
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Веб-компоненты в реализации Polymer от Google

Веб-компоненты — это новая эра веб-разработки и почувствовать ее мощь можно уже сегодня при помощи Polymer от Google. Вы можете создавать свои собственные «элементы» (тэги), содержащие шаблон и инкапсулированные стили и логику (js), а так же воспользоваться богатой коллекцией уже готовых элементов.
Что такое Polymer?
------------------
Polymer это библиотека (сами они называют это, набором полифилов и синтаксического сахара) для создания и использования веб-компонент. А веб-компоненты это некий набор стандартов W3C, который в будущем ~~будет поддерживаться~~ [уже поддерживается некоторыми](http://jonrimmer.github.io/are-we-componentized-yet/) браузерами. Если совсем по-простому, то веб-компонента это некий выделенный в отдельный блок кусок html кода с шаблонированием, стилями и логикой. Это позволяет повысить структурированность вашего html кода, повысить читаемость и повторное использование. Один раз написал (или выбрал из [стандартных](http://www.polymer-project.org/docs/elements/)) и используй везде.
> *Если вы думаете, что html5 изменил веб, то подождите и увидите, что сделают Веб-компоненты. © чей-то.*
Проникнуться идеей веб-компонент можно на [webcomponents.org](http://webcomponents.org/). Поковыряться в чужих компонентах можно на [component.kitchen](http://component.kitchen/).
Ну и еще существует большая вероятность, что Polymer-ное виденье будущего станет реальностью, и вы в будущем просто отключите **полифилы** Polymer-а (`platform.js`) и все продолжит работать нативно **(UPD: внес уточнение. Спасибо [nazarpc](https://habrahabr.ru/users/nazarpc/))**. Как мы понимаем, такие компании, как Google и Mozilla (они разрабатывают похожий x-tag) могут менять будущее веба.
Инфраструктура
--------------
Для того, чтобы теорию подкрепить практикой, нам нужна инфраструктура. Самый простой способ создать ее – это [yeoman](http://yeoman.io) и [генератор Polymer](https://github.com/yeoman/generator-polymer) для него (и конечно нужен [Bower](http://bower.io/)). Ниже необходимые команды (уже установленное у вас — пропускайте).
```
npm install -g bower
npm install -g yo
npm install -g generator-polymer
mkdir my-project
cd my-project
yo polymer
```
В результате получаем начальный скелет приложения с парой собственных элементов, а также папку со всей коллекцией готовых элементов. Для того, чтобы посмотреть, как это выглядит в работе, нужно запустить сервер.
```
grunt serve
```
После запуска откроется браузер и Вы увидите такую картинку:
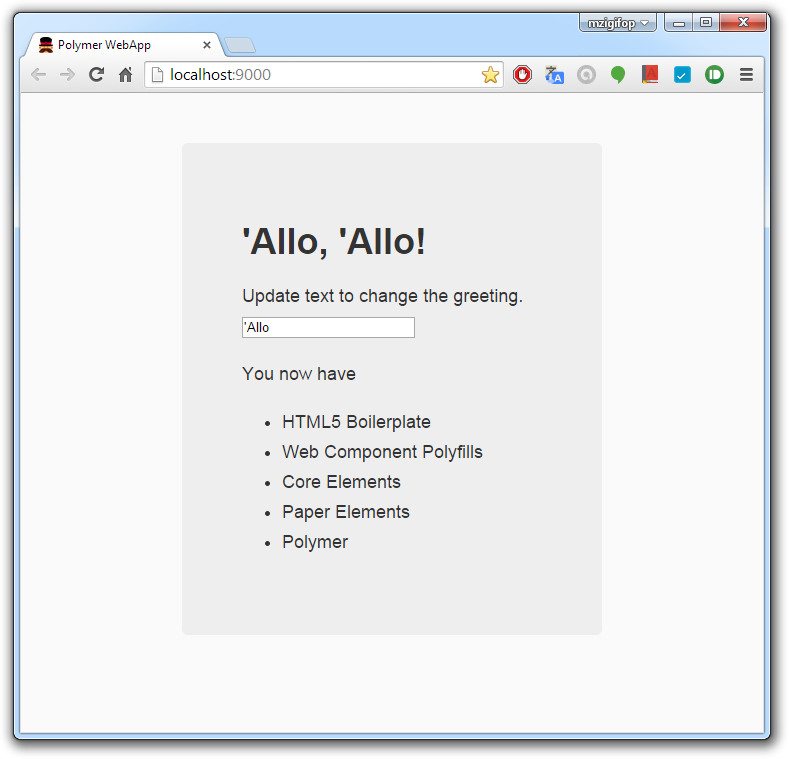
Итак, когда инфраструктура налажена, приступим к изучению:
Использование готовых компонент и элементов.
--------------------------------------------
Polymer содержит [две основные коллекции элементов](http://www.polymer-project.org/docs/elements/):
* **Core-elements** – это набор элементов, включающий визуальные элементы (панельки, кнопки, инпуты и пр) и не визуальные элементы (ajax, localstorage и т.д ).
* **Paper-elements** – это набор элементов, реализующий новый [material design](http://www.google.com/design/spec), последнее время широко используемый Google.
Для использования элементов в `index.html` должен быть подключен (у нас уже все подключено) `platform.js`:
```
```
Также нужно импортировать при помощи тега нужные нам элементы до их использования:
```
```
Потом просто вставляете нужные теги в ваш код и все:
```
```
Для API Google есть готовые компоненты, например . Это позволяет легко встраивать сервисы Google в наше приложение. Смотрите список компонент на [googlewebcomponents.github.io](http://googlewebcomponents.github.io/).
По быстрому накидать готовых компонент на страницу, подправить стили и js код, посмотреть, как это все выглядит можно при помощи [Design tool](http://www.polymer-project.org/tools/designer/). С помощью нее можно потом сохранить полученный код как Github Gist.
[Вот](http://youtu.be/djQh8XKRzRg) небольшое видео о работе в этом «редакторе».
Создание элементов
------------------
Это, пожалуй, самая главная фишка веб-компонент и Polymer-а (по крайней мере для меня). Это похоже на директиву Angular, только с нормальным html со стилями и логикой. При чем все это изолированно и работает в своем скопе и ни кто из вне ничего не поломает.
Выглядит это так: (я создам элемент . Начну с пустого `habrauser-card.html` в папке `app/elements`):
```
:host {
display: block;
padding: 10px;
color: {{usercolor}};
}
polyfill-next-selector { content: ':host h3'; }
:host ::content h3 {
margin: 0;
text-decoration: underline;
}
- I am habrauser **{{habrauser}}**
-
Polymer('habrauser-card', {
habrauser: 'DefaultValue',
usercolor: 'green'
});
```
Давайте разберем:
Сначала подключаем `polymer.html` или любую другую компоненту, внутри которой уже есть линк на `polymer.html`.
Затем в тэге определяем наш элемент *(Важно! Имя должно быть обязательно со знаком '–')*. В свойстве `attributes` перечисляем внешние (которые будем использовать при вызове) свойства. Я бы назвал это интерфейсом веб-компоненты. Их еще можно задать через js и свойство `publish:`, но способ задания через аргумент предпочтительнее.
Дальше идет шаблон на языке html (то, что заключено в теги ).
Стили можно писать прямо здесь в тэг | https://habr.com/ru/post/237421/ | null | ru | null |
# Yii 2.0.9
Вышла версия 2.0.9 PHP-фреймворка Yii. Минорный релиз содержит около [60 небольших улучшений и исправлений](https://github.com/yiisoft/yii2/blob/2.0.9/framework/CHANGELOG.md). [Инструкции по установке](http://www.yiiframework.com/download/) можно найти на официальном сайте.
В данной версии есть два изменения, которые, хоть это и маловероятно, могут затронуть ваши приложения. Ознакомьтесь с [UPGRADE.md](https://github.com/yiisoft/yii2/blob/2.0.9/framework/UPGRADE.md).
Спасибо [сообществу Yii](https://github.com/yiisoft/yii2/graphs/contributors) за пулл-реквесты и обсуждения.
Этот релиз вышел благодаря вам!
За разработкой фреймворка можно наблюдать [на GitHub](https://github.com/yiisoft/yii2). Также у нас есть [Twitter](https://twitter.com/yiiframework)
и [Facebook](https://www.facebook.com/groups/yiitalk/).
Далее мы рассмотрим самые интересные улучшения подробней. Полный список изменений и исправлений можно найти в [CHANGELOG](https://github.com/yiisoft/yii2/blob/2.0.9/framework/CHANGELOG.md).
Фильтр action
-------------
`\yii\base\ActionFilter` теперь поддерживает маски для `only` и `except`, что полезно когда
фильтр навешивается на модуль или приложение целиком:
```
return [
'as filter' => [
'class' => 'app\filters\SomeFilter',
'only' => [
'particular/*', // все действия контроллера 'particular'
'*/captcha', // все действия 'captcha' всех контроллеров
],
],
// ...
];
```
Улучшения производительности
----------------------------
* Улучшили производительность перевода сообщений при использовании базы данных. Добавили нужные индексы.
* Схема Oracle теперь считывается быстрее.
Построитель схемы и миграции
----------------------------
Был улучшен построитель схемы, который используется в миграциях. Добавили новый метод `null()` чтобы указывать возможность записи `null` явно. Метод применяется автоматически, если значение по умолчанию — `null`.
```
$type = $this->string(42)->null();
```
Также добавили метод для своего SQL:
```
$type = $this->string(15)->notNull()->append('collate ascii_bin')->append('character set ascii');
```
Синтаксис команды для генерации миграций был немного изменён: `_table` и `_column` теперь обязательны:
```
./yii migrate/create create_user_table
./yii migrate/create add_name_column_to_user_table
```
Провайдеры данных и виджеты
---------------------------
Все улучшения в данном релизе касаются заголовков. В `\yii\data\ArrayDataProvider` добавили свойство `$modelClass`, через которое можно указать модель для получения заголовков полей. В дополнение `\yii\grid\DataColumn`, который определяет поведение для всех столбцов с данными, теперь пытается получить заголовки из `filterModel` грида.
Рефакторинг
-----------
Из интерфейса `ManagerInterface` RBAC выделили `CheckAccessInterface`, который может быть полезен при реализации своей проверки доступа.
`\yii\web\User::loginByCookie()` отрефакторен для большей расширяемости.
Asset-ы
-------
При перечислении файлов в пакетах asset-ов теперь можно задать путь в `null`. В этом случае файлы не регистрируются. Это полезно, например, для регистрации дополнительных файлов для рабочего окружения:
```
namespace common\assets;
use yii\web\AssetBundle;
class ReactAsset extends AssetBundle
{
public $sourcePath = null;
public $js = [
YII_ENV_DEV ? "//fb.me/react-15.0.1.js" : "//fb.me/react-15.0.1.min.js",
YII_ENV_DEV ? "//fb.me/react-dom-15.0.1.js" : "//fb.me/react-dom-15.0.1.min.js",
YII_ENV_DEV ? "//cdnjs.cloudflare.com/ajax/libs/babel-core/5.6.15/browser.js" : null,
];
}
```
Логирование
-----------
`\yii\log\Target::$logVars` теперь можно настроить более тонко:
* `_SESSION` — пишем глобальную переменную сессии. Всё как и было.
* `_SESSION.id` — пишем только `id` из сессии.
* `!_SESSION.secret` — не пишем ключ `secret` из сессии.
Логика такой фильтрации вынесена в `\yii\helpers\ArrayHelper::filter()`. При необходимости можно использовать у себя.
Markdown
--------
Тип синтаксиса по умолчанию для `yii\helpers\Markdown` теперь можно задать через `$defaultFlavor`. | https://habr.com/ru/post/305432/ | null | ru | null |
# SiteLock – визуальный генератор пароля для сайтов от PHPShop
 Мы часто сталкиваемся с задачей по созданию дополнительного пароля на сайт и панель управления — это дает большую уверенность в сохранности данных, и, конечно, рекомендуем использовать этот метод всем и почаще. Конечно, есть много способов поставить пароль, но все-таки, все они требуют наличия определенных знаний от клиента. Для облегчения жизни клиентам, мы создали **бесплатный визуальный интерфейс генерации паролей — SiteLock, который подходит не только к PHPShop, но и к любым другим CMS**. Сгенерированные пароли, в связке .htaccess + .htpassw, сразу копируются на сайт, через встроенный ftp-менеджер.
#### Какие варианты защиты сайта лучше?
Как известно, самая распространенная дополнительная защита – это [Basic Authentication](http://ru.wikipedia.org/wiki/.htpasswd), она используется на большинстве web-проектов, в роутерах и подобных аппаратах. Таким паролем хорошо защищать сайт от чужих глаз на время его создания и тестирования. Ставить дополнительный пароль рекомендуют [специалисты](http://www.revisium.com/ai/) по поиску и лечению веб-вирусов.
На некоторых хостингах пароль можно выставить через встроенный файловый менеджер (DirectAdmin, cPanel и т.д.). Однако, как показывает практика, хостер обычно советует создавать пароль через SSH, что для обычного пользователя является почти невыполнимой задачей.
В первое время, мы давали клиентам такую инструкцию по установке через FTP и генератора паролей:
* Создать файл .htaccess с содержанием:
```
AuthName "Member's Area"
AuthType Basic
AuthUserFile /home/username/username.ru/.htpasswd
require valid-user
```
* Создать файл /home/username/username.ru/.htpasswd. Для генерации логина и пароля воспользуемся онлайн сервисом [htpasswd-generator](http://www.htaccesstools.com/htpasswd-generator/).
У некоторых пользователей эта инструкция вызывала шок, либо они не могли определить верный путь AuthUserFile, и сайт начинал выдавать 500 ошибку, что отбивало все дальнейшее желание этим заниматься.
Мы решили использовать более дружественный подход по созданию пароля и создали бесплатную утилиту **SiteLock, где, кроме указания ftp-паролей и выбора действия над сайтом, ничего не требуется**.
**SiteLock подойдет не только для PHPShop, его можно использовать для любой CMS**. Sitelock предлагает выбрать папку для паролирования через встроенный ftp-менеджер. После подключения, утилита создаст дерево каталогов сервера. Если сайт на PHPShop, то утилита распознает его автоматически и предлагает создать пароль на папку авторизации панели управления магазином.
**Скриншоты процесса установки пароля**

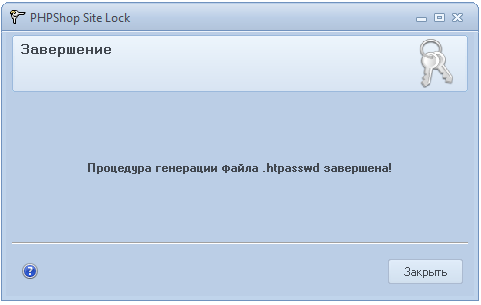

SiteLock входит в комплект наших фирменных бесплатных утилит [EasyControl](http://www.phpshop.ru/loads/files/setup.exe).
Про некоторые их них мы уже [писали](http://habrahabr.ru/company/phpshop/blog/).
SiteLock так же доступен отдельно в виде скачиваемого [приложения](http://www.phpshop.ru/loads/files/sitelock.exe) (700 Кб) для использования на сторонних проектах.
Надеемся, что SiteLock будет вам полезен. Пожелания по доработке SiteLock приветствуются. | https://habr.com/ru/post/226003/ | null | ru | null |
# Комитет Госдумы: за лайки и репосты сохранится уголовная ответственность

*Пользователь «Вконтакте» Элина Мамедова из села Чехово (Большая Ялта), которую [обвинили](https://pravo.ru/news/205109/) по 282 статье УК РФ за репосты, сделанные в 2014 и 2015 гг, попросили сдать образец ДНК, слюны и голоса для «базы экстремистов»*
Комитет Госдумы по безопасности и противодействию коррупции [подготовил отрицательное заключение](https://ria.ru/society/20180913/1528500219.html) на проект закона, исключающий уголовную ответственность за репосты в интернете.
За лайки и репосты часто вменяется [статья 282 УК РФ](http://www.consultant.ru/document/cons_doc_LAW_10699/d350878ee36f956a74c2c86830d066eafce20149/) «Возбуждение ненависти либо вражды, а равно унижение человеческого достоинства» (до 5 лет тюремного заключения). Администрация «Вконтакте» помогает устанавливать личности пользователей даже без документально подтверждённого запроса правоохранительных органов.
Десятки пользователей соцсетей уже осуждены по уголовной статье за лайки и репосты. В таких условиях появилась идея вывести данную область из сферы действия уголовного кодекса. Соответствующий законопроект был [опубликован](http://sozd.parliament.gov.ru/bill/495566-7) на сайте системы обеспечения законотворческой деятельности в июне 2018 года. Экспертный совет Госдумы по развитию информационного общества при молодёжном парламенте тоже [предложил изменить меру ответственности за лайки и репосты в социальных сетях](https://www.kommersant.ru/doc/3739330).
Но законопроект и предложения экспертного совета не нашли понимания у коллег. Депутат Госдумы от «Единой России» Сергей Железняк [заявил](https://www.kommersant.ru/doc/3739330), что «нельзя потворствовать манипулированию и информационным войнам», а потому нельзя смягчать наказание за репосты.
«Идея юридически прописана неправильно. Надо по-другому сформулировать, тогда мы поработаем, пообщаемся с экспертами. Проект не поддержан никем», — [сказал](https://ria.ru/society/20180913/1528500219.html) глава комитета Василий Пискарев. Он подчеркнул, что проект о декриминализации лайков и репостов в соцсетях не поддержали правительство РФ и Верховный суд.
«Вконтакте» помогает
====================
Уголовные дела в России чаще всего заводят именно за публикации «Вконтакте». Почему? Это [популярно объясняют](https://t.me/zalayk/13) авторы телеграм-канала [«Ты сядешь за лайк»](https://t.me/zalayk).
Дело в том, что администрация российского сервиса охотно идёт на контакт и активно помогает правоохранительным органам. Списки IP-адресов и другие конфиденциальные данные иногда высылают даже без официального запроса, просто по желанию, которое сотрудник правоохранительных органов выразил в письме по электронной почте.
Администрация «Вконтакте» сообщает IP-адреса посетителей страницы и телефонный номер, к которым привязана страница любого своего пользователя. После этого делается запрос оператору связи, который обслуживает данный телефонный номер: кто заходил с данного IP на страницу в указанное в ответе от ВКонтакте время. Ответы на эти запросы являются доказательством того, что страница принадлежит конкретному человеку.
[](https://habrastorage.org/webt/sw/hw/fm/swhwfm7e-vlnm4jvyj6x61gzz-8.jpeg)
*Образец ответа «Ростелекома» (оригинал открывается по щелчку)*
И всё — доказательная база собрана. Можно заводить уголовное дело, проводить обыск у подозреваемого и изымать компьютерную технику из квартиры для поиска улик.

*Пользователь «Вконтакте» Мария Мотузная, на которую завели уголовное дело [за публикацию мемов](https://twitter.com/La72La/status/1022767362439827456) про религию. Девушку обвинили в «унижении негроидной расы». Пятое судебное заседание по делу Мотузной [состоится 25 сентября](https://zona.media/online/2018/09/11/motuznaya-4)*
Проблема в том, что по закону ресурсы обязаны отвечать на такие запросы только по решению суда. Но у «Вконтакте» есть специальный почтовый ящик, куда сотрудники любых органов отправляют сканы или даже фотографии запросов, а иногда даже просто текстовые запросы с абсолютно случайных почтовых адресов: «Как вы думаете, что должна сделать законопослушная социальная сеть в ответ на такой запрос? — Правильно, проигнорировать эту филькину грамоту и запросить решение суда. Но ВКонтакте — не просто законопослушная социальная сеть, а очень законопослушная, она дружит с государственными органами. Поэтому ВКонтакте отдаёт информацию вообще на любые письма с запросами. Страшно представить, сколько там фейковых запросов от мамкиных дианонщиков. Да-да, вы правильно поняли — **ВКонтакте помогает сажать своих пользователей**», — пишут авторы канала «Ты сядешь за лайк». Они также опубликовали почтовый ящик для таких запросов (*[email protected]*) и приложили распечатку ответа от администрации социальной сети.
[](https://habrastorage.org/webt/s3/nb/i3/s3nbi3wbkiaodji9ex0xmder4ig.jpeg)
*Пример ответа от сотрудника «Вконтакте» на неофициальный запрос персональных данных, полученный с почтового ящика `@mail.ru` (оригинал открывается по щелчку)*
В последнее время администрация [просит правоохранителей](https://t.me/pchikov/1459) присылать запросы на выдачу конфиденциальных данных по электронной почте хотя бы с официального почтового адреса, а не с `@mail.ru`.
Общественное мнение
===================
По [данным](https://fom.ru/Bezopasnost-i-pravo/14091) фонда «Общественное мнение» (ФОМ), 55% россиян одобряют идею уголовного наказания за публикации в соцсетях, а также считают, что за репосты россиянин должен нести такую же ответственность, как и за свой собственный материал. По мнению респондентов общероссийского опроса, репост является источником распространения информации и он может расшатывать общество и тем самым вредить ему.
После отрицательного заключения профильного комитета перспектива принятия законопроекта о декриминализации лайков и репостов выглядит сомнительной.
> **Предупреждение по просьбе администрации сайта:** «При комментировании этого материала просим соблюдать правила. Пожалуйста, воздержитесь от оскорблений и токсичного поведения. В комментариях работает постмодерация». | https://habr.com/ru/post/423211/ | null | ru | null |
# Компоненты. Тестирование-консоль
[в начало заметок о компонентах](http://habrahabr.ru/post/209350/)
текущая версия vs. v1
---------------------
Компоненты можно тестировать в консоли, как обычные `node.js` модули. К сожалению, к текущей версии в этом случае есть проблемы с использованием зависимостей, например, завязаных на DOM. То есть если я тестирую компоненту к консоли, запуская, скажем node `node mocha ...`, я не могу просто сделать `require` другой компоненты, завязаной на DOM. В любом случае в консоли `require` подхватит модуль node.js, а не компоненту. А в модуле domify node.js нет объекта document. В будущих версиях билдера компонент ситуация изменится. См. <https://github.com/component/component/issues/41>. Пока что для тестирования этих компонент в консоли можно использовать phantom.
В текущей версии приходится использовать (причем в теле компоненты, но только для целей тестирования) что-то вроде (см. `component/router`):
```
try {
var Route = require('route-component');
} catch (err) {
var Route = require('route');
}
```
Я на этом останавливаться не буду, подождем v1. В данном посте сначала посмотрим, как устроено юнит-тестирование компонент на низком уровне, т.е. вручную, потом я напишу об автоматизации этого процесса. О интегральном тестировании js-приложений тоже написано много, я на этом также останавливаться не буду.
Простые же компоненты, не имеющие отличий (кроме обертки) от параллельного node-модуля, такие как, например `component/indexof`, `component/each`, использовать как зависимости можно уже прямо сейчас, mocha-тесты в консоли будут работать.
Код примера доступен по адресу <https://github.com/mbykov/component-testing-example>. Клонируйте и посмотрите его.
юнит vs. интегральные тесты
---------------------------
Что такое интегральный тест понятно — мы тестируем само приложение, в боевой позиции (если отвлечься от stubs & mocks). Мы используем Cucumber, Selenium, Capybara и смотрим, чтобы отклик приложения как целого соответствовал ожиданиям. Юнит-тест — это тест отдельного метода в компоненте. Вызывается *только* данный метод, и если затрагивается что-то еще, то это плохо. Такое вот доморощенное определение. Компоненты, однако, именно так и проектируются. В них есть внутренние функции, недоступные снаружи, и они, естественно, недоступны и для тестирования. И экспортируемые методы, которые мы вполне способны вызвать откуда угодно.
test/test.js
------------
Создадим простейшую компоненту для консольного теста. Пусть нам нужно узнать, скажем, следующую букву. Мы забыли, что идет вслед за `в` — `г` или `д`. Или, скажем, вслед за `ξ` — `η` или `λ`? (Этот «игрушечный» метод годится только для символов без акцентов).
Пусть в компоненте у нас будут два метода, `sym` для преобразования символа, и `word` — для слова. В нем воспользуемся готовой компонентой `component/map` для удобства.
в компоненте должно быть всего лишь
```
var map = require('map-component');
module.exports = nextSym;
function nextSym() {
if (!(this instanceof nextSym)) return new nextSym();
return this;
}
```
и два метода,
```
nextSym.prototype.sym = function(sym){
return String.fromCharCode(sym.charCodeAt(0)+1);
}
nextSym.prototype.word = function(word){
var self = this;
var arr = word.split('');
var res = map(arr, function(sym) {
return self.sym(sym);
})
return res.join('');
}
```
строка if (!(this instanceof example)) return new example() является магическим заклинанием, означающим, что нам не нужно будет писать оператор new при вызове компоненты.
```
$ make
```
package.json, mocha & should
----------------------------
будем использовать фреймворк mocha (кофе мокко) того же автора, [TJ Holowaychuk](http://visionmedia.github.io/mocha/) и [Should Assertion Library](https://github.com/visionmedia/should.js).
Теперь мы используем, по-сути, не компоненты, а node.js, так что создадим файл `package.json`
```
$ npm init
```
в файле `package.json` укажем необходимые нам зависимости
```
"version": "0.0.1",
"dependencies": {
"map-component": "*"
},
"devDependencies": {
"mocha": "*",
"should": "*"
},
```
map-component необходима как пример зависимости для работы компоненты, а mocha и should — для выполнения тестов.
```
$ npm install
```
makefile & test.js
------------------
чтобы не вызывать тесты в консоли руками, в фале Makefile запишем пункт test;
```
test:
@./node_modules/.bin/mocha \
--require should \
--reporter spec
```
mocha по умолчанию ищет тесты в директории test. Создадим файл test.js
```
var nextSym = require('..')();
describe('component console example', function(){
describe('symbol', function() {
it('б before а', function() {
var next = nextSym.sym('а');
next.should.be.equal('б');
})
})
describe('word', function() {
it('shifted qwerty is rxfsuz', function() {
var shifted= nextSym.word('qwerty');
shifted.should.be.equal('rxfsuz');
})
})
})
```
выполняем тест
```
component console example
symbol
✓ б before а
word
✓ shifted qwerty is rxfsuz
2 passing (19ms)
```
Однако компоненты предназначены для работы в браузере. Так что и тестирование в консоли — скорее исключение. Тестирование должно производиться в браузере, и быть удобным. См. след. разделы.
*продолжение следует* | https://habr.com/ru/post/209372/ | null | ru | null |
# Кастомизация каптчи в Zend Framework 2
Компонент *Zend\Captcha* может принимать различные формы, в том числе задавать логические вопросы, генерировать искаженные шрифты, и передавать несколько изображений, установив между ними связь. *Zend\Captcha* имеет целью обеспечить разнообразие серверных решений, которые могут быть использованы либо в автономном режиме либо в сочетании с *Zend\Form* компонентой.
Элемент Captcha имеет более одного поля, которые рендерятся друг за другом. Встроеный генератор изображений каптч (*Zend\Captcha\Image.php*) использует свой собственный хелпер (*Zend\Form\View\Helper\Captcha\Image.php*) для создания изображения. Так-же, в *Zend\Captcha\Image.php* находится метод 'getHelperName'. Этот метод передает имя хелпера для рендеринга изображения каптчи. По умолчанию 'getHelperName' передает 'captcha/image' — экземпляр класса *Zend\Form\View\Helper\Captcha\Image.php*. Если углубиться с помощью дебаггера, можно увидеть, что в свойстве экземпляра *phpRenderer::\_\_helpers*, в *invokablesClasses* располагается хелпер 'captchaimage'. Это и есть *Zend\Form\View\Helper\Captcha\Image.php*, упомянутый ранее. Грубо говоря — вы просто создаете изображение, а всё остальное делает за вас рендерер используя хелпер, хотя такое положение вещей устраивает не всех.
Когда же вы создаете элемент формы Captcha (*Zend\Form\Element\Captcha.php*), вы передаете этому элементу изображение каптчи(*Zend\Captcha\Image.php*). Элемент формы Captcha, в свою очередь, имеет тоже свой хелпер (*Zend\Form\View\Helper\FormCaptcha.php*). В методе render этого хелпера вы увидите, что изображение каптчи (*Zend\Captcha\Image.php*) загружается с помощью ElementInterface:
```
//Zend\Form\View\Helper\FormCaptcha.php
public function render(ElementInterface $element)
{
$captcha = $element->getCaptcha();
```
после чего вызывается хелпер через метод 'getHelperName':
```
$helper = $captcha->getHelperName();
```
В итоге мы получаем экземпляр класса хелпера посредством экземпляра PhpRenderer и возвращаем представление:
```
$helper = $renderer->plugin($helper);
return $helper($element);
```
Нам нужно четко представлять различие между 'элементом формы Captcha и его хелпером' и 'изображением Captcha также со своим хелпером'. Мы передадим 'изображение каптчи' 'элементу формы Captcha', который уже располагает привязанным хелпером. Метод render 'элемента формы Captcha' встроит экземпляр 'изображения Captcha', который мы передали, используя хелпер для генерации изображения и вернет представление. Все, что нужно сделать, это передать 'изображению Captcha' новый хелпер, который отобразит представление так, как нас устроит и переписать *Zend\Captcha\Image.php*, чтоб он получил наш новый хелпер, а не свой по умолчанию.
Перед тем как начать, давайте обратим внимание на несколько деталей:
хелпер *Zend\Form\View\Helper\Captcha\Image.php* для отображения каптчи определяет паттерн как %s%s%s:
```
$pattern = '%s%s%s';
```
Таким образом, первое, что необходимо — наш кастомный хелпер с собственным паттерном. Давайте создадим его в модуле Application:
```
//module\Application\src\Application\View\Helper\Form\Captcha\ViewHelperCaptcha.php
php
namespace Application\View\Helper\Form\Captcha;
use Zend\Form\View\Helper\Captcha\AbstractWord;
use Application\View\Helper\Form\Captcha\CustomCaptcha as CaptchaAdapter;
use Zend\Form\ElementInterface;
use Zend\Form\Exception;
class ViewHelperCaptcha extends AbstractWord
{
/**
* Override
*
* Render the captcha
*
* @param ElementInterface $element
* @throws Exception\DomainException
* @return string
*/
public function render(ElementInterface $element)
{
//Мы можем установить здесь разделитель между изображением и полем ввода.
$this-setSeparator('')
$captcha = $element->getCaptcha();
if ($captcha === null || !$captcha instanceof CaptchaAdapter) {
throw new Exception\DomainException(sprintf(
'%s requires that the element has a "captcha" attribute of type Zend\Captcha\Image; none found',
__METHOD__
));
}
//Как долго будет храниться изображение (по умолчанию 600).
$captcha->setExpiration(10);
//Как часто выполнять очистку файлов(по умолчанию 10). При данной конфигурации старый файл затирается вновь созданным.
$captcha->setGcFreq(1);
$captcha->generate();
$imgAttributes = array(
'width' => $captcha->getWidth(),
'height' => $captcha->getHeight(),
'alt' => $captcha->getImgAlt(),
'src' => $captcha->getImgUrl() . $captcha->getId() . $captcha->getSuffix(),
);
$closingBracket = $this->getInlineClosingBracket();
$img = sprintf(
'![]()createAttributesString($imgAttributes),
$closingBracket
);
$position = $this->getCaptchaPosition();
$separator = $this->getSeparator();
$captchaInput = $this->renderCaptchaInputs($element);
//Наш измененный паттерн
$pattern = '
%s
%s
%s'
if ($position == self::CAPTCHA_PREPEND) {
return sprintf($pattern, $captchaInput, $separator, $img);
}
return sprintf($pattern, $img, $separator, $captchaInput);
}
}
```
Класс нашего хелпера дублирует класс *Zend\Form\View\Helper\Captcha\Image.php* с небольшими изменениями. Наш хелпер не использует *Zend\Captcha\Image.php* для генерации изображения, в отличие от оригинального. Помните, что *Zend\Captcha\Image.php* предоставляет метод 'getHelperName' который возвращает жёстко закодированное имя хелпера 'captcha/image', таким образом, когда форма будет генерировать изображение, она получит для этого не свой хелпер по умолчанию, а только что созданный нами. Что еще нужно, так это передать в phpRenderer наш кастомный хелпер и сгенерировать новое изображение каптчи, которое будет расширять оригинальный класс *Zend\Captcha\Image.php* и перепишет метод 'getHelperName' установив имя хелпера, который мы создали.
Итак, давайте добавим наш класс в конфигурацию хелперов phpRenderer invokables. Реализуем это в module.config.php:
```
//module\Application\config\module.config.php
...
'view_helpers' => array(
'invokables' => array(
'viewhelpercaptcha' => 'Application\View\Helper\Form\Captcha\ViewHelperCaptcha',
),
),
```
Следующим шагом будет создание изображения каптчи, которое возвратит наш хелпер добавленный в конфигурацию модуля как phpRenderer invokables класс. Нет нужды переопределять весь класс *Zend\Captcha\Image.php*, достаточно указать методу 'getHelperName' наш кастомный класс хелпера в качестве параметра. Для этого создадим класс, и назовем его, например, *CustomCaptcha.php* в папке *module\Application\src\Application\View\Helper\Form\Captcha*. Мы собираемся расширить оригинальный класс *Zend\Captcha\Image.php* и переопределить метод 'getHelperName' чтобы он вернул наш хелпер 'viewhelpercaptcha'. Не помешает также переопределить сообщения об ошибках в свойстве $messageTemplates. На ваше усмотрение.
```
//module\Application\src\Application\View\Helper\Form\Captcha\CustomCaptcha.php
php
namespace Application\View\Helper\Form\Captcha;
//Оригинальный класс, который мы расширим.
use Zend\Captcha\Image as CaptchaImage;
//Новая версия класса, в которой мы изменим только необходимое.
class CustomCaptcha extends CaptchaImage
{
protected $messageTemplates = array(
self::MISSING_VALUE = 'Отсутствует значение',
self::MISSING_ID => 'Поле ID отсутствует',
self::BAD_CAPTCHA => 'Неверно введено значение',
public function getHelperName()
{
return 'viewhelpercaptcha';
}
}
```
Последнее, что нам нужно сделать — использовать наше CustomCaptcha изображение в форме. Для этого создадим две папки: одну для шрифта (zf2folder/data/fonts), который понадобится чтобы генерировать слова каптчи, и другую, для хранения файлов изображений каптч (zf2folder/public/img/captcha). Естественно, в папку fonts скопируем шрифт \*.ttf, например arial.ttf.
Для примера можно взять форму из официального туториала:
```
php
namespace Album\Form;
use Zend\Form\Form;
use Application\Form\View\Helper\Captcha\CustomCaptcha;
class AlbumForm extends Form
{
public function __construct($name = null)
{
//Имя формы можно игнорировать
parent::__construct('album');
$this-setAttribute('method', 'post');
//Здесь расположены стандартные элементы
...
//Здесь будем создавать элемент Captcha
$dirdata = './data';
//Создаем новый CustomCaptcha класс
$captchaImage = new CustomCaptcha(array(
'font' => $dirdata . '/fonts/arial.ttf',
'width' => 120,
'height' => 60,
'fsize' => 20,
'wordLen' => 5,
'dotNoiseLevel' => 25,
'lineNoiseLevel' => 2
));
//Назначаем директорию для хранения файлов
$captchaImage->setImgDir('public/img/captcha/');
//Назначаем путь для загрузки файлов каптчи
$captchaImage->setImgUrl('/img/captcha/');
$captchaImage->setImgAlt('Вы человек или робот?');
//Создаем элемент формы Captcha куда добавим нашу CustomCaptcha, созданную выше
$this->add(array(
'type' => 'Zend\Form\Element\Captcha',
'name' => 'captcha',
'options' => array(
'captcha' => $captchaImage,
),
'attributes' => array(
'class' => 'some_class',
)
));
$this->add(array(
'name' => 'submit',
'attributes' => array(
'type' => 'submit',
'value' => 'Go',
'id' => 'submitbutton',
),
));
}
}
```
Добавим в файл вида элемент нашей капчи
```
echo $this->formRow($form->get('captcha')) . PHP_EOL;
```
Изучив структуру html документа, получившегося на выходе, вы увидите, что теперь изображение и поле ввода каптчи обернуты в div-ы. Мы получили более упорядоченный дизайн.
Использованные источники:
[framework.zend.com/manual/2.2/en/modules/zend.captcha.intro.html](http://framework.zend.com/manual/2.2/en/modules/zend.captcha.intro.html)
[framework.zend.com/manual/2.2/en/modules/zend.captcha.operation.html](http://framework.zend.com/manual/2.2/en/modules/zend.captcha.operation.html)
[framework.zend.com/manual/2.2/en/modules/zend.captcha.adapters.html](http://framework.zend.com/manual/2.2/en/modules/zend.captcha.adapters.html)
[framework.zend.com/manual/2.2/en/user-guide/forms-and-actions.html](http://framework.zend.com/manual/2.2/en/user-guide/forms-and-actions.html)
[zendtemple.blogspot.com/2012/12/zend-framework-2-zf2-creating-view.html](http://zendtemple.blogspot.com/2012/12/zend-framework-2-zf2-creating-view.html)
[samsonasik.wordpress.com/2012/09/12/zend-framework-2-using-captcha-image-in-zend-form](http://samsonasik.wordpress.com/2012/09/12/zend-framework-2-using-captcha-image-in-zend-form/) | https://habr.com/ru/post/183232/ | null | ru | null |
# Yii 2.0.6
Состоялся релиз PHP фреймворка Yii версии 2.0.6.
Инструкции по установке и обновлению доступны по адресу <http://www.yiiframework.com/download/>.
Версия 2.0.6 является патч-релизом для ветки 2.0 и содержит [более 70 небольших улучшений и исправлений](https://github.com/yiisoft/yii2/blob/2.0.6/framework/CHANGELOG.md), многочисленные улучшения документации и значительный прогресс с её переводом.
Спасибо всем, кто [участвует в разработке фреймворка](https://github.com/yiisoft/yii2/graphs/contributors). Ваши pull-request-ы, обсуждения и другая помощь незаменимы.
За процессом разработки фреймворка можно следить [поставив звёздочку или нажав кнопку «watch» на GitHub](https://github.com/yiisoft/yii2).
Также можно подписаться на наши [Twitter](https://twitter.com/yiiframework) и [Facebook](https://www.facebook.com/groups/yiitalk/).
Далее представлен небольшой обзор самых интересных нововведений.
Улучшенный синтаксис миграций
-----------------------------
Изначально мы планировали построитель схемы в версии 2.1, но [pana1990](https://github.com/pana1990) и [vaseninm](https://habrahabr.ru/users/vaseninm/) отлично поработали и теперь синтаксис в миграциях стал намного более приятным:
```
$this->createTable('example_table', [
'id' => $this->primaryKey(),
'name' => $this->string(64)->notNull(),
'type' => $this->integer()->notNull()->defaultValue(10),
'description' => $this->text(),
'rule_name' => $this->string(64),
'data' => $this->text(),
'created_at' => $this->datetime()->notNull(),
'updated_at' => $this->datetime(),
]);
```
Обработка ошибок
----------------
В данном релизе довольно много исправлений и улучшений, призванных сделать обработку ошибок ещё более стабильной и полезной:
— Yii теперь отлично справляется с фатальными ошибками HHVM.
— Если `FileCache` не сумел записать в файл, это будет видно в логах.
— `yii\web\ErrorAction` теперь показывает 404, а не пустую страницу в случае прямого перехода по URL.
— Когда `yii migrate` отказывается работать из за отсутствующей директории, путь к ней показывается в ошибке.
— `Json::encode()` и `Json::decode()` лучше обрабатывают ошибки, кидая понятные исключения.
— `ErrorHandler::logException()` теперь логирует весь объект, а не только его строковое представление.
Больше контроля над ActiveForm из JavaScript
--------------------------------------------
Вы можете обновлять ошибки для определённых полей:
```
// добавить ошибку
$('#contact-form').yiiActiveForm('updateAttribute', 'contactform-subject', ["I have an error..."]);
// убрать ошибку
$('#contact-form').yiiActiveForm('updateAttribute', 'contactform-subject', '');
```
Или для всех полей и резюме сразу:
```
$('#contact-form').yiiActiveForm('updateMessages', {
'contactform-subject': ['Really?'],
'contactform-email': ['I don\'t like it!']
}, true);
```
Улучшения `yii message`
-----------------------
Теперь поддерживается создание файлов `.pot`.
Команда теперь отлично переваривает вложенные вызовы:
```
Yii::t('app', 'There are new {messages} for you!', [
'messages' => Html::a(Yii::t('app', 'messages'), ['user/notifications']),
]);
```
Также теперь сортировка происходит даже при отсутствии новых строк, что позволяет получить меньший diff.
Кроме того, была добавлена опция `markUnused`, позволяющая отключить добавление `@@` к неиспользуемым строкам.
Asset-ы
-------
Теперь можно настроить, что публиковать, а что нет:
```
class MyAsset extends AssetBundle
{
public $sourcePath = '@app/assets/js';
public $js = [
'app.js',
];
public $depends = [
'yii\web\YiiAsset',
];
public $publishOptions = [
'except' => '*.ts', // exclude TypeScript sources
// 'only' => '*.js', // include JavaScript only
];
}
```
Можно изменить алгоритм хеширования для имён директорий из `web/assets`. Сделать это можно прямо из конфигурации приложения:
```
return [
// ...
'components' => [
'assetManager' => [
'hashCallback' => function ($path) {
return hash('md4', $path);
}
],
],
];
```
Дополнительные поля в хранилище сессий
--------------------------------------
Теперь вы можете легко хранить дополнительные данные в хранилище сессий. Пока поддерживается только `yii\web\DbSession`, но в будущем поддержка может быть расширена. Для конфигурации надо изменить конфигурацию приложения:
```
return [
// ...
'components' => [
'session' => [
'class' => 'yii\web\DbSession',
'readCallback' => function ($fields) {
return [
'expireDate' => Yii::$app->formatter->asDate($fields['expire']),
];
},
'writeCallback' => function ($session) {
return [
'user_id' => Yii::$app->user->id,
'ip' => $_SERVER['REMOTE_ADDR'],
'is_trusted' => $session->get('is_trusted', false),
];
}
],
],
];
``` | https://habr.com/ru/post/264159/ | null | ru | null |
# Отзывчивые изображения на практике (Часть 3)
Последняя часть истории об отзывчивых изображениях, которую мы начали [здесь](http://habrahabr.ru/company/paysto/blog/244175/) и продолжили [тут](http://habrahabr.ru/company/paysto/blog/244177/), рассказывая о применении srcset и sizes. Сегодня речь пойдет об использовании тега для обертывания изображений.
**Вторая стадия: picture и режиссура**
> srcset для ленивых, picture для безумных
>
> Мэт Маркес
>
>
Итак, для изображений, которые просто нужно масштабировать, мы приводим список наших исходников и их ширину в пикселях в srcset, позволяем браузеру выбирать, какая ширина изображения будет отображаться с помощью sizes, и отпускаем наше безумное желание все контролировать. Но! Иногда нам захочется адаптировать наши изображения, выходя за рамки масштабирования. В таком случае, нам нужно вернуть небольшую часть контроля над подбором исходников. Вводим picture.
У наших детальных изображений большое соотношение сторон – 16:9. На больших экранах они выглядят отлично, но на телефоне они становятся крошечными. Простежка и вышивка, которые нужно показать на детальных изображения, слишком мелкие, чтобы их рассмотреть.
Было бы неплохо, если бы мы могли «увеличивать» изображения на маленьких экранах, представляя их в более плотном и высоком виде.

Такие вещи – подгон контента изображений под отдельные среды – называются «режиссурой». Каждый раз, когда мы обрезаем или иным образом изменяем изображение, чтобы оно соответствовало контрольной точке (вместо изменения размера всего), мы занимаемся режиссурой.
Если мы включаем увеличенные обрезанные изображения в srcset, неизвестно, где они подойдут, а где – нет. С помощью picture и source media мы можем сделать наши желания реальностью: загружать широкие прямоугольные кадры только когда окно шире 36 em. А в небольших окнах всегда загружать квадратные картинки.
```

```
Элемент picture содержит любое количество исходных элементов и один img. Браузер просматривает все исходники изображений, пока не найдет атрибут media, который соответствует текущей среде. Он отправляет srcset подходящего исходника в img, который до сих пор остается тем элементом, который мы «видим» на странице.
Вот более простой пример:
```

```
В окнах с альбомной ориентацией в img подается landscape.jpg. При книжной ориентации (или если браузер не поддерживает picture) img не изменяется, и загружается portrait.jpg.
Это поведение может показаться вам слегка удивительным, если вы привыкли к аудио и видео. В отличие от этих элементов, picture представляет собой невидимую обложку: волшебный span, который задает изображению значение srcset.
Еще один способ кадрирования: img – это не шаг назад. Мы прогрессивно улучшаем img, обертывая его в picture.
На практике это означает, что любые стили, которые мы хотим применить к нашему изображению на экране, необходимо настраивать с учетом img, а не picture. Код picture { width: 100% } ничего не делает. Код picture > img { width: 100% } делает то, что нам нужно.
Вот наша страница лоскутных одеял с примененным шаблоном. Вспоминаем, что целью использования picture было предоставить пользователям с небольшими экранами больше (и более полезных) пикселей, и смотрим на то, как развивается производительность:
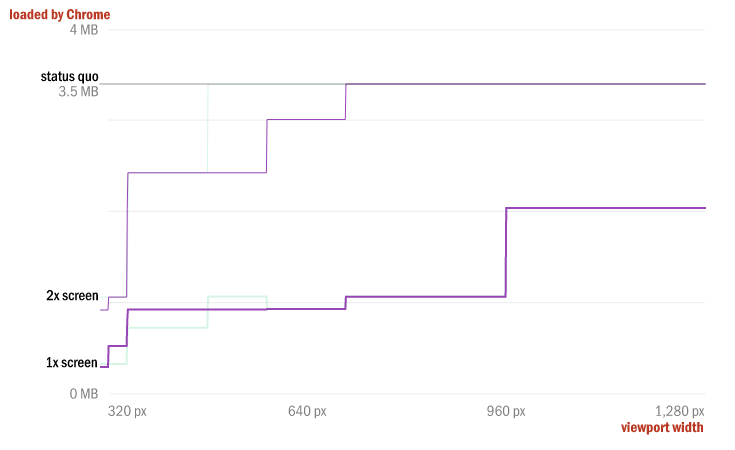
Неплохо! Мы отправляем немного больше байтов на 1х-экранах. Но по каким-то сложным причинам, имеющим отношение к размерам наших исходных изображений, мы фактически увеличили диапазон размеров экранов, которые ощущают рост производительности на 2х. Экономия на первой стадии изменения страницы остановилась на 480 пикселях для 2х-экранов, но после нашей второй стадии она расширилась вплоть до 700 пикселей.
Теперь наша страница загружается быстрее и лучше выглядит на небольших устройствах. Но мы еще не закончили.
**Третья стадия: делаем несколько форматов с помощью source type**
За 25-летнюю историю интернета в нем доминировали два растровых формата: JPEG и GIF. PNG потребовалось десять мучительных лет, чтобы вступить в этот эксклюзивный клуб. Новые форматы, такие как WebP и JPEG XR, уже стоят на пороге, обещая разработчикам превосходное сжатие и предлагая такие полезные функции, как альфа-каналы и режимы без потерь. Но ввиду одинокого атрибута изображений src, внедрение происходит очень медленно – разработчикам нужна практически универсальная поддержка формата, прежде чем они смогут его использовать. Но не сегодня. picture позволяет легко использовать несколько форматов, следуя той же модели source type, которая установлена для audio и video:
```

```
Если браузер поддерживает атрибут type исходника, он отправит srcset этого исходника в img.
Это довольно простой пример, но когда мы наслаиваем переключение source type поверх нашей существующей страницы лоскутных одеял чтобы, скажем, добавить поддержку WebP, все становится слишком сложным (и повторяющимся):
```

```
Получается слишком много кода для одного изображения. Кроме того, теперь у нас еще и большое количество файлов: целых 12! Три разрешения, два формата и два типа кадрирования на каждое изображение – это реально много. Все, чего мы добились в отношении производительности и функциональности, получается за счет предварительного столкновения со сложностями и дальнейшей возможности сопровождения.
Автоматизация – ваш друг; если подразумевается, что ваша страница будет содержать массивные блоки кода, ссылающиеся на большое количество различных версий изображения, лучше не делать это все вручную.
То же самое с пониманием, что хорошего должно быть понемногу. Я использовал все инструменты из спецификаций на нашем примере. Это почти никогда не будет рассудительным. Огромного увеличения эффективности можно добиться, используя любую из новых функций по отдельности, и вы должны тщательно рассмотреть все сложности их наслоения, прежде чем сохранять и делать все нужное и ненужное.
Но все-таки, давайте посмотрим, что WebP может сделать для наших одеял.

Дополнительные 25-30% экономии свыше того, чего мы уже достигли – не только на нижнем пределе, но и по всему диапазону – это определенно не шутка! Моя методология здесь ни в коем случае не является точной; ваша производительность с WebP может отличаться. Суть в том, что новые форматы, которые обеспечивают значительную выгоду по сравнению с текущим положением JPEG/GIF/PNG, уже существуют и продолжают появляться. Атрибуты picture и source type снижают барьер доступа, навечно расчищая путь для инноваций в области форматов изображений.
**Используем size уже сегодня**
На протяжении многих лет мы знали, что отягощает наши отзывчивые страницы: изображения. Огромные изображения, созданные специально для огромных экранов, которые мы отправляли всем. Мы также знали, как решить эту проблему: отправлять различные исходники разным клиентам. Новая разметка позволяет нам делать именно это. srcset дает возможность предложить несколько версий изображения браузеру, который с помощью атрибута sizes подбирает из пачки наиболее подходящий исходник и загружает его. Атрибуты picture и source позволяют нам вмешаться и взять на себя немного больше контроля, гарантируя, что некоторые исходники будут выбраны, основываясь либо на медиа-запросах, либо на поддержке типа файла.
Вместе эти функции позволяют нам создавать адаптивные, гибкие и отзывчивые изображения. Они позволяют нам отправлять каждому нашему пользователю исходник, созданный специально для его устройства, обеспечивая значительный рост производительности. Вооруженные превосходным полизаполнением и имея понимание будущего, разработчики должны начать использовать такую разметку прямо сейчас!
**Полезные решения Paysto для читателей Хабра:** → [Получите оплату банковской картой прямо сейчас. Без сайта, ИП и ООО.](http://linkcharge.ru/email)
→ [Принимайте оплату от компаний через Интернет. Без сайта, ИП и ООО.](http://linkcharge.ru)
→ [Приём платежей от компаний для Вашего сайта. С документооборотом и обменом оригиналами.](http://linkcharge.ru/api)
→ [Автоматизация продаж и обслуживание сделок с юр.лицами. Без посредника в расчетах.](http://linkcharge.ru/automat) | https://habr.com/ru/post/244241/ | null | ru | null |
# Кастомизируем дашборды в Grafana для инженеров по холодоснабжению ЦОДа
Система мониторинга инженерной инфраструктуры – это нервная система дата-центра. С ее помощью инженеры вовремя видят неприятные симптомы на графиках и предотвращают проблемы в работе кондиционеров, бесперебойников, сетевых устройств и других элементов инженерных систем.
Наша система мониторинга на базе Nagios развивается вместе с сетью дата-центров, и мы уже много рассказывали о ее работе (например, в этом [цикле](https://uni.dtln.ru/digest/monitoring-inzhenernoy-infrastruktury-v-data-centre-chast-1-osnovnye-momenty)). Но нет предела совершенству, и чем дальше, тем больше хочется улучшить что-то еще: добавить новый “разрез” анализа, взглянуть на оборудование под другим углом.
В этой статье расскажем, как и для каких задач наши инженеры создают кастомные дашборды с помощью графического плагина [FlowCharting](https://grafana.com/grafana/plugins/agenty-flowcharting-panel/) для Grafana.
Что хотелось улучшить в мониторинге
-----------------------------------
Наша система мониторинга работает в более чем 10 дата-центрах и собирает сотни тысяч метрик о работе оборудования. Ее используют сразу несколько групп инженеров с разной специализацией:
* Дежурные инженеры – наша первая линия. Они следят за видеостеной в центре мониторинга, разбирают падающие в систему алерты от оборудования и ИТ-систем, эскалируют их на профильных инженеров.
Наша “дежурка” в OST.* Профильные инженеры из групп холодоснабжения, энергетики, сети и т.д. Они отслеживают показатели здоровья конкретной системы: от нагрузки на оборудование до статистики замены запчастей.
Каждой группе требуются разные данные для разных целей, поэтому для системы мониторинга важна гибкость в представлении информации:
* На видеостену в “дежурке” выносятся ключевые показатели, чтобы инженеры на смене сразу замечали проблемы и быстро принимали решения. Работа дежурных ведется по четким инструкциям, которые оттачивались годами, и следование им отрабатывается чуть ли не поминутно.
При этом инженеры ротируются между объектами. Поэтому отображение информации для видеостен стандартизировано и постоянно совершенствовалось нашей группой разработки (мы уже можем на этом материале написать диссертацию по инженерной психологии :))
* Профильные инженеры “проваливаются” в базу мониторинга глубже. Например, если дежурным достаточно знать статус работы кондиционера и температуру в зале, то инженерам-холодильщикам для своевременного обслуживания понадобятся десятки параметров: давление в контуре, степень открытия клапана, степень загрузки чиллера и т.д.
Такие оперативные данные нужны по каждой конкретной единице оборудования. Выносить их на общую видеостену не имеет смысла – не хватит места, либо дашборд получится таким перегруженным, что его придется читать с лупой.
Профильный инженер может посмотреть необходимую информацию из Nagios у себя на мониторе.
Например, так представлены в базе Nagios параметры одного из кондиционеров.А так выглядит часть параметров одного зала.В принципе, жить и работать с этим можно: есть фильтрация, группировка, – но для восприятия тяжело. От множества одинаковых строчек с мелким текстом устают глаза и “замыливается” взгляд.
Назрела необходимость создать отдельные дашборды для специализированных групп, где каждый инженер может настроить представление под себя.
Сделать это можно было несколькими инструментами:
1. Прикрутить визуализацию с помощью плагинов Nagios. Мы попробовали – нас не устроила сильно ограниченная функциональность.
2. Попросить сделать дашборды нашу группу разработки. Визуализации мониторинга для видеостен создавались так: движок писался на CFML, для конфигов использовался JSON. Для разработки новых дашбордов тоже потребовался бы программист. Чтобы разобраться в узкой инженерной логике, ему пришлось бы плотно пообщаться с каждой группой инженеров, а они у нас обычно сильно загружены “в полях”. Это сильно замедлило бы процесс.
Вдобавок в существующем фронтенде уже есть определенная доля легаси, и важно при изменениях ничего не сломать. К этой системе сложно предоставлять точечный доступ, чтобы не нарушить все зависимости. Поэтому и нельзя было поручить задачу разработчику-аутсорсеру.
Эту визуализацию для видеостены наша группа разработки выполнила с нуля. Самописный дашборд берет данные из Nagios и отображает графически.
3. Найти надстройку, с помощью которой можно делать простые визуализации с понятным UI и минимальным конфигурированием. В этом случае Nagios выступает в роли сборщика данных, а для фронтенда используется стороннее решение с возможностью визуального кодинга/конфигурирования.
Мы остановились на третьем варианте.
Почему Grafana
--------------
В качестве надстройки выбрали [Grafana](https://grafana.com/): мы давно [используем](https://habr.com/ru/company/dataline/blog/569024/) ее для отображения графиков на дашбордах, так что опыт имеется. Это опенсорс (есть платная лицензионная версия Grafana Enterprise, но мы обошлись бесплатной).
В Grafana есть и классические графики, и пайчарты, и тепловые карты.Создать простую визуализацию инженер может сам всего за пару часов. А значит, по трудозатратам выходит очень дешево, можно экспериментировать и не бояться ошибиться.
Из этого следует еще несколько возможностей:
1. В разных ЦОДах можно делать совершенно разные визуализации для разного оборудования. Наши дата-центры проектируются, строятся и эксплуатируются по единым стандартам, мониторинг внедряется по отлаженной схеме, но у каждого ЦОДа есть свои изюминки. Например, мы регулярно тестируем новое оборудование – значит, можно пробовать различные способы за ним наблюдать.
2. Можно проверять гипотезы и чуть ли не А/Б-тесты делать: как быстрее оповестить о проблеме, красной заливкой или мигающей рамкой? А как между собой соотносятся вот эти показатели; что, если отслеживать их вместе вот на таком графике?
Начали мы с усовершенствования мониторинга системы кондиционирования на площадке NORD. Дело было в июне, когда системам холодоснабжения ЦОДов приходится нелегко: летит тополиный пух, который может забиваться в решетки внешних блоков и ухудшать тепло-/воздухообмен. В это время особенно важно следить за параметрами кондиционеров и реагировать, не дожидаясь падения производительности или отказа оборудования.
Мы решили, что возможность видеть на одном экране основные параметры всех кондиционеров ЦОДа придется инженерам холодоснабжения очень кстати. Быстро сделали несколько дашбордов и вывели на мониторы в кабинетах холодильщиков.
Расскажем подробнее о том, как это происходило.
Как выглядит создание дашбордов для ЦОДа
----------------------------------------
Визуализация метрик в Grafana выглядит так:
Или так:
Или даже так:
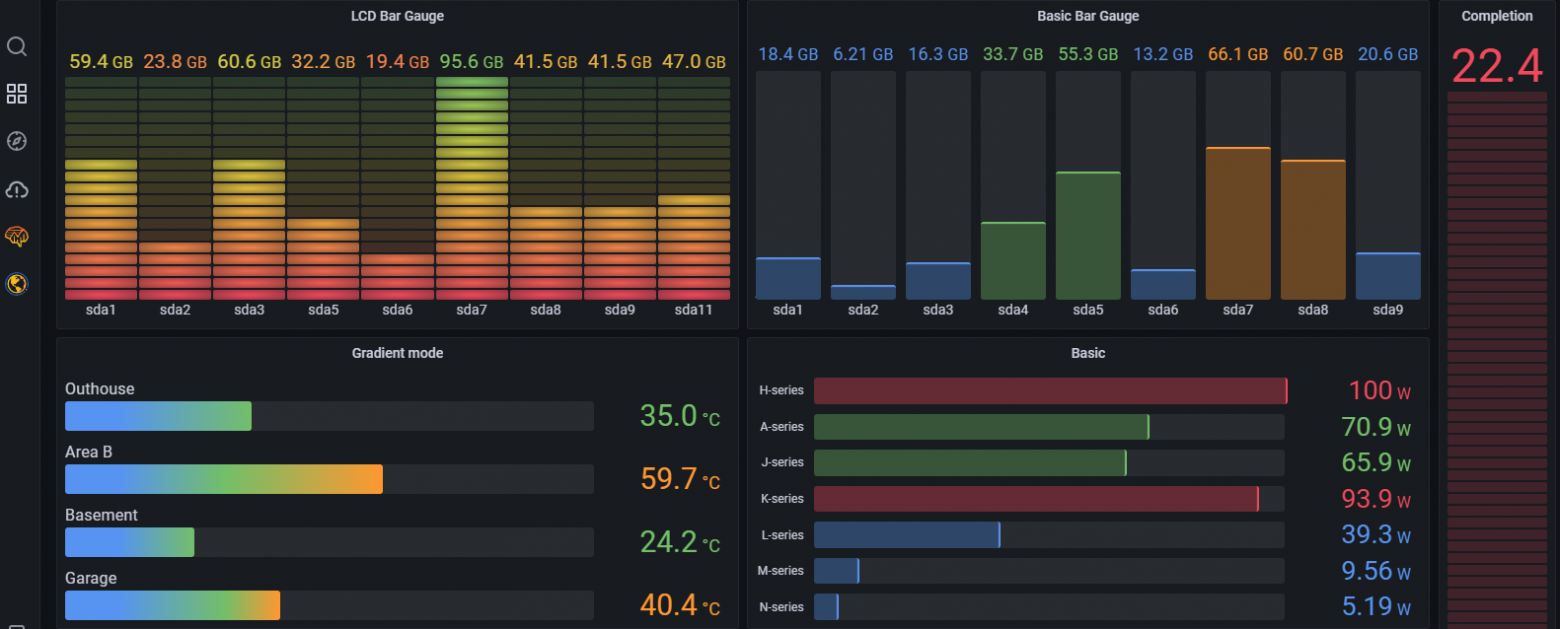Но нам требовалось уместить на один дашборд много метрик, причем отображающих актуальные данные в реальном времени (типовые графики Grafana отображают временные ряды).
Поэтому мы выбрали сторонний плагин [FlowCharting](https://grafana.com/grafana/plugins/agenty-flowcharting-panel/), разработанный специально для рисования в Grafana сложных диаграмм. В качестве графической библиотеки он использует [Draw.io](https://app.diagrams.net/) – еще один бесплатный онлайн-сервис для создания инфографики.
Чтобы избежать риска утечки данных через гипотетически возможные уязвимости в опенсорсном ПО, мы развернули графическую систему во внутренней инфраструктуре DataLine, без доступа во внешнюю сеть.
Вот такой “бутерброд” получился.С помощью Draw.io FlowCharting может создавать самые разные типы диаграмм: от схем программной архитектуры и промышленных процессов до планов этажей в зданиях.
Спектр возможностей для работы с графикой здесь заметно шире, чем в Grafana. Каждому графическому объекту Draw.io автоматически присваивает ID. К этому ID можно привязать данные. В зависимости от данных векторные объекты могут трансформироваться: менять цвет, прозрачность, вращаться и т.д. Можно добавить ссылку. Можно импортировать готовую картинку (например, EPS или JPG) и указать, какие запросы будут взаимодействовать с ней.
Пример работы с импортированной картинкой: FlowCharting определил фото котика как объект, присвоил ему ID 37 и выделил рамкой.А теперь покажем этапы разработки дашборда для системы охлаждения. Мы взяли конкретный ЦОД, в котором хотелось видеть данные по каждой единице системы кондиционирования: что там с температурой, давлением конденсации и т.д.
1. Для начала хорошо бы представить, какое оборудование у нас есть в ЦОДе и какие показатели по нему мы хотим получать.
Создаем подложку в Draw.io.
2. Выгружаем выбранные данные из базы:
Составляем для этого запросы с помощью редактора.
3. Задаем правила: указываем, какие метрики и куда выводить, при необходимости присваиваем пороговые значения, меняем свойства объектов:
 давления в контуре выбираем наиболее красноречивые цвета. Можно еще и красивым градиентом залить.")Для разных пороговых значений (Threshold) давления в контуре выбираем наиболее красноречивые цвета. Можно еще и красивым градиентом залить.Можно настроить события, при которых выбранный объект будет мигать, выделяться рамкой, изменяться в размерах, вращаться и т.д.
4. Готово:
А вот и дашборд.Теперь наблюдатель одновременно видит базовые параметры всех кондиционеров ЦОДа: вкл./выкл. каждого контура, вкл./выкл. компрессоров, давление конденсации и степень открытия ЭТРВ (электронных терморегулирующих вентилей), активные аварии, выход показателей за пороговые значения. Для удобства в правом верхнем углу отображаются данные с метеостанции ЦОДа.
.")Пример работающего дашборда (скрин сделан прошлым летом).Похожий дашборд сделали, чтобы следить за состоянием чиллеров.
Так выглядят данные по всем чиллерам в машзале.Схемы выключенных чиллеров выделяются цветом – становятся серыми. А если происходит авария, на схеме появляется мигающий красный сигнал. Показатели чиллеров отображаются в виде динамических полосок:
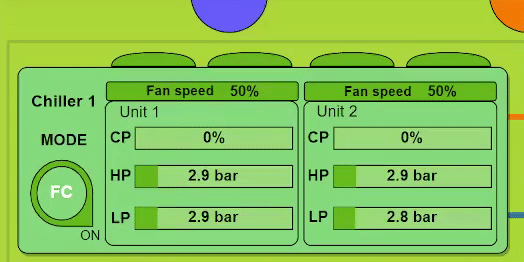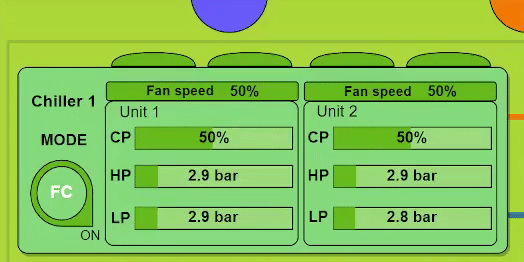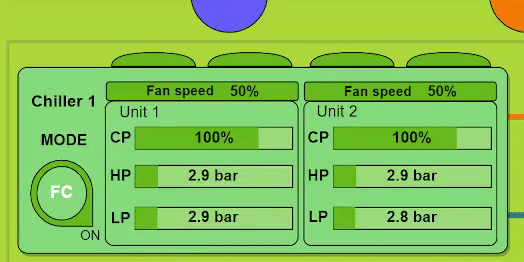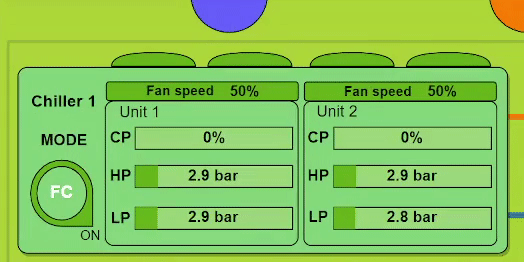Кстати, такое отображение появилось в порядке эксперимента. Но идея так всем понравилась, что мы добавили ее в рабочий вариант.
Параметров у каждого чиллера, конечно, больше основных. Чтобы можно было увидеть их все, мы планируем добавить гиперссылку на каждый чиллер и по ней погружаться на уровень глубже.
Кроме того, в ближайших планах у нас создание похожих дашбордов для дизелей.
Как телеграм-бот помогает холодильщикам
---------------------------------------
Мы не смогли остановиться. Чтобы помочь профильным инженерам “в полях”, где пользоваться ноутбуком и планшетом не всегда удобно, с помощью BotFather создали телеграм-бота, который умеет по запросу отправлять в мессенджер скриншоты наших дашбордов. Фрагмент настройки бота:
```
@bot.message_handler(commands=['nord'])
def start_message(message):
if message.from_user.id not in ids:
bot.send_message(message.chat.id, 'Зарегистрируйся /auth')
else:
img = open('img1.png', 'rb')
bot.send_photo(message.chat.id, img)
img = open('img2.png', 'rb')
bot.send_photo(message.chat.id, img)
img = open('img3.png', 'rb')
bot.send_photo(message.chat.id, img)
```
Мы сами написали специальный скрипт, который ежеминутно скринит выбранные дашборды и сохраняет под заданными именами. Процесс цикличен: названия остаются, сами скрины регулярно меняются на свежие. В папке всегда лежит одинаковое число джипегов. Получив запрос, бот по названию находит в папке нужный файл и отправляет его в мессенджер пользователю.
")Вот так он работает, наш безымянный труженик группы холодоснабжения :)Кстати, этот телеграм-бот – не единственный.
Еще у нас есть, например, боты-напоминалки, которые следят за изменением уставок. Во время ТО часть кондиционеров отключают для проверки и ремонта, а на работающих занижают уставки температур, чтобы в машзале не произошло перегрева. После ТО необходимо вернуть уставкам прежние значения. Теперь, если инженер изменил уставки на кондиционерах, бот напоминает ему, что нужно вернуть все обратно.
Но об этой разработке мы подробно расскажем в следующий раз. | https://habr.com/ru/post/664460/ | null | ru | null |
# Splunk. Введение в анализ машинных данных — часть 2. Обогащение данных из внешних справочников и работа с гео-данными

Мы продолжаем рассказывать и показывать как работает Splunk, в частности говорить о возможностях языка поисковых запросов SPL.
В этой статье на основе [тестовых данных](https://yadi.sk/d/OjbNMbSn3GJUYT) (логи веб сервера) доступных всем желающим для загрузки мы покажем:
* Как обогатить логи информацией из внешних справочников
* Как можно визуализировать географические данные (данные с координатами)
* Как группировать цепочки событий в транзакции и работать с ними
Под катом вы найдете как сами примеры поисковых запросов, так и результат их выполнения. Вы можете [скачать](http://tssolution.ru/splunk/) бесплатную версию Splunk, загрузить [тестовые данные](https://yadi.sk/d/OjbNMbSn3GJUYT) и повторить все на своем локальном компьютере.
О том как установить Splunk и загрузить тестовые данные мы рассказывали в [предыдущих](https://habrahabr.ru/company/tssolution/blog/324136/) статях нашего блога.
Обогащение данных информацией из внешних справочников
-----------------------------------------------------
Рассмотрим имеющиеся у нас данные.
```
sourcetype=access*
```

Это события access лога, в которых содержится информация о действиях посетителей сайта (по легенде это сайт интернет-магазина компании, занимающейся продажей компьютерных игр). Поэтому в логах у нас есть такие поля, как (наиболее интересные для обработки и запросов):
* action — действия посетителя сайта
* clientip — ip-адресс посетителя сайта
* productId — код продукта
* categoryId — категория продукта
* JSESSIONID — сковозной id сессии
Как мы уже рассказывали в [предыдущем посте](https://habrahabr.ru/company/tssolution/blog/324136/), с помощью Splunk мы можем построить различную аналитику посредством поисковых запросов. Например, мы можем посчитать сколько и каких продуктов покупали, за опредленный временной период:
```
sourcetype=access* action=purchase | stats count by productId | sort -count
```

**Но!** Так как в наших логах кроме productId нет больше никакой информации о продукте, мы не видим что это за товар, сколько он стоит и так далее. Поэтому было бы удобно подгрузить соответствующие поля из внешнего справочника.
В качестве справочника возьмем [простой csv](https://yadi.sk/i/a2SXKomg3GHAb8) файл с интересующей нас информацией о названии продукта и его цене, и загрузим его в Splunk. Сразу скажу, что это самый простой ручной способ обогащения. Понятно, что Splunk может забирать данные из реляционных баз данных, делать запросы к API и прочее.
После того как Вы скачали справочник, нужно загрузить его в Splunk и разметить поля. Подробная инструкция [здесь](https://docs.splunk.com/Documentation/Splunk/6.5.2/PivotTutorial/AddlookupfilestoSplunk). Если Вы все сделали правильно, то должны получить следующие результаты поискового запроса:
```
| inputlookup prices_lookup
```
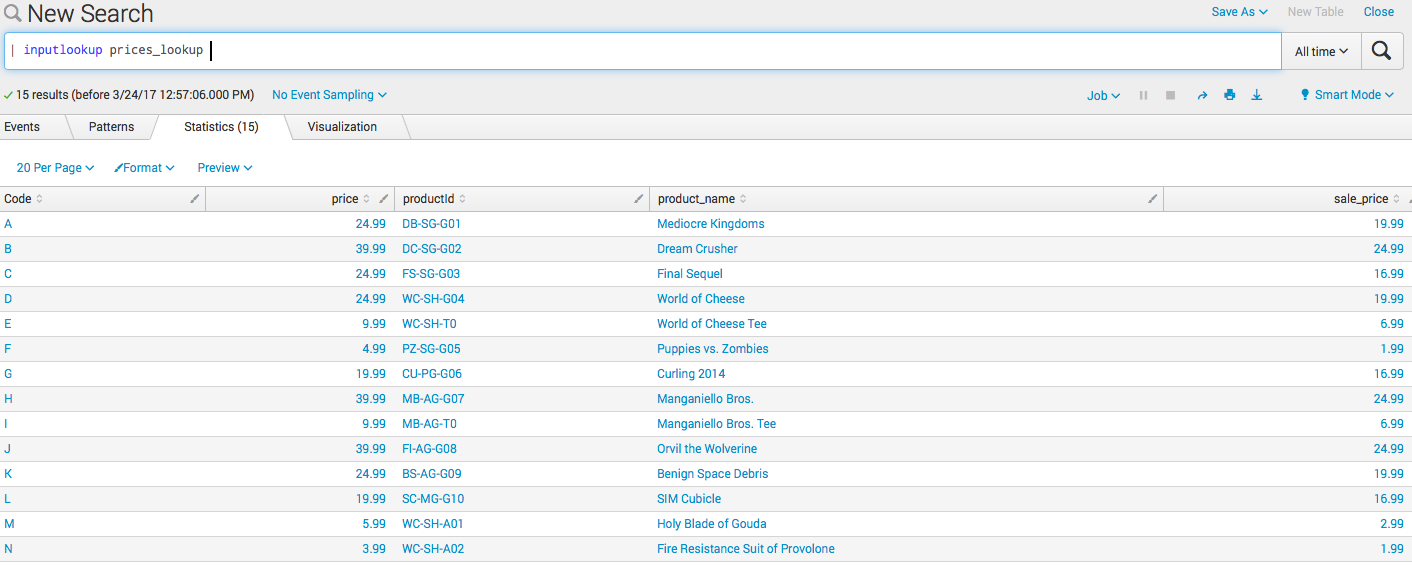
По сути мы просто добавили табличку со справочником в Splunk, теперь давайте сделаем так, чтобы система «дописала» значения этих полей к нашим событиям. Понятно, что она никак не изменит исходные события, а просто логически подтянет поля.
Заходим во вкладку Settings → Lookups → Automatic lookups → New
**Name:** — любое имя
**Lookup table:** prices\_lookup (или как вы нававли Вашу таблицу)
**Sourcetype:** access\_combined\_wcookie
**Lookup input fields:** productId=productId
**Lookup output fields:** price=price, product\_name=product\_name, sale\_price=sale\_price

После чего все сохраняем и меняем *Permissions* на *All Apps* и *Read/Write everyone* как предыдущей инструкции.
Если все сделано правильно, то теперь при поиске по данному sourcetype должны быть достпны добавленные нами поля (чтобы они отображались снизу каждого события нужно зайти во вкладку *All fields* и выбрать их в качестве *Interesting fields*). Заметьте, что в самих событиях этой информации нет, так как они не изменялись.
```
sourcetype="access_combined_wcookie" product_name="*"
```
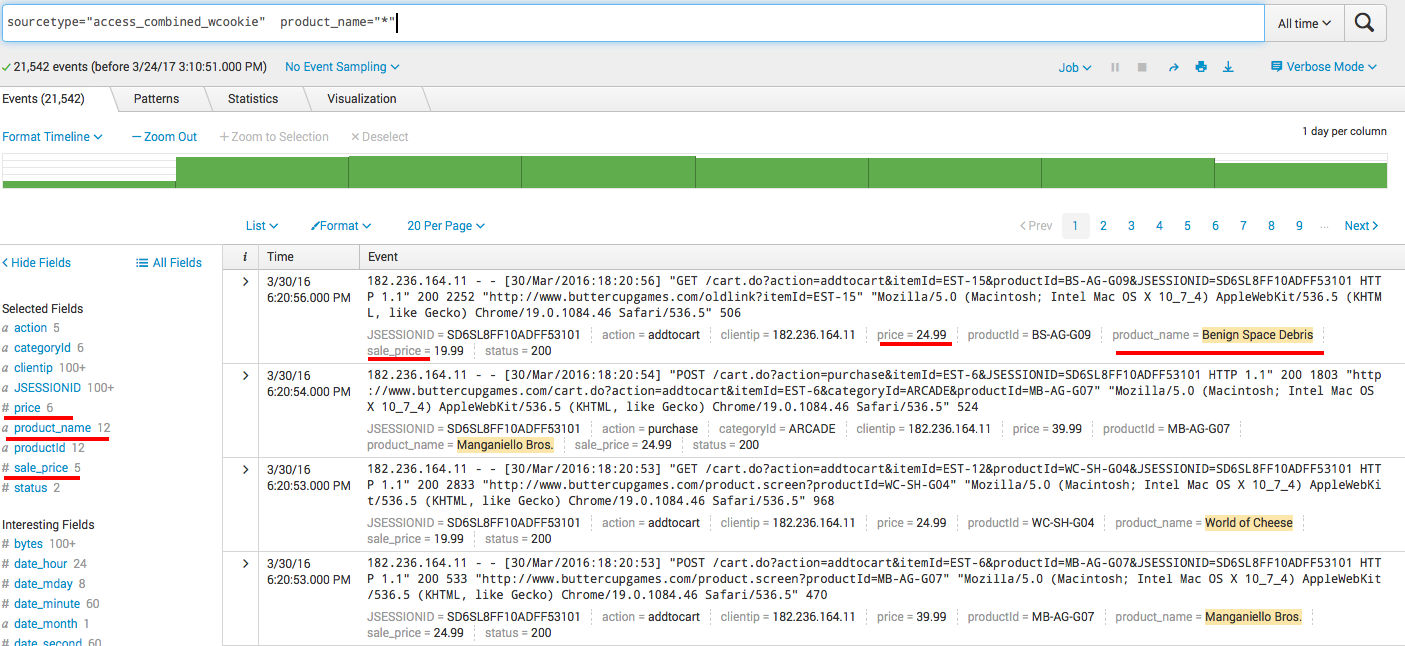
Вот теперь результаты наших запросов могут быть куда интереснее. К примеру, мы можем посчитать ту же самую аналитику только уже с привязкой к деньгам и финансовым результатам.
```
sourcetype="access_combined_wcookie" action=purchase
| eval profit=price-sale_price
| stats values(productId) as "Код продукта", values(sale_price) as "Цена покупки", values(price) as "Цена продажи", count as "Количество", sum(profit) as "Итого", by product_name
| sort -"Итого"
| rename product_name as "Наименование"
```

Понятно, что этот пример больше про BI историю. Однако, этот пример с подключением справочников тиражируем и в другие предметные области. К примеру, если говорить про информационную безопасность — мы можем подгружать по CVE коду информацию из баз данных уязвимостей.
И да, совсем забыл! Для удобного редактирования справочников у Splunk есть специальное приложение [Lookup Editor](https://splunkbase.splunk.com/app/1724/), которое можно бесплатно скачать со SplunkBase.
Визуализация данных с географическими координатами
--------------------------------------------------
Иногда бывает очень полезно нанести результаты аналитических запросов на географическую карту. Тут ситуация разделяется на 2 случая: первый — когда в данных уже есть такие поля как широта и долгота (именно благодаря им мы можем нанести что-либо на карту), второй — когда этих полей нет. В нашем примере, то есть в наших данных, как раз второй случай (мы имеем много посетителей интернет магазина из разных мест, но данных об их широте и долготе у нас нет, зато у нас есть их ip-адрес). У Splunk есть встроенный функционал определения широты и долготы (а также города, страны и региона) на основе ip-адреса, команда [iplocation](https://docs.splunk.com/Documentation/Splunk/6.5.2/SearchReference/Iplocation).
```
sourcetype="access_combined_wcookie" | iplocation clientip
```
В результате этого запроса у вас должны появится поля с широтой, долготой, названием города, страны и региона.

Теперь строим какой-нибудь аналитический запрос и наносим на карту. К примеру, посчитаем прибыль по каждому продукту и посмотрим где это покупалось. Для этого используем встроенную функцию [geostats](https://docs.splunk.com/Documentation/Splunk/6.5.2/SearchReference/Geostats).
```
sourcetype="access_combined_wcookie" action=purchase
| iplocation clientip
| eval profit=price-sale_price
| geostats sum(profit) by product_name
```

Также можем воспользоваться другим вариантом визуализации и посмотреть прибыльность в разрезе по странам, для этого используется команда [geom](http://docs.splunk.com/Documentation/Splunk/6.5.2/SearchReference/Geom).
```
sourcetype="access_combined_wcookie" action=purchase
| iplocation clientip
| eval profit=price-sale_price
| stats sum(profit) by Country
| geom geo_countries featureIdField=Country
```

По дефолту, есть маппинг по странам и штатам США, но вы всегда можете сделать свой, на основе широты и долготы и добавить его в Splunk. Например, это могут быть регионы Росиии, или городские округа.
Транзакции или группировка цепочки событий во времени
-----------------------------------------------------
В том случае, когда у нас есть последовательная цепочка событий, например, процесс пересылки электронной почты, какая-нибудь финансовая операция, или как в случае с нашими данными — посещение web сайта, бывает необходимо объединить эти события в транзакции. То есть из группы отдельных событий событий явно выделить цепочку, группируя их по конкретному признаку.
В нашем случае это поле JSESSIONID — уникальный номер сессии пользователя. Для группировки используем команду [transaction](https://docs.splunk.com/Documentation/Splunk/6.5.2/SearchReference/Transaction).
```
sourcetype="access_combined_wcookie" | transaction JSESSIONID endswith="purchase"
```
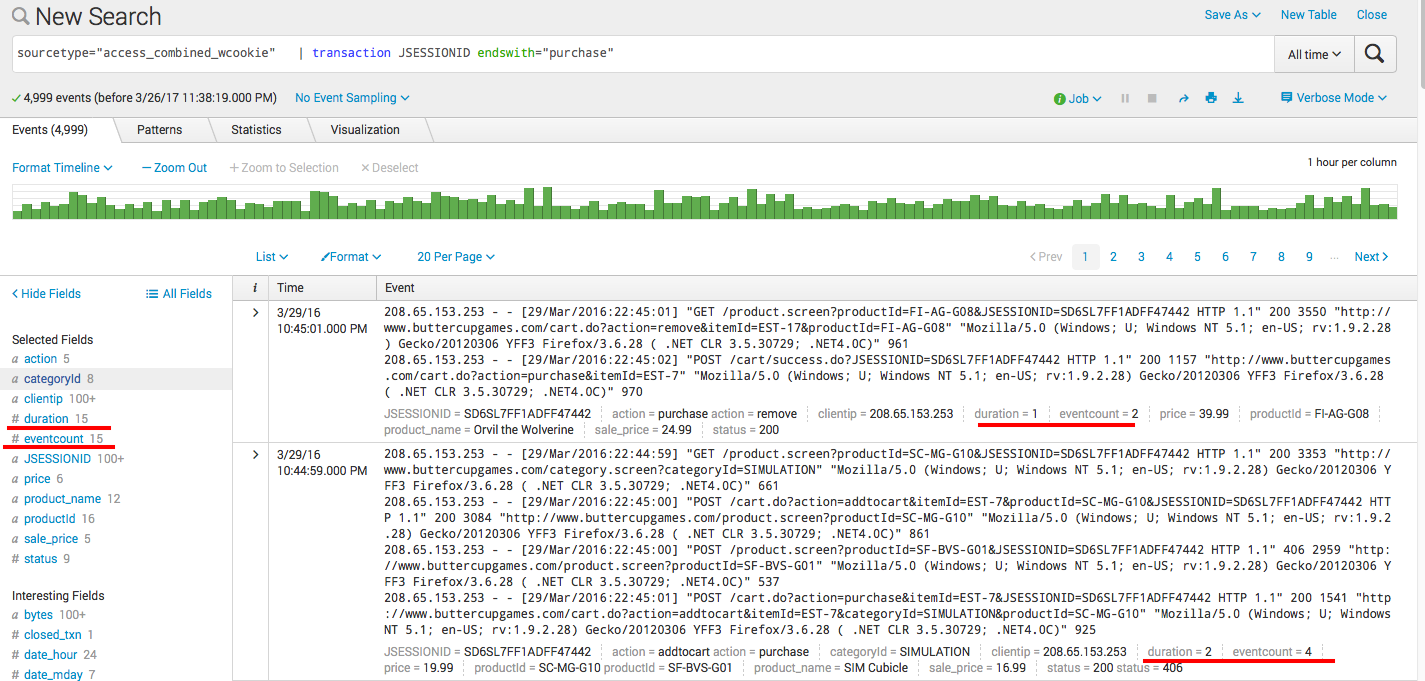
После чего получаем сгруппированные события, а также новые поля: длительность транзакции, и количество сгруппированных событий.
Теперь можно посчитать, к примеру, статистику по длительности сессий, то есть время за которое посетители решались совершить покупку.
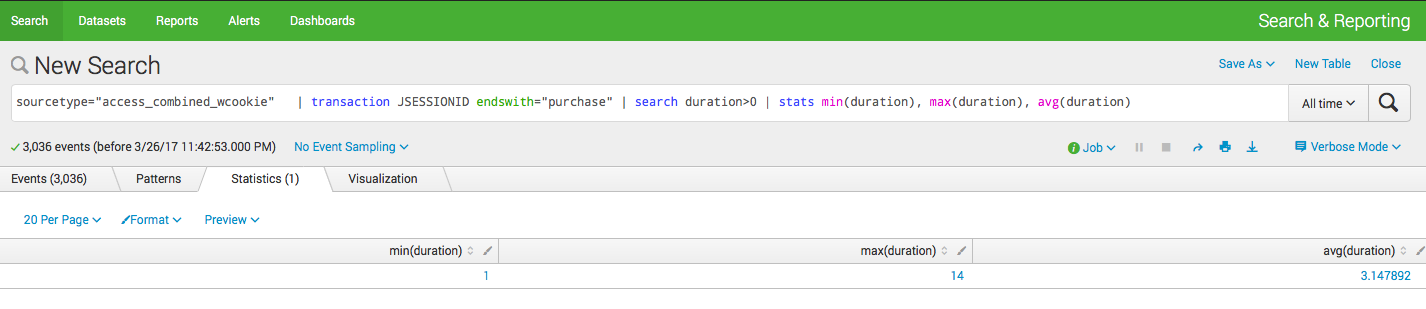
```
sourcetype="access_combined_wcookie" | transaction JSESSIONID endswith="purchase" | search duration>0 | stats min(duration), max(duration), avg(duration)
```
Также можно посчитать количество конкурентных сессий в каждый период времени, для этого есть команда [concurrency](https://docs.splunk.com/Documentation/Splunk/latest/SearchReference/Concurrency).
```
sourcetype="access_combined_wcookie" | transaction JSESSIONID | concurrency duration=duration
```

В результате, создается новое поле *concurrency*, которое и считает конкурентные сессии, но, к сожалению, из-за того что наши данные синтетические у нас в любой момент времени есть только одна конкурентная сессия, поэтому этот пример не очень результативен.
Заключение
----------
Конечно, примеры очень простые, но надеюсь, репрезентативные.
На этом мы заканчиваем данную статью!
Пишите свои вопросы если что-то не заработало или не получилось =)
Еще раз сылки на загрузку [данных](https://yadi.sk/d/OjbNMbSn3GJUYT) и [справочника c ценами](https://yadi.sk/i/a2SXKomg3GHAb8). | https://habr.com/ru/post/324716/ | null | ru | null |
# Re: Командная строка на службе фотографа-линуксоида
Недавно опубликована статья «[Командная строка на службе фотографа-линуксоида](http://habrahabr.ru/blogs/linux/128493/)», где автор пишет о решении разных типовых задач, встающих перед фотографом-линуксоидом, но он рассмотрел явно не всё.
Первая, а точнее, нулевая задача — скопировать изображения. Казалось бы, в ней нет чего-то такого, что бы подлежало оптимизации и автоматизации: всегда можно нажать F5 в mc либо перетащить файлы мышкой или же воспользоваться каким-нибудь менеджером фотографий наподобие digiKam. Можно — но не нужно: слишком много лишних движений. Фотографу-линуксоиду (а точнее, линуксоиду, время от времени занимающемуся фотографией) обычно надо лишь забрать фотографии с карты памяти, аккуратно сложить их на жёсткий диск, рассортировав, например, по времени съёмки и, если лишние буквы раздражают взгляд, убрать их.
Другая задача, о которой говорили в комментариях — пакетное уменьшение фотографий и их подписывание. Один из методов — использовать ImageMagick, к которому доступны различные интерфейсы: как интерфейс командной строки (программы convert, mogrify, montage), так и API для различных языков программирования. В случае с перлом — модуль [Image::Magick](http://search.cpan.org/perldoc?Image::Magick). ImageMagick позволит и уменьшить фотографию, и подписать её.
Я подобные задачи автоматизировал следующим образом:
Перенос фотографий:
```
#!/usr/bin/perl -wl
use strict;
use File::Find;
use File::Path qw(make_path);
use File::Copy;
use Image::ExifTool qw(:Public);
# You can change these variables
my $PATH_SRC = '/media/NIKON/DCIM'; # path to memory card
my $PATH_DST = $ENV{'HOME'} . '/photo'; # path to destination. Don't use ~ for your homedir
my $PRECISION = 2; # 0 for year .. 5 for second
my $MODE = 0644; # for chmod
# Don't touch the rest of file
find( \&wanted, $PATH_SRC );
sub wanted {
return unless /\.jpg/i;
my $new_name = lc $_;
$new_name =~ s/^\D+//;
my $info = ImageInfo( $File::Find::name );
my @date = split /\D+/, $info->{'DateTimeOriginal'};
$#date = $PRECISION;
my $new_dir = join '/', $PATH_DST, @date;
make_path $new_dir
unless -d $new_dir;
my $new_path = "$new_dir/$new_name";
-d $new_dir
and move $File::Find::name, $new_path
and chmod $MODE, $new_path
and print "$File::Find::name => $new_path";
} # sub wanted
```
Уменьшение и подписывание:
```
#!/usr/bin/perl -w
use strict;
use Image::ExifTool ':Public';
use Image::Magick;
use Getopt::Long;
# Constants
my %preferred_fonts = (
'date' => [ qw/ DejaVuSans DejaVu-Sans Bitstream-Vera-Sans BitstreamVeraSans Verdana / ], # Normal width
'name' => [ qw/ DejaVuSansC DejaVu-Sans-Condensed Tahoma / ], # Narrow
'site' => [ qw/ DejaVuSansB BitstreamVeraSansB VerdanaB TahomaB / ], # Bold
);
my $color = '#fff2';
my $gap = 10;
my $name = (getpwuid $>)[6];
$name =~ s/,+$//;
my $prefix = 'small.';
my $site = 'your-site.ru';
my $size = '50%';
# Override with options
GetOptions(
'color:s' => \$color,
'gap:i' => \$gap,
'name:s' => \$name,
'prefix:s' => \$prefix,
'site:s' => \$site,
'size:s' => \$size,
);
# Try to find suitable fonts
my $image = new Image::Magick;
my @available_fonts = $image->QueryFont();
my ( %seen, %fonts );
map { $seen{$_} = 1 } @available_fonts;
while ( my ( $scope, $list ) = each %preferred_fonts ) {
foreach ( @$list ) {
$fonts{ $scope } = $_
and last
if $seen{$_};
} # foreach
} # while
foreach my $file ( @ARGV ) {
my $info = ImageInfo($file, 'CreateDate');
my $date = $$info{'CreateDate'};
my $new_file_name = $file;
$new_file_name =~ s{([^/]+)$}{$prefix$1};
$date =~ s/^(\d{4}):(\d{2}):(\d{2}).*/$3.$2.$1/;
my $p = new Image::Magick or next;
$p->Read( $file );
$p->AutoOrient;
$p->Resize(
'geometry' => $size,
'filter' => 'Lanczos',
'blur' => 0.5,
);
my ( $width, $height ) = $p->Get('width', 'height');
my ( $x, $y ) = ( $width - $gap, $height - $gap );
$p->Set(
'pointsize' => 12,
'fill' => $color,
);
$p->Annotate(
'font' => $fonts{'name'},
'text' => $name,
'rotate' => -90,
'x' => $x,
'y' => $y,
);
$y -= (
$p->QueryFontMetrics(
'font' => $fonts{'name'},
'text' => $name,
)
)[4] + $gap;
$p->Annotate(
'font' => $fonts{'site'},
'text' => $site,
'rotate' => -90,
'x' => $x,
'y' => $y,
);
$y -= (
$p->QueryFontMetrics(
'font' => $fonts{'site'},
'text' => $site,
)
)[4] + $gap;
$p->Annotate(
'font' => $fonts{'date'},
'text' => $date,
'rotate' => -90,
'x' => $x,
'y' => $y,
);
$p->Sharpen(
'radius' => 1,
'sigma' => 2,
);
$p->Write($new_file_name);
print "$file - $date\n";
} # foreach
```
Готовые скрипты и документация к ним выложены на github.com:
* [move-images.pl](https://gist.github.com/483212)
* [resize-mark.pl](https://gist.github.com/600484) | https://habr.com/ru/post/128527/ | null | ru | null |
# PHP-фреймворк Badoo
 Код нашего сайта повидал уже не одну версию PHP. Он неоднократно дополнялся, переписывался, модифицировался, рефакторился — в общем, жил и развивался своей жизнью. В это время в мире появлялись и исчезали новые best practice, подходы, фреймворки и тому подобные явления, облегчающие жизнь разработчику и готовые решить все основные проблемы, возникающие в процессе создания веб-сайтов.
В этой статье мы расскажем о нашем пути: как был организован код изначально, какие возникали проблемы и как появился текущий фреймворк.
#### Что было
Проект начали делать еще в 2005 году. Тогда никаких жестких правил по написанию кода и четко структурированного фреймворка не было. Код писали несколько разработчиков, они легко в нем ориентировались и его поддерживали, каждый привносил что-то свое. В то время известные сейчас фреймворки только создавались, поэтому примеров для подражания было мало. Так что можно сказать, что наш фреймворк образовался стихийно.
С архитектурной точки зрения это выглядело так: были объекты страниц, наследуемые от целой иерархии базовых классов, отвечающих за инициализацию окружения, сессии, пользователя и т.п. Каждая страница сама решала, когда, как и что ей выводить, делать редирект и т.п. В иерархии базовых классов было собрано много вспомогательных функций для инициализации и генерации стандартных блоков страниц, проверки пользователей, показа промежуточных промо-страниц и т.п. Со временем большинство из них было переопределено наследниками до неузнаваемости, что в разы усложнило и понимание того, как работает сайт, и саму поддержку кода.
Были пакеты — наборы классов, к которым обращались страницы, чтобы получить данные или обработать каким-то образом. Были представления, которые отвечали за шаблонизацию и вывод. В обычном случае каждая страница получала какие-то данные, передавала их в класс View, который расставлял их в структуру blitz-шаблона и выводил. Так сложилось, что для каждой страницы был свой шаблон (не было базового), и отличался он набором подключаемых скриптов, стилей и центральной частью.
В принципе, это выглядело как обычная MVC-подобная схема. Но без четкой организации кода и с ростом количества разработчиков такой код стало все сложнее поддерживать.
Что же, собственно, нас не устраивало и нужно было улучшить?
**1. Использование глобального контекста и статичных переменных.**
С одной стороны, это удобно, когда можно из любой точки кода получить глобальный объект. С другой — он становится зависимым, повышается связанность. С началом unit-тестирования мы поняли, что такой код ужасно тяжело тестировать: первый тест легко ломает следующий, за этим необходимо очень жестко следить. К тому же код, который использует глобальные объекты, а не имеет лишь вход и выход, требует много mock-объектов для тестирования.
**2. Большая связанность контроллеров с представлениями.**
Подготовка данных зачастую происходила под конкретный View, т. е. под конкретный шаблон. Целые иерархии контроллеров, наследуемых друг от друга, по частям собирают данные для blitz-шаблона. Поддержка такого кода крайне затруднительна. Создание версии с абсолютно другим шаблоном (например, мобильной версии) становилась порой почти неосуществимой задачей, поэтому было проще написать все с нуля.
**3. Использование публичных свойств как норма.**
Изначально PHP не поддерживал приватные свойства объектов. Поскольку наш код имеет достаточно большую историю, то в нем осталось много мест, где свойства объявляются через var, и много кода, который использует это. Вполне нормально встретить объект, который передается в другой объект, а тот что-то устанавливает или производит какие-то манипуляции со свойствами первого. Такой код очень сложен в понимании и отладке. В идеале нужно всегда делать геттеры и сеттеры для свойств классов — это сэкономит уйму времени и нервов вам и вашим коллегам!
**4. Ассоциативные массивы как контейнер для передачи параметров.**
Большой проблемой для нас стало то, что данные, полученные из одного источника, переносятся в какой-нибудь обработчик или контроллер, а по пути туда может быть дописано что угодно и в неограниченном количестве. В итоге все это постоянно обрастает новыми параметрами и в таком виде отправляется в класс View. Хотя лучше было бы использовать какую-нибудь типизацию или интерфейс, чтобы избежать хаоса.
**5. Отсутствие единой точки входа.**
Каждая страница — это отдельный php-файл, содержащий класс, наследуемый от базового. Если входные данные в такой схеме контролировать в одном месте возможно, то на выходе сделать что-то массово будет уже крайне сложно. Заведение маршрута, отличного от имени папки, файла или содержащего переменные, требует правки конфигов nginx. А это усложняет тестирование в стандартном рабочем процессе, требует предоставления дополнительного доступа и сложнее поддерживается при большом количестве разработчиков.
#### Новые задачи для фреймворка
Естественно, мы хотели решить большинство вышеперечисленных проблем. Мы хотели иметь возможность «из коробки» отображать одни и те же данные в разном представлении (JSON, мобильной или веб-версии). До этого задача решалась только набором IF-ов в каждом конкретном случае.
Безусловно, новый фреймворк должен был быть достаточно легко совместим со старым кодом, а не вызывать у разработчиков сложностей при переходе. Именно поэтому мы не стали переходить на популярные фреймворки, а лишь воспользовались некоторыми идеями из них. Гораздо сложнее было бы переучить всех писать под какой-то конкретный популярный фреймворк. К тому же у нас много кода, заточенных под нас стандартных компонентов, которые есть в любом фреймворке, и пришлось бы проводить не самую простую интеграцию.
При проектировании мы старались сделать максимально удобный для разработчика фреймворк, чтобы было легко пользоваться авто-подстановками, генерацией кода и другими полезными функциями, ускоряющими и упрощающими разработку и, что немаловажно, рефакторинг.
#### Какова архитектура фреймворка?
На основе глобальных переменных окружения создается объект Request, который передается приложению для получения ответа.
```
$Request = new Request($_GET, $_POST, $_COOKIE, $_SERVER);
$App = new Application();
$Response = $App->handle($Request);
$Response->send();
```
В процессе работы приложение генерирует события «Получен запрос», «Найден контроллер», «Получены данные», «Поймано исключение», «Рендеринг данных», «Получен ответ».
```
$Dispatcher = new EventDispatcher();
$Dispatcher->setListeners($Request->getProject()->loadListeners());
$RequestEvent = new Event_ApplicationRequest($Request);
$Dispatcher->dispatch($RequestEvent);
```
На каждое событие есть набор подписчиков, которые реагируют специальным образом. Например, Listener\_Router по клиенту (в основном по HTTP\_USER\_AGENT) и значению REQUEST\_URI находит контроллер (например, Controller\_Mobile\_Index) и устанавливает его в объект события. После диспетчеризации этого события приложение либо вызывает найденный контроллер, либо кидает исключение Exception\_HttpNotFound, которое будет выведено как ответ сервера 404. Пример списка подписчиков:
```
$listeners = [
\Framework\Event_ApplicationRequest::class => [
[\Framework\Listener_Platform::class, 'onApplicationRequest'],
[\Framework\Listener_Client::class, 'onApplicationRequest'],
[\Framework\Listener_Router::class, 'onApplicationRequest'],
],
];
```
Каждый контроллер представляет из себя отдельный класс с набором методов — action-ов. Фреймворк находит по карте маршрутов соответствующий класс и метод, создает объект Action (для удобства, вместо callable-массива). Пример карты маршрутов:
```
$routes = [
Routes::PAGE_INDEX => [
'path' => '/',
'action' => [Controller_Index::class, 'actionIndex'],
],
Routes::PAGE_PROFILE => [
'path' => '/profile/{user_login}',
'action' => [Controller_Profile::class, 'actionProfile'],
],
];
```
В массиве маршрутов указаны базовые классы. Если класс имеет наследника под текущего клиента, то будет использован именно он. Имена маршрутов в константах позволяют удобным образом генерировать URL-ы в любом месте проекта.
Далее происходит диспетчеризация события «Найден контроллер». Поведением подписчиков этого события можно управлять из контроллера.
```
$ActionEvent = new Event_ApplicationAction($Request, $RequestEvent->getAction());
$Dispatcher->dispatch($ActionEvent);
```
Например, для всех контроллеров, к которым обращается JavaScript, мы автоматом проверяем request-token для защиты от CSRF-уязвимостей. За это отвечает отдельный класс Listener\_WebService. Но бывают сервисы, для которых нам это не требуется. В таком случае контроллер наследует интерфейс Listener\_WebServiceTokenCheckInterface и реализует метод checkToken:
```
public function checkToken($method_name)
{
return true;
}
```
Здесь $method\_name — имя метода контроллера, который будет вызван.
За работу с данными (например, загрузку из БД) у нас отвечают пакеты (packages) — наборы классов, объединенные одной областью применения. Контроллер получает данные из пакетов и, вместо использования массива для передачи данных во View, устанавливает их в объект ViewModel — по сути, в контейнер с набором сеттеров и геттеров. За счет этого внутри View всегда известно, какие данные переданы. Если набор данных меняется, все использования методов класса ViewModel можно запросто найти и поправить нужным образом. Будь это массив, пришлось бы искать по всему репозиторию, а потом и среди всех вхождений, особенно, если ключ массива назван простым и распространенным словом, например, “name”.
Хотя такое обилие классов может казаться излишним, но в крупном проекте с большим количеством разработчиков это ощутимо помогает при поддержке кода. Сначала мы сделали возможность установки данных сразу во View, но быстро от нее отказались, поскольку у нас может быть не один проект, в котором требуется один и тот же контроллер, но данные отображаются по-разному. В любом случае придется создавать ViewModel и делать дополнительные View, поэтому лучше сразу написать чуть больше кода, что избавит в будущем от рефакторинга и дополнительного тестирования. Сейчас мы рассматриваем разные варианты оптимизации, поскольку многие разработчики считают, что кода стало очень много.
На основе поступивших данных View готовит итоговый результат — это строка или специальный объект ParseResult. Это сделано, чтобы реализовать отложенный рендеринг: сначала идет подготовка всех данных, и лишь потом финальный рендеринг всего разом. Самый частый случай — создание страницы на основе blitz-шаблона и некоторых данных, подставляемых в него. В таком случае объект ParseResult будет содержать имя шаблона и массив с готовыми для шаблонизации данными, которые достаточно в нужный момент отправить в Blitz и получить итоговый HTML. Данные для шаблонизации могут содержать вложенные объекты ParseResult, поэтому финальный рендеринг производится рекурсивно. Тут хочется предостеречь вас от использования функции array\_walk\_recursive: она ходит не только по массивам, но и по публичным свойствам объектов. В связи с этим некоторые страницы у нас падали по памяти, пока мы не сделали собственную простую рекурсивную функцию:
```
function arrayWalkRecursive($data, $function)
{
if (!is_array($data)) {
return call_user_func($function, $data);
}
foreach ($data as $k => $item) {
$data[$k] = arrayWalkRecursive($item, $function);
}
return $data;
}
```
Поскольку общение между PHP и JavaScript у нас очень тесное, то для него реализована соответствующая поддержка. Каждый объект View — это конкретный блок на сайте: header, sidebar, footer, центральная часть и т.п. Для каждого блока или компонента может быть свой собственный обработчик на JavaScript, который настраивается при помощи определенного набора данных — js\_vars. Например, через js\_vars передаются настройки для comet-соединения, по которому приходят разные обновления — счетчики, всплывающие уведомления и т.п. Все такие данные передаются через единую точку, определенную в blitz-шаблоне:
```
$vars = {{JS\_VARS}};
```
Помимо этого, у нас есть контроллеры, к которым обращается только JS и получает в качестве результата JSON. Мы называем их веб-сервисами. Относительно недавно мы начали описывать протокол общения PHP и JS с использованием Google Protocol Buffers (protobuf). На основе proto-файлов генерируются PHP-классы с набором сеттеров, автоматически валидирующие устанавливаемые в них данные, что позволяет оптимальным образом формализовать договоренность между front-end и back-end разработчиками. Ниже приведен пример proto-файла для описания оверлея и использование PHP-класса, сгенерированного на его основе:
```
package base;
message Ovl {
optional string html = 1;
optional string url = 2;
optional string type = 3;
}
```
```
$Ovl = \GPBJS\base\Ovl::createInstance();
$Ovl->setHtml($CloudView);
$Ovl->setType('cloud');
```
На выходе получаем JSON:
```
{"$gpb":"base.Ovl","html":"here goes html","type":"cloud"}
```
Среди всего прочего, в данных для JS может быть и HTML, получаемый из blitz-шаблонов. Каждый блок устанавливает js\_vars от корня, и они рекурсивно сливаются в одну структуру при помощи функции array\_replace\_recursive. Пример структуры, готовой к рендерингу:
```
ParseResult Object
(
[js_vars:protected] => Array
(
[Sidebar] => Array
(
[show_menu] => 1
)
[Popup] => Array
(
[html] => ParseResult Object
(
[js_vars:protected] => Array ()
[template:protected] => popup.tpl
[tpl_data:protected] => Array
(
[name] => Alex
)
)
)
)
[template:protected] => index.tpl
[tpl_data:protected] => Array
(
[title] => Main page
)
)
```
Обычно контроллер готовит один блок на сайте — его центральную часть, а остальные блоки либо скрываются или показываются, либо определенным образом меняют свое поведение в зависимости от текущего контроллера. Для управления всем «каркасом» страницы используется объект Layout (грубо говоря, это базовый объект View), который устанавливает стандартные блоки и центральную часть в объект ParseResult для базового шаблона. Чтобы объявить, какой Layout будет использован, контроллер наследует специальный интерфейс HasLayoutInterface и реализует метод getLayout.
Помимо сборки всей страницы, Layout несет дополнительную функцию: он формирует результат в виде JSON для «бесшовных» переходов между страницами. Уже достаточно давно наш сайт работает как веб-приложение: переходы между страницами осуществляются без перезагрузки всей страницы, меняются только определенные элементы (URL, заголовок, центральная часть, показываются или скрываются определенные блоки).
#### Интеграция
Первой и одной из самых сложных задач при переходе на новый фреймворк стала необходимость создания единой инициализации сайта. Изначально мы проверяли работу на одной из простых страниц и запускали из старого фреймворка, где выполнялась вся инициализация.
```
class TestPage extends CommonPage
{
public function run()
{
\Framework\Application::run(); // Запуск нового фреймворка
}
}
$TestPage = new TestPage();
$TestPage->init(); // Инициализация старого фреймворка
$TestPage->run();
```
Чтобы сделать независимый запуск нового фреймворка и оставить единую инициализацию, необходимо было вынести все, что происходит в init(), в отдельные классы и использовать и там, и там. Это было выполнено поэтапно, и в итоге получилось порядка 40 классов.
После этого для пробы мы перевели несколько небольших проектов. Одним из первых было переведено наше расширение для браузера Chrome ([Badoo Chrome Extension](https://chrome.google.com/webstore/detail/badoo-notifications-exten/gngmhdpofjbdiecihebaaooakicnjjmc?hl=en)). А первым большим проектом стал сайт [Hot Or Not](http://hotornot.com/), целиком написанный на новом фреймворке. В настоящее время мы постепенно переводим на него и наш основной сайт [Badoo](http://badoo.com).
Проекты, полностью реализованные на новом фреймворке, работают через фронт-контроллер, то есть единую точку входа — index.phtml. Для badoo.com мы имеем множество правил в nginx, последнее из которых отправляет на профиль. Т.е. badoo.com/something либо откроет профиль пользователя something, либо вернет 404. Именно поэтому, пока профиль полностью не переведен на новый фреймворк, у нас еще остается множество \*.phtml файлов, которые содержат в себе лишь запуск фреймворка.
```
php
/*... includes ...*/
\Framework\Application::run();
</code
```
Раньше в этих файлах был код на старом фреймворке. После рефакторинга код был перенесен в контроллеры нового фреймворка, но сами файлы не могут быть удалены. Они должны существовать, чтобы nginx запускал их, а не отправлял запрос на профиль.
#### Заключение
В итоге мы решили достаточно большой пласт проблем: создали единую точку входа, убрали много уровней наследования, максимально уменьшили использование глобального контекста, код стал более объектным и типизированным. В основном изменения коснулись маршрутизации и всего процесса работы веб-скриптов, от запроса до ответа сервера. Также появилась кардинально новая система работы с представлением данных. Мы пробовали создать единую схему по доступу к данным, но пока не нашли решение, которое бы нас полностью устраивало. Но получившееся можно смело считать уверенным шагом в сторону удобной разработки и поддержки кода.
Александр [Treg](http://habrahabr.ru/users/treg/) Трегер, разработчик. | https://habr.com/ru/post/238987/ | null | ru | null |
# jQuery 1.7 Released
jQuery 1.7 готов к загрузке! Можно скачать с jQuery CDN:
[code.jquery.com/jquery-1.7.js](http://code.jquery.com/jquery-1.7.js)
[code.jquery.com/jquery-1.7.min.js](http://code.jquery.com/jquery-1.7.min.js)
Так же этот релиз будет готов к загрузке с Google и Microsoft CDNs в течении дня или двух.
Команда jQuery благодарит всех, кто принимал участие в тестировании и и поиске багов в бета-версиях и верит в прочность и стабильность релиза. И просит всех, кто найдёт какие-либо баги, рапортовать о них на [баг-трекер](http://bugs.jquery.com/) и по-возможности подкреплять тестами для воспроизведения на [jsFiddle](http://jsfiddle.net/) для более быстрого анализа проблем.
#### Что нового в версии 1.7
Краткий список нововведений можно быстро получить просмотрев [описание API с тегом 1.7](http://api.jquery.com/category/version/1.7/), а ниже будет описание больших новшеств версии 1.7 и некоторые вещи, которые пока ещё не вошли в документацию по API.
##### Новый API событий: .on() и .off()
Новый **.on() и .off() API** делает универсальным и более удобным привязку к событиям в документе.
```
$(elements).on( events [, selector] [, data] , handler );
$(elements).off( [ events ] [, selector] [, handler] );
```
Когда указан `selector`, то метод `.on()` работает так же, как `.delegate()` — привязывает обработчики события, фильтруя элементы по селектору. Если же `selector` не указан или равен `null`, то вызов работает как обычный `.bind()`. Существует некоторая неоднозначность: если аргумент `data` является строкой, требуется явно передавать аргумент `selector` в виде строки или `null`, чтобы `data` не был ошибочно принят за селектор. Передавая в качестве `data` объект, не требуется специально беспокоится об указании селектора.
Все существующие виды привязок к событиям (и соответствующие им метода отвязки от событий) доступны и в версии 1.7, но рекомендуется использовать именно `.on()` для новых проектов, где гарантированно будет использоваться версия 1.7 или старше. Ниже приведены небольшие примеры, демонстрирующие аналогичные привязки к событиям с использованием старого и нового API:
```
$('a').bind('click', myHandler);
$('a').on('click', myHandler);
$('form').bind('submit', { val: 42 }, fn);
$('form').on('submit', { val: 42 }, fn);
$(window).unbind('scroll.myPlugin');
$(window).off('scroll.myPlugin');
$('.comment').delegate('a.add', 'click', addNew);
$('.comment').on('click', 'a.add', addNew);
$('.dialog').undelegate('a', 'click.myDlg');
$('.dialog').off('click.myDlg', 'a');
$('a').live('click', fn);
$(document).on('click', 'a', fn);
$('a').die('click');
$(document).off('click', 'a');
```
##### Улучшена производительность делегированных событий (Delegated Events)
Делегирование событий (event delegation) приобретает всё большую важность с ростом размера и сложности страниц. Такие фреймворки, как Backbone и Sproutcore, широко используют делегирование событий. Имея это в виду, обработка событий в jQuery 1.7 была переработана с целью ускорить процесс обработки событий, особенно для наиболее распространённых случаев.
Чтобы оптимизировать код для часто встречающихся видов селекторов, команда jQuery рассмотрела срез с Google Codesearch. Почти две третьих всех селекторов, используемых в `.live()` и `.delegate()`, имеют вид `tag#id.class`, где используются один или несколько тегов, id или классов. В оптимизации разбора этих простых селекторов команда jQuery добилась таких успехов, что смогла обойти даже время нативного `matchesSelector` браузеров во время обработки событий. Для разбора более сложных селекторов по-прежнему используется Sizzle движок.
В конечном результате имеет почти двукратное ускорение по сравнению с версией 1.6.4:
##### Улучшение поддержки HTML 5 в IE 6/7/8
Любой, кто пробовал использовать новые теги из HTML5, например, такие как , гарантировано имели проблемы не только с тем, что IE 6/7/8 не понимают этих тегов, но ещё и совсем удаляют их из документа. В jQuery 1.7 есть встроенная поддержка тегов HTML5 для старых IE в таких методах, как `.html()`. Этот механизм реализован на том же уровне, что и ранее [innerShiv](http://jdbartlett.com/innershiv/). **По-прежнему требуется подключать [HTML5Shiv](http://code.google.com/p/html5shiv/) в секции `head` документа для поддержки HTML5-тегов в старых IE.** Подробности смотрите на [The Story of the HTML5 Shiv](http://paulirish.com/2011/the-history-of-the-html5-shiv/).
##### Интуитивная работа переключения анимации
В предыдущих версиях jQuery переключение анимации, такое как `.slideToggle()` или `.fadeToggle()`, не срабатывало правильно, если несколько анимаций были запущены последовательно и предыдущая была прервана методом `.stop()`. Это было исправлено в версии 1.7, теперь перед запуском анимации запоминаются начальные значения, и происходит сброс значений, если переключение анимации было прервано преждевременно.
##### Asynchronous Module Definition (AMD)
Теперь jQuery [поддерживает](http://bugs.jquery.com/ticket/7102) асинхронное определение модуля — [AMD API](https://github.com/amdjs/amdjs-api/wiki/AMD). Это не означает, что jQuery является загрузчиком скриптов (script loader); jQuery всего лишь использует AMD-совместимую модель определения модуля, поддерживаемую, например, RequireJS или curl.js, поэтому jQuery может быть подключена динамически таким загрузчиком, и событие `ready` также является подконтрольным ему. Теперь AMD-совместимые загрузчики могут подключать немодифицированную версию jQuery с CDN (например, от Google или Microsoft). Особая благодарность выражается James Burke (@jrburke) за предоставленные патч и тесты и ожидание включения их сборку.
##### jQuery.Deferred
Объект [jQuery.Deferred](http://api.jquery.com/category/deferred-object/) был расширен новыми обработчиками прогресса и методами уведомления, вызывающими этими обработчики. Это позволяет асинхронно уведомлять слушателей о прогрессе исполнения без завершения или отмены запроса. Дополнительно появился метод `state()`, который возвращает состояние Deferred-объекта, это в первую очередь полезно при отладке.
Теперь Deferreds реализованы через использование новой функциональности — [jQuery.Callbacks](http://api.jquery.com/category/callbacks-object/), обобщающей функции вызова очереди или серии колбэков. Эта новая функциональность может быть интересно писателям плагинов, хотя Deferreds и система событий обеспечивают более высокий уровень подобной функциональности.
##### jQuery.isNumeric()
Внутри jQuery было найдено несколько ситуаций, когда необходимо знать, является ли аргумент числом или может быть успешно сконвертирован в число. И было решено написать и задокументировать метод [jQuery.isNumeric()](http://api.jquery.com/jQuery.isNumeric) как полезную утилиту. Передайте внутрь него любой аргумент и получите `true` или `false` в качестве результата.
#### Удаленная функциональность
**event.layerX и event.layerY:** в версии 1.7 удалены эти нестандартные свойства. Хотя ранее они никому не мешали, Chrome 16 показывает множество предупреждений в консоли. Поэтому было решено отказаться от них и удалить. Там, где ещё поддерживаются эти свойства, они будут доступны через `event.originalEvent.layerX` и `event.originalEvent.layerY`.
**jQuery.isNaN():** эта недокументированная утилита была также удалена. Она имела имя встроенной функции JavaScript, но семантически не соответствовала ей. Новая функция `jQuery.isNumeric()` позволяет делать тоже самое. Несмотря на то, что функция `jQuery.isNaN()` была недокументирована, некоторые проекты на Github использовали её. Команда jQuery связалась с ними и предупредили о проблеме и возможных решениях.
**jQuery.event.proxy():** этот недокументированный и устаревший метод был удалён. Вместо него следует использовать задокуентированный метод `jQuery.proxy`.
*Прочие благодарности и change log со списком всех поправленных багов можно прочитать в конце оригинальной статьи [blog.jquery.com/2011/11/03/jquery-1-7-released](http://blog.jquery.com/2011/11/03/jquery-1-7-released/)* | https://habr.com/ru/post/131884/ | null | ru | null |
# Node.js и переход с PHP на JavaScript
Больше десяти лет я был PHP-разработчиком, но недавно перешёл на JavaScript, используя его серверные и клиентские возможности. До этого я уже был знаком с JS. Сначала работал с jQuery, потом освоил Angular, и, наконец, начал пользоваться React.
Когда я начинал писать на PHP, я встраивал его в HTML-файлы. Получался не код, а полный бардак. Поэтому, для того, чтобы привести мои разработки в приличный вид, я начал пользоваться фреймворками, в частности, ZF1 и ZF2. Через некоторое время подход, при использовании которого начинают разработку с API, привёл к тому, что у меня оказался сервер, состоящий из сгенерированных REST API и из нескольких сотен строк моего собственного кода.
[](https://habrahabr.ru/company/ruvds/blog/339176/)
Так как лишь небольшая и не самая важная часть наших проектов была написана на PHP, возник вопрос о том, можем ли мы от него избавиться. И, если можем, чего нам это будет стоить, и что мы от этого получим. В этом материале я поделюсь опытом с теми, кто, как и я, хочет, понимая, что и зачем он делает, уйти из мира PHP и встать под знамёна JavaScript во всех его проявлениях.
Сегодня я расскажу, в основном, о своём путешествии с серверной стороны PHP на серверную сторону JS в виде Node.js. Здесь я не буду рассказывать о Webpack, React и о других клиентских технологиях JS.
Эволюция стека технологий
-------------------------
Начнём с общей схемы, которая описывает эволюцию используемого нами стека технологий при переходе с PHP на Node.js.
*Основные изменения используемого нами стека технологий*
Node.js — это основной компонент нашего нового набора технологий. Он отличается высокой производительностью.
Node.js делает своё дело настолько хорошо, что для множества инструментов, ранее написанных на низкоуровневых языках, теперь имеются эквиваленты на JavaScript. Установка обычных программ под используемые нами платформы была такой трудоёмкой, что нам приходилось использовать Ansible для развёртывания рабочей среды. Так как новые инструменты зависят теперь только от Node.js, единственное, что нам приходится устанавливать самостоятельно — это [NVM](https://github.com/creationix/nvm/blob/master/README.md) (Node Version Manager) — средство, предназначенное для установки Node.js.
Как правильно устанавливать Node.js с помощью NVM
-------------------------------------------------
Когда мы устанавливали Node.js вручную, или используя менеджер пакетов операционной системы, это быстро создало массу проблем при попытках переключаться между версиями Node. В итоге мы пришли к использованию NVM.
Этот инструмент очень легко установить и использовать:
```
wget -qO- https://raw.githubusercontent.com/creationix/nvm/v0.33.2/install.sh | bash
nvm install node
nvm use v6.9.1
```
После его установки нам стали доступны следующие возможности:
* Установка различных версий Node.js на одной системе с использованием одной команды.
* Удобное переключение между установленными версиями Node.js.
Кроме того, что особенно приятно, NVM работает на Linux, на Mac, и на [Windows](https://github.com/coreybutler/nvm-windows).
JavaScript в 2017-м году
------------------------
Начиная изучать JavaScript, я воспринимал его как второсортный язык, без которого «к сожалению, не обойтись» при создании динамических веб-сайтов. В результате я никогда и не пытался как следует в нём разобраться. Я учил JavaScript, в основном, по постам в блогах, да по ответам на Stack Owerflow. Теперь я об этом сожалею.

*Учите матчасть!*
Я был не готов начать использовать современные фреймворки и инструменты JavaScript. В 2017-м JavaScript стал совсем другим благодаря новым возможностям. Среди них можно отметить следующие:
* Классы.
* Промисы (теперь — встроенные в язык).
* Операторы деструктурирования и расширения.
* Модули и загрузчики модулей.
* Структуры Map / Set и их варианты со слабыми ссылками.
* Async / Await.
В итоге я выделил время на то, чтобы проработать кучу материала и как следует изучить JavaScript. Например, сайт [Babeljs.io](https://babeljs.io/learn-es2015/) дал мне замечательный обзор того, что такое современное программирование на JavaScript.
Переход с Composer на Yarn
--------------------------
Composer — отличный, но медленный инструмент. У NPM есть тот же недостаток, поэтому мы, вместо него, выбрали [Yarn](https://yarnpkg.com/en/). Это — самая быстрая альтернатива NPM.
В прошлом проекте у нас было около тысячи зависимостей. Команда разработчиков состоит из 10 человек, папка `node_modules` меняется, как минимум, 2 раза в день. Прикинем, сколько времени займёт установка пакетов за два месяца по следующей формуле:
(10 разработчиков + 3 окружения) \* 2 установки в день \* 60 дней \* 3 минуты на установку = 78 часов.
Оказывается, две недели рабочего времени было потрачено на наблюдение за ходом загрузки пакетов и на чтение Reddit. Три минуты — достаточно длинный отрезок времени, который способен вылиться в большие потери, но слишком короткий, чтобы, пока идёт установка, можно было бы переключиться на какую-нибудь другую задачу.
Благодаря Yarn нам удалось снизить время установки с 3-х минут до одной минуты. Это позволило сэкономить 46 часов рабочего времени. И, я вам скажу, это — отличный результат.
Создание API в JavaScript
-------------------------
Пожалуй, вместо того, чтобы рассказывать об этом самому, дам слово коду. Вот минимальный пример API, основанного на следующих пакетах:
* [Express](https://expressjs.com/en/starter/hello-world.html) — легковесный JS-эквивалент Zend Frameword 2 / Symfony.
* [Sequelize](http://docs.sequelizejs.com/manual/installation/getting-started.html) — альтернатива Doctrine.
* [Epilogue](https://github.com/dchester/epilogue) — альтернатива Apigility.
```
const Sequelize = require('sequelize'),
epilogue = require('epilogue'),
express = require('express'),
bodyParser = require('body-parser');
// Определим модели с помощью Sequelize
// Это - эквивалент определения сущностей Doctrine
let database = new Sequelize('database', 'root', 'password');
let User = database.define('User', {
username: Sequelize.STRING
});
// Создадим сервер Express
let app = express();
app.use(bodyParser.json());
app.use(bodyParser.urlencoded({ extended: false }));
// Подключим Epilogue к Express
epilogue.initialize({
app: app,
sequelize: database
});
// Настроим, с помощью Epilogue, конечные точки ресурсов REST
let userResource = epilogue.resource({
model: User,
endpoints: ['/users', '/users/:id']
});
//Вот и всё, теперь для User доступны запросы GET/POST и DELETE.
app.listen(() => {
console.log('Server started!');
});
```
Несколько строк кода — и у нас есть REST API, которое поддаётся настройке и расширению.
После того как мы создали более 50 конечных точек API с помощью Apigility, мы поняли две вещи. Во-первых — это возможно, во-вторых — эффективно.
Например, Epilogue без проблем генерирует 10 конечных точек. Имеется и возможность подключать собственный код к стандартному каркасу для поддержки сложных условий, вроде прав пользователей. То, что нельзя сгенерировать автоматически, создаётся в виде простых конечных точек Express RPC с помощью Sequelize.
Не спорю с тем, что Zend Framework 2 обладает гораздо большими возможностями, чем Express. Но Express оказался экономичным и простым решением, которого было достаточно для всех наших нужд. При переходе на него нам не пришлось от чего-либо отказываться.
Flow: спасательный круг для тех, кто утонул в море типов данных
---------------------------------------------------------------
В PHP можно было добавлять подсказки типов данных только тогда, когда это было нужно. Это — одна из моих любимых особенностей PHP. Здесь имеется мощная, но гибкая система типов.
```
php
class UserService {
public function createUser(string $name, User $parent = null, $isAdmin) : User
{
$user = new User($name);
...
return $user
}
}</code
```
Многие годы я думал, что нечто подобное в JS невозможно, что единственный выход — переход на TypeScript. Однако, я ошибался.
Я обнаружил библиотеку Flow, так же известную как [Flow-type](https://twitter.com/hashtag/flowtype), и смог без проблем добавлять информацию о типах в мои JS-тексты.
Установить библиотеку Flow несложно:
```
yarn add --save-dev flow-bin
node_modules/.bin/flow init
```
Так же просто её подключить, добавив одну строчку кода в верхнюю часть файлов, которые необходимо контролировать:
```
/* @flow */ или // @flow
```
Затем команда `flow check` позволяет получить отчёт, основанный на выведенных типах.
Если ваш проект использует транспилятор, вроде Babel, для поддержки подсказок типов Flow в JS можно добавить новые правила. В результате, с типами можно будет работать так же удобно, как и в PHP.
*Подсказки Flow*
Падение серверов и мониторинг с помощью PM2
-------------------------------------------
В мире PHP сбой скрипта означает необработанный запрос. В случае с Node.js, если падает сервер, перестаёт функционировать весь веб-сайт. Поэтому процессы необходимо мониторить.
В поиске хорошей системы мониторинга мы перешли с [Supervisord](http://supervisord.org/index.html) на его конкурента, написанного на JavaScript. Вот он:
→ [PM2 (Process Manager 2)](http://pm2.keymetrics.io/docs/usage/quick-start/)
Мне так нравится PM2, что я просто не могу удержаться от того, чтобы вставить сюда пару сердечек.
PM2 можно устанавливать с помощью Yarn, что само по себе очень хорошо, но и у самого PM2 есть немало сильных сторон. Так, в плане возможностей, он превосходит Supervisord. Он умеет отслеживать нагрузку, которую каждый процесс создаёт на систему, и занимаемую процессом память, его можно настроить так, чтобы он перезапускал процессы при изменении их кода.

*Команда pm2 list позволяет вывести сведения обо всех управляемых PM2 процессах*
Команда `pm2 monit` выдаёт подробный отчёт о том, что происходит с каждым процессом в реальном времени. Кроме того, PM2 упрощает логирование, так как мы можем, без дополнительных усилий, пользоваться стандартными командами `console.log()/.warn()/.error()`.
*PM2 визуализирует вывод служб и может отслеживать заданные пользователем метрики*
Скажу больше. В то время, как сфера возможностей Supervisord ограничена управлением процессами, PM2 может заменить некоторые скрипты, используемые для развёртывания проектов, простыми конфигурационными файлами:

*Конфигурационный файл, который позволяет удобно описывать и разворачивать процессы*
PM2 для меня — одно из важнейших преимущества перехода на JavaScript. Кроме того, мы можем использовать его для проектов, написанных на любом языке, единственный минус — в подобных случаях, нет столь же тесной интеграции, как при работе с проектами, основанными на JS.
Конфигурирование проектов с помощью .env
----------------------------------------
В наших проектах [Phing](https://www.phing.info/) использовался для решения трёх задач:
* Конфигурирование проекта.
* Написание скриптов.
* Хранение полезных команд.
В мире JavaScript задачи конфигурирования можно решить с помощью отличной библиотеки [DotEnv](https://github.com/motdotla/dotenv) и файлов `.env`. Библиотека позволяет использовать переменные окружения для настройки приложения. Это — один из рекомендованных приёмов из методологии [The Twelve-Factor App](http://12factor.net/config), которую мы используем на постоянной основе.
Те задачи, которые решались благодаря скриптовым возможностям Phing, больше не требуют от нас использования специальных инструментов. Раньше все наши скрипты были либо привязаны к конфигурированию ПО за пределами мира PHP, такого, как Supervisord, либо могли быть оформлены как независимые сценарии командной строки.
В итоге, единственная роль, которую мог бы выполнять Phing, заключается в хранении команд и создании для них сокращений. Эту задачу отлично решает Yarn (или NPM):
```
{
"name": "my project name",
"...": "...",
"scripts": {
"release": "standard-version",
"db-reset": "rm -rf data/main.db && sequelize db:migrate && sequelize db:seed:all",
"db-migrate": "sequelize db:migrate",
"dev": "pm2 delete all; pm2 startOrReload ecosystem.config.js && pm2 start react-scripts --name web -- start",
"start": "pm2 startOrReload ecosystem.config.js",
"build": "react-scripts build",
"test": "react-scripts test --env=jsdom",
"flow": "flow"
}
}
```
В итоге мы смогли полностью избавиться от Phing и вызывать наши команды примерно следующим образом:
```
yarn run db-migrate
```
Поиск и использование хорошего опенсорсного редактора
-----------------------------------------------------
Разрабатывая на PHP, я пользовался PhpStorm, платной IDE, так как те, что распространялись бесплатно, либо казались медленными, либо страдали от недостатка плагинов.
В мире JavaScript выбор достойных редакторов кода гораздо богаче. Мы остановились на [VS Code](https://code.visualstudio.com/). Этот редактор написан на JavaScript, его поддержкой занимается сообщество энтузиастов и Microsoft.

*Логотип VS Code*
До сих пор всё в VS Code нам нравится. Работает он быстро, обладает замечательной системой автозавершения кода, за ним стоит отличное сообщество.
Здесь мне очень нравится возможность задавать то, какие плагины использовать в проекте, и делиться конфигурациями. Благодаря ей можно подготовить рабочее место программиста буквально за пару кликов.
Избавление от ручного линтинга с помощью Prettier
-------------------------------------------------
В PHP у нас была одна замечательная штука. Это — стандарты [PSR](http://www.php-fig.org/psr/). Эти стандарты по-настоящему полезны при подготовке правил оформления кода.
Мы настроили наши IDE так, чтобы код соответствовал стандартам PSR 1 и 2. Так как не было функции автоисправления, каждый был ответственен за то, чтобы самостоятельно их применять. Это было не так уж и хорошо.
При переходе на JavaScript неоценимым помощником в этой области стал для нас Prettier. Prettier — это средство форматирования кода, основанное на правилах. Оно, при каждом сохранении файла, удаляет всю самодеятельную стилизацию и приводит код к виду, соответствующему единому стилю.

*Prettier в действии*
В результате — нет больше споров о стиле кода, нет тренингов по этому направлению, нет потерь времени на то, чтобы объединять файлы, в которых модифицировано только форматирование.
Все в команде используют и любят Prettier. Программисты делают свою работу, а Prettier отвечает за детали форматирования.
Итоги
-----
Рассмотрим плюсы и минусы, с которыми мы столкнулись при переходе с PHP на JS:
**Плюсы:**
* Наш стек легче устанавливать и развёртывать.
* Клиентский и серверный код написан на одном языке.
* Мы больше не полагаемся на сложные установочные скрипты.
**Минусы:**
* Потребовалось немало усилий на то, чтобы сформировать набор технологий, соответствующий нашим нуждам.
* Пришлось организовать множество тренингов для того, чтобы изучить современное программирование на JavaScript.
Надо отметить, что после перехода мы смогли быстро генерировать серверные API. Это похоже на то, что мы делали на PHP. Я ни о чём не жалею после перехода и чувствую, что ничего не потерял. Все инструменты, на которые мы переключились, либо являются эквивалентами тех, что мы использовали ранее, либо лучше их.
Если вы подумываете о переходе с PHP на JS, желаем вам успеха и надеемся, что наш рассказ поможет вам сориентироваться в мире JS и выбрать именно то, что вам нужно.
Уважаемые читатели! Если вы пользуетесь PHP, расскажите пожалуйста, как вам живётся, планируете ли переходить на JavaScript? | https://habr.com/ru/post/339176/ | null | ru | null |
# 5 нестандартных лайфхаков для Dvorak, чтобы повысить удобство набора текста
В своё время Август Дворак (*August Dvorak*) и Уильям Дили (*William Dealey*) с целью повышения удобства набора текста и скорости обучения спроектировали "Упрощённую" раскладку известную как "Раскладка Дворака" или "Dvorak Simplified".
Идеальных раскладок не бывает, и Dvorak - не исключение. Главным недостатком данной раскладки многие интернет-пользователи считают расположение символов L и I.
Однако, я считаю, что многие жалобы в сторону раскладка Дворака вызваны причиной неправильного его использования, и не совсем правильной модели печати, в частности. Я расскажу и покажу, что же можно предпринять, чтобы работа с Dvorak стала более удобной и быстрой. Некоторые лайфхаки применимы и ко всем остальным раскладкам.
И, да, рассуждений здесь очень много!!!
**Лайфхак №0: чтобы удалить слово, вместо множества Backspace'ов, прожимайте Ctrl + Backspace**
**Содержание кратко:**
1. Переназначьте Backspace на место Capslock - разгрузите правый мизинец.
2. Переназначьте спец-символы так, как вам нужно.
3. Перестаньте пытаться двигать пальцами независимо друг от друга! Ничего "крутого" из этого не получится!
4. Не удерживайте пальцы в домашнем ряду, когда тянете один из них в цифровой ряд.
5. \*Попробуйте прожимать GH, CT, TW, RN, NV, LS, YI **одним нажатием** сразу на две клавиши.
\*Штука **спорная**, подойдёт не всем
1: Разгружаем правый мизинец
----------------------------
> Если ваш правый мизинец устаёт, значит, вы совершаете много ошибок при вводе текста!
>
>
В книге "*Typewriting Behavior, Psychology applied to teaching and learning Typewriting*" представлена следующая схема раскладки:
Помимо необычного расположения цифр и знаков препинания, необходимо особенно обратить внимание на **расположение** **Backspace**'a. По задумке авторов, Backspace нажимается именно левым мизинцем. Всё-таки, он нагружен гораздо меньше, чем правый, не говоря о том, что на момент появления раскладки (1936-й год) ребята печатали сразу на бумагу, что не давало право "косячить" при вводе текста.
Кстати, автор Colemak, Шай Коулман, тоже предлагает прожимать Backspace на месте Capslock
> Зачем очень редко (почти никогда) нажимать Capslock, если можно "часто" прожимать на его месте Backspace??? Незачем...
>
>
**Лайфхак №1: переназначьте Capslock на Backspace** (прога для переназначения: [SharpKeys | randyrants.com](https://www.randyrants.com/category/sharpkeys/))
Переназначение CapsLock на Backspace в SharpKeys2: Открываем для себя AltGr
---------------------------
Наверняка, в виду особенностей вашей профессиональной работы, частенько приходится вводить, разного рода, спец-символы - скобки, проценты, математические символы или даже весь греческий алфавит, чтобы закидать читателей константами и формулами.
Так вот, не всегда хочется лишний раз открывать word и мотать мышкой чтобы ввести ОДИН символ. Так же не хочется далеко тянутся, чтобы ввести фигурную скобку.
Чтобы решить все эти проблемы, необходимо модифицировать нашу раскладку, точнее создать новую, но основные символы будут располагаться как обычно.
Для этих целей используется MSKLC: [Download Microsoft Keyboard Layout Creator (MSKLC) Version 1.4 from Official Microsoft Download Center](https://www.microsoft.com/en-us/download/details.aspx?id=102134)
Интерфейс очень простой, разуберётесь за 5 минут. Чтобы не вбивать ничего с нуля, необходимо перейти в File->Load Existing Keyboard и там выбрать раскладку, на основе которой сделаете более удобную.
СлоефикаторыИ тут можно заметить слоефикатор AltGr - это правый Alt клавиатуре
AltGr очень удобно прожимать правым больши́м пальцем. Поэтому я рекомендую им пользоваться - многие программистские символы я назначил именно на слой AltGr
После того, как расставите все клавиши, необходимо задать такие параметры, как
* Название раскладки
* Её описание - то, что вы видите при переключении раскладок
* Company и Copyright
* Язык
Project->Properties открывает окно с параметрами раскладки
А потом, жмём Build DLL and Setup Package, открываем папку, запускаем установщик, перезагружаем ПК - раскладка установлена. Вот, что получилось я меня (слева сверху: основной символ, справа сверху: с Shift, справа снизу: с AltGr)
")Раскладка автора поста (визуализация: CustomLearning)Вот и получился **лайфхак №2: расставь специальные символы (можно и буквы) как удобно тебе!**
3: Разбирается с нашими пальцами
--------------------------------
В процессе изучения раскладки с программой, которая отображает постановку пальцев для нажатия того или иного символа, часто возникает ситуация, когда практически невозможно без боли повторить постановку пальцев, показанную в тренажёре (мой CustomLearning этим тоже грешит)
Просто посмотрите на эту "суперсилу" тренажёра и на то, как у меня не получается это повторить:
Вот ещё пару примеров не очень удобного прожимания:
Главная причина сего дискомфорта: попытка повторить эти изображения из тренажёров точь-в-точь. Оно же независимое движение пальцев. Как на крути, но движение одного пальца провоцирует движение остальных в разной степени.
Иначе говоря, подражание такой модели печати - самый простой способ корячиться на ровном месте. Собственно, именно на этой почве появились раскладки Workman и Klausler.
Шкала "усилий" для нажатия на символы, согласно вышеописанной модели с сайта workmanlayout.orgКак уже многие успели догадаться, **я не согласен** с таким распределением, хотя бы потому, что она в большинстве своём не соответствует действительности. В этом плане всё намного сложнее. Много интересных мыслей было высказано в посте: [О вопросах сравнения и оптимизации клавиатурных раскладок / Хабр (habr.com)](https://habr.com/ru/post/210826/)
Итог такой, пальцы двигаются **зависимо** друг от друга. В этом плане Dvorak и буква L - очень показательная раскладка: посмотрите на правую часть верхнего ряда ещё раз: вы заметите, что все эти буквы: F, G, C, R часто сочетаются с L при этом стоя перед ней: FL, GL, CL, RL. То же с R: GR, CR.
Шкала "усилий" по субъективному мнению автора поста с учётом всего вышесказанного
Вот он - тот самый фокус: (например, жмём, CL) сначала тянется средний палец: он так или иначе тянет за собой мизинец наверх, C нажата, и мизинцу остаётся пройти всего чуть-чуть, чтобы дотянуться до L. Соответственно, придётся тратить намного меньше усилий если символы могут сочетаться так, чтобы начинал сильный палец для помощи более слабому.
Вот он **лайфхак №3: Перестаньте пытаться двигать пальцами независимо друг от друга! Ничего "крутого" из этого не получится!**
4: И с верхним рядом так можно?
-------------------------------
Да! С верхним рядом всё очень просто: можно двигать всю ладонь, не проблема. Опять же, не нужно удерживать неиспользуемые пальцы в домашнем ряду - будете корячиться.
Кстати, при проектировании раскладки лучше всего в верхнем ряду грузить самыми частотными знаками препинания, что не вошли в основное поле, самые длинные пальцы: безымянные и средние. Тогда, движения будут сведены к минимуму.
Вот как расположены знаки препинания в моей русской раскладке: самое частотное находится в основном поле, менее частотное - под самыми длинными пальцами
А теперь просто сравните программу, попытку повторить программу и мои "зависимые" движения:
**Лайфхак №4: Не удерживайте пальцы в домашнем ряду, когда тянете один из них в цифровой ряд.**
5: Облегчаем прожимания соседних символов
-----------------------------------------
Следующий приём я подсмотрел у стенографистов. У них, чтобы ввести какое-нибудь слово, необходимо зажать одновременно несколько символов. Например, чтобы ввести слово great, необходимо прожать кодовое слово `GRAET`, но поскольку в стенографической клавиатуре слева нет G, то вместо G прожимается сочетание `TKPW.`
Любопытно, что левый безымянный **одновременно** прожимает T и K, а средний P и W.
Так вот, почему нельзя прожимать некоторые сочетания так же, одним пальцем и одновременно??? Штука спорная, но кому-то может стать полезна.
Прожимать можно, но не все, потому что компьютер каждый раз последовательно считывает каждую клавишу начиная сверху слева. Соответственно, одним пальцем можно прожать только пару клавиш из соседних рядов, при этом символ сверху будет всегда первым, а символ снизу - всегда вторым.
У Dvorak таких сочетаний не так уж и мало: GH, CT, TW, RN, NV, LS, YI. Особняком стоит LS, что также разгружает правый мизинец (особенно довольны будут сисадмины и программисты, которым то и дело в терминале нужно прописать команду `ls`), теперь вместо 3-х кликов, 2.
Автор прожимает сочетание GH одним кликомПолучаем **лайфхак №5: попробуйте прожимать GH, CT, TW, RN, NV, LS, YI *одним нажатием* сразу на две клавиши.**
Надеюсь, что данный пост был интересен и принёс хотя бы минимальную пользу. Также, я буду благодарен за высказанные мысли в комментариях. | https://habr.com/ru/post/574020/ | null | ru | null |
# Telegram-клиент на PHP (и получение сообщений с помощью MadelineProto)
Решив заняться бессовестным копипастом (а точнее его автоматизацией) постов с чужого Telegram-канала в свой, я первым делом полез в документацию по телеграм-ботам. Но как выяснилось, боты не только не имеют методов для получения сообщений, их просто-напросто нельзя добавить в чужой канал.
Решение нужно было на PHP и следующий час был потрачен на его поиск. Удивительно, как об этом мало информации *(хотя нет, не удивительно… кто вообще пишет такое на PHP...)*. В общем, дорога со StackOverflow привела к **[MadelineProto](https://docs.madelineproto.xyz/API_docs/)**. На библиотеку довольно мало ссылок в сети.
Что такое **Madeline**? Это Telegram-клиент на PHP, предоставляющий методы для работы как от имени пользователя, так и от имени бота. Цель статьи — в первую очередь сократить путь поиска **Madeline** и привлечь к нему внимание. Также интересно узнать у хабравчан что есть подобное на других ЯП?
Ну и разумеется, опубликовать для примера кусочек кода, который решил мою задачу:
```
//Подключение Madeline с гитхаба
if (!file_exists(__DIR__ . '/madeline.php')) {
copy('https://phar.madelineproto.xyz/madeline.php', __DIR__ . '/madeline.php');
}
include __DIR__ . '/madeline.php';
$MadelineProto = new \danog\MadelineProto\API('session.madeline');
$MadelineProto->start();
$me = $MadelineProto->get_self();
\danog\MadelineProto\Logger::log($me);
/* Получим историю сообщений */
$messages = $MadelineProto->messages->getHistory([
/* Название канала, без @ */
'peer' => 'chatname',
'offset_id' => 0,
'offset_date' => 0,
'add_offset' => 0,
'limit' => 20,
'max_id' => 9999999,
/* ID сообщения, с которого начинаем поиск */
'min_id' => $lastid,
]);
/* Сообщения, сортировка по дате (новые сверху) */
$messages = $messages['messages'];
foreach(array_reverse($messages) as $i => $message){
/* Шлем сообщение на свой канал */
$MadelineProto->messages->sendMessage([
'peer' => 'mychatname',
'message' => $message['message']
]);
}
```
UPD от [mopkob](https://habr.com/users/mopkob/): У проекта есть активное комьюнити: рускоязычное [@pwrtelegramgroupru](http://t.me/pwrtelegramgroupru) и интернациональное [@pwrtelegramgroup](http://t.me/pwrtelegramgroup). | https://habr.com/ru/post/433268/ | null | ru | null |
# Кое-что о Вэльюхост, Никхост и Сайт5
Раньше я хостился на вэльюхосте. С проектом «Русские улицы». Вэльюхост меня раздражал тем, что после того, как оставался месяц до истечения срока оплаты домена или хостинга, напоминания шли каждый день. И даже если я платил в тот же день и отсылал им мылом скан квитанции, напоминания всё равно валились ещё неделю-полторы. Я им звонил, писал, но меня уверяли, что отключить это не могут, что пока платёж не пройдёт, напоминания всё равно будут идти. Закончилось это тем, что очередной платёж за домен я сделать просто забыл. Не знаю, что случилось у них. Может, сломалось что, а может — так радикально вняли моим мольбам, что решили не присылать мне напоминаний вообще. Так проект «Русские улицы» прекратил своё существование. Как и моё сотрудничество с Valuehost.
Воспоминания впрочем про вэльюхост остались нормальные. Особенно радовали оперативные (в теч. 20 минут) ответы поддержки, если оставлял вопрос через форму на сайте, и круглосуточная поддержка на телефоне.
Но, когда мы в семье собрались заводить ещё пару-тройку доменов и покупать под них хостинг мы почему-то (не помню, почему) остановили выбор на руцентре (RU-CENTER, [www.nic.ru](http://www.nic.ru/)).
Ну, что сказать? Как к регистратору к руцентру претензий нет. А вот как к хостеру — одни сплошные претензии.
Главная — сайты постоянно недоступны. Даже в договоре сказано, что сайт может быть недоступен по вине хостера до двух часов в месяц. Это много. Но мы подумали, что это они страхуются на крайний случай, что в обычном режиме всё будет в порядке. Чёрта с два. Сайты лежали гораздо дольше, чем по два часа в месяц. Они пропадали на два часа в неделю, на три и больше. Когда это случилось впервые, мы с изумлением выяснили, что телефонная поддержка руцентра работает только в будни, с 10 до 19 часов. То есть, представьте, в 19.01 пятницы вы выясняете, что недоступна база данных вашего сайта, а поддержка ответит вам только утром понедельника. Красота. Вы надеетесь, что админы там сами что-нибудь сделают (следит же кто-то там за работой серверов?), но сайт недоступен и через час, и через четыре, а по телефону вам отвечает автоответчик, предлагающий позвонить в рабочее время. Вы пишете в поддержку письмо, ждёте ещё несколько часов, устаёте и ложитесь спать. В воскресенье сайт работает, а поддержка в среду отвечает на ваш запрос: «В настоящее время всё работает, никаких проблем нет. Напишите, сохраняется ли проблема».
Сайты были недоступны недопустимо часто. Когда это случалось в рабочее время, мы звонили или писали в поддержку и получали объяснение: «На другой сайт [тарифа 201](http://nic.ru/dns/contract-zao/sup2_price.html) ведётся ддос-атака. Поэтому наблюдаются проблемы в работе всех сайтов тарифа 201».
В конце концов мне это надоело и я написал обстоятельное письмо, в котором пытался объяснить, что дальнейшая работа в таком режиме недопустима, и спрашивал, могут ли они гарантировать, что переход на более дорогой тариф (301) эту проблему решит? Потому что если нет, мне придётся искать другой хостинг. Мне не ответили. То есть вообще. Я подождал несколько дней и повторил вопрос, дополнив его просьбой: «Если вы не можете ответить на мой вопрос, найдите, пожалуйста, того, кто может». Мне не ответили опять. Тогда я написал ещё одно большое письмо с историей проблемы и тем же вопросом: «Ваши сотрудники, мол, постоянно акцентируют внимание на том, что проблемы при ддос-атаках наблюдаются на сайтах тарифа 201, значит ли это, что если я перейду на тариф 301, проблемы прекратятся?» Это письмо я разослал на все адреса, какие нашёл на сайте руцентра. Ни ответа, ни привета.
Выждав ещё несколько дней, я позвонил в поддержку, рассказал всю эту историю и попросил мне всё-таки ответить. Сотрудник по ту сторону телефона сказал: «Вижу ваше письмо». «И что скажете?» — спросил я. «Вам ответят». «Когда?» «В ближайшее время». И так и не ответили.
После этого ещё неоднократно случались и «ддос-атаки», и недоступность базы, и ситуация, когда поддержка хостера утверждает, что «все работает, это проблемы у вашего провайдера», а трэйсроут через разные службы из самых разных точек земного шара, включая мою квартиру, подключенную через корбину, показывает, что сайт недоступен. И что, более того, недоступны все мои сайты и вообще все сайты, о которых я знаю, что они хостятся на никхосте. Также бывало, что сайт вроде бы доступен, а друзья из Санкт-Петербурга сообщают, что не видят его. Друзья из Германии рассказали, что клиенты крупнейшего немецкого провайдера «Алиса» вообще не могли видеть мои сайты.
В общем, я отчаялся добиться чего-либо от никхоста и стал присматривать нового хостера. Но пока сайты лежали у них и то и дело бывали недоступны. Это раздражало мою жену, с которой мы ведём наши проекты вместе. Теперь переписываться с поддержкой никхоста стала она. В процессе переписки узнала много нового. Например, что если сайт недоступен по причине ддос-атаки или из-за неполадок с оборудованием, то это не значит, что он недоступен по вине хостера. Кроме того, разные сотрудники в письмах и телефонных разговорах часто просто друг другу противоречили, что наводило на неприятные мысли об их добросовестности. Получив несколько раз совершенно недопустимый фидбэк от саппорта, Александра повторила мой приём и написала на несколько адресов, найденных на сайте, — не в саппорт. Уж не знаю, почему, но ей ответили — сотрудник PR-службы забеспокоился, что саппорт своими тупыми действиями создаёт для компании дурной имидж и попробовал помочь. По крайней мере, пообещал провести служебную проверку и разобраться. Попросил прислать подробности. Приведу большую часть письма, написанного нами в ответ на его просьбу, т.к. в нём как раз описаны кое-какие проблемы (имена сотрудников и номера тикетов и договоров опущу):
*Добрый день.
К сожалению, сотрудники, отвечающие по телефону, не представляются, поэтому я не могу сказать вам их фамилии. Но всё, что касается переписки, у меня сохранено.
Тикет…:
Письмо: «Объясните, пожалуйста, причины недоступности базы данных моих сайтов, расположенных на ваших площадках, 11 февраля 2009 в период примерно с 15-50 до 16-28».
Ответ от…: «В указанное Вами время были технические неполадки в работе сервера БД, обслуживающего ваш хостинг. В настоящее время неполадки устранены. Приносим извинения за доставленные неудобства».
Этот ответ никак не объяснил мне причины поломок. В рамках той же переписки зафиксировано моё второе обращение (через 2 недели) по поводу проблем с тем же сервером базы данных.
В одном из разговоров с сотрудником службы поддержки (по другому вопросу, о котором будет ниже) мне было сообщено, что были проблемы с конкретным севером бд, и что я, если желаю, могу написать заявление и перенести свою площадку на другой сервер баз данных. Я сделала это сегодня, 19 марта, потому что утром с 8 до 8-45 утра база данных была снова недоступна (тикет ...). Но ситауция, когда сервер не в порядке, и клиенту (мне) предлагают писать заявления, чтобы получить нормально работающий сервер, кажется мне дикой. Тем более, что о проблеме мне сообщили далеко не сразу, в первых двух письмах заверяли, что всё в порядке.
Посетители очень часто жалуются на недоступность моих сайтов. Когда жалоб стало очень много (и после 2-х падений базы данных, зафиксированных мной лично), я решила срочно разбираться с проблемой. Служба поддержки регулярно напоминала мне, что по договору сайты могут быть недоступны по вине хостера до 2 часов в месяц. Но у меня были подозрения, что они недоступны дольше. Чтобы разобраться и найти истинную причину недоступности моих сайтов (я допускаю вероятность того, что в этом вина не ник-ру как хостера — есть много других факторов), я позвонила в службу поддержки, где мне сказали, что я могу написать заявление на получение отчёта о количестве времени, которое сайты моей площадки были недоступны по вине хостера.
Тикет ...:
Письмо: «Этим письмом заявляю о своём желании получить отчёт о количестве времени, которое сайты моей площадки (...) были недоступны по вине хостера».
Ответ от ..., 11 марта 2009 года: «Сегодня в 15:50 могли наблюдаться проблемы доступа к сайтам, размещенным на сервере виртуального хостинга. Проблемы были устранены нашими специалистами к 16:19 по мск. В настоящее время все сервисы работают корректно. Приносим извинения за доставленные неудобства».
Трудно поверить, что сотрудник службы поддержки прочитал и понял моё письмо — о заявке нет ни слова. Я написала ещё одно письмо (в рамках той же переписки), а потом, решив, что мои объяснения о заявке по какой-то причине не были поняты службой поддержки, позвонила. Мне попался вежливый сотрудник, который меня выслушал (он же посоветовал перенести сайты на другой сервер бд). За 23 минуты разговора мне удалось убедить его, что отчёт мне на самом деле нужен. Он пообещал, что отчёт будет мне направлен.
Через несколько дней мне пришло письмо (тикет тот же):
«Дата Время недоступности
14.01.2009 16:40 — 16:43
19.01.2009 15:22 — 15:35
25.02.2009 20:29 — 20:31
11.03.2009 16:05 — 16:19»
Я не знаю, откуда взялись эти данные. Они неверны. Там нет даже тех периодов недоступности сайтов, о которых я писала в службу поддержки ранее, а период, о котором мне перед этим сообщала сотрудник компании (фрагмент приведён выше), сокращен на 15 минут. Не говоря уже о том, что я могу не знать о каких-то периодах недоступности, поскольку не каждый час проверю свои сайты. Этот «отчёт» очень сильно пошатнул мою и без того несильную уверенность в том, что я могу получить в ник-ру хостинг приемлемого качества.
В рамках всё того же тикета мы обменялись со службой поддержки ещё несколькими письмами, но ни объяснения присылания мне неверных данных, ни самого отчёта я не получила.
Сегодня, 19 марта 2009 года, после того, как все мои сайты снова были недоступны в течение как минимум 45 минут (опять же, тикет ...), пришлось несколько раз звонить в службу поддержки. В итоге мне посчастливилось попасть на — как показалось — хорошего сотрудника службы поддержки. Сотрудник вежливо и подробно объяснил мне причину недоступности сайтов, и я заодно спросила его о возможности получения отчётов. Сотрудник заверил меня, что с этим не должно возникнуть трудностей, что он возьмёт мою заявку об отчёте (написанную ещё 11 марта 2009 года, тикет ...) на себя и вышлет мне этот отчёт.
Для меня остаётся загадкой, почему другие сотрудники не могли внимательно прочитать мои письма, выслушать мои вопросы и просто прислать мне этот многострадальный отчёт. Не очень хочется при каждом обращении в службу поддержки играть в рулетку: повезёт ли попасть на хорошего специалиста, или не повезёт (по моему опыту — в большинстве случаев), и придётся тратить уйму сил и времени на письма и звонки.*
Сотрудник PR-отдела вежливо и оперативно ответил на это письмо, поблагодарил и обещал провести служебное расследование. Перестали после этого падать сайты? Нет. Никакого внятного объяснения причин их регулярной недоступности мы тоже так и не получили.
Вскоре мы, дотошно сравнив условия, предлагаемые компаниями Мастерхост, McHost и Valuehost, остановили свой выбор на [американском хостинг-провайдере Site5.com](http://www.site5.com/hosting/). Купили у него тариф hostPro и вскоре перенесли к ним один сайт. В процессе переноса возникла пара вопросов. Написали в саппорт — ответ получили почти мгновенно. Правда, на английском, но тут уж — что поделаешь — американцы они, русского не знают. Другой сайт пока оставался у никхоста. Ради интереса, я внёс оба сайта в систему [basicstate.com](http://basicstate.com/), которая каждые 15 минут проверяет доступность зарегистрированных в ней ресурсов. Вот её отчёты за те несколько дней, в течение которых один наш проект отвечал уже с сайт5, а второй ещё с руцентра:
`hrenovina.net (site5)
----------------------------------------------------------------------
date uptime dns connect request ttfb ttlb
2009-04-16 100.00 0.068 0.129 0.129 0.626 1.029
2009-04-15 100.00 0.080 0.142 0.142 0.631 1.027
2009-04-14 100.00 0.102 0.165 0.165 0.713 1.144
2009-04-13 100.00 0.149 0.212 0.212 0.705 1.117
2009-04-12 100.00 0.123 0.183 0.183 0.654 1.049
yatsutko.net (hosting.nic.ru)
----------------------------------------------------------------------
date uptime dns connect request ttfb ttlb
2009-04-16 100.00 0.008 0.155 0.155 0.960 1.572
2009-04-15 100.00 0.008 0.194 0.194 0.843 1.327
2009-04-14 96.74 0.008 0.150 0.150 0.691 1.254
2009-04-13 55.43 0.014 0.091 0.091 0.492 0.719
2009-04-12 0.00 0.025 0.000 0.000 0.000 0.000`
То есть, из пяти дней сайт, лежавший на никхосте был нормально доступен только два дня. Один день — ни единого ответа вообще. Ну, сами видите, в общем.
Сайты на Site5.com пока, тьфу-тьфу, работают без проблем.
Подытожу. Хоститься на ник.ру не пожелаю даже врагу. Ради справедливости повторю, впрочем, что как к регистратору у меня к ним претензий нет. | https://habr.com/ru/post/57895/ | null | ru | null |
# PHPUnit. Часть 03 Написание тестов для PHPUnit
*Предисловие переводчика
Эта статья продолжает серию переводов официальной документации по PHPUnit на русский язык.
[Часть 1](http://habrahabr.ru/blogs/php/87922), [Часть 2](http://www.smartyit.ru/php/84)*
[Пример 4.1](#writing-tests-for-phpunit.examples.StackTest.php "Пример 4.1: Тестирование массива с использвованием PHPUnit") демонстрирует как с помощью PHPUnit можно выполнить тестирование операций с массивами PHP. В этом примере показаны базовые соглашения и шаги, свойственные тестам PHPUnit:
* Наименование тестирующего класса образуется путем добавления постфикса `Test` к наименованию тестируемого класса. Например тестируемый класс называется `Class`, тестирующий — `ClassTest`.
* `ClassTest` наследуется (в большинстве случаев) от PHPUnit\_Framework\_TestCase.
* Наименования тестирующих методов образуются путем добавления приставки `test` к наименованиям тестируемых методов.
* Внутри тестовых методов утверждения задаются специальными функциями `assertEquals()`
(смотрите [раздел PHPUnit\_Framework\_Assert](http://www.phpunit.de/manual/3.4/en/api.html#api.assert "PHPUnit_Framework_Assert")). `assertEquals()` задает соответствие реально полученного значения и ожидаемого.
**Пример 4.1: Тестирование операций с массивами PHP при с использованием PHPUnit**
> `php<br
>
> require\_once 'PHPUnit/Framework.php';`
> | https://habr.com/ru/post/89175/ | null | ru | null |
# И ещё пару слов о SandCastle, TFS и магии…
По мотивам только-только проскочившей публикации [«Sandcastle и SHFB»](http://habrahabr.ru/post/243039/) решил поделиться своими болями и печалями, а также и success-story при работе с этим продуктом.
В тексте **не будет** скриншотов с подписями "*нажмите кнопку ДОБАВИТЬ*" и описания настроек/плагинов.
В тексте **будет** описание процесса реализации конкретного кейса: сборки документации SHFB в TFS.
Итак, имеющееся окружение:
* Team Foundation Server 2013
* VisualStudio 2014
В чём проблема
--------------
Моей первой и главной заботой при организации документации было максимально отдаление разработчика от дальнейшего процесса построения документации. Т.е. чтоб условный джуниор мог писать код, коммитить его в TFS, а документация сама собиралась уже при удачном билде релизной версии.
Так мы подходим к первой проблеме. Заключается она как раз-таки в это джуниор-разработчике. Как заставить его ставить комментарии? С этим нам поможет…
#### Stylecop
А точнее [StyleCop checkin policy](https://stylecopcheckinpolicy.codeplex.com/). Мне пришлось немного допилить его, чтоб забирал конфиг-файл прям из TFS (чтоб не разливать всем разработчикам новую версию каждый раз). Но в целом принцип понятен, да? Настраиваем нужные нам правила, касающиеся документации, включаем policy и настраиваем в TFS оповещение на каждый Policy override — мы не можем совсем запретить его (технически [можем](http://blogs.msmvps.com/vstsblog/2014/05/13/turning-off-policy-overrides-in-tfs/), но случаи, когда действительно нужно будет сделать override, превратятся в совершенно запредельную боль), но можем вырисовываться изниоткуда над плечом разработчика через минуту после того, как он нажал "*Override policy*" и доходчиво объяснять, в чём он неправ. Удобно. Наглядно. Внушает.
Итак, с чекинами и форматированием кода разобрались. Едем дальше.
Джуниор регулярно ноет, что ему надоело писать одно и то же. Регулярно возникают ситуации, когда в методе исправили описание, а в его пяти перегрузках — забыли. С этим нам поможет…
####
SHFB поддерживает тэг . Он позволяет избавиться от массы копи-пасты в атрибутах описания. Ради его приемлимого функционирования надо немного поплясать с бубном, поугадывать его возможности (*потому что официальная документация довольно пространная и не вдаётся в технические детали реализации этой функции — мне пришлось покопаться в сырцах, чтоб отловить, откуда же он, например, берёт списки файлов для генерации дерева унаследованных типов*).
Для примера, имеем класс:
```
///
/// Имплементация логгера для NLog.
public class NLogWrapper : ILogger, IWithTags
{
///
public virtual bool IsTraceEnabled
{
get { return InnerLogger.IsTraceEnabled; }
}
///
public string Name { get; set; }
///
public HashSet Tags { get; set; }
...
}
```
В результирующей документации по классу *NLogWrapper* описания пропертей *IsTraceEnabled* и *Name* будут унаследованы от *ILogger*, а *Tags* — от *IWithTags*. Удобно. Казалось бы — вот оно, счастье! Ан нет.
Печаль #1 с этим *inheritdoc* заключается в том, что работает он на эфирных материях через астральные тела и практически никогда нельзя быть уверенным, что какой-то из кейсов будет работать, пока не попробуешь. Для примера:
* Нельзя наследовать описания перегруженных методов в рамках одного класса/интерфейса;
* Не всегда достаточно повесить метку у унаследованного метода — *иногда* требуется ещё поставить его на самом классе, чтоб SHFB догадался, что его предков надо бы просканировать;
* Необходимо руками добавлять библиотеки с базовыми классами в *DocumentationSources* (об этом ниже);
* Необходимы [дополнительные манипуляции](https://shfb.codeplex.com/discussions/551113) для IntelliSense, потому что «из коробки» в результирующем .xml получаются эти самые , которых Visual Studio не ест.
И тд. В целом штука полезная, но надо хорошо подумать, прежде чем её использовать.
Ну, на этом с подготовкой закончили, давайте уже приступать к основному.
TFS Build
---------
Итак, что мы хотим? А хотим мы, чтоб для нашей сборки вместе со всеми проектами в ней была документация.
Для начала ставим SHFB на сервер, где крутится наш билд-агент. Иначе работать не будет. Он использует переменные окружения, кучу своих локальных файлов… В-общем надо ставить.
Далее открываем gui SHFB, настраиваем проект, добавляем в качестве Documentation Sources наш **.sln**-файл, сохраняем. Читаем [инструкцию](http://www.ewoodruff.us/shfbdocs/html/ec822059-b179-4add-984d-485580050ffb.htm). Всё выглядит довольно тривиально. Создаём файлик build.proj по инструкции, чтоб обмануть пляски с *OutputDir* (без него пробовал — там такой ад с путями начинается, что правда — лучше сделать лишний .proj-обёртку):
```
xml version="1.0" encoding="utf-8"?
```
Запускаем:
```
SHFB : error BE0040: Project assembly does not exist
```
Эмммм, чо? Ты кто такой?
А это, друзья, грабли: файлик sfhbproj хоть и является по сути msbuild-проектом, и даже позволяет оперировать .sln-файлами в качестве источников, вот только **саму сборку он не делает**. Т.е. он этот файл .sln он использует только для того, чтоб найти список проектов, а в них найти OutputFolder для указанной конфигурации и оттуда уже **взять готовые .dll/xml-файлы**.
Вот ведь ленивая скотинка-то. Ладно, сейчас обучим новым трюкам. Лезем в файл, видим там
Ага. После довольно быстрого озарения понимаем, что *$(SHFBROOT)* это ни что иное, как папка установки бинарников самого SHFB. Там и находим этот файл. Смотрим, куда бы нам вклиниться… Ага, вот оно:
```
PreBuildEvent;
BeforeBuildHelp;
CoreBuildHelp;
AfterBuildHelp;
PostBuildEvent
```
Возьмём, например, *BeforeBuildHelp*. Ещё один кусок документации, который нам поможет жить, находится [здесь](http://www.ewoodruff.us/shfbdocs/html/8ffc0d37-0215-4609-b6f8-dba53a6c5063.htm). Слегка модифицируем наш build.proj:
```
xml version="1.0" encoding="utf-8"?
```
(добавили *CustomAfterSHFBTargets*) и создаём вот такой файлик shfbcustom.targets:
```
xml version="1.0" encoding="utf-8"?
```
Здесь немножко магии. В файле My.Api.shfbproj в свойстве хранится… XML. Строкой. Вот такой хитрый ход. Супротив него мы можем применить только такой же хитрый ход: наша перегрузка таргета *BeforeBuildHelp* берёт эту строку, скармливает её в XmlPeek таск и забирает оттуда все *@sourceFile* с нод, у которых есть *@configuration*. Затем скармливает этот массив в таск MSBuild.
Да, при этом мы теряем по-проектные настройки Configuration|Platform, которые могли быть указаны в SHFB для этих источников, но эту боль я смог пережить просто: для документации используется специальная конфигурация сборки под названием Doc (как видно выше в коде). Это копия релиза, с отключенными тестовыми проектами и прочими лишними вещами, которые иначе мешали бы генерировать нормальную доку. Т.е. можно было бы сделать этот файлик в три раза толще, разбирать для каждого .sln его параметры, но в нашем случае оно того не стоило.
Запускаем ещё раз… Ух ты — собирается!
Так, т.е. у нас уже есть проект, который можно настраивать в SHFB, включая новые .sln, а потом просто запускать билд в TFS и получать на выходе chm + html?! Прекрасно. Смотрим… ой, что такое? В логе ошибки:
```
SHFB: Warning GID0002: No comments found for cref 'T:System.Web.Http.Dependencies.IDependencyResolver' on member 'T:My.Api.Server.DependencyResolver'
```
Смотрим код:
```
///
/// DependencyResolver для Unity
///
///
[System.Diagnostics.CodeAnalysis.SuppressMessage("Microsoft.Design", "CA1063:ImplementIDisposableCorrectly", Justification = "IDisposable реализован в базовом классе.")]
public class DependencyResolver : DependencyScope, IDependencyResolver
{
///
public DependencyResolver(IUnityContainer container)
: base(container)
{
}
///
public IDependencyScope BeginScope()
{
Log.Trace("Beginning new scope");
return new DependencyScope(Container.CreateChildContainer());
}
}
```
Вроде, всё чисто, есть, прописан нормально — должен находиться!
#### [ вырезано ]
Выше вырезаны несколько часов поисков, ковыряний в настройках, затем в исходниках самого SHFB и его кусков… В итоге выяснилось:
**В качестве источника для берутся ИСКЛЮЧИТЕЛЬНО данные, указанные в *DocumentationSources*. При этом они должны быть прописаны прямо в файле.**
Никакие плагины не помогут. Никакие References не учитываются. Никакая магия MSBuild, позволяющая на лету модифицировать переменные, тоже не поможет. Потому что в конце концов запускается файлик *GenerateInheritedDocs.exe*, который тупо парсит файл .shfbproj, достаёт через XPath из него содержимое ноды и перебирает указанные там файлы. Всё, приехали. Я попытался, было, распилить это мракобесие, но там на каждом шагу вставлена прямая работа с файлом — каждый компонент сам по себе лезет в него и читает то, что ему надо — ни о каком общем контексте речи не идёт. Так что я эту затею забросил.
**Так что если хотите, чтоб в вашу документацию вставились строчки из компонентов, которые вы используете в проекте** (в данном случае я хотел, чтоб там было описание методов из *System.Web.Http*), **то придётся включить эти компоненты в *DocumentationSources***.
Да, можно включать не саму сборку, а только .xml-файл от неё. От этого не сильно легче.
На этом месте мы явно получаем геморрой с поддержкой файла .shfbproj — надо обновлять его каждый раз, когда используются новые компоненты. Надо обновлять его каждый раз, когда обновляем nuget-пакет — потому как меняется путь к файлу! Ужас-ужас. И никак не автоматизировать же.
Нет, конечно, можно сделать такой target, чтоб перебирал содержимое */packages/\*\** и вытаскивал оттуда все .xml… А, нет, нельзя — каждый пакет же может содержать несколько версий под разные версии .net runtime. Значит, надо заходить с другого конца — после сборки каждого проекта перебирать всё содержимое $(OutDir), и все xml/dll-файлы оттуда вписывать в… А вот куда?
Здесь можно немного обыграть: поддерживается включение .shfbproj в качестве Documentation Source. Так что можно на лету создать файл минимального содержимого, в котором будет только *DocumentationSources*, а его держать единственным включением в основной файл… Но чем-то попахивает от этого, мне кажется.
К (не-)счастью я всем этим занимался в качестве факультатива и из личной заинтересованности, вскоре пришлось заняться другим проектом, а это всё так и осталось в таком виде — собирается, публикуется, но вот обновлять/поддерживать — боль.
Что в остатке?
--------------
* По кнопке «Build project» (или само по правилу Continuos Integration) собирается и публикуется документация в .chm и html для проекта. Это хорошо;
* По пути сделали правило для контроля нерадивых джуниоров, чтоб они быстрее приходили к просветлению. Это тоже хорошо;
* Поддерживать и развивать это будет кто-то другой. Просто прекрасно. | https://habr.com/ru/post/243171/ | null | ru | null |
# Скрываем часть номера телефона
Представьте, что вам нужно скрыть часть номер под звездочками. Заменить +79999999999 на +799\*\*\*\*9999 не трудно, а теперь представьте, что масок номеров не одна, а на много больше, номера эти как российские, так и канадские или любые другие. В этой функции я постарался захватить как можно больше номеров.
Является строка номером телефона:
> /^(\(?\+?\d{1,2}\)? ?\(?\d{1,3}\)? ?\d+\-? ?\d+\-? ?\d+)$/
Кушает:
```
'+7 999 999-99-99',
'+79999999999',
'79999999999',
'+7 (495) 150 41-32',
'+55 11 99999-5555',
'(+44) 0848 9123 456',
'+1 284 852 5500',
'+1 345 9490088',
'+32 2 702-9200',
'+65 6511 9266',
'+86 21 2230 1000',
'(123) 456 7899',
'123-456-7899',
'123 456 7899',
'1234567899',
'1 800 5551212',
'800 555 1212',
'8005551212',
'18005551212',
'234-911-5678',
'+54 9 2982 123456',
'02982 15 123456',
'(719) 309-3829'
```
Функция замены:
```
function hideNumber(string, replaceTo = '*', elemsHide = 4, sliceFromback = 4) {
result = string.match(/^(\(?\+?\d{1,2}\)? ?\(?\d{1,3}\)? ?\d+\-? ?\d+\-? ?\d+)$/);
if (result !== null) {
// тут мы выдергиваем n элементов после среза x
const regex = new RegExp(`((\\(?\\ ?\\-?\\d\\ ?\\-?\\)?){${elemsHide}})((\\ ?\\-?\\d\\ ?\\-?){${sliceFromback}}$)`, 'gm');
let m;
while ((m = regex.exec(string)) !== null) {
if (m.index === regex.lastIndex) {
regex.lastIndex++;
}
const forRex = m[1];
const str = m[1].replace(/(\d)/gm, replaceTo);
const lasts = m[3];
const full = string;
const noBack = full.slice(0, -lasts.length).slice(0, -forRex.length);
const out = noBack+''+str+''+lasts;
return out;
}
return string;
} else {
return string;
}
}
```
**Демо**
```
const str = [
'+7 999 999-99-99',
'+79999999999',
'79999999999',
'+7 (495) 150 41-32',
'+55 11 99999-5555',
'(+44) 0848 9123 456',
'+1 284 852 5500',
'+1 345 9490088',
'+32 2 702-9200',
'+65 6511 9266',
'+86 21 2230 1000',
'(123) 456 7899',
'123-456-7899',
'123 456 7899',
'1234567899',
'1 800 5551212',
'800 555 1212',
'8005551212',
'18005551212',
'234-911-5678',
'+54 9 2982 123456',
'02982 15 123456',
'(719) 309-3829',
'Judi'
];
str.forEach(i => {
console.log(i +' => '+hideNumber(i));
})
```
console:
```
+7 999 999-99-99 => +7 99* ***-99-99
+79999999999 => +799****9999
79999999999 => 799****9999
+7 (495) 150 41-32 => +7 (49*) *** 41-32
+55 11 99999-5555 => +55 11 9****-5555
(+44) 0848 9123 456 => (+44) 084* ***3 456
+1 284 852 5500 => +1 28* *** 5500
+1 345 9490088 => +1 34* ***0088
+32 2 702-9200 => +32 * ***-9200
+65 6511 9266 => +65 **** 9266
+86 21 2230 1000 => +86 21 **** 1000
(123) 456 7899 => (12*) *** 7899
123-456-7899 => 12*-***-7899
123 456 7899 => 12* *** 7899
1234567899 => 12****7899
1 800 5551212 => 1 80* ***1212
800 555 1212 => 80* *** 1212
8005551212 => 80****1212
18005551212 => 180****1212
234-911-5678 => 23*-***-5678
+54 9 2982 123456 => +54 9 29** **3456
02982 15 123456 => 02982 ** **3456
(719) 309-3829 => (71*) ***-3829
Judi => Judi
```
Если один из ваших номеров (который мог бы существовать на деле) не подошел, пишите, дополню.
#### P.S.
В комментарии [mwizard](https://habr.com/ru/users/mwizard/) добавил реализацию без регулярки:
```
type Context = {
readonly offset: number;
readonly filtered: string;
}
function hidePhone(phone: string): string {
return Array.from(phone).reduceRight((ctx: Context, char: string): Context => {
const isDigit = char >= '0' && char <= '9';
const offset = ctx.offset + (isDigit ? 1 : 0);
const filteredChar = isDigit ? (offset >= 4 && offset < 8) ? '*' : char : char;
const filtered = filteredChar + ctx.filtered;
return { offset, filtered };
}, { offset: -1, filtered: '' }).filtered;
}
``` | https://habr.com/ru/post/493598/ | null | ru | null |
# Как malloc память ест
 Нет, здесь не будет ничего из серии «Аааа, я сделал malloc (new), и забыл сделать free (delete)!»
Здесь будет нечто изощренное: мы будем отрезать кусочки памяти по чуть-чуть, прятать их в укромное место… А когда операционная система ~~заплатит выкуп~~ скажет «Хватит!», мы попробуем вернуть все обратно. Казалось бы, простейшая операция выделения и освобождения памяти — ничего не предвещает беды.
Тем кому интересно как ~~уничтожить~~ забить память — прошу под хабракат
#### Немножко предыстории
По долгу службы приходится много работать с большими буфферами памяти (представьте себе изображение 5000x40000 пиксел). Порой (из-за фрагментации) не получается выделять непрерывный кусок памяти для всего. Поэтому был написан некоторый менеджер памяти, который выделял сколько есть, возможно, несколькими кусками. Естественно, менеджер памяти должен как выделять, так и удалять. Тогда была обнаружена следующая интересная вещь: Task Manager после освобождения показывает уровень использования памяти такой же как и до выделения блока. Однако никакой новый блок памяти в программе не может быть выделен. Использование средств анализа виртуальной памяти (VMMap от Марка Русиновича) показывает, что память остается занята несмотря на ее освобождение в коде и несмотря на показания TM.
#### Анализ
Напишем быстренько какую-нибудь программку, которая выделяет и освобождает память. Что нибудь такое, сродни «Hello, World!»:
```
int main(void)
{
const int blockCount = 1024;
const int blockSize = 1024*1024;
char **buf;
printf("Hit something...\n");
getchar();
buf = (char**)malloc(blockCount*sizeof(char*));
for (int i=0; i
```
Несложными подсчетами можно убедиться, что программа должна выделить 1 ГБ памяти, а затем все освободить. После запуска и проверки вся память освобождается. Хм, кажется, система шантажу не поддается. Впрочем, мы резали большие куски.
Теперь возьмем и немножко поправим исходный код:
```
const int blockSize = 520133 //К примеру...;
```
В этом случае мы получим, что память выделилась, но не освободилась:
До «Memory freed»:

После «Memory freed»:

Пытливый ум программиста не остановился на достигнутом! Я начал искать пороговое значение, при котором возникает такой эффект. После недолгого бинарного подбора выяснилось, что при размере равном
* **520168** байт и выше — освобождение проходит нормально
* **520167** байт и ниже — имеем описанную проблему
Забегая вперед скажу, что никаким образом подобное значение порога я объяснить не смог. ~~Оно не делится даже на 1024!~~
#### Возможное объяснение
После длительных бдений за гуглом и изучения форумов я пришел к следующим выводам.
Оказывается что после выделения памяти с помощью функций malloc/new в том случае если выделяется маленький кусок, то память не освобождается функциями free/delete, а переходит из разряда committed в разряд reserved. И если мы обращаемся к данной памяти тут же после удаления (по всей видимости в рамках одного хипа), то она может быть выделена повторно. Однако при попытке выделить память из другого класса (либо статической функции) мы получим исключение — не достаточно памяти. По всей видимости при выделении памяти из статической функции память выделяется не в том же хипе, что и при обычном выделении изнутри класса приложения.
В результате после создания большого блока памяти (из маленьких кусочков) мы исчерпываем память и не можем в дальнейшем выделить себе еще немножко ~~ну хоть чуть-чуть!~~ памяти.
#### Неправильное решение
Использование функций VirtualAlloc/VirtualFree ([MSDN](http://msdn.microsoft.com/en-us/library/windows/desktop/aa366887(v=vs.85).aspx)) решает данную проблему, память полностью возвращается процессу после использования (ключ MEM\_RELEASE), однако при использовании VirtualAlloc происходит сильная фрагментация памяти, и где-то 800Мб памяти не доступно для использования, т.к. максимальный размер свободного блока — 28Кб. Классический malloc в этом плане работает лучше, т.к. там есть некоторый дефрагментатор.
#### Окончательное решение
Нашел стороннюю реализацию malloc и free (как выясняется, широко известную в узких кругах), которая имеет классический недостаток дефрагментации памяти, но в месте с тем освобождает полностью память после использования. Плюс еще и заметно быстрее работает.
Для любопытствующих и жаждущих имеется [ссылка](http://g.oswego.edu/dl/html/malloc.html)
#### Ремарки
Под ОС \*NIX (Ubuntu, Debian, CentOS) повторить проблему не удалось)
Под ОС Windows проблема была воспроизведена на Windows Server 2003 x64, Windows 7 x64, Windows XP x32.
Не стоит прямо так сразу доверять давно проверенным функциям, в них может крыться подвох.
UPD: Для компиляции на Windows используется MS VS 2010 | https://habr.com/ru/post/158347/ | null | ru | null |
# Разворачиваем MySQL: репликации и секционирование
[В первой статье](https://habr.com/ru/company/otus/blog/712768/) мы развернули сервер MySQL под управлением ОС Linux. Однако, одного сервера для серьезной инсталляции будет явно недостаточно, так как отсутствие реплик накладывает некоторые ограничения на эффективность использование СУБД. Например, инсталляция, состоящая из одного сервера, не обладает отказоустойчивостью. В случае сбоя мы можем рассчитывать только на резервную копию, если она есть. Кроме того, построение отчетов, выполнение того же бэкапа и другие ресурсоемкие операции создают нагрузку на сервер, снижая его производительность. А для серьезных систем отдельно можно упомянуть необходимость горизонтального масштабирования. Даже если ваш сервер живет в облаке, ресурсы этого облака не бесконечны, и вы можете столкнуться с тем, что вам не хватает ядер или памяти, а добавить уже нельзя.
Эти доводы нас подводят к тому, что необходимо реплицировать данные с основного сервера для того, чтобы иметь рабочую копию данных на случай сбоя, а также второй узел, на котором можно запускать ресурсоемкие операции, не опасаясь просадки производительности.
Также в целях оптимизации производительности можно также настроить секционирование больших таблиц.
В этой статье мы сначала настроим репликацию данных на второй сервер, а затем рассмотрим различные варианты секционирования.
Зачем реплицировать
-------------------
Но сначала мы немного поговорим о теории – в данном случае о том, какие механизмы синхронизации бывают. Под репликацией мы будем понимать процесс копирования данных из одного источника на множество других. При репликации изменения, сделанные в одной копии объекта, могут быть распространены в другие копии. Репликация может быть синхронной или асинхронной (как вариант полусинхронной).
При синхронной репликации, если основная реплика обновляется, все другие реплики того же фрагмента данных тоже обновляются в одной и той же транзакции. Логически это означает, что существует лишь одна версия данных. Например, если мы помещаем данные в базу, мы должны дождаться пока данные не будут помещены в 50% реплик + 1 реплика, иначе коммит не произойдет. Синхронные репликации создают дополнительную нагрузку при выполнении транзакций и могут вызывать проблемы, связанные с доступностью данных.
На рисунке ниже, коммит будет получен только после выполнения шага 4.
И в завершении этого абзаца скажу главное о синхронной репликации в MySQL – ее нет!
Особенностью асинхронной репликации является то, что обновление одной реплики распространяется на другие спустя некоторое время, а не в той же транзакции. При асинхронной репликации у нас появляется задержка, или время ожидания, в течение которого отдельные реплики могут быть фактически неидентичными.
Рассмотрим на примере, как работает асинхронная репликация.
Запрос выполняется на мастере, далее бинлог мастера передается по запросу через потоки в relay log на Slave. При этом, на мастере происходит коммит. На слейве Relay Log проигрывается, применяется и сохраняется и затем на нем тоже происходит коммит. Очевидным недостатком такого подхода является наличие задержки на стороне подчиненного сервера.
Полусинхронная репликация предполагает коммит на Мастере только после получения доставки relay log на все подчиненные серверы.
При таком подходе у нас задержки меньше (реплики меньше отстают), но снижается скорость работы Мастера из-за необходимости ждать подтверждения от подчиненных узлов.
В MySQL мы можем выбрать, какую репликацию хотим использовать асинхронную или полусинхронную. Но выбор должен быть сделан для всей БД.
Настраиваем асинхронную репликацию
----------------------------------
В качестве примера настройки репликации мы выполним синхронную репликацию между двумя серверами MySQL. Информация по узлам представлена на следующей схеме:
Перед началом у нас уже должны быть развернуты СУБД на обоих серверах и созданы тестовые таблицы. Прежде, чем начать настройку репликации необходимо убедиться в наличии соединения на нижних уровнях модели OSI. Проще говоря проверить пинг на IP адреса и телнет на порты 3306.
Сначала выполняем настройки на Мастере.
Узнаем его ID
```
select @@server_id;
```
Должна быть 1.
Далее идем в файл конфигов /etc/mysql/mysql.conf.d/mysqld.cnf и правим значение bind-address
```
nano /etc/mysql/mysql.conf.d/mysqld.cnf
bind-address = 192.168.60.140
Рестартуем базу.
service mysql restart
```
Далее выполняем на Мастере следующие команды:
```
create user [email protected] IDENTIFIED WITH caching_sha2_password BY 'oTUSlave#2020';
GRANT REPLICATION SLAVE ON *.* TO [email protected];
SELECT User, Host FROM mysql.user;
SHOW MASTER STATUS;
```
Мы создали пользователя repl и дали ему права на репликацию на 192.168.60.139.
Теперь настраиваем подчиненный узел. Если спросить у него ID то мы получим значение 1, а нам необходимо его поменять. Для этого правим /etc/mysql/mysql.conf.d/mysqld.cnf:
```
nano /etc/mysql/mysql.conf.d/mysqld.cnf
server_id = 2
```
И перезапускаем mysql.
```
sudo service mysql restart
```
Далее на слейве выполняем следующие команды:
```
CHANGE MASTER TO MASTER_HOST='192.168.60.140', MASTER_USER='repl', MASTER_PASSWORD='oTUSlave#2020', MASTER_LOG_FILE='binlog.000004', MASTER_LOG_POS=900, GET_MASTER_PUBLIC_KEY = 1;
START SLAVE;
```
Не забудьте указать `GET_MASTER_PUBLIC_KEY = 1` , иначе получите ошибку из-за отсутствия публичного ключа.
Посмотрим состояние:
```
show slave status\G
```
Также можно посмотреть статусы репликации с помощью следующих команд:
```
use performance_schema;
show tables like '%replic%';
```
И в завершение настройки рекомендуется включать для слейва следующий параметр, иначе на нем можно будет вносить изменения, что будет не очень хорошо для целостности данных.
```
set global innodb_read_only = ON
```
Секционирование
---------------
Секционирование, также используют термин Партиционирование (Partitioning) – разбиение таблицы на секции, по ключу секционирования. Обычно этот механизм используют для разбиения больших таблиц на логические части по выбранным критериям с целью ускорения процесса выборки данных. Преимуществом партиционирования является возможность сохранять большее количество данных в одной таблице, чем может быть записано на одиночном диске или файловой системе. С помощью секционирования можно легко удалить не нужные данные, удалив соответствующий раздел. Наоборот, процесс добавления новых данных в некоторых случаях может быть значительно облегчен, при добавлении нового раздела специально для этих данных.
Если рассматривать секционирование непосредственно в MySQL, то на нижнем уровне для myISAM таблиц, это будут физически разные файлы, по 3 на каждую партицию (описание таблицы, файл индексов, файл данных). Для innoDB таблиц в конфигурации по умолчанию – разные пространства таблиц в файлах innoDB.
В MySQL предусмотрены четыре способа «разделения» данных:
* RANGE
* LIST
* HASH
* KEY
Рассмотрим каждый из них подробнее:
RANGE
-----
Секционирование по диапазону значений. Если у нас в поле file\_id хранятся значения для записей, то мы можем создать несколько разделов, в каждом из которых будут записи из определенных диапазонов file\_id.
```
PARTITION BY RANGE (file_id) (
PARTITION f0 VALUES LESS THAN (10),
PARTITION f1 VALUES LESS THAN (20),
PARTITION f3 VALUES LESS THAN (30)
);
```
LIST
----
Секционирование по точному списку значений. Задаем список значений и по ним данные помещаются в разделы:
```
PARTITION BY LIST(file_id) (
PARTITION pOne VALUES IN (3,5,6,9,17),
PARTITION pTwo VALUES IN (1,2,10,11,19,20)
)
```
HASH
----
При использовании метода HASH у вас нет возможности как-то повлиять на разделение данных, вы просто указываете по какому полю строить хэш.
```
PARTITION BY HASH(file_id)
PARTITIONS 4;
```
KEY
---
Аналогично HASH, но по ключу. То есть, производится выборка по указанному ключевому полю.
```
PARTITION BY KEY(s1)
PARTITIONS 10;
```
Выбор метода секционирования как правило зависит от структуры данных в базе, а также от времени заполнения таблиц. Если необходимо просто разделить данные по времени, то лучше всего подойдет RANGE, LIST подойдет там, где необходимо разделить данные по определенному признаку. Оставшиеся два типа подойдут при необходимости равномерного распределения данных.
Заключение
----------
В этой статье мы рассмотрели виды репликации данных, используемых в MySQL. Но при этом осталась за кадром такая интересная тема, как траблшутинг. Мы вернемся к ней в последующих статьях по администрированию БД.
Секционирование поможет ускорить работу базы, а также может пригодиться при выполнении бэкапов, о которых мы будем говорить в следующей статье.
---
В заключение рекомендую к посещению открытое занятие, посвященное погружению в PostgreSQL. Урок будет включать в себя:
1. Знакомство с базой данных – особенности, немножко истории, полезность и актуальность.
2. Способы развертывания и установки, сама установка.
3. Практическая часть: рассмотрим особенность, присущую этой базе данных – например, способ хранения данных, разбор сложной задачи и различных вариантов построения архитектуры ее решения.
Записаться можно [на странице курса «Базы данных».](https://otus.pw/Jevn/) | https://habr.com/ru/post/714522/ | null | ru | null |
# Эксперименты с микроконтроллерами в Jupyter Notebook
Jupyter Notebook — любимый инструмент-среда для data scientist'ов, аналитиков, инженеров, математиков, студентов и даже для нас — самых обычных ученых в экспериментальной физике.
Этот инструмент предназначен для работы с интерпретируемыми языками и удобного графического представления данных. Долгое время мы просто считали на нем, используя Python и математические библиотеки (numpy, SciPy, matplot и т.д.). Но оказывается данная среда не так проста и имеет гораздо больший потенциал. Очень неожиданно, но Jupyter позволяет легко манипулировать электронными устройствами на микроконтроллерах, может служить чем-то вроде REPL среды для МК только без слабенького MicroPython и внушительной поддержкой переферии чипа, причем все это почти из коробки.

