелененьким обязательное поле Duplicate ID, тем самым визуально указывая мне верный путь после выставления статуса Duplicate у отчета об ошибке:
```
```
2. ###### Изменение доступности
```
[Appearance("ChangeManagerAvailabilityAgainstStaff", "Staff.Count = 0",
Enabled = false)]
IPerson Manager { get; set; }
```
Это правило сделает поле Manager недоступным, если коллекция Staff будет пуста:

3. ###### Изменения видимости
Если мы слегка поменяем предыдущее правило, то сможем контролировать видимость вместо доступности:
```
[Appearance("ChangeManagerAvailabilityAgainstStaff", "Staff.Count = 0",
Visibility = ViewItemVisibility.Hide)]
```

Перечисление ViewItemVisibility содержит следующие значения: Hide, Show, ShowEmptySpace. Hide не оставляет никакой «дырки» после себя, в то время как ShowEmptySpace буквально оставит «дырку» на форме (у наших пользователей были сценарии, когда это не так уж и плохо, ну или просто не все пользователи любят, когда на форме у них что-то двигается и перестраивается). Важно отметить, что если в контейнере полей на форме в результате скрытия ничего не окажется, то он и сам рекурсивно скроется.
Все эти правила будут также работать и в List View, неважно находится ли оно в режиме просмотра или редактирования (см. картинку из нашего демо приложения):
Опять же, вы можете задавать такие правила не только через атрибуты в коде, но и через метаданные приложения:

##### Изменение значения полей в зависимости от бизнес правила
Хотел привести пару примеров, как сделать поля на форме вычисляемыми. Для этого в Domain Components используется *CalculatedAttribute*, который принимает выражение для вычисления на нашем языке критериев. При этом, если поля из выражения хранятся в базе данных, выражение будет посчитано на сервере, а не на клиенте. Вот парочка примеров таких вычисляемых полей:
```
[Calculated("Concat(FirstName, ' ', LastName)")]
string FullName { get; }
[Calculated("Invoices[Status == 'Completed'].Sum(Amount)")]
decimal SaleAmount { get; }
```
Что-то более сложное уже можно запрограммировать без использования атрибутов.
#### Добавим огня...
По умолчанию большинство ПУЗов пересчитывается не моментально, а при уходе фокуса с редактора какого-либо изменившегося поля, т.е. когда значение из редактора поля попадает непосредственно в объект. Пересчет также часто может быть вызван какими-то внешним факторами или событиями, например сохранением, обновлением, сменой текущего объекта на форме и др. Такое поведение приемлемо во многих случаях, так как позволяет избежать лишнего «шума» на форме, не говоря уже о запросах на сервер. Тем не менее, есть ряд сценариев, где просто необходимо, чтобы наши ПУЗы были «порасторопнее». Для этого наш фреймворк предоставляет специальный атрибут — *ImmediatePostDataAttribute*, который, будучи примененным к полю бизнес сущности, вызывает событие изменения значения моментально, а не дожидаясь ухода фокуса с редактора этого поля.
К сожалению, бывали случаи, когда этот атрибут приносил и сомнительную пользу. Не могу не вспомнить индивидуумов, которые имели порядка 80-ти правил настройки внешнего вида полей на одной форме в купе с ImmediatePostDataAttribute (не знаю, правда, от большой ли это любви к атрибутам, то ли от странности исходных бизнес требований). Нам пришлось немного попотеть, чтобы производительность оставалась «на уровне», и форма не «умирала» от таких инсинуаций.
Дело в том, что при изменении значения одного из полей, сначала необходимо пересчитать всю эту сотню правил («брутфорс»-подход), а потом в лучшем случае поменять цвета и доступность полей, а в худшем многократно перестраивать структуру формы. Не сильно вдаваясь в детали нашей реализации, скажу, что нам удалось достигнуть поставленной цели в основном за счет «ленивого» создания редакторов полей, грамотного кэширования и смены состояния элемента формы, только если его текущее состояние отличается от нового, вычисленного по правилу. Наверное, в теории, можно было бы еще улучшить производительность путем исключения некоторых правил с помощью хитрой эвристики, которая бы разбирала критерий ПУЗа и применяла бы его, только если он реально зависит от измененного поля, брр…
#### Продолжение следует...
В следующих частях я надеюсь рассказать поподробнее о предназначении и возможностях метаданных приложения, определяющих как наши формы в конце концов будут выглядеть и вести себя. Также я думаю, что сообществу будет интересно побольше узнать про технологию Domain Components (все привыкли к классам, а тут какие-то интерфейсы вдруг появились непонятные), которую я использовал при создании бизнес сущностей. Если вкратце, эта технология была придумана нами для более гибкого и удобного создания повторно используемых библиотек бизнес сущностей. Пока, кому интересно, можно посмотреть [статью на Code Project](http://www.codeproject.com/Articles/231457/Using-Domain-Components-DC-in-XAF-DevExpress-Part) или [документацию на английском](http://documentation.devexpress.com/#Xaf/CustomDocument3261). | https://habr.com/ru/post/140323/ | null | ru | null |
# Книга «Python. Исчерпывающее руководство»
[](https://habr.com/ru/company/piter/blog/699502/)Привет, Хаброжители.
По плану у нас руководство по Python.
Разнообразие возможностей современного Python становится испытанием для разработчиков всех уровней. Как программисту на старте карьеры понять, с чего начать, чтобы это испытание не стало для него непосильным? Как опытному разработчику Python понять, эффективен или нет его стиль программирования? Как перейти от изучения отдельных возможностей к мышлению на Python на более глубоком уровне? «Python. Исчерпывающее руководство» отвечает на эти, а также на многие другие актуальные вопросы.
Эта книга делает акцент на основополагающих возможностях Python (3.6 и выше), а примеры кода демонстрируют «механику» языка и учат структурировать программы, чтобы их было проще читать, тестировать и отлаживать. Дэвид Бизли знакомит нас со своим уникальным взглядом на то, как на самом деле работает этот язык программирования.
Перед вами практическое руководство, в котором компактно изложены такие фундаментальные темы программирования, как абстракции данных, управление программной логикой, структура программ, функции, объекты и модули, лежащие в основе проектов Python любого масштаба.
5.16. ПЕРЕДАЧА АРГУМЕНТОВ ФУНКЦИЯМ ОБРАТНОГО ВЫЗОВА
---------------------------------------------------
Одна серьезная проблема с функциями обратного вызова связана с передачей аргументов передаваемой функции. Возьмем написанную ранее функцию after():
```
import time
def after(seconds, func):
time.sleep(seconds)
func()
```
В этом коде func() фиксируется для вызова без аргументов. Если вы захотите передать дополнительные аргументы, можно попытаться сделать так:
```
def add(x, y):
print(f'{x} + {y} -> {x+y}')
return x + y
after(10, add(2, 3)) # Ошибка: add() вызывается немедленно
```
Здесь функция add(2, 3) выполняется немедленно, возвращая 5. Потом after() вызывает ошибку, пытаясь выполнить 5(). Это определенно не то, чего вы ожидали. Но на первый взгляд нет очевидного способа заставить программу работать при вызове add() с нужными аргументами.
Это указывает на более масштабную проблему проектирования, связанную с использованием функций и функциональным программированием вообще, — композицию функций. Когда функции по-разному сочетаются, нужно думать, как соединяются их входные и выходные данные. Это не всегда просто.
В нашем случае одно из возможных решений основано на упаковке вычисления в функцию с нулем аргументов при помощи lambda:
```
after(10, lambda: add(2, 3))
```
Такие маленькие функции с нулем аргументов иногда называют преобразователями (thunk). Это выражение, которое будет вычислено позднее, когда будет вызвано как функция с нулем аргументов. Этот способ может стать приемом общего назначения, позволяющим отложить вычисление любого выражения на будущее. Поместите выражение в lambda и вызовите функцию, когда вам понадобится значение.
Вместо использования лямбда-функции можно воспользоваться вызовом functools.partial() для создания частично вычисленной функции:
```
from functools import partial
after(10, partial(add, 2, 3))
```
partial() создает вызываемый объект, один или несколько аргументов которого уже были заданы и кешированы. Это может быть удобным способом привести неподходящие функции в соответствие с ожидаемыми сигнатурами в обратных вызовах и других возможных применениях. Несколько примеров использования partial():
```
def func(a, b, c, d):
print(a, b, c, d)
f = partial(func, 1, 2) # Зафиксировать a=1, b=2
f(3, 4) # func(1, 2, 3, 4)
f(10, 20) # func(1, 2, 10, 20)
g = partial(func, 1, 2, d=4) # Зафиксировать a=1, b=2, d=4
g(3) # func(1, 2, 3, 4)
g(10) # func(1, 2, 10, 4)
```
partial() и lambda могут использоваться для похожих целей. Но между этими двумя решениями есть важные семантические различия. С partial() вычисление и связывание аргументов происходит при первом определении частичной функции. При использовании лямбда-функции с нулем аргументов вычисление и связывание аргументов выполняется во время фактического выполнения лямбда-функции (все вычисления откладываются):
```
>>> def func(x, y):
... return x + y
...
>>> a = 2
>>> b = 3
>>> f = lambda: func(a, b)
>>> g = partial(func, a, b)
>>> a = 10
>>> b = 20
>>> f() # Использует текущие значения a, b
30
>>> g() # Использует текущие значения a, b
5
>>>
```
Частичные выражения вычисляются полностью, поэтому вызов partial() создает объекты, способные сериализоваться в последовательности байтов, сохраняться в файлах и даже передаваться по сети (например, средствами модуля стандартной библиотеки pickle). С лямбда-функциями это невозможно. Поэтому в приложениях с передачей функций (возможно, с интерпретаторами Python, работающими в разных процессах или на разных компьютерах) решение c partial() оказывается более гибким.
Замечу, что применение частичных функций тесно связано с концепцией, называемой каррированием (currying). Это прием функционального программирования, где функция с несколькими аргументами выражается цепочкой вложенных функций с одним аргументом:
```
# Функция с тремя аргументами
def f(x, y, z):
return x + y + z
# Каррированная версия
def fc(x):
return lambda y: (lambda z: x + y + z)
# Пример использования
a = f(2, 3, 4) # Функция с тремя аргументами
b = fc(2)(3)(4) # Каррированная версия
```
Этот прием не относится к общепринятому стилю программирования Python, и причины для его практического применения встречаются редко. Но иногда слово «каррирование» мелькает в разговорах с программистами, которые провели много времени, разбираясь в таких вещах, как лямбда-счисление. Этот метод обработки нескольких аргументов был назван в честь знаменитого логика Хаскелла Карри. Полезно знать, что это такое, например, если вы столкнетесь с группой функциональных программистов, ожесточенно спорящих на каком-нибудь светском мероприятии.
Вернемся к исходной проблеме передачи аргументов. Другой вариант передачи аргументов функции обратного вызова основан на их передаче в отдельных аргументах внешней вызывающей функции. Рассмотрим следующую версию функции after():
```
def after(seconds, func, *args):
time.sleep(seconds)
func(*args)
after(10, add, 2, 3) # Вызывает add(2, 3) через 10 секунд
```
Заметьте, что передача ключевых аргументов func() не поддерживается. Это было сделано намеренно. Одна из проблем ключевых аргументов в том, что имена аргументов заданной функции могут конфликтовать с уже используемыми именами (то есть seconds и func). Ключевые аргументы могут быть зарезервированы для передачи параметров самой функции after():
```
def after(seconds, func, *args, debug=False):
time.sleep(seconds)
if debug:
print('About to call', func, args)
func(*args)
```
Но не все потеряно. Задать ключевые аргументы для func() можно при помощи partial():
```
after(10, partial(add, y=3), 2)
```
Если вы хотите, чтобы функция after() получала ключевые аргументы, безопасным решением может стать использование только позиционных аргументов:
```
def after(seconds, func, debug=False, /, *args, **kwargs):
time.sleep(seconds)
if debug:
print('About to call', func, args, kwargs)
func(*args, **kwargs)
after(10, add, 2, y=3)
```
Есть и другой настораживающий факт: after() представляет два разных вызова функций, объединенных вместе. Возможно, проблема передачи аргументов может быть решена декомпозицией на две функции:
```
def after(seconds, func, debug=False):
def call(*args, **kwargs):
time.sleep(seconds)
if debug:
print('About to call', func, args, kwargs)
func(*args, **kwargs)
return call
after(10, add)(2, y=3)
```
Теперь конфликты между аргументами after() и func полностью исключены. Но такие решения могут породить конфликты с вашими коллегами, которые будут читать ваш код.
5.17. ВОЗВРАЩЕНИЕ РЕЗУЛЬТАТОВ ИЗ ОБРАТНЫХ ВЫЗОВОВ
-------------------------------------------------
В прошлом разделе не упоминалась еще одна проблема: возвращение результатов вычислений. Рассмотрим измененную функцию after():
```
def after(seconds, func, *args):
time.sleep(seconds)
return func(*args)
```
Она работает, но есть неочевидные граничные случаи, возникающие из-за того, что в ней задействованы две разные функции: сама функция after() и переданный обратный вызов func.
Одна из сложностей связана с обработкой исключений. Опробуйте следующие два примера:
```
after("1", add, 2, 3) # Ошибка: TypeError (ожидается целое число)
after(1, add, "2", 3) # Ошибка: TypeError (конкатенация int
# со str невозможна)
```
В обоих случаях выдается ошибка TypeError, но по разным причинам и в разных функциях. Первая ошибка обусловлена проблемой в самой функции after(): функции time.sleep() передается неправильный аргумент. Вторая ошибка возникает из-за проблемы с выполнением функции обратного вызова func(\*args).
Есть несколько вариантов, чтобы различить эти два случая. В одном из них используются цепочки исключений. Идея в том, чтобы упаковать ошибки из обратного вызова особым способом, позволяющим обрабатывать их отдельно от других ошибок:
```
class CallbackError(Exception):
pass
def after(seconds, func, *args):
time.sleep(seconds)
try:
return func(*args)
except Exception as err:
raise CallbackError('Callback function failed') from err
```
Измененный код отделяет ошибки от переданного обратного вызова в отдельную категорию исключений. Он используется примерно так:
```
try:
r = after(delay, add, x, y)
except CallbackError as err:
print("It failed. Reason", err.__cause__)
```
При возникновении проблемы с выполнением самой функции after() это исключение будет распространяться наружу без перехвата. С другой стороны, проблемы, связанные с выполнением переданной функции обратного вызова, будут перехватываться, и программа будет сообщать о них исключением CallbackError.
Вся эта схема неочевидна. Но на практике обработка ошибок — достаточно сложная тема. Такой подход позволяет точнее управлять распределением ответственности и упрощает документирование поведения after(). Если с обратным вызовом возникают проблемы, программа всегда сообщает о ней в виде CallbackError.
Другой вариант — упаковка результата функции обратного вызова в экземпляр-результат, содержащий и значение, и ошибку. Например, класс можно определить так:
```
class Result:
def __init__(self, value=None, exc=None):
self._value = value
self._exc = exc
def result(self):
if self._exc:
raise self._exc
else:
return self._value
```
Далее используйте этот класс для возвращения результатов из функции after():
```
def after(seconds, func, *args):
time.sleep(seconds)
try:
return Result(value=func(*args))
except Exception as err:
return Result(exc=err)
# Пример использования:
r = after(1, add, 2, 3)
print(r.result()) # Выводит 5
s = after("1", add, 2, 3) # Немедленно выдает TypeError -
# недопустимый аргумент sleep().
t = after(1, add, "2", 3) # Возвращает "Result"
print(t.result()) # Выдает TypeError
```
Второй способ основан на выделении выдачи результата функции обратного вызова в отдельный шаг. При возникновении проблемы с after() о ней будет сообщено немедленно. Если возникнет проблема с обратным вызовом func(), уведомление о ней будет отправлено при попытке пользователя получить результат вызовом метода result().
Этот стиль упаковки результата в специальный экземпляр для распаковки в будущем все чаще встречается в современных языках программирования. Одна из причин в том, что он упрощает проверку типов. Если вам понадобится включить аннотацию типа в after(), ее поведение полностью определено — она всегда возвращает Result и ничего другого:
```
def after(seconds, func, *args) -> Result:
...
```
Этот паттерн еще не так часто встречается в коде Python, но он регулярно возникает при работе с примитивами синхронизации (потоками и процессами). Например, экземпляры Future ведут себя так при работе с пулами потоков:
```
from concurrent.futures import ThreadPoolExecutor
pool = ThreadPoolExecutor(16)
r = pool.submit(add, 2, 3) # Возвращает Future
print(r.result()) # Распаковывает результат Future
```
**Об авторе**
**Дэвид Бизли** — автор книг Python Essential Reference, 4-е издание (Addison-Wesley, 2010) и Python Cookbook, 3-е издание (O’Reilly, 2013). Сейчас ведет учебные курсы повышения квалификации в своей компании Dabeaz LLC ([www.dabeaz.com](http://www.dabeaz.com)). Он пишет на Python и преподает его с 1996 года.
Более подробно с книгой можно ознакомиться на [сайте издательства](https://www.piter.com/product/python-ischerpyvayuschee-rukovodstvo):
» [Оглавление](https://www.piter.com/product/python-ischerpyvayuschee-rukovodstvo#Oglavlenie-1)
» [Отрывок](https://www.piter.com/product/python-ischerpyvayuschee-rukovodstvo#Otryvok-1)
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.
Для Хаброжителей скидка 25% по купону — **Python** | https://habr.com/ru/post/699502/ | null | ru | null |
# 5 JavaScript-библиотек для работы со строками
Работа со строками может оказаться непростым делом из-за того, что она подразумевает решение множества разноплановых задач. Например, для простого приведения строки к «верблюжьему» стилю понадобится несколько строк кода:
```
function camelize(str) {
return str.replace(/(?:^\w|[A-Z]|\b\w|\s+)/g, function(match, index) {
if (+match === 0) re
turn ""; // или if (/\s+/.test(match)) для пробелов
return index === 0 ? match.toLowerCase() : match.toUpperCase();
});
}
```
Этот фрагмент кода, кстати, в роли ответа на [вопрос](https://stackoverflow.com/questions/2970525/converting-any-string-into-camel-case?answertab=votes#tab-top) о приведении строк к «верблюжьему» стилю, собрал больше всего голосов на Stack Overflow. Но даже он не в состоянии правильно обработать, например, такую строку:
```
---Foo---bAr---
```

*Результат обработки строки ---Foo---bAr---*
А как быть, если такие строки, всё же, нужно обрабатывать? Можно подправить этот пример, а можно прибегнуть к помощи специализированных библиотек. Они упрощают реализацию сложных алгоритмов и, кроме того, дают программисту инструменты, обладающие куда большей гибкостью и универсальностью, чем, скажем, вышеприведённый пример. Это вполне может означать, что для решения некоей непростой задачи понадобится вызвать всего один метод.
Поговорим о нескольких JavaScript-библиотеках, предназначенных для работы со строками.
1. String.js
------------
Библиотека `string.js`, или просто `S`, это маленькая (менее 5 Кб в минифицированном и сжатом виде) JavaScript-библиотека, которую можно использовать в браузере и в среде Node.js. Она даёт в распоряжение программиста большой набор методов для работы со строками. Это — методы объекта `string.js`, в состав которых, для удобства, включены и стандартные методы строк. Объект `string.js` — это нечто вроде обёртки для обычных строк.
### ▍Установка
Для того чтобы установить библиотеку `string.js`, достаточно воспользоваться следующей командой:
```
npm i string
```
### ▍Примечательные методы
#### Метод between
Метод `between(left, right)` извлекает из строки подстроку, содержащуюся между строками `left` и `right`. Например, этот метод можно использовать для извлечения элементов, находящихся между двумя HTML-тегами:
```
var S = require('string');
S('This is a link').between('', '').s
// 'This is a link'
```
#### Метод camelize
Метод `camelize()` удаляет из обрабатываемой строки пробелы, символы подчёркивания, тире, и приводит эту строку к «верблюжьему» стилю. Этот метод можно использовать для решения задачи, упомянутой в начале материала.
```
var S = require('string');
S('---Foo---bAr---').camelize().s;
//'fooBar'
```
#### Метод humanize
Метод `humanize()` приводит обрабатываемую строку к виду, удобному для чтения. Если бы нечто подобное нужно было бы реализовать с нуля, то потребовалось бы написать довольно много строк кода.
```
var S = require('string');
S(' capitalize dash-CamelCase_underscore trim ').humanize().s
//'Capitalize dash camel case underscore trim'
```
#### Метод stripPunctuation
Метод `stripPunctuation()` удаляет из строки знаки препинания и различные специальные символы вроде звёздочек и квадратных скобок. Если создавать подобную функцию самостоятельно — высок риск забыть о каком-нибудь символе, который она должна обрабатывать.
```
var S = require('string');
S('My, st[ring] *full* of %punct)').stripPunctuation().s;
//My string full of punct
```
→ [Здесь](https://github.com/jprichardson/string.js) можно найти более подробные сведения об этой библиотеке и о реализуемых ей методах
2. Voca
-------
JavaScript-библиотека `Voca` предлагает нам ценные функции, повышающие удобство работы со строками. Среди её возможностей можно отметить следующие:
* Изменение регистра символов.
* Удаление заданных символов, находящихся в начале и в конце сроки.
* Дополнение строки до заданной длины.
* Преобразование строки в строку, слова, имеющиеся в которой, разделены дефисами.
* Запись строки латиницей.
* Сборка строк по шаблонам.
* Обрезка строк до достижения ими заданной длины
* Экранирование специальных символов для HTML.
Модульный дизайн библиотеки позволяет, при необходимости, загружать не всю библиотеку, а отдельные функции. Это позволяет оптимизировать бандлы приложений, использующих эту библиотеку. Код библиотеки полностью протестирован, качественно документирован и хорошо поддерживается.
### ▍Установка
Для установки `Voca` выполните следующую команду:
```
npm i voca
```
### ▍Примечательные методы
#### Метод camelCase
Метод `camelCase()` преобразует переданную ему строку в строку, записанную в «верблюжьем» стиле.
```
var v = require('voca');
v.camelCase('foo Bar');
// => 'fooBar'
v.camelCase('FooBar');
// => 'fooBar'
v.camelCase('---Foo---bAr---');
// => 'fooBar'
```
#### Метод latinize
Метод `latinize()` возвращает результат преобразованию переданной ему строки в строку, записанную латиницей.
```
var v = require('voca');
v.latinise('cafe\u0301'); // or 'café'
// => 'cafe'
v.latinise('août décembre');
// => 'aout decembre'
v.latinise('как прекрасен этот мир');
// => 'kak prekrasen etot mir'
```
#### Метод isAlphaDigit
Метод `isAlphaDigit()` возвращает `true` в том случае, если в переданной ему строке содержатся только алфавитно-цифровые символы.
```
var v = require('voca');
v.isAlphaDigit('year2020');
// => true
v.isAlphaDigit('1448');
// => true
v.isAlphaDigit('40-20');
// => false
```
#### Метод countWords
Метод `countWords()` возвращает количество слов, имеющихся в переданной ему строке.
```
var v = require('voca');
v.countWords('gravity can cross dimensions');
// => 4
v.countWords('GravityCanCrossDimensions');
// => 4
v.countWords('Gravity - can cross dimensions!');
// => 4
```
#### Метод escapeRegExp
Метод `escapeRegExp()` возвращает строку, основанную на переданной ему строке, в которой экранированы специальные символы.
```
var v = require('voca');
v.escapeRegExp('(hours)[minutes]{seconds}');
// => '\(hours\)\[minutes\]\{seconds\}'
```
→ Подробности о библиотеке `Voca` можно узнать [здесь](https://vocajs.com/)
3. Anchorme.js
--------------
Это — компактная и быстрая JavaScript-библиотека, предназначенная для поиска URL и адресов электронной почты в тексте и для преобразования их в рабочие гиперссылки. Вот её основные характеристики:
* Высокая чувствительность, низкий процент ложноположительных срабатываний.
* Валидация ссылок и адресов электронной почты по полному списку IANA.
* Валидация номеров портов (при их наличии).
* Валидация IP-адресов (при их наличии).
* Поддержка URL, записанных символами, отличными от символов латиницы.
### ▍Установка
Для установки `anchorme.js` выполните следующую команду:
```
npm i anchorme
```
### ▍Использование
```
import anchorme from "anchorme";
//или
//var anchorme = require("anchorme").default;
const input = "some text with a link.com";
const resultA = anchorme(input);
//some text with a [link.com](http://link.com)
```
Процесс обработки строк поддаётся настройке с помощью объекта с параметрами, который можно передать библиотеке.
→ Подробности об `anchorme.js` можно узнать [здесь](http://alexcorvi.github.io/anchorme.js/)
4. Underscore.string
--------------------
Библиотека `underscore.string` — это расширение `underscore.js` для работы со строками, которое можно использовать и отдельно от `underscore.js`. На эту библиотеку повлияли идеи проектов `prototype.js`, `right.js` и `underscore.js`.
Эта библиотека даёт разработчику множество полезных функций, предназначенных для работы со строками. Вот некоторые из них:
* capitalize();
* clean();
* includes();
* count();
* escapeHTML();
* unescapeHTML();
* insert();
* splice();
* startsWith();
* endsWith();
* titleize();
* trim();
* truncate().
### ▍Установка
Вот команда, которой можно установить библиотеку:
```
npm i underscore.string
```
### ▍Примечательные методы
#### Метод numberFormat
Метод `numberFormat()` предназначен для форматирования чисел.
```
var _ = require("underscore.string");
_.numberFormat(1000, 3)
// "1,000.000"
_.numberFormat(123456789.123, 5, '.', ',');
// "123,456,789.12300"
```
#### Метод levenshtein
Метод `levenshtein()` возвращает расстояние Левенштейна между двумя строками. Подробнее об алгоритме, используемом в этом методе, можно прочитать [здесь](https://dzone.com/articles/the-levenshtein-algorithm-1).
```
var _ = require("underscore.string");
_.levenshtein('kitten', 'kittah');
// 2
```
#### Метод chop
Метод `chop()` разделяет переданную ему строку на части.
```
var _ = require("underscore.string");
_.chop('whitespace', 3);
// ['whi','tes','pac','e']
```
→ [Вот](http://gabceb.github.io/underscore.string.site/#chop) страница, на которой можно найти подробности о библиотеке `underscore.string`
5. Stringz
----------
Главная особенность библиотеки `stringz` заключается в том, что она умеет работать с Unicode-символами.
Если, без использования каких-либо библиотек, выполнить следующий код, то окажется, что длина строки составляет 2.

Всё дело в том, что метод JS-строк `length()` возвращает количество кодовых точек строки, а не количество символов. На самом деле, некоторые символы в диапазонах `010000–03FFFF` и `040000–10FFFF` могут использовать до 4 байт (32 бита) на кодовую точку, но это не меняет ответ: для того чтобы представить некоторые символы, нужно больше 2 байт, в результате они представлены более чем одной кодовой точкой.
→ [Вот](https://mathiasbynens.be/notes/javascript-unicode) материал о проблемах обработки Unicode-символов в JavaScript.
### ▍Установка
Для установки данной библиотеки нужна такая команда:
```
npm i stringz
```
### ▍Примечательные методы
#### Метод limit
Метод `limit()` приводит строку к заданной длине.

#### Метод toArray
Метод `toArray()` преобразует строку в массив.

→ [Вот](https://github.com/sallar/stringz) страница репозитория библиотеки
**А какие вспомогательные инструменты вы используете для работы со строками?**
> Напоминаем, что у нас продолжается [**конкурс прогнозов**](http://habr.com/ru/company/ruvds/blog/500508/?utm_source=habr&utm_medium=perevod&utm_campaign=5-javascript-bibliotek), в котором можно выиграть новенький iPhone. Еще есть время ворваться в него, и сделать максимально точный прогноз по злободневным величинам.
[](http://ruvds.com/ru-rub/?utm_source=habr&utm_medium=perevod&utm_campaign=5-javascript-bibliotek#order) | https://habr.com/ru/post/501632/ | null | ru | null |
# SSL pinning во Flutter
Для большинства мобильных приложений рано или поздно приходит время роллаута. И если к этому моменту вы ещё не позаботились хотя бы о минимальной защите от атак, то чем ближе будет подходить время массового запуска, тем острее будет стоять данный вопрос.
Для мобильных приложений, работающих с сервером и конфиденциальными данными, однозначно стоит позаботиться о безопасности своих пользователей от довольно популярной атаки — MITM.

MITM
====
Давайте разберёмся, что же это за атака. **Атака посредника**, или атака «**человек посередине**» (англ. *Man in the middle*) — вид атаки в криптографии и компьютерной безопасности, когда злоумышленник тайно ретранслирует и при необходимости изменяет связь между двумя сторонами, которые считают, что они непосредственно общаются друг с другом. Является методом компрометации канала связи, при котором взломщик, подключившись к каналу между контрагентами, осуществляет вмешательство в протокол передачи, удаляя или искажая информацию.
Изначально протокол Http является уязвимым для данного типа атаки и для исправления данной уязвимости была создана защищённая версия этого протокола Https. Он использует [SSL](https://developer.mozilla.org/ru/docs/Glossary/SSL) или [TLS](https://developer.mozilla.org/ru/docs/Glossary/TLS) для шифрования соединения между клиентом и сервером. Работают эти схемы следующим образом: в начале общения сервер посылает клиенту свой сертификат, чтобы клиент идентифицировал его. Данный сертификат стандарта X.509 является файлом, в котором содержится следующая информация:
* Название
* Публичный ключ
* Серийный номер
* Алгоритм сертификата
* Цифровая подпись
Идентификация проходит по нескольким пунктам:
1. Имя сервера должно совпадать с указанным в сертификате, иначе сертификат можно считать скомпрометированным.
2. Цепочку SSL сертификата можно проследить от личного SSL сертификата через промежуточные и до корневого сертификата доверенного центра сертификации.
Рассмотрим второй пункт более подробно.
Поскольку установка каждого сертификата отдельно была бы просто невозможна, ведь их огромное количество, работает следующая система управления сертификатами. Так как сертификаты являются фактически удостоверениями серверов, то они не появляются сами — их выпускают центры сертификации (Certificate Authority). Самыми важными являются сертификаты CA, их еще называют корневыми. CA являются общеизвестными, и их ключи являются доверенными по умолчанию. Они как правило встраиваются в операционную систему и обновляются при следующих обновлениях. Сертификаты работают по строгой иерархии. Сертификаты СА могут подписывать другие сертификаты, они в свою очередь подписывают сертификаты следующего уровня и так далее. В случае компрометации сертификата, он может быть отозван и вместе с ним автоматически отзываются все дочерние сертификаты.
Выглядит довольно надёжно, но что если пользователь сам скомпрометирует хранилище сертификатов в своей системе, установив в доверенные сертификат злоумышленника.
SSL-pinning
===========
**SSL-pinning** – привязка сертификата или публичного ключа сервера к клиенту. В случае с мобильным приложением, одним из эффективных способов является внедрение в приложение SSL сертификата, которому мы собираемся доверять. В данном случае мы игнорируем хранилище системы и сами определяем какому сертификату мы будем доверять. Этот способ может помочь нам при необходимости использовать самоподписанный сертификат, не утруждая конечного пользователя его установкой.
SSL-pinning в Dart
==================
Http запросы в Dart осуществляются при помощи класса *HttpClient*, точнее при помощи его приватной стандартной реализации. Каким будет подключение обычным или защищённым определяется исходя из схемы адреса к которому мы подключаемся.
*bool isSecure = (uri.scheme == «https»);*
В случае использования защищённого соединения, будет использован *SecureSocket*, который попытается установить защищённое соединение. При неудаче нас уведомят, что соединение использует скомпрометированный сертификат, если мы заранее зарегистрировали функцию обработки данной ситуации.
Регистрируется она с помощью поля *badCertificateCallback* у *HttpClient*.При помощи этой функции мы можем не только узнать, что сертификат скомпрометирован, но и обработать данный момент. Надо принять решение — продолжаем мы данный запрос или нет.
Если мы не станем добавлять обработчик, соединение будет разорвано при провале стадии проверки сертификата.
На что же опирается *SecureSocket* во время проверки сертификата? Стандартное поведение в данном случае — проверка с учётом тех сертификатов, которые зарегистрированы в системе. Как мы уже определили раньше, не самое лучшее решение для надёжной проверки. Нам необходима возможность проверки именно конкретного сертификата или цепочки сертификатов.
В реализации dart за это отвечает класс *SecurityContext*. Исходя из его описания мы узнаём, что он является объектом, хранящим сертификаты, которым доверяют при создании безопасного клиентского соединения, а также цепочку сертификатов и закрытый ключ для обслуживания с безопасного сервера. Этот объект можно передать *HttpClient*при создании, и в таком случае, клиент будет опираться в проверки именно на данные, хранящиеся в контексте, игнорируя доверяет или нет этим сертификатам система.
*SecurityContext* может создаваться через различные конструкторы и в зависимости от этого будет иметь разное содержание. Например, дефолтный конструктор создаст абсолютно пустой контекст, без зарегистрированных ключей.
Конструктор же *SecurityContext.defaultContext* создаст контекст, который содержит некоторые наборы доверенных сертификатов, в зависимости от системы. В случае Windows или Linux будут использованы сертифика хранилища Mozilla Firefox. В случае MacOS, iOS, Android будут зарегистрированы сертификаты, которым доверяет система.
Помимо этого контекст имеет методы для регистраций приватного ключа, доверенного сертификата и цепочки сертификатов.
Для регистрации доверенного сертификата предлагается использовать один из двух методов.
```
void setTrustedCertificates(String file, {String password});
```
Данный метод позволяет указать путь до сертификата.
```
void setTrustedCertificatesBytes(List certBytes, {String password});
```
Этот же метод использует для регистрации содержание сертификата в байтовом представлении.
Даже если не обращать внимание на предупреждение разработчиков:
> NB: This function calls [File.readAsBytesSync], and will block on file IO. Prefer using [setTrustedCertificatesBytes],
мне кажется более предпочтительным использование *setTrustedCertificatesBytes*. Причина довольно проста: если какой-то «нехороший человек» захочет навредить нам, ему для этого потребуется гораздо больше ресурсов. Если мы положим файл сертификата в обычном виде в ресурсы, при декомпиляции он сможет легко найти его и подменить. Да, он не сможет самостоятельно подписать пересобранное приложение, но никто не вредит пользователю с таким же усердием, как сам пользователь. Поэтому факт невозможности переподписать приложение теми же ключами, может не стать решающим фактором.
Что если мы зашьём байтовое представление ключа в виде кода в приложение?
Flutter при сборке приложения в release режиме использует AOT компиляцию, поэтому мы создадим довольно много проблем тому, кто захочет просто подменить сертификат, вскрыв приложение.
Практическая реализация SSL-pinning
===================================
Во-первых, для установки доверенного соединения вам потребуется сам файл сертификата, который использует сервер. Если вы по какой-то причине не можете обратиться к системным администраторам, или нет времени ждать пока вам его предоставят, можете довольно легко получить его с помощью браузера. В данном примере я разберу вариант с Google Chrome, но с таким же успехом можете сделать это в большинстве других браузеров.
Переходим по адресу, сертификат которого собираемся получить. Например [www.facebook.com](https://www.facebook.com/). Если соединение защищено, в адресной строке мы увидим изображение замка, при нажатии на который мы откроем информацию о соединении.
Нас интересует сертификат, переходим внутрь.
В открывшемся окне мы видим цепочку подписания сертификатов. Конечный сертификат и будет принадлежать данному ресурсу.
Перетащив сертификат в любую директорию на своём компьютере вы сохраните файл сертификата.
Другой способ получить тот же самый файл сертификата.
В инструментах разработчика переходим на вкладку Security. Нажатие на View Certificate открывает уже знакомое нам окно просмотра сертификата, откуда его мы сохраняем на компьютер.
Данный файл сертификата будет иметь суффикс .cer, одно из представлений файла сертификата. Один и тот же сертификат может быть представлен в различных форматах и от этого зависит способ кодирования данных о сертификате и тд. Если мы прочитаем документацию к методам добавления сертификатов в доверенные в *SecurityContext*, то узнаем, что нам нужен определённый формат сертификата — **PEM** или **PKCS12**.
Суффикс *.cer* для сертификата используется в нескольких форматах: PEM и DER. Один для нас подходящий, второй — нет. Чтобы определить, что перед нами находится, нужно открыть сертификат в текстовом редакторе и посмотреть на содержимое. Если видим, что текст кода в нём начинается с тега "----- BEGIN CERTIFICATE -----" и заканчивая тегом "----- END CERTIFICATE -----", то всё отлично. Если увидим, что просто открыли бинарный файл в текстовом виде, то перед нами DER.
В случае если формат не подходит, придётся конвертировать. Для конвертации можно воспользоваться любым из сервисов, я рассмотрю один из способов.
В командной строке на уровне, где находится файл сертификата выполняем команду:
*openssl x509 -inform der -in certificate.cer -out certificate.pem*
В которой certificate.cer имя сертификата, который конвертируется, а certificate.pem имя сертификата после конвертации.
Итак, у нас есть сертификат в нужном нам формате. Нам нужно прочитать его в виде байтов и сохранить это значение, чтобы в дальнейшем использовать в приложении. Для хранения этих данных вполне подойдёт List. Для удобства я написал небольшой скрипт, который считывает сертификат в виде набора байт и создаёт Dart файл с переменной, хранящей данное значение.
```
/// Util for byte list representation of certificate.
///
/// You should set certificate name in args.
/// Certificate should be in certs folder.
///
/// Call example:
/// dart main.dart cert.pem
///
/// Exit codes:
/// 0 - success
/// 1 - error
void main(List arguments) {
exitCode = 0;
final parser = ArgParser();
var args = parser.parse(arguments).arguments;
if (args.length < 1) {
exitCode = 1;
throw Exception('You should set certificate name.');
}
var fileName = args[0];
var certFile = File("certs/$fileName");
if (!certFile.existsSync()) {
exitCode = 1;
throw Exception('File certificate ${certFile.path} not found.');
}
String fileNameWithoutExt = basenameWithoutExtension(certFile.path);
var cert = certFile.readAsBytesSync();
var res = "List $fileNameWithoutExt = [${cert.join(', ')}];";
var resFile = File("res/$fileNameWithoutExt.dart");
if (!resFile.existsSync()) {
resFile.createSync(recursive: true);
}
resFile.writeAsString(res);
}
```
Теперь нам нужно лишь скопировать данный файл в проект. Использование в проекте будет довольно простым.
```
SecurityContext context = SecurityContext();
context.setTrustedCertificatesBytes(cert);
var http = new HttpClient(context: context);
http.badCertificateCallback =
(X509Certificate cert, String host, int port) {
print("!!!!Bad certificate");
return false;
};
await http
.openUrl("GET", Uri.parse(_url).normalizePath(),)
.timeout(Duration(milliseconds: 3000));
```
Если мы попытаемся обратиться по адресу, и сертификат предоставленный им при проверке будет не совпадать с тем, который мы зашили в приложение, будет выброшена ошибка *HandshakeException*.
Заключение
==========
Надеюсь, эта статья будет полезна при [разработке приложений](https://surf.ru/flutter/) и поможет лучше защитить ваших пользователей от данного типа атак.
Спасибо, за внимание!
*Используемые материалы:*
[Атака посредника](https://ru.wikipedia.org/wiki/%D0%90%D1%82%D0%B0%D0%BA%D0%B0_%D0%BF%D0%BE%D1%81%D1%80%D0%B5%D0%B4%D0%BD%D0%B8%D0%BA%D0%B0)
[Формат SSL сертификата: как конвертировать сертификат в .PEM, .CER, .CRT, .DER, PKCS ИЛИ PFX?](https://www.emaro-ssl.ru/blog/convert-ssl-certificate-formats/)
[MDN](https://developer.mozilla.org/ru/) | https://habr.com/ru/post/504914/ | null | ru | null |
# Инструменты кросскомпиляции для ARM
В сети есть достаточно много источников на тему сборки приложений под архитектуру ARM, но когда я впервые столкнулся с такой задачей, то набил не одну шишку. Этот топик будет про самые начала кросскомпиляции и различные подходы к этому вопросу.
Моё устройство принадлежит к архитектуре ARMv5TE и разработка велась на x86 машине с Ubuntu Linux.
Так как это введение, то собирать будем простую [программу](http://pastebin.com/zehNSssR) для высчитывания факториала числа.
*Подход 1. Коммерческий.*
Компанией CodeSourcery выпускается коммерческая интегрированная среду разработки Sourcery G++, основанная на инструментах GNU (gcc, gdb, binutils) и имеющая интерфейс на базе Eclipse. Пожалуй, это самый простой и быстрый способ создания приложений, так как при установке ставятся и все необходимые библиотеки, и сам кросскомпилятор. На официальном [сайте](http://www.codesourcery.com/sgpp) кроме возможности покупки можно воспользоваться триальной версией на 30 дней. Благодаря близкому «родству» с Eclipse настройки интуитивно понятны и писать подробно нет смысла.
Для разовых задач подходит идеально, но есть и абсолютно бесплатные решения.
*Подход 2. QEMU.*
Широко известная программа эмуляции [QEMU](http://ru.wikipedia.org/wiki/QEMU) поддерживает в том числе и ARM платформу, чем грех не воспользоваться.
Для начала устанавливаем саму программу:
`sudo apt-get install qemu-kvm-extras-static`
Разработчики QEMU сделали отдельную команду для простоты установки окружения (в моём случае это debian lenny):
`sudo build-arm-chroot lenny qemu`
В результате у нас создастся каталог qemu с образом системы lenny под нужную нам архитектуру.
Не хватает сети и необходимых пакетов для компиляции. Отредактируем sources.list нашей qemu-машины:
`sudo nano qemu/etc/apt/sources.list`
И добавим туда
`deb ftp.us.debian.org/debian lenny main contrib non-free
deb-src ftp.us.debian.org/debian lenny main contrib non-free`
Обновляемся, устанавливаем необходимые пакеты и в самой QEMU собираем наш factorial.
*Подход 3. Собираем crosstool.*
Crosstool — это набор скриптов для сборки и проверки работы gcc и glibc для всех архитектур, поддерживаемых glibc. При сборке различных кросстулов ([так](http://kegel.com/crosstool/) или [так](http://ymorin.is-a-geek.org/projects/crosstool)) у меня возникали проблемы с совместимостью различных компонентов. Так, например, gcc не дружил с binutils из-за разницы в версиях и приходилось чуть ли не методом тыка подбирать работающие связки. К счастью, и этот процесс уже был автоматизирован и сделан предельно простым. За что спасибо пользователю сайта linux.org.ru [mskmsk1985](http://www.linux.org.ru/people/mskmsk1985/profile):
Написанный им [скрипт](http://www.antario.org.ru/downloads/build-toolchain) собирает тулчейн для arm-linux-gnueabi- архитектуры из последних версий GNU инструментов. Собираются С и С++ кросс компиляторы, кросс-отладчик и отладочный сервер для целевой архитектуры. Подробнее можно прочитать [тут](http://www.linux.org.ru/forum/development/5519881).
*Подход 4. Gentoo-way.*
Как и писал, собиралось это всё на компьютере с Ubuntu, но стоит всё же сказать, что в Gentoo есть отдельная программа [crossdev](http://en.gentoo-wiki.com/wiki/Crossdev), которая занимается тем же самым и собирает бинарники для нужной архитектуры.
*Подход 5. Ubuntu-way.*
Мои долгие поиски наиболее простого способа кросскомпиляции шли весьма запутанно и, конечно же, я пропустил решение, которое было слишком очевидным и простым чтобы даже об этом думать. Но оказалось что да, кросскомпилятор можно поставить из репозиториев и одной командой:
`sudo apt-get install libc6-dev-armel-cross gcc-arm-linux-gnueabi`
*Вместо заключения.*
Способы кросскомпиляции не ограничиваются приведенными выше примерами. Существуют многостраничные описания, варианты создания необходимых инструментов 'from scratch', но если нужно быстро написать и запустить простенькое приложение на другой архитектуре, часто не хватает времени для полного изучения, да и количество нюансов и программных несовместимостей могут отбить любое желание заниматься этим.
Надеюсь, мой небольшой обзор поможет вам избежать моих ошибок и быстро получить работающий инструмент для создания приложение на ARM-архитектуре. Удачи! | https://habr.com/ru/post/114230/ | null | ru | null |
# В Сафари сломалось время
Будьте осторожны — сегодня в Сафари сломалась установка кук, видимо в связи с переходом на летнее время. Период жизни кук сокращается ровно на час, а меньше чем на час куки вообще не сохраняются.
Test case:
Проверено в Safari 4 Public Beta (528.16) под Windows. | https://habr.com/ru/post/55828/ | null | ru | null |
# CoffeeScript в деле — Пять вещей, которые можно сделать и с JavaScript
**От переводчика**: В статье есть несколько JavaScript нюансов, которые могут быть интересны и тем, кто далек от CoffeeScript
Как и все программисты, я осторожен в отношение [CoffeeScript](http://en.wikipedia.org/wiki/CoffeeScript). Как может, немного синтаксического сахара, оправдать дополнительный шаг компиляции?
Но, после того как я поиграл с CoffeeScript, всего несколько дней, я понял, я никогда не вернусь назад. Синтаксический сахар — это только начало. Я стал писать код быстрее, и с меньшим количеством ошибок, потому что он, стал намного *чище*. CoffeeScript помогает придерживаться хорошего стиля в написание кода. Ниже я приведу несколько примеров на Javascript и опишу их более изящное решение с помощью CoffeeScript.
### 1. Объявление переменных
Многие новички считают, что **var x** означает: «Я объявил переменную с именем Х». На самом деле, **var**, лишь предотвращает Х от роуминга за пределы текущей области. Если вы напишете:
`x = 'Hello from the JavaScript Nation!';`
и не будете использовать **var**, тогда **X** автоматически станет глобальной. Сделайте подобную ошибку в двух частях вашего приложения, и одна глобальная переменная будет перекрывать другую, создавая ошибку.
Даже опытные профи часто делают подобную ошибку, особенно когда объявляют переменные сцеплением: **var a = 1, b = 2** и присваивают новое значение в пределах окружения, тогда как **var a = 1; b = 2** присваивает значение, глобальной переменной **b**.
**От переводчика**: Для тех, кто сомневается, что может перепутать "," и ";" приведу другой пример: **var a = b = 3**
#### Путь CoffeeScript
С CoffeeScript, все переменные, автоматически попадают в текущее окружение. Когда вы пишете:
`x = 'Welcome to CoffeeScriptville!'`
вы можете быть уверены, что не переопределили какую нибудь глобальную переменную. Мало того, благодаря CoffeeScript компилятору, **Х** автоматические ограничивается текущим файлом.
### 2. Другой **this**
Один из самых распространенных источников путаници в JavaScript, ключевое слово **this**. Вы делаете простой вызов:
````
tinman.prototype.loadBrain = function() {
this.brain = 'loading...';
$.get('ajax/brain', function(data) { this.brain = data; });
};
````
но получаете ошибку, потому что, внутри вызова данных, **this** указывает не на тот же объект, на который он указывал, за ее пределами.
#### Путь CoffeeScript
Во-первых, ключевое слово **this**, имеет псевдоним @, для того, что бы было визуальное отличие от обычных переменных.
Во-вторых, для того, что бы передать переменные @ в связанную функцию, необходимо использовать => (жирная стрелка), в отличие от обычного символа ->, объявляющего функцию:
````
tinman::loadBrain = ->
@brain = 'loading...'
$.get 'ajax/brain', (data) =>
@brain = data
````
### 3. Сокращенные условия
Тернарный оператор, занимает особое место в JavaScript: В отличие от других условных структур (**if**, **switch**), он возвращает результат. Это означает, что программисту приходится выбирать, между краткостью тернарного оператора:
````
closestEdge = x > width / 2 ? 'right' : x < width / 2 ? 'left' : 'center';
````
или логической цепочкой:
````
if (x > width / 2) {
closestEdge = 'right';
} else if (x < width / 2) {
closestEdge = 'left';
} else {
closestEdge = 'center';
}
````
#### Путь CoffeeScript
Все условия в CoffeeScript, возвращают результат. Это дает нам ясный второй подход, без бессмысленного повторения:
````
closestEdge =
if x > width / 2
'right'
else if x < width / 2
'left'
else
'center'
````
### 4. Асинхронный функционал
Популярный тест «Так ли хорошо вы знаете JavaScript» содержит задачу:
````
for (var i = 1; i <= 3; i++) {
setTimeout(function() { console.log(i); }, 0);
}
````
результат будет:
`4
4
4`
Почему? Даже если в setTimeout таймаут равен 0, данная функция заработает только после завершения цикла. И когда функция выполнится, i будет равно 4-ом. Для того, что бы захватить каждое значение i, вам придется выполнить:
````
for (var i = 1; i <= 3; i++) {
(function(i) {
setTimeout(function() { console.log(i); }, 0);
})(i);
}
````
#### Путь CoffeeScript
Хотя, CoffeeScript не захватывает автоматически переменные в цикле, он дает возможность сделать краткий захват:
````
for i in [1..3]
do (i) ->
setTimeout (-> console.log i), 0
````
результат будет:
`1
2
3`
### 5. Повторение, повторение
Код говорит сам за себя:
````
x = sprite.x;
y = sprite.y;
css = {
opacity: opacity,
fontFamily: fontFamily
};
function(request) {
body = request.body;
status = request.status;
// ...
}
````
#### Путь CoffeeScript
Каждый фрагмент выше, превращается в одну строчку:
````
{x, y} = sprite
css = {opacity, fontFamily}
({body, status}) -> ...
````
### Заключение
CoffeeScript это не только более красивый код, речь идет о более гибком коде. Речь идет, о большей уверенности, что вы сделаете правильный код с первого раза, и легко изменените его в будущем.
Если вам по душе шаблоны проектирования и быстрой интерации, вы должны дать CoffeeScript шанс. Даже, если в последствие вы решите, что это не для вас, вы в любом случае начнете лучше понимать JavaScript.
(Конечно, если вы обновитесь до Rails 3.1, у вас [не будет](http://doihavetousecoffeescriptinrails.com/) выбора)
**От переводчика**: Что бы не вводить никого в заблуждение, скажу, это шутка! Выбор конечно есть, достаточно убрать строчку из Gemfile.
**От переводчика**: Поздравляю всех RoR разработчиков с выходом [Rails 3.1 beta 1](http://weblog.rubyonrails.org/2011/5/5/rails-3-1-beta-1-released). Все не точности в переводе, прошу слать в ЛС. | https://habr.com/ru/post/118721/ | null | ru | null |
# .NET и работа с неуправляемым кодом. Часть 1
**.NET и работа с неуправляемым кодом. Часть 1**
.NET и работа с неуправляемым кодом
Сегодня я хочу показать один из способов работы с неуправляемым кодом, посредством специального класса Marshal. Большинство методов, определенных в этом классе, обычно используются разработчиками, которым нужно обеспечить сопряжение между моделями управляемого и неуправляемого программирования.
Маршалинг взаимодействия определяет, какие данные передаются в аргументах и возвращаемых значений методов между управляемой и неуправляемой памятью во время вызова. Маршалинг взаимодействия — это процесс времени выполнения, выполняемый службой маршалинга среды CLR.
Мне не хотелось бы полностью описывать всю структуру взаимодействия, т.к. это заняло бы значительную часть статьи. В этой статье я опишу принцип взаимодействия на конкретных примерах, опишу способы выделения и очистки выделенной памяти.
Для начала возьмём пример небольшой структуры, описанной в C и посмотрим, как сделать аналогичную структуру для C#.
**Код на C**
> `struct test
>
> {
>
> struct innerstr
>
> {
>
> char str[300];
>
> int Int;
>
> int\* in\_pInt;
>
> } in;
>
> char str[2][50];
>
> int IntArr[10];
>
> int\* pInt;
>
> innerstr\* pStruct;
>
> int\* ptr;
>
> };
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
**Код на C#**
> `[StructLayout(LayoutKind.Sequential)]
>
> public struct Test
>
> {
>
> public Innerstr \_in;
>
> [MarshalAs(UnmanagedType.ByValArray, SizeConst = 50 \* 2)]
>
> public char[] str;;
>
> [MarshalAs(UnmanagedType.ByValArray, SizeConst = 10)]
>
> public int[] IntArr;
>
> public IntPtr pInt;
>
> public IntPtr pStruct;
>
> public IntPtr ptr;
>
>
>
> [StructLayout(LayoutKind.Sequential)]
>
> public struct Innerstr
>
> {
>
> [MarshalAs(UnmanagedType.ByValTStr, SizeConst = 300)]
>
> internal string str;
>
> public int \_Int;
>
> public IntPtr in\_pInt;
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Как можете заметить, все указатели из C были заменения на тип IntPtr из C#. Двумерные массивы — на одномерные, аналогичной длины. А сама структура подписана аттрибутом [StructLayout]. Значение LayoutKind параметра Sequential используется для принудительного последовательного размещения членов в порядке их появления.
Для массивов необходимо указать их тип как UnmanagedType.ByValArray и сразу же указать их точный размер. Даже если размер самой переменной будет отличаться — при передаче, он автоматически будет уравнен в необходимый размер.
**Вызов неуправляемого кода**
Код на C
> `extern "C" \_\_declspec(dllexport) int ExpFunc(test\* s, bool message)
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Код на C#:
> `[return:MarshalAs(UnmanagedType.I4)]
>
> [DllImport("TestTkzDLL.dll")]
>
> public static extern int ExpFunc([In, Out] IntPtr c, [In]bool message);
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Как вы наверное заметили, перед вызово необходимо сначало объявить все IntPtr. Для этого необходимо использовать примерно следующий код:
> `Test test = new Test();
>
>
>
> ...
>
>
>
> // для получения указателя на => int\* pInt
>
> int \_pInt = 2010; // значение числа
>
> IntPtr \_pInt\_buffer = Marshal.AllocCoTaskMem(Marshal.SizeOf(\_pInt)); // выделили кусочек памяти
>
> Marshal.StructureToPtr(\_pInt, \_pInt\_buffer, false); // записали содержимое
>
> test.pInt = \_pInt\_buffer; // сохранили
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
По аналогии, и для innerstr\* pStruct, и для всех остальных указателей.
> `Test.Innerstr inner2 = new Test.Innerstr();
>
> IntPtr \_pStruct\_buffer = Marshal.AllocCoTaskMem(Marshal.SizeOf(inner2));
>
> Marshal.StructureToPtr(inner2, \_pStruct\_buffer, false);
>
> test.pStruct = \_pStruct\_buffer;
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Вот и всё, всё просто. Теперь осталось из кода вызвать метод
> `///////////////////////////////////////`
>
>
В данном случае я перенес всю структуру в неуправляемую память, а затем передал ссылку на этот кусок, который затем в C был прочитан. Этого можно не делать, если передавать по ref, но я столкнулся с тем, что огромные структуры ref просто не мог перенести в неуправляемую память, а способ передавать ссылку работает всегда
Затем не забудьте почистить память. В отличие от управляемого кода, сборщик мусора не может чистить неуправляемый. Поэтому необходимо вызвать `Marshal.FreeCoTaskMem(ptr);` для всех ссылок IntPtr
PS: добавлено позже… аттрибут [StructLayout(LayoutKind.Sequential)], также может указывать на используемую таблицу символов, ANSI или UNICODE. Для этого необходимо написать [StructLayout(LayoutKind.Sequential, CharSet = CharSet.Ansi)], [StructLayout(LayoutKind.Sequential, CharSet = CharSet.Unicode)] или [StructLayout(LayoutKind.Sequential, CharSet = CharSet.Auto)]. По-умолчанию используется ANSI.
---
Ну вот и всё, на это первая часть статьи завершается. В следующей части я опишу, каким образом возможно использовать динамический размер массивом, как можно быстро преобразовать многомерные массивы в одномерные и наоборот, чтобы передавать в неуправляемый код, как организовать удобную для программиста структуру для прозрачной работы с маршалингом и некоторые другие
**Обновлено**
Добавлены исходники тестового проекта. [Скачать](http://cid-ab57b530becd4687.skydrive.live.com/self.aspx/.Public/TestMarshaling.zip) | https://habr.com/ru/post/84076/ | null | ru | null |
# Task framework
### О фреймворке
Task framework основан на MVC парадигме с удобством использования и минимум функционала для решения простых задач.
В отличие от стандартных решений вместо контроллера тут используется задача (task)
Cсылка на фреймворк, который также использует task.
[jsock-framework-tutorial.blogspot.com](https://jsock-framework-tutorial.blogspot.com/)
[java-framework-jsocket.blogspot.com](https://java-framework-jsocket.blogspot.com/)
[github.com/nnpa/jsock](https://github.com/nnpa/jsock)
#### Установка фреймворка task
1. [Скачайте архив с фреймворком](https://yadi.sk/d/XmXpeoI909FM-w)
2. Распакуйте в папку task в директорию где у вас хранятся сайты.
3. [Скачайте каркас для приложения](https://yadi.sk/d/aPGHvD_dN6lslA)
4. Распакуйте в папку site в в директорию где у вас хранятся сайты.
5. Создайте базу данных в mysql.
6. [Скачайте таблицу users](https://yadi.sk/d/_Y2oVSKYiZWGDQ) и экспортируйте в созданную базу данных.
Должно получится такое дерево каталогов
```
/webroot/task
/webroot/site
```
7. Настройте веб сервер что бы корневая папка /webroot/site была привязана к определенному хосту при помощи веб сервера который вы используете.
8. Зайдите в папку config и откройте config.php и отредактируйте массив подключения к базе данных на ваши значения подключения и переменную host.
#### MVC парадигма
Task framework использует [MVC парадигму](https://ru.wikipedia.org/wiki/Model-View-Controller) для лучшего разделения логики шаблонов представлений, моделей и контроллера.
Вместо контроллера в Task framework используются задачи Task — задачи расположены в папке tasks и предназначены для выполнения логики приложения.
Модели хранятся в папке models и предназначены для работы с логикой базы данных.
Представления хранятся в папке view и предназначены для работы с логикой представления.
#### Task
Task (или Controller) располагаются в папке tasks.
Task создаются по переменной в url сайта request:
Если переменная request = test то будет создан экземпляр класса Task который хранится в папке tasks в файле test.php и называется test.
```
index.php?request=test
```
Пример класса test.php:
```
include_once('WebTask.php');
class Test extends WebTask{
public function run(){
//логика приложения
}
}
```
Обязательно task должен быть унаследован от WebTask и в нем должен быть создан метод run()
#### Models
Models располагаются в папке models и отвечают за логику работы с базой данных.
Модели привычнее всего создавать в tasks.
Модель должна быть создана в папке models и быть унаследована от Model так же должно быть прописано поле $table\_name.
Пример класса models/users.php:
```
class Users extends Model{
public $table_name = 'users';
}
```
В классе Model заранее реализован набор методов для работы с базой данных.
**findBySql**
```
$users = new Users();
$users->findBySql("SELECT * FROM `users`");
foreach($users as $user) {
echo $user['email'] . "
";
}
``` | https://habr.com/ru/post/523828/ | null | ru | null |
# .NET в целом: обзор от Скотта Хансельмана
Скотт Хансельман — ключевой человек для .NET-сообщества: например, на конференции Microsoft Build он ведёт презентацию для разработчиков, а у его микроблога в Twitter около 250 000 подписчиков.
При этом в мире .NET он очень давно. Ещё в 2003-м преподавал C#, то есть был глубоко погружён в тему практически с её появления. А последние 13 лет работает в Microsoft, наблюдая за всем изнутри и общаясь с разработчиками из других компаний.
Поэтому ему хорошо видна общая картина: он лично наблюдал, как эта экосистема развивалась со временем, и знает, как она используется разными разработчиками для разных целей. И этим летом на нашей конференции **[DotNext](https://dotnext-moscow.ru/?utm_source=habr&utm_medium=526554)** он выступил с докладом, посвящённым не каким-то конкретным деталям, а как раз общему обзору .NET — от прошлого до будущего. А мы решили сделать для Хабра текстовую расшифровку, чтобы стало можно не только [посмотреть доклад](https://youtu.be/lhugRATRB2E) на английском, но и прочитать на русском.
.NET сейчас
-----------
Название доклада менялось несколько раз. Вначале он назывался «Прошлое и будущее .NET», потом «.NET 5», потом «Будущее .NET», потом «Куда идёт .NET». На самом деле, формулировка не так уж важна, основная мысль следующая: .NET стал платформой, на которой можно создать всё, что угодно. Приложения для ASP.NET, веб-приложения, приложения для консолей, десктопные приложения, огромные облачные приложения, приложения для iPhone, Android, Apple Watch. Множество игр создано при помощью C# и Unity, и они основаны на .NET. У меня .NET также запущен на Raspberry Pi. Наконец, в последнее время .NET стали также использовать в области ИИ и машинного обучения. Благодаря этому многообразию с .NET сегодня сложилась интересная ситуация.
Предположим, вы устроились на работу программистом ASP.NET, работаете в основном с веб-приложениями и воспринимаете себя как веб-программиста. Если вас кто-то спросит, кем вы работаете, вы ответите — веб-программистом. Но на самом деле было бы правильнее сказать — .NET-программистом, или C#-программистом. Если занимаетесь веб-программированием на .NET, то вполне можете попробовать поднять .NET на Raspberry Pi, и я рекомендую это попробовать. Если вы всю жизнь писали приложения Windows Forms, ничто не мешает вам попробовать написать игру.

.NET сейчас очень активно развивается, что наглядно демонстрирует статистика на слайде. Как видим, C# сейчас входит в 5 наиболее популярных языков на GitHub. На .NET и ASP.NET выполняется очень большой объём работы, то есть происходит много коммитов, много людей участвует в опенсорсных проектах. Интересно, что около 40% новых пользователей .NET — учащиеся. Я очень рад тому, что люди знакомятся с этой платформой в университетах и в школах. А вот другой важный и, возможно, неожиданный показатель развития .NET: в Visual Studio в общей сложности было выполнено более 1 миллиона публикаций на Linux. Работу с .NET на Linux мы ещё обсудим позднее, я расскажу о том, как я портировал свой сайт. У .NET в ближайшем будущем появится новая версия, но .NET 3 тоже вполне хороша, и её будут поддерживать ещё многие годы. Сейчас я рекомендую пользоваться именно ей. Кстати говоря, Stack Overflow недавно перешёл на .NET Core 3.1.
.NET-код
--------
Давайте теперь посмотрим на .NET-код, и для этого откроем командную строку. Конечно, я мог бы показать вам код в Visual Studio, но мне нравится работать именно через командную строку. Это всё равно, что копаться под капотом автомобиля: значительно лучше видно, как он устроен. Итак, я создаю папку `myweirddemo` и ввожу в ней команду `dotnet new`. В результате на экран выводится список возможных шаблонов и их краткие имена. По большому счёту, это то же самое, что команда File — New Project в Visual Studio. Самое интересное, что здесь можно добавлять свои шаблоны, то есть если я создам опенсорсный проект scott, можно будет ввести команду `dotnet new scott`. Изначально в `dotnet new` доступны WPF, Windows Forms, специальный проект для Worker, четыре различных плагина для тестирования, а также множество других шаблонов.
Попробуем ввести команду `dotnet new console`, а затем откроем текст созданной таким образом программы в блокноте.

Добавим там команду `Console.ReadLine()`.

Её исполнение будет приостанавливать исполнение программы. Попробуем вначале запустить программу без этой новой команды. Как видим, вывод простого Hello world занимает у нас 2–3 секунды. Давайте разберёмся, почему так долго. Взглянем на содержимое нашей папки с демкой (команда `dir`): как видим, в ней есть папка `bin`. Нас будет интересовать исполняемый файл `bin\Debug\net5.0\myweirddemo.exe`. Если мы запустим его, то Hello world будет выведено практически мгновенно. То есть команда `dotnet run` явно делает что-то ещё помимо исполнения собственно файла программы. Интересно, что в папке с исполняемым файлом также лежит библиотека myweirddemo.dll. Если выполнить `dotnet .\myweirddemo.dll`, то мы снова увидим на экране Hello world. Это значит, что программа на самом деле находится в этой библиотеке, а exe-файл сделан исключительно для вашего удобства и спокойствия. В прошлых версиях .NET exe-файл появлялся только после выполнения команды publish.
Итак, вернёмся к `dotnet run`. Почему исполнение этой команды занимает больше секунды для такой простой программы? Дело в том, что она вначале вызывает `dotnet restore`, затем `dotnet build` и лишь затем обращается к dll-файлу программы. Давайте теперь попробуем выполнить нашу программу с добавленной командой `.ReadLine()`. Как и ожидалось, программа выводит на экран Hello world, а затем приостанавливает выполнение в ожидании дополнительных команд. Пока она ожидает, откроем Process Explorer — это продвинутый вариант Task Manager, который можно скачать на Sysinternals.

Мы видим дерево запущенных процессов, в котором можно найти процесс нашей команды.
Оговорюсь, что для работы с .NET вовсе не обязательно знать всю ту подноготную, которую мы с вами сейчас исследуем. Но, на мой взгляд, всегда полезно понимать, как работает устройство, которым вы пользуетесь. Чтобы вызвать такси, вовсе не обязательно знать, как устроен автомобиль, но это знание может оказаться полезным, если автомобиль сломается.
Итак, мы видим, что работающий сейчас процесс .NET расположен в `C:\Program Files\dotnet\dotnet.exe`.