Небольшое интро.
Как то раз из братского НИИ к нам пришел измерительный прибор, хотя прибор — это громко сказано, скорее примитивный сенсор, данные с которого требуется еще обрабатывать. Алгоритм простой, всего лишь нужно измерять время нарастания фронта сигнала. Что-то типа такого:
К сожалению, данные и форму реального сигнала, привести увы, не могу.
Измерения временого интервала по осцилографу не сложно было делать первые пару раз, дальше стало понятно что требуется автоматизация процесса измерения, для которой как всегда нету оборудования.
Очень не хотелось сидеть и портить глаза об экран осцилографа и примитивные расчеты. А дело мог исправить какой-нибудь USB или Ethernet осцилограф, хотя бы на несколько десятков килогерц, однако который стоит десяток килогривен. С его помощью можно было получать данные сигнала на компьютер и там уже обрабатывать в Python.
Из того что было: обычно вечно выручающая ардуинка не вытягивала такой sample rate для оцифровки сигнала — только [10,000 times a second](https://www.arduino.cc/reference/en/language/functions/analog-io/analogread/) а по факту меньше, что то около 8,000 times a second. Нужно было верхнюю частоту хотя бы 40,000 -50,000 times a second.
Была даже отчайная мысль, поставить смартфон и сделать распознование сигнала с осцилографа на камеру. Но сигнал с сенсора сильно меняется по частоте(на порядок) поэтому все равно придется сидеть рядом с осцилографом и подправлять развертку на нем, что бы сигнал оптимально отображался на экране. Уже лучше, но опять же от осцилографа далеко не отойдешь, к тому же точность скорее всего будет не очень и в конце концов для нас, самыx обычных физиков, computer vision это настоящий rocket science. Увы.
Опрос по коллегам показал, что самое бюджетное решение в таком случае использовать более мощную электронную плату чем ардуино и на её основе делать измерительное устройство, и мне даже вручили набор подобного оборудования. Однако работы для такого варианта все равно было много, нужно разбираться с программированием микроконтроллеров, со средой програмирования микроконтроллера и еще нужно написать софт который будет принимать данные с устройства. Трудозатрат получается все равно очень много.
Самый дельный совет, дал мой эмигрировавший однокурсник Боря. В его европейском университете есть интересная методика для работы с микропроцессорной техникой. Там студенты изучают функционирование устройств на микроконтроллерах с помощью Jupyter Notebook. Здесь Jupyter выступает в качестве REPL среды для исполнения команд на МК, это очень похоже на принцип MicroPython. Только MicroPython запускается на микроконтроллере и исполняет код, который пользователь пишет в терминал COM-порта.
*<https://www.youtube.com/watch?v=5LbgyDmRu9s>*
А в случае с Jupyter подход другой. Jupyter Notebook запускается на обычном компьютере, а взаимодействие с МК происходит через удаленный вызов процедур библиотеки драйверов. К примеру для микроконтроллеров STM32 и STM8, такую библиотеку драйверов предоставляет производитель этих микроконтроллеров — компания STMicroelectronics. Называется библиотека [Standard Peripheral Library](https://www.st.com/content/st_com/en/products/embedded-software/mcu-mpu-embedded-software/stm8-embedded-software/stsw-stm8016.html)
Посмотрим на примере: в этой библиотеки для чипа STM8 есть ф-ция для работы с АЦП.
```
uint16_t ADC_GetConversionValue(ADC_TypeDef* ADCx);
```
Она возращает значение оцифрованного сигнала. Её можно очень просто вызвать в Jupyter:

Как вы могли заметить **ADC\_GetConversionValue** имеет сигнатуру *С/С++* ф-ция, как же я её вызвала из Jupyter?! Есть полезный плагин [xeus-cling](https://anaconda.org/conda-forge/xeus-cling), который к Jupyter добавляет интерпретатор С++. Огорчает только одно, на Windows этот плагин не работает. Так что здесь, мне давней пользовательнице продукта Microsoft, пришлось воспользоваться вирутальной машиной c установленной Ubuntu. Можно воспользоваться MacOS, но откуда бы MacBook у нас взялся в лаборатории...
**xeus-cling** это только С/С++ интерпретатор, трансляцией вызова ф-ции из среды Jupyter NoteBook в микроконтроллер занимается библиотека [REMCU](https://remotemcu.com). Это обычная динамическая библиотека, которая предоставляет такой же API, как у **Standard Peripheral Library** т.е. можно подключить заголовочные(header) файлы из **Standard Peripheral Library**, а вернее для STM8LDiscovery всего один основной заголовочный файл требуется для работы с периферией:
```
#include "stm8l15x.h"
```
И можно пользоваться всеми функциями из этого заголовочного файла, передавать туда необходимые параметры для работы с периферией, как это обычно делается при написании прошивки для микроконтроллера. Библиотека сама все оттранслирует в МК без написания дополнительных оберток.
По сути дела, работа с аппаратными модулями микроконтроллера в Jupyter в таком случае, ничем не отличается от работы с периферией из прошивки микроконтролера. Конечно, напрямую к регистрам обращаться нельзя, вроде такого:
```
/* Init GPIO Port C PC7 output push-pull up to 10MHz blue LED4*/
GPIOC->DDR |= 0x80;
GPIOC->CR1 |= 0x80;
GPIOC->CR2 |= 0x80;
```
*Пример [WavesGenerator](https://github.com/tanbras/MCU_Experiments/blob/master/Standard_Peripheral_Library_STM8L_V1.4.0/Project/WavesGenerator/src/main.c)*
Потому как Jupyter запущен на компьютере и закономерно упадет при такой операции. Но и через **Standard Peripheral Library** все аппартные блоки доступны для управления.
Предлагаю уже попробовать попрактиковаться. Нам понадобится:
* Компьютер (или вирутальная машина) с Ubuntu или MacOS на ней должна быть установлена Anaconda, Jupyter Notebook и к нему плагины [xeus-cling](https://anaconda.org/conda-forge/xeus-cling) и [xplots](https://anaconda.org/conda-forge/xplot)(для построения графиков)
* Электронная плата STM8LDiscovery — по совету коллеги, как самый простой вариант среди доступного тогда оборудования. Можно использовать и другие платы, к примеру c STM32.
* Библиотека REMCU для STM8LDiscovery, в прошлом году со мной поделился Борис. Но сейчас библиотека уже доступна для скачивания с [сайта](https://remotemcu.com/download).
**Как скачать**Для платы STM8LDiscovery выбрать **STM8L152C6** в поле ***MCU name:***, библиотеку StdPeriph\_Driver и я использовала версию 1.4.0
И скачать архив с библиотекой.

* OpenOCD утилита, нужна для работы с REMCU. Рекомендую скачивать из этого [репозитория](https://github.com/ilg-archived/openocd/tree/v0.10.0-12-20190422), потому как OpenOCD, который ставится в Ubuntu через *apt install* не имел поддержки платы STM8LDiscovery.
* ST-Link stick — отдельный программатор для STM8LDiscovery, стоит меньше чем сто гривен. Хотя вроде бы STM8LDiscovery полноценная отладочная плата, но встроенный программтор не может работать с OpenOCD.
*UPD. В [комментариях](https://habr.com/ru/post/486598/#comment_21446088) к статье дали способ обойтись без внешнего ST-Link*
Первым делом подключаем программтор ST-Link к STM8LDiscovery и далее к компьютеру.
**Схема**
Запускамем OpenOCD с такими параметрами:
```
./openocd -f interface/stlink-v2.cfg -f target/stm8l.cfg
```
Теперь можно запускать Jupyter и проводить эксперименты с STM8LDiscovery. Однако библиотека **Standard Peripheral Library** оказалась не такая простая как библиотека Arduino. Она имеет гораздо больше возможностей и настроек, но из-за этого ей очень сложно пользоваться новичкам, при том что документация очень скудная. Спасает только большое кол-во [примеров](https://github.com/tanbras/MCU_Experiments/tree/master/Standard_Peripheral_Library_STM8L_V1.4.0/Project), которые идут с ней.
Для начала я выбрала самый простой пример [GPIO\_Toggle](https://github.com/tanbras/MCU_Experiments/tree/master/Standard_Peripheral_Library_STM8L_V1.4.0/Project/GPIO/GPIO_Toggle) — просто поморгать светодиодами на плате. Шаблон для работы c REMCU мне тогда дали, сейчас этот [шаблон](https://github.com/remotemcu/remcu_examples/tree/master/stm32f4_discovery/jupyter-notebook) можно найти в [GitHub репозитории](https://github.com/remotemcu/remcu_examples) с примерами REMCU. У меня получился вот такой вот [notebook](https://github.com/tanbras/MCU_Experiments/blob/master/stm8l_discovery_GPIO_Toggle.ipynb):
**код с минимум комментариев :**STM8L-Discovery GPIO example
============================
Load [REMCU](https://remotemcu.com) shared libray
```
.L libremcu.so
```
Add path with header files
```
.I remcu_include
```
Including necessary header files. The [“remcu.h”](http://remcu_include/remcu.h) header must be always included before any MCU header files.
```
#include "remcu.h"
#include "stm8l15x.h"
```
```
remcu_connect2OpenOCD(debug_server_ip, default_openocd_port, timeout_sec)
```
```
remcu_resetRemoteUnit(__HALT)
```
Setting up microcontroller peripherals:
---------------------------------------
```
GPIO_Init(GPIOE, GPIO_Pin_7, GPIO_Mode_Out_PP_High_Fast)
```
```
GPIO_Init(GPIOC, GPIO_Pin_7, GPIO_Mode_Out_PP_High_Fast)
```
```
GPIO_ResetBits(GPIOE, GPIO_Pin_7);
GPIO_ResetBits(GPIOC, GPIO_Pin_7);
```
Открываем notebook в Jupyter.
Первые 6 ячеек c кодом иницилизируют работу REMCU. После этих строчек можно уже вставлять код из **Standard Peripheral Library** и экспериментировать. Что моргунть светодиодами на плате STM8L-Discovery, нужно вызвать всего две ф-ции:
```
void GPIO_Init(GPIO_TypeDef* GPIOx, uint8_t GPIO_Pin, GPIO_Mode_TypeDef GPIO_Mode);
void GPIO_ResetBits(GPIO_TypeDef* GPIOx, uint8_t GPIO_Pin);
```
Но параметры из [примера](https://github.com/tanbras/MCU_Experiments/tree/master/Standard_Peripheral_Library_STM8L_V1.4.0/Project/GPIO/GPIO_Toggle) что шли в SDK, мне не подходили. Пример сделан для другой платы *STM8L15X\_EVAL*. В интеренете удалось найти параметры подходящие для моего устройства:
```
GPIO_Init(GPIOE, GPIO_Pin_7, GPIO_Mode_Out_PP_High_Fast);
GPIO_Init(GPIOC, GPIO_Pin_7, GPIO_Mode_Out_PP_High_Fast);
```
Что бы запустить пример, надо распокавать архив с REMCU библиотекой в папку с notebook файлом.
OpenOCD должен быть запущен.
Выполняем все ячейки в notebook, при выполнении ф-ции *GPIO\_Init* светодиоды зажглись:

И когда выполняем ф-ции *GPIO\_ResetBits*, они гаснут
Здесь все просто как в Arduino. С АЦП тоже несложно работать:
**ADC code**
```
/* Enable ADC1 clock */
CLK_PeripheralClockConfig(CLK_Peripheral_ADC1, ENABLE);
/* Initialize and configure ADC1 */
ADC_Init(ADC1, ADC_ConversionMode_Continuous, ADC_Resolution_12Bit, ADC_Prescaler_2);
/* ADC channel used for IDD measurement */
ADC_SamplingTimeConfig(ADC1, ADC_Group_SlowChannels, ADC_SamplingTime_384Cycles);
/* Enable ADC1 */
ADC_Cmd(ADC1, ENABLE);
/* Start ADC1 Conversion using Software trigger*/
ADC_SoftwareStartConv(ADC1);
/* Get conversion value */
ADCData = ADC_GetConversionValue(ADC1);
```
Однако удаленный вызов ф-ции в микроконтроллере STM8 далеко не быстрый процесс и достигнуть хотя бы 40,000 sample rate у меня не получится. Спасает ситуацию здесь буферизация данных, у STM8L продвинутый процессор и в нем есть полезный модуль DMA — это аппаратный блок в микроконтроллере, который позволяет буферизировать данные с АЦП(и других периферийных блоков) в память чипа. А Jupyter Notebook может читать накопленные данные из памяти МК — это как раз то что нам нужно. Можно обрабатывать полученные значения и высчитывать необходимое время нарастания сигнала.
В обратную сторону, когда из компьютера записываем данные в память, а потом эти данные передаются в периферию тоже можно делать. Дальше будет пример с ЦАП, где как раз такая передача данных из памяти в периферию, будет использоваться для генерации синусоидального сигнала.
Для работы с DMA я взяла пример [ADC\_DMA](https://github.com/tanbras/MCU_Experiments/tree/master/Standard_Peripheral_Library_STM8L_V1.4.0/Project/ADC/ADC_DMA), получился такой [notebook](https://github.com/tanbras/MCU_Experiments/blob/master/stm8l_discovery-DMA.ipynb)
Здесь с помощью Xplots строим график данных с АЦП. Генератор сигнала следует подключить к ножке PC7 платы STM8LDiscovery.
Запускаем и полученная картинка совсем не похожа на подаваемый сигнал(синус в нашем случае):
Я долго билась с таким непонятным поведением. А оказалось вот чем дело, у процессорного ядра есть такая х-ка как [интерпретация порядка байт](https://en.wikipedia.org/wiki/Endianness), а конкретно их там всего две интерпретации little-endian и big-endian. Прямой и обратный порядок байт, на всех наших офисных ПК используется little-endian, а в STM8LDiscovery, big-endian! Поэтому в данных, что приходят из АЦП поменяны старший байт с младшим. Если сделать престановку байт, то картинка будет как и предполагалось для синусоидального сигнала.
```
#include
for(int i = 0; i < 0xFF; i++){
uint16\_t temp = adc\_data[i];
temp = htons(temp);
adc\_data[i] = temp;
}
line.y = adc\_data; //plot graph
fig
```
Но можно заметить, что на графике есть артефакты.
Это из-за того что буфер в памяти МК перезаписывается значениями АЦП по кругу. В какой-то момент времени мы останавливаем запись и читаем из памяти STM8LDiscovery сохраненные значения. К сожалению, запись останавливается в произвольный момент времени, поэтому мы видим такие артефакты. Конечно было бы удобнее если бы запись останавливался бы в конце буфера, но мне не понятно как это сделать.
Так как данные записываются по кругу, то можно их просто все сдвинуть вперед или назад на позицию текущей перезаписываемой ячейки памяти, что бы она оказалась на правой или левой границе графика.
Тогда мы получим график сигнала без артефактов посередине. Делается это просто:
```
//временный буфер
int osc_data[ADC_BUFFER_SIZE] = {0};
//На какой ячейке остановилась запись DMA
size_t shift = DMA_GetCurrDataCounter(DMA1_Channel0);
//сохраняем начальные данные
for(int i = 0; i < ADC_BUFFER_SIZE; i++){ osc_data[i] = adc_data[i];}
//считаем смещение, на которое надо сдвинуть сигнал что бы он стал ровный как на картинке осцилографа
shift = ADC_BUFFER_SIZE - shift;
//сдвигаем
for(size_t i = 0; i < ADC_BUFFER_SIZE; i++){
int shift_pos = (i + shift) % ADC_BUFFER_SIZE;
adc_data[i] = osc_data[shift_pos];
}
line.y = adc_data; //plot graph
fig
```
Можно вообще не заморачиваться с перестановкой байт в данных. А просто перевести АЦП в режим 8бит. Когда один байт — никаких проблем с его порядком нет!
Огорчил меня немного модуль DMA у STM8LDiscovery. Он позволяет держать буфер всего в 255 значений. Это очень мало для работы с нашим сигналом, у которого частота меняется на порядок. Желательно ну хотя бы 10.000 значений. Кстати, в примерах к плате собрату STM8LDiscovery — [STM32F4Discovery](https://github.com/remotemcu/remcu_examples/tree/master/stm32f4_discovery/jupyter-notebook). Для STM32F4 чипа можно задавать буфер DMA в более чем 64 тысячи значений, это было бы удобно для нашей задачи. Но в то время, пришлось иметь дело с тем что было и пришлось динамически задавать sample rate для АЦП, так что бы один период сигнала оптимально умещался в 255 значениях.
Частотой сэмплирования АЦП, управляет таймер TIM1. Настроить его можно с помощью ф-ции :
```
void TIM1_TimeBaseInit(uint16_t TIM1_Prescaler,
TIM1_CounterMode_TypeDef TIM1_CounterMode,
uint16_t TIM1_Period,
uint8_t TIM1_RepetitionCounter);
```
Здесь много параметров, которые по хорошему надо высчитывать по документации на чип. Но мы не физики-теоретики, а экспериментаторы. Поэтому я просто подбирала параметры экспериментируя. Для меня самое удобное оказалось это регулировать частоту опроса с помощью аргумента TIM1\_Period, при остальных фиксированных аргументах. От TIM1\_Period идет почти линейная зависимость частоты опроса, а от остальных нет.
В этом коде АЦП работает на максимальной скорости опроса, вернее максимально, что у меня получилось подобрать при таких параметрах:
```
SamplingTime = ADC_SamplingTime_4Cycles;
TIM1_Prescaler = 0x0;
TIM1_Period = 0x2;
TIM1_RepetitionCounter = 0;
```
Это, по моим оценкам, примерно 600-660 кГц. Вы можете изменить скорость для своих нужд подбирая переменные выше.
На всякий случай, если у вас нет сигнального генератора для эксперимента с АЦП, я добавила в [notebook](https://github.com/tanbras/MCU_Experiments/blob/master/stm8l_discovery-DMA.ipynb), еще и работу с ЦАП(он же DAC) микроконтроллера STM8LDiscovery. ЦАП, опять же, с помощью DMA генерирует на ножку PF0 синусоидальный сигнал, который, кстати, наблюдаем на картинках выше, достаточно просто ножки PC7(вход АЦП) и PF0(выход ЦАП) соединить проводом. Выполните эти ячейки в notebook, что бы ЦАП начал работу:
**Код**DAC-DMA example
---------------
```
const uint16_t MEM_ADDRESS = ADC_BUFFER_SIZE*sizeof(adc_data.front()) + 1;
const uint8_t MEM_SIZE = 130;
uint8_t SINUS_TABLE[130] = {110,115,121,126,131,137,142,147,
152,157,161,166,171,175,179,183,187,191,195,198,201,204,207,209,
211,213,215,216,218,219,219,220,220,220,220,219,218,217,216,214,
212,210,208,205,202,199,196,193,189,185,181,177,173,168,164,159,
154,149,144,139,134,129,123,118,113,107,102,97,91,86,81,76,
71,66,61,56,52,47,43,39,35,31,27,24,21,18,15,12,
10,8,6,4,3,2,1,0,0,0,0,1,1,2,4,5,7,9,11,13,16,19,22,25,29,33,37,41,45,49,54,59,
63,68,73,78,83,89,94,99,105,110, };
```
```
CLK_PeripheralClockConfig(CLK_Peripheral_DAC, ENABLE);
CLK_PeripheralClockConfig(CLK_Peripheral_TIM4, ENABLE);
for(int i = 0 ; i < 130*sizeof(SINUS_TABLE[0]); i+=10){
remcu_store2mem(MEM_ADDRESS + i, (uint8_t*)SINUS_TABLE + i, 10);
}
```
```
/* DMA channel3 Config -----------------------------------------------------*/
#define DAC_CH1RDHRH_ADDRESS 0x5388
#define DAC_CH1RD8_ADDRESS 0x5390
#define DAC_CH1RDHLH_ADDRESS 0x538C
DMA_DeInit(DMA1_Channel3);
DMA_Init(DMA1_Channel3, MEM_ADDRESS,
DAC_CH1RD8_ADDRESS,
MEM_SIZE, DMA_DIR_MemoryToPeripheral, DMA_Mode_Circular,
DMA_MemoryIncMode_Inc, DMA_Priority_High,
DMA_MemoryDataSize_Byte
);
/* DMA1 Channel 3 enable */
DMA_Cmd(DMA1_Channel3, ENABLE);
DMA_GlobalCmd(ENABLE);
```
```
/* DAC Channel1 Config: 12bit right ----------------------------------------*/
/* DAC deinitialize */
DAC_DeInit();
/* Fill DAC Init param DAC_Trigger_T4_TRGO and DAC Channel1 Init */
DAC_Init(DAC_Channel_1, DAC_Trigger_T4_TRGO, DAC_OutputBuffer_Enable);
/* Enable DAC Channel1 */
DAC_Cmd(DAC_Channel_1, ENABLE);
/* Enable DMA for DAC Channel1 */
DAC_DMACmd(DAC_Channel_1, ENABLE);
```
```
TIM4_DeInit();
/* Time base configuration */
TIM4_TimeBaseInit(TIM4_Prescaler_1, 0x1);
/* TIM4 TRGO selection */
TIM4_SelectOutputTrigger(TIM4_TRGOSource_Update);
/* TIM4 enable counter */
TIM4_Cmd(ENABLE);
```
Код для работы с ЦАП взят из этого [примера](https://github.com/tanbras/MCU_Experiments/tree/master/Standard_Peripheral_Library_STM8L_V1.4.0/Project/DAC/DAC_SignalsGeneration). Здесь я не стала заморачиваться с переводом данных в big-endian, а просто перевела ЦАП в режим 8-bit.
Замечу, что некоторые примеры из Standard Peripheral Library у меня не завелись. К примеру, код из [DAC\_Noise&TriangleGenerator](https://github.com/tanbras/MCU_Experiments/tree/master/Standard_Peripheral_Library_STM8L_V1.4.0/Project/DAC/DAC_NoiseTriangleGenerator) у меня выдавал ошибку, что не найдена следующая ф-ция:
```
DAC_SetTriangleWaveAmplitude
```
Такой ф-ции нет в **Standard Peripheral Library** версии 1.4.0. Поэтому имейте это ввиду если будете запускать другие примеры, возможно их придется адаптировать под версию 1.4.0 либо использовть более новую версию REMCU.
Еще один ноутбук я подготовила для работы с LCD экраном на плате, его работу вы можете наблюдать на первом gif-изображении. ЖК экран не требуется нам для автоматизации физических опытов, с ним поиграться я решила скорее из любопытства. Сделать его было очень тривиально, буквально за 15 минут он заработал. Я просто скопировала код из [примера](https://github.com/tanbras/MCU_Experiments/tree/master/Standard_Peripheral_Library_STM8L_V1.4.0/Project/Discover/src) к плате STM8LDiscovery для работы с LCD экраном. Немного подправила и добавила всего одну ф-цию:
```
void LCD_print(std::string str);
```
С помощью которой можно печатать текст на ЖК экране.
Мои подготовленные notebook'и можно найти на [Github](https://github.com/tanbras/MCU_Experiments).
Вот такие были мои эксперименты с микроконтроллерои STM8L151 в Jupyter Notebok. Это была моя первая практика работы с чем-то кроме ардуино, с чем то более профессиональным чем ардуино и более низкоуровненым. Все прошло довольно легко, кроме ситуации с big-endian. На поиск причины в столь странных данных с АЦП у меня ушло больше всего времени и если мне не помогли, я, вероятно, не смогла бы разобраться в столь заковыристой особенности микропроцессора.
Полученный опыт считаю успешным, мы и дальше планируем применять STM8LDiscovery и более профессиональную модель STM32F4Discovery для автоматизации экспериментов. А сейчас даже уже появились байдинги библиотеки REMCU для Python. Поэтому можно уже обойтись без виртуальной машины с Linux или MacOS, а писать скрипты в родной оконной системе.
Всем интересных опытов,
Да прибудет с вами Jupyter! | https://habr.com/ru/post/486598/ | null | ru | null |
# Коэффициент однозначности и алгоритм Витерби
Речь пойдёт об алгоритме Витерби, коэффициенте однозначности, о смысловом их сходстве и различии.
Для Витерби должны быть даны или рассчитаны: вероятности скрытых начальных состояний, переходные вероятности и вероятности выбросов.
https://towardsdatascience.com/markov-chains-and-hmms-ceaf2c854788Его математическая суть:
где x- текущее скрытое состояние, y - следующее скрытое состояние, f - наблюдаемое состояние.
С учётом Байеса эту формулу можно преобразовать.
* **P(F)**: вероятность действия F (что соответствует состоянию в Витерби)
* **P(X|F)**: вероятность состояния Х (скрытое состояние в Витерби) при условии действия F
* **P(Y|X)**: вероятность следующего состояния Y (следующее скрытое в Витерби) при условии состояния X
В этой формуле, при допущении значений этих вероятностей близких единице, **P(Y)=P(F)\*P(X|F)\*P(Y|X)** однозначно выдаст следующее состояние Y. Идейно это тот же модус поненс. Зная F, можно получить Y.
Хотя алгоритм, рассчитывающий коэффициент однозначности, и алгоритм Витерби, решают внешне схожие задачи, назначение у них разное. С коэффициентом однозначности неважно предварительное знание вероятностей и неважно является ли последовательность (как действий, так и состояний) марковской. Что позволяет использовать его «на лету». Суть в том, что если известна последовательность действий, то в силу значения коэффициента равным единице или почти единице, последовательность состояний однозначно выводима.
Другими словами, если есть не детерминированный конечный автомат, то можно подобрать такие действия, что он становится детерминированным. Или почти детерминированным. С учётом ограничения на этот коэффициент как гиперпараметра.
```
#Пусть имеется три последовательности и нужно понять влияют ли они друг на друга
[1, 2, 1, 1, 2, 2, 1, 2, 2, 1]
[3, 4, 4, 3, 3, 4, 3, 3, 4, 3]
[5, 6, 5, 6, 5, 6, 5, 6, 5, 5]
```
В этом случае можно составить несколько пар последовательностей. И по каждой паре проверить коэффициент однозначности. Видно по выводу ниже, что [3, 4, 4, 3, 3, 4, 3, 3, 4, 3] являются действиями для состояний [1, 2, 1, 1, 2, 2, 1, 2, 2, 1]. Однозначность для этой пары 100%. Как следствие - возможность прокладывать маршруты в таком графе.
Для сравнения проанализируем алгоритмом Витерби. Если взять те же последовательности, то налицо ошибки 2/6.
С другой стороны, если рассмотреть последовательности как [здесь](https://towardsdatascience.com/markov-chains-and-hmms-ceaf2c854788), то результат будет обратным. Коэффициент однозначности низкий. Витерби дает большую предсказуемость.
eДля Витерби важно условие, чтобы последовательность являлась марковской.
Проверяем последовательность из книги Эшби и из статьи. Ни та, ни другая ею не являются. После (Holidays, Work) Holidays даже не следует. По крайней мере для той ее длины.
Итак, для алгоритма Витерби нужно предварительное длинное наблюдение, чтобы иметь вероятности, рассчитанные в результате этих наблюдений Также он ограничен марковским свойством. Алгоритм с расчетом на коэффициент однозначности лишен этих недостатков, но и предназначение у него иное: он нацелен на выявление детерминированных или почти детерминированных явлений.
```
import random
import matplotlib.pyplot as plt
class Hd():
def __init__(self, graph):
self.graph = graph
def rnd_get(self, v):
return random.choice(v.split("|"))
def show(self, graph):
for x in graph:
print(x, ":", graph[x])
def get_ku(self, graph):
'''return (коэффициент однозначности, размер)'''
n = 0; u = 0
for x in graph:
for y in graph[x]:
if y[0]:
u += y[0].count("|")
n += 1
if n != 0:
return (round(1- u/(n+u), 3), n+u)
else:
return (None, None)
def get_states(self, x, f_list = [], n=11):
''' На входе последовательность действий и начальное состояние
На выходе последоваельность состояний'''
x_list = []
x_list.append(x)
if f_list != []:
for f in f_list:
xf = [xf for xf in g[x] if xf[1] == f]
if not xf:
x_list.append(''); f_list[len(x_list)-2] = ''
return (x_list, f_list[:len(x_list)-1])
x = self.rnd_get(xf[0][0])
x_list.append(x)
else:
for i in range(n):
if not self.graph[x]:
x_list.append(''); f_list.append('')
break
t = random.choice(self.graph[x])
f = t[1]
x = random.choice(t[0].split('|'))
x_list.append(x); f_list.append(f)
if len(f_list) == len(x_list) -1:
return (x_list, f_list)
else:
return ([], [])
def get_yfx(self, f_list, x_list, t = True):
'''возвращаем список кортежей (x, f, y)'''
if len(x_list) == len(f_list):
x_list.append('')
path = []
for i in range(len(f_list)):
path.append((x_list[i], f_list[i], x_list[i+1]))
if t:
return path
else:
p = []
for xfy in path:
if xfy[2] != '':
p.append(xfy[2]+'='+xfy[1]+'('+xfy[0]+')')
return p
def flow(self, path, rnd=False):
if not path: return []
fl = []
for p in path:
if not rnd:
fl.append(p[:-1])
else:
pr = list(p[:-1])
random.shuffle(pr)
fl.append(tuple(pr))
return fl
def fORx(self, flow, f=0):
'''на входе поток, на выходе две гипотезы
index: f=0, x=1 or x=0, f=1'''
def add_empty():
empty = []
for k in graph:
for x in graph[k]:
z = list(set(x[0].split('|')) - set(list(graph.keys())))
if z:
empty.append(z[0])
return empty
if not flow: return []
graph = {}
fli = flow[0]
for t in flow[1:]:
if f == 0:
if fli[1] not in graph:
graph[fli[1]] = []
r = [(i, xf) for i,xf in enumerate(graph[fli[1]]) if xf[1] == fli[0]]
if r:
if t[1] not in r[0][1][0]:
x_new = r[0][1][0] + "|" + t[1]
if x_new != '':
graph[fli[1]][r[0][0]] = (x_new, r[0][1][1])
if not r:
if t[1] != '':
graph[fli[1]].append((t[1], fli[0]))
if f == 1:
if fli[0] not in graph:
graph[fli[0]] = []
r = [(i, xf) for i,xf in enumerate(graph[fli[0]]) if xf[1] == fli[1]]
if r:
if t[0] not in r[0][1][0]:
x_new = r[0][1][0] + "|" + t[0]
if x_new != '':
graph[fli[0]][r[0][0]] = (x_new, r[0][1][1])
if not r:
if t[0] != '':
graph[fli[0]].append((t[0], fli[1]))
fli = t
em = add_empty()
if em:
graph[em[0]] = []
return graph
def merge(self, g1, g2):
'''объединяет два графа в один'''
def find_index():
for i in range(len(graph[k])):
if graph[k][i][1] == x[1]:
return i
return -1
all_keys = set(list(g1.keys()) + list(g2.keys()))
graph = {}
for k in all_keys:
if k not in graph:
if k in g1:
graph[k] = g1[k]
else:
graph[k] = g2[k]
if k in g2:
for x in g2[k]:
ind = find_index()
if ind != -1:
if x[0] != []:
t1 = x[0].split('|')
if graph[k][ind] != -1:
t2 = graph[k][ind][0].split('|')
z = "|".join(set(t1+t2))
xf = [z, graph[k][ind][1]]
graph[k][ind] = xf
else:
graph[k].append(x)
return graph
class Vm():
def print_dptable(self, V):
'''https://russianblogs.com/article/255172857/'''
for i in range(len(V)): print("%8d" % i, end="")
print()
for y in V[0].keys():
print("%.5s: " % y, end=" ")
for t in range(len(V)):
print("%.7s" % V[t][y], end=" ")
print()
def viterbi(self, obs, states, start_p, trans_p, emit_p):
'''https://russianblogs.com/article/255172857/'''
V = [{}]
path = {}
for y in states:
V[0][y] = start_p[y] * emit_p[y][obs[0]]
path[y] = [y]
for t in range(1, len(obs)):
V.append({})
newpath = {}
for y in states:
(prob, state) = max([(V[t - 1][y0] * trans_p[y0][y] * emit_p[y][obs[t]], y0) for y0 in states])
V[t][y] = prob
newpath[y] = path[state] + [y]
path = newpath
self.print_dptable(V)
(prob, state) = max([(V[len(obs) - 1][y], y) for y in states])
return prob, path[state]
def startProbability(self, x_list):
'''расчет начальной вероятности'''
start_probability = {}
for z in x_list:
if z not in start_probability:
start_probability[z] = 1
else:
start_probability[z] +=1
start_probability = {z:start_probability[z]/(len(x_list)) for z in start_probability}
return start_probability
def transitionProbability(self, x_list):
'''расчет переходной вероятности'''
transition_probability = {}
for i,z in enumerate(x_list):
if z not in transition_probability:
transition_probability[z] = {}
if i == 0:
z_old = z
continue
if z not in transition_probability[z_old]:
transition_probability[z_old][z] = 1
else:
transition_probability[z_old][z] = transition_probability[z_old][z] +1
z_old = z
for z_old in transition_probability:
z_list = [transition_probability[z_old][z] for z in transition_probability[z_old]]
for z in transition_probability[z_old]:
transition_probability[z_old][z] = transition_probability[z_old][z] / sum(z_list)
return transition_probability
def emissionProbability(self, x_list, f_list):
'''расчет вероятности выброса'''
emission_probability = {}
for i,z in enumerate(x_list):
if z not in emission_probability:
emission_probability[z] = {}
if f_list[i] not in emission_probability[z]:
emission_probability[z][f_list[i]] = 1
else:
emission_probability[z][f_list[i]] += 1
for z_old in emission_probability:
z_list = [emission_probability[z_old][z] for z in emission_probability[z_old]]
for z in emission_probability[z_old]:
emission_probability[z_old][z] = emission_probability[z_old][z] / sum(z_list)
return emission_probability
def isMarkov(self, w_list, prev_s, s):
'''проверка на марковское свойство'''
transition_probability = {}
for i,z in enumerate(w_list):
if z not in transition_probability:
transition_probability[z] = {}
if i == 0:
z_old = z
continue
if z not in transition_probability[z_old]:
transition_probability[z_old][z] = 1
else:
transition_probability[z_old][z] = transition_probability[z_old][z] +1
z_old = z
zz_old = z_old
transition_probability_ = {}
for i,z in enumerate(w_list):
if z not in transition_probability_ and z == s:
transition_probability_[z] = {}
if i == 0:
z_old = z
continue
if i == 1:
zz_old = z_old
z_old = z
continue
if zz_old == prev_s and z_old == s:
if z not in transition_probability_[z_old]:
transition_probability_[z_old][z] = 1
else:
transition_probability_[z_old][z] = transition_probability_[z_old][z] +1
zz_old = z_old
z_old = z
return ((prev_s, s), transition_probability_[s], transition_probability[s])
#--------- main ---------#
if __name__ == "__main__":
g = {}
hd = Hd(g)
print("\n__ Две последовательности")
x_list = [str(x) for x in [1, 2, 1, 1, 2, 2, 1, 2, 2, 1]]
f_list = [str(f) for f in [3, 4, 4, 3, 3, 4, 3, 3, 4, 3]]
print(x_list)
print(f_list)
path = hd.get_yfx(f_list, x_list)
print("\n гипотеза 1: первая последовательность - последовательность действий")
gn = hd.fORx(hd.flow(path), f=0)
hd.show(gn)
ku = hd.get_ku(gn)
print("ku =", ku[0])
print("\n гипотеза 2: первая последовательность - последовательность состояний")
gn = hd.fORx(hd.flow(path), f=1)
hd.show(gn)
ku = hd.get_ku(gn)
print("ku =", ku[0])
###########################
print("\n__ Две последовательности")
x_list = [str(x) for x in [1, 2, 1, 1, 2, 2, 1, 2, 2, 1]]
f_list = [str(f) for f in [5, 6, 5, 6, 5, 6, 5, 6, 5, 5]]
'''
x = "Work Work Work Holidays Holidays Holidays Work Work Holidays Holidays Holidays Holidays Holidays Holidays Holidays"
f = "Python Python Python Bear Bear Python Python Bear Python Python Bear Bear Bear Bear Bear"
x_list = x.split()
f_list = f.split()
'''
print(" гипотеза 1: первая последовательность - последовательность действий")
path = hd.get_yfx(f_list, x_list)
gn = hd.fORx(hd.flow(path), f=0)
hd.show(gn)
ku = hd.get_ku(gn)
print("ku =", ku[0])
print("\n гипотеза 2: первая последовательность - последовательность состояний")
gn = hd.fORx(hd.flow(path), f=1)
hd.show(gn)
ku = hd.get_ku(gn)
print("ku =", ku[0])
print("\n__Витерби")
x_list = [str(x) for x in [1, 2, 1, 1, 2, 2, 1, 2, 2, 1]]
f_list = [str(f) for f in [3, 4, 4, 3, 3, 4, 3, 3, 4, 3]]
'''
x = "Work Work Work Holidays Holidays Holidays Work Work Holidays Holidays Holidays Holidays Holidays Holidays Holidays"
f = "Python Python Python Bear Bear Python Python Bear Python Python Bear Bear Bear Bear Bear"
x_list = x.split()
f_list = f.split()
'''
states_x = set(x_list)
states_f = set(f_list)
observations = f_list[1:7]
states = states_x
vm = Vm()
start_probability = vm.startProbability(x_list)
transition_probability = vm.transitionProbability(x_list)
emission_probability = vm.emissionProbability(x_list, f_list)
r = vm.viterbi(observations,
states,
start_probability,
transition_probability,
emission_probability)
print("\n", observations, "#наблюдаемая последовательность состояний")
print(x_list[1:7], "#последовательность скрытых состояний (оригинал)")
print(r[1], "#последовательность скрытых состояний (витерби)")
print("\n__isMarkov")
w = 'A A B B A B B A A B B A B B A B B A B B A A B B A B B A B A B A'
w_list = w.split()
r = vm.isMarkov(w_list, 'A', 'B')
print(*r)
r = vm.isMarkov(w_list, 'B', 'B')
print(*r, "\n")
w = "Work Work Work Holidays Holidays Holidays Work Work Holidays Holidays Holidays Holidays Holidays Holidays Holidays"
w_list = w.split()
r = vm.isMarkov(w_list, 'Holidays', 'Work')
print(*r)
r = vm.isMarkov(w_list, 'Work', 'Work')
print(*r, "\n")
```
P.S. Для последовательностей [1, 2, 1, 1, 2, 2, 1, 2, 2, 1], [3, 4, 4, 3, 3, 4, 3, 3, 4, 3] им соответствующие графы будут выглядеть так, где пунктирной линией неоднозначность выделена. Коэффициент однозначности для первой гипотезы 0,67, т.к всего переходов 2+1+2+1, а если бы были только однозначны, то 4.
* 4|3 = 1(3) # из состояния 3 при действии 1 следует либо 4, либо 3
* 4 = 2(3) # из состояния 3 при действии 2 следует только 4.
* 4|3 = 2(4)
* 3 = 1(4)
 | https://habr.com/ru/post/678604/ | null | ru | null |
# Препарирование файлов .XLSX: строковые значения, разметка ячеек
Итак, продолжаем разговор. На всякий случай уточню, что начало [здесь](https://habrahabr.ru/post/347550/).
Про строковые значения и метод их хранения я уже вскользь упоминал в первой части, а сейчас поговорим подробнее. Представим, что у нас есть таблица, заполненная строковыми данными, и что она большая. При этом крайне маловероятно, что все значения в ней будут уникальны. Некоторые из них нет-нет, да повторятся где-нибудь в разных частях таблицы. Хранить такой массив «как есть» внутри XML-разметки листа нерационально с точки зрения ресурсов ПК. Поэтому все строковые значения вынесены в отдельный файл, %file%/xl/sharedStrings.xml. Часть его, которая нас интересует, выглядит, допустим, так:
```
Вася
Петя
Саша
```
Обратите внимание на атрибуты тега «count» и «uniqueCount»: их значения различаются. Дело в том, что в книге одну из строк я использовал дважды. При этом атрибуты не обязательны, то есть если их убрать, то Excel ошибки не выдаст, но при сохранении файла нарисует опять.
Здесь же можно сказать, что здесь, внутри тега можно играть с настройками шрифта. Для этого используется доработанная напильником система *пробегов*, применяемая в MS Word (до него мы еще доберемся). Выглядит это примерно так:
```
Мама
мыла
раму
```
Обратите внимание: в корневой тег в предыдущем примере был встроен непосредственно тег , содержавший текст. Здесь же он обернут тегом , то есть Run; по-русски его принято назвать «пробег». Пробег — это, если в двух словах — кусок текста, имеющий одинаковые стилевые настройки.
В этом примере строковое значение содержит 3 пробега. Чтобы было удобнее их рассматривать, я, пожалуй, вынесу их отдельными сорсами.
*Первый:*
```
Мама
```
Этот пробег не содержит секции , поэтому использует стилевые настройки ячейки, в которой находится. В нем интересно другое: атрибут *xml:space=«preserve»*. Дело в том, что по умолчанию что Excel, что Word обрезают концевые пробелы со всех пробегов. Может показаться, что в этом случае в месте стыка пробегов всегда должна получаться примерно такая картина: **Вася***Петя*. Но по опыту общения с тем же MS Word мы знаем, что это не так. Из-за чего? Вот как раз из-за xml:space=«preserve».
*Второй:*
```
мыла
```
Здесь нет атрибута xml:space=«preserve». Нам без разницы, что Excel сделает с концевыми пробелами, которых нет. Зато есть блок . В принципе, в него можно поместить любые настройки шрифта, которые только есть в Excel. Я же сделал всего один, чтобы не раздувать объем примера.
*Третий:*
```
раму
```
А здесь у нас есть и блок настроек шрифта и сохранение концевых пробелов.
Ну и еще коротенькая ремарка. Если есть необходимость сделать многострочную запись в ячейке, то здесь в строке просто будет обычный символ переноса, chr(10). Сам атрибут многострочности ячейки расположен в файле разметки листа. В однострочной ячейке символ переноса будет проигнорирован. Excel просто сделает вид, что его нет.
Перейдем в папку %file%/xl/worksheets. Здесь, как говорилось выше, каждый лист, содержащийся в книге, представлен файлом .xml.
Файл разметки листа содержит следующие ключевые элементы (и, что важно, желательно располагать их именно в таком порядке):
1. Тег . Необязателен. Служит, насколько я смог понять, для указания системе размера занятой области, то есть на сколько прорисовывать строки и столбцы
2. Тег . Необязателен, но иногда полезен. Я его использовал для указания на необходимость закрепления верхней строки: это полезно для больших отчетов. Выглядит это примерно так:
```
```
Здесь надо дать пояснение. Собственно закрепление строки — тег . И вот какие здесь использованы атрибуты:
* **ySplit** — показывает количество закрепленных *строк*. Для закрепления столбцов есть аналогичный атрибут **xSplit**;
* **topLeftCell** — указание левой верхней ячейки видимой по умолчанию НЕзакрепленной области;
* **activePane** — указание местонахождения НЕзакрепленной области. В руководствах сказано, что этот атрибут регулирует, с какой стороны будет НЕзакрепленная область. Правда, попробовав разные значения, я почему-то получил одинаковый результат. Как вариант «by default» я для себя выбрал *bottomRight*;
* **state** — указатель состояния закрепленной области. Для простого закрепления строки используется значение *frozen*
3. Тег . Пример:
```
```
Интересен нам здесь в основном атрибут *defaultRowHeight*, то есть высота столбца по умолчанию. Стандартный, привычный нам вариант — 15 у.е. Если назначить его, скажем, 30 у.е., то строки, для которых высота не указана отдельно, станут в 2 раза выше. Однако, для того чтоб применить значение, отличное от дефолтного, необходимо указать атрибут *customHeight* со значением «true». Выглядит это примерно так:
```
```
4. Тег . Помогает установить ширину столбцов отличную от дефолтной. В заполненном виде выглядит примерно так:
```
```
Вложенные теги обозначают не каждый один столбец, как могло показаться, а группу столбцов, идущих подряд и имеющих единую ширину.
* Атрибут **min** — первый столбец группы;
* Атрибут **max** — последний столбец группы;
* Атрибут **width** — ширина столбца из группы;
* Атрибут **customWidth** — флаг применения кастомной ширины, без него ширина все равно будет дефолтной;
5. Тег — это, собственно, зона, где хранится содержимое ячеек, или, в зависимости от типа, ссылок на него. В среднем выглядит он так:
```
0
1
2
1
37539
14
2
33227
21
```
Как видно, в тег вложены теги с атрибутом «r», обозначающим фактический (а не порядковый) номер строки: надо помнить, что, скажем, строка 1 может быть пустой, а строка 2 — нет.
*«Букв, что ли, пожалели?» — спросите вы. «Экономия памяти» — ответит Microsoft. Если вспомнить про ограничение в 16 миллионов с гаком ячеек, становится понятна их мотивация. Выходит, в теории один (!) лишний символ в имени атрибута может привести к миллионам лишних символов при чтении всего файла.*
В тег вложены теги *<с />* — ячейки. В примере видно, что основных атрибутов у ячейки три:
* **r** — адрес ячейки;
* **s** — стиль ячейки. Вспоминаем первую часть данной статьи: в файле styles.xml есть раздел , в котором перечислены зарегистрированные стили оформления ячеек. атрибут «s» тега *<с />* — как раз ссылка на элемент этого списка, начиная с 0;
* **t** — указание на необходимость обращения к таблице строковых значений в файле sharedStrings.xml. Если атрибут указан — обращаемся, если нет — пишем как есть то, что в теле тега. Примечательно, что при попытке вписать в тело тега текст без указания данного атрибута, Excel при открытии файла ругнется, но послушно перенесет нашу фразу туда, где ей место (хотя я на его сообразительность рекомендую не полагаться и сразу писать строки в sharedStrings.xml);
Когда я говорил про файл sharedStrings.xml, я упомянул, что многострочные ячейки помечаются в файле разметки листа. Делается это, к примеру, так:
```
3
```
То есть, строго говоря, нам надо указать кастомную высоту ячейки и поставить флаг применения этой самой кастомной высоты.
6. Тег . Как мы знаем, в Excel есть возможность объединения ячеек. Все объединенные ячейки на листе перечислены здесь. В заполненном виде тег выглядит примерно так:
```
```
Как видно, одна объединенная ячейка обозначена одним тегом с единственным атрибутом ref, задающим диапазон объединения.
7. Тег . Фильтры, которые так любят видеть в отчетах наши пользователи. В заполненном виде тег выглядит так:
```
```
Нетрудно понять, что атрибут «ref» задает зону, занимаемую активными ячейками фильтров.
Ну и «на сладкое» в файле идут настройки страницы для печати. Вот пример из одного моего файла:
```
```
Тег задает поля, а тег — предпочтительные настройки бумаги.
В комментариях к первой части была просьба поговорить собственно о редактировании этого чуда техники средствами PL/SQL. Следующая часть будет именно об этом. | https://habr.com/ru/post/347616/ | null | ru | null |
# Черные дыры при разработке Веб проекта
Речь пойдет о PHP,JavaScript и MySQL как стартовой точке. Я также приведу некоторые цифры тестов производительности и потери времени, которые могут убить проект, на примере одного из продуктов, которые мне пришлось недавно вскрыть на предмет поиска проблемных мест, и покажу как можно в три шага убить проект.

#### Предисловие.
Недавно мне была поставлена задача, помочь найти проблемы в одном из веб проектов, созданных как обычно на PHP+MySQL, и все это кроме того завернуто в Symfony Framework. База данных начала сильно расти, так-как люди собирали эвенты поведения (допустим автопарка) которые вливались буквально каждые 5 минут. Естественно таблица эвентов выросла, и дабы MySQL с ней хоть как то справлялась, ее разбили на партиции. В итоге все это сводилось к разного рода выборкам и отчетам, т.е. аналитике. В итоге, даже простая выборка за период, плюс небольшой подсчет, занимали от 11 сек и выше. Видимо поэтому и было принято решение, ограничивать выбираемый период в днях.
И так поехали:
#### Проблема 1 – База
База была выбрана MySQL. Видимо то, что она бесплатна, подкупает всех. Но вот вешать на эту базу третьего эшелона, тяжелую аналитику, считаю первой ошибкой и самой главной. На тестовом примере в **700K** записей в таблице эвентов, выборка за период возрастала до **30 сек**. Вся сложность оказывалась в данных. Таблица events имела запись “события разного типа” со свойством ON или OFF, т.е. начало и конец определенного эвента. Все довольно таки стандартно, и любой бы с легкостью сделал выборку:
```
SELECT
ev1.event_point,ev1.event_date,
(select event_date from test_events
where ev1.event_point = event_point
and event_type = (CASE WHEN ev1.event_type = 1 THEN 2 ELSE 1 END)
and event_date > ev1.event_date limit 1) as end_date
FROM test_events as ev1
WHERE
ev1.event_date BETWEEN '2012-1-1' AND '2012-1-31' AND ev1.event_type IN (1 , 2)
```
для примера и теста использовался один тип события 1 начало и 2 конец, хотя в базе их порядка 40 пар. В итоге просто выбор записей за период, с добавлением сразу конца этого события, забирает у MySQL порядка **20-30 сек**.
Для сравнения, была взята также бесплатная база, SQL Server 2008 в редакции Web, все это было запущено на MS Server 2008 R2 на виртуальной среде VirtualBоx. Скажу сразу что Web редакция хоть и бесплатна, но не имеет ряда важных опций, особенно важных для аналитики, например нет оптимизации и кэширования View и Procedure.
Все тесты показали что MS SQL с легкостью выполняет запрос менее чем за **1 сек** при **1КК** данных.
Далее нужно было сделать простой подсчет и выбрать сколько времени занимали те или иные типы событий за определенный кусок времени. Такое подсчитать на уровне SQL сервера не составляет никакого труда, накладываем сверху условие и получаем готовый отчет:
```
SELECT event_point,SUM(TIMESTAMPDIFF(HOUR,event_date,end_date)) FROM (
SELECT
ev1.event_point,ev1.event_date,
(select event_date from test_events
where ev1.event_point = event_point
and event_type = (CASE WHEN ev1.event_type = 1 THEN 2 ELSE 1 END)
and event_id > ev1.event_id limit 1) as end_date
FROM test_events as ev1
WHERE
ev1.event_date BETWEEN '2012-1-1' AND '2012-1-31' AND ev1.event_type IN (1 , 2)
) report
GROUP BY event_point
```
Вот такой пример на той же MS SQL базе выполняется мгновенно, менее чем за 1 сек. А вот с MySQL можно и не дождаться результата, увеличивая период, база ложилась намертво. Видимо те, кто собирал проект, это поняли и решили остановится на обработке выборки прямо в PHP. И дабы не терять все также 20-30 сек на JOIN, было решено делать простой SELECT за период, закинуть все в Array и там уже пробежкой найти начало и конец и потом с легкостью выдать суммы. Что и было сделано, в итоге я снова пришел тупик, рост периода начинал забирать до 1 мин. на расчет. И я начал изучать вторую проблему, пытаясь понять, почему просто прогон по Array занимает такое огромное время. Я надеялся что там будет просто опечатка или ошибка, но оказалось что просто пробежка по Array занимает огромное время. Вот и вторая проблема.
#### Проблема 2 – Array в PHP
Изучив все данные, я понял, что PHP не может быстро обрабатывать большие массивы. Почитав на различных форумах, я увидел обсуждения, подтверждающие эту версию. Это проблема PHP. Было решено написать простой тест для проверки фактов.
```
php
$summary[] = array();
$count = 5000;
for($i1=0;$i1<$count;++$i1){
$summary[$i1] = $i1;
}
$t = microtime(true);
for($i1=0;$i1<$count;++$i1){
for($i2=0;$i2<$count;++$i2){
if("5468735354987"!="654654655465"){
$summary[$i1] = $i1*$i2;
}
}
}
echo "<litime: ".(microtime(true)-$t).' ms';
$sum = 0;
for($i1=0;$i1<$count;++$i1){
$sum = $sum + $summary[$i1];
}
echo "- test["+$sum+"]";
?>
```
Код был создан на основе задачи в проекте. В данном тесте идет перебор 5000\*5000 = 25КК циклов, причем даже использовалось ++$i вместо $i++ для поднятия скорости. В результате данный тест выдал **11 сек**. Попытка запустить этот код просто прямо в консоли без Веб сервера, выдало мне **10 сек**. И это все запускалось на моем компьютере а не на хосте или виртуальном машине, и все при конфигурации: Intel Core i5, 8GB. PHP 5.3.9
Понимая что для PHP это предел что можно выжать, я решил проверить этот код на других платформах, имея под рукой виртуальную машину c MS Server 2008 R2. Код теста был легко перекинут в ASP, ASPX, WSC,VBS а также NodeJS. В итоге я получил такие данные:
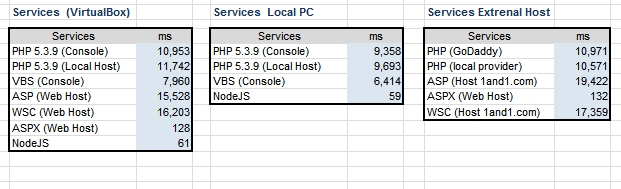
На скриншоте мы видим три варианта теста. 1) виртуальная машина 2) мой компьютер 3) доступные мне сервера в интернете.
1. PHP на удивление выдал очень близкие результаты, учитывая что запускалось все совершенно на разных ресурсах и мощностях.
2. ASP близкий аналог PHP выдал результат хуже, причем это еще и зависит от мощностей среды.
3. WCS сильно разочаровал, учитывая что Microsoft его в свое время описывал как компилируемый вариант ASP, который должен работать гораздо быстрее, что оказалось совершенно не так.
4. VBS это чисто консольный вариант скрипта, хоть он и показал результат лучше чем PHP, но для веб проекта он неприемлем.
5. ASPX показал просто отличный результат. Тут я не удивлен, все таки это C#
6. NodeJS также выдал, как и предполагалось, просто отличные показатели.
Вот все варианты скриптов:
**test.php**
```
php
$summary[] = array();
$count = 5000;
for($i1=0;$i1<$count;++$i1){
$summary[$i1] = $i1;
}
$t = microtime(true);
for($i1=0;$i1<$count;++$i1){
for($i2=0;$i2<$count;++$i2){
if("5468735354987"!="654654655465"){
$summary[$i1] = $i1*$i2;
}
}
}
echo "<litime: ".(microtime(true)-$t).' ms';
$sum = 0;
for($i1=0;$i1<$count;++$i1){
$sum = $sum + $summary[$i1];
}
echo "- test["+$sum+"]";
?>
```
**test.asp**
```
<%
count = 5000
Dim summary(5000)
for i1=0 to count
summary(i1) = i1
next
t = timer()
for i1=0 to count
for i2=0 to count
if ("5468735354987"<>"654654655465") then
summary(i1) = i1*i2
end if
next
next
response.write timer()-t
sum = 0
for i1=0 to count
sum = sum + summary(i1)
next
response.write "sum:"∑
response.write "
test-wsc
"
Dim obj
Set obj = GetObject("script:"&Server.MapPath("test.wsc"))
Call obj.run()
%>
``` | https://habr.com/ru/post/162885/ | null | ru | null |
# Чёрная Лямбда ефрейтора Волкова: новое направление и гранты на летнюю школу
[](https://habrahabr.ru/company/goto/blog/333828/)
Не далее чем в июле прошла очередная школа GoTo. В этот раз мы решили внести некоторое разнообразие в стандартный набор Ардуин, Питонов, и прочих, и случился Хаскелль. Небольшое отделение из 6 юношей (кусочек нашего общего взвода в 60 человек) бодро промаршивало по -исчислению, основам синтаксиса, прошло посвящение в ФП написанием факториала, посворачивало списки, научилось словосочетанию "параметрически полиморфная функция высшего порядка" и присущему этому пониманию типов и тайпклассов под предводительством [ефрейтора Волкова](https://habrahabr.ru/users/wldhx).
А ещё у нас были элементы инфобеза, криптовалюты, React Native, `nix`, и, конечно, `git`.
И мы начали писать книгу про Haskell.
В общем, получилось задорно.
*(Под катом картинки участников, лямбды, илосос, анонс нового направления и гранты)*
---
Для того, чтобы завлечь детей, мы назвали направление "Прикладное Программирование: Курс Молодого Бойца 2" (как логическое продолжение КМБ1). В уверенности, что их ждёт логическое продолжение Telegram-ботов, они даже не подозревали...
Начали мы с -исчисления.

Через интересные выражения типа  мы выяснили, почему , что сходится, а что расходится, что такое  equivalence и parser combinators, только без parser. И узнали, как работает каррирование.
Одной из концепций направления было как бы сочетание в себе других: биоинформатики, прикладного программирования и анализа данных, и задачи были соответствующие: найти комплементарную ДНК-цепочку, закодировав ДНК в типах, сделать HTTP-клиент для школьного банка и определить класс илососа по вектору сэмплов качества его работы.
```
data AA = A | C | G | T
```
В конце первой недели участников ждала прогрессивная преподавательская концепция: спортивный зачёт. Узнав свой вопрос, нужно было пробежать ~350м и ответить сразу после; думать во время бега.
*Дверь в нашу аудиторию*
Где-то здесь мы изучили `git`; я посчитал своим долгом сказать про посылку патчей по почте, но мы всё же использовали GitHub и GitLab. Сделали простые сайты на Pages.
`$ git format-patch <...>`
Прошли функции высшего порядка и затронули свёртки (folds). Решили задачу про илососов: дана квадратная матрица `ilosos_id` / `sample_id` (строки — илососы, столбцы — измерения качества сосания), найти класс (первый, второй, ...) каждого из илососов.
`[0.2, 0.44, 0.9, 0.3, 0.6]` => `0.488` => `Ilosos3`
Сначала вектор сворачивается в среднее (здесь — арифметическое), а потом преобразуется в конкретный тип: `Ilosos3 :: Ilosos`.
Ещё мы начали использовать `stack`: эту задачу можно было сдавать только как stack-проект, и только через `git`.
Прошёл второй зачёт с устной и письменной частями (в обоих случаях средний балл — `0.6`) и лекция по MapReduce [tenich](https://habrahabr.ru/users/tenich/), и настало время инфобез-интермиссии (спонтанные получасовочки случались и раньше; эта же интермиссия продлилась три пары).
Мы обсудили, как работают криптовалюты from the ground up — от хэшей и до (почти) биткоина, что не так с мессенджерами (централизация коммуникаций, фрагментация, не-secure by default...), и — немножко — в чём вообще важность свобод и почему глобальная слежка — не всегда замечательная идея.

Попутно выяснилось, что антиутопии нынче не в ходу: 80% аудитории не читало ни "1984", ни "Мы", ни "Дивный новый мир".
Происходило это уже не в аудитории, а в открытом λектории.

*До: интересные плакаты и иллюстратор книги, Степан Дмитриев*

*После: слева направо: закатывают глаза, опускают глаза, \*тело\**
Обнаружилось неожиданное: если что-то услышать, но не сделать на это упражнений (как с Haskell) или не записать, то это легко забыть. Поэтому появилась концепция: писать конспект. Но не просто, а вместе (в Etherpad).
> Я здесь уже пишу, функтор ты контравариантный!
Стало понятно, что тимворк — это сложно.
После окончания интермиссии мы разделились: маленькие любители криптографии пошли писать RSA (и прочие MapReduce), а маленькие графоманы — писать книгу по Haskell.
Потому что если во время курса тебе было сложно читать из множества источников теорию на английском — то почему бы не написать свою, хорошую, годную и нестрашную?

*Обложка книги*
И написали же! (Пока что только главу, но всё же.) — More on that later.
А ещё были мастерклассы: по React Native (@kulikovpavel) и Scala (@tvorogme).
В общем, получилось задорно.
---
Но мало. Так, внимательный читатель заметит, что слова на букву "м" выше нет. И про криптовалюты мы только поговорили, а свою не сделали. И даже распределённый чатик на [libp2p](https://libp2p.io/) не успели.
Поэтому хочется повторить, и с размахом.
Поэтому мы вводим новое направление: **Чёрная Лямбда**.

Обычно прикладные программисты живут на этаком среднем уровне абстракции: не зная, что происходит в виртуальной машине / компиляторе их языка (и тем более в железе) в особенных подробностях, но и не погружаясь в механизмы абстрагирования более вовлечённые, чем классы и функции — типа макросов или шаблонов. Или математики.
Это не плохо, но несколько ограничивает.
Поэтому на Лямбде мы будем двигаться в две стороны: в одну — абстракции срывая, и в другую — абстракции вводя. Вниз и вверх, в железо и в математику соответственно. Напишем hello world на Питоне — и расковыряем его интерпретатор. Напишем свой питон. Поковыряем байткод и структуры данных. Клавиатуру и её прошивку и merkle-деревья. Таки сделаем свою криптовалюту. На Rust'е. Попишем на C, чтобы понять, зачем Rust нужен. Изучим моноиды, и поймём, почему полугруппа — это как группа, только чуть меньше.
В планах — пары на улице, прогулочный семинар, странные плакаты и светодиоды в волосах. И ботать.
**[Приходите](https://docs.google.com/forms/d/e/1FAIpQLSfJ5i2JdwfeoeIYHA2gC6V_hAofXdnlEx682_19y9qOAZIPRQ/viewform). Будет приятно~~, вдвойне~~.** Следующая смена — [с 16 по 29 августа](https://goto.msk.ru/camp_summer/).
А если поботать — можно получить скидку или даже грант на приход. [Вот таски](https://gitlab.com/goto-ru/school-17.08/blacklambda/_/snippets/1669849).

Веселитесь.
*К участию мы приглашаем юных программистов с 13 до 18 лет включительно, подробности о школе [здесь](https://goto.msk.ru/camp_summer). Для участия необходимо пройти небольшой диагностический тест, также есть возможность получить гранты и скидки, выполнив одно из заданий наиболее выдающимся макаром.
Если вам уже есть 18, возможно, вам было бы интересно быть ментором или спикером — [пишите](mailto:[email protected]).* | https://habr.com/ru/post/333828/ | null | ru | null |
# Разрабатываем компилятор для учебного языка Cool на языке C# под .NET (Часть 1)
#### Введение
Здравствуй, уважаемый хабраюзер.Я хотел бы тебе представить материал о практическом создании компилятора, который будет транслировать код, написанный на языке Cool, в код виртуальной машины **CIL** (Common Intermediate Language) под платформу **.NET**.Данный материал я решил разбить на две части ~~из-за лени все сразу это описывать~~
В **первой** части будет описан процесс написания грамматики с учетом приоритетов операторов в среде ANTLR, а также генерации лексера и парсера под язык C#. Также в ней будут рассмотрены подводные камни, которые встретились у меня на пути. Таким образом я постараюсь хоть кому-нибудь сэкономить время (может быть для себя в будущем).
Во **[второй](http://habrahabr.ru/blogs/compilers/136714/)** же части будет описан процесс построения **семантического анализатора** кода, **генерации кода** и самопальной ~~никому не нужной~~ **оптимизации** кода. Также будет описано, как сделать красивый интерфейс ~~с блекджеком и шлюхами~~ с подсветкой синтаксиса и сворачиванием блоков, как в современных IDE. В конце второй части я, конечно же, выложу все исходники моего солюшена и расскажу о дальнейшей улучшении архитектуры и кода, во всяком случае как это представляется мне.
*Предупреждение*: перед разработкой данного компилятора я практически не изучал никакой тематической литературы. Всё обошлось чтением нескольких интересующих меня статей, просмотром [видеоуроков](http://javadude.com/articles/antlr3xtut/) по ANTLR на официально сайте и разговорами с «шарящими» одногруппниками. Так что разработанное ПО является ~~УГ~~ далеко не идеальным.
Чтобы читатель лучше понимал меня, я дам в начале сначала некоторые определения (из Википедии):* **Токен** — последовательности символов в лексическом анализе в информатике, соответствующий лексеме.
* **Лексер** — модуль для аналитического разбора входной последовательности символов (например, такой как исходный код на одном из языков программирования) с целью получения на выходе последовательности символов, называемых «токенами» (подобно группировке букв в слова).
* **Парсер** — модуль для сопоставления линейной последовательности лексем (слов, токенов) языка с его формальной грамматикой. Результатом является дерево разбора или синтаксическое дерево.
На хабрахабре, да и не только, есть много статей, подробно объясняющих как написать грамматику для математических выражений и языков, так что подробно останавливаться на настройке среды я не буду. Также я не буду углубляться в теоретические вопросы конструирования компиляторов, так как на эту тему тоже есть ряд неплохих статей, например [данный цикл.](http://habrahabr.ru/blogs/programming/99162/)
Итак, для разработки компилятора были использованы следующие программы и библиотеки:1. [**ANTLRWorks**](http://www.antlr.org/works/index.html) — IDE для написания грамматик и генерации кода лексеров и парсеров под различные языки (C, C#, Java, JavaScript, Objective-C, Perl, Python, Ruby и др.). Основана на LL(\*) парсинге.
2. [**ANTLR C# runtime distribution**](http://www.antlr.org/wiki/display/ANTLR3/Antlr+3+CSharp+Target) (Antlr3.Runtime.dll) используется в сгенерированном лексере и парсере.
3. **Visual Studio 2010** В следующей статье будет рассмотрен компонент под WPF, расширенный текстовый редактор для подсветки синтаксиса и автодополнения кода [AvalonEdit](http://www.codeproject.com/KB/edit/AvalonEdit.aspx)).
4. **Java Runtime Environment** (так как ANTLRWorks написана на Java).
5. **IL Disassembler** будет использоваться во второй части для того, чтобы понимать, как компилятор, например языка C#, генерирует CIL код и как он должен выглядеть.
#### Описание языка Cool
**Cool** — Classroom Object-Oriented Language является, как мы видим из названия, учебным ~~никому не нужным~~ языком программирования, включающий классы и объекты. Cool является функциональным строготипизированным языком, т.е. проверка типов происходит статически на этапе компиляции. Программа по сути является набором классов. Классы включают в себя набор полей и функций (тут они называются *feature*).
Все поля являются видимыми внутри базового и производного классов. Все функции являются видимыми отовсюду (public).
Данный язык построен на выражениях (*expression*). Все функции в качестве аргументов могут принимать выражения и телами всех функций являются выражения, который возвращают какой-либо результат. Даже такие функции, как вывод строки, возвращают результат, а именно экземпляр класса, из которого они вызваны.
Cool содержит также и статические классы String, Int, Bool, от которых нельзя наследоваться и которые не могут принимать значения null (здесь это называется *void*). Объекты данных классов передаются по *значению*, а не по ссылке.
Ключевые слова данного языка: class, else, false, fi, if, in, inherits, isvoid, let, loop, pool, then, while,case, esac, new, of, not, true
Хочу обратить внимание, что некоторые операторы заканчивается не фигурной скобкой (как в С-подобных) или словом end; (как в ~~мертвом~~ паскале), а названием названием этого же оператора в обратном порядке (if -> fi, loop -> pool, case -> esac).
Как вы думаете, если каждый оператор возвращает какой-то результат, то что же должен возвращать if? Ведь он может возвратить вариант из двух альтернатив. Правильный ответ: наиболее близкий общий предок (в учебнике написано про это как-то сложно, там еще специальный оператор используется). Привожу для наглядности картинку:
Рисунок 1.
Здесь у классов A и B наиболее близким общим предком является класс D.
Оператор **case** подобен оператору if, примененному несколько раз.
В конструкции **while** всегда возвращается void (если конечно цикл не зацикливается).
Такая конструкция { ;… ; } возвращает объект выражения exprn, т.е. последнего выражения.
Функции здесь могут вызываться не только у класса и его предка (виртуальные функции), но и вообще у любых предков данного класса. Это можно осуществить, использовав оператор '@'. В качестве примера рассмотрим иерархию классов на рисунке 1. Пусть класс E имеет функцию func(), все остальные потомки переопределяют ее по своему. Тогда, если мы имеет экземпляр объекта A и хотим вызывать функцию func из класса D, нужно использовать следующий синтаксис:
```
result <- (new A)@D.func()
```
Ключевое слово **SELF\_TYPE** используется как синоним класса, в котором описывается определенная функция. Идентификатор **self** же является указатель на текущий класс (т.е. this в других языка).
Локальных переменные вводятся в языке Cool с помощью оператора **let** и они могут использоваться только в рамках данного блока let.
**void** — аналог null, признак того, что объект не создан.
Думаю все остальные операторы в пояснениях не нуждаются, а если не понятно, то вы можете изучить мануал по данному диалекту языка Cool по ссылке, указанной в конце статьи.
#### Написание грамматики языка Cool в ANTLRWorks
Итак, исходная грамматика задана в следующей форме:
```
program ::= [[class; ]]+
class ::= class TYPE [inherits TYPE] { [[feature; ]]*}
feature ::= ID( [ formal [[, formal]]*] ) : TYPE { expr } | ID : TYPE [ <- expr ]
formal ::= ID : TYPE
expr ::=
ID <- expr
| expr[@TYPE].ID( [ expr [[, expr]]*] )
| ID( [ expr [[, expr]]*] )
| if expr then expr else expr fi
| while expr loop expr pool
| { [[expr; ]] +}
| let ID : TYPE [ <- expr ] [[, ID : TYPE [ <- expr ]]]* in expr
| case expr of [[ID : TYPE => expr; ]]+ esac
| new TYPE
| isvoid expr
| expr + expr
| expr ? expr
| expr ? expr
| expr / expr
| ~expr
| expr < expr
| expr <= expr
| expr = expr
| not expr
| (expr)
| ID
| integer
| string
| true
| false
```
Обозначения:[[]]\* — итерация; [[]]+ — положительная итерация;Итак, что нужно сделать, увидев такую грамматику? ~~Забыть навсегда про нее и про компиляторы. Кому нужен еще один недоязык??~~ Итак, если данную грамматику сразу переписать в ANTLR и сгенерировать код лексера и парсера, то ничего хорошего не выйдет из-за следующих причин:* Существование **левой рекурсии**. Конечно, ANTLRWorks, основанная на методе рекурсивного спуска, это сразу определит и выдаст ошибку такого рода:*[fatal] rule compilation\_unit has non-LL(\*) decision due to recursive rule invocations reachable from alts… Resolve by left-factoring or using syntactic predicates or using backtrack=true option…* И, конечно же, в ANTLR есть опция backtrack=true, которая позволяет преодолеть данное ограничение. Но применив ее, придется смириться с еще одним узлом в сгенерированном КА для выражения с левой рекурсией. Так что все-таки хорошо бы от нее избавиться. К тому же, как видно из этой [статьи](http://www.antlr.org/wiki/display/ANTLR3/How+to+remove+global+backtracking+from+your+grammar), данная опция замедляет работу парсера и автор рекомендует по возможности отказываться от нее.
* Но главное, что в этой форме грамматики не учтен **приоритет операторов**. Если левая рекурсия влияет только на эффективность парсера, то игнорирование данной проблемы приведет к неправильной генерации кода уже потом (например 2 + 2 \* 2 будет равно 8, а не 6)
Читаем руководство дальше. А дальше как раз и написано про приоритеты операций. Они принимают следующий вид (вверху — наивысший, внизу — наинизший приоритеты).* .
* @
* ~
* isvoid
* \* /
* + -
* <= < =
* not
* <-
Итак, нужно построить нашу грамматику с учетом этих операций. Для этого придерживаемся такого правила построения:Для каждого оператора более низкого приоритета создаем новое правило, которое будет в правой части содержать оператор данного приоритета и нетерминал для оператора более высокого приоритета.Знаю, что звучит сумбурно, поэтому привожу данное построение для нашей исходной грамматики:
```
expr:
(ID ASSIGN^)* not;
not:
(NOT^)* relation;
relation:
addition ((LE^ | LT^ | GE^ | GT^ | EQUAL^) addition)*;
addition:
multiplication ((PLUS^ | MINUS^) multiplication)*;
multiplication:
isvoid ((MULT^ | DIV^) isvoid)*;
isvoid:
(ISVOID^)* neg;
neg:
(NEG^)* dot;
dot:
term ((ATSIGN typeName)? DOT ID LPAREN invokeExprs? RPAREN)? ->
^(Term term ID? typeName? invokeExprs?);
```
Терм в данном случае включает в себя все оставшиеся выражения, которые не были рассмотрены, т.е. выражения с одинаковым приоритетом.
Комментарии в языке по сути являются последовательностью символов, которую нужно проигнорировать при лексическом разборе. Для этого в ANTLR используется конструкция
```
{$channel = Hidden;};
```
, написанная справа от каждого правила, описывающего комментарии. Например:
```
COMMENT : '--' .* ('\n'|'\r') {$channel = Hidden;};
```
#### Операторы ANTLR
Далее я опишу используемые операторы ANTLR:1. **!** — нужен для того, чтобы лишние токены языка не мешали при разборе. Например, скобки и другие операторы, которые нужны только для парсера (например те же окончания синтаксических конструкций fi, esac). Данные оператор нужен для того, чтобы строилось именно [синтаксическое дерево](http://ru.wikipedia.org/wiki/Абстрактное_синтаксическое_дерево) из потока токенов, а не дерева разбора).
2. **->** — нужен для того, чтобы преобразовывать последовательность токенов, стоящих в левой части, в последовательность токенов, стоящих в правой части, которую было бы удобно обрабатывать при генерации кода.Вместе с этим оператором используется также и оператор ^.
3. **^** используется для того, чтобы в генерируемом синтаксическом дереве создавался новый узел из токена, помеченного этим оператором, и его потомков. Существует две формы у этого оператора:
* **Постфиксная.** Например для такого правила:
```
relation: addition ((LE^ | LT^ | GE^ | GT^ | EQUAL^) addition)*;
```
в синтаксическое дерево вставится узел с одним из операторов, указанных в скобках, и детьми *addition*, который слева от оператора и *addition*, который справа от оператора.
* **Префиксная.** Например для такого правила:
```
CLASS typeName (INHERITS typeName)? LCURLY featureList RCURLY -> ^(Class typeName featureList typeName?)
```
в синтаксическое дерево вставится узел-родитель *Class* с потомками *typeName featureList typeName?*
Все остальные используемые операторы ANTLR в комментариях не нуждаются (для человека, изучавшего дискретную математику), а если и нуждаются, то в небольших:1. **\*** — Итерация.
2. **+** — Положительная итерация.
3. **?** — Левостоящий токен или группа токенов может как присутствовать, так и отсутствовать.
Хочу отметить, что при использовании операторов '->' и '^', возникает необходимость вводить новые токены. Это делается в соответствующем разделе tokens { }.Кстати, я сторонник того, чтобы в файле .g было минимум кода, предназначенного для конкретного языка лексера и парсера (в нашем случае для C#). Тем не менее такой код все же пришлось использовать для токена STRING:
```
STRING: '"'
{ StringBuilder b = new StringBuilder(); }
( '"' '"' { b.Append('"');}
| c=~('"'|'\r'|'\n') { b.Append((char)c);}
)*
'"'
{ Text = b.ToString(); }
;
```
Здесь используется StringBuilder для того, чтобы обработка строк была эффективной.В принципе, для оптимизации лексера допустимы и другие вкрапления такого кода, но не для всех правил.Для того, чтобы в C# коде лексера и парсера указать пространства имен (например System.Text для StringBuilder), используются следующие конструкции (здесь также отключаются некоторые «ненужные» предупреждения):
```
@lexer::header {#pragma warning disable 3021
using System;
using System.Text;
}
@parser::header {#pragma warning disable 3021
using System.Text;}
```
После того, как мы составили грамматику в ANTLRWorks, нужно сгенерировать C# код лексера и парсера (спасибо, кэп).
ANTLRWorks с заданными настройками генерирует 3 файла: * CoolGrammar.tokens
* CoolGrammarLexer.cs
* CoolGrammarParser.cs
#### Использование сгенерированного лексера в C# коде
Получение списка всех токенов в сгенерированном C# коде выглядит не очень тривиально (хоть это и не всегда нужно):
```
var stream = new ANTLRStringStream(Source); // Source - исходный код.
lexer = new CoolGrammarLexer(stream, new RecognizerSharedState() { errorRecovery = true });
IToken token;
token = lexer.NextToken();
while (token.Type != CoolGrammarLexer.EOF)
{
// Здесь обрабатываем каждый токен.
// Имя токена: CoolTokens.Dictionary[token.Type] (Например для '(' это LPAREN,
// используется дополнительный заранее подготовленный словарь, сопоставляющий имя токена и его значение)
// Текст токена: token.Text (Например для '(' это просто "(")
// Номер линии токена в коде: token.Line
// Позиция токена в коде от начала строки: token.Column
token = lexer.NextToken(); // Читаем следующий токен, то тех пор, пока не дойдем до конца файла.
}
// Далее перегружаем поток токенов и устанавливаем позицию в коде в 0,
// чтобы использовать этот же поток токенов потом (читай в парсере).
lexer.Reset();
```
CoolTokens.Dictionary должен генерироваться следующим образом:
```
var Lines = File.ReadAllLines(fileName);
Dictionary = new Dictionary(Lines.Length);
foreach (var line in Lines)
{
var parts = line.Split('=');
if (!Dictionary.ContainsKey(int.Parse(parts[1])))
Dictionary.Add(int.Parse(parts[1]), parts[0]);
}
```
fileName — Путь к файлу CoolCompiler.tokens
#### Использование сгенерированного парсера в C# коде
```
var tokenStream = new CommonTokenStream(lexer); // как получить lexer, было описано ранее.
parser = new CoolGrammarParser(tokenStream);
Tree = parser.program(); // Самый верхний узел, отвечающий за аксиому грамматики (т.е. program в нашем случае).
```
Для обхода же синтаксического дерева используются следующие свойства и методы интерфейса IList:* treeNode.ChildCount — количество детей у узла treeNode
* treeNode.GetChild(i) — получение ребенка у узла treeNode под номером i
* treeNode.Type — токен данного узла. Имеет тип int и должен сравниваться с константами, объявленными в классе лексера. Например:treeNode.Type == CoolGrammarLexer.EQUAL (является ли данный токен знаком '=').Хочу обратить внимание, что при обходе дерева нужно использовать именно свойство Type, а не Text, поскольку сранивание чисел быстрее, чем сравнивание строк, к тому же вероятность ошибки уменьшается, поскольку все константы генерируются автоматически.
* treeNode.Line — номер линии токена в коде
* treeNode.CharPositionInLine — позиция токена в коде от начала строки
Также я хотел обратить особое внимание на то, что при генерации кода из грамматики в C#, необходимо ставить модификатор **public** перед аксиомой грамматики (в данном случае перед program), чтобы можно было ее потом вызывать из кода (а иначе она будет private)
#### Заключение
В этой статье было рассказано, как описать грамматику в среде ANTLRWorks, которая затем используется для генерации кода лексеров и парсеров на языке C#, а также как использовать лексер и парсер. В следующей статье будет рассказано про обработку семантики языка (т.е. проверке типов, обработке семантических ошибок), как обходить каждый узел синтаксического дерева и генерировать CIL код для соответствующей синтаксической конструкции с объяснением CIL инструкций, объяснением работы стека виртуальной машины и использование встроенной в .NET библиотеки System.Reflection.Emit для облегчении генерации кода. Разумеется, я опишу и подводные камни, которые встретились у меня на пути (В частности, создание иерархии классов с помощью System.Reflection.Emit). Также там будет описано, как сделать ~~красивые обои~~ красивый и современный интерфейс! Впрочем, о том, что написано в заключении, уже частично написано во вступлении.
Напоследок я бы хотел задать один вопрос хабрасообществу, ответ на который мне найти не удалось:
Для C# лексера у меня всегда генерируется такой код для исключения NoViableAltException, причем этот throw невозможно никак перехватить:
```
catch (NoViableAltException nvae) {
DebugRecognitionException(nvae);
throw;
}
```
*Как мне написать файл грамматики, чтобы в этой строчке не просто стояло throw, а вызывалось например мое исключение или вообще лексер продолжал работу?* А то приходится при каждой генерации C# кода исправлять эту строчку.Примечание: манипуляции с @rulecatch в ANTLR ни к чему не привели.
Было бы приятно, если кто-нибудь разобрался с этой проблемой и написал ответ в комментариях.
#### Рекомендуемая к прочтению литература
* Definite ANTLR Reference, Terence Parr, 2007.
* Компиляторы. Принципы, технологии и инструментарий, 2008, Альфред В. Ахо, Моника С. Лам, Рави Сети, Джеффри Д. Ульман
[Мануал по языку Cool, файл его грамматики с расширением .g, среда ANTLRWorks](http://narod.ru/disk/37785883001/CoolGrammar.7z.html) | https://habr.com/ru/post/136528/ | null | ru | null |
# Брутим crackme#03 от korsader
### Вступление
У меня нет опыта в реверсе, есть некие базовые знания ассемблера, позволяющие сделать битхак условных переходов, чтобы данное приложение всегда выходило на success-path независимо от введенного значения. Но так как это слишком банально для того, чтобы быть опубликованным здесь, а до полного воспроизведения алгоритма проверки введенного ключа я еще не дорос, я решил попробовать метод брута, т.е. последовательного подбора ключей. Конечно же, я не могу сказать, что и этот способ отличается своей крутизной, но по крайней мере подробное описание этого способа не так часто встречается среди статей по реверсу.

### Источник
Ссылка на оригинальный пост [crackme#03](https://forum.reverse4you.org/showthread.php?t=1602).
В ветке, где опубликован этот крякми, пользователь ARCHANGEL опубликовал метод брута на C++, который действительно выдает правильный пароль для этого крякми. Он мог позволить себе написать брут на языке высокого уровня, так как смог воспроизвести алгоритм и нашел значение 0x23a06032, с которым сравнивается полученное crc.
Я же пока не научился так глубоко анализировать алгоритмы на asm-е, поэтому буду работать не отходя от кассы, используя алгоритм проверки в самом крякми как черный ящик.
### Анализ условных переходов
Запускаем крякми и выключаем звук на компьютере (видимо именно этого добивался автор, добавив звуковое сопровождение).

Запускаю OllyDbg 2.01 c плагином OllyExt, в котором выставлены приведенные ниже настройки:
Этот плагин поможет избавиться от некоторых потенциальных приемов анти-отладки.
Аттачимся из Ольги к выполняемому процессу crackme#03.exe: File → Attach…
Далее пробуем ввести любое значение в поле ввода и без труда находим код, в котором оно обрабатывается. Сделать это можно выставив breakpoint-ы на потенциальные функции получения текста (в частности GetDlgItemTextA) или пролистать код исходного модуля — благо здесь он небольшой. Нажимаем кнопку Check.

Срабатывает breakpoint, жмем один раз F8 и смотрим листинг. Видим, что введенная нами строка хранится по адресу **004095BC**. Также смотрим на инструкцию по адресу **0040101F**. Она сравнивает длину введенной строки со значением 12 и в случае неравенства выбрасывает нас на **004010AF**.
Далее, обратите внимание на инструкцию по адресу **00401028**, которая сравнивает 12-ый байт введенного значения со значением 72, а это буква r в ASCII-кодировке. В случае неравенства снова выбрасывает нас на **004010AF**. Что же это за адрес такой? Об этом чуть позже.
Теперь обратим внимание на инструкции в диапазоне **00401031** — **0040104C**. Покурив справочник команд ассемблера по командам repne и scas, а также потрассировав выделенную область кода, приходим к выводу, что aehnprwy — это допустимый алфавит требуемого ключа.
Теперь посмотрим, что же у нас расположено по адресу **004010AF**. Там вывод сообщения о неудачном вводе пароля.
Итак, подведем итоги первичного анализа:
1) Ключ должен состоять из 12 символов;
2) Последний символ ключа должен быть r;
3) Символы ключа должны принадлежать алфавиту aehnprwy.
### Брутфорс
Приступим к реализации брут-метода. Реализуем его сначала на концептуальном уровне. Можно на блок-схеме, можно на языке высокого уровня. Я реализовал его прототип на C++. Для понимания дальнейшего материала необходимо переварить код под спойлером.
**Скрытый текст**
```
#include
#include
const char \*Alphabet = "aeyhpnwr";
int Password\_len = 12;
int CheckPassword(char pass[]) // функция проверки введенного пароля.
{
if (strcmp(pass, "aaaaaaahaahr") == 0) // проверка на заглушку
return 0;
return 1;
}
int main()
{
int Alphabet\_len = strlen(Alphabet);
char\* CodeArray = new char[Password\_len + 1];
char\* Password = new char[Password\_len + 1];
int n;
// Инициализируем пароль, чтобы все символы были равны первому (т.е. нулевому) символу алфавита
Password[Password\_len] = 0;
for (int i = 0; i < Password\_len; i++)
{
CodeArray[i] = 0;
Password[i] = Alphabet[CodeArray[i]];
}
// последний символ всегда r
Password[Password\_len - 1] = 'r';
while (true)
{
//printf("\nCurrent pass = %s", Password);
if (CheckPassword(Password) == 0)
{
printf("\nRight Password = %s\n", Password);
break;
}
n = Password\_len - 2;
while (n >= 0)
{
CodeArray[n]++;
if (CodeArray[n] >= Alphabet\_len)
{
CodeArray[n] = 0;
Password[n] = Alphabet[0];
n--;
continue;
}
Password[n] = Alphabet[CodeArray[n]];
break;
}
}
delete[] CodeArray;
delete[] Password;
}
```
Основные этапы:
1) Инициализация ключа (пароля) начальным значением.
2) Проверка ключа.
3) Если ключ неверен, то генерим следующий ключ и переходим к шагу 2. Если ключ верный, переходим к шагу 4. Если мы перебрали все ключи и ни один из них не подошел, переходим к шагу 5.
4) Crackme взломан.
5) Crackme не взломан. Где-то мы ошиблись.
### Инициализация ключа
Программа хранит и обращается к ключу по адресу **004095BC** — там и будем его инициализировать. Алфавит расположен по адресу **00409071**.
**004095CC** — это адрес памяти, где мы будем хранить наш массив CodeArray.
Для инициализации ключа находим неиспользуемую область секции кода и вставляем туда наши инструкции. Я выбрал адрес **00404122**.
Чтобы собственно эта инициализация выполнилась, идем к тому месту, где вызывается GetDlgItemTextA, аккуратно заменяем ее вызов на безусловный переход к нашему коду по адресу **00404122**, а предшествующие ей push-команды заменяем nop-ами. Все делаем аккуратно, чтобы адрес команды CMP EAX, 0C остался прежним: **0040101F**.

На рисунке ниже представлен сам код инициализации. По ее окончанию переходим к алгоритму валидации ключа в результате безусловного перехода на **0040101F**.
**Скрытый текст**Обнулить массив CodeArray, состоящего из 12 однобайтовых значений, можно в 3 итерации по 4 байта за итерацию.
```
00404122 B9 03000000 MOV ECX,3
00404127 BA CC954000 MOV EDX,004095CC ; адрес массива CodeArray
0040412C C7448A FC 000 MOV DWORD PTR DS:[ECX*4+EDX-4],0
00404134 E2 F6 LOOP SHORT 0040412C
```
Далее выполняем проставление первого (т.е. нулевого) символа алфавита для каждого байта строки по адресу **004095BC**
```
for (int i = 0; i < Password_len; i++)
{
Password[i] = Alphabet[CodeArray[i]];
}
```
```
00404136 BB BC954000 MOV EBX,004095BC ; Адрес введенного ключа, к которому обращается crackme
0040413B B9 0C000000 MOV ECX,0C
00404140 31C0 XOR EAX,EAX
00404142 8A4411 FF MOV AL,BYTE PTR DS:[EDX+ECX-1]
00404146 8A80 71904000 MOV AL,BYTE PTR DS:[EAX+409071] ; 409071 - адрес алфавита
0040414C 884419 FF MOV BYTE PTR DS:[EBX+ECX-1],AL
00404150 E2 F0 LOOP SHORT 00404142
00404152 C643 0B 72 MOV BYTE PTR DS:[EBX+0B],72 ; Последний символ всегда r
00404156 C643 0C 00 MOV BYTE PTR DS:[EBX+0C],0 ; Закрываем строку нулевым символом
0040415A B8 0C000000 MOV EAX,0C ; Обозначаем длину ключа как 12
0040415F ^ E9 BFCEFFFF JMP 0040101F ; Возврат к коду валидации ключа
```
### Получение следующего значения ключа
Теперь нам нужно реализовать код получения следующего значения ключа. Выбираем для этого адрес **00404165** (сразу после кода инициализации) и делаем переход на него с того места, где программа обзывает нас ламерами.
Модифицируем инструкции по адресам **004010AF** и **004010B1**.

Ну и по адресу **00404165** реализуем код получения нового ключа.

**Скрытый текст**
```
00404165 B9 0B000000 MOV ECX,0B ; Количество символов ключа, которые подлежат изменению
0040416A BA CC954000 MOV EDX,004095CC ; Адрес массива CodeArray
0040416F BB BC954000 MOV EBX,004095BC ; Адрес введенного ключа, к которому обращается crackme
00404174 31C0 XOR EAX,EAX
00404176 FE4411 FF INC BYTE PTR DS:[EDX+ECX-1] ; Получаем следующий порядковый номер символа в алфавите
0040417A 807C11 FF 08 CMP BYTE PTR DS:[EDX+ECX-1],8 ; Проверяем, не вышли ли за пределы алфавита
0040417F 7D 15 JGE SHORT 00404196
00404181 8A4411 FF MOV AL,BYTE PTR DS:[EDX+ECX-1] ; Если не вышли, грузим номер в AL
00404185 8A80 71904000 MOV AL,BYTE PTR DS:[EAX+409071] ; Получаем символ из алфавита по порядковому номеру. 409071 - адрес алфавита
0040418B 884419 FF MOV BYTE PTR DS:[EBX+ECX-1],AL ; Записываем букву в соотв-ий символ ключа
0040418F B8 0C000000 MOV EAX,0C ; Обозначаем длину ключа как 12
00404194 ^ EB C9 JMP SHORT 0040415F ; Прыгаем на код валидации ключа
00404196 83F9 01 CMP ECX,1 ; Если вышли за пределы алфавита, смотрим, не первый ли это символ ключа
00404199 7F 02 JG SHORT 0040419D ;
0040419B CD 03 INT 3 ; Перебор закончен, правильный ключ не найден
0040419D C64411 FF 00 MOV BYTE PTR DS:[EDX+ECX-1],0 ; Если ecx (i) > 1, CodeArray[i] = 0;
004041A2 A0 71904000 MOV AL,BYTE PTR DS:[409071] ; В AL записываем первый (нулевой) символ алфавита. 409071 - адрес алфавита
004041A7 884419 FF MOV BYTE PTR DS:[EBX+ECX-1],AL ; Записываем букву в соотв-ий символ ключа
004041AB 49 DEC ECX ; Переходим к след. элементу
004041AC ^ EB C6 JMP SHORT 00404174 ; Повторяем итерацию для следующего элемента
```
### Запуск
Жмем кнопку Check и идем пить чай. Черт, и чай-то давно уж вскипел, придется кипятить заново.

Через некоторое время получаем:

Смотрим, что же у нас по адресу **004095BC**

**happynewyear** — это и есть искомый ключ. | https://habr.com/ru/post/324884/ | null | ru | null |
# ABBYY FlexiCapture Engine 10.0: тренируем гибкость с новым инструментом
 В ряду наших продуктов для разработчиков пополнение – выпущена очередная версия ABBYY FlexiCapture Engine. Напомню, что это продукт, позволяющий встраивать технологию ввода данных из изображений (data capture) в пользовательские решения.
Одной из интересных фич новой версии стала возможность быстрой настройки на извлечение данных из документов простых типов. Мои коллеги [уже рассказывали](http://habrahabr.ru/company/abbyy/blog/130459/) читателям хабра про то, как эта функция реализована во FlexiLayout Studio 10. В новую версию продукта добавлено API, дающее полный программный доступ к этой функциональности. Кроме этого мы сделали простой в использовании инструмент (доступный также в виде исходного кода), который позволяет всего за несколько минут (как показано вот в [этом видео](http://youtu.be/3aNKJ4Xu6Z4)) настроиться на задачу пользователя и сделать быстрый работающий прототип решения, не вникая глубоко в тонкости технологии.
Эта статья написана разработчиком для разработчиков и расскажет вам о возможностях и ограничениях данной технологии – то, чего вы не найдёте в маркетинговых материалах.
Одной из известных проблем, стоящих на пути широкого использования технологий data capture, являются высокие начальные инвестиции времени и сил на настройку работы с требуемыми типами изображений. Разработчку-интегратору необходимо научиться работать с целым рядом инструментов и разобраться в тонкостях достаточно сложной технологии, которая чаще всего не соответствует его основному профилю работы и предыдущему опыту. Только после этого он может собрать самый простой прототип готового решения и дать оценку эффективности и целесообразности всего проекта.
Новый инструментарий позволяет отложить глубокое знакомство с технологией либо на этап тонкой настройки готового решения перед выпуском, либо даже на версию номер два. Он не может полностью заменить продвинутый инструмент типа FlexiLayout Studio, но позволяет не переусложнять работу в простых случаях или в более сложных случаях быстро получить упрощённый работающий прототип.
Как мы уже описывали вот [в этой статье](http://habrahabr.ru/company/abbyy/blog/125347/), собственно извлечение данных с помощью API требует всего несколько строк кода, среди которых, однако, есть вот такая:
```
// Создадим экземпляр процессора и сконфигурируем его одним или более определениями документов
IFlexiCaptureProcessor processor = engine.CreateFlexiCaptureProcessor();
processor.AddDocumentDefinitionFile( sampleFolder + "Invoice_eng.fcdot" );
```
Эта одиночная строка кода и настраивает работу на определённый тип документа. Файл с расширением FCDOT (**F**lexi**C**apture **DО**cument **T**emplate) содержит описание извлекаемых данных с накладываемыми ограничениями, способ нахождения этих данных на изображении, настройки распознавания и, опционально, настройки экспорта данных документа.
При работе с примерами всё просто – нужный файл определения документа прилагается. Однако как получить подобное определение документа для текущей задачи, чтобы просто “пощупать”, как оно будет работать?
До выхода 10-ки для этого в любом случае требовалось установить настольную версию FlexiCapture и научиться работать как минимум с редактором определений документов (для работы с документами с жёсткой структурой с хорошо определёнными реперами), а в большинстве более “жизненных” случаев нужно было ещё и научиться работать с инструментом для описания гибкой разметки документов FlexiLayout Studio. При этом у вас вряд ли получилось бы создать даже простейший работающий вариант “слёту” – практически наверняка пришлось бы вдумчиво почитать документацию для обоих инструментов или пройти курс обучения.
Что же теперь? Теперь у нас есть простой пример-инструмент **Automatic Template Generation**, сделанный в виде wizard-а, который поможет вам получить удовлетворительно работающий прототип за несколько минут. Посмотрим на примере, как это работает.
#### Задача
[](http://habrastorage.org/storage2/526/ade/9a7/526ade9a7db7ec9b76669b6a09608330.jpg) Предположим, мы хотим написать приложение для регистрации чеков в некоторой бухгалтерской системе и у нас есть пачка отсканированных чеков. Отберём из этой пачки однотипные чеки и попробуем сделать прототип определения документа (шаблон документа) для нашего приложения.
Заранее скажу о возможностях и ограничениях:
• мы **не сможем** сделать универсальный шаблон, хорошо работающий с произвольными чеками – наш шаблон будет хорошо работать с более-менее **однотипными** чеками желательно из одного источника
• в текущей версии мы **не сможем** описать сложные структуры типа таблиц; для подобных вещей потребуется изучить FlexiLayout Studio
• но мы вполне сможем извлечь такие “плоские” данные как **номер, дата, сумма** и т.п.
#### Решение
Итак, начнём. Для начала нам понадобиться папочка с несколькими (3-5 шт.) изображениями интересующего нас типа. Это будет папка с изображениями для обучения (training images). На данном этапе нам желательны изображения хорошего качества, для того чтобы в данных не было лишнего “шума” и шаблон соответствовал бы случаю с идеальным распознаванием.
1. Запускаем визард и указываем путь к нашей папке:
[](http://habrastorage.org/storage2/9e5/583/1ff/9e55831fff0d4dd3bec29424a1c70f07.png)
2. Выбираем язык:
[](http://habrastorage.org/storage2/35e/75c/12c/35e75c12c82a043d5400251cf6656a99.png)
3. “Рисуем” извлекаемые поля и даём им названия:
[](http://habrastorage.org/storage2/1d1/850/1a3/1d18501a3f5956d5963fe3f4cc18252f.png)
4. Теперь нам нужно нарисовать опорные элементы (reference elements). Это единственный не совсем тривиальный шаг во всём процессе. Опорные элементы – это несколько отобранных статических (то есть постоянных) объектов на изображении (обычно текст), относительно которых ищутся поля с переменным содержанием. Обычно, как в нашем примере (см. скриншот), названия полей – это хорошие кандидаты на роль опорных элементов.
**Хозяйке на заметку**NB. Опорный элемент необязательно должен быть у каждого поля. Это может быть одна постоянная строчка на небольшом документе, относительно которой поля расположены достаточно жёстко. Опорных элементов не должно быть слишком много, чтобы не вносить лишнюю путаницу. Текст опорного элемента может меняться, главное, чтобы сохранялась семантика: в нашем случае вместо “Всего:” на некоторых чеках могло бы быть “Итого:” – в процессе обучения нужно было бы просто единожды указать, что это одно и то же. Важно, чтобы текст был уникальным – например, если на документе одновременно присутствуют “Итого” и “Итого с НДС”, то отдельное слово “Итого” будет плохой опорой.
[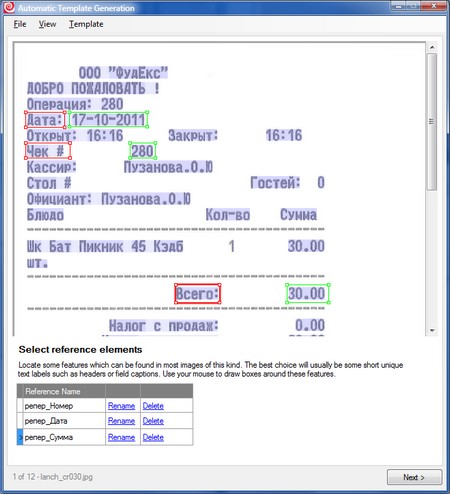](http://habrastorage.org/storage2/64c/96c/58e/64c96c58e554bb8254aeb764ec79d878.png)
5. Далее мы последовательно проходим через все изображения в нашем тренировочном пакете и проверяем разметку. Система для каждой картинки предлагает вариант разметки, который получается по результатам обучения на уже проверенных картинках. Наша задача – исправить ошибки: исправить геометрию полей, нарисовать ненайденные, удалить лишние. В нашем случае ошибок в наложении нет уже после первой картинки, но есть мелкие проблемы с распознаванием.
**Хозяйке на заметку**NB. Проблемы с распознаванием случаются из-за того, что у нас используются параметры распознавания по умолчанию там, где можно было бы их уточнить (например, задать тип шрифта – матричный принтер и ограничить возможный алфавит или задать регулярное выражение для некоторых полей). В API такая возможность есть уже сейчас, но в рассматриваемом инструменте такой функциональности пока нет.
NB. Некоторое поле может отсутствовать на некоторых изображениях.
NB. Через меню Template\Modify Language and Fields можно в любой момент вернуться к редактированию языка и полей, если что-то забыли.
[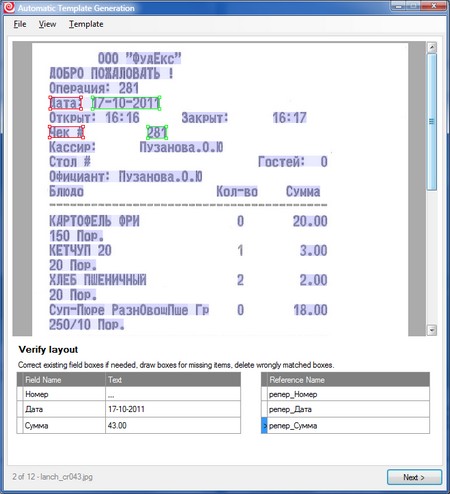](http://habrastorage.org/storage2/d55/698/c4a/d55698c4a55cfd9aa16902ba4529cc90.png)
6. После того как мы закончили обучение на отобранных изображениях, предлагается проверить получившийся шаблон. Мы отвечаем «да» и выбираем в качестве тестовой папку, где лежат все изображения нужного типа, которые у нас есть.
Последовательно для каждой картинки из папки нам предлагаются результаты наложения. Наша задача нажимать Succeeded или Failed для сбора статистики. Если шаблон не наложился на некоторую картинку, а картинка выглядит вполне нормальной, мы можем добавить её в пакет для тестирования, нажав на кнопку Add current image to the training batch. После завершения теста можно будет “дообучиться на добавленных картинках” и, таким образом, последовательно улучшать шаблон.
**Хозяйке на заметку**NB. На этом этапе можно подмешивать в пакет для обучения изображения худшего качества, чтобы учесть часто встречающиеся ошибки. Главное, с этим не переусердствовать.
NB. Работу с приложением можно в любой момент прервать. При повторном запуске можно будет продолжить с того места, где закончили. Более того мы всегда можем вернуться к нашему “проекту”, если у нас через неделю или месяц появились новые изображения, на которых мы хотим улучшить работу.
[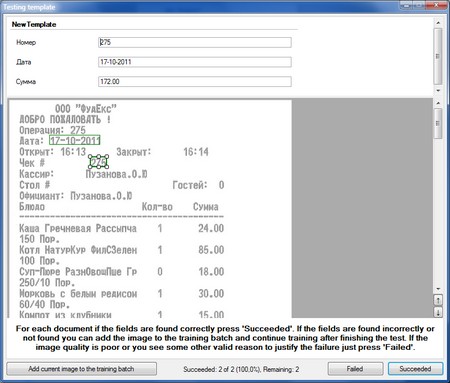](http://habrastorage.org/storage2/c13/4fe/f1c/c134fef1c959ed72e2c9fc1eb0889998.png)
7. После того как результат нас удовлетворил, последнее, что нам осталось сделать – это экспортировать получившийся шаблон в FCDOT файл, с чего всё и началось, и вернуться к написанию кода нашего приложения.
[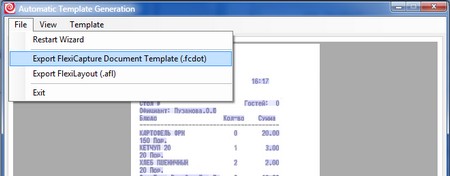](http://habrastorage.org/storage2/f79/2c9/adc/f792c9adc5941219e74671e4578030bf.png)
#### Результат
В результате мы получили шаблон, который на наши изображения накладывается очень неплохо (с качеством выше 90), но есть некоторые проблемы при распознавании полей, так как не учтены особенности шрифта и типы данных полей (дата, число и т.п.). Для прототипа он вполне неплох.
Ещё раз повторюсь, что описанный инструмент не претендует на универсальность. Если нужна универсальность, то придётся научиться использовать FlexiLayout Studio и язык гибких описаний. Но для действительно простых задач типа “извлечь несколько полей”, он работает вполне прилично и позволяет получить работающее решение быстрее и проще.
#### Немного об API
Описанный инструмент полностью написан на общедоступном API, поставляется с исходными кодами, и наши клиенты могут модифицировать его под свои нужды или использовать в качестве базы для изготовления инструментов для конечных пользователей. Конечным пользователям подобная функциональность может быть полезна для возможности быстрой настройки системы на новые документы.
Работа примера на уровне вызовов API выглядит так (дальше см. комментарии):
###### СЦЕНАРИЙ 1 – ЛИНЕЙНЫЙ. ИДЁМ ПРЕДСКАЗУЕМО ОТ НАЧАЛА ДО КОНЦА. ПРОЩЕ ДЛЯ ПОНИМАНИЯ
**Код**
```
// Создаём пакет для обучения и наполняем изображениями
ITrainingBatch trainingBatch = engine.CreateTrainingBatch( rootFolder, "_TrainingBatch", "English" );
try {
trainingBatch.AddImageFile( rootFolder + "\\00.jpg" );
trainingBatch.AddImageFile( rootFolder + "\\01.jpg" );
// На первом изображении определяем структуру документа
ITrainingPage firstPage = trainingBatch.Pages[0];
// Перед началом работы страницу нужно подготовить. На этом этапе изображение анализируется и извлекаются
// примитивные объекты (которые можно использовать в UI для подсказок пользователю)
firstPage.PrepareLayout();
// Пользователь “рисует” на изображении поля и опорные элементы. Эмулируем этот процесс
for( int j = 0; j < firstPage.ImageObjects.Count; j++ ) {
ITrainingImageObject obj = firstPage.ImageObjects[j];
string text = obj.RecognizedText;
// Пользователь “видит” текст
if( text == "978-1-4095-3439-6" ) {
// “Рисует” поле
ITrainingField isbnField = trainingBatch.Definition.Fields.AddNew( "ISBN", TrainingFieldTypeEnum.TFT_Field );
firstPage.SetFieldBlock( isbnField, obj.Region );
break;
}
}
for( int j = 0; j < firstPage.ImageObjects.Count; j++ ) {
ITrainingImageObject obj = firstPage.ImageObjects[j];
string text = obj.RecognizedText;
// Пользователь “видит” текст опорного элемента
if( text == "ISBN" ) {
// “Рисует” опорный элемент
ITrainingField isbnTag = trainingBatch.Definition.Fields.AddNew( "ISBNTag", TrainingFieldTypeEnum.TFT_ReferenceText );
firstPage.SetFieldBlock( isbnTag, obj.Region );
break;
}
}
assert( trainingBatch.Definition.Fields.Count == 2 );
// Структура определена и разметка проверена
trainingBatch.SubmitPageForTraining( firstPage );
// Проверяем последовательно разметку всех страниц
for( int i = 1; i < trainingBatch.Pages.Count; i++ ) {
ITrainingPage page = trainingBatch.Pages[i];
// Кроме извлечения примитивных объектов, система пытается предсказать разметку
page.PrepareLayout();
// Пользователь проверил разметку
trainingBatch.SubmitPageForTraining( page );
}
// Экпортируем гибкую разметку. На её основе шаблон создаётся одним вызовом CreateDocumentDefinitionFromAFL
trainingBatch.Definition.ExportToAFL( rootFolder + "\\_TrainingBatch\\NewTemplate.afl" );
} finally {
trainingBatch.Close();
}
```
###### СЦЕНАРИЙ 2 – НЕЛИНЕЙНЫЙ. ПОЛЬЗОВАТЕЛЬ ИТЕРИРУЕТ ПО СТРАНИЦАМ И В ЛЮБОЙ МОМЕН МОЖЕТ ИЗМЕНИТЬ ОПИСАНИЕ. УДОБНЕЕ ДЛЯ ПОЛЬЗОВАТЕЛЯ
**Код**
```
// Создаём пакет для обучения и наполняем изображениями
ITrainingBatch trainingBatch = engine.CreateTrainingBatch( rootFolder, "_TrainingBatch", "English" );
try {
trainingBatch.AddImageFile( rootFolder + "\\00.jpg" );
trainingBatch.AddImageFile( rootFolder + "\\01.jpg" );
// Перебираем страницы, пока пользователь не проверит разметку на всех
ITrainingPage page = trainingBatch.PrepareNextPageNotSubmittedForTraining();
while( page != null ) {
// Пользователь может в любой момент дорисовать поле, при этом цикл проверки будет пройден заново. В этой
// эмуляции предполагаем, что пользователь определяет все нужные поля уже на первой странице
if( page == trainingBatch.Pages[0] ) {
for( int j = 0; j < page.ImageObjects.Count; j++ ) {
TrainingImageObject obj = page.ImageObjects[j];
string text = obj.RecognizedText;
// Пользователь “видит” текст
if( text == "978-1-4095-3439-6" ) {
// “Рисует” поле
ITrainingField isbnField = trainingBatch.Definition.Fields.AddNew( "ISBN", TrainingFieldTypeEnum.TFT_Field );
page.SetFieldBlock( isbnField, obj.Region );
break;
}
}
for( int j = 0; j < page.ImageObjects.Count; j++ ) {
ITrainingImageObject obj = page.ImageObjects[j];
string text = obj.RecognizedText;
// Пользователь “видит” текст опорного элемента
if( text == "ISBN" ) {
// “Рисует” опорный элемент
ITrainingField isbnTag = trainingBatch.Definition.Fields.AddNew( "ISBNTag", TrainingFieldTypeEnum.TFT_ReferenceText );
page.SetFieldBlock( isbnTag, obj.Region );
break;
}
}
assert( trainingBatch.Definition.Fields.Count == 2 );
}
// Пользователь проверил разметку
trainingBatch.SubmitPageForTraining( page );
// Даём ему следующую на проверку
page = trainingBatch.PrepareNextPageNotSubmittedForTraining();
}
// Экпортируем гибкую разметку. На её основе шаблон создаётся одним вызовом CreateDocumentDefinitionFromAFL
trainingBatch.Definition.ExportToAFL( rootFolder + "\\_TrainingBatch\\NewTemplate.afl" );
} finally {
trainingBatch.Close();
}
```
#### В заключение
Кроме описанного из новых фич, интересных разработчикам, у нас теперь есть:
• Продвинутые **инструменты предобработки изображений**. Среди них продвинутый шумодав и настраиваемый фильтр, работающий в частотной области, наподобие wavelet-ов. Этот фильтр после настройки позволяет значительно улучшить качество работы с фотографиями (лёгкая расфокусировка, шумы).
• API для доступа к **вариантам распознавания слов и символов**. Это позволяет в некоторых случаях, когда хорошо известна модель извлекаемых данных, программно выбрать вариант наиболее подходящий под эту модель и улучшить качество на выходе. Например, можно осмысленно сравнивать с данными, содержащимися в некоторой БД, или считать контрольную сумму.
• **По замечаниям читателей хабра!** Приличная **поддержка Java** – в дистрибутив включён JAR, содержащий структуру объектов и интерфейсов (повторяющий интерфейсы, как они выглядят из .Net), и dll-ку со всеми необходимым JNI-переходниками для вызовов. Для 99% случаев можно использовать прямо “из коробки”. Нет только поддержки callback-ов, которую пользователи могут при сильной необходимости выборочно реализовать сами (мы расскажем как).
Более подробно об ABBYY FlexiCapture Engine вы можете прочитать [на сайте ABBYY](http://www.abbyy.ru/flexicapture_engine/).
*Алексей Калюжный [AlekseyKa](http://habrahabr.ru/users/alekseyka/)
Руководитель группы разработки FlexiCapture Engine* | https://habr.com/ru/post/146679/ | null | ru | null |
# Загрузка Linux с VHD на компьютере с BIOS
Загрузка Linux с [VHD](https://ru.wikipedia.org/wiki/VHD) может пригодиться в различных сценариях, например, когда на компьютере установлена Windows и есть необходимость в Linux, но WSL или виртуальной машины с Linux недостаточно, а разбивать диск на разделы нет желания. Microsoft позволяет грузить Windows с VHD «из коробки» начиная со старших редакций Windows 7. Но что делать, если возникла необходимость загрузить таким способом Linux?
На форумах часто можно встретить мнение, что загрузить Linux с VHD либо [нельзя](https://forum.ubuntu.ru/index.php?topic=284154.0), либо [очень сложно](https://forum.ru-board.com/topic.cgi?forum=5&topic=37297&start=340#2). Полезной информации в интернете на эту тему действительно мало. Базовая идея, как это осуществить, описана [тут](http://reboot.pro/index.php?showtopic=20603&page=5#entry210378). Суть в следующем:
1. Необходимо убедиться в поддержке NTFS на всех этапах.
2. Необходимо убедиться в поддержке [loop](https://help.ubuntu.ru/wiki/loop)-[устройств](https://en.wikipedia.org/wiki/Loop_device).
3. Добавить в загрузочные скрипты ОС команду монтирования loop-устройства.
4. Перестроить initramfs.
5. Убедиться, что все необходимые утилиты добавлены в образ, обновить initramfs внутри VHD.
6. В случае legacy-зарузки (BIOS) и использования штатного загрузчика Windows добавить grub4dos в меню bootmgr, а в меню grub4dos добавить пункт для загрузки с VHD.
Практическое применение этой идеи для Arch Linux описано [тут](http://reboot.pro/index.php?showtopic=20603&page=2#entry200203). В этой статье я проведу аналогичный эксперимент с [Debian](https://www.debian.org/). Предполагается, что читатель имеет представление о работе с консолью в Windows и в Linux, умеет работать со стандартными системными утилитами, с ПО для виртуализации и т.п. — элементарные вещи подробно не расписаны.
Процесс загрузки будет выглядеть так: bootmgr -> grub4dos -> initramfs -> debian. Рассмотрим подготовку каждого этапа справа налево.
#### Установка Linux на VHD
Для начала необходимо создать пустой образ VHD с фиксированным размером. Если нужно минимизировать размер образа, то для экспериментов с CLI достаточно создать диск объемом ~1,5 Гб. Для рабочей системы с GUI можно ограничиться объемом 10 Гб (с условием хранения пользовательских данных вне VHD).
Создадим VHD с помощью diskpart.exe:
```
create vdisk file=\debian.vhd type=fixed maximum=1500
```
Далее необходимо установить Debian на VHD. Я для этого воспользовался [VirtualBox 6.1](https://www.virtualbox.org/), устанавливал [debian-10.8.0-amd64-netinst.iso](https://www.debian.org/). Параметры виртуальной машины — по умолчанию, новый диск создавать не надо, достаточно подключить ранее созданный debian.vhd.
Параметры VirtualBox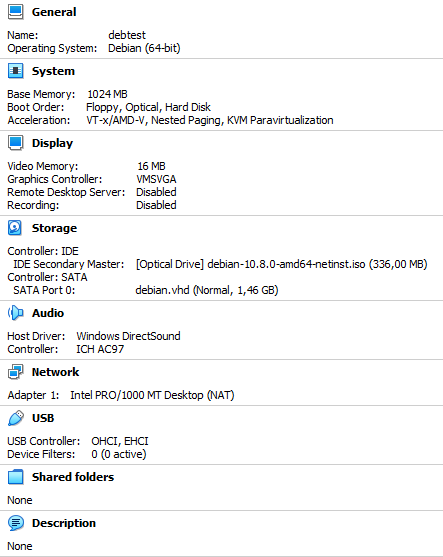Установка Debian стандартна, обращу внимание только на некоторые моменты.
При разметке диска я создал один загрузочный раздел ext4. Раздел подкачки на VHD я делать не стал, после установки можно разместить файл или раздел подкачки в удобном месте.
Разметка диска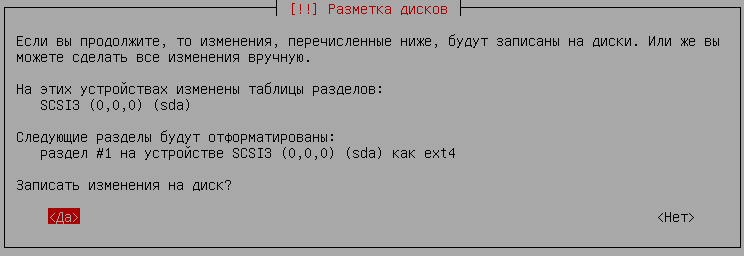При выборе дополнительного ПО для установки я оставил только SSH-сервер и стандартные системные утилиты. Всё остальное можно поставить потом, по необходимости. GRUB установлен в MBR. Если при установке была выбрана русская локаль, то после установки можно добавить локаль en\_US командой `dpkg-reconfigure locales`.
#### Подготовка Linux к загрузке с VHD
В установленную систему необходимо добавить поддержку NTFS и утилиту partprobe, которая [позволяет сообщить](http://rus-linux.net/MyLDP/BOOKS/LSA/ch05.html) ядру ОС о необходимости повторного чтения таблицы разделов жёсткого диска.
```
apt-get install ntfs-3g parted
```
Затем надо подготовить скрипты для initramfs.
> [initramfs](https://wiki.gentoo.org/wiki/Initramfs/Guide/ru) — это начальная файловая система в оперативной памяти, которая содержит утилиты и скрипты, требуемые для монтирования файловых систем перед вызовом init, располагающегося в корневой файловой системе.
>
>
Скрипты для initramfs созданы на основе [документации](http://manpages.ubuntu.com/manpages/xenial/man8/initramfs-tools.8.html). Наши дополнения для initramfs мы будем размещать в следующих каталогах.
* `/etc/initramfs-tools/hooks/` — здесь размещаются скрипты, которые запускаются при генерации initramfs-образа. Тут мы разместим скрипт для добавления в initramfs утилиты partprobe с необходимыми библиотеками.
* `/etc/initramfs-tools/scripts/local-top/` — после выполнения этих скриптов загрузчик считает, что root-устройство смонтировано. Т.е. здесь будет скрипт для монтирования VHD.
Скрипт для добавления partprobe в initramfs возьмем из [этой статьи](https://habr.com/ru/post/457260/) с добавлением еще одной библиотеки. Надо создать файл partcopy и сделать его исполняемым:
partcopy
```
#!/bin/sh
cp -p /sbin/partprobe "$DESTDIR/bin/partprobe"
cp -p /lib/x86_64-linux-gnu/libparted.so.2 "$DESTDIR/lib/x86_64-linux-gnu/libparted.so.2"
cp -p /lib/x86_64-linux-gnu/libreadline.so.7 "$DESTDIR/lib/x86_64-linux-gnu/libreadline.so.7"
cp -p /lib/x86_64-linux-gnu/libtinfo.so.6 "$DESTDIR/lib/x86_64-linux-gnu/libtinfo.so.6"
```
Скрипт для монтирования VHD сделан на основе [скрипта для Arch Linux](http://reboot.pro/index.php?showtopic=20603&page=2#entry200203) с учетом особенностей выбранного дистрибутива Linux. Скрипт необходимо сохранить под именем loop\_boot\_vhd и сделать исполняемым:
loop\_boot\_vhd
```
#!/bin/sh
PREREQ=""
prereqs()
{
echo "$PREREQ"
}
case $1 in
# get pre-requisites
prereqs)
prereqs
exit 0
;;
esac
cmdline=$(cat /proc/cmdline)
#cmdline="root=/dev/loop0p1 loop_file_path=/debtst.vhd loop_dev_path=/dev/sda2"
for x in $cmdline; do
value=${x#*=}
case ${x} in
root=*) value_loop_check=${value#*loop}
if [ x$value_loop_check != x$value ]
then loop_dev=${value%p*}
loop_part_num=${value##*p}
else echo "Root device is not a loop device. loopboot hook will be terminated."; return
fi ;;
loop_file_path=*) loop_file_path=$value ;;
loop_dev_path=*) loop_dev_path=$value ;;
esac
done
if [ -z $loop_file_path ] || [ -z $loop_dev_path ]
then echo "Either loop_file_path or loop_dev_path parameter does not specified. loopboot hook will be terminated."; return
fi
#modprobe fuse
modprobe loop max_part=64 max_loop=8
loop_dev_type=$(blkid -s TYPE -o value $loop_dev_path)
if [ ! -d /host ]; then
mkdir /host
fi
if [ "$loop_dev_type" != "ntfs" ]
then mount -t $loop_dev_type $loop_dev_path /host; echo "mount -t $loop_dev_type $loop_dev_path /host"; echo "mounted using mount";
else ntfs-3g $loop_dev_path /host; echo "mounted using ntfs-3g";
fi
losetup $loop_dev /host$loop_file_path
partprobe $loop_dev
```
Немного подробнее поясню логику работы скрипта. Обработка `prereqs` рекомендована в [документации](http://manpages.ubuntu.com/manpages/xenial/man8/initramfs-tools.8.html). В переменную `cmdline` попадает строка инициализации из grub4dos, например, `root=/dev/loop0p1 loop_file_path=/debian.vhd loop_dev_path=/dev/sda2`. Далее идет разбор этой строки и из нее определяется номер партиции на loop-устройстве, а в переменные `loop_dev_path` и `loop_file_path` сохраняются путь к устройству, на котором хранится VHD-файл, и путь к VHD-файлу на устройстве. Если данные для этих переменных не переданы, то скрипт прекращает работу и система пытается загрузиться в обычном режиме. Если переменные определены, то загружается модуль ядра для подержки loop-устройств с указанием в параметрах максимального количества loop-устройств и максимального количества таблиц разделов на loop-устройстве. Затем командой `blkid` определяется тип файловой системы диска, на котором хранится VHD-файл. Если VHD лежит на NTFS, то монтирование производится с помощью команды `ntfs-3g`, иначе — командой `mount`. Монтирование производится в каталог `/host` (который при необходимости предварительно создается). После этого VHD подключается в систему командой `losetup`, а затем partprobe сообщает ядру о новом диске.
После размещения скриптов в нужные каталоги (`/etc/initramfs-tools/scripts/local-top/loop_boot_vhd` и `/etc/initramfs-tools/hooks/partcopy`) необходимо пересобрать initramfs командой:
```
update-initramfs -c -k all
```
Для дальнейшей настройки надо запомнить номер версии ядра: /boot/initrd.img-4.19.0-14-amd64 и /boot/vmlinuz-4.19.0-14-amd64.
На этом образ готов к запуску на реальном железе, можно выключать виртуальную машину и приступать к подготовке загрузчика. Готовый образ debian.vhd надо скопировать в корень диска C:, дальнейшие скрипты написаны исходя из предположения, что VHD находится в корне NTFS-раздела.
#### Настройка grub4dos
Для начала надо скачать актуальную версию [grub4dos](https://github.com/chenall/grub4dos/releases). Работа с этой утилитой в различных источниках описана [достаточно подробно](http://greenflash.su/Grub4Dos/Grub4dos.htm). Настройка сводится к следующему:
* необходимо найти раздел, в корне которого лежит VHD-файл, и сделать его корневым для всех команд в текущем пункте меню (команда `find --set-root`);
* затем загрузить образ жесткого диска (команды `map ...vhd` и `map --hook`);
* далее подключенный образ указать как корневое устройство (команда `root`);
* и указать параметры запуска Linux (`kernel` и `initrd`).
Получается файл `menu.lst` с таким содержимым:
menu.lst
```
title debian
find --set-root --ignore-floppies --ignore-cd /debian.vhd
map /debian.vhd (hd3)
map --hook
root (hd3,0)
kernel /boot/vmlinuz-4.19.0-14-amd64 root=/dev/loop0p1 rw loop_file_path=/debian.vhd loop_dev_path=/dev/sda2
initrd /boot/initrd.img-4.19.0-14-amd64
```
Тут надо обратить внимание на один момент: в команде `kernel` инициализируются переменные, которые передаются в initramfs и используются в ранее созданном скрипте `loop_boot_vhd`.
В моем примере переменные заполнены исходя из моей конфигурации компьютера: один диск с Windows, разбитый на два раздела (загрузочный "System Reserved" и основной NTFS), а внутри VHD — один раздел ext4.
#### Настройка загрузчика bootmgr
Обратите внимание: в зависимости от версии Windows и особенностей установки ОС возможны незначительные отличия.
Первое, что надо сделать, — подключить скрытый раздел с bootmgr, в примере ниже я подключаю скрытый раздел "System Reserved" в каталог `C:\mnt` (каталог должен быть предварительно создан). Команды выполняются в diskpart.exe:
```
list volume
Volume 1 System Rese NTFS Partition 549 MB Healthy System
Volume 2 C NTFS Partition 49 GB Healthy Boot
select volume 1
assign mount=C:\mnt
```
После этого надо распаковать в каталог `C:\mnt\` файлы из архива с [grub4dos](https://github.com/chenall/grub4dos/releases): `grldr` и `grldr.mbr`. В этот же каталог надо скопировать файл `menu.lst`, созданный на предыдущем шаге. После этого раздел можно отключить в diskpart.exe:
```
remove mount=C:\mnt
```
Чтобы настроить отображение пункта меню при загрузке Windows, надо сделать следующее:
```
bcdedit.exe -create -d grub4dos -application bootsector
*The entry {GUID} was successfully created.
```
В ответ будет сообщен GUID нового пункта меню. Полученный GUID используется в следующих командах:
```
bcdedit.exe -set {GUID} device boot
bcdedit.exe -set {GUID} path \grldr.mbr
bcdedit.exe -displayorder {GUID} -addlast
```
Тут подробно не останавливаюсь, все команды очевидны и хорошо описаны в документации. Ну, и чтобы не переключаться лишний раз между графическим и текстовым режимами:
```
bcdedit.exe /set {default} bootmenupolicy legacy
```
На этом всё: можно перезагрузить компьютер, выбрать в меню загрузки grub4dos, затем Debian, после чего должен загрузиться Linux.
#### Что делать, если не грузится?
В этом случае, скорее всего, неверно указаны параметры с путями к устройству, на котором находится VHD-файл, или раздел на loop-устройстве. Если загрузка останавливается на уровне grub4dos, то в консоли надо последовательно вводить команды, перечисленные в `menu.lst`, и смотреть на результаты, в зависимости от которых правильно указать параметры для загрузки Linux. Если загрузка останавливается в initramfs, то надо проверить доступность необходимых устройств на этом этапе. Проверить можно, последовательно вводя команды из скрипта `loop_boot_vhd` (основное: смонтировать нужные разделы, найти VHD, подключить его, проверить присвоенный номер партиции с Linux, в моем примере — loop0p1).
#### А как же UEFI?
Это немного другая история, надеюсь, позже найду время и проведу аналогичный эксперимент с UEFI.
UPD. [Продолжение про UEFI](https://habr.com/ru/company/domclick/blog/552170/) | https://habr.com/ru/post/547150/ | null | ru | null |
# Язык программирования Monkey
[](http://monkeycoder.co.nz/)
Всем привет!
В этой статье я хотел бы рассказать о Monkey — языке программирования, направленного, в первую очередь, на создание кроссплатформенных 2D-игр. Этот инструмент, на мой взгляд, несколько незаслуженно обделен вниманием разработчиков и я хотел бы это исправить.
Monkey ни в коем случае не является «убийцей» Unity и других подобных инструментов. Но он может заинтересовать начинающих, а также независимых разработчиков игр, чей бюджет в значительной степени ограничен. Если мне удалось вас заинтересовать, добро пожаловать под кат.
### Язык
Monkey — объектно-ориентированный, транслируемый язык программирования, кроссплатформенность которого достигается за счет транслирования кода Monkey в нативный для платформы язык.
Официально, код Monkey может быть транслирован в следующие языки программирования: С++, C#, Java, JavaScript и ActionScript. Тем не менее, этот список может быть расширен, путем написания собственных трансляторов. Так, сообществом Monkey, были успешно разработаны трансляторы для Python и BlitzMax.
Monkey относится к семье языков с BASIC-подобным синтаксисом. Но в нем также отчетливо прослеживается влияние Java. Язык имеет статическую типизацию, обеспечивает модульность, поддерживает абстракцию, инкапсуляцию, наследование и полиморфизм, а также интерфейсы, обобщённые типы, свойства, итераторы и исключения.
**Пример кода, написанного на Monkey**
```
' включение строгого режима
Strict
' импорт модуля mojo
Import mojo
' точка входа приложения monkey
Function Main:Int()
New GameApp
Return 0
End
' основной класс, расширяющий класс mojo app
Class GameApp Extends App
Field player:Player
' переопределение метода mojo oncreate
Method OnCreate:Int()
' загрузка изображения player.png в переменную img, медиаданные должны хранится в папке project.data
Local img:Image = LoadImage("player.png")
player = New Player(img, 100, 100)
' установка обновлений в секунду равным 60
SetUpdateRate 60
Return 0
End
' переопределение метода mojo onupdate
Method OnUpdate:Int()
player.x+=1
If player.x > 100
player.x = 0
End
Return 0
End
' переопределение метода mojo onrender
Method OnRender:Int()
' очистка экрана заданным цветом (красный, зеленый, синий)
Cls 32, 64, 128
player.Draw()
Return 0
End
End
' класс игрока
Class Player
Field x:Float, y:Float
Field image:Image
' конструктор
Method New(img:Image, x:Int, y:Int)
self.image = img
self.x = x
self.y = y
End
' рисование спрайта
Method Draw:Void()
DrawImage image, x, y
End
End
```
Автором языка является новозеландский разработчик Марк Сибли — основатель Blitz Research Ltd. Этот человек известен некоторым разработчикам по таким инструментам для создания игр, как BlitzBasic, Blitz3D и BlitzMax. По сути, Monkey является эволюцией линейки всех предшествующих продуктов компании Blitz Research Ltd.
##### Кроссплатформенность

Как я уже писал выше, кроссплатформенность достигается за счет транслирования. По сути, все что умеет транслятор Monkey — это проверять и транслировать код, собирать валидный для платформы проект, и запускать нативные средства для сборки приложений. В связи с этим, для сборки итогового приложения, вам понадобится установить SDK для всех требуемых платформ. Ниже приведена таблица доступных на данный момент платформ и список необходимого ПО.
| Платформа | Необходимое ПО |
| --- | --- |
| HTML5 | не требуется |
| Flash | Flex SDK, Java SE |
| GLFW (Windows, Mac) | MS VC++ или MinGW, OpenAL |
| Android | Android SDK, Java SE (32-bit), ANT (Windows) |
| iOS | OS X 10.6, XCode |
| XNA (Windows, WP7, XBox 360) | XNA Game Studio 4.0, MS VC#, WP SDK 7.1 |
| PSM (PS Vita) | PSM SDK |
Таким образом, нам удается избежать использования различных лаунчеров и плагинов для запуска итоговых приложений. Все выглядит так, как если бы мы писали приложение самостоятельно. Конечно, транслированный код получается малочитаемым и не всегда оптимальным, но вместе с этим дает все преимущества нативной разработки.
Как видно из приведенной выше таблицы, на данный момент поддерживаются следующие платформы: **HTML5**, **Flash**, **Android**, **iOS**, **WP7**, **PS Vita**, **Xbox 360**, **Windows** и **Mac**. **Linux** также поддерживается, но пока неофициально. Как и в случае с трансляторами, этот список может быть расширен путем собственной реализации поддержки необходимых вам платформ.
##### Транслятор
Транслятор, как бы странно это не звучало, написан на Monkey. Но как и в случае с яйцом и курицей, был промежуточный этап, когда транслятор был написан на BlitzMax. Исходный код транслятора полностью открыт, поэтому, в случае необходимости, вы можете вносить изменения и пересобирать его в Monkey, используя целевую платформу Stdcpp (стандартный C++).
##### Препроцессор
Monkey использует простой препроцессор для разделения специфичных участков кода для различных платформ, установки дополнительных параметров конфигурации, а также для включения или исключения блоков кода в зависимости от конфигурации сборки.
##### Использование нативного кода
Для написания платформозависимого кода может быть использован нативный для платформы язык. С помощью директивы Extern, в код Monkey могут быть включены классы и функции, использующие специфичные особенности платформы. Это дает возможность практически без ограничений расширять функционал вашего приложения.
### Модули

Возможности языка могут быть расширены с помощью модулей, которые можно писать как непосредственно на Monkey, так и на нативном для платформы языке.
«Из коробки» Monkey поставляется со следующими модулями:
* monkey (базовые возможности языка)
* brl (набор классов и функций для работы с потоками)
* reflection (отражение)
* os (модуль для работы с операционной системой)
* dom (модуль для работы с DOM-деревом HTML-документа)
* mojo (2D-фреймворк)
* opengl (модуль для работы c OpenGL)
В дополнение к этому списку, сообществом разработчиков было написано более 20-ти дополнительных модулей, включая порты различных физических движков (**Box2D**, **Chipmunk** и **Fling**), **GUI**-системы, модули для работы со шрифтами, модули для реализации **IAP** (in-app purchase), модули для работы с **XML**, **JSON** и различными сервисами. Список большинства доступных, на данный момент, модулей можно посмотреть [здесь](http://monkeycoder.co.nz/Community/modules.php).
### Разработка игр

Вот мы и подошли к самому главному. В начале статьи я сказал, что Monkey, в основном, используется для создания 2D-игр. Но, как видите, сам язык под это дело не заточен.
##### Mojo
Для разработки игр используется модуль mojo, который поставляется вместе с Monkey. Этот модуль предоставляет разработчику кроссплатформенный API для работы с 2D-графикой, звуком и устройствами ввода. Возможности фреймворка несколько ограничены и связано это, в первую очередь, с необходимостью поддержки множества платформ. Не все возможности доступные на одной платформе доступны на другой. Если какая-то «фишка» недоступна хотя бы на одной из платформ, то она не будет включена в mojo. Конечно, это несколько радикально. Но в тоже время, вы сможете быть уверены, что ваше приложение будет одинаково работать на всех платформах.
Вторая причина столь скромного функционала — простота добавления новых платформ. Технологии меняются с невероятной скоростью. То тут, то там появляются новые устройства и операционные системы. Именно поэтому, возможность оперативного добавления поддержки новой платформы, дает неоспоримое преимущество перед другими подобными инструментами.
##### Игровые фреймворки

Конечно, функционала mojo недостаточно для написания полноценной игры. Ведь игра — это не только работа с графикой, звуком и устройствами ввода, но и пользовательский интерфейс, различные состояния, тайлы, анимация, физика и прочее. Всего этого в mojo, к сожалению, нет. Но на помощь приходят игровые фреймворки, и другие модули, созданные сообществом Monkey.
**Список популярных игровых фреймворков для Monkey**[Diddy](http://code.google.com/p/diddy/). Один из самых популярных фреймворков для Monkey. Помимо, непосредственно, фреймворка, предоставляет большое количество дополнительного функционала.
[FantomEngine](http://code.google.com/p/fantomengine/). Создателем фреймворка является автор книги «Monkey Game Development», все примеры в которой сделаны с использованием fantomEngine.
[Flixel](http://devolonter.github.com/flixel-monkey/). Порт популярного flash-фреймворка flixel. Портированием данного фреймворка занимаюсь я, но на данный момент, в виду отсутствия времени, работа над ним приостановлена.
[Playniax](http://www.playniax.com/). Единственный коммерческий фреймворк, но с неплохими отзывами. Автором является разработчик одноименного фреймворка для BlitzMax.
Помимо этих 4-х фреймворков, на официальном сайте можно найти ссылки еще на 4-5 подобных инструмента различной степени завершенности.
##### 3D
Если же вашей целью является создание 3D-игр, то в вашем распоряжении есть модуль opengl (работает не на всех платформах) или фреймворк [minib3d](https://github.com/adamredwoods/minib3d-monkey). Но в целом, в этом плане, все довольно-таки плохо.
##### Игры, сделанные на Monkey
**Список популярных игр, сделанных на Monkey*** [Zombie Trailer Park](http://ninjakiwi.com/Games/Strategy/Zombie-Trailer-Park.html) — Flash and iOS
* [New Star Soccer Mobile](http://www.newstarsoccer.com/nssmobile.php) — Android, iOS, Flash and HTML5
* [Ninjah](http://chrismingay.co.uk/colourfy/ninjah/) — Xbox 360, PC, Mac
* [Jet Worm](http://www.avaloid.com/jet-worm/iphone) — iPhone and iPad
* [Blotty Pots](http://www.blottypots.com/) — Android, iOS, WP7
Наиболее полный список игр вы можете посмотреть [здесь](http://monkeycoder.co.nz/Community/posts.php?topic=3783).
### Стоимость и модель распространения
Стоимость pro-лицензии Monkey составляет **$99**. За эту сумму вы получаете: пожизненную поддержку и обновления, доступ к форуму официального сайта, модуль mojo для всех официально поддерживаемых платформ и возможность создания коммерческих игр.
Также, для загрузки доступна демо-версия, в состав которой входит mojo для HTML5. С помощью этой версии вы **не сможете** создавать коммерческие игры.
На самом деле, говоря о демо и pro-версиях я имею в виду только mojo, так как сам Monkey является общественным достоянием и распространяется совершенно бесплатно. К сожалению, у Monkey отсутствует официальный репозиторий, поэтому вы можете скачать только пользовательские форки.
На данный момент, известны два форка Monkey:
* [The Monkey Language with Extras](http://code.google.com/p/monkey-ext/)
* [Monkey by Michael Contento](https://github.com/michaelcontento/monkey)
Из этих двух, я порекомендовал бы использовать первый, так как он чаще обновляется и включает большее количество доработок.
### Недостатки
Как и любой программный продукт, Monkey имеет свои минусы. Ниже, я постараюсь рассказать о самых важных из них, а также предложить способы их решения.
##### IDE
Наверное, это самая серьезная проблема — отсутствие нормальной среды разработки. Несмотря на то, что Monkey поставляется с двумя IDE (Monk и Ted), ни одну из них нельзя назвать полноценной. Я бы скорее назвал их чуть продвинутым блокнотом, не более. Писать на них серьезные проекты весьма проблематично.

Для решения этой проблемы можно воспользоваться коммерческой [Jungle IDE](http://www.jungleide.com/) (есть бесплатная lite-версия) или одним из [нескольких](http://www.gingerbeardman.com/monkey/) плагинов для популярных текстовых редакторов. Тем не менее, проблема с IDE, к сожалению, остается одной из ключевых.
##### Отсутствие вспомогательных инструментов
Большинство профессиональных инструментов для создания игр поставляются вместе с редакторами уровней, спрайтов, анимации и т. д. В Monkey подобных инструментов вы не увидите. Есть только язык, модули и IDE.
На выручку приходит стороннее ПО, как платное так и бесплатное. Обычно, сделать импорт проектов из подобных инструментов, не составляет больших проблем. К тому же, если поискать по официальному форуму, можно найти уже готовые решения, такие как, импорт текстурных атласов из TexturePacker, импорт тайловых карт из Dame и Tiled и т.д.
##### Производительность HTML5
HTML5-версия mojo использует 2D-контекст, что отрицательно сказывается на производительности игр. К сожалению, WebGL не поддерживается в IE. И как я уже писал ранее, если какая-то особенность где-то не поддерживается, то она не используется вовсе.
Чтобы исправить эту ситуацию, можно попробовать воспользоваться экспериментальным патчем для mojo — [Mojo HTML5 GL](https://github.com/devolonter/mojo-html5-gl), который заменяет 2D-контекст на WebGL, что дает существенный прирост производительности.
##### Официальный сайт
Еще один привет из прошлого — официальный сайт. Да, он справляется со своей прямой обязанностью — предоставлять пользователям возможность задавать вопросы и получать ответы, но в остальном это очень примитивный форум с ужасным дизайном. Многие из тех, кто заинтересовался Monkey, начинали сомневаться сразу после просмотра главной страницы. А когда переходили к демкам, с ужасом убегали и никогда не возвращались (я не преувеличиваю). Несмотря на то, что проблема не касается непосредственно разработки, я считаю ее одной из самых серьезных второстепенных проблем.
##### Название
Многие пользователи жалуются на то, что искать информацию о Monkey очень тяжело, так как они постоянно натыкаются на информацию об обезьянах. К тому же, словосочетание monkey coder имеет негативный окрас, из-за схожести с [Code Monkey](http://lurkmore.to/%D0%91%D1%8B%D0%B4%D0%BB%D0%BE%D0%BA%D0%BE%D0%B4%D0%B5%D1%80).
### Monkey и Haxe

Haxe — универсальный объектно-ориентированный язык программирования высокого уровня, со схожим с Monkey принципом действия. И учитывая, что Haxe появился раньше, можно полагать, что разработчик Monkey черпал свое вдохновение именно от него.
Подобно mojo, у Haxe есть NME — фреймворк повторяющий Flash API. В виду подобного количества совпадений возникает закономерный вопрос: «Чем Monkey и mojo лучше Haxe и NME?». Оговорюсь сразу, я не знаком близко с Haxe и возможно в чем-то ошибаюсь, но тем не менее, постараюсь быть максимально объективным.
Плюсами связки Monkey и mojo, на мой взгляд, являются:
* большее количество официально поддерживаемых платформ
* поддержка таких важных платформ как PS Vita, WP7, Xbox 360, HTML5 (в NME эта платформа в зачаточной стадии)
* стабильная трансляция в C# и Java (в Haxe эти языки находятся в статусе beta)
* одинаковое или ожидаемое поведение на всех платформах. В NME разница между платформами выглядит [значительнее](http://www.haxenme.org/documentation/features/)
* относительная простота добавления поддержки новых платформ
* платность, как гарантия развития
Плюсы связки Haxe и NME:
* более «продвинутый» язык
* большие возможности фреймворка NME
* знакомый многим разработчикам игр Flash API
* FlashDevelop, как основная IDE
* большое сообщество
* бесплатность
Как видите, у каждого инструмента есть свои сильные и слабые стороны. И получить однозначного ответа на вопрос, какой из них лучше, не представляется возможным. Многое зависит от того, что вы ожидаете получить от выбранного вами инструмента.
### В завершение
Спасибо, что дочитали данный пост до конца. Я не ожидал, что он получится таким длинным, поэтому извините, если зря потратил ваше время. Тем не менее, я надеюсь, что мне удалось полностью раскрыть тему и рассказать о Monkey максимально объективно.
Для всех, кто заинтересовался Monkey — [официальный сайт проекта](http://www.monkey-x.com/).
Спасибо за внимание!
На этом все. Пока! | https://habr.com/ru/post/159377/ | null | ru | null |
# Состояние и производительность решений для постоянного хранения данных в Kubernetes
***Прим. перев.**: хотя этот обзор не претендует на статус тщательно проработанного технического сравнения существующих решений для постоянного хранения данных в Kubernetes, он может стать хорошей отправной точкой для администраторов, которым актуален данный вопрос. Наибольшего внимания здесь удостоилось решение Piraeus, знакомство с которым пойдет на пользу не только любителям Linstor, но и тем, кто об этих проектах ещё не слышал.*

Это ненаучный обзор решений для хранения данных для Kubernetes. Постановка задачи: требуется возможность создания Persistent Volume на дисках узла, данные которого будут сохранны в случае повреждения или перезапуска узла.
Мотивация для проведения этого сравнения — потребность миграции серверного парка компании со множества выделенных bare metal-серверов в кластер Kubernetes.
Моя компания — стартап [Escavador](https://www.escavador.com/) из Бразилии с огромными потребностями в вычислительной мощности (преимущественно в CPU) и весьма ограниченным бюджетом. Мы разрабатываем решения в области NLP для структурирования юридических данных.
*Из-за кризиса с COVID-19 бразильский реал подешевел до рекордно низкого уровня по отношению к доллару США*
Наша национальная валюта на самом деле очень недооценена, поэтому средняя зарплата старшего разработчика составляет всего 2000 USD в месяц. Таким образом, мы не можем позволить себе роскошь тратить значительные средства на облачные сервисы. Когда я проводил расчеты в последний раз, [благодаря использованию своих серверов] мы экономили 75 % в сравнении с тем, что пришлось бы заплатить за AWS. Другими словами, на сэкономленные деньги можно нанять еще одного разработчика — думаю, что это гораздо более рациональное использование средств.
Вдохновленный серией публикаций от Vito Botta, я решил создать кластер K8s с помощью Rancher (и с ним пока всё хорошо…). Vito также провел [отличный анализ](https://vitobotta.com/2019/08/06/kubernetes-storage-openebs-rook-longhorn-storageos-robin-portworx/) различных решений для хранения. Явным победителем оказался Linstor (он даже выделил его в [особую лигу](https://vitobotta.com/2020/01/04/linstor-storage-the-kubernetes-way/)). *Спойлер: я с ним согласен.*
В течение некоторого времени я слежу за движением вокруг Kubernetes, но только недавно решил поучаствовать в нем. Связано это в первую очередь с тем, что у используемого провайдера появилась новая линейка процессоров Ryzen. И тогда я сильно удивился, увидев, что многие решения до сих пор находятся в разработке или незрелом состоянии (особенно это касается кластеров на bare metal: виртуализация VM, MetalLB и т.д.). Хранилища на bare metal всё ещё пребывают в стадии созревания, хоть и представлены множеством коммерческих и Open Source-решений. Я решил сравнить основные перспективные и бесплатные решения (попутно протестировав один коммерческий продукт, чтобы понять, чего лишаюсь).

*Спектр решений для хранения в [CNCF Landscape](https://landscape.cncf.io/)*
**Но прежде всего хочу предупредить, что являюсь новичком в области K8s.**
Для экспериментов использовались 4 worker'a со следующей конфигурацией: процессор Ryzen 3700X, 64 GB памяти ECC, NVMe размером 2 TB. Бенчмарки делались с помощью образа `sotoaster/dbench:latest` (на fio) с флагом `O_DIRECT`.
Longhorn
--------
* Лицензия: Apache 2
* Коммерческая поддержка: Rancher
* URL: [github.com/longhorn/longhorn](https://github.com/longhorn/longhorn)
* Звезды на GitHub: 1,3 тыс.
Longhorn мне очень понравился. Он полностью интегрирован с Rancher и установить его через Helm можно одним кликом.
*Установка Longhorn из Rancher*
Это инструмент с открытым исходным кодом и статусом sandbox-проекта от Cloud Native Computing Foundation (CNCF). Его разработку финансирует Rancher — довольно успешная компания с известным [одноименным] продуктом.
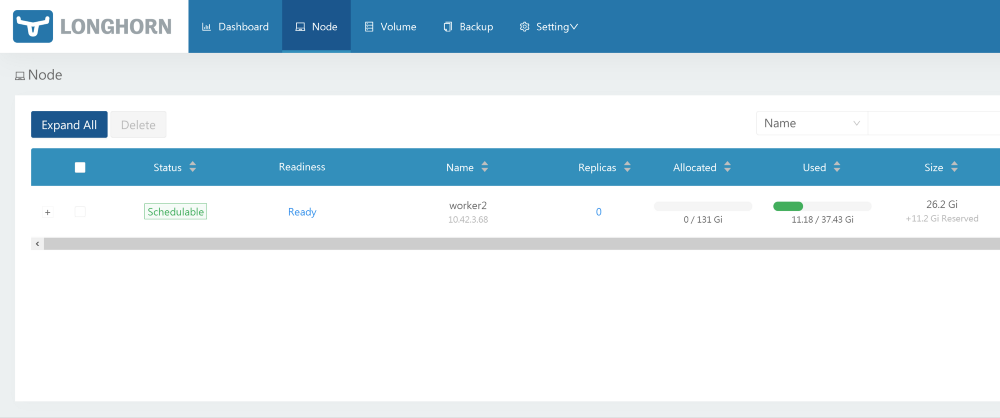
**Также доступен отличный графический интерфейс** — все можно делать из него. С производительностью все в порядке. Проект пока находится на бета-стадии, что подтверждают issues на GitHub.
При тестировании я запустил бенчмарк с использованием 2 реплик и Longhorn 0.8.0:
* Случайное чтение/запись, IOPS: 28.2k / 16.2k;
* Пропускная способность чтения/записи: 205 Мб/с / 108 Мб/с;
* Средняя задержка чтения/записи (usec): 593.27 / 644.27;
* Последовательное чтение/запись: 201 Мб/с / 108 Мб/с;
* Смешанное случайное чтение/запись, IOPS: 14.7k / 4904.
OpenEBS
-------
* Лицензия: Apache 2
* Коммерческая поддержка: несколько компаний(?); [mayadata.io](https://mayadata.io/) представляется самой большой
* URL: [github.com/openebs/openebs](https://github.com/openebs/openebs)
* Звезды на GitHub: 6 тыс.
Этот проект также имеет статус sandbox от CNCF. С большим числом звезд на GitHub он выглядит вполне перспективным решением. В своем обзоре Vito Botta пожаловался на недостаточную производительность. Вот что ему на это [ответил](https://twitter.com/epowell101/status/1189734468937895937) гендиректор Mayadata:
> Информация сильно устарела. OpenEBS раньше поддерживал 3, а сейчас поддерживает 4 движка, если включить динамическое обеспечение и оркестрацию localPV, которая может работать на скоростях NVMe. Вдобавок, движок MayaStor теперь открыт и уже получает положительные отзывы (хотя и имеет альфа-статус).
На странице проекта OpenEBS есть такое пояснение по его статусу:
> OpenEBS — одна из наиболее широко используемых и проверенных инфраструктур для хранения данных под Kubernetes. OpenEBS приобрела статус sandbox-проекта CNCF в мае 2019-го и является первой и единственной системой хранения, обеспечивающей согласованный набор программно-определяемых возможностей на различных бэкендах (local, nfs, zfs, nvme) как в on-premise, так и в облачных системах. OpenEBS первой открыла свой фреймворк для хаос-инжиниринга под stateful-нагрузки — Litmus Project, — который позволяет сообществу автоматически проверять на готовность ежемесячные обновления OpenEBS. Корпоративные клиенты используют OpenEBS в production с 2018 года; еженедельно выполняется более 2,5 млн docker pull'ов.
У него есть множество движков, и последний из них представляется довольно перспективным в плане производительности: «MayaStor — alpha engine with NVMe over Fabrics». Увы, я не стал его тестировать из-за статуса альфа-версии.
В тестах же использовалась версия 1.8.0 на движке jiva. Кроме того, ранее я проверял и cStor, но не сохранял результаты, которые, впрочем, оказались чуть медленнее jiva. Для бенчмарка был установлен Helm-чарт со всеми настройками по умолчанию и использовался Storage Class, стандартно созданный Helm'ом (`openebs-jiva-default`). Производительность оказалась самой плохой из всех рассматриваемых решений (буду признателен за советы по ее повышению).
OpenEBS 1.8.0 с движком jiva (3 реплики?):
* Случайное чтение/запись, IOPS: 2182 / 1527;
* Пропускная способность чтения/записи: 65.0 Мб/с / 41.9 Мб/с;
* Средняя задержка чтения/записи (usec): 1825.49 / 2612.87;
* Последовательное чтение/запись: 95.5 Мб/с / 37.8 Мб/с;
* Смешанное случайное чтение/запись, IOPS: 2607 / 856.
***Дополнение от переводчика**. Эти результаты [прокомментировал](https://medium.com/@epowell101/thanks-for-doing-this-bruno-6ce8b30166bd) Evan Powell, возглавляющий проект OpenEBS (также он известен тем, что ранее основал StackStorm и Nexenta):*
> *Спасибо за проделанную работу, Bruno! Мы немного не согласны с выводами по сравнению OpenEBS с альтернативами. Был использован движок Jiva, который в основном применяется на ARM или схожих конфигурациях для минимального overhead'а и простоты. Клиенты же вроде Bloomberg предпочитают работать с DynamicLocal PV от OpenEBS. Такой же подход рекомендуется ребятами вроде Elastic и для других рабочих нагрузок, требующих отказоустойчивости. К слову, всеми движками можно управлять всегда бывшим бесплатным OpenEBS Director (https://account.mayadata.io/signup). В любом случае — спасибо за обзор и надеюсь, что мы останемся на связи.*
StorageOS
---------
* Лицензия: коммерческая
* URL: [storageos.com](https://storageos.com/)
Это коммерческое решение, которое бесплатно при использовании до 110 ГБ пространства. Бесплатную лицензию *(Developer license)* можно получить, зарегистрировавшись через пользовательский интерфейс продукта; она дает до 500 ГБ пространства. В Rancher'е оно значится как партнерское, поэтому установка с помощью Helm'а прошла легко и беззаботно.
Пользователю предлагается базовая контрольная панель. Тестирование этого продукта было ограниченным, поскольку он является коммерческим и по своей стоимости нам не подходит. Но все равно хотелось поглядеть, на что способны коммерческие проекты.
В тесте задействован имеющийся Storage Class под названием «Fast» (Template 0.2.19, 1 Master + 0 Replica?). Результаты поразили. Они значительно превзошли предыдущие решения.
* Случайное чтение/запись, IOPS: 117k / 90.4k;
* Пропускная способность чтения/записи: 2124 Мб/с / 457 Мб/с;
* Средняя задержка чтения/записи (usec): 63.44 / 86.52;
* Последовательное чтение/запись: 1907 Мб/с / 448 Мб/с;
* Смешанное случайное чтение/запись, IOPS: 81.9k / 27.3k.
Piraeus (основан на Linstor)
----------------------------
Лицензия: GPLv3
* Коммерческая поддержка: [LINBIT](https://www.linbit.com/en/linstor/)
* URL: [github.com/piraeusdatastore/piraeus](https://github.com/piraeusdatastore/piraeus)
* Основан на: [github.com/LINBIT/linstor-server](https://github.com/LINBIT/linstor-server)
* Звезды на GitHub: менее 100 (не скупитесь, поставьте звездочку проекту!)
Уже упомянутый Vito Botta в конечном итоге остановился именно на Linstor, что стало дополнительным поводом попробовать это решение. На первый взгляд, проект выглядит довольно странно. Почти нет звезд на GitHub, необычное название и его даже нет на CNCF Landscape. Но при ближайшем рассмотрении все оказывается не так страшно, поскольку:
* В качестве базового механизма репликации используется DRBD (на самом деле, он разработан теми же людьми). При этом DRBD 8.x уже более 10 лет входит в состав официального ядра Linux. И мы говорим о технологии, которая оттачивается более 20 лет.
* Носителями управляет LINSTOR — также зрелая технология от той же компании. Первая версия [Linstor-server](https://github.com/LINBIT/linstor-server) появилась на GitHub в феврале 2018-го. Она совместима с различными технологиями/системами, такими как Proxmox, OpenNebula и OpenStack.
* По всей видимости, Linbit активно развивает проект, постоянно внедряет в него новые функции и улучшения. 10-я версия DRBD пока имеет [альфа-статус](https://lists.gt.net/drbd/users/30884), но уже может похвастаться некоторыми уникальными возможностями, такими как erasure coding *(аналог функциональности из RAID5/6 — прим. перев.)*.
* Компания предпринимает [определенные меры](https://www.cncf.io/wp-content/uploads/2019/08/LINSTOR_August_2019.pdf), чтобы попасть в число проектов CNCF.
Окей, проект выглядит достаточно убедительно, чтобы доверить ему свои драгоценные данные. Но способен ли он переиграть альтернативы? Давайте посмотрим.
### Установка
Vito рассказывает об установке Linstor [здесь](https://vitobotta.com/2020/01/04/linstor-storage-the-kubernetes-way/). Однако в комментариях один из разработчиков Linstor рекомендует новый проект под названием Piraeus. Насколько я понял, [Piraeus](https://github.com/piraeusdatastore/piraeus/) становится Open Source-проектом Linbit, который объединяет в себе всё связанное с K8s. Команда работает над [соответствующим оператором](https://github.com/piraeusdatastore/piraeus-operator), а пока Piraeus можно установить с помощью этого YAML-файла:
```
kubectl apply -f https://raw.githubusercontent.com/bratao/piraeus/master/deploy/all.yaml
```
**Внимание! Вы забираете конфиги из моего личного репозитория. Проверьте официальный репозиторий! Я обновил версии образов, чтобы решить ошибку, возникающую при использовании в Ubuntu.**
**Официальный репозиторий Piraeus доступен [здесь](https://github.com/piraeusdatastore/piraeus/).**
Также можно воспользоваться репозиторием от kvaps (он кажется даже более динамичным, чем официальный репозиторий piraeus): <https://github.com/kvaps/kube-linstor> *(пользуясь случаем, передаем привет Андрею [kvaps](https://habr.com/ru/users/kvaps/) — прим. перев.)*.
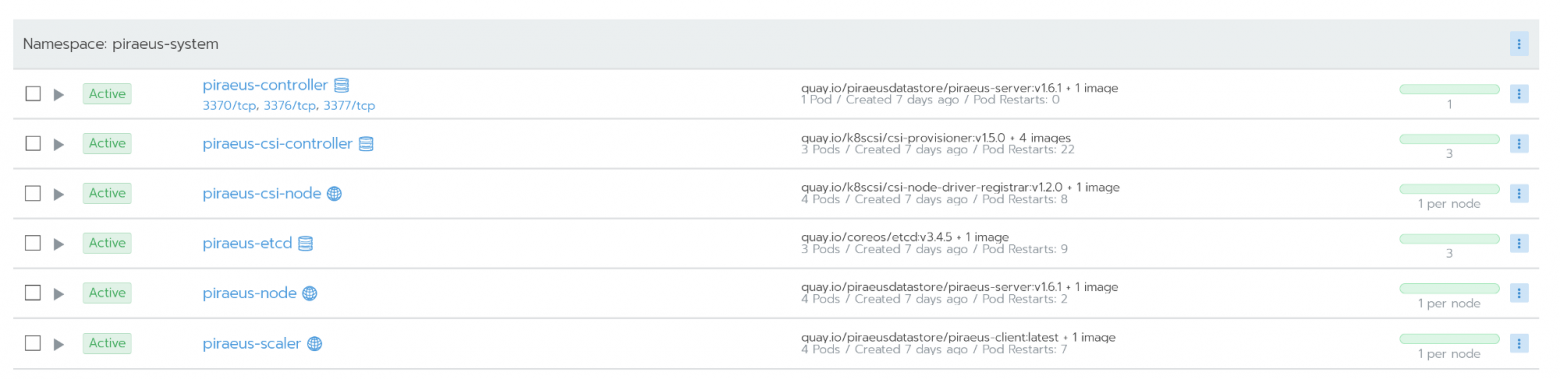
*Все узлы работают после установки*
### Администрирование
Администрирование осуществляется с помощью командной строки. Доступ к ней возможен из командной оболочки узла piraeus-controller.

На controller-узле запущен linstor-server. Он представляет собой слой абстракции над drbd, способный управлять всем парком узлов. На скриншоте ниже приведены некоторые полезные команды для наиболее востребованных задач, например:
* `linstor node list` — вывести список подключенных узлов и их статус;
* `linstor volume list` — показать список созданных томов и их местоположение;
* `linstor node info` — показать возможности каждого узла.
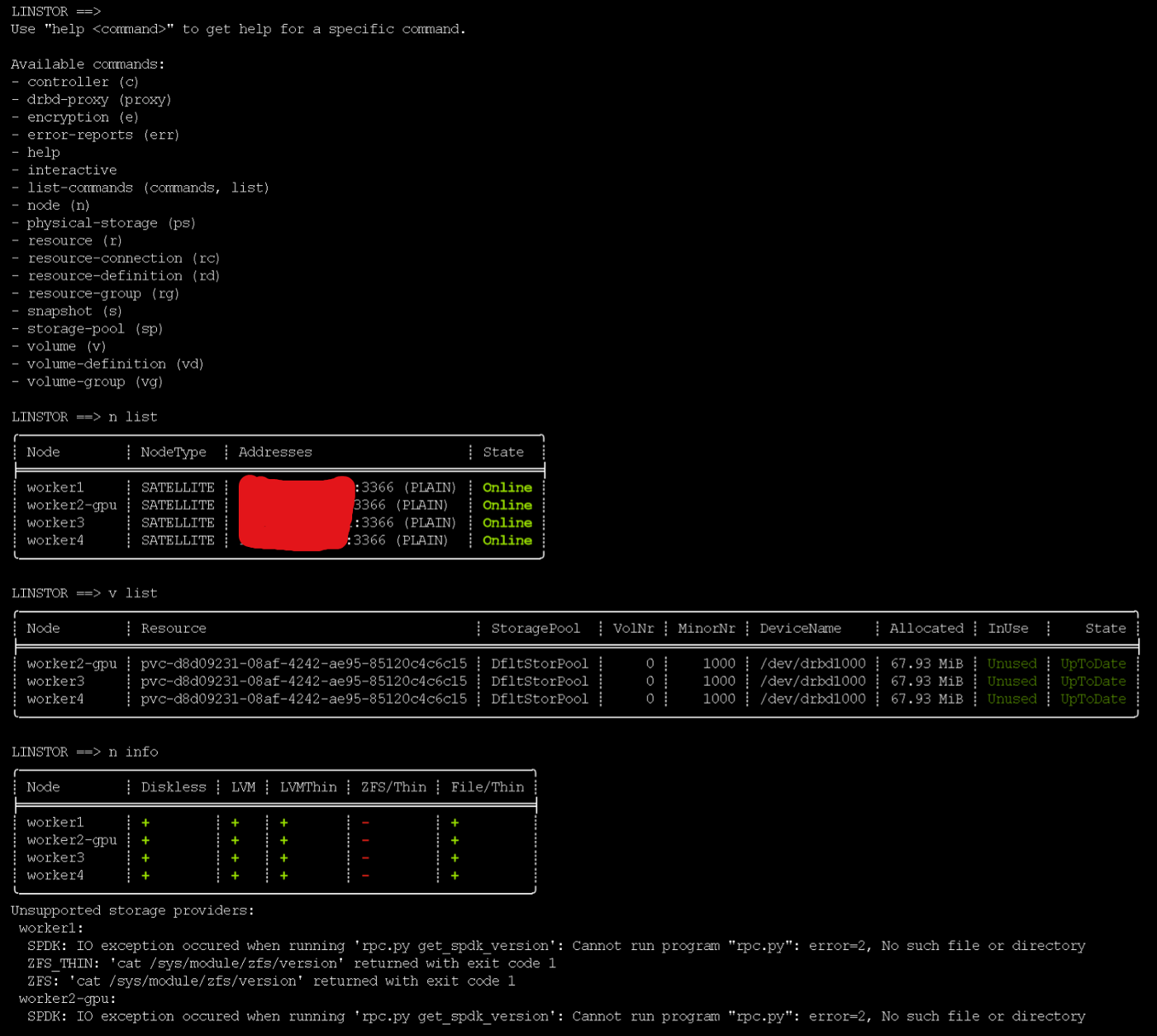
*Команды Linstor*
Полный список команд доступен в официальной документации: [User´s Guide LINSTOR](https://www.linbit.com/drbd-user-guide/users-guide-linstor/).
В случае возникновения ситуаций вроде split brain доступ к drbd можно получить непосредственно через узлы.
### Восстановление после сбоев
Я изо всех сил старался уронить свой кластер, в том числе делал hard reset'ы на узлах. Но linstor оказался удивительно живуч.
Drbd отлично распознает проблему, называемую split brain. В моей ситуации вторичный узел выпал из репликации.
> Split brain — это ситуация, когда из-за временного сбоя сетевых подключений между узлами кластера, вмешательства ПО для управления кластером или из-за человеческой ошибки оба узла становятся Primary, находясь в «оторванном» состоянии. Опасность этого состояния в том, что измененные данные на любом из узлов не будут реплицированы на другой. Другими словами, могут возникнуть два расходящихся набора данных, которые невозможно объединить тривиальным образом.
>
>
>
> Split brain в DRBD отличается от кластерного, который означает потерю связности хостов, управляемых распределенным ПО для управления кластером вроде Heartbeat.
Подробности можно почерпнуть из [официальной документации drbd](https://www.linbit.com/drbd-user-guide/drbd-guide-9_0-en/).
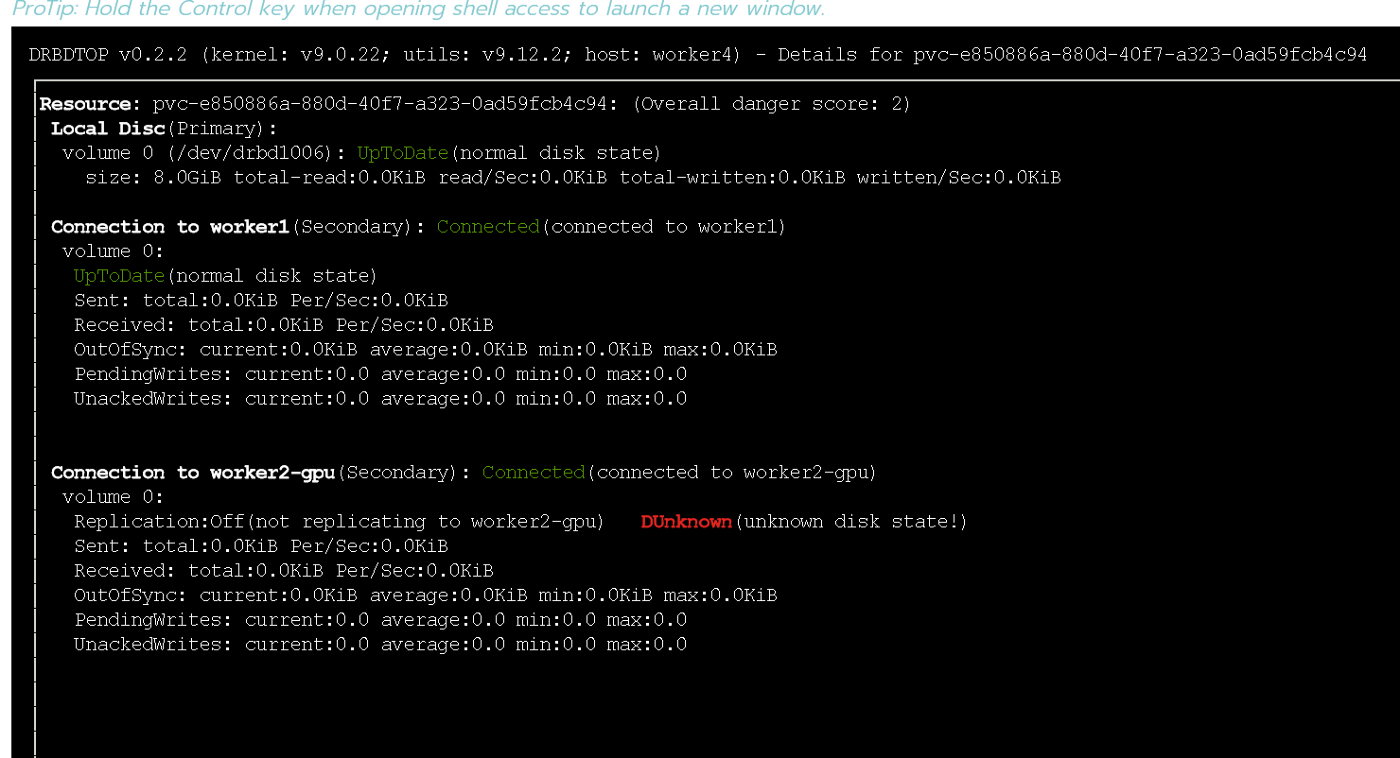
*Вторичный узел выпал из репликации*
В моем случае для решения проблемы я отбросил вторичные данные и запустил синхронизацию с primary-узлом. Поскольку предпочитаю графические интерфейсы, воспользовался для этого утилитой drbdtop. С ее помощью можно визуально контролировать состояние и выполнять команды внутри узлов.
Мне понадобилось зайти в консоль на проблемном узле piraues (им был `worker2-gpu`):

*Заходим на узел*
Там я установил drdbtop. Скачать эту утилиту можно здесь:
```
wget https://github.com/LINBIT/drbdtop/releases/download/v0.2.2/drbdtop-linux-amd64
chmod +x drbdtop-linux-amd64
./drbdtop-linux-amd64
```
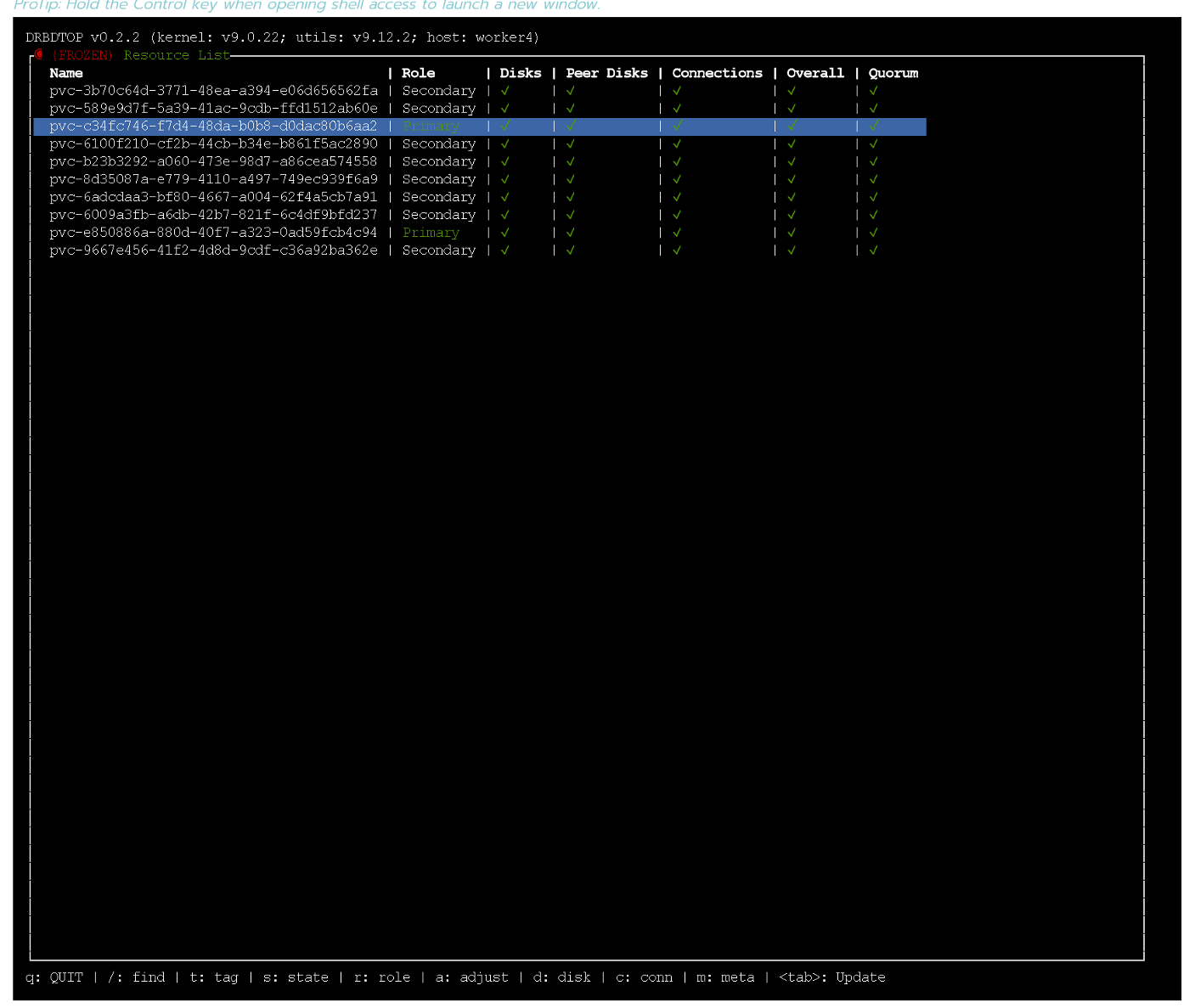
*Работающая утилита drbdtop*
Взгляните на нижнюю панель. На ней расположены команды, с помощью которых можно исправить split brain:

После это узлы подключаются и синхронизируются автоматически.
### Как повысить скорость?
По умолчанию Piraeus/Linstor/drbd демонстрируют отличную производительность (в этом вы можно убедиться ниже). Настройки по умолчанию разумны и безопасны. Однако скорость записи оказалась слабовата. Поскольку серверы в моем случае разбросаны по разным ЦОД (хотя и физически они находятся сравнительно недалеко), я решил попробовать подстроить их производительность.
Отправной пункт оптимизации — определение протокола репликации. По умолчанию используется Protocol C, предусматривающий ожидание подтверждения записи на удаленном вторичном узле. Ниже приведено описание возможных протоколов:
* **Protocol A** — протокол асинхронной репликации. Локальные операции записи на первичном узле считаются завершенными, как только произошла запись на локальный диск, а репликационный пакет был помещен в локальный TCP-буфер на отправку. Важный нюанс заключается в том, что буфер отправки TCP ОЧЕНЬ мал. Его можно увеличить до определенного предела.
* **Protocol B** — протокол полусинхронной репликации. Локальные операции записи на первичном узле считаются завершенными, как только произошла запись на локальный диск, а репликационный пакет дошел до другого узла.
* **Protocol C** (по умолчанию) — протокол синхронной репликации. Локальная операция на первичном узле считается завершенной только после подтверждения записи на локальный и удаленный диски.
Из-за этого в Linstor я также использую асинхронный протокол (он поддерживает синхронную/полусинхронную/асинхронную репликацию). Включить его можно следующей командой:
```
linstor c drbd-options --protocol A --after-sb-0pri=discard-zero-changes --after-sb-1pri=discard-secondary --after-sb-2pri=disconnect --max-buffers 131072 --sndbuf-size 1085760 --rcvbuf-size 1085760 --c-max-rate 4194304 --c-fill-target 1048576
```
Результатом ее выполнения станет активация асинхронного протокола и увеличение буфера до 1 Мб. Это относительно безопасно. Или можно использовать следующую команду (она игнорирует сбросы на диск и значительно увеличивает буфер):
```
linstor c drbd-options --protocol A --after-sb-0pri=discard-zero-changes --after-sb-1pri=discard-secondary --after-sb-2pri=disconnect --max-buffers 131072 --sndbuf-size 10485760 --rcvbuf-size 10485760 --disk-barrier no --disk-flushes no --c-max-rate 4194304 --c-fill-target 1048576
```
Учтите, что при выходе из строя первичного узла небольшая часть данных может не дойти до реплик.
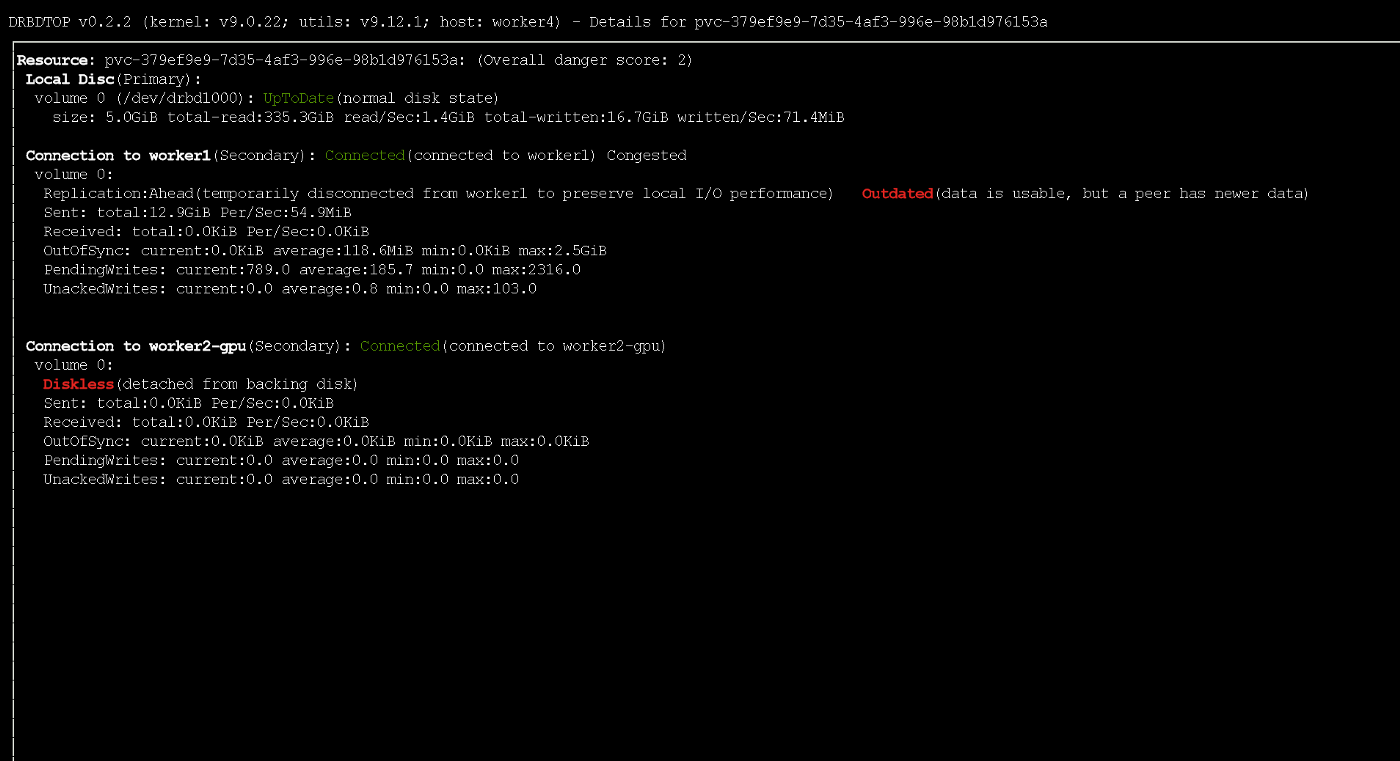
*Во время активной записи узел временно получил статус outdated при использовании протокола ASYNC*
### Тестирование
Все бенчмарки проводились с использованием следующей Job:
```
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: dbench
spec:
storageClassName: STORAGE_CLASS
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
---
apiVersion: batch/v1
kind: Job
metadata:
name: dbench
spec:
template:
spec:
containers:
- name: dbench
image: sotoaster/dbench:latest
imagePullPolicy: IfNotPresent
env:
- name: DBENCH_MOUNTPOINT
value: /data
- name: FIO_SIZE
value: 1G
volumeMounts:
- name: dbench-pv
mountPath: /data
restartPolicy: Never
volumes:
- name: dbench-pv
persistentVolumeClaim:
claimName: dbench
backoffLimit: 4
```
Задержка между машинами составляет: `ttl=61 time=0.211 ms`. Измеренная пропускная способность между ними составила 943 Мбит/с. Все узлы работают под управлением Ubuntu 18.04.
[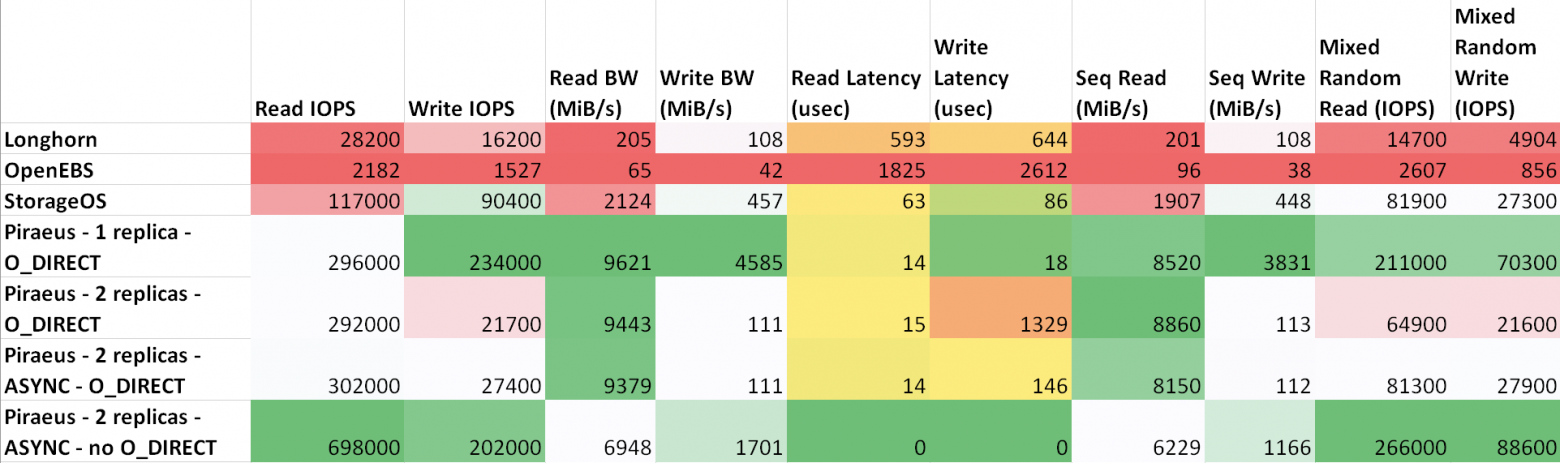](https://habrastorage.org/webt/le/ez/0k/leez0ktywscyuz0jyl_9gel2q6g.png)
*Результаты ([таблица на sheetsu.com](https://sheetsu.com/tables/725556311a))*
Как видно из таблицы, лучшие результаты показали Piraeus и StorageOS. Лидером стал Piraeus с двумя репликами и асинхронным протоколом.
Выводы
------
Я провел простое и, возможно, не слишком корректное сравнение некоторых решений для хранения в Kubernetes.
Больше всего мне понравился Longhorn из-за его приятного графического интерфейса и интеграции с Rancher. Однако результаты не вдохновляют. Очевидно, разработчики в первую очередь фокусируются на безопасности и корректности, оставив скорость на потом.
Уже некоторое время я использую Linstor/Piraeus в production-средах некоторых проектов. До сих пор все было отлично: диски создавались и удалялись, узлы перезапускались без простоев…
По моему мнению, Piraeus вполне готов к использованию в production, но нуждается в доработке. О некоторых багах написал в канал проекта в Slack'e, но в ответ мне только посоветовали подучить Kubernetes (и это правильно, поскольку я еще плохо в нем разбираюсь). После небольшой переписки мне все же удалось убедить авторов, что в их init-скрипте есть баг. Вчера, после обновления ядра и перезагрузки, узел отказался загружаться. Оказалось, что компиляция скрипта, который интегрирует модуль drbd в ядро, [завершилась неудачно](https://github.com/piraeusdatastore/piraeus/issues/30). Проблему решил откат к предыдущей версии ядра.
Вот, в общем, и все. Учитывая, что они реализовали его поверх drbd, получилось очень надежное решение с отличной производительностью. В случае возникновения каких-либо проблем можно напрямую обратиться к управлению drbd и все исправить. В интернете есть множество вопросов и примеров по данной теме.
Если я сделал что-то не так, если что-то можно улучшить или вам требуется помощь, обращайтесь ко мне в [Twitter](https://twitter.com/BrunoPotelo) или на [GitHub](https://github.com/bratao).
P.S. от переводчика
-------------------
Читайте также в нашем блоге:
* «[Longhorn, распределённое хранилище для K8s от Rancher, передано в CNCF](https://habr.com/ru/company/flant/blog/474208/)»;
* «[Наши руки не для скуки: восстановление кластера Rook в K8s](https://habr.com/ru/company/flant/blog/477680/)»;
* «[Rook или не Rook — вот в чём вопрос](https://habr.com/ru/company/flant/blog/451818/)»;
* «[Плагины томов для хранилищ в Kubernetes: от Flexvolume к CSI](https://habr.com/ru/company/flant/blog/465417/)». | https://habr.com/ru/post/503712/ | null | ru | null |
# Заблуждения программистов о тексте

Возжелавший прильнуть к жанру вестернов обратится либо к десятой строчке [топ-250 лучших фильмов по версии IMDb](https://www.imdb.com/chart/top), либо уже будет обладать знанием, что начинать нужно с «Хороший, плохой, злой». Там он увидит жадных потных мужчин, которые заканчивают фильм напряжённым [мексиканским противостоянием](https://ru.wikipedia.org/wiki/%D0%9C%D0%B5%D0%BA%D1%81%D0%B8%D0%BA%D0%B0%D0%BD%D1%81%D0%BA%D0%BE%D0%B5_%D0%BF%D1%80%D0%BE%D1%82%D0%B8%D0%B2%D0%BE%D1%81%D1%82%D0%BE%D1%8F%D0%BD%D0%B8%D0%B5). Жалкая охота за золотом конфедератов разворачивается на фоне кровавых битв Гражданской войны между «Севером» и «Югом». Таким зритель запомнит вестерны как жанр.
В реальности «Хороший» — это не классика, а яркий представитель поджанра ревизионистских вестернов, снят в Европе и наоборот, критикует американскую идеологию направления. В нём нет ничего общего с картинами, где герой встаёт на защиту правильного и справедливого общества от злодеев или кровожадных индейцев. В пятидесятых и шестидесятых классический вестерн сошёл на нет, но в коллективном сознании критика быстро заместила критикуемый объект. Когда Марти Макфлай [жалуется](https://www.youtube.com/watch?v=msqefONJwC8) на анахронизм наряда, он сравнивает себя с антигероями Клинта Иствуда, а не бравыми ковбоями в исполнении [Джона Уэйна](https://ru.wikipedia.org/wiki/%D0%A4%D0%B8%D0%BB%D1%8C%D0%BC%D0%BE%D0%B3%D1%80%D0%B0%D1%84%D0%B8%D1%8F_%D0%94%D0%B6%D0%BE%D0%BD%D0%B0_%D0%A3%D1%8D%D0%B9%D0%BD%D0%B0).
Иногда нашему восприятию требуются корректировки. Собственные заблуждения необходимо не забыть при проектировании информационных систем. Помнить нужно о многом: для [времени](/post/703360/), [карт](/post/685928/) и [почтовых адресов](/post/691088/) получаются длинные списки. Для текста неожиданностей мало.
### Заблуждение 1. Любые символы, кроме управляющих, имеют предсказуемую ширину
В реальности ширина символов может отличаться даже в моноширных шрифтах.
В блоке символов Юникода `U+FF00–FFEF` «[Полуширинные и полноширинные формы](https://en.wikipedia.org/wiki/Halfwidth_and_Fullwidth_Forms_(Unicode_block))» находятся 52 символа хангыля, 55 катаканы, 66 общих и 52 символа полуширинной латиницы. В Юникоде этот блок выделили для совместимости с азиатскими стандартами, где символы либо полноширинные, либо полуширинные. Обычное слово «Cat» и полноширинное «Cat» отличаются.
Важно не забывать, что полноширинные символы латиницы — это не азиатское письмо. Создатель одного из ботов-переводчиков для Reddit этого не учёл. Бот [натравился](https://old.reddit.com/r/japancirclejerk/comments/4wonh9/the_testament_for_the_desire_to_learn_a_new/) на чьё-то сообщение из полноширинных символов, а затем вошёл в бесконечный цикл, пытаясь перевести собственные ответы.
Полноширинные символы азиатского письма примерно в полтора раза шире даже в моноширных шрифтах. Для сравнения:
`Cat
ネコ`
Самая наглядная демонстрация непостоянства ширины — это символ `﷽`. Это одна кодовая позиция `U+FDFD`, а не комбинация нескольких. Но даже в моноширном шрифте символ будет шириной в несколько обычных.
### Заблуждение 2. Софт хорошо и однозначно интерпретирует все символы ASCII
Проблемы возникают с некоторыми управляющими символами в диапазоне от 0 по 31.
Символ горизонтальной табуляции `U+0009` унаследован из ASCII, но в Юникоде не имеет заданной ширины. В CSS ширина табуляции `U+0009` в пробелах `U+0020` [настраивается](https://developer.mozilla.org/en-US/docs/Web/CSS/tab-size) свойством `tab-size`.
Разные текстовые редакторы [испытывают](https://en.wikipedia.org/wiki/Newline#Representation) проблемы с символами перевода строки `U+000A` и возврата каретки `U+000D`.
### Заблуждение 3. Для записи современного английского достаточно ASCII, для современных западноевропейских языков — ISO Latin-1
В ASCII нет “английских” кавычек. Несколько слов в английском пишутся с буквами, которых в обычном алфавите языка нет. Поскольку на клавиатуре эти символы отсутствуют, «façade», «naïve» и «piñata» постепенно всё сильнее проигрывают более простым вариантам «facade», «naive» и «pinata» в популярности. По крайней мере, в поисковой выдаче Google «красивых» написаний меньше.
Иногда эти типографские изыски несут смысловой оттенок. «Résumé» позволяет избегать путаницы с другими значениями слова «resume». Поэтому вообще-то нельзя сказать, что для английского достаточно символов ASCII.
В ISO Latin-1 (известная как ISO 8859-1) отсутствуют некоторые символы. Нет редкоиспользуемой французской лигатуры «œ», опциональным остаётся эсцет («ẞ») немецкого языка.
### Заблуждение 4. Локализация под разные языки? Мне это ни к чему
Конечно, если это внутренняя корпоративная утилита для ограниченного числа пользователей, то разделять текст и код смысла мало.
Хорошо бы создать что-то один раз, а потом продавать по всему миру — игру, например. Рекомендации по локализации видеоигр обычно (статьи от [октября 2017](https://www.leveluptranslation.com/single-post/what-languages-to-localize-your-steam-game-into), [мая 2022](https://www.gamescribes.com/steam-games-popular-languages-localization-2022), [августа 2022](https://www.localizedirect.com/posts/which-languages)) выделяют 7–10 популярных мировых языков кроме английского: немецкий, французский, испанский (европейский вариант, но рекомендуется рассмотреть выделение отдельных версий для рынков Латинской Америки), бразильский вариант португальского, итальянский, русский, польский, китайский (упрощённый, чтобы попасть в аудиторию КНР, Сингапура и Малайзии), японский, корейский.
Выбор языков часто обосновывают числом носителей или логическими рассуждениями. К примеру, в Бразилии английский знают хуже, поэтому отсутствие локализации гарантирует низкий интерес к продукту. Более конкретные метрики — это средний среднедушевой доход в стране или же специальный индекс онлайн-расходов по языкам [T-Index](https://imminent.translated.com/t-index).
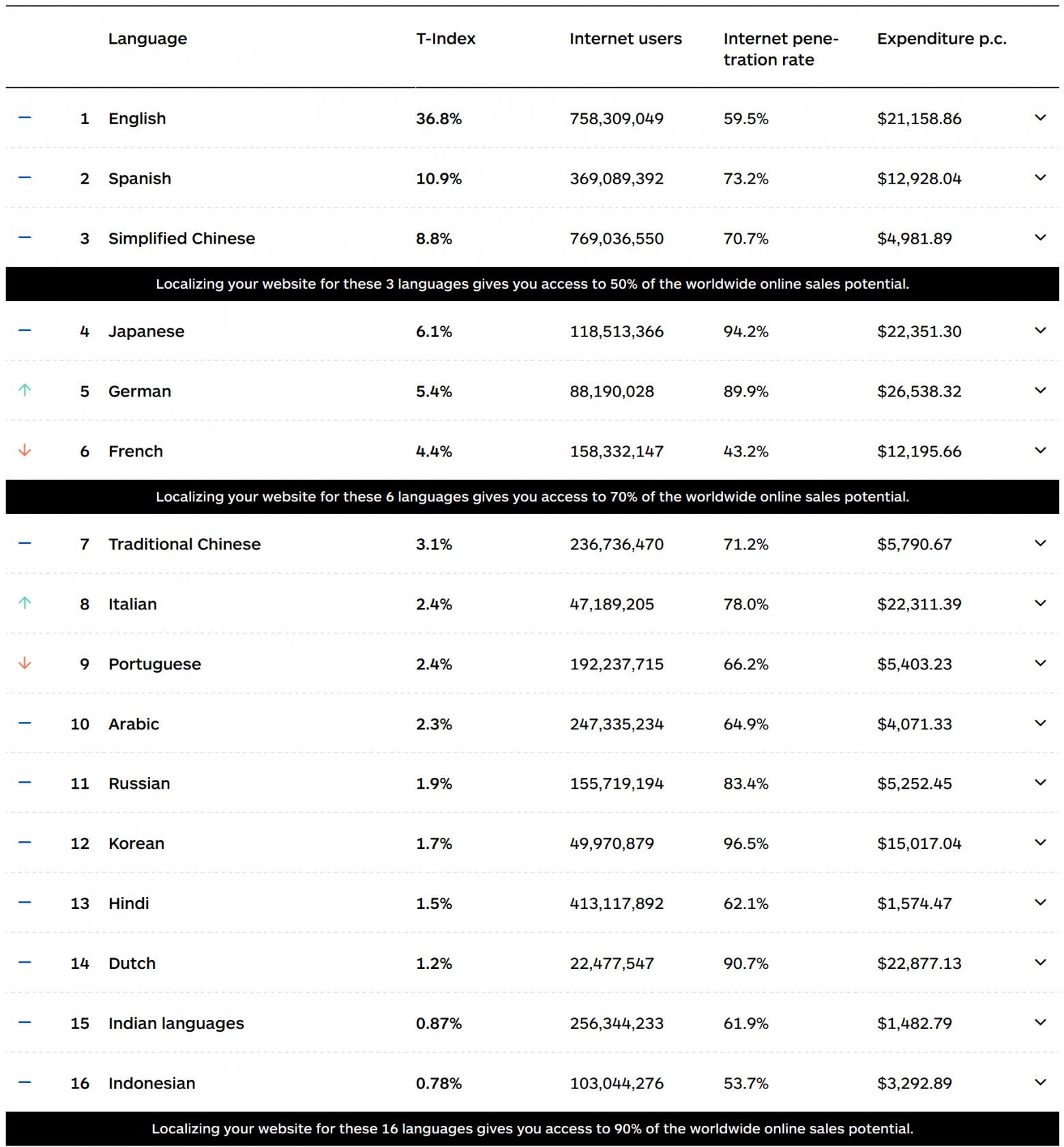
*T-Index указывает, что если продукт переведён на английский, испанский и упрощённый китайский, то получены 50 % потенциала мировых продаж. Чтобы получить 90 %, нужно перевести продукт на 16 языков. [Imminent](https://imminent.translated.com/t-index)*
Если планов покорить мир нет, перевод всё равно не помешает. Один и тот же язык имеет вариации в разных странах, а в одной стране говорят на нескольких языках.
Наконец, если человек знает несколько языков, это не значит, что у него нет предпочтений. Скорее всего, комфортнее будет пользоваться продуктом на родном языке, а не английском.
### Заблуждение 5. Перевод — это поменять несколько строчек
Поскольку цену за тысячу знаков обосновывать как-то приходится, бюро переводов с энтузиазмом докажут обратное. Но рассмотрим конкретные примеры.
Перевод — задача с несколькими правильными решениями. Один и тот же фрагмент текста можно перевести по-разному, и каждый из вариантов будет по-своему прав. Кстати, поэтому обсуждения переводов быстро скатываются в уровень вкусовщины и придирок к отдельным фразам. Конкретные определения адекватного перевода и уровни эквивалентности [даются](http://belpaese2000.narod.ru/Trad/Komissar/komissarind.htm) в хорошо известном слушателям одноимённого курса учебнике Вилена Наумовича Комиссарова «Теория перевода».
Отдельно стоит отметить, что у разных языков различается не только грамматика или последовательность слов в устоявшихся выражениях. Порядок исходной информации (тема) и новой (рема) отличаются от языка к языку. В русском новая информация уходит в конец (от темы к реме). Английский имеет более жёсткую структуру предложения и тяготеет к сообщению новой информации в начале (от ремы к теме). Именно поэтому перевод английских фраз на русский на уровне подстрочника звучит настолько неестественно.
При переводе софта многие слова или фразы придётся шаблонизировать по специальным правилам и «вшить» в предложения. Заставить ожить это чудовище Франкенштейна непросто по нескольким причинам.
В русском языке при указании числа чего-либо количественные числительные сочетаются с существительным по-разному. Для чисел от 2 по 4 нужно существительное в единственном числе родительного падежа («3 вакансии»), для чисел от 5 до 9 нужны существительные во множественном числе родительного падежа («5 вакансий»). Эта особенность русского языка и схожие сюрпризы в других добавляют немало проблем.

*Инструмент под названием «Матрица падежных форм», который [используют](/company/badoo/blog/485138/) для локализации в Badoo*
Даже перевод одного предложения не так прост. В некоторых языках два, три, четыре и [более грамматических родов](https://en.wikipedia.org/wiki/List_of_languages_by_type_of_grammatical_genders). Если в языке несколько артиклей, то они тоже могут зависеть от рода: сравните испанские слова «la cocina» (кухня) и «el baño» (ванная).
В русском род субъекта становится ясным, если глагол действия в прошедшем времени. Если аккаунт нажал на красное сердечко, то пользователь пост «лайкнул» или «лайкнула»?
Переведённый текст станет надписями на кнопках и прочих элементах управления. Длина надписей будет заметно отличаться. «Поплывшие» элементы придётся отловить на этапе тестирования.
### Заблуждение 6. У текста есть одно представление в Юникоде
Разные символы Юникода выглядят одинаково или полностью дублируют друг друга.
Если нужно поставить ударение над «е», то сгодится либо комбинация с символом акута `[U+0301](https://util.unicode.org/UnicodeJsps/character.jsp?a=0301)`, либо замена на символ со знаком ударения. При этом результат — «é» или «é» — выглядит одинаково.
*Основная многоязычная плоскость Юникода покрывает все современные языки. Всего в стандарте 16 плоскостей, каждая из которых содержит до 65 536 символов. Некоторые из дублей находятся в других плоскостях. [Drmccreedy](https://commons.wikimedia.org/w/index.php?title=File:Roadmap_to_Unicode_BMP_multilingual.svg&lang=ru)*
Греческий вопросительный знак `;` визуально выглядит как обычная точка с запятой, но компилятор языков семейства C его не примет. Римская цифра `Ⅴ` выглядит почти как буква `V`, но символы римских цифр из Юникода не снискали популярности. Некоторые символы кириллицы во многих шрифтах совпадают или почти совпадают с буквами латиницы, что осложняет написание фильтров мата.
### Заблуждение 7. Сортировка — это просто
Казалось бы, что может быть проще?
```
>>> words = ['cafeteria', 'caffeine', 'café']
>>> words.sort()
>>> words
['cafeteria', 'caffeine', 'café']
```
Получилось неправильно, поскольку Python сортирует по кодовым позициям символов, что для реального мира не работает. Правильный порядок: «café», «cafeteria», «caffeine».
Сортировка требует преобразований. К примеру, эсцет («ß») в немецком языке должен сортироваться так, будто это две буквы «ss».
Сортировка зависит от локали. Как нужно сортировать исландскую букву «æ»? Будет ли это правило из исландского языка работать для английского языка, где «æ» — это не буква, а лигатура?
Размер известного документа [Unicode Collation Algorithm](http://www.unicode.org/reports/tr10/) с описанием правил сортировки достигает почти 30 тысяч слов. Это длинное, тяжёлое в осмыслении руководство.
Для сортировки в Юникоде сначала проводят операцию case folding. Это как запись строчными буквами, но не всегда — стандарт приводит контрпример, что для языка чероки в результате case folding происходит запись заглавными. Лишь после этого возможно сравнение символов.
### Заблуждение 8. Регистров два, их легко поменять
Преобразование из одного регистра в другой сложно и не подчиняется никаким правилам.
Преобразования символов в верхний или в нижний регистры **зависит от локали**. Буква «i» соответствует «I» в английском языке, но для турецкой и азербайджанской локали эквивалент — «İ».
Результат преобразования **может зависеть от положения буквы в слове**. Греческая «Σ» `U+03A3` «GREEK CAPITAL LETTER SIGMA» преобразуется в «ς» `U+03C2` «GREEK SMALL LETTER FINAL SIGMA», если стоит на конце слова, и в «σ» `U+03C3` «GREEK SMALL LETTER SIGMA» в остальных случаях.
**Преобразование не биективно и не транзитивно**. В Юникоде есть как эсцет «ß», так и его заглавная форма «ẞ». Преобразование «ß» в верхний регистр выдаёт «SS», но «SS» при переводе в нижний регистр превращается в «ss».
Из пункта выше следует, что при смене регистра число символов и длина в байтах могут измениться.
Регистров символов в Юникоде три: верхний, нижний и titlecase, титульный. В титульном регистре каждое из слов пишется с заглавной буквы. При этом в зависимости от требований стилистики некоторые из слов (артикли, союзы, предлоги) всё равно будут начинаться со строчных. Пример символа титульного регистра — это диграф «Dz» по адресу `U+01F2`.
Понять регистр символа по внешнему виду возможно не всегда. Чем является символ `U+1D34` «ᴴ»? Несмотря на то, что он называется «MODIFIER LETTER CAPITAL H» и выглядит как заглавная буква «H», этот символ обладает свойством «нижний регистр».
Согласно стандарту Юникода, регистр символа известен только в том случае, если он указан. У большинства символов Юникода регистра просто нет.
### Заблуждение 9. Юникод — это чёрно-белые символы
В последние годы стандарт значительно разросся за счёт эмодзи, которые обычно отображаются на устройстве пользователя в виде цветных картинок.
Часть символов не предназначена для представления на экране вовсе. Это управляющие символы (перевод строки, удаление и так далее) и блок `U+2800` по `U+28FF`, который содержит все 256 комбинации восьмиточечного шрифта Брайля.
### Заблуждение 10. В Юникоде нет символов разметки
Такими можно назвать символы принудительного выбора направления письма.

*В выпуске «[RTL](https://xkcd.com/1137/)» (right to left, справа налево) веб-комикса xkcd Черная шляпа, чтобы закончить надоедливую беседу, переключает режим отображения символов с помощью `U+202E`. Чтобы вернуть всё обратно, собеседнику нужно было воспользоваться символом `U+202C`.*
### Заблуждение 11. Отображаемый символ — это кодовая позиция (code point)
В полной мере опровергнуть это заблуждение может хотя бы корейское письмо хангыль. «각» — это три кодовых позиции «ᄀ», «ᅡ» и «ᆨ», [идущие](https://r12a.github.io/uniview/?charlist=%E1%84%80%E1%85%A1%E1%86%A8) одна за другой. «ᄀᄀᄀ각ᆨᆨ» — это [шесть кодовых позиций](https://r12a.github.io/uniview/?charlist=%E1%84%80%E1%84%80%E1%84%80%EA%B0%81%E1%86%A8%E1%86%A8): три «ᄀ», один «각» и ещё два «ᆨ».
Многие эмодзи образованы «склеиванием», часто с участием знака нулевой ширины `U+200C`. Семья 👨👩👧👦 — это [склейка](https://r12a.github.io/uniview/?charlist=%F0%9F%91%A8%E2%80%8D%F0%9F%91%A9%E2%80%8D%F0%9F%91%A7%E2%80%8D%F0%9F%91%A6) мужчины, женщины, мальчика и девочки. Флаг 🇷🇺 — это стоящие рядом символы 🇷 и 🇺, в этом случае без «клея» `U+200C`.
На деле отображаемый символ может оказаться кластером из нескольких кодовых позиций. Операции редактирования (выбор символа, удаление, копирование/вырезание, вставка) будут применяться не к одной кодовой позиции, а ко всему символу.
### Заблуждение 12. Юникод — неэффективный и переусложнённый стандарт, от которого идут все проблемы
Юникод ставит целью закодировать все современные и вышедшие из употребления языки. В нём есть как графика из [PETSCII](https://en.wikipedia.org/wiki/PETSCII) (добавлено в [блоке наследия вычислительной техники](https://en.wikipedia.org/wiki/Symbols_for_Legacy_Computing)), так и встретившийся единожды в славянской летописи символ «[ꙮ](https://ru.wikipedia.org/wiki/%D0%9C%D1%83%D0%BB%D1%8C%D1%82%D0%B8%D0%BE%D0%BA%D1%83%D0%BB%D1%8F%D1%80%D0%BD%D0%B0%D1%8F_%D0%9E)».
Развитие стандарта шло не по прямой, а блуждало, что можно отследить в нарушенных принципах построения. Многие символы дублируют друг друга, тысячи кодовых позиций расходуются на эмодзи.
Тем не менее баги возникали бы и без Юникода.
Даже если текст записан 26 символами английского алфавита и без каких-либо знаков пунктуации, апострофов и дефисов, в мире достаточно других проблем.
На собственном опыте это [проверил](https://travel.stackexchange.com/questions/149323/my-name-causes-an-issue-with-any-booking-names-end-with-mr-and-mrs) Амр Эладави. Ему всего лишь повезло обладать именем, которое в записи латиницей (Amr) содержит комбинацию символов, похожую на суффикс «Mr.» (мистер, господин). Амр с удивлением обнаруживал, что при бронировании авиабилета его имя было указано либо как `A`, либо как `AMRMR`
Источник ошибок — стандарты телетайпа, которые остаются в ходу. В своё время авиаоператоры и железнодорожные компании в числе первых вводили инновационные информационные системы, которые затем обновляли слабо. За век форматы разрослись в махровый клубок унаследованных систем, поскольку жизнь ставила проблемы и преподносила идеи.
К примеру, если у пассажира нога в гипсе, то ему придётся купить отдельные места для своей нижней конечности. Документ ирландского лоукостера Ryanair (текст сохранился только в виде [копии](https://www.benidormseriously.com/flying-with-a-plaster-cast) на стороннем сайте) описывает этот процесс. Купить можно до двух дополнительных мест. Первое покупается на пассажира по фамилии «LEGSEAT ONE» и имени «EXTRA», если нужно ещё одно — «LEGSEAT TWO» и «EXTRA». Какой караул случится, если на одном борту полетят два и более тяжело загипсованных, документ Ryanair умалчивает. Эти места ведь нужно не только учесть в списке, но и рассадить в специальном порядке — пересадить ногу в соседний ряд без хирургической пилы невозможно.
Легаси авиалиний не только устарело и содержит много неприятных особенностей. Также тяжело со стандартизацией. В качестве де-факто стандартов закрепились документы от [SITA](https://ru.wikipedia.org/wiki/SITA), но участники индустрии придерживаются их в меру своих умений и предпочтений, иногда опуская неудобные фрагменты, отлавливая ошибки парсинга или вводя свои.
Вероятно, имя Амра записывают продукты компаний Sabre или Amadeus. На странице 33 документа [Amadeus Quick Reference Guide](http://web.archive.org/web/20180127045902/https://amadeus.com/bg/documents/aco/bg/basic-qrg.pdf) описано, как правильно передавать элемент имени:
`**NM**1SMITH/JOHN MR`
Значения полей:
* `NM`: команда «Name», имя.
* `1`: количество пассажиров (один).
* `SMITH`: фамилия.
* `JOHN`: имя.
* `MR`: название лица, то есть форма обращения.
В результате имя Амра передаётся строкой вида `**NM**1ELADAWY/AMR`. Системы распарсят это как `NM, 1, ELADAWY, A, MR`. Часть агентств добавляет пробел после имени (`**NM**1ELADAWY/AMR MR`), что исключает неправильное толкование.
Описанный выше случай — это не что-то редкое. Это арабское имя популярно: только в англоязычной «Википедии» [28](https://en.wikipedia.org/wiki/Amr_(name)) различных Амров, в основном египтян. Также Mr. — не единственный суффикс: человеку Oleksandr иногда «[присваивается](https://www.reddit.com/r/programming/comments/dtfa8s/when_your_clever_tricks_break_the_user_experience/f6whrxa/)» учёная степень с заменой имени на Dr. Oleksan.

*Скриншот штрафов из [выступления Джозефа Тартаро](https://www.youtube.com/watch?v=TwRE2QK1Ibc) на DEF CON 27 и его [презентации](https://media.defcon.org/DEF%20CON%2027/DEF%20CON%2027%20presentations/DEFCON-27-droogie-go-null-yourself.pdf)*
В США номерные знаки обычно состоят из псевдослучайной комбинации чисел и символов, но отделы транспортных средств за плату выдают знаки с любым кодом (не без [премодерации](https://www.lamag.com/citythinkblog/rejected-vanity-plates/)). Хакер Джозеф Тартаро в 2016 году выбирал для себя что-нибудь в тему инфобеза. Он рассматривал `SEGFAULT` и `VOID`, но остановил выбор на `NULL`.
Проблемы начались уже в следующем году: при продлении регистрации форма на сайте отказалась принимать `NULL` как номерной знак. Джозеф вышел из положения и в тот раз продлил регистрацию по иному идентификатору, а не номерному знаку. Затем на Тартаро посыпались штрафы: под `NULL` попадали любые записи без номерного знака, постепенно накрутившись до $12 049. Штрафы всё же аннулировали, поскольку некоторые датировались 2014 годом, а в большинстве мест из описаний Тартаро просто не бывал.
Как видно, глупые ситуации случаются даже без Юникода.
---
Миллиарды людей с необычным для нас письмом ни в чём себе не отказывают. Они создают музыку, переписываются в чатах и заказывают товары с доставкой. Дашборд автомобиля должен не [показать квадратики вместо тэгов MP3](https://twitter.com/averyanov/status/1620844738915233795), смартфон — не [входить в бутлуп от арабских символов](https://habr.com/ru/post/259007/), служба доставки — не [упасть в обморок от необычного названия компании-получателя](https://habrastorage.org/webt/kl/lh/xn/kllhxnkfsqdklgcr6hncofhfptg.png).
В жизни у информационных систем не всегда получается обработать не только сложные фрагменты текста, но и строку из латиницы, содержащую имя. Происходит это на ровном месте, без специфики комбинаций Юникода или коварства триграфов в C.
А без имени прожить никто не может. Даже у Человека без имени в каждой из частей «[долларовой трилогии](https://ru.wikipedia.org/wiki/%D0%94%D0%BE%D0%BB%D0%BB%D0%B0%D1%80%D0%BE%D0%B2%D0%B0%D1%8F_%D1%82%D1%80%D0%B8%D0%BB%D0%BE%D0%B3%D0%B8%D1%8F)» есть клички.

По материалам блогов [Маттиаса Вейсмана Тиаса](https://wiesmann.codiferes.net/wordpress/archives/30296), [Eevee](https://eev.ee/blog/2015/09/12/dark-corners-of-unicode/), [Бена Фредериксона](http://www.benfrederickson.com/unicode-insanity/), [Джеймс Беннтта](https://www.b-list.org/weblog/2018/nov/26/case/), [Маниша Горегаокара](https://manishearth.github.io/blog/2017/01/14/stop-ascribing-meaning-to-unicode-code-points/) и [Бена Хэмилла](http://garbled.benhamill.com/2017/04/18/falsehoods-programmers-believe-about-language), [Wired](https://www.wired.com/story/null-license-plate-landed-one-hacker-ticket-hell/) и [ответа на Stack Exchange](https://travel.stackexchange.com/a/149371). | https://habr.com/ru/post/714818/ | null | ru | null |
# Opera Unite для веб разработчиков
Как создать простой счетчик в качестве сервиса Opera Unite?
Это поможет понять как вообще писать веб приложения на Opera Unite (так же называемые «сервисы» или «плагины»).

15 строк JavaScript + 7 на XML.
Очевидно, сначала скачайте [Opera Unite](http://unite.opera.com/), установите (если уже Опера поставлена — по желанию произойдет апдейт).
Создайте любую папку, где нужно создать 2 файла:
1. Создайте config.xml:
```
Test
```
2. Создайте index.html файл:
```
var counter = 0;
window.onload = function () {
webserver = opera.io.webserver
if (webserver) {
webserver.addEventListener('\_index', start\_page, false);
}
}
function start\_page( r ) { // пробелы не обязательны, просто хабр это на (r) заменяет
counter++;
var o = r.connection.response;
o.write('This page has been seen <b>'+counter+' times</b>!!');
o.close();
}
Мое приложение
```
Это явно не самый полный пример. Можно его расширять, вынеся script в отдельный файл.
\* Активируйте Opera Unite если он не активен (Опера спросит об этом на следущем шаге, так что можно пропустить)
4. Перетаскиваем config.xml в Opera. Она спросит — устанавливать ли? Подтверждаем.
**Все готово. Видим картинку в начале поста.**
(На англ. — как сделать [простой блог в 60 строк JavaScript](http://dev.opera.com/articles/view/opera-unite-developer-primer/))
5. Если мы чего поменяем в index.html — будет показываться старая версия — решение для отладки: Правый клик на иконке Unite -> «Manage Services» (или F4), правый клик на «Test» -> «Stop service», затем то же, только «Start service». Исходники перезагрузятся. Счетчик сбросится (проблему persistence, я пока ищу как решать, скорее всего что-то с fileio библиотекой + JSON будет или REST базами данных).
6. Чтобы поделиться с кем-то своим творчеством копируем URL (F8 — Ctrl+C в Opera) и меняем это так:
unite:// -> http://
так что,
unite://my\_compute.my\_opera\_login.operaunite.com/test/
становится
http://my\_compute.my\_opera\_login.operaunite.com/test/
7. Исопользуем [Markuper](http://dev.opera.com/libraries/markuper/) для HTML шаблонов
Стоит ли использовать Unite для разработки веба? У меня много разных мыслей на этот счет, но, перевести их нет времени. Если с английским порядок — читайте <http://unitehowto.com/Why>.
Если очень кратко:
* Для PHP/MySQL программеров это будет не круто (это не оскорбление, а как факт, как например 3D моделерам — SketchUp — не круто, функций и гибкости маловато)
* Нагрузка не будет являться проблемой для большинства, дальше — PHP/MySQL или см. ниже.
* Вполне подойдет для прототипирования веб приложения или создания локальных приложений (например биллинг для моих клиентов).
* Для не-специалистов по PHP/MySQL и другим серверным языкам — самое оно для создания сайтов — веб приложений.
* Создавать приложения на Unite — оооочень просто. Есть много плюсов и мало минусов, но минус большой — нужно держать браузер открытым.
* Cross-platform (win/lin/mac)
* «Server»-side (быстрый) JavaScript!
* В конце концов кто-нибудь сделает основанный на V8 production server под \*nix/\*BSD чтобы прямо туда публиковать отлаженные на локальной Опере приложения (примерно как Google App Engine). (Вполне может быть даже модуль для nginx)
Буду по мере нахождения решения этих проблем публиковать ответы на [unitehowto.com](http://unitehowto.com/).
#### Как сделать чтобы счетчик не сбрасывался
Проблему persistence решил (Opera, давайте маленьких примеров больше!)
1. Изменяем config.xml:
`Test`
Это мы подключаем разрешение Опере использовать файловую систему (там она хитрая в sandbox'ах вся). Теперь меняем скрипт:
```
var counter = 0;
```
заменяем на
```
var dir = opera.io.filesystem.mountSystemDirectory('storage');
try {
stream = dir.open(dir.resolve('/storage/newfile'), opera.io.filemode.READ);
if (stream) {
var counter = parseInt(stream.readLine());
stream.close();
};
} catch(err) { // message: FILE_NOT_FOUND_ERR
var counter = 0;
};
```
Опера заявляет метод .exists(), но я его так и не нашел (почти все варианты перепробовал у чего его вызывать), а dir.open(...) сразу же дает исключение, если файла нет.
По поводу того как обращаться к файлам в другой песочнице (не в /storage/) — читайте доки [fileio](http://dev.opera.com/libraries/fileio/docs/overview-summary-file-io.js.dml) (english).
Этими строками мы подгружаем переменную из файла (/storage/newfile) — на самом деле этот файл будет хранится у пользователя где-то в /Documents and settings/..../Local settings/..../4393408934/ (и т.п.), т.е. — это — не абсолютный путь, а путь внутри песочницы.
По идее нам надо бы сохранять JSON представление объекта, тогда можно хранить сложные вложыенные структуры, а не просто Int.
В конце start\_page добавляем сохранение:
```
var stream = dir.open('/storage/newfile', opera.io.filemode.WRITE);
stream.writeLine(counter);
stream.close();
```
Это не лучший вариант — сохранять файл после каждого обращения, но window.onunload по-моему в Opera забыли сделать (window.onload сделали).
Полный исходник с сохранением: [t9.zip](http://unitehowto.com/files/t9.zip)
#### Отладка скриптов, подводные камни
Помните, что это alpha релиз Оперы, так что все сказанное — без обвинений:
Перезагрузка исходников: «Stop service» -> «Start service» -> (проверяем Error Console) -> F5. (Иногда еще и реинсталляция нужна.)
Можно пытаться найти намек на то, что произошло в Tools -> Advanced -> Error Console, но там тоже ошибки с бессмысленными названиями часто. [Update]Откройте URL [opera:config#UserPrefs|Exceptions Have Stacktrace](http://opera:config#UserPrefs|Exceptions Have Stacktrace), поставьте галочку, не забудьте внизу нажать кнопку Save. Это делает ошибки в Error Console читаемыми.
Ошибки синтаксиса находятся проверкой Error Console сразу после каждого «Stop service» -> «Start service».
Если изменили config.xml — приходится изменять название директории где он лежит и заново инсталлировать скрипт (перетаскиванием), иначе опера старую версию из памяти берет.
Ни в коем случае не использовать alert() и window.onunload в скриптах (убил оперу, баг репорт отправил).
Ошибка «Resource not found» может обозначать как ошибку синтаксиса, так и что угодно.
В общем, пока-то что отладка — ужасы.
Но, в общем и целом — Опера — гиганты! Сделать веб, который по настоящему p2p теперь — это сила! А те проблемы, что здесь и по ссылке "/Why" описаны — думаю исправят.

Йои Хаджи,
[вид с Хабра](http://yoihj.habrahabr.ru/blog/) | https://habr.com/ru/post/62208/ | null | ru | null |
# Фильтрация черного списка сайтов по URL
В данной статье рассмотрена связка Squid+TPROXY стоящий на отдельной машине. Как оказалось это тема почти не освещена на просторах интернета.
По роду занятия возникла задача фильтрации черного списка сайтов от [РОСКОМНАДЗОРА](http://vigruzki.rkn.gov.ru). В ходе проверки нам пригрозили что если мы это не сделаем то введут санкции. Сказано сделано (всего на несколько минут) тупая и не очень дружественная к нашим клиентам реализация, которая просто не давала доступа ко всем сайтам внесенным в черный список. При этом фильтрация была просто по IP. И естественно перекрывала доступ ко всем сайтам на IP.
Нужно было переделывать, да еще и грамотно переделывать. Во первых это не красиво/коряво, во вторых задача сама по себе очень интересная.
В этой статье я не буду рассказывать как настроить автоматическое получение этого списка. Скажу лишь одно, я не стал заморачиваться с постоянным подписывание запроса, а сделал это один раз на компьютере с установленным ПО и ключом.
### Начнем с машины с установленным Squid3.
Почти все настройки были взяты из официального [Squid+TPROXY](http://wiki.squid-cache.org/Features/Tproxy4)
```
ip -f inet rule add fwmark 1 lookup 100
ip -f inet route add local default dev eth0 table 100
```
```
cat /etc/sysctl.conf:
....
net.ipv4.ip_forward = 1
net.ipv4.conf.default.rp_filter = 0
net.ipv4.conf.all.rp_filter = 0
net.ipv4.conf.eth0.rp_filter = 0
```
Чтобы мы могли определить какой трафик уже прошел проверку, а кой нет мы создаем отдельный VLAN, в нашем случае 5, для исходящих пакетов. Напомню что в режиме TPROXY IP у адреса источника не меняется.
```
default via 192.168.70.2 dev eth0.5
192.168.1.35/25 dev eth0 proto kernel scope link src 192.168.1.36
192.168.70.0/30 dev eth0.5 proto kernel scope link src 192.168.70.1
```
Правила iptables
```
iptables -t mangle -N DIVERT
iptables -t mangle -A DIVERT -j MARK --set-mark 1
iptables -t mangle -A DIVERT -j ACCEPT
```
Чтобы уже существующие соединения не попадали в правило TPROXY
```
iptables -t mangle -A PREROUTING -p tcp -m socket -j DIVERT
```
Собственно само правило TPROXY
```
iptables -t mangle -A PREROUTING -p tcp --dport 80 -j TPROXY --tproxy-mark 0x1/0x1 --on-port 3129
```
Основные настройки.
```
http_port 3129 tproxy disable-pmtu-discovery=off
...
acl bad_urls url_regex "/etc/squid3/bad_hosts.list"
....
http_access deny bad_urls
http_access allow localnet
deny_info http://www.somehost.ru bad_urls
...
```
Последняя строка в конфиге сделает REDIRECT на указанный сайт в случае если пользователь запросит один из запрещенных сайтов.
Остальные настройки в squid3 по вкусу.
### Настройки на роутере
Эти настройки нам потребуется применить и к маршрутизатору.
```
cat /etc/sysctl.conf:
....
net.ipv4.ip_forward = 1
net.ipv4.conf.default.rp_filter = 0
net.ipv4.conf.all.rp_filter = 0
net.ipv4.conf.eth0.rp_filter = 0
```
Естественно включен NAT серых подсетей.
Создаем цепочку в которой будем производиться фильтрацию
```
iptables -t mangle -F DIVERT
```
В этой цепочке будем маркировать все пакеты у которых исходящий или порт назначения 80 (только при написании статьи понял что указания портов здесь лишние, но оставил, вдруг кому так легче понять)
```
iptables -t mangle -A DIVERT ! -i eth1.5 -p tcp --dport 80 -j MARK --set-mark 1
iptables -t mangle -A DIVERT ! -i eth1.5 -p tcp --sport 80 -j MARK --set-mark 1
```
Отправим в эту цепочку все пакеты у которых адреса источника или назначение 80 при этом эти пакеты мы получили не из 5 VLAN (может кто подскажет почему в этом случае соединение не трассируется и приходится делать обратную проверку)
```
iptables -t mangle -A PREROUTING ! -i eth1.5 -p tcp -m set --match-set badip dst -m tcp --dport 80 -j DIVERT
iptables -t mangle -A PREROUTING ! -i eth1.5 -p tcp -m set --match-set badip src -m tcp --sport 80 -j DIVERT
```
Создаем правило которое в случае если на пакете стоит метка 1 отправит его в 101 таблицу маршрутизации
```
ip rule add fwmark 1 lookup 101
```
Собственно сама таблица маршрутизации
```
ip route list table 101
default via 192.168.1.35 dev eth1.3
```
И на последок. Вот так у нас сформирован список плохих сайтов
```
create badip hash:ip
ipset flush badip
ipset add badip 111.111.111.111
ipset add badip 2.2.2.2
...
```
Списки блокируемых сайтов на обеих машинах загружаются автоматически, но интерпретируются уже по разному.
### Схема движения пакетов
Синяя — линия исходящий пакет
Зеленая — обратный пакет. | https://habr.com/ru/post/219435/ | null | ru | null |
# Встраиваем локальные уведомления
Что самое ужасное в случае удаления приложения? Правильно, потеря связи с аудиторией и невозможность проинформировать о том, что у приложения сменился адрес прописки и имя пакета. Задачу решают Push уведомления, но это довольно хлопотно и не всегда удобно. А иногда и дорого.
Поэтому мы напишем свои, простые как барабан и надежные как танк — локальные push уведомления. Код получился универсальным, и в принципе, его можно использовать как альтернативу обычным «пушам», например для новостной рассылки о том, что вышла новая версия приложения или для клянчанья рейтинга, да для чего угодно.
Начнем с конфига. Это обычный текстовый файл в json-формате.
```
{
"notifications":
[
{
"id": 1 ,
"title": "Sorry we are deleted from GPlay" ,
"text": "Please click for download new app" ,
"version": 105 ,
"action": "market://search?q=freemp" ,
"locale": "ru_Ru"
}
]
}
```
где
— id: unique number of message
— title: title of message
— text: text of message
— version: if not set message for all (optional)
— action: default action (optional)
— locale: optional
Данный файл размещаем, например на гитхабе и добавляем на него ссылку:
public static final String MESSAGEURL = «[github.com/recoilme/freemp/blob/master/message.json?raw=true](https://github.com/recoilme/freemp/blob/master/message.json?raw=true)»;
Затем где нибудь в районе onCreate основного активити вызываем:
new UpdateUtils(activity);
Готово. С настройкой покончено. Теперь как это работает.
При старте приложение чекает массив уведомлений и показывает следующее сообщение из тех, что не были показаны ранее.
При последующем старте — показывает следующее и так, пока уведомления не кончатся. Таким образом можно организовывать очередь сообщений. Я не знаю пока точно зачем, но наверняка пригодится.
Существуют два вида фильтров:
version — если задать, например 105 — то будет показываться только в 105 версии приложения. Можно, например, написать для пользователей версии 105, что вышла версия 106)
locale — локаль текста, если например необходимо сделать сообщение на русском, для русскоязычных пользователей
Параметр action — опциональный, это Uri, который будет вызван при клике на уведомлении. Можно, например, направить в маркет ну или в другое активити (в том числе свое).
Собственно это все. Довольно просто, и в то же время позволит нивелировать ущерб от возможного удаления. Ну или наладить диалог с пользователями.
Код, в действии можно посмотреть тут: <https://github.com/recoilme/freemp>
Но собственно пока это один файл. Возможно библиотека будет развиваться, добавлю возможность скачивания обновления или что то вроде того. Пока же код комфортно поместится и тут:
```
package org.freemp.android;
import android.app.Activity;
import android.app.Notification;
import android.app.NotificationManager;
import android.app.PendingIntent;
import android.content.Context;
import android.content.Intent;
import android.content.pm.PackageManager;
import android.net.Uri;
import android.os.AsyncTask;
import android.preference.PreferenceManager;
import android.support.v4.app.NotificationCompat;
import android.text.TextUtils;
import org.apache.http.HttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.DefaultHttpClient;
import org.json.JSONArray;
import org.json.JSONException;
import org.json.JSONObject;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.Locale;
/**
* Created by recoil on 06.08.14.
* example file:
{
"notifications": [{ "id":1, "title":"Sorry we are deleted from GPlay", "text":"Please click for download new app",
"version":105 , "action":"market://search?q=freemp", "locale":"ru_Ru"}]
}
- id: unique number of message
- title: title of message
- text: text of message
- version: if not set message for all (may be not set)
- action: default action (may be not set)
- locale: may be not set
*/
public class UpdateUtils {
public static final String MESSAGEURL = "https://github.com/recoilme/freemp/blob/master/message.json?raw=true";
private Context context;
private Activity activity;
private int versionCode;
private String locale;
public UpdateUtils(Activity activity) {
this.activity = activity;
context = activity.getApplicationContext();
new Update().execute();
}
private class Update extends AsyncTask {
@Override
protected String doInBackground(Void... params) {
try {
versionCode = context.getPackageManager()
.getPackageInfo(context.getPackageName(), 0).versionCode;
} catch (PackageManager.NameNotFoundException e) {
e.printStackTrace();
}
locale = Locale.getDefault().toString();
String response = "";
DefaultHttpClient client = new DefaultHttpClient();
HttpGet httpGet = new HttpGet(MESSAGEURL);
try {
HttpResponse httpResponse = client.execute(httpGet);
InputStream content = httpResponse.getEntity().getContent();
BufferedReader buffer = new BufferedReader(new InputStreamReader(content));
String s = "";
while ((s = buffer.readLine()) != null) {
response += s;
}
}
catch (Exception e) {
e.printStackTrace();
}
return response;
}
@Override
protected void onPostExecute(String result) {
if (!TextUtils.equals("",result)) {
JSONObject jsonResult = null;
try {
jsonResult = new JSONObject(result);
}
catch (JSONException e) {
e.printStackTrace();
return;
}
//process notifications if exists
JSONArray notifications = jsonResult.optJSONArray("notifications");
if (notifications==null) {
return;
}
if (context==null) {
return;
}
//string with showed messages
String showedMessages = PreferenceManager.getDefaultSharedPreferences(context).getString(MESSAGEURL,"");
for (int i=0;i0 && version!=versionCode) {
continue;
}
final String localeTarget = jsonNotification.optString("locale","all");
if (!TextUtils.equals("all",localeTarget) && !TextUtils.equals(localeTarget,locale)) {
continue;
}
final int id = jsonNotification.optInt("id");
if (showedMessages.contains(id+";")) {
continue;
}
else {
showedMessages+=id+";";
PreferenceManager.getDefaultSharedPreferences(context).edit().putString(MESSAGEURL,showedMessages).commit();
Intent intent = null;
if (!TextUtils.equals("",jsonNotification.optString("action",""))) {
// if has action add it
intent = new Intent(Intent.ACTION\_VIEW, Uri.parse(
jsonNotification.optString("action","")));
intent.setFlags(Intent.FLAG\_ACTIVITY\_NEW\_TASK);
}
else {
// if no - just inform
intent = new Intent(activity,activity.getClass());
}
PendingIntent pIntent = PendingIntent.getActivity(context, id, intent, 0);
// if you don't use support library, change NotificationCompat on Notification
Notification noti = new NotificationCompat.Builder(context)
.setContentTitle(jsonNotification.optString("title",""))
.setContentText(jsonNotification.optString("text",""))
.setSmallIcon(R.drawable.icon)//change this on your icon
.setContentIntent(pIntent).build();
NotificationManager notificationManager = (NotificationManager) context.getSystemService(context.NOTIFICATION\_SERVICE);
// hide the notification after its selected
noti.flags |= Notification.FLAG\_AUTO\_CANCEL;
notificationManager.notify(id, noti);
break;
}
}
}
}
}
}
```
Буду рад если никому не пригодится использовать ее в тех целях, для которых она создавалась) | https://habr.com/ru/post/232453/ | null | ru | null |
# Знакомство с Ruby on Rails (часть 2)
В продолжении статьи ”[Первое знакомство с Ruby on Rails](http://www.habrahabr.ru/blog/ruby/18937.html)” мы научимся работать с базой данных, и создадим каталог статей.
Узнаем как написать плагин, попробуем использовать AJAX и рассмотрим некоторые проблемы при развёртывании приложения на хостинге.
Начнем с базы данных.
---------------------
Я работаю с MySQL, поэтому примеры установки будут для неё.
Пользователям Windows нужно скачать и установить [MySQL-5.0](http://dev.mysql.com/downloads/mysql/5.0.html#win32).
Пользователям Linux (Ubuntu) еще проще:
```
$>sudo apt-get install mysql-server-5.0 libmysql-ruby
```
После установки проверим что сервер работает:
```
$>mysqladmin ping -u root
mysqld is alive
```
Настало время создать нужные базы данных. Потребуется их две – одна для разработки и одна для тестирования:
```
$>mysqladmin create example_development -u root
$>mysqladmin create example_test -u root
```
Теперь давайте посмотрим на файл `config/database.yml`. Тут находятся параметры соединения с базой данных. Обычно ничего менять не требуется, по умолчанию mysql создаёт пользователя root со всеми правами и без пароля.
Осталось протестировать соединение приложения с базой данных. Идём в папку с приложением и набираем
```
$>rake
```
Если появляются сообщения об ошибках, значит где-то вы ошиблись в настройках соединения, проверьте их.
Введение в работу с БД.
-----------------------
Связь объектов и баз данных в рельсах осуществляется с помощью [OR меппера](http://ru.wikipedia.org/wiki/ORM), который называется [ActiveRecord](http://wiki.rubyonrails.org/rails/pages/ActiveRecord). Он занимается отображением полей из таблицы БД в поля объекта, валидацией объектов перед сохранением, генерацией кода для представления связей между объектами.
Чтобы создать новую модель достаточно наследоваться от класса `ActiveRecord::Base`
```
class Article < ActiveRecord::Base
end
```
По умолчанию ActiveRecord будет работать с таблицей названной также как класс, только во множественном числе. В нашем случае Articles.
Ко всем полям таблицы можно получить доступ с помощью методов с тем же названием:
```
#Пусть в таблице Articles есть поле title
Article.create(:title => 'Hello World!')
article = Article.find(1)
print article.title
#=> Hello World!
```
ActiveRecord наглядно демонстрирует суть принципа “Convention over Configuration” – не требуется писать код для того, чтобы программа заработала, код нужен только когда программа должна работать не как обычно. Например:
* нужно использовать таблицу с другим именем – добавляем в класс строчку `set_table_name "mytablename"`
* в таблице криво названы поля – пожалуй лучше написать для полей методы доступа с нормальными названиями
* один объект отображается на несколько таблиц – придётся писать свой ORM :)
ActiveRecord предоставляет много полезных функций, вот некоторые из них:
* `Article.find(id)` – найти статью по id (PrimaryKey в БД, обычно это Integer)
* `Article.find(:all)` – выбрать все статьи
* `Article.find_by_title('Hello World!')` – найти статью с заголовком “Hello World!”
* `Article.create(:title => 'Hello World!')` – создать статью и сохранить в БД
* `article.update(:title => 'Goodbye World!')` – обновить статью в БД
* `article.destroy` – удалить статью из БД
Что бы посмотреть документацию по ActiveRecord и другим установленным гемам нужно запустить
```
`$>gem_server`
```
и открыть в браузере
<http://localhost:8808/>
Теперь давайте попробуем создать каталог.
-----------------------------------------
Мы будем использовать `script/generate` чтобы создать модель, контроллер и вьюшки для каталога.
```
$>ruby script/generate scaffold_resource article title:string body_format:string body:text
```
Я не буду включать в текст исходный код, чтобы не раздувать статью, его можно [посмотреть online](http://rurails.googlecode.com/svn/branches/second_article/example), я буду описывать для чего нужны различные куски кода.
Рельсы сгенерировали несколько файлов, посмотрим на некоторые из них:
* `app/models/article.rb` – модель для статьи
* `app/controllers/articles\_controller.rb` – контроллер для управления каталогом статей
* `config/routes.rb` – добавлена строчка `map.resources :articles`
* `app/views/articles/...` – вьюшки для создания, редактирования и просмотра статей
* `app/views/layouts/articles.rhtml` – шаблон страниц для работы к каталогом
* `db/migrate/001_create_articles.rb` – создание таблицы для статей в базе данных
С моделью думаю всё понятно, посмотрим на контроллер. У контроллера есть 7 методов:
* `index` – страница отображает всю коллекцию статей
* `show` – страница отображает одну статью
* `new` – страница для создания новой статьи
* `edit` – страница для редактирования существующей статьи
* `create` – обработчик поста формы создания новой статьи
* `update` – обработчик поста формы редактирования статьи
* `destroy` – обработчик запроса удаления статьи
Строчка `map.resources :articles` в файле `config/routes.rb` добавляет нужные правила маршрутизации урлов. Вот как выглядят созданные урлы:
* `/articles (GET)` – index
* `/articles/:id (GET)` – show (:id – идентификатор статьи)
* `/articles;new (GET)` – new
* `/articles/:id;edit (GET)` – edit
* `/articles (POST)` – create
* `/articles/:id (PUT)` – update
* `/articles/:id (DELETE)` – destroy
PUT и DELETE это методы HTTP, как GET и POST.
Таким образом получилось уместить все необходимые для управления коллекцией методы в небольшой и понятный для пользователя набор урлов.
Принцип разбиения приложения на наборы ресурсов и предоставления универсального формата доступа к ресурсам (способа построения урлов) называется [REST](http://en.wikipedia.org/wiki/Representational_State_Transfer). Идея в том, чтобы использовать для работы с ресурсами протокол без состояния (вся необходимая информация содержится в урле), что улучшит масштабируемость приложения и упростит кеширование.
Поскольку ресурс однозначно идентифицируется урлом, основная работа приложения сводится к двум задачам – отдавать пользователю странички с указанным в урле ресурсом и проверять права доступа если ресурс не общедоступный. Поэтому писать и сопровождать веб приложения в стиле REST очень просто.
Посмотрим на результат, запускаем сервер
```
`$>ruby script/server`
```
и идем
<http://localhost:3000/articles>
Я получил вот такую ошибку:
```
Mysql::Error: Table 'example_development.articles' doesn't exist: SELECT * FROM articles
```
В базе данных нет таблицы `articles`, надо бы её создать.
Изменения таблиц БД в рельсах делаются через механизм миграций. Одну миграцию рельсы сгенерировали для нас – создание таблицы `articles` ([`db/migrate/001_create_articles.rb`](http://rurails.googlecode.com/svn/branches/second_article/example/db/migrate/001_create_articles.rb)). Нужно применить её к базе данных, идём в папку с приложением и запускаем
```
$>rake db:migrate
```
В результате миграции в базе данных была создана таблица articles, и теперь мы можем нажать в браузере F5 и поиграть с приложением.
Несколько слов о Rake.
----------------------
Rake это замена утилит типа `make`, `ant`, `maven`.
Чтобы узнать что Rake может сделать для нас выполним следующее:
```
$>rake -T
```
Получим длинный список задач, которые Rake умеет делать. Задачи пишутся на Ruby и находятся в файле [Rakefile](http://rurails.googlecode.com/svn/branches/second_article/example/Rakefile). Изначально файл содержит только стандартный набор задач, которые подключаются с помощью `require 'tasks/rails'`. Вот так например выглядит описание задачи `db:migrate`:
```
desc "Migrate the database through scripts in db/migrate. Target specific version with VERSION=x"
task :migrate => :environment do
ActiveRecord::Migrator.migrate("db/migrate/", ENV["VERSION"] ? ENV["VERSION"].to_i : nil)
Rake::Task["db:schema:dump"].invoke if ActiveRecord::Base.schema_format == :ruby
end
```
Прелесть Rake в том, что описание задачи это обычный код на Ruby. Это сильно упрощает добавление новых задач по сравнению с `ant` или `maven`.
У Мартина Фаулера есть [отличная статья](http://www.martinfowler.com/articles/rake.html) о Rake (на английском).
Будем знакомиться с Rake по мере необходимости. Сейчас нам уже известно что задача `db:migrate` запускает миграции, при чем можно как применять так и откатывать изменения. Если мы посмотрим в файлик [`db/migrate/001_create_articles.rb`](http://rurails.googlecode.com/svn/branches/second_article/example/db/migrate/001_create_articles.rb), то увидим что у класса `CreateArticles` есть два метода: up и down. Эти методы вызываются когда миграция применяется и откатывается соответственно. Цифры `001` в названии файла это порядковый номер миграции, он используется для определения очерёдности применения миграций, при этом рельсы хранят в базе данных её версию, чтобы не применять одну миграцию несколько раз. Чтобы мигрировать базу до определенной версии нужно запустить `db:migrate` с параметром VERSION:
```
$>rake db:migrate VERSION=0
```
В результате база мигрирует до нулевой версии, когда еще не было создано ни одной таблицы. Это удобный способ очистить базу после экспериментов с приложением. Потом можно снова вызвать `db:migrate` без параметров, в итоге будут применены все миграции.
Каталог это здорово, но статьи не форматируются.
------------------------------------------------
Надеюсь вы уже посмотрели на каталог и убедились в этом. Время заняться главной задачей приложения – форматированием статей.
У нас уже есть код для форматирования, теперь нужно понять как его использовать. В первой версии у нас был только контроллер, поэтому код располагался прямо в нем, теперь появилась модель `Article`, но если мы расположим код в модели, то жестко свяжем форматирование с конкретной моделью, а это приведет к тому, что мы не сможем повторно использовать код, хотя он никак не зависит от модели которую будет форматировать.
Будем писать плагин.
--------------------
В рельсах это естественный путь добавления функциональности к приложению. При этом код форматирования будет отделен от модели, что позволит использовать его в других приложениях.
Хочется чтобы плагин обеспечил поддержку форматирования без лишних слов, например так:
```
class Article < ActiveRecord::Base
acts_as_formatted :body
end
```
При этом исходный текст находится в поле `body`, а отформатированиый текст статьи можно получить с помощью метода `body_as_html`. Формат, в котором написана статья, находится в поле `body_format`.
Начнем. Прежде всего доверим рельсам создать для нас скелет плагина:
```
$>ruby script/generate plugin acts_as_formatted
```
В папке [`vendor/plugins`](http://rurails.googlecode.com/svn/branches/second_article/example/vendor/plugins) появился наш плагин. Что внутри:
* `lib` – в этой папке размещается код
* `lib/acts_as_formatted.rb` – тут будет код плагина
* `tasks` – плагин может добавлять задачи для Rake, они появятся в общем списке
* `test` – плагин должен быть хорошо протестирован
* `init.rb` – этот файл выполняется при загрузке, отсюда включаются файлы плагина, которые лежат в `lib`
* `install.rb`, `uninstall.rb` – эти файлы выполняются при установке и удалении плагина, нам они не потребуются
* `Rakefile` – файл с задачами Rake для плагина (запуск тестов и генерация документации)
Теперь осталось написать код для форматирования и добавить поддержку в ActiveRecord.
Как это сделать? Задача сводится к тому, чтобы добавить метод `acts_as_formatted` к `ActiveRecord::Base`. А в этом методе сгенерировать код, необходимый для поддержки форматирования. Для этого нам понадобится знать как это можно сделать в Ruby.
Как в Ruby добавить функциональность к существующему классу.
------------------------------------------------------------
В Ruby все является обьектом, в этой простенькой программе
```
print "Hello World!"
```
вызывается метод обьекта. У какого обьекта? Это объект типа модуль (аналог namespace, package), глобальный модуль называется Kernel. Модули похожи на классы, отличаются тем, что могут содержать только методы, константы и другие модули и классы. При этом руби позволяет подмешивать (mixin) модули в другие модули и классы, это делается с помощью методов `extend` и `include` у модулей и классов, например:
```
class MyClass
extend Enumerable
end
```
или
```
class MyClass
end
MyClass.extend(Enumerable)
```
При этом в классе `MyClass` появятся все методы, константы, классы и модули, определенные в модуле `Enumerable`.
Пишем плагин.
-------------
Практически весь код плагина будет в файле [`acts_as_formatted.rb`](http://rurails.googlecode.com/svn/branches/second_article/example/vendor/plugins/acts_as_formatted/lib/acts_as_formatted.rb).
Плагин состоит из двух модулей:
* `ActiveRecord::Acts::ActsAsFormatted::Formatting` – код отвечающий за форматирование
* `ActiveRecord::Acts::ActsAsFormatted::ClassMethods` – единственный в нем метод – `acts_as_formatted`, этот модуль добавим к `ActiveRecord::Base`
Посмотрим что делает метод `acts_as_formatted`.
Сначала узнаем какие форматы поддерживаются и какие поля будут использоваться (в нашем случае `body`, `body_format`, `body_as_html`), затем добавляем правило валидации, чтобы проверить что поле формата содержит допустимый формат (обьект невозможно сохранить если не прошла валидация), и добавляем классу два метода для получения поддерживаемых форматов и отформатированного поля (`supported_formats` и `body_as_html`).
Вся работа по форматированию происходит в модуле `ActiveRecord::Acts::ActsAsFormatted::Formatting`. Здесь есть методы которые форматируют текст: `format`, `format_markdown` и `format_textile`, и метод `supported_formats`, который определяет поддерживаемые форматы, иcходя из методов, которые есть в модуле.
Теперь в `init.rb` добавим код инициализации:
```
require 'acts_as_formatted'
ActiveRecord::Base.extend(ActiveRecord::Acts::ActsAsFormatted::ClassMethods)
```
и можно пробовать плагин в деле. Нужно поправить вьюшки, чтобы отображать отформатированный текст.
Причешем вьюшки и сделаем preview
---------------------------------
Прежде всего стоит избавиться от дублирования кода в new и edit формах и создать одну форму, которую можно использовать создания и редактирования статей. Единственное отличие форм – урл и метод отправки. Поэтому удобно сделать вспомогательный метод, который будет определять урл и метод в зависимости от того, как используется форма, для редактирования или для создания статьи.
Для вспомогательных методов рельсы создают модули-помощники (helpers), разместим код в [`app/helpers/application_helper.rb`](http://rurails.googlecode.com/svn/branches/second_article/example/app/helpers/application_helper.rb). Метод `edit_form_for` определяет была ли модель уже сохранена и, в зависимости от этого, генерирует форму для создания или обновления модели. Методы `submit_edit` и `cancel_edit` создают кнопку для отправки формы и линку для возврата из формы.
Теперь создадим вьюшку для формы. Повторно используемые куски вьюшек в рельсах называются partials. Названия файлов partials начинаются с подчёркивания. Обычно они находятся [там же где вьюшки, которые их используют](http://rurails.googlecode.com/svn/branches/second_article/example/app/views/articles).
После такого рефакторинга код вьюшек `new` и `edit` становится совсем простым и сводится к одной строчке:
```
<%= render :partial => 'article', :object => @article %>
```
Осталось добавить preview. Для этого в [контроллере](http://rurails.googlecode.com/svn/branches/second_article/example/app/controllers/articles_controller.rb) создадим метод `preview`, который будет возвращать отформатированный текст статьи.
```
def preview
article = Article.new(params[:article])
render_text article.body_as_html
end
```
Затем добавим правило в таблицу маршрутизации.
```
map.resources :articles,
:collection => { :preview => :any }
```
Вторая строчка добавляет правило для урла `/articles;preview`. `:collection` означает что будет использоваться урл коллекции (`/articles`), поскольку не важно для какой конкретно статьи генерируется preview. Вместо `:collection` можно использовать `:member`, тогда урл будет для конкретной статьи (`/articles/:id`), в нашем случае это не позволит делать preview создаваемых статей. `:any` означает что для вызова можно использовать любой HTTP метод, в нашем случае будут использоваться POST при создании и PUT при редактировании.
Теперь добавим поддержку на форму. Чтобы не загромождать вьюшку кодом сделаем [вспомогательный метод](http://rurails.googlecode.com/svn/branches/second_article/example/app/helpers/articles_helper.rb). Этот метод создаёт кнопку, при нажатии на которую форма асинхронно отправляется на сервер и ответ отображается в переданном в метод элементе. Остаётся добавить кнопку и элемент для отображения отформатированной статьи во [вьюшку](http://rurails.googlecode.com/svn/branches/second_article/example/app/views/articles/_article.rhtml).
Поскольку кнопка preview использует библиотеку [prototype](http://www.prototypejs.org/) для асинхронной отправки запросов на сервер, нужно добавить её загрузку в [шаблон страницы](http://rurails.googlecode.com/svn/branches/second_article/example/app/views/layouts/articles.rhtml).
```
<%= javascript_include_tag 'prototype' %>
```
На этом функциональность второй версии можно считать завершённой.
Теперь можно убрать код, оставшийся с первой версии.
```
script/destroy controller input preview
```
И напоследок.
Немного об установке приложения у хостера.
------------------------------------------
Может случиться так, что дома у вас все работает, а на хостинге категорически отказывается. Причин может быть много, но наиболее частая из них – не хватает каких-то гемов, или у хостера они не той версии. Это касается как самих рельсов, так и гемов, от которых зависит ваше приложение.
Сначала разберемся с зависимостью от рельсов. Перед тем как заливать ваше приложение на хостинг очень полезно сделать следующее:
```
$>rake rails:freeze:gems
```
В результате в папке `vendor/rails` появится копия рельсов с которой вы разрабатываете ваше приложение, и сервер будет использовать её, так что беспокоиться о том, какая версия есть у хостера, больше не потребуется.
Помимо рельсов, приложение часто зависит еще от каких-то гемов, в нашем слечае это RedCloth и Maruku. Для решения проблем с этими зависимостями [Dr Nic](http://drnicwilliams.com/) написал замечательный плагин – [Gems on Rails](http://drnicwilliams.com/2007/02/09/railsrally-2007-and-gemsonrails/). Работает он по такому же принципу – делает локальные копии гемов. Давайте его установим и научимся использовать:
```
$>gem install gemsonrails
```
Идем в папку с приложением и запускаем
```
$>gemsonrails
Installed gems_on_rails 0.6.4 to ./vendor/plugins/gemsonrails
```
Теперь у нас установлен плагин [Gems on Rails](http://drnicwilliams.com/2007/02/09/railsrally-2007-and-gemsonrails/), который добавил полезные задачи для Rake.
```
$>rake -T
...
rake gems:freeze # Freeze a RubyGem into this Rails application; init.rb will be loaded on startup.
rake gems:link # Link a RubyGem into this Rails application; init.rb will be loaded on startup.
rake gems:unfreeze # Unfreeze/unlink a RubyGem from this Rails application
...
```
* `gems:link` – добавляет в `vendor/gems` код, который загружает гем при загрузке приложения, если гема нет, то приложение не загрузится (удобно узнавать об отсутствии гемов сразу, а не во время работы)
* `gems:freeze` – делает локальную копию гема, именно эта копия будет использоваться в приложении
* `gems:unfreeze` – удаляет локальную копию и код сгенерированный `gems:link`
Давайте сделаем локалные копии гемов, нужных нашему приложению:
```
$>rake gems:freeze GEM=maruku
$>rake gems:freeze GEM=redcloth
```
У меня в папке `vendor/gems` появились папки `maruku-0.5.6` и `RedCloth-3.0.4`.
На этом все. Задавайте вопросы, читайте [документацию](http://www.noobkit.com/) и [книгу о рельсах](http://www.pragmaticprogrammer.com/titles/rails/).
Главное пишите код!
-------------------
PS. Пока писал последние строчки наткнулся на интересный [сайт со скринкастами](http://railscasts.com/) о рельсах. | https://habr.com/ru/post/12570/ | null | ru | null |
# Пишем установщик на WixSharp. Плюшки, проблемы, возможности
Каждый маломальский проект сталкивается с дистрибьюцией продукта. В нашем случае это коробочный вариант и так исторически сложилось, что мы предоставляем нашим заказчикам установщик, который должен сделать уйму всего в системе, тем самым упростив заказчику этап внедрения.
В первой своей реинкарнации это было решение из множества приложений, которые дергали друг друга и все это подавалось под соусом InnoSetup. Масштабировать функционал уже не представлялось возможным. И мы пришли к решению пересесть на "новые рельсы" и тут понеслось…
### Знакомство с Wix, а затем и WixSharp
Выбор пал на Wix. Но желающих писать xml скрипты Wix в команде не оказалось. Основной приоритет отдавали C#. И, ура, был замечен фреймворк называемый Wix# (WixSharp).
По Wix# написано немало статей в сети и есть интересный перевод статьи на Хабре. В каждой статье авторы пытаются донести свой уникальный опыт и помочь читателям с пользой воспользоваться материалом. Поэтому и мы решили поделиться своим опытом с вами.
Wix# позволяет реализовать большинство сценариев установки и обновления msi. Также, есть возможность дополнить функционал путем подключения wix расширений и описания новых сущностей Wix. Приятно было обнаружить возможность прикрутить WPF. Однако на начальном этапе мы приняли решение написать формы на WinForm. И в процессе мы выявили ряд важных моментов, про которые расскажем ниже.
### Особенности работы с WinForm
При проработке форм установщика мы поняли, что сделать простые, не перегруженные формы для наших потребностей невозможно. Поэтому каждая форма требовала лаконичного размещения контролов с учетом ограничений в размерах форм в msi.
Пример формыВ итоге по формам мы смогли более менее раскидать необходимый функционал. И его можно расширить, добавив еще пару-тройку новых форм. Но...
Первое, что стало бросаться в глаза при добавлении новых форм, это то, что отрисовка была с "запозданием". Наблюдалось мерцание форм при переходе от одной к другой. Происходило это при подгонке размеров контролов во вновь инициализированной форме под разрешение текущего экрана. В этом оказалось особенность работы с WinForm msi.
На данный момент мы остановились на этой реализации. А в ближайшее время запланировали переписать UI на WPF.
### Основной модуль
В основном модуле мы описываем все необходимые опции проекта. В примерах разработчика Wix# обычно это один модуль, в котором перечислена реализация всех опций. Выглядит это так:
```
var binaries = new Feature("Binaries", "Product binaries", true, false);
var docs = new Feature("Documentation", "Product documentation (manuals and user guides)", true);
var tuts = new Feature("Tutorials", "Product tutorials", false);
docs.Children.Add(tuts);
var project =
new ManagedProject("ManagedSetup",
new Dir(@"%ProgramFiles%\My Company\My Product",
new File(binaries, @"Files\bin\MyApp.exe"),
new Dir("Docs",
new File(docs, "readme.txt"),
new File(tuts, "setup.cs"))));
project.Binaries = new[]
{
new Binary(new Id("EchoBin"), @"Files\Echo.exe")
};
project.Actions = new WixSharp.Action[]
{
new InstalledFileAction("registrator_exe", "/u", Return.check, When.Before, Step.InstallFinalize, Condition.Installed),
new InstalledFileAction("registrator_exe", "", Return.check, When.After, Step.InstallFinalize, Condition.NOT_Installed),
new PathFileAction(@"%WindowsFolder%\notepad.exe", @"C:\boot.ini", "INSTALLDIR", Return.asyncNoWait, When.After, Step.PreviousAction, Condition.NOT_Installed),
new ScriptAction(@"MsgBox ""Executing VBScript code...""", Return.ignore, When.After, Step.PreviousAction, Condition.NOT_Installed),
new ScriptFileAction(@"Files\Sample.vbs", "Execute" , Return.ignore, When.After, Step.PreviousAction, "NOT Installed"),
new BinaryFileAction("EchoBin", "Executing Binary file...", Return.check, When.After, Step.InstallFiles, Condition.NOT_Installed)
{
Execute = Execute.deferred
}
};
project.Properties = new[]
{
new Property("Gritting", "Hello World!"),
new Property("Title", "Properties Test"),
new PublicProperty("NOTEPAD_FILE", @"C:\boot.ini")
}
project.GUID = new Guid("6f330b47-2577-43ad-9095-1861ba25889b");
project.ManagedUI = ManagedUI.Default;
project.UIInitialized += Project_UIInitialized;
project.Load += msi_Load;
project.AfterInstall += msi_AfterInstall;
```
В своем проекте у нас получилось гораздо больше различных опций и их реализаций. Поэтому мы разнесли все опции по модулям и получили лаконичный вид:
```
var project = new ManagedProject(ProjectConstants.PROJECT_NAME)
{
GUID = new Guid(ProjectConstants.PROJECT_GUID),
Platform = Platform.x64,
UpgradeCode = new Guid(ProjectConstants.PROJECT_GUID),
InstallScope = InstallScope.perMachine,
Description = ProjectConstants.COMPANY_NAME,
Language = "ru-RU",
LocalizationFile = @"WixUI_ru-ru.wxl",
ControlPanelInfo = productInfo,
MajorUpgradeStrategy = upgradeStrategy,
MajorUpgrade = majorUpgrade,
DefaultRefAssemblies = RefAssembliesGenerator.InitializeRefAssemblies(),
GenericItems = GenericEntitiesGenerator.InitializeGenericEntities(),
Properties = PropertiesGenerator.InitializeProperties(),
Dirs = DirsGenerator.InitializeDirs(),
Binaries = BinariesGenerator.InitializeBinaries(),
Actions = ActionsGenerator.InitializeActions(),
ManagedUI = new ManagedUI(),
ReinstallMode = "amus"
};
```
### Глобальные переменные msi
В нашем проекте мы столкнулись с необходимостью объявить не один десяток свойств (Property), которые, подобно глобальным переменным, могут использоваться практически во всех местах установки, как при работе с формами, так и при обработке Custom Action.
Обращение к этим переменным происходит по их имени в текстовом виде. Например, объявив свойство `new Property("Gritting", "Hello World!")` в конструкторе проекта, далее, чтобы получить к этому свойству доступ, например, из диалога, нужно обратиться к `Runtime.Session["Gritting "]`
Такое обращение к переменным требовало от разработчика помнить, как называется нужное ему свойство и в случае некорректного значения, ошибка была бы обнаружена только в runtime и при отработке именно того куска кода, где была допущена опечатка.
В итоге мы решили переместить все свойства и их значения в enum и упростить работу с чтением и записью этих свойств. Объявление свойств стало выглядеть следующим образом:
```
public enum eProperties
{
[Value("Hello World!"))]
GRITTING,
[Value("Properties Test "))]
TITLE,
// перечисление других свойств
}
```
А сама генерация свойств на основе enum так:
```
public static class PropertiesGenerator
{
private static Property InizializeProperty(string propertyName, string propertyValue)
{
return new Property(new Id(propertyName), propertyName, propertyValue) { IsDeferred = true };
}
private static IList ToTypedList(Type entityType, Func createFunc)
{
if (createFunc != null
&& entityType.IsEnum)
{
return Enum.GetValues(entityType)
.Cast()
.Select(createFunc)
.ToList();
}
return null;
}
public static Property[] InitializeProperties()
{
return ToTypedList(typeof(eProperties),
e => InizializeProperty(e.ToString(), e.GetPropertyValue()))
.ToArray();
}
}
```
Обращение к свойствам из диалога тоже изменилось. На чтение стало `this.GetData(GRITTING)`, а на запись`this.SetData(GRITTING, “New value”)`, где GetData() и SetData() методы расширения для класса ManagedForm.
Для обращения из Custom Action стало `session.Data(GRITTING)`
### MSI нужны зависимые библиотеки
В ходе работы над установщиком у нас появилась необходимость подключать дополнительные библиотеки (например для работы с СУБД Postgre). Сначала мы подключали все ручками, как было описано в документации Wix#:
```
project.DefaultRefAssemblies.Add("FontAwesome.Sharp.dll");
project.DefaultRefAssemblies.Add("Newtonsoft.Json.dll");
project.DefaultRefAssemblies.Add("ManagedOpenSsl.dll");
```
Однако из-за того, что стало возрастать количество зависимостей в проекте, мы решили не делать точечное добавление библиотек, а написали метод, который считывает список всевозможных dll из указанного ресурса:
```
private static List GetResourceList(string resourcesDirPath) =>
Directory.GetFiles($@"{resourcesDirPath}\")
.Where(file => file.EndsWith("dll"))
.ToList();
public static List InitializeRefAssemblies() =>
GetResourceList(Application.StartupPath)
.Concat(GetResourceList("Resources"))
.ToList();
```
### Инициализация каталогов
C добавлением каталогов все оказалось, более или менее, очевидно и понятно. Указываем иерархию каталогов с добавлением в них необходимых артефактов и, по необходимости, фильтруем файлы по названиям и расширениям:
```
private static bool ServicePredicate(string file) => !file.EndsWith(".pdb");
private static IEnumerable InitializeDirWixEntities(object dirName)
{
var items = new List();
items.AddRange(new List
{
new Dir("logs"),
new DirFiles($@"Sources\{dirName}\\*.\*", ServicePredicate)
});
return new[] { new Dir(dirName.ToString(), items.ToArray()) };
}
private static WixEntity[] InilizeDirItems() =>
new List()
.Concat(InitializeDirWixEntities(FirstService))
.Concat(InitializeDirWixEntities(SecondService))
.Concat(InitializeDirWixEntities(ThirdService))
.Concat(InitializeDirWixEntities(FourthService))
.ToArray();
public static Dir[] InitializeDirs() =>
new[]
{
new Dir(@"%ProgramFiles%\CompanyName\",
new Dir("distr",
new Dir(FluentMigrator, GetMigratorFileList("FluentMigrator")),
),
new Dir("app", InilizeDirItems())
)
};
```
### Развертывание сайтов на IIS
Одна из задач нашего установщика - это развернуть определенное количество сайтов/сервисов на IIS, при этом должна учитываться возможность включения https с указанием сертификата ssl. Из коробки Wix# такого не умел (до выпуска версии 1.14.3). Поэтому была описана кастомная сущность Wix, которая использовала расширение WixExtension.Iis.
Базовый класс, описывающий Wix сущность для создания сайта на IIS:
```
public abstract class IISWebSite: WixEntity, IGenericEntity
{
[Xml]
public string Condition;
[Xml]
public string Description;
[Xml]
public string IpAddress;
[Xml]
public string Port;
protected string Prefix { get; }
protected XElement Component { get; private set; }
protected string DirId { get; private set; }
protected string DirName { get; private set; }
protected string WebAppPoolId { get; private set; }
protected IISWebSite(string prefix)
{
Prefix = prefix;
}
public virtual void Process(ProcessingContext context)
{
context.Project.Include(WixExtension.IIs);
DirId = context.XParent.Attribute("Id").Value;
DirName = context.XParent.Attribute("Name").Value;
var componentId = $"{DirName}.{Prefix}.Component.Id";
Component = new XElement(XName.Get("Component"),
new XAttribute("Id", componentId),
new XAttribute("Guid", WixGuid.NewGuid(componentId)),
new XAttribute("KeyPath", "yes"));
context.XParent.Add(Component);
Component.Add(new XElement("Condition", new XCData(Condition)));
WebAppPoolId = $"{DirName}.{Prefix}.WebAppPool.Id";
Component.Add(new XElement(WixExtension.IIs.ToXName("WebAppPool"),
new XAttribute("Id", WebAppPoolId),
new XAttribute("Name", $"AppPool{Description}")
));
}
}
```
Далее класс-наследник, для cоздания сайта с подключением по http:
```
public sealed class IISWebSiteHttp : IISWebSite
{
public IISWebSiteHttp() : base("Http")
{
}
public override void Process(ProcessingContext context)
{
base.Process(context);
Component.Add(new XElement(WixExtension.IIs.ToXName("WebSite"),
new XAttribute("Id", $"{DirName}.{Prefix}.WebSite.Id"),
new XAttribute("Description", Description),
new XAttribute("Directory", DirId),
new XElement(WixExtension.IIs.ToXName("WebAddress"),
new XAttribute("Id", $"{DirName}.{Prefix}.WebAddress.Id"),
new XAttribute("IP", IpAddress),
new XAttribute("Port", Port),
new XAttribute("Secure", "no")
),
new XElement(WixExtension.IIs.ToXName("WebApplication"),
new XAttribute("Id", $"{DirName}.{Prefix}.WebSiteApplication.Id"),
new XAttribute("WebAppPool", WebAppPoolId),
new XAttribute("Name", $"AppPool{Description}"))
));
}
}
```
И класс-наследник для создания сайта с подключением по https и с возможностью привязки сертификата ssl:
```
public sealed class IISWebSiteHttps : IISWebSite
{
private readonly bool _haveCertRef;
public IISWebSiteHttps(bool haveCertRef) : base(haveCertRef ? "HttpsCertRef" : "Https")
{
_haveCertRef = haveCertRef;
}
public override void Process(ProcessingContext context)
{
base.Process(context);
var siteConfig = new XElement(WixExtension.IIs.ToXName("WebSite"),
new XAttribute("Id", $"{DirName}.{Prefix}.WebSite.Id"),
new XAttribute("Description", Description),
new XAttribute("Directory", DirId),
new XElement(WixExtension.IIs.ToXName("WebAddress"),
new XAttribute("Id", $"{DirName}.{Prefix}.WebAddress.Id"),
new XAttribute("IP", IpAddress),
new XAttribute("Port", Port),
new XAttribute("Secure", "yes")
),
new XElement(WixExtension.IIs.ToXName("WebApplication"),
new XAttribute("Id", $"{DirName}.{Prefix}.WebSiteApplication.Id"),
new XAttribute("WebAppPool", WebAppPoolId),
new XAttribute("Name", $"AppPool{Description}")));
if (_haveCertRef)
{
siteConfig.Add(new XElement(WixExtension.IIs.ToXName("CertificateRef"),
new XAttribute("Id", IISConstants.CERTIFICATE_ID)));
}
Component.Add(siteConfig);
}
}
```
Все параметры сайта указываются на формах и передаются через глобальные переменные в новый экземпляр объекта.
Через некоторое время в релиз Wix# добавили схожее расширение. Но, в отличии от реализации во фреймворке, наше расширение позволяет менять протокол у сайтов и делать привязку сертификата ssl.
Инициализация наших объектов получилась следующая:
```
new List
{
new IISWebSiteHttp
{
Condition = HttpSiteCondition, Description = siteName,
IpAddress = ipAddress,
Port = port
},
new IISWebSiteHttps(false)
{
Condition = HttpsSiteWithoutCertCondition, Description = siteName,
IpAddress = ipAddress,
Port = port
},
new IISWebSiteHttps(true)
{
Condition = HttpsSiteWithCertCondition, Description = siteName,
IpAddress = ipAddress,
Port = port
}
}
```
### Создаем БД из msi
В предыдущей версии установщика, создание/обновление БД делало внешнее приложение. Так как Wix# позволяет запускать свои Custom Action, мы решили добавить возможность создания и обновления БД прямо в msi.
В формах заносятся первичные данные по БД (провайдер, адрес сервер, название) и в Custom Action передаются эти данные через глобальные переменные:
```
[CustomAction]
public static ActionResult ExecMigratorRunner(Session session)
{
var workDir = session.Data(MIGRATOR_FILE_DIR);
var appCmdFile = $@"{workDir}{session.Data(MIGRATOR_FILE_NAME)}";
var args = session.Data(MIGRATOR_ARGS);
return ProccessHelper.RunApplication(appCmdFile, args);
}
```
Опытный читатель, скорее всего, спросит, почему не использовали коробочные решения Wix#? Например такое:
```
var project = new Project("MyProduct",
new Dir(@"%ProgramFiles%\My Company\My Product",
new File(@"Files\Bin\MyApp.exe")),
new User("James") { Password = "Password1" },
new Binary(new Id("script"), "script.sql"),
new SqlDatabase("MyDatabase0", ".\\SqlExpress", SqlDbOption.CreateOnInstall,
new SqlScript("script", ExecuteSql.OnInstall),
new SqlString("alter login Bryce with password = 'Password1'", ExecuteSql.OnInstall)
)
);
```
Все просто. В нашем проекте используется Fluent Migrator. И для разворачивания новой БД нужна только собранная библиотека, которую нужно вызвать через командную строку с параметрами, содержащими информацию по создаваемой БД. А поддержка различных провайдеров СУБД ложится уже на саму библиотеку.
Сценарий обновления БД реализуется по всем канонам накатывания миграций.
### Какой еще функционал мы реализовали?
* Назначение прав доступа на папки приложения. Через CustomAction, т.к. коробочное решение раздает права в определенные момент установки, и мы не нашли возможности переиспользовать наработки Wix.
* Добавление пользователей БД и СУБД (через CustomAction, по тем же причинам).
* Добавление сертификата ssl в локальное хранилище.
* Привязка вновь добавленных сертификатов ssl к сайтам на IIS (через CustomAction).
* Принудительный запуск сайтов на IIS (через CustomAction).
* Обновление старой версии БД (до внедрения Fluent Migrator) путем запуска скрипта t-sql (через CustomAction).
* Проверка соединения с сервером БД (на форме).
* Проверка соединения с сервером RabbitMQ (на форме).
* Проверка сайтов и их адресов на уникальность на текущей IIS (на форме).
* Проверка необходимых компонентов на текущей машине (на форме).
### А как же обновление?
Да. Без этого сценария, установщик для нас и заказчиков стал бы бесполезным.
Мы рассмотрели различные варианты обновлений доступных через msi и остановились на major upgrade. Нам нет необходимости хранить устаревшие исполняемые файлы и, например, выпускать патчи. Нас устроил вариант с полным удалением старой версии ПО и установкой новой версии.
Wix# из коробки позволяет сделать достаточно неплохую схему обновления. Но, в нашем случае, все-таки пришлось добавить несколько своих событий.
Во-первых, мы сделали сохранение глобальных переменных в реестр в зашифрованном виде, чтобы была связь с предыдущей установкой. Это дало возможность отображать ранее введенные данные в формах по установленной версии.
Далее добавили собственную проверку установленной версии продукта, для совместимости с предыдущими версиями установщика (приложения установленные через InnoSetup не определялись msi как тот же продукт).
И защитили БД от удаления в режиме обновления.
### Какие у нас планы по расширению функционала?
* Конфигурирование очередей на сервере RabbitMQ.
* Разворачивание сервиса на IIS, написанного на Python.
* Реализовать режим Modify средствами msi (возможность изменить введенные ранее в установщике настройки приложения).
* Переписать UI c WinForms на WPF.
Надеемся, что наш опыт будет полезен и ждем ваши вопросы и комментарии по нашей реализации. | https://habr.com/ru/post/543032/ | null | ru | null |
# Установка для монтажа изделий электронной техники
Привет, Хабр!
Предлагаю вашему вниманию первую из серии статей о производстве установок для присоединения кристаллов и поверхностного монтажа для многокристальной и многоуровневой сборки изделий электронной техники.
Установка для монтажа изделий электронной техникиРабота подобной установки:
Видео роликиDisclaimer: Все написанное в этой и последующих статьях не является рекламой, основано исключительно на личном опыте работы и имеет целью ознакомление заинтересованных читателей с основами построения системы управления упомянутых установок.
Меня зовут Дмитрий, мне 41 год, последние 7 лет работаю в Германии на одной из фирм, производящих оборудование, указанное в 1м абзаце. Являюсь тимлидом группы, занимающейся разработкой встроенного программного обеспечения для контроллера управления фирмы Elmo Motion Control на языке С++. А также в рамках магистерской диссертации разрабатывал методы распознавания изображений (электронных компонентов) в системах технического зрения. Возможно, в одной из статей освещу и эту тему.
Вот сам контроллер:
Master-контроллер Platinum Maestro фирмы Elmo<https://www.elmomc.com/product/platinum-maestro/>
Platinum Maestro является контроллером, обеспечивающим интерфейс доступа к внутренней сети управления машиной для управляющей программы из внешней TCP/IP сети.
Внутренняя сеть - шина EtherCAT, обеспечивает обмен данными управления и обратной связи между master-контроллером и slave-контроллерами приводов (драйверами), модулями аналоговых и цифровых портов ввода-вывода.
Отдельно о шине EtherCAT можно посмотреть здесь:
Видео, ссылкаа также на <https://ru.wikipedia.org/wiki/EtherCAT>
Под интерфейсом доступа понимается программная библиотека c API от Elmo, модули которой обеспечивают трансляцию переданных вызывающей программой входных данных в команды управления устройствами на шине. Библиотека написана на языке С/С++ и поставляется Elmo в виде динамических библиотек в двух вариантах – для Windows и Linux. Версия под Linux используется для создания программ как на базе внешнего по отношению к master-контроллеру x86 под управлением ОС Linux, так и для запуска на самом master-контроллере Platinum Maestro.
Для знакомых с TwinCAT или Codesys – Platinum Maestro является (самым) компактным промышленным компьютером для выполнения тех же самых функций – конфигурирования топологии шины EtherCAT и управления устройствами на ней в реальном времени. Плюсом является интеграция в корпус любой даже самой требовательной к габаритам установки и собственная алгоритмическая база для обеспечения интеллектуального смешивания движений, наложенных движений, сплайнового профилирования многоосевых движений с высокой точностью, – встроенная и поставляемая сразу без дополнительных условий (или докупаемых модулей) вместе с контроллером. Кроме С++ доступна библиотека для .NET, модули для интеграции в MATLAB Simulink, собственная среда разработки и удаленной отладки программ на С++ на базе Eclipse, примеры программирования и колоссально отзывчивая техническая поддержка. Это не реклама, а опыт взаимодействия.
Интерфейс программы для настройки топологии сети EtherCAT и устройств к ней подключенных будет темой одной из последующих статей. Называется программа Elmo Application Studio II, или EASII, и аббревиатура действительно соответствует ожиданиям – она проста и одновременно удивительно функциональна.
Пока что мне хотелось бы сконцентрироваться на библиотеке для управления (уже сконфигурированной) установкой.
Для начала, что установка из себя представляет с точки зрения топологии подключения устройств управления и контроля.
Пример топологии сети установки с 1-го фотоРозовым цветом выделена внутренняя шина EtherCAT, зеленым – внешняя TCP/IP.
В левой части между этими шинами – master-контроллер, связанный с ними обеими. В левом нижнем углу – компьютер с интерфейсом пользователя.
Теперь подробнее о библиотеке, обеспечивающей доступ к устройствам на шине EtherCAT.
1. [Архив скачивается с официального сайта](https://www.elmomc.com/products/application-studio/download-resource-center/)
2. После разархивирования вы получаете папку includes с заголовочными файлами С++, и две папки с бинарными файлами библиотеки – lib и libwin32.
Теперь можно отобразить простейший код подключения к master-контроллеру Maestro Platinum:
```
// Windows:
CMMCConnection m_cConn;
MMC_CONNECT_HNDL m_gConnHndl;
m_gConnHndl = m_cConn.ConnectRPCEx("192.168.35.10", "192.168.35.4", 0x7fffffff,
reinterpret_cast(CallbackFunc));
```
```
// Linux:
m_gConnHndl = m_cConn.ConnectIPCEx(0x7fffffff, reinterpret_cast(CallbackFunc));
```
Под Windows: первый IP-адрес является адресом master-контроллера на стороне TCP/IP, второй - адресом сетевой карты компьютера, подключенной к той же шине.
Под Linux: указание IP адресов не требуется.
Это чуть ли не единственное место во всей программе, где потребовалось указать под какой операционной системой происходит обращение к функциям библиотеки. Весь остальной код моей достаточно большой программы – переносимый без дополнительных трудозатрат.
Функция обратного вызова CallbackFunc – нужна для обратной связи и получения информации об асинхронных событиях, генерируемых библиотекой. Хотя есть и более удобный инструмент – возможность зарегистрировать функции обратного вызова для основных событий по отдельности. Делается это так:
```
m_cConn.RegisterEventCallback(MMCPP_HOME_ENDED, (void*)HomeEnded_Received);
m_cConn.RegisterEventCallback(MMCPP_MOTIONENDED, (void*)MotionEnded_Received);
m_cConn.RegisterEventCallback(MMCPP_FB_NOTIFICATION, (void*)FBNotifyEvent_Received);
m_cConn.RegisterEventCallback(MMCPP_PDORCV, (void*)PDO_Received);
m_cConn.RegisterEventCallback(MMCPP_HBEAT, (void*)HeartBeat_Received);
m_cConn.RegisterEventCallback(MMCPP_EMCY, (void*)EmergencyEvent_Received);
m_cConn.RegisterEventCallback(MMCPP_MODBUS_WRITE, (void*)ModbusWrite_Received);
m_cConn.RegisterEventCallback(MMCPP_ASYNC_REPLY, (void*)AsyncReplyEvent_Received);
m_cConn.RegisterEventCallback(MMCPP_GLOBAL_ASYNC_REPLY, (void*)GlobalAsyncReply_Received);
m_cConn.RegisterEventCallback(MMCPP_TOUCH_PROBE_ENDED, (void*)TouchProbeEndEvent_Received);
m_cConn.RegisterEventCallback(MMCPP_NODE_ERROR, (void*)NodeErrorEvent_Received);
m_cConn.RegisterEventCallback(MMCPP_STOP_ON_LIMIT, (void*)StopOnLimit_Received);
m_cConn.RegisterEventCallback(MMCPP_TABLE_UNDERFLOW, (void*)TableUnderflowEvent_Received);
m_cConn.RegisterEventCallback(MMCPP_NODE_CONNECTED, (void*)NodeConnectedEvent_Received);
m_cConn.RegisterEventCallback(MMCPP_NODE_INIT, (void*)NodeInitEvent_Received);
m_cConn.RegisterEventCallback(MMCPP_POLICY_ENDED, (void*)PolicyEndedEvent_Received);
```
Где, например, первая – вызывается, когда любой из моторов выполнит команду поиска нуля:
```
void HomeEnded_Received(unsigned short usAxisRef, short sErrCode,...)
{
ldbg << "home ended for axis " << usAxisRef << endl;
//.....
}
```
Single Axis Motion
------------------
Теперь возникает вопрос – что дальше? Вам нужно включить воображение, и представить, что на шине EtherCAT «висит» контроллер управления сервоприводом от Elmo, например КМ1 в левом верхнем углу нашей диаграммы. Выглядит он так - <https://www.elmomc.com/servo-drives/> или любого другого производителя. Вы хотите выполнить одномерное движение - заставить этот мотор переместить управляемый им объект из положения А (сейчас) в положение Б (новая координата) с какой-то скоростью. В установке это будет равносильно перемещению, например, инструмента из левого положения в правое в рабочем пространстве.
```
MMC_MOVEABSOLUTEEX_IN in;
MMC_MOVEABSOLUTEEX_OUT out;
in.dAcceleration = m_ParamsMoveUU.dAcceleration;
in.dDeceleration = m_ParamsMoveUU.dDeceleration;
in.dJerk = m_ParamsMoveUU.dJerk;
in.dVelocity = m_ParamsMoveUU.dVelocity;
in.dbPosition = PositionToUU(target);
in.eBufferMode = m_ParamsMoveUU.eBufferMode;
in.eDirection = m_ParamsMoveUU.eDirection;
in.ucExecute = 1;
int rc = getGmasController()->wrp_MMC_MoveAbsoluteExCmd(*this, ref, ∈, &out);
if (rc != 0)
{
if (out.usErrorID == 1009) // already there
{
MotorRunning(0);
EVENT->Trigger_MotionEnded(ref, true);
m_smHelper->SetSubState(2,st_DONE);
return st_DONE;
}
else
{
GMASERROR(out.usErrorID);
return st_ERROR;
}
}
```
Где MMC\_MOVEABSOLUTEEX\_IN – структура с параметрами команды, задающими новую координату, максимальную скорость, ускорение – в единицах, указанных при конфигурировании системы.
MultiAxis Vector Motion
-----------------------
Однако, вся мощь контроллера Platinum Maestro проявляется в обработке серии команд на перемещение объекта, положение которого зависит от группы моторов. Как правило, это инструмент, выполняющий какую-то работу, в нашем случае монтаж электронного компонента. Каждая из таких команд задает новую координату объекта в пространстве. В этом случае программист может в цикле передать в библиотеку несколько точек траектории, с указанием скорости и ускорения для каждого отрезка траектории. Размерность передаваемых координат точки соответствует количеству моторов, выполняющих команду.
Таким образом, код подготовки команды для движения группы осей будет отличаться от команды для одномерного движения только тем, что каждая координата in.dbPosition – это вектор состоящий из координат каждой из осей группы, а параметры in.dVelocity, in.dAcceleration и т.п. – скорость и ускорение перемещаемого объекта. Встроенный алгоритм контроллера рассчитает линейную скорость каждой из осей так чтобы соблюсти заданные условия и обеспечить плавное движение объекта, в том числе при огибании точек траектории.
```
// v_Trajectory - вектор
//
for (size_t idx=0; idx < v_Trajectory.size(); idx++)
{
cMMC_MOTIONPARAMS_GROUP par = v_Trajectory[idx];
MMC_MOVELINEARABSOLUTE_IN in;
MMC_MOVELINARABSOLUTE_OUT out;
in.fAcceleration = par.fAcceleration;
in.fDeceleration = par.fDeceleration;
in.fVelocity = par.fVelocity;
in.fJerk = par.fJerk;
// how to interpolate the corners?
in.eTransitionMode = MC_TM_CORNER_DIST_CV_POLYNOM5;
in.eBufferMode = MC_BLENDING_LOW_MODE;
in.ucSuperimposed = 0;
in.eCoordSystem = MC_MCS_COORD;
for (int i = 0; i < v_group.size(); ++i)
{
in.dbPosition[i] = par.dEndPoint[i];
in.fTransitionParameter[i] = par.fTransitionParameter[i];
}
int rc = getGmasController()->wrp_MMC_MoveLinearAbsoluteCmd(*this, getAxisRef(), ∈, &out);
if (rc != 0)
{
// ERROR
}
}
```
В листинге выше происходит вызов функции MMC\_MoveLinearAbsoluteCmd() в цикле по количеству точек траектории. Вложенный цикл задает вектор пространственных координат in.dbPosition. Несколько параметров задают способ огибания углов в точках перелома.
К слову, EASII позволяет моделировать пространственное движение, как на картинке ниже.
Панель Path Editor из программы EASIIУ пытливого читателя возникнет вопрос, кто задает координаты для каждой последующей команды? Откуда они берутся в программе, запущенной на встроенном контроллере?
Лирическое отступление о программном комплексе управления
---------------------------------------------------------
Без объяснения этого момента все последующее описание функций библиотеки Elmo будет казаться сухой инструкцией. Тогда как я бы хотел, чтобы читатели понимали Для Чего эти функции вообще нужны и образно представляли результат их вызова.
В общем случае, установка, работающая в автоматическом режиме сутки напролет, должна быть обеспечена пользовательским интерфейсом, задающим параметры циклически повторяющегося процесса монтажа. Для универсальной установки каждый шаг процесса определяется тем, что за продукт вы хотите получить, из каких исходных электронных компонентов, и какие условия сборки хотите обеспечить. Здесь не обойтись без сложного программного комплекса, обеспечивающего пользователю:
* составление процесса из разветвленного дерева конфигурируемых шагов
* для каждого шага процесса - выбор из доступных способов монтажа с выбором параметров – источник компонентов и плат (конвейер, ленты с SMD, кремниевая пластина с кристаллами и т. п.), температура пайки, наличие катализаторов, усилия прижима, график приложения всех этих воздействий и т. п.,
* выбор из базы доступных электронных компонентов с указанием особенности монтажа и ограничений для каждого из них,
* интерфейс обучения системы технического зрения - алгоритмов распознавания различных визуальных паттернов и меток отдельно для каждого шага, автоматический пересчет полученных точек на изображении в системе координат установки, и затем – в системе координат моторов,
* передача адекватных команд моторам для их перемещения, параллельно отработка сигналов и управление дополнительными устройствами, участвующими в процессе (устройств поддерживающих воздействия – нагреватели, вакуумные вентили, вентили газа, регуляторы прижима и т.п.)
* учет использованных ресурсов и компонентов – с хранением в глобальной базе данных предприятия, зачастую по промышленным стандартам.
Программный комплекс должен обеспечивать интерфейс для настройки всех компонентов системы и отслеживание параметров воздействий в процессе сборки, обработку ошибок.
Такие комплексы разрабатываются годами, являются гордостью производителей и в совокупности с определенными аппаратными решениями защищены патентами.
Возвращаясь к вопросу, одна из функций программного комплекса – хранение данных о системе координат установки. Если вы видите где-то в окне программы координату XYZ, это не обязательно те же самые координаты, которыми оперирует библиотека Elmo. (Она в свою очередь «видит» только те координаты, которые может считать с датчиков положения самих приводов – соответствующие входы для подключения датчиков есть у драйвера, а он их передает мастеру по шине EtherCAT). То есть, систему координат установки надо как-то соотнести с координатами, в которых работают контроллеры. Вообще, расчет координат довольно сложная тема сама по себе, ведь кроме абсолютной общей системы координат рабочего пространства установки есть еще и несколько вложенных. Например, кристаллы, расфасованные в трее или до фасовки - на сепарированной кремниевой пластине, будут иметь координаты, привязанные к трею/пластине, а они в свою очередь – будут иметь координаты в системе установки. При этом каждый кристалл будет иметь метки в системе координат кристалла. Поэтому перемещение нашего объекта (инструмента с вакуумным каналом для захвата кристалла) в центр кристалла из произвольной точки рабочего пространстве установки будет выполняться в несколько этапов:
1. уточнение координат меток кристалла с помощью камеры, передающей снятое изображение алгоритму распознавания,
2. пересчет координат камеры в момент снятия изображения в координаты относительно трея или кремниевой пластины, которые также имели свои координаты в тот же момент съемки,
3. вычисление положения и угла поворота кристалла по изображению,
4. пересчет результата в системе координат установки,
5. трансформация в систему координат каждой из осей,
6. подготовка безопасной траектории перемещения инструмента (как минимум, подход к кристаллу должен выполняться сверху, а не сбоку или по касательной), обход потенциальных столкновений,
7. касание и захват кристалла включением вакуума,
8. поднятие кристалла и перенос его к камере, для уточнения координат по меткам снизу,
9. перенос кристалла к месту монтажа по тому же принципу.
К слову, оценка вертикальной координаты кристалла или места монтажа выполняется как правило по фокусному расстоянию камеры, координаты которой известны.
Таким образом, программный комплекс с откалиброванными камерами и встроенной системой пересчета координат – должен быть в состоянии рассчитать траекторию движения инструмента на любом шаге процесса.
В моем случае передача координат на каждом шаге процесса происходит по внутреннему протоколу обмена командами между программным комплексом установки и master-контроллером по TCP/IP. По сути, программа запущенная на master, является посредником, транслирующим команды, полученные от ПК, во внутреннюю сеть EtherCAT посредством программного интерфейса Elmo, и осуществляющем контроль их выполнения самими устройствами. Например, команда от ПК «перемести стол с кремниевой пластиной в положение X`Y`» раскладывается в master-контроллере на составляющие – какие моторы участвуют, в каком они положении сейчас, какие функции API для этого нужно вызвать, с какими параметрами, дождаться выполнения и рапортовать обратно о выполнении.
Кроме этого, программа на master-контроллере обеспечивает соблюдение параметров воздействий, контроль которых возможен только в системе реального времени, которой Windows не является. Например, обеспечение давления на кристалл во время пайки по определенному графику возможно только на стороне master-контроллера. Когда приходит очередь этого шага процесса – параметры воздействия передаются программе контроллера по TCP/IP, и она запускает PID регулятор. Давление на кристалл обеспечивается передачей контроллеру оси Z команды на перемещение вниз (для усиления давления) или вверх. Роль пружины играет вся механическая система – люфты сборки, подложка, датчик силы. Ошибка на доли микрометра может сломать кристалл.
Что будет дальше
----------------
Чтобы подогреть интерес, выложу примерную схему взаимодействия модулей программы master-контроллера.
Обратите внимание на те же две шины, они на этой диаграмме внизу.
Примеры объектов, с которыми приходится иметь дело - ниже.
Трей с кристалламиКремниевая пластина### Предпосылки технического отставания России после разделения мира на зоны
Теперь ~~кратко~~ (кратко не получилось) о том, зачем я затеял создание серии статей на эту тему. Это попытка ответить самому себе на следующие вопросы.
Можно ли повысить долю собственных роботизированных систем среди ежегодно устанавливаемых в России, а также повысить в целом их количество? [Навеяно этой статьей](https://habr.com/ru/company/ruvds/blog/591905/). К сожалению, поиск в тексте по комбинации «Росс» не дал результатов. Это более чем печально.
**Можно ли задействовать высокий интеллектуальный потенциал российских программистов и перетянуть специалистов из области, направленной на оцифровку людей и банковских данных**, в область оцифровки **экономики, промышленности** и создание новых рабочих мест в области производства автоматических роботизированных систем? Мне кажется, это в перспективе должно оказаться гораздо более прибыльным делом и стратегически оправдано. По-моему, мы достаточно потренировались на улицах, автострадах и в банках. Я думаю, нет смысла детально расписывать кадровый пылесос, устроенный последнее время крупными, в т.ч. отечественными, цифровыми гигантами, деятельность которых далеко не всегда направлена на благо для нашего государства.
Дальнейшее окукливание и цементирование оболочки цифрового контроля выродится в ситуацию, когда мы разучимся (так и не научившись) делать что-либо свое кроме бесконечных алгоритмов сбора и обработки биг-дата, с неизменной 100%-й зависимостью на аппаратном уровне от иностранных поставщиков. Мы разучимся окончательно поднимать попу из-за стола с компьютером и производить что-либо кроме цифровых продуктов, работающих на чужой аппаратной базе.
Мир меняется, границы закрываются. В нашем евроазиатском регионе утвердится в качестве промышленного (а следовательно, и социального, идеологического, религиозного, **военного**, и т. п.) лидера тот, кто имеет преимущество не в системах контроля за собственным населением, а в системах производства промышленного оборудования и автоматизированных беспилотных средств вооружения. И пока часть интеллекта китайских товарищей направлена на оцифровку себя, у нас остался последний шанс занять хоть какую-то нишу в производстве робототехники. Конкурентен и независим от внешнеполитической конъюнктуры в новом мире будет тот, кто в состоянии обеспечить всю цепочку производства товаров, а не только цифровую ее часть. Сегодня на нас давит США. Завтра нам будет выламывать руки и ставить условия любой региональный монополист, Германия, да или хотя бы Китай, если 90% электроники, а также / или даже львиная доля оборудования для ее производства будет импортироваться. Невозможно говорить об импортозамещении процессоров, если сами процессоры литографируются не у нас, а в Корее. Невозможно говорить и об импортозамещении компьютеров, если вы собираете их на импортных машинах сборки материнских плат, пусть даже устанавливаете на них «свои» процессоры.
Master-контроллер, про который я рассказываю в этой статье, тоже не российский, а израильский. Но с чего-то надо начинать, и сборка машин на нашей территории позволит от ввоза цельных систем с высокой добавленной стоимостью перейти ко ввозу комплектующих для них. А затем и дроблению производства, и постепенному импортозамещению самих комплектующих. Дойдет дело и до контроллеров.
Отдельно нужно сказать о наработанных алгоритмах распознавания изображений. Есть хорошие алгоритмы? Направьте их мощь в «мирное» русло распознавания электронных компонентов, маркеров позиционирования на процессорах и печатных платах, штрих-кодов продуктов и компонентов. Там поле непаханое, знаю по опыту работы. Каждая фирма разрабатывает свои алгоритмы, трясясь над их сохранностью, преемственностью и защищенностью от конкурентов. Некоторые из специальных библиотек, например Halcon, продаются с лицензией на рабочее место за хорошие деньги. Беда для нас в том, что все эти библиотеки – зарубежные. Из свободно распространяемых далеко не всегда можно составить конкурентный алгоритм, как по времени его работы, так и по качеству получаемых данных, да и по объему ресурсов на разработку конечного продукта. Обратите внимание, речь идет не об отбраковке товаров, распознавании лиц, рукописных бланков, номеров машин или QR-кодов. Речь идет о создании алгоритмов и установок, позволяющих позиционировать электронные компоненты с точностью **до долей микрон** в **механических** системах под управлением системы технического зрения в реальном времени. Разработка медицинского оборудования находится на том же уровне технологических достижений. В этой области мы тоже зависим от импорта.
Я знаю пару компаний, производящих установки для присоединения кристаллов и монтажа выводов, находящихся, например, в Беларуси. Как вы думаете, долго ли они протянут, если часть комплектующих и программных модулей, закупаемых на западе, окажутся под расширяющимся санкционным давлением? Далеко ли до блокировки поставок аналогичных товаров или целых систем в Россию? | https://habr.com/ru/post/593433/ | null | ru | null |
# Балансировка S3 хранилища с помощью GoBetween+VRRP
Используя Ceph для хранения бэкапов c помощью их S3-совместимого хранилища RadosGW, мы пришли к тому, что один radosGW не справляется с возложенной на него нагрузкой и решили, что пора бы его разбалансировать с сопутствующей отказоустойчивостью. В итоге пришли к решению балансировки с помощью GoBetween (очень лёгкий L4 балансировщик, подробнее на [gobetween.io](https://gobetween.io)), а отказоустойчивость организовали с помощью VRRP.
Вышла такая схема:
1. master нода vrrp получает поток данных по http(s);
2. gobetween раскидывает весь трафик на себя же и backup ноду vrrp;
3. radosgw в свою очередь пишут непосредственно в ceph;
4. в случае падения master ноды vrrp, backup нода берёт всю нагрузку на себя до тех пор, пока мастер не поднимется
Нашу реализацию данного действа читайте ниже
**Дано:**
1. Кластер Ceph (Jewel)
* IP мониторов: 10.0.1.1, 10.0.1.2, 10.0.1.3
2. Два железных сервера (CentOS)
* Первый сервер 10.0.0.1 (назовём его gbt1.example.com)
* Второй сервер 10.0.0.2 (gbt2.example.com)
* Общий IP будет 10.0.0.3 (s3.example.com)
3. Домен example.com
**Задача:**
Сделать балансировку с отказоустойчивостью для S3 хранилища, организованному с помощью RadosGW
**Этапы:**
1. Развернуть RadosGW на двух серверах
2. Организовать отказоустойчивость с поомщью VRRP
3. Организовать балансировку S3 трафика с помощью GoBetween
4. Проверить
### Подготовка (на обеих машинах всё идентично)
На серверах установлен CentOS 7.4, сразу после установки ОС обновим всё:
```
# yum -y update
```
Установим весь софт, который нам потребуется по ТЗ (кроме самого ceph, ибо сначала ставится только его репозиторий):
```
# yum -y install keepalived centos-release-ceph-jewel wget
```
В данный момент у нас ещё не установлен Ceph, поэтому установим его:
```
# yum -y install ceph-radosgw
```
Сразу настроим фаерволл, окрыв нужные порты и разрешив сервисы:
```
# firewall-cmd --permanent --add-port=18080/tcp
# firewall-cmd --direct --permanent --add-rule ipv4 filter INPUT 0 --in-interface enp2s0 --destination 224.0.0.18 --protocol vrrp -j ACCEPT
# firewall-cmd --direct --permanent --add-rule ipv4 filter OUTPUT 0 --out-interface enp2s0 --destination 224.0.0.18 --protocol vrrp -j ACCEPT
# firewall-cmd --permanent --add-port=10050/tcp
# firewall-cmd --reload
```
Выключим SELinux (на всякий случай):
```
# sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/sysconfig/selinux
# setenforce 0
```
### Разворачиваем RadosGW
Изначально кластер Ceph уже поднят, думаю, подробностей касаться мы тут не будем, тема не этой статьи, сразу перейдём к настройке radosGW.
Конфиг приведён для примера, в вашем случае некоторые параметры могут отличаться:
```
# cat /etc/ceph/ceph.conf
[global]
fsid = 01dea7f3-91f4-48d1-9d44-ba93d4a103c5
mon_host = 10.0.1.1, 10.0.1.2, 10.0.1.3
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
public_network = 10.0.1.0/24
[client]
rbd_cache = true
[client.radosgw.gateway]
rgw_frontends = civetweb port=18080
rgw_region = example
rgw_region_root_pool = .example.rgw.root
rgw_zone = example-s3
rgw_zone_root_pool = .example-s3.rgw.root
host = s3
keyring = /etc/ceph/client.radosgw.gateway
rgw_dns_name = s3.example.com
rgw_print_continue = true
```
Не забываем скопировать ключ /etc/ceph/client.radosgw.gateway с любой ноды кластера Ceph
Запустим radosgw:
```
# systemctl start [email protected]
```
И добавим его в автостарт:
```
# systemctl enable [email protected]
```
### Разворачиваем VRRP
На master ноде (разница в опциях state и priority):
```
# cat /etc/keepalived/keepalived.conf
global_defs {
notification_email {
[email protected]
}
notification_email_from [email protected]
smtp_server mail.example.com
smtp_connect_timeout 30
router_id GBT1
}
vrrp_instance VI_1 {
state MASTER
interface enp2s0
virtual_router_id 33
priority 101
advert_int 1
smtp_alert
authentication {
auth_type PASS
auth_pass 123123123
}
virtual_ipaddress {
10.0.0.3
}
}
```
На backup ноде:
```
# cat /etc/keepalived/keepalived.conf
global_defs {
notification_email {
[email protected]
}
notification_email_from [email protected]
smtp_server mail.example.com
smtp_connect_timeout 30
router_id GBT1
}
vrrp_instance VI_1 {
state BACKUP
interface enp2s0
virtual_router_id 33
priority 100
advert_int 1
smtp_alert
authentication {
auth_type PASS
auth_pass 123123123
}
virtual_ipaddress {
10.0.0.3
}
}
```
Перезапускаем и добавляем в автостарт (обе ноды):
```
# systemctl restart keepalived
# systemctl enable keepalived
```
### Разворачиваем GoBetween
Для начала скачаем и распакуем бинарник gobetween:
```
# wget https://github.com/yyyar/gobetween/releases/download/0.5.0/gobetween_0.5.0_linux_amd64.tar.gz
# tar -xzf gobetween_0.5.0_linux_amd64.tar.gz -C /usr/local/bin/
```
Пишем конфиг gobetween (для SSL соединений указываем местонахождение ключей). Конфиг на обеих нодах одинаковый:
```
# cat /etc/gobetween.toml
[logging]
level = "debug" # "debug" | "info" | "warn" | "error"
output = "/var/log/gobetween.log"
[api]
enabled = true # true | false
bind = ":8888" # "host:port"
cors = false # cross-origin resource sharing
[defaults]
max_connections = 0 # Maximum simultaneous connections to the server
client_idle_timeout = "0" # Client inactivity duration before forced connection drop
backend_idle_timeout = "0" # Backend inactivity duration before forced connection drop
backend_connection_timeout = "0" # Backend connection timeout (ignored in udp)
[servers]
[servers.sample]
protocol = "tls"
bind = "0.0.0.0:443"
balance = "roundrobin"
[servers.sample.discovery]
kind = "static"
static_list = [
"10.0.0.1:18080 weight=1",
"10.0.0.2:18080 weight=1"
]
[servers.sample.tls]
root_ca_cert_path = "/etc/exampleSSC-CA.crt"
cert_path = "/etc/s3.example.com.crt"
key_path = "/etc/s3.example.com.key"
[servers.sample.healthcheck]
fails = 1
passes = 1
interval = "2s"
timeout="1s"
kind = "ping"
ping_timeout_duration = "500ms"
[servers.sample2]
protocol = "tcp"
bind = "0.0.0.0:80"
balance = "roundrobin"
[servers.sample2.discovery]
kind = "static"
static_list = [
"10.0.0.1:18080 weight=1",
"10.0.0.2:18080 weight=1"
]
[servers.sample2.healthcheck]
fails = 1
passes = 1
interval = "2s"
timeout="1s"
kind = "ping"
ping_timeout_duration = "500ms"
```
Запуск gobetween производится следующей командой (в автостарт добавляйте любым удобным для вас способом):
```
# /usr/local/bin/gobetween -c /etc/gobetween.toml
```
### Проверка
Для проверки можно использовать любой S3 клиент, например, такие, как s3cmd или DragonDisk. Вариант проверки для s3cmd будет выглядеть так (при учёте, что в конфиге уже указан в качестве сервера s3.example.com):
```
# s3cmd ls
```
Если у вас там уже есть хоть какой то bucket, то в выхлопе будет его имя, если бакетов нет, то будет пустой выхлоп.
Как это выглядит сейчас — можете увидеть на скрине снизу. Статистика за сутки (графики в гигабайтах в секунду):

### Итоги
Нагрузка снизилась значительно, затупов не осталось и теперь все бекапы успевают собраться за ночь (до этого уже в разгар рабочего дня могло ещё собираться).
Надеюсь, данная хаутушка поможет вам в ускорении и уменьшении нагрузки на radosgw | https://habr.com/ru/post/346436/ | null | ru | null |
# Поиск устройств в сети по SSDP с помощью Poco
В данной небольшой заметке-примере я опишу как найти устройства в сети по протоколу **SSDP** (Simple Service Discovery Protocol) используя библиотеку Poco на C++.
Оговорю, что в платную полную версию Poco входят классы для работы UpnP. Но для моих целей вполне хватило базовой версии Poco, которая и так умет работать с UDP.
На счет протокола SSDP, он довольно старый единственной нормальной документацией по нему которую я смог найти оказался [черновик официальной спецификации](https://tools.ietf.org/html/draft-cai-ssdp-v1-03). С довольной большим количеством буковок. ;-)
Суть работы протокола следующая:
Послать в сети широковещательный (broadcast) запрос — UDP пакет по адресу 239.255.255.250, порт назначения 1900.
Само тело запроса (пакета) можно посмотреть в исходном коде. Оговорюсь, что единственным полем, значение которого возможно придется меня это ST: в нем указывается тип устройств от которых мы хотим получить ответ.
Так как это протокол UDP, тут нет гарантированного ответа как вы могли привыкнуть при работе с HTTP. HTTP работает по принципу запрос-ответ.
В нашем же случае просто все устройства которые анонсируют себя в сеть, посылают UDP пакет в ответ на адрес с которого был послан запрос, ВАЖНО, ответ приходит не на 1900 порт, а на порт с которого был послан запрос (Source Port).
Так как UPD не дает никаких гарантий кроме целостности самих пакетов. То будем на протяжении 3 секунд слушать Socket (порт) с которого был отправлен запрос.
Собираем все ответы, а потом парсим ответы с помощью регулярных выражений с той же библиотеки Poco.
Есть другой вариант, просто слушать MulticastSocket, этот вариант приведен [в документации к Poco](https://pocoproject.org/slides/200-Network.pdf) на странице 17.
Но мне он не подошел, так как искомое мной устройство не анонсируют себя в сеть.
В запросе поле ST может принимать значения:
* upnp:rootdevice
* ssdp:all
Это для поиска всех устройств. В моем случае здесь я указываю конкретный класс устройств от которых хочу получить. Но для статьи я оставил upnp:rootdevice
Также оговорюсь, что C++ для меня новый язык.
Итак:
```
#include
#include "Poco/Net/DatagramSocket.h"
#include "Poco/Net/SocketAddress.h"
#include "Poco/Timespan.h"
#include "Poco/Exception.h"
#include "Poco/RegularExpression.h"
#include "Poco/String.h"
using std::string;
using std::vector;
using std::cin;
using std::cout;
using std::endl;
using Poco::Net::SocketAddress;
using Poco::Net::DatagramSocket;
using Poco::Timespan;
using Poco::RegularExpression;
void MakeSsdpRequest(vector& responses,string st = "") {
if (st.empty()) st = "upnp:rootdevice";
//if (st.empty()) st = "ssdp:all";
string message = "M-SEARCH \* HTTP/1.1\r\n"
"HOST: 239.255.255.250:1900\r\n"
"ST:" + st + "\r\n"
"MAN: \"ssdp:discover\"\r\n"
"MX:1\r\n\r\n";
DatagramSocket dgs;
SocketAddress destAddress("239.255.255.250", 1900);
dgs.sendTo(message.data(), message.size(), destAddress);
dgs.setSendTimeout(Timespan(1, 0));
dgs.setReceiveTimeout(Timespan(3, 0));
char buffer[1024];
try {
// Здесь можно и бесконечный цикл, так как отвалимся по timeout. Но на всякий ограничиваю 1000 пакетами, так как, если кто-то решит отвечать постоянно, timeout не наступит.
for (int i = 0; i < 1000; i++) {
int n = dgs.receiveBytes(buffer, sizeof(buffer));
buffer[n] = '\0';
responses.push\_back(string(buffer));
}
}
catch (const Poco::TimeoutException &) { }
}
string ParseIP(string str) {
try {
RegularExpression re("(location:.\*://)([a-zA-Z\_0-9\\.]\*)([:/])", RegularExpression::RE\_CASELESS);
vector vec;
re.split(str, 0, vec);
if (vec.size() > 2) return vec[2];
}
catch (const Poco::RegularExpressionException&) { cout << "RegularExpressionException" << endl; }
return "";
}
int main()
{
vector ips, responses;
MakeSsdpRequest(responses);
for (string response : responses) {
// Проверяю статус ответа.
if (response.find("HTTP/1.1 200 OK", 0) == 0) {
string ip = ParseIP(response);
if (!ip.empty()) ips.push\_back(ip);
}
}
sort(ips.begin(), ips.end());
ips.erase(unique(ips.begin(), ips.end()), ips.end());
for (const string& ip : ips) {
cout << "IP: " << ip << endl;
}
cout << "Press Enter" << endl;
cin.get();
return 0;
}
``` | https://habr.com/ru/post/328726/ | null | ru | null |
# Простой, но показательный пример использования TDD
Я, как и многие программисты, довольно много слышал и читал о практиках [TDD](http://en.wikipedia.org/wiki/Test-driven_development). О пользе хорошего покрытия кода юнит-тестами — и о вреде его отсутствия — я знаю по собственному опыту в коммерческих проектах, но применять TDD в чистом виде не получалось по разным причинам. Начав на днях писать свой игровой проект, я решил, что это хорошая возможность попробовать. Как оказалось, разницу по сравнению с обычным подходом можно почувствовать даже при реализации простейшего класса. Я распишу этот пример по шагам и в конце опишу результаты, которые для себя увидел. Думаю топик будет полезен тем, кто интересуется TDD. От более опытных коллег хотелось бы услышать комментарии и критику.
Теорию описывать не буду, ее можно легко найти самостоятельно. Пример написан на Java, в качестве Unit-test фреймворка использован TestNG.
Задача
------
Я начал с разработки базового класса для боевой единицы — юнита. На базовом уровне мне нужно чтобы юнит имел запас здоровья и урон, который он может наносить другим юнитам.
Казалось бы, что может быть проще:
```
public class Unit {
private int health;
private int damage;
public int getHealth() {
return health;
}
public int setHealth(int health) {
this.health = health;
}
public int getDamage() {
return damage;
}
public int setDamage(int damage) {
this.damage = damage;
}
}
```
Реализация очень наивная. Наверняка, когда я начну использовать этот класс, придется в него добавить более удобные методы, конструктор и т.д. Но пока я не знаю, что понадобится, а что нет, и не хочу сразу писать лишнее.
Итак, это то, что получилось традиционным методом «в лоб». Теперь попробуем реализовать тот же класс через TDD.
Применяем TDD
-------------
В реальности я не писал приведенную выше реализацию, изначально никакого класса Unit не существует. Мы начинаем с создания класса теста.
```
@Test
public class UnitTest {
}
```
Начинаем думать о требованиях к классу юнита. Первое, что приходит в голову — неплохо бы уметь создавать юнит, задавая его здоровье и урон. Так и пишем.
```
@Test
public class UnitTest {
@Test
public void youCreateAUnitGivenItsHealthAndDamage() {
new Unit(100, 25);
}
}
```
Тест, понятное дело, даже не компилируется — делаем так чтобы он прошел.
```
public class Unit {
public Unit(int health, int damage) {
}
}
```
Рефакторить пока нечего. Пишем следующий тест — я хочу иметь возможность узнать текущее здоровье юнита.
```
@Test
public class UnitTest {
@Test
public void youCreateAUnitGivenItsHealthAndDamage() {
new Unit(100, 25);
}
@Test
public void youCheckUnitHealthWithGetter() {
Unit unit = new Unit(100, 25);
assertEquals(100, unit.getHealth());
}
}
```
Тест падает из-за ошибки компиляции — метода getHealth у класса Unit нет. Правим код, чтобы тест прошел.
```
public class Unit {
private int health;
public Unit(int health, int damage) {
this.health = health;
}
public int getHealth() {
return health;
}
}
```
Рефакторить опять нечего. Думаем дальше — наверное было бы неплохо, чтобы юнит умел получать урон.
```
@Test
public class UnitTest {
@Test
public void youCreateAUnitGivenItsHealthAndDamage() {
new Unit(100, 25);
}
@Test
public void youCheckUnitHealthWithGetter() {
Unit unit = new Unit(100, 25);
assertEquals(100, unit.getHealth());
}
@Test
public void unitCanTakeDamage() {
Unit unit = new Unit(100, 25);
unit.takeDamage(25);
}
}
```
Правим код, чтобы тест прошел.
```
public class Unit {
private int health;
public Unit(int health, int damage) {
this.health = health;
}
public int getHealth() {
return health;
}
public void takeDamage(int damage) {
}
}
```
Ах да, полученный урон должен вычитаться из здоровья юнита. Напишу отдельный тест для этого.
```
@Test
public class UnitTest {
@Test
public void youCreateAUnitGivenItsHealthAndDamage() {
new Unit(100, 25);
}
@Test
public void youCheckUnitHealthWithGetter() {
Unit unit = new Unit(100, 25);
assertEquals(100, unit.getHealth());
}
@Test
public void unitCanTakeDamage() {
Unit unit = new Unit(100, 25);
unit.takeDamage(25);
}
@Test
public void damageTakenReducesUnitHealth() {
Unit unit = new Unit(100, 25);
unit.takeDamage(25);
assertEquals(75, unit.getHealth());
}
}
```
Первый тест, который падает из-за поведения класса. Правим.
```
public class Unit {
private int health;
public Unit(int health, int damage) {
this.health = health;
}
public int getHealth() {
return health;
}
public void takeDamage(int damage) {
health -= damage;
}
}
```
Тут уже можно немного порефакторить. Тут можно оставить и так, но я привык что геттеры находятся в конце класса.
```
public class Unit {
private int health;
public Unit(int health, int damage) {
this.health = health;
}
public void takeDamage(int damage) {
health -= damage;
}
public int getHealth() {
return health;
}
}
```
Двигаемся дальше. Наш юнит уже имеет запас здоровья и ему можно наносить урон. Научим его наносить урон другим юнитам!
```
@Test
public class UnitTest {
@Test
public void youCreateAUnitGivenItsHealthAndDamage() {
new Unit(100, 25);
}
@Test
public void youCheckUnitHealthWithGetter() {
Unit unit = new Unit(100, 25);
assertEquals(100, unit.getHealth());
}
@Test
public void unitCanTakeDamage() {
Unit unit = new Unit(100, 25);
unit.takeDamage(25);
}
@Test
public void damageTakenReducesUnitHealth() {
Unit unit = new Unit(100, 25);
unit.takeDamage(25);
assertEquals(75, unit.getHealth());
}
@Test
public void unitCanDealDamageToAnotherUnit() {
Unit damageDealer = new Unit(100, 25);
Unit damageTaker = new Unit(100, 25);
damageDealer.dealDamage(damageTaker);
}
}
```
Дорабатываем класс юнита.
```
public class Unit {
private int health;
public Unit(int health, int damage) {
this.health = health;
}
public void takeDamage(int damage) {
health -= damage;
}
public void dealDamage(Unit damageTaker) {
}
public int getHealth() {
return health;
}
}
```
Понятное дело, если наш юнит нанес урон другому юниту, у того должно уменьшиться здоровье.
```
@Test
public class UnitTest {
@Test
public void youCreateAUnitGivenItsHealthAndDamage() {
new Unit(100, 25);
}
@Test
public void youCheckUnitHealthWithGetter() {
Unit unit = new Unit(100, 25);
assertEquals(100, unit.getHealth());
}
@Test
public void unitCanTakeDamage() {
Unit unit = new Unit(100, 25);
unit.takeDamage(25);
}
@Test
public void damageTakenReducesUnitHealth() {
Unit unit = new Unit(100, 25);
unit.takeDamage(25);
assertEquals(75, unit.getHealth());
}
@Test
public void unitCanDealDamageToAnotherUnit() {
Unit damageDealer = new Unit(100, 25);
Unit damageTaker = new Unit(100, 25);
damageDealer.dealDamage(damageTaker);
}
@Test
public void unitThatDamageDealtToTakesDamageDealerUnitDamage() {
Unit damageDealer = new Unit(100, 25);
Unit damageTaker = new Unit(100, 25);
damageDealer.dealDamage(damageTaker);
assertEquals(75, damageTaker.getHealth());
}
}
```
Свеженаписаный тест падает — поправим класс юнита.
```
public class Unit {
private int health;
private int damage;
public Unit(int health, int damage) {
this.health = health;
this.damage = damage;
}
public void takeDamage(int damage) {
health -= damage;
}
public void dealDamage(Unit damageTaker) {
damageTaker.takeDamage(damage);
}
public int getHealth() {
return health;
}
}
```
Наведем немного блеска: переменная damage может быть final, параметр в методе takeDamage неплохо бы переименовать чтобы не путать с переменной класса.
```
public class Unit {
private int health;
private final int damage;
public Unit(int health, int damage) {
this.health = health;
this.damage = damage;
}
public void takeDamage(int incomingDamage) {
health -= incomingDamage;
}
public void dealDamage(Unit damageTaker) {
damageTaker.takeDamage(damage);
}
public int getHealth() {
return health;
}
}
```
Дальше нужно писать тесты на то, что здоровье не может упасть ниже нуля, если оно на нуле юнит должен уметь сказать что он мертв и т.д. Чтобы не добавлять лишнего объема, я остановлюсь тут. Думаю для понимания примера достаточно и можно сделать некоторые выводы.
Выводы
------
1. На реализацию простейшего класса потрачено времени в несколько раз больше, чем при реализации «в лоб» — это то, что так часто пугает менеджеров и не владеющих данной техникой программистов в TDD.
2. Можно сравнить первую наивную реализацию и последнюю, полученную через TDD. Главное отличие в том, что последняя реализация действительно объектно-ориентированная, с юнитом можно работать как с самостоятельным объектом, спрашивать его состояние и просить выполнить определенные действия. Код, который будет работать с этим классом также будет более объектно-ориентированным.
3. Кроме самого класса мы получили полный набор тестов к нему. Знаю по своему опыту, что большего блага для разработчика, чем полностью покрытый тестами код, сложно представить. Из того же опыта, если тесты пишутся после кода, бывает сложно обеспечить полное покрытие — на что-то обязательно забудут написать тест, что-то будет выглядеть слишком простым, чтобы тестировать и т.п. Сами тесты часто получаются сложными и громоздкими, т.к. велик соблазн одним тестом проверить несколько аспектов работы тестируемого кода. Здесь же мы получили набор простых, легких в понимании тестов, которые будет гораздо проще поддерживать.
4. Мы получили живую документацию к коду! Любому человеку достаточно прочитать названия методов в тесте, чтобы понять задумку автора, назначение и поведение класса. Разбираться в коде, имея эту информацию, будет на порядок проще и не нужно отвлекать коллег с просьбами объяснить что тут к чему.
5. Предыдущие пункты и так хорошо известны, но я сделал для себя один новый вывод — при разработке через TDD гораздо лучше продумывается что хочется получить от класса, его поведение и варианты использования. Имея хорошее понимание уже разработанных компонент, будет понятнее как писать более сложные.
6. Не относится к данному примеру, но захотелось добавить сюда еще один пункт. При разработке через тесты адекватнее оцениваешь трудоемкость задач — всегда знаешь что уже работает, что осталось доделать. Без тестов часто возникает ощущение, что все уже написано, но оказывается, что на отладку и доработку нужно еще значительное количество времени.
Я понимаю что пример очень простой и прошу к этому не придираться. Топик не о том как написать класс из двух полей, а о том что можно увидеть преимущества TDD даже на таком элементарном примере.
Всем спасибо за внимание. Изучайте прогрессивные техники программирования и получайте удовольствие от работы! | https://habr.com/ru/post/151639/ | null | ru | null |
# Карманная книга по TypeScript. Часть 2. Типы на каждый день

Мы продолжаем серию публикаций адаптированного и дополненного перевода [`"Карманной книги по TypeScript`".](https://www.typescriptlang.org/docs/handbook/intro.html)
Другие части:
* [Часть 1. Основы](https://habr.com/ru/company/macloud/blog/559902/)
* [Часть 2. Типы на каждый день](https://habr.com/ru/company/macloud/blog/559976/)
* [Часть 3. Сужение типов](https://habr.com/ru/company/macloud/blog/560594/)
* [Часть 4. Подробнее о функциях](https://habr.com/ru/company/macloud/blog/561470/)
* [Часть 5. Объектные типы](https://habr.com/ru/company/macloud/blog/562054/)
* [Часть 6. Манипуляции с типами](https://habr.com/ru/company/macloud/blog/562786/)
* [Часть 7. Классы](https://habr.com/ru/company/macloud/blog/563408/)
* [Часть 8. Модули](https://habr.com/ru/company/macloud/blog/563722/)
*Обратите внимание*: для большого удобства в изучении книга была оформлена в виде [прогрессивного веб-приложения](https://typescript-handbook.ru/).
Примитивы: `string`, `number` и `boolean`
-----------------------------------------
В `JS` часто используется 3 [примитива](https://developer.mozilla.org/ru/docs/Glossary/Primitive): `string`, `number` и `boolean`. Каждый из них имеет соответствующий тип в `TS`:
* `string` представляет строковые значения, например, `'Hello World'`
* `number` предназначен для чисел, например, `42`. `JS` не различает целые числа и числа с плавающей точкой (или запятой), поэтому не существует таких типов, как `int` или `float` — только `number`
* `boolean` — предназначен для двух значений: `true` и `false`
*Обратите внимание*: типы `String`, `Number` и `Boolean` (начинающиеся с большой буквы) являются легальными и ссылаются на специальные встроенные типы, которые, однако, редко используются в коде. Для типов всегда следует использовать `string`, `number` или `boolean`.
Массивы
-------
Для определения типа массива `[1, 2, 3]` можно использовать синтаксис `number[]`; такой синтаксис подходит для любого типа (например, `string[]` — это массив строк и т.д.). Также можно встретить `Array`, что означает тоже самое. Такой синтаксис, обычно, используется для определения общих типов или дженериков (generics).
*Обратите внимание*: `[number]` — это другой тип, кортеж (tuple).
### `any`
`TS` предоставляет специальный тип `any`, который может использоваться для отключения проверки типов:
```
let obj: any = { x: 0 }
// Ни одна из строк ниже не приведет к возникновению ошибки на этапе компиляции
// Использование `any` отключает проверку типов
// Использование `any` означает, что вы знакомы со средой выполнения кода лучше, чем `TS`
obj.foo()
obj()
obj.bar = 100
obj = 'hello'
const n: number = obj
```
Тип `any` может быть полезен в случае, когда мы не хотим писать длинное определение типов лишь для того, чтобы пройти проверку.
#### `noImplicitAny`
При отсутствии определения типа и когда `TS` не может предположить его на основании контекста, неявным типом значение становится `any`.
Обычно, мы хотим этого избежать, поскольку `any` является небезопасным с точки зрения системы типов. Установка флага [`noImplicitAny`](https://www.typescriptlang.org/tsconfig/#noImplicitAny) позволяет квалифицировать любое неявное `any` как ошибку.
Аннотации типа для переменных
-----------------------------
При объявлении переменной с помощью `const`, `let` или `var` опционально можно определить ее тип:
```
const myName: string = 'John'
```
Однако, в большинстве случаев этого делать не требуется, поскольку `TS` пытается автоматически определить тип переменной на основе типа ее инициализатора, т.е. значения:
```
// В аннотации типа нет необходимости - `myName` будет иметь тип `string`
const myName = 'John'
```
Функции
-------
В `JS` функции, в основном, используются для работы с данными. `TS` позволяет определять типы как для входных (input), так и для выходных (output) значений функции.
### Аннотации типа параметров
При определении функции можно указать, какие типы параметров она принимает:
```
function greet(name: string) {
console.log(`Hello, ${name.toUpperCase()}!`)
}
```
Вот что произойдет при попытке вызвать функцию с неправильным аргументом:
```
greet(42)
// Argument of type 'number' is not assignable to parameter of type 'string'. Аргумент типа 'number' не может быть присвоен параметру типа 'string'
```
*Обратите внимание*: количество передаваемых аргументов будет проверяться даже при отсутствии аннотаций типа параметров.
### Аннотация типа возвращаемого значения
Также можно аннотировать тип возвращаемого функцией значения:
```
function getFavouriteNumber(): number {
return 26
}
```
Как и в случае с аннотированием переменных, в большинстве случаев `TS` может автоматически определить тип возвращаемого функцией значения на основе инструкции `return`.
### Анонимные функции
Анонимные функции немного отличаются от обычных. Когда функция появляется в месте, где `TS` может определить способ ее вызова, типы параметров такой функции определяются автоматически.
Вот пример:
```
// Аннотации типа отсутствуют, но это не мешает `TS` обнаруживать ошибки
const names = ['Alice', 'Bob', 'John']
// Определение типов на основе контекста вызова функции
names.forEach(function (s) {
console.log(s.toUppercase())
// Property 'toUppercase' does not exist on type 'string'. Did you mean 'toUpperCase'? Свойства 'toUppercase' не существует в типе 'string'. Вы имели ввиду 'toUpperCase'?
})
// Определение типов на основе контекста также работает для стрелочных функций
names.forEach((s) => {
console.log(s.toUppercase())
// Property 'toUppercase' does not exist on type 'string'. Did you mean 'toUpperCase'?
})
```
Несмотря на отсутствие аннотации типа для `s`, `TS` использует типы функции `forEach`, а также предполагаемый тип массива для определения типа `s`. Этот процесс называется определением типа на основе контекста (contextual typing).
Типы объекта
------------
Объектный тип — это любое значение со свойствами. Для его определения мы просто перечисляем все свойства объекта и их типы. Например, так можно определить функцию, принимающую объект с координатами:
```
function printCoords(pt: { x: number, y: number }) {
console.log(`Значение координаты 'x': ${pt.x}`)
console.log(`Значение координаты 'y': ${pt.y}`)
}
printCoords({ x: 3, y: 7 })
```
Для разделения свойств можно использовать `,` или `;`. Тип свойства является опциональным. Свойство без явно определенного типа будет иметь тип `any`.
### Опциональные свойства
Для определения свойства в качестве опционального используется символ `?` после названия свойства:
```
function printName(obj: { first: string, last?: string }) {
// ...
}
// Обе функции скомпилируются без ошибок
printName({ first: 'John' })
printName({ first: 'Jane', last: 'Air' })
```
В `JS` при доступе к несуществующему свойству возвращается `undefined`. По этой причине, при чтении опционального свойства необходимо выполнять проверку на `undefined`:
```
function printName(obj: { first: string, last?: string }) {
// Ошибка - приложение может сломаться, если аргумент `last` не будет передан в функцию
console.log(obj.last.toUpperCase()) // Object is possibly 'undefined'. Потенциальным значением объекта является 'undefined'
if (obj.last !== undefined) {
// Теперь все в порядке
console.log(obj.last.toUpperCase())
}
// Безопасная альтернатива, использующая современный синтаксис `JS` - оператор опциональной последовательности (`?.`)
console.log(obj.last?.toUpperCase())
}
```
Объединения (unions)
--------------------
*Обратите внимание*: в литературе, посвященной `TS`, `union`, обычно, переводится как объединение, но фактически речь идет об альтернативных типах, объединенных в один тип.
### Определение объединения
Объединение — это тип, сформированный из 2 и более типов, представляющий значение, которое может иметь один из этих типов. Типы, входящие в объединение, называются членами (members) объединения.
Реализуем функцию, которая может оперировать строками или числами:
```
function printId(id: number | string) {
console.log(`Ваш ID: ${id}`)
}
// OK
printId(101)
// OK
printId('202')
// Ошибка
printId({ myID: 22342 })
// Argument of type '{ myID: number }' is not assignable to parameter of type 'string | number'. Type '{ myID: number }' is not assignable to type 'number'. Аргумент типа '{ myID: number }' не может быть присвоен параметру типа 'string | number'. Тип '{ myID: number }' не может быть присвоен типу 'number'
```
### Работа с объединениями
В случае с объединениями, `TS` позволяет делать только такие вещи, которые являются валидными для каждого члена объединения. Например, если у нас имеется объединение `string | number`, мы не сможем использовать методы, которые доступны только для `string`:
```
function printId(id: number | string) {
console.log(id.toUpperCase())
// Property 'toUpperCase' does not exist on type 'string | number'. Property 'toUpperCase' does not exist on type 'number'.
}
```
Решение данной проблемы заключается в сужении (narrowing) объединения. Например, `TS` знает, что только для `string` оператор `typeof` возвращает `'string'`:
```
function printId(id: number | string) {
if (typeof id === 'string') {
// В этой ветке `id` имеет тип 'string'
console.log(id.toUpperCase())
} else {
// А здесь `id` имеет тип 'number'
console.log(id)
}
}
```
Другой способ заключается в использовании функции, такой как `Array.isArray`:
```
function welcomePeople(x: string[] | string) {
if (Array.isArray(x)) {
// Здесь `x` - это 'string[]'
console.log('Привет, ' + x.join(' и '))
} else {
// Здесь `x` - 'string'
console.log('Добро пожаловать, одинокий странник ' + x)
}
}
```
В некоторых случаях все члены объединения будут иметь общие методы. Например, и массивы, и строки имеют метод `slice`. Если каждый член объединения имеет общее свойство, необходимость в сужении отсутствует:
```
function getFirstThree(x: number[] | string ) {
return x.slice(0, 3)
}
```
Синонимы типов (type aliases)
-----------------------------
Что если мы хотим использовать один и тот же тип в нескольких местах? Для этого используются синонимы типов:
```
type Point = {
x: number
y: number
}
// В точности тоже самое, что в приведенном выше примере
function printCoords(pt: Point) {
console.log(`Значение координаты 'x': ${pt.x}`)
console.log(`Значение координаты 'y': ${pt.y}`)
}
printCoords({ x: 3, y: 7 })
```
Синонимы можно использовать не только для объектных типов, но и для любых других типов, например, для объединений:
```
type ID = number | string
```
*Обратите внимание*: синонимы — это всего лишь синонимы, мы не можем создавать на их основе другие "версии" типов. Например, такой код может выглядеть неправильным, но `TS` не видит в нем проблем, поскольку оба типа являются синонимами одного и того же типа:
```
type UserInputSanitizedString = string
function sanitizeInput(str: string): UserInputSanitizedString {
return sanitize(str)
}
// Создаем "обезвреженный" инпут
let userInput = sanitizeInput(getInput())
// По-прежнему имеем возможность изменять значение переменной
userInput = 'new input'
```
Интерфейсы
----------
Определение интерфейса — это другой способ определения типа объекта:
```
interface Point {
x: number
y: number
}
function printCoords(pt: Point) {
console.log(`Значение координаты 'x': ${pt.x}`)
console.log(`Значение координаты 'y': ${pt.y}`)
}
printCoords({ x: 3, y: 7 })
```
`TS` иногда называют структурно типизированной системой типов (structurally typed type system) — `TS` заботит лишь соблюдение структуры значения, передаваемого в функцию `printCoords`, т.е. содержит ли данное значение ожидаемые свойства.
### Разница между синонимами типов и интерфейсами
Синонимы типов и интерфейсы очень похожи. Почти все возможности `interface` доступны в `type`. Ключевым отличием между ними является то, что `type` не может быть повторно открыт для добавления новых свойств, в то время как `interface` всегда может быть расширен.
Пример расширения интерфейса:
```
interface Animal {
name: string
}
interface Bear extends Animal {
honey: boolean
}
const bear = getBear()
bear.name
bear.honey
```
Пример расширения типа с помощью пересечения (intersection):
```
type Animal {
name: string
}
type Bear = Animal & {
honey: boolean
}
const bear = getBear()
bear.name
bear.honey
```
Пример добавления новых полей в существующий интерфейс:
```
interface Window {
title: string
}
interface Window {
ts: TypeScriptAPI
}
const src = 'const a = 'Hello World''
window.ts.transpileModule(src, {})
```
Тип не может быть изменен после создания:
```
type Window = {
title: string
}
type Window = {
ts: TypeScriptAPI
}
// Ошибка: повторяющийся идентификатор 'Window'.
```
*Общее правило*: используйте `interface` до тех пор, пока вам не понадобятся возможности `type`.
Утверждение типа (type assertion)
---------------------------------
В некоторых случаях мы знаем о типе значения больше, чем `TS`.
Например, когда мы используем `document.getElementById`, `TS` знает лишь то, что данный метод возвращает какой-то `HTMLElement`, но мы знаем, например, что будет возвращен `HTMLCanvasElement`. В этой ситуации мы можем использовать утверждение типа для определения более конкретного типа:
```
const myCanvas = document.getElementById('main_canvas') as HTMLCanvasElement
```
Для утверждения типа можно использовать другой синтаксис (е в TSX-файлах):
```
const myCanvas = document.getElementById('main\_canvas')
```
`TS` разрешает утверждения более или менее конкретных версий типа. Это означает, что преобразования типов выполнять нельзя:
```
const x = 'hello' as number
// Conversion of type 'string' to type 'number' may be a mistake because neither type sufficiently overlaps with the other. If this was intentional, convert the expression to 'unknown' first.
// Преобразование типа 'string' в тип 'number' может быть ошибкой, поскольку эти типы не перекрываются. Если это было сделано намерено, то выражение сначала следует преобразовать в 'unknown'
```
Иногда это правило может быть слишком консервативным и мешать выполнению более сложных валидных преобразований. В этом случае можно использовать двойное утверждение: сначала привести тип к `any` (или `unknown`), затем к нужному типу:
```
const a = (expr as any) as T
```
Литеральные типы (literal types)
--------------------------------
В дополнение к общим типам `string` и `number`, мы можем ссылаться на конкретные строки и числа, находящиеся на определенных позициях.
Вот как `TS` создает типы для литералов:
```
let changingString = 'Hello World'
changingString = 'Olá Mundo'
// Поскольку `changingString` может представлять любую строку, вот
// как TS описывает ее в системе типов
changingString
// let changingString: string
const constantString = 'Hello World'
// Поскольку `constantString` может представлять только указанную строку, она
// имеет такое литеральное представление типа
constantString
// const constantString: 'Hello World'
```
Сами по себе литеральные типы особой ценности не представляют:
```
let x: 'hello' = 'hello'
// OK
x = 'hello'
// ...
x = 'howdy'
// Type '"howdy"' is not assignable to type '"hello"'.
```
Но комбинация литералов с объединениями позволяет создавать более полезные вещи, например, функцию, принимающую только набор известных значений:
```
function printText(s: string, alignment: 'left' | 'right' | 'center') {
// ...
}
printText('Hello World', 'left')
printText("G'day, mate", "centre")
// Argument of type '"centre"' is not assignable to parameter of type '"left" | "right" | "center"'.
```
Числовые литеральные типы работают похожим образом:
```
function compare(a: string, b: string): -1 | 0 | 1 {
return a === b ? 0 : a > b ? 1 : -1
}
```
Разумеется, мы можем комбинировать литералы с нелитеральными типами:
```
interface Options {
width: number
}
function configure(x: Options | 'auto') {
// ...
}
configure({ width: 100 })
configure('auto')
configure('automatic')
// Argument of type '"automatic"' is not assignable to parameter of type 'Options | "auto"'.
```
### Предположения типов литералов
При инициализации переменной с помощью объекта, `TS` будет исходить из предположения о том, что значения свойств объекта в будущем могут измениться. Например, если мы напишем такой код:
```
const obj = { counter: 0 }
if (someCondition) {
obj.counter = 1
}
```
`TS` не будет считать присвоение значения `1` полю, которое раньше имело значение `0`, ошибкой. Это объясняется тем, что `TS` считает, что типом `obj.counter` является `number`, а не `0`.
Тоже самое справедливо и в отношении строк:
```
const req = { url: 'https://example.com', method: 'GET' }
handleRequest(req.url, req.method)
// Argument of type 'string' is not assignable to parameter of type '"GET" | "POST"'.
```
В приведенном примере предположительный типом `req.method` является `string`, а не `'GET'`. Поскольку код может быть вычислен между созданием `req` и вызовом функции `handleRequest`, которая может присвоить `req.method` новое значение, например, `GUESS`, `TS` считает, что данный код содержит ошибку.
Существует 2 способа решить эту проблему.
1. Можно утвердить тип на каждой позиции:
```
// Изменение 1
const req = { url: 'https://example.com', method: 'GET' as 'GET' }
// Изменение 2
handleRequest(req.url, req.method as 'GET')
```
1. Для преобразования объекта в литерал можно использовать `as const`:
```
const req = { url: 'https://example.com', method: 'GET' } as const
handleRequest(req.url, req.method)
```
`null` и `undefined`
--------------------
В `JS` существует два примитивных значения, сигнализирующих об отсутствии значения: `null` и `undefined`. `TS` имеет соответствующие типы. То, как эти типы обрабатываются, зависит от настройки `strictNullChecks` (см. часть 1).
### Оператор утверждения ненулевого значения (non-null assertion operator)
`TS` предоставляет специальный синтаксис для удаления `null` и `undefined` из типа без необходимости выполнения явной проверки. Указание `!` после выражения означает, что данное выражение не может быть нулевым, т.е. иметь значение `null` или `undefined`:
```
function liveDangerously(x?: number | undefined) {
// Ошибки не возникает
console.log(x!.toFixed())
}
```
### Перечисления (enums)
Перечисления позволяют описывать значение, которое может быть одной из набора именованных констант. Использовать перечисления не рекомендуется.
### Редко используемые примитивы
#### `bigint`
Данный примитив используется для представления очень больших целых чисел `BigInt`:
```
// Создание `bigint` с помощью функции `BigInt`
const oneHundred: bigint = BigInt(100)
// Создание `bigint` с помощью литерального синтаксиса
const anotherHundred: bigint = 100n
```
Подробнее о `BigInt` можно почитать [здесь](https://www.typescriptlang.org/docs/handbook/release-notes/typescript-3-2.html#bigint).
#### `symbol`
Данный примитив используется для создания глобально уникальных ссылок с помощью функции `Symbol()`:
```
const firstName = Symbol('name')
const secondName = Symbol('name')
if (firstName === secondName) {
// This condition will always return 'false' since the types 'typeof firstName' and 'typeof secondName' have no overlap.
// Символы `firstName` и `lastName` никогда не будут равными
}
```
Подробнее о символах можно почитать [здесь](https://www.typescriptlang.org/docs/handbook/symbols.html).
---
Облачные серверы от [Маклауд](https://macloud.ru/?partner=4189mjxpzx) идеально подходят для разработки на TypeScript.
Зарегистрируйтесь по ссылке выше или кликнув на баннер и получите 10% скидку на первый месяц аренды сервера любой конфигурации!
[](https://macloud.ru/?partner=4189mjxpzx&utm_source=habr&utm_medium=perevod&utm_campaign=igor) | https://habr.com/ru/post/559976/ | null | ru | null |
# Авторизация в Ubuntu через Microsoft Azure AD / Office 365
Все пользователи Microsoft Office 365 (для бизнеса) проходят авторизацию именно через Microsoft Azure AD. Так, при добавлении каждого нового пользователя (емейла) в Office 365, для него автоматически создается соответствующая запись в Microsoft Azure AD.
Здесь я расскажу как можно использовать Microsoft Azure AD для авторизации пользователей Ubuntu 14.04. То есть, как в Ubuntu сделать SSO c Microsoft Azure AD / Office 365.
1. Предварительные требования
-----------------------------
* Аккаунт Microsoft Azure AD / Office 365 (business)
* Ubuntu сервер с подключением к интернет
2. Настройка Microsoft Azure AD
-------------------------------
Для начала, идем на Microsoft Azure Portal на [manage.windowsazure.com](https://manage.windowsazure.com) или Офис365 меню -> Admin -> Azure AD.
Затем, заходим в нужную ветку Active Directory (если Вы не используете сложную ветвистую структуру AD, то здесь будет лишь одна запись).
Выбираем «Applications» («Приложения»):

Добавляем новое приложение, нажав на «Add» («Добавить»):
Выбираем «Add an application my organization is developing» («Добавить приложение, разрабатываемое моей организацией»):
Придумайте понятное название для чего будет использоваться этот метод авторизации (например, «Linux Test Servers»), указываем его в поле «Name» («Имя»), а также выбираем тип приложения «Native Client Application» («Собственное клиентское приложение»).
На следующей странице предлагается ввести «Redirect URI» («URI перенаправления»). Можно указать любое значение, похожее на URI, т.к. это поле ни на что не повлияет, в данном случае.