Перейдём к его местоположению в командной строке. Обратите внимание, что для перехода к другому каталогу я пользуюсь командой `z`, а не `cd`, она значительно удобнее, поскольку не требует вводить имя каталога целиком. Далее, выполним команду `start .`, это откроет Explorer, и мы увидим содержимое папки `C:\Program Files\dotnet\sdk`. Здесь будет необходимо небольшое отступление. Прошлые версии .NET работали только под Windows, не были опенсорсными и не поддерживали параллельное выполнение.
Версии .NET
-----------
Существовало несколько различных .NET: просто .NET для приложений Windows, Xamarin для мобильных приложений, и кросс-платформенный .NET Core. Поскольку .NET не поддерживал параллельное выполнение, при переходе на более позднюю версию .NET работа приложения, использующего .NET, могла быть нарушена. Xamarin был основан на Mono, это написанная с нуля опенсорсная версия .NET, причём у её создателей не было доступа к исходникам .NET. Мы ещё о ней поговорим чуть позже. А .NET Core была создана специально для обеспечения микросервисов, она заточена под максимальное быстродействие бэкенда.
Ситуация, когда было три различных варианта .NET, была терпимой, но то, к чему мы переходим сейчас — однозначно шаг вперёд. Давайте разберёмся, как устроена новая система версий .NET. В нашей папке `sdk` несколько различных версий .NET.
У меня установлена ознакомительная версия .NET 5.0, а также несколько версий .NET 2 и 3, в том числе 3.1 — версия с долгосрочной поддержкой. Вернёмся в папку нашей демки и введём команду `dotnet --version`.
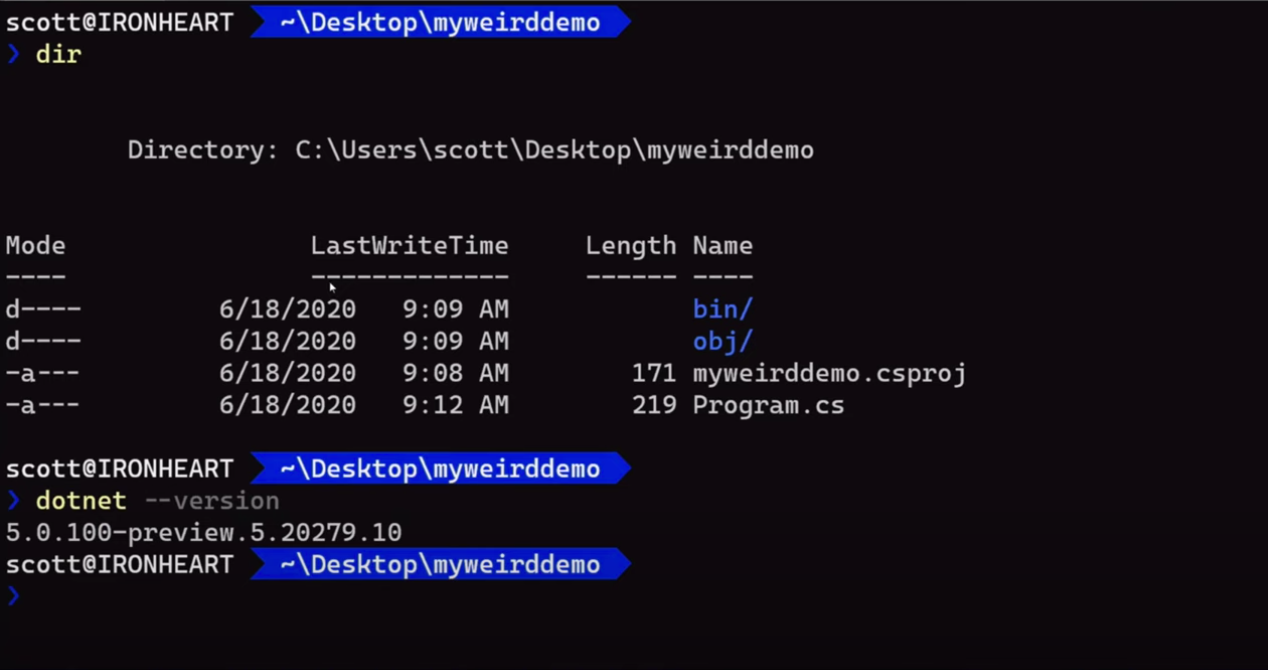
Мы увидим, что сейчас мы используем .NET 5. Если мы теперь создадим новую папку для другого проекта, `myweirddemo2`, и проверим версию, мы, как и следует ожидать, снова увидим .NET 5.
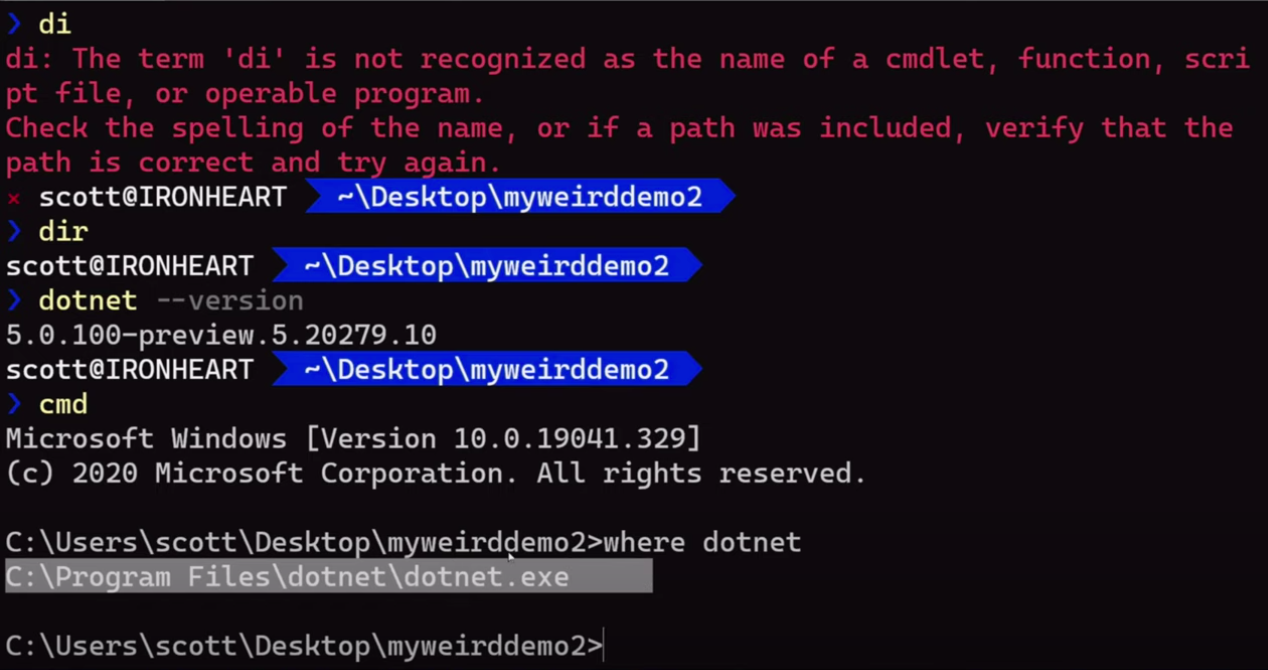
Взгляните на путь к выполняемому файлу: `C:\Program Files\dotnet\dotnet.exe`. В этом пути никак не указана версия .NET. Теперь выполним `dotnet new globaljson`. Будет создан файл, который мы откроем в блокноте, и поменяем номер используемой версии .NET.
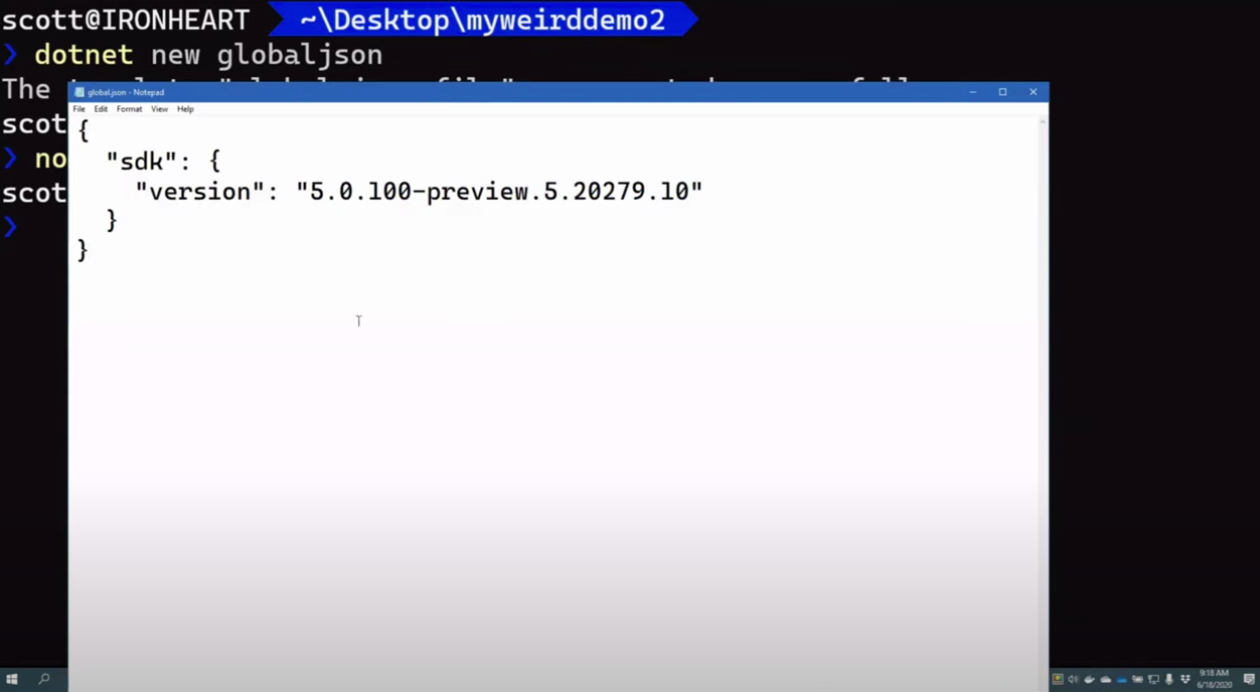
Обратите внимание, что в папке второй демки нет ничего, кроме этого файла `global.json`. Если мы теперь снова проверим версию (`dotnet --version`), то увидим, что используется .NET 3.1.300. Затем вернёмся в папку первой демки (`myweirddemo)` и проверим версию там: в ней по-прежнему используется 5.0.100. Интересно, не правда ли? Перейдём на рабочий стол и проверим версию там: вновь 5.0.100. Всё дело в том, что у вас может быть множество различных экземпляров .NET. Это очень ценное свойство фреймворка.
В .NET 5 и 6 все три платформы объединены в платформу с единым SDK, единой BCL (базовая библиотека классов) и единым набором инструментов. С помощью этого нового .NET можно будет создавать кросс-платформенные UI, он будет отлично работать в контейнерах и крупномасштабных системах вроде Kubernetes. Что касается времени выхода .NET 5 и 6, новые версии будут выходить каждый год в ноябре, и каждый нечётный год это будут версии с долгосрочной поддержкой. Так что в этом году вы можете поэкспериментировать с .NET 5, а в следующем перейти на .NET 6.
> Примечание от организаторов DotNext: про нововведения .NET 5 (от System.Text.Json API до перформансных оптимизаций) на декабрьской конференции будет отдельный [доклад](https://dotnext-moscow.ru/2020/msk/talks/7qz00l78bdqxarivp6bgx0/?utm_source=habr&utm_medium=526554) Раффаэля Риальди.
Возможности .NET
----------------
Вернёмся к нашей демке. Как мы помним, в папке `myweirddemo` располагается dll-файл и исполняемый файл демки. А где же собственно .NET? Мы его установили в C:\Program Files\dotnet. Помимо прочего, тут находится папка `sdk` с компиляторами и папка `shared` с рантаймами. Вообще говоря, любой компьютер всегда стоит загружать по минимуму. Современный .NET весит около гигабайта и требует много ресурсов. Но его не обязательно устанавливать целиком, можно обойтись небольшим рантаймом только с теми компонентами, которые необходимы. Как это сделать? Если я просто скопирую на флешку папку с демкой и вы попробуете её запустить у себя, у вас ничего не выйдет. Предварительно нам нужно будет выполнить команду `publish`, тогда мы получим самодостаточное приложение, которое можно запустить, не устанавливая .NET на компьютере.
Прежде чем выполнять `publish`, попробуем вначале выполнить `dotnet run`. Как видим, команда возвращает ошибку.
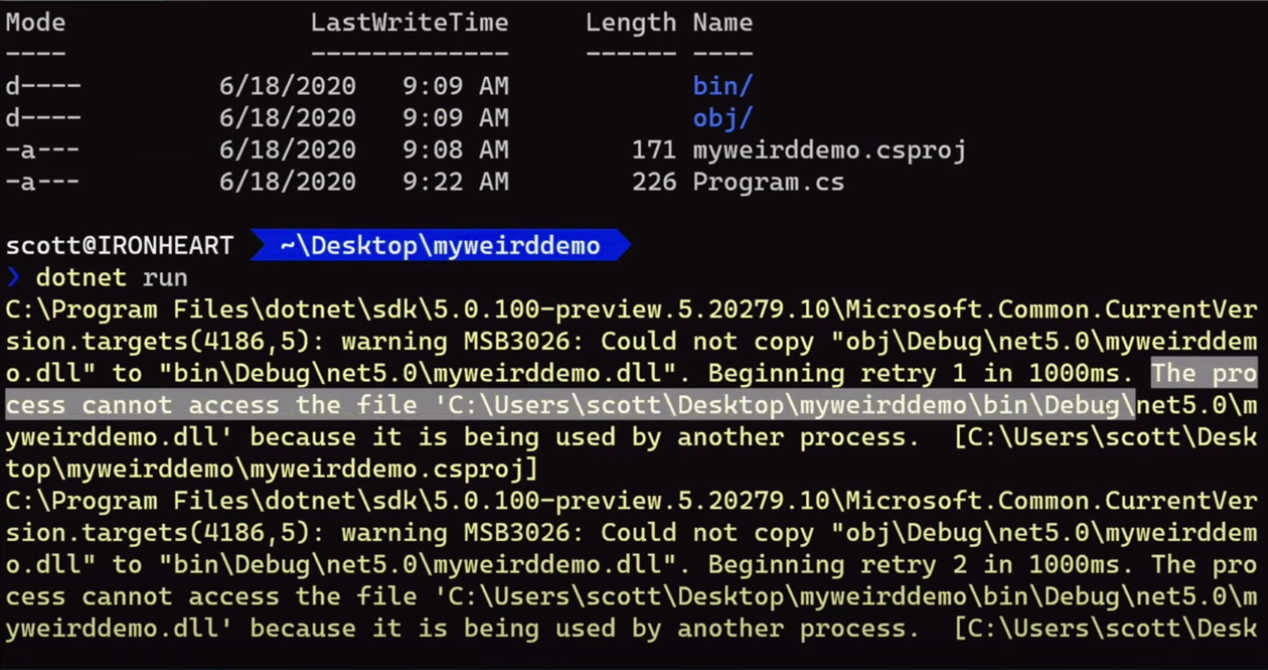
Мне нравится, когда такое происходит во время доклада, поскольку это позволяет лучше разобраться в том, что происходит. В данном случае процесс не может получить доступ к dll-файлу, потому что тот используется другим процессом. Закроем программу, в которой открыт этот dll, и повторим команду.
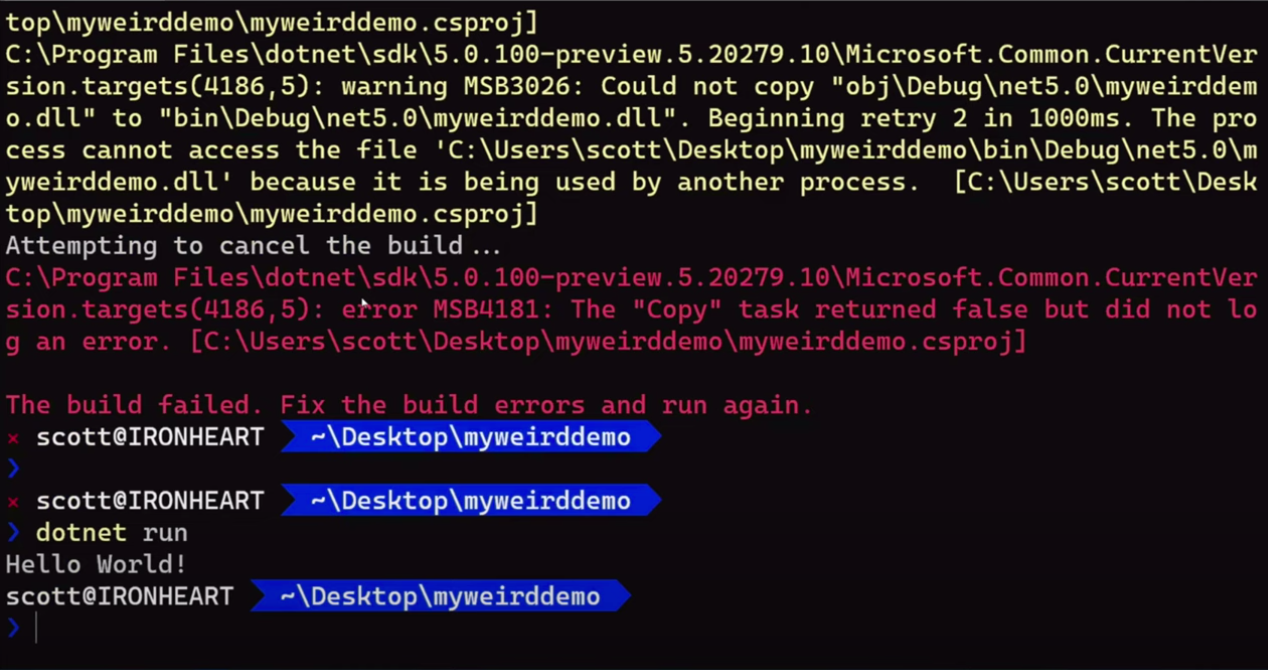
Как видим, всё работает. Теперь выполним `dotnet publish -r win-x64`.
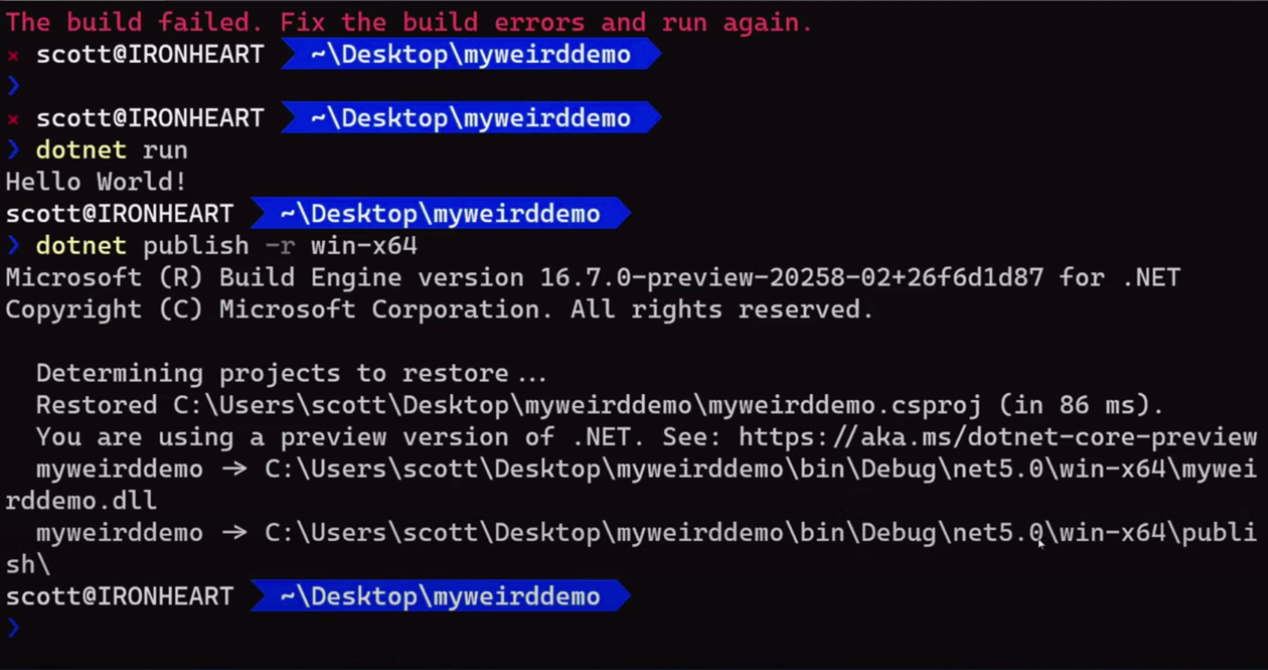
Эта команда создала новую папку, перейдём к ней.

Как видим, здесь находится всё необходимое для того, чтобы запустить нашу программу: полная копия .NET, а также выполняемый файл программы и dll-файл. Однако значительная часть файлов .NET для запуска нашей программы не потребуется. Если бы мы писали микросервис, то нам точно следовало бы избавиться от них. Например, нам ни к чему `System.Drawing.dll` или `System.Globalization.Calendars.dll`. Правда, общий размер нашей папки не такой уж и большой: 65 мегабайт. И всё же 65 мегабайт для Hello world многовато. Организация этих файлов тоже не самая удобная, они просто свалены кучей в одну папку.
Попробуем снова выполнить `publish`, но в этот раз добавим несколько параметров к команде: `publish -r win-x64 -p:PublishSingleFile=true -p:PublishTrimmed=true`. Откроем получившуюся папку.

Как видим, в ней не осталось ненужного, а вес сократился с 65 мегабайт до 23. Конечно, это несопоставимо с весом программы на C, и для Hello world это по-прежнему много, но не забывайте: здесь содержатся все базовые компоненты .NET. Если наша программа будет вдвое длиннее, её размер не вырастет ещё на 20 мегабайт. Для микросервиса это вполне допустимый вес. И, повторюсь, для запуска этой программы не нужно устанавливать .NET на компьютере.
В начале моего доклада мы с вами рассматривали варианты шаблонов, предлагаемые командой `dotnet new`, в их числе были WPF, Windows Forms, Workers и так далее. Представьте теперь, что вы можете сделать приложение с любым из этих шаблонов в виде самодостаточного исполняемого файла, который можно запустить где угодно. Попробуем сделать это с Windows Forms. Это довольно старая платформа, но она пользуется большой популярностью, и с её помощью можно очень быстро создать приложение. Итак, выполним `dotnet new winforms` и запустим его: `dotnet run`. Перед нами откроется пустое приложение Windows Forms. Предположим, у вас есть приложение, состоящее из текстовых полей поверх данных, которое работает уже 10 или 15 лет. Его можно портировать на .NET Core и запустить как отдельный исполняемый файл. Это позволяет очень легко превратить ваше приложение в сервис или запустить его на чужой машине. Кроме того, при таком подходе не нужно постоянно обновлять версию .NET на машине, где это приложение выполняется. В версии .NET 5 (которая, напомню, является опенсорсной) появится поддержка WPF и Windows Forms, а также некоторых сторонних инструментов, так что унаследованные приложения вроде того, которое мы сейчас обсуждали, можно будет запускать без лишнего труда.
В качестве примера использования .NET я хотел бы показать вам сайт моего подкаста, Hanselminutes. Я делаю этот подкаст уже много лет, в нём больше 700 эпизодов. Если вы перейдёте на домашнюю страницу сайта и прокрутите её до самого низа, то увидите следующую фразу: Powered by .NET Core 3.1.8 and deployed from commit 5bbc4d via build 20200930.1. Мне очень нравится это свойство .NET: на моём сайте запущен собственный экземпляр .NET с долгосрочной поддержкой, и я могу точно указать, из какого коммита он собран и какой номер сборки. Давайте теперь взглянем в Visual Studio на исходный код моего сайта.
Я выделил курсором строку кода, которая возвращает номер используемой версии .NET. Ниже мы получаем номер коммита при помощи git hash. Подробнее обо всём этом написано у меня в блоге.
Приложение для моего подкаста первоначально работало только под Windows, но затем я портировал его на .NET Core, и сейчас использую Razor Pages. Благодаря этому я смог запустить приложение под Linux, а в облаке разместить такое приложение немного дешевле, так что в итоге я сэкономил деньги.

В Visual Studio сейчас видна структура приложения, в нём две главных папки: `hanselminutes.core` и `hanselminutes.core.tests`. Сборка и тестирование приложения выполняется при помощи скриптов PowerShell. Я это всё рассказываю для того, чтобы продемонстрировать новый образ мышления, к которому приходят в мире .NET. В главной папке с кодом приложения, `hanselminutes.core`, есть скрипт .\dockerbuild.ps1, давайте его выполним. Он произведёт сборку приложения при помощи Docker, хотя мы сейчас работаем под Windows. То есть вместо того, чтобы устанавливать .NET под Windows, мы запускаем его SDK внутри docker-контейнера. А это значит, что разработчики .NET могут работать с любым фреймворком в любой операционной системе. Я могу запустить приложение под Windows командой `dotnet run`, я могу запустить его на Linux в облаке, или выполнить сборку и тестирование под Linux на моём компьютере. Этой возможности у нас раньше не было. Я могу открыть локальную версию моего подкаста на моём компьютере под Windows и параллельно с этим выполнить скрипт .\dockerrun.psl, который запустит тот же подкаст под Linux. Пока он загружается, я выйду на портал Azure. Там у меня есть панель инструментов, показывающая состояние моей системы. В частности, она отображает запущенные сессии и время использования сервера, а также стоимость используемого времени. Мы можем отобразить информацию по запущенному под Linux в контейнере сервису Hanselminutes.
В данный момент в этом контейнере запущено в общей сложности пять приложений. Это даёт мне экономию где-то в 30%. Я это говорю не к тому, чтобы вы использовали только Linux или только Windows, а к тому, что вы можете пользоваться той системой, которая вам комфортнее. И чем дальше, тем в .NET будет больше такой гибкости.
Кстати говоря, если вы хотите узнать о последних нововведениях в .NET, рекомендую [нашу страницу](https://dotnet.microsoft.com/learn). В частности, там есть встроенный редактор кода, который работает в браузере, то есть для него не нужно устанавливать .NET на компьютер. Хочу также обратить ваше внимание на [обучающую страницу](https://docs.microsoft.com/en-us/learn/azure/), там недавно появился мастер-класс по C#. На этом сайте можно получить сертификаты по представленным там темам. Там же есть онлайн-курсы по C#, .NET и многому другому. Недавно мы выложили там целую книгу по микросервисам, причём она не ограничивается Azure. Книга называется *.NET Microservices: Architecture for Containerized .NET Applications*. Кроме того, не так давно на этом же сайте было выложено руководство по микросервисам, которое не привязано к Azure. Так что возможности для обучения микросервисам на .NET без Azure вполне есть.
Давайте снова взглянем на приложение, на котором запущен мой подкаст. В сущности, это несколько страниц Razor. Приложение с самого начала писалось на .NET Core, но так обстоит дело далеко не со всеми приложениями. Мой блог был написан 18 лет назад на .NET 2.0, и недавно я обновил его до .NET Core, со всем накопленным за 18 лет материалом. Блог был написан на Web Forms, то есть он работает под Windows, требует запуска виртуальной машины, не масштабируется, перенести его на другой хост я не могу, и у него некрасивые URL-адреса. Сейчас я пишу новый сайт с адресом staging.hanselman.com, который является копией старого, но с .NET Core. Вы можете взять любой адрес с моего старого сайта, заменить www на staging, и попадёте на ту же страницу нового сайта.
Портирование сайта мы делали по частям. Приложение подкаста довольно простое, я его написал за несколько недель. А вот приложение для блога значительно более сложное, у него несколько уровней.

На экране можно увидеть его структуру (das Blog — это «блог» по-немецки). Чтобы портировать приложение, нам было необходимо удалить из него все обращения к Windows. Мы уже обсуждали эту тему в начале доклада: когда мы делаем вызов Console.WriteLine(), у нас происходит обращение к Windows. Если же мы хотим, чтобы приложение было кросс-платформенным, нам нужно убрать из кода всё, что будет работать только в Windows — например, обращения к реестру или использование названия диска C:. Для этой цели существует очень полезный инструмент под названием .NET Portability Analyzer, к нему есть расширение в Visual Studio, но им можно пользоваться и из командной строки. Этот инструмент анализирует приложение и сообщает, насколько оно портируемо и гибко. С помощью этого инструмента мы поняли, что переписать необходимо только фронтенд. Мы разбили фронтенд по паттерну Model — View — Controller.
У моего блога есть база данных, которая представляет собой просто файлы на диске. Когда необходимо отобразить некоторый пост, приложение получает его из базы данных, а затем отображает в качестве страниц Razor, в то время как раньше для этого использовались Web Forms. Портированный блог я смог разместить в облаке, и мне не нужно больше использовать виртуальную машину в качестве хоста. Больше того, я могу запустить это приложение на Linux, в то время как вся разработка шла под Windows. Подробнее о том, как именно я портировал блог, можно прочитать в самом блоге.
Я думаю, что в .NET 5 и 6 этот процесс станет ещё проще, потому что планируется предоставить максимальную поддержку кросс-платформенности, это предоставит разработчикам больше выбора. Кроме того, .NET будет ориентироваться на то, чтобы приложения были как можно меньше. Это значит, что для простого блога не нужно будет поднимать виртуальную машину. Поскольку сейчас всё популярнее становятся Kubernetes, Docker и Docker Compose, растёт потребность в механизмах координации и оркестрации. Для этого мы создаём обратные прокси и Project Tye. Это позволит вам использовать наиболее комфортный для вас инструмент, будь то IIS, Apache, nginx или Azure.
.NET MAUI
---------
Хочу рассказать ещё об одном проекте, над которым сейчас ведётся работа, это .NET MAUI (Multi-Platform App UI, UI для мультиплатформенных приложений). Если вы захотите больше о нём узнать, послушайте мой доклад на Build, он находится в открытом доступе. В основе MAUI лежит мысль о том, что нативный UI можно сделать поверх .NET в рамках одного проекта. В имеющихся сегодня решениях (например, в Xamarin) для этого необходимо создать несколько проектов — один для Android, один для iPhone и так далее. В сущности, MAUI — это следующий этап в эволюции Xamarin.Forms. В конце этого года будут представлены ознакомительные версии MAUI, а окончательный вариант предполагается завершить к выходу .NET 6. Это значит, что в командной строке станет доступна команда `dotnet new maui`. В особенности MAUI будет полезен пользователям Xamarin, потому что мы стараемся не менять пространства имён и API для Android и iOS. Если вам нравится Xamarin, то вам ещё больше понравится MAUI.
В общем, в мире .NET сейчас происходит очень много интересного. В ноябре будет проходить виртуальная конференция .NET Conf 2020, она будет привязана к выходу .NET 5. Я её очень рекомендую, сделайте себе пометку в календаре. Что касается .NET 5, то на него не обязательно переходить прямо сейчас, он пока что доступен только в ознакомительной версии. Но его вполне можно запускать параллельно с уже существующим кодом, никак не нарушая работу приложения. Если вы используете версию .NET 3.1 — не переживайте, она будет поддерживаться ещё много лет. Параллельно с ней вы вполне можете протестировать работу ваших приложений с .NET 5, и мы будем очень рады вашим отзывам — вы можете оставить их по адресу dot.net/get-dotnet5. Это позволит нам максимально приблизить .NET 5 и 6 к вашим потребностям и предоставить вам как можно больше возможностей.
Сферы использования .NET
------------------------
.NET становится всё более универсальной платформой. У себя я также использую .NET для веб-приложений. Его вполне можно разворачивать в облаке. Мы не успели рассмотреть использование .NET на мобильных устройствах, но если вы пользовались Xamarin, то вы уже имеете какое-то об этом представление. А в MAUI мы получим усовершенствованный вариант Xamarin, и с ним можно будет создавать кросс-платформенные приложения на .NET, которые смогут работать где угодно.
Стоит также сказать про сферу применения .NET, о которой часто забывают: игры. Возможно, вы знаете, что Unity работает на C#. Но помимо неё есть отличная опенсорсная платформа MonoGame. О них и о многом другом можно узнать на сайте .NET, там есть специальный раздел, посвященный разработке игр. На этом же сайте есть раздел о машинном обучении. Модели, созданные, скажем, в TensorFlow или ONNX можно преобразовывать в код на .NET. Так что если ваши коллеги занимаются машинным обучением и пишут на Python, вы вполне можете работать с ними, при этом оставаясь на .NET. Что касается десктопных приложений, .NET Core работает с WPF и WinForms.
Есть ещё одна очень интересная область использования .NET Core — это IoT, в частности, Raspberry Pi. Если вы загуглите dotnet raspberry pi и моё имя, то найдёте руководство по созданию кластера Kubernetes на Raspberry Pi.
На кластере запущены приложения ASP.NET. Этот пример демонстрирует, что .NET отлично работает на процессорах ARM. Чтобы дополнительно в этом убедиться, давайте вернёмся к нашей первой демке и выполним в её папке `publish -r linux-arm`.
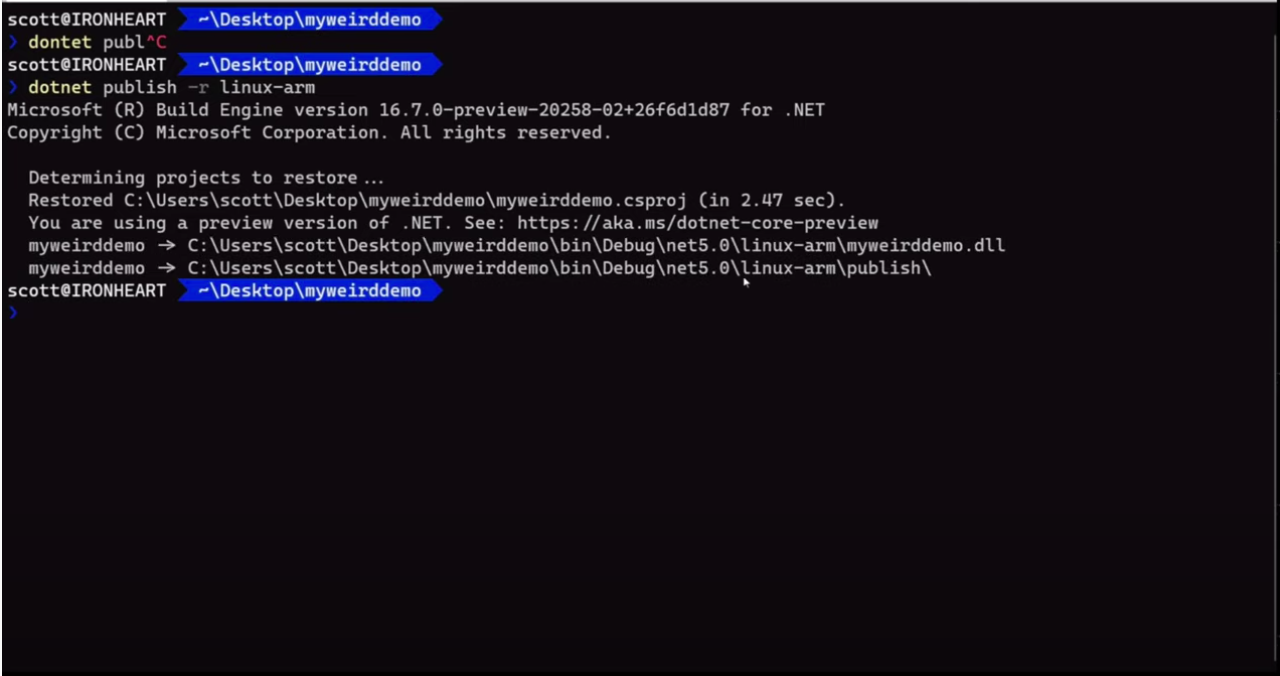
Этой командой мы только что создали на Windows приложение .NET для Raspberry Pi, и нам для этого понадобилось не больше минуты. Новый .NET написан так, чтобы вы могли работать с ним в среде, комфортной именно для вас. Главное, что эта платформа опенсорсная, и у неё очень дружелюбное сообщество. В разделе Community на сайте .NET всегда можно узнать о ближайших конференциях и встречах. Мы всегда рады новым людям, так что пишите нам в Twitter или Stack Overflow. Кроме того, в .NET-сообществе мы проводим онлайн-встречи, и стараемся охватить ими как можно больше часовых поясов, чтобы сделать их доступными для всех, в том числе для наших участников из России. Гости со всего мира выступают у нас с онлайн-докладами о .NET, и им можно задавать вопросы. Мы хотим, чтобы вся наша работа была на виду у сообщества и была максимально открытой для вас.
> Это был общий обзор .NET от Скотта Хансельмана, а если вам хочется послушать доклады на более конкретные темы, то стоит заглянуть на [сайт](https://dotnext-moscow.ru/?utm_source=habr&utm_medium=526554) следующей конференции DotNext, которая пройдёт в начале декабря. Вот для примера: изменения сборки мусора в .NET 5 [осветит](https://dotnext-moscow.ru/2020/msk/talks/2orx0d4ats6wlphmsize9l/?utm_source=habr&utm_medium=526554) Маони Стивенс, которая и отвечает за .NET GC в Microsoft. А также осветим и производительность, и внутреннее устройство платформ, и архитектуру и best practices — каждый .NET-разработчик найдёт там что-то для себя. | https://habr.com/ru/post/526554/ | null | ru | null |
# Исследование шейдера песка игры Journey
[Начало серии статей здесь](https://habr.com/ru/post/476448/)

Часть 4: зеркальное отражение
-----------------------------
В этой части мы сосредоточимся на зеркальных отражениях, благодаря которым дюны напоминают океан песка.
Один из самых интригующих эффектов рендеринга песка *Journey* заключается в том, как дюны сверкают в лучах света. Такое отражение называется **зеркальным (specular)**. Название произошло от латинского слова *speculum*, означающего *«зеркало»*. **Specular reflection** — это «зонтичное» понятие, объединяющее в себе все типы взаимодействий, при которых свет сильно отражается в одном направлении, а не рассеивается и не поглощается. Именно благодаря зеркальным отражениям и вода, и отполированные поверхности под определённым углом выглядят сверкающими.
В *Journey* представлено три типа зеркальных отражений: **свечение краёв (rim lighting)**, **зеркальное отражение океана (ocean specular)** и **отражение отблесков (glitter reflections)**, показанные на схеме ниже. В этой части мы рассмотрим первые два типа.


*До и после применения зеркальных отражений*
Rim Lighting
------------
Можно заметить, что на каждом уровне *Journey* представлен ограниченный набор цветов. И хотя это создаёт сильную и чистую эстетику, такой подход усложняет рендеринг песка. Дюны рендерятся только ограниченным количеством оттенков, поэтому игроку сложно понять, где на далёком расстоянии заканчивается одна и начинается другая.
Чтобы компенсировать это, край каждой дюны имеет небольшой эффект сияния, подсвечивающий её контуры. Это позволяет дюнам не скрываться в горизонт и создаёт иллюзию гораздо более обширного и сложного окружения.
Прежде чем начинать разбираться, как можно реализовать этот эффект, давайте расширим **функцию освещения**, добавив в неё **diffuse colour** (рассмотренный нами в предыдущей части статьи) и новый обобщённый компонент зеркального отражения.
```
float4 LightingJourney (SurfaceOutput s, fixed3 viewDir, UnityGI gi)
{
// Lighting properties
float3 L = gi.light.dir;
float3 N = s.Normal;
// Lighting calculation
float3 diffuseColor = DiffuseColor (N, L);
float3 rimColor = RimLighting (N, V);
// Combining
float3 color = diffuseColor + rimColor;
// Final color
return float4(color * s.Albedo, 1);
}
```
В показанном выше фрагменте кода мы видим, что зеркальный компонент свечения краёв (rim lighting), который называется `rimColor`, просто прибавляется к исходному diffuse colour.
**Эффекты High Dynamic Range и Bloom**
И диффузный компонент, и свечение краёв — это цвета RGB в интервале от  до . Окончательный цвет определяется их суммой. Это означает, что он потенциально может оказаться больше .
Если вы не новичок в кодировании шейдеров, то можете знать, что цвета должны быть ограничены интервалом от  до . Однако существуют случаи, когда нам нужно, чтобы цвета превышали . Если у камеры включена поддержка [High Dynamic Range](https://docs.unity3d.com/Manual/HDR.html), то пиксели с яркостью выше  будут «пропускать» свет на ближайшие пиксели. Эта техника используется для имитации эффектов bloom, гало и зеркальных засветов. Однако для выполнения этой операции требуется **эффект постобработки**.
### Отражения по Френелю
Свечение краёв можно реализовать множеством разных способов. Наиболее популярный в кодировании шейдеров использует хорошо известную **модель отражений по Френелю**.
Чтобы понять уравнение, лежащее в основе отражения по Френелю, полезно визуализировать то, где оно происходит. На схеме ниже показано, как дюна видна через камеру (синим цветом). Красной стрелкой обозначена **нормаль поверхности** вершины дюны, где и должно быть зеркальное отражение. Легко заметить, что все края дюны имеют общее свойство: их нормаль (, красного цвета) перпендикулярна **направлению взгляда** (, синего цвета).
Аналогично тому, что мы сделали в части про Diffuse Colour, можно использовать **скалярное произведение**  и , чтобы получить меру их параллельности. В данном случае  равняется , ведь два единичных вектора перпендикулярны; вместо этого мы можем использовать  для получения меры их непараллельности.
Непосредственное использование  не даст нам хороших результатов, потому что отражение будет слишком сильным. Если мы хотим сделать отражение *резче*, то можем просто взять выражение в степени. Степень величины от  до  остаётся ограниченной одним интервалом, но переход между темнотой и светом становится резче.
В модели отражений по Френелю заявляется, что яркость света  задаётся следующим образом:

где  и  — это два параметра, которые можно использовать для управления контрастностью и силой эффекта. Параметры  и  иногда называют *specular* и *gloss*, однако названия могут и меняться.
Уравнение (1) очень легко преобразовать в код:
```
float _TerrainRimPower;
float _TerrainRimStrength;
float3 _TerrainRimColor;
float3 RimLighting(float3 N, float3 V)
{
float rim = 1.0 - saturate(dot(N, V));
rim = saturate(pow(rim, _TerrainRimPower) * _TerrainRimStrength);
rim = max(rim, 0); // Never negative
return rim * _TerrainRimColor;
}
```
Его результат показан на анимации ниже.
Ocean Specular
--------------
Одним самых оригинальных аспектов геймплея *Journey* стало то, что иногда игрок в буквальном смысле может «сёрфить» по дюнам. Ведущий инженер Джон Эдвардс объяснил, что [thatgamecompany](https://twitter.com/thatgamecompany) стремилась, чтобы песок больше ощущался не твёрдым, а жидким.
И это не совсем ошибочно, ведь песок можно воспринимать как очень грубую аппроксимацию жидкости. А в определённых условиях, например, в песочных часах, он даже ведёт себя подобно жидкости.
Чтобы подкрепить идею о том, что песок может иметь компонент жидкости, в *Journey* был добавлен второй эффект отражения, который часто встречается в жидких телах. Джон Эдвардс называет его **ocean specular (зеркальным отражением океана)**: идея заключается в том, чтобы получить тот же тип отражений, который виден на поверхности океана или озера на закате солнца (см. ниже).

Как и прежде, внесём изменения в функцию освещения `LightingJourney`, чтобы добавить в неё новый тип зеркального отражения.
```
float4 LightingJourney (SurfaceOutput s, fixed3 viewDir, UnityGI gi)
{
// Lighting properties
float3 L = gi.light.dir;
float3 N = s.Normal;
float3 V = viewDir;
// Lighting calculation
float3 diffuseColor = DiffuseColor (N, L);
float3 rimColor = RimLighting (N, V);
float3 oceanColor = OceanSpecular (N, L, V);
// Combining
float3 specularColor = saturate(max(rimColor, oceanColor));
float3 color = diffuseColor + specularColor;
// Final color
return float4(color * s.Albedo, 1);
}
```
**Почему мы берём максимум от двух компонентов отражения?**
Есть большая вероятность того, что возникнет наложение **rim lighting** и **ocean specular**. Некоторые части дюны, особенно расположенные под углами скольжения, могут одновременно демонстрировать отражения по Френелю и по Блинну-Фонугу. Если их суммировать, то дюна будет слишком блестеть.
Мы берём максимум из них, и это эффективный способ избежать такой проблемы.
Зеркальные отражения на воде часто реализуются при помощи **отражения по Блинну-Фонгу**, являющегося малозатратным решением для блестящих материалов. Впервые оно было описано Джеймсом Ф. Блинном в 1977 году (статья: "[Models of Light Reflection for Computer Synthesized Pictures](http://citeseerx.ist.psu.edu/viewdoc/download;jsessionid=D97C4795B8C3D9B479421AC3B7882EE3?doi=10.1.1.131.7741&rep=rep1&type=pdf)") как аппроксимация более ранней техники затенения, разработанной Буй Тыонг Фонгом в 1973 году (статья: "[Illumination for Computer Generated Pictures](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.330.4718&rep=rep1&type=pdf)").
При использовании затенения по Блинну-Фонгу светимость (luminosity)  поверхности задаётся следующим уравнением:

где

Знаменатель уравнения (3) делит вектор  на его длину. Это гарантирует, что  имеет длину . Эквивалентная шейдерная функция для выполнения этой операции — это `normalize`. С геометрической точки зрения,  представляет вектор «между»  и , и поэтому называется **полувектором (half vector)**.

**Почему H находится между V и L?**
Возможно, не совсем понятно, почему  — вектор между  и .
Чтобы разобраться давайте вспомним [тождество параллелограмма](https://en.wikipedia.org/wiki/Parallelogram_law), дающее геометрическую интерпретацию суммы между двумя векторами. Сумму  и  можно найти переносом  в конец  и проведением нового вектора от начала  к концу .
Следующим шагом к пониманию станет то, что две величины,  и , одинаковы. Это значит, что одинаковы два следующих геометрических построения:

Мы можем объединить их, образовав параллелограмм, стороны которого имеют одинаковую длину. Благодаря этому можно гарантировать, что диагональ (то есть ) делит угол пополам. Это значит, что синий и жёлтый углы равны (внизу слева).
Теперь мы знаем, что  — это вектор между  и , но его длина необязательно должна равняться . Нормализация обозначает растягивание его, пока он не достигнет длины , что превратит его в единичный вектор (вверху справа).
Более подробное описание отражения по Блинну-Фонгу можно найти в туториале [Physically Based Rendering and Lighting Models](https://www.alanzucconi.com/2015/06/24/physically-based-rendering/). Ниже представлено его простая реализация в коде шейдера.
```
float _OceanSpecularPower;
float _OceanSpecularStrength;
float3 _OceanSpecularColor;
float3 OceanSpecular (float3 N, float3 L, float3 V)
{
// Blinn-Phong
float3 H = normalize(V + L); // Half direction
float NdotH = max(0, dot(N, H));
float specular = pow(NdotH, _OceanSpecularPower) * _OceanSpecularStrength;
return specular * _OceanSpecularColor;
}
```
В анимации представлено сравнение традиционого диффузного затенения по Ламберту и зеркального по Блинну-Фонгу:
Часть 5: блестящее отражение
----------------------------
В этой части мы воссоздадим блестящие отражения, которые обычно видны на песчаных дюнах.
Вскоре после публикации моей серии статей [Джулиан Обербек](https://twitter.com/fleity) и [Пол Нэделек](https://twitter.com/littleBugHunter) предприняли собственную попытку воссоздания в Unity сцены, вдохновлённой игрой Journey. В твите ниже видно как они усовершенствовали блестящие отражения, чтобы обеспечить бОльшую временную целостность. Подробнее об их реализации можно прочитать в статье на IndieBurg [Mip Map Folding](https://indieburg.com/blog/posts/20200110-mip-map-folding).
> Made a journey like shader just for fun starting of from [@AlanZucconi](https://twitter.com/AlanZucconi?ref_src=twsrc%5Etfw) tutorial and a little help form [@littleBugHunter](https://twitter.com/littleBugHunter?ref_src=twsrc%5Etfw) expanding on it for better glittering. So much glitter :D
> \*Rocks from asset store [#shader](https://twitter.com/hashtag/shader?src=hash&ref_src=twsrc%5Etfw) [#madewithunity](https://twitter.com/hashtag/madewithunity?src=hash&ref_src=twsrc%5Etfw) [#unity3d](https://twitter.com/hashtag/unity3d?src=hash&ref_src=twsrc%5Etfw) [#Unity](https://twitter.com/hashtag/Unity?src=hash&ref_src=twsrc%5Etfw) [pic.twitter.com/nt7MOrxbnt](https://t.co/nt7MOrxbnt)
>
> — Julian Oberbeck (@fleity) [January 8, 2020](https://twitter.com/fleity/status/1214857483715567616?ref_src=twsrc%5Etfw)
В предыдущей части курса мы раскрыли реализацию двух функций зеркальных отражений в рендеринге песка *Journey*: **rim lighting** и **ocean specular**. В этой части я объясню, как реализовать последний вариант зеркального отражения: **блеск (glitter)**.

Если вы когда-нибудь бывали в пустыни, то наверняка замечали, насколько песок на самом деле блестящий. Как говорилось в части о нормалях песка, каждая песчинка потенциально может отражать свет в случайном направлении. Благодаря самой природе случайных чисел часть этих отражённых лучей попадёт в камеру. Из-за этого случайные точки песка будут казаться очень яркими. Этот блеск очень чувствителен к движению, так как малейший сдвиг помешает отражённым лучам попадать в камеру.
В других играх, например, в [Astroneer](https://store.steampowered.com/app/361420/ASTRONEER/) и [Slime Rancher](https://store.steampowered.com/app/433340/Slime_Rancher/) блестящие отражения использовались для песка и пещер.


*Блеск: до и после наложения эффекта*
Проще оценить эти характеристики блеска в увеличенном изображении:

Без всяких сомнений, эффект блеска на реальных дюнах полностью зависит от того, что некоторые песчинки случайным образом отражают свет нам в глаза. Строго говоря, именно это мы уже смоделировали во второй части курса, посвящённой нормалям песка, когда мы моделировали случайное распределение нормалей. Так зачем же нам нужен для этого ещё один эффект?
Ответ может быть не слишком очевиден. Давайте представим, что мы пытаемся воссоздать эффект блеска только при помощи нормалей. Даже если все нормали будут направлены в камеру, песок всё равно не будет блестеть, потому что нормали могут отражать только ту величину света, которая доступна в сцене. То есть в лучшем случае мы отразим только 100% света (если песок совершенно белый).
Но нам нужно нечто другое. Если мы хотим, чтобы пиксель казался таким ярким, чтобы свет *растекался* на соседние с ним пиксели, то цвет должен быть больше . Так получилось потому, что в Unity при применении к камере **фильтра bloom** при помощи **эффекта постобработки**, цвета ярче  распространяются на соседние пиксели и приводят к появлению гало, создающего ощущение того, что некоторые пиксели светятся. Это фундамент **HDR-рендеринга**.
Так что нет, наложение нормалей невозможно простым образом использовать для создания блестящих поверхностей. Поэтому такой эффект удобнее реализовать как отдельный процесс.
Теория микрограней
------------------
Чтобы подойти к ситуации более формально, нам нужно воспринимать дюны как состоящие из микроскопических зеркал, каждое из которых имеет случайное направление. Такой подход называется **теорией микрограней (microfacet theory)**, где **микрогранью (microfacet)** называется каждое из этих крошечных зеркал. Математический фундамент большинства современных моделей затенения основан на теории микрограней, в том числе и модели [Standard shader из Unity](https://docs.unity3d.com/Manual/shader-StandardShader.html).
Первым шагом будет разделение поверхности дюны на микрограни и определение ориентации каждой из них. Как уже говорилось, мы делали нечто подобное в части туториала, посвящённой нормалям песка, где UV-позиция 3D-модели дюны использовалась для сэмплирования случайной текстуры. Тот же подход можно использовать и здесь, чтобы привязать к каждой микрограни случайную ориентацию. Размер каждой микрограни будет зависеть от масштаба тектуры и от её **уровня mip-текстурирования**. Наша задача заключается в воссоздании определённой эстетики, а не стремлении к фотореализму; такой подход будет достаточно хорош для нас.
После сэмплирования случайной текстуры мы сможем связать с каждой песчинкой/микрогранью дюны случайное направление. Давайте назовём его . Оно обозначает **направление блеска**, то есть **направление нормали** песчинки, на которую мы смотрим. Луч света, падающий на песчинку, будет отражаться с учётом того, что микрогрань — это идеальное зеркало, ориентированное в направлении . В камеру должен попасть получившийся отражённый луч света  (см. ниже).
Здесь мы снова можем использовать **скалярное произведение**  и  для получения меры их параллельности.
Один из подходов заключается в возведении в степень , как объяснено в предыдущей (четвёртой) части статьи. Если попробовать так сделать, то мы увидим, что результат очень отличается от того, что есть в *Journey*. Блестящие отражения должны быть редкими и очень яркими. Проще всего будет учитывать только те блестящие отражения, для которых  находится ниже определённого порогового значения.
Реализация
----------
Мы можем с лёгкостью реализовать описанный выше эффект блеска при помощи функции `reflect` в Cg, которая позволяет очень просто вычислять .
```
sampler2D_float _GlitterTex;
float _GlitterThreshold;
float3 _GlitterColor;
float3 GlitterSpecular (float2 uv, float3 N, float3 L, float3 V)
{
// Random glitter direction
float3 G = normalize(tex2D(_GlitterTex, uv).rgb * 2 - 1); // [0,1]->[-1,+1]
// Light that reflects on the glitter and hits the eye
float3 R = reflect(L, G);
float RdotV = max(0, dot(R, V));
// Only the strong ones (= small RdotV)
if (RdotV > _GlitterThreshold)
return 0;
return (1 - RdotV) * _GlitterColor;
}
```
Строго говоря, если  совершенно случайно, то  тоже будет совершенно случайным. Может показаться, что использовать `reflect` необязательно. И хотя это верно для статического кадра, но что произойдёт, если источник освещения перемещается? Это может быть или из-за движения самого солнца, или из-за точечного источника света, привязанного к игроку. В обоих случаях песок потеряет временнУю целостность между текущим и последующим кадром, из-за чего эффект блеска будет появляться в случайных местах. Однако использование функции `reflect` обеспечивает гораздо более стабильный рендеринг.
Результаты показаны ниже:
Как мы помним из самой первой части туториала, компонент блеска добавляется к окончательному цвету.
```
#pragma surface surf Journey fullforwardshadows
float4 LightingJourney (SurfaceOutput s, fixed3 viewDir, UnityGI gi)
{
float3 diffuseColor = DiffuseColor ();
float3 rimColor = RimLighting ();
float3 oceanColor = OceanSpecular ();
float3 glitterColor = GlitterSpecular ();
float3 specularColor = saturate(max(rimColor, oceanColor));
float3 color = diffuseColor + specularColor + glitterColor;
return float4(color * s.Albedo, 1);
}
```
Существует большая вероятность того, что некоторые пиксели в конечном итоге получат цвет больше , что приведёт к эффекту bloom. Именно это нам и нужно. Эффект также добавляется поверх уже существующего зеркального отражения (рассмотренного в предыдущей части статьи), поэтому блестящие песчинки могут находиться даже там, где дюны хорошо освещены.
Существует множество способов усовершенствования этой техники. Всё зависит от итога, которого вы хотите достичь. В [Astroneer](https://store.steampowered.com/app/361420/ASTRONEER/) и [Slime Rancher](https://store.steampowered.com/app/433340/Slime_Rancher/), например, этот эффект используется только ночью. Этого можно добиться снижением силы эффекта блеска в зависимости от направления солнечного света.
Например, величина `max(dot(L, fixed3(0,1,0),0))` равна , когда солнце падает сверху, и равна нулю, когда оно за горизонтом. Но вы можете создать собственную систему, внешний вид которой зависит от ваших предпочтений.
**Почему в отражении по Блинну-Фонгу не используется reflect?**
Эффект **ocean specular**, рассмотренный нами в предыдущей части, был реализован с помощью **отражения по Блинну-Фонгу**.
Это очень популярная модель, которая использовалась на ранних этапах развития 3D-графики для затенения поверхностью с высокой отражаемостью, например, металла и пластика. Но проблема в том, что функция `reflect` может быть затратной. Для направленных вперёд поверхностей отражения по Блинну-Фонгу заменяют на , что является очень близкой аппроксимацией.
Часть 6: волны
--------------
В последней части статьи мы воссоздадим типичные волны песка, возникающие вследствие взаимодействия дюн и ветра.



*Волны на поверхности дюн: до и после*
Теоретически логично эту часть было бы поставить после части о нормалях песка. Я оставил её напоследок потому, что это самый сложный из эффектов туториала. Частично эта сложность вызвана тем, как хранятся и обрабатываются карты нормалей поверхностным шейдером, выполняющим множество дополнительных шагов.
Карты нормалей
--------------
В предыдущей (пятой) части мы исследовали способ получения неоднородного песка. В части, посвящённой нормалям песка для изменения способа взаимодействия света с поверхностью геометрии была использовала очень популярная техника **наложения карт нормалей (normal mapping)**. Она часто применяется в 3D-графике для создания иллюзии того, что объект имеет более сложную геометрию, и обычно используется, чтобы сделать кривые поверхности более плавными (см. ниже).
Чтобы достичь такого эффекта, каждый пиксель сопоставляется с **направлением нормали**, обозначающим его ориентацию. И оно используется для вычисления освещения вместо истинной ориентации меша.
Считывая направления нормалей из кажущейся случайной текстуры, мы смогли имитировать зернистость. Несмотря на физическую неточность, она всё равно выглядит правдоподобно.
Волны на песке
--------------
Однако песчаные дюны демонстрируют и другую особенность, которую невозможно игнорировать: волны. На каждой дюне есть дюны поменьше, появляющиеся из-за воздействия ветра и удерживаемые вместе трением отдельных песчинок.
Эти волны очень заметны и видны на большинстве дюн. На показанной ниже фотографии, сделанной в Омане, видно, что ближняя часть дюны имеет выраженный волнистый узор.

Эти волны значительно изменяются в зависимости не только от формы дюны, но и от состава, направления и скорости ветра. У большинства дюн с острым пиком волны присутствуют только с одной стороны (см. ниже).

Представленный в туториале эффект рассчитан на более плавные дюны, имеющие волны по обеим сторонам. Это не всегда физически точно, но достаточно реалистично для того, чтобы быть правдоподобным, и является хорошим первым шагом к более сложным реализациям.
Реализация волн
---------------
Существует множество способов реализации волн. Наименее затратным будет простое рисование их на текстуре, но в туториале мы хотим достичь иного. Причина проста: волны не «плоские» и должны правильно взаимодействовать со светом. Если просто нарисовать их, то невозможно будет добиться реалистичного эффекта при движении камеры (или солнца).
Ещё одним способом добавления волн является изменение геометрии модели дюны. Но повышать сложность модели не рекомендуется, потому что это сильно влияет на общую производительность.
Как мы видели в части про нормали песка, обойти эту проблему можно при помощи *карт нормалей*. По сути, они отрисовываются на поверхности как традиционные текстуры, но используются в вычислении освещения для имитации более сложной геометрии.
То есть задача превратилась в другую: как создать эти карты нормалей. Ручная отрисовка будет слишком затратной по времени. Кроме того, при каждом изменении дюны нужно будет перерисовывать волны заново. Это значительно замедлит процесс создания ресурсов, чего стремятся избегать многие технические художники.
Гораздо более эффективным и оптимальным решением будет добавление волн *процедурным* образом. Это значит, что направления нормалей дюны изменяются на основании локальной геометрии, чтобы учесть не только песчинки, но и волны.
Так как волны нужно имитировать на 3D-поверхности, будет логичнее реализовать изменение направления нормалей для каждого пикселя. Для этого проще использовать бесшовную карту нормалей с волновым паттерном. Затем эта карта будет скомбинирована с уже имеющейся картой нормалей, ранее использованной для песка.
Карты нормалей
--------------
До этого момента мы встречались с тремя разными *нормалями*:
* **Нормаль геометрии**: ориентация каждой грани 3D-модели, которая хранится непосредственно в вершинах;
* **Нормаль песка**: вычисляется при помощи текстуры шума;
* **Нормаль волн**: новый эффект, обсуждаемый в этой части.
На примере ниже, взятом со страницы Unity [Surface Shader examples](https://docs.unity3d.com/Manual/SL-SurfaceShaderExamples.html), демонстрируется стандартный способ перезаписи нормали 3D-модели. Для этого требуется изменить значение `o.Normal`, что обычно выполняется после сэмплирования текстуры (чаще всего называемой **картой нормалей**).
```
Shader "Example/Diffuse Bump" {
Properties {
_MainTex ("Texture", 2D) = "white" {}
_BumpMap ("Bumpmap", 2D) = "bump" {}
}
SubShader {
Tags { "RenderType" = "Opaque" }
CGPROGRAM
#pragma surface surf Lambert
struct Input {
float2 uv_MainTex;
float2 uv_BumpMap;
};
sampler2D _MainTex;
sampler2D _BumpMap;
void surf (Input IN, inout SurfaceOutput o) {
o.Albedo = tex2D (_MainTex, IN.uv_MainTex).rgb;
o.Normal = UnpackNormal (tex2D (_BumpMap, IN.uv_BumpMap));
}
ENDCG
}
Fallback "Diffuse"
}
```
Точно такую же технику мы использовали для замены нормали геометрии нормалью песка.
**Что такое UnpackNormal?**
Каждый пиксель **карты нормалей** обозначает **направление нормали**. Это **единичный вектор** (вектор с длиной 1), указывающий в направлении, куда должна быть ориентирована поверхность. Компоненты X, Y и Z направления нормали хранится в каналах R, G и B карты нормалей.
Компоненты единичных векторов находятся в интервале от  до . Однако хранящиеся в текстуре значения находятся в интервале от  до . Это означает, что перед копированием в текстуру значения нужно «сжать» в другой интервал и «растянуть» их перед использованием. Эти два этапа называются **упаковкой нормалей (normal packing)** и **распаковкой нормалей (normal unpacking)**. Их можно выполнить при помощи этих очень простых уравнений:

и обратных им:

В Unity есть встроенная функция для уравнений (2), которая называется `UnpackNormal`. Её часто используют для извлечения векторов нормалей из карт нормалей.
Подробнее об этом можно почитать на странице [Normal Map Technical Details](http://wiki.polycount.com/wiki/Normal_Map_Technical_Details) в вики сайта polycount.
Крутизна дюн
------------
Однако первая сложность связана с тем, что форма волн изменяется в зависимости остроты дюн. Невысокие, плоские дюны имеют небольшие волны; на крутых дюнах волновые паттерны более отчётливы. Это значит, что нужно учитывать *крутизну* дюны.
Проще всего обойти эту проблему, создав две разные карты нормалей, соответственно для плоских и крутых дюн. Основная идея заключается в том, чтобы выполнять смешение между этими двумя картами нормалей на основании крутизны дюны.

*Карта нормалей для крутой дюны*

*Карта нормалей для плоской дюны*
**Карты нормалей и синий канал**
Многие карты нормалей обрабатывают синий канал немного иначе, чем остальные два.
Так получилось, потому что хранящаяся в нём информация по сути является избыточной. Единичные векторы должны иметь единичную длину, то есть после определения двух размерностей (X и Y) значение третьей (Z) полностью определено.

и это значит:

Это отражено непосредственно в функции `UnpackNormal` движка Unity. В зависимости от используемого Shader API она извлекает информацию нормалей из трёх или двух каналов.
```
inline fixed3 UnpackNormal(fixed4 packednormal)
{
#if defined(SHADER_API_GLES) defined(SHADER_API_MOBILE)
return packednormal.xyz * 2 - 1;
#else
fixed3 normal;
normal.xy = packednormal.wy * 2 - 1;
normal.z = sqrt(1 - normal.x*normal.x - normal.y * normal.y);
return normal;
#endif
}
```
По умолчанию Unity хранит карты нормалей в формате **DXT5nm**, который использует вместо красного и зелёного каналов (`packednormal.xy`) альфа-канал и зелёный канал (`packednormal.wy`).
Подробнее о других способах хранения нормалей можно почитать в статье [Normal Map Compression](http://wiki.polycount.com/wiki/Normal_Map_Compression) в вики сайта polycount.
**Почему карты нормалей кажутся сиреневыми?**
Если вы раньше пользовались картами нормалей, то знаете, что многие из них преимущественно сиреневатые.
Когда *карты нормалей* кодируют *направления нормалей* в **касательном пространстве**, каждый вектор обозначает новую ориентацию поверхности на относительно действительной ориентации геометрии. Это означает, что направленный вверх вектор нормали ![$\left[0, 0, 1\right]$](https://habrastorage.org/getpro/habr/formulas/3d8/a3c/660/3d8a3c660c27759d949fec941d9fe266.svg) не вносит никаких изменений в способ вычисления освещения.
При кодировании в цвет вектор ![$\left[0, 0, 1\right]$](https://habrastorage.org/getpro/habr/formulas/3d8/a3c/660/3d8a3c660c27759d949fec941d9fe266.svg) преобразуется в ![$\left[0.5, 0.5, 1\right]$](https://habrastorage.org/getpro/habr/formulas/aaa/195/a84/aaa195a845af12eb4e5bbab7062244a2.svg), что и в самом деле соответствует сиреневому цвету в цветовом пространстве RGB.
Карты нормалей часто изменят нормали поверхностей только на небольшую величину; это означает, что в среднем они примерно находятся в окрестностях ![$\left[0, 0, 1\right]$](https://habrastorage.org/getpro/habr/formulas/3d8/a3c/660/3d8a3c660c27759d949fec941d9fe266.svg).
Кроме того, некоторые карты нормалей не позволяют векторам нормалей указывать «внутрь». Это значит, что компонент B часто находится не в интервале от  до , а в интервале от  до . Поэтому все пиксели в готовой карте нормалей имеют хотя бы небольшой оттенок синего.
Крутизну можно вычислить при помощи **скалярного произведения**, которое часто применяется в кодировании шейдеров для вычисления степени «параллельности» двух направлений. В данном случае мы берём направление нормали геометрии (ниже показана синим) и сравниваем её с вектором, указывающим в небо (ниже показан жёлтым). Скалярное произведение этих двух векторов возвращает значения, близкие к , когда векторы почти параллельны (плоские дюны), и близкие к , когда между ними угол 90 градусов (крутые дюны).
Однако мы сталкиваемся с первой проблемой — в этой операции участвует два вектора. Вектор нормали, получаемый из функции `surf` при помощи `o.Normal`, выражен в **касательном пространстве**. Это значит, что **система координат**, использованная для кодирования направления нормали, относительна к локальной геометрии поверхности (см. ниже). Мы вкратце касались этой темы в части про нормали песка.

Вектор же, указывающий в небо, выражен в **мировом пространстве**. Чтобы получить правильное скалярное произведение, оба вектора нужно выразить в одной системе координат. Это означает, что нам нужно преобразовать один из них, чтобы оба были выражены в одном пространстве.
К счастью, нам на помощь приходит Unity с функцией `WorldNormalVector`, позволяющей преобразовать вектор нормали из *касательного пространства* в *мировое пространство*. Чтобы эта функция заработала, нам нужно изменить структуру `Input`, чтобы в неё были включены `float3 worldNormal` и `INTERNAL_DATA`:
```
struct Input
{
...
float3 worldNormal;
INTERNAL_DATA
};
```
Это объясняется в статье из документации Unity [Writing Surface Shaders](https://docs.unity3d.com/Manual/SL-SurfaceShaders.html), где говорится:
> `INTERNAL_DATA` — содержит вектор нормали мирового пространства, если поверхностный шейдер выполняет запись в `o.Normal`.
>
>
>
> Чтобы получить вектор нормали из попиксельной карты нормалей, используйте `WorldNormalVector (IN, o.Normal)`.
Часто это становится основным источником проблем при написании поверхностных шейдеров. По сути, значение `o.Normal`, доступное в функции `surf`, *меняется* в зависимости от того, как используется. Если вы только считываете его, `o.Normal` содержит *вектор нормали* текущего пикселя в *мировом пространстве*. Если вы изменяете его значение, `o.Normal` находится в *касательном пространстве*.
Если вы выполняете запись в `o.Normal`, но вам всё равно нужен доступ к нормали в *мировом пространстве* (как в нашем случае), тогда можно использовать `WorldNormalVector (IN, o.Normal)`. Однако для этого нужно внести небольшое изменение в показанную выше структуру `Input`.
**Что такое INTERNAL\_DATA?**
Значение `INTERNAL_DATA` не очень хорошо объяснено в документации Unity.
Чтобы понять его влияние, необходимо разобраться с тем, что делает функция `WorldNormalVector`. Она получает вектор, выраженный в *касательном пространстве*, и преобразует его в *мировое пространство*. Такая смена системы координат в **линейной алгебре** называется **заменой базиса** (подробнее в [Википедии](https://en.wikipedia.org/wiki/Change_of_basis)).
Если не вдаваться в дебри математики, то замену базиса можно реализовать простым умножением 3D-вектора на специально созданную матрицу 3×3. Эта матрица, как можно догадаться, называется **матрицей преобразования из касательного в мировое пространство (tangent to world matrix)**, что Unity сокращает до **TtoW**.
Данные `INTERNAL_DATA` добавляют матрицу TtoW к структуре `Input`. Это легко можно увидеть, открыв скомпилированный код шейдера с помощью кнопки «Show generated code» в инспекторе:
Вы увидите, что `INTERNAL_DATA` — это сокращение от следующего макроса, который и в самом деле содержит матрицу TtoW:
```
#define INTERNAL_DATA
half3 internalSurfaceTtoW0;
half3 internalSurfaceTtoW1;
half3 internalSurfaceTtoW2;
```
Матрица включается не как `half3x3`, а как три отдельные строки `half3`.
В скомпилированном коде шейдера также можно найти определение `WorldNormalVector`, которое является макросом, просто выполняющим умножение входящего вектора нормали (выраженного в *касательном пространстве*) на матрицу TtoW:
```
#define WorldNormalVector(data,normal)
fixed3
(
dot(data.internalSurfaceTtoW0, normal),
dot(data.internalSurfaceTtoW1, normal),
dot(data.internalSurfaceTtoW2, normal)
)
```
Это можно было сделать с помощью оператора матричного умножения `mul`, но поскольку матрица TtoW разделена на три отдельных строки, было использовано *скалярное произведение*.
На самом деле, это эквивалентно:

Подробнее о математике наложения нормалей можно узнать из статьи на сайте [LearnOpenGL](https://learnopengl.com/Advanced-Lighting/Normal-Mapping).
### Реализация
Фрагмент представленного ниже кода преобразует нормаль из *касательного* в *мировое пространство* и вычисляет крутизну относительно *направления «вверх»*.
```
// Calculates normal in world space
float3 N_WORLD = WorldNormalVector(IN, o.Normal);
float3 UP_WORLD = float3(0, 1, 0);
// Calculates "steepness"
// => 0: steep (90 degrees surface)
// => 1: shallow (flat surface)
float steepness = saturate(dot(N_WORLD, UP_WORLD));
```
Теперь, когда мы вычислили крутизну дюны, можно использовать её для смешения двух карт нормалей. Сэмплируются обе карты нормалей, и плоская, и крутая (в коде ниже они называются `_ShallowTex` и `_SteepTex`). Затем они смешиваются на основании значения `steepness`:
```
float2 uv = W.xz;
// [0,1]->[-1,+1]
float3 shallow = UnpackNormal(tex2D(_ShallowTex, TRANSFORM_TEX(uv, _ShallowTex)));
float3 steep = UnpackNormal(tex2D(_SteepTex, TRANSFORM_TEX(uv, _SteepTex )));
// Steepness normal
float3 S = normalerp(steep, shallow, steepness);
```
Как говорилось в части о нормалях песка, правильно комбинировать карты нормалей довольно сложно, и это невозможно сделать при помощи `lerp`. В данном случае правильнее использовать `slerp`, но вместо неё используется менее затратная функция под названием `normalerp`.
### Смешение волн
Если мы используем показанный выше код, то результаты могут нас разочаровать. Так происходит потому, что дюны имеют очень небольшую крутизну, что приводит к слишком сильному смешиванию двух текстур нормалей. Чтобы исправить это, мы можем применить к крутизне нелинейное преобразование, что повысит резкость смешения:
```
// Steepness to blending
steepness = pow(steepness, _SteepnessSharpnessPower);
```
При смешении двух текстур для регулирования их резкости и контрастности часто используется `pow`. Мы узнали, как и почему это работает в моём туториале [Physically Based Rendering](https://www.alanzucconi.com/2015/06/24/physically-based-rendering/).
Ниже мы видим два градиента. На верхнем представлены цвета от чёрного к белому, линейно интерполированные по оси X с помощью `c = uv.x`. На нижнем тот же градиент представлен при помощи `c = pow(uv.x*1.5)*3.0`:


Легко заметить, что `pow` позволяет создать гораздо более резкий переход между чёрным и белым. Когда мы работаем с текстурами, это уменьшает их наложение друг на друга, создавая более чёткие края.
Направление дюн
---------------
Всё, что мы сделали ранее, работает идеально. Но нам нужно решить ещё одну последнюю проблему. Волны изменяются в зависимости от *крутизны*, но не от *направления*. Как говорилось выше, волны обычно не бывают симметричными из-за того, что ветер преимущественно дует в одном направлении.
Чтобы сделать волны ещё реалистичнее, нам нужно добавить ещё две карты нормалей (см. таблицу ниже). Их можно смешивать в зависимости от параллельности дюны оси X или оси Z.
| | | |
| --- | --- | --- |
| | **Крутая** | **Плоская** |
| **X** | крутой x | плоский x |
| **Z** | крутой z | плоский z |
Здесь нам нужно реализовать вычисление параллельности дюны относительно оси Z. Это можно сделать аналогично вычислению крутизны, но вместо `float3 UP_WORLD = float3(0, 1, 0);` можно использовать `float3 Z_WORLD = float3(0, 0, 1);`.
Этот последний шаг я оставлю вам. Если у вас возникнут проблемы, то в конце этого туториала есть ссылка на скачивание полного пакета Unity.
Заключение
----------
Это последняя часть серии туториалов о рендеринге песка игры Journey.
Ниже показано, как далеко мы смогли продвинуться в этой серии:


*До и после*
Хочу поблагодарить вас за то, что дочитали до конца этот довольно длинный туториал. Надеюсь, вам понравилось изучать и воссоздавать этот шейдер.
### Благодарности
Видеоигра [Journey](http://thatgamecompany.com/journey/) была разработана **Thatgamecompany** и издана **Sony Computer Entertainment**. Она доступна для PC ([Epic Store](https://www.epicgames.com/store/en-US/product/journey/home)) и PS4 ([PS Store](https://www.playstation.com/en-gb/games/journey-ps4/)).
3D-модели дюн, фоны и параметры освещения были созданы [Jiadi Deng](https://github.com/AtwoodDeng/JourneySand).
3D-модель персонажа Journey найдена на форуме FacePunch (ныне закрытом).
Пакет Unity
-----------
Если вы хотите воссоздать этот эффект, то полный пакет Unity доступен для скачивания на [Patreon](https://www.patreon.com/posts/30540389/). В нём есть всё необходимое, от шейдеров до 3D-моделей. | https://habr.com/ru/post/487154/ | null | ru | null |
# Flickr API в Android App. Авторизация
Привет, хабралюди!
Хочу поделиться с вами небольшим опытом использования Flickr API в Android приложениях и рассказать об авторизации пользователя Flickr. Которую в дальнейшем можно будет использовать например для вывода списка альбомов и изображений.
#### Регистрация приложения
Первым делом нам нужно получить API Key, приложения будем использовать не в коммерческих целях, для регистрации переходим по ссылке [Create an App](https://www.flickr.com/services/apps/create/noncommercial/?).
Нас просят ввести «Название», «Цель» и «Соглашения с правами», отправляем наши данные и в результати получаем API Key и API Secret. Они нужны нам в дальнейшем для формирования запроса к серверу.