Приложение AD создано! Далее, нажимаем «Configure» («Настройки»).
Запоминаем/записываем значение поля «Client ID» («Код клиента») — оно нам потребуется еще.
3. Настройка Ubuntu 14.04
-------------------------
Заходим на сервер по SSH (в данном случае, пользователем user123, которому разрешено исполнение команд sudo):

Переходим на root и устанавливаем git:
```
sudo su -
apt-get install git
```
Клонируем git-репозитарий [github.com/bureado/aad-login](https://github.com/bureado/aad-login):
```
git clone https://github.com/bureado/aad-login
```

Входим в склонированный каталог, создаем каталог /opt/aad-login, копируем aad-login.js package.json в /opt/aad-login/, копируем aad-login в /usr/local/bin/:
```
cd aad-login/
mkdir -p /opt/aad-login
cp aad-login.js package.json /opt/aad-login/
cp aad-login /usr/local/bin/
```

Входим в каталог /opt/aad-login/, устанавливаем приложение npm:
```
cd /opt/aad-login/
apt-get install npm
```

Устанавливаем требуемые компоненты npm:
```
npm install
```
Редактируем файл ./aad-login.js:

Заполняем значение переменной directory вашим доменным именем, которое используется в Microsoft Azure AD / Office 365, а clientid — значением «Client ID» («Код клиента»), ранее полученном на портале Microsoft Azure AD:
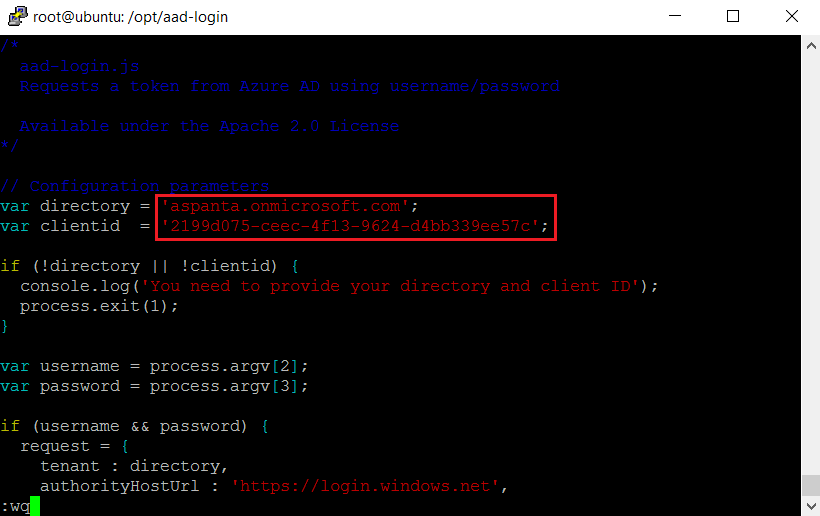
Редактируем файл /etc/pam.d/common-auth:
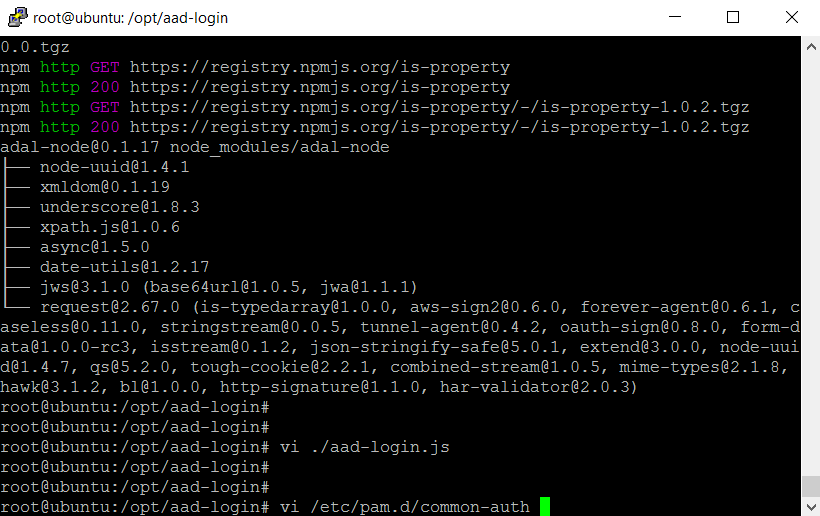
Добавляем вызов pam\_exec, чтобы он был первым в списке:
`auth sufficient pam_exec.so expose_authtok /usr/local/bin/aad-login`

Устанавливаем nodejs:
```
apt-get install nodejs
```

Удаляем устаревший node, создаем символическую ссылку /usr/bin/nodejs -> /usr/bin/node:
```
apt-get --purge remove node
ln -s /usr/bin/nodejs /usr/bin/node
```

Создаем пользователей, которым разрешен вход (пароль устанавливать не нужно). Логин таких пользователей должен совпадать с Alias емейла. Например, создаем пользователя support, емейл которого [email protected].
```
useradd -m support
```

Все готово!
Пробуем войти под созданным пользователем и паролем, установленным в Microsoft Azure AD / Office 365.
 | https://habr.com/ru/post/274249/ | null | ru | null |
# Не только работой едины — ARK+K3S+MetalLB
Предыстория
-----------
Всем привет! Я работаю DevOps-MLops инженером и мне нравится постоянно что-то новое изучать и пытаться применять эти технологии везде где только можно.
Как-то играя в ark я захотел играть на своем сервере вместе с друзьями и как раз под это дело у меня есть свой домашний сервер и выделенный ip, характеристик сервера более чем достаточно, в моем случае это ryzen 7 1700x, 32Gb RAM и 1500Gb дисковой памяти.
Как основу я взял контейнернизацию lxc и настроил внутри ark сервер по первой инструкции что нашёл в интернете, настроил service для ark чтобы руками его не запускать все время и в целом месяца 3 все работало ок, потом по неизвестной причине мой ark сервер стал грузить всё что-то постоянно и вообще стал вести себя странно, сидеть изучать что не так у меня не было особо желания, да и времени, поэтому я подумал а не лучше мне попробовать перенести сервер в более что-то удобное для обслуживания нежели держать его где-то в отдельной среде куда нужно еще подключаться, делать кучу действий чтобы произвести анализ.
Приступим!
----------
И так чтобы сделать красиво (по своему мнению), я взял:
* k3s - скажем так это как ванильный k8s только из него вырезали около 1000 строчек кода как заявляют разработчики, кстати он построен на containerD.
* metalLB - это инструмент позволяющий нам создать свой loadbalancer и использовать его, далее про него более подробно расскажу.
* ubuntu 20.04 LTS - собственно то на чем всё будет крутится.
k3s
---
K3s (с офф сайт) — это сертифицированный дистрибутив Kubernetes с высокой доступностью, предназначенный для производственных рабочих нагрузок в автоматических, ограниченных по ресурсам, удаленных местах или внутри устройств IoT. (взято с офф сайт).
k3s (описание от меня) - это оркестратор контейнеров который может:
* Запускать контейнеры (для контейнера мы можем также задать переменные, директории с нашего хоста или вообще с удаленного сервера, контейнер который будет запускаться до старта нашего основного контейнера, благодаря чему мы можем как пример подготовить какие либо файлы или выполнить скрипт для корректной работы нашего основного контейнера).
* Ставить лимиты по ресурсам для контейнеров. (Как пример что приложение не сможет потреблять больше 2 Gb RAM или 2 CPU).
* Задавать политики рестарта контейнеров.
* Управлять доступностью к приложениям по сети.
* Позволяет удобно читать логи.
* Анализировать метрики.
* Автомасштабированием контейнеров при повышении нагрузки ( к примеру если наше приложение в контейнере начинает грузится скажем под 80% по RAM или CPU оркестратор поднимет еще контейнеры и будет балансировать автоматическим сам нагрузку между ними).
* И т.д.
* И самое главное для нас мы можем описать это в манифесте один раз и потом переиспользовать и даже передавать кому угодно чтобы они могли запустить у себя или же наоборот мы можем запустить у себя чужой манифест.
И так я поставил чистую ubuntu 20.04 LTS, выделил ей 4 CPU 8 GB RAM, 50GB Disk и на неё первым делом мы будем ставить k3s.
1. Открываем сайт <https://k3s.io>, на нем нам говорят чтобы это не займет много времени.
2. Копируем команду и дописываем параметр который понадобится нам потом дальше, выполняем.
```
curl -sfL https://get.k3s.io | INSTALL_K3S_EXEC="server --disable servicelb" sh -
```
3. Далее всего менее 30 секунд и кластер готов.
4. Прописываем sudo kubectl get nodes и видим что наш кластер готов!
5. Далее, чтобы мы могли работать удобно из под своей УЗ нам требуется скопировать kubeconfig в свою домашнюю папку и выполнить пару команд:
> Kubeconfig - это манифест в котором описано подключение к кластеру kubernetes. Вы можете его скопировать на любую машину у которой есть сетевой доступ до кластера и от туда им управлять.
>
>
```
mkdir ~/.kube
sudo cp /etc/rancher/k3s/k3s.yaml ~/.kube/config
sudo chown ark:ark .kube/config
echo "export KUBECONFIG=~/.kube/config" >> ~/.bashrc
source ~/.bashrc
kubectl get node
```
* Cоздаем папку где будет хранится кубконфиг по умолчанию.
* Копируем kubeconfig в ранее созданную папку.
* Задаем права для kubeconfig на нашего пользователя и группу.
* Загружаем в bashrc строчку которая будет задавать kubeconfig по умолчанию для kubectl при каждом входе в систему.
* И смотрим готов ли наш кластер с одной нодой.

> Все управление кластером осущетвляется через утилиту kubeclt
>
>
И так буквально пару действий и у нас есть есть готовый кластер k3s почти со всеми преимуществами kubernetes готовый к работе.
Запускаем ARK server
--------------------
И так давайте для тех кто не сильно погружен в специфику kubernetes я обозначу четыре сущности с которыми мы будем работать:
> Pods - Это абстрактный объект Kubernetes, представляющий собой «обертку» для одного или группы контейнеров. Контейнеры в поде запускаются и работают вместе, имеют общие сетевые ресурсы и хранилище. Kubernetes не управляет контейнерами напрямую, он собирает их в поды и работает с ими.
>
>
> Deployments - Это ресурс предназначенный для для развертывания приложений и их обновления декларативным образом.
>
>
> PVC - Это запрос на создание постоянного хранилища (Если по очень простому и для данной задачи нам этого понимания более чем достаточно. Вообще отмечу еще что PVC обращается к PV. В kubernetes все контейнеры что запускаются не имеют своего постоянного хранилища, то есть если он упадет всё данные пропадут, для этого нам и нужен будет PVC).
>
>
> StorageClass - позволяет описать классы хранения, которые предлагают хранилища. (в k3s уже есть по умолчанию это [rancher.io/local-path](http://rancher.io/local-path)).
>
>
> namespace - пространство в котором мы запускаем поды, загружаем конфиги и в общем ведем всю свою деятельность (удобно для разделения разных проектов/приложений в одном кластере).
>
>
1. Начнем с того что создадим namespace
```
kubectl create ns ark
```
2. Далее нам нужно составить манифесты PVC в которых мы будем хранить данные файлы сервера ARK, а это в районе 20 GB и файлы состоянии сервера не более 1 GB.
> Всем манифесты для kubernetes описываются в виде yaml, требуется внимательно следить за пробелами.
>
>
3. И так откроем редактор.
```
vi ark-pvc.yaml
```
4. И впишем
```
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: ark-server
namespace: ark
spec:
storageClassName: local-path
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 30G
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: ark-save
namespace: ark
spec:
storageClassName: local-path
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10G
```
В данном манифесте мы описали сразу два PVC, для нас имеет значение сейчас такие значения как:
* name - имя нашего PVC
* kind - описание того что будем заводить в kubernetes
* spec - под ним описываем более детально нашу сущность
* namespace - наше пространство
* storageClassName - local-path по умолчанию есть в k3s, если будете использовать не k3s то нужно будет заменить на тот что есть у вас (или можно смонтировать папку с хоста)
* storage - размер PVC
5. Далее применим наш манифест
```
kubeclt apply -f ark-pvc.yaml
```
> Кстати чтобы удалить то что мы создали через манифест необходимо выполнить `kubeclt delete -f ark-pvc.yaml`
>
>
После того как мы подготовили PVC можем начинать подготовку и запуск нашего deployment.
6. Подготовим наш yaml
```
vi deployment.yaml
```
```
apiVersion: apps/v1
kind: Deployment
metadata:
name: ark-deploy
namespace: ark
labels:
app: ARK
spec:
replicas: 1
selector:
matchLabels:
app: ARK
template:
metadata:
labels:
app: ARK
spec:
containers:
- name: ark-server
image: hermsi/ark-server
resources:
requests:
memory: "500Mi"
cpu: "250m"
limits:
memory: "5000i"
cpu: "2000m"
volumeMounts:
- mountPath: /home/steam/ARK-Backups
name: ark-save
- mountPath: /app
name: ark-server
env:
- name: SESSION_NAME
value: ark_world
- name: SERVER_MAP
value: TheIsland
- name: SERVER_PASSWORD
value: iAmSuperman
- name: ADMIN_PASSWORD
value: iAmSuperman
- name: MAX_PLAYERS
value: "20"
ports:
- name: server-list
containerPort: 27015
protocol: UDP
- name: game-client
containerPort: 7777
protocol: UDP
- name: udp-socket
containerPort: 7778
protocol: UDP
- name: rcon
containerPort: 27020
protocol: UDP
volumes:
- name: ark-save
persistentVolumeClaim:
claimName: ark-save
- name: ark-server
persistentVolumeClaim:
claimName: ark-server
```
7. Давайте тут тоже опишем дополнительные моменты:
* spec - под первым мы описываем параметры deployment, по втором мы описываем работу нашего pod.
* containers - описываем с какими параметрами будет подниматься наш контейнер.
* image - какой образ нужно будет использовать.
* selector - задаем по ним лейбл который нам понадобится дальше.
* resources - описываем сколько выделяем фиксированно ресурсов для пода и сколько максимум он может забрать, то есть его лимиты и реквесты.
* volumeMounts - прописываем куда монтировать наши PVC.
* volumes - объявляем наши PVC.
* env - тут задаем переменные для нашего приложения (сервера ark), в нашем случае это пароли, карты, имя сервера.
* port - указываем какие порты открыть из контейнеры.
> Замечу что ark server весьма прожорливый, когда мы запускаем в первый раз он потребляет в районе 3 GB. Мой сервер с 1800 днями уже 7 GB
>
> Вот что пишут в интернете:
>
> 8GB RAM
> 20GB Disk Space Minimum (50-75GB Recommended)
> 2 CPU Cores @ 3.0GHz+ (For 10-15 players)
> 64 Bit Windows or Linux OS (CentOS Linux Recommended for a standalone server)
> A reliable network connection, 100Mbps+ recommended
>
>
8. После применим его командой.
```
kubeclt apply -f deployment.yaml
```
И так после того как мы применили все манифесты, kubectl должен ответить что все было создано и нет проблем

> Кстати мы можем проверить что всё корректно создалось
>
> `kubectl get pvc -n ark`
>
> `kubectl get deployment -n ark`
>
>
9. Далее следует проверить что наш под запустился и не падает.
```
kubeclt get pods -n ark
```
Вывод должен быть примерно таким
10. Теперь проверим логи пода чтобы понять что нет проблем и идёт подготовка сервера.
```
kubeclt logs <> -n ark
```
По выводу можно понять что всё работает и наш сервер ark начал загружать файлы, остается только подождать.
metalLB
-------
Пока загружается наш сервер самое время озаботится тем как мы будет получать доступ к серверу. Для этого нам нужен service который будет перенаправлять трафик с пода наружу и наоборот.
Собственно он так и называется service, через него мы и можем перенаправить трафик наружу, и так service бывает:
> ClusterIP — это тип службы по умолчанию в Kubernetes. Он создает службу внутри кластера Kubernetes, к которой могут обращаться другие приложения в кластере, не разрешая внешний доступ.
>
>
> NodePort - открывает определенный порт на всех узлах в кластере, и любой трафик, отправляемый на этот порт, перенаправляется в службу. Доступ к службе невозможен с IP-адреса кластера.
>
>
> LoadBalancer — это стандартный способ предоставления службы Kubernetes извне, чтобы к ней можно было получить доступ через Интернет. Если вы используете Google Kubernetes Engine (GKE), это создает балансировщик сетевой нагрузки с одним IP-адресом, к которому могут получить доступ внешние пользователи, а затем они перенаправляются на соответствующий узел в вашем кластере Kubernetes. Доступ к LoadBalancer можно получить так же, как к ClusterIP или NodePort.
>
>
То есть получается нам тут подходит только два варианты NodePort и LoadBalancer, но NodePort ввиду того что может использовать порты только c 30,000 по 32,767 не очень удобен в эксплуатации, остается только LoadBalancer, однако данная услуга поставляется обычно в облаке.
И тут на помощь приходит metalLB! Мы развернем дома свой LoadBalancer, направим его на наш домашний роутер и наш под будет прям с него получать свой IP. Нам не придется мучаться с NodePort, пробросом портов и мы сможем сделать всё это красиво.
1. И так, шаг первый нужно установить helm:
> Helm — это средство упаковки с открытым исходным кодом, которое помогает установить приложения Kubernetes и управлять их жизненным циклом.
>
> Если упросить благодаря ему можно шаблонизировать наши манифесты таким образом чтобы из одних и тех же манифестов можно поднять разные инстансы приложения, достаточно в одном файле поменять значения или при установки helm указать новое имя и у нас уже отдельно приложение со своими сущностями.
>
>
> Кстати если на первом шаге не был отключен встроенный servicelb то будет конфликт и MetalLB не будет работать, [тут](https://blog.differentpla.net/blog/2021/12/20/disabling-klipper/) описано как его отключить если вы не отключили его ранее.
>
>
Ставим helm
```
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3
chmod 700 get_helm.sh
./get_helm.sh
```
Взято отсюда <https://helm.sh/docs/intro/install/>
2. Далее клонируем репозиторий и запускаем helm с metalLB и запускаем.
```
git clone https://github.com/general-rj45/helm-ark-survival-evolved.git
helm install metallb helm-ark-survival-evolved/charts/metallb/ --create-namespace --namespace metallb
```
После выполнения команды мы увидим что helm применился и никаких ошибок нет.
3. Проверим что все поды metallb запустились и нет рестартов.
4. Теперь нужно добавить из какого пула адресов будет назначаться ip для наших подов и добавить еще один конфиг для MetalLB.
```
vi metallb-IPAddressPool.yaml
```
```
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: first-pool
namespace: metallb
spec:
addresses:
- 192.168.1.100-192.168.1.200
---
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: example
namespace: metallb
```
* IPAddressPool - задаем диапазон ip для подов.
* addresses - указываем диапазон ip.
* L2Advertisement - для нас сейчас достаточно просто запустить, чтобы более конкретно погрузиться что это и для чего стоит почитать на офф [сайте](https://metallb.universe.tf/concepts/).
5. Применим манифест.
```
kubectl apply -f metallb-IPAddressPool.yaml
```
6. Теперь нам нужно создать service типа loadbalancer.
```
vi service-ark.yaml
```
```
apiVersion: v1
kind: Service
metadata:
name: ark-service
namespace: ark
spec:
type: LoadBalancer
loadBalancerIP: 192.168.1.183
selector:
app: ARK
ports:
- port: 27015
targetPort: 27015
protocol: UDP
name: server-list
# Port for connections from ARK game client
- port: 7777
targetPort: 7777
protocol: UDP
name: game-client
# Raw UDP socket port (always Game client port +1)
- port: 7778
targetPort: 7778
protocol: UDP
name: always-game-client
# RCON management port
- port: 27020
targetPort: 27020
protocol: UDP
name: rcon-management-port
```
* type - тут задается тип service.
* port - порт который будет выведен наружу.
* targetPort - порт пода который будет перенаправляться.
* protocol - задаем протокол tcp или udp
* selector - тут указывается лейб по которому service сможет понять к какому поду подключить и перенаправлять трафик.
7. Применяем манифест
```
kubeclt apply -f service-ark.yaml
```
8. Проверим что наш service успешно создался.
```
kubeclt get svc -n ark
```
Отлично! Наш сервис создан и готов к работе.
Последние шаги.
---------------
1. Проверяем закончил ли подготовку сервера наш под (у меня заняло часа два, медленный HDD, может быть еще из за CPU).

Из вывода мы видим что сервер успешно запущен и готов принимать первых игроков.
Самое время подключиться! Добавляем в избранное через стим.
Вуаля!
Заходим на сервер (возможно ошибка при подключении, нужно через ark повторно подключиться просто).
Поздравляю! Теперь у вас есть свой сервер ark в kubernetes где вы может играть с друзьями! Или в одиночестве но с осознанием того что это ваш сервер =)
Итог
----
Я думал что это будет инструкция на одну страничку но вышло, длиннее.....
И так чем это лучше и проще чем просто взять ВМ и поставить туда сервер ark без всех эти надстроек?
* Проще поднимать еще дополнительные серверы ark, достаточно просто поменять имена, ip в манифестах и применить.
* Мы можем удобно отслеживать состояние pod в котором работает наше приложение и делать простую аналитику по потреблению памяти, цпу, сети, диска.
* Удобно читать логи.
* В случае сбоя работы приложения kubernetes просто перезапустит наш pod и никаких проблем не будет (почти не будет).
* Наше приложение находится в изолированной среде, а это значит если мы будем делать какие либо изменения на хосте или внутри контейнера они не будут влиять друг на друга (почти не будут).
* Всё что мы создаем, описывается декларативно в манифестах, то есть один раз написав, потом можно будет переиспользовать много раз или перенести на другой хост и поднять уже там.
* Подход с декларативным описанием манифестов позволяет удобно менять настройки сервера, к примеру хотите поменять имя сервера, просто изменили его в манифесте и применили, даже не обязательно с того хоста где стоит наш kubernetes. В случае с ВМ нам нужно будет руками подключаться, менять значение, перезапускать скриптами или руками, в общем не очень удобно.
Всё что я описал это моя реализация, которая удобна мне. Может для других такие методы будут избыточны и бессмысленны.
Вообще мне очень нравится концепция контейнеров, ведь она нас освобождает от многих проблем, к примеру что мы минимизируем проблемы с зависимостями, так как каждое приложение живет в своём контейнере и не мешает другим, а так все это было бы в одном месте и создавало хаос, в котором сложно может быть найти виновника тормозов.
Спасибо что дочитали мой первый пост, надеюсь он будет вам полезен или просто интересен. Планирую в будущем еще писать всякие интересности, если дойду. | https://habr.com/ru/post/703624/ | null | ru | null |
# Использование SVG ресурсов в Xamarin
При разработке мобильного приложения есть масса моментов, на которые необходимо обращать внимание. Это и выбор технологии, на которой оно будет написано, и разработка архитектуры приложения, и, собственно, написание кода. Рано или поздно наступает момент, когда костяк приложения есть, вся логика прописана и приложение , в общем-то, работает, но… нет внешнего вида. Тут стоит задуматься о графических ресурсах, которые будут использованы, поскольку графика составляет львиную долю размера итоговой сборки, будь то .apk на Android или .ipa на iOS. Сборки огромных размеров в принципе ожидаемы для мобильных игр, уже сейчас из PlayMarket порой приходится загружать объемы данных вплоть до 2 Гб и хорошо, если во время загрузки есть возможность подключиться к Wi-Fi или мобильный оператор предоставляет скоростное безлимитное подключение. Но для игр это ожидаемо, а бизнес-приложение, обладающее таким размером, невольно вызывает вопрос “Откуда столько?”. Одной из причин большого размера сборки бизнес-приложения может стать значительное количество иконок и картинок, которые в нем приходится отображать. А также не следует забывать о том, что большое количество графики пропорционально влияет на быстродействие приложения.
При создании графической составляющей приложения часто возникает серьезная проблема. Мобильных устройств существует великое множество начиная с часов и заканчивая планшетами, и разрешения их экранов очень разнятся. Из-за этого зачастую приходится включать в сборку графические ресурсы отдельными файлами для каждого из существующих типов. По 5 копий для Android и по 3 для iOS. Это существенно влияет на размер итоговой сборки, которую Вы будете выкладывать в сторы.
О том, что можно сделать для того, чтобы не попасть в такую ситуацию, мы расскажем в этой статье.
Сравнение форматов PNG и SVG
----------------------------
Основное различие между форматами PNG и SVG заключается в том, что PNG — формат растровой графики, а SVG — векторной.
Растровое изображение представляет собой сетку пикселей на мониторе и используется повсеместно, будь то небольшие иконки или огромные баннеры. Среди преимуществ этого типа графики также следует отметить следующее:
1. Растровая графика позволяет создавать рисунки практически любой сложности, без ощутимых потерь в размере файла;
2. Если не требуется масштабирование изображения, то скорость обработки сложных изображений весьма высока;
3. Растровое представление изображений естественно для большинства устройств ввода-вывода.
Однако, есть и минусы.
Например, растровое изображение невозможно идеально масштабировать. При увеличении небольшой картинки изображение «мылится» и видно пиксели из которых оно состоит.


Также, простые изображения, состоящие из большого количества точек — имеют большой размер. В связи с этим простые рисунки рекомендуется хранить в векторном формате. Все вышеперечисленное справедливо как для формата PNG, так и для любого другого формата растровой графики.
Формат SVG, в свою очередь, является не совсем изображением. Согласно [статье на википедии](https://ru.wikipedia.org/wiki/SVG#%D0%94%D0%BE%D1%81%D1%82%D0%BE%D0%B8%D0%BD%D1%81%D1%82%D0%B2%D0%B0_%D1%84%D0%BE%D1%80%D0%BC%D0%B0%D1%82%D0%B0) SVG является языком разметки масштабируемой векторной графики, что позволяет читать и при необходимости редактировать файл.
Также, будучи языком разметки, SVG позволяет внутри документа применять фильтры (например, размытие, выдавливание и т.д.). Они объявляются тегами, за визуализацию которых отвечает средство просмотра, а значит, они не влияют на размер исходного файла.
Помимо перечисленного, формат SVG имеет еще ряд преимуществ:
1. Будучи векторным форматом, SVG позволяет масштабировать любую часть изображения без потерь в качестве;
2. В SVG-документ можно вставлять растровую графику;
3. Легко интегрируется с HTML- и XHTML-документами.
Однако, есть и недостатки данного формата:
1. Чем больше в изображении мелких деталей, тем быстрее растет размер SVG-данных. В ряде случаев, SVG не только не дает преимуществ, но и проигрывает растру;
2. Сложность использования в картографических приложениях, поскольку для корректного отображения малой части изображения, требуется прочитать документ целиком.
В случае с разработкой мобильных приложений на платформе Xamarin есть еще один недостаток.
Для корректной работы с этим форматом необходимо подключать дополнительные библиотеки, либо искать обходные пути.
Работа с форматом SVG в Xamarin.Android
---------------------------------------
Как уже было сказано выше, Xamarin “из коробки” не поддерживает работу с форматом SVG. Чтобы решить эту проблему – можно использовать сторонние библиотеки или VectorDrawable. В последнее время разработчики все чаще отдают предпочтение последним, так как большая часть библиотек для Xamarin ориентирована на кроссплатформенное использование в Xamarin.Forms, а решения для нативного андроида либо больше не поддерживаются их разработчиками и устарели, либо возникают серьезные проблемы при попытке создать на их основе библиотеку для Xamarin. В связи с этим здесь рассмотрим использование VectorDrawable.
Для реализации данного подхода потребуется использовать Vector Asset Studio. Найти ее достаточно просто для этого всего лишь нужна Android Studio. Итак, начнем:
1. Создаем новый проект в Android Studio с помощью File -> New -> New Project;
Поскольку все, для чего нам понадобится этот проект — это использование Vector Asset Studio, то его можно создать пустым.
2. Правый клик на папке drawable -> New -> Vector Asset;

Это откроет Asset Studio. Она предоставляет возможность конвертировать иконки из Material Design, а также файлы SVG и PSD, в xml-файлы. Таким образом мы сможем использовать их в приложении.
3. Окно Asset Studio

Здесь мы выбираем, что именно нужно сделать, размер итогового изображения и настраиваем прозрачность.
4. По нажатию на кнопку Next открывается окно сохранения итогового файла

После его сохранения мы сможем использовать его в своем проекте Xamarin.Android.
Достаточно емкая подготовительная работа, требующая наличия установленной Android Studio. К сожалению, на момент написания статьи нам не удалось найти корректно работающих онлайн-конвертеров. Некоторые при попытке конвертации представленного файла SVG выдавали ошибку, некоторые указывали, что лучше воспользоваться Vector Asset Studio.
Как бы то ни было, мы получили требуемый файл и теперь можем использовать его в своем проекте. Не будем описывать процесс создания проекта Xamarin.Android, перейдем сразу к сути.
Первым делом мы поместили полученный файл в папку drawable проекта, затем в качестве демонстрации работы с этим файлом, создали 3 ImageView на экране.
**код здесь**
```
xml version="1.0" encoding="utf-8"?
```
В первом ImageView мы попытались присвоить оригинальный файл SVG в свойстве android:src, во втором — конвертированный XML-файл в том же свойстве, а в третьем — в свойстве app:srcCompat (обратите внимание, что это пространство имен необходимо прописать как указано в коде).
Результаты были заметны уже в дизайнере, до запуска приложения — единственно верный способ корректно отобразить наш файл, приведен в третьем ImageView.

Теперь необходимо убедиться, что изображение отображается корректно на разных устройствах. Для сравнения мы выбрали Huawei Honor 20 Pro и Nexus 5. А также, вместо некорректных способов отображения указали нужный и изменили размеры ImageView на 150х150 dp, 200x200 dp и 300х300 dp.
**Результаты работы**
#### Huawei Honor 20 Pro

#### Nexus 5

Как видно, качество изображений одинаковое, а значит, мы добились нужного результата.
Полученный файл используется из кода так же, как и обычно
`image.SetImageResource(Resource.Drawable.<имя файла>);`
Работа с форматом SVG в Xamarin.iOS
-----------------------------------
В случае с Xamarin.iOS дело обстоит так же, как и с Xamarin.Android, в том смысле, что “из коробки” работа с SVG-файлами не поддерживается. Однако, для ее реализации не требуется особых усилий. В случае нативной iOS-разработки для использования SVG требуется подключить SVGKit. Он позволяет обрабатывать такие файлы, не прибегая к сторонним решениям. В случае с Xamarin.iOS мы можем использовать библиотеку [SVGKit.Binding](https://github.com/sushihangover/SVGKit.Binding). Это С# обертка над оригинальной SVGKit.
Все, что нам потребуется это подключить NuGet-пакет в наш проект. На момент написания статьи последняя версия — 1.0.4.
К сожалению, судя по всему, поддержка этой библиотеки прекращена, но для использования в проекте она вполне годится.
Здесь реализован класс SVGKImage (собственно SVG-изображение) и SVGKFastImageView (контрол для отображения таких изображений).
**код для использования**
```
void CreateControls()
{
var image_bundle_resource = new SVGKImage("SVGImages/question.svg");
img1 = new SVGKFastImageView(image_bundle_resource);
Add(img1);
img1.Frame = new CGRect(View.Frame.Width / 4, 50, View.Frame.Width / 2, View.Frame.Width / 2);
var image_content = new SVGKImage(Path.Combine(NSBundle.MainBundle.BundlePath, "SVGImages/question1.svg"));
img2 = new SVGKFastImageView(image_content);
Add(img2);
img2.Frame = new CGRect(5, img1.Frame.Bottom + 5, View.Frame.Width - 5, View.Frame.Width - 5);
}
```
Для создания SVGKImage в библиотеке реализовано два варианта в зависимости от BuildAction файла — BundleResource (в коде обозначен image\_bundle\_resource) и Content (в коде обозначен image\_content).
К сожалению, в библиотеке есть ряд недостатков:
1. У SVGKFastImageView не поддерживается инициализация без предоставления SVGKImage — выдается ошибка, указывающая на необходимость использования приведенного в коде конструктора;
2. Нет возможности использования SVG-файлов в других контролах. Однако, если в этом нет необходимости, то использовать ее можно.
**Итог работы программы**

В случае если для приложения критично использование SVG-файлов не только в ImageView, можно воспользоваться другими библиотеками. Например, [FFImageLoading](https://github.com/luberda-molinet/FFImageLoading/wiki/SVG-support). Это мощная библиотека, позволяющая не только выгружать SVG-изображения в родной для Xamarin.iOS UIImage, но и делать это напрямую в нужный контрол, экономя время на разработку. Также имеется функционал для загрузки изображений из интернета, но рассматривать его в этой статье мы не будем.
Для использования библиотеки понадобится подключить в проект два NuGet-пакета — Xamarin.FFImageLoading и Xamarin.FFImageLoading.SVG.
В тестовом приложении мы использовали метод, загружающий SVG-изображение в UIImageView напрямую и выгружающий изображение в родной UIImage.
**Пример кода**
```
private async Task CreateControls()
{
img1 = new UIImageView();
Add(img1);
img1.Frame = new CGRect(View.Frame.Width / 4, 50, View.Frame.Width/2, View.Frame.Width/2);
ImageService.Instance
.LoadFile("SVGImages/question.svg")
.WithCustomDataResolver(new SvgDataResolver((int)img1.Frame.Width, 0, true))
.Into(img1);
var button = new UIButton() { BackgroundColor = UIColor.Red};
Add(button);
button.Frame = new CGRect(View.Frame.Width/2 - 25, img1.Frame.Bottom + 20, 50, 50);
UIImage imageSVG = await ImageService.Instance
.LoadFile("SVGImages/question.svg")
.WithCustomDataResolver(new SvgDataResolver((int)View.Frame.Width, 0, true))
.AsUIImageAsync();
if(imageSVG != null)
button.SetBackgroundImage(imageSVG, UIControlState.Normal);
}
```
Также в этой библиотеке имеется метод, позволяющий перегнать строковое представление SVG в UIImage, но он имеет смысл исключительно для небольших файлов.
**Пример кода**
```
var svgString = @"";
UIImage img = await ImageService.Instance
.LoadString(svgString)
.WithCustomDataResolver(new SvgDataResolver(64, 0, true))
.AsUIImageAsync();
```
В библиотеке также имеется еще ряд функционала, однако рассматривать его здесь мы не будем. Единственное, о чем действительно стоит упомянуть, данная библиотека может быть использована и в Xamarin.Android проектах. Для использования в проектах Xamarin.Forms есть аналоги этой библиотеки, о работе с которыми мы расскажем далее.
Работа с форматом SVG в Xamarin.Forms
-------------------------------------
По большому счету необязательно искать библиотеки для форм, можно просто подключить известные в проекты платформ и долго, и муторно переписывать рендеры для каждого контрола, которым вы захотите воспользоваться. К счастью, есть решение, о котором мы расскажем.
Это уже описанные библиотеки Xamarin.FFImageLoading и Xamarin.FFImageLoading.SVG, точнее их вариант для Xamarin.Forms (Xamarin.FFImageLoading.Forms и Xamarin.FFImageLoading.SVG.Forms). Как при работе с большинством библиотек в Xamarin.Forms перед тем, как ее использовать, необходима небольшая стартовая настройка проекта:
1. Во все проекты (PCL и проекты платформ) необходимо добавить два NuGet-пакета — Xamarin.FFImageLoading.Forms и Xamarin.FFImageLoading.SVG.Forms;
2. Прописать в AppDelegate.cs iOS-проекта:
```
public override bool FinishedLaunching( UIApplication app, NSDictionary options )
{
global::Xamarin.Forms.Forms.Init();
FFImageLoading.Forms.Platform.CachedImageRenderer.Init();
CachedImageRenderer.InitImageSourceHandler();
var ignore = typeof(SvgCachedImage);
LoadApplication(new App());
return base.FinishedLaunching(app, options);
}
```
3. Прописать в MainActivity.cs Android-проекта:
```
protected override void OnCreate( Bundle savedInstanceState )
{
TabLayoutResource = Resource.Layout.Tabbar;
ToolbarResource = Resource.Layout.Toolbar;
base.OnCreate(savedInstanceState);
Xamarin.Essentials.Platform.Init(this, savedInstanceState);
global::Xamarin.Forms.Forms.Init(this, savedInstanceState);
FFImageLoading.Forms.Platform.CachedImageRenderer.Init(true);
CachedImageRenderer.InitImageViewHandler();
var ignore = typeof(SvgCachedImage);
LoadApplication(new App());
}
```
После этого библиотекой можно пользоваться.
В библиотеке реализованы обращения к SVG-ресурсам, находящимся как в платформенных проектах, так и EmbeddedResouce PCL проекта. Для отображения SVG-картинок используется SvgCachedImage. В отличие от оригинального контрола Image, использующегося в Xamarin.Forms и принимающего в себя ImageSource, SvgCachedImage работает с SvgImageSource.
**ВАЖНО!**
Перед использованием пространства имен svg, показанного далее, необходимо его объявить:
```
xmlns:svg="clr-namespace:FFImageLoading.Svg.Forms;assembly=FFImageLoading.Svg.Forms"
```
Предоставить его можно несколькими способами:
1. Указать в XAML-файле имя SVG-файла, находящегося в ресурсах проектов платформ:
```
```
2. Указать в XAML-файле полный путь к файлу SVG, являющегося встроенным ресурсом PCL-проекта:
```
```
При загрузке из встроенных ресурсов можно указать имя другой сборки:
```
resource://SVGFormsTest.SVG.question1.svg?assembly=[ASSEMBLY FULL NAME]
```
3. При работе из кода сначала даем контролы имя:
```
```
Затем, в зависимости от того какой ресурс используется, выбираем один из вариантов:
* для использования встроенных ресурсов
```
image.Source = SvgImageSource.FromResource("SVGFormsTest.SVG.question1.svg");
```
* для использования платформенных ресурсов
```
image.Source = SvgImageSource.FromFile("question.svg");
```
4. С помощью Binding есть 2 варианта:
* хранить в переменной модели, на которую осуществлена привязка самого SvgImageSource. В этом случае со стороны кода ничего не изменяется, а в XAML-файле остается стандартная привязка:
```
```
* хранить в переменной модели строку с путем к файлу либо ко встроенному ресурсу. В этом случае необходимо использование конвертера, предоставляемого библиотекой. Для этого его нужно добавить в ресурсы страницы:
```
```
затем указать необходимость его использования при привязке:
```
```
В переменную модели можно передавать строку с именем файла для ресурса платформы:
```
public MainVM()
{
source1 = "question.svg";
}
string source1;
public string Source1
{
get => source1;
set
{
source1 = value;
}
}
```
или путь к данным встроенного ресурса:
```
public MainVM()
{
source1 = "resource://SVGFormsTest.SVG.question1.svg";
}
string source1;
public string Source1
{
get => source1;
set
{
source1 = value;
}
}
```
Однако, при предоставлении пути к файлу встроенного ресурса в качестве строки конвертер не срабатывает и изображение не загружается. Разумеется, можно создать свой конвертер, наследовать его от предоставленного библиотекой и обработать этот случай.
Недостатки и исключения
-----------------------
Недостатки использования SVG-ресурсов в проектах, прямо вытекают из недостатков самого формата. К примеру, если графическая составляющая вашего приложения очень сложна и в ней должны использоваться изображения с множеством мелких деталей, градиентом, большим количеством цветовых переходов, и таких изображений не одно и не два, то использовать их, как SVG-ресурсы может быть невыгодно. Кроме того, PNG-файлы готовы к отображению быстрее, чем SVG, поэтому для использования на экране загрузки приложения подходят больше.
Еще у SVG-ресурсов есть незначительный минус. Их нельзя предоставить в качестве иконки приложения, так как в соответствии с гайд-лайнами Google и Apple в качестве иконки могут использоваться только PNG и JPEG файлы. | https://habr.com/ru/post/516576/ | null | ru | null |
# Создание образа Мона Лизы в Игре «Жизнь»
[](https://habr.com/ru/company/ruvds/blog/546920/)
Клеточные автоматы представляют большой интерес и являются предметом исследования во многих областях, включая математику, физику, биологию, программирование и прочие. В статье мы разберем базовую реализацию и оптимизацию алгоритма для поиска состояния Жизни, из которого в течение нескольких поколений будет генерироваться образ Мона Лизы.
На загрузку этого видео может уйти несколько секунд. Рекомендую прищуриться – так удастся лучше разглядеть результат:)
Как видите, итог эксперимента получился не совсем запланированный, но я посчитал, что об этом все же стоит написать. Мой ум долго будоражила идея относительно [Игры «Жизнь»](https://ru.wikipedia.org/wiki/Игра_): «Интересно, можно ли задействовать какой-нибудь стохастический алгоритм, дающий начальное состояние, которое бы через множество циклов формировало разборчивый текст».
Недавно мне попалась [одноименная статья](https://kevingal.com/blog/mona-lisa-gol.html) Кевина Галлигана, которая натолкнула меня на мысль, что можно добиться аналогичных результатов, но спомощью другого подхода. Что если вместо решателя задач выполнимости булевых формул применить определенный эвристический алгоритм, который сможет «запрограммировать» огромный мир Игры «Жизнь» так, чтобы спустя несколько поколений формировалось изображение?
Этого реально добиться другими путями. Например, поместить натюрморты (устойчивые фигуры) в определенных пикселях, как описано в [вопросе на Codegolf](https://codegolf.stackexchange.com/questions/38573/paint-a-still-life-or-a-moving-one-draw-an-image-in-the-game-of-life).
Мой же замысел был отобразить картину Мона Лизы для одного кадра/поколения Жизни без натюрморта.
Алгоритм
--------
Для подтверждения этой идеи я решил использовать поиск с восхождением к вершине, итеративно изменяя случайное состояние Игры, пока n-поколение не даст изображение Мона Лизы.
Вот весь алгоритм:
```
best_score := infinity
target := mona lisa with dimensions m x n
canvas := random matrix of m x n
best_result := canvas
do
modified_canvas := Copy of canvas with a single random cell inverted
nth_modified_canvas := Run N generations of Game of Life modified_canvas
Compute a score of how close nth_modified_canvas is with target
if score < best_score then
best_score := score
best_result := modified_canvas
canvas := best_result
while(max_iterations limit passed or best_score < threshold)
```
Изначально я создал прототип для выполнения на одном ядре.
```
def modify(canvas, shape):
x,y = shape
px = int(np.random.uniform(x+1))-1
py = int(np.random.uniform(y+1))-1
canvas[px][py] = not canvas[px][py]
return canvas
def rmse(predictions,targets):
return np.sqrt(np.mean((predictions-targets)**2))
while best_score>limit:
canvases = np.tile(np.copy(best_seed), (batch_size, 1, 1))
rms_errors = []
for canvas in range(len(canvases)):
canvases[canvas] = modify(states[state], (m,n))
rmse_val = rmse(target, nth_generation(np.copy(canvases[canvas])))
rms_errors.append(rmse_val)
lowest = min(rms_errors)
if lowest < best_score:
best_score = lowest
best_result = canvases[rms_errors.index(lowest)]
```
Принцип работы поиска с восхождением к вершине заключается в определении ближайшего к текущему соседнего состояния с наименьшей ошибкой по сравнению с `target_state`, представляющим Мона Лизу. Ближайший сосед на каждом шаге находится через создание копии лучшего текущего решения и инвертирования случайной клетки. Столь небольшое изменение не вызывает риска выхода из локального минимума. В качестве метрики для сравнения лучшего состояния с целевым используется среднеквадратичная ошибка (RMSE).
Спустя несколько дней CPU-вычислений я смог получить изображение, напоминающее Мона Лизу, через воспроизведение 4 поколений Жизни.
Это доказывало, что мой алгоритм работает, но я также понимал, что допустил много ошибок и, конечно же, речи о масштабировании или высокой скорости тут не шло.
Препроцессинг
-------------
В качестве целевого изображения Мона Лизы, с которым алгоритм сравнивает случайное состояние, использовалась версия среднего разрешения, взятая из Википедии и преобразованная в черно-белую форму с помощью инструкции Python Imaging Library `Image.open('target.png').convert('L')`.

При сравнении с логическими переменными лучше использовать бинарную матрицу, а не весь диапазон оттенков серого. Для этого я просто округлил значения оттенков серого до 0 и 1. Все же это было ошибкой, потому что в итоге утратилось много деталей.

Можно было вообще не округлять и сравнивать с версией в оттенках серого, но есть способ получше.
Состояния Сада Эдема
--------------------
Не каждая случайная матрица 0 и 1 представляет допустимое состояние Игры «Жизнь». Состояния, которые никогда не могут быть n-поколением (n>0) любого клеточного автомата называются Сад Эдема.
Практически нереально, чтобы наша округленная черно-белая вариация Мона Лизы оказалась возможным поколением Жизни. Поэтому остается искать решение, которое окажется просто максимально приближенным к цели.

*Это часть 4-го поколения только что подготовленного состояния*
Проанализировав текстуру, способ развития паттернов Жизни и просто поэкспериментировав с изображениями, я выяснил, что если делать сравнение с прошедшей дизеринг 1-битной версией цели, то результат должен получаться лучше.

*1-битная версия Мона Лизы*
В таком изображении приблизительно равно распределены клетки 0 и 1, что в некоторой степени соответствует случайно инициализированному состоянию Игры, получаемому спустя несколько поколений. Это свойство также сохраняется при масштабировании изображения, которое мы вскоре реализуем.
Получить такой вариант изображения можно с помощью [функции дизеринга Флойда-Стейнберга](https://en.wikipedia.org/wiki/Floyd%E2%80%93Steinberg_dithering) библиотеки PIL, использовав инструкцию `Image.open('target.png').convert('1')`.

Кроме того, по последнему результату видно, что невозможно получить непрерывный массив белых клеток, так как они уничтожаются правилом перенаселенности. При этом полностью темные области оказываются в Жизни стабильными. В конечном результате получится более контрастная, но затемненная версия Мона Лизы. При высоких разрешениях этот эффект становится не столь заметен.
Векторизация с помощью JAX
--------------------------
Версия для одного ядра CPU без использования векторизации оказывается чрезвычайно медленной. Я пробовал выполнять ее и на своем Core i7 восьмого поколения, и на машинах Google Colab, но для получения похожего на цель результата приходится всякий раз ждать часы или даже дни, в зависимости от разрешения.
К счастью, эта задача отлично поддается распараллеливанию.

JAX – это библиотека Python, которая позволяет использовать *numpy*-версию и компилировать ее в высоко векторизованный код, который можно выполнять на графических и тензорных процессорах. В нашем случае нужно переработать этот алгоритм конкретно для графического (GPU).
GPU, как правило, применяются для вычислений, предполагающих высокую скорость передачи и хороший параллелизм данных. Для достижения повышенной скорости выполнения мы будем использовать архитектуру SIMD (один поток команд и несколько потоков данных).
Мы экструдируем `target` (Мона Лиза) и `canvas` (начальное случайное состояние) в 3-е измерение, в котором они формируют многослойные тензорные структуры (loafs) с длиной равной `batch_size`.


Прежде чем переходить к циклу восхождения к вершине, мы устанавливаем `best_canvas` как начальный случайный холст.
Дополнительно для каждой итерации этого цикла нужно производить случайный тензор, называемый мутатором (той же формы, что `target`), со следующим свойством: в каждом слое должна присутствовать только одна 1, расположенная в случайном месте.

Вот пример мутатора формы 5, 3, 2, где 5 — это размер `batch-size`:
```
array([[[1, 0],
[0, 0],
[0, 0]],
[[1, 0],
[0, 0],
[0, 0]],
[[0, 0],
[0, 1],
[0, 0]],
[[0, 1],
[0, 0],
[0, 0]],
[[1, 0],
[0, 0],
[0, 0]]])
```
Идея в том, чтобы в каждом цикле с помощью мутатора вычислять ближайший набор соседних с `best_canvas` состояний: `canvas = (best_canvas + mutator)%2`.
Мы вычисляем N поколений Игры в каждом слое этого модифицируемого холста, после чего определяем показатель RMSE (среднее вычисляется только для слоя) холста N-поколения в отношении к Мона Лизе и находим слой с наименьшей ошибкой. Далее этот слой экструдируется и устанавливается как `best_canvas`, после чего данный цикл повторяется в течение конечного числа итераций.
Код
---
Весь код этого проекта [доступен на GitHub](https://github.com/avinayak/mona_lisa_gol_jax/blob/main/mona_lisa_overdrive.ipynb). В текущем же разделе я поясню, что в нем означает каждый блок. Если вы хотите сразу увидеть результаты, просто промотайте к концу статьи. Основа проекта, а именно функция Игры «Жизнь» взята из [этого поста](http://www.bnikolic.co.uk/blog/python/jax/2020/04/19/game-of-life-jax.html).
Выражаю благодарность Бояну Николичу. Я следовал его условию импорта `jax.numpy` в качестве `N`, а `jax.lax` в качестве `L`.
```
%matplotlib inline
import jax
N=jax.numpy
L=jax.lax
from jax.experimental import loops
from jax import ops
import matplotlib.pyplot as plt
import numpy as onp
import time
from PIL import Image
from google.colab import files
```
Далее выполняем `wget` Мона Лизы:
```
!wget -O target.png https://upload.wikimedia.org/wikipedia/commons/thumb/e/ec/Mona_Lisa%2C_by_Leonardo_da_Vinci%2C_from_C2RMF_retouched.jpg/483px-Mona_Lisa%2C_by_Leonardo_da_Vinci%2C_from_C2RMF_retouched.jpg?download
```
Это скромная версия шириной в 483px.
```
batch_size = 100
image_file = Image.open("target.png")
image_file = image_file.convert('1')
lisa = N.array(image_file, dtype=N.int32)
width,height = lisa.shape
lisa_loaf = onp.repeat(lisa[onp.newaxis, :, :,], batch_size, axis = 0)
```
Здесь выполняется дизеринг изображения Мона Лизы и его экструдирование до глубины равной `batch_size`:
```
key = jax.random.PRNGKey(42)
canvas_loaf = jax.random.randint(key, (batch_size, width, height), 0, 2, dtype= N.int32)
#для тестов инициализируем случайное изображение Лизы
```
Здесь создается начальное значение JAX PRNG (вскоре я поясню, о чем речь), а также начальный случайный `canvas_loaf` с целыми числами 0 и 1.
```
@jax.jit
def rgen(a):
# Это сокращение превосходит численностью соседей живых клеток, так как включает в себя #саму центральную клетку. Чтобы это исправить, нужно вычесть массив
nghbrs=L.reduce_window(a, 0, L.add, (3,3), (1,1), "SAME")-a
birth=N.logical_and(a==0, nghbrs==3)
underpop=N.logical_and(a==1, nghbrs<2)
overpop=N.logical_and(a==1, nghbrs>3)
death=N.logical_or(underpop, overpop)
na=L.select(birth,
N.ones(a.shape, N.int32),
a)
na=L.select(death,
N.zeros(a.shape, N.int32),
na)
return na
vectorized_rgen = jax.vmap(rgen)
@jax.jit
def nv_rgen(state):
for _ in range(n_generations):
state = vectorized_rgen(state)
return state
```
Пояснение функции `rgen`, которая воспроизводит одно поколение Жизни, можете найти в [статье](http://www.bnikolic.co.uk/blog/python/jax/2020/04/19/game-of-life-jax.html) упомянутого мной Бояна Николича.
`jax.vmap` позволяет создать функцию, которая отображает входную функцию на оси аргументов (выполняет векторизацию). Это дает возможность воспроизвести поколение Жизни для каждого слоя холста.
`nv_rgen` воспроизводит на холсте N-поколений Жизни.
Помимо этого, декоратор `@jax.jit` обуславливает JIT-компиляцию данной функции (Just-in-time, то есть компиляцию в процессе выполнения программы). Не уверен, произошли ли в данном случае какие-либо улучшения, так как `nv_rgen` просто складывается из других функций, также компилируемых при выполнении.
```
def mutate_nj(b, w, h, subkey):
a = jax.random.normal(subkey, (b, w, h))
return (a == a.max(axis=(1,2))[:,None,None]).astype(int)
mutate = jax.jit(mutate_nj, static_argnums=(0,1,2))
```
`mutate_nj` (nj означает без JIT) генерирует тензор мутатора с помощью `jax.random.normal`, устанавливая для каждого слоя максимум одну 1 и остальные 0. Аргумент `subkey` я объясню чуть позже.
Далее мы JIT-компилируем эту функцию как `mutate`, а также отмечаем аргументы `b, w, h` как статические, указывая компилятору, что в процессе выполнения они изменяться не будут.
```
def rmse_nj(original, canvas, b, w, h):
return N.sqrt(N.mean(L.reshape((original-canvas)**2,(b,w*h)) , axis=1))
rmse = jax.jit(rmse_nj, static_argnums=(2,3,4))
```
`rmse` говорит сама за себя. Единственное существенное отличие от CPU-версии в том, что среднее вычисляется по 1-й оси (оси длины экструдированной структуры).
```
def hill_climb(original, canvas, prng_key, iterations):
with loops.Scope() as s:
s.best_score = N.inf
s.best_canvas = canvas
s.canvas = canvas
s.prng_key = prng_key
for run in s.range(iterations):
s.prng_key, subkey = jax.random.split(s.prng_key)
s.canvas+=modify(batch_size, width, height, subkey)
s.canvas%=2
rmse_vals = rmse(original, nv_rgen( s.canvas ), batch_size, width, height)
curr_min = N.min(rmse_vals)
for _ in s.cond_range(curr_min < s.best_score):
s.best_score = curr_min
s.best_canvas = N.repeat((s.canvas[N.argmin(rmse_vals)])[N.newaxis, :, :,], batch_size, axis = 0)
s.canvas = s.best_canvas
return s.canvas
```
`hill_climb` является основной функцией программы. Это одна большая конструкция цикла JAX. Можно было использовать здесь стандартные циклы Python, но нужно по максимуму задействовать возможности JAX.
Циклы в JAX (модуль `jax.experimental.loops`) – это функции, представляющие синтаксический сахар, например `lax.fori`\_loop и `lax.cond`. Циклы `lax` (фактически, циклы XLA), которые содержат больше нескольких инструкций и вложения, становятся очень сложными. Тем не мене в JAX они приближены к стандартным циклам Python. Единственная загвоздка в том, что состояние цикла, то есть все, что изменяется по ходу итераций, должно храниться как член его области. В нашем случае сюда относятся `best_score`, `best_canvas`, временный холст, где мы воспроизводим Жизнь, а также ключ PRNG.
JAX PRNG
--------
В NumPy для всех функций, предполагающих наличие случайных чисел, используется управляемый генератор псевдослучайных чисел (PRNG). То есть NumPy полностью отвечает за определение для него начального числа (seed) и последующую обработку состояния. Как я понимаю, при параллельном выполнении, а также в ситуациях, требующих большого количества случайных чисел, этот метод имеет свои недостатки. С его помощью сложно обеспечить достаточную энтропию для производства нужного количества случайных значений.
В отличие от NumPy, JAX не управляет случайной генерацией чисел. Каждой функции `jax.random` в качестве первого аргумента необходимо предоставлять текущее состояние PRNG, и при каждом выполнении одной из этих функций состояние PRNG должно обновляться через `jax.random.split`.
Если состояние не обновлять, то это быстро приведет к повторяющейся генерации одинаковых наборов случайных чисел. Я не до конца понимал этот момент, когда первый раз писал цикл, и в результате алгоритм перестал находить новые вариации состояния холста. Причина в том, что генерируется одинаковый тензор-мутатор.
Генерацию каждым параллельным компонентом алгоритма различных случайных чисел можно также обеспечить с помощью разделения состояния PRNG. Подробнее о структуре PRNG в JAX можно почитать [здесь](https://github.com/google/jax/blob/master/design_notes/prng.md).
### cond\_range
Почему в JAX условные конструкции также являются циклами? Честно, я не совсем это понимаю. У `cond_range` должна быть возможность выводить стандартное логическое значение вместо итератора длиной 0/1, но по какой-то причине спроектирована конструкция именно так.
Если мы находим более соответствующий слой холста, то экструдируем его и устанавливаем как `best_canvas`, а его показатель ошибки как `best_score`.
Спустя конечное число итераций мы получаем состояние Жизни, которое через N поколений формирует образ Мона Лизы.
Итоги
-----
Выполнение ~1000 итераций для изображения шириной 483px на GPU Google Colab занимает всего ~40 секунд. Если сравнивать с версией программы для CPU, которая даже изображение меньшего разрешения обрабатывала несколько часов, можно считать, что цели мне достичь удалось.

Состояние Жизни, дающее наибольшее сходство с целевым изображением, было достигнуто через ~23 000 итераций, что заняло 10 минут. После 23 000 повторений прирост качества прекращается, и даже при достижении 100 000 итераций видимых улучшений не наблюдается.
Также отмечу, что изображения, получаемые при меньшем числе поколений, как и ожидалось, проявляют большее сходство с целью.
Мона Лиза, 10 поколений:
Тестовый образец шахматной доски, 7 поколений:
Тестовый образец текста, 5 поколений:
Давид (работа Микеланджело), 3 поколения:
Луна, 7 поколений (https://unsplash.com/photos/pd4lo70LdbI):
Нил Армстронг, 7 поколений:
Заключение
----------
В действительности я просто искал предлог для применения библиотеки JAX, который не требовал бы использования ее возможностей автоматического дифференцирования. JAX можно применять для любых вычислительных задач, где участвуют тензоры. Я уверен, что допустил в этом проекте множество ошибок, но при этом он принес мне огромный опыт.
Джон Хортон Конвей (26 декабря 1937 — 11 апреля 2020), RIP:
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=Bright-translate&utm_content=sozdanie_obraza_mona_lizy_v_igre_zhizn#order) | https://habr.com/ru/post/546920/ | null | ru | null |
# В Raspberry Pi OS появилась встроенная поддержка SATA
[](https://habr.com/ru/company/ruvds/news/t/571154/)
Спустя несколько месяцев [тестирования различных SATA-карт](https://pipci.jeffgeerling.com/#sata-cards-and-storage) на Raspberry Pi Compute Module 4, в ядро Raspberry Pi OS наконец-то была [добавлена встроенная поддержка SATA](https://github.com/raspberrypi/linux/pull/4256).
До этого апдейта, если вы хотели использовать SATA HDD или SSD на их нативных скоростях и иметь при этом возможность собрать RAID-массив, то требовалось перекомпилировать ядро Linux, добавив поддержку SATA и AHCI.
Конечно же, всегда можно было использовать HDD и SSD через адаптеры SATA – USB, но это решение отнимало 10-20% от их быстродействия и не давало возможности собрать RAID-массив, по крайней мере не без дополнительных ухищрений.
> Кому интересно, у этой статьи есть видео версия: [SATA support is now built into Raspberry Pi OS!](https://www.youtube.com/watch?v=ZSx1BRwz1bs)
Перекомпиляция ядра – это в общем-то не ракетостроение, и я даже собрал [среду кросс-компиляции](https://github.com/geerlingguy/raspberry-pi-pcie-devices/tree/master/extras/cross-compile), чтобы данный процесс упростить. Но все же задача эта помимо того, что напрягает, так еще отнимает драгоценное время и требует регулярного повторения, если мы хотим поддерживать актуальность Pi.
Однако в этом месяце Raspberry Pi OS получила-таки встроенную поддержку практически всех контроллеров PCI Express – SATA. Теперь для ее активации достаточно лишь выполнить:
```
sudo apt upgrade
```
Это означает, что все обладатели Compute Module 4 могут вставить SATA-карту и подключать HDD или SSD, которые при условии достаточного питания будут прекрасно работать.
Подобная возможность меня особенно радует, потому что одна из основных мотиваций добавить поддержку возникла, когда я проводил [тестирование совместимости PCI Express-карт с Pi для соответствующей базы данных](https://pipci.jeffgeerling.com/). При этом сам код, добавляющий поддержку, стал [моим первым пул-реквестом к ветке ядра Linux для Raspberry Pi](https://github.com/raspberrypi/linux/pull/4256).
А если задуматься, то буквально год назад я вообще не имел опыта компиляции ядра.
Нативная поддержка SATA означает возможность использования таких инструментов, как [OpenMediaVault](https://www.openmediavault.org/), для создания RAID NAS на базе Raspberry Pi без необходимости обслуживания кастомного ядра или выполнения дополнительной настройки.
В качестве же личного опыта я понял, что писать патчи для ядра Linux не так сложно, как мне казалось (хотя, если честно, мне не пришлось работать со списком рассылки, поскольку мой патч ушел прямиком в ветку дерева ядра Pi OS).
Хочу также отметить техническую скромность Raspberry Pi, благодаря которой я успешно реализовал проект. Именно дешевизна этого устройства и удобство его перепрошивки добавили смелости моим экспериментам, так как я знал, что в случае ошибки, она обойдется недорого.
Думаю, что многие, кто привык к работе с громоздкими настольными системами и серверами, не понимают то чувство облегчения, которое испытываешь от возможности использовать крохотный любительский компьютер, наподобие Pi.
Жаль только, что пока нельзя загружать Pi с SATA-диска. Можно загрузить его с USB, microSD, а [на последних OS даже с NVMe](https://www.jeffgeerling.com/blog/2021/raspberry-pi-can-boot-nvme-ssds-now), но в своей текущей версии загрузчик Raspberry Pi при старте не сканирует устройства SATA. Хотя это только пока.
Перевод новости Jeff Geerling: [Raspberry Pi OS now has SATA support built-in](https://www.jeffgeerling.com/blog/2021/raspberry-pi-os-now-has-sata-support-built)
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=Bright_Translate&utm_content=v_raspberry_pi_os_poyavilas_vstroennaya_podderzhka_sata) | https://habr.com/ru/post/571154/ | null | ru | null |
# Говорящий пингвин
На бескрайних просторах интернета немало статей про умные дома, очки дополненной реальности, новомодный «интернет вещей» и другие преспективы вообразимого будущего. Будет ли оно светлым или в «добрых» традициях нуарного киберпанка, время покажет, а пока мы сделаем маленький шаг навстречу ему.
Как вы догадались по заголовку публикации, речь пойдёт о синтезе речи. Я расскажу, как реализовал, c чем столкнулся. Буду не оригинальным, использовал festival.
#### **Начало**
Подопытный:
* Ноутбук HP
* Звук alsa (позднее поставил pulseaudio)
— Установка, никаких проблем не должно возникать. [Пример](https://wiki.archlinux.org/index.php/Festival_%28%D0%A0%D1%83%D1%81%D1%81%D0%BA%D0%B8%D0%B9%29)
— [Примеры скриптов](http://ru.festivalspeaker.wikia.com/wiki/%D0%91%D0%B0%D0%BD%D0%BA_%D1%81%D0%BA%D1%80%D0%B8%D0%BF%D1%82%D0%BE%D0%B2_%D0%B4%D0%BB%D1%8F_%D0%B3%D0%BE%D0%BB%D0%BE%D1%81%D0%BE%D0%B2%D0%BE%D0%B3%D0%BE_%D0%B4%D0%B2%D0%B8%D0%B6%D0%BA%D0%B0_Festival)
#### **Оповещение заряда батареи**
*Скрипт узнает статус и заряд. Сообщает о заряде, если не подключен к зарядке и заряд < 50%.*
```
#!/bin/bash
scripts="$HOME/.bin/festival/"
charge=$(cat /sys/class/power_supply/BAT0/capacity)
procent=$(${scripts}pluralform.sh $charge процент процента процентов)
status=$(cat /sys/class/power_supply/BAT0/status)
text=$(echo "Заряд батареи $charge $procent")
critical="Критический заряд батареи."
if [ "$status" == 'Discharging' ] && [ $charge -gt 10 -a $charge -lt 50 ];
then
${scripts}say.sh "$text"
elif [ "$status" == 'Discharging' ] && [ $charge -lt 10 ];
then
${scripts}say.sh "$critical"
fi
exit
```
*Склонение*
```
#!/usr/bin/env bash
n=$(($1 % 100))
n1=$(($n % 10))
if [ $n -gt 10 -a $n -lt 20 ]; then echo $4;
elif [ $n1 -gt 1 -a $n1 -lt 5 ]; then echo $3;
elif [ $n1 -eq 1 ]; then echo $2;
else echo $4
fi
```
*Скрипт генерирует wav c учётом файлов в dat`е. Запоминает текущую громкость, ставит оптимальную. Проигрывает и возвращает громкость обратно. Удаляет текущий wav-файл.*
```
#!/bin/bash
data="$HOME/.bin/festival/data"
ru="(voice_msu_ru_nsh_clunits)"
volume=$(amixer | grep -o [0-9]* | sed "5 ! d")
i=$(ls -r $data | grep -o [0-9]* | sed "1 ! d")
if test -z "$i";
then i=1;
elif test -f "$data/saytext_$i.wav";
then i=$(($i+1));
fi
echo "$1" | text2wave -o $data/saytext_$i.wav -eval $ru > /dev/null 2>&1
amixer set Master 67% > /dev/null 2>&1
aplay $data/saytext_$i.wav > /dev/null 2>&1
aplay=$(ps -el | grep aplay | wc -l)
if [ $aplay -eq 0 ];
then amixer set Master $volume% > /dev/null 2>&1;
fi
rm -f $data/saytext_$i.wav
```
#### **Проверка почты gmail**
*Нашёл почти готовое решение gem [gmail](https://github.com/gmailgem/gmail).
Плюсы этого решения:
— Оповещение о кол-ве сообщений по лейблам. Предварительно нужно создать фильтры с лейблами на сайте.
— Возможность прочитать заголовок сообщения и текст (не реализовывал).*
```
# coding: utf-8
require 'gmail'
require 'yaml'
Gmail.new("login", "password") do |gmail|
@festival = "$HOME/.bin/festival/"
@labels = {"INBOX" => "Входящие", "Search job" => "Поиск работы",
"Music" => "Музыка", "Advertising" => "Реклама",
"Education" => "Обучение", "Interesting" => "Интересное"}
def check_letters(gmail)
counts = {}
@labels.each do |k,v|
h = {k => gmail.mailbox(k).count(:unread)}
counts.merge!(h)
end
return counts
end
def read_counts_letters
unless File.exist?(".gmail.yml")
return {}
end
old_counts = YAML::load(File.open(".gmail.yml"))
return old_counts
end
def save_counts_letters(counts)
system("touch .gmail.yml") if File.exist?(".gmail.yml")
File.open(".gmail.yml", "w") do |f|
f.write counts.to_yaml
end
end
def check_new_counts_letters(counts, old_counts)
counts.each do |k, v|
if old_counts.empty? || v < old_counts[k]
count = v
else
count = v - old_counts[k]
end
say_new_counts(k, count)
end
end
def say_new_counts(k, count)
unless count == 0
text = pluralform(count)
count = "Одн+о" if count == 1
all = "У вас #{count} #{text}"
part = "#{count} #{text} в разделе #{@labels[k]}"
if k == "INBOX"
system("#{@festival}say.sh '#{all}'")
else
system("#{@festival}say.sh '#{part}'")
end
end
end
def pluralform(count)
n = count % 100
m = n % 10
msg = ['сообщение',
'сообщения',
'сообщений']
if n > 10 && n < 20
return msg[2]
elsif m > 1 && m < 5
return msg[1]
elsif m == 1
return msg[0]
else
return msg[2]
end
end
counts = check_letters(gmail)
old_counts = read_counts_letters
check_new_counts_letters(counts, old_counts)
save_counts_letters(counts)
gmail.logout
end
```
#### **Возникшие проблемы**
* При старте системы с задачами в crontab устройство было занято (в ручном режиме без проблем);
* Перепады громкости.
#### **Переосмысление**
Спустя некоторое время, испробовав многие варианты, оставил pulseaudio для управления потоками.
```
pcm.pulse {
type pulse
}
ctl.pulse {
type pulse
}
pcm.!default {
type pulse
}
ctl.!default {
type pulse
}
```
Переписал bash script`ы на ruby, написав gem [fest](https://github.com/AfsmNGhr/fest).
```
# coding: utf-8
#
class Fest
def say(string, params = {})
init(params)
check_conditions
make_wav(string)
expect_if_paplay_now
check_optimal_volume
play_wav
end
def init(params) # получаем все параметры
@params = params
@path = @params[:path] || '/tmp'
@current_volume = `amixer | grep -o '[0-9]*' | sed "5 ! d"`.to_i
@index = `ls -r #{@path} | grep -o '[0-9]*' | sed "1 ! d"`.to_i
@min_volume = @params[:down_volume[0]] || 20
@max_volume = @params[:down_volume[1]] || 60
@step = @params[:down_volume[2]] || 4
end
def check_optimal_volume # получаем громкость пониженную
@volume = @current_volume - @current_volume / 10 * @step
optimize_min_and_max_volume
end
def optimize_min_and_max_volume
@optimize_volume = (
if @current_volume > @max_volume
@max_volume
elsif @current_volume < @min_volume
@min_volume
else
@current_volume
end
)
end
def check_conditions # проверка условий
check_light
check_home_theater
check_say_wav
end
def check_light # молчим, если экран потушен
exit if @params[:backlight].nil? && `xbacklight`.to_i == 0
end
def check_home_theater # при просмотре фильмов тоже разумеется
xbmc = `ps -el | grep xbmc | wc -l`.to_i
vlc = `ps -el | grep vlc | wc -l`.to_i
kodi = `ps -el | grep kodi | wc -l`.to_i
exit if xbmc > 0 || vlc > 0 || kodi > 0
end
def check_say_wav # index wav file
@index > 0 ? @index += 1 : @index = 1
end
def make_wav(string) # создаём wav (c mp3 возникли проблемы)
system("echo '#{string}' | text2wave -o #{@path}/say_#{@index}.wav \
-eval '(#{@params[:language] || 'voice_msu_ru_nsh_clunits'})' \
> /dev/null 2>&1")
end
def change_volume(volume) # ставим громкость
system("amixer set Master #{volume}% > /dev/null 2>&1")
end
def expect_if_paplay_now # ожидаем конца сообщения
loop do
break if `ps -el | grep paplay | wc -l`.to_i == 0
sleep 1
end
end
# получаем текущие источники
# пошагово понижаем громкость
def turn_down_volume
@inputs = `pactl list sink-inputs | grep № | grep -o '[0-9]*'`.split("\n")
@inputs.each do |input|
volume = @current_volume
loop do
system("pactl set-sink-input-volume #{input} '#{volume * 655}'")
volume -= @step
break if volume < @volume
end
end
end
def play_wav # воспроизводим wav
turn_down_volume
system("paplay #{@path}/say_#{@index}.wav \
--volume='#{@optimize_volume * 655}' > /dev/null 2>&1")
return_current_volume
delete_wav
end
# пошагово возвращаем громкость
def return_current_volume
@inputs.each do |input|
volume = @volume
loop do
system("pactl set-sink-input-volume #{input} '#{volume * 655}'")
volume += @step
break if volume > @current_volume
end
end
end
def delete_wav # удаляем wav
system("rm -f #{@path}/say_#{@index}.wav")
end
def pluralform(number, array) # склонение
n = number % 100
m = n % 10
if n > 10 && n < 20
array[2]
elsif m > 1 && m < 5
array[1]
elsif m == 1
array[0]
else
array[2]
end
end
end
```
#### **Crontab**
```
PATH=$(echo $PATH)
SHELL=/bin/bash
GEM_HOME=$(gem environment gemdir)
GEM_PATH=$(gem environment gemdir)
DISPLAY=:0
*/10 * * * * ~/.bin/festival/charge
*/20 * * * * ~/.bin/festival/gmail
*/30 * * * * ~/.bin/festival/quotes
```
#### **Результат**
— Стабильная работа в crontab
— Музыка играет на заднем фоне
— Плавное понижение громкости и возврат
— Сообщение играет с текущей громкостью (если в пределах min и max)
Неприятные моменты:
— После просмотра фильмов стоит сбрасывать громкость
— Иногда озвучка искажается эхом (редко)
— Нет женского голоса
#### **P.S.**
Все скрипты, кроме gem «fest», старых версий. [Переписанные скрипты](https://github.com/AfsmNGhr/fest-scripts) и [демонстрация](http://youtu.be/VV3BAWrGRLg)
Спасибо за внимание. | https://habr.com/ru/post/251205/ | null | ru | null |
# Рефакторинг схем баз данных
Я хочу рассказать о рефакторинге схем баз данных MS SQL Server.
> Рефакторинг — изменение во внутренней структуре программного обеспечения, имеющее целью облегчить понимание его работы и упростить модификацию, не затрагивая наблюдаемого поведения.
*— Martin Fowler*
О рефакторинге кода говорят уже давно. На данный момент написано немало литературы, создано множество инструментов, помогающих выполнять рефакторинг кода.
А вот про рефакторинг схем баз данных не так уж и много информации. Я решил немного восполнить этот пробел и поделиться своим опытом.
Как понять что настала пора проводить рефакторинг?
--------------------------------------------------
> Делая что-то в первый раз, вы просто это делаете. Делая что-то аналогичное во второй раз, вы морщитесь от необходимости повторения, но все-таки повторяете то же самое. Делая что-то похожее в третий раз, вы начинаете рефакторинг.
>
>
*— Don Roberts*
[Мартин Фаулер](https://ru.wikipedia.org/wiki/%D0%A4%D0%B0%D1%83%D0%BB%D0%B5%D1%80,_%D0%9C%D0%B0%D1%80%D1%82%D0%B8%D0%BD) ввел понятие «Код с душком», обозначив так код который нужно подвергнуть рефакторингу.
С душком называется код в котором:
* встречается дублирование
* есть большие методы
* существуют методы с большим количеством параметров
* встречается оператор *switch*
По аналогии с этим можно выделить общие недостатки схемы базы данных, которые указывают на необходимость применения рефакторинга. К этим недостаткам можно выделить следующие.
* *Многоцелевые столбцы (или столбцы используемые не по назначению).* Допустим у нас есть таблица содержащая информацию по заказам. В таблице есть необязательное для заполнения поле *InvoiceId* типа *int*. Представим что процесс продаж в компании построен таким образом, что это поле никогда не заполняется. Начиная с нового года менеджерам стало необходимо проставлять у заказов оценку клиента (от 1 до 10 по результатам обзвона). Такого поля в таблице нет и менеджеры начинают вбивать эти данные в поле InvoiceId (например потому, что IT-шники сказали им что на добавление нового поля уйдет целый месяц). Это приведет к проблемам когда поле InvoiceId станет использоваться по назначению.
* *Многоцелевые таблицы.* Примером может послужить таблица Customer в которой хранится информация о физических и юридических лицах. В подобном случае неизбежно появляются столбы с *NULL* значениями.
* *Избыточные данные.* Например, наличие поля *Адрес клиента* в таблице заказов может привести к случаю когда у нескольких заказов одного и того же клиента будут разные адреса.
* *Таблицы с большим количеством столбцов.* Наличие большого количества столбцов может означать что в таблице хранятся атрибуты более чем одной сущности. В таком случае вероятно нужно применить рефакторинг «Разбиение таблицы».
* *Многозначные столбцы.* Многозначными называются столбцы, в которых в различных позициях представлено несколько разных фрагментов информации. Например в таблице заказов есть поле *OrderNumber* содержащее данные вида XXX20150908000125. Где XXX — код товара, 20150908 — дата заказа, 000125 — порядковый номер заказа. На практике часто обнаруживается необходимость разбить поле на части, чтобы можно было проще обрабатывать эти поля в виде отдельных элементов.
Несколько полезных советов по применению рефакторинга
-----------------------------------------------------
1. **Оцените масштаб бедствий**.
Прежде чем что-то менять убедитесь что Вы не сломаете внешние приложения, использующие Вашу базу данных. Если Вам пришлось поддерживать базу данных, которая досталась «по наследству», вероятнее всего Вы не знаете кто (что) и как ее используют. Составьте список приложений, использующих Вашу базу. Попросите, по возможности, коллег разрабатывающих эти приложения выдать Вам список объектов, которые они используют. После чего согласуйте с ними Ваши изменения, договоритесь о совместном тестировании.
Особое внимание уделите таблицам базы на которые выданы права. Это потенциальный источник проблем.
Обсудите с коллегами чтобы они вместо таблиц перешли на использование представлений (процедур).
Когда все обращения к базе будут реализованы посредством процедур/представлений/функций, Вам будет намного легче проводить рефакторинг.
2. **Не делайте много изменений за один раз**.
Чем меньше будет изменение, тем проще будет найти ошибку в случае сбоя.
3. **Проверяйте изменения тестами**.
После каждого изменения запускайте тесты, чтобы убедиться что ничего не сломалось.
4. **Используйте песочницы**.
Не нужно заниматься рефакторингом на продуктиве, даже если изменение ничтожно мало. Используйте для рефакторинга тестовые площадки. После чего проводите полное регрессионное тестирование. И только после этого выполняйте изменение в продуктивной базе данных.
Практические примеры
--------------------
Я покажу применение некоторых методов рефакторинга на примере базы данных Northwind ([ссылка на скачивание](https://northwinddatabase.codeplex.com/downloads/get/269239)).
В качестве инструмента я буду использовать SQL Server Management Studio (SSMS) с установленным плагином [SQL Refactor Studio](http://sqlrefactorstudio.com/). Данный плагин добавляет в SSMS функции рефакторинга.
### Исходная схема
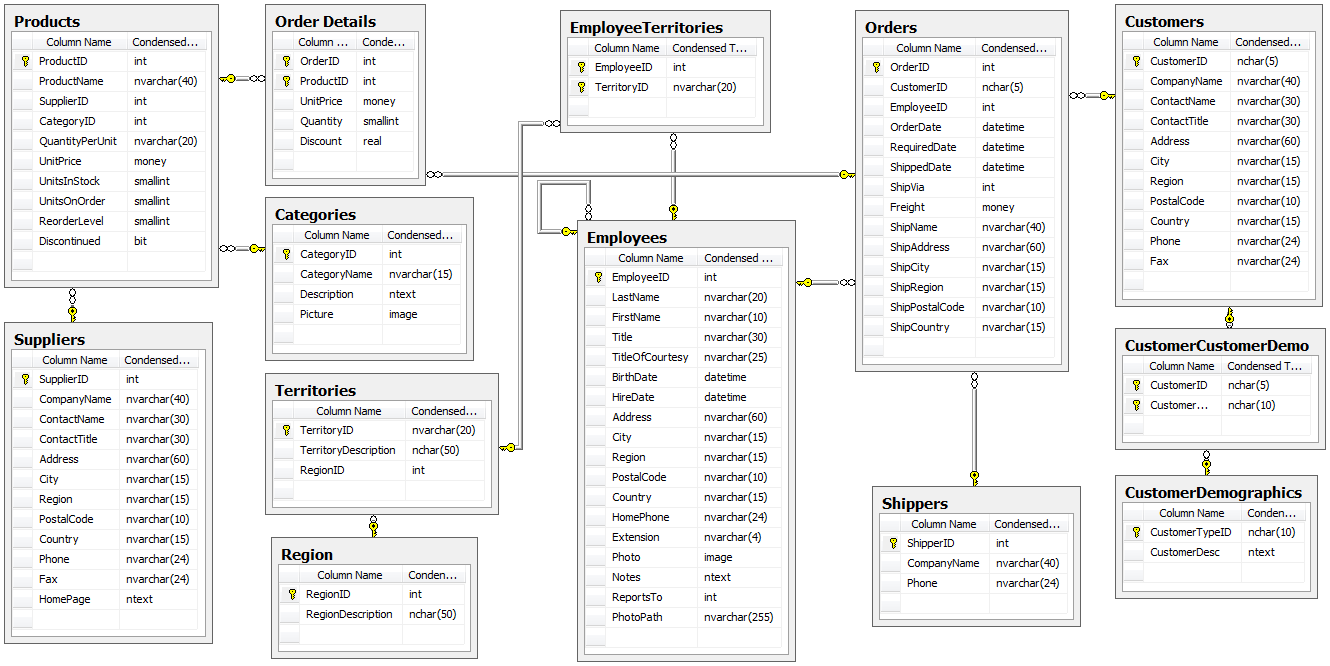
### Тестирование
После каждого изменения мы будем запускать тест, чтобы убедиться что все по прежнему работает.
Для примера я создал процедуру *dbo.RunTests*, которая выбирает данные из всех представлений в базе (разумеется это не обеспечивает нам полное покрытие тестами).
Если в процессе работы процедуры не было ошибок, процедура выдает OK, иначе Failed.
```
CREATE PROCEDURE dbo.RunTests
AS
DECLARE
@Script nvarchar(max) = '',
@Failed bit = 0
DECLARE crs CURSOR FOR
SELECT 'IF OBJECT_ID(''tempdb..#tmp'') IS NOT NULL DROP TABLE #tmp
SELECT * INTO #tmp FROM [' + object_schema_name(o.object_id) + '].[' + o.name + ']'
FROM sys.objects o
WHERE o.type = 'V'
OPEN crs
FETCH NEXT FROM crs INTO @Script
WHILE @@fetch_status = 0
BEGIN
BEGIN TRY
EXEC sp_executesql @Script
END TRY
BEGIN CATCH
SET @Failed = 1
SELECT 'Failed' AS Status, ERROR_MESSAGE() AS Details, @Script AS [Script]
END CATCH
FETCH NEXT FROM crs INTO @Script
END
CLOSE crs
DEALLOCATE crs
IF @Failed = 0
SELECT 'OK' AS [Status]
RETURN 0
/*
EXEC dbo.RunTests
*/
GO
```
### Рефакторинг «Переименование объекта»
Не знаю конечно как Вы, но я при создании таблицы даю ей имя в единственном числе (dbo.Entry а не dbo.Entries).
Итак, давайте попробуем переименовать таблицу *dbo.Customers* в *dbo.Customer*. Тут есть один неприятный (и очень рутинный) процесс. Нужно переименовать таблицу так чтобы не сломался код использующий ее. Для этого его нужно найти и внести в него исправление. Воспользовавшись стандартным *View Dependencies* видим что таблица используется в одном преставлении и есть две таблицы ссылающиеся на *dbo.Customers*.
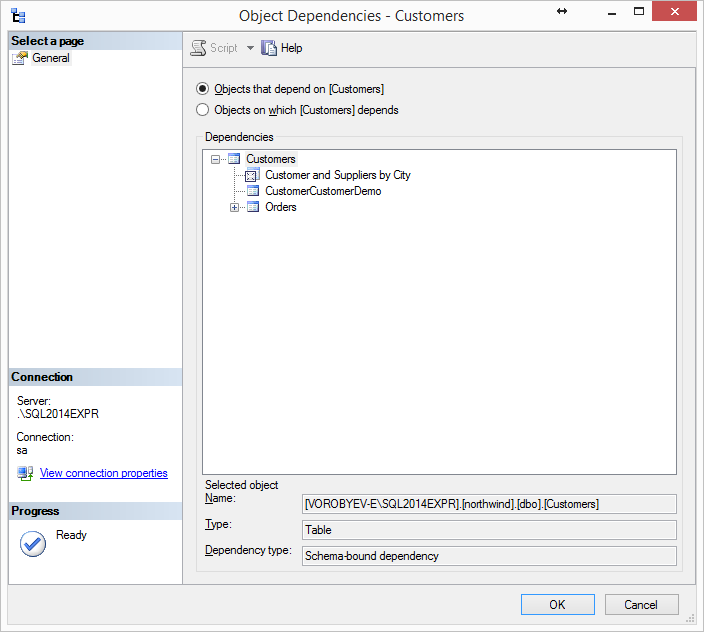
В принципе, внести исправление в одно представление после переименования таблицы — плевое дело.
Ну что же, в бой! Переименовываем таблицу и запускаем тест (должна сломаться вьюха *dbo.Customer and Suppliers by City*).
Однако, вместо ожидаемой одной строки тест мне выдал целых пять.
Тогда я решил проверить зависимости таблицы используя расширенный *[View Dependencies](http://sqlrefactorstudio.com/Features/Details/ViewDependencies)* входящий в состав пакета SQL Refactor Studio. Он уже насчитал пять вьюшек (тест показал что сломалось именно пять представлений) и нашел одну процедуру (не покрыта тестами).
Шесть объектов — это уже посерьезнее. А представьте себе что Вам нужно поправить код в 50+ объектах. Вы все еще хотите переименовать таблицу? :) Ручками будет уже тяжело, поэтому, прибегнем к автоматизации.
Воспользуемся функцией *Rename* входящий в пакет SQL Refactor Studio. Выбираем таблицу в Object Explorer (далее OE), из контекстного меню выбираем пункт *SQL Refactor Studio -> Rename*. Вводим новое имя (Customer) и нажимаем кнопку *Genarate rename script*. Тут также есть возможность посмотреть зависимости и снять галочки напротив объектов в которых не нужно производить переименование.
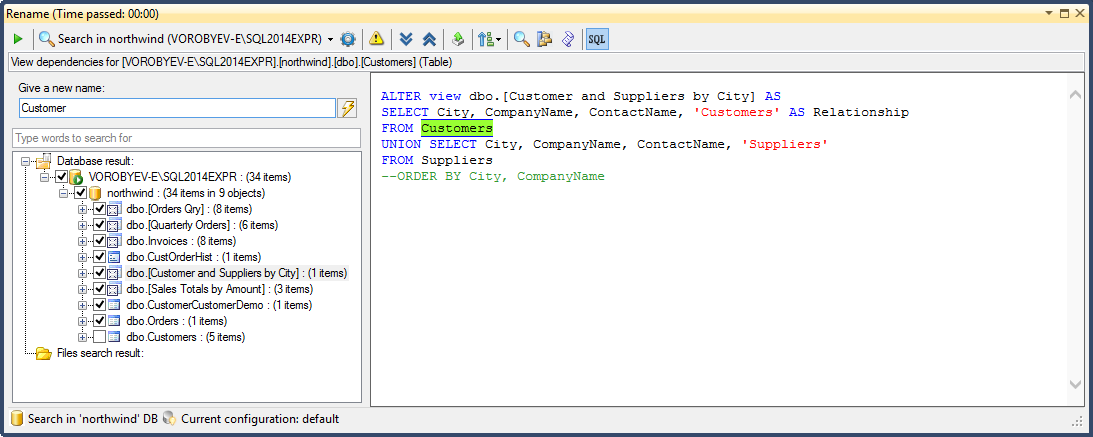
В результате открылась новая вкладка с сформированным скриптом.
**Сгенерированный скрипт**
```
use northwind
go
set transaction isolation level serializable
set xact_abort on
go
if object_id('tempdb..#err') is not null
drop table #err
go
create table #err(flag bit)
go
begin transaction
go
exec sp_rename 'dbo.Customers', 'Customer', 'OBJECT'
go
if (@@error <> 0) and (@@trancount > 0)
rollback transaction
go
if (@@trancount = 0)
begin
insert into #err(flag) select cast(1 as bit)
begin transaction
end
go
ALTER view dbo.[Orders Qry] AS
SELECT Orders.OrderID, Orders.CustomerID, Orders.EmployeeID, Orders.OrderDate, Orders.RequiredDate,
Orders.ShippedDate, Orders.ShipVia, Orders.Freight, Orders.ShipName, Orders.ShipAddress, Orders.ShipCity,
Orders.ShipRegion, Orders.ShipPostalCode, Orders.ShipCountry,
Customer.CompanyName, Customer.Address, Customer.City, Customer.Region, Customer.PostalCode, Customer.Country
FROM Customer INNER JOIN Orders ON Customer.CustomerID = Orders.CustomerID
go
raiserror('update view ...', 0, 1) with nowait
go
if (@@error <> 0) and (@@trancount > 0)
rollback transaction
go
if (@@trancount = 0)
begin
insert into #err(flag) select cast(1 as bit)
begin transaction
end
go
ALTER view dbo.[Quarterly Orders] AS
SELECT DISTINCT Customer.CustomerID, Customer.CompanyName, Customer.City, Customer.Country
FROM Customer RIGHT JOIN Orders ON Customer.CustomerID = Orders.CustomerID
WHERE Orders.OrderDate BETWEEN '19970101' And '19971231'
go
raiserror('update view ...', 0, 1) with nowait
go
if (@@error <> 0) and (@@trancount > 0)
rollback transaction
go
if (@@trancount = 0)
begin
insert into #err(flag) select cast(1 as bit)
begin transaction
end
go
ALTER view dbo.Invoices AS
SELECT Orders.ShipName, Orders.ShipAddress, Orders.ShipCity, Orders.ShipRegion, Orders.ShipPostalCode,
Orders.ShipCountry, Orders.CustomerID, Customer.CompanyName AS CustomerName, Customer.Address, Customer.City,
Customer.Region, Customer.PostalCode, Customer.Country,
(FirstName + ' ' + LastName) AS Salesperson,
Orders.OrderID, Orders.OrderDate, Orders.RequiredDate, Orders.ShippedDate, Shippers.CompanyName As ShipperName,
"Order Details".ProductID, Products.ProductName, "Order Details".UnitPrice, "Order Details".Quantity,
"Order Details".Discount,
(CONVERT(money,("Order Details".UnitPrice\*Quantity\*(1-Discount)/100))\*100) AS ExtendedPrice, Orders.Freight
FROM Shippers INNER JOIN
(Products INNER JOIN
(
(Employees INNER JOIN
(Customer INNER JOIN Orders ON Customer.CustomerID = Orders.CustomerID)
ON Employees.EmployeeID = Orders.EmployeeID)
INNER JOIN "Order Details" ON Orders.OrderID = "Order Details".OrderID)
ON Products.ProductID = "Order Details".ProductID)
ON Shippers.ShipperID = Orders.ShipVia
go
raiserror('update view ...', 0, 1) with nowait
go
if (@@error <> 0) and (@@trancount > 0)
rollback transaction
go
if (@@trancount = 0)
begin
insert into #err(flag) select cast(1 as bit)
begin transaction
end
go
ALTER PROCEDURE dbo.CustOrderHist @CustomerID nchar(5)
AS
SELECT ProductName, Total=SUM(Quantity)
FROM Products P, [Order Details] OD, Orders O, Customer C
WHERE C.CustomerID = @CustomerID
AND C.CustomerID = O.CustomerID AND O.OrderID = OD.OrderID AND OD.ProductID = P.ProductID
GROUP BY ProductName
go
raiserror('update storedprocedure ...', 0, 1) with nowait
go
if (@@error <> 0) and (@@trancount > 0)
rollback transaction
go
if (@@trancount = 0)
begin
insert into #err(flag) select cast(1 as bit)
begin transaction
end
go
ALTER view dbo.[Customer and Suppliers by City] AS
SELECT City, CompanyName, ContactName, 'Customers' AS Relationship
FROM Customer
UNION SELECT City, CompanyName, ContactName, 'Suppliers'
FROM Suppliers
--ORDER BY City, CompanyName
go
raiserror('update view ...', 0, 1) with nowait
go
if (@@error <> 0) and (@@trancount > 0)
rollback transaction
go
if (@@trancount = 0)
begin
insert into #err(flag) select cast(1 as bit)
begin transaction
end
go
ALTER view dbo.[Sales Totals by Amount] AS
SELECT "Order Subtotals".Subtotal AS SaleAmount, Orders.OrderID, Customer.CompanyName, Orders.ShippedDate
FROM Customer INNER JOIN
(Orders INNER JOIN "Order Subtotals" ON Orders.OrderID = "Order Subtotals".OrderID)
ON Customer.CustomerID = Orders.CustomerID
WHERE ("Order Subtotals".Subtotal >2500) AND (Orders.ShippedDate BETWEEN '19970101' And '19971231')
go
raiserror('update view ...', 0, 1) with nowait
go
if (@@error <> 0) and (@@trancount > 0)
rollback transaction
go
if (@@trancount = 0)
begin
insert into #err(flag) select cast(1 as bit)
begin transaction
end
go
if exists (select \* from #err)
begin
print 'the database update failed'
rollback transaction
end
else
begin
print 'the database update succeeded'
commit transaction
end
go
```
Запускаем скрипт на выполнение.
Запускаем тест.
Вуаля! Мы переименовали таблицу и не сломали существующий код.
Поступим также со всеми таблицами, имена которых заканчиваются на *s*. Это ведь так просто, неправда ли?
### Рефакторинг «Добавление поисковой таблицы»
Эта операция позволяет создать поисковую таблицу для существующего столбца.
Необходимость этой операции может быть обусловлена следующими причинами:
* Введение ссылочной целостности для обеспечения качества данных;
* Предоставление подробных описаний. Например, может понадобится добавить в описание той или иной сущности новый атрибут. Если сущность при этой не выделена в таблицу — придется добавлять этот атрибут в нужные таблицы, что приведет к денормализации схемы.
Посмотрим еще раз на нашу таблицу *dbo.Customer*. Вас не смущает наличие полей City, Region и Country в одном месте? Это ведь атрибуты одной сущности.
В таблице *dbo.Employees* та же беда. На вид явное нарушение 3-й нормальной формы.
Давайте начинать исправлять дело следующим образом:
1. Создадим справочник dbo.City(CityId, CityName)
2. В таблице *dbo.Customer* добавим поле CityId.
3. Создадим внешний ключ.
Опять же, для экономии времени, используем функцию [Add Lookup Table](http://sqlrefactorstudio.com/Features/Details/AddLookupTable). В OE выбираем поле *City* таблицы *dbo.Customer* и в контекстном меню вызываем пункт *SQL Refactor Studio -> Add Lookup Table*.
В появившемся окне заполняем поля. Жмем *Next*, потом *Finish* и в новом окне формируется скрипт.
Скрипт создает таблицу dbo.City, заполняет ее данными, создает поле *CityId* в таблице *dbo.Customer*, создает внешний ключ.
**Сгенерированный скрипт**
```
use northwind
go
-- Step 1. Create lookup table.
CREATE TABLE dbo.City (
CityId INT NOT NULL identity(1, 1)
,CityName NVARCHAR(15) NULL
,CONSTRAINT PK_City PRIMARY KEY CLUSTERED (CityId)
,CONSTRAINT City_ixCityName UNIQUE (CityName)
)
GO
-- Step 2. Fill lookup table.
INSERT dbo.City (CityName)
SELECT DISTINCT City
FROM dbo.Customer
GO
-- Step 3. Add column.
ALTER TABLE dbo.Customer ADD CityId INT NULL
GO
-- Step 4. Update table dbo.Customer.
UPDATE s
SET s.CityId = t.CityId
FROM dbo.Customer s
INNER JOIN dbo.City t ON s.City = t.CityName
GO
-- Step 5. Create foreign key constraint.
ALTER TABLE dbo.Customer ADD CONSTRAINT FK_Customer_City FOREIGN KEY (CityId) REFERENCES dbo.City (CityId)
GO
```
Запускаем скрипт и тесты (хотя тут мы вроде ничего не должны были сломать).
Все готово. Идем далее.
### Рефакторинг «Перемещение полей»
Итак, с полем *City* мы разобрались. Осталось разобраться с полями Region и Country. Данные поля являются атрибутами сущности *City*. Так давайте же перенесем их из таблицы *dbo.Customer* в *dbo.City*.
Опять же, SQL Refactor Studio предоставляет функцию [Move Columns](http://sqlrefactorstudio.com/Features/Details/MoveColumns). Ею и воспользуемся!
Выбираем в OE таблицу *dbo.Customer*, в контекстном меню выбираем пункт *«SQL Refactor Studio -> Move columns»*. В появившемся диалоге, в выпадающем списке, выбираем таблицу *dbo.City*. Переносим поля *Region* и *Country* в *dbo.City*.
Если при переносе поля, вы получите сообщение о том, что нельзя переместить поле на котором построен индекс — удалите на время этот индекс.
Нажимаем *Next*, потом *Finish*. Получаем скрипт в новом окне.
Скрипт создает поля *Region* и *Country* в таблице *dbo.City* и заполняет их данными.
В скрипте есть также закомментированный код удаляющий поля и приведен список объектов в которых нужно внести изменения.
Давайте не будем сейчас удалять поля, сделаем это на следующем шаге.
**Сгенерированный скрипт**
```
USE northwind
GO
-- STEP 1. Add new column(s) --
IF NOT EXISTS (
SELECT *
FROM syscolumns s
WHERE s.NAME = 'Region'
AND s.id = object_id(N'dbo.City')
)
BEGIN
ALTER TABLE dbo.City ADD Region NVARCHAR(15) NULL
END
GO
IF NOT EXISTS (
SELECT *
FROM syscolumns s
WHERE s.NAME = 'Country'
AND s.id = object_id(N'dbo.City')
)
BEGIN
ALTER TABLE dbo.City ADD Country NVARCHAR(15) NULL
END
GO
GO
-- STEP 2. Copy data --
-- (You can modify this query if needed)
SET IDENTITY_INSERT dbo.City ON
INSERT INTO dbo.City WITH (TABLOCKX) (CityId)
SELECT CityId
FROM dbo.Customer src
WHERE NOT EXISTS (
SELECT *
FROM dbo.City dest
WHERE src.CityId = dest.CityId
)
SET IDENTITY_INSERT dbo.City OFF
UPDATE dest
WITH (TABLOCKX)
SET dest.Region = src.Region
,dest.Country = src.Country
FROM dbo.City dest
INNER JOIN dbo.Customer src ON (src.CityId = dest.CityId)
GO
-- STEP 3. Check and modify this dependent objects --
/*
northwind.dbo.[Orders Qry] /*View*/
northwind.dbo.[Quarterly Orders] /*View*/
northwind.dbo.Invoices /*View*/
northwind.dbo.CustOrderHist /*StoredProcedure*/
northwind.dbo.[Customer and Suppliers by City] /*View*/
northwind.dbo.[Sales Totals by Amount] /*View*/
*/
-- STEP 4. Drop column(s) --
-- (Uncomment or run separately this query)
/*
alter table dbo.Customer drop column Region
alter table dbo.Customer drop column Country
*/
GO
```
Выполняем скрипт и тесты.
Переходим к следующему шагу.
### Рефакторинг «Удаление объекта»
Выполняя предыдущие рефакторинги, мы оставили немного мусора (поля *City, Region, Country* в таблице *dbo.Customer*).
Давайте наводить чистоту! Но если мы просто так удалим поля, у нас опять все сломается.
Можно воспользоваться рефакторингом [Encapsulate Table With View](http://databaserefactoring.com/EncapsulateTableWithView.html).
Создадим представление *dbo.CustomerV* и заменим использование таблицы его представлением во всей базе данных.
```
CREATE VIEW dbo.CustomerV
AS
SELECT
c.CustomerID,
c.CompanyName,
c.ContactName,
c.ContactTitle,
c.Address,
ct.CityName City,
ct.Region,
c.PostalCode,
ct.Country,
c.Phone,
c.Fax,
c.CityId
FROM dbo.Customer AS c
LEFT JOIN dbo.City AS ct
ON c.CityId = ct.CityId
```
Далее, при помощи View Dependencies смотрим зависимости для таблицы *dbo.Customer*:

Просматриваем каждый объект. Если в каком-либо объекте используются наши поля, скриптуем объект (кнопка *Script object* на тулбаре) и вносим изменения.
В результате у меня получился вот такой скрипт:
**Encapsulate Table With View**
```
ALTER view dbo.[Sales Totals by Amount] AS
SELECT st.Subtotal AS SaleAmount, o.OrderID, c.CompanyName, o.ShippedDate
FROM dbo.CustomerV c
JOIN (
dbo.Orders o
JOIN "Order Subtotals" st
ON o.OrderID = st.OrderID
)
ON c.CustomerID = o.CustomerID
WHERE (st.Subtotal >2500) AND (o.ShippedDate BETWEEN '19970101' And '19971231')
GO
ALTER view dbo.[Quarterly Orders]
AS
SELECT DISTINCT c.CustomerID, c.CompanyName, c.City, c.Country
FROM dbo.CustomerV c
RIGHT JOIN dbo.Orders o
ON c.CustomerID = o.CustomerID
WHERE
o.OrderDate BETWEEN '19970101' And '19971231'
GO
ALTER view dbo.[Orders Qry]
AS
SELECT o.OrderID, o.CustomerID, o.EmployeeID, o.OrderDate, o.RequiredDate,
o.ShippedDate, o.ShipVia, o.Freight, o.ShipName, o.ShipAddress, o.ShipCity,
o.ShipRegion, o.ShipPostalCode, o.ShipCountry,
c.CompanyName, c.Address, c.City, c.Region, c.PostalCode, c.Country
FROM dbo.CustomerV c
INNER JOIN dbo.Orders o
ON c.CustomerID = o.CustomerID
GO
ALTER view dbo.Invoices AS
SELECT Orders.ShipName, Orders.ShipAddress, Orders.ShipCity, Orders.ShipRegion, Orders.ShipPostalCode,
Orders.ShipCountry, Orders.CustomerID, Customer.CompanyName AS CustomerName, Customer.Address, Customer.City,
Customer.Region, Customer.PostalCode, Customer.Country,
(FirstName + ' ' + LastName) AS Salesperson,
Orders.OrderID, Orders.OrderDate, Orders.RequiredDate, Orders.ShippedDate, Shippers.CompanyName As ShipperName,
"Order Details".ProductID, Products.ProductName, "Order Details".UnitPrice, "Order Details".Quantity,
"Order Details".Discount,
(CONVERT(money,("Order Details".UnitPrice * Quantity*(1-Discount)/100))*100) AS ExtendedPrice, Orders.Freight
FROM Shippers INNER JOIN
(Products INNER JOIN
(
(Employees INNER JOIN
(dbo.CustomerV Customer INNER JOIN Orders ON Customer.CustomerID = Orders.CustomerID)
ON Employees.EmployeeID = Orders.EmployeeID)
INNER JOIN "Order Details" ON Orders.OrderID = "Order Details".OrderID)
ON Products.ProductID = "Order Details".ProductID)
ON Shippers.ShipperID = Orders.ShipVia
GO
ALTER view dbo.[Customer and Suppliers by City] AS
SELECT City, CompanyName, ContactName, 'Customers' AS Relationship
FROM dbo.CustomerV
UNION SELECT City, CompanyName, ContactName, 'Suppliers'
FROM Suppliers
--ORDER BY City, CompanyName
GO
```
Запускаем скрипт, после чего удаляем поля и прогоняем тесты.
Если все ОК — Вы молодец, все аккуратно сделали.
### Рефакторинг «Добавление методов CRUD»
Данный рефакторинг предусматривает создание хранимых процедур, обеспечивающих доступ (SELECT, INSERT, UPDATE, DELETE) к таблицам базы данных.
Можно выделить следующие причины использовать этот рефакторинг:
* Скрыть от внешних приложений структуру базы данных. Внешние приложения будут обращаться к базе данных только посредством хранимых процедур. Это позволит с легкостью изменять структуру базы данных без изменения внешних приложений.
* Реализация в процедурах дополнительных проверок (бизнес-логики, прав доступа и т.д.);
* Сохранение информации о том кто и когда какие данные запрашивал;
* Проблемы с производительностью эффективнее решать когда SQL-код находится в базе данных.
Итак, давайте создадим для нашей замученной таблицы *dbo.Customer* методы доступа. Воспользуемся методом [Add CRUD Methods](http://sqlrefactorstudio.com/Features/Details/CRUD) из пакета SQL Refactor Studio. Выбираем в OE таблицу, далее в контекстном меню выбираем пункт *SQL Refactor Studio -> Add CRUD Methods*.
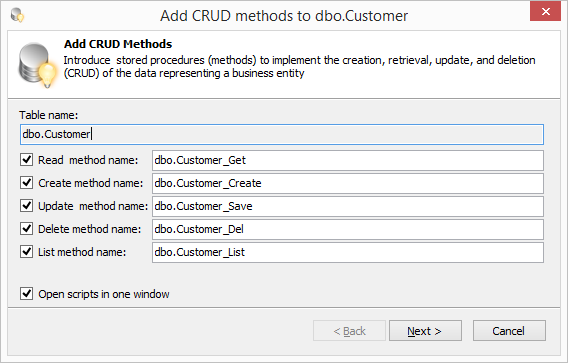
В появившемся диалоге выбираем какие методы нам нужно создать. При необходимости меняем названия методов. Жмем *Next*. При желании можно настроить права на процедуры, для этого нужно отметить нужные роли. Нажимаем *Finish* и получаем скрипт с хранимыми процедурами. Выполняем скрипт.
**Сгенерированный скрипт**
```
IF (object_id(N'dbo.Customer_Create') IS NULL)
BEGIN
EXEC ('create procedure dbo.Customer_Create as return 0')
END
GO
-- =============================================
--
-- dbo.Customer_Create
--
-- Create method.
--
-- Date: 07.09.2015, @HabraUser
--
-- =============================================
ALTER PROCEDURE dbo.Customer_Create
@CustomerID NCHAR(5)
,@CompanyName NVARCHAR(40)
,@ContactName NVARCHAR(30) = NULL
,@ContactTitle NVARCHAR(30) = NULL
,@Address NVARCHAR(60) = NULL
,@PostalCode NVARCHAR(10) = NULL
,@Phone NVARCHAR(24) = NULL
,@Fax NVARCHAR(24) = NULL
,@CityId INT = NULL
AS
BEGIN
SET NOCOUNT ON
INSERT INTO dbo.Customer (
CustomerID
,CompanyName
,ContactName
,ContactTitle
,Address
,PostalCode
,Phone
,Fax
,CityId
)
VALUES (
@CustomerID
,@CompanyName
,@ContactName
,@ContactTitle
,@Address
,@PostalCode
,@Phone
,@Fax
,@CityId
)
RETURN 0
END
/*
declare
@CustomerID NChar(5),
@CompanyName NVarChar(40),
@ContactName NVarChar(30),
@ContactTitle NVarChar(30),
@Address NVarChar(60),
@PostalCode NVarChar(10),
@Phone NVarChar(24),
@Fax NVarChar(24),
@CityId Int
select
@CustomerID = 'CustomerID',
@CompanyName = 'CompanyName',
@ContactName = 'ContactName',
@ContactTitle = 'ContactTitle',
@Address = 'Address',
@PostalCode = 'PostalCode',
@Phone = 'Phone',
@Fax = 'Fax',
@CityId = null
exec dbo.Customer_Create
@CustomerID = @CustomerID,
@CompanyName = @CompanyName,
@ContactName = @ContactName,
@ContactTitle = @ContactTitle,
@Address = @Address,
@PostalCode = @PostalCode,
@Phone = @Phone,
@Fax = @Fax,
@CityId = @CityId
*/
GO
IF (object_id(N'dbo.Customer_Get') IS NULL)
BEGIN
EXEC ('create procedure dbo.Customer_Get as return 0')
END
GO
-- =============================================
--
-- dbo.Customer_Get
--
-- Read method.
--
-- Date: 07.09.2015, @HabraUser
--
-- =============================================
ALTER PROCEDURE dbo.Customer_Get
@CustomerID NCHAR(5)
AS
BEGIN
SET NOCOUNT ON
SELECT
CustomerID
,CompanyName
,ContactName
,ContactTitle
,Address
,PostalCode
,Phone
,Fax
,CityId
FROM dbo.Customer
WHERE
CustomerID = @CustomerID
RETURN 0
END
/*
declare
@CustomerID NChar(5)
select
@CustomerID = ?
exec dbo.Customer_Get
@CustomerID = @CustomerID
*/
GO
IF (object_id(N'dbo.Customer_Save') IS NULL)
BEGIN
EXEC ('create procedure dbo.Customer_Save as return 0')
END
GO
-- =============================================
--
-- dbo.Customer_Save
--
-- Update method.
--
-- Date: 07.09.2015, @HabraUser
--
-- =============================================
ALTER PROCEDURE dbo.Customer_Save
@CustomerID NCHAR(5)
,@CompanyName NVARCHAR(40)
,@ContactName NVARCHAR(30) = NULL
,@ContactTitle NVARCHAR(30) = NULL
,@Address NVARCHAR(60) = NULL
,@PostalCode NVARCHAR(10) = NULL
,@Phone NVARCHAR(24) = NULL
,@Fax NVARCHAR(24) = NULL
,@CityId INT = NULL
AS
BEGIN
SET NOCOUNT ON
UPDATE t
SET t.CompanyName = @CompanyName
,t.ContactName = @ContactName
,t.ContactTitle = @ContactTitle
,t.Address = @Address
,t.PostalCode = @PostalCode
,t.Phone = @Phone
,t.Fax = @Fax
,t.CityId = @CityId
FROM dbo.Customer AS t
WHERE
t.CustomerID = @CustomerID
RETURN 0
END
/*
set nocount on
set quoted_identifier, ansi_nulls, ansi_warnings, arithabort, concat_null_yields_null, ansi_padding on
set numeric_roundabort off
set transaction isolation level read uncommitted
declare
@CustomerID NChar(5),
@CompanyName NVarChar(40),
@ContactName NVarChar(30),
@ContactTitle NVarChar(30),
@Address NVarChar(60),
@PostalCode NVarChar(10),
@Phone NVarChar(24),
@Fax NVarChar(24),
@CityId Int
select
@CustomerID = 'CustomerID',
@CompanyName = 'CompanyName',
@ContactName = 'ContactName',
@ContactTitle = 'ContactTitle',
@Address = 'Address',
@PostalCode = 'PostalCode',
@Phone = 'Phone',
@Fax = 'Fax',
@CityId = null
begin try
begin tran
exec dbo.Customer_Save
@CustomerID = @CustomerID,
@CompanyName = @CompanyName,
@ContactName = @ContactName,
@ContactTitle = @ContactTitle,
@Address = @Address,
@PostalCode = @PostalCode,
@Phone = @Phone,
@Fax = @Fax,
@CityId = @CityId
select t.*
from dbo.Customer as t
where
t.CustomerID = @CustomerID
if @@trancount > 0
rollback tran
end try
begin catch
if @@trancount > 0
rollback tran
declare
@err nvarchar(2000)
set @err =
'login: ' + suser_sname() + char(10)
+ 'ErrorNumber: ' + cast(isnull(error_number(), 0) as varchar) + char(10)
+ 'ErrorProcedure: ' + isnull(error_procedure(), '') + char(10)
+ 'ErrorLine: ' + cast(isnull(error_line(), 0) as varchar) + char(10)
+ 'ErrorMessage: ' + isnull(error_message(), '') + char(10)
+ 'Date: ' + cast(getdate() as varchar) + char(10)
print @err
raiserror(@err, 16, 1)
end catch
*/
GO
IF (object_id(N'dbo.Customer_Del') IS NULL)
BEGIN
EXEC ('create procedure dbo.Customer_Del as return 0')
END
GO
-- =============================================
--
-- dbo.Customer_Del
--
-- Delete method.
--
-- Date: 07.09.2015, @HabraUser
--
-- =============================================
ALTER PROCEDURE dbo.Customer_Del @CustomerID NCHAR(5)
AS
BEGIN
SET NOCOUNT ON
BEGIN TRY
BEGIN TRAN
/* uncomment if needed
delete from dbo.CustomerCustomerDemo where CustomerID = ?
delete from dbo.Orders where CustomerID = ?
*/
DELETE
FROM dbo.Customer
WHERE CustomerID = @CustomerID
COMMIT TRAN
END TRY
BEGIN CATCH
IF @@trancount > 0
ROLLBACK TRAN
-- catch exception (add you code here)
DECLARE @err NVARCHAR(2000)
SET @err = ERROR_MESSAGE()
RAISERROR (@err, 16, 1)
END CATCH
RETURN 0
END
/*
declare
@CustomerID NChar(5)
select
@CustomerID = ?
exec dbo.Customer_Del
@CustomerID = @CustomerID
*/
GO
IF (object_id(N'dbo.Customer_List') IS NULL)
BEGIN
EXEC ('create procedure dbo.Customer_List as return 0')
END
GO
-- =============================================
--
-- dbo.Customer_List
--
-- List method.
--
-- Date: 07.09.2015, @HabraUser
--
-- =============================================
ALTER PROCEDURE dbo.Customer_List
AS
BEGIN
SET NOCOUNT ON
SELECT
CustomerID
,CompanyName
,ContactName
,ContactTitle
,Address
,PostalCode
,Phone
,Fax
,CityId
FROM dbo.Customer
/* uncomment if needed
left join dbo.City as t1 on t1.CityId = t.CityId
*/
RETURN 0
END
/*
exec dbo.Customer_List
*/
GO
```
Если Вам нужно поправить тело генерируемых процедур, заходим в настройки.
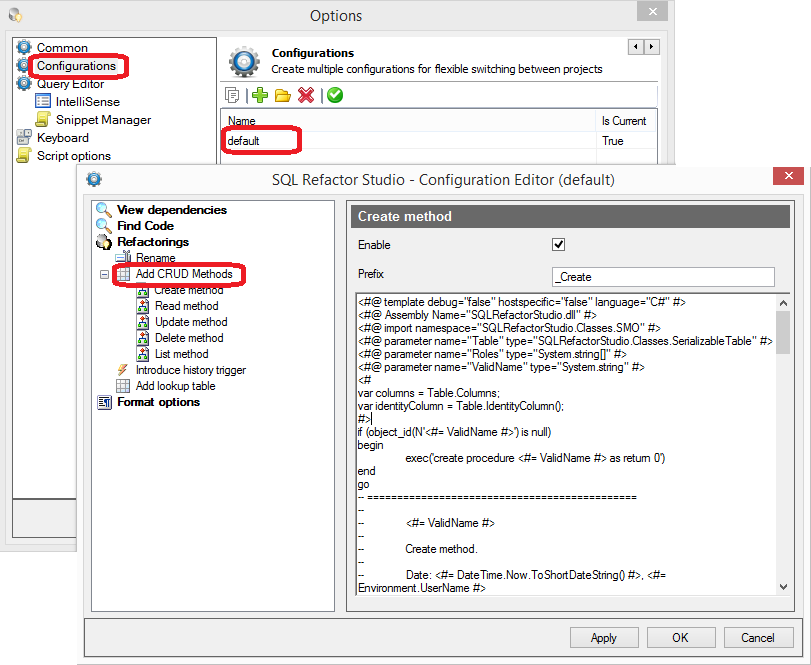
Каждая процедура представляет собой шаблон T4. Про T4 можно почитать [тут](http://www.olegsych.com/2009/09/t4-preprocessed-text-templates/) и [тут](http://www.olegsych.com/2008/09/t4-tutorial-creating-reusable-code-generation-templates/).
### Рефакторинг «Введение триггера для накопления исторических данных»
Эта операция позволяет ввести новый триггер, предназначенный для накопления информации об изменениях в данных в целях изучения истории внесения изменений или проведения аудита.
Необходимость в применении операции «Введение триггера для накопления исторических данных» в основном обусловлена требованием передать функции отслеживания изменений в данных самой базе данных. Такой подход гарантирует, что в случае модификации важных данных в любом внешнем приложении это изменение можно будет отследить и подвергнуть аудиту.
Единственным недостатком, на мой взгляд, является тот факт что наличие триггера будет увеличивать время выполнения операции DML.
Как альтернативу данному методу можно рассмотреть [Change Data Capture](https://technet.microsoft.com/ru-ru/library/Bb522489(v=SQL.105).aspx) (работает асинхронно, тем самым не увеличивает время операции, но имеет ряд особенностей).
Давайте для таблицы *dbo.Customer* применим данный рефакторинг.
Выбираем таблицу в OE, выбираем в контекстном меню пункт *SQL Refactor Studio — Introduce Trigger for History*. Выбираем поля таблицы для отслеживания изменений.
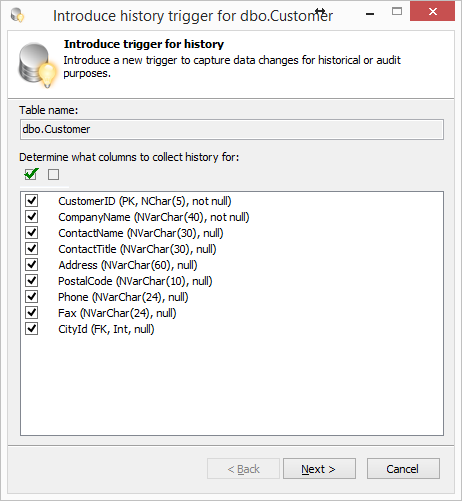
Жмем *Next*. Изменяем при необходимости имя создаваемой таблицы и триггера.

Жмем *Finish* и получаем скрипт. Скрипт создает триггер и таблицу для хранения истории изменений.
**Сгенерированный скрипт**
```
CREATE TABLE [dbo].[CustomerHistory] (
[id] [bigint] IDENTITY NOT NULL
,[action_type] [char](1) NOT NULL
,[modified_date] [datetime] CONSTRAINT [DF_CustomerHistory_modified_date] DEFAULT getdate()
,[modified_login] [sysname] CONSTRAINT [DF_CustomerHistory_modified_login] DEFAULT suser_sname()
,[host_name] [nvarchar](128) CONSTRAINT [DF_CustomerHistory_host_name] DEFAULT host_name()
,[program_name] [nvarchar](128) CONSTRAINT [DF_CustomerHistory_program_name] DEFAULT program_name()
,[CompanyName_old] [nvarchar](40)
,[CompanyName_new] [nvarchar](40)
,[ContactName_old] [nvarchar](30)
,[ContactName_new] [nvarchar](30)
,[ContactTitle_old] [nvarchar](30)
,[ContactTitle_new] [nvarchar](30)
,[Address_old] [nvarchar](60)
,[Address_new] [nvarchar](60)
,[PostalCode_old] [nvarchar](10)
,[PostalCode_new] [nvarchar](10)
,[Phone_old] [nvarchar](24)
,[Phone_new] [nvarchar](24)
,[Fax_old] [nvarchar](24)
,[Fax_new] [nvarchar](24)
,[CityId_old] [int]
,[CityId_new] [int]
,[CustomerID_old] [nchar](5)
,[CustomerID_new] [nchar](5)
,CONSTRAINT [PK_CustomerHistory] PRIMARY KEY ([id])
)
GO
CREATE TRIGGER [dbo].[trg_CustomerHistory] ON [dbo].[Customer]
AFTER INSERT, DELETE, UPDATE
AS
SET NOCOUNT ON
DECLARE @action_type CHAR(1)
IF EXISTS (SELECT *FROM inserted) AND EXISTS (SELECT * FROM deleted)
SET @action_type = 'U'
ELSE IF EXISTS (SELECT * FROM inserted) AND NOT EXISTS (SELECT * FROM deleted)
SET @action_type = 'I'
ELSE IF NOT EXISTS (SELECT * FROM inserted) AND EXISTS (SELECT * FROM deleted)
SET @action_type = 'D'
INSERT INTO dbo.CustomerHistory (
action_type
,CompanyName_old
,CompanyName_new
,ContactName_old
,ContactName_new
,ContactTitle_old
,ContactTitle_new
,Address_old
,Address_new
,PostalCode_old
,PostalCode_new
,Phone_old
,Phone_new
,Fax_old
,Fax_new
,CityId_old
,CityId_new
,CustomerID_old
,CustomerID_new
)
SELECT
@action_type
,d.CompanyName
,i.CompanyName
,d.ContactName
,i.ContactName
,d.ContactTitle
,i.ContactTitle
,d.Address
,i.Address
,d.PostalCode
,i.PostalCode
,d.Phone
,i.Phone
,d.Fax
,i.Fax
,d.CityId
,i.CityId
,d.CustomerID
,i.CustomerID
FROM inserted i
FULL OUTER JOIN deleted d
ON (i.CustomerID = d.CustomerID)
GO
```
На этом пока всё. Надеюсь информация Вам пригодится и в Ваших базах данных всегда будет полный порядок.
Удачи!
Полезные ресурсы
----------------
* [http://databaserefactoring.com](http://databaserefactoring.com/)
* Скотт Амблер, Прамодкумар Дж. Садаладж [Рефакторинг баз данных. Эволюционное проектирование](http://www.ozon.ru/context/detail/id/3261793/)
* Мартин Фаулер [Рефакторинг.Улучшение существующего кода](http://www.ozon.ru/context/detail/id/1308678/)
* Плагин для SSMS [SQL Refactor Studio](http://sqlrefactorstudio.com/) | https://habr.com/ru/post/258629/ | null | ru | null |
# Tensorflow: Используем трансферное обучение для классификации пневмонии и оптимизируем нашу модель
##### Автор статьи: Рустем Галиев
IBM Senior DevOps Engineer & Integration Architect
Привет, Хабр! На связи Рустем, IBM Senior DevOps Engineer & Integration Architect.
Сегодня мы будем работать с открытым набором данных по рентгенографии грудной клетки которые, использовали для этого [исследования](https://www.cell.com/cell/fulltext/S0092-8674%2818%2930154-5), с предварительно обученной моделью MobileNet\_v2 для классификации изображений TensorFlow и переносом обучения для создания классификатора пневмонии, который работает с рентгенограммами грудной клетки.
Целью этой статьи является не столько получение навыков классификации изображений, а сколько понимание того, насколько легко вы можете создать соответствующую модель.
Я надеюсь, вам понравится это!
### Загрузка модулей и данных
Я знаю, вы хотите сразу приступить к разработке методов обнаружения пневмонии, но сначала давайте импортируем некоторые необходимые модули:
```
import numpy as np
import os
import pathlib
import matplotlib.pylab as plt
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_datasets as tfds
tfds.disable_progress_bar()
from tqdm import tqdm
AUTOTUNE = tf.data.experimental.AUTOTUNE
```
Теперь давайте загрузим данные в память.
```
data_dir = pathlib.Path('tflite/images')
image_count_train = len(list(data_dir.glob('train/*/*.jpeg')))
image_count_test = len(list(data_dir.glob('test/*/*.jpeg')))
image_count_val = len(list(data_dir.glob('val/*/*.jpeg')))
BATCH_SIZE = 32
IMG_HEIGHT = 224
IMG_WIDTH = 224
IMG_SHAPE = (IMG_HEIGHT, IMG_WIDTH, 3)
STEPS_PER_EPOCH = np.ceil(image_count_train/BATCH_SIZE)
EPOCHS = 10
SAVED_MODEL = "pneumonia_saved_model"
(image_count_test, image_count_train, image_count_val)
```
Теперь, когда у нас есть все изображения BATCH\_SIZE для обучения, мы настроим классы для обучения (метки):
```
CLASS_NAMES = np.array([item.name for item in data_dir.glob('train/*') if item.name != "LICENSE.txt"])
num_classes = len(CLASS_NAMES)
CLASS_NAMES
```
Изображения находятся в папках train, test или val. Например, чтобы увидеть изображение, вам нужно выполнить:
```
pneumonia = list(data_dir.glob('train/PNEUMONIA/*.jpeg'))
for image_path in pneumonia[:3]:
Image.open(str(image_path))
```
### Создание наборов данных
Теперь, когда все загружено, мы можем создать итераторы, которые будут давать каждому набор изображений для обучения. TensorFlow предлагает отличные утилиты для этой задачи в наборах данных TensorFlow:
```
test_ds = tf.data.Dataset.list_files(str(data_dir/'test/*/*'))
train_ds = tf.data.Dataset.list_files(str(data_dir/'train/*/*'))
val_ds = tf.data.Dataset.list_files(str(data_dir/'val/*/*'))
for f in test_ds.take(5):
print(f.numpy())
print('Datasets loaded')
```
На данном этапе мы видим, что у нас есть итераторы для каждой группы: обучение, тестирование и проверка. Теперь нам нужно сделать несколько вещей:
* Мы должны декодировать каждое изображение в каналы RGB.
* Мы должны изменить размер каждого изображения до наших предопределенных размеров.
* Для каждого изображения мы должны вычислить метку, дающую 1 одному классу и 0 другому.
* Мы должны применить каждый из этих шагов к итераторам, чтобы мы могли перебирать изображения с измененными размерами с их метками.
Для этих задач мы будем использовать следующие ютилити методы:
```
def get_label(file_path):
parts = tf.strings.split(file_path, os.path.sep)
return parts[-2] == CLASS_NAMES[0]
def decode_img(img):
img = tf.image.decode_jpeg(img, channels=3)
img = tf.image.convert_image_dtype(img, tf.float32)
return tf.image.resize(img, [IMG_WIDTH, IMG_HEIGHT])
def process_path(file_path):
label = get_label(file_path)
img = tf.io.read_file(file_path)
img = decode_img(img)
return img, label
def format_image(image, label):
image = tf.image.resize(image, IMAGE_SIZE) / 255.0
return image, label
print('Utility methods loaded!')
```
Применив это к нашим итераторам, теперь мы можем итерировать тестовые примеры, чтобы они имели соответствующие шейпы:
```
train_examples = train_ds.map(process_path, num_parallel_calls=AUTOTUNE)
test_examples = test_ds.map(process_path, num_parallel_calls=AUTOTUNE)
validation_examples = val_ds.map(process_path, num_parallel_calls=AUTOTUNE)
for image, label in test_examples.take(5):
print("Image shape: ", image.numpy().shape)
print("Label: ", label.numpy())
print('Check the shapes!')
```
Интересно отметить, что теперь каждая итерация набора данных выдает тензорное изображение и тензорную метку.
Теперь, на этом шаге, нам нужно пакетировать каждый набор данных, добавить кэш для повышения производительности и выполнить предварительную выборку по мере необходимости! Этот метод обычно повышает производительность пакетной обработки в 10 раз и взят непосредственно из учебника Google:
```
def prepare_for_training(ds, cache=True, shuffle_buffer_size=1000):
if cache:
if isinstance(cache, str):
ds = ds.cache(cache)
else:
ds = ds.cache()
ds = ds.shuffle(buffer_size=shuffle_buffer_size)
ds = ds.repeat()
ds = ds.batch(BATCH_SIZE)
ds = ds.prefetch(buffer_size=AUTOTUNE)
return ds
train_examples_dataset = prepare_for_training(train_examples)
test_examples_dataset = prepare_for_training(test_examples)
validation_examples_dataset = prepare_for_training(validation_examples)
```
Можем сделать вызов
`image_batch, label_batch = next(iter(test_examples_dataset))`
Приступим к определению модели!
### Обучение модели
Теперь, когда у нас есть итератор, все дело в модели!
Все, что нам нужно сделать, это поместить линейный классификатор поверх слоя `feature_extractor_layer` с помощью модуля Hub.
Для скорости мы начинаем с необучаемого feature\_extractor\_layer, но вы также можете включить тонкую настройку для большей точности.
Модули-концентраторы для TensorFlow 1.x здесь не будут работать, поэтому мы можем использовать один из следующих вариантов:
```
module_selection = ("mobilenet_v2", 224, 1280) #or use ["(\"mobilenet_v2\", 224, 1280)", "(\"inception_v3\", 299, 2048)"] {type:"raw", allow-input: true}
handle_base, pixels, FV_SIZE = module_selection
MODULE_HANDLE ="https://tfhub.dev/google/tf2-preview/{}/feature_vector/4".format(handle_base)
IMAGE_SIZE = (pixels, pixels)
print("Using {} with input size {} and output dimension {}".format(MODULE_HANDLE, IMAGE_SIZE, FV_SIZE))
```
Обратите внимание, что мы используем вектор признаков, а не полную модель. Это потому, что мы не хотим тонкой настройки (для избежания проблем со временем). Однако, если вы хотите выполнить точную настройку, загрузите полную модель (она находится в TensorFlow Hub).
Загрузите модуль TFHub:
```
feature_extractor = hub.KerasLayer(MODULE_HANDLE,
input_shape=IMAGE_SIZE + (3,),
output_shape=[FV_SIZE],
trainable=False)
feature_extractor.trainable = False
print("Building model with", MODULE_HANDLE)
model = tf.keras.Sequential([ feature_extractor, tf.keras.layers.Dense(num_classes, activation='softmax')])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.summary()
```
Как видите, большинство наших параметров не поддаются обучению (см. параметр из MobileNet), поэтому обучение должно быть быстрым. Для обучения нам потребуется запустить следующее:
```
hist = model.fit(train_examples_dataset, epochs=EPOCHS, steps_per_epoch=image_count_train/BATCH_SIZE, validation_steps=np.floor(image_count_val/BATCH_SIZE), validation_data=validation_examples_dataset)
tf.saved_model.save(model, SAVED_MODEL)
```
Мы можем проверить, что модель имеет правильную подпись, загрузив ее снова и показав информацию:
```
loaded = tf.saved_model.load(SAVED_MODEL)
print(list(loaded.signatures.keys()))
infer = loaded.signatures["serving_default"]
print(infer.structured_input_signature)
print(infer.structured_outputs)
```
Мы используем следующую команду, чтобы проверить, можете ли вы также использовать интерфейс командной строки TensorFlow для проверки подписи (вне Python):
`saved_model_cli show --dir $1 --tag_set serve --signature_def serving_default`
Это было невероятно легко; с трансферным обучением мы можем легко, в четыре строки кода, проделать работу целых исследовательских групп!
Теперь, когда у нас есть рабочая модель, давайте перейдем к работе по ее оптимизации.
#### Преобразование классификатора пневмонии TensorFlow в TensorFlow Lite с помощью квантования
Мы можем легко преобразовать модель из обычного TensorFlow в TensorFlow Lite с помощью Python Converter API. Этот шаг необходим для запуска наших моделей на периферийных и мобильных устройствах.
#### Квантование с помощью конвертера TensorFlow Lite
Теперь, когда у нас есть сохраненный объект SavedModel, первое, что вам нужно сделать, чтобы преобразовать его в модель TensorFlow Lite, — создать экземпляр преобразователя:
```
import numpy as np
import os
import pathlib
import matplotlib.pylab as plt
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_datasets as tfds
tfds.disable_progress_bar()
from tqdm import tqdm
AUTOTUNE = tf.data.experimental.AUTOTUNE
SAVED_MODEL = "pneumonia_saved_model"
converter = tf.lite.TFLiteConverter.from_saved_model(SAVED_MODEL)
```
Помните, что мы можем создать конвертер из моделей SavedModel, ConcreteFunction или Keras!
#### Квантование после обучения
Простейшая форма квантования после обучения квантует от плавающей запятой до 8-битной точности. Этот метод включен в качестве опции в конвертере TensorFlow Lite. При выводе вес преобразуются из 8-битной точности в числа с плавающей запятой и вычисляются с использованием ядер с плавающей запятой. Это преобразование выполняется один раз и кэшируется для уменьшения задержки.
```
converter.optimizations = [tf.lite.Optimize.DEFAULT]
```
Эта оптимизация была сделана путем размышления между оптимизацией размера и задержки. Если бы мы хотели оптимизировать только размер, мы могли бы сделать следующее:
```
converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_SIZE]
```
Точно так же мы можем преобразовать нашу модель, и она будет квантована:
```
tflite_model = converter.convert()
tflite_model_file = 'converted_model.tflite'
with open(tflite_model_file, "wb") as f:
f.write(tflite_model)
print('Done quantizing')
```
Это было удивительно просто и быстро, хотя квантование модели звучит сложно и красиво на бэкэнде, но ее весьма легко реализовать.
Проверка уменьшения размера
Давайте проверим, что квантованная модель действительно меньше:
```
from pathlib import Path
saved_model = Path(SAVED_MODEL)
full_model_size = sum(f.stat().st_size for f in saved_model.glob('**/*') if f.is_file() )/(1024*1024)
print(f'Full model size {full_model_size} MB')
converted_model = Path(tflite_model_file)
converted_model_size = converted_model.stat().st_size / (1024*1024)
print(f'Converted model size {converted_model_size} MB')
```
Мы видим, что за одно простое квантование мы увеличили размер почти на 80%
Мы можем добиться дальнейшего улучшения задержки, сокращения пикового использования памяти и доступа к аппаратным ускорителям только для целых чисел, убедившись, что вся математика модели квантована. Для этого нам нужно измерить динамический диапазон активаций и входов с репрезентативным набором данных. Таким образом, вы просто создадите генератор входных данных и предоставите его вашему конвертеру:
Для этого сначала вернём наш тестовый набор данных:
```
def get_label(file_path):
parts = tf.strings.split(file_path, os.path.sep)
return parts[-2] == CLASS_NAMES[0]
@tf.autograph.experimental.do_not_convert
def decode_img(img):
img = tf.image.decode_jpeg(img, channels=3)
img = tf.image.convert_image_dtype(img, tf.float32)
return tf.image.resize(img, [IMG_WIDTH, IMG_HEIGHT])
@tf.autograph.experimental.do_not_convert
def process_path(file_path):
label = get_label(file_path)
img = tf.io.read_file(file_path)
img = decode_img(img)
return img, label
def format_image(image, label):
image = tf.image.resize(image, IMAGE_SIZE) / 255.0
return image, label
def prepare_for_training(ds, cache=True, shuffle_buffer_size=1000):
if cache:
if isinstance(cache, str):
ds = ds.cache(cache)
else:
ds = ds.cache()
ds = ds.shuffle(buffer_size=shuffle_buffer_size)
ds = ds.repeat()
ds = ds.batch(BATCH_SIZE)
ds = ds.prefetch(buffer_size=AUTOTUNE)
return ds
data_dir = pathlib.Path('tflite/images')
BATCH_SIZE = 32
IMG_HEIGHT = 224
IMG_WIDTH = 224
IMG_SHAPE = (IMG_HEIGHT, IMG_WIDTH, 3)
CLASS_NAMES = np.array([item.name for item in data_dir.glob('train/*') if item.name != "LICENSE.txt"])
test_ds = tf.data.Dataset.list_files(str(data_dir/'test/*/*'))
test_examples = test_ds.map(process_path, num_parallel_calls=AUTOTUNE)
test_examples_dataset = prepare_for_training(test_examples)
```
А теперь давайте определим репрезентативный набор данных. Это будет настроено на то, чтобы преобразователь выполнял некоторые выводы по мере квантования, чтобы поддерживать как можно большую точность, а также преобразовывать все возможные веса и активации в INT8:
```
def representative_data_gen():
for image_batch, label_batch in test_examples_dataset.take(1):
for image in image_batch:
yield [[image]]
len(list(representative_data_gen()))
converter.representative_dataset = representative_data_gen
```
Результирующая модель будет полностью квантована, но для удобства по-прежнему будет принимать входные и выходные данные с плавающей запятой.
Операции, которые не имеют квантованных реализаций, автоматически останутся с плавающей запятой. Это позволяет выполнять преобразование гладко, но может ограничивать развертывание ускорителями, поддерживающими float.
*Полноцелочисленное квантование (необязательно, просто для знания)*
Чтобы преобразователь выдавал только целочисленные операции, можно указать:
`converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]`
Однако имейте в виду, что если преобразователь не может найти поддерживаемую INT8-совместимую операцию с вашей моделью, он не будет работать. Этот шаг обычно необязателен, но в некоторых случаях, например при развертывании на TPU, он необходим, поскольку это оборудование поддерживает только операции INT8.
Преобразование и проверка модели
Наконец, давайте преобразуем нашу модель:
```
tflite_model = converter.convert()
tflite_model_file = 'converted_model_int8.tflite'
with open(tflite_model_file, "wb") as f:
f.write(tflite_model)
print('Done quantizing with Representative Dataset')
```
### Сравнение размеров
Можно подумать, что новая переделанная модель меньше, но это не всегда так. Преобразование в операции INT8 в значительной степени сосредоточено на требованиях к памяти и скорости:
```
from pathlib import Path
quantized_weights = Path('converted_model.tflite')
weights_quantized_size = quantized_weights.stat().st_size/(1024*1024)
print(f'Quantized for weights model size {weights_quantized_size} MB')
weights_and_activations_model = Path('converted_model_int8.tflite')
weights_and_activations_model_size = weights_and_activations_model.stat().st_size/(1024*1024)
print(f'Quantized for weights and activations size {weights_and_activations_model_size} MB')
```
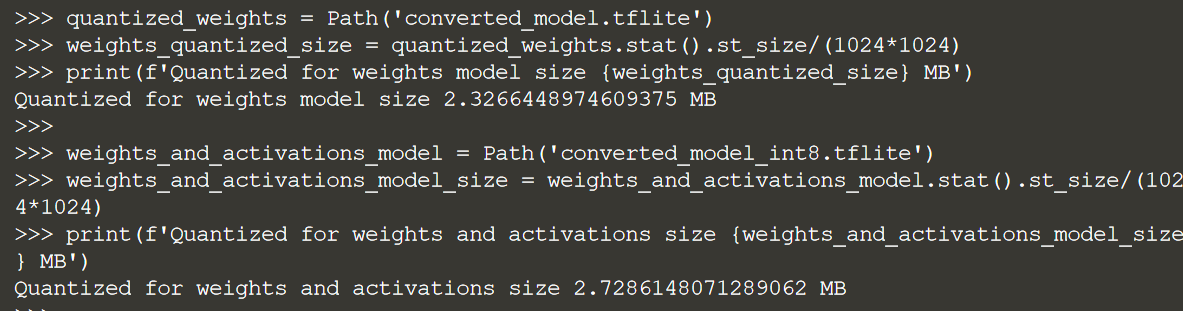И мы видим, что оба размера одинаковы. На следующем этапе мы рассмотрим, что происходит со скоростью!
**Протестируем модель TensorFlow Lite с помощью интерпретатора Python.**
Теперь, когда у нас есть наши квантованные модели, мы можем протестировать их и проверить их точность!
Во-первых, давайте загрузим квантованную модель весов. Для этого нам нужно выделить тензоры для прогнозов:
```
weights_tflite_model_file = 'converted_model.tflite'
interpreter = tf.lite.Interpreter(model_path=weights_tflite_model_file)
interpreter.allocate_tensors()
input_index = interpreter.get_input_details()[0]["index"]
output_index = interpreter.get_output_details()[0]["index"]
```
Теперь давайте создадим простую партию из 15 изображений (из соображений производительности) и проверим ее показатели:
```
import time
start_time = time.time()
predictions = []
test_labels, test_imgs = [], []
debug = 0
image_batch, label_batch = next(iter(test_examples_dataset))
for img, label in zip(image_batch, label_batch):
debug += 1
if debug % 5 == 1:
print(f'I am treating image {debug} with label {label}')
if debug == 15:
break
interpreter.set_tensor(input_index, np.array([img]))
interpreter.invoke()
predictions.append(interpreter.get_tensor(output_index))
test_labels.append(label.numpy())
test_imgs.append(img)
print(f'Predictions calculated in {time.time() - start_time} seconds')
```
Теперь у нас есть все прогнозы. Рассчитаем точность, чувствительность и специфичность:
```
ok_value = 0
wrong_value = 0
true_positives = 0
total = 0
true_negatives = 0
false_positives = 0
false_negatives = 0
for predictions_array, true_label in zip(predictions, test_labels):
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
ok_value += 1
if CLASS_NAMES[int(true_label)] == 'NORMAL':
true_negatives += 1
else:
true_positives += 1
else:
wrong_value += 1
if CLASS_NAMES[predicted_label] == 'NORMAL':
false_negatives +=1
else:
false_positives += 1
total += 1
print(f'Accuracy: {(true_positives + true_negatives) / total} \n ')
print(f'Sensitivity: {true_positives/ (true_positives + false_negatives)} \n ')
print(f'Specificity: {true_negatives / (true_negatives + false_positives)}')
```
Наша модель очень хороша: ее, наверное, можно было бы улучшить, но получить такой результат за 30 минут — это очень хорошо!
Теперь давайте проверим квантованную модель весов и активаций:
```
weights_tflite_model_file = 'converted_model_int8.tflite'
interpreter = tf.lite.Interpreter(model_path=weights_tflite_model_file)
interpreter.allocate_tensors()
input_index = interpreter.get_input_details()[0]["index"]
output_index = interpreter.get_output_details()[0]["index"]
```
Как и раньше, давайте создадим простую партию из 15 изображений (опять же, из соображений производительности) и проверим ее метрики:
```
import time
start_time = time.time()
predictions = []
test_labels, test_imgs = [], []
debug = 0
image_batch, label_batch = next(iter(test_examples_dataset))
for img, label in zip(image_batch, label_batch):
debug += 1
if debug % 5 == 1:
print(f'I am treating image {debug} with label {label}')
if debug == 15:
break
interpreter.set_tensor(input_index, np.array([img]))
interpreter.invoke()
predictions.append(interpreter.get_tensor(output_index))
test_labels.append(label.numpy())
test_imgs.append(img)
print(f'Predictions calculated in {time.time() - start_time} seconds')
```
Теперь у нас есть все прогнозы. Рассчитаем точность, чувствительность и специфичность:
```
ok_value = 0
wrong_value = 0
true_positives = 0
total = 0
true_negatives = 0
false_positives = 0
false_negatives = 0
for predictions_array, true_label in zip(predictions, test_labels):
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
ok_value += 1
if CLASS_NAMES[int(true_label)] == 'NORMAL':
true_negatives += 1
else:
true_positives += 1
else:
wrong_value += 1
if CLASS_NAMES[predicted_label] == 'NORMAL':
false_negatives +=1
else:
false_positives += 1
total += 1
print(f'Accuracy: {(true_positives + true_negatives) / total} \n ')
print(f'Sensitivity: {true_positives/ (true_positives + false_negatives)} \n ')
print(f'Specificity: {true_negatives / (true_negatives + false_positives)}')
```
Мы видим, что, хотя модель с оптимизацией весов немного меньше и лучше, модель INT8 намного быстрее. Идея квантования INT8 состоит в том, чтобы потерять точность (немного) для увеличения скорости.
Резюмируя:
* Мы загрузили набор рентгеновских данных из репозитория лаборатории.
* Мы создали данные наборы данных с помощью наборов данных TensorFlow, которые создают итераторы из наших изображений.
* Мы узнали, как адаптировать эти наборы данных, сопоставив несколько методов, которые позволяли переформатировать изображения до 224 x 224 x 3 и возвращали правильную метку, причем все в пакетном режиме.
* Мы создали, обучили и сохранили нашу модель с передачей обучения, используя MobileNet v2 и простой слой softmax над ним.
* Мы квантовали сохраненную модель классификации пневмонии для весов в качестве оптимизации после обучения.
* Мы подтвердили, что мы увеличиваем размер на 80%, просто делая это.
* Мы узнали о квантовании активаций с репрезентативным набором данных и о квантовании с полным целым числом.
* Мы оценили обе модели, чтобы проверить производительность.
Так как статья подготовлена в преддверии старта курса [Machine Learning. Professional](https://otus.pw/DSuI/), хочу пригласить всех на [бесплатный урок курса](https://otus.pw/DSuI/), где преподаватели OTUS расскажут какие подходы к ансамблированию сегодня существуют в машинном обучении, как устроены такие популярные техники ансамблирования как Bagging, Random Forest и Gradient Boosting. Когда и как их стоит применять для решения ML-задач.
* [Зарегистрироваться на бесплатный урок](https://otus.pw/DSuI/) | https://habr.com/ru/post/703186/ | null | ru | null |
# Глупый метеокороб на E-Ink

Уже как полтора года назад я купил пару E-Ink экранов с eBay на базе драйвера SSD1606, как раз для метеостанции. И вот 4 месяца назад, перед новыми годом, появился он.
Скажу сразу, что часов в ней нет, поскольку дома часы есть буквально везде! Но умеет он показывать следующее:
* текущую температуру по Цельсию;
* текущую влажность в процентах;
* текущее давление в мм.рт.ст;
* историю давления за последние 15 часов в виде графика;
* напряжение батареи.
Собственно и все. Необходимый минимум и предельная простота!
**Даже нет вот такого GUI**
### Принцип работы
---
Контроллер должен по нажатию кнопки выводить на экран актуальную информацию. Большую часть времени контроллер спит, как и дисплей, находящийся в глубоком сне.
Контроллер периодически просыпается по watchDog и раз в 5 минут делает замеры давления, для построения графика изменения давления.
С графиком вышло очень интересно, так как давление может меняться очень быстро и сильно (погода в северном городе вообще непредсказуема), то в какой-то момент может возникнуть зашкаливание графа. Для этого раз в пару часов происходит перекалибровка средней точки измерений (давление может идти как вверх, так и вниз). Однако благодаря этому, наглядная разница предыдущих значений упрощает чтение графа (пример на КПДВ).
### Железо
---
Основным мозгом является микроконтроллер ATMega328P, в качестве ~~всеметра~~ барометра используется BME280, а для экрана уже описанный ранее E-Ink второй ревизии на базе SSD1606 от Smart-Prototyping.
Это почти тот же экран, что и waveShare epaper 2,7“, только старее (даташиты у них ну очень похожи).
Все это работает на аккумуляторе от ~~игрушечного~~ вертолета на 120 мАч. Заряжается аккумулятор при помощи модуля с защитой от глубокого разряда и перезаряда на базе TP4056 с установленным резистором на 47 кОм для зарядки током около 20мА.
### Оптимизация энергопотребления
---
Крепкий и здоровый сон наше все! Поэтому нужно спать по максимуму!
Поскольку софта для работы с экраном не было, только базовый пример кода с комментариями на языке поднебесной и даташит (экран полтора года назад только появился), то большую часть всего пришлось делать самому, благо уже был опыт работы с разными экранами.
В даташите был найден режим DeepSleep, в нем экран потребляет всего ничего — 1.6мкА!
Барометр имеет режим замера по требованию (ака standby), в нем датчик потребляет минимум энергии, при этом предоставляя достаточную точность для простой индикации изменений (в даташите указано, что он как раз для метеостанций). Включение этого режима дало потребление на уровне 6,2 мкА. Далее на модуле был перепаян LDO регулятор с LM6206N3 (а может и XC6206, они оба маскируются как 662k) на MCP1700.

Это дало выигрыш еше на 2 мкА.
Поскольку нужно добиться минимального энергопотребления, то была использована библиотека LowPower. В ней есть удобная работа с watchDog, на основе чего и сделан сон атмеги. Однако, сам по себе он потребляет около 4мкА. Решение этой проблемы мне видится использованием внешнего таймера на основе Texas Instruments TPL5010 или аналогичным.
Таже для уменьшения энергопотребления нужно было прошить атмегу другими FUSE битами и загрузчиком, что и было успешно сделано с USBasp, а в файл boards.txt был добавлен
**Следующий текст:**`## Arduino Pro or Pro Mini (1.8V, 1 MHz Int.) w/ ATmega328p
## internal osc div8, also now watchdog, no LED on boot
## bootloader size: 402 bytes
## http://homes-smart.ru/index.php/oborudovanie/arduino/avr-zagruzchik
## http://homes-smart.ru/fusecalc/?prog=avrstudio∂=ATmega328P
## http://www.engbedded.com/fusecalc
## -------------------------------------------------
pro.menu.cpu.1MHzIntatmega328=ATmega328 (1.8V, 1 MHz Int., BOD off)
pro.menu.cpu.1MHzIntatmega328.upload.maximum_size=32256
pro.menu.cpu.1MHzIntatmega328.upload.maximum_data_size=2048
pro.menu.cpu.1MHzIntatmega328.upload.speed=9600
pro.menu.cpu.1MHzIntatmega328.bootloader.low_fuses=0x62
pro.menu.cpu.1MHzIntatmega328.bootloader.high_fuses=0xD6
pro.menu.cpu.1MHzIntatmega328.bootloader.extended_fuses=0x07
pro.menu.cpu.1MHzIntatmega328.bootloader.file=atmega/a328p_1MHz_62_d6_5.hex
pro.menu.cpu.1MHzIntatmega328.build.mcu=atmega328p
pro.menu.cpu.1MHzIntatmega328.build.f_cpu=1000000L`
Также положить в папку «bootloaders/atmega/» загрузчик собранный из optiboot:
**a328p\_1MHz\_62\_d6\_5.hex**`:107E0000F894112484B714BE81FFDDD082E0809302
:107E1000C00088E18093C10086E08093C2008CE0BE
:107E20008093C4008EE0B9D0CC24DD2488248394D0
:107E3000B5E0AB2EA1E19A2EF3E0BF2EA2D08134A3
:107E400061F49FD0082FAFD0023811F0013811F43F
:107E500084E001C083E08DD089C0823411F484E1D4
:107E600003C0853419F485E0A6D080C0853579F447
:107E700088D0E82EFF2485D0082F10E0102F00278F
:107E80000E291F29000F111F8ED068016FC0863583
:107E900021F484E090D080E0DECF843609F040C049
:107EA00070D06FD0082F6DD080E0C81680E7D8065C
:107EB00018F4F601B7BEE895C0E0D1E062D089932E
:107EC0000C17E1F7F0E0CF16F0E7DF0618F0F60147
:107ED000B7BEE89568D007B600FCFDCFA601A0E0CC
:107EE000B1E02C9130E011968C91119790E0982F91
:107EF0008827822B932B1296FA010C0187BEE895F6
:107F000011244E5F5F4FF1E0A038BF0751F7F60133
:107F1000A7BEE89507B600FCFDCF97BEE89526C042
:107F20008437B1F42ED02DD0F82E2BD03CD0F601D2
:107F3000EF2C8F010F5F1F4F84911BD0EA94F80143
:107F4000C1F70894C11CD11CFA94CF0CD11C0EC0EF
:107F5000853739F428D08EE10CD085E90AD08FE03E
:107F60007ACF813511F488E018D01DD080E101D09E
:107F700065CF982F8091C00085FFFCCF9093C600FD
:107F800008958091C00087FFFCCF8091C00084FDE0
:107F900001C0A8958091C6000895E0E6F0E098E160
:107FA000908380830895EDDF803219F088E0F5DF5B
:107FB000FFCF84E1DECF1F93182FE3DF1150E9F7E5
:107FC000F2DF1F91089580E0E8DFEE27FF27099494
:0400000300007E007B
:00000001FF`
Собственно как вы, скорее всего, догадались, все это делалось на базе Arduino, а именно pro mini на 8МГц 3.3В. С этой платы был выпаян LDO-регулятор mic5203 (слишком прожорлив при малых токах) и отпаян резистор светодиода для индикации питания.
В итоге удалось добиться энергопотребления в 10 мкАч в спящем режиме, что дает около 462,96 дней работы. От этого числа смело можно вычесть треть, получив тем самым около 10 месяцев, что пока соответствует реальности.
Версию на ионисторах тестировал, при конечной емкости 3мАч работает не более 6 дней (высокий саморазряд). Расчет емкости ионистора делался по формуле C\*V/3,6 = X мАч. Думаю, что версия с солнечной батареей и MSP430 будет вообще вечной.
**Объявления:**`#include
#include
#include
#include
//#include // local optimisation
#include
#include
#include
#define TIME\_X\_POS 0
#define TIME\_Y\_POS 12
#define DATE\_X\_POS 2
#define DATE\_Y\_POS 9
#define WEECK\_X\_POS 65
#define WEECK\_Y\_POS 9
// ====================================== //
#define TEMP\_X\_POS 105
#define TEMP\_Y\_POS 15
#define PRESURE\_X\_POS 105
#define PRESURE\_Y\_POS 12
#define HUMIDITY\_X\_POS 105
#define HUMIDITY\_Y\_POS 9
// ====================================== //
#define BATT\_X\_POS 65
#define BATT\_Y\_POS 15
#define ONE\_PASCAL 133.322
// ==== for presure history in graph ==== //
#define MAX\_MESURES 171
#define BAR\_GRAPH\_X\_POS 0
#define BAR\_GRAPH\_Y\_POS 0
#define PRESURE\_PRECISION\_RANGE 4.0 // -/+ 4 mm
#define PRESURE\_GRAPH\_MIN 30 // vertical line graph for every N minutes
#define PRESURE\_PRECISION\_VAL 10 // max val 100
#define PRESURE\_CONST\_VALUE 700.0 // const val what unneed in graph calculations
#define PRESURE\_ERROR -1000 // calibrated value
// ====================================== //
#define VCC\_CALIBRATED\_VAL 0.027085714285714 // == 3.792 V / 140 (real / mesured)
//#define VCC\_CALIBRATED\_VAL 0.024975369458128 // == 5.070 V / 203 (real / mesured)
#define VCC\_MIN\_VALUE 2.95 // min value to refresh screen
#define CALIBRATE\_VCC 1 // need for battery mesure calibration
// 37 ~296 sec or 5 min \* MAX\_MESURES = 14,33(3) hours for full screen
#define SLEEP\_SIZE 37
#ifdef BME280\_ADDRESS
#undef BME280\_ADDRESS
#define BME280\_ADDRESS 0x76
#endif
#define ISR\_PIN 3 // other mega328-based 2, 3
#define POWER\_OFF\_PIN 4 // also DONEPIN
#define E\_CS 6 // CS ~ D6
#define E\_DC 5 // D/C ~ D5
#define E\_BSY 7 // BUSY ~ D7
#define E\_RST 2 // RST ~ D2
#define E\_BS 8 // BS ~ D8
/\*
MOSI ~ D11
MISO ~ D12
CLK ~ D13
\*/
EPD\_SSD1606 Eink(E\_CS, E\_DC, E\_BSY, E\_RST);
Adafruit\_BME280 bme;
volatile bool adcDone;
bool updateSreen = true;
bool normalWakeup = false;
float battVal =0;
uint8\_t battValcV =0;
uint8\_t timeToSleep = 0;
float presure =0;
float temperature =0;
float humidity =0;
float presure\_mmHg =0;
unsigned long presureMin =0;
unsigned long presureMax =0;
uint8\_t currentMesure = MAX\_MESURES;
uint8\_t presureValHistoryArr[MAX\_MESURES] = {0};
typedef struct {
uint8\_t \*pData;
uint8\_t pos;
uint8\_t size;
unsigned long valMax;
unsigned long valMin;
} history\_t;`
**Инициализация:**`void setup()
{
saveExtraPower();
Eink.begin();
initBME();
// https://www.arduino.cc/en/Reference/attachInterrupt
pinMode(ISR_PIN, INPUT_PULLUP);
attachInterrupt(digitalPinToInterrupt(ISR_PIN), ISRwakeupPin, RISING);
//drawDefaultGUI();
drawDefaultScreen();
// tiiiiny fix....
checkBME280();
updatePresureHistory();
}
void saveExtraPower(void)
{
power_timer1_disable();
power_timer2_disable();
// Disable digital input buffers:
DIDR0 = 0x3F; // on ADC0-ADC5 pins
DIDR1 = (1 << AIN1D) | (1 << AIN0D); // on AIN1/0
}
void initBME(void)
{
bme.begin(BME280_ADDRESS); // I2C addr
LowPower.powerDown(SLEEP_250MS, ADC_OFF, BOD_OFF); // wait for chip to wake up.
while(bme.isReadingCalibration()) { // if chip is still reading calibration, delay
LowPower.powerDown(SLEEP_120MS, ADC_OFF, BOD_OFF);
}
bme.readCoefficients();
bme.setSampling(Adafruit_BME280::MODE_FORCED,
Adafruit_BME280::SAMPLING_X1, // temperature
Adafruit_BME280::SAMPLING_X1, // pressure
Adafruit_BME280::SAMPLING_X1, // humidity
Adafruit_BME280::FILTER_OFF);
}`
**Основной код:**`void loop()
{
for(;;) { // i hate func jumps when it's unneed!
checkVCC();
if(normalWakeup) {
checkBME280();
updatePresureHistory();
} else {
normalWakeup = true;
}
updateEinkData();
enterSleep();
}
}
// func to exec in pin ISR
void ISRwakeupPin(void)
{
// Keep this as short as possible. Possibly avoid using function calls
normalWakeup = false;
updateSreen = true;
timeToSleep = 1;
}
ISR(ADC_vect)
{
adcDone = true;
}
void debounceFix(void)
{
normalWakeup = true;
updateSreen = false;
}
//https://github.com/jcw/jeelib/blob/master/examples/Ports/bandgap/bandgap.ino
uint8_t vccRead(void)
{
uint8_t count = 4;
set_sleep_mode(SLEEP_MODE_ADC);
ADMUX = bit(REFS0) | 14; // use VCC and internal bandgap
bitSet(ADCSRA, ADIE);
do {
adcDone = false;
while(!adcDone) sleep_mode();
} while (--count);
bitClear(ADCSRA, ADIE);
// convert ADC readings to fit in one byte, i.e. 20 mV steps:
// 1.0V = 0, 1.8V = 40, 3.3V = 115, 5.0V = 200, 6.0V = 250
return (55U * 1023U) / (ADC + 1) - 50;
}
unsigned long getHiPrecision(double number)
{
// what if presure will be more 800 or less 700? ...
number -= PRESURE_CONST_VALUE; // remove constant value
number *= PRESURE_PRECISION_VAL; // increase precision by PRESURE_PRECISION_VAL
return (unsigned long)number; // Extract the integer part of the number
}
void checkVCC(void)
{
// reconstruct human readable value
battValcV = vccRead();
battVal = battValcV * VCC_CALIBRATED_VAL;
if(battVal <= VCC_MIN_VALUE) { // not enought power to drive E-Ink or work propetly
detachInterrupt(digitalPinToInterrupt(ISR_PIN));
// to prevent full discharge: just sleep
bme.setSampling(Adafruit_BME280::MODE_SLEEP);
LowPower.powerDown(SLEEP_2S, ADC_OFF, BOD_OFF);
Eink.sleep(true);
LowPower.powerDown(SLEEP_FOREVER, ADC_OFF, BOD_OFF);
}
}
void checkBME280(void)
{
bme.takeForcedMeasurement(); // wakeup, make new mesure and sleep
temperature = bme.readTemperature();
humidity = bme.readHumidity();
presure = bme.readPressure();
}
void updatePresureHistory(void)
{
// convert Pa to mmHg; 1 mmHg == 133.322 Pa
presure_mmHg = (presure + PRESURE_ERROR)/ONE_PASCAL;
// === calc presure history in graph === //
if((++currentMesure) >= (MAX_MESURES/3)) { // each 4,75 hours
currentMesure =0;
presureMin = getHiPrecision(presure_mmHg - PRESURE_PRECISION_RANGE);
presureMax = getHiPrecision(presure_mmHg + PRESURE_PRECISION_RANGE);
}
// 36 == 4 pixels in sector * 9 sectors
presureValHistoryArr[MAX_MESURES-1] = map(getHiPrecision(presure_mmHg), presureMin, presureMax, 0, 35);
for(uint8_t i=0; i < MAX_MESURES; i++) {
presureValHistoryArr[i] = presureValHistoryArr[i+1];
}
}
void updateEinkData(void)
{
if(updateSreen) {
updateSreen = false;
Eink.sleep(false);
// bar history
Eink.fillRect(BAR_GRAPH_X_POS, BAR_GRAPH_Y_POS, MAX_MESURES, 9, COLOR_WHITE);
for(uint8_t i=1; i <= (MAX_MESURES/PRESURE_GRAPH_MIN); i++) {
Eink.drawVLine(BAR_GRAPH_X_POS+i*PRESURE_GRAPH_MIN, BAR_GRAPH_Y_POS, 35, COLOR_DARKGREY);
}
for(uint8_t i=0; i <= MAX_MESURES; i++) {
Eink.drawPixel(i, BAR_GRAPH_Y_POS+presureValHistoryArr[i], COLOR_BLACK);
}
#if CALIBRATE_VCC
Eink.setCursor(BATT_X_POS, BATT_Y_POS);
Eink.print(battVal);
Eink.setCursor(BATT_X_POS, BATT_Y_POS-3);
Eink.print(battValcV);
#endif
Eink.setCursor(TEMP_X_POS, TEMP_Y_POS);
Eink.print(temperature);
Eink.setCursor(PRESURE_X_POS, PRESURE_Y_POS);
Eink.print(presure_mmHg);
Eink.setCursor(HUMIDITY_X_POS, HUMIDITY_Y_POS);
Eink.print(humidity);
updateEinkSreen();
Eink.sleep(true);
}
}
void updateEinkSreen(void)
{
Eink.display(); // update Eink RAM to screen
LowPower.idle(SLEEP_15MS, ADC_OFF, TIMER2_OFF, TIMER1_OFF, TIMER0_OFF, SPI_OFF, USART0_OFF, TWI_OFF);
Eink.closeChargePump();
// as Eink display acts not like in DS, then just sleep for 2 seconds
LowPower.powerDown(SLEEP_2S, ADC_OFF, BOD_OFF);
}
void effectiveIdle(void)
{
LowPower.idle(SLEEP_30MS, ADC_OFF, TIMER2_OFF, TIMER1_OFF, TIMER0_OFF, SPI_OFF, USART0_OFF, TWI_OFF);
}
void drawDefaultScreen(void)
{
Eink.fillScreen(COLOR_WHITE);
Eink.printAt(TEMP_X_POS, TEMP_Y_POS, F("00.00 C"));
Eink.printAt(PRESURE_X_POS, PRESURE_Y_POS, F("000.00 mm"));
Eink.printAt(HUMIDITY_X_POS, HUMIDITY_Y_POS, F("00.00 %"));
#if CALIBRATE_VCC
Eink.printAt(BATT_X_POS, BATT_Y_POS, F("0.00V"));
// just show speed in some kart racing game in mushr... kingdom \(^_^ )/
Eink.printAt(BATT_X_POS, BATT_Y_POS-3, F("000cc"));
#endif
}
void drawDefaultGUI(void)
{
Eink.drawHLine(0, 60, 171, COLOR_BLACK); // split 2 areas
// draw window
Eink.drawRect(0, 0, 171, 71, COLOR_BLACK);
// frame for text
Eink.drawRect(BATT_X_POS, BATT_Y_POS, 102, 32, COLOR_BLACK);
}
void snooze(void)
{
do {
LowPower.powerDown(SLEEP_8S, ADC_OFF, BOD_OFF);
} while(--timeToSleep);
}
void disablePower(void)
{
digitalWrite(POWER_OFF_PIN, HIGH);
delay(1);
digitalWrite(POWER_OFF_PIN, LOW);
LowPower.powerDown(SLEEP_FOREVER, ADC_OFF, BOD_OFF);
}
void enterSleep(void)
{
// wakeup after ISR signal;
timeToSleep = SLEEP_SIZE;
debounceFix();
snooze();
}`
### Корпус
---
Поскольку 3D принтера не имею, но имею 3D ручку MyRiwell RP800A. Оказалось, что делать планарные и ровные структуры ей не так-то просто. Рисовалось все PLA пластиком, который был на тот момент, поэтому корпус вышел разноцветным, что в прочем придает некий шарм (потом переделаю под дерево, когда приедет пластик с древесной крошкой).
Первые части рисовались напрямую на бумаге, после чего отрывались. Это оставляло следы на пластике. Более того детали были кривыми и их было нужно как-то выпрямлять!

Решение оказалось до банального простым — рисовать на стекле, а под него положить «чертежи» нужных элементов корпуса.
И вот что вышло:

Кнопка обновления экрана просто обязана была быть красной на белом фоне!

Задняя стенка сделана с простейшим узором, создавая тем самым вентиляционные отверстия.

Кнопка была закреплена на горизонтальной распорке внутри (желтым цветом) так же сделанной ручкой.

Сама кнопка взята от старого компьютерного корпуса (у нее приятный звук).

Внутри все закреплено термоклеем и пластиком, так, что разобрать это все непросто.

Конечно же, оставлены разъем для зарядки и обновления прошивки. Корпус, к сожалению, пришлось сделать монолитным для большей прочности.
### Заключение
---
Прошло 4 месяца, а после не полной зарядки (до 4В) напряжение на батарее село всего до 3.58В, что гарантирует еще долгий срок службы до следующей зарядки.
Домашние к этой штуковине сильно привыкли и в случае головных болей или если нужно узнать точный прогноз погоды на ближайшие час-два, то сразу идут к ней и смотрят что было с давлением. На КПДВ например, видно сильное падение давления, как итог пошел сильный снег с ветром.
Ссылки на репозитории:
→ [библиотека для экрана](https://github.com/Bismuth208/SSD1606_EPD)
→ [библиотека для lowPower](https://github.com/rocketscream/Low-Power)
→ [библиотека для BME280](https://github.com/adafruit/Adafruit_BME280_Library)
Обновлено:
В связи с повышенным интересом к корпусу выложил еще изображения. Экран Smart-Prototyping второй ревизии. Аналог ему на Али [здесь](https://ru.aliexpress.com/item/296x128-2-9inch-E-Ink-display-module-SPI-interfac-Without-PCB-Communicate-via-SPI-interface-Supports/32811510579.html).
**Нажми меня:**


P.S. КПДВ было сделано вечером, как итог сегодня ночью выпало очень, очень много снега в Санкт-Петербурге.
P.P.S Синюю изоленту известным причинам добавлять в опрос не стал. | https://habr.com/ru/post/410949/ | null | ru | null |
# Как использовать свойство Exception.Data, чтобы логировать дополнительные сведения об исключениях
Хорошее, подробное исключение — мощный инструмент, который помогает найти и исправить проблему. Поэтому в исключения стоит вносить больше деталей.
Один из способов — добавить в текст сообщения исключения дополнительные сведения. Как в коде ниже.
```
try
{
return await _ordersRepository.Get(id, cancellationToken);
}
catch (Exception exception)
{
throw new Exception($"Unable to get order info, user {userName}, order id {id}", exception);
}
```
Но при таком подходе затруднительно создавать сообщения. И небезопасно: сообщение может быть отправлено пользователю в случаях, когда исключение не было корректно обработано. Нам следует избегать отправки пользователю такой информации, как идентификаторы. Все, что нужно, чтобы исправить ошибку, — залогировать дополнительные сведения и информацию об оригинальном исключении на стороне сервера.
Другой подход — создать свое исключение с определенными свойствами. Но создать множество классов исключений и так достаточно сложно, а главная проблема — настроить логирование свойств этих классов.
Класс .NET Framework Exception имеет свойство [Data](https://docs.microsoft.com/en-us/dotnet/api/system.exception.data?view=net-6.0), которое уже обеспечивает хранение дополнительных сведений в виде коллекции заданных пар «ключ — значение». Так как это свойство базового класса, я уверен, вы сможете настроить логгер. В наших примерах ниже мы будем использовать NLog, который настраивается достаточно легко. Чтобы избежать [конфликта ключей](https://docs.microsoft.com/en-us/dotnet/api/system.exception.data#key-conflicts) и обработать ошибку наиболее эффективным способом, советую также создать свое исключение.
Половина классов исключений .NET Framework имеет свойства, которые не логируются, — вы можете добавить эти данные в свойство Exception.Data вашего нового исключения. Свойство [InnerException](https://docs.microsoft.com/en-us/dotnet/api/system.exception.innerexception) будет содержать ссылку на оригинальное исключение.
Код ниже демонстрирует, как использовать свойство Exception.Data.
```
try
{
return await _ordersRepository.Get(id, cancellationToken);
}
catch (Exception exception)
{
const string message = "Unable to get order info";
var yourException = new YourAppException(message, exception);
yourException.Data[nameof(userName)] = userName;
yourException.Data[nameof(id)] = id;
throw yourException;
}
```
Упс. Похоже, мы добавили больше кода — но можем исправить это, создав расширения, которые позволят задействовать паттерн Fluent interface. Пример ниже демонстрирует, как сделать код более читабельным и простым в использовании.
```
try
{
return await _ordersRepository.Get(id, cancellationToken);
}
catch (Exception exception)
{
throw exception.With("Unable to get order info")
.DetailData(nameof(userName), userName)
.DetailData(nameof(id), id);
}
```
Давайте рассмотрим пример настройки [NLog layout](https://github.com/nlog/NLog/wiki/Exception-Layout-Renderer) для логирования свойства Exception.Data.
```
${shortdate} ${time} [${level:uppercase=true}]: ${message:withException=true}${when:when=length('${exception:format=Data}')>0:Inner=${newline}--- Exception Data ---${newline}${exception:format=Data:exceptionDataSeparator=,\r\n}}
```
Как это выглядит в консоли.
Этот пример работает замечательно, если добавлять простые структуры: NLog вызывает ToString(), чтобы записать значения в targets. Поэтому мы можем правильно залогировать объекты, только если они корректно переопределяют метод ToString().
Но переопределить ToString для всех классов практически невозможно. Наиболее простой способ представить объект в виде строки — сериализовать его в JSON. Код ниже добавляет C#-класс, который это делает.
```
///
/// Defines a value/json pair to represent an exception data value as JSON
///
public record ExceptionDataEntry
{
private static readonly JsonSerializerOptions SerializerOptions = new()
{
PropertyNamingPolicy = JsonNamingPolicy.CamelCase,
Converters = {new JsonStringEnumConverter(JsonNamingPolicy.CamelCase)},
WriteIndented = true
};
private ExceptionDataEntry(in object value, in string json)
{
Value = value;
Json = json;
}
public object Value { get; }
public string Json { get; }
public static ExceptionDataEntry FromValue(in object value)
{
if (value == null)
{
throw new ArgumentNullException(nameof(value));
}
var json = JsonSerializer.Serialize(value, SerializerOptions);
return new ExceptionDataEntry(value, json);
}
///
/// Represents an exception data value as JSON
///
///
public override string ToString()
{
return Json;
}
}
```
А этот код добавляет расширение.
```
public static YourAppException DetailData(this YourAppException exception, in string key, in object value)
{
try
{
exception.Data[key] = ExceptionDataEntry.FromValue(value);
}
catch
{
// ignored, because we use it inside another exception catch block
// so, we should avoid throwing a new exception to keep the original exception
}
return exception;
}
```
Как это будет выглядеть в консоли в нашем примере.
Я надеюсь, этот подход к использованию Exception.Data для логирования дополнительных сведений поможет вам в поддержке приложений. Если у вас есть идеи, как улучшить предложенный подход, пожалуйста, пишите в комментариях. Спасибо =) | https://habr.com/ru/post/597421/ | null | ru | null |
# Banana Pi: через U-Boot к Arch Linux
Уже четвёртый год подряд, с момента выпуска Raspberry Pi, на рынки всего мира поставляются различные микрокомпьютеры на отличных от x86 архитектурах, которые выполняют роль медиацентров, контроллеров умных домов, веб-серверов и чего только душа гика не пожелает!
К 2014-2015 году не все были довольны вычислительными возможностями «малинки» и начался выпуск десятков его клонов с более мощным железом. У большинства из них есть недостатки: фиксированная устаревшая версия ядра и загрузчика, небольшой выбор дистрибутивов. Под катом расскажу о том, как сбросить оковы вендора на примере Banana Pi.
#### Предыстория
Во второй половине 2014 года захотелось иметь домашний сервер, выбор встал между классическим на архитектуре x86 с процессором серии Intel Atom и чем-то новым для меня — микрокомпьютером на базе ARM.
После оценки соотношений цены/производительности/возможностей выбор пал на Banana Pi — кроху с двухъядерным Allwinner A20, 1 гигабайтом DDR3, гигабитным LAN'ом, SATA разъёмом и прочими прелестями подобных устройств. Наигравшись пару дней, я смастерил из пластмассовых деталей корпус, в который Banana и была заточена и долго служила для всяких мелких задач.
Дистрибутив стоял Bananian — это Debian 7 Wheezy урезанный во многом для экономии ресурсов. Более нового Debian 8.x нет и по сей день, можете сами представить насколько там старый софт, который получает лишь заплатки безопасности. Всё это безобразие продолжалось до середины лета…

Наконец в июле возникла необходимость поднять веб-сервер и сопутствующие ему сервисы для своего pet project. Пора было сменить старый Debian на что-то менее консервативное и более удобное для меня.
#### Постановка задачи
К дистрибутиву было поставлено несколько требований: должен «из коробки» иметь репозитории покрывающие все нужды, программы в них должны быть наиболее приближённые к последним доступным версиям. Я слежу за развитием дистрибутивов и входящих в них программ, но при этом ленюсь компилировать всё из сорцов, поэтому очевидным выбором стал Arch Linux.
На сайте производителя в разделе загрузок меня ждал просроченный на год образ с зашитым необновляемым ядром (3.4.100), загрузчиком такой же давности причём от другого устройства (Cubieboard 2). На сайте [Arch Linux'а](http://archlinuxarm.org/) поддержки Banana Pi не было заявлено. Исходя из всего этого оставалось только одно: скомпоновать и запустить дистрибутив самому.
#### Матчасть

**Das U-Boot** (происхождение названия как-то связано с субмаринами и игрой слов на немецком и английском языках, [см. U-boat](https://en.wikipedia.org/wiki/U-boat))
Это загрузчик операционной системы, ориентированный на устройства c архитектурами MIPS, PowerPC, ARM и другими. Умеет он многое: загружает систему с NAND, NOR, SPI, MMC, SATA, USB, TFTP, NFS, может сам храниться в ПЗУ устройства или внешней памяти, имеет встроенный dhcp клиент и shell, принимает сигналы с клавиатуры, выводит на UART, HDMI, VGA, аналоговое видео. Естественно для поддержки всего этого нужно иметь драйверы.
Тут и начинается отличие от x86 платформ — ARM не имеет ACPI (усовершенствованного интерфейса управления конфигурацией и питанием) и UEFI (интерфейса взаимодействия между операционной системой и «прошивкой» устройства) и именно поэтому не существует как таковых унифицированных дистрибутивов для ARM компьютеров, но движение в сторону [UEFI и ACPI](http://ru.fedoracommunity.org/content/arm64-%D1%82%D0%B5-aarch64-%D0%B8-%D0%BD%D0%B5%D0%BF%D1%80%D0%BE%D1%81%D1%82%D0%BE%D0%B9-%D0%BF%D1%83%D1%82%D1%8C-%D0%BF%D0%B5%D1%80%D0%B5%D1%85%D0%BE%D0%B4%D0%B0-arm-%D0%BD%D0%B0-%D0%BD%D0%BE%D0%B2%D1%8B%D0%B5-%D1%81%D1%82%D0%B0%D0%BD%D0%B4%D0%B0%D1%80%D1%82%D1%8B) идёт уже несколько лет. А пока это движение идёт мы находимся в реальном суровом мире и загрузчик нужно компилировать самостоятельно для разного железа. Железо это описывается в структуре данных под названием **Device Tree (dt)**. Подробнее о DT можно узнать на посвящённом ему сайте: [devicetree.org](http://www.devicetree.org/Main_Page).
В комплекте с исходными кодами загрузчика поставляется набор конфигурационных файлов для компиляции, а также Device Tree для 1089 устройств. Гугл, к сожалению, не находит этот список, поэтому он доступен по ссылке: [U-boot supported devices](https://gist.github.com/evgenymarkov/6e8cf27f712d74d23b03).

**Linux Kernel**
О нём много писано, много сказано, а сейчас пригодится лишь несколько фактов:
1. Встреченные мною дистрибутивы хранят ядро в нескольких формах:
* Image — не сжатый образ.
* zImage — сжатый самораспаковываяющийся образ.
* uImage — образ, который имеет обёртку, включающую некоторую информацию для U-Boot'а.
Ранее uImage использовались обширно для устройств с U-Boot, но за последние года разработчики научили загрузчик работать с zImage, который стал общепринятой практикой хранения образа ядра в дистрибутиве Arch Linux ARM.
2. Радостная новость! Ядро в пределах одной архитектуры(ARMv5, ARMv6, ARMv7, ARMv8) с большой вероятностью не придётся компилировать для каждого устройства. Оно использует свою версию **Device Tree**, называемую **Device Tree Binary (dtb)**. Это небольшие по объёму файлы, указывающие ядру какие модули нужно подгружать. Больше информации о dtb можно узнать [тут](http://www.armadeus.com/wiki/index.php?title=Kernel-with-device-tree).
#### От теории к практике
Понадобится:
* Banana Pi или другой микрокомпьютер из [списка](#github_gist) поддерживаемых U-Boot'ом устройств
* Карта памяти и кардридер
* Компьютер с Linux
* Установленный тулчейн для нужной архитектуры
**Где взять?** Наиболее простым способом я считаю следующий:
1. Скачать готовый тулчейн для своей платформы с сайта [Linaro](https://www.linaro.org/downloads/).
Для Banana Pi нужен *linaro-toolchain-binaries (little-endian)*.
2. Добавить папку bin тулчейна в PATH:
```
export PATH=~/your_toolchain_path/bin/:$PATH
```
* Утилиты bc и dtc нужные для компиляции загрузчика, пакеты dosfstools и uboot-tools для создания файловой системы и компиляции скриптов загрузчика, соответственно
Скачаем и распакуем исходные коды последней версии U-Boot:
```
wget ftp://ftp.denx.de/pub/u-boot/u-boot-latest.tar.bz2
tar -jxf u-boot-latest.tar.bz2
```
Находим в появившемся каталоге **u-boot-2015.07/configs** свою «железку» и запоминаем название файла. Для Banana Pi конфигурационный файл называется **Bananapi\_defconfig**.
Ещё помните, что ядро Arch Linux ARM дистрибутиве хранится в zImage? Об этом нужно позаботиться заранее и перед компиляцией добавить возможность загружать самораспаковывающиеся ядра. Точной информации о том уже включено ли это по умолчанию у меня нет, поэтому в каталоге **u-boot-2015.07/include/configs/** нужно найти заголовочный файл для платформы Вашего микрокомпьютера (для Banana Pi это **sun7i.h**) и написать внутри:
```
#ifndef __CONFIG_H
#define __CONFIG_H
...
#endif /* __CONFIG_H */
```
строку
```
#define CONFIG_CMD_BOOTZ
```
Это добавит возможность использовать в загрузчике команду **bootz** для запуска самораспаковывающихся сжатых программ.[Источник](http://unix.stackexchange.com/questions/122526/how-to-convert-a-zimage-into-uimage-for-booting-with-u-boot)
Теперь этап компиляции. Все операции происходят в каталоге **u-boot-2015.07**.
**А что если без кросс-компиляции?**Если компилируете на той же архитектуре (например, на компьютере с ARMv7), то для make можно опустить флаг CROSS\_COMPILE.
```
make CROSS_COMPILE=arm-linux-gnueabihf- Bananapi_defconfig
```
Непосредственно компиляция загрузчика:
```
make CROSS_COMPILE=arm-linux-gnueabihf-
```
В итоге в нашей рабочей папке должно появиться много файлов с префиксом u-boot. u-boot.bin содержит исполняемый файл загрузчика, но нужен нам файл с постфиксом «with-spl». SPL — небольшая программа, которая располагается непосредственно перед загрузчиком и загружает сам U-Boot в оперативную память. Для Banana Pi это файл **u-boot-sunxi-with-spl.bin**. Сохраним его, он пригодится чуть позже.
Следующий шаг — подготовка флеш-карты с которой будет загружаться система. Как должна выглядеть её разметка:

Подключим флеш-карту через кард-ридер и запустим утилиту fdisk:
```
fdisk /dev/sdb
```
**Как узнать какое имя у Вашей карты?**В каталоге /dev/ должен появиться новый файл, соответствующий вставленной карте. Она определится либо как SCSI-устройство (sda, sdb, sdc...), либо как блочная MMC память (mmcblk0, mmcblk1 ...).
Добавим MBR разметку:
```
Command (m for help): o
Created a new DOS disklabel with disk identifier 0xa53166ce.
```
И обязательно как минимум два раздела:
1. 50-100 Мб
**fdisk, разметка первого**
```
Command (m for help): n
Partition type
p primary (0 primary, 0 extended, 4 free)
e extended (container for logical partitions)
Select (default p): p
Partition number (1-4, default 1): 1
First sector (2048-7831551, default 2048): 2048
Last sector, +sectors or +size{K,M,G,T,P} (2048-7831551, default 7831551): +75M
Created a new partition 1 of type 'Linux' and of size 75 MiB.
```
2. 2 Гб и более
**fdisk, разметка второго**
```
Command (m for help): n
Partition type
p primary (1 primary, 0 extended, 3 free)
e extended (container for logical partitions)
Select (default p): p
Partition number (2-4, default 2): 2
First sector (155648-7831551, default 155648): 155648
Last sector, +sectors or +size{K,M,G,T,P} (155648-7831551, default 7831551): +3G
Created a new partition 2 of type 'Linux' and of size 3 GiB.
```
После всего этого ввести «w», тем самым записать изменения на диск.
**Почему именно такие разделы?** U-Boot'ом можно управлять с помощью скриптов, он читает их **только из первого раздела** накопителя, причём раздел этот должен быть с файловой системой **FAT**. В этот же раздел будет смонтирован каталог /boot будущего Arch Linux'а для удобного доступа к ядрам как из U-Boot скриптов, так и для быстрой подмены ядер с любого попавшегося компьютера. Второй раздел предназначен для корня системы. Остальные по желанию.
После разметки нужно очистить место для загрузчика. Крайне важно не затереть первые 512 байт(MBR) и не затронуть 1024 секторы и далее (исходя из таблицы выше):
```
dd if=/dev/zero of=/dev/sdb bs=1K count=1023 seek=1
```
Запишем U-Boot:
```
dd if=u-boot-sunxi-with-spl.bin of=/dev/sdb bs=1024 seek=8
```
Теперь уже можно вставить флешку в устройство назначения, включить его и посмотреть как оно весело мигает LED'ами, подхватывает ip-адрес через dhcp, пытается достучаться до tftp сервера чтобы загрузиться и дружелюбно приглашает Вас в свой Shell показывая его через выдеовыход или UART.
Но одного загрузчика мало, остаётся ещё несколько компонентов: скрипт для управления U-Boot'ом и сам дистрибутив Arch Linux.
Отправляемся на [os.archlinuxarm.org](http://os.archlinuxarm.org/os/) и скачиваем архив с подходящим нашей архитектуре дистрибутивом. Для Banana это ArchLinuxARM-armv7-latest.tar.gz. Распаковываем в отдельную директорию и продолжаем манипуляции с флеш-картой.
Создадим файловые системы и примонтируем их в заданном порядке:
```
mkfs.vfat /dev/sdb1
mkfs.ext4 /dev/sdb2
mount /dev/sdb2 /mnt
mkdir /mnt/boot
mount /dev/sdb1 /mnt/boot
```
Скопируем всё содержимое распакованного архива в /mnt:
```
cp -r ~/ArchLinux-generic-armv7/* /mnt
```
Заглянем в первый раздел флешки (/mnt/boot). Внутри нас ждёт папка dtbs и сжатый образ ядра — zImage. dtbs — это именно те Device Tree Binary, о которых шла речь [выше](#dtb).
Для ARMv7 есть целых 301 dtb. Список можно увидеть [здесь](https://gist.github.com/evgenymarkov/225f4ee293c7d5cfcb6c) или непосредственно открыв директорию boot/dtbs дистрибутива на своём компьютере. Если dtb есть, то ядро заведётся с почти 100% вероятностью. Для Banana Pi нужный файл — **sun7i-a20-bananapi.dtb**. Он нужен нам для последнего и завершающего этапа — написания скрипта для U-Boot'а и, естественно, запуска всей полученной системы.
Приступим. Создадим прямо на месте (в **/mnt/boot**) файл boot.cmd и начнём писать.
Первым делом прикажем U-Boot'у загружать в RAM образ ядра:
```
fatload mmc 0 0x46000000 zImage
```
Затем dtb для нужного девайса:
```
fatload mmc 0 0x49000000 dtbs/sun7i-a20-bananapi.dtb
```
Установим параметры для запуска ядра:
```
setenv bootargs console=ttyS0,115200 earlyprintk root=/dev/mmcblk0p2 rw rootwait panic=10
```
И скажем ему загружаться из этой области памяти, тем самым передавая управление уже ядру Linux.
```
bootz 0x46000000 - 0x49000000
```
*Области памяти доступные для загрузки у каждой модели свои и к сожалению я не знаю как определять их самостоятельно. Буду очень рад, если кто-то расскажет об этом простыми словами в комментариях.*
Написанный нами скрипт остаётся только скомпилировать. Для этого в пакете uboot-tools есть утилита mkimage, воспользуемся ей:
```
mkimage -C none -A arm -T script -d boot.cmd boot.scr
```
boot.cmd при желании можно удалить, загрузчику нужен лишь boot.scr.
**А бывает ещё что-то вроде boot.scr?**Да, бывает. U-Boot для некоторых устройств можно сконфигурировать через простой текстовый файл uEnv.txt, это зависит от вендора, но с Banana Pi такой трюк не прокатит.
И последний штрих — добавляем в etc/fstab новой системы разделы, которые будут подключаться при запуске:
```
/dev/mmcblk0p2 / ext4 rw,relatime,data=ordered 0 1
/dev/mmcblk0p1 /boot vfat rw,relatime,fmask=0022,dmask=0022,codepage=437,iocharset=iso8859-1,shortname=mixed,errors=remount-ro 0 2
```
Флешку можно вставлять в девайс и радоваться свежей системе. Демон dhcpd сам подхватит адрес если в Вашей сети есть DHCP сервер. SSH сервер по умолчанию добавлен в автозагрузку. Аккаунт на дефолтных образах Arch Linux ARM изначально всегда один: root/root. Обязательно смените пароль и добавьте юзера с ограниченными полномочиями.

#### Итог
Что получили? Звёзды так сошлись, что поддержка моего микрокомпьютера есть в списке из 1089 устройств поддерживаемых U-Boot и среди 301-го среди поддерживаемых mainline ядром для ARMv7. Поэтому получили именно то, что и хотели: систему с самым свежим программым обеспечением, которое стабильно обновляется из репозиториев, включая ядро системы (на данный момент уже 4.1.4). Стабильная ветка загрузчика обновляется раз в 3 месяца и требуется лишь скомпилировать его и повторить процедуру установки, как сделано выше.
**Что не работает "out of the box"?**В составе ядра и дистрибутиве нет ни ядерной, ни userspace частей драйвера Mali. Это обусловлено тем, что полнофункциональный билд возможен только с помощью проприетарного SDK, который предоставляется только партнёрам компании ARM.
#### Для ленивых
Подготовил образ для Banana Pi:
[Ссылка](https://yadi.sk/d/GAKWSs4oiHfkP), [Зеркало #1](https://drive.google.com/file/d/0B6u5SF2VYG5gTEhES2twMnVQcmc/view?usp=sharing), [Зеркало #2](https://cloud.mail.ru/public/2HN3/kxBWWpWqg).
md5 образа в архиве: f36d707c4c1fd857b50d37501b4a3d7a
Записать образ на флеш-карту можно с помощью утилиты dd, либо win32diskimager (для Windows пользователей).
#### Источники
[linux-sunxi.org/Mainline\_U-boot](https://linux-sunxi.org/Mainline_U-boot)
[elinux.org/RPi\_Hub](http://elinux.org/RPi_Hub)
[ru.wikipedia.org/wiki/Das\_U-Boot](https://ru.wikipedia.org/wiki/Das_U-Boot)
Желаю удачи тем, кто захочет повторить это у себя дома и буду рад справедливой критике.
 | https://habr.com/ru/post/264259/ | null | ru | null |
# Применения — слева, аргументы — справа
В предыдущей статье ([Заберите свои скобки](https://habr.com/ru/post/561176/)), мы попытались избавиться от скобочек с помощью нового оператора для передачи аргументов. На основе своего опыта пользования оператором, можно конечно подобрать нужный приоритет, но он все равно будет конфликтовать в случаях, которые мы не предусмотрели. Что же делать? У меня есть идея.
Вспомним оператор применения, который обозначается долларом (как поговаривают знающие люди, это единственное место, где Haskell-программисты могут его увидеть):
```
($) :: (a -> b) -> a -> b
f $ x = f x
```
Он выглядит каким-то бесполезным - без него не можем что ли функцию применить к аргументу, оставив между ними обычный пробел? Вы будете абсолютно правы, потому что он нужен нам за его определенный приоритет и ассоциативность (хорошо про ассоциативность написано [в этой статье](https://kowainik.github.io/posts/fixity)). Оператор правоассоциативный (на что указывает буква `r` в `infixr`), поэтому и скобки будут группироваться справа:
```
infixr 0
f $ (g $ (h $ (x)))
```
Чем выше это число, тем сильнее операторы будут связаны со своими аргументами. У этого оператора самый низкий приоритет из всех возможных, поэтому его можно использовать где угодно и не боятся, что он окажется внутри у аргументов другого оператора.
А что если мы попробуем изменить его ассоциативность на противоположную?
```
infixl 0
(((f) $ x) $ y) $ z
```
Вуаля, теперь это оператор передачи аргументов!
Но мы не можем объявить один и тот же оператор с разными ассоциативностями, поэтому пока возьмем то самое имя, которое мы придумали в [прошлой статье](https://habr.com/ru/post/561176/) - `#`.
Хоть это и звучит достаточно тривиально, но теперь у нас есть доказательство того, что применение функции к ее аргументу и передача аргументов функции - это одно и то же, разница лишь в ассоциативности:
```
($) :: (a -> b) -> a -> b
(#) :: (a -> b) -> a -> b
```
Есть у этих двух операторов еще одно важное сходство: мы можем применять оператор сколько угодно раз.
* Для применения это работает, потому что мы по сути каждый раз применяем вновь к одному аргументу - результату предудущего применения справа:
```
(f :: c -> d) $ (g :: b -> c) $ (h :: a -> b) $ (x :: a)
```
* А для передачи аргументов это работает благодаря частичному применению функции (ведь функции в Haskell уже находятся в каррированной форме)!
```
a -> b -> c -> d = a -> (b -> (c -> d))
(f :: a -> b -> c -> d) # (x :: a) # (y :: b) # (z :: c)
```
Но что если мы хотим применять много раз левоассоциативный оператор # к выражениям без скобок, в которых уже сть эти операторы? У нас ничего не получится, так как компилятор будет считать функцию за отдельный аргумент:
```
bigger # smaller # a # b # c -- не сработает
```
Но можно создать еще одни оператор, у которого будет меньше приоритет, а значит, он не будет принимать во внимание операторы с крепче связанными аргументами:
```
infixl 5 #
infixl 4 ##
bigger ## smaller # a # b # c
```
Но вообще хорошо, когда операторы своими символами тебе дают подсказку об их назначении. [Не секрет, что мы очень любим стрелки](https://kowainik.github.io/posts/arrows-zoo). Этот случай не станет исключением - будем использовать стрелки, чтобы не забыть: применения - справа, аргументы - слева.
```
infixr --> _
(-->) :: (a -> b) -> a -> b
infixl <-- _
(<--) :: (a -> b) -> a -> b
```
Мало того, что в Haskell многие авторы библиотек любят выдумывать новые операторы (прямо как мы сейчас), которые бывает тяжело запомнить; так еще и приоритеты они выбирают исходя из их собственного опыта, который может отличаться от вашего. Операторы выглядят красиво в готовом коде, но при готовке нужно постоянно думать об их приоритетах.
Думать больше не придется! У меня есть немного безумная идея: что если мы сможем определять приоритет оператора, просто посмотрев на сам оператор? Нет, мы не будет включать число (которое нельзя использовать вместе с другими символами). Просто операторы с приоритетом пониже, будут длиннее, а значит, их использование будет уместно лишь в крайней необходимости.
Раз так, то мы можем просто насоздать много таких операторов (максимум 9) с разными приоритетами и использовать их вместе. Закодируем приоритет операторов передачи аргументов с тире:
```
infixl 1 <---------
infixl 2 <--------
infixl 3 <-------
infixl 4 <------
infixl 5 <-----
infixl 6 <----
infixl 7 <---
infixl 8 <--
```
Приоритет оператора можно посчитать так: 10 - количество тире в операторе. Благодаря наглядному приоритету, мы можем применять операторы с постепенным повышением приоритета, чтобы использовать их в каких-нибудь сложных выражениях.
Было бы неплохо провернуть тоже самое и с применениями:
```
infixr 1 --------->
infixr 2 -------->
infixr 3 ------->
infixr 4 ------>
infixr 5 ----->
infixr 6 ---->
infixr 7 --->
infixr 8 -->
```
А теперь давайте применим их на практике. Пример программы: пытаемся прочесть число из строки пользовательского ввода, если не получается, возвращаем 0. Но обязательно указываем, каким образом мы получили итоговое число.
```
handle :: String -> String
handle input = ("Result: " ++)
<---- either
<--- (++ " (default)") . show
<--- (++ " (by user)") . show
<--- maybe
<-- Left 0
<-- Right
<-- readMaybe @Int input
main = print . handle =<< getLine
```
Это вполне себе работает, но читать код будет намного легче, если мы добавим отступов:
```
handle :: String -> String
handle input = ("Result: " ++)
<---- either
<--- (++ " (default)") . show
<--- (++ " (by user)") . show
<--- maybe
<-- Left 0
<-- Right
<-- readMaybe @Int input
main = print . handle =<< getLine
```
```
$ 123
"Result: 123 (by user)"
$ hello
"Result: 0 (default)"
```
Вообще в последнее время все больше отдаю предпочтение композиции справа-налево, а не классической слева-направо. И это вовсе не из-за увлечения семитскими языками, просто так удобнее читать программы сверху-вниз, от общего к деталям. Да и смешение двух противоположных направлений композиции заставляет бегать глаза невпопад, сравните:
```
main = getLine {- 1 -} >>= print {- 3 -} . handle {- 2 -}
```
```
main = print {- 3 -} . handle {- 2 -} =<< getLine {- 1 -}
```
Первый вариант можно конечно переписать так, чтобы выражения выполнялись в правильно порядке, но для этого придется пожертвовать `.` и, как следствие, лаконичностью.
Да и аппликативные цепочки можно так же рассматривать как композиции справа-налево, так как это по сути передача недостающих аргументов с эффектом (хоть и порядок вычислений тут тоже выходит немного невпопад):
```
print {- 4 -} =<< (,,,) <$> getLine {- 1 -} <*> getLine {- 2 -} <*> getLine {- 3 -}
```
Я попробовал так же закодировать операторы функторов/монад/сопряжений в своей экспериментальной базовой библиотеке (да-да, все только ради того, чтобы избавиться от скобочек) и это выглядит даже [читаемо](https://github.com/iokasimov/pandora/blob/master/Pandora/Paradigm/Structure/Some/Splay.hs#L60). | https://habr.com/ru/post/647575/ | null | ru | null |
# Вся правда об ОСРВ. Статья #17. Группы флагов событий: введение и базовые службы

Группы флагов событий уже упоминались ранее в одной из предыдущих статей (#5). В Nucleus SE они похожи на сигналы, но являются более гибкими. Они предоставляют малозатратный и гибкий способ передачи простых сообщений между задачами.
Предыдущие статьи серии:
[Статья #16. Сигналы](https://habr.com/post/427439/)
[Статья #15. Разделы памяти: службы и структуры данных](https://habr.com/post/426477/)
[Статья #14. Разделы памяти: введение и базовые службы](https://habr.com/post/426425/)
[Статья #13. Структуры данных задач и неподдерживаемые вызовы API](https://habr.com/post/425353/)
[Статья #12. Службы для работы с задачами](https://habr.com/post/424713/)
[Статья #11. Задачи: конфигурация и введение в API](https://habr.com/post/424481/)
[Статья #10. Планировщик: дополнительные возможности и сохранение контекста](https://habr.com/post/423967/)
[Статья #9. Планировщик: реализация](https://habr.com/post/422615/)
[Статья #8. Nucleus SE: внутреннее устройство и развертывание](https://habr.com/post/422617/)
[Статья #7. Nucleus SE: введение](https://habr.com/post/418601/)
[Статья #6. Другие сервисы ОСРВ](https://habr.com/post/418677/)
[Статья #5. Взаимодействие между задачами и синхронизация](https://habr.com/post/415429/)
[Статья #4. Задачи, переключение контекста и прерывания](https://habr.com/post/415427/)
[Статья #3. Задачи и планирование](https://habr.com/post/415329/)
[Статья #2. ОСРВ: Структура и режим реального времени
Статья #1. ОСРВ: введение.](https://habr.com/post/414093/)
Использование флагов событий
----------------------------
В Nucleus SE флаги событий определяются на этапе сборки. Максимальное количество групп флагов событий в приложении – 16. Если группы флагов событий не определены, то код, относящийся к структурам данных и служебным вызовам групп флагов событий, не будет включен в приложение.
Группа флагов событий – набор из восьми битовых флагов, доступ к которым регулируется таким образом, чтобы одним флагом могли безопасно пользоваться несколько задач. Одна задача может установить или очистить любую комбинацию флагов событий. Другая задача может прочитать группу флагов в любое время, а также может дождаться определенной последовательности флагов (по опросу или с приостановкой).
Настройка групп флагов событий
------------------------------
### Количество групп флагов событий
Как и в большинстве объектов Nucleus SE, настройка групп флагов событий задается директивами **#define** в **nuse\_config.h**. Основным параметром является **NUSE\_EVENT\_GROUP\_NUMBER**, который определяет, сколько групп флагов событий будет определено в приложении. По умолчанию, этот параметр установлен в 0 (т.е. группы флагов событий не используются) и может иметь любое значение вплоть до 16. Некорректное значение приведет к ошибке при компиляции, которая будет сгенерирована проверкой в **nuse\_config\_check.h** (она включается **nuse\_config.c**, а значит компилируется вместе с этим модулем), в результате сработает директива **#error**. Выбор ненулевого значения служит главным активатором групп флагов событий. Этот параметр используется при определении структур данных и от его значения зависит их размер (более подробно об этом в следующих статьях). Кроме того, ненулевое значение активирует настройки API.
### Активация вызовов API
Каждая функция API (служебный вызов) в Nucleus SE активируется директивой **#define** в **nuse\_config.h**. Для групп флагов событий к ним относятся:
`NUSE_EVENT_GROUP_SET
NUSE_EVENT_GROUP_RETRIEVE
NUSE_EVENT_GROUP_INFORMATION
NUSE_EVENT_GROUP_COUNT`
По умолчанию, им присвоено значение **FALSE**, таким образом, отключая каждый служебный вызов и блокируя включение реализующего их кода. Для настройки групп флагов событий нужно выбрать необходимые вызовы API и присвоить соответствующим директивам значение **TRUE**.
Ниже приведена выдержка из файла nuse\_config.h по умолчанию.
```
#define NUSE_EVENT_GROUP_NUMBER 0 /* Number of event groups
in the system - 0-16 */
#define NUSE_EVENT_GROUP_SET FALSE /* Service call enabler */
#define NUSE_EVENT_GROUP_RETRIEVE FALSE /* Service call enabler */
#define NUSE_EVENT_GROUP_INFORMATION FALSE /* Service call enabler */
#define NUSE_EVENT_GROUP_COUNT FALSE /* Service call enabler */
```
Активированная функция API при отсутствии в приложении групп флагов событий приведет к ошибке компиляции (кроме **NUSE\_Event\_Group\_Count()**, которая разрешена всегда). Если ваш код использует вызов API, который не был активирован, возникнет ошибка компоновки, так как реализующий код не был включен в приложение.
Служебные вызовы флагов событий
-------------------------------
Nucleus RTOS поддерживает семь служебных вызов, которые предоставляют следующий функционал:
* Установка флагов событий. В Nucleus SE реализовано в функции **NUSE\_Event\_Group\_Set()**.
* Считывание флагов событий. В Nucleus SE реализовано в **NUSE\_Event\_Group\_Retrieve()**.
* Предоставление информации о конкретной группе флагов событий. В Nucleus SE реализовано в **NUSE\_Event\_Group\_Information()**.
* Возвращение количества сконфигурированных на данный момент групп флагов событий в приложении. В Nucleus SE реализовано в **NUSE\_Event\_Group\_Count()**.
* Добавление новой группы флагов событий в приложение. В Nucleus SE не реализовано.
* Удаление группы флагов событий из приложения. В Nucleus SE не реализовано.
* Возвращение указателей на все группы флагов событий в приложении. В Nucleus SE не реализовано.
Реализация каждого из этих служебных вызовов подробно рассмотрена ниже.
Стоит заметить, что функции сброса нет ни в Nucleus RTOS, ни в Nucleus SE. Это сделано намерено. Функция сброса подразумевает преобладание особого состояния флагов. Для групп флагов событий единственным «особым» состоянием является обнуление всех флагов, которое может быть выполнено при помощи **NUSE\_Event\_Group\_Set()**.
Служебные вызовы установки и считывания групп флагов событий
------------------------------------------------------------
Фундаментальные операции, которые могут быть выполнены над группой флагов событий – установка значения одного и более флагов, а также считывание текущих значений флагов. Nucleus RTOS и Nucleus SE предоставляют четыре базовых вызова API для этих операций.
Поскольку флаги событий являются битами, их лучше всего визуализировать в виде двоичных чисел. Так как стандарт С исторически не поддерживает представление двоичных констант (только восьмеричных и шестнадцатеричных), Nucleus SE имеет полезный заголовочный файл **nuse\_binary.h**, который содержит символы **#define** вида **b01010101** для всех 256 8-битных значений.
### Установка флагов событий
Служебный вызов Nucleus RTOS API для установки флагов очень гибкий и позволяет устанавливать и очищать значения флагов при помощи операций **И** и **ИЛИ**. Nucleus SE предоставляет аналогичный функционал, но приостановка задач является опциональной.
***Вызов для установки флагов в Nucleus RTOS***
Прототип служебного вызова:
**STATUS NU\_Set\_Events(NU\_EVENT\_GROUP \*group, UNSIGNED event\_flags, OPTION operation);**
Параметры:
**group** – указатель на предоставленный пользователем блок управления группой флагов событий;
**event\_flags** – значение битовой маски группы флагов;
**operation** – выполняемая операция, **NU\_OR** (для установки флагов) или **NU\_AND** (для очистки флагов).
Возвращаемое значение:
**NU\_SUCCESS** – вызов был успешно завершен;
**NU\_INVALID\_GROUP** – некорректный указатель на группу флагов событий;
**NU\_INVALID\_OPERATION** – указанная операция отличается от **NU\_OR** и **NU\_AND**.
***Вызов для установки флагов в Nucleus SE***
Этот вызов API поддерживает основной функционал Nucleus RTOS API.
Прототип служебного вызова:
**STATUS NUSE\_Event\_Group\_Set(NUSE\_EVENT\_GROUP group, U8 event\_flags, OPTION operation);**
Параметры:
**group** – индекс (ID) группы событий, флаги которой устанавливаются/очищаются;
**event\_flags** – значение битовой макси группы флагов;
**operation** – выполняемая операция, **NUSE\_OR** (для установки флагов) или **NUSE\_AND** (для очистки флагов).
Возвращаемое значение:
**NUSE\_SUCCESS** – вызов был успешно завершен;
**NUSE\_INVALID\_GROUP** – некорректный индекс группы флагов событий;
**NUSE\_INVALID\_OPERATION** – указанная операция отличается от **NUSE\_OR** и **NUSE\_AND**.
***Реализация установки флагов событий в Nucleus SE***
Начальный код функции API **NUSE\_Event\_Group\_Set()** является общим (после проверки параметров), вне зависимости от того, активирована поддержка API вызовов блокировки (приостановки задач) или нет. Логика довольно проста:
```
NUSE_CS_Enter();
if (operation == NUSE_OR)
{
NUSE_Event_Group_Data[group] |= event_flags;
}
else /* NUSE_AND */
{
NUSE_Event_Group_Data[group] &= event_flags;
}
```
Битовая маска **event\_flags** накладывается (при помощи операции **И** или **ИЛИ**) на значение выбранной группы флагов событий.
Оставшийся код включается только при активированной блокировке задач:
```
#if NUSE_BLOCKING_ENABLE
while (NUSE_Event_Group_Blocking_Count[group] != 0)
{
U8 index; /* check whether any tasks are blocked */
/* on this event group */
for (index=0; index
```
Если какие-либо задачи приостановлены (для чтения) из этой группы флагов, они возобновляются. Когда перед ними открывается возможность продолжить выполнение (это зависит от планировщика), они могут определить, удовлетворены условия их возобновления или нет (см. чтение флагов событий).
### Чтение флагов событий
Служебные вызовы Nucleus RTOS API для чтения очень гибкие и позволяют приостанавливать задачи на неопределенное время либо с определенным таймаутом, если операция не может быть выполнена немедленно (например, если вы попытаетесь считать определенную последовательность флагов событий, которая не представляет текущее состояние). Nucleus SE предоставляет те же функции, только приостановка задачи опциональна, а таймаут не реализован.
***Вызов для чтения флагов в Nucleus RTOS***
Прототип служебного вызова:
**STATUS NU\_Retrieve\_Events(NU\_EVENT\_GROUP \*group, UNSIGNED requested\_events, OPTION operation, UNSIGNED \*retrieved\_events, UNSIGNED suspend);**
Параметры:
**group** – указатель на предоставленный пользователем блок управления группой флагов событий;
**requested\_events** – битовая маска, определяющая считываемые флаги;
**operation** – доступны четыре операции: **NU\_AND**, **NU\_AND\_CONSUME**, **NU\_OR** и **NU\_OR\_CONSUME**. Операции **NU\_AND** и **NU\_AND\_CONSUME** указывают, что необходимы все запрашиваемые флаги. Операции **NU\_OR** и **NU\_OR\_CONSUME** указывают, что достаточно одного или нескольких из запрошенных флагов. Параметр **CONSUME** автоматически очищает существующие флаги после успешного запроса;
**retrieved\_events** – указатель на хранилище для значений считываемых флагов событий;
**suspend** – спецификация для приостановки задач; может принимать значения **NU\_NO\_SUSPEND** или **NU\_SUSPEND**, либо значение таймаута в тактах системного таймера (от 1 до 4,294,967,293).
Возвращаемое значение:
**NU\_SUCCESS** – вызов был успешно завершен;
**NU\_NOT\_PRESENT** – указанная операция не вернула события (ни одного события в случае NU\_OR и не все события в случае NU\_AND);
**NU\_INVALID\_GROUP** – некорректный указатель на группу флагов событий;
**NU\_INVALID\_OPERATION** – указанная операция была некорректна;
**NU\_INVALID\_POINTER** – нулевой указатель на хранилище флагов событий (NULL);
**NU\_INVALID\_SUSPEND** – попытка выполнить приостановку из не связанного с задачей потока;
**NU\_TIMEOUT** – требуемая комбинация флагов событий не установилась даже после указанного таймаута;
**NU\_GROUP\_DELETED** – группа флагов событий была удалена, в то время как задача была приостановлена.
***Вызов для чтения флагов в Nucleus SE***
Этот вызов API поддерживает основной функционал Nucleus RTOS API.
Прототип служебного вызова:
**STATUS NUSE\_Event\_Group\_Retrieve(NUSE\_EVENT\_GROUP group, U8 requested\_events, OPTION operation, U8 \*retrieved\_events, U8 suspend);**
Параметры:
**group** – индекс (ID) считываемой группы флагов событий;
**requested\_events** – битовая маска, определяющая считываемые флаги;
**operation** – спецификация, указывающая на количество необходимых флагов: **NUSE OR** (некоторые флаги) или **NUSE AND** (все флаги);
**retrieved\_events** – указатель на хранилище для действительных значений считанных флагов событий (при операции **NUSE\_AND** это будет то же, что передано в параметре **requested\_events**);
**suspend** – спецификация для приостановки задачи, может принимать значения **NUSE\_NO\_SUSPEND** или **NUSE\_SUSPEND**.
Возвращаемое значение:
**NUSE\_SUCCESS** – вызов был успешно завершен;
**NUSE\_NOT\_PRESENT** – указанная операция не вернула события (ни одного события в случае **NUSE\_OR** и не все события в случае **NUSE\_AND**);
**NUSE\_INVALID\_GROUP** – некорректный индекс группы флагов событий;
**NUSE\_INVALID\_OPERATION** – указанная операция отличается от **NUSE\_OR** или **NUSE\_AND**;
**NUSE\_INVALID\_POINTER** – нулевой указатель на хранилище считанных флагов событий (**NULL**);
**NUSE\_INVALID\_SUSPEND** – попытка выполнить приостановку из не связанного с задачей потока или при отключенной поддержке блокирующих API вызовов.
***Реализация считывания флагов событий в Nucleus SE***
Вариант кода функции API **NUSE\_Event\_Group\_Retrieve()** (после проверки параметров) выбирается во время условной компиляции в зависимости от того, активирована поддержка API вызовов блокировки (приостановки) задач или нет. Рассмотрим эти два варианта отдельно.
Если блокировка отключена, полный код этого вызова API будет иметь следующий вид:
```
temp_events = NUSE_Event_Group_Data[group] & requested_events;
if (operation == NUSE_OR)
{
if (temp_events != 0)
{
return_value = NUSE_SUCCESS;
}
else
{
return_value = NUSE_NOT_PRESENT;
}
}
else /* operation == NUSE_AND */
{
if (temp_events == requested_events)
{
return_value = NUSE_SUCCESS;
}
else
{
return_value = NUSE_NOT_PRESENT;
}
}
```
Требуемые флаги событий выбираются из указанной группы флагов событий. Значение сравнивается с требуемыми событиями, учитывая операцию **И/ИЛИ**, а также возвращаемый результат и непосредственные значения запрашиваемых флагов.
Если блокировка задач активирована, код становится более сложным:
```
do
{
temp_events = NUSE_Event_Group_Data[group] & requested_events;
if (operation == NUSE_OR)
{
if (temp_events != 0)
{
return_value = NUSE_SUCCESS;
}
else
{
return_value = NUSE_NOT_PRESENT;
}
}
else /* operation == NUSE_AND */
{
if (temp_events == requested_events)
{
return_value = NUSE_SUCCESS;
}
else
{
return_value = NUSE_NOT_PRESENT;
}
}
if (return_value == NUSE_SUCCESS)
{
suspend = NUSE_NO_SUSPEND;
}
else
{
if (suspend == NUSE_SUSPEND) /* block task */
{
NUSE_Event_Group_Blocking_Count[group]++;
NUSE_Suspend_Task(NUSE_Task_Active, (group << 4) |
NUSE_EVENT_SUSPEND);
return_value =
NUSE_Task_Blocking_Return[NUSE_Task_Active];
if (return_value != NUSE_SUCCESS)
{
suspend = NUSE_NO_SUSPEND;
}
}
}
} while (suspend == NUSE_SUSPEND);
```
Код помещен в цикл **do…while**, который работает, пока параметр **suspend** имеет значение **NUSE\_SUSPEND**.
Запрашиваемые флаги событий считываются также, как и при вызове без блокировки. Если считывание не прошло успешно и параметр **suspend** имеет значение **NUSE\_NO\_SUSPEND**, вызову API присваивается значение **NUSE\_NOT\_PRESENT**. Если параметру **suspend** было присвоено значение **NUSE\_SUSPEND**, задача приостанавливается. При возврате (когда задача возобновляется), если возвращаемое значение **NUSE\_SUCCESS**, указывающее, что задача была возобновлена, потому что флаги событий в этой группе были установлены или очищены, — цикл начинается с начала, флаги считываются и проверяются. Поскольку не существует функции API для сброса групп флагов событий, это является единственной причиной для возобновления задачи, но процесс проверки **NUSE\_Task\_Blocking\_Return[]** был оставлен в системе для совместимости управления блокировкой с другими типами объектов.
В следующей статье будут описаны дополнительные вызовы API, связанные с группами флагов событий, а также их структуры данных.
**Об авторе:** Колин Уоллс уже более тридцати лет работает в сфере электронной промышленности, значительную часть времени уделяя встроенному ПО. Сейчас он — инженер в области встроенного ПО в Mentor Embedded (подразделение Mentor Graphics). Колин Уоллс часто выступает на конференциях и семинарах, автор многочисленных технических статей и двух книг по встроенному ПО. Живет в Великобритании. Профессиональный [блог Колина](http://blogs.mentor.com/colinwalls), e-mail: colin\[email protected]. | https://habr.com/ru/post/428131/ | null | ru | null |
# Управление загрузками в Xcode
Начиная с Xcode 14, симуляторы для watchOS и tvOS доступны в виде отдельных загрузок (iOS и macOS по-прежнему «встроены»). Данное решение позволяет значительно уменьшать размер загрузки приложения, однако теперь вам придется самостоятельно управлять этими большими (3-4 ГБ) компонентами.
При первом запуске Xcode 14 вам будет предложено загрузить дополнительные платформы. Также подсказка появится, когда вы попытаетесь запустить код без среды выполнения.
Но что это за загрузки и где они хранятся? Первый совет — откройте дисковую утилиту (Disk Utility). Вы увидите кучу новых томов «Симулятор», смонтированных в разделе «Образы дисков» (Disk Images):
Дисковая утилита, показывающая четыре среды выполнения симулятора.
Выбрав эти тома, вы увидите, что все они монтируются в /Library/Developer/CoreSimulator/Volumes. В каждом томе вы найдете PDF-файл и путь к пакету .simruntime в каталоге Runtimes. Эта структура аналогична дополнительным средам выполнения iOS в /Library/Developer/CoreSimulator/Profile/Runtimes. Пакеты .simruntime содержат всю информацию, необходимую для работы симулятора.
Теперь, когда вы знаете, что использует Xcode, вам будет интересно, откуда он берет образ диска. Он расположен в каталоге: /Library/Developer/CoreSimulator/Images. Эта папка также содержит файл images.plist, в котором хранятся метаданные для образов дисков. Там всего несколько файлов, но на моем Mac они занимают 13 ГБ дискового пространства.
И еще пару часов назад эта папка содержала 7 ГБ данных, которые были несовместимы с текущей версией Xcode. Мне пришлось удалить эти файлы вручную. Но как? Самый простой способ управлять этим пространством — использовать новую панель «Платформы» (Platforms) в настройках Xcode:
Настройки Xcode, показывающие все встроенные и загруженные среды выполнения симулятора.
В этом окне также показано, когда вы в последний раз использовали среду выполнения: благодаря скрину становится понятно, что я могу избавиться от сред выполнения iOS 14 и tvOS 16.0 и сэкономить около 25 ГБ памяти. При необходимости легко вернуть эти рабочие среды, достаточно нажать кнопку +. (После загрузки новой среды выполнения ее можно использовать в окнах «Устройства и симулятор» (Devices & Simulator) для создания нового тестового устройства.)
Если вам больше нравится работать с командной строкой, вы можете использовать xcrun для получения той же информации:
```
$ xcrun simctl runtime list
```
Добавьте туда -v опцию, если вы хотите получить более подробную информацию (из упомянутого выше images.plist). Чтобы удалить любой из перечисленных элементов, используйте указанный GUID в этой команде:
```
$ xcrun simctl runtime delete
```
В конце концов, этот короткий пост сэкономил мне 32 ГБ дискового пространства. Если вы разрабатываете для платформ, отличных от текущей iOS, вы, вероятно, увидите что-то подобное. Со временем вам нужно будет самому следить за этим: Xcode не может навести порядок за вас, потому что он понятия не имеет, что вам *нужно*.
Дополнительные сведения см. в документации Apple по [установке и управлению средами выполнения Simulator](https://developer.apple.com/documentation/xcode/installing-additional-simulator-runtimes). Спасибо [Джейсону Яо](https://twitter.com/jasonyaocoder/status/1590095544911040512) за то, что он помог мне разобраться во многих этих вещах!
[Оригинал статьи](https://furbo.org/2022/11/09/managing-xcode-downloads)
*Подписывайся на наши соцсети:*[*Telegram*](https://t.me/swiftbook_news)*/*[*VKontakte*](https://vk.com/swiftbook) *Вступай в открытый чат для iOS-разработчиков:*[*t.me/swiftbook\_chat*](https://zen.yandex.ru/profile/editor/id/62305a2685b4d86601d09326/630e1238f8df182ac8cc30ab/t.me/swiftbook_chat) *Смотри*[*бесплатные уроки по iOS-разработке с нуля*](https://clck.ru/32iWcH) | https://habr.com/ru/post/701862/ | null | ru | null |
# Тестирование и отладка MapReduce
В «Ростелекоме» мы используем Hadoop для хранения и обработки данных, загруженных из многочисленных источников с помощью java-приложений. Сейчас мы переехали на новую версию hadoop с Kerberos Authentication. При переезде столкнулись с рядом проблем, в том числе и с использованием YARN API. Работа Hadoop с Kerberos Authentication заслуживает отдельной статьи, а в этой мы поговорим об отладке Hadoop MapReduce.

При выполнении заданий в кластере запуск отладчика усложняется тем, что мы не знаем, какой узел будет обрабатывать ту или иную часть входных данных, и не можем заранее настроить свой отладчик.
Можно использовать проверенный временем `System.out.println("message")`. Но как проанализировать вывод `System.out.println("message")` разбросанных по этим узлам?
Мы можем выводить сообщения в стандартный поток ошибок. Все, что пишется в stdout или stderr,
направляется в соответствующий файл журнала, который можно найти на веб-странице расширенной информации о задаче или в журнальных файлах.
Мы также можем включить в код средство отладки, обновлять сообщения о состоянии задачи и использовать пользовательские счетчики, которые помогут нам понять масштаб бедствия.
Приложение Hadoop MapReduce можно отлаживать во всех трех режимах, в которых может работать Hadoop:
* standalone
* pseudo-distributed mode
* fully distributed
Более подробно мы остановимся на первых двух.
### Pseudo-distributed mode (псевдораспределенный режим)
Псевдораспределенный режим используется для имитации реального кластера. И может использоваться для тестирования в среде, максимально приближенной к продуктивной. В данном режиме все демоны Hadoop будут работать на одном узле!
Если у вас есть dev-сервер или другая песочница (например, Virtual Machine с настроенной средой разработки, такой как Hortonworks Sanbox с HDP), то можно отладить управляющую программу, используя средства удаленной отладки (remote debugging).
Для запуска отладки нужно задать значение переменной окружения: `YARN_OPTS`. Ниже приведен пример. Для удобства можно создать файл startWordCount.sh и добавить в него необходимые параметры для запуска приложения.
```
#!/bin/bash
source /etc/hadoop/conf/yarn-env.sh
export YARN_OPTS='-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=6000 ${YARN_OPTS}'
yarn jar wordcount-0.0.1.jar ru.rtc.example.WordCount /input /output
```
Теперь, запустив скрипт ``./startWordCount.sh``, мы увидим сообщение
```
Listening for transport dt_socket at address: 6000
```
Осталось настроить IDE для удаленной отладки (remote debugging). Я использую intellij IDEA. Перейдем в меню Run -> Edit Configurations… Добавим новую конфигурацию `Remote`.
Поставим breakpoint в main и запустим.
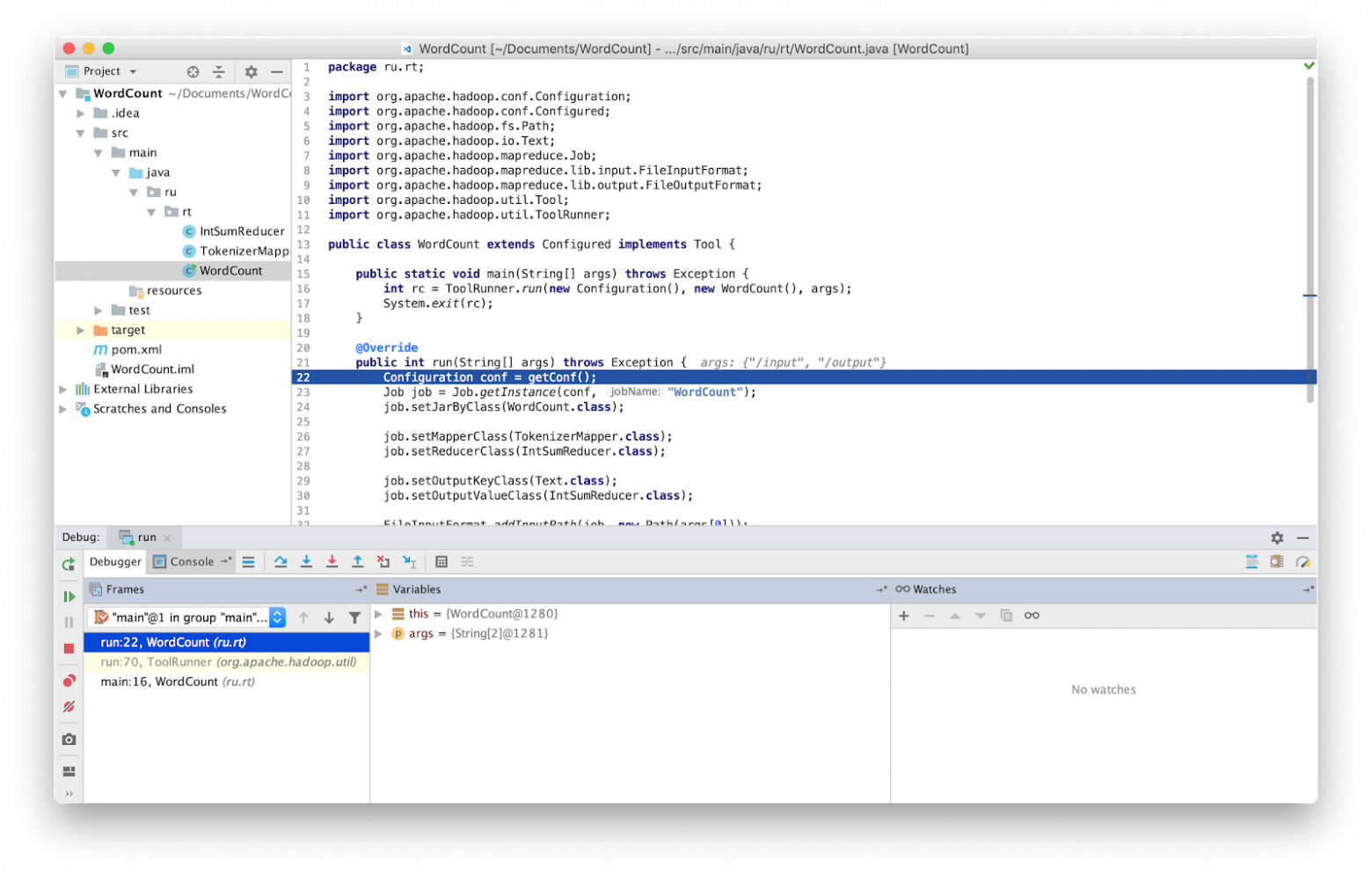
Все, теперь мы можем отлаживать программу как обычно.
> ВНИМАНИЕ. Вы должны убедиться, что работаете с последней версией исходного кода. Если нет, то у вас могут быть различия в строках, в которых отладчик выполняет остановку.
>
>
В ранних версиях Hadoop поставлялся специальный класс, который позволял повторно запустить сбойное задание — isolationRunner. Данные, вызвавшие сбой, сохранялись на диск по адресу, указанному в переменной окружения Hadoop mapred.local.dir. К сожалению, в последних версиях Hadoop такой класс больше не поставляется.
### Standalone (локальный запуск)
Standalone — это стандартный режим, в котором работает Hadoop. Он подходит для отладки там, где не используется HDFS. При такой отладке можно использовать ввод и вывод через локальную файловую систему. Standalone-режим обычно является самым быстрым режимом Hadoop, так как он использует локальную файловую систему для всех входных и выходных данных.
Как упоминалось ранее, можно внедрить в код средство отладки, например, счетчики. Счетчики определяются перечислением ([enum](https://ru.wikipedia.org/wiki/%D0%9F%D0%B5%D1%80%D0%B5%D1%87%D0%B8%D1%81%D0%BB%D1%8F%D0%B5%D0%BC%D1%8B%D0%B9_%D1%82%D0%B8%D0%BF#Java)) Java. Имя перечисления определяет имя группы, а поля перечисления определяют имена счетчиков. Счетчик может пригодиться для оценки проблемы,
и может использоваться как дополнение к отладочному выводу.
Объявление и использование счетчика:
```
package ru.rt.example;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class Map extends Mapper {
private Text word = new Text();
enum Word {
TOTAL\_WORD\_COUNT,
}
@Override
public void map(LongWritable key, Text value, Context context) {
String[] stringArr = value.toString().split("\\s+");
for (String str : stringArr) {
word.set(str);
context.getCounter(Word.TOTAL\_WORD\_COUNT).increment(1);
}
}
}
}
```
Для инкремента счетчика нужно использовать метод `increment(1)`.
```
...
context.getCounter(Word.TOTAL_WORD_COUNT).increment(1);
...
```
После успешного завершения MapReduce задача в конце выводит значения счетчиков.
```
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
ru.rt.example.Map$Word
TOTAL_WORD_COUNT=655
```
Ошибочные данные можно выводить в stderr или в stdout, или писать выходные данные в hdfs, используя класс `MultipleOutputs` для дальнейшего анализа. Полученные данные можно передавать на вход приложению в standalone режиме или при написании unit-тестов.
В Hadoop есть библиотека MRUnit, которая используется совместно с фреймворками тестирования (например, JUnit). При написании модульных тестов мы проверяем, что на выходе функция выдает ожидаемый результат. Мы используем класс MapDriver из пакета MRUnit, в свойствах которого устанавливаем тестируемый класс. Для этого используется метод `withMapper()`, входные значения `withInputValue()` и ожидаемый результат `withOutput()` или `withMultiOutput()`, если используется множественный вывод.
Вот наш тест.
```
package ru.rt.example;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mrunit.mapreduce.MapDriver;
import org.apache.hadoop.mrunit.types.Pair;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
public class TestWordCount {
private MapDriver mapDriver;
@Before
public void setUp() {
Map mapper = new Map();
mapDriver.setMapper(mapper)
}
@Test
public void mapperTest() throws IOException {
mapDriver.withInput(new LongWritable(0), new Text("msg1"));
mapDriver.withOutput(new Pair(new Text("msg1"), new IntWritable(1)));
mapDriver.runTest();
}
}
```
### Fully distributed mode (полностью распределенный режим)
Как следует из названия, это режим, в котором используется вся мощность Hadoop. Запущенная программа MapReduce может работать на 1000 серверов. Всегда сложно отлаживать программу MapReduce, так как у вас есть Mappers, работающие на разных машинах с разными входными данными.
Заключение
----------
Как оказалось, тестирование MapReduce не такая простая задача как кажется на первый взгляд.
Чтобы сэкономить время в поисках ошибки в MapReduce, я использовал все перечисленные методы и советую всем тоже их применять. Это особенно полезно в случае с большими инсталляциями, подобных таким, какие работают в «Ростелекоме». | https://habr.com/ru/post/432828/ | null | ru | null |
# Открываем ссылки "mailto:" в Gmail
В июне 2011 года браузер Chrome научился обрабатывать [спецссылки](http://support.google.com/chrome/bin/answer.py?hl=en&answer=1382847) типа `mailto:` и `webcal:`. Это один из тех редких случаев, когда Chrome последним среди всех браузеров внедряет какую-то полезную технологию: например, в Firefox [такая фича](http://starkravingfinkle.org/blog/2008/04/firefox-3-web-protocol-handlers/) присутствует ещё с 2008 (!) года, с версии Firefox 3.
Это тем более удивительно, что Google больше всех заинтересован, чтобы ссылки вида `mailto:` и `webcal:` передавались не в офлайновую программу, а в веб-приложение.
Браузер может обрабатывать не только `mailto:`, но любые другие, произвольные спецссылки. При этом весь HREF просто пересылается в зарегистрированный обработчик (handler), заменяя `%s`, как показано в примере.
```
navigator.registerProtocolHandler("mailto",
"https://www.example.com/?uri=%s",
"Example Mail");
```
См. [руководство](https://developer.mozilla.org/en/Web-based_protocol_handlers) по установке веб-хэндлеров на своей странице.
Отключить Web Handlers можно в настройках **Under the Hood** в разделе **Content settings**.

Там же можно указать, в какое именно приложение передавать эти ссылки.
[UPD](http://habrahabr.ru/blogs/google_chrome/139068/#comment_4647298). Судя по [updates.html5rocks.com/2011/06/Registering-a-custom-protocol-handler](http://updates.html5rocks.com/2011/06/Registering-a-custom-protocol-handler), эта функция была в браузере аж с июня прошлого года. Новость лишь в том, что в Gmail внедрили соответствующий код. Пару месяцев назад такой же код появился на Google Calendar. | https://habr.com/ru/post/139068/ | null | ru | null |
# Подводные камни разработки Google Play Instant

Привет, Хабр! Меня зовут Камо Сперцян, я занимаюсь Android-разработкой в PROFI.RU. Недавно я написал приложение с мгновенным запуском для наших клиентов. Если вы ещё не знакомы с технологией, приглашаю вас сначала посетить [Android Developers](https://developer.android.com/topic/google-play-instant/).
С презентации Instant Apps (Google Play Instant) на Google I/O 2016 прошло больше двух лет. В сети множество статей о том, как создавать приложения с мгновенным запуском. Судя по ним, ничего сложного в этом нет. Но на деле это не совсем так. Я постараюсь описать основные трудности, через которые мне пришлось пройти от создания пустого проекта до публикации Instant App в Google Play. Надеюсь, статья окажется полезной разработчикам, которым этот путь ещё предстоит.
### Выбор подхода
В большинстве источников описывается процесс конвертирования основного приложения целиком в Instant App. Однако наше приложение никак не соответствовало ограничению в 4 МБ и предоставляло гораздо большую функциональность, чем требовалось для ознакомления с сервисом перед установкой. Сейчас Google в тестовом режиме увеличил допустимый размер приложения с мгновенным запуском до 10 МБ.
У меня был выбор из двух подходов к созданию Instant App. Первый — взять готовое приложение и вырезать из него ненужную функциональность. Второй — создать пустой проект и перенести в него функциональность, которая необходима. Посчитав первый вариант быстрым, мы с коллегами опробовали его на локальном хакатоне и тогда же убедились в его безнадёжности. Во-первых, на это ушло много времени (порядка 40 человеко-часов). Во-вторых, размер приложения оказался очень большим из-за лишнего кода и ресурсов. В-третьих, лишний код усложнял сопровождение. Мы судорожно пытались уместить получившееся приложение в 4 МБ за время хакатона, и в итоге всё равно не успели.
### Перенос функциональности
Наученный горьким опытом, я создал пустой проект и стал копировать в него только нужные модули приложения. У нас поддерживается модульная архитектура, поэтому сделать это было несложно. Здесь я столкнулся с первой проблемой — в Instant Apps нельзя использовать сервисы. В моём случае это ограничение не оказалось критичным: мы использовали сервис для загрузки фотографий, а в Instant App от этой фичи отказались, мотивируя пользователей скачать основное приложение. Но этот момент стоит учитывать, если ваше приложение тоже использует сервисы.
К моему удивлению, полученное копированием только нужных кусков кода приложение всё равно не влезло в допустимые 4 МБ и весило около 5 МБ. В [этой статье](https://developer.android.com/topic/google-play-instant/guides/reduce-module-size) Google даёт советы на этот случай, но мне они мало помогли. Единственное, от чего мы могли отказаться, — кастомные шрифты, но их вес существенно не влиял на размер APK.
Тут я вспомнил, что ProGuard у нас в проекте отключён на debug-сборках. Простое включение
```
minifyEnabled true
```
сократило размер приложения чуть ли не вдвое. О чудо — ограничение в 4 МБ соблюдено!
### Миграция данных
Далее предстояло решить вопрос с миграцией данных. Как известно, Instant Apps поддерживаются операционной системой Android с версии 5.0. При этом автоматическая миграция данных работает только начиная с Android 8.0. Для этого достаточно использовать в обоих приложениях файлы shared preferences с одинаковым названием. Для версий с 5.0 по 7.1 миграцию нужно писать вручную с помощью [Cookie API](https://github.com/googlesamples/android-instant-apps/tree/master/cookie-api) или [Storage API](https://github.com/googlesamples/android-instant-apps/tree/master/storage-api). Я воспользовался Cookie и с особыми проблемами не столкнулся — правда, это потребовало изменений не только на стороне Instant App, но и в устанавливаемом приложении. Так что в итоге пришлось выпустить новую версию приложения и раскатить её на всю аудиторию для релиза Instant App.
### Отладка
С отладкой всё оказалось не так просто.
Во-первых, Google Play Instant не поддерживает незащищённые сетевые соединения, так что забудьте про http, только https. Для меня это означало тестирование на production-серверах, так как все тестовые стенды работали по http. Не критично, но приятного мало.
Во-вторых, сам запуск Instant App: вы можете тестировать приложение как обычное, устанавливаемое, но лишь до поры до времени. При запусках через Android Studio невозможно проверить обновление Instant App до «полноценного» приложения. Например, протестировать, насколько корректно перенесутся данные пользователя. Для этого нужно запускать приложение с мгновенным запуском именно как Instant App. Сделать это можно двумя способами:
1. запустить приложение с помощью специальной утилиты из Android SDK;
2. выложить его в консоль для внутреннего тестирования и запустить через Play Market.
Первый способ достаточно удобен. Утилита входит в Android SDK, но по умолчанию не установлена. Для установки в Android Studio нужно выполнить следующие шаги:
1. зайти в *Preferences* -> *Appearance & Behavior* -> *System Settings* -> *Android SDK*;
2. выбрать вкладку *SDK Tools*;
3. поставить галочку возле *Google Play Instant Development SDK* и нажать *Apply*.
На последнем шаге обратите внимание на директорию, в которую будет установлена утилита. Далее относительно этого пути нас будет интересовать файл ./extras/google/instantapps/ia. С его помощью можно сымитировать мгновенный запуск приложения, выполнив команду
```
ia run <путь к APK-файлу, bundle-у или URL>
```
До момента, как я наткнулся на эту утилиту, я использовал второй способ, с постоянной публикацией приложения в Google Play Console. Но так как опубликованное приложение появляется в магазине не сразу, а по истечении неопределённого времени (у меня это занимало от получаса до суток), такой способ тестирования никуда не годился. Впрочем, он для этого и не предназначен. Кстати, если вы публикуете Instant App в Google Play Console с большой частотой, советую предусмотреть возможность после запуска определить код версии приложения. Иначе бывает сложно понять, запустилась последняя опубликованная версия или предыдущая.
### Публикация
Наконец, когда ваше приложение протестировано и готово к публикации, не спешите расслабляться! Во-первых, код версии (*versionCode*) Instant App не должен превышать код версии устанавливаемого приложения. Рекомендую заранее дать простор для творчества: указать при релизе основного приложения заведомо большое значение кода, чтобы не связывать себе руки. Удалить выпущенный Instant App из консоли с целью «высвободить» код версии для другой сборки не получится. Формально у вас имеется `*N-M*` возможностей зарелизить Instant App, пока у вас в Google Play основное приложение с `*versionCode = N*` и приложение с мгновенным запуском с `*versionCode = M*`.
Также для релиза Instant App убедитесь, что оно будет доступно не большей аудитории, чем основное приложение. Иными словами, каждый пользователь Instant App должен иметь возможность установить основное приложение.
На аудиторию в первую очередь влияют разрешения приложения, указываемые в Manifest-файле (*permissions*), — они должны быть одинаковыми для обоих приложений (за исключением разрешений, не влияющих на аудиторию). Скажем, если ваше основное приложение требует разрешение на определение геопозиции, а в Instant App это не нужно, всё равно нужно его указать и там, и там.
Также некоторые вспомогательные библиотеки могут сузить круг конечных пользователей. Так было и в нашем случае. Консоль выдавала ошибку *«targeting apk difference»*, хотя разрешения обоих приложений были одинаковыми. В поисках решения я наткнулся на [этот вопрос](https://stackoverflow.com/questions/45975231/google-play-console-error-non-upgradable-to-installed-app) со Stack Overflow, где советуют прогнать APK файлы приложений через утилиту *aapt*. Она выведет подробную информацию о файлах, включая все зависимости. Вычислив разницу в выдаче по обоим файлам, я заметил зацепку: у устанавливаемого приложения была строка `uses-gl-es: '0x20000'`, которая отсутствовала в Instant App. Недолгий сёрфинг по сети привёл меня к разгадке: эта строка говорит, что приложение использует библиотеку OpenGL, которая, в свою очередь, используется в картах. И действительно, наше основное приложение использовало библиотеку `play-services-maps`, а Instant App — нет. Добавление этой зависимости в Instant App позволило мне в конце концов зарелизить приложение.
### Подытожим
1. В Instant Apps нельзя использовать сервисы и незащищённые сети (http). Размер конечного APK-файла не должен превышать 4 МБ (возможно, скоро это ограничение упростят до 10 МБ).
2. Для уменьшения размера APK-файла можно применять оптимизаторы и обфускаторы кода (например, ProGuard).
3. Перенос SharedPreferences из Instant App в основное приложение происходит автоматически для Android 8.0+, для более ранних версий необходимо писать вручную через [Cookie API](https://github.com/googlesamples/android-instant-apps/tree/master/cookie-api) или [Storage API](https://github.com/googlesamples/android-instant-apps/tree/master/storage-api). Стоит учесть необходимость релиза подготовленного к миграции данных устанавливаемого приложения перед релизом Instant App.
4. Для отладки Instant App можно воспользоваться специальной утилитой из Google Play Instant Development SDK, входящего в Android SDK.
5. Появление опубликованного в консоли Instant App на конечных устройствах может происходить с задержкой от получаса до суток. Стоит позаботиться о возможности однозначно определить, какая версия Instant App сейчас запустилась из Play Market.
6. Код версии Instant App не должен превышать код версии основного приложения.
7. Список устройств, которым будет доступен Instant App, не должен превышать список устройств, которым доступно основное приложение. Для этого следует указывать в Manifest-файлах одинаковые разрешения, а также обратить внимание на возможные ограничения из-за вспомогательных библиотек.
На этом всё. Надеюсь, эта информация окажется для вас полезной. Буду рад любой обратной связи!
#### Полезные источники:
1. [Документация по Google Play Instant на Android Developers](https://developer.android.com/topic/google-play-instant/)
2. [Советы по уменьшению размера APK-файла Instant App](https://developer.android.com/topic/google-play-instant/guides/reduce-module-size)
3. [FAQ по Google Play Instant](https://developer.android.com/topic/google-play-instant/faqs)
4. [Миграция данных с помощью Cookie API](https://github.com/googlesamples/android-instant-apps/tree/master/cookie-api)
5. [Миграция данных с помощью Storage API](https://github.com/googlesamples/android-instant-apps/tree/master/storage-api) | https://habr.com/ru/post/436780/ | null | ru | null |
# И ещё раз про распознавание номеров
Весной администрация хабра любезно предоставила нам блог, чтобы мы рассказали о нашем экзерсисе с распознаванием номеров. Всё поддержание этой системы делалось просто из интереса и на энтузиазме, зато позволило пообщаться с интересными людьми, некоторым людям помочь, а самим найти подработку по совершенно другим тематикам.

В любых задачах обработки изображений 90% успеха — хорошая база данных. Репрезентативная и большая. Весной мы обещали выложить полную базу изображений того, что нам придёт. Подписка блога заканчивается, поэтому время выполнить обещание (блог может продлят, а может и нет). Наш сервер работал 95% времени, начиная с первого поста. Всё что пришло теперь доступно + мы сделали отдельные базы по вырезанным номерам и нарезанным символам.
Под катом ссылки на базу + её анализ + немного кода + небольшой рассказ о том, что будет сделано дальше с нашим сервером/жизнью проекта.
#### Сама база
Базы по номерам у нас не размечены (нигде нет файла с правильной расшифровкой). Размечена только база по символам.
[База](https://yadi.sk/d/0H2AipxrcrXqy) необрезанных фотографий автомобилей (1.4 ГБ). Примерно 9300 кадров.
Размеры будут от пары сотен пикселей до десятка мегапикселей. Выглядят картинки так:

[База](https://yadi.sk/d/EAfnQ947criHW) вырезанных номеров + контрпримеров (260 МБ). Примерно 5000 номеров + 1200 контрпримеров.
Выглядят картинки так:

[База](https://yadi.sk/d/U41QZ8v7cpJ6R) нарезанных символов для российских номеров (60 МБ). Примерно 18 тысяч букв, цифр и контрпримеров.
\*Маленькое дополнение. Папка «17» — пустая. В ней были буквы «O», но классификаторы не делали различия от неё и нуля, поэтому мы их объединили в папке «0».
Выглядят картинки так:
#### Пара слов про базу
База основана на том, что мы собирали сами + на том, что нам присылали + ручное прореживание от плохих кадров. Для буков дана нарезанная база отрицательных примеров (папка за номером 22). Без отрицательной выборки почти невозможна работа реального алгоритма, буквы будут определяться на любом шуме. В отрицательной выборке содержатся куски буков, без этого порезанная пополам восьмёрка может быть принята за тройку. В конце статьи будет пример такого использования такой базы. Отрицательная выборка дана и для вырезанных номеров, если найдутся желающие обучить каскад по ним.
Из минусов базы:
— порядочно кадров снятых с монитора
— некоторые номера встречаются неоднократно и чаще других
— есть дубликаты изображений, хотя и не очень много
— прореживание кадров для базы с большими фотографиями неидеальное. На сервер приходили всё: совершенно не относящиеся к делу фотографии, пустые фотографии, фотографии с нечитаемыми номерами. Большую часть я вычистил, но остатки могут быть.
#### Зачем это нужно?
Как ни странно, но задача распознавания номеров актуальна в множестве ситуаций, зачастую не связанных с номерами. И, несмотря на то, что вроде как существуют десятки решений, есть множество проектов, где её нужно решить независимо и с нуля. Такая база является подспорьем таким проектам.
Интересна она и для тестирования алгоритмов машинного распознавания и классификации. Взять тот же [MNIST](http://en.wikipedia.org/wiki/MNIST_database). Синтетическая задача, но до сих пор многим интересна. А тут имеется возможность реального применения обученного алгоритма.
#### Дальнейшая жизнь проекта
Сервер с распознаванием номеров мы планирует поддерживать в рабочем состоянии + иногда мы апдейтим алгоритм. Приложение на телефоны, как мы и предполагали, особо не выстрелило. Оно доступно в [PlayStore](http://habrahabr.ru/company/recognitor/blog/222539/) + есть версия под [iPhone](http://habrahabr.ru/company/recognitor/blog/228195/). Приложения в целом рабочие, но какой-то дальнейшей их поддержки мы делать не будем. Да и особо большой базы не собралось. Код для [обоих](https://github.com/CodeGenerator/Recognitor) приложений [открыт](https://github.com/ZlodeiBaal/Recognitor). Если хотите, можете допиливать самостоятельно.
С другой стороны мы были приятно удивлены, что наш сервер зачастую стали использовать как некий эталон для проверки своих алгоритмов. Раза три нам загоняли на сервер огромные базы. Точно мы не знаем, кто и зачем. Но, приятно. Видно, что люди потратили время, чтобы сравнить свой алгоритм с нашим, пусть даже далёким от идеала.
Отсюда родилась идея: небольшой кусок базы мы оставили себе. Если вдруг кому будет интересно, можем прогнать алгоритм по нашей базе (или дать базу вам), на условиях нераспространения базы и публикации результатов. Результаты мы опубликуем [тут](http://eye-recognition.ru/platerec.html) и [тут](https://docs.google.com/spreadsheets/d/1wANpQfbkE1mVC4GMUhMIwIKwVHVw1olB3IbZSbRmwEo/edit?usp=sharing), при публикации ставим ссылку на ваш сайт/контакт.
Нераспространение такой тестовой базы нужно чтобы избежать подгонки результатов, как делают при наличии открытых баз (например MNIST).
Если блог нам продлят, то о результатах и методологии оценки будем отчитываться на Хабре.
#### Про каскад
Нас уже раз пять просили обновить каскад. На это нужно потратить ещё несколько вечеров, но сейчас времени нет. Обязательно сделаем, представленная тут упорядоченная база — это большой кусок работы в этом направлении. Новая версия появится в нашем [репозитории](https://github.com/ZlodeiBaal/Recognitor). Ориентировочно займусь на праздники январские, но могу не успеть. В принципе, если кому не лень, можно использовать представленную тут базу и посчитать по ней каскад. Как это сделать [вот](http://habrahabr.ru/post/208092/) инструкция. Если сделаете, киньте нам, или прямо на гитхаб, мы обновим каскад на него.
#### Обучение распознавания букв
Не смотря на то, что всю логику и алгоритмы мы опубликовали в прошлых статьях, исходники куска, где происходит распознавание букв номера мы пока публиковать не хотим (если вдруг решим отключить сервер окончательно, то, конечно, опубликуем).
Но всё же, нам хотелось бы показать способ, как можно распознавать номера быстро и просто. Поэтому мы перебрали несколько вариантов простых алгоритмов позволяющих распознать буквы, которые легко обучить (при наличии большой базы) и обучили по базе, которую выложили выше. Наилучшие проценты и наиболее простая работа на наш взгляд у SVM в библиотеке Accord (ML-библиотека проекта AForge). В принципе, всё аналогично делается и в OpenCV, SVM есть и там.
Обучение:
```
using Accord.MachineLearning.VectorMachines;
using Accord.MachineLearning.VectorMachines.Learning;
using Accord.Statistics.Kernels;
//Набор входных изображений, развёрнутых в одномерные массивы
double[][] inputs;
//Набор ответов чем являются входные изображения
int[] outputs;
//"Размазанность" гауссианы при обучении. Чем ниже значение, тем больше "обобщения" делает SVM
double sigma = 12;
//Количество классов при обучении. В номерах 10 цифр, 12 букв, + 1 класс с отрицательной выборкой
int classCount=23;
MulticlassSupportVectorLearning teacher = null;
//Параметры распознающей машины: длина массива на каждую фотографию, параметр ядра обучения, количество классов
//sigma - единственный настраиваемый параметр обучения. Я ставил где-то 10-20, изменялась точность незначительно.
machine = new MulticlassSupportVectorMachine(width*height, new Gaussian(sigma), classCount);
//Инициализация обучения
teacher = new MulticlassSupportVectorLearning(machine, inputs, outputs);
teacher.Algorithm = (svm, classInputs, classOutputs, i, j) => new SequentialMinimalOptimization(svm, classInputs, classOutputs) { CacheSize = 0 };
teacher.Run();
machine.Save("MachineForSymbol");
```
Распознавание реализуется двумя строчками:
```
MulticlassSupportVectorMachine machine = MulticlassSupportVectorMachine.Load("MachineForSymbol");
int output = machine.Compute(input);
```
Важно, чтобы входные данные были бинаризованы. Это значительно повышает точность работы. Приведу пример загрузки:
```
using AForge.Imaging;
using AForge.Imaging.Filters;
private static List test(string str)
{
Bitmap bmp = new Bitmap(str);
//При обучении нужно, чтобы все изображения были единого размера. База которую мы привели позволяет обучатся на размере 34\*60. Тут мы её немножко ужимаем, для скорости работы.
ResizeNearestNeighbor filter = new ResizeNearestNeighbor(17, 30);
int count = 0;
BitmapData bitmapData = bmp.LockBits(new Rectangle(0, 0, bmp.Width, bmp.Height),
ImageLockMode.ReadWrite, PixelFormat.Format24bppRgb);
List res = new List();
int width = bitmapData.Width;
int height = bitmapData.Height;
int stride = bitmapData.Stride;
int offset = stride - width\*3;
unsafe
{
byte\* ptr = (byte\*)bitmapData.Scan0.ToPointer();
double summ = 0;
for (int y = 0; y < bitmapData.Height; y++)
{
for (int x = 0; x < bitmapData.Width; x++, ptr+=3)
{
//Можно загрузить ЧБ изображения, но тут предполагается, что работаем с цветными изображениями
res.Add((ptr[0] + ptr[1] + ptr[2]) / (3\*255.0));
summ += (ptr[0] + ptr[1] + ptr[2]);
}
ptr += offset;
}
summ = summ / (3\*255.0\* bitmapData.Height \* bitmapData.Width);
//Бинаризуем по среднему цвету изображения
for (int i = 0; i < res.Count; i++)
{
if (res[i]
```
[Пример](https://yadi.sk/d/es2D5USMcupjD) обученного SVM'a. Процент правильно распознанных символов по независимой от обучающей выборке — 96%.
#### P.S.
Из историй связанных с номерами. Сейчас в Казахстане происходит (или происходил) какой-то массовый тендер на установку систем распознавания номеров. Но компетентных фирм, связанных с системными решениями IT там не то очень мало, не то нет совсем. Где-то раз-два в месяц с нами связывается очередной менеджер оттуда и предлагает поставить им систему немедленно, уже обученную под номера страны. При этом путая слова «сервер» и «камера»… | https://habr.com/ru/post/243919/ | null | ru | null |
# Почему массивы начинаются с нуля
Самое очевидное объяснение: индекс — это смещение относительно начала массива. Так элементы массива легче адресовать в памяти.
Проверим это на C.
```
#include
int main()
{
int data[3] = {1, 2, 3};
int i = 0;
printf("Array address: %p\n", data);
do {
printf("Array[%u] = %p\n", i, (void \*)(&data[i]));
i++;
} while(i < 3);
}
```
Получим результат:
`Array address: 0x7ffd7c514a6c
Array[0] = 0x7ffd7c514a6c
Array[1] = 0x7ffd7c514a70
Array[2] = 0x7ffd7c514a74`
Как первый (нулевой) элемент, так и сам массив находятся по одному и тому же адресу, поскольку 0-й элемент удалён на 0 элементов от начала. Эта связь между указателями и массивами в C настолько тесная, что их даже можно рассматривать вместе.
Однако **это ответ на вопрос «зачем», а не «почему»**. Нумеровать массивы с нуля стали не сразу. Удивительно, но развитие такого простого вопроса не умещается в предложении или абзаце.
### Потому что так удобнее
К началу 1960-х годов сформировалось три подхода к организации структуры, которую сегодня мы называем статическим массивом:
1. Исчисление с 0. Нижняя граница массива начинается с нуля.
Непривычно для обывателя, если это не житель Германии, свыкшийся с нумерацией этажей в зданиях. Последний элемент массива из, скажем, 8 элементов имеет номер 7.
Многие современные языки программирования имеют хоть какое-то родство с C (или [им желательно породниться](https://faultlore.com/blah/c-isnt-a-language/)), поэтому эта схема не вызывает никакого удивления и даже кажется стандартной.
2. Исчисление с 1. Нижняя граница массива начинается с единицы.
Это удобно, поскольку так мы считаем объекты в реальном мире. Такое встречается, к примеру, в MATLAB или Lua — не самых низкоуровневых языках программирования.
3. Произвольные границы массива, когда нижняя граница может быть любым числом. Подобное знакомо учившим, например, Delphi.
Часто нумерацию с нуля объясняют тем, что такую традицию заложил C. Подразумевается, что до появления указателей, структур и Unix ни один язык не начинал массивы с нуля, полагаясь на нумерацию с 1.
Не всё так однозначно. Единообразия даже у самых первых языков программирования не существовало:
1. Нумерация с нуля: [LISP 1.5](https://www.softwarepreservation.org/projects/LISP/book/LISP%201.5%20Programmers%20Manual.pdf), [APL](https://web.archive.org/web/20141027172442/http://www.softwarepreservation.org/projects/apl/Books/APROGRAMMING%20LANGUAGE) (допускает выбор при запуске программы).
2. Нумерация с единицы: [APL](https://web.archive.org/web/20141027172442/http://www.softwarepreservation.org/projects/apl/Books/APROGRAMMING%20LANGUAGE), Бейсик, [ранний Фортран](http://archive.computerhistory.org/resources/text/Fortran/102649787.05.01.acc.pdf).
3. Произвольные границы: Алгол-60, затем Фортран, [CPL](http://www.ancientgeek.org.uk/CPL/CPL_Elementary_Programming_Manual.pdf), [SIMULA](https://web.archive.org/web/20040923044556/http://www.macs.hw.ac.uk/~rjp/bookhtml/chap10.html), [CLU](http://publications.csail.mit.edu/lcs/pubs/pdf/MIT-LCS-TR-225.pdf), [PL/1](http://www.bitsavers.org/pdf/ibm/360/pli/C28-6571-1_PL_I_Language_Specifications_Jul65.pdf), [Кобол](https://www.livingcomputers.org/UI/UserDocs/Tops-10-v7-04/6_COBOL-68_Language_Manual.pdf), Паскаль, Алгол-68, [JOVIAL](https://apps.dtic.mil/sti/pdfs/ADA101061.pdf).
Как видно, чаще всего массивы начинались не с единицы.
Конечно, это не самый сильный аргумент. Часто языки снабжались синтаксическим сахаром для нумерации с 1. К примеру, в Алголе массив `V[0:3]` начинается с 0, а массив `V[3]` — с 1.

*Создатель языка APL Кеннет Айверсон в книге «[A Programming Language](https://web.archive.org/web/20141027172442/http://www.softwarepreservation.org/projects/apl/Books/APROGRAMMING%20LANGUAGE)» объясняет, почему далее по тексту он будет пользоваться нумерацией элементов массива с нуля. При этом язык допускает отсчёт как с единицы, так и с нуля. Айверсон приводит уже описанный выше аргумент о сдвигах в позиционной нумерации.*
Тем не менее и в эпоху до C звучали [предложения выбирать нумерацию с 0](https://academic.oup.com/comjnl/article-pdf/10/4/321/1258064/10-4-321.pdf). Логично предположить, что это была историческая неизбежность, до которой оставалось несколько лет.
### Потому что парусные регаты мешали вычислениям
В 1967 году Мартин Ричардс впервые реализует компилятор своего детища — BCPL (Basic Combined Programming Language). Этот язык программирования был призван исправить проблемы созданного в начале шестидесятых языка CPL путём отказа от технологий, затрудняющих компиляцию.
Первый компилятор BCPL был написан для операционной системы CTSS машины IBM 7094 Массачусетского технологического института. На тот момент компьютеры — это уже не целые комнаты и электронные лампы, но всё ещё огромные шкафы с транзисторами и консоли управления без экранов. Ресурсов серии 7090 [хватило](https://www.ibm.com/ibm/history/exhibits/space/space_chronology2.html), чтобы запустить американца в космос. Но мощность измерялась в тысячах машинных слов, микросекундах тактов и килофлопсах, а цена — в миллионах долларов.
В пятидесятых и шестидесятых IBM [выдавала](https://multicians.org/thvv/7094.html) институту щедрые скидки на свои научные компьютеры или даже предоставляла их бесплатно. В 1963 году в МТИ поставили IBM 7094. На компьютер уговор был такой: 8 часов в сутки получают специалисты института, 8 часов — другие колледжи и университеты Новой Англии, а третью смену отдавали самой IBM для личных нужд.
На этом особенности не кончались. Несколько раз в год IBM обсчитывала регаты: президент IBM соревновался в заплыве на больших яхтах в проливе Лонг-Айленд, и каждое из судов получало очки гандикапа по [специальной сложной формуле](https://en.wikipedia.org/wiki/Handicap_(sailing)). Когда в вычислительный центр приходило задание, операторам полагалось всё бросить и запустить вычисления этих очков.

*Машинный зал с установленным компьютером IBM 7094 в Колумбийском университете США. [Фотоархив](http://www.columbia.edu/cu/computinghistory/1965.html)*
Вообще, и без этого был шанс не получить результат вычислений. Изначально 7094 работал в режиме пакетной обработки. Вспомогательная система на IBM 1401 загружала пакет задач с перфокарт на ленту, а затем запускала задачи одну за другой и записывала результаты для последующей печати. Для каждой задачи приводилась оценка времени. Если задача выходила за пределы отпущенного, её принудительно прерывали.
В итоге компиляция в BCPL была оптимизирована по максимуму. То есть и указатели на элементы массива должны максимально близко походить на машинный код, без необходимости вычитать единицу при указании на элемент массива. Хотя во время выполнения программы не играет роли схема организации массивов, нумерация с нуля могла появиться для оптимизации времени компиляции.
Впрочем, конкретно эта версия — лишь [гипотеза Майка Хойе](https://exple.tive.org/blarg/2013/10/22/citation-needed/). Ей нет никаких подтверждений от собствено Ричардса или хотя бы упоминаний в литературе. Мартин Ричардс в переписке с Хойе лишь приводит общие соображения о том, что он хотел достичь близости к машинному коду, поэтому указатель `p` и `p + 0` — это одна и та же переменная. Ни на какие яхты Ричардс не жалуется.
К тому же на момент появления первого компилятора BCPL уже была готова операционка Compatible Time-Sharing System. В ней на одной машине с разделением времени компьютер выполняет одну задачу за один раз, но с оптимизацией ввода и вывода, чтобы паузы одного пользователя заполнялись работой других. Это уже не былая пакетная обработка задач.
Точно известно, что в дальнейшем BCPL значительно повлиял на все современные языки программирования.
В 1969 году Кен Томпсон урезал функциональность BCPL до языка B. В дальнейшем, для развития операционной системы Unix, Деннис Ритчи улучшил B добавлением функций PDP-11, в результате чего и получился C. Полвека спустя список языков, на которые оказал влияние C, занимает в «Википедии» [целую страницу](https://en.wikipedia.org/wiki/Category:C_programming_language_family).
В языке BCPL `v!5` и `5!v` совпадают, поскольку являются указателем на `!(v+5)` или `!(5+v)`. Аналогично в C `v[5]` эквивалентно `5[v]`.
### Потому что так предложил Дейкстра
В 1982 году Эдсгер Дейкстра [опубликовал](https://www.cs.utexas.edu/users/EWD/transcriptions/EWD08xx/EWD831.html) статью «Почему нумерация должна начинаться с нуля». В ней он низверг как нумерацию с единицы, так и произвольные границы индексов. Очевидно, что Дейкстра — не человек, который легко поддаётся влиянию C, но также он раскритиковал Алгол-60, своё собственное детище, и Паскаль.

*Известно, что Дейкстра ближе к концу жизни всё больше писал от руки, а не набирал тексты на машинке. [Архив рукописей Эдсгера Вибе Дейкстры](https://www.cs.utexas.edu/~EWD/)*
Если необходимо записать интервал натуральных чисел 2, 3, …, 12 без опухоли из точек, возможны четыре варианта:
1. `2 ⩽ i < 13`
2. `1 < i ⩽ 12`
3. `2 ⩽ i ⩽ 12`
4. `1 < i < 13`
Дейкстра указывает, что не все из предложенных вариантов эквивалентны. В первом и втором варианте разница между началом и концом последовательности равна её длине. Также в этих вариантах в случае смежных последовательностей конец одного промежутка будет началом другого.
Затем автор замечает, что для нижней границы предпочтителен знак «⩽», поскольку наименьшее натуральное число существует. В противном случае, если последовательность начинается с наименьшего натурального числа, нижняя граница не будет натуральным числом.
Аналогично для верхней границы Дейкстра рекомендует использовать «<», поскольку так удобнее для записи подпоследовательностей нулевого размера. Иначе верхняя граница рискует не оказаться натуральным числом.
Затем статья делает вывод, что из соображений простоты для последовательности из N членов предпочтительнее диапазон `0 ⩽ i < N`, а не `1 ⩽ i < N+1`.
Куда менее известный документ — это полушуточная техническая заметка от 1 апреля 1980 года [IEN 137](https://www.rfc-editor.org/ien/ien137.txt) под названием «О священных войнах и призыв к миру» [On Holy Wars and a Plea for Peace].
В заметке Дэнни Коэн приводит интересный аргумент: в системе счисления с основанием `b` при отсчёте с нуля первые `b ^ N` неотрицательных чисел представляются ровно `N` цифрами. Например, если речь про двоичную запись, то `2 ^ 3 = 8`, и восьмой элемент массива будет иметь номер 1112, а не 10002. Понятно, что с такими преобразованиями легко бы мог справиться компилятор.
### Потому что так более элегантно
Это объяснение может раздражать субъективностью. Соображения о красоте у каждого свои и совпадать не обязаны. Но авторы языков программирования — тоже люди со своими предпочтениями.
В конце восьмидесятых Гвидо ван Россум при создании Python как учёл свой предыдущий опыт с языком ABC, так и задумал привлечь аудиторию хакеров от мира Unix и C.
С 1983 года Гвидо работал в Центре математики и информатики в Амстердаме над реализацией языка ABC. Проект ставил целью создать язык программирования, пригодный для обычных людей, но не настолько ужасно реализованный, как Бейсик. Нумерация массивов в ABC начиналась с единицы. Такой же схемы придерживались другие знакомые Россуму языки — Алгол, Фортран и Паскаль.
Однако в вышедшем в 1991 году Python нумерация начинается с нуля, а не единицы. Получилось так в результате долгих размышлений.
Одна из причин — слайсы. Чаще всего при создании слайса используются операции «получить первые n элементов» и «начиная с i, получить следующие n элементов». При этом первый случай эквивалентен `i == первый индекс`. Гвидо посчитал, что лучше, если обе операции возможны без лишней головной боли в виде коррекции +1 и −1.
Если первый элемент имеет номер 1, то возможно указывать первый элемент и число элементов, которые нужно получить. Россум уже был знаком с подобным [по ABC](https://homepages.cwi.nl/~steven/abc/qr.html#EXPRESSIONS) и вполне мог бы положиться на этот опыт.
Тем не менее автора Python очаровал синтаксис слайсов полуоткрытого интервала, если нумерация начинается с нуля: `a[:n]` (или `a[0:n]`) и `a[i:i+n]`. К примеру, строку `a` легко разбить на три части `a[:i]`, `a[i:j]` и `a[j:]`.
Заметим, что в воспоминаниях Гвидо не приводит ни призывы гениев информатики, ни практики других языков, ни принципы, заложенные мастодонтами компьютерных вычислений шестидесятых. Зато слово «элегантность» в пяти абзацах его объяснения встречается 3 раза.
### Почему же массивы начинаются с нуля?
Так исторически сложилось.
По материалам блогов [Альберта Козловски](https://albertkoz.com/why-does-array-start-with-index-0-65ffc07cbce8), [Майка Хойе](https://exple.tive.org/blarg/2013/10/22/citation-needed/), [Гвидо ван Россума](http://python-history.blogspot.com/2013/10/why-python-uses-0-based-indexing.html), [Хиллеля Уэйна](https://buttondown.email/hillelwayne/archive/why-do-arrays-start-at-0/) и [ответа Хойе](https://exple.tive.org/blarg/2022/08/25/zero-again/). | https://habr.com/ru/post/696666/ | null | ru | null |
# Книга «GraphQL: язык запросов для современных веб-приложений»
[](https://habr.com/ru/company/piter/blog/441194/) Привет, Хаброжители! У нас вышла книга по языку запросов GraphQL. Мы решили поделиться переводом главы «Анатомия запросов GraphQL»
«Снежный клык» (Snowtooth) — выдуманный горнолыжный курорт. Ради примеров в данной главе мы сделаем вид, что это настоящая гора и мы там работаем. Мы рассмотрим, как веб-команда «Снежного клыка» использует GraphQL для предоставления информации в режиме реального времени: сведений о состоянии подъемников и лыжных трасс. Лыжный патруль «Снежного клыка» может открывать и закрывать подъемники и трассы непосредственно со смартфона. Чтобы следовать примерам в этой главе, обратитесь к интерфейсу «Снежного клыка» на платформе GraphQL Playground (snowtooth.moonhighway.com/).
Вы можете использовать операцию query для запроса данных из API. Запрос описывает данные, которые вы хотите получить от сервера GraphQL. Когда вы отправляете запрос, вы запрашиваете единицы данных по полям. Эти поля отображаются в том же поле в ответе данных в формате JSON, который вы получаете с сервера. Например, если вы отправляете запрос allLifts и запрашиваете поля name и status, вы должны получить ответ в формате JSON, содержащий массив allLifts и строки name и status каждого подъемника, как показано здесь:
```
query {
allLifts {
name
status
}
}
```
> Обработка ошибок
>
> Успешные запросы возвращают JSON-документ, содержащий ключ «данные». Неудачные запросы возвращают JSON-документ, содержащий ключ «ошибки». Детали того, что пошло не так, передаются в виде данных в формате JSON под этим ключом. Ответ JSON может содержать как «данные», так и «ошибки».
Вы можете добавить несколько запросов к документу запроса, но одновременно можно инициировать только одну операцию. Например, вы можете разместить две операции запроса в документе запроса:
```
query lifts {
allLifts {
name
status
}
}
query trails {
allTrails {
name
difficulty
}
}
```
Когда вы нажмете кнопку воспроизведения, среда GraphQL Playground предложит вам выбрать одну из этих двух операций.
Если требуется отправить один запрос всех указанных данных, вам нужно поместить все в один и тот же запрос:
```
query liftsAndTrails {
liftCount(status: OPEN)
allLifts {
name
status
}
allTrails {
name
difficulty
}
}
```
Здесь налицо преимущества GraphQL. Мы можем получать разные типы данных в одном запросе. Мы запрашиваем liftCount по статусу, который позволяет нам узнать количество подъемников, имеющих в настоящее время этот статус. Мы также запрашиваем name и status каждого подъемника. Наконец, мы запрашиваем name и status каждой трассы.
query — это тип GraphQL. Мы называем его корневым типом, потому что это тип, который сопоставляется с операцией, а операции представляют собой корни нашего документа запроса. Поля, доступные для запроса в API GraphQL, определены в данной схеме API. В документации указывается, какие поля доступны для выбора в типе query.
Документация указывает нам, что мы можем выбирать поля liftCount, allLifts и allTrails при запросе этого API. Она также определяет больше полей, которые доступны для выбора, но весь смысл запроса заключается в том, что мы можем выбрать, какие поля нам нужны, а какие необходимо опустить.
Когда мы пишем запросы, мы выбираем поля, которые нам нужны, заключая их в фигурные скобки. Эти блоки называются выборками. Поля, которые мы определяем в выборке, напрямую связаны с типами GraphQL. Поля liftCount, allLifts и allTrails определены в типе query.
Вы можете встраивать множество выборок одну в другую. Поскольку поле allLifts возвращает список Lift, нам нужно использовать фигурные скобки для создания новой выборки для этого типа. Есть все виды данных, которые мы можем запросить о подъемнике, но в указанном примере нам нужны только name и status подъемника. Аналогично запрос allTrails будет возвращать типы Trail.
Ответ в формате JSON содержит все данные, которые мы запросили. Эти данные форматируются как JSON и поставляются в том же виде, что и наш запрос. Каждому полю JSON выдается то же имя, что и поле в нашей выборке. Мы можем изменить имена полей в объекте ответа в запросе, указав псевдонимы, как показано ниже:
```
query liftsAndTrails {
open: liftCount(status: OPEN)
chairlifts: allLifts {
liftName: name
status
}
skiSlopes: allTrails {
name
difficulty
}
}
```
Ниже приводится ответ:
```
{
"data": {
"open": 5,
"chairlifts": [
{
"liftName": "Astra Express",
"status": "open"
}
],
"skiSlopes": [
{
"name": "Ditch of Doom",
"difficulty": "intermediate"
}
]
}
}
```
Теперь мы возвращаем данные в одну и ту же форму, но в нашем ответе мы переименовали несколько полей. Способ фильтрации результатов GraphQL-запроса состоит в передаче аргументов запроса. Аргументы — это пара значений ключа (или пары), связанная с полем запроса. Если требуются только имена закрытых подъемников, мы можем отправить аргумент, который будет фильтровать наш ответ:
```
query closedLifts {
allLifts(status: "CLOSED" sortBy: "name") {
name
status
}
}
```
Вы также можете использовать аргументы для выбора данных. Например, предположим, что нам нужно запросить статус отдельной канатной дороги. Мы можем выбрать подъемник по его уникальному идентификатору:
```
query jazzCatStatus {
Lift(id: "jazz-cat") {
name
status
night
elevationGain
}
}
```
Здесь мы видим, что ответ содержит name, status, night и elevationGain для канатной дороги Jazz Cat.
» Более подробно с книгой можно ознакомиться на [сайте издательства](https://www.piter.com/collection/best/product/graphql-yazyk-zaprosov-dlya-sovremennyh-veb-prilozheniy)
» [Оглавление](https://storage.piter.com/upload/contents/978544611143/978544611143_X.pdf)
» [Отрывок](https://storage.piter.com/upload/contents/978544611143/978544611143_p.pdf)
Для Хаброжителей скидка 25% по купону — **GraphQL**
По факту оплаты бумажной версии книги на e-mail высылается электронная версия книги. | https://habr.com/ru/post/441194/ | null | ru | null |
# Я решил отключить Google AMP на своём сайте
Меня связывает с проектом Google’s Accelerated Mobile Pages (AMP) [долгая история](https://www.alexkras.com/please-make-google-amp-optional/), но вчера чаша терпения переполнилась.
Я зашёл в Twitter (в Safari на iPhone 6) и заметил, что кто-то сослался на мой сайт, поставив ссылку AMP. Я ответил и указал настоящую ссылку, но когда нажал на неё, то меня перенаправило обратно на версию AMP моей страницы.
> Thanks for sharing here is non amp link so all images load: <https://t.co/6drRK5Cugz>
>
> — Alex Kras (@akras14) [June 23, 2017](https://twitter.com/akras14/status/878321621227917314)
Я скопировал ссылку, сгенерированную Twitter, и заметил, что она выглядит так:
`https://t.co/6drRK5Cugz?amp=1`
Обратите внимание на `amp=1` в ссылке. Когда на неё нажимаешь, она возвращает такую HTML-страницу:
```
https://www.alexkras.com/simple-guide-to-finding-a-javascript-memory-leak-in-node-js/amp/
window.opener = null;
location
.replace(`https:\/\/www.alexkras.com\/
simple-guide-to-finding-a-javascript-memory-leak-in-node-js\
/amp\/`)
```
Единственное предназначение этой страницы — перенаправить читателя на версию AMP.
Мои проблемы с AMP как издателя
-------------------------------
Когда проект AMP появился, я воспринял его оптимистично. Его целью было сделать веб быстрее, а я уважаю такую цель.
Что мне [ОЧЕНЬ](https://www.alexkras.com/google-may-be-stealing-your-mobile-traffic/) не понравилось как издателю — это то, что Google кэшировал контент AMP и выдавал его из своего собственного кэша и под собственным доменным именем. В результате, ссылки выглядели так:
`https://www.google.com/amp/www.bbc.co.uk/news/amp/39130072`
Другими словами, вместо выдачи контента с BBC.co.uk, он поставлялся с Google.com.
У такого подхода есть несколько проблем:
1. Он «заманивает» пользователей на Google. Если человек нажмёт “x” на верхнем скриншоте, его отправят обратно к результатам поиска Google. Нормальный редирект отправил бы пользователя на реальный сайт BBC, увеличивая шансы, что он останется на том сайте. Вместо этого AMP делает проще для пользователей вернуться на Google. Это функциональность, которая в браузере всегда доступна по кнопке «Назад». Это плохо для издателей, но скорее всего неуместно и для самих пользователей.
2. Он делает систему уязвимой для злоупотреблений. Например, фейковые новости при публикации через AMP могут показаться достоверными неподготовленному читателю, поскольку они поставляются с Google.com — очень уважаемого домена.
**Как ни странно, это НЕ то, что делает Twitter**
Думаю, что Twitter исходит из предположения, что контент в формате AMP лучше для пользователей. По этой причине они просто пытаются оказать пользователям услугу и доставить контент в наилучшем формате.
Мои проблемы с AMP как пользователя
-----------------------------------
AMP состоит из трёх компонентов: HTML, библиотека JavaScript и кэш. В предыдущем разделе я говорил о своих претензиях к кэшу. Преимущетво кэша, как [объяснили мне разработчики Google AMP](https://www.alexkras.com/i-had-lunch-with-google-amp-team/), в том, что он позволяет Google (или любой другой платформе) осуществлять предварительную загрузку контента для пользователя. Когда пользователь нажимает на ссылку AMP, Google может вывести результат практически мгновенно, поскольку он уже получен в фоновом режиме.
И опять, как ни странно, Twitter не использует этот кэширующий слой. Twitter предполагает, что мобильные пользователи предпочитают читать отрендеренный в формате AMP контент, даже если он не был предзагружен в кэш.
Для меня проблема в том, что **мне не нравится читать контент AMP**. Есть много мелких вещей, которые меня реально раздражают в AMP.
Например:
### Неудобная прокрутка
На iPhone AMP переназначает дефолтную прокрутку в браузере. В результате скроллинг на страницах AMP как будто отсутствует.
### Трудно делиться ссылками
AMP затрудняет обмен ссылками на оригинальный контент.
Вместо того, чтобы просто перейти в адресную строку и скопировать ссылку, пользователю нужно [нажать специальную кнопку](https://www.alexkras.com/amp-toolbar-now-has-a-button-to-view-and-copy-original-url/), чтобы увидеть оригинальный URL. Затем пользователю нужно нажать на оригинальный URL, подождать редиректа и скопировать его из адресной строки вверху.
*Примечание: Какой бы она ни была неудобной, но кнопка с оригинальной ссылкой — большой шаг вперёд в интерфейсе AMP. Изначально пользователям приходилось вручную удалять часть `https://www.google.com/amp/` из адреса.*
Я готов пройти через эти трудности, потому что мне не нравится читать контент AMP и потому что я хочу убедиться, что **доверяю верному источнику по этой ссылке**. Уверен, что большинство пользователей не производят всех этих шагов. Они просто копируют полную ссылку AMP, вроде `https://www.google.com/amp/www.bbc.co.uk/news/amp/39130072`, и делятся ею. Моя жена, например, постоянно присылает мне такие ссылки. Для меня действительно удивительно, что большие издатели не обеспокоены этим фактом настолько же, насколько я.
### Контент AMP обычно разделён на части
Вспомните времена, когда нам приходилось загружать WAP-страницы — специальные веб-страницы, которые создавались для мобильных устройств. Подписка на AMP для издателя — это словно возвращение в те времена. Вместо использования адаптивного дизайна (когда одна версия сайта хорошо работает на всех устройствах) издатели вынуждены поддерживать две версии каждой страницы — обычную версию для устройств большего размера и мобильных телефонов, которые не используют Google, а также версию AMP.
Преимущество технологии AMP в том, что она накладывает жёсткие ограничения на контент, тем самым гарантируя его быструю загрузку. Проблема такого подхода заключается в том, что в AMP попадает не весь контент. Например, комментарии часто удаляются.
Я также заметил, что [загрузка изображений в AMP глючит](https://github.com/ampproject/amphtml/issues/9397). AMP пытается загрузить изображение только когда оно попадает в область видимости для пользователя, а изначально отображается белый квадрат. По моему опыту, часто происходит так, что белый квадрат там и остаётся вместо изображения.
Есть много других маленьких нюансов для разных сайтов. Например, комментарии Reddit (очень важная часть сайта) кэшируются в AMP. В результате, новые комментарии, которые видны в десктопной версии Reddit, не отображаются в версии AMP, пока кэш для этой страницы не обновится.
### AMP обязателен для пользователей
Издатель сам решает, хочет ли он добавить поддержку AMP для своего сайта. А вот пользователи [не имеют возможности отключить AMP](https://www.alexkras.com/please-make-google-amp-optional/).
[](https://twitter.com/slightlylate/status/820344221450125312)
Было бы замечательно, если бы Google предоставлял пользователю настройки с возможностью [отключить результаты рендеринга AMP](https://www.alexkras.com/please-make-google-amp-optional/). К сожалению, даже если они добавят такую опцию, это не сильно поможет в условиях, когда Twitter или Facebook поддерживают AMP на сервере.
Почему я изначально подключил AMP для своего сайта
--------------------------------------------------
Я изначально подключил AMP для своего сайта только по одной причине — хорошее место результатах поиска Google.
Незадолго до появления AMP компания Google объявила, что будет опускать в выдаче сайты, которые недостаточно быстро отображаются на мобильных устройствах. У моего веб-сайта был адаптивный дизайн, но я не был уверен, что он достаточно оптимизирован для мобильных устройств. Поэтому, когда я узнал о наличии плагина AMP для WordPress, то сразу подключил его. И хотя Google официально заявила, что поддержка AMP не влияет на место в результатах поиска, я решил, что она не помешает.
Ещё одним преимуществом AMP для ранжирования в поиске было то, что только сайты с поддержкой AMP отображались в функции «карусели» на сайте Google. Хотя мой сайт вряд ли попадёт в «карусель», но такая возможность должна быть важной для крупных издателей.

Она распространяется
--------------------
Я подумал об отключении AMP, когда впервые узнал, что [Google загружает мой сайт из кэша](https://www.alexkras.com/google-may-be-stealing-your-mobile-traffic/), но передумал по двум основным причинам:
1. Я хотел сохранить позиции в поиске.
2. Я хотел оставить AMP как опцию для тех читателей, кому это нужно.
Чего я не понимал до истории с Twitter, так это того, что активируя AMP я тем самым разрешаю другим сайтам выбирать, как они хотят ссылаться на мой контент.
Менее двух недель назад я [написал следующее](https://www.alexkras.com/please-make-google-amp-optional/):
> «У меня нет проблем с самой библиотекой AMP. Меня не волнует, что Facebook Instant Articles или Pinterest используют AMP».
Как я ошибался. Я думал, что меня это не волнует, пока не увидел свою ссылку в Twitter с указанием рендеринга в формате AMP.
Пользователям это не нужно
--------------------------
Несколько недель назад кто-то в Twitter обвинил меня в том, что я не люблю AMP, потому что у меня «привилегия» быстрого интернета. Хотя у меня и вправду быстрый интернет, не думаю, что использовал бы AMP даже на медленном соединении. **Я бы скорее отключил JavaScript в браузере** (может быть, даже изображения, если всё действительно настолько плохо). Это может работать не для всех сайтов, но мой сайт рендерится и кэшируется на стороне сервера. Пользователям нужно всего лишь скачать немного HTML, чтобы увидеть любую страницу. Зачем заставлять их скачивать библиотеку AMP JavaScript?
Конечно, у нас есть AMP, потому что Google хочет, чтобы пользователи видели рекламу, которая практически отсутствует при [отключенном JavaScript](https://www.wired.com/2015/11/i-turned-off-javascript-for-a-whole-week-and-it-was-glorious/). Я тоже хочу, чтобы пользователи видели рекламу (рекламу Google, между прочим), так я оплачиваю расходы на сервер. Тем не менее, я радостью позволю человеку на плохом соединении отказаться от этой части сделки.
В любом случае, для проверки своей теории я открыл Chrome Developer Tools, чтобы придушить своё соединение до максимально медленного варианта, и отключил JavaScript. Я открыл статью на своём сайте, и она загружалась **три секунды**. Я попытался использовать поиск Google, и он оказался ошеломительно быстрым, но там не было никаких ссылок AMP. Конечно не было, ведь они показываются только при включенном JavaScript.
Я снова включил JavaScript (сохранив низкой сетевую скорость) и попытался поискать какой-нибудь контент AMP. Заняло **более 10 секунд** просто загрузить «карусель» с новостями.
Как и ожидалось, статический контент (без JavaScript) по-прежнему на высоте.
Пожалуйста, высказывайтесь
--------------------------
Впервые я написал о своих опасениях насчёт AMP девять месяцев назад. Та статья привлекла некоторое внимание на Hacker News, и ребята с отдела Google AMP активно участвовали в [обсуждении на Hacker News](https://news.ycombinator.com/item?id=12722590) и в [комментариях к моей статье](https://news.ycombinator.com/item?id=12731311). Они даже зашли настолько далеко, что пригласили меня на обед, чтобы лучше узнать о моих опасениях.
Две недели назад я написал похожую статью под названием «[Пожалуйста, сделайте Google AMP необязательным](https://www.alexkras.com/please-make-google-amp-optional/)». Он получил намного больше внимания на [Hacker News](https://news.ycombinator.com/item?id=14529376), чем первоначальная статья (вошёл в Топ-300 постов за всю историю), но по-прежнему никак не повлиял на позицию разработчиков Google AMP.
Возможно, сотрудники Google AMP осознали, что они совсем немного выиграют, если прислушаются к маленькой части сообщества разработчиков, которым не нравится AMP. Они знают, что мы в меньшинстве, и мы не их целевая аудитория. Моя мама и моя жена не ходят на Hacker News. Они не знают, что такое AMP и не особенно озабочены проблемами открытого веба.
В то же время в Google много инженеров, для которых открытый веб важен. Меня действительно удивляет, что я не слышу их высказываний против AMP. Могу предположить, что этот проект получил благословение на самом верху, так что политически опасно гнать волну.
Однако те из нас, кому не по душе AMP, должны сражаться.
У вас есть сайт WordPress? Отключите AMP или не включайте его, если он отключен.
Вы работаете на издателя, у которого включена поддержка AMP? Попробуйте объяснить своему работодателю опасности AMP, как он может терять трафик и узнаваемость бренда.
Вы просто веб-разработчик? Попробуйте делать более быстрые сайты и избегайте перегрузки скриптами. Есть множество справочных ресурсов, которые помогут справиться с этой задачей (например, см. [заметки с Chrome Dev Summit](https://www.alexkras.com/chrome-dev-summit-2016-highlights/)). Будет проще бороться с AMP, если большинство сайтов будут быстро загружаться, даже на слабых соединениях.
Решение отключить AMP пришло не сразу. К счастью, отключить его на WordPress было почти так же просто, как и подключить. Достаточно просто дезактивировать плагин. Менее чем через 24 часа Google прекратил показывать версию AMP моего сайта в своих результатах поиска.
**Дополнение**. Здесь я записал конкретные шаги, которые сделал, включая установку редиректа для старых ссылок AMP: <https://www.alexkras.com/how-to-disable-amp-on-wordpress/>. | https://habr.com/ru/post/331958/ | null | ru | null |
# Не пора ли реляционным базам данных на свалку истории?
Здравствуйте, меня зовут Дмитрий Карловский и я… антиконформист, то есть человек, который не держится за свои привычки и всегда готов их поменять, если в том есть необходимость. Например, как и многие разработчики, я начинал изучение баз данных с реляционных. Хотя реляционная алгебра и довольно красива в своей простоте, я постоянно ловил себя на мысли, что пытаюсь впихнуть круглую фигуру в квадратное отверстие и получалось как-то [не герметично](http://russian.joelonsoftware.com/Articles/LeakyAbstractions.html).

Нет, я не буду рассказывать вам про MongoDB или ещё какую неполноценную «убийцу SQL». Статей на тему «SQL vs NoSQL» сравнивающих на самом деле реляционные субд с документными и так полно:
* [MongoDB или как разлюбить SQL](http://habrahabr.ru/post/74144/)
* [Реляционные базы данных обречены?](http://habrahabr.ru/post/103021/)
* [NoSQL базы данных: понимаем суть](http://habrahabr.ru/post/152477/)
* [Почему нужно 1000 раз подумать, прежде чем использовать noSQL](http://habrahabr.ru/post/153859/)
* [SQL — гибок или почему я боюсь NoSQL](http://habrahabr.ru/post/164361/)
* [NoSQL и Big Data – обман трудящихся?](http://habrahabr.ru/company/jelastic/blog/166845/)
* [Чем поможет архитектору «NoSQL» и… поможет ли?](http://habrahabr.ru/company/bitrix/blog/193360/)
* [Сравнение производительности MongoDB vs PostgreSQL. Часть I: No index](http://habrahabr.ru/post/197590/)
* [Сравнение производительности MongoDB vs PostgreSQL. Часть II: Index](http://habrahabr.ru/post/197630/)
* [Разбираем ACID по буквам в NoSQL](http://habrahabr.ru/post/228327/)
* [Почему вы никогда не должны использовать MongoDB](http://habrahabr.ru/post/231213/)
* [Почему мы выбрали MongoDB](http://habrahabr.ru/post/232539/)
* [Недостатки RDBMS или RDBMS vs NoSQL](http://habrahabr.ru/post/236523/)
* [Почему вы никогда не должны говорить «никогда»](http://habrahabr.ru/post/243431/)
* [Еж с ужом в одной корзине, а также немного об отсутствии схемы](http://habrahabr.ru/post/244005/)
* [Почему реляционные СУБД отлично подходят для стартапов: Пример из истории разработки мессенджера Kato](http://habrahabr.ru/company/kato/blog/247961/)
* [Прощай, MongoDB, здравствуй, PostgreSQL](http://habrahabr.ru/post/253075/)
Но у большинства из них есть фатальный недостаток — авторы просто не в курсе, что [моделей данных в СУБД есть куда больше, чем два упомянутых](http://db-engines.com/en/articles): от узкоспециализированных [«словарей»](http://db-engines.com/en/article/Key-value+Stores), то универсальных [«графов»](http://db-engines.com/en/article/Graph+DBMS). А популярные [«реляционные»](http://db-engines.com/en/article/Relational+DBMS) и [«документные»](http://db-engines.com/en/article/Document+Stores) находятся лишь где-то по середине между универсальностью и специализированностью.
Давайте [сравним типичных представителей упомянутых типов СУБД](http://db-engines.com/en/system/HBase%3BMongoDB%3BOracle%3BOrientDB%3BRedis) (от большего к меньшему).
* Популярность: Oracle, MongoDB, Redis, HBase, OrientDB.
* Функциональность: OrientDB, Oracle, MongoDB, HBase, Redis.
* Скорость: очень сильно зависит от задачи, данных и реализации приложения. Я пересмотрел кучу бенчмарков, везде всё по разному.
#### **SQL**
Силы тысяч разработчиков направлены на то, чтобы довольно простые модели предметной области расположить в табличках так, чтобы это было быстро, гибко и не слишком сложно. Получается плохо. Пишутся огромные ORM фреймворки, зубодробительные SQL запросы, создаются огромные индексы, и дублируются данные.
В качестве примера приведу одну из типичных задач — работа с деревьями. Это может быть дерево комментариев, дерево разделов сайта, дерево тэгов. Деревьев очень много в предметных областях, но работая с реляционными СУБД их стараются избегать, так как работа с ними вызывает много боли.
Вот, сколько статей на одном только Хабре написано о проблеме, которая есть исключительно в РСУБД ввиду попытки упихнуть всё многообразие моделей предметной области в прямоугольные таблицы:
* [Решение проблемы сортировки деревьев с помощью бинарного Materialized Path](http://habrahabr.ru/post/226741/)
* [MS SQL: hierarchyid — иерархия по-новому](http://habrahabr.ru/post/27774/)
* [Иерархические (рекурсивные) запросы](http://habrahabr.ru/post/43955/)
* [Иерархические структуры данных и Doctrine](http://habrahabr.ru/post/46659/)
* [Иерархические структуры данных и производительность](http://habrahabr.ru/post/47280/)
* [Nested Sets + PostgreSQL TRIGGER](http://habrahabr.ru/post/63416/)
* [Nested Sets + MySQL TRIGGER](http://habrahabr.ru/post/63883/)
* [Full Hierarchy — иерархические структуры в базах данных](http://habrahabr.ru/post/67722/)
* [Задача отображения деревьев в MySql. Способ отображения на хранимых процедурах](http://habrahabr.ru/post/72700/)
* [Рекурсивные (Иерархические) запросы в PostgreSQL](http://habrahabr.ru/post/73700/)
* [Реализация иерархии — объединение Adjacency List и Materialized Path через one-to-many](http://habrahabr.ru/post/138947/)
* [Строим Nested Set дерево без рекурсии](http://habrahabr.ru/post/153861/)
* [Степени — ключ к быстрой иерархии (пример на Django)](http://habrahabr.ru/post/165713/)
* [Иерархические данные. В поиске оптимального решения](http://habrahabr.ru/post/187664/)
* [Хранение деревьев в базе данных. Часть первая, теоретическая](http://habrahabr.ru/post/193166/)
* [Денормализация деревьев](http://habrahabr.ru/post/212847/)
* [Где смерть Кащеева?](http://habrahabr.ru/post/251871/)
* [Nested Intervals и их реализация под Yii2](http://habrahabr.ru/post/263447/)
* [Хранение иерархических структур. Симбиоз «Closure Table» и «Adjacency List»](http://habrahabr.ru/post/263629/)
* [Cartesius — метод хранения и извлечения древовидных структур в реляционных базах данных или SQL деревья без червей и тараканов](http://habrahabr.ru/post/264989/)
Все решения сводятся к трём основным:
**Таблица смежности.** Потомок хранит ссылку на родителя. Тут не сохраняется порядок потомков (чтобы его сохранять нужно вводить дополнительную нумерацию, по которой сортировать, что замедляет как вставки так и выборки). Требуются рекурсивные запросы или денормализация таблиц смежностей.
Рекурсивный запрос поддерева:
```
WITH RECURSIVE Rec(id, parent, name, ord)
AS (
SELECT id, parent, name, ord FROM tree
UNION ALL
SELECT Rec.id, Rec.parent, Rec.name, Rec.ord
FROM Rec, tree
WHERE Rec.id = tree.parent
)
SELECT * FROM Rec
WHERE parent = 123
ORDER BY ord
```
Запрос поддерева по денормализованной таблице смежности:
```
SELECT navi.id , navi.name , navi.parent
FROM tree , navi
WHERE tree.ancestor = 123 AND navi.id = tree.node
ORDER BY ord
```
**Материализованный путь.** Потомок хранит номера всех предков (с сохранением их порядка). В худшем случае изменение иерархии приводит к обновлению данных всех узлов. При отсутствии соответствующего АПИ со стороны СУБД, требует фигурной манипуляции над строками, что не во всех случаях приемлемо по скорости. Не допускает вхождение одного потомка в несколько предков.
Запрос поддерева с использованием [ordpath](https://rsdn.ru/article/db/ordpath.xml):
```
SELECT RowId, name FROM dbo.Tree WHERE @ParentId.IsDescendant(RowId) = 123
```
**Вложенные интервалы.** Каждый узел хранит два числа, которые определяют его точное положение в иерархии. В худшем случае изменение иерархии приводит к обновлению данных всех узлов. Не допускает вхождение одного потомка в несколько предков. Относительно сложные алгоритмы требуют повышенной аккуратности.
Запрос поддерева:
```
SELECT node.id, node.name
FROM tree AS node, tree AS parent
WHERE node.left BETWEEN parent.left AND parent.right
AND parent.id = 123
ORDER BY node.left;
```
Изменение деревьев гораздо сложнее, примеры кода можно найти по ссылкам выше.
Как видим, каждый тип решения имеет свои серьёзные ограничения на представимую им модель и эффективность разных типов запросов. А знаете почему нет такого большого числа обстоятельных статей про хранение деревьев, например, в графовых СУБД? Да потому, что там в принципе нет этих проблем, так как дерево — это частный случай графа. Так что вопрос «как же мне так исхитриться и сохранить в базу иерархию» в графовых базах вообще не стоит.
Запрос поддерева в графе:
```
SELECT name , parent FROM ( TRAVERSE child FROM #1:123 )
```
Да, нереляционные СУБД, не смотря на общее название «NoSQL», тоже могут поддерживать Structured Query Language, расширяя его своими операторами :-)
Многие SQL-профи тут обычно заявляют, мол деревья и тем более графы в предметных областях почти не встречаются. Но стоит немного выйти из [зоны комфорта](http://lurkmore.to/Квадратно-гнездовой_способ_мышления) как тут же увидишь, что любая предметная область на самом деле представляет из себя граф — набор сущностей, между которыми есть разнообразные отношения. Если отношения эти 1-к-1 или хотя бы 1-ко-многим и при этом связывают лишь разнотипные сущности, то такие модели относительно легко ложатся на реляционную модель (если не учитывать разные виды джойнов с костылями в виде индексов). Но обычно всё не так. Во многих местах можно встретить отношения многие-ко-многим. В РСУБД для каждого такого отношения приходится заводить отдельную таблицу и несколько индексов к ней, а это усложнение архитектуры, раздувание данных и замедление работы с ними.
Некоторые, особо «передовые» программисты, предлагают хранить каждый тип моделей в своей СУБД. «Важные данные» в реляционных, деревья в графовых, а примитивные вообще в словарях. Но подобные подходы вида «всякой задаче свой инструмент» лишь добавляют головной боли (и как следствие багов разной степени тяжести) на тему консистентности данных в разных частях приложения.
Программная разработка — штука очень динамичная. Сегодня мастер у вас должен иметь одну профессию и вы просто даёте ему текстовое поле вписать её. Завтра потребуется, чтобы он мог указать профессию лишь из предложенных вами и вы даёте ему селект для выбора нужной, сохраняя id профессии в модель мастера (один-ко-многим). После завтра потребуется, чтобы он мог выбрать несколько профессий разом (многие-ко-многим). А через неделю вам срочно потребуется реализовать уже иерархический каталог профессий. В реляционной СУБД сложность каждого следующего перехода значительно превосходит предыдущий. С графовой — вы больше времени потратите на обсуждение, чем на реализацию. Так что при старте проекта имеет смысл брать наиболее гибкий инструмент, который позволит вам не терять темп разработки в процессе изменения бизнес требований (или лучшего понимания оных). Да, специализированные инструменты могут в некоторых случаях быть быстрее и именно в этих случаях, **если в этом есть необходимость**, стоит заниматься такого рода оптимизацией.
#### **NoSQL**
Часто толковые SQL-разработчики берут какую-нибудь MongoDB, о которой говорят на каждом углу, и пытаются примерить к своему проекту, но разобравшись с ней, недоумевающе крутят пальцем у виска. Бестолковые так и остаются на MongoDB, мирясь с отсутствием транзакций и отношений между документами, ради мифической скорости и возможности засунуть в документ любой json.
Нет, MongoDB даже среди документных СУБД — так себе, а уж в качестве альтернативы полноценным реляционным её в принципе нельзя рассматривать. А вот другая документная СУБД — OrientDB, бьёт реляционные по всем фронтам. Да, OrientDB на самом деле документная СУБД, которая, благодаря прямым ссылкам между документами позволяет описывать произвольные графы.
Давайте развеем несколько типичных мифов по поводу NoSQL, о котором судят по наиболее громким представителям — MongoDB и Redis:
1. Они не контролируют структуру записываемых пользователем данных. У отсутствия схем есть и плюсы (можно делать миграции данных в фоне, можно хранить не только кортежи примитивов), но и минусы (нужно внимательно следить что записываешь в базу, не эффективно хранятся данные). В OrientDB нашли разумный компромисс: вы можете указать схему и указанные там поля будут валидироваться в соответствии с ней при записи и не будут тратить место на имена полей, а не указанные валидироваться не будут, но будут занимать чуть больше места. Тут важно отметить, что изменение схемы не приводит к изменению самих документов — просто вы не сможете изменить их пока не приведёте к новому формату.
2. Они не удовлетворяют требованиям [ACID](https://ru.wikipedia.org/wiki/ACID) (Атомарность, Согласованность, Изолированность, Надёжность). OrientDB этим требованиям удовлетворяет. Более того, она из коробки умеет партицирование и мастер-мастер репликацию, так что поддерживает в том числе и распределённые транзакции. При этом вы можете регулировать баланс между согласованностью и скоростью ответа:
writeQuorum определяет число узлов, которые должны подтвердить запись, прежде чем СУБД вернёт ответ, об успешном завершении транзакции.
readQuorum определяет число узлов, которые должны подтвердить актуальность данных, прежде чем данные вернутся в ответ на запрос.
По умолчанию все транзакции синхронны (дожидаемся ответа всех реплик), а чтение соответственно происходит без подтверждения актуальности (за её не надобностью в этом случае).
Примечательной особенностью является прозрачная поддержка map-reduce: если узел содержит не все данные, то он сам делает запрос к остальным узлам и сливает их ответы. Клиент может работать с партицированной базой данных как с цельной. Есть даже автобалансировщик, раскидывающий документы в кластеры по разным стратегиям.
3. Они не поддерживают SQL и предоставляют лишь простой специализированный API. OrientDB написана на Java и может быть интегрирована в другое Java приложение в качестве библиотеки. При этом есть [несколько уровней публичного API](http://orientdb.com/docs/last/Tutorial-Java.html):
Объектное. Низкоуровневый доступ к записям. Не рекомендуется к использованию, так как через него вы можете нарушить совместимость с двумя остальными API.
Документное. Тут вы имеете весь основной функционал основанный на документах и перекрёстных ссылках.
Графовое. Оно предоставляет дополнительные удобства для организации графов, но на практике всё же удобней оказалось использовать документное апи.
В качестве фронтенда к этим Java-API есть несколько библиотек, позволяющих писать запросы на разных языках (SQL, Gremlin, SPARQL).
Можно расширять функционал плагинами на Java. Собственно Lucene индекс и админка реализованы в качестве плагинов.
Так что не все NoSQL одинаково бесполезны :-)
#### **NewSQL**
Для сравнения подходов работы с графовой и реляционной СУБД, давайте создадим простейшую бизнес сущность — персону:
SQL
```
create table Persons (
name text,
age smallint
)
```
OSQL
```
create class Person
create property Person.name string
create property Person.age short
```
Тут всё просто и почти одинаково. Теперь добавим отношение «друзья»:
SQL
```
create table Persons_friends (
subject integer,
object integer
)
create unique index Persons_friends on Persons_friends ( subject , object )
```
OSQL
```
create property Person.friend linkset Person
```
Недостатки РСУБД уже начинают вылезать — нам потребовалась дополнительная таблица и уникальный индекс на ней. Индекс этот с одной стороны гарантирует, что у нас не будет дубликатов связей, а с другой позволяет быстро находить друзей по идентификатору пользователя.
Выведем основные данные о друзьях одного из пользователей:
SQL
```
select
Persons.rowid ,
Persons.name ,
Persons.age
from
Persons_friends as friends,
Persons
where
friends.subject = 123 ,
friends.object = Persons.rowid
```
OSQL
```
select expand( friend )
from #19:0
fetchplan *:-2 name:0 age:0
```
В РСУБД мы не можем хранить ссылки между записями — только их идентификаторы. Поэтому появляется хитрая конструкция, объясняющая как данные из одной таблицы соотносятся с другой. В графовой же мы просто разворачиваем ссылки.
А теперь найдём друзей его друзей:
SQL
```
select
Persons_1.rowid ,
Persons_1.name ,
Persons_1.age ,
Persons_2.rowid ,
Persons_2.name ,
Persons_2.age
from
Persons_friends as friends_1 ,
Persons_friends as friends_2 ,
Persons as Persons_1 ,
Persons as Persons_2
where
friends_1.subject = 123 ,
friends_1.object = Persons_1.rowid ,
friends_1.object = friends_2.subject ,
friends_2.object = Persons_2.rowid
```
OSQL
```
select expand( friend )
from #19:0
fetchplan *:-2
name:0
age:0
friend.name:0
friend.age:0
```
В РСУБД запрос заметно усложнился. По хорошему его нужно усложнить ещё сильнее, чтобы данные друзей первого уровня не дублировались для каждого друга второго уровня.
Продолжать можно долго, но суть, я думаю, уже ясна. Немного больше подробностей о различиях реляционного подхода и графового можно почерпнуть из презентации "[How Graph Databases started the Multi Model revolution](//www.slideshare.net/lvca/how-graph-databases-started-the-multi-model-revolution "How Graph Databases started the Multi Model revolution")".
На последок отмечу, что в реляционных базах данные хранятся таблицами, но они крайне не эффективны при запросах, поэтому к ним добавляют автогенерируемое дерево — индекс. Причём индексы стараются делать покрывающими, то есть не требующими обращения к собственно таблицам за данными. Так вот, если вырезать таблицы и позволить индексному дереву иметь циклы, то мы получим ни что иное как графовую СУБД, где вся база данных — это один большой максимально эффективный индекс.
#### **Хватит теории. Что на практике-то?**
Последний год я занимался разработкой бэкенда для проекта [SKEDDY](https://skeddy.pro/) (Поиск мастеров и запись к ним на услуги). Звучит вроде бы не сложно, однако число бизнес сущностей сейчас уже равно 20 (20 таблиц сущностей, если бы я использовал РСУБД): person, mail, phone, social, token, application, profession, service, meeting, assessment, album, image, notification, place, track, payment, article, aspect, facet, salon.
Между ними порядка 50 отношений, из них около 20 являются многими-ко-многим (ещё 20 таблиц смежностей и 20-40 индексов в РСУБД). В OrientDB же потребовался лишь один индекс для трансляции внешних айдишников во внутренние (внешние — человекопонятные и изменяемые, внутренние — персистентные и «странные»), один для фасетного поиска услуг плюс ещё пяток полнотекстовых и всё. Граф полностью нормализован, большинство запросов идут по прямым ссылкам между узлами, что позволяет делать глубокие выборки, не теряя в производительности и наглядности запросов.
Благодаря графовой модели данных, отображение на неё бизнес модели происходит легко и просто — единожды написанный простой обобщённый код для синхронизации с базой данных, позволил программировать в терминах бизнес сущностей без лишних забот об оптимизации запросов к СУБД. Собственно борьба с AngularJS отняла куда больше времени, но это уже совсем другая история…
Теперь о недостатках:
[Документация](http://orientdb.com/docs/last/) довольно не плоха для основного функционала, но некоторые аспекты в ней отражены крайне слабо. Например, информацию о хуках приходится собирать по крупицам.
Больше что-то на ум ничего не приходит :-)
На этом всё. Кто заинтересовался, но что-то недопонял — не стесняйтесь задавать вопросы в комментариях. | https://habr.com/ru/post/267079/ | null | ru | null |
# Как покрасить вкладку Chrome

Если вы заходили с мобильного хрома в фейсбук, то наверняка видели, что интерфейс браузера красится в фирменный синий цвет соцсети. Но зачем и как?
Мобильные сайты все больше походят на приложения, нежели на просто сайт с информацией, и Google поддерживает эту тенденцию. Посмотрите хотя бы на то, что в последних версиях мобильного хрома по умолчанию вкладки браузера смешиваются со списком недавно запущенных приложений. Но что не хватает сайту, чтобы стать еще чуточку больше приложением? Конечно же кастомизации оболочки (интрефейса). [Начиная с 39 версии хрома](https://developers.google.com/web/updates/2014/11/Support-for-theme-color-in-Chrome-39-for-Android) для Android Lollipop была внедрена возможность менять цвет интерфейса браузера веб-разработчиками.
Сделать это просто, нужно в добавить новый мета-тег:
```
```
Как видно из кода, в content мы записываем цвет, в который окрасится браузер.
Google также рекомендует использовать иконку высокого качества, чтобы это выглядело еще лучше:
```
```
Через инспектор устройств хрома, я сделал пример, как это могло бы выглядеть на мобильной версии хабра:

Замечание: Если у пользователя не включено смешивание вкладок с приложениями, то он увидит выбранный вами цвет вкладки на вашем сайте, но в списке вкладок, она по прежнему будет серой.
P.S. Мне хотелось бы, чтобы этот цвет можно было задавать через css, так как это более логичный вариант, да и можно было бы воспользоваться переменной… | https://habr.com/ru/post/277753/ | null | ru | null |
# Vim и переключение раскладки клавиатуры
 Все команды Vim нужно вводить на английском языке. Если основной текст вводится на каком-либо другом языке, то это представляет из себя проблему, т.к. нужно часто переключать раскладку. Одно из решений представлено [тут](http://habrahabr.ru/post/98393/), однако оно заставляет привыкать к новой горячей клавише для переключения раскладки. Так же существует множество платформенно-зависимых решений с вызовом тех или иных утилит. Целью плагина [vim-xkbswitch](http://www.vim.org/scripts/script.php?script_id=4503) является предоставить единое поведение для многих операционных систем и языков.
Предысторию разработки плагина с моей стороны можно посмотреть [тут](http://habrahabr.ru/post/162483/), со стороны Алексея [тут](http://lin-techdet.blogspot.com/2012/04/vim.html) и [тут](http://lin-techdet.blogspot.com/2012/12/vim-xkb-switch-libcall.html).
Плагин использует платформенно-зависимые библиотеки для смены раскладки средствами операционной системы. На данный момент поддерживаются:
1. UNIX / X Server через библиотеку [xkb-switch](https://github.com/ierton/xkb-switch)
2. Windows 32/64bit, для которой пришлось сделать свой [велосипед](https://github.com/DeXP/xkb-switch-win)
3. Mac OS X через [Xkbswitch-macosx](https://github.com/myshov/xkbswitch-macosx)
Так что кроме непосредственной установки плагина в Vim необходимо эти библиотеки скачать и указать в конфиге Vim, откуда эти библиотеки загружать. Например, под Windows работающий функционал можно получить так:
1. Скачать и установить плагин: [отсюда](http://www.vim.org/scripts/script.php?script_id=4503) либо [отсюда](https://github.com/lyokha/vim-xkbswitch)
2. Скачать библиотеку переключения языка (бинарные файлы для [32-х бит](http://download.dexp.in/libxkbswitch32.dll) и для [64-х бит](http://download.dexp.in/libxkbswitch64.dll), около 5kb) и скопировать её в корневую директорию вима
3. Добавить в vimrc следующие строки:
```
let g:XkbSwitchEnabled = 1
let g:XkbSwitchIMappings = ['ru']
```
Приближаемся к ещё одной интересной возможности плагина — добавление локализованных горячих клавиш. Например, если я в режиме редактирования нажму v, то у меня отобразится NerdTree. Но если я редактирую текст на русском языке, то будет нажато "м" и плагин, естественно, не запустится. Однако если опция плагина «g:XkbSwitchIMappings» установлена, то плагин переберёт все маппинги режима редактирования с создаст аналогичные локализованные, т.е. добавит для меня "м".
По умолчанию из коробки поддерживаются маппинги только для русского языка. Однако плагин умеет загружать языковые карты из файла, что позволит создать локализованные imap'ы для любого языка. Под Windows это может помочь сделать [charmapgen](https://github.com/DeXP/xkb-switch-win/tree/master/charmap).
Если есть желание получить работающий плагин под другую ОС, то нужно сделать Vim-совместимую библиотеку. У кого есть желание и возможность — пишите в личку. | https://habr.com/ru/post/175709/ | null | ru | null |
# Два с половиной приема при работе с argparse

Приемы, описанные здесь, есть в официальной документации к модулю *argparse* (я использую Python 2.7), ничего нового я не изобрел, просто, попользовавшись ими некоторое время, убедился в их мощности. Они позволяют улучшить структуру программы и решить следующие задачи:
1. Вызов определенной функции в ответ на заданный параметр командной строки с лаконичной диспетчеризацией.
2. Инкапсуляция обработки и валидации введенных пользователем данных.
Побудительным мотивом к написанию данной заметки стало обсуждение в тостере приблизительно такого вопроса:
> как вызвать определенную функцию в ответ на параметр командной строки
и ответы на него в духе
> я использую argparse и if/elif
> посмотрите в сторону sys.argv
В качестве подопытного возьмем сферический скрипт с двумя ветками параметров.
```
userdb.py append
userdb.py show
```
Цель, которую позволяет достичь первый прием, будет такой:
***хочу, чтобы для каждой ветки аргументов вызывалась своя функция, которая будет отвечать за обработку всех аргументов ветки, и чтобы эта функция выбиралась автоматически модулем argparse, без всяких if/elif, и еще чтобы… стоп, достаточно пока.***
Рассмотрим первый прием на примере первой ветви аргументов **append**.
```
import argparse
def create_new_user(args):
"""Эта функция будет вызвана для создания пользователя"""
#скучные проверки корректности данных, с ними разберемся позже
age = int(args.age)
User.add(name=args.username, age=args.age)
def parse_args():
"""Настройка argparse"""
parser = argparse.ArgumentParser(description='User database utility')
subparsers = parser.add_subparsers()
parser_append = subparsers.add_parser('append', help='Append a new user to database')
parser_append.add_argument('username', help='Name of user')
parser_append.add_argument('age', help='Age of user')
parser_append.set_defaults(func=create_new_user)
# код для других аргументов
return parser.parse_args()
def main():
"""Это все, что нам потребуется для обработки всех ветвей аргументов"""
args = parse_args()
args.func(args)
```
теперь, если пользователь запустит наш скрипт с параметрами, к примеру:
```
userdb.py append RootAdminCool 20
```
в недрах программы будет вызвана функция *create\_new\_user()*, которая все и сделает. Поскольку у нас для каждой ветви будет сконфигурирована своя функция, точка входа *main()* получилась по-спартански короткой. Как вы уже заметили, вся хитрость кроется в вызове метода *set\_defaults()*, который и позволяет задать фиксированный параметр с предустановленным значением, в нашем случае во всех ветках должен быть параметр **func** со значением — вызываемым объектом, принимающим один аргумент.
Кстати, пользователь, если у него возникнет такое желание, не сможет «снаружи» подсунуть свой параметр в качестве func, не влезая в скрипт (у меня не вышло, по крайней мере).
Теперь ничего не остается, кроме как рассмотреть второй прием на второй ветке аргументов нашего userdb.py.
```
userdb.py show
```
Цель для второго приема сформулируем так: **хочу, чтобы данные, которые передает пользователь, не только валидировались, ~~это слишком просто,~~ но и чтобы моя программа оперировала более комплексными объектами, сформированными на основе данных пользователя. В нашем примере, хочу, чтобы программа, вместо userid получала объект ORM, соответствующий пользователю с заданным ID.**
Обратите внимание, как в первом приеме, в функции *create\_new\_user()*, мы делали «нудные проверки» на валидность данных. Сейчас мы научимся переносить их туда, где им самое место.
В *argparse*, в помощь нам, есть параметр, который можно задать для каждого аргумента — **type**. В качестве **type** может быть задан любой исполняемый объект, возвращающий значение, которое запишется в свойство объекта *args*. Простейшими примерами использования *type* могут служить
```
parser.add_argument(..., type=file)
parser.add_argument(..., type=int)
```
но мы пройдем по этому пути немного дальше:
```
import argparse
def user_from_db(user_id):
"""Возвращает объект-пользователя, если id прошел валидацию, или
генерирует исключение.
"""
# валидируем user_id
id = int(user_id)
return User.select(id=id) # создаем объект ORM и передаем его программе
def print_user(args):
"""Отображение информации о пользователе.
Обращаем внимание на то, что args.userid содержит уже не ID, а объект ORM.
Этот факт запутывает, но ниже мы с этим разберемся (те самые пол-приема уже близко!)
"""
user_obj = args.userid
print str(user_obj)
def parse_args():
"""Настройка argparse"""
parser = argparse.ArgumentParser(description='User database utility')
# код для других аргументов
subparsers = parser.add_subparsers()
parser_show = subparsers.add_parser('show', help='Show information about user')
parser_show.add_argument('userid', type=user_from_db, help='ID of user')
parser_show.set_defaults(func=print_user)
return parser.parse_args()
```
Точка входа *main()* не меняется!
Теперь, если мы позже поймем, что заставлять пользователя вводить ID как параметр жестоко, мы можем спокойно переключиться на, к примеру, username. Для этого нам потребуется только изменить код *user\_from\_db()*, а функция *print\_user()* так ни о чем и не узнает.
Используя параметр **type**, стоит обратить внимание на то, что исключения, которые возникают внутри исполняемых объектов, переданных как значения этого параметра, обрабатываются внутри *argparse*, до пользователя доводится информация об ошибке в соответствующем аргументе.
##### Пол-приема.
Данный трюк не заслужил звания полноценного приема, поскольку является расширением второго, но это не уменьшает его пользы. Если взглянуть на документацию (я про \_\_doc\_\_) к *print\_user()* мы увидим, что на вход подается *args.userid*, в котором, на самом деле, уже не ID, а более сложный объект с полной информацией о пользователе. Это запутывает код, требует комментария, что некрасиво. Корень зла — несоответствие между информацией, которой оперирует пользователь, и той информацией, которой оперирует наша программа.
Самое время сформулировать задачу:
**хочу, чтобы названия параметров были понятны пользователю, но, при этом, чтобы код, работающий с этими параметрами был выразительным.**
Для этого у позиционных аргументов в *argparse* есть параметр **metavar**, задающий отображаемое пользователю название аргумента (для опциональных аргументов больше подойдет параметр **dest**).
Теперь попробуем модифицировать код из второго примера, чтобы решить задачу.
```
def print_user(args):
"""Отображение информации о пользователе"""
print str(args.user_dbobj)
def parse_args():
"""Настройка argparse"""
# код для других аргументов
parser = argparse.ArgumentParser(description='User database utility')
subparsers = parser.add_subparsers()
parser_show = subparsers.add_parser('show', help='Show information about user')
parser_show.add_argument('user_dbobj', type=user_from_db, metavar='userid', help='ID of user')
parser_show.set_defaults(func=print_user)
return parser.parse_args()
```
Сейчас пользователь видит свойство *userid*, а обработчик параметра — *user\_dbobj*.
По-моему получилось решить обе 2.5 поставленные задачи. В результате код, обрабатывающий данные от пользователя, отделен от основного кода программы, точка входа программы не перегружена ветвлениями, а пользователь и программа работают каждый в своих терминах.
Рабочий код примера, где уже сразу все “по феншую” находится [здесь](https://gist.github.com/brake/a1a002d4238c66ee186a#file-argparse_demo-py). | https://habr.com/ru/post/252333/ | null | ru | null |
# Go быстрее Rust, Mail.Ru Group сделала замеры
С такой фразой мне кинули ссылку на статью компании Mail.Ru Group от 2015 [«Как выбрать язык программирования?»](https://habrahabr.ru/company/mailru/blog/273341/). Если кратко, они сравнили производительность Go, Rust, Scala и Node.js. За первое место боролись Go и Rust, но Go победил.
Как написал автор статьи [gobwas](https://habrahabr.ru/users/gobwas/) (здесь и далее орфография сохранена):
> Эти тесты показывают, как ведут себя голые серверы, без «прочих нюансов» которые зависят от рук программистов.
К моему большому сожалению, тесты не были эквивалентными, ошибка всего лишь в 1 строчке кода поставила под сомнение объективность и вывод статьи.
В статье будет много копипасты из исходной статьи, но я надеюсь, что мне это простят.
Суть тестов
-----------
> При тестировании выяснилось, что все претенденты работают примерно с одинаковой производительностью в такой постановке — все упиралось в производительность V8. Однако реализация задания не была лишней — разработка на каждом из языков позволила составить значительную часть субъективных оценок, которые так или иначе могли бы повлиять на окончательный выбор.
Итак, мы имеем два сценария. Первый — это просто приветствие по корневому URL:
```
GET / HTTP/1.1
Host: service.host
HTTP/1.1 200 OK
Hello World!
```
Второй — приветствие клиента по его имени, переданному в пути URL:
```
GET /greeting/user HTTP/1.1
Host: service.host
HTTP/1.1 200 OK
Hello, user
```
Первоначальный исходный код тестов
----------------------------------
**Node.js**
```
var cluster = require('cluster');
var numCPUs = require('os').cpus().length;
var http = require("http");
var debug = require("debug")("lite");
var workers = [];
var server;
cluster.on('fork', function(worker) {
workers.push(worker);
worker.on('online', function() {
debug("worker %d is online!", worker.process.pid);
});
worker.on('exit', function(code, signal) {
debug("worker %d died", worker.process.pid);
});
worker.on('error', function(err) {
debug("worker %d error: %s", worker.process.pid, err);
});
worker.on('disconnect', function() {
workers.splice(workers.indexOf(worker), 1);
debug("worker %d disconnected", worker.process.pid);
});
});
if (cluster.isMaster) {
debug("Starting pure node.js cluster");
['SIGINT', 'SIGTERM'].forEach(function(signal) {
process.on(signal, function() {
debug("master got signal %s", signal);
process.exit(1);
});
});
for (var i = 0; i < numCPUs; i++) {
cluster.fork();
}
} else {
server = http.createServer();
server.on('listening', function() {
debug("Listening %o", server._connectionKey);
});
var greetingRe = new RegExp("^\/greeting\/([a-z]+)$", "i");
server.on('request', function(req, res) {
var match;
switch (req.url) {
case "/": {
res.statusCode = 200;
res.statusMessage = 'OK';
res.write("Hello World!");
break;
}
default: {
match = greetingRe.exec(req.url);
res.statusCode = 200;
res.statusMessage = 'OK';
res.write("Hello, " + match[1]);
}
}
res.end();
});
server.listen(8080, "127.0.0.1");
}
```
**Go**
```
package main
import (
"fmt"
"net/http"
"regexp"
)
func main() {
reg := regexp.MustCompile("^/greeting/([a-z]+)$")
http.ListenAndServe(":8080", http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
switch r.URL.Path {
case "/":
fmt.Fprint(w, "Hello World!")
default:
fmt.Fprintf(w, "Hello, %s", reg.FindStringSubmatch(r.URL.Path)[1])
}
}))
}
```
**Rust**
```
extern crate hyper;
extern crate regex;
use std::io::Write;
use regex::{Regex, Captures};
use hyper::Server;
use hyper::server::{Request, Response};
use hyper::net::Fresh;
use hyper::uri::RequestUri::{AbsolutePath};
fn handler(req: Request, res: Response) {
let greeting\_re = Regex::new(r"^/greeting/([a-z]+)$").unwrap();
match req.uri {
AbsolutePath(ref path) => match (&req.method, &path[..]) {
(&hyper::Get, "/") => {
hello(&req, res);
},
\_ => {
greet(&req, res, greeting\_re.captures(path).unwrap());
}
},
\_ => {
not\_found(&req, res);
}
};
}
fn hello(\_: &Request, res: Response) {
let mut r = res.start().unwrap();
r.write\_all(b"Hello World!").unwrap();
r.end().unwrap();
}
fn greet(\_: &Request, res: Response, cap: Captures) {
let mut r = res.start().unwrap();
r.write\_all(format!("Hello, {}", cap.at(1).unwrap()).as\_bytes()).unwrap();
r.end().unwrap();
}
fn not\_found(\_: &Request, mut res: Response) {
\*res.status\_mut() = hyper::NotFound;
let mut r = res.start().unwrap();
r.write\_all(b"Not Found\n").unwrap();
}
fn main() {
let \_ = Server::http("127.0.0.1:8080").unwrap().handle(handler);
}
```
**Scala**
```
package lite
import akka.actor.{ActorSystem, Props}
import akka.io.IO
import spray.can.Http
import akka.pattern.ask
import akka.util.Timeout
import scala.concurrent.duration._
import akka.actor.Actor
import spray.routing._
import spray.http._
import MediaTypes._
import org.json4s.JsonAST._
object Boot extends App {
implicit val system = ActorSystem("on-spray-can")
val service = system.actorOf(Props[LiteActor], "demo-service")
implicit val timeout = Timeout(5.seconds)
IO(Http) ? Http.Bind(service, interface = "localhost", port = 8080)
}
class LiteActor extends Actor with LiteService {
def actorRefFactory = context
def receive = runRoute(route)
}
trait LiteService extends HttpService {
val route =
path("greeting" / Segment) { user =>
get {
respondWithMediaType(`text/html`) {
complete("Hello, " + user)
}
}
} ~
path("") {
get {
respondWithMediaType(`text/html`) {
complete("Hello World!")
}
}
}
}
```
Подлый удар в спину
-------------------
Я спрятал ошибку под спойлер, дабы дать желающим возможность проверить свои навыки.
**Don't click**Дело в том, что в примере Node.js и Go компиляция регулярного выражения происходит единожды, тогда как в Rust компиляция выполняется на каждый запрос. Про Scala ничего сказать не могу.
Выдержка из документации к [regex](https://doc.rust-lang.org/regex/regex/index.html) для Rust:
> #### Example: Avoid compiling the same regex in a loop
>
>
>
>
>
> It is an anti-pattern to compile the same regular expression in a loop since compilation is typically expensive. (It takes anywhere from a few microseconds to a few milliseconds depending on the size of the regex.) Not only is compilation itself expensive, but this also prevents optimizations that reuse allocations internally to the matching engines.
>
>
>
> In Rust, it can sometimes be a pain to pass regular expressions around if they're used from inside a helper function. Instead, we recommend using the lazy\_static crate to ensure that regular expressions are compiled exactly once.
>
>
>
> For example:
>
>
>
>
> ```
> #[macro_use] extern crate lazy_static;
> extern crate regex;
>
> use regex::Regex;
>
> fn some_helper_function(text: &str) -> bool {
> lazy_static! {
> static ref RE: Regex = Regex::new("...").unwrap();
> }
> RE.is_match(text)
> }
>
> fn main() {}
> ```
>
>
> Specifically, in this example, the regex will be compiled when it is used for the first time. On subsequent uses, it will reuse the previous compilation.
Выдержка из документации к [regex](https://github.com/StefanSchroeder/Golang-Regex-Tutorial/blob/master/01-chapter1.markdown) для Go:
> But you should avoid the repeated compilation of a regular expression in a loop for performance reasons.
Как допустили такую ошибку? Я не знаю… Для такого прямолинейного теста это является существенной просадкой в производительности, ведь даже в комментариях автор указал на тормознутость регулярок:
> Спасибо! Я тоже думал было переписать на split во всех примерах, но потом показалось, что с regexp будет более жизненно. При оказии попробую прогнать wrk со split.
Упс.
Восстанавливаем справедливость
------------------------------
**Исправленный тест Rust**
```
extern crate hyper;
extern crate regex;
#[macro_use] extern crate lazy_static;
use std::io::Write;
use regex::{Regex, Captures};
use hyper::Server;
use hyper::server::{Request, Response};
use hyper::net::Fresh;
use hyper::uri::RequestUri::{AbsolutePath};
fn handler(req: Request, res: Response) {
lazy\_static! {
static ref GREETING\_RE: Regex = Regex::new(r"^/greeting/([a-z]+)$").unwrap();
}
match req.uri {
AbsolutePath(ref path) => match (&req.method, &path[..]) {
(&hyper::Get, "/") => {
hello(&req, res);
},
\_ => {
greet(&req, res, GREETING\_RE.captures(path).unwrap());
}
},
\_ => {
not\_found(&req, res);
}
};
}
fn hello(\_: &Request, res: Response) {
let mut r = res.start().unwrap();
r.write\_all(b"Hello World!").unwrap();
r.end().unwrap();
}
fn greet(\_: &Request, res: Response, cap: Captures) {
let mut r = res.start().unwrap();
r.write\_all(format!("Hello, {}", cap.at(1).unwrap()).as\_bytes()).unwrap();
r.end().unwrap();
}
fn not\_found(\_: &Request, mut res: Response) {
\*res.status\_mut() = hyper::NotFound;
let mut r = res.start().unwrap();
r.write\_all(b"Not Found\n").unwrap();
}
fn main() {
let \_ = Server::http("127.0.0.1:3000").unwrap().handle(handler);
}
```
Я умышленно исправил только лишь багу, а стиль кода оставил без изменений.
### Окружение
Все тесты запускались на локалхосте, без всяких виртуалок, ибо лень. Будет замечательно, если автор предоставит бенчмарки со своего железа, я вставлю апдейтом, вот специально для него [репозиторий с тестами](https://github.com/kpp/rust_vs_go_habr_273341), где, кстати, зафиксированы растовые библиотеки на момент написания оригинальной статьи 2015.12.17 (я надеюсь, что все).
1. Ноут
* Intel® Core(TM) i7-6820HQ CPU @ 2.70GHz, 4+4
* CPU Cache L1: 128 KB, L2: 1 MB, L3: 8 MB
* 8+8 GB 2133MHz DDR3
2. Десктоп
* Intel® Core(TM) i3 CPU 560 @ 3.33GHz, 2+2
* CPU Cache L1: 64 KB, L2: 4 MB
* 4+4 GB 1333MHz DDR3
3. go 1.6.2, released 2016/04/20
4. rust 1.5.0, released 2015/12/10. Да, я специально взял старую версию Rust.
5. Простите, любители Scala и Node.js, этот холивар не про вас.
Интрига
-------
**ab**
Попробуем выполнить 50 000 запросов за 10 секунд, с 256 возможными параллельными запросами.
#### Десктоп
`ab -n50000 -c256 -t10 "http://127.0.0.1:3000/`
| Label | Time per request, ms | Request, #/sec |
| --- | --- | --- |
| Rust | 11.729 | 21825.65 |
| Go | 13.992 | 18296.71 |
`ab -n50000 -c256 -t10 "http://127.0.0.1:3000/greeting/hello"`
| Label | Time per request, ms | Request, #/sec |
| --- | --- | --- |
| Rust | 11.982 | 21365.36 |
| Go | 14.589 | 17547.04 |
#### Ноут
`ab -n50000 -c256 -t10 "http://127.0.0.1:3000/"`
| Label | Time per request, ms | Request, #/sec |
| --- | --- | --- |
| Rust | 8.987 | 28485.53 |
| Go | 9.839 | 26020.16 |
`ab -n50000 -c256 -t10 "http://127.0.0.1:3000/greeting/hello"`
| Label | Time per request, ms | Request, #/sec |
| --- | --- | --- |
| Rust | 9.148 | 27984.13 |
| Go | 9.689 | 26420.82 |
— Подожди, — скажет читатель. — И стоило тебе строчить статью ради каких-то 500rps?! Ведь это доказывает, что не важно на чем писать, все языки одинаковые!
И тут вступает в дело мой шнур. Шнур для зарядки ноутбука, разумеется.
#### Ноут на подзарядке
`ab -n50000 -c256 -t10 "http://127.0.0.1:3000/"`
| Label | Time per request, ms | Request, #/sec |
| --- | --- | --- |
| Rust | 5.601 | 45708.98 |
| Go | 6.770 | 37815.62 |
`ab -n50000 -c256 -t10 "http://127.0.0.1:3000/greeting/hello"`
| Label | Time per request, ms | Request, #/sec |
| --- | --- | --- |
| Rust | 5.736 | 44627.28 |
| Go | 6.451 | 39682.85 |
Стой, Go, ты куда?

Выводы
------
Я допускаю, что статья компании Mail.Ru Group содержала непреднамеренную ошибку. Тем не менее, за 1.5 года ее прочитали **45 тысяч раз**, и её выводы могли сформировать предвзятое отношение в пользу Go при выборе инструментов, ведь Mail.Ru Group, несомненно, прогрессивная и технологичная компания, к чьим словам стоит прислушаться.
И всё это время Rust совершенствовался, посмотрите на «The Computer Language Benchmarks Game» **Rust** vs **Go** за [2015](https://web.archive.org/web/20150924132832/https://benchmarksgame.alioth.debian.org/u64q/compare.php?lang=rust&lang2=go) и [2017](https://web.archive.org/web/20170316050138/https://benchmarksgame.alioth.debian.org/u64q/compare.php?lang=rust&lang2=go) года. Отрыв в производительности только растет.
Если тебе, дорогой читатель, по нраву Go, пиши на нём. Но не стоит сравнивать его производительность с Rust, ибо она будет не в пользу твоего любимого языка, уж точно не на таких синтетических тестах.
Я надеюсь, что я был объективен и непредвзят, справедливость восторжествовала, а моя статья не содержит ошибок.
**Let the Holy War begin!** | https://habr.com/ru/post/338268/ | null | ru | null |
# Как мы парсили декларации о доходах при помощи открытых данных
Уже второй год я занимаюсь государственными открытыми данными РФ и работой с госорганами и пора бы начинать рассказывать интересные истории о том, как появляются данные. Однако сегодня речь пойдет о более привычной для разработчика области — парсинге данных для проекта «Декларатор» и о том, какую неожиданную пользу могут при этом принести открытые данные.

«Декларатор» — это постоянно пополняемая база деклараций о доходах и имуществе публичных должностных лиц: депутатов, чиновников, судей, представителей региональной и муниципальной власти, иных органов, госкорпораций и госкомпанией. Проект работает как информационно-справочная база для СМИ, активистов, занимающихся общественным контролем, и исследователей.
В России сведения о доходах должны публиковать более миллиона человек.
Интересный факт: существуют единые правила для госсайтов по размещению деклараций о доходах (в частности, они всегда находятся в разделе «Противодействие коррупции») и отвечает за всю эту тему Министерство труда и социальной защиты РФ. Массовое размещение деклараций происходит в мае. Далее у Минтруда есть всего месяц на то, чтобы провести мониторинг по всем без исключения сайтам, обязанным размещать информацию. Мониторинг проводится вручную.
Есть несколько проблем, связанных с публикацией деклараций:
* каждое ведомство делает это на собственном сайте;
* не существует единого стандарта для публикации деклараций;
* информацию могут удалить вскоре после публикации;
* являясь общедоступными по закону, декларации до сих пор не публикуются в машиночитаемом виде.
**Матчасть**
Согласно пункту 2 Порядка размещения сведений о доходах, расходах, об имуществе и обязательствах имущественного характера отдельных категорий лиц и членов их семей на официальных сайтах федеральных государственных органов, органов государственной власти субъектов Российской Федерации и организаций и предоставления этих сведений общероссийским средствам массовой информации для опубликования, утвержденного [Указом Президента Российской Федерации от 8 июля 2013 г. № 613 «Вопросы противодействия коррупции»](http://goo.gl/Ikr9Xk), федеральные государственные органы власти, Центральный банк Российской Федерации, Пенсионный фонд Российской Федерации, Фонд социального страхования Российской Федерации, Федеральный фонд обязательного медицинского страхования, государственные корпорации (компании), иные организации, созданные на основании федеральных законов, обязаны публично размещать сведения о доходах за прошедший календарный год.
Интересующиеся могут прочитать подробности в [приказе Минтруда 530н](http://www.rosmintrud.ru/docs/mintrud/orders/157/), а если кратко: раздел «Противодействие коррупции» должен находиться в одном клике от главной страницы и содержать несколько обязательных подразделов с жестко заданными названиями, среди которых нас интересует один – «Сведения о доходах, расходах, об имуществе и обязательствах имущественного характера». Именно в нем, без ограничения доступа, в табличной форме, в том числе в форматах .doc, .docx, .excel, .rtf (п.15 Требований), размещаются декларации о доходах госчиновников.
При этом, как прямо указано в документе, «должна быть обеспечена возможность поиска по тексту файла и копирования фрагментов текста» — вот это и делает возможным создание парсеров.
О декларациях
-------------
Декларация о доходах каждого чиновника содержит информацию об объектах недвижимости, находящихся в собственности, в пользовании, сведения о транспортных средствах, сведения о доходах и источниках доходов. В декларации перечислены не только чиновники, но и члены их семей. Если повезет, сводный файл создается по предложенному Минтрудом [шаблону формы сведений о доходах](http://www.rosmintrud.ru/docs/mintrud/orders/157/Prilozhenie_1.doc), что сильно облегчает задачи написания универсального парсера.

Первым объектом интереса стало Министерство образования и науки. Пробный [парсер](https://github.com/Shorstko/DeclaratorParser), для [деклараций о доходах федеральных государственных служащих за 2014 год](http://%D0%BC%D0%B8%D0%BD%D0%BE%D0%B1%D1%80%D0%BD%D0%B0%D1%83%D0%BA%D0%B8.%D1%80%D1%84/media/events/files/41d56010ef2047959b2c.doc) на 306 человек, был написан быстро и достаточно безболезненно. После этого мы решили перейти к тому, что обычно вызывает наибольшее количество запросов исследователей – сведениям о доходах ректоров вузов. И тут-то начались сложности с [декларациями за 2014 год подведомственных учреждений Минобрнауки](http://%D0%BC%D0%B8%D0%BD%D0%BE%D0%B1%D1%80%D0%BD%D0%B0%D1%83%D0%BA%D0%B8.%D1%80%D1%84/media/events/files/41d56010e2e950409427.doc).
Быстрый анализ показал, что только ректоров в этом файле 272 человека и их явно надо как-то группировать. Группировать решили по регионам. Однако в декларации указывается лишь должность и название учреждения.
Почти три сотни уникальных высших учебных заведений разыскивать руками совсем не хотелось. Вот здесь и пригодились открытые данные Рособрнадзора под названием [«Реестр организаций, осуществляющих образовательную деятельность по аккредитованным образовательным программам»](http://obrnadzor.gov.ru/otkrytoe-pravitelstvo/opendata/7701537808-raoo/) (**upd: исправлена ссылка 10.06.2021**). Реестр очень информативный, но имеет достаточно сложный формат и заслуживает отдельной статьи. К чести Рособрнадзора, он представлен в формате xml вместо традиционного для госорганов csv, и не содержит ошибок в структуре, поэтому его удалось использовать в качестве базы данных без какой-либо предварительной обработки.
О задаче
--------
Итак, исходная задача: вытащить из декларации о доходах данные по ректорам, определить для них регион и сгенерировать файлы xml [специального формата](https://goo.gl/xZO54G) для плагина Заполнятор, через который происходит загрузка данных на сайт Декларатора.

Плагин имитирует действия пользователя на сайте, автоматически заполняя формы. И как выяснилось в процессе тестирования, у него есть ограничения на количество записей, которые он способен обработать за один раз…
На входе имеем [файл формата .doc](http://%D0%BC%D0%B8%D0%BD%D0%BE%D0%B1%D1%80%D0%BD%D0%B0%D1%83%D0%BA%D0%B8.%D1%80%D1%84/media/events/files/41d56010e2e950409427.doc), содержащий в себе данные о доходах 1561 чиновников. Так как нам нужны данные не только по чиновникам, но и по членам их семей, по факту мы должны обработать информацию по 3347 людям.
Реализация
----------
Детали реализации парсера деклараций смотрите на [гитхабе](https://github.com/Shorstko/DeclaratorParser), скажу только, что понадобилось много предварительной обработки для удаления лишних и зачастую неожиданных символов: *@"[\r\n\a\b\u000b]"*, а также шаманство с транспортными средствами, до сих пор не законченное из-за таких вот случаев (это одна ячейка таблицы в MS Word):

Реестр
------
Переходим к основной задаче – матчингу названий вузов деклараций и реестра Рособрнадзора. Ее решение с подбором регулярных выражений в результате заняло значительно больше времени, чем написание самого парсера. Хотя кода там получилось намного меньше.
Записи для каждой лицензии в реестре Рособрнадзора имеют (в очень сокращенном виде) такую структуру:
```
г. Москва
77
федеральное государственное бюджетное образовательное учреждение высшего профессионального образования «Московский государственный университет дизайна и технологии»
ФГБОУ ВПО «МГУДТ»
58302c2c-16f2-0772-3cf1-ebacbde89ecd
федеральное государственное бюджетное образовательное учреждение высшего профессионального образования «Московский государственный университет дизайна и технологии»
ФГБОУ ВПО «МГУДТ»
г. Москва
77
…
```
*EduOrgFullName* — это сведения о самой лицензии, для головной организации. В тегах *ActualEducationOrganization* содержится информация обо всех учреждениях, подчиненных головной организации (а их может быть очень много — институты в составе университета, филиалы и многое другое). Поэтому решение выглядело просто и очевидно: найти соответствия названий из деклараций для тега *FullName* или *ShortName* реестра и выяснить, какой регион им соответствует.
Особенности реестра: в качестве кавычек используются исключительно «елки», наименование типа учреждения («федеральное государственное…») в теге FullName записывается полностью в нижнем регистре.
Препроцессинг
-------------
Однако, по-видимому, формат написания названий вузов в декларациях был ограничен лишь фантазией тех, кто подавал декларации. В итоге имеем разнообразие регистров и написаний, от *Федеральное государственное бюджетное учреждение высшего образования «Московский государственный университет технологий и управления имени К.Г. Разумовского (ПКУ)»* и *ФГАОУ ВПО «Национальный исследовательский ядерный университет „МИФИ“ до ФГАОУ „ВПО БФУ ИМ.И.КАНТА“* (причем в другом месте декларации он был записан уже как *ФГАОУ ВПО „Балтийский федеральный университет имени Иммануила Канта“*). Свой вуз я долго не могла найти парсером. Неудивительно для *ФГБОУ ВПО „МГУДТ“*…
Большое разнообразие наблюдалось в написании кавычек. В основном в декларациях записаны прямые «английские» кавычки вместо привычных русских елочек, самый убийственный вариант для парсинга был *»Санкт-Петербургский государственный электротехнический университет «ЛЭТИ» им. В.И. Ульянова (Ленина)"* (похоже, его не осилил и парсер хабра). Дважды встретились экзотические *«“”»* (Волгоград, Москва), а в Ростове додумались до варианта *ФГБОУ ВПО <<Ростовский государственный экономический университет (РИНХ)>>* (между прочим, 10 вхождений в декларации).
Так вот, оказалось, что XPath в xml ищет очень быстро, умеет находить частичные соответствия, но увы – только в полном соответствии с регистром букв. Если переопределить функцию поиска, проблема исчезает, и с ней заодно исчезает и скорость.
Первым делом пришлось убрать повторяющуюся часть — тип учреждения — и оставить только фактическое название. И здесь ждало открытие: помимо ФГБОУ (а также ФГАОУ, ФГБУ) ВПО, ДПО ли ВО оказалось, что есть еще учреждения «инклюзивного высшего образования», то есть ФГБОУИ ВО… А стандартная формулировка «федеральное государственное бюджетное образовательное учреждение высшего профессионального образования» может заменяться на «федеральное государственное бюджетное учреждение высшего профессионального образования» — сможете найти отличие?
В итоге получилась вот такая конструкция на регулярных выражениях:
```
orgname = Regex.Replace(orgname, @"(.*)(ФГ(Б|А)ОУ\s)((В|Д)П?О)?", "");
orgname = Regex.Replace(orgname,
@"(федеральн[а-яё]*\s|Федеральн[а-яё]*\s)?(государственн[а-яё]*\s|Государственн[а-яё]*\s)?(.*)?(учрежден[а-яё]*\s|Учрежден[а-яё]*\s)(инклюзивн[а-яё]*\s|инклюзивн[а-яё]*\s)?(дополнит[а-яё]*\s|Дополнит[а-яё]*\s|высше[а-яё]*\s|Высше[а-яё]*\s)(профессиональн[а-яё]*\s|Профессиональн[а-яё]*\s)?(образован[а-яё]*|Образован[а-яё]*)", "");
orgname = Regex.Replace(orgname, @"(федеральн[а-яё]*\s|Федеральн[а-яё]*\s)?(государственн[а-яё]*\s|Государственн[а-яё]*\s)?(.*)?(учрежден[а-яё]*\s|Учрежден[а-яё]*\s)", "");
```
Причем порядок команд здесь имеет большое значение. Ну и борьба с кавычками:
```
if (orgname.Contains("<<"))
orgname = Regex.Replace(orgname, @"(.*<<)(.+)(>>.*)", "$2");
if (orgname.Contains('«'))
orgname = Regex.Replace(orgname, @"(.*«)(.+)(».*)", "$2");
if (orgname.Contains('“'))
orgname = Regex.Replace(orgname, @"(.*“)(.+)(”.*)", "$2");
```
Большая проблема оказалась с вузами, которые были названы в чью-то честь, так как:
* могли встретиться варианты «им.» и «имени» и в различных регистрах;
* само имя могло быть написано любым вариантом в любом регистре и с любым количеством пробелов (или без них), например: ИМ.И.КАНТА, имени Ивана Федорова, им. В.И. Ульянова (Ленина), им.Н.И.Лобачевского.
Из-за непредсказуемости написания было проще убрать «имени кого» целиком:
```
orgname = Regex.Replace(orgname, "(имени.*)", "");
orgname = Regex.Replace(orgname, @"(им\..*)", "");
```
К счастью, название вуза при этом не теряло в уникальности.
И все равно оставались «упрямые» случаи, которые не хотели находиться никаким образом. Это были вузы, названия которых состояли из аббревиатур: ЛЭТИ, НИНХ, СТАНКИН и снова мой любимый МГУДТ. Решение:
```
Match tempmatch = Regex.Match(orgname, @"[А-ЯЁ]{2,}");
tempname = orgname.Substring(tempmatch.Index, tempmatch.Length);
```
Как ни странно, даже после этого в неопознанные попало несколько десятков вузов. Анализ показал, что часть их них были написаны с опечатками, в основном из-за пропуска или перестановки букв. Лидером стала опечатка «Москвоский». А в Кузбассе, судя по капсу, очень любят свой вуз, но вот грамотность у них подкачала: *«Федеральное государственное бюджетное образовательное учереждение высшего профессионального образования КУЗБАССКИЙ ГОСУДАРСТВЕННЫЙ ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ ИМЕНИ Т.Ф. ГОРБАЧЕВА»*.
Много проблем было с пробелами:
* в реестре Рособрнадзора в некоторых названия попадаются сдвоенные пробелы;
* в названиях некоторых вузов есть тире. И эти тире абсолютно по-разному могли сочетаться с пробелами. Например, в декларации прописан *«Волгодонский инженерно — технический институт — филиал федерального государственного автономного образовательного учреждения высшего профессионального образования «Национальный исследовательский ядерный университет „МИФИ“»*, в реестре то же самое название выглядит как *«Волгодонский инженерно-технический институт…»*. При этом был и такой случай: *«Федеральное государственное бюджетное образовательное учреждение высшего профессионального образования „Государственный университет — учебно-научно-производственный комплекс“»*.
Но количество неопознанных вузов почему-то не спешило сокращаться. И дело было в совсем неожиданной проблеме, которая в итоге привела к модификации алгоритма поиска. Оказалось, что лицензия на образовательную деятельность могла быть зарегистрирована на одно название учреждения, а официальное название вуза чуть-чуть, но отличалось. Например, были пары «академия – университет», «институт – университет».
В реестре это выглядело так:
```
федеральное государственное бюджетное образовательное учреждение высшего профессионального образования «Брянская государственная инженерно-технологическая академия»
ФГБОУ ВПО «БГИТА»)
```
и
```
федеральное государственное бюджетное образовательное учреждение высшего образования «Брянский государственный инженерно-технологический университет»
ФГБОУ ВО «Брянский государственный инженерно-технологический университет», ФГБОУ ВО «БГИТУ», БГИТУ
```
Причем в декларации могло быть указано любое из них. Несколько вузов по не известной пока причине вообще не имели тегов FullName и ShortName.
Отдельно про Крым: *»федеральное государственное автономное образовательное учреждение высшего образования «Крымский федеральный университет имени В.И. Вернадского»* вообще не имело в реестре указания на регион.
Окончательная на данный момент [версия алгоритма парсинга](https://github.com/Shorstko/DeclaratorParser) выдает вот такие [результаты](https://goo.gl/EIUw3z).
Пример готового [файла для Заполнятора](https://goo.gl/Xk56n2) (вузы для г.Москва).
Немного статистики
------------------
В декларации подведов Минобрнауки 1561 работников организаций, вместе с членами семей их 3347 человек, в файле 770 страниц, неожиданно 32 таблицы.
272 ректора, т.е. более 272 уникальных вузов, из них 8 вузов написаны с ошибками или опечатками.
4 вуза вообще не значатся в реестре Рособрнадзора. Это:
* Федеральное государственное бюджетное образовательное учреждение высшего образования «Арктический государственный институт культуры и искусств»;
* Федеральное государственное бюджетное образовательное учреждение дополнительного профессионального образования «Государственный институт новых форм обучения»;
* Федеральное государственное бюджетное образовательное учреждение дополнительного профессионального образования «Институт непрерывного образования взрослых»;
* Федеральное государственное бюджетное образовательное учреждение дополнительного профессионального образования «Новомосковский институт повышения квалификации руководящих работников и специалистов химической промышленности».
В заключение еще раз [ссылка на проект](https://github.com/Shorstko/DeclaratorParser). Парсер будет работать и на декларациях других госорганов, созданных по тому же шаблону.
Полезные ссылки
---------------
НПА:
[Указ Президента Российской Федерации от 8 июля 2013 г. № 613 «Вопросы противодействия коррупции»](http://goo.gl/Ikr9Xk), ст. 6 про обязанности Министерства труда и социальной защиты.
[Указ Президента Российской Федерации от 8 июля 2013 г. № 613 «Вопросы противодействия коррупции»](http://goo.gl/Ikr9Xk), Порядок размещения сведений о доходах, расходах, об имуществе и обязательствах имущественного характера отдельных категорий лиц и членов их семей на официальных сайтах федеральных государственных органов, органов государственной власти субъектов Российской Федерации и организаций и предоставления этих сведений общероссийским средствам массовой информации для опубликования про обязанности Министерства труда и социальной защиты, п. 4 «Сведения о доходах, расходах, об имуществе и обязательствах имущественного характера … ежегодно обновляются в течение 14 рабочих дней со дня истечения срока, установленного для их подачи».
[Указ Президента Российской Федерации от 8 июля 2013 г. № 613 «Вопросы противодействия коррупции»](http://goo.gl/Ikr9Xk), Статья 8. Обязанность представлять сведения о доходах, об имуществе и обязательствах имущественного характера.
Все НПА по [антикоррупционному законодательству](http://fsin.su/anticorrup2014/document/zakonodatelstvo/).
[НПА Минтруда](http://www.rosmintrud.ru/ministry/anticorruption/legislation/1)
Программирование:
[Сервис проверки регулярных выражений](http://planetcalc.ru/708/)
[Хелп по регулярным выражениям в C#](http://professorweb.ru/my/csharp/charp_theory/level4/4_10.php)
[Классы знаков регулярных выражений для C#](https://msdn.microsoft.com/ru-ru/library/20bw873z%28v=vs.110%29.aspx), а также проект с простой реализацией безрегистрового поиска по xml: [ссылка](http://www.codeproject.com/Articles/15372/Custom-XPath-Functions). | https://habr.com/ru/post/301436/ | null | ru | null |
# Ускоряем трафаретные вычисления: сборка и запуск YASK на процессорах Intel
Трафаретные вычисления нашли широкое применение в научных и технических приложениях. Их используют для решения дифференциальных уравнений методом конечных разностей, в задачах вычислительной механики.
Высокопроизводительные вычисления (HPC, High Performance Computing), идёт ли речь о суперкомпьютере, или о системе, построенной на одном-двух многоядерных процессорах – это вычисления параллельные. Если алгоритм поддаётся разбивке на блоки, которые можно обрабатывать одновременно, это значит, что он способен будет эффективно исполняться в параллельной среде. Но не только это важно: не стоит забывать об оптимизации кода, учитывающей, кроме прочего, особенности работы с данными на уровне отдельных видов памяти, доступной процессорам. В частности, речь идёт об эффективной работе с кэш-памятью.
[](https://habrahabr.ru/company/intel/blog/305128/)
При прочих равных условиях, распараллеленный алгоритм, который лучше всего учитывает особенности кэш-памяти, будет работать быстрее других. И, естественно, если говорить о скорости вычислений, то код, который наиболее полно использует возможности конкретной платформы, на уровне инструкций и архитектуры процессора, окажется в выигрыше. Существуют специализированные программные пакеты для подготовки такого кода. Один из них – YASK.
Что такое YASK
--------------
[YASK](https://01.org/yask), или Yet Another Stencil Kernel – это набор инструментов для разработки приложений, использующих трафаретные вычисления, призванный облегчить исследование и проектирование вычислительных ядер HPC и их оптимизацию. YASK задействует такие техники, как свёртка векторов, разбиение циклов на блоки для повышения эффективности использования кэш-памяти, управление размещением данных в памяти, настройка структуры циклов, временное разбиение на блоки волн вычислений и другие.
YASK содержит специализированный транслятор, который конвертирует обычную трафаретную программу на C++ в SIMD-оптимизированный код.
Здесь мы поговорим о настройке вычислительных ядер для процессоров Intel Xeon Phi и Intel Xeon. А именно, такая настройка способна заставить код на Xeon Phi работать до 2.8 раз быстрее, чем на Intel Xeon.
Преимущества в производительности у Intel Xeon Phi можно отнести к более высокой пропускной способности его подсистемы памяти и 512-битным SIMD-инструкциям.
О трафаретных вычислениях
-------------------------
Очень важная сфера высокопроизводительных вычислений заключается в использовании трафаретных вычислений для работы с временными и пространственными значениями данных. Например, ядро типичного трёхмерного итеративного трафаретного алгоритма Якоби можно показать в следующем псевдокоде, который обходит точки в трёхмерной сетке:
```
for t = 1 to T do
for i = 1 to Dx do
for j = 1 to Dy do
for k = 1 to Dz do
u(t + 1, i, j, k) ← S(t, i, j, k)
end for
end for
end for
end for
```
Здесь T – это количество шагов по параметру времени, Dx, Dy, и Dz – размерности пространства задачи а S(t, i, j, k) – трафаретная функция.
В случае очень простых одномерных и двумерных трафаретных вычислений, современные компиляторы нередко способны распознать шаблоны доступа к данным и оптимизировать создаваемый код для того, чтобы он мог воспользоваться особенностями векторных регистров, учитывал бы длину строк кэша. Но, для более сложных вычислений, которые планируется производить на современных процессорах, оснащённых несколькими ядрами, использующих общую память, с задачей производства оптимального кода большинство компиляторов не справляется.
YASK – это инструмент, который позволяет программисту экспериментировать с различными способами распределения данных в памяти, включая свёртку векторов и оптимизацию структур циклов, которые могут привести к получению более производительного кода, нежели тот, который получен после обычных оптимизаций компиляторов. В настоящее время YASK сосредоточен на оптимизации в пределах одного вычислительного узла OpenMP.
Вот, как выглядит типичная модель работы с YASK.