После этого нам нужно редактировать некоторые данные, в этом же окне переходим на [Edit auth flow for this app](https://www.flickr.com/services/apps/72157650173683580/auth).
Описания и логотип нам не интересны, вводить можете по желанию. В поле Callback URL нам обязательно нужно задать адрес обратного вызова, который мы будем использовать для возвращения к нашему Activity. В моем случае я задаю **appforflickr://callback**. В болке это буде выглядеть следующим образом:
```
...
...
```
App Type — выбираем Web Application и Сохраняем изменения.
Далее переходим непосредственно к построения самого приложения.
В манифесте приложения добавляем *«android.permission.INTERNET»* и блок в результате получаем:
```
xml version="1.0" encoding="utf-8"?
```
#### Создание ссылки для авторизации пользователя
Для авторизации пользователей в приложении мы будем запускать Activity с WebView. Но сначала сформируем адрес для входа. Шаблон выглядет следующим образом:
```
http://flickr.com/services/auth/?api_key=[api_key]&perms=[perms]&api_sig=[api_sig]
```
[api\_key] — это наш ключ полученый при регистрации приложения. [perms] — уровень доступа к аккаунту, может принимать следующие значения:
* read — разрешения на чтения личной информации
* write — разрешения на добавления и редактирования фотографий и информации(включает в себя 'read')
* delete — разрешения на удаления фотографий(включает в себя 'read' и 'write ')
[api\_sig] — подпись, она включает в себя *Secret* полученый при регистрации приложения и список аргументов в алфавитном порядке, имя и значения.
В нашем случае API Key: *5744fadec815a7e8142d03901065c97b*, API Secret: *8b2c12e80b67970b*, права доступа *write*, подпись это строка из:
```
secret + 'api_key' + [api_key] + 'perms' + [perms]
```
, то есть мы имеем: *8b2c12e80b67970bapi\_key5744fadec815a7e8142d03901065c97bpermswrite* и теперь нужно зашифровать эту строку в MD5. Для этого используем следующий метод:
```
public static final String md5SumOfString(final String s) {
try {
MessageDigest digest = java.security.MessageDigest.getInstance("MD5");
digest.update(s.getBytes());
byte messageDigest[] = digest.digest();
StringBuffer hexString = new StringBuffer();
for (int i = 0; i < messageDigest.length; i++)
hexString.append(Integer.toHexString(0xFF & messageDigest[i]));
return hexString.toString();
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
}
return "";
}
```
и получем значения [api\_sig].
В итоге адрес для авторизация пользователя будет выглядеть следующим образом:
```
http://www.flickr.com/services/auth/?api_key=9a0554259914a86fb9e7eb014e4e5d52&perms=write&api_sig=b8d7c1ae026d5f86f1f44944f5257f3
```
В onCreate() добавляем
```
startActivity(new Intent(Intent.ACTION_VIEW, Uri.parse(url)));
```
, где url — это вышеуказанный адрес. После запуска приложения мы открываем веб-страницу, чтобы указать логин и пароль. Если введеные данные будут верны нас по *Callback URL* автоматически перенаправит на наше приложеня. К url добавляеться параметр *frob* из значениям, то есть в нашем случае это выглядит так:
```
appforflickr://callback?frob=72157650137623777-b09eae52121bf8ad-130818926
```
*Frob* нужен для получения *Access token*.
Добавим условия в onCreate(), чтобы получить *frob:*
```
Uri uri = getIntent().getData();
if (uri != null) {
String frob = uri.getQueryParameter("frob");
} else
startActivity(new Intent(Intent.ACTION_VIEW, Uri.parse(url)));
```
После того обработки вызываем метод [flickr.auth.getToken](https://www.flickr.com/services/api/flickr.auth.getToken.html) из [API](https://www.flickr.com/services/api/) для получения *token* и *nsid*, которые понадобятся для дальнейших запросов, а так же *username* и *fullname* пользователя.
Для отправки запросов создадим class HttpRequest:
```
public class HttpRequest extends AsyncTask {
public static final String TAG = HttpRequest.class.getSimpleName();
@Override
protected void onPreExecute() {
Log.d(TAG, "START");
}
@Override
protected String doInBackground(String... params) {
String result = "";
try {
String uri = params[0];
HttpGet httpGet = new HttpGet(uri);
HttpResponse response = HttpClientHelper.getHttpClient().execute(httpGet);
HttpEntity entity = response.getEntity();
if (entity != null) {
InputStream inStream = entity.getContent();
result = InputStreamConverter.convertStreamToString(inStream);
inStream.close();
}
return result;
} catch (IllegalStateException e) {
return result;
} catch (ClientProtocolException e) {
return result;
} catch (IOException e) {
return result;
}
}
@Override
protected void onPostExecute(String result) {
Log.d(TAG, "STOP");
}
}
```
Class HttpClientHelper для получения HttpClient:
```
public class HttpClientHelper {
private static HttpClient httpClient = null;
private static final int REGISTRATION_TIMEOUT = 30 * 1000;
private static final int WAIT_TIMEOUT = 30 * 1000;
private HttpClientHelper() {}
public static synchronized HttpClient getHttpClient() {
if (httpClient == null) {
HttpParams params = new BasicHttpParams();
HttpProtocolParams.setVersion(params, HttpVersion.HTTP_1_1);
HttpProtocolParams.setContentCharset(params, HTTP.DEFAULT_CONTENT_CHARSET);
HttpProtocolParams.setUseExpectContinue(params, true);
ConnManagerParams.setTimeout(params, WAIT_TIMEOUT);
HttpConnectionParams.setConnectionTimeout(params, REGISTRATION_TIMEOUT);
HttpConnectionParams.setSoTimeout(params, WAIT_TIMEOUT);
SchemeRegistry schemeReg = new SchemeRegistry();
schemeReg.register(new Scheme("http", PlainSocketFactory.getSocketFactory(), 80));
schemeReg.register(new Scheme("https", SSLSocketFactory.getSocketFactory(), 443));
ClientConnectionManager connectionMgr = new ThreadSafeClientConnManager(params, schemeReg);
httpClient = new DefaultHttpClient(connectionMgr, params);
}
return httpClient;
}
}
```
Class InputStreamConverter для конвертации InputStream в String:
```
public class InputStreamConverter {
private InputStreamConverter() {}
public static String convertStreamToString(InputStream inputStream) {
BufferedReader reader = new BufferedReader(new InputStreamReader( inputStream));
StringBuilder builder = new StringBuilder();
String line = null;
try {
while ((line = reader.readLine()) != null) {
builder.append(line + "\n");
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return builder.toString();
}
}
```
Адрес для получения token:
```
https://api.flickr.com/services/rest/?method=flickr.auth.getToken&api_key=9a0554259914a86fb9e7eb014e4e5d52&frob=72157650137623777-b09eae52121bf8ad-130818926&format=json&nojsoncallback=1&perms=write&api_sig=8fd09b55f670ec9a4ba07c076e520ae8
```
, чтобы ответ пришел в виде json мы добавили пераметры из значениями *format=json* и *nojsoncallback=1*
Вносим еще раз изминения в onCreate() для отправки запроса:
```
Uri uri = getIntent().getData();
if (uri != null) {
String frob = uri.getQueryParameter("frob");
String url = "..."; // Наш сформированый адрес для получения token
String response = "";
HttpRequest httpRequest = new HttpRequest(this);
httpRequest.execute(url);
try {
response = httpRequest.get();
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
} else
startActivity(new Intent(Intent.ACTION_VIEW, Uri.parse(url)));
```
Далее полученый ответ:
```
{"auth":{"token":{"_content":"12134650097774510-014feda8303a4a64"},"perms":{"_content":"write"},"user":{"nsid":"230211065@N05","username":"user","fullname":"User Alex"}},"stat":"ok"}
```
можна розпарсить получить желанный **token** и **nsid** при помощи таких библиотек как [gson](https://code.google.com/p/google-gson/) или [jackson](http://jackson.codehaus.org/) это уже на любителя.
Надеюсь моя статья будет кому-то полезна.
PS. Это мой первый пост на Хабре, так что извините за немногословность и не судите строго. | https://habr.com/ru/post/249961/ | null | ru | null |
# О новых стандартах C++
Сегодня у меня довольно короткий пост. Я бы его и не писал, наверное, но на Хабре в комментах довольно часто можно встретить мнение, что плюсы становятся хуже, комитет делает непонятно что непонятно зачем, и вообще верните мне мой 2007-й. А тут такой наглядный пример вдруг попался.
Почти ровно пять лет назад я [писал](https://habr.com/ru/post/238879/) о том, как на C++ сделать каррирование. Ну, чтобы если можно написать `foo(bar, baz, quux)`, то можно было бы писать и `Curry(foo)(bar)(baz)(quux)`. Тогда C++14 только вышел и еле-еле поддерживался компиляторами, так что код использовал только C++11-фишки (плюс пара костылей для симуляции библиотечных функций из C++14).
А тут я что-то на этот код снова наткнулся, и мне прямо резануло глаза, насколько он многословный. Плюс ещё и календарь не так давно переворачивал и заметил, что сейчас уже 2019-й год, и можно посмотреть, как C++17 может облегчить нашу жизнь.
Посмотрим?
Хорошо, посмотрим.
Исходная реализация, от которой будем плясать, выглядит примерно так:
```
template
class CurryImpl
{
const F m\_f;
const std::tuple m\_prevArgs;
public:
CurryImpl (F f, const std::tuple& prev)
: m\_f { f }
, m\_prevArgs { prev }
{
}
private:
template
std::result\_of\_t invoke (const T& arg, int) const
{
return invokeIndexed (arg, std::index\_sequence\_for {});
}
template
struct Invoke
{
template
auto operator() (IF fr, IArgs... args) -> decltype (fr (args...))
{
return fr (args...);
}
};
template
struct Invoke
{
R operator() (R (C::\*ptr) (Args...), C c, Args... rest)
{
return (c.\*ptr) (rest...);
}
R operator() (R (C::\*ptr) (Args...), C \*c, Args... rest)
{
return (c->\*ptr) (rest...);
}
};
template
auto invokeIndexed (const T& arg, std::index\_sequence) const ->
decltype (Invoke {} (m\_f, std::get (m\_prevArgs)..., arg))
{
return Invoke {} (m\_f, std::get (m\_prevArgs)..., arg);
}
template
auto invoke (const T& arg, ...) const -> CurryImpl
{
return { m\_f, std::tuple\_cat (m\_prevArgs, std::tuple { arg }) };
}
public:
template
auto operator() (const T& arg) const -> decltype (invoke (arg, 0))
{
return invoke (arg, 0);
}
};
template
CurryImpl Curry (F f)
{
return { f, {} };
}
```
В `m_f` лежит сохранённый функтор, в `m_prevArgs` — сохранённые на предыдущих вызовах аргументы.
Тут `operator()` должен определить, можно ли уже звать сохранённый функтор, или же надо продолжать накапливать аргументы, поэтому он делает довольно стандартный SFINAE при помощи хелпера `invoke`. Кроме того, для того, чтобы вызвать функтор (или проверить его вызываемость), мы покрываем всё это ещё одним слоем SFINAE, чтобы понять, как именно это делать (ибо вызывать указатель на член и, скажем, свободную функцию надо по-разному), и для этого мы используем вспомогательную структуру `Invoke`, которая наверняка неполна… Короче, много всего.
Ну и эта штука совершенно отвратительно работает с move semantics, perfect forwarding и прочими милыми сердцу плюсовика нашего времени словами. Починить это будет чуть сложнее, чем необходимо, так как кроме непосредственно решаемой задачи есть ещё куча не совсем относящегося к ней кода.
Ну и опять же, в C++11 нет вещей типа `std::index_sequence` и сопутствующих, или алиаса `std::result_of_t`, так что чистый C++11-код был бы ещё тяжелее.
Итак, перейдём, наконец, к C++17.
Во-первых, нам не нужно указывать возвращаемый тип `operator()`, можно написать просто:
```
template
auto operator() (const T& arg) const
{
return invoke (arg, 0);
}
```
Технически это не совсем то же самое (по-разному выведется «ссылочность»), но в рамках нашей задачи это несущественно.
Кроме того, нам не нужно руками делать SFINAE для проверки вызываемости `m_f` с сохранёнными аргументами. C++17 даёт нам две клёвые фичи: `constexpr if` и `std::is_invocable`. Выкинем всё, что у нас было раньше, и напишем скелет нового `operator()`:
```
template
auto operator() (const T& arg) const
{
if constexpr (std::is\_invocable\_v)
// вызвать функцию
else
// вернуть ещё одну обёртку с сохранённым arg
}
```
Вторая ветка тривиальная, можно скопировать тот код, который уже был:
```
template
auto operator() (const T& arg) const
{
if constexpr (std::is\_invocable\_v)
// вызвать функцию
else
return CurryImpl { m\_f, std::tuple\_cat (m\_prevArgs, std::tuple { arg }) };
}
```
Первая ветка будет поинтереснее. Нам нужно вызвать `m_f`, передавая все аргументы, сохранённые в `m_prevArgs`, плюс `arg`. К счастью, нам больше не нужны никакие `integer_sequence`: в C++17 есть стандартная библиотечная функция `std::apply` для вызова функции с аргументами, сохранёнными в `tuple`. Только нам нужно засунуть в конец тупла ещё один аргумент (`arg`), так что мы можем либо сделать `std::tuple_cat`, либо просто распаковать `std::apply`'ем имеющийся тупл в дженерик-лямбду (ещё одна фича, появившаяся после C++11, хоть и не в 17-м!). По моему опыту инстанциирование туплов медленное (в компилтайме, естественно), поэтому я выберу второй вариант. В самой лямбде мне понадобится вызвать `m_f`, и чтобы сделать это правильно, я могу использовать ещё однну появившуюся в C++17 библиотечную функцию, `std::invoke`, выкинув написанный руками хелпер `Invoke`:
```
template
auto operator() (const T& arg) const
{
if constexpr (std::is\_invocable\_v)
{
auto wrapper = [this, &arg] (auto&&... args)
{
return std::invoke (m\_f, std::forward (args)..., arg);
};
return std::apply (std::move (wrapper), m\_prevArgs);
}
else
return CurryImpl { m\_f, std::tuple\_cat (m\_prevArgs, std::tuple { arg }) };
}
```
Полезно заметить, как `auto`-выводимый тип возвращаемого значения позволяет возвращать значения разных типов в разных ветках `if constexpr`.
В любом случае, это по большому счёту всё. Или вместе с необходимой обвязкой:
```
template
class CurryImpl
{
const F m\_f;
const std::tuple m\_prevArgs;
public:
CurryImpl (F f, const std::tuple& prev)
: m\_f { f }
, m\_prevArgs { prev }
{
}
template
auto operator() (const T& arg) const
{
if constexpr (std::is\_invocable\_v)
{
auto wrapper = [this, &arg] (auto&&... args)
{
return std::invoke (m\_f, std::forward (args)..., arg);
};
return std::apply (std::move (wrapper), m\_prevArgs);
}
else
return CurryImpl { m\_f, std::tuple\_cat (m\_prevArgs, std::tuple { arg }) };
}
};
template
CurryImpl Curry (F f, Args&&... args)
{
return { f, std::forward\_as\_tuple (std::forward (args)...) };
}
```
Мне кажется, это значительное улучшение по сравнению с исходной версией. И читать проще. Даже как-то скучно, *челленджа нет*.
Кроме того, мы могли бы также избавиться от фукнции `Curry` и напрямую использовать `CurryImpl`, положившись на deduction guides, но это лучше сделать, когда мы разберёмся с perfect forwarding'ом и прочим подобным. Что плавно подводит нас...
Теперь совершенно очевидно, насколько это ужасная реализация с точки зрения копирования аргументов, этого несчастного perfect forwarding'а и тому подобного. Но что куда более важно, исправить это теперь куда легче. Но это мы, впрочем, сделаем как-нибудь в следующем посте.
Вместо заключения
=================
Во-первых, в C++20 появится `std::bind_front`, который покроет львиную долю моих юзкейсов, в которых такая штука мне нужна. Можно вообще будет выкинуть. Грустно.
Во-вторых, писать на плюсах становится всё легче, даже если писать какой-то шаблонный код с метапрограммированием. Больше не нужно думать, какой вариант SFINAE выбрать, как распаковать тупл, как вызвать функцию. Просто берёшь и пишешь, `if constexpr`, `std::apply`, `std::invoke`. С одной стороны, это хорошо, к C++14 или, тем более, 11 возвращаться не хочется. С другой — ощущение, будто львиный пласт навыков становится ненужным. Нет, всё равно полезно уметь что-то там этакое на шаблонах навернуть и понимать, как внутри себя вся эта библиотечная магия работает, но если раньше это было нужно постоянно, то теперь — ну, существенно реже. Это вызывает какие-то странные эмоции. | https://habr.com/ru/post/466985/ | null | ru | null |
# Делаем голову шинного USB-анализатора на базе комплекса Redd
В прошлой паре статей мы рассмотрели пример «прошивки» для комплекса Redd, делающей его ПЛИСовую часть логическим анализатором общего применения. Дальше у меня было желание сделать следующий шаг и превратить его в шинный USB-анализатор. Дело в том, что фирменные анализаторы такого вида очень дорогие, а мне необходимо провести проверку, почему одна и та же USB поделка, если её подключить к машине, работает, а если включить машину, когда всё уже воткнуто в разъём, не работает. То есть, программные анализаторы тут не справятся. По мере написания я как-то увлёкся и написал блок из пяти статей. Теперь можно сказать, что в них показан не только сам анализатор, но и типовой процесс его создания в режиме «на скорую руку». В статье будет показано, как сделать такой анализатор не только на базе Redd, но и на готовых макетных платах, которые можно приобрести на Ali Express.

**Предыдущие статьи цикла**
1. [Разработка простейшей «прошивки» для ПЛИС, установленной в Redd, и отладка на примере теста памяти](https://habr.com/ru/post/452656/)
2. [Разработка простейшей «прошивки» для ПЛИС, установленной в Redd. Часть 2. Программный код](https://habr.com/ru/post/453682/)
3. [Разработка собственного ядра для встраивания в процессорную систему на базе ПЛИС](https://habr.com/ru/post/454938/)
4. [Разработка программ для центрального процессора Redd на примере доступа к ПЛИС](https://habr.com/ru/post/456008/)
5. [Первые опыты использования потокового протокола на примере связи ЦП и процессора в ПЛИС комплекса Redd](https://habr.com/ru/post/462253/)
6. [Веселая Квартусель, или как процессор докатился до такой жизни](https://habr.com/ru/post/464795/)
7. [Методы оптимизации кода для Redd. Часть 1: влияние кэша](https://habr.com/ru/post/467353/)
8. [Методы оптимизации кода для Redd. Часть 2: некэшируемая память и параллельная работа шин](https://habr.com/ru/post/468027/)
9. [Экстенсивная оптимизация кода: замена генератора тактовой частоты для повышения быстродействия системы](https://habr.com/ru/post/469985/)
10. [Доступ к шинам комплекса Redd, реализованным на контроллерах FTDI](https://habr.com/ru/post/477662/)
11. [Работа с нестандартными шинами комплекса Redd](https://habr.com/ru/post/483724/)
12. [Практика в работе с нестандартными шинами комплекса Redd](https://habr.com/ru/post/484706/)
13. [Проброс USB-портов из Windows 10 для удалённой работы](https://habr.com/ru/post/493630/)
14. [Использование процессорной системы Nios II без процессорного ядра Nios II](https://habr.com/ru/post/496508/)
15. [Практическая работа с ПЛИС в комплекте Redd. Осваиваем DMA для шины Avalon-ST и коммутацию между шинами Avalon-MM](https://habr.com/ru/post/500016/)
16. [Разработка простейшего логического анализатора на базе комплекса Redd](https://habr.com/ru/post/506464/)
17. [Разработка логического анализатора на базе Redd – проверяем его работу на практике](https://habr.com/ru/post/508138/)
Пожалуй, я сегодня даже нарушу традицию и буду отлаживать проект не на комплексе Redd, а на обычной макетке. Во-первых, я отдаю себе отчёт, что у подавляющего большинства читателей нет доступа к такому комплексу, но есть доступ к Ali Express. Ну, а во-вторых, мне просто лень городить огород с подключением пары из USB-устройства и хоста, а также бороться с возникающими наводками.
В далёком 2017-м году я искал в сети готовые решения и нашёл вот такую [замечательную вещь](http://openvizsla.org/), вернее, её предка. Сейчас у них всё уже на специализированной плате, а тогда везде были фотографии простой макетки от Xilinx, к которой была подключена плата от WaveShare (узнать про неё можно [тут](https://www.waveshare.com/usb3300-usb-hs-board.htm)). Давайте посмотрим на фотографию этой платы.

На ней имеется сразу два разъёма USB. Причём из схемы видно, что они запараллелены. В розетку типа A можно вставлять свои USB-устройства, а к разъёму mini USB можно подключить кабель, который будем втыкать в хост. А в описании проекта OpenVizsla говорится, что этот путь работает. Жаль только, что сам проект довольно трудно читаемый. Его можно взять на github, но я дам ссылку не на тот аккаунт, который указан на странице, его все и так найдут, но он переделан для MiGen, а тот вариант, который я нашёл в 2017-м: <http://github.com/ultraembedded/cores>, он на чистом Verilog, а там — ветка usb\_sniffer. Там всё идёт не напрямую через ULPI, а через преобразователь ULPI в UTMI (оба этих неприличных слова — это такие микросхемы физического уровня, согласующие скоростной канал USB 2.0 с шинами, понятными процессорам и ПЛИС), а уже потом – работа с этим UTMI. Как там всё работает, я так и не разобрался. Поэтому предпочёл сделать свою разработку с нуля, благо мы скоро увидим, что там скорее всё страшно, чем трудно.
На каком железе можно работать
------------------------------
Ответ на вопрос из заголовка прост: на любом, где есть ПЛИС и внешняя память. Разумеется, в этом цикле мы рассматриавем только ПЛИС Altera (Intel). Правда, имейте в виду, что данные из микросхемы ULPI (именно она стоит на той платочке) идут на частоте 60 МГц. Длинные провода тут неприемлемы. Ещё важно подключать линию CLK к входу ПЛИС из группы GCK, иначе всё будет то работать, то сбоить. Лучше не рисковать. Программно пробрасывать не советую. Я пробовал. Кончилось всё проводом к ноге из группы GCK.
Для сегодняшних опытов по моей просьбе знакомый спаял мне вот такую систему:

Микромодуль с ПЛИС и SDRAM (ищите его на АЛИ экспресс по фразе **FPGA AC608**) и та самая плата ULPI от WaveShare. Вот так выглядит модуль на фотографиях от одного из продавцов. Просто мне лень его отвинчивать от корпуса:

Кстати, вентиляционные отверстия, как на фото моего корпуса, делаются очень интересно. На модели рисуем сплошной слой, а в слайсере ставим заполнение, скажем, 40% и говорим, что снизу и сверху надо сделать ноль сплошных слоёв. В итоге, 3D принтер сам рисует эту вентиляцию. Очень удобно.
В общем, подход к поиску железа понятен. Теперь начинаем проектировать анализатор. Вернее, сам анализатор мы уже сделали в прошлых двух статьях ([тут работали с железом](https://habr.com/ru/post/508138/), [а тут — с доступом к нему](https://habr.com/ru/post/506464/)), сейчас же просто спроектируем проблемно-ориентированную голову, которая ловит данные, приходящие из микросхемы ULPI.
Что должна уметь делать голова
------------------------------
В случае с логическим анализатором всё было легко и просто. Есть данные. Мы к ним подключились и начали паковать, да слать в шину AVALON\_ST. Здесь всё сложнее. Спецификацию ULPI можно найти [тут](https://www.sparkfun.com/datasheets/Components/SMD/ULPI_v1_1.pdf) . Девяносто три листа занудного текста. Лично меня такое вгоняет в уныние. Чуть более простым выглядит описание на микросхему USB3300, которая стоит в плате от WaveShare. Его можно взять [тут](http://ww1.microchip.com/downloads/en/DeviceDoc/00001783C.pdf) . Хотя я всё равно копил смелость с того самого декабря 2017-го года, иногда почитывая документ и сразу закрывая его, как чувствовал приближение депрессии.
Из описания ясно, что у ULPI имеется набор регистров, которые следует заполнить перед началом работы. В первую очередь, это связано с подтягивающими и терминирующими резисторами. Вот рисунок, поясняющий суть:
В зависимости от роли (хост или устройство), а также выбранной скорости, надо включать разные резисторы. Но мы не являемся ни хостом, ни устройством! Мы должны все резисторы отключить, чтобы не мешать основным устройствам на шине! Это делается через запись в регистры.
Ну, и скорость. Надо выбрать рабочую скорость. Для этого также надо произвести запись в регистры.
Когда мы всё настроили, можно приступать к ловле данных. Но в названии ULPI буквы «LP» означают «Low Pins». И вот это самое уменьшение числа ножек привело к такому зубодробительному протоколу, что только держись! Давайте рассмотрим протокол подробнее.
Протокол ULPI
-------------
Протокол ULPI несколько непривычен для простого человека. Но если посидеть с документом и помедитировать, то начинают проявляться некоторые более-менее понятные черты. Становится ясно, что разработчики приложили все усилия, чтобы действительно уменьшить число используемых контактов.
Я не буду здесь перепечатывать полную документацию. Ограничимся самыми важными вещами. Наиважнейшая из них — направление сигналов. Его невозможно запомнить, лучше каждый раз смотреть на рисунок:
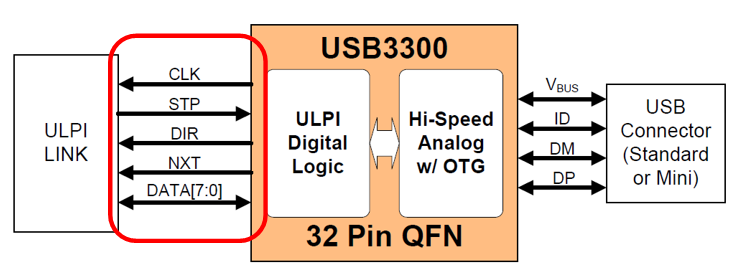
ULPI LINK — это наша ПЛИС.
Временная диаграмма приёма данных
---------------------------------
В состоянии покоя мы должны выдавать на шину данных константу 0x00, что соответствует команде IDLE. Если из шины USB приходят данные, протокол обмена будет выглядеть так:

Цикл начнётся с того, что в единицу взлетит сигнал DIR. Сначала, он там будет находиться один такт, чтобы система успела переключить направление шины данных. Дальше — начинаются чудеса экономии. Видите имя сигнала NXT? Это он при передаче от нас значит NEXT. А здесь — это совсем другой сигнал. Когда DIR равен единице, NXT я бы назвал C/D. Низкий уровень — перед нами команда. Высокий — данные.
То есть, мы должны фиксировать 9 бит (шину DATA и сигнал NXT) либо всегда при высоком DIR (затем программно отфильтровывая первый такт), либо начиная со второго такта после взлёта DIR. Если линия DIR упала в ноль — переключаем шину данных на запись и снова начинаем вещать команду IDLE.
С приёмом данных — понятно. Теперь разбираем работу с регистрами.
Временная диаграмма записи в регистр ULPI
-----------------------------------------
Для записи в регистр используется следующая времянка (я специально перешёл на жаргон, так как чувствую, что меня клонит в сторону ГОСТ 2.105, а это – скучно, так что отойду от него):

Перво-наперво, мы должны дождаться состояние DIR=0. На такте T0, мы должны выставить на шину данных константу TXD CMD. Что это значит? Сразу и не разберёшь, но если чуть покопаться по документам, выясняется, что нужное значение можно найти тут:
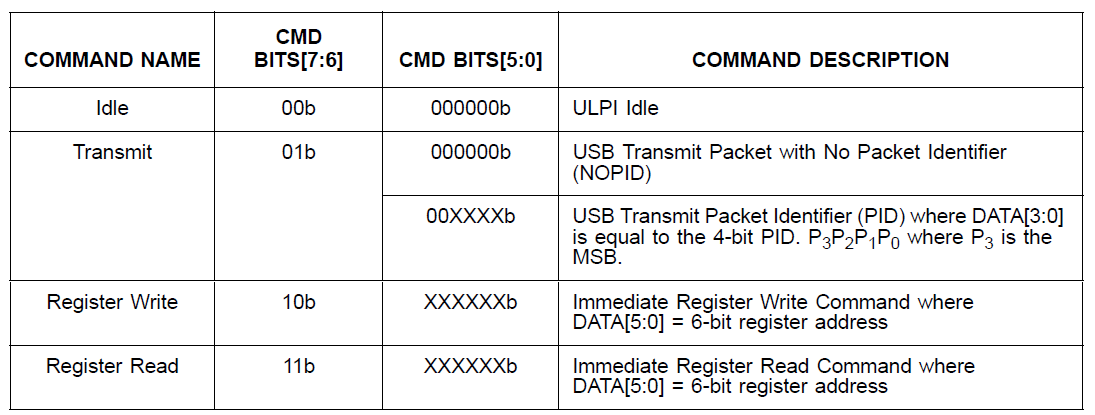
То есть, в старшие биты данных следует положить значение «10» (для всего байта получится маска 0x80), а в младшие — номер регистра.
Далее, следует дождаться взлёта сигнала NXT. Этим сигналом микросхема подтверждает, что услышала нас. На рисунке выше мы дождались его на такте T2 и выставили на следующем такте (T3) данные. На такте T4 ULPI примет данные и снимет NXT. А мы отметим конец цикла обмена единицей в STP. На также T5 данные будут защёлкнуты во внутренний регистр. Процесс завершён. Вот такая расплата за малое число выводов. Но нам надо будет записать данные только при старте, так что помучиться с разработкой, конечно, придётся, но на работу особо всё это влиять не будет.
Временная диаграмма чтения из регистра ULPI
-------------------------------------------
Честно говоря, для практических задач чтение регистров не так и важно, но давайте рассмотрим и его. Чтение будет полезно хотя бы для того, чтобы убедиться, что мы верно реализовали запись.
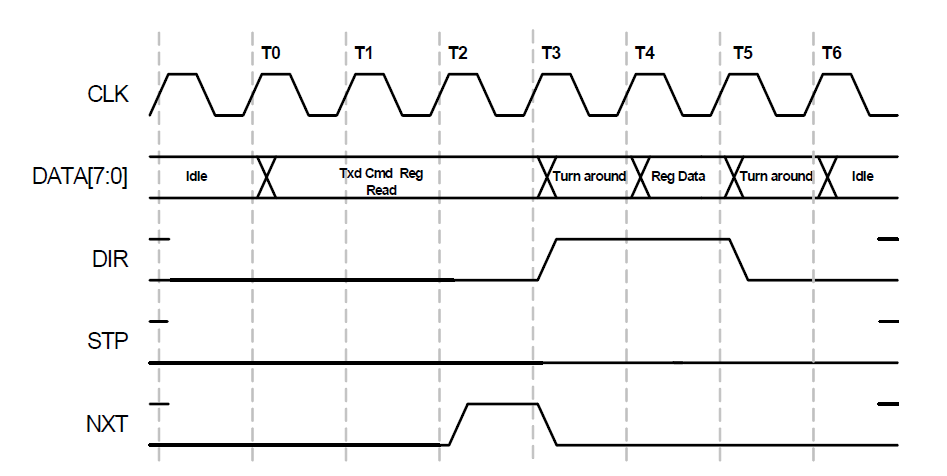
Мы видим, что перед нами гремучая смесь из предыдущих двух времянок. Адрес мы задаём так, как это делали для записи в регистр, а данные забираем по правилам чтения данных.
Ну, что? Приступаем к проектированию автомата, который будет нам всё это формировать?
Структурная схема головы
------------------------
Как видно из описания выше, голова должна быть подключена сразу к двум шинам: AVALON\_MM для доступа к регистрам и AVALON\_ST для выдачи данных на сохранение в ОЗУ. Главное в голове — это мозг. И вот им должен стать конечный автомат, который будет формировать временные диаграммы, рассмотренные нами ранее.
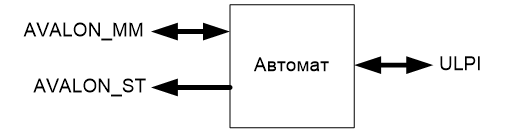
Начнём его разработку с функции приёма данных. Здесь следует учитывать, что мы никак не можем повлиять на поток из шины ULPI. Данные оттуда если начали идти, то будут идти. Им всё равно, есть готовность у шины AVALON\_ST или её нет. Поэтому мы просто будем игнорировать неготовность шины. В реальный анализатор можно будет добавить индикацию аварии в случае выдачи данных без готовности. В рамках статьи всё должно быть просто, поэтому просто запомним это на будущее. А обеспечивать наличие готовности шины, как в логическом анализаторе, нам будет внешний блок FIFO. Итого, граф переходов автомата для приёма потока данных получается таким:

Взлетел DIR – начали приём. Один такт повисели в wait1, затем – принимаем, пока DIR равен единице. Упал в ноль – через такт (правда, не факт, что он нужен, но пока заложим состояние wait2) вернулись в idle.
Пока всё просто. Не забываем, что в шину AVALON\_ST должны уходить не только линии D0\_D7, но и линия NXT, так как она определяет, что сейчас передаётся: команда или данные.
Цикл записи регистра может иметь непредсказуемое время исполнения. С точки зрения шины AVALON\_MM, это не очень хорошо. Поэтому сделаем его чуть хитрее. Заведём буферный регистр. Данные будут попадать в него, после чего шина AVALON\_MM сразу освободится. С точки зрения разрабатываемого автомата, появляется входной сигнал have\_reg (получены данные в регистре, которые следует отправить) и выходной сигнал reg\_served (означающий, что процесс выдачи регистра завершён). Добавляем логику записи в регистр на граф переходов автомата.

Я выделил условие DIR=1 красным, чтобы было ясно, что оно имеет наивысший приоритет. Тогда можно в новой ветке автомата исключить ожидание нулевого значения сигнала DIR. Вход в ветку с иным его значением будет просто невозможен. Состояние SET\_CMDw имеет синий цвет, так как наиболее вероятно, будет чисто виртуальным. Это же просто выполняемые действия! Никто не мешает установить на шине данных соответствующую константу и просто при переходе! В состоянии STPw, среди прочего, можно также на один такт взвести сигнал reg\_served, чтобы сбросить сигнал BSY для шины AVALON\_MM, разрешив новый цикл записи.
Ну, и осталось добавить ветку чтения регистра ULPI. Здесь же — всё наоборот. Автомат, обслуживающий шину, шлёт нам запрос и ждёт нашего ответа. Когда данные получены, он сможет обработать их. А будет он работать с приостановкой шины или по опросу, это уже проблемы того автомата. Конкретно сегодня я решил работать по опросу. Запросили данные – появился BSY. Как BSY пропал – можно принимать считанные данные. Итого, граф принимает вид:
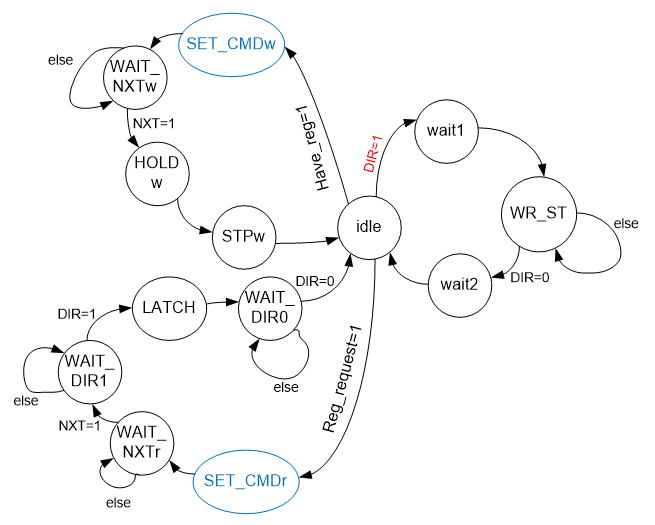
Возможно, по ходу разработки будут какие-то коррективы, но пока — будем придерживаться этого графа. В конце концов, это же не отчёт, а инструкция по методике разработки. А методика такова, что сначала надо нарисовать граф переходов, а затем – делать логику, согласно этому рисунку с поправкой на всплывающие подробности.
Особенности реализации автомата со стороны AVALON\_MM
-----------------------------------------------------
При работе с шиной AVALON\_MM, можно пойти двумя путями. Первый — создавать задержки доступа к шине. Мы этот механизм исследовали в [одной из предыдущих статей](https://habr.com/ru/post/454938/), и я предупреждал, что он чреват проблемами. Второй путь — классика. Ввести регистр состояния. При начале транзакции взводить сигнал BSY, при её завершении — сбрасывать. И возложить ответственность за всё на логику мастера шины (процессор Nios II или мост JTAG). Каждый из вариантов имеет свои достоинства и свои недостатки. Раз мы уже делали варианты с задержками шины, давайте сегодня, для разнообразия, сделаем всё через регистр состояния.
Проектируем основной автомат
----------------------------
Первое, на что хотелось бы обратить внимание — мои любимые RS-триггеры. У нас есть два автомата. Первый обслуживает шину AVALON\_MM, второй — интерфейс ULPI. Мы выяснили, что связь между ними идёт через пару флагов. В каждый флаг может писать только один процесс. Каждый автомат реализуется своим процессом. Как быть? С некоторых пор я просто стал добавлять RS-триггер. У нас два бита, значит их должны вырабатывать два RS-триггера. Вот они:
```
// Формирование регистра статуса
always_ff @(posedge ulpi_clk)
begin
// Приоритет у сброса выше
if (reg_served)
write_busy <= 0;
else if (have_reg)
write_busy <= 1;
// Приоритет у сброса выше
if (read_finished)
read_busy <= 0;
else if (reg_request)
read_busy <= 1;
end
```
Один процесс взводит reg\_served, второй — have\_reg. А RS-триггер в своём собственном процессе на их основе формирует сигнал write\_busy. Аналогично, из read\_finished и reg\_request формируется read\_busy. Можно это делать и иначе, но на данном этапе творческого пути, мне нравится именно такой метод.
Вот так устанавливаются флаги BSY. Жёлтый – для процесса записи, голубой – для процесса чтения. Верилоговский процесс имеет одну очень интересную особенность. В нём можно присваивать значения не один, а несколько раз. Поэтому, если я хочу, чтобы какой-то сигнал взлетал на один такт, я зануляю его в начале процесса (мы видим, что оба сигнала там занулены), а в единицу выставляю по условию, которое выполняется на протяжении одного такта. Вход в условие, перекроет значение по умолчанию. Во всех остальных случаях – будет работать именно оно. Таким образом, запись в порт данных инициирует взлёт сигнала have\_reg на один такт, а запись бита 0 в порт управления – взлёт сигнала reg\_request.

**То же самое текстом.**
```
// Обслуживание AVALON_MM на запись
always_ff @(posedge ulpi_clk)
begin
// Назначение вещей по умолчанию, они могут быть перекрыты
// внутри условия сроком на один такт
have_reg <= 0;
reg_request <= 0;
if (write == 1)
begin
case (address)
0 : addr_to_ulpi <= writedata [5:0];
// Запись в регистр данных требует сложной работы
1 : begin
data_to_ulpi <= writedata [7:0];
have_reg <= 1;
end
2 : begin
// Младший бит регистра инициирует процесс чтения
reg_request <= writedata[0];
force_reset = writedata [31];
end
3: begin end
endcase
end
end
```
Как мы видели выше, одного такта достаточно, чтобы соответствующий RS-триггер установился в единицу. И с этого момента из регистра статуса начинает читаться установленный сигнал BSY:
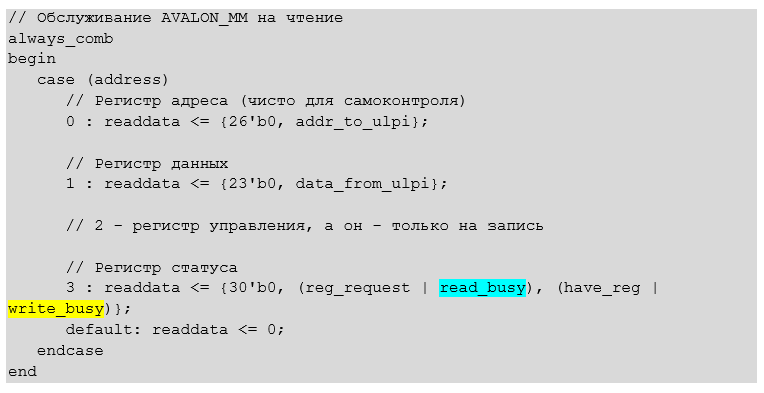
**То же самое текстом.**
```
// Обслуживание AVALON_MM на чтение
always_comb
begin
case (address)
// Регистр адреса (чисто для самоконтроля)
0 : readdata <= {26'b0, addr_to_ulpi};
// Регистр данных
1 : readdata <= {23'b0, data_from_ulpi};
// 2 - регистр управления, а он - только на запись
// Регистр статуса
3 : readdata <= {30'b0, (reg_request | read_busy), (have_reg | write_busy)};
default: readdata <= 0;
endcase
end
```
Собственно, так непринуждённо мы познакомились с процессами, обслуживающими работу с шиной AVALON\_MM.
Давайте я также напомню про принципы работы с шиной ulpi\_data. Эта шина двунаправленная. Поэтому следует применять стандартный приём для работы с ней. Вот так объявлен соответствующий порт:
```
inout [7:0] ulpi_data,
```
Читать из этой шины мы можем, а вот писать напрямую – нельзя. Вместо этого, мы заводим копию для записи
```
logic [7:0] ulpi_d = 0;
```
И подключаем эту копию к основной шине через такой мультиплексор:
```
// Так традиционно назначается выходное значение inout-линии
assign ulpi_data = (ulpi_dir == 0) ? ulpi_d : 8'hzz;
```
Логику работы основного автомата я постарался по максимуму прокомментировать внутри Verilog кода. Как я и предполагал по ходу разработки графа переходов, при реальной реализации, логика в несколько изменилась. Часть состояний была выкинута. Тем не менее, сравнивая граф и исходный текст, надеюсь, вы поймёте всё, что там сделано. Поэтому я не буду рассказывать про этот автомат. Лучше приведу для справки полный текст модуля, актуальный на момент до модификации по результатам практических опытов.
**Полный текст модуля.**
```
module ULPIhead
(
input reset,
output clk66,
// AVALON_MM
input [1:0] address,
input write,
input [31:0] writedata,
input read,
output logic [31:0] readdata = 0,
// AVALON_ST
input logic source_ready,
output logic source_valid = 0,
output logic [15:0] source_data = 0,
// ULPI
inout [7:0] ulpi_data,
output logic ulpi_stp = 0,
input ulpi_nxt,
input ulpi_dir,
input ulpi_clk,
output ulpi_rst
);
logic have_reg = 0;
logic reg_served = 0;
logic reg_request = 0;
logic read_finished = 0;
logic [5:0] addr_to_ulpi;
logic [7:0] data_to_ulpi;
logic [7:0] data_from_ulpi;
logic write_busy = 0;
logic read_busy = 0;
logic [7:0] ulpi_d = 0;
logic force_reset = 0;
// Формирование регистра статуса
always_ff @(posedge ulpi_clk)
begin
// Приоритет у сброса выше
if (reg_served)
write_busy <= 0;
else if (have_reg)
write_busy <= 1;
// Приоритет у сброса выше
if (read_finished)
read_busy <= 0;
else if (reg_request)
read_busy <= 1;
end
// Обслуживание AVALON_MM на чтение
always_comb
begin
case (address)
// Регистр адреса (чисто для самоконтроля)
0 : readdata <= {26'b0, addr_to_ulpi};
// Регистр данных
1 : readdata <= {23'b0, data_from_ulpi};
// 2 - регистр управления, а он - только на запись
// Регистр статуса
3 : readdata <= {30'b0, (reg_request | read_busy), (have_reg | write_busy)};
default: readdata <= 0;
endcase
end
// Обслуживание AVALON_MM на запись
always_ff @(posedge ulpi_clk)
begin
// Назначение вещей по умолчанию, они могут быть перекрыты
// внутри условия сроком на один такт
have_reg <= 0;
reg_request <= 0;
if (write == 1)
begin
case (address)
0 : addr_to_ulpi <= writedata [5:0];
// Запись в регистр данных требует сложной работы
1 : begin
data_to_ulpi <= writedata [7:0];
have_reg <= 1;
end
2 : begin
// Младший бит регистра инициирует процесс чтения
reg_request <= writedata[0];
force_reset = writedata [31];
end
3: begin end
endcase
end
end
// Самый главный автомат
enum {idle,
wait1,wr_st,
wait_nxt_w,hold_w,
wait_nxt_r,wait_dir1,latch,wait_dir0
} state = idle;
always_ff @ (posedge ulpi_clk)
begin
if (reset)
begin
state <= idle;
end else
begin
// Присвоение сигналов по умолчанию
source_valid <= 0;
reg_served <= 0;
ulpi_stp <= 0;
read_finished <= 0;
case (state)
idle: begin
if (ulpi_dir)
state <= wait1;
else if (have_reg)
begin
// Как я и рассуждал в документе, команду
// мы выставим прямо тут, не будем плодить
// состояния
ulpi_d [7:6] <= 2'b10;
ulpi_d [5:0] <= addr_to_ulpi;
state <= wait_nxt_w;
end
else if (reg_request)
begin
// Логика - как для записи
ulpi_d [7:6] <= 2'b11;
ulpi_d [5:0] <= addr_to_ulpi;
state <= wait_nxt_r;
end
end
// Здесь мы просто пропускаем такт TURN_AROUND
wait1 : begin
state <= wr_st;
// Начиная со следующего такта, можно ловить данные
source_valid <= 1;
source_data <= {7'h0,!ulpi_nxt,ulpi_data};
end
// Пока не изменится сигнал DIR - гоним данные в AVALON_ST
wr_st : begin
if (ulpi_dir)
begin
// На следующем тактеа, всё ещё ловим данные
source_valid <= 1;
source_data <= {7'h0,!ulpi_nxt,ulpi_data};
end else
// В документе было ещё состояние wait2,
// но я решил, что оно - лишнее.
state <= idle;
end
wait_nxt_w : begin
if (ulpi_nxt)
begin
ulpi_d <= data_to_ulpi;
state <= hold_w;
end
end
hold_w: begin
// при моделировании выяснилось, что ULPI может
// быть не готова принимать данные. и снять NXT
// Добавил условие...
if (ulpi_nxt) begin
// Всё, по AVALON_MM можно принимать следующий байт
reg_served <= 1;
ulpi_d <= 0; // Шину в idle
ulpi_stp <= 1; // На один такт взвели STP
state <= idle; // А потом - уйдём в состояние idle
end
end
// От состояния STPw я решил отказаться...
// ...
// Это уже начало чтения. Ждём, когда скажут NXT
// И тем самым подтвердят, что наша команда распознана
wait_nxt_r : begin
if (ulpi_nxt)
begin
ulpi_d <= 0; // Номер регистра можно убирать
state <= wait_dir1;
end
end
// Ждём, когда нам выдадут данные
wait_dir1: begin
if (ulpi_dir)
state <= latch;
end
// Тут мы защёлкиваем данные
// и без каких-либо условий идём дальше
latch: begin
data_from_ulpi <= ulpi_data;
state <= wait_dir0;
end
// Ждём, когда шина вернётся к чтению
wait_dir0: begin
if (!ulpi_dir)
begin
state <= idle;
read_finished <= 1;
end
end
default: begin
state <= idle;
end
endcase
end
end
// Так традиционно назначается выходное значение inout-линии
assign ulpi_data = (ulpi_dir == 0) ? ulpi_d : 8'hzz;
// reset мог прийти извне, а могли его и мы сформировать
assign ulpi_rst = reset | force_reset;
assign clk66 = ulpi_clk;
endmodule
```
Руководство программиста
------------------------
### Порт адреса регистра ULPI(+0)
В порт со смещением +0 следует помещать адрес регистра ULPI шины, с которым будет идти работа
### Порт данных регистра ULPI (+4)
При записи в данный порт: автоматически начинается процесс записи в регистр ULPI, адрес которого был задан в порту адреса регистра. Запрещается писать в данный порт, пока не завершился процесс предыдущей записи.
При чтении: из данного порта будет возвращено значение, полученное в результате последней операции чтения регистра ULPI.
### Порт управления ULPI (+8)
На чтение всегда равен нулю. На запись назначение битов следующее:
Бит 0 – При записи единичного значения, инициирует процесс чтения регистра ULPI, адрес которого задан в порту адреса регистра ULPI.
Бит 31 – При записи единицы подаёт сигнал RESET на микросхему ULPI.
Остальные биты зарезервированы.
### Порт состояния (+0x0C)
Доступен только на чтение.
Бит 0 – WRITE\_BUSY. Если равен единице – идёт процесс записи в регистр ULPI.
Бит 1 – READ\_BUSY. Если равен единице – идёт процесс чтения из регистра ULPI.
Остальные биты зарезервированы.
Заключение
----------
Мы познакомились с методикой физической организации головы USB-анализатора, спроектировали базовый автомат для работы с микросхемой ULPI и реализовали черновой SystemVerilog-модуль этой головы. В последующих статьях мы рассмотрим процесс моделирования, проведём моделирование этого модуля, а затем проведём практические опыты с ним, по результатам которых начисто доработаем код. То есть, до конца нам предстоит ещё минимум четыре статьи. | https://habr.com/ru/post/510234/ | null | ru | null |
# Ошибка в рекурсивной обработке CSS в IE 6/7/8 (CVE-2010-3971)
Не так давно, а точнее в начале декабря была раскрыта [информация](http://seclists.org/fulldisclosure/2010/Dec/110) о найденной ошибке в рекурсивной обработке CSS в различных версиях IE. Представленный PoC мог только ронять браузер, но выжить из него чего то более осмысленное не могли до начала этой недели, пока в Metasploit не появился [эксплойт](https://www.metasploit.com/redmine/projects/framework/repository/entry/modules/exploits/windows/browser/ms11_xxx_ie_css_import.rb) с полноценной эксплуатацией этой уязвимости.
Первоначально PoC выглядел так:
> `<code>
>
> <div style="position: absolute; top: -999px;left: -999px;">
>
> <link href="css.css" rel="stylesheet" type="text/css" />
>
> code>
>
>
>
> <code of css.css>
>
> \*{
>
> color:red;
>
> }
>
> @import url("css.css");
>
> @import url("css.css");
>
> @import url("css.css");
>
> @import url("css.css");
>
> code>`
Ошибка кроется в повреждении памяти в парсере HTML страниц (mshtml.dll), в процессе обработки страниц содержащих рекурсивные включения CSS объект *CStyleSheet::Notify* удаляется и позже эта область памяти может быть использована для передачи управления произвольному коду.
`mshtml!CSharedStyleSheet::Notify:
3ced63a5 8bff mov edi,edi
3ced63a7 55 push ebp
3ced63a8 8bec mov ebp,esp
3ced63aa 51 push ecx
3ced63ab 56 push esi
3ced63ac 8bb1d0000000 mov esi,dword ptr [ecx+0D0h] ; esi = 0x14
3ced63b2 57 push edi
3ced63b3 8bb9d8000000 mov edi,dword ptr [ecx+0D8h] ; pointer to array of CStyleSheet objects
3ced63b9 33c0 xor eax,eax
3ced63bb c1ee02 shr esi,2 ; esi = 0x5`
В принципе в этой уязвимости нет ничего особо интересного, но вот реализация ее эксплуатации от рябят из Metasploit действительно заслуживает внимания. Интересно то, что помимо стандартного heap-spray, использовалась техника ROP (return oriented programming) через .NET, что достаточно не типично. А точнее использовалась особенность загрузки mscorie.dll от .NET Framework 2.0, которая была скомпилирована без флага и загружается всегда по одинаковому базовому адресу (0х63f00000). Это упущение со стороны разработчиков позволяет использовать техники ROP для вызова системных функций из шеллкода.
Пример stack pivot gadget для ROP:
`mscorie!_chkstk+0x1b:
63f0575b 94 xchg eax,esp
63f0575c 8b00 mov eax,dword ptr [eax]
63f0575e 890424 mov dword ptr [esp],eax
63f05761 c3 ret`
Microsoft выпустила вчера [Security Advisory 2488013](http://blogs.technet.com/b/msrc/archive/2010/12/22/microsoft-releases-security-advisory-2488013.aspx) по теме и видимо уязвимость будет закрыта в следующей пачке апдейтов. Пока граждане из MS [рекомендуют](http://blogs.technet.com/b/srd/archive/2010/12/22/new-internet-explorer-vulnerability-affecting-all-versions-of-ie.aspx) использовать [EMET](http://blogs.technet.com/b/srd/archive/2010/09/02/enhanced-mitigation-experience-toolkit-emet-v2-0-0.aspx) (The Enhanced Mitigation Experience Toolkit) для противодействия обхода ASLR через выше описанный ROP вектор. | https://habr.com/ru/post/110590/ | null | ru | null |
# Загадочный случай фантомного сертификата
В этой статье я расскажу про практический случай одной конфигурационной ошибки, которая привела к неожиданному эффекту, заняла меня на пару часов исследований и показала как важно понимать, что скрывает под собой тотальная автоматизация. Я подумал, что процесс отлова был достаточно интересным, чтобы им поделиться.
Началось все со следующей задачи: в k8s инфраструктуре был развернут [minio кластер](https://github.com/minio/minio) с публичным ингрессом для s3 api (на всякий случай уточню, [minio](https://github.com/minio/minio) - это S3 хранилище на самообслуживании). И требовалось перевести взаимодействие компонентов внутри кластера на приватную сеть. В деталях это означало завести внутренний CA, выписать сертификат на внутри-кластерное имя (вида minio.minio.svc.cluster.local), отдать его напрямую TLS серверу minio и разложить CA сертификат в доверительные хранилища сертификатов на стороне приложений. Задача была выполнена, все заработало, трафик перебросился на внутренние сетевые интерфейсы, сертификат был не самоподписанный, всё выглядело красиво.
Однако логи приложений стали бросать периодические ошибки вида:
```
sun.security.validator.ValidatorException:
PKIX path building failed:
sun.security.provider.certpath.SunCertPathBuilderException:
unable to find valid certification path to requested target
```
При этом приложение почти полностью работало, и проявлялись ошибки в случайных непрогруженных картинках то там, то тут. Поведение было нестабильным. Переключение minio клиента назад на публичный ендпоинт ошибки убирало. Было непонятно, в первую очередь, отчего такое непостоянное поведение? Азарт возрастал.
Моя первая мысль: подозрение падает на сторону клиента, как-то некорректно он работает с доверяемыми CA. Чтобы проверить это за рамками приложения, воспользовался инструментом [SSLPoke](https://github.com/MichalHecko/SSLPoke) и, в общем-то, получил искомое:
```
# for i in {1..20}; do $JAVA_HOME/bin/java SSLPoke minio.minio.svc.cluster.local 443; done
Successfully connected
Successfully connected
Successfully connected
Successfully connected
Successfully connected
Successfully connected
Successfully connected
Successfully connected
Successfully connected
Successfully connected
Successfully connected
Successfully connected
Successfully connected
Successfully connected
Successfully connected
Successfully connected
Successfully connected
Successfully connected
sun.security.validator.ValidatorException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target
at java.base/sun.security.validator.PKIXValidator.doBuild(Unknown Source)
at java.base/sun.security.validator.PKIXValidator.engineValidate(Unknown Source)
at java.base/sun.security.validator.Validator.validate(Unknown Source)
at java.base/sun.security.ssl.X509TrustManagerImpl.validate(Unknown Source)
at java.base/sun.security.ssl.X509TrustManagerImpl.checkTrusted(Unknown Source)
at java.base/sun.security.ssl.X509TrustManagerImpl.checkServerTrusted(Unknown Source)
at java.base/sun.security.ssl.CertificateMessage$T13CertificateConsumer.checkServerCerts(Unknown Source)
at java.base/sun.security.ssl.CertificateMessage$T13CertificateConsumer.onConsumeCertificate(Unknown Source)
at java.base/sun.security.ssl.CertificateMessage$T13CertificateConsumer.consume(Unknown Source)
at java.base/sun.security.ssl.SSLHandshake.consume(Unknown Source)
at java.base/sun.security.ssl.HandshakeContext.dispatch(Unknown Source)
at java.base/sun.security.ssl.HandshakeContext.dispatch(Unknown Source)
at java.base/sun.security.ssl.TransportContext.dispatch(Unknown Source)
at java.base/sun.security.ssl.SSLTransport.decode(Unknown Source)
at java.base/sun.security.ssl.SSLSocketImpl.decode(Unknown Source)
at java.base/sun.security.ssl.SSLSocketImpl.readHandshakeRecord(Unknown Source)
at java.base/sun.security.ssl.SSLSocketImpl.startHandshake(Unknown Source)
at java.base/sun.security.ssl.SSLSocketImpl.ensureNegotiated(Unknown Source)
at java.base/sun.security.ssl.SSLSocketImpl$AppOutputStream.write(Unknown Source)
at java.base/sun.security.ssl.SSLSocketImpl$AppOutputStream.write(Unknown Source)
at SSLPoke.main(SSLPoke.java:31)
Caused by: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target
at java.base/sun.security.provider.certpath.SunCertPathBuilder.build(Unknown Source)
at java.base/sun.security.provider.certpath.SunCertPathBuilder.engineBuild(Unknown Source)
at java.base/java.security.cert.CertPathBuilder.build(Unknown Source)
... 21 more
Successfully connected
```
Итак, мы видим, что один из двадцати вызовов к нашему серверу падает. Повторяя эксперимент, это случайное поведение оставалось стабильным в своей случайности.
Следующий шаг: исключим из уравнения Java и перейдем на уровень чистого Linux. А именно, произведем тот же эксперимент с чистым curl, что увидим?
```
# for i in {1..20}; do curl https://minio.minio.svc.cluster.local; done
```
Результат оказался тем же - примерно один раз из десяти получаю ошибку сертификата:
```
curl: (60) SSL certificate problem: unable to get local issuer certificate
More details here: https://curl.se/docs/sslcerts.html
curl failed to verify the legitimacy of the server and therefore could not
establish a secure connection to it. To learn more about this situation and
how to fix it, please visit the web page mentioned above.
```
В этот момент в голову полезли стандартные мысли: это точно какие-то глюки сети kubernetes, ведь всем известно, что там могут происходить [невероятные вещи](https://k8s.af/)...
Идем дальше, можем смело отбросить сеть, если произведем тот же эксперимент локально с ноды в контейнер и внутри самого контейнера. Результат остался тем же, сеть как таковая не причем. Проблема находится внутри самого minio server.
Следующая мысль: раз у нас ошибка сертификата, надо уже наконец посмотреть, что за сертификат мы получаем. Смотрим на хороший и плохой случай с помощью openssl:
* сертификат здорового человека
```
depth=1 CN = cluster-ca
verify return:1
depth=0 CN = s3.example.com
verify return:1
```
* сертификат курильщика
```
depth=0 O = system:nodes, CN = system:node:*.example-1-hl.minio.svc.cluster.local
verify error:num=20:unable to get local issuer certificate
verify return:1
depth=0 O = system:nodes, CN = system:node:*.example-1-hl.minio.svc.cluster.local
verify error:num=21:unable to verify the first certificate
verify return:1
depth=0 O = system:nodes, CN = system:node:*.example-1-hl.minio.svc.cluster.local
verify return:1
```
Видим необычное имя `system:node:*.example-1-hl.minio.svc.cluster.local` и при этом группа `system:nodes` намекает на сертификат, выписанный самим k8s.
Не очень люблю сидеть и гадать, откуда что появляется, поэтому ~~расчехлил старое ружье на стене~~ обратился к strace, он меня никогда не подводил. Натравив его на процесс minio во время того же цикла curl, увидел, что он действительно обращается в разный момент времени к разным файлам:
```
# strace -vvvtTfs1024 -o /tmp/strace.log -p 1
... запускаем for-loop с командой curl ...
CTRL+C
# grep crt /tmp/strace.log
2523784 09:14:44.028695 openat(AT_FDCWD, "/tmp/certs/public.crt", O_RDONLY|O_CLOEXEC) = 14 <0.000031>
2543764 09:14:46.847463 openat(AT_FDCWD, "/tmp/certs/public.crt", O_RDONLY|O_CLOEXEC) = 14 <0.000030>
2561965 09:14:47.028695 openat(AT_FDCWD, "/tmp/certs/public.crt", O_RDONLY|O_CLOEXEC) = 14 <0.000031>
2635591 09:14:47.029252 openat(AT_FDCWD, "/tmp/certs/hostname-1/public.crt", O_RDONLY|O_CLOEXEC
```
Дальше меня насторожил один нюанс, что при старте minio получает не точный путь до конкретных файлов сертификата, а просто директорию, в которой они лежат:
```
- args:
- server
- --certs-dir
- /tmp/certs
- --console-address
- :9443
```
И внутри по какой-то причине лежат два разных сертификата. [Исходники minio](https://github.com/minio/minio/blob/1a40c7c27c32166945d828a87dd096a73909fee4/cmd/common-main.go#L888) как бы поясняют, что это скорее фича, а не баг, чтобы упростить работу с предоставляемыми сертификатами.
```
// MinIO has support for multiple certificates. It expects the following structure:
// certs/
// │
// ├─ public.crt
// ├─ private.key
// │
// ├─ example.com/
// │ │
// │ ├─ public.crt
// │ └─ private.key
// └─ foobar.org/
// │
// ├─ public.crt
// └─ private.key
// ...
//
// Therefore, we read all filenames in the cert directory and check
// for each directory whether it contains a public.crt and private.key.
// If so, we try to add it to certificate manager.
```
Развязка
--------
Когда стало понятно, что все идет по плану и так и было задумано, после очередного прочтения [tls.md](https://github.com/minio/operator/blob/master/docs/tls.md#using-cert-manager) я уже стал догадываться, что в нашу картину вмешивается автоматизированный процесс, и так как он описан в секции **Automatic TLS** я наконец осознал, что именно пошло не так.
> Once you enable `requestAutoCert` field and create the Tenant, MinIO Operator creates a CSR for this instance and sends to the Kubernetes API server.
>
>
Когда я переходил к своему сертификату, в настройках объекта Minio Tenant я убрал ключ `requestAutoCert` и добавил `externalCertSecret`, и ожидал, что я таким образом выключил автогенерацию. Но я просто оставил значение `true` по умолчанию. Если побродить по их прочим инструкциям этот момент проскальзывает, например так:
> MinIO Operator can automatically generate TLS secrets and mount these secrets to the MinIO, Console, and/or KES pods (enabled by default). To disable this, set the `requestAutoCert` field to `false`.
>
>
Но когда я шел по тем шагам, что нужны были мне, этот момент был упущен.
Получается, minio operator производил одновременно два процесса: брал мой сертификат из секрета, а также автоматически запрашивал сертификат у k8s и добавлял в этот же секрет. Для полноты всей этой картины, выяснилось, что я дал имя секрету ровно такое, какое зашито в автогенерации. Занавес!
Для успокоения своей совести и защиты от дурака в будущем, я оформил PR на то, чтобы улучшить этот момент в документации: <https://github.com/minio/operator/pull/1184>.
Благодарю за внимание!
 | https://habr.com/ru/post/672992/ | null | ru | null |
# Пилотируем облачную MongoDB через VanillaJS или как бесплатно сделать приватный todo-лист за 15 минут

###### *На фото: Том Круз в фильме Лучший Стрелок*
В этой статье мы рассмотрим взаимодействие Single Page HTML Application с облачной MongoDB через JavaScript. В качестве MongoDB-as-a-Service я возьму [Mongolab](https://mongolab.com). Стоимость развернутой MongoDB, с объёмом в 500мб, обойдется нам всего-лишь в 0 USD.
Для того, чтобы создать todo-лист, нам не потребуется бекенд. Взаимодействовать с Mongolab мы будем через REST API, а обертку для него в клиентской части мы напишем не прибегая к помощи сторонних JavaScript-фреймворков.
#### Навигация по статье
[1. Регистрация на Mongolab и получение API-ключа](#reg)
[2. Безопасность данных при общении браузера с MongoDB](#sec)
[3. Область применения подобных решений](#use)
[4. Давайте уже к делу](#go)
[5. Разбираем код приложения](#src)
[6. Демо готового проекта](#demo)
#### 1. Регистрация на Mongolab и получение API-ключа
##### Шаг первый — регистрируемся

Регистрация простая и не требует привязки карт оплаты. Mongolab — довольно полезный сервис. В нашей компании мы используем его в качестве песочницы во время разработки веб-приложений.
##### Шаг второй — заходим в меню пользователя
Справа на экране будет ссылка в пользовательское меню. В этом меню нас и будет ждать наш заветный API-key.
##### Шаг третий — забираем API-ключ

После получения API-ключа мы можем работать с [Mongolab REST API](http://docs.mongolab.com/restapi/)
#### 2. Безопасность данных при общении браузера с MongoDB

###### *На фото: Том Круз смеётся*
Хочу предупредить — статья носит чисто учебный характер. Коммуникация с облачной базой данных из браузера может оказаться фатальной ошибкой. Думаю очевидно, что злоумышленник может легко получить доступ к базе просто открыв консоль разработчика. Использование read-only пользователя базы решает эту проблему только в том случае, если, абсолютно все данные находящиеся в облачной MongoDB — не несут никакой важности и приватности.
#### 3. Область применения подобных решений
Основываясь на таком подходе мы с вами можем создать todo-list application, который можно будет держать у себя на компьютере, написать приложение под Android/iOS/Windows Phone/Windows 8.1 используя всего лишь один html и javascript.
#### 4. Давайте уже к делу
На написание todo приложения у меня ушло ровно 15 минут, на написание этой статьи (+ комментирование кода) я потратил два часа. Цветовая схема была [взята у Google](http://www.google.com/design/spec/style/color.html#color-color-palette), которую заботливо вынес в LESS [один добрый человек](https://github.com/shuhei/material-colors). То, что у меня получилось, я залил на github чтобы вы смогли оценить работу с облачной базой не растрачивая своё драгоценное время. Ссылку вы найдёте в конце статьи.
Коммуникацию с REST API будем осуществлять через [XMLHttpRequest](https://developer.mozilla.org/ru/docs/Web/API/XMLHttpRequest). Современный мир веб-разработки очень уверенно сфокусировался на решениях вроде jQuery или Angular — суют их везде и где попало. Зачастую обойтись можно спокойно и без них. Объект `new XMLHttpRequest ()` — своего рода поток, связанный с js-объектом, у которого есть основные методы **open** и **send** (открыть соединение и отправить данные) и основное событие **onreadystatechange**. Для общения с REST нам потребуется установить заголовок **Content-Type:application/json;charset=UTF-8**, для этого мы используем метод **setRequestHeader**.
###### Вот так может выглядеть простое REST-приложение:
```
var api = new XMLHttpRequest();
api.onreadystatechange = function () {
if (this.readyState != 4 || this.status != 200) return;
console.log(this.responseText);
}; // вместо onreadystatechange можно использовать onload
api.open('GET', 'https://api.mongolab.com/api/1/databases?apiKey=XXX');
api.setRequestHeader('Content-Type', 'application/json;charset=UTF-8');
api.send();
```
###### А метод вам не завернуть?
```
var api = new XMLHttpRequest();
api.call = function (method, resource, data, callback) {
this.onreadystatechange = function () {
if (this.readyState != 4 || this.status != 200) return;
return (callback instanceof Function) ? callback(JSON.parse(this.responseText)) : null;
};
this.open(method, 'https://api.mongolab.com/api/1/' + resource + '?apiKey=XXX');
this.setRequestHeader('Content-Type', 'application/json;charset=UTF-8');
this.send(data ? JSON.stringify(data) : null);
};
/** код ниже выглядит намного удобнее и его можно вызывать несколько раз */
api.call('GET', 'databases', null, function (databases) {
console.log(databases);
});
```
###### Внести новую запись в коллекцию demo с title: test
```
var test = {
title: 'test'
};
api.call('POST', 'databases/mydb/demo', test, function (result) {
test = result; // получить ID из базы после добавления
});
```
###### Проблема синхронного потока
Наша переменная api является лишь одним потоком, поэтому следующий код ошибочен:
```
api.call('POST', 'databases/mydb/demo', test1);
api.call('POST', 'databases/mydb/demo', test2);
```
Для того, чтобы обойти синхронность, нам потребуется два отдельных потока — для первого POST и для второго. Чтобы каждый раз не описывать метод call — мы приходим к решению собрать «псевдо-класс» **MongoRESTRequest**, который на самом деле являлся бы функцией, возвращающей новый объект XMLHttpRequest с готовым методом call:
```
var MongoRESTRequest = function () {
var api = new XMLHttpRequest();
api.call = function (method, resource, data, callback) {
this.onreadystatechange = function () {
if (this.readyState != 4 || this.status != 200) return;
return (callback instanceof Function) ? callback(JSON.parse(this.responseText)) : null;
};
this.open(method, 'https://api.mongolab.com/api/1/' + resource + '?apiKey=XXX');
this.setRequestHeader('Content-Type', 'application/json;charset=UTF-8');
this.send(data ? JSON.stringify(data) : null);
};
return api;
};
var api1 = new MongoRESTRequest();
var api2 = new MongoRESTRequest();
api1.call('POST', 'databases/mydb/demo', test1);
api2.call('POST', 'databases/mydb/demo', test2);
```
Теперь этот код будет исполнен корректно.
Продолжая модифицировать наш MongoRESTRequest мы придём приблизительно к тому варианту, который будет изложен в исходном коде приложения ниже.
###### Немного про то, как можно обойтись без шаблонизатора:
Обычно я наблюдаю в коде среднестатистического фаната jQuery нечто такое:
```
$('#myDiv').html('');
```
А теперь взгляните, как это должно быть на самом деле, без подключения лишних 93.6кб (compressed, production jQuery 1.11.2)
```
var myDiv = document.getElementById('myDiv');
var newDiv = document.createElement('div'); // создать div
newDiv.classList.add('red'); // добавить класс red
myDiv.appendChild(newDiv); // вставить в myDiv
```
Ладно, ладно, конечно все мы знаем что это можно сделать и так:
```
document.getElementById('myDiv').innerHTML = '';
```
###### Ещё немного про работу с DOM в Vanilla:
Используем map для создания списка (ReactJS-way):
```
var myList = document.getElementById('myList');
var items = ['первый', 'второй', 'третий'];
items.map(function (item) {
var itemElement = document.createElement('li');
itemElement.appendChild(document.createTextNode(item));
myList.appendChild(itemElement);
});
```
На выходе имеем ([ссылка на jsFiddle поиграться](http://jsfiddle.net/1gLsyuwu/)):
```
* первый
* второй
* третий
```
Преимуществом такой работы JavaScript является возможность полноценной работы с объектами:
```
var myList = document.getElementById('myList');
var items = [{id: 1, name: 'первый'}, {id: 2, name: 'второй'}, {id: 3, name: 'третий'}];
items.map(function (item) {
var itemElement = document.createElement('li');
itemElement.appendChild(document.createTextNode(item.name));
itemElement.objectId = item.id; // присваиваем свойство objectId для каждого itemElement
itemElement.onclick = function () {
alert('item #' + this.objectId);
};
myList.appendChild(itemElement);
});
```
[Ссылка на jsFiddle для проверки](http://jsfiddle.net/rqe2unwp/)
#### 5. Разбираем код приложения
**Я постарался прокомментировать каждую строчку кода**
```
Список дел
Список дел
/\*\*
\* Получаем необходимые DOM элементы в переменные:
\* header - <header></header> (у нас только один такой header)
\* taskInput - <input name="task"> (у нас только один такой input)
\* taskBtn - <button></button> (у нас лишь одна такая кнопка на странице)
\* extendable - <div id="extendable"></div>
\*/
var header = document.getElementsByTagName('header')[0];
var taskInput = document.getElementsByName('task')[0];
var taskBtn = document.getElementsByTagName('button')[0];
var extendable = document.getElementById('extendable');
/\*\*
\* Функция отображения блока extendable.
\*/
extendable.show = function () {
/\*\*
\* Устанавливаем CSS {display: block} (показываем блок) для extendable.
\*/
this.style.display = 'block';
/\*\*
\* переводим фокус браузера на taskInput.
\*/
taskInput.focus();
};
/\*\*
\* Функция скрытия блока extendable.
\*/
extendable.hide = function () {
/\*\*
\* Устанавливаем CSS {display: none} (убираем блок) для extendable.
\*/
this.style.display = 'none';
};
/\*\*
\* Обработчик события клика по header.
\*/
header.onclick = function () {
/\*\*
\* Внутренняя переменная secondState используется как
\* память состояния отображения блока extendable.
\* Тут конечно можно и красивее код сделать, что-то вроде:
\* this.secondState = !this.secondState;
\* extendable.show(this.secondState);
\*/
if (!this.secondState) {
extendable.show();
this.secondState = true;
} else {
extendable.hide();
this.secondState = false;
}
};
/\*\*
\* Обработчик свободного нажатия tab в браузере.
\* Так как у fake-header стоит tabindex = 1, то она будет выделена при нажатии tab.
\* При выделении будет выполнен callback onfocus.
\*/
document.getElementById('fake-header').onfocus = function () {
extendable.show();
header.secondState = true;
};
/\*\*
\* Обработчик события клика по кнопке добавления taskBtn.
\*/
taskBtn.onclick = function () {
/\*\*
\* Добавить новую задачу
\*/
tasks.add({title: taskInput.value});
/\*\*
\* Очистить taskInput
\*/
taskInput.value = '';
};
/\*\*
\* Обработчик событий клавиатуры на taskInput.
\*/
taskInput.onkeyup = function (event) {
/\*\*
\* При нажатии кнопки enter скрываем extendable и
\* кликаем по taskBtn (добавляем задачу).
\*/
if (event.keyCode == 13) {
extendable.hide();
header.secondState = false;
taskBtn.onclick();
}
};
/\*\*
\* Синтаксический сахар для псевдо-модели todoList.
\* firstRender - переменная обозначающая что рендеринг еще не происходил.
\* render(items) - метод для перерисовки списка задач, принимает массив задач.
\*
\* По сути я просто хочу делать так: todoList.render(tasks);
\* и взято это из ReactJS.
\*
\* Для интересующихся:
\* http://facebook.github.io/react/index.html#todoExample
\*/
var todoList = {
firstRender: true,
render: function (items) {
/\*\*
\* todoContainer получает <div id="container"></div>.
\*/
var todoContainer = document.getElementById('container');
/\*\*
\* Каждый вызов document.createElement создаёт новый DOM-элемент.
\*/
var listElement = document.createElement('ul');
/\*\*
\* У каждого DOM-элемента есть свойство innerHTML, которое
\* позволяет писать/читать HTML-код в виде чистого текста.
\*
\* В данном случае происходит полная очистка содержимого todoContainer.
\*/
todoContainer.innerHTML = '';
/\*\*
\* Вызываем map от items, тем самым мы создаем дешевый цикл по обходу
\* переданных элементов в функцию и для каждого объекта выполняем
\* создание li >
\* label >
\* input[type="checkbox"] + i + item.title.
\*/
items.map(function (item) {
var itemElement = document.createElement('li'),
itemLabel = document.createElement('label'),
itemCheck = document.createElement('input'),
itemFACheck = document.createElement('i'),
/\*\*
\* TextNode это просто текст, мы можем
\* вставлять его в какой-либо DOM-элемент.
\*/
itemText = document.createTextNode(item.title);
/\*\*
\* Указываем что itemCheck это не просто input.
\* На самом деле использовать именно checkbox
\* в данном примере не обязательно.
\*
\* Вы можете обойтись и без него, сохраняя состояние
\* в собственную переменную (смотрите ниже).
\*/
itemCheck.type = 'checkbox';
/\*\*
\* JavaScript не запрещает нам задавать у объекта
\* желаемые свойства.
\*
\* Мы будем использовать objectId в будущем - для удаления.
\* В item.\_id.$oid MongoDB присылает нам
\* создаваемый автоматически ID объекта.
\*/
itemCheck.objectId = item.\_id.$oid;
/\*\*
\* Для более красивого checkbox'а я решил
\* в процессе разработки заменить стандартный checkbox
\* на решение от Font-Awesome.
\*
\* http://fortawesome.github.io/Font-Awesome/examples/#list
\*
\* classList - это удобный регистр классов DOM-элемента.
\* classList.add - добавляет новый класс.
\* classList.remove - соответственно удаляет.
\*
\* Подробнее:
\* https://developer.mozilla.org/en-US/docs/Web/API/Element.classList
\*/
itemFACheck.classList.add('fa');
itemFACheck.classList.add('fa-square');
itemFACheck.classList.add('fa-check-fixed');
/\*\*
\* appendChild - это простой метод для добавления
\* указанного DOM-элемента внутрь текущего.
\*
\* Напоминаю структуру:
\* li >
\* label >
\* input[type="checkbox"] + i + item.title.
\*/
itemLabel.appendChild(itemCheck);
itemLabel.appendChild(itemFACheck);
itemLabel.appendChild(itemText);
itemElement.appendChild(itemLabel);
if (todoList.firstRender) {
/\*
\* Класс, добавляющий анимацию появления, но
\* только при первом рендеринге (смотрите условие выше).
\*
\* Хороший комплект готовых решений по анимации находится на:
\* http://daneden.github.io/animate.css/
\*/
itemElement.classList.add('fadeInLeft');
}
listElement.appendChild(itemElement);
/\*\*
\* Задаем обработчик для события клика на наш checkbox.
\*/
itemCheck.onclick = function (event) {
itemFACheck.classList.remove('fa-check');
itemFACheck.classList.add('fa-check-square');
/\*\*
\* textDecoration line-through зачеркивает текст.
\*/
itemLabel.style.textDecoration = 'line-through';
/\*\*
\* Берем заранее положенное свойство objectId из нашего DOM-элемента
\* и удаляем его.
\*/
tasks.remove(this.objectId);
/\*\*
\* Чистим текущее событие.
\*/
this.onclick = function () {};
};
});
/\*\*
\* Завершаем рендеринг вставляя наше сгенерированное DOM-дерево в чистый container.
\*/
todoContainer.appendChild(listElement);
if (todoList.firstRender) {
todoList.firstRender = false;
}
}
};
/\*\*
\* MongoRESTRequest - это функция, которая на простом, объектно-ориентированном
\* языке является классом, который наследуется от стандартного XMLHttpRequest.
\*
\* MongoRESTRequest принимает объект (хеш) с параметрами для MongoDB REST-сервера:
\* server - адрес сервера с http://
\* apiKey - API ключ
\* collections - путь до коллекций (для облегчения синтаксиса)
\*
\* Код ниже с пояснением:
\* var x = new MongoRESTRequest({
\* server: 'http://server/api/1', apiKey: '123', collections: '/databases/abc/collections'
\* });
\*
\* @param {{server:string, apiKey:string, collections:string}} apiConfig
\* @returns {XMLHttpRequest}
\* @constructor
\*/
var MongoRESTRequest = function (apiConfig) {
/\*\*
\* Создаем объект XMLHttpRequest.
\*/
var api = new XMLHttpRequest();
/\*\*
\* И заносим в него необходимые нам параметры.
\*/
api.server = apiConfig.server;
api.key = apiConfig.apiKey;
api.collections = apiConfig.collections;
/\*\*
\* Добавляем метод обработки события ошибки.
\*/
api.error = function () {
console.error('database connection error');
};
/\*\*
\* И регистрируем его как обработчик события error.
\*/
api.addEventListener('error', api.error, false);
/\*\*
\* Пишем основной метод обращения к REST-API
\* Методы ниже будут являться лишь синтаксической оберткой над этим методом.
\*
\* Рекомендую ознакомиться с:
\* http://docs.mongolab.com/restapi/#overview
\*
\* @param method - используемый в REST метод (GET, POST, PUT или DELETE)
\* @param resource - ресурс MongoDB, к которому мы обращаемся, например коллекция users
\* @param data - отправляемый на сервер объект, к примеру новый документ в коллекцию
\* @param callback - обработчик по готовности, который получит распарсенный JSON-ответ от сервера
\*/
api.call = function (method, resource, data, callback) {
/\*\*
\* Регистрируем наш обработчик callback.
\*/
this.onreadystatechange = function () {
if (this.readyState != 4 || this.status != 200) return;
return (callback instanceof Function) ? callback(JSON.parse(this.responseText)) : null;
};
/\*\*
\* Открываем синхронное соединение методом method на необходимый нам адрес.
\* Параметр bypass позволяет нам избежать лишнего кеширования на стороне клиента.
\*/
this.open(method, api.server
+ this.collections + '/' + resource + '?apiKey=' + this.key
+ '&bypass=' + (new Date()).getTime().toString());
/\*\*
\* Указываем, что мы будем посылать JSON в теле запроса.
\*/
this.setRequestHeader('Content-Type', 'application/json;charset=UTF-8');
/\*\*
\* Отправляем запрос.
\*/
this.send(data ? JSON.stringify(data) : null);
};
/\*\*
\* Ниже четыре метода для синтаксического сахара.
\*/
api.get = function () {
var bIsFunction = arguments[1] instanceof Function, resource = arguments[0],
data = bIsFunction ? null : arguments[1],
callback = bIsFunction ? arguments[1] : arguments[2];
return this.call('GET', resource, data, callback);
};
api.post = function () {
var bIsFunction = arguments[1] instanceof Function, resource = arguments[0],
data = bIsFunction ? null : arguments[1],
callback = bIsFunction ? arguments[1] : arguments[2];
return this.call('POST', resource, data, callback);
};
api.put = function () {
var bIsFunction = arguments[1] instanceof Function, resource = arguments[0],
data = bIsFunction ? null : arguments[1],
callback = bIsFunction ? arguments[1] : arguments[2];
return this.call('PUT', resource, data, callback);
};
/\*\*
\* Вообще в JavaScript не рекомендуется использование reserved words,
\* однако я думаю что в данном контексте это слово уместно.
\*/
api.delete = function () {
var bIsFunction = arguments[1] instanceof Function, resource = arguments[0],
data = bIsFunction ? null : arguments[1],
callback = bIsFunction ? arguments[1] : arguments[2];
return this.call('DELETE', resource, data, callback);
};
return api;
};
/\*\*
\* Задаем конфигурацию.
\*/
var config = {
server: 'https://api.mongolab.com/api/1',
apiKey: 'ключ\_API',
collections: '/databases/имя\_базы/collections'
};
/\*\*
\* Обозначаем переменную tasks как массив.
\* На самом деле мы вызываем var tasks = new Array();
\*
\* https://developer.mozilla.org/ru/docs/Web/JavaScript/Reference/Global\_Objects/Array
\*/
var tasks = [];
/\*\*
\* Создаем новый поток XMLHttpRequest из нашего MongoRESTRequest.
\* Проще говоря - делаем новый объект класса MongoRESTRequest.
\*/
var api = new MongoRESTRequest(config);
/\*\*
\* Подключаем DuelJS (что это такое читать на http://habrahabr.ru/post/247739/ ).
\*
\* На самом деле DuelJS в этом приложении АБСОЛЮТНО не требуется.
\*
\* Добавлена DuelJS в это приложение ТОЛЬКО для примера
\* возможного потенциального использования DuelJS.
\*/
var channel = duel.channel('task\_tracker');
/\*\*
\* Несмотря на то, что tasks - это массив, массив (Array) есть
\* ничто иное как объект в JS который создан из new Array.
\*
\* Добавим в объект tasks нужные нам методы, превратив его во
\* что-то, подобное Data-Mapper object.
\*
\* Метод sync будет использоваться нами для обновления данных.
\*/
tasks.sync = function () {
/\*\*
\* Основной код этого метода находится под условием if.
\* window.isMaster() - это метод DuelJS, который позволяет
\* убедиться что метод выполняется в активной вкладке, а не в фоне.
\*/
if (window.isMaster()) {
/\*\*
\* Выполняем REST-запрос на наш PaaS MongoDB сервер.
\*
\* http://docs.mongolab.com/restapi/#list-documents
\*
\* Выглядит как:
\* GET /databases/{database}/collections/tasks
\*
\* Если вы прочитали эту строчку вы молодец.
\*
\* На самом деле запроса будет ДВА, первый запрос будет с методом OPTIONS.
\* Вы сможете увидеть это, проанализировав вкладку Network
\* вашей Developer Toolbar в браузере.
\*
\* api.get('tasks', function (result) { ...
\* очень легко читается и удобно используется.
\* Оно как бы говорит "получить коллекцию tasks и работать с ней в result"
\*/
api.get('tasks', function (result) {
/\*\*
\* Отчищаем tasks, сохраняя при этом все методы и сам tasks.
\*/
tasks.splice(0);
/\*\*
\* При использовании DuelJS мы оповещаем все остальные вкладки о произошедшем событии.
\* Это сделано для экономии трафика и меньшей нагрузки на сервер.
\* Повторюсь что в данном приложении использование DuelJS практически не несет
\* смысла, и добавлено сюда лишь в целях обучения возможностям DuelJS.
\*/
channel.broadcast('tasks.sync', result);
for (var i = result.length - 1; i >= 0; i--) {
/\*\*
\* Вносим в массив поочередно объекты из result.
\* Мы делаем так потому, что не можем написать
\* tasks = result
\* так как это очистит наши методы.
\*/
tasks.push(result[i]);
}
/\*\*
\* Идея использования подобного синтаксиса пришла мне когда я начал изучать ReactJS.
\* Да простят меня за это фанаты React, но 128кб ради одного метода render -
\* я был использовать не намерен.
\*
\* React по сути компилирует свой JSX в почти что VanillaJS.
\*/
todoList.render(tasks);
});
} else {
/\*\*
\* Этот блок кода делает то же что и блок выше.
\* Выполняться он будет только на неактивных страницах.
\* Уже полученный с сервера tasks будет передан в первый (нулевой)
\* аргумент этой функции.
\*/
tasks.splice(0);
var result = arguments[0];
for (var i = result.length - 1; i >= 0; i--) {
tasks.push(result[i]);
}
todoList.render(tasks);
}
};
/\*\*
\* К сожалению я так и не реализовал использование метода
\* переименования в этом приложении.
\*
\* Даёшь НЕТ прокрастинации!
\*/
tasks.rename = function (id, title) {
for (var i = tasks.length - 1; i >= 0; i--) {
if (tasks[i].\_id.$oid === id) {
tasks[i].title = title;
todoList.render(tasks);
if (window.isMaster()) {
channel.broadcast('tasks.rename', id, title);
var api = new MongoRESTRequest(config);
/\*\*
\* Вот так просто можно отредактировать документ на сервере.
\*
\* http://docs.mongolab.com/restapi/#view-edit-delete-document
\*/
api.put('tasks/' + id, {title: title});
}
break;
}
}
};
/\*\*
\* Метод для добавления нового документа task в коллекцию tasks.
\*/
tasks.add = function (task) {
/\*\*
\* Снова проверяем активная ли это вкладка.
\* Снова повторяю что это лишь для примера использования DuelJS
\* в разработке своих приложений.
\*/
if (window.isMaster()) {
/\*\*
\* Нам потребуется два новых, отдельных потока (хотя на самом деле один).
\* Они будут заняты исключительно передачей новых документов
\* на сервер и им будет всё равно на судьбу остальных потоков.
\*
\* Первый поток будет занят новым документом task.
\* Второй поток будет занят новым документом log.
\* Использование коллекции logs для логирования показано тут
\* в целях обучения и на деле никак не обрабатывается нашим приложением.
\*
\* Если вы будете делать своё приложение на основе этого, то вы сможете
\* написать в качестве примера визулальный график создания/решения задач.
\*/
var apiThread1 = new MongoRESTRequest(config);
var apiThread2 = new MongoRESTRequest(config);
apiThread1.post('tasks', task, function (result) {
/\*\*
\* Обратите внимание что прежде чем добавить task на страницу
\* мы прежде вносим его в базу данных.
\*
\* Сделано это для получения ID документа, который сгенерирует
\* MongoDB и отдаст нам в наш callback.
\*
\* http://docs.mongolab.com/restapi/#insert-document
\*/
tasks.push(result);
channel.broadcast('tasks.add', result);
todoList.render(tasks);
});
/\*\*
\* Очень легко можно передать текущую дату и время в MongoDB.
\*/
apiThread2.post('logs', {
when: new Date(),
type: 'created'
});
} else {
/\*\*
\* Этот блок кода делает то же что и блок выше.
\* Выполняться он будет только на неактивных страницах.
\* Уже полученный с сервера task, вместе с его ID, будет передан в первый (нулевой)
\* аргумент этой функции.
\*/
tasks.push(arguments[0]);
todoList.render(tasks);
}
};
/\*\*
\* Метод ниже служит нам для удаления документов из базы по ID документа.
\*/
tasks.remove = function (id) {
/\*\*
\* Простой перебор массива tasks для поиска нужного документа.
\*/
for (var i = tasks.length - 1; i >= 0; i--) {
if (tasks[i].\_id.$oid === id) {
/\*\*
\* После того, как мы нашли документ в массиве tasks, у которого ID
\* равен искомому ID.
\*/
if (window.isMaster()) {
/\*\*
\* Делаем запрос на удаление из активного окна.
\*
\* Как и в случае с POST - мы логируем удаление и
\* поэтому нам потребуется два потока.
\*
\* Нам не требуется удалять что-то из массива, потому
\* что в нашем приложении используется автоматическое обноление
\* массива tasks, каждые 30 секунд.
\*/
var apiThread1 = new MongoRESTRequest(config);
var apiThread2 = new MongoRESTRequest(config);
apiThread1.delete('tasks/' + id);
apiThread2.post('logs', {
when: new Date(),
type: 'done'
});
}
break;
}
}
};
/\*\*
\* Простое обновление данных, с периодом в 30 секунд.
\*/
setInterval(function () {
if (window.isMaster()) {
tasks.sync();
}
}, 30000);
/\*\*
\* Так как мы используем DuelJS - зададим callbacks для событий.
\*/
channel.on('tasks.add', tasks.add);
channel.on('tasks.sync', tasks.sync);
channel.on('tasks.rename', tasks.rename);
/\*\*
\* Последнее что мы сделаем при загрузке страницы - обновим данные на ней.
\*/
tasks.sync();
```
**Как изменить цветовую схему всего проекта, поменяв всего одну переменную**В файле main.less имеется следующий код (приведен не до конца, главное понять суть):
```
@import 'palette';
@themeRed: 'red';
@themePink: 'pink';
@themePurple: 'purple';
@themeDeepPurple: 'deep-purple';
@themeIndigo: 'indigo';
@themeBlue: 'blue';
@themeLightBlue: 'light-blue';
@themeCyan: 'cyan';
@themeTeal: 'teal';
@themeGreen: 'green';
@themeLightGreen: 'light-green';
@themeLime: 'lime';
@themeYellow: 'yellow';
@themeAmber: 'amber';
@themeOrange: 'orange';
@themeDeepOrange: 'deep-orange';
@themeBrown: 'brown';
@themeGrey: 'grey';
@themeBlueGrey: 'blue-grey';
/**
* http://www.google.com/design/spec/style/color.html#color-color-palette
* thanks to https://github.com/shuhei/material-colors
*/
@theme: @themeBlueGrey;
@r50: 'md-@{theme}-50';
@r100: 'md-@{theme}-100';
@r200: 'md-@{theme}-200';
@r300: 'md-@{theme}-300';
@r400: 'md-@{theme}-400';
@r500: 'md-@{theme}-500';
@r600: 'md-@{theme}-600';
@r700: 'md-@{theme}-700';
@r800: 'md-@{theme}-800';
@r900: 'md-@{theme}-900';
@color50: @@r50;
@color100: @@r100;
@color200: @@r200;
@color300: @@r300;
@color400: @@r400;
@color500: @@r500;
@color600: @@r600;
@color700: @@r700;
@color800: @@r800;
@color900: @@r900;
@font-face {
font-family: 'Roboto Medium';
src: url('../fonts/Roboto-Regular.ttf') format('truetype');
}
body {
font-family: 'Roboto Medium', Roboto, sans-serif;
font-size: 24px;
background-color: @color900;
color: @color50;
margin: 0;
padding: 0;
}
```
Меняем `@theme` на любую из перечисленных и при этом получаем изменение темы всего приложения целиком. Раньше я не раз вытворял подобные трюки с LESS. К примеру можно делать таким образом (можете расценить это как бонус для людей, которые никогда не видели LESS):
```
@baseColor: #000000;
@textColor: contrast(@baseColor);
@someLightenColor: lighten(@baseColor, 1%);
```
#### 6. Демо готового проекта
**[-> Заветная демка тут](https://noblecode-izhevsk.github.io/cloudtasktracker/)**
**[-> Исходный код демки на GitHub](https://github.com/noblecode-izhevsk/cloudtasktracker/)** | https://habr.com/ru/post/248605/ | null | ru | null |
# Съёмка показаний счетчика на телефон с последующим распознаванием
 #### Вступление
Так сложилось, что я живу в коттеджном поселке, где нет центрального отопления, а значит, каждый греет свою квартиру самостоятельно. Чаще всего для этих целей используются газовые котлы, метод достаточно дешевый, жаловаться не на что, но есть одна тонкость. Для корректной работы газового котла (внезапно) необходимо наличие газа в трубе.
Возможно, так ведут себя не все котлы, но наш отключается даже при кратковременном перебое с подачей газа и не включается обратно, если подача восстановится. Если кто-то есть дома, то это не проблема, нажал кнопку и котел греет дальше, но если вдруг так сложилось, что мы решили всей семьей поехать в отпуск, а на дворе зима, хорошая такая, чтоб -20°C, то последствия могут быть плачевными.
Решение простое — оставить ключи родственникам/друзьям/соседям, чтобы они могли приехать и включить котел, случись какая-нибудь неприятность. Хорошо, если есть сосед, который будет каждый день заходить и проверять, всё ли в порядке. А если нет? Или он тоже решит уехать куда-нибудь на выходные?
Итак, я решил наладить выкладывание показаний счётчика куда-нибудь в Интернет, чтоб я мог находясь где-нибудь в дальней поездке периодически проверять, тратится ли газ, а если вдруг перестанет тратиться, то срочно звонить родственникам/друзьям/соседям (или кому там я оставил ключи), чтобы приехали и нажали кнопку.
Конечно, после простого выкладывания показаний в Интернет я решил не останавливаться на достигнутом и замутил ещё распознавание показаний и графическое представление, об этом читайте в части 2 данного топика.
#### Часть 1. Снятие показаний со счетчика и выкладывание их в Интернет
Здесь надо оговориться, что счётчики бывают в природе совершенно разные, некоторые из них имеют специальные шины и интерфейсы для автоматизированного съема показаний. Если у Вас такой, то дальше, наверное, можно не читать. Но у меня самый обычный без подобных интерфейсов (по крайней мере, я не нашёл, может, плохо искал), модель GALLUS iV PSC. Поэтому остается один вариант — визуальный съём показаний. В сети предлагают готовые решения, но они стоят немалых денег, а главное, это совсем не спортивно, поэтому будем делать всё сами.
##### Что нам понадобиться?
Для снятия показаний со счетчика с последующей отправкой этих показаний в интернет нам понадобится любой ненужный android смартфон. Я, например, использовал для этих целей Samsung Galaxy S III (SCH-I535). Да, наверное, не у каждого читателя есть валяющийся без дела с-третий галакси, но нужно понимать, что требования к смартфону не так уж и велики:
* он должен загружаться
* должна работать камера
* должен работать WiFi
Вот, собственно и все, наличие работающего экрана, тач-скрина, микрофона, динамика и т.п. совершенно не требуется. Данный факт значительно снижает стоимость.
Имея хобби покупать на ebay разные битые телефоны и собирать из них работающие, я легко нашел у себя в загашнике материнскую плату от sgs3 с неработающим микрофоном (~$10), а также б/у-шную камеру (~$10) и китайскую батарейку (~300р). Также для удобства крепления батарейки к плате использовал фрейм с битым дисплеем.