*Высокоуровневая модель работы с YASK*
Начало работы
-------------
Полное руководство по работе с YASK можно найти [на сайте YASK](https://github.com/01org/yask/blob/master/docs/YASK-intro.pdf). Здесь мы рассмотрим сборку и запуск заданий YASK на Intel Xeon Phi и Intel Xeon, но сначала поговорим о некоторых методах оптимизации, применяемых в данном наборе инструментов.
Многомерная векторизация
------------------------
Многомерная векторизация, или свёртка векторов, это процесс заполнения векторных регистров блоками данных, при этом блоки необязательно расположены в том порядке, в котором они следуют в исходных данных. Это нужно для оптимизации повторного использования данных и содержимого кэша. Вот [материал](https://software.intel.com/sites/default/files/managed/3b/f4/vec-folding-hpcc15.pdf), из которого вы можете узнать подробности о многомерной векторизации и её применении в трафаретных вычислениях. Ручная свёртка векторов– это сложная задача, чреватая ошибками. YASK же предлагает программный инструмент для преобразования стандартного кода, предусматривающего последовательное выполнение операций, в новый код, который, после компиляции, позволяет производить более быстрые и эффективные вычисления.
Тонкая настройка структуры циклов
---------------------------------
В комбинации со свёрткой векторов, использование нескольких потоков для исполнения циклов даёт дополнительный прирост производительности вычислений. YASK, позволяя программисту экспериментировать со структурой цикла посредством инструментов OpenMP, даёт ещё один путь оптимизации кода: оптимизацию циклов.
Есть три основных подхода к настройке циклов:
* «Rank» – задача разбивается на области OpenMP.
* «Region» – области OpenMP разбивают на блоки кэша.
* «Block» – производится проход по каждому векторному кластеру в блоке кэша.
Исследование производительности вычислений
------------------------------------------
Здесь мы рассмотрим два примера сборки и запуска ядер YASK на процессорах Intel Xeon и Intel Xeon Phi.
В системе на Intel Xeon задействован процессор Dual Socket Intel Xeon E5-2697 v4 2.3 ГГц с включенным режимом Turbo. На один сокет приходится 18 ядер, всего в системе 36 ядер (72 потока, режим HT включён). Тестовая платформа оснащена 128 Гб DDR4-памяти (2400 МГц), на ней установлена ОС Red Hat Enterprise Linux Server 7.2.
В системе на Intel Xeon Phi используется процессор Intel Xeon Phi 7250 (68 ядер, 272 потока). Частота ядра составляет 1400 МГц, частота вспомогательных систем процессора – 1700 МГц. Здесь имеется 16 Гб MCDRAM, 7.2 Гт/с (используется режим Flat). В системе есть 96 Гб DDR4-памяти (2400 МГц), используется режим quad cluster. Версия BIOS – 86B.0010.R00, установленная ОС – Red Hat Enterprise Linux Server 6.7.
Код, инструкции по сборке и запуску которого мы рассмотрим ниже, можно загрузить [отсюда](https://github.com/01org/yask).
### Задача AWP-ODC
Одно из вычислительных трафаретных ядер, включённых в YASK – это [awp-odc](http://hpgeoc.sdsc.edu/AWPODC). Здесь используется сетка с двойной системой узлов, ядро реализует метод конечных разностей, используемый для приближённого решения трёхмерных динамических уравнений теории упругости. Приложения, которые используют это ядро, моделируют эффект землетрясений, что помогает проектировать сооружения, находящиеся в зоне риска. Пространство задачи состоит из 1024\*384\*768 узлов сетки. Использование процессора Intel Xeon Phi 7250 для решения данной задачи даёт прирост в производительности до 2.8 раз по сравнению с процессором Intel Xeon E5-2697 v4.
*Результаты тестирования на задаче AWP-ODC*
Вот, как проведён этот тест.
В системе на **Intel Xeon** надо выполнить следующие команды:
```
make stencil=awp arch=hsw cluster=x=2,y=2,z=2 fold=y=8 omp_schedule=guided mpi=1
./stencil-run.sh -arch hsw -ranks 2 -bx 74 -by 192 -bz 20 -pz 2 -dx 512 -dy 384 -dz 768
```
В системе на **Intel Xeon Phi** это делается так:
```
make stencil=awp arch=knl INNER_BLOCK_LOOP_OPTS='prefetch(L1,L2)'
./stencil-run.sh -arch knl -bx 128 -by 32 -bz 32 -dx 1024 -dy 384 -dz 768
```
### Задача ISO3DFD
Ещё одно трафаретное ядро, включённое в YASK – это iso3dfd. Оно занимается решением акустического изотропного волнового уравнения 16-го порядка дискретизации по пространству и 2-го порядка дискретизации по времени. Подобные вычисления используются в приложениях сейсмической визуализации, применяемыми компаниями, занимающимися сейсморазведкой, при поиске нефтяных и газовых месторождений. Пространство задачи состоит из 1536\*1024\*768 узлов сетки. Применение к этой задаче процессора Intel Xeon Phi 7250 позволяет улучшить производительность до 2.6 раз по сравнению с Intel Xeon E5-2697 v4.
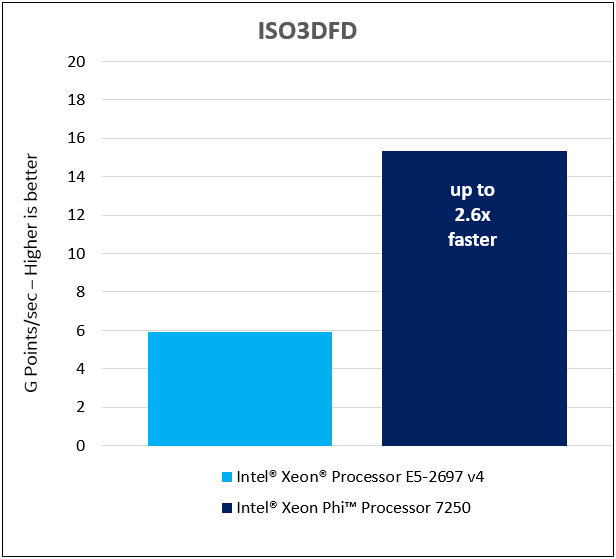
*Результаты тестирования на задаче ISO3DFD*
Вот, как мы проводили это испытание.
В системе, построенной на базе **Intel Xeon**, используются следующие команды:
```
make stencil=iso3dfd arch=hsw mpi=1
./stencil-run.sh -arch hsw -ranks 2 -bx 256 -by 64 -bz 64 -dx 768 -dy 1024 -dz 768
```
На платформе, оснащённой **Intel Xeon Phi**, используется такая последовательность команд:
```
make stencil=iso3dfd arch=knl
./stencil-run.sh -arch knl -bx 192 -by 96 -bz 96 -dx 1536 -dy 1024 -dz 768
```
Итоги
-----
Высокопроизводительные вычисления – это область, где наилучших результатов можно достичь благодаря объединению нескольких факторов. Среди них – правильный подбор алгоритмов, их оптимизация, использование мощных современных платформ для проведения расчётов.
Набор инструментов YASK и процессор Intel Xeon Phi 7250 способны дать науке и бизнесу всё необходимое для быстрого решения сложных практических задач. | https://habr.com/ru/post/305128/ | null | ru | null |
# UDB. Что же это такое? Часть 6. Модуль управления и статуса/Status and Control Module

В прошлых статьях-переводах документации Cypress очень предметно рассматривался операционный автомат — Datapath. Постепенно переходим к изучению других модулей UDB, в частности — модуль управления и статуса.
Общее содержание цикла «UDB. Что же это такое?»
[Часть 1. Введение. PLD.](https://habr.com/post/432764/)
[Часть 2. Datapath.](https://habr.com/post/433018/)
[Часть 3. Datapath FIFO.](https://habr.com/ru/post/434706/)
[Часть 4. Datapath ALU.](https://habr.com/ru/post/437096/)
[Часть 5. Datapath. Полезные мелочи.](https://habr.com/ru/post/438818/)
Часть 6. Модуль управления и статуса. (Текущая статья)
[Часть 7. Модуль управления тактированием и сбросом](https://habr.com/ru/post/449108/)
[Часть 8. Адресация UDB](https://habr.com/ru/post/452606/)
21.3.3. Модуль управления и статуса
-----------------------------------
Высокоуровневый вид модуля управления и статуса показан на рисунке 21-28. Состояния битов регистра управления передаются на трассировочные ресурсы, давая программе возможность управлять поведением UDB. Регистр статуса получает данные из трассировочных линий, благодаря чему программа может производить мониторинг операций, выполняемых UDB.

*Рисунок 21-28. Регистры управления и статуса.*
Подробнее структура модуля управления и статуса показана на рисунке 21-29. Основной целью этого блока является координация взаимодействия программы процессорного ядра с работой внутренних элементов UDB. Однако из-за сильной связи с трассировочной матрицей этот блок может быть сконфигурирован для выполнения других функций.

*Рисунок 21-29. Модуль управления и состояния.*
Режимы работы:
* **Ввод статуса/Status Input**. Состояние линий, заведённых извне, может быть введено и захвачено, как статус, после чего — считано CPU или DMA.
* **Вывод управления/Control Output**. CPU или DMA могут записать данные в регистр управления. Эти данные будут задавать состояние линий, уходящих в трассировочные ресурсы.
* **Параллельный ввод/Parallel Input** – к параллельному входу Datapath.
* **Параллельный вывод/Parallel Output** – от параллельного выхода Datapath .
* **Режим счетчика/Counter Mode**. В этом режиме регистр управления работает как 7-битный убывающий счетчик с программируемым периодом и автоматической перезагрузкой. Входы трассировочных каналов могут быть сконфигурированы для управления как включением, так и сбросом счетчика. Когда этот режим активирован, функциональность регистра управления недоступна.
* **Синхронный режим/Sync Mode**. В этом режиме регистр статуса работает как 4-битный двойной синхронизатор. Когда этот режим активирован, функциональность регистра статуса недоступна.
21.3.3.1 Режим управления и статуса (Status and Control Mode)
-------------------------------------------------------------
При работе в режиме управления и статуса этот модуль работает как регистр статуса, регистр прерывания наложения маски и регистр управления в конфигурации, показанной на рисунке 21-30.

*Рисунок 21-30. Работа управления и статуса.*
#### Работа регистра статуса
Каждому UDB доступен один 8-битный регистр статуса. Данные на вход этого регистра поступают от любого сигнала цифровой трассировочной структуры. Регистр статуса разрушаемый: он теряет свое состояние во время сна и после пробуждения имеет значение 0х00. Каждый бит можно независимо запрограммировать на работу в одном из двух режимов.
Таблица 21-19. Регистр статуса.
| **STAT MD** | **Описание** |
| --- | --- |
| 0 | Обычное чтение. Возвращает текущее значение входного сигнала. |
| 1 | Залипание, очищается при чтении. Высокий уровень на входе защёлкивается
по тактовому сигналу. Очищается после того, как регистр прочитан. |
Важной особенностью операции очистки регистра статуса является то, что очищаются только взведенные биты. Это позволяет остальным битам продолжать захват статуса для сохранения непрерывности процесса.
#### Обычное чтение статуса
По умолчанию, CPU прозрачно считывает состояние соответствующей цепи. Этот режим можно использовать для чтения данных, защёлкнутых внутри UDB.
#### Залипание статуса с очисткой после чтения
В этом режиме входные сигналы регистра статуса дискретизируются на каждом цикле тактирования управления и статуса. Если сигнал на данном такте высокий, он захватывается в бит статуса и остается высоким, вне зависимости от последующих состояний входа. Когда CPU или DMA считывает регистр статуса, бит очищается. Очистка регистра статуса не зависит от режима и происходит даже при отключенном тактировании UDB; оно базируется на тактировании шины и происходит в рамках операции чтения.
#### Защелкивание статуса во время чтения
Рисунок 21-31 показывает структуру логики чтения статуса. За регистром залипающего статуса следует защелка, которая защелкивает данные регистра статуса и держит его стабильным во время цикла чтения, вне зависимости от количества тактов ожиданий в текущей операции чтения.

*Рисунок 21-31. Логика чтения статуса.*
#### Генерация прерываний
В большинстве функций генерация прерываний привязана к параметрам битов статуса. Как показано на рисунке 21-31, эта особенность встроена в логику регистра статуса в виде операции наложения маски и применения операции **ИЛИ** к статусу. Только младшие 7 бит входа статуса можно использовать вместе со встроенными генераторами прерываний. Старший бит (Most Significant Bit, MSB) обычно используется в качестве выхода прерывания и может быть проброшен на контроллер прерываний при помощи цифровых трассировочных каналов. В этой конфигурации из старшего бита регистра статуса считывается состояние бита запроса на прерывание.
21.3.3.2 Работа регистра управления (Control Register Operation)
----------------------------------------------------------------
Каждому UDB доступен один 8-битный регистр управления. Он работает как стандартный регистр чтения/записи на системной шине, где выход этих битов регистров управляют линиями цифровой трассировочной структуры.
Регистр управления разрушаемый: он теряет свое состояние во время сна и после пробуждения имеет значение 0х00.
#### Режимы работы регистра управления
Каждый бит может быть сконфигурирован в одном из трех режимов. Конфигурация задаётся при помощи объединения битов двух 8-битных регистров CTL\_MD1[7:0] и CTL\_MD0[7:0]. Например, {CTL\_MD1[0], CTL\_MD0[0]} управляет режимом нулевого бита регистра управления (см. таблицу 21-20).
Таблица 21-20. Режим нулевого бита регистра управления
| **CTL MD** | **Описание** |
| --- | --- |
| 00 | Прямой режим / Direct Mode |
| 01 | Синхронный режим / Sync Mode |
| 10 | (зарезервировано) |
| 11 | Импульсный режим / Pulse Mode |
#### Прямой режим регистра управления
По умолчанию, режим является прямым. Как показано на рисунке 21-32, когда в регистр управления записывает CPU или DMA, на том же цикле выход регистра управления направляется напрямую на трассировочную линию.

*Рисунок 21-32. Прямой режим регистра управления.*
#### Синхронный режим регистра управления
В синхронном режиме, как показано на рисунке 21-33, выход регистра управления пересинхронизируется с тактированием равным текущему тактированию управления и статуса (Status and Control, SC). Это позволяет управлять временными диаграммами выхода на выбранной частоте SC, а не на частоте тактирования шины.

*Рисунок 21-33. Синхронный режим регистра управления.*
#### Импульсный режим регистра управления
Импульсный режим похож на синхронный режим, так как в нем бит управления повторно дискретизируется на частоте SC; импульс начинается на первом цикле тактирования SC и следует за циклом записи шины. Выход бита управления задается в течение одного полного цикла тактирования SC. В конце данного цикла тактирования бит управления автоматически сбрасывается.
При таком режиме работы программа может записать 1 в бит регистра управления для генерации импульса. После того как биту присвоено значение 1, программа будет читать его как 1 до завершения импульса, после чего он будет считываться как 0. После этого программа может записать еще одну 1, чтобы начать новый импульс. Таким образом, подавать импульс получится не чаще, чем на каждом втором такте сигнала SC.
#### Сброс регистра управления
Регистр управления имеет два режима сброса, управляемых битом конфигурации EXT RES, как показано на рисунке 21-34. Когда EXT RES равен 0 (по умолчанию), в синхронном или импульсном режиме трассируемый вход сброса сбрасывает синхронизированный выход, но не сам бит управления. Когда EXT RES равен 1, трассируемый вход сброса сбрасывает как бит управления, так и синхронизированный выход.

*Рисунок 21-34. Сброс регистра управления.*
21.3.3.3 Режим параллельного ввода/вывода (Parallel Input/Output Mode)
----------------------------------------------------------------------
В этом режиме трассировка управления и статуса подключена к сигналам parallel in и parallel out (параллельный ввод/вывод) Datapath. Чтобы активировать этот режим, необходимо взвести биты конфигурации SC OUT для выбора параллельного выхода Datapath. Связь с parallel input (параллельным входом) всегда доступна, однако эти трассировочные связи разделяются со входами регистров статуса, входам управления счетчиком и выходам прерывания.

*Рисунок 21-35. Режим параллельного ввода/вывода.*
21.3.3.4 Режим счётчика (Counter Mode)
--------------------------------------
Как показано на рисунке 21-36, когда блок работает в режиме счётчика, 7-битный убывающий счётчик доступен для использования как для операций внутри UDB, так и для нужд программы. К особенностям счётчика относятся:
* 7-битный регистр периода, (доступен для чтения/записи).
* 7-битный регистр счета, (доступен для чтения/записи). Доступ возможен только при остановленном счётчике.
* Автоматическая перезагрузка периода в регистр счёта при достижении нуля.
* Программно доступный бит управления в регистре вспомогательного управления CNT START, используемый для запуска и остановки счётчика. (Он перекрывает аппаратный сигнал ENABLE и должен быть установлен, чтобы опциональный аппаратный сигнал ENABLE начал функционировать).
* Выбираемые биты трассировочных каналов опционального динамического управления счётчика для функций запуска и загрузки:
— EN, трассируемый сигнал для запуска или остановки счёта.
— LD, трассируемый сигнал загрузки, который вызывает перезагрузку периода. Когда этот сигнал взведен, он перекрывает ожидающий сигнал окончания счёта. Он чувствителен к уровню, и пока сигнал взведён, период продолжает загружаться.
* 7-битный счётчик может передаваться в трассировочные ресурсы как sc\_out[6:0].
* Сигнал окончания счёта может входить в трассировочные ресурсы как sc\_out[7].
* В режиме «по умолчанию» для сигнала окончания счёта используется режим с защёлкиванием. В альтернативном режиме он переключается в комбинационный режим.
* В режиме «по умолчанию» опциональный аппаратный сигнал EN, если он используется, должен быть установлен для разрешения работы аппаратного сигнала LD. В альтернативном режиме аппаратные сигналы LD и EN независимы.

*Рисунок 21-36. Режим счётчика*
> ***Примечание переводчика:***
>
> Примерно к этому месту я понял, что совершенно ничего не понимаю из документа. Нигде не рассказывается про эти режимы «по умолчанию» и «альтернативный». После долгих поисков, удалось найти какой-никакой, а пример.
>
> Файл: C:\Program Files (x86)\Cypress\PSoC Creator\4.2\PSoC Creator\psoc\content\CyComponentLibrary\CyComponentLibrary.cylib\bScanComp\_v1\_10\bScanComp\_v1\_10.v
>
> Поясняющий код:
>
>
>
> 
>
>
>
> **То же самое текстом:**
> ```
> cy_psoc3_count7 #(.cy_period(Period),.cy_route_ld(0),.cy_route_en(1), .cy_alt_mode(1))
> ChannelCounter(
> /* input */ .clock(clk_int),
> /* input */ .reset(1'b0),
> /* input */ .load(1'b0),
> /* input */ .enable(enable_int),
> /* output [06:00] */ .count(count),
> /* output */ .tc(tc_o)
> );
>
> ```
>
>
>
>
> Само же объявление компонента cy\_psoc3\_count7 я нашёл только для языка VHDL, похоже, для Verilog оно встроено в средства разработки. Теперь вы примерно знаете, где искать обсуждаемые биты настройки.
>
>
>
> Здесь же рассмотрим таинственные биты, которые называются то SC OUT CTL, то SC\_OUT\_CTL, но их значения не документированы. Их я не нашёл вообще нигде. Из текста ясно, что они переключают компонент STATUS\_CONTROL между режимами. Но в упомянутом ранее VHDL файле C:\Program Files (x86)\Cypress\PSoC Creator\4.2\PSoC Creator\warp\lib\lcpsoc3\cpsoc3.vhd
>
>
>
> **мы видим отдельно уже известный нам счётчик**
> ```
> component cy_psoc3_count7
> generic(cy_period : std_logic_vector (6 downto 0) := "1111111";
> cy_init_value : std_logic_vector (6 downto 0) := "0000000";
> cy_route_ld : boolean := false;
> cy_route_en : boolean := false;
> cy_alt_mode : boolean := false);
> port (clock : in std_logic;
> reset : in std_logic;
> load : in std_logic;
> enable : in std_logic;
> count : out std_logic_vector (6 downto 0);
> tc : out std_logic);
> end component;
>
> ```
>
>
>
>
> **отдельно — статус и управление**
> ```
> attribute atomic_rtl of cy_psoc3_status : component is rtl_generic;
> attribute cpu_access of cy_psoc3_status : component is true;
> component cy_psoc3_statusi
> generic(cy_force_order : boolean := false;
> cy_md_select : std_logic_vector (6 downto 0) := "0000000";
> cy_int_mask : std_logic_vector (6 downto 0) := "0000000");
> port (reset : in std_logic := '0';
> clock : in std_logic := '0';
> status : in std_logic_vector (6 downto 0);
> interrupt : out std_logic);
> end component;
>
> attribute atomic_rtl of cy_psoc3_statusi : component is rtl_generic;
> attribute cpu_access of cy_psoc3_statusi : component is true;
> component cy_psoc3_control
> generic(cy_init_value : std_logic_vector (7 downto 0) := "00000000";
> cy_force_order : boolean := false;
> cy_ctrl_mode_1 : std_logic_vector (7 downto 0) := "00000000";
> cy_ctrl_mode_0 : std_logic_vector (7 downto 0) := "00000000";
> cy_ext_reset : boolean := false);
> port (reset : in std_logic := '0';
> clock : in std_logic := '0';
> control : out std_logic_vector (7 downto 0));
> end component;
>
> ```
>
>
>
>
> **отдельно — синхронизатор**
> ```
> component cy_psoc3_sync
> port (clock : in std_logic := '0';
> sc_in : in std_logic;
> sc_out : out std_logic);
> end component;
>
> ```
>
>
>
>
> Повторю, что в Verilog версии этих объявлений совсем нет (есть только поведенческие модели в каталоге C:\Program Files (x86)\Cypress\PSoC Creator\4.2\PSoC Creator\warp\lib\sim, поэтому я считаю, что биты, устанавливающие режимы, простым программистам недоступны. При чтении этого раздела следует держать данный факт в уме. Кое-что даётся чисто для справки, нам, программистам, оно неподвластно.
Чтобы включить режим счётчика, в битах SC\_OUT\_CTI[1:0] должен быть выбран выход счётчика. В этом режиме нормальная работа регистра управления недоступна. В то же время, регистр статуса можно использовать для операций чтения, но для генерации прерывания его использовать не стоит, так как регистр наложения маски также используется в качестве регистра периода счётчика. Регистр периода не разрушается и сохраняет свое состояние после пробуждения. Для периода из N тактов, в регистр периода должно быть загружено значение N-1. Значение N = 1 (период равен нулю) в качестве значения делителя частоты не поддерживается и приведет к постоянной единице на выходе ТС (Terminal count, TC). Доступность режима SYNC зависит от того, используется динамическое управление (LD/EN) или нет. Если оно не используется, это не влияет на режим SYNC. Если оно используется, режим SYNC недоступен.
21.3.3.5 Синхронный режим (Sync Mode)
-------------------------------------
Как показано на рисунке 21-37, регистр статуса может работать как 4-битный двойной синхронизатор, тактируемый текущим значением SC\_CLK, если бит SYNC MD задан. Этот режим можно использовать для реализации локальной синхронизации асинхронных сигналов (например, входов GPIO). При этом синхронизируемые сигналы выбираются из SC\_IN[3:0], выходы пробрасываются на контакты SC\_IO\_OUT[3:0], а SYNC MD автоматически переводит контакты SC\_IO в режим выхода. В этом режиме нормальная работа регистра статуса недоступна, а режим залипающего бита статуса принудительно отключен, вне зависимости от настроек управления режима. Данный режим не влияет на регистр управления. Счётчик всё ещё можно использовать, но с ограничениями. При таком режиме работы нельзя использовать динамические входы (LD/EN).

*Рисунок 21-37. Синхронный режим.*
21.3.3.6 Тактирование управления и статуса (Status and Control Clocking)
------------------------------------------------------------------------
Регистры управления и статуса требуют выбора тактирования в любом из следующих режимов работы:
* регистр статуса с любым битом в режиме залипания с очисткой после чтения,
* регистр управления в режиме счётчика,
* синхронный режим.
Тактирование назначается в модуле тактирования и сброса. См. 21.3.4. Модуль управления тактированием и сбросом.
21.3.3.7 Вспомогательный регистр управления (Auxiliary Control Register)
------------------------------------------------------------------------
Вспомогательный регистр управления для чтения и записи – специальный регистр, который управляет жёстко заданной аппаратурой UDB. Этот регистр позволяет CPU или DMA динамически управлять прерываниями, FIFO и работой счётчика. Биты регистров и их описание приведены ниже:
| **Вспомогательный регистр управления** |
| --- |
| **7** | **6** | **5** | **4** | **3** | **2** | **1** | **0** |
| | | CNT
START | INT EN | FIFO1
LVL | FIFO0
LVL | FIFO1
CLR | FIFO0
CLR |
#### Очистка FIFO0 и FIFO1 (FIFO0 Clear, FIFO1 Clear)
Биты FIFO0 CLR и FIFO1 CLR используются для сброса состояния соответствующих FIFO. Когда в эти биты записывается 1, состояние соответствующего FIFO сбрасывается. Для продолжения работы FIFO в эти биты необходимо записать 0. Когда эти биты остаются взведенными FIFO работают как простые однобайтные буферы без статуса.
#### Уровень FIFO0 и FIFO1 (FIFO0 Level, FIFO1 Level)
Биты FIFO0 LVL и FIFO1 LVL задают уровень, при котором 4-байтный FIFO взводит статус шины (когда шина читает или записывает в FIFO). Значение статуса шины FIFO зависит от сконфигурированного направления, как показано в таблице ниже.
Таблица 21-21. Биты управления уровнем FIFO.
| **FIFOx
LVL** | **Режим ввода
(Шина записывает в FIFO)** | **Режим вывода
(Шина читает из FIFO)** |
| --- | --- | --- |
| 0 | **Не полон.**
Можно записать хотя бы 1 байт. | **Не пуст.**
Для чтения доступен хот бы 1 байт. |
| 1 | **Опустошен как минимум на половину.**
Можно записать хотя бы 2 байта. | **Заполнен как минимум на половину.**
Для чтения доступны хотя бы 2 байта. |
#### Активатор прерывания (Interrupt Enable)
Когда логика генерации регистра статуса активирована, бит INT EN разрешает прохождение сформированного сигнала прерывания.
#### Запуск счётчика/счёта? (Count Start)
Бит CNT START можно использовать для запуска и остановки счётчика (доступно только если биты SC\_OUT\_CTL[1:0] сконфигурированы для режима выхода счётчика).
21.3.3.8 Краткий итог по регистрам управления и статуса
-------------------------------------------------------
Таблица ниже обобщает функции регистров управления и статуса. Обратите внимание, что регистры наложения маски и управления совмещены с регистрами счетчиков и периода, а значение этих регистров не зависит от режима работы.
Таблица 21-22. Краткий итог по работе регистров управления и статуса
| Режим | Управление/Счётчик
(Control/Count) | Статус/Синхронизация
(Status/SYNC) | Наложение маски/Период
(Mask/Period) |
| --- | --- | --- | --- |
| Управление (Control) | Выход управления (Control Out) | Вход статуса или синхронизация (Status In or SYNC) | Наложение маски статуса (Status Mask) |
| Счётчик (Count) | Выход счётчика (Count Out) | Период счётчикаa (Count Period) |
| Статус (Status) | Выход управления или выход счётчика (Control Out or Count Out) | Вход статуса (Status In) | Наложение маски статуса (Status Mask) |
| Синхронизация (SYNC) | Синхронизация (SYNC) | Не доступноb (NA) |
а. – обратите внимание, что в режиме счётчика регистр наложения маски работает как регистр периода и не может работать как регистр наложения маски. Следовательно, выход прерывания недоступен при активированном режиме счётчика.
b. – обратите внимание, что в режиме синхронизации регистр статуса недоступен, а, следовательно, регистр наложения маски использовать невозможно. Однако его можно использовать в качестве регистра периода для режима счётчика.
Продолжение следует… | https://habr.com/ru/post/443380/ | null | ru | null |
# Пишем nest.js с нуля на typescript
Цитата из документации:
> Nest предоставляет готовую архитектуру приложений, которая позволяет разработчикам и командам создавать высокопроверяемые, масштабируемые, слабо связанные и легко обслуживаемые приложения. Архитектура в значительной степени вдохновлена Angular.
>
>
Nest построен на основе шаблона проектирования - dependency injection. Мы увидим как он реализован в Nest и как это влияет на весь остальной код.
Для начала посмотрим на самый простой код для запуска приложения nestjs из документации:
**main.ts**
```
import { NestFactory } from "@nestjs/core";
import { AppModule } from "./app.module";
async function bootstrap() {
const app = await NestFactory.create(AppModule);
await app.listen(3000);
}
bootstrap();
```
Итак. *NestFactory* главный класс nest с чего все и начинается. Его метод *create* сканирует существующие модули, которые доступны в дереве зависимостей из корневого модуля AppModule, после чего сканирует зависимости полученных модулей в виде контроллеров, сервисов и других модулей, и добавляет все это в контейнер. После сканирования возвращает экземпляр приложения. При запуске метода listen происходит инициализация сервера и регистрация роутеров, созданных в контроллере, с необходимыми для каждого обратными вызовами, которые уже хранятся в контейнере.
К созданию подобной функциональности мы придем чуть позже, а сначала посмотрим какие у нас есть контроллер, провайдер и модуль.
**app.controller.ts**
```
import { Controller, Get, Post, Body, Param } from 'nestjs/common';
import { AppService } from './app.service';
@Controller()
export class AppController {
constructor(private readonly appService: AppService) {}
@Get()
getHello(): string {
return this.appService.getHello();
}
@Post('body/:id')
recieveBody(@Body() data: { recieveData: string }, @Param('id') id: string) {
return 'body: ' + data.recieveData + ' has been recieved and id: ' + id;
}
}
```
Что интересно в этом коде, так это то, что создавая методы запроса, мы просто навешиваем декораторы на функции, которые и становятся callbacks для роутеров. Мы не знаем, когда они регистрируется и как именно, нам не нужно думать о реализации, все, что мы делаем, это следуем заданной архитектуре. Мы говорим, что мы хотим сделать, а не как, то есть, в качестве пользователей Nest, используем декларативный подход. Соответственно мы реализуем данную функциональность в этой статье.
Также здесь есть зависимость AppService, которую Nest внедряет самостоятельно. Для нас же, это рабочий код. Зависимости в Nest разрешаются по типу, и мы рассмотрим как именно.
**app.service.ts**
```
import { Injectable } from 'nestjs/common';
@Injectable()
export class AppService {
getHello(): string {
return 'Hello World!';
}
}
```
Здесь мы видим декоратор Injectable, который, по описанию в документации, определяет AppService как класс, которым может управлять контейнер Nest, что является не совсем правдой. На самом деле все, что он делает, это добавляет метаданные о времени жизни класса. По умолчанию оно совпадает с временем жизни приложения, и сам Nest не рекомендует изменять это поведение. Поэтому если вы не хотите это изменить, то Injectable можно опустить. А управлять им контейнер Nest может только в том случае, если он будет присутствовать в providers модуля, в котором он используется.
**app.module.ts**
```
import { Module } from 'nestjs/common';
import { AppController } from './app.controller';
import { AppService } from './app.service';
@Module({
imports: [],
controllers: [AppController],
providers: [AppService],
})
export class AppModule {}
```
Итак. Возвращаясь к **main.ts**, реализуем **NestFactory** класс.
Стоит оговориться, некоторые вспомогательные функции, вроде проверки на null и т.д., а также интерфейсы будут опущены в статье, но будут находиться в исходном коде.
**./core/nest-factory.ts**
```
import { NestApplication } from "./nest-application";
import { NestContainer } from "./injector/container";
import { InstanceLoader } from "./injector/instance-loader";
import { DependenciesScanner } from "./scanner";
import { ExpressAdapter } from '../platform-express/express.adapter';
export class NestFactoryStatic {
public async create(module: any) {
const container = new NestContainer();
// Сканирует зависимости, создает экземпляры
// и внедряет их
await this.initialize(module, container);
// Инициализирует http сервер и регистрирует роутеры
// при запуске instance.listen(3000)
const httpServer = new ExpressAdapter()
container.setHttpAdapter(httpServer);
const instance = new NestApplication(
container,
httpServer,
applicationConfig,
);
return instance;
}
private async initialize(
module: any,
container: NestContainer,
) {
const instanceLoader = new InstanceLoader(container)
const dependenciesScanner = new DependenciesScanner(container);
await dependenciesScanner.scan(module);
await instanceLoader.createInstancesOfDependencies();
}
}
/**
* Используйте NestFactory для создания экземпляра приложения.
*
* ### Указание входного модуля
*
* Передайте требуемый *root module* (корневой модуль) для приложения
* через параметр модуля. По соглашению он обычно называется
* `AppModule`. Начиная с этого модуля Nest собирает граф
* зависимостей и создает экземпляры классов, необходимых для запуска
* вашего приложения.
*
* @publicApi
*/
export const NestFactory = new NestFactoryStatic();
```
Итак. Из кода мы видим, что сперва сканируются все существующие модули, а также их зависимости, а после создается http сервер. Поэтому сейчас мы реализуем класс DependenciesScanner. Он получится чуть больше, чем предыдущий, но не будем пугаться, ведь ничего сложного, на самом деле, там нет.
**./core/scanner.ts**
```
import { MODULE_METADATA } from "../common/constants";
import { NestContainer } from "./injector/container";
import 'reflect-metadata';
import { Module } from "./injector/module";
export class DependenciesScanner {
constructor(private readonly container: NestContainer) {}
public async scan(module: any) {
// Сначала сканирует все модули, которые есть в приложении, и добавляет их в контейнер
await this.scanForModules(module);
// После у каждого модуля сканирует зависимости, такие как Controllers и Providers
await this.scanModulesForDependencies();
}
public async scanForModules(module: any) {
// Добавляет модуль в контейнер и возвращает при этом его экземпляр
const moduleInstance = await this.insertModule(module);
// Получает модули, которые были импортированы в этот модуль в массив imports.
// Так как AppModule - корневой модуль, то от него идет дерево модулей.
const innerModules = [...this.reflectMetadata(moduleInstance, MODULE_METADATA.IMPORTS)];
// Перебирает внутренние модули этого модуля, чтобы сделать с ними тоже самое.
// То есть, происходит рекурсия.
for (const [index, innerModule] of innerModules.entries()) {
await this.scanForModules(innerModule)
}
return moduleInstance
}
/**
* Добавляет модуль в контейнер
*/
public async insertModule(module: any) {
return this.container.addModule(module);
}
/**
* Получает из контейнера все модули, и сканирует у них
* зависимости, которые хранятся в reflect объекте.
*/
public async scanModulesForDependencies() {
const modules: Map = this.container.getModules();
for (const [token, { metatype }] of modules) {
await this.reflectAndAddImports(metatype, token);
this.reflectAndAddProviders(metatype, token);
this.reflectAndAddControllers(metatype, token);
}
}
public async reflectAndAddImports(
module: any,
token: string,
) {
// Получает по модулю imports зависимости и добавляет их в контейнер
const modules = this.reflectMetadata(module, MODULE\_METADATA.IMPORTS);
for (const related of modules) {
await this.container.addImport(related, token);
}
}
public reflectAndAddProviders(
module: any,
token: string,
) {
// Получает по модулю providers зависимости и добавляет их в контейнер
const providers = this.reflectMetadata(module, MODULE\_METADATA.PROVIDERS);
providers.forEach((provider: any) =>
this.container.addProvider(provider, token),
);
}
public reflectAndAddControllers(module: any, token: string) {
// Получает по модулю controllers зависимости и добавляет их в контейнер
const controllers = this.reflectMetadata(module, MODULE\_METADATA.CONTROLLERS);
controllers.forEach((controller: any) =>
this.container.addController(controller, token),
);
}
/\*\*
\* Метод, который получает нужные зависимости по модулю и ключу зависимостей.
\*/
public reflectMetadata(metatype: any, metadataKey: string) {
return Reflect.getMetadata(metadataKey, metatype) || [];
}
}
```
Смотря на код, мы видим, что модули и их зависимости добавляются в контейнер, и это возможно благодаря двум классам используемым здесь - NestContainer и Module. На самом деле в контейнере хранятся модули как экземпляры класса Module, и их зависимости, такие как другие модули, контроллеры и провайдеры, хранятся в Module, в таких структурах данных как Map и Set. А сами зависимости, контроллеры и провайдеры, являются экземплярами класса InstanceWrapper.
Классы Module и InstanceWrapper в нашей реализации являются довольно простыми, особенно второй, поэтому сначала реализуем наш контейнер.
**./core/injector/container.ts**
```
import { Module } from "./module";
import { ModuleTokenFactory } from "./module-token-factory";
import { AbstractHttpAdapter } from "../adapters";
export class NestContainer {
private readonly modules = new Map();
private readonly moduleTokenFactory = new ModuleTokenFactory();
private httpAdapter: AbstractHttpAdapter | undefined;
/\*\*
\* Создает экземпляр класса Module и сохраняет его в контейнер
\*/
public async addModule(module: any) {
// Создает токен модуля, который будет являться его ключом Map,
// который и будет использоваться для проверки и получения этого модуля.
const token = this.moduleTokenFactory.create(module);
if (this.modules.has(module.name)) {
return;
}
const moduleRef = new Module(module);
moduleRef.token = token;
this.modules.set(token, moduleRef);
return moduleRef;
}
/\*\*
\* Возвращает все модули, для сканирования зависимостей,
\* создания экземпляров этих зависимостей, и для использования в качестве callbacks
\* при создании роутеров его контроллеров, с разрешенными зависимостями.
\*/
public getModules(): Map {
return this.modules;
}
/\*\*
\* Контейнер также устанавливает и хранит единственный экземпляр http сервера,
\* в нашем случае express. Этот метод вызывается в классе NestFactory.
\*/
public setHttpAdapter(httpAdapter: any) {
this.httpAdapter = httpAdapter;
}
/\*\*
\* Будет вызван при создании роутеров в классе RouterExplorer.
\*/
public getHttpAdapterRef() {
return this.httpAdapter;
}
/\*\*
\* При сканировании зависимостей для полученных модулей в DependenciesScanner,
\* у них также берется токен, по которому здесь находится модуль,
\* и с помощью своего метода добавляет к себе импортированный модуль.
\*/
public async addImport(
relatedModule: any,
token: string,
) {
if (!this.modules.has(token)) {
return;
}
const moduleRef = this.modules.get(token);
if (!moduleRef) {
throw Error('MODULE NOT EXIST')
}
const related = this.modules.get(relatedModule.name);
if (!related) {
throw Error('RELATED MODULE NOT EXIST')
}
moduleRef.addRelatedModule(related);
}
/\*\*
\* Также как и для импортированных модулей, подобная функциональность
\* работает и для провайдеров.
\*/
public addProvider(provider: any, token: string) {
if (!this.modules.has(token)) {
throw new Error('Module not found.');
}
const moduleRef = this.modules.get(token);
if (!moduleRef) {
throw Error('MODULE NOT EXIST')
}
moduleRef.addProvider(provider)
}
/\*\*
\* Также как и для импортированных модулей, подобная функциональность
\* работает и для контроллеров.
\*/
public addController(controller: any, token: string) {
if (!this.modules.has(token)) {
throw new Error('Module not found.');
}
const moduleRef = this.modules.get(token);
if (!moduleRef) {
throw Error('MODULE NOT EXIST')
}
moduleRef.addController(controller);
}
}
```
Мы увидели здесь также класс ModuleTokenFactory, который создаёт токен, по которому хранится модуль. На самом деле, здесь можно обойтись и обычным созданием уникального id, например с помощью пакета uuid. Поэтому вы можете сильно не обращать на это внимание, но, кому интересно, вот максимально приближенная реализация этого класса к реализации Nest, только несколько упрощенная.
**./core/injector/module-token-factory.ts**
```
import hash from 'object-hash';
import { v4 as uuid } from 'uuid';
import { Type } from '../../common/interfaces/type.interface';
export class ModuleTokenFactory {
// Здесь хранятся данные о том, какие модули уже были отсканированы.
// На случай того, если один модуль является зависимостью у нескольких,
// чтобы не было дубликатов.
private readonly moduleIdsCashe = new WeakMap, string>()
public create(metatype: Type): string {
const moduleId = this.getModuleId(metatype);
const opaqueToken = {
id: moduleId,
module: this.getModuleName(metatype),
};
return hash(opaqueToken, { ignoreUnknown: true });
}
public getModuleId(metatype: Type): string {
let moduleId = this.moduleIdsCashe.get(metatype);
if (moduleId) {
return moduleId;
}
moduleId = uuid();
this.moduleIdsCashe.set(metatype, moduleId);
return moduleId;
}
public getModuleName(metatype: Type): string {
return metatype.name;
}
}
```
Теперь рассмотрим класс Module.
**./core/injector/module.ts**
```
import { InstanceWrapper } from "./instance-wrapper";
import { randomStringGenerator } from "../../common/utils/random-string-generator.util";
export class Module {
private readonly _imports = new Set();
private readonly \_providers = new Map();
private readonly \_controllers = new Map();
private \_token: string | undefined;
constructor(
private readonly module: any,
) {}
get providers(): Map {
return this.\_providers;
}
get controllers(): Map {
return this.\_controllers;
}
get metatype() {
return this.module;
}
get token() {
return this.\_token!;
}
set token(token: string) {
this.\_token = token;
}
public addProvider(provider: any) {
this.\_providers.set(
provider.name,
new InstanceWrapper({
name: provider.name,
metatype: provider,
instance: null,
}),
)
}
public addController(controller: any) {
this.\_controllers.set(
controller.name,
new InstanceWrapper({
name: controller.name,
metatype: controller,
instance: null,
}),
);
this.assignControllerUniqueId(controller);
}
public assignControllerUniqueId(controller: any) {
Object.defineProperty(controller, 'CONTROLLER\_ID', {
enumerable: false,
writable: false,
configurable: true,
value: randomStringGenerator(),
});
}
public addRelatedModule(module: Module) {
this.\_imports.add(module);
}
}
```
Комментарии здесь излишни. Все, что он делает, это хранит зависимости определенного модуля, сам модуль и его токен.
Теперь рассмотрим еще более простой класс InstanceWrapper.
**./core/injector/instance-wrapper.ts**
```
import { Type } from '../../common/interfaces/type.interface';
export class InstanceWrapper {
public readonly name: string;
public metatype: Type | Function;
public instance: any;
public isResolved = false
constructor(metadata: any) {
Object.assign(this, metadata);
this.instance = metadata.instance;
this.metatype = metadata.metatype;
this.name = metadata.name
}
}
```
При его создании к instance присваивается null. В дальнейшем, например, если контроллер имеет зависимость в виде провайдера в его конструкторе, то при внедрении зависимостей, экземпляр этого провайдера будет уже создан, и при создании экземпляра контроллера, будет добавлен в его конструктор. Собственно так и разрешаются зависимости. Собственно этим мы дальше и займемся.
Сейчас у нас есть функциональность сканирования модулей и их зависимостей. Модули добавляются в контейнер, хранятся по созданным токеном в виде класса Module, в котором они все и представлены и хранят свои зависимости, которые находятся в объекте reflect, в структурах данных Map и Set.
А теперь снова вернемся к классу NestContainer и взглянем на его метод initialize
```
private async initialize(
module: Module,
container: NestContainer,
) {
const instanceLoader = new InstanceLoader(container)
const dependenciesScanner = new DependenciesScanner(container);
await dependenciesScanner.scan(module);
await instanceLoader.createInstancesOfDependencies();
```
на его метод initialize
Сейчас, когда мы просканировали модули, нам нужно создать экземпляры их зависимостей. Поэтому сейчас реализуем класс InstanceLoader.
**./core/injector/instance-loader.ts**
```
import { NestContainer } from "./container";
import { Injector } from "./injector";
import { Module } from "./module";
export class InstanceLoader {
private readonly injector = new Injector();
constructor(private readonly container: NestContainer) {}
public async createInstancesOfDependencies() {
const modules = this.container.getModules();
await this.createInstances(modules);
}
/**
* Сначала создаются экземпляры провайдеров,
* потому что если они являются зависимостями контроллеров,
* при создании экземпляров для контроллеров, они уже должны
* существовать.
*/
private async createInstances(modules: Map) {
await Promise.all(
[...modules.values()].map(async module => {
await this.createInstancesOfProviders(module);
await this.createInstancesOfControllers(module);
})
)
}
private async createInstancesOfProviders(module: Module) {
const { providers } = module;
const wrappers = [...providers.values()];
await Promise.all(
wrappers.map(item => this.injector.loadProvider(item, module)),
)
}
private async createInstancesOfControllers(module: Module) {
const { controllers } = module;
const wrappers = [...controllers.values()];
await Promise.all(
wrappers.map(item => this.injector.loadControllers(item, module)),
)
}
}
```
Тоже не сложный класс. Все, что она делает вызывает методы класса Injector. Что здесь стоит отметить, что уже написано в комментарии к методу createInstances, это то, что созданные экземпляры провайдеров будут добавляться в конструкторы соответствующих контроллеров при создании их экземпляров.
Сейчас рассмотрим класс Injector, который несколько интереснее остальных, и который и производит внедрение зависимостей.
**./core/injector/injector.ts**
```
import { Module } from "./module";
import { InstanceWrapper } from './instance-wrapper';
import { Type } from '../../common/interfaces/type.interface';
export class Injector {
public async loadInstance(
wrapper: InstanceWrapper,
collection: Map,
moduleRef: Module,
) {
const { name } = wrapper;
const targetWrapper = collection.get(name);
if (!targetWrapper) {
throw Error('TARGET WRAPPER NOT FOUNDED')
}
const callback = async (instances: unknown[]) => {
await this.instantiateClass(
instances,
wrapper,
targetWrapper,
);
}
await this.resolveConstructorParams(
wrapper,
moduleRef,
callback,
);
}
public async loadProvider(
wrapper: any,
moduleRef: Module,
) {
const providers = moduleRef.providers;
await this.loadInstance(
wrapper,
providers,
moduleRef,
);
}
public async loadControllers(
wrapper: any,
moduleRef: Module,
) {
const controllers = moduleRef.controllers;
await this.loadInstance(
wrapper,
controllers,
moduleRef,
);
}
/\*\*
\* design:paramtypes создается автоматически объектом reflect
\* для зависимостей, указанных в конструкторе класса.
\* Как видно, если провайдеру нужно разрешить зависимости,
\* то они также должны быть провайдерами.
\* callback, как видно из метода loadInstance, вызывает метод
\* instantiateClass для найденных зависимостей в виде провайдеров.
\*/
public async resolveConstructorParams(
wrapper: InstanceWrapper,
moduleRef: Module,
callback: (args: unknown[]) => void | Promise,
) {
const dependencies = Reflect.getMetadata('design:paramtypes', wrapper.metatype)
const resolveParam = async (param: Function, index: number) => {
try {
let providers = moduleRef.providers
const paramWrapper = providers.get(param.name);
return paramWrapper?.instance
} catch (err) {
throw err;
}
};
const instances = dependencies ? await Promise.all(dependencies.map(resolveParam)) : [];
await callback(instances);
}
/\*\*
\* Создает экземпляр зависимости, которая хранится в InstanceLoader,
\* как metatype, с ее зависимостями, которые являются провайдерами,
\* и добавляет этот экземпляр в instance поле класса InstanceLoader,
\* для дальнейшего извлечения при создании роутеров.
\*/
public async instantiateClass(
instances: any[],
wrapper: InstanceWrapper,
targetMetatype: InstanceWrapper,
): Promise {
const { metatype } = wrapper;
targetMetatype.instance = instances
? new (metatype as Type)(...instances)
: new (metatype as Type)();
return targetMetatype.instance;
}
}
```
Отлично. Теперь у нас есть просканированные модули, и созданные экземпляры зависимостей. Идем дальше.
Сейчас еще раз вернемся к NestFactory, а именно к его методу create.
```
public async create(module: Module) {
const applicationConfig = new ApplicationConfig();
const container = new NestContainer();
await this.initialize(module, container);
const httpServer = new ExpressAdapter()
container.setHttpAdapter(httpServer);
const instance = new NestApplication(
container,
httpServer,
applicationConfig,
);
return instance;
```
У нас здесь есть класс ExpressAdapter, который наследуется от класса AbstractHttpAdapter. То есть здесь используется паттерн проектирования известный как адаптер. При желании можно создать и класс FastifyAdapter для использования fastify вместо express. Так и сделано в nest, но здесь мы возьмем express из-за его большей распространенности.
Сначала рассмотрим AbstractHttpAdapter.
**./core/adapters/http-adapter.ts**
```
import { HttpServer } from "../../common/interfaces/http-server.interface";
export abstract class AbstractHttpAdapter<
TServer = any,
TRequest = any,
TResponse = any
> implements HttpServer {
protected httpServer: TServer | undefined;
constructor(protected readonly instance: any) {}
public use(...args: any[]) {
return this.instance.use(...args);
}
public get(...args: any[]) {
return this.instance.get(...args);
}
public post(...args: any[]) {
return this.instance.post(...args);
}
public listen(port: any) {
return this.instance.listen(port);
}
public getHttpServer(): TServer {
return this.httpServer as TServer;
}
public setHttpServer(httpServer: TServer) {
this.httpServer = httpServer;
}
public getInstance(): T {
return this.instance as T;
}
abstract initHttpServer(): any;
abstract reply(response: any, body: any, statusCode?: number): any;
abstract registerBodyParser(prefix?: string): any;
}
```
Видим, что он реализует несколько обычных методов http сервера. Для упрощения кода, у нашего nest будет только два http метода, а именно post и get.
А это интерфейс, который реализует адаптер
```
interface HttpServer {
reply(response: any, body: any, statusCode?: number): any;
get(handler: RequestHandler): any;
get(path: string, handler: RequestHandler): any;
post(handler: RequestHandler): any;
post(path: string, handler: RequestHandler): any;
listen(port: number | string): any;
getInstance(): any;
getHttpServer(): any;
initHttpServer(): void;
registerBodyParser(): void
}
```
Теперь посмотрим на класс ExpressAdapter
**./platform-express/express.adapter.ts**
```
import { AbstractHttpAdapter } from '../core/adapters';
import { isNil, isObject } from '../common/utils/shared.utils'
import express from 'express';
import * as http from 'http';
import {
json as bodyParserJson,
urlencoded as bodyParserUrlencoded,
} from 'body-parser';
export class ExpressAdapter extends AbstractHttpAdapter {
constructor() {
super(express());
}
/**
* Является response методом. С помощью него отправляются все данные.
*/
public reply(response: any, body: any) {
if (isNil(body)) {
return response.send();
}
return isObject(body) ? response.json(body) : response.send(String(body));
}
/**
* Запускает сервер на выборном порте
*/
public listen(port: any) {
return this.httpServer.listen(port);
}
public registerBodyParser() {
const parserMiddleware = {
jsonParser: bodyParserJson(),
urlencodedParser: bodyParserUrlencoded({ extended: true }),
};
Object.keys(parserMiddleware)
.forEach((parserKey: any) => this.use((parserMiddleware as any)[parserKey]));
}
public initHttpServer() {
this.httpServer = http.createServer(this.getInstance());
}
}
```
Собственно здесь реализуется запуск и настройка express. В конструкторе, в методе super, экземпляр express передается в AbstractHttpAdapter, из которого и будут вызываться методы post, get и use.
Теперь, снова возвращаясь к NestFactory,
```
public async create(module: Module) {
const container = new NestContainer();
await this.initialize(module, container);
const httpServer = new ExpressAdapter()
container.setHttpAdapter(httpServer);
const instance = new NestApplication(
container,
httpServer,
);
return instance;
}
```
нам нужно реализовать класс NestApplication, который является экземпляром всего приложения Nest. Именно из него вызывается метод listen,
```
async function bootstrap() {
const app = await NestFactory.create(AppModule);
await app.listen(3000);
}
```
который запускает приложение.
**./core/nest-application.ts**
```
import { HttpServer } from '../common/interfaces/http-server.interface';
import { Resolver } from './router/interfaces/resolver.interface';
import { addLeadingSlash } from '../common/utils/shared.utils';
import { NestContainer } from './injector/container';
import { RoutesResolver } from './router/routes-resolver';
export class NestApplication {
private readonly routesResolver: Resolver;
public httpServer: any;
constructor(
private readonly container: NestContainer,
private readonly httpAdapter: HttpServer,
) {
this.registerHttpServer();
this.routesResolver = new RoutesResolver(
this.container,
);
}
public registerHttpServer() {
this.httpServer = this.createServer();
}
/**
* Начинает процесс инициализации выбранного http сервера
*/
public createServer(): T {
this.httpAdapter.initHttpServer();
return this.httpAdapter.getHttpServer() as T;
}
public async init(): Promise {
this.httpAdapter.registerBodyParser();
await this.registerRouter();
return this;
}
/\*\*
\* Метод, с помощью которого запускается приложение Nest.
\* Он запускает процесс инициализации http сервера, регистрации
\* созданных роутеров, и запуска сервера на выбранном порте.
\*/
public async listen(port: number | string) {
await this.init();
this.httpAdapter.listen(port);
return this.httpServer;
}
/\*\*
\* Метод, который запускает регистрацию роутеров,
\* которые были созданы с помощью декораторов http методов,
\* таких как post и get.
\*/
public async registerRouter() {
const prefix = ''
const basePath = addLeadingSlash(prefix);
this.routesResolver.resolve(this.httpAdapter, basePath);
}
}
```
И это подводит нас к роутерам, а именно к классу RoutesResolver.
**./core/router/routes-resolver.ts**
```
import { NestContainer } from '../injector/container';
import { Resolver } from '../router/interfaces/resolver.interface';
import { MODULE_PATH } from '../../common/constants';
import { HttpServer } from '../../common/interfaces/http-server.interface';
import { InstanceWrapper } from '../injector/instance-wrapper';
import { RouterExplorer } from './router-explorer';
export class RoutesResolver implements Resolver {
private readonly routerExplorer: RouterExplorer;
constructor(
private readonly container: NestContainer,
) {
this.routerExplorer = new RouterExplorer(
this.container,
);
}
/**
* Для каждого модуля сначала находит базовый путь, который
* указывается в декораторе Module,
* и передает его и контроллеры в метод registerRouters
*/
public resolve(applicationRef: any, basePath: string): void {
const modules = this.container.getModules();
modules.forEach(({ controllers, metatype }) => {
let path = metatype ? this.getModulePathMetadata(metatype) : undefined;
path = path ? basePath + path : basePath;
this.registerRouters(controllers, metatype.name, path, applicationRef);
});
}
/**
* Для каждого контроллера в модуле, запускает метод explore
* класса routerExplorer, который отвечает за всю логику
* регистрации роутеров
*/
public registerRouters(
routes: Map>,
moduleName: string,
basePath: string,
applicationRef: HttpServer,
) {
routes.forEach(instanceWrapper => {
const { metatype } = instanceWrapper;
// Находит путь для декоратора контроллера, например @Controller('cats')
const paths = this.routerExplorer.extractRouterPath(
metatype as any,
basePath,
);
// Если путь был передан как @Controllers('cats'), то будет вызвано один раз.
// Дело в том, что reflect возвращает массив
paths.forEach(path => {
this.routerExplorer.explore(
instanceWrapper,
moduleName,
applicationRef,
path,
);
});
});
}
private getModulePathMetadata(metatype: object): string | undefined {
return Reflect.getMetadata(MODULE\_PATH, metatype);
}
}
```
Код выше делает так, чтобы для каждого контроллера был вызван метод explore класса RouterExplorer. Класс RouterExplorer реализует основную логику регистрации роутеров. Он создает http методы, добавляет контроллеры в качестве их callbacks, привязывает эти контроллеры к пространству модуля, в котором он находится, и реализует функциональность ответов и их обработки для запросов.
**./core/router/routes-explorer.ts**
```
import { NestContainer } from '../injector/container';
import { RouterProxyCallback } from './router-proxy';
import { addLeadingSlash } from '../../common/utils/shared.utils';
import { Type } from '../../common/interfaces/type.interface';
import { Controller } from '../../common/interfaces/controller.interface';
import { PATH_METADATA, METHOD_METADATA, ROUTE_ARGS_METADATA, PARAMTYPES_METADATA } from '../../common/constants';
import { RequestMethod } from '../../common/enums/request-method.enum';
import { HttpServer } from '../../common/interfaces/http-server.interface';
import { InstanceWrapper } from '../injector/instance-wrapper';
import { RouterMethodFactory } from '../helpers/router-method-factory';
import {
isConstructor,
isFunction,
isString,
} from '../../common/utils/shared.utils';
import { RouteParamtypes } from '../../common/enums/route-paramtypes.enum';
export interface RoutePathProperties {
path: string[];
requestMethod: RequestMethod;
targetCallback: RouterProxyCallback;
methodName: string;
}
export class RouterExplorer {
private readonly routerMethodFactory = new RouterMethodFactory();
constructor (
private readonly container: NestContainer,
) {
}
public explore(
instanceWrapper: InstanceWrapper,
module: string,
router: T,
basePath: string,
) {
const { instance } = instanceWrapper;
const routePaths: RoutePathProperties[] = this.scanForPaths(instance);
// Для каждого метода контроллера запускает регистрацию роутеров
(routePaths || []).forEach((pathProperties: any) => {
this.applyCallbackToRouter(
router,
pathProperties,
instanceWrapper,
module,
basePath,
);
})
}
/\*\*
\* Метод, который сканирует контроллер, и находит у него методы
\* запроса с определенными путями, например метод, на который
\* навешен декоратор @post('add\_to\_database').
\* В таком случае эта функция возвращает массив методов контроллера
\* с путями, телами этих методов, методом request и именами, которые
\* получаются в методе exploreMethodMetadata
\*/
public scanForPaths(
instance: Controller,
): RoutePathProperties[] {
const instancePrototype = Object.getPrototypeOf(instance);
let methodNames = Object.getOwnPropertyNames(instancePrototype);
const isMethod = (prop: string) => {
const descriptor = Object.getOwnPropertyDescriptor(instancePrototype, prop);
if (descriptor?.set || descriptor?.get) {
return false;
}
return !isConstructor(prop) && isFunction(instancePrototype[prop]);
};
return methodNames.filter(isMethod).map(method => this.exploreMethodMetadata(instance, instancePrototype, method))
}
/\*\*
\* Для определенного метода контроллера возвращает его свойства,
\* для метода scanForPaths
\*/
public exploreMethodMetadata(
instance: Controller,
prototype: object,
methodName: string,
): RoutePathProperties {
const instanceCallback = (instance as any)[methodName];
const prototypeCallback = (prototype as any)[methodName];
const routePath = Reflect.getMetadata(PATH\_METADATA, prototypeCallback);
const requestMethod: RequestMethod = Reflect.getMetadata(
METHOD\_METADATA,
prototypeCallback,
);
const path = isString(routePath)
? [addLeadingSlash(routePath)]
: routePath.map((p: string) => addLeadingSlash(p));
return {
path,
requestMethod,
targetCallback: instanceCallback,
methodName,
};
}
private applyCallbackToRouter(
router: T,
pathProperties: RoutePathProperties,
instanceWrapper: InstanceWrapper,
moduleKey: string,
basePath: string,
) {
const {
path: paths,
requestMethod,
targetCallback,
methodName,
} = pathProperties;
const { instance } = instanceWrapper;
// Получает определенный http метод
const routerMethod = this.routerMethodFactory
.get(router, requestMethod)
.bind(router);
// Создает callback для определенного метода
const handler = this.createCallbackProxy(
instance,
targetCallback,
methodName,
);
// Если декоратор используется как @Post('add\_to\_database'),
// то будет вызвано один раз для этого пути.
paths.forEach(path => {
const fullPath = this.stripEndSlash(basePath) + path;
// Региструет http метод. Сопоставляет путь метода, и его callback,
// полученный из контроллера. Ответ же производится reply методом,
// реализованным в классе ExpressAdapter
routerMethod(this.stripEndSlash(fullPath) || '/', handler);
});
}
public stripEndSlash(str: string) {
return str[str.length - 1] === '/' ? str.slice(0, str.length - 1) : str;
}
public createCallbackProxy(
instance: Controller,
callback: (...args: any[]) => unknown,
methodName: string,
) {
// Достает ключи данных запроса указанных ранее в декораторах @Body() и @Param()
const metadata = Reflect.getMetadata(ROUTE\_ARGS\_METADATA, instance.constructor, methodName) || {};
const keys = Object.keys(metadata);
const argsLength = Math.max(...keys.map(key => metadata[key].index)) + 1
// Извлеченные данные из request, такие как тело и параметры запроса.
const paramsOptions = this.exchangeKeysForValues(keys, metadata);
const fnApplyParams = this.resolveParamsOptions(paramsOptions)
const handler = (
args: any[],
req: TRequest,
res: TResponse,
next: Function,
) => async () => {
// так как args это объект, а не примитивная переменная,
// то он передается по ссылке, а не по значению,
// поэтому он изменяется, и после вызова fnApplyParams,
// в args хранятся аргументы, полученные из request
fnApplyParams && (await fnApplyParams(args, req, res, next));
// Здесь мы привязываем один из методов контроллера,
// например, добавление данных в базу данных, и аргументы из request,
// и теперь он может ими управлять, как и задумано
return callback.apply(instance, args);
};
const targetCallback = async (
req: TRequest,
res: TResponse,
next: Function,
) => {
// Заполняется undefined для дальнейшего изменения реальными данными
// из request
const args = Array.apply(null, { argsLength } as any).fill(undefined);
// result это экземпляр контроллера с пространством данных аргументов
// из request
const result = await handler(args, req, res, next)()
const applicationRef = this.container.getHttpAdapterRef()
if(!applicationRef) {
throw new Error(`Http server not created`)
}
return await applicationRef.reply(res, result);
}
return async (
req: TRequest,
res: TResponse,
next: () => void,
) => {
try {
await targetCallback(req, res, next);
} catch (e) {
throw e
}
};
}
/\*\*
\* extractValue здесь это метод exchangeKeyForValue.
\* И ему передается request, для извлечения данных запроса
\*/
public resolveParamsOptions(paramsOptions: any) {
const resolveFn = async (args: any, req: any, res: any, next: any) => {
const resolveParamValue = async (param: any) => {
const { index, extractValue } = param;
const value = extractValue(req, res, next);
args[index] = value
}
await Promise.all(paramsOptions.map(resolveParamValue));
}
return paramsOptions && paramsOptions.length ? resolveFn : null;
}
/\*\*
\* Перебирает ключи данных запроса для вызова для каждого
\* метода exchangeKeyForValue, который достанет соответствующие данные,
\* которые были определены ранее в декораторах @Body() и @Param(),
\* из request.
\*/
public exchangeKeysForValues(
keys: string[],
metadata: Record,
): any[] {
return keys.map((key: any) => {
const { index, data } = metadata[key];
const numericType = Number(key.split(':')[0]);
const extractValue = (
req: TRequest,
res: TResponse,
next: Function,
) =>
this.exchangeKeyForValue(numericType, data, {
req,
res,
next,
});
return { index, extractValue, type: numericType, data }
})
}
/\*\*
\* Проверяет чему соответствует ключ данных, телу или параметрам запроса.
\* Это определяется в соответствующих декораторах @Body() и @Param().
\* И теперь, когда запрос на соответствующий api выполнен, мы пытаемся
\* достать их из request, если они были переданы.
\*/
public exchangeKeyForValue<
TRequest extends Record = any,
TResponse = any,
TResult = any
>(
key: RouteParamtypes | string,
data: string | object | any,
{ req, res, next }: { req: TRequest; res: TResponse; next: Function },
): TResult | null {
switch (key) {
case RouteParamtypes.BODY:
return data && req.body ? req.body[data] : req.body;
case RouteParamtypes.PARAM:
return data ? req.params[data] : req.params;
default:
return null;
}
}
public extractRouterPath(metatype: Type, prefix = ''): string[] {
let path = Reflect.getMetadata(PATH\_METADATA, metatype);
if (Array.isArray(path)) {
path = path.map(p => prefix + addLeadingSlash(p));
} else {
path = [prefix + addLeadingSlash(path)];
}
return path.map((p: string) => addLeadingSlash(p));
}
}
```
Что к этому стоит добавить, так это то, что в методе applyCallbackToRouter для получения http метода используется класс RouterMethodFactory, который, на самом деле, имеет всего один метод
**./core/helpers/router-method-factory.ts**
```
import { HttpServer } from '../../common/interfaces/http-server.interface';
import { RequestMethod } from '../../common/enums/request-method.enum';
export class RouterMethodFactory {
public get(target: HttpServer, requestMethod: RequestMethod): Function {
switch (requestMethod) {
case RequestMethod.POST:
return target.post;
default: {
return target.get;
}
}
}
}
```
Что ж. Если вы еще здесь, поздравляю! Мы написали все ядро нашего мини Nest фреймворка. Теперь, все, что осталось, это написать декораторы, на которых мы и пишем Nest приложение в качестве пользователей.
Начнем с декоратора @Module(), и сперва посмотрим на пример его использования из документации
```
import { Module } from '@nestjs/common';
import { CatsController } from './cats.controller';
import { CatsService } from './cats.service';
@Module({
controllers: [CatsController],
providers: [CatsService],
})
export class CatsModule {}
```
Мы видим, что метаданные указываются как параметры декоратора, теперь реализуем его.
**./common/decorators/module.decorator.ts**
```
import { MODULE_METADATA as metadataConstants } from '../constants';
const metadataKeys = [
metadataConstants.IMPORTS,
metadataConstants.EXPORTS,
metadataConstants.CONTROLLERS,
metadataConstants.PROVIDERS,
];
/**
* Проверяет, чтобы были указаны только правильные массивы,
* соответствующие metadataKeys
*/
export function validateModuleKeys(keys: string[]) {
const validateKey = (key: string) => {
if (metadataKeys.includes(key)) {
return;
}
throw new Error(`NOT INVALID KEY: ${key}`);
};
keys.forEach(validateKey);
}
/**
* Сохраняет зависимости в объект Reflect.
* Где property название одной из зависимости,
* например controllers. Именно благодаря этому,
* у нас есть возможность извлекать данные после.
*/
export function Module(metadata: any): ClassDecorator {
const propsKeys = Object.keys(metadata);
validateModuleKeys(propsKeys);
return (target: Function) => {
for (const property in metadata) {
if (metadata.hasOwnProperty(property)) {
Reflect.defineMetadata(property, (metadata as any)[property], target);
}
}
};
}
```
Довольно не сложно, не так ли? Действительно, декораторы одна из довольно простых частей Nest.
Теперь рассмотрим декоратор @Controller(), который, все, что делает, это сохраняет базовый путь контроллера, ведь сам контроллер уже сохранен в Reflect по модулю, в котором он используется.
**./common/decorators/controller.decorator.ts**
```
import { PATH_METADATA } from "../constants";
import { isUndefined } from "../utils/shared.utils";
export function Controller(
prefix?: string,
): ClassDecorator {
const defaultPath = '/';
const path = isUndefined(prefix) ? defaultPath : prefix
return (target: object) => {
Reflect.defineMetadata(PATH_METADATA, path, target);
};
}
```
Помните про декоратор @Injectable(), который якобы помечает класс как провайдер? Как уже написано выше, он лишь устанавливает время жизни провайдера. Класс помечается как провайдер, только если он передается в массив providers соответствующего модуля. И хоть мы не реализовали возможность изменения времени жизни для провайдера, но для полноты, все равно рассмотрим этот декоратор.
**./common/decorators/injectable.decorator.ts**
```
import { SCOPE_OPTIONS_METADATA } from '../constants';
export enum Scope {
DEFAULT,
TRANSIENT,
REQUEST,
}
export interface ScopeOptions {
scope?: Scope;
}
export type InjectableOptions = ScopeOptions;
export function Injectable(options?: InjectableOptions): ClassDecorator {
return (target: object) => {
Reflect.defineMetadata(SCOPE_OPTIONS_METADATA, options, target);
};
}
```
Теперь у нас осталось всего четыре декоратора для реализации, для данных запроса, а именно @Body() и @Param(), и для http методов, @Post() и @Get().
Сперва рассмотрим первые два.
**./common/decorators/route-params.decorator.ts**
```
import { ROUTE_ARGS_METADATA } from "../constants";
import { RouteParamtypes } from "../enums/route-paramtypes.enum";
import { isNil, isString } from "../utils/shared.utils";
/**
* Здесь используется неизменяемость данных, для того, чтобы
* использовать один метод для нескольких типов запроса.
*/
const createPipesRouteParamDecorator = (paramtype: RouteParamtypes) => (
data?: any,
): ParameterDecorator => (target, key, index) => {
const hasParamData = isNil(data) || isString(data);
const paramData = hasParamData ? data : undefined;
const args =
Reflect.getMetadata(ROUTE_ARGS_METADATA, target.constructor, key) || {};
// Где paramtype это body или param, а index его
// положение в параметрах функции, где находится декоратор,
// для правильного присвоения после получения из request
Reflect.defineMetadata(
ROUTE_ARGS_METADATA,
{
...args,
[`${paramtype}:${index}`]: {
index,
data: paramData,
},
},
target.constructor,
key,
);
};
export function Body(
property?: string,
): ParameterDecorator {
return createPipesRouteParamDecorator(RouteParamtypes.BODY)(
property,
);
}
export function Param(
property?: string,
): ParameterDecorator {
return createPipesRouteParamDecorator(RouteParamtypes.PARAM)(
property,
);
}
```
И последнее, декораторы post и get, которые сохраняют в объект Reflect для определенных методов контроллеров их пути и методы запроса.
**./common/decorators/request-mapping.decorator.ts**
```
import { METHOD_METADATA, PATH_METADATA } from '../constants';
import { RequestMethod } from '../enums/request-method.enum';
export interface RequestMappingMetadata {
path?: string | string[];
method?: RequestMethod;
}
const defaultMetadata = {
[PATH_METADATA]: '/',
[METHOD_METADATA]: RequestMethod.GET,
};
export const RequestMapping = (
metadata: RequestMappingMetadata = defaultMetadata,
): MethodDecorator => {
const pathMetadata = metadata[PATH_METADATA];
const path = pathMetadata && pathMetadata.length ? pathMetadata : '/';
const requestMethod = metadata[METHOD_METADATA] || RequestMethod.GET;
return (
target: object,
key: string | symbol,
descriptor: TypedPropertyDescriptor,
) => {
Reflect.defineMetadata(PATH\_METADATA, path, descriptor.value);
Reflect.defineMetadata(METHOD\_METADATA, requestMethod, descriptor.value);
return descriptor;
};
};
const createMappingDecorator = (method: RequestMethod) => (
path?: string | string[],
): MethodDecorator => {
return RequestMapping({
[PATH\_METADATA]: path,
[METHOD\_METADATA]: method,
});
};
/\*\*
\* Обработчик маршрута (метод) Decorator. Направляет запросы HTTP POST по указанному пути.
\*
\* @publicApi
\*/
export const Post = createMappingDecorator(RequestMethod.POST);
/\*\*
\* Обработчик маршрута (метод) Decorator. Направляет запросы HTTP GET по указанному пути.
\*
\* @publicApi
\*/
export const Get = createMappingDecorator(RequestMethod.GET);
```
Хорошая работа, наш мини Nest готов!
Теперь мы можем создать директорию project-view на уровне других директорий nest, и написать простое приложение
**./project-view/main.ts**
```
import { NestFactory } from '../core';
import { AppModule } from './app.module';
async function bootstrap() {
const app = await NestFactory.create(AppModule);
await app.listen(3000);
}
bootstrap();
```
**./project-view/app.controller.ts**
```
import { Controller, Get, Post, Body, Param } from '../common';
import { AppService } from './app.service';
@Controller()
export class AppController {
constructor(private readonly appService: AppService) {}
@Get()
getHello(): string {
return this.appService.getHello();
}
@Post('body/:id')
recieveBody(@Body() data: any, @Param('id') id: string) {
return 'body: ' + data.data + ' has been received and id: ${id}';
}
}
```
**./project-view/app.service.ts**
```
import { Injectable } from '../common';
@Injectable()
export class AppService {
getHello(): string {
return 'Hello World!';
}
}
```
**./project-view/app.module.ts**
```
import { Module } from '../common';
import { AppController } from './app.controller';
import { AppService } from './app.service';
@Module({
imports: [],
controllers: [AppController],
providers: [AppService],
})
export class AppModule {}
```
После чего инициализировать typescript проект, создав tsconfig.json файл с помощью команды
```
tsc --init
```
и настроить его как-то вот так
```
{
"compilerOptions": {
"target": "es2017",
"experimentalDecorators": true,
"emitDecoratorMetadata": true,
"module": "commonjs",
"outDir": "./",
"esModuleInterop": true,
"forceConsistentCasingInFileNames": true,
"strict": true,
"skipLibCheck": true,
},
"include": ["packages/**/*", "integration/**/*", "./core/", "./common/", "./project-view/", "./platform-express/"],
"exclude": ["node_modules", "**/*.spec.ts"]
}
```
Теперь мы можем скомпилировать typescript в js с помощью следующей команды
```
tsc --build
```
перейти в директорию нашего пользовательского приложения
```
cd project-view
```
и запустить скомпилированный входной файл
```
node main.js
```
Вы можете проверить результат, например, через postman, и поиграться с body и params для post запроса.
Теперь вы знаете Nest чуть лучше :)
> [Гитхаб репозиторий со всем кодом](https://github.com/Nikitala0014/mini-nest)
>
>
Контакты для связи: почта — [[email protected]](mailto:[email protected]), telegram — @NLavrenov00 | https://habr.com/ru/post/651139/ | null | ru | null |
# Уж такой элементарный C/С++: может->является
Вопрос на пять: что напечатает эта простая программа:
```
#include
typedef int a;
a b = 5;
int main()
{
a(b);
printf("%d\n", b);
return 0;
}
```
Уже натерпевшиеся от своего любимого языка, но ещё не прошерстившие всех бизонов `gcc`, почувствуют подвох — и правильно. **Подсказка номер ноль:** это скушает С++, но и простой С не подавится.
**Подсказка один.** Вот что она напечатает:
| | | |
| --- | --- | --- |
| **Ось** | **Компиляторы** | **Результат** |
| ArchLinux 64 | clang 2.9, gcc 4.5.2 | `0` |
| Win7 32 | Visual С++ 2005, 2008, 2010 | `1` |
но только теперь вопрос другой: а что такое `a(b)`? Ведь я ключиками повертел: и С++, и С — всё одно. Точнее: clang и gcc печатают одно (0), а вижуальники другое (1).
Здесь уже должно допереть. Нет? **Подсказка два:** уберите шум, и разверните тип:
```
int(b);
```
**Подсказка два++**. Прив**и**дение приведения типа запросто может постоять и слева от равна, но теперь уже и Майкрософт выдаст ноль:
```
int(b) = 0;
```
Люди с заточенными под 45o мозгами, вообще ещё и думать не начинали — запастили код в <http://ideone.com> или закомпиляли прямо из буфера — знаем же на нюхах про `xsel`? Результат такой механической работы с включенным `-Wall` и есть **подсказка три**:
```
[aviaconstructor@arch64 tmp]# xsel | gcc -xc++ -Wall -
: In function ‘int main()’:
:9:25: warning: ‘b’ is used uninitialized in this function
```
Программуля-то простая, какой уж тут C++11! Но если вы начали сразу с книжек Александреску и чураетесь святой простоты С, восполняю пробел. Точнее, ставлю один единственный пробел между типом и скобкой. Для самых недогадливых, **подсказка четыре** (пять, если по счёту):
```
int (b);
```
В этом месте нашего повествования пню ясно, что `a(b)` или `int(b)` — это объявление локальной переменной, то же, что и `int b`. Она-то и закрывает своей грудью глобальную переменную с таким же именем. Уже в комментах к этому посту мы можем посудачить и подебачить на тему:* Почему значение стековой (`auto`) переменной как правило будет детерминировано даже на системах без обнуления свободной памяти?
* Может ли какая-нибудь правильная реализация на системах с обнулением памяти при каждом запуске выдавать разные значения?
* И вообще, что выдают другие компиляторы и среды?
Кстати, подвигайте переменную по стеку, если интересно. Конечно, там не только нули и единицы. А здесь и сейчас мы поедем дальше.
Вообще, если озарило до обидного поздно, то вера в человечество может быть восстановлена благим словом, ибо про С и С++ конструкции сказано, что всё, что может быть определением, определением и является. Ещё раз: `a(b)` смахивает на приведение типа в С++, но на декларацию переменной оно похоже больше. Вот и разгадка не только задачки, но и заглавия нашего поста: стрелочка там — это матзнак следования.
Всё это было бы нечистой воды курьёзом, когда бы у нас, умных, ползали по коду ну только очень умные баги. Вот классика:
```
std::string a("my string");
std::string b();
```
Две строки, и одна пуста? Ни-фи-га! Второе — определение беспараметральной функции `b`, возвращающей строку. Руганётся при использовании, слава Богу! Куда хуже, когда хотели как всегда:
```
QMutexLocker lock(&globalLock);
```
а вышло:
```
void MyClass::MyFunc()
{
QMutexLocker lock(); // видим?
ThisFuncShallBeProtectedByGlobalLock();
++objectVarCounter;
}
```
Даже предупреждения не дождётесь — подумаешь, объявление неиспользуемой функции! И работать будет, вот только без лока (Шишков, прости за сплошные англицизмы). В крайнем примере путали объявление переменной с декларацией функции, а вот совсем другой косяк:
```
{
QMutexLocker(&globalLock); // где переменная?
...
```
Нужно ли объяснять почему такой локер работать будет только на себя? А есть у меня ещё и сказочка: мышка бежала, хвостиком вильнула — бдэмс — и вместо равна натоптала точку с запятой в неположенном месте:
```
MyEnum myEnumMask ; MyEnum(i);
```
Нет, уж этот пример надуман! Кривыми хвостиками и не то выписывали — до сих пор работает! Ну да, ну да. Согласен. Я со всем согласен. Но любимый язык мой — враг мой. Будьте внимательны! | https://habr.com/ru/post/117596/ | null | ru | null |
# Проверка автокорреляции с использованием критерия Дарбина-Уотсона средствами Python
Постановка задачи
-----------------
**Критерий Дарбина-Уотсона (Durbin–Watson statistic)** - один из самых распространенных критериев для проверки автокорреляции.
Данный критерий входит в стандартный инструментарий **python**:
* присутствует в таблице выдачи результатов регрессионного анализа модуля линейной регрессии [**Linear Regression**](https://www.statsmodels.org/stable/regression.html);
* может быть рассчитан с помощью функции [**statsmodels.stats.stattools.durbin\_watson**](https://www.statsmodels.org/stable/generated/statsmodels.stats.stattools.durbin_watson.html).
К сожалению, стандартные инструменты **python** не позволяют получить табличные значения статистики критерия Дарбина-Уотсона, нам предлагается воспользоваться методом грубой оценки: считается, что при расчетном значении статистики критерия в интервале **[1; 2]** автокорреляция отсутствует (см. [Durbin–Watson statistic](https://en.wikipedia.org/wiki/Durbin%E2%80%93Watson_statistic)). Однако, для качественного статистического анализа такой подход неприемлем.
Представляет интерес реализовать в полной мере критерий Дарбина-Уотсона средствами **python**, добавив этот важный критерий в инструментарий специалиста **DataScience**.
В данном обзоре мы коснемся только собственно критерия Дарбина-Уотсона и его применения для выявления автокорреляции. Особенности построения регрессионных моделей и прогнозирования в условиях автокорреляции (двухшаговый метод наименьших квадратов и пр.) мы рассматривать не будем.
#### Применение пользовательских функций
Как и в предыдущем обзоре, здесь будут использованы несколько пользовательских функций для решения разнообразных задач. Все эти функции созданы для облегчения работы и уменьшения размера программного кода. Данные функции загружается из пользовательского модуля **my\_module\_\_stat.py**, который доступен в моем [репозитории на GitHub](https://github.com/AANazarov/MyModulePython).
Вот перечень данных функций:
* **graph\_plot\_sns\_np** - функция строит линейный график средствами **seaborn**;
* **graph\_regression\_plot\_sns** - функция строит график регрессионной модели и график остатков средствами **seaborn**;
* **regression\_error\_metrics** - функция возвращает ошибки аппроксимации регрессионной модели;
* **graph\_hist\_boxplot\_probplot\_sns** - функция позволяет визуализировать исходные данные для одной переменной путем одновременного построения гистограммы, коробчатой диаграммы и вероятностного графика средствами **seaborn**; имеется возможность выбирать, какие графики строить (h - hist, b - boxplot, p - probplot);
* **norm\_distr\_check** - проверка нормальности распределения исходных данных с использованием набора из нескольких статистических тестов.
* **Goldfeld\_Quandt\_test**, **Breush\_Pagan\_test**, **White\_test** - проверка гетероскедастичности с использование тестов Голдфелда-Квандта, Бриша-Пэгана и Уайта соответственно;
* **graph\_regression\_pair\_predict\_plot\_sns** - прогнозирование: построение графика регрессионной модели (с доверительными интервалами) и вывод расчетной таблицы с данными для заданной области значений **X**.
В процессе данного обзора мы создаем пользовательскую функцию **Durbin\_Watson\_test**, которая проверяет гипотезу о наличии автокорреляции (она тоже включена в пользовательский модуль **my\_module\_\_stat.py**).
Основы теории
-------------
Информацию о критерии Дарбина-Уотсона можно почерпнуть в [1, с.659], [2, с.117], [3, с.239], [4, с.188], а также:
* [Durbin–Watson statistic](https://en.wikipedia.org/wiki/Durbin%E2%80%93Watson_statistic)
* [Критерий Дарбина — Уотсона](https://ru.wikipedia.org/wiki/%D0%9A%D1%80%D0%B8%D1%82%D0%B5%D1%80%D0%B8%D0%B9_%D0%94%D0%B0%D1%80%D0%B1%D0%B8%D0%BD%D0%B0_%E2%80%94_%D0%A3%D0%BE%D1%82%D1%81%D0%BE%D0%BD%D0%B0)
Итак, предположим, мы рассматриваем регрессионную модель:
или в матричном виде:
Критерий Дарбина-Уотсона применяется в ситуации, когда регрессионные остатки связаны **автокорреляционной зависимостью 1-го порядка** [2, с.111]:
где  - некоторое число (), а случайные величины  удовлетворяют требованиям, предъявляемым к регрессионным остаткам классической модели (т.е. равенство нулю среднего значения, постоянство дисперсии и некоррелированность между собой):
Проверяется **нулевая гипотеза** об отсутствии автокорреляции:

**Альтернативной гипотезой** может быть:
* существование отрицательной автокорреляции (левосторонняя критическая область):

* существование положительной автокорреляции (правосторонняя критическая область):

* существование автокорреляции вообще (двусторонняя критическая область):

**Расчетное значение** статистики критерия Дарбина-Уотсона имеет вид:
где  - остатки (невязки) регрессионной модели.
По таблицам (см. [1, с.659], [2, с.402], [3, с.291]) в зависимости от уровня значимости  (5%, 2.5%, 1%), числа параметров регрессионной модели  (кроме свободного члена ) (от 1 до 5) и объема выборки  (от 15 до 100) определяются **критические значения статистики Дарбина-Уотсона**: нижний  и верхний  предел.
Правила принятия гипотез по критерию Дарбина-Уотсона выглядят довольно своеобразно - критические значения образуют пять областей различных статистических решений (причем критические границы принятия  и непринятия  не совпадают):
| Значение DW_{calc} | Принимается гипотеза | Вывод |
| --- | --- | --- |
| 0 \leq DW_{calc} < d_L | отвергается H_0, принимается H_1: \rho > 0 | есть положительная автокорреляция |
| d_L \leq DW_{calc} \leq d_U | | неопределенность |
| d_U < DW_{calc} < 4-d_U | принимается H_0 | автокорреляция отсутствует |
| 4-d_U \leq DW_{calc} \leq 4-d_L | | неопределенность |
| 4-d_L < DW_{calc} \leq 4 | отвергается H_0, принимается H_1: \rho < 0 | есть отрицательная автокорреляция |
Есть очень удачная мнемоническая схема, приведенная в [3, с.240]:
**Особенности критерия Дарбина-Уотсона:**
1. Критические значения критерия табулированы для объема выборки от 15 до 100, аппроксимаций мне обнаружить не удалось. При меньших значениях критерий применять нельзя, при больших - очевидно, приходиться пользоваться грубым оценочным правилом: при расчетном значении статистики критерия в интервале **[1; 2]** автокорреляция отсутствует (см. [https://en.wikipedia.org/wiki/Durbin–Watson\_statistic](https://en.wikipedia.org/wiki/Durbin%E2%80%93Watson_statistic)).
2. Критерий позволяет выявить только автокорреляцию 1-го порядка. Отклонение нулевой гипотезы не означает, что автокорреляции нет вообще - возможно наличие автокорреляции более высоких порядков.
3. Критерий построен в предположении, что регрессоры  и ошибки  не коррелированы, поэтому его нельзя применять, в частности, для моделей авторегрессии [4, с.191].
4. Критерий не подходит для моделей без свободного члена .
5. Критерий имеет зону неопределенности, когда нет оснований ни принимать, ни отвергать нулевую гипотезу.
6. Между статистикой критерия и коэффициентом автокорреляции существует приближенное соотношение:
Существуют и другие критерии для проверки автокорреляции (тест Бройша-Годфри, Льюнга-Бокса и пр.).
Как было указано выше, большой проблемой является отсутствие табличных значений статистики критерия Дарбина-Уостона в стандартном инструментарии **python**. Для реализации возможностей данного критерия в полном объеме нам потребуется оцифровка весьма объемных таблиц критических значений.
Оцифровка табличных значений статистики критерия Дарбина - Уотсона
------------------------------------------------------------------
Я решил добавить в обзор этот раздел, хотя, строго говоря, можно было обойтись и без него, а сразу воспользоваться оцифрованными таблицами статистики критерия Дарбина-Уотсона.
Однако, если мы хотим выполнять качественный статистический анализ, неизбежно придется работать с большим количеством статистических критериев и далеко не все из них реализованы в **python**. Критерий Дарбина-Уотсона - это только один из многих. Количество критериев, рассматриваемых в литературе по прикладной статистике в последние годы постоянно увеличивается. Специалисту придется реализовывать многие критерии самостоятельно и одна из проблем, с которой придется столкнуться - это таблицы критических значений. Далеко не все табличные значения имеют аппроксимации, а значит придется каким-то образом оцифровывать эти таблицы. Небольшие таблицы можно сохранить в файлах вручную, а вот такой подход с объемными таблицами (как в нашем случае) - это слишком непроизводительно и нерационально.
В общем, на мой взгляд, представляет интерес разобрать пример оцифровки статистических таблиц на примере нашего критерия Дарбина-Уотсона - это позволит специалистам сэкономить человеко-часы работы и облегчить совершенствование инструментов статистического анализа.
Замечу сразу, что я не являюсь глубоким специалистом в области анализа и обработки изображений и текстов на **python** - это не совсем мой профиль. Профессионалы в этой области, возможно, раскритикуют то, как решается поставленная задача и предложат более удачное решение. Если будет так - то заранее спасибо. Я же эту задачу старался решить наиболее простым и рациональным способом, доступным для широкого круга специалистов. На всякий случай могу процитировать Давоса Сиворта из "Игры престолов": "Простите за то, что увидите".
**Алгоритм действий:**
Для оцифровки я использовал таблицы, приведенные в [3, с.290-292].
1. Сканируем таблицы, сохраняем в виде jpg-файлов (**Durbin\_Watson\_test\_1.jpg**, **Durbin\_Watson\_test\_2.jpg**, **Durbin\_Watson\_test\_3.jpg**) в папке **text\_processing**, расположенной внутри папки с рабочим **.ipynb-файлом**:
2. Распознаем текст (я воспользовался онлайн-сервисом <https://convertio.co/>), полученные текстовые файлы **Durbin-Watson-test-1.ocr.txt**, **Durbin-Watson-test-2.ocr.txt**, **Durbin-Watson-test-3.ocr.txt** также помещаем в папке **text\_processing**.
3. Откроем файлы, запишем содержимое файлов в переменные, каждая из которых соответствует одной странице:
```
with open('text_processing\Durbin-Watson-test-1.ocr.txt') as f1:
Durbin_Watson_test_1 = f1.readlines()
display(Durbin_Watson_test_1, type(Durbin_Watson_test_1), len(Durbin_Watson_test_1))
```
С остальными файлами - действуем аналогично:
```
with open('text_processing\Durbin-Watson-test-2.ocr.txt') as f2:
Durbin_Watson_test_2 = f2.readlines()
display(Durbin_Watson_test_2, type(Durbin_Watson_test_2), len(Durbin_Watson_test_2))
with open('text_processing\Durbin-Watson-test-3.ocr.txt') as f3:
Durbin_Watson_test_3 = f3.readlines()
display(Durbin_Watson_test_3, type(Durbin_Watson_test_3), len(Durbin_Watson_test_3))
```
Видим, что переменные представляют собой списки, элементами которых является строки.
Для облегчения дальнейшей обработки данных создадим список, элементами которого являются переменные-страницы:
```
Durbin_Watson_test = [Durbin_Watson_test_1, Durbin_Watson_test_2, Durbin_Watson_test_3]
```
Далее я не стал публиковать здесь скриншоты с обработкой страниц - из-за экономии места. В ipyng-файле, который доступен в [моем репозитории](https://github.com/AANazarov/Statistical-methods), весь процесс обработки представлен достаточно подробно.
4. Исключаем все строки, которые начинаются не с цифр; при этом воспользуемся алгоритмом перезаписи списка:
```
# создаем новый список
Durbin_Watson_test_new = list()
# удаляем строки
for page in Durbin_Watson_test:
page_temp = list() # временная страница
for line in page:
if line[0].isdigit():
page_temp.append(line) # перезаписываем список
Durbin_Watson_test_new.append(page_temp)
```
5. Исключаем из текста управляющие символы (\t, \n) - с помощью регулярных выражений (regex) (модуль **re**):
```
# задаем шаблон для удаления символов
pattern = r'[\t+\n+]'
# выполняем обработку
Durbin_Watson_test_new = [
[re.sub(pattern, ' ', elem) for elem in page]
for page in Durbin_Watson_test_new]
```
6. Удаляем все символы, кроме цифр, точек, запятых и пробелов:
```
# задаем шаблон для удаления символов
pattern = r'[^0-9,. ]'
# выполняем обработку
Durbin_Watson_test_new = [
[re.sub(pattern, '', elem) for elem in page]
for page in Durbin_Watson_test_new]
```
7. Заменяем запятые на точки:
```
# задаем шаблон для удаления символов
pattern = r'[,]'
# выполняем обработку
Durbin_Watson_test_new = [
[re.sub(pattern, '.', elem) for elem in page]
for page in Durbin_Watson_test_new]
```
8. Разделяем строки:
```
# задаем шаблон
pattern = r'[ ]+'
# выполняем обработку
Durbin_Watson_test_new = [[re.split(pattern, elem) for elem in page]
for page in Durbin_Watson_test_new]
```
9. Сохраняем данные в DataFrame - для этого создадим список **Durbin\_Watson\_list\_df**, элементами которого являются отдельные DataFrame, каждый из которых соответствует отдельной странице:
```
# создаем новый список
Durbin_Watson_list_df = list()
for page in Durbin_Watson_test_new:
Durbin_Watson_list_df.append(pd.DataFrame(page))
```
10. Исправляем вручную отдельные аномалии, возникшие при распознавании отсканированных данных - к сожалению, работы вручную совсем избежать не удается.
* Корректируем DataFrame, соответствующий 1-й странице:
```
# создаем временный DataFrame
temp_df = Durbin_Watson_list_df[0]
# удаляем последние столбцы
temp_df = temp_df.drop(columns=[11, 12])
# корректируем вручную отдельные ошибки
temp_df.loc[[4],] = [19, 1.18, 1.40, 1.08, 1.53, 0.97, 1.68, 0.86, 1.85, 0.75, 2.02]
temp_df.loc[[8],[3]] = 1.17
temp_df.loc[[10],[3]] = 1.21
temp_df.loc[[17],[9]] = 1.11
temp_df.loc[[21],[4]] = 1.59
temp_df.loc[[25],[5]] = 1.34
temp_df.loc[[31],[10]] = 1.77
# записываем изменения
Durbin_Watson_list_df[0] = temp_df
```
* Корректируем DataFrame, соответствующий 2-й странице:
```
# создаем временный DataFrame
temp_df = Durbin_Watson_list_df[1]
# удаляем последние столбцы
temp_df = temp_df.drop(columns=[11, 12])
# корректируем вручную отдельные ошибки
temp_df.loc[[2],[8]] = 1.77
temp_df.loc[[10],[9]] = 0.86
temp_df.loc[[10],[10]] = 1.77
temp_df.loc[[14],[9]] = 0.96
temp_df.loc[[17],[10]] = 1.71
temp_df.loc[[34],[10]] = 1.71
# записываем изменения
Durbin_Watson_list_df[1] = temp_df
```
* Корректируем DataFrame, соответствующий 3-й странице:
```
# создаем временный DataFrame
temp_df = Durbin_Watson_list_df[2]
# удаляем последние столбцы
temp_df = temp_df.drop(columns=[11, 12])
# корректируем вручную отдельные ошибки
temp_df.loc[[2],[9]] = 0.48
temp_df.loc[[13],] = [28, 1.10, 1.24, 1.04, 1.32, 0.97, 1.41, 0.90, 1.51, 0.83, 1.62]
temp_df.loc[[20],[3]] = 1.14
temp_df.iloc[21:26, 7] = [1.04, 1.06, 1.07, 1.09, 1.10]
temp_df.loc[[26],[9]] = 1.11
temp_df.loc[[35],] = [90, 1.50, 1.54, 1.47, 1.56, 1.45, 1.59, 1.43, 1.61, 1.41, 1.64]
# записываем изменения
Durbin_Watson_list_df[2] = temp_df
```
Обращаем внимание, что откорректированные вручную значения являются числовыми, а все остальные значения - еще имеют строковый тип.
11. Преобразуем значения из строкового в числовой тип:
```
for elem_df in Durbin_Watson_list_df:
for col in elem_df.columns:
elem_df[col] = pd.to_numeric(elem_df[col], errors='ignore')
```
12. Корректируем структуру DataFrame:
* меняем индекс - индексом теперь будет объем выборки *n*
* каждый DataFrame снабжаем **мультииндексом** по столбцам (подробнее см. [7, с.169])
```
# меняем индекс
Durbin_Watson_list_df = [
elem_df.set_index([0])
for elem_df in Durbin_Watson_list_df]
# добавляем мультииндекс по столбцам
multi_index_list = ['p=0.95', 'p=0.975', 'p=0.99'] # список, содержащий значения для верхней строки мульииндекса
for i, elem_df in enumerate(Durbin_Watson_list_df):
elem_df.index.name = 'n'
elem_df.columns = pd.MultiIndex.from_product(
[[multi_index_list[i]],
['m=1', 'm=2', 'm=3', 'm=4', 'm=5'],
['dL','dU']])
```
13. Объединяем отдельные DataFrame в один:
```
Durbin_Watson_test_df = Durbin_Watson_list_df[0].copy()
for i, elem_df in enumerate(Durbin_Watson_list_df):
if i > 0:
Durbin_Watson_test_df = Durbin_Watson_test_df.join(elem_df)
display(Durbin_Watson_test_df)
```

```
Durbin_Watson_test_df.info()
```
Итак, мы сформировали DataFrame с оцифрованными данными таблиц критических значений статистики Дарбина-Уотсона. Получить доступ к данным теперь очень просто - например, нам требуется вывести табличные значения статистики критерия при объеме выборки , доверительной вероятности  и числе параметров регрессионной модели :
```
n = 40
p = 0.95
m=2
Durbin_Watson_test_df.loc[[n], (f'p={p}', f'm={m}')]
```
14. Построим график табличных значений.
График получился весьма объемным - 3х5 элементов - однако он необходим: на графике можно увидеть те ошибки (пики и впадины), которые мы могли пропустить при ручной обработке ранее (некорректно отсканированные и распознанные цифры), тогда придется вернуться к этапу 10.
```
# меняем настройки Mathplotlib
plt.rcParams['axes.titlesize'] = 10 # шрифт заголовка
plt.rcParams['legend.fontsize'] = 9 # шрифт легенды
plt.rcParams['xtick.labelsize'] = 8 # шрифт подписей меток
plt.rcParams['ytick.labelsize'] = 8
fig = plt.figure(figsize=(297/INCH, 420/INCH))
ax_1_1 = plt.subplot(5,3,1)
ax_2_1 = plt.subplot(5,3,2)
ax_3_1 = plt.subplot(5,3,3)
ax_1_2 = plt.subplot(5,3,4)
ax_2_2 = plt.subplot(5,3,5)
ax_3_2 = plt.subplot(5,3,6)
ax_1_3 = plt.subplot(5,3,7)
ax_2_3 = plt.subplot(5,3,8)
ax_3_3 = plt.subplot(5,3,9)
ax_1_4 = plt.subplot(5,3,10)
ax_2_4 = plt.subplot(5,3,11)
ax_3_4 = plt.subplot(5,3,12)
ax_1_5 = plt.subplot(5,3,13)
ax_2_5 = plt.subplot(5,3,14)
ax_3_5 = plt.subplot(5,3,15)
fig.suptitle('Табличные значения статистики критерия Дарбина-Уотсона', fontsize = 16)
(Ymin, Ymax) = (0.3, 2.2)
x = Durbin_Watson_test_df.index
title_fontsize = 10
name_1_1 = ['p=0.95', 'm=1']
ax_1_1.set_title(name_1_1[0] + ' ' + name_1_1[1])
ax_1_1.plot(x, Durbin_Watson_test_df[tuple(name_1_1 + ['dL'])],
x, Durbin_Watson_test_df[tuple(name_1_1 + ['dU'])])
name_1_2 = ['p=0.95', 'm=2']
ax_1_2.set_title(name_1_2[0] + ' ' + name_1_2[1])
ax_1_2.plot(x, Durbin_Watson_test_df[tuple(name_1_2 + ['dL'])],
x, Durbin_Watson_test_df[tuple(name_1_2 + ['dU'])])
name_1_3 = ['p=0.95', 'm=3']
ax_1_3.set_title(name_1_3[0] + ' ' + name_1_3[1])
ax_1_3.plot(x, Durbin_Watson_test_df[tuple(name_1_3 + ['dL'])],
x, Durbin_Watson_test_df[tuple(name_1_3 + ['dU'])])
name_1_4 = ['p=0.95', 'm=4']
ax_1_4.set_title(name_1_4[0] + ' ' + name_1_4[1])
ax_1_4.plot(x, Durbin_Watson_test_df[tuple(name_1_4 + ['dL'])],
x, Durbin_Watson_test_df[tuple(name_1_4 + ['dU'])])
name_1_5 = ['p=0.95', 'm=5']
ax_1_5.set_title(name_1_5[0] + ' ' + name_1_5[1])
ax_1_5.plot(x, Durbin_Watson_test_df[tuple(name_1_5 + ['dL'])],
x, Durbin_Watson_test_df[tuple(name_1_5 + ['dU'])])
name_2_1 = ['p=0.975', 'm=1']
ax_2_1.set_title(name_2_1[0] + ' ' + name_2_1[1])
ax_2_1.plot(x, Durbin_Watson_test_df[tuple(name_2_1 + ['dL'])],
x, Durbin_Watson_test_df[tuple(name_2_1 + ['dU'])])
name_2_2 = ['p=0.975', 'm=2']
ax_2_2.set_title(name_2_2[0] + ' ' + name_2_2[1])
ax_2_2.plot(x, Durbin_Watson_test_df[tuple(name_2_2 + ['dL'])],
x, Durbin_Watson_test_df[tuple(name_2_2 + ['dU'])])
name_2_3 = ['p=0.975', 'm=3']
ax_2_3.set_title(name_2_3[0] + ' ' + name_2_3[1])
ax_2_3.plot(x, Durbin_Watson_test_df[tuple(name_2_3 + ['dL'])],
x, Durbin_Watson_test_df[tuple(name_2_3 + ['dU'])])
name_2_4 = ['p=0.975', 'm=4']
ax_2_4.set_title(name_2_4[0] + ' ' + name_2_4[1])
ax_2_4.plot(x, Durbin_Watson_test_df[tuple(name_2_4 + ['dL'])],
x, Durbin_Watson_test_df[tuple(name_2_4 + ['dU'])])
name_2_5 = ['p=0.975', 'm=5']
ax_2_5.set_title(name_2_5[0] + ' ' + name_2_5[1])
ax_2_5.plot(x, Durbin_Watson_test_df[tuple(name_2_5 + ['dL'])],
x, Durbin_Watson_test_df[tuple(name_2_5 + ['dU'])])
name_3_1 = ['p=0.99', 'm=1']
ax_3_1.set_title(name_3_1[0] + ' ' + name_3_1[1])
ax_3_1.plot(x, Durbin_Watson_test_df[tuple(name_3_1 + ['dL'])],
x, Durbin_Watson_test_df[tuple(name_3_1 + ['dU'])])
name_3_2 = ['p=0.99', 'm=2']
ax_3_2.set_title(name_3_2[0] + ' ' + name_3_2[1])
ax_3_2.plot(x, Durbin_Watson_test_df[tuple(name_3_2 + ['dL'])],
x, Durbin_Watson_test_df[tuple(name_3_2 + ['dU'])])
name_3_3 = ['p=0.99', 'm=3']
ax_3_3.set_title(name_3_3[0] + ' ' + name_3_3[1])
ax_3_3.plot(x, Durbin_Watson_test_df[tuple(name_3_3 + ['dL'])],
x, Durbin_Watson_test_df[tuple(name_3_3 + ['dU'])])
name_3_4 = ['p=0.99', 'm=4']
ax_3_4.set_title(name_3_4[0] + ' ' + name_3_4[1])
ax_3_4.plot(x, Durbin_Watson_test_df[tuple(name_3_4 + ['dL'])],
x, Durbin_Watson_test_df[tuple(name_3_4 + ['dU'])])
name_3_5 = ['p=0.99', 'm=5']
ax_3_5.set_title(name_3_5[0] + ' ' + name_3_5[1])
ax_3_5.plot(x, Durbin_Watson_test_df[tuple(name_3_5 + ['dL'])],
x, Durbin_Watson_test_df[tuple(name_3_5 + ['dU'])])
ax_1_1.set_ylim(Ymin, Ymax)
ax_2_1.set_ylim(Ymin, Ymax)
ax_3_1.set_ylim(Ymin, Ymax)
ax_1_2.set_ylim(Ymin, Ymax)
ax_2_2.set_ylim(Ymin, Ymax)
ax_3_2.set_ylim(Ymin, Ymax)
ax_1_3.set_ylim(Ymin, Ymax)
ax_2_3.set_ylim(Ymin, Ymax)
ax_3_3.set_ylim(Ymin, Ymax)
ax_1_4.set_ylim(Ymin, Ymax)
ax_2_4.set_ylim(Ymin, Ymax)
ax_3_4.set_ylim(Ymin, Ymax)
ax_1_5.set_ylim(Ymin, Ymax)
ax_2_5.set_ylim(Ymin, Ymax)
ax_3_5.set_ylim(Ymin, Ymax)
legend = (r'$d_L$', r'$d_U$')
ax_1_1.legend(legend)
ax_2_1.legend(legend)
ax_3_1.legend(legend)
ax_1_2.legend(legend)
ax_2_2.legend(legend)
ax_3_2.legend(legend)
ax_1_3.legend(legend)
ax_2_3.legend(legend)
ax_3_3.legend(legend)
ax_1_4.legend(legend)
ax_2_4.legend(legend)
ax_3_4.legend(legend)
ax_1_5.legend(legend)
ax_2_5.legend(legend)
ax_3_5.legend(legend)
plt.show()
# возвращаем настройки Mathplotlib
plt.rcParams['axes.titlesize'] = f_size + 10 # шрифт заголовка
plt.rcParams['legend.fontsize'] = f_size + 6 # шрифт легенды
plt.rcParams['xtick.labelsize'] = f_size + 4 # шрифт подписей меток
plt.rcParams['ytick.labelsize'] = f_size + 4
```
15. Сохраняем полученный DataFrame в csv-файл, помещаем его в папку **table**, расположенную внутри папки с рабочим **.ipynb-файлом** (в которой папку **table** у нас хранятся файлы с данными из статистических таблиц):
```
Durbin_Watson_test_df.to_csv(
path_or_buf='table\Durbin_Watson_test_table.csv',
mode='w+',
sep=';',
index_label='n')
```
Табличные значения статистики критерия Дарбина-Уотсона у нас теперь имеются, можем приступать к созданию пользовательской функции.
Создание пользовательской функции для реализации критерия Дарбина - Уотсона
---------------------------------------------------------------------------
Рассчитать статистику критерия Дарбина-Уотсона мы можем с помощью функции **statsmodels.stats.stattools.durbin\_watson**.
Создадим пользовательскую функцию **Durbin\_Watson\_test** для проверки гипотезы об автокорреляции:
```
def Durbin_Watson_test(
data,
m = None,
p_level: float=0.95):
a_level = 1 - p_level
data = np.array(data)
n = len(data)
# расчетное значение статистики критерия
DW_calc = sms.stattools.durbin_watson(data)
# табличное значение статистики критерия
if (n >= 15) and (n <= 100):
# восстанавливаем структуру DataFrame из csv-файла
DW_table_df = pd.read_csv(
filepath_or_buffer='table/Durbin_Watson_test_table.csv',
sep=';',
#index_col='n'
)
DW_table_df = DW_table_df.rename(columns={'Unnamed: 0': 'n'})
DW_table_df = DW_table_df.drop([0, 1, 2])
for col in DW_table_df.columns:
DW_table_df[col] = pd.to_numeric(DW_table_df[col], errors='ignore')
DW_table_df = DW_table_df.set_index('n')
DW_table_df.columns = pd.MultiIndex.from_product(
[['p=0.95', 'p=0.975', 'p=0.99'],
['m=1', 'm=2', 'm=3', 'm=4', 'm=5'],
['dL','dU']])
# интерполяция табличных значений
key = [f'p={p_level}', f'm={m}']
f_lin_L = sci.interpolate.interp1d(DW_table_df.index, DW_table_df[tuple(key + ['dL'])])
f_lin_U = sci.interpolate.interp1d(DW_table_df.index, DW_table_df[tuple(key + ['dU'])])
DW_table_L = float(f_lin_L(n))
DW_table_U = float(f_lin_U(n))
# проверка гипотезы
Durbin_Watson_scale = {
1: DW_table_L,
2: DW_table_U,
3: 4 - DW_table_U,
4: 4 - DW_table_L,
5: 4}
Durbin_Watson_comparison = {
1: ['0 ≤ DW_calc < DW_table_L', 'H1: r > 0'],
2: ['DW_table_L ≤ DW_calc ≤ DW_table_U', 'uncertainty'],
3: ['DW_table_U < DW_calc < 4 - DW_table_U', 'H0: r = 0'],
4: ['4 - DW_table_U ≤ DW_calc ≤ 4 - DW_table_L', 'uncertainty'],
5: ['4 - DW_table_L < DW_calc ≤ 4', 'H1: r < 0']}
r_scale = list(Durbin_Watson_scale.values())
for i, elem in enumerate(r_scale):
if DW_calc <= elem:
key_scale = list(Durbin_Watson_scale.keys())[i]
comparison = Durbin_Watson_comparison[key_scale][0]
conclusion = Durbin_Watson_comparison[key_scale][1]
break
elif n < 15:
comparison = '-'
conclusion = 'count less than 15'
else:
comparison = '-'
conclusion = 'count more than 100'
# формируем результат
result = pd.DataFrame({
'n': (n),
'm': (m),
'p_level': (p_level),
'a_level': (a_level),
'DW_calc': (DW_calc),
'ρ': (1 - DW_calc/2),
'DW_table_L': (DW_table_L if (n >= 15) and (n <= 100) else '-'),
'DW_table_U': (DW_table_U if (n >= 15) and (n <= 100) else '-'),
'comparison of calculated and critical values': (comparison),
'conclusion': (conclusion)
},
index=['Durbin-Watson_test'])
return result
```
Протестируем созданную функцию - будем моделировать временные ряды с различными свойствами и выполнять проверку автокорреляции:
```
y_func = lambda x, b0, b1: b0 + b1*x
N = 30 # число наблюдений
(mu, sigma) = (0, 25) # параметры моделируемой случайной компоненты (среднее и станд.отклонение)
```
1. Смоделируем **временной ряд с трендом, без автокорреляции остатков**:
```
# моделирование
T_model = np.linspace(1, N, N) # независимая переменная - номер наблюдения
(b0, b1) = (100, 5) # параметры моделируемого временного ряда
Y_model = np.array(y_func(T_model, b0, b1)) + np.random.normal(mu, sigma, N)
# визуализация
axes = sns.jointplot(
x=T_model, y=Y_model,
kind='reg')
plt.show()
# проверка автокорреляции
display(Durbin_Watson_test(Y_model, m=1, p_level=0.95))
```
```
# моделирование
T_model = np.linspace(1, N, N) # независимая переменная - номер наблюдения
(b0, b1) = (100, -5) # параметры моделируемого временного ряда
Y_model = np.array(y_func(T_model, b0, b1)) + np.random.normal(mu, sigma, N)
# визуализация
axes = sns.jointplot(
x=T_model, y=Y_model,
kind='reg')
plt.show()
# проверка автокорреляции
display(Durbin_Watson_test(Y_model, m=1, p_level=0.95))
```
2. Смоделируем **временной ряд без тренда**:
```
# моделирование
T_model = np.linspace(1, N, N) # независимая переменная - номер наблюдения
(b0, b1) = (100, 0) # параметры моделируемого временного ряда
Y_model = np.array(y_func(T_model, b0, b1)) + np.random.normal(mu, sigma, N)
# визуализация
axes = sns.jointplot(
x=T_model, y=Y_model,
kind='reg')
plt.show()
# проверка автокорреляции
display(Durbin_Watson_test(Y_model, m=1, p_level=0.95))
```
```
# моделирование
T_model = np.linspace(1, N, N) # независимая переменная - номер наблюдения
(b0, b1) = (0, 0) # параметры моделируемого временного ряда
Y_model = np.array(y_func(T_model, b0, b1)) + np.random.normal(mu, sigma, N)
# визуализация
axes = sns.jointplot(
x=T_model, y=Y_model,
kind='reg')
plt.show()
# проверка автокорреляции
display(Durbin_Watson_test(Y_model, m=1, p_level=0.95))
```
3. Смоделируем **временной ряд с трендом, с положительной автокорреляцией**:
```
# моделирование
T_model = np.linspace(1, N, N) # независимая переменная - номер наблюдения
(b0, b1) = (100, 5) # параметры моделируемого временного ряда
E = np.array([np.random.normal(mu, sigma, 1)])
r = 0.9
for i in range(1, N):
elem = r*E[i-1] + np.random.normal(mu, sigma, 1)
E = np.append(E, elem)
Y_model = np.array(y_func(T_model, b0, b1)) + E
# визуализация
axes = sns.jointplot(
x=T_model, y=Y_model,
kind='reg')
plt.show()
# проверка автокорреляции
display(Durbin_Watson_test(Y_model, m=1, p_level=0.95))
```
4. Смоделируем **временной ряд с трендом, с отрицательной автокорреляцией**:
```
# моделирование
T_model = np.linspace(1, N, N) # независимая переменная - номер наблюдения
(b0, b1) = (100, 5) # параметры моделируемого временного ряда
E = np.array([np.random.normal(mu, sigma, 1)])
r = -0.9
for i in range(1, N):
elem = r*E[i-1] + np.random.normal(mu, sigma, 1)
E = np.append(E, elem)
Y_model = np.array(y_func(T_model, b0, b1)) + E
# визуализация
axes = sns.jointplot(
x=T_model, y=Y_model,
kind='reg')
plt.show()
# проверка автокорреляции
display(Durbin_Watson_test(Y_model, m=1, p_level=0.95))
```
5. Смоделируем **временной ряд без тренда, с положительной автокорреляцией**:
```
# моделирование
T_model = np.linspace(1, N, N) # независимая переменная - номер наблюдения
(b0, b1) = (100, 0) # параметры моделируемого временного ряда
E = np.array([np.random.normal(mu, sigma, 1)])
r = 0.9
for i in range(1, N):
elem = r*E[i-1] + np.random.normal(mu, sigma, 1)
E = np.append(E, elem)
Y_model = np.array(y_func(T_model, b0, b1)) + E
# визуализация
axes = sns.jointplot(
x=T_model, y=Y_model,
kind='reg')
plt.show()
# проверка автокорреляции
display(Durbin_Watson_test(Y_model, m=1, p_level=0.95))
```
```
# моделирование
T_model = np.linspace(1, N, N) # независимая переменная - номер наблюдения
(b0, b1) = (0, 0) # параметры моделируемого временного ряда
E = np.array([np.random.normal(mu, sigma, 1)])
r = 0.9
for i in range(1, N):
elem = r*E[i-1] + np.random.normal(mu, sigma, 1)
E = np.append(E, elem)
Y_model = np.array(y_func(T_model, b0, b1)) + E
# визуализация
axes = sns.jointplot(
x=T_model, y=Y_model,
kind='reg')
plt.show()
# проверка автокорреляции
display(Durbin_Watson_test(Y_model, m=1, p_level=0.95))
```
6. Смоделируем **временной ряд без тренда, с отрицательной автокорреляцией**:
```
# моделирование
T_model = np.linspace(1, N, N) # независимая переменная - номер наблюдения
(b0, b1) = (100, 0) # параметры моделируемого временного ряда
E = np.array([np.random.normal(mu, sigma, 1)])
r = -0.9
for i in range(1, N):
elem = r*E[i-1] + np.random.normal(mu, sigma, 1)
E = np.append(E, elem)
Y_model = np.array(y_func(T_model, b0, b1)) + E
# визуализация
axes = sns.jointplot(
x=T_model, y=Y_model,
kind='reg')
plt.show()
# проверка автокорреляции
display(Durbin_Watson_test(Y_model, m=1, p_level=0.95))
```
```
# моделирование
T_model = np.linspace(1, N, N) # независимая переменная - номер наблюдения
(b0, b1) = (0, 0) # параметры моделируемого временного ряда
E = np.array([np.random.normal(mu, sigma, 1)])
r = -0.9
for i in range(1, N):
elem = r*E[i-1] + np.random.normal(mu, sigma, 1)
E = np.append(E, elem)
Y_model = np.array(y_func(T_model, b0, b1)) + E
# визуализация
axes = sns.jointplot(
x=T_model, y=Y_model,
kind='reg')
plt.show()
# проверка автокорреляции
display(Durbin_Watson_test(Y_model, m=1, p_level=0.95))
```
Конечно, данный вычислительный эксперимент не может претендовать на всеобъемлемость, однако определенный любопытный предварительный вывод можно сделать: при наличии любого тренда (даже если этот тренда представляет собой равенство постоянной величине ) критерий Дарбина-Уотсона выдает нам наличие положительной автокорреляции (даже если в модели автокорреляция не заложена нет или она отрицательная). Такой вывод нужно исследовать более глубоко, но это не входит в цель данного обзора. Специалист должен помнить об особенностях критерия Дарбина-Уотсона.
Теперь мы можем перейти к практическим примерам.
Пример 1: проверка автокорреляции модели временного ряда
--------------------------------------------------------
#### Формирование исходных данных
В качестве исходных данных рассмотрим динамику показателей индексов пересчета сметной стоимости проектно-изыскательских работ в РФ. Эти показатели ежеквартально публикует Министерство строительства и ЖКХ РФ, а все проектные и изыскательские организации используют эти показатели при составлении смет на свои работы.
В данном случае мы имеем набор показателей в виде временного ряда, для которого будем строить регрессионную модель долговременной тенденции (тренда), и остатки этой регрессионной модели будем исследовать на автокорреляцию.
Исходные данные содержаться в файле **Ежеквартальные индексы ПИР.xlsx**, который помещен в папку **data**.
Прочитаем xlsx-файл:
```
data_df = pd.read_excel('data/Ежеквартальные индексы ПИР.xlsx', sheet_name='БД')
#display(data_df)
display(data_df.head(), data_df.tail())
data_df.info()
```
Не будем подробно останавливаться на содержимом файла и его первичной обработке - это выходит за пределы данного обзора. Специалисты, причастные к сфере строительства и проектирования, поймут, а для остальных специалистов эти цифры можно воспринимать по аналогии с индексами инфляции Росстата и Минэкономразвития.
Прочитаем из этого файла интересующие нас данные - **индексы изменения сметной стоимости проектных работ к уровню цен на 01.01.2001 г.**:
```
Ind_design_2001 = np.array(data_df['Ипроект2001'])
print(Ind_design_2001, '\n', type(Ind_design_2001), len(Ind_design_2001))
```
Сохраним также вспомогательные (технические) переменные, необходимые при анализе временных рядов - дату (**Date**) и номер наблюдения (**T**):
```
# Дата показателя
Date = np.array(data_df['ДАТА'])
# Номер наблюдения
T = np.array(data_df['N'])
```
Для удобства дальнейшей работы сформируем сформируем отдельный DataFrame:
```
dataset_df = pd.DataFrame({
'T': T,
'Date': Date,
'Ind_design_2001': Ind_design_2001})
display(dataset_df.head(), dataset_df.tail())
```
#### Визуализация
Настройка заголовков:
```
# Общий заголовок проекта
Task_Project = "Анализ динамики индексов изменения сметной стоимости проектно-изыскательских работ в РФ"
# Заголовок, фиксирующий момент времени
AsOfTheDate = "за 2008-2022 гг."
# Заголовок раздела проекта
Task_Theme = ""
# Общий заголовок проекта для графиков
Title_String = f"{Task_Project}\n{AsOfTheDate}"
# Наименования переменных
Variable_Name_T_month = "Ежемесячные данные"
Variable_Name_Ind_design_2001 = "Индекс изменения сметной стоимости проектных работ к уровню цен на 01.01.2001 г."
# Границы значений переменных (при построении графиков):
(X_min_graph, X_max_graph) = (0.0, max(T))
(Y_min_graph, Y_max_graph) = (2.0, 6.0)
```
```
graph_plot_sns_np(
Date, Ind_design_2001,
Ymin_in=Y_min_graph, Ymax_in=Y_max_graph,
color='orange',
title_figure=Title_String, title_figure_fontsize=12,
title_axes=Variable_Name_Ind_design_2001, title_axes_fontsize=15,
x_label=Variable_Name_T_month, label_fontsize=12)
```
#### Построение и анализ регрессионной модели
Построим линейную регрессионную модель и проведем ее экспресс-анализ:
```
model_linear_ols_1 = smf.ols(formula='Ind_design_2001 ~ T', data=dataset_df)
result_linear_ols_1 = model_linear_ols_1.fit()
print(result_linear_ols_1.summary2())
```
Формализация модели:
```
# Функция линейной регрессионной модели (SLRM - simple linear regression model)
SLRM_func = lambda x, b0, b1: b0 + b1*x
# параметры модели
b0 = result_linear_ols_1.params['Intercept']
b1 = result_linear_ols_1.params['T']
# уравнение модели
regr_model_linear_ols_1_func = lambda x: SLRM_func(x, b0, b1)
```
График модели:
```
R2 = round(result_linear_ols_1.rsquared, DecPlace)
legend_equation = f'линейная регрессия ' + r'$Y$' + f' = {b0:.4f} + {b1:.5f}{chr(183)}' + r'$X$' if b1 > 0 else \
f'линейная регрессия ' + r'$Y$' + f' = {b0:.4f} - {abs(b1):.5f}{chr(183)}' + r'$X$'
# Пользовательская функция
graph_regression_plot_sns(
T, Ind_design_2001,
regression_model=regr_model_linear_ols_1_func,
#Xmin=X_min_graph, Xmax=X_max_graph,
Ymin=Y_min_graph, Ymax=Y_max_graph,
display_residuals=True,
title_figure=Variable_Name_Ind_design_2001, title_figure_fontsize=16,
title_axes = 'Линейная регрессионная модель',
x_label=Variable_Name_T_month,
#y_label=Variable_Name_Ind_design_2001,
label_legend_regr_model = legend_equation + '\n' + r'$R^2$' + f' = {R2}',
s=60)
```
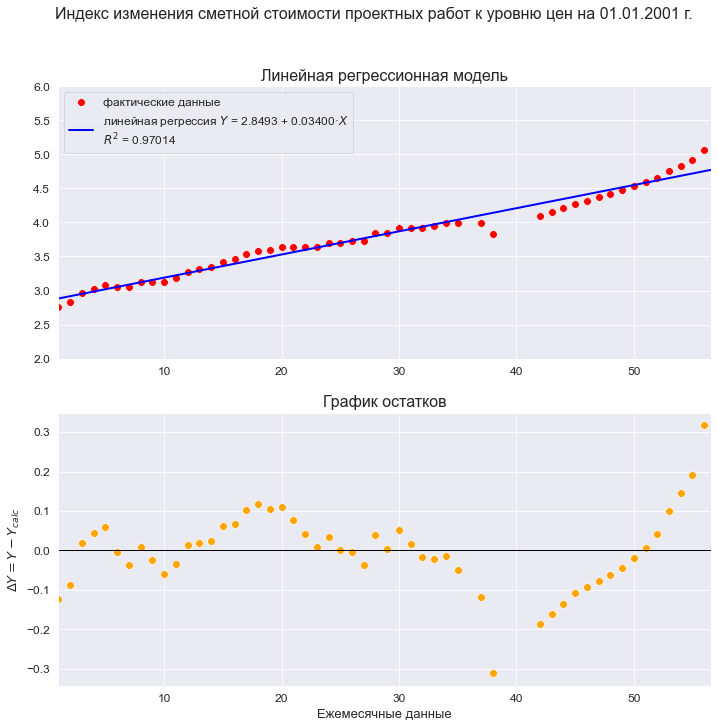Ошибки аппроксимации модели:
```
(model_error_metrics, result) = regression_error_metrics(model_linear_ols_1, model_name='linear_ols')
display(result)
```
Проверка нормальности распределения остатков:
```
res_Y_1 = np.array(result_linear_ols_1.resid)
# Пользовательская функция
graph_hist_boxplot_probplot_sns(
data=res_Y_1,
data_min=-0.25, data_max=0.25,
graph_inclusion='hbp',
data_label=r'$ΔY = Y - Y_{calc}$',
#title_figure=Task_Project,
title_axes='Остатки линейной регрессионной модели', title_axes_fontsize=16)
```

```
norm_distr_check(res_Y_1)
```
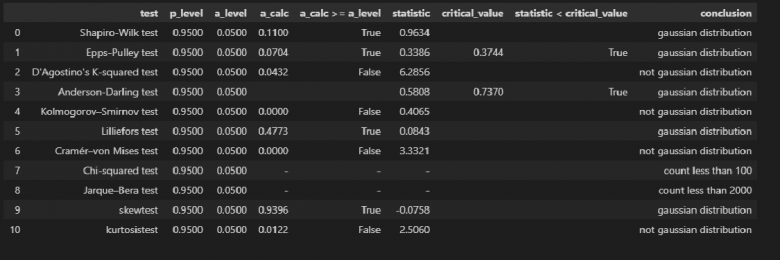Проверка гетероскедастичности:
```
Goldfeld_Quandt_test_df = Goldfeld_Quandt_test(result_linear_ols_1, p_level=0.95, model_name='linear_ols')
Breush_Pagan_test_df = Breush_Pagan_test(result_linear_ols_1, p_level=0.95, model_name='linear_ols')
White_test_df = White_test(result_linear_ols_1, p_level=0.95, model_name='linear_ols')
heteroscedasticity_tests_df = pd.concat([Breush_Pagan_test_df, White_test_df, Goldfeld_Quandt_test_df])
display(heteroscedasticity_tests_df)
```
Проверка автокорреляции:
```
sms.stattools.durbin_watson(res_Y_1)
```
Как видим, результат совпадает со значением статистики критерия в таблице выдачи регрессионного анализа.
```
display(Durbin_Watson_test(res_Y_1, m=1, p_level=0.95))
```
**Выводы по результатам анализа модели:**
Итак, мы провели статистический анализ регрессионной модели и установили:
1. Регрессионная модель хорошо аппроксимирует фактические данные.
2. Остатки модели имеют нормальное распределение (хотя результаты тестов противоречивы).
3. Коэффициент детерминации значим; модель объясняет 97% вариации независимой переменной.
4. Коэффициенты регрессии значимы.
5. Обнаружена гетероскедастичность.
6. Тест критерия Дарбина-Уотсона свидетельствует о наличии значимой положительной автокорреляции остатков.
**Резюме** - несмотря на вроде бы формально хорошие качественные показатели, нам следует признать эту модель некачественной и отвергнуть по следующим негативным причинам:
1. На графике модели хорошо заметна точка излома, которая говорит о смене тенденции (существуют специальные статистические тесты для проверки гипотез о смене тенденции, например, тест Чоу, но мы в данном обзоре рассматривать их не будем).
2. График остатков показывает нам крайне неприглядную картину: на начальном этапе тенденции явно прослеживаются колебания, а после точки излома тенденция вообще кардинально меняется.
3. Противоречивость тестов проверки нормальности распределения остатков.
4. Наличие гетероскедастичности.
5. Наличие автокорреляции. Явление автокорреляции может возникать в случае смены тенденции [5, с.118].
Тот факт, что распределение остатков признается нормальным по результатам таких тестов как Шапиро-Уилка, Эппса-Палли, Андерсона-Дарлинга может иметь разные причины, например, мы можем иметь дело со смесью двух распределений. Этот вопрос требует отдельного тщательного исследования.
Применение построенной модели приведет к ошибке, так как модель хорошо аппроксимирует существующие данные, но из-за смены тенденции неспособна дать качественный прогноз. Проиллюстрировать это можно, построив доверительный интервалы прогноза (формально мы можем это сделать, так как распределение остатков признано нормальным):
```
graph_regression_pair_predict_plot_sns(
model_fit=result_linear_ols_1,
regression_model_in=regr_model_linear_ols_1_func,
Xmin=X_min_graph, Xmax=X_max_graph+12, Nx=25,
Ymin_graph=2.0, Ymax_graph=Y_max_graph,
title_figure=Variable_Name_Ind_design_2001, title_figure_fontsize=16,
title_axes='Линейная регрессионная модель', title_axes_fontsize=14,
#x_label=Variable_Name_X,
#y_label=Variable_Name_Y,
label_legend_regr_model=f'линейная регрессия Y = {b0:.3f} + {b1:.4f}*X',
s=50,
result_output=False)
```
Нет, такой прогноз нам не нужен.
Пример 2: проверка автокорреляция регрессионной модели
------------------------------------------------------
#### Формирование исходных данных
Рассмотрим пример множественной линейной регрессионной модели, приведенный в источнике [6, с.192].
В качестве исходных данных рассматриваются ряд макроэкономических показателей США за 1960-1985 гг. (в сопоставимых ценах 1982 г., млрд.долл):
* **DPI** - годовой совокупный располагаемый личный доход;
* **CONS** - годовые совокупные потребительские расходы;
* **ASSETS** - финансовые активы населения на начало календарного года.
Предполагается, что между переменной **CONS** и регрессорами **DPI**, **ASSETS** имеется линейная регрессионная связь.
Исходные данные содержаться в файле **Macroeconomic\_indicators\_USA\_1960\_1985.csv**, который помещен в папку **data**.
Прочитаем csv-файл:
```
data_df = pd.read_csv(filepath_or_buffer='data/Macroeconomic_indicators_USA_1960_1985.csv', sep=';')
display(data_df)
#display(data_df.head(), data_df.tail())
data_df.info()
```
#### Визуализация
```
fig, axes = plt.subplots(figsize=(297/INCH, 210/INCH))
title_figure = 'Анализ макроэкономических показателей США за 1960-1985 гг.'
fig.suptitle(title_figure, fontsize = 18)
sns.lineplot(
x = data_df['YEAR'], y = data_df['DPI'],
linewidth=3,
legend=True,
label='DPI',
ax=axes)
sns.lineplot(
x = data_df['YEAR'], y = data_df['CONS'],
linewidth=3,
legend=True,
label='CONS',
ax=axes)
sns.lineplot(
x = data_df['YEAR'], y = data_df['ASSETS'],
linewidth=3,
legend=True,
label='ASSETS',
ax=axes)
axes.set_xlabel('Year')
axes.set_ylabel('US$ billion')
plt.show()
```
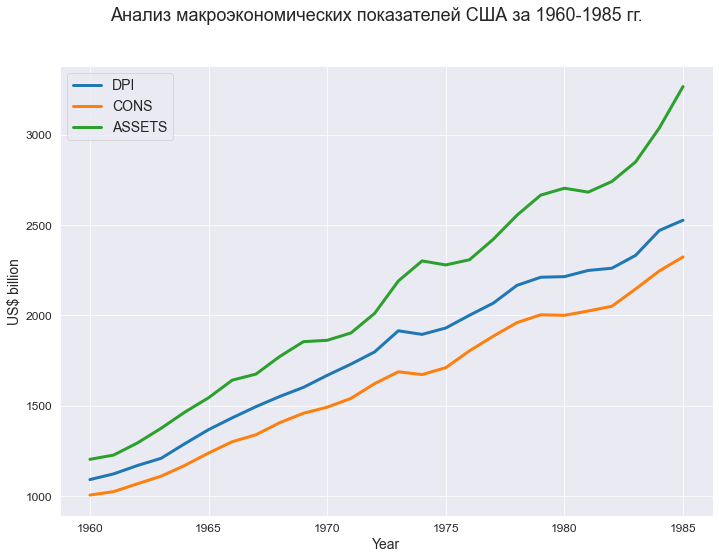#### Построение и анализ регрессионной модели
Построим линейную регрессионную модель и проведем ее экспресс-анализ:
```
y = data_df['CONS']
X = data_df[['DPI', 'ASSETS']]
X = sm.add_constant(X)
model_linear_ols_2 = sm.OLS(y, X)
result_linear_ols_2 = model_linear_ols_2.fit()
print(result_linear_ols_2.summary2())
```
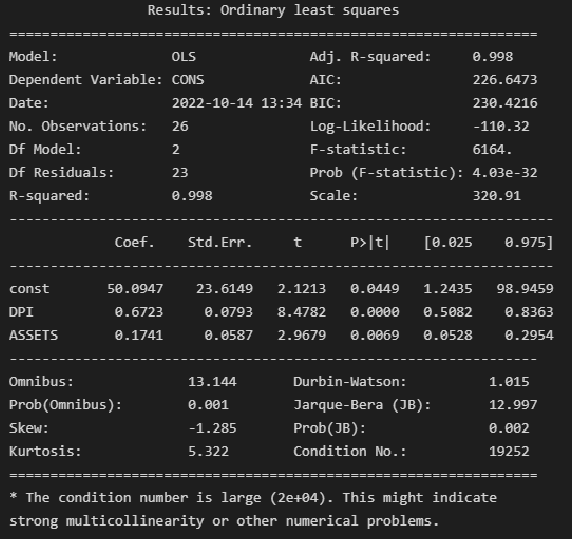График модели:
```
fig = plt.figure(figsize=(297/INCH, 420/INCH/1.5))
ax1 = plt.subplot(2,1,1)
ax2 = plt.subplot(2,1,2)
title_figure = 'Анализ макроэкономических показателей США за 1960-1985 гг.'
fig.suptitle(title_figure, fontsize = 18)
fig = sm.graphics.plot_fit(
result_linear_ols_2, 'DPI',
vlines=True, # это параметр отвечает за отображение доверительных интервалов для Y
ax=ax1)
ax1.set_ylabel('CONS (US$ billion)', fontsize = 12)
ax1.set_xlabel('DPI (US$ billion)', fontsize = 12)
ax1.set_title('Fitted values vs. DPI', fontsize = 15)
fig = sm.graphics.plot_fit(
result_linear_ols_2, 'ASSETS',
vlines=True, # это параметр отвечает за отображение доверительных интервалов для Y
ax=ax2)
ax2.set_ylabel('CONS (US$ billion)', fontsize = 12)
ax2.set_xlabel('ASSETS (US$ billion)', fontsize = 12)
ax2.set_title('Fitted values vs. ASSETS', fontsize = 15)
plt.show()
```
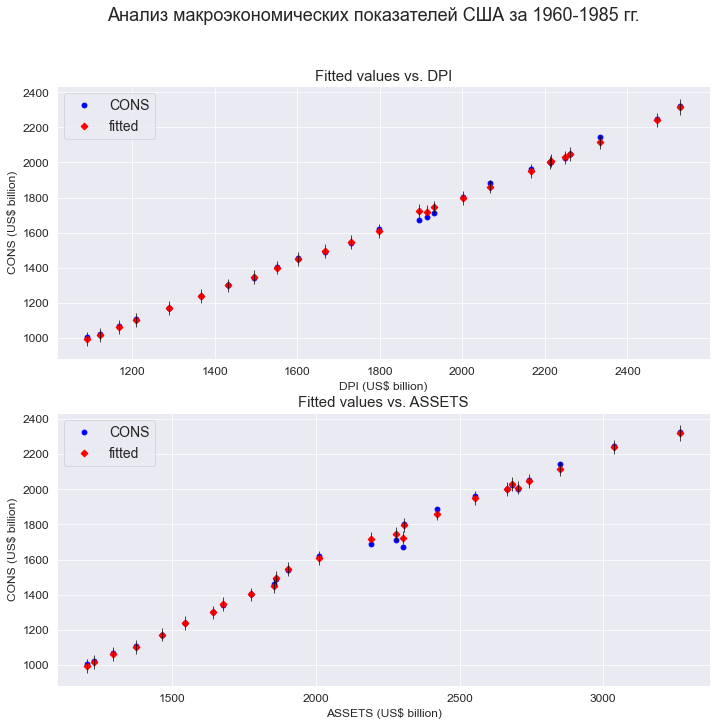Ошибки аппроксимации модели:
```
(model_error_metrics, result) = regrpy
ession_error_metrics(model_linear_ols_2, model_name='linear_ols')
display(result)
```
Проверка нормальности распределения остатков:
```
res_Y_2 = np.array(result_linear_ols_2.resid)
# Пользовательская функция
graph_hist_boxplot_probplot_sns(
data=res_Y_2,
data_min=-60, data_max=60,
graph_inclusion='hbp',
data_label=r'$ΔY = Y - Y_{calc}$',
#title_figure=Task_Project,
title_axes='Остатки линейной регрессионной модели', title_axes_fontsize=16)
norm_distr_check(res_Y_2)
```
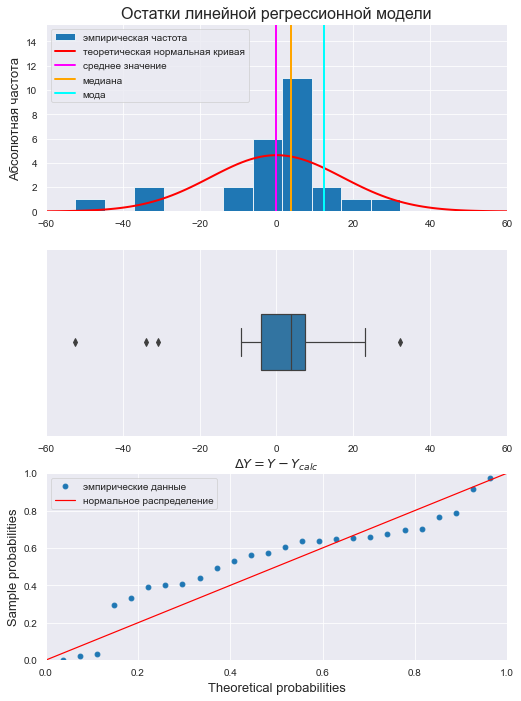Прроверка гетероскедастичности:
```
Goldfeld_Quandt_test_df = Goldfeld_Quandt_test(result_linear_ols_2, p_level=0.95, model_name='linear_ols')
Breush_Pagan_test_df = Breush_Pagan_test(result_linear_ols_2, p_level=0.95, model_name='linear_ols')
White_test_df = White_test(result_linear_ols_2, p_level=0.95, model_name='linear_ols')
heteroscedasticity_tests_df = pd.concat([Breush_Pagan_test_df, White_test_df, Goldfeld_Quandt_test_df])
display(heteroscedasticity_tests_df)
```
Проверка автокорреляции:
```
display(Durbin_Watson_test(res_Y_2, m=1, p_level=0.95))
```
**Выводы по результатам анализа модели:**
Как видим, в целом результаты расчетов совпадают с результатами из первоисточника [6], в части выявления автокорреляции аналогично.
**Информация к размышлению.**
Анализ показывает, что модель хорошо аппроксимирует фактические данные, но имеет место отклонение от нормального закона распределения остатков, противоречивые выводы о гетероскедастичности и наличие автокорреляции, то есть модель некачественная.
Также мы видим, что динамика макроэкономических показателей свидетельствует о наличии трендов, однако, если в модель добавить еще один фактор - год или номер наблюдения - то, этот фактор окажется незначимым.
В дальнейшем автор при анализе остатков модели [6, с.198] выявляет структурный сдвиг (обусловленный мировым топливно-энергетическим кризисом в 1973 г.) и вводит в модель фиктивные переменные, учитывающие этот структурный сдвиг
Итоги
-----
Итак, подведем итоги:
* мы рассмотрели способы реализации в полной мере критерия Дарбина-Уотсона средствами **python**, создали пользовательскую функцию, уменьшающую размер кода;
* разобрали пример оцифровки таблицы критических значений статистического критерия для реализации пользовательской функции.
Исходный код находится в моем [репозитории на GitHub](https://github.com/AANazarov/Statistical-methods).
Надеюсь, данный обзор поможет специалистам **DataScience** в работе.
Литература
----------
1. Кобзарь А.И. Прикладная математическая статистика. Для инженеров и научных работников. - М.: ФИЗМАТЛИТ, 2006. - 816 с.
2. Айвазян С.А. Прикладная статистика. Основы эконометрики: В 2 т. - Т.2: Основы эконометрики. - 2-е изд., испр. - М.: ЮНИТИ-ДАНА, 2001. - 432 с.
3. Фёрстер Э., Рёнц Б. Методы корреляционного и регрессионного анализа / пер с нем. - М.: Финансы и статистика, 1983. - 302 с.
4. Магнус Я.Р. и др. Эконометрика. Начальный курс - М.: Дело, 2004. - 576 с.
5. Тихомиров Н.П., дорохина Е.Ю. Эконометрика. - М.: Экзамен, 2003. - 512 с.
6. Носко В.П. Эконометрика. Кн.1. Ч.1, 2. - М.: Издательский дом "Дело" РАНХиГС, 2011. - 672 с.
7. Вандер Плас Дж. Python для сложных задач: наука о данных и машинное обучение. - СПб: Питер, 2018. - 576 с. | https://habr.com/ru/post/693402/ | null | ru | null |
# Пример простой нейросети, как результат разобраться что к чему
Нейросети — это та тема, которая вызывает огромный интерес и желание разобраться в ней. Но, к сожалению, поддаётся она далеко не каждому. Когда видишь тома непонятной литературы, теряешь желание изучить, но всё равно хочется быть в курсе происходящего.
В конечном итоге, как мне показалось, нет лучше способа разобраться, чем просто взять и создать свой маленький проект.
Можно прочитать лирическую предысторию, разворачивая текст, а можно это пропустить и перейти непосредственно к [описанию нейросети.](#description)
**В чём смысл делать свой проект.**Плюсы:
1. Лучше понимаешь, как устроены нейронки
2. Лучше понимаешь, как работать с уже с существующими библиотеками
3. Параллельно изучаешь что-то новое
4. Щекочешь своё Эго, создавая что-то своё
Минусы:
1. Создаёшь велосипед, притом скорее всего хуже существующих
2. Всем плевать на твой проект
**Выбор языка.**На момент выбора языка я более-менее знал С++, и был знаком с основами Python. Работать с нейронками проще на Python, но С++ знал лучше и нет проще распараллеливания вычислений, чем OpenMP. Поэтому я выбрал С++, а API под Python, чтобы не заморачиваться, будет создавать [swig](http://www.swig.org/), который работает на Windows и Linux. ([Пример](https://www.youtube.com/watch?v=YhAFOBcSoLw&list=PL8fA_qjSFodf_RiWz-7441XQu8Cm0F25z&index=4), как сделать из кода С++ библиотеку для Python)
**OpenMP и GPU ускорение.**На данный момент в Visual Studio установлена OpenMP версии 2.0., в которой есть только CPU ускорение. Однако начиная с версии 3.0 OpenMP поддерживает и GPU ускорение, при этом синтаксис директив не усложнился. Осталось лишь дождаться, когда OpenMP 3.0 будет поддерживаться всеми компиляторами. А пока, для простоты, только CPU.
**Мои первые грабли.**В вычислении значения нейрона есть следующий момент: перед тем, как мы вычисляем функцию активации, нам надо сложить перемножение весов на входные данные. Как учат это делать в университете: прежде чем суммировать большой вектор маленьких чисел, его надо отсортировать по возрастанию. Так вот. В нейросетях кроме как замедление работы программы в N раз ничего это не даёт. Но понял я это лишь тогда, когда уже тестировал свою сеть на MNIST.
**Выкладывание проекта на GitHub.**Я не первый, кто выкладывает своё творение на GitHub. Но в большинстве случаев, перейдя по ссылке, видишь лишь кучу кода с надписью в README.md *«Это моя нейросеть, смотрите и изучайте»*. Чтобы быть лучше других хотя бы в этом, более-менее описал [README.md](https://github.com/RadioRedFox/FoxNN) и заполнил [Wiki](https://github.com/RadioRedFox/FoxNN/wiki). Посыл же простой — **заполняйте Wiki.** Интересное наблюдение: если заголовок в Wiki на GitHub написан на русском языке, то *якорь* на этот заголовок не работает.
**Лицензия.**Когда создаёшь свой маленький проект, лицензия — это опять же способ пощекотать своё Эго. Вот интересная [статья](https://habr.com/ru/post/243091/) на тему, для чего нужна лицензия. Я же остановил свой выбор на [APACHE 2.0](http://www.apache.org/licenses/LICENSE-2.0).
Описание сети.
--------------
Характеристики:
| | |
| --- | --- |
| Название | [FoxNN (Fox-Neural-Network](https://github.com/RadioRedFox/FoxNN)) |
| Операционная система | Windows, Linux |
| Языки | C++, Python |
| Ускорение | CPU (GPU в планах) |
| Внешние зависимости | Нет (чистый С++, STL, OpenMP) |
| Флаги компиляции | -std=c++14 -fopenmp |
| Слои | линейные (сверточные в планах) |
| Оптимизации | [Адам, Нестеров](http://ruder.io/optimizing-gradient-descent/) |
| Случайное изменение весов | Есть |
| Википедия (инструкция) | [Есть](https://github.com/RadioRedFox/FoxNN/wiki) |
Основным преимуществом моей библиотеки является создание сети одной строчкой кода.
Легко заметить, что в линейных слоях количество нейронов в одном слое равняется количеству входных параметров в следующем слое. Ещё одно очевидное утверждение — число нейронов в последнем слое равняется количеству выходных значений сети.
Давайте создадим сеть, получающую на вход три параметра, имеющую три слоя с 5-ью, 4-мя и 2-мя нейронами.
```
import foxnn
nn = foxnn.neural_network([3, 5, 4, 2])
```
Если взглянуть на рисунок, то можно как раз увидеть: сначала 3 входных параметра, затем слой с 5-ью нейронами, затем слой с 4-мя нейронами и, наконец, последний слой с 2-мя нейронами.
По умолчанию все функции активации являются сигмоидами (мне они больше нравятся).
При желании, на любом слое можно поменять на другую функцию.
**В наличии самые популярные функции активации.*** [sigmoid](https://en.wikipedia.org/wiki/Activation_function) — сигмоида
* [sinusoid](https://en.wikipedia.org/wiki/Activation_function) — синус
* [gaussian](https://en.wikipedia.org/wiki/Activation_function) — Гаус
* [relu](https://en.wikipedia.org/wiki/Activation_function) — линейный выпрямитель
* [identity\_x — тождественная](https://en.wikipedia.org/wiki/Activation_function)
* [tan\_h](https://en.wikipedia.org/wiki/Activation_function) — th
* [arctan](https://en.wikipedia.org/wiki/Activation_function) — арктангенс
* [elu](https://en.wikipedia.org/wiki/Activation_function) — экспоненциальная линейная функция
```
nn.get_layer(0).set_activation_function("gaussian")
```
Легко создать обучающую выборку. Первый вектор — входные данные, второй вектор — целевые данные.
```
data = foxnn.train_data()
data.add_data([1, 2, 3], [1, 0]) #на вход три параметра, на выход два параметра
```
Обучение сети:
```
nn.train(data_for_train=data, speed=0.01, max_iteration=100, size_train_batch=98)
```
Включение оптимизации:
```
nn.settings.set_mode("Adam")
```
И метод, чтобы просто получить значение сети:
```
nn.get_out([0, 1, 0.1])
```
**Немного о названии метода.**Отдельно *get* переводится как *получить*, а *out* — *выход*. Хотел получить название "*дай выходное значение*", и получил это. Лишь позже заметил, что получилось *выметайся*. Но так забавнее, и решил оставить.
### Тестирование
Уже вошло в негласную традицию тестировать любую сеть на базе [MNIST](http://yann.lecun.com/exdb/mnist/). И я не стал исключением. Весь код с комментариями можно посмотреть [тут](https://github.com/RadioRedFox/FoxNN/wiki/%D0%9F%D1%80%D0%B8%D0%BC%D0%B5%D1%80-%D0%B8%D1%81%D0%BF%D0%BE%D0%BB%D1%8C%D0%B7%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F.-MNIST.).
**Создаёт тренировочную выборку:**
```
from mnist import MNIST
import foxnn
mndata = MNIST('C:download/')
mndata.gz = True
imagesTrain, labelsTrain = mndata.load_training()
def get_data(images, labels):
train_data = foxnn.train_data()
for im, lb in zip(images, labels):
data_y = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0] # len(data_y) == 10
data_y[lb] = 1
data_x = im
for j in range(len(data_x)):
# приводим пиксель в диапазон (-1, 1)
data_x[j] = ((float(data_x[j]) / 255.0) - 0.5) * 2.0
train_data.add_data(data_x, data_y) # добавляем в обучающую выборку
return train_data
train_data = get_data(imagesTrain, labelsTrain)
```
**Создаём сеть: три слоя, на вход 784 параметра, и 10 на выход:**
```
nn = foxnn.neural_network([784, 512, 512, 10])
nn.settings.n_threads = 7 # распараллеливаем процесс обучения на 7 процессов
nn.settings.set_mode("Adam") # используем оптимизацию Адама
```
**Обучаем:**
```
nn.train(data_for_train=train_data, speed=0.001, max_iteration=10000, size_train_batch=98)
```
Что получилось:
Примерно за 10 минут (только CPU ускорение), можно получить точность 75%. С оптимизацией Адама за 5 минут можно получить точность 88% процентов. В конечном итоге мне удалось достичь точности в 97%.
**Основные недостатки (уже есть в планах на доработку):**1. В Python ещё не протянуты ошибки, т.е. в python ошибка не будет перехвачена и программа просто завершится с ошибкой.
2. Пока обучение указывается в итерациях, а не в эпохах, как это принято в других сетях.
3. Нет GPU ускорения
4. Пока нет других видов слоёв.
5. Надо залить проект на PyPi.
Для маленькой завершённости проекта не хватало как раз этой статьи. Если хотя бы десять человек заинтересуются и поиграются, то уже будет победа. Добро пожаловать на мой [GitHub](https://github.com/RadioRedFox/FoxNN).
P.S.: Если вам для того, чтобы разобраться, нужно создать что-то своё, не бойтесь и творите. | https://habr.com/ru/post/459822/ | null | ru | null |
# «Hero Image» — баннеры в параллаксе
С CSS 3D Transforms у вас есть безграничные возможности. Но могущество влечет за собой ответственность. Вы будете сталкиваться с ситуациями, когда вы сможете воспользоваться всеми трехмерными преимуществами CSS. Однако в большинстве проектов вы сможете лишь слегка приукрасить некоторые вещи.
Сегодняшнее сокровище – это эффект, который завоевывает все большую популярность и создается за счет 3D Transforms. Благодаря этому мы поместили несколько изображений на ось z, после чего использовали мышь в качестве ложной трехмерной камеры, таким образом, чтобы перспектива изменялась при передвижении курсора мыши. На самом деле в этом случае мы поворачиваем изображение в трехмерном пространстве в соответствии с положением мыши.
[Демо](http://codyhouse.co/demo/parallax-hero-image/index.html)
Так как этот эффект зависит от движения мыши, на мобильных устройствах он будет незаметен.
Этот замечательный эффект можно посмотреть на таких сайтах, как [Squarespace](http://www.squarespace.com/) и [HelloMonday](http://hellomonday.com/).
#### Создание структуры
Мы используем элемент figure, который содержит наш баннер (hero image) (здесь мы использовали 3 разных ) и обернут в элемент .cd-background-wrapper.
```

```
Размеры используемых изображений должны быть одинаковыми.
#### Добавление стиля
Чтобы создать hero image, мы накладываем элементы поверх друг друга: первый имеет статичное положение, а остальные находятся в абсолютном положении; каждому из них присваивается отдельное значение translateZ.
В чем заключается идея параллакс-эффекта: когда пользователь двигает мышкой на «hero image» баннере, элемент .cd-floating-background вращается (вдоль осей X и Y), в зависимости от положения мыши. Так как элементы имеют разные значения translateZ, каждый из них вращается по-разному.
Чтобы в полной мере добиться этого эффекта, нам необходимо убедиться, что наши -элементы правильно расположены в трехмерном пространстве: сначала мы указываем значение перспективы для .cd-background-wrapper, который создает трехмерное пространство, в котором располагаются его дочерние элементы; потом мы назначаем transform-style: preserve-3d для .cd-floating-background таким образом, чтобы эти дочерние элементы размещались в трехмерном пространстве, а не в плоском (как установлено по умолчанию). Остальное делает TranslateZ!
```
.cd-background-wrapper {
overflow: hidden;
perspective: 4000px;
}
.cd-floating-background {
transform-style: preserve-3d;
}
.cd-floating-background img:first-child {
transform: translateZ(50px);
}
.cd-floating-background img:nth-child(2) {
transform: translateZ(290px);
}
.cd-floating-background img:nth-child(3) {
transform: translateZ(400px);
}
```
**Об IE**: IE9 не поддерживает CSS3 3D Transforms, а IE10+ не поддерживает свойство «transform-style: preserve-3d». Поэтому в браузере IE эффект параллакса не будет виден, и вы увидите стандартное изображение.
#### Обработка событий
Мы привязываем функцию initBackground() к событию загрузки изображения: эта функция изменяет значение свойства положения элемента с относительного на абсолютное (используется класс «is-absolute»). В этом случае нам нужно указать правильную высоту элемента .cd-background-wrapper (так как его дочерний элемент находится в абсолютном положении, его высота по умолчанию равна 0) и правильные размеры .cd-floating-background (он должен быть больше, чем оболочка – тогда при вращении не обнаружатся пустые границы).
Мы оцениваем соотношение сторон и ширину обзора изображения и назначаем для .cd-background-wrapper высоту, равную значениям viewportWidth/heroAspectRatio. Высота и ширина .cd-floating-background должны быть пропорциональны .cd-background-wrapper, а параметры левой и верхней стороны должны быть установлены таким образом, чтобы изображение располагалось по центру внутри родительского элемента.
После этого мы привязываем событие mousemove к .cd-background-wrapper: положение мыши оценивается с помощью event.pageX и event.pageY, после чего элементу .cd-floating-background назначается соответствующее значение rotateX и rotateY.
**Примечание**: Modernizr пока не определяет «preserve-3d». Поэтому, чтобы создать этот эффект для тех браузеров, которые его не определяют, мы использовали функцию getPerspective, которая назначает для класс «preserve-3d/no-preserve-3d» в соответствии с поддержкой браузера.
**Полезные решения Paysto для читателей Хабра:** → [Получите оплату банковской картой прямо сейчас. Без сайта, ИП и ООО.](http://linkcharge.ru/email)
→ [Принимайте оплату от компаний через Интернет. Без сайта, ИП и ООО.](http://linkcharge.ru)
→ [Приём платежей от компаний для Вашего сайта. С документооборотом и обменом оригиналами.](http://linkcharge.ru/api)
→ [Автоматизация продаж и обслуживание сделок с юр.лицами. Без посредника в расчетах.](http://linkcharge.ru/automat) | https://habr.com/ru/post/251591/ | null | ru | null |
# Менеджеры зависимостей

В этой статье я расскажу, в чем менеджеры зависимостей (package manager) схожи по внутреннему устройству, алгоритму работы, и в чем их принципиальные отличия. Я рассматривал package manager’ы, предназначенные для разработки под iOS/OS X, но содержание статьи с некоторыми допущениями применимо и к другим.
Разновидности менеджеров зависимостей
-------------------------------------
* Системные менеджеры зависимостей – устанавливают недостающие утилиты в операционную систему. Например, [Homebrew](https://brew.sh).
* Менеджеры зависимостей языка – собирают исходники, написанные на одном из языков программирования, в конечные исполняемые программы. Например, [go build](https://golang.org/pkg/go/build/).
* Менеджеры зависимостей проекта – управляют зависимостями в разрезе конкретного проекта. То есть, в их задачи входит описание зависимостей, скачивание, обновление их исходного кода. Это, например, [Cocoapods](https://cocoapods.org).
Основное отличие между ними в том, кому они «служат». Системные МЗ – пользователям, МЗ проекта – разработчикам, а МЗ языка – и тем, и тем сразу.
Далее я буду рассматривать менеджеры зависимостей проекта – мы их используем чаще всего, и они проще для понимания.
Схема проекта при использовании менедежера зависимостей
-------------------------------------------------------
Рассмотрим на примере популярного package manager’а [Cocoapods](https://cocoapods.org).
Обычно мы выполняем условную команду *pod install*, а затем менеджер зависимостей все делает за нас. Рассмотрим, из чего должен состоять проект, чтобы эта команда завершилась успешно.

1. Есть наш код, в котором мы используем ту или иную зависимость, скажем, библиотеку [Alamofire](https://github.com/Alamofire/).
2. Из manifest-файла менеджер зависимостей знает, какие зависимости мы используем в исходном коде. Если мы забудем указать там какую-либо библиотеку, зависимость не установится, и проект в итоге не соберется.
3. Lock-файл – генерируемый менеджером зависимостей файл определенного формата, в котором перечисляются все зависимости, успешно установленные в проект.
4. Код зависимостей – внешний исходный код, который «подтягивает» менеджер зависимостей и который будет вызываться из нашего кода.
Это было бы невозможно без конкретного алгоритма, который запускается каждый раз после команды установки зависимостей.
Все 4 компонента перечислены друг за другом, т.к. последующий компонент формируется исходя из предыдущего.

Не у всех менеджеров зависимостей есть все 4 компонента, но с учетом функций менеджера зависимостей наличие всех — оптимальный вариант.
После установки зависимостей все 4 компонента идут на вход компилятору либо интерпретатору в зависимости от языка.

Также обращу внимание, что за первые две составляющие ответственны разработчики – мы пишем этот код, а за оставшиеся две – сам менеджер зависимостей – он генерирует файл(ы) и скачивает исходный код зависимостей.
Алгоритм работы менеджера зависимостей
--------------------------------------
С составными частями более-менее разобрались, теперь перейдем к алгоритмической части работы МЗ.
Типовой алгоритм работы выглядит так:
1. Валидация проекта и среды окружения. За это отвечает объект, который именуется *Analyzer*.
2. Построение графа. Из зависимостей МЗ должен выстроить граф. Этим занимается объект *Resolver*.
3. Скачивание зависимостей. Очевидно, что исходный код зависимостей должен быть скачан для того, чтобы мы его использовали в своих исходниках.
4. Интеграция зависимостей. Того, что исходный код зависимостей лежит в соседней директории на диске, может быть недостаточно, поэтому их еще нужно прикрепить к нашему проекту.
5. Обновление зависимостей. Этот шаг выполняется не сразу за шагом 4, а при необходимости обновиться на новую версии библиотек. Здесь есть свои особенности, поэтому я выделил их в отдельный шаг — о них далее.
### Валидация проекта и среды окружения
Валидация включает проверку версий ОС, вспомогательных утилит, которые необходимы менеджеру зависимостей, а также линтовку настроек проекта и manifest-файла: начиная от проверки на синтаксис, заканчивая несовместимыми настройками.
Типовой [podfile](https://guides.cocoapods.org/syntax/podfile.html)
```
source 'https://github.com/CocoaPods/Specs.git'
source 'https://github.com/RedMadRobot/cocoapods-specs'
platform :ios, '10.0'
use_frameworks!
project 'Project.xcodeproj'
workspace 'Project.xcworkspace'
target 'Project' do
project 'Project.xcodeproj'
pod 'Alamofire'
pod 'Fabric'
pod 'GoogleMaps'
end
```
Возможные предупреждения и ошибки при проверке podfile:
* Не найдена зависимость ни в одном из [spec-репозитории](https://guides.cocoapods.org/making/specs-and-specs-repo.html);
* Явно не указана операционная система и версия;
* Некорректное имя workspace или проекта.
### Построение графа зависимостей
Так как у нужных нашему проекту зависимостей могут быть свои зависимости, а у тех в свою очередь — собственные вложенные зависимости или подзависимости, менеджеру использовались корректные версии. Схематично все зависимости в результате должны выстроиться в [направленный ацикличный граф](https://ru.wikipedia.org/wiki/%D0%9D%D0%B0%D0%BF%D1%80%D0%B0%D0%B2%D0%BB%D0%B5%D0%BD%D0%BD%D1%8B%D0%B9_%D0%B0%D1%86%D0%B8%D0%BA%D0%BB%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B9_%D0%B3%D1%80%D0%B0%D1%84).
Построение направленного ацикличного графа сводится к задаче топологической сортировки. У нее есть несколько алгоритмов решения.
1. [Алгоритм Кана](https://ru.wikipedia.org/wiki/%D0%A2%D0%BE%D0%BF%D0%BE%D0%BB%D0%BE%D0%B3%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B0%D1%8F_%D1%81%D0%BE%D1%80%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%BA%D0%B0#%D0%90%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC_%D0%9A%D0%B0%D0%BD%D0%B0_(1962)) – перебор вершин, сложность O(n).
2. [Алгоритм Тарьяна](https://ru.wikipedia.org/wiki/%D0%A2%D0%BE%D0%BF%D0%BE%D0%BB%D0%BE%D0%B3%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B0%D1%8F_%D1%81%D0%BE%D1%80%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%BA%D0%B0#%D0%90%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC_%D0%A2%D0%B0%D1%80%D1%8C%D1%8F%D0%BD%D0%B0_(1976)) – на основе поиска в глубину, сложность O(n).
3. Алгоритм Демукрона – послойное разбиение графа.
4. Параллельные алгоритмы, использующие полиномиальное количество процессоров. В таком случае сложность «упадет» до O(log(n)^2)
Сама по себе задача является NP-полной, тот же алгоритм используется в компиляторах и машинном обучении.
Результатом решения является созданный lock-файл, который полностью описывает отношения между зависимостями.
Какие проблемы могут возникать при работе данного алгоритма? Рассмотрим пример: есть проект с зависимостями A, B, E с вложенными зависимостями C, F, D.
Зависимости A и B имеют общую зависимость C. И здесь С должна удовлетворить требованиям зависимости A и B. Какой-то менеджер зависимостей допускает установку отдельных версий, если это необходимо, а cocoapods, например, нет. Поэтому в случае несовместимости требований: A требует версию, равную 2.0 зависимости С, а B требует версию 1.0, установка завершится с ошибкой. А если зависимости A нужна версия 1.0 и выше до версии 2.0, а зависимости B версия 1.2 или менее до 1.0, будет установлена максимально совместимая для A и В версия 1.2.
Не стоит забывать, что может возникнуть ситуация циклической зависимости, пусть даже не напрямую – в этом случае установка также завершится с ошибкой.
Рассмотрим, как это выглядит в коде наиболее популярных менеджеров зависимостей для iOS.
#### Carthage
```
typealias DependencyGraph = [Dependency: Set]
public enum Dependency {
/// A repository hosted on GitHub.com or GitHub Enterprise.
case gitHub(Server, Repository)
/// An arbitrary Git repository.
case git(GitURL)
/// A binary-only framework
case binary(URL)
}
/// Protocol for resolving acyclic dependency graphs.
public protocol ResolverProtocol {
init(
versionsForDependency: @escaping (Dependency) -> SignalProducer,
dependenciesForDependency: @escaping (Dependency, PinnedVersion) -> SignalProducer<(Dependency, VersionSpecifier), CarthageError>,
resolvedGitReference: @escaping (Dependency, String) -> SignalProducer
)
func resolve(
dependencies: [Dependency: VersionSpecifier],
lastResolved: [Dependency: PinnedVersion]?,
dependenciesToUpdate: [String]?
) -> SignalProducer<[Dependency: PinnedVersion], CarthageError>
}
```
Реализация Resolver находится [тут](https://github.com/Carthage/Carthage/blob/master/Source/CarthageKit/Resolver.swift), а NewResolver [тут](https://github.com/Carthage/Carthage/blob/master/Source/CarthageKit/NewResolver.swift), Analyzer как такового нет.
#### Cocoapods
Реализация алгоритма построения графа выделена в отдельный [репозиторий](https://github.com/CocoaPods/Molinillo). Здесь же реализация [графа](https://github.com/CocoaPods/Molinillo/blob/04dd4c8789823654bde00569d28b189a79926c9f/lib/molinillo/dependency_graph.rb) и [Resolver](https://github.com/CocoaPods/Molinillo/blob/1f66e42351ae27167aefdd76bc914598e4b0e5f2/lib/molinillo/resolution.rb). В [Analyzer](https://github.com/CocoaPods/CocoaPods/blob/31de1ad65c8853ddaf2c83466b09e5d3b4957584/lib/cocoapods/installer/analyzer.rb) можно найти, что проверяется соответствие версий cocoapods системы и lock-файла.
```
def validate_lockfile_version!
if lockfile && lockfile.cocoapods_version > Version.new(VERSION)
STDERR.puts '[!] The version of CocoaPods used to generate ' \
"the lockfile (#{lockfile.cocoapods_version}) is "\
"higher than the version of the current executable (#{VERSION}). " \
'Incompatibility issues may arise.'.yellow
end
end
```
Из исходников также видно, что Analyzer генерирует таргеты для зависимостей.
Типовой lock-файл cocoapods выглядит примерно так:
```
PODS:
- Alamofire (4.7.0)
- Fabric (1.7.5)
- GoogleMaps (2.6.0):
- GoogleMaps/Maps (= 2.6.0)
- GoogleMaps/Base (2.6.0)
- GoogleMaps/Maps (2.6.0):
- GoogleMaps/Base
SPEC CHECKSUMS:
Alamofire: 907e0a98eb68cdb7f9d1f541a563d6ac5dc77b25
Fabric: ae7146a5f505ea370a1e44820b4b1dc8890e2890
GoogleMaps: 42f91c68b7fa2f84d5c86597b18ceb99f5414c7f
PODFILE CHECKSUM: 5294972c5dd60a892bfcc35329cae74e46aac47b
COCOAPODS: 1.4.0
```
В секции PODS перечисляются прямые и вложенные зависимости с указанием версий, далее подсчитываются их контрольные суммы в отдельности и вместе и указывается версия cocoapods, которая использовалась для установки.
### Скачивание зависимостей
После успешного построения графа и создания lock-файла, менеджер зависимостей переходит к их скачиванию. Необязательно это будут исходные коды, это могут быть так же исполняемые файлы или собранные фреймворки. Также все менеджеры зависимостей как правило поддерживают возможность установки по локальному пути.

Нет ничего сложного, чтобы их скачать по ссылке (которую, конечно же, нужно откуда-то взять), поэтому я не буду рассказывать как происходит само скачивание, а остановлюсь на вопросах централизации и безопасности.
#### Централизация
Говоря простым языком, менеджер зависимостей имеет два пути при скачивании зависимостей:
1. Сходить в какой-то перечень доступных зависимостей и по названию получить ссылку для скачивания.
2. Мы должны явно указать источник для каждой зависимости в manifest-файле.
По первому пути идут централизованные менеджеры зависимостей, по второму – децентрализованные.
#### Безопасность
Если вы скачиваете зависимости по https или ssh, то можете спать спокойно. Тем не менее, часто разработчики предоставляют http-ссылки на свои официальные библиотеки. И здесь мы можем столкнуться с атакой [«человек посередине»](https://ru.wikipedia.org/wiki/%D0%90%D1%82%D0%B0%D0%BA%D0%B0_%D0%BF%D0%BE%D1%81%D1%80%D0%B5%D0%B4%D0%BD%D0%B8%D0%BA%D0%B0), когда злоумышленник подменит исходный код, исполняемый файл или фреймворк. Какие-то менеджеры зависимостей не защищаются от этого, а некоторые делают это следующим образом.
##### Homebrew
[Проверка curl](https://github.com/Homebrew/brew/blob/837ea74f448092d822a42ff137642c0aaf076650/Library/Homebrew/extend/os/mac/diagnostic.rb) в устаревших версиях OS X.
```
def check_for_bad_curl
return unless MacOS.version <= "10.8"
return if Formula["curl"].installed?
<<~EOS
The system curl on 10.8 and below is often incapable of supporting
modern secure connections & will fail on fetching formulae.
We recommend you:
brew install curl
EOS
end
```
Также есть [проверка хэша SHA256](https://github.com/Homebrew/brew/blob/02591bdf341b4c33383b5eb537bcff0e49157a82/Library/Homebrew/utils/curl.rb) при скачивании по http.
```
def curl_http_content_headers_and_checksum(url, hash_needed: false, user_agent: :default)
max_time = hash_needed ? "600" : "25"
output, = curl_output(
"--connect-timeout", "15", "--include", "--max-time", max_time, "--location", url,
user_agent: user_agent
)
status_code = :unknown
while status_code == :unknown || status_code.to_s.start_with?("3")
headers, _, output = output.partition("\r\n\r\n")
status_code = headers[%r{HTTP\/.* (\d+)}, 1]
end
output_hash = Digest::SHA256.digest(output) if hash_needed
{
status: status_code,
etag: headers[%r{ETag: ([wW]\/)?"(([^"]|\\")*)"}, 2],
content_length: headers[/Content-Length: (\d+)/, 1],
file_hash: output_hash,
file: output,
}
end
```
А еще [можно запретить](https://github.com/Homebrew/brew/blob/9b56b133a546d0d40cd6b020290f6a59fc14729f/docs/Manpage.md) небезопасные редиректы на http (переменная *HOMEBREW\_NO\_INSECURE\_REDIRECT*).
##### Carthage и Cocoapods
Здесь все попроще – [нельзя использовать](https://github.com/Carthage/Carthage/blob/192a61d37b6ad27ec5d20d0d267ea3e70917689a/Source/CarthageKit/BinaryProject.swift) http на исполняемые файлы.
```
guard binaryURL.scheme == "file" || binaryURL.scheme == "https" else { return .failure(BinaryJSONError.nonHTTPSURL(binaryURL)) }
```
```
def validate_source_url(spec)
return if spec.source.nil? || spec.source[:http].nil?
url = URI(spec.source[:http])
return if url.scheme == 'https' || url.scheme == 'file'
warning('http', "The URL (`#{url}`) doesn't use the encrypted HTTPs protocol. " \
'It is crucial for Pods to be transferred over a secure protocol to protect your users from man-in-the-middle attacks. '\
'This will be an error in future releases. Please update the URL to use https.')
end
```
Полный код [тут](https://github.com/CocoaPods/CocoaPods/blob/master/lib/cocoapods/validator.rb).
##### Swift Package Manager
На данный момент ничего, связанного с безопасностью, найти не удалось, но в предложениях по развитию есть короткое упоминание про [некий механизм](https://github.com/apple/swift-package-manager/blob/57c5be1db1c1e12e089dff02241ffbce5722fb0e/Documentation/PackageManagerCommunityProposal.md#security-and-signing) подписи пакетов с помощью сертификатов.
### Интеграция зависимостей
Под интеграцией я понимаю подключение зависимостей к проекту таким образом, чтобы мы беспрепятственно могли их использовать, и они компилировались с основным кодом приложения.
Интеграция может быть либо ручной (Carthage), либо автоматической (Cocoapods). Плюсы автоматической – минимум телодвижений со стороны разработчика, но может добавиться много магии в проект.
**Diff после установки зависимостей в проект с помощью Cocoapods**
```
--- a/PODInspect/PODInspect.xcodeproj/project.pbxproj
+++ b/PODInspect/PODInspect.xcodeproj/project.pbxproj
@@ -12,6 +12,7 @@
5132347E1FE94F0900031F77 /* Main.storyboard in Resources */ = {isa = PBXBuildFile; fileRef = 5132347C1FE94F0900031F77 /* Main.storyboard */; };
513234801FE94F0900031F77 /* Assets.xcassets in Resources */ = {isa = PBXBuildFile; fileRef = 5132347F1FE94F0900031F77 /* Assets.xcassets */; };
513234831FE94F0900031F77 /* LaunchScreen.storyboard in Resources */ = {isa = PBXBuildFile; fileRef = 513234811FE94F0900031F77 /* LaunchScreen.storyboard */; };
+ 80BFE252F8CC89026D002347 /* Pods_PODInspect.framework in Frameworks */ = {isa = PBXBuildFile; fileRef = F92C797D84680452FD95785F /* Pods_PODInspect.framework */; };
/* End PBXBuildFile section */
/* Begin PBXFileReference section */
@@ -22,6 +23,9 @@
5132347F1FE94F0900031F77 /* Assets.xcassets */ = {isa = PBXFileReference; lastKnownFileType = folder.assetcatalog; path = Assets.xcassets; sourceTree = ""; };
513234821FE94F0900031F77 /\* Base \*/ = {isa = PBXFileReference; lastKnownFileType = file.storyboard; name = Base; path = Base.lproj/LaunchScreen.storyboard; sourceTree = ""; };
513234841FE94F0900031F77 /\* Info.plist \*/ = {isa = PBXFileReference; lastKnownFileType = text.plist.xml; path = Info.plist; sourceTree = ""; };
+ 700D806167013759DC590135 /\* Pods-PODInspect.debug.xcconfig \*/ = {isa = PBXFileReference; includeInIndex = 1; lastKnownFileType = text.xcconfig; name = "Pods-PODInspect.debug.xcconfig"; path = "Pods/Target Support Files/Pods-PODInspect/Pods-PODInspect.debug.xcconfig"; sourceTree = ""; };
+ E03230E2AEDEF09BD80A4BCB /\* Pods-PODInspect.release.xcconfig \*/ = {isa = PBXFileReference; includeInIndex = 1; lastKnownFileType = text.xcconfig; name = "Pods-PODInspect.release.xcconfig"; path = "Pods/Target Support Files/Pods-PODInspect/Pods-PODInspect.release.xcconfig"; sourceTree = ""; };
+ F92C797D84680452FD95785F /\* Pods\_PODInspect.framework \*/ = {isa = PBXFileReference; explicitFileType = wrapper.framework; includeInIndex = 0; path = Pods\_PODInspect.framework; sourceTree = BUILT\_PRODUCTS\_DIR; };
/\* End PBXFileReference section \*/
/\* Begin PBXFrameworksBuildPhase section \*/
@@ -29,6 +33,7 @@
isa = PBXFrameworksBuildPhase;
buildActionMask = 2147483647;
files = (
+ 80BFE252F8CC89026D002347 /\* Pods\_PODInspect.framework in Frameworks \*/,
);
runOnlyForDeploymentPostprocessing = 0;
};
@@ -40,6 +45,8 @@
children = (
513234771FE94F0900031F77 /\* PODInspect \*/,
513234761FE94F0900031F77 /\* Products \*/,
+ 78E8125D6DC3597E7EBE4521 /\* Pods \*/,
+ 7DB1871A5E08D43F92A5D931 /\* Frameworks \*/,
);
sourceTree = "";
};
@@ -64,6 +71,23 @@
path = PODInspect;
sourceTree = "";
};
+ 78E8125D6DC3597E7EBE4521 /\* Pods \*/ = {
+ isa = PBXGroup;
+ children = (
+ 700D806167013759DC590135 /\* Pods-PODInspect.debug.xcconfig \*/,
+ E03230E2AEDEF09BD80A4BCB /\* Pods-PODInspect.release.xcconfig \*/,
+ );
+ name = Pods;
+ sourceTree = "";
+ };
+ 7DB1871A5E08D43F92A5D931 /\* Frameworks \*/ = {
+ isa = PBXGroup;
+ children = (
+ F92C797D84680452FD95785F /\* Pods\_PODInspect.framework \*/,
+ );
+ name = Frameworks;
+ sourceTree = "";
+ };
/\* End PBXGroup section \*/
/\* Begin PBXNativeTarget section \*/
@@ -71,9 +95,12 @@
isa = PBXNativeTarget;
buildConfigurationList = 513234871FE94F0900031F77 /\* Build configuration list for PBXNativeTarget "PODInspect" \*/;
buildPhases = (
+ 5A5E7D86F964C22F5DF60143 /\* [CP] Check Pods Manifest.lock \*/,
513234711FE94F0900031F77 /\* Sources \*/,
513234721FE94F0900031F77 /\* Frameworks \*/,
513234731FE94F0900031F77 /\* Resources \*/,
+ 5FD616368597C8B1F8138B2B /\* [CP] Embed Pods Frameworks \*/,
+ F5ECBE5F431B568B7F8C9B0B /\* [CP] Copy Pods Resources \*/,
);
buildRules = (
);
@@ -131,6 +158,62 @@
};
/\* End PBXResourcesBuildPhase section \*/
+/\* Begin PBXShellScriptBuildPhase section \*/
+ 5A5E7D86F964C22F5DF60143 /\* [CP] Check Pods Manifest.lock \*/ = {
+ isa = PBXShellScriptBuildPhase;
+ buildActionMask = 2147483647;
+ files = (
+ );
+ inputPaths = (
+ "${PODS\_PODFILE\_DIR\_PATH}/Podfile.lock",
+ "${PODS\_ROOT}/Manifest.lock",
+ );
+ name = "[CP] Check Pods Manifest.lock";
+ outputPaths = (
+ "$(DERIVED\_FILE\_DIR)/Pods-PODInspect-checkManifestLockResult.txt",
+ );
+ runOnlyForDeploymentPostprocessing = 0;
+ shellPath = /bin/sh;
+ shellScript = "diff \"${PODS\_PODFILE\_DIR\_PATH}/Podfile.lock\" \"${PODS\_ROOT}/Manifest.lock\" > /dev/null\nif [ $? != 0 ] ; then\n # print error to STDERR\n echo \"error: The sandbox is not in sync with the Podfile.lock. Run 'pod install' or update your CocoaPods installation.\" >&2\n exit 1\nfi\n# This output is used by Xcode 'outputs' to avoid re-running this script phase.\necho \"SUCCESS\" > \"${SCRIPT\_OUTPUT\_FILE\_0}\"\n";
+ showEnvVarsInLog = 0;
+ };
+ 5FD616368597C8B1F8138B2B /\* [CP] Embed Pods Frameworks \*/ = {
+ isa = PBXShellScriptBuildPhase;
+ buildActionMask = 2147483647;
+ files = (
+ );
+ inputPaths = (
+ "${SRCROOT}/Pods/Target Support Files/Pods-PODInspect/Pods-PODInspect-frameworks.sh",
+ "${BUILT\_PRODUCTS\_DIR}/Alamofire/Alamofire.framework",
+ "${BUILT\_PRODUCTS\_DIR}/HTTPTransport/HTTPTransport.framework",
+ );
+ name = "[CP] Embed Pods Frameworks";
+ outputPaths = (
+ "${TARGET\_BUILD\_DIR}/${FRAMEWORKS\_FOLDER\_PATH}/Alamofire.framework",
+ "${TARGET\_BUILD\_DIR}/${FRAMEWORKS\_FOLDER\_PATH}/HTTPTransport.framework",
+ );
+ runOnlyForDeploymentPostprocessing = 0;
+ shellPath = /bin/sh;
+ shellScript = "\"${SRCROOT}/Pods/Target Support Files/Pods-PODInspect/Pods-PODInspect-frameworks.sh\"\n";
+ showEnvVarsInLog = 0;
+ };
+ F5ECBE5F431B568B7F8C9B0B /\* [CP] Copy Pods Resources \*/ = {
+ isa = PBXShellScriptBuildPhase;
+ buildActionMask = 2147483647;
+ files = (
+ );
+ inputPaths = (
+ );
+ name = "[CP] Copy Pods Resources";
+ outputPaths = (
+ );
+ runOnlyForDeploymentPostprocessing = 0;
+ shellPath = /bin/sh;
+ shellScript = "\"${SRCROOT}/Pods/Target Support Files/Pods-PODInspect/Pods-PODInspect-resources.sh\"\n";
+ showEnvVarsInLog = 0;
+ };
+/\* End PBXShellScriptBuildPhase section \*/
+
/\* Begin PBXSourcesBuildPhase section \*/
513234711FE94F0900031F77 /\* Sources \*/ = {
isa = PBXSourcesBuildPhase;
@@ -272,6 +355,7 @@
};
513234881FE94F0900031F77 /\* Debug \*/ = {
isa = XCBuildConfiguration;
+ baseConfigurationReference = 700D806167013759DC590135 /\* Pods-PODInspect.debug.xcconfig \*/;
buildSettings = {
ASSETCATALOG\_COMPILER\_APPICON\_NAME = AppIcon;
CODE\_SIGN\_STYLE = Automatic;
@@ -287,6 +371,7 @@
};
513234891FE94F0900031F77 /\* Release \*/ = {
isa = XCBuildConfiguration;
+ baseConfigurationReference = E03230E2AEDEF09BD80A4BCB /\* Pods-PODInspect.release.xcconfig \*/;
buildSettings = {
ASSETCATALOG\_COMPILER\_APPICON\_NAME = AppIcon;
CODE\_SIGN\_STYLE = Automatic;
```
В случае ручной, вы, следуя, например, [этой](https://github.com/Carthage/Carthage#getting-started) инструкции Carthage, полностью контролируете процесс добавления зависимостей в проект. Надежно, но дольше.
### Обновление зависимостей
Контролировать исходный код зависимостей в проекте можно с помощью их версий.
В менеджерах зависимостей используются 3 способа:
1. Версии библиотеки. Наиболее удобный и распространенный способ. Можно указать как конкретную версию, так и интервал. Вполне предсказуемый способ для поддержки совместимости зависимостей при условии корректного изменения версий авторами библиотек.
2. Ветка. При обновлении ветки и дальнейшем обновлении зависимости мы не можем предсказать, какие изменения произойдут.
3. Коммит или тэг. При выполнении команды на обновление, зависимости со ссылками на конкретный коммит или тэг (если его не изменят) никогда не будут обновляться.
Заключение
----------
В статье я дал поверхностное понимание внутреннего устройства менеджеров зависимостей. Если хотите узнать больше, стоит покопаться в исходном коде package manager'a. Проще всего найти тот, которой написан на знакомом языке. Описанная схема является типовой, но в отдельно взятом менеджере зависимостей может что-то отсутствовать или наоборот появиться новое.
Замечания и обсуждение в комментариях приветствуется. | https://habr.com/ru/post/412945/ | null | ru | null |
# Готовим IndexedDB

На Хабре [уже рассказывали](http://habrahabr.ru/post/117473/) про IndexedDB — стандарт хранения больших структурированных данных на клиенте. Но это было давно и API сильно изменился. Несмотря на это в поиске статья всплывает одной из первых и вводит в заблуждение многих, кто начинает пытатся работать с этой технологией. Поэтому я решил написать новую статью с информацией об актуальном API.
Что такое IndexedDB
-------------------
**IndexedDB** — это объектная база данных, которая намного мощнее, эффективнее и надежней, чем веб-хранилище пар ключ/значение, доступное посредством прикладного интерфейса Web Storage. Как и в случае прикладных интерфейсов к веб-хранилищам и файловой системе, доступность базы данных определяется происхождением создавшего ее документа.
Для каждого происхождения может быть создано произвольное число баз данных IndexedDB. Каждая база данных имеет имя, которое должно быть уникальным для данного происхождения. С точки зрения прикладного интерфейса IndexedDB база данных является простой коллекцией именованных хранилищ объектов. Каждый объект должен иметь ключ, под которым он сохраняется и извлекается из хранилища. Ключи должны быть уникальными и они должны иметь естественный порядок следования, чтобы их можно было сортировать. IndexedDB может автоматически генерировать уникальные ключи для каждого объекта, добавляемого в базу данных. Однако, часто объекты, сохраняемые в хранилище объектов, уже будут иметь свойство, пригодное для использования в качестве ключа. В этом случае при создании хранилища объектов достаточно просто определить **ключевое свойство**.
Помимо возможности извлекать объекты из хранилища по значению первичного ключа существует также возможность выполнять поиск по значениям других свойств объекта. Чтобы обеспечить эту возможность, в хранилище объектов можно определить любое количество индексов. Каждый **индекс** определяет вторичный ключ хранимых объектов. Эти индексы в целом могут быть неуникальными, и одному и тому же ключу может соответствовать множество объектов. Поэтому в операциях обращения к хранилищу объектов с использованием индекса обычно используется **курсор**, определяющий прикладной интерфейс для извлечения объектов из потока результата по одному.
IndexedDB гарантирует атомарность операций: операции чтения и записи в базу данных объединяются в транзакции, благодаря чему либо они все будут успешно выполнены, либо ни одна из них не будет выполнена, и база данных никогда не останется в неопределенном, частично измененном состоянии.
Приступим
---------
IE > 9, Firefox > 15 и Chrome > 23 поддерживают работу без префиксов, но все-таки лучше проверять все варианты:
```
var indexedDB = window.indexedDB || window.mozIndexedDB || window.webkitIndexedDB || window.msIndexedDB;
var IDBTransaction = window.IDBTransaction || window.webkitIDBTransaction || window.msIDBTransaction;
```
### Подключение к базе данных
Работа с базой данных начинается с запроса на открытие:
```
var request = indexedDB.open("myBase", 1);
```
Метод **open** возвращает объект IDBOpenDBRequest, в котором нас интересует три обработчика событий:
* **onerror**;
* **onsuccess**;
* **onupgradeneeded**.
**Onerror** будет вызван в случае возникновения ошибки и получит в параметрах объект ошибки.
**Onsuccess** будет вызван если все прошло успешно, но экземпляр открытой базы данных в качестве параметра метод не получит. Открытая БД доступна из объекта запроса: **request.result**.
Пока все было как и раньше, но теперь начинаются отличия. Вторым аргументом методу **open** передается версия базы данных. Версией может быть только натуральное число. Если передать дробное, то оно будет округлено до целого. Если базы с указанной версией не найдется, то будет вызван **onupgradeneeded**, в котором можно модифицировать базу, если существует старая версия, или создать базу, если ее вообще не существует.
Таким образом универсальная функция подключения к базе данных может выглядеть, например, так:
```
function connectDB(f){
var request = indexedDB.open("myBase", 1);
request.onerror = function(err){
console.log(err);
};
request.onsuccess = function(){
// При успешном открытии вызвали коллбэк передав ему объект БД
f(request.result);
}
request.onupgradeneeded = function(e){
// Если БД еще не существует, то создаем хранилище объектов.
e.currentTarget.result.createObjectStore("myObjectStore", { keyPath: "key" });
connectDB(f);
}
}
```
где f — это функция, которой будет передана открытая база данных.
### Структура базы данных
IndexedDB оперирует не таблицами, а хранилищами объектов: **ObjectStore**. При создании ObjectStore можно указывать его имя и параметры: имя ключевого поля (строковое свойство объекта настроек: keyPath) и автогенерацию ключа (булево свойство объекта настроек: autoIncrement).
Относительно ключевого поля существует 4 стратегии поведения:
* Ключевое поле не указано, и атогенерация ключа не включена — тогда вы должны вручную указывать ключ при каждом добавлении новой записи;
* Ключевое поле указано, автогенерация выключена — ключевое поле является ключом;
* Ключевое поле не указано, автогенерация включена — IndexedDB сам генерирует значение ключа, но можно указать свое значение ключа при добавлении новой записи;
* Ключевое поле указано, автогенерация включена — если у нового элемента отсутствует ключевое свойство, то IndexedDB сгенерирует новое значение.
Для разных типов записей подходят разные варианты. Например, если вы хотите хранить примитивы, то для них ключевое поле лучше генерировать. Я обычно храню объекты и использую свое ключевое поле.
Создавать ObjectStore можно с помощью метода **createObjectStore**. При создании ObjectStore можно указать его имя и параметры, например, ключевое поле. Индекс базы данных можно создавать с помощью метода **createIndex**. При создании индекса можно указать его имя, поле по которому его необходимо построить, и параметры, например, уникальность ключа:
```
objectStore.createIndex("name", "name", { unique: false });
```
### Работа с записями
Как уже говорилось во введении, любые операции с записями в IndexedDB происходят в рамках транзакции. Транзакция открывается методом **transaction**. В методе необходимо указать какие ObjectStore вам нужны и режим доступа: чтение, чтение и запись, смена версии. Режим смены версии по сути аналогичен методу onupgradeneeded.
Конкретные цифры не замерял, но думаю с точки зрения производительности лучше внимательно подходить к выставлению параметров транзакции: открывать только нужные вам ObjectStore и не просить запись, когда вам достаточно только чтения.
```
db.transaction(["myObjectStore"], "readonly");
```
Теперь, когда у нас есть открытая транзакция, мы можем получить наш ObjectStore у которого есть следующие методы для работы с записями:
* **add** — добавляет строго новую запись, если попытаться добавить запись с уже существующим ключом, то получим ошибку;
* **put** — перезаписывает или создает новую запись по указанному ключу;
* **get** — возвращает запись по ключу;
* **delete** — удаляет запись по указанному ключу.
##### Курсор
Метод get удобно использовать, если вы знаете ключ по которому хотите получить данные. Если вы хотите пройти через все записи в ObjectStore, то можно воспользоваться курсором:
```
var customers = [];
objectStore.openCursor().onsuccess = function(event) {
var cursor = event.target.result;
if (cursor) {
customers.push(cursor.value);
cursor.continue();
}
else {
alert("Got all customers: " + customers);
}
};
```
Но ребятам из Mozilla, как и мне, такой способ получения всех записей показался неудобным и они сделали метод который сразу возвращает все содержимое ObjectStore: **mozGetAll**. Надеюсь, в будущем и остальные браузеры его реализуют.
##### Индекс
Если вы хотите получить значение используя индекс, то все тоже довольно просто:
```
var index = objectStore.index("name");
index.get("Donna").onsuccess = function(event) {
alert("Donna's SSN is " + event.target.result.ssn);
};
```
Ограничения
-----------
##### Размер
По размеру ограничений почти что нет. Firefox ограничивает только размерами жесткого диска, но при условии, что на каждые дополнительные 50 мегабайт потребуется подтверждение пользователя. Chrome может занять под базы данных всех веб-страниц, которые их создали, половину жесткого диска, при этом ограничивая каждую базу данных 20% от этой половины.
##### Поддержка браузерами
Поддерживается всеми новыми браузерами кроме сафари и мобильной оперы, что, по-моему, не беда.
Пример
------
Обычно во всех статьях в качестве примера рассматривают адресную книгу, но я решил для разнообразия показать хранение файлов, хотя разницы по сути никакой и код в целом универсальный.
```
var indexedDB = window.indexedDB || window.mozIndexedDB || window.webkitIndexedDB || window.msIndexedDB,
IDBTransaction = window.IDBTransaction || window.webkitIDBTransaction || window.msIDBTransaction,
baseName = "filesBase",
storeName = "filesStore";
function logerr(err){
console.log(err);
}
function connectDB(f){
var request = indexedDB.open(baseName, 1);
request.onerror = logerr;
request.onsuccess = function(){
f(request.result);
}
request.onupgradeneeded = function(e){
e.currentTarget.result.createObjectStore(storeName, { keyPath: "path" });
connectDB(f);
}
}
function getFile(file, f){
connectDB(function(db){
var request = db.transaction([storeName], "readonly").objectStore(storeName).get(file);
request.onerror = logerr;
request.onsuccess = function(){
f(request.result ? request.result : -1);
}
});
}
function getStorage(f){
connectDB(function(db){
var rows = [],
store = db.transaction([storeName], "readonly").objectStore(storeName);
if(store.mozGetAll)
store.mozGetAll().onsuccess = function(e){
f(e.target.result);
};
else
store.openCursor().onsuccess = function(e) {
var cursor = e.target.result;
if(cursor){
rows.push(cursor.value);
cursor.continue();
}
else {
f(rows);
}
};
});
}
function setFile(file){
connectDB(function(db){
var request = db.transaction([storeName], "readwrite").objectStore(storeName).put(file);
request.onerror = logerr;
request.onsuccess = function(){
return request.result;
}
});
}
function delFile(file){
connectDB(function(db){
var request = db.transaction([storeName], "readwrite").objectStore(storeName).delete(file);
request.onerror = logerr;
request.onsuccess = function(){
console.log("File delete from DB:", file);
}
});
}
```
Заключение
----------
**IndexedDB** уже в полной мере поддерживается браузерами и готово к употреблению. Это прекрасный инструмент для создания автономных веб-приложений, но использовать его нужно все-таки с умом. Где можно обойтись WebStorage — лучше обойтись WebStorage. Где можно ничего не хранить на клиенте, лучше ничего не хранить на клиенте.
Сейчас становится все больше библиотек, которые инкапсулируют внутри себя работу с WebStorage, FileSystem API, IndexedDB и WebSQL, но, по-моему, лучше написать хотя бы раз свой код, чтобы потом не тащить, когда не нужно, кучу чужого кода без понимания его работы.
Больше информации на [MDN](https://developer.mozilla.org/en-US/docs/IndexedDB/Using_IndexedDB). | https://habr.com/ru/post/213515/ | null | ru | null |
# Что нам стоит… загрузить JSON в Data Platform
Всем привет!
В [недавней статье](https://habr.com/ru/company/leroy_merlin/blog/561072/) мы рассказали, как мы шли к построению нашей Data Platform. Сегодня хотелось бы глубже погрузиться в «желудок» нашей платформы и попутно рассказать вам о том, как мы решали одну из задач, которая возникла в связи с ростом разнообразия интегрируемых источников данных.
То есть, если возвращаться к финальной картинке из упомянутой выше статьи (специально дублирую ее, чтобы уважаемым читателям было удобнее), то сегодня мы будем более углубленно говорить о реализации «правой части» схемы — той, что лежит после Apache NiFi.
Схема из прошлой нашей статьи.Напомним, что в нашей компании более 350 реляционных баз данных. Естественно, не все они «уникальны» и многие представляют собой по сути разные экземпляры одной и той же системы, установленной во всех магазинах торговой сети, но все же «зоопарк разнообразия» присутствует. Поэтому без какого-либо Framework’а, упрощающего и ускоряющего интеграцию источников в Data Platform, не обойтись.
Общая схема доставки данных из источников в ODS-слой Greenplum посредством разработанного нами framework’а приведена ниже:
Общая схема доставки данных в ODS-слой Greenplum 1. Данные из систем-источников пишутся в Kafka в AVRO-формате, обрабатываются в режиме реального времени Apache NiFi, который сохраняет их в формате parquet на S3.
2. Затем эти файлы с «сырыми» данными с помощью Spark’а обрабатываются в два этапа:
1. Compaction – на данном этапе выполняется объединение для снижения количества выходных файлов с целью оптимизации записи и последующего чтения (то есть несколько более мелких файлов объединяются в несколько файлов «побольше»), а также производится дедубликация данных: простой *distinct()* и затем *coalesce(*). Результат сохраняется на S3. Эти файлы используются затем для parsing'а , а также являются своеобразным архивом сырых необработанных данных в формате «как есть»;
2. Parsing – на этой фазе производится разбор входных данных и сохранение их в плоские структуры согласно маппингу, описанному в метаданных. В общем случае из одного входного файла можно получить на выходе несколько плоских структур, которые в виде сжатых (как правило gzip) CSV-файлов сохраняются на S3.
3. Заключительный этап – загрузка данных CSV-файлов в ODS-слой хранилища: создается временная external table над данными в S3 через [PXF S3 connector](https://docs.greenplum.org/6-8/pxf/read_s3_s3select.html), после чего данные уже простым pgsql переливаются в таблицы ODS-слоя Greenplum
4. Все это оркестрируется с помощью Airflow.
DAG’и для Airflow у нас генерируются динамически на основании метаданных. Parsing файлов и разложение их в плоские структуры также производится с использованием метаданных. Это приводит к упрощению интеграции нового источника, так как, для этого необходимо всего лишь:
* создать в ODS-слое Хранилища таблицы-приемники данных;
* в репозитории метаданных в Git согласно принятым стандартам прописать в виде отдельных YAML-файлов:
+ общие настройки источника (такие как: расписание загрузки, входной и выходной формат файлов с данными, S3-бакет, имя сервисного пользователя, имя и email владельца для нотификации в случае сбоя загрузки и т.п.);
+ маппинг данных объектов источника на таблицы слоя ODS (при этом поддерживаются как плоские, так и вложенные структуры и массивы, а также есть возможность данные из одного объекта раскладывать в ODS-слое по нескольким таблицам). То есть описать, как необходимо сложную вложенную структуру разложить в плоские таблицы;
До недавнего времени такой подход удовлетворял текущие наши потребности, но количество и разнообразие источников данных растет. У нас стали появляться источники, которые не являются реляционными базами данных, а генерируют данные в виде потока JSON-объектов. Кроме того на горизонте уже маячила интеграция источника, который под собой имел MongoDB и поэтому будет использовать MongoDB Kafka source connector для записи данных в Kafka. Поэтому остро встала необходимость доработки нашего framework’а для поддержки такого сценария. Хотелось, чтобы данные источника сразу попадали на S3 в формате JSON - то есть в формате "как есть", без лишнего шага конвертации в parquet посредством Apache NiFi.
В первую очередь необходимо было доработать шаг Compaction. Его код, если убрать всю «обвязку» и выделить только главное, очень простой:
```
df = spark.read.format(in_format) \
.options(**in_options) \
.load(path) \
.distinct()
new_df = df.coalesce(div)
new_df.write.mode("overwrite") \
.format(out_format) \
.options(**out_options) \
.save(path)
```
Но если мы проделаем все те же манипуляции с JSON-данными, то волей-неволей внесем изменения во входные данные, так как при чтении JSON’ов Spark автоматом определит и сделает mergeSchema, т.е. мы тем самым можем исказить входные данные, чего не хотелось бы. Ведь наша задача на этом шаге – только укрупнить файлы и дедублицировать данные, без какого-либо вмешательства в их структуру и наполнение. То есть сохранить их «как есть».
По-хорошему, нам надо было просто прочитать данные как обычный текст, дедублицировать строки, укрупнить файлы и положить обратно на S3. Для этого был предложен достаточно изящный способ:
> *рассматривать файлы с JSON-объектами как DataFrame с одной колонкой, содержащей весь JSON-объект.*
>
>
Попробуем сделать это. Допустим, мы имеем следующий файл данных:
**file1:**
```
{«productId»: 1, «productName»: «ProductName 1», «tags»: [«tag 1», «tag 2»], «dimensions»: {«length»: 10, «width»: 12, «height»: 12.5}}
{«productId»: 2, «price»: 10.01, «tags»: [«tag 1», «tag 2»], «dimensions»: {«length»: 10, «width»: 12, «height»: 12.5}}
```
Обратите внимание на формат этого файла. Это файл с JSON-объектами, где 1 строка = 1 объект. Оставаясь, по сути, JSON-ом, он при этом не пройдет синтаксическую JSON-валидацию. Именно в таком виде мы сохраняем JSON-данные на S3 (есть специальная "галочка в процессоре Apache NiFi).
Прочитаем файл предлагаемым способом:
```
# Читаем данные
df = spark.read \
.format("csv") \
.option("sep", "\a") \
.load("file1.json")
# Схема получившегося DataFrame
df.printSchema()
root
|-- _c0: string (nullable = true)
# Сами данные
df.show()
+--------------------+
| _c0|
+--------------------+
|{"productId": 1, ...|
|{"productId": 2, ...|
+--------------------+
```
То есть мы тут читаем JSON как обычный CSV, указывая разделитель, который никогда заведомо не встретится в наших данных. Например, [Bell character](https://en.wikipedia.org/wiki/Bell_character). В итоге мы получим DataFrame из одного поля, к которому можно будет также применить *dicstinct()* и затем *coalesce()*, то есть менять существующий код не потребуется. Нам остается только определить опции в зависимости от формата:
```
# Для parquet
in_format = "parquet"
in_options = {}
# Для JSON
in_format = "csv"
in_options = {"sep": "\a"}
```
Ну и при сохранении этого же DataFrame обратно на S3 в зависимости от формата данных опять применяем разные опции:
```
df.write.mode("overwrite") \
.format(out_format) \
.options(**out_options) \
.save(path)
# для JSON
out_format = "text"
out_options = {"compression": "gzip"}
# для parquet
out_format = input_format
out_options = {"compression": "snappy"}
```
Следующей точкой доработки был шаг Parsing. В принципе, ничего сложного, если бы задача при этом упиралась в одну маленькую деталь: JSON -файл, в отличии от parquet, не содержит в себе схему данных. Для разовой загрузки это не является проблемой, так как при чтении JSON-файла Spark умеет сам определять схему, и даже в случае, если файл содержит несколько JSON-объектов с немного отличающимся набором полей, корректно выполнит mergeSchema. Но для регулярного процесса мы не могли уповать на это. Банально может случиться так, что во всех записях какого-то файла с данными может не оказаться некоего поля «*field\_1*», так как, например, в источнике оно заполняется не во всех случаях. Тогда в получившемся Spark DataFrame вообще не окажется этого поля, и наш Parsing, построенный на метаданных, просто-напросто упадет с ошибкой из-за того, что не найдет прописанное в маппинге поле.
Проиллюстрирую. Допустим,у нас есть два файла из одного источника со следующим наполнением:
**file1** (тот же что и в примере выше):
```
{«productId»: 1, «productName»: «ProductName 1», «tags»: [«tag 1», «tag 2»], «dimensions»: {«length»: 10, «width»: 12, «height»: 12.5}}
{«productId»: 2, «price»: 10.01, «tags»: [«tag 1», «tag 2»], «dimensions»: {«length»: 10, «width»: 12, «height»: 12.5}}
```
**file2**:
```
{«productId»: 3, «productName»: «ProductName 3», «dimensions»: {«length»: 10, «width»: 12, «height»: 12.5, «package»: [10, 20.5, 30]}}
```
Теперь прочитаем Spark’ом их и посмотрим данные и схемы получившихся DataFrame:
```
df = spark.read \
.format("json") \
.option("multiline", "false") \
.load(path)
df.printSchema()
df.show()
```
Первый файл (схема и данные):
```
root
|-- dimensions: struct (nullable = true)
| |-- height: double (nullable = true)
| |-- length: long (nullable = true)
| |-- width: long (nullable = true)
|-- price: double (nullable = true)
|-- productId: long (nullable = true)
|-- productName: string (nullable = true)
|-- tags: array (nullable = true)
| |-- element: string (containsNull = true)
+--------------+-----+---------+-------------+--------------+
| dimensions|price|productId| productName| tags|
+--------------+-----+---------+-------------+--------------+
|[12.5, 10, 12]| null| 1|ProductName 1|[tag 1, tag 2]|
|[12.5, 10, 12]|10.01| 2| null|[tag 1, tag 2]|
+--------------+-----+---------+-------------+--------------+
```
Второй файл (схема и данные)*:*
```
root
|-- dimensions: struct (nullable = true)
| |-- height: double (nullable = true)
| |-- length: long (nullable = true)
| |-- package: array (nullable = true)
| | |-- element: double (containsNull = true)
| |-- width: long (nullable = true)
|-- productId: long (nullable = true)
|-- productName: string (nullable = true)
+--------------------+---------+-------------+
| dimensions|productId| productName|
+--------------------+---------+-------------+
|[12.5, 10, [10.0,...| 3|ProductName 3|
+--------------------+---------+-------------+
```
Как видно, Spark корректно выстроил схему отдельно для каждого файла. Если в какой-либо записи не было обнаружено поля, имеющегося в другой, то в DataFrame мы видим корректное проставление null (поля price и productName для первого файла).
Но в целом схемы получились разные, и если у нас в маппинге прописано, что нам нужно распарсить эти данные (то есть оба файла) в следующую плоскую структуру,
```
root
|-- price: double (nullable = true)
|-- productId: long (nullable = true)
|-- productName: string (nullable = true)
```
а во входных данных у нас присутствуют только файлы «а-ля *file2*», где поля «*price*» нет ни у одной записи, то Spark упадет с ошибкой, так как не найдет поля «price» для формирования выходного DataFrame. С parquet-файлами такой проблемы как правило не возникает, так как сам parquet-файл генерируется из AVRO, который уже содержит полную схему данных и, соответственно, эта полная схема есть и в parquet-файле.
Еще надо отметить, что, естественно, мы хотели по максимум переиспользовать уже существующий и зарекомендовавший себя код нашего framework’а, а не городить какую-то полностью отдельную ветку для обработки JSON’ов – то есть все изменения хотелось сделать на этапе чтения JSON-файлов с S3.
Таким образом очевидно, что для корректной загрузки данных из JSON-файлов необходимо предопределить схему JSON-файла с данными и читать файлы уже с применением этой схемы. Тогда у нас даже если в JSON’е нет какого-то поля, то в самом DataFrame это поле будет, но его значение подставится как null:
```
df = spark.read \
.format("json") \
.option("multiline","false") \
.schema(df_schema) \
.load(path)
```
Первая мысль была использовать для хранения схемы имеющийся сервис метаданных - то есть описать схему в YAML-формате и сохранить в имеющемся репозитории. Но с учетом того, что все данные источников у нас проходят через Kafka, решили, что логично для хранения схем использовать имеющийся Kafka Schema Registry, а схему хранить в [стандартном для JSON формате](https://json-schema.org/) (другой формат, кстати говоря, Kafka Schema Registry не позволил бы хранить).
В общем, вырисовывалась следующая реализация:
* Читаем из Kafka Schema Registry схему
* Импортируем ее в pyspark.sql.types.StructType – что-то типа такого:
```
# 1. получаем через Kafka Schema Registry REST API схему данных
# 2. записываем ее в переменную schema и далее:
df_schema = StructType.fromJson(schema)
```
* Ну и с помощью полученной схемы читаем JSON-файлы
Звучит хорошо, если бы… Давайте посмотрим на формат JSON-схемы, понятной Spark’у. Пусть имеем простой JSON из *file2* выше. Посмотреть его схему в формате JSON можно, выполнив:
```
df.schema.json()
```
Получившаяся схема
```
{
"fields":
[
{
"metadata": {},
"name": "dimensions",
"nullable": true,
"type":
{
"fields":
[
{"metadata":{},"name":"height","nullable":true,"type":"double"},
{"metadata":{},"name":"length","nullable":true,"type":"long"},
{"metadata":{},"name":"width","nullable":true,"type":"long"}
],
"type": "struct"
}
},
{
"metadata": {},
"name": "price",
"nullable": true,
"type": "double"
},
{
"metadata": {},
"name": "productId",
"nullable": true,
"type": "long"
},
{
"metadata": {},
"name": "productName",
"nullable": true,
"type": "string"
},
{
"metadata": {},
"name": "tags",
"nullable": true,
"type":
{
"containsNull": true,
"elementType": "string",
"type": "array"
}
}
],
"type": "struct"
}
```
Как видно, это совсем не стандартный формат JSON-схемы.
«Но мы же наверняка не первые, у кого встала задача конвертировать стандартную JSON-схему в формат, понятный Spark’у*»* -подумали мы и … В принципе, не ошиблись, но несколько часов поиска упорно выводили исключительно на примеры, из серии:
> *как сохранить схему уже прочитанного DataFrame в JSON, затем использовать повторно*
>
>
либо на репозиторий <https://github.com/zalando-incubator/spark-json-schema>, который нам бы подошел, если мы использовали Scala, а не pySpark …
В общем, на горизонте маячила перспектива писать SchemaConverter. Сперва решили отделаться малой кровью и написать простенький конвертер – никаких ссылок и прочих сложных конструкций. Конвертер был успешно протестирован на синтетических данных, после чего захотелось «скормить» ему что-то приближенное к реальности.
К счастью, у нас уже был один источник, генерирующий данные в формате JSON. Как временное решение схема его интеграции в DataPlatform была незамысловата: NiFi читал данные из Kafka, преобразовывал их в parquet, использую «прибитую гвоздями» в NiFi схему в формате AVRO-schema, и складывал на S3. Схема данных была действительно непростой и с кучей вложенных структур и нескольких десятков полей - неплохой тест-кейс в общем-то:
Посмотреть длинную портянку, если кому интересно :)
```
root
|-- taskId: string (nullable = true)
|-- extOrderId: string (nullable = true)
|-- taskStatus: string (nullable = true)
|-- taskControlStatus: string (nullable = true)
|-- documentVersion: long (nullable = true)
|-- buId: long (nullable = true)
|-- storeId: long (nullable = true)
|-- priority: string (nullable = true)
|-- created: struct (nullable = true)
| |-- createdBy: string (nullable = true)
| |-- created: string (nullable = true)
|-- lastUpdateInformation: struct (nullable = true)
| |-- updatedBy: string (nullable = true)
| |-- updated: string (nullable = true)
|-- customerId: string (nullable = true)
|-- employeeId: string (nullable = true)
|-- pointOfGiveAway: struct (nullable = true)
| |-- selected: string (nullable = true)
| |-- available: array (nullable = true)
| | |-- element: string (containsNull = true)
|-- dateOfGiveAway: string (nullable = true)
|-- dateOfGiveAwayEnd: string (nullable = true)
|-- pickingDeadline: string (nullable = true)
|-- storageLocation: string (nullable = true)
|-- currentStorageLocations: array (nullable = true)
| |-- element: string (containsNull = true)
|-- customerType: string (nullable = true)
|-- comment: string (nullable = true)
|-- totalAmount: double (nullable = true)
|-- currency: string (nullable = true)
|-- stockDecrease: boolean (nullable = true)
|-- offline: boolean (nullable = true)
|-- trackId: string (nullable = true)
|-- transportationType: string (nullable = true)
|-- stockRebook: boolean (nullable = true)
|-- notificationStatus: string (nullable = true)
|-- lines: array (nullable = true)
| |-- element: struct (containsNull = true)
| | |-- lineId: string (nullable = true)
| | |-- extOrderLineId: string (nullable = true)
| | |-- productId: string (nullable = true)
| | |-- lineStatus: string (nullable = true)
| | |-- lineControlStatus: string (nullable = true)
| | |-- orderedQuantity: double (nullable = true)
| | |-- confirmedQuantity: double (nullable = true)
| | |-- assignedQuantity: double (nullable = true)
| | |-- pickedQuantity: double (nullable = true)
| | |-- controlledQuantity: double (nullable = true)
| | |-- allowedForGiveAwayQuantity: double (nullable = true)
| | |-- givenAwayQuantity: double (nullable = true)
| | |-- returnedQuantity: double (nullable = true)
| | |-- sellingScheme: string (nullable = true)
| | |-- stockSource: string (nullable = true)
| | |-- productPrice: double (nullable = true)
| | |-- lineAmount: double (nullable = true)
| | |-- currency: string (nullable = true)
| | |-- markingFlag: string (nullable = true)
| | |-- operations: array (nullable = true)
| | | |-- element: struct (containsNull = true)
| | | | |-- operationId: string (nullable = true)
| | | | |-- type: string (nullable = true)
| | | | |-- reason: string (nullable = true)
| | | | |-- quantity: double (nullable = true)
| | | | |-- dmCodes: array (nullable = true)
| | | | | |-- element: string (containsNull = true)
| | | | |-- timeStamp: string (nullable = true)
| | | | |-- updatedBy: string (nullable = true)
| | |-- source: array (nullable = true)
| | | |-- element: struct (containsNull = true)
| | | | |-- type: string (nullable = true)
| | | | |-- items: array (nullable = true)
| | | | | |-- element: struct (containsNull = true)
| | | | | | |-- assignedQuantity: double (nullable = true)
|-- linkedObjects: array (nullable = true)
| |-- element: struct (containsNull = true)
| | |-- objectType: string (nullable = true)
| | |-- objectId: string (nullable = true)
| | |-- objectStatus: string (nullable = true)
| | |-- objectLines: array (nullable = true)
| | | |-- element: struct (containsNull = true)
| | | | |-- objectLineId: string (nullable = true)
| | | | |-- taskLineId: string (nullable = true)
```
Естественно, я не захотел перебивать руками захардкоженную схему, а воспользовался одним из многочисленных онлайн-конвертеров, позволяющих из Avro-схемы сделать JSON-схему. И тут меня ждал неприятный сюрприз: все перепробованные мною конвертеры на выходе использовали гораздо больше синтаксических конструкций, чем «понимала» первая версия конвертера. Дополнительно пришло осознание, что также как и я, наши пользователи (а для нас пользователями в данном контексте являются владельцы источников данных) с большой вероятностью могут использовать подобные конвертеры для того, чтобы получить JSON-схему, которую надо зарегистрировать в Kafka Schema Registry, из «того, что у них есть».
В результате наш SparkJsonSchemaConverter был доработан – появилась поддержка более сложных конструкций, таких как *definitions*, *refs* (только внутренние) и *oneOf*. Сам же парсер был оформлен уже в отдельный класс, который сразу «собирал» на основании JSON-схемы объект *pyspark.sql.types.StructType*
> *У нас почти сразу же родилась мысль, что хорошо бы было поделиться им с сообществом, так как мы в Леруа Мерлен сами активно используем продукты Open Source, созданные и поддерживаемые энтузиастами со всего мира, и хотим не просто их использовать, но и контрибьютить обратно, участвуя в разработке Open Source продуктов и поддерживая сообщество. В настоящий момент мы решаем внутренние орг.вопросы по схеме выкладывания данного конвертера в Open Source и, уверен, что в ближайшее время поделимся с сообществом этой наработкой!*
>
>
В итоге благодаря написанному SparkJsonSchemaConverter’у доработка шага Parsing свелась только к небольшому «тюнингу» чтения данных с S3: в зависимости от формата входных данных источника (получаем из сервиса метаданных) читаем файлы с S3 немного по-разному:
```
# Для JSON
df = spark.read.format(in_format)\
.option("multiline", "false")\
.schema(json_schema) \
.load(path)
# Для parquet:
df = spark.read.format(in_format)\
.load(path)
```
А дальше отрабатывает уже существующий код, раскрывающий все вложенные структуры согласно маппингу и сохраняющий данные DataFrame’а в несколько плоских CSV-файлов.
В итоге мы смогли при относительном минимуме внесенных изменений в код текущего framework’а добавить в него поддержку интеграции в нашу Data Platform JSON-источников данных. И результат нашей работы уже заметен:
* Всего через месяц после внедрения доработки у нас на ПРОДе проинтегрировано 4 новых JSON-источника!
* Все текущие интеграции даже «не заметили» расширения функционала framework’а, а значит, мы точно ничего не «сломали» произведенной доработкой. | https://habr.com/ru/post/563066/ | null | ru | null |
# Переход на Google Talk
[](http://www.google.com/talk/intl/ru/) Когда-то в [своем блоге](http://www.solargate.ru) я [написал небольшую статью](http://www.solargate.ru/perekhod-na-google-talk) по поводу безболезненного перехода на Google Talk. Статья оказалась достаточно полезной и помогла многим моим знакомым перейти на Google Talk. Выкладываю ее и здесь. Надеюсь, она кому-нибудь поможет.
Я считаю, что Google Talk сейчас — самая перспективная IM-технология. Всем моим друзьям и знакомым я теперь настоятельно рекомендую тоже подключиться к Google Talk. Во всяком случае меня гораздо проще найти именно там. В аське я могу и не быть, она у меня теперь работает не всегда, но в GTalk я нахожусь всегда, когда я в онлайне. Инерция мышления заставляет некоторых людей считать, что Google Talk — это сложно. Многие вообще не хотят уходить с глючной, но родной аськи. Все это сподвигло меня написать некую инструкцию для начинающих по простому переходу на GTalk. Но вначале о преимуществах технологии.
***Зачем вообще уходить на Google Talk?***
За последние годы ICQ обросла массой недостатков:
* В последнее время ICQ из-за работ на сервере работает крайне нестабильно.
* Протокол ICQ закрытый. Кроме того, компания AOL имеет дурную привычку этот протокол постоянно менять. Думаю, все периодически сталкиваются с необходимостью скачивать последнюю версию своего клиента из-за очередных изменений протокола.
* Иногда возникают глюки в передаче сообщений между различными асечными клиентами.
* Реклама в «родном» клиенте.
Преимущества Google Talk:
* GTalk основан на открытой технологии Jabber. Это позволяет использовать как родной клиент, так и любой сторонний jabber-клиент.
* Стабильность. Это Google. Излишни напоминания о том, насколько развита эта компания.
* При регистрации в [GMail](http://www.gmail.com/) вместе с почтовым ящиком автоматически заводится и аккаунт GTalk. Не думаю, что кому-то еще требуется рассказывать про GMail, этим сервисом пользуются уже очень многие.
* Хранение истории переписки на сервере. Это очень удобная фича. Вся переписка доступна из аккаунта Gmail, нет зависимости от IM-клиентов, вашей операционной системы или местоположения. К примеру, я могу общаться на работе и дома, но у меня единая история переписки.
* Синхронизация контактов GTalk с адресной книгой в GMail.
* Возможность подключения транспортов для любых сторонних протоколов (ICQ, AIM, MSN, Yahoo), тоже с хранением истории переписки на сервере.
Подробней о GTalk можно почитать [здесь](http://www.google.com/talk/intl/ru/about.html).
Я понимаю, что полностью отказываться от ICQ сейчас мало кто захочет. Но это и не обязательно. Я постараюсь описать, как можно безболезненно перейти на GTalk, не отказываясь от ICQ. Как я уже говорил, для того, чтобы подключиться к GTalk, достаточно просто зарегистрировать себе [ящик на GMail](http://www.gmail.com/). А вот при настройке клиента можно поступить тремя способами, в зависимости от личных предпочтений.
***Способ 1. Использование родного клиента***
Если у вас нет желания отказываться от любимого ICQ-клиента, то можно просто скачать GTalk-клиента [отсюда](http://www.google.com/talk/intl/ru/). И просто использовать его отдельно, в паре с ICQ-клиентом. В этом случае есть еще и возможность использования голосовых переговоров (аналог Skype). Кроме того, можно использовать Web-клиент. Подробней о клиенте GTalk можно почитать [здесь](http://www.google.com/talk/intl/ru/start.html).
***Способ 2. Мультипротокольные клиенты***
Можно использовать мультипротокольные клиенты. Например, [Miranda](http://www.miranda-im.org/), [SIM](http://sim-icq.sourceforge.net/ru/), [Kopete](http://kopete.kde.org/), [Pidgin](http://www.pidgin.im/) и т.д. Не буду останавливаться на этом подробно. Пользователи этих клиентов и так знают, что нужно сделать, чтобы просто добавить новую учетную запись. ;-) Недостаток этого подхода в том, что история сообщений ICQ не будет сохраняться на сервере GMail.
***Способ 3. Использование Jabber-клиента с подключением транспортов***
Здесь постараюсь рассказать подробней, потому что не все нюансы на первый взгляд кажутся тривиальными. Постольку поскольку GTalk основан на технологии Jabber, можно использовать любой Jabber-клиент. Их написано великое множество — [Psi](http://psi.affinix.com/), [Gajim](http://www.gajim.org/), [Tkabber](http://tkabber.jabber.ru/), [JAJC](http://jajc.jrudevels.org/) и т.д.
Мне больше всего нравится Psi, поэтому я буду рассказывать на его примере. У остальных клиентов все настраивается примерно так же. Настройка аккаунта в Psi весьма тривиальна и детально описана [здесь](http://www.google.com/support/talk/bin/answer.py?answer=24074&topic=1415). Я же остановлюсь на подключении ICQ-транспорта.
Jabber — распределенная система. Существует очень много серверов, на которых есть транспорты в различные IM-системы, включая ICQ. К своему GTalk-аккаунту можно подключить транспорты практически с любого другого стороннего Jabber-сервера. В случае с транспортами ICQ есть один нюанс. К сожалению, не все транспорты поддерживают корректное подтягивание никнеймов. В случае, если ник не подтягивается, то асечный контакт будет виден только как цифры. Чтобы это исправить, надо в файле "\User\PsiData\profiles\default\config.xml" строчку
`false`
заменить на
`true`
После этого ники должны подтягиваться нормально. Теперь можно подключать транспорт. Для этого выбираем «Service Discovery» и в строке адреса вводим выбранный нами Jabber-сервер. Список публичных серверов смотрим [здесь](http://www.jabber.org/user/publicservers.shtml). Появится список доступных сервисов. Если среди них есть нужный транспорт, необходимо его зарегистрировать.
Транспорт запросит логин, пароль и авторизацию. После ее подтверждения должны подтянуться асечные ники. Вот и все. Таким же образом можно подключать любые другие транспорты (AIM, MSN, Yahoo). Таким образом можно сделать, чтобы в одном аккаунте GTalk уживалось несколько IM-систем. Причем вся переписка будет сохраняться на сервере. Удобно.
***Ложка дегтя***
При использовании транспортов можно наткнуться на некоторые трудности. Далеко не все зарубежные сервера корректно работают с кириллицей. Поэтому я рекомендую использовать сервера в зоне .ru. Но у них иногда бывают проблемы со стабильностью. Впрочем, они не настолько уж и частые. И вообще, это ведь не остановит настоящих гиков, не так ли? ;-) Централизованное хранение переписки со всех IM-систем того стоит. Кроме того, никто не отменял первые два из описанных мной способов, для тех кто не хочет вообще заморачиваться с транспортами. Сама технология очень перспективна и то, что ее активно развивает Google, дает уверенность, что GTalk будет набирать популярность. Это уже происходит.
***Ссылки по теме***
Google Mail: <http://www.gmail.com/>
Скачать GTalk Client: <http://www.google.com/talk/intl/ru/>
О программе Google Talk: <http://www.google.com/talk/intl/ru/about.html>
Настройка Google Talk: <http://www.google.com/talk/intl/ru/start.html>
Psi Homepage: <http://psi-im.org/>
Настройка Psi для GTalk: <http://www.google.com/support/talk/bin/answer.py?answer=24074>
Список публичных серверов Jabber: <http://www.jabber.org/user/publicservers.shtml>
Надеюсь, что эта маленькая статья окажется кому-нибудь полезна. | https://habr.com/ru/post/14435/ | null | ru | null |
# Я сделаю свое приложение, с блэкджеком и таблицами! Или как вырастить и кормить доброго монстра
Небольшая история, как из пробного проекта вырастить приложение, которое охватывает большую часть деятельности ИТ отдела.
Сразу скажу, приложение выросло из любительского проекта, начатого для изучения новой технологии. Наверняка существуют похожие решения, которые делают все то же самое и гораздо лучше, а я зачем-то изобретаю велосипед. Наверняка такие "велосипеды" есть, более модные, красивые и с позолоченными спицами. Но этот "велосипед" мой и я на нем успешно и с комфортом еду.
С чего все началось? Давным-давно придя в организацию, в которой до сих пор работаю, я столкнулся с проблемой, что ИТ отдел совершенно не занимался учетом аппаратного обеспечения. Существовала база 1С бухгалтерии, в которой ставились на учет системные блоки, мониторы, принтеры и прочее оборудование. Кладовщик рисовал инвентарные номера и на этом все заканчивалось. Сотрудники отдела получали новую технику, настраивали, устанавливали и дальше о том где какая техника знал только кладовщик и то не всегда. Ситуация более чем странная, во всяком случае для меня.
Казалось бы простые вопросы: какие из рабочих мест нам нужно обновить в этом году или где принтер уже износился так, что его постоянный ремонт стоит больше, чем купить новый и множество мелких других вопросов, ответы на которые можно получить только имея более полную информацию.
Поговорив с начальством и получив "добро" на попытку создания системы учета компьютерного хозяйства - приступил к работе.
Готовых решений я не нашел, был 2005 год. Можно было бы копаться в 1С, пытаясь приспособить ее к моему представлению того, как должен выглядеть учет техники не для бухгалтера, а для администратора, но не хотелось. Ключи на 1С были только у бухгалтерии, для нас их бы никто не стал покупать.
По основной специальности я программист и мне хотелось изучить возможности SQL сервера от Microsoft. С нашей версией 1С поставлялся MS SQL 2000. По сравнению с версией MS SQL 7, это была уже довольно удобная база, с продуманным инструментом для управления. И конечно удобнее MS Access (от этого слова и продукта до сих пор мороз по коже, хотя и в нем есть приятные мелочи). До этого мне приходилось писать клиент-серверные приложения на C++ Builder в связке с базой Oracle. Так почему бы не попробовать свои силы в похожей связке, но в качестве базы использовать MS SQL 2000?
Итак, в свободное от основной работы время я приступил к созданию программы для учета компьютерной техники в организации.
Первая итерация.
----------------
Сперва я заглянул в 1С, для поиска в ней информации об оборудовании на балансе. Покопавшись в таблицах нашел где притаились сведения об инвентарных и серийных номерах, наименованиях, годах покупки. Больше ничего особо интересного я там не увидел.
Выдернув первоначальные данные, создал первое простенькое приложение (к сожалению, или к счастью, скриншотов с него не осталось). Это был простой список оборудования, с возможностью поиска, сортировки. Карточка оборудования содержала, помимо данных из 1С: вид оборудования (монитор, системный блок, принтер, копировальный аппарат и т.п.), расположение (кабинет), владелец (ФИО кто использует технику) и что-то еще по мелочи, за давностью лет, уже не помню.
Раскрасил табличку в разные цвета, чтобы каждый вид техники у меня выделялся отдельным цветом.
Сначала замахнулся на задание каждому виду отдельного цвета, но получилась такая мешанина, что глаз дергаться начинал. Поэтому в итоге осталось четыре основных цвета (системный блок, монитор, принтер и копир).
На первые грабли при проектировании я прыгнул, когда первичным ключом таблицы с оборудованием решил сделать инвентарный номер. Эх молодость... Это в дальнейшем я множество раз в разных умных книгах читал, что не стоит в качестве первичного ключа делать какую-либо сущность из тех данных, что у вас в таблице. В 99% случаев пользователь, даже для самых уникальных данных, найдет причину почему здесь должны быть одинаковые значения. Так и в моем случае - я очень быстро понял, что инвентарный номер это далеко не уникальная штука. Например, купило предприятие одинаковые мониторы, и ставит их на учет под одинаковыми номерами - скопом, поскольку по документам они идут одной строкой с количеством. Поэтому - переделываем.
Идем дальше. Первой идеей было взять наименование устройства из 1С, оно же было так куплено и в документах проходит... ну-ну. Чего я только не увидел в качестве названий: русские транскрипции или латиницу на одно и тоже оборудование, например могли написать "HP Laser Jet", или "Лазер Джет", или "HP LJ", да просто "Принтер" наконец. Синтаксические ошибки, орфографические... в наименовании могло быть написано что угодно, все зависело от фантазии бухгалтера, который забивал эту позицию в 1С, а также от его зрения, что он увидел, то написал. Если увидел нечетко, то и написал примерно.
Поэтому очень быстро появилась вторая строка с наименованием, которое было уже универсальное, а затем модель оборудования просто стала браться из справочника, который заполнялся администратором самостоятельно.
Исходя из того бардака (с моей точки зрения), который творился в 1С, от постоянной связки с ней пришлось отказаться. И моя база стала заполняться параллельно от 1С, для нужд ИТ отдела.
Немного забегая вперед хочу сказать, что сейчас зачастую уже кладовщики и бухгалтера иногда считают мою базу более верной чем свою, и в случаях каких-либо поисков оборудования или спорных ситуаций обращаются к ней.
Понемногу "скелет" базы начал обрастать "мясом" в виде данных об оборудовании, различных группировок для удобства поиска, отчетов. В карточку устройства записывалось не только у кого и где оно находится, но и была привязка к справочнику отделов и управлений организации, добавился год покупки, состояние оборудования (рабочее или сломанное). Можно было просматривать все оборудование в каком-нибудь кабинете, или все что располагается у какого-то отдела.
База заполнялась в ручном режиме, кое какая автоматизация придет позже, но об этом потом.
Главное в таких вещах, это актуальность и достоверность информации. Если обращаясь к данным, ты не уверен, что здесь отражено реальное положение дел, то весь ваш труд напрасен.
Видя очевидные преимущества от использования даже такой простой системы учета, руководство отдела обязало админов заполнять базу на регулярной основе. Переставил принтер от сотрудника к сотруднику - отметь! Теперь идя по вызову к работнику на другом конце здания, администратор мог не по памяти ориентироваться на то, с чем придется столкнуться, а просто заглянуть в базу.
Помимо основной функциональности добавились чисто эстетические составляющие, например логотипы фирм производящих оборудование, они появлялись в таблице рядом с названием техники. Была сделана связь с приложением отдела кадров, которое реализовывалось на Access, в карточку оборудования вставлялось ФИО человека. Также была сделана привязка к телефонному справочнику организации.
*Но скажу сразу, эти нововведения долго не прожили. Логотипы стали бессмысленными, когда оборудования разных марок стало слишком много. Связь с отделом кадров и телефонным справочником тоже отпала, чтобы возродиться несколько в другом варианте.*
Еще одной полезной штукой была реализация справочника видов оборудования с фотографией самого устройства. Зачастую очень полезно для различных моделей принтеров, которые отличаются одной буквой в названии, а функционал может быть очень различным. Когда моделей по зданию десятки, то на память полагаться сложно. А видя фотографию, сразу понятно, с чем имеешь дело.
Дополнительно возникла еще одна функция – история изменений этой базы. На самом SQL сервере это реализовывалось довольно топорно и просто – на update и insert в базу был добавлен триггер, который брал текущую строку таблицы и записывал ее в отдельную таблицу изменений. В итоге мы получили полную историю изменений по оборудованию. Например можно было увидеть, у кого за эти года побывал монитор или системный блок.
Собственно, с тех времен скриншот уже остался.
Один из первых вариантов внешнего вида приложенияСогласен, выглядит по нынешним временам (да и по тем тоже), не очень. Но она работала и очень облегчала жизнь.
Вторая итерация.
----------------
Пришло время и государство решило всерьез взяться за борьбу с компьютерным пиратством. Мы закон чтили, но вот с отчетностью и учетом было также очень плохо. Опять же где-то в недрах 1С были платежки за программное обеспечение, но никакого учета по серийным номерам, срокам действия, местам установки не существовало. Время от времени из МВД или Microsoft приходили грозные письма, с требованиями отчитаться о наличии и использовании лицензионного программного обеспечения. Причем Microsoft действовало хитро, естественно они от нас не имела права требовать отчета, но в письме писали, что если мы не предоставим никакой информации об их продуктах, то они будут уже действовать по линии МВД, т.е. писать запросы туда. Приходилось отчитываться. Примерно так же действовали и Autodesk и IBM.
Придумывать что-то новое я не стал и решил просто расширить существующую базу. Первоначально сделал справочник видов программного обеспечения по группам: коммерческое ПО, собственные разработки, бесплатное ПО. Внутри уже шло деление по типам ПО: антивирусное ПО, CAD системы, офисное ПО, среды программирования и т.п.
Карточка определенного программного обеспечения уже включала в себя информацию о наименовании, производителе и детальную информацию о лицензии: количество, у кого приобретено, каков срок действия, регистрационные и серийные номера.
Далее возник следующий вопрос: список лицензий, это замечательно – но нужна понимать куда они установлены. Решено было сделать карточки рабочих мест. В них должен быть отражен состав программного и аппаратного обеспечения.
Здесь возник еще один вопрос. Что считать рабочим местом? Создавать какую-то отдельную сущность? Или привязывать к чему-то реальному? Покрутив и так и эдак, я решил сделать привязку опосредованно к системному блоку, как к некоему основополагающему признаку. Ведь к нему подключаются все остальные устройства и на него устанавливаются все лицензии. В итоге родилось вот какое решение: есть некая сущность названная по определенному шаблону, здесь мы коллегиально решили называть компьютеры в сети как "PC\_%%%%", где на местах % указываются последние 4 цифры инвентарного номера системного блока (например PC\_0134, где полный инвентарный номер выглядел как 0001360134). Начало инвентарных номеров было одинаковое, отличие было только в последних четырех знаках.
Пока не ушел дальше, сразу скажу о плюсах и минусах такого решения:
* плюсы: когда системный блок назван с участием инвентарного номера, то при стирании того же номера с корпуса, всегда его можно было восстановить, просто включив компьютер и посмотрев сетевое имя.
* минусы: не уникальность номеров, т.е. у нас стали появляться рабочие места PC\_0135-1, PC\_0135-2 и т.п.
Еще одна оплошность при стандартизации таких имен, это символ "\_". На момент принятия нами его в качестве разделителя, в сетях Windows этот символ воспринимался корректно. Но в современной ситуации не все DNS сервера могут адекватно переварить это имя. И уже сам Windows предлагает вместо "\_" использовать "-", что мы собственно и делаем - переименовывая машины.
Помимо удлинения номера машины, за счет не уникальности номера возникала еще проблема получения этого номера от бухгалтерии, то они неправильно выдадут, то слишком долго не оприходуют, то еще какая-нибудь "беда". В итоге мы пришли к следующему стандарту "PC-%%%%", где % просто порядковый номер. Еще для удобства иногда к буквам добавляем дополнительные символы для обозначения подразделений, чтобы их машины группировались при обзоре сети. Например подразделение "Централизованная бухгалтерия" имена машин "PCCB-%%%%" и т.д.
Но что-то уже много текста, давайте покажу как это выглядит на текущий момент.
Главное окно приложенияДавайте заглянем внутрь какой-нибудь карточки рабочего места.
Учетная карточка рабочего местаМы можем присоединить к рабочему месту любое устройство из общего списка оборудования или программного обеспечения. Естественно учитывается, что нельзя одно устройство добавить на разные рабочие места (с этим можно поспорить, но мы считаем так), так же автоматически уменьшается количество доступных лицензий на программное обеспечение, если они ограничены. И лишнее вы просто не установите.
Здесь вы можете увидеть две кнопки "Обращение" и "Информация" по ним я расскажу чуть позже, тут нужна предыстория.
Заглянем еще глубже, например посмотрим на принтер из карточки рабочего места.
Учетная карточка оборудованияТипичная карточка любого оборудования. Инвентарный номер, наименование, принадлежность какому-либо подразделению, информация о продавце с данными о гарантии.
Если переключиться на вкладку обслуживание, то увидим следующее:
Вкладка "обслуживание" в карточке оборудованияЗаправка картриджей и технический ремонт осуществляется по контракту проведенного с помощью конкурсных процедур. Чтобы контролировать подрядчика, к контракту я добавил в обязательное требование - заполнение обходного листа для исполнителя, т.е. если происходит заправка картриджа, то подрядчик должен в карточке написать вид работ, на каком оборудовании, в каком количестве и взять подпись того лица, которое обратилось с заявкой на работу. Потом в конце месяца эти листы сдаются мне, я сверяю список работ по выставленному счету с этим листом. С него же, данные вносятся с базу.
Также, помимо контроля за исполнением работ, я уже вижу износ и нагрузку каждого принтера. И конечно, при такой системе, подрядчику сложнее пытаться нас обмануть (а они пытаются) вставляя лишние заправки или не заказанные работы.
Итоговую сводку работ по всей организации я могу увидеть в другом отчете:
Отчет по заправкам и ремонтамНо давайте я пройду еще дальше и нажму на кнопку "Описание". Не обращайте внимание на поля "сайт производителя" и "драйвер", это уже атавизм и надо удалять.
Справочник моделей устройствЗдесь уже видим более детальную информацию об устройстве и о том что оно умеет, а также какие расходные материалы ему нужны и их количестве на складе.
Щелкаем по картриджу из списка и проваливаемся еще глубже:
Справочник расходных материаловЗдесь уже видим информацию о самом картридже, к какому оборудованию он подходит и примерному ресурсу.
Справочники заполняются руками.
И еще немного о картриджах. Чтобы знать, сколько остатков есть на складе, нужно знать, что у тебя на складе, и вовремя учитывать приход и расход материалов.
Учет картриджейНа момент моего трудоустройства, организацию обслуживала фирма, в обязанности которой входили функции по заправке картриджей, техническому обслуживанию и ремонту техники, они же составляли потребность в картриджах, которые затем покупались. Но постепенно финансовых средств становилось все меньше, нас заставили уменьшить размер контракта по обслуживанию офисной техники, а соответственно и обязанности подрядчика.
Когда уже я был назначен на должность начальника ИТ отдела, вся эта головная боль досталась мне. Пришлось самому разобраться во всех тонкостях прогнозирования потребностей в запчастях и картриджах, для этого и была создана довольно примитивная система учета, которая позволяла учитывать сколько и какого оборудования у меня есть, какие картриджи подходят для этого оборудования и сколько их осталось. Можно было задавать остатки на складе, осуществлять приход и расход по факту установки новых картриджей со склада пользователям.
В результате получилась довольно удобная система: если в мой отдел звонит пользователь и просит новый картридж, я открываю карточку рабочего места человека, смотрю модель принтера и сразу вижу остаток на складе. Если человеку действительно нужно установить новый картридж (а это далеко не всегда, да и картриджи оригинальные и дорогие), то прямо из карточки создается запись расхода, которая уменьшает остатки на складе. Ну и в качестве приятного бонуса, я подсвечиваю таблицу разными цветами, когда у меня кончились картриджи, или наоборот оборудования больше нет, а картридж остался. Сразу визуально понятно, где нехватка, а где излишки.
Еще о работе начальника отдела. Так уж вышло, что руководство моей организации время от времени меняется, и каждый новый руководитель начинает свой трудовой путь с оптимизации и сокращения расходов. Начинаются проверки эффективности сотрудников, отчеты о проделанной работе, планы о предстоящих задачах и прочее, прочее. Ну вы и сами знаете.
На моем веку, отдел ИТ реорганизовывали уже раз 5. Сокращали, заново создавали, переформировывали и даже хотели вообще от него отказаться и использовать аутсорс. Вся эта чехарда изрядно портит нервы и заставляет кучу времени тратить на бесполезные отчеты. И здесь наступает...
Третья итерация
---------------
Чтобы автоматизировать создание отчетов о работе, было решено немного формализовать работу внутри отдела. В этот уже разросшийся программный комплекс был добавлен модуль с неожиданным названием "Работа отдела". Я не стал бюрократизировать процесс обращения в отдел для пользователей, заставлять их писать заявки в какую-нибудь Jira. Организация не такая большая и мне бы этого сделать не дали. Просто я обязал своих сотрудников все заявки в отдел записывать в базу. Учитывалась тематика заявки, краткое содержание, кто обратился, время. Ну и такие вещи как: выполнялось ли это во вне рабочее время, пришлось ли куда-либо выезжать, возможно иногородние поездки. Времени такая запись занимает минимум, но это кардинально изменило "баланс сил". Теперь на придирки руководства, а чем это у нас занимаются системные администраторы, если их вдруг не видно бегающими по зданию, ответ генерировался мгновенно. Я мог продемонстрировать занятость по часам, дням, месяцам. Такой отчет я стал делать с периодичностью раз в месяц, полгода, год и рассылать непосредственным руководителям. Тем более они еще до этого, внесли в мою должностную инструкцию обязанность предоставления таких отчетов. И всё... наступила тишина, больше никаких вопросов чем мы тут занимается просто не было.
Вот пример того, как это выглядит:
Учет обращений в отделАдминистратор вносит в таблицу полученную заявку и она везде идет с его фамилией. Сейчас у нас пытаются внедрять систему с показателями эффективности каждого сотрудника, если прижмёт, то из этой системы я также это легко получу. Но пока не смотрю на то, кто обработал заявку, главное чтобы она была исполнена. Еще одно преимущество - это коллективная память отдела. Узнать, что мы делали в этот день 5 лет назад - легко. Что произошло пока меня не было в отпуске - открывай и смотри.
Четвертая итерация – накопление информации.
-------------------------------------------
Дальнейшим шагом по контролю за состоянием рабочих станций и принтеров стала автоматизация сбора информации.
Для начала рассмотрим рабочие станции. Мне хотелось бы знать, сколько установлено оперативной памяти на компьютере, какая версия операционной системы (хотя версия указана в карточке рабочего места, но бывают ситуации «даунгрейда», когда покупалась одна версия, но пришлось официально установить более раннюю), сколько свободного места на дисках, скорость сетевого адаптера. Подобная информация просто необходима для планов модернизации техники.
В обычной карточке учета оборудования на рабочем месте пользователя ничего этого нет. Заполнять руками совсем не вариант. Нужно чтобы станции как-то эту информацию отдали самостоятельно.
Сперва был сделан скрипт на PowerShell, который собирал информацию из реестра Windows и записывал ее в текстовый файл в сетевой папке, другой скрипт потом объединял эти файлики сформированные компьютерами и автоматически грузил в мою базу. Решение работало, но было очень медленным. Поскольку скрипт был вставлен в стартовую процедуру подключения к домену, то пользователи начали жаловаться, на медленное включение компьютера по утру. Уж не знаю почему PowerShell повел себя именно так, но пришлось от него отказаться и переписать все на встроенный в Windows jscript, он отрабатывал практически мгновенно.
Получился вот такой скрипт (пользуйтесь, если пригодится):
```
/*---------------------------------------------------------------------------------------------------------------
Сбор статистической информации о компьютере.
Формируется накопительный текстовый файл, один запуск - одна строка.
---------------------------------------------------------------------------------------------------------------*/
// Переменные, в которых сохраняется итоговая информация для записи в файл отчета.
var StartTime,
Machine,
TotalRam = 0,
OS,
LocalDrives,
FIO,
Processor,
Socket,
MaxSpeed,
MemoryBank,
NetCard;
// Формируем текущую дату. --------------------------------------------------------------------------------------
var d = new Date, mon, day;
mon = "" + (d.getMonth()+1);
day = "" + d.getDate();
if(mon.length == 1) { // Дополняем месяц и дату до двух цифр, если нет ведущего нуля.
mon = "0" + mon;
}
if(day.length == 1) {
day = "0" + day;
}
StartTime = day + "." + mon + "."+d.getFullYear()+";"+d.getHours()+":"+d.getMinutes()+":"+d.getSeconds();
var root = GetObject("winmgmts:\\\\.\\root\\cimv2"); //Подключились к WMI локального компьютера (".")
// Получаем информацию об оперативной памяти. -------------------------------------------------------------------
var querry = root.ExecQuery("Select * from Win32_PhysicalMemory"); // Запрос данных об оперативной памяти.
var accitem;
MemoryBank = "";
for(var acc = new Enumerator(querry); !acc.atEnd(); acc.moveNext()) {
accitem = acc.item();
TotalRam += accitem.Capacity / 1024 / 1024 / 1024; // В гигабайтах.
MemoryBank += accitem.BankLabel + "[" + (accitem.Capacity / 1024/ 1024/ 1024) + "] ";
}
// Получаем информацию об операционной системе. -----------------------------------------------------------------
querry = root.ExecQuery("SELECT * FROM Win32_OperatingSystem"); // Запрос об операционной системе.
for(var acc = new Enumerator(querry); !acc.atEnd(); acc.moveNext()) {
accitem = acc.item();
}
OS = accitem.Caption;
FIO = accitem.Description;
Machine = accitem.CSName;
// Получаем информацию об процессоре. ---------------------------------------------------------------------------
querry = root.ExecQuery("SELECT * FROM Win32_Processor"); // Запрос о процессоре.
for(var acc = new Enumerator(querry); !acc.atEnd(); acc.moveNext()) {
accitem = acc.item();
}
Processor = accitem.Name;
Socket = accitem.SocketDesignation;
// Получаем информацию о сетевой карте. -------------------------------------------------------------------------
querry = root.ExecQuery("SELECT * FROM Win32_NetworkAdapter WHERE AdapterType = 'Ethernet 802.3'"); // Запрос об адаптере.
MaxSpeed = "";
for(var acc = new Enumerator(querry); !acc.atEnd(); acc.moveNext()) {
accitem = acc.item();
MaxSpeed += "[" + accitem.Speed / 1000000 + "] ";
}
querry = root.ExecQuery("SELECT * FROM Win32_NetworkAdapterConfiguration WHERE IPEnabled = TRUE"); // Запрос о конфигурации адаптера.
NetCard = "";
for(var acc = new Enumerator(querry); !acc.atEnd(); acc.moveNext()) {
accitem = acc.item();
NetCard += "[" + accitem.MACAddress + " " + accitem.IPAddress(0) + "] ";
}
// Получаем информацию о дисковой системе. ----------------------------------------------------------------------
querry = root.ExecQuery("SELECT * FROM Win32_LogicalDisk WHERE DriveType = 3 and Size != NULL"); // Запрос о логических дисках.
LocalDrives = "";
for(var acc = new Enumerator(querry); !acc.atEnd(); acc.moveNext()) {
accitem = acc.item();
LocalDrives += accitem.Caption;
var temp = "" + accitem.Size/1024/1024/1024; // Полное пространство в Гигабайтах.
LocalDrives += "[" + temp.substr(0,temp.indexOf(".")+3) + "]"
temp = "" + accitem.FreeSpace/1024/1024/1024; // Свободное пространство в Гигабайтах.
LocalDrives += " " + temp.substr(0,temp.indexOf(".")+3) + " ";
}
// Пишем в файл итоговую строку. -------------------------------------------------------------------------------------
var FSO = WScript.CreateObject("Scripting.FileSystemObject");
var ts = FSO.OpenTextFile("\\\\Server\\stat\\" + Machine + ".INFO.LOG", 8, true);
var f = FSO.getfile("\\\\Server\\stat\\" + Machine + ".INFO.LOG");
ts.WriteLine(StartTime + ";" +
Machine + ";" +
TotalRam + ";" +
OS + ";" +
LocalDrives + ";" +
FIO + ";" +
NetCard + ";" +
Processor + ";" +
Socket + ";" +
MaxSpeed + ";" +
MemoryBank);
ts.Close();
```
В итоге получаем ежедневную информацию о состоянии оборудования, на основе которой опять же можно принимать решение об апгрейде того или иного компонента. Если еще помните, то я при рассказе о карточке рабочего места обещал рассказать о кнопках «Информация» и «Обращения»? Вот как раз кнопка «Информация» показывает, что насобирал скрипт:
Информация о системном блокеПо итогу на основании такого сбора информации я могу получать следующее:
* распределение оперативной памяти – может быть нужно увеличить;
* процентное соотношение операционных систем - для понимания как все плохо или хорошо;
* где можно ускорить компьютерную сеть - или почему вдруг упала скорость, может кабель перебили;
* так как скрипт срабатывает каждый раз при авторизации в сети, то можно отлавливать аномальное количество перезагрузок, что свидетельствует о странном поведении системного блока. Пользователь не всегда бежит жаловаться, если у него все зависло и пришлось перезагружать;
* так же можно отследить факты несанкционированного изменения оборудования. Если вдруг изменился состав оперативной памяти, а в карточку никто ничего из моего отдела не занес, то можно предположить, что кто-то решил плашку памяти себе забрать. Но таких случаев у нас не было.
Так как мы записываем все обращения от пользователей (ну как минимум стараемся), то можно установить связь по фамилии владельца, со всеми его обращениями в отдел, и посмотреть их все. Для этого и служит кнопка «Обращения». Иногда бывает полезно.
То что система делалась для себя и ее можно менять как угодно, открывает большие горизонты для «творчества», и для аналитики происходящего. Помимо технической информации о рабочих станциях, мне удалось создать небольшие скрипты, которые автоматизируют еще вот какую работу:
* Каждый день с серверов забираются логи с ошибками и предупреждениями и также помещаются в базу. Таким образом, утром включив компьютер, администратор видит происходящее на серверах внутри нашего программного комплекса, при чем данные об ошибках сравниваются с предыдущими днями, сигнализируя админу, происходит снижение или возрастание ошибок. Результат вы видели на экране с обращениями в отдел.
* С помощью доменных политик настроены специальные журналы на серверах, в которые попадают события о печати документов на локальных принтерах и сетевых принтерах, которые заведены на принт-сервер. Ежедневно эти логи копируются в мой комплекс и я могу видеть название распечатанного документа, количество листов и страниц в документе. Для чего мне это?
Ну во первых для некоторых разбирательств с пользователями, когда у человека вдруг заканчивается только что заправленный картридж, и он утверждает, что ничего такого не печатал, кроме рабочих документов, я могу поверить на слово, но можно ведь и проверить. Заправка картриджа это деньги, бумага это деньги - их всегда мало.
Когда я только внедрил эту систему и просто наблюдал за печатью, был очень неприятно удивлен, сколько печатают в личных целях. Я все понимаю, все мы можем что-то распечатать в личных целях, но не художественную литературу же, в 300-400 листов… Ругаться с каждым не хотелось и я сделал очень простую вещь, каждый понедельник всем руководителям управлений и отделов в автоматическом режиме присылается письмо с выборкой по его сотрудникам, но не по всем подряд, а так называемый топ 10, десять самых больших распечатанных документов за неделю – количество листов и название. Хотите верьте, хотите нет, но мои расходы на заправку реально сократились. Разбираться с сотрудниками уже пришлось их непосредственным руководителям.
Во вторых я получил некую оценку загруженности принтера уже не по количествам заправок, а по количеству распечатанных документов. Что позволило мне перераспределить принтера по учреждению. Где высокая нагрузка поставить аппараты мощнее, что опять же привело к экономии на заправках и ремонте.
В третьих, это оказало пользу уже не мне, а нашему завхозу, который отвечает за закупку офисной бумаги на все учреждение. С помощью этой статистики можно было увидеть расход бумаги по подразделениям и по организации в целом для планирования дальнейших закупок.
* Настроенные процедуры резервного копирования из различных комплексов также отправляют некую статистику в этот программный комплекс. Я вижу изменения размеров резервных копий, а также соотношение объемов данных по комплексам.
* Еще одна маленькая функция позволяет учитывать то, что учесть автоматизированным способом нельзя. Это поступление и выдачу каких-то материалов, например компакт дисков, флэшек, мышей, клавиатур. Сначала такой учет возник из-за требований бухгалтерии в отчете о расходовании закупаемых "расходников" (например вы купили 100 CD-R дисков и бухгалтерия просит отчет о каждом из них... такое бывает), но потом он пригодился при анализе потребности в том или ином материале при ежегодных закупках. Мы записываем в специальную форму приход таких материалов, потом их расход, кому и что отдали.
* Также на мой отдел возложена функция работы с электронными подписями пользователей, генерация, учет, отслеживание сроков действия. Для этого был сделан маленький модуль, в котором хранятся все сроки подписей и он сигнализирует, когда подходит срок окончания той или иной подписи, а поскольку их уже под сотню, то без автоматизации просто не обойтись.
Теперь немного об аналитике и отчетности. Информации в базе уже довольно много и самой разной. О том что я отправляю самые разнообразные отчеты о работе руководству, я уже говорил, но сейчас немного продемонстрирую. Типичный ежемесячный отчет. Все страницы показывать не буду, только несколько интересных:
Отчет для руководителя - общая информацияОтчет для руководителя - некоторые сводные графики о работе отделаОтчет для руководителя - графики обслуживания техники и количества печатиОтчет для руководителя - печать на локальных принтерах и резервное копированиеЭто как раз информация из отчета для руководства, специально сделано в виде графиков и картинок для наглядности.
Недавно программный комплекс расширился за счет еще одного модуля, это ведение телефонного справочника организации. Во время очередной оптимизации внутри организации (рифма здесь случайна), на отдел были переданы все контракты по обслуживанию всех видов связи: обслуживание мини АТС, сотовая связь, межгород, местная и т.д. Когда первый шок прошел, нужно было что-то с этим делать. Начал с самого простейшего: инвентаризация. Прошерстил все контракты, выявил всех поставщиков связи и все услуги, которые они предоставляют. Попытался сопоставить все предоставляемые номера телефонов с реальным положением дел. Был удивлен, сколько мы не используем.
Телефонный справочник организации и раньше был в ведении моего отдела. Разработано специальное приложение, с быстрым поиском телефона и владельца. В этот же справочник внесена структура организации в виде древовидного списка, где узлы располагаются в зависимости от подчиненности подразделений друг другу. Еще добавлены планы здания, и когда вы наводите мышью на кабинет, вам показывается кто в этом кабинете располагается и их телефоны, или фотографию этого места.
Общий вид телефонного справочникаПланы зданияКстати, в этот же справочник мы до кучи, сделали функцию бронирования актовых залов под мероприятия. Теперь любой человек может посмотреть какой зал свободен или занят, с фотографией зала, характеристиками (посадочные места, наличие оборудования и т.п.). Запись в зал могут осуществлять только секретари руководителей, во избежание хаоса в этом вопросе. Первоначально такую функцию мы сделали в SharePoint, но слишком тяжелое получилось решение для простой функции и всё запрограммировали нативно. Из этого справочника данные попадают в наше приложение по учету всего и вся. На вкладке обращений в отдел высвечиваются намеченные на сегодняшний день мероприятия и заявки на оборудование. Что нам очень облегчило жизнь.
Расписание актовых заловЕсли уж до конца рассказывать о справочнике, то здесь скрываются еще пара полезных функций. Раньше нас отвлекали звонками о том, что хорошо бы сделать то или иное объявление по зданию. Мы пользовались обычной командой net send, после чего на включенных компьютерах выдавалось сообщение. Пользователи сами такую команду выучить были не в состоянии, поэтому чтобы снять с себя эту рутину сделали такую функцию внутри справочника, поскольку он установлен у всех.
Правда когда внедрялась Windows 7, мы нежданно узнали, что такой функции больше в системе нет. Пришлось искать альтернативные варианты и остановились на маленьком бесплатном приложении "winsent messenger". В составе него есть консольное приложение, которое можно использовать для отправки сообщений, а прием осуществляется его клиентом с GUI.
И последняя функция этого "мультитула" - "Помощник". Для обмена не конфиденциальными документами между пользователями сделан отдельный ресурс. Чтобы он не превратился в помойку, каждую ночь происходит его очистка, предварительно сняв с данных копию. Так вот, если пользователь не успел забрать днем, что ему накидали, то он звонит нам и мы восстанавливаем из копии. Но почему бы не сделать механизм, который бы отслеживал появление файлов на таком ресурсе. Для этого и сделан помощник - он заглядывает в указанную ему папку через определенные интервалы времени и сообщает человеку, если там что-то появилось, при желании помощник может эти файлы забрать и положить куда настроено.
Так вот, данные о телефонном справочнике у меня уже были, для их редактирования была написана простая программка, в виде отдельного приложения. Теперь же мне нужно было быть в курсе, сколько у меня есть телефонных номеров, какие из них заняты, какие свободны, на каких есть межгород, кто к ним подключен и т.п. Пришлось автоматизировать.
Все доступные телефоны были заведены в таблицу "телефонный пул", где каждому номеру был указан провайдер (а у нас их несколько), наличие межгорода, автоматически номер сопоставлялся с телефонным справочником. Так я увидел какие номера не задействованы, на основании чего довольно сильно проредил контракты, уменьшив количество номеров и сократив стоимость контрактов.
Чтобы не держать отдельное приложение для ведения телефонного справочника, все функции были переданы в мое общее приложение.
Вот так из любительского тестового проекта выросло уже довольно большое приложение наполненное функциональностью на все случаи админской жизни. Я далеко не про все вам рассказал, там еще есть многое. Написано оно так, что не требует никаких телодвижений по сопровождению. Лезть в исходники приходится только для изменения функциональности, иногда между изменениями может пройти больше года.
Программа всё также функционирует на базе MS SQL, но уже конечно не 2000. Она благополучно переносилась между версиями, практически без проблем.
Приложение первоначально создавалось с помощью Borland Builder C++ 6 версии, сейчас это версия XE2, использовались компоненты Ehlib и FastReport.
Всё на чем это сделано - честным образом куплено, без иронии.
Я понимаю, что такие разработки завязаны на людей, которые их создают и при смене человека, все может пойти прахом. Но в отделе опыт передается и исходники содержат достаточное количество комментариев и документации.
Я понимаю, что многие скажут, что писать на таком "г.... мамонта" в наше время уже не модно, почему не C#, Java или \_\_\_\_\_\_\_ можете сами вписать что-то свое. Но эта среда разработки довольно удобна и наглядна, опять же на мой взгляд. Генератор отчетов FastReport очень функционален и прост в освоении. Я пробовал когда-то Crystal Report - не зашло.
В планах попробовать перевести это все в браузер, чтобы сделать платформо-независимое приложение.
Хотелось поделиться своим опытом систематизировать работу системных администраторов. Как ограниченными силами попытаться охватить как можно больший круг своих обязанностей и не свихнуться при этом.
Всем добра! | https://habr.com/ru/post/654597/ | null | ru | null |
# Как переиспользовать код с бандлами Symfony 5? Часть 1. Минимальный бандл
Поговорим о том, как прекратить копипастить между проектами и вынести код в переиспользуемый подключаемый бандл Symfony 5. Серия статей, обобщающих мой опыт работы с бандлами, проведет на практике от создания минимального бандла и рефакторинга демо-приложения, до тестов и релизного цикла бандла.
В первой части:
* Зачем нужны бандлы
* Example Project: Calendar
* Настраиваем окружение: 2 способа разработки
* Создаем минимальный бандл
* Подключение бандла в проект
**Содержание серии**
**Часть 1. Минимальный бандл**
[Часть 2. Выносим код и шаблоны в бандл](https://habr.com/ru/post/498536/)
[Часть 3. Интеграция бандла с хостом: шаблоны, стили, JS](https://habr.com/ru/post/498610/)
[Часть 4. Интерфейс для расширения бандла](https://habr.com/ru/post/499074/)
[Часть 5. Параметры и конфигурация](https://habr.com/ru/post/499076/)
[Часть 6. Тестирование, микроприложение внутри бандла](https://habr.com/ru/post/500044/)
[Часть 7. Релизный цикл, установка и обновление](https://habr.com/ru/post/500596/)
Что такое бандл и зачем он нужен?
---------------------------------
Symfony Bundle понадобится вам тогда (и только тогда), когда вы устанете копипастить код из проекта в проект и задумаетесь о его переиспользовании. Рано или поздно приходит понимание, что удобнее выделить код в переиспользуемый подключаемый модуль. Symfony Bundle — это и есть такой модуль в экосистеме Symfony.
> **Бандл — это пакет переиспользуемого PHP кода на стероидах Symfony Framework.**
Бандлы отличатся от обычных PHP-пакетов использованием компонентов и общепринятых соглашений, упрощающих интеграцию с Symfony-приложением. Благодаря следованию принятым в экосистеме соглашениям именования и структуры кода, бандлы могут автоматически подключаться, конфигурироваться и расширяться в приложении-хосте Symfony. Бандлы подключаются к проекту через менеджер зависимостей `composer`.
У такой тесной интеграции есть и обратная сторона, — пакет становится зависим от фреймворка. Хотя грамотная организация кода, использование DDD-подхода к разработке может помочь эту связность снизить.
**Пример KnpMenuBundle**
Взгляните на код одного из самых популярных бандлов Symfony: [KnpMenuBundle](https://github.com/KnpLabs/KnpMenuBundle).
Это бандл, упрощающий генерацию и работу с меню сайта. Но можно заметить, что в этом репозитории слишком мало файлов.
Дело в том, что вы смотрите именно на "стероидную" часть бандла, отвечающую за интеграцию с Symfony приложениями. Вся бизнес-логика (домен) вынесена разработчиками [в отдельный, независимый от фреймворка PHP-пакет](https://github.com/KnpLabs/KnpMenu), который сам подключается в бандл через Composer.
Example Project: Calendar
-------------------------
Разбираться с бандлами будем на примере рефакторинга приложения календаря.

*Дизайн заимствован у Яндекса и используется исключительно для образовательных целей.*
Представьте, что вы написали красивый календарь мероприятий. Посмотрев на этот сайт к вам пришел еще один клиент попросил такой же на свой сайт. Вы копируете код сайта в новый проект, слегка правите дизайн. Спустя какое-то время вы находите ошибку в коде, и вам приходится обновлять код на двух сайтах.
Ваш календарь имеет успех, и еще 10 клиентов заказывают себе такой же.
Один из них заказывает новую фичу: уведомления о новых мероприятиях.
Остальные клиенты тоже хотят получить эту новую фичу, и теперь вам приходится копировать файлы между проектами, вручную обновлять файлы у всех 12 клиентов.
Очень скоро уследить за изменениями в каждом проекте становиться невозможно, поддержка кода превращается в кошмар.
А теперь представьте, что вы выделили весь код вашего календаря в один, независимый от конкретного проекта, бандл. Теперь, при появлении ошибки, вам достаточно исправить код в одном месте, а в каждом из проектов для обновления достаточно выполнить `composer update`.
> **Попробуем отрефакторить приложение и вынести общую для календаря логику в бандл.**
[Склонируйте код из репозитория](https://github.com/bravik/symfony-bundles-tutorial)
В `README.md` короткая инструкция как развернуть и запустить приложение.
Приложение устроено просто:
* сущность `Event`
* 2 контроллера для отображения и редактирования мероприятий
* сервис для экспорта календаря в различные форматы
* набор шаблонов для виджета календаря и редактора
* немного стилей, собираемых через `webpack-encore`
Начнем рефакторинг.
Настраиваем окружение
---------------------
Первый вопрос, а как вообще разрабатывать бандл?
Ведь с одной стороны бандл — это отдельный проект, рука тянется к `File -> New... -> Symfony Project`. А с другой стороны он не может запускаться отдельно от приложения-хоста, в которое подключается.
Здесь есть 2 пути:
1. Если бандл разрабатывается с нуля, можно создать микроприложение Symfony для разработки прямо внутри бандла. Мы вернемся к этому варианту в любом случае, так как микроприложение понадобится для тестирования.
| Плюсы | Минусы |
| --- | --- |
| чистота подхода | сложно новичкам, ведь нужно хорошо понимать Symfony |
| - | нужно потратить время на создание микроприложения |
| - | наличие лишнего кода приложения хоста в проекте |
2. Если рефакторим существующий проект и хотим выделить его часть в бандл, то удобнее начать разработку прямо внутри этого проекта. Для этого выделяется отдельное место в проекте, например папка `./bundles`.
| Плюсы | Минусы |
| --- | --- |
| быстро и просто | привязка к приложению хосту, для доработки потребуется иметь доступ к двум репозиториям |
| вы можете постепенно выносить логику в бандл и сразу же тестировать его на готовой инфраструктуре приложения-хоста | нужно иметь в виду 2 репозитория в одном проекте (хотя PhpStorm отлично умеет разделять и справляться с этим) |
| все в одном окне IDE, так проще | требует внимательности: можно при разработки неочевидно воспользоваться зависимостями приложения хоста, что породит проблемы при подключении бандла в другой проект |
К первому пути мы вернемся в статье о тестировании бандлов, а сейчас пойдем по второму пути.
Создаем минимальный бандл
-------------------------
Внутри `./bundles` создадим основную папку будущего бандла `CalendarBundle`,
и внутри неё минимальный набор файлов:
```
src/CalendarBundle.php
composer.json
```
Всего 2 файла!
### Разбираемся с `composer.json`
Скопируйте в `composer.json` бандла:
```
{
"name": "bravik/calendar-bundle",
"version": "0.1.0",
"type": "symfony-bundle",
"description": "Symfony bundles tutorial example project",
"license": "proprietary",
"require": {
"php": "^7.3"
},
"require-dev": {
},
"config": {
"sort-packages": true
},
"autoload": {
"psr-4": {
"bravik\\CalendarBundle\\": "src/"
}
},
"autoload-dev": {
"psr-4": {
"bravik\\CalendarBundle\\Tests\\": "tests/"
}
},
"scripts": {
"test" : "./vendor/bin/simple-phpunit"
},
"extra": {
"symfony": {
"allow-contrib": false,
"require": "5.0.*"
}
}
}
```
Разберем содержимое:
```
"name": "bravik/calendar-bundle",
"description": "Health check bundle",
```
Эти обязательные поля устанавливают название пакета и описание. Для именования пакета по общепринятому соглашению используется название вендора и бандла. При установке с помощью менеджера зависимостей `composer`, код бандла будет помещен в соответствующую папку `vendor/bravik/calendar-bundle`
```
"type": "symfony-bundle"
```
Укажет Symfony, что этот пакет является бандлом. Благодаря специальному расширению для `composer`, — `Symfony Flex`, — при установке в приложение-хост, бандл автоматически будет подключен в ядро хоста (добавится в `bundles.php`), а так же запустится его "рецепт".
Рецепты — это механизм Symfony Flex, который позволяет при установке бандла выполнить специальный скрипт, задающий дополнительные действия по первичной настройке бандла.
```
"version": "0.1.0",
```
Задаст версию бандла. Менеджер зависимостей composer отслеживает и загружает обновления всех установленных в проект пакетов. С помощью [семантического версионирования](https://semver.org/lang/ru/) вы можете контролировать этот процесс. Подробней об этом позже
```
"autoload": {
"psr-4": {
"bravik\\CalendarBundle\\": "src"
}
},
"autoload-dev": {
"psr-4": {
"bravik\\CalendarBundle\\Tests\\": "tests"
}
},
```
Здесь задается пространство имен бандла для [автолоадера composer](https://getcomposer.org/doc/01-basic-usage.md#autoloading). По конвенции оно выбирается в формате `//Bundle`.
Благодаря этим строкам мы указываем механизму автозагрузки composer, что файлы с пространством имен `bravik\\CalendarBundle` нужно искать в папке `./src` относительно расположения `composer.json` бандла. При установке бандла в приложение-хост, эти настройки будут автоматически добавлены в общий автолоадер хоста, благодаря чему хост сможет использовать код бандла через `use /`.
Дополнительно укажем пространство имен для тестов для `dev`-окружения. Оно понадобиться нам позднее.
```
"require": {
"php": "^7.3"
},
"require-dev": {},
```
В секции `require` и `require-dev` определяются зависимости для prod и dev окружения. Все эти зависимости будут добавлены в дерево зависимостей приложения-хоста и загружены автоматически при установке бандла. После установки их обновления будут отслеживаться через `composer` хоста. Кроме `php` нам пока ничего здесь не требуется.
Остальные опции нам не интересны.
### Основной класс бандла
Создайте в `./src` бандла файл `CalendarBundle.php` и скопируйте туда код:
```
php
namespace bravik\CalendarBundle;
use Symfony\Component\HttpKernel\Bundle\Bundle;
class CalendarBundle extends Bundle
{
}</code
```
Это главный класс бандла. Он используется фреймворком для подключения бандла в хост и настройки его поведения.
Имя файла имеет фиксированный формат: `Bundle.php`, — оно задает имя бандла и заканчивается словом `Bundle`. Если [придерживаться этих конвенций](https://symfony.com/doc/current/bundles/best_practices.html#bundle-name), то Symfony при установке автоматически распознает и подключит ваш бандл, а так же создаст его псевдоним для внутреннего использования в ресурсах проекта (например в шаблонах).
> **Не нарушайте общепринятые соглашения без необходимости,
>
> чтобы не усложнять себе жизнь.**
Внутри файла мы используем корневое пространство имен `bravik\CalendarBundle`, как мы установили в `composer.json`. Остальное содержимое главного класса бандла может быть пустым.
Подключение бандла в приложение-хост
------------------------------------
Бандлы подключаются через `composer` с помощью привычной команды:
```
composer require bravik/calendar-bundle
```
Но если вы выполните её сейчас, `composer` не сможет найти нужный пакет: ведь его нет в официальных репозиториях.
Чтобы указать его местоположение, нужно добавить секцию `repositories` в `composer.json` хоста.
На время разработки вместо удаленного репозитория, мы подключим локальную папку `bundles/CalendarBundle`:
```
"repositories": [
{
"type" : "path",
"url" : "./bundles/CalendarBundle"
}
],
```
При таком подключении в папке `vendor` создасться не скачанная с репозитория копия нашего проекта, а симлинк `bravik/calendar-bundle`, указывающий на нашу локальную папку. Это позволит работать с бандлом как с внешней зависимостью из `vendors`, но иметь возможность редактировать файлы на локальной папки и сразу же видеть изменения.
Когда бандл достигнет релиза, мы вынесем его в отдельный git-репозиторий так:
```
"repositories": [
{
"type" : "vcs",
"url" : "[email protected]:bravik/calendarbundle.git"
}
],
```
В такой конфиграции `composer` склонирует git-репозиторий в папку `vendors/bravik/calendar-bundle`.
[Подробнее о репозиториях composer.](https://getcomposer.org/doc/05-repositories.md)
Теперь после выполнения команды `composer require bravik/calendar-bundle` в `composer.json` хоста добавиться наш бандл в качестве зависимости, и подключиться к ядру. Чтобы убедиться в последнем, откроем `config/bundles.php`:
```
php
return [
//...
bravik\CalendarBundle\CalendarBundle::class = ['all' => true],
];
```
Мы видим, что наш бандл был подключен в проект с помощью его основного класса!
Инициализация репозиториев
--------------------------
На практике создавая бандл в локальной папке приложения-хоста, я сразу добавлю папку `./bundles` в `.gitignore` приложения хоста, а внутри `bundles/CalendarBundle` инициализирую новый репозиторий: `composer init`. Зачем засорять репозиторий хоста лишним кодом, сразу можно выносить код бандла в отдельный репозиторий.
Это так же удобно если вы хотите временно подключить уже готовый бандл, чтобы "на лету" внести какие-то изменения отдебажить какой-то баг, проявляющийся на конкретном хосте.
Но для удобства этой статьи, я храню код в монорепозитории.
Резюме
------
* Минимальный Symfony бандл без полезной нагрузки состоит всего из 2х файлов: `composer.json` и класс `MyBundle`.
* Начинать разработку бандла удобно прямо в проекте-доноре в одном окне IDE в одном GIT-репозитории, подключая локальную папку бандла через composer.
* Когда бандл дойдет до стадии самостоятельного работоспособного пакета, выносите его в отдельный репозиторий.
* Чтобы окончательно оторваться от хоста, можно создать микроприложение прямо внутри бандла.
Финальный код Example Project для этой статьи можно посмотреть в ветке [1-bundle-mockup](https://github.com/bravik/symfony-bundles-tutorial/tree/1-bundle-mockup).
В [следующей статье](https://habr.com/ru/post/498536/) займемся переносом кода, шаблонов и ассетов в бандл, рассмотрим настройки роутинга и механизм подключения ресурсов бандла, а так же создадим конфигурационный файл для DI-контейнера.
Другие статьи серии:
--------------------
**Часть 1. Минимальный бандл**
[Часть 2. Выносим код и шаблоны в бандл](https://habr.com/ru/post/498536/)
[Часть 3. Интеграция бандла с хостом: шаблоны, стили, JS](https://habr.com/ru/post/498610/)
[Часть 4. Интерфейс для расширения бандла](https://habr.com/ru/post/499074/)
[Часть 5. Параметры и конфигурация](https://habr.com/ru/post/499076/)
[Часть 6. Тестирование, микроприложение внутри бандла](https://habr.com/ru/post/500044/)
[Часть 7. Релизный цикл, установка и обновление](https://habr.com/ru/post/500596/) | https://habr.com/ru/post/498134/ | null | ru | null |
# Обзор программы С++ Russia 2019 Piter: асинхронность, модули, библиотеки… и такси

Что общего у этих людей, помимо того, что все они известны в мире C++?
* Sean Parent
* Eric Niebler
* Marshall Clow
* Bryce Adelstein Lelbach
* Антон Полухин
* Андрей Давыдов
Ответ: все они приедут на C++ Russia. Теперь, когда лето кончилось и все вернулись из отпусков, пора ждать следующую большую C++-конференцию: [C++ Russia 2019 Piter](https://cppconf-piter.ru/?utm_source=habr&utm_medium=465895). На ней выступят не только люди из этого списка, но и многие другие международные докладчики. 30 докладов, 2 полных дня с 10 утра до 7 вечера, никаких вводных историй и чтения документации по слогам — сразу сплошной хардкор.
Это оказалась одна из самых быстро и качественно организованных наших конференций, половина программы стала известна уже летом: спикеры чётко знают, какие вещи хотят рассказать на C++ Russia. Сейчас программа почти стабилизировалась, и настало время приоткрыть завесу тайны.
Все доклады мы делим на «категории планирования», которые потом наполняем интересными темами. Вот они:
* Возможности новых стандартов
* Практичный C++
* Инфраструктура
* Многопоточность
* Метапрограммирование
* Функциональное программирование
Категории идут в порядке убывания количества докладов: начиная с девяти докладов про новые фишки стандартов, и заканчивая единственным на данный момент докладом про функциональщину — [«Compile-time type tagging»](https://cppconf-piter.ru/2019/spb/talks/4giham7ikcamg95qtvyrai/?utm_source=habr&utm_medium=465895) Ивана Чукича. Впрограмме всё ещё есть немного белых пятен, которые заполнятся буквально в ближайшую пару недель. Давайте посмотрим, что же получилось в результате.
Хэдлайнеры
----------
Все докладчики — известные в сообществе деятели, писать о них можно было бы бесконечно. Давайте подробно расскажем хотя бы о тех, кого мы перечислили до ката.
**Sean Parent** — один из главных исследователей и архитекторов в мобильном подразделении Adobe. У него сложилась яркая карьера в компаниях с мировым именем. В период с 1988-1993 он помогал Apple писать их знаменитые операционки для PowerPC, с 1993 года начал разрабатывать Photoshop, 2009 год провел в Google, разрабатывая ChromeOS, и снова вернулся в Adobe. Что нам может рассказать человек с такой богатой историей? Прямо сейчас можно найти на YouTube множество роликов с его участием, например — серию докладов [Better Code](https://www.youtube.com/playlist?list=PLKYyNgc4Sz-ypY7CwwV0bhQZbcw57_d04), которая говорит сама за себя. Он не в первый раз у нас на C++ Russia: на заре истории конференции, в далеком 2015 году, именно он [делал первый открывающий доклад](https://www.youtube.com/watch?v=dr9sxBNrEGc), а в 2017 году мы сделали с ним [получасовое интервью](https://www.youtube.com/watch?v=OkKOiAesnaY). Всё, что рассказывает Sean Parent отличается глубиной и проработкой, это не материал вида «посмотрел и забыл», а нечто такое, что стоит запомнить и возвращаться снова и снова.
Сейчас он прилетает к нам с новым докладом из серии BetterCode: [Relationships](https://cppconf-piter.ru/2019/spb/talks/7enb77fkgnlp3pypufciga/?utm_source=habr&utm_medium=465895), и вы точно не хотите это пропустить. Именно поэтому доклад выбран кейноутом конференции — его смогут посмотреть все участники до того, как разойдутся по отдельным залам.
Второй кейноут ведёт **Eric Niebler**. Тут бы и закончить рассказ, потому что в последнее время его имя более чем на слуху, благодаря [Standard Ranges](https://habr.com/ru/company/jugru/blog/438260/), а ставшие термином *[ниблоиды](https://habr.com/ru/company/jugru/blog/447900/)* (см. разметку на [CppReference](https://en.cppreference.com/mwiki/index.php?title=cpp/algorithm/ranges)) названы его именем. Но, вообще говоря, все это просто хайп, а сделал он для C++ очень многое.
Эрик — активный член Комитета по стандартизации C++, старший разработчик в Facebook, и именно в это время он начал заниматься ренжами. В дофейсбучные времена он был консультантом, работал как индивидуально, так и с [BoostPro Computing](https://github.com/boostpro). В бусте он не только написал несколько своих библиотек и выполнял роль релиз-менеджера, но и стал членом управляющего комитета Boost Steering Committee, который (в соответствии с названием) занимается стратегическими вопросами развития. Пунктик Эрика — написание мощного и одновременно элегантного кода, разработка красивых абстракций (что, в общем вы и можете увидеть в ranges… или не увидеть, в зависимости от предпочтений). Что не менее важно, мысли он может доносить не только кодом, но и в виде внятных доходчивых докладов.
Эрик приезжает с докладом [«A unifying abstraction for async in C++»](https://cppconf-piter.ru/2019/spb/talks/7grsmkz0chvltkfhgw0o6e/?utm_source=habr&utm_medium=465895). Коротко о проблеме: асинхронность в C++ сейчас на самом дне, её надо чинить. Стандартные инструменты вроде промисов, фьючерсов, тредов, локов, даже `std::async` — все они работают или неэффективно, или просто сломаны, или то и другое одновременно. Жуть. Даже хуже, не существует никакого стандартного способа сказать, где именно должна производится работа. А тем не менее, у нас есть куча C++-специфичных задач, которым это нужно: параллельные алгоритмы, гетерогенные вычисления, сеть и IO, реактивные стримы… все критически важные базовые технологии, годами ожидающие стандартной абстракции для отражения идеи асинхронного вычисления. В этом докладе Эрик вместе с нами будет копать исследования Комитета, в которых они определяли базисные операции, лежащие за любыми асинхронными вычислениями. Мы посмотрим, почему фьючеры и промисы так тормозят, что такое executor, что общего между коллбэками и корутинами, и как абстракция «Task» (которую сейчас активно изучают в Facebook R&D) может сделать в асинхронщине ту же революцию, которая произошла с появлением итераторов в обычном синхронном коде.
 Если Эрик — это крутой инженер и исследователь, который выступает редко да метко, то **Marshall Clow** — звезда международных конференций. Если зайти на YouTube и [вписать в поиск](https://www.youtube.com/results?search_query=Marshall+Clow) его имя, то ютуб становится его личной домашней страничкой. CppCon, C++Now, ACCU, EuroLLVM — всё, что только можно представить. И теперь вот C++ Russia. Интересно, что при всём этом он не какой-то очередной проходной евангелист, а C++-разработчик с 35-летним стажем, изначальный автор `Boost.Algorithm` (и вообще контрибьютор буста в течение 15 с лишним лет), глава рабочей группы по библиотекам в Комитете по стандартизации C++ и ведущий разработчик libc++ (стандартная библиотека для LLVM). Живая легенда и человек, который мастерски писал на C++ когда половина из читающих этот текст ещё не родилась.
Маршалл приедет с докладом ["Hardening the C++ Standard Template Library"](https://cppconf-piter.ru/2019/spb/talks/7cvpnd2hetfx6ji8pemp3l/?utm_source=habr&utm_medium=465895), суть такова: поскольку стандартная библиотека используется всеми подряд, она должна быть очень хорошо написана и не ломаться где попало. Доклад посвящен обсуждению приёмов и инструментов, благодаря которым libc++ из LLVM удовлетворяет этим требованиям: отладка, наборы тестов и покрытие, статический и динамический анализ, фаззинг. Конечно, это доклад не только для разработчиков LLVM, каждый может вынести из него свои идеи и сделать свои выводы.
 **Bryce Adelstein Lelbach** изучал C++ чуть меньше Маршалла, но ему есть, чем удивить. Он — один из глобальных лидеров сообщества C++. Его общественная деятельность заключается в том, что Брайс сейчас программный директор основных C++ конференций — CppCon и С++Now, глава C++ User Group в Сан-Франциско и Кремниевой долине. В Комитете по стандартизации он участвует в JTC1/SC22/WG21, является председателем Tooling Study Group (SG15) и Library Evolution Incubator (SG18), а в C++ 17 занимался длинным списком вещей (parallel algorithms, executors, futures, senders/receivers, multidimensional arrays, modules). Кроме всего прочего, Брайс возглавляет рабочую группу по разработке CUDA в компании NVIDIA, временами помогает LLVMLinux и коммитит в Boost.
Брайс приезжает с докладом [«The C++20 synchronization library»](https://cppconf-piter.ru/2019/spb/talks/3p8hcoy8dxsaltspayz57b/?utm_source=habr&utm_medium=465895). С тех пор, как вышел C++ 11 прошло куда больше десятка лет, мир изменился! Во времена C++ 11, многоядерные процессоры уже прочно вошли в обиход, но нормальным количеством ядер было штуки две или четыре. Всё, что больше десяти, как у древних людей, обозначалось словом «много». «Два», «четыре» и «много». Сейчас нормально иметь десятки голов и мириться с задержками синхронизации длиной в целые миллисекунды. Обычным делом стало иметь десятки и сотни тредов, а слово «много» теперь обозначает «сотни тысяч». Десять лет назад вряд ли кто-то мог чётко представить современные проблемы многопоточности. Используя традиционные инструменты сегодня, мы сталкиваемся или с неприемлемо высокой латентностью, или с неприемлемым контеншеном на синхронизации потоков. Библиотека C++ 20 предлагает новые решения — легковесные примитивы, которые могут работать с сотнями тысяч потоков.`std::atomic::wait`,`std::atomic::notify_*`,`std::atomic_ref`,`std::counting_semaphore`,`std::latch`,`std::barrier`… Этот доклад построен как последовательность примеров, на которых мы будем учиться использованию всех этих инструментов для того, чтобы построить современное приложение, которое может параллельно исполняться на почти любом железе, от эмбеддеда и серверных CPU до новых GPU.
Следующий докладчик — известный российский разработчик **Антон Полухин**. Известен докладами о сферах, [где C++ считается незаменимым](https://cppconf.ru/talks/6m9dubhdowimis6g8womwe/?utm_source=habr&utm_medium=465895) и дополнительных вещах, которые неплохо бы иметь в C++. Представитель России в ISO на международных заседаниях рабочей группы по стандартизации C++, автор нескольких принятых предложений к стандарту языка C++. В ходе подготовки предыдущей конференции, мы [опубликовали интервью с ним на Хабре](https://habr.com/ru/company/jugru/blog/441800/). Вообще, тема участия россиян в Комитете уже довольно широко обсуждалась и на Хабре, и везде (глядите, Яндекс даже в VK [написал про это пост](https://vk.com/@yandex4developers-kto-i-kak-razvivaet-c%D1%85)), и давайте сейчас не вскрывать эту тему. Можно сходить [stdcpp.ru](https://stdcpp.ru/) и увидеть список представителей, сейчас это: Антон Полухин, Антон Бикинеев и Александр Фокин. Антон также является автором нескольких библиотек Boost: TypeIndex, DLL, Stacktrace, активно занимается поддержкой Any, Conversion, LexicalCast, Variant. Он написал книги «Boost C++ Application Development Cookbook» и «Boost C++ Application Development Cookbook, Second Edition».
В этот раз Антон приезжает с докладом [«C++ трюки из Такси»](https://cppconf-piter.ru/2019/spb/talks/2hevsikfsytinb2lrwm7cx/?utm_source=habr&utm_medium=465895) (доклад так называется, очевидно, потому что Антон работает в Яндекс.Такси). Суть трюков в том, как красиво и более эффективно писать казалось бы всем известные решения — например, из Pimpl можно выбросить динамическую аллокацию и прикрутить кэш.
Давайте разбавим наш список кем-то, кто не работает в Комитете. Поприветствуйте **Андрея Давыдова** из JetBrains — он уже три года работает в команде ReSharper C++, и многие из нас каждый день пользуются результатами его работы. В докладе Андрей собирается рассказать о том, как появление модулей повлияет на ядро языка C++: если раньше компилятор работал с единицами трансляции по одной, то с появлением модулей правила игры поменялись. Будут обсуждаться следующиетемы:
* что такое reachable entity и чем это отличается от visible;
* как модули влияют на ADL;
* могут ли entities с internal linkage протечь в другой модуль;
* может ли импортировать класс одновременно как complete, и как incomplete;
* что будет с inline-функциями в модульном мире.
Заметьте, что это не вводный доклад в модули для начинающих. От слушателей ожидается общее знакомство с принципами работы модулей и понимание, зачем модули вообще нужны. Хорошая новость в том, что, во-первых, разобраться в этом довольно просто (достаточно нагуглить какую-нибудь хорошую статью), а во-вторых, на этой C++ Russia будет ещё один парный вводный [доклад про модули от Дмитрия Кожевникова](https://cppconf-piter.ru/2019/spb/talks/5xref5n4pttjxxftndxcjy/?utm_source=habr&utm_medium=465895) (он тоже работает в JetBrains).
Вся остальная программа
-----------------------
Совершенно очевидно, что как следует рассказать о 30 людях и их 30 докладах в коротком посте-анонсе на Хабре невозможно. Поэтому более подробно всё это описано на [официальном сайте конференции](https://cppconf-piter.ru/schedule/?utm_source=habr&utm_medium=465895). Важно отметить, что программа продолжает изменяться: например, поскольку докладчики с помощью Программного комитета продолжают совершенствовать свои доклады, их описания тоже обновляются. Так что ближе к 31 октября всё будет выглядеть немного по-другому, но общий смысл останется тот же.
Доклады — это ещё не всё!
-------------------------
Конечно, конференция — это не только доклады, но и море общения. Этим живое присутствие отличается от онлайн-трансляции, которую мы тоже планируем сделать. Поглядите на список выше — с большей частью этих людей хотелось бы встретиться и обсудить что-то важное. Такая возможность у нас есть: после окончания доклада все направляются в дискуссионную зону и общаются там столько, на сколько хватит времени. В конце дня организуются так называемые BOF-сессии (что-то вроде круглого стола, но только участвуют все).
Можно просто встретиться с интересными людьми из сообщества, которые тоже пришли, но без доклада. Можно найти интересующие компании, что-нибудь узнать у их представителей и поучаствовать в конкурсах. Будут разные побочные активности, которые мы сейчас продумываем. Словом, всё что можно представить о большой конференции.
Мастер-классы
-------------
Помимо основной программы конференции, будут ещё и мастер-классы (участие в них оформляется и оплачивается отдельно). Они будут проводиться за день до конференции и, в отличие от докладов, будут занимать не менее нескольких часов каждый. С подробными описаниями и условиями участия в мастер-классах можно ознакомиться [на официальном сайте](https://cppconf-piter.ru/2019/trainings/).
### Антон Полухин — «Шустрый и современный C++»
Антон — известный российский разработчик, о котором мы говорили чуть выше в этой статье. Его опыт как автора библиотек Boost, участника и Комитета по стандартизации, а также большая практика, позволяют писать ему грамотный шустрый код на C++ и обучать этому других.
В любой большой кодовой базе можно встретить куски абсолютно непонятного кода. Как правило, такой код пишется, чтобы немного выиграть в производительности приложения… и, как правило, такой код не нужен в принципе, так как оптимизирует не то, что нужно, не в том месте, где это нужно, и не так, как надо.
Мастер-класс начнётся с небольшого примера, где встретятся все частые ошибки преждевременной оптимизации. После чего пойдёт с основ и рассмотрит такие вещи, как алгоритмы и контейнеры стандартной библиотеки (и не только стандартной), move-семантику и её неожиданное поведение, многопоточность. Это совершенно практический мастер-класс с использованием Google Benchmark и заданиями, которые выглядят как задачи на оптимизацию конкретного кода.
### Rainer Grimm — «Embedded Programming with Modern C++»
Rainer Grimm — опытный тренер по программированию на С++, Python и разработчик софта из Германии. Embedded — один из основных областей применения современного C++. C++ позволяет напрямую общаться с железом и предоставляет абстракции для построения сложных систем. В современном C++ появилось множество вещей, помогающих в embedded. Это такие штуки, как move-семантика и constexpr-функции (для повышения производительности), user-defined literals и type-traits (для систем, для которых критична максимальная безопасность), smart pointers и `std::array` (чтобы меньше возиться с ресурсами).
Этот мастер-класс учит, как более грамотно пользоваться возможностями C++ применительно к embedded. В частности, дает ответы на широкий спектр вопросов про уникальные ограничения таких систем. Этот мастер-класс ведется на английском языке.
### Павел Филонов — «Continuous Integration для C++-разработчика»
Павел Филонов считает, что процесс разработки не должен заканчиваться после коммита, поэтому представит мастер-класс по Continuous Integration. Цель мастер-класса — сделать следующий шаг навстречу непрерывной интеграции (CI, англ. Continuous Integration) и автоматизировать разрешение зависимостей, сборку и модульное тестирование под все целевые платформы. В итоге участники полностью самостоятельно смогут развернуть всю необходимую для CI инфраструктуру и подготовить проект на C++ для автоматической сборки и модульного тестирования.
Что дальше?
-----------
А дальше нужно приходить на C++ Russia 2019 Piter! Конференция пройдёт 31 октября — 1 ноября в Санкт-Петербурге. Билеты можно приобрести [на официальном сайте](https://cppconf-piter.ru/registration/?utm_source=habr&utm_medium=465895). Там же можно подробно ознакомиться с [актуальной версией программы](https://cppconf-piter.ru/schedule/?utm_source=habr&utm_medium=465895#schedule)(напоминаю, что она продолжает изменяться).
Важное замечание про цены и скидки. Система покупки билетов умеет выдавать билеты четырех типов: Academic, Personal, Standard и Online. Почему это важно: если вы покупаете билеты себе сами, то это будет стоить сильно дешевле, чем билет для компании. А если вы студент, аспирант или преподаватель (и имеется соответствующий документ для подтверждения), то скидка получается особенно внушительной. Подробные условия, конечно, [нужно читать на сайте](https://cppconf-piter.ru/schedule/?utm_source=habr&utm_medium=465895) — всё выше написанное было только для ознакомления.
В ожидании C++ Russia 2019 Piter можно посмотреть записи с двух предыдущих конференций, которые прошли этой весной [в Москве](https://www.youtube.com/watch?v=QOJ2hsop6hM&list=PLZN9ZGiWZoZo3hYXXOn6NZAi3YzUETzy2) и [в Новосибирске](https://www.youtube.com/watch?v=BEmwnPGfcTU&list=PLZN9ZGiWZoZof_AvWub4hAk6Yg4U5rTpT).Вообще все записи за прошлые годы аккуратно лежат на нашем [YouTube-канале](https://www.youtube.com/channel/UCJ9v015sPgEi0jJXe_zanjA/featured). Таким образом вы можете наглядно оценить качество докладов.
Встретимся на C++ Russia 2019 Piter! | https://habr.com/ru/post/465895/ | null | ru | null |
# Ошибочно предсказанное ветвление может в разы увеличить время выполнения программы
Современные процессоры суперскалярны, то есть способны выполнять несколько инструкций одновременно. Например, некоторые процессоры могут обрабатывать за цикл от четырёх до шести инструкций. Более того, многие такие процессоры способны инициировать команды не по порядку: они могут начать работать с командами, расположенными в коде намного позже.
В то же время, код часто содержит ветвления (операторы `if–then`). Такие ветвления часто реализуются как «переходы», при которых процессор или переходит к выполнению инструкции ниже по коду, или продолжает текущий путь.
При суперскалярном выполнении команд вне порядка с ветвлениями справляться сложно. Для этого у процессоров имеются изощрённые блоки предсказания ветвления. То есть процессор пытается предсказать будущее. Когда он видит ветвление, а значит, переход, то пытается догадаться, каким путём пойдёт программа.
Очень часто это работает достаточно хорошо. Например, большинство циклов реализовано как ветвления. В конце каждой итерации цикла процессор должен предсказывать, будет ли выполняться следующая итерация. Часто для процессора безопаснее предсказать, что цикл будет продолжаться (вечно). В таком случае процессор ошибочно предскажет только одно ветвление на цикл.
Существуют и другие распространённые примеры. Если вы выполняете доступ к содержимому массива, то многие языки программирования перед совершением доступа к значению массива добавляют «контроль границ» (bound checking) — скрытую проверку правильности индекса. Если индекс неверен, то генерируется ошибка, в противном случае код продолжает выполняться обычным образом. Проверки границ предсказуемы, потому что в обычной ситуации все операции доступа должны быть правильными. Следовательно, большинство процессоров должно почти идеально предсказывать результат.
Что происходит, если ветвление сложно предсказать?
--------------------------------------------------
Внутри процессора все инструкции, которые были выполнены, но находятся на неверно предсказанном ветвлении, должны быть отменены, и вычисления необходимо начинать заново. Следует ожидать, что за каждую ошибку предсказания ветвления мы расплачиваемся более чем 10 циклами. Из-за этого время выполнения программы может возрасти в разы.
Давайте рассмотрим простой код, в котором мы записываем случайные целые числа в выходной массив:
```
while (howmany != 0) {
out[index] = random();
index += 1;
howmany--;
}
```
Мы можем генерировать подходящее случайное число в среднем за 3 цикла. То есть общая задержка генератора случайных чисел может быть равна 10 циклам. Но наш процессор является суперскалярным, то есть мы можем выполнять одновременно несколько вычислений случайных чисел. Следовательно, мы сможем генерировать новое случайное число примерно каждые 3 цикла.
Давайте немного изменим функцию, чтобы в массив записывались только нечётные числа:
```
while (howmany != 0) {
val = random();
if( val is an odd integer ) {
out[index] = val;
index += 1;
}
howmany--;
}
```
Можно наивно подумать, что эта новая функция может быть быстрее. И в самом деле, ведь нам нужно в среднем записывать только одно из двух целых чисел. В коде есть ветвление, но для проверки чётности целого числа достаточно проверить один бит.
Я провёл бенчмарк этих двух функций на C++ на процессоре Skylake:
| | |
| --- | --- |
| Запись всех случайных чисел | 3,3 цикла на integer |
| Запись только нечётных случайных чисел | 15 циклов на integer |
Вторая функция работает примерно в пять раз дольше!
Можно ли тут что-нибудь исправить? Да, мы можем просто устранить ветвление. Нечётное целое число можно характерировать таким образом, что это побитовое логическое И со значением 1, равным единице. Хитрость в том, чтобы выполнять инкремент индекса массива на единицу, только если случайное значение нечётно.
```
while (howmany != 0) {
val = random();
out[index] = val;
index += (val bitand 1);
howmany--;
}
```
В этой новой версии мы всегда записываем случайное значение в выходной массив, даже если это не требуется. На первый взгляд, это пустая трата ресурсов. Однако она избавляет нас от ошибочно предсказанных ветвлений. На практике производительность оказывается почти такой же, как у первоначального кода, и намного лучше, чем у версии с ветвлениями:
| | |
| --- | --- |
| Запись всех случайных чисел | 3,3 цикла на integer |
| запись только нечётных случайных чисел | 15 циклов на integer |
| **с устранённым ветвлением** | **3,8 цикла на integer** |
Мог ли компилятор решить эту проблему самостоятельно? В общем случае ответ отрицательный. Иногда у компиляторов есть опции полного исключения ветвлений, даже если в исходном коде есть оператор `if-then`. Например, ветвления иногда можно заменить «условными перемещениями» (conditional move) или другими арифметическими трюками. Однако такие трюки небезопасны для использования в компиляторах.
Важный вывод: ошибочно предсказанное ветвление — это не малозначительная проблема, оно имеет большое влияние.
[Мой исходный код на Github](https://github.com/lemire/Code-used-on-Daniel-Lemire-s-blog/tree/master/2019/10/14).
Создание бенчмарков — сложная задача: процессоры учатся предсказывать ветвления
-------------------------------------------------------------------------------
[Прим. пер.: эта часть была у автора [отдельной статьёй](https://lemire.me/blog/2019/10/16/benchmarking-is-hard-processors-learn-to-predict-branches/), но я объединил её с предыдущей, потому что они имеют общую тему.]
В предыдущей части я показал, что большая часть времени выполнения программы может быть вызвана неверным предсказанием ветвлений. Мой бенчмарк заключался в записи 64 миллионов случайных целочисленных значений в массив. Когда я попробовал записывать только нечётные случайные числа, производительность из-за ошибочных предсказаний сильно снизилась.
Почему я использовал 64 миллиона целых чисел, а не, допустим, 2000? Если выполнить всего один тест, то это не будет иметь значения. Однако что будет, если мы выполним множество попыток? Количество ошибочно предсказанных ветвлений быстро снизится до нуля. Показатели процессора Intel Skylake говорят сами за себя:
| Количество тестов | Неверно предсказанные ветвления (Intel Skylake) |
| --- | --- |
| 1 | 48% |
| 2 | 38% |
| 3 | 28% |
| 4 | 22% |
| 5 | 14% |
Как видно из показанных ниже графиков, «обучение» продолжается и дальше. Постепенно доля ошибочно предсказанных ветвлений падает примерно до 2%.

То есть если продолжить измерения времени, занимаемого одной и той же задачей, то оно становится всё меньше и меньше, потому что процессор учится лучше предсказывать результат. Качество «обучения» зависит от конкретной модели процессора, но стоит ожидать, что более новые процессоры должны учиться лучше.
Новейшие серверные процессоры AMD учатся почти идеально предсказывать ветвление (в пределах 0,1%) менее, чем за 10 попыток.
| Количество тестов | Неверно предсказанные ветвления (AMD Rome) |
| --- | --- |
| 1 | 52% |
| 2 | 18% |
| 3 | 6% |
| 4 | 2% |
| 5 | 1% |
| 6 | 0,3% |
| 7 | 0,15% |
| 8 | 0,15% |
| 9 | 0,1% |
Это идеальное предсказание на AMD Rome исчезает, если увеличить в задаче число значений с 2000 до 10 000: наилучшее предсказание меняется с доли ошибок в 0,1% до 33%.
Вероятно, стоит избегать бенчмаркинга кода с ветвлением на малых задачах.
[Мой код на Github](https://github.com/lemire/Code-used-on-Daniel-Lemire-s-blog/tree/master/2019/10/15).
**Благодарность**: значения по AMD Rome предоставлены Велу Эрваном.
**Дополнительное чтение**: [A case for (partially) TAgged GEometric history length branch prediction](https://www.irisa.fr/caps/people/seznec/JILP-COTTAGE.pdf) (Seznec et al.) | https://habr.com/ru/post/472214/ | null | ru | null |
# Один день из жизни разработчика PVS-Studio, или как я отлаживал диагностику, оказавшуюся внимательнее трёх программистов
Главное предназначение статических анализаторов – найти те ошибки, которые остались незамеченными разработчиком. И недавно команда PVS-Studio снова столкнулась с интересным примером мощи этой методики.
Работа с инструментами статического анализа кода требует внимательности. Часто код, на который указал анализатор, кажется корректным. В таких случаях хочется посчитать предупреждение ложным срабатыванием. На днях мы сами попали в такую ловушку. Вот как это получилось.
Недавно мы [доработали ядро анализатора](https://pvs-studio.com/ru/blog/posts/cpp/0824/), и коллега, который просматривал новые срабатывания, обнаружил среди них ложное. Он выписал срабатывание для тимлида, тот бегло просмотрел код и создал задачу. Задачу взял я. Таким нехитрым образом и образовалась цепочка из трёх программистов.
Предупреждение анализатора: [V645](https://pvs-studio.com/ru/w/v645/) The 'strncat' function call could lead to the 'а.consoleText' buffer overflow. The bounds should not contain the size of the buffer, but a number of characters it can hold.
Фрагмент кода:
```
struct A
{
char consoleText[512];
};
void foo(A a)
{
char inputBuffer[1024];
....
strncat(a.consoleText, inputBuffer, sizeof(a.consoleText) –
strlen(a.consoleText) - 5);
....
}
```
Перед изучением примера давайте вспомним, что делает функция *strncat*:
```
char *strncat(
char *strDest,
const char *strSource,
size_t count
);
```
где:
* 'destination' — строка-получатель;
* 'source' — строка-источник;
* 'count' — максимальное число символов, которое можно добавить.
На первый взгляд, кажется, что с кодом всё отлично. В нём вычисляется количество пустого места в буфере. При этом там даже запас в 4 байта вроде как есть... И именно из-за этого ощущения, что с кодом всё хорошо, он и был выписан как пример, где анализатор выдаёт ложное предупреждение.
Давайте разберёмся, как обстоят дела на самом деле. В выражении:
```
sizeof(a.consoleText) – strlen(a.consoleText) – 5
```
максимальное значение может быть достигнуто при минимальном значении второго операнда:
```
strlen(a.consoleText) = 0
```
Тогда результатом будет 507, и никакого переполнения не случится. О чём же тогда говорит PVS-Studio? Давайте немного углубимся во внутренние механизмы анализатора и попробуем разобраться.
В статическом анализаторе за подсчёт таких выражений отвечает механизм анализа потока данных (data-flow). В большинстве случаев, когда выражение состоит из констант времени компиляции, data-flow вернёт строгое значение выражения. В остальных случаях, как и в случае с предупреждением, он сформирует только диапазон возможных значений выражения.
В данном случае значение операнда *strlen(a.consoleText)* неизвестно нам на этапе компиляции. Давайте посмотрим диапазон.
Спустя несколько минут отладки мы получаем от data-flow аж 2 диапазона:
```
[0, 507] U [0xFFFFFFFFFFFFFFFC, 0xFFFFFFFFFFFFFFFF]
```
На первый взгляд, кажется, что второй диапазон лишний. Однако это не так. Просто мы забыли о том, что результатом выражения может стать отрицательное число. Например, такое может случиться при *strlen(a.consoleText) = 508*. В таком случае произойдет переполнение беззнакового числа, и результатом выражения будет максимальное значение результирующего типа, в данном случае — *size\_t*.
Получается, что анализатор прав! В данном выражении к полю *consoleText* может добавиться гораздо большее количество символов, чем его размер, что приведёт к [переполнению буфера](https://pvs-studio.com/ru/blog/terms/0067/) и, как следствие, [неопределённому поведению](https://pvs-studio.com/ru/blog/terms/0066/). Причина неожиданного предупреждения – то, что ложного срабатывания тут нет!
Вот так мы снова получили подтверждение, что ключевое преимущество статического анализа над человеком – его внимательность. Вдумчивое изучение предупреждений анализатора помогает разработчику сэкономить время при отладке и нервы, уберегает от ошибок и скоропалительных выводов.
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Vladislav Stolyarov. [One Day in the Life of PVS-Studio Developer, or How I Debugged Diagnostic That Surpassed Three Programmers](https://habr.com/en/company/pvs-studio/blog/566230/). | https://habr.com/ru/post/566238/ | null | ru | null |
# IP KVM своими руками
Эта статья написана под впечатлением от [другой](https://habrahabr.ru/post/233361/) — большое спасибо автору! В этой статье почти удалось сделать собственный IP KVM Switch, и это круто! Но объясню, почему почти. Да, там все работает как и написал автор… До момента перезагрузки в биос — там вся магия рассеивается и сколько не старайся, ничего не происходит.
Решено было исправить это досадное недоразумение и как можно дешевле и компактней. Начнем со стереотипов Raspberry Pi и Arduino, а в следующей [статье](https://habrahabr.ru/post/326112/) будет продолжение уже на другом железе.
Итак, что нам понадобится:
**1.** Плата видеозахвата обязательно с поддержкой UVC драйвера, вроде этой.Вариантов
полно на алиекспрессе и других китайских магазинах.

UVC это стандартизированный открытый драйвер который по умолчанию входит в большинство линукс дистрибутивов, с другими драйверами могут быть проблемы.
**2.** VGA to AV Конвертер:


Обратите внимание! Нужен именно VGA to AV, а не наоборот.
**3.** Arduino UNO, именно UNO, так как на ней есть чип Atmega16u2, он нас интересует в первую очередь. Вот он рядом с USB портом, так же бывают ардуины с чипом Atmega8u2 подойдут и с тем и с тем.

**4.** Ну и конечно Raspberry Pi, у меня был версии 2 b поэтому все написанное в этой статье актуально именно для него, но в целом думаю не должно возникнуть особых сложностей и с другими моделями малины.
#### Заливаем дистрибутив
Что ж вводные данные даны, пожалуй приступим.Я использовал дистрибутив 2015-05-05-raspbian-wheezy, вероятно это не принципиально, дальнейшие манипуляции должны подойти для любого дистрибутива основанного на Debian.
Подключаем плату видеозахвата к распберри, подключать лучше напрямую к USB не используя USB удлинителей особенно того что идет в комплекте с платой, иначе может возникнуть торможение видео, подвисания распберри и т.д.
Переходим в консоль, обновляем пакеты:
```
sudo apt-get update && sudo apt-get upgrade –y
```
Передача видео
==============
Проверяем определилась ли плата:
```
ls /dev/video*
```
Должно выдать что-то вроде: /dev/video0.
Устанавливаем Motion, трансляцию захваченного изображения будем вести именно через него:
```
sudo apt-get install motion -y
```
Редактируем конфиг автозапуска:
```
sudo nano /etc/default/motion
```
В строке `start_motion_daemon` ставим ‘yes’. Сохраняем изменения Ctrl + x, y, Enter.
Редактируем конфиг самого motion(а):
```
sudo nano /etc/motion/motion.conf
```
Меняем значения параметров как указано далее:
Параметр определяет запуск приложения в качестве службы:
```
daemon on
```
Эти параметры определяют разрешение передаваемого изображения, смысла ставить большее разрешение нет, т.к. захват видео ограничен стандартами PAL или SECAM, разрешение коих 720х576. Это кстати досадный недостаток, но об этом позднее.
```
width 800
height 600
```
Частота захвата кадров:
```
framerate 25
```
Отключаем сохранение скриншотов:
```
output_normal off
```
Качество передачи изображения:
```
webcam_quality 100
```
Частота передачи кадров:
```
webcam_maxrate 25
```
Отмена ограничения на подключение с других ip
```
webcam_localhost off
```
Сохраняем изменения Ctrl + x, y, Enter.
Перезагружаем распберри:
```
sudo reboot
```
Ждем пару минут если все сделали правильно должен загореться светодиод на плате видео захвата.
Подключаемся браузером к порту 8081 распберри и видим серый или синий прямоугольник с бегущим снизу временем.
Процесс пошел, ищем жертву для захвата сигнала с VGA порта, подключаем к порту “VGA IN” конвертера, а плату видеозахвата к “VIDEO OUT”. Должна получиться примерно такая картинка, не пугайтесь у меня плохой кабель поэтому изображение «двоит», пробовал с другим изображение было лучше, но разрешение не изменить. 720х576 это ограничение конвертера и платы видео захвата, которое при всем желании не преодолеть.

Что ж передавать изображение научились, осталось дело за малым — передать управление.
Передача управления
===================
Для этого, как вы уже догадались, будем использовать ардуину. Выбор пал на Arduino UNO неспроста, там есть очень нужная для наших целей микросхема с названием Atmega16u2, только благодаря ей мне удалось заставить БИОС компьютера определить arduino как USB клавиатуру. По умолчанию в составе платы ардуино эта микросхема выполняет роль USB to Serial конвертера для заливки прошивки в микроконтроллер Atmega328p, большая прямоугольная микросхема на плате ардуино. По сути же Atmega16u2 является то же микроконтроллером, но с важным отличием, она способна напрямую работать с шиной USB. Atmega16u2, при наличии нужной прошивки, может эмулировать практически любое USB устройство. Понимаете к чему я веду? Мы прошьем это чудо инженерной мысли и заставим трудиться на благо общества.
### Прошивка Atmega16u2
На просторах интернета была найдена [прошивка](https://github.com/coopermaa/USBKeyboard/tree/master/firmware), которая превращает Atmega16u2 в USB клавиатуру принимающую команды, определенного вида, через Serial Port.
Инструкция в данной статье написана для windows, линуксоиды же могут воспользоваться [этой](https://www.arduino.cc/en/Hacking/DFUProgramming8U2).
И так приступим, для прошивки потребуется утилита от производителя под названием [Flip](http://www.atmel.com/tools/FLIP.aspx). Качаем, устанавливаем, запускаем и вот перед нами окно программы:
Сначала кнопки(галки) не активны, это нормально, подключаем ардуину к компьютеру и замыкаем – размыкаем два крайних контакта со стороны USB порта, RESET и GND.

В системе должно появиться новое устройство под названием, как ни странно, ATmega16u2 устанавливаем драйвер(в папке с программой), выбираем в программе flip вкладку «Settings» → «Communication» → «USB» → «open», кнопки должны стать активны. На всякий случай можно сделать бэкап прошивки, чтоб можно было все вернуть на место. В меню «File» нажимаем «Load HEX File», программа требовательна к путям, лучше всего положить файл прошивки в корень диска C:, выбираем нужный hex файл с прошивкой, проверяем стоят ли галки «Erase», «Program», «Verify» и нажимаем «Run». Отключаем — подключаем arduino и вуаля… Теперь мы больше не сможем загружать прошивки в ардуино через встроенный USB, зато получили отличную клавиатуру без кнопок.
Не переживайте по поводу прошивки arduino, прошивку можно будет загрузить из Arduino IDE через отдельный USB To TTL адаптер, хотя надо сказать, теперь это будет менее удобно.
Подключаем USB To TTL адаптер, например такой:

Нам понадобятся Белый, зеленый и черный контакты это RX, TX и GND соответственно, подключаем их к пинам с такими же обозначениями на ардуине, только наоборот RX к TX, а TX к RX. Красный контакт использовать не следует!
Подключаем USB To TTL к компьютеру, устанавливаем драйвера, в диспетчере устройств должен появиться новый COM Port. Открываем arduino IDE и выставляем: Плата — Arduino/Genuino Uno, Порт – наш новоиспеченный последовательный порт.
### Приступаем к прошивке arduino
Добавим необходимую библиотеку в arduino IDE: Переходим по ссылке [github.com/SFE-Chris/UNO-HIDKeyboard-Library](https://github.com/SFE-Chris/UNO-HIDKeyboard-Library) нажимаем «Clone or download» → «Download ZIP». далее в arduino IDE выбираем вкладку «Скетч» → «Подключить библиотеку» → «Добавить .ZIP библиотеку» и выбираем только что скачанный zip архив.
Подготовка закончена, переходим непосредственно к прошивке. Копируем мою писанину:
**Arduino - Sketch**
```
#include
HIDKeyboard keyboard;
int sbor;
void setup() {
keyboard.begin();
}
void loop() {
while (Serial.available()) {//запуск цикла при появлении данных
sbor += Serial.read();//считывание данных, сложение в десятичном виде
if (sbor == 27){//появление символа управляющей последовательности
for (int i=0; i<=4; i++ ){//сложение последовательности
if (sbor == 165) {//для определения F1-F12 на разных терминалах могут быть разные значения
sbor += sbor;
}
sbor += Serial.read();
delay(1);
}
}
}
if (sbor > 0) {
//переход по десятичной сумме последовательности
switch (sbor){
case 505: keyboard.pressSpecialKey(F1); break;
case 506: keyboard.pressSpecialKey(F2); break;
case 507: keyboard.pressSpecialKey(F3); break;
case 508: keyboard.pressSpecialKey(F4); break;
case 509: keyboard.pressSpecialKey(F5); break;
case 511: keyboard.pressSpecialKey(F6); break;
case 512: keyboard.pressSpecialKey(F7); break;
case 513: keyboard.pressSpecialKey(F8); break;
case 340: keyboard.pressSpecialKey(F9); break;
case 341: keyboard.pressSpecialKey(F10); break;
case 343: keyboard.pressSpecialKey(F11); break;
case 344: keyboard.pressSpecialKey(F12); break;
case 13: keyboard.pressSpecialKey(ENTER); break;
case 22: keyboard.pressSpecialKey(ESCAPE); break;
case 127: keyboard.pressSpecialKey(BACKSPACE); break;
case 9: keyboard.pressSpecialKey(TAB); break;
case 32: keyboard.pressSpecialKey(SPACEBAR); break;
case 26: keyboard.pressSpecialKey(PAUSE); break;
case 292: keyboard.pressSpecialKey(INSERT); break;
case 456: keyboard.pressSpecialKey(HOME); break;
case 295: keyboard.pressSpecialKey(PAGEUP); break;
case 294: keyboard.pressSpecialKey(END); break;
case 296: keyboard.pressSpecialKey(PAGEDOWN); break;
case 182: keyboard.pressSpecialKey(RIGHTARROW); break;
case 183: keyboard.pressSpecialKey(LEFTARROW); break;
case 181: keyboard.pressSpecialKey(DOWNARROW); break;
case 180: keyboard.pressSpecialKey(UPARROW); break;
case 293: keyboard.pressSpecialKey(DELETE); break;
case 320: keyboard.pressSpecialKey((CTRL | ALT), DELETE); break; //для вызова ctl+alt+del нажать alt + del
case 346: keyboard.pressSpecialKey(ALT, F4); break; //для вызова alt+f4 нажать shift + F4
default: keyboard.pressKey(sbor); break;
}
//Serial.println(sbor);//только для отладки без подключения к usb
keyboard.releaseKey();
sbor = NULL;
}
}
```
вставляем в arduino IDE и нажимаем кнопку проверки. Вот сейчас начнется самый ответственный этап, тут самое главное поймать момент, мало у кого получается с первого раза. Нажимаем кнопку загрузки в arduino IDE, сначала побегут белые строчки с логом компиляции, за ними последуют оранжевые, это уже установка соединения с последовательным портом, вот этот самый момент надо поймать и успеть нажать на плате ардуины кнопку RESET. Должна произойти загрузка прошивки, если все удачно вы увидите надпись вроде этой
```
avrdude: reading on-chip flash data:
Reading | ################################################## | 100% 0.34s
avrdude: verifying ...
avrdude: 2934 bytes of flash verified
avrdude done. Thank you.
```
Если после нескольких попыток загрузка прошивки так и не произошла, попробуйте поменять местами контакты RX и TX, а также проверьте надежно ли подключен контакт GND.
### Финишная прямая
Открываем консоль на распберри и пишем:
```
sudo raspi-config
```
Откроется меню настройки распберри, выбираем «Advanced Options» → «Serial» и выбираем «No».
Возможно эти манипуляции и не понадобятся, так, перестраховка. Этот параметр определяет, будет ли ОС на малине взаимодействовать с serial портом, это взаимодействие нужно в основном для отладки, так что смело отключаем, нам оно будет только мешать, т.к. с ардуиной мы будем общаться именно через этот порт, а система будет засорять эфир.
Устанавливаем программу minicom.
Minicom — простенькая программа для работы с serial портом.
```
sudo apt-get install minicom -y
```
Задаем права на доступ к устройству, /dev/ttyAMA0 — это тот самый сериал порт.
```
sudo chown pi /dev/ttyAMA0
sudo chmod 744 /dev/ttyAMA0
```
Запускаем minicom:
```
sudo minicom -s
```
Откроется меню программы, выбираем пункт «Serial port setup», откроется еще одно меню, выбираем «Serial Device» нажатием на клавишу A, прописываем /dev/ttyAMA0, нажимаем Enter, далее выбираем пункт Bps/Par/Bits под буквой E, появляется очередное меню нажимаем C и Q строчка Current: должна выглядеть вот так «9600 8N1» нажимаем Enter. Убедимся что в строчках F — Hardware Flow Control: и G — Software Flow Control: стоит No, в общем все должно быть как на скриншоте ниже, нажимаем Enter.

Сохраним эти настройки как настройки по умолчанию «Save setup as dfl» и закрываем «Exit from Minicom».
### Подключение
Едем дальше, теперь у нас практически все готово, осталось только подключить ардуину к serial порту малины, вот как-то так:

Здесь есть один момент, у ардуино и распберри разные уровни напряжения и по идее их нужно согласовать, советую ознакомиться со [статьей](http://we.easyelectronics.ru/Shematech/soglasovanie-logicheskih-urovney-5v-i-33v-ustroystv.html).
Хотя у меня все заработало напрямую без согласования, не следует подражать плохому примеру и приобрести преобразователь логических уровней, самый простой выглядит так:

Или хотя бы собрать делитель напряжения на резисторах.
Запуск
======
Все готово, можно начинать.
Проверяем все соединения, вкючаем raspberry pi, переходим в консоль малины, запускаем minicom. Сразу оговорюсь я подключался к малине через ssh, в качестве клиента использовал KiTTY(модифицированную версию PuTTY), это важно т.к. с другими терминалами значения передаваемых клавиш могут быть иными и соответственно нужно будет сделать поправку на ветер — поменять номер перехода switch case.
В общем передаю вам в руки как говорится «as is». Что ж на этом пожалуй закончу, самодельный IP KVM готов.
### P. S.
На последок опишу что получилось в сухом остатке.
#### Плюсы:
**— Цена**
— Устройство получилось относительно недорогим
— Raspberry Pi: примерно 2700руб.
— Arduino UNO: примерно 400руб.
— VGA to AV конвертер: примерно 700руб.
— Плата видеозахвата: 500руб.
— Итого: 4300руб.
**— Тонкая настройка**
Можно перехватывать практически любые комбинации и назначать на них практически любые клавиши вплоть до KEYBOARDPOWER и VOLUMEUP, кстати возможные значения можно посмотреть в заголовочном файле HIDKeyboard.h, а можно и добавить свои.
#### Минусы:
— Торможение как видео, так и передачи нажатий
— Второй и самый большой это **качество изображения**, здесь просто необходим грустный смайлик, оно ужасно, даже если убавить разрешение на целевом компьютере до минимума, максимум что можно будет сделать, это настроить БИОС и выбрать пункт в загрузчике. Но разве собственно не для этого нужен KVM?.. А для всего остального существует радмин и ему подобные.
[To be continued…](https://habrahabr.ru/post/326112/) | https://habr.com/ru/post/325918/ | null | ru | null |
# jspm — менеджер пакетов для браузера

* jspm — это менеджер пакетов для SystemJS, сделаный на основе ES6 module loader
* Позволяет загружать все форматы модулей (ES6, AMD, CommonJS и Globals) непосредственно из npm или Github с управлением зависимостями. Также позволяет использовать любые не стандартные источники модулей, реализованные через Registry API
* В разработке: Загружает модули ES6 как отдельные файлы, и компилирует их в прямо в браузере
* В продакшене: Собирает модули в один или несколько бандлов, с единой командой для запуска всего приложения
Начнем
------
### Устанавливаем jspm cli
```
npm install jspm -g
```
### Создаем проект
```
cd my-project
npm install jspm
```
Рекомендуется также локально установить jspm, дабы зафиксировать его версию для данного проекта. Это позволит сохранить поведение вашего приложения в случае, если глобальный jspm обновится. Для подтверждения локальной версии выполните jspm -v.
Создадим кофигурацию для нового проекта:
```
jspm init
Package.json file does not exist, create it? [yes]:
Would you like jspm to prefix the jspm package.json properties under jspm? [yes]:
Enter server baseURL (public folder path) [.]:
Enter jspm packages folder [./jspm_packages]:
Enter config file path [./config.js]:
Configuration file config.js doesn't exist, create it? [yes]:
Enter client baseURL (public folder URL) [/]:
Which ES6 transpiler would you like to use, Traceur or Babel? [traceur]:
```
Это создаст фаил package.json и конфигурационный файл. Также jspm init запускается автоматически, если вы, устанавливаете jspm в пустой проект.
* baseURL — путь к корневой папке вашего http сервера (public) относительно файла package.json. По умолчанию это та же папка где и сам package.json.
* jspm packages folder — папка куда jspm будет устанавливать все внешние зависимости.
* Config file path — конфигурационный фаил для вашего приложения. Должен находится в baseURL и включен в систему контроля версий.
* Client baseURL — URL папки public для браузера
* Transpiler — используемый транспайлер. Эта опцию можно менять в любой момент командой jspm dl-loader --babel (по умолчанию traceur). Для более тонкой настроики можно определить babelOptions и traceurOptions
Если вам когда-нибудь понадобится поменять какие либо из этих настроек — можно напрямую редактировать package.json и ваше приложение подхватит новые настройки, когда вы запустите jspm install или jspm init.
### Устанавливаем любые пакеты из репозитория jspm, Github или npm
```
jspm install npm:lodash-node
jspm install github:components/jquery
jspm install jquery
jspm install myname=npm:underscore
```
Установку нескольких пакетов можно обьединить в одну строку разделив пробелами.
Любой пакет npm или Github можно установить подобным образом.
Большинство npm пакетов установятся без каких-либо дополнительных настроек. Это происходит потому что репозиторий npm применяет трансформацию, основываясь на системе разрешения зависимостей Node require (от переводчика — имеется ввиду [это](https://nodejs.org/api/modules.html#modules_loading_from_node_modules_folders)) — это делает Node и пакеты в стиле npm совместимыми с jspm.
Пакеты Github возможно, нуждаются в некой конфигурации перед использованием в jspm ([подробности](https://github.com/jspm/registry/wiki/Configuring-Packages-for-jspm), англ.)
Имена всех установленных пакетов сохраняются в package.json — таким образом, папка jspm\_packages, а также конфигурационный файл могут быть полностью восстановлены одной коммандой jspm install. Это идеальное решение для тех, кто использует системы контроля версий и не хочет помещать сторонние пакеты в свой репозиторий.
В фаил config.js помещается информация о версиях зависимостей и номера версий фиксируются. Таким образом, файл config.js становится фиксатором версий и он должен быть добавлен в систему контроля версий (от переводчика — некий аналог rails Gemfile.lock).
### Пишем код приложения
Теперь можно начать создавать отдельные модули (включая модули формата ES6), например в папку lib:
lib/bootstrap.js
```
import _ from 'lodash-node/modern/lang/isEqual';
import $ from 'jquery';
import underscore from 'myname';
export function bootstrap() {
// bootstrap code here
}
```
lib/main.js
```
import {bootstrap} from './bootstrap';
bootstrap();
```
### Запускаем наше приложение
HTML страницы должен включать скачанный автоматически при jspm init — загрузчик SystemJS, а также конфигурационный фаил, после чего импортируем основной модуль нашего приложения:
```
System.import('lib/main');
```
Запускаем локальный сервер и смотрим на нашу страницу.
### Сборка для продакшена
Запускаем следующую команду в консоли и обновляем страницу в браузере:
```
jspm bundle lib/main --inject
```
Все наше приложение было скомпановано в один bundle.js. Как вариант, можно использовать
```
jspm bundle-sfx lib/main
```
Это создаст единый файл всего приложения, который можно использовать в script таге без использования config.js и system.js.
### Еще по теме
**Видео скринкасты и выступления**
**Статьи**[JavaScript Modules and Dependencies with jspm](http://javascriptplayground.com/blog/2014/11/js-modules-jspm-systemjs/)
[JavaScript in 2015](http://glenmaddern.com/articles/javascript-in-2015)
<http://jspm.io/> | https://habr.com/ru/post/256095/ | null | ru | null |
# Pure Storage ActiveCluster в связке с VMware: обзор и тестирование

Не так давно компания Pure Storage анонсировала новую функциональность ActiveCluster – active/active метрокластер между хранилищами данных. Это технология синхронной репликации, при которой логический том растянут между двумя хранилищами и доступен на чтение/запись на обоих. Эта функциональность доступна с новой версией прошивки Purity//FA 5 и является абсолютно бесплатной. Также Pure Storage пообещали, что настройка растянутого кластера никогда не была еще такой простой и понятной.
В данной статье мы расскажем про ActiveCluster: из чего состоит, как работает и настраивается. Отчасти статья является переводом официальной документации. Помимо этого, мы поделимся опытом тестирования его на отказоустойчивость в VMware-окружении.
Конкурентные решения
--------------------
Представленная функциональность не является чем-то инновационным, аналогичные решения есть у большинства крупных производителей СХД: Hitachi GAD (Global Active Device), IBM HyperSwap, HPE 3PAR Peer Persistance, Fujitsu Storage Cluster, Dell Compellent Live Volume, [Huawei HyperMetro](https://habr.com/company/jetinfosystems/blog/326082/).
Однако мы решили выделить некоторые плюсы ActiveCluster по сравнению с конкурентными решениями:
* Не требует дополнительных лицензий. Функциональность доступна «из коробки».
* Простое управление репликацией (мы попробовали — это действительно удобно и просто).
* Облачный медиатор (Quorum device). Не требует наличия третьей площадки и развертывания на ней кворум сервера.
Обзор ActiveCluster
-------------------
Рассмотрим компоненты, из которых состоит ActiveCluster:
* **Transparent Failover Mediation**. Cloud Mediator – это кворум сервер/устройство, которое принимает решение, какой из массивов продолжит работать и предоставлять доступ к данным, а какой должен прекратить работу в случае различных сбоев.
* **Active/Active Clustered Arrays** – массивы PureStorage с настроенной синхронной репликацией между ними. Предоставляют доступ к консистентной копии данных как с одного массива, так и с другого.
* **Stretched Storage Containers** – контейнеры, содержащие объекты, которые должны реплицироваться между двумя массивами.
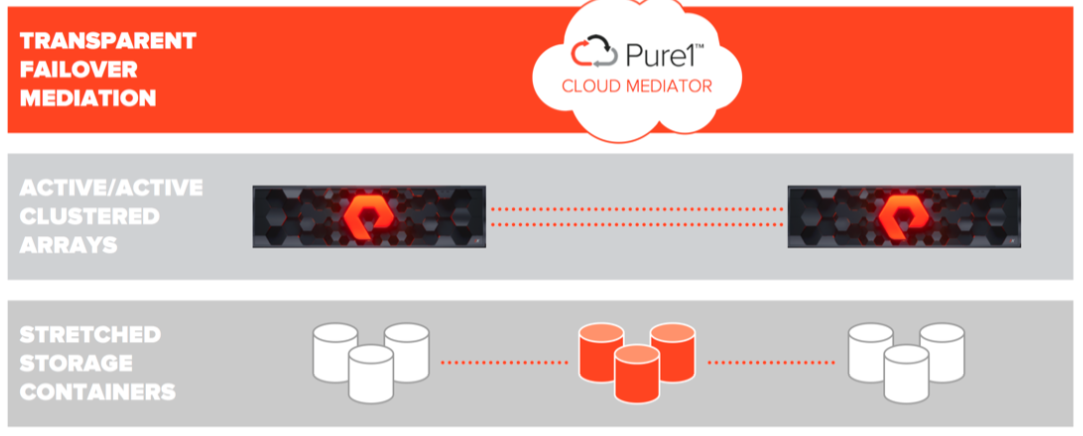
В ActiveCluster появились новые объекты – Pods. Pod – это контейнер, содержащий другие объекты. Если между двумя массивами существует репликационный канал, то в pod можно добавить несколько массивов и тогда все объекты в этом pod будут реплицироваться между массивами. Растянутыми pod`ами можно управлять с любого массива.
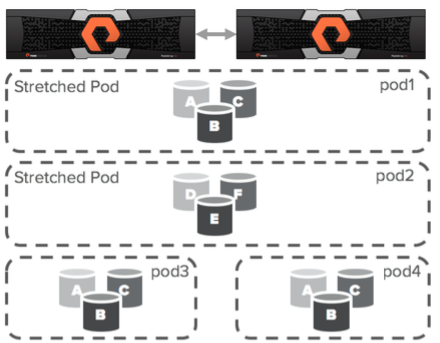
Pod может содержать volumes, snapshots, protection groups и другую конфигурационную информацию. Pod функционирует как consistency group, то есть гарантирует согласованный порядок записи томов в одном pod.
ActiveCluster: схемы доступа хостов к массивам
----------------------------------------------
Доступ хостов к данным может быть настроен двумя моделями доступа: uniform и non-uniform. В uniform модели каждый хост на обеих площадках имеет доступ к обоим массивам на чтение/запись. В non-uniform модели каждый хост имеет доступ только к локально расположенному массиву на чтение/запись.
Uniform-модель доступа
----------------------
Uniform-модель доступа к данным может использоваться в окружениях, где для соединения хостов с массивами используется Fibre Channel или Ethernet (iSCSI) и между массивами используется Ethernet-соединение (10g) для репликации. В данной конфигурации хост имеет доступ к данным через оба массива: как через локальный, так и через удаленный. Это решение поддерживается только при максимальной задержке между массивами по каналам репликации в 5 мс.
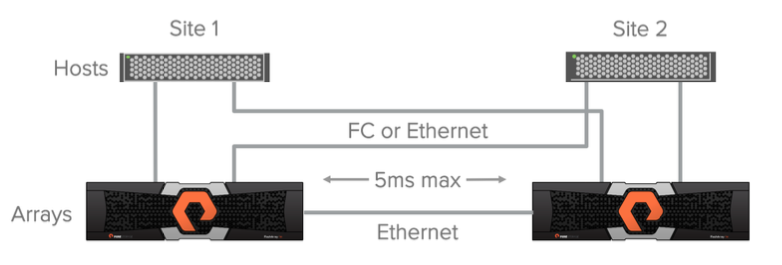
Схема выше иллюстрирует логические пути от хостов до массивов, а также канал репликации между массивами в схеме доступа Uniform. Предполагается, что данные доступны обоим хостам вне зависимости от того, на какой площадке они находятся. Важно понимать, что пути до локального массива будут иметь меньшую задержку, чем до удаленного.
Оптимизация производительности при использовании Uniform-модели
---------------------------------------------------------------
Для лучшей производительности ввода/вывода при использовании active/active синхронной репликации хост не должен использовать пути до удаленного массива. Для примера рассмотрим представленную ниже картинку. Если «VM 2A» будет выполнять операцию записи на том «A», используя массив «Array A», то эта операция записи повлечет за собой двойную задержку передачи данных через канал репликации, а также задержку от хоста до удаленного массива.

Предлагаю разобрать более подробно. Предположим, что задержка по каналу репликации между массивами у нас 3ms. В случае соединения «Host B» <-> «Array B» задержка 1ms. А в случае «Host B» <-> «Array A» – 3ms. Команда записи будет отправлена от хоста «VM 2A» на удаленную площадку к массиву «Array A» с задержкой в 3ms. Далее команда записи будет отправлена через канал репликации на массив «Array B» с задержкой в 6ms (3ms + 3ms). После этого ответ об успешной записи будет отправлен обратно от массива «Array B» к массиву «Array A» через канал репликации (6ms + 3ms = 9ms). Далее ответ об успешной записи будет отправлен обратно на хост “VM 2A” (9ms + 3ms = 12ms). Итого мы получаем задержку в 12ms на операцию записи в случае использования удаленного массива. Если посчитаем точно по такому же принципу использование локального массива – то получим 8ms.
ActiveCluster позволяет использовать ALUA (Asymmetric Logical Unit Access), для предоставления путей до локальных хостов как active/optimized и предоставления путей до удаленных хостов как active/non-optimized. Оптимальный путь определяется для каждой связки host <-> volume устанавливая опцию preferred array. Таким образом, не важно на каком из хостов работает ваше приложение или виртуальная машина, хост всегда будет знать какой массив для него локальный (имеет оптимальные пути), а какой удаленный (имеет не оптимальные пути).
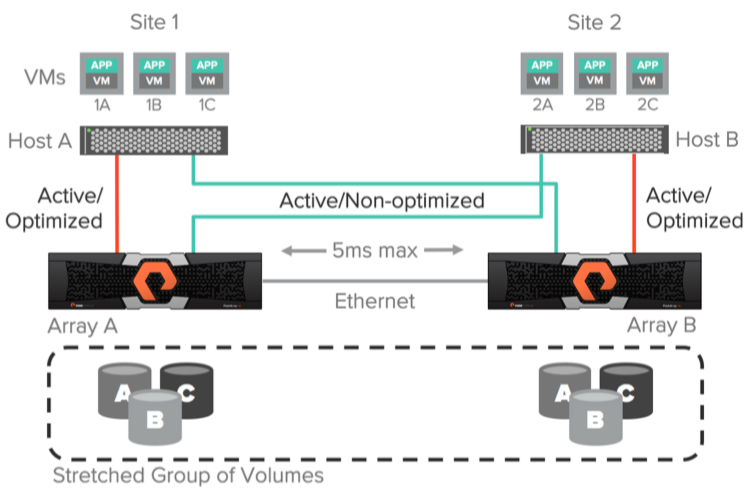
Используя ActiveCluster, можно конфигурировать действительно active/active датацентры, не заботясь о том, на какой площадке работает ваша виртуальная машина или приложение. Все операции чтения/записи всегда будут идти через локальный для хоста массив.
Non-uniform модель доступа
--------------------------
Модель доступа Non-uniform также используется в окружениях, где для соединения хостов с массивами используется Fibre Channel или Ethernet (iSCSI). В данной модели хосты имеют доступ только к локальному массиву и не имеют доступа к удаленному массиву. Данное решение также предполагает использование репликационных соединений между массивами с задержкой не более 5ms.

Плюсы и минусы этих моделей доступа
-----------------------------------
Модель доступа Uniform обеспечивает более высокий уровень отказоустойчивости, так как выход из строя одного массива не повлечет за собой рестарт виртуальных машин или приложений, использовавших этот массив, – доступ к данным будет продолжен через другой. Конечно данная модель предполагает работающий и настроенный мультипасинг (multipathing) на стороне хостов, который распределял бы запросы ввода/вывода по active/optimized путям и по active/non-optimized в случае, когда первые недоступны.
В случае использования модели Non-uniform хосты имеют доступ только к локальному массиву и, соответственно, только по active/optimized путям. В случае выхода из строя локального массива все виртуальные машины или приложения потеряют доступ к данным на этой площадке и будут перезапущены (например, средствами VMware HA) на другой площадке, используя доступ к данным через другой массив.
Настройка Active Cluster
------------------------
Ребята из Pure Storage заявляют об очень простой, интуитивной настройке ActiveCluster. Что же, давайте посмотрим. Настройка производится в 4 шага:
**Шаг 1**: Соединение двух Flash массивов.
Соединяем наши массивы двумя каналами Ethernet 10Gb/s и через GUI настраиваем тип соединения как Sync Replication.

**Шаг 2**: Создание и растягивание pod.
Для создания pod мы будем использовать CLI (через GUI тоже можно). Команда purepod используется для создания и «растягивания» pod. Как мы уже говорили ранее, pod – это контейнер, который создан для упрощения управления в active/active среде. Pod определяет, какие объекты должны синхронно реплицироваться между массивами. Управлять растянутыми pod’ами и объектами в них можно с любого из массивов. Pod может содержать в себе тома, снапшоты, клоны, протекшен группы и другую конфигурационную информацию.
Создаем pod на массиве Array A:
`arrayA> purepod create pod1`
Растягиваем pod на Array B:
`arrayA> purepod add --array arrayB pod1`
Теперь любые тома, снапшоты или клоны, помещенные в этот pod, будут автоматически реплицироваться между массивами «Array A» и «Array B».
**Шаг 3**: Создание томов
На любом из массивов создаем том vol1 размеров 1TB и помещаем его в pod1:
`> purevol create --size 1T pod1::vol1`
Вместо создания тома мы можем переместить любой уже имеющийся том в pod1 и он начнет реплицироваться.
**Шаг 4**: Презентация тома на хост.
Еще раз отметим, что ActiveCluster – это настоящее active/active решение, которое позволяет читать и писать на один и тот же логический том, используя оба массива.
Создаем хост и презентуем том vol1 этому хосту:
`> purehost create --preferred-array arrayA --wwnlist
> purehost connect --vol pod1::vol1 ESX-1`
Прошу обратить внимание, что мы указываем опцию –preferred-array которая означает, что пути с массива «ArrayA» будут для этого хоста оптимальными (active/optimized).
Это все! Теперь ESX-1 имеет доступ к тому vol1 через оба массива «ArrayA» и «ArrayB». Быстро и просто, неправда ли?
Дополнительно проверим состояние медиатора. Мы используем облачный медиатор Pure, для доступа к нему массивы должны иметь выход в интернет. Если политика безопасности не позволяет этого сделать, то есть возможность скачать и развернуть локальный медиатор.
`purepod list --mediator
Name Source Mediator Mediator Version Array Status Frozen At Mediator Status
pod1 - purestorage 1.0 Array-A online – online
Array-B online - online`
Функциональное тестирование ActiveCluster в среде VMware
--------------------------------------------------------
Перед нами стояла задача функционального тестирования связки двух Flash Array//m20 в конфигурации ActiveCluster и VMware (2 ESX хоста) в части обеспечения отказоустойчивой работы виртуальных машин. Мы эмулировали наличие двух площадок, на каждой из которой был ESX-хост и Flash Array. Использовалась версия VMware 6.5 U1 и версия Pure//FA 5.0.1.
У нас были следующие критерии успеха:
1. Эмулируемые отказы дискового массива не приводят к перебою в работе виртуальных машин.
2. Эмулируемые отказы ESX-сервера позволяют автоматически (средствами VMware HA) запустить виртуальные машины на другом ESX сервере.
3. Эмулируемые отказы площадки (массив + esx-сервер) позволяют автоматически (средствами VMware HA) запустить виртуальные машины на другой площадке.
4. Проверить работу vMotion в конфигурации с VMware + ActiveCluster.
Схема нашего стенда представлена ниже:

Между массивами m20 #1 и m20 #2 был собран ActiveCluster с использованием репликационного канала на 10 Гбит/с. На одном массиве был создан pod, а затем растянут добавлением в него второго массива. На обоих массивах создан том размером 200GB и добавлен в растянутый pod, тем самым запустив репликацию этих томов между массивами. Реплицируемый том был презентован обоим ESX-хостам по схеме Uniform access с конфигурацией preferred array для хост-групп. Для хоста ESX1 preferred array был m20 #1, а для ESX2 соответственно m20 #2. Таким образом со стороны ESX-хостов пути до датасторов были active (I/O optimized) до локального массива и active (non-optimized) до удаленного.
Эмуляция отказа дискового массива
---------------------------------
Для тестирования была проинсталлирована виртуальная машина с Windows 2012 r2. Файлы ВМ располагались на общем датасторе на растянутом томе с Pure Storage. Также в эту ВМ был презентован еще один диск на 100GB с этого же датастора, на который мы запустили синтетическую нагрузку средствами IOmeter. Отмечу, что у нас не было цели замерять производительность, нам необходимо было сгенерировать любую I/O активность, чтобы при наших тестированиях отловить моменты, когда SCSI команды чтения/записи могли подвиснуть при переключении путей до массивов.
Итак, все готово: тестовая ВМ работает на ESX1, хост ESX1 использует оптимальные пути до массива m20 #1 для операций ввода/вывода. Мы идем в серверную и отрубаем по питанию массив m20 #1 и наблюдаем за IOmeter в ВМ. Никакого прерывания в вводе/выводе не происходит. Смотрим состояние путей до датастора: пути до m20 #1 в состоянии dead, пути до m20 #2 перешли в состояние active (I/O). Тест проводился несколько раз с немного разными входными данными, но результат всегда был успешным. Тест считаем успешно пройденным.
P.S. После включения массива m20 #1 пути переключились обратно на него, то есть на локальную для этого ESX-хоста площадку.
Эмуляция отказа ESX-хоста
-------------------------
Этот тест не очень интересный, так как мы, по сути, проверяем не Pure Storage, а работу VMware HA. Мы в любом случае ожидали downtime для ВМ и последующее ее воскрешение кластером на другом ESX хосте.
В общем, мы сходили в серверную и дернули по питанию хост ESX1. VMware HA отработал штатно, и наша ВМ успешно поднялась на хосте ESX2. Тест считаем успешным.
Эмуляция отказа всей площадки
-----------------------------
По сути, это первый и второй тест, проводимые одновременно. И в любом случае это downtime для виртуальной машины, так как мы отключаем ESX хост. Исходные данные такие же, как и в первом тесте: ВМ работает на ESX1, хост ESX1 использует для ввода/вывода массива m20 #1, в ВМ запущен IOmeter для синтетической нагрузки на массив.
Мы идем в серверную и отключаем питание у ESX1 и m20 #1. Наблюдаем. В течении 1-2 минут VMware HA поднимает виртуальную машину на ESX2, пути на ESX2 в состоянии dead для m20 #1 и в состоянии active (I/O) для массива m20 #2. Тест считаем успешным.
Проверка работоспособности vMotion в конфигурации ActiveCluster
---------------------------------------------------------------
Весьма формальный тест. Нам необходимо было проверить, что он работает и нет никаких подводных камней. Погоняли vMotion как на включенной виртуальной машине, так и на выключенной, со сменой датастора и без, никаких проблем не выявлено. Тест успешно пройден.
Заключение
----------
Технология синхронной репликации уже не нова и есть практически у каждого крупного вендора СХД, но Pure Storage выделяются среди них тем, что не требуют дополнительных лицензий на ее использование, которые зачастую могут составлять немалую часть от стоимости самой СХД. Также ребята из Pure вывели на новый уровень удобство управлением репликацией, теперь не требуется изучение множества десятков страниц документации для того, чтобы её настроить, а весь процесс интуитивно понятен. Для повышения собственных компетенций и в рамках организации Proof of Concept мы проводим различные тестирования как у себя, так и у заказчиков. Вместе с дистрибьютором OCS (второй массив мы взяли у них), мы развернули первый в России Pure Storage ActiveCluster, на котором проводили тестирования.
*Сергей Сурнин, эксперт Сервисного центра компании «Инфосистемы Джет»* | https://habr.com/ru/post/359076/ | null | ru | null |
# Читалка ithappens
Вот-с, собственно вечерком накодил читалку [ithappens](http://ithappens.ru) на питоне. Умеет сохранять цитаты в формат fortune (правда я не проверял :D) и выводить в файл, либо на терминал.
```
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#Public domain
'''Ithappens - show random quote'''
#только для python2
from __future__ import unicode_literals
from __future__ import print_function
from textwrap import fill
import os,sys
from lxml import etree
if sys.version_info[0] == 2: #подменяю open
from codecs import open
def getTerminalSize(): #http://stackoverflow.com/questions/566746/how-to-get-console-window-width-in-python
'''Get tuple of terminal size'''
env = os.environ
def ioctl_GWINSZ(fd):
try:
import fcntl, termios, struct
cr = struct.unpack('hh', fcntl.ioctl(fd, termios.TIOCGWINSZ,'1234'))
except:
return None
return cr
cr = ioctl_GWINSZ(0) or ioctl_GWINSZ(1) or ioctl_GWINSZ(2)
if not cr:
try:
fd = os.open(os.ctermid(), os.O_RDONLY)
cr = ioctl_GWINSZ(fd)
os.close(fd)
except:
pass
if not cr:
try:
cr = (env['LINES'], env['COLUMNS'])
except:
cr = (25, 80)
return int(cr[1]), int(cr[0])
def print_quote(url,file=sys.stdout, fortune=False):
'''print quote to given file'''
path='/body/table/tr/td[@class="main"]/table[@class="content"]/tr/td[@class="text"]/div[@class="text"]/p[@class="text"]'
parser = etree.HTMLParser()
tree = etree.parse(url,parser)
title = tree.find('/head/title').text.split('—')[1].strip()
w,h = getTerminalSize()
charno = (w-len(title)+2)/2
print ('{chars} {title} {chars}'.format(title=title, chars='#'*charno))
elem=tree.find(path)
for i in elem.iter():
if i.text is not None:
text, end = i.text, i.tail if i.tail is not None else ''
elif i.tail is not None:
text,end = i.tail, ''
else:
continue
print (fill(text + end, w),file=file)
if fortune:
print ('%',file=file)
if __name__ == '__main__':
usage = """usage: {file}
-h: Show help message
-f: write a fortune file format
-o write to file (default is stdout)
If no IDs passed, then print random quote""".format(file=os.path.basename(sys.argv[0]))
fortune = False
file = False
quotes = []
for arg in sys.argv[1:]:
if arg == '-f': #fortune
fortune = True
elif arg == '-o': #file
file = True
elif arg in ('--usage','--help','-h'):
print (usage)
exit()
elif file is True:
file = arg
else:
try:
int(arg)
except ValueError:
print ('Failed to parse Quote ID argument - seems like it is not int',file=sys.stderr)
exit()
else:
quotes.append(arg)
if not file:
out=sys.stdout
elif file is True:
print('Output to file requested in -o but no file specified')
exit()
else:
out = open(file, 'at',encoding='utf-8')
if not quotes:
print\_quote('http://ithappens.ru/random/',file=out, fortune=fortune)
for q in quotes:
print\_quote('http://ithappens.ru/story/{id}'.format(id=q),file=out, fortune=fortune)
out.close()
```
использование
```
chmod +x ithappens.py
./ithappens.py
``` | https://habr.com/ru/post/149297/ | null | ru | null |
# Идем по приборам

Много ли нужно, чтобы изменить пробег или залезть в память приборной панели?
Есть только один способ узнать — попробовать сделать это самому.
### Постановка задачи
В данной статье мы покопаемся в механизмах диагностики нескольких приборных панелей и посмотрим, насколько далеко можно зайти без специализированного дилерского оборудования. Основными инструментами будут скрипты на Python и обычный CAN-USB адаптер. Все воздействия будут сводиться к сообщениям на CAN-шине. Так будет сложнее, но интереснее, так как все сделанное таким способом теоретически можно повторить на настоящем автомобиле через OBDII-разъем. В первую очередь нас будет интересовать доступ к памяти устройства где хранятся его конфигурация и пробег.
Немного дисклеймеров:
**Работая с CAN-шиной реального автомобиля есть риск вывести его из строя. Ни в коем случае не беритесь за работу с CAN-шиной без должного опыта, инструментов и мер предосторожности.**
**Корректировка пробега с корыстной целью — занятие для редисок.**
### Поиск испытуемых
Чтобы разнообразить эксперимент, мы будем использовать три приборных панели от автомобилей разных производителей. С этой целью на Авито и авторазборках были закуплены три б/у панели согласно следующим критериям:
* низкая цена детали (возможно с дефектом);
* популярность автомобиля в прошедшем десятилетии;
* доступность автомобиля на вторичном рынке;
* в выборке панелей не должно быть родственных автопроизводителей (например, Hyundai и Kia, Mitsubishi и Citroen и т.п.)
Итак, в порядке закупки и повествования:

Приборная панель Hyundai Solaris 2013 г.в.
Партномер: 94003-4l715
Установлен сегментый экран с фиксированным количеством символов и обозначений. По сравнению с остальными просто набита разъемами, целых 4 штуки. Много сигналов поступает не по CAN-шине, а "аналоговым" методом по отдельным проводам.

Приборная панель Ford Focus 3 2012 г.в.
Партномер: BM5T-10849-BAE
Стоит монохромный экран малого разрешения. При подаче питания находится в состоянии спячки, чтобы увидеть экран и побаловаться со стрелками нужно периодически будить CAN-сообщениями.

Приборная панель Mitsubishi Lancer X 2008 г.в.
Партномер: 8100A117A
Оказалась достаточно распространенной и устанавливалась сразу на ряд моделей Mitsubishi, Citroen и Peugeout. Самая шумная из всех, при каждой подаче питания громко пищит и дает понять, что существовать отдельно от автомобиля ей не нравится.
Ни одним из данных автомобилей я не владел, поэтому в случае неточностей в описании прошу понять и простить.
### Основы диагностики
Прежде чем идти дальше, сделаем короткую остановку и ознакомимся с используемыми диагностическими протоколами. Большинство систем диагностики строятся на двух схожих между собой протоколах: **KWP2000** (Keyword Protocol 2000) и **UDS** (Unified Diagnostic Services). Первым появился KWP2000, затем на его базе был создан UDS, как более современная реализация. Применение этих протоколов предоставляет следующие возможности для автопроизводителей и автосервисов:
* чтение кодов неисправностей;
* запись/чтение прошивки;
* запись/чтение конфигурации и отдельных настроек;
* чтение данных с датчиков;
* приведение в действие актуаторов.
Например, автопроизводитель может пользоваться этими механизмами, чтобы сконфигурировать ЭБУ под конкретную комплектацию собранного автомобиля, а в автосервисе могут использовать команду разжатия колодок при обслуживании тормозной системы.
В обоих протоколах основными участниками процесса являются две сущности: **клиент** и **сервер**. Клиент представляет интересы тестового оборудования, а сервер — интересы ЭБУ. Работа с каждым из ЭБУ ведется отдельно и для налаживания взаимодействия по CAN нужно знать адресную пару клиент-сервер. Упрощенно такую систему можно представить так:
**Сессией** определяется текущее состояние сервера и набор доступных сервисов. То есть при выборе стандартной сессии вряд ли будут доступны перезагрузка модуля или перепрошивка, так как это не предусмотрено в обычном состоянии. В то же время при переходе в сессию пререпрошивки модуль перестанет принимать/рассылать рабочий трафик и будет ждать передачи данных.
Для защиты важных сервисов могут использоваться разные **уровни доступа**. Как правило, для заполучения нужного уровня доступа нужно запросить у сервера "семя" и подготовить корректный ответ с помощью заранее известного алгоритма.
Каждый отдельный **сервис** выполняет только одну определенную функцию, например чтение памяти по адресу или сброс ошибок.
Получается, чтобы составить беглое представление о неизвестном модуле и возможных операциях над ним, нужно совершить следующие шаги:
1. Определить адреса клиента и сервера;
2. Найти все доступные сессии (стандартные, расширенные, диагностические и т.д.);
3. Для каждой из сессий найти все существующие уровни доступа (0x01, 0x03, 0x05 и т.д.);
4. Для каждой из сессий найти все доступные сервисы (чтение/запись по адресу, управление рутинами и т.д.)
### Инструментарий
Начнем с **программной** составляющей.
Для взаимодействия с устройством использовались Python-библиотеки:
* [python-udsoncan](https://github.com/pylessard/python-udsoncan) (диагностический клиент, предоставлет возможность пользоваться сервисами);
* [python-can-isotp](https://github.com/pylessard/python-can-isotp) (транспортный уровень ISO 15765-2, позволяет передавать данные длиной более 8 байт);
* [python-can](https://github.com/hardbyte/python-can/tree/master) (API для общения по CAN-шине).
Они интересны по нескольким причнам:
* подробная документация с множеством примеров;
* широкая поддержка железа + не так сложно добавить новое;
* их можно подключать по мере надобности, начиная с голого CAN и поднимаясь выше;
* из них можно собрать полноценный стек для UDS-диагностики.