Сначала думал обойтись только материнской платой и камерой, но оказалось, что даже при подключении к зарядке плата не включается без батарейки, поэтому пришлось ещё добавить фрейм и батарейку. Но и в этом случае бюджет получился порядка $30, если использовать аппараты попроще sgs3, то можно уложиться и в меньшую сумму.
Правда, у такого решения есть и свои минусы, смартфон без дисплея и тачскрина не так удобно настраивать, поэтому немного расскажу о том, как пришлось решать эту проблему.
##### Настройка аппарата
Будем исходить из наихудшего сценария. Предположим, что нет ни дисплея, ни тачскрина, на смартфоне отсутствует root, adb отладка отключена, прошивка неизвестна.
###### Реанимация
**Внимание!** Дальнейшая инструкция подходит для аппарата Samsung Galaxy S III (SCH-I535), если у Вас другой смартфон, то действия могут отличаться.
Предполагается, что Вы хорошо знакомы с такими понятиями как adb, прошивки и пр.
Чтобы привести смартфон в более-менее известное нам состояние для начала прошьем стоковую прошивку VRBMB1 [отсюда](http://forum.xda-developers.com/showthread.php?t=1755386) используя [Odin](http://androidp1.ru/odin-firmware-samsung/). Не буду подробно описывать, как это делается, в Интернете полно инструкций, как пользоваться Odin-ом. Odin в нашем случае хорош тем, что с ним легко работать не используя экран смартфона, нужно только включить смартфон в режиме загрузки (Vol Down+Home+Power — подержать несколько секунд, затем Vol Up, подключить по usb к винде и всё, дальше дело Odin-а).
После того, как Odin прошьет сток, телефон загрузит систему, отключаем его от usb и вынимаем батарейку, чтобы он выключился. Эту операцию нужно делать каждый раз после завершения прошивки Odin-ом, чтобы начинать следующую операцию с выключенного состояния.
Далее шьем CWM recovery и root по [инструкции](http://www.droidviews.com/root-and-install-cwmtwrp-recovery-on-verizon-galaxy-s3-sch-i535-android-4-1-14-1-2/). Если вкратце, то так:
* Через Odin прошиваем кастомный бутчейн [VRALEC.bootchain.tar.md5](http://d-h.st/4MU)
* Через Odin прошиваем [CWM recovery](http://d-h.st/qnB)
* Через CWM recovery прошиваем [SuperSU\_Bootloader\_FIXED.zip](http://d-h.st/OXI). В инструкции написано, что zip нужно закинуть на sd-карту, но ввиду отсутствия экрана проще это сделать через sideload:
Включаем тело зажав Vol Up+Home+Power — держим несколько секунд, потом еще секунд 5 загрузка, попадаем в режим CWM-recovery.
Проверяем это, набрав в консоли в ubuntu `adb devices` (тело, само собой должно быть подключено по usb и должен быть установлен adb — `sudo apt-get install android-tools-adb`):
```
malefic@lepeshka:~$ adb devices
List of devices attached
64cb5c59 recovery
```
Если видим последнюю строчку, значит все в порядке, жмем на девайсе Vol Down, Vol Down, Power — переходим в режим adb sideload (по крайней мере в версии CWM из инструкции это вторая строчка сверху), остается только набрать в консоли ubuntu:
```
malefic@lepeshka:~$ adb sideload SuperSU_Bootloader_FIXED.zip
sending: 'sideload' 100%
```
и root улетает на девайс, после чего не забываем выключать девайс, вытащив из него батарейку.
* Через Odin прошиваем стоковый бутчейн, соответствующий поставленной до этого стоковой прошивке [VRBMB1\_Bootchain.tar.md5](http://d-h.st/nyI)
Далее нам нужно включить usb-отладку на смартфоне, для этого запускаем смартфон в режим CWM-recovery, проверяем:
```
malefic@lepeshka:~$ adb devices
List of devices attached
64cb5c59 recovery
```
Монтируем system:
```
malefic@lepeshka:~$ adb shell mount -o rw -t ext4 /dev/block/platform/msm_sdcc.1/by-name/system /system
```
Добавляем строчку в /system/build.prop:
```
malefic@lepeshka:~$ adb shell "echo \"persist.service.adb.enable=1\" >> /system/build.prop"
```
Перезагружаем:
```
malefic@lepeshka:~$ adb reboot
```
Ждем загрузки, проверяем в терминале статус adb:
```
malefic@lepeshka:~$ adb devices
List of devices attached
64cb5c59 device
```
Бинго! Отладка включена, давайте посмотрим, что там у нас творится на смартфоне, для этого запускаем [AndroidScreenCast](http://androidscreencast.googlecode.com/svn/trunk/AndroidScreencast/dist/androidscreencast.jnlp) с помощью Java Web Start и видим:
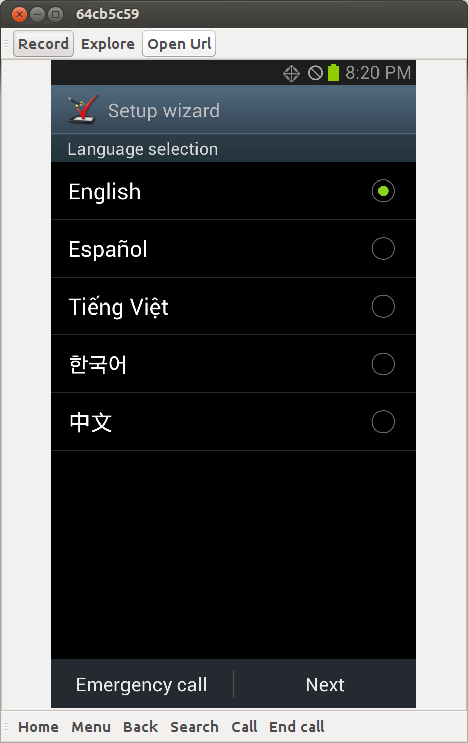
Это экран активации симкарты Verizon, у меня такой симки нет, поэтому я просто пропускаю активацию, действуя по инструкции:
> на экране выбора языка последовательно касаемся на экране левый нижний угол (над кнопкой экстренный вызов), правый нижний угол, левый нижний, правый нижний и громкость+
А именно:
```
malefic@lepeshka:~$ adb shell input tap 10 1150
malefic@lepeshka:~$ adb shell input tap 710 1150
malefic@lepeshka:~$ adb shell input tap 10 1150
malefic@lepeshka:~$ adb shell input tap 710 1150
```
затем нажимаю на смартфоне кнопку Vol Up, теперь видим:
Ставим галочку и нажимаем ОК:
```
malefic@lepeshka:~$ adb shell input tap 50 600
malefic@lepeshka:~$ adb shell input tap 650 600
```
Свайпаем, чтобы разлочить экран:
```
malefic@lepeshka:~$ adb shell input swipe 100 100 500 100
```
Теперь нужно поставить какой-нибудь vnc-сервер для Android, например, [Android VNC Server](http://4pda.ru/forum/index.php?showtopic=183128). Устанавливаем его на смартфон:
```
malefic@lepeshka:~$ adb install droid+VNC+server+v1.1RC0.apk
4055 KB/s (2084419 bytes in 0.501s)
pkg: /data/local/tmp/droid+VNC+server+v1.1RC0.apk
Success
```
Будим смартфон, так как он скорее всего уснул, пока мы устанавливали vnc-сервер, и свайпаем, чтоб разлочить экран:
```
malefic@lepeshka:~$ adb shell input keyevent 26
malefic@lepeshka:~$ adb shell input swipe 100 100 500 100
```
Запускаем vnc-сервер:
```
malefic@lepeshka:~$ adb shell am start -a android.intent.action.Main -n org.onaips.vnc/.MainActivity
```
Жмем ОК:
```
malefic@lepeshka:~$ adb shell input tap 50 900
```

Жмем Start:
```
malefic@lepeshka:~$ adb shell input tap 350 300
```
Жмем предоставить доступ:
```
malefic@lepeshka:~$ adb shell input tap 600 1000
```

Отлично, теперь пробрасываем порты через adb:
```
malefic@lepeshka:~$ adb forward tcp:5801 tcp:5801
malefic@lepeshka:~$ adb forward tcp:5901 tcp:5901
```
и заходим на смартфон через браузер или любимый vnc клиент.
Далее работаем как с обычным Android телефоном, только через компьютер, удобно сразу настроить WiFi подключение, тогда можно будет заходить по vnc через WiFi, а не держать телефон всё время подключенным к компьютеру (ведь газовый счётчик не всегда расположен в непосредственной близости от компьютера).
Теперь, когда взаимодействие с девайсом полностью налажено, можно перейти к настройке фотосъемки и публикации данных в Интернет.
###### Периодическая фотосъемка
Устанавливаем приложение [Tasker](http://4pda.ru/forum/index.php?showtopic=173935), создаем в нем временной профиль с 00:00 до 23:59 каждые 30 минут выполнять действие — делать фото. Параметры съемки подбираем наиболее подходящие для расположения телефона и счётчика. У меня это макросъемка с обязательной вспышкой.
Вот так, собственно, я расположил свой телефон (вид сверху):

Картонная коробка, привязанная к счетчику веревочкой, в ней живет смартфон, упаковка от яиц там для фиксации смартфона в вертикальном положении. Затем я ещё доработал конструкцию с помощью скотча и картона, чтобы вспышка не била напрямую в циферблат, это дает серьезные блики, мешающие распознаванию. Сверху закрыл все крышкой, чтобы внутри было темно, иначе при ярком внешнем освещении не всегда правильно срабатывает автофокус.
В настройках смартфона в средствах разработчика обязательно надо поставить галочку, чтоб смартфон не засыпал при подключенной зарядке, а то в какой-то момент он перестает фотографировать и продолжает только если его потревожить.
###### Выкладываем в Интернет
Для перемещения отснятых изображений счётчика в Интернет я использовал первое попавшееся приложение — [FolderSync Lite](https://play.google.com/store/apps/details?id=dk.tacit.android.foldersync.lite). Оно умеет синхронизировать папку на смартфоне с папкой, например, на Google диске.
Таким образом, я теперь могу из любой точки мира, где есть Интернет, зайти в свой Google диск и проверить, что газовый котёл работает в штатном режиме.
#### Часть 2. Распознавание показаний
Итак, после отправки показаний счётчика в Интернет, меня заинтересовала возможность автоматического распознавания показаний. Это позволит:
* проводить статистический анализ потребления газа
* автоматически отслеживать перебои с подачей газа (с возможностью предупреждения по e-mail или sms)
В качестве языка разработки был выбран python, для работы с изображениями использовалась библиотека [OpenCV](http://docs.opencv.org/trunk/doc/py_tutorials/py_tutorials.html).
Вот код основной программы, которая запускается по крону раз в час:
```
import sys
import os
from models import getImage, sess
from gdrive import getImagesFromGDrive, createImageFromGDriveObject
if __name__ == '__main__':
# получаем список новых фото с гугл диска
images, http = getImagesFromGDrive()
# поочередно обрабатываем их в цикле
for img_info in images:
# скачиваем изображение
img = createImageFromGDriveObject (img_info, http)
file_name = img_info['title']
# ищем запись в базе
try:
dbimage = getImage(os.path.basename(file_name))
dbimage.img = img
dbimage.download_url = img_info["downloadUrl"]
dbimage.img_link = img_info['webContentLink'].replace('&export=download','')
except ValueError as e:
print e
continue
# распознаем показания
dbimage.identifyDigits()
# сохраняем данные в базу
sess.commit()
```
Здесь используются функции, код которых я выложу ниже:
* `getImagesFromGDrive` — функция, возвращающая список ещё не распознанных изображений с Google Диска
* `createImageFromGDriveObject` — функция, скачивающая само изображение и преобразующая его в формат OpenCV
* `getImage` — функция ищет запись об изображении в базе данных, если таковой нет, то создает её
* `identifyDigits` — метод, распознающий показания на данном изображении
* `http` — авторизованный клиент для доступа к Google Диску, подробно про доступ к API Диска читаем [здесь](https://developers.google.com/drive/web/quickstart/quickstart-python)
* `sess` — объект подключения к базе данных, используется библиотека [SQL Alchemy](http://www.sqlalchemy.org/)
##### Работа с Google Диском
Первое, что мы делаем, это получаем с Google Диска список изображений:
```
import os
from datetime import tzinfo, timedelta, date
from dateutil.relativedelta import relativedelta
from apiclient.discovery import build
from models import getLastRecognizedImage
def getImagesFromGDrive():
# определяем id папки Google Диска, в которой лежат изображения
FOLDER_ID = '0B5mI3ROgk0mJcHJKTm95Ri1mbVU'
# создаем объект авторизованного клиента
http = getAuthorizedHttp()
# объект сервиса Диска
drive_service = build('drive', 'v2', http=http)
# для начала удаляем с Диска все изображения старше месяца, они нам уже не интересны
month_ago = date.today() + relativedelta( months = -1 )
q = "'%s' in parents and mimeType = 'image/jpeg' and trashed = false and modifiedDate<'%s'" % (FOLDER_ID, month_ago.isoformat())
files = drive_service.files().list(q = q, maxResults=1000).execute()
for image in files.get('items'):
drive_service.files().trash(fileId=image['id']).execute()
# теперь делаем запрос к базе, возвращающий последнее распознанное изображение
last_image = getLastRecognizedImage()
# получаем с Диска список изображений, дата изменения которых больше даты съемки последнего распознанного изображения
page_size = 1000
result = []
pt = None
# так как API Диска не позволяет за раз получить более 1000 изображений,
# то скачиваем список постранично по 1000 штук и складываем в один массив
while True:
q = "'%s' in parents and trashed = false and mimeType = 'image/jpeg' and modifiedDate>'%s'" % (FOLDER_ID, last_image.check_time.replace(tzinfo=TZ()).isoformat('T'))
files = drive_service.files().list(q = q, maxResults=page_size, pageToken=pt).execute()
result.extend(files.get('items'))
pt = files.get('nextPageToken')
if not pt:
break
# переворачиваем список, чтобы обработка шла в порядке времени съемки
result.reverse()
return result, http
```
Авторизованный клиент Диска создается следующим образом:
```
import httplib2
import ConfigParser
from oauth2client.client import OAuth2WebServerFlow
from oauth2client.file import Storage
def getAuthorizedHttp():
# достаем из файла config.ini записанные там CLIENT_ID и CLIENT_SECRET
config = ConfigParser.ConfigParser()
config.read([os.path.dirname(__file__)+'/config.ini'])
CLIENT_ID = config.get('gdrive','CLIENT_ID')
CLIENT_SECRET = config.get('gdrive','CLIENT_SECRET')
# OAuth 2.0 scope that will be authorized.
# Check https://developers.google.com/drive/scopes for all available scopes.
OAUTH_SCOPE = 'https://www.googleapis.com/auth/drive'
# Redirect URI for installed apps
REDIRECT_URI = 'urn:ietf:wg:oauth:2.0:oob'
# в файле client_secrets.json будем хранить токен
storage = Storage(os.path.dirname(__file__) + '/client_secrets.json')
credentials = storage.get()
# если в файле ничего нет, то запускаем процедуру авторизации
if not credentials:
# Perform OAuth2.0 authorization flow.
flow = OAuth2WebServerFlow(CLIENT_ID, CLIENT_SECRET, OAUTH_SCOPE, REDIRECT_URI)
authorize_url = flow.step1_get_authorize_url()
# выводим в консоль ссылку, по которой надо перейти для авторизации
print 'Go to the following link in your browser: ' + authorize_url
# запрашиваем ответ
code = raw_input('Enter verification code: ').strip()
credentials = flow.step2_exchange(code)
# сохраняем токен
storage.put(credentials)
# создаем http клиент и авторизуем его
http = httplib2.Http()
credentials.authorize(http)
return http
```
Для получения CLIENT\_ID и CLIENT\_SECRET в [Google Developers Console](https://console.developers.google.com/project) нужно создать проект и для этого проекта в разделе **APIs & auth** — **Credentials** — **OAuth** нажать **CREATE NEW CLIENT ID**, там выбрать **Installed application** — **Other**:
При первом запуске скрипт напишет в консоли url по которому нужно перейти, чтобы получить токен, вставляем его в адресную строку браузера, разрешаем доступ приложения к Google Диску, копируем выданный гуглом верификационный код из браузера и отдаем скрипту. После этого скрипт сохранит все необходимое в файл `client_secrets.json` и при последующих запусках не будет ничего спрашивать.
Функция скачивания изображения предельно проста:
```
import cv2
import numpy as np
def downloadImageFromGDrive (downloadUrl, http=None):
if http==None:
http = getAuthorizedHttp()
# Скачиваем изображение
resp, content = http.request(downloadUrl)
# Создаем объект изображения OpenCV
img_array = np.asarray(bytearray(content), dtype=np.uint8)
return cv2.imdecode(img_array, cv2.IMREAD_COLOR)
def createImageFromGDriveObject (img_info, http=None):
return downloadImageFromGDrive(img_info['downloadUrl'], http)
```
##### Поиск показаний на фото
Первое, что необходимо сделать, после того, как мы получили фото, это найти на нём цифры, которые мы будем распознавать. Этим занимается метод `extractDigitsFromImage`:
```
def extractDigitsFromImage (self):
img = self.img
```
Изначально фото выглядит вот так:

Поэтому сначала мы его поворачиваем, чтобы оно приобрело нужную ориентацию.
```
# вращаем на 90 градусов
h, w, k = img.shape
M = cv2.getRotationMatrix2D((w/2,h/2),270,1)
img = cv2.warpAffine(img,M,(w,h))
```

```
# обрезаем черные поля, появившиеся после вращения
img = img[0:h, (w-h)/2:h+(w-h)/2]
h, w, k = img.shape
```
Теперь рассмотрим кусочек изображения, обведённый красной рамкой. Он достаточно уникален в пределах всего фото, можно использовать его для поиска циферблата. Я положил его в файл `sample.jpg` и написал следующий код для нахождения его координат:
```
# загружаем искомый кусочек фото из файла
sample = cv2.imread(os.path.dirname(__file__)+"/sample.jpg")
sample_h, sample_w, sample_k = sample.shape
# ищем наилучшее совпадение его с фото
res = cv2.matchTemplate(img,sample,cv2.TM_CCORR_NORMED)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
# вычисляем координаты центра наилучшего совпадения
x_center = max_loc[0] + sample_w/2
y_center = max_loc[1] + sample_h/2
# этот небольшой кусок кода обрезает левую часть фото, если найденная точка оказалось слишком справа,
# чтобы циферблат оказался примерно по середине фото
if x_center>w*0.6:
img = img[0:h, 0.2*w:w]
h, w, k = img.shape
x_center = x_center-0.2*w
```

Точкой на рисунке обозначены найденные координаты, то, что мы и хотели. Далее запускаем алгоритм поиска границ, предварительно переведя изображение в серые тона. 100 и 200 — значения пороговых значений, подобранные эмпирически.
```
# переводим изображение в градации серого
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
# ищем границы алгоритмом Canny
edges = cv2.Canny(gray, 100, 200)
```
Теперь запускаем алгоритм поиска линий на полученном изображении с границами. Кроме самого изображения метод `HoughLines` также принимает в качестве параметров величины шагов поиска по расстоянию и углу поворота и пороговое значение отвечающее за минимальное кол-во точек, которые должны образовать линию. Чем меньше этот порог, тем больше линий найдёт алгоритм.
```
# находим прямые линии
lines = cv2.HoughLines(edges, 1, np.pi/180, threshold=100)
```

Из всех найденных линий рассматриваем только более-менее горизонтальные и находим две наиболее приближенные к обнаруженному ранее центру (одну сверху, другую снизу).
```
# инициализируем необходимые переменные
rho_below = rho_above = np.sqrt(h*h+w*w)
line_above = None
line_below = None
for line in lines:
rho,theta = line[0]
sin = np.sin(theta)
cos = np.cos(theta)
# выбрасываем не горизонтальные линии
if (sin<0.7):
continue
# вычисляем ро для линии параллельной текущей линии, но проходящей через "центральную" точку
rho_center = x_center*cos + y_center*sin
# сравниваем с ближайшей линией сверху
if rho_center>rho and rho_center-rho1.7 or rho\_below/rho\_above<0.6:
mylogger.warn("Wrong lines found: %f" % (rho\_below/rho\_above))
return False
```

Поворчиваем изображение так, чтобы найденные линии стали совсем горизонтальными:
```
# поворачиваем
M = cv2.getRotationMatrix2D((0,(line_below["rho"]-line_above["rho"])/2+line_above["rho"]),line_above["theta"]/np.pi*180-90,1)
img = cv2.warpAffine(img,M,(w,h))
```

Теперь обрежем все, что находится за найденными линиями:
```
# обрезаем
img = img[line_above["rho"]:line_below["rho"], 0:w]
h, w, k = img.shape
```

Далее нам нужно найти левый и правый край циферблата, переводим изображение в черно-белое:
```
# бинаризируем изображение
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
thres = cv2.adaptiveThreshold(gray,255,cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 31, 2)
```

Правый край ищем по той же технологии, что и «центральную» точку, шаблон обведён красной рамкой:
```
sample_right = cv2.imread(os.path.dirname(__file__)+"/sample_right.jpg",cv2.IMREAD_GRAYSCALE)
# определяем наилучшее совпадение с шаблоном
res = cv2.matchTemplate(thres,sample_right,cv2.TM_CCORR_NORMED)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
# вычисляем правую границу
x_right = max_loc[0]-6
```
Для поиска левой границы применим преобразование закрытия для удаления шума:
```
# удаляем шум
kernel = np.ones((7,7),np.uint8)
thres = cv2.morphologyEx(thres, cv2.MORPH_CLOSE, kernel)
```

Далее будем перебирать все пиксели начиная с самого левого, пока не встретиться черный, это и будет левый край:
```
# ищем левый край
x_left=0
while x_left
```

Обрежем изображение по левому и правому краю:
```
# обрезаем слева и справа
img = img[:, x_left:x_right]
h, w, k = img.shape
```
Проведём небольшую проверку, что найденное изображение по соотношению сторон соответствует циферблату:
```
# проверяем соотношение сторон
if float(w)/float(h)<6.5 or float(w)/float(h)>9.5:
mylogger.warn("Image has bad ratio: %f" % (float(w)/float(h)))
return False
self.digits_img = img
return True
```
##### Разбиение на цифры
Разбиением выделенного предыдущей функцией циферблата на отдельные цифры занимается метод `splitDigits`:
```
def splitDigits (self):
# проверяем, если циферблат ещё не выделен, то делаем это
if None == self.digits_img:
if not self.extractDigitsFromImage():
return False
img = self.digits_img
h, w, k = img.shape
```
Для начала просто разрежем наш циферблат на 8 равных частей:

Обрабатывать будем только первые 7 частей, так как 8-я цифра постоянно крутится, её бесполезно распознавать.
Каждую часть переводим в ч/б цвет используя метод `adaptiveThreshold`, параметры подобраны эмпирически:
```
# разбиваем циферблат на 8 равных частей и обрабатываем каждую часть
for i in range(1,8):
digit = img[0:h, (i-1)*w/8:i*w/8]
dh, dw, dk = digit.shape
# переводим в ч/б
digit_gray = cv2.cvtColor(digit,cv2.COLOR_BGR2GRAY)
digit_bin = cv2.adaptiveThreshold(digit_gray,255,cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 9, 0)
```

Немного удаляем шум с помощью преобразования открытия (используется ядро всего 2х2). Без этого можно было бы и обойтись, но иногда это помогает отрезать от цифры большие белые куски подсоединённые тонкими перемычками:
```
# удаляем шум
kernel = np.ones((2,2),np.uint8)
digit_bin = cv2.morphologyEx(digit_bin, cv2.MORPH_OPEN, kernel)
```

Запускаем алгоритм поиска контуров
```
# ищем контуры
other, contours, hierarhy = cv2.findContours(digit_bin.copy(),cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)
```

Далее выбросим все слишком маленькие контуры и контуры по краям изображения, потом найдём самый большой контур из оставшихся:
```
# анализируем контуры
biggest_contour = None
biggest_contour_area = 0
for cnt in contours:
M = cv2.moments(cnt)
# пропускаем контуры со слишком маленькой площадью
if cv2.contourArea(cnt)<30:
continue
# пропускаем контуры со слишком маленьким периметром
if cv2.arcLength(cnt,True)<30:
continue
# находим центр масс контура
cx = M['m10']/M['m00']
cy = M['m01']/M['m00']
# пропускаем контур, если центр масс находится где-то с краю
if cx/dw<0.3 or cx/dw>0.7:
continue
# находим наибольший контур
if cv2.contourArea(cnt)>biggest_contour_area:
biggest_contour = cnt
biggest_contour_area = cv2.contourArea(cnt)
biggest_contour_cx = cx
biggest_contour_cy = cy
# если не найдено ни одного подходящего контура, то помечаем цифру не распознанной
if biggest_contour==None:
digit = self.dbDigit(i, digit_bin)
digit.markDigitForManualRecognize (use_for_training=False)
mylogger.warn("Digit %d: no biggest contour found" % i)
continue
```

Самый большой контур это и есть наша цифра, выбросим всё, что лежит за его пределами с помощью наложения маски:
```
# убираем всё, что лежит за пределами самого большого контура
mask = np.zeros(digit_bin.shape,np.uint8)
cv2.drawContours(mask,[biggest_contour],0,255,-1)
digit_bin = cv2.bitwise_and(digit_bin,digit_bin,mask = mask)
```

Теперь опишем вокруг каждой цифры прямоугольник стандартного размера с центром в центре масс контура:
```
# задаем параметры описывающего прямоугольника
rw = dw/2.0
rh = dh/1.4
# проверяем, чтобы прямоугольник не выходил за пределы изображения
if biggest_contour_cy-rh/2 < 0:
biggest_contour_cy = rh/2
if biggest_contour_cx-rw/2 < 0:
biggest_contour_cx = rw/2
```

Обрезаем изображение по прямоугольнику и масштабируем до заданного размера, у меня это `digit_base_h = 2`4, `digit_base_w = 16`. Результат сохраняем в базу.
```
# вырезаем прямоугольник
digit_bin = digit_bin[int(biggest_contour_cy-rh/2):int(biggest_contour_cy+rh/2), int(biggest_contour_cx-rw/2):int(biggest_contour_cx+rw/2)]
# изменяем размер на стандартный
digit_bin = cv2.resize(digit_bin,(digit_base_w, digit_base_h))
digit_bin = cv2.threshold(digit_bin, 128, 255, cv2.THRESH_BINARY)[1]
# сохраняем в базу
digit = self.dbDigit(i, digit_bin)
return True
```

##### Распознавание цифр
Вот метод `identifyDigits`, который вызывается из основной программы для каждого изображения:
```
def identifyDigits(self):
# если число уже распознано, то ничего не делаем
if self.result!='':
return True
# если цифры ещё не выделены
if len(self.digits)==0:
# если изображение не задано, то ничего не получится
if self.img == None:
return False
# выделяем цифры
if not self.splitDigits():
return False
# утверждаем изменения в базу, которые сделаны при выделении цифр
sess.commit()
# пытаемся распознать каждую цифру
for digit in self.digits:
digit.identifyDigit()
# получаем текстовые значения цифр
str_digits = map(str,self.digits)
# если хотя бы одна цифра не распознана, то показание также не может быть распознано
if '?' in str_digits:
return False
# склеиваем все цифры для получения числа
self.result = ''.join(str_digits)
return True
```
Тут все тривиально, кроме метода `identifyDigit`:
```
def identifyDigit (self):
# если цифра уже распознана, то ничего не делаем
if self.result!='?':
return True
if not KNN.recognize(self):
# если не удалось распознать цифру, то помечаем её для ручной обработки
self.markDigitForManualRecognize()
# если это 7-я цифра, то считаем её равной "0", так как это последняя цифра и не критичная, а часто бывает, что она не распознается
if self.i==7:
self.result = 0
return True
return False
else:
self.use_for_training = True
return True
```
Метод `identifyDigit` тоже тривиален, распознавание происходит в методе `KNN.recognize`, используется алгоритм поиска ближайших соседей из OpenCV:
```
@staticmethod
def recognize(dbdigit):
# тренируем, если ещё не тренирован
if not KNN._trained:
KNN.train()
# проверяем размер изображения, если не правильный, то не пытаемся распознать
h,w = dbdigit.body.shape
if h!=digit_base_h or w!=digit_base_w:
dbdigit.markDigitForManualRecognize(use_for_training=False)
mylogger.warn("Digit %d has bad resolution: %d x %d" % (dbdigit.i,h,w))
return False
# преобразуем двумерное бинарное изображение в одномерный массив
sample = dbdigit.body.reshape(digit_base_h*digit_base_w).astype(np.float32)
test_data = np.array([sample])
# запускаем метод определения ближайших соседей, кол-во соседей - 5
knn = KNN.getKNN()
ret,result,neighbours,dist = knn.find_nearest(test_data,k=5)
# фильтруем вероятно неверные результаты
if result[0,0]!=neighbours[0,0]:
# результат не равен наиболее похожей цифре
dbdigit.markDigitForManualRecognize()
return False
if neighbours[0,1]!=neighbours[0,0] or neighbours[0,2]!=neighbours[0,0]:
# три наиболее похожих цифры не равны между собой
dbdigit.markDigitForManualRecognize()
return False
if dist[0,0]>3000000 or dist[0,1]>3500000 or dist[0,2]>4000000:
# расхождения с тремя наиболее похожими цифрами слишком большие
dbdigit.markDigitForManualRecognize()
return False
# если всё в порядке, то считаем распознавание удачным и сохраняем результат
dbdigit.result = str(int(ret))
return True
```
Тренировка описана в методе `KNN.train`:
```
@staticmethod
def getKNN():
# метод обеспечивает единстенную инициализацию объекта cv2.KNearest
if KNN._knn==None:
KNN._knn = cv2.KNearest()
return KNN._knn
@staticmethod
def train():
knn = KNN.getKNN()
# достаем из базы распознанные цифры для тренировки
train_digits = sess.query(Digit).filter(Digit.result!='?').filter_by(use_for_training=True).all()
train_data = []
responses = []
for dbdigit in train_digits:
h,w = dbdigit.body.shape
# пропускаем цифры плохого размера
if h*w != digit_base_h*digit_base_w:
continue
# преобразуем в одномерный массив
sample = dbdigit.body.reshape(digit_base_h*digit_base_w).astype(np.float32)
train_data.append(sample)
responses.append(int(dbdigit.result))
# тренируем KNN
knn.train(np.array(train_data), np.array(responses))
KNN._trained = True
```
Привожу выдержку из файла `models.py`, если у читателя остались вопросы по работе некоторых использованных, но не описанных функций.
**Отсутствующие в статье описания функций и методов**
```
import datetime
from sqlalchemy import Column, Integer, String, Text, Boolean, ForeignKey, DateTime, PickleType
from sqlalchemy.orm import relationship
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
import base64
import cv2
import numpy as np
import os
import logging
import sys
dbengine = create_engine('sqlite:///' + os.path.dirname(__file__) + '/../db/images.db', echo=False)
Session = sessionmaker(bind=dbengine)
sess = Session()
Base = declarative_base()
# image class
class Image(Base):
__tablename__ = 'images'
id = Column(Integer, primary_key=True)
file_name = Column(String)
img_link = Column(Text)
download_url = Column(Text)
check_time = Column(DateTime)
result = Column(String(8))
digits = relationship("Digit", backref="image")
img = None # source image
digits_img = None # cropped source image
def __init__(self, file_name):
self.file_name = file_name
self.check_time = datetime.datetime.strptime(file_name, "gaz.%Y-%m-%d.%H.%M.%S.jpg")
self.result = ""
def __repr__(self):
return "" % (self.id, self.file_name, self.result)
def dbDigit(self, i, digit_img):
digit = sess.query(Digit).filter_by(image_id=self.id).filter_by(i=i).first()
if not digit:
digit = Digit(self, i, digit_img)
sess.add(digit)
else:
digit.body = digit_img
return digit
## некоторый код остутствует
# digit class
class Digit(Base):
__tablename__ = 'digits'
id = Column(Integer, primary_key=True)
image_id = Column(Integer, ForeignKey("images.id"))
i = Column(Integer)
body = Column(PickleType)
result = Column(String(1))
use_for_training = Column(Boolean)
def __init__(self, image, i, digit_img):
self.image_id = image.id
self.i = i
self.body = digit_img
self.markDigitForManualRecognize()
def __repr__(self):
return "%s" % self.result
def markDigitForManualRecognize (self, use_for_training=False):
self.result = '?'
self.use_for_training = use_for_training
def getEncodedBody (self):
enc = cv2.imencode('.png',self.body)[1]
b64 = base64.b64encode(enc)
return b64
## некоторый код остутствует
Base.metadata.create_all(bind=dbengine)
# function to get Image object by file_name and img
def getImage(file_name):
image = sess.query(Image).filter_by(file_name=file_name).first()
if not image:
image = Image(file_name)
sess.add(image)
# store image object to base
sess.commit()
image.digits_img = None
return image
def getLastRecognizedImage():
return sess.query(Image).filter(Image.result!='').order_by(Image.check_time.desc()).first()
def dgDigitById(digit_id):
digit = sess.query(Digit).get(digit_id)
return digit
```
Для анализа показаний и ручного распознавания я написал также небольшой web-интерфейс на фреймворке [Flask](http://ru.wikibooks.org/wiki/Flask). Приводить код я здесь не буду, кому интересно, тот может посмотреть его, а также весь остальной код на [Github](https://github.com/maleficxp/gaz-counter).
Интерфейс имеет всего две страницы, одна для просмотра показаний в виде графика, например, за день или за неделю:
Вторая страница для ручного распознавания цифр. После того, как я руками вбил первые 20-30 показаний, робот стал довольно исправно распознавать показания сам. Изредка исключения все-таки встречаются и распознать цифру не удаётся, это чаще всего связано с вращением циферблата:



Тогда приходится вводить пропущенные цифры руками:
Либо можно такие показания просто игнорировать, они будут пропущены на графике, и ничего плохого не случится.
В планах ещё доработать скрипт, чтобы отправлял e-mail в случае совпадения нескольких последних показаний.
Вот и всё, о чём хотел рассказать, спасибо, если дочитали до конца. | https://habr.com/ru/post/220869/ | null | ru | null |
# Легальный взлом как разминка для ума
IT-шники часто придумывают себе упражнения для ума, пытливый ум постоянно требует разминки. Хочу рассказать об одном из самых жестких и спорных способах – взлом специально защищенных программ-головоломок (Часто их называют crackme).
Одно из мест, где такие головоломки собраны — [crackmes.de](http://crackmes.de).
Здесь находятся много интересных программ, на которых можно испробовать свои силы по взлому. Никакого криминала – программы специально написаны для этой цели (так называемые crackme и reverseme);
Часто любят говорить «Все защиты можно взломать». Поковыряв некоторые из crackme вы возможно измените своё мнение.
#### Итак приступим:
Общая схема работы многих crackme — а давайте какую-то процеду в коде зашифруем, и «верный-неверный пароль» — в зависимости от сделанного хеша из расшифрованных этим паролем данных?
Или как вариент — заюзаем SEH (Structured Exception Handling – механизм обработки аппаратных и программных исключений), в который положим месседжбокс о плохом пароле, перед этим передав управление на наш «расшифрованный» код, при этом если пароль – правильный, то в расшифрованном коде будут «верные» опкоды команд, а если нет, то процессор сгенерит исключение о неверном опкоде и «кошерно» задействует SEH, в котором у нас стоит уведомление об ошибке. Надо сказать, что в общем этот вариант не «святой» поскольку после расшифровки возможны и «полувалидные» опкоды- к примеру jmp-команда за пределами этой нашей процедуры.
Но на первых порах и этого достаточно.
Итак берём крекми отсюда: [crackmes.de/users/sharpe/unlockme\_crackme\_8\_by\_sharpe/download](http://crackmes.de/users/sharpe/unlockme_crackme_8_by_sharpe/download) или отсюда:
[crackmes.de/users/sharpe/unlockme\_crackme\_7\_by\_sharpe/download](http://crackmes.de/users/sharpe/unlockme_crackme_7_by_sharpe/download) (седьмой, кстати, не взломан пока) и загружаем в дебаггер- я использовал олю (OllyDBG)- програмка – очень маленькая- сегмент кода всего 0х2В6=694 байта, очень легко найти часть кода отвечающего за чтение пароля:
````
0040107F |. 3D F3030000 CMP EAX,3F3
00401084 |. 75 4E JNZ SHORT 004010D4
00401086 |. 6A 21 PUSH 21 ; /Count = 21 (33.)
00401088 |. 68 88314000 PUSH 403188 ; |Buffer = eight.00403188
0040108D |. 68 F1030000 PUSH 3F1 ; |ControlID = 3F1 (1009.)
00401092 |. FF75 08 PUSH DWORD PTR SS:[EBP+8] ; |hWnd
00401095 |. E8 04020000 CALL 0040129E ; \GetDlgItemTextA
0040109A |. 83F8 07 CMP EAX,7 здесь сравниваем длину пароля
0040109D |. 76 1F JBE SHORT 004010BE переход на смерть
0040109F |. 83F8 20 CMP EAX,20 здесь тоже сравниваем длину пародя
004010A2 |. 73 1A JNB SHORT 004010BE
004010A4 |. E8 D9000000 CALL 00401182 преобразователь пароля
004010A9 |. FF75 08 PUSH DWORD PTR SS:[EBP+8]
004010AC |. E8 FD000000 CALL 004011AE расшифровщтк кода
004010B1 |. FF75 08 PUSH DWORD PTR SS:[EBP+8]
004010B4 |. E8 61010000 CALL 0040121A не интересно
004010B9 |. E9 85000000 JMP 00401143 ; eight.00401143
004010BE |> 6A 30 PUSH 30 а здесь прыгать не надо)))
004010C0 |. 68 34314000 PUSH 403134 ; |Title = "-=[ Unlock Code Error"
004010C5 |. 68 4A314000 PUSH 40314A ; |Text = "The entered Unlock Code is invalid.
004010CA |. FF75 08 PUSH DWORD PTR SS:[EBP+8] ; |hOwner
004010CD |. E8 D8010000 CALL 004012AA ; \MessageBoxA
004010D2 |. EB 6F JMP SHORT 00401143 ; eight.00401143
````
Итак, на основании этого видим что длина пароля долна быть в диапазоне 8-32 знака, и если это так то прыгаем в функцию преобразования изначального пароля:
````
00401182 /$ 57 PUSH EDI
00401183 |. 33FF XOR EDI,EDI
00401185 |. BE 88314000 MOV ESI,403188 ; здесь в регистр пишем указатель на пароль
0040118A |. B9 20000000 MOV ECX,20
0040118F |. C705 A8314000 >MOV DWORD PTR DS:[4031A8],0 ;здесь мы запишем преобразован «хеш»
00401199 |> AC /LODS BYTE PTR DS:[ESI]
0040119A |. 85C0 |TEST EAX,EAX
0040119C |. 74 08 |JE SHORT 004011A6 ; eight.004011A6
0040119E |. 8BC8 |MOV ECX,EAX ;здесь мы сохраним «хеш» с пароля
004011A0 |. 03F8 |ADD EDI,EAX ;процедура преобразования пароля
004011A2 |. D3C7 |ROL EDI,CL ; процедура преобразования пароля
004011A4 |.^EB F3 \JMP SHORT 00401199 ; eight.00401199
004011A6 |> 893D A8314000 MOV DWORD PTR DS:[4031A8],EDI; сохраняем и выходим
004011AC |. 5F POP EDI
004011AD \. C3 RETN
````
А вот здесь живет расшифровщик кода:
````
004011AE /$ 55 PUSH EBP
004011AF |. 8BEC MOV EBP,ESP
004011B1 |. 83EC 04 SUB ESP,4
004011B4 |. 68 88314000 PUSH 403188 ; здесь вновь проверяем длину пароля
004011B9 |. E8 C2000000 CALL 00401280 ; но это – не обязательно
004011BE |. 8945 FC MOV DWORD PTR SS:[EBP-4],EAX
004011C1 |. 837D FC 01 CMP DWORD PTR SS:[EBP-4],1
004011C5 |. 77 16 JA SHORT 004011DD ; eight.004011DD
004011C7 |. 6A 30 PUSH 30
004011C9 |. 68 34314000 PUSH 403134 ; |Title = "-=[ Unlock Code Error"
004011CE |. 68 4A314000 PUSH 40314A ; |Text = "The entered Unlock Code is invalid.
004011D3 |. FF75 08 PUSH DWORD PTR SS:[EBP+8] ; |hOwner
004011D6 |. E8 CF000000 CALL 004012AA ; \MessageBoxA
004011DB |. EB 1E JMP SHORT 004011FB ; eight.004011FB
004011DD |> B8 49114000 MOV EAX,401149 ; А вот здесь начинается расшифровка пароля
004011E2 |. B9 7F114000 MOV ECX,40117F
004011E7 |. 2BC8 SUB ECX,EAX
004011E9 |. 33DB XOR EBX,EBX
004011EB |> 8B1418 /MOV EDX,DWORD PTR DS:[EAX+EBX]
004011EE |. 3315 A8314000 |XOR EDX,DWORD PTR DS:[4031A8]; как видем простая ксор-функция
004011F4 |. 891418 |MOV DWORD PTR DS:[EAX+EBX],EDX
004011F7 |. 43 |INC EBX
004011F8 |. 49 |DEC ECX
004011F9 |.^75 F0 \JNZ SHORT 004011EB ; и выходим
004011FB |> C9 LEAVE
004011FC \. C2 0400 RETN 4
````
Итак, теперь понятно: но как найти правильный хеш-код?
Перебором?
Это очень долго: надо сначала расшифровать, потом посчитать «энтропию» полученного кода и возможно код с минимумом «энтропии»- рабочий, но для этого надо писать или использовать уже написанные дизассемблерные движки;
а можно использовать SEH, в теле которого прописать код брумфорсера, но тогда даже одна «ложно-правильная» инструкция может полностю изменить верный ход исполнения программы.
Но я заметил, что хоть программа написана на чистом ассемблере, но автор всё-же много использовал в своём коде «открытие» стека, поэтому давайте думать, что первые правильные 4 байта в нашем «зашифрованном» коде:
````
PUSH EBP
MOV EBP,ESP
````
Значение: 0х55, 0х8В, 0хЕС
А сейчас(до прохождения процедуры шифрования) значения: 0x66, 0x71, 0x77, но мы же помним (можем посмотреть) свойства «ксор» функции и увидеть что тогда конечный хеш станет извесным:
Не забываем о «little-endian» соглашении:
````
77 71 66 ^
АА ВВ СС ^
ВВ СС ^
СС
**********
ЕС 8В 55
````
Итак, посчитав это дело в «Калькуляторе» мы видем, что СС=0х33; ВВ=0хС9; АА=0х61,
Полученная последовательность: ХХ61C93.
Последний байт, к сожалению, пришлось искать перебором с использованием «self-keygening»a (патчинга бинарника), и в конце получаем: E961C933.
А расшифрованная процедура в действительности содержит много мусора(«обфускация»)
Но «открытие стека» нас спасло, и расшифрованая процедура (в теле):
````
00401149 $ 55 PUSH EBP
0040114A . 8BEC MOV EBP,ESP
0040114C . D3C8 ROR EAX,CL
0040114E . 58 POP EAX
0040114F . EB 04 JMP SHORT 00401155 ; eight.00401155
00401151 D6 DB D6
00401152 FE DB FE
00401153 . 32C9 XOR CL,CL
00401155 > BE 9C314000 MOV ESI,40319C ; ASCII "Secret: Marius!"
0040115A . C706 53656372 MOV DWORD PTR DS:[ESI],72636553
00401160 . C746 04 65743A>MOV DWORD PTR DS:[ESI+4],203A7465
00401167 . C746 08 4D6172>MOV DWORD PTR DS:[ESI+8],6972614D
0040116E . C746 0C 757321>MOV DWORD PTR DS:[ESI+C],217375
00401175 . EB 00 JMP SHORT 00401177 ; eight.00401177
00401177 > 58 POP EAX
00401178 . FFE0 JMP EAX
0040117A F7 DB F7
0040117B ED DB ED
0040117C 12 DB 12
0040117D DA DB DA
0040117E 3F DB 3F ; CHAR '?'
0040117F 4E DB 4E ; CHAR 'N'
00401180 40 DB 40 ; CHAR '@'
00401181 C4 DB C4
````
Всё что делает ета процедура-записывает слово: Secret: Marius! по соответственому указателю.
Далее осталось узнать исходный пароль – Ну, тут – брутфорс вам в помощь))))
Процедуру преобразования можна «ripp»ать у нашей програмы и оформить это дело как ассемблерную вставку.
````
mov dword ptr [znach], 0
xor edi, edi
mov esi, [str1]
m:
lodsb
test al, al
jz m1
mov ecx, eax
add edi, eax
rol edi, cl
jmp m
````
Да, исходный пароль-005sj[Vg
Только, если брутфорс будете писать под какую-то экзотику типа cuda или под шейдеры- помните там нет инструкции циклического сдвига- rol eax, 5 и ёё надо заменить на два простых сдвига (один влево и один вправо) и потом «or» над полученным; реализация в виде: #define ROT (n, m) (((n)<<(m))|((n)>>(32-(m))))
В следующих постах вы узнаете о других интересных способах взлома неломаемых защит.
PS. Автор статьи (ash — его пока нет на хабре) попросил меня опубликовать эту статью. | https://habr.com/ru/post/74817/ | null | ru | null |
# Инструменты DevOps-инженера: Librarian
Данная статья предназначена для тех, кто использует или планирует начать использовать систему управления конфигурацией [Opscode Chef](http://www.opscode.com/chef/).
Основная задача внедрения любой системы управления конфигурацией, будь то [Chef](http://www.opscode.com/chef/), [Puppet](https://puppetlabs.com/puppet/puppet-open-source/) или что-то еще, — повторяемо воспроизводить и обновлять окружение всех сред, использующихся при разработке ПО (dev, CI, QA, stage, production). Отсюда следует, что само описание конфигурации необходимо однозначно хранить и обновлять. К сожалению, возможности по версионированию, которые есть в Chef, достаточно ограничены. Поэтому в связке с Chef в последнее время стали активно использовать [Librarian](http://rubygems.org/gems/librarian). Но перед тем, как рассказать о нем, поговорим немного о кукбуках.
Кукбуки (более подробно о том, что это такое, можно прочитать [здесь](http://docs.opscode.com/essentials_cookbooks.html)) можно разделить на 3 вида:
1. кукбуки с сайта [community.opscode.com](http://community.opscode.com/cookbooks);
2. кукбуки с GitHub и других мест;
3. собственные кукбуки проекта.
В вашем проекте все кукбуки могут лежать в папке cookbooks под управлением системы контроля версий. И если для собственных кукбуков это единственный разумный способ, то для кукбуков первых двух видов это решение кажется достаточно странным. По той простой причине, что проверять обновление, управлять зависимостями и обновлять такие кукбуки вам придется в „ручном“ режиме. Помимо всего прочего, если вы возьмете кукбук и просто добавите его в папку cookbooks, вспомнить потом, откуда вы его взяли, будет крайне непросто. Кукбуки с GitHub можно хранить как git submodules, но это не решает большинства проблем, которые здесь перечислены.
Более того, если какой-то из используемых вами кукбуков имеет зависимости (они прописаны в файле metadata.rb кукбука), то добавлять зависимости в проект вам придется вручную.
Все эти проблемы можно избежать, если использовать [Librarian](https://github.com/applicationsonline/librarian-chef). Это инструмент, который помогает управлять зависимостями и версиями ваших кукбуков.
Есть еще похожий проект, который делает почти то же самое, — [Berkshelf](http://berkshelf.com/). Он появился позже Librarian, тянет с собою кучу зависимостей, имеет в 2 раза меньше инсталляций ([судя по rubygems](http://rubygems.org/gems/berkshelf)), но зато чуть лучше документирован. Выбор одного из них — исключительно дело вкуса. В любой момент можно перейти на другой инструмент, потому что файлы описания зависимостей у них идентичны. Мы используем Librarian, но то, что написано дальше, практически полностью актуально и для Berkshelf.
Представим себе очень простой проект, в котором используется совсем немного кукбуков. Начнем использовать librarian с помощью команды `init`, которая создает начальный файл `Cheffile` — в нем будет храниться описание используемых вами кукбуков.
```
$ librarian-chef init
create Cheffile
$ cat Cheffile
site 'http://community.opscode.com/api/v1'
```
Добавим в наш файл одну строчку и выполним `librarian-chef install`
```
$ cat Cheffile
site 'http://community.opscode.com/api/v1'
cookbook 'lvm'
$ librarian-chef install
Installing lvm (0.8.6)
```
Данная команда поставит все необходимые кукбуки в папку cookbooks и создаст файл `Cheffile.lock`.
```
$ ls cookbooks
lvm
$ cat Cheffile.lock
SITE
remote: http://community.opscode.com/api/v1
specs:
lvm (0.8.6)
DEPENDENCIES
lvm (>= 0)
```
Мы храним локальные для проекта кукбуки в папке inhouse-cookbooks. Это те кукбуки, которые специфичны именно для этого проекта. В `Cheffile` мы добавляем следующее:
```
cookbook 'project42',
:path => 'inhouse-cookbooks/project42'
```
Также в `Cheffile` можно ссылаться на конкретные ревизии кукбуков в гите.
```
cookbook "postgresql",
:git => "[email protected]:express42-cookbooks/postgresql.git",
:ref => "0.1.4"
cookbook "newrelic",
:git => "[email protected]:heavywater/chef-newrelic.git",
:ref => "b2309495b367da4bfe6f1761876b5d58e2455d6a"
```
Такая комбинация возможностей позволяет легко и удобно всегда собирать одни и те же кукбуки в папке cookbooks.
Надо четко понимать, что актуальный «срез» всех кукбуков хранится в файле Cheffile.lock, а файл Cheffile является только «подсказкой» о том, как Cheffile.lock собирать, и его одного для версионирования кукбуков недостаточно. Если у вас нет Cheffile.lock, то в зависимости от того, в какое время вы выполнили команду `librarian-chef install`, Cheffile.lock у вас получится разным. Даже если вы зафиксируете явно все версии используемых кукбуков в Cheffile (чего делать категорически не советуется), то кукбуки, которые соберутся по зависимостям, могут отличаться.
Более того, если вы явно укажете версии необходимых вам кукбуков, обновление кукбуков станет гораздо более сложным.
Но что делать, если необходимо обновить какой-то кукбук? Например, мы узнали, что вышла версия кукбука lvm, с какими-то нужными нам изменениями. Тогда мы делаем следующее:
```
$ librarian-chef update lvm
```
Данная команда обновит кукбук lvm на последний доступный. Более того, она обновит все зависимости кукбука lvm, если это будет необходимо. Мы рекомендуем после этого делать `git diff Cheffile.lock`, чтобы убедиться, что поменялось ровно то, что вы хотели. Кстати, если вы пропишете в Cheffile версию для какого-то кукбука, от которого зависит lvm, то lvm может и не обновиться, и вам долго придется гадать, почему это происходит.
Можно это понимать еще и так: Cheffile — это описание необходимых требований к версиям кукбуков на текущий момент, а Cheffile.lock — это срез, удовлетворяющий этим требованиям на текущий момент.
И еще один момент, который не стоит забывать, при работе с librarian. Каждый раз перед тем, как залить какой-то рецепт на chef-server, необходимо делать `git pull` и `librarian-chef install`. Потому что если кто-то залил более свежий рецепт, в вашей локальной папке cookbooks автоматически ничего не поменяется.
Возможно, такой подход может показаться несколько сложным, но он того стоит. Ведь он гарантирует всегда актуальный срез кукбуков, автоматическое управление зависимостями, а также гибкость использования локальных кукбуков, кукбуков с сайта Opscode и кукбуков из различных git-репозитариев, в том числе с гитхаба. | https://habr.com/ru/post/182264/ | null | ru | null |
# «Когда часы двенадцать бьют». Или гирлянда в браузере
Предположим, у нас есть несколько мониторов. И нам захотелось использовать эти мониторы в качестве гирлянды. Например, заставить их моргать одновременно. Или, может быть, синхронно менять цвет согласно какому-то умному алгоритму. И что, если сделать это в браузере – ведь тогда можно будет подключить к этому и смартфоны, и планшеты. Всё что есть под рукой.

И, раз уж мы используем браузер, можно добавить ещё и звуковое оформление. Ведь если достаточно точно синхронизировать устройства по времени, то можно воспроизводить звуки на каждом так, будто звучит одна многоканальная система.
---
*С чем можно столкнуться при синхронизации Web Audio и геймплейных часов внутри javascript-приложения; сколько вообще разных «часов» есть в javasctipt (три!) и зачем все они нужны, а также [готовое приложение](http://habr.snowtime.fun) для node.js – под катом.*
---
Сверим часы
-----------
Для любой условной онлайн-гирлянды необходима точная синхронизация часов. Ведь тогда можно игнорировать любые (даже непостоянные) сетевые задержки. Достаточно снабдить управляющие команды временнóй меткой и генерировать эти команды немного «в будущее». На клиентах они будут буферизованы и затем выполнены синхронно и точно в срок.
Или даже можно пойти ещё дальше – взять старый добрый детерминированный random-алгоритм и использовать один общий seed (выдаваемый сервером единожды, при подключении) на всех устройствах. Если использовать такой seed *вместе* с точным временем – можно полностью предопределить поведение алгоритма на всех устройствах. Просто представьте: по сути вам не нужна ни сеть, ни сервер чтобы уникально и синхронно изменять состояние. Seed уже содержит в себе всю (условно-бесконечную) «видеозапись» действий наперёд. Главное – точное время.
---
*Каждый метод имеет свои границы применимости. С моментальным пользовательским вводом, конечно, уже ничего не поделаешь, его остается передавать «как есть». Но всё, что может быть предрассчитано – должно быть предрассчитано. В своей реализации я использую все три подхода в зависимости от ситуации.*
---
Субъективное «одновременно»
---------------------------
В идеале, чтобы всё звучало «одновременно» – нужно не более ±10 мс расхождения для худшей пары среди объединенных устройств. Рассчитывать на такую точность от системного времени не приходится, а стандартные способы синхронизации времени по протоколу NTP в браузере недоступны. Поэтому свелосипедим свой сервер синхронизации. Принцип простой: шлем «пинги» и принимаем «понги» с временнóй меткой сервера. Если делать это много раз подряд, можно статистически нивелировать ошибку, и получить среднее время задержки.
**Код: вычисление серверного времени на клиенте**
```
let pingClientTime = 1; // performace.now() time when ping started
let pongClientTime = 3; // performace.now() time when pong received
let pongServerTime = 20; // server timstamp in pong answer
let clientServerRawOffset = pongServerTime - pongClientTime;
let pingPongOffset = pongClientTime - pingClientTime; // roundtrip
let estimatedPingOffset = pingPongOffset / 2; // one-way
let offset = clientServerRawOffset + estimatedPingOffset;
console.log(estimatedPingOffset) // 1
console.log(offset); // 18
let sharedServerTime = performace.now() + offset;
```
Websockets и решения на его основе подходят лучше всего, так как не требуют времени на создание TCP-соединения, и по ним можно «общаться» в обе стороны. Не UDP и не ICMP, конечно, но несравнимо быстрее, чем обычное холодное соединение по HTTP API. Поэтому, socket.io. Там всё очень легко:
**Код: реализация на socket.io**
```
// server
socket.on('ping', (pongCallback) => {
let pongServerTime = performace.now();
pongCallback(pongServerTime);
});
//client
const binSize = 100;
let clientServerCalculatedOffset;
function ping() {
socket.emit('ping', pongCallback);
const pingClientTime = performace.now();
function pongCallback(pongServerTime) {
const pongClientTime = performace.now();
const clientServerRawOffset = pongServerTime - pongClientTime;
const pingPongOffset = pongClientTime - pingClientTime; // roundtrip
const estimatedPingOffset = pingPongOffset / 2; // one-way
const offset = clientServerRawOffset + estimatedPingOffset;
offsets.unshift(offset);
offsets.splice(binSize);
let offsetSum = 0;
offsets.forEach((offset) => {
offsetSum += offset;
});
clientServerCalculatedOffset = offsetSum / offset.length();
}
}
```
*Неплохо бы, вместо вычисления среднего, посчитать медиану – это улучшит точность при нестабильном соединении. Выбор методов фильтрации остается за читателем. Я намеренно упрощаю здесь и далее код в пользу схематичности. Мое полное решение можно найти в репозитории.*
performance.now()
-----------------
Напомню, объект `performance` – это API предоставляющее доступ к таймеру высокого разрешения. Сравним:
* **`Date.now()`** возвращает количество миллисекунд с 1 января 1970, и делает это в **целочисленном** виде. То есть погрешность только лишь от округления составляет 0.5 мс в среднем. Например, на одной операции вычитания `a-b` можно неудачно «потерять» до 2 мс. Кроме того, исторически и концептуально, сам счетчик времени не гарантирует высокой точности и заточен под работу с бóльшим масштабом времени.
* **`performance.now()`** возвращает количество миллисекунд [c момента открытия веб-страницы](https://developer.mozilla.org/en-US/docs/Web/API/DOMHighResTimeStamp#The_time_origin).
Это относительно свежее API, «заточенное» специально для аккуратного замера временных промежутков. Возвращает **значение c плавающей точкой**, теоретически давая уровень точности близкий к возможностям самой ОС.
Думаю, эта информация известна почти всем javascript разработчикам. Но не всем известно, что…
Spectre
-------
Из-за нашумевшей в 2018 тайминговой атаки Spectre, всё идет к тому что таймер высокого разрешения будет искусственно огрублен, если не найдется другого решения проблемы с уязвимостью. Firefox, ещё начиная с версии 60, округляет значение этого таймера до миллисекунды, а Edge, и того хуже.
Вот что говорит [MDN](https://developer.mozilla.org/en-US/docs/Web/API/Performance/now):
> The timestamp is not actually high-resolution. To mitigate security threats such as Spectre, browsers currently round the results to varying degrees. (Firefox started rounding to 1 millisecond in Firefox 60.) Some browsers may also slightly randomize the timestamp. The precision may improve again in future releases; browser developers are still investigating these timing attacks and how best to mitigate them.
Давайте запустим тест и взглянем на графики. Это результат работы теста на промежутке 10 мс:
**Код теста: замер времени в цикле**
```
function measureTimesLoop(length) {
const d = new Array(length);
const p = new Array(length);
for (let i = 0; i < length; i++) {
d[i] = Date.now();
p[i] = performance.now();
}
return { d, p }
}
```
`Date.now()`
`performance.now()`
### Edge

**статистика**
Версия браузера: 44.17763.771.0
### Date.now()
средний интервал: 1.0538336052202284 мс
отклонение от среднего интервала, RMS: 0.7547819181245603 мс
медиана интервала: 1 мс
### performance.now()
средний интервал: 1.567100970873786 мс
отклонение от среднего интервала, RMS: 0.6748006785171455 мс
медиана интервала: 1.5015000000003056 мс
### Firefox

**статистика**
Версия браузера: 71.0
### Date.now()
средний интервал: 1.0168350168350169 мс
отклонение от среднего интервала, RMS: 0.21645930182417966 мс
медиана интервала: 1 мс
### performance.now()
средний интервал: 1.0134453781512605 мс
отклонение от среднего интервала, RMS: 0.1734108492762375 мс
медиана интервала: 1 мс
### Chrome

**статистика**
Версия браузера: 79.0.3945.88
### Date.now()
средний интервал: 1.02442996742671 мс
отклонение от среднего интервала, RMS: 0.49858684744384 мс
медиана интервала: 1 мс
### performance.now()
средний интервал: 0.005555847229948915 мс
отклонение от среднего интервала, RMS: 0.027497846727194235 мс
медиана интервала: 0.0050000089686363935 мс
Ok, Chrome, zoom to 1 msec.

Итак, Сhrome всё еще держится, и его реализация `performance.now()` пока не задушена и шаг составляет красивые 0.005 мс. Под Edge таймер `performance.now()` грубее чем `Date.now()`! В Firefox оба таймера обладают одинаковой миллисекундной точностью.
На этом этапе можно уже сделать некоторые выводы. Но есть ещё один таймер в javascript (без которого нам никак не обойтись).
Таймер WebAudio API
-------------------
Это несколько иной зверь. Он используется для отложенной аудио-очереди. Дело в том, что аудио-события (проигрывания нот, управление эффектами) не могут полагаться на стандартные асинхронные средства javascript: `setInterval` и `setTimeout` – из-за их слишком большой погрешности. И это не просто погрешность *значений* таймера, (с которой мы имели дело ранее), а это погрешность, с которой event-машина выполняет события. И она составляет уже что-то около 5-25 мс даже в тепличных условиях.
**Графики для асинхронного случая под спойлером**
Результат работы теста на промежутке 100 мс:
**Код теста: замер времени в асинхронном цикле**
```
function pause(duration) {
return new Promise((resolve) => {
setInterval(() => {
resolve();
}, duration);
});
}
async function measureTimesInAsyncLoop(length) {
const d = new Array(length);
const p = new Array(length);
for (let i = 0; i < length; i++) {
d[i] = Date.now();
p[i] = performance.now();
await pause(1);
}
return { d, p }
}
```
`Date.now()`
`performance.now()`
### Edge

**статистика**
Версия браузера: 44.17763.771.0
### Date.now()
средний интервал: 25.595959595959595 мс
отклонение от среднего интервала, RMS: 10.12639235162126 мс
медиана интервала: 28 мс
### performance.now()
средний интервал: 25.862596938775525 мс
отклонение от среднего интервала, RMS: 10.123711255512573 мс
медиана интервала: 27.027099999999336 мс
### Firefox

**статистика**
Версия браузера: 71.0
### Date.now()
средний интервал: 1.6914893617021276 мс
отклонение от среднего интервала, RMS: 0.6018870280772611 мс
медиана интервала: 2 мс
### performance.now()
средний интервал: 1.7865168539325842 мс
отклонение от среднего интервала, RMS: 0.6442818510935484 мс
медиана интервала: 2 мс
### Chrome
**статистика**
Версия браузера: 79.0.3945.88
### Date.now()
средний интервал: 4.787878787878788, мс
отклонение от среднего интервала, RMS: 0.7557553886872682 мс
медиана интервала: 5 мс
### performance.now()
средний интервал: 4.783989898979516 мс
отклонение от среднего интервала, RMS: 0.6483716900974945 мс
медиана интервала: 4.750000000058208 мс
Может кто-то вспомнит первые экспериментальные HTML аудиоприложения. До того, как полноценное WebAudio пришло в браузеры – они все звучали, будто немного пьяно, расхлябанно. Как раз потому что использовали `setTimeout` в качестве секвенсора.
Современный WebAudio API, в противовес этому дает гарантированное разрешение аж до 0.02 мсек (спекуляция исходя из частоты дискретизации в 44100Hz). Это происходит благодаря тому, что для отложенного воспроизведения звука используется иной механизм, чем `setTimeout`:
```
source.start(when);
```
Фактически, любое воспроизведение аудиосемпла – «отложенное». Просто, чтобы проиграть его «не отложено», нужно отложить его «до сейчас».
```
source.start(audioCtx.currentTime);
```
**О программно-генерируемой музыке «в реальном времени»**
Если воспроизводить программно-синтезируемую мелодию из нот – то эти ноты нужно немного заранее добавить в очередь воспроизведения. Тогда, не смотря на все фундаментальные ограничения и неровности таймеров, мелодия воспроизведется идеально ровно.
Иначе говоря, синтезируемая в реальном времени мелодия должна быть «придумана» не в реальном времени, а чуть-чуть заранее.
One timer to rule them all
--------------------------
Раз уж `audioCtx.currentTime` такой стабильный и точный, может быть нам его использовать как основной источник относительного времени? Давайте ещё раз запустим тест.
**Код теста: замер синхронного замера времени в цикле**
```
function measureTimesInLoop(length) {
const d = new Array(length);
const p = new Array(length);
const a = new Array(length);
for (let i = 0; i < length; i++) {
d[i] = Date.now();
p[i] = performance.now();
a[i] = audioCtx.currentTime * 1000;
}
return { d, p, a }
}
```
`Date.now()`
`performance.now()`
`audioCtx.currentTime`
### Edge
**статистика**
Версия браузера: 44.17763.771.0
### Date.now()
средний интервал: 1.037037037037037 мс
отклонение от среднего интервала, RMS: 0.6166609846299806 мс
медиана интервала: 1 мс
### performance.now()
средний интервал: 1.5447103117505993 мс
отклонение от среднего интервала, RMS: 0.4390514285320851 мс
медиана интервала: 1.5015000000000782 мс
### audioCtx.currentTime
средний интервал: 2.955751134714949 мс
отклонение от среднего интервала, RMS: 0.6193645611529503 мс
медиана интервала: 2.902507781982422 мс
### Firefox

**статистика**
Версия браузера: 71.0
### Date.now()
средний интервал: 1.005128205128205 мс
отклонение от среднего интервала, RMS: 0.12392867665225249 мс
медиана интервала: 1 мс
### performance.now()
средний интервал: 1.00513698630137 мс
отклонение от среднего интервала, RMS: 0.07148844433269844 мс
медиана интервала: 1 мс
### audioCtx.currentTime
В сихнронном цикле Firefox не обновляет значение аудиотаймера
### Chrome

**статистика**
Версия браузера: 79.0.3945.88
### Date.now()
средний интервал: 1.0207612456747406 мс
отклонение от среднего интервала, RMS: 0.49870223457982504 мс
медиана интервала: 1 мс
### performance.now()
средний интервал: 0.005414502034674972 мс
отклонение от среднего интервала, RMS: 0.027441293974958335 мс
медиана интервала: 0.004999999873689376 мс
### audioCtx.currentTime
средний интервал: 3.0877599266656963 мс
отклонение от среднего интервала, RMS: 1.1445555956407658 мс
медиана интервала: 2.9024943310650997 мс
**Графики для асинхронного случая под спойлером**
**Код теста: замер времени в асинхронном цикле**
Результат работы теста на промежутке 100 мс:
```
function pause(duration) {
return new Promise((resolve) => {
setInterval(() => {
resolve();
}, duration);
});
}
async function measureTimesInAsyncLoop(length) {
const d = new Array(length);
const p = new Array(length);
const a = new Array(length);
for (let i = 0; i < length; i++) {
d[i] = Date.now();
p[i] = performance.now();
await pause(1);
}
return { d, p }
}
```
`Date.now()`
`performance.now()`
`audioCtx.currentTime`
### Edge

**статистика**
Версия браузера: 44.17763.771.0
### Date.now():
средний интервал: 24.505050505050505 мс
отклонение от среднего интервала: 11.513166584195204 мс
медиана интервала: 26 мс
### performance.now():
средний интервал: 24.50935757575754 мс
отклонение от среднего интервала: 11.679091435527388 мс
медиана интервала: 25.525499999999738 мс
### audioCtx.currentTime:
средний интервал: 24.76005164944396 мс
отклонение от среднего интервала: 11.311571546205316 мс
медиана интервала: 26.121139526367187 мс
### Firefox
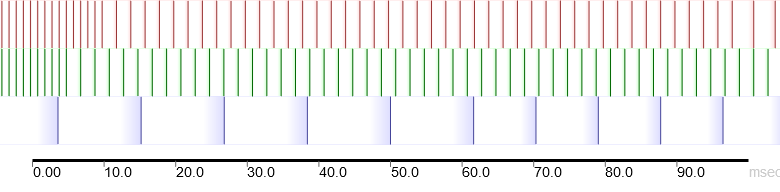
**статистика**
Версия браузера: 71.0
### Date.now():
средний интервал: 1.6875 мс
отклонение от среднего интервала: 0.6663410663216448 мс
медиана интервала: 2 мс
### performance.now():
средний интервал: 1.7234042553191489 мс
отклонение от среднего интервала: 0.6588877688171075 мс
медиана интервала: 2 мс
### audioCtx.currentTime:
средний интервал: 10.158730158730123 мс
отклонение от среднего интервала: 1.4512471655330046 мс
медиана интервала: 8.707482993195299 мс
### Chrome

**статистика**
Версия браузера: 79.0.3945.88
### Date.now():
средний интервал: 4.585858585858586 мс
отклонение от среднего интервала: 0.9102125516015199 мс
медиана интервала: 5 мс
### performance.now():
средний интервал: 4.59242424242095 мс
отклонение от среднего интервала: 0.719936993603155 мс
медиана интервала: 4.605000001902226 мс
### audioCtx.currentTime:
средний интервал: 10.12648022171832 мс
отклонение от среднего интервала: 1.4508887886499262 мс
медиана интервала: 8.707482993197118 мс
Чтож, не получится. «Снаружи» этот таймер оказывается самым неточным. Firefox не обновляет значение таймера внутри цикла. А в целом: разрешение 3 мс и хуже и заметный джиттер. Возможно, значение `audioCtx.currentTime` отражает позицию в кольцевом буфере драйвера аудиокарты. Иными словами, он показывает минимальное время, на которое ещё возможно безопасно отложить воспроизведение.
И что же делать? Ведь нам нужен одновременно и точный таймер для синхронизации с сервером и запуска javascript событий на экране, и аудиотаймер для звуковых событий!
Выходит, что нужно синхронизировать все таймеры друг с другом:
* Клиентский `audioCtx.currentTime` с клиентским `performance.now()` на клиенте.
* И клиентский `performance.now()` c `performance.now()` серверным.
Синхронизировали, синхронизировали
-----------------------------------
Вообще, это довольно забавно, если задуматься: можно иметь два хороших источника времени A и B, каждый из которых на выходе очень сильно огрублен и зашумлен (A' = A + errA; B' = B + errB) так, что может даже быть непригоден для использования сам по себе. Но разницу d между исходными незашумленными источниками при этом можно восстановить очень точно.
Поскольку истинное временнóе расстояние между идеальными часами – это константа, проведя измерения n раз, мы уменьшим ошибку измерения err в n раз соответственно. Если, конечно, часы идут с одной скоростью.
Да не высинхронизировали
------------------------
Плохая новость заключается в том, что нет, не идут они с одной скоростью. И я говорю не о расхождении часов не сервере и на клиенте – это понятно и ожидаемо. Что более неожиданно: `audioCtx.currentTime` постепенно расходится с `performance.now()`. Именно внутри клиента. Мы можем не замечать, но иногда, при нагрузке, аудиосистема может не проглотить небольшой кусок данных и, (вопреки природе кольцевого буфера) аудиовремя сдвинется относительно системного. Это происходит не так уж и редко, просто это мало кого заботит: но если например, запустить, одновременно два youtube видео синхронно на разных компьютерах – не факт что они закончат играть одновременно. И дело, конечно же, не в рекламе.
Таким образом, для стабильной и синхронной работы. Нам нужно *регулярно* пересверять все часы друг с другом, используя серверное время – как опорное. И тут появляется trade-off в том, сколько замеров использовать для усреднения: чем больше – тем точнее, но тем больше шанс что во временное окно, в рамках которого мы фильтруем значения, попал резкий скачок в `audioCtx.currentTime`. Тогда, если мы, например, используем минутное окно, то всю минуту мы будем иметь съехавшее время. Выбор фильтров широк: [экспоненциальный](https://ru.wikipedia.org/wiki/%D0%AD%D0%BA%D1%81%D0%BF%D0%BE%D0%BD%D0%B5%D0%BD%D1%86%D0%B8%D0%B0%D0%BB%D1%8C%D0%BD%D0%BE%D0%B5_%D1%81%D0%B3%D0%BB%D0%B0%D0%B6%D0%B8%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5), [медианный](https://ru.wikipedia.org/wiki/%D0%9C%D0%B5%D0%B4%D0%B8%D0%B0%D0%BD%D0%B0_(%D1%81%D1%82%D0%B0%D1%82%D0%B8%D1%81%D1%82%D0%B8%D0%BA%D0%B0)), [фильтр Калмана](https://ru.wikipedia.org/wiki/%D0%A4%D0%B8%D0%BB%D1%8C%D1%82%D1%80_%D0%9A%D0%B0%D0%BB%D0%BC%D0%B0%D0%BD%D0%B0), и т.п. Но этот trade-off есть в любом случае.
Временнóе окно
--------------
В случае сихронизации `audioCtx.currentTime` с `performance.now()`, в асинхронном цикле, чтобы не мешать UI, мы можем делать одно измерение, допустим, в 100 мс.
Предположим, что ошибка измерения err=errA + errB = 1+3 = 4 мс
Соответственно за 1 секунду мы можем её снизить до 0.4 мс, а за 10 секунд до 0.04 мс. Дальнейшее улучшение результата не имеет смысла, и хорошим окном для фильтрации будет: 1 – 10 секунд.
В случае с синхронизацией по сети, задержки и ошибки уже намного более весомые, но зато нет резкого скачкообразного изменения времени, как в случае с лагающим `audioCtx.currentTime`. И можно позволить себя накопить действительно большую статистику. Ведь err для пинга может составлять и 500 мс. А сами измерения мы можем делать не настолько же часто.
На этом месте я предлагаю остановиться. Если кому-то было интересно, я с удовольствием расскажу как «нарисовал остальную сову». Но а рамках истории о таймерах, считаю свой рассказ оконченным.
И хочу поделиться тем, что получилось у меня. Всё таки новый год.
Что получилось
--------------
Disclaimer: Технически это пиар сайта на Хабре, но это совершенно некоммерческий opensource pet-проект, на котором я обещаю никогда: ни ставить рекламу, ни как-либо ещё зарабатывать. Наоборот, я из своих денег поднял сейчас побольше инстансов чтобы пережить возможный хабраэффект. По-этому, пожалуйста, добрые люди, не ломайте меня и не ддосьте. Это всё чисто по-фану.
С наступающим новым годом, Хабр!
---
### [snowtime.fun](http://habr.snowtime.fun)
Можно крутить ручки и управлять визуализацией, музыкой и аудиоэффектами. Если у вас нормальная видеокарта, заходите в настройки и ставьте количество частиц 100%.
Требуется наличие WebAudio и WebGL.
---
**UPD:** Не работает в Safari под macOS Mojave. К сожалению, быстро разобраться в чём дело нет возможности, ввиду отсутствия этого самого Safari. iOS вроде бы работает.
**UPD2:** Если [snowtime.fun](http://snowtime.fun) и [web.snowtime.fun](http://web.snowtime.fun) не отвечает, попробуйте новый поддомен [**habr**.snowtime.fun](http://habr.snowtime.fun). Перевел сервер в другой датацентр, а старый IP закешировался в DNS, `expire=1w`. :(
Репозиторий: [bitbucket](https://bitbucket.org/barkalov/snowtime.fun/src)
При написании статьи были использованы иллюстрации [macrovector / Freepik](http://www.freepik.com) | https://habr.com/ru/post/482168/ | null | ru | null |
# Внедрение Spring Security в связку ZK+Spring Framework+Hibernate: часть первая
Всем доброго времени суток. Как и обещал, попытаюсь осветить тему секьюрности в веб-приложении, написанном на [ZK Framework](http://www.zkoss.org/product/zk). Почему часть первая? Потому что в данной статье я покажу вам наиболее быстрый и простой метод внедрения [Spring Security](http://static.springsource.org/spring-security/site/) с использованием в качестве страницы авторизации- jsp страницу; в последующей(их) статье(ях) будут описаны более сложные и интересные методы с использованием zul в качестве построения страницы авторизации.
Веб-приложение писать с нуля не будем, а за основу возьмем мое прошлое приложение, которое я описывал [в этом топике](http://habrahabr.ru/blogs/webdev/129189/).
Что нам понадобится: * библиотеки самой Spring Security, которые возьмем [отсюда](http://static.springsource.org/spring-security/site/downloads.html)
* библиотеку [zk-spring-security](http://zkspring.googlecode.com/files/zk-spring-security-src-3.0.zip)
* jstl, которую берем [с сайта](http://jstl.java.net/download.html)
Данный метод можно реализовывать тоже по-разному, либо хранить юзеров, их пароли и права в xml конфигурации Spring Security, либо хранить в базе данных. Так как наше приложение и так работает с базой Oracle, так чего бы и юзеров не хранить в базе. Как говорит нам документация спринга, при дефолтном развертывании Spring Security смотрит в базу на 2 таблицы (users и authorities). При групповой политики, требуется наличие еще и таких таблиц, как :groups, group\_authorities, group\_members (скрипты таблиц можно взять [отсюда](https://www.google.com/url?sa=t&source=web&cd=1&sqi=2&ved=0CBwQFjAA&url=http%3A%2F%2Fstatic.springsource.org%2Fspring-security%2Fsite%2Fdocs%2F3.0.x%2Freference%2Fappendix-schema.html&ei=BiWDTsnzO4uz8QP9oewJ&usg=AFQjCNEVedbNrm29_rZky8geoJlf8UEyxg&sig2=BF4atQ4xe1qt-Gma17wOfw)).
Значит создаем в базе 2 таблицы вида:
```
CREATE TABLE users
(
username varchar2 (50) NOT NULL PRIMARY KEY,
password varchar2 (50) NOT NULL,
enabled number NOT NULL
);
```
```
CREATE TABLE authorities
(
username varchar2 (50) NOT NULL,
authority varchar2 (50) NOT NULL,
CONSTRAINT fk_authorities_users FOREIGN KEY
(username)
REFERENCES users (username)
);
CREATE UNIQUE INDEX ix_auth_username
ON authorities (username, authority);
```
Следующим шагом сконфигурируем наш Spring Security. В файл spring-config.xml внесем следующие изменения
```
xml version="1.0" encoding="UTF-8"?
java:comp/env/jdbc/taskdb
org.hibernate.dialect.OracleDialect
false
```
```
```
Остановлюсь на некоторых моментах:
* `secured-annotations="enabled" jsr250-annotations="enabled" />` — дает нам возможность использовать аннотации вида **@RolesAllowed(«ROLE\_ADMIN»)**, для группы прав данная строка будет иметь вид @RolesAllowed({«ROLE\_ADMIN»,«ROLE\_USER»});
* `access="IS_AUTHENTICATED_ANONYMOUSLY" />` — говорим, что все могут заходить на страницу login.jsp;
* `access="ROLE_ADMIN,ROLE_USER" />` — только пользователи, которые имеют права ROLE\_ADMIN и/или ROLE\_USER могут заходить на все страницы
* `default-target-url="/index.zul" always-use-default-target="true"
authentication-failure-url="/login.jsp?login_error=1" />` — при правильном логине/пароле переходим на страницу index.zul (конечно если права у данного пользователя позволяют это сделать), в противном случае выводим код ошибки.
Также не забудем добавить в web.xml:
```
springSecurityFilterChain
org.springframework.web.filter.DelegatingFilterProxy
springSecurityFilterChain
/\*
```
Все, с конфигурацией покончено. Теперь напишем страничку авторизации login.jsp.
```
<%@ page language="java" contentType="text/html; charset=utf-8"
pageEncoding="utf-8"%>
<%@ taglib prefix='c' uri='http://java.sun.com/jstl/core_rt'%>
Форма Авторизации
body {
background: #63bad8 50% 0px repeat-x;
text-align: center;
}
div.main {
margin: 50px auto;
padding: 0 0 0 0;
width: 340px;
border-color: black;
}
Авторизация
===========
Не правильный логин или пароль. Попробуйте
заново.
| | |
| --- | --- |
| Пользователь: | |
| Пароль: | |
| |
```
Можно запускать и смотреть на наши плоды.
Давайте теперь поиграемся с разграничением прав. К примеру, разрешим только пользователю с правами ROLE\_ADMIN, удалять пользователей из системы. Для этого в процедуре ([PersonImpl](http://habrahabr.ru/blogs/webdev/129189/#PersonImpl)) перед процедурой удаления пользователя, напишем следующее:
`@RolesAllowed("ROLE_ADMIN")
public boolean delete(Person pers)`
Также отобразим имя вошедшего пользователя.
Для начала создадим компоненты Label с id = «labelLogin», который будет служить для отображения имени пользователя и Toolbarbutton, который будет служить нам кнопкой выхода пользователя. В файле [index.zul](http://habrahabr.ru/blogs/webdev/129189/#mainForm) перед строкой `, добавим следующее:
```
/
```
Ну и [в классе PersonInfo](http://habrahabr.ru/blogs/webdev/129189/#PersonInfo) внутри метода public void onCreate() реализуем возможность вывода имени пользователя:
```
UserDetails userDetails = (UserDetails) SecurityContextHolder.getContext().getAuthentication().getPrincipal();
((Label) this.getFellow("labelLogin")).setValue(userDetails.getUsername());
```
В данном коде мы получаем все данные пользователя, которые содержатся в [UserDetails](http://static.springsource.org/spring-security/site/docs/3.0.x/apidocs/org/springframework/security/core/userdetails/UserDetails.html) и компонент Label с id = «labelLogin» из формы index.zul, в который мы передадим имя пользователя.
Теперь, запустив наше приложении, по адресу
```
http://localhost:port/NameOfProject
```
мы увидим, что автоматом нас перенаправили на страницу login.jsp.` | https://habr.com/ru/post/129392/ | null | ru | null |
# Поле ввода числовых значений в Android
В этой статье я бы хотел осветить вопрос ввода пользователем чисел с заданной точностью.
Давайте посмотрим что имеется в арсенале Android и решим эту задачу.
#### Начнем с требований
Основные требования:
* Реализовать поле ввода, позволяющее вводить только числа с задаваемой точностью.
* Точность задается количеством значимых цифр перед и после десятичной запятой.
Дополнительные требования:
* Поддержка курсора ввода.
* Стандартные опции редактирования: копировать, вырезать и вставить.
#### Анализ
Из всего спектра элементов управления в `Android` нас интересует виджет [`EditText`](http://developer.android.com/reference/android/widget/EditText.html).
Обратимся к документации и посмотрим, что нам предлагает Android SDK.
[`EditText`](http://developer.android.com/reference/android/widget/EditText.html) наследуется от `TextView`, который, в свою очередь, обладает свойствами:
**XML-разметка**
[`digits`](http://developer.android.com/reference/android/widget/TextView.html#attr_android:digits)– позволяет установить набор специальных символов, которые может принимать поле и автоматически включает режим ввода чисел.
[`numeric`](http://developer.android.com/reference/android/widget/TextView.html#attr_android:numeric) – задает обработчик ввода чисел.
[`inputType`](http://developer.android.com/reference/android/widget/TextView.html#attr_android:inputType) – с помощью набора константных значений позволяет сгенерировать требуемый обработчик ввода.
**Публичные методы класса**
[`setFilters`](http://developer.android.com/reference/android/widget/TextView.html#setFilters(android.text.InputFilter[])) – позволяет задать набор фильтров, которые будут применяться при вводе значений в поле.
`digits`, `numeric` и `inputType` позволяют ограничить набор вводимых символов, но никак не влияют на точность числа, а вот `setFilters`, как раз то, что нам нужно.
#### Реализация
Перед созданием собственного фильтра, сделаем так, чтобы в поле можно было вводить только числа и десятичный разделитель.
```
numberEditText.setInputType(InputType.TYPE_CLASS_NUMBER | InputType.TYPE_NUMBER_FLAG_DECIMAL);
```
Теперь зададим собственный фильтр для поля ввода, чтобы принимать только значения соответствующие заданной точности.
Нам потребуется реализовать интерфейс `InputFilter`, а конкретно переопределить метод `filter`.
[Согласно документации](http://developer.android.com/reference/android/text/InputFilter.html#filter(java.lang.CharSequence, int, int, android.text.Spanned, int, int)), этот метод вызывается при замене значения в поле ввода (dest) в диапазоне от dstart до dend на текст из буфера (source) в диапазоне от start до end.
**Пример, для понимания написанного выше**Поле ввода содержит 123456 (dest), курсор находится в 1[23]456 (dstart = 1, dend = 3), из буфера вставляется значение 789 (source = 789, start = 0, end 3).
Метод возвращает объект класса `CharSequence`, который будет установлен в поле ввода взамен текущему значению. Если заменять значение поля ввода не требуется, то в методе следует вернуть `null`.
В конструктор нашего фильтра будем передавать количество символов до и после десятичного разделителя.
**Конструктор фильтра**
```
public NumberInputFilter(int digsBeforeDot, int digsAfterDot) {
this.digsBeforeDot = digsBeforeDot;
this.digsAfterDot = digsAfterDot;
}
```
Переопределяем метод `filter`. Алгоритм проверки вводимых значений следующий:
1. До помещения буферного значения в поле ввода мы будем вставлять это значение в некоторую переменную.
2. Если полученное значение удовлетворяет нашим требованиям точности, то мы разрешаем ввод, вернув `null`.
3. В противном случае возвращаем пустую строку, тем самым отказываясь от вводимого значения.
Формируем будущее значение после ввода пользователя:
Для удобства манипуляция со строкой, создадим экземпляр класса `StringBuilder` на основе исходного значения поля ввода и произведем необходимые замены с учетом вводимого значения.
```
StringBuilder newText = new StringBuilder(dest).replace(dstart, dend, source.toString());
```
В результате в переменной `newText` будет содержаться будущее значения текстового поля.
Теперь нам следует проверить корректность нового значения.
Оно должно удовлетворять следующим условиям:
1. Количество десятичных разделителей не должно превышать 1.
123, 123.45 — верно, 12.3.4 — неверно.
2. Количество символов целой и дробной частей числа должно удовлетворять заданной точности.
Проверим количество разделителей, для этого мы переберем все символы результирующей строки.
Если найдется десятичный разделитель, то запомним его индекс. В случае повторного нахождения разделителя, ввод считается некорректным и цикл останавливается.
**поиск десятичного разделителя**
```
int size = newText.length();
int decInd = -1; // индекс десятичного разделителя
// проверяем десятичный разделитель
// количество разделителей не должно превышать 1
for (int i = 0; i < size; i++) {
if (newText.charAt(i) == '.') {
if (decInd < 0) {
decInd = i; // запоминаем индекс разделителя
} else { // разделителей более 1, некорректный ввод
isValid = false;
break;
}
}
}
```
Проверим корректность самого числа. Нам уже известен индекс десятичного разделителя, либо он отсутствует.
Остается только сравнить длину всего числа относительно индекса разделителя.
**Проверка точности числа**
```
if (decInd < 0) { // случай когда разделителя нет
if (size > integerSize) { // проверяем длину всего числа
isValid = false;
}
} else if (decInd > digsBeforeDot) {// проверяем длину целой части
isValid = false;
} else if (size - decInd - 1 > digsAfterDot) { // проверяем длину дробной части
isValid = false;
}
```
В завершении возвращаем результат.
Если ввод корректный, то возвращаем `null`, тем самым принимая вводимые значения,
в противном случае возвращаем пустую строку, чтобы не передавать в поле ввода значения.
```
if (isValid) {
return null;
} else {
return "";
}
```
[Полный исходный код@github](https://github.com/hyperax/Android-NumberEditText/blob/master/app/src/main/java/ru/softbalance/widgets/filters/NumberInputFilter.java)
#### Отладка
Запускаем проект и вводим наш контрольный пример, пытаясь выйти за его границы.
В качестве контрольного примера будем использовать число 123.45. Нельзя вводить число более 999.99 и менее 0.01.
**Видео**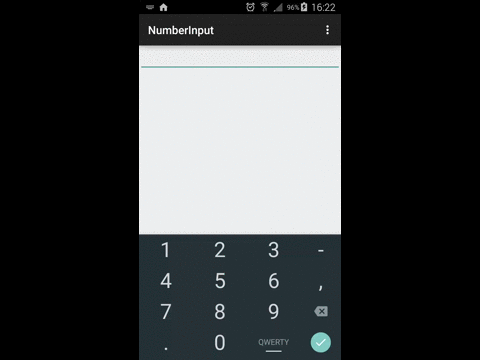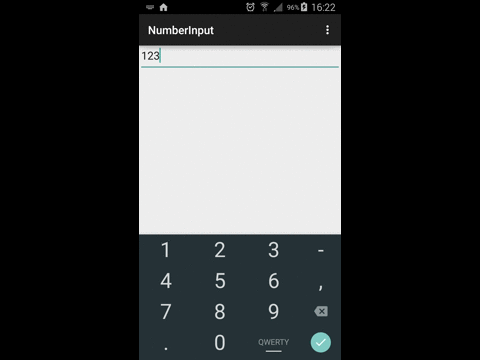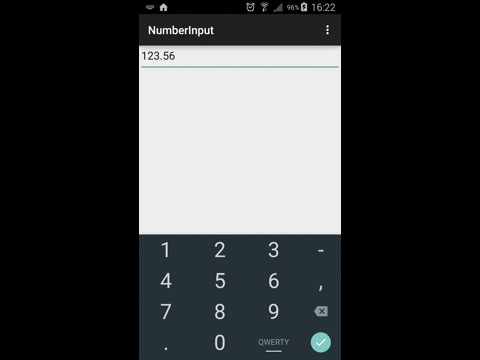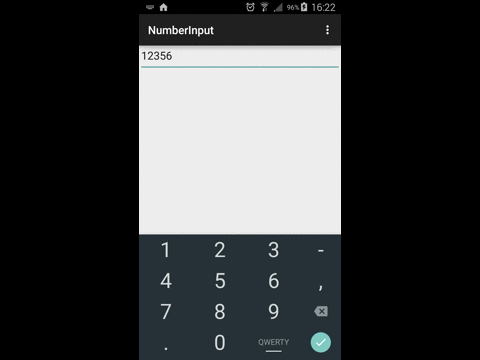
Видим, что приложение корректно обрабатывает целую и дробную части числа, запрещает вводить несколько десятичных разделителей.
Однако наблюдается интересная ситуация, если удалить десятичный разделитель, то мы выходим за границы точности.
Об этом упоминается в документации
> Be careful to not to reject 0-length replacements, as this is what happens when you delete text.
Нужно быть осторожным с заменами нулевой длины, как это происходит при удалении текста.
Что же произошло на самом деле?
Наш алгоритм отработал корректно и в условии проверки длины целой части числа выявил, что допустимая точность нарушена и вернул пустую строку. Но само действие удаления символов было применено к исходному значению поля ввода.
Решим эту проблему следующим образом — выявим факт удаления символов. Документация подсказывает, что в этом случае происходит замена с нулевой длиной. Выделим из исходного значения поля ввода удаляемые символы и вернем их в качестве результата нашего метода, тем самым откажемся от удаления.
Нам потребуется изменить блок кода, где возвращается результат
**Обработка удаления символов**
```
if (isValid) {
return null;
} else if (source.equals("")) { // обрабатываем удаление
return dest.subSequence(dstart, dend); // возвращаем удаленные символы
} else {
return "";
}
```
Запускаем проект и проверяем.
**Видео**
Таким образом контрольный пример выполнен, заданная точность достигнута.
Библиотека успешно используется в продакшене.
Подключить её можно с помощью Gradle
```
repositories {
maven { url "https://raw.githubusercontent.com/hyperax/Android-NumberEditText/master/maven-repo" }
}
compile 'ru.softbalance.widgets:NumberEditText:1.1.2'
```
[Полный исходный код проекта@github](https://github.com/hyperax/Android-NumberEditText.git).
#### Бонус
Часто бывает необходимым запретить отображение системной клавиатуры для поля ввода.
Например, если используется клавиатура из приложения.
На помощь приходит метод класса EditText, появившийся в Android версии 21 и выше:
[setShowSoftInputOnFocus(boolean show)](http://developer.android.com/reference/android/widget/TextView.html#setShowSoftInputOnFocus(boolean))
Вообще-то, этот метод был и в ранних версиях, но был приватным.
**добавим свой метод для поля ввода showSoftInputOnFocusCompat**public void showSoftInputOnFocusCompat(boolean isShow) {
```
showSoftInputOnFocus = isShow;
if (Build.VERSION.SDK_INT >= 21) {
setShowSoftInputOnFocus(showSoftInputOnFocus);
} else {
try {
final Method method = EditText.class.getMethod("setShowSoftInputOnFocus", boolean.class);
method.setAccessible(true);
method.invoke(this, showSoftInputOnFocus);
} catch (Exception e) {
// ignore
}
}
}
```
Да это «хак», однако это наиболее простой и короткий способ скрыть системную клавиатуру для поля ввода. | https://habr.com/ru/post/264493/ | null | ru | null |
# Сервис на языке Dart: flutter web-страница
**Оглавление**
1. 1. [Введение](https://habr.com/ru/company/surfstudio/blog/511880/)
2. 2. Backend
3. 2.1. [Инфраструктура](https://habr.com/ru/company/surfstudio/blog/511880/).
4. 2.2. [Доменное имя. SSL](https://habr.com/ru/company/surfstudio/blog/512528/)
5. 2.3. Серверное приложение на Дарт
6. ...
7. 3. Web
8. 3.1. FlutterWeb страница (мы находимся здесь)
9. ...
10. 4. Mobile
11. ...
Подготовка
----------
В [прошлый раз](https://habr.com/ru/company/surfstudio/blog/512528/) мы закончили на том, что наш веб-сервер получил доменное имя и научился устанавливать безопасное соединение с клиентом. Однако нам пока совсем нечего показать нашему будущему пользователю. Хотя мы уже можем поделиться идеей стартапа и сообщить дату релиза [MVP](https://ru.wikipedia.org/wiki/%D0%9C%D0%B8%D0%BD%D0%B8%D0%BC%D0%B0%D0%BB%D1%8C%D0%BD%D0%BE_%D0%B6%D0%B8%D0%B7%D0%BD%D0%B5%D1%81%D0%BF%D0%BE%D1%81%D0%BE%D0%B1%D0%BD%D1%8B%D0%B9_%D0%BF%D1%80%D0%BE%D0%B4%D1%83%D0%BA%D1%82). Для такой задачи подойдёт информационная web-страница. Напишем её на Dart с использованием фреймворка FlutterWeb ([здесь](https://surf.ru/pochemu-flutter-ispolzuet-dart-a-ne-kotlin-ili-javascript/) рассказываем, почему Flutter использует именно Dart). Все наши клиентские приложения сервиса станут расширением именно этой страницы. Постараемся вести разработку максимально адаптивно и структурировано, чтобы развитие и сборки под нужные платформы (web-android-iOS) стали просто рутиной.

Начнём с установки Flutter:
* Установим [git](https://git-scm.com/downloads)
* Склонируем репозиторий с **beta** версией Flutter командой
```
git clone https://github.com/flutter/flutter.git -b beta
```
* Для запуска команд flutter из командной строки необходимо указать в операционной системе путь до его исполняемых файлов. Откроем переменные ОС, для этого начнём вводить «изменение переменных среды текущего пользователя» в строке поиска

В окне выберем переменную **Path** и нажмём **Изменить**. В открывшемся списке создадим новую строку с адресом до исполняемых файлов flutter в файловой системе, например **C:\flutter\bin**
* Установим расширение [VScode для flutter](https://marketplace.visualstudio.com/items?itemName=Dart-Code.flutter)
* Перезапустим VScode (чтобы применились новые переменные ОС) и в терминале проверим состояние flutter командой
```
flutter doctor
```
здесь самое важное, что flutter установлен в beta версии (с поддержкой web разработки)
* Теперь активируем веб разработку командой
```
flutter config --enable-web
```
Создание нового проекта и запуск отладки
----------------------------------------
Создаём новый проект командой
```
flutter create <название проекта>
```
Сразу откроем его в VScode командой
```
code <название проекта>
```
Откроем файл **main.dart** в папке **lib** и запустим отладку командой **F5**:

Возможно при первом запуске отладки понадобится выбрать Chrome устройством для отладки:

Удалим содержимое файла **main.dart**. Добавим пустой метод **main** и корневой класс приложения, возвращающий в методе **build()** экземпляр **MaterialApp**:
Далее создадим следующий набор вложенных папок проекта:

Кратко опишем назначение каждой из них:
* **di** — механизм для связи между компонентами приложения. Здесь будут создаваться и регистрироваться все необходимые сервисы, репозитории, сетевые клиенты, необходимые для работы приложения. Я буду использовать библиотеку [GetIt](https://pub.dev/packages/get_it)
* **domain** — data-объекты. Классы представления данных
* **res** — цвета, строки, импорты путей к картинкам и шрифтам. Всё, что связано со статическими ресурсами
* **service** — сервисы для работы с данными
* **ui** — интерфейс
* **utils** — вспомогательные классы
В файле pubspec.yaml добавим необходимые зависимости:
Подготовка к масштабированию элементов UI
-----------------------------------------
Предполагается, что наша страница должна адаптироваться в зависимости от размеров экрана клиентского устройства и его расположения (портретный или ландшафтный режим).
Начнём с картинок заднего фона. Их подготовка не входит в тему статьи, поэтому просто оставлю здесь эти две ссылки:
* [Pixabay.com](https://pixabay.com/ru/) — хранилище контентных фотографий
* [Paint.net](http://paintnet.ru/download/) — графический редактор
Готовые картинки разместим в папке /assets/images, в файле pubspec.yaml добавим этот путь к ресурсам:

Я предпочитаю доступ к ресурсам в виде дерева c параметрами. В данном случае путь к картинке заднего фона заглушки:
```
images.background(bool isPortrait).stub
```
Для этого в папке **res** создадим файл **images.dart** с классами адресов картинок:
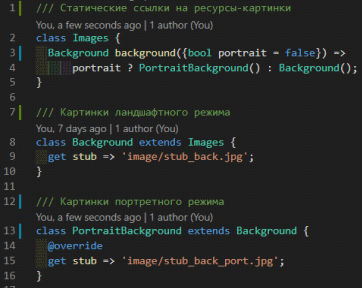
Для масштабирования размеров интерфейса и шрифтов мы подключили библиотеку [ScreenUtil](https://pub.dev/packages/flutter_screenutil). Её функциональность сводится к двум вещам:
* Регистрация «базового» размера экрана. Здесь необходимо задать ширину и высоту экрана, для которого ведётся основная верстка и необходимость масштабирования шрифтов.
* Набор расширений, позволяющий для чисел (num) применить масштабирующий коэффициент. Например **100.w** означает, что результатом этого выражения будет для экрана шириной 1920dp => 100dp, а для экрана iPhone8 с шириной 414dp => 100х(414/1920) = 21,6dp. То есть в пять раз меньше. Также предусмотрены расширения для параметра высоты и размера шрифтов.
Создадим файл **/utils/screen\_util\_ext.dart** и статический метод инициализации в нём:

Вызов метода инициализации масштабирования добавим в метод **build()** корневого виджета:

Расширим функциональность библиотеки масштабирования несколькими дополнительными расширениями в файле **/utils/screen\_util\_ext.dart**:



Инъекция зависимостей
---------------------
Пришло время внедрить механизм создания и регистрации компонентов приложения с помощью библиотеки **GetIt**. В папке **lib/DI/** создадим файл **di\_container.dart**. В нём напишем статический метод **getItInit()** и инициализируем экземпляр контейнера **GetIt**. Зарегистрируем первый компонент — экземпляр класса **Images**:
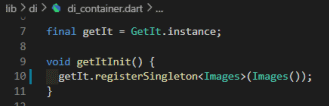
Вызов метода инициализации добавим в **main()**:
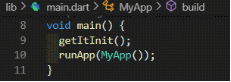
Доступ к компоненту **Images** будет выглядеть так:

Таким же образом зарегистрируем класс с ресурсами строками.
Страница-заглушка
-----------------
Теперь в папке **UI** создадим файл **stub.dart** с классом страницы заглушки **StubScreen**, расширим базовый класс **StatelessWidget** и переопределим его абстрактный метод **build()**. Наша страница представляет собой картинку на заднем плане и два информационных блока перед ней, размещающихся в зависимости от ориентации экрана.

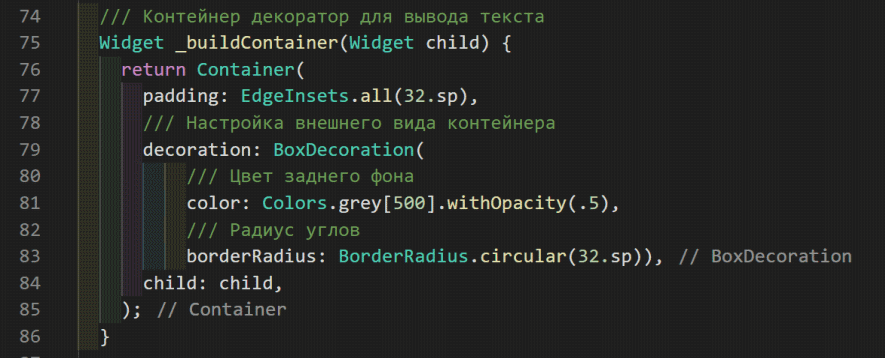

Репозитории и сервис
--------------------
Для динамического отображения оставшегося до релиза времени необходимо:
1. Получить с сервера настройки с датами начала разработки и релиза
2. Создать поток событий изменения оставшегося времени
3. Объединить эти данные, передав в выходной поток для отображения на UI
Опишем доменные объекты (POJO) для этих данных:


Репозитории для получения настроек и создания потока событий:

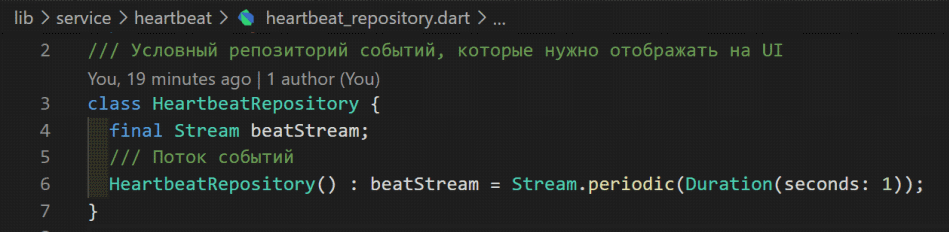
Сервис для логики событий:
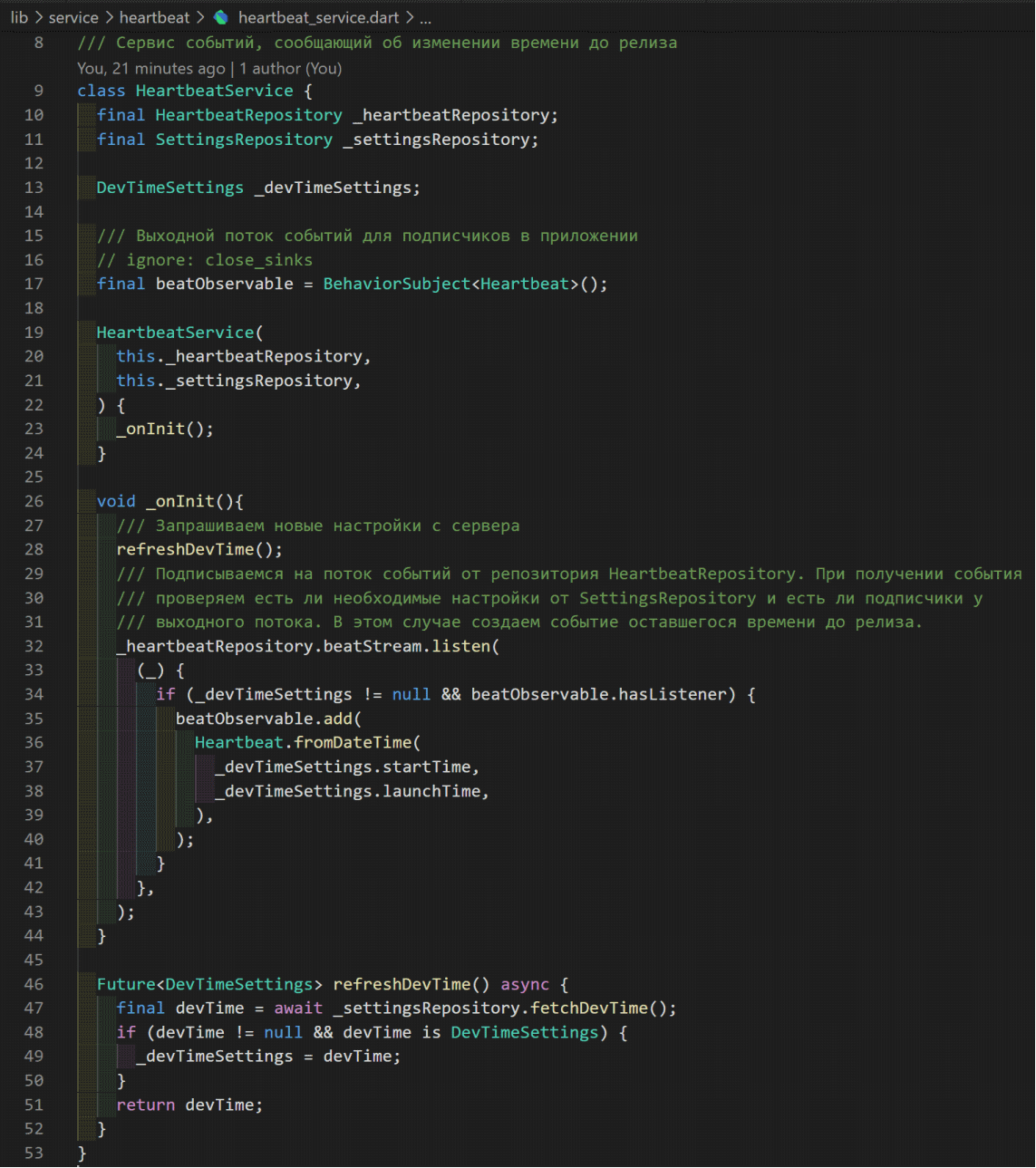
Зарегистрируем эти компоненты в DI контейнере:

Виджет оставшегося времени
--------------------------
Оставшееся до релиза время можно представить как 4 числа: дни, часы, минуты, секунды. Представим эти параметры в виде перечисления:

Добавим функциональности параметрам с помощью расширения:
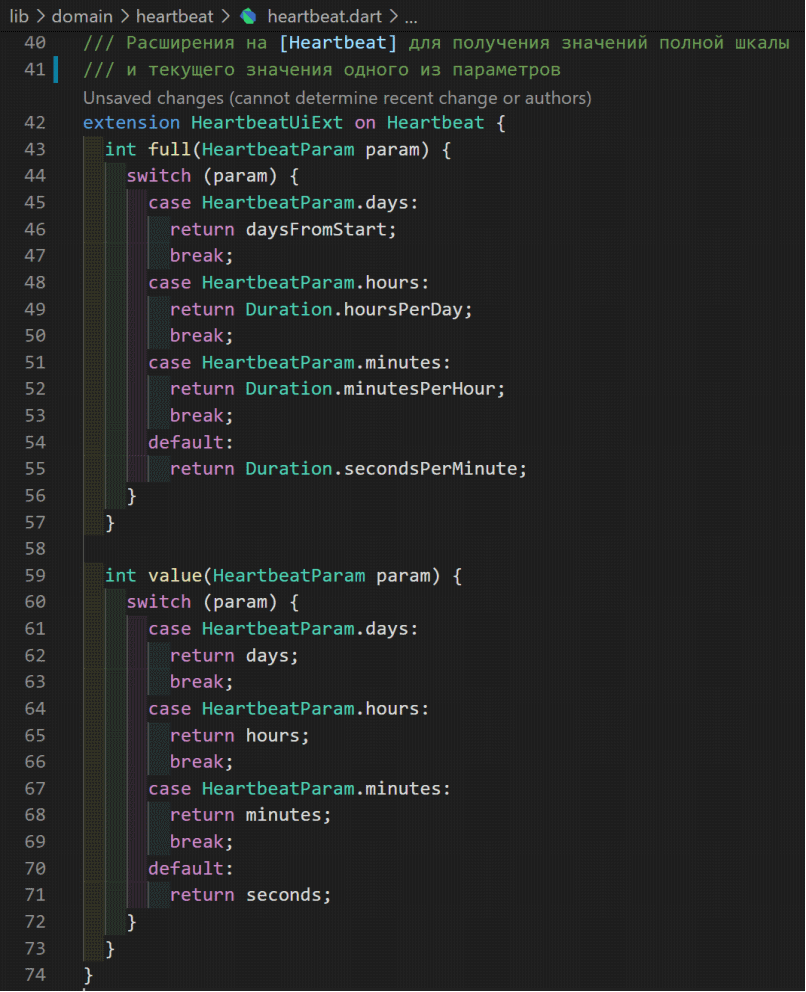
Виджет для отображения круговой шкалы, числа и подписи будет анимированным, для этого расширим класс **StatefulWidget**. Его особенность в том, что **Element** (построенное и отображаемое представление) соотносится не с самим виджетом, а с его состоянием (**State**). Состояние, в отличие от виджета мутабельно. То есть его поля могут быть изменены без полного пересоздания экземпляра.
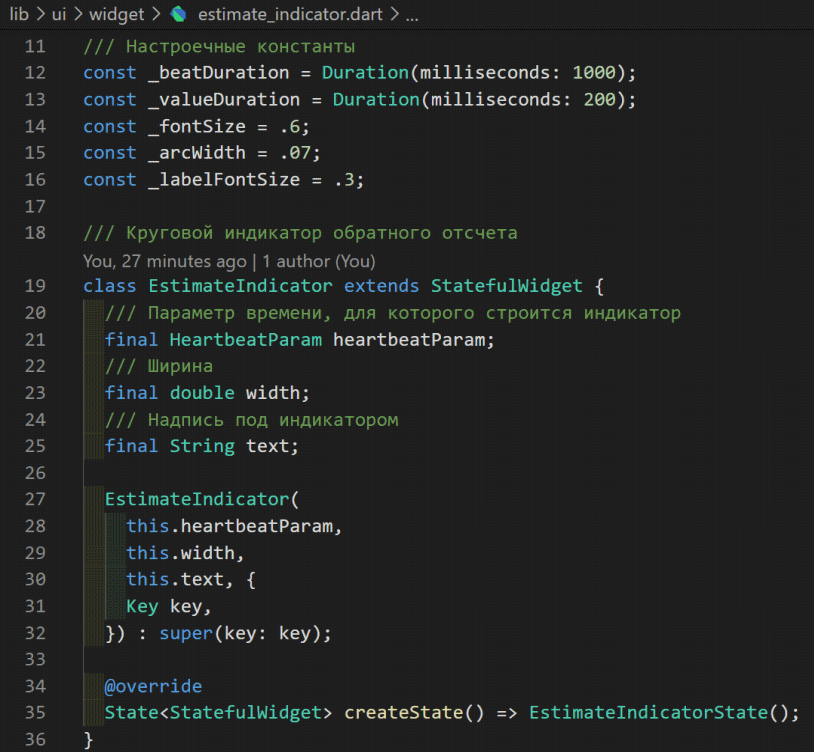

Здесь необходимо уточнить, что такое **Animation**, **AnimationController** и **TickerProviderStateMixin**. Итак **AnimationController** — обёртка над простым параметром **double value**. Значение этого параметра меняется линейно в пределах от 0,0 до 1,0 (также его можно менять в обратную сторону или сбрасывать в 0,0). Однако для изменения этого параметра используется специальный объект **TickerProviderStateMixin**, который является обязательным параметром для **AnimationController** и сообщает ему, что графический движок готов построить новый кадр. Получив такой сигнал **AnimationController** рассчитывает сколько времени прошло от предыдущего кадра и вычисляет насколько нужно изменить значение своего **value**. Объекты **Animation** подписываются на **AnimationController** и содержат в себе некоторую функцию зависимости выходного значения от линейного (по времени) изменения значения **AnimationController**.
Метод инициализации состояния **initState()** вызывается один раз при создании:

При уничтожении состояния виджета вызывается метод **dispose()**:
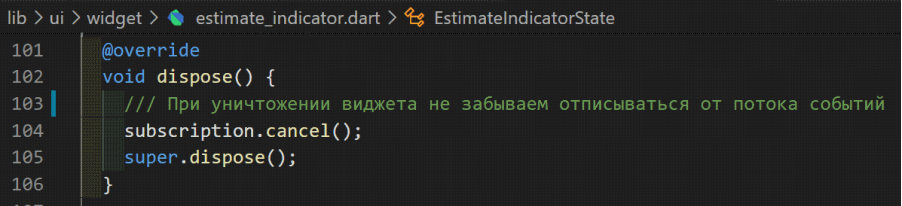
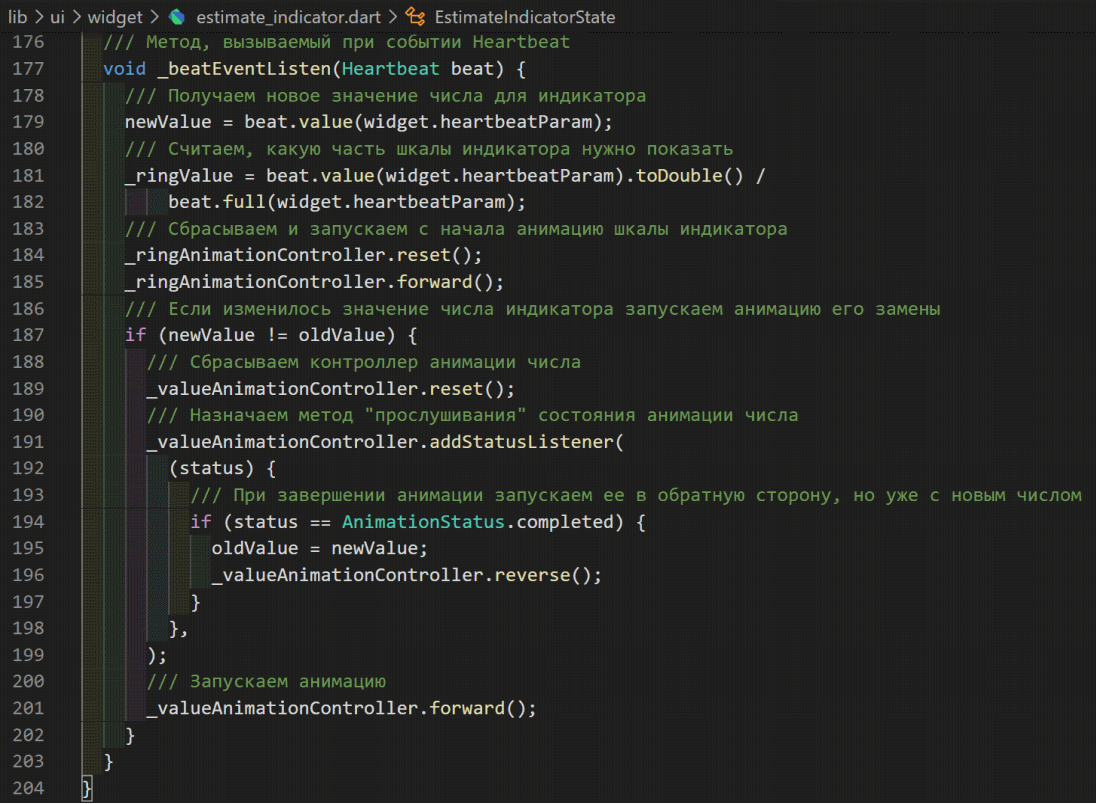
Представлением виджета будет стек (**Stack**), с помещёнными в него **AnimatedBuilder** для числа и шкалы:
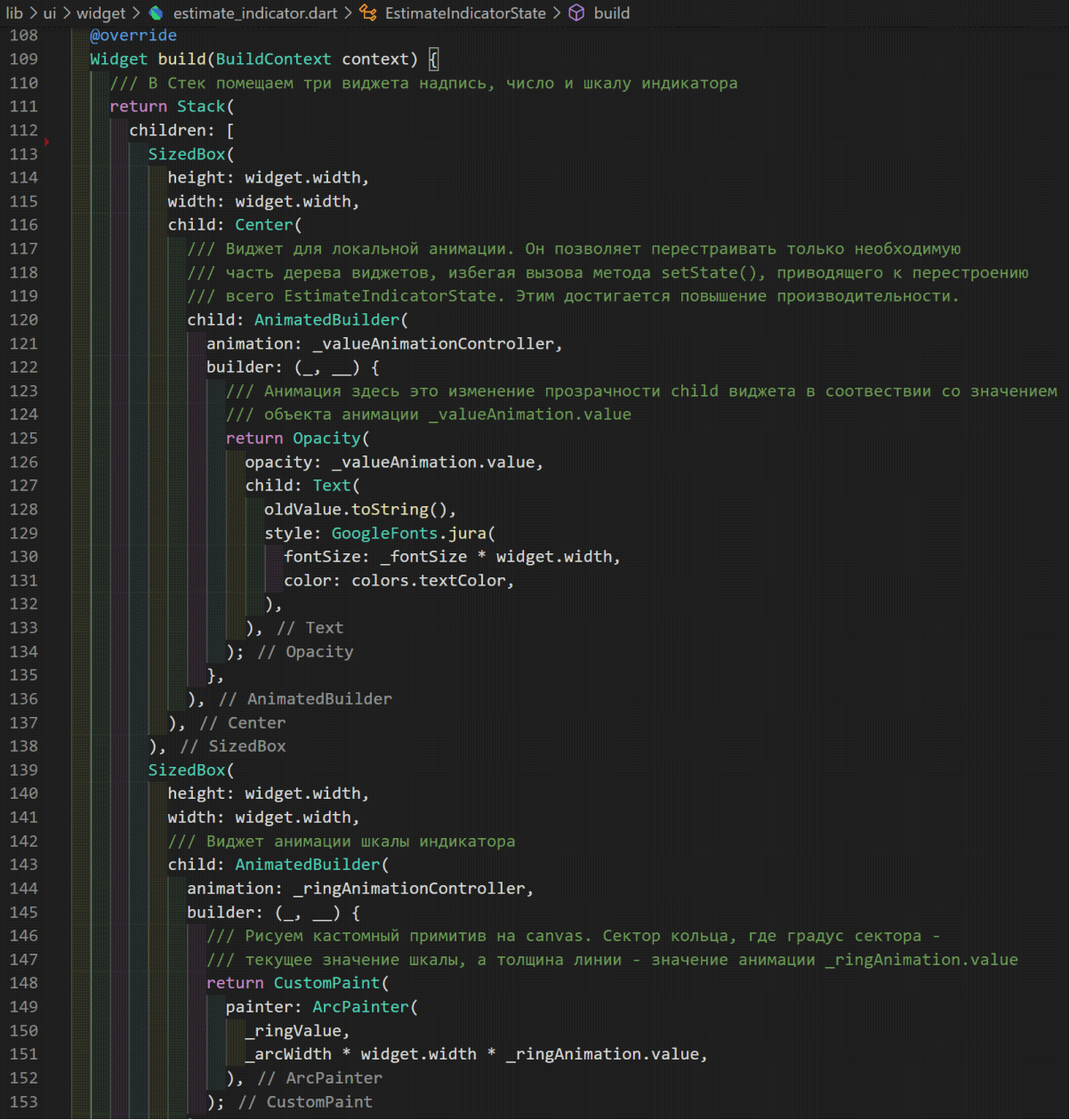
Остаётся реализовать графический примитив в виде дуги:

Добавим 4 таких виджета на экран заглушки:
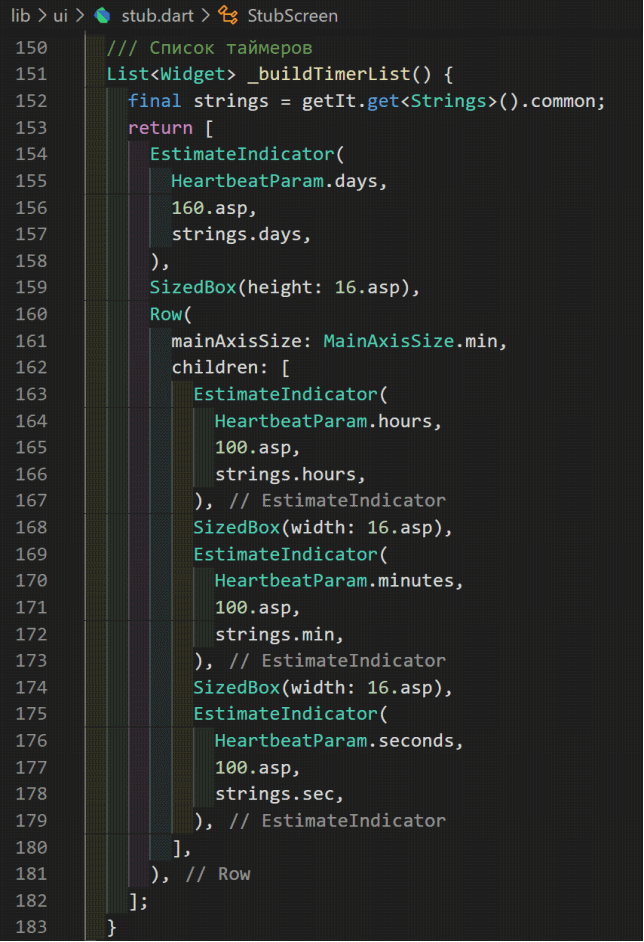
Сборка и релиз
--------------
Перед сборкой приложения необходимо заменить название и описание приложения в файлах **./web/index.html** **./web/manifest.json** и **pubspec.yaml**.
Останавливаем отладку и собираем релиз приложения командой
```
flutter build web
```
Готовое приложение находится в директории **./build/web/**. Обратите внимание, что файлы **.last\_build\_id** и **main.dart.js.map** служебные и могут быть удалены.
Разместим приложение на сервере, подготовленном в предыдущей статье. Для этого достаточно скопировать содержимое директории **./build/web/** в **/public/** нашего сервера:
```
scp -r ./* [email protected]:/public/
```
[Результат](https://dartservice.ru/#/)
Исходный код [github](https://github.com/AndX2/dart_service_web/tree/0.0.1-pre)
Вопросы и комментарии приветствуются. Пообщаться с автором можно в [Telegram канале](https://t.me/SurfGear).
Вместо заключения
-----------------
Наше клиентское приложение уже готово получить первые данные с сервера — сведения о дате релиза. Для этого в четвертой статье мы создадим каркас серверного приложения и разместим его на сервере. | https://habr.com/ru/post/514640/ | null | ru | null |
# Получение и вывод GPS координат на Arduino
Однажды у меня возник интерес к GPS, а еще чуть раньше — к платформе Arduino. Поэтому со Sparkfun были заказаны, с разницей в пару дней, Arduino Duemilanove, [GPS Shield](http://www.sparkfun.com/products/9817) и [GPS приемник EM-406A](http://www.sparkfun.com/products/465).
Заказ пришел и частично лежал на полке, а недавно дошли руки до этого комплекта…
###### Собранный GPS Shield, подключенный к Arduino
[](http://lh5.ggpht.com/_U6SpPmi3bmM/TOwCjTCr9EI/AAAAAAAAABQ/7_pQ-1yHmjM/with_shield.jpg)
#### Аппаратная часть
* Arduino Duemilanove
* GPS Shield
* GPS приемник EM-406A
* LCD WH-0802A
Для большей мобильности платформа запитана от отдельного аккумулятора и подключается к компьютеру только для заливки нового скетча.
##### Распиновка GPS модуля EM-406A
[](http://lh3.ggpht.com/_U6SpPmi3bmM/TOwCik3YyQI/AAAAAAAAABI/gSCHrgCEsHA/gps_pinout.jpg)
При наличии щилда распиновка, по большому счету, не так важна — нужно просто вставить два разъема. Если щилд отсутствует, то нужно подключить выводы GND к GND, Rx — к digital pin 2, Tx — к digital pin 3, VCC — к POWER 5V. Внимание, серый провод не 1, а 6й!
На GPS модуле имеется светодиодный индикатор состояния:
* индикатор горит постоянно — идет поиск спутников и определение координат
* индикатор моргает — координаты установлены, идет их передача
* индикатор не горит, питание на шилд подано — плохой контакт в разъемах или модуль переключился в бинарный SiRF протокол
##### Переключатель UART/DLINE
[](http://lh3.ggpht.com/_U6SpPmi3bmM/TOwCis5ssFI/AAAAAAAAABM/OPKYq0rLPtQ/sield_switch.JPG)
С помощью переключателя можно подключить Rx и Tx GPS модуля к ногам Tx и Rx Arduino (позиция UART) или к pin digital 2 и digital 3 (позиция DLINE, если не снимать перемычки из припоя). Нужно убедиться, что переключатель находится в положении «DLINE», иначе возможны проблемы с заливкой скетчей в Arduino.
##### Подключение знакосинтезирующего ЖК индикатора
Я не покупал отдельный shield под экран и подключал уже имеющийся индикатор — WH-0802A в 4х битном режиме. В принципе, так можно подключить любой другой знакосинтезирующий индикатор. Для этого нужно найти в даташите распиновку разъема и подключить линии RS, E, D4, D5, D6, D7 к любым цифровым pin'ам (кроме 0…3) и не забыть сконфигурировать куда подключены эти линии в коде, Vss, R/W — к GND, Vdd — к 5V. Вывод Vo (настройка контрастности) нужно подключить к потенциометру, включенному между GND и 5V, но я просто подключил к GND — полученная контрастность меня устроила.
##### Назначение выводов индикатора WH-0802A
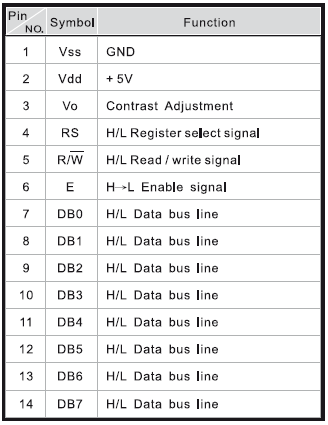
##### Мой вариант подключения индикатора к Arduino
* RS — pin 13
* E — pin 12
* D4 — pin 11
* D5 — pin 10
* D6 — pin 9
* D7 — pin 8
* Vss, R/W, Vo — GND
* Vdd — 5V
#### Программная часть
Для работы с GPS потребуются две библиотеки [TinyGPS](http://arduiniana.org/libraries/tinygps/) и [NewSoftSerial](http://arduiniana.org/libraries/newsoftserial/). Библиотеки распаковываются в каталог libraries.
> `#include
>
> #include
>
> #include
>
> TinyGPS gps;
>
> //Tx, Rx
>
> NewSoftSerial nss(2, 3);
>
> //Конфигурация линий, куда подключен lcd: RS, E, D4, D5, D6, D7
>
> LiquidCrystal lcd(13, 12, 11, 10, 9, 8);
>
> bool feedgps();
>
> void setup() {
>
> //4800 скорость обмена с GPS приемником
>
> nss.begin(4800);
>
> //8 символов, 2 строки
>
> lcd.begin(8, 2);
>
> lcd.print("waiting");
>
> }
>
> void loop() {
>
> bool newdata = false;
>
> unsigned long start = millis();
>
> long lat, lon;
>
> unsigned long age;
>
> //задержка в секунду между обновлениями координат
>
> while (millis() - start < 1000) {
>
> if (readgps())
>
> newdata = true;
>
> }
>
> if (newdata) {
>
> gps.get\_position(⪫, &lon, &age);
>
> lcd.setCursor(0, 0);
>
> lcd.print(lat);
>
> lcd.setCursor(0, 1);
>
> lcd.print(lon);
>
> }
>
> }
>
> bool readgps() {
>
> while (nss.available()) {
>
> int b = nss.read();
>
> //в TinyGPS есть баг, когда не обрабатываются данные с \r и \n
>
> if('\r' != b) {
>
> if (gps.encode(b))
>
> return true;
>
> }
>
> }
>
> return false;
>
> }`
После включения GPS модуля и заливки скетча нужно подождать как минимум 42 секунды (время холодного старта) для того чтобы модуль определил свое местоположение и начал выдавать валидные координаты. Когда модуль перейдет в рабочий режим он начнет моргать светодиодом. У меня на рабочем столе модуль не всегда может найти спутники — приходится переносить его на окно.
##### Работающий модуль с подключенным дисплеем и полученными координатами
[](http://lh4.ggpht.com/_U6SpPmi3bmM/TOwCj1xE4pI/AAAAAAAAABU/9mjObJJm94o/s640/work_gps.jpg)
Справа к дисплею подключён источник питания для подсветки.
После определения спутников на дисплее появляются координаты и обновляются раз в секунду.
В итоге получен опыт работы и база для дальнейшего освоения GPS.
#### «Используемая литература»
* [Sparkfun: GPS Shield Quickstart Guide](http://www.sparkfun.com/tutorials/173)
* [Arduino playground: Connecting a Parallax GPS module to the Arduino](http://www.arduino.cc/playground/Tutorials/GPS)
* [Wikipedia: NMEA](http://ru.wikipedia.org/wiki/NMEA) | https://habr.com/ru/post/108797/ | null | ru | null |
# Написать Telegram клиент — легко
Чем отличается Telegram от других популярных мессенджеров? Он — открытый!
Другие мессенджеры тоже имеют API, но почему-то именно телеграм известен как наиболее открытый из самых популярных?
Начнем с того, что у Telegram действительно полностью открытый клиентский
[код](https://github.com/TelegramOrg). К сожалению, мы не видим комиты каждый день прямо на GitHub, но у нас есть код под открытой лицензией. Архитектура Telegram подразумевает, что и Bot и API имеет практически такие же методы — <https://core.telegram.org/methods>.
На самом деле, Telegram представляет не просто чат-мессенджер, а социальную платформу, доступ к которой открыт для разного рода приложений. Они могут предоставлять дополнительные фишки пользователям, взамен используя готовую сеть пользователей и сервера для доставки сообщений. Звучит настолько привлекательно, что нам захотелось попробовать написать своего "клиента" для Телеграм.
### Суть приложения
В основном мы занимаемся картами и навигацией, поэтому мы сразу смотрели что-нибудь связанные с геолокацией. Мне очень понравилось, что в Telegram, раньше всех остальных приложений, появился удобный способ делится местоположением в реальном времени (<https://telegram.org/blog/live-locations>) и я достаточно часто этим пользуюсь: помочь сориентироваться другу, показать дорогу и самое главное ответить на главный вопрос "Когда ты будешь?". В принципе, этого хватает большинству людей, но как всегда есть сценарии, когда простых возможностей не хватает. Например, это может быть группа более 10 человек, с разными устройствами (некоторые устройства возможно не являются телефонами) и разными людьми. Этим людям было бы удобно обмениваться сообщениями в группе, а также видеть перемещения друг друга на карте.
Во главу угла мы поставили задачу создать дополнительную ценность для Telegram, а не пытаться использовать его не по назначению. Мы не хотели, чтобы люди у которых нет специального клиента Телеграм, видели в чате месиво сообщений или что-то невразумительное. У людей с "улучшенным" клиентом, появляются же дополнительные возможности, например:
1. Более тонкое управление временем при отправке локации в реальном времени в чат.
2. Просмотр местоположения контактов на карте.
3. Подключение к чату маячковых устройств, через внешний API (Bot).
### Как мы это делали
К счастью, весь код, который мы пишем — Open-Source, поэтому я сразу могу дать ссылку на его реализацию — [Реализация Bot](https://github.com/osmandapp/OsmAnd-tools/blob/master/java-tools/OsmAndServer/src/main/java/net/osmand/server/assist/OsmAndAssistantBot.java) и [Реализация Telegram Client на Kotlin](https://github.com/osmandapp/Osmand/tree/master/OsmAnd-telegram).
##### Bot — основы
По реализации Bot существует достаточно много документации и примеров, но все же хочется пройтись и рассказать про некоторые подводные камни. Для начала, мы писали серверную часть
на Java и выбрали библиотеку org.telegram:telegrambots. Так как наш сервер — это обычный SpringBoot, то инициализация крайне простая:
```
// Gradle implementation "org.telegram:telegrambots:3.6"
TelegramBotsApi telegramBotsApi = new TelegramBotsApi();
telegramBotsApi.registerBot(new TelegramLongPollingBot() {...});
```
Основная особенность передачи location, что его надо часто обновлять, и боту необходимо редактировать уже отправленные сообщения. Если бы не было такой возможности, то Bot бы просто заспамил чат и это, конечно, был бы Epic Fail. Слава богу, Telegram предоставляет права боту редактировать сообщения на протяжении 24 часов (минимум, возможно и дольше).
Передать сообщение можно многими способами. Есть тип Plain Text, Venue, Location, Game, Contact, Invoice и т.д. Казалось, что для нашей задачи отлично подходит Location, но вскрылась неприятная особенность. Location можно передать только с одного устройства для одного аккаунта или бота одновременно! Представьте у вас 2 телефона и с двух телефонов вы отправили свой Location в один чат. Так вот, на сервере случится ошибка и первый Location Sharing просто остановится. Казалось бы, это явно неральный случай, но представьте, у вас много китайских маячков, которые умеют отправлять Location по заданному URL, но они не умеют отправлять прямо в Telegram. Вы пишите Bot, который забирает с сервера и пушит в телеграм. Вот тут и вылазит, то что Bot не сможет отправить больше одного сообщения маячка с типом Location. Получается, это отлично подходит для единоразовой отправки, но не подходит для Live Location.
Решение простое — отправлять текстовые сообщения, а клиент будет парсить текст и показывать локации на карте. К сожалению в стандартном клиенте Telegram будут видны только текстовые сообщения, но там можно вставить ссылку, чтобы открыть карту.
##### Bot — Подводные камни
К сожалению, Bot пришлось переписывать аж 2.5 раза. Основная проблема — неправильный дизайн коммуникации.
1. Почему-то вначале казалось хорошей идеей, если бот будет полноценным участником чата и отправлять сообщения. Но, это плохо и с точки зрения Privacy переписки и с точки зрения взаимодействия с ботом. Правильное решение, использовать [Inline bots](https://core.telegram.org/bots/inline). Таким образом, гарантируется, что бот не видит ничего кроме своего Location и его можно использовать в любом чате. По-человечески говоря, некультурно тащить своего бота в какой-то общий чат, а нужно пообщаться с ботом один на один и настроить его, а дальше он сможет отправлять нужные сообщения в любой выбранный чат.
2. В Telegram Message API есть исторически 2 типа взаимодействия: кнопки под текстом ( (inline buttons)[<https://core.telegram.org/bots/2-0-intro#switch-to-inline-buttons>] ) и ответы боту напрямую текстом. В общем, ответы с ботом безнадежно устарели. Кнопки немного сложнее с точки зрения реализации, но это полностью окупается удобством использования и именно их надо использовать для всего нетекстового ввода.
3. В качестве примера бота можно посмотреть популярный @vote\_bot или наш @osmand\_bot.
##### Telegram Client
Найти примеры готовых telegram client, кроме основного, нам не удалось, но достаточно простая структура tdlib помогла нам создать базовый клиент буквально за пару дней.
**Настройка Gradle:**
```
task downloadTdLibzip {
doLast {
ant.get(src: 'https://core.telegram.org/tdlib/tdlib.zip', dest: 'tdlib.zip', skipexisting: 'true')
ant.unzip(src: 'tdlib.zip', dest: 'tdlib/')
}
}
task copyNativeLibs(type: Copy) {
dependsOn downloadTdLibzip
from "tdlib/libtd/src/main/libs"
into "libs"
}
task copyJavaSources(type: Copy) {
dependsOn downloadTdLibzip
from "tdlib/libtd/src/main/java/org/drinkless/td"
into "src/org/drinkless/td"
}
dependencies {
implementation fileTree(dir: 'libs', include: ['*.jar'])
}
```
Практически все внутренности Телеграмма написаны на С++ и с точки зрения Android виден только класс API на 1.5 Мб прокси методов [TdApi.java](https://raw.githubusercontent.com/ihorvitruk/Telegram-Client/master/libtd/src/main/java/org/drinkless/td/libcore/telegram/TdApi.java). Путем сопоставления документации ботов и названия методов, можно достаточно просто сориентироваться куда двигаться.
**Инициализация клиента с global handler:**
```
fun init(): Boolean {
return if (libraryLoaded) {
// create client
client = Client.create(UpdatesHandler(), null, null)
true
} else {
false
}
}
```
**Запрос фото пользователя:**
```
private fun requestUserPhoto(user: TdApi.User) {
val remotePhoto = user.profilePhoto?.small?.remote
if (remotePhoto != null && remotePhoto.id.isNotEmpty()) {
downloadUserFilesMap[remotePhoto.id] = user
client!!.send(TdApi.GetRemoteFile(remotePhoto.id, null)) { obj ->
when (obj.constructor) {
TdApi.Error.CONSTRUCTOR -> {
val error = obj as TdApi.Error
val code = error.code
if (code != IGNORED_ERROR_CODE) {
listener?.onTelegramError(code, error.message)
}
}
TdApi.File.CONSTRUCTOR -> {
val file = obj as TdApi.File
client!!.send(TdApi.DownloadFile(file.id, 10), defaultHandler)
}
else -> listener?.onTelegramError(-1, "Receive wrong response from TDLib: $obj")
}
}
}
}
```
##### Telegram Client — подводные камни
1. Регистрация/Login и Logout. При регистрации необходимо учесть разные сценарии: когда код доступа присылается SMS или в другой телеграм клиент, двухфакторную авторизацию и т.п. Самая большая сложность — это тестирование. Любая авторизация более 3-х раз вела к блокировке аккаунта на 24 часа, поэтому тестировать Logout было особенно весело. Несмотря на то, что регистрация нужна всего лишь один раз, наверное это самая сложная часть интеграции.
2. Определить как и в каком порядке вычитывать сообщения. Любой клиент имеет доступ ко всем сообщениям во всех чатах, но вычитывать их надо последовательно. В нашем случае 99% сообщений нужно отбрасывать. Сначала мы почему-то сделали чтение всех сообщений за последние 3 дня при логине, но в дальнейшем это только вызвало проблемы и при рестарте у нас пропадали сообщения. Поэтому сейчас мы читаем только новые сообщения, а для тех сообщений, что нам нужны сохраняем id во внутренней БД.
### Что получилось
Наверное, зная все подводные камни можно было бы все сделать в разы быстрее, но получилось где-то 1-2 месяца на трех человек. Финальное приложение можно найти в [Google Play](https://play.google.com/store/apps/details?id=net.osmand.telegram).
Главный вопрос в этой истории, насколько правильно это взаимодействие с точки зрения Телеграма и понравятся ли пользователям такого рода интеграции. В любом случае, сама идея нишевая и отдельных клиентов она уже нашла.
Буду рад ответить на ваши вопросы. | https://habr.com/ru/post/424245/ | null | ru | null |
# Адаптивные колонки
При создании колонок обычно приходится применять специальные CSS-классы к первому и последнему элементу. В этой статье рассказано о небольшом трюке, который упрощает верстку колонок, а также делает их адаптивными.
Суть метода сводится к использованию псевдокласса **nth-of-type**: количество и ширина колонок меняется на экранах разных размеров ([Демонстрация](http://koulikov.com/wp-content/uploads/2012/12/columns/)).
Недостатки использования классов для первого и последнего элементов
-------------------------------------------------------------------
Применять классы .first и .last для колонок в каждой строке для корректного отображения очень утомительно, к тому же возникают проблемы при верстке адаптивно:

Использование nth-of-type
-------------------------
Выражение :nth-of-type(An+B) помогает очень легко очистить float'ы и отступы элементов, например:
* **.grid4 .col:nth-of-type(4n+1)**— каждый четвертый элемент .col начинается с новой строки
* **.grid2 .col:nth-of-type(2n+1)** — каждый второй элемент .col начинается с новой строки

```
.grid4 .col:nth-of-type(4n+1),
.grid3 .col:nth-of-type(3n+1),
.grid2 .col:nth-of-type(2n+1) {
margin-left: 0;
clear: left;
}
```
Добавление адаптивности
-----------------------
Для того, чтобы страница стала адаптивной, используем media queries, все значения в процентах:
```
/* col */
.col {
background: #eee;
float: left;
margin-left: 3.2%;
margin-bottom: 30px;
}
/* grid4 col */
.grid4 .col {
width: 22.6%;
}
/* grid3 col */
.grid3 .col {
width: 31.2%;
}
/* grid2 col */
.grid2 .col {
width: 48.4%;
}
```
Вот как происходит переход с четырехколоночной на трехколоночную сетку при изменении размера окна (менее 740px):
* Меняется .grid4 .col, если ширина становится менее 31,2% (треть всей ширины окна)
* Сбрасывается левый отступ
* Переопределяется левый отступ с помощью nth-of-type(3n+1) для создания трехколоночной сетки

```
@media screen and (max-width: 740px) {
.grid4 .col {
width: 31.2%;
}
.grid4 .col:nth-of-type(4n+1) {
margin-left: 3.2%;
clear: none;
}
.grid4 .col:nth-of-type(3n+1) {
margin-left: 0;
clear: left;
}
}
```
Переход с четырехколоночной и трехколоночной на двухколоночную сетку происходит при ширине окна менее 600px:
```
@media screen and (max-width: 600px) {
/* change grid4 to 2-column */
.grid4 .col {
width: 48.4%;
}
.grid4 .col:nth-of-type(3n+1) {
margin-left: 3.2%;
clear: none;
}
.grid4 .col:nth-of-type(2n+1) {
margin-left: 0;
clear: left;
}
/* change grid3 to 2-column */
.grid3 .col {
width: 48.4%;
}
.grid3 .col:nth-of-type(3n+1) {
margin-left: 3.2%;
clear: none;
}
.grid3 .col:nth-of-type(2n+1) {
margin-left: 0;
clear: left;
}
}
```
Для растягивания по всей ширине используем следующий код:
```
@media screen and (max-width: 400px) {
.col {
width: 100% !important;
margin-left: 0 !important;
clear: none !important;
}
}
```
Работа в Internet Explorer
--------------------------
В Internet Explorer версии 8 и младше не поддерживается media queries и nth-of-type. Для решения этой проблемы можно использовать [selectivizr.js](http://selectivizr.com/) (фикс nth-of-type) и [respond.js](https://github.com/scottjehl/Respond) (фикс media queries). к сожалению selectivizr.js и respond.js не очень хорошо работают вместе: nth-of-type не будет работать внутри media queries. | https://habr.com/ru/post/161923/ | null | ru | null |
# Unit-тестирование в Codeception
Неделю назад [я уже писал о Codeception](http://habrahabr.ru/blogs/php/136477/) и об его использования для тестирования PHP приложений. После прошлого поста несколько багов было исправлено. Спасибо за багрепорты. Если вы ещё не пробовали Codeception, советую посмотреть прошлую статью и испытать его для приемочных тестов.
Сегодня я хочу рассказать, как в Codeception реализовано юнит-тестирование в BDD-стиле.
Замечу, что модуль для тестирования юнитов пока экспериментальный. Не в значении «нестабильный», а в значении «может и будет расширяться для удоволетворения всех необходимых нужд».
Прежде чем начать рассказывать о BDD-тестировании юнитов, я отвечу на вполне логичный вопрос, который у вас естественно возникнет: нафига козе баян? То есть, зачем нужны какие-то приблуды к юнит-тестам, если они и так отлично работают в том же PHPUnit'е. Зачем переписывать их в сценарной парадигме?
Все тесты должны быть читабельными. В особенности юнит-тесты, где тест по сути описывает функциональность метода. Но он бывает перегружен приготовлением среды, созданием стабов и моков. В нем бывает намешано много разных вызовов и порой напрочь отсутствуют комментарии. И новому человеку, сломавшему тест, бывает трудно вникнуть в то что же тут тестируется и как.
Codeception предлагает подход, где каждый шаг описывает выполняемое действие.
Вот например, так:
```
php
class UserCest {
function setNameAndSave(CodeGuy $I)
{
$I-wantToTest('getter and setter of User model');
$I->execute(function () {
$user = new Model\User;
$user->setName('davert');
$user->save();
});
$I->seeInDatabase('users',array('name' => 'davert');
}
}
?>
```
И зачем это нужно? Так отделяется исполняемый код от проверок. Впрочем, никто не запрещает использовать ассерты и внутри блока кода:
```
php
$I-wantToTest('getter and setter of User model');
$I->execute(function () {
$user = new Model\User;
$user->setName('davert');
assertEquals('davert', $user->getName());
$user->save();
});
$I->seeInDatabase('users',array('name' => 'davert');
```
Чем сложнее становится тест, тем больше требуется для поддержания его читабельности.
Codeception становится интересен когда вам нужно протестировать классы бизнес-логики. Они обычно не существуют в изоляции, а в зависимости от других классов, и результат их выполнения порой не так просто проверить, как для геттера.
Возьмем вот такой простой контроллер из воображаемого MVC-фреймворка.
```
php
class UserController extends AbtractController {
public function show($id)
{
$user = $this-db->find('users',$id);
if (!$user) return $this->render404('User not found');
$this->render('show.html.php', array('user' => $user));
return true;
}
}
?>
```
Что он делает, впринципе понятно. Показывает страницу профиля пользователя. Но тестировать его сложно, ведь прежде чем тестировать, нужно изолировать контроллер от View и Model. Вот как мы сделаем это в Codeception.
```
php
class UserControllerCest {
public $class = 'UserController';
public function show(CodeGuy $I) {
$I-haveStub($controller = Stub::makeEmptyExcept($this->class, 'show'))
->haveStub($db = Stub::make('DbConnector', array(
'find' => function($id) { return $id ? new User() : null )))
->setProperty($controller, 'db', $db);
$I->wantTo('render profile page for valid user')
->executeTestedMethodOn($controller, 1)
->seeResultEquals(true)
->seeMethodInvoked($controller, 'render');
$I->expect('it will render page 404 for unexistent user')
->executeTestedMethodOn($controller, 0)
->seeResultNotEquals(true)
->seeMethodInvoked($controller, 'render404','User not found')
->seeMethodNotInvoked($controller, 'render');
}
}
```
Как тот же тест я написал в PHPUnit можете посмотреть [здесь](https://gist.github.com/1498755). Получилось в 1,5 раза длиннее, и код, конечно, понятен, но если вы гуру PHPUnit.
Что хорошо в нашем коде: он имеет четкую структуру. Сначала мы создаем среду, дальше выполняем действия и проверяем результаты. Обратите внимание, мы проверяем был ли выполнен метод 'render' из контроллера **после** того, как выполнили наш метод 'show' с параметром 1. Таким образом, мы не смешиваем определение стабов с ассертами. Все проверки идут после выполнения тестируемого кода.
Насчет читабельности. Попробуем творчески перевести этот код в текст:
With this method I can render profile page for valid user
If I execute this method
I will see result equals: true
I will see method invoked: $controller, 'render'
I expect it will render page 404 for unexistent user
If I execute this method
I will see result not equals: true
I will see method invoked: $controller, 'render404'
I will see method not invoked: $controller, 'render'
Хоть бери и пиши в документацию. Возможно, вскоре генерация документации будет добавлена, но пока я просто хочу продемонстрировать, насколько четко и понятно сам код теста описывает тестируемый код.
Обратите внимание, как создаются стабы. Любой стаб делается одной командой. Например:
```
php
// создаем простой класс с переопределенным методом save
$user = Stub::make('User', array('save' = function () {}));
// создаем пустой класс с указанными свойствами
$user = Stub::makeEmpty('User', array('name' => 'davert'));
// создаем пустой класс при помощи конструктора
$user = Stub::constructEmpty('Template', array('show.html', 'html'));
?>
```
Это проще, чем то что предлагает PHPUnit. Вспомните хотя бы сколько параметров требует mockBuilder и что они все значат. Но что самое интересное, класс Stub это просто обертка над mockBuilder'ом. Заметьте, мы создаем только стабы, т.е. среду. А из них, динамически, той же командой seeMethodInvoked стаб превращаем в мок.
Больше информации в [документации](http://codeception.com/docs/07-UnitTestsPractice) и в модуле [Unit](http://codeception.com/docs/modules/Unit)
Как я говорил вначале, эта штука экспериментальна, а значит, можно обсуждать. Но писалась она не для «сферического кода в вакууме», а исходя из своих же реальных потребностей. Впрочем, советую попробовать для своего проекта. Если какие-то моменты плохо освещены в документации — спрашивайте.
P.S. На оф сайте появилась [статья](http://codeception.com/01-27-2012/bdd-with-zend-framework.html) про интеграцию Codeception и Zend Framework | https://habr.com/ru/post/137097/ | null | ru | null |
# Пара слов об именовании переменных и методов
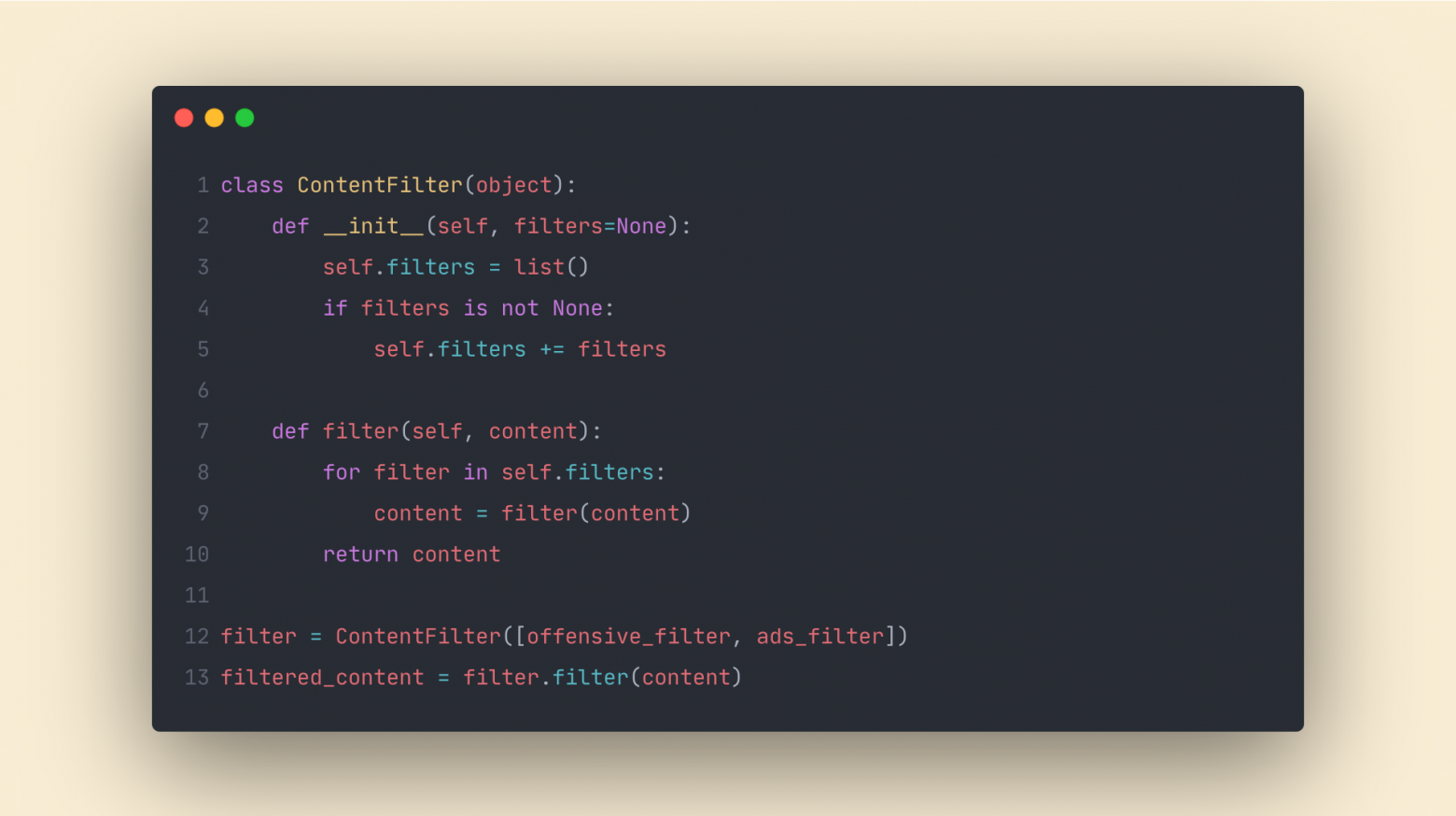
Правильное именование переменных, функций, методов и классов — это один важнейших признаков элегантного и чистого кода. Кода, который чётко и ясно передает намерения программиста и не терпит допущений о том, что же имелось в виду.
В этой статье мы будем говорить о коде, являющемся полной противоположностью описанного выше — о коде, к написанию которого подходили второпях, безответственно и невдумчиво. Эта статья — небольшая исповедь, ведь и мне, как и любому другому программисту, так же доводилось писать подобный код. В этом нет ничего ужасного до тех пор, пока мы понимаем, что это плохо и над этим нужно работать.
Чтобы не оставлять тех, кто ожидает более глубокого анализа, разочарованными, я оставлю в конце статьи список литературы, которую будет полезно почитать, дабы понять важность данной темы и глубже погрузиться в ее изучение, но уже опираясь на источники, написанные такими профессионалами, коими мы все стремимся когда-нибудь стать.
Не будем затягивать и, пожалуй, начнем.
Переменные
----------
Один из самых раздражающих видов переменных — это такие переменные, что дают ложное представление о природе данных, которые они хранят. Эдакие переменные-мошенники.
В среде Python-разработчиков крайне популярна библиотека `requests`, и если вы когда-либо искали что-то связанное с `requests`, то наверняка натыкались на подобный код:
```
import requests
req = requests.get('https://api.example.org/endpoint')
req.json()
```
Всякий раз, когда я вижу такое, я испытываю раздражение и не столько из-за сокращенной записи, сколько из-за того, что название переменной преступным образом не соответствует тому, что в этой переменной хранится.
Когда вы делаете запрос (`requests.Request`), то [получаете ответ](https://requests.readthedocs.io/en/master/api/#requests.request) (`requests.Response`), так отразите это у себя в коде:
```
response = requests.get('https://api.example.org/endpoint')
response.json()
```
Не `r`, не `res`, не `resp` и уж точно не `req`, а именно `response`. `res`, `r`, `resp` (про `req` и вовсе молчу) — это все переменные, содержание которых можно понять, только взглянув на их объявление, а зачем прыгать к объявлению, когда можно изначально дать подходящее название?
Давайте рассмотрим еще один пример, но теперь из Django:
```
users_list = User.objects.filter(age__gte=22)
```
Когда вы видите где-то в коде `users_list`, то вы совершенно справедливо ожидаете, что сможете сделать так:
```
users_list.append(User.objects.get(pk=3))
```
Но нет, вы этого сделать не можете, так как `.filter()` возвращает `QuerySet`, а `QuerySet` далеко не `list`:
```
Traceback (most recent call last):
# ...
# ...
AttributeError: 'QuerySet' object has no attribute 'append'
```
Если вам очень важно указывать суффикс, то укажите хотя бы такой, который соответствует действительности:
```
users_queryset = User.objects.all()
users_queryset.order_by('-age')
```
Если же вам очень хочется написать именно `_list`, то будьте добры позаботиться о том, чтобы в переменную и правда попадал список:
```
users_list = list(User.objects.all())
```
Привязка названия переменной к типу хранящихся в ней данных — это чаще всего плохая идея, особенно когда вы работаете с динамическими языками. В случаях, когда очень нужно отметить, что объект представляет собой контейнерный тип данных, достаточно просто указать название переменной во множественном числе:
```
users = User.objects.all()
```
или, если вам уж совсем неймется и вы в любом случае намерены использовать суффиксы, то лучше добавить суффикс `_seq` (меньшее из зол), чтобы отметить, что это последовательность:
```
users_seq = [1, 2, 3]
# или
users_seq = (1, 2, 3)
# или
users_seq = {1, 2, 3}
```
Таким образом, вы будете знать, что в переменной хранится последовательность и что по ней можно итерировать, но не будете делать предположений о прочих свойствах и методах объекта.
Еще одним видом раздражающих переменных являются переменные с сокращенными именами.
Вернемся к `requests` и рассмотрим этот код:
```
s = requests.Session()
# ...
# ...
s.close()
```
Это яркий пример совершенно неоправданного сокращения названия переменной. Это ужасная практика, и ее ужасы становятся еще более очевидны, когда такой код занимает больше 10-15 строк кода.
Конкретно в случае `requests` скрипя зубами можно простить подобное сокращение, когда код занимает не более 5-10 строк и записывается вот так:
```
with requests.Session() as s:
# ...
# ...
s.get('https://api.example.org/endpoint')
```
Тут контекстный менеджер позволяет дополнительно выделить объемлющий блок для переменной `s`.
Но гораздо лучше написать как есть, а именно:
```
session = requests.Session()
# ...
# ...
session.get('https://api.example.org/endpoint')
# ...
# ...
session.close()
```
или
```
with requests.Session() as session:
session.get('https://api.example.org/endpoint')
```
Вы можете возразить, что это ведь более многословный вариант, но я вам отвечу, что это окупается, когда вы читаете код и сразу понимаете, что `session` — это `Session`. Поймете ли вы это по переменной `s`, не взглянув на ее определение?
Рассмотрим еще один пример:
```
info_dict = {'name': 'Isaak', 'age': 25}
# ...
# ...
info_dict = list(info_dict)
# ...
# ...
```
Вы видите `dict` и можете захотеть сделать так:
```
for key, value in info_dict.items():
print(key, value)
```
Но вместо этого получите ошибку, ведь вас ввели в заблуждение, и поймете вы это, только если пройдете к объявлению и прочитаете весь код сверху вниз, вплоть до участка, с которого начинали прыжок к объявлению — такова цена подобных переменных.
Таким образом, когда вы указываете в названии переменной тип хранящихся в ней данных, вы по сути выступаете гарантом того, что в этой переменной в любой момент времени выполнения программы должен содержаться указанный тип данных. Зачем нам брать на себя такую ответственность, если это прямая обязанность интерпретатора или компилятора? Лучше потратить время на придумывание хорошего названия переменной, чем на попытки понять, почему переменные ведут себя не так, как вы ожидаете.
В приведенном выше примере выбор переменной достаточно неудачный, и можно было бы дать имя, точнее выражающее контекст (не нужно бояться использовать имена, относящиеся к предметной области), однако даже в этом случае можно было бы сделать этот код лучше:
```
info_dict = {'name': 'Isaak', 'age': 25}
# ...
# ...
info_keys = list(info_dict)
# ...
# ...
```
или даже так, что более идиоматично:
```
info_dict = {'name': 'Isaak', 'age': 25}
# ...
# ...
info_keys = info_dict.keys()
# ...
# ...
```
Комментарии-кэпы
----------------
Комментарии – это то, что может как испортить ваш код, так и сделать его лучше. Хороший комментарий требует времени на обдумывание и написание, и потому чаще всего мы все сталкиваемся с отвратительными комментариями, которые не представляют собой ничего, кроме визуального мусора.
Возьмем небольшой пример из JavaScript:
```
// Remove first five letters
const errorCode = errorText.substr(5)
```
Первое, что мелькает в голове, когда видишь такое — это "Спасибо, кэп!". Зачем описывать то, что и так понятно без комментария? Зачем дублировать информацию, которую нам уже рассказывает код? Этим и отличается хороший комментарий от плохого — хороший комментарий заставляет вас испытать благодарность тому, кто его написал, а плохой — лишь раздражение.
Давайте попробуем сделать этот комментарий полезным:
```
// Remove "net::" from error text
const errorCode = errorText.substr(5)
```
А еще лучше прибегнуть к более декларативному подходу и избавиться от комментария вообще:
```
const errorCode = errorText.replace('net::', '')
```
Говоря о комментариях, нельзя не упомянуть мертвый код. Мертвый код, пожалуй, раздражает куда больше, чем бесполезные комментарии, так как вы еще и должны разбираться, был ли код закомментирован временно (для отладки каких-то частей системы) или все же разработчик просто забыл его удалить?
Как бы там ни было, мертвому коду не место в модулях и он должен быть удален! Если вдруг окажется, что это было что-то важное, то вы сможете просто откатиться к нужной версии (если, конечно, вы не программист-амиш, что не пользуется системой контроля версий).
Методы
------
Умное именование функций и методов — это то, что приходит только с опытом проектирования API, и потому достаточно часто можно встретить случаи, когда методы ведут себя не так, как мы ожидаем.
Рассмотрим пример с методом:
```
>>> person = Person()
>>> person.has_publications()
['Post 1', 'Post 2', 'Post 3']
```
В коде мы выразили весьма однозначный вопрос: "Имеются ли у этого человека публикации?", но какой ответ мы получили?
Мы не спрашивали, какие у человека есть публикаций. Название этого метода подразумевает, что возвращаемое значение должно иметь булевый тип, а именно `True` или `False`:
```
>>> person = Person()
>>> person.has_publications()
True
```
А для получения постов вы можете использовать более подходящее название:
```
>>> person.get_publications()
['Post 1', 'Post 2', 'Post 3']
```
или
```
>>> person.publications()
['Post 1', 'Post 2', 'Post 3']
```
Мы часто любим называть программирование творческой деятельностью, и таковой оно в действительности и является. Однако, если вы пишете код, который можете прочитать только вы, и затем оправдываете это "творчеством", то у меня для вас плохие новости.
Список литературы для изучения вопроса
--------------------------------------
Как и обещал, оставляю список выдающейся релевантной литературы, написанной известными профессионалами в области. Большая часть приведенных ниже книг переведена на русский язык.
1. [Robert Martin — Clean Code](https://www.amazon.com/Clean-Code-Handbook-Software-Craftsmanship/dp/0132350882)
2. [Robert Martin — Clean Architecture](https://www.amazon.com/Clean-Architecture-Craftsmans-Software-Structure/dp/0134494164)
3. [Robert Martin — The Clean Coder: A Code of Conduct for Professional Programmers](https://www.amazon.com/Clean-Coder-Conduct-Professional-Programmers/dp/0137081073)
4. [Martin Fowler — Refactoring: Improving the Design of Existing Code](https://www.martinfowler.com/books/refactoring.html)
5. [Colin J. Neill — Antipatterns: Managing Software Organizations and People](https://www.amazon.com/Antipatterns-Managing-Software-Organizations-Engineering/dp/1439861862) | https://habr.com/ru/post/508238/ | null | ru | null |
# Реализация алгоритма Дейкстры на C#
#### Введение
Всем привет, пишу данный топик как логическое продолжение [данной статьи](http://habrahabr.ru/blogs/algorithm/61884/) о максимальном потоке минимальной стоимости, в конце которой был затронут алгоритм Дейксты. Соглашусь с автором, что описание и различные реализации алгоритма можно найти без проблем, и «колесо» я не изобретаю, но тем не менее опишу здесь практическую реализацию на языке C#. Кстати отмечу, что использую LINQ, так что для работы необходим NET 3.5.
**UPD**Наконец-то подчистил код :)
#### Немного теории
Чтобы сразу не кидали камни в мой огород дам [ссылку](http://ru.wikipedia.org/wiki/%D0%90%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC_%D0%94%D0%B5%D0%B9%D0%BA%D1%81%D1%82%D1%80%D1%8B) на очень хорошее описание алгоритма на таком незаметном ресурсе как Википедия :). Там вполне доступно описан алгоритм и особенно рекомендую посмотреть пример. Копировать оттуда материал считаю бессмысленно. Все, считаем что теорию изучили.
#### Начало
Данный код представляет реализацию алгоритма на взвешенном **неориентированном** графе. Рассмотрим реализацию этого алгоритма.
Объектами данного алгоритма являются три класса:
• Apoint – класс, реализующий вершину графа
• Rebro – класс, реализующий ребро графа
• DekstraAlgoritm – класс, реализующий алгоритм Дейкстры.
Рассмотрим подробнее данные классы и самые важные методы.
**APoint**
Данный класс содержит в себе 5 полей:
•public float ValueMetka { get; set; } данное поле отвечает за хранение значений метки данной вершины. В программе под бесконечностью берется очень большое число, например 99999.
•public string Name { get; set; } – имя метки. Данное поле необходимо лишь для выведения удобно читаемого результата.
•public bool IsChecked { get; set; } – означает помечена метка или нет
•public APoint predPoint { get; set; } – «предок» точки, т.е. та точка которая является предком текущей в кратчайшем маршруте.
•public object SomeObj { get; set; } – некий объект
Каких-либо значимых методов данный класс не содержит.
**Rebro**
Данный класс содержит 3 поля:
•public APoint FirstPoint { get; set; } – начальная вершина ребра
•public APoint SecondPoint { get; set; } – конечная вершина ребра
•public float Value { get; set; } – весовой коэффициент.
Каких-либо значимых методов данный класс не содержит.
**DekstraAlgorim**
Данный класс представляет собой граф и реализацию алгоритма Дейкстры. Содержит 2 поля:
•public APoint[] points { get; set; } – массив вершин
•public Rebro[] rebra { get; set; }- массив ребер
Таким образом, эти 2 массива отражают граф. Рассмотрим методы:
•private APoint GetAnotherUncheckedPoint()
Данный метод возвращает очередную неотмеченную вершину, наименее удаленную, согласно алгоритму.
•public void OneStep(APoint beginpoint)
Данный метод делает один шаг алгоритма для заданной точке.
•private IEnumerable Pred(APoint currpoint)
Данный метод ищет соседей для заданной точки и возвращает коллекцию точек.
•public string MinPath(APoint begin,APoint end)
Данный метод возвращает кратчайший путь, найденный в алгоритме от начальной точке до конечной. Этот метод используется для наглядного отображения пути
•public void AlgoritmRun(APoint beginp)
Данный метод запускает алгоритм и принимает в качестве входа начальную точку.
Все основные методы описаны, представим процесс работы алгоритма в целом на рис.1. Основной метод OneStep представлен на рисунке 2.

Рис.1. Работа алгоритма в целом

Рис.2. Работа метода OneStep
#### Код
Наконец, рассмотрим сам код. В каждом классе написал подробные комментарии.
> `///
>
> /// Реализация алгоритма Дейкстры. Содержит матрицу смежности в виде массивов вершин и ребер
>
> ///
>
> class DekstraAlgorim
>
> {
>
>
>
> public Point[] points { get; private set; }
>
> public Rebro[] rebra { get; private set; }
>
> public Point BeginPoint { get; private set; }
>
>
>
> public DekstraAlgorim(Point[] pointsOfgrath, Rebro[] rebraOfgrath)
>
> {
>
> points = pointsOfgrath;
>
> rebra = rebraOfgrath;
>
> }
>
> ///
>
> /// Запуск алгоритма расчета
>
> ///
>
> ///
>
> public void AlgoritmRun(Point beginp)
>
> {
>
> if (this.points.Count() == 0 || this.rebra.Count() == 0)
>
> {
>
> throw new DekstraException("Массив вершин или ребер не задан!");
>
> }
>
> else
>
> {
>
> BeginPoint = beginp;
>
> OneStep(beginp);
>
> foreach (Point point in points)
>
> {
>
> Point anotherP = GetAnotherUncheckedPoint();
>
> if (anotherP != null)
>
> {
>
> OneStep(anotherP);
>
> }
>
> else
>
> {
>
> break;
>
> }
>
>
>
> }
>
> }
>
>
>
> }
>
> ///
>
> /// Метод, делающий один шаг алгоритма. Принимает на вход вершину
>
> ///
>
> ///
>
> public void OneStep(Point beginpoint)
>
> {
>
> foreach(Point nextp in Pred(beginpoint))
>
> {
>
> if (nextp.IsChecked == false)//не отмечена
>
> {
>
> float newmetka = beginpoint.ValueMetka + GetMyRebro(nextp, beginpoint).Weight;
>
> if (nextp.ValueMetka > newmetka)
>
> {
>
> nextp.ValueMetka = newmetka;
>
> nextp.predPoint = beginpoint;
>
> }
>
> else
>
> {
>
>
>
> }
>
> }
>
> }
>
> beginpoint.IsChecked = true;//вычеркиваем
>
> }
>
> ///
>
> /// Поиск соседей для вершины. Для неориентированного графа ищутся все соседи.
>
> ///
>
> ///
>
> ///
>
> private IEnumerable Pred(Point currpoint)
>
> {
>
> IEnumerable firstpoints = from ff in rebra where ff.FirstPoint==currpoint select ff.SecondPoint;
>
> IEnumerable secondpoints = from sp in rebra where sp.SecondPoint == currpoint select sp.FirstPoint;
>
> IEnumerable totalpoints = firstpoints.Concat(secondpoints);
>
> return totalpoints;
>
> }
>
> ///
>
> /// Получаем ребро, соединяющее 2 входные точки
>
> ///
>
> ///
>
> ///
>
> ///
>
> private Rebro GetMyRebro(Point a, Point b)
>
> {//ищем ребро по 2 точкам
>
> IEnumerable myr = from reb in rebra where (reb.FirstPoint == a & reb.SecondPoint == b) || (reb.SecondPoint == a & reb.FirstPoint == b) select reb;
>
> if (myr.Count() > 1 || myr.Count() == 0)
>
> {
>
> throw new DekstraException("Не найдено ребро между соседями!");
>
> }
>
> else
>
> {
>
> return myr.First();
>
> }
>
> }
>
> ///
>
> /// Получаем очередную неотмеченную вершину, "ближайшую" к заданной.
>
> ///
>
> ///
>
> private Point GetAnotherUncheckedPoint()
>
> {
>
> IEnumerable pointsuncheck = from p in points where p.IsChecked == false select p;
>
> if (pointsuncheck.Count() != 0)
>
> {
>
> float minVal = pointsuncheck.First().ValueMetka;
>
> Point minPoint = pointsuncheck.First();
>
> foreach (Point p in pointsuncheck)
>
> {
>
> if (p.ValueMetka < minVal)
>
> {
>
> minVal = p.ValueMetka;
>
> minPoint = p;
>
> }
>
> }
>
> return minPoint;
>
> }
>
> else
>
> {
>
> return null;
>
> }
>
> }
>
>
>
> public List MinPath1(Point end)
>
> {
>
> List listOfpoints = new List();
>
> Point tempp = new Point();
>
> tempp = end;
>
> while (tempp != this.BeginPoint)
>
> {
>
> listOfpoints.Add(tempp);
>
> tempp = tempp.predPoint;
>
> }
>
>
>
> return listOfpoints;
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
> `///
>
> /// Класс, реализующий ребро
>
> ///
>
> class Rebro
>
> {
>
> public Point FirstPoint { get; private set; }
>
> public Point SecondPoint { get; private set; }
>
> public float Weight { get; private set; }
>
>
>
> public Rebro(Point first, Point second, float valueOfWeight)
>
> {
>
> FirstPoint = first;
>
> SecondPoint = second;
>
> Weight = valueOfWeight;
>
> }
>
>
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
> `///
>
> /// Класс, реализующий вершину графа
>
> ///
>
> class Point
>
> {
>
> public float ValueMetka { get; set; }
>
> public string Name { get; private set; }
>
> public bool IsChecked { get; set; }
>
> public Point predPoint { get; set; }
>
> public object SomeObj { get; set; }
>
> public Point(int value,bool ischecked)
>
> {
>
> ValueMetka = value;
>
> IsChecked = ischecked;
>
> predPoint = new Point();
>
> }
>
> public Point(int value, bool ischecked,string name)
>
> {
>
> ValueMetka = value;
>
> IsChecked = ischecked;
>
> Name = name;
>
> predPoint = new Point();
>
> }
>
> public Point()
>
> {
>
> }
>
>
>
>
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
> `//
>
> /// для печати графа
>
> ///
>
> static class PrintGrath
>
> {
>
> public static List<string> PrintAllPoints(DekstraAlgorim da)
>
> {
>
> List<string> retListOfPoints = new List<string>();
>
> foreach (Point p in da.points)
>
> {
>
> retListOfPoints.Add(string.Format("point name={0}, point value={1}, predok={2}", p.Name, p.ValueMetka, p.predPoint.Name ?? "нет предка"));
>
> }
>
> return retListOfPoints;
>
> }
>
> public static List<string> PrintAllMinPaths(DekstraAlgorim da)
>
> {
>
> List<string> retListOfPointsAndPaths = new List<string>();
>
> foreach (Point p in da.points)
>
> {
>
>
>
> if (p != da.BeginPoint)
>
> {
>
> string s = string.Empty;
>
> foreach (Point p1 in da.MinPath1(p))
>
> {
>
> s += string.Format("{0} ", p1.Name);
>
> }
>
> retListOfPointsAndPaths.Add(string.Format("Point ={0},MinPath from {1} = {2}", p.Name, da.BeginPoint.Name, s));
>
> }
>
>
>
> }
>
> return retListOfPointsAndPaths;
>
>
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
> `class DekstraException:ApplicationException
>
> {
>
> public DekstraException(string message):base(message)
>
> {
>
>
>
> }
>
>
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
#### Результат работы
Вот пример работы алгоритма для графа, описанного в теории:
*point name=1, point value=0, predok=нет предка
point name=2, point value=9999, predok=нет предка
point name=3, point value=9999, predok=нет предка
point name=4, point value=9999, predok=нет предка
point name=5, point value=9999, predok=нет предка
point name=6, point value=9999, predok=нет предка
===========
point name=1, point value=0, predok=нет предка
point name=2, point value=7, predok=1
point name=3, point value=9, predok=1
point name=4, point value=20, predok=3
point name=5, point value=20, predok=6
point name=6, point value=11, predok=3
Кратчайшие пути
Point =2,MinPath from 1 = 2
Point =3,MinPath from 1 = 3
Point =4,MinPath from 1 = 4 3
Point =5,MinPath from 1 = 5 6 3
Point =6,MinPath from 1 = 6 3*
#### Заключение
Просьба особо не пинать, моя 1 статья :) Любые замечания приветствую! Надеюсь, кому-нибудь код понадобится. | https://habr.com/ru/post/63347/ | null | ru | null |
# Как написать компонент к Firefox на C++
Как написать на C++ компонент для Firefox, так, чтобы его потом можно было использовать из яваскриптового extension или даже из обычной веб-страницы.
Предыстория
===========
Мне нужно было сделать тулбар для IE и Firefox. Осложнялось всё тем, что использовался некий нестандартный бинарный протокол, реализовала который C-дллька. Использовать её из C# (на котором я писал тулбар для IE) не составило никакой проблемы, однако для FF пришлось писать Wrapper — XPCOM-компонент, к которому я мог бы обратиться из javascript, который передавал бы данные в dll и возвращал бы результат.
XPCOM — это аналог Microsoftовского COM'а от Мозиллы, который от COM отличается практически ничем. Вообще, не очень понятно, почему Mozilla вместо хорошо описанного и привычного COM решили изобрести свой велосипед, но так уж вышло, и нам, разработчикам, придётся принимать всё так, как оно есть.
Open Source — это прекрасно, но до тех пор, пока не столкнёшься с документацией и отсутствием работающих примеров. Примеров XPCOM-компонентов я, кстати, нашёл в интернете аж 4, ни один из которых не заработал. Кроме того, самый свежий из них датировался 2006ым годом, в описаниях значилась старинная версия XULRunner'а, а в обсуждении к примеру были вопросы о совместимости с «новым Firefox 1.3» и несколько десятков вопросов «how to get it work?».
Поехали!
========
1. Вначале разберёмся с environment.
Запускаем в командной строке `subst o: d:\myworkfolder\_firefox` — в эту папку мы будем складывать все нужные файлы.
Можно даже записать эту команду в bat-файл.
2. Скачиваем последний XULRunner (сейчас это 1.9.0.6) — [releases.mozilla.org/pub/mozilla.org/xulrunner/releases](http://releases.mozilla.org/pub/mozilla.org/xulrunner/releases/)
Нам нужен SDK. Скачиваем и распаковываем его в O:\xulrunner-sdk
3. Создаём O:\console.bat следующего содержания:
`set path=%path%;O:\xulrunner-sdk\bin;O:\xulrunner-sdk\sdk\bin
cmd.exe`
(на всякий случай, вдруг потребуется что-нибудь сделать руками)
4. Создаём папку O:\dll-src, и в ней — IDemo.idl
`#include "nsISupports.idl"
#include "nsrootidl.idl"
**[**scriptable**,** uuid**(**CB934085-D019-47d5-A6F0-623885873281**)****]**
interface IDemo : nsISupports
**{**
**long** func1**(**in **long** inP**,** out **long** outP**)****;**
**long** func2**(**in wstring inP**,** out wstring outP**)****;**
**}****;**`
5. Там же создаём два бат-файла, build-pre.bat и build-post.bat. Второй оставляем пустым, а в первый пишем:
`set path=%path%;O:\xulrunner-sdk\bin;O:\xulrunner-sdk\sdk\bin
xpidl -I O:\xulrunner-sdk\idl -m header IDemo.idl
xpidl -I O:\xulrunner-sdk\idl -m typelib IDemo.idl`
По нашему idl-файлы с помощью xpidl будет автоматически генерироваться хедер и xpt-описание интерфейса (аналог майрософтовского .tlb файла)
6. Создаём новый проект Win32 / Dll library / empty

7. Запускаем build-pre.bat и переносим получившийся IDemo.h в наш проект.
8. Создаём в VS файл Demo.h и копируем из IDemo.h наш темплейт. Приводим его в человеческий вид:
`#ifndef _DEMO_H_
#define _DEMO_H_
#include "IDemo.h"
#define DEMO_CONTRACTID "@demo.com/XPCOMDemo/Demo;1"
#define DEMO_CLASSNAME "XPCOM Demo LOL"
#define DEMO_CID **{**0xcb934086**,** 0xd019**,** 0x47d5**,** **{** 0xa6**,** 0xf0**,** 0x62**,** 0x38**,** 0x85**,** 0x87**,** 0x32**,** 0x81 **}****}**
**class** Demo : **public** IDemo
**{**
**public**:
NS_DECL_ISUPPORTS
NS_DECL_IDEMO
Demo**(****)****;**
**virtual** ~Demo**(****)****;**
**}****;**
#endif`
9. Создаём в VS файл Demo.cpp и копируем туда закомментированную часть из IDemo.h — там уже есть шаблон реализации. Меняем название класса.
`#include "Demo.h"
#include <nsMemory**.**h>
#include <nsStringAPI**.**h>
NS_IMPL_ISUPPORTS1**(**Demo**,** IDemo**)**
Demo::Demo**(****)** **{**
**}**
Demo::~Demo**(****)** **{**
**}**
NS_IMETHODIMP Demo::Func1**(**PRInt32 inP**,**PRInt32 \*outP**,**PRInt32 \*_retval**)** **{**
**if** **(**inP>100**)** **{**
\*_retval = 1**;**
\*outP = 0**;**
**}** **else** **{**
\*_retval = 0**;**
\*outP = inP\*2**;**
**}**
**return** NS_OK**;**
**}**
NS_IMETHODIMP Demo::Func2**(****const** PRUnichar \*inP**,**PRUnichar \*\*outP**,**PRInt32 \*_retval**)** **{**
**const** wchar_t \*msg = L"привет"**;**
\*outP = **(**PRUnichar \***)** nsMemory::Clone**(**msg**,** **(**wcslen**(**msg**)**+1**)**\***sizeof****(**wchar_t**)****)****;**
\*_retval = 0**;**
**return** NS_OK**;**
**}**`
10. Создаём в VS файл DemoModule.cpp:
Это — наш главный файл и точка входа в наше приложение. Тут мы отдаём ядру XPCOM'а те компоненты, которые реализует наш модуль.
`#include "nsIGenericFactory.h"
#include "Demo.h"
NS_GENERIC_FACTORY_CONSTRUCTOR**(**Demo**)**
**static** nsModuleComponentInfo components**[****]** =
**{**
**{**
DEMO_CLASSNAME**,**
DEMO_CID**,**
DEMO_CONTRACTID**,**
DemoConstructor**,**
**}**
**}****;**
NS_IMPL_NSGETMODULE**(**"DemoModule"**,** components**)**`
11. Открываем свойства проекта
C/C++ — General — Additional Include Directories пишем O:\xulrunner-sdk\sdk\include;O:\xulrunner-sdk\include
C/C++ — Preprocessor — Preprocessor Definitions добавляем ;XPCOM\_GLUE
C/C++ — Advanced — Force Includes пишем mozilla-config.h
Linker — Additional Library Directories пишем O:\xulrunner-sdk\sdk\lib
Linker — Input — Additional Dependencies — пишем xpcom.lib nspr4.lib xpcomglue\_s.lib
Build events — Pre-build event — Command Line — пишем там O:\dll-src\build-pre.bat
Build events — Post-build event — Command Line — пишем там O:\dll-src\build-post.bat
12. Пришла пора создавать ярлык для файрфокса.
Делаем его и в свойствах пишем: «C:\Program Files\Mozilla Firefox\firefox.exe» -no-remote -P dev
Запускаем. Открылся Profile Manager — создаём профиль dev и указываем вручную папку для него: C:\Documents and settings\test\Application Data\Mozilla\Firefox\Profiles\dev1 (создаём через кнопку «создать»).
Файрфокс запускается, и когда запустится, мы его закрываем
13. Теперь редактируем build-post.bat.
`set path=%path%;O:\xulrunner-sdk\bin;O:\xulrunner-sdk\sdk\bin
del /f "C:\Documents and Settings\test\Application Data\Mozilla\Firefox\Profiles\dev\xpti.dat"
del /f "C:\Documents and Settings\test\Application Data\Mozilla\Firefox\Profiles\dev\compreg.dat"
copy /Y IDemo.xpt "C:\Program Files\Mozilla Firefox\components\"
copy /Y debug\Demo.dll "C:\Program Files\Mozilla Firefox\components\"`
14. Билдим проект!
15. Создаём файлик O:\demo.html
(код приведён частично)
`netscape**.**security**.**PrivilegeManager**.**enablePrivilege**(**"UniversalXPConnect"**)****;**
obj = Components**.**classes**[**"@demo.com/XPCOMDemo/Demo;1"**]****.**createInstance**(****)****;** *//помните это имя? оно есть в Demo.h*myobject = obj**.**QueryInterface**(**Components**.**interfaces**.**IDemo**)****;**
**var** x = **{****}****;**
**var** res = myobject**.**func1**(**10**,**x**)****;**
alert**(**'func1(10,x) returned ' + res + '. x is '+x**.**value**)****;**
res = myobject**.**func2**(**"asd"**,**x**)****;**
alert**(**'func2("ads",x) returned ' + res + '. x is '+x**.**value**)****;**`
16. Запускаем файрфокс через наш ярлык и открываем file://o:\demo.html
17. Жмём на кнопку, соглашаемся с вопросом про UNSAFE, смотрим результаты.
Вопрос про UNSAFE возникает на строчке с «PrivilegeManager.enablePrivilege» — эта строчка просит позволения работать с XPCOM-компонентами и, конечно, в веб-страницах содержаться не должна.
Если же мы делаем Firefox Extension — какую-нибудь панельку инструментов — то нам работать с XPCOM уже позволено. Поэтому в коде расширения этой строчки быть не должно, никакого предупреждения не возникает и всё работает молча.
18. Ура! Работает!
**PS1.** Все файлы проекта можно скачать [по этой ссылке](http://narod.ru/disk/6240310000/demo.zip.html) (82 кб)
**PS2.** У нас есть «интерфейс» (или несколько) и есть «компонент», который этот интерфейс реализует. Каждый из них имеет свой UID. Для генерации UID нам понадобится Guidgen из VS, обычно она лежит в «C:\Program Files\Microsoft SDKs\Windows\v6.0A\Bin\guidgen.exe». Чтобы сгенерировать другие UID'ы, отличные от тех, которые приведены в моём примере, нужно запустить guidgen, выбирать там третий вариант, скопировать его и руками вставить в IDemo.idl. Потом сгенерировать ещё ID и скопировать в уже в Demo.h. Это нужно будет делать, если вы не будете останавливаться на Demo-компоненте и будете делать свой компонент.
**PS3.** idl-файлы для XPCOM отличаются от idl-файлов для COM, поэтому microsoft'овские утилиты tlbimp и midl не понимают эти idl-файлы. Если вы решите добавить IDemo.idl в проект, не забудьте установить в его свойствах «не компилировать». | https://habr.com/ru/post/53312/ | null | ru | null |
# Внутренний мир: Project Reactor
**Привет, Хабр!**
У многих из нас, при использовании какого-либо инструмента программирования, возникал вопрос: “Как? Как это работает?”. Часто при возникновении подобных вопросов я обращаюсь к гуглу, который популярным образом рассказывает общие принципы работы того или иного механизма. Но наверняка среди читателей есть те, которые, прочитав несколько статей, подумали: "Да, это интересно и, вроде, понятно. Но, все-таки, как оно работает?".
Так вот, я тоже вхожу в число таких читателей. Поработав с каким-то механизмом, становится интересен принцип его работы. Поняв принцип работы, становится интересна сама реализация механизма. Я попробовал посмотреть Project Reactor изнутри и решил написать статью, в которой и систематизировать полученные знания. Если она окажется еще и интересной и найдет свою аудиторию, возможно, я попробую выйти на целый цикл статей под кодовым названием "внутренний мир".
В данной статье не будет глубокого описания идей реактивного программирования - подобных статей уже написано чуть меньше, чем много, поэтому для читателей, которым это интересно я оставлю ссылки в конце на ресурсы по теме. Однако, некоторые основы я напишу.
Общая информация
----------------
Реактивное программирование - это асинхронная обработка потоковых данных. Сама реализация построена на широко известном паттерне "Наблюдатель" (а точнее, его частном случае "Издатель-Подписчик"): есть поток, который выполняет роль издателя, на события которого подписывается множество подписчиков. В Java 9 был добавлен стандарт реактивных стримов (пакет `org.reactivestreams`), содержащих 4 интерфейса:
1. `Publisher` - издатель, имеющий точку соединения между издателем и подписчиком.
Интерфейс Publisher
```
public interface Publisher {
void subscribe(Subscriber super T var1);
}
```
2. `Subscriber` - подписчик, имеющий следующие методы обработки реактивного потока:
* `onSubscribe()` выполняется при подписке;
* `onNext()` выполняется для каждого элемента потока;
* `onError()` выполняется в случае возникновения ошибки;
* `onComplete()` выполняется при завершении потока.Интерфейс Subscriber
```
public interface Subscriber {
void onSubscribe(Subscription var1)
void onNext(T var1);
void onError(Throwable var1);
void onComplete();
}
```
3. `Subscription` - объект подписки. С его помощью можно запросить следующий объект, или отменить подписку.
Интерфейс Subscription
```
public interface Subscription {
void request(long var1);
void cancel();
}
```
4. `Processor` - обработчик, преобразовывающий объекты в потоке.
Интерфейс Processor
```
public interface Processor extends Subscriber, Publisher {
}
```
В целом, идея довольно проста:
1. `Subscriber` подписывается на события `Publisher`.
2. В методе `Subscriber.onSubscribe()` посредством `Subscription.request()` выполняется запрос на события.
3. События проходят через цепочку `Processor`'ов и попадают в метод `Subscriber.onNext()`.
4. По завершению потока событий вызывается метод `Subscriber.onComplete()`.
Стоит отметить одну важную вещь, называемую back-pressure (обратное давление). Можно заметить, что в методе запроса передается некое количество. Это сделано для того, чтобы ограничить передачу данных рамками возможностей обработки.
Для того, что бы получить данные, необходимо вызвать `Subscription.request()` в методе `Subscriber.onSubscribe()`. Если необходимо непрерывное получение данных, можно передать `Long.MAX_VALUE`. Если же мы используем механизм back-pressure, необходимо вызывать `Subscription.request()` в методе `Subscriber.onNext()`, что бы получать данные по мере их обработки.
В целом, это и есть вся "общая" информация о реактивных стримах. Теперь хотелось бы перейти к самому Project Reactor (далее - реактор).
Механизм стримов в реакторе
---------------------------
В реакторе появился новый интерфейс `Disposable`. Разница между ним и `Subscription` в том, что `Subscription` используется для управления подпиской внутри подписчика, а `Disposable` - извне.
Попробуем разобраться, как работает сам стрим в реакторе. Мы будем смотреть на примере `Flux`, но все, описанное ниже актуально и для `Mono`.
Для примера будет проверять числа на простоту. Функция специально сделана максимально примитивно, что бы занимала время.
Предикат проверки на простоту
```
private final Predicate checker = num -> {
for (int i = 2; i < num; i++) {
if (num % i == 0) {
return false;
}
}
return true;
};
```
Функция генерации массива
```
private Integer[] generateIntArray(int size) {
Integer[] array = new Integer[size];
for (int i = 0; i < size; i++) {
array[i] = ThreadLocalRandom.current().nextInt(90_000_000, 100_000_000);
}
return array;
}
```
Теперь перейдем к самому стриму:
Первый стрим
```
@Test
public void reactorStream() {
Integer[] array = generateIntArray(100);
Flux.fromArray(array)
.filter(i -> i % 2 != 0)
.map(i -> "Number " + i + " is prime: " + checker.test(i))
.subscribe(System.out::println);
}
```
Пример вывода
```
Number 94296669 is prime: false
Number 94305859 is prime: false
Number 92332843 is prime: true
Number 90404043 is prime: false
Number 99827085 is prime: false
Number 90833557 is prime: false
```
На таком маленьком примере мы начнем изучение внутренней работы реактора. Итак, что тут происходит? Условно, работу стрима можно поделить на 3 части: сборка, подписка и выполнение.
Наш стрим начинается с фабричного метода `Flux.fromArray()`. Провалившись в него мы увидим, что класс `Flux` является абстрактным, а возвращается нам его реализация в виде `FluxArray`. Для себя я назвал такой flux "порождающим", поскольку он всегда стоит в начале цепочки и транслирует дальше элементы для обработки из передаваемого в него ресурса. Такой "порождающий" flux не единственный: например, `Flux.fromIterable()`, `Flux.fromStream()` и `Flux.range()` возвращают `FluxIterable`, `FluxStream` и `FluxRange` соответственно. Каждый "порождающий" flux возвращает собственную реализацию.
Далее мы сразу отсеиваем четные числа, поскольку они нас не интересуют, вызвав метод `filter()`. Провалившись в него, мы узнаем, что он тоже возвращает собственную реализацию flux - `FluxFilter`.
Получается, существует не только много "порождающих" версий flux, но и "модифицирующих". Так, вызванный нами метод `filter()` возвращает уже `FluxFilter`, ресурсом для которого является вышестоящий flux (в нашем случае - `FluxArray`). Вызванный нами далее map() в этом плане имеет точно такое же поведение, но возвращает уже `FluxMap` (а ресурсом для него является `FluxFilter`).
Для большей наглядности покажу, как могло бы выглядеть все вышеописанное без реактора:
Псевдокод: этап сборки
```
Flux sourceFlux = Flux.fromArray(array);
Flux filterFlux = new FluxFilter(sourceFlux, i -> i / 2 != 0);
Flux mapFlux = new FluxMap(filterFlux, i -> "Number " + i + " is prime: " + checker.isPrimeNumber(i));
```
Результирующий flux можно описать таким псевдокодом: `FluxMap(FluxFilter(FluxArray(source)))`
На вызове метода `subscribe()` заканчивается этап сборки и начинается этап подписки.
Несколько слов о subscribe()Прежде чем мы приступим к этапу подписки, хотелось бы написать несколько слов о самом методе `subscribe()`.
Условно реализации метода `subscribe()` в реакторе можно поделить на 2 части: методы, принимающих лямбды для обработки различных сигналов стрима, и метод, принимающий полноценную реализацию `CoreSubscriber`.
В первом варианте мы можем передать функции для обработки сигналов стрима в различных вариациях: одну функцию (для обработки элементов), две функции (для обработки элементов и ошибок), три функции (для обработки элементов, ошибок и действие при завершении стрима) и так далее. Впоследствии из них собирается `LambdaSubscriber`.
Во втором варианте мы можем передать полностью свою реализацию `CoreSubscriber`. Для его реализации рекомендуется использовать абстрактный класс `BaseSubscriber`, предоставленный реактором.
Отмечу, что метод `subscribe()` возвращает нам объект `Disposable`, с помощью которого мы можем отменить подписку на стрим "снаружи".
Метод `subscribe()` для "модифицирующих" flux реализован в абстрактном классе `InternalFluxOperator`, который они наследуют. Внутри него происходит новое "оборачивание", уже подписчиков: для каждого "модифицирующего" flux существует своя версия `CoreSubscriber` (в нашем случае это `FilterSubscriber` и `MapSubscriber`). Условным псевдокодом это можно описать так:
Псевдокод: этап подписки
```
mapFlux.subscribe(Subscriber){
MapSubscriber mapSubscriber = new MapSubscriber(Subscriber);
filterFlux.subscribe(mapSubscriber) {
FilterSubscriber filterSubscriber = new FilterSubscriber(mapSubscriber);
arrayFlux.subscribe(filterSubscriber) {
// Реальная подписка и передача элементов
}
}
}
```
Результирующего Subscriber можно описать таким псевдокодом: `FilterSubscriber(MapSubscriber(Subscriber))`
На этом заканчивается этап подписки и начинается этап выполнения потока.
"Порождающие" flux не оборачивают `Subscriber` - они непосредственно вызывают у него метод `onSubscribe()` и передают в него свою реализацию `Subscription`. Каждый "порождающий" flux имеет свою реализацию `Subscription`: `ArraySubscription`, `IterableSubscription`, `StreamSubscription`, `RangeSubscription` и т.д. Каждый `Subscriber` в методе `onSubscribe()` сохраняет у себя ссылку на `Subscription` и передает ее вышестоящему подписчику, вплоть до конечной реализации, в которой метод `onSubscribe()` должен содержать логику запроса данных (а именно - вызов метода `Subscription.request()`) для того, чтобы стрим стартовал.
LambdaSubscriber как примерЕсли мы передали функцию `Consumer` в методе подписки стрима - вызовется она (`subscriptionConsumer` в коде), иначе `LambdaSubscriber` по умолчанию сделает запрос на получение данных по мере их поступления.
```
public final void onSubscribe(Subscription s) {
if (Operators.validate(subscription, s)) {
this.subscription = s;
if (subscriptionConsumer != null) {
try {
subscriptionConsumer.accept(s);
}
catch (Throwable t) {
Exceptions.throwIfFatal(t);
s.cancel();
onError(t);
}
}
else {
s.request(Long.MAX_VALUE);
}
}
}
```
`Subscription` и является итоговым источником последовательности - она содержит соответствующий ресурс (массив, стрим и т.д.) и при вызове метода `request()`начинает передачу данных по потоку. Так же `Subscription` хранит и ссылку на конечного `Subscriber` (в нашем случае - `FilterSubscriber`), в которого и начинает транслировать последовательность, вызывая у него метод `onNext()`. Именно в реализациях подписчиков и выполняется вся логика потока. Для понятности опишу последовательность выполнения нашего стрима:
1. `LambdaSubscriber` вызывает `ArraySubscription.request(Long.MAX_VALUE)`.
2. `ArraySubscription` вызывает `FilterSubscriber.onNext()`.
3. `FilterSubscriber` выполняет логику переданного нами предиката, и затем вызывает `MapSubscriber.onNext()` для элементов, прошедших проверку.
4. `MapSubscriber` выполняет логику переданной нами функции преобразования и вызывает `LambdaSubscriber.onNext()`.
5. `LambdaSubscriber` выполняет переданную нами в методе subscribe() логику.
6. В конце последовательности `ArraySubscription` вызывает `FilterSubscriber.onComplete()`, который транслируется по той же цепочке до `LambdaSubscriber` и выполняется переданная пользователем логика (в нашем случае мы никакую логику не передавали, потому никаких действий не произойдет).
Это примерная логика работы стрима. Внимательный читатель может резонно заметить: а где же асинхронность? И действительно, в вышестоящем примере никакой асинхронности нет, все выполняется в одном потоке. Для того, что бы сделать наш код асинхронным, выполним ряд преобразований.
Управление потоками
-------------------
Для начала немного изменим логику нашего стрима. С помощью `Flux.create()` создадим тестовую последовательность, которую будем преобразовывать в массивы чисел. Далее мы фильтруем массив на четные числа, и начинаем проверять оставшиеся на простоту в операторе `flatMap()`. `FluxFlatMap` принимает функцию, преобразующую элемент в `Publisher` - другой стрим - и встраивает его в основную цепочку преобразований. Сам подписчик `FlatMapMain` отличается от остальных - его реализация на порядок сложнее.
Синхронный стрим
```
@Test
public void syncStream() {
Flux.create(s -> {
s.next(50);
s.next(50);
s.next(50);
s.next(50);
s.next(100);
s.next(100);
s.next(100);
s.next(100);
s.next(150);
s.next(150);
s.next(150);
s.next(150);
s.complete();
}).map(this::generateIntArray)
.map(array -> Arrays.stream(array)
.filter(i -> (i % 2 != 0))
.collect(Collectors.toList()))
.flatMap(list -> Flux.fromIterable(list)
.map(i -> "Number " + i + " is prime: " + checker.test(i)))
.subscribe(result -> System.out.println("IN thread [" + Thread.currentThread().getName() + "] -> " + result));
}
```
Часть вывода
```
IN thread [main] -> Number 99126449 is prime: false
IN thread [main] -> Number 99453773 is prime: true
IN thread [main] -> Number 98450499 is prime: false
IN thread [main] -> Number 90454073 is prime: false
IN thread [main] -> Number 93393817 is prime: false
```
После выполнения отметим, что все объекты обрабатываются в main потоке.
Теперь добавим в цепочку оператор `subscribeOn()` с аргументом `Schedulers.boundedElastic()`. `Schedulers` - аналог `ExecutorService` в реакторе, а сам `Schedulers.boundedElastic()` - аналог `Executors.newCachedThreadPool()`. Оператор `subscribeOn()` позволяет изменить рабочий поток выполнения стрима, начиная с подписки.
Немного о шедулерахВ реакторе представлены 3 типа шедулеров, по аналогии с `ExecutorService`:
* `Schedulers.boundedElastic()`: аналог `Executors.newCachedThreadPool()`. Динамически создает рабочие потоки и кэширует пулы потоков выполнения. Максимальное число создаваемых пулов потоков выполнения не ограничивается, поэтому этот планировщик можно использовать для организации выполнения задач, связанных с вводом/выводом.
* `Schedulers.parallel()`: аналог `Executors.newFixedThreadPool()`. Имеет фиксированный размер пула рабочих потоков (по умолчанию количество потоков ограничивается числом ядер процессора). Поддерживает планирование задач по времени.
* `Schedulers.single()`: аналог `Executors.newSingleThreadExecutor()`. Используется для выполнения задач в одном выделенном потоке. Поддерживает планирование задач по времени.
Каждый из них также имеет методы создания с параметрами, а так же имеется возможность создать свой шедулер из `Executor` или `ExecutorService`.
Будьте осторожны: методы `Schedulers.boundedElastic()`, `Schedulers.parallel()` и `Schedulers.single()` создают шедулер единожды при первом вызове и кэшируют его. Дальнейшие вызовы этих методов вернут кэшированный экземпляр шедулера, что может быть особенно критично при использовании `Schedulers.parallel()` и `Schedulers.single()`.
Асинхронный стрим
```
@Test
public void asyncStream() {
Flux.create(s -> {
s.next(50);
s.next(50);
s.next(50);
s.next(50);
s.next(100);
s.next(100);
s.next(100);
s.next(100);
s.next(150);
s.next(150);
s.next(150);
s.next(150);
s.complete();
}).map(this::generateIntArray)
.map(array -> Arrays.stream(array)
.filter(i -> (i % 2 != 0))
.collect(Collectors.toList()))
.flatMap(list -> Flux.fromIterable(list)
.map(i -> "Number " + i + " is prime: " + checker.test(i)))
.subscribeOn(Schedulers.boundedElastic())
.subscribe(result -> System.out.println("IN thread [" + Thread.currentThread().getName() + "] -> " + result));
}
```
Запустим наш стрим и... увидим, что ничего не выполнилось. Программа просто завершилась. Это произошло, потому что выполнение стрима перенеслось в другой поток, а поток main попросту завершился вместе с программой. В реальном приложении такое вряд ли произойдет, но для нашего теста добавим замок для основного потока.
Асинхронный стрим 2
```
@Test
public void asyncStream() throws InterruptedException {
var cdl = new CountDownLatch(1);
Flux.create(s -> {
s.next(50);
s.next(50);
s.next(50);
s.next(50);
s.next(100);
s.next(100);
s.next(100);
s.next(100);
s.next(150);
s.next(150);
s.next(150);
s.next(150);
s.complete();
}).map(this::generateIntArray)
.map(array -> Arrays.stream(array)
.filter(i -> (i % 2 != 0))
.collect(Collectors.toList()))
.flatMap(list -> Flux.fromIterable(list)
.map(i -> "Number " + i + " is prime: " + checker.test(i)))
.subscribeOn(Schedulers.boundedElastic())
.doFinally(ignore -> cdl.countDown())
.subscribe(result -> System.out.println("IN thread [" + Thread.currentThread().getName() + "] -> " + result));
cdl.await();
}
```
Часть вывода
```
IN thread [boundedElastic-1] -> Number 90553495 is prime: false
IN thread [boundedElastic-1] -> Number 97965125 is prime: false
IN thread [boundedElastic-1] -> Number 95508257 is prime: false
IN thread [boundedElastic-1] -> Number 92073469 is prime: true
IN thread [boundedElastic-1] -> Number 93561047 is prime: false
IN thread [boundedElastic-1] -> Number 90207993 is prime: false
IN thread [boundedElastic-1] -> Number 90418581 is prime: false
```
В методе `doFinaly()` добавим уменьшение счетчика для нашего замка. Отмечу, что если в созданной последовательности не указать `s.complete()`, данный метод вызван не будет, поскольку сигнала об окончании последовательности не поступит.
Запустим, и увидим, что все действия выполнялись в другом потоке.
Снова изменим наш стрим, заменив `subscribeOn()` на `publishOn()`.
Оператор publishOn()Данный оператор позволяет перенести определенный этап выполнения в другой поток. `publishOn()` имеет очередь, в которую записываются поступившие элементы, которые впоследствии извлекает и обрабатывает рабочий поток. Как следствие, последовательность разбивается на два независимых этапа обработки данных.
Асинхронный стрим 3
```
@Test
public void asyncStream() throws InterruptedException {
var cdl = new CountDownLatch(1);
Flux.create(s -> {
s.next(50);
s.next(50);
s.next(50);
s.next(50);
s.next(100);
s.next(100);
s.next(100);
s.next(100);
s.next(150);
s.next(150);
s.next(150);
s.next(150);
s.complete();
}).map(this::generateIntArray)
.map(array -> {
System.out.println("IN thread [" + Thread.currentThread().getName() + "] -> filtering array with size: " + array.length);
return Arrays.stream(array)
.filter(i -> (i % 2 != 0))
.collect(Collectors.toList());
})
.publishOn(Schedulers.boundedElastic())
.flatMap(list -> Flux.fromIterable(list)
.map(i -> "Number " + i + " is prime: " + checker.test(i)))
.doFinally(ignore -> cdl.countDown())
.subscribe(result -> System.out.println("IN thread [" + Thread.currentThread().getName() + "] -> " + result));
cdl.await();
}
```
Часть вывода
```
IN thread [main] -> filtering array with size: 150
IN thread [main] -> filtering array with size: 150
IN thread [main] -> filtering array with size: 150
IN thread [main] -> filtering array with size: 150
IN thread [boundedElastic-1] -> Number 97321949 is prime: false
IN thread [boundedElastic-1] -> Number 92914819 is prime: false
IN thread [boundedElastic-1] -> Number 94001827 is prime: false
```
Запустим, и увидим, что первая часть стрима отрабатывает в main потоке, а оканчивается в другом. Мы разделили выполнение стрима на 2 части - формирование данных и их обработка.
Однако, что, если мы хотим больше? Например, обработать каждый сгенерированный массив в отдельном потоке?
Асинхронный стрим 4
```
@Test
public void researchReactor_2_4() throws InterruptedException {
var cdl = new CountDownLatch(1);
Flux.create(s -> {
s.next(50);
s.next(50);
s.next(50);
s.next(50);
s.next(100);
s.next(100);
s.next(100);
s.next(100);
s.next(150);
s.next(150);
s.next(150);
s.next(150);
s.complete();
}).map(this::generateIntArray)
.map(array -> {
System.out.println("IN thread [" + Thread.currentThread().getName() + "] -> filtering array with size: " + array.length);
return Arrays.stream(array)
.filter(i -> (i % 2 != 0))
.collect(Collectors.toList());
})
.flatMap(list -> Flux.fromIterable(list)
.publishOn(Schedulers.boundedElastic())
.map(i -> "Number " + i + " is prime: " + checker.test(i)))
.doFinally(ignore -> cdl.countDown())
.subscribe(result -> System.out.println("IN thread [" + Thread.currentThread().getName() + "] -> " + result));
cdl.await();
}
```
Часть вывода
```
IN thread [main] -> filtering array with size: 150
IN thread [main] -> filtering array with size: 150
IN thread [boundedElastic-2] -> Number 98846721 is prime: false
IN thread [boundedElastic-2] -> Number 92572645 is prime: false
IN thread [boundedElastic-2] -> Number 98842737 is prime: false
IN thread [boundedElastic-12] -> Number 95426589 is prime: false
IN thread [boundedElastic-12] -> Number 91028725 is prime: false
IN thread [boundedElastic-3] -> Number 91457669 is prime: true
IN thread [boundedElastic-3] -> Number 95625013 is prime: false
IN thread [boundedElastic-4] -> Number 91923637 is prime: false
```
Прекрасно, теперь каждый массив обрабатывается в отдельном потоке. Но что если мы хотим выделить поток для каждой задачи? Например, проверка происходит не в нашем приложении, а производится rest вызов, и мы хотим для каждого элемента сделать асинхронный запрос?
Асинхронный стрим 5
```
@Test
public void researchReactor_2_5() throws InterruptedException {
var cdl = new CountDownLatch(1);
Flux.create(s -> {
s.next(50);
s.next(50);
s.next(50);
s.next(50);
s.next(100);
s.next(100);
s.next(100);
s.next(100);
s.next(150);
s.next(150);
s.next(150);
s.next(150);
s.complete();
}).map(this::generateIntArray)
.map(array -> {
System.out.println("IN thread [" + Thread.currentThread().getName() + "] -> filtering array with size: " + array.length);
return Arrays.stream(array)
.filter(i -> (i % 2 != 0))
.collect(Collectors.toList());
})
.flatMap(list -> Flux.fromIterable(list)
.flatMap(i -> Mono.defer(() -> Mono.just("Number " + i + " is prime: " + checker.test(i)))
.subscribeOn(Schedulers.boundedElastic()))
)
.doFinally(ignore -> cdl.countDown())
.subscribe(result -> System.out.println("IN thread [" + Thread.currentThread().getName() + "] -> " + result));
cdl.await();
}
```
Часть вывода
```
IN thread [main] -> filtering array with size: 100
IN thread [boundedElastic-30] -> Number 92187347 is prime: false
IN thread [boundedElastic-9] -> Number 96199459 is prime: false
IN thread [boundedElastic-24] -> Number 96286047 is prime: false
```
И вот мы применили целых 5 стратегий выполнения потока: синхронно полностью в основном потоке, синхронно полностью в выбранном потоке, асинхронно в двух потоках (в одном подготовка, в другом обработка), асинхронно по потоку на массив, асинхронно по потоку на элемент, при этом почти не меняя сам код.
Холодные и горячие потокиХолодные потоки генерируют всю последовательность заново для каждого нового подписчика. Примеры таких стримов приведены выше.
Горячие потоки генерируют последовательность независимо от наличия подписчиков. При появлении подписчика такой стрим посылает ему только новые данные. Таким образом, подписчик получает только те данные, на которые успел подписаться. Например, если запустить следующий код, первый подписчик начнет обрабатывать элементы, начиная с 3, а второй - с 7.
```
@Test
public void hotStream() throws InterruptedException {
var cdl = new CountDownLatch(1);
Flux stream = Flux.range(0, 10)
.delayElements(Duration.ofMillis(500))
.doFinally(ignore -> cdl.countDown())
.subscribeOn(Schedulers.single())
.share();
stream.subscribe();
Thread.sleep(2000);
stream.subscribe(o -> System.out.println("[" + Thread.currentThread().getName() + "] Subscriber 1 -> " + o));
Thread.sleep(2000);
stream.subscribe(o -> System.out.println("[" + Thread.currentThread().getName() + "] Subscriber 2 -> " + o));
cdl.await();
}
```
Пример бесконечной горячей последовательности
```
@Test
public void hotStream() throws InterruptedException {
var cdl = new CountDownLatch(1);
Flux stream = Flux.create(fluxSink -> {
while (true) {
fluxSink.next(System.currentTimeMillis());
}
})
.sample(Duration.ofMillis(500))
.doFinally(ignore -> cdl.countDown())
.subscribeOn(Schedulers.single())
.share();
stream.subscribe(o -> System.out.println("[" + Thread.currentThread().getName() + "] Subscriber 1 -> " + o));
Thread.sleep(4000);
stream.subscribe(o -> System.out.println("[" + Thread.currentThread().getName() + "] Subscriber 2 -> " + o));
cdl.await();
}
```
Работа с контекстом
-------------------
Еще одной интересной особенностью реактора является контекст стрима. В “классическом” программировании (“поток на задачу”) контекст задачи сделать довольно просто, реализовав его `ThreadLocal` переменной. В реактивных стримах такой возможности нет, т.к. одну задачу могут выполнять разные потоки в разное время. Соответственно, есть необходимость как то хранить контекст для задачи, не привязываясь к потоку-исполнителю. Рассмотрим контекст на простом примере - наш стрим будет проверять, является ли число в контексте делителем числа из потока.
В реакторе есть несколько способов создать контекст потока:
* передать его в качестве аргумента в методе подписки
Пример инициализации контекста 1
```
@Test
public void reactorContext_1() {
String ctxKey = "key";
Flux.fromArray(generateIntArray(10))
.flatMap(i -> Mono.deferContextual(ctx -> {
int value = ctx.getOrEmpty(ctxKey).orElseThrow(() -> new IllegalArgumentException("Ctx key not found!"));
String result = i % value == 0
? String.format("Thread [%s] -> %d divisor of the number %d", Thread.currentThread().getName(), value, i)
: String.format("Thread [%s] -> %d NOT divisor of the number %d", Thread.currentThread().getName(), value, i);
return Mono.just(result);
})
).subscribe(System.out::println,
null,
null,
Context.of(ctxKey, ThreadLocalRandom.current().nextInt(2, 10)));
}
```
Пример вывода
```
Thread [main] -> 6 NOT divisor of the number 96484372
Thread [main] -> 6 NOT divisor of the number 99751334
Thread [main] -> 6 NOT divisor of the number 98114603
Thread [main] -> 6 NOT divisor of the number 94526528
Thread [main] -> 6 NOT divisor of the number 99601715
Thread [main] -> 6 NOT divisor of the number 94450652
Thread [main] -> 6 NOT divisor of the number 96186878
Thread [main] -> 6 divisor of the number 95334678
Thread [main] -> 6 NOT divisor of the number 91412254
Thread [main] -> 6 divisor of the number 97741992
```
* передать его в операторе `contextWrite()`
Пример инициализации контекста 2
```
@Test
public void reactorContext_2() {
String ctxKey = "key";
Flux.fromArray(generateIntArray(10))
.flatMap(i -> Mono.deferContextual(ctx -> {
int value = ctx.getOrEmpty(ctxKey).orElseThrow(() -> new IllegalArgumentException("Ctx key not found!"));
String result = i % value == 0
? String.format("Thread [%s] -> %d divisor of the number %d", Thread.currentThread().getName(), value, i)
: String.format("Thread [%s] -> %d NOT divisor of the number %d", Thread.currentThread().getName(), value, i);
return Mono.just(result);
})
).contextWrite(ctx -> ctx.put(ctxKey, ThreadLocalRandom.current().nextInt(2, 10)))
.subscribe(System.out::println);
}
```
Пример вывода
```
Thread [main] -> 3 divisor of the number 94070187
Thread [main] -> 3 NOT divisor of the number 96881164
Thread [main] -> 3 NOT divisor of the number 93117008
Thread [main] -> 3 NOT divisor of the number 99847222
Thread [main] -> 3 NOT divisor of the number 99232121
Thread [main] -> 3 divisor of the number 90207831
Thread [main] -> 3 divisor of the number 98137233
Thread [main] -> 3 divisor of the number 93991545
Thread [main] -> 3 divisor of the number 99188091
Thread [main] -> 3 divisor of the number 99287157
```
Пример инициализации контекста 3
```
@Test
public void reactorContext_2_1() {
String ctxKey = "key";
Flux.fromArray(generateIntArray(10))
.flatMap(i -> Mono.deferContextual(ctx -> {
int value = ctx.getOrEmpty(ctxKey).orElseThrow(() -> new IllegalArgumentException("Ctx key not found!"));
String result = i % value == 0
? String.format("Thread [%s] -> %d divisor of the number %d", Thread.currentThread().getName(), value, i)
: String.format("Thread [%s] -> %d NOT divisor of the number %d", Thread.currentThread().getName(), value, i);
return Mono.just(result);
})
).contextWrite(Context.of(ctxKey, ThreadLocalRandom.current().nextInt(2, 10)))
.subscribe(System.out::println);
}
```
Пример вывода
```
Thread [main] -> 4 divisor of the number 94968444
Thread [main] -> 4 divisor of the number 98424152
Thread [main] -> 4 NOT divisor of the number 99689442
Thread [main] -> 4 divisor of the number 97327236
Thread [main] -> 4 NOT divisor of the number 94170947
Thread [main] -> 4 divisor of the number 96579680
Thread [main] -> 4 NOT divisor of the number 91238971
Thread [main] -> 4 NOT divisor of the number 90252134
Thread [main] -> 4 divisor of the number 95264784
Thread [main] -> 4 NOT divisor of the number 99502289
```
Контекст будет виден во всех операторах, объявленных выше по цепочке. Если мы объявим контекст в начале стрима, то увидим ошибку
Ошибочное обращение к контексту 1
```
@Test
public void reactorContext_3() {
String ctxKey = "key";
Flux.fromArray(generateIntArray(10))
.contextWrite(ctx -> ctx.put(ctxKey, 4))
.flatMap(i -> Mono.deferContextual(ctx -> {
int value = ctx.getOrEmpty(ctxKey).orElseThrow(() -> new IllegalArgumentException("Ctx key not found!"));
String result = i % value == 0
? String.format("Thread [%s] -> %d divisor of the number %d", Thread.currentThread().getName(), value, i)
: String.format("Thread [%s] -> %d NOT divisor of the number %d", Thread.currentThread().getName(), value, i);
return Mono.just(result);
})
).subscribe(System.out::println);
}
```
Пример вывода
```
[ERROR] (main) Operator called default onErrorDropped - reactor.core.Exceptions$ErrorCallbackNotImplemented: java.lang.IllegalArgumentException: Ctx key not found!
reactor.core.Exceptions$ErrorCallbackNotImplemented: java.lang.IllegalArgumentException: Ctx key not found!
Caused by: java.lang.IllegalArgumentException: Ctx key not found!
at ru.brutforcer.reactor.aricle.ReactorTests.lambda$reactorContext_3$62(ReactorTests.java:340)
at java.base/java.util.Optional.orElseThrow(Optional.java:403)
```
Также мы можем объявить контекст для “внутренней” цепочки. В примере специально в контекст установлено рандомное число: в примерах выше оно генерируется единожды и является единым для всего стрима. В новом примере для каждого элемента последовательности генерируется свое число для проверки.
Пример инициализации контекста 4
```
@Test
public void reactorContext_4() {
String ctxKey = "key";
Flux.fromArray(generateIntArray(10))
.flatMap(i -> Mono.deferContextual(ctx -> {
int value = ctx.getOrEmpty(ctxKey).orElseThrow(() -> new IllegalArgumentException("Ctx key not found!"));
String result = i % value == 0
? String.format("Thread [%s] -> %d divisor of the number %d", Thread.currentThread().getName(), value, i)
: String.format("Thread [%s] -> %d NOT divisor of the number %d", Thread.currentThread().getName(), value, i);
return Mono.just(result);
}).contextWrite(ctx -> ctx.put(ctxKey, ThreadLocalRandom.current().nextInt(2, 10)))
).subscribe(System.out::println);
}
```
Пример вывода
```
Thread [main] -> 4 NOT divisor of the number 91486019
Thread [main] -> 2 NOT divisor of the number 95953267
Thread [main] -> 5 NOT divisor of the number 95931323
Thread [main] -> 4 NOT divisor of the number 99936074
Thread [main] -> 4 divisor of the number 99891164
Thread [main] -> 3 divisor of the number 96090381
Thread [main] -> 9 NOT divisor of the number 97190858
Thread [main] -> 9 NOT divisor of the number 97639514
Thread [main] -> 4 divisor of the number 90896348
Thread [main] -> 4 NOT divisor of the number 98617771
```
И важная особенность: контекст, объявленный во “внутренней” цепочке, не будет виден во “внешней”. В примере ниже выйдет ошибка.
Ошибочное обращение к контексту 2
```
@Test
public void reactorContext_5() {
String ctxKey = "key";
Flux.fromArray(generateIntArray(10))
.flatMap(i -> Mono.deferContextual(ctx -> {
int v = ctx.getOrEmpty(ctxKey).orElseThrow(() -> new IllegalArgumentException("Ctx key not found!"));
return Mono.just(i);
}))
.flatMap(i -> Mono.deferContextual(ctx -> Mono.just(i))
.contextWrite(ctx -> ctx.put(ctxKey, ThreadLocalRandom.current().nextInt(2, 10))))
.subscribe(System.out::println);
}
```
Полезные ссылки
---------------
* ***Олег Докука, Игорь Лозинский “Практика реактивного программирования в Spring 5”*** - прекрасная книга для изучения и начала работы в реактивной парадигме. Единственный минус - часть про реактор актуальна для 2 версии реактора: в примерах книги в некоторых местах используются deprecated методы, а описание механизмов может быть неточным для актуальной версии.
* [Спецификация реактивных стримов](https://www.reactive-streams.org/)
* [Реактивный манифест](https://www.reactivemanifesto.org/)
* [Реактивное программирование со Spring, часть 1 Введение](https://habr.com/ru/post/565004/)
* [Реактивное программирование со Spring, часть 2 Project Reactor](https://habr.com/ru/post/565050/)
* [Реактивное программирование на Java: как, зачем и стоит ли?](https://habr.com/ru/company/oleg-bunin/blog/545702/) | https://habr.com/ru/post/694850/ | null | ru | null |
# Запуск кода CUDA на видеокартах AMD
Многим известно, что CUDA является наиболее часто используемой платформой для ускорения массовых параллельных вычислений, применяемых в различных практических и исследовательских областях.
В 2016 году AMD представила в буквальном смысле клон платформы CUDA — ROCm. Альтернативы модулей CUDA для ROCm можно увидеть в таблице с официального сайта AMD.
Таблица соответствия модулей платформ
| | |
| --- | --- |
| Модуль платформы CUDA | Модуль платформы ROCm |
| cuBLAS | rocBLAS |
| cuFFT | rocFFT |
| cuSPARSE | rocSPARSE |
| cuSolver | rocSOLVER |
| AMG-X | rocALUTION |
| Thrust | rocThrust |
| CUB | rocPRIM |
| cuDNN | MIOpen |
| cuRAND | rocRAND |
| EIGEN | EIGEN |
| NCCL | RCCL |
Данная библиотека позволяет в автоматическом режиме переносить исходный код предназначенный для платформы CUDA на ROCm и выполнять его компиляцию. Одним из недостатков данной платформы является исключительная ориентированность на ОС Linux.
Перейдем непосредственно к переносу кода и сравнению производительности платформ.
### Тестовая конфигурация
| | | |
| --- | --- | --- |
| | ПК 1 | ПК 2 |
| Операционная система | Windows 10 Pro 21H1 | Ubuntu 22.04 5.15.0-53-generic |
| CPU | x2 Intel Xeon Gold 6132 | i5-12600K |
| RAM | x4 DDR4 16GB | x1 DDR4 32GB |
| GPU | GeForce RTX 3070 8GB | Radeon RX 6800 XT 16GB |
### 1. Установка CUDA на ОС Windows
Переходим на сайт NVidia (<https://developer.nvidia.com/cuda-downloads>) и скачиваем последнюю версию CUDA Toolkit для необходимой платформы. На скриншоте ниже представлена минимально необходимая конфигурация для компиляции и запуска платформы CUDA на ОС Windows.
Минимально необходимая конфигурация установки### 2. Установка ROCm на ОС Linux
Рассмотрим ход установки ROCm на ОС Ubuntu 22.04. (<https://docs.amd.com/bundle/ROCm-Installation-Guide-v5.3/page/How_to_Install_ROCm.html> - на данном веб-сайте перечислены способы установки для некоторых других дистрибутивов Linux)
2.1 Загружаем пакет установщика и устанавливаем его.
```
sudo apt-get update
wget https://repo.radeon.com/amdgpu-install/5.3/ubuntu/jammy/amdgpu-install_5.3.50300-1_all.deb
sudo apt-get install ./amdgpu-install_5.3.50300-1_all.deb
```
2.2 Установка необходимых компонентов ROCm
```
sudo amdgpu-install --usecase=dkms,rocm,rocmdevtools,lrt,hip,hiplibsdk,mllib,mlsdk
```
В процессе установки могут появиться ошибки, однако они никак не должны повлиять на работу платформы. На самом деле я на 100% не уверен, что это минимально необходимый набор модулей для установки, но путем проб и ошибок я пришел именно к этому набору.
2.3 Установка CUDA.
Для портирования кода CUDA на ROCm также необходимо установить CUDA Toolkit. Проще всего это сделать следующей командой. (Другие версии CUDA и методы установки можно найти на данной веб-странице <https://developer.nvidia.com/cuda-downloads>)
```
wget https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda_11.8.0_520.61.05_linux.run
sudo sh cuda_11.8.0_520.61.05_linux.run
```
Конфигурация установки CUDA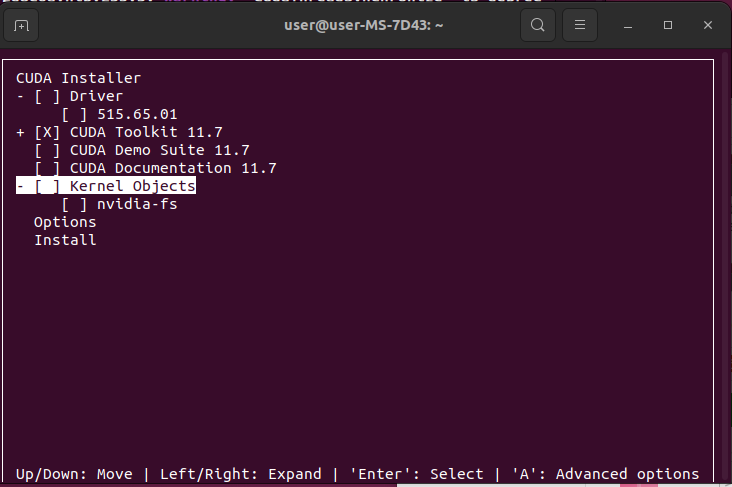### 3. Компиляция исходного кода на ОС Windows
В качестве тестового примера возьмем код перемножения матриц случайных целых 32-битных чисел с Github (<https://github.com/lzhengchun/matrix-cuda>).
С помощью команд PowerShell представленных ниже скачиваем и компилируем исходные файлы. После выполнения приведенных ниже команд в директории с исходным кодом появится исполняемый файл "a.exe".
```
git clone https://github.com/lzhengchun/matrix-cuda
cd matrix-cuda
nvcc ./matrix_cuda.cu
```
### 4. Преобразование кода CUDA в код ROCm и его компиляция на ОС Ubuntu
Преобразование кода CUDA в ROCm выполняется при помощи утилиты платформы ROCm HIPIFY(от HIP - язык программирования платформы ROCm)
```
git clone https://github.com/lzhengchun/matrix-cuda
cd matrix-cuda
/opt/rocm-5.3.0/bin/hipify-clang matrix_cuda.cu
```
После выполнения данных команд в директории рядом с файлом matrix\_cuda.cu появится файл matrix\_cuda.cu.hip, который является файлом исходного кода для платформы ROCm.
Компиляция кода для платформы ROCm выполняется при помощи компилятора HIPCC. После выполнения приведенных ниже команд в директории с исходным кодом появится исполняемый файл "a.out".
```
/opt/rocm-5.3.0/bin/hipсс matrix_cuda.cu.hip
```
### 5. Сравнение производительности платформ
| | | |
| --- | --- | --- |
| Размер матриц | Время выполнения CUDA | Время выполнения ROCm |
| 1000x1000 | 2.536 мс | 5.812 мс |
| 10000x10000 | 195.123 мс | 297.219 мс |
В данном примере мы видим, что из-за особенностей архитектуры AMD (меньшее количество блоков для операций над 32-битными числами) наблюдается отставание в производительности в полтора-два раза.
Преобразуем исходные файлы для произведения операций над 16-битными числами и снова протестируем производительность платформ.
| | | |
| --- | --- | --- |
| Размер матриц | Время выполнения CUDA | Время выполнения ROCm |
| 1000x1000 | 0.83256 мс | 1.421 мс |
| 10000x10000 | 153.241699 | 16.105 мс |
| 20000x20000 | 256.836761 мс | 52.155 мс |
В случае с операциями на 16-битными числами преимущество в скорости вычислений на стороне платформы ROCm.
### 6. Заключение
Таким образом у владельцев видеоускорителей AMD Radeon последнего поколения имеется возможность за пару кликов преобразовать код CUDA в код, который будет также быстро работать на "красных" видеокартах.
P.S.
Это моя первая статья на habr. Решил написать, так как очень долго сам провозился с настройкой всего этого дела. Может быть кто-то с её помощью сэкономит своё время. | https://habr.com/ru/post/701712/ | null | ru | null |
# Принцип работы SIP клиента в браузере
Пообщавшись в комментариях к [посту](http://habrahabr.ru/post/144293/), я понял, что не все до конца понимают принцип работы SIP в браузере. Поэтому, решил экспромтом написать небольшую статью, где в общих чертах раскрыть эту тему.
Действующие лица:
#### HTTP сервер
Ничего особенного от него не требуется, только поддержка HTTP протокола.
#### SIP сервер
Помимо обычных для SIP протоколов — UDP, TCP, TLS, требуется поддержка [WebSocket](http://tools.ietf.org/html/rfc6455). WebSocket очень простой протокол, работает он следущим образом:
* клиент подключается к серверу по TCP или TLS
* передает HTTP запрос, в котором есть признак того, что клиент хочет переключиться на WebSocket
* сервер отвечает 101 Protocol Switching
* WebSocket подключение готово для передачи данных в дуплексном режиме, это практически TCP с небольшим заголовком для каждого блока передаваемых данных
В некоторых заголовках SIP сообщения есть информация о протоколе транспортного уровня, например:
`Via: SIP/2.0/UDP 192.168.1.1;branch=z9hG4bKyQz1234567`
А так как WebSocket не описан в основном документе по [SIP](http://www.ietf.org/rfc/rfc3261.txt), потребовалось [расширение](http://tools.ietf.org/html/draft-ibc-sipcore-sip-websocket-02), это еще не стандарт, но его уже можно использовать. В этом документе нет принципиальных изменений rfc3261, по большой части он просто разрешает очевидные вещи, например, такой заголовок:
`Via: SIP/2.0/**WS df7jal23ls0d.invalid**;branch=z9hG4bKyQz1234567`
#### Браузер
Здесь все сложнее, требуется целый букет технологий: WebSocket для подключения к SIP серверу; SIP стэк, который можно реализовать на JavaScript; WebRTC для передачи аудио и видео.
#### Как оно работает
Уже наверное понятно, прелесть всей схемы в том, что не требуется никаких согласующих протоколы агентов. Клиент в браузере является полноценным участником и взаимодействует напрямую с любым SIP сервером, и любыми клиентами, например, с хардварным IP телефоном. Единственное требование — это поддержка WebRTC кодеков.
#### Как потестировать
Информацию о том может ли Asterisk общаться по WebSocket мне найти не удалось. Но есть другие SIP сервера с поддержкой WebSocket, они конечно уступают по функционалу, но для тестирования его достаточно. Например, [сервер](http://www.officesip.com/) для Windows, начиная с версии 3.2 поддерживает WebSocket и даже имеет встроенный HTTP сервер. | https://habr.com/ru/post/144391/ | null | ru | null |
# Превозмогая трудности: Gravity Defied на sed
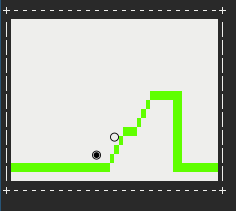 Итак, эта статья посвящается тем, кто любит решать нестандартные задачи на не предназначенных для этого инструментах. Здесь я опишу основные проблемы, с которыми столкнулся во время создания аналога игры Gravity defied с использованием потокового текстового редактора (sed).
*Далее предполагается, что читатель хотя бы немного знаком с синтаксисом sed'ом и и написанием скриптов под bash.*
Мирный вечер декабря перестал быть мирным, когда мне пришло сообщение от преподавателя примерно такого содержания:
> На sed:
>
> Gravity defied
>
> …
>
> Это должно быть круто
>
>
Признаться, первые полчаса я сидел с мыслью о том, как это вообще возможно. Но потом мне удалось взять себя в руки и я начал разбираться.
Попытки гуглить на тему игр на sed привели к [арканоиду и сокобану](https://github.com/aureliojargas/sed-scripts/).
Прежде, чем мы начнём разбор проблем, хочу поделиться [репозиторием с проектом](https://github.com/Firemoon777/gravity-defied) и [видео-демонстрацией](https://asciinema.org/a/9clhjp8g01qg4vo5if80xhbkn) результата
Итак, **Проблема первая:** представление в памяти sed должен как-то хранить текущее состояние игры. В нашем распоряжении два места для магии **hold space **и** pattern space**.
Hold space будет хранить состояние игры между итерациями (итерацией я буду называть обработку одного входящего символа), а в pattern space мы будем изменять состояние игры.
Алгоритм примерно такой:
1. Переходим к действию, которое привязано к символу, который мы получили на вход
2. Записываем в pattern space содержимое hold space
3. Изменяем содержимое pattern space в соотвествии с логикой действия
4. Записываем содержимое pattern space в hold space
5. Производим наложение эффектов на pattern space (на этом шаге мы из нашего «служебного» состояния игры в то, что будет видеть пользователь)
6. Выводим содержимое pattern space на экран
7. Повторить с п.1 для каждого введённого символа
Для упрощения разбора введённого текста примем на веру, что из всей входящей строки лишь первый символ нам важен.
Первым делом — инициализация. Создадим метку print, которая будет создавать поле игры в начальный момент времени. С момента запуска игры лишь один раз возникнет ситуация, когда на вход sed'у передаётся пустая строка: самый старт игры.
Таким образом,
```
/^$/b print
...
:print
# Начало любого действия, которое иницируется извне
g
s/.*/\
+-----------------------+\
|BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB1\
|BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB2\
|BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB3\
|BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB4\
|BBBBBBBBBBBBBBBBBBBBBUPPABBBBBBBBBBBB5\
|BBBBBBBBBBBBBBBBBBBBUBBBABBBBBAPPPPPP6\
|DBBBBBBBBBBBBBBBBBUPBBBBABBBBBABBBBBB7\
|BDBSBFBBBBBBBBBBBUBBBBBBABBBBBABBBBBB8\
|BBPPPPPPPPPPPPPPPBBBBBBBPPPPPPPBBBBBB9\
+-----------------------+\
b end
```
На этом этапе всё зависит от вашего воображения. Вы сами решаете, за что отвечает каждый символ. У меня B — это пустое место, F и S — колёса байка, в A, D, P, U — дорога (четыре вида, для красоты, но об этом — позднее).
Нам необходимо вывести всё полученное на экран. Как вы могли заметить, в конце print мы переходим к метке end.
end — это общее завершение **любого** действия.
```
:end
# Сохраняем все изменения в hold space
h
# Здесь позднее провернём всю пост-обработку нашего игрового пространства
# Отправляем символ очистки экрана
i\
^[[H
# Печатаем содержимое pattern space на экран
p
```
**Примечание:** ^[[H не стоит копипастить, это escape-последовательность. Например, в vim она вводится так: Ctrl+V Ctrl+ESC [ H
Запустим наш скрипт с помощью `sed -nf gravity.sed`. Поздравляю с статической картинкой!
Когда у нас есть поле, достаточно просто написать команды, которые будут двигать влево-вправо наши импровизированные колёса:
```
s/FB/BF/
s/SB/BS/
```
Движение вверх чуть сложнее но мы же не боимся сложностей, правда?
```
s/B(.{39})F)/F\1B/
```
Тут вся суть в цифре 39. Это количество символов в строке.
Добавляем пару меток и «привязываем» их к нужным клавишам, и вуаля, у нас есть некий абстрактный байк (ладно, два колеса), для которого не существует границ и физики. Но если вы захотите писать лабиринт, то вам как раз это и нужно.
Проверить игру не сложно, но нажимать Enter после каждого введённого символа — удовольствие ниже среднего, так что нужно автоматизировать этот процесс.
**Проблема вторая:** тактование
Так как «сердце» игры — sed, нужна оболочка, которая за нас будет нажимать enter каждый раз, когда мы нажали кнопку. Бесконечный цикл — самое оно.
Примерный код:
```
(while true
do
read -s -n 1 key # считываем одно нажатие клавиши без вывода на экран в переменную key
echo $key
done) | sed ...
```
Игра теперь будет станет чуть более радостной, но в ней всё ещё есть большой недочёт: игрок может влиять на ход времени. Чем быстрее тыкает игрок по клавишам, тем быстрее ход игры. Нас такое не устраивает, поэтому нужно **тактование**. Теперь у нас два источника данных — тактовый генератор и пользователь. Самое простое решение, которое приходит в голову — воспользоваться ключом -t у read. Если пользователь ничего не введёт за указанное кол-во секунд, то read не станет блокировать скрипт. Это решение меня не устроило: на SunOS read отказывался принимать дробное количество секунд, а динамичная игра с одним кадром в секунду — это как-то странно. Второе решение — использовать именнованый pipe:
```
# Удаляем (на всякий случай) pipe и создаём новый
rm -f gravity-fifo;
mkfifo gravity-fifo;
# Эта строчка будет держать pipe открытым достаточно долго
sleep 99999999 > gravity-fifo &
# Запустим игру
sed -nf gravity.sed gravity-fifo &
# Тактовый генератор, который раз в $TIME * 10^-6 секунд будет записывать символ t в pipe
while true
do
echo t > gravity-fifo
usleep $TIME
done &
# Пользовательский ввод
(while true
do
read -s -n 1 key
echo $key
[[ $key == "q" ]] && pkill -P $$
done ) | $SED -u -e '/t/d' > gravity-fifo
```
Немного пояснений:
pkill — хороший способ убить тактовый генератор и sleep.
А если вам непонятно, зачем нужен этот sleep, то можете проверить без него: с первым же echo pipe закроется и sed поймает EOF. Попутно мы запрещаем пользователю писать тактирующий символ — мы тут байк водим, а не временем управляем.
**Проблема третья:** физика
У нас есть тактирующий символ, который вызывается через константные промежутки времени. Именно в обработчике этого символа можно прописать всю физику игры. Тут не могу дать общих советом, вся физика — это набор регулярок, которые проверяют всё, что проверяется.
**Проблема четвёртая:** пост-обработка
Сразу после того, как мы перешли к метке end и сохранили изменения в hold space, мы можем приступать к наложению эффектов. Ранее я упоминал, что я использую четыре типа дорог. К этому я пришёл методом проб и ошибок. В первых версиях дороги были одного типа: R, а на этапе пост-обработки я пытался написать регулярки, которые бы делали подъем/спуск в зависимости от взаимного расположения дорог.
Идея была отвергнута: алгоритм постоянно сбоил, проще прописать тип дорог.
Вооружаемся [таблицей ANSI Escape-последовательностей](http://ascii-table.com/ansi-escape-sequences.php), я ещё дополнительно воспользовался таблицей Unicode и получилось…
```
s/A/^[[107;38;5;82m█^[[0m/g
s/D/^[[107;38;5;82m▚^[[0m/g
s/P/^[[107;38;5;82m▀^[[0m/g
s/U/^[[107;38;5;82m▞^[[0m/g
```
Подводные камни есть и здесь: при использовании юникода pattern поиска не должен содержать точное количество символов. Unicode-символы распознаются как два символа и логика такой регулярки ломается.
**Проблема пятая:** маленькое пространство
На экран у нас влезает не так уж много символов, а карту хотелось бы сделать больше. Здесь на помощь приходит Scroll Buffer. Это такое место, невидимое для пользователя, которое будет хранить в себе кусочек продолжения карты. Для комфортного скроллинга стоит пронумеровать строчки, а в самом конце добавить строку, которая нумерует зону, например, z1.
Алгоритм работы:
1. Если любая часть игрока ближе, чем на N символов к правому краю карты, переходим к следующему пункту
2. Удаляем второй символ карты (первый у нас — рамочка)
3. К концу каждой строки, перед цифрой добавляем #
4. Если у нас набралось ровно M символов #, то выполняем следующий пункт, иначе — пропускаем
5. Проверяем номер текущей зоны и заменяем все # на соответствующую данной зоне карту, меняем имя зоны на имя следующей зоны
6. Переходим к метке end
7. На этапе пост-процессинга обрезаем видимую часть так, чтобы символы # никогда не попадали в видимую область, а так же удаляем вспомогательные данные, например, номер зоны.
Ура! Теперь у нас есть базовые знания, как создать игру на sed. Зачем? Потому что можем.
**P.S.** Задание любезно предоставлено Жмылёвым С.А. Надеюсь, следующие поколения примут часть моего опыта и сделают что-нибудь ещё более замечательное. х) | https://habr.com/ru/post/317638/ | null | ru | null |
# Выбор СУБД для мобильного Delphi-приложения
Данная статья написана по мотивам – мотивам разработки мобильного приложения, недавно вышедшего на платформах iOS и Android. Это событие можно было бы назвать заурядным и мало кому интересным, если бы не одно большое и несколько незначительных «но»: вся разработка (включая сервер) велась на Delphi, а в качестве СУБД, как ни странно, задействована совсем не SQLite. Автор, безусловно, понимает, что на текущий момент уже существуют мобильные Delphi-приложения, включая доступные в официальных магазинах, однако не наблюдает обилия русскоязычных публикаций, призванных, как минимум, предостеречь читателей от ошибок, сделанных разработчиком таких проектов. Написанное же здесь преследует цель помочь тем, кто сейчас выбирает СУБД для своего творения, либо уже остановился на каком-то варианте, но желает убедиться в правильности своего решения.
Прежде чем начать, необходимо дать краткое представление о разработанном приложении – это список покупок, имеющий в своём запасе некоторый уникальный функционал. Если кто-то сам уже пользуется (или пользовался) одним из многочисленных аналогов, то сейчас мог скептически хмыкнуть – мол зачем ещё один, и так есть из чего выбрать, на что можно лишь посоветовать продолжить чтение, чтобы ознакомиться с его принципиальной особенностью.
### Меж двух огней
Безусловным лидером мобильных СУБД является SQLite, однако некоторые её недостатки и наличие у приложения функционала, требующего нетривиального анализа данных, не позволили остановиться на ней – поиск альтернатив привёл к [Interbase XE7](http://docwiki.embarcadero.com/InterBase/XE7/en/Main_Page), точнее к его встраиваемой (embedded) версии, которая, что удобно, сразу поставляется с Delphi и требует минимума усилий по включению в состав приложения. Interbase, конечно же, идеалом тоже не является и обладает минусами, способы борьбы с которыми приводятся ниже. Важно отметить, что эта СУБД коммерческая, поэтому предлагаются две редакции: IBLite – бесплатная, именно о ней будет идти речь, и Interbase ToGo – платная, но с такой ценовой политикой, что полностью исключает её использование в бесплатных приложениях; [ограничения](http://docwiki.embarcadero.com/InterBase/XE7/en/Comparing_IBLite,_ToGo,_and_InterBase_Server_Edition) IBLite суровы, но будут показаны способы существования и с ними (в связке с [FireDAC](http://docwiki.embarcadero.com/RADStudio/Berlin/en/FireDAC)).
### Основное преимущество Interbase
Итак, начнём обоснование выбора СУБД с ключевой возможности проекта – рекомендаций по наполнению списков товарами. Суть действа в следующем: представьте, что в позапрошлые выходные Вы добавляли в списки такие товары, как зубная паста, апельсины и говядина, а в прошлые – свинину, снова апельсины и ириску. С немалой степенью вероятности можно утверждать, что в эти субботу и воскресенье новый список необходимо наполнить апельсинами и мясом (именно в таком обобщённом виде, т. к. о конкретном виде мяса ничего сказать нельзя). Собственно эти два продукта и будут предложены пользователю. Пример с закономерностью в выходные – это лишь один из вариантов, бывают товары, добавляемые каждый день, через день, в начале месяца и т. д. – всего приложение анализирует 21 случай, что, вкупе с необходимостью обобщения, делает объём вычислений весьма приличным.
На устройстве рекомендации выглядят примерно так:

Подобные расчёты оптимальнее всего выполнять полностью на стороне СУБД, ибо накладные расходы на копирование данных из БД в структуры приложения, а также сложность и, как следствие, подверженность ошибкам алгоритмов обработки этих структур, могут довести время ожидания до десятков секунд, что неприемлемо. Решение – хранимые процедуры (далее ХП), которые присутствуют только в Interbase.
Другим серьёзным доводом за ХП являются требования фонового выполнения операции (без блокировки интерфейса), а также её досрочной отмены – ведь речь о длительностях в несколько секунд. В случае SQLite сложность решения такой задачи много больше, т. к. требуется вынести все многочисленные запросы к БД и обработку их результатов в отдельный поток и самостоятельно реагировать на флаг отмены. Вызов же одной ХП в FireDAC можно сделать [асинхронным](http://docwiki.embarcadero.com/RADStudio/Berlin/en/Asynchronous_Execution_(FireDAC)), что автоматически решает поставленные задачи:
* нужно лишь установить свойство `TFDStoredProc.ResourceOptions.CmdExecMode` в `amAsync`
* вызвать метод `TFDStoredProc.Open`
* для прерывания использовать вызов `TFDStoredProc.AbortJob(True)`
* обработать завершение ХП в событии `TFDStoredProc.AfterOpen`
Хранимые процедуры обладают ещё одним, неочевидным, преимуществом – возможностью отслеживать зависимости как между собой, так и от прочих объектов БД: таблиц, представлений и всего остального. Если в ходе разработки потребовалось, к примеру, изменить или удалить поле в таблице, а код запросов хранится в приложении в `TFDQuery`, то задача будет простой только при их количестве до нескольких десятков; когда запросов станет более сотни, уследить за всеми – большая проблема. ХП и любая профессиональная IDE сведут такие сложности почти до нуля.
#### Три довода в пользу SQLite
После немаленькой ложки мёда из процедур, перейдём к такой же большой ложке дёгтя из отсутствия некоторых возможностей в Interbase. Горечь будет идти по нарастающей, чтобы сразу не шокировать читателя некоторыми, так скажем, особенностями этой СУБД.
###### *CTE*
[Выше говорилось](#Goods_generalization) о требовании обобщать товары при выдаче рекомендаций, что реализовано, в том числе, за счёт иерархического справочника товаров. Так вот SQLite имеет средства для ускорения работы с деревьями за счёт [обобщённых табличных выражений](http://www.sqlite.org/lang_with.html) (CTE) вида
```
WITH RECURSIVE CTE_NAME(Field1...FieldN) AS
(
SELECT ...
UNION ALL
SELECT ...
)
SELECT Field1...FieldN FROM CTE_NAME;
```
а соперник – нет, предлагая решать такие задачи через [рекурсивные ХП](http://docwiki.embarcadero.com/InterBase/XE7/en/EXECUTE_PROCEDURE_(Procedures)).
Примечание. Написанное справедливо на момент публикации статьи, однако в вышедший недавно [Interbase 2017](http://docwiki.embarcadero.com/InterBase/2017/en/Main_Page) добавлена [частичная поддержка CTE](http://docwiki.embarcadero.com/InterBase/2017/en/SQL_Derived_Table_Support) — без рекурсивной части, которая обещана позднее.
###### *Полнотекстовый поиск*
Следующий неприятный сюрприз связан с индексированным поиском по строковым полям. При добавлении нового товара, приложение предлагает пользователю варианты, основанные на уже введённых символах:

SQLite на такой случай даёт очень мощный (даже избыточный для этого примера) [механизм полнотекстового поиска](http://www.sqlite.org/fts5.html), обладающий заведомо высокой скоростью работы; Interbase же задействует индекс только при поиске по началу строки, тогда как требуется искать совпадение с любой позиции. Другими словами, это условие будет использовать индекс
```
WHERE STRING_FIELD_UPPER LIKE 'ТОР%'
```
а применяемое в приложении уже нет
```
WHERE STRING_FIELD_UPPER CONTAINING 'ТОР'
```
На небольшом наборе данных проблема слабо проявляет себя – текущий справочник товаров содержит 700 записей, безындексный перебор которых на iPhone 5c занимает, в худшем случае, 240 мс, что заметно при наборе, но ещё находится в зоне комфорта.
###### *Производные таблицы*
Самым горьким, даже ошарашивающим недостатком Interbase (особенно учитывая какой сегодня год) стала невозможность применять производные (derived) таблицы:
```
SELECT ...
FROM
TABLE_1
JOIN
(
SELECT ...
FROM TABLE_2
WHERE ...
GROUP BY ...
) ON ...
```
Вместо этого необходимо создавать представление (что предпочтительнее варианта далее, потому что оно может быть «развёрнуто» оптимизатором) и выполнять соединение с ним
```
SELECT ...
FROM
TABLE_1
JOIN VIEW_NAME ON ...
```
либо применять ХП, изменив тип соединения
```
SELECT ...
FROM
TABLE_1 T_1
LEFT JOIN SP_NAME(T_1.FIELD_NAME) ON 0 = 0
```
Левое внешнее соединение приходится задействовать из-за одной застарелой проблемы, которая *может* проявиться при выполнении такого кода: при внутреннем соединении (`JOIN`) СУБД не учитывает зависимость вызова процедуры от полей таблицы, в результате значения для параметров ХП не могут быть определены из-за ещё непрочитанных записей таблицы.
Примечание. Написанное справедливо на момент публикации статьи, однако в вышедший недавно [Interbase 2017](http://docwiki.embarcadero.com/InterBase/2017/en/Main_Page) добавлена [поддержка производных таблиц](http://docwiki.embarcadero.com/InterBase/2017/en/SQL_Derived_Table_Support).
#### Работа с данными в потоке
Вторая важная функция приложения – синхронизация списков между устройствами.
Она, в случае очень медленного сетевого канала и большого объёма данных (при наличии фото), вполне может занять несколько минут – соответственно требуется её вынос в отдельный поток. Однако из-за цепочки ограничений реализация усложнится: во-первых, FireDAC обязывает [устанавливать новое соединение](http://docwiki.embarcadero.com/RADStudio/Berlin/en/Multithreading_(FireDAC)) к БД, которое станут использовать компоненты, работающие в неосновном потоке, но, и это во-вторых, IBLite не позволяет создать несколько одновременных соединений. Очевидным решением проблемы будет закрытие первого, основного соединения, через которое получены данные, отображаемые в интерфейсе; если проделать это обычным способом, через метод `TFDConnection.Close`, то все связанные с этим соединением наборы данных очистятся, в результате чего пользователь будет обескуражен опустевшими списками. К счастью, сам же FireDAC и предлагает выход из ситуации – [режим работы без установленного соединения](http://docwiki.embarcadero.com/RADStudio/Berlin/en/Offlining_Connection_(FireDAC)), сохраняющий наборы данных открытыми. Полная последовательность действий становится такой:
* войти в особый режим работы главного соединения через метод `TFDConnection.Offline`, что разорвёт физическую связь с БД, но визуальных изменений не привнесёт;
* стартовать новый поток, где выполнить второе (условно) подключение к БД;
* дождаться окончания работы потока;
* закрыть второе соединение;
* если свойство `TFDConnection.ResourceOptions.AutoConnect = True`, то больше ничего не требуется, ибо главное соединение автоматически перейдёт в обычный режим при любом действии, требующем обращения к БД через него.
#### Проблема нестабильного курсора
К сожалению, автор не знает, существует ли подобная загвоздка в SQLite, но Interbase ей подвержен, поэтому упоминание будет нелишним – суть в том, что обновление таблицы в цикле `FOR`, построенном на ней же, *может* приводить к неожидаемому поведению. Речь ведётся о конструкции, подобной этой:
```
FOR
SELECT
REC_ID, /* Первичный ключ. */
...
FROM
TABLE_1
...
WHERE
...
INTO
REC_ID,
...
DO
BEGIN
UPDATE TABLE_1
SET ...
WHERE REC_ID = :REC_ID;
...
END
```
Способов борьбы два: первый заключается в добавлении искусственной сортировки в цикл
```
FOR
SELECT
REC_ID, /* Первичный ключ. */
...
FROM
TABLE_1
...
WHERE
...
ORDER BY
REC_ID DESC
INTO
REC_ID,
...
DO
BEGIN
UPDATE TABLE_1
SET ...
WHERE REC_ID = :REC_ID;
...
END
```
а второй – в использовании временной таблицы
```
INSERT INTO TMP_TABLE
SELECT
REC_ID, /* Первичный ключ. */
...
FROM
TABLE_1
...
WHERE
...;
FOR
SELECT
REC_ID,
...
FROM
TMP_TABLE
INTO
REC_ID,
...
DO
BEGIN
UPDATE TABLE_1
SET ...
WHERE REC_ID = :REC_ID;
...
END
```
#### Защита БД
Самым надёжным способом защитить структуру базы и её данные можно назвать шифрование; оно имеется в SQLite, но беспощадно вырезано из бесплатного IBLite. Хорошей новостью будет то, что имеется другой механизм, позволяющий блокировать подключение к БД любопытствующим, не знающим пароль, причём он действует и в случае копирования БД на машину, где установлен сервер Interbase с полным административным доступом, – способ заключается во включении [Embedded User Authentication](http://docwiki.embarcadero.com/InterBase/XE7/en/Enabling_Embedded_User_Authentication) (EUA) для нужной базы данных. Если БД только создаётся, то код будет выглядеть так:
```
CREATE DATABASE 'Путь_к_файлу' WITH ADMIN OPTION
```
В противном случае применяется команда
```
ALTER DATABASE ADD ADMIN OPTION;
```
Переход на EUA, кроме всего прочего, даёт возможность исключить файл *admin.ib* из состава приложения, сэкономив почти 500 Кб:

После задействования EUA, рекомендуется повысить [надёжность хранения пароля](http://docwiki.embarcadero.com/InterBase/XE7/en/Implementing_Stronger_Password_Protection) (одновременно увеличив ограничение на его длину с 8 до 32 байт):
```
ALTER DATABASE SET PASSWORD DIGEST 'SHA-1';
ALTER USER SYSDBA SET PASSWORD 'Ваш_пароль';
```
Последним рубежом обороны – в случае извлечения пароля из исполняемого файла или ручной правки самой базы данных, может стать удаление исходного кода ХП, триггеров и представлений при помощи скрипта, модифицирующего [системные таблицы](http://docwiki.embarcadero.com/InterBase/XE7/en/System_Tables):
```
UPDATE RDB$PROCEDURES
SET RDB$PROCEDURE_SOURCE = NULL
WHERE COALESCE(RDB$SYSTEM_FLAG, 0) = 0;
UPDATE RDB$TRIGGERS
SET RDB$TRIGGER_SOURCE = NULL
WHERE
COALESCE(RDB$SYSTEM_FLAG, 0) = 0
AND RDB$FLAGS = 1
AND RDB$TRIGGER_NAME STARTING WITH 'TR_';
UPDATE RDB$RELATIONS
SET RDB$VIEW_SOURCE = NULL
WHERE
COALESCE(RDB$SYSTEM_FLAG, 0) = 0
AND RDB$FLAGS = 1
AND RDB$RELATION_TYPE = 'VIEW'
AND RDB$RELATION_NAME STARTING WITH 'VW_';
```
где строки 'TR\_' и 'VW\_' необходимо заменить на Ваши шаблоны именования триггеров и представлений соответственно. | https://habr.com/ru/post/311658/ | null | ru | null |
# Не создавайте собственный ЯП (DSL) для расширения функционала приложения
Когда вы хотите дать пользователю возможность писать плагины для своего приложения, вы встаете перед выбором того, как предоставлять API. Под катом я покажу, почему худшим решением для этого будет изобретение собственного языка программирования и парсинг исходников, а также причем здесь мебель.

ЯП – это не основная функция приложения
---------------------------------------
Представим, что мы открыли производство модульной мебели. Есть некие базовые элементы: столешницы, подставки, тумбочки и т.п. Есть линия производства, связанная с обработкой дерева: станки, пилы, лаки, все по последнему слову техники. Но все это надо как-то скреплять. Мы знаем, что есть 100500 компаний, которые специализируются на производстве скобяных изделий и болтов, есть некоторые стандарты для мебельного крепежа, которые были придуманы сообществом профессионалов для облегчения жизни их клиентам. Насколько же дальновидным решением будет развернуть дополнительную линию по производству собственных болтов, гаек и уголков?
Что мы можем выиграть?
* Можем таким образом брендировать наш товар, чтобы хомячок чувствовал свою "илитарность", и нес больше денег.
* Может это позволит нам не платить копирайт за какой-то из болтов, или решить проблему логистики.
* Можем войти в новый для себя рынок болтов и гаек, установив свой стандарт, который быстрее, лучшее и выше.
Но давайте на чистоту.
* "Илитарность" – это работа продажников. Продажник сделает или не сделает бренд Элитой как с новой линией производства, так и без.
* Копирайт, как правило (не всегда, конечно), дешевле, чем разработка с нуля. А решая проблему доставки одного элемента развертыванием новой линии производства, вы только усугубляете ее.
* Если мы хотим попробовать для себя новую сферу деятельности – не надо связывать ее с тем, в чем мы и так профи. Может показаться, что с мебелью болты толкнуть легче, но если болты не взлетят – они и мебель утащат с собой. По крайней мере, ту, которая уже стоит у клиентов.
Возвращаясь к нашим баранам: если вы делаете экосистему для расширений вашего приложения, значит у вас есть **приложение**. Оно делает что-то хорошо, что-то, в чем хороши вы.
KSP – Kontakt Script Processor, или линия производства болтов в мире digital audio
----------------------------------------------------------------------------------
Расскажу одну историю про такой язык:
**Kontakt** — это ромплер (сэмплер) от австрийской компании **Native Instruments**. В настоящее время очень сложно найти проект с использованием виртуальных инструментов, в котором он не употребляется. За последние 10 лет Kontakt занял большую часть рынка сэмплированных инструментов. Секрет прост: в свое время, Kontakt предложил две инновации, которые перевернули подход к разработке сэмплированных виртуальных инструментов.
Первая инновация была прямо связана с его основной функцией: он очень бережно обходился с памятью (а сэмплы в wav – это тот еще отжиратель, как HDD так и RAM). **NI** сделали формат *lossless* компрессии с быстрым декодингом и написали революционную для своего времени систему буферизации аудио.
### Второй инновацией стал KSP
До контакта было два способа функционально организовать записанные сэмплы в инструмент, управляемый посредством MIDI:
* Писать собственный движок с нуля на С++, или другом языке, способном использовать VST SDK от Steinberg (а ведь еще существуют и другие форматы плагинов, допустим AAX).
* Использовать готовый сэмплер, сделанный для музыкантов, не знакомых с программированием, но имеющим звуки, которые должны быть организованы в какую-то систему. Допустим, **Giga Studio**. Но такие ромплеры, как правило, были либо закрытые, либо для допиливания под свои нужды требовали не меньшего штата, чем голая разработка под VST SDK.
Контакт же угодил и тем, и этим: для быстрого прототипирования есть удобный GUI, понятный любому музыканту, прочитавшему мануал, а для дальнейшей доводки есть ни много ни мало **язык программирования**, с условиями, функциями (с версии 4) и стандартной библиотекой, представляющей API к большей части реализуемого через GUI функционала, а также к параметрам воспроизведения сэмплов напрямую. Кроме прочего, с версии 2 появилась возможность кастомизации интерфейса всякими свистелками и перделками, что позволило проявлять свою уникальность в почти что безграничных масштабах. А код разработчиков скрыт от глаз дважды: обфускацией и защитой от изменения инструментов.
Учитывая нарастающую популярность движка, а также внушительный срок активной разработки ромплера, на сегодняшний день Kontakt представляет из себя что-то вроде автомата Калашникова в мире Digital Audio. Прост в изучении, надежен как танк, имеет возможность допилки в разумных пределах под себя любимого, и держит под собой огромный рынок довольных юзеров.
### Не все так радужно
Случилось неизбежное: инновация в виде KSP стала бичом. Пытаясь сделать синтаксис доступным для чайников, которыми являются музыканты, вместо решения реализации API на человеческом ЯП, Нативы написали собственный интерпретатор собственного языка, архитектура которого изначально не предполагала такого бурного полета фантазии разработчиков инструментов, который мы наблюдаем сейчас. Уже к версии 3 Нативы потеряли надежду угнаться за аппетитами пользователей, и просто стали клепать новые функции стандартной библиотеки, позволяя юзерам разбираться со средой разработки кода самостоятельно.
Тем более, что уже тогда появился **Nils Lieberg KScriptEditor**, форкнутый со **Scintilla**, долгое время служивший основной IDE для KSP. Смешно сказать, но когда Нативы поняли, что контакт не справляется с размерами скармливаемых исходников, они ввели в язык функции, даже не озаботившись передачей в них аргументов. И через месяц в KScriptEditor появились `taskfunc`, передающие аргументы в функции, не принимающие аргументов.
Спустя время, Нилс понял, что наступает на грабли Нативов: собственную IDE разрабатывать смысла нет. Он перенес компилятор и реализованный функционал IDE на SublimeText2, и помахал ручкой. В настоящий момент бразды правления SublimeKSP несет разработчик, кажется, из Fluffy Audio.

### Ну вы поняли)
И снова, уже кодогенератор, представляющий собой ни много ни мало язык, с системой импортов, парсером, компилятором, синтаксисом, отличным от KSP, но-таки поддерживающим обратную с ним совместимость, по неизвестной науке причине оказывается страшной горой из костылей, которые невозможно выбросить по причине обратной совместимости проектов разработчиков библиотек, которые разрабатывают свои KSP-движки годами.
Допустим, система импортов работает глобально по отношению к файлу, из которого запускается компиляция, поэтому для того, чтобы скомпилировать один модуль, находящийся во вложенной папке, надо полностью менять ему пути в импортах, в соответствии с его положением в структуре проекта. И Парень, поддерживающий его рад бы это поменять, но тогда он сломает проекты тех же Spitfire Audio далеко и надолго. А уже один этот факт усложняет модульное (уж промолчим про юнит) тестирование до чертиков.
Казалось бы, решение проблемы — в использовании симлинков, но что-то где-то там работает не так, как предполагается, и симлинки работают только частично. Такого рода проблем не одна штука. Кроме всего прочего, после Нилса, разработка велась не модификацией самого компилятора, получающего уже распарсенный код. А, опять же, из соображений обратной совместимости, добавлением отключаемых плагинов расширенного синтаксиса, каждый из которых получает первоначально порезанные на строки исходники, парсят их самостоятельно, и проводят модификации.
Учитывая то, что большая часть логики препроцессора держится на макросах и inline-функциях, которые разворачивают код в огромное полотно, хранящее в себе 80% всегда истинных или всегда ложных условий (за счет подставления констант на вход условия), которые сворачиваются обратно уже на этапе разбора AST, время компиляции "правильных" исходников сопоставимо с С проектами, это в интерпретируемом-то языке для чайников.
Сказать, что для разработчиков KSP стал болью – ничего не сказать.
### Не контактом единым.
Я не могу привести примеры из других областей, но вот из сферы DigitalAudio:
* **Lemur** – приложение для лопат с десктопным редактором, позволяющая быстро делать красивые интерфейсы для общения лопаты по протоколу OSC. Имеет свой ЯП, который можно использовать в особых *script*-объектах, разбросанных по всему дереву проекта. Способа сделать для него компилятор типа того, что сделан для KSP – нет.
* **Reaper** – DAW с развитой экосистемой разработки расширений. В итоге там, где можно, продублировала свой ЯП *JSFX(ReaScript)* в виде API для C++, lua и Python.
* **HISE** – молодой комбайн для написания и сборки VST\VSTi, который рано или поздно убьет Kontakt от Шведского разработчика *Christoph Haart*. Внутри собственно редактора позволяет писать на модифицированном JavaScript, который парсится и компилируется в бинарник уже объектами C++. Идея с собственным парсером для введения дополнительных сущностей (допустим, регистровых переменных, если я правильно перевел) работала до тех пор, пока пользователи не перенесли свой код из редактора HISE в любимые IDE с подсветкой синтаксиса, статическим анализом и инструментами форматирования по *JsPrettier*. Сейчас Кристоф набросал пару заголовочных файлов для компиляции статических библиотек на C++, которые потом могут быть использованы как модули в редакторе. Параллельно он продолжает дополнять уже HISEScript (потому что назвать его JavaScript теперь нельзя) новыми функциями, но мы то знаем...
Вывод
=====
Пишите ваше собственное приложение, посвящая себя его основному функционалу, не разбазаривайте время на парсер, семантику и синтаксис. Это интересно, пока вы начинаете, но с большой вероятностью приведет в тупик. Язык программирования не может быть частью приложения: это своего рода – отдельная линия производства, требующая огромного времени на обслуживание, модификацию и поддержку комьюнити. В свою очередь, если вы надеетесь, что понизите порог входа для чайников – бросьте это дело. Настоящий чайник, как правило, боится вообще что-либо напечатать, и не будет себя утруждать и вашим простым синтаксисом.
В то время, как начинающим разработчикам плагинов для вашей программы можно просто сделать небольшой *QuickStartGuide*, знакомящий их с основными концепциями выбранного вами ЯП для расширения функционала и потихоньку скармливать ему ваш API, являющийся частью экосистемы этого языка.
*P.S. Нет, писать свой собственный парсер для готового ЯП – тоже плохая идея.*
Буду рад любой критике к статье, первый блин и все дела. | https://habr.com/ru/post/436682/ | null | ru | null |
# LDAP для интернет-проекта. Часть 4
Прошу прощения за перерыв в написании последней части статьи, продолжаем!
Ссылки на остальные части: [раз](https://habr.com/ru/post/52978/), [два](https://habr.com/ru/post/53082/), [три](https://habr.com/ru/post/53383/), [пять](http://habrahabr.ru/blogs/sysadm/58028/)
В этой части мы научимся авторизоваться на наших Linux/Unix серверах.
Как я уже говорил, не так сложно настроить авторизацию, насколько сложно спланировать структуру нашего каталога. У меня это сделано так:
Пользователей я храню в объектах типа posixAccount, unix-группы в объектах posixGroup.
Сами пользователи хранятся в контейнерах типа ou=developers,ou=shell-users,dc=habr,dc=ru
Сервера являются не объектами, а контейнерами, в которых хранятся объекты типа groupOfUniqueNames для определения доступа пользователей к данному серверу, объекты для прав sudo. Также там удобно хранить информацию об IP и прочее. Например, DN-объекта, в котором хранятся пользователи, имеющие доступ к сверверу:
cn=developers,ou=dev.habr.ru,ou=datacenter01,ou=servers,dc=habr,dc=ru
Мой пример может быть не удобен в вашем случае, так или иначе, нужно порисовать структуру.
Перейдём непосредственно к настройке:
Для авторизации используются модули nss\_ldap и pam\_ldap, разработанные компанией со звучным названием [PADL](http://padl.com).
Устанавливаем необходимые пакеты:
`apt-get install libpam-ldap libnss-ldap`
Установщик задаст следующие воросы:
* LDAP URI — пишем ldap://ldap.habr.ru
* База поиска — пишем ou=shell-users,dc=habr,dc=ru
* Версия LDAP — 3
* Local root database admin — нам не требуется, отвечаем Нет
* Следующий вопрос про необходимость клона для локальной базы — отвечаем Нет
* Аккаунт для управления LDAP — нам тоже не потребуется, у нас настроена авторизация для анонимных пользователей. Иначе, вводим cn=admin,dc=habr,dc=ru
* И пароль для этого аккаунта, если в предыдущем пункте выбрали второе
Проверить настройку можно в файлах `/etc/pam_ldap.conf` и `/etc/libnss-ldap.conf`
У меня они одинаковые, поэтому я сделал символические ссылки:
`ln -sf /etc/libnss-ldap.conf /etc/pam_ldap.conf`
Если вводили пароль для администратора, то:
`ln -sf /etc/libnss-ldap.secret /etc/pam_ldap.secret`
Дальше нам нужно поправить конфигурацию PAM (**будьте внимательны**):
> `cat > /etc/pam.d/common-account << "EOF"
>
> account required pam_ldap.so ignore_authinfo_unavail ignore_unknown_user
>
> account required pam_unix.so
>
> EOF`
>
>
> `cat > /etc/pam.d/common-auth << "EOF"
>
> auth sufficient pam_ldap.so
>
> auth required pam_unix.so nullok_secure
>
> EOF`
>
>
> `cat > /etc/pam.d/common-password << "EOF"
>
> password sufficient pam_ldap.so
>
> password required pam_unix.so nullok obscure min=4 max=8 md5
>
> EOF`
>
>
> `cat > /etc/pam.d/common-session << "EOF"
>
> session required pam_mkhomedir.so umask=0077 skel=/etc/skel/ silent #эта строка создаёт home-директорию, если её нет
>
> session sufficient pam_ldap.so
>
> session required pam_unix.so
>
> EOF`
>
>
Правим файл /etc/nsswitch.conf:
> `passwd: files ldap
>
> group: files ldap
>
> shadow: files ldap`
>
>
Собственно после этого система будет пропускать любого пользователя, находящегося в ou=shell-users,dc=habr,dc=ru и ниже, но ведь нам нужно пускать пользователей по определённому признаку — тут есть несколько вариантов:
**1.**
Использовать groupOfUniqueNames и в /etc/pam\_ldap.conf прописать следующие строки:
> `pam_groupdn cn=developers,ou=dev.habr.ru,ou=datacenter01,ou=servers,dc=habr,dc=ru
>
> pam_member_attribute uniqueMember`
>
>
Вроде бы всё хорошо, кроме того, что такая группа может быть только одна.
**2.**
Использовать дополнительный модуль PAM — pam\_listfile или pam\_succed\_if
Эти модули умеют проверять пользователя по атрибутам user, group, rhost, tty…
Но тут группа будет posixGroup — это не очень удобно, хотя можно приспособиться. Мне не понравилось.
**3.**
Собственно это первый вариант, но со специальным патчем от padl.com, который позволяет использовать несколько записей pam\_groupdn в конфигурации. Делается это примерно так:
> `apt-get install build-essential fakeroot dpkg-dev
>
> cd /usr/src
>
> apt-get source libpam-ldap
>
> apt-get build-dep libpam-ldap
>
> cd /usr/src/libpam-ldap-184 (может отличаться, в зависимости от версии debian)
>
> wget "http://bugzilla.padl.com/attachment.cgi?id=227" -O - | sed s=orig/pam=pam= | sed s=new/pam=pam= > debian/patches/99pam_ldap.patch
>
> dpkg-buildpackage -rfakeroot -uc -b
>
> dpkg -i ../libpam-ldap*.deb`
>
>
Для Debian Squeeze немного по-другому накладываются патчи:
> `wget -q "http://bugzilla.padl.com/attachment.cgi?id=227" -O - | sed s=orig/pam=pam= | sed s=new/pam=pam= > debian/patches/multi_groupdn
>
> echo multi_groupdn >> debian/patches/series`
>
>
Собственно всё.
Восстанавливаем наши символические ссылки на /etc/pam\_ldap.conf (у меня dpkg их затрёт):
`ln -sf /etc/libnss-ldap.conf /etc/pam_ldap.conf`
~~`ln -sf /etc/libnss-ldap.secret /etc/pam_ldap.secret`~~
И прописываем нужные pam\_groupdn:
> `pam_groupdn cn=developers,ou=dev.habr.ru,ou=datacenter01,ou=servers,dc=habr,dc=ru
>
> pam_groupdn cn=admins,dc=habr,dc=ru`
>
>
Проверяем авторизацию — радуемся.
Ещё остался вопрос про sudo, там довольно много материала — видимо придётся выйти за рамки 4-х топиков.
Спасибо за внимание! | https://habr.com/ru/post/53279/ | null | ru | null |
# Управление устройством по блютус
Эта статья служит продолжением предыдущей статьи «Смартфон управляет игрушечным автомобилем» и должна помочь пользователям, решившим повторить проект, управлять своим устройством с помощью блютус, используя среду программирования BASIC!..
Управление голосом эффектное, но не очень надежное средство управления, особенно когда расстояние до объекта управления более 2 метров. Мешает затухание и реверберация звука и посторонние шумы, кроме того нужен постоянный доступ к интернету. Надежнее управление по блютус.
Для этого написаны две программы.
Одна программа, назову её «Сервер», работает на смартфоне, управляющем устройством. Сервер будет слушать канал связи, получать команды и выполнять их.
Другая, назову ее «Клиент», работает на смартфоне, который выполняет роль пульта ДУ. Клиент будет инициировать связь, формировать команду, передавать ее по блютус серверу.
Команда представляет собой текстовое сообщение. Например, “right”, а можно “r”, что должно интерпретироваться как «вправо», и означать включение привода руля вправо и маршевого двигателя вперёд на 300 миллисекунд.
Перед началом работы программ между смартфонами надо будет организовать доступ. Для этого откройте настройку, включите блютус, включите поиск доступных устройств и выберите смартфоны.
Перед запуском сервера и клиента выключайте блютус, для того чтобы ОС запрашивала разрешение на включение блютус, иначе соединение может и не создастся.
Сначала запускается программа «Сервер», после того как Вы убедитесь, что она начала слушать канал связи, запускаете Клиент и управляете устройством.
Этими программами демонстрируется только передача команд, интерпретация их в световые пятна на экране была показана в прошлой статье. Остановка работы программ производится клиентом. Если возникает необходимость остановить работу сервера непосредственно на смартфоне, нажмите три раза клавишу возврат.
Листинг программы «Сервер»
```
FN.DEF speak(t$)
TTS.INIT
TTS.SPEAK t$
TTS.STOP
FN.END
speak("начало работы сервера")
ONERROR:
newConnection:
BT.OPEN
speak ("Жду запрос на соединение ")
DO % ++++++++
BT.STATUS s
IF s = 1
!speak("Слушаю")
ELSEIF s =2
speak( "Соединяюсь")
ELSEIF s = 3
speak( "Соединение создано")
ENDIF
PAUSE 1000
UNTIL s = 3 % ++++++
BT.DEVICE.NAME device$
DO %---------
BT.STATUS s
IF (s<> 3)
speak( "Соединение разорвано")
GOTO new_connection
ENDIF
DO % ======
BT.READ.READY rr
IF rr
BT.READ.BYTES s$
PRINT ":";s$
s$ =mid$(s$,1,len(s$)-1)
speak(s$)
IF (s$="end") THEN GOTO xEnd
ENDIF
UNTIL rr = 0 % ======
UNTIL 0 % --------
xEnd:
speak("Сервер остановлен")
BT.CLOSE
END
Листинг программы «Клиент»
ARRAY.LOAD menucom$[], "Вперед", "Назад", "Вправо", "Влево", "Остановить клиент", "Остановить сервер"
BT.OPEN
BT.CONNECT
n = 0
DO %+++++++++++
BT.STATUS s
IF s = 1
PRINT "Слушаю, секунды: ", n++
ELSEIF s =2
PRINT "Соединяюсь, секунды: ",n++
ELSEIF s = 3
PRINT "Есть соединение"
ENDIF
PAUSE 1000
UNTIL s = 3 %+++++++++
BT.DEVICE.NAME device$
PRINT device$
PAUSE 1000
x = 0
DO %#########
SELECT menu, menuCom$[], "Выбери команду"
IF menu = 1 THEN BT.WRITE "forward"
IF menu = 2 THEN BT.WRITE "backward"
IF menu = 3 THEN BT.WRITE "right"
IF menu = 4 THEN BT.WRITE "left"
IF menu = 5 THEN x=1
IF menu = 6 THEN BT.WRITE "end"
UNTIL x=1 %#########
BT.CLOSE
END
``` | https://habr.com/ru/post/426249/ | null | ru | null |
# PHP не любит деструкторы
Столько воды утекло с тех пор как ПХП провозгласил себя ООП языком. Мне не удалось уточнить когда именно, но «On July 13, 2004, PHP 5 was released, powered by the new Zend Engine II. PHP 5 included new features such as improved support for object-oriented programming».
Т.е теоретически уже тогда появились конструкторы и деструкторы. Сам пользуюсь версией 5.3.2, но диву даюсь что он вытворяет.
Немного о себе. Я программист С++, опыт 4 года. Специализация — компьютерная графика и работа с сетью. А именно создание сетевых игр. Но таким играм нужен сервер, а серверу база игроков. А игроки хотят еще и сайт. «Зачем нанимать веб-программиста, я ведь и сам неплох. Заодно и язык изучу.»
Так я думал пол года назад, но до сих пор не могу понять!
##### Классическое
Думаю многие кто работал с деструкторами однажды столкнулся:
PHP Fatal error: Exception thrown without a stack frame in Unknown on line 0
Первая реакция — недоумение. Вторая матная. И ведь впихивание exit() везде не дает результата, ведь догадка о том что эксепшен в деструкторе приходит далеко не сразу, а если он происходит, то скорее всего кодовая база значительная.
Ответ c [bugs.php.net/bug.php?id=33598](https://bugs.php.net/bug.php?id=33598)
`**[email protected]:**
Throwing exceptions in __desctruct() is not allowed.
Should be documented..
**[email protected]:**
Thank you for the report, and for helping us make our documentation better.
"Attempting to throw an exception from a desctructor causes a fatal error."`
Весело? Лично мне не очень.
Воспроизводится ошибка с неявным исключением очень просто.
`class a
{
// ...
public function __destruct()
{
global $_SESSION;
$_SESSION = "Some information";
}
}
$dummy = new a();`
^Примечание, явные исключения иногда работают верно. Буду ставить эксперементы что влияет.
##### Реверсный порядок очистки
Пусть в некоторой области видимости(глобальной и неочень) у нас следующий код:
`$earth = new world();
$vasya = new human($earth);`
Соответственно в коде конструктора человека идет его пришпандоривание к миру. (Предполагается что без мира вася существовать не будет, отбросим философию, нам проект скорее закрыть.)
Ну а в коде деструктора вася лежит аля $this->my\_world->RemoveHumanFromWorld($this), в котором вызываются RemoveAllMyStuff, CalculateKarma и прочее. (Предположим у нас в мире не хранится ссылка на васю, так как это не требовалось в рамках задачи)
Что делает пхп при выходе из области видимости? Уничтожает мир и падает с ошибкой «Fatal error: Call to a member function RemoveHumanFromWorld() on a non-object in /home/god/my\_projects/earth/creatures/reasonable/homo\_sapiens.php on line 1956».
(Поэтому кстати мир был написан на С++, ведь богу не нужно что бы он запускался на любой вселенной. Виртуальный космос с сборщиком мусора. Ха Ха.)
Ответ с [bugs.php.net/bug.php?id=36759](https://bugs.php.net/bug.php?id=36759)
**[email protected]**
Fixed in CVS HEAD and PHP\_5\_2.
Найти бы этого дмитрия и ткнуть носом как в той картинке. Не знаю как там в последних версиях, пока не обновляюсь, но в 5.3 актуально.
##### Завершение скрипта — исключительная ситуация
Ох, про это столько можно писать. Глобальные переменные (аля сессий) перестают быть валидными, доступ к файловой системе обрубается. И вообще как я понимаю корректная работа скрипта не гарантируется. Так что не дай бог вам выполнять что то в деструкторе глобального обьекта…
Но это опустим. В документации пхп 5.1 и ранее (строфу и стих не найду) сказано: «The destructor method will be called as soon as there are no other references to a particular object», что в принципе логично для языка без строгого требования конструкции delete (лат. unset).
После баг репорта [bugs.php.net/bug.php?id=38572](https://bugs.php.net/bug.php?id=38572)
Документация изменилась «The destructor method will be called as soon as there are no other references to a particular object, or in any order during the shutdown sequence»
Удобно? По мне — не очень.
##### Только прямые ссылки
Пусть согласно логике языка обьект $a должен удалиться раньше $b.
Но пусть в обьекте $b хранится ссылка на поле $a->some\_data.
Тогда по логике обьект $b должен удалиться раньше. Увы, в пхп не так. Подобной баги я не нашел, но ситуация специфическая(и не побоюсь слова исключительная). Избегается несильным патчем до ссылки на $a, терпимо и репортить я не стал.
##### Дедлок в стиле пхп
$a->ref = $b;
$b->ref = $a;
Мне в свое время было интересно, как пхп справится с перекресными ссылками. Зависнет ли? Упадет ли с ошибкой «нельзя покинуть область видимости», и как она будет звучать на английском. Увы, теплица показала — все переменные будут существовать до конца, пока не придет как говорится «or in any order during the shutdown sequence»
###### Заключение
На данный момент все что я вспомнил. А может и все что я встречал. Но создалось впечатление что деструкторы в ПХП это костыль, так что скорее всего скоро опять наткнусь.
Мне кажется будущее ООП веб-программирование за интерпретатором c++, и возможно он будет готов. Возможно кто то однажды возьмется изменить с++, добавить стандартных конструкций что бы он стал ориентированным под веб. Но пока я альтернатив не нашел.
###### Ссылки
[en.wikipedia.org/wiki/PHP](http://en.wikipedia.org/wiki/PHP)
[php.net/manual/en/language.oop5.decon.php](http://php.net/manual/en/language.oop5.decon.php)
Хотя чего там мелочиться:
[http://].\*php\.net.\* | https://habr.com/ru/post/140762/ | null | ru | null |
# Мониторинг пет-проектов на коленке: Netdata, Monitoror, N8N
")Инди-разработчик изучает мониторинг чужого проекта (кадр из «Кремниевой долины»)Привет, я Паша из Ozon. В рабочее время занимаюсь тестированием поиска, а по вечерам надеваю маску инди-разработчика. И моя самая частая задача — написать скрипт → залить его на сервер → периодически мониторить, что сервер доступен. Эта статья как раз и будет строиться вокруг последнего пункта.
Вы наверняка в курсе, что существуют Grafana, Prometheus, Kibana, LogDNA и другие инструменты для мониторинга, визуализации и анализа данных. C первыми двумя я вплотную познакомился в Ozon, а про Kibana слышал когда-то давно и только в паре со словом «логи». Чтобы графики в Grafana рисовать — придется штат аналитиков нанять (ба-дум-тсс). Для пет-проекта это перебор, нужно что-то сильно проще (с точки зрения стоимости, простоты настройки и удобства). Ниже расскажу, какие готовые инструменты для мониторинга небольших проектов я нашёл в пучинах интернета, а также оставлю комментарии и рекомендации по использованию.
> ***Disclaimer:*** *все проекты рассматриваются с точки зрения маленького сайта/скрипта/бота/приложения, поэтому видение автора может сильно отличаться от видения enterprise-разработчиков.*
>
>
Netdata
-------
Из заголовка [сайта](https://www.netdata.cloud/) проекта многое сразу понятно: **Monitor everything in real time. For free.** Про него уже есть [статья](https://habr.com/ru/company/selectel/blog/318284/) на Хабре, не вижу смысла описывать детальнее. Очень просто устанавливается. Одна команда «скачать», вторая «запустить» — и графики уже можно смотреть.
Дашборд Netdata С помощью Netdata можно отслеживать огромнейшее количество показателей: статистику использования процессора, потребления памяти, операций ввода-вывода и прочего. Netdata разработана для администраторов, DevOps и разработчиков. Так что если сложно — есть [раздел](https://learn.netdata.cloud/) с документацией, рекомендую на старте, помогает внести ясность по базовым метрикам и настройке алертов.
**Плюсы**
* легко устанавливается;
* есть алерты;
* огромное количество метрик;
* «для DevOps».
**Минусы**
* масштабирование (на кластер поставить нельзя, только отдельно на каждый сервер);
* нужно следить за логами (сколько их и где они);
* конфигурация через SSH;
* «для DevOps».
Из описания следует, что сервис больше ориентирован на низкоуровневые показатели железа, а значит требует больших знаний и внимания — что не совсем подходит для серверных скриптов. Зато инструмент поможет понять, когда настало время масштабироваться, вертикально уж точно.
> *«Для DevOps» и в плюсах, и в минусах — зависит от того, кто читает. Я не смог настроить алерты, поэтому использую как дашборд: смотрю средние значения по нагрузке на CPU.*
>
>
Monitoror
---------
Предыдущий инструмент, Netdata, я нашел случайно по запросу "*dashboard"*. Но это не совсем то, чего я хотел. Я бы хотел красивые плитки с простой и гибкой настройкой. Первое, что лежит на поверхности — [Smashing](https://smashing.github.io/). Но с ним у меня не задалось. Написан на Ruby, и я его даже запустить не смог, не то что настроить. А посмотрев обзоры и готовые доски — еще и не захотел.
Как оказалось, я всё время искал то, что сделали разработчики [Monitoror](https://monitoror.com/). Потрясающе гибкая (во всех смыслах) доска с поддержкой CI/CD провайдеров. Просто взгляните на скриншоты:
Источник: GoogleРабочий дашборд MonitororУстанавливается легко, через бинарник. Настраивается через JSON файл. Выглядит он примерно так:
```
{
"version": "2.0",
"columns": 3,
"tiles": [
{
"type": "HTTP-RAW",
"label": "plumber stars",
"params": {
"url": "https://github.com/pashkatrick/Plumber",
"regex": "(\\d+) users starred"
}
},
{
"type": "HTTP-RAW",
"label": "grpc-client",
"params": {
"url": "https://marketplace.visualstudio.com/items?itemName=pashkatrick.grpc-client",
"regex": "(\\d+) installs"
}
},
{
"type": "HTTP-RAW",
"label": "udecoder",
"params": {
"url": "https://marketplace.visualstudio.com/items?itemName=pashkatrick.vscode-udecoder",
"regex": "(\\d+) installs"
}
},
{
"type": "HTTP-RAW",
"label": "vscode-etcd",
"params": {
"url": "https://marketplace.visualstudio.com/items?itemName=pashkatrick.vscode-etcd",
"regex": "(\\d+) installs"
}
}
]
}
```
Кому интересно подробнее — оставлю ссылку на [официальную](https://monitoror.com/documentation/#http) документацию. От себя скажу лишь, что помимо *HTTP-RAW* есть *HTTP-FORMATTED* и *HTTP-STATUS*. Но это для типа плитки *HTTP* соответственно*.* Поддерживаются следующие типы плиток:
Скриншот из документации Monitoror**Плюсы**
* дизайн и удобство;
* простая и понятная настройка.
**Минусы**
* чем больше блоков — тем хуже читаемость;
* отсутствие алертов.
Подходит как для маленьких проектов, «сервачков», сбора интересных цифр (таких как количество скачиваний), так и для стартапов средней величины, где уже выстроен процесс доставки кода.
> Сам я *CI/CD не настраивал, не было необходимости. Жаль, алертов никаких, да и в проекте последняя активность была год назад. Но в целом очень нравится; все, что нужно — есть.*
>
>
Поскольку оповещений нет — пришлось сделать [свою](https://github.com/pashkatrick/monitoror-alerts) парсилку логов. Это простой Python-скрипт, который внутри себя запускает Monitoror в debug-режиме, а после выполнения складывает логи рядом с собой. Соответственно, если ответ не «200 ок» — можно послать уведомление. Сыро, но, если будут звезды, можем докрутить до рабочего состояния.
N8N (etc.)
----------
Следующий пункт в обзоре — *no-code* платформы, где можно «собрать» систему оповещения под свои нужды.
**Например:**
* [Integromat](https://www.integromat.com/en),
* [Albato](https://albato.ru/) (rus),
* [N8N](https://n8n.io/) (круто),
* [Corezoid](https://corezoid.com/ru/) (дороговато стало),
* [IFTTT](https://ifttt.com/) (интерфейс отличается),
* [Zapier](https://zapier.com/),
* [Apix-Drive](https://apix-drive.com/ru) (rus).
Я выбрал N8N как бесплатную для тех, у кого есть Docker. Установка потребует некоторых IT-навыков, но в целом ничего сложного.
Рабочее пространство N8NЕсть хорошая [статья](https://n8n.io/blog/database-monitoring-and-alerting-with-n8n/) с разбором мониторинга базы данных. Но покажу на своём примере:
*Пусть каждые 15 сек отправляется запрос на все мои сайты, и если в ответ приходит* ***НЕ*** «*200 ОК*»*, то отправляется уведомление о проблеме. После собираем отчёт по всем сайтам и отправляем его менеджеру на почту и в Notion.*
Пара минут на придумывание flow + соединить всё стрелочками + пару часов на все credentials и API-ключи. Получается довольно быстро c полным соответствием поставленным требованиям.
")Рабочее пространство N8N (1)**Плюсы**
* абсолютная гибкость;
* несложная установка;
* хорошее [комьюнити](https://community.n8n.io/);
* документация/инструкции/туториалы;
* своих денег стоит.
**Минусы**
* не нашел.
Сфера применений широчайшая. От бэкенда (можно RabbitMQ, Postgres, Redis — все есть) до управления автоматической поилкой собаки. Процесс масштабирования непростой, но авторы сделали [инструкции](https://docs.n8n.io/getting-started/installation/advanced/scaling-n8n.html#configuring-workers) на популярные кейсы, так что вопросов не остается. А если остаются — в комьюнити можно быстро найти на них ответ.
> *Крайне рекомендую N8N, к тому же можно добавлять свои/новые сервисы. Мейнтейнеры проекта проверяют пулл-реквест около недели и присылают рекомендации, если потребуются.*
>
>
Уже не на коленке
-----------------
На десерт оставил сервисы из категории «всё уже написано за нас». Установка не требуется, только регистрация. Рекомендую посмотреть:
* [DataDog](https://www.datadoghq.com/),
* [Hyperping](https://hyperping.io/),
* [Uptime](https://uptime.com/),
* [PingDom](https://www.pingdom.com/),
* [BetterUptime](https://betteruptime.com/)
* [UptimeRobot](https://uptimerobot.com/).
 ")Скриншот из Hyperping (источник: Google) На борту: мониторы сайтов, значение uptime'a за настроенные периоды (98% за год), отчёты, страница status page (которую можно показывать всем желающим, хвастаясь стабильностью), а также функция пинга сайтов из разных точек мира и VPN/Proxy запросы. Лично не пробовал, но звучит интересно.
Много функций — конечно, хорошо, но разделение на команды внутри сервиса и инцидент-менеджмент кажутся лишними... Лично мне только уведомления нужны на случай, если что-то сломается. Но тут уже на вкус и цвет.
**Плюсы**
* SaaS и всё из него вытекающее;
* красиво и удобно;
* алерты, отчеты, интеграции.
**Минусы**
* очень платно (начинаются от 30$ в месяц);
* бывает перегружен интерфейс (например, инцидент-менеджмент).
> Я *пользуюсь* [*Better Uptime*](https://betteruptime.com/)*: интерфейс приятный и понятный, да ещё и раз в неделю приходит отчет по всем сайтам. Бесплатного тарифа хватает, но буду ещё тестировать уведомления в Slack/Telegram. Также хочу посмотреть на Proxy-пинг, который доступен по умолчанию, — интересно.*
>
>
Скриншот из Better UptimeКонец
-----
Не люблю стандартные итоги в стиле «выбор сервиса зависит от поставленной задачи», так что скажу так: пробуйте, пользуйтесь, делитесь опытом и находками!
Если я не упомянул еще более крутые сервисы — сообщите мне любым способом, например, в комментариях к статье. Я увижу, запущу сервис, оценю и обновлю статью. Благодарю за внимание!
**P.S.**
По итогу «аналитической работы» я решил делать свой сервис с отчетами, алертами и запахом смузи. Там пока ничего нет, но если интересно поучаствовать — [welcome](https://github.com/pashkatrick/upper)! | https://habr.com/ru/post/572150/ | null | ru | null |
# Как web-страницу легко превратить в PDF?