Использованный набор библиотек отчасти и мотивировал меня написать данную статью, поскольку показался любопытным и полезным для быстрых экспериментов. Связка в виде скриптов на Python и адаптера CAN-USB дают гибкость и способность на лету прикидывать последовательности обмена данными. Можно автоматизированно подбирать пароли к уровням доступа, притворяться дилерским диагностическим оборудованием, просто слушать CAN-шину и многое другое.
Об отрицательном опыте использования: не всегда получалось добиться отклика в заданных временных рамках, например, скрипт мог не успеть отправить flow-control сообщение и тем самым обрывал пересылку большого куска данных. Также были случаи, когда CAN-сообщения отправлялись в неправильном порядке, но разбор полетов показал, что корень проблемы находился не в библиотеках. В конечном счете данные проблемы получилось обойти, главное всегда помнить, что настольный ПК это все-таки не real-time устройство.
Для некоторых задач, например подбора адресов клиента и сервера, нам пригодится утилита [caringcaribou](https://github.com/CaringCaribou/caringcaribou), которая тоже использует python-can.
Что касается **аппаратной** части и адаптеров CAN-USB, то в ход шло все, что удавалось раздобыть и одолжить, библиотеки это позволяют. В данном конкретном случае, работа была проделана с помощью Vector VN1610 и VN1611, а также адаптера на базе протокола Lawicel.
Что до последнего, то он сравнительно прост и предcтавляет из себя виртуальный COM-порт, который преобразует по определенным правилам строки в CAN-сообщения и наборот. При некотором желании похожий девайс можно сделать своими силами, на хабре есть интересная статья ["CAN-USB адаптер из stm32vldiscovery"](https://habr.com/ru/post/256493/) на эту тему.
Для работы с приборными панелями на столе достаточно иметь блок питания, способный выдать 12 В. В обзоре на каждую панель будут приведены краткие справки по железу, распиновке и настройке CAN.
Приборная панель Hyundai Solaris
--------------------------------
### Обзор
Железо:

Распиновка панели и конфигурация CAN:

*Замечание: у панели Solaris сзади 4 разъема, поэтому они обозначены слева направо как A, B, C, D.*
Сессии и уровни доступа:
Таблица сервисов:
Знаки вопросов указывают на предполагаемое имя сессии, поскольку точной информации нет.
Нумерация сессий почему-то перемешана, 0x03 взят из UDS, а 0x85 и 0x90 взяты из KWP2000.
Из результатов сканирования видно, что панель достаточно демократично относится к чтению и записи в память, эти операции доступны во всех сессиях, в том числе сразу после подачи питания. В таком случае, можно не терять время и сразу приступить к сканированию адресов и типов памяти.
### В поисках памяти
Для чтения памяти и в KWP2000 и в UDS используется сервис `ReadMemoryByAddress` (0x23), есть только некоторые отличия по формату запроса. Для KWP2000 он будет выглядеть вот так:
| Byte # | Value | Parameter |
| --- | --- | --- |
| 0 | 23 | Service ID |
| 1-3 | XX | memoryAddress[3] |
| 4 | XX | memorySize |
Все просто, указывается ID сервиса, адрес чтения и сколько байт нужно прочитать. В некоторых системах старший байт может быть использован как `memoryIdentifier`, чтобы выбирать из какой именно памяти произодится чтение (EEPROM, flash), но при этом ширина адреса уменьшается до 16 бит.
Теперь про UDS:
| Byte # | Value | Parameter |
| --- | --- | --- |
| 0 | 23 | Service ID |
| 1 | XX | addressAndLengthFormatIdentifier |
| ~ | XX | memoryAddress[] |
| ~ | XX | memorySize[] |
Здесь ширина адреса и размера памяти может меняться, это настраивается байтом `addressAndLengthFormatIdentifier`, в котором старший ниббл определяет ширину `memorySize`, а младший — `memoryAddress`. Например, для 32-битного `memoryAddress` и 16-битного `memorySize` этот байт будет равен 24. Старший байт адреса так же может быть использован как `memoryIdentifier`.
С этими знаниями, можно наконец приступать к чтению памяти и обнаружить, что они не совсем работают. Вернее, вообще не работают, в обоих случаях. Провозившись с этим некоторое время, было принято решение отойти от стандартов и поиграться с телом запроса, меняя ширину полей и их значения. И вот, получился рабочий вариант:
| Byte # | Value | Parameter |
| --- | --- | --- |
| 0 | 23 | Service ID |
| 1-4 | XX | memoryAddress[4] |
| 5 | XX | memorySize[2] |
То есть нечто промежуточное: поля шире, чем в KWP2000, но при этом `addressAndLengthFormatIdentifier` из UDS не применяется. Далее перебираем адреса и находим, что старший байт адреса выбирает тип памяти: 0x00 для флеш-памяти микроконтроллера (виден кусочек таблицы векторов прерываний):
```
TX: <7C6> (8) 07 23 00 00 00 00 00 04
RX: <7CE> (8) 05 63 80 07 00 07 00 00
```
и 0x04 для внешней EEPROM.
```
TX: <7C6> (8) 07 23 04 00 00 00 00 04
RX: <7CE> (8) 05 63 0d a8 00 00 00 00
```
**Скрипт чтения флеш-памяти и EEPROM**
```
import can
import isotp
import logging
import time
import argparse
def process_stack_receive(stack, timeout=1):
t1 = time.time()
while time.time() - t1 < timeout:
stack.process()
if stack.available():
break
time.sleep(stack.sleep_time())
return stack.recv()
def process_stack_send(stack, timeout=1):
t1 = time.time()
while time.time() - t1 < timeout:
stack.process()
if not stack.transmitting():
break
time.sleep(stack.sleep_time())
def my_error_handler(error):
logging.warning('IsoTp error happened : %s - %s' % (error.__class__.__name__, str(error)))
def print_frame(frame):
if frame:
print(''.join(format(x, '02x') for x in frame))
else:
print("None")
bus = can.interface.Bus(bustype='slcan',
channel="COM3",
ttyBaudrate=115200,
bitrate=500000)
addr = isotp.Address(isotp.AddressingMode.Normal_11bits, rxid=0x7ce, txid=0x7c6)
stack = isotp.CanStack(bus, address=addr, error_handler=my_error_handler, params = {'tx_padding':0})
parser = argparse.ArgumentParser()
parser.add_argument("-e", "--eeprom", help="read EEPROM", action="store_true")
parser.add_argument("-f", "--flash", help="read Flash", action="store_true")
args = parser.parse_args()
if args.eeprom:
for addr in range(0x00000000, 0x000007ff, 0x10):
addr0 = (addr >> 0) & 0xff
addr1 = (addr >> 8) & 0xff
array = [0x23, 0x04, 0x00, addr1, addr0, 0x00, 0x10]
stack.send(bytearray(array))
process_stack_send(stack)
print_frame(process_stack_receive(stack))
if args.flash:
for addr in range(0x00000000, 0x0003ffff, 0x10):
addr0 = (addr >> 0) & 0xff
addr1 = (addr >> 8) & 0xff
addr2 = (addr >> 16) & 0xff
array = [0x23, 0x00, addr2, addr1, addr0, 0x00, 0x10]
stack.send(bytearray(array))
process_stack_send(stack)
print_frame(process_stack_receive(stack))
bus.shutdown()
```
Раз уж получилось прочесть, почему бы не попробовать и записать что-нибудь? Берем сервис `WriteMemoryByAddress` (0x3d) и, наученные прошлым опытом, поменьше верим стандартам и побольше — собственным догадкам. Рабочим вариантом зароса оказывается:
| Byte # | Value | Parameter |
| --- | --- | --- |
| 0 | 3d | Service ID |
| 1-4 | XX | memoryAddress[4] |
| 5-N | XX | dataRecord |
то есть не нужно даже указывать `memorySize`, достаточно просто указать адрес и сами байты.
Теперь пишем один байт и тут же читаем назад для проверки. Запрос записи во флеш-память подтверждается успешным ответом 0x7d, но по факту память остается нетронутой:
```
TX: <7C6> (8) 06 3d 00 00 00 00 81 00
RX: <7CE> (8) 01 7d 00 00 00 00 00 00
TX: <7C6> (8) 07 23 00 00 00 00 00 04
RX: <7CE> (8) 05 63 80 07 00 07 00 00
```
что в принципе ожидаемо, т.к. просто так изменить прошивку без применения загрузчика вряд ли получится.
А вот запись в EEPROM прошла успешно:
```
TX: <7C6> (8) 06 3d 04 00 00 00 0e 00
RX: <7CE> (8) 01 7d 00 00 00 00 00 00
TX: <7C6> (8) 07 23 04 00 00 00 00 04
RX: <7CE> (8) 05 63 0e a8 00 00 00 00
```
байт 0x0d поменял значение на 0x0e.
Этого достаточно, чтобы переходить к следующему этапу: поиску и изменению значений пробега.
### Загадка со змейкой
Сейчас нам необходимо понять какие именно из байт EEPROM отвечают за хранение пробега. Для этого применяется очень простой подход: посылаем на панель сигнал скорости, пока она не увеличивает пробег на 1 км, снова читаем EEPROM и сравниваем с предыдущим дампом. Для симуляции сигнала скорости необходимо найти CAN-сообщение, отвечающее за скорость и отправлять его с определенным периодом. Впрочем, бывают и исключения, как в случае с данной панелью: она оказалась от автомобиля с МКПП, где скорость передается отдельным импульсным сигналом.
Итак, 1 км пройден, давайте сравнивать:

Из всего EEPROM поменялся только **один** байт и его значение **уменьшилось** на 0x20? Явно надо идти глубже.
"Накатываем" еще 23 км:
И начинаем наблюдать некоторые закономерности:
1. для хранения используются 64 байта
2. pост пробега = вычитание значений
3. таблица проходится зигзагом в 2 отдельных прохода:
4. вычитаемое определяется номером столбца:
| 0,1 | 2,3 | 4,5 | 6,7 | 8,9 | A,B | C,D | E,F |
| --- | --- | --- | --- | --- | --- | --- | --- |
| -0x01 | -0x02 | -0x04 | -0x08 | -0x10 | -0x20 | -0x40 | -0x80 |
Более подробный разбор спрятан под спойлер, так как он занимает много места.
**Разгадка**
Итак, начнем с исходных данных для пробега 64890 км, для удобства разбитых на четыре группы:
```
[13, F8, 27, F0, 4F, E0, 9F, C0, 3F, 81, 7F, 02, FE, 04, FC, 09]
[F8, 13, F0, 27, E0, 4F, C0, 9F, 81, 3F, 02, 9F, 05, 3E, 0A, 7C]
[13, F8, 27, F0, 4F, E0, 9F, C0, 3F, 81, 7F, 02, FE, 04, FC, 09]
[F8, 13, F0, 27, E0, 4F, C0, 9F, 81, 3F, 02, 9F, 05, 3E, 0A, 7C]
```
Далее для 0-ой и 2-ой строк попарно меняем значения в столбцах:
```
[F8, 13, F0, 27, E0, 4F, C0, 9F, 81, 3F, 02, 7F, 04, FE, 09, FC]
[F8, 13, F0, 27, E0, 4F, C0, 9F, 81, 3F, 02, 9F, 05, 3E, 0A, 7C]
[F8, 13, F0, 27, E0, 4F, C0, 9F, 81, 3F, 02, 7F, 04, FE, 09, FC]
[F8, 13, F0, 27, E0, 4F, C0, 9F, 81, 3F, 02, 9F, 05, 3E, 0A, 7C]
```
Вычитаем каждый байт из FF, чтобы заменить разности суммами:
```
[07, EC, 0F, D8, 1F, B0, 3F, 60, 7E, C0, FD, 80, FB, 01, F6, 03]
[07, EC, 0F, D8, 1F, B0, 3F, 60, 7E, C0, FD, 60, FA, C1, F5, 83]
[07, EC, 0F, D8, 1F, B0, 3F, 60, 7E, C0, FD, 80, FB, 01, F6, 03]
[07, EC, 0F, D8, 1F, B0, 3F, 60, 7E, C0, FD, 60, FA, C1, F5, 83]
```
Попарно объединяем значения в каждой строке, чтобы получить 2-ух байтные:
```
[07EC, 0FD8, 1FB0, 3F60, 7EC0, FD80, FB01, F603]
[07EC, 0FD8, 1FB0, 3F60, 7EC0, FD60, FAC1, F583]
[07EC, 0FD8, 1FB0, 3F60, 7EC0, FD80, FB01, F603]
[07EC, 0FD8, 1FB0, 3F60, 7EC0, FD60, FAC1, F583]
```
Для переполненных значений переносим младшие разряды в старшие:
```
[07EC, 0FD8, 1FB0, 3F60, 7EC0, FD80, 1FB00, 3F600]
[07EC, 0FD8, 1FB0, 3F60, 7EC0, FD60, 1FAC0, 3F580]
[07EC, 0FD8, 1FB0, 3F60, 7EC0, FD80, 1FB00, 3F600]
[07EC, 0FD8, 1FB0, 3F60, 7EC0, FD60, 1FAC0, 3F580]
```
Теперь нормализуем значения, чтобы получить набор простых счетчиков; не забываем, что делитель зависит от номера столбца:
```
[07EC, 07EC, 07EC, 07EC, 07EC, 07EC, 07EC, 07EC]
[07EC, 07EC, 07EC, 07EC, 07EC, 07EB, 07EB, 07EB]
[07EC, 07EC, 07EC, 07EC, 07EC, 07EC, 07EC, 07EC]
[07EC, 07EC, 07EC, 07EC, 07EC, 07EB, 07EB, 07EB]
```
Наконец, суммируем все счетчики и получаем ожидаемые FD7A (64890).
Осталось только преобразовать желаемый пробег в соответствующую таблицу, записать ее обратно в EEPROM и:

Шалость удалась!
Приборная панель Ford Focus 3
-----------------------------
### Обзор
Железо:

Распиновка панели и конфигурация CAN:

*Замечание: к панели Focus подключаются 2 CAN-шины: MS (Medium Speed) и MM (Multimedia). Нам понадобится MS CAN.*
Сессии и уровни доступа:
Таблица сервисов:
По результатам сканирования видно, что реализация диагностического сервера придерживается стандарта UDS вплоть до нумерации сессий. Сессия 0x01 используется по умолчанию при каждой подаче питания, сессия 0x02 используется для изменения прошивки и сессия 0x03 применяется для изменения настроек. Прямого доступа к памяти посредством `ReadMemoryByAddress`/`WriteMemoryByAddress` нет ни в одной из сессий, поэтому начинаем с чтения всех возможных DID с помощью сервиса `ReadDataByIdentifier`.
### Первая попытка
Перебирая DID, читаем значения одно за другим, пока на глаза не попадается DID 0x61BB размером в 3-байта, в котором содержится значение пробега:
```
RX: <720> (8) 03 22 61 bb 00 00 00 00
RX: <728> (8) 06 62 61 bb 00 e9 20 00
```
Просто так перезаписать это значение вызовом `WriteDataByIdentifier` не вышло, для этого необходимо перейти в расширенную диагностическую сессию и получить уровень доступа 0x03.
*Краткое отступление по поводу алгоритма*. При запросе нужного уровня доступа сервер вернет "семя" длиной 3 байта, для которого нужно подобрать корректный ответ той же длины. Подсказки как правильно это сделать, можно найти в публикациях [Beneath the Bonnet: a Breakdown of Diagnostic Security](https://research.birmingham.ac.uk/portal/files/50643148/Beneath_the_Bonnet.pdf) и [Adventures in Automotive Networks and Control Units](https://ioactive.com/pdfs/IOActive_Adventures_in_Automotive_Networks_and_Control_Units.pdf).
Получив уровень доступа 0x03, пробуем произвести запись еще раз, увеличив значение на 1 км:
```
RX: <720> (8) 02 10 03 00 00 00 00 00
RX: <728> (8) 06 50 03 00 32 01 f4 00
RX: <720> (8) 02 27 03 00 00 00 00 00
RX: <728> (8) 05 67 03 XX XX XX 00 00
RX: <720> (8) 05 27 04 XX XX XX 00 00
RX: <728> (8) 02 67 04 00 00 00 00 00
RX: <720> (8) 06 2e 61 bb 00 e9 21 00
RX: <728> (8) 03 6e 61 bb 00 00 00 00
```
Тут же читаем обратно, чтобы проверить:
```
RX: <720> (8) 03 22 61 bb 00 00 00 00
RX: <728> (8) 06 62 61 bb 00 e9 21 00
```
Все получилось. А если уменьшить значение?.. Пробуем:
```
RX: <720> (8) 02 10 03 00 00 00 00 00
RX: <728> (8) 06 50 03 00 32 01 f4 00
RX: <720> (8) 02 27 03 00 00 00 00 00
RX: <728> (8) 05 67 03 XX XX XX 00 00
RX: <720> (8) 05 27 04 XX XX XX 00 00
RX: <728> (8) 02 67 04 00 00 00 00 00
RX: <720> (8) 06 2e 61 bb 00 e9 20 00
RX: <728> (8) 03 7f 2e 31 00 00 00 00
```
Панель отвечает ошибкой 0x31 `requestOutOfRange`, то есть новое значение не проходит проверку. Что ж, значит нужно искать другой путь.
### Вторичный загрузчик
Если вернуться к результатам сканирования, то можно найти в них `reprogrammingSession`. Обычно использование этой сессии подразумевает наличие вторичного загрузчика, и в случае с Ford его легко можно найти в открытом доступе. Поэтому мы попробуем его загрузить и посмотреть, что будет. Вдруг у него есть доступ к EEPROM?
Вторичный загрузчик (Secondary Bootloader) применяется для обновления прошивки ЭБУ следующим образом: SBL загружается в ОЗУ устройства, затем происходит передача управления SBL, после чего начинается чтение/запись флеш-памяти микроконтроллера. Упрощенно это можно представить так:
Для работы с прошивками Ford испольует формат VBF или Volvo Binary Format. Такой файл состоит из двух частей: человекочитаемого заголовка с адресом загрузки, типом данных и контрольной суммой; и бинарными данными для отправки в ЭБУ.
Последовательность загрузки SBL состоит из следующих шагов:
1. `DiagnosticSessionControl`: переход в сессию программирования 0x02;
2. `SecurityAccess`: получениe уровня доступа 0x01;
3. `RequestDownload`: адрес загрузки 0x03ff0000 (начало ОЗУ), размер передачи указывается как в VBF-файле;
4. `TransferData`: непосредственный процесс передачи данных;
5. `RequestTransferExit`: запрос завершения передачи данных;
6. `RoutineControl`: запуск рутины 0x0301, которая передает управление SBL.
После этого можно приступать к работе с флеш-памятью микроконтроллера: читать ее с помощью `RequestUpload` и записывать с помощью `RequestDownload`.
**Скрипт чтения флеш-памяти (работает с извлеченным из VBF бинарником)**
```
import can
import isotp
import time
import binascii
from udsoncan.connections import PythonIsoTpConnection
from udsoncan.client import Client
from udsoncan import Response, MemoryLocation, DataFormatIdentifier
from ford_glfsr import calculate_key
download_payload_size = 0xc8
upload_payload_size = 0x20
def my_error_handler(error):
logging.warning('IsoTp error happened : %s - %s' % (error.__class__.__name__, str(error)))
bus = can.interface.Bus(bustype='slcan',
channel="COM3",
ttyBaudrate=115200,
bitrate=125000)
tp_addr = isotp.Address(isotp.AddressingMode.Normal_11bits, txid=0x720, rxid=0x728)
stack = isotp.CanStack(bus=bus,
address=tp_addr,
params = {'tx_padding':0},
error_handler=my_error_handler)
conn = PythonIsoTpConnection(stack)
# wake up the IPC
ping_msg = can.Message(arbitration_id=0x080,
data=[0xff, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00],
is_extended_id=False)
bus.send(ping_msg)
time.sleep(0.2)
with Client(conn) as client:
# TesterPresent
client.tester_present()
# ChangeSession
client.change_session(0x02)
time.sleep(0.3)
# SecurityAccess
response = client.request_seed(0x01)
seed_int = int.from_bytes(response.service_data.seed, "little")
key_int = calculate_key(seed_int, 0x01)
key_bytes = key_int.to_bytes(3, byteorder="big")
client.send_key(0x01, key_bytes)
# RequestDownload
memloc = MemoryLocation(address=0x03ff0000,
memorysize=0x54d4,
address_format=32,
memorysize_format=32)
dfi = DataFormatIdentifier(compression=0, encryption=0)
client.request_download(memory_location=memloc, dfi=dfi)
# TransferData
f = open("BM5T-14C025-AD.bin", "rb")
ipc_sbl = f.read()
f.close()
end_block = 0x6d # memorysize/upload_payload_size
print("DOWNLOAD END BLOCK:", (hex(end_block)))
# sequence should start with "0x01", not "0x00"
for block_num in range(0x01, end_block + 0x01):
print(hex(block_num))
start_i = (block_num - 0x01) * download_payload_size
end_i = start_i + download_payload_size
client.transfer_data(block_num, ipc_sbl[start_i:end_i])
# TransferExit
client.request_transfer_exit()
# StartRoutine
client.start_routine(0x0301, data = b'\x03\xff\x00\x00')
# RequestUpload
memloc = MemoryLocation(address=0x00007000,
memorysize=0x000f9000,
address_format=32,
memorysize_format=32)
dfi = DataFormatIdentifier(compression=0, encryption=0)
client.request_upload(memory_location=memloc, dfi=dfi)
upload_result = bytearray()
end_block = 0x7c80 # memorysize/upload_payload_size
print("UPLOAD END BLOCK:", (hex(end_block)))
# sequence should start with "0x01", not "0x00"
for block_num in range(0x01, end_block + 0x01):
print(hex(block_num))
response = client.transfer_data(block_num % 0x100)
upload_result.extend(response.service_data.parameter_records)
f = open("flash_dump.bin", "wb")
f.write(upload_result)
f.close()
# TransferExit
try:
client.request_transfer_exit()
except:
pass
# ECUReset
client.ecu_reset(1)
```
Тем не менее, оказалось, что у SBL нет доступа к внешней EEPROM. Было перепробовано несколько разных SBL, но все попытки закончились ничем. С положительной стороны — у нас теперь есть возможность читать и записывать прошивку микроконтроллера. Что мешает отредактировать ее и залить обратно?
### Модификация прошивки
Получается, что есть отдельный DID для значений пробега, но запись работает только на увеличение; сам пробег лежит в EEPROM, куда прямого доступа у нас нет, ни из основной программы, ни из вторичного загрузчика. С такими входными данными нам стоит попробовать модифицировать родную прошивку таким образом, чтобы получить возможность мотать пробег назад. Для этого с помощью уже изученного процесса выкачивается содержимое флеш-памяти и изучается на предмет интересных функций.
Перед этим был экспериментально получен предел увеличения километража: по какой-то странной причине максимально возможное для установки значение составляет 4294967 км.
Этот "волшебное" число пригодилось для поиска операций с граничными значениями, в пределах которых можно изменять пробег в меньшую сторону. Найдя нечто похожее, заменяем одну из проверок на "nop":
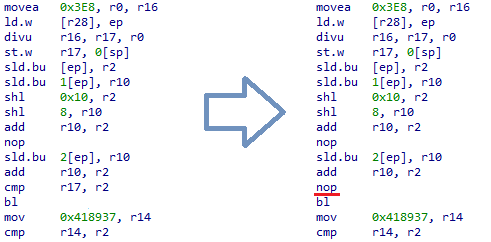
затем заливаем прошивку обратно, повторяем эксперимент:
```
TX: <720> (8) 02 10 03 00 00 00 00 00
RX: <728> (8) 06 50 03 00 32 01 f4 00
TX: <720> (8) 02 27 03 00 00 00 00 00
RX: <728> (8) 05 67 03 XX XX XX 00 00
TX: <720> (8) 05 27 04 XX XX XX 00 00
RX: <728> (8) 02 67 04 00 00 00 00 00
TX: <720> (8) 03 22 61 bb 00 00 00 00
RX: <728> (8) 06 62 61 bb 01 e2 40 00
TX: <720> (8) 06 2e 61 bb 01 38 d5 00
RX: <728> (8) 03 6e 61 bb 00 00 00 00
TX: <720> (8) 03 22 61 bb 00 00 00 00
RX: <728> (8) 06 62 61 bb 01 38 d5 00
```
Теперь все работает и можно мотать пробег в меньшую сторону, как самый настоящий злодей:

Скорее всего, коммерческие инструменты для изменения пробега работают другим способом, менее хлопотным.
### Подмена битмапов
После того, как основная работа проделана, можно и с битмапами поиграться. Например, взять и поменять приветственное лого панели.
Начинается все снова с изучения дампа, но в этот раз нужно найти в нем графические данные. Для этого очень удобно визуализировать файл дампа целиком, пример такого анализа с помощью GIMP был взят [отсюда](https://jergling.wordpress.com/2015/08/29/extracting-bitmaps-from-a-firmware-binary/).
Если вкратце, то нужно скормить GIMPу файл под видом raw-данных и, меняя цветовое представление и ширину поля, искать нечто похожее на изображения. Экран у выбранной панели монохромный (бинарный), поэтому тип изображения устанавливаем как "Ч/б 1 бит", а ширину подбираем экспериментально.
При ширине визуализации в 16 пикселей, обнаруживаются первые изображения (шрифт для 1, 2, 3, 4, 5, 6). Но при включении панели отображается логотип Ford, поэтому нужно продолжать поиски. Как оказалось, шрифты и маленькие иконки найти проще, чем крупное изображение, разбитое на куски. Поэтому логотип попался на глаза не с первой попытки:
Видите эти загогулины? Это два верхних участка буквы F в логотипе Ford. Если собрать все части воедино и склеить в картинку, то мы увидим следующий результат:

**Битмап Ford**
```
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 30 00 FC 00 FE 00 FF 80 E3 80 C1 C0 C0 40 C0 60 E0 60 E0 20 70 30 18 30 00 30 00 30 00 30 80 30 C0 20 F0 60 38 60 1C 60 0C 60 06 60 03 C0 C1 C0 20 C0 20 C0 C0 C0 00 C0 01 C0 01 80 01 80 01 80 03 80 03 80 03 80 07 80 07 80 07 80 07 80 0F 80 0F 80 0F 80 07 80 07 80 07 80 03 80 03 C0 01 C0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 80 00 C0 00 C0 00 C0 00 40 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 18 00 7E 00 FF 80 FF C0 E1 E0 C0 70 C0 30 80 10 80 00 80 01 C0 01 C0 03 E0 03 F0 01 F0 11 78 08 3C 04 1F 84 0F C4 07 E4 01 FE 80 3F C0 0F E0 07 78 03 FC 02 FF 82 CF C2 03 C2 01 E2 00 63 00 66 00 29 80 00 80 40 E0 60 F8 C0 7F C0 1F 00 06 00 07 80 83 C0 E1 E0 F0 60 FC 70 3E F0 1F E0 07 80 0F 80 39 C0 70 E0 70 F0 31 F0 31 E0 19 00 FC 00 FE 00 FF 80 1F 80 07 C0 01 E0 00 E0 00 70 80 70 C0 E0 E0 E0 FF 80 7F 80 3F E0 0F F0 07 FC 80 7E C0 1F E0 0F 60 03 00 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 01 00 01 00 03 00 03 00 07 00 07 00 07 00 07 00 03 00 03 00 01 00 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 01 00 01 00 00 00 00 00 01 00 03 00 07 00 07 00 07 00 07 00 07 00 03 00 03 00 03 00 01 00 00 00 00 00 00 00 04 00 07 00 07 00 07 00 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 03 00 07 00 0F 00 0E 00 0E 00 0E 00 06 00 07 00 03 00 07 00 0F 00 0F 00 0C 00 0C 00 06 00 07 00 03 00 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
```
Получается, что размер лого составляет 114x48 пикселей, оно состоит из 6 фрагментов, а адрес можно приблизительно понять с помощью сетки координат GIMP. Нам остается только отредактировать этот участок прошивки, загрузить его обратно:
и получить новое стартовое лого.
**Битмап Habr**
```
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 FC 00 FC 00 FC 00 FC 00 FC 00 FC 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 FC 00 FC 00 FC 00 FC 00 FC 00 FC 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 FF FF FF FF FF FF FF FF FF FF FF FF F0 01 F8 00 7C 00 7C 00 FC 00 FC 01 FC FF FC FF F8 FF F0 FF E0 FF C0 FF 00 00 00 00 00 00 00 3C 80 FF C0 FF E0 FF F0 FF F8 FF F8 C3 F8 81 F8 00 F8 00 F8 00 F8 00 F0 81 E0 C3 F8 FF F8 FF F8 FF F8 FF F8 FF 00 00 00 00 00 00 00 00 FF FF FF FF FF FF FF FF FF FF FF FF E0 C3 F0 81 F8 00 F8 00 F8 00 F8 00 F8 81 F8 C3 F8 FF F0 FF E0 FF C0 FF 80 FF 00 3C 00 00 00 00 00 00 F8 FF F8 FF F8 FF F8 FF F8 FF F8 FF E0 03 F0 01 F8 00 78 00 7C 00 FC 00 F8 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 1F 00 1F 00 1F 00 1F 00 1F 00 1F 00 00 00 00 00 00 00 00 00 00 00 00 00 1F 00 1F 00 1F 00 1F 00 1F 00 1F 00 00 00 00 00 00 00 00 00 01 00 03 00 07 00 0F 00 1F 00 1F 00 1F 00 1F 00 1F 00 1F 00 1F 00 0F 00 07 00 1F 00 1F 00 1F 00 1F 00 1F 00 00 00 00 00 00 00 00 00 1F 00 1F 00 1F 00 1F 00 1F 00 1F 00 07 00 0F 00 1F 00 1F 00 1F 00 1F 00 1F 00 1F 00 1F 00 0F 00 07 00 03 00 01 00 00 00 00 00 00 00 00 00 1F 00 1F 00 1F 00 1F 00 1F 00 1F 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
```
Приборная панель Mitsubishi Lancer X
------------------------------------
### Обзор
Железо:

*Замечание: точно определить модель микроконтроллера не получилось, т.к. маркировка не соответствует модели.*
Распиновка панели и конфигурация CAN:

Сессии и уровни доступа:
Таблица сервисов:
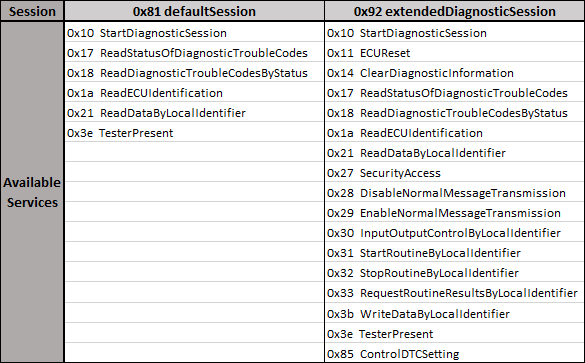
Сканирование показало, что доступны только две сессии: сессия по умолчанию и расширенная диагностическая. Установить точные наименования сессий и внести некоторую ясность помогла удачная находка. На просторах интернета можно найти обрывки документации начала 2000-х, в которой описаны основы применения KWP2000 для диагностики автомобилей альянса DaimlerChrysler-Mitsubishi, а именно марок Dodge, Chrysler, Jeep, Mitsubishi, Mercedes-Benz и Smart. Этот альянс уже давно распался, что добавляет нашим экспериментам немного автомобильной археологии.
Возвращаясь к доступным сервисам — их очень мало в `defaultSession`, по сути доступны только чтение ошибок, идентификационных данных и некоторых настроек. Записывать ничего нельзя, доступ к памяти отсутствует. В `extenedDiagnosticSession` открываются возможности запуска рутин и записи данных по идентификатору, но доступа к памяти все равно нет. В таком случае остается только перебирать доступные для чтения значения с помощью `ReadDataByLocalIdentifier` и попытаться изменить некоторые из них.
### Не все коту масленица
В этот раз перебор значений закончился гораздо быстрее, т.к. сервис `ReadDataByLocalIdentifier` может адресовать только 0xFF уникальных идентификаторов, в отличии от `ReadDataByIdentifier` где их может быть до 0xFFFF.
Значения пробега были обнаружены под DID 0xAD в виде трех байт:
```
TX: <6A0> (8) 02 21 ad 00 00 00 00 00
RX: <514> (8) 05 61 ad d0 18 03 00 00
```
Если попробуем использовать сервис `WriteDataByLocalIdentifier` и записать значение на 1 км больше, то сервер ответит отказом:
```
TX: <6A0> (8) 05 3b ad d1 18 03 00 00
RX: <514> (8) 03 7f 3b 12 00 00 00 00
```
Код ошибки 0x12 в ответном сообщении означает "Sub Function Not Supported" — то есть сервис записи по идентификатору работает корректно, но запись для него невозможна.
У нас осталось еще несколько непроверенных уровней доступа: вдруг если мы их получим, то операция станет возможной или откроются другие способы корректировки? Но для этого надо знать, как правильно это сделать. Поиск информации привел к очень полезной статье на хабре ["Что можно сделать через разъем OBD в автомобиле"](https://habr.com/ru/post/448658/), где автор смог извлечь алгоритм из более свежей цветной панели Mitsubishi с микроконтроллером другой архитектуры внутри. Оказалось, что алгоритм работает и для панели постарше, с помощью этой информации удалось подобрать и получить все три уровня доступа (0x01, 0x07 и 0x09). Самое время для повторной попытки:
```
TX: <6A0> (8) 02 10 92 00 00 00 00 00
RX: <514> (8) 02 50 92 d0 18 03 1e 00
TX: <6A0> (8) 02 27 01 00 00 00 00 00
RX: <514> (8) 06 67 01 XX XX XX XX 00
TX: <6A0> (8) 06 27 02 XX XX XX XX 00
RX: <514> (8) 03 67 02 34 1c ad 4f 00
TX: <6A0> (8) 02 27 07 00 00 00 00 00
RX: <514> (8) 06 67 07 XX XX XX XX 00
TX: <6A0> (8) 06 27 08 XX XX XX XX 00
RX: <514> (8) 03 67 08 34 36 74 26 00
TX: <6A0> (8) 02 27 09 00 00 00 00 00
RX: <514> (8) 06 67 09 XX XX XX XX 00
TX: <6A0> (8) 06 27 0a XX XX XX XX 00
RX: <514> (8) 03 67 0a 34 9f 1f f5 00
TX: <6A0> (8) 05 3b ad d1 18 03 00 00
RX: <514> (8) 03 7f 3b 12 9f 1f f5 00
```
которая снова возвращает ошибку. Кстати, забавный момент, по какой-то причине в ответах сервера застревают байты от предыдущих сообщений. Кто-то из разработчиков забыл про очистку буфера?
Множество других попыток и изысканий тоже закончилось ничем, что вызвало подозрения. Возникла идея проверить возможно ли это в принципе, а именно попробовать найти коммерческий инструмент для корректировки пробега, который может работать через OBDII с именно этой панелью и с этим микроконтроллером. В интернете таких инструментов нашлось много, но все они работали только с более свежими панелями.
Из упомянутой ранее документации можно узнать, что теоретически должна существовать еще одна сессия: `ECUFlashReprogrammingSession` (0x85) в которой открываются возможности для загрузки прошивки, но найти способ попасть в нее так и не удалось.
На этом этапе можно было бы взять программатор EEPROM, разобрать панель и просто перезаписать значения, но это отходит от диагностической темы данной статьи.
Впрочем, вполне вероятно, что-то было упущено и истина была где-то рядом.
### Извлеченный урок
Тем не менее, время потраченное на изучение панели Mitsubishi не пропало зря, поскольку в процессе получилось изучить отличия KWP2000 и UDS поближе, а также составить сравнительную таблицу:
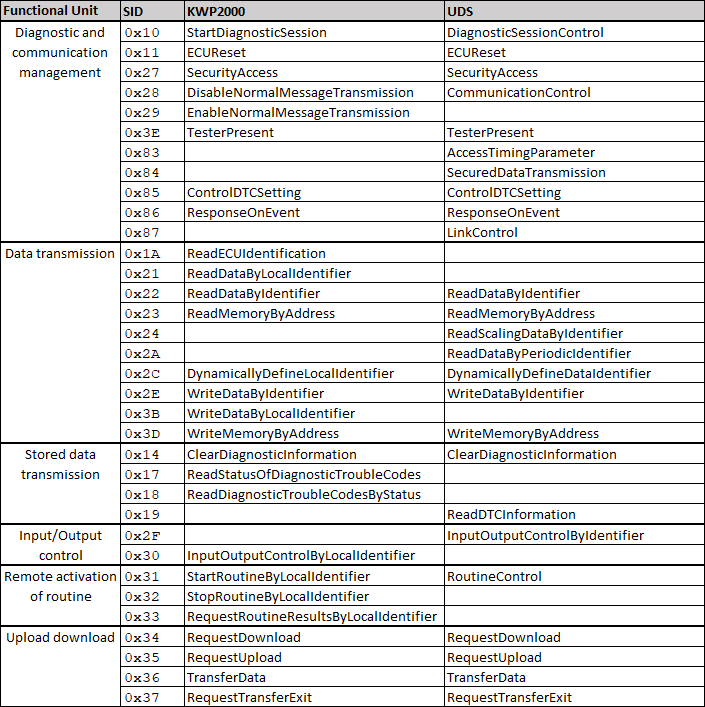
Для сравнения были использованы подмножество KWP2000 DaimlerChrysler-Mitsubishi, которое немного отличается от "чистого" KWP2000 и стандарт UDS 2006 года.
Сравнение интересно тем, что можно увидеть эволюцию, которую прошли протоколы диагностики. Например, избыточные сочетания сервисов были заменены одним сервисом, но с выбором подфункций: `DisableNormalMessageTransmission` / `EnableNormalMessageTransmission` заменены на `CommunicationControl`. То же касается и тройки `StartRoutineByLocalIdentifier` / `StopRoutineByLocalIdentifier` / `RequestRoutineResultsByLocalIdentifier`, которая превратилась в `RoutineControl`.
Если присмотреться внимательнее, то можно заметить, что в KWP2000 не хватает пары для `StartDiagnosticSession`, которая называлась бы `StopDiagnosticSession` и сбрасывала бы сервер в сессию по умолчанию. На самом деле, такой сервис может существовать, но он не входит в стандарт ISO 14230-3, и легко заменятся обычным вызовом `StartDiagnosticSession` с указанием перейти в сессию 0x81.
Поменялась логика чтения кодов неисправностей, добавлен сервис `AccessTimingParameter` для настройки продолжительности устанавливаемого соединения, `SecuredDataTransmission` для защиты сессии от прослушивания, `LinkControl` для настройки скорости соединения во время сессии.
Ну и самое заметное отличие — это упразднение `ReadECUIdentification`, который использовался для чтения идентификационных параметров модуля: VIN, серийный номер и т.д. В UDS вся эта информация читается обычным `ReadDataByIdentifier`, а для стандартных DID добавляется префикс 0xF1. Например для чтения VIN KWP2000 использует команду 0x1A90, а UDS — 0x22**F1**90. Этим удобно пользоваться, когда в руки попал незнакомый модуль и нужно быстро понять, какой из протоколов применять.
Заключение
----------
На основании проведенных экспериментов, можно сделать простой вывод — добиться необходимого результата можно если не средствами диагностики, то редактированием прошивки или EEPROM. Для разграничений уровней доступа применяются относительно несложные алгоритмы, подсказки к решению которых можно найти в диагностическом ПО, самой прошивке или прослушанной сессии. В некоторых случаях производитель может использовать проприентарный подход для сокрытия важной информации, который тоже можно обойти.
Тем не менее, ситуация может изменится к лучшему, совсем недавно вышла новая редакция стандарта UDS 14229-1:2020, в которой был добавлен отдельный сервис `Authentication` (0x29) для применения более сложных методов аутентификации. Также все больше автомобилей комплектуются телематикой и IoT услугами, откуда могут перекочевать ~~новые дыры в безопасности~~ разнообразные механизмы защиты, например secure boot, anti-rollback прошивки и т.п.
Так что вполне вероятно, что провернуть похожий трюк лет 10 спустя станет сложнее. | https://habr.com/ru/post/526734/ | null | ru | null |
# Идеальный инструмент для работы с СУБД без SQL для Node.js или Все, что вы хотели знать о Sequelize. Часть 3
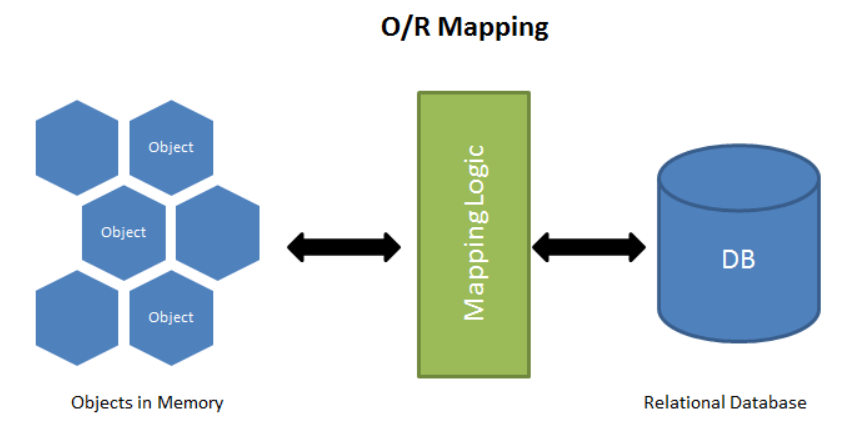
Доброго времени суток, друзья!
Представляю вашему вниманию руководство по `Sequelize`.
[`Sequelize`](https://sequelize.org/master/) — это [`ORM`](https://ru.wikipedia.org/wiki/ORM) (Object-Relational Mapping — объектно-реляционное отображение или преобразование) для работы с такими [СУБД](https://ru.wikipedia.org/wiki/%D0%A1%D0%B8%D1%81%D1%82%D0%B5%D0%BC%D0%B0_%D1%83%D0%BF%D1%80%D0%B0%D0%B2%D0%BB%D0%B5%D0%BD%D0%B8%D1%8F_%D0%B1%D0%B0%D0%B7%D0%B0%D0%BC%D0%B8_%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85) (системами управления (реляционными) базами данных, Relational Database Management System, RDBMS), как `Postgres`, `MySQL`, `MariaDB`, `SQLite` и `MSSQL`. Это далеко не единственная `ORM` для работы с названными базами данных (далее — БД), но, на мой взгляд, одна из самых продвинутых и, что называется, "battle tested" (проверенных временем).
`ORM` хороши тем, что позволяют взаимодействовать с БД на языке приложения (`JavaScript`), т.е. без использования специально предназначенных для этого языков (`SQL`). Тем не менее, существуют ситуации, когда запрос к БД легче выполнить с помощью `SQL` (или можно выполнить только c помощью него). Поэтому перед изучением настоящего руководства рекомендую бросить хотя бы беглый взгляд на `SQL`. Вот [соответствующая шпаргалка](https://habr.com/ru/company/macloud/blog/564390/).
Это третья и последняя часть руководства, в которой мы поговорим об областях видимости ассоциаций, полиморфных ассоциациях, транзакциях, хуках, интерфейсе запросов, подзапросах, индексах, а также о многом другом.
[Первая часть](https://habr.com/ru/company/macloud/blog/565062/).
[Вторая часть](https://habr.com/ru/post/566036/).
Я постараюсь быть максимально лаконичным (надеюсь, без ущерба для полноты изложения материала). Я также постараюсь излагать материал максимально простым языком. Большинство примеров, приводимых в руководстве, заимствованы из официальной документации.
Содержание
----------
* [Область видимости ассоциаций](#%D0%BE%D0%B1%D0%BB%D0%B0%D1%81%D1%82%D1%8C-%D0%B2%D0%B8%D0%B4%D0%B8%D0%BC%D0%BE%D1%81%D1%82%D0%B8-%D0%B0%D1%81%D1%81%D0%BE%D1%86%D0%B8%D0%B0%D1%86%D0%B8%D0%B9)
* [Полиморфные ассоциации](#%D0%BF%D0%BE%D0%BB%D0%B8%D0%BC%D0%BE%D1%80%D1%84%D0%BD%D1%8B%D0%B5-%D0%B0%D1%81%D1%81%D0%BE%D1%86%D0%B8%D0%B0%D1%86%D0%B8%D0%B8)
* [Транзакции](#%D1%82%D1%80%D0%B0%D0%BD%D0%B7%D0%B0%D0%BA%D1%86%D0%B8%D0%B8)
* [Хуки](#%D1%85%D1%83%D0%BA%D0%B8)
* [Интерфейс запросов](#%D0%B8%D0%BD%D1%82%D0%B5%D1%80%D1%84%D0%B5%D0%B9%D1%81-%D0%B7%D0%B0%D0%BF%D1%80%D0%BE%D1%81%D0%BE%D0%B2)
* [Стратегии именования](#%D1%81%D1%82%D1%80%D0%B0%D1%82%D0%B5%D0%B3%D0%B8%D0%B8-%D0%B8%D0%BC%D0%B5%D0%BD%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F)
* [Области видимости](#%D0%BE%D0%B1%D0%BB%D0%B0%D1%81%D1%82%D0%B8-%D0%B2%D0%B8%D0%B4%D0%B8%D0%BC%D0%BE%D1%81%D1%82%D0%B8)
* [Подзапросы](#%D0%BF%D0%BE%D0%B4%D0%B7%D0%B0%D0%BF%D1%80%D0%BE%D1%81%D1%8B)
* [Ограничения и циклические ссылки](#%D0%BE%D0%B3%D1%80%D0%B0%D0%BD%D0%B8%D1%87%D0%B5%D0%BD%D0%B8%D1%8F-%D0%B8-%D1%86%D0%B8%D0%BA%D0%BB%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B5-%D1%81%D1%81%D1%8B%D0%BB%D0%BA%D0%B8)
* [Индексы](#%D0%B8%D0%BD%D0%B4%D0%B5%D0%BA%D1%81%D1%8B)
* [Пул соединений](#%D0%BF%D1%83%D0%BB-%D1%81%D0%BE%D0%B5%D0%B4%D0%B8%D0%BD%D0%B5%D0%BD%D0%B8%D0%B9)
* [Миграции](#%D0%BC%D0%B8%D0%B3%D1%80%D0%B0%D1%86%D0%B8%D0%B8)
Область видимости ассоциаций
----------------------------
Область видимости ассоциаций (assosiation scopes) похожа на области видимости моделей в том, что обе автоматически применяют к запросам такие вещи, как предложение `where`; разница между ними состоит в том, что область модели применяется к вызовам статических методов для поиска, а область ассоциации — к вызовам поисковых методов экземпляра (таким как миксины).
Пример применения области ассоциации для отношений один-ко-многим:
```
// настройка
const Foo = sequelize.define('foo', { name: DataTypes.STRING })
const Bar = sequelize.define('bar', { status: DataTypes.STRING })
Foo.hasMany({Bar, {
scope: {
status: 'open'
},
as: 'openBars'
}})
await sequelize.sync()
const foo = await Foo.create({ name: 'Foo' })
await foo.getOpenBars()
```
Последний вызов приводит к генерации такого запроса:
```
SELECT
`id`, `status`, `createdAt`, `updatedAt`, `fooId`
FROM `bars` AS `bar`
WHERE `bar`.`status` = 'open' AND `bar`.`fooId` = 1;
```
Мы видим, что область ассоциации `{ status: 'open' }` была автоматически добавлена в предложение `WHERE`.
На самом деле, мы можем добиться такого же поведения с помощью стандартной области видимости:
```
Bar.addScope('open', {
where: {
status: 'open',
},
})
Foo.hasMany(Bar)
Foo.hasMany(Bar.scope('open'), { as: 'openBars' })
```
После этого, вызов `foo.getOpenBars()` вернет аналогичный результат.
**[↑ Наверх](#)**
Полиморфные ассоциации
----------------------
Полиморфная ассоциация (polymorphic assosiation) состоит из двух и более ассоциаций, взаимодействующих с одним внешним ключом.
Предположим, что у нас имеется три модели: `Image`, `Video` и `Comment`. Первые две модели — это то, что может разместить пользователь. Мы хотим разрешить комментирование этих вещей. На первый вгляд, может показаться, что требуются такие ассоциации:
* ассоциация один-ко-многим между `Image` и `Comment`
```
Image.hasMany(Comment)
Comment.belongsTo(Image)
```
* ассоциация один-ко-многим между `Video` и `Comment`
```
Video.hasMany(Comment)
Comment.belongsTo(Video)
```
Однако, это может привести к тому, что `Sequelize` создаст в таблице `Comment` два внешних ключа: `imageId` и `videoId`. Такая структура означает, что комментарий добавляется одновременно к одному изображению и одному видео, что не соответствует действительности. Нам нужно, чтобы `Comment` указывал на единичный `Commentable`, абстрактную полиморфную сущность, представляющую либо `Image`, либо `Video`.
Перед настройкой такой ассоциации, рассмотрим пример ее использования:
```
const image = await Image.create({ url: 'http://example.com' })
const comment = await image.createComment({ content: 'Круто!' })
copnsole.log(comment.commentableId === image.id) // true
// Мы можем получать информацию о том, с каким типом `commentable` связан комментарий
console.log(comment.commentableType) // Image
// Мы можем использовать полиморфный метод для извлечения связанного `commentable`,
// независимо от того, чем он является, `Image` или `Video`
const associatedCommentable = await comment.getCommentable()
// Обратите внимание: `associatedCommentable` - это не тоже самое, что `image`
```
**Создание полиассоциации один-ко-многим**
Для настройки полиассоциации для приведенного выше примера (полиассоциации один-ко-многим) необходимо выполнить следующие шаги:
* определить строковое поле `commentableType` в модели `Comment`
* определить ассоциацию `hasMany` и `belongsTo` между `Image` / `Video` и `Comment`
+ отключить ограничения (`{ constraints: false }`), поскольку один и тот же внешний ключ будет ссылаться на несколько таблиц
+ определить соответствущую область видимости ассоциации
* для поддержки ленивой загрузки — определить новый метод экземпляра `getCommentable()` в модели `Comment`, который под капотом будет вызывать правильный миксин для получения соответствующего `commentable`
* для поддержки нетерпеливой загрузки — определить хук `afterFind()` в модели `Comment`, автоматически заполняющий поле `commentable` каждого экземпляра
* для предотвращения ошибок при нетерпеливой загрузке, можно удалять поля `image` и `video` из экземпляров комментария в хуке `afterFind()`, оставляя в них только абстрактное поле `commentable`
```
// Вспомогательная функция
const capitilize = ([first, ...rest]) =>
`${first.toUpperCase()}${rest.join('').toLowerCase()}`
const Image = sequelize.define('image', {
title: DataTypes.STRING,
url: DataTypes.STRING,
})
const Video = sequelize.define('video', {
title: DataTypes.STRING,
text: DataTypes.STRING,
})
// в данном случае нам необходимо создать статическое поле, поэтому мы используем расширение `Model`
class Comment extends Model {
getCommentable(options) {
if (!this.commentableType) return Promise.resolve(null)
const mixinMethodName = `get${capitilize(this.commentableType)}`
return this[mixinMethodName](options)
}
}
Comment.init(
{
title: DataTypes.STRING,
commentableId: DataTypes.INTEGER,
commentableType: DataTypes.STRING,
},
{ sequelize, modelName: 'comment' }
)
Image.hasMany(Comment, {
foreignKey: 'commentableId',
constraints: false,
scope: {
commentableType: 'image',
},
})
Comment.belongsTo(Image, { foreignKey: 'commentableId', constraints: false })
Video.hasMany(Comment, {
foreignKey: 'commentableId',
constraints: false,
scope: {
commentableType: 'video',
},
})
Comment.belongsTo(Video, { foreignKey: 'commentableId', constraints: false })
Comment.addHook('afterFind', (findResult) => {
if (!Array.isArray(findResult)) findResult = [findResult]
for (const instance of findResult) {
if (instance.commentableType === 'image' && instance.image !== undefined) {
instance.commentable = instance.image
} else if (
instance.commentableType === 'video' &&
instance.video !== undefined
) {
instance.commentable = instance.video
}
// Для предотвращения ошибок
delete instance.image
delete inctance.dataValues.image
delete instance.video
delete instance.dataValues.video
}
})
```
Поскольку колонка `commentableId` ссылается на несколько таблиц (в данном случае две), мы не можем применить к ней ограничение `REFERENCES`. Поэтому мы указываем `constraints: false`.
Обратите внимание на следующее:
* ассоциация `Image -> Comment` определяет область `{ commentableType: 'image' }`
* ассоциация `Video -> Comment` определяет область `{ commentableType: 'video' }`
Эти области автоматически применяются при использовании ассоциативных функций. Несколько примеров:
* `image.getComments()`
```
SELECT 'id', 'title', 'commentableType', 'commentableId', 'createdAt', 'updatedAt'
FROM 'comments' AS 'comment'
WHERE 'comment'.'commentableType' = 'image' AND 'comment'.'commentableId' = 1;
```
Мы видим, что `'comment'.'commentableType' = 'image'` была автоматически добавлена в предложение `WHERE`. Это именно то, чего мы хотели добиться.
* `image.createComment({ title: 'Круто!' })`
```
INSERT INTO 'comments' (
'id', 'title', 'commentableType', 'commentableId', 'createdAt', 'updatedAt'
) VALUES (
DEFAULT, 'Круто!', 'image', 1,
'[timestamp]', '[timestamp]'
) RETURNING *;
```
* `image.addComment(comment)`
```
UPDATE 'comments'
SET 'commentableId'=1, 'commentableType'='image', 'updatedAt'='2018-04-17 05:38:43.948 +00:00'
WHERE 'id' IN (1)
```
**Полиморфная ленивая загрузка**
Метод экземпляра `getCommentable()` предоставляет абстракцию для ленивой загрузки связанного `commentable` — комментария, принадлежащего `Image` или `Video`.
Это работает благодаря преобразованию строки `commentableType` в вызов правильного миксина (`getImage()` или `getVideos()`, соответственно).
Обратите внимание, что приведенная выше реализация `getCommentable()`:
* возвращает `null` при отсутствии ассоциации
* позволяет передавать объект с настройками в `getCommentable(options)`, подобно любому другому (стандартному) методу. Это может пригодиться, например, при определении условий или включений.
**Полиморфная нетерпеливая загрузка**
Теперь мы хотим выполнить полиморфную нетерпеливую загрузку связанных `commentable` для одного (или более) комментария:
```
const comment = await Comment.findOne({
include: [
/* Что сюда поместить? */
],
})
console.log(comment.commentable) // Наша цель
```
Решение состоит во включении `Image` и `Video` для того, чтобы хук `afterFind()` мог автоматически добавить поле `commentable` в экземпляр.
Например:
```
const comments = await Comment.findAll({
include: [Image, Video],
})
for (const comment of comments) {
const message = `Найден комментарий #${comment.id} с типом '${comment.commentableType}':\n`
console.log(message, comment.commentable.toJSON())
}
```
Вывод:
```
Найден комментарий #1 с типом 'image':
{
id: 1,
title: 'Круто!',
url: 'http://example.com',
createdAt: [timestamp],
updatedAt: [timestamp]
}
```
**Настройка полиассоциации многие-ко-многим**
Предположим, что вместо комментариев у нас имеются теги. Соответственно, вместо `commentables` у нас будут `taggables`. Один `taggable` может иметь несколько тегов, в то же время один тег может быть помещен в несколько `taggable`.
Для настройки рассматриваемой полиассоциации необходимо выполнить следующие шаги:
* явно создать соединительную модель, определив в ней два внешних ключа: `tagId` и `taggableId` (данная таблица будет соединять `Tag` и `taggable`)
* определить в соединительной таблице строковое поле `taggableType`
* определить ассоциацию `belongsToMany()` между двумя моделями и `Tag`:
* отключить ограничения (`{ constraints: false }`), поскольку один и тот же внешний ключ будет ссылаться на несколько таблиц
* определить соответствующие области видимости ассоциаций
* определить новый метод экземпляра `getTaggables()` в модели `Tag`, который под капотом будет вызывать правильный миксин для получения соответствующих `taggables`
```
class Tag extends Model {
getTaggables(options) {
const images = await this.getImages(options)
const videos = this.getVideos(options)
// Объединяем изображения и видео в один массив `taggables`
return images.concat(videos)
}
}
Tag.init({
name: DataTypes.STRING
}, { sequelize, moelName: 'tag' })
// Явно определяем соединительную таблицу
const Tag_Taggable = sequelize.define('tag_taggable', {
tagId: {
type: DataTypes.INTEGER,
unique: 'tt_unique_constraint'
},
taggableId: {
type: DataTypes.INTEGER,
unique: 'tt_unique_contraint'
},
taggableType: {
type: DataTypes.STRING,
unique: 'tt_unique_constraint'
}
})
Image.belongsToMany(Tag, {
through: {
model: Tag_Taggable,
unique: false,
scope: {
taggableType: 'image'
}
},
foreignKey: 'taggableId',
constraints: false
})
Tag.belongsToMany(Image, {
through: {
model: Tag_Taggable,
unique: false,
foreignKey: 'tagId',
constraints: false
}
})
Video.belongsToMany(Tag, {
through: {
model: Tag_Taggable,
unique: false,
scope: {
taggableType 'video'
}
},
foreignKey: 'taggableId',
constraints: false
})
Tag.belongsToMany(Video, {
through: {
model: Tag_Taggable,
unique: false
},
foreignKey: 'tagId',
constraints: false
})
```
* `image.getTags()`
```
SELECT
`tag`.`id`,
`tag`.`name`,
`tag`.`createdAt`,
`tag`.`updatedAt`,
`tag_taggable`.`tagId` AS `tag_taggable.tagId`,
`tag_taggable`.`taggableId` AS `tag_taggable.taggableId`,
`tag_taggable`.`taggableType` AS `tag_taggable.taggableType`,
`tag_taggable`.`createdAt` AS `tag_taggable.createdAt`,
`tag_taggable`.`updatedAt` AS `tag_taggable.updatedAt`
FROM `tags` AS `tag`
INNER JOIN `tag_taggables` AS `tag_taggable` ON
`tag`.`id` = `tag_taggable`.`tagId` AND
`tag_taggable`.`taggableId` = 1 AND
`tag_taggable`.`taggableType` = 'image';
```
* `tag.getTaggables()`
```
SELECT
`image`.`id`,
`image`.`url`,
`image`.`createdAt`,
`image`.`updatedAt`,
`tag_taggable`.`tagId` AS `tag_taggable.tagId`,
`tag_taggable`.`taggableId` AS `tag_taggable.taggableId`,
`tag_taggable`.`taggableType` AS `tag_taggable.taggableType`,
`tag_taggable`.`createdAt` AS `tag_taggable.createdAt`,
`tag_taggable`.`updatedAt` AS `tag_taggable.updatedAt`
FROM `images` AS `image`
INNER JOIN `tag_taggables` AS `tag_taggable` ON
`image`.`id` = `tag_taggable`.`taggableId` AND
`tag_taggable`.`tagId` = 1;
SELECT
`video`.`id`,
`video`.`url`,
`video`.`createdAt`,
`video`.`updatedAt`,
`tag_taggable`.`tagId` AS `tag_taggable.tagId`,
`tag_taggable`.`taggableId` AS `tag_taggable.taggableId`,
`tag_taggable`.`taggableType` AS `tag_taggable.taggableType`,
`tag_taggable`.`createdAt` AS `tag_taggable.createdAt`,
`tag_taggable`.`updatedAt` AS `tag_taggable.updatedAt`
FROM `videos` AS `video`
INNER JOIN `tag_taggables` AS `tag_taggable` ON
`video`.`id` = `tag_taggable`.`taggableId` AND
`tag_taggable`.`tagId` = 1;
```
**Применение области ассоциации к целевой модели**
Область ассоциации может применяться не только к соединительной таблице, но и к целевой модели.
Добавим тегам статус. Для получения всех тегов со статусом `pending` определим еще одну ассоциацию `belongsToMany()` между `Image` и `Tag`, применив область ассоциации как к соединительной таблице, так и к целевой модели:
```
Image.belongsToMany(Tag, {
through: {
model: Tag_Taggable,
unique: false,
scope: {
taggableType: 'image',
},
},
scope: {
status: 'pending',
},
as: 'pendingTags',
foreignKey: 'taggableId',
constraints: false,
})
```
После этого, вызов `image.getPendingTags()` приведет к генерации такого запроса:
```
SELECT
`tag`.`id`,
`tag`.`name`,
`tag`.`status`,
`tag`.`createdAt`,
`tag`.`updatedAt`,
`tag_taggable`.`tagId` AS `tag_taggable.tagId`,
`tag_taggable`.`taggableId` AS `tag_taggable.taggableId`,
`tag_taggable`.`taggableType` AS `tag_taggable.taggableType`,
`tag_taggable`.`createdAt` AS `tag_taggable.createdAt`,
`tag_taggable`.`updatedAt` AS `tag_taggable.updatedAt`
FROM `tags` AS `tag`
INNER JOIN `tag_taggables` AS `tag_taggable` ON
`tag`.`id` = `tag_taggable`.`tagId` AND
`tag_taggable`.`taggableId` = 1 AND
`tag_taggable`.`taggableType` = 'image'
WHERE (
`tag`.`status` = 'pending'
);
```
Мы видим, что обе области были автоматически применены:
* в `INNER JOIN` было добавлено `tag_taggable.taggableType = 'image'`
* в `WHERE` — `tag.status = 'pending'`
**[↑ Наверх](#)**
Транзакции
----------
`Sequelize` поддерживает выполнение двух видов транзакций:
1. Неуправляемые (unmanaged): завершение транзакции и отмена изменений выполняются вручную (путем вызова соответствующих методов)
2. Управляемые (managed): при возникновении ошибки изменения автоматически отменяются, а при успехе транзакции автоматически выполняется фиксация (commit) изменений
**Неуправляемые транзакции**
Начнем с примера:
```
// Сначала мы запускаем транзакцию и сохраняем ее в переменную
const t = await sequelize.transaction()
try {
// Затем при выполнении операций передаем транзакцию в качестве соответствующей настройки
const user = await User.create(
{
firstName: 'John',
lastName: 'Smith',
},
{ transaction: t }
)
await user.addSibling(
{
firstName: 'Jane',
lastName: 'Air',
},
{ transaction: t }
)
// Если выполнение кода достигло этой точки,
// значит, выполнение операций завершилось успешно -
// фиксируем изменения
await t.commit()
} catch (err) {
// Если выполнение кода достигло этой точки,
// значит, во время выполнения операций возникла ошибка -
// отменяем изменения
await t.rollback()
}
```
**Управляемые тразакции**
Для выполнения управляемой транзакции в `sequelize.transaction()` передается функция обратного вызова. Далее происходит следующее:
* `Sequelize` автоматически запускает транзакцию и создает объект `t`
* Затем выполняется переданный колбэк, которому передается `t`
* При возникновении ошибки, изменения автоматически отменяются
* При успехе транзакции, изменения автоматически фиксируются
Таким образом, `sequelize.transaction()` либо разрешается с результатом, возвращаемым колбэком, либо отклоняется с ошибкой.
```
try {
const result = await sequelize.transaction(async (t) => {
const user = await User.create(
{
firstName: 'John',
lastName: 'Smith',
},
{ transaction: t }
)
await user.addSibling(
{
firstName: 'Jane',
lastName: 'Air',
},
{ transaction: t }
)
return user
})
// Если выполнение кода достигло этой точки,
// значит, выполнение операций завершилось успешно -
// фиксируем изменения
} catch (err) {
// Если выполнение кода достигло этой точки,
// значит, во время выполнения операций возникла ошибка -
// отменяем изменения
}
```
*Обратите внимание*: при выполнении управляемой транзакции, нельзя вручную вызывать методы `commit()` и `rollback()`.
**Автоматическая передача транзакции во все запросы**
В приведенных примерах транзакция передавалась вручную — `{ transaction: t }`. Для автоматической передачи транзакции во все запросы необходимо установить модуль [`cls-hooked`](https://github.com/Jeff-Lewis/cls-hooked) (CLS — Continuation Local Storage, "длящееся" локальное хранилище) и инстанцировать пространство имен (namespace):
```
const cls = require('cls-hooked')
const namespace = cls.createNamespace('my-namespace')
```
Затем следует использовать это пространство имен следующим образом:
```
const Sequelize = require('sequelize')
Sequelize.useCLS(namespace)
new Sequelize(/* ... */)
```
*Обратите внимание*: мы вызываем метод `useCLS()` на конструкторе, а не на экземпляре. Это означает, что пространство имен будет доступно всем экземплярам, а также, что `CLS` — это "все или ничего", нельзя включить его только для некоторых экземпляров.
`CLS` представляет собой что-то вроде локального хранилища в виде потока для колбэков. На практике это означает, что разные цепочки из колбэков могут использовать локальные переменные из одного пространства `CLS`. После включения `CLS`, `t` автоматически передается при создании транзакции. Поскольку переменные являются частными для цепочки колбэков, одновременно может выполняться несколько транзакций:
```
sequelize.transaction((t1) => {
console.log(namespace.get('transaction') === t1) // true
})
sequelize.transaction((t2) => {
console.log(namespace.get('transaction') === t2) // true
})
```
В большинстве случаев, в явном вызове `namespace.get('transaction')` нет необходимости, поскольку все запросы автоматически получают транзакцию из пространства имен:
```
sequelize.transaction((t1) => {
// С включенным CLS пользователь будет создан внутри транзакции
return User.create({ name: 'John' })
})
```
**Параллельные/частичные транзакции**
С помощью последовательности запросов можно выполнять параллельные транзакции. Также имеется возможность исключать запросы из транзакции. Для управления тем, каким транзакциям принадлежит запрос, используется настройка `transaction` (обратите внимание: `SQLite` не поддерживает одновременное выполнение более одной транзакции).
С включенным `CLS`:
```
sequelize.transaction((t1) => {
return sequelize.transaction((t2) => {
// С включенным `CLS` все запросы здесь по умолчанию будут использовать `t2`
// Настройка `transaction` позволяет это изменить
return Promise.all([
User.create({ name: 'John' }, { transaction: null }),
User.create({ name: 'Jane' }, { transaction: t1 }),
User.create({ name: 'Alice' }), // этот запрос будет использовать `t2`
])
})
})
```
**Уровни изоляции**
Возможные уровни изоляции при запуске транзакции:
```
const { Transaction } = require('sequelize')
Transaction.ISOLATION_LEVELS.READ_UNCOMMITTED
Transaction.ISOLATION_LEVELS.READ_COMMITTED
Transaction.ISOLATION_LEVELS.REPEATABLE_READ
Transaction.ISOLATION_LEVELS.SERIALIZABLE
```
По умолчанию `Sequelize` использует уровень изоляции БД. Для изменения уровня изоляции используется настройка `isolationLevel`:
```
const { Transaction } = require('sequelize')
await sequelize.transaction(
{
isolationLevel: Transaction.ISOLATION_LEVELS.SERIALIZABLE,
},
async (t) => {
// ...
}
)
```
Или на уровне всего приложения:
```
const sequelize = new Sequelize('sqlite::memory:', {
isolationLevel: Transaction.ISOLATION_LEVELS.SERIALIZABLE,
})
```
**Использование транзакции совместно с другими методами**
Обычно, `transaction` передается в метод вместе с другими настройками в качестве первого аргумента.
Для методов, принимающих значения, таких как `create()`, `update()` и т.п., `transaction` передается в качестве второго аргумента.
```
await User.create({ name: 'John' }, { transaction: t })
await User.findAll({
where: {
name: 'Jane',
},
transaction: t,
})
```
**Хук `afterCommit()`**
Объект `transaction` позволяет регистрировать фиксацию изменений. Хук `afterCommit()` может быть добавлен как к управляемым, так и к неуправляемым объектам транзакции:
```
// Управляемая транзакция
await sequelize.transaction(async (t) => {
t.afterCommit(() => {
// ...
})
})
// Неуправляемая транзакция
const t = await sequelize.transaction()
t.afterCommit(() => {
// ...
})
await t.commit()
```
Колбэк, передаваемый в `afterCommit()`, является асинхронным. В данном случае:
* для управляемой транзакции: вызов `sequelize.transaction()` будет ждать его завершения
* для неуправляемой транзакции: вызов `t.commit()` будет ждать его завершения
*Обратите внимание* на следующее:
* `afterCommit()` не запускается при отмене изменений
* он не модифицирует значение, возвращаемое транзакцией (в отличие от других хуков)
Хук `afterCommit()` можно использовать в дополнение к хукам модели для определения момента сохранения экземпляра и его доступности за пределами транзакции:
```
User.afterSave((instance, options) => {
if (options.transaction) {
// Ожидаем фиксации изменений для уведомления подписчиков о сохранении экземпляра
options.transaction.afterCommit(() => /* Уведомление */)
return
}
})
```
**[↑ Наверх](#)**
Хуки
----
Хуки или события жизненного цикла (hooks) — это функции, которые вызываются до или после вызова методов `Sequelize`. Например, для установки значения модели перед ее сохранением можно использовать хук `beforeUpdate()`.
*Обратите внимание*: хуки могут использоваться только на уровне моделей.
**Доступные хуки**
`Sequelize` предоставляет большое количество хуков. Их полный список можно найти [здесь](https://github.com/sequelize/sequelize/blob/v6/lib/hooks.js#L73). Порядок вызова наиболее распространенных хуков следующий:
```
(1)
beforeBulkCreate(instances, options)
beforeBulkDestroy(options)
beforeBulkUpdate(options)
(2)
beforeValidate(instance, options)
[... здесь выполняется валидация ...]
(3)
afterValidate(instance, options)
validationFailed(instance, options, error)
(4)
beforeCreate(instance, options)
beforeDestroy(instance, options)
beforeUpdate(instance, options)
beforeSave(instance, options)
beforeUpsert(values, options)
[... здесь выполняется создание/обновление/удаление ...]
(5)
afterCreate(instance, options)
afterDestroy(instance, options)
afterUpdate(instance, options)
afterSave(instance, options)
afterUpsert(created, options)
(6)
afterBulkCreate(instances, options)
afterBulkDestroy(options)
afterBulkUpdate(options)
```
**Определение хуков**
Аргументы в хуки передаются по ссылкам. Это означает, что мы можем модифицировать значения и это отразится на соответствующих инструкциях. Хук может содержать асинхронные операции — в этом случае функция должна возвращать промис.
Существует три способа программного добавления хуков:
```
// 1) через метод `init()`
class User extends Model {}
User.init(
{
username: DataTypes.STRING,
mood: {
type: DataTypes.ENUM,
values: ['счастливый', 'печальный', 'индифферентный'],
},
},
{
hooks: {
beforeValidate: (user, options) => {
user.mood = 'счастливый'
},
afterValidate: (user, options) => {
user.username = 'Ванька'
},
},
sequelize,
}
)
// 2) через метод `addHook()`
User.addHook('beforeValidate', (user, options) => {
user.mood = 'счастливый'
})
User.addHook('afterValidate', 'someCustomName', (user, options) => {
return Promise.reject(
new Error('К сожалению, я не могу позволить вам этого сделать.')
)
})
// 3) напрямую
User.beforeCreate(async (user, options) => {
const hashedPassword = await hashPassword(user.password)
user.password = hashedPassword
})
User.afterValidate('myAfterHook', (user, options) => {
user.username = 'Ванька'
})
```
*Обратите внимание*, что удаляться могут только именованные хуки:
```
const Book = sequelize.define('book', {
title: DataTypes.STRING,
})
Book.addHook('afterCreate', 'notifyUsers', (book, options) => {
// ...
})
Book.removeHook('afterCreate', 'notifyUsers')
```
**Глобальные/универсальные хуки**
Глобальными называются хуки, которые выполняются для всех моделей. Особенно полезными такие хуки являются в плагинах. Они определяются двумя способами:
* в настройках конструктора (хуки по умолчанию)
```
const sequelize = new Sequelize(/*...*/, {
define: {
hooks: {
beforeCreate() {
// ...
}
}
}
})
// Дефолтные хуки запукаются при отсутствии в модели аналогичных хуков
const User = sequelize.define('user', {})
const Project = sequelize.define('project', {}, {
hooks: {
beforeCreate() {
// ...
}
}
})
await User.create({}) // запускается глобальный хук
await Project.create({}) // запускается локальный хук
```
* с помощью `sequelize.addHook()` (постоянные хуки)
```
sequelize.addHook('beforeCreate', () => {
// ...
})
// Такой хук запускается независимо от наличия у модели аналогичного хука
const User = sequelize.define('user', {})
const Project = sequelize.define(
'project',
{},
{
hooks: {
beforeCreate() {
// ...
},
},
}
)
await User.create({}) // запускается глобальный хук
await Project.create({}) // сначала запускается локальный хук, затем глобальный
```
**Хуки, связанные с подключением к БД**
Существует 4 хука, выполняемые до и после подключения к БД и отключения от нее:
* `sequelize.beforeConnect(callback)` — колбэк имеет сигнатуру `async (config) => {}`
* `sequelize.afterConnect(callback)` — `async (connection, config) => {}`
* `seuqelize.beforeDisconnect(callback)` — `async (connection) => {}`
* `sequelize.afterDisconnect(callback)` — `async (connection) => {}`
Эти хуки могут использоваться для асинхронного получения полномочий (credentials) для доступа к БД или получения прямого доступа к низкоуровневому соединению с БД после его установки.
Например, мы можем асинхронно получить пароль от БД из хранилища токенов и модифицировать объект с настройками:
```
sequelize.beforeConnect(async (config) => {
config.password = await getAuthToken()
})
```
Рассматриваемые хуки могут быть определены только как глобальные, поскольку соединение является общим для всех моделей.
**Хуки экземпляров**
Следующие хуки будут запускаться при редактировании единичного объекта:
* `beforeValidate`
* `afterValidate`/`validationFailed`
* `beforeCreate`/`beforeUpdate`/`beforeSave`/`beforeDestroy`
* `afterCreate`/`afterUpdate`/`afterSave`/`afterDestroy`
```
User.beforeCreate((user) => {
if (user.accessLevel > 10 && user.username !== 'Сенсей') {
throw new Error(
'Вы не можете предоставить этому пользователю уровень доступа выше 10'
)
}
})
// Будет выброшено исключение
try {
await User.create({ username: 'Гуру', accessLevel: 20 })
} catch (err) {
console.error(err) // Вы не можете предоставить этому пользователю уровень доступа выше 10
}
// Ок
const user = await User.create({
username: 'Сенсей',
accessLevel: 20,
})
```
**Хуки моделей**
При вызове методов `bulkCreate()`, `update()` и `destroy()` запускаются следующие хуки:
* `beforeBulkCreate(callback)` — колбэк имеет сигнатуру `(instances, options) => {}`
* `beforeBulkUpdate(callback)` — `(options) => {}`
* `beforeBulkDestroy(callback)` — `(options) => {}`
* `afterBulkCreate(callback)` — `(instances, options) => {}`
* `afterBulkUpdate(callback)` — `(options) => {}`
* `afterBulkDestroy(callback)` — `(options) => {}`
*Обратите внимание*: вызов методов моделей по умолчанию приводит к запуску только хуков с префиксом `bulk`. Это можно изменить с помощью настройки `{ individualHooks: true }`, но имейте ввиду, что это может крайне негативно сказаться на производительности.
```
await Model.destroy({
where: { accessLevel: 0 },
individualHooks: true,
})
await Model.update(
{ username: 'John' },
{
where: { accessLevel: 0 },
individualHooks: true,
}
)
```
**Хуки и ассоциации**
*Один-к-одному и один-ко-многим*
* при использовании миксинов `add`/`set` запускаются хуки `beforeUpdate()` и `afterUpdate()`
* хуки `beforeDestroy()` и `afterDestroy()` запускаются только при наличии у ассоциаций `onDelete: 'CASCADE'` и `hooks: true`
```
const Project = sequelize.define('project', {
title: DataTypes.STRING,
})
const Task = sequelize.define('task', {
title: DataTypes.STRING,
})
Project.hasMany(Task, { onDelete: 'CASCADE', hooks: true })
Task.belongsTo(Project)
```
По умолчанию `Sequelize` пытается максимально оптимизировать запросы. Например, при вызове каскадного удаления `Sequelize` выполняет:
```
DELETE FROM `table` WHERE associatedIdentifier = associatedIdentifier.primaryKey;
```
Однако, добавление `hooks: true` отключает оптимизации. В этом случае `Sequelize` сначала выполняет выборку связанных объектов с помощью `SELECT` и затем уничтожает каждый экземпляр по одному для обеспечения вызова соответствующих хуков с правильными параметрами.
*Многие-ко-многим*
* при использовании миксинов `add` для отношений `belongsToMany()` (когда в соединительной таблице создается как минимум одна запись) запускаются хуки `beforeBulkCreate()` и `afterBulkCreate()` соединительной таблицы
* если указано `{ individualHooks: true }`, то также вызываются индивидуальные хуки
* при использовании миксинов `remove` запускаются хуки `beforeBulkDestroy()` и `afterBulkDestroy()`, а также индивидуальные хуки при наличии `{ individualHooks: true }`
**Хуки и транзакции**
Если в оригинальном вызове была определена транзакция, она будет передана в хук вместе с другими настройками:
```
User.addHook('afterCreate', async (user, options) => {
// Мы можем использовать `options.transaction` для выполнения другого вызова
// с помощью той же транзакции, которая запустила данный хук
await User.update(
{ mood: 'печальный' },
{
where: {
id: user.id,
},
transaction: options.transaction,
}
)
})
await sequelize.transaction(async (t) => {
await User.create({
username: 'Ванька',
mood: 'счастливый',
transaction: t,
})
})
```
Если мы не передадим транзакцию в вызов `User.update()`, обновления не произойдет, поскольку созданный пользователь попадет в БД только после фиксации транзакции.
Важно понимать, что `Sequelize` автоматически использует транзакции при выполнении некоторых операций, таких как `Model.findOrCreate()`. Если хуки выполняют операции чтения или записи на основе объекта из БД или модифицируют значения объекта как в приведенном выше примере, всегда следует определять `{ transaction: options.transaction }`.
**[↑ Наверх](#)**
Интерфейс запросов
------------------
Каждый экземпляр использует интерфейс запросов (query interface) для взаимодействия с БД. Методы этого интерфейса являются низкоуровневыми в сравнении с обычными методами. Но, разумеется, по сравнению с запросами SQL, они являются высокоуровневыми.
Рассмотрим несколько примеров использования методов названного интерфейса (полный список методов можно найти [здесь](https://sequelize.org/master/class/lib/dialects/abstract/query-interface.js~QueryInterface.html)).
Получение интерфейса запросов:
```
const { Sequelize, DataTypes } = require('sequelize')
const sequelize = new Sequelize(/* ... */)
const queryInterface = sequelize.getQueryInterface()
```
Создание таблицы:
```
queryInterface.createTable('Person', {
name: DataTypes.STRING,
isBetaMember: {
type: DataTypes.BOOLEAN,
defaultValue: false,
allowNull: false,
},
})
```
Генерируемый `SQL`:
```
CREATE TABLE IF NOT EXISTS `Person` (
`name` VARCHAR(255),
`isBetaMember` TINYINT(1) NOT NULL DEFAULT 0
);
```
Добавление в таблицу новой колонки:
```
queryInterface.addColumn('Person', 'petName', { type: DataTypes.STRING })
```
`SQL`:
```
ALTER TABLE `Person` ADD `petName` VARCHAR(255);
```
Изменение типа данных колонки:
```
queryInterface.changeColumn('Person', 'foo', {
type: DataTypes.FLOAT,
defaultValue: 3.14,
allowNull: false,
})
```
`SQL`:
```
ALTER TABLE `Person` CHANGE `foo` `foo` FLOAT NOT NULL DEFAULT 3.14;
```
Удаление колонки:
```
queryInterface.removeColumn('Person', 'petName', {
/* настройки */
})
```
`SQL`:
```
ALTER TABLE 'public'.'Person' DROP COLUMN 'petName';
```
**[↑ Наверх](#)**
Стратегии именования
--------------------
`Sequelize` предоставляет настройку `underscored` для моделей. Когда эта настройка имеет значение `true`, значение настройки `field` (название поля) всех атрибутов приводится к `snake_case`. Это также справедливо по отношению к внешним ключам и другим автоматически генерируемым полям.
```
const User = sequelize.define(
'user',
{ username: DataTypes.STRING },
{
underscored: true,
}
)
const Task = sequelize.define(
'task',
{ title: DataTypes.STRING },
{
underscored: true,
}
)
User.hasMany(Task)
Task.belongsTo(User)
```
У нас имеется две модели, `User` и `Task`, обе с настройками `underscored`. Между этими моделями установлена ассоциация один-ко-многим. Также, поскольку настройка `timestamps` по умолчанию имеет значение `true`, в обеих таблицах будут автоматически созданы поля `createdAt` и `updatedAt`.
Без настройки `underscored` произойдет автоматическое создание:
* атрибута `createdAt` для каждой модели, указывающего на колонку `createdAt` каждой таблицы
* атрибута `updatedAt` для каждой модели, указывающего на колонку `updatedAt` каждой таблицы
* атрибута `userId` в модели `Task`, указыващего на колонку `userId` таблицы `task`
С настройкой `underscored` будут автоматически созданы:
* атрибут `createdAt` для каждой модели, указывающего на колонку `created_at` каждой таблицы
* атрибут `updatedAt` для каждой модели, указывающего на колонку `updated_at` каждой таблицы
* атрибут `userId` в модели `Task`, указыващего на колонку `user_id` таблицы `task`
*Обратите внимание*: в обоих случаях названия полей именуются в стиле `camelCase`.
Во втором случае вызов `sync()` приведет к генерации такого `SQL`:
```
CREATE TABLE IF NOT EXISTS "users" (
"id" SERIAL,
"username" VARCHAR(255),
"created_at" TIMESTAMP WITH TIME ZONE NOT NULL,
"updated_at" TIMESTAMP WITH TIME ZONE NOT NULL,
PRIMARY KEY ("id")
);
CREATE TABLE IF NOT EXISTS "tasks" (
"id" SERIAL,
"title" VARCHAR(255),
"created_at" TIMESTAMP WITH TIME ZONE NOT NULL,
"updated_at" TIMESTAMP WITH TIME ZONE NOT NULL,
"user_id" INTEGER REFERENCES "users" ("id") ON DELETE SET NULL ON UPDATE CASCADE,
PRIMARY KEY ("id")
);
```
**Использование единственного и множественного чисел**
При определении моделей:
```
// При определении модели должно использоваться единственное число
sequelize.define('foo', { name: DataTypes.STRING })
```
В данном случае названием соответствующей таблицы будет `foos`.
При определении ссылок в модели:
```
sequelize.define('foo', {
name: DataTypes.STRING,
barId: {
type: DataTypes.INTEGER,
allowNull: false,
references: {
model: 'bars',
key: 'id',
},
onDelete: 'CASCADE',
},
})
```
При извлечении данных при нетерпеливой загрузке.
При добавлении в запрос `include`, в возвращаемом объекте создается дополнительное поле согласно следующим правилам:
* при включении данных из единичной ассоциации (`hasOne()` или `belongsTo()`) — название поля указывается в единственном числе
* при включении данных из множественной ассоциации (`hasMany()` или `belongsToMany()`) — название поля указывается во множественном числе
```
// Foo.hasMany(Bar)
const foo = Foo.findOne({ include: Bar })
// foo.bars будет массивом
// Foo.hasOne(Bar)
const foo = Foo.findOne({ include: Bar })
// foo.bar будет объектом
// и т.д.
```
**Кастомизация названий при определении синонимов**
При определении синонима для ассоциации вместо `{ as: 'myAlias' }` можно передать объект с единичной и множественной формами таблицы:
```
Project.belongsToMany(User, {
as: {
singular: 'líder',
plural: 'líderes',
},
})
```
Если модель будет использовать один и тот же синоним во всех ассоциациях, формы можно указать прямо в модели:
```
const User = sequelize.define(
'user',
{
/* ... */
},
{
name: {
singular: 'líder',
plural: 'líderes',
},
}
)
Project.belongsToMany(User)
```
При этом, в миксинах будут использоваться правильные формы, например, `getLíder()`, `setLíderes()` и т.д.
*Обратите внимание*: при использовании `as` для изменения названия ассоциации, также будет изменено название внешнего ключа. Поэтому в данном случае также рекомендуется явно определять название внешнего ключа, причем, в обоих вызовах:
```
Invoice.belongsTo(Subscription, {
as: 'TheSubscription',
foreignKey: 'subscription_id',
})
Subscription.hasMany(Invoice, { foreignKey: 'subscription_id' })
```
**[↑ Наверх](#)**
Области видимости
-----------------
Области видимости (scopes) (далее — области) облегчают повторное использование кода. Они позволяют определить часто используемые настройки, такие как `where`, `include`, `limit` и т.д.
**Определение**
Области определяются при создании модели и могут быть поисковыми объектами или функциями, возвращающими такие объекты, за исключением дефолтной области, которая может быть только объектом:
```
const Project = sequelize.define(
'project',
{
/* ... */
},
{
defaultScope: {
where: {
active: true,
},
},
scopes: {
deleted: {
where: {
deleted: true,
},
},
activeUsers: {
include: [
{
model: User,
where: { active: true }
}
],
},
random() {
return {
where: {
someNum: Math.random(),
},
}
},
accessLevel(value) {
return {
where: {
accesLevel: {
[Op.gte]: value,
},
},
}
},
},
}
)
```
Области также могут определяться с помощью метода `Model.addScope()`. Это может быть полезным при определении областей для включений, когда связанная модель может быть не определена в момент создания основной модели.
Дефолтная область применяется всегда. Это означает, что в приведенном примере вызов `Project.findAll()` сгенерирует такой запрос:
```
SELECT * FROM projects WHERE active = true;
```
Дефолтная область может быть удалена с помощью `unscoped()`, `scope(null)` или посредством вызова другой области:
```
await Project.scope('deleted').findAll()
```
```
SELECT * FROM projects WHERE deleted = true;
```
Также имеется возможность включать модели из области в определение области. Это позволяет избежать дублирования `include`, `attributes` или `where`:
```
Project.addScope('activeUsers', {
include: [
{ model: User.scope('active') }
],
})
```
**Использование**
Области применяются путем вызова метода `scope(scopeName)`. Этот метод возвращает полнофункциональный экземпляр модели со всеми обычными методами: `findAll()`, `update()`, `count()`, `destroy()` и т.д.
```
const DeletedProjects = Project.scope('deleted')
await DeletedProjects.findAll()
// Это эквивалентно следующему
await Project.findAll({
where: {
deleted: true,
},
})
```
Области применяются к `find()`, `findAll()`, `count()`, `update()`, `increment()` и `destroy()`.
Области-функции могут вызываться двумя способами. Если область не принимает аргументов, она вызывается как обычно. Если область принимает аргументы, ей передается объект:
```
await Project.scope('random', { method: ['accessLevel', 10] })
```
`SQL`:
```
SELECT * FROM projects WHERE someNum = 42 AND accessLevel >= 10;
```
**Объединение областей**
Объединяемые области указываются через запятую или передаются в виде массива:
```
await Project.scope('deleted', 'activeUsers').findAll()
await Project.scope(['deleted', 'activeUsers']).findAll()
```
`SQL`:
```
SELECT * FROM projects
INNER JOIN users ON projects.userId = users.id
WHERE projects.deleted = true
AND users.active = true;
```
Объединение дефолтной и кастомной областей:
```
await Project.scope('defaultScope', 'deleted').findAll()
```
При вызове нескольких областей, ключи последующих областей перезаписывают ключи предыдущих областей (по аналогии с `Object.assign()`), за исключением `where` и `include`, в которых ключи объединяются. Рассмотрим две области:
```
Model.addScope('scope1', {
where: {
firstName: 'John',
age: {
[Op.gt]: 20,
},
},
limit: 20,
})
Model.addScope('scope2', {
where: {
age: {
[Op.gt]: 30,
},
},
limit: 10,
})
```
Вызов `scope('scope1', 'scope2')` приведет к генерации такого предложения `WHERE`:
```
WHERE firstName = 'John' AND age > 30 LIMIT 10;
```
Атрибуты `limit` и `age` были перезаписаны, а `firstName` сохранен.
При объединении ключей атрибутов из нескольких областей предполагается `attributes.exclude()`. Это обеспечивает учет регистра полей при объединении, т.е. сохранение чувствительных полей в финальном результате.
Такая же логика объединения используется при прямой передаче поискового объекта в `findAll()` (и аналогичные методы):
```
Project.scope('deleted').findAll({
where: {
firstName: 'Jane',
},
})
```
`SQL`:
```
WHERE deleted = true AND firstName = 'Jane';
```
Если мы передадим `{ firstName: 'Jane', deleted: false }`, область `deleted` будет перезаписана.
**Объединение включений**
Включения объединяются рекурсивно на основе включаемых моделей.
Предположим, что у нас имеются такие модели с ассоциацией один-ко-многим:
```
const Foo = sequelize.define('Foo', { name: DataTypes.STRING })
const Bar = sequelize.define('Bar', { name: DataTypes.STRING })
const Baz = sequelize.define('Baz', { name: DataTypes.STRING })
const Qux = sequelize.define('Qux', { name: DataTypes.STRING })
Foo.hasMany(Bar, { foreignKey: 'fooId' })
Bar.hasMany(Baz, { foreignKey: 'barId' })
Baz.hasMany(Qux, { foreignKey: 'bazId' })
```
Далее, предположим, что мы определили для модели `Foo` такие области:
```
Foo.adScope('includeEverything', {
indluce: {
model: Bar,
include: [
{
model: Baz,
include: Qux,
},
],
},
})
Foo.addScope('limitedBars', {
include: [
{
model: Bar,
limit: 2,
},
],
})
Foo.addScope('limitedBazs', {
include: [
{
model: Bar,
include: [
{
model: Baz,
limit: 2,
},
],
},
],
})
Foo.addScope('excludedBazName', {
include: [
{
model: Bar,
include: [
{
model: Baz,
attributes: {
exclude: ['name'],
},
},
],
},
],
})
```
Эти 4 области легко (и глубоко) объединяются. Например, вызов `Foo.scope('includeEverything', 'limitedBars', 'limitedBazs', 'excludedBazName')` эквивалентен следующему:
```
await Foo.findAll({
include: {
model: Bar,
limit: 2,
include: [
{
model: Baz,
limit: 2,
attributes: {
exclude: ['name'],
},
include: Qux,
},
],
},
})
```
**[↑ Наверх](#)**
Подзапросы
----------
Предположим, что у нас имеется две модели, `Post` и `Reaction`, с ассоциацией один-ко-многим:
```
const Post = sequelize.define(
'Post',
{
content: DataTypes.STRING,
},
{ timestamps: false }
)
const Reaction = sequelize.define(
'Reaction',
{
type: DataTypes.STRING,
},
{ timestamps: false }
)
Post.hasMany(Reaction)
Reaction.belongsTo(Post)
```
Заполним эти таблицы данными:
```
const createPostWithReactions = async (content, reactionTypes) => {
const post = await Post.create({ content })
await Reaction.bulkCreate(
reactionTypes.map((type) => ({ type, postId: post.id }))
)
return post
}
await createPostWithReactions('My First Post', [
'Like',
'Angry',
'Laugh',
'Like',
'Like',
'Angry',
'Sad',
'Like',
])
await createPostWithReactions('My Second Post', [
'Laugh',
'Laugh',
'Like',
'Laugh',
])
```
Допустим, что мы хотим вычислить `laughReactionsCount` для каждого поста. С помощью подзапроса `SQL` это можно сделать так:
```
SELECT *, (
SELECT COUNT(*)
FROM reactions AS reaction
WHERE
reaction.postId = post.id
AND
reaction.type = 'Laugh'
) AS laughReactionsCount
FROM posts AS post;
```
Результат:
```
[
{
"id": 1,
"content": "My First Post",
"laughReactionsCount": 1
},
{
"id": 2,
"content": "My Second Post",
"laughReactionsCount": 3
}
]
```
`Sequelize` предоставляет специальную утилиту `literal()` для работы с подзапросами. Данная утилита принимает подзапрос `SQL`. Т.е. `Sequelize` помогает с основным запросом, но подзапрос должен быть реализован вручную:
```
Post.findAll({
attributes: {
include: [
[
sequelize.literal(`(
SELECT COUNT(*)
FROM reactions AS reaction
WHERE
reaction.postId = post.id
AND
reaction.type = 'Laugh'
)`),
'laughReactionsCount',
],
],
},
})
```
Результат выполнения данного запроса будет таким же, как при выполнении SQL-запроса.
При использовании подзапросов можно выполнять группировку возвращаемых значений:
```
Post.findAll({
attributes: {
include: [
[
sequelize.literal(`(
SELECT COUNT(*)
FROM reactions AS reaction
WHERE
reaction.postId = post.id
AND
reaction.type = 'Laugh'
)`),
'laughReactionsCount',
],
],
},
order: [
[sequelize.literal('laughReactionsCount'), 'DESC']
],
})
```
Результат:
```
[
{
"id": 2,
"content": "My Second Post",
"laughReactionsCount": 3
},
{
"id": 1,
"content": "My First Post",
"laughReactionsCount": 1
}
]
```
**[↑ Наверх](#)**
Ограничения и циклические ссылки
--------------------------------
Добавление ограничений между таблицами означает, что таблицы должны создаваться в правильном порядке при использовании `sequelize.sync()`. Если `Task` содержит ссылку на `User`, тогда таблица `User` должна быть создана первой. Иногда это может привести к циклическим ссылкам, когда `Sequelize` не может определить порядок синхронизации. Предположим, что у нас имеются документы и версии. Документ может иметь несколько версий. Он также может содержать ссылку на текущую версию.
```
const Document = sequelize.define('Document', {
author: DataTypes.STRING,
})
const Version = sequelize.define('Version', {
timestamp: DataTypes.STRING,
})
Document.hasMany(Version)
Document.belongsTo(Version, {
as: 'Current',
foreignKey: 'currentVersionId',
})
```
Однако, это приведет к возникновению ошибки:
```
Cyclic dependency found. documents is dependent of itself. Dependency chain: documents -> versions => documents
```
Для решения этой проблемы необходимо передать `constraints: false` в одну из ассоциаций:
```
Document.hasMany(Version)
Document.belongsTo(Version, {
as: 'Current',
foreignKey: 'currentVersionId',
constraints: false,
})
```
Иногда может потребоваться указать ссылку на другую таблицу без создания ограничений или ассоциаций. В этом случае ссылку и отношения между таблицами можно определить явно:
```
const Trainer = sequelize.define('Trainer', {
firstName: DataTypes.STRING,
lastName: DataTypes.STRING,
})
// `Series` будет содержать внешнюю ссылку `trainerId = Trainer.id`
// после вызова `Trainer.hasMany(series)`
const Series = sequelize.define('Series', {
title: DataTypes.STRING,
subTitle: DataTypes.STRING,
description: DataTypes.TEXT,
// Определяем отношения один-ко-многим с `Trainer`
trainerId: {
type: DataTypes.INTEGER,
references: {
model: Trainer,
key: 'id',
},
},
})
// `Video` будет содержэать внешнюю ссылку `seriesId = Series.id`
// после вызова `Series.hasOne(Video)`
const Video = sequelize.define('Video', {
title: Sequelize.STRING,
sequence: Sequelize.INTEGER,
description: Sequelize.TEXT,
// Устанавливаем отношения один-ко-многим с `Series`
seriesId: {
type: DataTypes.INTEGER,
references: {
model: Series, // Может быть как строкой, представляющей название таблицы, так и моделью
key: 'id',
},
},
})
Series.hasOne(Video)
Trainer.hasMany(Series)
```
**[↑ Наверх](#)**
Индексы
-------
`Sequelize` поддерживает индексирование моделей:
```
const User = sequelize.define(
'User',
{
/* атрибуты */
},
{
indexes: [
// Создаем уникальный индекс для адреса электронной почты
{
unique: true,
fields: ['email'],
},
// Создание обратного индекса для данных с помощью оператора `jsonb_path_ops`
{
fields: ['data'],
using: 'gin',
operator: 'jsonb_path_ops',
},
// По умолчанию название индекса будет иметь вид `[table]_[fields]`
// Создаем частичный индекс для нескольких колонок
{
name: 'public_by_author',
fields: ['author', 'status'],
where: {
status: 'public',
},
},
// Индекс `BTREE` с сортировкой
{
name: 'title_index',
using: 'BTREE',
fields: [
'author',
{
attribute: 'title',
collate: 'en_US',
order: 'DESC',
length: 5,
},
],
},
],
}
)
```
**[↑ Наверх](#)**
Пул соединений
--------------
Подключение к БД с помощью одного процесса означает создание одного экземпляра `Sequelize`. При инициализации `Sequelize` создает пул соединений (connection pool). Этот пул может быть настроен с помощью настройки `pool`:
```
const sequelize = new Sequelize(/* ... */, {
// ...
pool: {
min: 0,
max: 5,
acquire: 30000,
idle: 10000
}
})
```
При подключении к БД с помощью нескольких процессов, для каждого процесса создается отдельный экземпляр с максимальным размером пула подключений с учетом общего максимального размера.
**[↑ Наверх](#)**
Миграции
--------
Подобно тому, как вы используете систему контроля версий, такую как `Git`, для контроля за изменениями кодовой базы, миграции (migrations) позволяют контролировать изменения, вносимые в БД. Миграции позволяют переводить БД из одного состояния в другое и обратно: изменения состояния сохраняются в файлах миграции, описывающих, как получить новое состояние или как отменить изменения для того, чтобы вернуться к предыдущему состоянию.
Для работы с миграциями, а также для генерации шаблона проекта, используется [`интерфейс командной строки Sequelize`](https://github.com/sequelize/cli).
Миграция — это JS-файл, из которого экспортируется 2 функции, `up` и `down`, описывающие выполнение миграции и ее отмену, соответственно. Эти функции определяются вручную, но вызываются с помощью `CLI`. В функциях указываются необходимые запросы с помощью `sequelize.query()` или других методов.
**Установка `CLI`:**
```
yarn add sequelize-cli
# или
npm i sequelize-cli
```
**Генерация шаблона**
Для создания пустого проекта используется команда `init`:
```
sequelize-cli init
```
Будут созданы следующие директории:
* `config` — файл с настройками подключения к БД
* `models` — модели для проекта
* `migrations` — файлы с миграциями
* `seeders` — файлы для заполнения БД начальными (фиктивными) данными
**Настройка**
Далее нам нужно сообщить `CLI`, как подключиться к БД. Для этого откроем файл `config/config.json`. Он выглядит примерно так:
```
{
"development": {
"username": "root",
"password": null,
"database": "database_development",
"host": "127.0.0.1",
"dialect": "mysql"
},
"test": {
"username": "root",
"password": null,
"database": "database_test",
"host": "127.0.0.1",
"dialect": "mysql"
},
"production": {
"username": "root",
"password": null,
"database": "database_production",
"host": "127.0.0.1",
"dialect": "mysql"
}
}
```
Редактируем этот файл, устанавливая правильные ключи для доступа к БД и диалект `SQL`.
*Обратите внимание*: для создания БД можно выполнить команду `db:create`.
**Создание первой модели и миграции**
После настройки `CLI` можно приступать к созданию миграций. Мы создадим ее с помощью команды `model:generate`. Это команда принимает 2 настройки:
* `name`: название модели
* `attributes`: список атрибутов модели
```
sequelize-cli model:generate --name User --attributes firstName:string,lastName:string, email:string
```
Данная команда создаст:
* файл `user.js` в директории `models`
* файл `XXXXXXXXXXXXXX-create-user.js` в директории `migrations`
**Запуск миграций**
Для создания таблицы в БД используется команда `db:migrate`:
```
sequelize-cli db:migrate
```
Данная команда выполняет следующее:
* создает в БД таблицу `SequelizeMeta`. Это таблица используется для записи миграций, выполняемых для текущей БД
* выполняет поиск файлов с миграциями, которые еще не запускались. В нашем случае будет запущен файл `XXXXXXXXXXXXXX-create-user.js`
* создается таблица `Users` с колонками, определенными в миграции
**Отмена миграций**
Для отмены миграций используется команда `db:migrate:undo`:
```
sequelize-cli db:migrate:undo
```
Для отмены всех миграций используется команда `db:migrate:undo:all`, а для отката к определенной миграции — `db:migrate:undo:all --to XXXXXXXXXXXXXX-create-posts.js`.
**Создание скрипта для наполнения БД начальными данными**
Предположим, что мы хотим создать дефолтного пользователя в таблице `Users`. Для управления миграциями данных можно использовать сеятелей (seeders). Засеивание файла — это наполнение таблицы начальными или тестовыми данными.
Создадим файл с кодом, при выполнении которого будет выполняться создание дефолтного пользователя в таблице `Users`.
```
sequelize-cli seed:generate --name demo-user
```
После выполнения этой команды в директории `seeders` появится файл `XXXXXXXXXXXXXX-demo-user.js`. В нем используется такая же семантика `up / down`, что и в файлах миграций.
Отредактриуем этот файл:
```
module.exports = {
up: (queryInterface, Sequelize) => {
return queryInterface.bulkInsert('Users', [
{
firstName: 'John',
lastName: 'Smith',
email: '[email protected]',
createdAt: new Date(),
updatedAt: new Date(),
},
])
},
down: (queryInterface, Sequelize) =>
queryInterface.bulkDelete('Users', null, {}),
}
```
Для запуска сеятеля используется команда `db:seed:all`:
```
sequelize-cli db:seed:all
```
Для отмены последнего сеятеля используется команда `db:seed:undo`, для отмены определенного сеятеля — `db:seed:undo --seed seedName`, для отмены всех сеятелей — `db:seed:undo:all`.
*Обратите внимание*: отменяемыми являются только те сеятели, которые используют какое-либо хранилище (см. ниже; в отличие от миграций, информация о сеятелях не сохраняется в таблице `SequelizeMeta`).
**Шаблон миграции**
Шаблон миграции выглядит так:
```
module.exports = {
up: (queryInterface, Sequelize) => {
// Логика перехода к новому состоянию
},
down: (queryIntarface, Sequelize) => {
// Логика отмены изменений
},
}
```
Мы можем создать этот файл с помощью `migration:generate`. Эта команда создаст файл `xxx-migration-skeleton.js` в директории для миграций.
```
sequelize-cli migration:generate --name migrationName
```
Объект `queryInterface` используется для модификации БД. Объект `Sequelize` содержит доступные типы данных, такие как `STRING` или `INTEGER`. Функции `up()` и `down()` должны возвращать промис. Рассмотрим простой пример создания/удаления таблицы `User`:
```
module.exports = {
up: (queryInterface, { DataTypes }) =>
queryInterface.createTable('User', {
name: DataTypes.STRING,
isBetaMember: {
type: DataTypes.BOOLEAN,
defaultValue: false,
allowNull: false,
},
}),
down: (queryInterface) => queryInterface.dropTable('User'),
}
```
В следующем примере миграция производит два изменения в БД (добавляет две колонки в таблицу `User`) с помощью управляемой транзакции, обеспечивающей успешное выполнение всех операций или отмену изменений при возникновении ошибки:
```
module.exports = {
up: (queryInterface, { DataTypes }) =>
queryInterface.sequelize.transaction((transaction) =>
Promise.all([
queryInterface.addColumn('User', 'petName', {
DataTypes.STRING
}, { transaction }),
queryInterface.addColumn('User', 'favouriteColor', {
type: DataTypes.STRING
}, { transaction })
])
),
down: (queryInterface) =>
queryInterface.sequelize.transaction((transaction) =>
Promise.all([
queryInterface.removeColumn('User', 'petName', { transaction }),
queryInterface.removeColumn('User', 'favouriteColor', { transaction })
])
)
}
```
Следующий пример демонстрирует использование в миграции внешнего ключа:
```
module.exports = {
up: (queryInterface, { DataTypes }) =>
queryInterface.createTable('Person', {
name: DataTypes.STRING,
isBetaMember: {
type: DataTypes.BOOLEAN,
defaultValue: false,
allowNull: false,
},
userId: {
type: DataTypes.INTEGER,
references: {
model: {
tableName: 'users',
schema: 'schema',
},
key: 'id',
},
allowNull: false,
},
}),
down: (queryInterface) => queryInterface.dropTable('Person'),
}
```
Следующий пример демонстирует использование синтаксиса `async/await`, создание уникального индекса для новой колонки и неуправляемой транзакции:
```
module.exports = {
async up(queryInterface, { DataTypes }) {
const transaction = await queryInterface.sequelize.transaction()
try {
await queruyInterface.addColumn(
'Person',
'petName',
{ type: DataTypes.STRING },
{ transaction }
)
await queryInterface.addIndex(
'Person',
'petName',
{
fields: 'petName',
unique: true,
transaction
}
)
await transaction.commit()
} catch (err) {
await transaction.rollback()
throw err
}
},
async down(queryInterface) {
const transaction = await queryInterface.sequelize.transaction()
try {
await queryInterface.removeColumn('Person'. 'petName', { transaction })
await transaction.commit()
} catch (err) {
await transaction.rollback()
throw err
}
}
}
```
Следующий пример демонстрирует создание уникального индекса на основе композиции из нескольких полей с условием, которое позволяет отношениям существовать много раз, но только одно будет удовлетворять условию:
```
modulex.exports = {
up: (queryInterface, { DataTypes }) =>
queryInterface
.createTable('Person', {
name: DataTypes.STRING,
bool: {
type: DataTypes.BOOLEAN,
defaultValue: false,
},
})
.then((queryInterface) =>
queryInterface.addIndex('Person', ['name', 'bool'], {
indicesType: 'UNIQUE',
where: { bool: true },
})
),
down: (queryInterface) => queryInterface.dropTable('Person'),
}
```
**Хранилище**
Существует три вида хранилища:
* `sequelize` — хранит миграции и сеятелей в таблице в БД
* `json` — хранит миграции и сеятелей в JSON-файле
* `none` — ничего не хранит
*Хранилище миграций*
По умолчанию `CLI` создает в БД таблицу `SequelizeMeta` для хранения записей о миграциях. Для изменения этого поведения существует 3 настройки, которые можно добавить в файл конфигурации `.sequelizerc`. Тип хранилища указывается в настройке `migrationStorage`. При выборе типа `json`, путь к файлу можно указать в настройке `migrationStoragePath` (по умолчанию данные будут записываться в файл `sequelize-meta.json`). Для изменения названия таблицы для хранения информации о миграциях в БД используется настройка `migrationStorageTableName`. Свойства `migrationStorageTableSchema` позволяет изменить используемую таблицей `SequelizeMeta` схему.
```
{
"development": {
"username": "root",
"password": null,
"database": "database_development",
"host": "127.0.0.1",
"dialect": "mysql",
// Используем другой тип хранилища. По умолчанию: sequelize
"migrationStorage": "json",
// Используем другое название файла. По умолчанию: sequelize-meta.json
"migrationStoragePath": "sequelizeMeta.json",
// Используем другое название таблицы. По умолчанию: SequelizeMeta
"migrationStorageTableName": "sequelize_meta",
// Используем другую схему для таблицы `SequelizeMeta`
"migrationStorageTableSchema": "custom_schema"
}
}
```
*Хранилище сеятелей*
По умолчанию `Sequelize` не хранит информацию о сеятелях. Настройки файла конфигурации, которые позволяют это изменить:
* `seederStorage` — тип хранилища
* `seederStoragePath` — путь к хранилищу (по умолчанию `sequelize-data.json`)
* `seederStorageTableName` — название таблицы (по умолчанию `SequelizeData`)
```
{
"development": {
"username": "root",
"password": null,
"database": "database_development",
"host": "127.0.0.1",
"dialect": "mysql",
// Определяем другой тип хранилища. По умолчанию: none
"seederStorage": "json",
// Определяем другое название для файла. По умолчанию: sequelize-data.json
"seederStoragePath": "sequelizeData.json",
// Определяем другое название для таблицы. По умолчанию: SequelizeData
"seederStorageTableName": "sequelize_data"
}
}
```
**[↑ Наверх](#)**
На этом третья часть руководства завершена, как и руководство в целом. Мы с вами рассмотрели почти все возможности, предоставляемые `Sequelize`. Если вам все же потребуются более подробные сведения, то остается только официальная документация.
Благодарю за внимание и хорошего дня! | https://habr.com/ru/post/567912/ | null | ru | null |
# Почему Microsoft Internet Explorer 11 — худшее, что могло случиться с нами

Я давеча [написал](http://habrahabr.ru/company/microsoft/blog/201108/#comment_6946870) комментарий о том, что компании Майкрософт давно пора перестать издеваться над веб-разработчиками и перейти на движок Gecko. Многие, видимо, посчитали это неуместной шуткой; тем не менее, это таки вовсе не шутка, а констатация факта. Те, кто с этим не согласен, видимо не пытались ещё разрабатывать под этот замечательный браузер.
Давайте я расскажу вам, какой это замечательный процесс.
Сколько браузеров вы поддерживаете, дорогие разработчики? Не так давно, пять лет назад, этот список был довольно прост: IE6, IE7, Opera, Firefox, Chrome. Пять браузеров, плюс кое-какие минорные вариации между 2 и 3 Firefox и 9 и 10 Оперой.
Сколько браузеров мы поддерживаем теперь?
Firefox, Chrome и Opera никуда не делись. Файрфокс и Хром давно перешли на короткий релизный цикл, последний артефакт неавтоматического обновления (Firefox 3.6) не так давно наконец-то потерялся с приборов. Опера должна перейти на тот же цикл в ближайшее время — да и последние версии Оперы/Престо особой головной боли не добавляли. Добавился Яндекс.Браузер, который внутре тот же Хромиум, хоть и обновляется реже.
Ну и, наконец, к вопросу про IE: сколько версий IE мы вынуждены поддерживать? В октябре по li.ru доли разных версий Internet Explorer в рунете были такими: IE10 — 4%, IE8 — 2.3%, IE9 — 1.7%, IE7 — 0.7% плюс невидимый на приборах IE11, который с выходом Windows 8.1 должен отбить у IE10 какую-то долю. Т.е. нам кажется, что это одна-две версии браузера, если вы готовы пожертвовать 4.7% аудитории, или три-пять — если не готовы или вдруг вы пишете продукт для страны с более высокой долей IE.
Как бы не так! Слушайте внимательно.
Internet Explorer, начиная с, прости господи, восьмой версии поставляется с набором движков от предыдущих версий. IE8 умеет работать в режиме IE7 и в режиме Quirks Mode (фактически, IE5.5!). IE9 умеет работать в режимах 9, 8, 7 и Quirks. IE10 умеет работать в режимах 10, 9, 8, 7 и Quirks. IE11 умеет работать в режимах 11, 10, 9, 8, 7 и Quirks. И это, внимание, РАЗНЫЕ движки! Не знаю, чем они там упарывались, когда принимали это решение, но режим IE10 в IE11 — вовсе не IE10! Вот, например, в IE9-10 есть [баг с неправильный позиционированием канваса по z-index](http://stackoverflow.com/questions/7070457/z-index-of-canvas-in-ie-9-problem), который решался выставлением ему background-color: rgba(255, 255, 255, 0). В IE11 в режиме IE10 этот баг был тщательно портирован прекрасными разработчиками из Редмонда, а вот workaround портировать позабыли, и теперь канвас с абсолютным позиционированием там как бэ использовать нельзя. Совсем.
Итого, если вы, совершенно случайно, пишете какую-нибудь библиотеку или просто хотите реюзать код на разных доменах — то вам вот прям сейчас нужно поддерживать (сколько-сколько?) ДВАДЦАТЬ разных версий Internet Explorer! Двадцать версий браузера, который использует менее 10% аудитории! На секундочку, у файрфокса за всё время его существования было 28 мажорных релизов, у Хрома — 32.

И это только начало, ребята. Дух старой школы невероятно силён в Редмонде: все эти версии Internet Explorer [будут поддерживаться](http://blogs.msdn.com/b/ie/archive/2011/06/27/a-browser-for-all-windows-customers-it-s-about-and-not-or.aspx) Майкрософтом (сколько-сколько?) 10 лет! Занимательная задачка на устный счет: посчитать, сколько версий IE нам придётся поддерживать через 5 лет.
Пол Айриш написал про это прекрасную статью ещё в 2011: [www.paulirish.com/2011/browser-market-pollution-iex-is-the-new-ie6](http://www.paulirish.com/2011/browser-market-pollution-iex-is-the-new-ie6/). Но даже он не смог предсказать всю упоротость разработчиков Майкрософта.
### Шо?! Это ещё не всё?!
Это ещё далеко не всё, мои маленькие красноглазики. В IE10-11 Майкрософт презентовал ещё маленькую тележку свежих и революционных идей.
Начнём с того, что IE11 поставляется вот с таким юзер-агентом:
`Mozilla/5.0 (Windows NT 6.3; Trident/7.0; rv:11.0) like Gecko`
Что в нём прекрасно? В нём НЕТ ВЕРСИИ самого Internet Explorer-а! Вообще слов «MSIE» больше нет. Знаете, почему? Потому что [Майкрософт считает](http://msdn.microsoft.com/en-us/library/ie/hh869301%28v=vs.85%29.aspx), что их браузер, внимание, не нужно детектить по юзер-агенту, поскольку он поддерживает все новейшие стандарты и его не надо отличать от других новых браузеров.
Давайте я повторю ещё раз: разработчики браузера, который поставляется с 6 разными движками, эмулирующими баги предыдущих версий этого браузера, начиная с 1999 года, заявляют, что его не нужно определять по юзер-агенту.
При этом абсолютно те же люди между последним Developer Preview IE11 и финальным RTM релизом берут и отрывают вендорские префиксы и ломают ещё пару десятков обратных совместимостей, о чём любезно сообщают в своём msdn-е: [msdn.microsoft.com/en-us/library/ie/dn304886%28v=vs.85%29.aspx](http://msdn.microsoft.com/en-us/library/ie/dn304886%28v=vs.85%29.aspx)
Да-да. Если ваш код отлично работает в Developer Preview, это совершенно не значит, что он заработает в релизной версии, которая внезапно одномоментно раскатится паре десятков миллионов человек по всему миру. Но вы ни в коем случае не занимайтесь детектом версии по юзер-агенту!
Фиг с ним, с Developer Preview. В их прекрасной поделке нужно отличать версию оси, под которой она работает! Я серьёзно.
Вот сидят люди. В трудовой у них, наверняка, написано что-то типа Senior Software Architect. Придумывают [стандарт PointerEvents](http://www.w3.org/TR/pointerevents/), в котором, чин чинарём, всё по-взрослому — специальный флаг navigator.pointerEventsEnabled показывает, поддерживает ли браузер пойнтер-события или нет. Чтобы, понимаешь, никто ничего по юзер-агенту не детектил, а всё как в нормальных браузерах.
А потом внезапно выясняется, что у тех же людей обработка жестов падает в IE10/Win7. Вот прям в msdn-е так и написано:
> **Note** The APIs we discuss in this section aren't supported in Windows 7 or earlier.
[msdn.microsoft.com/en-us/library/ie/dn433243%28v=vs.85%29.aspx](http://msdn.microsoft.com/en-us/library/ie/dn433243%28v=vs.85%29.aspx)
Так что помимо 20 разных версий IE у вас есть как минимум две разных версии ОСи — Win7 и Win8. На самом деле, их больше — есть ещё Windows Phone и Windows RT, а в Windows 8 ещё есть два режима браузера — метро и десктоп. Они все отличаются. Нам повезло, мы не нашли прям заметных багов, чтобы держать отдельные ветки кода ещё и под эти оси — не факт, что вы окажетесь столь же удачливыми. Ну что, сколько там версий IE получилось? Я уже запутался, но, наверное, под сотню.
А теперь — десерт! Вот допустим вы просто пишете веб-странички, вам плевать на режимы браузера и вы вообще недоумеваете, чего париться — сайт ведь не может сам перейти в какой-нибудь режим совместимости, правда?
У меня есть для вас плохие новости, ребята. Заходите вот сюда:
[iecvlist.microsoft.com/ie10/201206/iecompatviewlist.xml](https://iecvlist.microsoft.com/ie10/201206/iecompatviewlist.xml)
И ищите там свой сайт.
Знаете, что это? Это глобальный Compatibility List, в который заносятся сайты, которые, по мнению Майкрософт, нужно показывать в каком-нибудь из режимов совместимости.
Нет, серьёзно, они отсматривают весь Интернет и составляют реестр сайтов, которые плохо себя вели!
Знаете, как сайты попадают в этот список? Майкрософт выпускает превью-версии своих браузеров. В них есть специальная кнопочка в адресной строке — показать этот сайт в режиме совместимости. Майкрософт собирает анонимную статистику — если в эту кнопку часто тыкают, сайт попадает в реестр.
Серьёзно, они этого даже не скрывают. Похоже, даже немножечко гордятся.
[msdn.microsoft.com/ru-ru/library/gg699485%28v=vs.85%29.aspx](http://msdn.microsoft.com/ru-ru/library/gg699485%28v=vs.85%29.aspx)
Выбраться из этого списка очень просто — написать в саппорт Майкрософт, ага.
Ну и вишенка на торте: допустим я вас убедил и вы регулируете, в каком режиме показывать страницу, с помощью [специальной меты](http://msdn.microsoft.com/ru-ru/library/ms533876%28v=vs.85%29.aspx), дабы избежать ненужных проблем. Так вот, в IE11 (по крайней мере в RTM-версии, сейчас лень проверять) она не работает — факт нахождения в списке совместимости приоритетнее заданного вебмастером X-UA-Compatible!

Дорогая Microsoft! Прекрати, пожалуйста, над нами издеваться и вкрути движок Gecko в свой так сказать продукт. | https://habr.com/ru/post/201172/ | null | ru | null |
# Как устранить баг с конвейерами в Factorio
[Factorio](https://www.factorio.com/) — это игра про строительство фабрики, в которой множество конвейерных лент. Реализующий эти ленты код является чудом оптимизации, однако, к сожалению, он не может справляться со всеми конструкциями.
### Проблема с суши-конвейером
Проблема возникает, когда конвейер представляет собой петлю. Поначалу помещённые на конвейер предметы работают нормально, двигаясь как возвращаемый пассажирам багаж в аэропорту. Но как только конвейер достигает полной загрузки, он останавливается.
### Что же происходит?
У меня нет доступа к исходному коду Factorio, но мне кажется, что я могу объяснить, почему это происходит. Представьте упрощённую версию Factorio, в которой конвейеры представляют собой одну линию и содержат только по одному предмету на тайл:
Для обновления мы многократно итеративно обходим каждый предмет на ленте, ища предметы, перед которыми есть пустой тайл. Когда мы находим такие предметы, мы передвигаем их вперёд по конвейеру и продолжаем итерации.

*До*

*После*
Если тайл перед предметом не пуст, мы *пока* не можем передвинуть предмет, но, возможно, его можно будет передвинуть на следующей итерации. Например, предмет «A» на рисунке ниже не может переместиться, пока не сдвинется предмет «B», и это может занять несколько итераций.

Выполнять итерации можно в различном порядке (и некоторые порядки эффективнее других), но ради правильности самое важное — со временем достигнуть фиксированной точки. Алгоритм останавливается, когда больше нельзя передвинуть ни один предмет.
Наконец, важно то, что когда предмет перемещается, он не переместился снова, пока алгоритм не завершит свою работу. В противном случае предметы будут телепортироваться по ленте с непостоянными скоростями. Нужно помечать каждый передвинувшийся предмет и исключать его из будущих итераций.

*До*

*После*
Вот псевдокод:
````
do
set MADE_PROGRESS to false
for each item, I
if I has not already moved
let B be the belt under I
let B' be the belt B outputs to
if B' has no item
move I from B to B'
mark I as moved
set MADE_PROGRESS to true
while MADE_PROGRESS is true
````
А вот визуализация полного выполнения алгоритма:
### Пограничный случай Factorio
Чтобы по этому алгоритму предмет двигался, у него должно быть свободное место, в которое можно переместиться. Но когда предметы тесно упакованы в круг, то свободного места нет, и на всём конвейере образуется пробка.

*Ой-ёй!*
### Устраняем проблему при помощи оптимизма
Показанный выше алгоритм пытается проверить, какие предметы могут двигаться, пессимистически предполагая, что какой-то предмет не может подтвердить возможность движения, то он не будет перемещён.
Но что если мы сделаем наоборот? Рассмотрим алгоритм, оптимистически допускающий, что все предметы перемещаются, а затем проверяющий, какие из них не смогут этого сделать.
Как же это можно сделать? Если предмет находится в конце конвейера, то можно с уверенностью сказать, что он не может двигаться. На рисунке ниже мы пометим такие предметы красным «X», чтобы показать, что они не могут двигаться.

*До*

*После*
Аналогично, если предмет заблокирован другим недвижимым предметом, то он тоже не может двигаться. После того, как мы пометим предмет красным «X», предмет перед ним тоже должен быть помечен.

*До*

*После*
Этот новый алгоритм тоже выполняется, пока не достигнет фиксированной точки. Затем все предметы без красного «X» могут быть перемещены вперёд.
Если попробовать этот алгоритм на кольцевом конвейере, то вы заметите, что он завершается, не расставив ни единого «X»! Но это правильно: все предметы на конвейере будут перемещаться по нему, потому что ни один из них не оказался недвижимым.

### Слияния
Прежде чем показывать псевдокод, нужно разобраться с ещё одним аспектом. Что произойдёт при объединении двух или трёх конвейерных лент, как показано на рисунке ниже?

По определению, второй алгоритм будет перемещать оба предмета на объединённый конвейер одновременно, потому что они не окажутся недвижимыми. Мы нашли баг! Правильное поведение, которое и реализовано в первом алгоритме, заключается в том, чтобы двигать один или другой предмет, но не оба.
Мы можем исправить второй алгоритм, задав каждому из объединяемых конвейеров приоритет. Тайл конвейера с меньшим приоритетом будет считаться недвижимым, если на конвейере с более высоким приоритетом есть предмет. Ниже показан конвейер «A» с высоким приоритетом и конвейер «B» с низким. «A» занят, поэтому «B» должен быть недвижимым.
*До*
*После*
В играх наподобие Factorio эти приоритеты могут переключаться через каждый кадр, чтобы содержимое обоих контейнеров поступало на общий подобно застёжке-молнии.
### Готовый псевдокод
Показанный ниже код состоит из трёх этапов.
1. Обработка соединений конвейеров
2. Разметка недвижимых конвейеров (красным «X»)
3. Перемещение всех предметов на конвейерах, не помеченных как недвижимые
````
for each belt intersection, S
set BLOCKED to false
for each input belt to S, B
if BLOCKED is true
mark B as immobile
if B has an item
set BLOCKED to true
do
set MADE_PROGRESS to false
for each item, I
let B be the belt under I
let B' be the belt B outputs to
if B' doesn't exist or if B' is immobile
mark B as immobile
set MADE_PROGRESS to true
while MADE_PROGRESS is true
for each item, I
let B be the belt under I
let B' be the belt B outputs to
if B is not immobile
move I from B to B'
````
### Плюсы и минусы
С точки зрения корректности, второй алгоритм совершеннее, но нужно признать, что для него требуется больше кода и он менее очевиден, чем первая структура. Также он усложняет реализацию других компонентов (манипуляторов, фабрик и сундуков), однако для начинаемых с нуля проектов это может и не являться проблемой. Подозреваю, что Factorio уже слишком развилась для того, чтобы вносить изменения в алгоритм действия конвейеров, но надеюсь, что новые игры используют рекомендуемый мной подход.
Также важно заметить, что второй алгоритм обеспечивает применимый результат только когда алгоритм завершает работу. В то же время, первый алгоритм может выполняться инкрементно. Каждая итерация перемещает игровое состояние из одной допустимой позиции в следующую, что иногда может быть полезным.
### Интересная связь с исследованиями компиляторов
Я писал эту статью о Factorio, но используемый принцип можно обобщить. Переворот задачи и замена местами того, что нужно доказать — очень полезный навык!
Изначально я у знал об этой технике из статьи об исследованиях компиляторов: *«Combining Analyses, Combining Optimizations»* Клиффа Клика. Любопытно, что в статье эта техника используется тоже для работы с циклами, только в программировании. Разумеется, Клифф Клик не первым проделал нечто подобное. Математики уже давно практикуют это.
### Вопросы и ответы
* #### Вы играли в Factorio?
Да я дважды прошёл игру и даже пытался создать собственную игру-клон. Статья появилась в результате этой работы.
* #### Код неэффективный! Factorio гораздо более оптимизирована.
Да, я знаю, и я глубоко изучал Factorio перед написанием статьи. Однако добавление оптимизаций в моё объяснение запутало и удлинило бы статью.
* #### То есть оптимизировать решение нельзя?
Можно. Самой большой оптимизацией было бы комбинирование длинных прямых сегментов конвейеров в единые узлы, а-ля [этого поста из блога Factorio](https://www.factorio.com/blog/post/fff-176). Это уменьшает размер графа конвейера, но почти не изменяет алгоритмы. Можно представить это как написание алгоритма поиска путей на основе прямоугольной сетки с последующей адаптацией поиска путей на мешах.
* #### Почему бы не сделать попроще? Если конвейеры впадают сами в себя, то пусть образуют петлю.
Разумеется, но это сработает только в самых тривиальных случаях. Граф конвейера может быть довольно сложным, с петлями, состоящими из множества сегментов. В подобных случаях пришлось бы реализовывать обнаружение циклов, а это совершенно точно не лучше второго алгоритма.
* #### Но в Factorio есть двухдорожечные конвейеры!
Как говорилось ранее в статье, мои объяснения построены на конвейерах из одной ленты, в каждом тайле которых может находиться только один предмет. Это позволило не усложнять исследование. Если вы сможете реализовать это, то почти без трудностей сможете и реализовать двухдорожечные конвейеры со множеством предметов.
* #### В Factorio можно решить проблему при помощи разделителей.
Благодаря разделителям на линии суши-конвейеры работают гораздо лучше и обычно не вызывают проблем, но они не являются панацеей. В них всё равно может возникнуть пробка, хотя вероятность её и меньше.
* #### Такое поведение реализовано специально/вызвано каким-то другим поведением.
Возможно. Я не разработчик Factorio и у меня нет доступа к коду, поэтому с моей стороны эта статья — всего лишь догадки. Но она всё равно оказалась хорошим способом демонстрации отличной техники. | https://habr.com/ru/post/581290/ | null | ru | null |
# MIRO — открытая платформа indoor-робота. Часть 3 — Программная составляющая: ESP8266

Начинаем разбирать программную составляющую платформы MIRO. Посмотрим, как правильно «готовить» ARDUINO UNO с помощью ESP8266 для прошивки и взаимодействия без проводов.
Оглавление: [Часть 1](https://habr.com/ru/post/472380/), [Часть 2](https://habr.com/ru/post/472802/), [Часть 3](https://habr.com/ru/post/473368/), [Часть 4](https://habr.com/ru/post/475512/), [Часть 5](https://habr.com/ru/post/477118/).
Я вообще не хотел, чтобы мы что-то разрабатывали для ESP8266. Был уверен, что давно существует готовое решение с нужным мне функционалом. А для MIRO этот функционал был достаточно простым:
1. ПО должно иметь веб-интерфейс для настройки сети;
2. ПО должно реализовывать беспроводную прошивку ATMEGA328;
3. ПО должно иметь функционал моста WiFi-UART для беспроводной отладки и управления.
 Наверное, по большинству этих функций существует всем известный [ESP-LINK](https://github.com/jeelabs/esp-link). И он действительно мощный. Мы его применяли еще в нескольких проектах в качестве моста между различными интерфейсами – очень удобно. Но вот несколько месяцев назад, когда мы сели плотно заниматься этим вопросом, оказалось, что не прошивает он ARDUINO UNO. Везде пишут, что прошивает, а он не прошивал. И в тот момент я даже глубоко не разбирался почему и какова типовая процедура. Мы с товарищами просто настраивали на хосте виртуальный COM-порт по определенному IP-адресу ESP, в самом ESP-LINK указывали линию сброса и пробовали прошить. Сброс ATMEGA328 успешно проходил, а прошивка так и не заливалась. Причем, в сети куча уроков по организации такой прошивки именно с ESP-LINK. Но если почитать их issue, то у них там постоянно что-то у кого-то не прошивается.
Разочаровавшись, стал искать альтернативы. И нашел ее в виде [форка](https://github.com/jandrassy/arduino-firmware-wifilink) оригинального Arduino WiFi на GitHub у разработчика с ником jandrassy.
Еще в феврале того года там в README была монструозная инструкция по настройке всего, начиная от прошивки до среды разработки, но сейчас она значительно упростилась. Но тем не менее, для настройки среды все еще требуются небольшие усилия. Однако, прошивка ARDUINO происходит идеально. Проверено и из Windows и из Linux (на MacOS мы кажется вообще ничего никогда не проверяли – нет его ни у кого в ближайшем окружении проекта).
Порядок подготовки среды там такой:
1. Скачать и установить библиотеку dfu [отсюда](https://github.com/jandrassy/arduino-firmware-wifilink/wiki/lib/dfu.zip);
2. По умолчанию в этой библиотеке (в файле esp8266-serial-arduinouno-hacked.cpp) объявлено, что линия Reset чипа ATMEGA328 подключена к линии GPIO5 ESP8266. Для MIRO здесь нужно внести изменения – поменять на GPIO2.
**Что именно поменять**Было:
```
esp8266_serial_arduinouno_hacked_target_reset(struct dfu_interface *iface)
{
pinMode(5, OUTPUT);
digitalWrite(5, 0);
delay(1);
digitalWrite(5, 1);
delay(200);
return 0;
}
```
Стало:
```
esp8266_serial_arduinouno_hacked_target_reset(struct dfu_interface *iface)
{
pinMode(2, OUTPUT);
digitalWrite(2, 0);
delay(1);
digitalWrite(2, 1);
delay(200);
return 0;
}
```
Автор jandrassy, указывает, что его реализация работает только с такой конфигурацией целевого чипа и загрузчика (ATMEGA328P с Optiboot).
Уверен, что есть еще решения и возможно даже более лучшие. Если кто-то точно знает работающие варианты – сообщайте. Потому что, несмотря на большое количество готового кода, мы проверяли помимо ESP-LINK еще 2 или 3 проекта – они не работали. В каких-то случаях прошивка проходила через раз, в каких-то случаях вообще не работала.
Пожалуй, один из главных плюсов найденного решения – относительно небольшая кодовая база проекта и то, что разработана прошивка под Arduino Core.
Чего не было в проекте jandrassy, так это беспроводного моста WiFi-UART. Уже в исходном Arduino.org WiFi Link firmware была вырезана страничка с терминальным окошком, позволяющая через браузер работать с UART чипа ATMEGA328. Точно так же как это можно делать в ESP-LINK. И если обратиться к первым публикациям про Arduino UNO WiFi (например [вот](http://wiki.amperka.ru/%D0%BF%D1%80%D0%BE%D0%B4%D1%83%D0%BA%D1%82%D1%8B:arduino-uno-wifi) и [вот](https://www.arduino.cc/en/Guide/ArduinoUnoWiFi)), то видно, что в первых версиях прошивки и окно и соответствующий пункт меню («WiFi Console») есть. И даже в релизе 1.0.0 в архиве файл console.js (он как раз и реализовывал эту страничку) лежит, но фактически в сервере не задействован никак (мы проверяли). Зачем и почему выпилили – не понятно.
Пришлось кое-что дописать. Теперь в прошивке есть еще один сервер – TELNET на очевидном порту 23, с которым без проблем работает множество терминальных программ.
Правда, в данный момент, чтобы все работало, мне пришлось удалить из кода jandrassy часть, отвечающую за беспроводную прошивку самой ESP. В исходных требованиях у меня этого функционала не было, поэтому и ладно. Однако, если читатели в комментариях смогут мне утвердительно сказать можно ли в одной прошивке реализовать возможность беспроводной прошивки как самого ESP8266, так и «внешнего» MCU (в данном случае – ATMEGA328), то я задумаюсь о возвращении в прошивку ESP этой возможности. Уже при подготовке статьи, косвенно, увидел подтверждение этому вот в этом [проекте](https://github.com/DIYOSEPP/EspUnoWiFi) канадцев. Но не проверял.
А пока – ESP прошивается исключительно по проводу, но ARDUINO имеет возможность как беспроводной прошивки, так и связи по TELNET мостом WiFi-UART. И это очень удобно! Моя цель достигнута.
Ну и в проекте, как и в исходном, есть WEB-интерфейс для настройки (картинки кликабельны).
[](https://habrastorage.org/webt/wq/sg/bx/wqsgbxgr8td9zkvr3ch7wkph7xu.png)
[](https://habrastorage.org/webt/em/sj/ls/emsjlsa04svbal1xbryaslea4si.png)
Мы изменили файлы CSS стилей WEB-интерфейса под наш проект и ввели небольшой «костыль» – теперь ESP всегда находится в режиме AP+STA. Этот костыль сделан для того, чтобы исключить возможность переключения ESP в режим «только STA», при котором при переносе робота в другую подсеть, у пользователя теряется возможность сконфигурировать робота в новую сеть – к новой сети робот подключиться не может, а доступа извне тоже нет – приходится перепрошивать ESP. В режиме AP+STA пользователь всегда может подключиться к точке доступа робота и сконфигурировать подключение к новой сети WiFi.
О том, как прошить ESP8266 этим «монстриком». В общем случае для произвольного модуля на чипе ESP8266 порядок такой:
1. Включить плату (подключить к usb);
2. Установить параметры платы как на рисунке;
Очень важно выбрать «v1.4 Higher Bandwidth» – если выбрать «v2», то к плате после прошивки не удается подключиться по WiFi (точка доступа видна, но процедура подключения не проходит — кто знает с чем это связано — напишите в комментариях).
3. Выбрать порт (в примере на скриншоте – COM3).
4. Запустить прошивку. Во время процедуры загрузки платы, вначале производится стирание памяти микроконтроллера, а затем прошивка.
5. После завершения процедуры прошивки, нужно сбросить плату, с помощью кнопки сброса.
6. Выбрать в меню Arduino IDE ESP8266 Sketch Data Upload и загрузить SPIFFS.
7. Сбросить плату.
Для конфигурации же с нашей «модифицированной платой» UNO+WiFi (см. [первую часть](https://habr.com/ru/post/472380/)) все чуточку сложнее из-за аппаратных особенностей платы, которую затруднительно комфортно исследовать по причине большого количества ошибок в документе с принципиальной схемой. Мы написали более подробную инструкцию в файле «MIRO ESP Firmware upload manual» [репозитория](https://github.com/fbezruchko/miro_firmware_esp) – если действовать строго по ней, прошивка проходит 100 из 100.
Мы подходим к очень интересной части — программной составляющей MIRO, возложенной на ATMEGA328. Там работы побольше и пространства для обсуждения тех или иных решений тоже.
Всем спасибо! | https://habr.com/ru/post/473368/ | null | ru | null |
# Избавляемся от StandardStyles.xaml в Windows 8.1
Если вы когда-либо создавали Windows 8 приложение используя XAML, то вы, скорее всего, могли видеть добавленный в ваше приложение файл с названием StandardStyles.xaml в папке Common. Так как я видел много разработанных приложений, то мне приходилось наблюдать, что люди довольно часто относят этот файл к системным компонентам и совершенно не изменяют его. Иногда это хорошо, но чаще это плохо. Среди приложений, которые мне попадались было множество таких, которые совершенно не используют стили из этого словаря ресурсов, но и не делают ничего, чтобы обрезать файл или удалить его совсем, так как он не нужен.
Это файл был добавлен в шаблоны проектов Windows 8 Visual Studio для того, чтобы помочь стилизовать некоторые области шаблона. В поисках повышения производительности Windows 8.1 мы отметили, что разработчики не удаляют этот файл или неиспользуемые стили из этого файла. Мы также заметили, что есть некоторые плюсы от включения этого файла во фреймворк, так как некоторые стили/шаблоны отложенной загрузки мы реализовали в самой Windows 8.1. По этой причине почти для всех приложений, которые мы наблюдали на практике, стили, имеющиеся в Windows 8/VS2012 StandardStyles.xaml файле, могут быть удалены из приложения и заменены на стили содержащиеся в XAML фреймворке.
#### Текстовые стили
Большая часть функций файла была в предоставлении некоторых текстовых стилей, которые сопоставляли таблицу типографских шрифтов для языка дизайна Windows. Около 100 строк текстовых стилей сейчас могут быть перенесены на новые предоставленные фреймворком стили. Далее идет сопоставление того, что вы должны заменить в своем приложении Windows 8.1:
| | |
| --- | --- |
| StandardStyles.xaml (в VS 2012) | имена предоставленные Windows 8.1 XAML |
| BasicTextStyle | BaseTextBlockStyle |
| BaselineTextStyle | недоступен (совмещен с BaseTextBlockStyle) |
| HeaderTextStyle | HeaderTextBlockStyle |
| SubheaderTextStyle | SubheaderTextBlockStyle |
| TitleTextStyle | TitleTextBlockStyle |
| SubtitleTextStyle | SubtitleTextBlockStyle |
| BodyTextStyle | BodyTextBlockStyle |
| CaptionTextStyle | CaptionTextBlockStyle |
| BaseRichTextStyle | BaseRichTextBlockStyle |
| BaselineRichTextStyle | недоступен (совмещен с BaseRichTextBlockStyle) |
| BodyRichTextStyle | BodyRichTextBlockStyle |
| ItemRichTextStyle | недоступен (был таким же как и BodyRichTextBlockStyle) |
Замена довольно проста, так как в местах, где вы использовали {StaticResource SomeTextStyle} вы должны использовать {StaticResource FrameworkProvidedStyle} (разумеется, указав корректно соответствующее имя). Как и в других случаях при совершении изменений, протестируйте ваше приложение чтобы убедится в том, что ваш UI точно соответствует вашим ожиданиям. Если вам необходимо продолжить изменение стиля, то вы можете использовать эти стили для того, чтобы создать ваш BasedOn собственный.
#### Стили кнопок
Другой составляющей был набор стилей кнопок вроде кнопки «назад», кнопок текстблока и наиболее используемых стилей AppBarButton. Стиль TextButtonStyle сейчас является TextBlockButtonStyle и служит как стилизованная кнопка для таких областей, как доступные для кликов секции заголовков GridView и т.п.
Было также несколько стилей для кнопки «назад». После введения в Windows 8.1 AppBarButton мы можем предложить лучший/особый шаблон стиля, предоставленный сразу с верными символами для стрелок. Вместо того, чтобы использовать BackButtonStyle/SnappedBackButtonStyle из StandardStyles.xaml вы должны использовать NavigationBackButtonNormalStyle и NavigationBackButtonSmallStyle. Стиль Normal – это основной стиль, который вы должны использовать на страницах и он равен стандартной кнопке 41x41 px. Стиль Small это стиль кнопки 30x30 px, который вы можете использовать для состояния narrow (ранее называемого snapped) или в других случаях.
Вероятно, одними из наиболее используемых объектов были стили AppBarButton. Приблизительно около 1100 строк стиля для набора стилей различных символов кнопок аппбара. Сейчас мы предоставляем вам типовые кнопки, которые оптимизированы для UI и на данный момент имеют 190 различных типов иконок. В качестве примера, вот что у вас могло быть в приложении для Windows 8:
```
```
А сейчас это может быть заменено на:
```
```
Это сокращает необходимость присутствия базового стиля AppBarButtonStyle а также и других иконочных стилей. Если вам необходима возможность написания текста RTL, то вы можете добавить свойство FlowDirection. Свойство Label будет напрямую сопоставлено по умолчанию значению AutomationProperties.Name в том числе и для нужд прямого доступа.
#### Шаблоны/стили элементов List/Grid
В шаблонах Grid/Split ранее также находились стили шаблона элемента для использования на страницах с этими шаблонами. В поиске места где они реально используются, они были перенесены только на страницы которым они нужны. Многие люди думают, что их стили/шаблоны должны быть в App.xaml, но это не так, и, как правило, это не особо хорошее решение в плане быстродействия. Если ваш стиль используется только на одной странице, то разместите его в ресурсах этой страницы! Это то что было сделано в специфических стилях для шаблонов проектов VS 2013. Некоторые были удалены в соответствии с руководством о размерах приложений.
#### Использование Visual Studio 2013 для редактирования стилей
Вы можете спросить себя как же это можно использовать все это, знать все это или даже как можно выучить все это на память! К счастью, в Visual Studio 2013 добавлено несколько замечательных функций в инструменты, для того, чтобы добавить этим новым стилям больше видимости. Панель ресурсов осталась на своем месте и показывает стили предоставляемые фреймворком так как, например, на следующем скриншоте в Blend:

Даже если вы предпочитаете редактор, то для вас все равно есть хорошие новости, так как в VS был добавлен IntelliSense для стилей!!! Если вы используете StaticResource вы получите автозаполнение стилей, которые применяются к стилю элемента на котором вы сейчас. Нопример, на TextBlock-е вы увидите только стили, которые применимы к TargetType=TextBlock, как показано на следующем скриншоте:

Этот IntelliSence будет точно так же хорошо работать и с вашими личными кастомными стилями и это отличное улучшение производительности инструментария. Это одно из моих самых любимых нововведений в VS!
Если вы хотите увидеть все детали этих стилей, то вы можете использовать замечательную возможность редактирования шаблонов, которая есть в Visual Studio/Blend для того, чтобы проинспектировать их всех. Если у вас есть стиль, то достаточно нажать F12 (Перейти к определению/Go To Definition), находясь курсором на наименовании стиля. Это перенесет вас к определению стиля в generic.xaml фреймворка:

Эта замечательная, повышающая продуктивность, функция доступна для всех стилей в XAML, опять же включая ваши собственные. Эти стили могут быть проинспектированы и вручную через просмотр файла generic.xaml который нам предоставляет Windows SDK (расположен он в %programfiles%\Windows Kits\8.1\Include\WinRT\XAML\Design).
**Резюме**
Одной из основных целей было улучшение общей производительности Windows 8.1 для всех пользователей. Оптимизация перемещения всех наиболее используемых стилей внутрь фреймворка дала разработчикам новые преимущества для систематичности и производительности как для сообщества пользователей использующих общие шаблоны, а также сократило время закрузки/парсинга для каждого приложения в отдельности необходимое для предоставления этих стилей.
Надеюсь, это вам поможет! | https://habr.com/ru/post/248813/ | null | ru | null |
# MongoDB vs MySQL (vs Cassandra): А теперь чуть более правильный ответ
Собственно, сегодня был запощен топик "[Сравниваем производительность MongoDB и MySQL на простом примере](http://habrahabr.ru/blogs/webdev/87492/)", в котором указывалось, что MongoDB превышает по производительности MySQL в разы. Хех, когда такое пишут — я сразу лезу проверять и сомневаться. Я полез в исходники оригинального теста (спасибо за публикацию). И как оказалось автор оригинального топика сделал ошибку в три символа и на самом деле не все так:1. В оригинале: MongoDB быстрее MySQL пишет в 1.5 раза (ДА, правда у меня в 3 раза)
2. В оригинале: MongoDB быстрее MySQL читает в 10 раз (НЕТ, на самом деле — MongoDB примерно на равных плюс-минус 10-30%)
3. InnoDB vs MyISAM — плюс-минус (в оригинале не тестировалось)
**Сравнение здесь происходит только как key-value storage (запись-чтение по primary key).**

*На графике — число операций в секунду, (больше — лучше), шкала логарифмическая.
Последняя строка — то, что тестировал автор оригинального топика (неправильное, не в критику — все мы ошибаемся и учимся).*
А теперь подробнее об ошибке...
Итак, ошибка оригинала была в том, что он делал SELECT так:
`test.find({'_id':random.randrange(1, 999999)})`
что возвращало Cursor(!), но не сам объект. То есть обращение к базе не происходит (или по крайней мере чтения данных не происходит). А вот что надо было:
`test.find({'_id':random.randrange(1, 999999)})**[0]**`
Если бы автор проверял бы, что сохраненное значение (INSERT) равняется вытащенному (SELECT) — такой ошибки не было бы.
В своем тесте я добавил assert, проверяющий что то, что сохранили — то же, что и читаем. И добавил сравнение с InnoDB (в комментах многие спорили, что может быть намного лучше). Настройки InnoDB дефолтовые.
Сам тест: по сути оба в качестве «key-value storage» (сохраняем по primary key + value, выбираем по primary key, читаем value). *Да, сферический, да, в вакууме.*
Да, внутри теста там есть вызовы assert и str. Разумеется они отжирают часть производительности, но для обоих тестов — их одинаковое число. А нам же просто СРАВНИТЬ производительность надо.
Больше результатов: **Core2duo / WinXP SP3**.

Больше 10000 записей тестировал — соотношение сохраняется. И вроде ни Mongo, ни MyISAM не сдуваются по скорости.
Исходник:
[yoihj.ru/habr/mongo\_vs\_mysql.py](http://yoihj.ru/habr/mongo_vs_mysql.py)
Я не говорю, что 100% прав (может и я в чем ошибся), так что проверяйте меня тоже.
P.S. Да, у меня выборка была последовательная, если же переключить ее на случайную (доставать каждый раз элемент со случайным номером) — ситуация меняется, но не кардинально, расположение сил все то же. Убедиться можно заменив в SELECTах `i1 = str(i+1)` на `i1 = str(random.randint(1,cnt-1)+1)`.
В комментах [fallen](https://habrahabr.ru/users/fallen/) [протестировал этим же кодом](http://habrahabr.ru/blogs/mysql/87620/#comment_2625002) все под Linux + InnoDB\_Plugin. Соотношение сил — примерно то же, но ровнее:
**Linux + InnoDB\_Plugin**

«Core i7 920, 2GB RAM, Fedora 12 x64, mysql 5.1.44 + InnoDB 1.0.6 скомпилированные icc, mongodb 1.2.4 x64, sata диск обычный.»
#### Выводы:
1. На запись MongoDB быстрее, если использовать как key-value storage;
2. Чтение примерно одинаково происходит;
3. **Обе системы — вполне приличные, никто не устарел, никто никого не убил, явного проигрывающего нет**.
#### vs Cassandra
И **интереса ради** добавлена Cassandra + pycassa (под win32) — сразу скажу — с ней у меня никакого опыта и много непонятного (.remove() не удаляет записи, а только очищает их, сами они остаются… + eventual consistency — оооооооочень трудно тестировать!) — полное прыгание с бубном в темноте, так что считайте просто **развлекательным тестом**.
[](https://habrastorage.org/storage/habraeffect/c1/ef/c1ef8d04f48508dcb1d10185582ed4f8.png "Хабрэффект.ру")
```
import pycassa
client = pycassa.connect()
cf = pycassa.ColumnFamily(client, 'Keyspace1', 'Standard1')
# CASSANDRA INSERT
start_time = time.clock()
for i in xrange(cnt):
i1 = str(i+1)
cf.insert(i1, {'value': i1})
report('Cassandra INSERTs')
list(cf.get_range())
# CASSANDRA SELECT
start_time = time.clock()
for i in xrange(cnt):
i1 = str(i+1)
obj = cf.get(i1)['value']
assert(obj == i1)
report('Cassandra SELECTs')
```

Йои Хаджи,
[вид с Хабра](http://yoihj.habrahabr.ru/blog/) | https://habr.com/ru/post/87620/ | null | ru | null |
# Скрипт архивации баз данных Microsoft SQL Server с полной моделью восстановления
В продолжение своей [предыдущей](https://habr.com/ru/post/316658/) статьи по архивации БД MSSQL и негативному отклику в связи с отсутствием возможности архивации логов транзакций, работаю я теперь в компании, где понадобилось автоматизировать этот момент для баз в том числе с полной моделью восстановления.
Скрип работает универсально для баз с различной моделью восстановления, в начале скрипта добавлены настройки для относительно гибкого формирования расписания. Скрипт можно поставить с SQL Agent и удобным интервалом (у меня, например, 1 раз час), первый запуск в сутках будет проверять, надо создавать или нет полную или разностную копию сегодня и далее в течении дня для БД с полной моделью восстановления будут создаваться бэкапы лога журнала транзакций.
```
-- пути до бэкапов
declare @FullPath varchar(500) = 'D:\SQLBackup'
declare @DiffPath varchar(500) = 'D:\SQLBackup'
declare @LogPath varchar(500) = 'D:\SQLBackup'
-- архивируемые и исключенные из архивации БД
declare @IncludeBase varchar(500) = 'master, msdb' -- если не пусто, то только эти минус исключенные, если пусто то все минус исключенные
declare @ExcludeBase varchar(500) = 'tempdb'
-- настроки для полного бэкапа
-- минимум хранить дней
declare @MinFullDay int = 181
-- выполнять каждые дней
declare @MinFullExecDay int = 7
-- настроки для разностного бэкапа
-- минимум хранить дней
declare @MinDiffDay int = 181
-- выполнять каждые дней
declare @MinDiffExecDay int = 1
-- настроки для бэкапа журнала
-- минимум хранить дней
declare @MinLogDay int = 35
-- как часто создавать master (дни)
declare @MinDayMaster int = 1
-- сколько хранить информацию об архивах в msdb (дни)
--declare @DayHistory int = @MinFullDay + 30
-- включим сжатие
EXEC sp_configure 'show advanced options', 1; EXEC sp_configure 'backup compression default', 1; RECONFIGURE WITH OVERRIDE;
-- включим xp_cmdshell (нужно для удаления старых бэкапов)
EXEC sp_configure 'show advanced options', 1; EXEC sp_configure 'xp_cmdshell', 1; RECONFIGURE WITH OVERRIDE;
declare @tempcmd varchar(500) =''
declare @tempname varchar(500) =''
-- создание путей
set @tempcmd= 'md '+@FullPath
exec xp_cmdshell @tempcmd, no_output
set @tempcmd= 'md '+@DiffPath
exec xp_cmdshell @tempcmd, no_output
set @tempcmd= 'md '+@LogPath
exec xp_cmdshell @tempcmd, no_output
-- определяем список БД для архивации
declare @BaseListIncl table (name varchar(200))
declare @BaseListExcl table (name varchar(200))
if @IncludeBase=''
insert into @BaseListIncl select name from sys.databases where state_desc='ONLINE'
else
while len(@IncludeBase)>0
begin
if CHARINDEX (',',@IncludeBase)>0
begin
insert into @BaseListIncl select name from sys.databases where state_desc='ONLINE' and name = SUBSTRING(@IncludeBase,1, CHARINDEX (',',@IncludeBase)-1)
set @IncludeBase=LTRIM(RTRIM(SUBSTRING(@IncludeBase,CHARINDEX (',',@IncludeBase)+1, LEN(@IncludeBase))))
end
else
begin
insert into @BaseListIncl select name from sys.databases where state_desc='ONLINE' and name = @IncludeBase
set @IncludeBase=''
end
end
if @ExcludeBase<>''
while len(@ExcludeBase)>0
begin
if CHARINDEX (',',@ExcludeBase)>0
begin
insert into @BaseListExcl select name from sys.databases where state_desc='ONLINE' and name = SUBSTRING(@ExcludeBase,1, CHARINDEX (',',@ExcludeBase)-1)
set @ExcludeBase=LTRIM(RTRIM(SUBSTRING(@ExcludeBase,CHARINDEX (',',@ExcludeBase)+1, LEN(@ExcludeBase))))
end
else
begin
insert into @BaseListExcl select name from sys.databases where state_desc='ONLINE' and name = @ExcludeBase
set @ExcludeBase=''
end
end
-- итоговый список БД для бэкапа
delete from @BaseListIncl
where name in (select name from @BaseListExcl)
declare BaseList cursor for
select name from @BaseListIncl
declare @BaseName varchar(500) =''
declare @BackupType varchar(10) = ''
open BaseList
fetch next from BaseList into @BaseName
while @@FETCH_STATUS = 0
begin
-- получаем тип бэкапа, который надо сделать (для мастера специальные условия, он не может ни каких кроме FULL)
SET @BackupType =
( CASE
WHEN @BaseName = 'master' AND
(EXISTS (SELECT * FROM msdb.dbo.backupset s
INNER JOIN msdb.dbo.backupmediafamily mf ON s.media_set_id = mf.media_set_id
WHERE s.database_name=@BaseName and s.TYPE='D' and DATEDIFF(day, CAST(s.backup_finish_date AS DATE), CAST(GETDATE() AS DATE)) < @MinDayMaster))
THEN ''
WHEN @BaseName = 'master' AND
(NOT EXISTS (SELECT * FROM msdb.dbo.backupset s
INNER JOIN msdb.dbo.backupmediafamily mf ON s.media_set_id = mf.media_set_id
WHERE s.database_name=@BaseName and s.TYPE='D' and DATEDIFF(day, CAST(s.backup_finish_date AS DATE), CAST(GETDATE() AS DATE)) < @MinDayMaster))
THEN 'FULL'
WHEN (NOT EXISTS (SELECT * FROM msdb.dbo.backupset s
INNER JOIN msdb.dbo.backupmediafamily mf ON s.media_set_id = mf.media_set_id
WHERE s.database_name=@BaseName and s.TYPE='D' and DATEDIFF(day, CAST(s.backup_finish_date AS DATE), CAST(GETDATE() AS DATE)) < @MinFullExecDay))
THEN 'FULL'
WHEN (NOT EXISTS (SELECT * FROM msdb.dbo.backupset s
INNER JOIN msdb.dbo.backupmediafamily mf ON s.media_set_id = mf.media_set_id
WHERE s.database_name=@BaseName and s.TYPE IN ('I','D') and DATEDIFF(day, CAST(s.backup_finish_date AS DATE), CAST(GETDATE() AS DATE)) < @MinDiffExecDay))
THEN 'DIFF'
WHEN (EXISTS (select * from sys.databases as a where a.recovery_model_desc = 'FULL' and a.name = @BaseName))
THEN 'LOG'
ELSE ''
END
)
IF @BackupType <> ''
begin
--создаем папку для БД
SET @tempcmd =
(CASE
WHEN @BackupType='FULL' OR @BaseName='master' THEN 'md '+@FullPath+'\'+@BaseName
WHEN @BackupType='DIFF' THEN 'md '+@DiffPath+'\'+@BaseName
ELSE 'md '+@LogPath+'\'+@BaseName
END)
exec xp_cmdshell @tempcmd, no_output
if @BackupType='FULL'
begin
-- full backup
set @tempname = @FullPath+'\'+@BaseName+'\'+@BaseName+'_'+CONVERT(varchar(8), GETDATE(), 112)+ '-' + REPLACE(CONVERT(varchar, GETDATE(),114),':','') +'_FULL.BAK'
backup database @BaseName to disk = @tempname
end
else if @BackupType='DIFF'
begin
-- diff backup
set @tempname = @DiffPath+'\'+@BaseName+'\'+@BaseName+'_'+CONVERT(varchar(8), GETDATE(), 112)+ '-' + REPLACE(CONVERT(varchar, GETDATE(),114),':','') +'_DIFF.BAK'
backup database @BaseName to disk = @tempname with differential
end
else
begin
-- log backup
set @tempname = @LogPath+'\'+@BaseName+'\'+@BaseName+'_'+CONVERT(varchar(8), GETDATE(), 112)+ '-' + REPLACE(CONVERT(varchar, GETDATE(),114),':','') +'_LOG.TRN'
BACKUP LOG @BaseName to disk = @tempname
end
-- удаляем истекшие бэкапы
declare @delpath varchar(500)=''
declare delbackup cursor for
SELECT mf.physical_device_name
FROM msdb.dbo.backupset s
INNER JOIN msdb.dbo.backupmediafamily mf ON s.media_set_id = mf.media_set_id
WHERE s.database_name=@BaseName and s.TYPE='D'
and DATEDIFF(day, CAST(s.backup_finish_date AS DATE), CAST(GETDATE() AS DATE)) > @MinFullDay
and is_copy_only = 0
union all
SELECT mf.physical_device_name
FROM msdb.dbo.backupset s
INNER JOIN msdb.dbo.backupmediafamily mf ON s.media_set_id = mf.media_set_id
WHERE s.database_name=@BaseName and s.TYPE='I'
and DATEDIFF(day, CAST(s.backup_finish_date AS DATE), CAST(GETDATE() AS DATE)) > @MinDiffDay
and is_copy_only = 0
union all
SELECT mf.physical_device_name
FROM msdb.dbo.backupset s
INNER JOIN msdb.dbo.backupmediafamily mf ON s.media_set_id = mf.media_set_id
WHERE s.database_name=@BaseName and s.TYPE='L'
and DATEDIFF(day, CAST(s.backup_finish_date AS DATE), CAST(GETDATE() AS DATE)) > @MinLogDay
and is_copy_only = 0
open delbackup
fetch next from delbackup into @delpath
while @@FETCH_STATUS = 0
begin
set @tempcmd= 'del /f /q '+QUOTENAME(@delpath,'"')
exec xp_cmdshell @tempcmd, no_output
fetch next from delbackup into @delpath
end
close delbackup
deallocate delbackup
end
fetch next from BaseList into @BaseName
end
close BaseList
deallocate BaseList
-- чистим в MSDB информацию о старых архивах
--declare @oldest DATETIME
--SET @oldest = DATEADD(DAY, -@DayHistory, GETDATE())
--EXEC msdb.dbo.sp_delete_backuphistory @oldest_date = @oldest
```
Так же добавлю скрипт для создания бэкапов "длительного хранения". Создаются с опцией ONLY\_COPY и не участвуют в общей цепочке восстановления, я обычно использую раз - два в месяц для снятия полной копии или по необходимости
```
-- ========== СОЗДАЕМ ТОЛЬКО ПОЛНЫЕ БЭКАПЫ С ОПЦИЕЙ ONLY_COPY (не учавствуют в общей цепочке)
-- пути до бэкапов (для типовых)
declare @Path varchar(500) = 'I:\SQLBackupOnlyCopy'
-- архивируемые и исключенные из архивации БД
declare @IncludeBase varchar(500) = 'buh, zup' -- если не пусто, то только эти минус исключенные, если пусто то все минус исключенные
declare @ExcludeBase varchar(500) = 'tempdb'
-- включим сжатие
EXEC sp_configure 'show advanced options', 1; EXEC sp_configure 'backup compression default', 1; RECONFIGURE WITH OVERRIDE;
-- включим xp_cmdshell (нужно для удаления старых бэкапов)
EXEC sp_configure 'show advanced options', 1; EXEC sp_configure 'xp_cmdshell', 1; RECONFIGURE WITH OVERRIDE;
declare @tempcmd varchar(500) =''
declare @tempname varchar(500) =''
-- создание путей
set @tempcmd= 'md '+@Path
exec xp_cmdshell @tempcmd, no_output
-- определяем список БД для архивации
declare @BaseListIncl table (name varchar(200))
declare @BaseListExcl table (name varchar(200))
if @IncludeBase=''
insert into @BaseListIncl select name from sys.databases where state_desc='ONLINE'
else
while len(@IncludeBase)>0
begin
if CHARINDEX (',',@IncludeBase)>0
begin
insert into @BaseListIncl select name from sys.databases where state_desc='ONLINE' and name = SUBSTRING(@IncludeBase,1, CHARINDEX (',',@IncludeBase)-1)
set @IncludeBase=LTRIM(RTRIM(SUBSTRING(@IncludeBase,CHARINDEX (',',@IncludeBase)+1, LEN(@IncludeBase))))
end
else
begin
insert into @BaseListIncl select name from sys.databases where state_desc='ONLINE' and name = @IncludeBase
set @IncludeBase=''
end
end
if @ExcludeBase<>''
while len(@ExcludeBase)>0
begin
if CHARINDEX (',',@ExcludeBase)>0
begin
insert into @BaseListExcl select name from sys.databases where state_desc='ONLINE' and name = SUBSTRING(@ExcludeBase,1, CHARINDEX (',',@ExcludeBase)-1)
set @ExcludeBase=LTRIM(RTRIM(SUBSTRING(@ExcludeBase,CHARINDEX (',',@ExcludeBase)+1, LEN(@ExcludeBase))))
end
else
begin
insert into @BaseListExcl select name from sys.databases where state_desc='ONLINE' and name = @ExcludeBase
set @ExcludeBase=''
end
end
-- итоговый список БД для бэкапа
delete from @BaseListIncl
where name in (select name from @BaseListExcl)
declare BaseList cursor for
select name from @BaseListIncl
declare @BaseName varchar(500) =''
declare @BackupType varchar(10) = ''
open BaseList
fetch next from BaseList into @BaseName
while @@FETCH_STATUS = 0
begin
--создаем папку для БД
SET @tempcmd = 'md '+@Path+'\'+@BaseName
exec xp_cmdshell @tempcmd, no_output
--создаем архив
set @tempname = @Path+'\'+@BaseName+'\'+@BaseName+'_'+CONVERT(varchar(8), GETDATE(), 112)+ '-' + REPLACE(CONVERT(varchar, GETDATE(),114),':','') +'_FULL_CopyOnly.BAK'
backup database @BaseName to disk = @tempname WITH COPY_ONLY
fetch next from BaseList into @BaseName
end
close BaseList
deallocate BaseList
``` | https://habr.com/ru/post/676188/ | null | ru | null |
# Compose End to End тестирование. Основы
Всем привет! Меня зовут [Максим Новиков](https://habr.com/ru/users/MaksimNovikov/), я Android-разработчик в команде мобильного приложения оператора Yota.
Последнее время многие проекты начали переходить или пробовать у себя Compose. Вот и мы не остались в стороне и решили сделать на нём первую фичу. Частью процесса разработки фичи в нашей команде является написание автоматизированных UI тестов. Они помогают нам ускорить выпуск фичей и уменьшить время регрессионного тестирования.
Автотестирование View системы развивается уже достаточно давно. У нас есть множество инструментов, зарекомендовавших себя очень хорошо. Compose, напротив, только начинает обрастать различными решениями и фреймворками, например, у kaspresso на момент написания статьи [Compose находится в раннем доступе](https://github.com/KasperskyLab/Kaspresso/blob/master/wiki/10_Jetpack-Compose.md).
Сегодня разберём в чём же особенности нативного тестирования на Compose, наступим на пару граблей и напишем свои первые тесты. А в следующей статье уже будем копать вглубь и посмотрим, как это всё работает под капотом.
Что же такое E2E тесты и зачем они нужны?Они позволяют проверить наш продукт полностью: бизнес логику, слой данных (наши базы данных и запросы) и нашу логику отображения. Главная цель, с которой пишутся автоматические тесты - ускорение прохождения регрессионного тестирования.
В чём суть: мы запускаем приложение и проходим какой-то пользовательский сценарий. К примеру, в нашем приложении это может быть заказ sim-карты. Соответственно, нам необходимо совершать действия за пользователя и на каждом шаге проверять состояние UI: текста, отображение или скрытие каких-то элементов, их состояние и так далее.
Хотелось бы отметить, что [Google подготовили довольно хорошую документацию](https://developer.android.com/jetpack/compose/testing), по тому как работает автотестирование.
Причём открывая документацию сразу видим предупреждение, что подход в тестировании Compose будет совершенно отличным от View:
> **Note:** Testing a UI created with Compose is different from testing a View-based UI. The View-based UI toolkit clearly defines what a View is. A View occupies a rectangular space and has properties, like identifiers, position, margin, padding, and so on. In Compose, only some composables *emit* UI into the UI hierarchy, therefore a different approach to matching UI elements is needed.
>
>
Давайте разберёмся, в чём же отличия. Возьмём самый простой пример со счётчиком:
### Пример со счётчиком

```
@Composable
private fun Counter() {
Box(Modifier.fillMaxSize()) {
val count = remember { mutableStateOf(0) }
Text(
text = count.value.toString(),
modifier = Modifier
.align(Alignment.Center)
)
Button(
onClick = { count.value = count.value + 1 },
modifier = Modifier
.align(Alignment.BottomCenter)
) {
Text(text = "Add")
}
}
}
```
Поскольку мы тестируем только через Activity, понадобится одна зависимость:
```
androidTestImplementation("androidx.compose.ui:ui-test-junit4:$compose_version")
```
Первое, что нужно в тесте - это подключить AndroidComposeTestRule:
```
@get:Rule
val composeTestRule = createAndroidComposeRule()
```
Если же нам необходимо модифицировать Intent нашего Activity:
```
@get:Rule
val activityScenarioRule = ActivityScenarioRule(createIntent())
@get:Rule
val composeTestRule = AndroidComposeTestRule(activityScenarioRule) {
var activity: MainActivity? = null
it.scenario.onActivity { activity = it }
activity!!
}
private fun createIntent() = Intent(
InstrumentationRegistry.getInstrumentation().targetContext,
MainActivity::class.java
).apply {
// Modify your Intent here
}
```
Момент с onActivity выглядит не сильно хорошо, но он необходим для правильной последовательности инициализации двух Rule. Возможно в будущем, это [будет исправлено](https://issuetracker.google.com/issues/223815266#comment13).
Приступим к самому тесту.
Что мы хотим?
1. Нажать на кнопку;
2. Проверить, что текст изменился на 1;
3. Нажать ещё раз;
4. Проверить, что текст изменился на 2.
Первое, что необходимо сделать, это понять, как найти наши Composable функции. Так как нам необходимо работать с функцией как с объектом (к примеру получать текст), в тестовом фреймворке была добавлена абстракция [SemanticNode](https://developer.android.com/reference/kotlin/androidx/compose/ui/semantics/SemanticsNode). Чтобы обратиться к этим нодам воспользуемся `composeTestRule` и его функциями `onNode*():`
* `composeTestRule.onNodeWithText("1")` - ищем ноду с текстом, подходит для Text() и TextField().
* `composeTestRule.onNodeWithContentDescription("1")` - ищем ноду с описанием, подходит для Image, Icon и некоторых других.
* `composeTestRule.onNodeWithTag("TAG")` - поскольку в Composable в отличие от View, нет id, для тестирования была сделана система тестовых тегов.
Добавляем класс для удобного обращения к тегам:
```
object CounterTags {
const val TEXT = "CounterTags:TEXT"
const val BUTTON = "CounterTags:BUTTON"
}
```
Добавляем сами теги:
```
Text(
modifier = Modifier
.align(Alignment.Center)
.testTag(CounterTags.TEXT) <- тут
)
Button(
modifier = Modifier
.align(Alignment.BottomCenter)
.testTag(CounterTags.BUTTON) <- и тут
)
```
Переходим к этапу симуляции действий пользователя.
Для этого уже написаны основные extension функции:
```
fun SemanticsNodeInteraction.perform*()
```
`SemanticsNodeInteraction` мы получаем как результат `onNode*()`
Нам необходим `performClick()`:
```
composeTestRule.onNodeWithTag(CounterTags.BUTTON).performClick()
```
Переходим к этапу проверки состояния UI.
Для этого уже служат функции:
```
fun SemanticsNodeInteraction.assert*()
```
В нашем случае необходимо просто проверить текст, для этого используем assertTextEquals().
```
composeTestRule.onNodeWithTag(CounterTags.BUTTON).performClick()
composeTestRule.onNodeWithTag(CounterTags.TEXT).assertTextEquals("1")
composeTestRule.onNodeWithTag(CounterTags.BUTTON).performClick()
composeTestRule.onNodeWithTag(CounterTags.TEXT).assertTextEquals("2")
```
Запускаем:
И всё работает!
Теперь представим, что текст у нас на кнопке динамический и мы хотим его проверить.
Добавляем tag для текста:
```
Text(
text = "Add",
modifier = Modifier
.testTag(CounterTags.BUTTON_TEXT)
)
```
И в конце теста проверяем его:
```
composeTestRule.onNodeWithTag(CounterTags.BUTTON_TEXT).assertTextEquals("Add")
```
Запускаем и... ~~Всё работает~~ падает ошибка.

```
java.lang.AssertionError: Failed to assert the following: (Text + EditableText = [Add])
Reason: Expected exactly '1' node but could not find any node that satisfies: (TestTag = 'CounterTags:BUTTON_TEXT')
However, the unmerged tree contains '1' node that matches. Are you missing `useUnmergedNode = true` in your finder?
```
Видим, что сейчас нет composable функции с тегом BUTTON\_TEXT, однако нам подсказывают, что возможно мы забыли указать “useUnmergedNode = true”.
Здесь и начинается главное отличие Compose.
При тестировании View системы мы обращались непосредственно к иерархии View, которую мы построили в xml/коде. В Compose создаётся отдельное семантическое дерево, которое представляет наш UI, НО не является им. Причём данное дерево также используется для обеспечения [доступности интерфейса](https://developer.android.com/jetpack/compose/accessibility). Кроме того, присутствует дополнительная оптимизация, которая мерджит представления наших Compose функций в одну ноду.
Чтобы вывести дерево в логах есть следующая функция:
```
fun SemanticsNodeInteraction.printToLog(tag: String)
```
Принтим весь UI:
```
composeTestRule.onRoot(useUnmergedTree = false).printToLog(“{здесь обычный тег логирования}")
```
Давайте посмотрим, что мы имеем:
Дерево с параметром useUnmergedTree = 'true'
```
Node #10 at (l=0.0, t=66.0, r=1080.0, b=2028.0)px - это наш Surface
|-Node #11 at (l=0.0, t=66.0, r=1080.0, b=2028.0)px - это наш Box
|-Node #12 at (l=528.0, t=1018.0, r=553.0, b=1077.0)px, Tag: 'CounterTags:TEXT' - это наш текст счётчика
| Text = '[2]'
| Actions = [GetTextLayoutResult]
|-Node #14 at (l=452.0, t=1913.0, r=628.0, b=2012.0)px, Tag: 'CounterTags:BUTTON' - это наша кнопка
Role = 'Button'
Focused = 'false'
Actions = [OnClick, RequestFocus]
MergeDescendants = 'true'
|-Node #17 at (l=502.0, t=1937.0, r=579.0, b=1989.0)px, Tag: 'CounterTags:BUTTON_TEXT' - это наш текст в кнопке
Text = '[Add]'
Actions = [GetTextLayoutResult]
```
Дерево с параметром useUnmergedTree = 'false'
```
Node #10 at (l=0.0, t=66.0, r=1080.0, b=2028.0)px - это наш Surface
|-Node #11 at (l=0.0, t=66.0, r=1080.0, b=2028.0)px - это наш Box
|-Node #12 at (l=528.0, t=1018.0, r=553.0, b=1077.0)px, Tag: 'CounterTags:TEXT' - это наш текст счётчика
| Text = '[2]'
| Actions = [GetTextLayoutResult]
|-Node #14 at (l=452.0, t=1913.0, r=628.0, b=2012.0)px, Tag: 'CounterTags:BUTTON' - это наша кнопка вместе с текстом
Role = 'Button'
Focused = 'false'
Text = '[Add]'
Actions = [OnClick, RequestFocus, GetTextLayoutResult]
MergeDescendants = 'true'
```
И здесь мы видим, что вместо текста с кнопкой у нас просто кнопка. Причём у кнопки теперь есть свойство Text, и мы даже можем увидеть его значение: Text = '[Add]'.
И дополнительные свойства:
Role = 'Button' - что данный composable это кнопка.
Focused = 'false' - что она не в фокусе.
[OnClick, RequestFocus, GetTextLayoutResult] - действия, которые с ней можно совершать.
И самое интересное MergeDescendants = 'true' - говорит нам, что данная нода будет пытаться соединить в себе потомков при возможности. Причём именно “Потомков”, а не “Детей”.
Разница между потомками и детьмисын и дочь - дети
сын, дочь, внучка, внук - потомки
К примеру, если мы добавим дополнительную вложенность вот так:
```
Button() {
Box { - добавили вложенности
Text()
}
}
```
Наше смёрдженное дерево никак не изменится.
В итоге для решения нашей задачи можно либо использовать `useUnmergedTree = true'`
```
composeTestRule.onNodeWithTag(CounterTags.BUTTON_TEXT,useUnmergedTree = true' ).assertTextEquals("Add")
```
либо просто использовать саму кнопку
```
composeTestRule.onNodeWithTag(CounterTags.BUTTON).assertTextEquals("Add")
```
Кроме функции вывод дерева в логи, его также можно посмотреть при помощи LayoutInspector:
Посмотрим на самый интересный момент - Кнопку:
Здесь мы видим два раздела:
* Declared Semantics - свойства, которые добавляет непосредственно эта нода.
* Merged Semantics - смердженные свойства самой ноды и её потомков. Видим, что кнопка также включает наш текст.
С использованием простых нод разобрались, давайте попробуем сделать что-то чуть более сложное - работу со списками.
Пример со списком
-----------------
Задача: список, у каждой ячейки может быть ошибочное состояние (иконка с восклицательным знаком). Необходимо проверить её наличие или отсутствие. При нажатии на иконку, необходимо удалить элемент.
Для упрощения у ячеек, чья позиция кратна 5, выставляем ошибочное состояние.
```
@Composable
fun ListExample() {
val data = remember { mutableStateOf((1 until 100).map { it.toString() }) }
LazyColumn(Modifier.testTag(ListTags.LIST)) {
items(data.value, { it }) { item ->
Row(
modifier = Modifier
.padding(10.dp)
.testTag(ListTags.ITEM)
) {
Text("item $item", Modifier.testTag(ListTags.TEXT))
if (item.toInt() % 5 == 0) {
Image(
painter = painterResource(R.drawable.ic_error),
contentDescription = null,
modifier = Modifier
.testTag(ListTags.ICON)
.clickable { data.value = data.value.filter { it != item } },
)
}
}
}
}
}
object ListTags {
const val LIST = "ListTags:LIST"
const val TEXT = "ListTags:TEXT"
const val ITEM = "ListTags:ITEM"
const val ICON = "ListTags:ICON"
}
```
Выглядит вот так:
Для усложнения задачи будем проверять item 20 и 21. Необходимая последовательность действий:
1. Скролим к ячейке с текстом "item 20";
2. Проверяем что у этой ячейки отображается иконка;
3. Проверяем что у ячейки с текстом "item 21" не отображается иконка;
4. Нажимаем на иконку у ячейки “item 20”;
5. Проверяем, что ячейка “item 20” удалена.
Первое что нужно, это проскролить до нашей ячейки.
Находим наш список:
```
composeTestRule.onNodeWithTag(ListTags.LIST)
```
И дальше у нас есть на выбор 3 функции как скролить:
* `performScrollToKey(key: Any)` - в случае, если вы знаете ключ, который вы установили в списке. Если ваш key - это id генерируемый на сервере, то способ вам не подходит;
* `performScrollToIndex(index: Int)` - если вы уверены в позиции вашего элемента;
* `performScrollToNode(matcher: SemanticsMatcher)` - здесь мы можем задать кастомные матчеры для поиска нашей ячейки. Им и воспользуемся.
С `SemanticsMatcher` мы уже сегодня работали, но они были скрыты за функциями.
Если посмотрим на `onNodeWithTag(testTag: String)` упрощенно внутри выглядит так: `onNode(hasTestTag(testTag))`.
Функция `hasTestTag` - возвращает нам SemanticsMatcher.
Аналогично есть `hasText()`, `hasContentDescription()`, `hasClickAction()` и многие другие.
Скролим к ячейке, у которой в потомках есть нода с текстом “item 20”:
```
composeTestRule.onNodeWithTag(ListTags.LIST)
.performScrollToNode(hasAnyDescendant(hasText("item 20")))
```
`hasAnyDescendant(matcher: SemanticsMatcher): SemanticsMatcher` - проверяет, что у потомков текущей ноды есть нода соответствующая переданному матчеру.
Теперь посмотрим на Api работы со списками.
Поиск элемента выглядит похоже:
* onAllNodes()
* onAllNodesWithText()
* onAllNodesWithContentDescription()
* onAllNodesWithTag()
Главная разница в том, что получаем вместо `SemanticsNodeInteraction` следующий класс `SemanticsNodeInteractionCollection`.
Работа с ним похожа на `koltin.Collections`.
Можем отфильтровать ноды:
```
filter(matcher: SemanticsMatcher) :SemanticsNodeInteractionCollection.
```
Можем взять первый элемент по условию:
```
filterToOne(matcher: SemanticsMatcher) :SemanticsNodeInteractionCollection.
```
Получить по индексу:
```
get(index: Int): SemanticsNodeInteraction
```
И многое другое.
Итак, задача проверить, что ячейка с текстом “item 20” имеет статус ошибки, у нас это иконка.
Ищем элементы списка:
```
composeTestRule.onAllNodesWithTag(ListTags.ITEM)
```
Далее найдём ячейку, в которой есть текст “item 20” и также есть иконка:
```
.filterToOne(hasAnyDescendant(hasText("item 20")) and hasAnyDescendant(hasTestTag(ListTags.ICON)))
```
Для объединений матчеров используется инфиксная логическая функция “and”. Также есть функция “or” и operator функция отрицания “not”, которую можно использовать следующим образом: “!hasText()”
И наконец проверим, что она отображается:
```
.assertIsDisplayed()
```
Итого:
```
composeTestRule.onAllNodesWithTag(ListTags.ITEM)
.filterToOne(hasAnyDescendant(hasText("item 20")) and hasAnyDescendant(hasTestTag(ListTags.ICON)))
.assertIsDisplayed()
```
Аналогично, проверим что у “item 21” отсутствует иконка ошибки, используя функцию “not”:
```
composeTestRule.onAllNodesWithTag(ListTags.ITEM)
.filterToOne(hasAnyDescendant(hasText("item 21")) and !hasAnyDescendant(hasTestTag(ListTags.ICON)))
.assertIsDisplayed()
```
Теперь получим саму ноду иконки и нажмём на неё. Также находим нужную ячейку, получаем её детей onChildren(). Затем аналогично ячейке находим нашу иконку:
```
composeTestRule.onAllNodesWithTag(ListTags.ITEM)
.filterToOne(hasAnyDescendant(hasText("item 20")) and hasAnyDescendant(hasTestTag(ListTags.ICON)))
.onChildren()
.filterToOne(hasTestTag(ListTags.ICON))
.performClick()
```
И теперь проверим, что ячейка удалена через функцию `assertDoesNotExist()`:
```
composeTestRule.onAllNodesWithTag(ListTags.ITEM)
.filterToOne(hasAnyDescendant(hasText("item 20")) and hasAnyDescendant(hasTestTag(ListTags.ICON)))
.assertDoesNotExist()
```
Весь код теста
```
composeTestRule.onNodeWithTag(ListTags.LIST)
.performScrollToNode(hasAnyDescendant(hasText("item 20")))
composeTestRule.onAllNodesWithTag(ListTags.ITEM)
.filterToOne(hasAnyDescendant(hasText("item 20")) and hasAnyDescendant(hasTestTag(ListTags.ICON)))
.assertIsDisplayed()
composeTestRule.onAllNodesWithTag(ListTags.ITEM)
.filterToOne(hasAnyDescendant(hasText("item 21")) and !hasAnyDescendant(hasTestTag(ListTags.ICON)))
.assertIsDisplayed()
composeTestRule.onAllNodesWithTag(ListTags.ITEM)
.filterToOne(hasAnyDescendant(hasText("item 20")) and hasAnyDescendant(hasTestTag(ListTags.ICON)))
.onChildren()
.filterToOne(hasTestTag(ListTags.ICON))
.performClick()
composeTestRule.onAllNodesWithTag(ListTags.ITEM)
.filterToOne(hasAnyDescendant(hasText("item 20")) and hasAnyDescendant(hasTestTag(ListTags.ICON)))
.assertDoesNotExist()
```
В этот раз без сюрпризов всё работает:
В первый раз начиная работать с новым фреймворком очень легко потеряться в многообразии API. Чтобы этого не произошло был сделан очень удобный [cheat sheet](https://developer.android.com/jetpack/compose/testing-cheatsheet):
### Заключение
Сегодня мы познакомились с основами, которых хватит на большинство кейсов, необходимых для покрытия вашего приложения UI тестами. В следующей статье уже посмотрим, как же оно работает под капотом на примере hasText, научимся делать свой matcher и встретим некоторые ограничения.
[Исходный код тестов](https://github.com/Maksim-Novikov/ComposeUiTestsBug) | https://habr.com/ru/post/674112/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.