Для меня было очень неожиданно то, что в хабе по Java практически нет информации по работе с PDF документами, поэтому я, из личного опыта, хочу на примере сервлета показать как легко можно любую web-страницу превратить в PDF документ.
##### **Преамбула:**
Напишем простой сервлет, который будет брать указанную нами web-страницу по HTTP протоколу и генерировать на её основе полноценный PDF документ.
##### **Используемые библиотеки:**
* Flying Saucer PDF — основная библиотека, которая поможет создать нам PDF документ из HTML/CSS
* iText — библиотека, которая включена в состав той, что описана выше, но я не мог не включить ее в список библиотек, т.к. именно на основе неё будет генерироваться PDF документ
* HTML Cleaner — библиотека, которая будет приводить наш HTML код в порядок
**Описания библиотек для Maven конфигурации (pom.xml)**
```
org.xhtmlrenderer
flying-saucer-pdf
9.0.4
net.sourceforge.htmlcleaner
htmlcleaner
2.6.1
```
##### **Формирование страницы:**
Одним из самый важных моментов является формирование страницы. Дело в том, что именно из самой страницы, посредством CSS, задаются параметры будущего PDF документа.
Рассмотрим макет:
**page.jsp**
```
<%@ page import="java.util.Date" %>
<%@ page import="java.text.SimpleDateFormat" %>
<%@ page contentType="text/html;charset=UTF-8" language="java" %>
<%!
private SimpleDateFormat sdf = new SimpleDateFormat("HH:mm:ss");
%>
Пример
@font-face {
font-family: "HabraFont";
src: url(http://localhost:8080/resources/fonts/tahoma.ttf);
-fs-pdf-font-embed: embed;
-fs-pdf-font-encoding: Identity-H;
}
@page {
margin: 0px;
padding: 0px;
size: A4 portrait;
}
@media print {
.new\_page {
page-break-after: always;
}
}
body {
background-image: url(http://localhost:8080/resources/images/background.png);
}
body \*{
padding: 0;
margin: 0;
}
\* {
font-family: HabraFont;
}
#block {
width: 90%;
margin: auto;
background-color: white;
border: dashed #dbdbdb 1px;
}
#logo {
margin-top: 5px;
width: 100%;
text-align: center;
border-bottom: dashed #dbdbdb 1px;
}
#content {
padding-left: 10px;
}

Привет, хабр! Текущее время: <%=sdf.format(new Date())%>
Новая страница!
```
Здесь хочу остановиться на нескольких моментах. Для начала самое важное: все пути должны быть абсолютными! Картинки, стили, адреса шрифтов и др., на всё должны быть прописаны абсолютные пути. А теперь пройдемся по CSS правилам (то, что начинается с символа @).
**@ font-face** — это правило, которое скажет нашему PDF генератору какой нужно взять шрифт, и откуда. Проблема в том, что библиотека, которая будет генерировать PDF документ не содержит шрифтов, включающих в себя кириллицу. Именно поэтому таким образом придется определять ВСЕ шрифты, которые используются в Вашей странице, пусть это будут даже стандартные шрифты: Arial, Verdana, Tahoma, и пр., в противном случае Вы рискуете не увидеть кириллицу в Вашем документе.
Обратите внимание на такие свойства как "-fs-pdf-font-embed: embed;" и "-fs-pdf-font-encoding: Identity-H;", эти свойства необходимы, их просто не забывайте добавлять.
**@ page** — это правило, которое задает отступы для PDF документа, ну и его размер. Здесь хотелось бы отметить, что если Вы укажите размер страницы A3 (а как показывает практика, это часто необходимо, т.к. страница не помещается в документ по ширине), то это не значит, что пользователю необходимо будет распечатывать документ (при желании) в формате A3, скорее просто весь контент будет пропорционально уменьшен/увеличен до желаемого (чаще A4). Т.е. относитесь к значению свойства size скептически, но знайте, что оно может сыграть для Вас ключевую роль.
**@ media** — правило, позволяющее создавать CSS классы для определенного типа устройств, в нашем случае это «print». Внутри этого правила мы создали класс, после которого наш генератор PDF документа создаст новую страницу.
##### **Сервлет:**
Теперь напишем сервлет, который будет возвращать нам сгенерированный PDF документ:
**PdfServlet.java**
```
package ru.habrahabr.web_to_pdf.servlets;
import org.htmlcleaner.CleanerProperties;
import org.htmlcleaner.HtmlCleaner;
import org.htmlcleaner.PrettyXmlSerializer;
import org.htmlcleaner.TagNode;
import org.xhtmlrenderer.pdf.ITextRenderer;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.*;
import java.net.HttpURLConnection;
import java.net.URL;
import java.net.URLConnection;
/**
* Date: 31.03.2014
* Time: 9:33
*
* @author Ruslan Molchanov ([email protected])
*/
public class PdfServlet extends HttpServlet {
private static final String PAGE_TO_PARSE = "http://localhost:8080/page.jsp";
private static final String CHARSET = "UTF-8";
@Override
protected void service(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
try {
resp.setContentType("application/pdf");
byte[] pdfDoc = performPdfDocument(PAGE_TO_PARSE);
resp.setContentLength(pdfDoc.length);
resp.getOutputStream().write(pdfDoc);
} catch (Exception ex) {
resp.setContentType("text/html");
PrintWriter out = resp.getWriter();
out.write("**Something wrong**
");
ex.printStackTrace(out);
ex.printStackTrace();
}
}
/**
* Метод, подготавливащий PDF документ.
* @param path путь до страницы
* @return PDF документ
* @throws Exception
*/
private byte[] performPdfDocument(String path) throws Exception {
// Получаем HTML код страницы
String html = getHtml(path);
// Буффер, в котором будет лежать отформатированный HTML код
ByteArrayOutputStream out = new ByteArrayOutputStream();
// Форматирование HTML кода
/* эта процедура не обязательна, но я настоятельно рекомендую использовать этот блок */
HtmlCleaner cleaner = new HtmlCleaner();
CleanerProperties props = cleaner.getProperties();
props.setCharset(CHARSET);
TagNode node = cleaner.clean(html);
new PrettyXmlSerializer(props).writeToStream(node, out);
// Создаем PDF из подготовленного HTML кода
ITextRenderer renderer = new ITextRenderer();
renderer.setDocumentFromString(new String(out.toByteArray(), CHARSET));
renderer.layout();
/* заметьте, на этом этапе Вы можете записать PDF документ, скажем, в файл
* но раз мы пишем сервлет, который будет возвращать PDF документ,
* нам нужен массив байт, который мы отдадим пользователю */
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
renderer.createPDF(outputStream);
// Завершаем работу
renderer.finishPDF();
out.flush();
out.close();
byte[] result = outputStream.toByteArray();
outputStream.close();
return result;
}
private String getHtml(String path) throws IOException {
URLConnection urlConnection = new URL(path).openConnection();
((HttpURLConnection) urlConnection).setInstanceFollowRedirects(true);
HttpURLConnection.setFollowRedirects(true);
boolean redirect = false;
// normally, 3xx is redirect
int status = ((HttpURLConnection) urlConnection).getResponseCode();
if (HttpURLConnection.HTTP_OK != status &&
(HttpURLConnection.HTTP_MOVED_TEMP == status ||
HttpURLConnection.HTTP_MOVED_PERM == status ||
HttpURLConnection.HTTP_SEE_OTHER == status)) {
redirect = true;
}
if (redirect) {
// get redirect url from "location" header field
String newUrl = urlConnection.getHeaderField("Location");
// open the new connnection again
urlConnection = new URL(newUrl).openConnection();
}
urlConnection.setConnectTimeout(30000);
urlConnection.setReadTimeout(30000);
BufferedReader in = new BufferedReader(new InputStreamReader(urlConnection.getInputStream(), CHARSET));
StringBuilder sb = new StringBuilder();
String line;
while (null != (line = in.readLine())) {
sb.append(line).append("\n");
}
return sb.toString().trim();
}
@Override
public String getServletInfo() {
return "The servlet that generate and returns pdf file";
}
}
```
Кстати, совсем не обязательно писать для этих целей сервлет, Вы можете перенести логику этого сервлета хоть в консольное приложение, которое будет сохранять PDF документы в файлы. Как Вы могли заметить, в сервлете не нужно ничего настраивать, менять, дополнять, и т.д. (ну за исключением пути до страницы и, возможно, кодировки), соответственно вся работа по подготовке PDF документа очень проста и происходит исключительно во вьюшке.
В конечном итоге у Вас должен получиться примерно такой PDF документ: [github.com/ruslanys/example-web-to-pdf/blob/master/web-to-pdf-example.pdf](https://github.com/ruslanys/example-web-to-pdf/blob/master/web-to-pdf-example.pdf)
Я немного дополнил свой документ информацией (распарсил главную страницу Хабра) и у меня получился такой вот документ: [github.com/ruslanys/sample-html-to-pdf/blob/master/web-to-pdf-habra.pdf](https://github.com/ruslanys/sample-html-to-pdf/blob/master/web-to-pdf-habra.pdf)
Ссылка на исходники: [github.com/ruslanys/sample-html-to-pdf](https://github.com/ruslanys/sample-html-to-pdf)
P.S. В принципе, на основе этого примера можно написать целый сервис, который будет по любому адресу страницы создавать PDF документ. Единственное, что будет необходимо сделать — это привести HTML код страницы в соответствие с нашими правилами, т.е. в первую очередь нужно будет переписать все относительные пути на абсолютные (благо это делается не сложно), и в соответствии с какой-то логикой задать размеры документа. | https://habr.com/ru/post/217561/ | null | ru | null |
# Автоматизация логирования входов в функции
У нас в компании с незапамятных времен существует гласно-негласное правило о логировании входа в каждую функцию. И ладно бы это ограничивалось простой строчкой Logger.LogEntering() в их начале (хотя, наверное, тоже надоело бы), так еще и наш «замечательный» доморощенный логгер получать названия функций из которых он вызван не умеет, и как следствие, эта единственная строчка разрасталась до эпического Logger.Log(«Classname.FunctionName — Entering») or something like that.
Неудивительно, что под воздействием [недавних](http://habrahabr.ru/blogs/net/95211/) [топиков](http://habrahabr.ru/blogs/net/108947/) о Mono.Cecil и родилась задача автоматизации процесса.
Для того, чтобы продукт представлял не только внутрикорпоративную ценность, но и был общественно полезным, решено было поддержкой «внутреннего» логгера не ограничиваться, а также поддержать сторонние log4net и nlog (благо, и для внутренних нужд мы плавно переходим на log4net).
Конкретизируя задачу, необходимо добавлять вызовы логгера в начало функций, а также логировать не только сам факт входа, но и параметры, с которыми функция была вызвана.
Вступление затянулось, и пора переходить от слов к делу.
Реализация — это msbuild-task, который запускается на этапе пост-компиляции и производит инъекцию вызовов Logger.Debug(«Entering») в начало каждой функции. Вернее, не каждой, а только помеченные атрибутом *[Log]*. Или во все функции классов, помеченные этим атрибутом. Ну или всё-таки в начало каждой функции модуля, если атрибут *[Log]* затесался в AssemblyInfo. Если же какие-то функции логировать ну никак не хочется, то их можно пометить атрибутом *[NoLog]*.
Чтобы эта msbuild-задача выполнялась, в .csproj\.vbproj необходимо добавить её вызов. Например, так:
```
```
Ну или чуть-чуть изменив, если вы предпочитаете log4net.
Кроме этого, конечно, необходимо создать инстанс логгера, в который это всё и будет логироваться. LoggingMagic на данный момент подразумевает, что экземпляр логгера доступен через статичное поле какого-либо класса.
```
//имя класса - Logger - имеет значение. Можно менять, но тогда надо его менять и в .targets-файле
public class Logger
{
public static NLog.Logger Log = NLog.LogManager.GetLogger("NlogConsoleApp");
}
```
На этом и всё. Фильтрация результирующего потока логов возлагается целиком и полностью на логирующую библиотеку. LoggingMagic достаточно легко расширяется, имена атрибутов и класса с логгером меняются в параметрах msbuild task'a.
Серьезным недостатком является отсутствие поддержки методики logger-per-class (которая пропагандируется, к примеру, nlog'ом), логирование возможно либо через статичное поле, либо через статичную функцию. В комментариях было бы любопытно узнать, каким способом логирования пользуетесь вы :) Логирование per-class возможно будет добавлено при настойчивых требованиях сообщества :)
Итог получился урезанным подобием [Log4Postsharp](http://code.google.com/p/postsharp-user-plugins/wiki/Log4PostSharp), но без привязки к проприетарным компонентам и без необходимости линковки с чем-либо сторонним и поставки этого при инсталяциях (библиотеки loggingmagic дальше Buildserver'a никуда не уходят).
Исходные коды всего этого безобразия выложены на [codeplex](http://loggingmagic.codeplex.com/)
P.S. надеюсь, что к дискуссии о нужности-ненужности собственно логирования входов всё не сведется, потому что это чаще всего определяется предметной областью. В нашем конкретном случае это порой единственный способ сбора детальной информации при обнаружении проблем на клиентских инсталляциях. | https://habr.com/ru/post/114107/ | null | ru | null |
# 5 алгоритмов регрессии в машинном обучении, о которых вам следует знать

*Источник: Vecteezy*
Да, линейная регрессия не единственная
Быстренько назовите пять алгоритмов машинного обучения.
Вряд ли вы назовете много алгоритмов регрессии. В конце концов, единственным широко распространенным алгоритмом регрессии является линейная регрессия, главным образом из-за ее простоты. Однако линейная регрессия часто неприменима к реальным данным из-за слишком ограниченных возможностей и ограниченной свободы маневра. Ее часто используют только в качестве базовой модели для оценки и сравнения с новыми подходами в исследованиях.
Команда [Mail.ru Cloud Solutions](https://mcs.mail.ru/) перевела статью, автор которой описывает 5 алгоритмов регрессии. Их стоит иметь в своем наборе инструментов наряду с популярными алгоритмами классификации, такими как SVM, дерево решений и нейронные сети.
1. Нейросетевая регрессия
-------------------------
### Теория
Нейронные сети невероятно мощные, но их обычно используют для классификации. Сигналы проходят через слои нейронов и обобщаются в один из нескольких классов. Однако их можно очень быстро адаптировать в регрессионные модели, если изменить последнюю функцию активации.
Каждый нейрон передает значения из предыдущей связи через функцию активации, служащую цели обобщения и нелинейности. Обычно активационная функция — это что-то вроде сигмоиды или функции ReLU (выпрямленный линейный блок).
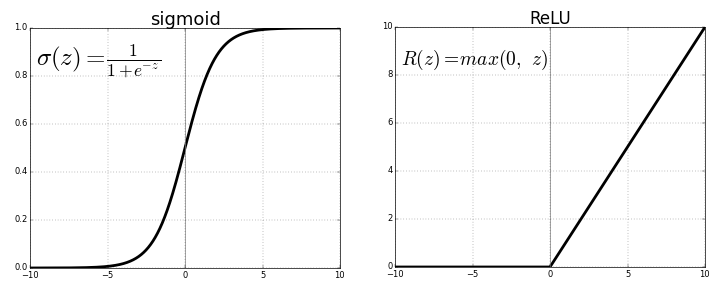
*[Источник](https://i.stack.imgur.com/dnvwL.png). Свободное изображение*
Но, заменив последнюю функцию активации (выходной нейрон) *линейной* функцией активации, выходной сигнал можно отобразить на множество значений, выходящих за пределы фиксированных классов. Таким образом, на выходе будет не вероятность отнесения входного сигнала к какому-либо одному классу, а непрерывное значение, на котором фиксирует свои наблюдения нейронная сеть. В этом смысле можно сказать, что нейронная сеть как бы дополняет линейную регрессию.
Нейросетевая регрессия имеет преимущество нелинейности (в дополнение к сложности), которую можно ввести с сигмоидной и другими нелинейными функциями активации ранее в нейронной сети. Однако чрезмерное использование ReLU в качестве функции активации может означать, что модель имеет тенденцию избегать вывода отрицательных значений, поскольку ReLU игнорирует относительные различия между отрицательными значениями.
Это можно решить либо ограничением использования ReLU и добавлением большего количества отрицательных значений соответствующих функций активации, либо нормализацией данных до строго положительного диапазона перед обучением.
### Реализация
Используя Keras, построим структуру искусственной нейронной сети, хотя то же самое можно было бы сделать со сверточной нейронной сетью или другой сетью, если последний слой является либо плотным слоем с линейной активацией, либо просто слоем с линейной активацией. (*Обратите внимание, что импорты Keras не указаны для экономии места*).
> `model = Sequential()
>
> model.add(Dense(100, input_dim=3, activation='sigmoid'))
>
> model.add(ReLU(alpha=1.0))
>
> model.add(Dense(50, activation='sigmoid'))
>
> model.add(ReLU(alpha=1.0))
>
> model.add(Dense(25, activation='softmax'))
>
>
>
> #IMPORTANT PART
>
> model.add(Dense(1, activation='linear'))`
Проблема нейронных сетей всегда заключалась в их высокой дисперсии и склонности к переобучению. В приведенном выше примере кода много источников нелинейности, таких как SoftMax или sigmoid.
Если ваша нейронная сеть хорошо справляется с обучающими данными с чисто линейной структурой, возможно, лучше использовать регрессию с усеченным деревом решений, которая эмулирует линейную и высокодисперсную нейронную сеть, но позволяет дата-сайентисту лучше контролировать глубину, ширину и другие атрибуты для контроля переобучения.
2. Регрессия дерева решений
---------------------------
### Теория
Деревья решений в классификации и регрессии очень похожи, поскольку работают путем построения деревьев с узлами «да/нет». Однако в то время как конечные узлы классификации приводят к одному значению класса (например, 1 или 0 для задачи бинарной классификации), деревья регрессии заканчиваются значением в непрерывном режиме (например, 4593,49 или 10,98).
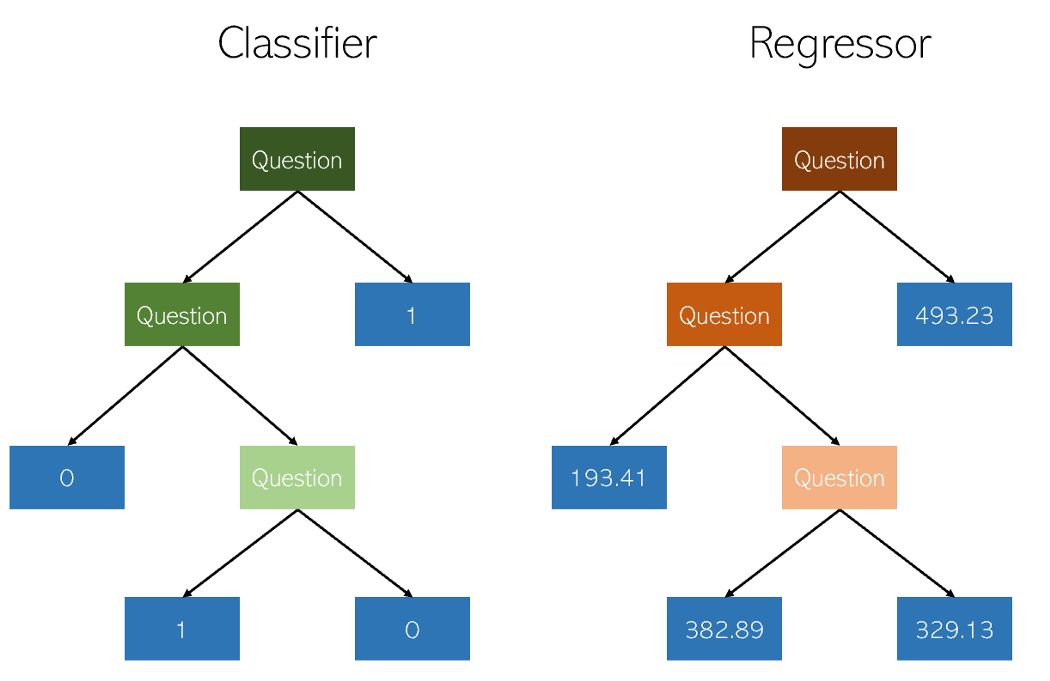
*Иллюстрация автора*
Из-за специфической и высокодисперсной природы регрессии просто как задачи машинного обучения, регрессоры дерева решений следует тщательно обрезать. Тем не менее, подход к регрессии нерегулярен — вместо того, чтобы вычислять значение в непрерывном масштабе, он приходит к заданным конечным узлам. Если регрессор обрезан слишком сильно, у него слишком мало конечных узлов, чтобы должным образом выполнить свою задачу.
Следовательно, дерево решений должно быть обрезано так, чтобы оно имело наибольшую свободу (возможные выходные значения регрессии — количество конечных узлов), но недостаточно, чтобы оно было слишком глубоким. Если его не обрезать, то и без того высокодисперсный алгоритм станет чрезмерно сложным из-за природы регрессии.
### Реализация
Регрессия дерева решений может быть легко создана в `sklearn`:
```
from sklearn.tree import DecisionTreeRegressor
model = DecisionTreeRegressor()
model.fit(X_train, y_train)
```
Поскольку параметры регрессора дерева решений очень важны, рекомендуется использовать инструмент оптимизации поиска параметров `GridCV` из `sklearn`, чтобы найти правильные рекомендации для этой модели.
При формальной оценке производительности используйте тестирование `K-fold` вместо стандартного `train-test-split`, чтобы избежать случайности последнего, которая может нарушить чувствительные результаты модели с высокой дисперсией.
**Бонус**: близкий родственник дерева решений, алгоритм random forest (алгоритм случайного леса), также может быть реализован в качестве регрессора. Регрессор случайного леса может работать лучше или не лучше, чем дерево решений в регрессии (в то время как он обычно работает лучше в классификации) из-за тонкого баланса между избыточным и недостаточным в природе алгоритмов построения дерева.
```
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor()
model.fit(X_train, y_train)
```
3. Регрессия LASSO
------------------
Метод регрессии лассо (LASSO, Least Absolute Shrinkage and Selection Operator) — это вариация линейной регрессии, специально адаптированная для данных, которые демонстрируют сильную мультиколлинеарность (то есть сильную корреляцию признаков друг с другом).
Она автоматизирует части выбора модели, такие как выбор переменных или исключение параметров. LASSO использует сжатие коэффициентов (shrinkage), то есть процесс, в котором значения данных приближаются к центральной точке (например среднему значению).
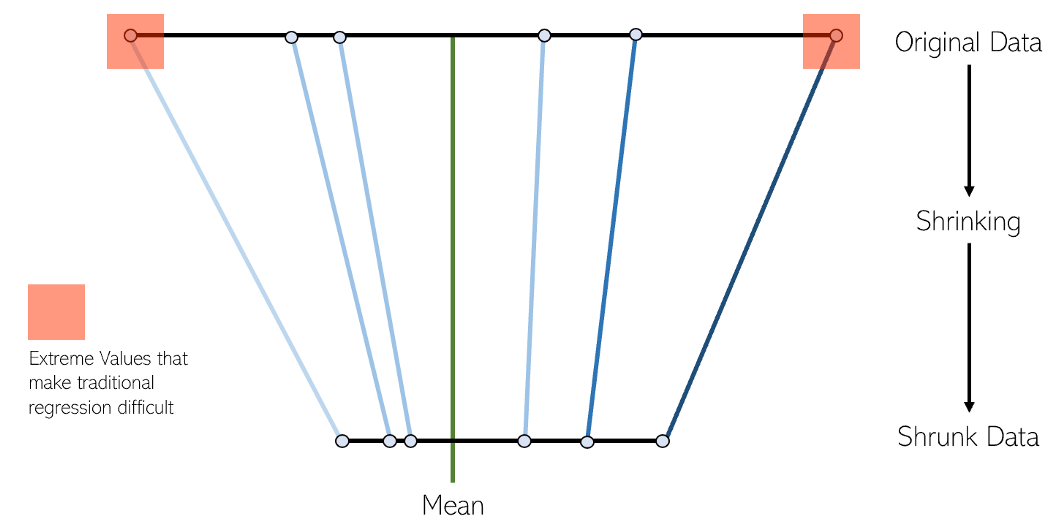
*Иллюстрация автора. Упрощенная визуализация процесса сжатия*
Процесс сжатия добавляет регрессионным моделям несколько преимуществ:
* Более точные и стабильные оценки истинных параметров.
* Уменьшение ошибок выборки и отсутствия выборки.
* Сглаживание пространственных флуктуаций.
Вместо того чтобы корректировать сложность модели, компенсируя сложность данных, подобно методам регрессии с высокой дисперсией нейронных сетей и дерева решений, лассо пытается уменьшить сложность данных так, чтобы их можно было обрабатывать простыми методами регрессии, искривляя пространство, на котором они лежат. В этом процессе лассо автоматически помогает устранить или исказить сильно коррелированные и избыточные функции в методе с низкой дисперсией.
Регрессия лассо использует регуляризацию L1, то есть взвешивает ошибки по их абсолютному значению. Вместо, например, регуляризации L2, которая взвешивает ошибки по их квадрату, чтобы сильнее наказывать за более значительные ошибки.
Такая регуляризация часто приводит к более разреженным моделям с меньшим количеством коэффициентов, так как некоторые коэффициенты могут стать нулевыми и, следовательно, будут исключены из модели. Это позволяет ее интерпретировать.
### Реализация
В `sklearn` регрессия лассо поставляется с моделью перекрестной проверки, которая выбирает наиболее эффективные из многих обученных моделей с различными фундаментальными параметрами и путями обучения, что автоматизирует задачу, которую иначе пришлось бы выполнять вручную.
```
from sklearn.linear_model import LassoCV
model = LassoCV()
model.fit(X_train, y_train)
```
4. Гребневая регрессия (ридж-регрессия)
---------------------------------------
### Теория
Гребневая регрессия или ридж-регрессия очень похожа на регрессию LASSO в том, что она применяет сжатие. Оба алгоритма хорошо подходят для наборов данных с большим количеством признаков, которые не являются независимыми друг от друга (коллинеарность).
Однако самое большое различие между ними в том, что гребневая регрессия использует регуляризацию L2, то есть ни один из коэффициентов не *становится* нулевым, как это происходит в регрессии LASSO. Вместо этого коэффициенты всё больше приближаются к нулю, но не имеют большого стимула достичь его из-за природы регуляризации L2.

*Сравнение ошибок в регрессии лассо (слева) и гребневой регрессии (справа). Поскольку гребневая регрессия использует регуляризацию L2, ее площадь напоминает круг, тогда как регуляризация лассо L1 рисует прямые линии. Свободное изображение. [Источник](https://i.stack.imgur.com/VptNz.png)*
В лассо улучшение от ошибки 5 до ошибки 4 взвешивается так же, как улучшение от 4 до 3, а также от 3 до 2, от 2 до 1 и от 1 до 0. Следовательно, больше коэффициентов достигает нуля и устраняется больше признаков.
Однако в гребневой регрессии улучшение от ошибки 5 до ошибки 4 вычисляется как 5² − 4² = 9, тогда как улучшение от 4 до 3 взвешивается только как 7. Постепенно вознаграждение за улучшение уменьшается; следовательно, устраняется меньше признаков.
Гребневая регрессия лучше подходит в ситуации, когда мы хотим сделать приоритетными большое количество переменных, каждая из которых имеет небольшой эффект. Если в модели требуется учитывать несколько переменных, каждая из которых имеет средний или большой эффект, лучшим выбором будет лассо.
### Реализация
Гребневую регрессию в `sklearn` можно реализовать следующим образом (см. ниже). Как и для регрессии лассо, в `sklearn` есть реализация для перекрестной проверки выбора лучших из многих обученных моделей.
```
from sklearn.linear_model import RidgeCV
model = Ridge()
model.fit(X_train, y_train)
```
5. Регрессия ElasticNet
-----------------------
### Теория
ElasticNet стремится объединить лучшее из гребневой регрессии и регрессии лассо, комбинируя регуляризацию L1 и L2.
Лассо и гребневая регрессия представляют собой два различных метода регуляризации. В обоих случаях λ — это ключевой фактор, который контролирует размер штрафа:
1. Если λ = 0, то задача становится аналогичной простой линейной регрессии, достигая тех же коэффициентов.
2. Если λ = ∞, то коэффициенты будут равны нулю из-за бесконечного веса на квадрате коэффициентов. Всё, что меньше нуля, делает цель бесконечной.
3. Если 0 < λ < ∞, то величина λ определяет вес, придаваемый различным частям объекта.
К параметру λ регрессия ElasticNet добавляет дополнительный параметр *α*, который измеряет, насколько «смешанными» должны быть регуляризации L1 и L2. Когда параметр *α* равен 0, модель является чисто гребневой регрессией, а когда он равен 1 — это чистая регрессия лассо.
«Коэффициент смешивания» α просто определяет, сколько регуляризации L1 и L2 следует учитывать в функции потерь. Все три популярные регрессионные модели — гребневая, лассо и ElasticNet — нацелены на уменьшение размера своих коэффициентов, но каждая действует по-своему.
### Реализация
ElasticNet можно реализовать с помощью модели перекрестной валидации sklearn:
```
from sklearn.linear_model import ElasticNetCV
model = ElasticNetCV()
model.fit(X_train, y_train)
```
Что еще почитать по теме:
1. [Анализ больших данных в облаке: как компании стать дата-ориентированной.](https://mcs.mail.ru/blog/analiz-bolshih-dannyh-v-oblake)
2. [Форматы файлов в больших данных.](https://mcs.mail.ru/blog/formaty-faylov-v-bolshikh-dannykh-kratkiy-likbez)
3. [Наш телеграм-канал о цифровой трансформации.](https://tele.click/zavtra_oblachno) | https://habr.com/ru/post/513842/ | null | ru | null |
# Создаем простой API-шлюз в ASP.NET Core
Привет, Хабр! Представляю вашему вниманию перевод статьи "[Creating a simple API Gateway in ASP.NET Core](https://medium.com/@mirceaoprea/api-gateway-aspnet-core-a46ef259dc54)".
*Время чтения: ~10 минут*
В моей предыдущей статье, [JWT аутентификация для микросервисов в .NET](https://www.red-gate.com/simple-talk/dotnet/net-development/jwt-authentication-microservices-net/), я рассмотрел процесс создания микросервиса для аутентификации пользователей. Это может быть использовано для проверки личности пользователя перед совершением любых действий в других компонентах системы.

Другой жизненно необходимый компонент для работы продукта это API-шлюз — система между приложением и бэкэндом, которая, во-первых, маршрутизирует входящие запросы на соответствующий микросервис, и во-вторых, авторизует пользователя.
Существует много фреймворков которые могут быть использованы для создания API-шлюза, например, Ocelot в .NET core или Netflix Zuul в Java. Тем не менее, в этой статье я опишу процесс создания простого API-шлюза с нуля в .NET Core.
Создание проекта
----------------
Для начала создадим новое приложение, выбрав *ASP.NET Core Web Application* в окне создания проекта и *Empty* в качестве шаблона.


В проекте будут лежать классы **Startup** и **Program**. Для нас самой важной частью является метод **Configure** класса **Startup**. Здесь мы можем обработать входящий HTTP-запрос и ответить на него. Возможно, в методе **Configure** будет находится следующий код:
```
app.Run(async (context) =>
{
await context.Response.WriteAsync("Hello, World!");
});
```
Написание маршрутизатора
------------------------
Так как именно в методе **Configure** мы будем обрабатывать запросы, напишем необходимую логику:
```
Router router = new Router("routes.json");
app.Run(async (context) =>
{
var content = await router.RouteRequest(context.Request);
await context.Response.WriteAsync(await content.Content.ReadAsStringAsync());
});
```
Сначала мы создаем объект типа **Router**. В его задачи входит хранение существующих маршрутов, валидация и отправка запросов согласно маршрутам. Чтобы сделать код более чистым, будем подгружать маршруты из JSON-файла.
В итоге получается следующая логика: после того, как запрос поступит на шлюз, он будет перенаправлен маршрутизатору, который, в свою очередь, отправит его на соответствующий микросервис.
Перед тем как писать класс **Router**, создадим файл *routes.json*. В этом файле укажем список маршрутов, каждый из которых будет содержать внешний адрес (endpoint) и адрес назначения (destination). Также, мы добавим флаг, сигнализирующий о необходимости авторизации пользователя перед перенаправлением.
Вот как примерно может выглядеть такой файл:
```
{
"routes": [
{
"endpoint": "/movies",
"destination": {
"uri": "http://localhost:8090/movies/",
"requiresAuthentication": "true"
}
},
{
"endpoint": "/songs",
"destination": {
"uri": "http://localhost:8091/songs/",
"requiresAuthentication": "false"
}
}
],
"authenticationService": {
"uri": "http://localhost:8080/api/auth/"
}
}
```
Создаем класс Destination
-------------------------
Мы теперь знаем, что каждый **Route** должен иметь `endpoint` и `destination`, а каждый **Destination** должен иметь поля `uri` и `requiresAuthentication`.
Теперь напишем класс **Destination**, помня о том. Я добавлю два поля, два конструктора и приватный конструктор без параметров для JSON-десериализации.
```
public class Destination
{
public string Uri { get; set; }
public bool RequiresAuthentication { get; set; }
public Destination(string uri, bool requiresAuthentication)
{
Uri = path;
RequiresAuthentication = requiresAuthentication;
}
public Destination(string uri)
:this(uri, false)
{
}
private Destination()
{
Uri = "/";
RequiresAuthentication = false;
}
}
```
Также, будет правильно написать в этом классе метод `SendRequest`. Этим мы покажем, что каждый объект класса **Destination** будет ответственнен за отправку запроса. Этот метод будет принимать объект типа `HttpRequest`, который описывает входящий запрос, вынимать оттуда всю необходимую информацию и отправлять запрос на целевой URI. Для этого напишем вспомогательный метод `CreateDestinationUri`, который будет соединять строки с адресом и параметры адресной строки (query string) от клиента.
```
private string CreateDestinationUri(HttpRequest request)
{
string requestPath = request.Path.ToString();
string queryString = request.QueryString.ToString();
string endpoint = "";
string[] endpointSplit = requestPath.Substring(1).Split('/');
if (endpointSplit.Length > 1)
endpoint = endpointSplit[1];
return Uri + endpoint + queryString;
}
```
Теперь мы можем написать метод `SendRequest`, который будет отправлять запрос на микросервис и получать ответ обратно.
```
public async Task SendRequest(HttpRequest request)
{
string requestContent;
using (Stream receiveStream = request.Body)
{
using (StreamReader readStream = new StreamReader(receiveStream, Encoding.UTF8))
{
requestContent = readStream.ReadToEnd();
}
}
HttpClient client = new HttpClient();
HttpRequestMessage newRequest = new HttpRequestMessage(new HttpMethod(request.Method), CreateDestinationUri(request));
HttpResponseMessage response = await client.SendAsync(newRequest);
return response;
}
```
Создаем JSON-парсер.
--------------------
Перед написанием класса **Router**, нам нужно создать логику для десериализации JSON-файла с маршрутами. Я создам для этого вспомогательный класс, в котором будет два метода: один для создания объекта из JSON-файла, а другой для десериализации.
```
public class JsonLoader
{
public static T LoadFromFile(string filePath)
{
using (StreamReader reader = new StreamReader(filePath))
{
string json = reader.ReadToEnd();
T result = JsonConvert.DeserializeObject(json);
return result;
}
}
public static T Deserialize(object jsonObject)
{
return JsonConvert.DeserializeObject(Convert.ToString(jsonObject));
}
}
```
Класс Router.
-------------
Последнее, что мы сделаем перед написанием **Router** — опишем модель маршрута:
```
public class Route
{
public string Endpoint { get; set; }
public Destination Destination { get; set; }
}
```
Теперь напишем класс Router, добавив туда поля и констурктор.
```
public class Router {
public List Routes { get; set; }
public Destination AuthenticationService { get; set; }
public Router(string routeConfigFilePath)
{
dynamic router = JsonLoader.LoadFromFile(routeConfigFilePath);
Routes = JsonLoader.Deserialize>(
Convert.ToString(router.routes)
);
AuthenticationService = JsonLoader.Deserialize(
Convert.ToString(router.authenticationService)
);
}
}
```
Я использую динамический тип (dynamic type) для чтения из JSON и записи в него свойств объекта.
Теперь все готово для описания главной фнукциональности API-шлюза: маршрутизация и авторизация пользователя, которая будет происходить в методе `RouteRequest`. Нам нужно распаковать базовую часть внешнего адреса (base endpoint) из объекта запроса. Например, для адреса `/movies/add` базой будет `/movies/`. После этого, нам нужно проверить, есть ли описание данного маршрута. Если да, то авторизуем пользователя и отправляем запрос, иначе возвращаем ошибку. Я также создал класс **ConstructErrorMessage** для удобства.
Для авторизации, я предпочел следующий путь: извлекаем токен из заголовка запроса и отправляем как параметр запроса. Возможен и другой вариант: оставить токен в заголовке, тогда извлекать его должен уже микросервис, которому предназначается запрос.
```
public async Task RouteRequest(HttpRequest request)
{
string path = request.Path.ToString();
string basePath = '/' + path.Split('/')[1];
Destination destination;
try
{
destination = Routes.First(r => r.Endpoint.Equals(basePath)).Destination;
}
catch
{
return ConstructErrorMessage("The path could not be found.");
}
if (destination.RequiresAuthentication)
{
string token = request.Headers["token"];
request.Query.Append(new KeyValuePair("token", new StringValues(token)));
HttpResponseMessage authResponse = await AuthenticationService.SendRequest(request);
if (!authResponse.IsSuccessStatusCode) return ConstructErrorMessage("Authentication failed.");
}
return await destination.SendRequest(request);
}
private HttpResponseMessage ConstructErrorMessage(string error)
{
HttpResponseMessage errorMessage = new HttpResponseMessage
{
StatusCode = HttpStatusCode.NotFound,
Content = new StringContent(error)
};
return errorMessage;
}
```
Заключение
----------
Создание базового API-шлюза не требует много усилий, но он не предоставит должной фукнциональности. Если вам нужен балансировщик нагрузки, вы можете посмотреть на уже существующие фреймворки или платформы, которые предлагают библиотеки для маршрутизации запросов.
Весь код из этой статьи доступен в [репозитории на GitHub](https://github.com/Mirch/OzNet) | https://habr.com/ru/post/419393/ | null | ru | null |
# Устройство NVRAM в UEFI-совместимых прошивках, часть вторая
 Продолжаем разговор о форматах NVRAM в UEFI-совместимых прошивках, начатый [в первой части](https://habrahabr.ru/post/281242). На этот раз на повестке дня форматы блока Fsys из прошивок компании Apple, блока FTW из прошивок, следующих заветам проекта TianoCore, и блока FDC, который можно найти в прошивках, основанных на кодовой базе компании Insyde.
Если вам интересно, зачем нужны и как выглядят не-NVRAM данные, которые можно обнаружить рядом с NVRAM в прошивках различных производителей — добро пожаловать под кат.
#### **Отказ от ответственности №2**
Как всегда, автор не несет ответственности ни за что, кроме возможных очепяток, все баги автоматически признаются фичами, вы используете полученные сведения на свой страх и риск, короче, вы уже и так в курсе. Если вам все еще непонятно, что в этой статье происходит, куда бежать, что делать, и кто виноват — почитайте [тут](https://habrahabr.ru/post/267491/) и [здесь](https://habrahabr.ru/post/281242/), и возвращайтесь. Вернулись или не уходили? Отлично, можно продолжать.
#### **Блок Fsys**
Начнем с формата блока Fsys, в котором Apple хранит настройки для конкретной модели железа. Настройки эти затем при помощи специального DXE-драйвера превращаются в данные SMBIOS (те самые, которые из ОС можно прочитать утилитой *dmidecode*).
Формат, понятное дело, специфичен для прошивок компании Apple, и «был всегда», т.е. встречается как в самых ранних, так и в самых новых прошивках. Блок данных в этом формате обычно находится сразу за первыми двумя хранилищами VSS (основным и резервным), и, по идее, не должен изменяться пользователем, а данные из него не доступны через UEFI runtime-сервисы, поэтому я и не считаю их NVRAM'ом, но если уж им (не) повезло лежать с NVRAM в одном томе — пришлось разобраться и с ними, тем более, что формат оказался тривиальным, и его можно почти весь показать на одном скриншоте без всяких C-структур. Заголовок блока и переменные выглядят вот так:
Начинается блок с четырехбайтовой сигнатуры, обычно это Fsys (на относительно старых машинах был еще второй блок того же формата с сигнатурой Gaid, на более современных все кладут в один блок Fsys). За сигнатурой следуют 5 неизвестных байт, во всех дампах, что есть у меня, они равны 0x01 0x0E 0x00 0x00 0x00, но у вас они, понятно, могут отличаться. За ними следует двухбайтовый общий размер блока, сразу за которым начинаются переменные, без всякого выравнивания и с максимальной упаковкой. Переменная (лучше назвать эту сущность «записью», т.к. изменять эти данные Apple конечному пользователю не разрешает) хранится так: однобайтовая длина имени, имя в кодировке ASCII, двухбайтовая длина данных, и сами данные. Получается, что на скриншоте видны, кроме заголовка, 3 с половиной записи — *dckt*, *dckh*, *dck\_* и *overrides*.
Обратите внимание на начало данных последней: BZ — сигнатура, h — указание на использование кода Хаффмана, 1 — указание на размер блока, а затем и вообще закодированное в BCD число Пи… Ба, старый знакомый, [формат Bzip2](https://en.wikipedia.org/wiki/Bzip2#File_format)! Достаем, распаковываем, и получаем вот такое:**overrides.txt**ADD\_DEVICE () [class=«USBPort»,type=«USB 2.0»,location=«right»,speed=«480»,uhci-id=«0xFA133000»,ehci-id=«0xFA130000»]
ADD\_DEVICE () [class=«USBPort»,type=«USB 2.0»,location=«left»,speed=«480»,uhci-id=«0xFD113000»,ehci-id=«0xFD110000»]
ADD\_DEVICE () [class=«SensorController»,location=«U5510»,model=«EMC1413»,device-key=«SensorController@U5510»]
ADD\_DEVICE () [class=«SensorController»,location=«U5530»,model=«EMC1704»,device-key=«SensorController@U5530»]
ADD\_DEVICE () [class=«ThunderboltPort»,location=«Left»,port1=«1»,port2=«2»,mcuaddr=«0x26»]
SET\_PROPERTY (class=«Processor») [ptype=«iCore»]
SET\_PROPERTY (class=«Battery») [cell-count=«2»]
SET\_PROPERTY (class=«Sensor»&location=«VC0C») [low-limit=«0.0»,high-limit=«1.23»,type=«Voltage»,description=«VOLTAGE Sensor CPU 0 VCore»]
SET\_PROPERTY (class=«Sensor»&location=«VP0R») [low-limit=«7.2»,high-limit=«8.9»,type=«Voltage»,description=«VOLTAGE Sensor PBus 0 Rail»]
SET\_PROPERTY (class=«Sensor»&location=«VN0C») [low-limit=«0.0»,high-limit=«1.23»,type=«Voltage»,description=«VOLTAGE Sensor AGX 0 VCore»]
SET\_PROPERTY (class=«Sensor»&location=«VD0R») [low-limit=«13.5»,high-limit=«15.5»,type=«Voltage»,description=«VOLTAGE Sensor DCIN»]
SET\_PROPERTY (class=«Sensor»&location=«VC1R») [low-limit=«7.2»,high-limit=«8.9»,type=«Voltage»,description=«VOLTAGE Sensor CPU highside»]
SET\_PROPERTY (class=«Sensor»&location=«ID0R») [low-limit=«0.0»,high-limit=«3.5»,type=«Current»,description=«CURRENT Sensor DC IN 0 Rail AMON»]
SET\_PROPERTY (class=«Sensor»&location=«IB0R») [low-limit=«0.0»,high-limit=«10.0»,type=«Current»,description=«CURRENT Sensor CHGR 0 Rail BMON»]
SET\_PROPERTY (class=«Sensor»&location=«IC0R») [low-limit=«0.0»,high-limit=«12.0»,type=«Current»,description=«CURRENT Sensor Chipset 0 INA Highside»]
SET\_PROPERTY (class=«Sensor»&location=«IC1R») [low-limit=«0.0»,high-limit=«12.0»,type=«Current»,description=«CURRENT Sensor Chipset 0 SMBUS Highside»]
SET\_PROPERTY (class=«Sensor»&location=«IC0C») [low-limit=«0.0»,high-limit=«25.0»,type=«Current»,description=«CURRENT Sensor CPU 0 VCore»]
SET\_PROPERTY (class=«Sensor»&location=«IN0C») [low-limit=«0.0»,high-limit=«10.0»,type=«Current»,description=«CURRENT Sensor IG GFX VCore»]
SET\_PROPERTY (class=«Sensor»&location=«IM0R») [low-limit=«0.0»,high-limit=«10.0»,type=«Current»,description=«CURRENT Sensor Memory Power»]
SET\_PROPERTY (class=«Sensor»&location=«Ts0P») [noise-tolerance=«3.0»,low-limit=«10»,high-limit=«50»,type=«Temperature»,description=«TEMP Sensor MLB»]
SET\_PROPERTY (class=«Sensor»&location=«TPCD») [noise-tolerance=«3.0»,low-limit=«15»,high-limit=«100»,type=«Temperature»,description=«TEMP Sensor PCH»]
SET\_PROPERTY (class=«Sensor»&location=«TC0D») [noise-tolerance=«3.0»,low-limit=«10»,high-limit=«110»,type=«Temperature»,description=«TEMP Sensor CPU 0 Die»]
SET\_PROPERTY (class=«Sensor»&location=«TC0P») [noise-tolerance=«3.0»,low-limit=«20»,high-limit=«87»,type=«Temperature»,description=«TEMP Sensor CPU 0 Proximity»]
SET\_PROPERTY (class=«Sensor»&location=«TM0P») [noise-tolerance=«3.0»,low-limit=«20»,high-limit=«75»,type=«Temperature»,description=«TEMP Sensor Inlet»]
SET\_PROPERTY (class=«Sensor»&location=«Ta0P») [noise-tolerance=«3.0»,low-limit=«20»,high-limit=«80»,type=«Temperature»,description=«TEMP Sensor Inlet»]
SET\_PROPERTY (class=«Sensor»&location=«Tm1P») [noise-tolerance=«3.0»,low-limit=«10»,high-limit=«65»,type=«Temperature»,description=«TEMP Sensor Inlet»]
SET\_PROPERTY (class=«Sensor»&location=«Tm0P») [noise-tolerance=«3.0»,low-limit=«10»,high-limit=«65»,type=«Temperature»,description=«TEMP Sensor Inlet»]
SET\_PROPERTY (class=«Sensor»&location=«THSP») [noise-tolerance=«3.0»,low-limit=«10»,high-limit=«65»,type=«Temperature»,description=«TEMP Sensor PCH Proximity»]
SET\_PROPERTY (class=«Sensor»&location=«Th1H») [noise-tolerance=«3.0»,low-limit=«10»,high-limit=«65»,type=«Temperature»,description=«TEMP Sensor Fin Stack»]
SET\_PROPERTY (class=«Sensor»&location=«TB1T») [noise-tolerance=«1.0»,low-limit=«10»,high-limit=«50»,type=«Temperature»,description=«TEMP Sensor BMU 1»]
SET\_PROPERTY (class=«Sensor»&location=«TB2T») [noise-tolerance=«1.0»,low-limit=«10»,high-limit=«50»,type=«Temperature»,description=«TEMP Sensor BMU 2»]
SET\_PROPERTY (class=«Sensor»&location=«TB0T») [noise-tolerance=«1.0»,low-limit=«10»,high-limit=«50»,type=«Temperature»,description=«TEMP Sensor Battery»]
SET\_PROPERTY (class=«Sensor»&location=«TC0C») [noise-tolerance=«1.0»,low-limit=«15»,high-limit=«105»,type=«Temperature»,description=«TEMP Sensor CPU Die — Digital Core 0»]
SET\_PROPERTY (class=«Sensor»&location=«TC1C») [noise-tolerance=«1.0»,low-limit=«15»,high-limit=«105»,type=«Temperature»,description=«TEMP Sensor CPU Die — Digital Core 1»]
SET\_PROPERTY (class=«Sensor»&location=«PCPT») [noise-tolerance=«1.0»,low-limit=«0»,high-limit=«55»,type=«Power»,description=«POWER Sensor CPU Package Total Power»]
SET\_PROPERTY (class=«Sensor»&location=«PCPG») [noise-tolerance=«1.0»,low-limit=«0»,high-limit=«22»,type=«Power»,description=«POWER Sensor CPU Package Gfx Power»]
SET\_PROPERTY (class=«Sensor»&location=«PCPC») [noise-tolerance=«1.0»,low-limit=«0»,high-limit=«33»,type=«Power»,description=«POWER Sensor CPU Package Core Power»]
SET\_PROPERTY (class=«Sensor»&location=«MO\_X») [type=«Accelerometer»,description=«Motion Sensor»]
SET\_PROPERTY (class=«Sensor»&location=«MSC0») [low-limit=«9750»,high-limit=«14500»,type=«CalibrationKeys»,description=«Calibration Key 0»]
SET\_PROPERTY (class=«Sensor»&location=«MSLD») [type=«Magnetometer»,description=«Magnetometer»]
SET\_PROPERTY (class=«HardDrive»&type=«SSD») [throttling-support=«TRUE»]
REMOVE\_DEVICE (class=«Sensor») (class=«Sensor»&type="?")
Записи в блоке следуют друг за другом, пока не встречается запись с говорящим именем EOF, после которой до самого конца блока следуют нули, а в последних четырех байтах записана контрольная сумма CRC32 всего содержимого блока, кроме тех самых последних четырех байт. Apple вообще очень любит CRC32, и считают они её буквально для всего — для записей Fsys, для переменных VSS NVRAM, для исполняемых файлов EFI, для томов и для всего образа целиком тоже. *Целостности богу целостности, контроля к трону контроля!*
Если разбирать вручную нет настроения, на помощь снова приходит [UEFITool NE](https://github.com/LongSoft/UEFITool/tree/new_engine), в котором блок Fsys со скришнота выше выглядит вот так:

#### **Блок FTW**
Следующий блок в нашем списке на препарирование — FTW, который используется для поддержки транзакционной записи в NVRAM, и помогает восстановить её целостность после отключения питания во время записи. К сожалению (или, наверное, к счастью), мне еще не попадались дампы прошивки с какими-либо записями в этом блоке, так что тут получится разобрать только заголовок, а за форматом содержимого придется идти в [код проекта TianoCore](https://github.com/tianocore/edk2/blob/master/MdeModulePkg/Include/Guid/SystemNvDataGuid.h). Впрочем, теория теорией, а на практике вместо одного красивого и приятного заголовка в прошивках внезапно встречается два почти одинаковых, вот такой:
```
struct EFI_FAULT_TOLERANT_WORKING_BLOCK_HEADER32 {
EFI_GUID Signature; // EFI_SYSTEM_NV_DATA_FV_GUID
UINT32 Crc; // CRC32 от заголовка с пустыми полями Crc и State.
// Значение пустого байта определяется битом ErasePolarity тома NVRAM
UINT8 State; // Состояние блока, валидный (0xFE или 0x01, в зависимости от ErasePolarity) или нет (остальные значения)
UINT8 Reserved[3]; // Зарезервированное поле
UINT32 WriteQueueSize; // Размер данных блока, внезапно UINT32
//UINT8 WriteQueue[WriteQueueSize]; // Данные
};
```
И такой:
```
struct EFI_FAULT_TOLERANT_WORKING_BLOCK_HEADER64 {
EFI_GUID Signature; // EFI_SYSTEM_NV_DATA_FV_GUID или EDKII_WORKING_BLOCK_SIGNATURE_GUID
UINT32 Crc; // ~~~
UINT8 State; // ~~~
UINT8 Reserved[3]; // ~~~
UINT64 WriteQueueSize; // Нормальный UINT64, как написано в спецификации
//UINT8 WriteQueue[WriteQueueSize]; // ~~~
};
```
Такое неожиданное разнообразие создает определенные трудности при попытке угадать, какой именно вариант структуры перед нами. К счастью, чаще всего суммарный размер блока FTW кратен 16 байтам, и потому достаточно проверить значение *WriteQueueSize* на делимость нацело на 16, если делится — перед нами второй вариант, если в остатке 4 — первый, если в остатке что-то другое — мы нашли еще один вариант этой структуры, ура.
На скриншоте я покажу только второй тип заголовка, т.к. первый встречается лишь в некоторых старых прошивках времен царя Гороха:

Все по спецификации, GUID — FFF12B8D-7696-4C8B-A985-2747075B4F50, CRC32 — 0xB0458FB9, состояние блока — валидный, размер данных — 0xFE0, что отлично делится на 16, поэтому последние 4 байта заголовка — все-таки еще заголовок, а не уже кусок данных.
В UEFITool NE тот же самый блок выглядит вот так:

#### **Блок FDC**
После того, как UEFI Forum решил хранить ключи для SecureBoot в NVRAM, понадобилось не только серьезно переделать формат VSS (о котором я рассказывал в [первой части](https://habrahabr.ru/post/281242/)), но и решать вопрос с хранением «умолчаний» для этих переменных, причем вендорам опять позволили решать его самостоятельно. Одно из таких решений от компании Insyde, а именно блок FDC, мы сейчас и разберем.
Формат там очень простой, но мне совершенно не ясно, чем руководствовался его разработчик. Заголовок блока вот такой:
```
struct FDC_VOLUME_HEADER {
UINT32 Signature; // Сигнатура _FDC
UINT32 Size; // Полный размер блока вместе с заголовком
//EFI_FIRMWARE_VOLUME_HEADER VolumeHeader; // Заголовок NVRAM-тома, зачем он тут - совершенно непонятно
//VSS_VARIABLE_STORE_HEADER VssHeader; // Заголовок хранилища VSS, тоже нужен как собаке пятое колесо
// Еще и размер в нем указан неверный, чаще всего
};
```
На скриншоте весь этот кошмар выглядит вот так:

Итого: сигнатура — \_FDC, общий размер блока — 0x4000, заголовок NVRAM-тома, из которого не используется вообще ничего, сигнатура хранилища VSS с незаполненным размером в отформатированном и здоровом состоянии, и область с переменными. Получается что целых 88 байт потрачено на заголовки, которые вообще ни для чего не нужны, мой внутренний оптимизатор негодует.
В UEFITool NE я решил не выводить все эти ненужные заголовки вообще, и потому тот же блок FDC в нем выглядит вот так:

#### **Заключение**
Ну вот, определились и с форматом всяких странных блоков, хранящихся посреди тома NVRAM, на сладкое остались EVSA и NVAR, о которых поговорим в третьей части. Спасибо за внимание. | https://habr.com/ru/post/281412/ | null | ru | null |
# В «osu!» играй, про ошибки не забывай

Приветствуем всех любителей экзотических и не очень ошибок в коде. Сегодня на тестовом стенде PVS-Studio достаточно редкий гость – игра на языке C#. А именно – «osu!». Как обычно: ищем ошибки, думаем, играем.
Игра
----
Osu! – музыкальная ритм-игра с открытым исходным кодом. Судя по информации с [сайта игры](https://osu.ppy.sh/home) – довольно популярная, так как заявлено более 15 миллионов зарегистрированных игроков. Проект характеризуют бесплатный геймплей, красочное оформление с возможностью кастомизации карт, продвинутые возможности для составления онлайн-рейтинга игроков, наличие мультиплеера, большой набор музыкальных композиций. Подробно описывать игру не буду, интересующиеся легко найдут всю информацию в сети. Например, [тут](https://en.wikipedia.org/wiki/Osu!).
Мне больше интересен исходный код проекта, который доступен для загрузки с [GitHub](https://github.com/ppy/osu). Сразу привлекает внимание значительное число коммитов (более 24 тысяч) в репозиторий, что говорит об активном развитии проекта, которое продолжается и в настоящее время (игра была выпущена в 2007 году, но работы, вероятно, были начаты раньше). При этом исходного кода не так много – 1813 файлов .cs, которые содержат 135 тысяч строк кода без учёта пустых. В этом коде присутствуют тесты, которые я обычно не учитываю в проверках. Код тестов содержится в 306 файлах .cs и, соответственно, 25 тысячах строк кода без учёта пустых. Это маленький проект: для сравнения, ядро C# анализатора PVS-Studio содержит около 300 тысяч строк кода.
Итого, для проверки игры на ошибки я использовал не тестовые проекты, содержащие 1507 файлов исходного кода и 110 тысяч строк. Однако результат меня отчасти порадовал, так как нашлось несколько интересных ошибок, о которых я спешу вам рассказать.
Ошибки
------
[V3001](https://www.viva64.com/ru/w/v3001/) There are identical sub-expressions 'result == HitResult.Perfect' to the left and to the right of the '||' operator. DrawableHoldNote.cs 266
```
protected override void CheckForResult(....)
{
....
ApplyResult(r =>
{
if (holdNote.hasBroken
&& (result == HitResult.Perfect || result == HitResult.Perfect))
result = HitResult.Good;
....
});
}
```
Хороший пример копипаст-ориентированного программирования. Шуточный термин, который недавно использовал (ввёл) мой коллега Валерий Комаров в своей статье "[Топ 10 ошибок в проектах Java за 2019 год](https://www.viva64.com/ru/b/0699/)".
Итак, две идентичных проверки следуют одна за другой. Одна из проверок, скорее всего, должна содержать другую константу перечисления *HitResult*:
```
public enum HitResult
{
None,
Miss,
Meh,
Ok,
Good,
Great,
Perfect,
}
```
Какую именно константу нужно было использовать, или вторая проверка вообще не нужна? Вопросы, на которые способен ответить только разработчик. В любом случае, допущена ошибка, искажающая логику работы программы.
[V3001](https://www.viva64.com/ru/w/v3001/) There are identical sub-expressions 'family != GetFamilyString(TournamentTypeface.Aquatico)' to the left and to the right of the '&&' operator. TournamentFont.cs 64
```
public static string GetWeightString(string family, FontWeight weight)
{
....
if (weight == FontWeight.Regular
&& family != GetFamilyString(TournamentTypeface.Aquatico)
&& family != GetFamilyString(TournamentTypeface.Aquatico))
weightString = string.Empty;
....
}
```
И снова copy-paste. Я отформатировал код, поэтому ошибка легко заметна. В первоначальном варианте всё условие было записано одной строкой. Здесь также трудно сказать, каким образом можно исправить код. Перечисление *TournamentTypeface* содержит единственную константу:
```
public enum TournamentTypeface
{
Aquatico
}
```
Возможно, в условии дважды по ошибке использована переменная *family*, но это не точно.
[V3009](https://www.viva64.com/ru/w/v3009/) [CWE-393] It's odd that this method always returns one and the same value of 'false'. KeyCounterAction.cs 19
```
public bool OnPressed(T action, bool forwards)
{
if (!EqualityComparer.Default.Equals(action, Action))
return false;
IsLit = true;
if (forwards)
Increment();
return false;
}
```
Метод всегда вернёт *false*. Для таких ошибок я обычно проверяю вызывающий код, так как там часто просто нигде не используют возвращаемое значение, тогда ошибки (кроме некрасивого стиля программирования) нет. В данном случае мне встретился такой код:
```
public bool OnPressed(T action) =>
Target.Children
.OfType>()
.Any(c => c.OnPressed(action, Clock.Rate >= 0));
```
Как видим, результат, возвращаемый методом *OnPressed*, используется. И так как он всегда *false*, то и результат вызывающего *OnPressed* также будет всегда *false*. Думаю, следует лишний раз перепроверить этот код, так как высока вероятность ошибки.
Ещё одна подобная ошибка:
* V3009 [CWE-393] It's odd that this method always returns one and the same value of 'false'. KeyCounterAction.cs 30
[V3042](https://www.viva64.com/ru/w/v3042/) [CWE-476] Possible NullReferenceException. The '?.' and '.' operators are used for accessing members of the 'val.NewValue' object TournamentTeam.cs 41
```
public TournamentTeam()
{
Acronym.ValueChanged += val =>
{
if (....)
FlagName.Value = val.NewValue.Length >= 2 // <=
? val.NewValue?.Substring(0, 2).ToUpper()
: string.Empty;
};
....
}
```
В условии оператора *?:* с переменной *val.NewValue* работают небезопасно. Анализатор сделал такой вывод, так как далее в then-ветке для доступа к переменной используют безопасный вариант работы через оператор условного доступа *val.NewValue?.Substring(....)*.
Ещё одна подобная ошибка:
* V3042 [CWE-476] Possible NullReferenceException. The '?.' and '.' operators are used for accessing members of the 'val.NewValue' object TournamentTeam.cs 48
[V3042](https://www.viva64.com/ru/w/v3042/) [CWE-476] Possible NullReferenceException. The '?.' and '.' operators are used for accessing members of the 'api' object SetupScreen.cs 77
```
private void reload()
{
....
new ActionableInfo
{
Label = "Current User",
ButtonText = "Change Login",
Action = () =>
{
api.Logout(); // <=
....
},
Value = api?.LocalUser.Value.Username,
....
},
....
}
private class ActionableInfo : LabelledDrawable
{
....
public Action Action;
....
}
```
Данный код менее однозначен, но я думаю, что ошибка тут всё же присутствует. Создают объект типа *ActionableInfo*. Поле *Action* инициализируют лямбдой, в теле которой небезопасно работают с потенциально нулевой ссылкой *api*. Анализатор посчитал такой паттерн ошибкой, так как далее при инициализации параметра *Value* с переменной *api* работают безопасно. Ошибку я назвал неоднозначной, потому что код лямбды предполагает отложенное выполнение и тогда, возможно, разработчик как-то гарантирует ненулевое значение ссылки *api*. Но это только предположение, так как тело лямбды не содержит никаких признаков безопасной работы со ссылкой (предварительных проверок, например).
[V3066](https://www.viva64.com/ru/w/v3066/) [CWE-683] Possible incorrect order of arguments passed to 'Atan2' method: 'diff.X' and 'diff.Y'. SliderBall.cs 182
```
public void UpdateProgress(double completionProgress)
{
....
Rotation = -90 + (float)(-Math.Atan2(diff.X, diff.Y) * 180 / Math.PI);
....
}
```
Анализатор заподозрил, что при работе с методом *Atan2* класса *Math* разработчик перепутал порядок следования аргументов. Объявление *Atan2*:
```
// Parameters:
// y:
// The y coordinate of a point.
//
// x:
// The x coordinate of a point.
public static double Atan2(double y, double x);
```
Как видим, были переданы значения в обратном порядке. Не берусь судить, ошибка ли это, так как метод *UpdateProgress* содержит довольно много нетривиальных вычислений. Просто отмечу факт возможной проблемы в коде.
[V3080](https://www.viva64.com/ru/w/v3080/) [CWE-476] Possible null dereference. Consider inspecting 'Beatmap'. WorkingBeatmap.cs 57
```
protected virtual Track GetVirtualTrack()
{
....
var lastObject = Beatmap.HitObjects.LastOrDefault();
....
}
```
Анализатор указал на опасность доступа по нулевой ссылке *Beatmap*. Вот что она собой представляет:
```
public IBeatmap Beatmap
{
get
{
try
{
return LoadBeatmapAsync().Result;
}
catch (TaskCanceledException)
{
return null;
}
}
}
```
Ну что же, анализатор прав.
Подробнее про то, как PVS-Studio находит такие ошибки, а также о нововведениях C# 8.0, связанных с подобной тематикой (работа с потенциально нулевыми ссылками), можно узнать из статьи "[Nullable Reference типы в C# 8.0 и статический анализ](https://www.viva64.com/ru/b/0631/)".
[V3083](https://www.viva64.com/ru/w/v3083/) [CWE-367] Unsafe invocation of event 'ObjectConverted', NullReferenceException is possible. Consider assigning event to a local variable before invoking it. BeatmapConverter.cs 82
```
private List convertHitObjects(....)
{
....
if (ObjectConverted != null)
{
converted = converted.ToList();
ObjectConverted.Invoke(obj, converted);
}
....
}
```
Некритичная и довольно часто встречающаяся ошибка. Между проверкой события на равенство *null* и его инвокацией, от события могут отписаться, что приведет к падению программы.
Один из вариантов исправления:
```
private List convertHitObjects(....)
{
....
converted = converted.ToList();
ObjectConverted?.Invoke(obj, converted);
....
}
```
[V3095](https://www.viva64.com/ru/w/v3095/) [CWE-476] The 'columns' object was used before it was verified against null. Check lines: 141, 142. SquareGraph.cs 141
```
private void redrawProgress()
{
for (int i = 0; i < ColumnCount; i++)
columns[i].State = i <= progress ? ColumnState.Lit : ColumnState.Dimmed;
columns?.ForceRedraw();
}
```
Обход коллекции *columns* в цикле производят небезопасно. При этом разработчик предполагал, что ссылка *columns* может быть нулевой, так как далее в коде для доступа к коллекции используют оператор условного доступа.
[V3119](https://www.viva64.com/ru/w/v3119/) Calling overridden event 'OnNewResult' may lead to unpredictable behavior. Consider implementing event accessors explicitly or use 'sealed' keyword. DrawableRuleset.cs 256
```
private void addHitObject(TObject hitObject)
{
....
drawableObject.OnNewResult += (_, r) => OnNewResult?.Invoke(r);
....
}
public override event Action OnNewResult;
```
Анализатор предупреждает об опасности использования переопределённого или виртуального события. В чём именно заключается опасность – предлагаю почитать в [описании](https://www.viva64.com/ru/w/v3119/) к диагностике. Также в своё время я писал на эту тему статью "[Виртуальные события в C#: что-то пошло не так](https://www.viva64.com/ru/b/0453/)".
Ещё одна подобная небезопасная конструкция в коде:
* V3119 Calling an overridden event may lead to unpredictable behavior. Consider implementing event accessors explicitly or use 'sealed' keyword. DrawableRuleset.cs 257
[V3123](https://www.viva64.com/ru/w/v3123/) [CWE-783] Perhaps the '??' operator works in a different way than it was expected. Its priority is lower than priority of other operators in its left part. OsuScreenStack.cs 45
```
private void onScreenChange(IScreen prev, IScreen next)
{
parallaxContainer.ParallaxAmount =
ParallaxContainer.DEFAULT_PARALLAX_AMOUNT *
((IOsuScreen)next)?.BackgroundParallaxAmount ?? 1.0f;
}
```
Для лучшего понимания проблемы – приведу синтетический пример того, как сейчас работает код:
```
x = (c * a) ?? b;
```
Ошибка была допущена вследствие того, что оператор "\*" имеет более высокий приоритет, чем оператор "??". Исправленный вариант кода (добавлены скобки):
```
private void onScreenChange(IScreen prev, IScreen next)
{
parallaxContainer.ParallaxAmount =
ParallaxContainer.DEFAULT_PARALLAX_AMOUNT *
(((IOsuScreen)next)?.BackgroundParallaxAmount ?? 1.0f);
}
```
Ещё одна подобная ошибка в коде:
[V3123](https://www.viva64.com/ru/w/v3123/) [CWE-783] Perhaps the '??' operator works in a different way than it was expected. Its priority is lower than priority of other operators in its left part. FramedReplayInputHandler.cs 103
```
private bool inImportantSection
{
get
{
....
return IsImportant(frame) &&
Math.Abs(CurrentTime - NextFrame?.Time ?? 0) <=
AllowedImportantTimeSpan;
}
}
```
Здесь, как и в предыдущем фрагменте кода, не учли приоритет операторов. Сейчас выражение, передаваемое в метод *Math.Abs*, вычисляется так:
```
(a – b) ?? 0
```
Исправленный код:
```
private bool inImportantSection
{
get
{
....
return IsImportant(frame) &&
Math.Abs(CurrentTime – (NextFrame?.Time ?? 0)) <=
AllowedImportantTimeSpan;
}
}
```
[V3142](https://www.viva64.com/ru/w/v3142/) [CWE-561] Unreachable code detected. It is possible that an error is present. DrawableHoldNote.cs 214
```
public override bool OnPressed(ManiaAction action)
{
if (!base.OnPressed(action))
return false;
if (Result.Type == HitResult.Miss) // <=
holdNote.hasBroken = true;
....
}
```
Анализатор утверждает, что код обработчика *OnPressed*, начиная со второго оператора *if*, является недостижимым. Это следует из предположения, что первое условие всегда истинно, то есть метод *base.OnPressed* всегда вернет *false*. Взглянем на метод *base.OnPressed*:
```
public virtual bool OnPressed(ManiaAction action)
{
if (action != Action.Value)
return false;
return UpdateResult(true);
}
```
Переходим далее к методу *UpdateResult*:
```
protected bool UpdateResult(bool userTriggered)
{
if (Time.Elapsed < 0)
return false;
if (Judged)
return false;
....
return Judged;
}
```
Обратите внимание, реализация свойства *Judged* здесь не важна, так как из логики метода *UpdateResult* следует, что последний оператор *return* эквивалентен такому:
```
return false;
```
Таким образом, метод *UpdateResult* всегда вернет *false*, что и приведет к возникновению ошибки с недостижимым кодом в коде выше по стеку.
[V3146](https://www.viva64.com/ru/w/v3146/) [CWE-476] Possible null dereference of 'ruleset'. The 'FirstOrDefault' can return default null value. APILegacyScoreInfo.cs 24
```
public ScoreInfo CreateScoreInfo(RulesetStore rulesets)
{
var ruleset = rulesets.GetRuleset(OnlineRulesetID);
var mods = Mods != null ? ruleset.CreateInstance() // <=
.GetAllMods().Where(....)
.ToArray() : Array.Empty();
....
}
```
Анализатор считает небезопасным вызов *ruleset.CreateInstance()*. Переменная *ruleset* ранее получает значение в результате вызова *GetRuleset*:
```
public RulesetInfo GetRuleset(int id) =>
AvailableRulesets.FirstOrDefault(....);
```
Как видим, предупреждение анализатора обосновано, так как цепочка вызовов содержит *FirstOrDefault*, который может вернуть значение *null*.
Заключение
----------
В целом проект игры «osu!» порадовал небольшим числом ошибок. Тем не менее, я рекомендую разработчикам обратить внимание на обнаруженные проблемы. И пусть игра и далее радует своих поклонников.
А для любителей поковыряться в коде напоминаю, что хорошим подспорьем будет анализатор PVS-Studio, который легко [скачать](https://www.viva64.com/ru/pvs-studio-download/) с официального сайта. Также замечу, что разовые проверки проектов, подобные описанной выше, не имеют ничего общего с использованием статического анализатора в реальной работе. Максимальной эффективности в борьбе с ошибками можно добиться лишь при регулярном использовании инструмента как на сборочном сервере, так и непосредственно на компьютере разработчика (инкрементальный анализ). При этом задача максимум – вовсе не допустить попадания ошибок в систему контроля версий, исправляя дефекты уже на этапе написания кода.
Удачи и творческих успехов!
Ссылки
------
Это первая публикация в 2020 году. Пользуясь случаем, я приведу ссылки на статьи о проверке C#-проектов за прошлый год:
* [Ищем ошибки в исходном коде Amazon Web Services SDK для .NET](https://www.viva64.com/ru/b/0605/)
* [Проверяем исходный код Roslyn](https://www.viva64.com/ru/b/0622/)
* [Nullable Reference типы в C# 8.0 и статический анализ](https://www.viva64.com/ru/b/0631/)
* [WinForms: ошибки, Холмс](https://www.viva64.com/ru/b/0653/)
* [История о том, как PVS-Studio нашёл ошибку в библиотеке, используемой в… PVS-Studio](https://www.viva64.com/ru/b/0654/)
* [Проверка исходного кода библиотек .NET Core статическим анализатором PVS-Studio](https://www.viva64.com/ru/b/0656/)
* [Проверяем Roslyn analyzers](https://www.viva64.com/ru/b/0664/)
* [Проверка Telerik UI for UWP для знакомства с PVS-Studio](https://www.viva64.com/ru/b/0677/)
* [Azure PowerShell: «в основном безвреден»](https://www.viva64.com/ru/b/0678/)
* [Ищем и анализируем ошибки в коде Orchard CMS](https://www.viva64.com/ru/b/0681/)
* [Проверка обёртки OpenCvSharp над OpenCV с помощью PVS-Studio](https://www.viva64.com/ru/b/0683/)
* [Azure SDK for .NET: история о непростом поиске ошибок](https://www.viva64.com/ru/b/0692/)
* [SARIF SDK и его ошибки](https://www.viva64.com/ru/b/0694/)
* [Топ 10 ошибок в проектах C# за 2019 год](https://www.viva64.com/ru/b/0698/)
[](https://habr.com/en/company/pvs-studio/blog/483436/)
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Sergey Khrenov. [Play «osu!», but Watch Out for Bugs](https://habr.com/en/company/pvs-studio/blog/483436/). | https://habr.com/ru/post/483438/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.